[0-9]+(?:\.[0-9]+)*) # release segment
- (?P # pre-release
- [-_\.]?
- (?P(a|b|c|rc|alpha|beta|pre|preview))
- [-_\.]?
- (?P[0-9]+)?
- )?
- (?P # post release
- (?:-(?P[0-9]+))
- |
- (?:
- [-_\.]?
- (?Ppost|rev|r)
- [-_\.]?
- (?P[0-9]+)?
- )
- )?
- (?P # dev release
- [-_\.]?
- (?Pdev)
- [-_\.]?
- (?P[0-9]+)?
- )?
- )
- (?:\+(?P[a-z0-9]+(?:[-_\.][a-z0-9]+)*))? # local version
-"""
-
-
-class Version(_BaseVersion):
-
- _regex = re.compile(r"^\s*" + VERSION_PATTERN + r"\s*$", re.VERBOSE | re.IGNORECASE)
-
- def __init__(self, version: str) -> None:
-
- # Validate the version and parse it into pieces
- match = self._regex.search(version)
- if not match:
- raise InvalidVersion(f"Invalid version: '{version}'")
-
- # Store the parsed out pieces of the version
- self._version = _Version(
- epoch=int(match.group("epoch")) if match.group("epoch") else 0,
- release=tuple(int(i) for i in match.group("release").split(".")),
- pre=_parse_letter_version(match.group("pre_l"), match.group("pre_n")),
- post=_parse_letter_version(
- match.group("post_l"), match.group("post_n1") or match.group("post_n2")
- ),
- dev=_parse_letter_version(match.group("dev_l"), match.group("dev_n")),
- local=_parse_local_version(match.group("local")),
- )
-
- # Generate a key which will be used for sorting
- self._key = _cmpkey(
- self._version.epoch,
- self._version.release,
- self._version.pre,
- self._version.post,
- self._version.dev,
- self._version.local,
- )
-
- def __repr__(self) -> str:
- return f""
-
- def __str__(self) -> str:
- parts = []
-
- # Epoch
- if self.epoch != 0:
- parts.append(f"{self.epoch}!")
-
- # Release segment
- parts.append(".".join(str(x) for x in self.release))
-
- # Pre-release
- if self.pre is not None:
- parts.append("".join(str(x) for x in self.pre))
-
- # Post-release
- if self.post is not None:
- parts.append(f".post{self.post}")
-
- # Development release
- if self.dev is not None:
- parts.append(f".dev{self.dev}")
-
- # Local version segment
- if self.local is not None:
- parts.append(f"+{self.local}")
-
- return "".join(parts)
-
- @property
- def epoch(self) -> int:
- _epoch: int = self._version.epoch
- return _epoch
-
- @property
- def release(self) -> Tuple[int, ...]:
- _release: Tuple[int, ...] = self._version.release
- return _release
-
- @property
- def pre(self) -> Optional[Tuple[str, int]]:
- _pre: Optional[Tuple[str, int]] = self._version.pre
- return _pre
-
- @property
- def post(self) -> Optional[int]:
- return self._version.post[1] if self._version.post else None
-
- @property
- def dev(self) -> Optional[int]:
- return self._version.dev[1] if self._version.dev else None
-
- @property
- def local(self) -> Optional[str]:
- if self._version.local:
- return ".".join(str(x) for x in self._version.local)
- else:
- return None
-
- @property
- def public(self) -> str:
- return str(self).split("+", 1)[0]
-
- @property
- def base_version(self) -> str:
- parts = []
-
- # Epoch
- if self.epoch != 0:
- parts.append(f"{self.epoch}!")
-
- # Release segment
- parts.append(".".join(str(x) for x in self.release))
-
- return "".join(parts)
-
- @property
- def is_prerelease(self) -> bool:
- return self.dev is not None or self.pre is not None
-
- @property
- def is_postrelease(self) -> bool:
- return self.post is not None
-
- @property
- def is_devrelease(self) -> bool:
- return self.dev is not None
-
- @property
- def major(self) -> int:
- return self.release[0] if len(self.release) >= 1 else 0
-
- @property
- def minor(self) -> int:
- return self.release[1] if len(self.release) >= 2 else 0
-
- @property
- def micro(self) -> int:
- return self.release[2] if len(self.release) >= 3 else 0
-
-
-def _parse_letter_version(
- letter: str, number: Union[str, bytes, SupportsInt]
-) -> Optional[Tuple[str, int]]:
-
- if letter:
- # We consider there to be an implicit 0 in a pre-release if there is
- # not a numeral associated with it.
- if number is None:
- number = 0
-
- # We normalize any letters to their lower case form
- letter = letter.lower()
-
- # We consider some words to be alternate spellings of other words and
- # in those cases we want to normalize the spellings to our preferred
- # spelling.
- if letter == "alpha":
- letter = "a"
- elif letter == "beta":
- letter = "b"
- elif letter in ["c", "pre", "preview"]:
- letter = "rc"
- elif letter in ["rev", "r"]:
- letter = "post"
-
- return letter, int(number)
- if not letter and number:
- # We assume if we are given a number, but we are not given a letter
- # then this is using the implicit post release syntax (e.g. 1.0-1)
- letter = "post"
-
- return letter, int(number)
-
- return None
-
-
-_local_version_separators = re.compile(r"[\._-]")
-
-
-def _parse_local_version(local: str) -> Optional[LocalType]:
- """
- Takes a string like abc.1.twelve and turns it into ("abc", 1, "twelve").
- """
- if local is not None:
- return tuple(
- part.lower() if not part.isdigit() else int(part)
- for part in _local_version_separators.split(local)
- )
- return None
-
-
-def _cmpkey(
- epoch: int,
- release: Tuple[int, ...],
- pre: Optional[Tuple[str, int]],
- post: Optional[Tuple[str, int]],
- dev: Optional[Tuple[str, int]],
- local: Optional[Tuple[SubLocalType]],
-) -> CmpKey:
-
- # When we compare a release version, we want to compare it with all of the
- # trailing zeros removed. So we'll use a reverse the list, drop all the now
- # leading zeros until we come to something non zero, then take the rest
- # re-reverse it back into the correct order and make it a tuple and use
- # that for our sorting key.
- _release = tuple(
- reversed(list(itertools.dropwhile(lambda x: x == 0, reversed(release))))
- )
-
- # We need to "trick" the sorting algorithm to put 1.0.dev0 before 1.0a0.
- # We'll do this by abusing the pre segment, but we _only_ want to do this
- # if there is not a pre or a post segment. If we have one of those then
- # the normal sorting rules will handle this case correctly.
- if pre is None and post is None and dev is not None:
- _pre: PrePostDevType = NegativeInfinity
- # Versions without a pre-release (except as noted above) should sort after
- # those with one.
- elif pre is None:
- _pre = Infinity
- else:
- _pre = pre
-
- # Versions without a post segment should sort before those with one.
- if post is None:
- _post: PrePostDevType = NegativeInfinity
-
- else:
- _post = post
-
- # Versions without a development segment should sort after those with one.
- if dev is None:
- _dev: PrePostDevType = Infinity
-
- else:
- _dev = dev
-
- if local is None:
- # Versions without a local segment should sort before those with one.
- _local: LocalType = NegativeInfinity
- else:
- # Versions with a local segment need that segment parsed to implement
- # the sorting rules in PEP440.
- # - Alpha numeric segments sort before numeric segments
- # - Alpha numeric segments sort lexicographically
- # - Numeric segments sort numerically
- # - Shorter versions sort before longer versions when the prefixes
- # match exactly
- _local = tuple(
- (i, "") if isinstance(i, int) else (NegativeInfinity, i) for i in local
- )
-
- return epoch, _release, _pre, _post, _dev, _local
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/command/egg_info.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/command/egg_info.py
deleted file mode 100644
index 25888ed8642ffe2e078bed5440bcc720f076904f..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/command/egg_info.py
+++ /dev/null
@@ -1,763 +0,0 @@
-"""setuptools.command.egg_info
-
-Create a distribution's .egg-info directory and contents"""
-
-from distutils.filelist import FileList as _FileList
-from distutils.errors import DistutilsInternalError
-from distutils.util import convert_path
-from distutils import log
-import distutils.errors
-import distutils.filelist
-import functools
-import os
-import re
-import sys
-import io
-import warnings
-import time
-import collections
-
-from .._importlib import metadata
-from .. import _entry_points
-
-from setuptools import Command
-from setuptools.command.sdist import sdist
-from setuptools.command.sdist import walk_revctrl
-from setuptools.command.setopt import edit_config
-from setuptools.command import bdist_egg
-from pkg_resources import (
- Requirement, safe_name, parse_version,
- safe_version, to_filename)
-import setuptools.unicode_utils as unicode_utils
-from setuptools.glob import glob
-
-from setuptools.extern import packaging
-from setuptools.extern.jaraco.text import yield_lines
-from setuptools import SetuptoolsDeprecationWarning
-
-
-def translate_pattern(glob): # noqa: C901 # is too complex (14) # FIXME
- """
- Translate a file path glob like '*.txt' in to a regular expression.
- This differs from fnmatch.translate which allows wildcards to match
- directory separators. It also knows about '**/' which matches any number of
- directories.
- """
- pat = ''
-
- # This will split on '/' within [character classes]. This is deliberate.
- chunks = glob.split(os.path.sep)
-
- sep = re.escape(os.sep)
- valid_char = '[^%s]' % (sep,)
-
- for c, chunk in enumerate(chunks):
- last_chunk = c == len(chunks) - 1
-
- # Chunks that are a literal ** are globstars. They match anything.
- if chunk == '**':
- if last_chunk:
- # Match anything if this is the last component
- pat += '.*'
- else:
- # Match '(name/)*'
- pat += '(?:%s+%s)*' % (valid_char, sep)
- continue # Break here as the whole path component has been handled
-
- # Find any special characters in the remainder
- i = 0
- chunk_len = len(chunk)
- while i < chunk_len:
- char = chunk[i]
- if char == '*':
- # Match any number of name characters
- pat += valid_char + '*'
- elif char == '?':
- # Match a name character
- pat += valid_char
- elif char == '[':
- # Character class
- inner_i = i + 1
- # Skip initial !/] chars
- if inner_i < chunk_len and chunk[inner_i] == '!':
- inner_i = inner_i + 1
- if inner_i < chunk_len and chunk[inner_i] == ']':
- inner_i = inner_i + 1
-
- # Loop till the closing ] is found
- while inner_i < chunk_len and chunk[inner_i] != ']':
- inner_i = inner_i + 1
-
- if inner_i >= chunk_len:
- # Got to the end of the string without finding a closing ]
- # Do not treat this as a matching group, but as a literal [
- pat += re.escape(char)
- else:
- # Grab the insides of the [brackets]
- inner = chunk[i + 1:inner_i]
- char_class = ''
-
- # Class negation
- if inner[0] == '!':
- char_class = '^'
- inner = inner[1:]
-
- char_class += re.escape(inner)
- pat += '[%s]' % (char_class,)
-
- # Skip to the end ]
- i = inner_i
- else:
- pat += re.escape(char)
- i += 1
-
- # Join each chunk with the dir separator
- if not last_chunk:
- pat += sep
-
- pat += r'\Z'
- return re.compile(pat, flags=re.MULTILINE | re.DOTALL)
-
-
-class InfoCommon:
- tag_build = None
- tag_date = None
-
- @property
- def name(self):
- return safe_name(self.distribution.get_name())
-
- def tagged_version(self):
- return safe_version(self._maybe_tag(self.distribution.get_version()))
-
- def _maybe_tag(self, version):
- """
- egg_info may be called more than once for a distribution,
- in which case the version string already contains all tags.
- """
- return (
- version if self.vtags and self._already_tagged(version)
- else version + self.vtags
- )
-
- def _already_tagged(self, version: str) -> bool:
- # Depending on their format, tags may change with version normalization.
- # So in addition the regular tags, we have to search for the normalized ones.
- return version.endswith(self.vtags) or version.endswith(self._safe_tags())
-
- def _safe_tags(self) -> str:
- # To implement this we can rely on `safe_version` pretending to be version 0
- # followed by tags. Then we simply discard the starting 0 (fake version number)
- return safe_version(f"0{self.vtags}")[1:]
-
- def tags(self) -> str:
- version = ''
- if self.tag_build:
- version += self.tag_build
- if self.tag_date:
- version += time.strftime("-%Y%m%d")
- return version
- vtags = property(tags)
-
-
-class egg_info(InfoCommon, Command):
- description = "create a distribution's .egg-info directory"
-
- user_options = [
- ('egg-base=', 'e', "directory containing .egg-info directories"
- " (default: top of the source tree)"),
- ('tag-date', 'd', "Add date stamp (e.g. 20050528) to version number"),
- ('tag-build=', 'b', "Specify explicit tag to add to version number"),
- ('no-date', 'D', "Don't include date stamp [default]"),
- ]
-
- boolean_options = ['tag-date']
- negative_opt = {
- 'no-date': 'tag-date',
- }
-
- def initialize_options(self):
- self.egg_base = None
- self.egg_name = None
- self.egg_info = None
- self.egg_version = None
- self.broken_egg_info = False
- self.ignore_egg_info_in_manifest = False
-
- ####################################
- # allow the 'tag_svn_revision' to be detected and
- # set, supporting sdists built on older Setuptools.
- @property
- def tag_svn_revision(self):
- pass
-
- @tag_svn_revision.setter
- def tag_svn_revision(self, value):
- pass
- ####################################
-
- def save_version_info(self, filename):
- """
- Materialize the value of date into the
- build tag. Install build keys in a deterministic order
- to avoid arbitrary reordering on subsequent builds.
- """
- egg_info = collections.OrderedDict()
- # follow the order these keys would have been added
- # when PYTHONHASHSEED=0
- egg_info['tag_build'] = self.tags()
- egg_info['tag_date'] = 0
- edit_config(filename, dict(egg_info=egg_info))
-
- def finalize_options(self):
- # Note: we need to capture the current value returned
- # by `self.tagged_version()`, so we can later update
- # `self.distribution.metadata.version` without
- # repercussions.
- self.egg_name = self.name
- self.egg_version = self.tagged_version()
- parsed_version = parse_version(self.egg_version)
-
- try:
- is_version = isinstance(parsed_version, packaging.version.Version)
- spec = "%s==%s" if is_version else "%s===%s"
- Requirement(spec % (self.egg_name, self.egg_version))
- except ValueError as e:
- raise distutils.errors.DistutilsOptionError(
- "Invalid distribution name or version syntax: %s-%s" %
- (self.egg_name, self.egg_version)
- ) from e
-
- if self.egg_base is None:
- dirs = self.distribution.package_dir
- self.egg_base = (dirs or {}).get('', os.curdir)
-
- self.ensure_dirname('egg_base')
- self.egg_info = to_filename(self.egg_name) + '.egg-info'
- if self.egg_base != os.curdir:
- self.egg_info = os.path.join(self.egg_base, self.egg_info)
- if '-' in self.egg_name:
- self.check_broken_egg_info()
-
- # Set package version for the benefit of dumber commands
- # (e.g. sdist, bdist_wininst, etc.)
- #
- self.distribution.metadata.version = self.egg_version
-
- # If we bootstrapped around the lack of a PKG-INFO, as might be the
- # case in a fresh checkout, make sure that any special tags get added
- # to the version info
- #
- pd = self.distribution._patched_dist
- if pd is not None and pd.key == self.egg_name.lower():
- pd._version = self.egg_version
- pd._parsed_version = parse_version(self.egg_version)
- self.distribution._patched_dist = None
-
- def write_or_delete_file(self, what, filename, data, force=False):
- """Write `data` to `filename` or delete if empty
-
- If `data` is non-empty, this routine is the same as ``write_file()``.
- If `data` is empty but not ``None``, this is the same as calling
- ``delete_file(filename)`. If `data` is ``None``, then this is a no-op
- unless `filename` exists, in which case a warning is issued about the
- orphaned file (if `force` is false), or deleted (if `force` is true).
- """
- if data:
- self.write_file(what, filename, data)
- elif os.path.exists(filename):
- if data is None and not force:
- log.warn(
- "%s not set in setup(), but %s exists", what, filename
- )
- return
- else:
- self.delete_file(filename)
-
- def write_file(self, what, filename, data):
- """Write `data` to `filename` (if not a dry run) after announcing it
-
- `what` is used in a log message to identify what is being written
- to the file.
- """
- log.info("writing %s to %s", what, filename)
- data = data.encode("utf-8")
- if not self.dry_run:
- f = open(filename, 'wb')
- f.write(data)
- f.close()
-
- def delete_file(self, filename):
- """Delete `filename` (if not a dry run) after announcing it"""
- log.info("deleting %s", filename)
- if not self.dry_run:
- os.unlink(filename)
-
- def run(self):
- self.mkpath(self.egg_info)
- os.utime(self.egg_info, None)
- for ep in metadata.entry_points(group='egg_info.writers'):
- writer = ep.load()
- writer(self, ep.name, os.path.join(self.egg_info, ep.name))
-
- # Get rid of native_libs.txt if it was put there by older bdist_egg
- nl = os.path.join(self.egg_info, "native_libs.txt")
- if os.path.exists(nl):
- self.delete_file(nl)
-
- self.find_sources()
-
- def find_sources(self):
- """Generate SOURCES.txt manifest file"""
- manifest_filename = os.path.join(self.egg_info, "SOURCES.txt")
- mm = manifest_maker(self.distribution)
- mm.ignore_egg_info_dir = self.ignore_egg_info_in_manifest
- mm.manifest = manifest_filename
- mm.run()
- self.filelist = mm.filelist
-
- def check_broken_egg_info(self):
- bei = self.egg_name + '.egg-info'
- if self.egg_base != os.curdir:
- bei = os.path.join(self.egg_base, bei)
- if os.path.exists(bei):
- log.warn(
- "-" * 78 + '\n'
- "Note: Your current .egg-info directory has a '-' in its name;"
- '\nthis will not work correctly with "setup.py develop".\n\n'
- 'Please rename %s to %s to correct this problem.\n' + '-' * 78,
- bei, self.egg_info
- )
- self.broken_egg_info = self.egg_info
- self.egg_info = bei # make it work for now
-
-
-class FileList(_FileList):
- # Implementations of the various MANIFEST.in commands
-
- def __init__(self, warn=None, debug_print=None, ignore_egg_info_dir=False):
- super().__init__(warn, debug_print)
- self.ignore_egg_info_dir = ignore_egg_info_dir
-
- def process_template_line(self, line):
- # Parse the line: split it up, make sure the right number of words
- # is there, and return the relevant words. 'action' is always
- # defined: it's the first word of the line. Which of the other
- # three are defined depends on the action; it'll be either
- # patterns, (dir and patterns), or (dir_pattern).
- (action, patterns, dir, dir_pattern) = self._parse_template_line(line)
-
- action_map = {
- 'include': self.include,
- 'exclude': self.exclude,
- 'global-include': self.global_include,
- 'global-exclude': self.global_exclude,
- 'recursive-include': functools.partial(
- self.recursive_include, dir,
- ),
- 'recursive-exclude': functools.partial(
- self.recursive_exclude, dir,
- ),
- 'graft': self.graft,
- 'prune': self.prune,
- }
- log_map = {
- 'include': "warning: no files found matching '%s'",
- 'exclude': (
- "warning: no previously-included files found "
- "matching '%s'"
- ),
- 'global-include': (
- "warning: no files found matching '%s' "
- "anywhere in distribution"
- ),
- 'global-exclude': (
- "warning: no previously-included files matching "
- "'%s' found anywhere in distribution"
- ),
- 'recursive-include': (
- "warning: no files found matching '%s' "
- "under directory '%s'"
- ),
- 'recursive-exclude': (
- "warning: no previously-included files matching "
- "'%s' found under directory '%s'"
- ),
- 'graft': "warning: no directories found matching '%s'",
- 'prune': "no previously-included directories found matching '%s'",
- }
-
- try:
- process_action = action_map[action]
- except KeyError:
- raise DistutilsInternalError(
- "this cannot happen: invalid action '{action!s}'".
- format(action=action),
- )
-
- # OK, now we know that the action is valid and we have the
- # right number of words on the line for that action -- so we
- # can proceed with minimal error-checking.
-
- action_is_recursive = action.startswith('recursive-')
- if action in {'graft', 'prune'}:
- patterns = [dir_pattern]
- extra_log_args = (dir, ) if action_is_recursive else ()
- log_tmpl = log_map[action]
-
- self.debug_print(
- ' '.join(
- [action] +
- ([dir] if action_is_recursive else []) +
- patterns,
- )
- )
- for pattern in patterns:
- if not process_action(pattern):
- log.warn(log_tmpl, pattern, *extra_log_args)
-
- def _remove_files(self, predicate):
- """
- Remove all files from the file list that match the predicate.
- Return True if any matching files were removed
- """
- found = False
- for i in range(len(self.files) - 1, -1, -1):
- if predicate(self.files[i]):
- self.debug_print(" removing " + self.files[i])
- del self.files[i]
- found = True
- return found
-
- def include(self, pattern):
- """Include files that match 'pattern'."""
- found = [f for f in glob(pattern) if not os.path.isdir(f)]
- self.extend(found)
- return bool(found)
-
- def exclude(self, pattern):
- """Exclude files that match 'pattern'."""
- match = translate_pattern(pattern)
- return self._remove_files(match.match)
-
- def recursive_include(self, dir, pattern):
- """
- Include all files anywhere in 'dir/' that match the pattern.
- """
- full_pattern = os.path.join(dir, '**', pattern)
- found = [f for f in glob(full_pattern, recursive=True)
- if not os.path.isdir(f)]
- self.extend(found)
- return bool(found)
-
- def recursive_exclude(self, dir, pattern):
- """
- Exclude any file anywhere in 'dir/' that match the pattern.
- """
- match = translate_pattern(os.path.join(dir, '**', pattern))
- return self._remove_files(match.match)
-
- def graft(self, dir):
- """Include all files from 'dir/'."""
- found = [
- item
- for match_dir in glob(dir)
- for item in distutils.filelist.findall(match_dir)
- ]
- self.extend(found)
- return bool(found)
-
- def prune(self, dir):
- """Filter out files from 'dir/'."""
- match = translate_pattern(os.path.join(dir, '**'))
- return self._remove_files(match.match)
-
- def global_include(self, pattern):
- """
- Include all files anywhere in the current directory that match the
- pattern. This is very inefficient on large file trees.
- """
- if self.allfiles is None:
- self.findall()
- match = translate_pattern(os.path.join('**', pattern))
- found = [f for f in self.allfiles if match.match(f)]
- self.extend(found)
- return bool(found)
-
- def global_exclude(self, pattern):
- """
- Exclude all files anywhere that match the pattern.
- """
- match = translate_pattern(os.path.join('**', pattern))
- return self._remove_files(match.match)
-
- def append(self, item):
- if item.endswith('\r'): # Fix older sdists built on Windows
- item = item[:-1]
- path = convert_path(item)
-
- if self._safe_path(path):
- self.files.append(path)
-
- def extend(self, paths):
- self.files.extend(filter(self._safe_path, paths))
-
- def _repair(self):
- """
- Replace self.files with only safe paths
-
- Because some owners of FileList manipulate the underlying
- ``files`` attribute directly, this method must be called to
- repair those paths.
- """
- self.files = list(filter(self._safe_path, self.files))
-
- def _safe_path(self, path):
- enc_warn = "'%s' not %s encodable -- skipping"
-
- # To avoid accidental trans-codings errors, first to unicode
- u_path = unicode_utils.filesys_decode(path)
- if u_path is None:
- log.warn("'%s' in unexpected encoding -- skipping" % path)
- return False
-
- # Must ensure utf-8 encodability
- utf8_path = unicode_utils.try_encode(u_path, "utf-8")
- if utf8_path is None:
- log.warn(enc_warn, path, 'utf-8')
- return False
-
- try:
- # ignore egg-info paths
- is_egg_info = ".egg-info" in u_path or b".egg-info" in utf8_path
- if self.ignore_egg_info_dir and is_egg_info:
- return False
- # accept is either way checks out
- if os.path.exists(u_path) or os.path.exists(utf8_path):
- return True
- # this will catch any encode errors decoding u_path
- except UnicodeEncodeError:
- log.warn(enc_warn, path, sys.getfilesystemencoding())
-
-
-class manifest_maker(sdist):
- template = "MANIFEST.in"
-
- def initialize_options(self):
- self.use_defaults = 1
- self.prune = 1
- self.manifest_only = 1
- self.force_manifest = 1
- self.ignore_egg_info_dir = False
-
- def finalize_options(self):
- pass
-
- def run(self):
- self.filelist = FileList(ignore_egg_info_dir=self.ignore_egg_info_dir)
- if not os.path.exists(self.manifest):
- self.write_manifest() # it must exist so it'll get in the list
- self.add_defaults()
- if os.path.exists(self.template):
- self.read_template()
- self.add_license_files()
- self.prune_file_list()
- self.filelist.sort()
- self.filelist.remove_duplicates()
- self.write_manifest()
-
- def _manifest_normalize(self, path):
- path = unicode_utils.filesys_decode(path)
- return path.replace(os.sep, '/')
-
- def write_manifest(self):
- """
- Write the file list in 'self.filelist' to the manifest file
- named by 'self.manifest'.
- """
- self.filelist._repair()
-
- # Now _repairs should encodability, but not unicode
- files = [self._manifest_normalize(f) for f in self.filelist.files]
- msg = "writing manifest file '%s'" % self.manifest
- self.execute(write_file, (self.manifest, files), msg)
-
- def warn(self, msg):
- if not self._should_suppress_warning(msg):
- sdist.warn(self, msg)
-
- @staticmethod
- def _should_suppress_warning(msg):
- """
- suppress missing-file warnings from sdist
- """
- return re.match(r"standard file .*not found", msg)
-
- def add_defaults(self):
- sdist.add_defaults(self)
- self.filelist.append(self.template)
- self.filelist.append(self.manifest)
- rcfiles = list(walk_revctrl())
- if rcfiles:
- self.filelist.extend(rcfiles)
- elif os.path.exists(self.manifest):
- self.read_manifest()
-
- if os.path.exists("setup.py"):
- # setup.py should be included by default, even if it's not
- # the script called to create the sdist
- self.filelist.append("setup.py")
-
- ei_cmd = self.get_finalized_command('egg_info')
- self.filelist.graft(ei_cmd.egg_info)
-
- def add_license_files(self):
- license_files = self.distribution.metadata.license_files or []
- for lf in license_files:
- log.info("adding license file '%s'", lf)
- pass
- self.filelist.extend(license_files)
-
- def prune_file_list(self):
- build = self.get_finalized_command('build')
- base_dir = self.distribution.get_fullname()
- self.filelist.prune(build.build_base)
- self.filelist.prune(base_dir)
- sep = re.escape(os.sep)
- self.filelist.exclude_pattern(r'(^|' + sep + r')(RCS|CVS|\.svn)' + sep,
- is_regex=1)
-
- def _safe_data_files(self, build_py):
- """
- The parent class implementation of this method
- (``sdist``) will try to include data files, which
- might cause recursion problems when
- ``include_package_data=True``.
-
- Therefore, avoid triggering any attempt of
- analyzing/building the manifest again.
- """
- if hasattr(build_py, 'get_data_files_without_manifest'):
- return build_py.get_data_files_without_manifest()
-
- warnings.warn(
- "Custom 'build_py' does not implement "
- "'get_data_files_without_manifest'.\nPlease extend command classes"
- " from setuptools instead of distutils.",
- SetuptoolsDeprecationWarning
- )
- return build_py.get_data_files()
-
-
-def write_file(filename, contents):
- """Create a file with the specified name and write 'contents' (a
- sequence of strings without line terminators) to it.
- """
- contents = "\n".join(contents)
-
- # assuming the contents has been vetted for utf-8 encoding
- contents = contents.encode("utf-8")
-
- with open(filename, "wb") as f: # always write POSIX-style manifest
- f.write(contents)
-
-
-def write_pkg_info(cmd, basename, filename):
- log.info("writing %s", filename)
- if not cmd.dry_run:
- metadata = cmd.distribution.metadata
- metadata.version, oldver = cmd.egg_version, metadata.version
- metadata.name, oldname = cmd.egg_name, metadata.name
-
- try:
- # write unescaped data to PKG-INFO, so older pkg_resources
- # can still parse it
- metadata.write_pkg_info(cmd.egg_info)
- finally:
- metadata.name, metadata.version = oldname, oldver
-
- safe = getattr(cmd.distribution, 'zip_safe', None)
-
- bdist_egg.write_safety_flag(cmd.egg_info, safe)
-
-
-def warn_depends_obsolete(cmd, basename, filename):
- if os.path.exists(filename):
- log.warn(
- "WARNING: 'depends.txt' is not used by setuptools 0.6!\n"
- "Use the install_requires/extras_require setup() args instead."
- )
-
-
-def _write_requirements(stream, reqs):
- lines = yield_lines(reqs or ())
-
- def append_cr(line):
- return line + '\n'
- lines = map(append_cr, lines)
- stream.writelines(lines)
-
-
-def write_requirements(cmd, basename, filename):
- dist = cmd.distribution
- data = io.StringIO()
- _write_requirements(data, dist.install_requires)
- extras_require = dist.extras_require or {}
- for extra in sorted(extras_require):
- data.write('\n[{extra}]\n'.format(**vars()))
- _write_requirements(data, extras_require[extra])
- cmd.write_or_delete_file("requirements", filename, data.getvalue())
-
-
-def write_setup_requirements(cmd, basename, filename):
- data = io.StringIO()
- _write_requirements(data, cmd.distribution.setup_requires)
- cmd.write_or_delete_file("setup-requirements", filename, data.getvalue())
-
-
-def write_toplevel_names(cmd, basename, filename):
- pkgs = dict.fromkeys(
- [
- k.split('.', 1)[0]
- for k in cmd.distribution.iter_distribution_names()
- ]
- )
- cmd.write_file("top-level names", filename, '\n'.join(sorted(pkgs)) + '\n')
-
-
-def overwrite_arg(cmd, basename, filename):
- write_arg(cmd, basename, filename, True)
-
-
-def write_arg(cmd, basename, filename, force=False):
- argname = os.path.splitext(basename)[0]
- value = getattr(cmd.distribution, argname, None)
- if value is not None:
- value = '\n'.join(value) + '\n'
- cmd.write_or_delete_file(argname, filename, value, force)
-
-
-def write_entries(cmd, basename, filename):
- eps = _entry_points.load(cmd.distribution.entry_points)
- defn = _entry_points.render(eps)
- cmd.write_or_delete_file('entry points', filename, defn, True)
-
-
-def get_pkg_info_revision():
- """
- Get a -r### off of PKG-INFO Version in case this is an sdist of
- a subversion revision.
- """
- warnings.warn(
- "get_pkg_info_revision is deprecated.", EggInfoDeprecationWarning)
- if os.path.exists('PKG-INFO'):
- with io.open('PKG-INFO') as f:
- for line in f:
- match = re.match(r"Version:.*-r(\d+)\s*$", line)
- if match:
- return int(match.group(1))
- return 0
-
-
-class EggInfoDeprecationWarning(SetuptoolsDeprecationWarning):
- """Deprecated behavior warning for EggInfo, bypassing suppression."""
diff --git a/spaces/Audio-AGI/AudioSep/README.md b/spaces/Audio-AGI/AudioSep/README.md
deleted file mode 100644
index 9a7c85e03be2a4e982cb29e6f4f3b6cd6f0f5a73..0000000000000000000000000000000000000000
--- a/spaces/Audio-AGI/AudioSep/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
----
-title: AudioSep
-emoji: 🐠
-colorFrom: red
-colorTo: purple
-sdk: gradio
-sdk_version: 3.47.1
-app_file: app.py
-pinned: false
-license: mit
----
\ No newline at end of file
diff --git a/spaces/Audio-AGI/AudioSep/train.py b/spaces/Audio-AGI/AudioSep/train.py
deleted file mode 100644
index acde85b20c7e1abd4b5f8fc732470a80c8428d82..0000000000000000000000000000000000000000
--- a/spaces/Audio-AGI/AudioSep/train.py
+++ /dev/null
@@ -1,307 +0,0 @@
-import argparse
-import logging
-import os
-import pathlib
-from typing import List, NoReturn
-import lightning.pytorch as pl
-from lightning.pytorch.strategies import DDPStrategy
-from torch.utils.tensorboard import SummaryWriter
-from data.datamodules import *
-from utils import create_logging, parse_yaml
-from models.resunet import *
-from losses import get_loss_function
-from models.audiosep import AudioSep, get_model_class
-from data.waveform_mixers import SegmentMixer
-from models.clap_encoder import CLAP_Encoder
-from callbacks.base import CheckpointEveryNSteps
-from optimizers.lr_schedulers import get_lr_lambda
-
-
-def get_dirs(
- workspace: str,
- filename: str,
- config_yaml: str,
- devices_num: int
-) -> List[str]:
- r"""Get directories and paths.
-
- Args:
- workspace (str): directory of workspace
- filename (str): filename of current .py file.
- config_yaml (str): config yaml path
- devices_num (int): 0 for cpu and 8 for training with 8 GPUs
-
- Returns:
- checkpoints_dir (str): directory to save checkpoints
- logs_dir (str), directory to save logs
- tf_logs_dir (str), directory to save TensorBoard logs
- statistics_path (str), directory to save statistics
- """
-
- os.makedirs(workspace, exist_ok=True)
-
- yaml_name = pathlib.Path(config_yaml).stem
-
- # Directory to save checkpoints
- checkpoints_dir = os.path.join(
- workspace,
- "checkpoints",
- filename,
- "{},devices={}".format(yaml_name, devices_num),
- )
- os.makedirs(checkpoints_dir, exist_ok=True)
-
- # Directory to save logs
- logs_dir = os.path.join(
- workspace,
- "logs",
- filename,
- "{},devices={}".format(yaml_name, devices_num),
- )
- os.makedirs(logs_dir, exist_ok=True)
-
- # Directory to save TensorBoard logs
- create_logging(logs_dir, filemode="w")
- logging.info(args)
-
- tf_logs_dir = os.path.join(
- workspace,
- "tf_logs",
- filename,
- "{},devices={}".format(yaml_name, devices_num),
- )
-
- # Directory to save statistics
- statistics_path = os.path.join(
- workspace,
- "statistics",
- filename,
- "{},devices={}".format(yaml_name, devices_num),
- "statistics.pkl",
- )
- os.makedirs(os.path.dirname(statistics_path), exist_ok=True)
-
- return checkpoints_dir, logs_dir, tf_logs_dir, statistics_path
-
-
-def get_data_module(
- config_yaml: str,
- num_workers: int,
- batch_size: int,
-) -> DataModule:
- r"""Create data_module. Mini-batch data can be obtained by:
-
- code-block:: python
-
- data_module.setup()
-
- for batch_data_dict in data_module.train_dataloader():
- print(batch_data_dict.keys())
- break
-
- Args:
- workspace: str
- config_yaml: str
- num_workers: int, e.g., 0 for non-parallel and 8 for using cpu cores
- for preparing data in parallel
- distributed: bool
-
- Returns:
- data_module: DataModule
- """
-
- # read configurations
- configs = parse_yaml(config_yaml)
- sampling_rate = configs['data']['sampling_rate']
- segment_seconds = configs['data']['segment_seconds']
-
- # audio-text datasets
- datafiles = configs['data']['datafiles']
-
- # dataset
- dataset = AudioTextDataset(
- datafiles=datafiles,
- sampling_rate=sampling_rate,
- max_clip_len=segment_seconds,
- )
-
-
- # data module
- data_module = DataModule(
- train_dataset=dataset,
- num_workers=num_workers,
- batch_size=batch_size
- )
-
- return data_module
-
-
-def train(args) -> NoReturn:
- r"""Train, evaluate, and save checkpoints.
-
- Args:
- workspace: str, directory of workspace
- gpus: int, number of GPUs to train
- config_yaml: str
- """
-
- # arguments & parameters
- workspace = args.workspace
- config_yaml = args.config_yaml
- filename = args.filename
-
- devices_num = torch.cuda.device_count()
- # Read config file.
- configs = parse_yaml(config_yaml)
-
- # Configuration of data
- max_mix_num = configs['data']['max_mix_num']
- sampling_rate = configs['data']['sampling_rate']
- lower_db = configs['data']['loudness_norm']['lower_db']
- higher_db = configs['data']['loudness_norm']['higher_db']
-
- # Configuration of the separation model
- query_net = configs['model']['query_net']
- model_type = configs['model']['model_type']
- input_channels = configs['model']['input_channels']
- output_channels = configs['model']['output_channels']
- condition_size = configs['model']['condition_size']
- use_text_ratio = configs['model']['use_text_ratio']
-
- # Configuration of the trainer
- num_nodes = configs['train']['num_nodes']
- batch_size = configs['train']['batch_size_per_device']
- sync_batchnorm = configs['train']['sync_batchnorm']
- num_workers = configs['train']['num_workers']
- loss_type = configs['train']['loss_type']
- optimizer_type = configs["train"]["optimizer"]["optimizer_type"]
- learning_rate = float(configs['train']["optimizer"]['learning_rate'])
- lr_lambda_type = configs['train']["optimizer"]['lr_lambda_type']
- warm_up_steps = configs['train']["optimizer"]['warm_up_steps']
- reduce_lr_steps = configs['train']["optimizer"]['reduce_lr_steps']
- save_step_frequency = configs['train']['save_step_frequency']
- resume_checkpoint_path = args.resume_checkpoint_path
- if resume_checkpoint_path == "":
- resume_checkpoint_path = None
- else:
- logging.info(f'Finetuning AudioSep with checkpoint [{resume_checkpoint_path}]')
-
- # Get directories and paths
- checkpoints_dir, logs_dir, tf_logs_dir, statistics_path = get_dirs(
- workspace, filename, config_yaml, devices_num,
- )
-
- logging.info(configs)
-
- # data module
- data_module = get_data_module(
- config_yaml=config_yaml,
- batch_size=batch_size,
- num_workers=num_workers,
- )
-
- # model
- Model = get_model_class(model_type=model_type)
-
- ss_model = Model(
- input_channels=input_channels,
- output_channels=output_channels,
- condition_size=condition_size,
- )
-
- # loss function
- loss_function = get_loss_function(loss_type)
-
- segment_mixer = SegmentMixer(
- max_mix_num=max_mix_num,
- lower_db=lower_db,
- higher_db=higher_db
- )
-
-
- if query_net == 'CLAP':
- query_encoder = CLAP_Encoder()
- else:
- raise NotImplementedError
-
- lr_lambda_func = get_lr_lambda(
- lr_lambda_type=lr_lambda_type,
- warm_up_steps=warm_up_steps,
- reduce_lr_steps=reduce_lr_steps,
- )
-
- # pytorch-lightning model
- pl_model = AudioSep(
- ss_model=ss_model,
- waveform_mixer=segment_mixer,
- query_encoder=query_encoder,
- loss_function=loss_function,
- optimizer_type=optimizer_type,
- learning_rate=learning_rate,
- lr_lambda_func=lr_lambda_func,
- use_text_ratio=use_text_ratio
- )
-
- checkpoint_every_n_steps = CheckpointEveryNSteps(
- checkpoints_dir=checkpoints_dir,
- save_step_frequency=save_step_frequency,
- )
-
- summary_writer = SummaryWriter(log_dir=tf_logs_dir)
-
- callbacks = [checkpoint_every_n_steps]
-
- trainer = pl.Trainer(
- accelerator='auto',
- devices='auto',
- strategy='ddp_find_unused_parameters_true',
- num_nodes=num_nodes,
- precision="32-true",
- logger=None,
- callbacks=callbacks,
- fast_dev_run=False,
- max_epochs=-1,
- log_every_n_steps=50,
- use_distributed_sampler=True,
- sync_batchnorm=sync_batchnorm,
- num_sanity_val_steps=2,
- enable_checkpointing=False,
- enable_progress_bar=True,
- enable_model_summary=True,
- )
-
- # Fit, evaluate, and save checkpoints.
- trainer.fit(
- model=pl_model,
- train_dataloaders=None,
- val_dataloaders=None,
- datamodule=data_module,
- ckpt_path=resume_checkpoint_path,
- )
-
-
-if __name__ == "__main__":
-
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--workspace", type=str, required=True, help="Directory of workspace."
- )
- parser.add_argument(
- "--config_yaml",
- type=str,
- required=True,
- help="Path of config file for training.",
- )
-
- parser.add_argument(
- "--resume_checkpoint_path",
- type=str,
- required=True,
- default='',
- help="Path of pretrained checkpoint for finetuning.",
- )
-
- args = parser.parse_args()
- args.filename = pathlib.Path(__file__).stem
-
- train(args)
\ No newline at end of file
diff --git a/spaces/AzinZ/vitscn/text/cleaners.py b/spaces/AzinZ/vitscn/text/cleaners.py
deleted file mode 100644
index 27852685b892256fe57c3e1ff66b6ca56ff41c3d..0000000000000000000000000000000000000000
--- a/spaces/AzinZ/vitscn/text/cleaners.py
+++ /dev/null
@@ -1,108 +0,0 @@
-""" from https://github.com/keithito/tacotron """
-
-'''
-Cleaners are transformations that run over the input text at both training and eval time.
-
-Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners"
-hyperparameter. Some cleaners are English-specific. You'll typically want to use:
- 1. "english_cleaners" for English text
- 2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using
- the Unidecode library (https://pypi.python.org/pypi/Unidecode)
- 3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update
- the symbols in symbols.py to match your data).
-'''
-
-import re
-from unidecode import unidecode
-from phonemizer import phonemize
-from text.mandarin import chinese_to_pinyin
-
-
-# Regular expression matching whitespace:
-_whitespace_re = re.compile(r'\s+')
-
-# List of (regular expression, replacement) pairs for abbreviations:
-_abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [
- ('mrs', 'misess'),
- ('mr', 'mister'),
- ('dr', 'doctor'),
- ('st', 'saint'),
- ('co', 'company'),
- ('jr', 'junior'),
- ('maj', 'major'),
- ('gen', 'general'),
- ('drs', 'doctors'),
- ('rev', 'reverend'),
- ('lt', 'lieutenant'),
- ('hon', 'honorable'),
- ('sgt', 'sergeant'),
- ('capt', 'captain'),
- ('esq', 'esquire'),
- ('ltd', 'limited'),
- ('col', 'colonel'),
- ('ft', 'fort'),
-]]
-
-
-def expand_abbreviations(text):
- for regex, replacement in _abbreviations:
- text = re.sub(regex, replacement, text)
- return text
-
-
-# def expand_numbers(text):
-# return normalize_numbers(text)
-
-
-def lowercase(text):
- return text.lower()
-
-
-def collapse_whitespace(text):
- return re.sub(_whitespace_re, ' ', text)
-
-
-def convert_to_ascii(text):
- return unidecode(text)
-
-
-def basic_cleaners(text):
- '''Basic pipeline that lowercases and collapses whitespace without transliteration.'''
- text = lowercase(text)
- text = collapse_whitespace(text)
- return text
-
-
-def transliteration_cleaners(text):
- '''Pipeline for non-English text that transliterates to ASCII.'''
- text = convert_to_ascii(text)
- text = lowercase(text)
- text = collapse_whitespace(text)
- return text
-
-
-def english_cleaners(text):
- '''Pipeline for English text, including abbreviation expansion.'''
- text = convert_to_ascii(text)
- text = lowercase(text)
- text = expand_abbreviations(text)
- phonemes = phonemize(text, language='en-us', backend='espeak', strip=True)
- phonemes = collapse_whitespace(phonemes)
- return phonemes
-
-
-def english_cleaners2(text):
- '''Pipeline for English text, including abbreviation expansion. + punctuation + stress'''
- text = convert_to_ascii(text)
- text = lowercase(text)
- text = expand_abbreviations(text)
- phonemes = phonemize(text, language='en-us', backend='espeak', strip=True, preserve_punctuation=True, with_stress=True)
- phonemes = collapse_whitespace(phonemes)
- return phonemes
-
-
-def chinese_cleaners(text):
- text = chinese_to_pinyin(text)
- text = lowercase(text)
- text = collapse_whitespace(text)
- return text
\ No newline at end of file
diff --git a/spaces/Benson/text-generation/Examples/Aethersx2 ltima Versin Descarga.md b/spaces/Benson/text-generation/Examples/Aethersx2 ltima Versin Descarga.md
deleted file mode 100644
index 8c336f03e8307cdc5357d478847bb801d08cfa63..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Aethersx2 ltima Versin Descarga.md
+++ /dev/null
@@ -1,90 +0,0 @@
-
-AetherSX2: La guía definitiva para jugar juegos de PS2 en Android
-¿Echas de menos jugar a tus juegos favoritos de PlayStation 2 pero no tienes una consola o un PC para ejecutarlos? ¿Le gustaría poder disfrutar de ellos en su teléfono inteligente o tableta Android en cualquier momento, en cualquier lugar? Si es así, entonces estás de suerte, porque hay un nuevo emulador de PS2 para Android que puede hacer sus sueños realidad. Se llama AetherSX2, y es el mejor emulador de PS2 para Android que puedes encontrar.
-En este artículo te contamos todo lo que necesitas saber sobre AetherSX2, desde su historia y desarrollo hasta sus requerimientos y compatibilidad. También te mostraremos cómo instalarlo y configurarlo en tu dispositivo Android, así como algunas de las características y consejos que harán que tu experiencia de juego sea aún mejor. Finalmente, lo compararemos con algunos de los otros emuladores de PS2 disponibles para Android y veremos lo que los usuarios tienen que decir al respecto. Al final de este artículo, estarás listo para descargar AetherSX2 y comenzar a jugar tus juegos favoritos de PS2 en tu dispositivo Android.
-aethersx2 última versión descarga
Download --->>> https://bltlly.com/2v6LEk
- Una breve historia de AetherSX2
-AetherSX2 es la creación de una persona, un desarrollador que va por el mango Tahlreth. El desarrollador realmente utilizó el emulador PCSX2 como base para su emulador basado en Android. PCSX2 es un emulador de larga duración, bien establecido en la PC, por lo que tiene sentido aprovechar el trabajo que ha ido en este programa.
-El desarrollador de AetherSX2 tiene la luz verde para utilizar el código PCSX2 de los propios desarrolladores y está licenciado bajo la licencia LGPL - a diferencia de los desarrolladores DamonPS2, que robaron el código y no siguieron la licencia requerida. En cualquier caso, el emulador fue lanzado inicialmente en diciembre de 2021 a través de Google Play Store como una beta abierta. También puedes descargar el APK a través del sitio web AetherSX2. Le recomendamos que se mantenga alejado de cualquier otro sitio web que afirma ofrecer el APK.
-
- Requisitos y compatibilidad de AetherSX2
-Una de las cosas más importantes a considerar antes de descargar e instalar AetherSX2 es si su dispositivo Android puede manejarlo. La emulación de PS2 no es una tarea fácil, y requiere mucha potencia de procesamiento y memoria para funcionar sin problemas. AetherSX2 no es una excepción, y tiene algunas especificaciones mínimas y recomendadas que debes cumplir o superar para obtener los mejores resultados.
-Las especificaciones mínimas para ejecutar AetherSX2 son las siguientes:
-
-- Un dispositivo Android con Android 7.0 Nougat o superior
-- CPU de cuatro núcleos con una velocidad de reloj mínima de 1,8 GHz
-- Al menos 3 GB de RAM
-- Al menos 5 GB de espacio de almacenamiento gratuito
-- Una GPU compatible con OpenGL ES 3.0 o superior
-
-Las especificaciones recomendadas para ejecutar AetherSX2 son las siguientes:
-
-- Un dispositivo Android con Android 10 o superior
-- CPU hexa-core o octa-core con una velocidad de reloj mínima de 2,5 GHz
-- Al menos 4 GB de RAM
-- Al menos 10 GB de espacio de almacenamiento gratuito
-- Una GPU compatible con Vulkan o OpenGL ES 3.1 o superior
-
-Como puedes ver, AetherSX2 no es una aplicación ligera, y exigirá mucho de tu dispositivo. Si el dispositivo no cumple con las especificaciones mínimas, es posible que experimente retrasos, tartamudeo, fallos o problemas gráficos. Si tu dispositivo cumple o supera las especificaciones recomendadas, deberías poder disfrutar de la mayoría de los juegos de PS2 a máxima velocidad y alta resolución.
-Hablando de juegos, AetherSX2 tiene una lista de compatibilidad bastante decente, que puede comprobar en el sitio web oficial. La lista muestra los juegos que han sido probados por el desarrollador y los usuarios, y su estado (jugable, en el juego, menú, introducción, o nada). También puedes ver el modelo de dispositivo, la CPU, la GPU, la RAM, la versión de Android y la configuración del emulador utilizada para cada juego. La lista se actualiza constantemente a medida que se prueban más juegos y se proporcionan más comentarios.
-
-
-
-- Dios de la Guerra y Dios de la Guerra II
-- Final Fantasy X y Final Fantasy XII
-- Grand Theft Auto: San Andreas y Grand Theft Auto: Vice City
-- Metal Gear Solid 2: Sons of Liberty y Metal Gear Solid 3: Snake Eater
-- Sombra del Coloso e Ico
-- Corazones del Reino y Corazones del Reino II
-- Resident Evil 4 y Resident Evil: Código Verónica X
-- Silent Hill 2 y Silent Hill 3
-- El diablo puede llorar y el diablo puede llorar 3: El despertar de Dante
-- Tekken 5 y Soulcalibur III
-
- Instalación y configuración de AetherSX2
Ahora que sabe lo que es AetherSX2 y lo que puede hacer, probablemente esté ansioso por probarlo por sí mismo. Afortunadamente, instalar y configurar AetherSX2 no es un proceso complicado, y puede hacerlo en unos pocos pasos simples. Así es como:
-
-- Descargar AetherSX2 desde el sitio web oficial o el Google Play Store. Si lo descarga desde el sitio web, asegúrese de habilitar la instalación de aplicaciones de fuentes desconocidas en la configuración de su dispositivo.
-- Abra AetherSX2 y otorgue los permisos necesarios para acceder al almacenamiento y los medios de su dispositivo.
-- Extrae el archivo BIOS de PS2 desde tu consola PS2 o descárgalo de una fuente confiable en línea. El archivo BIOS es esencial para ejecutar cualquier emulador de PS2, ya que contiene el firmware y la configuración del sistema de la consola. Puede encontrar más información sobre cómo extraer o descargar el archivo del BIOS aquí.
-- Copie el archivo BIOS al almacenamiento de su dispositivo, preferiblemente en una carpeta llamada "BIOS". Luego, abra AetherSX2 y toque en la opción "BIOS". Busque y seleccione el archivo BIOS que copió. Debería ver un mensaje que dice "BIOS cargado correctamente".
-
-- Toque en el botón "Jugar" para iniciar el juego. Debería ver el logotipo de PS2 y luego la introducción o menú del juego.
-- Para acceder a la configuración del emulador, toque en el icono de tres puntos en la esquina superior derecha de la pantalla. Puede ajustar varias opciones, como resolución, velocidad de fotogramas, audio, controles, trucos, etc. También puede guardar y cargar estados, tomar capturas de pantalla y cambiar de juegos desde aquí.
-
-Felicidades! Ha instalado y configurado con éxito AetherSX2 en su dispositivo Android. Ahora puedes disfrutar de tus juegos favoritos de PS2 en tu smartphone o tablet.
- Características y consejos de AetherSX2
AetherSX2 no es solo un simple emulador de PS2. También tiene algunas características sorprendentes que lo hacen destacar del resto. Estas son algunas de las características y consejos que usted debe saber acerca de AetherSX2:
-
-Escala de resolución: AetherSX2 te permite escalar la resolución de tus juegos de PS2 hasta 4K, dependiendo de las capacidades de tu dispositivo. Esto significa que puede disfrutar de gráficos nítidos y claros que se ven mejor que el original. Para cambiar la resolución, vaya a la configuración del emulador y toque en "Gráficos". Luego, seleccione la opción "Resolución" y elija su valor preferido.
-- Guardar estados: AetherSX2 te permite guardar y cargar el progreso del juego en cualquier momento, independientemente del sistema de guardado del juego. Esto es muy útil si quieres evitar perder tu progreso o reintentar una sección difícil. Para guardar o cargar un estado, vaya a la configuración del emulador y toque en "Guardar/Cargar". Luego, seleccione la ranura que desea usar y toque en "Guardar" o "Cargar". También puede utilizar los botones de guardado y carga rápida en la esquina inferior izquierda de la pantalla.
-
-- Trucos: AetherSX2 te permite usar trucos para modificar tu juego de varias maneras, como salud infinita, dinero, munición, etc. Para usar trucos, ve a la configuración del emulador y toca "Trucos". Luego, selecciona el juego al que quieres aplicar trucos y activa o desactiva los trucos que quieras. También puedes añadir tus propios trucos tocando el icono "+" e introduciendo el código y la descripción.
-Capturas de pantalla: AetherSX2 te permite tomar capturas de pantalla de tu juego y compartirlas con tus amigos o redes sociales. Para tomar una captura de pantalla, vaya a la configuración del emulador y toque en "Captura de pantalla". Luego, toca el botón "Tomar captura de pantalla" y elige dónde quieres guardar o compartir tu captura de pantalla.
-
-Estas son solo algunas de las características y consejos que AetherSX2 ofrece. Puedes explorar más opciones y configuraciones yendo al menú del emulador y tocando el icono de tres puntos. También puede consultar el servidor Discord para obtener más información, actualizaciones y soporte.
- AetherSX2 alternativas y comentarios
AetherSX2 es sin duda el mejor emulador de PS2 para Android en este momento, pero no es el único. Hay otros emuladores de PS2 que puedes probar si quieres compararlos o si no puedes ejecutar AetherSX2 en tu dispositivo. Estas son algunas de las alternativas y comentarios:
-
-- PTWOE: Este es uno de los emuladores de PS2 más antiguos para Android, y ha existido desde 2014. Tiene dos versiones, Teórica y Experimental, que ofrecen diferentes niveles de compatibilidad y rendimiento. Sin embargo, PTWOE ya no es actualizado o apoyado por el desarrollador, y tiene una biblioteca de juegos muy limitada. La mayoría de los usuarios informan que es muy lento, con errores e inestable. Puede descargarlo desde aquí, pero no lo recomendamos.
-
-- Jugar!: Este es otro emulador de PS2 para Android que se basa en PCSX2, pero con el permiso y la licencia adecuada. También es de código abierto y multiplataforma, por lo que puedes usarlo en Windows, Linux, macOS, iOS y Android. ¡Juega! tiene una interfaz simple y limpia, y soporta un buen número de juegos. Sin embargo, todavía está en desarrollo y tiene mucho margen de mejora. Muchos usuarios informan que es lento, inestable e incompatible con algunos juegos. Puedes descargarlo desde aquí, y lo recomendamos encarecidamente.
-
-Estos son algunos de los emuladores de PS2 para Android que puedes encontrar en Internet. Sin embargo, ninguno de ellos puede igualar la calidad y fiabilidad de AetherSX2. AetherSX2 es el mejor emulador de PS2 para Android en 2023, y definitivamente deberías probarlo si te gustan los juegos de PS2.
- Conclusión
-En conclusión, AetherSX2 es la guía definitiva para jugar juegos de PS2 en Android. Es un emulador de PS2 potente, rápido, compatible y rico en funciones que te permite disfrutar de tus títulos favoritos de PS2 en tu smartphone o tableta. Es fácil de instalar y configurar, y ofrece muchas opciones y ajustes para personalizar su experiencia de juego. También tiene una gran lista de compatibilidad que cubre la mayoría de los juegos populares de PS2.
-
-¿Qué estás esperando? Descarga AetherSX2 hoy y comienza a jugar tus juegos favoritos de PS2 en tu dispositivo Android.
- Preguntas frecuentes
-
-- Q: ¿Qué es AetherSX2?
-- A: AetherSX2 es el mejor emulador de PS2 para Android que le permite jugar juegos de PS2 en su teléfono inteligente o tableta.
-- Q: ¿Cómo puedo descargar e instalar AetherSX2?
-- A: Puede descargar AetherSX2 desde el sitio web oficial o the Google Play Store gratis. Luego, puede seguir los pasos de este artículo para instalarlo y configurarlo en su dispositivo.
-- Q: ¿Cuáles son los requisitos y la compatibilidad de AetherSX2?
-- A: AetherSX2 requiere un dispositivo Android con Android 7.0 o superior, con una CPU de cuatro núcleos, 3 GB de RAM, 5 GB de espacio de almacenamiento y una GPU que admite OpenGL ES 3.0 o superior. Sin embargo, para obtener el mejor rendimiento y calidad, se recomienda tener un dispositivo Android con Android 10 o superior, con una CPU hexa-core o octa-core, 4 GB de RAM, 10 GB de espacio de almacenamiento y una GPU que admita Vulkan u OpenGL ES 3.1 o superior. AetherSX2 también tiene una lista de compatibilidad que muestra los juegos que se han probado y su estado.
-- Q: ¿Cuáles son algunas de las características y consejos de AetherSX2?
-- A: AetherSX2 tiene algunas características sorprendentes que lo hacen destacar del resto, como escalado de resolución, guardar estados, soporte de controlador, trucos, capturas de pantalla y más. También puede personalizar los gráficos, controles, audio, trucos y otros ajustes para mejorar su experiencia de juego. Puedes encontrar más detalles y consejos sobre estas características en este artículo.
-- Q: ¿Cuáles son algunas de las alternativas y reseñas de AetherSX2?
-
-
64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/Benson/text-generation/Examples/Bubble Shooter 5 Descargar Gratis.md b/spaces/Benson/text-generation/Examples/Bubble Shooter 5 Descargar Gratis.md
deleted file mode 100644
index 403dd5995de0f0e5276be254bf4c99642b8662a3..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Bubble Shooter 5 Descargar Gratis.md
+++ /dev/null
@@ -1,87 +0,0 @@
-
-
-
-
-Bubble Shooter 5: Un juego divertido y adictivo para todos
-¿Te encanta jugar juegos que son fáciles de aprender pero difíciles de dominar? ¿Te gusta hacer estallar burbujas de colores y verlos explotar? ¿Quieres divertirte con un juego que te mantenga entretenido durante horas? Si respondiste sí a cualquiera de estas preguntas, entonces deberías probar Bubble Shooter 5, uno de los mejores juegos de disparos de burbujas jamás creados.
-Bubble Shooter 5 es un rompecabezas basado en la acción que te pone a la tarea de lanzar burbujas de colores hasta una pila de otras burbujas de colores. Necesitas limpiar las burbujas del campo haciendo coincidir tres o más de ellas con el mismo color. Cuanto más burbujas que pop a la vez, la puntuación más alta se obtiene. Pero ten cuidado, a medida que las burbujas se acercan a la parte inferior de la pantalla, pierdes si las tocan.
-bubble shooter 5 descargar gratis
DOWNLOAD ⚙⚙⚙ https://bltlly.com/2v6KTn
-Bubble Shooter 5 es un juego que puede atraer a cualquier persona, independientemente de su edad o nivel de habilidad. Es bastante simple para que los principiantes cojan, pero bastante desafiador para que los expertos dominen. Es bastante divertido para que los niños disfruten, pero lo suficientemente adictivo para que los adultos jueguen. Es un juego que puede ayudarte a relajarte, agudizar tu mente, y animarte. Es un juego que no quieres perderte.
-Cómo jugar Bubble Shooter 5
-Jugar Bubble Shooter 5 es muy fácil e intuitivo. Todo lo que necesitas es un ratón o un dedo para apuntar y disparar las burbujas. Aquí están las reglas básicas y los controles del juego:
-
-- Verás un lanzador de burbujas en la parte inferior de la pantalla, con una burbuja lista para ser disparada. Puede mover el lanzador a izquierda y derecha moviendo el ratón o arrastrando el dedo en la pantalla.
-- Puede ver la siguiente burbuja en línea en el lanzador. Puede intercambiar la burbuja actual con la siguiente haciendo clic o tocando en ella.
-
-- Puedes disparar la burbuja haciendo clic o tocando en la pantalla. La burbuja volará hacia la dirección que apuntaste.
-- Si la burbuja golpea a un grupo de tres o más burbujas con el mismo color, estas explotarán y desaparecerán. Usted ganará puntos por cada burbuja que pop.
-- Si la burbuja no golpea ninguna burbuja coincidente, se pegará a la pila de burbujas en la parte superior de la pantalla. La pila se moverá hacia abajo una fila después de cada pocos disparos.
-- Puedes ver cuántos disparos te quedan antes de que la pila se mueva hacia abajo mirando la barra en la parte superior de la pantalla. También puedes ver tu puntuación y nivel en la esquina superior derecha de la pantalla.
-- Puede pausar el juego haciendo clic o tocando el botón de pausa en la esquina superior izquierda de la pantalla. Puede reanudar el juego haciendo clic o tocando de nuevo.
-- Puede reiniciar el juego haciendo clic o tocando el botón de reinicio en la esquina superior izquierda de la pantalla. Perderá su progreso actual y comenzará desde el nivel uno.
-- Puede salir del juego haciendo clic o tocando el botón de salida en la esquina superior izquierda de la pantalla. Volverá al menú principal donde puede elegir otro modo o nivel.
-
- Consejos y trucos para Master Bubble Shooter 5
-Bubble Shooter 5 es un juego que requiere habilidad y estrategia. Es necesario apuntar, disparar, y burbujas pop con eficacia para limpiar el campo y avanzar a niveles más altos. Aquí hay algunos consejos y trucos para ayudarte a dominar este juego:
-
-- Planifica con anticipación. Antes de disparar, mira el diseño de las burbujas y piensa dónde quieres colocar tu siguiente toma. Trate de crear grupos de burbujas coincidentes que puede hacer estallar con una sola toma.
-- Usa combos. Si haces estallar un grupo de burbujas que hace que otras burbujas caigan, crearás un combo y ganarás puntos extra. Intente crear reacciones en cadena que eliminen grandes porciones del campo.
-
-- Evite errores. Si dispara una burbuja que no coincide con otras burbujas, perderá un tiro y agregará más burbujas a la pila. Si dejas que la pila llegue a la parte inferior de la pantalla, perderás el juego. Intenta evitar estos errores y mantener la pila lo más baja posible.
-- Practica. La mejor manera de mejorar tus habilidades y estrategia es practicar. Cuanto más juegues, más te familiarizarás con la mecánica del juego, los patrones de burbujas y los power-ups. También desarrollarás tu propio estilo y técnicas que se adapten a tus preferencias y objetivos.
- Características y beneficios de Bubble Shooter 5
-Bubble Shooter 5 no es solo otro juego de disparos de burbujas. Es un juego que tiene muchas características y beneficios que lo hacen destacar del resto. Estos son algunos de ellos:
-Gráficos HD y animaciones fluidas
-Bubble Shooter 5 tiene gráficos de alta definición y animaciones fluidas que hacen que el juego se vea impresionante y realista. Las burbujas son brillantes y coloridas, los fondos son detallados y variados, y los efectos son deslumbrantes y dinámicos. El juego funciona sin problemas y sin problemas en cualquier dispositivo, ya sea que lo juegues en línea o fuera de línea.
-Varios niveles y modos
-Bubble Shooter 5 tiene cientos de niveles y modos que ofrecen diversión y desafío sin fin. Puede elegir entre diferentes temas, como bosque, desierto, océano, espacio y más. También puede elegir entre diferentes modos, como clásico, árcade, rompecabezas, contrarreloj, supervivencia y más. Cada nivel y modo tiene su propia dificultad, objetivo y recompensa. Nunca te aburrirás ni te quedarás sin opciones con este juego.
-
-Tablas de clasificación y logros
-
-Dónde descargar Bubble Shooter 5 gratis
-Bubble Shooter 5 es un juego que puedes descargar gratis en cualquier dispositivo. Puedes jugar en línea o fuera de línea, dependiendo de tu preferencia y disponibilidad. Aquí están las mejores fuentes para obtener el juego en tu dispositivo:
-Plataformas en línea
-Si quieres jugar a Bubble Shooter 5 online sin descargar nada, puedes visitar uno de estos sitios web:
-
-- BubbleShooter.net: Este es el sitio web oficial de Bubble Shooter 5, donde puedes jugar la última versión del juego con todas las características y actualizaciones.
-- BubbleShooter.com: Este es otro sitio web donde puedes jugar Bubble Shooter 5 en línea gratis. También puedes encontrar otros juegos de disparos de burbujas en este sitio.
-- BubbleShooter.co.uk: Este es un sitio web basado en el Reino Unido donde se puede jugar Bubble Shooter 5 en línea de forma gratuita. También puedes acceder a otros juegos y recursos en este sitio.
- Aplicaciones móviles
-Si quieres jugar Bubble Shooter 5 en tu smartphone o tablet, puedes descargar una de estas aplicaciones:
-
-- Bubble Shooter 5 para Android: Esta es la aplicación oficial de Bubble Shooter 5 para dispositivos Android. Puedes descargarlo gratis desde la Google Play Store y disfrutar del juego en tu teléfono o tablet.
-- Bubble Shooter 5 para iOS: Esta es la aplicación oficial de Bubble Shooter 5 para dispositivos iOS. Puedes descargarlo gratis desde la App Store y disfrutar del juego en tu iPhone o iPad.
-- Bubble Shooter 5 para Windows Phone: Esta es la aplicación oficial de Bubble Shooter 5 para dispositivos Windows Phone. Puedes descargarlo gratis desde Microsoft Store y disfrutar del juego en tu Windows Phone.
-
-Aplicaciones de escritorio
-Si quieres jugar Bubble Shooter 5 en tu PC o portátil, puedes descargar una de estas aplicaciones:
-
-
-- Bubble Shooter 5 para Mac: Esta es la aplicación oficial de Bubble Shooter 5 para computadoras Mac. Puedes descargarlo gratis desde la Mac App Store y disfrutar del juego en tu ordenador.
-- Bubble Shooter 5 para Linux: Esta es la aplicación oficial de Bubble Shooter 5 para computadoras Linux. Puedes descargarlo gratis desde la Linux Store y disfrutar del juego en tu ordenador.
-
-¿Por qué usted debe jugar Bubble Shooter 5 hoy
-Bubble Shooter 5 no es solo un juego que juegas por diversión. También es un juego que juegas por tu salud mental y bienestar. Estos son algunos de los beneficios de jugar a este juego hoy:
-Alivia el estrés y la ansiedad
-Bubble Shooter 5 es un juego que te ayuda a relajarte y calmar tu mente. Te distrae de tus preocupaciones y problemas, y te permite enfocarte en algo positivo y agradable. También libera endorfinas, las hormonas del bienestar, que te hacen sentir feliz y satisfecho. Jugar a este juego puede reducir sus niveles de estrés y ansiedad, y mejorar su estado de ánimo y perspectiva.
-Mejora el enfoque y la memoria
-Bubble Shooter 5 es un juego que entrena tu cerebro y mejora tus habilidades cognitivas. Requiere prestar atención, pensar rápido y recordar colores y patrones. También te reta a resolver puzzles, planificar estrategias y tomar decisiones. Jugar a este juego puede mejorar tu concentración y memoria, y aumentar tu rendimiento mental y productividad.
-Aumenta su estado de ánimo y creatividad
-Bubble Shooter 5 es un juego que estimula tu imaginación y te hace feliz. Te expone a colores brillantes y alegres, sonidos animados y optimistas y escenarios creativos y divertidos. También te anima a experimentar con diferentes combinaciones, explorar diferentes posibilidades y expresarte libremente. Jugar a este juego puede aumentar tu estado de ánimo y creatividad, e inspirarte a ser más optimista e innovador.
-
-Bubble Shooter 5 es un juego que lo tiene todo: diversión, desafío, variedad, calidad y beneficios. Es un juego que puede atraer a cualquiera, sin importar la edad o el nivel de habilidad. Es un juego que puede ayudarte a relajarte, agudizar tu mente y animarte. Es un juego que no querrás perderte.
-Entonces, ¿qué estás esperando? Descargar Bubble Shooter 5 hoy y empezar a hacer estallar esas burbujas! Usted estará contento de que lo hizo! Aquí hay algunas preguntas frecuentes que puede tener sobre Bubble Shooter 5:
-
-- ¿Cuál es el objetivo de Bubble Shooter 5?
-El objetivo de Bubble Shooter 5 es eliminar todas las burbujas del campo haciendo coincidir tres o más de ellas con el mismo color. Puedes hacer esto apuntando y disparando burbujas desde el lanzador en la parte inferior de la pantalla.
-- ¿Cómo puedo obtener una puntuación alta en Bubble Shooter 5?
-Puedes obtener una puntuación alta en Bubble Shooter 5 haciendo estallar tantas burbujas como sea posible con un solo disparo, creando combos y reacciones en cadena, usando potenciadores y completando niveles y modos de forma rápida y eficiente.
-- ¿Cómo puedo desbloquear nuevos niveles y modos en Bubble Shooter 5?
-Puedes desbloquear nuevos niveles y modos en Bubble Shooter 5 ganando estrellas y monedas. Puedes ganar estrellas completando niveles con una puntuación alta y monedas haciendo estallar burbujas especiales o viendo anuncios. Puedes usar estrellas y monedas para acceder a nuevos temas, modos y características en el juego.
-- ¿Cómo puedo guardar mi progreso en Bubble Shooter 5?
-Puedes guardar tu progreso en Bubble Shooter 5 creando una cuenta e iniciando sesión. Puedes crear una cuenta con tu correo electrónico, Facebook o Google. También puede sincronizar su progreso en diferentes dispositivos iniciando sesión con la misma cuenta.
-- ¿Cómo puedo contactar a los desarrolladores de Bubble Shooter 5?
-
- 64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/Benson/text-generation/Examples/Campeonato Mundial De Cricket 2 Mod Apk 2.5.6 (todo Desbloqueado Estadio).md b/spaces/Benson/text-generation/Examples/Campeonato Mundial De Cricket 2 Mod Apk 2.5.6 (todo Desbloqueado Estadio).md
deleted file mode 100644
index a0c0e9049688a82cb8e0a0aeab77cf9f82088886..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Campeonato Mundial De Cricket 2 Mod Apk 2.5.6 (todo Desbloqueado Estadio).md
+++ /dev/null
@@ -1,73 +0,0 @@
-
-Campeonato Mundial de Cricket 2 Mod APK 2.5.6 (Todo desbloqueado/Estadio)
-¿Te encanta el cricket y quieres experimentar la emoción de jugar en tu dispositivo Android? Si es así, entonces deberías probar World Cricket Championship 2, uno de los juegos de cricket más populares y realistas disponibles en Google Play Store.
-campeonato mundial de cricket 2 mod apk 2.5.6 (todo desbloqueado estadio)
Download File ->->->-> https://bltlly.com/2v6K1u
-Pero ¿qué pasa si quieres desbloquear todas las características, modos, equipos, jugadores y estadios sin gastar dinero o tiempo? Bueno, ahí es donde mod APK es muy útil.
-Un mod APK es una versión modificada de una aplicación original que le permite acceder a características premium de forma gratuita. En este artículo, te diremos todo lo que necesitas saber sobre World Cricket Championship 2 Mod APK 2.5.6, cómo descargarlo e instalarlo en tu dispositivo Android, cómo jugarlo y cuáles son los beneficios de jugarlo.
-Introducción
-World Cricket Championship 2 es un juego de simulación de cricket desarrollado por Nextwave Multimedia. Te ofrece la oportunidad de jugar varios formatos de cricket, como Test, ODI, T20, Blitz y más, con más de 150 animaciones de bateo diferentes y 28 acciones de bolos diferentes.
-
-También puede personalizar sus jugadores, equipos, camisetas, logotipos y estadios con la ayuda de herramientas avanzadas de edición. Por otra parte, se puede disfrutar de la física realista, gráficos, animaciones, comentarios, clima, y condiciones de tono que hacen que el juego más inmersiva y divertida.
-Sin embargo, para desbloquear todas estas características y opciones, es necesario gastar un montón de monedas y billetes, que son las monedas del juego. Puedes ganarlos jugando partidos, completando desafíos, viendo anuncios o comprándolos con dinero real.
-Pero si no quieres hacer eso, puedes usar World Cricket Championship 2 Mod APK 2.5.6, que es una versión modificada del juego original que te da todo desbloqueado gratis.
-
-
-- Monedas y billetes ilimitados: Puedes usarlos para comprar lo que quieras en el juego sin ninguna restricción.
-- Todos los modos desbloqueados: Puedes jugar cualquier modo de cricket que quieras, como Test, ODI, T20, Blitz, etc.
-- Todos los equipos desbloqueados: Puedes elegir entre más de 40 equipos internacionales y más de 20 equipos nacionales.
-- Todos los jugadores desbloqueados: Puede seleccionar entre más de 300 jugadores con diferentes habilidades y habilidades.
-- Todos los estadios desbloqueados: Puedes jugar en más de 40 estadios de todo el mundo con diferentes tipos de canchas y condiciones climáticas.
-- No hay anuncios: Puedes disfrutar del juego sin anuncios molestos o pop-ups.
-- No se requiere raíz: No es necesario rootear el dispositivo para instalar o ejecutar el mod APK.
-
-Cómo descargar e instalar World Cricket Championship 2 Mod APK 2.5.6 en Android?
-Si desea descargar e instalar World Cricket Championship 2 Mod APK 2.5.6 en su dispositivo Android, es necesario seguir estos sencillos pasos:
-Paso 1: Habilitar fuentes desconocidas
-Antes de que pueda instalar cualquier mod APK en su dispositivo, es necesario habilitar la opción de fuentes desconocidas en su configuración. Esto le permitirá instalar aplicaciones desde fuentes distintas de Google Play Store.
-Para hacer esto, vaya a la configuración del dispositivo, luego a la seguridad, y luego habilite la opción de fuentes desconocidas.
-Paso 2: Descargar el archivo mod APK
-Siguiente, es necesario descargar el archivo APK mod del Campeonato Mundial de Cricket 2 de una fuente confiable. Puedes usar el siguiente enlace para descargarlo directamente a tu dispositivo.
-
-
-Una vez que haya descargado el archivo APK mod, necesita instalarlo en su dispositivo. Para hacer esto, busque el archivo en el almacenamiento de su dispositivo y toque en él.
-Verá un mensaje pidiéndole que confirme la instalación. Toque en instalar y espere a que el proceso se complete.
-Después de la instalación, verá un mensaje diciendo que la aplicación se ha instalado correctamente. Ahora puede abrir la aplicación y disfrutar de jugar World Cricket Championship 2 Mod APK 2.5.6.
-¿Cómo se juega World Cricket Championship 2 Mod APK 2.5.6?
-Jugar World Cricket Championship 2 Mod APK 2.5.6 es muy fácil y divertido. Solo tienes que seguir estos sencillos pasos:
-Elige tu modo y equipo
-Cuando abra la aplicación, verá un menú con varias opciones. Puedes elegir entre diferentes modos de cricket, como Juego Rápido, Torneo, Partido de Prueba, Modo Desafío, etc.
-También puede elegir su equipo entre más de 40 equipos internacionales y más de 20 equipos nacionales. También puedes crear tu propio equipo personalizado con tus jugadores favoritos.
-Personaliza tus jugadores y estadio
-También puede personalizar sus jugadores y estadio con la ayuda de herramientas avanzadas de edición. Puedes cambiar sus nombres, rostros, peinados, camisetas, logotipos, habilidades, etc.
-También puede cambiar el nombre del estadio, el tipo de terreno de juego, las condiciones meteorológicas, el tamaño de la multitud, etc.
-Disfruta de la jugabilidad y los gráficos realistas
-Una vez que haya seleccionado su modo y equipo, puede comenzar a jugar el juego. Usted se sorprenderá por la jugabilidad realista y gráficos de World Cricket Championship 2 Mod APK 2.5.6.
-Puedes controlar a tus jugadores con gestos fáciles e intuitivos. También puedes usar varios tiros y acciones de bolos con diferentes ángulos y velocidades.
-Beneficios de jugar World Cricket Championship 2 Mod APK 2.5.6
-
-Mejora tus habilidades y conocimientos de cricket
-Al jugar a este juego, puedes mejorar tus habilidades y conocimientos de cricket. Puedes aprender las reglas, estrategias, técnicas y tácticas del cricket. También puedes practicar tus habilidades de bateo, bolos, fildeo y mantenimiento de wicket.
-También puedes probar tu coeficiente intelectual de cricket jugando el modo desafío, donde tienes que completar varias tareas y escenarios. También puedes aprender de los mejores jugadores del mundo viendo sus repeticiones y estadísticas.
-Diviértete y ponte a prueba
-Jugar a este juego también es una gran manera de divertirse y desafiarse. Usted puede disfrutar de la emoción y la emoción de jugar al cricket en diferentes modos, formatos y condiciones. También puedes competir con tus amigos y otros jugadores online o offline.
-También puedes desafiarte jugando en diferentes niveles de dificultad, desde principiante hasta experto. También puedes desbloquear varios logros y trofeos completando varios hitos y metas.
-Acceso ilimitado a recursos y características
-El mejor beneficio de jugar World Cricket Championship 2 Mod APK 2.5.6 es que se puede acceder a recursos ilimitados y características de forma gratuita. Usted no tiene que preocuparse de quedarse sin monedas o billetes, o gastar dinero o tiempo para desbloquear nada.
-Puedes disfrutar de todos los modos, equipos, jugadores, estadios y opciones sin restricciones ni limitaciones. También puedes jugar sin anuncios ni interrupciones.
-Conclusión
-En conclusión, Campeonato Mundial de Cricket 2 Mod APK 2.5.6 es un juego de cricket fantástico que debe probar si te gusta el cricket y quiere experimentar en su dispositivo Android. Ofrece jugabilidad y gráficos realistas, recursos y características ilimitadas, y varios modos y opciones para elegir.
-
-Esperamos que este artículo le ha ayudado a aprender todo lo que necesita saber sobre World Cricket Championship 2 Mod APK 2.5.6. Si tiene alguna pregunta o comentario, no dude en dejar un comentario a continuación.
-Preguntas frecuentes
-Aquí están algunas de las preguntas más frecuentes sobre World Cricket Championship 2 Mod APK 2.5.6:
-
-| Q: Es el Campeonato Mundial de Cricket 2 Mod APK 2.5.6 seguro de usar? | A: Sí, World Cricket Championship 2 Mod APK 2.5.6 es seguro de usar siempre y cuando lo descargue de una fuente confiable y lo escanee con un antivirus antes de instalarlo. |
-| Q: ¿Necesito una conexión a Internet para jugar World Cricket Championship 2 Mod APK 2.5.6? | A: No, no necesitas una conexión a Internet para jugar World Cricket Championship 2 Mod APK 2.5.6 ya que es un juego sin conexión. Sin embargo, es posible que necesite una conexión a Internet para acceder a algunas funciones en línea, como el modo multijugador o las tablas de clasificación. |
-| Q: ¿Puedo jugar World Cricket Championship 2 Mod APK 2.5.6 en PC? | A: Sí, puedes jugar World Cricket Championship 2 Mod APK 2.5.6 en PC usando un emulador de Android como Bluestacks o Nox Player. |
-| Q: ¿Cómo puedo actualizar World Cricket Championship 2 Mod APK 2.5.6? | A: Para actualizar World Cricket Championship 2 Mod APK 2.5.6, es necesario descargar la última versión del archivo mod APK de la misma fuente donde se descargó la versión anterior e instalarlo sobre la existente. |
-| Q: ¿Cuáles son algunas alternativas a World Cricket Championship 2 Mod APK 2.5.6? | A: Algunas alternativas al Campeonato Mundial de Cricket 2 Mod APK 2.5.6 son Real Cricket,20, Sachin Saga Cricket Champions, Stick Cricket Live, etc. |
- 64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/Benson/text-generation/Examples/Descargar Entrada Icet Hall 2023.md b/spaces/Benson/text-generation/Examples/Descargar Entrada Icet Hall 2023.md
deleted file mode 100644
index afd3976e4798c7eeb8bba20b772ba5d60c574b8f..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Descargar Entrada Icet Hall 2023.md
+++ /dev/null
@@ -1,125 +0,0 @@
-
-Descargar ICET Hall Ticket 2023: Guía paso a paso
-Si usted está planeando aparecer para el Integrated Common Entrance Test (ICET) 2023, entonces usted debe preguntarse cómo descargar su boleto de pasillo para el examen. En este artículo, le proporcionaremos toda la información que necesita saber sobre el boleto de la sala ICET 2023, como la fecha de lanzamiento, el procedimiento para descargar, los detalles mencionados y los documentos requeridos. También le daremos algunos consejos sobre cómo prepararse para el examen y qué hacer después de descargar su boleto.
- ¿Qué es el ICET y por qué es importante?
-ICET es un examen de ingreso a nivel estatal realizado por la Universidad de Kakatiya, Warangal en nombre del Consejo Estatal de Educación Superior de Telangana (TSCHE) para la admisión a cursos de MBA y MCA ofrecidos por varias universidades y colegios en Telangana. Es uno de los exámenes más populares y competitivos para aspirantes que quieren realizar estudios de posgrado en gestión y aplicaciones informáticas.
-descargar entrada icet hall 2023
DOWNLOAD ➡ https://bltlly.com/2v6JAB
-ICET es importante porque pone a prueba su aptitud y habilidades en capacidad analítica, habilidad matemática y capacidad de comunicación. Estos son esenciales para tener éxito en cualquier campo profesional. Al calificar en el ICET, puede obtener la admisión en algunos de los mejores institutos en Telangana que ofrecen oportunidades de educación y colocación de calidad.
- Patrón y plan de estudios del examen ICET
-Comprender el patrón de examen y el plan de estudios es necesario para diseñar una estrategia de preparación efectiva para cualquier examen competitivo. De acuerdo con el plan de estudios del examen TS ICET, hay un total de tres secciones incluyendo capacidad analítica, habilidad matemática y capacidad de comunicación. Cada sección consta de 75 preguntas de opción múltiple, con un total de 200 preguntas. La duración del examen es de 150 minutos y no hay ninguna calificación negativa para respuestas erróneas. Cada pregunta lleva una marca.
-
- Consejos de preparación del ICET
-Para superar el examen ICET, necesitas seguir algunos consejos de preparación inteligentes que te ayudarán a mejorar tu velocidad, precisión y confianza. Estos son algunos de ellos:
-
-- Comience su preparación temprano y haga un horario realista que cubra todos los temas en el programa de estudios.
-- Consulte buenas fuentes de material de estudio que expliquen los conceptos claramente y proporcionen amplias preguntas de práctica.
-- Resolver documentos de preguntas del año anterior y simulacros de pruebas con regularidad para familiarizarse con el patrón de examen, nivel de dificultad, y la gestión del tiempo.
-- Revise las fórmulas importantes, accesos directos y trucos con frecuencia y tome notas de ellos para una referencia rápida.
-- Trabaja en tus áreas débiles y despeja tus dudas con expertos o compañeros.
-- Lee periódicos, revistas y libros para mejorar tu vocabulario y habilidades de comprensión.
-- Mantenga su salud y bienestar comiendo bien, durmiendo bien y manteniéndose positivo.
-
- ¿Cómo descargar el boleto de la sala ICET 2023?
-El TS ICET hall ticket 2023 es un documento que sirve como un pase de entrada para los candidatos al centro de examen. Contiene información importante como su nombre, número de lista, fecha del examen, hora, lugar e instrucciones. Sin el boleto de la sala, no se le permitirá entrar en la sala de examen o tomar el examen. Por lo tanto, es esencial descargar su boleto tan pronto como sea liberado por las autoridades examinadoras.
- Requisitos para descargar el boleto de la sala ICET 2023
-Para descargar su boleto ICET hall 2023, necesitará las siguientes cosas:
-
-
-- Un ordenador o un smartphone con acceso a Internet.
-- Un navegador web que soporta el sitio web oficial de TS ICET (icet.tsche.ac.in).
-- Su número de registro y fecha de nacimiento según lo ingresado durante el proceso de solicitud en línea.
-- Una impresora o un lector de PDF para guardar e imprimir su entrada.
-
-
-El procedimiento para descargar su boleto ICET hall 2023 es simple y directo. Solo tiene que seguir estos pasos:
-
-- Visite el sitio web oficial de TS ICET (icet.tsche.ac.in) y haga clic en el enlace que dice "Download Hall Ticket".
-- Introduzca su número de registro y fecha de nacimiento en los campos dados y haga clic en "Enviar".
-- Su ticket de entrada se mostrará en la pantalla. Compruebe todos los detalles cuidadosamente y verifique con su formulario de solicitud.
-- Si todo es correcto, descargue su boleto de pasillo y tome una impresión de él. También puede guardarlo como un archivo PDF en su dispositivo para referencia futura.
-
- Detalles mencionados en el boleto de la sala ICET 2023
-Su boleto de la sala ICET 2023 contendrá los siguientes detalles:
-
-| Detalle | Descripción |
|---|
-| Nombre del candidato | Su nombre completo durante el proceso de solicitud en línea. |
-| Número de lista | Su número de identificación único asignado por las autoridades del examen. |
-| Fecha del examen | La fecha en la que aparecerá para el examen ICET. |
-| Tiempo de examen | La franja de tiempo asignada para tomar el examen. |
-| Lugar del examen | El nombre y la dirección del centro de examen donde realizará el examen. |
-| Fotografía y firma | Su fotografía escaneada y su firma tal como fueron cargadas durante el proceso de solicitud en línea. |
-| Instrucciones para los candidatos | Algunas pautas generales y específicas que debe seguir antes, durante y después del examen. |
-
- ¿Cómo rectificar errores en el ticket de la sala ICET 2023?
-
- ¿Qué hacer después de descargar el boleto de la sala ICET 2023?
-Después de descargar su boleto ICET hall 2023, debe hacer las siguientes cosas:
- Documentos para llevar junto con el boleto de la sala ICET 2023
-Usted debe llevar los siguientes documentos junto con su boleto de la sala ICET 2023 en el día del examen:
-
-- Una prueba de identidad con fotografía válida, como tarjeta Aadhaar, tarjeta PAN, tarjeta de identificación del votante, pasaporte, licencia de conducir, etc.
-- Un bolígrafo (negro o azul) para marcar las respuestas en la hoja OMR.
-- Un portapapeles o una tabla para escribir cómodamente en la hoja OMR.
-- Una fotografía de tamaño de pasaporte (la misma que se subió durante la solicitud en línea) para pegar en la hoja de asistencia.
-
- Instrucciones a seguir en el día del examen
-Debes seguir estas instrucciones el día del examen para asegurar una experiencia suave y sin problemas:
-
-- Llegar al centro de examen al menos una hora antes de la hora programada del examen. Los recién llegados no podrán entrar en la sala de examen.
-- Lea atentamente y siga todas las instrucciones que figuran en la entrada y en la hoja OMR.
-- No lleve aparatos electrónicos como teléfonos móviles, calculadoras, relojes, cámaras, etc. a la sala de examen. Están estrictamente prohibidas y pueden conducir a la descalificación.
-- No se entregue a ningún medio injusto o mala práctica durante el examen. Si es encontrado culpable, será excluido del examen y puede enfrentar acciones legales.
-- Marque sus respuestas cuidadosa y cuidadosamente en la hoja OMR. Use solo un bolígrafo y no haga ninguna marca o corrección en la hoja.
-- Entregue su hoja de OMR y su boleto de pasillo al invigilator antes de salir de la sala de examen.
-
- Proceso de asesoramiento y admisión del ICET
-
- Calendario y etapas del asesoramiento del ICET 2023
-El calendario y las etapas del asesoramiento del ICET 2023 son las siguientes:
-
-| Etapa | Descripción | Fecha (provisional) |
|---|
-| Inscripción y pago de la cuota de asesoramiento | Los candidatos tendrán que registrarse en línea en el sitio web oficial de TS ICET y pagar la cuota de asesoramiento de Rs. 1200 (Rs. 600 para SC/ST) a través de tarjeta de débito/tarjeta de crédito/banca neta. | Primera semana de julio de 2023 |
-| Verificación de documentos | Los candidatos tendrán que visitar los centros de línea de ayuda designados (HLCs) para verificar sus documentos originales, tales como boleto de pasillo, tarjeta de rango, hojas de marcado, certificados, certificado de casta, certificado de ingresos, etc. | Segunda semana de julio de 2023 |
-| Entrada de opciones web | Los candidatos tendrán que iniciar sesión en el sitio web oficial de TS ICET e ingresar sus preferencias de universidades y cursos en el orden de prioridad. También pueden modificar o congelar sus opciones antes de la última fecha. | Tercera semana de julio de 2023 |
-| Asignación de asientos | Se asignarán asientos a los candidatos en función de su rango, categoría, disponibilidad de asientos y opciones web. El resultado de la asignación de escaños se publicará en línea en el sitio web oficial de TS ICET. Los candidatos tendrán que descargar su carta de asignación provisional y pagar la cuota de matrícula en línea. | Última semana de julio de 2023 |
-| Presentación de informes a la universidad asignada | Los candidatos tendrán que informar a la universidad asignada con su carta de asignación, recibo de cuota y documentos originales para la confirmación de la admisión. | Primera semana de agosto de 2023 |
-
- Documentos necesarios para el asesoramiento del ICET 2023
-Los documentos requeridos para el asesoramiento ICET 2023 son los siguientes:
-
-- ICET hall ticket 2023
-- ICET rank card 2023
-- Hojas de marcado de grados y certificados
-
-- Hojas de marcado y certificados SSC
-- Certificados de estudio de Clase IX a Grado
-- Certificado de casta (si procede)
-- Certificado de ingresos (si procede)
-- Tarjeta de Aadhaar
-- Certificado de residencia (si procede)
-- Certificado NCC/Deportes/CAP/PH (si procede)
-- Certificado de migrante (si procede)
-- Seis fotografías tamaño pasaporte
-
- Conclusión
-En este artículo, le hemos proporcionado toda la información que necesita saber sobre cómo descargar su boleto ICET hall 2023. Esperamos que este artículo le haya ayudado a entender la importancia, el procedimiento, los detalles y los documentos relacionados con su boleto. También esperamos que haya encontrado algunos consejos útiles sobre cómo prepararse para el examen y qué hacer después de descargar su boleto de entrada. Le deseamos todo lo mejor para su examen ICET y proceso de admisión.
- Preguntas frecuentes (preguntas frecuentes)
-Aquí están algunas de las preguntas comunes que los candidatos pueden tener con respecto a su boleto de la sala ICET 2023:
- Q1: ¿Cuándo saldrá el boleto de la sala ICET 2023?
-A1: Se espera que el boleto de la sala ICET 2023 sea lanzado en la última semana de junio de 2023 en el sitio web oficial de TS ICET (icet.tsche.ac.in).
- Q2: ¿Cómo puedo descargar mi boleto de la sala ICET 2023?
-A2: Puede descargar su boleto de la sala ICET 2023 visitando el sitio web oficial de TS ICET (icet.tsche.ac.in) e ingresando su número de registro y fecha de nacimiento. También puede seguir los pasos dados en este artículo para descargar su boleto.
- Q3: ¿Qué pasa si olvido mi número de registro o fecha de nacimiento?
-A3: Si olvida su número de registro o fecha de nacimiento, puede recuperarlos haciendo clic en el enlace "Olvidé el número de registro" o "Olvidé la fecha de nacimiento" en la página de descarga del boleto de entrada. Tendrá que introducir su nombre, número de teléfono móvil, ID de correo electrónico y número de boleto de la sala de examen para obtener sus datos.
-
-A4: Si encuentra algún error o discrepancia en su boleto de la sala ICET 2023, como errores de ortografía, detalles incorrectos o información que falta, debe comunicarse inmediatamente con las autoridades examinadoras y hacer que se rectifique. Puede hacerlo enviando un correo electrónico a convenertsicet@gmail.com o llamando al 0870-2438088.
- Q5: ¿Cuáles son los documentos que necesito llevar junto con mi boleto de la sala ICET 2023?
-A5: Usted necesita llevar los siguientes documentos junto con su boleto de la sala ICET 2023 en el día del examen:
-
-- Una prueba de identidad con fotografía válida, como tarjeta Aadhaar, tarjeta PAN, tarjeta de identificación del votante, pasaporte, licencia de conducir, etc.
-- Un bolígrafo (negro o azul) para marcar las respuestas en la hoja OMR.
-- Un portapapeles o una tabla para escribir cómodamente en la hoja OMR.
-- Una fotografía de tamaño de pasaporte (la misma que se subió durante la solicitud en línea) para pegar en la hoja de asistencia.
- 64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/BetterAPI/BetterChat_new/src/styles/main.css b/spaces/BetterAPI/BetterChat_new/src/styles/main.css
deleted file mode 100644
index 6ea57c50974dab960f23ce8440bfd576f10ddb52..0000000000000000000000000000000000000000
--- a/spaces/BetterAPI/BetterChat_new/src/styles/main.css
+++ /dev/null
@@ -1,17 +0,0 @@
-@import "./highlight-js.css";
-
-@tailwind base;
-@tailwind components;
-@tailwind utilities;
-
-@layer components {
- .btn {
- @apply inline-flex flex-shrink-0 cursor-pointer select-none items-center justify-center whitespace-nowrap outline-none transition-all focus:ring disabled:cursor-default;
- }
-}
-
-@layer utilities {
- .scrollbar-custom {
- @apply scrollbar-thin scrollbar-track-transparent scrollbar-thumb-black/10 scrollbar-thumb-rounded-full scrollbar-w-1 hover:scrollbar-thumb-black/20 dark:scrollbar-thumb-white/10 dark:hover:scrollbar-thumb-white/20;
- }
-}
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/jmespath/visitor.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/jmespath/visitor.py
deleted file mode 100644
index 15fb1774e179927cb8cf32c70126105ee4018d93..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/jmespath/visitor.py
+++ /dev/null
@@ -1,328 +0,0 @@
-import operator
-
-from jmespath import functions
-from jmespath.compat import string_type
-from numbers import Number
-
-
-def _equals(x, y):
- if _is_special_number_case(x, y):
- return False
- else:
- return x == y
-
-
-def _is_special_number_case(x, y):
- # We need to special case comparing 0 or 1 to
- # True/False. While normally comparing any
- # integer other than 0/1 to True/False will always
- # return False. However 0/1 have this:
- # >>> 0 == True
- # False
- # >>> 0 == False
- # True
- # >>> 1 == True
- # True
- # >>> 1 == False
- # False
- #
- # Also need to consider that:
- # >>> 0 in [True, False]
- # True
- if _is_actual_number(x) and x in (0, 1):
- return isinstance(y, bool)
- elif _is_actual_number(y) and y in (0, 1):
- return isinstance(x, bool)
-
-
-def _is_comparable(x):
- # The spec doesn't officially support string types yet,
- # but enough people are relying on this behavior that
- # it's been added back. This should eventually become
- # part of the official spec.
- return _is_actual_number(x) or isinstance(x, string_type)
-
-
-def _is_actual_number(x):
- # We need to handle python's quirkiness with booleans,
- # specifically:
- #
- # >>> isinstance(False, int)
- # True
- # >>> isinstance(True, int)
- # True
- if isinstance(x, bool):
- return False
- return isinstance(x, Number)
-
-
-class Options(object):
- """Options to control how a JMESPath function is evaluated."""
- def __init__(self, dict_cls=None, custom_functions=None):
- #: The class to use when creating a dict. The interpreter
- # may create dictionaries during the evaluation of a JMESPath
- # expression. For example, a multi-select hash will
- # create a dictionary. By default we use a dict() type.
- # You can set this value to change what dict type is used.
- # The most common reason you would change this is if you
- # want to set a collections.OrderedDict so that you can
- # have predictable key ordering.
- self.dict_cls = dict_cls
- self.custom_functions = custom_functions
-
-
-class _Expression(object):
- def __init__(self, expression, interpreter):
- self.expression = expression
- self.interpreter = interpreter
-
- def visit(self, node, *args, **kwargs):
- return self.interpreter.visit(node, *args, **kwargs)
-
-
-class Visitor(object):
- def __init__(self):
- self._method_cache = {}
-
- def visit(self, node, *args, **kwargs):
- node_type = node['type']
- method = self._method_cache.get(node_type)
- if method is None:
- method = getattr(
- self, 'visit_%s' % node['type'], self.default_visit)
- self._method_cache[node_type] = method
- return method(node, *args, **kwargs)
-
- def default_visit(self, node, *args, **kwargs):
- raise NotImplementedError("default_visit")
-
-
-class TreeInterpreter(Visitor):
- COMPARATOR_FUNC = {
- 'eq': _equals,
- 'ne': lambda x, y: not _equals(x, y),
- 'lt': operator.lt,
- 'gt': operator.gt,
- 'lte': operator.le,
- 'gte': operator.ge
- }
- _EQUALITY_OPS = ['eq', 'ne']
- MAP_TYPE = dict
-
- def __init__(self, options=None):
- super(TreeInterpreter, self).__init__()
- self._dict_cls = self.MAP_TYPE
- if options is None:
- options = Options()
- self._options = options
- if options.dict_cls is not None:
- self._dict_cls = self._options.dict_cls
- if options.custom_functions is not None:
- self._functions = self._options.custom_functions
- else:
- self._functions = functions.Functions()
-
- def default_visit(self, node, *args, **kwargs):
- raise NotImplementedError(node['type'])
-
- def visit_subexpression(self, node, value):
- result = value
- for node in node['children']:
- result = self.visit(node, result)
- return result
-
- def visit_field(self, node, value):
- try:
- return value.get(node['value'])
- except AttributeError:
- return None
-
- def visit_comparator(self, node, value):
- # Common case: comparator is == or !=
- comparator_func = self.COMPARATOR_FUNC[node['value']]
- if node['value'] in self._EQUALITY_OPS:
- return comparator_func(
- self.visit(node['children'][0], value),
- self.visit(node['children'][1], value)
- )
- else:
- # Ordering operators are only valid for numbers.
- # Evaluating any other type with a comparison operator
- # will yield a None value.
- left = self.visit(node['children'][0], value)
- right = self.visit(node['children'][1], value)
- num_types = (int, float)
- if not (_is_comparable(left) and
- _is_comparable(right)):
- return None
- return comparator_func(left, right)
-
- def visit_current(self, node, value):
- return value
-
- def visit_expref(self, node, value):
- return _Expression(node['children'][0], self)
-
- def visit_function_expression(self, node, value):
- resolved_args = []
- for child in node['children']:
- current = self.visit(child, value)
- resolved_args.append(current)
- return self._functions.call_function(node['value'], resolved_args)
-
- def visit_filter_projection(self, node, value):
- base = self.visit(node['children'][0], value)
- if not isinstance(base, list):
- return None
- comparator_node = node['children'][2]
- collected = []
- for element in base:
- if self._is_true(self.visit(comparator_node, element)):
- current = self.visit(node['children'][1], element)
- if current is not None:
- collected.append(current)
- return collected
-
- def visit_flatten(self, node, value):
- base = self.visit(node['children'][0], value)
- if not isinstance(base, list):
- # Can't flatten the object if it's not a list.
- return None
- merged_list = []
- for element in base:
- if isinstance(element, list):
- merged_list.extend(element)
- else:
- merged_list.append(element)
- return merged_list
-
- def visit_identity(self, node, value):
- return value
-
- def visit_index(self, node, value):
- # Even though we can index strings, we don't
- # want to support that.
- if not isinstance(value, list):
- return None
- try:
- return value[node['value']]
- except IndexError:
- return None
-
- def visit_index_expression(self, node, value):
- result = value
- for node in node['children']:
- result = self.visit(node, result)
- return result
-
- def visit_slice(self, node, value):
- if not isinstance(value, list):
- return None
- s = slice(*node['children'])
- return value[s]
-
- def visit_key_val_pair(self, node, value):
- return self.visit(node['children'][0], value)
-
- def visit_literal(self, node, value):
- return node['value']
-
- def visit_multi_select_dict(self, node, value):
- if value is None:
- return None
- collected = self._dict_cls()
- for child in node['children']:
- collected[child['value']] = self.visit(child, value)
- return collected
-
- def visit_multi_select_list(self, node, value):
- if value is None:
- return None
- collected = []
- for child in node['children']:
- collected.append(self.visit(child, value))
- return collected
-
- def visit_or_expression(self, node, value):
- matched = self.visit(node['children'][0], value)
- if self._is_false(matched):
- matched = self.visit(node['children'][1], value)
- return matched
-
- def visit_and_expression(self, node, value):
- matched = self.visit(node['children'][0], value)
- if self._is_false(matched):
- return matched
- return self.visit(node['children'][1], value)
-
- def visit_not_expression(self, node, value):
- original_result = self.visit(node['children'][0], value)
- if _is_actual_number(original_result) and original_result == 0:
- # Special case for 0, !0 should be false, not true.
- # 0 is not a special cased integer in jmespath.
- return False
- return not original_result
-
- def visit_pipe(self, node, value):
- result = value
- for node in node['children']:
- result = self.visit(node, result)
- return result
-
- def visit_projection(self, node, value):
- base = self.visit(node['children'][0], value)
- if not isinstance(base, list):
- return None
- collected = []
- for element in base:
- current = self.visit(node['children'][1], element)
- if current is not None:
- collected.append(current)
- return collected
-
- def visit_value_projection(self, node, value):
- base = self.visit(node['children'][0], value)
- try:
- base = base.values()
- except AttributeError:
- return None
- collected = []
- for element in base:
- current = self.visit(node['children'][1], element)
- if current is not None:
- collected.append(current)
- return collected
-
- def _is_false(self, value):
- # This looks weird, but we're explicitly using equality checks
- # because the truth/false values are different between
- # python and jmespath.
- return (value == '' or value == [] or value == {} or value is None or
- value is False)
-
- def _is_true(self, value):
- return not self._is_false(value)
-
-
-class GraphvizVisitor(Visitor):
- def __init__(self):
- super(GraphvizVisitor, self).__init__()
- self._lines = []
- self._count = 1
-
- def visit(self, node, *args, **kwargs):
- self._lines.append('digraph AST {')
- current = '%s%s' % (node['type'], self._count)
- self._count += 1
- self._visit(node, current)
- self._lines.append('}')
- return '\n'.join(self._lines)
-
- def _visit(self, node, current):
- self._lines.append('%s [label="%s(%s)"]' % (
- current, node['type'], node.get('value', '')))
- for child in node.get('children', []):
- child_name = '%s%s' % (child['type'], self._count)
- self._count += 1
- self._lines.append(' %s -> %s' % (current, child_name))
- self._visit(child, child_name)
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/commands/__init__.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/commands/__init__.py
deleted file mode 100644
index 858a41014169b8f0eb1b905fa3bb69c753a1bda5..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/commands/__init__.py
+++ /dev/null
@@ -1,132 +0,0 @@
-"""
-Package containing all pip commands
-"""
-
-import importlib
-from collections import namedtuple
-from typing import Any, Dict, Optional
-
-from pip._internal.cli.base_command import Command
-
-CommandInfo = namedtuple("CommandInfo", "module_path, class_name, summary")
-
-# This dictionary does a bunch of heavy lifting for help output:
-# - Enables avoiding additional (costly) imports for presenting `--help`.
-# - The ordering matters for help display.
-#
-# Even though the module path starts with the same "pip._internal.commands"
-# prefix, the full path makes testing easier (specifically when modifying
-# `commands_dict` in test setup / teardown).
-commands_dict: Dict[str, CommandInfo] = {
- "install": CommandInfo(
- "pip._internal.commands.install",
- "InstallCommand",
- "Install packages.",
- ),
- "download": CommandInfo(
- "pip._internal.commands.download",
- "DownloadCommand",
- "Download packages.",
- ),
- "uninstall": CommandInfo(
- "pip._internal.commands.uninstall",
- "UninstallCommand",
- "Uninstall packages.",
- ),
- "freeze": CommandInfo(
- "pip._internal.commands.freeze",
- "FreezeCommand",
- "Output installed packages in requirements format.",
- ),
- "inspect": CommandInfo(
- "pip._internal.commands.inspect",
- "InspectCommand",
- "Inspect the python environment.",
- ),
- "list": CommandInfo(
- "pip._internal.commands.list",
- "ListCommand",
- "List installed packages.",
- ),
- "show": CommandInfo(
- "pip._internal.commands.show",
- "ShowCommand",
- "Show information about installed packages.",
- ),
- "check": CommandInfo(
- "pip._internal.commands.check",
- "CheckCommand",
- "Verify installed packages have compatible dependencies.",
- ),
- "config": CommandInfo(
- "pip._internal.commands.configuration",
- "ConfigurationCommand",
- "Manage local and global configuration.",
- ),
- "search": CommandInfo(
- "pip._internal.commands.search",
- "SearchCommand",
- "Search PyPI for packages.",
- ),
- "cache": CommandInfo(
- "pip._internal.commands.cache",
- "CacheCommand",
- "Inspect and manage pip's wheel cache.",
- ),
- "index": CommandInfo(
- "pip._internal.commands.index",
- "IndexCommand",
- "Inspect information available from package indexes.",
- ),
- "wheel": CommandInfo(
- "pip._internal.commands.wheel",
- "WheelCommand",
- "Build wheels from your requirements.",
- ),
- "hash": CommandInfo(
- "pip._internal.commands.hash",
- "HashCommand",
- "Compute hashes of package archives.",
- ),
- "completion": CommandInfo(
- "pip._internal.commands.completion",
- "CompletionCommand",
- "A helper command used for command completion.",
- ),
- "debug": CommandInfo(
- "pip._internal.commands.debug",
- "DebugCommand",
- "Show information useful for debugging.",
- ),
- "help": CommandInfo(
- "pip._internal.commands.help",
- "HelpCommand",
- "Show help for commands.",
- ),
-}
-
-
-def create_command(name: str, **kwargs: Any) -> Command:
- """
- Create an instance of the Command class with the given name.
- """
- module_path, class_name, summary = commands_dict[name]
- module = importlib.import_module(module_path)
- command_class = getattr(module, class_name)
- command = command_class(name=name, summary=summary, **kwargs)
-
- return command
-
-
-def get_similar_commands(name: str) -> Optional[str]:
- """Command name auto-correct."""
- from difflib import get_close_matches
-
- name = name.lower()
-
- close_commands = get_close_matches(name, commands_dict.keys())
-
- if close_commands:
- return close_commands[0]
- else:
- return None
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/modeling/meta_arch/panoptic_fpn.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/modeling/meta_arch/panoptic_fpn.py
deleted file mode 100644
index 32d2b5a2abfbf56cfa8706ea1d5d113a576d19c9..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/modeling/meta_arch/panoptic_fpn.py
+++ /dev/null
@@ -1,218 +0,0 @@
-# -*- coding: utf-8 -*-
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-
-import torch
-from torch import nn
-
-from detectron2.structures import ImageList
-
-from ..backbone import build_backbone
-from ..postprocessing import detector_postprocess, sem_seg_postprocess
-from ..proposal_generator import build_proposal_generator
-from ..roi_heads import build_roi_heads
-from .build import META_ARCH_REGISTRY
-from .semantic_seg import build_sem_seg_head
-
-__all__ = ["PanopticFPN"]
-
-
-@META_ARCH_REGISTRY.register()
-class PanopticFPN(nn.Module):
- """
- Main class for Panoptic FPN architectures (see https://arxiv.org/abs/1901.02446).
- """
-
- def __init__(self, cfg):
- super().__init__()
-
- self.device = torch.device(cfg.MODEL.DEVICE)
-
- self.instance_loss_weight = cfg.MODEL.PANOPTIC_FPN.INSTANCE_LOSS_WEIGHT
-
- # options when combining instance & semantic outputs
- self.combine_on = cfg.MODEL.PANOPTIC_FPN.COMBINE.ENABLED
- self.combine_overlap_threshold = cfg.MODEL.PANOPTIC_FPN.COMBINE.OVERLAP_THRESH
- self.combine_stuff_area_limit = cfg.MODEL.PANOPTIC_FPN.COMBINE.STUFF_AREA_LIMIT
- self.combine_instances_confidence_threshold = (
- cfg.MODEL.PANOPTIC_FPN.COMBINE.INSTANCES_CONFIDENCE_THRESH
- )
-
- self.backbone = build_backbone(cfg)
- self.proposal_generator = build_proposal_generator(cfg, self.backbone.output_shape())
- self.roi_heads = build_roi_heads(cfg, self.backbone.output_shape())
- self.sem_seg_head = build_sem_seg_head(cfg, self.backbone.output_shape())
-
- pixel_mean = torch.Tensor(cfg.MODEL.PIXEL_MEAN).to(self.device).view(3, 1, 1)
- pixel_std = torch.Tensor(cfg.MODEL.PIXEL_STD).to(self.device).view(3, 1, 1)
- self.normalizer = lambda x: (x - pixel_mean) / pixel_std
- self.to(self.device)
-
- def forward(self, batched_inputs):
- """
- Args:
- batched_inputs: a list, batched outputs of :class:`DatasetMapper`.
- Each item in the list contains the inputs for one image.
-
- For now, each item in the list is a dict that contains:
-
- * "image": Tensor, image in (C, H, W) format.
- * "instances": Instances
- * "sem_seg": semantic segmentation ground truth.
- * Other information that's included in the original dicts, such as:
- "height", "width" (int): the output resolution of the model, used in inference.
- See :meth:`postprocess` for details.
-
- Returns:
- list[dict]:
- each dict is the results for one image. The dict contains the following keys:
-
- * "instances": see :meth:`GeneralizedRCNN.forward` for its format.
- * "sem_seg": see :meth:`SemanticSegmentor.forward` for its format.
- * "panoptic_seg": available when `PANOPTIC_FPN.COMBINE.ENABLED`.
- See the return value of
- :func:`combine_semantic_and_instance_outputs` for its format.
- """
- images = [x["image"].to(self.device) for x in batched_inputs]
- images = [self.normalizer(x) for x in images]
- images = ImageList.from_tensors(images, self.backbone.size_divisibility)
- features = self.backbone(images.tensor)
-
- if "proposals" in batched_inputs[0]:
- proposals = [x["proposals"].to(self.device) for x in batched_inputs]
- proposal_losses = {}
-
- if "sem_seg" in batched_inputs[0]:
- gt_sem_seg = [x["sem_seg"].to(self.device) for x in batched_inputs]
- gt_sem_seg = ImageList.from_tensors(
- gt_sem_seg, self.backbone.size_divisibility, self.sem_seg_head.ignore_value
- ).tensor
- else:
- gt_sem_seg = None
- sem_seg_results, sem_seg_losses = self.sem_seg_head(features, gt_sem_seg)
-
- if "instances" in batched_inputs[0]:
- gt_instances = [x["instances"].to(self.device) for x in batched_inputs]
- else:
- gt_instances = None
- if self.proposal_generator:
- proposals, proposal_losses = self.proposal_generator(images, features, gt_instances)
- detector_results, detector_losses = self.roi_heads(
- images, features, proposals, gt_instances
- )
-
- if self.training:
- losses = {}
- losses.update(sem_seg_losses)
- losses.update({k: v * self.instance_loss_weight for k, v in detector_losses.items()})
- losses.update(proposal_losses)
- return losses
-
- processed_results = []
- for sem_seg_result, detector_result, input_per_image, image_size in zip(
- sem_seg_results, detector_results, batched_inputs, images.image_sizes
- ):
- height = input_per_image.get("height", image_size[0])
- width = input_per_image.get("width", image_size[1])
- sem_seg_r = sem_seg_postprocess(sem_seg_result, image_size, height, width)
- detector_r = detector_postprocess(detector_result, height, width)
-
- processed_results.append({"sem_seg": sem_seg_r, "instances": detector_r})
-
- if self.combine_on:
- panoptic_r = combine_semantic_and_instance_outputs(
- detector_r,
- sem_seg_r.argmax(dim=0),
- self.combine_overlap_threshold,
- self.combine_stuff_area_limit,
- self.combine_instances_confidence_threshold,
- )
- processed_results[-1]["panoptic_seg"] = panoptic_r
- return processed_results
-
-
-def combine_semantic_and_instance_outputs(
- instance_results,
- semantic_results,
- overlap_threshold,
- stuff_area_limit,
- instances_confidence_threshold,
-):
- """
- Implement a simple combining logic following
- "combine_semantic_and_instance_predictions.py" in panopticapi
- to produce panoptic segmentation outputs.
-
- Args:
- instance_results: output of :func:`detector_postprocess`.
- semantic_results: an (H, W) tensor, each is the contiguous semantic
- category id
-
- Returns:
- panoptic_seg (Tensor): of shape (height, width) where the values are ids for each segment.
- segments_info (list[dict]): Describe each segment in `panoptic_seg`.
- Each dict contains keys "id", "category_id", "isthing".
- """
- panoptic_seg = torch.zeros_like(semantic_results, dtype=torch.int32)
-
- # sort instance outputs by scores
- sorted_inds = torch.argsort(-instance_results.scores)
-
- current_segment_id = 0
- segments_info = []
-
- instance_masks = instance_results.pred_masks.to(dtype=torch.bool, device=panoptic_seg.device)
-
- # Add instances one-by-one, check for overlaps with existing ones
- for inst_id in sorted_inds:
- score = instance_results.scores[inst_id].item()
- if score < instances_confidence_threshold:
- break
- mask = instance_masks[inst_id] # H,W
- mask_area = mask.sum().item()
-
- if mask_area == 0:
- continue
-
- intersect = (mask > 0) & (panoptic_seg > 0)
- intersect_area = intersect.sum().item()
-
- if intersect_area * 1.0 / mask_area > overlap_threshold:
- continue
-
- if intersect_area > 0:
- mask = mask & (panoptic_seg == 0)
-
- current_segment_id += 1
- panoptic_seg[mask] = current_segment_id
- segments_info.append(
- {
- "id": current_segment_id,
- "isthing": True,
- "score": score,
- "category_id": instance_results.pred_classes[inst_id].item(),
- "instance_id": inst_id.item(),
- }
- )
-
- # Add semantic results to remaining empty areas
- semantic_labels = torch.unique(semantic_results).cpu().tolist()
- for semantic_label in semantic_labels:
- if semantic_label == 0: # 0 is a special "thing" class
- continue
- mask = (semantic_results == semantic_label) & (panoptic_seg == 0)
- mask_area = mask.sum().item()
- if mask_area < stuff_area_limit:
- continue
-
- current_segment_id += 1
- panoptic_seg[mask] = current_segment_id
- segments_info.append(
- {
- "id": current_segment_id,
- "isthing": False,
- "category_id": semantic_label,
- "area": mask_area,
- }
- )
-
- return panoptic_seg, segments_info
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/doc/TOOL_QUERY_DB.md b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/doc/TOOL_QUERY_DB.md
deleted file mode 100644
index b0a764b8740597c6af634127b80b53d28913726f..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/DensePose/doc/TOOL_QUERY_DB.md
+++ /dev/null
@@ -1,105 +0,0 @@
-
-# Query Dataset
-
-`query_db` is a tool to print or visualize DensePose data from a dataset.
-It has two modes: `print` and `show` to output dataset entries to standard
-output or to visualize them on images.
-
-## Print Mode
-
-The general command form is:
-```bash
-python query_db.py print [-h] [-v] [--max-entries N]
-```
-
-There are two mandatory arguments:
- - ``, DensePose dataset specification, from which to select
- the entries (e.g. `densepose_coco_2014_train`).
- - ``, dataset entry selector which can be a single specification,
- or a comma-separated list of specifications of the form
- `field[:type]=value` for exact match with the value
- or `field[:type]=min-max` for a range of values
-
-One can additionally limit the maximum number of entries to output
-by providing `--max-entries` argument.
-
-Examples:
-
-1. Output at most 10 first entries from the `densepose_coco_2014_train` dataset:
-```bash
-python query_db.py print densepose_coco_2014_train \* --max-entries 10 -v
-```
-
-2. Output all entries with `file_name` equal to `COCO_train2014_000000000036.jpg`:
-```bash
-python query_db.py print densepose_coco_2014_train file_name=COCO_train2014_000000000036.jpg -v
-```
-
-3. Output all entries with `image_id` between 36 and 156:
-```bash
-python query_db.py print densepose_coco_2014_train image_id:int=36-156 -v
-```
-
-## Visualization Mode
-
-The general command form is:
-```bash
-python query_db.py show [-h] [-v] [--max-entries N] [--output ]
-```
-
-There are three mandatory arguments:
- - ``, DensePose dataset specification, from which to select
- the entries (e.g. `densepose_coco_2014_train`).
- - ``, dataset entry selector which can be a single specification,
- or a comma-separated list of specifications of the form
- `field[:type]=value` for exact match with the value
- or `field[:type]=min-max` for a range of values
- - ``, visualizations specifier; currently available visualizations are:
- * `bbox` - bounding boxes of annotated persons;
- * `dp_i` - annotated points colored according to the containing part;
- * `dp_pts` - annotated points in green color;
- * `dp_segm` - segmentation masks for annotated persons;
- * `dp_u` - annotated points colored according to their U coordinate in part parameterization;
- * `dp_v` - annotated points colored according to their V coordinate in part parameterization;
-
-One can additionally provide one of the two optional arguments:
- - `--max_entries` to limit the maximum number of entries to visualize
- - `--output` to provide visualization file name template, which defaults
- to `output.png`. To distinguish file names for different dataset
- entries, the tool appends 1-based entry index to the output file name,
- e.g. output.0001.png, output.0002.png, etc.
-
-The following examples show how to output different visualizations for image with `id = 322`
-from `densepose_coco_2014_train` dataset:
-
-1. Show bounding box and segmentation:
-```bash
-python query_db.py show densepose_coco_2014_train image_id:int=322 bbox,dp_segm -v
-```
-
-
-2. Show bounding box and points colored according to the containing part:
-```bash
-python query_db.py show densepose_coco_2014_train image_id:int=322 bbox,dp_i -v
-```
-
-
-3. Show bounding box and annotated points in green color:
-```bash
-python query_db.py show densepose_coco_2014_train image_id:int=322 bbox,dp_segm -v
-```
-
-
-4. Show bounding box and annotated points colored according to their U coordinate in part parameterization:
-```bash
-python query_db.py show densepose_coco_2014_train image_id:int=322 bbox,dp_u -v
-```
-
-
-5. Show bounding box and annotated points colored according to their V coordinate in part parameterization:
-```bash
-python query_db.py show densepose_coco_2014_train image_id:int=322 bbox,dp_v -v
-```
-
-
-
diff --git a/spaces/CVPR/LIVE/thrust/thrust/detail/type_traits/is_metafunction_defined.h b/spaces/CVPR/LIVE/thrust/thrust/detail/type_traits/is_metafunction_defined.h
deleted file mode 100644
index c278e5bdb23121f7271fe339a1d9678ab415e9a9..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/detail/type_traits/is_metafunction_defined.h
+++ /dev/null
@@ -1,41 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#pragma once
-
-#include
-#include
-
-namespace thrust
-{
-
-namespace detail
-{
-
-__THRUST_DEFINE_HAS_NESTED_TYPE(is_metafunction_defined, type)
-
-template
- struct enable_if_defined
- : thrust::detail::lazy_enable_if<
- is_metafunction_defined::value,
- Metafunction
- >
-{};
-
-} // end detail
-
-} // end thrust
-
diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/detail/generic/count.h b/spaces/CVPR/LIVE/thrust/thrust/system/detail/generic/count.h
deleted file mode 100644
index 218369e386e18219906a043171b4a99c489a643a..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/system/detail/generic/count.h
+++ /dev/null
@@ -1,51 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-
-#pragma once
-
-#include
-#include
-
-namespace thrust
-{
-namespace system
-{
-namespace detail
-{
-namespace generic
-{
-
-
-template
-__host__ __device__
-typename thrust::iterator_traits::difference_type
-count(thrust::execution_policy &exec, InputIterator first, InputIterator last, const EqualityComparable& value);
-
-
-template
-__host__ __device__
-typename thrust::iterator_traits::difference_type
-count_if(thrust::execution_policy &exec, InputIterator first, InputIterator last, Predicate pred);
-
-
-} // end namespace generic
-} // end namespace detail
-} // end namespace system
-} // end namespace thrust
-
-#include
-
diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/uninitialized_copy.h b/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/uninitialized_copy.h
deleted file mode 100644
index bda06ac13e9ca1d14ee5e047986884f5207d3d2b..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/system/tbb/detail/uninitialized_copy.h
+++ /dev/null
@@ -1,23 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#pragma once
-
-#include
-
-// this system inherits uninitialized_copy
-#include
-
diff --git a/spaces/CVPR/LIVE/winding_number.h b/spaces/CVPR/LIVE/winding_number.h
deleted file mode 100644
index 8791a4cdeeeb6136e12182782ea66946053cb554..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/winding_number.h
+++ /dev/null
@@ -1,202 +0,0 @@
-#pragma once
-
-#include "diffvg.h"
-#include "scene.h"
-#include "shape.h"
-#include "solve.h"
-#include "vector.h"
-
-DEVICE
-int compute_winding_number(const Circle &circle, const Vector2f &pt) {
- const auto &c = circle.center;
- auto r = circle.radius;
- // inside the circle: return 1, outside the circle: return 0
- if (distance_squared(c, pt) < r * r) {
- return 1;
- } else {
- return 0;
- }
-}
-
-DEVICE
-int compute_winding_number(const Ellipse &ellipse, const Vector2f &pt) {
- const auto &c = ellipse.center;
- const auto &r = ellipse.radius;
- // inside the ellipse: return 1, outside the ellipse: return 0
- if (square(c.x - pt.x) / square(r.x) + square(c.y - pt.y) / square(r.y) < 1) {
- return 1;
- } else {
- return 0;
- }
-}
-
-DEVICE
-bool intersect(const AABB &box, const Vector2f &pt) {
- if (pt.y < box.p_min.y || pt.y > box.p_max.y) {
- return false;
- }
- if (pt.x > box.p_max.x) {
- return false;
- }
- return true;
-}
-
-DEVICE
-int compute_winding_number(const Path &path, const BVHNode *bvh_nodes, const Vector2f &pt) {
- // Shoot a horizontal ray from pt to right, intersect with all curves of the path,
- // count intersection
- auto num_segments = path.num_base_points;
- constexpr auto max_bvh_size = 128;
- int bvh_stack[max_bvh_size];
- auto stack_size = 0;
- auto winding_number = 0;
- bvh_stack[stack_size++] = 2 * num_segments - 2;
- while (stack_size > 0) {
- const BVHNode &node = bvh_nodes[bvh_stack[--stack_size]];
- if (node.child1 < 0) {
- // leaf
- auto base_point_id = node.child0;
- auto point_id = - node.child1 - 1;
- assert(base_point_id < num_segments);
- assert(point_id < path.num_points);
- if (path.num_control_points[base_point_id] == 0) {
- // Straight line
- auto i0 = point_id;
- auto i1 = (point_id + 1) % path.num_points;
- auto p0 = Vector2f{path.points[2 * i0], path.points[2 * i0 + 1]};
- auto p1 = Vector2f{path.points[2 * i1], path.points[2 * i1 + 1]};
- // intersect p0 + t * (p1 - p0) with pt + t' * (1, 0)
- // solve:
- // pt.x + t' = v0.x + t * (v1.x - v0.x)
- // pt.y = v0.y + t * (v1.y - v0.y)
- if (p1.y != p0.y) {
- auto t = (pt.y - p0.y) / (p1.y - p0.y);
- if (t >= 0 && t <= 1) {
- auto tp = p0.x - pt.x + t * (p1.x - p0.x);
- if (tp >= 0) {
- if (p1.y - p0.y > 0) {
- winding_number += 1;
- } else {
- winding_number -= 1;
- }
- }
- }
- }
- } else if (path.num_control_points[base_point_id] == 1) {
- // Quadratic Bezier curve
- auto i0 = point_id;
- auto i1 = point_id + 1;
- auto i2 = (point_id + 2) % path.num_points;
- auto p0 = Vector2f{path.points[2 * i0], path.points[2 * i0 + 1]};
- auto p1 = Vector2f{path.points[2 * i1], path.points[2 * i1 + 1]};
- auto p2 = Vector2f{path.points[2 * i2], path.points[2 * i2 + 1]};
- // The curve is (1-t)^2p0 + 2(1-t)tp1 + t^2p2
- // = (p0-2p1+p2)t^2+(-2p0+2p1)t+p0
- // intersect with pt + t' * (1 0)
- // solve
- // pt.y = (p0-2p1+p2)t^2+(-2p0+2p1)t+p0
- float t[2];
- if (solve_quadratic(p0.y-2*p1.y+p2.y,
- -2*p0.y+2*p1.y,
- p0.y-pt.y,
- &t[0], &t[1])) {
- for (int j = 0; j < 2; j++) {
- if (t[j] >= 0 && t[j] <= 1) {
- auto tp = (p0.x-2*p1.x+p2.x)*t[j]*t[j] +
- (-2*p0.x+2*p1.x)*t[j] +
- p0.x-pt.x;
- if (tp >= 0) {
- if (2*(p0.y-2*p1.y+p2.y)*t[j]+(-2*p0.y+2*p1.y) > 0) {
- winding_number += 1;
- } else {
- winding_number -= 1;
- }
- }
- }
- }
- }
- } else if (path.num_control_points[base_point_id] == 2) {
- // Cubic Bezier curve
- auto i0 = point_id;
- auto i1 = point_id + 1;
- auto i2 = point_id + 2;
- auto i3 = (point_id + 3) % path.num_points;
- auto p0 = Vector2f{path.points[2 * i0], path.points[2 * i0 + 1]};
- auto p1 = Vector2f{path.points[2 * i1], path.points[2 * i1 + 1]};
- auto p2 = Vector2f{path.points[2 * i2], path.points[2 * i2 + 1]};
- auto p3 = Vector2f{path.points[2 * i3], path.points[2 * i3 + 1]};
- // The curve is (1 - t)^3 p0 + 3 * (1 - t)^2 t p1 + 3 * (1 - t) t^2 p2 + t^3 p3
- // = (-p0+3p1-3p2+p3) t^3 + (3p0-6p1+3p2) t^2 + (-3p0+3p1) t + p0
- // intersect with pt + t' * (1 0)
- // solve:
- // pt.y = (-p0+3p1-3p2+p3) t^3 + (3p0-6p1+3p2) t^2 + (-3p0+3p1) t + p0
- double t[3];
- int num_sol = solve_cubic(double(-p0.y+3*p1.y-3*p2.y+p3.y),
- double(3*p0.y-6*p1.y+3*p2.y),
- double(-3*p0.y+3*p1.y),
- double(p0.y-pt.y),
- t);
- for (int j = 0; j < num_sol; j++) {
- if (t[j] >= 0 && t[j] <= 1) {
- // t' = (-p0+3p1-3p2+p3) t^3 + (3p0-6p1+3p2) t^2 + (-3p0+3p1) t + p0 - pt.x
- auto tp = (-p0.x+3*p1.x-3*p2.x+p3.x)*t[j]*t[j]*t[j]+
- (3*p0.x-6*p1.x+3*p2.x)*t[j]*t[j]+
- (-3*p0.x+3*p1.x)*t[j]+
- p0.x-pt.x;
- if (tp > 0) {
- if (3*(-p0.y+3*p1.y-3*p2.y+p3.y)*t[j]*t[j]+
- 2*(3*p0.y-6*p1.y+3*p2.y)*t[j]+
- (-3*p0.y+3*p1.y) > 0) {
- winding_number += 1;
- } else {
- winding_number -= 1;
- }
- }
- }
- }
- } else {
- assert(false);
- }
- } else {
- assert(node.child0 >= 0 && node.child1 >= 0);
- const AABB &b0 = bvh_nodes[node.child0].box;
- if (intersect(b0, pt)) {
- bvh_stack[stack_size++] = node.child0;
- }
- const AABB &b1 = bvh_nodes[node.child1].box;
- if (intersect(b1, pt)) {
- bvh_stack[stack_size++] = node.child1;
- }
- assert(stack_size <= max_bvh_size);
- }
- }
- return winding_number;
-}
-
-DEVICE
-int compute_winding_number(const Rect &rect, const Vector2f &pt) {
- const auto &p_min = rect.p_min;
- const auto &p_max = rect.p_max;
- // inside the rectangle: return 1, outside the rectangle: return 0
- if (pt.x > p_min.x && pt.x < p_max.x && pt.y > p_min.y && pt.y < p_max.y) {
- return 1;
- } else {
- return 0;
- }
-}
-
-DEVICE
-int compute_winding_number(const Shape &shape, const BVHNode *bvh_nodes, const Vector2f &pt) {
- switch (shape.type) {
- case ShapeType::Circle:
- return compute_winding_number(*(const Circle *)shape.ptr, pt);
- case ShapeType::Ellipse:
- return compute_winding_number(*(const Ellipse *)shape.ptr, pt);
- case ShapeType::Path:
- return compute_winding_number(*(const Path *)shape.ptr, bvh_nodes, pt);
- case ShapeType::Rect:
- return compute_winding_number(*(const Rect *)shape.ptr, pt);
- }
- assert(false);
- return 0;
-}
diff --git a/spaces/CVPR/Leaderboard/app.py b/spaces/CVPR/Leaderboard/app.py
deleted file mode 100644
index 8ffb4ca17ba8a9c08f1faf48d4c96650498516ef..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Leaderboard/app.py
+++ /dev/null
@@ -1,43 +0,0 @@
-import os
-import requests
-import pandas as pd
-import gradio as gr
-from huggingface_hub.hf_api import SpaceInfo
-from pathlib import Path
-
-
-path = f"https://huggingface.co/api/spaces"
-os.system("git clone https://github.com/YangtaoWANG95/TokenCut.git")
-os.chdir("TokenCut")
-os.system("wget https://raw.githubusercontent.com/YangtaoWANG95/TokenCut/master/examples/VOC07_000064.jpg -O parrot.jpg")
-
-
-
-def get_blocks_party_spaces():
- r = requests.get(path)
- d = r.json()
- spaces = [SpaceInfo(**x) for x in d]
- blocks_spaces = {}
- for i in range(0,len(spaces)):
- if spaces[i].id.split('/')[0] == 'CVPR' and hasattr(spaces[i], 'likes') and spaces[i].id != 'CVPR/Leaderboard' and spaces[i].id != 'CVPR/README':
- blocks_spaces[spaces[i].id]=spaces[i].likes
- df = pd.DataFrame(
- [{"Spaces_Name": Spaces, "likes": likes} for Spaces,likes in blocks_spaces.items()])
- df = df.sort_values(by=['likes'],ascending=False)
- return df
-
-
-block = gr.Blocks()
-
-with block:
- gr.Markdown("""Leaderboard for the most popular CVPR Spaces. To learn more and join, see CVPR Event""")
- with gr.Tabs():
- with gr.TabItem("CVPR Leaderboard"):
- with gr.Row():
- data = gr.outputs.Dataframe(type="pandas")
- with gr.Row():
- data_run = gr.Button("Refresh")
- data_run.click(get_blocks_party_spaces, inputs=None, outputs=data)
-
- block.load(get_blocks_party_spaces, inputs=None, outputs=data)
-block.launch()
diff --git a/spaces/CVPR/lama-example/saicinpainting/training/visualizers/base.py b/spaces/CVPR/lama-example/saicinpainting/training/visualizers/base.py
deleted file mode 100644
index 675f01682ddf5e31b6cc341735378c6f3b242e49..0000000000000000000000000000000000000000
--- a/spaces/CVPR/lama-example/saicinpainting/training/visualizers/base.py
+++ /dev/null
@@ -1,73 +0,0 @@
-import abc
-from typing import Dict, List
-
-import numpy as np
-import torch
-from skimage import color
-from skimage.segmentation import mark_boundaries
-
-from . import colors
-
-COLORS, _ = colors.generate_colors(151) # 151 - max classes for semantic segmentation
-
-
-class BaseVisualizer:
- @abc.abstractmethod
- def __call__(self, epoch_i, batch_i, batch, suffix='', rank=None):
- """
- Take a batch, make an image from it and visualize
- """
- raise NotImplementedError()
-
-
-def visualize_mask_and_images(images_dict: Dict[str, np.ndarray], keys: List[str],
- last_without_mask=True, rescale_keys=None, mask_only_first=None,
- black_mask=False) -> np.ndarray:
- mask = images_dict['mask'] > 0.5
- result = []
- for i, k in enumerate(keys):
- img = images_dict[k]
- img = np.transpose(img, (1, 2, 0))
-
- if rescale_keys is not None and k in rescale_keys:
- img = img - img.min()
- img /= img.max() + 1e-5
- if len(img.shape) == 2:
- img = np.expand_dims(img, 2)
-
- if img.shape[2] == 1:
- img = np.repeat(img, 3, axis=2)
- elif (img.shape[2] > 3):
- img_classes = img.argmax(2)
- img = color.label2rgb(img_classes, colors=COLORS)
-
- if mask_only_first:
- need_mark_boundaries = i == 0
- else:
- need_mark_boundaries = i < len(keys) - 1 or not last_without_mask
-
- if need_mark_boundaries:
- if black_mask:
- img = img * (1 - mask[0][..., None])
- img = mark_boundaries(img,
- mask[0],
- color=(1., 0., 0.),
- outline_color=(1., 1., 1.),
- mode='thick')
- result.append(img)
- return np.concatenate(result, axis=1)
-
-
-def visualize_mask_and_images_batch(batch: Dict[str, torch.Tensor], keys: List[str], max_items=10,
- last_without_mask=True, rescale_keys=None) -> np.ndarray:
- batch = {k: tens.detach().cpu().numpy() for k, tens in batch.items()
- if k in keys or k == 'mask'}
-
- batch_size = next(iter(batch.values())).shape[0]
- items_to_vis = min(batch_size, max_items)
- result = []
- for i in range(items_to_vis):
- cur_dct = {k: tens[i] for k, tens in batch.items()}
- result.append(visualize_mask_and_images(cur_dct, keys, last_without_mask=last_without_mask,
- rescale_keys=rescale_keys))
- return np.concatenate(result, axis=0)
diff --git a/spaces/Caoyunkang/Segment-Any-Anomaly/GroundingDINO/setup.py b/spaces/Caoyunkang/Segment-Any-Anomaly/GroundingDINO/setup.py
deleted file mode 100644
index a045b763fb4a4f61bac23b735544a18ffc68d20a..0000000000000000000000000000000000000000
--- a/spaces/Caoyunkang/Segment-Any-Anomaly/GroundingDINO/setup.py
+++ /dev/null
@@ -1,208 +0,0 @@
-# coding=utf-8
-# Copyright 2022 The IDEA Authors. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ------------------------------------------------------------------------------------------------
-# Modified from
-# https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/ops/setup.py
-# https://github.com/facebookresearch/detectron2/blob/main/setup.py
-# https://github.com/open-mmlab/mmdetection/blob/master/setup.py
-# https://github.com/Oneflow-Inc/libai/blob/main/setup.py
-# ------------------------------------------------------------------------------------------------
-
-import glob
-import os
-import subprocess
-
-import torch
-from setuptools import find_packages, setup
-from torch.utils.cpp_extension import CUDA_HOME, CppExtension, CUDAExtension
-
-# groundingdino version info
-version = "0.1.0"
-package_name = "groundingdino"
-cwd = os.path.dirname(os.path.abspath(__file__))
-
-
-sha = "Unknown"
-try:
- sha = subprocess.check_output(["git", "rev-parse", "HEAD"], cwd=cwd).decode("ascii").strip()
-except Exception:
- pass
-
-
-def write_version_file():
- version_path = os.path.join(cwd, "groundingdino", "version.py")
- with open(version_path, "w") as f:
- f.write(f"__version__ = '{version}'\n")
- # f.write(f"git_version = {repr(sha)}\n")
-
-
-requirements = ["torch", "torchvision"]
-
-torch_ver = [int(x) for x in torch.__version__.split(".")[:2]]
-
-
-def get_extensions():
- this_dir = os.path.dirname(os.path.abspath(__file__))
- extensions_dir = os.path.join(this_dir, "groundingdino", "models", "GroundingDINO", "csrc")
-
- main_source = os.path.join(extensions_dir, "vision.cpp")
- sources = glob.glob(os.path.join(extensions_dir, "**", "*.cpp"))
- source_cuda = glob.glob(os.path.join(extensions_dir, "**", "*.cu")) + glob.glob(
- os.path.join(extensions_dir, "*.cu")
- )
-
- sources = [main_source] + sources
-
- extension = CppExtension
-
- extra_compile_args = {"cxx": []}
- define_macros = []
-
- if torch.cuda.is_available() and CUDA_HOME is not None:
- print("Compiling with CUDA")
- extension = CUDAExtension
- sources += source_cuda
- define_macros += [("WITH_CUDA", None)]
- extra_compile_args["nvcc"] = [
- "-DCUDA_HAS_FP16=1",
- "-D__CUDA_NO_HALF_OPERATORS__",
- "-D__CUDA_NO_HALF_CONVERSIONS__",
- "-D__CUDA_NO_HALF2_OPERATORS__",
- ]
- else:
- print("Compiling without CUDA")
- define_macros += [("WITH_HIP", None)]
- extra_compile_args["nvcc"] = []
- return None
-
- sources = [os.path.join(extensions_dir, s) for s in sources]
- include_dirs = [extensions_dir]
-
- ext_modules = [
- extension(
- "groundingdino._C",
- sources,
- include_dirs=include_dirs,
- define_macros=define_macros,
- extra_compile_args=extra_compile_args,
- )
- ]
-
- return ext_modules
-
-
-def parse_requirements(fname="requirements.txt", with_version=True):
- """Parse the package dependencies listed in a requirements file but strips
- specific versioning information.
-
- Args:
- fname (str): path to requirements file
- with_version (bool, default=False): if True include version specs
-
- Returns:
- List[str]: list of requirements items
-
- CommandLine:
- python -c "import setup; print(setup.parse_requirements())"
- """
- import re
- import sys
- from os.path import exists
-
- require_fpath = fname
-
- def parse_line(line):
- """Parse information from a line in a requirements text file."""
- if line.startswith("-r "):
- # Allow specifying requirements in other files
- target = line.split(" ")[1]
- for info in parse_require_file(target):
- yield info
- else:
- info = {"line": line}
- if line.startswith("-e "):
- info["package"] = line.split("#egg=")[1]
- elif "@git+" in line:
- info["package"] = line
- else:
- # Remove versioning from the package
- pat = "(" + "|".join([">=", "==", ">"]) + ")"
- parts = re.split(pat, line, maxsplit=1)
- parts = [p.strip() for p in parts]
-
- info["package"] = parts[0]
- if len(parts) > 1:
- op, rest = parts[1:]
- if ";" in rest:
- # Handle platform specific dependencies
- # http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
- version, platform_deps = map(str.strip, rest.split(";"))
- info["platform_deps"] = platform_deps
- else:
- version = rest # NOQA
- info["version"] = (op, version)
- yield info
-
- def parse_require_file(fpath):
- with open(fpath, "r") as f:
- for line in f.readlines():
- line = line.strip()
- if line and not line.startswith("#"):
- for info in parse_line(line):
- yield info
-
- def gen_packages_items():
- if exists(require_fpath):
- for info in parse_require_file(require_fpath):
- parts = [info["package"]]
- if with_version and "version" in info:
- parts.extend(info["version"])
- if not sys.version.startswith("3.4"):
- # apparently package_deps are broken in 3.4
- platform_deps = info.get("platform_deps")
- if platform_deps is not None:
- parts.append(";" + platform_deps)
- item = "".join(parts)
- yield item
-
- packages = list(gen_packages_items())
- return packages
-
-
-if __name__ == "__main__":
- print(f"Building wheel {package_name}-{version}")
-
- with open("LICENSE", "r", encoding="utf-8") as f:
- license = f.read()
-
- write_version_file()
-
- setup(
- name="groundingdino",
- version="0.1.0",
- author="International Digital Economy Academy, Shilong Liu",
- url="https://github.com/IDEA-Research/GroundingDINO",
- description="open-set object detector",
- license=license,
- install_requires=parse_requirements("requirements.txt"),
- packages=find_packages(
- exclude=(
- "configs",
- "tests",
- )
- ),
- ext_modules=get_extensions(),
- cmdclass={"build_ext": torch.utils.cpp_extension.BuildExtension},
- )
diff --git a/spaces/Catmeow/Count_objects_in_picture/README.md b/spaces/Catmeow/Count_objects_in_picture/README.md
deleted file mode 100644
index c7a8899af8e5ac70b38518d568e8e2dbba135d55..0000000000000000000000000000000000000000
--- a/spaces/Catmeow/Count_objects_in_picture/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Count Objects In Picture yolov5s
-emoji: 🏢
-colorFrom: indigo
-colorTo: pink
-sdk: gradio
-sdk_version: 3.8.2
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/CikeyQI/meme-api/meme_generator/memes/hutao_bite/__init__.py b/spaces/CikeyQI/meme-api/meme_generator/memes/hutao_bite/__init__.py
deleted file mode 100644
index 9cfbf7497f6374d77bf28e2b5e5cde1de0c0850b..0000000000000000000000000000000000000000
--- a/spaces/CikeyQI/meme-api/meme_generator/memes/hutao_bite/__init__.py
+++ /dev/null
@@ -1,25 +0,0 @@
-from pathlib import Path
-from typing import List
-
-from PIL.Image import Image as IMG
-from pil_utils import BuildImage
-
-from meme_generator import add_meme
-from meme_generator.utils import save_gif
-
-img_dir = Path(__file__).parent / "images"
-
-
-def hutao_bite(images: List[BuildImage], texts, args):
- img = images[0].convert("RGBA").square().resize((100, 100))
- frames: List[IMG] = []
- locs = [(98, 101, 108, 234), (96, 100, 108, 237)]
- for i in range(2):
- frame = BuildImage.open(img_dir / f"{i}.png")
- w, h, x, y = locs[i]
- frame.paste(img.resize((w, h)), (x, y), below=True)
- frames.append(frame.image)
- return save_gif(frames, 0.1)
-
-
-add_meme("hutao_bite", hutao_bite, min_images=1, max_images=1, keywords=["胡桃啃"])
diff --git a/spaces/Cvandi/remake/realesrgan/archs/__init__.py b/spaces/Cvandi/remake/realesrgan/archs/__init__.py
deleted file mode 100644
index f3fbbf3b78e33b61fd4c33a564a9a617010d90de..0000000000000000000000000000000000000000
--- a/spaces/Cvandi/remake/realesrgan/archs/__init__.py
+++ /dev/null
@@ -1,10 +0,0 @@
-import importlib
-from basicsr.utils import scandir
-from os import path as osp
-
-# automatically scan and import arch modules for registry
-# scan all the files that end with '_arch.py' under the archs folder
-arch_folder = osp.dirname(osp.abspath(__file__))
-arch_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(arch_folder) if v.endswith('_arch.py')]
-# import all the arch modules
-_arch_modules = [importlib.import_module(f'realesrgan.archs.{file_name}') for file_name in arch_filenames]
diff --git a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/data/datasets/evaluation/word/util/t.py b/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/data/datasets/evaluation/word/util/t.py
deleted file mode 100644
index 72ee2de7dadfe782f0f9092e2dc0233d93e468a5..0000000000000000000000000000000000000000
--- a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/data/datasets/evaluation/word/util/t.py
+++ /dev/null
@@ -1,25 +0,0 @@
-#encoding=utf-8
-"""
-for theano shortcuts
-"""
-import theano
-import theano.tensor as T
-import util.rand
-
-trng = T.shared_randomstreams.RandomStreams(util.rand.randint())
-scan_until = theano.scan_module.until
-
-def add_noise(input, noise_level):
- noise = trng.binomial(size = input.shape, n = 1, p = 1 - noise_level)
- return noise * input
-
-def crop_into(large, small):
- """
- center crop large image into small.
- both 'large' and 'small' are 4D: (batch_size, channels, h, w)
- """
-
- h1, w1 = large.shape[2:]
- h2, w2 = small.shape[2:]
- y, x = (h1 - h2) / 2, (w1 - h2)/2
- return large[:, :, y: y + h2, x: x + w2 ]
\ No newline at end of file
diff --git a/spaces/DAMO-NLP-SG/Video-LLaMA/video_llama/runners/test.py b/spaces/DAMO-NLP-SG/Video-LLaMA/video_llama/runners/test.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/misc/fixedTools.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/misc/fixedTools.py
deleted file mode 100644
index 330042871c521231f2a396add543dd425783722b..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/misc/fixedTools.py
+++ /dev/null
@@ -1,253 +0,0 @@
-"""
-The `OpenType specification `_
-defines two fixed-point data types:
-
-``Fixed``
- A 32-bit signed fixed-point number with a 16 bit twos-complement
- magnitude component and 16 fractional bits.
-``F2DOT14``
- A 16-bit signed fixed-point number with a 2 bit twos-complement
- magnitude component and 14 fractional bits.
-
-To support reading and writing data with these data types, this module provides
-functions for converting between fixed-point, float and string representations.
-
-.. data:: MAX_F2DOT14
-
- The maximum value that can still fit in an F2Dot14. (1.99993896484375)
-"""
-
-from .roundTools import otRound, nearestMultipleShortestRepr
-import logging
-
-log = logging.getLogger(__name__)
-
-__all__ = [
- "MAX_F2DOT14",
- "fixedToFloat",
- "floatToFixed",
- "floatToFixedToFloat",
- "floatToFixedToStr",
- "fixedToStr",
- "strToFixed",
- "strToFixedToFloat",
- "ensureVersionIsLong",
- "versionToFixed",
-]
-
-
-MAX_F2DOT14 = 0x7FFF / (1 << 14)
-
-
-def fixedToFloat(value, precisionBits):
- """Converts a fixed-point number to a float given the number of
- precision bits.
-
- Args:
- value (int): Number in fixed-point format.
- precisionBits (int): Number of precision bits.
-
- Returns:
- Floating point value.
-
- Examples::
-
- >>> import math
- >>> f = fixedToFloat(-10139, precisionBits=14)
- >>> math.isclose(f, -0.61883544921875)
- True
- """
- return value / (1 << precisionBits)
-
-
-def floatToFixed(value, precisionBits):
- """Converts a float to a fixed-point number given the number of
- precision bits.
-
- Args:
- value (float): Floating point value.
- precisionBits (int): Number of precision bits.
-
- Returns:
- int: Fixed-point representation.
-
- Examples::
-
- >>> floatToFixed(-0.61883544921875, precisionBits=14)
- -10139
- >>> floatToFixed(-0.61884, precisionBits=14)
- -10139
- """
- return otRound(value * (1 << precisionBits))
-
-
-def floatToFixedToFloat(value, precisionBits):
- """Converts a float to a fixed-point number and back again.
-
- By converting the float to fixed, rounding it, and converting it back
- to float again, this returns a floating point values which is exactly
- representable in fixed-point format.
-
- Note: this **is** equivalent to ``fixedToFloat(floatToFixed(value))``.
-
- Args:
- value (float): The input floating point value.
- precisionBits (int): Number of precision bits.
-
- Returns:
- float: The transformed and rounded value.
-
- Examples::
- >>> import math
- >>> f1 = -0.61884
- >>> f2 = floatToFixedToFloat(-0.61884, precisionBits=14)
- >>> f1 != f2
- True
- >>> math.isclose(f2, -0.61883544921875)
- True
- """
- scale = 1 << precisionBits
- return otRound(value * scale) / scale
-
-
-def fixedToStr(value, precisionBits):
- """Converts a fixed-point number to a string representing a decimal float.
-
- This chooses the float that has the shortest decimal representation (the least
- number of fractional decimal digits).
-
- For example, to convert a fixed-point number in a 2.14 format, use
- ``precisionBits=14``::
-
- >>> fixedToStr(-10139, precisionBits=14)
- '-0.61884'
-
- This is pretty slow compared to the simple division used in ``fixedToFloat``.
- Use sporadically when you need to serialize or print the fixed-point number in
- a human-readable form.
- It uses nearestMultipleShortestRepr under the hood.
-
- Args:
- value (int): The fixed-point value to convert.
- precisionBits (int): Number of precision bits, *up to a maximum of 16*.
-
- Returns:
- str: A string representation of the value.
- """
- scale = 1 << precisionBits
- return nearestMultipleShortestRepr(value / scale, factor=1.0 / scale)
-
-
-def strToFixed(string, precisionBits):
- """Converts a string representing a decimal float to a fixed-point number.
-
- Args:
- string (str): A string representing a decimal float.
- precisionBits (int): Number of precision bits, *up to a maximum of 16*.
-
- Returns:
- int: Fixed-point representation.
-
- Examples::
-
- >>> ## to convert a float string to a 2.14 fixed-point number:
- >>> strToFixed('-0.61884', precisionBits=14)
- -10139
- """
- value = float(string)
- return otRound(value * (1 << precisionBits))
-
-
-def strToFixedToFloat(string, precisionBits):
- """Convert a string to a decimal float with fixed-point rounding.
-
- This first converts string to a float, then turns it into a fixed-point
- number with ``precisionBits`` fractional binary digits, then back to a
- float again.
-
- This is simply a shorthand for fixedToFloat(floatToFixed(float(s))).
-
- Args:
- string (str): A string representing a decimal float.
- precisionBits (int): Number of precision bits.
-
- Returns:
- float: The transformed and rounded value.
-
- Examples::
-
- >>> import math
- >>> s = '-0.61884'
- >>> bits = 14
- >>> f = strToFixedToFloat(s, precisionBits=bits)
- >>> math.isclose(f, -0.61883544921875)
- True
- >>> f == fixedToFloat(floatToFixed(float(s), precisionBits=bits), precisionBits=bits)
- True
- """
- value = float(string)
- scale = 1 << precisionBits
- return otRound(value * scale) / scale
-
-
-def floatToFixedToStr(value, precisionBits):
- """Convert float to string with fixed-point rounding.
-
- This uses the shortest decimal representation (ie. the least
- number of fractional decimal digits) to represent the equivalent
- fixed-point number with ``precisionBits`` fractional binary digits.
- It uses nearestMultipleShortestRepr under the hood.
-
- >>> floatToFixedToStr(-0.61883544921875, precisionBits=14)
- '-0.61884'
-
- Args:
- value (float): The float value to convert.
- precisionBits (int): Number of precision bits, *up to a maximum of 16*.
-
- Returns:
- str: A string representation of the value.
-
- """
- scale = 1 << precisionBits
- return nearestMultipleShortestRepr(value, factor=1.0 / scale)
-
-
-def ensureVersionIsLong(value):
- """Ensure a table version is an unsigned long.
-
- OpenType table version numbers are expressed as a single unsigned long
- comprising of an unsigned short major version and unsigned short minor
- version. This function detects if the value to be used as a version number
- looks too small (i.e. is less than ``0x10000``), and converts it to
- fixed-point using :func:`floatToFixed` if so.
-
- Args:
- value (Number): a candidate table version number.
-
- Returns:
- int: A table version number, possibly corrected to fixed-point.
- """
- if value < 0x10000:
- newValue = floatToFixed(value, 16)
- log.warning(
- "Table version value is a float: %.4f; " "fix to use hex instead: 0x%08x",
- value,
- newValue,
- )
- value = newValue
- return value
-
-
-def versionToFixed(value):
- """Ensure a table version number is fixed-point.
-
- Args:
- value (str): a candidate table version number.
-
- Returns:
- int: A table version number, possibly corrected to fixed-point.
- """
- value = int(value, 0) if value.startswith("0") else float(value)
- value = ensureVersionIsLong(value)
- return value
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/h11/tests/test_connection.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/h11/tests/test_connection.py
deleted file mode 100644
index 73a27b98bebd949cb3b99e19a3a8a484455b58d7..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/h11/tests/test_connection.py
+++ /dev/null
@@ -1,1122 +0,0 @@
-from typing import Any, cast, Dict, List, Optional, Tuple, Type
-
-import pytest
-
-from .._connection import _body_framing, _keep_alive, Connection, NEED_DATA, PAUSED
-from .._events import (
- ConnectionClosed,
- Data,
- EndOfMessage,
- Event,
- InformationalResponse,
- Request,
- Response,
-)
-from .._state import (
- CLIENT,
- CLOSED,
- DONE,
- ERROR,
- IDLE,
- MIGHT_SWITCH_PROTOCOL,
- MUST_CLOSE,
- SEND_BODY,
- SEND_RESPONSE,
- SERVER,
- SWITCHED_PROTOCOL,
-)
-from .._util import LocalProtocolError, RemoteProtocolError, Sentinel
-from .helpers import ConnectionPair, get_all_events, receive_and_get
-
-
-def test__keep_alive() -> None:
- assert _keep_alive(
- Request(method="GET", target="/", headers=[("Host", "Example.com")])
- )
- assert not _keep_alive(
- Request(
- method="GET",
- target="/",
- headers=[("Host", "Example.com"), ("Connection", "close")],
- )
- )
- assert not _keep_alive(
- Request(
- method="GET",
- target="/",
- headers=[("Host", "Example.com"), ("Connection", "a, b, cLOse, foo")],
- )
- )
- assert not _keep_alive(
- Request(method="GET", target="/", headers=[], http_version="1.0") # type: ignore[arg-type]
- )
-
- assert _keep_alive(Response(status_code=200, headers=[])) # type: ignore[arg-type]
- assert not _keep_alive(Response(status_code=200, headers=[("Connection", "close")]))
- assert not _keep_alive(
- Response(status_code=200, headers=[("Connection", "a, b, cLOse, foo")])
- )
- assert not _keep_alive(Response(status_code=200, headers=[], http_version="1.0")) # type: ignore[arg-type]
-
-
-def test__body_framing() -> None:
- def headers(cl: Optional[int], te: bool) -> List[Tuple[str, str]]:
- headers = []
- if cl is not None:
- headers.append(("Content-Length", str(cl)))
- if te:
- headers.append(("Transfer-Encoding", "chunked"))
- return headers
-
- def resp(
- status_code: int = 200, cl: Optional[int] = None, te: bool = False
- ) -> Response:
- return Response(status_code=status_code, headers=headers(cl, te))
-
- def req(cl: Optional[int] = None, te: bool = False) -> Request:
- h = headers(cl, te)
- h += [("Host", "example.com")]
- return Request(method="GET", target="/", headers=h)
-
- # Special cases where the headers are ignored:
- for kwargs in [{}, {"cl": 100}, {"te": True}, {"cl": 100, "te": True}]:
- kwargs = cast(Dict[str, Any], kwargs)
- for meth, r in [
- (b"HEAD", resp(**kwargs)),
- (b"GET", resp(status_code=204, **kwargs)),
- (b"GET", resp(status_code=304, **kwargs)),
- ]:
- assert _body_framing(meth, r) == ("content-length", (0,))
-
- # Transfer-encoding
- for kwargs in [{"te": True}, {"cl": 100, "te": True}]:
- kwargs = cast(Dict[str, Any], kwargs)
- for meth, r in [(None, req(**kwargs)), (b"GET", resp(**kwargs))]: # type: ignore
- assert _body_framing(meth, r) == ("chunked", ())
-
- # Content-Length
- for meth, r in [(None, req(cl=100)), (b"GET", resp(cl=100))]: # type: ignore
- assert _body_framing(meth, r) == ("content-length", (100,))
-
- # No headers
- assert _body_framing(None, req()) == ("content-length", (0,)) # type: ignore
- assert _body_framing(b"GET", resp()) == ("http/1.0", ())
-
-
-def test_Connection_basics_and_content_length() -> None:
- with pytest.raises(ValueError):
- Connection("CLIENT") # type: ignore
-
- p = ConnectionPair()
- assert p.conn[CLIENT].our_role is CLIENT
- assert p.conn[CLIENT].their_role is SERVER
- assert p.conn[SERVER].our_role is SERVER
- assert p.conn[SERVER].their_role is CLIENT
-
- data = p.send(
- CLIENT,
- Request(
- method="GET",
- target="/",
- headers=[("Host", "example.com"), ("Content-Length", "10")],
- ),
- )
- assert data == (
- b"GET / HTTP/1.1\r\n" b"Host: example.com\r\n" b"Content-Length: 10\r\n\r\n"
- )
-
- for conn in p.conns:
- assert conn.states == {CLIENT: SEND_BODY, SERVER: SEND_RESPONSE}
- assert p.conn[CLIENT].our_state is SEND_BODY
- assert p.conn[CLIENT].their_state is SEND_RESPONSE
- assert p.conn[SERVER].our_state is SEND_RESPONSE
- assert p.conn[SERVER].their_state is SEND_BODY
-
- assert p.conn[CLIENT].their_http_version is None
- assert p.conn[SERVER].their_http_version == b"1.1"
-
- data = p.send(SERVER, InformationalResponse(status_code=100, headers=[])) # type: ignore[arg-type]
- assert data == b"HTTP/1.1 100 \r\n\r\n"
-
- data = p.send(SERVER, Response(status_code=200, headers=[("Content-Length", "11")]))
- assert data == b"HTTP/1.1 200 \r\nContent-Length: 11\r\n\r\n"
-
- for conn in p.conns:
- assert conn.states == {CLIENT: SEND_BODY, SERVER: SEND_BODY}
-
- assert p.conn[CLIENT].their_http_version == b"1.1"
- assert p.conn[SERVER].their_http_version == b"1.1"
-
- data = p.send(CLIENT, Data(data=b"12345"))
- assert data == b"12345"
- data = p.send(
- CLIENT, Data(data=b"67890"), expect=[Data(data=b"67890"), EndOfMessage()]
- )
- assert data == b"67890"
- data = p.send(CLIENT, EndOfMessage(), expect=[])
- assert data == b""
-
- for conn in p.conns:
- assert conn.states == {CLIENT: DONE, SERVER: SEND_BODY}
-
- data = p.send(SERVER, Data(data=b"1234567890"))
- assert data == b"1234567890"
- data = p.send(SERVER, Data(data=b"1"), expect=[Data(data=b"1"), EndOfMessage()])
- assert data == b"1"
- data = p.send(SERVER, EndOfMessage(), expect=[])
- assert data == b""
-
- for conn in p.conns:
- assert conn.states == {CLIENT: DONE, SERVER: DONE}
-
-
-def test_chunked() -> None:
- p = ConnectionPair()
-
- p.send(
- CLIENT,
- Request(
- method="GET",
- target="/",
- headers=[("Host", "example.com"), ("Transfer-Encoding", "chunked")],
- ),
- )
- data = p.send(CLIENT, Data(data=b"1234567890", chunk_start=True, chunk_end=True))
- assert data == b"a\r\n1234567890\r\n"
- data = p.send(CLIENT, Data(data=b"abcde", chunk_start=True, chunk_end=True))
- assert data == b"5\r\nabcde\r\n"
- data = p.send(CLIENT, Data(data=b""), expect=[])
- assert data == b""
- data = p.send(CLIENT, EndOfMessage(headers=[("hello", "there")]))
- assert data == b"0\r\nhello: there\r\n\r\n"
-
- p.send(
- SERVER, Response(status_code=200, headers=[("Transfer-Encoding", "chunked")])
- )
- p.send(SERVER, Data(data=b"54321", chunk_start=True, chunk_end=True))
- p.send(SERVER, Data(data=b"12345", chunk_start=True, chunk_end=True))
- p.send(SERVER, EndOfMessage())
-
- for conn in p.conns:
- assert conn.states == {CLIENT: DONE, SERVER: DONE}
-
-
-def test_chunk_boundaries() -> None:
- conn = Connection(our_role=SERVER)
-
- request = (
- b"POST / HTTP/1.1\r\n"
- b"Host: example.com\r\n"
- b"Transfer-Encoding: chunked\r\n"
- b"\r\n"
- )
- conn.receive_data(request)
- assert conn.next_event() == Request(
- method="POST",
- target="/",
- headers=[("Host", "example.com"), ("Transfer-Encoding", "chunked")],
- )
- assert conn.next_event() is NEED_DATA
-
- conn.receive_data(b"5\r\nhello\r\n")
- assert conn.next_event() == Data(data=b"hello", chunk_start=True, chunk_end=True)
-
- conn.receive_data(b"5\r\nhel")
- assert conn.next_event() == Data(data=b"hel", chunk_start=True, chunk_end=False)
-
- conn.receive_data(b"l")
- assert conn.next_event() == Data(data=b"l", chunk_start=False, chunk_end=False)
-
- conn.receive_data(b"o\r\n")
- assert conn.next_event() == Data(data=b"o", chunk_start=False, chunk_end=True)
-
- conn.receive_data(b"5\r\nhello")
- assert conn.next_event() == Data(data=b"hello", chunk_start=True, chunk_end=True)
-
- conn.receive_data(b"\r\n")
- assert conn.next_event() == NEED_DATA
-
- conn.receive_data(b"0\r\n\r\n")
- assert conn.next_event() == EndOfMessage()
-
-
-def test_client_talking_to_http10_server() -> None:
- c = Connection(CLIENT)
- c.send(Request(method="GET", target="/", headers=[("Host", "example.com")]))
- c.send(EndOfMessage())
- assert c.our_state is DONE
- # No content-length, so Http10 framing for body
- assert receive_and_get(c, b"HTTP/1.0 200 OK\r\n\r\n") == [
- Response(status_code=200, headers=[], http_version="1.0", reason=b"OK") # type: ignore[arg-type]
- ]
- assert c.our_state is MUST_CLOSE
- assert receive_and_get(c, b"12345") == [Data(data=b"12345")]
- assert receive_and_get(c, b"67890") == [Data(data=b"67890")]
- assert receive_and_get(c, b"") == [EndOfMessage(), ConnectionClosed()]
- assert c.their_state is CLOSED
-
-
-def test_server_talking_to_http10_client() -> None:
- c = Connection(SERVER)
- # No content-length, so no body
- # NB: no host header
- assert receive_and_get(c, b"GET / HTTP/1.0\r\n\r\n") == [
- Request(method="GET", target="/", headers=[], http_version="1.0"), # type: ignore[arg-type]
- EndOfMessage(),
- ]
- assert c.their_state is MUST_CLOSE
-
- # We automatically Connection: close back at them
- assert (
- c.send(Response(status_code=200, headers=[])) # type: ignore[arg-type]
- == b"HTTP/1.1 200 \r\nConnection: close\r\n\r\n"
- )
-
- assert c.send(Data(data=b"12345")) == b"12345"
- assert c.send(EndOfMessage()) == b""
- assert c.our_state is MUST_CLOSE
-
- # Check that it works if they do send Content-Length
- c = Connection(SERVER)
- # NB: no host header
- assert receive_and_get(c, b"POST / HTTP/1.0\r\nContent-Length: 10\r\n\r\n1") == [
- Request(
- method="POST",
- target="/",
- headers=[("Content-Length", "10")],
- http_version="1.0",
- ),
- Data(data=b"1"),
- ]
- assert receive_and_get(c, b"234567890") == [Data(data=b"234567890"), EndOfMessage()]
- assert c.their_state is MUST_CLOSE
- assert receive_and_get(c, b"") == [ConnectionClosed()]
-
-
-def test_automatic_transfer_encoding_in_response() -> None:
- # Check that in responses, the user can specify either Transfer-Encoding:
- # chunked or no framing at all, and in both cases we automatically select
- # the right option depending on whether the peer speaks HTTP/1.0 or
- # HTTP/1.1
- for user_headers in [
- [("Transfer-Encoding", "chunked")],
- [],
- # In fact, this even works if Content-Length is set,
- # because if both are set then Transfer-Encoding wins
- [("Transfer-Encoding", "chunked"), ("Content-Length", "100")],
- ]:
- user_headers = cast(List[Tuple[str, str]], user_headers)
- p = ConnectionPair()
- p.send(
- CLIENT,
- [
- Request(method="GET", target="/", headers=[("Host", "example.com")]),
- EndOfMessage(),
- ],
- )
- # When speaking to HTTP/1.1 client, all of the above cases get
- # normalized to Transfer-Encoding: chunked
- p.send(
- SERVER,
- Response(status_code=200, headers=user_headers),
- expect=Response(
- status_code=200, headers=[("Transfer-Encoding", "chunked")]
- ),
- )
-
- # When speaking to HTTP/1.0 client, all of the above cases get
- # normalized to no-framing-headers
- c = Connection(SERVER)
- receive_and_get(c, b"GET / HTTP/1.0\r\n\r\n")
- assert (
- c.send(Response(status_code=200, headers=user_headers))
- == b"HTTP/1.1 200 \r\nConnection: close\r\n\r\n"
- )
- assert c.send(Data(data=b"12345")) == b"12345"
-
-
-def test_automagic_connection_close_handling() -> None:
- p = ConnectionPair()
- # If the user explicitly sets Connection: close, then we notice and
- # respect it
- p.send(
- CLIENT,
- [
- Request(
- method="GET",
- target="/",
- headers=[("Host", "example.com"), ("Connection", "close")],
- ),
- EndOfMessage(),
- ],
- )
- for conn in p.conns:
- assert conn.states[CLIENT] is MUST_CLOSE
- # And if the client sets it, the server automatically echoes it back
- p.send(
- SERVER,
- # no header here...
- [Response(status_code=204, headers=[]), EndOfMessage()], # type: ignore[arg-type]
- # ...but oh look, it arrived anyway
- expect=[
- Response(status_code=204, headers=[("connection", "close")]),
- EndOfMessage(),
- ],
- )
- for conn in p.conns:
- assert conn.states == {CLIENT: MUST_CLOSE, SERVER: MUST_CLOSE}
-
-
-def test_100_continue() -> None:
- def setup() -> ConnectionPair:
- p = ConnectionPair()
- p.send(
- CLIENT,
- Request(
- method="GET",
- target="/",
- headers=[
- ("Host", "example.com"),
- ("Content-Length", "100"),
- ("Expect", "100-continue"),
- ],
- ),
- )
- for conn in p.conns:
- assert conn.client_is_waiting_for_100_continue
- assert not p.conn[CLIENT].they_are_waiting_for_100_continue
- assert p.conn[SERVER].they_are_waiting_for_100_continue
- return p
-
- # Disabled by 100 Continue
- p = setup()
- p.send(SERVER, InformationalResponse(status_code=100, headers=[])) # type: ignore[arg-type]
- for conn in p.conns:
- assert not conn.client_is_waiting_for_100_continue
- assert not conn.they_are_waiting_for_100_continue
-
- # Disabled by a real response
- p = setup()
- p.send(
- SERVER, Response(status_code=200, headers=[("Transfer-Encoding", "chunked")])
- )
- for conn in p.conns:
- assert not conn.client_is_waiting_for_100_continue
- assert not conn.they_are_waiting_for_100_continue
-
- # Disabled by the client going ahead and sending stuff anyway
- p = setup()
- p.send(CLIENT, Data(data=b"12345"))
- for conn in p.conns:
- assert not conn.client_is_waiting_for_100_continue
- assert not conn.they_are_waiting_for_100_continue
-
-
-def test_max_incomplete_event_size_countermeasure() -> None:
- # Infinitely long headers are definitely not okay
- c = Connection(SERVER)
- c.receive_data(b"GET / HTTP/1.0\r\nEndless: ")
- assert c.next_event() is NEED_DATA
- with pytest.raises(RemoteProtocolError):
- while True:
- c.receive_data(b"a" * 1024)
- c.next_event()
-
- # Checking that the same header is accepted / rejected depending on the
- # max_incomplete_event_size setting:
- c = Connection(SERVER, max_incomplete_event_size=5000)
- c.receive_data(b"GET / HTTP/1.0\r\nBig: ")
- c.receive_data(b"a" * 4000)
- c.receive_data(b"\r\n\r\n")
- assert get_all_events(c) == [
- Request(
- method="GET", target="/", http_version="1.0", headers=[("big", "a" * 4000)]
- ),
- EndOfMessage(),
- ]
-
- c = Connection(SERVER, max_incomplete_event_size=4000)
- c.receive_data(b"GET / HTTP/1.0\r\nBig: ")
- c.receive_data(b"a" * 4000)
- with pytest.raises(RemoteProtocolError):
- c.next_event()
-
- # Temporarily exceeding the size limit is fine, as long as its done with
- # complete events:
- c = Connection(SERVER, max_incomplete_event_size=5000)
- c.receive_data(b"GET / HTTP/1.0\r\nContent-Length: 10000")
- c.receive_data(b"\r\n\r\n" + b"a" * 10000)
- assert get_all_events(c) == [
- Request(
- method="GET",
- target="/",
- http_version="1.0",
- headers=[("Content-Length", "10000")],
- ),
- Data(data=b"a" * 10000),
- EndOfMessage(),
- ]
-
- c = Connection(SERVER, max_incomplete_event_size=100)
- # Two pipelined requests to create a way-too-big receive buffer... but
- # it's fine because we're not checking
- c.receive_data(
- b"GET /1 HTTP/1.1\r\nHost: a\r\n\r\n"
- b"GET /2 HTTP/1.1\r\nHost: b\r\n\r\n" + b"X" * 1000
- )
- assert get_all_events(c) == [
- Request(method="GET", target="/1", headers=[("host", "a")]),
- EndOfMessage(),
- ]
- # Even more data comes in, still no problem
- c.receive_data(b"X" * 1000)
- # We can respond and reuse to get the second pipelined request
- c.send(Response(status_code=200, headers=[])) # type: ignore[arg-type]
- c.send(EndOfMessage())
- c.start_next_cycle()
- assert get_all_events(c) == [
- Request(method="GET", target="/2", headers=[("host", "b")]),
- EndOfMessage(),
- ]
- # But once we unpause and try to read the next message, and find that it's
- # incomplete and the buffer is *still* way too large, then *that's* a
- # problem:
- c.send(Response(status_code=200, headers=[])) # type: ignore[arg-type]
- c.send(EndOfMessage())
- c.start_next_cycle()
- with pytest.raises(RemoteProtocolError):
- c.next_event()
-
-
-def test_reuse_simple() -> None:
- p = ConnectionPair()
- p.send(
- CLIENT,
- [Request(method="GET", target="/", headers=[("Host", "a")]), EndOfMessage()],
- )
- p.send(
- SERVER,
- [
- Response(status_code=200, headers=[(b"transfer-encoding", b"chunked")]),
- EndOfMessage(),
- ],
- )
- for conn in p.conns:
- assert conn.states == {CLIENT: DONE, SERVER: DONE}
- conn.start_next_cycle()
-
- p.send(
- CLIENT,
- [
- Request(method="DELETE", target="/foo", headers=[("Host", "a")]),
- EndOfMessage(),
- ],
- )
- p.send(
- SERVER,
- [
- Response(status_code=404, headers=[(b"transfer-encoding", b"chunked")]),
- EndOfMessage(),
- ],
- )
-
-
-def test_pipelining() -> None:
- # Client doesn't support pipelining, so we have to do this by hand
- c = Connection(SERVER)
- assert c.next_event() is NEED_DATA
- # 3 requests all bunched up
- c.receive_data(
- b"GET /1 HTTP/1.1\r\nHost: a.com\r\nContent-Length: 5\r\n\r\n"
- b"12345"
- b"GET /2 HTTP/1.1\r\nHost: a.com\r\nContent-Length: 5\r\n\r\n"
- b"67890"
- b"GET /3 HTTP/1.1\r\nHost: a.com\r\n\r\n"
- )
- assert get_all_events(c) == [
- Request(
- method="GET",
- target="/1",
- headers=[("Host", "a.com"), ("Content-Length", "5")],
- ),
- Data(data=b"12345"),
- EndOfMessage(),
- ]
- assert c.their_state is DONE
- assert c.our_state is SEND_RESPONSE
-
- assert c.next_event() is PAUSED
-
- c.send(Response(status_code=200, headers=[])) # type: ignore[arg-type]
- c.send(EndOfMessage())
- assert c.their_state is DONE
- assert c.our_state is DONE
-
- c.start_next_cycle()
-
- assert get_all_events(c) == [
- Request(
- method="GET",
- target="/2",
- headers=[("Host", "a.com"), ("Content-Length", "5")],
- ),
- Data(data=b"67890"),
- EndOfMessage(),
- ]
- assert c.next_event() is PAUSED
- c.send(Response(status_code=200, headers=[])) # type: ignore[arg-type]
- c.send(EndOfMessage())
- c.start_next_cycle()
-
- assert get_all_events(c) == [
- Request(method="GET", target="/3", headers=[("Host", "a.com")]),
- EndOfMessage(),
- ]
- # Doesn't pause this time, no trailing data
- assert c.next_event() is NEED_DATA
- c.send(Response(status_code=200, headers=[])) # type: ignore[arg-type]
- c.send(EndOfMessage())
-
- # Arrival of more data triggers pause
- assert c.next_event() is NEED_DATA
- c.receive_data(b"SADF")
- assert c.next_event() is PAUSED
- assert c.trailing_data == (b"SADF", False)
- # If EOF arrives while paused, we don't see that either:
- c.receive_data(b"")
- assert c.trailing_data == (b"SADF", True)
- assert c.next_event() is PAUSED
- c.receive_data(b"")
- assert c.next_event() is PAUSED
- # Can't call receive_data with non-empty buf after closing it
- with pytest.raises(RuntimeError):
- c.receive_data(b"FDSA")
-
-
-def test_protocol_switch() -> None:
- for (req, deny, accept) in [
- (
- Request(
- method="CONNECT",
- target="example.com:443",
- headers=[("Host", "foo"), ("Content-Length", "1")],
- ),
- Response(status_code=404, headers=[(b"transfer-encoding", b"chunked")]),
- Response(status_code=200, headers=[(b"transfer-encoding", b"chunked")]),
- ),
- (
- Request(
- method="GET",
- target="/",
- headers=[("Host", "foo"), ("Content-Length", "1"), ("Upgrade", "a, b")],
- ),
- Response(status_code=200, headers=[(b"transfer-encoding", b"chunked")]),
- InformationalResponse(status_code=101, headers=[("Upgrade", "a")]),
- ),
- (
- Request(
- method="CONNECT",
- target="example.com:443",
- headers=[("Host", "foo"), ("Content-Length", "1"), ("Upgrade", "a, b")],
- ),
- Response(status_code=404, headers=[(b"transfer-encoding", b"chunked")]),
- # Accept CONNECT, not upgrade
- Response(status_code=200, headers=[(b"transfer-encoding", b"chunked")]),
- ),
- (
- Request(
- method="CONNECT",
- target="example.com:443",
- headers=[("Host", "foo"), ("Content-Length", "1"), ("Upgrade", "a, b")],
- ),
- Response(status_code=404, headers=[(b"transfer-encoding", b"chunked")]),
- # Accept Upgrade, not CONNECT
- InformationalResponse(status_code=101, headers=[("Upgrade", "b")]),
- ),
- ]:
-
- def setup() -> ConnectionPair:
- p = ConnectionPair()
- p.send(CLIENT, req)
- # No switch-related state change stuff yet; the client has to
- # finish the request before that kicks in
- for conn in p.conns:
- assert conn.states[CLIENT] is SEND_BODY
- p.send(CLIENT, [Data(data=b"1"), EndOfMessage()])
- for conn in p.conns:
- assert conn.states[CLIENT] is MIGHT_SWITCH_PROTOCOL
- assert p.conn[SERVER].next_event() is PAUSED
- return p
-
- # Test deny case
- p = setup()
- p.send(SERVER, deny)
- for conn in p.conns:
- assert conn.states == {CLIENT: DONE, SERVER: SEND_BODY}
- p.send(SERVER, EndOfMessage())
- # Check that re-use is still allowed after a denial
- for conn in p.conns:
- conn.start_next_cycle()
-
- # Test accept case
- p = setup()
- p.send(SERVER, accept)
- for conn in p.conns:
- assert conn.states == {CLIENT: SWITCHED_PROTOCOL, SERVER: SWITCHED_PROTOCOL}
- conn.receive_data(b"123")
- assert conn.next_event() is PAUSED
- conn.receive_data(b"456")
- assert conn.next_event() is PAUSED
- assert conn.trailing_data == (b"123456", False)
-
- # Pausing in might-switch, then recovery
- # (weird artificial case where the trailing data actually is valid
- # HTTP for some reason, because this makes it easier to test the state
- # logic)
- p = setup()
- sc = p.conn[SERVER]
- sc.receive_data(b"GET / HTTP/1.0\r\n\r\n")
- assert sc.next_event() is PAUSED
- assert sc.trailing_data == (b"GET / HTTP/1.0\r\n\r\n", False)
- sc.send(deny)
- assert sc.next_event() is PAUSED
- sc.send(EndOfMessage())
- sc.start_next_cycle()
- assert get_all_events(sc) == [
- Request(method="GET", target="/", headers=[], http_version="1.0"), # type: ignore[arg-type]
- EndOfMessage(),
- ]
-
- # When we're DONE, have no trailing data, and the connection gets
- # closed, we report ConnectionClosed(). When we're in might-switch or
- # switched, we don't.
- p = setup()
- sc = p.conn[SERVER]
- sc.receive_data(b"")
- assert sc.next_event() is PAUSED
- assert sc.trailing_data == (b"", True)
- p.send(SERVER, accept)
- assert sc.next_event() is PAUSED
-
- p = setup()
- sc = p.conn[SERVER]
- sc.receive_data(b"")
- assert sc.next_event() is PAUSED
- sc.send(deny)
- assert sc.next_event() == ConnectionClosed()
-
- # You can't send after switching protocols, or while waiting for a
- # protocol switch
- p = setup()
- with pytest.raises(LocalProtocolError):
- p.conn[CLIENT].send(
- Request(method="GET", target="/", headers=[("Host", "a")])
- )
- p = setup()
- p.send(SERVER, accept)
- with pytest.raises(LocalProtocolError):
- p.conn[SERVER].send(Data(data=b"123"))
-
-
-def test_close_simple() -> None:
- # Just immediately closing a new connection without anything having
- # happened yet.
- for (who_shot_first, who_shot_second) in [(CLIENT, SERVER), (SERVER, CLIENT)]:
-
- def setup() -> ConnectionPair:
- p = ConnectionPair()
- p.send(who_shot_first, ConnectionClosed())
- for conn in p.conns:
- assert conn.states == {
- who_shot_first: CLOSED,
- who_shot_second: MUST_CLOSE,
- }
- return p
-
- # You can keep putting b"" into a closed connection, and you keep
- # getting ConnectionClosed() out:
- p = setup()
- assert p.conn[who_shot_second].next_event() == ConnectionClosed()
- assert p.conn[who_shot_second].next_event() == ConnectionClosed()
- p.conn[who_shot_second].receive_data(b"")
- assert p.conn[who_shot_second].next_event() == ConnectionClosed()
- # Second party can close...
- p = setup()
- p.send(who_shot_second, ConnectionClosed())
- for conn in p.conns:
- assert conn.our_state is CLOSED
- assert conn.their_state is CLOSED
- # But trying to receive new data on a closed connection is a
- # RuntimeError (not ProtocolError, because the problem here isn't
- # violation of HTTP, it's violation of physics)
- p = setup()
- with pytest.raises(RuntimeError):
- p.conn[who_shot_second].receive_data(b"123")
- # And receiving new data on a MUST_CLOSE connection is a ProtocolError
- p = setup()
- p.conn[who_shot_first].receive_data(b"GET")
- with pytest.raises(RemoteProtocolError):
- p.conn[who_shot_first].next_event()
-
-
-def test_close_different_states() -> None:
- req = [
- Request(method="GET", target="/foo", headers=[("Host", "a")]),
- EndOfMessage(),
- ]
- resp = [
- Response(status_code=200, headers=[(b"transfer-encoding", b"chunked")]),
- EndOfMessage(),
- ]
-
- # Client before request
- p = ConnectionPair()
- p.send(CLIENT, ConnectionClosed())
- for conn in p.conns:
- assert conn.states == {CLIENT: CLOSED, SERVER: MUST_CLOSE}
-
- # Client after request
- p = ConnectionPair()
- p.send(CLIENT, req)
- p.send(CLIENT, ConnectionClosed())
- for conn in p.conns:
- assert conn.states == {CLIENT: CLOSED, SERVER: SEND_RESPONSE}
-
- # Server after request -> not allowed
- p = ConnectionPair()
- p.send(CLIENT, req)
- with pytest.raises(LocalProtocolError):
- p.conn[SERVER].send(ConnectionClosed())
- p.conn[CLIENT].receive_data(b"")
- with pytest.raises(RemoteProtocolError):
- p.conn[CLIENT].next_event()
-
- # Server after response
- p = ConnectionPair()
- p.send(CLIENT, req)
- p.send(SERVER, resp)
- p.send(SERVER, ConnectionClosed())
- for conn in p.conns:
- assert conn.states == {CLIENT: MUST_CLOSE, SERVER: CLOSED}
-
- # Both after closing (ConnectionClosed() is idempotent)
- p = ConnectionPair()
- p.send(CLIENT, req)
- p.send(SERVER, resp)
- p.send(CLIENT, ConnectionClosed())
- p.send(SERVER, ConnectionClosed())
- p.send(CLIENT, ConnectionClosed())
- p.send(SERVER, ConnectionClosed())
-
- # In the middle of sending -> not allowed
- p = ConnectionPair()
- p.send(
- CLIENT,
- Request(
- method="GET", target="/", headers=[("Host", "a"), ("Content-Length", "10")]
- ),
- )
- with pytest.raises(LocalProtocolError):
- p.conn[CLIENT].send(ConnectionClosed())
- p.conn[SERVER].receive_data(b"")
- with pytest.raises(RemoteProtocolError):
- p.conn[SERVER].next_event()
-
-
-# Receive several requests and then client shuts down their side of the
-# connection; we can respond to each
-def test_pipelined_close() -> None:
- c = Connection(SERVER)
- # 2 requests then a close
- c.receive_data(
- b"GET /1 HTTP/1.1\r\nHost: a.com\r\nContent-Length: 5\r\n\r\n"
- b"12345"
- b"GET /2 HTTP/1.1\r\nHost: a.com\r\nContent-Length: 5\r\n\r\n"
- b"67890"
- )
- c.receive_data(b"")
- assert get_all_events(c) == [
- Request(
- method="GET",
- target="/1",
- headers=[("host", "a.com"), ("content-length", "5")],
- ),
- Data(data=b"12345"),
- EndOfMessage(),
- ]
- assert c.states[CLIENT] is DONE
- c.send(Response(status_code=200, headers=[])) # type: ignore[arg-type]
- c.send(EndOfMessage())
- assert c.states[SERVER] is DONE
- c.start_next_cycle()
- assert get_all_events(c) == [
- Request(
- method="GET",
- target="/2",
- headers=[("host", "a.com"), ("content-length", "5")],
- ),
- Data(data=b"67890"),
- EndOfMessage(),
- ConnectionClosed(),
- ]
- assert c.states == {CLIENT: CLOSED, SERVER: SEND_RESPONSE}
- c.send(Response(status_code=200, headers=[])) # type: ignore[arg-type]
- c.send(EndOfMessage())
- assert c.states == {CLIENT: CLOSED, SERVER: MUST_CLOSE}
- c.send(ConnectionClosed())
- assert c.states == {CLIENT: CLOSED, SERVER: CLOSED}
-
-
-def test_sendfile() -> None:
- class SendfilePlaceholder:
- def __len__(self) -> int:
- return 10
-
- placeholder = SendfilePlaceholder()
-
- def setup(
- header: Tuple[str, str], http_version: str
- ) -> Tuple[Connection, Optional[List[bytes]]]:
- c = Connection(SERVER)
- receive_and_get(
- c, "GET / HTTP/{}\r\nHost: a\r\n\r\n".format(http_version).encode("ascii")
- )
- headers = []
- if header:
- headers.append(header)
- c.send(Response(status_code=200, headers=headers))
- return c, c.send_with_data_passthrough(Data(data=placeholder)) # type: ignore
-
- c, data = setup(("Content-Length", "10"), "1.1")
- assert data == [placeholder] # type: ignore
- # Raises an error if the connection object doesn't think we've sent
- # exactly 10 bytes
- c.send(EndOfMessage())
-
- _, data = setup(("Transfer-Encoding", "chunked"), "1.1")
- assert placeholder in data # type: ignore
- data[data.index(placeholder)] = b"x" * 10 # type: ignore
- assert b"".join(data) == b"a\r\nxxxxxxxxxx\r\n" # type: ignore
-
- c, data = setup(None, "1.0") # type: ignore
- assert data == [placeholder] # type: ignore
- assert c.our_state is SEND_BODY
-
-
-def test_errors() -> None:
- # After a receive error, you can't receive
- for role in [CLIENT, SERVER]:
- c = Connection(our_role=role)
- c.receive_data(b"gibberish\r\n\r\n")
- with pytest.raises(RemoteProtocolError):
- c.next_event()
- # Now any attempt to receive continues to raise
- assert c.their_state is ERROR
- assert c.our_state is not ERROR
- print(c._cstate.states)
- with pytest.raises(RemoteProtocolError):
- c.next_event()
- # But we can still yell at the client for sending us gibberish
- if role is SERVER:
- assert (
- c.send(Response(status_code=400, headers=[])) # type: ignore[arg-type]
- == b"HTTP/1.1 400 \r\nConnection: close\r\n\r\n"
- )
-
- # After an error sending, you can no longer send
- # (This is especially important for things like content-length errors,
- # where there's complex internal state being modified)
- def conn(role: Type[Sentinel]) -> Connection:
- c = Connection(our_role=role)
- if role is SERVER:
- # Put it into the state where it *could* send a response...
- receive_and_get(c, b"GET / HTTP/1.0\r\n\r\n")
- assert c.our_state is SEND_RESPONSE
- return c
-
- for role in [CLIENT, SERVER]:
- if role is CLIENT:
- # This HTTP/1.0 request won't be detected as bad until after we go
- # through the state machine and hit the writing code
- good = Request(method="GET", target="/", headers=[("Host", "example.com")])
- bad = Request(
- method="GET",
- target="/",
- headers=[("Host", "example.com")],
- http_version="1.0",
- )
- elif role is SERVER:
- good = Response(status_code=200, headers=[]) # type: ignore[arg-type,assignment]
- bad = Response(status_code=200, headers=[], http_version="1.0") # type: ignore[arg-type,assignment]
- # Make sure 'good' actually is good
- c = conn(role)
- c.send(good)
- assert c.our_state is not ERROR
- # Do that again, but this time sending 'bad' first
- c = conn(role)
- with pytest.raises(LocalProtocolError):
- c.send(bad)
- assert c.our_state is ERROR
- assert c.their_state is not ERROR
- # Now 'good' is not so good
- with pytest.raises(LocalProtocolError):
- c.send(good)
-
- # And check send_failed() too
- c = conn(role)
- c.send_failed()
- assert c.our_state is ERROR
- assert c.their_state is not ERROR
- # This is idempotent
- c.send_failed()
- assert c.our_state is ERROR
- assert c.their_state is not ERROR
-
-
-def test_idle_receive_nothing() -> None:
- # At one point this incorrectly raised an error
- for role in [CLIENT, SERVER]:
- c = Connection(role)
- assert c.next_event() is NEED_DATA
-
-
-def test_connection_drop() -> None:
- c = Connection(SERVER)
- c.receive_data(b"GET /")
- assert c.next_event() is NEED_DATA
- c.receive_data(b"")
- with pytest.raises(RemoteProtocolError):
- c.next_event()
-
-
-def test_408_request_timeout() -> None:
- # Should be able to send this spontaneously as a server without seeing
- # anything from client
- p = ConnectionPair()
- p.send(SERVER, Response(status_code=408, headers=[(b"connection", b"close")]))
-
-
-# This used to raise IndexError
-def test_empty_request() -> None:
- c = Connection(SERVER)
- c.receive_data(b"\r\n")
- with pytest.raises(RemoteProtocolError):
- c.next_event()
-
-
-# This used to raise IndexError
-def test_empty_response() -> None:
- c = Connection(CLIENT)
- c.send(Request(method="GET", target="/", headers=[("Host", "a")]))
- c.receive_data(b"\r\n")
- with pytest.raises(RemoteProtocolError):
- c.next_event()
-
-
-@pytest.mark.parametrize(
- "data",
- [
- b"\x00",
- b"\x20",
- b"\x16\x03\x01\x00\xa5", # Typical start of a TLS Client Hello
- ],
-)
-def test_early_detection_of_invalid_request(data: bytes) -> None:
- c = Connection(SERVER)
- # Early detection should occur before even receiving a `\r\n`
- c.receive_data(data)
- with pytest.raises(RemoteProtocolError):
- c.next_event()
-
-
-@pytest.mark.parametrize(
- "data",
- [
- b"\x00",
- b"\x20",
- b"\x16\x03\x03\x00\x31", # Typical start of a TLS Server Hello
- ],
-)
-def test_early_detection_of_invalid_response(data: bytes) -> None:
- c = Connection(CLIENT)
- # Early detection should occur before even receiving a `\r\n`
- c.receive_data(data)
- with pytest.raises(RemoteProtocolError):
- c.next_event()
-
-
-# This used to give different headers for HEAD and GET.
-# The correct way to handle HEAD is to put whatever headers we *would* have
-# put if it were a GET -- even though we know that for HEAD, those headers
-# will be ignored.
-def test_HEAD_framing_headers() -> None:
- def setup(method: bytes, http_version: bytes) -> Connection:
- c = Connection(SERVER)
- c.receive_data(
- method + b" / HTTP/" + http_version + b"\r\n" + b"Host: example.com\r\n\r\n"
- )
- assert type(c.next_event()) is Request
- assert type(c.next_event()) is EndOfMessage
- return c
-
- for method in [b"GET", b"HEAD"]:
- # No Content-Length, HTTP/1.1 peer, should use chunked
- c = setup(method, b"1.1")
- assert (
- c.send(Response(status_code=200, headers=[])) == b"HTTP/1.1 200 \r\n" # type: ignore[arg-type]
- b"Transfer-Encoding: chunked\r\n\r\n"
- )
-
- # No Content-Length, HTTP/1.0 peer, frame with connection: close
- c = setup(method, b"1.0")
- assert (
- c.send(Response(status_code=200, headers=[])) == b"HTTP/1.1 200 \r\n" # type: ignore[arg-type]
- b"Connection: close\r\n\r\n"
- )
-
- # Content-Length + Transfer-Encoding, TE wins
- c = setup(method, b"1.1")
- assert (
- c.send(
- Response(
- status_code=200,
- headers=[
- ("Content-Length", "100"),
- ("Transfer-Encoding", "chunked"),
- ],
- )
- )
- == b"HTTP/1.1 200 \r\n"
- b"Transfer-Encoding: chunked\r\n\r\n"
- )
-
-
-def test_special_exceptions_for_lost_connection_in_message_body() -> None:
- c = Connection(SERVER)
- c.receive_data(
- b"POST / HTTP/1.1\r\n" b"Host: example.com\r\n" b"Content-Length: 100\r\n\r\n"
- )
- assert type(c.next_event()) is Request
- assert c.next_event() is NEED_DATA
- c.receive_data(b"12345")
- assert c.next_event() == Data(data=b"12345")
- c.receive_data(b"")
- with pytest.raises(RemoteProtocolError) as excinfo:
- c.next_event()
- assert "received 5 bytes" in str(excinfo.value)
- assert "expected 100" in str(excinfo.value)
-
- c = Connection(SERVER)
- c.receive_data(
- b"POST / HTTP/1.1\r\n"
- b"Host: example.com\r\n"
- b"Transfer-Encoding: chunked\r\n\r\n"
- )
- assert type(c.next_event()) is Request
- assert c.next_event() is NEED_DATA
- c.receive_data(b"8\r\n012345")
- assert c.next_event().data == b"012345" # type: ignore
- c.receive_data(b"")
- with pytest.raises(RemoteProtocolError) as excinfo:
- c.next_event()
- assert "incomplete chunked read" in str(excinfo.value)
diff --git a/spaces/Dagfinn1962/prodia2/play.py b/spaces/Dagfinn1962/prodia2/play.py
deleted file mode 100644
index 242f19c417ae80f983aff123dccfab2d2720eaee..0000000000000000000000000000000000000000
--- a/spaces/Dagfinn1962/prodia2/play.py
+++ /dev/null
@@ -1,82 +0,0 @@
-import ast
-import requests
-
-#Using Gradio Demos as API - This is Hot!
-API_URL_INITIAL = "https://ysharma-playground-ai-exploration.hf.space/run/initial_dataframe"
-API_URL_NEXT10 = "https://ysharma-playground-ai-exploration.hf.space/run/next_10_rows"
-
-#define inference function
-#First: Get initial images for the grid display
-def get_initial_images():
- response = requests.post(API_URL_INITIAL, json={
- "data": []
- }).json()
- #data = response["data"][0]['data'][0][0][:-1]
- response_dict = response['data'][0]
- return response_dict #, [resp[0][:-1] for resp in response["data"][0]["data"]]
-
-#Second: Process response dictionary to get imges as hyperlinked image tags
-def process_response(response_dict):
- return [resp[0][:-1] for resp in response_dict["data"]]
-
-response_dict = get_initial_images()
-initial = process_response(response_dict)
-initial_imgs = '\n' + "\n".join(initial[:-1])
-
-#Third: Load more images for the grid
-def get_next10_images(response_dict, row_count):
- row_count = int(row_count)
- #print("(1)",type(response_dict))
- #Convert the string to a dictionary
- if isinstance(response_dict, dict) == False :
- response_dict = ast.literal_eval(response_dict)
- response = requests.post(API_URL_NEXT10, json={
- "data": [response_dict, row_count ] #len(initial)-1
- }).json()
- row_count+=10
- response_dict = response['data'][0]
- #print("(2)",type(response))
- #print("(3)",type(response['data'][0]))
- next_set = [resp[0][:-1] for resp in response_dict["data"]]
- next_set_images = ' \n' + "\n".join(next_set[:-1])
- return response_dict, row_count, next_set_images #response['data'][0]
-
-#get_next10_images(response_dict=response_dict, row_count=9)
-#position: fixed; top: 0; left: 0; width: 100%; background-color: #fff; padding: 20px; box-shadow: 0 5px 10px rgba(0, 0, 0, 0.2);
-
-#Defining the Blocks layout
-with gr.Blocks(css = """#img_search img {width: 100%; height: 100%; object-fit: cover;}""") as demo:
- gr.HTML(value="top of page", elem_id="top",visible=False)
- gr.HTML("""
-
-
- Using Gradio Demos as API - 2
- """)
- with gr.Accordion(label="Details about the working:", open=False, elem_id='accordion'):
- gr.HTML("""
-
- ▶️Do you see the "view api" link located in the footer of this application?
- By clicking on this link, a page will open which provides documentation on the REST API that developers can use to query the Interface function / Block events.
- ▶️In this demo, I am making such an API request to the Playground_AI_Exploration Space.
- ▶️I am exposing an API endpoint of this Gradio app as well. This can easily be done by one line of code, just set the api_name parameter of the event listener.
-
""")
-
- with gr.Column(): #(elem_id = "col-container"):
- b1 = gr.Button("Load More Images").style(full_width=False)
- df = gr.Textbox(visible=False,elem_id='dataframe', value=response_dict)
- row_count = gr.Number(visible=False, value=19 )
- img_search = gr.HTML(label = 'Images from PlaygroundAI dataset', elem_id="img_search",
- value=initial_imgs ) #initial[:-1] )
-
- gr.HTML(''' 
- ''')
- b1.click(get_next10_images, [df, row_count], [df, row_count, img_search], api_name = "load_playgroundai_images" )
\ No newline at end of file
diff --git a/spaces/Dalun/andite-anything-v4.0/README.md b/spaces/Dalun/andite-anything-v4.0/README.md
deleted file mode 100644
index 196f98d4cf63a9abf7c8e1c01c78731478b74b30..0000000000000000000000000000000000000000
--- a/spaces/Dalun/andite-anything-v4.0/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Andite Anything V4.0
-emoji: 🐨
-colorFrom: blue
-colorTo: red
-sdk: gradio
-sdk_version: 3.19.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Dorado607/ChuanhuChatGPT/assets/html/update.html b/spaces/Dorado607/ChuanhuChatGPT/assets/html/update.html
deleted file mode 100644
index 3160c277aaa02b51a186e7a9ef8ef5ef6cad9aaf..0000000000000000000000000000000000000000
--- a/spaces/Dorado607/ChuanhuChatGPT/assets/html/update.html
+++ /dev/null
@@ -1,25 +0,0 @@
-
-
-
- {current_version}
- {version_time}
-
-
- Latest Version: getting latest version...
-
-
-
- Getting Release Note...
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/spaces/DragGan/DragGan/stylegan_human/pti/pti_configs/global_config.py b/spaces/DragGan/DragGan/stylegan_human/pti/pti_configs/global_config.py
deleted file mode 100644
index ce793517213d2325a98b061314755c2edf69fbd9..0000000000000000000000000000000000000000
--- a/spaces/DragGan/DragGan/stylegan_human/pti/pti_configs/global_config.py
+++ /dev/null
@@ -1,12 +0,0 @@
-## Device
-cuda_visible_devices = '0'
-device = 'cuda:0'
-
-## Logs
-training_step = 1
-image_rec_result_log_snapshot = 100
-pivotal_training_steps = 0
-model_snapshot_interval = 400
-
-## Run name to be updated during PTI
-run_name = 'exp'
diff --git a/spaces/EXPOSUREEE/Ai-Image-Enhancer/realesrgan/data/__init__.py b/spaces/EXPOSUREEE/Ai-Image-Enhancer/realesrgan/data/__init__.py
deleted file mode 100644
index a3f8fdd1aa47c12de9687c578094303eb7369246..0000000000000000000000000000000000000000
--- a/spaces/EXPOSUREEE/Ai-Image-Enhancer/realesrgan/data/__init__.py
+++ /dev/null
@@ -1,10 +0,0 @@
-import importlib
-from basicsr.utils import scandir
-from os import path as osp
-
-# automatically scan and import dataset modules for registry
-# scan all the files that end with '_dataset.py' under the data folder
-data_folder = osp.dirname(osp.abspath(__file__))
-dataset_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(data_folder) if v.endswith('_dataset.py')]
-# import all the dataset modules
-_dataset_modules = [importlib.import_module(f'realesrgan.data.{file_name}') for file_name in dataset_filenames]
diff --git a/spaces/EdBianchi/ThemeParksAccidents_RDF-SPARQL/README.md b/spaces/EdBianchi/ThemeParksAccidents_RDF-SPARQL/README.md
deleted file mode 100644
index ee1d18b6845283828eb94bbb5ad2dcebf8855a94..0000000000000000000000000000000000000000
--- a/spaces/EdBianchi/ThemeParksAccidents_RDF-SPARQL/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: ThemeParksAccidents RDF-SPARQL
-emoji: 🦀
-colorFrom: yellow
-colorTo: blue
-sdk: streamlit
-sdk_version: 1.10.0
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/EuroPython2022/mmocr-demo/configs/_base_/recog_models/seg.py b/spaces/EuroPython2022/mmocr-demo/configs/_base_/recog_models/seg.py
deleted file mode 100644
index 291e547ff45de81ddd512bf04ce0af7957b89ae7..0000000000000000000000000000000000000000
--- a/spaces/EuroPython2022/mmocr-demo/configs/_base_/recog_models/seg.py
+++ /dev/null
@@ -1,21 +0,0 @@
-label_convertor = dict(
- type='SegConvertor', dict_type='DICT36', with_unknown=True, lower=True)
-
-model = dict(
- type='SegRecognizer',
- backbone=dict(
- type='ResNet31OCR',
- layers=[1, 2, 5, 3],
- channels=[32, 64, 128, 256, 512, 512],
- out_indices=[0, 1, 2, 3],
- stage4_pool_cfg=dict(kernel_size=2, stride=2),
- last_stage_pool=True),
- neck=dict(
- type='FPNOCR', in_channels=[128, 256, 512, 512], out_channels=256),
- head=dict(
- type='SegHead',
- in_channels=256,
- upsample_param=dict(scale_factor=2.0, mode='nearest')),
- loss=dict(
- type='SegLoss', seg_downsample_ratio=1.0, seg_with_loss_weight=True),
- label_convertor=label_convertor)
diff --git a/spaces/Everymans-ai/GPT-knowledge-management/search.py b/spaces/Everymans-ai/GPT-knowledge-management/search.py
deleted file mode 100644
index 04c23e064ef0d55c26c9410134c12b00cefc8adf..0000000000000000000000000000000000000000
--- a/spaces/Everymans-ai/GPT-knowledge-management/search.py
+++ /dev/null
@@ -1,60 +0,0 @@
-
-
-import pinecone
-index_name = "abstractive-question-answering"
-
-# check if the abstractive-question-answering index exists
-if index_name not in pinecone.list_indexes():
- # create the index if it does not exist
- pinecone.create_index(
- index_name,
- dimension=768,
- metric="cosine"
- )
-
-# connect to abstractive-question-answering index we created
-index = pinecone.Index(index_name)
-
-# we will use batches of 64
-batch_size = 64
-
-for i in tqdm(range(0, len(df), batch_size)):
- # find end of batch
- i_end = min(i+batch_size, len(df))
- # extract batch
- batch = df.iloc[i:i_end]
- # generate embeddings for batch
- emb = retriever.encode(batch["passage_text"].tolist()).tolist()
- # get metadata
- meta = batch.to_dict(orient="records")
- # create unique IDs
- ids = [f"{idx}" for idx in range(i, i_end)]
- # add all to upsert list
- to_upsert = list(zip(ids, emb, meta))
- # upsert/insert these records to pinecone
- _ = index.upsert(vectors=to_upsert)
-
-# check that we have all vectors in index
-index.describe_index_stats()
-
-# from transformers import BartTokenizer, BartForConditionalGeneration
-
-# # load bart tokenizer and model from huggingface
-# tokenizer = BartTokenizer.from_pretrained('vblagoje/bart_lfqa')
-# generator = BartForConditionalGeneration.from_pretrained('vblagoje/bart_lfqa')
-
-# def query_pinecone(query, top_k):
-# # generate embeddings for the query
-# xq = retriever.encode([query]).tolist()
-# # search pinecone index for context passage with the answer
-# xc = index.query(xq, top_k=top_k, include_metadata=True)
-# return xc
-
-# def format_query(query, context):
-# # extract passage_text from Pinecone search result and add the tag
-# context = [f" {m['metadata']['passage_text']}" for m in context]
-# # concatinate all context passages
-# context = " ".join(context)
-# # contcatinate the query and context passages
-# query = f"question: {query} context: {context}"
-# return query
diff --git a/spaces/FL33TW00D/whisper-turbo/404.html b/spaces/FL33TW00D/whisper-turbo/404.html
deleted file mode 100644
index 96d1303d9dbf07c0e3e7be9b18be6b545a58e736..0000000000000000000000000000000000000000
--- a/spaces/FL33TW00D/whisper-turbo/404.html
+++ /dev/null
@@ -1,12 +0,0 @@
- 404: This page could not be found404This page could not be found.
\ No newline at end of file
diff --git a/spaces/Faridmaruf/rvc-genshin-v2/README.md b/spaces/Faridmaruf/rvc-genshin-v2/README.md
deleted file mode 100644
index 409c420f5e6e7d132809bfec88e3d45868bf7081..0000000000000000000000000000000000000000
--- a/spaces/Faridmaruf/rvc-genshin-v2/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: RVC V2 Genshin Impact
-emoji: 🎤
-colorFrom: red
-colorTo: purple
-sdk: gradio
-sdk_version: 3.36.1
-app_file: app.py
-pinned: true
-license: mit
-duplicated_from: mocci24/rvc-genshin-v2
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/FridaZuley/RVC_HFKawaii/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py b/spaces/FridaZuley/RVC_HFKawaii/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
deleted file mode 100644
index b412ba2814e114ca7bb00b6fd6ef217f63d788a3..0000000000000000000000000000000000000000
--- a/spaces/FridaZuley/RVC_HFKawaii/lib/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
+++ /dev/null
@@ -1,86 +0,0 @@
-from lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
-import pyworld
-import numpy as np
-
-
-class HarvestF0Predictor(F0Predictor):
- def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
- self.hop_length = hop_length
- self.f0_min = f0_min
- self.f0_max = f0_max
- self.sampling_rate = sampling_rate
-
- def interpolate_f0(self, f0):
- """
- 对F0进行插值处理
- """
-
- data = np.reshape(f0, (f0.size, 1))
-
- vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
- vuv_vector[data > 0.0] = 1.0
- vuv_vector[data <= 0.0] = 0.0
-
- ip_data = data
-
- frame_number = data.size
- last_value = 0.0
- for i in range(frame_number):
- if data[i] <= 0.0:
- j = i + 1
- for j in range(i + 1, frame_number):
- if data[j] > 0.0:
- break
- if j < frame_number - 1:
- if last_value > 0.0:
- step = (data[j] - data[i - 1]) / float(j - i)
- for k in range(i, j):
- ip_data[k] = data[i - 1] + step * (k - i + 1)
- else:
- for k in range(i, j):
- ip_data[k] = data[j]
- else:
- for k in range(i, frame_number):
- ip_data[k] = last_value
- else:
- ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
- last_value = data[i]
-
- return ip_data[:, 0], vuv_vector[:, 0]
-
- def resize_f0(self, x, target_len):
- source = np.array(x)
- source[source < 0.001] = np.nan
- target = np.interp(
- np.arange(0, len(source) * target_len, len(source)) / target_len,
- np.arange(0, len(source)),
- source,
- )
- res = np.nan_to_num(target)
- return res
-
- def compute_f0(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.harvest(
- wav.astype(np.double),
- fs=self.hop_length,
- f0_ceil=self.f0_max,
- f0_floor=self.f0_min,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.fs)
- return self.interpolate_f0(self.resize_f0(f0, p_len))[0]
-
- def compute_f0_uv(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.harvest(
- wav.astype(np.double),
- fs=self.sampling_rate,
- f0_floor=self.f0_min,
- f0_ceil=self.f0_max,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
- return self.interpolate_f0(self.resize_f0(f0, p_len))
diff --git a/spaces/FridaZuley/RVC_HFKawaii/utils/backups_test.py b/spaces/FridaZuley/RVC_HFKawaii/utils/backups_test.py
deleted file mode 100644
index f3edf15811b5035ee82f21e54e87b7e87ce413eb..0000000000000000000000000000000000000000
--- a/spaces/FridaZuley/RVC_HFKawaii/utils/backups_test.py
+++ /dev/null
@@ -1,138 +0,0 @@
-
-import os
-import shutil
-import hashlib
-import time
-
-LOGS_FOLDER = '/content/Applio-RVC-Fork/logs'
-WEIGHTS_FOLDER = '/content/Applio-RVC-Fork/weights'
-GOOGLE_DRIVE_PATH = '/content/drive/MyDrive/RVC_Backup'
-
-def import_google_drive_backup():
- print("Importing Google Drive backup...")
- GOOGLE_DRIVE_PATH = '/content/drive/MyDrive/RVC_Backup' # change this to your Google Drive path
- LOGS_FOLDER = '/content/Applio-RVC-Fork/logs'
- WEIGHTS_FOLDER = '/content/Applio-RVC-Fork/weights'
- weights_exist = False
- files_to_copy = []
- weights_to_copy = []
-
- def handle_files(root, files, is_weight_files=False):
- for filename in files:
- filepath = os.path.join(root, filename)
- if filename.endswith('.pth') and is_weight_files:
- weights_exist = True
- backup_filepath = os.path.join(WEIGHTS_FOLDER, os.path.relpath(filepath, GOOGLE_DRIVE_PATH))
- else:
- backup_filepath = os.path.join(LOGS_FOLDER, os.path.relpath(filepath, GOOGLE_DRIVE_PATH))
- backup_folderpath = os.path.dirname(backup_filepath)
- if not os.path.exists(backup_folderpath):
- os.makedirs(backup_folderpath)
- print(f'Created folder: {backup_folderpath}', flush=True)
- if is_weight_files:
- weights_to_copy.append((filepath, backup_filepath))
- else:
- files_to_copy.append((filepath, backup_filepath))
-
- for root, dirs, files in os.walk(os.path.join(GOOGLE_DRIVE_PATH, 'logs')):
- handle_files(root, files)
-
- for root, dirs, files in os.walk(os.path.join(GOOGLE_DRIVE_PATH, 'weights')):
- handle_files(root, files, True)
-
- # Copy files in batches
- total_files = len(files_to_copy)
- start_time = time.time()
- for i, (source, dest) in enumerate(files_to_copy, start=1):
- with open(source, 'rb') as src, open(dest, 'wb') as dst:
- shutil.copyfileobj(src, dst, 1024*1024) # 1MB buffer size
- # Report progress every 5 seconds or after every 100 files, whichever is less frequent
- if time.time() - start_time > 5 or i % 100 == 0:
- print(f'\rCopying file {i} of {total_files} ({i * 100 / total_files:.2f}%)', end="")
- start_time = time.time()
- print(f'\nImported {len(files_to_copy)} files from Google Drive backup')
-
- # Copy weights in batches
- total_weights = len(weights_to_copy)
- start_time = time.time()
- for i, (source, dest) in enumerate(weights_to_copy, start=1):
- with open(source, 'rb') as src, open(dest, 'wb') as dst:
- shutil.copyfileobj(src, dst, 1024*1024) # 1MB buffer size
- # Report progress every 5 seconds or after every 100 files, whichever is less frequent
- if time.time() - start_time > 5 or i % 100 == 0:
- print(f'\rCopying weight file {i} of {total_weights} ({i * 100 / total_weights:.2f}%)', end="")
- start_time = time.time()
- if weights_exist:
- print(f'\nImported {len(weights_to_copy)} weight files')
- print("Copied weights from Google Drive backup to local weights folder.")
- else:
- print("\nNo weights found in Google Drive backup.")
- print("Google Drive backup import completed.")
-
-def backup_files():
- print("\n Starting backup loop...")
- last_backup_timestamps_path = os.path.join(LOGS_FOLDER, 'last_backup_timestamps.txt')
- fully_updated = False # boolean to track if all files are up to date
- try:
- with open(last_backup_timestamps_path, 'r') as f:
- last_backup_timestamps = dict(line.strip().split(':') for line in f)
- except:
- last_backup_timestamps = {}
-
- while True:
- updated = False
- files_to_copy = []
- files_to_delete = []
-
- for root, dirs, files in os.walk(LOGS_FOLDER):
- for filename in files:
- if filename != 'last_backup_timestamps.txt':
- filepath = os.path.join(root, filename)
- if os.path.isfile(filepath):
- backup_filepath = os.path.join(GOOGLE_DRIVE_PATH, os.path.relpath(filepath, LOGS_FOLDER))
- backup_folderpath = os.path.dirname(backup_filepath)
-
- if not os.path.exists(backup_folderpath):
- os.makedirs(backup_folderpath)
- print(f'Created backup folder: {backup_folderpath}', flush=True)
-
- # check if file has changed since last backup
- last_backup_timestamp = last_backup_timestamps.get(filepath)
- current_timestamp = os.path.getmtime(filepath)
- if last_backup_timestamp is None or float(last_backup_timestamp) < current_timestamp:
- files_to_copy.append((filepath, backup_filepath)) # add to list of files to copy
- last_backup_timestamps[filepath] = str(current_timestamp) # update last backup timestamp
- updated = True
- fully_updated = False # if a file is updated, all files are not up to date
-
- # check if any files were deleted in Colab and delete them from the backup drive
- for filepath in list(last_backup_timestamps.keys()):
- if not os.path.exists(filepath):
- backup_filepath = os.path.join(GOOGLE_DRIVE_PATH, os.path.relpath(filepath, LOGS_FOLDER))
- if os.path.exists(backup_filepath):
- files_to_delete.append(backup_filepath) # add to list of files to delete
- del last_backup_timestamps[filepath]
- updated = True
- fully_updated = False # if a file is deleted, all files are not up to date
-
- # Copy files in batches
- if files_to_copy:
- for source, dest in files_to_copy:
- shutil.copy2(source, dest)
- print(f'Copied or updated {len(files_to_copy)} files')
-
- # Delete files in batches
- if files_to_delete:
- for file in files_to_delete:
- os.remove(file)
- print(f'Deleted {len(files_to_delete)} files')
-
- if not updated and not fully_updated:
- print("Files are up to date.")
- fully_updated = True # if all files are up to date, set the boolean to True
- copy_weights_folder_to_drive()
-
- with open(last_backup_timestamps_path, 'w') as f:
- for filepath, timestamp in last_backup_timestamps.items():
- f.write(f'{filepath}:{timestamp}\n')
- time.sleep(15) # wait for 15 seconds before checking again
diff --git a/spaces/GT4SD/paccmann_gp/README.md b/spaces/GT4SD/paccmann_gp/README.md
deleted file mode 100644
index c859678347b787b6030a9b576167488200538320..0000000000000000000000000000000000000000
--- a/spaces/GT4SD/paccmann_gp/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
----
-title: PaccMann^GP
-emoji: 💡
-colorFrom: green
-colorTo: blue
-sdk: gradio
-sdk_version: 3.46.0
-app_file: app.py
-pinned: false
-python_version: 3.8.13
-pypi_version: 20.2.4
-duplicated_from: jannisborn/gt4sd-paccmann-rl
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/Gen-Sim/Gen-Sim/cliport/generated_tasks/__init__.py b/spaces/Gen-Sim/Gen-Sim/cliport/generated_tasks/__init__.py
deleted file mode 100644
index 85478fc1c1413e7f737e6a636563290bf32cc327..0000000000000000000000000000000000000000
--- a/spaces/Gen-Sim/Gen-Sim/cliport/generated_tasks/__init__.py
+++ /dev/null
@@ -1,19 +0,0 @@
-import os
-from pprint import pprint
-
-# automatically import all defined task classes in this directory
-new_names = {}
-dir_path = os.path.dirname(os.path.realpath(__file__))
-for file in os.listdir(dir_path):
- if 'init' not in file and 'cache' not in file:
- code_file = open(f"{dir_path}/{file}").read()
- code_lines = code_file.split("\n")
- class_def = [line for line in code_lines if line.startswith('class')]
- task_name = class_def[0]
- task_name = task_name[task_name.find("class "): task_name.rfind("(Task)")][6:]
- file_name = file.replace('.py','')
- exec(f"from cliport.generated_tasks.{file_name} import {task_name}")
- new_names[file_name.replace("_", "-")] = eval(task_name)
-
-
-# pprint(new_names)
diff --git a/spaces/GolDNenex/Super-Resolution-Anime-Diffusion/RealESRGANv030/scripts/extract_subimages.py b/spaces/GolDNenex/Super-Resolution-Anime-Diffusion/RealESRGANv030/scripts/extract_subimages.py
deleted file mode 100644
index 50a819d6148b53ee0482f4f6133a41b9620c0b0a..0000000000000000000000000000000000000000
--- a/spaces/GolDNenex/Super-Resolution-Anime-Diffusion/RealESRGANv030/scripts/extract_subimages.py
+++ /dev/null
@@ -1,148 +0,0 @@
-import argparse
-import cv2
-import numpy as np
-import os
-import sys
-from basicsr.utils import scandir
-from multiprocessing import Pool
-from os import path as osp
-from tqdm import tqdm
-
-
-def main(args):
- """A multi-thread tool to crop large images to sub-images for faster IO.
-
- opt (dict): Configuration dict. It contains:
- n_thread (int): Thread number.
- compression_level (int): CV_IMWRITE_PNG_COMPRESSION from 0 to 9. A higher value means a smaller size
- and longer compression time. Use 0 for faster CPU decompression. Default: 3, same in cv2.
- input_folder (str): Path to the input folder.
- save_folder (str): Path to save folder.
- crop_size (int): Crop size.
- step (int): Step for overlapped sliding window.
- thresh_size (int): Threshold size. Patches whose size is lower than thresh_size will be dropped.
-
- Usage:
- For each folder, run this script.
- Typically, there are GT folder and LQ folder to be processed for DIV2K dataset.
- After process, each sub_folder should have the same number of subimages.
- Remember to modify opt configurations according to your settings.
- """
-
- opt = {}
- opt["n_thread"] = args.n_thread
- opt["compression_level"] = args.compression_level
- opt["input_folder"] = args.input
- opt["save_folder"] = args.output
- opt["crop_size"] = args.crop_size
- opt["step"] = args.step
- opt["thresh_size"] = args.thresh_size
- extract_subimages(opt)
-
-
-def extract_subimages(opt):
- """Crop images to subimages.
-
- Args:
- opt (dict): Configuration dict. It contains:
- input_folder (str): Path to the input folder.
- save_folder (str): Path to save folder.
- n_thread (int): Thread number.
- """
- input_folder = opt["input_folder"]
- save_folder = opt["save_folder"]
- if not osp.exists(save_folder):
- os.makedirs(save_folder)
- print(f"mkdir {save_folder} ...")
- else:
- print(f"Folder {save_folder} already exists. Exit.")
- sys.exit(1)
-
- # scan all images
- img_list = list(scandir(input_folder, full_path=True))
-
- pbar = tqdm(total=len(img_list), unit="image", desc="Extract")
- pool = Pool(opt["n_thread"])
- for path in img_list:
- pool.apply_async(worker, args=(path, opt), callback=lambda arg: pbar.update(1))
- pool.close()
- pool.join()
- pbar.close()
- print("All processes done.")
-
-
-def worker(path, opt):
- """Worker for each process.
-
- Args:
- path (str): Image path.
- opt (dict): Configuration dict. It contains:
- crop_size (int): Crop size.
- step (int): Step for overlapped sliding window.
- thresh_size (int): Threshold size. Patches whose size is lower than thresh_size will be dropped.
- save_folder (str): Path to save folder.
- compression_level (int): for cv2.IMWRITE_PNG_COMPRESSION.
-
- Returns:
- process_info (str): Process information displayed in progress bar.
- """
- crop_size = opt["crop_size"]
- step = opt["step"]
- thresh_size = opt["thresh_size"]
- img_name, extension = osp.splitext(osp.basename(path))
-
- # remove the x2, x3, x4 and x8 in the filename for DIV2K
- img_name = (
- img_name.replace("x2", "").replace("x3", "").replace("x4", "").replace("x8", "")
- )
-
- img = cv2.imread(path, cv2.IMREAD_UNCHANGED)
-
- h, w = img.shape[0:2]
- h_space = np.arange(0, h - crop_size + 1, step)
- if h - (h_space[-1] + crop_size) > thresh_size:
- h_space = np.append(h_space, h - crop_size)
- w_space = np.arange(0, w - crop_size + 1, step)
- if w - (w_space[-1] + crop_size) > thresh_size:
- w_space = np.append(w_space, w - crop_size)
-
- index = 0
- for x in h_space:
- for y in w_space:
- index += 1
- cropped_img = img[x : x + crop_size, y : y + crop_size, ...]
- cropped_img = np.ascontiguousarray(cropped_img)
- cv2.imwrite(
- osp.join(opt["save_folder"], f"{img_name}_s{index:03d}{extension}"),
- cropped_img,
- [cv2.IMWRITE_PNG_COMPRESSION, opt["compression_level"]],
- )
- process_info = f"Processing {img_name} ..."
- return process_info
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--input", type=str, default="datasets/DF2K/DF2K_HR", help="Input folder"
- )
- parser.add_argument(
- "--output", type=str, default="datasets/DF2K/DF2K_HR_sub", help="Output folder"
- )
- parser.add_argument("--crop_size", type=int, default=480, help="Crop size")
- parser.add_argument(
- "--step", type=int, default=240, help="Step for overlapped sliding window"
- )
- parser.add_argument(
- "--thresh_size",
- type=int,
- default=0,
- help="Threshold size. Patches whose size is lower than thresh_size will be dropped.",
- )
- parser.add_argument("--n_thread", type=int, default=20, help="Thread number.")
- parser.add_argument(
- "--compression_level", type=int, default=3, help="Compression level"
- )
- args = parser.parse_args()
-
- main(args)
diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/configs/ghm/retinanet_ghm_x101_64x4d_fpn_1x_coco.py b/spaces/Gradio-Blocks/uniformer_image_detection/configs/ghm/retinanet_ghm_x101_64x4d_fpn_1x_coco.py
deleted file mode 100644
index 88013f5ffa2334fe3eccd30616a0b033c258ad87..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_detection/configs/ghm/retinanet_ghm_x101_64x4d_fpn_1x_coco.py
+++ /dev/null
@@ -1,13 +0,0 @@
-_base_ = './retinanet_ghm_r50_fpn_1x_coco.py'
-model = dict(
- pretrained='open-mmlab://resnext101_64x4d',
- backbone=dict(
- type='ResNeXt',
- depth=101,
- groups=64,
- base_width=4,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- frozen_stages=1,
- norm_cfg=dict(type='BN', requires_grad=True),
- style='pytorch'))
diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/configs/rpn/rpn_r50_fpn_1x_coco.py b/spaces/Gradio-Blocks/uniformer_image_detection/configs/rpn/rpn_r50_fpn_1x_coco.py
deleted file mode 100644
index 26f95a3402f9fd2d54c5919484e2f4958beb8a34..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_detection/configs/rpn/rpn_r50_fpn_1x_coco.py
+++ /dev/null
@@ -1,18 +0,0 @@
-_base_ = [
- '../_base_/models/rpn_r50_fpn.py', '../_base_/datasets/coco_detection.py',
- '../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
-]
-img_norm_cfg = dict(
- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
-train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadAnnotations', with_bbox=True, with_label=False),
- dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
- dict(type='RandomFlip', flip_ratio=0.5),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='DefaultFormatBundle'),
- dict(type='Collect', keys=['img', 'gt_bboxes']),
-]
-data = dict(train=dict(pipeline=train_pipeline))
-evaluation = dict(interval=1, metric='proposal_fast')
diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/configs/rpn/rpn_x101_32x4d_fpn_1x_coco.py b/spaces/Gradio-Blocks/uniformer_image_detection/configs/rpn/rpn_x101_32x4d_fpn_1x_coco.py
deleted file mode 100644
index 83bd70032cb24be6b96f988522ef84f7b4cc0e6a..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_detection/configs/rpn/rpn_x101_32x4d_fpn_1x_coco.py
+++ /dev/null
@@ -1,13 +0,0 @@
-_base_ = './rpn_r50_fpn_1x_coco.py'
-model = dict(
- pretrained='open-mmlab://resnext101_32x4d',
- backbone=dict(
- type='ResNeXt',
- depth=101,
- groups=32,
- base_width=4,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- frozen_stages=1,
- norm_cfg=dict(type='BN', requires_grad=True),
- style='pytorch'))
diff --git a/spaces/HESOAYM/ElviraMulti/assets/custom.css b/spaces/HESOAYM/ElviraMulti/assets/custom.css
deleted file mode 100644
index 4e92c5455f1085afb6d57259713dc7125ae7f0af..0000000000000000000000000000000000000000
--- a/spaces/HESOAYM/ElviraMulti/assets/custom.css
+++ /dev/null
@@ -1,355 +0,0 @@
-:root {
- --chatbot-color-light: #F3F3F3;
- --chatbot-color-dark: #121111;
-}
-
-#app_title {
- font-weight: var(--prose-header-text-weight);
- font-size: var(--text-xxl);
- line-height: 1.3;
- text-align: left;
- margin-top: 6px;
- white-space: nowrap;
- display: none;
-}
-#description {
- text-align: center;
- margin:16px 0
-}
-
-/* 覆盖gradio的页脚信息QAQ */
-/* footer {
- display: none !important;
-} */
-#footer {
- text-align: center;
-}
-#footer div {
- display: inline-block;
-}
-#footer .versions{
- font-size: 85%;
- opacity: 0.85;
-}
-
-#float_display {
- position: absolute;
- max-height: 30px;
-}
-/* user_info */
-#user_info {
- white-space: nowrap;
- position: absolute; left: 8em; top: .2em;
- z-index: var(--layer-2);
- box-shadow: var(--block-shadow);
- border: none; border-radius: var(--block-label-radius);
- background: var(--color-accent);
- padding: var(--block-label-padding);
- font-size: var(--block-label-text-size); line-height: var(--line-sm);
- width: auto; min-height: 30px!important;
- opacity: 1;
- transition: opacity 0.3s ease-in-out;
-}
-#user_info .wrap {
- opacity: 0;
-}
-#user_info p {
- color: white;
- font-weight: var(--block-label-text-weight);
-}
-#user_info.hideK {
- opacity: 0;
- transition: opacity 1s ease-in-out;
-}
-
-/* status_display */
-#status_display {
- display: flex;
- min-height: 2em;
- align-items: flex-end;
- justify-content: flex-end;
-}
-#status_display p {
- font-size: .85em;
- font-family: monospace;
- color: var(--body-text-color-subdued);
-}
-
-#status_display {
- transition: all 0.6s;
-}
-#chuanhu_chatbot {
- transition: height 0.3s ease;
-}
-
-/* usage_display */
-.insert_block {
- position: relative;
- margin: 0;
- padding: .5em 1em;
- box-shadow: var(--block-shadow);
- border-width: var(--block-border-width);
- border-color: var(--block-border-color);
- border-radius: var(--block-radius);
- background: var(--block-background-fill);
- width: 100%;
- line-height: var(--line-sm);
- min-height: 2em;
-}
-#usage_display p, #usage_display span {
- margin: 0;
- font-size: .85em;
- color: var(--body-text-color-subdued);
-}
-.progress-bar {
- background-color: var(--input-background-fill);;
- margin: 0 1em;
- height: 20px;
- border-radius: 10px;
- overflow: hidden;
-}
-.progress {
- background-color: var(--block-title-background-fill);
- height: 100%;
- border-radius: 10px;
- text-align: right;
- transition: width 0.5s ease-in-out;
-}
-.progress-text {
- /* color: white; */
- color: var(--color-accent) !important;
- font-size: 1em !important;
- font-weight: bold;
- padding-right: 10px;
- line-height: 20px;
-}
-
-.apSwitch {
- top: 2px;
- display: inline-block;
- height: 24px;
- position: relative;
- width: 48px;
- border-radius: 12px;
-}
-.apSwitch input {
- display: none !important;
-}
-.apSlider {
- background-color: var(--block-label-background-fill);
- bottom: 0;
- cursor: pointer;
- left: 0;
- position: absolute;
- right: 0;
- top: 0;
- transition: .4s;
- font-size: 18px;
- border-radius: 12px;
-}
-.apSlider::before {
- bottom: -1.5px;
- left: 1px;
- position: absolute;
- transition: .4s;
- content: "🌞";
-}
-input:checked + .apSlider {
- background-color: var(--block-label-background-fill);
-}
-input:checked + .apSlider::before {
- transform: translateX(23px);
- content:"🌚";
-}
-
-#submit_btn, #cancel_btn {
- height: 42px !important;
-}
-#submit_btn::before {
- background-image: url(https://static.wixstatic.com/media/8c35db_d83829a15f3a41809787e9785c44c076~mv2.png);
- background-size: contain;
- transform: rotate(180deg);
-}
-#cancel_btn::before {
- content: url("data:image/svg+xml,%3Csvg width='21px' height='21px' viewBox='0 0 21 21' version='1.1' xmlns='http://www.w3.org/2000/svg' xmlns:xlink='http://www.w3.org/1999/xlink'%3E %3Cg id='pg' stroke='none' stroke-width='1' fill='none' fill-rule='evenodd'%3E %3Cpath d='M10.2072007,20.088463 C11.5727865,20.088463 12.8594566,19.8259823 14.067211,19.3010209 C15.2749653,18.7760595 16.3386126,18.0538087 17.2581528,17.1342685 C18.177693,16.2147282 18.8982283,15.1527965 19.4197586,13.9484733 C19.9412889,12.7441501 20.202054,11.4557644 20.202054,10.0833163 C20.202054,8.71773046 19.9395733,7.43106036 19.4146119,6.22330603 C18.8896505,5.01555169 18.1673997,3.95018885 17.2478595,3.0272175 C16.3283192,2.10424615 15.2646719,1.3837109 14.0569176,0.865611739 C12.8491633,0.34751258 11.5624932,0.088463 10.1969073,0.088463 C8.83132146,0.088463 7.54636692,0.34751258 6.34204371,0.865611739 C5.1377205,1.3837109 4.07407321,2.10424615 3.15110186,3.0272175 C2.22813051,3.95018885 1.5058797,5.01555169 0.984349419,6.22330603 C0.46281914,7.43106036 0.202054,8.71773046 0.202054,10.0833163 C0.202054,11.4557644 0.4645347,12.7441501 0.9894961,13.9484733 C1.5144575,15.1527965 2.23670831,16.2147282 3.15624854,17.1342685 C4.07578877,18.0538087 5.1377205,18.7760595 6.34204371,19.3010209 C7.54636692,19.8259823 8.83475258,20.088463 10.2072007,20.088463 Z M10.2072007,18.2562448 C9.07493099,18.2562448 8.01471483,18.0452309 7.0265522,17.6232031 C6.03838956,17.2011753 5.17031614,16.6161693 4.42233192,15.8681851 C3.6743477,15.1202009 3.09105726,14.2521274 2.67246059,13.2639648 C2.25386392,12.2758022 2.04456558,11.215586 2.04456558,10.0833163 C2.04456558,8.95104663 2.25386392,7.89083047 2.67246059,6.90266784 C3.09105726,5.9145052 3.6743477,5.04643178 4.42233192,4.29844756 C5.17031614,3.55046334 6.036674,2.9671729 7.02140552,2.54857623 C8.00613703,2.12997956 9.06463763,1.92068122 10.1969073,1.92068122 C11.329177,1.92068122 12.3911087,2.12997956 13.3827025,2.54857623 C14.3742962,2.9671729 15.2440852,3.55046334 15.9920694,4.29844756 C16.7400537,5.04643178 17.3233441,5.9145052 17.7419408,6.90266784 C18.1605374,7.89083047 18.3698358,8.95104663 18.3698358,10.0833163 C18.3698358,11.215586 18.1605374,12.2758022 17.7419408,13.2639648 C17.3233441,14.2521274 16.7400537,15.1202009 15.9920694,15.8681851 C15.2440852,16.6161693 14.3760118,17.2011753 13.3878492,17.6232031 C12.3996865,18.0452309 11.3394704,18.2562448 10.2072007,18.2562448 Z M7.65444721,13.6242324 L12.7496608,13.6242324 C13.0584616,13.6242324 13.3003556,13.5384544 13.4753427,13.3668984 C13.6503299,13.1953424 13.7378234,12.9585951 13.7378234,12.6566565 L13.7378234,7.49968276 C13.7378234,7.19774418 13.6503299,6.96099688 13.4753427,6.78944087 C13.3003556,6.61788486 13.0584616,6.53210685 12.7496608,6.53210685 L7.65444721,6.53210685 C7.33878414,6.53210685 7.09345904,6.61788486 6.91847191,6.78944087 C6.74348478,6.96099688 6.65599121,7.19774418 6.65599121,7.49968276 L6.65599121,12.6566565 C6.65599121,12.9585951 6.74348478,13.1953424 6.91847191,13.3668984 C7.09345904,13.5384544 7.33878414,13.6242324 7.65444721,13.6242324 Z' id='shape' fill='%23FF3B30' fill-rule='nonzero'%3E%3C/path%3E %3C/g%3E %3C/svg%3E");
- height: 21px;
-}
-/* list */
-ol:not(.options), ul:not(.options) {
- padding-inline-start: 2em !important;
-}
-
-/* 亮色(默认) */
-#chuanhu_chatbot {
- background-color: transparent;
- color: #000000 !important;
-}
-[data-testid = "bot"] {
- background-color: transparent;
-}
-[data-testid = "user"] {
- background-color: transparent;
-}
-/* 暗色 */
-.dark #chuanhu_chatbot {
- background-color: none;
- color: #FFFFFF !important;
-}
-.dark [data-testid = "bot"] {
- background-color: none;
-}
-.dark [data-testid = "user"] {
- background-color: none;
-}
-
-/* 屏幕宽度大于等于500px的设备 */
-/* update on 2023.4.8: 高度的细致调整已写入JavaScript */
-@media screen and (min-width: 500px) {
- #chuanhu_chatbot {
- height: calc(100vh - 200px);
- }
- #chuanhu_chatbot .wrap {
- max-height: calc(100vh - 200px - var(--line-sm)*1rem - 2*var(--block-label-margin) );
- }
-}
-/* 屏幕宽度小于500px的设备 */
-@media screen and (max-width: 499px) {
- #chuanhu_chatbot {
- height: calc(100vh - 140px);
- }
- #chuanhu_chatbot .wrap {
- max-height: calc(100vh - 140px - var(--line-sm)*1rem - 2*var(--block-label-margin) );
- }
- [data-testid = "bot"] {
- max-width: 98% !important;
- }
- #app_title h1{
- letter-spacing: -1px; font-size: 22px;
- }
-}
-/* 对话气泡 */
-[class *= "message"] {
- border-radius: var(--radius-xl) !important;
- border: none;
- padding: var(--spacing-xl) !important;
- font-size: var(--text-md) !important;
- line-height: var(--line-md) !important;
- min-height: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
- min-width: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
-}
-[data-testid = "bot"] {
- max-width: 85%;
- border-bottom-left-radius: 0 !important;
-}
-[data-testid = "user"] {
- max-width: 85%;
- width: auto !important;
- border-bottom-right-radius: 0 !important;
-}
-/* 表格 */
-table {
- margin: 1em 0;
- border-collapse: collapse;
- empty-cells: show;
-}
-td,th {
- border: 1.2px solid var(--border-color-primary) !important;
- padding: 0.2em;
-}
-thead {
- background-color: rgba(175,184,193,0.2);
-}
-thead th {
- padding: .5em .2em;
-}
-/* 行内代码 */
-code {
- display: inline;
- white-space: break-spaces;
- border-radius: 6px;
- margin: 0 2px 0 2px;
- padding: .2em .4em .1em .4em;
- background-color: rgba(175,184,193,0.2);
-}
-/* 代码块 */
-pre code {
- display: block;
- overflow: auto;
- white-space: pre;
- background-color: hsla(0, 0%, 0%, 80%)!important;
- border-radius: 10px;
- padding: 1.4em 1.2em 0em 1.4em;
- margin: 1.2em 2em 1.2em 0.5em;
- color: #FFF;
- box-shadow: 6px 6px 16px hsla(0, 0%, 0%, 0.2);
-}
-/* 代码高亮样式 */
-.highlight .hll { background-color: #49483e }
-.highlight .c { color: #75715e } /* Comment */
-.highlight .err { color: #960050; background-color: #1e0010 } /* Error */
-.highlight .k { color: #66d9ef } /* Keyword */
-.highlight .l { color: #ae81ff } /* Literal */
-.highlight .n { color: #f8f8f2 } /* Name */
-.highlight .o { color: #f92672 } /* Operator */
-.highlight .p { color: #f8f8f2 } /* Punctuation */
-.highlight .ch { color: #75715e } /* Comment.Hashbang */
-.highlight .cm { color: #75715e } /* Comment.Multiline */
-.highlight .cp { color: #75715e } /* Comment.Preproc */
-.highlight .cpf { color: #75715e } /* Comment.PreprocFile */
-.highlight .c1 { color: #75715e } /* Comment.Single */
-.highlight .cs { color: #75715e } /* Comment.Special */
-.highlight .gd { color: #f92672 } /* Generic.Deleted */
-.highlight .ge { font-style: italic } /* Generic.Emph */
-.highlight .gi { color: #a6e22e } /* Generic.Inserted */
-.highlight .gs { font-weight: bold } /* Generic.Strong */
-.highlight .gu { color: #75715e } /* Generic.Subheading */
-.highlight .kc { color: #66d9ef } /* Keyword.Constant */
-.highlight .kd { color: #66d9ef } /* Keyword.Declaration */
-.highlight .kn { color: #f92672 } /* Keyword.Namespace */
-.highlight .kp { color: #66d9ef } /* Keyword.Pseudo */
-.highlight .kr { color: #66d9ef } /* Keyword.Reserved */
-.highlight .kt { color: #66d9ef } /* Keyword.Type */
-.highlight .ld { color: #e6db74 } /* Literal.Date */
-.highlight .m { color: #ae81ff } /* Literal.Number */
-.highlight .s { color: #e6db74 } /* Literal.String */
-.highlight .na { color: #a6e22e } /* Name.Attribute */
-.highlight .nb { color: #f8f8f2 } /* Name.Builtin */
-.highlight .nc { color: #a6e22e } /* Name.Class */
-.highlight .no { color: #66d9ef } /* Name.Constant */
-.highlight .nd { color: #a6e22e } /* Name.Decorator */
-.highlight .ni { color: #f8f8f2 } /* Name.Entity */
-.highlight .ne { color: #a6e22e } /* Name.Exception */
-.highlight .nf { color: #a6e22e } /* Name.Function */
-.highlight .nl { color: #f8f8f2 } /* Name.Label */
-.highlight .nn { color: #f8f8f2 } /* Name.Namespace */
-.highlight .nx { color: #a6e22e } /* Name.Other */
-.highlight .py { color: #f8f8f2 } /* Name.Property */
-.highlight .nt { color: #f92672 } /* Name.Tag */
-.highlight .nv { color: #f8f8f2 } /* Name.Variable */
-.highlight .ow { color: #f92672 } /* Operator.Word */
-.highlight .w { color: #f8f8f2 } /* Text.Whitespace */
-.highlight .mb { color: #ae81ff } /* Literal.Number.Bin */
-.highlight .mf { color: #ae81ff } /* Literal.Number.Float */
-.highlight .mh { color: #ae81ff } /* Literal.Number.Hex */
-.highlight .mi { color: #ae81ff } /* Literal.Number.Integer */
-.highlight .mo { color: #ae81ff } /* Literal.Number.Oct */
-.highlight .sa { color: #e6db74 } /* Literal.String.Affix */
-.highlight .sb { color: #e6db74 } /* Literal.String.Backtick */
-.highlight .sc { color: #e6db74 } /* Literal.String.Char */
-.highlight .dl { color: #e6db74 } /* Literal.String.Delimiter */
-.highlight .sd { color: #e6db74 } /* Literal.String.Doc */
-.highlight .s2 { color: #e6db74 } /* Literal.String.Double */
-.highlight .se { color: #ae81ff } /* Literal.String.Escape */
-.highlight .sh { color: #e6db74 } /* Literal.String.Heredoc */
-.highlight .si { color: #e6db74 } /* Literal.String.Interpol */
-.highlight .sx { color: #e6db74 } /* Literal.String.Other */
-.highlight .sr { color: #e6db74 } /* Literal.String.Regex */
-.highlight .s1 { color: #e6db74 } /* Literal.String.Single */
-.highlight .ss { color: #e6db74 } /* Literal.String.Symbol */
-.highlight .bp { color: #f8f8f2 } /* Name.Builtin.Pseudo */
-.highlight .fm { color: #a6e22e } /* Name.Function.Magic */
-.highlight .vc { color: #f8f8f2 } /* Name.Variable.Class */
-.highlight .vg { color: #f8f8f2 } /* Name.Variable.Global */
-.highlight .vi { color: #f8f8f2 } /* Name.Variable.Instance */
-.highlight .vm { color: #f8f8f2 } /* Name.Variable.Magic */
-.highlight .il { color: #ae81ff } /* Literal.Number.Integer.Long */
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/noisychannel/rerank_score_lm.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/noisychannel/rerank_score_lm.py
deleted file mode 100644
index e80948d78b02561cbd09d72c319222105f41f6bb..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/noisychannel/rerank_score_lm.py
+++ /dev/null
@@ -1,81 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import os
-
-from fairseq import options
-
-from examples.noisychannel import rerank_options, rerank_utils
-
-
-def score_lm(args):
- using_nbest = args.nbest_list is not None
- (
- pre_gen,
- left_to_right_preprocessed_dir,
- right_to_left_preprocessed_dir,
- backwards_preprocessed_dir,
- lm_preprocessed_dir,
- ) = rerank_utils.get_directories(
- args.data_dir_name,
- args.num_rescore,
- args.gen_subset,
- args.gen_model_name,
- args.shard_id,
- args.num_shards,
- args.sampling,
- args.prefix_len,
- args.target_prefix_frac,
- args.source_prefix_frac,
- )
-
- predictions_bpe_file = pre_gen + "/generate_output_bpe.txt"
- if using_nbest:
- print("Using predefined n-best list from interactive.py")
- predictions_bpe_file = args.nbest_list
-
- gen_output = rerank_utils.BitextOutputFromGen(
- predictions_bpe_file, bpe_symbol=args.post_process, nbest=using_nbest
- )
-
- if args.language_model is not None:
- lm_score_file = rerank_utils.rescore_file_name(
- pre_gen, args.prefix_len, args.lm_name, lm_file=True
- )
-
- if args.language_model is not None and not os.path.isfile(lm_score_file):
- print("STEP 4.5: language modeling for P(T)")
- if args.lm_bpe_code is None:
- bpe_status = "no bpe"
- elif args.lm_bpe_code == "shared":
- bpe_status = "shared"
- else:
- bpe_status = "different"
-
- rerank_utils.lm_scoring(
- lm_preprocessed_dir,
- bpe_status,
- gen_output,
- pre_gen,
- args.lm_dict,
- args.lm_name,
- args.language_model,
- args.lm_bpe_code,
- 128,
- lm_score_file,
- args.target_lang,
- args.source_lang,
- prefix_len=args.prefix_len,
- )
-
-
-def cli_main():
- parser = rerank_options.get_reranking_parser()
- args = options.parse_args_and_arch(parser)
- score_lm(args)
-
-
-if __name__ == "__main__":
- cli_main()
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/textless_nlp/gslm/unit2speech/tacotron2/symbols.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/textless_nlp/gslm/unit2speech/tacotron2/symbols.py
deleted file mode 100644
index 5f0d70fdad92ba4f554d971710b60f2f9e8d9298..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/textless_nlp/gslm/unit2speech/tacotron2/symbols.py
+++ /dev/null
@@ -1,18 +0,0 @@
-""" from https://github.com/keithito/tacotron """
-
-'''
-Defines the set of symbols used in text input to the model.
-
-The default is a set of ASCII characters that works well for English or text that has been run through Unidecode. For other data, you can modify _characters. See TRAINING_DATA.md for details. '''
-from . import cmudict
-
-_pad = '_'
-_punctuation = '!\'(),.:;? '
-_special = '-'
-_letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
-
-# Prepend "@" to ARPAbet symbols to ensure uniqueness (some are the same as uppercase letters):
-_arpabet = ['@' + s for s in cmudict.valid_symbols]
-
-# Export all symbols:
-symbols = [_pad] + list(_special) + list(_punctuation) + list(_letters) + _arpabet
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/data/legacy/block_pair_dataset.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/data/legacy/block_pair_dataset.py
deleted file mode 100644
index ba069b46052286c531b4f9706d96788732cd2ad2..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq/data/legacy/block_pair_dataset.py
+++ /dev/null
@@ -1,311 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import math
-
-import numpy as np
-import torch
-from fairseq.data import FairseqDataset
-
-
-class BlockPairDataset(FairseqDataset):
- """Break a Dataset of tokens into sentence pair blocks for next sentence
- prediction as well as masked language model.
-
- High-level logics are:
- 1. break input tensor to tensor blocks
- 2. pair the blocks with 50% next sentence and 50% random sentence
- 3. return paired blocks as well as related segment labels
-
- Args:
- dataset (~torch.utils.data.Dataset): dataset to break into blocks
- sizes: array of sentence lengths
- dictionary: dictionary for the task
- block_size: maximum block size
- break_mode: mode for breaking copurs into block pairs. currently we support
- 2 modes
- doc: respect document boundaries and each part of the pair should belong to on document
- none: don't respect any boundary and cut tokens evenly
- short_seq_prob: probability for generating shorter block pairs
- doc_break_size: Size for empty line separating documents. Typically 1 if
- the sentences have eos, 0 otherwise.
- """
-
- def __init__(
- self,
- dataset,
- dictionary,
- sizes,
- block_size,
- break_mode="doc",
- short_seq_prob=0.1,
- doc_break_size=1,
- ):
- super().__init__()
- self.dataset = dataset
- self.pad = dictionary.pad()
- self.eos = dictionary.eos()
- self.cls = dictionary.cls()
- self.mask = dictionary.mask()
- self.sep = dictionary.sep()
- self.break_mode = break_mode
- self.dictionary = dictionary
- self.short_seq_prob = short_seq_prob
- self.block_indices = []
-
- assert len(dataset) == len(sizes)
-
- if break_mode == "doc":
- cur_doc = []
- for sent_id, sz in enumerate(sizes):
- assert doc_break_size == 0 or sz != 0, (
- "when doc_break_size is non-zero, we expect documents to be"
- "separated by a blank line with a single eos."
- )
- # empty line as document separator
- if sz == doc_break_size:
- if len(cur_doc) == 0:
- continue
- self.block_indices.append(cur_doc)
- cur_doc = []
- else:
- cur_doc.append(sent_id)
- max_num_tokens = block_size - 3 # Account for [CLS], [SEP], [SEP]
- self.sent_pairs = []
- self.sizes = []
- for doc_id, doc in enumerate(self.block_indices):
- self._generate_sentence_pair(doc, doc_id, max_num_tokens, sizes)
- elif break_mode is None or break_mode == "none":
- # each block should have half of the block size since we are constructing block pair
- sent_length = (block_size - 3) // 2
- total_len = sum(dataset.sizes)
- length = math.ceil(total_len / sent_length)
-
- def block_at(i):
- start = i * sent_length
- end = min(start + sent_length, total_len)
- return (start, end)
-
- sent_indices = np.array([block_at(i) for i in range(length)])
- sent_sizes = np.array([e - s for s, e in sent_indices])
- dataset_index = self._sent_to_dataset_index(sent_sizes)
-
- # pair sentences
- self._pair_sentences(dataset_index)
- else:
- raise ValueError("Invalid break_mode: " + break_mode)
-
- def _pair_sentences(self, dataset_index):
- """
- Give a list of evenly cut blocks/sentences, pair these sentences with 50%
- consecutive sentences and 50% random sentences.
- This is used for none break mode
- """
- # pair sentences
- for sent_id, sent in enumerate(dataset_index):
- next_sent_label = (
- 1 if np.random.rand() > 0.5 and sent_id != len(dataset_index) - 1 else 0
- )
- if next_sent_label:
- next_sent = dataset_index[sent_id + 1]
- else:
- next_sent = dataset_index[
- self._skip_sampling(len(dataset_index), [sent_id, sent_id + 1])
- ]
- self.sent_pairs.append((sent, next_sent, next_sent_label))
-
- # The current blocks don't include the special tokens but the
- # sizes already account for this
- self.sizes.append(3 + sent[3] + next_sent[3])
-
- def _sent_to_dataset_index(self, sent_sizes):
- """
- Build index mapping block indices to the underlying dataset indices
- """
- dataset_index = []
- ds_idx, ds_remaining = -1, 0
- for to_consume in sent_sizes:
- sent_size = to_consume
- if ds_remaining == 0:
- ds_idx += 1
- ds_remaining = sent_sizes[ds_idx]
- start_ds_idx = ds_idx
- start_offset = sent_sizes[ds_idx] - ds_remaining
- while to_consume > ds_remaining:
- to_consume -= ds_remaining
- ds_idx += 1
- ds_remaining = sent_sizes[ds_idx]
- ds_remaining -= to_consume
- dataset_index.append(
- (
- start_ds_idx, # starting index in dataset
- start_offset, # starting offset within starting index
- ds_idx, # ending index in dataset
- sent_size, # sentence length
- )
- )
- assert ds_remaining == 0
- assert ds_idx == len(self.dataset) - 1
- return dataset_index
-
- def _generate_sentence_pair(self, doc, doc_id, max_num_tokens, sizes):
- """
- Go through a single document and genrate sentence paris from it
- """
- current_chunk = []
- current_length = 0
- curr = 0
- # To provide more randomness, we decrease target seq length for parts of
- # samples (10% by default). Note that max_num_tokens is the hard threshold
- # for batching and will never be changed.
- target_seq_length = max_num_tokens
- if np.random.random() < self.short_seq_prob:
- target_seq_length = np.random.randint(2, max_num_tokens)
- # loop through all sentences in document
- while curr < len(doc):
- sent_id = doc[curr]
- current_chunk.append(sent_id)
- current_length = sum(sizes[current_chunk])
- # split chunk and generate pair when exceed target_seq_length or
- # finish the loop
- if curr == len(doc) - 1 or current_length >= target_seq_length:
- # split the chunk into 2 parts
- a_end = 1
- if len(current_chunk) > 2:
- a_end = np.random.randint(1, len(current_chunk) - 1)
- sent_a = current_chunk[:a_end]
- len_a = sum(sizes[sent_a])
- # generate next sentence label, note that if there is only 1 sentence
- # in current chunk, label is always 0
- next_sent_label = (
- 1 if np.random.rand() > 0.5 and len(current_chunk) != 1 else 0
- )
- if not next_sent_label:
- # if next sentence label is 0, sample sent_b from a random doc
- target_b_length = target_seq_length - len_a
- rand_doc_id = self._skip_sampling(len(self.block_indices), [doc_id])
- random_doc = self.block_indices[rand_doc_id]
- random_start = np.random.randint(0, len(random_doc))
- sent_b = []
- len_b = 0
- for j in range(random_start, len(random_doc)):
- sent_b.append(random_doc[j])
- len_b = sum(sizes[sent_b])
- if len_b >= target_b_length:
- break
- # return the second part of the chunk since it's not used
- num_unused_segments = len(current_chunk) - a_end
- curr -= num_unused_segments
- else:
- # if next sentence label is 1, use the second part of chunk as sent_B
- sent_b = current_chunk[a_end:]
- len_b = sum(sizes[sent_b])
- # currently sent_a and sent_B may be longer than max_num_tokens,
- # truncate them and return block idx and offsets for them
- sent_a, sent_b = self._truncate_sentences(
- sent_a, sent_b, max_num_tokens
- )
- self.sent_pairs.append((sent_a, sent_b, next_sent_label))
- self.sizes.append(3 + sent_a[3] + sent_b[3])
- current_chunk = []
- curr += 1
-
- def _skip_sampling(self, total, skip_ids):
- """
- Generate a random integer which is not in skip_ids. Sample range is [0, total)
- TODO: ids in skip_ids should be consecutive, we can extend it to more generic version later
- """
- rand_id = np.random.randint(total - len(skip_ids))
- return rand_id if rand_id < min(skip_ids) else rand_id + len(skip_ids)
-
- def _truncate_sentences(self, sent_a, sent_b, max_num_tokens):
- """
- Trancate a pair of sentence to limit total length under max_num_tokens
- Logics:
- 1. Truncate longer sentence
- 2. Tokens to be truncated could be at the beginning or the end of the sentnce
- Returns:
- Truncated sentences represented by dataset idx
- """
- len_a, len_b = sum(self.dataset.sizes[sent_a]), sum(self.dataset.sizes[sent_b])
- front_cut_a = front_cut_b = end_cut_a = end_cut_b = 0
-
- while True:
- total_length = (
- len_a + len_b - front_cut_a - front_cut_b - end_cut_a - end_cut_b
- )
- if total_length <= max_num_tokens:
- break
-
- if len_a - front_cut_a - end_cut_a > len_b - front_cut_b - end_cut_b:
- if np.random.rand() < 0.5:
- front_cut_a += 1
- else:
- end_cut_a += 1
- else:
- if np.random.rand() < 0.5:
- front_cut_b += 1
- else:
- end_cut_b += 1
-
- # calculate ds indices as well as offsets and return
- truncated_sent_a = self._cut_sentence(sent_a, front_cut_a, end_cut_a)
- truncated_sent_b = self._cut_sentence(sent_b, front_cut_b, end_cut_b)
- return truncated_sent_a, truncated_sent_b
-
- def _cut_sentence(self, sent, front_cut, end_cut):
- """
- Cut a sentence based on the numbers of tokens to be cut from beginning and end
- Represent the sentence as dataset idx and return
- """
- start_ds_idx, end_ds_idx, offset = sent[0], sent[-1], 0
- target_len = sum(self.dataset.sizes[sent]) - front_cut - end_cut
- while front_cut > 0:
- if self.dataset.sizes[start_ds_idx] > front_cut:
- offset += front_cut
- break
- else:
- front_cut -= self.dataset.sizes[start_ds_idx]
- start_ds_idx += 1
- while end_cut > 0:
- if self.dataset.sizes[end_ds_idx] > end_cut:
- break
- else:
- end_cut -= self.dataset.sizes[end_ds_idx]
- end_ds_idx -= 1
- return start_ds_idx, offset, end_ds_idx, target_len
-
- def _fetch_block(self, start_ds_idx, offset, end_ds_idx, length):
- """
- Fetch a block of tokens based on its dataset idx
- """
- buffer = torch.cat(
- [self.dataset[idx] for idx in range(start_ds_idx, end_ds_idx + 1)]
- )
- s, e = offset, offset + length
- return buffer[s:e]
-
- def __getitem__(self, index):
- block1, block2, next_sent_label = self.sent_pairs[index]
- block1 = self._fetch_block(*block1)
- block2 = self._fetch_block(*block2)
- return block1, block2, next_sent_label
-
- def __len__(self):
- return len(self.sizes)
-
- @property
- def supports_prefetch(self):
- return getattr(self.dataset, "supports_prefetch", False)
-
- def prefetch(self, indices):
- prefetch_idx = set()
- for index in indices:
- for block1, block2, _ in [self.sent_pairs[index]]:
- for ds_idx in range(block1[0], block1[2] + 1):
- prefetch_idx.add(ds_idx)
- for ds_idx in range(block2[0], block2[2] + 1):
- prefetch_idx.add(ds_idx)
- self.dataset.prefetch(prefetch_idx)
diff --git a/spaces/HighCWu/anime-colorization-with-hint/gradio-modified/gradio/templates/frontend/assets/utils.27234e1d.js b/spaces/HighCWu/anime-colorization-with-hint/gradio-modified/gradio/templates/frontend/assets/utils.27234e1d.js
deleted file mode 100644
index 94055dff32d754a6e758de5e920daa2b1e53cccd..0000000000000000000000000000000000000000
--- a/spaces/HighCWu/anime-colorization-with-hint/gradio-modified/gradio/templates/frontend/assets/utils.27234e1d.js
+++ /dev/null
@@ -1,2 +0,0 @@
-function t(n,r){if(n==null)return null;if(typeof n=="string")return{name:"file_data",data:n};if(n.is_file)n.data=r+"file="+n.name;else if(Array.isArray(n))for(const a of n)t(a,r);return n}export{t as n};
-//# sourceMappingURL=utils.27234e1d.js.map
diff --git a/spaces/ICML2022/OFA/fairseq/examples/speech_recognition/new/__init__.py b/spaces/ICML2022/OFA/fairseq/examples/speech_recognition/new/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Ibtehaj10/cheating-detection-FYP/README.md b/spaces/Ibtehaj10/cheating-detection-FYP/README.md
deleted file mode 100644
index 078e2a73bab9fa6d585f4073283dfabcb3387110..0000000000000000000000000000000000000000
--- a/spaces/Ibtehaj10/cheating-detection-FYP/README.md
+++ /dev/null
@@ -1,51 +0,0 @@
----
-sdk: streamlit
-title: Exam-Cheating-Detector
-emoji: 🚀
-app_file: app.py
----
-# AIComputerVision
-This project contains various computer vision and AI related python scripts
-
-Link to full playlist: https://www.youtube.com/watch?v=UM9oDhhAg88&list=PLWw98q-Xe7iH8UHARl8RGk8MRj1raY4Eh
-
-Below is brief description for each script:
-
-1. Cat Dog detection:
-This script can detect cats and dogs in a frame. You can replace cat or dog with any other object you want to detect.
-
-2. Centroidtracker:
-This script helps in tracking any object in a frame. We have used this in person_tracking.py script in order to track persons in the frame.
-
-3. Dwell Time Calculation:
-This script calculates the time a person has spent in a frame. It is a good example of calculating total time a person was present in frame.
-
-4. Face Detection:
-This script detects face in person image or in a frame
-
-5. FPS Example:
-While inferencing on a video file or frame from a live usb webcam, it's always a good idea to keep a check on how much fps we are getting. This script shows approx fps on frame.
-
-6. OpenCV Example:
-This script shows the basic usage of OpenCV
-
-7. Person Detection in Image File:
-This script detects a person in an image file
-
-8. Person Detection in Video File:
-This script detects a person in the video file. Test video file is present in video dir.
-
-9. Person Tracking:
-This script detects people and keeps tracking them in the frame. It assigns a unique ID to each detected person.
-
-10. Monitor Social Distance
-This script monitors the social distance between the persons. If it is less than a threshold value, we display the bounding box in red otherwise green.
-
-11. Drawing tracking line:
-This script draws a line denoting where the person has entered in the frame and where he has moved in the frame.
-
-12. Face Mask Detection:
-This script checks if a person is wearing face mask or not
-
-13. Person Counter:
-This script counts the number of person present in the frame.
\ No newline at end of file
diff --git a/spaces/Ikaros521/VITS-fast-fine-tuning_nymph/download_model.py b/spaces/Ikaros521/VITS-fast-fine-tuning_nymph/download_model.py
deleted file mode 100644
index 9f1ab59aa549afdf107bf2ff97d48149a87da6f4..0000000000000000000000000000000000000000
--- a/spaces/Ikaros521/VITS-fast-fine-tuning_nymph/download_model.py
+++ /dev/null
@@ -1,4 +0,0 @@
-from google.colab import files
-files.download("./G_latest.pth")
-files.download("./finetune_speaker.json")
-files.download("./moegoe_config.json")
\ No newline at end of file
diff --git a/spaces/Illumotion/Koboldcpp/common/common.cpp b/spaces/Illumotion/Koboldcpp/common/common.cpp
deleted file mode 100644
index 0f55c33a713a7cde065be27c4a204cbc2a4bdd27..0000000000000000000000000000000000000000
--- a/spaces/Illumotion/Koboldcpp/common/common.cpp
+++ /dev/null
@@ -1,1356 +0,0 @@
-#include "common.h"
-#include "build-info.h"
-#include "llama.h"
-
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-#include
-
-#if defined(__APPLE__) && defined(__MACH__)
-#include
-#include
-#endif
-
-#if defined(_WIN32)
-#define WIN32_LEAN_AND_MEAN
-#ifndef NOMINMAX
-# define NOMINMAX
-#endif
-#include
-#include
-#include
-#include
-#include
-#else
-#include
-#include
-#include
-#endif
-
-#if defined(_MSC_VER)
-#pragma warning(disable: 4244 4267) // possible loss of data
-#endif
-
-int32_t get_num_physical_cores() {
-#ifdef __linux__
- // enumerate the set of thread siblings, num entries is num cores
- std::unordered_set siblings;
- for (uint32_t cpu=0; cpu < UINT32_MAX; ++cpu) {
- std::ifstream thread_siblings("/sys/devices/system/cpu"
- + std::to_string(cpu) + "/topology/thread_siblings");
- if (!thread_siblings.is_open()) {
- break; // no more cpus
- }
- std::string line;
- if (std::getline(thread_siblings, line)) {
- siblings.insert(line);
- }
- }
- if (!siblings.empty()) {
- return static_cast(siblings.size());
- }
-#elif defined(__APPLE__) && defined(__MACH__)
- int32_t num_physical_cores;
- size_t len = sizeof(num_physical_cores);
- int result = sysctlbyname("hw.perflevel0.physicalcpu", &num_physical_cores, &len, NULL, 0);
- if (result == 0) {
- return num_physical_cores;
- }
- result = sysctlbyname("hw.physicalcpu", &num_physical_cores, &len, NULL, 0);
- if (result == 0) {
- return num_physical_cores;
- }
-#elif defined(_WIN32)
- //TODO: Implement
-#endif
- unsigned int n_threads = std::thread::hardware_concurrency();
- return n_threads > 0 ? (n_threads <= 4 ? n_threads : n_threads / 2) : 4;
-}
-
-void process_escapes(std::string& input) {
- std::size_t input_len = input.length();
- std::size_t output_idx = 0;
-
- for (std::size_t input_idx = 0; input_idx < input_len; ++input_idx) {
- if (input[input_idx] == '\\' && input_idx + 1 < input_len) {
- switch (input[++input_idx]) {
- case 'n': input[output_idx++] = '\n'; break;
- case 'r': input[output_idx++] = '\r'; break;
- case 't': input[output_idx++] = '\t'; break;
- case '\'': input[output_idx++] = '\''; break;
- case '\"': input[output_idx++] = '\"'; break;
- case '\\': input[output_idx++] = '\\'; break;
- default: input[output_idx++] = '\\';
- input[output_idx++] = input[input_idx]; break;
- }
- } else {
- input[output_idx++] = input[input_idx];
- }
- }
-
- input.resize(output_idx);
-}
-
-bool gpt_params_parse(int argc, char ** argv, gpt_params & params) {
- bool invalid_param = false;
- std::string arg;
- gpt_params default_params;
- const std::string arg_prefix = "--";
-
- for (int i = 1; i < argc; i++) {
- arg = argv[i];
- if (arg.compare(0, arg_prefix.size(), arg_prefix) == 0) {
- std::replace(arg.begin(), arg.end(), '_', '-');
- }
-
- if (arg == "-s" || arg == "--seed") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.seed = std::stoul(argv[i]);
- } else if (arg == "-t" || arg == "--threads") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_threads = std::stoi(argv[i]);
- if (params.n_threads <= 0) {
- params.n_threads = std::thread::hardware_concurrency();
- }
- } else if (arg == "-tb" || arg == "--threads-batch") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_threads_batch = std::stoi(argv[i]);
- if (params.n_threads_batch <= 0) {
- params.n_threads_batch = std::thread::hardware_concurrency();
- }
- } else if (arg == "-p" || arg == "--prompt") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.prompt = argv[i];
- } else if (arg == "-e" || arg == "--escape") {
- params.escape = true;
- } else if (arg == "--prompt-cache") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.path_prompt_cache = argv[i];
- } else if (arg == "--prompt-cache-all") {
- params.prompt_cache_all = true;
- } else if (arg == "--prompt-cache-ro") {
- params.prompt_cache_ro = true;
- } else if (arg == "-f" || arg == "--file") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- std::ifstream file(argv[i]);
- if (!file) {
- fprintf(stderr, "error: failed to open file '%s'\n", argv[i]);
- invalid_param = true;
- break;
- }
- // store the external file name in params
- params.prompt_file = argv[i];
- std::copy(std::istreambuf_iterator(file), std::istreambuf_iterator(), back_inserter(params.prompt));
- if (!params.prompt.empty() && params.prompt.back() == '\n') {
- params.prompt.pop_back();
- }
- } else if (arg == "-n" || arg == "--n-predict") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_predict = std::stoi(argv[i]);
- } else if (arg == "--top-k") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.top_k = std::stoi(argv[i]);
- } else if (arg == "-c" || arg == "--ctx-size") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_ctx = std::stoi(argv[i]);
- } else if (arg == "--rope-freq-base") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.rope_freq_base = std::stof(argv[i]);
- } else if (arg == "--rope-freq-scale") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.rope_freq_scale = std::stof(argv[i]);
- } else if (arg == "--rope-scale") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.rope_freq_scale = 1.0f/std::stof(argv[i]);
- } else if (arg == "--memory-f32") {
- params.memory_f16 = false;
- } else if (arg == "--top-p") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.top_p = std::stof(argv[i]);
- } else if (arg == "--temp") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.temp = std::stof(argv[i]);
- } else if (arg == "--tfs") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.tfs_z = std::stof(argv[i]);
- } else if (arg == "--typical") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.typical_p = std::stof(argv[i]);
- } else if (arg == "--repeat-last-n") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.repeat_last_n = std::stoi(argv[i]);
- } else if (arg == "--repeat-penalty") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.repeat_penalty = std::stof(argv[i]);
- } else if (arg == "--frequency-penalty") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.frequency_penalty = std::stof(argv[i]);
- } else if (arg == "--presence-penalty") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.presence_penalty = std::stof(argv[i]);
- } else if (arg == "--mirostat") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.mirostat = std::stoi(argv[i]);
- } else if (arg == "--mirostat-lr") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.mirostat_eta = std::stof(argv[i]);
- } else if (arg == "--mirostat-ent") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.mirostat_tau = std::stof(argv[i]);
- } else if (arg == "--cfg-negative-prompt") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.cfg_negative_prompt = argv[i];
- } else if (arg == "--cfg-negative-prompt-file") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- std::ifstream file(argv[i]);
- if (!file) {
- fprintf(stderr, "error: failed to open file '%s'\n", argv[i]);
- invalid_param = true;
- break;
- }
- std::copy(std::istreambuf_iterator(file), std::istreambuf_iterator(), back_inserter(params.cfg_negative_prompt));
- if (!params.cfg_negative_prompt.empty() && params.cfg_negative_prompt.back() == '\n') {
- params.cfg_negative_prompt.pop_back();
- }
- } else if (arg == "--cfg-scale") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.cfg_scale = std::stof(argv[i]);
- } else if (arg == "-b" || arg == "--batch-size") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_batch = std::stoi(argv[i]);
- } else if (arg == "--keep") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_keep = std::stoi(argv[i]);
- } else if (arg == "--draft") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_draft = std::stoi(argv[i]);
- } else if (arg == "--chunks") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_chunks = std::stoi(argv[i]);
- } else if (arg == "-np" || arg == "--parallel") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_parallel = std::stoi(argv[i]);
- } else if (arg == "-ns" || arg == "--sequences") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.n_sequences = std::stoi(argv[i]);
- } else if (arg == "-m" || arg == "--model") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.model = argv[i];
- } else if (arg == "-md" || arg == "--model-draft") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.model_draft = argv[i];
- } else if (arg == "-a" || arg == "--alias") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.model_alias = argv[i];
- } else if (arg == "--lora") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.lora_adapter.push_back(std::make_tuple(argv[i], 1.0f));
- params.use_mmap = false;
- } else if (arg == "--lora-scaled") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- const char * lora_adapter = argv[i];
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.lora_adapter.push_back(std::make_tuple(lora_adapter, std::stof(argv[i])));
- params.use_mmap = false;
- } else if (arg == "--lora-base") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.lora_base = argv[i];
- } else if (arg == "-i" || arg == "--interactive") {
- params.interactive = true;
- } else if (arg == "--embedding") {
- params.embedding = true;
- } else if (arg == "--interactive-first") {
- params.interactive_first = true;
- } else if (arg == "-ins" || arg == "--instruct") {
- params.instruct = true;
- } else if (arg == "--infill") {
- params.infill = true;
- } else if (arg == "--multiline-input") {
- params.multiline_input = true;
- } else if (arg == "--simple-io") {
- params.simple_io = true;
- } else if (arg == "-cb" || arg == "--cont-batching") {
- params.cont_batching = true;
- } else if (arg == "--color") {
- params.use_color = true;
- } else if (arg == "--mlock") {
- params.use_mlock = true;
- } else if (arg == "--gpu-layers" || arg == "-ngl" || arg == "--n-gpu-layers") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
-#ifdef LLAMA_SUPPORTS_GPU_OFFLOAD
- params.n_gpu_layers = std::stoi(argv[i]);
-#else
- fprintf(stderr, "warning: not compiled with GPU offload support, --n-gpu-layers option will be ignored\n");
- fprintf(stderr, "warning: see main README.md for information on enabling GPU BLAS support\n");
-#endif
- } else if (arg == "--gpu-layers-draft" || arg == "-ngld" || arg == "--n-gpu-layers-draft") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
-#ifdef LLAMA_SUPPORTS_GPU_OFFLOAD
- params.n_gpu_layers_draft = std::stoi(argv[i]);
-#else
- fprintf(stderr, "warning: not compiled with GPU offload support, --n-gpu-layers-draft option will be ignored\n");
- fprintf(stderr, "warning: see main README.md for information on enabling GPU BLAS support\n");
-#endif
- } else if (arg == "--main-gpu" || arg == "-mg") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
-#ifdef GGML_USE_CUBLAS
- params.main_gpu = std::stoi(argv[i]);
-#else
- fprintf(stderr, "warning: llama.cpp was compiled without cuBLAS. It is not possible to set a main GPU.\n");
-#endif
- } else if (arg == "--tensor-split" || arg == "-ts") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
-#ifdef GGML_USE_CUBLAS
- std::string arg_next = argv[i];
-
- // split string by , and /
- const std::regex regex{R"([,/]+)"};
- std::sregex_token_iterator it{arg_next.begin(), arg_next.end(), regex, -1};
- std::vector split_arg{it, {}};
- GGML_ASSERT(split_arg.size() <= LLAMA_MAX_DEVICES);
-
- for (size_t i = 0; i < LLAMA_MAX_DEVICES; ++i) {
- if (i < split_arg.size()) {
- params.tensor_split[i] = std::stof(split_arg[i]);
- } else {
- params.tensor_split[i] = 0.0f;
- }
- }
-#else
- fprintf(stderr, "warning: llama.cpp was compiled without cuBLAS. It is not possible to set a tensor split.\n");
-#endif // GGML_USE_CUBLAS
- } else if (arg == "--no-mul-mat-q" || arg == "-nommq") {
-#ifdef GGML_USE_CUBLAS
- params.mul_mat_q = false;
-#else
- fprintf(stderr, "warning: llama.cpp was compiled without cuBLAS. Disabling mul_mat_q kernels has no effect.\n");
-#endif // GGML_USE_CUBLAS
- } else if (arg == "--no-mmap") {
- params.use_mmap = false;
- } else if (arg == "--numa") {
- params.numa = true;
- } else if (arg == "--verbose-prompt") {
- params.verbose_prompt = true;
- } else if (arg == "-r" || arg == "--reverse-prompt") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.antiprompt.push_back(argv[i]);
- } else if (arg == "-ld" || arg == "--logdir") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.logdir = argv[i];
-
- if (params.logdir.back() != DIRECTORY_SEPARATOR) {
- params.logdir += DIRECTORY_SEPARATOR;
- }
- } else if (arg == "--perplexity" || arg == "--all-logits") {
- params.logits_all = true;
- } else if (arg == "--ppl-stride") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.ppl_stride = std::stoi(argv[i]);
- } else if (arg == "--ppl-output-type") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.ppl_output_type = std::stoi(argv[i]);
- } else if (arg == "--hellaswag") {
- params.hellaswag = true;
- } else if (arg == "--hellaswag-tasks") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.hellaswag_tasks = std::stoi(argv[i]);
- } else if (arg == "--ignore-eos") {
- params.ignore_eos = true;
- } else if (arg == "--no-penalize-nl") {
- params.penalize_nl = false;
- } else if (arg == "-l" || arg == "--logit-bias") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- std::stringstream ss(argv[i]);
- llama_token key;
- char sign;
- std::string value_str;
- try {
- if (ss >> key && ss >> sign && std::getline(ss, value_str) && (sign == '+' || sign == '-')) {
- params.logit_bias[key] = std::stof(value_str) * ((sign == '-') ? -1.0f : 1.0f);
- } else {
- throw std::exception();
- }
- } catch (const std::exception&) {
- invalid_param = true;
- break;
- }
- } else if (arg == "-h" || arg == "--help") {
- gpt_print_usage(argc, argv, default_params);
-#ifndef LOG_DISABLE_LOGS
- log_print_usage();
-#endif // LOG_DISABLE_LOGS
- exit(0);
- } else if (arg == "--random-prompt") {
- params.random_prompt = true;
- } else if (arg == "--in-prefix-bos") {
- params.input_prefix_bos = true;
- } else if (arg == "--in-prefix") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.input_prefix = argv[i];
- } else if (arg == "--in-suffix") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.input_suffix = argv[i];
- } else if (arg == "--grammar") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- params.grammar = argv[i];
- } else if (arg == "--grammar-file") {
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- std::ifstream file(argv[i]);
- if (!file) {
- fprintf(stderr, "error: failed to open file '%s'\n", argv[i]);
- invalid_param = true;
- break;
- }
- std::copy(
- std::istreambuf_iterator(file),
- std::istreambuf_iterator(),
- std::back_inserter(params.grammar)
- );
-#ifndef LOG_DISABLE_LOGS
- // Parse args for logging parameters
- } else if ( log_param_single_parse( argv[i] ) ) {
- // Do nothing, log_param_single_parse automatically does it's thing
- // and returns if a match was found and parsed.
- } else if ( log_param_pair_parse( /*check_but_dont_parse*/ true, argv[i] ) ) {
- // We have a matching known parameter requiring an argument,
- // now we need to check if there is anything after this argv
- // and flag invalid_param or parse it.
- if (++i >= argc) {
- invalid_param = true;
- break;
- }
- if( !log_param_pair_parse( /*check_but_dont_parse*/ false, argv[i-1], argv[i]) ) {
- invalid_param = true;
- break;
- }
- // End of Parse args for logging parameters
-#endif // LOG_DISABLE_LOGS
- } else {
- fprintf(stderr, "error: unknown argument: %s\n", arg.c_str());
- gpt_print_usage(argc, argv, default_params);
- exit(1);
- }
- }
- if (invalid_param) {
- fprintf(stderr, "error: invalid parameter for argument: %s\n", arg.c_str());
- gpt_print_usage(argc, argv, default_params);
- exit(1);
- }
- if (params.prompt_cache_all &&
- (params.interactive || params.interactive_first ||
- params.instruct)) {
- fprintf(stderr, "error: --prompt-cache-all not supported in interactive mode yet\n");
- gpt_print_usage(argc, argv, default_params);
- exit(1);
- }
-
- if (params.escape) {
- process_escapes(params.prompt);
- process_escapes(params.input_prefix);
- process_escapes(params.input_suffix);
- for (auto & antiprompt : params.antiprompt) {
- process_escapes(antiprompt);
- }
- }
-
- return true;
-}
-
-void gpt_print_usage(int /*argc*/, char ** argv, const gpt_params & params) {
- printf("usage: %s [options]\n", argv[0]);
- printf("\n");
- printf("options:\n");
- printf(" -h, --help show this help message and exit\n");
- printf(" -i, --interactive run in interactive mode\n");
- printf(" --interactive-first run in interactive mode and wait for input right away\n");
- printf(" -ins, --instruct run in instruction mode (use with Alpaca models)\n");
- printf(" --multiline-input allows you to write or paste multiple lines without ending each in '\\'\n");
- printf(" -r PROMPT, --reverse-prompt PROMPT\n");
- printf(" halt generation at PROMPT, return control in interactive mode\n");
- printf(" (can be specified more than once for multiple prompts).\n");
- printf(" --color colorise output to distinguish prompt and user input from generations\n");
- printf(" -s SEED, --seed SEED RNG seed (default: -1, use random seed for < 0)\n");
- printf(" -t N, --threads N number of threads to use during generation (default: %d)\n", params.n_threads);
- printf(" -tb N, --threads-batch N\n");
- printf(" number of threads to use during batch and prompt processing (default: same as --threads)\n");
- printf(" -p PROMPT, --prompt PROMPT\n");
- printf(" prompt to start generation with (default: empty)\n");
- printf(" -e, --escape process prompt escapes sequences (\\n, \\r, \\t, \\', \\\", \\\\)\n");
- printf(" --prompt-cache FNAME file to cache prompt state for faster startup (default: none)\n");
- printf(" --prompt-cache-all if specified, saves user input and generations to cache as well.\n");
- printf(" not supported with --interactive or other interactive options\n");
- printf(" --prompt-cache-ro if specified, uses the prompt cache but does not update it.\n");
- printf(" --random-prompt start with a randomized prompt.\n");
- printf(" --in-prefix-bos prefix BOS to user inputs, preceding the `--in-prefix` string\n");
- printf(" --in-prefix STRING string to prefix user inputs with (default: empty)\n");
- printf(" --in-suffix STRING string to suffix after user inputs with (default: empty)\n");
- printf(" -f FNAME, --file FNAME\n");
- printf(" prompt file to start generation.\n");
- printf(" -n N, --n-predict N number of tokens to predict (default: %d, -1 = infinity, -2 = until context filled)\n", params.n_predict);
- printf(" -c N, --ctx-size N size of the prompt context (default: %d, 0 = loaded from model)\n", params.n_ctx);
- printf(" -b N, --batch-size N batch size for prompt processing (default: %d)\n", params.n_batch);
- printf(" --top-k N top-k sampling (default: %d, 0 = disabled)\n", params.top_k);
- printf(" --top-p N top-p sampling (default: %.1f, 1.0 = disabled)\n", (double)params.top_p);
- printf(" --tfs N tail free sampling, parameter z (default: %.1f, 1.0 = disabled)\n", (double)params.tfs_z);
- printf(" --typical N locally typical sampling, parameter p (default: %.1f, 1.0 = disabled)\n", (double)params.typical_p);
- printf(" --repeat-last-n N last n tokens to consider for penalize (default: %d, 0 = disabled, -1 = ctx_size)\n", params.repeat_last_n);
- printf(" --repeat-penalty N penalize repeat sequence of tokens (default: %.1f, 1.0 = disabled)\n", (double)params.repeat_penalty);
- printf(" --presence-penalty N repeat alpha presence penalty (default: %.1f, 0.0 = disabled)\n", (double)params.presence_penalty);
- printf(" --frequency-penalty N repeat alpha frequency penalty (default: %.1f, 0.0 = disabled)\n", (double)params.frequency_penalty);
- printf(" --mirostat N use Mirostat sampling.\n");
- printf(" Top K, Nucleus, Tail Free and Locally Typical samplers are ignored if used.\n");
- printf(" (default: %d, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0)\n", params.mirostat);
- printf(" --mirostat-lr N Mirostat learning rate, parameter eta (default: %.1f)\n", (double)params.mirostat_eta);
- printf(" --mirostat-ent N Mirostat target entropy, parameter tau (default: %.1f)\n", (double)params.mirostat_tau);
- printf(" -l TOKEN_ID(+/-)BIAS, --logit-bias TOKEN_ID(+/-)BIAS\n");
- printf(" modifies the likelihood of token appearing in the completion,\n");
- printf(" i.e. `--logit-bias 15043+1` to increase likelihood of token ' Hello',\n");
- printf(" or `--logit-bias 15043-1` to decrease likelihood of token ' Hello'\n");
- printf(" --grammar GRAMMAR BNF-like grammar to constrain generations (see samples in grammars/ dir)\n");
- printf(" --grammar-file FNAME file to read grammar from\n");
- printf(" --cfg-negative-prompt PROMPT\n");
- printf(" negative prompt to use for guidance. (default: empty)\n");
- printf(" --cfg-negative-prompt-file FNAME\n");
- printf(" negative prompt file to use for guidance. (default: empty)\n");
- printf(" --cfg-scale N strength of guidance (default: %f, 1.0 = disable)\n", params.cfg_scale);
- printf(" --rope-scale N RoPE context linear scaling factor, inverse of --rope-freq-scale\n");
- printf(" --rope-freq-base N RoPE base frequency, used by NTK-aware scaling (default: loaded from model)\n");
- printf(" --rope-freq-scale N RoPE frequency linear scaling factor (default: loaded from model)\n");
- printf(" --ignore-eos ignore end of stream token and continue generating (implies --logit-bias 2-inf)\n");
- printf(" --no-penalize-nl do not penalize newline token\n");
- printf(" --memory-f32 use f32 instead of f16 for memory key+value (default: disabled)\n");
- printf(" not recommended: doubles context memory required and no measurable increase in quality\n");
- printf(" --temp N temperature (default: %.1f)\n", (double)params.temp);
- printf(" --logits-all return logits for all tokens in the batch (default: disabled)\n");
- printf(" --hellaswag compute HellaSwag score over random tasks from datafile supplied with -f\n");
- printf(" --hellaswag-tasks N number of tasks to use when computing the HellaSwag score (default: %zu)\n", params.hellaswag_tasks);
- printf(" --keep N number of tokens to keep from the initial prompt (default: %d, -1 = all)\n", params.n_keep);
- printf(" --draft N number of tokens to draft for speculative decoding (default: %d)\n", params.n_draft);
- printf(" --chunks N max number of chunks to process (default: %d, -1 = all)\n", params.n_chunks);
- printf(" -np N, --parallel N number of parallel sequences to decode (default: %d)\n", params.n_parallel);
- printf(" -ns N, --sequences N number of sequences to decode (default: %d)\n", params.n_sequences);
- printf(" -cb, --cont-batching enable continuous batching (a.k.a dynamic batching) (default: disabled)\n");
- if (llama_mlock_supported()) {
- printf(" --mlock force system to keep model in RAM rather than swapping or compressing\n");
- }
- if (llama_mmap_supported()) {
- printf(" --no-mmap do not memory-map model (slower load but may reduce pageouts if not using mlock)\n");
- }
- printf(" --numa attempt optimizations that help on some NUMA systems\n");
- printf(" if run without this previously, it is recommended to drop the system page cache before using this\n");
- printf(" see https://github.com/ggerganov/llama.cpp/issues/1437\n");
-#ifdef LLAMA_SUPPORTS_GPU_OFFLOAD
- printf(" -ngl N, --n-gpu-layers N\n");
- printf(" number of layers to store in VRAM\n");
- printf(" -ngld N, --n-gpu-layers-draft N\n");
- printf(" number of layers to store in VRAM for the draft model\n");
- printf(" -ts SPLIT --tensor-split SPLIT\n");
- printf(" how to split tensors across multiple GPUs, comma-separated list of proportions, e.g. 3,1\n");
- printf(" -mg i, --main-gpu i the GPU to use for scratch and small tensors\n");
-#ifdef GGML_USE_CUBLAS
- printf(" -nommq, --no-mul-mat-q\n");
- printf(" use " GGML_CUBLAS_NAME " instead of custom mul_mat_q " GGML_CUDA_NAME " kernels.\n");
- printf(" Not recommended since this is both slower and uses more VRAM.\n");
-#endif // GGML_USE_CUBLAS
-#endif
- printf(" --verbose-prompt print prompt before generation\n");
- fprintf(stderr, " --simple-io use basic IO for better compatibility in subprocesses and limited consoles\n");
- printf(" --lora FNAME apply LoRA adapter (implies --no-mmap)\n");
- printf(" --lora-scaled FNAME S apply LoRA adapter with user defined scaling S (implies --no-mmap)\n");
- printf(" --lora-base FNAME optional model to use as a base for the layers modified by the LoRA adapter\n");
- printf(" -m FNAME, --model FNAME\n");
- printf(" model path (default: %s)\n", params.model.c_str());
- printf(" -md FNAME, --model-draft FNAME\n");
- printf(" draft model for speculative decoding (default: %s)\n", params.model.c_str());
- printf(" -ld LOGDIR, --logdir LOGDIR\n");
- printf(" path under which to save YAML logs (no logging if unset)\n");
- printf("\n");
-}
-
-std::string get_system_info(const gpt_params & params) {
- std::ostringstream os;
-
- os << "system_info: n_threads = " << params.n_threads;
- if (params.n_threads_batch != -1) {
- os << " (n_threads_batch = " << params.n_threads_batch << ")";
- }
- os << " / " << std::thread::hardware_concurrency() << " | " << llama_print_system_info();
-
- return os.str();
-}
-
-std::string gpt_random_prompt(std::mt19937 & rng) {
- const int r = rng() % 10;
- switch (r) {
- case 0: return "So";
- case 1: return "Once upon a time";
- case 2: return "When";
- case 3: return "The";
- case 4: return "After";
- case 5: return "If";
- case 6: return "import";
- case 7: return "He";
- case 8: return "She";
- case 9: return "They";
- }
-
- GGML_UNREACHABLE();
-}
-
-//
-// Model utils
-//
-
-struct llama_model_params llama_model_params_from_gpt_params(const gpt_params & params) {
- auto mparams = llama_model_default_params();
-
- if (params.n_gpu_layers != -1) {
- mparams.n_gpu_layers = params.n_gpu_layers;
- }
- mparams.main_gpu = params.main_gpu;
- mparams.tensor_split = params.tensor_split;
- mparams.use_mmap = params.use_mmap;
- mparams.use_mlock = params.use_mlock;
-
- return mparams;
-}
-
-struct llama_context_params llama_context_params_from_gpt_params(const gpt_params & params) {
- auto cparams = llama_context_default_params();
-
- cparams.n_ctx = params.n_ctx;
- cparams.n_batch = params.n_batch;
- cparams.n_threads = params.n_threads;
- cparams.n_threads_batch = params.n_threads_batch == -1 ? params.n_threads : params.n_threads_batch;
- cparams.mul_mat_q = params.mul_mat_q;
- cparams.seed = params.seed;
- cparams.f16_kv = params.memory_f16;
- cparams.logits_all = params.logits_all;
- cparams.embedding = params.embedding;
- cparams.rope_freq_base = params.rope_freq_base;
- cparams.rope_freq_scale = params.rope_freq_scale;
-
- return cparams;
-}
-
-std::tuple llama_init_from_gpt_params(gpt_params & params) {
- auto mparams = llama_model_params_from_gpt_params(params);
-
- llama_model * model = llama_load_model_from_file(params.model.c_str(), mparams);
- if (model == NULL) {
- fprintf(stderr, "%s: error: failed to load model '%s'\n", __func__, params.model.c_str());
- return std::make_tuple(nullptr, nullptr);
- }
-
- auto cparams = llama_context_params_from_gpt_params(params);
-
- llama_context * lctx = llama_new_context_with_model(model, cparams);
- if (lctx == NULL) {
- fprintf(stderr, "%s: error: failed to create context with model '%s'\n", __func__, params.model.c_str());
- llama_free_model(model);
- return std::make_tuple(nullptr, nullptr);
- }
-
- for (unsigned int i = 0; i < params.lora_adapter.size(); ++i) {
- const std::string& lora_adapter = std::get<0>(params.lora_adapter[i]);
- float lora_scale = std::get<1>(params.lora_adapter[i]);
- int err = llama_model_apply_lora_from_file(model,
- lora_adapter.c_str(),
- lora_scale,
- ((i > 0) || params.lora_base.empty())
- ? NULL
- : params.lora_base.c_str(),
- params.n_threads);
- if (err != 0) {
- fprintf(stderr, "%s: error: failed to apply lora adapter\n", __func__);
- llama_free(lctx);
- llama_free_model(model);
- return std::make_tuple(nullptr, nullptr);
- }
- }
-
- if (params.ignore_eos) {
- params.logit_bias[llama_token_eos(lctx)] = -INFINITY;
- }
-
- {
- LOG("warming up the model with an empty run\n");
-
- std::vector tmp = { llama_token_bos(lctx), llama_token_eos(lctx), };
- llama_decode(lctx, llama_batch_get_one(tmp.data(), std::min(tmp.size(), (size_t) params.n_batch), 0, 0));
- llama_kv_cache_tokens_rm(lctx, -1, -1);
- llama_reset_timings(lctx);
- }
-
- return std::make_tuple(model, lctx);
-}
-
-//
-// Vocab utils
-//
-
-std::vector llama_tokenize(
- const struct llama_context * ctx,
- const std::string & text,
- bool add_bos) {
- return llama_tokenize(llama_get_model(ctx), text, add_bos);
-}
-
-std::vector llama_tokenize(
- const struct llama_model * model,
- const std::string & text,
- bool add_bos) {
- // upper limit for the number of tokens
- int n_tokens = text.length() + add_bos;
- std::vector result(n_tokens);
- n_tokens = llama_tokenize(model, text.data(), text.length(), result.data(), result.size(), add_bos);
- if (n_tokens < 0) {
- result.resize(-n_tokens);
- int check = llama_tokenize(model, text.data(), text.length(), result.data(), result.size(), add_bos);
- GGML_ASSERT(check == -n_tokens);
- } else {
- result.resize(n_tokens);
- }
- return result;
-}
-
-std::string llama_token_to_piece(const struct llama_context * ctx, llama_token token) {
- std::vector result(8, 0);
- const int n_tokens = llama_token_to_piece(llama_get_model(ctx), token, result.data(), result.size());
- if (n_tokens < 0) {
- result.resize(-n_tokens);
- int check = llama_token_to_piece(llama_get_model(ctx), token, result.data(), result.size());
- GGML_ASSERT(check == -n_tokens);
- } else {
- result.resize(n_tokens);
- }
-
- return std::string(result.data(), result.size());
-}
-
-std::string llama_detokenize_spm(llama_context * ctx, const std::vector & tokens) {
- const llama_token bos_id = llama_token_bos(ctx);
-
- std::string piece;
- std::string result;
-
- for (size_t i = 0; i < tokens.size(); ++i) {
- piece = llama_token_to_piece(ctx, tokens[i]);
-
- // remove the leading space of the first non-BOS token
- if (((tokens[0] == bos_id && i == 1) || (tokens[0] != bos_id && i == 0)) && piece[0] == ' ') {
- piece = piece.substr(1);
- }
-
- result += piece;
- }
-
- return result;
-}
-
-std::string llama_detokenize_bpe(llama_context * ctx, const std::vector & tokens) {
- std::string piece;
- std::string result;
-
- for (size_t i = 0; i < tokens.size(); ++i) {
- piece = llama_token_to_piece(ctx, tokens[i]);
-
- result += piece;
- }
-
- // NOTE: the original tokenizer decodes bytes after collecting the pieces.
- return result;
-}
-
-//
-// Sampling utils
-//
-
-llama_token llama_sample_token(
- struct llama_context * ctx,
- struct llama_context * ctx_guidance,
- struct llama_grammar * grammar,
- const struct gpt_params & params,
- const std::vector & last_tokens,
- std::vector & candidates,
- int idx) {
- const int n_ctx = llama_n_ctx(ctx);
- const int n_vocab = llama_n_vocab(llama_get_model(ctx));
-
- const float temp = params.temp;
- const int32_t top_k = params.top_k <= 0 ? n_vocab : params.top_k;
- const float top_p = params.top_p;
- const float tfs_z = params.tfs_z;
- const float typical_p = params.typical_p;
- const int32_t repeat_last_n = params.repeat_last_n < 0 ? n_ctx : params.repeat_last_n;
- const float repeat_penalty = params.repeat_penalty;
- const float alpha_presence = params.presence_penalty;
- const float alpha_frequency = params.frequency_penalty;
- const int mirostat = params.mirostat;
- const float mirostat_tau = params.mirostat_tau;
- const float mirostat_eta = params.mirostat_eta;
- const bool penalize_nl = params.penalize_nl;
-
- llama_token id = 0;
-
- float * logits = llama_get_logits_ith(ctx, idx);
-
- // Apply params.logit_bias map
- for (auto it = params.logit_bias.begin(); it != params.logit_bias.end(); it++) {
- logits[it->first] += it->second;
- }
-
- candidates.clear();
- for (llama_token token_id = 0; token_id < n_vocab; token_id++) {
- candidates.emplace_back(llama_token_data{token_id, logits[token_id], 0.0f});
- }
-
- llama_token_data_array cur_p = { candidates.data(), candidates.size(), false };
-
- if (ctx_guidance) {
- llama_sample_classifier_free_guidance(ctx, &cur_p, ctx_guidance, params.cfg_scale);
- }
-
- // apply penalties
- if (!last_tokens.empty()) {
- const float nl_logit = logits[llama_token_nl(ctx)];
- const int last_n_repeat = std::min(std::min((int)last_tokens.size(), repeat_last_n), n_ctx);
-
- llama_sample_repetition_penalty(ctx, &cur_p,
- last_tokens.data() + last_tokens.size() - last_n_repeat,
- last_n_repeat, repeat_penalty);
- llama_sample_frequency_and_presence_penalties(ctx, &cur_p,
- last_tokens.data() + last_tokens.size() - last_n_repeat,
- last_n_repeat, alpha_frequency, alpha_presence);
-
- if (!penalize_nl) {
- for (size_t idx = 0; idx < cur_p.size; idx++) {
- if (cur_p.data[idx].id == llama_token_nl(ctx)) {
- cur_p.data[idx].logit = nl_logit;
- break;
- }
- }
- }
- }
-
- if (grammar != NULL) {
- llama_sample_grammar(ctx, &cur_p, grammar);
- }
-
- if (temp <= 0) {
- // Greedy sampling
- id = llama_sample_token_greedy(ctx, &cur_p);
- } else {
- if (mirostat == 1) {
- static float mirostat_mu = 2.0f * mirostat_tau;
- const int mirostat_m = 100;
- llama_sample_temp(ctx, &cur_p, temp);
- id = llama_sample_token_mirostat(ctx, &cur_p, mirostat_tau, mirostat_eta, mirostat_m, &mirostat_mu);
- } else if (mirostat == 2) {
- static float mirostat_mu = 2.0f * mirostat_tau;
- llama_sample_temp(ctx, &cur_p, temp);
- id = llama_sample_token_mirostat_v2(ctx, &cur_p, mirostat_tau, mirostat_eta, &mirostat_mu);
- } else {
- // Temperature sampling
- size_t min_keep = std::max(1, params.n_probs);
- llama_sample_top_k (ctx, &cur_p, top_k, min_keep);
- llama_sample_tail_free (ctx, &cur_p, tfs_z, min_keep);
- llama_sample_typical (ctx, &cur_p, typical_p, min_keep);
- llama_sample_top_p (ctx, &cur_p, top_p, min_keep);
- llama_sample_temp(ctx, &cur_p, temp);
-
- {
- const int n_top = 10;
- LOG("top %d candidates:\n", n_top);
-
- for (int i = 0; i < n_top; i++) {
- const llama_token id = cur_p.data[i].id;
- LOG(" - %5d: '%12s' (%.3f)\n", id, llama_token_to_piece(ctx, id).c_str(), cur_p.data[i].p);
- }
- }
-
- id = llama_sample_token(ctx, &cur_p);
-
- LOG("sampled token: %5d: '%s'\n", id, llama_token_to_piece(ctx, id).c_str());
- }
- }
- // printf("`%d`", candidates_p.size);
-
- if (grammar != NULL) {
- llama_grammar_accept_token(ctx, grammar, id);
- }
-
- return id;
-}
-
-//
-// YAML utils
-//
-
-// returns true if successful, false otherwise
-bool create_directory_with_parents(const std::string & path) {
-#ifdef _WIN32
- std::wstring_convert> converter;
- std::wstring wpath = converter.from_bytes(path);
-
- // if the path already exists, check whether it's a directory
- const DWORD attributes = GetFileAttributesW(wpath.c_str());
- if ((attributes != INVALID_FILE_ATTRIBUTES) && (attributes & FILE_ATTRIBUTE_DIRECTORY)) {
- return true;
- }
-
- size_t pos_slash = 0;
-
- // process path from front to back, procedurally creating directories
- while ((pos_slash = path.find('\\', pos_slash)) != std::string::npos) {
- const std::wstring subpath = wpath.substr(0, pos_slash);
- const wchar_t * test = subpath.c_str();
-
- const bool success = CreateDirectoryW(test, NULL);
- if (!success) {
- const DWORD error = GetLastError();
-
- // if the path already exists, ensure that it's a directory
- if (error == ERROR_ALREADY_EXISTS) {
- const DWORD attributes = GetFileAttributesW(subpath.c_str());
- if (attributes == INVALID_FILE_ATTRIBUTES || !(attributes & FILE_ATTRIBUTE_DIRECTORY)) {
- return false;
- }
- } else {
- return false;
- }
- }
-
- pos_slash += 1;
- }
-
- return true;
-#else
- // if the path already exists, check whether it's a directory
- struct stat info;
- if (stat(path.c_str(), &info) == 0) {
- return S_ISDIR(info.st_mode);
- }
-
- size_t pos_slash = 1; // skip leading slashes for directory creation
-
- // process path from front to back, procedurally creating directories
- while ((pos_slash = path.find('/', pos_slash)) != std::string::npos) {
- const std::string subpath = path.substr(0, pos_slash);
- struct stat info;
-
- // if the path already exists, ensure that it's a directory
- if (stat(subpath.c_str(), &info) == 0) {
- if (!S_ISDIR(info.st_mode)) {
- return false;
- }
- } else {
- // create parent directories
- const int ret = mkdir(subpath.c_str(), 0755);
- if (ret != 0) {
- return false;
- }
- }
-
- pos_slash += 1;
- }
-
- return true;
-#endif // _WIN32
-}
-
-void dump_vector_float_yaml(FILE * stream, const char * prop_name, const std::vector & data) {
- if (data.empty()) {
- fprintf(stream, "%s:\n", prop_name);
- return;
- }
-
- fprintf(stream, "%s: [", prop_name);
- for (size_t i = 0; i < data.size() - 1; ++i) {
- fprintf(stream, "%e, ", data[i]);
- }
- fprintf(stream, "%e]\n", data.back());
-}
-
-void dump_vector_int_yaml(FILE * stream, const char * prop_name, const std::vector & data) {
- if (data.empty()) {
- fprintf(stream, "%s:\n", prop_name);
- return;
- }
-
- fprintf(stream, "%s: [", prop_name);
- for (size_t i = 0; i < data.size() - 1; ++i) {
- fprintf(stream, "%d, ", data[i]);
- }
- fprintf(stream, "%d]\n", data.back());
-}
-
-void dump_string_yaml_multiline(FILE * stream, const char * prop_name, const char * data) {
- std::string data_str(data == NULL ? "" : data);
-
- if (data_str.empty()) {
- fprintf(stream, "%s:\n", prop_name);
- return;
- }
-
- size_t pos_start = 0;
- size_t pos_found = 0;
-
- if (!data_str.empty() && (std::isspace(data_str[0]) || std::isspace(data_str.back()))) {
- data_str = std::regex_replace(data_str, std::regex("\n"), "\\n");
- data_str = std::regex_replace(data_str, std::regex("\""), "\\\"");
- data_str = "\"" + data_str + "\"";
- fprintf(stream, "%s: %s\n", prop_name, data_str.c_str());
- return;
- }
-
- if (data_str.find('\n') == std::string::npos) {
- fprintf(stream, "%s: %s\n", prop_name, data_str.c_str());
- return;
- }
-
- fprintf(stream, "%s: |\n", prop_name);
- while ((pos_found = data_str.find('\n', pos_start)) != std::string::npos) {
- fprintf(stream, " %s\n", data_str.substr(pos_start, pos_found-pos_start).c_str());
- pos_start = pos_found + 1;
- }
-}
-
-std::string get_sortable_timestamp() {
- using clock = std::chrono::system_clock;
-
- const clock::time_point current_time = clock::now();
- const time_t as_time_t = clock::to_time_t(current_time);
- char timestamp_no_ns[100];
- std::strftime(timestamp_no_ns, 100, "%Y_%m_%d-%H_%M_%S", std::localtime(&as_time_t));
-
- const int64_t ns = std::chrono::duration_cast(
- current_time.time_since_epoch() % 1000000000).count();
- char timestamp_ns[11];
- snprintf(timestamp_ns, 11, "%09" PRId64, ns);
-
- return std::string(timestamp_no_ns) + "." + std::string(timestamp_ns);
-}
-
-void dump_non_result_info_yaml(FILE * stream, const gpt_params & params, const llama_context * lctx,
- const std::string & timestamp, const std::vector & prompt_tokens, const char * model_desc) {
- fprintf(stream, "build_commit: %s\n", BUILD_COMMIT);
- fprintf(stream, "build_number: %d\n", BUILD_NUMBER);
- fprintf(stream, "cpu_has_arm_fma: %s\n", ggml_cpu_has_arm_fma() ? "true" : "false");
- fprintf(stream, "cpu_has_avx: %s\n", ggml_cpu_has_avx() ? "true" : "false");
- fprintf(stream, "cpu_has_avx2: %s\n", ggml_cpu_has_avx2() ? "true" : "false");
- fprintf(stream, "cpu_has_avx512: %s\n", ggml_cpu_has_avx512() ? "true" : "false");
- fprintf(stream, "cpu_has_avx512_vbmi: %s\n", ggml_cpu_has_avx512_vbmi() ? "true" : "false");
- fprintf(stream, "cpu_has_avx512_vnni: %s\n", ggml_cpu_has_avx512_vnni() ? "true" : "false");
- fprintf(stream, "cpu_has_blas: %s\n", ggml_cpu_has_blas() ? "true" : "false");
- fprintf(stream, "cpu_has_cublas: %s\n", ggml_cpu_has_cublas() ? "true" : "false");
- fprintf(stream, "cpu_has_clblast: %s\n", ggml_cpu_has_clblast() ? "true" : "false");
- fprintf(stream, "cpu_has_fma: %s\n", ggml_cpu_has_fma() ? "true" : "false");
- fprintf(stream, "cpu_has_gpublas: %s\n", ggml_cpu_has_gpublas() ? "true" : "false");
- fprintf(stream, "cpu_has_neon: %s\n", ggml_cpu_has_neon() ? "true" : "false");
- fprintf(stream, "cpu_has_f16c: %s\n", ggml_cpu_has_f16c() ? "true" : "false");
- fprintf(stream, "cpu_has_fp16_va: %s\n", ggml_cpu_has_fp16_va() ? "true" : "false");
- fprintf(stream, "cpu_has_wasm_simd: %s\n", ggml_cpu_has_wasm_simd() ? "true" : "false");
- fprintf(stream, "cpu_has_blas: %s\n", ggml_cpu_has_blas() ? "true" : "false");
- fprintf(stream, "cpu_has_sse3: %s\n", ggml_cpu_has_sse3() ? "true" : "false");
- fprintf(stream, "cpu_has_vsx: %s\n", ggml_cpu_has_vsx() ? "true" : "false");
-
-#ifdef NDEBUG
- fprintf(stream, "debug: false\n");
-#else
- fprintf(stream, "debug: true\n");
-#endif // NDEBUG
-
- fprintf(stream, "model_desc: %s\n", model_desc);
- fprintf(stream, "n_vocab: %d # output size of the final layer, 32001 for some models\n", llama_n_vocab(llama_get_model(lctx)));
-
-#ifdef __OPTIMIZE__
- fprintf(stream, "optimize: true\n");
-#else
- fprintf(stream, "optimize: false\n");
-#endif // __OPTIMIZE__
-
- fprintf(stream, "time: %s\n", timestamp.c_str());
-
- fprintf(stream, "\n");
- fprintf(stream, "###############\n");
- fprintf(stream, "# User Inputs #\n");
- fprintf(stream, "###############\n");
- fprintf(stream, "\n");
-
- fprintf(stream, "alias: %s # default: unknown\n", params.model_alias.c_str());
- fprintf(stream, "batch_size: %d # default: 512\n", params.n_batch);
- dump_string_yaml_multiline(stream, "cfg_negative_prompt", params.cfg_negative_prompt.c_str());
- fprintf(stream, "cfg_scale: %f # default: 1.0\n", params.cfg_scale);
- fprintf(stream, "chunks: %d # default: -1 (unlimited)\n", params.n_chunks);
- fprintf(stream, "color: %s # default: false\n", params.use_color ? "true" : "false");
- fprintf(stream, "ctx_size: %d # default: 512\n", params.n_ctx);
- fprintf(stream, "escape: %s # default: false\n", params.escape ? "true" : "false");
- fprintf(stream, "file: # never logged, see prompt instead. Can still be specified for input.\n");
- fprintf(stream, "frequency_penalty: %f # default: 0.0 \n", params.frequency_penalty);
- dump_string_yaml_multiline(stream, "grammar", params.grammar.c_str());
- fprintf(stream, "grammar-file: # never logged, see grammar instead. Can still be specified for input.\n");
- fprintf(stream, "hellaswag: %s # default: false\n", params.hellaswag ? "true" : "false");
- fprintf(stream, "hellaswag_tasks: %zu # default: 400\n", params.hellaswag_tasks);
-
- const auto logit_bias_eos = params.logit_bias.find(llama_token_eos(lctx));
- const bool ignore_eos = logit_bias_eos != params.logit_bias.end() && logit_bias_eos->second == -INFINITY;
- fprintf(stream, "ignore_eos: %s # default: false\n", ignore_eos ? "true" : "false");
-
- dump_string_yaml_multiline(stream, "in_prefix", params.input_prefix.c_str());
- fprintf(stream, "in_prefix_bos: %s # default: false\n", params.input_prefix_bos ? "true" : "false");
- dump_string_yaml_multiline(stream, "in_suffix", params.input_prefix.c_str());
- fprintf(stream, "instruct: %s # default: false\n", params.instruct ? "true" : "false");
- fprintf(stream, "interactive: %s # default: false\n", params.interactive ? "true" : "false");
- fprintf(stream, "interactive_first: %s # default: false\n", params.interactive_first ? "true" : "false");
- fprintf(stream, "keep: %d # default: 0\n", params.n_keep);
- fprintf(stream, "logdir: %s # default: unset (no logging)\n", params.logdir.c_str());
-
- fprintf(stream, "logit_bias:\n");
- for (std::pair lb : params.logit_bias) {
- if (ignore_eos && lb.first == logit_bias_eos->first) {
- continue;
- }
- fprintf(stream, " %d: %f", lb.first, lb.second);
- }
-
- fprintf(stream, "lora:\n");
- for (std::tuple la : params.lora_adapter) {
- if (std::get<1>(la) != 1.0f) {
- continue;
- }
- fprintf(stream, " - %s\n", std::get<0>(la).c_str());
- }
- fprintf(stream, "lora_scaled:\n");
- for (std::tuple la : params.lora_adapter) {
- if (std::get<1>(la) == 1.0f) {
- continue;
- }
- fprintf(stream, " - %s: %f\n", std::get<0>(la).c_str(), std::get<1>(la));
- }
- fprintf(stream, "lora_base: %s\n", params.lora_base.c_str());
- fprintf(stream, "main_gpu: %d # default: 0\n", params.main_gpu);
- fprintf(stream, "memory_f32: %s # default: false\n", !params.memory_f16 ? "true" : "false");
- fprintf(stream, "mirostat: %d # default: 0 (disabled)\n", params.mirostat);
- fprintf(stream, "mirostat_ent: %f # default: 5.0\n", params.mirostat_tau);
- fprintf(stream, "mirostat_lr: %f # default: 0.1\n", params.mirostat_eta);
- fprintf(stream, "mlock: %s # default: false\n", params.use_mlock ? "true" : "false");
- fprintf(stream, "model: %s # default: models/7B/ggml-model.bin\n", params.model.c_str());
- fprintf(stream, "model_draft: %s # default:\n", params.model_draft.c_str());
- fprintf(stream, "multiline_input: %s # default: false\n", params.multiline_input ? "true" : "false");
- fprintf(stream, "n_gpu_layers: %d # default: -1\n", params.n_gpu_layers);
- fprintf(stream, "n_predict: %d # default: -1 (unlimited)\n", params.n_predict);
- fprintf(stream, "n_probs: %d # only used by server binary, default: 0\n", params.n_probs);
- fprintf(stream, "no_mmap: %s # default: false\n", !params.use_mmap ? "true" : "false");
- fprintf(stream, "no_mul_mat_q: %s # default: false\n", !params.mul_mat_q ? "true" : "false");
- fprintf(stream, "no_penalize_nl: %s # default: false\n", !params.penalize_nl ? "true" : "false");
- fprintf(stream, "numa: %s # default: false\n", params.numa ? "true" : "false");
- fprintf(stream, "ppl_output_type: %d # default: 0\n", params.ppl_output_type);
- fprintf(stream, "ppl_stride: %d # default: 0\n", params.ppl_stride);
- fprintf(stream, "presence_penalty: %f # default: 0.0\n", params.presence_penalty);
- dump_string_yaml_multiline(stream, "prompt", params.prompt.c_str());
- fprintf(stream, "prompt_cache: %s\n", params.path_prompt_cache.c_str());
- fprintf(stream, "prompt_cache_all: %s # default: false\n", params.prompt_cache_all ? "true" : "false");
- fprintf(stream, "prompt_cache_ro: %s # default: false\n", params.prompt_cache_ro ? "true" : "false");
- dump_vector_int_yaml(stream, "prompt_tokens", prompt_tokens);
- fprintf(stream, "random_prompt: %s # default: false\n", params.random_prompt ? "true" : "false");
- fprintf(stream, "repeat_penalty: %f # default: 1.1\n", params.repeat_penalty);
-
- fprintf(stream, "reverse_prompt:\n");
- for (std::string ap : params.antiprompt) {
- size_t pos = 0;
- while ((pos = ap.find('\n', pos)) != std::string::npos) {
- ap.replace(pos, 1, "\\n");
- pos += 1;
- }
-
- fprintf(stream, " - %s\n", ap.c_str());
- }
-
- fprintf(stream, "rope_freq_base: %f # default: 10000.0\n", params.rope_freq_base);
- fprintf(stream, "rope_freq_scale: %f # default: 1.0\n", params.rope_freq_scale);
- fprintf(stream, "seed: %d # default: -1 (random seed)\n", params.seed);
- fprintf(stream, "simple_io: %s # default: false\n", params.simple_io ? "true" : "false");
- fprintf(stream, "cont_batching: %s # default: false\n", params.cont_batching ? "true" : "false");
- fprintf(stream, "temp: %f # default: 0.8\n", params.temp);
-
- const std::vector tensor_split_vector(params.tensor_split, params.tensor_split + LLAMA_MAX_DEVICES);
- dump_vector_float_yaml(stream, "tensor_split", tensor_split_vector);
-
- fprintf(stream, "tfs: %f # default: 1.0\n", params.tfs_z);
- fprintf(stream, "threads: %d # default: %d\n", params.n_threads, std::thread::hardware_concurrency());
- fprintf(stream, "top_k: %d # default: 40\n", params.top_k);
- fprintf(stream, "top_p: %f # default: 0.95\n", params.top_p);
- fprintf(stream, "typical_p: %f # default: 1.0\n", params.typical_p);
- fprintf(stream, "verbose_prompt: %s # default: false\n", params.verbose_prompt ? "true" : "false");
-}
diff --git a/spaces/InpaintAI/Inpaint-Anything/third_party/lama/models/ade20k/resnet.py b/spaces/InpaintAI/Inpaint-Anything/third_party/lama/models/ade20k/resnet.py
deleted file mode 100644
index 3e1d521f171c984cf6a7ff3dcebd96f8c5faf908..0000000000000000000000000000000000000000
--- a/spaces/InpaintAI/Inpaint-Anything/third_party/lama/models/ade20k/resnet.py
+++ /dev/null
@@ -1,181 +0,0 @@
-"""Modified from https://github.com/CSAILVision/semantic-segmentation-pytorch"""
-
-import math
-
-import torch.nn as nn
-from torch.nn import BatchNorm2d
-
-from .utils import load_url
-
-__all__ = ['ResNet', 'resnet50']
-
-
-model_urls = {
- 'resnet50': 'http://sceneparsing.csail.mit.edu/model/pretrained_resnet/resnet50-imagenet.pth',
-}
-
-
-def conv3x3(in_planes, out_planes, stride=1):
- "3x3 convolution with padding"
- return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
- padding=1, bias=False)
-
-
-class BasicBlock(nn.Module):
- expansion = 1
-
- def __init__(self, inplanes, planes, stride=1, downsample=None):
- super(BasicBlock, self).__init__()
- self.conv1 = conv3x3(inplanes, planes, stride)
- self.bn1 = BatchNorm2d(planes)
- self.relu = nn.ReLU(inplace=True)
- self.conv2 = conv3x3(planes, planes)
- self.bn2 = BatchNorm2d(planes)
- self.downsample = downsample
- self.stride = stride
-
- def forward(self, x):
- residual = x
-
- out = self.conv1(x)
- out = self.bn1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
- out = self.bn2(out)
-
- if self.downsample is not None:
- residual = self.downsample(x)
-
- out += residual
- out = self.relu(out)
-
- return out
-
-
-class Bottleneck(nn.Module):
- expansion = 4
-
- def __init__(self, inplanes, planes, stride=1, downsample=None):
- super(Bottleneck, self).__init__()
- self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
- self.bn1 = BatchNorm2d(planes)
- self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
- padding=1, bias=False)
- self.bn2 = BatchNorm2d(planes)
- self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
- self.bn3 = BatchNorm2d(planes * 4)
- self.relu = nn.ReLU(inplace=True)
- self.downsample = downsample
- self.stride = stride
-
- def forward(self, x):
- residual = x
-
- out = self.conv1(x)
- out = self.bn1(out)
- out = self.relu(out)
-
- out = self.conv2(out)
- out = self.bn2(out)
- out = self.relu(out)
-
- out = self.conv3(out)
- out = self.bn3(out)
-
- if self.downsample is not None:
- residual = self.downsample(x)
-
- out += residual
- out = self.relu(out)
-
- return out
-
-
-class ResNet(nn.Module):
-
- def __init__(self, block, layers, num_classes=1000):
- self.inplanes = 128
- super(ResNet, self).__init__()
- self.conv1 = conv3x3(3, 64, stride=2)
- self.bn1 = BatchNorm2d(64)
- self.relu1 = nn.ReLU(inplace=True)
- self.conv2 = conv3x3(64, 64)
- self.bn2 = BatchNorm2d(64)
- self.relu2 = nn.ReLU(inplace=True)
- self.conv3 = conv3x3(64, 128)
- self.bn3 = BatchNorm2d(128)
- self.relu3 = nn.ReLU(inplace=True)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
-
- self.layer1 = self._make_layer(block, 64, layers[0])
- self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
- self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
- self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
- self.avgpool = nn.AvgPool2d(7, stride=1)
- self.fc = nn.Linear(512 * block.expansion, num_classes)
-
- for m in self.modules():
- if isinstance(m, nn.Conv2d):
- n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
- m.weight.data.normal_(0, math.sqrt(2. / n))
- elif isinstance(m, BatchNorm2d):
- m.weight.data.fill_(1)
- m.bias.data.zero_()
-
- def _make_layer(self, block, planes, blocks, stride=1):
- downsample = None
- if stride != 1 or self.inplanes != planes * block.expansion:
- downsample = nn.Sequential(
- nn.Conv2d(self.inplanes, planes * block.expansion,
- kernel_size=1, stride=stride, bias=False),
- BatchNorm2d(planes * block.expansion),
- )
-
- layers = []
- layers.append(block(self.inplanes, planes, stride, downsample))
- self.inplanes = planes * block.expansion
- for i in range(1, blocks):
- layers.append(block(self.inplanes, planes))
-
- return nn.Sequential(*layers)
-
- def forward(self, x):
- x = self.relu1(self.bn1(self.conv1(x)))
- x = self.relu2(self.bn2(self.conv2(x)))
- x = self.relu3(self.bn3(self.conv3(x)))
- x = self.maxpool(x)
-
- x = self.layer1(x)
- x = self.layer2(x)
- x = self.layer3(x)
- x = self.layer4(x)
-
- x = self.avgpool(x)
- x = x.view(x.size(0), -1)
- x = self.fc(x)
-
- return x
-
-
-def resnet50(pretrained=False, **kwargs):
- """Constructs a ResNet-50 model.
-
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- """
- model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)
- if pretrained:
- model.load_state_dict(load_url(model_urls['resnet50']), strict=False)
- return model
-
-
-def resnet18(pretrained=False, **kwargs):
- """Constructs a ResNet-18 model.
- Args:
- pretrained (bool): If True, returns a model pre-trained on ImageNet
- """
- model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
- if pretrained:
- model.load_state_dict(load_url(model_urls['resnet18']))
- return model
\ No newline at end of file
diff --git a/spaces/JCTN/stable-diffusion-webui-cpu/app.py b/spaces/JCTN/stable-diffusion-webui-cpu/app.py
deleted file mode 100644
index 70059469b4c3629b26b4e9bab4eefecf5bb6f1cf..0000000000000000000000000000000000000000
--- a/spaces/JCTN/stable-diffusion-webui-cpu/app.py
+++ /dev/null
@@ -1,96 +0,0 @@
-import os
-user_home = r"/home/user/app"
-os.chdir(user_home)
-#clone stable-diffusion-webui repo
-print("cloning stable-diffusion-webui repo")
-os.system("git clone \"https://github.com/AUTOMATIC1111/stable-diffusion-webui.git\" "+user_home+r"/stable-diffusion-webui")
-#install extensions
-print("installing extensions")
-os.system(r"git clone !git clone https://huggingface.co/embed/negative "+user_home+"/stable-diffusion-webui/embeddings/negative")
-os.system(r"git clone https://huggingface.co/embed/lora "+user_home+"/stable-diffusion-webui/models/Lora/positive")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/embed/upscale/resolve/main/4x-UltraSharp.pth -d "+user_home+"/stable-diffusion-webui/models/ESRGAN -o 4x-UltraSharp.ptharia2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/embed/upscale/resolve/main/4x-UltraSharp.pth -d "+user_home+"/stable-diffusion-webui/models/ESRGAN -o 4x-UltraSharp.pth")
-os.system(r"wget https://raw.githubusercontent.com/camenduru/stable-diffusion-webui-scripts/main/run_n_times.py -O "+user_home+"/stable-diffusion-webui/scripts/run_n_times.py")
-os.system(r"git clone https://github.com/deforum-art/deforum-for-automatic1111-webui "+user_home+"/stable-diffusion-webui/extensions/deforum-for-automatic1111-webui")
-os.system(r"git clone https://github.com/AlUlkesh/stable-diffusion-webui-images-browser "+user_home+"/stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser")
-os.system(r"git clone https://github.com/camenduru/stable-diffusion-webui-huggingface "+user_home+"/stable-diffusion-webui/extensions/stable-diffusion-webui-huggingface")
-os.system(r"git clone https://github.com/camenduru/sd-civitai-browser "+user_home+"/stable-diffusion-webui/extensions/sd-civitai-browser")
-os.system(r"git clone https://github.com/kohya-ss/sd-webui-additional-networks "+user_home+"/stable-diffusion-webui/extensions/sd-webui-additional-networks")
-os.system(r"git clone https://github.com/Mikubill/sd-webui-controlnet "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet")
-os.system(r"git clone https://github.com/fkunn1326/openpose-editor "+user_home+"/stable-diffusion-webui/extensions/openpose-editor")
-os.system(r"git clone https://github.com/jexom/sd-webui-depth-lib "+user_home+"/stable-diffusion-webui/extensions/sd-webui-depth-lib")
-os.system(r"git clone https://github.com/hnmr293/posex "+user_home+"/stable-diffusion-webui/extensions/posex")
-os.system(r"git clone https://github.com/nonnonstop/sd-webui-3d-open-pose-editor "+user_home+"/stable-diffusion-webui/extensions/sd-webui-3d-open-pose-editor")
-#中文本地化的请解除下一行的注释
-#os.system(r"git clone https://github.com/dtlnor/stable-diffusion-webui-localization-zh_CN.git "+user_home+"/stable-diffusion-webui/extensions/stable-diffusion-webui-localization-zh_CN")
-os.system(r"git clone https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git "+user_home+"/stable-diffusion-webui/extensions/a1111-sd-webui-tagcomplete")
-os.system(r"git clone https://github.com/camenduru/sd-webui-tunnels "+user_home+"/stable-diffusion-webui/extensions/sd-webui-tunnels")
-os.system(r"git clone https://github.com/etherealxx/batchlinks-webui "+user_home+"/stable-diffusion-webui/extensions/batchlinks-webui")
-os.system(r"git clone https://github.com/catppuccin/stable-diffusion-webui "+user_home+"/stable-diffusion-webui/extensions/stable-diffusion-webui-catppuccin")
-os.system(r"git clone https://github.com/KohakuBlueleaf/a1111-sd-webui-locon "+user_home+"/stable-diffusion-webui/extensions/a1111-sd-webui-locon")
-os.system(r"git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui-rembg "+user_home+"/stable-diffusion-webui/extensions/stable-diffusion-webui-rembg")
-os.system(r"git clone https://github.com/ashen-sensored/stable-diffusion-webui-two-shot "+user_home+"/stable-diffusion-webui/extensions/stable-diffusion-webui-two-shot")
-os.system(r"git clone https://github.com/camenduru/sd_webui_stealth_pnginfo "+user_home+"/stable-diffusion-webui/extensions/sd_webui_stealth_pnginfo")
-os.chdir(os.path.join(user_home,r"stable-diffusion-webui"))
-os.system(r"git reset --hard")
-os.system(r"git -C "+user_home+"/stable-diffusion-webui/repositories/stable-diffusion-stability-ai reset --hard")
-
-#download ControlNet models
-print("downloading ControlNet models")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11e_sd15_ip2p_fp16.safetensors -d "+user_home+""+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11e_sd15_ip2p_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11e_sd15_shuffle_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11e_sd15_shuffle_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15_canny_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_canny_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11f1p_sd15_depth_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11f1p_sd15_depth_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15_inpaint_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_inpaint_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15_lineart_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_lineart_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15_mlsd_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_mlsd_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15_normalbae_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_normalbae_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15_openpose_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_openpose_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15_scribble_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_scribble_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15_seg_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_seg_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15_softedge_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_softedge_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11p_sd15s2_lineart_anime_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15s2_lineart_anime_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/control_v11f1e_sd15_tile_fp16.safetensors -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11f1e_sd15_tile_fp16.safetensors")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11e_sd15_ip2p_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11e_sd15_ip2p_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11e_sd15_shuffle_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11e_sd15_shuffle_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15_canny_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_canny_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11f1p_sd15_depth_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11f1p_sd15_depth_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15_inpaint_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_inpaint_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15_lineart_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_lineart_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15_mlsd_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_mlsd_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15_normalbae_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_normalbae_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15_openpose_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_openpose_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15_scribble_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_scribble_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15_seg_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_seg_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15_softedge_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15_softedge_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11p_sd15s2_lineart_anime_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11p_sd15s2_lineart_anime_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/raw/main/control_v11f1e_sd15_tile_fp16.yaml -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o control_v11f1e_sd15_tile_fp16.yaml")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_style_sd14v1.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_style_sd14v1.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_sketch_sd14v1.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_sketch_sd14v1.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_seg_sd14v1.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_seg_sd14v1.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_openpose_sd14v1.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_openpose_sd14v1.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_keypose_sd14v1.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_keypose_sd14v1.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_depth_sd14v1.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_depth_sd14v1.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_depth_sd14v1.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_depth_sd14v1.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_canny_sd14v1.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_canny_sd14v1.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_canny_sd15v2.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_canny_sd15v2.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_depth_sd15v2.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_depth_sd15v2.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_sketch_sd15v2.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_sketch_sd15v2.pth")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/ControlNet-v1-1/resolve/main/t2iadapter_zoedepth_sd15v1.pth -d "+user_home+"/stable-diffusion-webui/extensions/sd-webui-controlnet/models -o t2iadapter_zoedepth_sd15v1.pth")
-
-try:
- os.mkdir(os.path.join(user_home,"stable-diffusion-webui/models/Stable-diffusion"))
-except(FileExistsError):
- print("exist")
-
-#download model
-#you can change model download address here
-print("downloading model")
-os.system(r"aria2c https://huggingface.co/ckpt/anything-v4.0/resolve/main/anything-v4.5-pruned.ckpt -d "+user_home+"/stable-diffusion-webui/models/Stable-diffusion -o anything-v4.5-pruned.ckpt")
-os.system(r"aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/anything-v4.0/resolve/main/anything-v4.0.vae.pt -d "+user_home+"/stable-diffusion-webui/models/Stable-diffusion -o anything-v4.5-pruned.vae.pt")
-
-#strt webui
-print("Done\nStarting Webui...")
-os.system(r"python3 launch.py --precision full --no-half --no-half-vae --enable-insecure-extension-access --medvram --skip-torch-cuda-test --enable-console-prompts")
-
-
-del os ,user_home
diff --git a/spaces/JFoz/dog-controlnet/README.md b/spaces/JFoz/dog-controlnet/README.md
deleted file mode 100644
index 95d5a98754650fd183f3d06f8cb37ebc999296f1..0000000000000000000000000000000000000000
--- a/spaces/JFoz/dog-controlnet/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
----
-title: Dog Controlnet
-emoji: 🌖
-colorFrom: blue
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.27.0
-app_file: app.py
-pinned: false
-license: openrail
-tags:
-- jax-diffusers-event
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/JeffJing/ZookChatBot/steamship/data/file.py b/spaces/JeffJing/ZookChatBot/steamship/data/file.py
deleted file mode 100644
index 180ed4083056b6200245d89cef946286ba803b39..0000000000000000000000000000000000000000
--- a/spaces/JeffJing/ZookChatBot/steamship/data/file.py
+++ /dev/null
@@ -1,290 +0,0 @@
-from __future__ import annotations
-
-import io
-from enum import Enum
-from typing import TYPE_CHECKING, Any, List, Optional, Type, Union
-
-from pydantic import BaseModel, Field
-
-from steamship import MimeTypes, SteamshipError
-from steamship.base.client import Client
-from steamship.base.model import CamelModel
-from steamship.base.request import GetRequest, IdentifierRequest, Request
-from steamship.base.response import Response
-from steamship.base.tasks import Task
-from steamship.data.block import Block
-from steamship.data.embeddings import EmbeddingIndex
-from steamship.data.tags import Tag
-from steamship.utils.binary_utils import flexi_create
-
-if TYPE_CHECKING:
- from steamship.data.operations.tagger import TagResponse
-
-
-class FileUploadType(str, Enum):
- FILE = "file" # A file uploaded as bytes or a string
- FILE_IMPORTER = "fileImporter" # A fileImporter will be used to create the file
- BLOCKS = "blocks" # Blocks are sent to create a file
-
-
-class FileClearResponse(Response):
- id: str
-
-
-class ListFileRequest(Request):
- pass
-
-
-class ListFileResponse(Response):
- files: List[File]
-
-
-class FileQueryRequest(Request):
- tag_filter_query: str
-
-
-class File(CamelModel):
- """A file."""
-
- client: Client = Field(None, exclude=True)
- id: str = None
- handle: str = None
- mime_type: MimeTypes = None
- workspace_id: str = None
- blocks: List[Block] = []
- tags: List[Tag] = []
- filename: str = None
-
- class CreateResponse(Response):
- data_: Any = None
- mime_type: str = None
-
- def __init__(
- self,
- data: Any = None,
- string: str = None,
- _bytes: Union[bytes, io.BytesIO] = None,
- json: io.BytesIO = None,
- mime_type: str = None,
- ):
- super().__init__()
- data, mime_type, encoding = flexi_create(
- data=data, string=string, json=json, _bytes=_bytes, mime_type=mime_type
- )
- self.data_ = data
- self.mime_type = mime_type
-
- @classmethod
- def parse_obj(cls: Type[BaseModel], obj: Any) -> Response:
- obj["data"] = obj.get("data") or obj.get("data_")
- if "data_" in obj:
- del obj["data_"]
- return super().parse_obj(obj)
-
- @classmethod
- def parse_obj(cls: Type[BaseModel], obj: Any) -> BaseModel:
- # TODO (enias): This needs to be solved at the engine side
- obj = obj["file"] if "file" in obj else obj
- return super().parse_obj(obj)
-
- def delete(self) -> File:
- return self.client.post(
- "file/delete",
- IdentifierRequest(id=self.id),
- expect=File,
- )
-
- @staticmethod
- def get(
- client: Client,
- _id: str = None,
- handle: str = None,
- ) -> File:
- return client.post(
- "file/get",
- IdentifierRequest(id=_id, handle=handle),
- expect=File,
- )
-
- @staticmethod
- def create(
- client: Client,
- content: Union[str, bytes] = None,
- mime_type: MimeTypes = None,
- handle: str = None,
- blocks: List[Block] = None,
- tags: List[Tag] = None,
- ) -> File:
-
- if content is None and blocks is None:
- if tags is None:
- raise SteamshipError(message="Either filename, content, or tags must be provided.")
- else:
- content = ""
- if content is not None and blocks is not None:
- raise SteamshipError(
- message="Please provide only `blocks` or `content` to `File.create`."
- )
-
- if blocks is not None:
- upload_type = FileUploadType.BLOCKS
- elif content is not None:
- upload_type = FileUploadType.FILE
- else:
- raise Exception("Unable to determine upload type.")
-
- req = {
- "handle": handle,
- "type": upload_type,
- "mimeType": mime_type,
- "blocks": [
- block.dict(by_alias=True, exclude_unset=True, exclude_none=True)
- for block in blocks or []
- ],
- "tags": [
- tag.dict(by_alias=True, exclude_unset=True, exclude_none=True) for tag in tags or []
- ],
- }
-
- file_data = (
- ("file-part", content, "multipart/form-data")
- if upload_type != FileUploadType.BLOCKS
- else None
- )
-
- # Defaulting this here, as opposed to in the Engine, because it is processed by Vapor
- return client.post(
- "file/create",
- payload=req,
- file=file_data,
- expect=File,
- )
-
- @staticmethod
- def create_with_plugin(
- client: Client,
- plugin_instance: str,
- url: str = None,
- mime_type: str = None,
- ) -> Task[File]:
-
- req = {
- "type": FileUploadType.FILE_IMPORTER,
- "url": url,
- "mimeType": mime_type,
- "pluginInstance": plugin_instance,
- }
-
- return client.post("file/create", payload=req, expect=File, as_background_task=True)
-
- def refresh(self) -> File:
- refreshed = File.get(self.client, self.id)
- self.__init__(**refreshed.dict())
- self.client = refreshed.client
- for block in self.blocks:
- block.client = self.client
- return self
-
- @staticmethod
- def query(
- client: Client,
- tag_filter_query: str,
- ) -> FileQueryResponse:
-
- req = FileQueryRequest(tag_filter_query=tag_filter_query)
- res = client.post(
- "file/query",
- payload=req,
- expect=FileQueryResponse,
- )
- return res
-
- def raw(self):
- return self.client.post(
- "file/raw",
- payload=GetRequest(
- id=self.id,
- ),
- raw_response=True,
- )
-
- def blockify(self, plugin_instance: str = None, wait_on_tasks: List[Task] = None) -> Task:
- from steamship.data.operations.blockifier import BlockifyRequest
- from steamship.plugin.outputs.block_and_tag_plugin_output import BlockAndTagPluginOutput
-
- req = BlockifyRequest(type="file", id=self.id, plugin_instance=plugin_instance)
-
- return self.client.post(
- "plugin/instance/blockify",
- payload=req,
- expect=BlockAndTagPluginOutput,
- wait_on_tasks=wait_on_tasks,
- )
-
- def tag(
- self,
- plugin_instance: str = None,
- wait_on_tasks: List[Task] = None,
- ) -> Task[TagResponse]:
- from steamship.data.operations.tagger import TagRequest, TagResponse
- from steamship.data.plugin import PluginTargetType
-
- req = TagRequest(type=PluginTargetType.FILE, id=self.id, plugin_instance=plugin_instance)
- return self.client.post(
- "plugin/instance/tag", payload=req, expect=TagResponse, wait_on_tasks=wait_on_tasks
- )
-
- def index(self, plugin_instance: Any = None) -> EmbeddingIndex:
- """Index every block in the file.
-
- TODO(ted): Enable indexing the results of a tag query.
- TODO(ted): It's hard to load the EmbeddingIndexPluginInstance with just a handle because of the chain
- of things that need to be created to it to function."""
-
- # Preserve the prior behavior of embedding the full text of each block.
- tags = [
- Tag(text=block.text, file_id=self.id, block_id=block.id, kind="block")
- for block in self.blocks or []
- ]
- return plugin_instance.insert(tags)
-
- @staticmethod
- def list(client: Client) -> ListFileResponse:
- return client.post(
- "file/list",
- ListFileRequest(),
- expect=ListFileResponse,
- )
-
- def append_block(
- self,
- text: str = None,
- tags: List[Tag] = None,
- content: Union[str, bytes] = None,
- url: Optional[str] = None,
- mime_type: Optional[MimeTypes] = None,
- ) -> Block:
- """Append a new block to this File. This is a convenience wrapper around
- Block.create(). You should provide only one of text, content, or url.
-
- This is a server-side operation, saving the new Block to the file. The new block
- is appended to this client-side File as well for convenience.
- """
- block = Block.create(
- self.client,
- file_id=self.id,
- text=text,
- tags=tags,
- content=content,
- url=url,
- mime_type=mime_type,
- )
- self.blocks.append(block)
- return block
-
-
-class FileQueryResponse(Response):
- files: List[File]
-
-
-ListFileResponse.update_forward_refs()
diff --git a/spaces/JeffJing/ZookChatBot/steamship/data/user.py b/spaces/JeffJing/ZookChatBot/steamship/data/user.py
deleted file mode 100644
index 6b889ff61e45bebe37d8fc3756f9c6f3880382de..0000000000000000000000000000000000000000
--- a/spaces/JeffJing/ZookChatBot/steamship/data/user.py
+++ /dev/null
@@ -1,24 +0,0 @@
-from __future__ import annotations
-
-from typing import Any, Type
-
-from pydantic import BaseModel, Field
-
-from steamship.base.client import Client
-from steamship.base.model import CamelModel
-
-
-class User(CamelModel):
- client: Client = Field(None, exclude=True)
- id: str = None
- handle: str = None
-
- @classmethod
- def parse_obj(cls: Type[BaseModel], obj: Any) -> BaseModel:
- # TODO (enias): This needs to be solved at the engine side
- obj = obj["user"] if "user" in obj else obj
- return super().parse_obj(obj)
-
- @staticmethod
- def current(client: Client) -> User:
- return client.get("account/current", expect=User)
diff --git a/spaces/Jo0xFF/4xArText/utils/architecture/__index__.py b/spaces/Jo0xFF/4xArText/utils/architecture/__index__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Juliojuse/human_health_gradio/code/contrast_phys/DeepPhysModel.py b/spaces/Juliojuse/human_health_gradio/code/contrast_phys/DeepPhysModel.py
deleted file mode 100644
index 5e95372e4f963669886064f57d1e2f1dabe5f398..0000000000000000000000000000000000000000
--- a/spaces/Juliojuse/human_health_gradio/code/contrast_phys/DeepPhysModel.py
+++ /dev/null
@@ -1,125 +0,0 @@
-"""DeepPhys - 2D Convolutional Attention Network.
-DeepPhys: Video-Based Physiological Measurement Using Convolutional Attention Networks
-ECCV, 2018
-Weixuan Chen, Daniel McDuff
-"""
-
-import torch
-import torch.nn as nn
-
-
-class Attention_mask(nn.Module):
- def __init__(self):
- super(Attention_mask, self).__init__()
-
- def forward(self, x):
- xsum = torch.sum(x, dim=2, keepdim=True)
- xsum = torch.sum(xsum, dim=3, keepdim=True)
- xshape = tuple(x.size())
- return x / xsum * xshape[2] * xshape[3] * 0.5
-
- def get_config(self):
- """May be generated manually. """
- config = super(Attention_mask, self).get_config()
- return config
-
-
-class DeepPhys(nn.Module):
-
- def __init__(self, in_channels=3, nb_filters1=32, nb_filters2=64, kernel_size=3, dropout_rate1=0.25,
- dropout_rate2=0.5, pool_size=(2, 2), nb_dense=128, img_size=36):
- """Definition of DeepPhys.
- Args:
- in_channels: the number of input channel. Default: 3
- img_size: height/width of each frame. Default: 36.
- Returns:
- DeepPhys model.
- """
- super(DeepPhys, self).__init__()
- self.in_channels = in_channels
- self.kernel_size = kernel_size
- self.dropout_rate1 = dropout_rate1
- self.dropout_rate2 = dropout_rate2
- self.pool_size = pool_size
- self.nb_filters1 = nb_filters1
- self.nb_filters2 = nb_filters2
- self.nb_dense = nb_dense
- # Motion branch convs
- self.motion_conv1 = nn.Conv2d(self.in_channels, self.nb_filters1, kernel_size=self.kernel_size, padding=(1, 1),
- bias=True)
- self.motion_conv2 = nn.Conv2d(self.nb_filters1, self.nb_filters1, kernel_size=self.kernel_size, bias=True)
- self.motion_conv3 = nn.Conv2d(self.nb_filters1, self.nb_filters2, kernel_size=self.kernel_size, padding=(1, 1),
- bias=True)
- self.motion_conv4 = nn.Conv2d(self.nb_filters2, self.nb_filters2, kernel_size=self.kernel_size, bias=True)
- # Apperance branch convs
- self.apperance_conv1 = nn.Conv2d(self.in_channels, self.nb_filters1, kernel_size=self.kernel_size,
- padding=(1, 1), bias=True)
- self.apperance_conv2 = nn.Conv2d(self.nb_filters1, self.nb_filters1, kernel_size=self.kernel_size, bias=True)
- self.apperance_conv3 = nn.Conv2d(self.nb_filters1, self.nb_filters2, kernel_size=self.kernel_size,
- padding=(1, 1), bias=True)
- self.apperance_conv4 = nn.Conv2d(self.nb_filters2, self.nb_filters2, kernel_size=self.kernel_size, bias=True)
- # Attention layers
- self.apperance_att_conv1 = nn.Conv2d(self.nb_filters1, 1, kernel_size=1, padding=(0, 0), bias=True)
- self.attn_mask_1 = Attention_mask()
- self.apperance_att_conv2 = nn.Conv2d(self.nb_filters2, 1, kernel_size=1, padding=(0, 0), bias=True)
- self.attn_mask_2 = Attention_mask()
- # Avg pooling
- self.avg_pooling_1 = nn.AvgPool2d(self.pool_size)
- self.avg_pooling_2 = nn.AvgPool2d(self.pool_size)
- self.avg_pooling_3 = nn.AvgPool2d(self.pool_size)
- # Dropout layers
- self.dropout_1 = nn.Dropout(self.dropout_rate1)
- self.dropout_2 = nn.Dropout(self.dropout_rate1)
- self.dropout_3 = nn.Dropout(self.dropout_rate1)
- self.dropout_4 = nn.Dropout(self.dropout_rate2)
- # Dense layers
- if img_size == 36:
- self.final_dense_1 = nn.Linear(3136, self.nb_dense, bias=True)
- elif img_size == 72:
- self.final_dense_1 = nn.Linear(16384, self.nb_dense, bias=True)
- elif img_size == 96:
- self.final_dense_1 = nn.Linear(30976, self.nb_dense, bias=True)
- else:
- raise Exception('Unsupported image size')
- self.final_dense_2 = nn.Linear(self.nb_dense, 1, bias=True)
-
- def forward(self, inputs, params=None):
-
- diff_input = inputs[:, :3, :, :]
- raw_input = inputs[:, 3:, :, :]
-
- d1 = torch.tanh(self.motion_conv1(diff_input))
- d2 = torch.tanh(self.motion_conv2(d1))
-
- r1 = torch.tanh(self.apperance_conv1(raw_input))
- r2 = torch.tanh(self.apperance_conv2(r1))
-
- g1 = torch.sigmoid(self.apperance_att_conv1(r2))
- g1 = self.attn_mask_1(g1)
- gated1 = d2 * g1
-
- d3 = self.avg_pooling_1(gated1)
- d4 = self.dropout_1(d3)
-
- r3 = self.avg_pooling_2(r2)
- r4 = self.dropout_2(r3)
-
- d5 = torch.tanh(self.motion_conv3(d4))
- d6 = torch.tanh(self.motion_conv4(d5))
-
- r5 = torch.tanh(self.apperance_conv3(r4))
- r6 = torch.tanh(self.apperance_conv4(r5))
-
- g2 = torch.sigmoid(self.apperance_att_conv2(r6))
- g2 = self.attn_mask_2(g2)
- gated2 = d6 * g2
-
- d7 = self.avg_pooling_3(gated2)
- d8 = self.dropout_3(d7)
- d9 = d8.reshape(d8.size(0), -1)
- d10 = torch.tanh(self.final_dense_1(d9))
- d11 = self.dropout_4(d10)
- out = self.final_dense_2(d11)
-
- return out
-
diff --git a/spaces/Lbin123/Lbingo/src/components/theme-toggle.tsx b/spaces/Lbin123/Lbingo/src/components/theme-toggle.tsx
deleted file mode 100644
index 67d3f1a2c163ccbeb52c40a7e42f107190237154..0000000000000000000000000000000000000000
--- a/spaces/Lbin123/Lbingo/src/components/theme-toggle.tsx
+++ /dev/null
@@ -1,31 +0,0 @@
-'use client'
-
-import * as React from 'react'
-import { useTheme } from 'next-themes'
-
-import { Button } from '@/components/ui/button'
-import { IconMoon, IconSun } from '@/components/ui/icons'
-
-export function ThemeToggle() {
- const { setTheme, theme } = useTheme()
- const [_, startTransition] = React.useTransition()
-
- return (
-
- )
-}
diff --git a/spaces/Liu-LAB/GPT-academic/request_llm/bridge_claude.py b/spaces/Liu-LAB/GPT-academic/request_llm/bridge_claude.py
deleted file mode 100644
index 6084b1f15c9832fd11a36bb58d8187f4e2a7a931..0000000000000000000000000000000000000000
--- a/spaces/Liu-LAB/GPT-academic/request_llm/bridge_claude.py
+++ /dev/null
@@ -1,228 +0,0 @@
-# 借鉴了 https://github.com/GaiZhenbiao/ChuanhuChatGPT 项目
-
-"""
- 该文件中主要包含2个函数
-
- 不具备多线程能力的函数:
- 1. predict: 正常对话时使用,具备完备的交互功能,不可多线程
-
- 具备多线程调用能力的函数
- 2. predict_no_ui_long_connection:在实验过程中发现调用predict_no_ui处理长文档时,和openai的连接容易断掉,这个函数用stream的方式解决这个问题,同样支持多线程
-"""
-
-import os
-import json
-import time
-import gradio as gr
-import logging
-import traceback
-import requests
-import importlib
-
-# config_private.py放自己的秘密如API和代理网址
-# 读取时首先看是否存在私密的config_private配置文件(不受git管控),如果有,则覆盖原config文件
-from toolbox import get_conf, update_ui, trimmed_format_exc, ProxyNetworkActivate
-proxies, TIMEOUT_SECONDS, MAX_RETRY, ANTHROPIC_API_KEY = \
- get_conf('proxies', 'TIMEOUT_SECONDS', 'MAX_RETRY', 'ANTHROPIC_API_KEY')
-
-timeout_bot_msg = '[Local Message] Request timeout. Network error. Please check proxy settings in config.py.' + \
- '网络错误,检查代理服务器是否可用,以及代理设置的格式是否正确,格式须是[协议]://[地址]:[端口],缺一不可。'
-
-def get_full_error(chunk, stream_response):
- """
- 获取完整的从Openai返回的报错
- """
- while True:
- try:
- chunk += next(stream_response)
- except:
- break
- return chunk
-
-
-def predict_no_ui_long_connection(inputs, llm_kwargs, history=[], sys_prompt="", observe_window=None, console_slience=False):
- """
- 发送至chatGPT,等待回复,一次性完成,不显示中间过程。但内部用stream的方法避免中途网线被掐。
- inputs:
- 是本次问询的输入
- sys_prompt:
- 系统静默prompt
- llm_kwargs:
- chatGPT的内部调优参数
- history:
- 是之前的对话列表
- observe_window = None:
- 用于负责跨越线程传递已经输出的部分,大部分时候仅仅为了fancy的视觉效果,留空即可。observe_window[0]:观测窗。observe_window[1]:看门狗
- """
- from anthropic import Anthropic
- watch_dog_patience = 5 # 看门狗的耐心, 设置5秒即可
- prompt = generate_payload(inputs, llm_kwargs, history, system_prompt=sys_prompt, stream=True)
- retry = 0
- if len(ANTHROPIC_API_KEY) == 0:
- raise RuntimeError("没有设置ANTHROPIC_API_KEY选项")
-
- while True:
- try:
- # make a POST request to the API endpoint, stream=False
- from .bridge_all import model_info
- anthropic = Anthropic(api_key=ANTHROPIC_API_KEY)
- # endpoint = model_info[llm_kwargs['llm_model']]['endpoint']
- # with ProxyNetworkActivate()
- stream = anthropic.completions.create(
- prompt=prompt,
- max_tokens_to_sample=4096, # The maximum number of tokens to generate before stopping.
- model=llm_kwargs['llm_model'],
- stream=True,
- temperature = llm_kwargs['temperature']
- )
- break
- except Exception as e:
- retry += 1
- traceback.print_exc()
- if retry > MAX_RETRY: raise TimeoutError
- if MAX_RETRY!=0: print(f'请求超时,正在重试 ({retry}/{MAX_RETRY}) ……')
- result = ''
- try:
- for completion in stream:
- result += completion.completion
- if not console_slience: print(completion.completion, end='')
- if observe_window is not None:
- # 观测窗,把已经获取的数据显示出去
- if len(observe_window) >= 1: observe_window[0] += completion.completion
- # 看门狗,如果超过期限没有喂狗,则终止
- if len(observe_window) >= 2:
- if (time.time()-observe_window[1]) > watch_dog_patience:
- raise RuntimeError("用户取消了程序。")
- except Exception as e:
- traceback.print_exc()
-
- return result
-
-
-def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_prompt='', stream = True, additional_fn=None):
- """
- 发送至chatGPT,流式获取输出。
- 用于基础的对话功能。
- inputs 是本次问询的输入
- top_p, temperature是chatGPT的内部调优参数
- history 是之前的对话列表(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误)
- chatbot 为WebUI中显示的对话列表,修改它,然后yeild出去,可以直接修改对话界面内容
- additional_fn代表点击的哪个按钮,按钮见functional.py
- """
- from anthropic import Anthropic
- if len(ANTHROPIC_API_KEY) == 0:
- chatbot.append((inputs, "没有设置ANTHROPIC_API_KEY"))
- yield from update_ui(chatbot=chatbot, history=history, msg="等待响应") # 刷新界面
- return
-
- if additional_fn is not None:
- from core_functional import handle_core_functionality
- inputs, history = handle_core_functionality(additional_fn, inputs, history, chatbot)
-
- raw_input = inputs
- logging.info(f'[raw_input] {raw_input}')
- chatbot.append((inputs, ""))
- yield from update_ui(chatbot=chatbot, history=history, msg="等待响应") # 刷新界面
-
- try:
- prompt = generate_payload(inputs, llm_kwargs, history, system_prompt, stream)
- except RuntimeError as e:
- chatbot[-1] = (inputs, f"您提供的api-key不满足要求,不包含任何可用于{llm_kwargs['llm_model']}的api-key。您可能选择了错误的模型或请求源。")
- yield from update_ui(chatbot=chatbot, history=history, msg="api-key不满足要求") # 刷新界面
- return
-
- history.append(inputs); history.append("")
-
- retry = 0
- while True:
- try:
- # make a POST request to the API endpoint, stream=True
- from .bridge_all import model_info
- anthropic = Anthropic(api_key=ANTHROPIC_API_KEY)
- # endpoint = model_info[llm_kwargs['llm_model']]['endpoint']
- # with ProxyNetworkActivate()
- stream = anthropic.completions.create(
- prompt=prompt,
- max_tokens_to_sample=4096, # The maximum number of tokens to generate before stopping.
- model=llm_kwargs['llm_model'],
- stream=True,
- temperature = llm_kwargs['temperature']
- )
-
- break
- except:
- retry += 1
- chatbot[-1] = ((chatbot[-1][0], timeout_bot_msg))
- retry_msg = f",正在重试 ({retry}/{MAX_RETRY}) ……" if MAX_RETRY > 0 else ""
- yield from update_ui(chatbot=chatbot, history=history, msg="请求超时"+retry_msg) # 刷新界面
- if retry > MAX_RETRY: raise TimeoutError
-
- gpt_replying_buffer = ""
-
- for completion in stream:
- try:
- gpt_replying_buffer = gpt_replying_buffer + completion.completion
- history[-1] = gpt_replying_buffer
- chatbot[-1] = (history[-2], history[-1])
- yield from update_ui(chatbot=chatbot, history=history, msg='正常') # 刷新界面
-
- except Exception as e:
- from toolbox import regular_txt_to_markdown
- tb_str = '```\n' + trimmed_format_exc() + '```'
- chatbot[-1] = (chatbot[-1][0], f"[Local Message] 异常 \n\n{tb_str}")
- yield from update_ui(chatbot=chatbot, history=history, msg="Json异常" + tb_str) # 刷新界面
- return
-
-
-
-
-# https://github.com/jtsang4/claude-to-chatgpt/blob/main/claude_to_chatgpt/adapter.py
-def convert_messages_to_prompt(messages):
- prompt = ""
- role_map = {
- "system": "Human",
- "user": "Human",
- "assistant": "Assistant",
- }
- for message in messages:
- role = message["role"]
- content = message["content"]
- transformed_role = role_map[role]
- prompt += f"\n\n{transformed_role.capitalize()}: {content}"
- prompt += "\n\nAssistant: "
- return prompt
-
-def generate_payload(inputs, llm_kwargs, history, system_prompt, stream):
- """
- 整合所有信息,选择LLM模型,生成http请求,为发送请求做准备
- """
- from anthropic import Anthropic, HUMAN_PROMPT, AI_PROMPT
-
- conversation_cnt = len(history) // 2
-
- messages = [{"role": "system", "content": system_prompt}]
- if conversation_cnt:
- for index in range(0, 2*conversation_cnt, 2):
- what_i_have_asked = {}
- what_i_have_asked["role"] = "user"
- what_i_have_asked["content"] = history[index]
- what_gpt_answer = {}
- what_gpt_answer["role"] = "assistant"
- what_gpt_answer["content"] = history[index+1]
- if what_i_have_asked["content"] != "":
- if what_gpt_answer["content"] == "": continue
- if what_gpt_answer["content"] == timeout_bot_msg: continue
- messages.append(what_i_have_asked)
- messages.append(what_gpt_answer)
- else:
- messages[-1]['content'] = what_gpt_answer['content']
-
- what_i_ask_now = {}
- what_i_ask_now["role"] = "user"
- what_i_ask_now["content"] = inputs
- messages.append(what_i_ask_now)
- prompt = convert_messages_to_prompt(messages)
-
- return prompt
-
-
diff --git a/spaces/Mahiruoshi/MyGO_VIts-bert/losses.py b/spaces/Mahiruoshi/MyGO_VIts-bert/losses.py
deleted file mode 100644
index b1b263e4c205e78ffe970f622ab6ff68f36d3b17..0000000000000000000000000000000000000000
--- a/spaces/Mahiruoshi/MyGO_VIts-bert/losses.py
+++ /dev/null
@@ -1,58 +0,0 @@
-import torch
-
-
-def feature_loss(fmap_r, fmap_g):
- loss = 0
- for dr, dg in zip(fmap_r, fmap_g):
- for rl, gl in zip(dr, dg):
- rl = rl.float().detach()
- gl = gl.float()
- loss += torch.mean(torch.abs(rl - gl))
-
- return loss * 2
-
-
-def discriminator_loss(disc_real_outputs, disc_generated_outputs):
- loss = 0
- r_losses = []
- g_losses = []
- for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
- dr = dr.float()
- dg = dg.float()
- r_loss = torch.mean((1 - dr) ** 2)
- g_loss = torch.mean(dg**2)
- loss += r_loss + g_loss
- r_losses.append(r_loss.item())
- g_losses.append(g_loss.item())
-
- return loss, r_losses, g_losses
-
-
-def generator_loss(disc_outputs):
- loss = 0
- gen_losses = []
- for dg in disc_outputs:
- dg = dg.float()
- l = torch.mean((1 - dg) ** 2)
- gen_losses.append(l)
- loss += l
-
- return loss, gen_losses
-
-
-def kl_loss(z_p, logs_q, m_p, logs_p, z_mask):
- """
- z_p, logs_q: [b, h, t_t]
- m_p, logs_p: [b, h, t_t]
- """
- z_p = z_p.float()
- logs_q = logs_q.float()
- m_p = m_p.float()
- logs_p = logs_p.float()
- z_mask = z_mask.float()
-
- kl = logs_p - logs_q - 0.5
- kl += 0.5 * ((z_p - m_p) ** 2) * torch.exp(-2.0 * logs_p)
- kl = torch.sum(kl * z_mask)
- l = kl / torch.sum(z_mask)
- return l
diff --git a/spaces/MathysL/AutoGPT4/autogpt/memory/weaviate.py b/spaces/MathysL/AutoGPT4/autogpt/memory/weaviate.py
deleted file mode 100644
index 5408e9a97aa3594ad443448cfc31f2546a01eb09..0000000000000000000000000000000000000000
--- a/spaces/MathysL/AutoGPT4/autogpt/memory/weaviate.py
+++ /dev/null
@@ -1,127 +0,0 @@
-import uuid
-
-import weaviate
-from weaviate import Client
-from weaviate.embedded import EmbeddedOptions
-from weaviate.util import generate_uuid5
-
-from autogpt.config import Config
-from autogpt.memory.base import MemoryProviderSingleton, get_ada_embedding
-
-
-def default_schema(weaviate_index):
- return {
- "class": weaviate_index,
- "properties": [
- {
- "name": "raw_text",
- "dataType": ["text"],
- "description": "original text for the embedding",
- }
- ],
- }
-
-
-class WeaviateMemory(MemoryProviderSingleton):
- def __init__(self, cfg):
- auth_credentials = self._build_auth_credentials(cfg)
-
- url = f"{cfg.weaviate_protocol}://{cfg.weaviate_host}:{cfg.weaviate_port}"
-
- if cfg.use_weaviate_embedded:
- self.client = Client(
- embedded_options=EmbeddedOptions(
- hostname=cfg.weaviate_host,
- port=int(cfg.weaviate_port),
- persistence_data_path=cfg.weaviate_embedded_path,
- )
- )
-
- print(
- f"Weaviate Embedded running on: {url} with persistence path: {cfg.weaviate_embedded_path}"
- )
- else:
- self.client = Client(url, auth_client_secret=auth_credentials)
-
- self.index = WeaviateMemory.format_classname(cfg.memory_index)
- self._create_schema()
-
- @staticmethod
- def format_classname(index):
- # weaviate uses capitalised index names
- # The python client uses the following code to format
- # index names before the corresponding class is created
- if len(index) == 1:
- return index.capitalize()
- return index[0].capitalize() + index[1:]
-
- def _create_schema(self):
- schema = default_schema(self.index)
- if not self.client.schema.contains(schema):
- self.client.schema.create_class(schema)
-
- def _build_auth_credentials(self, cfg):
- if cfg.weaviate_username and cfg.weaviate_password:
- return weaviate.AuthClientPassword(
- cfg.weaviate_username, cfg.weaviate_password
- )
- if cfg.weaviate_api_key:
- return weaviate.AuthApiKey(api_key=cfg.weaviate_api_key)
- else:
- return None
-
- def add(self, data):
- vector = get_ada_embedding(data)
-
- doc_uuid = generate_uuid5(data, self.index)
- data_object = {"raw_text": data}
-
- with self.client.batch as batch:
- batch.add_data_object(
- uuid=doc_uuid,
- data_object=data_object,
- class_name=self.index,
- vector=vector,
- )
-
- return f"Inserting data into memory at uuid: {doc_uuid}:\n data: {data}"
-
- def get(self, data):
- return self.get_relevant(data, 1)
-
- def clear(self):
- self.client.schema.delete_all()
-
- # weaviate does not yet have a neat way to just remove the items in an index
- # without removing the entire schema, therefore we need to re-create it
- # after a call to delete_all
- self._create_schema()
-
- return "Obliterated"
-
- def get_relevant(self, data, num_relevant=5):
- query_embedding = get_ada_embedding(data)
- try:
- results = (
- self.client.query.get(self.index, ["raw_text"])
- .with_near_vector({"vector": query_embedding, "certainty": 0.7})
- .with_limit(num_relevant)
- .do()
- )
-
- if len(results["data"]["Get"][self.index]) > 0:
- return [
- str(item["raw_text"]) for item in results["data"]["Get"][self.index]
- ]
- else:
- return []
-
- except Exception as err:
- print(f"Unexpected error {err=}, {type(err)=}")
- return []
-
- def get_stats(self):
- result = self.client.query.aggregate(self.index).with_meta_count().do()
- class_data = result["data"]["Aggregate"][self.index]
-
- return class_data[0]["meta"] if class_data else {}
diff --git a/spaces/Mixing/anime-remove-background/app.py b/spaces/Mixing/anime-remove-background/app.py
deleted file mode 100644
index 230a0d5f8a3da6ab18ecb8db1cd90016a489b96a..0000000000000000000000000000000000000000
--- a/spaces/Mixing/anime-remove-background/app.py
+++ /dev/null
@@ -1,52 +0,0 @@
-import gradio as gr
-import huggingface_hub
-import onnxruntime as rt
-import numpy as np
-import cv2
-
-
-def get_mask(img, s=1024):
- img = (img / 255).astype(np.float32)
- h, w = h0, w0 = img.shape[:-1]
- h, w = (s, int(s * w / h)) if h > w else (int(s * h / w), s)
- ph, pw = s - h, s - w
- img_input = np.zeros([s, s, 3], dtype=np.float32)
- img_input[ph // 2:ph // 2 + h, pw // 2:pw // 2 + w] = cv2.resize(img, (w, h))
- img_input = np.transpose(img_input, (2, 0, 1))
- img_input = img_input[np.newaxis, :]
- mask = rmbg_model.run(None, {'img': img_input})[0][0]
- mask = np.transpose(mask, (1, 2, 0))
- mask = mask[ph // 2:ph // 2 + h, pw // 2:pw // 2 + w]
- mask = cv2.resize(mask, (w0, h0))[:, :, np.newaxis]
- return mask
-
-
-def rmbg_fn(img):
- mask = get_mask(img)
- img = (mask * img + 255 * (1 - mask)).astype(np.uint8)
- mask = (mask * 255).astype(np.uint8)
- img = np.concatenate([img, mask], axis=2, dtype=np.uint8)
- mask = mask.repeat(3, axis=2)
- return mask, img
-
-
-if __name__ == "__main__":
- providers = ['CUDAExecutionProvider', 'CPUExecutionProvider']
- model_path = huggingface_hub.hf_hub_download("skytnt/anime-seg", "isnetis.onnx")
- rmbg_model = rt.InferenceSession(model_path, providers=providers)
- app = gr.Blocks()
- with app:
- gr.Markdown("# Anime Remove Background\n\n"
- "\n\n"
- "demo for [https://github.com/SkyTNT/anime-segmentation/](https://github.com/SkyTNT/anime-segmentation/)")
- with gr.Row():
- with gr.Column():
- input_img = gr.Image(label="input image")
- examples_data = [[f"examples/{x:02d}.jpg"] for x in range(1, 4)]
- examples = gr.Dataset(components=[input_img], samples=examples_data)
- run_btn = gr.Button(variant="primary")
- output_mask = gr.Image(label="mask")
- output_img = gr.Image(label="result", image_mode="RGBA")
- examples.click(lambda x: x[0], [examples], [input_img])
- run_btn.click(rmbg_fn, [input_img], [output_mask, output_img])
- app.launch()
diff --git a/spaces/Mountchicken/MAERec-Gradio/tools/dataset_converters/textrecog/openvino_converter.py b/spaces/Mountchicken/MAERec-Gradio/tools/dataset_converters/textrecog/openvino_converter.py
deleted file mode 100644
index 79b962bbdaa9ff35e8f726234fdd2c007fb8f105..0000000000000000000000000000000000000000
--- a/spaces/Mountchicken/MAERec-Gradio/tools/dataset_converters/textrecog/openvino_converter.py
+++ /dev/null
@@ -1,120 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import math
-import os
-import os.path as osp
-from argparse import ArgumentParser
-from functools import partial
-
-import mmengine
-from PIL import Image
-
-from mmocr.utils import dump_ocr_data
-
-
-def parse_args():
- parser = ArgumentParser(description='Generate training and validation set '
- 'of OpenVINO annotations for Open '
- 'Images by cropping box image.')
- parser.add_argument(
- 'root_path', help='Root dir containing images and annotations')
- parser.add_argument(
- 'n_proc', default=1, type=int, help='Number of processes to run')
- args = parser.parse_args()
- return args
-
-
-def process_img(args, src_image_root, dst_image_root):
- # Dirty hack for multi-processing
- img_idx, img_info, anns = args
- src_img = Image.open(osp.join(src_image_root, img_info['file_name']))
- labels = []
- for ann_idx, ann in enumerate(anns):
- attrs = ann['attributes']
- text_label = attrs['transcription']
-
- # Ignore illegible or non-English words
- if not attrs['legible'] or attrs['language'] != 'english':
- continue
-
- x, y, w, h = ann['bbox']
- x, y = max(0, math.floor(x)), max(0, math.floor(y))
- w, h = math.ceil(w), math.ceil(h)
- dst_img = src_img.crop((x, y, x + w, y + h))
- dst_img_name = f'img_{img_idx}_{ann_idx}.jpg'
- dst_img_path = osp.join(dst_image_root, dst_img_name)
- # Preserve JPEG quality
- dst_img.save(dst_img_path, qtables=src_img.quantization)
- labels.append({
- 'file_name': dst_img_name,
- 'anno_info': [{
- 'text': text_label
- }]
- })
- src_img.close()
- return labels
-
-
-def convert_openimages(root_path,
- dst_image_path,
- dst_label_filename,
- annotation_filename,
- img_start_idx=0,
- nproc=1):
- annotation_path = osp.join(root_path, annotation_filename)
- if not osp.exists(annotation_path):
- raise Exception(
- f'{annotation_path} not exists, please check and try again.')
- src_image_root = root_path
-
- # outputs
- dst_label_file = osp.join(root_path, dst_label_filename)
- dst_image_root = osp.join(root_path, dst_image_path)
- os.makedirs(dst_image_root, exist_ok=True)
-
- annotation = mmengine.load(annotation_path)
-
- process_img_with_path = partial(
- process_img,
- src_image_root=src_image_root,
- dst_image_root=dst_image_root)
- tasks = []
- anns = {}
- for ann in annotation['annotations']:
- anns.setdefault(ann['image_id'], []).append(ann)
- for img_idx, img_info in enumerate(annotation['images']):
- tasks.append((img_idx + img_start_idx, img_info, anns[img_info['id']]))
- labels_list = mmengine.track_parallel_progress(
- process_img_with_path, tasks, keep_order=True, nproc=nproc)
- final_labels = []
- for label_list in labels_list:
- final_labels += label_list
- dump_ocr_data(final_labels, dst_label_file, 'textrecog')
- return len(annotation['images'])
-
-
-def main():
- args = parse_args()
- root_path = args.root_path
- print('Processing training set...')
- num_train_imgs = 0
- for s in '125f':
- num_train_imgs = convert_openimages(
- root_path=root_path,
- dst_image_path=f'image_{s}',
- dst_label_filename=f'train_{s}_label.json',
- annotation_filename=f'text_spotting_openimages_v5_train_{s}.json',
- img_start_idx=num_train_imgs,
- nproc=args.n_proc)
- print('Processing validation set...')
- convert_openimages(
- root_path=root_path,
- dst_image_path='image_val',
- dst_label_filename='val_label.json',
- annotation_filename='text_spotting_openimages_v5_validation.json',
- img_start_idx=num_train_imgs,
- nproc=args.n_proc)
- print('Finish')
-
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/NATSpeech/DiffSpeech/inference/tts/ps_flow.py b/spaces/NATSpeech/DiffSpeech/inference/tts/ps_flow.py
deleted file mode 100644
index 59446cac4743d6526988de4777919f6750c2d820..0000000000000000000000000000000000000000
--- a/spaces/NATSpeech/DiffSpeech/inference/tts/ps_flow.py
+++ /dev/null
@@ -1,38 +0,0 @@
-import torch
-from inference.tts.base_tts_infer import BaseTTSInfer
-from modules.tts.portaspeech.portaspeech_flow import PortaSpeechFlow
-from utils.commons.ckpt_utils import load_ckpt
-from utils.commons.hparams import hparams
-
-
-class PortaSpeechFlowInfer(BaseTTSInfer):
- def build_model(self):
- ph_dict_size = len(self.ph_encoder)
- word_dict_size = len(self.word_encoder)
- model = PortaSpeechFlow(ph_dict_size, word_dict_size, self.hparams)
- load_ckpt(model, hparams['work_dir'], 'model')
- with torch.no_grad():
- model.store_inverse_all()
- model.eval()
- return model
-
- def forward_model(self, inp):
- sample = self.input_to_batch(inp)
- with torch.no_grad():
- output = self.model(
- sample['txt_tokens'],
- sample['word_tokens'],
- ph2word=sample['ph2word'],
- word_len=sample['word_lengths'].max(),
- infer=True,
- forward_post_glow=True,
- spk_id=sample.get('spk_ids')
- )
- mel_out = output['mel_out']
- wav_out = self.run_vocoder(mel_out)
- wav_out = wav_out.cpu().numpy()
- return wav_out[0]
-
-
-if __name__ == '__main__':
- PortaSpeechFlowInfer.example_run()
diff --git a/spaces/NATSpeech/DiffSpeech/utils/nn/model_utils.py b/spaces/NATSpeech/DiffSpeech/utils/nn/model_utils.py
deleted file mode 100644
index b81200e9a2629ac4d791a37d31d5f13330aefd30..0000000000000000000000000000000000000000
--- a/spaces/NATSpeech/DiffSpeech/utils/nn/model_utils.py
+++ /dev/null
@@ -1,14 +0,0 @@
-import numpy as np
-
-
-def print_arch(model, model_name='model'):
- print(f"| {model_name} Arch: ", model)
- num_params(model, model_name=model_name)
-
-
-def num_params(model, print_out=True, model_name="model"):
- parameters = filter(lambda p: p.requires_grad, model.parameters())
- parameters = sum([np.prod(p.size()) for p in parameters]) / 1_000_000
- if print_out:
- print(f'| {model_name} Trainable Parameters: %.3fM' % parameters)
- return parameters
diff --git a/spaces/NATSpeech/PortaSpeech/tasks/tts/fs2_orig.py b/spaces/NATSpeech/PortaSpeech/tasks/tts/fs2_orig.py
deleted file mode 100644
index ca5192f2c8ac64aa4de1c92d0bb02f42a14a77c4..0000000000000000000000000000000000000000
--- a/spaces/NATSpeech/PortaSpeech/tasks/tts/fs2_orig.py
+++ /dev/null
@@ -1,118 +0,0 @@
-import torch
-import torch.nn.functional as F
-from modules.tts.fs2_orig import FastSpeech2Orig
-from tasks.tts.dataset_utils import FastSpeechDataset
-from tasks.tts.fs import FastSpeechTask
-from utils.commons.dataset_utils import collate_1d, collate_2d
-from utils.commons.hparams import hparams
-
-
-class FastSpeech2OrigDataset(FastSpeechDataset):
- def __init__(self, prefix, shuffle=False, items=None, data_dir=None):
- super().__init__(prefix, shuffle, items, data_dir)
- self.pitch_type = hparams.get('pitch_type')
-
- def __getitem__(self, index):
- sample = super().__getitem__(index)
- item = self._get_item(index)
- hparams = self.hparams
- mel = sample['mel']
- T = mel.shape[0]
- sample['energy'] = (mel.exp() ** 2).sum(-1).sqrt()
- if hparams['use_pitch_embed'] and self.pitch_type == 'cwt':
- cwt_spec = torch.Tensor(item['cwt_spec'])[:T]
- f0_mean = item.get('f0_mean', item.get('cwt_mean'))
- f0_std = item.get('f0_std', item.get('cwt_std'))
- sample.update({"cwt_spec": cwt_spec, "f0_mean": f0_mean, "f0_std": f0_std})
- return sample
-
- def collater(self, samples):
- if len(samples) == 0:
- return {}
- batch = super().collater(samples)
- if hparams['use_pitch_embed']:
- energy = collate_1d([s['energy'] for s in samples], 0.0)
- else:
- energy = None
- batch.update({'energy': energy})
- if self.pitch_type == 'cwt':
- cwt_spec = collate_2d([s['cwt_spec'] for s in samples])
- f0_mean = torch.Tensor([s['f0_mean'] for s in samples])
- f0_std = torch.Tensor([s['f0_std'] for s in samples])
- batch.update({'cwt_spec': cwt_spec, 'f0_mean': f0_mean, 'f0_std': f0_std})
- return batch
-
-
-class FastSpeech2OrigTask(FastSpeechTask):
- def __init__(self):
- super(FastSpeech2OrigTask, self).__init__()
- self.dataset_cls = FastSpeech2OrigDataset
-
- def build_tts_model(self):
- dict_size = len(self.token_encoder)
- self.model = FastSpeech2Orig(dict_size, hparams)
-
- def run_model(self, sample, infer=False, *args, **kwargs):
- txt_tokens = sample['txt_tokens'] # [B, T_t]
- spk_embed = sample.get('spk_embed')
- spk_id = sample.get('spk_ids')
- if not infer:
- target = sample['mels'] # [B, T_s, 80]
- mel2ph = sample['mel2ph'] # [B, T_s]
- f0 = sample.get('f0')
- uv = sample.get('uv')
- energy = sample.get('energy')
- output = self.model(txt_tokens, mel2ph=mel2ph, spk_embed=spk_embed, spk_id=spk_id,
- f0=f0, uv=uv, energy=energy, infer=False)
- losses = {}
- self.add_mel_loss(output['mel_out'], target, losses)
- self.add_dur_loss(output['dur'], mel2ph, txt_tokens, losses=losses)
- if hparams['use_pitch_embed']:
- self.add_pitch_loss(output, sample, losses)
- if hparams['use_energy_embed']:
- self.add_energy_loss(output, sample, losses)
- return losses, output
- else:
- mel2ph, uv, f0, energy = None, None, None, None
- use_gt_dur = kwargs.get('infer_use_gt_dur', hparams['use_gt_dur'])
- use_gt_f0 = kwargs.get('infer_use_gt_f0', hparams['use_gt_f0'])
- use_gt_energy = kwargs.get('infer_use_gt_energy', hparams['use_gt_energy'])
- if use_gt_dur:
- mel2ph = sample['mel2ph']
- if use_gt_f0:
- f0 = sample['f0']
- uv = sample['uv']
- if use_gt_energy:
- energy = sample['energy']
- output = self.model(txt_tokens, mel2ph=mel2ph, spk_embed=spk_embed, spk_id=spk_id,
- f0=f0, uv=uv, energy=energy, infer=True)
- return output
-
- def add_pitch_loss(self, output, sample, losses):
- if hparams['pitch_type'] == 'cwt':
- cwt_spec = sample[f'cwt_spec']
- f0_mean = sample['f0_mean']
- uv = sample['uv']
- mel2ph = sample['mel2ph']
- f0_std = sample['f0_std']
- cwt_pred = output['cwt'][:, :, :10]
- f0_mean_pred = output['f0_mean']
- f0_std_pred = output['f0_std']
- nonpadding = (mel2ph != 0).float()
- losses['C'] = F.l1_loss(cwt_pred, cwt_spec) * hparams['lambda_f0']
- if hparams['use_uv']:
- assert output['cwt'].shape[-1] == 11
- uv_pred = output['cwt'][:, :, -1]
- losses['uv'] = (F.binary_cross_entropy_with_logits(uv_pred, uv, reduction='none')
- * nonpadding).sum() / nonpadding.sum() * hparams['lambda_uv']
- losses['f0_mean'] = F.l1_loss(f0_mean_pred, f0_mean) * hparams['lambda_f0']
- losses['f0_std'] = F.l1_loss(f0_std_pred, f0_std) * hparams['lambda_f0']
- else:
- super(FastSpeech2OrigTask, self).add_pitch_loss(output, sample, losses)
-
- def add_energy_loss(self, output, sample, losses):
- energy_pred, energy = output['energy_pred'], sample['energy']
- nonpadding = (energy != 0).float()
- loss = (F.mse_loss(energy_pred, energy, reduction='none') * nonpadding).sum() / nonpadding.sum()
- loss = loss * hparams['lambda_energy']
- losses['e'] = loss
diff --git a/spaces/NCTCMumbai/NCTC/models/research/cognitive_planning/preprocessing/cifarnet_preprocessing.py b/spaces/NCTCMumbai/NCTC/models/research/cognitive_planning/preprocessing/cifarnet_preprocessing.py
deleted file mode 100644
index 0b5a88fa4c31c13dca4cf92a5ee7614f08a935af..0000000000000000000000000000000000000000
--- a/spaces/NCTCMumbai/NCTC/models/research/cognitive_planning/preprocessing/cifarnet_preprocessing.py
+++ /dev/null
@@ -1,128 +0,0 @@
-# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Provides utilities to preprocess images in CIFAR-10.
-
-"""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import tensorflow as tf
-
-_PADDING = 4
-
-slim = tf.contrib.slim
-
-
-def preprocess_for_train(image,
- output_height,
- output_width,
- padding=_PADDING,
- add_image_summaries=True):
- """Preprocesses the given image for training.
-
- Note that the actual resizing scale is sampled from
- [`resize_size_min`, `resize_size_max`].
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- padding: The amound of padding before and after each dimension of the image.
- add_image_summaries: Enable image summaries.
-
- Returns:
- A preprocessed image.
- """
- if add_image_summaries:
- tf.summary.image('image', tf.expand_dims(image, 0))
-
- # Transform the image to floats.
- image = tf.to_float(image)
- if padding > 0:
- image = tf.pad(image, [[padding, padding], [padding, padding], [0, 0]])
- # Randomly crop a [height, width] section of the image.
- distorted_image = tf.random_crop(image,
- [output_height, output_width, 3])
-
- # Randomly flip the image horizontally.
- distorted_image = tf.image.random_flip_left_right(distorted_image)
-
- if add_image_summaries:
- tf.summary.image('distorted_image', tf.expand_dims(distorted_image, 0))
-
- # Because these operations are not commutative, consider randomizing
- # the order their operation.
- distorted_image = tf.image.random_brightness(distorted_image,
- max_delta=63)
- distorted_image = tf.image.random_contrast(distorted_image,
- lower=0.2, upper=1.8)
- # Subtract off the mean and divide by the variance of the pixels.
- return tf.image.per_image_standardization(distorted_image)
-
-
-def preprocess_for_eval(image, output_height, output_width,
- add_image_summaries=True):
- """Preprocesses the given image for evaluation.
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- add_image_summaries: Enable image summaries.
-
- Returns:
- A preprocessed image.
- """
- if add_image_summaries:
- tf.summary.image('image', tf.expand_dims(image, 0))
- # Transform the image to floats.
- image = tf.to_float(image)
-
- # Resize and crop if needed.
- resized_image = tf.image.resize_image_with_crop_or_pad(image,
- output_width,
- output_height)
- if add_image_summaries:
- tf.summary.image('resized_image', tf.expand_dims(resized_image, 0))
-
- # Subtract off the mean and divide by the variance of the pixels.
- return tf.image.per_image_standardization(resized_image)
-
-
-def preprocess_image(image, output_height, output_width, is_training=False,
- add_image_summaries=True):
- """Preprocesses the given image.
-
- Args:
- image: A `Tensor` representing an image of arbitrary size.
- output_height: The height of the image after preprocessing.
- output_width: The width of the image after preprocessing.
- is_training: `True` if we're preprocessing the image for training and
- `False` otherwise.
- add_image_summaries: Enable image summaries.
-
- Returns:
- A preprocessed image.
- """
- if is_training:
- return preprocess_for_train(
- image, output_height, output_width,
- add_image_summaries=add_image_summaries)
- else:
- return preprocess_for_eval(
- image, output_height, output_width,
- add_image_summaries=add_image_summaries)
diff --git a/spaces/Nephele/bert-vits2-multi-voice/bert_gen.py b/spaces/Nephele/bert-vits2-multi-voice/bert_gen.py
deleted file mode 100644
index 467655b2c4171608ad690fe7dec350db85f84f1b..0000000000000000000000000000000000000000
--- a/spaces/Nephele/bert-vits2-multi-voice/bert_gen.py
+++ /dev/null
@@ -1,53 +0,0 @@
-import torch
-from torch.utils.data import DataLoader
-from multiprocessing import Pool
-import commons
-import utils
-from data_utils import TextAudioSpeakerLoader, TextAudioSpeakerCollate
-from tqdm import tqdm
-import warnings
-
-from text import cleaned_text_to_sequence, get_bert
-
-config_path = 'configs/config.json'
-hps = utils.get_hparams_from_file(config_path)
-
-def process_line(line):
- _id, spk, language_str, text, phones, tone, word2ph = line.strip().split("|")
- phone = phones.split(" ")
- tone = [int(i) for i in tone.split(" ")]
- word2ph = [int(i) for i in word2ph.split(" ")]
- w2pho = [i for i in word2ph]
- word2ph = [i for i in word2ph]
- phone, tone, language = cleaned_text_to_sequence(phone, tone, language_str)
-
- if hps.data.add_blank:
- phone = commons.intersperse(phone, 0)
- tone = commons.intersperse(tone, 0)
- language = commons.intersperse(language, 0)
- for i in range(len(word2ph)):
- word2ph[i] = word2ph[i] * 2
- word2ph[0] += 1
- wav_path = f'{_id}'
-
- bert_path = wav_path.replace(".wav", ".bert.pt")
- try:
- bert = torch.load(bert_path)
- assert bert.shape[-1] == len(phone)
- except:
- bert = get_bert(text, word2ph, language_str)
- assert bert.shape[-1] == len(phone)
- torch.save(bert, bert_path)
-
-
-if __name__ == '__main__':
- lines = []
- with open(hps.data.training_files, encoding='utf-8' ) as f:
- lines.extend(f.readlines())
-
- # with open(hps.data.validation_files, encoding='utf-8' ) as f:
- # lines.extend(f.readlines())
-
- with Pool(processes=2) as pool: #A100 40GB suitable config,if coom,please decrease the processess number.
- for _ in tqdm(pool.imap_unordered(process_line, lines)):
- pass
diff --git a/spaces/NoCrypt/pixelization/README.md b/spaces/NoCrypt/pixelization/README.md
deleted file mode 100644
index 905417e6d3c2599643f7815b0a67a05e4d712d2b..0000000000000000000000000000000000000000
--- a/spaces/NoCrypt/pixelization/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: Pixelization
-emoji: 🪄
-colorFrom: indigo
-colorTo: blue
-sdk: gradio
-sdk_version: 3.33.1
-app_file: app.py
-pinned: false
----
\ No newline at end of file
diff --git a/spaces/OAOA/DifFace/basicsr/archs/arch_util.py b/spaces/OAOA/DifFace/basicsr/archs/arch_util.py
deleted file mode 100644
index 493e566112e85a2eb17d6b5aaf5241f4d0d882b7..0000000000000000000000000000000000000000
--- a/spaces/OAOA/DifFace/basicsr/archs/arch_util.py
+++ /dev/null
@@ -1,313 +0,0 @@
-import collections.abc
-import math
-import torch
-import torchvision
-import warnings
-from distutils.version import LooseVersion
-from itertools import repeat
-from torch import nn as nn
-from torch.nn import functional as F
-from torch.nn import init as init
-from torch.nn.modules.batchnorm import _BatchNorm
-
-from basicsr.ops.dcn import ModulatedDeformConvPack, modulated_deform_conv
-from basicsr.utils import get_root_logger
-
-
-@torch.no_grad()
-def default_init_weights(module_list, scale=1, bias_fill=0, **kwargs):
- """Initialize network weights.
-
- Args:
- module_list (list[nn.Module] | nn.Module): Modules to be initialized.
- scale (float): Scale initialized weights, especially for residual
- blocks. Default: 1.
- bias_fill (float): The value to fill bias. Default: 0
- kwargs (dict): Other arguments for initialization function.
- """
- if not isinstance(module_list, list):
- module_list = [module_list]
- for module in module_list:
- for m in module.modules():
- if isinstance(m, nn.Conv2d):
- init.kaiming_normal_(m.weight, **kwargs)
- m.weight.data *= scale
- if m.bias is not None:
- m.bias.data.fill_(bias_fill)
- elif isinstance(m, nn.Linear):
- init.kaiming_normal_(m.weight, **kwargs)
- m.weight.data *= scale
- if m.bias is not None:
- m.bias.data.fill_(bias_fill)
- elif isinstance(m, _BatchNorm):
- init.constant_(m.weight, 1)
- if m.bias is not None:
- m.bias.data.fill_(bias_fill)
-
-
-def make_layer(basic_block, num_basic_block, **kwarg):
- """Make layers by stacking the same blocks.
-
- Args:
- basic_block (nn.module): nn.module class for basic block.
- num_basic_block (int): number of blocks.
-
- Returns:
- nn.Sequential: Stacked blocks in nn.Sequential.
- """
- layers = []
- for _ in range(num_basic_block):
- layers.append(basic_block(**kwarg))
- return nn.Sequential(*layers)
-
-
-class ResidualBlockNoBN(nn.Module):
- """Residual block without BN.
-
- Args:
- num_feat (int): Channel number of intermediate features.
- Default: 64.
- res_scale (float): Residual scale. Default: 1.
- pytorch_init (bool): If set to True, use pytorch default init,
- otherwise, use default_init_weights. Default: False.
- """
-
- def __init__(self, num_feat=64, res_scale=1, pytorch_init=False):
- super(ResidualBlockNoBN, self).__init__()
- self.res_scale = res_scale
- self.conv1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=True)
- self.conv2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=True)
- self.relu = nn.ReLU(inplace=True)
-
- if not pytorch_init:
- default_init_weights([self.conv1, self.conv2], 0.1)
-
- def forward(self, x):
- identity = x
- out = self.conv2(self.relu(self.conv1(x)))
- return identity + out * self.res_scale
-
-
-class Upsample(nn.Sequential):
- """Upsample module.
-
- Args:
- scale (int): Scale factor. Supported scales: 2^n and 3.
- num_feat (int): Channel number of intermediate features.
- """
-
- def __init__(self, scale, num_feat):
- m = []
- if (scale & (scale - 1)) == 0: # scale = 2^n
- for _ in range(int(math.log(scale, 2))):
- m.append(nn.Conv2d(num_feat, 4 * num_feat, 3, 1, 1))
- m.append(nn.PixelShuffle(2))
- elif scale == 3:
- m.append(nn.Conv2d(num_feat, 9 * num_feat, 3, 1, 1))
- m.append(nn.PixelShuffle(3))
- else:
- raise ValueError(f'scale {scale} is not supported. Supported scales: 2^n and 3.')
- super(Upsample, self).__init__(*m)
-
-
-def flow_warp(x, flow, interp_mode='bilinear', padding_mode='zeros', align_corners=True):
- """Warp an image or feature map with optical flow.
-
- Args:
- x (Tensor): Tensor with size (n, c, h, w).
- flow (Tensor): Tensor with size (n, h, w, 2), normal value.
- interp_mode (str): 'nearest' or 'bilinear'. Default: 'bilinear'.
- padding_mode (str): 'zeros' or 'border' or 'reflection'.
- Default: 'zeros'.
- align_corners (bool): Before pytorch 1.3, the default value is
- align_corners=True. After pytorch 1.3, the default value is
- align_corners=False. Here, we use the True as default.
-
- Returns:
- Tensor: Warped image or feature map.
- """
- assert x.size()[-2:] == flow.size()[1:3]
- _, _, h, w = x.size()
- # create mesh grid
- grid_y, grid_x = torch.meshgrid(torch.arange(0, h).type_as(x), torch.arange(0, w).type_as(x))
- grid = torch.stack((grid_x, grid_y), 2).float() # W(x), H(y), 2
- grid.requires_grad = False
-
- vgrid = grid + flow
- # scale grid to [-1,1]
- vgrid_x = 2.0 * vgrid[:, :, :, 0] / max(w - 1, 1) - 1.0
- vgrid_y = 2.0 * vgrid[:, :, :, 1] / max(h - 1, 1) - 1.0
- vgrid_scaled = torch.stack((vgrid_x, vgrid_y), dim=3)
- output = F.grid_sample(x, vgrid_scaled, mode=interp_mode, padding_mode=padding_mode, align_corners=align_corners)
-
- # TODO, what if align_corners=False
- return output
-
-
-def resize_flow(flow, size_type, sizes, interp_mode='bilinear', align_corners=False):
- """Resize a flow according to ratio or shape.
-
- Args:
- flow (Tensor): Precomputed flow. shape [N, 2, H, W].
- size_type (str): 'ratio' or 'shape'.
- sizes (list[int | float]): the ratio for resizing or the final output
- shape.
- 1) The order of ratio should be [ratio_h, ratio_w]. For
- downsampling, the ratio should be smaller than 1.0 (i.e., ratio
- < 1.0). For upsampling, the ratio should be larger than 1.0 (i.e.,
- ratio > 1.0).
- 2) The order of output_size should be [out_h, out_w].
- interp_mode (str): The mode of interpolation for resizing.
- Default: 'bilinear'.
- align_corners (bool): Whether align corners. Default: False.
-
- Returns:
- Tensor: Resized flow.
- """
- _, _, flow_h, flow_w = flow.size()
- if size_type == 'ratio':
- output_h, output_w = int(flow_h * sizes[0]), int(flow_w * sizes[1])
- elif size_type == 'shape':
- output_h, output_w = sizes[0], sizes[1]
- else:
- raise ValueError(f'Size type should be ratio or shape, but got type {size_type}.')
-
- input_flow = flow.clone()
- ratio_h = output_h / flow_h
- ratio_w = output_w / flow_w
- input_flow[:, 0, :, :] *= ratio_w
- input_flow[:, 1, :, :] *= ratio_h
- resized_flow = F.interpolate(
- input=input_flow, size=(output_h, output_w), mode=interp_mode, align_corners=align_corners)
- return resized_flow
-
-
-# TODO: may write a cpp file
-def pixel_unshuffle(x, scale):
- """ Pixel unshuffle.
-
- Args:
- x (Tensor): Input feature with shape (b, c, hh, hw).
- scale (int): Downsample ratio.
-
- Returns:
- Tensor: the pixel unshuffled feature.
- """
- b, c, hh, hw = x.size()
- out_channel = c * (scale**2)
- assert hh % scale == 0 and hw % scale == 0
- h = hh // scale
- w = hw // scale
- x_view = x.view(b, c, h, scale, w, scale)
- return x_view.permute(0, 1, 3, 5, 2, 4).reshape(b, out_channel, h, w)
-
-
-class DCNv2Pack(ModulatedDeformConvPack):
- """Modulated deformable conv for deformable alignment.
-
- Different from the official DCNv2Pack, which generates offsets and masks
- from the preceding features, this DCNv2Pack takes another different
- features to generate offsets and masks.
-
- ``Paper: Delving Deep into Deformable Alignment in Video Super-Resolution``
- """
-
- def forward(self, x, feat):
- out = self.conv_offset(feat)
- o1, o2, mask = torch.chunk(out, 3, dim=1)
- offset = torch.cat((o1, o2), dim=1)
- mask = torch.sigmoid(mask)
-
- offset_absmean = torch.mean(torch.abs(offset))
- if offset_absmean > 50:
- logger = get_root_logger()
- logger.warning(f'Offset abs mean is {offset_absmean}, larger than 50.')
-
- if LooseVersion(torchvision.__version__) >= LooseVersion('0.9.0'):
- return torchvision.ops.deform_conv2d(x, offset, self.weight, self.bias, self.stride, self.padding,
- self.dilation, mask)
- else:
- return modulated_deform_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding,
- self.dilation, self.groups, self.deformable_groups)
-
-
-def _no_grad_trunc_normal_(tensor, mean, std, a, b):
- # From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
- # Cut & paste from PyTorch official master until it's in a few official releases - RW
- # Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
- def norm_cdf(x):
- # Computes standard normal cumulative distribution function
- return (1. + math.erf(x / math.sqrt(2.))) / 2.
-
- if (mean < a - 2 * std) or (mean > b + 2 * std):
- warnings.warn(
- 'mean is more than 2 std from [a, b] in nn.init.trunc_normal_. '
- 'The distribution of values may be incorrect.',
- stacklevel=2)
-
- with torch.no_grad():
- # Values are generated by using a truncated uniform distribution and
- # then using the inverse CDF for the normal distribution.
- # Get upper and lower cdf values
- low = norm_cdf((a - mean) / std)
- up = norm_cdf((b - mean) / std)
-
- # Uniformly fill tensor with values from [low, up], then translate to
- # [2l-1, 2u-1].
- tensor.uniform_(2 * low - 1, 2 * up - 1)
-
- # Use inverse cdf transform for normal distribution to get truncated
- # standard normal
- tensor.erfinv_()
-
- # Transform to proper mean, std
- tensor.mul_(std * math.sqrt(2.))
- tensor.add_(mean)
-
- # Clamp to ensure it's in the proper range
- tensor.clamp_(min=a, max=b)
- return tensor
-
-
-def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
- r"""Fills the input Tensor with values drawn from a truncated
- normal distribution.
-
- From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
-
- The values are effectively drawn from the
- normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
- with values outside :math:`[a, b]` redrawn until they are within
- the bounds. The method used for generating the random values works
- best when :math:`a \leq \text{mean} \leq b`.
-
- Args:
- tensor: an n-dimensional `torch.Tensor`
- mean: the mean of the normal distribution
- std: the standard deviation of the normal distribution
- a: the minimum cutoff value
- b: the maximum cutoff value
-
- Examples:
- >>> w = torch.empty(3, 5)
- >>> nn.init.trunc_normal_(w)
- """
- return _no_grad_trunc_normal_(tensor, mean, std, a, b)
-
-
-# From PyTorch
-def _ntuple(n):
-
- def parse(x):
- if isinstance(x, collections.abc.Iterable):
- return x
- return tuple(repeat(x, n))
-
- return parse
-
-
-to_1tuple = _ntuple(1)
-to_2tuple = _ntuple(2)
-to_3tuple = _ntuple(3)
-to_4tuple = _ntuple(4)
-to_ntuple = _ntuple
diff --git a/spaces/OAOA/DifFace/facelib/detection/retinaface/retinaface.py b/spaces/OAOA/DifFace/facelib/detection/retinaface/retinaface.py
deleted file mode 100644
index 02593556d88a90232bbe55a062875f4af4520621..0000000000000000000000000000000000000000
--- a/spaces/OAOA/DifFace/facelib/detection/retinaface/retinaface.py
+++ /dev/null
@@ -1,370 +0,0 @@
-import cv2
-import numpy as np
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from PIL import Image
-from torchvision.models._utils import IntermediateLayerGetter as IntermediateLayerGetter
-
-from facelib.detection.align_trans import get_reference_facial_points, warp_and_crop_face
-from facelib.detection.retinaface.retinaface_net import FPN, SSH, MobileNetV1, make_bbox_head, make_class_head, make_landmark_head
-from facelib.detection.retinaface.retinaface_utils import (PriorBox, batched_decode, batched_decode_landm, decode, decode_landm,
- py_cpu_nms)
-
-device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
-
-
-def generate_config(network_name):
-
- cfg_mnet = {
- 'name': 'mobilenet0.25',
- 'min_sizes': [[16, 32], [64, 128], [256, 512]],
- 'steps': [8, 16, 32],
- 'variance': [0.1, 0.2],
- 'clip': False,
- 'loc_weight': 2.0,
- 'gpu_train': True,
- 'batch_size': 32,
- 'ngpu': 1,
- 'epoch': 250,
- 'decay1': 190,
- 'decay2': 220,
- 'image_size': 640,
- 'return_layers': {
- 'stage1': 1,
- 'stage2': 2,
- 'stage3': 3
- },
- 'in_channel': 32,
- 'out_channel': 64
- }
-
- cfg_re50 = {
- 'name': 'Resnet50',
- 'min_sizes': [[16, 32], [64, 128], [256, 512]],
- 'steps': [8, 16, 32],
- 'variance': [0.1, 0.2],
- 'clip': False,
- 'loc_weight': 2.0,
- 'gpu_train': True,
- 'batch_size': 24,
- 'ngpu': 4,
- 'epoch': 100,
- 'decay1': 70,
- 'decay2': 90,
- 'image_size': 840,
- 'return_layers': {
- 'layer2': 1,
- 'layer3': 2,
- 'layer4': 3
- },
- 'in_channel': 256,
- 'out_channel': 256
- }
-
- if network_name == 'mobile0.25':
- return cfg_mnet
- elif network_name == 'resnet50':
- return cfg_re50
- else:
- raise NotImplementedError(f'network_name={network_name}')
-
-
-class RetinaFace(nn.Module):
-
- def __init__(self, network_name='resnet50', half=False, phase='test'):
- super(RetinaFace, self).__init__()
- self.half_inference = half
- cfg = generate_config(network_name)
- self.backbone = cfg['name']
-
- self.model_name = f'retinaface_{network_name}'
- self.cfg = cfg
- self.phase = phase
- self.target_size, self.max_size = 1600, 2150
- self.resize, self.scale, self.scale1 = 1., None, None
- self.mean_tensor = torch.tensor([[[[104.]], [[117.]], [[123.]]]]).to(device)
- self.reference = get_reference_facial_points(default_square=True)
- # Build network.
- backbone = None
- if cfg['name'] == 'mobilenet0.25':
- backbone = MobileNetV1()
- self.body = IntermediateLayerGetter(backbone, cfg['return_layers'])
- elif cfg['name'] == 'Resnet50':
- import torchvision.models as models
- backbone = models.resnet50(pretrained=False)
- self.body = IntermediateLayerGetter(backbone, cfg['return_layers'])
-
- in_channels_stage2 = cfg['in_channel']
- in_channels_list = [
- in_channels_stage2 * 2,
- in_channels_stage2 * 4,
- in_channels_stage2 * 8,
- ]
-
- out_channels = cfg['out_channel']
- self.fpn = FPN(in_channels_list, out_channels)
- self.ssh1 = SSH(out_channels, out_channels)
- self.ssh2 = SSH(out_channels, out_channels)
- self.ssh3 = SSH(out_channels, out_channels)
-
- self.ClassHead = make_class_head(fpn_num=3, inchannels=cfg['out_channel'])
- self.BboxHead = make_bbox_head(fpn_num=3, inchannels=cfg['out_channel'])
- self.LandmarkHead = make_landmark_head(fpn_num=3, inchannels=cfg['out_channel'])
-
- self.to(device)
- self.eval()
- if self.half_inference:
- self.half()
-
- def forward(self, inputs):
- out = self.body(inputs)
-
- if self.backbone == 'mobilenet0.25' or self.backbone == 'Resnet50':
- out = list(out.values())
- # FPN
- fpn = self.fpn(out)
-
- # SSH
- feature1 = self.ssh1(fpn[0])
- feature2 = self.ssh2(fpn[1])
- feature3 = self.ssh3(fpn[2])
- features = [feature1, feature2, feature3]
-
- bbox_regressions = torch.cat([self.BboxHead[i](feature) for i, feature in enumerate(features)], dim=1)
- classifications = torch.cat([self.ClassHead[i](feature) for i, feature in enumerate(features)], dim=1)
- tmp = [self.LandmarkHead[i](feature) for i, feature in enumerate(features)]
- ldm_regressions = (torch.cat(tmp, dim=1))
-
- if self.phase == 'train':
- output = (bbox_regressions, classifications, ldm_regressions)
- else:
- output = (bbox_regressions, F.softmax(classifications, dim=-1), ldm_regressions)
- return output
-
- def __detect_faces(self, inputs):
- # get scale
- height, width = inputs.shape[2:]
- self.scale = torch.tensor([width, height, width, height], dtype=torch.float32).to(device)
- tmp = [width, height, width, height, width, height, width, height, width, height]
- self.scale1 = torch.tensor(tmp, dtype=torch.float32).to(device)
-
- # forawrd
- inputs = inputs.to(device)
- if self.half_inference:
- inputs = inputs.half()
- loc, conf, landmarks = self(inputs)
-
- # get priorbox
- priorbox = PriorBox(self.cfg, image_size=inputs.shape[2:])
- priors = priorbox.forward().to(device)
-
- return loc, conf, landmarks, priors
-
- # single image detection
- def transform(self, image, use_origin_size):
- # convert to opencv format
- if isinstance(image, Image.Image):
- image = cv2.cvtColor(np.asarray(image), cv2.COLOR_RGB2BGR)
- image = image.astype(np.float32)
-
- # testing scale
- im_size_min = np.min(image.shape[0:2])
- im_size_max = np.max(image.shape[0:2])
- resize = float(self.target_size) / float(im_size_min)
-
- # prevent bigger axis from being more than max_size
- if np.round(resize * im_size_max) > self.max_size:
- resize = float(self.max_size) / float(im_size_max)
- resize = 1 if use_origin_size else resize
-
- # resize
- if resize != 1:
- image = cv2.resize(image, None, None, fx=resize, fy=resize, interpolation=cv2.INTER_LINEAR)
-
- # convert to torch.tensor format
- # image -= (104, 117, 123)
- image = image.transpose(2, 0, 1)
- image = torch.from_numpy(image).unsqueeze(0)
-
- return image, resize
-
- def detect_faces(
- self,
- image,
- conf_threshold=0.8,
- nms_threshold=0.4,
- use_origin_size=True,
- ):
- """
- Params:
- imgs: BGR image
- """
- image, self.resize = self.transform(image, use_origin_size)
- image = image.to(device)
- if self.half_inference:
- image = image.half()
- image = image - self.mean_tensor
-
- loc, conf, landmarks, priors = self.__detect_faces(image)
-
- boxes = decode(loc.data.squeeze(0), priors.data, self.cfg['variance'])
- boxes = boxes * self.scale / self.resize
- boxes = boxes.cpu().numpy()
-
- scores = conf.squeeze(0).data.cpu().numpy()[:, 1]
-
- landmarks = decode_landm(landmarks.squeeze(0), priors, self.cfg['variance'])
- landmarks = landmarks * self.scale1 / self.resize
- landmarks = landmarks.cpu().numpy()
-
- # ignore low scores
- inds = np.where(scores > conf_threshold)[0]
- boxes, landmarks, scores = boxes[inds], landmarks[inds], scores[inds]
-
- # sort
- order = scores.argsort()[::-1]
- boxes, landmarks, scores = boxes[order], landmarks[order], scores[order]
-
- # do NMS
- bounding_boxes = np.hstack((boxes, scores[:, np.newaxis])).astype(np.float32, copy=False)
- keep = py_cpu_nms(bounding_boxes, nms_threshold)
- bounding_boxes, landmarks = bounding_boxes[keep, :], landmarks[keep]
- # self.t['forward_pass'].toc()
- # print(self.t['forward_pass'].average_time)
- # import sys
- # sys.stdout.flush()
- return np.concatenate((bounding_boxes, landmarks), axis=1)
-
- def __align_multi(self, image, boxes, landmarks, limit=None):
-
- if len(boxes) < 1:
- return [], []
-
- if limit:
- boxes = boxes[:limit]
- landmarks = landmarks[:limit]
-
- faces = []
- for landmark in landmarks:
- facial5points = [[landmark[2 * j], landmark[2 * j + 1]] for j in range(5)]
-
- warped_face = warp_and_crop_face(np.array(image), facial5points, self.reference, crop_size=(112, 112))
- faces.append(warped_face)
-
- return np.concatenate((boxes, landmarks), axis=1), faces
-
- def align_multi(self, img, conf_threshold=0.8, limit=None):
-
- rlt = self.detect_faces(img, conf_threshold=conf_threshold)
- boxes, landmarks = rlt[:, 0:5], rlt[:, 5:]
-
- return self.__align_multi(img, boxes, landmarks, limit)
-
- # batched detection
- def batched_transform(self, frames, use_origin_size):
- """
- Arguments:
- frames: a list of PIL.Image, or torch.Tensor(shape=[n, h, w, c],
- type=np.float32, BGR format).
- use_origin_size: whether to use origin size.
- """
- from_PIL = True if isinstance(frames[0], Image.Image) else False
-
- # convert to opencv format
- if from_PIL:
- frames = [cv2.cvtColor(np.asarray(frame), cv2.COLOR_RGB2BGR) for frame in frames]
- frames = np.asarray(frames, dtype=np.float32)
-
- # testing scale
- im_size_min = np.min(frames[0].shape[0:2])
- im_size_max = np.max(frames[0].shape[0:2])
- resize = float(self.target_size) / float(im_size_min)
-
- # prevent bigger axis from being more than max_size
- if np.round(resize * im_size_max) > self.max_size:
- resize = float(self.max_size) / float(im_size_max)
- resize = 1 if use_origin_size else resize
-
- # resize
- if resize != 1:
- if not from_PIL:
- frames = F.interpolate(frames, scale_factor=resize)
- else:
- frames = [
- cv2.resize(frame, None, None, fx=resize, fy=resize, interpolation=cv2.INTER_LINEAR)
- for frame in frames
- ]
-
- # convert to torch.tensor format
- if not from_PIL:
- frames = frames.transpose(1, 2).transpose(1, 3).contiguous()
- else:
- frames = frames.transpose((0, 3, 1, 2))
- frames = torch.from_numpy(frames)
-
- return frames, resize
-
- def batched_detect_faces(self, frames, conf_threshold=0.8, nms_threshold=0.4, use_origin_size=True):
- """
- Arguments:
- frames: a list of PIL.Image, or np.array(shape=[n, h, w, c],
- type=np.uint8, BGR format).
- conf_threshold: confidence threshold.
- nms_threshold: nms threshold.
- use_origin_size: whether to use origin size.
- Returns:
- final_bounding_boxes: list of np.array ([n_boxes, 5],
- type=np.float32).
- final_landmarks: list of np.array ([n_boxes, 10], type=np.float32).
- """
- # self.t['forward_pass'].tic()
- frames, self.resize = self.batched_transform(frames, use_origin_size)
- frames = frames.to(device)
- frames = frames - self.mean_tensor
-
- b_loc, b_conf, b_landmarks, priors = self.__detect_faces(frames)
-
- final_bounding_boxes, final_landmarks = [], []
-
- # decode
- priors = priors.unsqueeze(0)
- b_loc = batched_decode(b_loc, priors, self.cfg['variance']) * self.scale / self.resize
- b_landmarks = batched_decode_landm(b_landmarks, priors, self.cfg['variance']) * self.scale1 / self.resize
- b_conf = b_conf[:, :, 1]
-
- # index for selection
- b_indice = b_conf > conf_threshold
-
- # concat
- b_loc_and_conf = torch.cat((b_loc, b_conf.unsqueeze(-1)), dim=2).float()
-
- for pred, landm, inds in zip(b_loc_and_conf, b_landmarks, b_indice):
-
- # ignore low scores
- pred, landm = pred[inds, :], landm[inds, :]
- if pred.shape[0] == 0:
- final_bounding_boxes.append(np.array([], dtype=np.float32))
- final_landmarks.append(np.array([], dtype=np.float32))
- continue
-
- # sort
- # order = score.argsort(descending=True)
- # box, landm, score = box[order], landm[order], score[order]
-
- # to CPU
- bounding_boxes, landm = pred.cpu().numpy(), landm.cpu().numpy()
-
- # NMS
- keep = py_cpu_nms(bounding_boxes, nms_threshold)
- bounding_boxes, landmarks = bounding_boxes[keep, :], landm[keep]
-
- # append
- final_bounding_boxes.append(bounding_boxes)
- final_landmarks.append(landmarks)
- # self.t['forward_pass'].toc(average=True)
- # self.batch_time += self.t['forward_pass'].diff
- # self.total_frame += len(frames)
- # print(self.batch_time / self.total_frame)
-
- return final_bounding_boxes, final_landmarks
diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/data/concat_sentences_dataset.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/data/concat_sentences_dataset.py
deleted file mode 100644
index 625a29370e90f9d1d7274024afb902ed83a22325..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/data/concat_sentences_dataset.py
+++ /dev/null
@@ -1,54 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import torch
-
-from . import FairseqDataset
-
-
-class ConcatSentencesDataset(FairseqDataset):
- def __init__(self, *datasets):
- super().__init__()
- self.datasets = datasets
- assert all(
- len(ds) == len(datasets[0]) for ds in datasets
- ), "datasets must have the same length"
-
- def __getitem__(self, index):
- return torch.cat([ds[index] for ds in self.datasets])
-
- def __len__(self):
- return len(self.datasets[0])
-
- def collater(self, samples):
- return self.datasets[0].collater(samples)
-
- @property
- def sizes(self):
- return sum(ds.sizes for ds in self.datasets)
-
- def num_tokens(self, index):
- return sum(ds.num_tokens(index) for ds in self.datasets)
-
- def size(self, index):
- return sum(ds.size(index) for ds in self.datasets)
-
- def ordered_indices(self):
- return self.datasets[0].ordered_indices()
-
- @property
- def supports_prefetch(self):
- return any(getattr(ds, "supports_prefetch", False) for ds in self.datasets)
-
- def prefetch(self, indices):
- for ds in self.datasets:
- if getattr(ds, "supports_prefetch", False):
- ds.prefetch(indices)
-
- def set_epoch(self, epoch):
- super().set_epoch(epoch)
- for ds in self.datasets:
- if hasattr(ds, "set_epoch"):
- ds.set_epoch(epoch)
diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/models/lstm.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/models/lstm.py
deleted file mode 100644
index e1e66a7d50fa1b1b313e9d1a6e7862ac9bfaa074..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/models/lstm.py
+++ /dev/null
@@ -1,753 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from typing import Dict, List, Optional, Tuple
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from fairseq import utils
-from fairseq.models import (
- FairseqEncoder,
- FairseqEncoderDecoderModel,
- FairseqIncrementalDecoder,
- register_model,
- register_model_architecture,
-)
-from fairseq.modules import AdaptiveSoftmax, FairseqDropout
-from torch import Tensor
-
-
-DEFAULT_MAX_SOURCE_POSITIONS = 1e5
-DEFAULT_MAX_TARGET_POSITIONS = 1e5
-
-
-@register_model("lstm")
-class LSTMModel(FairseqEncoderDecoderModel):
- def __init__(self, encoder, decoder):
- super().__init__(encoder, decoder)
-
- @staticmethod
- def add_args(parser):
- """Add model-specific arguments to the parser."""
- # fmt: off
- parser.add_argument('--dropout', type=float, metavar='D',
- help='dropout probability')
- parser.add_argument('--encoder-embed-dim', type=int, metavar='N',
- help='encoder embedding dimension')
- parser.add_argument('--encoder-embed-path', type=str, metavar='STR',
- help='path to pre-trained encoder embedding')
- parser.add_argument('--encoder-freeze-embed', action='store_true',
- help='freeze encoder embeddings')
- parser.add_argument('--encoder-hidden-size', type=int, metavar='N',
- help='encoder hidden size')
- parser.add_argument('--encoder-layers', type=int, metavar='N',
- help='number of encoder layers')
- parser.add_argument('--encoder-bidirectional', action='store_true',
- help='make all layers of encoder bidirectional')
- parser.add_argument('--decoder-embed-dim', type=int, metavar='N',
- help='decoder embedding dimension')
- parser.add_argument('--decoder-embed-path', type=str, metavar='STR',
- help='path to pre-trained decoder embedding')
- parser.add_argument('--decoder-freeze-embed', action='store_true',
- help='freeze decoder embeddings')
- parser.add_argument('--decoder-hidden-size', type=int, metavar='N',
- help='decoder hidden size')
- parser.add_argument('--decoder-layers', type=int, metavar='N',
- help='number of decoder layers')
- parser.add_argument('--decoder-out-embed-dim', type=int, metavar='N',
- help='decoder output embedding dimension')
- parser.add_argument('--decoder-attention', type=str, metavar='BOOL',
- help='decoder attention')
- parser.add_argument('--adaptive-softmax-cutoff', metavar='EXPR',
- help='comma separated list of adaptive softmax cutoff points. '
- 'Must be used with adaptive_loss criterion')
- parser.add_argument('--share-decoder-input-output-embed', default=False,
- action='store_true',
- help='share decoder input and output embeddings')
- parser.add_argument('--share-all-embeddings', default=False, action='store_true',
- help='share encoder, decoder and output embeddings'
- ' (requires shared dictionary and embed dim)')
-
- # Granular dropout settings (if not specified these default to --dropout)
- parser.add_argument('--encoder-dropout-in', type=float, metavar='D',
- help='dropout probability for encoder input embedding')
- parser.add_argument('--encoder-dropout-out', type=float, metavar='D',
- help='dropout probability for encoder output')
- parser.add_argument('--decoder-dropout-in', type=float, metavar='D',
- help='dropout probability for decoder input embedding')
- parser.add_argument('--decoder-dropout-out', type=float, metavar='D',
- help='dropout probability for decoder output')
- # fmt: on
-
- @classmethod
- def build_model(cls, args, task):
- """Build a new model instance."""
- # make sure that all args are properly defaulted (in case there are any new ones)
- base_architecture(args)
-
- if args.encoder_layers != args.decoder_layers:
- raise ValueError("--encoder-layers must match --decoder-layers")
-
- max_source_positions = getattr(
- args, "max_source_positions", DEFAULT_MAX_SOURCE_POSITIONS
- )
- max_target_positions = getattr(
- args, "max_target_positions", DEFAULT_MAX_TARGET_POSITIONS
- )
-
- def load_pretrained_embedding_from_file(embed_path, dictionary, embed_dim):
- num_embeddings = len(dictionary)
- padding_idx = dictionary.pad()
- embed_tokens = Embedding(num_embeddings, embed_dim, padding_idx)
- embed_dict = utils.parse_embedding(embed_path)
- utils.print_embed_overlap(embed_dict, dictionary)
- return utils.load_embedding(embed_dict, dictionary, embed_tokens)
-
- if args.encoder_embed_path:
- pretrained_encoder_embed = load_pretrained_embedding_from_file(
- args.encoder_embed_path, task.source_dictionary, args.encoder_embed_dim
- )
- else:
- num_embeddings = len(task.source_dictionary)
- pretrained_encoder_embed = Embedding(
- num_embeddings, args.encoder_embed_dim, task.source_dictionary.pad()
- )
-
- if args.share_all_embeddings:
- # double check all parameters combinations are valid
- if task.source_dictionary != task.target_dictionary:
- raise ValueError("--share-all-embeddings requires a joint dictionary")
- if args.decoder_embed_path and (
- args.decoder_embed_path != args.encoder_embed_path
- ):
- raise ValueError(
- "--share-all-embed not compatible with --decoder-embed-path"
- )
- if args.encoder_embed_dim != args.decoder_embed_dim:
- raise ValueError(
- "--share-all-embeddings requires --encoder-embed-dim to "
- "match --decoder-embed-dim"
- )
- pretrained_decoder_embed = pretrained_encoder_embed
- args.share_decoder_input_output_embed = True
- else:
- # separate decoder input embeddings
- pretrained_decoder_embed = None
- if args.decoder_embed_path:
- pretrained_decoder_embed = load_pretrained_embedding_from_file(
- args.decoder_embed_path,
- task.target_dictionary,
- args.decoder_embed_dim,
- )
- # one last double check of parameter combinations
- if args.share_decoder_input_output_embed and (
- args.decoder_embed_dim != args.decoder_out_embed_dim
- ):
- raise ValueError(
- "--share-decoder-input-output-embeddings requires "
- "--decoder-embed-dim to match --decoder-out-embed-dim"
- )
-
- if args.encoder_freeze_embed:
- pretrained_encoder_embed.weight.requires_grad = False
- if args.decoder_freeze_embed:
- pretrained_decoder_embed.weight.requires_grad = False
-
- encoder = LSTMEncoder(
- dictionary=task.source_dictionary,
- embed_dim=args.encoder_embed_dim,
- hidden_size=args.encoder_hidden_size,
- num_layers=args.encoder_layers,
- dropout_in=args.encoder_dropout_in,
- dropout_out=args.encoder_dropout_out,
- bidirectional=args.encoder_bidirectional,
- pretrained_embed=pretrained_encoder_embed,
- max_source_positions=max_source_positions,
- )
- decoder = LSTMDecoder(
- dictionary=task.target_dictionary,
- embed_dim=args.decoder_embed_dim,
- hidden_size=args.decoder_hidden_size,
- out_embed_dim=args.decoder_out_embed_dim,
- num_layers=args.decoder_layers,
- dropout_in=args.decoder_dropout_in,
- dropout_out=args.decoder_dropout_out,
- attention=utils.eval_bool(args.decoder_attention),
- encoder_output_units=encoder.output_units,
- pretrained_embed=pretrained_decoder_embed,
- share_input_output_embed=args.share_decoder_input_output_embed,
- adaptive_softmax_cutoff=(
- utils.eval_str_list(args.adaptive_softmax_cutoff, type=int)
- if args.criterion == "adaptive_loss"
- else None
- ),
- max_target_positions=max_target_positions,
- residuals=False,
- )
- return cls(encoder, decoder)
-
- def forward(
- self,
- src_tokens,
- src_lengths,
- prev_output_tokens,
- incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
- ):
- encoder_out = self.encoder(src_tokens, src_lengths=src_lengths)
- decoder_out = self.decoder(
- prev_output_tokens,
- encoder_out=encoder_out,
- incremental_state=incremental_state,
- )
- return decoder_out
-
-
-class LSTMEncoder(FairseqEncoder):
- """LSTM encoder."""
-
- def __init__(
- self,
- dictionary,
- embed_dim=512,
- hidden_size=512,
- num_layers=1,
- dropout_in=0.1,
- dropout_out=0.1,
- bidirectional=False,
- left_pad=True,
- pretrained_embed=None,
- padding_idx=None,
- max_source_positions=DEFAULT_MAX_SOURCE_POSITIONS,
- ):
- super().__init__(dictionary)
- self.num_layers = num_layers
- self.dropout_in_module = FairseqDropout(
- dropout_in*1.0, module_name=self.__class__.__name__
- )
- self.dropout_out_module = FairseqDropout(
- dropout_out*1.0, module_name=self.__class__.__name__
- )
- self.bidirectional = bidirectional
- self.hidden_size = hidden_size
- self.max_source_positions = max_source_positions
-
- num_embeddings = len(dictionary)
- self.padding_idx = padding_idx if padding_idx is not None else dictionary.pad()
- if pretrained_embed is None:
- self.embed_tokens = Embedding(num_embeddings, embed_dim, self.padding_idx)
- else:
- self.embed_tokens = pretrained_embed
-
- self.lstm = LSTM(
- input_size=embed_dim,
- hidden_size=hidden_size,
- num_layers=num_layers,
- dropout=self.dropout_out_module.p if num_layers > 1 else 0.0,
- bidirectional=bidirectional,
- )
- self.left_pad = left_pad
-
- self.output_units = hidden_size
- if bidirectional:
- self.output_units *= 2
-
- def forward(
- self,
- src_tokens: Tensor,
- src_lengths: Tensor,
- enforce_sorted: bool = True,
- ):
- """
- Args:
- src_tokens (LongTensor): tokens in the source language of
- shape `(batch, src_len)`
- src_lengths (LongTensor): lengths of each source sentence of
- shape `(batch)`
- enforce_sorted (bool, optional): if True, `src_tokens` is
- expected to contain sequences sorted by length in a
- decreasing order. If False, this condition is not
- required. Default: True.
- """
- if self.left_pad:
- # nn.utils.rnn.pack_padded_sequence requires right-padding;
- # convert left-padding to right-padding
- src_tokens = utils.convert_padding_direction(
- src_tokens,
- torch.zeros_like(src_tokens).fill_(self.padding_idx),
- left_to_right=True,
- )
-
- bsz, seqlen = src_tokens.size()
-
- # embed tokens
- x = self.embed_tokens(src_tokens)
- x = self.dropout_in_module(x)
-
- # B x T x C -> T x B x C
- x = x.transpose(0, 1)
-
- # pack embedded source tokens into a PackedSequence
- packed_x = nn.utils.rnn.pack_padded_sequence(
- x, src_lengths.cpu(), enforce_sorted=enforce_sorted
- )
-
- # apply LSTM
- if self.bidirectional:
- state_size = 2 * self.num_layers, bsz, self.hidden_size
- else:
- state_size = self.num_layers, bsz, self.hidden_size
- h0 = x.new_zeros(*state_size)
- c0 = x.new_zeros(*state_size)
- packed_outs, (final_hiddens, final_cells) = self.lstm(packed_x, (h0, c0))
-
- # unpack outputs and apply dropout
- x, _ = nn.utils.rnn.pad_packed_sequence(
- packed_outs, padding_value=self.padding_idx * 1.0
- )
- x = self.dropout_out_module(x)
- assert list(x.size()) == [seqlen, bsz, self.output_units]
-
- if self.bidirectional:
- final_hiddens = self.combine_bidir(final_hiddens, bsz)
- final_cells = self.combine_bidir(final_cells, bsz)
-
- encoder_padding_mask = src_tokens.eq(self.padding_idx).t()
-
- return tuple(
- (
- x, # seq_len x batch x hidden
- final_hiddens, # num_layers x batch x num_directions*hidden
- final_cells, # num_layers x batch x num_directions*hidden
- encoder_padding_mask, # seq_len x batch
- )
- )
-
- def combine_bidir(self, outs, bsz: int):
- out = outs.view(self.num_layers, 2, bsz, -1).transpose(1, 2).contiguous()
- return out.view(self.num_layers, bsz, -1)
-
- def reorder_encoder_out(self, encoder_out: Tuple[Tensor, Tensor, Tensor, Tensor], new_order):
- return tuple(
- (
- encoder_out[0].index_select(1, new_order),
- encoder_out[1].index_select(1, new_order),
- encoder_out[2].index_select(1, new_order),
- encoder_out[3].index_select(1, new_order),
- )
- )
-
- def max_positions(self):
- """Maximum input length supported by the encoder."""
- return self.max_source_positions
-
-
-class AttentionLayer(nn.Module):
- def __init__(self, input_embed_dim, source_embed_dim, output_embed_dim, bias=False):
- super().__init__()
-
- self.input_proj = Linear(input_embed_dim, source_embed_dim, bias=bias)
- self.output_proj = Linear(
- input_embed_dim + source_embed_dim, output_embed_dim, bias=bias
- )
-
- def forward(self, input, source_hids, encoder_padding_mask):
- # input: bsz x input_embed_dim
- # source_hids: srclen x bsz x source_embed_dim
-
- # x: bsz x source_embed_dim
- x = self.input_proj(input)
-
- # compute attention
- attn_scores = (source_hids * x.unsqueeze(0)).sum(dim=2)
-
- # don't attend over padding
- if encoder_padding_mask is not None:
- attn_scores = (
- attn_scores.float()
- .masked_fill_(encoder_padding_mask, float("-inf"))
- .type_as(attn_scores)
- ) # FP16 support: cast to float and back
-
- attn_scores = F.softmax(attn_scores, dim=0) # srclen x bsz
-
- # sum weighted sources
- x = (attn_scores.unsqueeze(2) * source_hids).sum(dim=0)
-
- x = torch.tanh(self.output_proj(torch.cat((x, input), dim=1)))
- return x, attn_scores
-
-
-class LSTMDecoder(FairseqIncrementalDecoder):
- """LSTM decoder."""
-
- def __init__(
- self,
- dictionary,
- embed_dim=512,
- hidden_size=512,
- out_embed_dim=512,
- num_layers=1,
- dropout_in=0.1,
- dropout_out=0.1,
- attention=True,
- encoder_output_units=512,
- pretrained_embed=None,
- share_input_output_embed=False,
- adaptive_softmax_cutoff=None,
- max_target_positions=DEFAULT_MAX_TARGET_POSITIONS,
- residuals=False,
- ):
- super().__init__(dictionary)
- self.dropout_in_module = FairseqDropout(
- dropout_in*1.0, module_name=self.__class__.__name__
- )
- self.dropout_out_module = FairseqDropout(
- dropout_out*1.0, module_name=self.__class__.__name__
- )
- self.hidden_size = hidden_size
- self.share_input_output_embed = share_input_output_embed
- self.need_attn = True
- self.max_target_positions = max_target_positions
- self.residuals = residuals
- self.num_layers = num_layers
-
- self.adaptive_softmax = None
- num_embeddings = len(dictionary)
- padding_idx = dictionary.pad()
- if pretrained_embed is None:
- self.embed_tokens = Embedding(num_embeddings, embed_dim, padding_idx)
- else:
- self.embed_tokens = pretrained_embed
-
- self.encoder_output_units = encoder_output_units
- if encoder_output_units != hidden_size and encoder_output_units != 0:
- self.encoder_hidden_proj = Linear(encoder_output_units, hidden_size)
- self.encoder_cell_proj = Linear(encoder_output_units, hidden_size)
- else:
- self.encoder_hidden_proj = self.encoder_cell_proj = None
-
- # disable input feeding if there is no encoder
- # input feeding is described in arxiv.org/abs/1508.04025
- input_feed_size = 0 if encoder_output_units == 0 else hidden_size
- self.layers = nn.ModuleList(
- [
- LSTMCell(
- input_size=input_feed_size + embed_dim
- if layer == 0
- else hidden_size,
- hidden_size=hidden_size,
- )
- for layer in range(num_layers)
- ]
- )
-
- if attention:
- # TODO make bias configurable
- self.attention = AttentionLayer(
- hidden_size, encoder_output_units, hidden_size, bias=False
- )
- else:
- self.attention = None
-
- if hidden_size != out_embed_dim:
- self.additional_fc = Linear(hidden_size, out_embed_dim)
-
- if adaptive_softmax_cutoff is not None:
- # setting adaptive_softmax dropout to dropout_out for now but can be redefined
- self.adaptive_softmax = AdaptiveSoftmax(
- num_embeddings,
- hidden_size,
- adaptive_softmax_cutoff,
- dropout=dropout_out,
- )
- elif not self.share_input_output_embed:
- self.fc_out = Linear(out_embed_dim, num_embeddings, dropout=dropout_out)
-
- def forward(
- self,
- prev_output_tokens,
- encoder_out: Optional[Tuple[Tensor, Tensor, Tensor, Tensor]] = None,
- incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
- src_lengths: Optional[Tensor] = None,
- ):
- x, attn_scores = self.extract_features(
- prev_output_tokens, encoder_out, incremental_state
- )
- return self.output_layer(x), attn_scores
-
- def extract_features(
- self,
- prev_output_tokens,
- encoder_out: Optional[Tuple[Tensor, Tensor, Tensor, Tensor]] = None,
- incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
- ):
- """
- Similar to *forward* but only return features.
- """
- # get outputs from encoder
- if encoder_out is not None:
- encoder_outs = encoder_out[0]
- encoder_hiddens = encoder_out[1]
- encoder_cells = encoder_out[2]
- encoder_padding_mask = encoder_out[3]
- else:
- encoder_outs = torch.empty(0)
- encoder_hiddens = torch.empty(0)
- encoder_cells = torch.empty(0)
- encoder_padding_mask = torch.empty(0)
- srclen = encoder_outs.size(0)
-
- if incremental_state is not None and len(incremental_state) > 0:
- prev_output_tokens = prev_output_tokens[:, -1:]
-
- bsz, seqlen = prev_output_tokens.size()
-
- # embed tokens
- x = self.embed_tokens(prev_output_tokens)
- x = self.dropout_in_module(x)
-
- # B x T x C -> T x B x C
- x = x.transpose(0, 1)
-
- # initialize previous states (or get from cache during incremental generation)
- if incremental_state is not None and len(incremental_state) > 0:
- prev_hiddens, prev_cells, input_feed = self.get_cached_state(
- incremental_state
- )
- elif encoder_out is not None:
- # setup recurrent cells
- prev_hiddens = [encoder_hiddens[i] for i in range(self.num_layers)]
- prev_cells = [encoder_cells[i] for i in range(self.num_layers)]
- if self.encoder_hidden_proj is not None:
- prev_hiddens = [self.encoder_hidden_proj(y) for y in prev_hiddens]
- prev_cells = [self.encoder_cell_proj(y) for y in prev_cells]
- input_feed = x.new_zeros(bsz, self.hidden_size)
- else:
- # setup zero cells, since there is no encoder
- zero_state = x.new_zeros(bsz, self.hidden_size)
- prev_hiddens = [zero_state for i in range(self.num_layers)]
- prev_cells = [zero_state for i in range(self.num_layers)]
- input_feed = None
-
- assert (
- srclen > 0 or self.attention is None
- ), "attention is not supported if there are no encoder outputs"
- attn_scores: Optional[Tensor] = (
- x.new_zeros(srclen, seqlen, bsz) if self.attention is not None else None
- )
- outs = []
- for j in range(seqlen):
- # input feeding: concatenate context vector from previous time step
- if input_feed is not None:
- input = torch.cat((x[j, :, :], input_feed), dim=1)
- else:
- input = x[j]
-
- for i, rnn in enumerate(self.layers):
- # recurrent cell
- hidden, cell = rnn(input, (prev_hiddens[i], prev_cells[i]))
-
- # hidden state becomes the input to the next layer
- input = self.dropout_out_module(hidden)
- if self.residuals:
- input = input + prev_hiddens[i]
-
- # save state for next time step
- prev_hiddens[i] = hidden
- prev_cells[i] = cell
-
- # apply attention using the last layer's hidden state
- if self.attention is not None:
- assert attn_scores is not None
- out, attn_scores[:, j, :] = self.attention(
- hidden, encoder_outs, encoder_padding_mask
- )
- else:
- out = hidden
- out = self.dropout_out_module(out)
-
- # input feeding
- if input_feed is not None:
- input_feed = out
-
- # save final output
- outs.append(out)
-
- # Stack all the necessary tensors together and store
- prev_hiddens_tensor = torch.stack(prev_hiddens)
- prev_cells_tensor = torch.stack(prev_cells)
- cache_state = torch.jit.annotate(
- Dict[str, Optional[Tensor]],
- {
- "prev_hiddens": prev_hiddens_tensor,
- "prev_cells": prev_cells_tensor,
- "input_feed": input_feed,
- },
- )
- self.set_incremental_state(incremental_state, "cached_state", cache_state)
-
- # collect outputs across time steps
- x = torch.cat(outs, dim=0).view(seqlen, bsz, self.hidden_size)
-
- # T x B x C -> B x T x C
- x = x.transpose(1, 0)
-
- if hasattr(self, "additional_fc") and self.adaptive_softmax is None:
- x = self.additional_fc(x)
- x = self.dropout_out_module(x)
- # srclen x tgtlen x bsz -> bsz x tgtlen x srclen
- if not self.training and self.need_attn and self.attention is not None:
- assert attn_scores is not None
- attn_scores = attn_scores.transpose(0, 2)
- else:
- attn_scores = None
- return x, attn_scores
-
- def output_layer(self, x):
- """Project features to the vocabulary size."""
- if self.adaptive_softmax is None:
- if self.share_input_output_embed:
- x = F.linear(x, self.embed_tokens.weight)
- else:
- x = self.fc_out(x)
- return x
-
- def get_cached_state(
- self,
- incremental_state: Dict[str, Dict[str, Optional[Tensor]]],
- ) -> Tuple[List[Tensor], List[Tensor], Optional[Tensor]]:
- cached_state = self.get_incremental_state(incremental_state, "cached_state")
- assert cached_state is not None
- prev_hiddens_ = cached_state["prev_hiddens"]
- assert prev_hiddens_ is not None
- prev_cells_ = cached_state["prev_cells"]
- assert prev_cells_ is not None
- prev_hiddens = [prev_hiddens_[i] for i in range(self.num_layers)]
- prev_cells = [prev_cells_[j] for j in range(self.num_layers)]
- input_feed = cached_state[
- "input_feed"
- ] # can be None for decoder-only language models
- return prev_hiddens, prev_cells, input_feed
-
- def reorder_incremental_state(
- self,
- incremental_state: Dict[str, Dict[str, Optional[Tensor]]],
- new_order: Tensor,
- ):
- if incremental_state is None or len(incremental_state) == 0:
- return
- prev_hiddens, prev_cells, input_feed = self.get_cached_state(incremental_state)
- prev_hiddens = [p.index_select(0, new_order) for p in prev_hiddens]
- prev_cells = [p.index_select(0, new_order) for p in prev_cells]
- if input_feed is not None:
- input_feed = input_feed.index_select(0, new_order)
- cached_state_new = torch.jit.annotate(
- Dict[str, Optional[Tensor]],
- {
- "prev_hiddens": torch.stack(prev_hiddens),
- "prev_cells": torch.stack(prev_cells),
- "input_feed": input_feed,
- },
- )
- self.set_incremental_state(incremental_state, "cached_state", cached_state_new),
- return
-
- def max_positions(self):
- """Maximum output length supported by the decoder."""
- return self.max_target_positions
-
- def make_generation_fast_(self, need_attn=False, **kwargs):
- self.need_attn = need_attn
-
-
-def Embedding(num_embeddings, embedding_dim, padding_idx):
- m = nn.Embedding(num_embeddings, embedding_dim, padding_idx=padding_idx)
- nn.init.uniform_(m.weight, -0.1, 0.1)
- nn.init.constant_(m.weight[padding_idx], 0)
- return m
-
-
-def LSTM(input_size, hidden_size, **kwargs):
- m = nn.LSTM(input_size, hidden_size, **kwargs)
- for name, param in m.named_parameters():
- if "weight" in name or "bias" in name:
- param.data.uniform_(-0.1, 0.1)
- return m
-
-
-def LSTMCell(input_size, hidden_size, **kwargs):
- m = nn.LSTMCell(input_size, hidden_size, **kwargs)
- for name, param in m.named_parameters():
- if "weight" in name or "bias" in name:
- param.data.uniform_(-0.1, 0.1)
- return m
-
-
-def Linear(in_features, out_features, bias=True, dropout=0.0):
- """Linear layer (input: N x T x C)"""
- m = nn.Linear(in_features, out_features, bias=bias)
- m.weight.data.uniform_(-0.1, 0.1)
- if bias:
- m.bias.data.uniform_(-0.1, 0.1)
- return m
-
-
-@register_model_architecture("lstm", "lstm")
-def base_architecture(args):
- args.dropout = getattr(args, "dropout", 0.1)
- args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 512)
- args.encoder_embed_path = getattr(args, "encoder_embed_path", None)
- args.encoder_freeze_embed = getattr(args, "encoder_freeze_embed", False)
- args.encoder_hidden_size = getattr(
- args, "encoder_hidden_size", args.encoder_embed_dim
- )
- args.encoder_layers = getattr(args, "encoder_layers", 1)
- args.encoder_bidirectional = getattr(args, "encoder_bidirectional", False)
- args.encoder_dropout_in = getattr(args, "encoder_dropout_in", args.dropout)
- args.encoder_dropout_out = getattr(args, "encoder_dropout_out", args.dropout)
- args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 512)
- args.decoder_embed_path = getattr(args, "decoder_embed_path", None)
- args.decoder_freeze_embed = getattr(args, "decoder_freeze_embed", False)
- args.decoder_hidden_size = getattr(
- args, "decoder_hidden_size", args.decoder_embed_dim
- )
- args.decoder_layers = getattr(args, "decoder_layers", 1)
- args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 512)
- args.decoder_attention = getattr(args, "decoder_attention", "1")
- args.decoder_dropout_in = getattr(args, "decoder_dropout_in", args.dropout)
- args.decoder_dropout_out = getattr(args, "decoder_dropout_out", args.dropout)
- args.share_decoder_input_output_embed = getattr(
- args, "share_decoder_input_output_embed", False
- )
- args.share_all_embeddings = getattr(args, "share_all_embeddings", False)
- args.adaptive_softmax_cutoff = getattr(
- args, "adaptive_softmax_cutoff", "10000,50000,200000"
- )
-
-
-@register_model_architecture("lstm", "lstm_wiseman_iwslt_de_en")
-def lstm_wiseman_iwslt_de_en(args):
- args.dropout = getattr(args, "dropout", 0.1)
- args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 256)
- args.encoder_dropout_in = getattr(args, "encoder_dropout_in", 0)
- args.encoder_dropout_out = getattr(args, "encoder_dropout_out", 0)
- args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 256)
- args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 256)
- args.decoder_dropout_in = getattr(args, "decoder_dropout_in", 0)
- args.decoder_dropout_out = getattr(args, "decoder_dropout_out", args.dropout)
- base_architecture(args)
-
-
-@register_model_architecture("lstm", "lstm_luong_wmt_en_de")
-def lstm_luong_wmt_en_de(args):
- args.encoder_embed_dim = getattr(args, "encoder_embed_dim", 1000)
- args.encoder_layers = getattr(args, "encoder_layers", 4)
- args.encoder_dropout_out = getattr(args, "encoder_dropout_out", 0)
- args.decoder_embed_dim = getattr(args, "decoder_embed_dim", 1000)
- args.decoder_layers = getattr(args, "decoder_layers", 4)
- args.decoder_out_embed_dim = getattr(args, "decoder_out_embed_dim", 1000)
- args.decoder_dropout_out = getattr(args, "decoder_dropout_out", 0)
- base_architecture(args)
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/gottbert/README.md b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/gottbert/README.md
deleted file mode 100644
index 1d58feb279a4a50222290546c3bb285d3cea98e6..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/gottbert/README.md
+++ /dev/null
@@ -1,64 +0,0 @@
-# GottBERT: a pure German language model
-
-## Introduction
-
-[GottBERT](http://arxiv.org/abs/2012.02110) is a pretrained language model trained on 145GB of German text based on RoBERTa.
-
-## Example usage
-
-### fairseq
-##### Load GottBERT from torch.hub (PyTorch >= 1.1):
-```python
-import torch
-gottbert = torch.hub.load('pytorch/fairseq', 'gottbert-base')
-gottbert.eval() # disable dropout (or leave in train mode to finetune)
-```
-
-##### Load GottBERT (for PyTorch 1.0 or custom models):
-```python
-# Download gottbert model
-wget https://dl.gottbert.de/fairseq/models/gottbert-base.tar.gz
-tar -xzvf gottbert.tar.gz
-
-# Load the model in fairseq
-from fairseq.models.roberta import GottbertModel
-gottbert = GottbertModel.from_pretrained('/path/to/gottbert')
-gottbert.eval() # disable dropout (or leave in train mode to finetune)
-```
-
-##### Filling masks:
-```python
-masked_line = 'Gott ist ! :)'
-gottbert.fill_mask(masked_line, topk=3)
-# [('Gott ist gut ! :)', 0.3642110526561737, ' gut'),
-# ('Gott ist überall ! :)', 0.06009674072265625, ' überall'),
-# ('Gott ist großartig ! :)', 0.0370681993663311, ' großartig')]
-```
-
-##### Extract features from GottBERT
-
-```python
-# Extract the last layer's features
-line = "Der erste Schluck aus dem Becher der Naturwissenschaft macht atheistisch , aber auf dem Grunde des Bechers wartet Gott !"
-tokens = gottbert.encode(line)
-last_layer_features = gottbert.extract_features(tokens)
-assert last_layer_features.size() == torch.Size([1, 27, 768])
-
-# Extract all layer's features (layer 0 is the embedding layer)
-all_layers = gottbert.extract_features(tokens, return_all_hiddens=True)
-assert len(all_layers) == 13
-assert torch.all(all_layers[-1] == last_layer_features)
-```
-## Citation
-If you use our work, please cite:
-
-```bibtex
-@misc{scheible2020gottbert,
- title={GottBERT: a pure German Language Model},
- author={Raphael Scheible and Fabian Thomczyk and Patric Tippmann and Victor Jaravine and Martin Boeker},
- year={2020},
- eprint={2012.02110},
- archivePrefix={arXiv},
- primaryClass={cs.CL}
-}
-```
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/fairseq/data/huffman/__init__.py b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/fairseq/data/huffman/__init__.py
deleted file mode 100644
index 9b61fafadba28f65fe78a28b2099368b83cfcf41..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/fairseq/data/huffman/__init__.py
+++ /dev/null
@@ -1,21 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from .huffman_coder import HuffmanCodeBuilder, HuffmanCoder
-from .huffman_mmap_indexed_dataset import (
- HuffmanMMapIndex,
- HuffmanMMapIndexedDataset,
- HuffmanMMapIndexedDatasetBuilder,
- vocab_file_path,
-)
-
-__all__ = [
- "HuffmanCoder",
- "HuffmanCodeBuilder",
- "HuffmanMMapIndexedDatasetBuilder",
- "HuffmanMMapIndexedDataset",
- "HuffmanMMapIndex",
- "vocab_file_path",
-]
diff --git a/spaces/OFA-Sys/OFA-Visual_Grounding/fairseq/examples/bart/README.glue.md b/spaces/OFA-Sys/OFA-Visual_Grounding/fairseq/examples/bart/README.glue.md
deleted file mode 100644
index a010934e1e6dec491eb1c704ec02ba7405760510..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Visual_Grounding/fairseq/examples/bart/README.glue.md
+++ /dev/null
@@ -1,99 +0,0 @@
-# Fine-tuning BART on GLUE tasks
-
-### 1) Download the data from GLUE website (https://gluebenchmark.com/tasks) using following commands:
-```bash
-wget https://gist.githubusercontent.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e/raw/17b8dd0d724281ed7c3b2aeeda662b92809aadd5/download_glue_data.py
-python download_glue_data.py --data_dir glue_data --tasks all
-```
-
-### 2) Preprocess GLUE task data (same as RoBERTa):
-```bash
-./examples/roberta/preprocess_GLUE_tasks.sh glue_data
-```
-`glue_task_name` is one of the following:
-`{ALL, QQP, MNLI, QNLI, MRPC, RTE, STS-B, SST-2, CoLA}`
-Use `ALL` for preprocessing all the glue tasks.
-
-### 3) Fine-tuning on GLUE task:
-Example fine-tuning cmd for `RTE` task
-```bash
-TOTAL_NUM_UPDATES=2036 # 10 epochs through RTE for bsz 16
-WARMUP_UPDATES=61 # 6 percent of the number of updates
-LR=1e-05 # Peak LR for polynomial LR scheduler.
-NUM_CLASSES=2
-MAX_SENTENCES=16 # Batch size.
-BART_PATH=/path/to/bart/model.pt
-
-CUDA_VISIBLE_DEVICES=0,1 fairseq-train RTE-bin/ \
- --restore-file $BART_PATH \
- --batch-size $MAX_SENTENCES \
- --max-tokens 4400 \
- --task sentence_prediction \
- --add-prev-output-tokens \
- --layernorm-embedding \
- --share-all-embeddings \
- --share-decoder-input-output-embed \
- --reset-optimizer --reset-dataloader --reset-meters \
- --required-batch-size-multiple 1 \
- --init-token 0 \
- --arch bart_large \
- --criterion sentence_prediction \
- --num-classes $NUM_CLASSES \
- --dropout 0.1 --attention-dropout 0.1 \
- --weight-decay 0.01 --optimizer adam --adam-betas "(0.9, 0.98)" --adam-eps 1e-08 \
- --clip-norm 0.0 \
- --lr-scheduler polynomial_decay --lr $LR --total-num-update $TOTAL_NUM_UPDATES --warmup-updates $WARMUP_UPDATES \
- --fp16 --fp16-init-scale 4 --threshold-loss-scale 1 --fp16-scale-window 128 \
- --max-epoch 10 \
- --find-unused-parameters \
- --best-checkpoint-metric accuracy --maximize-best-checkpoint-metric;
-```
-
-For each of the GLUE task, you will need to use following cmd-line arguments:
-
-Model | MNLI | QNLI | QQP | RTE | SST-2 | MRPC | CoLA | STS-B
----|---|---|---|---|---|---|---|---
-`--num-classes` | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 1
-`--lr` | 5e-6 | 1e-5 | 1e-5 | 1e-5 | 5e-6 | 2e-5 | 2e-5 | 2e-5
-`bsz` | 128 | 32 | 32 | 32 | 128 | 64 | 64 | 32
-`--total-num-update` | 30968 | 33112 | 113272 | 1018 | 5233 | 1148 | 1334 | 1799
-`--warmup-updates` | 1858 | 1986 | 6796 | 61 | 314 | 68 | 80 | 107
-
-For `STS-B` additionally add `--regression-target --best-checkpoint-metric loss` and remove `--maximize-best-checkpoint-metric`.
-
-**Note:**
-
-a) `--total-num-updates` is used by `--polynomial_decay` scheduler and is calculated for `--max-epoch=10` and `--batch-size=32/64/128` depending on the task.
-
-b) Above cmd-args and hyperparams are tested on Nvidia `V100` GPU with `32gb` of memory for each task. Depending on the GPU memory resources available to you, you can use increase `--update-freq` and reduce `--batch-size`.
-
-### Inference on GLUE task
-After training the model as mentioned in previous step, you can perform inference with checkpoints in `checkpoints/` directory using following python code snippet:
-
-```python
-from fairseq.models.bart import BARTModel
-
-bart = BARTModel.from_pretrained(
- 'checkpoints/',
- checkpoint_file='checkpoint_best.pt',
- data_name_or_path='RTE-bin'
-)
-
-label_fn = lambda label: bart.task.label_dictionary.string(
- [label + bart.task.label_dictionary.nspecial]
-)
-ncorrect, nsamples = 0, 0
-bart.cuda()
-bart.eval()
-with open('glue_data/RTE/dev.tsv') as fin:
- fin.readline()
- for index, line in enumerate(fin):
- tokens = line.strip().split('\t')
- sent1, sent2, target = tokens[1], tokens[2], tokens[3]
- tokens = bart.encode(sent1, sent2)
- prediction = bart.predict('sentence_classification_head', tokens).argmax().item()
- prediction_label = label_fn(prediction)
- ncorrect += int(prediction_label == target)
- nsamples += 1
-print('| Accuracy: ', float(ncorrect)/float(nsamples))
-```
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/fairseq/models/ema/__init__.py b/spaces/OFA-Sys/OFA-vqa/fairseq/fairseq/models/ema/__init__.py
deleted file mode 100644
index 503ceaa609b092e48bd32a0031f4e2ffb875483f..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/fairseq/models/ema/__init__.py
+++ /dev/null
@@ -1,20 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import importlib
-import os
-
-from .ema import EMA
-
-
-def build_ema(model, cfg, device):
- return EMA(model, cfg, device)
-
-
-# automatically import any Python files in the models/ema/ directory
-for file in sorted(os.listdir(os.path.dirname(__file__))):
- if file.endswith(".py") and not file.startswith("_"):
- file_name = file[: file.find(".py")]
- importlib.import_module("fairseq.models.ema." + file_name)
diff --git a/spaces/OpenGVLab/InternGPT/iGPT/models/grit_src/third_party/CenterNet2/detectron2/engine/defaults.py b/spaces/OpenGVLab/InternGPT/iGPT/models/grit_src/third_party/CenterNet2/detectron2/engine/defaults.py
deleted file mode 100644
index cc3faa15550a348dbe1445f7c7c91b26ba59d01b..0000000000000000000000000000000000000000
--- a/spaces/OpenGVLab/InternGPT/iGPT/models/grit_src/third_party/CenterNet2/detectron2/engine/defaults.py
+++ /dev/null
@@ -1,715 +0,0 @@
-# -*- coding: utf-8 -*-
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-"""
-This file contains components with some default boilerplate logic user may need
-in training / testing. They will not work for everyone, but many users may find them useful.
-
-The behavior of functions/classes in this file is subject to change,
-since they are meant to represent the "common default behavior" people need in their projects.
-"""
-
-import argparse
-import logging
-import os
-import sys
-import weakref
-from collections import OrderedDict
-from typing import Optional
-import torch
-from fvcore.nn.precise_bn import get_bn_modules
-from omegaconf import OmegaConf
-from torch.nn.parallel import DistributedDataParallel
-
-import detectron2.data.transforms as T
-from detectron2.checkpoint import DetectionCheckpointer
-from detectron2.config import CfgNode, LazyConfig
-from detectron2.data import (
- MetadataCatalog,
- build_detection_test_loader,
- build_detection_train_loader,
-)
-from detectron2.evaluation import (
- DatasetEvaluator,
- inference_on_dataset,
- print_csv_format,
- verify_results,
-)
-from detectron2.modeling import build_model
-from detectron2.solver import build_lr_scheduler, build_optimizer
-from detectron2.utils import comm
-from detectron2.utils.collect_env import collect_env_info
-from detectron2.utils.env import seed_all_rng
-from detectron2.utils.events import CommonMetricPrinter, JSONWriter, TensorboardXWriter
-from detectron2.utils.file_io import PathManager
-from detectron2.utils.logger import setup_logger
-
-from . import hooks
-from .train_loop import AMPTrainer, SimpleTrainer, TrainerBase
-
-__all__ = [
- "create_ddp_model",
- "default_argument_parser",
- "default_setup",
- "default_writers",
- "DefaultPredictor",
- "DefaultTrainer",
-]
-
-
-def create_ddp_model(model, *, fp16_compression=False, **kwargs):
- """
- Create a DistributedDataParallel model if there are >1 processes.
-
- Args:
- model: a torch.nn.Module
- fp16_compression: add fp16 compression hooks to the ddp object.
- See more at https://pytorch.org/docs/stable/ddp_comm_hooks.html#torch.distributed.algorithms.ddp_comm_hooks.default_hooks.fp16_compress_hook
- kwargs: other arguments of :module:`torch.nn.parallel.DistributedDataParallel`.
- """ # noqa
- if comm.get_world_size() == 1:
- return model
- if "device_ids" not in kwargs:
- kwargs["device_ids"] = [comm.get_local_rank()]
- ddp = DistributedDataParallel(model, **kwargs)
- if fp16_compression:
- from torch.distributed.algorithms.ddp_comm_hooks import default as comm_hooks
-
- ddp.register_comm_hook(state=None, hook=comm_hooks.fp16_compress_hook)
- return ddp
-
-
-def default_argument_parser(epilog=None):
- """
- Create a parser with some common arguments used by detectron2 users.
-
- Args:
- epilog (str): epilog passed to ArgumentParser describing the usage.
-
- Returns:
- argparse.ArgumentParser:
- """
- parser = argparse.ArgumentParser(
- epilog=epilog
- or f"""
-Examples:
-
-Run on single machine:
- $ {sys.argv[0]} --num-gpus 8 --config-file cfg.yaml
-
-Change some config options:
- $ {sys.argv[0]} --config-file cfg.yaml MODEL.WEIGHTS /path/to/weight.pth SOLVER.BASE_LR 0.001
-
-Run on multiple machines:
- (machine0)$ {sys.argv[0]} --machine-rank 0 --num-machines 2 --dist-url [--other-flags]
- (machine1)$ {sys.argv[0]} --machine-rank 1 --num-machines 2 --dist-url [--other-flags]
-""",
- formatter_class=argparse.RawDescriptionHelpFormatter,
- )
- parser.add_argument("--config-file", default="", metavar="FILE", help="path to config file")
- parser.add_argument(
- "--resume",
- action="store_true",
- help="Whether to attempt to resume from the checkpoint directory. "
- "See documentation of `DefaultTrainer.resume_or_load()` for what it means.",
- )
- parser.add_argument("--eval-only", action="store_true", help="perform evaluation only")
- parser.add_argument("--num-gpus", type=int, default=1, help="number of gpus *per machine*")
- parser.add_argument("--num-machines", type=int, default=1, help="total number of machines")
- parser.add_argument(
- "--machine-rank", type=int, default=0, help="the rank of this machine (unique per machine)"
- )
-
- # PyTorch still may leave orphan processes in multi-gpu training.
- # Therefore we use a deterministic way to obtain port,
- # so that users are aware of orphan processes by seeing the port occupied.
- port = 2 ** 15 + 2 ** 14 + hash(os.getuid() if sys.platform != "win32" else 1) % 2 ** 14
- parser.add_argument(
- "--dist-url",
- default="tcp://127.0.0.1:{}".format(port),
- help="initialization URL for pytorch distributed backend. See "
- "https://pytorch.org/docs/stable/distributed.html for details.",
- )
- parser.add_argument(
- "opts",
- help="""
-Modify config options at the end of the command. For Yacs configs, use
-space-separated "PATH.KEY VALUE" pairs.
-For python-based LazyConfig, use "path.key=value".
- """.strip(),
- default=None,
- nargs=argparse.REMAINDER,
- )
- return parser
-
-
-def _try_get_key(cfg, *keys, default=None):
- """
- Try select keys from cfg until the first key that exists. Otherwise return default.
- """
- if isinstance(cfg, CfgNode):
- cfg = OmegaConf.create(cfg.dump())
- for k in keys:
- none = object()
- p = OmegaConf.select(cfg, k, default=none)
- if p is not none:
- return p
- return default
-
-
-def _highlight(code, filename):
- try:
- import pygments
- except ImportError:
- return code
-
- from pygments.lexers import Python3Lexer, YamlLexer
- from pygments.formatters import Terminal256Formatter
-
- lexer = Python3Lexer() if filename.endswith(".py") else YamlLexer()
- code = pygments.highlight(code, lexer, Terminal256Formatter(style="monokai"))
- return code
-
-
-def default_setup(cfg, args):
- """
- Perform some basic common setups at the beginning of a job, including:
-
- 1. Set up the detectron2 logger
- 2. Log basic information about environment, cmdline arguments, and config
- 3. Backup the config to the output directory
-
- Args:
- cfg (CfgNode or omegaconf.DictConfig): the full config to be used
- args (argparse.NameSpace): the command line arguments to be logged
- """
- output_dir = _try_get_key(cfg, "OUTPUT_DIR", "output_dir", "train.output_dir")
- if comm.is_main_process() and output_dir:
- PathManager.mkdirs(output_dir)
-
- rank = comm.get_rank()
- setup_logger(output_dir, distributed_rank=rank, name="fvcore")
- logger = setup_logger(output_dir, distributed_rank=rank)
-
- logger.info("Rank of current process: {}. World size: {}".format(rank, comm.get_world_size()))
- logger.info("Environment info:\n" + collect_env_info())
-
- logger.info("Command line arguments: " + str(args))
- if hasattr(args, "config_file") and args.config_file != "":
- logger.info(
- "Contents of args.config_file={}:\n{}".format(
- args.config_file,
- _highlight(PathManager.open(args.config_file, "r").read(), args.config_file),
- )
- )
-
- if comm.is_main_process() and output_dir:
- # Note: some of our scripts may expect the existence of
- # config.yaml in output directory
- path = os.path.join(output_dir, "config.yaml")
- if isinstance(cfg, CfgNode):
- logger.info("Running with full config:\n{}".format(_highlight(cfg.dump(), ".yaml")))
- with PathManager.open(path, "w") as f:
- f.write(cfg.dump())
- else:
- LazyConfig.save(cfg, path)
- logger.info("Full config saved to {}".format(path))
-
- # make sure each worker has a different, yet deterministic seed if specified
- seed = _try_get_key(cfg, "SEED", "train.seed", default=-1)
- seed_all_rng(None if seed < 0 else seed + rank)
-
- # cudnn benchmark has large overhead. It shouldn't be used considering the small size of
- # typical validation set.
- if not (hasattr(args, "eval_only") and args.eval_only):
- torch.backends.cudnn.benchmark = _try_get_key(
- cfg, "CUDNN_BENCHMARK", "train.cudnn_benchmark", default=False
- )
-
-
-def default_writers(output_dir: str, max_iter: Optional[int] = None):
- """
- Build a list of :class:`EventWriter` to be used.
- It now consists of a :class:`CommonMetricPrinter`,
- :class:`TensorboardXWriter` and :class:`JSONWriter`.
-
- Args:
- output_dir: directory to store JSON metrics and tensorboard events
- max_iter: the total number of iterations
-
- Returns:
- list[EventWriter]: a list of :class:`EventWriter` objects.
- """
- PathManager.mkdirs(output_dir)
- return [
- # It may not always print what you want to see, since it prints "common" metrics only.
- CommonMetricPrinter(max_iter),
- JSONWriter(os.path.join(output_dir, "metrics.json")),
- TensorboardXWriter(output_dir),
- ]
-
-
-class DefaultPredictor:
- """
- Create a simple end-to-end predictor with the given config that runs on
- single device for a single input image.
-
- Compared to using the model directly, this class does the following additions:
-
- 1. Load checkpoint from `cfg.MODEL.WEIGHTS`.
- 2. Always take BGR image as the input and apply conversion defined by `cfg.INPUT.FORMAT`.
- 3. Apply resizing defined by `cfg.INPUT.{MIN,MAX}_SIZE_TEST`.
- 4. Take one input image and produce a single output, instead of a batch.
-
- This is meant for simple demo purposes, so it does the above steps automatically.
- This is not meant for benchmarks or running complicated inference logic.
- If you'd like to do anything more complicated, please refer to its source code as
- examples to build and use the model manually.
-
- Attributes:
- metadata (Metadata): the metadata of the underlying dataset, obtained from
- cfg.DATASETS.TEST.
-
- Examples:
- ::
- pred = DefaultPredictor(cfg)
- inputs = cv2.imread("input.jpg")
- outputs = pred(inputs)
- """
-
- def __init__(self, cfg):
- self.cfg = cfg.clone() # cfg can be modified by model
- self.model = build_model(self.cfg)
- self.model.eval()
- if len(cfg.DATASETS.TEST):
- self.metadata = MetadataCatalog.get(cfg.DATASETS.TEST[0])
-
- checkpointer = DetectionCheckpointer(self.model)
- checkpointer.load(cfg.MODEL.WEIGHTS)
-
- self.aug = T.ResizeShortestEdge(
- [cfg.INPUT.MIN_SIZE_TEST, cfg.INPUT.MIN_SIZE_TEST], cfg.INPUT.MAX_SIZE_TEST
- )
-
- self.input_format = cfg.INPUT.FORMAT
- assert self.input_format in ["RGB", "BGR"], self.input_format
-
- def __call__(self, original_image):
- """
- Args:
- original_image (np.ndarray): an image of shape (H, W, C) (in BGR order).
-
- Returns:
- predictions (dict):
- the output of the model for one image only.
- See :doc:`/tutorials/models` for details about the format.
- """
- with torch.no_grad(): # https://github.com/sphinx-doc/sphinx/issues/4258
- # Apply pre-processing to image.
- if self.input_format == "RGB":
- # whether the model expects BGR inputs or RGB
- original_image = original_image[:, :, ::-1]
- height, width = original_image.shape[:2]
- image = self.aug.get_transform(original_image).apply_image(original_image)
- image = torch.as_tensor(image.astype("float32").transpose(2, 0, 1))
-
- inputs = {"image": image, "height": height, "width": width}
- predictions = self.model([inputs])[0]
- return predictions
-
-
-class DefaultTrainer(TrainerBase):
- """
- A trainer with default training logic. It does the following:
-
- 1. Create a :class:`SimpleTrainer` using model, optimizer, dataloader
- defined by the given config. Create a LR scheduler defined by the config.
- 2. Load the last checkpoint or `cfg.MODEL.WEIGHTS`, if exists, when
- `resume_or_load` is called.
- 3. Register a few common hooks defined by the config.
-
- It is created to simplify the **standard model training workflow** and reduce code boilerplate
- for users who only need the standard training workflow, with standard features.
- It means this class makes *many assumptions* about your training logic that
- may easily become invalid in a new research. In fact, any assumptions beyond those made in the
- :class:`SimpleTrainer` are too much for research.
-
- The code of this class has been annotated about restrictive assumptions it makes.
- When they do not work for you, you're encouraged to:
-
- 1. Overwrite methods of this class, OR:
- 2. Use :class:`SimpleTrainer`, which only does minimal SGD training and
- nothing else. You can then add your own hooks if needed. OR:
- 3. Write your own training loop similar to `tools/plain_train_net.py`.
-
- See the :doc:`/tutorials/training` tutorials for more details.
-
- Note that the behavior of this class, like other functions/classes in
- this file, is not stable, since it is meant to represent the "common default behavior".
- It is only guaranteed to work well with the standard models and training workflow in detectron2.
- To obtain more stable behavior, write your own training logic with other public APIs.
-
- Examples:
- ::
- trainer = DefaultTrainer(cfg)
- trainer.resume_or_load() # load last checkpoint or MODEL.WEIGHTS
- trainer.train()
-
- Attributes:
- scheduler:
- checkpointer (DetectionCheckpointer):
- cfg (CfgNode):
- """
-
- def __init__(self, cfg):
- """
- Args:
- cfg (CfgNode):
- """
- super().__init__()
- logger = logging.getLogger("detectron2")
- if not logger.isEnabledFor(logging.INFO): # setup_logger is not called for d2
- setup_logger()
- cfg = DefaultTrainer.auto_scale_workers(cfg, comm.get_world_size())
-
- # Assume these objects must be constructed in this order.
- model = self.build_model(cfg)
- optimizer = self.build_optimizer(cfg, model)
- data_loader = self.build_train_loader(cfg)
-
- model = create_ddp_model(model, broadcast_buffers=False)
- self._trainer = (AMPTrainer if cfg.SOLVER.AMP.ENABLED else SimpleTrainer)(
- model, data_loader, optimizer
- )
-
- self.scheduler = self.build_lr_scheduler(cfg, optimizer)
- self.checkpointer = DetectionCheckpointer(
- # Assume you want to save checkpoints together with logs/statistics
- model,
- cfg.OUTPUT_DIR,
- trainer=weakref.proxy(self),
- )
- self.start_iter = 0
- self.max_iter = cfg.SOLVER.MAX_ITER
- self.cfg = cfg
-
- self.register_hooks(self.build_hooks())
-
- def resume_or_load(self, resume=True):
- """
- If `resume==True` and `cfg.OUTPUT_DIR` contains the last checkpoint (defined by
- a `last_checkpoint` file), resume from the file. Resuming means loading all
- available states (eg. optimizer and scheduler) and update iteration counter
- from the checkpoint. ``cfg.MODEL.WEIGHTS`` will not be used.
-
- Otherwise, this is considered as an independent training. The method will load model
- weights from the file `cfg.MODEL.WEIGHTS` (but will not load other states) and start
- from iteration 0.
-
- Args:
- resume (bool): whether to do resume or not
- """
- self.checkpointer.resume_or_load(self.cfg.MODEL.WEIGHTS, resume=resume)
- if resume and self.checkpointer.has_checkpoint():
- # The checkpoint stores the training iteration that just finished, thus we start
- # at the next iteration
- self.start_iter = self.iter + 1
-
- def build_hooks(self):
- """
- Build a list of default hooks, including timing, evaluation,
- checkpointing, lr scheduling, precise BN, writing events.
-
- Returns:
- list[HookBase]:
- """
- cfg = self.cfg.clone()
- cfg.defrost()
- cfg.DATALOADER.NUM_WORKERS = 0 # save some memory and time for PreciseBN
-
- ret = [
- hooks.IterationTimer(),
- hooks.LRScheduler(),
- hooks.PreciseBN(
- # Run at the same freq as (but before) evaluation.
- cfg.TEST.EVAL_PERIOD,
- self.model,
- # Build a new data loader to not affect training
- self.build_train_loader(cfg),
- cfg.TEST.PRECISE_BN.NUM_ITER,
- )
- if cfg.TEST.PRECISE_BN.ENABLED and get_bn_modules(self.model)
- else None,
- ]
-
- # Do PreciseBN before checkpointer, because it updates the model and need to
- # be saved by checkpointer.
- # This is not always the best: if checkpointing has a different frequency,
- # some checkpoints may have more precise statistics than others.
- if comm.is_main_process():
- ret.append(hooks.PeriodicCheckpointer(self.checkpointer, cfg.SOLVER.CHECKPOINT_PERIOD))
-
- def test_and_save_results():
- self._last_eval_results = self.test(self.cfg, self.model)
- return self._last_eval_results
-
- # Do evaluation after checkpointer, because then if it fails,
- # we can use the saved checkpoint to debug.
- ret.append(hooks.EvalHook(cfg.TEST.EVAL_PERIOD, test_and_save_results))
-
- if comm.is_main_process():
- # Here the default print/log frequency of each writer is used.
- # run writers in the end, so that evaluation metrics are written
- ret.append(hooks.PeriodicWriter(self.build_writers(), period=20))
- return ret
-
- def build_writers(self):
- """
- Build a list of writers to be used using :func:`default_writers()`.
- If you'd like a different list of writers, you can overwrite it in
- your trainer.
-
- Returns:
- list[EventWriter]: a list of :class:`EventWriter` objects.
- """
- return default_writers(self.cfg.OUTPUT_DIR, self.max_iter)
-
- def train(self):
- """
- Run training.
-
- Returns:
- OrderedDict of results, if evaluation is enabled. Otherwise None.
- """
- super().train(self.start_iter, self.max_iter)
- if len(self.cfg.TEST.EXPECTED_RESULTS) and comm.is_main_process():
- assert hasattr(
- self, "_last_eval_results"
- ), "No evaluation results obtained during training!"
- verify_results(self.cfg, self._last_eval_results)
- return self._last_eval_results
-
- def run_step(self):
- self._trainer.iter = self.iter
- self._trainer.run_step()
-
- def state_dict(self):
- ret = super().state_dict()
- ret["_trainer"] = self._trainer.state_dict()
- return ret
-
- def load_state_dict(self, state_dict):
- super().load_state_dict(state_dict)
- self._trainer.load_state_dict(state_dict["_trainer"])
-
- @classmethod
- def build_model(cls, cfg):
- """
- Returns:
- torch.nn.Module:
-
- It now calls :func:`detectron2.modeling.build_model`.
- Overwrite it if you'd like a different model.
- """
- model = build_model(cfg)
- logger = logging.getLogger(__name__)
- logger.info("Model:\n{}".format(model))
- return model
-
- @classmethod
- def build_optimizer(cls, cfg, model):
- """
- Returns:
- torch.optim.Optimizer:
-
- It now calls :func:`detectron2.solver.build_optimizer`.
- Overwrite it if you'd like a different optimizer.
- """
- return build_optimizer(cfg, model)
-
- @classmethod
- def build_lr_scheduler(cls, cfg, optimizer):
- """
- It now calls :func:`detectron2.solver.build_lr_scheduler`.
- Overwrite it if you'd like a different scheduler.
- """
- return build_lr_scheduler(cfg, optimizer)
-
- @classmethod
- def build_train_loader(cls, cfg):
- """
- Returns:
- iterable
-
- It now calls :func:`detectron2.data.build_detection_train_loader`.
- Overwrite it if you'd like a different data loader.
- """
- return build_detection_train_loader(cfg)
-
- @classmethod
- def build_test_loader(cls, cfg, dataset_name):
- """
- Returns:
- iterable
-
- It now calls :func:`detectron2.data.build_detection_test_loader`.
- Overwrite it if you'd like a different data loader.
- """
- return build_detection_test_loader(cfg, dataset_name)
-
- @classmethod
- def build_evaluator(cls, cfg, dataset_name):
- """
- Returns:
- DatasetEvaluator or None
-
- It is not implemented by default.
- """
- raise NotImplementedError(
- """
-If you want DefaultTrainer to automatically run evaluation,
-please implement `build_evaluator()` in subclasses (see train_net.py for example).
-Alternatively, you can call evaluation functions yourself (see Colab balloon tutorial for example).
-"""
- )
-
- @classmethod
- def test(cls, cfg, model, evaluators=None):
- """
- Evaluate the given model. The given model is expected to already contain
- weights to evaluate.
-
- Args:
- cfg (CfgNode):
- model (nn.Module):
- evaluators (list[DatasetEvaluator] or None): if None, will call
- :meth:`build_evaluator`. Otherwise, must have the same length as
- ``cfg.DATASETS.TEST``.
-
- Returns:
- dict: a dict of result metrics
- """
- logger = logging.getLogger(__name__)
- if isinstance(evaluators, DatasetEvaluator):
- evaluators = [evaluators]
- if evaluators is not None:
- assert len(cfg.DATASETS.TEST) == len(evaluators), "{} != {}".format(
- len(cfg.DATASETS.TEST), len(evaluators)
- )
-
- results = OrderedDict()
- for idx, dataset_name in enumerate(cfg.DATASETS.TEST):
- data_loader = cls.build_test_loader(cfg, dataset_name)
- # When evaluators are passed in as arguments,
- # implicitly assume that evaluators can be created before data_loader.
- if evaluators is not None:
- evaluator = evaluators[idx]
- else:
- try:
- evaluator = cls.build_evaluator(cfg, dataset_name)
- except NotImplementedError:
- logger.warn(
- "No evaluator found. Use `DefaultTrainer.test(evaluators=)`, "
- "or implement its `build_evaluator` method."
- )
- results[dataset_name] = {}
- continue
- results_i = inference_on_dataset(model, data_loader, evaluator)
- results[dataset_name] = results_i
- if comm.is_main_process():
- assert isinstance(
- results_i, dict
- ), "Evaluator must return a dict on the main process. Got {} instead.".format(
- results_i
- )
- logger.info("Evaluation results for {} in csv format:".format(dataset_name))
- print_csv_format(results_i)
-
- if len(results) == 1:
- results = list(results.values())[0]
- return results
-
- @staticmethod
- def auto_scale_workers(cfg, num_workers: int):
- """
- When the config is defined for certain number of workers (according to
- ``cfg.SOLVER.REFERENCE_WORLD_SIZE``) that's different from the number of
- workers currently in use, returns a new cfg where the total batch size
- is scaled so that the per-GPU batch size stays the same as the
- original ``IMS_PER_BATCH // REFERENCE_WORLD_SIZE``.
-
- Other config options are also scaled accordingly:
- * training steps and warmup steps are scaled inverse proportionally.
- * learning rate are scaled proportionally, following :paper:`ImageNet in 1h`.
-
- For example, with the original config like the following:
-
- .. code-block:: yaml
-
- IMS_PER_BATCH: 16
- BASE_LR: 0.1
- REFERENCE_WORLD_SIZE: 8
- MAX_ITER: 5000
- STEPS: (4000,)
- CHECKPOINT_PERIOD: 1000
-
- When this config is used on 16 GPUs instead of the reference number 8,
- calling this method will return a new config with:
-
- .. code-block:: yaml
-
- IMS_PER_BATCH: 32
- BASE_LR: 0.2
- REFERENCE_WORLD_SIZE: 16
- MAX_ITER: 2500
- STEPS: (2000,)
- CHECKPOINT_PERIOD: 500
-
- Note that both the original config and this new config can be trained on 16 GPUs.
- It's up to user whether to enable this feature (by setting ``REFERENCE_WORLD_SIZE``).
-
- Returns:
- CfgNode: a new config. Same as original if ``cfg.SOLVER.REFERENCE_WORLD_SIZE==0``.
- """
- old_world_size = cfg.SOLVER.REFERENCE_WORLD_SIZE
- if old_world_size == 0 or old_world_size == num_workers:
- return cfg
- cfg = cfg.clone()
- frozen = cfg.is_frozen()
- cfg.defrost()
-
- assert (
- cfg.SOLVER.IMS_PER_BATCH % old_world_size == 0
- ), "Invalid REFERENCE_WORLD_SIZE in config!"
- scale = num_workers / old_world_size
- bs = cfg.SOLVER.IMS_PER_BATCH = int(round(cfg.SOLVER.IMS_PER_BATCH * scale))
- lr = cfg.SOLVER.BASE_LR = cfg.SOLVER.BASE_LR * scale
- max_iter = cfg.SOLVER.MAX_ITER = int(round(cfg.SOLVER.MAX_ITER / scale))
- warmup_iter = cfg.SOLVER.WARMUP_ITERS = int(round(cfg.SOLVER.WARMUP_ITERS / scale))
- cfg.SOLVER.STEPS = tuple(int(round(s / scale)) for s in cfg.SOLVER.STEPS)
- cfg.TEST.EVAL_PERIOD = int(round(cfg.TEST.EVAL_PERIOD / scale))
- cfg.SOLVER.CHECKPOINT_PERIOD = int(round(cfg.SOLVER.CHECKPOINT_PERIOD / scale))
- cfg.SOLVER.REFERENCE_WORLD_SIZE = num_workers # maintain invariant
- logger = logging.getLogger(__name__)
- logger.info(
- f"Auto-scaling the config to batch_size={bs}, learning_rate={lr}, "
- f"max_iter={max_iter}, warmup={warmup_iter}."
- )
-
- if frozen:
- cfg.freeze()
- return cfg
-
-
-# Access basic attributes from the underlying trainer
-for _attr in ["model", "data_loader", "optimizer"]:
- setattr(
- DefaultTrainer,
- _attr,
- property(
- # getter
- lambda self, x=_attr: getattr(self._trainer, x),
- # setter
- lambda self, value, x=_attr: setattr(self._trainer, x, value),
- ),
- )
diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/core/evaluation/class_names.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/core/evaluation/class_names.py
deleted file mode 100644
index ffae816cf980ce4b03e491cc0c4298cb823797e6..0000000000000000000000000000000000000000
--- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/core/evaluation/class_names.py
+++ /dev/null
@@ -1,152 +0,0 @@
-import annotator.uniformer.mmcv as mmcv
-
-
-def cityscapes_classes():
- """Cityscapes class names for external use."""
- return [
- 'road', 'sidewalk', 'building', 'wall', 'fence', 'pole',
- 'traffic light', 'traffic sign', 'vegetation', 'terrain', 'sky',
- 'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle',
- 'bicycle'
- ]
-
-
-def ade_classes():
- """ADE20K class names for external use."""
- return [
- 'wall', 'building', 'sky', 'floor', 'tree', 'ceiling', 'road', 'bed ',
- 'windowpane', 'grass', 'cabinet', 'sidewalk', 'person', 'earth',
- 'door', 'table', 'mountain', 'plant', 'curtain', 'chair', 'car',
- 'water', 'painting', 'sofa', 'shelf', 'house', 'sea', 'mirror', 'rug',
- 'field', 'armchair', 'seat', 'fence', 'desk', 'rock', 'wardrobe',
- 'lamp', 'bathtub', 'railing', 'cushion', 'base', 'box', 'column',
- 'signboard', 'chest of drawers', 'counter', 'sand', 'sink',
- 'skyscraper', 'fireplace', 'refrigerator', 'grandstand', 'path',
- 'stairs', 'runway', 'case', 'pool table', 'pillow', 'screen door',
- 'stairway', 'river', 'bridge', 'bookcase', 'blind', 'coffee table',
- 'toilet', 'flower', 'book', 'hill', 'bench', 'countertop', 'stove',
- 'palm', 'kitchen island', 'computer', 'swivel chair', 'boat', 'bar',
- 'arcade machine', 'hovel', 'bus', 'towel', 'light', 'truck', 'tower',
- 'chandelier', 'awning', 'streetlight', 'booth', 'television receiver',
- 'airplane', 'dirt track', 'apparel', 'pole', 'land', 'bannister',
- 'escalator', 'ottoman', 'bottle', 'buffet', 'poster', 'stage', 'van',
- 'ship', 'fountain', 'conveyer belt', 'canopy', 'washer', 'plaything',
- 'swimming pool', 'stool', 'barrel', 'basket', 'waterfall', 'tent',
- 'bag', 'minibike', 'cradle', 'oven', 'ball', 'food', 'step', 'tank',
- 'trade name', 'microwave', 'pot', 'animal', 'bicycle', 'lake',
- 'dishwasher', 'screen', 'blanket', 'sculpture', 'hood', 'sconce',
- 'vase', 'traffic light', 'tray', 'ashcan', 'fan', 'pier', 'crt screen',
- 'plate', 'monitor', 'bulletin board', 'shower', 'radiator', 'glass',
- 'clock', 'flag'
- ]
-
-
-def voc_classes():
- """Pascal VOC class names for external use."""
- return [
- 'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
- 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
- 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
- 'tvmonitor'
- ]
-
-
-def cityscapes_palette():
- """Cityscapes palette for external use."""
- return [[128, 64, 128], [244, 35, 232], [70, 70, 70], [102, 102, 156],
- [190, 153, 153], [153, 153, 153], [250, 170, 30], [220, 220, 0],
- [107, 142, 35], [152, 251, 152], [70, 130, 180], [220, 20, 60],
- [255, 0, 0], [0, 0, 142], [0, 0, 70], [0, 60, 100], [0, 80, 100],
- [0, 0, 230], [119, 11, 32]]
-
-
-def ade_palette():
- """ADE20K palette for external use."""
- return [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
- [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
- [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
- [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
- [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
- [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
- [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
- [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
- [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
- [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
- [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
- [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
- [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
- [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
- [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255],
- [11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255],
- [0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0],
- [255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0],
- [0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255],
- [173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255],
- [255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20],
- [255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255],
- [255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255],
- [0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255],
- [0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0],
- [143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0],
- [8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255],
- [255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112],
- [92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160],
- [163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163],
- [255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0],
- [255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0],
- [10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255],
- [255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204],
- [41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255],
- [71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255],
- [184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194],
- [102, 255, 0], [92, 0, 255]]
-
-
-def voc_palette():
- """Pascal VOC palette for external use."""
- return [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0], [0, 0, 128],
- [128, 0, 128], [0, 128, 128], [128, 128, 128], [64, 0, 0],
- [192, 0, 0], [64, 128, 0], [192, 128, 0], [64, 0, 128],
- [192, 0, 128], [64, 128, 128], [192, 128, 128], [0, 64, 0],
- [128, 64, 0], [0, 192, 0], [128, 192, 0], [0, 64, 128]]
-
-
-dataset_aliases = {
- 'cityscapes': ['cityscapes'],
- 'ade': ['ade', 'ade20k'],
- 'voc': ['voc', 'pascal_voc', 'voc12', 'voc12aug']
-}
-
-
-def get_classes(dataset):
- """Get class names of a dataset."""
- alias2name = {}
- for name, aliases in dataset_aliases.items():
- for alias in aliases:
- alias2name[alias] = name
-
- if mmcv.is_str(dataset):
- if dataset in alias2name:
- labels = eval(alias2name[dataset] + '_classes()')
- else:
- raise ValueError(f'Unrecognized dataset: {dataset}')
- else:
- raise TypeError(f'dataset must a str, but got {type(dataset)}')
- return labels
-
-
-def get_palette(dataset):
- """Get class palette (RGB) of a dataset."""
- alias2name = {}
- for name, aliases in dataset_aliases.items():
- for alias in aliases:
- alias2name[alias] = name
-
- if mmcv.is_str(dataset):
- if dataset in alias2name:
- labels = eval(alias2name[dataset] + '_palette()')
- else:
- raise ValueError(f'Unrecognized dataset: {dataset}')
- else:
- raise TypeError(f'dataset must a str, but got {type(dataset)}')
- return labels
diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/datasets/ade.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/datasets/ade.py
deleted file mode 100644
index 5913e43775ed4920b6934c855eb5a37c54218ebf..0000000000000000000000000000000000000000
--- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/datasets/ade.py
+++ /dev/null
@@ -1,84 +0,0 @@
-from .builder import DATASETS
-from .custom import CustomDataset
-
-
-@DATASETS.register_module()
-class ADE20KDataset(CustomDataset):
- """ADE20K dataset.
-
- In segmentation map annotation for ADE20K, 0 stands for background, which
- is not included in 150 categories. ``reduce_zero_label`` is fixed to True.
- The ``img_suffix`` is fixed to '.jpg' and ``seg_map_suffix`` is fixed to
- '.png'.
- """
- CLASSES = (
- 'wall', 'building', 'sky', 'floor', 'tree', 'ceiling', 'road', 'bed ',
- 'windowpane', 'grass', 'cabinet', 'sidewalk', 'person', 'earth',
- 'door', 'table', 'mountain', 'plant', 'curtain', 'chair', 'car',
- 'water', 'painting', 'sofa', 'shelf', 'house', 'sea', 'mirror', 'rug',
- 'field', 'armchair', 'seat', 'fence', 'desk', 'rock', 'wardrobe',
- 'lamp', 'bathtub', 'railing', 'cushion', 'base', 'box', 'column',
- 'signboard', 'chest of drawers', 'counter', 'sand', 'sink',
- 'skyscraper', 'fireplace', 'refrigerator', 'grandstand', 'path',
- 'stairs', 'runway', 'case', 'pool table', 'pillow', 'screen door',
- 'stairway', 'river', 'bridge', 'bookcase', 'blind', 'coffee table',
- 'toilet', 'flower', 'book', 'hill', 'bench', 'countertop', 'stove',
- 'palm', 'kitchen island', 'computer', 'swivel chair', 'boat', 'bar',
- 'arcade machine', 'hovel', 'bus', 'towel', 'light', 'truck', 'tower',
- 'chandelier', 'awning', 'streetlight', 'booth', 'television receiver',
- 'airplane', 'dirt track', 'apparel', 'pole', 'land', 'bannister',
- 'escalator', 'ottoman', 'bottle', 'buffet', 'poster', 'stage', 'van',
- 'ship', 'fountain', 'conveyer belt', 'canopy', 'washer', 'plaything',
- 'swimming pool', 'stool', 'barrel', 'basket', 'waterfall', 'tent',
- 'bag', 'minibike', 'cradle', 'oven', 'ball', 'food', 'step', 'tank',
- 'trade name', 'microwave', 'pot', 'animal', 'bicycle', 'lake',
- 'dishwasher', 'screen', 'blanket', 'sculpture', 'hood', 'sconce',
- 'vase', 'traffic light', 'tray', 'ashcan', 'fan', 'pier', 'crt screen',
- 'plate', 'monitor', 'bulletin board', 'shower', 'radiator', 'glass',
- 'clock', 'flag')
-
- PALETTE = [[120, 120, 120], [180, 120, 120], [6, 230, 230], [80, 50, 50],
- [4, 200, 3], [120, 120, 80], [140, 140, 140], [204, 5, 255],
- [230, 230, 230], [4, 250, 7], [224, 5, 255], [235, 255, 7],
- [150, 5, 61], [120, 120, 70], [8, 255, 51], [255, 6, 82],
- [143, 255, 140], [204, 255, 4], [255, 51, 7], [204, 70, 3],
- [0, 102, 200], [61, 230, 250], [255, 6, 51], [11, 102, 255],
- [255, 7, 71], [255, 9, 224], [9, 7, 230], [220, 220, 220],
- [255, 9, 92], [112, 9, 255], [8, 255, 214], [7, 255, 224],
- [255, 184, 6], [10, 255, 71], [255, 41, 10], [7, 255, 255],
- [224, 255, 8], [102, 8, 255], [255, 61, 6], [255, 194, 7],
- [255, 122, 8], [0, 255, 20], [255, 8, 41], [255, 5, 153],
- [6, 51, 255], [235, 12, 255], [160, 150, 20], [0, 163, 255],
- [140, 140, 140], [250, 10, 15], [20, 255, 0], [31, 255, 0],
- [255, 31, 0], [255, 224, 0], [153, 255, 0], [0, 0, 255],
- [255, 71, 0], [0, 235, 255], [0, 173, 255], [31, 0, 255],
- [11, 200, 200], [255, 82, 0], [0, 255, 245], [0, 61, 255],
- [0, 255, 112], [0, 255, 133], [255, 0, 0], [255, 163, 0],
- [255, 102, 0], [194, 255, 0], [0, 143, 255], [51, 255, 0],
- [0, 82, 255], [0, 255, 41], [0, 255, 173], [10, 0, 255],
- [173, 255, 0], [0, 255, 153], [255, 92, 0], [255, 0, 255],
- [255, 0, 245], [255, 0, 102], [255, 173, 0], [255, 0, 20],
- [255, 184, 184], [0, 31, 255], [0, 255, 61], [0, 71, 255],
- [255, 0, 204], [0, 255, 194], [0, 255, 82], [0, 10, 255],
- [0, 112, 255], [51, 0, 255], [0, 194, 255], [0, 122, 255],
- [0, 255, 163], [255, 153, 0], [0, 255, 10], [255, 112, 0],
- [143, 255, 0], [82, 0, 255], [163, 255, 0], [255, 235, 0],
- [8, 184, 170], [133, 0, 255], [0, 255, 92], [184, 0, 255],
- [255, 0, 31], [0, 184, 255], [0, 214, 255], [255, 0, 112],
- [92, 255, 0], [0, 224, 255], [112, 224, 255], [70, 184, 160],
- [163, 0, 255], [153, 0, 255], [71, 255, 0], [255, 0, 163],
- [255, 204, 0], [255, 0, 143], [0, 255, 235], [133, 255, 0],
- [255, 0, 235], [245, 0, 255], [255, 0, 122], [255, 245, 0],
- [10, 190, 212], [214, 255, 0], [0, 204, 255], [20, 0, 255],
- [255, 255, 0], [0, 153, 255], [0, 41, 255], [0, 255, 204],
- [41, 0, 255], [41, 255, 0], [173, 0, 255], [0, 245, 255],
- [71, 0, 255], [122, 0, 255], [0, 255, 184], [0, 92, 255],
- [184, 255, 0], [0, 133, 255], [255, 214, 0], [25, 194, 194],
- [102, 255, 0], [92, 0, 255]]
-
- def __init__(self, **kwargs):
- super(ADE20KDataset, self).__init__(
- img_suffix='.jpg',
- seg_map_suffix='.png',
- reduce_zero_label=True,
- **kwargs)
diff --git a/spaces/PaulHilders/IEAI_CLIPGroundingExplainability/README.md b/spaces/PaulHilders/IEAI_CLIPGroundingExplainability/README.md
deleted file mode 100644
index 6a48fb4da55ce380a8fbf30feef0406a61d22737..0000000000000000000000000000000000000000
--- a/spaces/PaulHilders/IEAI_CLIPGroundingExplainability/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: IEAI CLIPGroundingExplainability
-emoji: 🚀
-colorFrom: yellow
-colorTo: green
-sdk: gradio
-sdk_version: 3.0.22
-app_file: app.py
-pinned: false
-license: afl-3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/PeepDaSlan9/De-limiter/prepro/delimit_valid_L_prepro.py b/spaces/PeepDaSlan9/De-limiter/prepro/delimit_valid_L_prepro.py
deleted file mode 100644
index bf56df01b4bd44dc203cc856608a86aaaf84544b..0000000000000000000000000000000000000000
--- a/spaces/PeepDaSlan9/De-limiter/prepro/delimit_valid_L_prepro.py
+++ /dev/null
@@ -1,41 +0,0 @@
-import os
-import json
-
-from torch.utils.data import DataLoader
-import soundfile as sf
-import tqdm
-
-from dataloader import DelimitValidDataset
-
-
-def main():
- # Parameters
- data_path = "/path/to/musdb18hq"
- save_path = "/path/to/musdb18hq_limited_L"
- batch_size = 1
- num_workers = 1
- sr = 44100
-
- # Dataset
- dataset = DelimitValidDataset(root=data_path, valid_target_lufs=-14.39)
- data_loader = DataLoader(
- dataset, batch_size=batch_size, num_workers=num_workers, shuffle=False
- )
- dict_valid_loudness = {}
- # Preprocessing
- for limited_audio, orig_audio, audio_name, loudness in tqdm.tqdm(data_loader):
- audio_name = audio_name[0]
- limited_audio = limited_audio[0].numpy()
- loudness = float(loudness[0].numpy())
- dict_valid_loudness[audio_name] = loudness
- # Save audio
- os.makedirs(os.path.join(save_path, "valid"), exist_ok=True)
- audio_path = os.path.join(save_path, "valid", audio_name)
- sf.write(f"{audio_path}.wav", limited_audio.T, sr)
- # write json write code
- with open(os.path.join(save_path, "valid_loudness.json"), "w") as f:
- json.dump(dict_valid_loudness, f, indent=4)
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/PeerChristensen/TrumpTweetsDevice/README.md b/spaces/PeerChristensen/TrumpTweetsDevice/README.md
deleted file mode 100644
index c0db4a4a3d1f2508b83b10e9f77396fa35617c6c..0000000000000000000000000000000000000000
--- a/spaces/PeerChristensen/TrumpTweetsDevice/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: TrumpTweetsDevice
-emoji: 📱
-colorFrom: purple
-colorTo: green
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/roi_heads/keypoint_head/roi_keypoint_feature_extractors.py b/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/roi_heads/keypoint_head/roi_keypoint_feature_extractors.py
deleted file mode 100644
index b4792859a5e4bca1531b409ba45b8b2d16931606..0000000000000000000000000000000000000000
--- a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/modeling/roi_heads/keypoint_head/roi_keypoint_feature_extractors.py
+++ /dev/null
@@ -1,96 +0,0 @@
-from torch import nn
-from torch.nn import functional as F
-
-from maskrcnn_benchmark.modeling.poolers import Pooler
-
-from maskrcnn_benchmark.layers import Conv2d
-from maskrcnn_benchmark.layers import ConvTranspose2d
-
-
-class KeypointRCNNFeatureExtractor(nn.Module):
- def __init__(self, cfg):
- super(KeypointRCNNFeatureExtractor, self).__init__()
-
- resolution = cfg.MODEL.ROI_KEYPOINT_HEAD.POOLER_RESOLUTION
- scales = cfg.MODEL.ROI_KEYPOINT_HEAD.POOLER_SCALES
- sampling_ratio = cfg.MODEL.ROI_KEYPOINT_HEAD.POOLER_SAMPLING_RATIO
- pooler = Pooler(
- output_size=(resolution, resolution),
- scales=scales,
- sampling_ratio=sampling_ratio,
- )
- self.pooler = pooler
-
- input_features = cfg.MODEL.BACKBONE.OUT_CHANNELS
- layers = cfg.MODEL.ROI_KEYPOINT_HEAD.CONV_LAYERS
- next_feature = input_features
- self.blocks = []
- for layer_idx, layer_features in enumerate(layers, 1):
- layer_name = "conv_fcn{}".format(layer_idx)
- module = Conv2d(next_feature, layer_features, 3, stride=1, padding=1)
- nn.init.kaiming_normal_(module.weight, mode="fan_out", nonlinearity="relu")
- nn.init.constant_(module.bias, 0)
- self.add_module(layer_name, module)
- next_feature = layer_features
- self.blocks.append(layer_name)
-
- def forward(self, x, proposals):
- x = self.pooler(x, proposals)
- for layer_name in self.blocks:
- x = F.relu(getattr(self, layer_name)(x))
- return x
-
-class KeypointRCNNFeature2XZoomExtractor(nn.Module):
- def __init__(self, cfg):
- super(KeypointRCNNFeature2XZoomExtractor, self).__init__()
-
- resolution = cfg.MODEL.ROI_KEYPOINT_HEAD.POOLER_RESOLUTION
- scales = cfg.MODEL.ROI_KEYPOINT_HEAD.POOLER_SCALES
- sampling_ratio = cfg.MODEL.ROI_KEYPOINT_HEAD.POOLER_SAMPLING_RATIO
- pooler = Pooler(
- output_size=(resolution, resolution),
- scales=scales,
- sampling_ratio=sampling_ratio,
- )
- self.pooler = pooler
-
- input_features = cfg.MODEL.BACKBONE.OUT_CHANNELS
- layers = cfg.MODEL.ROI_KEYPOINT_HEAD.CONV_LAYERS
- next_feature = input_features
- self.blocks = []
- for layer_idx, layer_features in enumerate(layers, 1):
- layer_name = "conv_fcn{}".format(layer_idx)
- module = Conv2d(next_feature, layer_features, 3, stride=1, padding=1)
- nn.init.kaiming_normal_(module.weight, mode="fan_out", nonlinearity="relu")
- nn.init.constant_(module.bias, 0)
- self.add_module(layer_name, module)
- if layer_idx==len(layers)//2:
- deconv_kernel = 4
- kps_upsacle = ConvTranspose2d(layer_features, layer_features, deconv_kernel,
- stride=2, padding=deconv_kernel//2-1)
- nn.init.kaiming_normal_(kps_upsacle.weight, mode="fan_out", nonlinearity="relu")
- nn.init.constant_(kps_upsacle.bias, 0)
- self.add_module("conv_fcn_upscale", kps_upsacle)
- self.blocks.append("conv_fcn_upscale")
-
- next_feature = layer_features
- self.blocks.append(layer_name)
-
- def forward(self, x, proposals):
- x = self.pooler(x, proposals)
- for layer_name in self.blocks:
- x = F.relu(getattr(self, layer_name)(x))
- return x
-
-
-_ROI_KEYPOINT_FEATURE_EXTRACTORS = {
- "KeypointRCNNFeatureExtractor": KeypointRCNNFeatureExtractor,
- "KeypointRCNNFeature2XZoomExtractor": KeypointRCNNFeature2XZoomExtractor
-}
-
-
-def make_roi_keypoint_feature_extractor(cfg):
- func = _ROI_KEYPOINT_FEATURE_EXTRACTORS[
- cfg.MODEL.ROI_KEYPOINT_HEAD.FEATURE_EXTRACTOR
- ]
- return func(cfg)
\ No newline at end of file
diff --git a/spaces/Pippoz/All_in_one/pages/chat.py b/spaces/Pippoz/All_in_one/pages/chat.py
deleted file mode 100644
index 800e6e88d74234218e20ae0e63d980c17a820c44..0000000000000000000000000000000000000000
--- a/spaces/Pippoz/All_in_one/pages/chat.py
+++ /dev/null
@@ -1,42 +0,0 @@
-import streamlit as st
-from streamlit_chat import message as st_message
-from transformers import BlenderbotTokenizer
-from transformers import BlenderbotForConditionalGeneration
-
-
-def app():
- @st.experimental_singleton(show_spinner=False, suppress_st_warning=True)
- def get_models():
- # it may be necessary for other frameworks to cache the model
- # seems pytorch keeps an internal state of the conversation
- model_name = "facebook/blenderbot-400M-distill"
- tokenizer = BlenderbotTokenizer.from_pretrained(model_name)
- model = BlenderbotForConditionalGeneration.from_pretrained(model_name)
- return tokenizer, model
-
-
- if "history" not in st.session_state:
- st.session_state.history = []
-
- st.title("IoT Chat Robot")
- st.write('Just chat with a friendly and smart AI developed by Meta')
- st.markdown('## ')
-
-
- def generate_answer():
- tokenizer, model = get_models()
- user_message = st.session_state.input_text
- inputs = tokenizer(st.session_state.input_text, return_tensors="pt")
- result = model.generate(**inputs)
- message_bot = tokenizer.decode(
- result[0], skip_special_tokens=True
- ) # .replace("", "").replace("", "")
-
- st.session_state.history.append({"message": user_message, "is_user": True})
- st.session_state.history.append({"message": message_bot, "is_user": False})
-
-
- st.text_input("Enter your prompt...", key="input_text", on_change=generate_answer)
-
- for chat in st.session_state.history:
- st_message(**chat) # unpacking
\ No newline at end of file
diff --git a/spaces/Purple11/Grounded-Diffusion/src/taming-transformers/scripts/extract_submodel.py b/spaces/Purple11/Grounded-Diffusion/src/taming-transformers/scripts/extract_submodel.py
deleted file mode 100644
index 559bc5e04281a7cf833a82e3cd48627b20f1a76d..0000000000000000000000000000000000000000
--- a/spaces/Purple11/Grounded-Diffusion/src/taming-transformers/scripts/extract_submodel.py
+++ /dev/null
@@ -1,17 +0,0 @@
-import torch
-import sys
-
-if __name__ == "__main__":
- inpath = sys.argv[1]
- outpath = sys.argv[2]
- submodel = "cond_stage_model"
- if len(sys.argv) > 3:
- submodel = sys.argv[3]
-
- print("Extracting {} from {} to {}.".format(submodel, inpath, outpath))
-
- sd = torch.load(inpath, map_location="cpu")
- new_sd = {"state_dict": dict((k.split(".", 1)[-1],v)
- for k,v in sd["state_dict"].items()
- if k.startswith("cond_stage_model"))}
- torch.save(new_sd, outpath)
diff --git a/spaces/Rajagopal/ImageBind_zeroshot_demo2/models/multimodal_preprocessors.py b/spaces/Rajagopal/ImageBind_zeroshot_demo2/models/multimodal_preprocessors.py
deleted file mode 100644
index b19711da3af3bf6174958ec8fe897431ae3407a5..0000000000000000000000000000000000000000
--- a/spaces/Rajagopal/ImageBind_zeroshot_demo2/models/multimodal_preprocessors.py
+++ /dev/null
@@ -1,687 +0,0 @@
-#!/usr/bin/env python3
-# Portions Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import gzip
-import html
-import io
-import math
-from functools import lru_cache
-from typing import Callable, List, Optional
-
-import ftfy
-
-import numpy as np
-import regex as re
-import torch
-import torch.nn as nn
-from iopath.common.file_io import g_pathmgr
-from timm.models.layers import trunc_normal_
-
-from models.helpers import cast_if_src_dtype, VerboseNNModule
-
-
-def get_sinusoid_encoding_table(n_position, d_hid):
- """Sinusoid position encoding table"""
-
- # TODO: make it with torch instead of numpy
- def get_position_angle_vec(position):
- return [
- position / np.power(10000, 2 * (hid_j // 2) / d_hid)
- for hid_j in range(d_hid)
- ]
-
- sinusoid_table = np.array(
- [get_position_angle_vec(pos_i) for pos_i in range(n_position)]
- )
- sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
- sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
-
- return torch.FloatTensor(sinusoid_table).unsqueeze(0)
-
-
-def interpolate_pos_encoding_2d(target_spatial_size, pos_embed):
- N = pos_embed.shape[1]
- if N == target_spatial_size:
- return pos_embed
- dim = pos_embed.shape[-1]
- # nn.functional.interpolate doesn't work with bfloat16 so we cast to float32
- pos_embed, updated = cast_if_src_dtype(pos_embed, torch.bfloat16, torch.float32)
- pos_embed = nn.functional.interpolate(
- pos_embed.reshape(1, int(math.sqrt(N)), int(math.sqrt(N)), dim).permute(
- 0, 3, 1, 2
- ),
- scale_factor=math.sqrt(target_spatial_size / N),
- mode="bicubic",
- )
- if updated:
- pos_embed, _ = cast_if_src_dtype(pos_embed, torch.float32, torch.bfloat16)
- pos_embed = pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
- return pos_embed
-
-
-def interpolate_pos_encoding(
- npatch_per_img,
- pos_embed,
- patches_layout,
- input_shape=None,
- first_patch_idx=1,
-):
- assert first_patch_idx == 0 or first_patch_idx == 1, "there is 1 CLS token or none"
- N = pos_embed.shape[1] - first_patch_idx # since it's 1 if cls_token exists
- if npatch_per_img == N:
- return pos_embed
-
- assert (
- patches_layout[-1] == patches_layout[-2]
- ), "Interpolation of pos embed not supported for non-square layouts"
-
- class_emb = pos_embed[:, :first_patch_idx]
- pos_embed = pos_embed[:, first_patch_idx:]
-
- if input_shape is None or patches_layout[0] == 1:
- # simple 2D pos embedding, no temporal component
- pos_embed = interpolate_pos_encoding_2d(npatch_per_img, pos_embed)
- elif patches_layout[0] > 1:
- # pos embed has a temporal component
- assert len(input_shape) == 4, "temporal interpolation not supported"
- # we only support 2D interpolation in this case
- num_frames = patches_layout[0]
- num_spatial_tokens = patches_layout[1] * patches_layout[2]
- pos_embed = pos_embed.view(1, num_frames, num_spatial_tokens, -1)
- # interpolate embedding for zeroth frame
- pos_embed = interpolate_pos_encoding_2d(
- npatch_per_img, pos_embed[0, 0, ...].unsqueeze(0)
- )
- else:
- raise ValueError("This type of interpolation isn't implemented")
-
- return torch.cat((class_emb, pos_embed), dim=1)
-
-
-def _get_pos_embedding(
- npatch_per_img,
- pos_embed,
- patches_layout,
- input_shape,
- first_patch_idx=1,
-):
- pos_embed = interpolate_pos_encoding(
- npatch_per_img,
- pos_embed,
- patches_layout,
- input_shape=input_shape,
- first_patch_idx=first_patch_idx,
- )
- return pos_embed
-
-
-class PatchEmbedGeneric(nn.Module):
- """
- PatchEmbed from Hydra
- """
-
- def __init__(self, proj_stem, norm_layer: Optional[nn.Module] = None):
- super().__init__()
-
- if len(proj_stem) > 1:
- self.proj = nn.Sequential(*proj_stem)
- else:
- # Special case to be able to load pre-trained models that were
- # trained with a standard stem
- self.proj = proj_stem[0]
- self.norm_layer = norm_layer
-
- def get_patch_layout(self, img_size):
- with torch.no_grad():
- dummy_img = torch.zeros(
- [
- 1,
- ]
- + img_size
- )
- dummy_out = self.proj(dummy_img)
- embed_dim = dummy_out.shape[1]
- patches_layout = tuple(dummy_out.shape[2:])
- num_patches = np.prod(patches_layout)
- return patches_layout, num_patches, embed_dim
-
- def forward(self, x):
- x = self.proj(x)
- # B C (T) H W -> B (T)HW C
- x = x.flatten(2).transpose(1, 2)
- if self.norm_layer is not None:
- x = self.norm_layer(x)
- return x
-
-
-class SpatioTemporalPosEmbeddingHelper(VerboseNNModule):
- def __init__(
- self,
- patches_layout: List,
- num_patches: int,
- num_cls_tokens: int,
- embed_dim: int,
- learnable: bool,
- ) -> None:
- super().__init__()
- self.num_cls_tokens = num_cls_tokens
- self.patches_layout = patches_layout
- self.num_patches = num_patches
- self.num_tokens = num_cls_tokens + num_patches
- self.learnable = learnable
- if self.learnable:
- self.pos_embed = nn.Parameter(torch.zeros(1, self.num_tokens, embed_dim))
- trunc_normal_(self.pos_embed, std=0.02)
- else:
- self.register_buffer(
- "pos_embed", get_sinusoid_encoding_table(self.num_tokens, embed_dim)
- )
-
- def get_pos_embedding(self, vision_input, all_vision_tokens):
- input_shape = vision_input.shape
- pos_embed = _get_pos_embedding(
- all_vision_tokens.size(1) - self.num_cls_tokens,
- pos_embed=self.pos_embed,
- patches_layout=self.patches_layout,
- input_shape=input_shape,
- first_patch_idx=self.num_cls_tokens,
- )
- return pos_embed
-
-
-class RGBDTPreprocessor(VerboseNNModule):
- def __init__(
- self,
- rgbt_stem: PatchEmbedGeneric,
- depth_stem: PatchEmbedGeneric,
- img_size: List = (3, 224, 224),
- num_cls_tokens: int = 1,
- pos_embed_fn: Callable = None,
- use_type_embed: bool = False,
- init_param_style: str = "openclip",
- ) -> None:
- super().__init__()
- stem = rgbt_stem if rgbt_stem is not None else depth_stem
- (
- self.patches_layout,
- self.num_patches,
- self.embed_dim,
- ) = stem.get_patch_layout(img_size)
- self.rgbt_stem = rgbt_stem
- self.depth_stem = depth_stem
- self.use_pos_embed = pos_embed_fn is not None
- self.use_type_embed = use_type_embed
- self.num_cls_tokens = num_cls_tokens
-
- if self.use_pos_embed:
- self.pos_embedding_helper = pos_embed_fn(
- patches_layout=self.patches_layout,
- num_cls_tokens=num_cls_tokens,
- num_patches=self.num_patches,
- embed_dim=self.embed_dim,
- )
- if self.num_cls_tokens > 0:
- self.cls_token = nn.Parameter(
- torch.zeros(1, self.num_cls_tokens, self.embed_dim)
- )
- if self.use_type_embed:
- self.type_embed = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
-
- self.init_parameters(init_param_style)
-
- @torch.no_grad()
- def init_parameters(self, init_param_style):
- if init_param_style == "openclip":
- # OpenCLIP style initialization
- scale = self.embed_dim**-0.5
- if self.use_pos_embed:
- nn.init.normal_(self.pos_embedding_helper.pos_embed)
- self.pos_embedding_helper.pos_embed *= scale
-
- if self.num_cls_tokens > 0:
- nn.init.normal_(self.cls_token)
- self.cls_token *= scale
- elif init_param_style == "vit":
- self.cls_token.data.fill_(0)
- else:
- raise ValueError(f"Unknown init {init_param_style}")
-
- if self.use_type_embed:
- nn.init.normal_(self.type_embed)
-
- def tokenize_input_and_cls_pos(self, input, stem, mask):
- # tokens is of shape B x L x D
- tokens = stem(input)
- assert tokens.ndim == 3
- assert tokens.shape[2] == self.embed_dim
- B = tokens.shape[0]
- if self.num_cls_tokens > 0:
- class_tokens = self.cls_token.expand(
- B, -1, -1
- ) # stole class_tokens impl from Phil Wang, thanks
- tokens = torch.cat((class_tokens, tokens), dim=1)
- if self.use_pos_embed:
- pos_embed = self.pos_embedding_helper.get_pos_embedding(input, tokens)
- tokens = tokens + pos_embed
- if self.use_type_embed:
- tokens = tokens + self.type_embed.expand(B, -1, -1)
- return tokens
-
- def forward(self, vision=None, depth=None, patch_mask=None):
- if patch_mask is not None:
- raise NotImplementedError()
-
- if vision is not None:
- vision_tokens = self.tokenize_input_and_cls_pos(
- vision, self.rgbt_stem, patch_mask
- )
-
- if depth is not None:
- depth_tokens = self.tokenize_input_and_cls_pos(
- depth, self.depth_stem, patch_mask
- )
-
- # aggregate tokens
- if vision is not None and depth is not None:
- final_tokens = vision_tokens + depth_tokens
- else:
- final_tokens = vision_tokens if vision is not None else depth_tokens
- return_dict = {
- "trunk": {
- "tokens": final_tokens,
- },
- "head": {},
- }
- return return_dict
-
-
-class AudioPreprocessor(RGBDTPreprocessor):
- def __init__(self, audio_stem: PatchEmbedGeneric, **kwargs) -> None:
- super().__init__(rgbt_stem=audio_stem, depth_stem=None, **kwargs)
-
- def forward(self, audio=None):
- return super().forward(vision=audio)
-
-
-class ThermalPreprocessor(RGBDTPreprocessor):
- def __init__(self, thermal_stem: PatchEmbedGeneric, **kwargs) -> None:
- super().__init__(rgbt_stem=thermal_stem, depth_stem=None, **kwargs)
-
- def forward(self, thermal=None):
- return super().forward(vision=thermal)
-
-
-def build_causal_attention_mask(context_length):
- # lazily create causal attention mask, with full attention between the vision tokens
- # pytorch uses additive attention mask; fill with -inf
- mask = torch.empty(context_length, context_length, requires_grad=False)
- mask.fill_(float("-inf"))
- mask.triu_(1) # zero out the lower diagonal
- return mask
-
-
-class TextPreprocessor(VerboseNNModule):
- def __init__(
- self,
- vocab_size: int,
- context_length: int,
- embed_dim: int,
- causal_masking: bool,
- supply_seq_len_to_head: bool = True,
- num_cls_tokens: int = 0,
- init_param_style: str = "openclip",
- ) -> None:
- super().__init__()
- self.vocab_size = vocab_size
- self.context_length = context_length
- self.token_embedding = nn.Embedding(vocab_size, embed_dim)
- self.pos_embed = nn.Parameter(
- torch.empty(1, self.context_length + num_cls_tokens, embed_dim)
- )
- self.causal_masking = causal_masking
- if self.causal_masking:
- mask = build_causal_attention_mask(self.context_length)
- # register the mask as a buffer so it can be moved to the right device
- self.register_buffer("mask", mask)
-
- self.supply_seq_len_to_head = supply_seq_len_to_head
- self.num_cls_tokens = num_cls_tokens
- self.embed_dim = embed_dim
- if num_cls_tokens > 0:
- assert self.causal_masking is False, "Masking + CLS token isn't implemented"
- self.cls_token = nn.Parameter(
- torch.zeros(1, self.num_cls_tokens, embed_dim)
- )
-
- self.init_parameters(init_param_style)
-
- @torch.no_grad()
- def init_parameters(self, init_param_style="openclip"):
- # OpenCLIP style initialization
- nn.init.normal_(self.token_embedding.weight, std=0.02)
- nn.init.normal_(self.pos_embed, std=0.01)
-
- if init_param_style == "openclip":
- # OpenCLIP style initialization
- scale = self.embed_dim**-0.5
- if self.num_cls_tokens > 0:
- nn.init.normal_(self.cls_token)
- self.cls_token *= scale
- elif init_param_style == "vit":
- self.cls_token.data.fill_(0)
- else:
- raise ValueError(f"Unknown init {init_param_style}")
-
- def forward(self, text):
- # text tokens are of shape B x L x D
- text_tokens = self.token_embedding(text)
- # concat CLS tokens if any
- if self.num_cls_tokens > 0:
- B = text_tokens.shape[0]
- class_tokens = self.cls_token.expand(
- B, -1, -1
- ) # stole class_tokens impl from Phil Wang, thanks
- text_tokens = torch.cat((class_tokens, text_tokens), dim=1)
- text_tokens = text_tokens + self.pos_embed
- return_dict = {
- "trunk": {
- "tokens": text_tokens,
- },
- "head": {},
- }
- # Compute sequence length after adding CLS tokens
- if self.supply_seq_len_to_head:
- text_lengths = text.argmax(dim=-1)
- return_dict["head"] = {
- "seq_len": text_lengths,
- }
- if self.causal_masking:
- return_dict["trunk"].update({"attn_mask": self.mask})
- return return_dict
-
-
-class Im2Video(nn.Module):
- """Convert an image into a trivial video."""
-
- def __init__(self, time_dim=2):
- super().__init__()
- self.time_dim = time_dim
-
- def forward(self, x):
- if x.ndim == 4:
- # B, C, H, W -> B, C, T, H, W
- return x.unsqueeze(self.time_dim)
- elif x.ndim == 5:
- return x
- else:
- raise ValueError(f"Dimension incorrect {x.shape}")
-
-
-class PadIm2Video(Im2Video):
- def __init__(self, ntimes, pad_type, time_dim=2):
- super().__init__(time_dim=time_dim)
- assert ntimes > 0
- assert pad_type in ["zero", "repeat"]
- self.ntimes = ntimes
- self.pad_type = pad_type
-
- def forward(self, x):
- x = super().forward(x)
- if x.shape[self.time_dim] == 1:
- if self.pad_type == "repeat":
- new_shape = [1] * len(x.shape)
- new_shape[self.time_dim] = self.ntimes
- x = x.repeat(new_shape)
- elif self.pad_type == "zero":
- padarg = [0, 0] * len(x.shape)
- padarg[2 * self.time_dim + 1] = self.ntimes - x.shape[self.time_dim]
- x = nn.functional.pad(x, padarg)
- return x
-
-
-# Modified from github.com/openai/CLIP
-@lru_cache()
-def bytes_to_unicode():
- """
- Returns list of utf-8 byte and a corresponding list of unicode strings.
- The reversible bpe codes work on unicode strings.
- This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
- When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
- This is a signficant percentage of your normal, say, 32K bpe vocab.
- To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
- And avoids mapping to whitespace/control characters the bpe code barfs on.
- """
- bs = (
- list(range(ord("!"), ord("~") + 1))
- + list(range(ord("¡"), ord("¬") + 1))
- + list(range(ord("®"), ord("ÿ") + 1))
- )
- cs = bs[:]
- n = 0
- for b in range(2**8):
- if b not in bs:
- bs.append(b)
- cs.append(2**8 + n)
- n += 1
- cs = [chr(n) for n in cs]
- return dict(zip(bs, cs))
-
-
-def get_pairs(word):
- """Return set of symbol pairs in a word.
- Word is represented as tuple of symbols (symbols being variable-length strings).
- """
- pairs = set()
- prev_char = word[0]
- for char in word[1:]:
- pairs.add((prev_char, char))
- prev_char = char
- return pairs
-
-
-def basic_clean(text):
- text = ftfy.fix_text(text)
- text = html.unescape(html.unescape(text))
- return text.strip()
-
-
-def whitespace_clean(text):
- text = re.sub(r"\s+", " ", text)
- text = text.strip()
- return text
-
-
-class SimpleTokenizer(object):
- def __init__(self, bpe_path: str, context_length=77):
- self.byte_encoder = bytes_to_unicode()
- self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
-
- with g_pathmgr.open(bpe_path, "rb") as fh:
- bpe_bytes = io.BytesIO(fh.read())
- merges = gzip.open(bpe_bytes).read().decode("utf-8").split("\n")
- merges = merges[1 : 49152 - 256 - 2 + 1]
- merges = [tuple(merge.split()) for merge in merges]
- vocab = list(bytes_to_unicode().values())
- vocab = vocab + [v + "" for v in vocab]
- for merge in merges:
- vocab.append("".join(merge))
- vocab.extend(["<|startoftext|>", "<|endoftext|>"])
- self.encoder = dict(zip(vocab, range(len(vocab))))
- self.decoder = {v: k for k, v in self.encoder.items()}
- self.bpe_ranks = dict(zip(merges, range(len(merges))))
- self.cache = {
- "<|startoftext|>": "<|startoftext|>",
- "<|endoftext|>": "<|endoftext|>",
- }
- self.pat = re.compile(
- r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
- re.IGNORECASE,
- )
- self.context_length = context_length
-
- def bpe(self, token):
- if token in self.cache:
- return self.cache[token]
- word = tuple(token[:-1]) + (token[-1] + "",)
- pairs = get_pairs(word)
-
- if not pairs:
- return token + ""
-
- while True:
- bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
- if bigram not in self.bpe_ranks:
- break
- first, second = bigram
- new_word = []
- i = 0
- while i < len(word):
- try:
- j = word.index(first, i)
- new_word.extend(word[i:j])
- i = j
- except:
- new_word.extend(word[i:])
- break
-
- if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
- new_word.append(first + second)
- i += 2
- else:
- new_word.append(word[i])
- i += 1
- new_word = tuple(new_word)
- word = new_word
- if len(word) == 1:
- break
- else:
- pairs = get_pairs(word)
- word = " ".join(word)
- self.cache[token] = word
- return word
-
- def encode(self, text):
- bpe_tokens = []
- text = whitespace_clean(basic_clean(text)).lower()
- for token in re.findall(self.pat, text):
- token = "".join(self.byte_encoder[b] for b in token.encode("utf-8"))
- bpe_tokens.extend(
- self.encoder[bpe_token] for bpe_token in self.bpe(token).split(" ")
- )
- return bpe_tokens
-
- def decode(self, tokens):
- text = "".join([self.decoder[token] for token in tokens])
- text = (
- bytearray([self.byte_decoder[c] for c in text])
- .decode("utf-8", errors="replace")
- .replace("", " ")
- )
- return text
-
- def __call__(self, texts, context_length=None):
- if not context_length:
- context_length = self.context_length
-
- if isinstance(texts, str):
- texts = [texts]
-
- sot_token = self.encoder["<|startoftext|>"]
- eot_token = self.encoder["<|endoftext|>"]
- all_tokens = [[sot_token] + self.encode(text) + [eot_token] for text in texts]
- result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
-
- for i, tokens in enumerate(all_tokens):
- tokens = tokens[:context_length]
- result[i, : len(tokens)] = torch.tensor(tokens)
-
- if len(result) == 1:
- return result[0]
- return result
-
-
-class IMUPreprocessor(VerboseNNModule):
- def __init__(
- self,
- kernel_size: int,
- imu_stem: PatchEmbedGeneric,
- embed_dim: int,
- img_size: List = (6, 2000),
- num_cls_tokens: int = 1,
- pos_embed_fn: Callable = None,
- init_param_style: str = "openclip",
- ) -> None:
- super().__init__()
- stem = imu_stem
- self.imu_stem = imu_stem
- self.embed_dim = embed_dim
- self.use_pos_embed = pos_embed_fn is not None
- self.num_cls_tokens = num_cls_tokens
- self.kernel_size = kernel_size
- self.pos_embed = nn.Parameter(
- torch.empty(1, (img_size[1] // kernel_size) + num_cls_tokens, embed_dim)
- )
-
- if self.num_cls_tokens > 0:
- self.cls_token = nn.Parameter(
- torch.zeros(1, self.num_cls_tokens, self.embed_dim)
- )
-
- self.init_parameters(init_param_style)
-
- @torch.no_grad()
- def init_parameters(self, init_param_style):
- nn.init.normal_(self.pos_embed, std=0.01)
-
- if init_param_style == "openclip":
- # OpenCLIP style initialization
- scale = self.embed_dim**-0.5
-
- if self.num_cls_tokens > 0:
- nn.init.normal_(self.cls_token)
- self.cls_token *= scale
- elif init_param_style == "vit":
- self.cls_token.data.fill_(0)
- else:
- raise ValueError(f"Unknown init {init_param_style}")
-
- def tokenize_input_and_cls_pos(self, input, stem):
- # tokens is of shape B x L x D
- tokens = stem.norm_layer(stem.proj(input))
- assert tokens.ndim == 3
- assert tokens.shape[2] == self.embed_dim
- B = tokens.shape[0]
- if self.num_cls_tokens > 0:
- class_tokens = self.cls_token.expand(
- B, -1, -1
- ) # stole class_tokens impl from Phil Wang, thanks
- tokens = torch.cat((class_tokens, tokens), dim=1)
- if self.use_pos_embed:
- tokens = tokens + self.pos_embed
- return tokens
-
- def forward(self, imu):
- # Patchify
- imu = imu.unfold(
- -1,
- self.kernel_size,
- self.kernel_size,
- ).permute(0, 2, 1, 3)
- imu = imu.reshape(imu.size(0), imu.size(1), -1)
-
- imu_tokens = self.tokenize_input_and_cls_pos(
- imu,
- self.imu_stem,
- )
-
- return_dict = {
- "trunk": {
- "tokens": imu_tokens,
- },
- "head": {},
- }
- return return_dict
diff --git a/spaces/RamAnanth1/T2I-Adapter/ldm/modules/image_degradation/utils_image.py b/spaces/RamAnanth1/T2I-Adapter/ldm/modules/image_degradation/utils_image.py
deleted file mode 100644
index 0175f155ad900ae33c3c46ed87f49b352e3faf98..0000000000000000000000000000000000000000
--- a/spaces/RamAnanth1/T2I-Adapter/ldm/modules/image_degradation/utils_image.py
+++ /dev/null
@@ -1,916 +0,0 @@
-import os
-import math
-import random
-import numpy as np
-import torch
-import cv2
-from torchvision.utils import make_grid
-from datetime import datetime
-#import matplotlib.pyplot as plt # TODO: check with Dominik, also bsrgan.py vs bsrgan_light.py
-
-
-os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
-
-
-'''
-# --------------------------------------------
-# Kai Zhang (github: https://github.com/cszn)
-# 03/Mar/2019
-# --------------------------------------------
-# https://github.com/twhui/SRGAN-pyTorch
-# https://github.com/xinntao/BasicSR
-# --------------------------------------------
-'''
-
-
-IMG_EXTENSIONS = ['.jpg', '.JPG', '.jpeg', '.JPEG', '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP', '.tif']
-
-
-def is_image_file(filename):
- return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
-
-
-def get_timestamp():
- return datetime.now().strftime('%y%m%d-%H%M%S')
-
-
-def imshow(x, title=None, cbar=False, figsize=None):
- plt.figure(figsize=figsize)
- plt.imshow(np.squeeze(x), interpolation='nearest', cmap='gray')
- if title:
- plt.title(title)
- if cbar:
- plt.colorbar()
- plt.show()
-
-
-def surf(Z, cmap='rainbow', figsize=None):
- plt.figure(figsize=figsize)
- ax3 = plt.axes(projection='3d')
-
- w, h = Z.shape[:2]
- xx = np.arange(0,w,1)
- yy = np.arange(0,h,1)
- X, Y = np.meshgrid(xx, yy)
- ax3.plot_surface(X,Y,Z,cmap=cmap)
- #ax3.contour(X,Y,Z, zdim='z',offset=-2,cmap=cmap)
- plt.show()
-
-
-'''
-# --------------------------------------------
-# get image pathes
-# --------------------------------------------
-'''
-
-
-def get_image_paths(dataroot):
- paths = None # return None if dataroot is None
- if dataroot is not None:
- paths = sorted(_get_paths_from_images(dataroot))
- return paths
-
-
-def _get_paths_from_images(path):
- assert os.path.isdir(path), '{:s} is not a valid directory'.format(path)
- images = []
- for dirpath, _, fnames in sorted(os.walk(path)):
- for fname in sorted(fnames):
- if is_image_file(fname):
- img_path = os.path.join(dirpath, fname)
- images.append(img_path)
- assert images, '{:s} has no valid image file'.format(path)
- return images
-
-
-'''
-# --------------------------------------------
-# split large images into small images
-# --------------------------------------------
-'''
-
-
-def patches_from_image(img, p_size=512, p_overlap=64, p_max=800):
- w, h = img.shape[:2]
- patches = []
- if w > p_max and h > p_max:
- w1 = list(np.arange(0, w-p_size, p_size-p_overlap, dtype=np.int))
- h1 = list(np.arange(0, h-p_size, p_size-p_overlap, dtype=np.int))
- w1.append(w-p_size)
- h1.append(h-p_size)
-# print(w1)
-# print(h1)
- for i in w1:
- for j in h1:
- patches.append(img[i:i+p_size, j:j+p_size,:])
- else:
- patches.append(img)
-
- return patches
-
-
-def imssave(imgs, img_path):
- """
- imgs: list, N images of size WxHxC
- """
- img_name, ext = os.path.splitext(os.path.basename(img_path))
-
- for i, img in enumerate(imgs):
- if img.ndim == 3:
- img = img[:, :, [2, 1, 0]]
- new_path = os.path.join(os.path.dirname(img_path), img_name+str('_s{:04d}'.format(i))+'.png')
- cv2.imwrite(new_path, img)
-
-
-def split_imageset(original_dataroot, taget_dataroot, n_channels=3, p_size=800, p_overlap=96, p_max=1000):
- """
- split the large images from original_dataroot into small overlapped images with size (p_size)x(p_size),
- and save them into taget_dataroot; only the images with larger size than (p_max)x(p_max)
- will be splitted.
- Args:
- original_dataroot:
- taget_dataroot:
- p_size: size of small images
- p_overlap: patch size in training is a good choice
- p_max: images with smaller size than (p_max)x(p_max) keep unchanged.
- """
- paths = get_image_paths(original_dataroot)
- for img_path in paths:
- # img_name, ext = os.path.splitext(os.path.basename(img_path))
- img = imread_uint(img_path, n_channels=n_channels)
- patches = patches_from_image(img, p_size, p_overlap, p_max)
- imssave(patches, os.path.join(taget_dataroot,os.path.basename(img_path)))
- #if original_dataroot == taget_dataroot:
- #del img_path
-
-'''
-# --------------------------------------------
-# makedir
-# --------------------------------------------
-'''
-
-
-def mkdir(path):
- if not os.path.exists(path):
- os.makedirs(path)
-
-
-def mkdirs(paths):
- if isinstance(paths, str):
- mkdir(paths)
- else:
- for path in paths:
- mkdir(path)
-
-
-def mkdir_and_rename(path):
- if os.path.exists(path):
- new_name = path + '_archived_' + get_timestamp()
- print('Path already exists. Rename it to [{:s}]'.format(new_name))
- os.rename(path, new_name)
- os.makedirs(path)
-
-
-'''
-# --------------------------------------------
-# read image from path
-# opencv is fast, but read BGR numpy image
-# --------------------------------------------
-'''
-
-
-# --------------------------------------------
-# get uint8 image of size HxWxn_channles (RGB)
-# --------------------------------------------
-def imread_uint(path, n_channels=3):
- # input: path
- # output: HxWx3(RGB or GGG), or HxWx1 (G)
- if n_channels == 1:
- img = cv2.imread(path, 0) # cv2.IMREAD_GRAYSCALE
- img = np.expand_dims(img, axis=2) # HxWx1
- elif n_channels == 3:
- img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # BGR or G
- if img.ndim == 2:
- img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB) # GGG
- else:
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # RGB
- return img
-
-
-# --------------------------------------------
-# matlab's imwrite
-# --------------------------------------------
-def imsave(img, img_path):
- img = np.squeeze(img)
- if img.ndim == 3:
- img = img[:, :, [2, 1, 0]]
- cv2.imwrite(img_path, img)
-
-def imwrite(img, img_path):
- img = np.squeeze(img)
- if img.ndim == 3:
- img = img[:, :, [2, 1, 0]]
- cv2.imwrite(img_path, img)
-
-
-
-# --------------------------------------------
-# get single image of size HxWxn_channles (BGR)
-# --------------------------------------------
-def read_img(path):
- # read image by cv2
- # return: Numpy float32, HWC, BGR, [0,1]
- img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # cv2.IMREAD_GRAYSCALE
- img = img.astype(np.float32) / 255.
- if img.ndim == 2:
- img = np.expand_dims(img, axis=2)
- # some images have 4 channels
- if img.shape[2] > 3:
- img = img[:, :, :3]
- return img
-
-
-'''
-# --------------------------------------------
-# image format conversion
-# --------------------------------------------
-# numpy(single) <---> numpy(unit)
-# numpy(single) <---> tensor
-# numpy(unit) <---> tensor
-# --------------------------------------------
-'''
-
-
-# --------------------------------------------
-# numpy(single) [0, 1] <---> numpy(unit)
-# --------------------------------------------
-
-
-def uint2single(img):
-
- return np.float32(img/255.)
-
-
-def single2uint(img):
-
- return np.uint8((img.clip(0, 1)*255.).round())
-
-
-def uint162single(img):
-
- return np.float32(img/65535.)
-
-
-def single2uint16(img):
-
- return np.uint16((img.clip(0, 1)*65535.).round())
-
-
-# --------------------------------------------
-# numpy(unit) (HxWxC or HxW) <---> tensor
-# --------------------------------------------
-
-
-# convert uint to 4-dimensional torch tensor
-def uint2tensor4(img):
- if img.ndim == 2:
- img = np.expand_dims(img, axis=2)
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.).unsqueeze(0)
-
-
-# convert uint to 3-dimensional torch tensor
-def uint2tensor3(img):
- if img.ndim == 2:
- img = np.expand_dims(img, axis=2)
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.)
-
-
-# convert 2/3/4-dimensional torch tensor to uint
-def tensor2uint(img):
- img = img.data.squeeze().float().clamp_(0, 1).cpu().numpy()
- if img.ndim == 3:
- img = np.transpose(img, (1, 2, 0))
- return np.uint8((img*255.0).round())
-
-
-# --------------------------------------------
-# numpy(single) (HxWxC) <---> tensor
-# --------------------------------------------
-
-
-# convert single (HxWxC) to 3-dimensional torch tensor
-def single2tensor3(img):
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float()
-
-
-# convert single (HxWxC) to 4-dimensional torch tensor
-def single2tensor4(img):
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().unsqueeze(0)
-
-
-# convert torch tensor to single
-def tensor2single(img):
- img = img.data.squeeze().float().cpu().numpy()
- if img.ndim == 3:
- img = np.transpose(img, (1, 2, 0))
-
- return img
-
-# convert torch tensor to single
-def tensor2single3(img):
- img = img.data.squeeze().float().cpu().numpy()
- if img.ndim == 3:
- img = np.transpose(img, (1, 2, 0))
- elif img.ndim == 2:
- img = np.expand_dims(img, axis=2)
- return img
-
-
-def single2tensor5(img):
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float().unsqueeze(0)
-
-
-def single32tensor5(img):
- return torch.from_numpy(np.ascontiguousarray(img)).float().unsqueeze(0).unsqueeze(0)
-
-
-def single42tensor4(img):
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float()
-
-
-# from skimage.io import imread, imsave
-def tensor2img(tensor, out_type=np.uint8, min_max=(0, 1)):
- '''
- Converts a torch Tensor into an image Numpy array of BGR channel order
- Input: 4D(B,(3/1),H,W), 3D(C,H,W), or 2D(H,W), any range, RGB channel order
- Output: 3D(H,W,C) or 2D(H,W), [0,255], np.uint8 (default)
- '''
- tensor = tensor.squeeze().float().cpu().clamp_(*min_max) # squeeze first, then clamp
- tensor = (tensor - min_max[0]) / (min_max[1] - min_max[0]) # to range [0,1]
- n_dim = tensor.dim()
- if n_dim == 4:
- n_img = len(tensor)
- img_np = make_grid(tensor, nrow=int(math.sqrt(n_img)), normalize=False).numpy()
- img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR
- elif n_dim == 3:
- img_np = tensor.numpy()
- img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR
- elif n_dim == 2:
- img_np = tensor.numpy()
- else:
- raise TypeError(
- 'Only support 4D, 3D and 2D tensor. But received with dimension: {:d}'.format(n_dim))
- if out_type == np.uint8:
- img_np = (img_np * 255.0).round()
- # Important. Unlike matlab, numpy.unit8() WILL NOT round by default.
- return img_np.astype(out_type)
-
-
-'''
-# --------------------------------------------
-# Augmentation, flipe and/or rotate
-# --------------------------------------------
-# The following two are enough.
-# (1) augmet_img: numpy image of WxHxC or WxH
-# (2) augment_img_tensor4: tensor image 1xCxWxH
-# --------------------------------------------
-'''
-
-
-def augment_img(img, mode=0):
- '''Kai Zhang (github: https://github.com/cszn)
- '''
- if mode == 0:
- return img
- elif mode == 1:
- return np.flipud(np.rot90(img))
- elif mode == 2:
- return np.flipud(img)
- elif mode == 3:
- return np.rot90(img, k=3)
- elif mode == 4:
- return np.flipud(np.rot90(img, k=2))
- elif mode == 5:
- return np.rot90(img)
- elif mode == 6:
- return np.rot90(img, k=2)
- elif mode == 7:
- return np.flipud(np.rot90(img, k=3))
-
-
-def augment_img_tensor4(img, mode=0):
- '''Kai Zhang (github: https://github.com/cszn)
- '''
- if mode == 0:
- return img
- elif mode == 1:
- return img.rot90(1, [2, 3]).flip([2])
- elif mode == 2:
- return img.flip([2])
- elif mode == 3:
- return img.rot90(3, [2, 3])
- elif mode == 4:
- return img.rot90(2, [2, 3]).flip([2])
- elif mode == 5:
- return img.rot90(1, [2, 3])
- elif mode == 6:
- return img.rot90(2, [2, 3])
- elif mode == 7:
- return img.rot90(3, [2, 3]).flip([2])
-
-
-def augment_img_tensor(img, mode=0):
- '''Kai Zhang (github: https://github.com/cszn)
- '''
- img_size = img.size()
- img_np = img.data.cpu().numpy()
- if len(img_size) == 3:
- img_np = np.transpose(img_np, (1, 2, 0))
- elif len(img_size) == 4:
- img_np = np.transpose(img_np, (2, 3, 1, 0))
- img_np = augment_img(img_np, mode=mode)
- img_tensor = torch.from_numpy(np.ascontiguousarray(img_np))
- if len(img_size) == 3:
- img_tensor = img_tensor.permute(2, 0, 1)
- elif len(img_size) == 4:
- img_tensor = img_tensor.permute(3, 2, 0, 1)
-
- return img_tensor.type_as(img)
-
-
-def augment_img_np3(img, mode=0):
- if mode == 0:
- return img
- elif mode == 1:
- return img.transpose(1, 0, 2)
- elif mode == 2:
- return img[::-1, :, :]
- elif mode == 3:
- img = img[::-1, :, :]
- img = img.transpose(1, 0, 2)
- return img
- elif mode == 4:
- return img[:, ::-1, :]
- elif mode == 5:
- img = img[:, ::-1, :]
- img = img.transpose(1, 0, 2)
- return img
- elif mode == 6:
- img = img[:, ::-1, :]
- img = img[::-1, :, :]
- return img
- elif mode == 7:
- img = img[:, ::-1, :]
- img = img[::-1, :, :]
- img = img.transpose(1, 0, 2)
- return img
-
-
-def augment_imgs(img_list, hflip=True, rot=True):
- # horizontal flip OR rotate
- hflip = hflip and random.random() < 0.5
- vflip = rot and random.random() < 0.5
- rot90 = rot and random.random() < 0.5
-
- def _augment(img):
- if hflip:
- img = img[:, ::-1, :]
- if vflip:
- img = img[::-1, :, :]
- if rot90:
- img = img.transpose(1, 0, 2)
- return img
-
- return [_augment(img) for img in img_list]
-
-
-'''
-# --------------------------------------------
-# modcrop and shave
-# --------------------------------------------
-'''
-
-
-def modcrop(img_in, scale):
- # img_in: Numpy, HWC or HW
- img = np.copy(img_in)
- if img.ndim == 2:
- H, W = img.shape
- H_r, W_r = H % scale, W % scale
- img = img[:H - H_r, :W - W_r]
- elif img.ndim == 3:
- H, W, C = img.shape
- H_r, W_r = H % scale, W % scale
- img = img[:H - H_r, :W - W_r, :]
- else:
- raise ValueError('Wrong img ndim: [{:d}].'.format(img.ndim))
- return img
-
-
-def shave(img_in, border=0):
- # img_in: Numpy, HWC or HW
- img = np.copy(img_in)
- h, w = img.shape[:2]
- img = img[border:h-border, border:w-border]
- return img
-
-
-'''
-# --------------------------------------------
-# image processing process on numpy image
-# channel_convert(in_c, tar_type, img_list):
-# rgb2ycbcr(img, only_y=True):
-# bgr2ycbcr(img, only_y=True):
-# ycbcr2rgb(img):
-# --------------------------------------------
-'''
-
-
-def rgb2ycbcr(img, only_y=True):
- '''same as matlab rgb2ycbcr
- only_y: only return Y channel
- Input:
- uint8, [0, 255]
- float, [0, 1]
- '''
- in_img_type = img.dtype
- img.astype(np.float32)
- if in_img_type != np.uint8:
- img *= 255.
- # convert
- if only_y:
- rlt = np.dot(img, [65.481, 128.553, 24.966]) / 255.0 + 16.0
- else:
- rlt = np.matmul(img, [[65.481, -37.797, 112.0], [128.553, -74.203, -93.786],
- [24.966, 112.0, -18.214]]) / 255.0 + [16, 128, 128]
- if in_img_type == np.uint8:
- rlt = rlt.round()
- else:
- rlt /= 255.
- return rlt.astype(in_img_type)
-
-
-def ycbcr2rgb(img):
- '''same as matlab ycbcr2rgb
- Input:
- uint8, [0, 255]
- float, [0, 1]
- '''
- in_img_type = img.dtype
- img.astype(np.float32)
- if in_img_type != np.uint8:
- img *= 255.
- # convert
- rlt = np.matmul(img, [[0.00456621, 0.00456621, 0.00456621], [0, -0.00153632, 0.00791071],
- [0.00625893, -0.00318811, 0]]) * 255.0 + [-222.921, 135.576, -276.836]
- if in_img_type == np.uint8:
- rlt = rlt.round()
- else:
- rlt /= 255.
- return rlt.astype(in_img_type)
-
-
-def bgr2ycbcr(img, only_y=True):
- '''bgr version of rgb2ycbcr
- only_y: only return Y channel
- Input:
- uint8, [0, 255]
- float, [0, 1]
- '''
- in_img_type = img.dtype
- img.astype(np.float32)
- if in_img_type != np.uint8:
- img *= 255.
- # convert
- if only_y:
- rlt = np.dot(img, [24.966, 128.553, 65.481]) / 255.0 + 16.0
- else:
- rlt = np.matmul(img, [[24.966, 112.0, -18.214], [128.553, -74.203, -93.786],
- [65.481, -37.797, 112.0]]) / 255.0 + [16, 128, 128]
- if in_img_type == np.uint8:
- rlt = rlt.round()
- else:
- rlt /= 255.
- return rlt.astype(in_img_type)
-
-
-def channel_convert(in_c, tar_type, img_list):
- # conversion among BGR, gray and y
- if in_c == 3 and tar_type == 'gray': # BGR to gray
- gray_list = [cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) for img in img_list]
- return [np.expand_dims(img, axis=2) for img in gray_list]
- elif in_c == 3 and tar_type == 'y': # BGR to y
- y_list = [bgr2ycbcr(img, only_y=True) for img in img_list]
- return [np.expand_dims(img, axis=2) for img in y_list]
- elif in_c == 1 and tar_type == 'RGB': # gray/y to BGR
- return [cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) for img in img_list]
- else:
- return img_list
-
-
-'''
-# --------------------------------------------
-# metric, PSNR and SSIM
-# --------------------------------------------
-'''
-
-
-# --------------------------------------------
-# PSNR
-# --------------------------------------------
-def calculate_psnr(img1, img2, border=0):
- # img1 and img2 have range [0, 255]
- #img1 = img1.squeeze()
- #img2 = img2.squeeze()
- if not img1.shape == img2.shape:
- raise ValueError('Input images must have the same dimensions.')
- h, w = img1.shape[:2]
- img1 = img1[border:h-border, border:w-border]
- img2 = img2[border:h-border, border:w-border]
-
- img1 = img1.astype(np.float64)
- img2 = img2.astype(np.float64)
- mse = np.mean((img1 - img2)**2)
- if mse == 0:
- return float('inf')
- return 20 * math.log10(255.0 / math.sqrt(mse))
-
-
-# --------------------------------------------
-# SSIM
-# --------------------------------------------
-def calculate_ssim(img1, img2, border=0):
- '''calculate SSIM
- the same outputs as MATLAB's
- img1, img2: [0, 255]
- '''
- #img1 = img1.squeeze()
- #img2 = img2.squeeze()
- if not img1.shape == img2.shape:
- raise ValueError('Input images must have the same dimensions.')
- h, w = img1.shape[:2]
- img1 = img1[border:h-border, border:w-border]
- img2 = img2[border:h-border, border:w-border]
-
- if img1.ndim == 2:
- return ssim(img1, img2)
- elif img1.ndim == 3:
- if img1.shape[2] == 3:
- ssims = []
- for i in range(3):
- ssims.append(ssim(img1[:,:,i], img2[:,:,i]))
- return np.array(ssims).mean()
- elif img1.shape[2] == 1:
- return ssim(np.squeeze(img1), np.squeeze(img2))
- else:
- raise ValueError('Wrong input image dimensions.')
-
-
-def ssim(img1, img2):
- C1 = (0.01 * 255)**2
- C2 = (0.03 * 255)**2
-
- img1 = img1.astype(np.float64)
- img2 = img2.astype(np.float64)
- kernel = cv2.getGaussianKernel(11, 1.5)
- window = np.outer(kernel, kernel.transpose())
-
- mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5] # valid
- mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]
- mu1_sq = mu1**2
- mu2_sq = mu2**2
- mu1_mu2 = mu1 * mu2
- sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq
- sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq
- sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2
-
- ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) *
- (sigma1_sq + sigma2_sq + C2))
- return ssim_map.mean()
-
-
-'''
-# --------------------------------------------
-# matlab's bicubic imresize (numpy and torch) [0, 1]
-# --------------------------------------------
-'''
-
-
-# matlab 'imresize' function, now only support 'bicubic'
-def cubic(x):
- absx = torch.abs(x)
- absx2 = absx**2
- absx3 = absx**3
- return (1.5*absx3 - 2.5*absx2 + 1) * ((absx <= 1).type_as(absx)) + \
- (-0.5*absx3 + 2.5*absx2 - 4*absx + 2) * (((absx > 1)*(absx <= 2)).type_as(absx))
-
-
-def calculate_weights_indices(in_length, out_length, scale, kernel, kernel_width, antialiasing):
- if (scale < 1) and (antialiasing):
- # Use a modified kernel to simultaneously interpolate and antialias- larger kernel width
- kernel_width = kernel_width / scale
-
- # Output-space coordinates
- x = torch.linspace(1, out_length, out_length)
-
- # Input-space coordinates. Calculate the inverse mapping such that 0.5
- # in output space maps to 0.5 in input space, and 0.5+scale in output
- # space maps to 1.5 in input space.
- u = x / scale + 0.5 * (1 - 1 / scale)
-
- # What is the left-most pixel that can be involved in the computation?
- left = torch.floor(u - kernel_width / 2)
-
- # What is the maximum number of pixels that can be involved in the
- # computation? Note: it's OK to use an extra pixel here; if the
- # corresponding weights are all zero, it will be eliminated at the end
- # of this function.
- P = math.ceil(kernel_width) + 2
-
- # The indices of the input pixels involved in computing the k-th output
- # pixel are in row k of the indices matrix.
- indices = left.view(out_length, 1).expand(out_length, P) + torch.linspace(0, P - 1, P).view(
- 1, P).expand(out_length, P)
-
- # The weights used to compute the k-th output pixel are in row k of the
- # weights matrix.
- distance_to_center = u.view(out_length, 1).expand(out_length, P) - indices
- # apply cubic kernel
- if (scale < 1) and (antialiasing):
- weights = scale * cubic(distance_to_center * scale)
- else:
- weights = cubic(distance_to_center)
- # Normalize the weights matrix so that each row sums to 1.
- weights_sum = torch.sum(weights, 1).view(out_length, 1)
- weights = weights / weights_sum.expand(out_length, P)
-
- # If a column in weights is all zero, get rid of it. only consider the first and last column.
- weights_zero_tmp = torch.sum((weights == 0), 0)
- if not math.isclose(weights_zero_tmp[0], 0, rel_tol=1e-6):
- indices = indices.narrow(1, 1, P - 2)
- weights = weights.narrow(1, 1, P - 2)
- if not math.isclose(weights_zero_tmp[-1], 0, rel_tol=1e-6):
- indices = indices.narrow(1, 0, P - 2)
- weights = weights.narrow(1, 0, P - 2)
- weights = weights.contiguous()
- indices = indices.contiguous()
- sym_len_s = -indices.min() + 1
- sym_len_e = indices.max() - in_length
- indices = indices + sym_len_s - 1
- return weights, indices, int(sym_len_s), int(sym_len_e)
-
-
-# --------------------------------------------
-# imresize for tensor image [0, 1]
-# --------------------------------------------
-def imresize(img, scale, antialiasing=True):
- # Now the scale should be the same for H and W
- # input: img: pytorch tensor, CHW or HW [0,1]
- # output: CHW or HW [0,1] w/o round
- need_squeeze = True if img.dim() == 2 else False
- if need_squeeze:
- img.unsqueeze_(0)
- in_C, in_H, in_W = img.size()
- out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
- kernel_width = 4
- kernel = 'cubic'
-
- # Return the desired dimension order for performing the resize. The
- # strategy is to perform the resize first along the dimension with the
- # smallest scale factor.
- # Now we do not support this.
-
- # get weights and indices
- weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
- in_H, out_H, scale, kernel, kernel_width, antialiasing)
- weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
- in_W, out_W, scale, kernel, kernel_width, antialiasing)
- # process H dimension
- # symmetric copying
- img_aug = torch.FloatTensor(in_C, in_H + sym_len_Hs + sym_len_He, in_W)
- img_aug.narrow(1, sym_len_Hs, in_H).copy_(img)
-
- sym_patch = img[:, :sym_len_Hs, :]
- inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(1, inv_idx)
- img_aug.narrow(1, 0, sym_len_Hs).copy_(sym_patch_inv)
-
- sym_patch = img[:, -sym_len_He:, :]
- inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(1, inv_idx)
- img_aug.narrow(1, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
-
- out_1 = torch.FloatTensor(in_C, out_H, in_W)
- kernel_width = weights_H.size(1)
- for i in range(out_H):
- idx = int(indices_H[i][0])
- for j in range(out_C):
- out_1[j, i, :] = img_aug[j, idx:idx + kernel_width, :].transpose(0, 1).mv(weights_H[i])
-
- # process W dimension
- # symmetric copying
- out_1_aug = torch.FloatTensor(in_C, out_H, in_W + sym_len_Ws + sym_len_We)
- out_1_aug.narrow(2, sym_len_Ws, in_W).copy_(out_1)
-
- sym_patch = out_1[:, :, :sym_len_Ws]
- inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(2, inv_idx)
- out_1_aug.narrow(2, 0, sym_len_Ws).copy_(sym_patch_inv)
-
- sym_patch = out_1[:, :, -sym_len_We:]
- inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(2, inv_idx)
- out_1_aug.narrow(2, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
-
- out_2 = torch.FloatTensor(in_C, out_H, out_W)
- kernel_width = weights_W.size(1)
- for i in range(out_W):
- idx = int(indices_W[i][0])
- for j in range(out_C):
- out_2[j, :, i] = out_1_aug[j, :, idx:idx + kernel_width].mv(weights_W[i])
- if need_squeeze:
- out_2.squeeze_()
- return out_2
-
-
-# --------------------------------------------
-# imresize for numpy image [0, 1]
-# --------------------------------------------
-def imresize_np(img, scale, antialiasing=True):
- # Now the scale should be the same for H and W
- # input: img: Numpy, HWC or HW [0,1]
- # output: HWC or HW [0,1] w/o round
- img = torch.from_numpy(img)
- need_squeeze = True if img.dim() == 2 else False
- if need_squeeze:
- img.unsqueeze_(2)
-
- in_H, in_W, in_C = img.size()
- out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
- kernel_width = 4
- kernel = 'cubic'
-
- # Return the desired dimension order for performing the resize. The
- # strategy is to perform the resize first along the dimension with the
- # smallest scale factor.
- # Now we do not support this.
-
- # get weights and indices
- weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
- in_H, out_H, scale, kernel, kernel_width, antialiasing)
- weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
- in_W, out_W, scale, kernel, kernel_width, antialiasing)
- # process H dimension
- # symmetric copying
- img_aug = torch.FloatTensor(in_H + sym_len_Hs + sym_len_He, in_W, in_C)
- img_aug.narrow(0, sym_len_Hs, in_H).copy_(img)
-
- sym_patch = img[:sym_len_Hs, :, :]
- inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(0, inv_idx)
- img_aug.narrow(0, 0, sym_len_Hs).copy_(sym_patch_inv)
-
- sym_patch = img[-sym_len_He:, :, :]
- inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(0, inv_idx)
- img_aug.narrow(0, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
-
- out_1 = torch.FloatTensor(out_H, in_W, in_C)
- kernel_width = weights_H.size(1)
- for i in range(out_H):
- idx = int(indices_H[i][0])
- for j in range(out_C):
- out_1[i, :, j] = img_aug[idx:idx + kernel_width, :, j].transpose(0, 1).mv(weights_H[i])
-
- # process W dimension
- # symmetric copying
- out_1_aug = torch.FloatTensor(out_H, in_W + sym_len_Ws + sym_len_We, in_C)
- out_1_aug.narrow(1, sym_len_Ws, in_W).copy_(out_1)
-
- sym_patch = out_1[:, :sym_len_Ws, :]
- inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(1, inv_idx)
- out_1_aug.narrow(1, 0, sym_len_Ws).copy_(sym_patch_inv)
-
- sym_patch = out_1[:, -sym_len_We:, :]
- inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(1, inv_idx)
- out_1_aug.narrow(1, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
-
- out_2 = torch.FloatTensor(out_H, out_W, in_C)
- kernel_width = weights_W.size(1)
- for i in range(out_W):
- idx = int(indices_W[i][0])
- for j in range(out_C):
- out_2[:, i, j] = out_1_aug[:, idx:idx + kernel_width, j].mv(weights_W[i])
- if need_squeeze:
- out_2.squeeze_()
-
- return out_2.numpy()
-
-
-if __name__ == '__main__':
- print('---')
-# img = imread_uint('test.bmp', 3)
-# img = uint2single(img)
-# img_bicubic = imresize_np(img, 1/4)
\ No newline at end of file
diff --git a/spaces/Rbrq/DeticChatGPT/tools/create_imagenetlvis_json.py b/spaces/Rbrq/DeticChatGPT/tools/create_imagenetlvis_json.py
deleted file mode 100644
index 4d5a0b3712b5a2fb94737b8dfe5d70202305926b..0000000000000000000000000000000000000000
--- a/spaces/Rbrq/DeticChatGPT/tools/create_imagenetlvis_json.py
+++ /dev/null
@@ -1,52 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import argparse
-import json
-import os
-import cv2
-from nltk.corpus import wordnet
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--imagenet_path', default='datasets/imagenet/ImageNet-LVIS')
- parser.add_argument('--lvis_meta_path', default='datasets/lvis/lvis_v1_val.json')
- parser.add_argument('--out_path', default='datasets/imagenet/annotations/imagenet_lvis_image_info.json')
- args = parser.parse_args()
-
- print('Loading LVIS meta')
- data = json.load(open(args.lvis_meta_path, 'r'))
- print('Done')
- synset2cat = {x['synset']: x for x in data['categories']}
- count = 0
- images = []
- image_counts = {}
- folders = sorted(os.listdir(args.imagenet_path))
- for i, folder in enumerate(folders):
- class_path = args.imagenet_path + folder
- files = sorted(os.listdir(class_path))
- synset = wordnet.synset_from_pos_and_offset('n', int(folder[1:])).name()
- cat = synset2cat[synset]
- cat_id = cat['id']
- cat_name = cat['name']
- cat_images = []
- for file in files:
- count = count + 1
- file_name = '{}/{}'.format(folder, file)
- img = cv2.imread('{}/{}'.format(args.imagenet_path, file_name))
- h, w = img.shape[:2]
- image = {
- 'id': count,
- 'file_name': file_name,
- 'pos_category_ids': [cat_id],
- 'width': w,
- 'height': h
- }
- cat_images.append(image)
- images.extend(cat_images)
- image_counts[cat_id] = len(cat_images)
- print(i, cat_name, len(cat_images))
- print('# Images', len(images))
- for x in data['categories']:
- x['image_count'] = image_counts[x['id']] if x['id'] in image_counts else 0
- out = {'categories': data['categories'], 'images': images, 'annotations': []}
- print('Writing to', args.out_path)
- json.dump(out, open(args.out_path, 'w'))
diff --git a/spaces/Realcat/image-matching-webui/third_party/SOLD2/sold2/model/nets/descriptor_decoder.py b/spaces/Realcat/image-matching-webui/third_party/SOLD2/sold2/model/nets/descriptor_decoder.py
deleted file mode 100644
index 449bac37e6b0e6ff7802c0dbcea92f4829786578..0000000000000000000000000000000000000000
--- a/spaces/Realcat/image-matching-webui/third_party/SOLD2/sold2/model/nets/descriptor_decoder.py
+++ /dev/null
@@ -1,20 +0,0 @@
-import torch
-import torch.nn as nn
-
-
-class SuperpointDescriptor(nn.Module):
- """Descriptor decoder based on the SuperPoint arcihtecture."""
-
- def __init__(self, input_feat_dim=128):
- super(SuperpointDescriptor, self).__init__()
- self.relu = torch.nn.ReLU(inplace=True)
- self.convPa = torch.nn.Conv2d(
- input_feat_dim, 256, kernel_size=3, stride=1, padding=1
- )
- self.convPb = torch.nn.Conv2d(256, 128, kernel_size=1, stride=1, padding=0)
-
- def forward(self, input_features):
- feat = self.relu(self.convPa(input_features))
- semi = self.convPb(feat)
-
- return semi
diff --git a/spaces/Redgon/bingo/src/lib/hooks/use-copy-to-clipboard.tsx b/spaces/Redgon/bingo/src/lib/hooks/use-copy-to-clipboard.tsx
deleted file mode 100644
index 62f7156dca246c46b213151af003a3a177977ccf..0000000000000000000000000000000000000000
--- a/spaces/Redgon/bingo/src/lib/hooks/use-copy-to-clipboard.tsx
+++ /dev/null
@@ -1,33 +0,0 @@
-'use client'
-
-import * as React from 'react'
-
-export interface useCopyToClipboardProps {
- timeout?: number
-}
-
-export function useCopyToClipboard({
- timeout = 2000
-}: useCopyToClipboardProps) {
- const [isCopied, setIsCopied] = React.useState(false)
-
- const copyToClipboard = (value: string) => {
- if (typeof window === 'undefined' || !navigator.clipboard?.writeText) {
- return
- }
-
- if (!value) {
- return
- }
-
- navigator.clipboard.writeText(value).then(() => {
- setIsCopied(true)
-
- setTimeout(() => {
- setIsCopied(false)
- }, timeout)
- })
- }
-
- return { isCopied, copyToClipboard }
-}
diff --git a/spaces/Rimi98/NegativeCommentClassifier/app.py b/spaces/Rimi98/NegativeCommentClassifier/app.py
deleted file mode 100644
index 8f4d3ab9a8d978b6408e97dad5257354c9b7a7e6..0000000000000000000000000000000000000000
--- a/spaces/Rimi98/NegativeCommentClassifier/app.py
+++ /dev/null
@@ -1,24 +0,0 @@
-import gradio as gr
-import onnxruntime
-from transformers import AutoTokenizer
-import torch, json
-
-token = AutoTokenizer.from_pretrained('distilroberta-base')
-
-types = ['Toxic','Severe_toxic','Obscene','Threat','Insult','Identity_hate']
-
-inf_session = onnxruntime.InferenceSession('classifier-quantized.onnx')
-input_name = inf_session.get_inputs()[0].name
-output_name = inf_session.get_outputs()[0].name
-
-def classify(review):
- input_ids = token(review)['input_ids'][:512]
- logits = inf_session.run([output_name], {input_name: [input_ids]})[0]
- logits = torch.FloatTensor(logits)
- probs = torch.sigmoid(logits)[0]
- return dict(zip(types, map(float, probs)))
-
-
-label = gr.outputs.Label(num_top_classes=5)
-iface = gr.Interface(fn=classify, inputs="text", outputs=label)
-iface.launch(inline=False)
\ No newline at end of file
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmcv/ops/voxelize.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmcv/ops/voxelize.py
deleted file mode 100644
index ca3226a4fbcbfe58490fa2ea8e1c16b531214121..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmcv/ops/voxelize.py
+++ /dev/null
@@ -1,132 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-from torch import nn
-from torch.autograd import Function
-from torch.nn.modules.utils import _pair
-
-from ..utils import ext_loader
-
-ext_module = ext_loader.load_ext(
- '_ext', ['dynamic_voxelize_forward', 'hard_voxelize_forward'])
-
-
-class _Voxelization(Function):
-
- @staticmethod
- def forward(ctx,
- points,
- voxel_size,
- coors_range,
- max_points=35,
- max_voxels=20000):
- """Convert kitti points(N, >=3) to voxels.
-
- Args:
- points (torch.Tensor): [N, ndim]. Points[:, :3] contain xyz points
- and points[:, 3:] contain other information like reflectivity.
- voxel_size (tuple or float): The size of voxel with the shape of
- [3].
- coors_range (tuple or float): The coordinate range of voxel with
- the shape of [6].
- max_points (int, optional): maximum points contained in a voxel. if
- max_points=-1, it means using dynamic_voxelize. Default: 35.
- max_voxels (int, optional): maximum voxels this function create.
- for second, 20000 is a good choice. Users should shuffle points
- before call this function because max_voxels may drop points.
- Default: 20000.
-
- Returns:
- voxels_out (torch.Tensor): Output voxels with the shape of [M,
- max_points, ndim]. Only contain points and returned when
- max_points != -1.
- coors_out (torch.Tensor): Output coordinates with the shape of
- [M, 3].
- num_points_per_voxel_out (torch.Tensor): Num points per voxel with
- the shape of [M]. Only returned when max_points != -1.
- """
- if max_points == -1 or max_voxels == -1:
- coors = points.new_zeros(size=(points.size(0), 3), dtype=torch.int)
- ext_module.dynamic_voxelize_forward(points, coors, voxel_size,
- coors_range, 3)
- return coors
- else:
- voxels = points.new_zeros(
- size=(max_voxels, max_points, points.size(1)))
- coors = points.new_zeros(size=(max_voxels, 3), dtype=torch.int)
- num_points_per_voxel = points.new_zeros(
- size=(max_voxels, ), dtype=torch.int)
- voxel_num = ext_module.hard_voxelize_forward(
- points, voxels, coors, num_points_per_voxel, voxel_size,
- coors_range, max_points, max_voxels, 3)
- # select the valid voxels
- voxels_out = voxels[:voxel_num]
- coors_out = coors[:voxel_num]
- num_points_per_voxel_out = num_points_per_voxel[:voxel_num]
- return voxels_out, coors_out, num_points_per_voxel_out
-
-
-voxelization = _Voxelization.apply
-
-
-class Voxelization(nn.Module):
- """Convert kitti points(N, >=3) to voxels.
-
- Please refer to `PVCNN `_ for more
- details.
-
- Args:
- voxel_size (tuple or float): The size of voxel with the shape of [3].
- point_cloud_range (tuple or float): The coordinate range of voxel with
- the shape of [6].
- max_num_points (int): maximum points contained in a voxel. if
- max_points=-1, it means using dynamic_voxelize.
- max_voxels (int, optional): maximum voxels this function create.
- for second, 20000 is a good choice. Users should shuffle points
- before call this function because max_voxels may drop points.
- Default: 20000.
- """
-
- def __init__(self,
- voxel_size,
- point_cloud_range,
- max_num_points,
- max_voxels=20000):
- super().__init__()
-
- self.voxel_size = voxel_size
- self.point_cloud_range = point_cloud_range
- self.max_num_points = max_num_points
- if isinstance(max_voxels, tuple):
- self.max_voxels = max_voxels
- else:
- self.max_voxels = _pair(max_voxels)
-
- point_cloud_range = torch.tensor(
- point_cloud_range, dtype=torch.float32)
- voxel_size = torch.tensor(voxel_size, dtype=torch.float32)
- grid_size = (point_cloud_range[3:] -
- point_cloud_range[:3]) / voxel_size
- grid_size = torch.round(grid_size).long()
- input_feat_shape = grid_size[:2]
- self.grid_size = grid_size
- # the origin shape is as [x-len, y-len, z-len]
- # [w, h, d] -> [d, h, w]
- self.pcd_shape = [*input_feat_shape, 1][::-1]
-
- def forward(self, input):
- if self.training:
- max_voxels = self.max_voxels[0]
- else:
- max_voxels = self.max_voxels[1]
-
- return voxelization(input, self.voxel_size, self.point_cloud_range,
- self.max_num_points, max_voxels)
-
- def __repr__(self):
- s = self.__class__.__name__ + '('
- s += 'voxel_size=' + str(self.voxel_size)
- s += ', point_cloud_range=' + str(self.point_cloud_range)
- s += ', max_num_points=' + str(self.max_num_points)
- s += ', max_voxels=' + str(self.max_voxels)
- s += ')'
- return s
diff --git a/spaces/Seogmin/NLP/style.css b/spaces/Seogmin/NLP/style.css
deleted file mode 100644
index 114adf441e9032febb46bc056b2a8bb651075f0d..0000000000000000000000000000000000000000
--- a/spaces/Seogmin/NLP/style.css
+++ /dev/null
@@ -1,28 +0,0 @@
-body {
- padding: 2rem;
- font-family: -apple-system, BlinkMacSystemFont, "Arial", sans-serif;
-}
-
-h1 {
- font-size: 16px;
- margin-top: 0;
-}
-
-p {
- color: rgb(107, 114, 128);
- font-size: 15px;
- margin-bottom: 10px;
- margin-top: 5px;
-}
-
-.card {
- max-width: 620px;
- margin: 0 auto;
- padding: 16px;
- border: 1px solid lightgray;
- border-radius: 16px;
-}
-
-.card p:last-child {
- margin-bottom: 0;
-}
diff --git a/spaces/ServerX/PorcoDiaz/infer/modules/train/extract/extract_f0_rmvpe_dml.py b/spaces/ServerX/PorcoDiaz/infer/modules/train/extract/extract_f0_rmvpe_dml.py
deleted file mode 100644
index 6abb1898550664ca600cebbb6d37ba0de8a3d312..0000000000000000000000000000000000000000
--- a/spaces/ServerX/PorcoDiaz/infer/modules/train/extract/extract_f0_rmvpe_dml.py
+++ /dev/null
@@ -1,139 +0,0 @@
-import os
-import sys
-import traceback
-
-import parselmouth
-
-now_dir = os.getcwd()
-sys.path.append(now_dir)
-import logging
-
-import numpy as np
-import pyworld
-
-from infer.lib.audio import load_audio
-
-logging.getLogger("numba").setLevel(logging.WARNING)
-
-exp_dir = sys.argv[1]
-import torch_directml
-
-device = torch_directml.device(torch_directml.default_device())
-f = open("%s/extract_f0_feature.log" % exp_dir, "a+")
-
-
-def printt(strr):
- print(strr)
- f.write("%s\n" % strr)
- f.flush()
-
-
-class FeatureInput(object):
- def __init__(self, samplerate=16000, hop_size=160):
- self.fs = samplerate
- self.hop = hop_size
-
- self.f0_bin = 256
- self.f0_max = 1100.0
- self.f0_min = 50.0
- self.f0_mel_min = 1127 * np.log(1 + self.f0_min / 700)
- self.f0_mel_max = 1127 * np.log(1 + self.f0_max / 700)
-
- def compute_f0(self, path, f0_method):
- x = load_audio(path, self.fs)
- # p_len = x.shape[0] // self.hop
- if f0_method == "rmvpe":
- if hasattr(self, "model_rmvpe") == False:
- from infer.lib.rmvpe import RMVPE
-
- print("Loading rmvpe model")
- self.model_rmvpe = RMVPE(
- "assets/rmvpe/rmvpe.pt", is_half=False, device=device
- )
- f0 = self.model_rmvpe.infer_from_audio(x, thred=0.03)
- return f0
-
- def coarse_f0(self, f0):
- f0_mel = 1127 * np.log(1 + f0 / 700)
- f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - self.f0_mel_min) * (
- self.f0_bin - 2
- ) / (self.f0_mel_max - self.f0_mel_min) + 1
-
- # use 0 or 1
- f0_mel[f0_mel <= 1] = 1
- f0_mel[f0_mel > self.f0_bin - 1] = self.f0_bin - 1
- f0_coarse = np.rint(f0_mel).astype(int)
- assert f0_coarse.max() <= 255 and f0_coarse.min() >= 1, (
- f0_coarse.max(),
- f0_coarse.min(),
- )
- return f0_coarse
-
- def go(self, paths, f0_method):
- if len(paths) == 0:
- printt("no-f0-todo")
- else:
- printt("todo-f0-%s" % len(paths))
- n = max(len(paths) // 5, 1) # 每个进程最多打印5条
- for idx, (inp_path, opt_path1, opt_path2) in enumerate(paths):
- try:
- if idx % n == 0:
- printt("f0ing,now-%s,all-%s,-%s" % (idx, len(paths), inp_path))
- if (
- os.path.exists(opt_path1 + ".npy") == True
- and os.path.exists(opt_path2 + ".npy") == True
- ):
- continue
- featur_pit = self.compute_f0(inp_path, f0_method)
- np.save(
- opt_path2,
- featur_pit,
- allow_pickle=False,
- ) # nsf
- coarse_pit = self.coarse_f0(featur_pit)
- np.save(
- opt_path1,
- coarse_pit,
- allow_pickle=False,
- ) # ori
- except:
- printt("f0fail-%s-%s-%s" % (idx, inp_path, traceback.format_exc()))
-
-
-if __name__ == "__main__":
- # exp_dir=r"E:\codes\py39\dataset\mi-test"
- # n_p=16
- # f = open("%s/log_extract_f0.log"%exp_dir, "w")
- printt(sys.argv)
- featureInput = FeatureInput()
- paths = []
- inp_root = "%s/1_16k_wavs" % (exp_dir)
- opt_root1 = "%s/2a_f0" % (exp_dir)
- opt_root2 = "%s/2b-f0nsf" % (exp_dir)
-
- os.makedirs(opt_root1, exist_ok=True)
- os.makedirs(opt_root2, exist_ok=True)
- for name in sorted(list(os.listdir(inp_root))):
- inp_path = "%s/%s" % (inp_root, name)
- if "spec" in inp_path:
- continue
- opt_path1 = "%s/%s" % (opt_root1, name)
- opt_path2 = "%s/%s" % (opt_root2, name)
- paths.append([inp_path, opt_path1, opt_path2])
- try:
- featureInput.go(paths, "rmvpe")
- except:
- printt("f0_all_fail-%s" % (traceback.format_exc()))
- # ps = []
- # for i in range(n_p):
- # p = Process(
- # target=featureInput.go,
- # args=(
- # paths[i::n_p],
- # f0method,
- # ),
- # )
- # ps.append(p)
- # p.start()
- # for i in range(n_p):
- # ps[i].join()
diff --git a/spaces/Shashashasha/so-vits-fork-yoshi/app.py b/spaces/Shashashasha/so-vits-fork-yoshi/app.py
deleted file mode 100644
index e9c63ca337f8dd0267d2e3fec65fd9c713a7f61b..0000000000000000000000000000000000000000
--- a/spaces/Shashashasha/so-vits-fork-yoshi/app.py
+++ /dev/null
@@ -1,120 +0,0 @@
-import json
-from pathlib import Path
-
-import gradio as gr
-import librosa
-import numpy as np
-import torch
-from huggingface_hub import hf_hub_download, list_repo_files
-from so_vits_svc_fork.hparams import HParams
-from so_vits_svc_fork.inference.core import Svc
-
-##########################################################
-# REPLACE THESE VALUES TO CHANGE THE MODEL REPO/CKPT NAME
-##########################################################
-repo_id = "Shashashasha/yoshi"
-ckpt_name = None # None will pick latest
-##########################################################
-
-# Figure out the latest generator by taking highest value one.
-# Ex. if the repo has: G_0.pth, G_100.pth, G_200.pth, we'd use G_200.pth
-if ckpt_name is None:
- latest_id = sorted(
- [
- int(Path(x).stem.split("_")[1])
- for x in list_repo_files(repo_id)
- if x.startswith("G_") and x.endswith(".pth")
- ]
- )[-1]
- ckpt_name = f"G_{latest_id}.pth"
-
-generator_path = hf_hub_download(repo_id, ckpt_name)
-config_path = hf_hub_download(repo_id, "config.json")
-hparams = HParams(**json.loads(Path(config_path).read_text()))
-speakers = list(hparams.spk.keys())
-device = "cuda" if torch.cuda.is_available() else "cpu"
-model = Svc(net_g_path=generator_path, config_path=config_path, device=device, cluster_model_path=None)
-
-
-def predict(
- speaker,
- audio,
- transpose: int = 0,
- auto_predict_f0: bool = False,
- cluster_infer_ratio: float = 0,
- noise_scale: float = 0.4,
- f0_method: str = "crepe",
- db_thresh: int = -40,
- pad_seconds: float = 0.5,
- chunk_seconds: float = 0.5,
- absolute_thresh: bool = False,
-):
- audio, _ = librosa.load(audio, sr=model.target_sample)
- audio = model.infer_silence(
- audio.astype(np.float32),
- speaker=speaker,
- transpose=transpose,
- auto_predict_f0=auto_predict_f0,
- cluster_infer_ratio=cluster_infer_ratio,
- noise_scale=noise_scale,
- f0_method=f0_method,
- db_thresh=db_thresh,
- pad_seconds=pad_seconds,
- chunk_seconds=chunk_seconds,
- absolute_thresh=absolute_thresh,
- )
- return model.target_sample, audio
-
-
-description=f"""
-Это йоши нейросеть! Настройки не крутите. А если вам пофиг крутите ломайте!
-
-А что тут написать?
-""".strip()
-
-article="""
-
- Github Repo
-
-""".strip()
-
-interface_mic = gr.Interface(
- predict,
- inputs=[
- gr.Dropdown(speakers, value=speakers[0], label="Target Speaker"),
- gr.Audio(type="filepath", source="microphone", label="Source Audio"),
- gr.Slider(-12, 12, value=0, step=1, label="Transpose (Semitones)"),
- gr.Checkbox(False, label="Auto Predict F0"),
- gr.Slider(0.0, 1.0, value=0.0, step=0.1, label='cluster infer ratio'),
- gr.Slider(0.0, 1.0, value=0.4, step=0.1, label="noise scale"),
- gr.Dropdown(choices=["crepe", "crepe-tiny", "parselmouth", "dio", "harvest"], value='crepe', label="f0 method"),
- ],
- outputs="audio",
- title="Voice Cloning",
- description=description,
- article=article,
-)
-interface_file = gr.Interface(
- predict,
- inputs=[
- gr.Dropdown(speakers, value=speakers[0], label="Target Speaker"),
- gr.Audio(type="filepath", source="upload", label="Source Audio"),
- gr.Slider(-12, 12, value=0, step=1, label="Transpose (Semitones)"),
- gr.Checkbox(False, label="Auto Predict F0"),
- gr.Slider(0.0, 1.0, value=0.0, step=0.1, label='cluster infer ratio'),
- gr.Slider(0.0, 1.0, value=0.4, step=0.1, label="noise scale"),
- gr.Dropdown(choices=["crepe", "crepe-tiny", "parselmouth", "dio", "harvest"], value='crepe', label="f0 method"),
- ],
- outputs="audio",
- title="Йоши Нейросеть",
- description=description,
- article=article,
-)
-interface = gr.TabbedInterface(
- [interface_mic, interface_file],
- ["Микрофон", "Аудио файл"],
-)
-
-
-if __name__ == '__main__':
- interface.launch()
\ No newline at end of file
diff --git a/spaces/Sonnt/Fracture_Webapp/app.py b/spaces/Sonnt/Fracture_Webapp/app.py
deleted file mode 100644
index 3f542e9d4c85061d23763746f21ee493d551bc84..0000000000000000000000000000000000000000
--- a/spaces/Sonnt/Fracture_Webapp/app.py
+++ /dev/null
@@ -1,62 +0,0 @@
-import streamlit as st
-from ui.UIConfigs import *
-
-#Streamlit dashboard------------------------------------------------------------------------------------------
-set_page_config(page='home', logo_size=200)
-hide_menu_button()
-condense_layout()
-
-st.sidebar.success("")
-st.markdown("""
-
-""", unsafe_allow_html=True)
-# st.markdown("""
-# VPI-MLOGs Web App
-# VPI-MLOGs is a web app designed for log data analysis and visualization. It provides various functions to help users process, analyze, and visualize log data.
-# 1. Read LAS Files and Convert to CSV Files
-
-# VPI-MLOGs allows users to upload LAS files and convert them to CSV format. This feature makes it easy to work with log data in other programs, such as Excel or Python.
-
-# 2. Explore Data Analysis with Multiple Charts
-
-# VPI-MLOGs provides several exploratory data analysis (EDA) functions, such as detecting missing data, generating histograms, and visualizing distribution. These functions help users understand the structure and characteristics of the log data.
-
-# 3. Training LGBM Model
-
-# VPI-MLOGs provides a machine learning feature that allows users to train a LGBM (Light Gradient Boosting Machine) model using their log data.
-
-# 4. Prediction
-
-# VPI-MLOGs Users can also make predictions using the trained model.
-# """
-st.markdown("""
-VPI-MLOGs Web App
-
-**Read LAS Files and Convert to CSV Files**
-
-VPI-MLOGs enables the reading of LAS files, a commonly used format for storing log data. Once uploaded, VPI-MLOGs can convert LAS files to the CSV format, which is more widely compatible with other programs like Excel or Python.
-
-**Explore Data Analysis with Multiple Charts**
-
-VPI-MLOGs offers various exploratory data analysis (EDA) functions to better understand the characteristics of log data. These EDA functions include:
-
-- **Missing Data Detection**: Identifies any missing data points in the log data.
-- **Histogram Generation**: Creates graphical representations of data value distributions.
-- **Distribution Visualization**: Creates graphical representations showcasing the spread of data values.
-- **Outliers Removal**: Identifies any data points that are significantly different from the rest of the data.
-
-**Training LGBM Model**
-
-VPI-MLOGs provides a machine learning feature that enables users to train a LGBM (Light Gradient Boosting Machine) model using their log data. LGBM is a versatile machine learning algorithm suitable for various tasks like classification and regression. Once trained, the LGBM model can be used to make predictions on new data.
-
-**Prediction**
-
-VPI-MLOGs allows users to make predictions using the trained model. These predictions can be applied to new data not present in the training set. This functionality proves beneficial for tasks like identifying potential drilling targets or predicting rock formation properties.
-
-In summary, VPI-MLOGs is a powerful tool for processing, analyzing, and visualizing log data. It offers a diverse range of functions that aid users in gaining a deeper understanding of their data, enabling them to make more informed decisions.
-"""
- ,unsafe_allow_html=True)
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/altair/vegalite/v5/__init__.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/altair/vegalite/v5/__init__.py
deleted file mode 100644
index 38202d89c0d86a9be7a39d4b189781c43427983e..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/altair/vegalite/v5/__init__.py
+++ /dev/null
@@ -1,20 +0,0 @@
-# ruff: noqa
-from .schema import *
-from .api import *
-
-from ...expr import datum, expr # type: ignore[no-redef]
-
-from .display import VegaLite, renderers
-
-from .data import (
- MaxRowsError,
- pipe,
- curry,
- limit_rows,
- sample,
- to_json,
- to_csv,
- to_values,
- default_data_transformer,
- data_transformers,
-)
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/anyio/__init__.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/anyio/__init__.py
deleted file mode 100644
index 29fb3561e4f2dc9d3a764e756439c0dea2c9897a..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/anyio/__init__.py
+++ /dev/null
@@ -1,169 +0,0 @@
-from __future__ import annotations
-
-__all__ = (
- "maybe_async",
- "maybe_async_cm",
- "run",
- "sleep",
- "sleep_forever",
- "sleep_until",
- "current_time",
- "get_all_backends",
- "get_cancelled_exc_class",
- "BrokenResourceError",
- "BrokenWorkerProcess",
- "BusyResourceError",
- "ClosedResourceError",
- "DelimiterNotFound",
- "EndOfStream",
- "ExceptionGroup",
- "IncompleteRead",
- "TypedAttributeLookupError",
- "WouldBlock",
- "AsyncFile",
- "Path",
- "open_file",
- "wrap_file",
- "aclose_forcefully",
- "open_signal_receiver",
- "connect_tcp",
- "connect_unix",
- "create_tcp_listener",
- "create_unix_listener",
- "create_udp_socket",
- "create_connected_udp_socket",
- "getaddrinfo",
- "getnameinfo",
- "wait_socket_readable",
- "wait_socket_writable",
- "create_memory_object_stream",
- "run_process",
- "open_process",
- "create_lock",
- "CapacityLimiter",
- "CapacityLimiterStatistics",
- "Condition",
- "ConditionStatistics",
- "Event",
- "EventStatistics",
- "Lock",
- "LockStatistics",
- "Semaphore",
- "SemaphoreStatistics",
- "create_condition",
- "create_event",
- "create_semaphore",
- "create_capacity_limiter",
- "open_cancel_scope",
- "fail_after",
- "move_on_after",
- "current_effective_deadline",
- "TASK_STATUS_IGNORED",
- "CancelScope",
- "create_task_group",
- "TaskInfo",
- "get_current_task",
- "get_running_tasks",
- "wait_all_tasks_blocked",
- "run_sync_in_worker_thread",
- "run_async_from_thread",
- "run_sync_from_thread",
- "current_default_worker_thread_limiter",
- "create_blocking_portal",
- "start_blocking_portal",
- "typed_attribute",
- "TypedAttributeSet",
- "TypedAttributeProvider",
-)
-
-from typing import Any
-
-from ._core._compat import maybe_async, maybe_async_cm
-from ._core._eventloop import (
- current_time,
- get_all_backends,
- get_cancelled_exc_class,
- run,
- sleep,
- sleep_forever,
- sleep_until,
-)
-from ._core._exceptions import (
- BrokenResourceError,
- BrokenWorkerProcess,
- BusyResourceError,
- ClosedResourceError,
- DelimiterNotFound,
- EndOfStream,
- ExceptionGroup,
- IncompleteRead,
- TypedAttributeLookupError,
- WouldBlock,
-)
-from ._core._fileio import AsyncFile, Path, open_file, wrap_file
-from ._core._resources import aclose_forcefully
-from ._core._signals import open_signal_receiver
-from ._core._sockets import (
- connect_tcp,
- connect_unix,
- create_connected_udp_socket,
- create_tcp_listener,
- create_udp_socket,
- create_unix_listener,
- getaddrinfo,
- getnameinfo,
- wait_socket_readable,
- wait_socket_writable,
-)
-from ._core._streams import create_memory_object_stream
-from ._core._subprocesses import open_process, run_process
-from ._core._synchronization import (
- CapacityLimiter,
- CapacityLimiterStatistics,
- Condition,
- ConditionStatistics,
- Event,
- EventStatistics,
- Lock,
- LockStatistics,
- Semaphore,
- SemaphoreStatistics,
- create_capacity_limiter,
- create_condition,
- create_event,
- create_lock,
- create_semaphore,
-)
-from ._core._tasks import (
- TASK_STATUS_IGNORED,
- CancelScope,
- create_task_group,
- current_effective_deadline,
- fail_after,
- move_on_after,
- open_cancel_scope,
-)
-from ._core._testing import (
- TaskInfo,
- get_current_task,
- get_running_tasks,
- wait_all_tasks_blocked,
-)
-from ._core._typedattr import TypedAttributeProvider, TypedAttributeSet, typed_attribute
-
-# Re-exported here, for backwards compatibility
-# isort: off
-from .to_thread import current_default_worker_thread_limiter, run_sync_in_worker_thread
-from .from_thread import (
- create_blocking_portal,
- run_async_from_thread,
- run_sync_from_thread,
- start_blocking_portal,
-)
-
-# Re-export imports so they look like they live directly in this package
-key: str
-value: Any
-for key, value in list(locals().items()):
- if getattr(value, "__module__", "").startswith("anyio."):
- value.__module__ = __name__
diff --git a/spaces/Superying/vits-uma-genshin-honkai/transforms.py b/spaces/Superying/vits-uma-genshin-honkai/transforms.py
deleted file mode 100644
index 4793d67ca5a5630e0ffe0f9fb29445c949e64dae..0000000000000000000000000000000000000000
--- a/spaces/Superying/vits-uma-genshin-honkai/transforms.py
+++ /dev/null
@@ -1,193 +0,0 @@
-import torch
-from torch.nn import functional as F
-
-import numpy as np
-
-
-DEFAULT_MIN_BIN_WIDTH = 1e-3
-DEFAULT_MIN_BIN_HEIGHT = 1e-3
-DEFAULT_MIN_DERIVATIVE = 1e-3
-
-
-def piecewise_rational_quadratic_transform(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails=None,
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
-
- if tails is None:
- spline_fn = rational_quadratic_spline
- spline_kwargs = {}
- else:
- spline_fn = unconstrained_rational_quadratic_spline
- spline_kwargs = {
- 'tails': tails,
- 'tail_bound': tail_bound
- }
-
- outputs, logabsdet = spline_fn(
- inputs=inputs,
- unnormalized_widths=unnormalized_widths,
- unnormalized_heights=unnormalized_heights,
- unnormalized_derivatives=unnormalized_derivatives,
- inverse=inverse,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative,
- **spline_kwargs
- )
- return outputs, logabsdet
-
-
-def searchsorted(bin_locations, inputs, eps=1e-6):
- bin_locations[..., -1] += eps
- return torch.sum(
- inputs[..., None] >= bin_locations,
- dim=-1
- ) - 1
-
-
-def unconstrained_rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails='linear',
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
- outside_interval_mask = ~inside_interval_mask
-
- outputs = torch.zeros_like(inputs)
- logabsdet = torch.zeros_like(inputs)
-
- if tails == 'linear':
- unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
- constant = np.log(np.exp(1 - min_derivative) - 1)
- unnormalized_derivatives[..., 0] = constant
- unnormalized_derivatives[..., -1] = constant
-
- outputs[outside_interval_mask] = inputs[outside_interval_mask]
- logabsdet[outside_interval_mask] = 0
- else:
- raise RuntimeError('{} tails are not implemented.'.format(tails))
-
- outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline(
- inputs=inputs[inside_interval_mask],
- unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
- unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
- unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
- inverse=inverse,
- left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative
- )
-
- return outputs, logabsdet
-
-def rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- left=0., right=1., bottom=0., top=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- if torch.min(inputs) < left or torch.max(inputs) > right:
- raise ValueError('Input to a transform is not within its domain')
-
- num_bins = unnormalized_widths.shape[-1]
-
- if min_bin_width * num_bins > 1.0:
- raise ValueError('Minimal bin width too large for the number of bins')
- if min_bin_height * num_bins > 1.0:
- raise ValueError('Minimal bin height too large for the number of bins')
-
- widths = F.softmax(unnormalized_widths, dim=-1)
- widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
- cumwidths = torch.cumsum(widths, dim=-1)
- cumwidths = F.pad(cumwidths, pad=(1, 0), mode='constant', value=0.0)
- cumwidths = (right - left) * cumwidths + left
- cumwidths[..., 0] = left
- cumwidths[..., -1] = right
- widths = cumwidths[..., 1:] - cumwidths[..., :-1]
-
- derivatives = min_derivative + F.softplus(unnormalized_derivatives)
-
- heights = F.softmax(unnormalized_heights, dim=-1)
- heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
- cumheights = torch.cumsum(heights, dim=-1)
- cumheights = F.pad(cumheights, pad=(1, 0), mode='constant', value=0.0)
- cumheights = (top - bottom) * cumheights + bottom
- cumheights[..., 0] = bottom
- cumheights[..., -1] = top
- heights = cumheights[..., 1:] - cumheights[..., :-1]
-
- if inverse:
- bin_idx = searchsorted(cumheights, inputs)[..., None]
- else:
- bin_idx = searchsorted(cumwidths, inputs)[..., None]
-
- input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
- input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
-
- input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
- delta = heights / widths
- input_delta = delta.gather(-1, bin_idx)[..., 0]
-
- input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
- input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
-
- input_heights = heights.gather(-1, bin_idx)[..., 0]
-
- if inverse:
- a = (((inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta)
- + input_heights * (input_delta - input_derivatives)))
- b = (input_heights * input_derivatives
- - (inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta))
- c = - input_delta * (inputs - input_cumheights)
-
- discriminant = b.pow(2) - 4 * a * c
- assert (discriminant >= 0).all()
-
- root = (2 * c) / (-b - torch.sqrt(discriminant))
- outputs = root * input_bin_widths + input_cumwidths
-
- theta_one_minus_theta = root * (1 - root)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * root.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - root).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, -logabsdet
- else:
- theta = (inputs - input_cumwidths) / input_bin_widths
- theta_one_minus_theta = theta * (1 - theta)
-
- numerator = input_heights * (input_delta * theta.pow(2)
- + input_derivatives * theta_one_minus_theta)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- outputs = input_cumheights + numerator / denominator
-
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * theta.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - theta).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, logabsdet
diff --git a/spaces/THUDM/GLM-130B/app.py b/spaces/THUDM/GLM-130B/app.py
deleted file mode 100644
index 918e678125f841537e9be09143b578c81219046f..0000000000000000000000000000000000000000
--- a/spaces/THUDM/GLM-130B/app.py
+++ /dev/null
@@ -1,138 +0,0 @@
-import gradio as gr
-import requests
-
-import json
-import os
-
-
-APIKEY = os.environ.get("APIKEY")
-APISECRET = os.environ.get("APISECRET")
-
-def predict(text, seed, out_seq_length, min_gen_length, sampling_strategy,
- num_beams, length_penalty, no_repeat_ngram_size,
- temperature, topk, topp):
- global APIKEY
- global APISECRET
-
- if text == '':
- return 'Input should not be empty!'
-
- url = 'https://tianqi.aminer.cn/api/v2/completions_130B'
-
- payload = json.dumps({
- "apikey": APIKEY,
- "apisecret": APISECRET ,
- "model_name": "glm-130b-v1",
- "prompt": text,
- "length_penalty": length_penalty,
- "temperature": temperature,
- "top_k": topk,
- "top_p": topp,
- "min_gen_length": min_gen_length,
- "sampling_strategy": sampling_strategy,
- "num_beams": num_beams,
- "max_tokens": out_seq_length,
- "no_repeat_ngram": no_repeat_ngram_size,
- "quantization": "int4",
- "seed": seed
- })
-
- headers = {
- 'Content-Type': 'application/json'
- }
-
- try:
- response = requests.request("POST", url, headers=headers, data=payload, timeout=(20, 100)).json()
- except Exception as e:
- return 'Timeout! Please wait a few minutes and retry'
-
- if response['status'] == 1:
- return response['message']['errmsg']
-
- answer = response['result']['output']['raw']
- if isinstance(answer, list):
- answer = answer[0]
-
- answer = answer.replace('[]', '')
-
- return answer
-
-
-if __name__ == "__main__":
-
- en_fil = ['The Starry Night is an oil-on-canvas painting by [MASK] in June 1889.']
- en_gen = ['Question: What\'s the best winter resort city? User: A 10-year professional traveler. Answer: [gMASK]'] #['Eight planets in solar system are [gMASK]']
- ch_fil = ['凯旋门位于意大利米兰市古城堡旁。1807年为纪念[MASK]而建,门高25米,顶上矗立两武士青铜古兵车铸像。']
- ch_gen = ['三亚位于海南岛的最南端,是[gMASK]']
- en_to_ch = ['Pencil in Chinese is [MASK].']
- ch_to_en = ['"我思故我在"的英文是"[MASK]"。']
-
- examples = [en_fil, en_gen, ch_fil, ch_gen, en_to_ch, ch_to_en]
-
- with gr.Blocks() as demo:
- gr.Markdown(
- """
- Dear friends,
-
- Nice to meet you here! This is a toy demo of GLM-130B, an open bilingual pre-trained model from Tsinghua Univeristy. GLM-130B uses two different mask tokens: `[MASK]` for short blank filling and `[gMASK]` for left-to-right long text generation. When the input does not contain any MASK token, `[gMASK]` will be automatically appended to the end of the text. We recommend that you use `[MASK]` to try text fill-in-the-blank to reduce wait time (ideally within seconds without queuing).
-
- This demo is a raw language model **without** instruction fine-tuning (which is applied to FLAN-* series) and RLHF (which is applied to ChatGPT); its ability is roughly between OpenAI `davinci` and `text-davinci-001`. Thus, it is currently worse than ChatGPT and other instruction fine-tuned models :(
-
- However, we are sparing no effort to improve it, and its updated versions will meet you soon! If you find the open-source effort useful, please star our [GitHub repo](https://github.com/THUDM/GLM-130B) to encourage our following development :)
- """)
-
- with gr.Row():
- with gr.Column():
- model_input = gr.Textbox(lines=7, placeholder='Input something in English or Chinese', label='Input')
- with gr.Row():
- gen = gr.Button("Generate")
- clr = gr.Button("Clear")
-
- outputs = gr.Textbox(lines=7, label='Output')
-
- gr.Markdown(
- """
- Generation Parameter
- """)
- with gr.Row():
- with gr.Column():
- seed = gr.Slider(maximum=100000, value=1234, step=1, label='Seed')
- out_seq_length = gr.Slider(maximum=256, value=128, minimum=32, step=1, label='Output Sequence Length')
- with gr.Column():
- min_gen_length = gr.Slider(maximum=64, value=0, step=1, label='Min Generate Length')
- sampling_strategy = gr.Radio(choices=['BeamSearchStrategy', 'BaseStrategy'], value='BaseStrategy', label='Search Strategy')
-
- with gr.Row():
- with gr.Column():
- # beam search
- gr.Markdown(
- """
- BeamSearchStrategy
- """)
- num_beams = gr.Slider(maximum=4, value=2, minimum=1, step=1, label='Number of Beams')
- length_penalty = gr.Slider(maximum=1, value=1, minimum=0, label='Length Penalty')
- no_repeat_ngram_size = gr.Slider(maximum=5, value=3, minimum=1, step=1, label='No Repeat Ngram Size')
- with gr.Column():
- # base search
- gr.Markdown(
- """
- BaseStrategy
- """)
- temperature = gr.Slider(maximum=1, value=1.0, minimum=0, label='Temperature')
- topk = gr.Slider(maximum=40, value=0, minimum=0, step=1, label='Top K')
- topp = gr.Slider(maximum=1, value=0.7, minimum=0, label='Top P')
-
- inputs = [model_input, seed, out_seq_length, min_gen_length, sampling_strategy, num_beams, length_penalty, no_repeat_ngram_size, temperature, topk, topp]
- gen.click(fn=predict, inputs=inputs, outputs=outputs)
- clr.click(fn=lambda value: gr.update(value=""), inputs=clr, outputs=model_input)
-
- gr_examples = gr.Examples(examples=examples, inputs=model_input)
-
- gr.Markdown(
- """
- Disclaimer inspired from [BLOOM](https://huggingface.co/spaces/bigscience/bloom-book)
-
- GLM-130B was trained on web-crawled data, so it's hard to predict how GLM-130B will respond to particular prompts; harmful or otherwise offensive content may occur without warning. We prohibit users from knowingly generating or allowing others to knowingly generate harmful content, including Hateful, Harassment, Violence, Adult, Political, Deception, etc.
- """)
-
- demo.launch()
\ No newline at end of file
diff --git a/spaces/TNR-5/Music-discord-bot/nicodl.py b/spaces/TNR-5/Music-discord-bot/nicodl.py
deleted file mode 100644
index 3eae6973ba92e6456b6434df3986283c979ca0ed..0000000000000000000000000000000000000000
--- a/spaces/TNR-5/Music-discord-bot/nicodl.py
+++ /dev/null
@@ -1,246 +0,0 @@
-# niconico_dl_async by tasuren
-
-from bs4 import BeautifulSoup as bs
-from asyncio import get_event_loop
-from aiohttp import ClientSession
-from aiofile import async_open
-from json import loads, dumps
-from time import time
-from requests import post
-from threading import Thread, Timer
-
-version = "1.1.0"
-
-
-class perpetualTimer():
- def __init__(self, t, hFunction, *args):
- self.t = t
- self.args = args
- self.hFunction = hFunction
- self.thread = Timer(self.t, self.handle_function)
-
- def handle_function(self):
- self.hFunction(*self.args)
- self.thread = Timer(self.t, self.handle_function)
- self.thread.start()
-
- def start(self):
- self.thread.start()
-
- def cancel(self):
- self.thread.cancel()
-
-
-def par(max_num, now):
- return now / max_num * 100
-
-
-class NicoNico():
- def __init__(self, nicoid, log=False):
- self._print = lambda content, end="\n": print(content, end=end
- ) if log else lambda: ""
- self.now_status = "..."
- self.url = None
- self.stop = True
- self.nicoid = nicoid
- self.now_downloading = False
- self.heartbeat_first_data = None
- self.tasks = []
-
- def wrap_heartbeat(self, *args):
- self.heartbeat(args[0])
-
- async def get_info(self):
- # 情報を取る。
- url = f"https://www.nicovideo.jp/watch/{self.nicoid}"
- self.headers = {
- "Access-Control-Allow-Credentials": "true",
- "Access-Control-Allow-Origin": "https://www.nicovideo.jp",
- 'Connection': 'keep-alive',
- "Content-Type": "application/json",
- 'User-Agent':
- 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Safari/537.36 Edg/89.0.774.45',
- 'Accept': '*/*',
- "Accept-Encoding": "gzip, deflate, br",
- 'Origin': 'https://www.nicovideo.jp',
- 'Sec-Fetch-Site': 'cross-site',
- 'Sec-Fetch-Mode': 'cors',
- 'Sec-Fetch-Dest': 'empty',
- "Origin": "https://www.nicovideo.jp",
- "Referer": "https://www.nicovideo.jp/",
- "Sec-Fetch-Dest": "empty",
- 'Accept-Language': 'ja,en;q=0.9,en-GB;q=0.8,en-US;q=0.7'
- }
-
- self._print(f"Getting niconico webpage ... : {url}")
-
- async with ClientSession() as session:
- async with session.get(url, headers=self.headers) as res:
- html = await res.text()
- soup = bs(html, "html.parser")
-
- data = soup.find("div", {
- "id": "js-initial-watch-data"
- }).get("data-api-data")
- self.data = loads(data)
- movie = self.data["media"]["delivery"]["movie"]
-
- # heartbeat用のdataを作る。
- session = movie["session"]
- data = {}
- data["content_type"] = "movie"
- data["content_src_id_sets"] = [{
- "content_src_ids": [{
- "src_id_to_mux": {
- "video_src_ids": [session["videos"][0]],
- "audio_src_ids": [session["audios"][0]]
- }
- }]
- }]
- data["timing_constraint"] = "unlimited"
- data["keep_method"] = {
- "heartbeat": {
- "lifetime": session["heartbeatLifetime"]
- }
- }
- data["recipe_id"] = session["recipeId"]
- data["priority"] = session["priority"]
- data["protocol"] = {
- "name": "http",
- "parameters": {
- "http_parameters": {
- "parameters": {
- "http_output_download_parameters": {
- "use_well_known_port":
- "yes"
- if session["urls"][0]["isWellKnownPort"] else "no",
- "use_ssl":
- "yes" if session["urls"][0]["isSsl"] else "no",
- "transfer_preset":
- ""
- }
- }
- }
- }
- }
- data["content_uri"] = ""
- data["session_operation_auth"] = {
- "session_operation_auth_by_signature": {
- "token": session["token"],
- "signature": session["signature"]
- }
- }
- data["content_id"] = session["contentId"]
- data["content_auth"] = {
- "auth_type": session["authTypes"]["http"],
- "content_key_timeout": session["contentKeyTimeout"],
- "service_id": "nicovideo",
- "service_user_id": str(session["serviceUserId"])
- }
- data["client_info"] = {"player_id": session["playerId"]}
-
- self.heartbeat_first_data = {"session": data}
-
- return self.data
-
- def start_stream(self):
- # 定期的に生きていることをニコニコに伝えるためのもの。
- self.get = False
- c = 0
-
- self._print(
- "Starting heartbeat ... : https://api.dmc.nico/api/sessions?_format=json"
- )
- res = post(f"https://api.dmc.nico/api/sessions?_format=json",
- headers=self.headers,
- data=dumps(self.heartbeat_first_data))
-
- self.result_data = loads(res.text)["data"]["session"]
- session_id = self.result_data["id"]
-
- self.get = True
-
- return session_id
-
- def heartbeat(self, session_id):
-
- res = post(
- f"https://api.dmc.nico/api/sessions/{session_id}?_format=json&_method=PUT",
- headers=self.headers,
- data=dumps({"session": self.result_data}))
-
- if res.status_code == 201 or res.status_code == 200:
- self.result_data = loads(res.text)["data"]["session"]
- else:
- raise
-
- async def get_download_link(self):
- if self.stop:
- self.stop = False
- await self.get_info()
- session_id = self.start_stream()
- self.heartbeat_task = perpetualTimer(40, self.wrap_heartbeat,
- session_id)
- self.heartbeat_task.start()
- self.now_downloading = True
-
- # 心臓が動くまで待機。
- while not self.get:
- pass
-
- return self.result_data["content_uri"]
- else:
- return self.result_data["content_uri"]
-
- async def download(self, path, chunk=1024):
- self.url = url = await self.get_download_link()
-
- params = (
- ("ht2_nicovideo",
- self.result_data["content_auth"]["content_auth_info"]["value"]), )
- headers = self.headers
- headers["Content-Type"] = "video/mp4"
-
- self._print(f"Getting file size ...")
- async with ClientSession(raise_for_status=True) as session:
- self._print(f"Starting download ... : {url}")
- async with session.get(
- url,
- headers=self.headers,
- params=params,
- ) as res:
-
- size = res.content_length
-
- now_size = 0
- async with async_open(path, "wb") as f:
- await f.write(b"")
- async with async_open(path, "ab") as f:
- async for chunk in res.content.iter_chunked(chunk):
- if chunk:
- now_size += len(chunk)
- await f.write(chunk)
- self._print(
- f"\rDownloading now ... : {int(now_size/size*100)}% ({now_size}/{size}) | Response status : {self.now_status}",
- end="")
- self._print("\nDownload was finished.")
- self.now_downloading = False
-
- def close(self):
- self.stop = True
- self.heartbeat_task.cancel()
-
- def __del__(self):
- self.close()
-
-
-if __name__ == "__main__":
-
- async def test():
- niconico = NicoNico("sm20780163", log=True)
- data = await niconico.get_info()
- print(await niconico.get_download_link())
- input()
- niconico.close()
-
- get_event_loop().run_until_complete(test())
\ No newline at end of file
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_internal/operations/build/wheel_editable.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_internal/operations/build/wheel_editable.py
deleted file mode 100644
index 719d69dd801b78b360c6c2234080eee638b8de82..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_internal/operations/build/wheel_editable.py
+++ /dev/null
@@ -1,46 +0,0 @@
-import logging
-import os
-from typing import Optional
-
-from pip._vendor.pyproject_hooks import BuildBackendHookCaller, HookMissing
-
-from pip._internal.utils.subprocess import runner_with_spinner_message
-
-logger = logging.getLogger(__name__)
-
-
-def build_wheel_editable(
- name: str,
- backend: BuildBackendHookCaller,
- metadata_directory: str,
- tempd: str,
-) -> Optional[str]:
- """Build one InstallRequirement using the PEP 660 build process.
-
- Returns path to wheel if successfully built. Otherwise, returns None.
- """
- assert metadata_directory is not None
- try:
- logger.debug("Destination directory: %s", tempd)
-
- runner = runner_with_spinner_message(
- f"Building editable for {name} (pyproject.toml)"
- )
- with backend.subprocess_runner(runner):
- try:
- wheel_name = backend.build_editable(
- tempd,
- metadata_directory=metadata_directory,
- )
- except HookMissing as e:
- logger.error(
- "Cannot build editable %s because the build "
- "backend does not have the %s hook",
- name,
- e,
- )
- return None
- except Exception:
- logger.error("Failed building editable for %s", name)
- return None
- return os.path.join(tempd, wheel_name)
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/util/ssl_match_hostname.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/util/ssl_match_hostname.py
deleted file mode 100644
index 1dd950c489607d06ecc5218292a1b55558b47be8..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/util/ssl_match_hostname.py
+++ /dev/null
@@ -1,159 +0,0 @@
-"""The match_hostname() function from Python 3.3.3, essential when using SSL."""
-
-# Note: This file is under the PSF license as the code comes from the python
-# stdlib. http://docs.python.org/3/license.html
-
-import re
-import sys
-
-# ipaddress has been backported to 2.6+ in pypi. If it is installed on the
-# system, use it to handle IPAddress ServerAltnames (this was added in
-# python-3.5) otherwise only do DNS matching. This allows
-# util.ssl_match_hostname to continue to be used in Python 2.7.
-try:
- import ipaddress
-except ImportError:
- ipaddress = None
-
-__version__ = "3.5.0.1"
-
-
-class CertificateError(ValueError):
- pass
-
-
-def _dnsname_match(dn, hostname, max_wildcards=1):
- """Matching according to RFC 6125, section 6.4.3
-
- http://tools.ietf.org/html/rfc6125#section-6.4.3
- """
- pats = []
- if not dn:
- return False
-
- # Ported from python3-syntax:
- # leftmost, *remainder = dn.split(r'.')
- parts = dn.split(r".")
- leftmost = parts[0]
- remainder = parts[1:]
-
- wildcards = leftmost.count("*")
- if wildcards > max_wildcards:
- # Issue #17980: avoid denials of service by refusing more
- # than one wildcard per fragment. A survey of established
- # policy among SSL implementations showed it to be a
- # reasonable choice.
- raise CertificateError(
- "too many wildcards in certificate DNS name: " + repr(dn)
- )
-
- # speed up common case w/o wildcards
- if not wildcards:
- return dn.lower() == hostname.lower()
-
- # RFC 6125, section 6.4.3, subitem 1.
- # The client SHOULD NOT attempt to match a presented identifier in which
- # the wildcard character comprises a label other than the left-most label.
- if leftmost == "*":
- # When '*' is a fragment by itself, it matches a non-empty dotless
- # fragment.
- pats.append("[^.]+")
- elif leftmost.startswith("xn--") or hostname.startswith("xn--"):
- # RFC 6125, section 6.4.3, subitem 3.
- # The client SHOULD NOT attempt to match a presented identifier
- # where the wildcard character is embedded within an A-label or
- # U-label of an internationalized domain name.
- pats.append(re.escape(leftmost))
- else:
- # Otherwise, '*' matches any dotless string, e.g. www*
- pats.append(re.escape(leftmost).replace(r"\*", "[^.]*"))
-
- # add the remaining fragments, ignore any wildcards
- for frag in remainder:
- pats.append(re.escape(frag))
-
- pat = re.compile(r"\A" + r"\.".join(pats) + r"\Z", re.IGNORECASE)
- return pat.match(hostname)
-
-
-def _to_unicode(obj):
- if isinstance(obj, str) and sys.version_info < (3,):
- # ignored flake8 # F821 to support python 2.7 function
- obj = unicode(obj, encoding="ascii", errors="strict") # noqa: F821
- return obj
-
-
-def _ipaddress_match(ipname, host_ip):
- """Exact matching of IP addresses.
-
- RFC 6125 explicitly doesn't define an algorithm for this
- (section 1.7.2 - "Out of Scope").
- """
- # OpenSSL may add a trailing newline to a subjectAltName's IP address
- # Divergence from upstream: ipaddress can't handle byte str
- ip = ipaddress.ip_address(_to_unicode(ipname).rstrip())
- return ip == host_ip
-
-
-def match_hostname(cert, hostname):
- """Verify that *cert* (in decoded format as returned by
- SSLSocket.getpeercert()) matches the *hostname*. RFC 2818 and RFC 6125
- rules are followed, but IP addresses are not accepted for *hostname*.
-
- CertificateError is raised on failure. On success, the function
- returns nothing.
- """
- if not cert:
- raise ValueError(
- "empty or no certificate, match_hostname needs a "
- "SSL socket or SSL context with either "
- "CERT_OPTIONAL or CERT_REQUIRED"
- )
- try:
- # Divergence from upstream: ipaddress can't handle byte str
- host_ip = ipaddress.ip_address(_to_unicode(hostname))
- except (UnicodeError, ValueError):
- # ValueError: Not an IP address (common case)
- # UnicodeError: Divergence from upstream: Have to deal with ipaddress not taking
- # byte strings. addresses should be all ascii, so we consider it not
- # an ipaddress in this case
- host_ip = None
- except AttributeError:
- # Divergence from upstream: Make ipaddress library optional
- if ipaddress is None:
- host_ip = None
- else: # Defensive
- raise
- dnsnames = []
- san = cert.get("subjectAltName", ())
- for key, value in san:
- if key == "DNS":
- if host_ip is None and _dnsname_match(value, hostname):
- return
- dnsnames.append(value)
- elif key == "IP Address":
- if host_ip is not None and _ipaddress_match(value, host_ip):
- return
- dnsnames.append(value)
- if not dnsnames:
- # The subject is only checked when there is no dNSName entry
- # in subjectAltName
- for sub in cert.get("subject", ()):
- for key, value in sub:
- # XXX according to RFC 2818, the most specific Common Name
- # must be used.
- if key == "commonName":
- if _dnsname_match(value, hostname):
- return
- dnsnames.append(value)
- if len(dnsnames) > 1:
- raise CertificateError(
- "hostname %r "
- "doesn't match either of %s" % (hostname, ", ".join(map(repr, dnsnames)))
- )
- elif len(dnsnames) == 1:
- raise CertificateError("hostname %r doesn't match %r" % (hostname, dnsnames[0]))
- else:
- raise CertificateError(
- "no appropriate commonName or subjectAltName fields were found"
- )
diff --git a/spaces/ThirdEyeData/Complaints_Roberta/clean_data.py b/spaces/ThirdEyeData/Complaints_Roberta/clean_data.py
deleted file mode 100644
index 09ad7e001440cf14e7436176dd18d9c5dbe2c32f..0000000000000000000000000000000000000000
--- a/spaces/ThirdEyeData/Complaints_Roberta/clean_data.py
+++ /dev/null
@@ -1,86 +0,0 @@
-import nltk
-from nltk.corpus import stopwords
-from nltk.stem import WordNetLemmatizer
-import warnings
-import re
-nltk.download("stopwords")
-nltk.download("wordnet")
-nltk.download("words")
-lemmatizer = WordNetLemmatizer()
-
-stop_words = set(stopwords.words('english'))
-
-contraction_mapping = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", "couldn't": "could not",
- "didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", "haven't": "have not",
- "he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is",
- "I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would",
- "i'd've": "i would have", "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would",
- "it'd've": "it would have", "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam",
- "mayn't": "may not", "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have",
- "mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have","o'clock": "of the clock",
- "oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have",
- "she'd": "she would", "she'd've": "she would have", "she'll": "she will", "she'll've": "she will have", "she's": "she is",
- "should've": "should have", "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as",
- "this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", "there'd": "there would",
- "there'd've": "there would have", "there's": "there is", "here's": "here is","they'd": "they would", "they'd've": "they would have",
- "they'll": "they will", "they'll've": "they will have", "they're": "they are", "they've": "they have", "to've": "to have",
- "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", "we'll": "we will", "we'll've": "we will have", "we're": "we are",
- "we've": "we have", "weren't": "were not", "what'll": "what will", "what'll've": "what will have", "what're": "what are",
- "what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", "where'd": "where did", "where's": "where is",
- "where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have",
- "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have",
- "would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all",
- "y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have",
- "you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have",
- "you're": "you are", "you've": "you have"}
-
-def cleaned_complaints(text):
- import nltk
- from nltk.corpus import stopwords
- from nltk.stem import WordNetLemmatizer
- from nltk.corpus import words
- import warnings
- import re
-
- lemmatizer = WordNetLemmatizer()
-
- stop_words = set(stopwords.words('english'))
-
- contraction_mapping = {"ain't": "is not", "aren't": "are not","can't": "cannot", "'cause": "because", "could've": "could have", "couldn't": "could not",
- "didn't": "did not", "doesn't": "does not", "don't": "do not", "hadn't": "had not", "hasn't": "has not", "haven't": "have not",
- "he'd": "he would","he'll": "he will", "he's": "he is", "how'd": "how did", "how'd'y": "how do you", "how'll": "how will", "how's": "how is",
- "I'd": "I would", "I'd've": "I would have", "I'll": "I will", "I'll've": "I will have","I'm": "I am", "I've": "I have", "i'd": "i would",
- "i'd've": "i would have", "i'll": "i will", "i'll've": "i will have","i'm": "i am", "i've": "i have", "isn't": "is not", "it'd": "it would",
- "it'd've": "it would have", "it'll": "it will", "it'll've": "it will have","it's": "it is", "let's": "let us", "ma'am": "madam",
- "mayn't": "may not", "might've": "might have","mightn't": "might not","mightn't've": "might not have", "must've": "must have",
- "mustn't": "must not", "mustn't've": "must not have", "needn't": "need not", "needn't've": "need not have","o'clock": "of the clock",
- "oughtn't": "ought not", "oughtn't've": "ought not have", "shan't": "shall not", "sha'n't": "shall not", "shan't've": "shall not have",
- "she'd": "she would", "she'd've": "she would have", "she'll": "she will", "she'll've": "she will have", "she's": "she is",
- "should've": "should have", "shouldn't": "should not", "shouldn't've": "should not have", "so've": "so have","so's": "so as",
- "this's": "this is","that'd": "that would", "that'd've": "that would have", "that's": "that is", "there'd": "there would",
- "there'd've": "there would have", "there's": "there is", "here's": "here is","they'd": "they would", "they'd've": "they would have",
- "they'll": "they will", "they'll've": "they will have", "they're": "they are", "they've": "they have", "to've": "to have",
- "wasn't": "was not", "we'd": "we would", "we'd've": "we would have", "we'll": "we will", "we'll've": "we will have", "we're": "we are",
- "we've": "we have", "weren't": "were not", "what'll": "what will", "what'll've": "what will have", "what're": "what are",
- "what's": "what is", "what've": "what have", "when's": "when is", "when've": "when have", "where'd": "where did", "where's": "where is",
- "where've": "where have", "who'll": "who will", "who'll've": "who will have", "who's": "who is", "who've": "who have",
- "why's": "why is", "why've": "why have", "will've": "will have", "won't": "will not", "won't've": "will not have",
- "would've": "would have", "wouldn't": "would not", "wouldn't've": "would not have", "y'all": "you all",
- "y'all'd": "you all would","y'all'd've": "you all would have","y'all're": "you all are","y'all've": "you all have",
- "you'd": "you would", "you'd've": "you would have", "you'll": "you will", "you'll've": "you will have",
- "you're": "you are", "you've": "you have"}
-
- newString=re.sub(r'@[A-Za-z0-9]+','',text) #removing user mentions
- newString=re.sub("#","",newString) #removing hashtag symbol
- newString= ' '.join([contraction_mapping[t] if t in contraction_mapping else t for t in newString.split(" ")]) #contraction mapping
- newString= re.sub(r'http\S+', '', newString) #removing links
- newString= re.sub(r"'s\b","",newString) #removing 's
- letters_only = re.sub("[^a-zA-Z]", " ", newString) #Fetching out only letters
- lower_case = letters_only.lower() #converting all words to lowercase
- tokens = [w for w in lower_case.split() if not w in stop_words]#stopwords removal
- tokens = [x for x in tokens if x in words.words()]
-# tokens= lower_case.split()
- newString=''
- for i in tokens:
- newString=newString+lemmatizer.lemmatize(i)+' ' #converting words using lemmatisation
- return newString.strip()
diff --git a/spaces/Tj/starcoder-playground/src/request.py b/spaces/Tj/starcoder-playground/src/request.py
deleted file mode 100644
index 316b72004e5a27132f15b978ea6fb7d0bb7d28b3..0000000000000000000000000000000000000000
--- a/spaces/Tj/starcoder-playground/src/request.py
+++ /dev/null
@@ -1,74 +0,0 @@
-from dataclasses import dataclass
-from typing import Dict, Any, Union
-
-from constants import (
- FIM_MIDDLE,
- FIM_PREFIX,
- FIM_SUFFIX,
- MIN_TEMPERATURE,
-)
-from settings import (
- FIM_INDICATOR,
-)
-
-@dataclass
-class StarCoderRequestConfig:
- temperature: float
- max_new_tokens: int
- top_p: float
- repetition_penalty: float
- version: str
-
- def __post_init__(self):
- self.temperature = min(float(self.temperature), MIN_TEMPERATURE)
- self.max_new_tokens = int(self.max_new_tokens)
- self.top_p = float(self.top_p)
- self.repetition_penalty = float(self.repetition_penalty)
- self.do_sample = True
- self.seed = 42
-
- def __repr__(self) -> str:
- """Returns a custom string representation of the Configurations."""
- values = dict(
- model = self.version,
- temp = self.temperature,
- tokens = self.max_new_tokens,
- p = self.top_p,
- penalty = self.repetition_penalty,
- sample = self.do_sample,
- seed = self.seed,
- )
- return f"StarCoderRequestConfig({values})"
-
- def kwargs(self) -> Dict[str, Union[Any, float, int]]:
- """
- Returns a custom dictionary representation of the Configurations.
- removing the model version.
- """
- values = vars(self).copy()
- values.pop("version")
- return values
-
-@dataclass
-class StarCoderRequest:
- prompt: str
- settings: StarCoderRequestConfig
-
- def __post_init__(self):
- self.fim_mode = FIM_INDICATOR in self.prompt
- self.prefix, self.suffix = None, None
- if self.fim_mode:
- try:
- self.prefix, self.suffix = self.prompt.split(FIM_INDICATOR)
- except Exception as err:
- print(str(err))
- raise ValueError(f"Only one {FIM_INDICATOR} allowed in prompt!") from err
- self.prompt = f"{FIM_PREFIX}{self.prefix}{FIM_SUFFIX}{self.suffix}{FIM_MIDDLE}"
-
- def __repr__(self) -> str:
- """Returns a custom string representation of the Request."""
- values = dict(
- prompt = self.prompt,
- configuration = self.settings,
- )
- return f"StarCoderRequest({values})"
diff --git a/spaces/UglyLemon/LEMONTR/README.md b/spaces/UglyLemon/LEMONTR/README.md
deleted file mode 100644
index 054badb0d4c0f172ccdd75749b08e85c5a085467..0000000000000000000000000000000000000000
--- a/spaces/UglyLemon/LEMONTR/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: LEMONTR
-emoji: 📚
-colorFrom: pink
-colorTo: indigo
-sdk: streamlit
-sdk_version: 1.26.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Wauplin/space_to_dataset_saver/app_parquet.py b/spaces/Wauplin/space_to_dataset_saver/app_parquet.py
deleted file mode 100644
index b8168bc8a632f900c79056707d64116b2deec343..0000000000000000000000000000000000000000
--- a/spaces/Wauplin/space_to_dataset_saver/app_parquet.py
+++ /dev/null
@@ -1,279 +0,0 @@
-# Taken from https://huggingface.co/spaces/hysts-samples/save-user-preferences
-# Credits to @@hysts
-import datetime
-import json
-import shutil
-import tempfile
-import uuid
-from pathlib import Path
-from typing import Any, Dict, List, Optional, Union
-
-import gradio as gr
-import pyarrow as pa
-import pyarrow.parquet as pq
-from gradio_client import Client
-from huggingface_hub import CommitScheduler
-from huggingface_hub.hf_api import HfApi
-
-#######################
-# Parquet scheduler #
-# Run in scheduler.py #
-#######################
-
-
-class ParquetScheduler(CommitScheduler):
- """
- Usage: configure the scheduler with a repo id. Once started, you can add data to be uploaded to the Hub. 1 `.append`
- call will result in 1 row in your final dataset.
-
- ```py
- # Start scheduler
- >>> scheduler = ParquetScheduler(repo_id="my-parquet-dataset")
-
- # Append some data to be uploaded
- >>> scheduler.append({...})
- >>> scheduler.append({...})
- >>> scheduler.append({...})
- ```
-
- The scheduler will automatically infer the schema from the data it pushes.
- Optionally, you can manually set the schema yourself:
-
- ```py
- >>> scheduler = ParquetScheduler(
- ... repo_id="my-parquet-dataset",
- ... schema={
- ... "prompt": {"_type": "Value", "dtype": "string"},
- ... "negative_prompt": {"_type": "Value", "dtype": "string"},
- ... "guidance_scale": {"_type": "Value", "dtype": "int64"},
- ... "image": {"_type": "Image"},
- ... },
- ... )
-
- See https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Value for the list of
- possible values.
- """
-
- def __init__(
- self,
- *,
- repo_id: str,
- schema: Optional[Dict[str, Dict[str, str]]] = None,
- every: Union[int, float] = 5,
- path_in_repo: Optional[str] = "data",
- repo_type: Optional[str] = "dataset",
- revision: Optional[str] = None,
- private: bool = False,
- token: Optional[str] = None,
- allow_patterns: Union[List[str], str, None] = None,
- ignore_patterns: Union[List[str], str, None] = None,
- hf_api: Optional[HfApi] = None,
- ) -> None:
- super().__init__(
- repo_id=repo_id,
- folder_path="dummy", # not used by the scheduler
- every=every,
- path_in_repo=path_in_repo,
- repo_type=repo_type,
- revision=revision,
- private=private,
- token=token,
- allow_patterns=allow_patterns,
- ignore_patterns=ignore_patterns,
- hf_api=hf_api,
- )
-
- self._rows: List[Dict[str, Any]] = []
- self._schema = schema
-
- def append(self, row: Dict[str, Any]) -> None:
- """Add a new item to be uploaded."""
- with self.lock:
- self._rows.append(row)
-
- def push_to_hub(self):
- # Check for new rows to push
- with self.lock:
- rows = self._rows
- self._rows = []
- if not rows:
- return
- print(f"Got {len(rows)} item(s) to commit.")
-
- # Load images + create 'features' config for datasets library
- schema: Dict[str, Dict] = self._schema or {}
- path_to_cleanup: List[Path] = []
- for row in rows:
- for key, value in row.items():
- # Infer schema (for `datasets` library)
- if key not in schema:
- schema[key] = _infer_schema(key, value)
-
- # Load binary files if necessary
- if schema[key]["_type"] in ("Image", "Audio"):
- # It's an image or audio: we load the bytes and remember to cleanup the file
- file_path = Path(value)
- if file_path.is_file():
- row[key] = {
- "path": file_path.name,
- "bytes": file_path.read_bytes(),
- }
- path_to_cleanup.append(file_path)
-
- # Complete rows if needed
- for row in rows:
- for feature in schema:
- if feature not in row:
- row[feature] = None
-
- # Export items to Arrow format
- table = pa.Table.from_pylist(rows)
-
- # Add metadata (used by datasets library)
- table = table.replace_schema_metadata(
- {"huggingface": json.dumps({"info": {"features": schema}})}
- )
-
- # Write to parquet file
- archive_file = tempfile.NamedTemporaryFile()
- pq.write_table(table, archive_file.name)
-
- # Upload
- self.api.upload_file(
- repo_id=self.repo_id,
- repo_type=self.repo_type,
- revision=self.revision,
- path_in_repo=f"{uuid.uuid4()}.parquet",
- path_or_fileobj=archive_file.name,
- )
- print(f"Commit completed.")
-
- # Cleanup
- archive_file.close()
- for path in path_to_cleanup:
- path.unlink(missing_ok=True)
-
-
-def _infer_schema(key: str, value: Any) -> Dict[str, str]:
- """
- Infer schema for the `datasets` library.
-
- See https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Value.
- """
- if "image" in key:
- return {"_type": "Image"}
- if "audio" in key:
- return {"_type": "Audio"}
- if isinstance(value, int):
- return {"_type": "Value", "dtype": "int64"}
- if isinstance(value, float):
- return {"_type": "Value", "dtype": "float64"}
- if isinstance(value, bool):
- return {"_type": "Value", "dtype": "bool"}
- if isinstance(value, bytes):
- return {"_type": "Value", "dtype": "binary"}
- # Otherwise in last resort => convert it to a string
- return {"_type": "Value", "dtype": "string"}
-
-
-#################
-# Gradio app #
-# Run in app.py #
-#################
-
-PARQUET_DATASET_DIR = Path("parquet_dataset")
-PARQUET_DATASET_DIR.mkdir(parents=True, exist_ok=True)
-
-scheduler = ParquetScheduler(repo_id="example-space-to-dataset-parquet")
-
-# client = Client("stabilityai/stable-diffusion") # Space is paused
-client = Client("runwayml/stable-diffusion-v1-5")
-
-
-def generate(prompt: str) -> tuple[str, list[str]]:
- """Generate images on 'submit' button."""
- # Generate from https://huggingface.co/spaces/stabilityai/stable-diffusion
- # out_dir = client.predict(prompt, "", 9, fn_index=1) # Space 'stabilityai/stable-diffusion' is paused
- out_dir = client.predict(prompt, fn_index=1)
- with (Path(out_dir) / "captions.json").open() as f:
- paths = list(json.load(f).keys())
-
- # Save config used to generate data
- with tempfile.NamedTemporaryFile(
- mode="w", suffix=".json", delete=False
- ) as config_file:
- json.dump(
- {"prompt": prompt, "negative_prompt": "", "guidance_scale": 9}, config_file
- )
-
- return config_file.name, paths
-
-
-def get_selected_index(evt: gr.SelectData) -> int:
- """Select "best" image."""
- return evt.index
-
-
-def save_preference(
- config_path: str, gallery: list[dict[str, Any]], selected_index: int
-) -> None:
- """Save preference, i.e. move images to a new folder and send paths+config to scheduler."""
- save_dir = PARQUET_DATASET_DIR / f"{uuid.uuid4()}"
- save_dir.mkdir(parents=True, exist_ok=True)
-
- # Load config
- with open(config_path) as f:
- data = json.load(f)
-
- # Add selected item + timestamp
- data["selected_index"] = selected_index
- data["timestamp"] = datetime.datetime.utcnow().isoformat()
-
- # Copy and add images
- for index, path in enumerate(x["name"] for x in gallery):
- name = f"{index:03d}"
- dst_path = save_dir / f"{name}{Path(path).suffix}"
- shutil.move(path, dst_path)
- data[f"image_{name}"] = dst_path
-
- # Send to scheduler
- scheduler.append(data)
-
-
-def clear() -> tuple[dict, dict, dict]:
- """Clear all values once saved."""
- return (gr.update(value=None), gr.update(value=None), gr.update(interactive=False))
-
-
-def get_demo():
- with gr.Group():
- prompt = gr.Text(show_label=False, placeholder="Prompt")
- config_path = gr.Text(visible=False)
- gallery = gr.Gallery(show_label=False).style(
- columns=2, rows=2, height="600px", object_fit="scale-down"
- )
- selected_index = gr.Number(visible=False, precision=0)
- save_preference_button = gr.Button("Save preference", interactive=False)
-
- # Generate images on submit
- prompt.submit(fn=generate, inputs=prompt, outputs=[config_path, gallery],).success(
- fn=lambda: gr.update(interactive=True),
- outputs=save_preference_button,
- queue=False,
- )
-
- # Save preference on click
- gallery.select(
- fn=get_selected_index,
- outputs=selected_index,
- queue=False,
- )
- save_preference_button.click(
- fn=save_preference,
- inputs=[config_path, gallery, selected_index],
- queue=False,
- ).then(
- fn=clear,
- outputs=[config_path, gallery, save_preference_button],
- queue=False,
- )
diff --git a/spaces/Xorbits/xinference/app.py b/spaces/Xorbits/xinference/app.py
deleted file mode 100644
index d26556bee16d90081b838de39d541104d806f14d..0000000000000000000000000000000000000000
--- a/spaces/Xorbits/xinference/app.py
+++ /dev/null
@@ -1,483 +0,0 @@
-# Copyright 2022-2023 XProbe Inc.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import asyncio
-import os
-import urllib.request
-import uuid
-from typing import TYPE_CHECKING, Dict, List, Optional, Tuple
-
-import gradio as gr
-
-from xinference.locale.utils import Locale
-from xinference.model import MODEL_FAMILIES, ModelSpec
-from xinference.core.api import SyncSupervisorAPI
-
-if TYPE_CHECKING:
- from xinference.types import ChatCompletionChunk, ChatCompletionMessage
-
-MODEL_TO_FAMILIES = dict(
- (model_family.model_name, model_family)
- for model_family in MODEL_FAMILIES
- if model_family.model_name != "baichuan"
-)
-
-
-class GradioApp:
- def __init__(
- self,
- supervisor_address: str,
- gladiator_num: int = 2,
- max_model_num: int = 2,
- use_launched_model: bool = False,
- ):
- self._api = SyncSupervisorAPI(supervisor_address)
- self._gladiator_num = gladiator_num
- self._max_model_num = max_model_num
- self._use_launched_model = use_launched_model
- self._locale = Locale()
-
- def _create_model(
- self,
- model_name: str,
- model_size_in_billions: Optional[int] = None,
- model_format: Optional[str] = None,
- quantization: Optional[str] = None,
- ):
- model_uid = str(uuid.uuid1())
- models = self._api.list_models()
- if len(models) >= self._max_model_num:
- self._api.terminate_model(models[0][0])
- return self._api.launch_model(
- model_uid, model_name, model_size_in_billions, model_format, quantization
- )
-
- async def generate(
- self,
- model: str,
- message: str,
- chat: List[List[str]],
- max_token: int,
- temperature: float,
- top_p: float,
- window_size: int,
- show_finish_reason: bool,
- ):
- if not message:
- yield message, chat
- else:
- try:
- model_ref = self._api.get_model(model)
- except KeyError:
- raise gr.Error(self._locale(f"Please create model first"))
-
- history: "List[ChatCompletionMessage]" = []
- for c in chat:
- history.append({"role": "user", "content": c[0]})
-
- out = c[1]
- finish_reason_idx = out.find(f"[{self._locale('stop reason')}: ")
- if finish_reason_idx != -1:
- out = out[:finish_reason_idx]
- history.append({"role": "assistant", "content": out})
-
- if window_size != 0:
- history = history[-(window_size // 2) :]
-
- # chatglm only support even number of conversation history.
- if len(history) % 2 != 0:
- history = history[1:]
-
- generate_config = dict(
- max_tokens=max_token,
- temperature=temperature,
- top_p=top_p,
- stream=True,
- )
- chat += [[message, ""]]
- chat_generator = await model_ref.chat(
- message,
- chat_history=history,
- generate_config=generate_config,
- )
-
- chunk: Optional["ChatCompletionChunk"] = None
- async for chunk in chat_generator:
- assert chunk is not None
- delta = chunk["choices"][0]["delta"]
- if "content" not in delta:
- continue
- else:
- chat[-1][1] += delta["content"]
- yield "", chat
- if show_finish_reason and chunk is not None:
- chat[-1][
- 1
- ] += f"[{self._locale('stop reason')}: {chunk['choices'][0]['finish_reason']}]"
- yield "", chat
-
- def _build_chatbot(self, model_uid: str, model_name: str):
- with gr.Accordion(self._locale("Parameters"), open=False):
- max_token = gr.Slider(
- 128,
- 1024,
- value=128,
- step=1,
- label=self._locale("Max tokens"),
- info=self._locale("The maximum number of tokens to generate."),
- )
- temperature = gr.Slider(
- 0.2,
- 1,
- value=0.8,
- step=0.01,
- label=self._locale("Temperature"),
- info=self._locale("The temperature to use for sampling."),
- )
- top_p = gr.Slider(
- 0.2,
- 1,
- value=0.95,
- step=0.01,
- label=self._locale("Top P"),
- info=self._locale("The top-p value to use for sampling."),
- )
- window_size = gr.Slider(
- 0,
- 50,
- value=10,
- step=1,
- label=self._locale("Window size"),
- info=self._locale("Window size of chat history."),
- )
- show_finish_reason = gr.Checkbox(
- label=f"{self._locale('Show stop reason')}"
- )
- chat = gr.Chatbot(label=model_name)
- text = gr.Textbox(visible=False)
- model_uid = gr.Textbox(model_uid, visible=False)
- text.change(
- self.generate,
- [
- model_uid,
- text,
- chat,
- max_token,
- temperature,
- top_p,
- window_size,
- show_finish_reason,
- ],
- [text, chat],
- )
- return (
- text,
- chat,
- max_token,
- temperature,
- top_p,
- show_finish_reason,
- window_size,
- model_uid,
- )
-
- def _build_chat_column(self):
- with gr.Column():
- with gr.Row():
- model_name = gr.Dropdown(
- choices=list(MODEL_TO_FAMILIES.keys()),
- label=self._locale("model name"),
- scale=2,
- )
- model_format = gr.Dropdown(
- choices=[],
- interactive=False,
- label=self._locale("model format"),
- scale=2,
- )
- model_size_in_billions = gr.Dropdown(
- choices=[],
- interactive=False,
- label=self._locale("model size in billions"),
- scale=1,
- )
- quantization = gr.Dropdown(
- choices=[],
- interactive=False,
- label=self._locale("quantization"),
- scale=1,
- )
- create_model = gr.Button(value=self._locale("create"))
-
- def select_model_name(model_name: str):
- if model_name:
- model_family = MODEL_TO_FAMILIES[model_name]
- formats = [model_family.model_format]
- model_sizes_in_billions = [
- str(b) for b in model_family.model_sizes_in_billions
- ]
- quantizations = model_family.quantizations
- return (
- gr.Dropdown.update(
- choices=formats,
- interactive=True,
- value=model_family.model_format,
- ),
- gr.Dropdown.update(
- choices=model_sizes_in_billions[:1],
- interactive=True,
- value=model_sizes_in_billions[0],
- ),
- gr.Dropdown.update(
- choices=quantizations,
- interactive=True,
- value=quantizations[0],
- ),
- )
- else:
- return (
- gr.Dropdown.update(),
- gr.Dropdown.update(),
- gr.Dropdown.update(),
- )
-
- model_name.change(
- select_model_name,
- inputs=[model_name],
- outputs=[model_format, model_size_in_billions, quantization],
- )
-
- components = self._build_chatbot("", "")
- model_text = components[0]
- chat, model_uid = components[1], components[-1]
-
- def select_model(
- _model_name: str,
- _model_format: str,
- _model_size_in_billions: str,
- _quantization: str,
- progress=gr.Progress(),
- ):
- model_family = MODEL_TO_FAMILIES[_model_name]
- cache_path, meta_path = model_family.generate_cache_path(
- int(_model_size_in_billions), _quantization
- )
- if not (os.path.exists(cache_path) and os.path.exists(meta_path)):
- if os.path.exists(cache_path):
- os.remove(cache_path)
- url = model_family.url_generator(
- int(_model_size_in_billions), _quantization
- )
- full_name = (
- f"{str(model_family)}-{_model_size_in_billions}b-{_quantization}"
- )
- try:
- urllib.request.urlretrieve(
- url,
- cache_path,
- reporthook=lambda block_num, block_size, total_size: progress(
- block_num * block_size / total_size,
- desc=self._locale("Downloading"),
- ),
- )
- # write a meta file to record if download finished
- with open(meta_path, "w") as f:
- f.write(full_name)
- except:
- if os.path.exists(cache_path):
- os.remove(cache_path)
-
- model_uid = self._create_model(
- _model_name, int(_model_size_in_billions), _model_format, _quantization
- )
- return gr.Chatbot.update(
- label="-".join(
- [_model_name, _model_size_in_billions, _model_format, _quantization]
- ),
- value=[],
- ), gr.Textbox.update(value=model_uid)
-
- def clear_chat(
- _model_name: str,
- _model_format: str,
- _model_size_in_billions: str,
- _quantization: str,
- ):
- full_name = "-".join(
- [_model_name, _model_size_in_billions, _model_format, _quantization]
- )
- return str(uuid.uuid4()), gr.Chatbot.update(
- label=full_name,
- value=[],
- )
-
- invisible_text = gr.Textbox(visible=False)
- create_model.click(
- clear_chat,
- inputs=[model_name, model_format, model_size_in_billions, quantization],
- outputs=[invisible_text, chat],
- )
-
- invisible_text.change(
- select_model,
- inputs=[model_name, model_format, model_size_in_billions, quantization],
- outputs=[chat, model_uid],
- postprocess=False,
- )
- return chat, model_text
-
- def _build_arena(self):
- with gr.Box():
- with gr.Row():
- chat_and_text = [
- self._build_chat_column() for _ in range(self._gladiator_num)
- ]
- chats = [c[0] for c in chat_and_text]
- texts = [c[1] for c in chat_and_text]
-
- msg = gr.Textbox(label=self._locale("Input"))
-
- def update_message(text_in: str):
- return "", text_in, text_in
-
- msg.submit(update_message, inputs=[msg], outputs=[msg] + texts)
-
- gr.ClearButton(components=[msg] + chats + texts)
-
- def _build_single(self):
- chat, model_text = self._build_chat_column()
-
- msg = gr.Textbox(label=self._locale("Input"))
-
- def update_message(text_in: str):
- return "", text_in
-
- msg.submit(update_message, inputs=[msg], outputs=[msg, model_text])
- gr.ClearButton(components=[chat, msg, model_text])
-
- def _build_single_with_launched(
- self, models: List[Tuple[str, ModelSpec]], default_index: int
- ):
- uid_to_model_spec: Dict[str, ModelSpec] = dict((m[0], m[1]) for m in models)
- choices = [
- "-".join(
- [
- s.model_name,
- str(s.model_size_in_billions),
- s.model_format,
- s.quantization,
- ]
- )
- for s in uid_to_model_spec.values()
- ]
- choice_to_uid = dict(zip(choices, uid_to_model_spec.keys()))
- model_selection = gr.Dropdown(
- label=self._locale("select model"),
- choices=choices,
- value=choices[default_index],
- )
- components = self._build_chatbot(
- models[default_index][0], choices[default_index]
- )
- model_text = components[0]
- model_uid = components[-1]
- chat = components[1]
-
- def select_model(model_name):
- uid = choice_to_uid[model_name]
- return gr.Chatbot.update(label=model_name), uid
-
- model_selection.change(
- select_model, inputs=[model_selection], outputs=[chat, model_uid]
- )
- return chat, model_text
-
- def _build_arena_with_launched(self, models: List[Tuple[str, ModelSpec]]):
- chat_and_text = []
- with gr.Row():
- for i in range(self._gladiator_num):
- with gr.Column():
- chat_and_text.append(self._build_single_with_launched(models, i))
-
- chats = [c[0] for c in chat_and_text]
- texts = [c[1] for c in chat_and_text]
-
- msg = gr.Textbox(label=self._locale("Input"))
-
- def update_message(text_in: str):
- return "", text_in, text_in
-
- msg.submit(update_message, inputs=[msg], outputs=[msg] + texts)
-
- gr.ClearButton(components=[msg] + chats + texts)
-
- def build(self):
- if self._use_launched_model:
- models = self._api.list_models()
- with gr.Blocks() as blocks:
- if len(models) >= 2:
- with gr.Tab(self._locale("Arena")):
- self._build_arena_with_launched(models)
- with gr.Tab(self._locale("Chat")):
- chat, model_text = self._build_single_with_launched(models, 0)
- msg = gr.Textbox(label=self._locale("Input"))
-
- def update_message(text_in: str):
- return "", text_in
-
- msg.submit(update_message, inputs=[msg], outputs=[msg, model_text])
- gr.ClearButton(components=[chat, msg, model_text])
- else:
- with gr.Blocks() as blocks:
- with gr.Tab(self._locale("Chat")):
- self._build_single()
- with gr.Tab(self._locale("Arena")):
- self._build_arena()
- blocks.queue(concurrency_count=40)
- return blocks
-
-
-async def launch_xinference():
- import xoscar as xo
- from xinference.core.service import SupervisorActor
- from xinference.core.api import AsyncSupervisorAPI
- from xinference.deploy.worker import start_worker_components
-
- pool = await xo.create_actor_pool(address="0.0.0.0", n_process=0)
- supervisor_address = pool.external_address
- await xo.create_actor(
- SupervisorActor, address=supervisor_address, uid=SupervisorActor.uid()
- )
- await start_worker_components(
- address=supervisor_address, supervisor_address=supervisor_address
- )
- api = AsyncSupervisorAPI(supervisor_address)
- supported_models = ["chatglm2", "chatglm", "vicuna-v1.3", "orca"]
- for model in supported_models:
- await api.launch_model(str(uuid.uuid4()), model)
-
- gradio_block = GradioApp(supervisor_address, use_launched_model=True).build()
- gradio_block.launch()
-
-
-if __name__ == "__main__":
- loop = asyncio.get_event_loop()
- task = loop.create_task(launch_xinference())
-
- try:
- loop.run_until_complete(task)
- except KeyboardInterrupt:
- task.cancel()
- loop.run_until_complete(task)
- # avoid displaying exception-unhandled warnings
- task.exception()
diff --git a/spaces/YeOldHermit/Super-Resolution-Anime-Diffusion/Waifu2x/utils/prepare_images.py b/spaces/YeOldHermit/Super-Resolution-Anime-Diffusion/Waifu2x/utils/prepare_images.py
deleted file mode 100644
index 7fd513d4cba4c88effbf7db0b605125ab2c96b6d..0000000000000000000000000000000000000000
--- a/spaces/YeOldHermit/Super-Resolution-Anime-Diffusion/Waifu2x/utils/prepare_images.py
+++ /dev/null
@@ -1,120 +0,0 @@
-import copy
-import glob
-import os
-from multiprocessing.dummy import Pool as ThreadPool
-
-from PIL import Image
-from torchvision.transforms.functional import to_tensor
-
-from ..Models import *
-
-
-class ImageSplitter:
- # key points:
- # Boarder padding and over-lapping img splitting to avoid the instability of edge value
- # Thanks Waifu2x's autorh nagadomi for suggestions (https://github.com/nagadomi/waifu2x/issues/238)
-
- def __init__(self, seg_size=48, scale_factor=2, boarder_pad_size=3):
- self.seg_size = seg_size
- self.scale_factor = scale_factor
- self.pad_size = boarder_pad_size
- self.height = 0
- self.width = 0
- self.upsampler = nn.Upsample(scale_factor=scale_factor, mode='bilinear')
-
- def split_img_tensor(self, pil_img, scale_method=Image.BILINEAR, img_pad=0):
- # resize image and convert them into tensor
- img_tensor = to_tensor(pil_img).unsqueeze(0)
- img_tensor = nn.ReplicationPad2d(self.pad_size)(img_tensor)
- batch, channel, height, width = img_tensor.size()
- self.height = height
- self.width = width
-
- if scale_method is not None:
- img_up = pil_img.resize((2 * pil_img.size[0], 2 * pil_img.size[1]), scale_method)
- img_up = to_tensor(img_up).unsqueeze(0)
- img_up = nn.ReplicationPad2d(self.pad_size * self.scale_factor)(img_up)
-
- patch_box = []
- # avoid the residual part is smaller than the padded size
- if height % self.seg_size < self.pad_size or width % self.seg_size < self.pad_size:
- self.seg_size += self.scale_factor * self.pad_size
-
- # split image into over-lapping pieces
- for i in range(self.pad_size, height, self.seg_size):
- for j in range(self.pad_size, width, self.seg_size):
- part = img_tensor[:, :,
- (i - self.pad_size):min(i + self.pad_size + self.seg_size, height),
- (j - self.pad_size):min(j + self.pad_size + self.seg_size, width)]
- if img_pad > 0:
- part = nn.ZeroPad2d(img_pad)(part)
- if scale_method is not None:
- # part_up = self.upsampler(part)
- part_up = img_up[:, :,
- self.scale_factor * (i - self.pad_size):min(i + self.pad_size + self.seg_size,
- height) * self.scale_factor,
- self.scale_factor * (j - self.pad_size):min(j + self.pad_size + self.seg_size,
- width) * self.scale_factor]
-
- patch_box.append((part, part_up))
- else:
- patch_box.append(part)
- return patch_box
-
- def merge_img_tensor(self, list_img_tensor):
- out = torch.zeros((1, 3, self.height * self.scale_factor, self.width * self.scale_factor))
- img_tensors = copy.copy(list_img_tensor)
- rem = self.pad_size * 2
-
- pad_size = self.scale_factor * self.pad_size
- seg_size = self.scale_factor * self.seg_size
- height = self.scale_factor * self.height
- width = self.scale_factor * self.width
- for i in range(pad_size, height, seg_size):
- for j in range(pad_size, width, seg_size):
- part = img_tensors.pop(0)
- part = part[:, :, rem:-rem, rem:-rem]
- # might have error
- if len(part.size()) > 3:
- _, _, p_h, p_w = part.size()
- out[:, :, i:i + p_h, j:j + p_w] = part
- # out[:,:,
- # self.scale_factor*i:self.scale_factor*i+p_h,
- # self.scale_factor*j:self.scale_factor*j+p_w] = part
- out = out[:, :, rem:-rem, rem:-rem]
- return out
-
-
-def load_single_image(img_file,
- up_scale=False,
- up_scale_factor=2,
- up_scale_method=Image.BILINEAR,
- zero_padding=False):
- img = Image.open(img_file).convert("RGB")
- out = to_tensor(img).unsqueeze(0)
- if zero_padding:
- out = nn.ZeroPad2d(zero_padding)(out)
- if up_scale:
- size = tuple(map(lambda x: x * up_scale_factor, img.size))
- img_up = img.resize(size, up_scale_method)
- img_up = to_tensor(img_up).unsqueeze(0)
- out = (out, img_up)
-
- return out
-
-
-def standardize_img_format(img_folder):
- def process(img_file):
- img_path = os.path.dirname(img_file)
- img_name, _ = os.path.basename(img_file).split(".")
- out = os.path.join(img_path, img_name + ".JPEG")
- os.rename(img_file, out)
-
- list_imgs = []
- for i in ['png', "jpeg", 'jpg']:
- list_imgs.extend(glob.glob(img_folder + "**/*." + i, recursive=True))
- print("Found {} images.".format(len(list_imgs)))
- pool = ThreadPool(4)
- pool.map(process, list_imgs)
- pool.close()
- pool.join()
diff --git a/spaces/Yeno/text-to-3D/app.py b/spaces/Yeno/text-to-3D/app.py
deleted file mode 100644
index 20bdb836f38f77fb2d0a321650ffbbe5d03e2dc4..0000000000000000000000000000000000000000
--- a/spaces/Yeno/text-to-3D/app.py
+++ /dev/null
@@ -1,264 +0,0 @@
-import os
-from PIL import Image
-import torch
-
-from point_e.diffusion.configs import DIFFUSION_CONFIGS, diffusion_from_config
-from point_e.diffusion.sampler import PointCloudSampler
-from point_e.models.download import load_checkpoint
-from point_e.models.configs import MODEL_CONFIGS, model_from_config
-from point_e.util.plotting import plot_point_cloud
-from point_e.util.pc_to_mesh import marching_cubes_mesh
-
-import skimage.measure
-
-from pyntcloud import PyntCloud
-import matplotlib.colors
-import plotly.graph_objs as go
-
-import trimesh
-
-import gradio as gr
-
-
-state = ""
-device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
-
-def set_state(s):
- print(s)
- global state
- state = s
-
-def get_state():
- return state
-
-set_state('Creating txt2mesh model...')
-t2m_name = 'base40M-textvec'
-t2m_model = model_from_config(MODEL_CONFIGS[t2m_name], device)
-t2m_model.eval()
-base_diffusion_t2m = diffusion_from_config(DIFFUSION_CONFIGS[t2m_name])
-
-set_state('Downloading txt2mesh checkpoint...')
-t2m_model.load_state_dict(load_checkpoint(t2m_name, device))
-
-
-def load_img2mesh_model(model_name):
- set_state(f'Creating img2mesh model {model_name}...')
- i2m_name = model_name
- i2m_model = model_from_config(MODEL_CONFIGS[i2m_name], device)
- i2m_model.eval()
- base_diffusion_i2m = diffusion_from_config(DIFFUSION_CONFIGS[i2m_name])
-
- set_state(f'Downloading img2mesh checkpoint {model_name}...')
- i2m_model.load_state_dict(load_checkpoint(i2m_name, device))
-
- return i2m_model, base_diffusion_i2m
-
-img2mesh_model_name = 'base40M' #'base300M' #'base1B'
-i2m_model, base_diffusion_i2m = load_img2mesh_model(img2mesh_model_name)
-
-
-set_state('Creating upsample model...')
-upsampler_model = model_from_config(MODEL_CONFIGS['upsample'], device)
-upsampler_model.eval()
-upsampler_diffusion = diffusion_from_config(DIFFUSION_CONFIGS['upsample'])
-
-set_state('Downloading upsampler checkpoint...')
-upsampler_model.load_state_dict(load_checkpoint('upsample', device))
-
-set_state('Creating SDF model...')
-sdf_name = 'sdf'
-sdf_model = model_from_config(MODEL_CONFIGS[sdf_name], device)
-sdf_model.eval()
-
-set_state('Loading SDF model...')
-sdf_model.load_state_dict(load_checkpoint(sdf_name, device))
-
-stable_diffusion = gr.Blocks.load(name="spaces/runwayml/stable-diffusion-v1-5")
-
-
-set_state('')
-
-def get_sampler(model_name, txt2obj, guidance_scale):
-
- global img2mesh_model_name
- global base_diffusion_i2m
- global i2m_model
- if model_name != img2mesh_model_name:
- img2mesh_model_name = model_name
- i2m_model, base_diffusion_i2m = load_img2mesh_model(model_name)
-
- return PointCloudSampler(
- device=device,
- models=[t2m_model if txt2obj else i2m_model, upsampler_model],
- diffusions=[base_diffusion_t2m if txt2obj else base_diffusion_i2m, upsampler_diffusion],
- num_points=[1024, 4096 - 1024],
- aux_channels=['R', 'G', 'B'],
- guidance_scale=[guidance_scale, 0.0 if txt2obj else guidance_scale],
- model_kwargs_key_filter=('texts', '') if txt2obj else ("*",)
- )
-
-def generate_txt2img(prompt):
-
- prompt = f"“a 3d rendering of {prompt}, full view, white background"
- gallery_dir = stable_diffusion(prompt, fn_index=2)
- imgs = [os.path.join(gallery_dir, img) for img in os.listdir(gallery_dir) if os.path.splitext(img)[1] == '.jpg']
-
- return imgs[0], gr.update(visible=True)
-
-def generate_3D(input, model_name='base40M', guidance_scale=3.0, grid_size=32):
-
- set_state('Entered generate function...')
-
- if isinstance(input, Image.Image):
- input = prepare_img(input)
-
- # if input is a string, it's a text prompt
- sampler = get_sampler(model_name, txt2obj=True if isinstance(input, str) else False, guidance_scale=guidance_scale)
-
- # Produce a sample from the model.
- set_state('Sampling...')
- samples = None
- kw_args = dict(texts=[input]) if isinstance(input, str) else dict(images=[input])
- for x in sampler.sample_batch_progressive(batch_size=1, model_kwargs=kw_args):
- samples = x
-
- set_state('Converting to point cloud...')
- pc = sampler.output_to_point_clouds(samples)[0]
-
- set_state('Saving point cloud...')
- with open("point_cloud.ply", "wb") as f:
- pc.write_ply(f)
-
- set_state('Converting to mesh...')
- save_ply(pc, 'mesh.ply', grid_size)
-
- set_state('')
-
- return pc_to_plot(pc), ply_to_obj('mesh.ply', '3d_model.obj'), gr.update(value=['3d_model.obj', 'mesh.ply', 'point_cloud.ply'], visible=True)
-
-def prepare_img(img):
-
- w, h = img.size
- if w > h:
- img = img.crop((w - h) / 2, 0, w - (w - h) / 2, h)
- else:
- img = img.crop((0, (h - w) / 2, w, h - (h - w) / 2))
-
- # resize to 256x256
- img = img.resize((256, 256))
-
- return img
-
-def pc_to_plot(pc):
-
- return go.Figure(
- data=[
- go.Scatter3d(
- x=pc.coords[:,0], y=pc.coords[:,1], z=pc.coords[:,2],
- mode='markers',
- marker=dict(
- size=2,
- color=['rgb({},{},{})'.format(r,g,b) for r,g,b in zip(pc.channels["R"], pc.channels["G"], pc.channels["B"])],
- )
- )
- ],
- layout=dict(
- scene=dict(xaxis=dict(visible=False), yaxis=dict(visible=False), zaxis=dict(visible=False))
- ),
- )
-
-def ply_to_obj(ply_file, obj_file):
- mesh = trimesh.load(ply_file)
- mesh.export(obj_file)
-
- return obj_file
-
-def save_ply(pc, file_name, grid_size):
-
- # Produce a mesh (with vertex colors)
- mesh = marching_cubes_mesh(
- pc=pc,
- model=sdf_model,
- batch_size=4096,
- grid_size=grid_size, # increase to 128 for resolution used in evals
- progress=True,
- )
-
- # Write the mesh to a PLY file to import into some other program.
- with open(file_name, 'wb') as f:
- mesh.write_ply(f)
-
-
-with gr.Blocks() as app:
- gr.Markdown("# Image-to-3D")
- gr.Markdown("Turn any image or prompt to a 3D asset! Powered by StableDiffusion and OpenAI Point-E. Check out (https://twitter.com/angrypenguinPNG) for a tutorial on how to best use this space.")
- gr.HTML("""To skip the queue you can duplicate this space:
-
 -
-
Don't forget to change space hardware to GPU after duplicating it.""")
-
- with gr.Row():
- with gr.Column():
- with gr.Tab("Image to 3D"):
- img = gr.Image(label="Image")
- gr.Markdown("Best results with images of 3D objects with no shadows on a white background.")
- btn_generate_img2obj = gr.Button(value="Generate")
-
- with gr.Tab("Text to 3D"):
- gr.Markdown("Generate an image with Stable Diffusion, then convert it to 3D. Just enter the object you want to generate.")
- prompt_sd = gr.Textbox(label="Prompt", placeholder="a 3d rendering of [your prompt], full view, white background")
- btn_generate_txt2sd = gr.Button(value="Generate image")
- img_sd = gr.Image(label="Image")
- btn_generate_sd2obj = gr.Button(value="Convert to 3D", visible=False)
-
- with gr.Accordion("Advanced settings", open=False):
- dropdown_models = gr.Dropdown(label="Model", value="base40M", choices=["base40M", "base300M"]) #, "base1B"])
- guidance_scale = gr.Slider(label="Guidance scale", value=3.0, minimum=3.0, maximum=10.0, step=0.1)
- grid_size = gr.Slider(label="Grid size (for .obj 3D model)", value=32, minimum=16, maximum=128, step=16)
-
- with gr.Column():
- plot = gr.Plot(label="Point cloud")
- # btn_pc_to_obj = gr.Button(value="Convert to OBJ", visible=False)
- model_3d = gr.Model3D(value=None)
- file_out = gr.File(label="Files", visible=False)
-
- # state_info = state_info = gr.Textbox(label="State", show_label=False).style(container=False)
-
-
- # inputs = [dropdown_models, prompt, img, guidance_scale, grid_size]
- outputs = [plot, model_3d, file_out]
-
- btn_generate_img2obj.click(generate_3D, inputs=[img, dropdown_models, guidance_scale, grid_size], outputs=outputs)
-
- prompt_sd.submit(generate_txt2img, inputs=prompt_sd, outputs=[img_sd, btn_generate_sd2obj])
- btn_generate_txt2sd.click(generate_txt2img, inputs=prompt_sd, outputs=[img_sd, btn_generate_sd2obj], queue=False)
- btn_generate_sd2obj.click(generate_3D, inputs=[img, dropdown_models, guidance_scale, grid_size], outputs=outputs)
-
- # btn_pc_to_obj.click(ply_to_obj, inputs=plot, outputs=[model_3d, file_out])
-
- gr.Examples(
- examples=[
- ["images/corgi.png"],
- ["images/cube_stack.jpg"],
- ["images/chair.png"],
- ],
- inputs=[img],
- outputs=outputs,
- fn=generate_3D,
- cache_examples=False
- )
-
- # app.load(get_state, inputs=[], outputs=state_info, every=0.5, show_progress=False)
-
- gr.HTML("""
-
-
- """)
-
-app.queue(max_size=250, concurrency_count=6).launch()
diff --git a/spaces/Yuelili/RealNagrse/realesrgan/utils.py b/spaces/Yuelili/RealNagrse/realesrgan/utils.py
deleted file mode 100644
index 10e7c23d04f777c250160e74470fdfacb16eab88..0000000000000000000000000000000000000000
--- a/spaces/Yuelili/RealNagrse/realesrgan/utils.py
+++ /dev/null
@@ -1,280 +0,0 @@
-import cv2
-import math
-import numpy as np
-import os
-import queue
-import threading
-import torch
-from basicsr.utils.download_util import load_file_from_url
-from torch.nn import functional as F
-
-ROOT_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
-
-
-class RealESRGANer():
- """A helper class for upsampling images with RealESRGAN.
-
- Args:
- scale (int): Upsampling scale factor used in the networks. It is usually 2 or 4.
- model_path (str): The path to the pretrained model. It can be urls (will first download it automatically).
- model (nn.Module): The defined network. Default: None.
- tile (int): As too large images result in the out of GPU memory issue, so this tile option will first crop
- input images into tiles, and then process each of them. Finally, they will be merged into one image.
- 0 denotes for do not use tile. Default: 0.
- tile_pad (int): The pad size for each tile, to remove border artifacts. Default: 10.
- pre_pad (int): Pad the input images to avoid border artifacts. Default: 10.
- half (float): Whether to use half precision during inference. Default: False.
- """
-
- def __init__(self, scale, model_path, model=None, tile=0, tile_pad=10, pre_pad=10, half=False):
- self.scale = scale
- self.tile_size = tile
- self.tile_pad = tile_pad
- self.pre_pad = pre_pad
- self.mod_scale = None
- self.half = half
-
- # initialize model
- self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- # if the model_path starts with https, it will first download models to the folder: realesrgan/weights
- if model_path.startswith('https://'):
- model_path = load_file_from_url(
- url=model_path, model_dir=os.path.join(ROOT_DIR, 'realesrgan/weights'), progress=True, file_name=None)
- loadnet = torch.load(model_path, map_location=torch.device('cpu'))
- # prefer to use params_ema
- if 'params_ema' in loadnet:
- keyname = 'params_ema'
- else:
- keyname = 'params'
- model.load_state_dict(loadnet[keyname], strict=True)
- model.eval()
- self.model = model.to(self.device)
- if self.half:
- self.model = self.model.half()
-
- def pre_process(self, img):
- """Pre-process, such as pre-pad and mod pad, so that the images can be divisible
- """
- img = torch.from_numpy(np.transpose(img, (2, 0, 1))).float()
- self.img = img.unsqueeze(0).to(self.device)
- if self.half:
- self.img = self.img.half()
-
- # pre_pad
- if self.pre_pad != 0:
- self.img = F.pad(self.img, (0, self.pre_pad, 0, self.pre_pad), 'reflect')
- # mod pad for divisible borders
- if self.scale == 2:
- self.mod_scale = 2
- elif self.scale == 1:
- self.mod_scale = 4
- if self.mod_scale is not None:
- self.mod_pad_h, self.mod_pad_w = 0, 0
- _, _, h, w = self.img.size()
- if (h % self.mod_scale != 0):
- self.mod_pad_h = (self.mod_scale - h % self.mod_scale)
- if (w % self.mod_scale != 0):
- self.mod_pad_w = (self.mod_scale - w % self.mod_scale)
- self.img = F.pad(self.img, (0, self.mod_pad_w, 0, self.mod_pad_h), 'reflect')
-
- def process(self):
- # model inference
- self.output = self.model(self.img)
-
- def tile_process(self):
- """It will first crop input images to tiles, and then process each tile.
- Finally, all the processed tiles are merged into one images.
-
- Modified from: https://github.com/ata4/esrgan-launcher
- """
- batch, channel, height, width = self.img.shape
- output_height = height * self.scale
- output_width = width * self.scale
- output_shape = (batch, channel, output_height, output_width)
-
- # start with black image
- self.output = self.img.new_zeros(output_shape)
- tiles_x = math.ceil(width / self.tile_size)
- tiles_y = math.ceil(height / self.tile_size)
-
- # loop over all tiles
- for y in range(tiles_y):
- for x in range(tiles_x):
- # extract tile from input image
- ofs_x = x * self.tile_size
- ofs_y = y * self.tile_size
- # input tile area on total image
- input_start_x = ofs_x
- input_end_x = min(ofs_x + self.tile_size, width)
- input_start_y = ofs_y
- input_end_y = min(ofs_y + self.tile_size, height)
-
- # input tile area on total image with padding
- input_start_x_pad = max(input_start_x - self.tile_pad, 0)
- input_end_x_pad = min(input_end_x + self.tile_pad, width)
- input_start_y_pad = max(input_start_y - self.tile_pad, 0)
- input_end_y_pad = min(input_end_y + self.tile_pad, height)
-
- # input tile dimensions
- input_tile_width = input_end_x - input_start_x
- input_tile_height = input_end_y - input_start_y
- tile_idx = y * tiles_x + x + 1
- input_tile = self.img[:, :, input_start_y_pad:input_end_y_pad, input_start_x_pad:input_end_x_pad]
-
- # upscale tile
- try:
- with torch.no_grad():
- output_tile = self.model(input_tile)
- except RuntimeError as error:
- print('Error', error)
- print(f'\tTile {tile_idx}/{tiles_x * tiles_y}')
-
- # output tile area on total image
- output_start_x = input_start_x * self.scale
- output_end_x = input_end_x * self.scale
- output_start_y = input_start_y * self.scale
- output_end_y = input_end_y * self.scale
-
- # output tile area without padding
- output_start_x_tile = (input_start_x - input_start_x_pad) * self.scale
- output_end_x_tile = output_start_x_tile + input_tile_width * self.scale
- output_start_y_tile = (input_start_y - input_start_y_pad) * self.scale
- output_end_y_tile = output_start_y_tile + input_tile_height * self.scale
-
- # put tile into output image
- self.output[:, :, output_start_y:output_end_y,
- output_start_x:output_end_x] = output_tile[:, :, output_start_y_tile:output_end_y_tile,
- output_start_x_tile:output_end_x_tile]
-
- def post_process(self):
- # remove extra pad
- if self.mod_scale is not None:
- _, _, h, w = self.output.size()
- self.output = self.output[:, :, 0:h - self.mod_pad_h * self.scale, 0:w - self.mod_pad_w * self.scale]
- # remove prepad
- if self.pre_pad != 0:
- _, _, h, w = self.output.size()
- self.output = self.output[:, :, 0:h - self.pre_pad * self.scale, 0:w - self.pre_pad * self.scale]
- return self.output
-
- @torch.no_grad()
- def enhance(self, img, outscale=None, alpha_upsampler='realesrgan'):
- h_input, w_input = img.shape[0:2]
- # img: numpy
- img = img.astype(np.float32)
- if np.max(img) > 256: # 16-bit image
- max_range = 65535
- print('\tInput is a 16-bit image')
- else:
- max_range = 255
- img = img / max_range
- if len(img.shape) == 2: # gray image
- img_mode = 'L'
- img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB)
- elif img.shape[2] == 4: # RGBA image with alpha channel
- img_mode = 'RGBA'
- alpha = img[:, :, 3]
- img = img[:, :, 0:3]
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
- if alpha_upsampler == 'realesrgan':
- alpha = cv2.cvtColor(alpha, cv2.COLOR_GRAY2RGB)
- else:
- img_mode = 'RGB'
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
-
- # ------------------- process image (without the alpha channel) ------------------- #
- self.pre_process(img)
- if self.tile_size > 0:
- self.tile_process()
- else:
- self.process()
- output_img = self.post_process()
- output_img = output_img.data.squeeze().float().cpu().clamp_(0, 1).numpy()
- output_img = np.transpose(output_img[[2, 1, 0], :, :], (1, 2, 0))
- if img_mode == 'L':
- output_img = cv2.cvtColor(output_img, cv2.COLOR_BGR2GRAY)
-
- # ------------------- process the alpha channel if necessary ------------------- #
- if img_mode == 'RGBA':
- if alpha_upsampler == 'realesrgan':
- self.pre_process(alpha)
- if self.tile_size > 0:
- self.tile_process()
- else:
- self.process()
- output_alpha = self.post_process()
- output_alpha = output_alpha.data.squeeze().float().cpu().clamp_(0, 1).numpy()
- output_alpha = np.transpose(output_alpha[[2, 1, 0], :, :], (1, 2, 0))
- output_alpha = cv2.cvtColor(output_alpha, cv2.COLOR_BGR2GRAY)
- else: # use the cv2 resize for alpha channel
- h, w = alpha.shape[0:2]
- output_alpha = cv2.resize(alpha, (w * self.scale, h * self.scale), interpolation=cv2.INTER_LINEAR)
-
- # merge the alpha channel
- output_img = cv2.cvtColor(output_img, cv2.COLOR_BGR2BGRA)
- output_img[:, :, 3] = output_alpha
-
- # ------------------------------ return ------------------------------ #
- if max_range == 65535: # 16-bit image
- output = (output_img * 65535.0).round().astype(np.uint16)
- else:
- output = (output_img * 255.0).round().astype(np.uint8)
-
- if outscale is not None and outscale != float(self.scale):
- output = cv2.resize(
- output, (
- int(w_input * outscale),
- int(h_input * outscale),
- ), interpolation=cv2.INTER_LANCZOS4)
-
- return output, img_mode
-
-
-class PrefetchReader(threading.Thread):
- """Prefetch images.
-
- Args:
- img_list (list[str]): A image list of image paths to be read.
- num_prefetch_queue (int): Number of prefetch queue.
- """
-
- def __init__(self, img_list, num_prefetch_queue):
- super().__init__()
- self.que = queue.Queue(num_prefetch_queue)
- self.img_list = img_list
-
- def run(self):
- for img_path in self.img_list:
- img = cv2.imread(img_path, cv2.IMREAD_UNCHANGED)
- self.que.put(img)
-
- self.que.put(None)
-
- def __next__(self):
- next_item = self.que.get()
- if next_item is None:
- raise StopIteration
- return next_item
-
- def __iter__(self):
- return self
-
-
-class IOConsumer(threading.Thread):
-
- def __init__(self, opt, que, qid):
- super().__init__()
- self._queue = que
- self.qid = qid
- self.opt = opt
-
- def run(self):
- while True:
- msg = self._queue.get()
- if isinstance(msg, str) and msg == 'quit':
- break
-
- output = msg['output']
- save_path = msg['save_path']
- cv2.imwrite(save_path, output)
- print(f'IO worker {self.qid} is done.')
diff --git a/spaces/Yusin/ChatGPT-Speech/models.py b/spaces/Yusin/ChatGPT-Speech/models.py
deleted file mode 100644
index 4c4585172a5c56aa36f1f3156762349fbec11a8b..0000000000000000000000000000000000000000
--- a/spaces/Yusin/ChatGPT-Speech/models.py
+++ /dev/null
@@ -1,498 +0,0 @@
-import math
-
-import torch
-from torch import nn
-from torch.nn import Conv1d, ConvTranspose1d, Conv2d
-from torch.nn import functional as F
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-
-import attentions
-import commons
-import modules
-from commons import init_weights, get_padding
-
-
-class StochasticDurationPredictor(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, n_flows=4, gin_channels=0):
- super().__init__()
- filter_channels = in_channels # it needs to be removed from future version.
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.log_flow = modules.Log()
- self.flows = nn.ModuleList()
- self.flows.append(modules.ElementwiseAffine(2))
- for i in range(n_flows):
- self.flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
- self.flows.append(modules.Flip())
-
- self.post_pre = nn.Conv1d(1, filter_channels, 1)
- self.post_proj = nn.Conv1d(filter_channels, filter_channels, 1)
- self.post_convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
- self.post_flows = nn.ModuleList()
- self.post_flows.append(modules.ElementwiseAffine(2))
- for i in range(4):
- self.post_flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3))
- self.post_flows.append(modules.Flip())
-
- self.pre = nn.Conv1d(in_channels, filter_channels, 1)
- self.proj = nn.Conv1d(filter_channels, filter_channels, 1)
- self.convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout)
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, filter_channels, 1)
-
- def forward(self, x, x_mask, w=None, g=None, reverse=False, noise_scale=1.0):
- x = torch.detach(x)
- x = self.pre(x)
- if g is not None:
- g = torch.detach(g)
- x = x + self.cond(g)
- x = self.convs(x, x_mask)
- x = self.proj(x) * x_mask
-
- if not reverse:
- flows = self.flows
- assert w is not None
-
- logdet_tot_q = 0
- h_w = self.post_pre(w)
- h_w = self.post_convs(h_w, x_mask)
- h_w = self.post_proj(h_w) * x_mask
- e_q = torch.randn(w.size(0), 2, w.size(2)).to(device=x.device, dtype=x.dtype) * x_mask
- z_q = e_q
- for flow in self.post_flows:
- z_q, logdet_q = flow(z_q, x_mask, g=(x + h_w))
- logdet_tot_q += logdet_q
- z_u, z1 = torch.split(z_q, [1, 1], 1)
- u = torch.sigmoid(z_u) * x_mask
- z0 = (w - u) * x_mask
- logdet_tot_q += torch.sum((F.logsigmoid(z_u) + F.logsigmoid(-z_u)) * x_mask, [1, 2])
- logq = torch.sum(-0.5 * (math.log(2 * math.pi) + (e_q ** 2)) * x_mask, [1, 2]) - logdet_tot_q
-
- logdet_tot = 0
- z0, logdet = self.log_flow(z0, x_mask)
- logdet_tot += logdet
- z = torch.cat([z0, z1], 1)
- for flow in flows:
- z, logdet = flow(z, x_mask, g=x, reverse=reverse)
- logdet_tot = logdet_tot + logdet
- nll = torch.sum(0.5 * (math.log(2 * math.pi) + (z ** 2)) * x_mask, [1, 2]) - logdet_tot
- return nll + logq # [b]
- else:
- flows = list(reversed(self.flows))
- flows = flows[:-2] + [flows[-1]] # remove a useless vflow
- z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale
- for flow in flows:
- z = flow(z, x_mask, g=x, reverse=reverse)
- z0, z1 = torch.split(z, [1, 1], 1)
- logw = z0
- return logw
-
-
-class DurationPredictor(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, gin_channels=0):
- super().__init__()
-
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.gin_channels = gin_channels
-
- self.drop = nn.Dropout(p_dropout)
- self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size, padding=kernel_size // 2)
- self.norm_1 = modules.LayerNorm(filter_channels)
- self.conv_2 = nn.Conv1d(filter_channels, filter_channels, kernel_size, padding=kernel_size // 2)
- self.norm_2 = modules.LayerNorm(filter_channels)
- self.proj = nn.Conv1d(filter_channels, 1, 1)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, in_channels, 1)
-
- def forward(self, x, x_mask, g=None):
- x = torch.detach(x)
- if g is not None:
- g = torch.detach(g)
- x = x + self.cond(g)
- x = self.conv_1(x * x_mask)
- x = torch.relu(x)
- x = self.norm_1(x)
- x = self.drop(x)
- x = self.conv_2(x * x_mask)
- x = torch.relu(x)
- x = self.norm_2(x)
- x = self.drop(x)
- x = self.proj(x * x_mask)
- return x * x_mask
-
-
-class TextEncoder(nn.Module):
- def __init__(self,
- n_vocab,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout):
- super().__init__()
- self.n_vocab = n_vocab
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
-
- if self.n_vocab != 0:
- self.emb = nn.Embedding(n_vocab, hidden_channels)
- nn.init.normal_(self.emb.weight, 0.0, hidden_channels ** -0.5)
-
- self.encoder = attentions.Encoder(
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout)
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths):
- if self.n_vocab != 0:
- x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h]
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
-
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return x, m, logs, x_mask
-
-
-class ResidualCouplingBlock(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- n_flows=4,
- gin_channels=0):
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.flows = nn.ModuleList()
- for i in range(n_flows):
- self.flows.append(
- modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers,
- gin_channels=gin_channels, mean_only=True))
- self.flows.append(modules.Flip())
-
- def forward(self, x, x_mask, g=None, reverse=False):
- if not reverse:
- for flow in self.flows:
- x, _ = flow(x, x_mask, g=g, reverse=reverse)
- else:
- for flow in reversed(self.flows):
- x = flow(x, x_mask, g=g, reverse=reverse)
- return x
-
-
-class PosteriorEncoder(nn.Module):
- def __init__(self,
- in_channels,
- out_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
-
- self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
- self.enc = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels)
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths, g=None):
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
- x = self.pre(x) * x_mask
- x = self.enc(x, x_mask, g=g)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
-
-class Generator(torch.nn.Module):
- def __init__(self, initial_channel, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates,
- upsample_initial_channel, upsample_kernel_sizes, gin_channels=0):
- super(Generator, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
- self.conv_pre = Conv1d(initial_channel, upsample_initial_channel, 7, 1, padding=3)
- resblock = modules.ResBlock1 if resblock == '1' else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- self.ups.append(weight_norm(
- ConvTranspose1d(upsample_initial_channel // (2 ** i), upsample_initial_channel // (2 ** (i + 1)),
- k, u, padding=(k - u) // 2)))
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- def forward(self, x, g=None):
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
-
- return x
-
- def remove_weight_norm(self):
- print('Removing weight norm...')
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- self.use_spectral_norm = use_spectral_norm
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))),
- norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(get_padding(kernel_size, 1), 0))),
- ])
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList([
- norm_f(Conv1d(1, 16, 15, 1, padding=7)),
- norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
- norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ])
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminator, self).__init__()
- periods = [2, 3, 5, 7, 11]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = []
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class SynthesizerTrn(nn.Module):
- """
- Synthesizer for Training
- """
-
- def __init__(self,
- n_vocab,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- n_speakers=0,
- gin_channels=0,
- use_sdp=True,
- **kwargs):
-
- super().__init__()
- self.n_vocab = n_vocab
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.n_speakers = n_speakers
- self.gin_channels = gin_channels
-
- self.use_sdp = use_sdp
-
- self.enc_p = TextEncoder(n_vocab,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout)
- self.dec = Generator(inter_channels, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates,
- upsample_initial_channel, upsample_kernel_sizes, gin_channels=gin_channels)
- self.enc_q = PosteriorEncoder(spec_channels, inter_channels, hidden_channels, 5, 1, 16,
- gin_channels=gin_channels)
- self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels)
-
- if use_sdp:
- self.dp = StochasticDurationPredictor(hidden_channels, 192, 3, 0.5, 4, gin_channels=gin_channels)
- else:
- self.dp = DurationPredictor(hidden_channels, 256, 3, 0.5, gin_channels=gin_channels)
-
- if n_speakers > 1:
- self.emb_g = nn.Embedding(n_speakers, gin_channels)
-
- def infer(self, x, x_lengths, sid=None, noise_scale=1, length_scale=1, noise_scale_w=1., max_len=None):
- x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths)
- if self.n_speakers > 0:
- g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1]
- else:
- g = None
-
- if self.use_sdp:
- logw = self.dp(x, x_mask, g=g, reverse=True, noise_scale=noise_scale_w)
- else:
- logw = self.dp(x, x_mask, g=g)
- w = torch.exp(logw) * x_mask * length_scale
- w_ceil = torch.ceil(w)
- y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long()
- y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype)
- attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1)
- attn = commons.generate_path(w_ceil, attn_mask)
-
- m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t']
- logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1,
- 2) # [b, t', t], [b, t, d] -> [b, d, t']
-
- z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale
- z = self.flow(z_p, y_mask, g=g, reverse=True)
- o = self.dec((z * y_mask)[:, :, :max_len], g=g)
- return o, attn, y_mask, (z, z_p, m_p, logs_p)
-
- def voice_conversion(self, y, y_lengths, sid_src, sid_tgt):
- assert self.n_speakers > 0, "n_speakers have to be larger than 0."
- g_src = self.emb_g(sid_src).unsqueeze(-1)
- g_tgt = self.emb_g(sid_tgt).unsqueeze(-1)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g_src)
- z_p = self.flow(z, y_mask, g=g_src)
- z_hat = self.flow(z_p, y_mask, g=g_tgt, reverse=True)
- o_hat = self.dec(z_hat * y_mask, g=g_tgt)
- return o_hat, y_mask, (z, z_p, z_hat)
diff --git a/spaces/ZJunTvT/ZJunChat/Dockerfile b/spaces/ZJunTvT/ZJunChat/Dockerfile
deleted file mode 100644
index 335c2dba28ba8c365de9306858462a59dea25f28..0000000000000000000000000000000000000000
--- a/spaces/ZJunTvT/ZJunChat/Dockerfile
+++ /dev/null
@@ -1,15 +0,0 @@
-FROM python:3.9 as builder
-RUN apt-get update && apt-get install -y build-essential
-COPY requirements.txt .
-COPY requirements_advanced.txt .
-RUN pip install --user -r requirements.txt
-# RUN pip install --user -r requirements_advanced.txt
-
-FROM python:3.9
-MAINTAINER iskoldt
-COPY --from=builder /root/.local /root/.local
-ENV PATH=/root/.local/bin:$PATH
-COPY . /app
-WORKDIR /app
-ENV dockerrun yes
-CMD ["python3", "-u", "ChuanhuChatbot.py", "2>&1", "|", "tee", "/var/log/application.log"]
diff --git a/spaces/Zaxxced/rvc-random-v2/lib/infer_pack/models.py b/spaces/Zaxxced/rvc-random-v2/lib/infer_pack/models.py
deleted file mode 100644
index 44c08d361bcb13b84b38dc29beff5cdaddad4ea2..0000000000000000000000000000000000000000
--- a/spaces/Zaxxced/rvc-random-v2/lib/infer_pack/models.py
+++ /dev/null
@@ -1,1124 +0,0 @@
-import math, pdb, os
-from time import time as ttime
-import torch
-from torch import nn
-from torch.nn import functional as F
-from lib.infer_pack import modules
-from lib.infer_pack import attentions
-from lib.infer_pack import commons
-from lib.infer_pack.commons import init_weights, get_padding
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-from lib.infer_pack.commons import init_weights
-import numpy as np
-from lib.infer_pack import commons
-
-
-class TextEncoder256(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(256, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return m, logs, x_mask
-
-
-class TextEncoder768(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(768, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return m, logs, x_mask
-
-
-class ResidualCouplingBlock(nn.Module):
- def __init__(
- self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- n_flows=4,
- gin_channels=0,
- ):
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.flows = nn.ModuleList()
- for i in range(n_flows):
- self.flows.append(
- modules.ResidualCouplingLayer(
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- mean_only=True,
- )
- )
- self.flows.append(modules.Flip())
-
- def forward(self, x, x_mask, g=None, reverse=False):
- if not reverse:
- for flow in self.flows:
- x, _ = flow(x, x_mask, g=g, reverse=reverse)
- else:
- for flow in reversed(self.flows):
- x = flow(x, x_mask, g=g, reverse=reverse)
- return x
-
- def remove_weight_norm(self):
- for i in range(self.n_flows):
- self.flows[i * 2].remove_weight_norm()
-
-
-class PosteriorEncoder(nn.Module):
- def __init__(
- self,
- in_channels,
- out_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
-
- self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
- self.enc = modules.WN(
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths, g=None):
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.pre(x) * x_mask
- x = self.enc(x, x_mask, g=g)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
- def remove_weight_norm(self):
- self.enc.remove_weight_norm()
-
-
-class Generator(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=0,
- ):
- super(Generator, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- def forward(self, x, g=None):
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
-
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-class SineGen(torch.nn.Module):
- """Definition of sine generator
- SineGen(samp_rate, harmonic_num = 0,
- sine_amp = 0.1, noise_std = 0.003,
- voiced_threshold = 0,
- flag_for_pulse=False)
- samp_rate: sampling rate in Hz
- harmonic_num: number of harmonic overtones (default 0)
- sine_amp: amplitude of sine-wavefrom (default 0.1)
- noise_std: std of Gaussian noise (default 0.003)
- voiced_thoreshold: F0 threshold for U/V classification (default 0)
- flag_for_pulse: this SinGen is used inside PulseGen (default False)
- Note: when flag_for_pulse is True, the first time step of a voiced
- segment is always sin(np.pi) or cos(0)
- """
-
- def __init__(
- self,
- samp_rate,
- harmonic_num=0,
- sine_amp=0.1,
- noise_std=0.003,
- voiced_threshold=0,
- flag_for_pulse=False,
- ):
- super(SineGen, self).__init__()
- self.sine_amp = sine_amp
- self.noise_std = noise_std
- self.harmonic_num = harmonic_num
- self.dim = self.harmonic_num + 1
- self.sampling_rate = samp_rate
- self.voiced_threshold = voiced_threshold
-
- def _f02uv(self, f0):
- # generate uv signal
- uv = torch.ones_like(f0)
- uv = uv * (f0 > self.voiced_threshold)
- return uv
-
- def forward(self, f0, upp):
- """sine_tensor, uv = forward(f0)
- input F0: tensor(batchsize=1, length, dim=1)
- f0 for unvoiced steps should be 0
- output sine_tensor: tensor(batchsize=1, length, dim)
- output uv: tensor(batchsize=1, length, 1)
- """
- with torch.no_grad():
- f0 = f0[:, None].transpose(1, 2)
- f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
- # fundamental component
- f0_buf[:, :, 0] = f0[:, :, 0]
- for idx in np.arange(self.harmonic_num):
- f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
- idx + 2
- ) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
- rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化
- rand_ini = torch.rand(
- f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
- )
- rand_ini[:, 0] = 0
- rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
- tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化
- tmp_over_one *= upp
- tmp_over_one = F.interpolate(
- tmp_over_one.transpose(2, 1),
- scale_factor=upp,
- mode="linear",
- align_corners=True,
- ).transpose(2, 1)
- rad_values = F.interpolate(
- rad_values.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(
- 2, 1
- ) #######
- tmp_over_one %= 1
- tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
- cumsum_shift = torch.zeros_like(rad_values)
- cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
- sine_waves = torch.sin(
- torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
- )
- sine_waves = sine_waves * self.sine_amp
- uv = self._f02uv(f0)
- uv = F.interpolate(
- uv.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(2, 1)
- noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
- noise = noise_amp * torch.randn_like(sine_waves)
- sine_waves = sine_waves * uv + noise
- return sine_waves, uv, noise
-
-
-class SourceModuleHnNSF(torch.nn.Module):
- """SourceModule for hn-nsf
- SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
- add_noise_std=0.003, voiced_threshod=0)
- sampling_rate: sampling_rate in Hz
- harmonic_num: number of harmonic above F0 (default: 0)
- sine_amp: amplitude of sine source signal (default: 0.1)
- add_noise_std: std of additive Gaussian noise (default: 0.003)
- note that amplitude of noise in unvoiced is decided
- by sine_amp
- voiced_threshold: threhold to set U/V given F0 (default: 0)
- Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
- F0_sampled (batchsize, length, 1)
- Sine_source (batchsize, length, 1)
- noise_source (batchsize, length 1)
- uv (batchsize, length, 1)
- """
-
- def __init__(
- self,
- sampling_rate,
- harmonic_num=0,
- sine_amp=0.1,
- add_noise_std=0.003,
- voiced_threshod=0,
- is_half=True,
- ):
- super(SourceModuleHnNSF, self).__init__()
-
- self.sine_amp = sine_amp
- self.noise_std = add_noise_std
- self.is_half = is_half
- # to produce sine waveforms
- self.l_sin_gen = SineGen(
- sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
- )
-
- # to merge source harmonics into a single excitation
- self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
- self.l_tanh = torch.nn.Tanh()
-
- def forward(self, x, upp=None):
- sine_wavs, uv, _ = self.l_sin_gen(x, upp)
- if self.is_half:
- sine_wavs = sine_wavs.half()
- sine_merge = self.l_tanh(self.l_linear(sine_wavs))
- return sine_merge, None, None # noise, uv
-
-
-class GeneratorNSF(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels,
- sr,
- is_half=False,
- ):
- super(GeneratorNSF, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
-
- self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates))
- self.m_source = SourceModuleHnNSF(
- sampling_rate=sr, harmonic_num=0, is_half=is_half
- )
- self.noise_convs = nn.ModuleList()
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- c_cur = upsample_initial_channel // (2 ** (i + 1))
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
- if i + 1 < len(upsample_rates):
- stride_f0 = np.prod(upsample_rates[i + 1 :])
- self.noise_convs.append(
- Conv1d(
- 1,
- c_cur,
- kernel_size=stride_f0 * 2,
- stride=stride_f0,
- padding=stride_f0 // 2,
- )
- )
- else:
- self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- self.upp = np.prod(upsample_rates)
-
- def forward(self, x, f0, g=None):
- har_source, noi_source, uv = self.m_source(f0, self.upp)
- har_source = har_source.transpose(1, 2)
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- x_source = self.noise_convs[i](har_source)
- x = x + x_source
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-sr2sr = {
- "32k": 32000,
- "40k": 40000,
- "48k": 48000,
-}
-
-
-class SynthesizerTrnMs256NSFsid(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr,
- **kwargs
- ):
- super().__init__()
- if type(sr) == type("strr"):
- sr = sr2sr[sr]
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- sr=sr,
- is_half=kwargs["is_half"],
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
- ): # 这里ds是id,[bs,1]
- # print(1,pitch.shape)#[bs,t]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- # print(-2,pitchf.shape,z_slice.shape)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs768NSFsid(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr,
- **kwargs
- ):
- super().__init__()
- if type(sr) == type("strr"):
- sr = sr2sr[sr]
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder768(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- sr=sr,
- is_half=kwargs["is_half"],
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
- ): # 这里ds是id,[bs,1]
- # print(1,pitch.shape)#[bs,t]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- # print(-2,pitchf.shape,z_slice.shape)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs256NSFsid_nono(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr=None,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=False,
- )
- self.dec = Generator(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- o = self.dec(z_slice, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs768NSFsid_nono(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr=None,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder768(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=False,
- )
- self.dec = Generator(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- o = self.dec(z_slice, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminator, self).__init__()
- periods = [2, 3, 5, 7, 11, 17]
- # periods = [3, 5, 7, 11, 17, 23, 37]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [
- DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
- ]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = [] #
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- # for j in range(len(fmap_r)):
- # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class MultiPeriodDiscriminatorV2(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminatorV2, self).__init__()
- # periods = [2, 3, 5, 7, 11, 17]
- periods = [2, 3, 5, 7, 11, 17, 23, 37]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [
- DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
- ]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = [] #
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- # for j in range(len(fmap_r)):
- # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(Conv1d(1, 16, 15, 1, padding=7)),
- norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
- norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ]
- )
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- self.use_spectral_norm = use_spectral_norm
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(
- Conv2d(
- 1,
- 32,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 32,
- 128,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 128,
- 512,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 512,
- 1024,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 1024,
- 1024,
- (kernel_size, 1),
- 1,
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- ]
- )
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
diff --git a/spaces/Zkins/Timmahw-SD2.1_Pokemon3D/app.py b/spaces/Zkins/Timmahw-SD2.1_Pokemon3D/app.py
deleted file mode 100644
index dc5203e70446aab25092916c0a97afe4d744fcc0..0000000000000000000000000000000000000000
--- a/spaces/Zkins/Timmahw-SD2.1_Pokemon3D/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/Timmahw/SD2.1_Pokemon3D").launch()
\ No newline at end of file
diff --git a/spaces/abdvl/datahub_qa_bot/docs/act-on-metadata/impact-analysis.md b/spaces/abdvl/datahub_qa_bot/docs/act-on-metadata/impact-analysis.md
deleted file mode 100644
index c40a9861aef6dcfdfdbc5aeebe269e556c6ed1ba..0000000000000000000000000000000000000000
--- a/spaces/abdvl/datahub_qa_bot/docs/act-on-metadata/impact-analysis.md
+++ /dev/null
@@ -1,93 +0,0 @@
-import FeatureAvailability from '@site/src/components/FeatureAvailability';
-
-# About DataHub Lineage Impact Analysis
-
-
-
-Lineage Impact Analysis is a powerful workflow for understanding the complete set of upstream and downstream dependencies of a Dataset, Dashboard, Chart, and many other DataHub Entities.
-
-This allows Data Practitioners to proactively identify the impact of breaking schema changes or failed data pipelines on downstream dependencies, rapidly discover which upstream dependencies may have caused unexpected data quality issues, and more.
-
-Lineage Impact Analysis is available via the DataHub UI and GraphQL endpoints, supporting manual and automated workflows.
-
-## Lineage Impact Analysis Setup, Prerequisites, and Permissions
-
-Lineage Impact Analysis is enabled for any Entity that has associated Lineage relationships with other Entities and does not require any additional configuration.
-
-Any DataHub user with “View Entity Page” permissions is able to view the full set of upstream or downstream Entities and export results to CSV from the DataHub UI.
-
-## Using Lineage Impact Analysis
-
-Follow these simple steps to understand the full dependency chain of your data entities.
-
-1. On a given Entity Page, select the **Lineage** tab
-
-
- 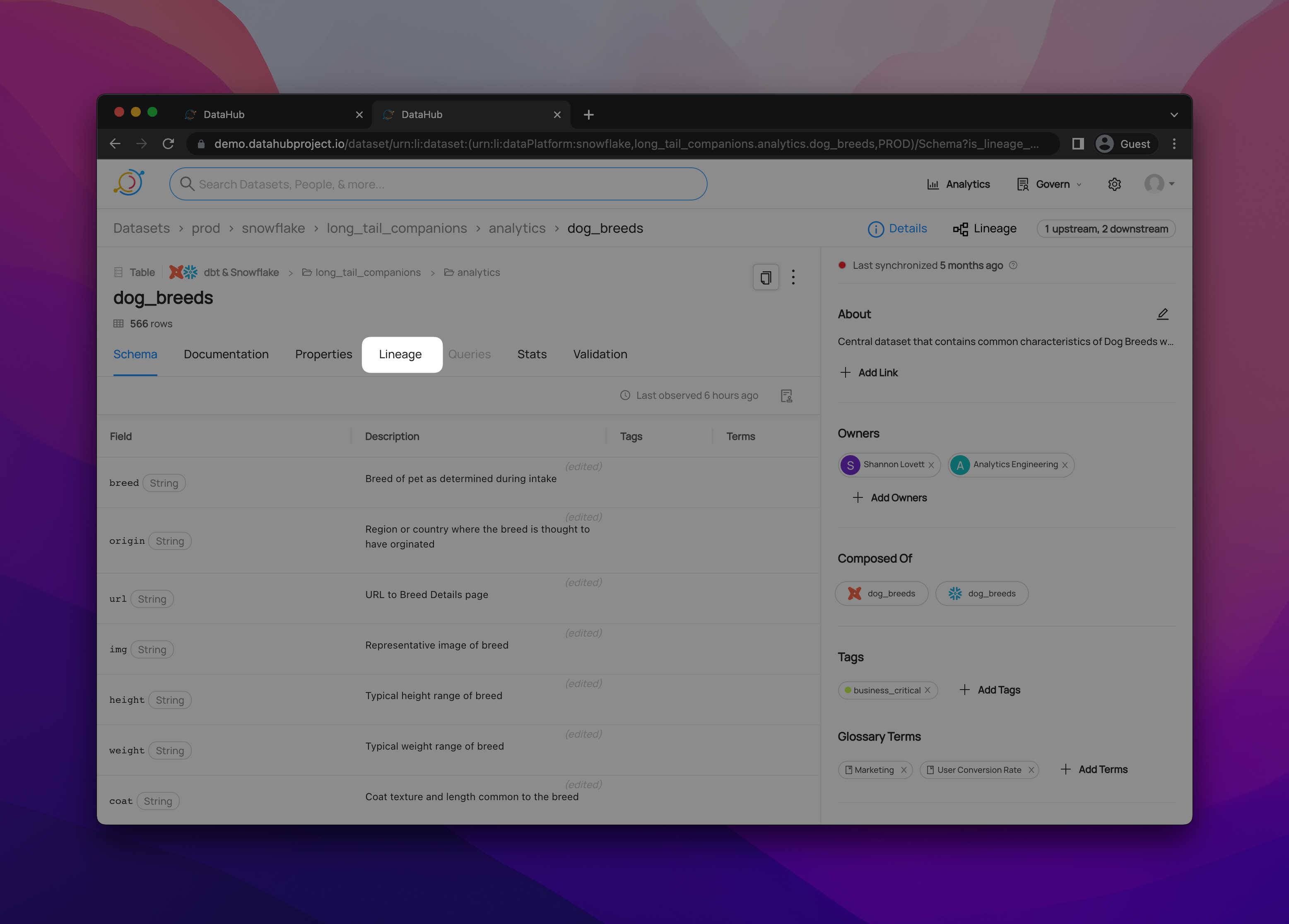 -
-
-
-2. Easily toggle between **Upstream** and **Downstream** dependencies
-
-
- 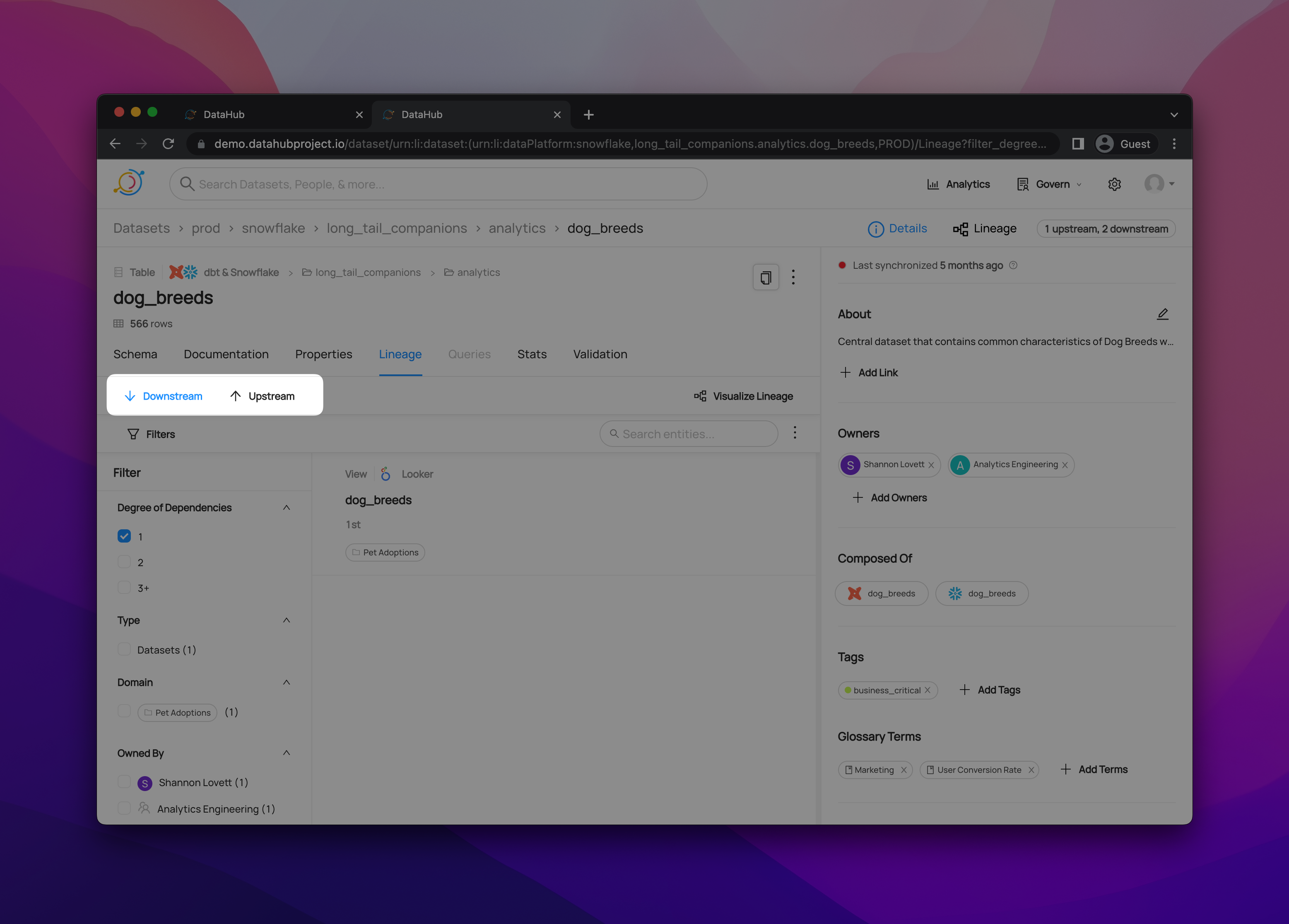 -
-
-
-3. Choose the **Degree of Dependencies** you are interested in. The default filter is “1 Degree of Dependency” to minimize processor-intensive queries.
-
-
- 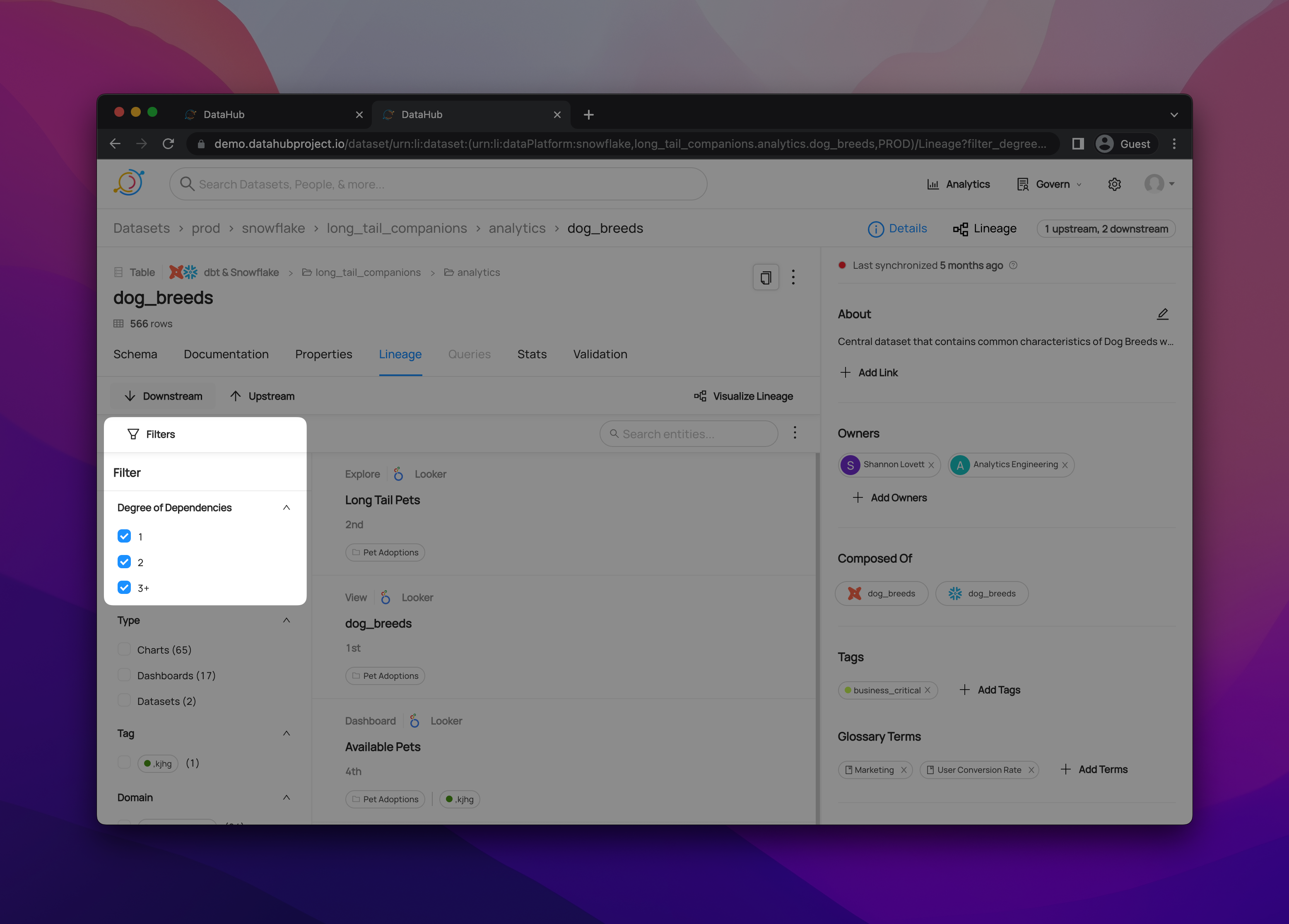 -
-
-
-4. Slice and dice the result list by Entity Type, Platfrom, Owner, and more to isolate the relevant dependencies
-
-
- 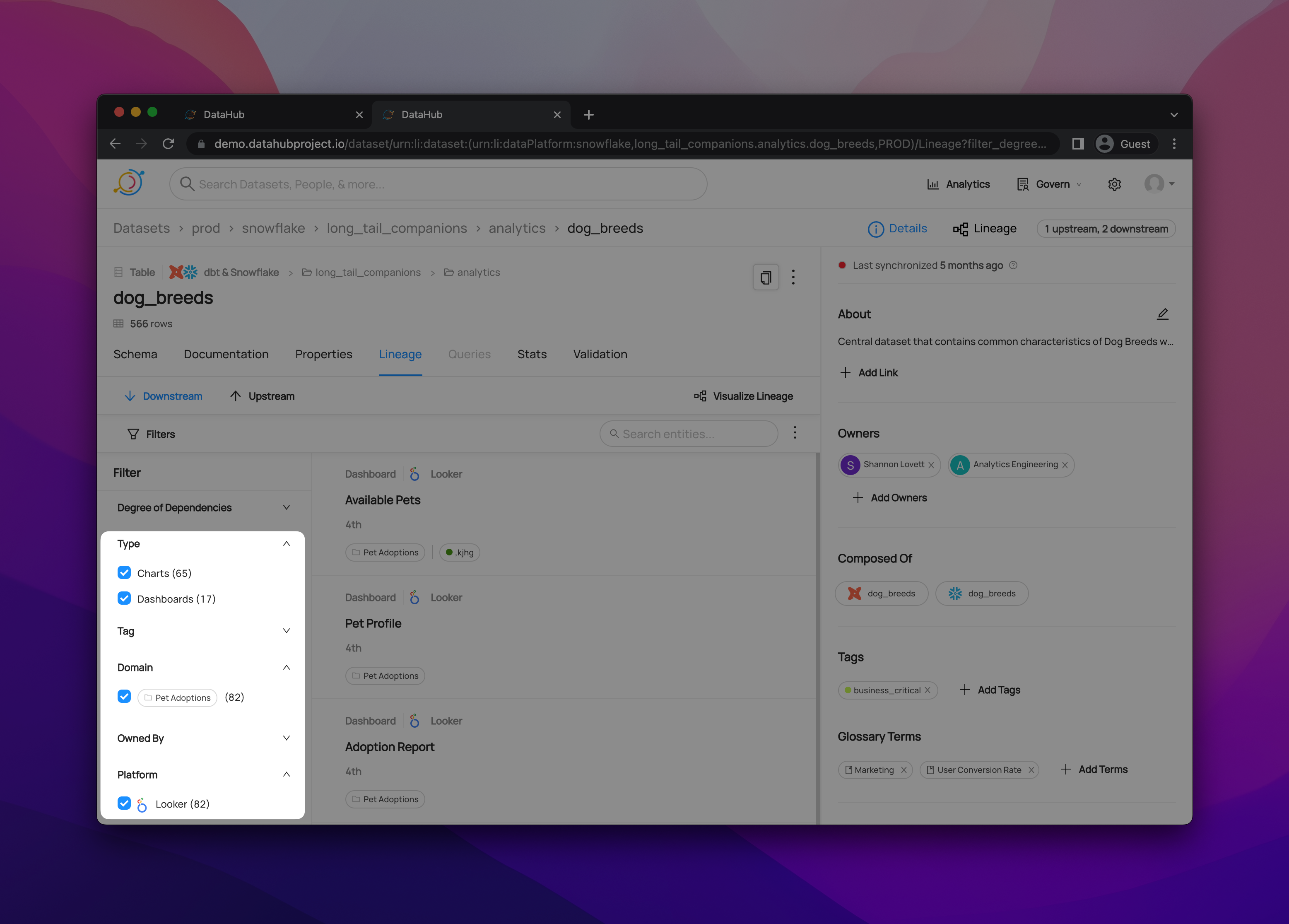 -
-
-
-5. Export the full list of dependencies to CSV
-
-
-  -
-
-
-6. View the filtered set of dependencies via CSV, with details about assigned ownership, domain, tags, terms, and quick links back to those entities within DataHub
-
-
-  -
-
-
-## Additional Resources
-
-### Videos
-
-**DataHub 201: Impact Analysis**
-
-
-
-
-
-### GraphQL
-
-* [searchAcrossLineage](../../graphql/queries.md#searchacrosslineage)
-* [searchAcrossLineageInput](../../graphql/inputObjects.md#searchacrosslineageinput)
-
-### DataHub Blog
-
-* [Dependency Impact Analysis, Data Validation Outcomes, and MORE! - Highlights from DataHub v0.8.27 & v.0.8.28](https://blog.datahubproject.io/dependency-impact-analysis-data-validation-outcomes-and-more-1302604da233)
-
-
-### FAQ and Troubleshooting
-
-**The Lineage Tab is greyed out - why can’t I click on it?**
-
-This means you have not yet ingested Lineage metadata for that entity. Please see the Lineage Guide to get started.
-
-**Why is my list of exported dependencies incomplete?**
-
-We currently limit the list of dependencies to 10,000 records; we suggest applying filters to narrow the result set if you hit that limit.
-
-*Need more help? Join the conversation in [Slack](http://slack.datahubproject.io)!*
-
-### Related Features
-
-* [DataHub Lineage](../lineage/lineage-feature-guide.md)
diff --git a/spaces/abhishek/sketch-to-image/annotator/midas/midas/midas_net.py b/spaces/abhishek/sketch-to-image/annotator/midas/midas/midas_net.py
deleted file mode 100644
index 356e7538f5b9691babe061342fbf8f092360999f..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/midas/midas/midas_net.py
+++ /dev/null
@@ -1,86 +0,0 @@
-'''
- * Copyright (c) 2023 Salesforce, Inc.
- * All rights reserved.
- * SPDX-License-Identifier: Apache License 2.0
- * For full license text, see LICENSE.txt file in the repo root or http://www.apache.org/licenses/
- * By Can Qin
- * Modified from ControlNet repo: https://github.com/lllyasviel/ControlNet
- * Copyright (c) 2023 Lvmin Zhang and Maneesh Agrawala
-'''
-
-"""MidashNet: Network for monocular depth estimation trained by mixing several datasets.
-This file contains code that is adapted from
-https://github.com/thomasjpfan/pytorch_refinenet/blob/master/pytorch_refinenet/refinenet/refinenet_4cascade.py
-"""
-import torch
-import torch.nn as nn
-
-from .base_model import BaseModel
-from .blocks import FeatureFusionBlock, Interpolate, _make_encoder
-
-
-class MidasNet(BaseModel):
- """Network for monocular depth estimation.
- """
-
- def __init__(self, path=None, features=256, non_negative=True):
- """Init.
-
- Args:
- path (str, optional): Path to saved model. Defaults to None.
- features (int, optional): Number of features. Defaults to 256.
- backbone (str, optional): Backbone network for encoder. Defaults to resnet50
- """
- print("Loading weights: ", path)
-
- super(MidasNet, self).__init__()
-
- use_pretrained = False if path is None else True
-
- self.pretrained, self.scratch = _make_encoder(backbone="resnext101_wsl", features=features, use_pretrained=use_pretrained)
-
- self.scratch.refinenet4 = FeatureFusionBlock(features)
- self.scratch.refinenet3 = FeatureFusionBlock(features)
- self.scratch.refinenet2 = FeatureFusionBlock(features)
- self.scratch.refinenet1 = FeatureFusionBlock(features)
-
- self.scratch.output_conv = nn.Sequential(
- nn.Conv2d(features, 128, kernel_size=3, stride=1, padding=1),
- Interpolate(scale_factor=2, mode="bilinear"),
- nn.Conv2d(128, 32, kernel_size=3, stride=1, padding=1),
- nn.ReLU(True),
- nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0),
- nn.ReLU(True) if non_negative else nn.Identity(),
- )
-
- if path:
- self.load(path)
-
- def forward(self, x):
- """Forward pass.
-
- Args:
- x (tensor): input data (image)
-
- Returns:
- tensor: depth
- """
-
- layer_1 = self.pretrained.layer1(x)
- layer_2 = self.pretrained.layer2(layer_1)
- layer_3 = self.pretrained.layer3(layer_2)
- layer_4 = self.pretrained.layer4(layer_3)
-
- layer_1_rn = self.scratch.layer1_rn(layer_1)
- layer_2_rn = self.scratch.layer2_rn(layer_2)
- layer_3_rn = self.scratch.layer3_rn(layer_3)
- layer_4_rn = self.scratch.layer4_rn(layer_4)
-
- path_4 = self.scratch.refinenet4(layer_4_rn)
- path_3 = self.scratch.refinenet3(path_4, layer_3_rn)
- path_2 = self.scratch.refinenet2(path_3, layer_2_rn)
- path_1 = self.scratch.refinenet1(path_2, layer_1_rn)
-
- out = self.scratch.output_conv(path_1)
-
- return torch.squeeze(out, dim=1)
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/detectors/atss.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/detectors/atss.py
deleted file mode 100644
index db7139c6b4fcd7e83007cdb785520743ddae7066..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/detectors/atss.py
+++ /dev/null
@@ -1,17 +0,0 @@
-from ..builder import DETECTORS
-from .single_stage import SingleStageDetector
-
-
-@DETECTORS.register_module()
-class ATSS(SingleStageDetector):
- """Implementation of `ATSS `_."""
-
- def __init__(self,
- backbone,
- neck,
- bbox_head,
- train_cfg=None,
- test_cfg=None,
- pretrained=None):
- super(ATSS, self).__init__(backbone, neck, bbox_head, train_cfg,
- test_cfg, pretrained)
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer_base/mmseg/models/decode_heads/__init__.py b/spaces/abhishek/sketch-to-image/annotator/uniformer_base/mmseg/models/decode_heads/__init__.py
deleted file mode 100644
index c99658f2cbd316c90232e2e5a5a835614dc99c24..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer_base/mmseg/models/decode_heads/__init__.py
+++ /dev/null
@@ -1,40 +0,0 @@
-'''
- * Copyright (c) 2023 Salesforce, Inc.
- * All rights reserved.
- * SPDX-License-Identifier: Apache License 2.0
- * For full license text, see LICENSE.txt file in the repo root or http://www.apache.org/licenses/
- * By Can Qin
- * Modified from ControlNet repo: https://github.com/lllyasviel/ControlNet
- * Copyright (c) 2023 Lvmin Zhang and Maneesh Agrawala
- * Modified from MMCV repo: From https://github.com/open-mmlab/mmcv
- * Copyright (c) OpenMMLab. All rights reserved.
-'''
-
-from .ann_head import ANNHead
-from .apc_head import APCHead
-from .aspp_head import ASPPHead
-from .cc_head import CCHead
-from .da_head import DAHead
-from .dm_head import DMHead
-from .dnl_head import DNLHead
-from .ema_head import EMAHead
-from .enc_head import EncHead
-from .fcn_head import FCNHead
-from .fpn_head import FPNHead
-from .gc_head import GCHead
-from .lraspp_head import LRASPPHead
-from .nl_head import NLHead
-from .ocr_head import OCRHead
-# from .point_head import PointHead
-from .psa_head import PSAHead
-from .psp_head import PSPHead
-from .sep_aspp_head import DepthwiseSeparableASPPHead
-from .sep_fcn_head import DepthwiseSeparableFCNHead
-from .uper_head import UPerHead
-
-__all__ = [
- 'FCNHead', 'PSPHead', 'ASPPHead', 'PSAHead', 'NLHead', 'GCHead', 'CCHead',
- 'UPerHead', 'DepthwiseSeparableASPPHead', 'ANNHead', 'DAHead', 'OCRHead',
- 'EncHead', 'DepthwiseSeparableFCNHead', 'FPNHead', 'EMAHead', 'DNLHead',
- 'APCHead', 'DMHead', 'LRASPPHead'
-]
diff --git a/spaces/abhishek/sketch-to-image/lib/attention.py b/spaces/abhishek/sketch-to-image/lib/attention.py
deleted file mode 100644
index 24bc36c1b1f24f6a001bbd83c16eae6609679e49..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/lib/attention.py
+++ /dev/null
@@ -1,356 +0,0 @@
-'''
- * Copyright (c) 2023 Salesforce, Inc.
- * All rights reserved.
- * SPDX-License-Identifier: Apache License 2.0
- * For full license text, see LICENSE.txt file in the repo root or http://www.apache.org/licenses/
- * By Can Qin
- * Modified from ControlNet repo: https://github.com/lllyasviel/ControlNet
- * Copyright (c) 2023 Lvmin Zhang and Maneesh Agrawala
-'''
-
-
-
-from inspect import isfunction
-import math
-import torch
-import torch.nn.functional as F
-from torch import nn, einsum
-from einops import rearrange, repeat
-from typing import Optional, Any
-
-from lib.util import checkpoint
-
-try:
- import xformers
- import xformers.ops
-
- XFORMERS_IS_AVAILBLE = True
-except:
- XFORMERS_IS_AVAILBLE = False
-
-# CrossAttn precision handling
-import os
-
-_ATTN_PRECISION = os.environ.get("ATTN_PRECISION", "fp32")
-
-
-def exists(val):
- return val is not None
-
-
-def uniq(arr):
- return {el: True for el in arr}.keys()
-
-
-def default(val, d):
- if exists(val):
- return val
- return d() if isfunction(d) else d
-
-
-def max_neg_value(t):
- return -torch.finfo(t.dtype).max
-
-
-def init_(tensor):
- dim = tensor.shape[-1]
- std = 1 / math.sqrt(dim)
- tensor.uniform_(-std, std)
- return tensor
-
-
-# feedforward
-class GEGLU(nn.Module):
- def __init__(self, dim_in, dim_out):
- super().__init__()
- self.proj = nn.Linear(dim_in, dim_out * 2)
-
- def forward(self, x):
- x, gate = self.proj(x).chunk(2, dim=-1)
- return x * F.gelu(gate)
-
-
-class FeedForward(nn.Module):
- def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
- super().__init__()
- inner_dim = int(dim * mult)
- dim_out = default(dim_out, dim)
- project_in = nn.Sequential(
- nn.Linear(dim, inner_dim),
- nn.GELU()
- ) if not glu else GEGLU(dim, inner_dim)
-
- self.net = nn.Sequential(
- project_in,
- nn.Dropout(dropout),
- nn.Linear(inner_dim, dim_out)
- )
-
- def forward(self, x):
- return self.net(x)
-
-
-def zero_module(module):
- """
- Zero out the parameters of a module and return it.
- """
- for p in module.parameters():
- p.detach().zero_()
- return module
-
-
-def Normalize(in_channels):
- return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
-
-
-class SpatialSelfAttention(nn.Module):
- def __init__(self, in_channels):
- super().__init__()
- self.in_channels = in_channels
-
- self.norm = Normalize(in_channels)
- self.q = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
- self.k = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
- self.v = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
- self.proj_out = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
-
- def forward(self, x):
- h_ = x
- h_ = self.norm(h_)
- q = self.q(h_)
- k = self.k(h_)
- v = self.v(h_)
-
- # compute attention
- b, c, h, w = q.shape
- q = rearrange(q, 'b c h w -> b (h w) c')
- k = rearrange(k, 'b c h w -> b c (h w)')
- w_ = torch.einsum('bij,bjk->bik', q, k)
-
- w_ = w_ * (int(c) ** (-0.5))
- w_ = torch.nn.functional.softmax(w_, dim=2)
-
- # attend to values
- v = rearrange(v, 'b c h w -> b c (h w)')
- w_ = rearrange(w_, 'b i j -> b j i')
- h_ = torch.einsum('bij,bjk->bik', v, w_)
- h_ = rearrange(h_, 'b c (h w) -> b c h w', h=h)
- h_ = self.proj_out(h_)
-
- return x + h_
-
-
-class CrossAttention(nn.Module):
- def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.):
- super().__init__()
- inner_dim = dim_head * heads
- context_dim = default(context_dim, query_dim)
-
- self.scale = dim_head ** -0.5
- self.heads = heads
-
- self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
- self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
- self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
-
- self.to_out = nn.Sequential(
- nn.Linear(inner_dim, query_dim),
- nn.Dropout(dropout)
- )
-
- def forward(self, x, context=None, mask=None):
- h = self.heads
-
- q = self.to_q(x)
- context = default(context, x)
- k = self.to_k(context)
- v = self.to_v(context)
-
- q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
-
- # force cast to fp32 to avoid overflowing
- if _ATTN_PRECISION == "fp32":
- with torch.autocast(enabled=False, device_type='cuda'):
- q, k = q.float(), k.float()
- sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
- else:
- sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
-
- del q, k
-
- if exists(mask):
- mask = rearrange(mask, 'b ... -> b (...)')
- max_neg_value = -torch.finfo(sim.dtype).max
- mask = repeat(mask, 'b j -> (b h) () j', h=h)
- sim.masked_fill_(~mask, max_neg_value)
-
- # attention, what we cannot get enough of
- sim = sim.softmax(dim=-1)
-
- out = einsum('b i j, b j d -> b i d', sim, v)
- out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
- return self.to_out(out)
-
-
-class MemoryEfficientCrossAttention(nn.Module):
- # https://github.com/MatthieuTPHR/diffusers/blob/d80b531ff8060ec1ea982b65a1b8df70f73aa67c/src/diffusers/models/attention.py#L223
- def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.0):
- super().__init__()
- print(f"Setting up {self.__class__.__name__}. Query dim is {query_dim}, context_dim is {context_dim} and using "
- f"{heads} heads.")
- inner_dim = dim_head * heads
- context_dim = default(context_dim, query_dim)
-
- self.heads = heads
- self.dim_head = dim_head
-
- self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
- self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
- self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
-
- self.to_out = nn.Sequential(nn.Linear(inner_dim, query_dim), nn.Dropout(dropout))
- self.attention_op: Optional[Any] = None
-
- def forward(self, x, context=None, mask=None):
- q = self.to_q(x)
- context = default(context, x)
- k = self.to_k(context)
- v = self.to_v(context)
-
- b, _, _ = q.shape
- q, k, v = map(
- lambda t: t.unsqueeze(3)
- .reshape(b, t.shape[1], self.heads, self.dim_head)
- .permute(0, 2, 1, 3)
- .reshape(b * self.heads, t.shape[1], self.dim_head)
- .contiguous(),
- (q, k, v),
- )
-
- # actually compute the attention, what we cannot get enough of
- out = xformers.ops.memory_efficient_attention(q, k, v, attn_bias=None, op=self.attention_op)
-
- if exists(mask):
- raise NotImplementedError
- out = (
- out.unsqueeze(0)
- .reshape(b, self.heads, out.shape[1], self.dim_head)
- .permute(0, 2, 1, 3)
- .reshape(b, out.shape[1], self.heads * self.dim_head)
- )
- return self.to_out(out)
-
-
-class BasicTransformerBlock(nn.Module):
- ATTENTION_MODES = {
- "softmax": CrossAttention, # vanilla attention
- "softmax-xformers": MemoryEfficientCrossAttention
- }
-
- def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, checkpoint=True,
- disable_self_attn=False):
- super().__init__()
- attn_mode = "softmax-xformers" if XFORMERS_IS_AVAILBLE else "softmax"
- assert attn_mode in self.ATTENTION_MODES
- attn_cls = self.ATTENTION_MODES[attn_mode]
- self.disable_self_attn = disable_self_attn
- self.attn1 = attn_cls(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout,
- context_dim=context_dim if self.disable_self_attn else None) # is a self-attention if not self.disable_self_attn
- self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
- self.attn2 = attn_cls(query_dim=dim, context_dim=context_dim,
- heads=n_heads, dim_head=d_head, dropout=dropout) # is self-attn if context is none
- self.norm1 = nn.LayerNorm(dim)
- self.norm2 = nn.LayerNorm(dim)
- self.norm3 = nn.LayerNorm(dim)
- self.checkpoint = checkpoint
-
- def forward(self, x, context=None):
- return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
-
- def _forward(self, x, context=None):
- x = self.attn1(self.norm1(x), context=context if self.disable_self_attn else None) + x
- x = self.attn2(self.norm2(x), context=context) + x
- x = self.ff(self.norm3(x)) + x
- return x
-
-
-class SpatialTransformer(nn.Module):
- """
- Transformer block for image-like data.
- First, project the input (aka embedding)
- and reshape to b, t, d.
- Then apply standard transformer action.
- Finally, reshape to image
- NEW: use_linear for more efficiency instead of the 1x1 convs
- """
-
- def __init__(self, in_channels, n_heads, d_head,
- depth=1, dropout=0., context_dim=None,
- disable_self_attn=False, use_linear=False,
- use_checkpoint=True):
- super().__init__()
- if exists(context_dim) and not isinstance(context_dim, list):
- context_dim = [context_dim]
- self.in_channels = in_channels
- inner_dim = n_heads * d_head
- self.norm = Normalize(in_channels)
- if not use_linear:
- self.proj_in = nn.Conv2d(in_channels,
- inner_dim,
- kernel_size=1,
- stride=1,
- padding=0)
- else:
- self.proj_in = nn.Linear(in_channels, inner_dim)
-
- self.transformer_blocks = nn.ModuleList(
- [BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim[d],
- disable_self_attn=disable_self_attn, checkpoint=use_checkpoint)
- for d in range(depth)]
- )
- if not use_linear:
- self.proj_out = zero_module(nn.Conv2d(inner_dim,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0))
- else:
- self.proj_out = zero_module(nn.Linear(in_channels, inner_dim))
- self.use_linear = use_linear
-
- def forward(self, x, context=None):
- # note: if no context is given, cross-attention defaults to self-attention
- if not isinstance(context, list):
- context = [context]
- b, c, h, w = x.shape
- x_in = x
- x = self.norm(x)
- if not self.use_linear:
- x = self.proj_in(x)
- x = rearrange(x, 'b c h w -> b (h w) c').contiguous()
- if self.use_linear:
- x = self.proj_in(x)
- for i, block in enumerate(self.transformer_blocks):
- x = block(x, context=context[i])
- if self.use_linear:
- x = self.proj_out(x)
- x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w).contiguous()
- if not self.use_linear:
- x = self.proj_out(x)
- return x + x_in
diff --git a/spaces/abidlabs/Webcam-background-remover/README.md b/spaces/abidlabs/Webcam-background-remover/README.md
deleted file mode 100644
index 10c354d9ac59e764f307889bf12f79ee9e28bd44..0000000000000000000000000000000000000000
--- a/spaces/abidlabs/Webcam-background-remover/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: Webcam Background Remover
-emoji: 📊
-colorFrom: purple
-colorTo: indigo
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/adwod/Streamlite_ViT_2000/app.py b/spaces/adwod/Streamlite_ViT_2000/app.py
deleted file mode 100644
index 2d578498cd106e1c01020642e1c1d85a6764deb3..0000000000000000000000000000000000000000
--- a/spaces/adwod/Streamlite_ViT_2000/app.py
+++ /dev/null
@@ -1,25 +0,0 @@
-import streamlit as st
-from transformers import pipeline
-from PIL import Image
-from transformers import (
- AutoImageProcessor,
- AutoModelForImageClassification
-)
-
-pre_process = AutoImageProcessor.from_pretrained("adwod/ViT_bluetab")
-
-
-st.title("What is it?")
-
-file_name = st.file_uploader("Upload a hot dog candidate image")
-
-if file_name is not None:
- col1, col2 = st.columns(2)
-
- image = Image.open(file_name)
- col1.image(image, use_column_width=True)
- inputs = pre_process(images=image, return_tensors="pt")
- input_pixels = inputs.pixel_values
- model = AutoModelForImageClassification.from_pretrained("adwod/ViT_bluetab")
- outputs = model(input_pixels)
- col2.header(model.config.id2label[outputs.logits.argmax(-1) .item()])
\ No newline at end of file
diff --git a/spaces/ahmedxeno/brain_tumor_vs_normal_classification/README.md b/spaces/ahmedxeno/brain_tumor_vs_normal_classification/README.md
deleted file mode 100644
index 02bf8905ad7dbb4804e84091eacc53f1479971cf..0000000000000000000000000000000000000000
--- a/spaces/ahmedxeno/brain_tumor_vs_normal_classification/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Brain Tumor Classification
-emoji: 🔥
-colorFrom: purple
-colorTo: purple
-sdk: gradio
-sdk_version: 3.17.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/akhaliq/Face_Mesh/app.py b/spaces/akhaliq/Face_Mesh/app.py
deleted file mode 100644
index e647139a09e2754c8f18954109011ae58a4a12fc..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/Face_Mesh/app.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import mediapipe as mp
-import gradio as gr
-import cv2
-import torch
-
-
-# Images
-torch.hub.download_url_to_file('https://artbreeder.b-cdn.net/imgs/c789e54661bfb432c5522a36553f.jpeg', 'face1.jpg')
-torch.hub.download_url_to_file('https://artbreeder.b-cdn.net/imgs/c86622e8cb58d490e35b01cb9996.jpeg', 'face2.jpg')
-
-mp_face_mesh = mp.solutions.face_mesh
-
-# Prepare DrawingSpec for drawing the face landmarks later.
-mp_drawing = mp.solutions.drawing_utils
-drawing_spec = mp_drawing.DrawingSpec(thickness=1, circle_radius=1)
-
-# Run MediaPipe Face Mesh.
-
-def inference(image):
- with mp_face_mesh.FaceMesh(
- static_image_mode=True,
- max_num_faces=2,
- min_detection_confidence=0.5) as face_mesh:
- # Convert the BGR image to RGB and process it with MediaPipe Face Mesh.
- results = face_mesh.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
-
- annotated_image = image.copy()
- for face_landmarks in results.multi_face_landmarks:
- mp_drawing.draw_landmarks(
- image=annotated_image,
- landmark_list=face_landmarks,
- connections=mp_face_mesh.FACEMESH_CONTOURS,
- landmark_drawing_spec=drawing_spec,
- connection_drawing_spec=drawing_spec)
- return annotated_image
-
-title = "Face Mesh"
-description = "demo for Face Mesh. To use it, simply upload your image, or click one of the examples to load them. Read more at the links below."
-article = "Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs | Github Repo "
-
-gr.Interface(
- inference,
- [gr.inputs.Image(label="Input")],
- gr.outputs.Image(type="pil", label="Output"),
- title=title,
- description=description,
- article=article,
- examples=[
- ["face1.jpg"],
- ["face2.jpg"]
- ]).launch(debug=True)
\ No newline at end of file
diff --git a/spaces/akhaliq/Mask2Former/demo/predictor.py b/spaces/akhaliq/Mask2Former/demo/predictor.py
deleted file mode 100644
index 189ec7976f4283b7f3116b6e15b3191fb8fe969f..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/Mask2Former/demo/predictor.py
+++ /dev/null
@@ -1,219 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-# Copied from: https://github.com/facebookresearch/detectron2/blob/master/demo/predictor.py
-import atexit
-import bisect
-import multiprocessing as mp
-from collections import deque
-
-import cv2
-import torch
-
-from detectron2.data import MetadataCatalog
-from detectron2.engine.defaults import DefaultPredictor
-from detectron2.utils.video_visualizer import VideoVisualizer
-from detectron2.utils.visualizer import ColorMode, Visualizer
-
-
-class VisualizationDemo(object):
- def __init__(self, cfg, instance_mode=ColorMode.IMAGE, parallel=False):
- """
- Args:
- cfg (CfgNode):
- instance_mode (ColorMode):
- parallel (bool): whether to run the model in different processes from visualization.
- Useful since the visualization logic can be slow.
- """
- self.metadata = MetadataCatalog.get(
- cfg.DATASETS.TEST[0] if len(cfg.DATASETS.TEST) else "__unused"
- )
- self.cpu_device = torch.device("cpu")
- self.instance_mode = instance_mode
-
- self.parallel = parallel
- if parallel:
- num_gpu = torch.cuda.device_count()
- self.predictor = AsyncPredictor(cfg, num_gpus=num_gpu)
- else:
- self.predictor = DefaultPredictor(cfg)
-
- def run_on_image(self, image):
- """
- Args:
- image (np.ndarray): an image of shape (H, W, C) (in BGR order).
- This is the format used by OpenCV.
- Returns:
- predictions (dict): the output of the model.
- vis_output (VisImage): the visualized image output.
- """
- vis_output = None
- predictions = self.predictor(image)
- # Convert image from OpenCV BGR format to Matplotlib RGB format.
- image = image[:, :, ::-1]
- visualizer = Visualizer(image, self.metadata, instance_mode=self.instance_mode)
- if "panoptic_seg" in predictions:
- panoptic_seg, segments_info = predictions["panoptic_seg"]
- vis_output = visualizer.draw_panoptic_seg_predictions(
- panoptic_seg.to(self.cpu_device), segments_info
- )
- else:
- if "sem_seg" in predictions:
- vis_output = visualizer.draw_sem_seg(
- predictions["sem_seg"].argmax(dim=0).to(self.cpu_device)
- )
- if "instances" in predictions:
- instances = predictions["instances"].to(self.cpu_device)
- vis_output = visualizer.draw_instance_predictions(predictions=instances)
-
- return predictions, vis_output
-
- def _frame_from_video(self, video):
- while video.isOpened():
- success, frame = video.read()
- if success:
- yield frame
- else:
- break
-
- def run_on_video(self, video):
- """
- Visualizes predictions on frames of the input video.
- Args:
- video (cv2.VideoCapture): a :class:`VideoCapture` object, whose source can be
- either a webcam or a video file.
- Yields:
- ndarray: BGR visualizations of each video frame.
- """
- video_visualizer = VideoVisualizer(self.metadata, self.instance_mode)
-
- def process_predictions(frame, predictions):
- frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
- if "panoptic_seg" in predictions:
- panoptic_seg, segments_info = predictions["panoptic_seg"]
- vis_frame = video_visualizer.draw_panoptic_seg_predictions(
- frame, panoptic_seg.to(self.cpu_device), segments_info
- )
- elif "instances" in predictions:
- predictions = predictions["instances"].to(self.cpu_device)
- vis_frame = video_visualizer.draw_instance_predictions(frame, predictions)
- elif "sem_seg" in predictions:
- vis_frame = video_visualizer.draw_sem_seg(
- frame, predictions["sem_seg"].argmax(dim=0).to(self.cpu_device)
- )
-
- # Converts Matplotlib RGB format to OpenCV BGR format
- vis_frame = cv2.cvtColor(vis_frame.get_image(), cv2.COLOR_RGB2BGR)
- return vis_frame
-
- frame_gen = self._frame_from_video(video)
- if self.parallel:
- buffer_size = self.predictor.default_buffer_size
-
- frame_data = deque()
-
- for cnt, frame in enumerate(frame_gen):
- frame_data.append(frame)
- self.predictor.put(frame)
-
- if cnt >= buffer_size:
- frame = frame_data.popleft()
- predictions = self.predictor.get()
- yield process_predictions(frame, predictions)
-
- while len(frame_data):
- frame = frame_data.popleft()
- predictions = self.predictor.get()
- yield process_predictions(frame, predictions)
- else:
- for frame in frame_gen:
- yield process_predictions(frame, self.predictor(frame))
-
-
-class AsyncPredictor:
- """
- A predictor that runs the model asynchronously, possibly on >1 GPUs.
- Because rendering the visualization takes considerably amount of time,
- this helps improve throughput a little bit when rendering videos.
- """
-
- class _StopToken:
- pass
-
- class _PredictWorker(mp.Process):
- def __init__(self, cfg, task_queue, result_queue):
- self.cfg = cfg
- self.task_queue = task_queue
- self.result_queue = result_queue
- super().__init__()
-
- def run(self):
- predictor = DefaultPredictor(self.cfg)
-
- while True:
- task = self.task_queue.get()
- if isinstance(task, AsyncPredictor._StopToken):
- break
- idx, data = task
- result = predictor(data)
- self.result_queue.put((idx, result))
-
- def __init__(self, cfg, num_gpus: int = 1):
- """
- Args:
- cfg (CfgNode):
- num_gpus (int): if 0, will run on CPU
- """
- num_workers = max(num_gpus, 1)
- self.task_queue = mp.Queue(maxsize=num_workers * 3)
- self.result_queue = mp.Queue(maxsize=num_workers * 3)
- self.procs = []
- for gpuid in range(max(num_gpus, 1)):
- cfg = cfg.clone()
- cfg.defrost()
- cfg.MODEL.DEVICE = "cuda:{}".format(gpuid) if num_gpus > 0 else "cpu"
- self.procs.append(
- AsyncPredictor._PredictWorker(cfg, self.task_queue, self.result_queue)
- )
-
- self.put_idx = 0
- self.get_idx = 0
- self.result_rank = []
- self.result_data = []
-
- for p in self.procs:
- p.start()
- atexit.register(self.shutdown)
-
- def put(self, image):
- self.put_idx += 1
- self.task_queue.put((self.put_idx, image))
-
- def get(self):
- self.get_idx += 1 # the index needed for this request
- if len(self.result_rank) and self.result_rank[0] == self.get_idx:
- res = self.result_data[0]
- del self.result_data[0], self.result_rank[0]
- return res
-
- while True:
- # make sure the results are returned in the correct order
- idx, res = self.result_queue.get()
- if idx == self.get_idx:
- return res
- insert = bisect.bisect(self.result_rank, idx)
- self.result_rank.insert(insert, idx)
- self.result_data.insert(insert, res)
-
- def __len__(self):
- return self.put_idx - self.get_idx
-
- def __call__(self, image):
- self.put(image)
- return self.get()
-
- def shutdown(self):
- for _ in self.procs:
- self.task_queue.put(AsyncPredictor._StopToken())
-
- @property
- def default_buffer_size(self):
- return len(self.procs) * 5
diff --git a/spaces/alex-mindspace/gpt-agents/swarmai/agents/GeneralPurposeAgent.py b/spaces/alex-mindspace/gpt-agents/swarmai/agents/GeneralPurposeAgent.py
deleted file mode 100644
index 47496eb503f1c0e5b61cc6a29d5be5d472552403..0000000000000000000000000000000000000000
--- a/spaces/alex-mindspace/gpt-agents/swarmai/agents/GeneralPurposeAgent.py
+++ /dev/null
@@ -1,57 +0,0 @@
-from swarmai.agents.AgentBase import AgentBase
-from swarmai.utils.ai_engines.GPTConversEngine import GPTConversEngine
-from swarmai.utils.task_queue.Task import Task
-from swarmai.utils.PromptFactory import PromptFactory
-
-class GeneralPurposeAgent(AgentBase):
- """Manager agent class that is responsible for breaking down the tasks into subtasks and assigning them into the task queue.
- """
-
- def __init__(self, agent_id, agent_type, swarm, logger):
- super().__init__(agent_id, agent_type, swarm, logger)
- self.engine = GPTConversEngine("gpt-3.5-turbo", 0.5, 1000)
-
- self.TASK_METHODS = {}
- for method in self.swarm.TASK_TYPES:
- if method != "breakdown_to_subtasks":
- self.TASK_METHODS[method] = self._think
-
- def perform_task(self):
- self.step = "perform_task"
- try:
- # self.task is already taken in the beginning of the cycle in AgentBase
- if not isinstance(self.task, Task):
- raise Exception(f"Task is not of type Task, but {type(self.task)}")
-
- task_type = self.task.task_type
- if task_type not in self.TASK_METHODS:
- raise Exception(f"Task type {task_type} is not supported by the agent {self.agent_id} of type {self.agent_type}")
-
- self.result = self.TASK_METHODS[task_type](self.task.task_description)
- return True
- except Exception as e:
- self.log(f"Agent {self.agent_id} of type {self.agent_type} failed to perform the task {self.task.task_description} with error {e}", level = "error")
- return False
-
- def share(self):
- pass
-
- def _think(self, task_description):
- self.step = "think"
- prompt = (
- "Act as an analyst and worker."
- f"You need to perform a task: {task_description}. The type of the task is {self.task.task_type}."
- "If you don't have capabilities to perform the task (for example no google access), return empty string (or just a space)"
- "Make sure to actually solve the task and provide a valid solution; avoid describing how you would do it."
- )
- # generate a conversation
- conversation = [
- {"role": "user", "content": prompt}
- ]
-
- result = self.engine.call_model(conversation)
-
- # add to shared memory
- self._send_data_to_swarm(result)
- self.log(f"Agent {self.agent_id} of type {self.agent_type} thought about the task:\n{task_description}\n\nand shared the following result:\n{result}", level = "info")
- return result
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/msgpack/ext.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/msgpack/ext.py
deleted file mode 100644
index 4eb9dd65adc9aff07547f5ef7541bdf2be91124a..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/msgpack/ext.py
+++ /dev/null
@@ -1,193 +0,0 @@
-# coding: utf-8
-from collections import namedtuple
-import datetime
-import sys
-import struct
-
-
-PY2 = sys.version_info[0] == 2
-
-if PY2:
- int_types = (int, long)
- _utc = None
-else:
- int_types = int
- try:
- _utc = datetime.timezone.utc
- except AttributeError:
- _utc = datetime.timezone(datetime.timedelta(0))
-
-
-class ExtType(namedtuple("ExtType", "code data")):
- """ExtType represents ext type in msgpack."""
-
- def __new__(cls, code, data):
- if not isinstance(code, int):
- raise TypeError("code must be int")
- if not isinstance(data, bytes):
- raise TypeError("data must be bytes")
- if not 0 <= code <= 127:
- raise ValueError("code must be 0~127")
- return super(ExtType, cls).__new__(cls, code, data)
-
-
-class Timestamp(object):
- """Timestamp represents the Timestamp extension type in msgpack.
-
- When built with Cython, msgpack uses C methods to pack and unpack `Timestamp`. When using pure-Python
- msgpack, :func:`to_bytes` and :func:`from_bytes` are used to pack and unpack `Timestamp`.
-
- This class is immutable: Do not override seconds and nanoseconds.
- """
-
- __slots__ = ["seconds", "nanoseconds"]
-
- def __init__(self, seconds, nanoseconds=0):
- """Initialize a Timestamp object.
-
- :param int seconds:
- Number of seconds since the UNIX epoch (00:00:00 UTC Jan 1 1970, minus leap seconds).
- May be negative.
-
- :param int nanoseconds:
- Number of nanoseconds to add to `seconds` to get fractional time.
- Maximum is 999_999_999. Default is 0.
-
- Note: Negative times (before the UNIX epoch) are represented as negative seconds + positive ns.
- """
- if not isinstance(seconds, int_types):
- raise TypeError("seconds must be an interger")
- if not isinstance(nanoseconds, int_types):
- raise TypeError("nanoseconds must be an integer")
- if not (0 <= nanoseconds < 10 ** 9):
- raise ValueError(
- "nanoseconds must be a non-negative integer less than 999999999."
- )
- self.seconds = seconds
- self.nanoseconds = nanoseconds
-
- def __repr__(self):
- """String representation of Timestamp."""
- return "Timestamp(seconds={0}, nanoseconds={1})".format(
- self.seconds, self.nanoseconds
- )
-
- def __eq__(self, other):
- """Check for equality with another Timestamp object"""
- if type(other) is self.__class__:
- return (
- self.seconds == other.seconds and self.nanoseconds == other.nanoseconds
- )
- return False
-
- def __ne__(self, other):
- """not-equals method (see :func:`__eq__()`)"""
- return not self.__eq__(other)
-
- def __hash__(self):
- return hash((self.seconds, self.nanoseconds))
-
- @staticmethod
- def from_bytes(b):
- """Unpack bytes into a `Timestamp` object.
-
- Used for pure-Python msgpack unpacking.
-
- :param b: Payload from msgpack ext message with code -1
- :type b: bytes
-
- :returns: Timestamp object unpacked from msgpack ext payload
- :rtype: Timestamp
- """
- if len(b) == 4:
- seconds = struct.unpack("!L", b)[0]
- nanoseconds = 0
- elif len(b) == 8:
- data64 = struct.unpack("!Q", b)[0]
- seconds = data64 & 0x00000003FFFFFFFF
- nanoseconds = data64 >> 34
- elif len(b) == 12:
- nanoseconds, seconds = struct.unpack("!Iq", b)
- else:
- raise ValueError(
- "Timestamp type can only be created from 32, 64, or 96-bit byte objects"
- )
- return Timestamp(seconds, nanoseconds)
-
- def to_bytes(self):
- """Pack this Timestamp object into bytes.
-
- Used for pure-Python msgpack packing.
-
- :returns data: Payload for EXT message with code -1 (timestamp type)
- :rtype: bytes
- """
- if (self.seconds >> 34) == 0: # seconds is non-negative and fits in 34 bits
- data64 = self.nanoseconds << 34 | self.seconds
- if data64 & 0xFFFFFFFF00000000 == 0:
- # nanoseconds is zero and seconds < 2**32, so timestamp 32
- data = struct.pack("!L", data64)
- else:
- # timestamp 64
- data = struct.pack("!Q", data64)
- else:
- # timestamp 96
- data = struct.pack("!Iq", self.nanoseconds, self.seconds)
- return data
-
- @staticmethod
- def from_unix(unix_sec):
- """Create a Timestamp from posix timestamp in seconds.
-
- :param unix_float: Posix timestamp in seconds.
- :type unix_float: int or float.
- """
- seconds = int(unix_sec // 1)
- nanoseconds = int((unix_sec % 1) * 10 ** 9)
- return Timestamp(seconds, nanoseconds)
-
- def to_unix(self):
- """Get the timestamp as a floating-point value.
-
- :returns: posix timestamp
- :rtype: float
- """
- return self.seconds + self.nanoseconds / 1e9
-
- @staticmethod
- def from_unix_nano(unix_ns):
- """Create a Timestamp from posix timestamp in nanoseconds.
-
- :param int unix_ns: Posix timestamp in nanoseconds.
- :rtype: Timestamp
- """
- return Timestamp(*divmod(unix_ns, 10 ** 9))
-
- def to_unix_nano(self):
- """Get the timestamp as a unixtime in nanoseconds.
-
- :returns: posix timestamp in nanoseconds
- :rtype: int
- """
- return self.seconds * 10 ** 9 + self.nanoseconds
-
- def to_datetime(self):
- """Get the timestamp as a UTC datetime.
-
- Python 2 is not supported.
-
- :rtype: datetime.
- """
- return datetime.datetime.fromtimestamp(0, _utc) + datetime.timedelta(
- seconds=self.to_unix()
- )
-
- @staticmethod
- def from_datetime(dt):
- """Create a Timestamp from datetime with tzinfo.
-
- Python 2 is not supported.
-
- :rtype: Timestamp
- """
- return Timestamp.from_unix(dt.timestamp())
diff --git a/spaces/ali-ghamdan/deoldify/deoldify/dataset.py b/spaces/ali-ghamdan/deoldify/deoldify/dataset.py
deleted file mode 100644
index 39154eaffa5e34bbd91e6871de33f76a78a7f964..0000000000000000000000000000000000000000
--- a/spaces/ali-ghamdan/deoldify/deoldify/dataset.py
+++ /dev/null
@@ -1,46 +0,0 @@
-from fastai import *
-from fastai.core import *
-from fastai.vision.transform import get_transforms
-from fastai.vision.data import ImageImageList, ImageDataBunch, imagenet_stats
-
-
-def get_colorize_data(
- sz: int,
- bs: int,
- crappy_path: Path,
- good_path: Path,
- random_seed: int = None,
- keep_pct: float = 1.0,
- num_workers: int = 8,
- stats: tuple = imagenet_stats,
- xtra_tfms=[],
-) -> ImageDataBunch:
-
- src = (
- ImageImageList.from_folder(crappy_path, convert_mode='RGB')
- .use_partial_data(sample_pct=keep_pct, seed=random_seed)
- .split_by_rand_pct(0.1, seed=random_seed)
- )
-
- data = (
- src.label_from_func(lambda x: good_path / x.relative_to(crappy_path))
- .transform(
- get_transforms(
- max_zoom=1.2, max_lighting=0.5, max_warp=0.25, xtra_tfms=xtra_tfms
- ),
- size=sz,
- tfm_y=True,
- )
- .databunch(bs=bs, num_workers=num_workers, no_check=True)
- .normalize(stats, do_y=True)
- )
-
- data.c = 3
- return data
-
-
-def get_dummy_databunch() -> ImageDataBunch:
- path = Path('./dummy/')
- return get_colorize_data(
- sz=1, bs=1, crappy_path=path, good_path=path, keep_pct=0.001
- )
diff --git a/spaces/aliabid94/crossword/game_manager.py b/spaces/aliabid94/crossword/game_manager.py
deleted file mode 100644
index 01234a4775acaf4e8dd93ae84a9aa7737d9be240..0000000000000000000000000000000000000000
--- a/spaces/aliabid94/crossword/game_manager.py
+++ /dev/null
@@ -1,262 +0,0 @@
-import threading
-import random
-from typing import Tuple
-import re
-import copy
-import os
-import json
-import openai
-import time
-
-openai.api_key = os.environ["OPENAI_KEY"]
-
-SIZE = 15
-RIDDLE_COUNT = 3
-MIN_WORD_SIZE = 4
-MAX_WORD_SIZE = 10
-WORD_LIMIT = 7500
-COMPLETE_GAME_TIMEOUT = 60 * 60
-INCOMPLETE_GAME_TIMEOUT = 60 * 60 * 24
-GUESS_TIMEOUT = 30
-
-
-with open("words.json", "r") as f:
- words = json.loads(f.read())
-
-with open("prompt.txt", "r") as f:
- RIDDLE_PROMPT = f.read()
-
-search_text = "\n".join(words)
-games = {}
-all_games_lock = threading.Lock()
-
-
-def get_riddle(answer):
- prompt = RIDDLE_PROMPT.format(
- answer,
- )
- while True:
- try:
- completions = openai.Completion.create(
- engine="text-davinci-003", prompt=prompt, max_tokens=200, n=1, temperature=0.5
- )
- riddle = completions["choices"][0]["text"]
- return riddle
- except Exception as e:
- print("OpenAI Error", e, "Retrying...")
- time.sleep(0.5)
-
-
-class Clue:
- def __init__(self, answer, location, across, solved):
- self.answer: str = answer
- self.location: Tuple[int, int] = location
- self.across: bool = across
- self.solved: bool = solved
- self.riddle: str = ""
- self.create_time: int
- self.solver: str = None
- self.timed_out: bool = False
-
- def __repr__(self):
- return f"{self.answer}: {self.location}, {'Across' if self.across else 'Down'}, {'Solved' if self.solved else 'Unsolved'}"
-
-
-class Game:
- def __init__(self, room_name, competitive, init_word):
- self.room_name = room_name
- self.competitive = competitive
- self.player_scores = {}
- self.grid = [[None for i in range(SIZE)] for j in range(SIZE)]
- self.grid = place_on_grid(
- self.grid, init_word, (SIZE // 2, SIZE // 2 - len(init_word) // 2), True
- )
- self.clues = [None] * RIDDLE_COUNT
- self.previous_clues = []
- self.lock = threading.Lock()
- self.complete = False
- self.last_update_index = 0
- self.last_update_time = time.time()
- self.last_riddle_update_time = None
- self.pending_request = False
-
- games[room_name] = self
-
- def update(self):
- self.last_update_index += 1
- self.last_update_time = time.time()
-
- def replace_clue(self, index):
- clue_grid = copy.deepcopy(self.grid)
- for j, clue in enumerate(self.clues):
- if clue and index != j:
- clue_grid = place_on_grid(clue_grid, clue.answer, clue.location, clue.across)
-
- if self.clues[index]:
- self.previous_clues.append(self.clues[index])
- clue = find_clue(clue_grid)
- if clue is None:
- self.complete = True
- return
- clue.create_time = time.time()
- self.pending_request = True
- clue.riddle = get_riddle(clue.answer)
- self.pending_request = False
- self.last_riddle_update_time = time.time()
- self.clues[index] = clue
-
- def add_player(self, player_name):
- with self.lock:
- self.update()
- if player_name not in self.player_scores:
- self.player_scores[player_name] = 0
-
- def player_guess(self, player_name, guess):
- guess = guess.lower()
- if self.pending_request:
- return
- with self.lock:
- self.update()
- matched_clues = [
- clue for clue in self.clues if not clue.solved and clue.answer == guess
- ]
- if len(matched_clues) == 0:
- return False
- for clue in matched_clues:
- clue.solved = True
- clue.solver = player_name
- place_on_grid(self.grid, clue.answer, clue.location, clue.across)
- self.player_scores[player_name] += 1
-
-
-def place_on_grid(grid, word, location, across):
- x, y = location
- if across:
- grid[x][y : y + len(word)] = word
- else:
- for i, letter in enumerate(word):
- grid[x + i][y] = letter
- return grid
-
-
-def find_clue(grid) -> Clue:
- all_coordinate_pairs = [
- (i, j) for i in range(SIZE) for j in range(SIZE) if grid[i][j] is not None
- ]
- random.shuffle(all_coordinate_pairs)
- for i, j in all_coordinate_pairs:
- regexes = []
- if (j == 0 or grid[i][j - 1] is None) and (
- j + 1 == SIZE or grid[i][j + 1] is None
- ):
- running_regex = ""
- possible_across_regexes = []
- for k in range(j, -1, -1):
- if (
- (i != 0 and grid[i - 1][k] is not None)
- or (i != SIZE - 1 and grid[i + 1][k] is not None)
- ) and grid[i][k] is None:
- break
- valid = k == 0 or grid[i][k - 1] is None
- running_regex = (grid[i][k] or ".") + running_regex
- possible_across_regexes.append(((i, k), running_regex, valid))
- possible_across_regexes = [p for p in possible_across_regexes if p[2]]
- for k in range(j + 1, SIZE):
- if (
- (i != 0 and grid[i - 1][k] is not None)
- or (i != SIZE - 1 and grid[i + 1][k] is not None)
- ) and grid[i][k] is None:
- break
- valid = k == SIZE - 1 or grid[i][k + 1] is None
- for start, possible_across_regex, _ in possible_across_regexes[:]:
- if start[1] + len(possible_across_regex) == k:
- possible_across_regexes.append(
- (start, possible_across_regex + (grid[i][k] or "."), valid)
- )
- possible_across_regexes = [
- (loc, regex, True)
- for loc, regex, valid in possible_across_regexes
- if len(regex) >= MIN_WORD_SIZE and valid
- ]
- regexes.extend(possible_across_regexes)
- elif (i == 0 or grid[i - 1][j] is None) and (
- i + 1 == SIZE or grid[i + 1][j] is None
- ):
- running_regex = ""
- possible_down_regexes = []
- for k in range(i, -1, -1):
- if (
- (j != 0 and grid[k][j - 1] is not None)
- or (j != SIZE - 1 and grid[k][j + 1] is not None)
- ) and grid[k][j] is None:
- break
- valid = k == 0 or grid[k - 1][j] is None
- running_regex = (grid[k][j] or ".") + running_regex
- possible_down_regexes.append(((k, j), running_regex, valid))
- possible_down_regexes = [p for p in possible_down_regexes if p[2]]
- for k in range(i + 1, SIZE):
- if (
- (j != 0 and grid[k][j - 1] is not None)
- or (j != SIZE - 1 and grid[k][j + 1] is not None)
- ) and grid[k][j] is None:
- break
- valid = k == SIZE - 1 or grid[k + 1][j] is None
- for start, possible_down_regex, _ in possible_down_regexes[:]:
- if start[0] + len(possible_down_regex) == k:
- possible_down_regexes.append(
- (start, possible_down_regex + (grid[k][j] or "."), valid)
- )
- possible_down_regexes = [
- (loc, regex, False)
- for loc, regex, valid in possible_down_regexes
- if len(regex) >= MIN_WORD_SIZE and valid
- ]
- regexes.extend(possible_down_regexes)
-
- random.shuffle(regexes)
- for loc, regex, across in regexes:
- matches = re.findall("^" + regex + "$", search_text, re.MULTILINE)
- if len(matches) > 1:
- random.shuffle(matches)
- answer = matches[0]
- clue = Clue(answer, loc, across, False)
- return clue
- return None
-
-
-def new_game(room_name):
- competitive = room_name != ""
- with all_games_lock:
- if room_name in games:
- return games[room_name]
- if not competitive:
- while room_name == "" or room_name in games:
- room_name = str(random.randint(0, 999999))
- init_word = random.choice(words)
- else:
- init_word = room_name
- return Game(room_name, competitive, init_word)
-
-
-def game_thread():
- while True:
- now = time.time()
- for room_name, game in games.items():
- idle_time = now - game.last_update_time
- if (game.complete and idle_time > COMPLETE_GAME_TIMEOUT) or (
- idle_time > INCOMPLETE_GAME_TIMEOUT
- ):
- del games[room_name]
- continue
- for i, clue in enumerate(game.clues):
- timed_out = now - clue.create_time > GUESS_TIMEOUT if clue is not None else None
- if timed_out:
- game.clues[i].timed_out = True
- if clue is None or clue.solved or timed_out:
- game.replace_clue(i)
-
- time.sleep(0.1)
-
-thread = threading.Thread(target=game_thread)
-thread.daemon = True
-thread.start()
\ No newline at end of file
diff --git a/spaces/allknowingroger/Image-Models-Test170/README.md b/spaces/allknowingroger/Image-Models-Test170/README.md
deleted file mode 100644
index f91e4b31ab345f987b425de029c057bfb69d9e1b..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Image-Models-Test170/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: More Image Models
-emoji: 😻
-colorFrom: red
-colorTo: gray
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-pinned: true
-duplicated_from: allknowingroger/Image-Models-Test
----
-
-
\ No newline at end of file
diff --git a/spaces/allknowingroger/Image-Models-Test180/README.md b/spaces/allknowingroger/Image-Models-Test180/README.md
deleted file mode 100644
index f91e4b31ab345f987b425de029c057bfb69d9e1b..0000000000000000000000000000000000000000
--- a/spaces/allknowingroger/Image-Models-Test180/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: More Image Models
-emoji: 😻
-colorFrom: red
-colorTo: gray
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-pinned: true
-duplicated_from: allknowingroger/Image-Models-Test
----
-
-
\ No newline at end of file
diff --git a/spaces/alphunt/diffdock-alphunt-demo/esm/esm/inverse_folding/gvp_encoder.py b/spaces/alphunt/diffdock-alphunt-demo/esm/esm/inverse_folding/gvp_encoder.py
deleted file mode 100644
index 4d28ff07c7b163976341b2ea8bb5d095b32db983..0000000000000000000000000000000000000000
--- a/spaces/alphunt/diffdock-alphunt-demo/esm/esm/inverse_folding/gvp_encoder.py
+++ /dev/null
@@ -1,56 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from argparse import Namespace
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-from .features import GVPGraphEmbedding
-from .gvp_modules import GVPConvLayer, LayerNorm
-from .gvp_utils import unflatten_graph
-
-
-
-class GVPEncoder(nn.Module):
-
- def __init__(self, args):
- super().__init__()
- self.args = args
- self.embed_graph = GVPGraphEmbedding(args)
-
- node_hidden_dim = (args.node_hidden_dim_scalar,
- args.node_hidden_dim_vector)
- edge_hidden_dim = (args.edge_hidden_dim_scalar,
- args.edge_hidden_dim_vector)
-
- conv_activations = (F.relu, torch.sigmoid)
- self.encoder_layers = nn.ModuleList(
- GVPConvLayer(
- node_hidden_dim,
- edge_hidden_dim,
- drop_rate=args.dropout,
- vector_gate=True,
- attention_heads=0,
- n_message=3,
- conv_activations=conv_activations,
- n_edge_gvps=0,
- eps=1e-4,
- layernorm=True,
- )
- for i in range(args.num_encoder_layers)
- )
-
- def forward(self, coords, coord_mask, padding_mask, confidence):
- node_embeddings, edge_embeddings, edge_index = self.embed_graph(
- coords, coord_mask, padding_mask, confidence)
-
- for i, layer in enumerate(self.encoder_layers):
- node_embeddings, edge_embeddings = layer(node_embeddings,
- edge_index, edge_embeddings)
-
- node_embeddings = unflatten_graph(node_embeddings, coords.shape[0])
- return node_embeddings
diff --git a/spaces/amankishore/sjc/sd1/ldm/data/personalized_style.py b/spaces/amankishore/sjc/sd1/ldm/data/personalized_style.py
deleted file mode 100644
index b6be7b15c4cafc7c3ec2649b0e9b8318c15ad4a1..0000000000000000000000000000000000000000
--- a/spaces/amankishore/sjc/sd1/ldm/data/personalized_style.py
+++ /dev/null
@@ -1,129 +0,0 @@
-import os
-import numpy as np
-import PIL
-from PIL import Image
-from torch.utils.data import Dataset
-from torchvision import transforms
-
-import random
-
-imagenet_templates_small = [
- 'a painting in the style of {}',
- 'a rendering in the style of {}',
- 'a cropped painting in the style of {}',
- 'the painting in the style of {}',
- 'a clean painting in the style of {}',
- 'a dirty painting in the style of {}',
- 'a dark painting in the style of {}',
- 'a picture in the style of {}',
- 'a cool painting in the style of {}',
- 'a close-up painting in the style of {}',
- 'a bright painting in the style of {}',
- 'a cropped painting in the style of {}',
- 'a good painting in the style of {}',
- 'a close-up painting in the style of {}',
- 'a rendition in the style of {}',
- 'a nice painting in the style of {}',
- 'a small painting in the style of {}',
- 'a weird painting in the style of {}',
- 'a large painting in the style of {}',
-]
-
-imagenet_dual_templates_small = [
- 'a painting in the style of {} with {}',
- 'a rendering in the style of {} with {}',
- 'a cropped painting in the style of {} with {}',
- 'the painting in the style of {} with {}',
- 'a clean painting in the style of {} with {}',
- 'a dirty painting in the style of {} with {}',
- 'a dark painting in the style of {} with {}',
- 'a cool painting in the style of {} with {}',
- 'a close-up painting in the style of {} with {}',
- 'a bright painting in the style of {} with {}',
- 'a cropped painting in the style of {} with {}',
- 'a good painting in the style of {} with {}',
- 'a painting of one {} in the style of {}',
- 'a nice painting in the style of {} with {}',
- 'a small painting in the style of {} with {}',
- 'a weird painting in the style of {} with {}',
- 'a large painting in the style of {} with {}',
-]
-
-per_img_token_list = [
- 'א', 'ב', 'ג', 'ד', 'ה', 'ו', 'ז', 'ח', 'ט', 'י', 'כ', 'ל', 'מ', 'נ', 'ס', 'ע', 'פ', 'צ', 'ק', 'ר', 'ש', 'ת',
-]
-
-class PersonalizedBase(Dataset):
- def __init__(self,
- data_root,
- size=None,
- repeats=100,
- interpolation="bicubic",
- flip_p=0.5,
- set="train",
- placeholder_token="*",
- per_image_tokens=False,
- center_crop=False,
- ):
-
- self.data_root = data_root
-
- self.image_paths = [os.path.join(self.data_root, file_path) for file_path in os.listdir(self.data_root)]
-
- # self._length = len(self.image_paths)
- self.num_images = len(self.image_paths)
- self._length = self.num_images
-
- self.placeholder_token = placeholder_token
-
- self.per_image_tokens = per_image_tokens
- self.center_crop = center_crop
-
- if per_image_tokens:
- assert self.num_images < len(per_img_token_list), f"Can't use per-image tokens when the training set contains more than {len(per_img_token_list)} tokens. To enable larger sets, add more tokens to 'per_img_token_list'."
-
- if set == "train":
- self._length = self.num_images * repeats
-
- self.size = size
- self.interpolation = {"linear": PIL.Image.LINEAR,
- "bilinear": PIL.Image.BILINEAR,
- "bicubic": PIL.Image.BICUBIC,
- "lanczos": PIL.Image.LANCZOS,
- }[interpolation]
- self.flip = transforms.RandomHorizontalFlip(p=flip_p)
-
- def __len__(self):
- return self._length
-
- def __getitem__(self, i):
- example = {}
- image = Image.open(self.image_paths[i % self.num_images])
-
- if not image.mode == "RGB":
- image = image.convert("RGB")
-
- if self.per_image_tokens and np.random.uniform() < 0.25:
- text = random.choice(imagenet_dual_templates_small).format(self.placeholder_token, per_img_token_list[i % self.num_images])
- else:
- text = random.choice(imagenet_templates_small).format(self.placeholder_token)
-
- example["caption"] = text
-
- # default to score-sde preprocessing
- img = np.array(image).astype(np.uint8)
-
- if self.center_crop:
- crop = min(img.shape[0], img.shape[1])
- h, w, = img.shape[0], img.shape[1]
- img = img[(h - crop) // 2:(h + crop) // 2,
- (w - crop) // 2:(w + crop) // 2]
-
- image = Image.fromarray(img)
- if self.size is not None:
- image = image.resize((self.size, self.size), resample=self.interpolation)
-
- image = self.flip(image)
- image = np.array(image).astype(np.uint8)
- example["image"] = (image / 127.5 - 1.0).astype(np.float32)
- return example
\ No newline at end of file
diff --git a/spaces/amgad59/Keras_cv_wedding_dress/share_btn.py b/spaces/amgad59/Keras_cv_wedding_dress/share_btn.py
deleted file mode 100644
index 34227f85459e1f5b7655e739189304fb3093e5d0..0000000000000000000000000000000000000000
--- a/spaces/amgad59/Keras_cv_wedding_dress/share_btn.py
+++ /dev/null
@@ -1,63 +0,0 @@
-"""
-Credits: https://huggingface.co/spaces/stabilityai/stable-diffusion/blob/main/share_btn.py
-"""
-community_icon_html = """"""
-
-loading_icon_html = """"""
-
-share_js = """async () => {
- async function uploadFile(file){
- const UPLOAD_URL = 'https://huggingface.co/uploads';
- const response = await fetch(UPLOAD_URL, {
- method: 'POST',
- headers: {
- 'Content-Type': file.type,
- 'X-Requested-With': 'XMLHttpRequest',
- },
- body: file, /// <- File inherits from Blob
- });
- const url = await response.text();
- return url;
- }
- const gradioEl = document.querySelector('body > gradio-app');
- const imgEls = gradioEl.querySelectorAll('#gallery img');
- const promptTxt = gradioEl.querySelector('#prompt-text-input input').value;
- const shareBtnEl = gradioEl.querySelector('#share-btn');
- const shareIconEl = gradioEl.querySelector('#share-btn-share-icon');
- const loadingIconEl = gradioEl.querySelector('#share-btn-loading-icon');
- if(!imgEls.length){
- return;
- };
- shareBtnEl.style.pointerEvents = 'none';
- shareIconEl.style.display = 'none';
- loadingIconEl.style.removeProperty('display');
- const files = await Promise.all(
- [...imgEls].map(async (imgEl) => {
- const res = await fetch(imgEl.src);
- const blob = await res.blob();
- const imgId = Date.now() % 200;
- const fileName = `diffuse-the-rest-${{imgId}}.jpg`;
- return new File([blob], fileName, { type: 'image/jpeg' });
- })
- );
- const urls = await Promise.all(files.map((f) => uploadFile(f)));
- const htmlImgs = urls.map(url => ` `);
- const descriptionMd = ` `);
- const descriptionMd = `
-${htmlImgs.join(`\n`)}
- `;
- const params = new URLSearchParams({
- title: promptTxt,
- description: descriptionMd,
- });
- const paramsStr = params.toString();
- window.open(`https://huggingface.co/spaces/stabilityai/stable-diffusion/discussions/new?${paramsStr}`, '_blank');
- shareBtnEl.style.removeProperty('pointer-events');
- shareIconEl.style.removeProperty('display');
- loadingIconEl.style.display = 'none';
-}"""
\ No newline at end of file
diff --git a/spaces/amirDev/crowd-counting-p2p/run_test.py b/spaces/amirDev/crowd-counting-p2p/run_test.py
deleted file mode 100644
index 51fe52d79f3bb427fa566ec9815e90f0d77bf623..0000000000000000000000000000000000000000
--- a/spaces/amirDev/crowd-counting-p2p/run_test.py
+++ /dev/null
@@ -1,102 +0,0 @@
-import argparse
-import datetime
-import random
-import time
-from pathlib import Path
-
-import torch
-import torchvision.transforms as standard_transforms
-import numpy as np
-
-from PIL import Image
-import cv2
-from crowd_datasets import build_dataset
-from engine import *
-from models import build_model
-import os
-import warnings
-warnings.filterwarnings('ignore')
-
-def get_args_parser():
- parser = argparse.ArgumentParser('Set parameters for P2PNet evaluation', add_help=False)
-
- # * Backbone
- parser.add_argument('--backbone', default='vgg16_bn', type=str,
- help="name of the convolutional backbone to use")
-
- parser.add_argument('--row', default=2, type=int,
- help="row number of anchor points")
- parser.add_argument('--line', default=2, type=int,
- help="line number of anchor points")
-
- parser.add_argument('--output_dir', default='',
- help='path where to save')
- parser.add_argument('--weight_path', default='',
- help='path where the trained weights saved')
-
- parser.add_argument('--gpu_id', default=0, type=int, help='the gpu used for evaluation')
-
- return parser
-
-def main(args, debug=False):
-
- os.environ["CUDA_VISIBLE_DEVICES"] = '{}'.format(args.gpu_id)
-
- print(args)
- device = torch.device('cpu')
- # get the P2PNet
- model = build_model(args)
- # move to GPU
- model.to(device)
- # load trained model
- if args.weight_path is not None:
- checkpoint = torch.load(args.weight_path, map_location='cpu')
- model.load_state_dict(checkpoint['model'])
- # convert to eval mode
- model.eval()
- # create the pre-processing transform
- transform = standard_transforms.Compose([
- standard_transforms.ToTensor(),
- standard_transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
- ])
-
- # set your image path here
- img_path = "./vis/demo1.jpg"
- # load the images
- img_raw = Image.open(img_path).convert('RGB')
- # round the size
- width, height = img_raw.size
- new_width = width // 128 * 128
- new_height = height // 128 * 128
- img_raw = img_raw.resize((new_width, new_height), Image.ANTIALIAS)
- # pre-proccessing
- img = transform(img_raw)
-
- samples = torch.Tensor(img).unsqueeze(0)
- samples = samples.to(device)
- # run inference
- outputs = model(samples)
- outputs_scores = torch.nn.functional.softmax(outputs['pred_logits'], -1)[:, :, 1][0]
-
- outputs_points = outputs['pred_points'][0]
-
- threshold = 0.5
- # filter the predictions
- points = outputs_points[outputs_scores > threshold].detach().cpu().numpy().tolist()
- predict_cnt = int((outputs_scores > threshold).sum())
-
- outputs_scores = torch.nn.functional.softmax(outputs['pred_logits'], -1)[:, :, 1][0]
-
- outputs_points = outputs['pred_points'][0]
- # draw the predictions
- size = 2
- img_to_draw = cv2.cvtColor(np.array(img_raw), cv2.COLOR_RGB2BGR)
- for p in points:
- img_to_draw = cv2.circle(img_to_draw, (int(p[0]), int(p[1])), size, (0, 0, 255), -1)
- # save the visualized image
- cv2.imwrite(os.path.join(args.output_dir, 'pred{}.jpg'.format(predict_cnt)), img_to_draw)
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser('P2PNet evaluation script', parents=[get_args_parser()])
- args = parser.parse_args()
- main(args)
\ No newline at end of file
diff --git a/spaces/anaclaudia13ct/insect_detection/utils/aws/resume.py b/spaces/anaclaudia13ct/insect_detection/utils/aws/resume.py
deleted file mode 100644
index b21731c979a121ab8227280351b70d6062efd983..0000000000000000000000000000000000000000
--- a/spaces/anaclaudia13ct/insect_detection/utils/aws/resume.py
+++ /dev/null
@@ -1,40 +0,0 @@
-# Resume all interrupted trainings in yolov5/ dir including DDP trainings
-# Usage: $ python utils/aws/resume.py
-
-import os
-import sys
-from pathlib import Path
-
-import torch
-import yaml
-
-FILE = Path(__file__).resolve()
-ROOT = FILE.parents[2] # YOLOv5 root directory
-if str(ROOT) not in sys.path:
- sys.path.append(str(ROOT)) # add ROOT to PATH
-
-port = 0 # --master_port
-path = Path('').resolve()
-for last in path.rglob('*/**/last.pt'):
- ckpt = torch.load(last)
- if ckpt['optimizer'] is None:
- continue
-
- # Load opt.yaml
- with open(last.parent.parent / 'opt.yaml', errors='ignore') as f:
- opt = yaml.safe_load(f)
-
- # Get device count
- d = opt['device'].split(',') # devices
- nd = len(d) # number of devices
- ddp = nd > 1 or (nd == 0 and torch.cuda.device_count() > 1) # distributed data parallel
-
- if ddp: # multi-GPU
- port += 1
- cmd = f'python -m torch.distributed.run --nproc_per_node {nd} --master_port {port} train.py --resume {last}'
- else: # single-GPU
- cmd = f'python train.py --resume {last}'
-
- cmd += ' > /dev/null 2>&1 &' # redirect output to dev/null and run in daemon thread
- print(cmd)
- os.system(cmd)
diff --git a/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/client/js/theme-toggler.js b/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/client/js/theme-toggler.js
deleted file mode 100644
index 67e1a9501b70d54ab8a717f34983c012328e74a0..0000000000000000000000000000000000000000
--- a/spaces/andryMLOPS/ASTA-GPT-3.8_web_ui/client/js/theme-toggler.js
+++ /dev/null
@@ -1,22 +0,0 @@
-var switch_theme_toggler = document.getElementById("theme-toggler");
-
-switch_theme_toggler.addEventListener("change", toggleTheme);
-
-function setTheme(themeName) {
- localStorage.setItem("theme", themeName);
- document.documentElement.className = themeName;
-}
-
-function toggleTheme() {
- var currentTheme = localStorage.getItem("theme");
- var newTheme = currentTheme === "theme-dark" ? "theme-light" : "theme-dark";
-
- setTheme(newTheme);
- switch_theme_toggler.checked = newTheme === "theme-dark";
-}
-
-(function () {
- var currentTheme = localStorage.getItem("theme") || "theme-dark";
- setTheme(currentTheme);
- switch_theme_toggler.checked = currentTheme === "theme-dark";
-})();
diff --git a/spaces/aodianyun/stable-diffusion-webui/extensions/deforum/scripts/deforum_helpers/deprecation_utils.py b/spaces/aodianyun/stable-diffusion-webui/extensions/deforum/scripts/deforum_helpers/deprecation_utils.py
deleted file mode 100644
index 9485b1b39629ce1c0c1c584e1294e64e300c06db..0000000000000000000000000000000000000000
--- a/spaces/aodianyun/stable-diffusion-webui/extensions/deforum/scripts/deforum_helpers/deprecation_utils.py
+++ /dev/null
@@ -1,20 +0,0 @@
-# This file is used to map deprecated setting names in a dictionary
-# and print a message containing the old and the new names
-# if the latter is removed completely, put a warning
-
-# as of 2023-02-05
-# "histogram_matching" -> None
-
-deprecation_map = {
- "histogram_matching": None,
- "flip_2d_perspective": "enable_perspective_flip"
-}
-
-def handle_deprecated_settings(settings_json):
- for old_name, new_name in deprecation_map.items():
- if old_name in settings_json:
- if new_name is None:
- print(f"WARNING: Setting '{old_name}' has been removed. It will be discarded and the default value used instead!")
- else:
- print(f"WARNING: Setting '{old_name}' has been renamed to '{new_name}'. The saved settings file will reflect the change")
- settings_json[new_name] = settings_json.pop(old_name)
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Cython/Compiler/AutoDocTransforms.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Cython/Compiler/AutoDocTransforms.py
deleted file mode 100644
index d3c0a1d0da4ca54fa06348b0ccea2e7b5cf4fd6d..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Cython/Compiler/AutoDocTransforms.py
+++ /dev/null
@@ -1,214 +0,0 @@
-from __future__ import absolute_import, print_function
-
-from .Visitor import CythonTransform
-from .StringEncoding import EncodedString
-from . import Options
-from . import PyrexTypes, ExprNodes
-from ..CodeWriter import ExpressionWriter
-
-
-class AnnotationWriter(ExpressionWriter):
-
- def visit_Node(self, node):
- self.put(u"")
-
- def visit_LambdaNode(self, node):
- # XXX Should we do better?
- self.put("")
-
-
-class EmbedSignature(CythonTransform):
-
- def __init__(self, context):
- super(EmbedSignature, self).__init__(context)
- self.class_name = None
- self.class_node = None
-
- def _fmt_expr(self, node):
- writer = AnnotationWriter()
- result = writer.write(node)
- # print(type(node).__name__, '-->', result)
- return result
-
- def _fmt_arg(self, arg):
- if arg.type is PyrexTypes.py_object_type or arg.is_self_arg:
- doc = arg.name
- else:
- doc = arg.type.declaration_code(arg.name, for_display=1)
-
- if arg.annotation:
- annotation = self._fmt_expr(arg.annotation)
- doc = doc + (': %s' % annotation)
- if arg.default:
- default = self._fmt_expr(arg.default)
- doc = doc + (' = %s' % default)
- elif arg.default:
- default = self._fmt_expr(arg.default)
- doc = doc + ('=%s' % default)
- return doc
-
- def _fmt_star_arg(self, arg):
- arg_doc = arg.name
- if arg.annotation:
- annotation = self._fmt_expr(arg.annotation)
- arg_doc = arg_doc + (': %s' % annotation)
- return arg_doc
-
- def _fmt_arglist(self, args,
- npargs=0, pargs=None,
- nkargs=0, kargs=None,
- hide_self=False):
- arglist = []
- for arg in args:
- if not hide_self or not arg.entry.is_self_arg:
- arg_doc = self._fmt_arg(arg)
- arglist.append(arg_doc)
- if pargs:
- arg_doc = self._fmt_star_arg(pargs)
- arglist.insert(npargs, '*%s' % arg_doc)
- elif nkargs:
- arglist.insert(npargs, '*')
- if kargs:
- arg_doc = self._fmt_star_arg(kargs)
- arglist.append('**%s' % arg_doc)
- return arglist
-
- def _fmt_ret_type(self, ret):
- if ret is PyrexTypes.py_object_type:
- return None
- else:
- return ret.declaration_code("", for_display=1)
-
- def _fmt_signature(self, cls_name, func_name, args,
- npargs=0, pargs=None,
- nkargs=0, kargs=None,
- return_expr=None,
- return_type=None, hide_self=False):
- arglist = self._fmt_arglist(args,
- npargs, pargs,
- nkargs, kargs,
- hide_self=hide_self)
- arglist_doc = ', '.join(arglist)
- func_doc = '%s(%s)' % (func_name, arglist_doc)
- if cls_name:
- func_doc = '%s.%s' % (cls_name, func_doc)
- ret_doc = None
- if return_expr:
- ret_doc = self._fmt_expr(return_expr)
- elif return_type:
- ret_doc = self._fmt_ret_type(return_type)
- if ret_doc:
- func_doc = '%s -> %s' % (func_doc, ret_doc)
- return func_doc
-
- def _embed_signature(self, signature, node_doc):
- if node_doc:
- return "%s\n%s" % (signature, node_doc)
- else:
- return signature
-
- def __call__(self, node):
- if not Options.docstrings:
- return node
- else:
- return super(EmbedSignature, self).__call__(node)
-
- def visit_ClassDefNode(self, node):
- oldname = self.class_name
- oldclass = self.class_node
- self.class_node = node
- try:
- # PyClassDefNode
- self.class_name = node.name
- except AttributeError:
- # CClassDefNode
- self.class_name = node.class_name
- self.visitchildren(node)
- self.class_name = oldname
- self.class_node = oldclass
- return node
-
- def visit_LambdaNode(self, node):
- # lambda expressions so not have signature or inner functions
- return node
-
- def visit_DefNode(self, node):
- if not self.current_directives['embedsignature']:
- return node
-
- is_constructor = False
- hide_self = False
- if node.entry.is_special:
- is_constructor = self.class_node and node.name == '__init__'
- if not is_constructor:
- return node
- class_name, func_name = None, self.class_name
- hide_self = True
- else:
- class_name, func_name = self.class_name, node.name
-
- nkargs = getattr(node, 'num_kwonly_args', 0)
- npargs = len(node.args) - nkargs
- signature = self._fmt_signature(
- class_name, func_name, node.args,
- npargs, node.star_arg,
- nkargs, node.starstar_arg,
- return_expr=node.return_type_annotation,
- return_type=None, hide_self=hide_self)
- if signature:
- if is_constructor:
- doc_holder = self.class_node.entry.type.scope
- else:
- doc_holder = node.entry
-
- if doc_holder.doc is not None:
- old_doc = doc_holder.doc
- elif not is_constructor and getattr(node, 'py_func', None) is not None:
- old_doc = node.py_func.entry.doc
- else:
- old_doc = None
- new_doc = self._embed_signature(signature, old_doc)
- doc_holder.doc = EncodedString(new_doc)
- if not is_constructor and getattr(node, 'py_func', None) is not None:
- node.py_func.entry.doc = EncodedString(new_doc)
- return node
-
- def visit_CFuncDefNode(self, node):
- if not self.current_directives['embedsignature']:
- return node
- if not node.overridable: # not cpdef FOO(...):
- return node
-
- signature = self._fmt_signature(
- self.class_name, node.declarator.base.name,
- node.declarator.args,
- return_type=node.return_type)
- if signature:
- if node.entry.doc is not None:
- old_doc = node.entry.doc
- elif getattr(node, 'py_func', None) is not None:
- old_doc = node.py_func.entry.doc
- else:
- old_doc = None
- new_doc = self._embed_signature(signature, old_doc)
- node.entry.doc = EncodedString(new_doc)
- if hasattr(node, 'py_func') and node.py_func is not None:
- node.py_func.entry.doc = EncodedString(new_doc)
- return node
-
- def visit_PropertyNode(self, node):
- if not self.current_directives['embedsignature']:
- return node
-
- entry = node.entry
- if entry.visibility == 'public':
- # property synthesised from a cdef public attribute
- type_name = entry.type.declaration_code("", for_display=1)
- if not entry.type.is_pyobject:
- type_name = "'%s'" % type_name
- elif entry.type.is_extension_type:
- type_name = entry.type.module_name + '.' + type_name
- signature = '%s: %s' % (entry.name, type_name)
- new_doc = self._embed_signature(signature, entry.doc)
- entry.doc = EncodedString(new_doc)
- return node
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/antlr4/atn/ATNDeserializer.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/antlr4/atn/ATNDeserializer.py
deleted file mode 100644
index cd0bb661a89c59e810e17618f33d9508542b9a96..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/antlr4/atn/ATNDeserializer.py
+++ /dev/null
@@ -1,528 +0,0 @@
-# Copyright (c) 2012-2017 The ANTLR Project. All rights reserved.
-# Use of this file is governed by the BSD 3-clause license that
-# can be found in the LICENSE.txt file in the project root.
-#/
-from uuid import UUID
-from io import StringIO
-from typing import Callable
-from antlr4.Token import Token
-from antlr4.atn.ATN import ATN
-from antlr4.atn.ATNType import ATNType
-from antlr4.atn.ATNState import *
-from antlr4.atn.Transition import *
-from antlr4.atn.LexerAction import *
-from antlr4.atn.ATNDeserializationOptions import ATNDeserializationOptions
-
-# This is the earliest supported serialized UUID.
-BASE_SERIALIZED_UUID = UUID("AADB8D7E-AEEF-4415-AD2B-8204D6CF042E")
-
-# This UUID indicates the serialized ATN contains two sets of
-# IntervalSets, where the second set's values are encoded as
-# 32-bit integers to support the full Unicode SMP range up to U+10FFFF.
-ADDED_UNICODE_SMP = UUID("59627784-3BE5-417A-B9EB-8131A7286089")
-
-# This list contains all of the currently supported UUIDs, ordered by when
-# the feature first appeared in this branch.
-SUPPORTED_UUIDS = [ BASE_SERIALIZED_UUID, ADDED_UNICODE_SMP ]
-
-SERIALIZED_VERSION = 3
-
-# This is the current serialized UUID.
-SERIALIZED_UUID = ADDED_UNICODE_SMP
-
-class ATNDeserializer (object):
-
- def __init__(self, options : ATNDeserializationOptions = None):
- if options is None:
- options = ATNDeserializationOptions.defaultOptions
- self.deserializationOptions = options
-
- # Determines if a particular serialized representation of an ATN supports
- # a particular feature, identified by the {@link UUID} used for serializing
- # the ATN at the time the feature was first introduced.
- #
- # @param feature The {@link UUID} marking the first time the feature was
- # supported in the serialized ATN.
- # @param actualUuid The {@link UUID} of the actual serialized ATN which is
- # currently being deserialized.
- # @return {@code true} if the {@code actualUuid} value represents a
- # serialized ATN at or after the feature identified by {@code feature} was
- # introduced; otherwise, {@code false}.
-
- def isFeatureSupported(self, feature : UUID , actualUuid : UUID ):
- idx1 = SUPPORTED_UUIDS.index(feature)
- if idx1<0:
- return False
- idx2 = SUPPORTED_UUIDS.index(actualUuid)
- return idx2 >= idx1
-
- def deserialize(self, data : str):
- self.reset(data)
- self.checkVersion()
- self.checkUUID()
- atn = self.readATN()
- self.readStates(atn)
- self.readRules(atn)
- self.readModes(atn)
- sets = []
- # First, read all sets with 16-bit Unicode code points <= U+FFFF.
- self.readSets(atn, sets, self.readInt)
- # Next, if the ATN was serialized with the Unicode SMP feature,
- # deserialize sets with 32-bit arguments <= U+10FFFF.
- if self.isFeatureSupported(ADDED_UNICODE_SMP, self.uuid):
- self.readSets(atn, sets, self.readInt32)
- self.readEdges(atn, sets)
- self.readDecisions(atn)
- self.readLexerActions(atn)
- self.markPrecedenceDecisions(atn)
- self.verifyATN(atn)
- if self.deserializationOptions.generateRuleBypassTransitions \
- and atn.grammarType == ATNType.PARSER:
- self.generateRuleBypassTransitions(atn)
- # re-verify after modification
- self.verifyATN(atn)
- return atn
-
- def reset(self, data:str):
- def adjust(c):
- v = ord(c)
- return v-2 if v>1 else v + 65533
- temp = [ adjust(c) for c in data ]
- # don't adjust the first value since that's the version number
- temp[0] = ord(data[0])
- self.data = temp
- self.pos = 0
-
- def checkVersion(self):
- version = self.readInt()
- if version != SERIALIZED_VERSION:
- raise Exception("Could not deserialize ATN with version " + str(version) + " (expected " + str(SERIALIZED_VERSION) + ").")
-
- def checkUUID(self):
- uuid = self.readUUID()
- if not uuid in SUPPORTED_UUIDS:
- raise Exception("Could not deserialize ATN with UUID: " + str(uuid) + \
- " (expected " + str(SERIALIZED_UUID) + " or a legacy UUID).", uuid, SERIALIZED_UUID)
- self.uuid = uuid
-
- def readATN(self):
- idx = self.readInt()
- grammarType = ATNType.fromOrdinal(idx)
- maxTokenType = self.readInt()
- return ATN(grammarType, maxTokenType)
-
- def readStates(self, atn:ATN):
- loopBackStateNumbers = []
- endStateNumbers = []
- nstates = self.readInt()
- for i in range(0, nstates):
- stype = self.readInt()
- # ignore bad type of states
- if stype==ATNState.INVALID_TYPE:
- atn.addState(None)
- continue
- ruleIndex = self.readInt()
- if ruleIndex == 0xFFFF:
- ruleIndex = -1
-
- s = self.stateFactory(stype, ruleIndex)
- if stype == ATNState.LOOP_END: # special case
- loopBackStateNumber = self.readInt()
- loopBackStateNumbers.append((s, loopBackStateNumber))
- elif isinstance(s, BlockStartState):
- endStateNumber = self.readInt()
- endStateNumbers.append((s, endStateNumber))
-
- atn.addState(s)
-
- # delay the assignment of loop back and end states until we know all the state instances have been initialized
- for pair in loopBackStateNumbers:
- pair[0].loopBackState = atn.states[pair[1]]
-
- for pair in endStateNumbers:
- pair[0].endState = atn.states[pair[1]]
-
- numNonGreedyStates = self.readInt()
- for i in range(0, numNonGreedyStates):
- stateNumber = self.readInt()
- atn.states[stateNumber].nonGreedy = True
-
- numPrecedenceStates = self.readInt()
- for i in range(0, numPrecedenceStates):
- stateNumber = self.readInt()
- atn.states[stateNumber].isPrecedenceRule = True
-
- def readRules(self, atn:ATN):
- nrules = self.readInt()
- if atn.grammarType == ATNType.LEXER:
- atn.ruleToTokenType = [0] * nrules
-
- atn.ruleToStartState = [0] * nrules
- for i in range(0, nrules):
- s = self.readInt()
- startState = atn.states[s]
- atn.ruleToStartState[i] = startState
- if atn.grammarType == ATNType.LEXER:
- tokenType = self.readInt()
- if tokenType == 0xFFFF:
- tokenType = Token.EOF
-
- atn.ruleToTokenType[i] = tokenType
-
- atn.ruleToStopState = [0] * nrules
- for state in atn.states:
- if not isinstance(state, RuleStopState):
- continue
- atn.ruleToStopState[state.ruleIndex] = state
- atn.ruleToStartState[state.ruleIndex].stopState = state
-
- def readModes(self, atn:ATN):
- nmodes = self.readInt()
- for i in range(0, nmodes):
- s = self.readInt()
- atn.modeToStartState.append(atn.states[s])
-
- def readSets(self, atn:ATN, sets:list, readUnicode:Callable[[], int]):
- m = self.readInt()
- for i in range(0, m):
- iset = IntervalSet()
- sets.append(iset)
- n = self.readInt()
- containsEof = self.readInt()
- if containsEof!=0:
- iset.addOne(-1)
- for j in range(0, n):
- i1 = readUnicode()
- i2 = readUnicode()
- iset.addRange(range(i1, i2 + 1)) # range upper limit is exclusive
-
- def readEdges(self, atn:ATN, sets:list):
- nedges = self.readInt()
- for i in range(0, nedges):
- src = self.readInt()
- trg = self.readInt()
- ttype = self.readInt()
- arg1 = self.readInt()
- arg2 = self.readInt()
- arg3 = self.readInt()
- trans = self.edgeFactory(atn, ttype, src, trg, arg1, arg2, arg3, sets)
- srcState = atn.states[src]
- srcState.addTransition(trans)
-
- # edges for rule stop states can be derived, so they aren't serialized
- for state in atn.states:
- for i in range(0, len(state.transitions)):
- t = state.transitions[i]
- if not isinstance(t, RuleTransition):
- continue
- outermostPrecedenceReturn = -1
- if atn.ruleToStartState[t.target.ruleIndex].isPrecedenceRule:
- if t.precedence == 0:
- outermostPrecedenceReturn = t.target.ruleIndex
- trans = EpsilonTransition(t.followState, outermostPrecedenceReturn)
- atn.ruleToStopState[t.target.ruleIndex].addTransition(trans)
-
- for state in atn.states:
- if isinstance(state, BlockStartState):
- # we need to know the end state to set its start state
- if state.endState is None:
- raise Exception("IllegalState")
- # block end states can only be associated to a single block start state
- if state.endState.startState is not None:
- raise Exception("IllegalState")
- state.endState.startState = state
-
- if isinstance(state, PlusLoopbackState):
- for i in range(0, len(state.transitions)):
- target = state.transitions[i].target
- if isinstance(target, PlusBlockStartState):
- target.loopBackState = state
- elif isinstance(state, StarLoopbackState):
- for i in range(0, len(state.transitions)):
- target = state.transitions[i].target
- if isinstance(target, StarLoopEntryState):
- target.loopBackState = state
-
- def readDecisions(self, atn:ATN):
- ndecisions = self.readInt()
- for i in range(0, ndecisions):
- s = self.readInt()
- decState = atn.states[s]
- atn.decisionToState.append(decState)
- decState.decision = i
-
- def readLexerActions(self, atn:ATN):
- if atn.grammarType == ATNType.LEXER:
- count = self.readInt()
- atn.lexerActions = [ None ] * count
- for i in range(0, count):
- actionType = self.readInt()
- data1 = self.readInt()
- if data1 == 0xFFFF:
- data1 = -1
- data2 = self.readInt()
- if data2 == 0xFFFF:
- data2 = -1
- lexerAction = self.lexerActionFactory(actionType, data1, data2)
- atn.lexerActions[i] = lexerAction
-
- def generateRuleBypassTransitions(self, atn:ATN):
-
- count = len(atn.ruleToStartState)
- atn.ruleToTokenType = [ 0 ] * count
- for i in range(0, count):
- atn.ruleToTokenType[i] = atn.maxTokenType + i + 1
-
- for i in range(0, count):
- self.generateRuleBypassTransition(atn, i)
-
- def generateRuleBypassTransition(self, atn:ATN, idx:int):
-
- bypassStart = BasicBlockStartState()
- bypassStart.ruleIndex = idx
- atn.addState(bypassStart)
-
- bypassStop = BlockEndState()
- bypassStop.ruleIndex = idx
- atn.addState(bypassStop)
-
- bypassStart.endState = bypassStop
- atn.defineDecisionState(bypassStart)
-
- bypassStop.startState = bypassStart
-
- excludeTransition = None
-
- if atn.ruleToStartState[idx].isPrecedenceRule:
- # wrap from the beginning of the rule to the StarLoopEntryState
- endState = None
- for state in atn.states:
- if self.stateIsEndStateFor(state, idx):
- endState = state
- excludeTransition = state.loopBackState.transitions[0]
- break
-
- if excludeTransition is None:
- raise Exception("Couldn't identify final state of the precedence rule prefix section.")
-
- else:
-
- endState = atn.ruleToStopState[idx]
-
- # all non-excluded transitions that currently target end state need to target blockEnd instead
- for state in atn.states:
- for transition in state.transitions:
- if transition == excludeTransition:
- continue
- if transition.target == endState:
- transition.target = bypassStop
-
- # all transitions leaving the rule start state need to leave blockStart instead
- ruleToStartState = atn.ruleToStartState[idx]
- count = len(ruleToStartState.transitions)
- while count > 0:
- bypassStart.addTransition(ruleToStartState.transitions[count-1])
- del ruleToStartState.transitions[-1]
-
- # link the new states
- atn.ruleToStartState[idx].addTransition(EpsilonTransition(bypassStart))
- bypassStop.addTransition(EpsilonTransition(endState))
-
- matchState = BasicState()
- atn.addState(matchState)
- matchState.addTransition(AtomTransition(bypassStop, atn.ruleToTokenType[idx]))
- bypassStart.addTransition(EpsilonTransition(matchState))
-
-
- def stateIsEndStateFor(self, state:ATNState, idx:int):
- if state.ruleIndex != idx:
- return None
- if not isinstance(state, StarLoopEntryState):
- return None
-
- maybeLoopEndState = state.transitions[len(state.transitions) - 1].target
- if not isinstance(maybeLoopEndState, LoopEndState):
- return None
-
- if maybeLoopEndState.epsilonOnlyTransitions and \
- isinstance(maybeLoopEndState.transitions[0].target, RuleStopState):
- return state
- else:
- return None
-
-
- #
- # Analyze the {@link StarLoopEntryState} states in the specified ATN to set
- # the {@link StarLoopEntryState#isPrecedenceDecision} field to the
- # correct value.
- #
- # @param atn The ATN.
- #
- def markPrecedenceDecisions(self, atn:ATN):
- for state in atn.states:
- if not isinstance(state, StarLoopEntryState):
- continue
-
- # We analyze the ATN to determine if this ATN decision state is the
- # decision for the closure block that determines whether a
- # precedence rule should continue or complete.
- #
- if atn.ruleToStartState[state.ruleIndex].isPrecedenceRule:
- maybeLoopEndState = state.transitions[len(state.transitions) - 1].target
- if isinstance(maybeLoopEndState, LoopEndState):
- if maybeLoopEndState.epsilonOnlyTransitions and \
- isinstance(maybeLoopEndState.transitions[0].target, RuleStopState):
- state.isPrecedenceDecision = True
-
- def verifyATN(self, atn:ATN):
- if not self.deserializationOptions.verifyATN:
- return
- # verify assumptions
- for state in atn.states:
- if state is None:
- continue
-
- self.checkCondition(state.epsilonOnlyTransitions or len(state.transitions) <= 1)
-
- if isinstance(state, PlusBlockStartState):
- self.checkCondition(state.loopBackState is not None)
-
- if isinstance(state, StarLoopEntryState):
- self.checkCondition(state.loopBackState is not None)
- self.checkCondition(len(state.transitions) == 2)
-
- if isinstance(state.transitions[0].target, StarBlockStartState):
- self.checkCondition(isinstance(state.transitions[1].target, LoopEndState))
- self.checkCondition(not state.nonGreedy)
- elif isinstance(state.transitions[0].target, LoopEndState):
- self.checkCondition(isinstance(state.transitions[1].target, StarBlockStartState))
- self.checkCondition(state.nonGreedy)
- else:
- raise Exception("IllegalState")
-
- if isinstance(state, StarLoopbackState):
- self.checkCondition(len(state.transitions) == 1)
- self.checkCondition(isinstance(state.transitions[0].target, StarLoopEntryState))
-
- if isinstance(state, LoopEndState):
- self.checkCondition(state.loopBackState is not None)
-
- if isinstance(state, RuleStartState):
- self.checkCondition(state.stopState is not None)
-
- if isinstance(state, BlockStartState):
- self.checkCondition(state.endState is not None)
-
- if isinstance(state, BlockEndState):
- self.checkCondition(state.startState is not None)
-
- if isinstance(state, DecisionState):
- self.checkCondition(len(state.transitions) <= 1 or state.decision >= 0)
- else:
- self.checkCondition(len(state.transitions) <= 1 or isinstance(state, RuleStopState))
-
- def checkCondition(self, condition:bool, message=None):
- if not condition:
- if message is None:
- message = "IllegalState"
- raise Exception(message)
-
- def readInt(self):
- i = self.data[self.pos]
- self.pos += 1
- return i
-
- def readInt32(self):
- low = self.readInt()
- high = self.readInt()
- return low | (high << 16)
-
- def readLong(self):
- low = self.readInt32()
- high = self.readInt32()
- return (low & 0x00000000FFFFFFFF) | (high << 32)
-
- def readUUID(self):
- low = self.readLong()
- high = self.readLong()
- allBits = (low & 0xFFFFFFFFFFFFFFFF) | (high << 64)
- return UUID(int=allBits)
-
- edgeFactories = [ lambda args : None,
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : EpsilonTransition(target),
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : \
- RangeTransition(target, Token.EOF, arg2) if arg3 != 0 else RangeTransition(target, arg1, arg2),
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : \
- RuleTransition(atn.states[arg1], arg2, arg3, target),
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : \
- PredicateTransition(target, arg1, arg2, arg3 != 0),
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : \
- AtomTransition(target, Token.EOF) if arg3 != 0 else AtomTransition(target, arg1),
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : \
- ActionTransition(target, arg1, arg2, arg3 != 0),
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : \
- SetTransition(target, sets[arg1]),
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : \
- NotSetTransition(target, sets[arg1]),
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : \
- WildcardTransition(target),
- lambda atn, src, trg, arg1, arg2, arg3, sets, target : \
- PrecedencePredicateTransition(target, arg1)
- ]
-
- def edgeFactory(self, atn:ATN, type:int, src:int, trg:int, arg1:int, arg2:int, arg3:int, sets:list):
- target = atn.states[trg]
- if type > len(self.edgeFactories) or self.edgeFactories[type] is None:
- raise Exception("The specified transition type: " + str(type) + " is not valid.")
- else:
- return self.edgeFactories[type](atn, src, trg, arg1, arg2, arg3, sets, target)
-
- stateFactories = [ lambda : None,
- lambda : BasicState(),
- lambda : RuleStartState(),
- lambda : BasicBlockStartState(),
- lambda : PlusBlockStartState(),
- lambda : StarBlockStartState(),
- lambda : TokensStartState(),
- lambda : RuleStopState(),
- lambda : BlockEndState(),
- lambda : StarLoopbackState(),
- lambda : StarLoopEntryState(),
- lambda : PlusLoopbackState(),
- lambda : LoopEndState()
- ]
-
- def stateFactory(self, type:int, ruleIndex:int):
- if type> len(self.stateFactories) or self.stateFactories[type] is None:
- raise Exception("The specified state type " + str(type) + " is not valid.")
- else:
- s = self.stateFactories[type]()
- if s is not None:
- s.ruleIndex = ruleIndex
- return s
-
- CHANNEL = 0 #The type of a {@link LexerChannelAction} action.
- CUSTOM = 1 #The type of a {@link LexerCustomAction} action.
- MODE = 2 #The type of a {@link LexerModeAction} action.
- MORE = 3 #The type of a {@link LexerMoreAction} action.
- POP_MODE = 4 #The type of a {@link LexerPopModeAction} action.
- PUSH_MODE = 5 #The type of a {@link LexerPushModeAction} action.
- SKIP = 6 #The type of a {@link LexerSkipAction} action.
- TYPE = 7 #The type of a {@link LexerTypeAction} action.
-
- actionFactories = [ lambda data1, data2: LexerChannelAction(data1),
- lambda data1, data2: LexerCustomAction(data1, data2),
- lambda data1, data2: LexerModeAction(data1),
- lambda data1, data2: LexerMoreAction.INSTANCE,
- lambda data1, data2: LexerPopModeAction.INSTANCE,
- lambda data1, data2: LexerPushModeAction(data1),
- lambda data1, data2: LexerSkipAction.INSTANCE,
- lambda data1, data2: LexerTypeAction(data1)
- ]
-
- def lexerActionFactory(self, type:int, data1:int, data2:int):
-
- if type > len(self.actionFactories) or self.actionFactories[type] is None:
- raise Exception("The specified lexer action type " + str(type) + " is not valid.")
- else:
- return self.actionFactories[type](data1, data2)
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/audioread/maddec.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/audioread/maddec.py
deleted file mode 100644
index 3a2a694497fcacaa9c3101ec862b9151563b5738..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/audioread/maddec.py
+++ /dev/null
@@ -1,84 +0,0 @@
-# This file is part of audioread.
-# Copyright 2011, Adrian Sampson.
-#
-# Permission is hereby granted, free of charge, to any person obtaining
-# a copy of this software and associated documentation files (the
-# "Software"), to deal in the Software without restriction, including
-# without limitation the rights to use, copy, modify, merge, publish,
-# distribute, sublicense, and/or sell copies of the Software, and to
-# permit persons to whom the Software is furnished to do so, subject to
-# the following conditions:
-#
-# The above copyright notice and this permission notice shall be
-# included in all copies or substantial portions of the Software.
-
-"""Decode MPEG audio files with MAD (via pymad)."""
-import mad
-from . import DecodeError
-
-
-class UnsupportedError(DecodeError):
- """The file is not readable by MAD."""
-
-
-class MadAudioFile(object):
- """MPEG audio file decoder using the MAD library."""
- def __init__(self, filename):
- self.fp = open(filename, 'rb')
- self.mf = mad.MadFile(self.fp)
- if not self.mf.total_time(): # Indicates a failed open.
- self.fp.close()
- raise UnsupportedError()
-
- def close(self):
- if hasattr(self, 'fp'):
- self.fp.close()
- if hasattr(self, 'mf'):
- del self.mf
-
- def read_blocks(self, block_size=4096):
- """Generates buffers containing PCM data for the audio file.
- """
- while True:
- out = self.mf.read(block_size)
- if not out:
- break
- yield bytes(out)
-
- @property
- def samplerate(self):
- """Sample rate in Hz."""
- return self.mf.samplerate()
-
- @property
- def duration(self):
- """Length of the audio in seconds (a float)."""
- return float(self.mf.total_time()) / 1000
-
- @property
- def channels(self):
- """The number of channels."""
- if self.mf.mode() == mad.MODE_SINGLE_CHANNEL:
- return 1
- elif self.mf.mode() in (mad.MODE_DUAL_CHANNEL,
- mad.MODE_JOINT_STEREO,
- mad.MODE_STEREO):
- return 2
- else:
- # Other mode?
- return 2
-
- def __del__(self):
- self.close()
-
- # Iteration.
- def __iter__(self):
- return self.read_blocks()
-
- # Context manager.
- def __enter__(self):
- return self
-
- def __exit__(self, exc_type, exc_val, exc_tb):
- self.close()
- return False
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/cachetools/__init__.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/cachetools/__init__.py
deleted file mode 100644
index 1f758a02d396272395ec85a88fba424a6fcf6f7d..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/cachetools/__init__.py
+++ /dev/null
@@ -1,844 +0,0 @@
-"""Extensible memoizing collections and decorators."""
-
-__all__ = (
- "Cache",
- "FIFOCache",
- "LFUCache",
- "LRUCache",
- "MRUCache",
- "RRCache",
- "TLRUCache",
- "TTLCache",
- "cached",
- "cachedmethod",
-)
-
-__version__ = "5.3.0"
-
-import collections
-import collections.abc
-import functools
-import heapq
-import random
-import time
-
-from . import keys
-
-
-class _DefaultSize:
-
- __slots__ = ()
-
- def __getitem__(self, _):
- return 1
-
- def __setitem__(self, _, value):
- assert value == 1
-
- def pop(self, _):
- return 1
-
-
-class Cache(collections.abc.MutableMapping):
- """Mutable mapping to serve as a simple cache or cache base class."""
-
- __marker = object()
-
- __size = _DefaultSize()
-
- def __init__(self, maxsize, getsizeof=None):
- if getsizeof:
- self.getsizeof = getsizeof
- if self.getsizeof is not Cache.getsizeof:
- self.__size = dict()
- self.__data = dict()
- self.__currsize = 0
- self.__maxsize = maxsize
-
- def __repr__(self):
- return "%s(%s, maxsize=%r, currsize=%r)" % (
- self.__class__.__name__,
- repr(self.__data),
- self.__maxsize,
- self.__currsize,
- )
-
- def __getitem__(self, key):
- try:
- return self.__data[key]
- except KeyError:
- return self.__missing__(key)
-
- def __setitem__(self, key, value):
- maxsize = self.__maxsize
- size = self.getsizeof(value)
- if size > maxsize:
- raise ValueError("value too large")
- if key not in self.__data or self.__size[key] < size:
- while self.__currsize + size > maxsize:
- self.popitem()
- if key in self.__data:
- diffsize = size - self.__size[key]
- else:
- diffsize = size
- self.__data[key] = value
- self.__size[key] = size
- self.__currsize += diffsize
-
- def __delitem__(self, key):
- size = self.__size.pop(key)
- del self.__data[key]
- self.__currsize -= size
-
- def __contains__(self, key):
- return key in self.__data
-
- def __missing__(self, key):
- raise KeyError(key)
-
- def __iter__(self):
- return iter(self.__data)
-
- def __len__(self):
- return len(self.__data)
-
- def get(self, key, default=None):
- if key in self:
- return self[key]
- else:
- return default
-
- def pop(self, key, default=__marker):
- if key in self:
- value = self[key]
- del self[key]
- elif default is self.__marker:
- raise KeyError(key)
- else:
- value = default
- return value
-
- def setdefault(self, key, default=None):
- if key in self:
- value = self[key]
- else:
- self[key] = value = default
- return value
-
- @property
- def maxsize(self):
- """The maximum size of the cache."""
- return self.__maxsize
-
- @property
- def currsize(self):
- """The current size of the cache."""
- return self.__currsize
-
- @staticmethod
- def getsizeof(value):
- """Return the size of a cache element's value."""
- return 1
-
-
-class FIFOCache(Cache):
- """First In First Out (FIFO) cache implementation."""
-
- def __init__(self, maxsize, getsizeof=None):
- Cache.__init__(self, maxsize, getsizeof)
- self.__order = collections.OrderedDict()
-
- def __setitem__(self, key, value, cache_setitem=Cache.__setitem__):
- cache_setitem(self, key, value)
- try:
- self.__order.move_to_end(key)
- except KeyError:
- self.__order[key] = None
-
- def __delitem__(self, key, cache_delitem=Cache.__delitem__):
- cache_delitem(self, key)
- del self.__order[key]
-
- def popitem(self):
- """Remove and return the `(key, value)` pair first inserted."""
- try:
- key = next(iter(self.__order))
- except StopIteration:
- raise KeyError("%s is empty" % type(self).__name__) from None
- else:
- return (key, self.pop(key))
-
-
-class LFUCache(Cache):
- """Least Frequently Used (LFU) cache implementation."""
-
- def __init__(self, maxsize, getsizeof=None):
- Cache.__init__(self, maxsize, getsizeof)
- self.__counter = collections.Counter()
-
- def __getitem__(self, key, cache_getitem=Cache.__getitem__):
- value = cache_getitem(self, key)
- if key in self: # __missing__ may not store item
- self.__counter[key] -= 1
- return value
-
- def __setitem__(self, key, value, cache_setitem=Cache.__setitem__):
- cache_setitem(self, key, value)
- self.__counter[key] -= 1
-
- def __delitem__(self, key, cache_delitem=Cache.__delitem__):
- cache_delitem(self, key)
- del self.__counter[key]
-
- def popitem(self):
- """Remove and return the `(key, value)` pair least frequently used."""
- try:
- ((key, _),) = self.__counter.most_common(1)
- except ValueError:
- raise KeyError("%s is empty" % type(self).__name__) from None
- else:
- return (key, self.pop(key))
-
-
-class LRUCache(Cache):
- """Least Recently Used (LRU) cache implementation."""
-
- def __init__(self, maxsize, getsizeof=None):
- Cache.__init__(self, maxsize, getsizeof)
- self.__order = collections.OrderedDict()
-
- def __getitem__(self, key, cache_getitem=Cache.__getitem__):
- value = cache_getitem(self, key)
- if key in self: # __missing__ may not store item
- self.__update(key)
- return value
-
- def __setitem__(self, key, value, cache_setitem=Cache.__setitem__):
- cache_setitem(self, key, value)
- self.__update(key)
-
- def __delitem__(self, key, cache_delitem=Cache.__delitem__):
- cache_delitem(self, key)
- del self.__order[key]
-
- def popitem(self):
- """Remove and return the `(key, value)` pair least recently used."""
- try:
- key = next(iter(self.__order))
- except StopIteration:
- raise KeyError("%s is empty" % type(self).__name__) from None
- else:
- return (key, self.pop(key))
-
- def __update(self, key):
- try:
- self.__order.move_to_end(key)
- except KeyError:
- self.__order[key] = None
-
-
-class MRUCache(Cache):
- """Most Recently Used (MRU) cache implementation."""
-
- def __init__(self, maxsize, getsizeof=None):
- Cache.__init__(self, maxsize, getsizeof)
- self.__order = collections.OrderedDict()
-
- def __getitem__(self, key, cache_getitem=Cache.__getitem__):
- value = cache_getitem(self, key)
- if key in self: # __missing__ may not store item
- self.__update(key)
- return value
-
- def __setitem__(self, key, value, cache_setitem=Cache.__setitem__):
- cache_setitem(self, key, value)
- self.__update(key)
-
- def __delitem__(self, key, cache_delitem=Cache.__delitem__):
- cache_delitem(self, key)
- del self.__order[key]
-
- def popitem(self):
- """Remove and return the `(key, value)` pair most recently used."""
- try:
- key = next(iter(self.__order))
- except StopIteration:
- raise KeyError("%s is empty" % type(self).__name__) from None
- else:
- return (key, self.pop(key))
-
- def __update(self, key):
- try:
- self.__order.move_to_end(key, last=False)
- except KeyError:
- self.__order[key] = None
-
-
-class RRCache(Cache):
- """Random Replacement (RR) cache implementation."""
-
- def __init__(self, maxsize, choice=random.choice, getsizeof=None):
- Cache.__init__(self, maxsize, getsizeof)
- self.__choice = choice
-
- @property
- def choice(self):
- """The `choice` function used by the cache."""
- return self.__choice
-
- def popitem(self):
- """Remove and return a random `(key, value)` pair."""
- try:
- key = self.__choice(list(self))
- except IndexError:
- raise KeyError("%s is empty" % type(self).__name__) from None
- else:
- return (key, self.pop(key))
-
-
-class _TimedCache(Cache):
- """Base class for time aware cache implementations."""
-
- class _Timer:
- def __init__(self, timer):
- self.__timer = timer
- self.__nesting = 0
-
- def __call__(self):
- if self.__nesting == 0:
- return self.__timer()
- else:
- return self.__time
-
- def __enter__(self):
- if self.__nesting == 0:
- self.__time = time = self.__timer()
- else:
- time = self.__time
- self.__nesting += 1
- return time
-
- def __exit__(self, *exc):
- self.__nesting -= 1
-
- def __reduce__(self):
- return _TimedCache._Timer, (self.__timer,)
-
- def __getattr__(self, name):
- return getattr(self.__timer, name)
-
- def __init__(self, maxsize, timer=time.monotonic, getsizeof=None):
- Cache.__init__(self, maxsize, getsizeof)
- self.__timer = _TimedCache._Timer(timer)
-
- def __repr__(self, cache_repr=Cache.__repr__):
- with self.__timer as time:
- self.expire(time)
- return cache_repr(self)
-
- def __len__(self, cache_len=Cache.__len__):
- with self.__timer as time:
- self.expire(time)
- return cache_len(self)
-
- @property
- def currsize(self):
- with self.__timer as time:
- self.expire(time)
- return super().currsize
-
- @property
- def timer(self):
- """The timer function used by the cache."""
- return self.__timer
-
- def clear(self):
- with self.__timer as time:
- self.expire(time)
- Cache.clear(self)
-
- def get(self, *args, **kwargs):
- with self.__timer:
- return Cache.get(self, *args, **kwargs)
-
- def pop(self, *args, **kwargs):
- with self.__timer:
- return Cache.pop(self, *args, **kwargs)
-
- def setdefault(self, *args, **kwargs):
- with self.__timer:
- return Cache.setdefault(self, *args, **kwargs)
-
-
-class TTLCache(_TimedCache):
- """LRU Cache implementation with per-item time-to-live (TTL) value."""
-
- class _Link:
-
- __slots__ = ("key", "expires", "next", "prev")
-
- def __init__(self, key=None, expires=None):
- self.key = key
- self.expires = expires
-
- def __reduce__(self):
- return TTLCache._Link, (self.key, self.expires)
-
- def unlink(self):
- next = self.next
- prev = self.prev
- prev.next = next
- next.prev = prev
-
- def __init__(self, maxsize, ttl, timer=time.monotonic, getsizeof=None):
- _TimedCache.__init__(self, maxsize, timer, getsizeof)
- self.__root = root = TTLCache._Link()
- root.prev = root.next = root
- self.__links = collections.OrderedDict()
- self.__ttl = ttl
-
- def __contains__(self, key):
- try:
- link = self.__links[key] # no reordering
- except KeyError:
- return False
- else:
- return self.timer() < link.expires
-
- def __getitem__(self, key, cache_getitem=Cache.__getitem__):
- try:
- link = self.__getlink(key)
- except KeyError:
- expired = False
- else:
- expired = not (self.timer() < link.expires)
- if expired:
- return self.__missing__(key)
- else:
- return cache_getitem(self, key)
-
- def __setitem__(self, key, value, cache_setitem=Cache.__setitem__):
- with self.timer as time:
- self.expire(time)
- cache_setitem(self, key, value)
- try:
- link = self.__getlink(key)
- except KeyError:
- self.__links[key] = link = TTLCache._Link(key)
- else:
- link.unlink()
- link.expires = time + self.__ttl
- link.next = root = self.__root
- link.prev = prev = root.prev
- prev.next = root.prev = link
-
- def __delitem__(self, key, cache_delitem=Cache.__delitem__):
- cache_delitem(self, key)
- link = self.__links.pop(key)
- link.unlink()
- if not (self.timer() < link.expires):
- raise KeyError(key)
-
- def __iter__(self):
- root = self.__root
- curr = root.next
- while curr is not root:
- # "freeze" time for iterator access
- with self.timer as time:
- if time < curr.expires:
- yield curr.key
- curr = curr.next
-
- def __setstate__(self, state):
- self.__dict__.update(state)
- root = self.__root
- root.prev = root.next = root
- for link in sorted(self.__links.values(), key=lambda obj: obj.expires):
- link.next = root
- link.prev = prev = root.prev
- prev.next = root.prev = link
- self.expire(self.timer())
-
- @property
- def ttl(self):
- """The time-to-live value of the cache's items."""
- return self.__ttl
-
- def expire(self, time=None):
- """Remove expired items from the cache."""
- if time is None:
- time = self.timer()
- root = self.__root
- curr = root.next
- links = self.__links
- cache_delitem = Cache.__delitem__
- while curr is not root and not (time < curr.expires):
- cache_delitem(self, curr.key)
- del links[curr.key]
- next = curr.next
- curr.unlink()
- curr = next
-
- def popitem(self):
- """Remove and return the `(key, value)` pair least recently used that
- has not already expired.
-
- """
- with self.timer as time:
- self.expire(time)
- try:
- key = next(iter(self.__links))
- except StopIteration:
- raise KeyError("%s is empty" % type(self).__name__) from None
- else:
- return (key, self.pop(key))
-
- def __getlink(self, key):
- value = self.__links[key]
- self.__links.move_to_end(key)
- return value
-
-
-class TLRUCache(_TimedCache):
- """Time aware Least Recently Used (TLRU) cache implementation."""
-
- @functools.total_ordering
- class _Item:
-
- __slots__ = ("key", "expires", "removed")
-
- def __init__(self, key=None, expires=None):
- self.key = key
- self.expires = expires
- self.removed = False
-
- def __lt__(self, other):
- return self.expires < other.expires
-
- def __init__(self, maxsize, ttu, timer=time.monotonic, getsizeof=None):
- _TimedCache.__init__(self, maxsize, timer, getsizeof)
- self.__items = collections.OrderedDict()
- self.__order = []
- self.__ttu = ttu
-
- def __contains__(self, key):
- try:
- item = self.__items[key] # no reordering
- except KeyError:
- return False
- else:
- return self.timer() < item.expires
-
- def __getitem__(self, key, cache_getitem=Cache.__getitem__):
- try:
- item = self.__getitem(key)
- except KeyError:
- expired = False
- else:
- expired = not (self.timer() < item.expires)
- if expired:
- return self.__missing__(key)
- else:
- return cache_getitem(self, key)
-
- def __setitem__(self, key, value, cache_setitem=Cache.__setitem__):
- with self.timer as time:
- expires = self.__ttu(key, value, time)
- if not (time < expires):
- return # skip expired items
- self.expire(time)
- cache_setitem(self, key, value)
- # removing an existing item would break the heap structure, so
- # only mark it as removed for now
- try:
- self.__getitem(key).removed = True
- except KeyError:
- pass
- self.__items[key] = item = TLRUCache._Item(key, expires)
- heapq.heappush(self.__order, item)
-
- def __delitem__(self, key, cache_delitem=Cache.__delitem__):
- with self.timer as time:
- # no self.expire() for performance reasons, e.g. self.clear() [#67]
- cache_delitem(self, key)
- item = self.__items.pop(key)
- item.removed = True
- if not (time < item.expires):
- raise KeyError(key)
-
- def __iter__(self):
- for curr in self.__order:
- # "freeze" time for iterator access
- with self.timer as time:
- if time < curr.expires and not curr.removed:
- yield curr.key
-
- @property
- def ttu(self):
- """The local time-to-use function used by the cache."""
- return self.__ttu
-
- def expire(self, time=None):
- """Remove expired items from the cache."""
- if time is None:
- time = self.timer()
- items = self.__items
- order = self.__order
- # clean up the heap if too many items are marked as removed
- if len(order) > len(items) * 2:
- self.__order = order = [item for item in order if not item.removed]
- heapq.heapify(order)
- cache_delitem = Cache.__delitem__
- while order and (order[0].removed or not (time < order[0].expires)):
- item = heapq.heappop(order)
- if not item.removed:
- cache_delitem(self, item.key)
- del items[item.key]
-
- def popitem(self):
- """Remove and return the `(key, value)` pair least recently used that
- has not already expired.
-
- """
- with self.timer as time:
- self.expire(time)
- try:
- key = next(iter(self.__items))
- except StopIteration:
- raise KeyError("%s is empty" % self.__class__.__name__) from None
- else:
- return (key, self.pop(key))
-
- def __getitem(self, key):
- value = self.__items[key]
- self.__items.move_to_end(key)
- return value
-
-
-_CacheInfo = collections.namedtuple(
- "CacheInfo", ["hits", "misses", "maxsize", "currsize"]
-)
-
-
-def cached(cache, key=keys.hashkey, lock=None, info=False):
- """Decorator to wrap a function with a memoizing callable that saves
- results in a cache.
-
- """
-
- def decorator(func):
- if info:
- hits = misses = 0
-
- if isinstance(cache, Cache):
-
- def getinfo():
- nonlocal hits, misses
- return _CacheInfo(hits, misses, cache.maxsize, cache.currsize)
-
- elif isinstance(cache, collections.abc.Mapping):
-
- def getinfo():
- nonlocal hits, misses
- return _CacheInfo(hits, misses, None, len(cache))
-
- else:
-
- def getinfo():
- nonlocal hits, misses
- return _CacheInfo(hits, misses, 0, 0)
-
- if cache is None:
-
- def wrapper(*args, **kwargs):
- nonlocal misses
- misses += 1
- return func(*args, **kwargs)
-
- def cache_clear():
- nonlocal hits, misses
- hits = misses = 0
-
- cache_info = getinfo
-
- elif lock is None:
-
- def wrapper(*args, **kwargs):
- nonlocal hits, misses
- k = key(*args, **kwargs)
- try:
- result = cache[k]
- hits += 1
- return result
- except KeyError:
- misses += 1
- v = func(*args, **kwargs)
- try:
- cache[k] = v
- except ValueError:
- pass # value too large
- return v
-
- def cache_clear():
- nonlocal hits, misses
- cache.clear()
- hits = misses = 0
-
- cache_info = getinfo
-
- else:
-
- def wrapper(*args, **kwargs):
- nonlocal hits, misses
- k = key(*args, **kwargs)
- try:
- with lock:
- result = cache[k]
- hits += 1
- return result
- except KeyError:
- with lock:
- misses += 1
- v = func(*args, **kwargs)
- # in case of a race, prefer the item already in the cache
- try:
- with lock:
- return cache.setdefault(k, v)
- except ValueError:
- return v # value too large
-
- def cache_clear():
- nonlocal hits, misses
- with lock:
- cache.clear()
- hits = misses = 0
-
- def cache_info():
- with lock:
- return getinfo()
-
- else:
- if cache is None:
-
- def wrapper(*args, **kwargs):
- return func(*args, **kwargs)
-
- def cache_clear():
- pass
-
- elif lock is None:
-
- def wrapper(*args, **kwargs):
- k = key(*args, **kwargs)
- try:
- return cache[k]
- except KeyError:
- pass # key not found
- v = func(*args, **kwargs)
- try:
- cache[k] = v
- except ValueError:
- pass # value too large
- return v
-
- def cache_clear():
- cache.clear()
-
- else:
-
- def wrapper(*args, **kwargs):
- k = key(*args, **kwargs)
- try:
- with lock:
- return cache[k]
- except KeyError:
- pass # key not found
- v = func(*args, **kwargs)
- # in case of a race, prefer the item already in the cache
- try:
- with lock:
- return cache.setdefault(k, v)
- except ValueError:
- return v # value too large
-
- def cache_clear():
- with lock:
- cache.clear()
-
- cache_info = None
-
- wrapper.cache = cache
- wrapper.cache_key = key
- wrapper.cache_lock = lock
- wrapper.cache_clear = cache_clear
- wrapper.cache_info = cache_info
-
- return functools.update_wrapper(wrapper, func)
-
- return decorator
-
-
-def cachedmethod(cache, key=keys.methodkey, lock=None):
- """Decorator to wrap a class or instance method with a memoizing
- callable that saves results in a cache.
-
- """
-
- def decorator(method):
- if lock is None:
-
- def wrapper(self, *args, **kwargs):
- c = cache(self)
- if c is None:
- return method(self, *args, **kwargs)
- k = key(self, *args, **kwargs)
- try:
- return c[k]
- except KeyError:
- pass # key not found
- v = method(self, *args, **kwargs)
- try:
- c[k] = v
- except ValueError:
- pass # value too large
- return v
-
- def clear(self):
- c = cache(self)
- if c is not None:
- c.clear()
-
- else:
-
- def wrapper(self, *args, **kwargs):
- c = cache(self)
- if c is None:
- return method(self, *args, **kwargs)
- k = key(self, *args, **kwargs)
- try:
- with lock(self):
- return c[k]
- except KeyError:
- pass # key not found
- v = method(self, *args, **kwargs)
- # in case of a race, prefer the item already in the cache
- try:
- with lock(self):
- return c.setdefault(k, v)
- except ValueError:
- return v # value too large
-
- def clear(self):
- c = cache(self)
- if c is not None:
- with lock(self):
- c.clear()
-
- wrapper.cache = cache
- wrapper.cache_key = key
- wrapper.cache_lock = lock
- wrapper.cache_clear = clear
-
- return functools.update_wrapper(wrapper, method)
-
- return decorator
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/dateutil/tzwin.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/dateutil/tzwin.py
deleted file mode 100644
index cebc673e40fc376653ebf037e96f0a6d0b33e906..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/dateutil/tzwin.py
+++ /dev/null
@@ -1,2 +0,0 @@
-# tzwin has moved to dateutil.tz.win
-from .tz.win import *
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/fairseq/criterions/label_smoothed_cross_entropy_latency_augmented.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/fairseq/criterions/label_smoothed_cross_entropy_latency_augmented.py
deleted file mode 100644
index d5fb390f84ae40c853b539a89029ed8896796d8d..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/fairseq/criterions/label_smoothed_cross_entropy_latency_augmented.py
+++ /dev/null
@@ -1,220 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from dataclasses import dataclass, field
-import torch
-from fairseq import metrics, utils
-from fairseq.criterions import register_criterion
-from fairseq.criterions.label_smoothed_cross_entropy import (
- LabelSmoothedCrossEntropyCriterion,
- LabelSmoothedCrossEntropyCriterionConfig,
-)
-
-try:
- from simuleval.metrics.latency import (
- AverageLagging,
- AverageProportion,
- DifferentiableAverageLagging,
- )
-
- LATENCY_METRICS = {
- "average_lagging": AverageLagging,
- "average_proportion": AverageProportion,
- "differentiable_average_lagging": DifferentiableAverageLagging,
- }
-except ImportError:
- LATENCY_METRICS = None
-
-
-@dataclass
-class LabelSmoothedCrossEntropyCriterionLatencyAugmentConfig(
- LabelSmoothedCrossEntropyCriterionConfig
-):
- latency_avg_weight: float = field(
- default=0.0,
- metadata={"help": "weight fot average latency loss."},
- )
- latency_var_weight: float = field(
- default=0.0,
- metadata={"help": "weight fot variance latency loss."},
- )
- latency_avg_type: str = field(
- default="differentiable_average_lagging",
- metadata={"help": "latency type for average loss"},
- )
- latency_var_type: str = field(
- default="variance_delay",
- metadata={"help": "latency typ for variance loss"},
- )
- latency_gather_method: str = field(
- default="weighted_average",
- metadata={"help": "method to gather latency loss for all heads"},
- )
- latency_update_after: int = field(
- default=0,
- metadata={"help": "Add latency loss after certain steps"},
- )
-
-
-@register_criterion(
- "latency_augmented_label_smoothed_cross_entropy",
- dataclass=LabelSmoothedCrossEntropyCriterionLatencyAugmentConfig,
-)
-class LatencyAugmentedLabelSmoothedCrossEntropyCriterion(
- LabelSmoothedCrossEntropyCriterion
-):
- def __init__(
- self,
- task,
- sentence_avg,
- label_smoothing,
- ignore_prefix_size,
- report_accuracy,
- latency_avg_weight,
- latency_var_weight,
- latency_avg_type,
- latency_var_type,
- latency_gather_method,
- latency_update_after,
- ):
- super().__init__(
- task, sentence_avg, label_smoothing, ignore_prefix_size, report_accuracy
- )
- assert LATENCY_METRICS is not None, "Please make sure SimulEval is installed."
-
- self.latency_avg_weight = latency_avg_weight
- self.latency_var_weight = latency_var_weight
- self.latency_avg_type = latency_avg_type
- self.latency_var_type = latency_var_type
- self.latency_gather_method = latency_gather_method
- self.latency_update_after = latency_update_after
-
- def forward(self, model, sample, reduce=True):
- net_output = model(**sample["net_input"])
- # 1. Compute cross entropy loss
- loss, nll_loss = self.compute_loss(model, net_output, sample, reduce=reduce)
-
- # 2. Compute cross latency loss
- latency_loss, expected_latency, expected_delays_var = self.compute_latency_loss(
- model, sample, net_output
- )
-
- if self.latency_update_after > 0:
- num_updates = getattr(model.decoder, "num_updates", None)
- assert (
- num_updates is not None
- ), "model.decoder doesn't have attribute 'num_updates'"
- if num_updates <= self.latency_update_after:
- latency_loss = 0
-
- loss += latency_loss
-
- sample_size = (
- sample["target"].size(0) if self.sentence_avg else sample["ntokens"]
- )
-
- logging_output = {
- "loss": loss.data,
- "nll_loss": nll_loss.data,
- "ntokens": sample["ntokens"],
- "nsentences": sample["target"].size(0),
- "sample_size": sample_size,
- "latency": expected_latency,
- "delays_var": expected_delays_var,
- "latency_loss": latency_loss,
- }
-
- if self.report_accuracy:
- n_correct, total = self.compute_accuracy(model, net_output, sample)
- logging_output["n_correct"] = utils.item(n_correct.data)
- logging_output["total"] = utils.item(total.data)
- return loss, sample_size, logging_output
-
- def compute_latency_loss(self, model, sample, net_output):
- assert (
- net_output[-1].encoder_padding_mask is None
- or not net_output[-1].encoder_padding_mask[:, 0].any()
- ), "Only right padding on source is supported."
- # 1. Obtain the expected alignment
- alpha_list = [item["alpha"] for item in net_output[1].attn_list]
- num_layers = len(alpha_list)
- bsz, num_heads, tgt_len, src_len = alpha_list[0].size()
-
- # bsz * num_layers * num_heads, tgt_len, src_len
- alpha_all = torch.cat(alpha_list, dim=1).view(-1, tgt_len, src_len)
-
- # 2 compute expected delays
- # bsz * num_heads * num_layers, tgt_len, src_len for MMA
- steps = (
- torch.arange(1, 1 + src_len)
- .unsqueeze(0)
- .unsqueeze(1)
- .expand_as(alpha_all)
- .type_as(alpha_all)
- )
-
- expected_delays = torch.sum(steps * alpha_all, dim=-1)
-
- target_padding_mask = (
- model.get_targets(sample, net_output)
- .eq(self.padding_idx)
- .unsqueeze(1)
- .expand(bsz, num_layers * num_heads, tgt_len)
- .contiguous()
- .view(-1, tgt_len)
- )
-
- src_lengths = (
- sample["net_input"]["src_lengths"]
- .unsqueeze(1)
- .expand(bsz, num_layers * num_heads)
- .contiguous()
- .view(-1)
- )
- expected_latency = LATENCY_METRICS[self.latency_avg_type](
- expected_delays, src_lengths, None, target_padding_mask=target_padding_mask
- )
-
- # 2.1 average expected latency of heads
- # bsz, num_layers * num_heads
- expected_latency = expected_latency.view(bsz, -1)
- if self.latency_gather_method == "average":
- # bsz * tgt_len
- expected_latency = expected_delays.mean(dim=1)
- elif self.latency_gather_method == "weighted_average":
- weights = torch.nn.functional.softmax(expected_latency, dim=1)
- expected_latency = torch.sum(expected_latency * weights, dim=1)
- elif self.latency_gather_method == "max":
- expected_latency = expected_latency.max(dim=1)[0]
- else:
- raise NotImplementedError
-
- expected_latency = expected_latency.sum()
- avg_loss = self.latency_avg_weight * expected_latency
-
- # 2.2 variance of expected delays
- expected_delays_var = (
- expected_delays.view(bsz, -1, tgt_len).var(dim=1).mean(dim=1)
- )
- expected_delays_var = expected_delays_var.sum()
- var_loss = self.latency_avg_weight * expected_delays_var
-
- # 3. Final loss
- latency_loss = avg_loss + var_loss
-
- return latency_loss, expected_latency, expected_delays_var
-
- @classmethod
- def reduce_metrics(cls, logging_outputs) -> None:
- super().reduce_metrics(logging_outputs)
- latency = sum(log.get("latency", 0) for log in logging_outputs)
- delays_var = sum(log.get("delays_var", 0) for log in logging_outputs)
- latency_loss = sum(log.get("latency_loss", 0) for log in logging_outputs)
- nsentences = sum(log.get("nsentences", 0) for log in logging_outputs)
- metrics.log_scalar("latency", latency.float() / nsentences, nsentences, round=3)
- metrics.log_scalar("delays_var", delays_var / nsentences, nsentences, round=3)
- metrics.log_scalar(
- "latency_loss", latency_loss / nsentences, nsentences, round=3
- )
diff --git a/spaces/aseuteurideu/audio_deepfake_detector/models/rawnet.py b/spaces/aseuteurideu/audio_deepfake_detector/models/rawnet.py
deleted file mode 100644
index 7f3c16800d40b9dd6ff029613b79d5d9784784d0..0000000000000000000000000000000000000000
--- a/spaces/aseuteurideu/audio_deepfake_detector/models/rawnet.py
+++ /dev/null
@@ -1,360 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import Tensor
-import numpy as np
-from torch.utils import data
-from collections import OrderedDict
-from torch.nn.parameter import Parameter
-
-
-class SincConv(nn.Module):
- @staticmethod
- def to_mel(hz):
- return 2595 * np.log10(1 + hz / 700)
-
- @staticmethod
- def to_hz(mel):
- return 700 * (10 ** (mel / 2595) - 1)
-
-
- def __init__(self, device,out_channels, kernel_size,in_channels=1,sample_rate=16000,
- stride=1, padding=0, dilation=1, bias=False, groups=1):
-
- super(SincConv,self).__init__()
-
- if in_channels != 1:
-
- msg = "SincConv only support one input channel (here, in_channels = {%i})" % (in_channels)
- raise ValueError(msg)
-
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.sample_rate=sample_rate
-
- # Forcing the filters to be odd (i.e, perfectly symmetrics)
- if kernel_size%2==0:
- self.kernel_size=self.kernel_size+1
-
- self.device=device
- self.stride = stride
- self.padding = padding
- self.dilation = dilation
-
- if bias:
- raise ValueError('SincConv does not support bias.')
- if groups > 1:
- raise ValueError('SincConv does not support groups.')
-
-
- # initialize filterbanks using Mel scale
- NFFT = 512
- f=int(self.sample_rate/2)*np.linspace(0,1,int(NFFT/2)+1)
- fmel=self.to_mel(f) # Hz to mel conversion
- fmelmax=np.max(fmel)
- fmelmin=np.min(fmel)
- filbandwidthsmel=np.linspace(fmelmin,fmelmax,self.out_channels+1)
- filbandwidthsf=self.to_hz(filbandwidthsmel) # Mel to Hz conversion
- self.mel=filbandwidthsf
- self.hsupp=torch.arange(-(self.kernel_size-1)/2, (self.kernel_size-1)/2+1)
- self.band_pass=torch.zeros(self.out_channels,self.kernel_size)
-
-
-
- def forward(self,x):
- for i in range(len(self.mel)-1):
- fmin=self.mel[i]
- fmax=self.mel[i+1]
- hHigh=(2*fmax/self.sample_rate)*np.sinc(2*fmax*self.hsupp/self.sample_rate)
- hLow=(2*fmin/self.sample_rate)*np.sinc(2*fmin*self.hsupp/self.sample_rate)
- hideal=hHigh-hLow
-
- self.band_pass[i,:]=Tensor(np.hamming(self.kernel_size))*Tensor(hideal)
-
- band_pass_filter=self.band_pass.to(self.device)
-
- self.filters = (band_pass_filter).view(self.out_channels, 1, self.kernel_size)
-
- return F.conv1d(x, self.filters, stride=self.stride,
- padding=self.padding, dilation=self.dilation,
- bias=None, groups=1)
-
-
-
-class Residual_block(nn.Module):
- def __init__(self, nb_filts, first = False):
- super(Residual_block, self).__init__()
- self.first = first
-
- if not self.first:
- self.bn1 = nn.BatchNorm1d(num_features = nb_filts[0])
-
- self.lrelu = nn.LeakyReLU(negative_slope=0.3)
-
- self.conv1 = nn.Conv1d(in_channels = nb_filts[0],
- out_channels = nb_filts[1],
- kernel_size = 3,
- padding = 1,
- stride = 1)
-
- self.bn2 = nn.BatchNorm1d(num_features = nb_filts[1])
- self.conv2 = nn.Conv1d(in_channels = nb_filts[1],
- out_channels = nb_filts[1],
- padding = 1,
- kernel_size = 3,
- stride = 1)
-
- if nb_filts[0] != nb_filts[1]:
- self.downsample = True
- self.conv_downsample = nn.Conv1d(in_channels = nb_filts[0],
- out_channels = nb_filts[1],
- padding = 0,
- kernel_size = 1,
- stride = 1)
-
- else:
- self.downsample = False
- self.mp = nn.MaxPool1d(3)
-
- def forward(self, x):
- identity = x
- if not self.first:
- out = self.bn1(x)
- out = self.lrelu(out)
- else:
- out = x
-
- out = self.conv1(x)
- out = self.bn2(out)
- out = self.lrelu(out)
- out = self.conv2(out)
-
- if self.downsample:
- identity = self.conv_downsample(identity)
-
- out += identity
- out = self.mp(out)
- return out
-
-
-
-
-
-class RawNet(nn.Module):
- def __init__(self, d_args, device):
- super(RawNet, self).__init__()
-
-
- self.device=device
-
- self.Sinc_conv=SincConv(device=self.device,
- out_channels = d_args['filts'][0],
- kernel_size = d_args['first_conv'],
- in_channels = d_args['in_channels']
- )
-
- self.first_bn = nn.BatchNorm1d(num_features = d_args['filts'][0])
- self.selu = nn.SELU(inplace=True)
- self.block0 = nn.Sequential(Residual_block(nb_filts = d_args['filts'][1], first = True))
- self.block1 = nn.Sequential(Residual_block(nb_filts = d_args['filts'][1]))
- self.block2 = nn.Sequential(Residual_block(nb_filts = d_args['filts'][2]))
- d_args['filts'][2][0] = d_args['filts'][2][1]
- self.block3 = nn.Sequential(Residual_block(nb_filts = d_args['filts'][2]))
- self.block4 = nn.Sequential(Residual_block(nb_filts = d_args['filts'][2]))
- self.block5 = nn.Sequential(Residual_block(nb_filts = d_args['filts'][2]))
- self.avgpool = nn.AdaptiveAvgPool1d(1)
-
- self.fc_attention0 = self._make_attention_fc(in_features = d_args['filts'][1][-1],
- l_out_features = d_args['filts'][1][-1])
- self.fc_attention1 = self._make_attention_fc(in_features = d_args['filts'][1][-1],
- l_out_features = d_args['filts'][1][-1])
- self.fc_attention2 = self._make_attention_fc(in_features = d_args['filts'][2][-1],
- l_out_features = d_args['filts'][2][-1])
- self.fc_attention3 = self._make_attention_fc(in_features = d_args['filts'][2][-1],
- l_out_features = d_args['filts'][2][-1])
- self.fc_attention4 = self._make_attention_fc(in_features = d_args['filts'][2][-1],
- l_out_features = d_args['filts'][2][-1])
- self.fc_attention5 = self._make_attention_fc(in_features = d_args['filts'][2][-1],
- l_out_features = d_args['filts'][2][-1])
-
- self.bn_before_gru = nn.BatchNorm1d(num_features = d_args['filts'][2][-1])
- self.gru = nn.GRU(input_size = d_args['filts'][2][-1],
- hidden_size = d_args['gru_node'],
- num_layers = d_args['nb_gru_layer'],
- batch_first = True)
-
-
- self.fc1_gru = nn.Linear(in_features = d_args['gru_node'],
- out_features = d_args['nb_fc_node'])
-
- self.fc2_gru = nn.Linear(in_features = d_args['nb_fc_node'],
- out_features = d_args['nb_classes'],bias=True)
-
-
- self.sig = nn.Sigmoid()
- self.logsoftmax = nn.LogSoftmax(dim=1)
-
- def forward(self, x, y = None):
-
-
- nb_samp = x.shape[0]
- len_seq = x.shape[1]
- x=x.view(nb_samp,1,len_seq)
-
- x = self.Sinc_conv(x)
- x = F.max_pool1d(torch.abs(x), 3)
- x = self.first_bn(x)
- x = self.selu(x)
-
- x0 = self.block0(x)
- y0 = self.avgpool(x0).view(x0.size(0), -1) # torch.Size([batch, filter])
- y0 = self.fc_attention0(y0)
- y0 = self.sig(y0).view(y0.size(0), y0.size(1), -1) # torch.Size([batch, filter, 1])
- x = x0 * y0 + y0 # (batch, filter, time) x (batch, filter, 1)
-
-
- x1 = self.block1(x)
- y1 = self.avgpool(x1).view(x1.size(0), -1) # torch.Size([batch, filter])
- y1 = self.fc_attention1(y1)
- y1 = self.sig(y1).view(y1.size(0), y1.size(1), -1) # torch.Size([batch, filter, 1])
- x = x1 * y1 + y1 # (batch, filter, time) x (batch, filter, 1)
-
- x2 = self.block2(x)
- y2 = self.avgpool(x2).view(x2.size(0), -1) # torch.Size([batch, filter])
- y2 = self.fc_attention2(y2)
- y2 = self.sig(y2).view(y2.size(0), y2.size(1), -1) # torch.Size([batch, filter, 1])
- x = x2 * y2 + y2 # (batch, filter, time) x (batch, filter, 1)
-
- x3 = self.block3(x)
- y3 = self.avgpool(x3).view(x3.size(0), -1) # torch.Size([batch, filter])
- y3 = self.fc_attention3(y3)
- y3 = self.sig(y3).view(y3.size(0), y3.size(1), -1) # torch.Size([batch, filter, 1])
- x = x3 * y3 + y3 # (batch, filter, time) x (batch, filter, 1)
-
- x4 = self.block4(x)
- y4 = self.avgpool(x4).view(x4.size(0), -1) # torch.Size([batch, filter])
- y4 = self.fc_attention4(y4)
- y4 = self.sig(y4).view(y4.size(0), y4.size(1), -1) # torch.Size([batch, filter, 1])
- x = x4 * y4 + y4 # (batch, filter, time) x (batch, filter, 1)
-
- x5 = self.block5(x)
- y5 = self.avgpool(x5).view(x5.size(0), -1) # torch.Size([batch, filter])
- y5 = self.fc_attention5(y5)
- y5 = self.sig(y5).view(y5.size(0), y5.size(1), -1) # torch.Size([batch, filter, 1])
- x = x5 * y5 + y5 # (batch, filter, time) x (batch, filter, 1)
-
- x = self.bn_before_gru(x)
- x = self.selu(x)
- x = x.permute(0, 2, 1) #(batch, filt, time) >> (batch, time, filt)
- self.gru.flatten_parameters()
- x, _ = self.gru(x)
- x = x[:,-1,:]
- x = self.fc1_gru(x)
- x = self.fc2_gru(x)
- output=self.logsoftmax(x)
- print(f"Spec output shape: {output.shape}")
-
- return output
-
-
-
- def _make_attention_fc(self, in_features, l_out_features):
-
- l_fc = []
-
- l_fc.append(nn.Linear(in_features = in_features,
- out_features = l_out_features))
-
-
-
- return nn.Sequential(*l_fc)
-
-
- def _make_layer(self, nb_blocks, nb_filts, first = False):
- layers = []
- #def __init__(self, nb_filts, first = False):
- for i in range(nb_blocks):
- first = first if i == 0 else False
- layers.append(Residual_block(nb_filts = nb_filts,
- first = first))
- if i == 0: nb_filts[0] = nb_filts[1]
-
- return nn.Sequential(*layers)
-
- def summary(self, input_size, batch_size=-1, device="cuda", print_fn = None):
- if print_fn == None: printfn = print
- model = self
-
- def register_hook(module):
- def hook(module, input, output):
- class_name = str(module.__class__).split(".")[-1].split("'")[0]
- module_idx = len(summary)
-
- m_key = "%s-%i" % (class_name, module_idx + 1)
- summary[m_key] = OrderedDict()
- summary[m_key]["input_shape"] = list(input[0].size())
- summary[m_key]["input_shape"][0] = batch_size
- if isinstance(output, (list, tuple)):
- summary[m_key]["output_shape"] = [
- [-1] + list(o.size())[1:] for o in output
- ]
- else:
- summary[m_key]["output_shape"] = list(output.size())
- if len(summary[m_key]["output_shape"]) != 0:
- summary[m_key]["output_shape"][0] = batch_size
-
- params = 0
- if hasattr(module, "weight") and hasattr(module.weight, "size"):
- params += torch.prod(torch.LongTensor(list(module.weight.size())))
- summary[m_key]["trainable"] = module.weight.requires_grad
- if hasattr(module, "bias") and hasattr(module.bias, "size"):
- params += torch.prod(torch.LongTensor(list(module.bias.size())))
- summary[m_key]["nb_params"] = params
-
- if (
- not isinstance(module, nn.Sequential)
- and not isinstance(module, nn.ModuleList)
- and not (module == model)
- ):
- hooks.append(module.register_forward_hook(hook))
-
- device = device.lower()
- assert device in [
- "cuda",
- "cpu",
- ], "Input device is not valid, please specify 'cuda' or 'cpu'"
-
- if device == "cuda" and torch.cuda.is_available():
- dtype = torch.cuda.FloatTensor
- else:
- dtype = torch.FloatTensor
- if isinstance(input_size, tuple):
- input_size = [input_size]
- x = [torch.rand(2, *in_size).type(dtype) for in_size in input_size]
- summary = OrderedDict()
- hooks = []
- model.apply(register_hook)
- model(*x)
- for h in hooks:
- h.remove()
-
- print_fn("----------------------------------------------------------------")
- line_new = "{:>20} {:>25} {:>15}".format("Layer (type)", "Output Shape", "Param #")
- print_fn(line_new)
- print_fn("================================================================")
- total_params = 0
- total_output = 0
- trainable_params = 0
- for layer in summary:
- # input_shape, output_shape, trainable, nb_params
- line_new = "{:>20} {:>25} {:>15}".format(
- layer,
- str(summary[layer]["output_shape"]),
- "{0:,}".format(summary[layer]["nb_params"]),
- )
- total_params += summary[layer]["nb_params"]
- total_output += np.prod(summary[layer]["output_shape"])
- if "trainable" in summary[layer]:
- if summary[layer]["trainable"] == True:
- trainable_params += summary[layer]["nb_params"]
- print_fn(line_new)
diff --git a/spaces/aseuteurideu/audio_deepfake_detector/utils/logger.py b/spaces/aseuteurideu/audio_deepfake_detector/utils/logger.py
deleted file mode 100644
index 869ce74a0758449a37dfce6d607aec773a268eb2..0000000000000000000000000000000000000000
--- a/spaces/aseuteurideu/audio_deepfake_detector/utils/logger.py
+++ /dev/null
@@ -1,58 +0,0 @@
-import logging
-import time
-from datetime import timedelta
-
-
-class LogFormatter:
- def __init__(self):
- self.start_time = time.time()
-
- def format(self, record):
- elapsed_seconds = round(record.created - self.start_time)
-
- prefix = "%s - %s - %s" % (
- record.levelname,
- time.strftime("%x %X"),
- timedelta(seconds=elapsed_seconds),
- )
- message = record.getMessage()
- message = message.replace("\n", "\n" + " " * (len(prefix) + 3))
- return "%s - %s" % (prefix, message)
-
-
-def create_logger(filepath, args):
- # create log formatter
- log_formatter = LogFormatter()
-
- # create file handler and set level to debug
- file_handler = logging.FileHandler(filepath, "a")
- file_handler.setLevel(logging.DEBUG)
- file_handler.setFormatter(log_formatter)
-
- # create console handler and set level to info
- console_handler = logging.StreamHandler()
- console_handler.setLevel(logging.INFO)
- console_handler.setFormatter(log_formatter)
-
- # create logger and set level to debug
- logger = logging.getLogger()
- logger.handlers = []
- logger.setLevel(logging.DEBUG)
- logger.propagate = False
- logger.addHandler(file_handler)
- logger.addHandler(console_handler)
-
- # reset logger elapsed time
- def reset_time():
- log_formatter.start_time = time.time()
-
- logger.reset_time = reset_time
-
- logger.info(
- "\n".join(
- "%s: %s" % (k, str(v))
- for k, v in sorted(dict(vars(args)).items(), key=lambda x: x[0])
- )
- )
-
- return logger
diff --git a/spaces/asgaardlab/CLIPxGamePhysics/README.md b/spaces/asgaardlab/CLIPxGamePhysics/README.md
deleted file mode 100644
index 71f07d391f9901b0d55e55fed995dc4193255621..0000000000000000000000000000000000000000
--- a/spaces/asgaardlab/CLIPxGamePhysics/README.md
+++ /dev/null
@@ -1,40 +0,0 @@
----
-title: CLIP GamePhysics
-emoji: 💻
-colorFrom: blue
-colorTo: red
-sdk: gradio
-sdk_version: 3.0.5
-app_file: app.py
-pinned: true
----
-
-[Paper](https://arxiv.org/abs/2203.11096)
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
\ No newline at end of file
diff --git a/spaces/attention-refocusing/Attention-refocusing/gligen/ldm/models/diffusion/gaussian_smoothing.py b/spaces/attention-refocusing/Attention-refocusing/gligen/ldm/models/diffusion/gaussian_smoothing.py
deleted file mode 100644
index eec81e48b935ae1d3111f2c71d8d9c430bf8c19c..0000000000000000000000000000000000000000
--- a/spaces/attention-refocusing/Attention-refocusing/gligen/ldm/models/diffusion/gaussian_smoothing.py
+++ /dev/null
@@ -1,119 +0,0 @@
-import math
-import numbers
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-
-class GaussianSmoothing(nn.Module):
- """
- Apply gaussian smoothing on a
- 1d, 2d or 3d tensor. Filtering is performed seperately for each channel
- in the input using a depthwise convolution.
- Arguments:
- channels (int, sequence): Number of channels of the input tensors. Output will
- have this number of channels as well.
- kernel_size (int, sequence): Size of the gaussian kernel.
- sigma (float, sequence): Standard deviation of the gaussian kernel.
- dim (int, optional): The number of dimensions of the data.
- Default value is 2 (spatial).
- """
- def __init__(self, channels, kernel_size, sigma, dim=2):
- super(GaussianSmoothing, self).__init__()
- if isinstance(kernel_size, numbers.Number):
- kernel_size = [kernel_size] * dim
- if isinstance(sigma, numbers.Number):
- sigma = [sigma] * dim
-
- # The gaussian kernel is the product of the
- # gaussian function of each dimension.
- kernel = 1
- meshgrids = torch.meshgrid(
- [
- torch.arange(size, dtype=torch.float32)
- for size in kernel_size
- ]
- )
- for size, std, mgrid in zip(kernel_size, sigma, meshgrids):
- mean = (size - 1) / 2
- kernel *= 1 / (std * math.sqrt(2 * math.pi)) * \
- torch.exp(-((mgrid - mean) / (2 * std)) ** 2)
-
- # Make sure sum of values in gaussian kernel equals 1.
- kernel = kernel / torch.sum(kernel)
-
- # Reshape to depthwise convolutional weight
- kernel = kernel.view(1, 1, *kernel.size())
- kernel = kernel.repeat(channels, *[1] * (kernel.dim() - 1))
-
- self.register_buffer('weight', kernel)
- self.groups = channels
-
- if dim == 1:
- self.conv = F.conv1d
- elif dim == 2:
- self.conv = F.conv2d
- elif dim == 3:
- self.conv = F.conv3d
- else:
- raise RuntimeError(
- 'Only 1, 2 and 3 dimensions are supported. Received {}.'.format(dim)
- )
-
- def forward(self, input):
- """
- Apply gaussian filter to input.
- Arguments:
- input (torch.Tensor): Input to apply gaussian filter on.
- Returns:
- filtered (torch.Tensor): Filtered output.
- """
- return self.conv(input, weight=self.weight.to(input.dtype), groups=self.groups)
-
-
-class AverageSmoothing(nn.Module):
- """
- Apply average smoothing on a
- 1d, 2d or 3d tensor. Filtering is performed seperately for each channel
- in the input using a depthwise convolution.
- Arguments:
- channels (int, sequence): Number of channels of the input tensors. Output will
- have this number of channels as well.
- kernel_size (int, sequence): Size of the average kernel.
- sigma (float, sequence): Standard deviation of the rage kernel.
- dim (int, optional): The number of dimensions of the data.
- Default value is 2 (spatial).
- """
- def __init__(self, channels, kernel_size, dim=2):
- super(AverageSmoothing, self).__init__()
-
- # Make sure sum of values in gaussian kernel equals 1.
- kernel = torch.ones(size=(kernel_size, kernel_size)) / (kernel_size * kernel_size)
-
- # Reshape to depthwise convolutional weight
- kernel = kernel.view(1, 1, *kernel.size())
- kernel = kernel.repeat(channels, *[1] * (kernel.dim() - 1))
-
- self.register_buffer('weight', kernel)
- self.groups = channels
-
- if dim == 1:
- self.conv = F.conv1d
- elif dim == 2:
- self.conv = F.conv2d
- elif dim == 3:
- self.conv = F.conv3d
- else:
- raise RuntimeError(
- 'Only 1, 2 and 3 dimensions are supported. Received {}.'.format(dim)
- )
-
- def forward(self, input):
- """
- Apply average filter to input.
- Arguments:
- input (torch.Tensor): Input to apply average filter on.
- Returns:
- filtered (torch.Tensor): Filtered output.
- """
- return self.conv(input, weight=self.weight, groups=self.groups)
diff --git a/spaces/awacke1/AW-04-GR-Seq-2-Seq-QA-Auto-Gen/app.py b/spaces/awacke1/AW-04-GR-Seq-2-Seq-QA-Auto-Gen/app.py
deleted file mode 100644
index c1cd92499cf1c7d2a91b4dc226bf2d558ff67661..0000000000000000000000000000000000000000
--- a/spaces/awacke1/AW-04-GR-Seq-2-Seq-QA-Auto-Gen/app.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import gradio as gr
-from qasrl_model_pipeline import QASRL_Pipeline
-
-models = ["kleinay/qanom-seq2seq-model-baseline",
- "kleinay/qanom-seq2seq-model-joint"]
-pipelines = {model: QASRL_Pipeline(model) for model in models}
-
-
-description = f"""Using Seq2Seq T5 model which takes a sequence of items and outputs another sequence this model generates Questions and Answers (QA) with focus on Semantic Role Labeling (SRL)"""
-title="Seq2Seq T5 Questions and Answers (QA) with Semantic Role Labeling (SRL)"
-examples = [[models[0], "In March and April the patient had two falls. One was related to asthma, heart palpitations. The second was due to syncope and post covid vaccination dizziness during exercise. The patient is now getting an EKG. Former EKG had shown that there was a bundle branch block. Patient had some uncontrolled immune system reactions like anaphylaxis and shortness of breath.", True, "fall"],
- [models[1], "In March and April the patient had two falls. One was related to asthma, heart palpitations. The second was due to syncope and post covid vaccination dizziness during exercise. The patient is now getting an EKG. Former EKG had shown that there was a bundle branch block. Patient had some uncontrolled immune system reactions like anaphylaxis and shortness of breath.", True, "reactions"],
- [models[0], "In March and April the patient had two falls. One was related to asthma, heart palpitations. The second was due to syncope and post covid vaccination dizziness during exercise. The patient is now getting an EKG. Former EKG had shown that there was a bundle branch block. Patient had some uncontrolled immune system reactions like anaphylaxis and shortness of breath.", True, "relate"],
- [models[1], "In March and April the patient had two falls. One was related to asthma, heart palpitations. The second was due to syncope and post covid vaccination dizziness during exercise. The patient is now getting an EKG. Former EKG had shown that there was a bundle branch block. Patient had some uncontrolled immune system reactions like anaphylaxis and shortness of breath.", False, "fall"]]
-
-input_sent_box_label = "Insert sentence here. Mark the predicate by adding the token ' ' before it."
-verb_form_inp_placeholder = "e.g. 'decide' for the nominalization 'decision', 'teach' for 'teacher', etc."
-links = """
-QASRL Website | Model Repo at Huggingface Hub
- """
-def call(model_name, sentence, is_nominal, verb_form):
- predicate_marker=""
- if predicate_marker not in sentence:
- raise ValueError("You must highlight one word of the sentence as a predicate using preceding ' '.")
-
- if not verb_form:
- if is_nominal:
- raise ValueError("You should provide the verbal form of the nominalization")
-
- toks = sentence.split(" ")
- pred_idx = toks.index(predicate_marker)
- predicate = toks(pred_idx+1)
- verb_form=predicate
- pipeline = pipelines[model_name]
- pipe_out = pipeline([sentence],
- predicate_marker=predicate_marker,
- predicate_type="nominal" if is_nominal else "verbal",
- verb_form=verb_form)[0]
- return pipe_out["QAs"], pipe_out["generated_text"]
-iface = gr.Interface(fn=call,
- inputs=[gr.inputs.Radio(choices=models, default=models[0], label="Model"),
- gr.inputs.Textbox(placeholder=input_sent_box_label, label="Sentence", lines=4),
- gr.inputs.Checkbox(default=True, label="Is Nominalization?"),
- gr.inputs.Textbox(placeholder=verb_form_inp_placeholder, label="Verbal form (for nominalizations)", default='')],
- outputs=[gr.outputs.JSON(label="Model Output - QASRL"), gr.outputs.Textbox(label="Raw output sequence")],
- title=title,
- description=description,
- article=links,
- examples=examples )
-
-iface.launch()
\ No newline at end of file
diff --git a/spaces/awacke1/Streamlit-Google-Maps-Minnesota/app.py b/spaces/awacke1/Streamlit-Google-Maps-Minnesota/app.py
deleted file mode 100644
index f36f8fabf9ed3f535bbc9bbc1f2dedf0d4ea8e21..0000000000000000000000000000000000000000
--- a/spaces/awacke1/Streamlit-Google-Maps-Minnesota/app.py
+++ /dev/null
@@ -1,105 +0,0 @@
-import streamlit as st
-import folium
-from folium.plugins import MarkerCluster
-from streamlit_folium import folium_static
-import googlemaps
-from datetime import datetime
-import os
-
-# Initialize Google Maps
-gmaps = googlemaps.Client(key=os.getenv('GOOGLE_KEY'))
-
-# Function to fetch directions
-def get_directions_and_coords(source, destination):
- now = datetime.now()
- directions_info = gmaps.directions(source, destination, mode='driving', departure_time=now)
- if directions_info:
- steps = directions_info[0]['legs'][0]['steps']
- coords = [(step['start_location']['lat'], step['start_location']['lng']) for step in steps]
- return steps, coords
- else:
- return None, None
-
-# Function to render map with directions
-def render_folium_map(coords):
- m = folium.Map(location=[coords[0][0], coords[0][1]], zoom_start=13)
- folium.PolyLine(coords, color="blue", weight=2.5, opacity=1).add_to(m)
- return m
-
-# Function to add medical center paths and annotate distance
-def add_medical_center_paths(m, source, med_centers):
- for name, lat, lon, specialty, city in med_centers:
- _, coords = get_directions_and_coords(source, (lat, lon))
- if coords:
- folium.PolyLine(coords, color="red", weight=2.5, opacity=1).add_to(m)
- folium.Marker([lat, lon], popup=name).add_to(m)
- distance_info = gmaps.distance_matrix(source, (lat, lon), mode='driving')
- distance = distance_info['rows'][0]['elements'][0]['distance']['text']
- folium.PolyLine(coords, color='red').add_to(m)
- folium.map.Marker(
- [coords[-1][0], coords[-1][1]],
- icon=folium.DivIcon(
- icon_size=(150, 36),
- icon_anchor=(0, 0),
- html=f' {distance} ',
- )
- ).add_to(m)
-
-# Driving Directions Sidebar
-st.sidebar.header('Directions 🚗')
-source_location = st.sidebar.text_input("Source Location", "Mound, MN")
-destination_location = st.sidebar.text_input("Destination Location", "Minneapolis, MN")
-if st.sidebar.button('Get Directions'):
- steps, coords = get_directions_and_coords(source_location, destination_location)
- if steps and coords:
- st.subheader('Driving Directions:')
- for i, step in enumerate(steps):
- st.write(f"{i+1}. {step['html_instructions']}")
- st.subheader('Route on Map:')
- m1 = render_folium_map(coords)
- folium_static(m1)
- else:
- st.write("No available routes.")
-
-# Minnesota Medical Centers
-st.markdown("### 🗺️ Maps - 🏥 Minnesota Medical Centers 🌳")
-m2 = folium.Map(location=[45.6945, -93.9002], zoom_start=6)
-marker_cluster = MarkerCluster().add_to(m2)
-
-# Define Minnesota medical centers data
-minnesota_med_centers = [
- ('Mayo Clinic', 44.0224, -92.4658, 'General medical and surgical', 'Rochester'),
- ('University of Minnesota Medical Center', 44.9721, -93.2595, 'Teaching hospital', 'Minneapolis'),
- ('Abbott Northwestern Hospital', 44.9526, -93.2622, 'Heart specialty', 'Minneapolis'),
- ('Regions Hospital', 44.9558, -93.0942, 'Trauma center', 'St. Paul'),
- ('St. Cloud Hospital', 45.5671, -94.1989, 'Multiple specialties', 'St. Cloud'),
- ('Park Nicollet Methodist Hospital', 44.9304, -93.3640, 'General medical and surgical', 'St. Louis Park'),
- ('Fairview Ridges Hospital', 44.7391, -93.2777, 'Community hospital', 'Burnsville'),
- ('Mercy Hospital', 45.1761, -93.3099, 'Acute care', 'Coon Rapids'),
- ('North Memorial Health Hospital', 45.0131, -93.3246, 'General medical and surgical', 'Robbinsdale'),
- ('Essentia Health-Duluth', 46.7860, -92.1011, 'Community hospital', 'Duluth'),
- ('M Health Fairview Southdale Hospital', 44.8806, -93.3241, 'Community hospital', 'Edina'),
- ('Woodwinds Health Campus', 44.9272, -92.9689, 'Community hospital', 'Woodbury'),
- ('United Hospital', 44.9460, -93.1052, 'Acute care', 'St. Paul'),
- ('Buffalo Hospital', 45.1831, -93.8772, 'Community hospital', 'Buffalo'),
- ('Maple Grove Hospital', 45.1206, -93.4790, 'Community hospital', 'Maple Grove'),
- ('Olmsted Medical Center', 44.0234, -92.4610, 'General medical and surgical', 'Rochester'),
- ('Hennepin Healthcare', 44.9738, -93.2605, 'Teaching hospital', 'Minneapolis'),
- ('St. Francis Regional Medical Center', 44.7658, -93.5143, 'Community hospital', 'Shakopee'),
- ('Lakeview Hospital', 45.0422, -92.8137, 'Community hospital', 'Stillwater'),
- ('St. Luke\'s Hospital', 46.7831, -92.1043, 'Community hospital', 'Duluth')
-]
-
-# Dropdown to select medical center to focus on
-medical_center_names = [center[0] for center in minnesota_med_centers]
-selected_medical_center = st.selectbox("Select Medical Center to Focus On:", medical_center_names)
-
-# Zoom into the selected medical center
-for name, lat, lon, specialty, city in minnesota_med_centers:
- if name == selected_medical_center:
- m2 = folium.Map(location=[lat, lon], zoom_start=15)
-
-# Annotate distances and paths for each medical center
-add_medical_center_paths(m2, source_location, minnesota_med_centers)
-
-folium_static(m2)
diff --git a/spaces/awfawfgehgewhfg/frawfafwafa/README.md b/spaces/awfawfgehgewhfg/frawfafwafa/README.md
deleted file mode 100644
index 96c551b6ae8d4b121c2b6a63e085aed15e5fd348..0000000000000000000000000000000000000000
--- a/spaces/awfawfgehgewhfg/frawfafwafa/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: Frawfafwafa
-emoji: 🚀
-colorFrom: pink
-colorTo: green
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/barani/ControlNet/app_scribble.py b/spaces/barani/ControlNet/app_scribble.py
deleted file mode 100644
index 17a8565cb741e12a65b46e3e7a66b20e7efb301c..0000000000000000000000000000000000000000
--- a/spaces/barani/ControlNet/app_scribble.py
+++ /dev/null
@@ -1,105 +0,0 @@
-#!/usr/bin/env python
-
-import gradio as gr
-
-from utils import randomize_seed_fn
-
-
-def create_demo(process, max_images=12, default_num_images=3):
- with gr.Blocks() as demo:
- with gr.Row():
- with gr.Column():
- image = gr.Image()
- prompt = gr.Textbox(label='Prompt')
- run_button = gr.Button('Run')
- with gr.Accordion('Advanced options', open=False):
- preprocessor_name = gr.Radio(
- label='Preprocessor',
- choices=['HED', 'PidiNet', 'None'],
- type='value',
- value='HED')
- num_samples = gr.Slider(label='Number of images',
- minimum=1,
- maximum=max_images,
- value=default_num_images,
- step=1)
- image_resolution = gr.Slider(label='Image resolution',
- minimum=256,
- maximum=512,
- value=512,
- step=256)
- preprocess_resolution = gr.Slider(
- label='Preprocess resolution',
- minimum=128,
- maximum=512,
- value=512,
- step=1)
- num_steps = gr.Slider(label='Number of steps',
- minimum=1,
- maximum=100,
- value=20,
- step=1)
- guidance_scale = gr.Slider(label='Guidance scale',
- minimum=0.1,
- maximum=30.0,
- value=9.0,
- step=0.1)
- seed = gr.Slider(label='Seed',
- minimum=0,
- maximum=1000000,
- step=1,
- value=0,
- randomize=True)
- randomize_seed = gr.Checkbox(label='Randomize seed',
- value=True)
- a_prompt = gr.Textbox(
- label='Additional prompt',
- value='best quality, extremely detailed')
- n_prompt = gr.Textbox(
- label='Negative prompt',
- value=
- 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality'
- )
- with gr.Column():
- result = gr.Gallery(label='Output', show_label=False).style(
- columns=2, object_fit='scale-down')
- inputs = [
- image,
- prompt,
- a_prompt,
- n_prompt,
- num_samples,
- image_resolution,
- preprocess_resolution,
- num_steps,
- guidance_scale,
- seed,
- preprocessor_name,
- ]
- prompt.submit(
- fn=randomize_seed_fn,
- inputs=[seed, randomize_seed],
- outputs=seed,
- ).then(
- fn=process,
- inputs=inputs,
- outputs=result,
- )
- run_button.click(
- fn=randomize_seed_fn,
- inputs=[seed, randomize_seed],
- outputs=seed,
- ).then(
- fn=process,
- inputs=inputs,
- outputs=result,
- api_name='scribble',
- )
- return demo
-
-
-if __name__ == '__main__':
- from model import Model
- model = Model(task_name='scribble')
- demo = create_demo(model.process_scribble)
- demo.queue().launch()
diff --git a/spaces/beihai/GFPGAN-V1.3-whole-image/basicsr/losses/__init__.py b/spaces/beihai/GFPGAN-V1.3-whole-image/basicsr/losses/__init__.py
deleted file mode 100644
index b1570dd2d683ba5983bfc715d37fc611af7b6ba5..0000000000000000000000000000000000000000
--- a/spaces/beihai/GFPGAN-V1.3-whole-image/basicsr/losses/__init__.py
+++ /dev/null
@@ -1,26 +0,0 @@
-from copy import deepcopy
-
-from basicsr.utils import get_root_logger
-from basicsr.utils.registry import LOSS_REGISTRY
-from .losses import (CharbonnierLoss, GANLoss, L1Loss, MSELoss, PerceptualLoss, WeightedTVLoss, g_path_regularize,
- gradient_penalty_loss, r1_penalty)
-
-__all__ = [
- 'L1Loss', 'MSELoss', 'CharbonnierLoss', 'WeightedTVLoss', 'PerceptualLoss', 'GANLoss', 'gradient_penalty_loss',
- 'r1_penalty', 'g_path_regularize'
-]
-
-
-def build_loss(opt):
- """Build loss from options.
-
- Args:
- opt (dict): Configuration. It must contain:
- type (str): Model type.
- """
- opt = deepcopy(opt)
- loss_type = opt.pop('type')
- loss = LOSS_REGISTRY.get(loss_type)(**opt)
- logger = get_root_logger()
- logger.info(f'Loss [{loss.__class__.__name__}] is created.')
- return loss
diff --git a/spaces/bgk/lodosalberttr1/README.md b/spaces/bgk/lodosalberttr1/README.md
deleted file mode 100644
index 7df9804522c9803ca6cce2cd669d7ea91fc7f852..0000000000000000000000000000000000000000
--- a/spaces/bgk/lodosalberttr1/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Siparis
-emoji: 🌖
-colorFrom: blue
-colorTo: red
-sdk: gradio
-sdk_version: 3.17.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/bigjoker/stable-diffusion-webui/javascript/imageMaskFix.js b/spaces/bigjoker/stable-diffusion-webui/javascript/imageMaskFix.js
deleted file mode 100644
index 9fe7a60309c95b4921360fb09d5bee2b2bd2a73c..0000000000000000000000000000000000000000
--- a/spaces/bigjoker/stable-diffusion-webui/javascript/imageMaskFix.js
+++ /dev/null
@@ -1,45 +0,0 @@
-/**
- * temporary fix for https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/668
- * @see https://github.com/gradio-app/gradio/issues/1721
- */
-window.addEventListener( 'resize', () => imageMaskResize());
-function imageMaskResize() {
- const canvases = gradioApp().querySelectorAll('#img2maskimg .touch-none canvas');
- if ( ! canvases.length ) {
- canvases_fixed = false;
- window.removeEventListener( 'resize', imageMaskResize );
- return;
- }
-
- const wrapper = canvases[0].closest('.touch-none');
- const previewImage = wrapper.previousElementSibling;
-
- if ( ! previewImage.complete ) {
- previewImage.addEventListener( 'load', () => imageMaskResize());
- return;
- }
-
- const w = previewImage.width;
- const h = previewImage.height;
- const nw = previewImage.naturalWidth;
- const nh = previewImage.naturalHeight;
- const portrait = nh > nw;
- const factor = portrait;
-
- const wW = Math.min(w, portrait ? h/nh*nw : w/nw*nw);
- const wH = Math.min(h, portrait ? h/nh*nh : w/nw*nh);
-
- wrapper.style.width = `${wW}px`;
- wrapper.style.height = `${wH}px`;
- wrapper.style.left = `0px`;
- wrapper.style.top = `0px`;
-
- canvases.forEach( c => {
- c.style.width = c.style.height = '';
- c.style.maxWidth = '100%';
- c.style.maxHeight = '100%';
- c.style.objectFit = 'contain';
- });
- }
-
- onUiUpdate(() => imageMaskResize());
diff --git a/spaces/bigslime/stablediffusion-infinity/js/w2ui.min.js b/spaces/bigslime/stablediffusion-infinity/js/w2ui.min.js
deleted file mode 100644
index ae849e5012ea6583f8d4f83151d94ad270c6bf4e..0000000000000000000000000000000000000000
--- a/spaces/bigslime/stablediffusion-infinity/js/w2ui.min.js
+++ /dev/null
@@ -1,486 +0,0 @@
-/* w2ui 2.0.x (nightly) (10/10/2022, 1:43:34 PM) (c) http://w2ui.com, vitmalina@gmail.com */
-class w2event{constructor(e,t){Object.assign(this,{type:t.type??null,detail:t,owner:e,target:t.target??null,phase:t.phase??"before",object:t.object??null,execute:null,isStopped:!1,isCancelled:!1,onComplete:null,listeners:[]}),delete t.type,delete t.target,delete t.object,this.complete=new Promise((e,t)=>{this._resolve=e,this._reject=t}),this.complete.catch(()=>{})}finish(e){e&&w2utils.extend(this.detail,e),this.phase="after",this.owner.trigger.call(this.owner,this)}done(e){this.listeners.push(e)}preventDefault(){this._reject(),this.isCancelled=!0}stopPropagation(){this.isStopped=!0}}class w2base{constructor(e){if(this.activeEvents=[],this.listeners=[],void 0!==e){if(!w2utils.checkName(e))return;w2ui[e]=this}this.debug=!1}on(e,r){return(e="string"==typeof e?e.split(/[,\s]+/):[e]).forEach(e=>{var t,i,s,l="string"==typeof e?e:e.type+":"+e.execute+"."+e.scope;"string"==typeof e&&([i,t]=e.split("."),[i,s]=i.replace(":complete",":after").replace(":done",":after").split(":"),e={type:i,execute:s??"before",scope:t}),(e=w2utils.extend({type:null,execute:"before",onComplete:null},e)).type?r?(Array.isArray(this.listeners)||(this.listeners=[]),this.listeners.push({name:l,edata:e,handler:r}),this.debug&&console.log("w2base: add event",{name:l,edata:e,handler:r})):console.log("ERROR: You must specify event handler function when calling .on() method of "+this.name):console.log("ERROR: You must specify event type when calling .on() method of "+this.name)}),this}off(e,r){return(e="string"==typeof e?e.split(/[,\s]+/):[e]).forEach(i=>{var e,t,s,l="string"==typeof i?i:i.type+":"+i.execute+"."+i.scope;if("string"==typeof i&&([t,e]=i.split("."),[t,s]=t.replace(":complete",":after").replace(":done",":after").split(":"),i={type:t||"*",execute:s||"",scope:e||""}),(i=w2utils.extend({type:null,execute:null,onComplete:null},i)).type||i.scope){r=r||null;let t=0;this.listeners=this.listeners.filter(e=>"*"!==i.type&&i.type!==e.edata.type||""!==i.execute&&i.execute!==e.edata.execute||""!==i.scope&&i.scope!==e.edata.scope||null!=i.handler&&i.handler!==e.edata.handler||(t++,!1)),this.debug&&console.log(`w2base: remove event (${t})`,{name:l,edata:i,handler:r})}else console.log("ERROR: You must specify event type when calling .off() method of "+this.name)}),this}trigger(e,i){if(1==arguments.length?i=e:(i.type=e,i.target=i.target??this),w2utils.isPlainObject(i)&&"after"==i.phase){if(!(i=this.activeEvents.find(e=>e.type==i.type&&e.target==i.target)))return void console.log(`ERROR: Cannot find even handler for "${i.type}" on "${i.target}".`);console.log("NOTICE: This syntax \"edata.trigger({ phase: 'after' })\" is outdated. Use edata.finish() instead.")}else i instanceof w2event||(i=new w2event(this,i),this.activeEvents.push(i));let s,t,l;Array.isArray(this.listeners)||(this.listeners=[]),this.debug&&console.log(`w2base: trigger "${i.type}:${i.phase}"`,i);for(let e=this.listeners.length-1;0<=e;e--){let t=this.listeners[e];if(!(null==t||t.edata.type!==i.type&&"*"!==t.edata.type||t.edata.target!==i.target&&null!=t.edata.target||t.edata.execute!==i.phase&&"*"!==t.edata.execute&&"*"!==t.edata.phase)&&(Object.keys(t.edata).forEach(e=>{null==i[e]&&null!=t.edata[e]&&(i[e]=t.edata[e])}),s=[],l=new RegExp(/\((.*?)\)/).exec(String(t.handler).split("=>")[0]),2===(s=l?l[1].split(/\s*,\s*/):s).length?(t.handler.call(this,i.target,i),this.debug&&console.log(" - call (old)",t.handler)):(t.handler.call(this,i),this.debug&&console.log(" - call",t.handler)),!0===i.isStopped||!0===i.stop))return i}e="on"+i.type.substr(0,1).toUpperCase()+i.type.substr(1);if(!("before"===i.phase&&"function"==typeof this[e]&&(t=this[e],s=[],l=new RegExp(/\((.*?)\)/).exec(String(t).split("=>")[0]),2===(s=l?l[1].split(/\s*,\s*/):s).length?(t.call(this,i.target,i),this.debug&&console.log(" - call: on[Event] (old)",t)):(t.call(this,i),this.debug&&console.log(" - call: on[Event]",t)),!0===i.isStopped||!0===i.stop)||null!=i.object&&"before"===i.phase&&"function"==typeof i.object[e]&&(t=i.object[e],s=[],l=new RegExp(/\((.*?)\)/).exec(String(t).split("=>")[0]),2===(s=l?l[1].split(/\s*,\s*/):s).length?(t.call(this,i.target,i),this.debug&&console.log(" - call: edata.object (old)",t)):(t.call(this,i),this.debug&&console.log(" - call: edata.object",t)),!0===i.isStopped||!0===i.stop)||"after"!==i.phase)){"function"==typeof i.onComplete&&i.onComplete.call(this,i);for(let e=0;e{this[t]=e})}static _fragment(e){let i=document.createElement("template");return i.innerHTML=e,i.content.childNodes.forEach(e=>{var t=Query._scriptConvert(e);t!=e&&i.content.replaceChild(t,e)}),i.content}static _scriptConvert(e){let t=e=>{var t=e.ownerDocument.createElement("script"),i=(t.text=e.text,e.attributes);for(let e=0;e{e.parentNode.replaceChild(t(e),e)}),e}static _fixProp(e){var t={cellpadding:"cellPadding",cellspacing:"cellSpacing",class:"className",colspan:"colSpan",contenteditable:"contentEditable",for:"htmlFor",frameborder:"frameBorder",maxlength:"maxLength",readonly:"readOnly",rowspan:"rowSpan",tabindex:"tabIndex",usemap:"useMap"};return t[e]||e}_insert(l,i){let r=[],n=this.length;if(!(n<1)){let e=this;if("string"==typeof i)this.each(e=>{var t=Query._fragment(i);r.push(...t.childNodes),e[l](t)});else if(i instanceof Query){let s=1==n;i.each(i=>{this.each(e=>{var t=s?i:i.cloneNode(!0);r.push(t),e[l](t),Query._scriptConvert(t)})}),s||i.remove()}else{if(!(i instanceof Node))throw new Error(`Incorrect argument for "${l}(html)". It expects one string argument.`);this.each(e=>{var t=1===n?i:Query._fragment(i.outerHTML);r.push(...1===n?[i]:t.childNodes),e[l](t)}),1{e=Array.from(e.querySelectorAll(t));0{(e===t||"string"==typeof t&&e.matches&&e.matches(t)||"function"==typeof t&&t(e))&&i.push(e)}),new Query(i,this.context,this)}next(){let t=[];return this.each(e=>{e=e.nextElementSibling;e&&t.push(e)}),new Query(t,this.context,this)}prev(){let t=[];return this.each(e=>{e=e.previousElementSibling;e&&t.push(e)}),new Query(t,this.context,this)}shadow(e){let t=[];this.each(e=>{e.shadowRoot&&t.push(e.shadowRoot)});var i=new Query(t,this.context,this);return e?i.find(e):i}closest(t){let i=[];return this.each(e=>{e=e.closest(t);e&&i.push(e)}),new Query(i,this.context,this)}host(t){let i=[],s=e=>e.parentNode?s(e.parentNode):e,l=e=>{e=s(e);i.push(e.host||e),e.host&&t&&l(e.host)};return this.each(e=>{l(e)}),new Query(i,this.context,this)}parent(e){return this.parents(e,!0)}parents(e,t){let i=[],s=e=>{if(-1==i.indexOf(e)&&i.push(e),!t&&e.parentNode)return s(e.parentNode)};this.each(e=>{e.parentNode&&s(e.parentNode)});var l=new Query(i,this.context,this);return e?l.filter(e):l}add(e){e=e instanceof Query?e.nodes:Array.isArray(e)?e:[e];return new Query(this.nodes.concat(e),this.context,this)}each(i){return this.nodes.forEach((e,t)=>{i(e,t,this)}),this}append(e){return this._insert("append",e)}prepend(e){return this._insert("prepend",e)}after(e){return this._insert("after",e)}before(e){return this._insert("before",e)}replace(e){return this._insert("replaceWith",e)}remove(){return this.each(e=>{e.remove()}),this}css(e,t){let s=e;var i,l=arguments.length;return 0===l||1===l&&"string"==typeof e?this[0]?(l=this[0].style,"string"==typeof e?(i=l.getPropertyPriority(e),l.getPropertyValue(e)+(i?"!"+i:"")):Object.fromEntries(this[0].style.cssText.split(";").filter(e=>!!e).map(e=>e.split(":").map(e=>e.trim())))):void 0:("object"!=typeof e&&((s={})[e]=t),this.each((i,e)=>{Object.keys(s).forEach(e=>{var t=String(s[e]).toLowerCase().includes("!important")?"important":"";i.style.setProperty(e,String(s[e]).replace(/\!important/i,""),t)})}),this)}addClass(e){return this.toggleClass(e,!0),this}removeClass(e){return this.toggleClass(e,!1),this}toggleClass(t,s){return"string"==typeof t&&(t=t.split(/[,\s]+/)),this.each(i=>{let e=t;(e=null==e&&!1===s?Array.from(i.classList):e).forEach(t=>{if(""!==t){let e=null!=s?s?"add":"remove":"toggle";i.classList[e](t)}})}),this}hasClass(e){if(null==(e="string"==typeof e?e.split(/[,\s]+/):e)&&0{i=i||e.every(e=>Array.from(t.classList??[]).includes(e))}),i}on(e,s,l){"function"==typeof s&&(l=s,s=void 0);let r;return s?.delegate&&(r=s.delegate,delete s.delegate),(e=e.split(/[,\s]+/)).forEach(e=>{let[t,i]=String(e).toLowerCase().split(".");if(r){let i=l;l=e=>{var t=query(e.target).parents(r);0{this._save(e,"events",[{event:t,scope:i,callback:l,options:s}]),e.addEventListener(t,l,s)})}),this}off(e,t,r){return"function"==typeof t&&(r=t,t=void 0),(e=(e??"").split(/[,\s]+/)).forEach(e=>{let[s,l]=String(e).toLowerCase().split(".");this.each(t=>{if(Array.isArray(t._mQuery?.events))for(let e=t._mQuery.events.length-1;0<=e;e--){var i=t._mQuery.events[e];null==l||""===l?i.event!=s&&""!==s||i.callback!=r&&null!=r||(t.removeEventListener(i.event,i.callback,i.options),t._mQuery.events.splice(e,1)):i.event!=s&&""!==s||i.scope!=l||(t.removeEventListener(i.event,i.callback,i.options),t._mQuery.events.splice(e,1))}})}),this}trigger(e,t){let i;return i=e instanceof Event||e instanceof CustomEvent?e:new(["click","dblclick","mousedown","mouseup","mousemove"].includes(e)?MouseEvent:["keydown","keyup","keypress"].includes(e)?KeyboardEvent:Event)(e,t),this.each(e=>{e.dispatchEvent(i)}),this}attr(t,i){if(void 0===i&&"string"==typeof t)return this[0]?this[0].getAttribute(t):void 0;{let e={};return"object"==typeof t?e=t:e[t]=i,this.each(i=>{Object.entries(e).forEach(([e,t])=>{i.setAttribute(e,t)})}),this}}removeAttr(){return this.each(t=>{Array.from(arguments).forEach(e=>{t.removeAttribute(e)})}),this}prop(t,i){if(void 0===i&&"string"==typeof t)return this[0]?this[0][t]:void 0;{let e={};return"object"==typeof t?e=t:e[t]=i,this.each(i=>{Object.entries(e).forEach(([e,t])=>{e=Query._fixProp(e);i[e]=t,"innerHTML"==e&&Query._scriptConvert(i)})}),this}}removeProp(){return this.each(t=>{Array.from(arguments).forEach(e=>{delete t[Query._fixProp(e)]})}),this}data(i,t){if(i instanceof Object)Object.entries(i).forEach(e=>{this.data(e[0],e[1])});else{if(i&&-1!=i.indexOf("-")&&console.error(`Key "${i}" contains "-" (dash). Dashes are not allowed in property names. Use camelCase instead.`),!(arguments.length<2))return this.each(e=>{null!=t?e.dataset[i]=t instanceof Object?JSON.stringify(t):t:delete e.dataset[i]}),this;if(this[0]){let t=Object.assign({},this[0].dataset);return Object.keys(t).forEach(e=>{if(t[e].startsWith("[")||t[e].startsWith("{"))try{t[e]=JSON.parse(t[e])}catch(e){}}),i?t[i]:t}}}removeData(e){return"string"==typeof e&&(e=e.split(/[,\s]+/)),this.each(t=>{e.forEach(e=>{delete t.dataset[e]})}),this}show(){return this.toggle(!0)}hide(){return this.toggle(!1)}toggle(l){return this.each(e=>{var t=e.style.display,i=getComputedStyle(e).display,s="none"==t||"none"==i;!s||null!=l&&!0!==l||(e.style.display=e._mQuery?.prevDisplay??(t==i&&"none"!=i?"":"block"),this._save(e,"prevDisplay",null)),s||null!=l&&!1!==l||("none"!=i&&this._save(e,"prevDisplay",i),e.style.setProperty("display","none"))})}empty(){return this.html("")}html(e){return this.prop("innerHTML",e)}text(e){return this.prop("textContent",e)}val(e){return this.prop("value",e)}change(){return this.trigger("change")}click(){return this.trigger("click")}}let query=function(e,t){if("function"!=typeof e)return new Query(e,t);"complete"==document.readyState?e():window.addEventListener("load",e)},w2ui=(query.html=e=>{e=Query._fragment(e);return query(e.children,e)},query.version=Query.version,{});class Utils{constructor(){this.version="2.0.x",this.tmp={},this.settings=this.extend({},{dataType:"HTTPJSON",dateStartYear:1950,dateEndYear:2030,macButtonOrder:!1,warnNoPhrase:!1},w2locale,{phrases:null}),this.i18nCompare=Intl.Collator().compare,this.hasLocalStorage=function(){var e="w2ui_test";try{return localStorage.setItem(e,e),localStorage.removeItem(e),!0}catch(e){return!1}}(),this.isMac=/Mac/i.test(navigator.platform),this.isMobile=/(iphone|ipod|ipad|mobile|android)/i.test(navigator.userAgent),this.isIOS=/(iphone|ipod|ipad)/i.test(navigator.platform),this.isAndroid=/(android)/i.test(navigator.userAgent),this.isSafari=/^((?!chrome|android).)*safari/i.test(navigator.userAgent),this.formatters={number(e,t){return 20'+w2utils.formatDate(i,t)+""},datetime(e,t){if(""===t&&(t=w2utils.settings.datetimeFormat),null==e||0===e||""===e)return"";let i=w2utils.isDateTime(e,t,!0);return''+w2utils.formatDateTime(i,t)+""},time(e,t){if(""===t&&(t=w2utils.settings.timeFormat),null==e||0===e||""===e)return"";let i=w2utils.isDateTime(e,t="h24"===(t="h12"===t?"hh:mi pm":t)?"h24:mi":t,!0);return''+w2utils.formatTime(e,t)+""},timestamp(e,t){if(""===t&&(t=w2utils.settings.datetimeFormat),null==e||0===e||""===e)return"";let i=w2utils.isDateTime(e,t,!0);return(i=!1===i?w2utils.isDate(e,t,!0):i).toString?i.toString():""},gmt(e,t){if(""===t&&(t=w2utils.settings.datetimeFormat),null==e||0===e||""===e)return"";let i=w2utils.isDateTime(e,t,!0);return(i=!1===i?w2utils.isDate(e,t,!0):i).toUTCString?i.toUTCString():""},age(e,t){if(null==e||0===e||""===e)return"";let i=w2utils.isDateTime(e,null,!0);return''+w2utils.age(e)+(t?" "+t:"")+""},interval(e,t){return null==e||0===e||""===e?"":w2utils.interval(e)+(t?" "+t:"")},toggle(e,t){return e?"Yes":""},password(t,e){let i="";for(let e=0;ei||!this.isInt(e[0])||2'+(r=l==e?this.lang("Yesterday"):r)+""}formatSize(e){var t;return this.isFloat(e)&&""!==e?0===(e=parseFloat(e))?0:(t=parseInt(Math.floor(Math.log(e)/Math.log(1024))),(Math.floor(e/Math.pow(1024,t)*10)/10).toFixed(0===t?0:1)+" "+(["Bt","KB","MB","GB","TB","PB","EB","ZB"][t]||"??")):""}formatNumber(e,t,i){return null==e||""===e||"object"==typeof e?"":(i={minimumFractionDigits:t,maximumFractionDigits:t,useGrouping:i},(null==t||t<0)&&(i.minimumFractionDigits=0,i.maximumFractionDigits=20),parseFloat(e).toLocaleString(this.settings.locale,i))}formatDate(e,t){if(t=t||this.settings.dateFormat,""===e||null==e||"object"==typeof e&&!e.getMonth)return"";let i=new Date(e);var s,l;return this.isInt(e)&&(i=new Date(Number(e))),"Invalid Date"===String(i)?"":(e=i.getFullYear(),s=i.getMonth(),l=i.getDate(),t.toLowerCase().replace("month",this.settings.fullmonths[s]).replace("mon",this.settings.shortmonths[s]).replace(/yyyy/g,("000"+e).slice(-4)).replace(/yyy/g,("000"+e).slice(-4)).replace(/yy/g,("0"+e).slice(-2)).replace(/(^|[^a-z$])y/g,"$1"+e).replace(/mm/g,("0"+(s+1)).slice(-2)).replace(/dd/g,("0"+l).slice(-2)).replace(/th/g,1==l?"st":"th").replace(/th/g,2==l?"nd":"th").replace(/th/g,3==l?"rd":"th").replace(/(^|[^a-z$])m/g,"$1"+(s+1)).replace(/(^|[^a-z$])d/g,"$1"+l))}formatTime(e,t){if(t=t||this.settings.timeFormat,""===e||null==e||"object"==typeof e&&!e.getMonth)return"";let i=new Date(e);if(this.isInt(e)&&(i=new Date(Number(e))),this.isTime(e)&&(e=this.isTime(e,!0),(i=new Date).setHours(e.hours),i.setMinutes(e.minutes)),"Invalid Date"===String(i))return"";let s="am",l=i.getHours();e=i.getHours();let r=i.getMinutes(),n=i.getSeconds();return r<10&&(r="0"+r),n<10&&(n="0"+n),-1===t.indexOf("am")&&-1===t.indexOf("pm")||(12<=l&&(s="pm"),12{i[t]=this.stripSpaces(e)}):(i=this.extend({},i),Object.keys(i).forEach(e=>{i[e]=this.stripSpaces(i[e])}))}return i}stripTags(i){if(null!=i)switch(typeof i){case"number":break;case"string":i=String(i).replace(/<(?:[^>=]|='[^']*'|="[^"]*"|=[^'"][^\s>]*)*>/gi,"");break;case"object":Array.isArray(i)?(i=this.extend([],i)).forEach((e,t)=>{i[t]=this.stripTags(e)}):(i=this.extend({},i),Object.keys(i).forEach(e=>{i[e]=this.stripTags(i[e])}))}return i}encodeTags(i){if(null!=i)switch(typeof i){case"number":break;case"string":i=String(i).replace(/&/g,"&").replace(/>/g,">").replace(/{i[t]=this.encodeTags(e)}):(i=this.extend({},i),Object.keys(i).forEach(e=>{i[e]=this.encodeTags(i[e])}))}return i}decodeTags(i){if(null!=i)switch(typeof i){case"number":break;case"string":i=String(i).replace(/>/g,">").replace(/</g,"<").replace(/"/g,'"').replace(/&/g,"&");break;case"object":Array.isArray(i)?(i=this.extend([],i)).forEach((e,t)=>{i[t]=this.decodeTags(e)}):(i=this.extend({},i),Object.keys(i).forEach(e=>{i[e]=this.decodeTags(i[e])}))}return i}escapeId(e){return""===e||null==e?"":(e+"").replace(/([\0-\x1f\x7f]|^-?\d)|^-$|[^\0-\x1f\x7f-\uFFFF\w-]/g,(e,t)=>t?"\0"===e?"�":e.slice(0,-1)+"\\"+e.charCodeAt(e.length-1).toString(16)+" ":"\\"+e)}unescapeId(e){return""===e||null==e?"":e.replace(/\\[\da-fA-F]{1,6}[\x20\t\r\n\f]?|\\([^\r\n\f])/g,(e,t)=>{e="0x"+e.slice(1)-65536;return t||(e<0?String.fromCharCode(65536+e):String.fromCharCode(e>>10|55296,1023&e|56320))})}base64encode(e){let t="",i,s,l,r,n,a,o,h=0;var d="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";for(e=function(t){t=String(t).replace(/\r\n/g,"\n");let i="";for(let e=0;e>6|192))+String.fromCharCode(63&s|128):(i=(i+=String.fromCharCode(s>>12|224))+String.fromCharCode(s>>6&63|128))+String.fromCharCode(63&s|128)}return i}(e);h>2,n=(3&i)<<4|s>>4,a=(15&s)<<2|l>>6,o=63&l,isNaN(s)?a=o=64:isNaN(l)&&(o=64),t=t+d.charAt(r)+d.charAt(n)+d.charAt(a)+d.charAt(o);return t}base64decode(e){let t="";var i,s,l,r,n,a;let o=0;var h="ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";for(e=e.replace(/[^A-Za-z0-9\+\/\=]/g,"");o>2,s=(3&n)<<6|(a=h.indexOf(e.charAt(o++))),t+=String.fromCharCode(l<<2|r>>4),64!==n&&(t+=String.fromCharCode(i)),64!==a&&(t+=String.fromCharCode(s));return t=function(e){let t="",i=0,s=0,l,r;for(;i{return Array.from(new Uint8Array(e)).map(e=>e.toString(16).padStart(2,"0")).join("")})}transition(r,n,a,o){return new Promise((e,t)=>{var i=getComputedStyle(r);let s=parseInt(i.width),l=parseInt(i.height);if(r&&n){switch(r.parentNode.style.cssText+="perspective: 900px; overflow: hidden;",r.style.cssText+="; position: absolute; z-index: 1019; backface-visibility: hidden",n.style.cssText+="; position: absolute; z-index: 1020; backface-visibility: hidden",a){case"slide-left":r.style.cssText+="overflow: hidden; transform: translate3d(0, 0, 0)",n.style.cssText+="overflow: hidden; transform: translate3d("+s+"px, 0, 0)",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; transform: translate3d(0, 0, 0)",r.style.cssText+="transition: 0.5s; transform: translate3d(-"+s+"px, 0, 0)"},1);break;case"slide-right":r.style.cssText+="overflow: hidden; transform: translate3d(0, 0, 0)",n.style.cssText+="overflow: hidden; transform: translate3d(-"+s+"px, 0, 0)",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; transform: translate3d(0px, 0, 0)",r.style.cssText+="transition: 0.5s; transform: translate3d("+s+"px, 0, 0)"},1);break;case"slide-down":r.style.cssText+="overflow: hidden; z-index: 1; transform: translate3d(0, 0, 0)",n.style.cssText+="overflow: hidden; z-index: 0; transform: translate3d(0, 0, 0)",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; transform: translate3d(0, 0, 0)",r.style.cssText+="transition: 0.5s; transform: translate3d(0, "+l+"px, 0)"},1);break;case"slide-up":r.style.cssText+="overflow: hidden; transform: translate3d(0, 0, 0)",n.style.cssText+="overflow: hidden; transform: translate3d(0, "+l+"px, 0)",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; transform: translate3d(0, 0, 0)",r.style.cssText+="transition: 0.5s; transform: translate3d(0, 0, 0)"},1);break;case"flip-left":r.style.cssText+="overflow: hidden; transform: rotateY(0deg)",n.style.cssText+="overflow: hidden; transform: rotateY(-180deg)",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; transform: rotateY(0deg)",r.style.cssText+="transition: 0.5s; transform: rotateY(180deg)"},1);break;case"flip-right":r.style.cssText+="overflow: hidden; transform: rotateY(0deg)",n.style.cssText+="overflow: hidden; transform: rotateY(180deg)",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; transform: rotateY(0deg)",r.style.cssText+="transition: 0.5s; transform: rotateY(-180deg)"},1);break;case"flip-down":r.style.cssText+="overflow: hidden; transform: rotateX(0deg)",n.style.cssText+="overflow: hidden; transform: rotateX(180deg)",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; transform: rotateX(0deg)",r.style.cssText+="transition: 0.5s; transform: rotateX(-180deg)"},1);break;case"flip-up":r.style.cssText+="overflow: hidden; transform: rotateX(0deg)",n.style.cssText+="overflow: hidden; transform: rotateX(-180deg)",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; transform: rotateX(0deg)",r.style.cssText+="transition: 0.5s; transform: rotateX(180deg)"},1);break;case"pop-in":r.style.cssText+="overflow: hidden; transform: translate3d(0, 0, 0)",n.style.cssText+="overflow: hidden; transform: translate3d(0, 0, 0); transform: scale(.8); opacity: 0;",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; transform: scale(1); opacity: 1;",r.style.cssText+="transition: 0.5s;"},1);break;case"pop-out":r.style.cssText+="overflow: hidden; transform: translate3d(0, 0, 0); transform: scale(1); opacity: 1;",n.style.cssText+="overflow: hidden; transform: translate3d(0, 0, 0); opacity: 0;",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; opacity: 1;",r.style.cssText+="transition: 0.5s; transform: scale(1.7); opacity: 0;"},1);break;default:r.style.cssText+="overflow: hidden; transform: translate3d(0, 0, 0)",n.style.cssText+="overflow: hidden; translate3d(0, 0, 0); opacity: 0;",query(n).show(),setTimeout(()=>{n.style.cssText+="transition: 0.5s; opacity: 1;",r.style.cssText+="transition: 0.5s"},1)}setTimeout(()=>{"slide-down"===a&&(query(r).css("z-index","1019"),query(n).css("z-index","1020")),n&&query(n).css({opacity:"1"}).css({transition:"",transform:""}),r&&query(r).css({opacity:"1"}).css({transition:"",transform:""}),"function"==typeof o&&o(),e()},500)}else console.log("ERROR: Cannot do transition when one of the divs is null")})}lock(i,s={}){if(null!=i){"string"==typeof s&&(s={msg:s}),arguments[2]&&(s.spinner=arguments[2]),s=this.extend({spinner:!1},s),i?.[0]instanceof Node&&(i=Array.isArray(i)?i:i.get()),s.msg||0===s.msg||(s.msg=""),this.unlock(i),query(i).prepend('');let e=query(i).find(".w2ui-lock");i=query(i).find(".w2ui-lock-msg"),i=(s.msg||i.css({"background-color":"transparent","background-image":"none",border:"0px","box-shadow":"none"}),!0===s.spinner&&(s.msg=``+s.msg),s.msg?i.html(s.msg).css("display","block"):i.remove(),null!=s.opacity&&e.css("opacity",s.opacity),e.css({display:"block"}),s.bgColor&&e.css({"background-color":s.bgColor}),getComputedStyle(e.get(0)));let t=i.opacity??.15;e.on("mousedown",function(){"function"==typeof s.onClick?s.onClick():e.css({transition:".2s",opacity:1.5*t})}).on("mouseup",function(){"function"!=typeof s.onClick&&e.css({transition:".2s",opacity:t})}).on("mousewheel",function(e){e&&(e.stopPropagation(),e.preventDefault())})}}unlock(e,t){null!=e&&(clearTimeout(e._prevUnlock),e?.[0]instanceof Node&&(e=Array.isArray(e)?e:e.get()),this.isInt(t)&&0{query(e).find(".w2ui-lock").remove()},t)):(query(e).find(".w2ui-lock").remove(),query(e).find(".w2ui-lock-msg").remove()))}message(r,s){let e,t,l;var i=()=>{var e=query(r?.box).find(".w2ui-message");0!=e.length&&"function"==typeof(s=e.get(0)._msg_options||{})?.close&&s.close()};let n=e=>{var t,i=e.box._msg_prevFocus;query(r.box).find(".w2ui-message").length<=1?r.owner?r.owner.unlock(r.param,150):this.unlock(r.box,150):query(r.box).find(`#w2ui-message-${r.owner?.name}-`+(e.msgIndex-1)).css("z-index",1500),i?0<(t=query(i).closest(".w2ui-message")).length?t.get(0)._msg_options.setFocus(i):i.focus():"function"==typeof r.owner?.focus&&r.owner.focus(),query(e.box).remove(),0===e.msgIndex&&(c.css("z-index",e.tmp.zIndex),query(r.box).css("overflow",e.tmp.overflow)),e.trigger&&l.finish()};if("object"!=typeof(s="string"!=typeof s&&"number"!=typeof s?s:{width:String(s).length<300?350:550,height:String(s).length<300?170:250,text:String(s)}))return void i();null!=s.text&&(s.body=`${s.text} `),null==s.width&&(s.width=350),null==s.height&&(s.height=170),null==s.hideOn&&(s.hideOn=["esc"]),null==s.on&&(h=s,s=new w2base,w2utils.extend(s,h)),s.on("open",e=>{w2utils.bindEvents(query(s.box).find(".w2ui-eaction"),s),query(e.detail.box).find("button, input, textarea, [name=hidden-first]").off(".message").on("keydown.message",function(e){27==e.keyCode&&s.hideOn.includes("esc")&&(s.cancelAction?s.action(s.cancelAction):s.close())}),s.setFocus(s.focus)}),s.off(".prom");let a={self:s,action(e){return s.on("action.prom",e),a},close(e){return s.on("close.prom",e),a},open(e){return s.on("open.prom",e),a},then(e){return s.on("open:after.prom",e),a}},o=(null==s.actions&&null==s.buttons&&null==s.html&&(s.actions={Ok(e){e.detail.self.close()}}),s.off(".buttons"),null!=s.actions&&(s.buttons="",Object.keys(s.actions).forEach(e=>{var t=s.actions[e];let i=e;"function"==typeof t&&(s.buttons+=``),"object"==typeof t&&(s.buttons+=``,i=Array.isArray(s.actions)?t.text:e),"string"==typeof t&&(s.buttons+=``,i=t),"string"==typeof i&&(i=i[0].toLowerCase()+i.substr(1).replace(/\s+/g,"")),a[i]=function(t){return s.on("action.buttons",e=>{e.detail.action[0].toLowerCase()+e.detail.action.substr(1).replace(/\s+/g,"")==i&&t(e)}),a}})),Array("html","body","buttons").forEach(e=>{s[e]=String(s[e]??"").trim()}),""===s.body&&""===s.buttons||(s.html=`
- ${s.body||""}
- ${s.buttons||""}
- `),getComputedStyle(query(r.box).get(0)));var h=parseFloat(o.width),d=parseFloat(o.height);let u=0,c=(0h&&(s.width=h-10),s.height>d-u&&(s.height=d-10-u),s.originalWidth=s.width,s.originalHeight=s.height,parseInt(s.width)<0&&(s.width=h+s.width),parseInt(s.width)<10&&(s.width=10),parseInt(s.height)<0&&(s.height=d+s.height-u),parseInt(s.height)<10&&(s.height=10),s.originalHeight<0&&(s.height=d+s.originalHeight-u),s.originalWidth<0&&(s.width=h+2*s.originalWidth),query(r.box).find(r.after));return s.tmp||(s.tmp={zIndex:c.css("z-index"),overflow:o.overflow}),""===s.html&&""===s.body&&""===s.buttons?i():(s.msgIndex=query(r.box).find(".w2ui-message").length,0===s.msgIndex&&"function"==typeof this.lock&&(query(r.box).css("overflow","hidden"),r.owner?r.owner.lock(r.param):this.lock(r.box)),query(r.box).find(".w2ui-message").css("z-index",1390),c.css("z-index",1501),d=`
-
-
- ${s.html}
-
- `,0{!0===(l=s.trigger("open",{target:this.name,box:s.box,self:s})).isCancelled?(query(r.box).find(`#w2ui-message-${r.owner?.name}-`+s.msgIndex).remove(),0===s.msgIndex&&(c.css("z-index",s.tmp.zIndex),query(r.box).css("overflow",s.tmp.overflow))):query(s.box).css({transition:"0.3s",transform:"translateY(0px)"})},0),t=setTimeout(()=>{query(r.box).find(`#w2ui-message-${r.owner?.name}-`+s.msgIndex).removeClass("animating").css({transition:"0s"}),l.finish()},300)),s.action=(e,t)=>{let i=s.actions[e];i instanceof Object&&i.onClick&&(i=i.onClick);e=s.trigger("action",{target:this.name,action:e,self:s,originalEvent:t,value:s.input?s.input.value:null});!0!==e.isCancelled&&("function"==typeof i&&i(e),e.finish())},s.close=()=>{!0!==(l=s.trigger("close",{target:"self",box:s.box,self:s})).isCancelled&&(clearTimeout(t),query(s.box).hasClass("animating")?(clearTimeout(e),n(s)):(query(s.box).addClass("w2ui-closing animating").css({transition:"0.15s",transform:"translateY(-"+s.height+"px)"}),0!==s.msgIndex&&query(r.box).find(`#w2ui-message-${r.owner?.name}-`+(s.msgIndex-1)).css("z-index",1499),e=setTimeout(()=>{n(s)},150)))},s.setFocus=e=>{var t=query(r.box).find(".w2ui-message").length-1;let s=query(r.box).find(`#w2ui-message-${r.owner?.name}-`+t),l="input, button, select, textarea, [contentEditable], .w2ui-input";(null!=e?isNaN(e)?s.find(l).filter(e).get(0):s.find(l).get(e):s.find("[name=hidden-first]").get(0))?.focus(),query(r.box).find(".w2ui-message").find(l+",[name=hidden-first],[name=hidden-last]").off(".keep-focus"),query(s).find(l+",[name=hidden-first],[name=hidden-last]").on("blur.keep-focus",function(e){setTimeout(()=>{var e=document.activeElement,t=0{if("object"==typeof i&&(i=(s=i).text),(s=s||{}).where=s.where??document.body,s.timeout=s.timeout??15e3,"function"==typeof this.tmp.notify_resolve&&(this.tmp.notify_resolve(),query(this.tmp.notify_where).find("#w2ui-notify").remove()),this.tmp.notify_resolve=t,this.tmp.notify_where=s.where,clearTimeout(this.tmp.notify_timer),i){if("object"==typeof s.actions){let t={};Object.keys(s.actions).forEach(e=>{t[e]=`${e}`}),i=this.execTemplate(i,t)}var e=`
- `;query(s.where).append(e),query(s.where).find("#w2ui-notify").find(".w2ui-notify-close").on("click",e=>{query(s.where).find("#w2ui-notify").remove(),t()}),s.actions&&query(s.where).find("#w2ui-notify .w2ui-notify-link").on("click",e=>{e=query(e.target).attr("value");s.actions[e](),query(s.where).find("#w2ui-notify").remove(),t()}),0{query(s.where).find("#w2ui-notify").remove(),t()},s.timeout))}})}confirm(e,t){w2utils.normButtons(t="string"==typeof t?{text:t}:t,{yes:"Yes",no:"No"});e=w2utils.message(e,t);return e&&e.action(e=>{e.detail.self.close()}),e}normButtons(i,s){i.actions=i.actions??{};var e=Object.keys(s);return e.forEach(t=>{var e=i["btn_"+t];e&&(s[t]={text:w2utils.lang(e.text??""),class:e.class??"",style:e.style??"",attrs:e.attrs??""},delete i["btn_"+t]),Array("text","class","style","attrs").forEach(e=>{i[t+"_"+e]&&("string"==typeof s[t]&&(s[t]={text:s[t]}),s[t][e]=i[t+"_"+e],delete i[t+"_"+e])})}),e.includes("yes")&&e.includes("no")&&(w2utils.settings.macButtonOrder?w2utils.extend(i.actions,{no:s.no,yes:s.yes}):w2utils.extend(i.actions,{yes:s.yes,no:s.no})),e.includes("ok")&&e.includes("cancel")&&(w2utils.settings.macButtonOrder?w2utils.extend(i.actions,{cancel:s.cancel,ok:s.ok}):w2utils.extend(i.actions,{ok:s.ok,cancel:s.cancel})),i}getSize(e,t){let i=0;if(0<(e=query(e)).length){e=e[0];var s=getComputedStyle(e);switch(t){case"width":i=parseFloat(s.width),"auto"===s.width&&(i=0);break;case"height":i=parseFloat(s.height),"auto"===s.height&&(i=0)}}return i}getStrWidth(e,t){query("body").append(`
-
- ${this.encodeTags(e)}
- `);t=query("#_tmp_width")[0].clientWidth;return query("#_tmp_width").remove(),t}execTemplate(e,i){return"string"==typeof e&&i&&"object"==typeof i?e.replace(/\${([^}]+)?}/g,function(e,t){return i[t]||t}):e}marker(e,s,l={onlyFirst:!1,wholeWord:!1}){Array.isArray(s)||(s=null!=s&&""!==s?[s]:[]);let r=l.wholeWord;query(e).each(t=>{for(var e=t,i=/\((.|\n|\r)*)\<\/span\>/gi;-1!==e.innerHTML.indexOf('{e=(e="string"!=typeof e?String(e):e).replace(/[-[\]{}()*+?.,\\^$|#\s]/g,"\\$&").replace(/&/g,"&").replace(//g,"<");e=new RegExp((r?"\\b":"")+e+(r?"\\b":"")+"(?!([^<]+)?>)","i"+(l.onlyFirst?"":"g"));t.innerHTML=t.innerHTML.replace(e,e=>''+e+"")})})}lang(e,t){if(!e||null==this.settings.phrases||"string"!=typeof e||"<=>=".includes(e))return this.execTemplate(e,t);let i=this.settings.phrases[e];return null==i?(i=e,this.settings.warnNoPhrase&&(this.settings.missing||(this.settings.missing={}),this.settings.missing[e]="---",this.settings.phrases[e]="---",console.log(`Missing translation for "%c${e}%c", see %c w2utils.settings.phrases %c with value "---"`,"color: orange","","color: #999",""))):"---"!==i||this.settings.warnNoPhrase||(i=e),"---"===i&&(i=`---`),this.execTemplate(i,t)}locale(l,i,r){return new Promise((s,t)=>{if(Array.isArray(l)){this.settings.phrases={};let i=[],t={};l.forEach((e,t)=>{5===e.length&&(e="locale/"+e.toLowerCase()+".json",l[t]=e),i.push(this.locale(e,!0,!1))}),void Promise.allSettled(i).then(e=>{e.forEach(e=>{e.value&&(t[e.value.file]=e.value.data)}),l.forEach(e=>{this.settings=this.extend({},this.settings,t[e])}),s()})}else(l=l||"en-us")instanceof Object?this.settings=this.extend({},this.settings,w2locale,l):(5===l.length&&(l="locale/"+l.toLowerCase()+".json"),fetch(l,{method:"GET"}).then(e=>e.json()).then(e=>{!0!==r&&(this.settings=i?this.extend({},this.settings,e):this.extend({},this.settings,w2locale,{phrases:{}},e)),s({file:l,data:e})}).catch(e=>{console.log("ERROR: Cannot load locale "+l),t(e)}))})}scrollBarSize(){return this.tmp.scrollBarSize||(query("body").append(`
-
- `),this.tmp.scrollBarSize=100-query("#_scrollbar_width > div")[0].clientWidth,query("#_scrollbar_width").remove()),this.tmp.scrollBarSize}checkName(e){return null==e?(console.log('ERROR: Property "name" is required but not supplied.'),!1):null!=w2ui[e]?(console.log(`ERROR: Object named "${e}" is already registered as w2ui.${e}.`),!1):!!this.isAlphaNumeric(e)||(console.log('ERROR: Property "name" has to be alpha-numeric (a-z, 0-9, dash and underscore).'),!1)}checkUniqueId(t,i,s,l){Array.isArray(i)||(i=[i]);let r=!0;return i.forEach(e=>{e.id===t&&(console.log(`ERROR: The item id="${t}" is not unique within the ${s} "${l}".`,i),r=!1)}),r}encodeParams(t,i=""){let s="";return Object.keys(t).forEach(e=>{""!=s&&(s+="&"),"object"==typeof t[e]?s+=this.encodeParams(t[e],i+e+(i?"]":"")+"["):s+=""+i+e+(i?"]":"")+"="+t[e]}),s}parseRoute(e){let n=[];e=e.replace(/\/\(/g,"(?:/").replace(/\+/g,"__plus__").replace(/(\/)?(\.)?:(\w+)(?:(\(.*?\)))?(\?)?/g,(e,t,i,s,l,r)=>(n.push({name:s,optional:!!r}),t=t||"",(r?"":t)+"(?:"+(r?t:"")+(i||"")+(l||(i?"([^/.]+?)":"([^/]+?)"))+")"+(r||""))).replace(/([\/.])/g,"\\$1").replace(/__plus__/g,"(.+)").replace(/\*/g,"(.*)");return{path:new RegExp("^"+e+"$","i"),keys:n}}getCursorPosition(e){if(null==e)return null;let t=0;var i,s=e.ownerDocument||e.document,l=s.defaultView||s.parentWindow;let r;return["INPUT","TEXTAREA"].includes(e.tagName)?t=e.selectionStart:l.getSelection?0<(r=l.getSelection()).rangeCount&&((i=(l=r.getRangeAt(0)).cloneRange()).selectNodeContents(e),i.setEnd(l.endContainer,l.endOffset),t=i.toString().length):(r=s.selection)&&"Control"!==r.type&&(l=r.createRange(),(i=s.body.createTextRange()).moveToElementText(e),i.setEndPoint("EndToEnd",l),t=i.text.length),t}setCursorPosition(s,l,t){if(null!=s){var r=document.createRange();let i,e=window.getSelection();if(["INPUT","TEXTAREA"].includes(s.tagName))s.setSelectionRange(l,t??l);else{for(let t=0;t").replace(/&/g,"&").replace(/"/g,'"').replace(/ /g," "):e).length){(i=(i=s.childNodes[t]).childNodes&&0i.length&&(l=i.length),r.setStart(i,l),t?r.setEnd(i,t):r.collapse(!0),e.removeAllRanges(),e.addRange(r))}}}parseColor(e){if("string"!=typeof e)return null;let t={};if(3===(e="#"===(e=e.trim().toUpperCase())[0]?e.substr(1):e).length)t={r:parseInt(e[0]+e[0],16),g:parseInt(e[1]+e[1],16),b:parseInt(e[2]+e[2],16),a:1};else if(6===e.length)t={r:parseInt(e.substr(0,2),16),g:parseInt(e.substr(2,2),16),b:parseInt(e.substr(4,2),16),a:1};else if(8===e.length)t={r:parseInt(e.substr(0,2),16),g:parseInt(e.substr(2,2),16),b:parseInt(e.substr(4,2),16),a:Math.round(parseInt(e.substr(6,2),16)/255*100)/100};else if(4{s[t]=this.clone(e,i)}):this.isPlainObject(e)?(s={},Object.assign(s,e),i.exclude&&i.exclude.forEach(e=>{delete s[e]}),Object.keys(s).forEach(e=>{s[e]=this.clone(s[e],i),void 0===s[e]&&delete s[e]})):e instanceof Function&&!i.functions||e instanceof Node&&!i.elements||e instanceof Event&&!i.events||(s=e),s}extend(i,s){if(Array.isArray(i)){if(!Array.isArray(s))throw new Error("Arrays can be extended with arrays only");i.splice(0,i.length),s.forEach(e=>{i.push(this.clone(e))})}else{if(i instanceof Node||i instanceof Event)throw new Error("HTML elmenents and events cannot be extended");if(i&&"object"==typeof i&&null!=s){if("object"!=typeof s)throw new Error("Object can be extended with other objects only.");Object.keys(s).forEach(e=>{var t;null!=i[e]&&"object"==typeof i[e]&&null!=s[e]&&"object"==typeof s[e]?(t=this.clone(s[e]),i[e]instanceof Node||i[e]instanceof Event?i[e]=t:(Array.isArray(i[e])&&this.isPlainObject(t)&&(i[e]={}),this.extend(i[e],t))):i[e]=this.clone(s[e])})}else if(null!=s)throw new Error("Object is not extendable, only {} or [] can be extended.")}if(2{"string"==typeof e||"number"==typeof e?i[t]={id:e,text:String(e)}:null!=e?(null!=e.caption&&null==e.text&&(e.text=e.caption),null!=e.text&&null==e.id&&(e.id=e.text),null==e.text&&null!=e.id&&(e.text=e.id)):i[t]={id:null,text:"null"}}),i):"function"==typeof i?(e=i.call(this,i,e),w2utils.normMenu.call(this,e)):"object"==typeof i?Object.keys(i).map(e=>({id:e,text:i[e]})):void 0}bindEvents(e,r){0!=e.length&&(e?.[0]instanceof Node&&(e=Array.isArray(e)?e:e.get()),query(e).each(s=>{let l=query(s).data();Object.keys(l).forEach(i=>{if(-1!=["click","dblclick","mouseenter","mouseleave","mouseover","mouseout","mousedown","mousemove","mouseup","contextmenu","focus","focusin","focusout","blur","input","change","keydown","keyup","keypress"].indexOf(String(i).toLowerCase())){let e=l[i],t=(e="string"==typeof e?e.split("|").map(e=>{"null"===(e="undefined"===(e="false"===(e="true"===e?!0:e)?!1:e)?void 0:e)&&(e=null);var t=["'",'"',"`"];return e="string"==typeof(e=parseFloat(e)==e?parseFloat(e):e)&&t.includes(e[0])&&t.includes(e[e.length-1])?e.substring(1,e.length-1):e}):e)[0];e=e.slice(1),query(s).off(i+".w2utils-bind").on(i+".w2utils-bind",function(i){switch(t){case"alert":alert(e[0]);break;case"stop":i.stopPropagation();break;case"prevent":i.preventDefault();break;case"stopPrevent":return i.stopPropagation(),i.preventDefault(),!1;default:if(null==r[t])throw new Error(`Cannot dispatch event as the method "${t}" does not exist.`);r[t].apply(r,e.map((e,t)=>{switch(String(e).toLowerCase()){case"event":return i;case"this":return this;default:return e}}))}})}})}))}}var w2utils=new Utils;class Dialog extends w2base{constructor(){super(),this.defaults={title:"",text:"",body:"",buttons:"",width:450,height:250,focus:null,actions:null,style:"",speed:.3,modal:!1,maximized:!1,keyboard:!0,showClose:!0,showMax:!1,transition:null,openMaximized:!1,moved:!1},this.name="popup",this.status="closed",this.onOpen=null,this.onClose=null,this.onMax=null,this.onMin=null,this.onToggle=null,this.onKeydown=null,this.onAction=null,this.onMove=null,this.tmp={},this.handleResize=e=>{this.options.moved||this.center(void 0,void 0,!0)}}open(s){let l=this;"closing"!=this.status&&!query("#w2ui-popup").hasClass("animating")||this.close(!0);var e=this.options;null!=(s=["string","number"].includes(typeof s)?w2utils.extend({title:"Notification",body:`${s} `,actions:{Ok(){l.close()}},cancelAction:"ok"},arguments[1]??{}):s).text&&(s.body=`${s.text} `),s=Object.assign({},this.defaults,e,{title:"",body:""},s,{maximized:!1}),this.options=s,0===query("#w2ui-popup").length&&(this.off("*"),Object.keys(this).forEach(e=>{e.startsWith("on")&&"on"!=e&&(this[e]=null)})),Object.keys(s).forEach(e=>{e.startsWith("on")&&"on"!=e&&s[e]&&(this[e]=s[e])}),s.width=parseInt(s.width),s.height=parseInt(s.height);let r,t,i;var{top:n,left:a}=this.center();let o={self:this,action(e){return l.on("action.prom",e),o},close(e){return l.on("close.prom",e),o},then(e){return l.on("open:after.prom",e),o}};if(null==s.actions||s.buttons||(s.buttons="",Object.keys(s.actions).forEach(e=>{var t=s.actions[e];let i=e;"function"==typeof t&&(s.buttons+=``),"object"==typeof t&&(s.buttons+=``,i=Array.isArray(s.actions)?t.text:e),"string"==typeof t&&(s.buttons+=``,i=t),"string"==typeof i&&(i=i[0].toLowerCase()+i.substr(1).replace(/\s+/g,"")),o[i]=function(t){return l.on("action.buttons",e=>{e.detail.action[0].toLowerCase()+e.detail.action.substr(1).replace(/\s+/g,"")==i&&t(e)}),o}})),0===query("#w2ui-popup").length){if(!0===(r=this.trigger("open",{target:"popup",present:!1})).isCancelled)return;this.status="opening",w2utils.lock(document.body,{opacity:.3,onClick:s.modal?null:()=>{this.close()}});let e="";s.showClose&&(e+=``),s.showMax&&(e+=``);a=`
- left: ${a}px;
- top: ${n}px;
- width: ${parseInt(s.width)}px;
- height: ${parseInt(s.height)}px;
- transition: ${s.speed}s
- `;t=``,query("body").append(t),query("#w2ui-popup")[0]._w2popup={self:this,created:new Promise(e=>{this._promCreated=e}),opened:new Promise(e=>{this._promOpened=e}),closing:new Promise(e=>{this._promClosing=e}),closed:new Promise(e=>{this._promClosed=e})},a=`${s.title?"":"top: 0px !important;"} `+(s.buttons?"":"bottom: 0px !important;"),t=`
-
-
-
-
-
- `,query("#w2ui-popup").html(t),s.title&&query("#w2ui-popup .w2ui-popup-title").append(w2utils.lang(s.title)),s.buttons&&query("#w2ui-popup .w2ui-popup-buttons").append(s.buttons),s.body&&query("#w2ui-popup .w2ui-popup-body").append(s.body),setTimeout(()=>{query("#w2ui-popup").css("transition",s.speed+"s").removeClass("w2ui-anim-open"),w2utils.bindEvents("#w2ui-popup .w2ui-eaction",this),query("#w2ui-popup").find(".w2ui-popup-body").show(),this._promCreated()},1),clearTimeout(this._timer),this._timer=setTimeout(()=>{this.status="open",l.setFocus(s.focus),r.finish(),this._promOpened(),query("#w2ui-popup").removeClass("animating")},1e3*s.speed)}else{if(!0===(r=this.trigger("open",{target:"popup",present:!0})).isCancelled)return;this.status="opening",null!=e&&(e.maximized||e.width==s.width&&e.height==s.height||this.resize(s.width,s.height),s.prevSize=s.width+"px:"+s.height+"px",s.maximized=e.maximized);n=query("#w2ui-popup .w2ui-box").get(0).cloneNode(!0);query(n).removeClass("w2ui-box").addClass("w2ui-box-temp").find(".w2ui-popup-body").empty().append(s.body),query("#w2ui-popup .w2ui-box").after(n),s.buttons?(query("#w2ui-popup .w2ui-popup-buttons").show().html("").append(s.buttons),query("#w2ui-popup .w2ui-popup-body").removeClass("w2ui-popup-no-buttons"),query("#w2ui-popup .w2ui-box, #w2ui-popup .w2ui-box-temp").css("bottom","")):(query("#w2ui-popup .w2ui-popup-buttons").hide().html(""),query("#w2ui-popup .w2ui-popup-body").addClass("w2ui-popup-no-buttons"),query("#w2ui-popup .w2ui-box, #w2ui-popup .w2ui-box-temp").css("bottom","0px")),s.title?(query("#w2ui-popup .w2ui-popup-title").show().html((s.showClose?``:"")+(s.showMax?``:"")).append(s.title),query("#w2ui-popup .w2ui-popup-body").removeClass("w2ui-popup-no-title"),query("#w2ui-popup .w2ui-box, #w2ui-popup .w2ui-box-temp").css("top","")):(query("#w2ui-popup .w2ui-popup-title").hide().html(""),query("#w2ui-popup .w2ui-popup-body").addClass("w2ui-popup-no-title"),query("#w2ui-popup .w2ui-box, #w2ui-popup .w2ui-box-temp").css("top","0px"));let t=query("#w2ui-popup .w2ui-box")[0],i=query("#w2ui-popup .w2ui-box-temp")[0];query("#w2ui-popup").addClass("animating"),w2utils.transition(t,i,s.transition,()=>{query(t).remove(),query(i).removeClass("w2ui-box-temp").addClass("w2ui-box");var e=query(i).find(".w2ui-popup-body");1==e.length&&(e[0].style.cssText=s.style,e.show()),l.setFocus(s.focus),query("#w2ui-popup").removeClass("animating")}),this.status="open",r.finish(),w2utils.bindEvents("#w2ui-popup .w2ui-eaction",this),query("#w2ui-popup").find(".w2ui-popup-body").show()}return s.openMaximized&&this.max(),s._last_focus=document.activeElement,s.keyboard&&query(document.body).on("keydown",e=>{this.keydown(e)}),query(window).on("resize",this.handleResize),i={resizing:!1,mvMove:function(e){1==i.resizing&&(e=e||window.event,i.div_x=e.screenX-i.x,i.div_y=e.screenY-i.y,!0!==(e=l.trigger("move",{target:"popup",div_x:i.div_x,div_y:i.div_y,originalEvent:e})).isCancelled&&(query("#w2ui-popup").css({transition:"none",transform:"translate3d("+i.div_x+"px, "+i.div_y+"px, 0px)"}),l.options.moved=!0,e.finish()))},mvStop:function(e){1==i.resizing&&(e=e||window.event,l.status="open",i.div_x=e.screenX-i.x,i.div_y=e.screenY-i.y,query("#w2ui-popup").css({left:i.pos_x+i.div_x+"px",top:i.pos_y+i.div_y+"px"}).css({transition:"none",transform:"translate3d(0px, 0px, 0px)"}),i.resizing=!1,query(document.body).off(".w2ui-popup"),i.isLocked||l.unlock())}},query("#w2ui-popup .w2ui-popup-title").on("mousedown",function(e){var t;l.options.maximized||(e=(e=e)||window.event,l.status="moving",t=query("#w2ui-popup").get(0).getBoundingClientRect(),Object.assign(i,{resizing:!0,isLocked:1==query("#w2ui-popup > .w2ui-lock").length,x:e.screenX,y:e.screenY,pos_x:t.x,pos_y:t.y}),i.isLocked||l.lock({opacity:0}),query(document.body).on("mousemove.w2ui-popup",i.mvMove).on("mouseup.w2ui-popup",i.mvStop),e.stopPropagation?e.stopPropagation():e.cancelBubble=!0,e.preventDefault&&e.preventDefault())}),o}load(s){return new Promise((i,e)=>{if(null==(s="string"==typeof s?{url:s}:s).url)console.log("ERROR: The url is not defined."),e("The url is not defined");else{this.status="loading";let[e,t]=String(s.url).split("#");e&&fetch(e).then(e=>e.text()).then(e=>{i(this.template(e,t,s))})}})}template(t,e,i={}){let s;try{s=query(t)}catch(e){s=query.html(t)}return e&&(s=s.filter("#"+e)),Object.assign(i,{width:parseInt(query(s).css("width")),height:parseInt(query(s).css("height")),title:query(s).find("[rel=title]").html(),body:query(s).find("[rel=body]").html(),buttons:query(s).find("[rel=buttons]").html(),style:query(s).find("[rel=body]").get(0).style.cssText}),this.open(i)}action(e,t){let i=this.options.actions[e];i instanceof Object&&i.onClick&&(i=i.onClick);e=this.trigger("action",{action:e,target:"popup",self:this,originalEvent:t,value:this.input?this.input.value:null});!0!==e.isCancelled&&("function"==typeof i&&i.call(this,t),e.finish())}keydown(e){var t;this.options&&!this.options.keyboard||!0!==(t=this.trigger("keydown",{target:"popup",originalEvent:e})).isCancelled&&(27===e.keyCode&&(e.preventDefault(),0==query("#w2ui-popup .w2ui-message").length&&(this.options.cancelAction?this.action(this.options.cancelAction):this.close())),t.finish())}close(e){let t=this.trigger("close",{target:"popup"});var i;!0!==t.isCancelled&&(i=()=>{query("#w2ui-popup").remove(),this.options._last_focus&&0{e.finish()},1e3*this.options.speed+50))}max(){if(!0!==this.options.maximized){let e=this.trigger("max",{target:"popup"});var t;!0!==e.isCancelled&&(this.status="resizing",t=query("#w2ui-popup").get(0).getBoundingClientRect(),this.options.prevSize=t.width+":"+t.height,this.resize(1e4,1e4,()=>{this.status="open",this.options.maximized=!0,e.finish()}))}}min(){if(!0===this.options.maximized){var t=this.options.prevSize.split(":");let e=this.trigger("min",{target:"popup"});!0!==e.isCancelled&&(this.status="resizing",this.options.maximized=!1,this.resize(parseInt(t[0]),parseInt(t[1]),()=>{this.status="open",this.options.prevSize=null,e.finish()}))}}clear(){query("#w2ui-popup .w2ui-popup-title").html(""),query("#w2ui-popup .w2ui-popup-body").html(""),query("#w2ui-popup .w2ui-popup-buttons").html("")}reset(){this.open(this.defaults)}message(e){return w2utils.message({owner:this,box:query("#w2ui-popup").get(0),after:".w2ui-popup-title"},e)}confirm(e){return w2utils.confirm({owner:this,box:query("#w2ui-popup"),after:".w2ui-popup-title"},e)}setFocus(e){let s=query("#w2ui-popup"),l="input, button, select, textarea, [contentEditable], .w2ui-input";null!=e?(isNaN(e)?s.find(l).filter(e).get(0):s.find(l).get(e))?.focus():(e=s.find("[name=hidden-first]").get(0))&&e.focus(),query(s).find(l+",[name=hidden-first],[name=hidden-last]").off(".keep-focus").on("blur.keep-focus",function(e){setTimeout(()=>{var e=document.activeElement,t=0{s.resizeMessages()},10);setTimeout(()=>{clearInterval(a),s.resizeMessages(),"function"==typeof i&&i()},1e3*this.options.speed+50)}resizeMessages(){query("#w2ui-popup .w2ui-message").each(e=>{var t=e._msg_options,i=query("#w2ui-popup"),s=(parseInt(t.width)<10&&(t.width=10),parseInt(t.height)<10&&(t.height=10),i[0].getBoundingClientRect()),i=parseInt(i.find(".w2ui-popup-title")[0].clientHeight),l=parseInt(s.width),s=parseInt(s.height);t.width=t.originalWidth,t.width>l-10&&(t.width=l-10),t.height=t.originalHeight,t.height>s-i-5&&(t.height=s-i-5),t.originalHeight<0&&(t.height=s+t.originalHeight-i),t.originalWidth<0&&(t.width=l+2*t.originalWidth),query(e).css({left:(l-t.width)/2+"px",width:t.width+"px",height:t.height+"px"})})}}function w2alert(e,t,i){let s;t={title:w2utils.lang(t??"Notification"),body:`${e} `,showClose:!1,actions:["Ok"],cancelAction:"ok"};return(s=0{"function"==typeof e.detail.self?.close&&e.detail.self.close(),"function"==typeof i&&i()}),s}function w2confirm(e,t,i){let s,l=e;return(l=["string","number"].includes(typeof l)?{msg:l}:l).msg&&(l.body=`${l.msg} `,delete l.msg),w2utils.extend(l,{title:w2utils.lang(t??"Confirmation"),showClose:!1,modal:!0,cancelAction:"no"}),w2utils.normButtons(l,{yes:"Yes",no:"No"}),(s=0{"function"==typeof e.detail.self?.close&&e.detail.self.close(),"function"==typeof i&&i(e.detail.action)}),s}function w2prompt(e,t,i){let s,l=e;return(l=["string","number"].includes(typeof l)?{label:l}:l).label&&(l.focus=0,l.body=l.textarea?``:`
-
-
- `),w2utils.extend(l,{title:w2utils.lang(t??"Notification"),showClose:!1,modal:!0,cancelAction:"cancel"}),w2utils.normButtons(l,{ok:"Ok",cancel:"Cancel"}),(s=0{e=e.detail.box||query("#w2ui-popup .w2ui-popup-body").get(0);w2utils.bindEvents(query(e).find("#w2prompt"),{keydown(e){27==e.keyCode&&e.stopPropagation()},change(e){var t=s.self.trigger("change",{target:"prompt",originalEvent:e});!0!==t.isCancelled&&(13==e.keyCode&&e.ctrlKey&&s.self.action("Ok",e),27==e.keyCode&&s.self.action("Cancel",e),t.finish())}}),query(e).find(".w2ui-eaction").trigger("keyup")}).on("action:after.prompt",e=>{"function"==typeof e.detail.self?.close&&e.detail.self.close(),"function"==typeof i&&i(e.detail.action)}),s}let w2popup=new Dialog;class Tooltip{static active={};constructor(){this.defaults={name:null,html:"",style:"",class:"",position:"top|bottom",align:"",anchor:null,anchorClass:"",anchorStyle:"",autoShow:!1,autoShowOn:null,autoHideOn:null,arrowSize:8,margin:0,margin:1,screenMargin:2,autoResize:!0,offsetX:0,offsetY:0,maxWidth:null,maxHeight:null,watchScroll:null,watchResize:null,hideOn:null,onThen:null,onShow:null,onHide:null,onUpdate:null,onMove:null}}static observeRemove=new MutationObserver(e=>{let t=0;Object.keys(Tooltip.active).forEach(e=>{e=Tooltip.active[e];e.displayed&&(e.anchor&&e.anchor.isConnected?t++:e.hide())}),0===t&&Tooltip.observeRemove.disconnect()});trigger(e,t){var i;if(2==arguments.length&&(i=e,(e=t).type=i),e.overlay)return e.overlay.trigger(e);console.log("ERROR: cannot find overlay where to trigger events")}get(e){return 0==arguments.length?Object.keys(Tooltip.active):!0===e?Tooltip.active:Tooltip.active[e.replace(/[\s\.#]/g,"_")]}attach(t,s){let l,r,n=this;if(0!=arguments.length){1==arguments.length&&t.anchor?t=(l=t).anchor:2===arguments.length&&"string"==typeof s?s=(l={anchor:t,html:s}).html:2===arguments.length&&null!=s&&"object"==typeof s&&(s=(l=s).html),l=w2utils.extend({},this.defaults,l||{}),!(s=!s&&l.text?l.text:s)&&l.html&&(s=l.html),delete l.anchor;let e=l.name||t.id;t!=document&&t!=document.body||(t=document.body,e="context-menu"),e||(e="noname-"+Object.keys(Tooltip.active).length,console.log("NOTICE: name property is not defined for tooltip, could lead to too many instances")),e=e.replace(/[\s\.#]/g,"_"),Tooltip.active[e]?((r=Tooltip.active[e]).prevOptions=r.options,r.options=l,r.anchor=t,r.prevOptions.html==r.options.html&&r.prevOptions.class==r.options.class&&r.prevOptions.style==r.options.style||(r.needsUpdate=!0),l=r.options):(r=new w2base,Object.assign(r,{id:"w2overlay-"+e,name:e,options:l,anchor:t,displayed:!1,tmp:{observeResize:new ResizeObserver(()=>{this.resize(r.name)})},hide(){n.hide(e)}}),Tooltip.active[e]=r),Object.keys(r.options).forEach(e=>{var t=r.options[e];e.startsWith("on")&&"function"==typeof t&&(r[e]=t,delete r.options[e])}),!0===l.autoShow&&(l.autoShowOn=l.autoShowOn??"mouseenter",l.autoHideOn=l.autoHideOn??"mouseleave",l.autoShow=!1),l.autoShowOn&&(s="autoShow-"+r.name,query(t).off("."+s).on(l.autoShowOn+"."+s,e=>{n.show(r.name),e.stopPropagation()}),delete l.autoShowOn),l.autoHideOn&&(s="autoHide-"+r.name,query(t).off("."+s).on(l.autoHideOn+"."+s,e=>{n.hide(r.name),e.stopPropagation()}),delete l.autoHideOn),r.off(".attach");let i={overlay:r,then:t=>(r.on("show:after.attach",e=>{t(e)}),i),show:t=>(r.on("show.attach",e=>{t(e)}),i),hide:t=>(r.on("hide.attach",e=>{t(e)}),i),update:t=>(r.on("update.attach",e=>{t(e)}),i),move:t=>(r.on("move.attach",e=>{t(e)}),i)};return i}}update(e,t){var i=Tooltip.active[e];i?(i.needsUpdate=!0,i.options.html=t,this.show(e)):console.log(`Tooltip "${e}" is not displayed. Cannot update it.`)}show(i){if(i instanceof HTMLElement||i instanceof Object){let e=i,t=(i instanceof HTMLElement&&((e=arguments[1]||{}).anchor=i),this.attach(e));return query(t.overlay.anchor).off(".autoShow-"+t.overlay.name).off(".autoHide-"+t.overlay.name),setTimeout(()=>{this.show(t.overlay.name)},1),t}let t,r=this,n=Tooltip.active[i.replace(/[\s\.#]/g,"_")];if(n){let l=n.options;if(!n||n.displayed&&!n.needsUpdate)this.resize(n?.name);else{var s=l.position.split("|"),s=["top","bottom"].includes(s[0]);let e="both"==l.align&&s?"":"white-space: nowrap;";if(l.maxWidth&&w2utils.getStrWidth(l.html,"")>l.maxWidth&&(e="width: "+l.maxWidth+"px; white-space: inherit; overflow: auto;"),e+=" max-height: "+(l.maxHeight||window.innerHeight-40)+"px;",""!==l.html&&null!=l.html){if(n.box){if(!0===(t=this.trigger("update",{target:i,overlay:n})).isCancelled)return void(n.prevOptions&&(n.options=n.prevOptions,delete n.prevOptions));query(n.box).find(".w2ui-overlay-body").attr("style",(l.style||"")+"; "+e).removeClass().addClass("w2ui-overlay-body "+l.class).html(l.html)}else{if(!0===(t=this.trigger("show",{target:i,overlay:n})).isCancelled)return;query("body").append(``),n.box=query("#"+w2utils.escapeId(n.id))[0],n.displayed=!0;s=query(n.anchor).data("tooltipName")??[];s.push(i),query(n.anchor).data("tooltipName",s),w2utils.bindEvents(n.box,{}),n.tmp.originalCSS="",0{r.hide(n.name)},i=query(n.anchor),s="tooltip-"+n.name;query("body").off("."+s),l.hideOn.includes("doc-click")&&(["INPUT","TEXTAREA"].includes(n.anchor.tagName)&&i.off(`.${s}-doc`).on(`click.${s}-doc`,e=>{e.stopPropagation()}),query("body").on("click."+s,t));l.hideOn.includes("focus-change")&&query("body").on("focusin."+s,e=>{document.activeElement!=n.anchor&&r.hide(n.name)});["INPUT","TEXTAREA"].includes(n.anchor.tagName)&&(i.off("."+s),l.hideOn.forEach(e=>{-1==["doc-click","focus-change"].indexOf(e)&&i.on(e+"."+s,{once:!0},t)}))}{var a=document.body;let e="tooltip-"+n.name,t=a;"BODY"==a.tagName&&(t=a.ownerDocument);query(t).off("."+e).on("scroll."+e,e=>{Object.assign(n.tmp,{scrollLeft:a.scrollLeft,scrollTop:a.scrollTop}),r.resize(n.name)})}return query(n.box).show(),n.tmp.observeResize.observe(n.box),Tooltip.observeRemove.observe(document.body,{subtree:!0,childList:!0}),query(n.box).css("opacity",1).find(".w2ui-overlay-body").html(l.html),setTimeout(()=>{query(n.box).css({"pointer-events":"auto"}).data("ready","yes")},100),delete n.needsUpdate,n.box.overlay=n,t&&t.finish(),{overlay:n}}r.hide(i)}}}hide(e){let i;if(0==arguments.length)Object.keys(Tooltip.active).forEach(e=>{this.hide(e)});else if(e instanceof HTMLElement)(query(e).data("tooltipName")??[]).forEach(e=>{this.hide(e)});else if("string"==typeof e&&(e=e.replace(/[\s\.#]/g,"_"),i=Tooltip.active[e]),i&&i.box){delete Tooltip.active[e];e=this.trigger("hide",{target:e,overlay:i});if(!0!==e.isCancelled){var s="tooltip-"+i.name;i.tmp.observeResize?.disconnect(),i.options.watchScroll&&query(i.options.watchScroll).off(".w2scroll-"+i.name);let t=0;Object.keys(Tooltip.active).forEach(e=>{Tooltip.active[e].displayed&&t++}),0==t&&Tooltip.observeRemove.disconnect(),query("body").off("."+s),query(document).off("."+s),i.box.remove(),i.box=null,i.displayed=!1;var l=query(i.anchor).data("tooltipName")??[];-1!=l.indexOf(i.name)&&l.splice(l.indexOf(i.name),1),0==l.length?query(i.anchor).removeData("tooltipName"):query(i.anchor).data("tooltipName",l),i.anchor.style.cssText=i.tmp.originalCSS,query(i.anchor).off("."+s).removeClass(i.options.anchorClass),e.finish()}}}resize(i){if(0==arguments.length)Object.keys(Tooltip.active).forEach(e=>{e=Tooltip.active[e];e.displayed&&this.resize(e.name)});else{var s=Tooltip.active[i.replace(/[\s\.#]/g,"_")];let t=this.getPosition(s.name);var l=t.left+"x"+t.top;let e;s.tmp.lastPos!=l&&(e=this.trigger("move",{target:i,overlay:s,pos:t})),query(s.box).css({left:t.left+"px",top:t.top+"px"}).then(e=>{null!=t.width&&e.css("width",t.width+"px").find(".w2ui-overlay-body").css("width","100%"),null!=t.height&&e.css("height",t.height+"px").find(".w2ui-overlay-body").css("height","100%")}).find(".w2ui-overlay-body").removeClass("w2ui-arrow-right w2ui-arrow-left w2ui-arrow-top w2ui-arrow-bottom").addClass(t.arrow.class).closest(".w2ui-overlay").find("style").text(t.arrow.style),s.tmp.lastPos!=l&&e&&(s.tmp.lastPos=l,e.finish())}}getPosition(e){let g=Tooltip.active[e.replace(/[\s\.#]/g,"_")];if(g&&g.box){let t=g.options;(g.tmp.resizedY||g.tmp.resizedX)&&query(g.box).css({width:"",height:"",scroll:"auto"});var e=w2utils.scrollBarSize(),y=!(document.body.scrollWidth==document.body.clientWidth),w=!(document.body.scrollHeight==document.body.clientHeight);let i={width:window.innerWidth-(w?e:0),height:window.innerHeight-(y?e:0)};var b,v=("auto"==t.position?"top|bottom|right|left":t.position).split("|");let s=["top","bottom"].includes(v[0]),l=g.box.getBoundingClientRect(),r=g.anchor.getBoundingClientRect(),n=(g.anchor==document.body&&({x,y:_,width:q,height:C}=t.originalEvent,r={left:x-2,top:_-4,width:q,height:C,arrow:"none"}),t.arrowSize),a=("none"==r.arrow&&(n=0),{top:r.top,bottom:i.height-(r.top+r.height)-+(y?e:0),left:r.left,right:i.width-(r.left+r.width)+(w?e:0)});l.width<22&&(l.width=22),l.height<14&&(l.height=14);let o,h,d,u,c="",p={offset:0,class:"",style:`#${g.id} { --tip-size: ${n}px; }`},f={left:0,top:0},m={posX:"",x:0,posY:"",y:0};v.forEach(e=>{["top","bottom"].includes(e)&&(!c&&l.height+n/1.893m.y&&Object.assign(m,{posY:e,y:a[e]})),["left","right"].includes(e)&&(!c&&l.width+n/1.893m.x&&Object.assign(m,{posX:e,x:a[e]}))}),c=c||(s?m.posY:m.posX),t.autoResize&&(["top","bottom"].includes(c)&&(l.height>a[c]?(u=a[c],g.tmp.resizedY=!0):g.tmp.resizedY=!1),["left","right"].includes(c)&&(l.width>a[c]?(d=a[c],g.tmp.resizedX=!0):g.tmp.resizedX=!1));var x=c;switch(p.class=r.arrow||"w2ui-arrow-"+x,x){case"top":o=r.left+(r.width-(d??l.width))/2,h=r.top-(u??l.height)-n/1.5+1;break;case"bottom":o=r.left+(r.width-(d??l.width))/2,h=r.top+r.height+n/1.25+1;break;case"left":o=r.left-(d??l.width)-n/1.2-1,h=r.top+(r.height-(u??l.height))/2;break;case"right":o=r.left+r.width+n/1.2+1,h=r.top+(r.height-(u??l.height))/2}if(s)"left"==t.align&&(f.left=r.left-o,o=r.left),"right"==t.align&&(f.left=r.left+r.width-(d??l.width)-o,o=r.left+r.width-(d??l.width)),["top","bottom"].includes(c)&&t.align.startsWith("both")&&(b=t.align.split(":")[1]??50,r.width>=b&&(o=r.left,d=r.width)),"top"==t.align&&(f.top=r.top-h,h=r.top),"bottom"==t.align&&(f.top=r.top+r.height-(u??l.height)-h,h=r.top+r.height-(u??l.height)),["left","right"].includes(c)&&t.align.startsWith("both")&&(b=t.align.split(":")[1]??50,r.height>=b&&(h=r.top,u=r.height));{let e;(["left","right"].includes(t.align)&&r.width<(d??l.width)||["top","bottom"].includes(t.align)&&r.height<(u??l.height))&&(e=!0);var _="right"==c?n:t.screenMargin,q="bottom"==c?n:t.screenMargin,C=i.width-(d??l.width)-("left"==c?n:t.screenMargin),y=i.height-(u??l.height)-("top"==c?n:t.screenMargin)+3;(["top","bottom"].includes(c)||t.autoResize)&&(o<_&&(e=!0,f.left-=o,o=_),o>C&&(e=!0,f.left-=o-C,o+=C-o));(["left","right"].includes(c)||t.autoResize)&&(hy&&(e=!0,f.top-=h-y,h+=y-h));e&&(_=s?"left":"top",C=s?"width":"height",p.offset=-f[_],q=l[C]/2-n,Math.abs(p.offset)>q+n&&(p.class=""),Math.abs(p.offset)>q&&(p.offset=p.offset<0?-q:q),p.style=w2utils.stripSpaces(`#${g.id} .w2ui-overlay-body:after,
- #${g.id} .w2ui-overlay-body:before {
- --tip-size: ${n}px;
- margin-${_}: ${p.offset}px;
- }`))}w="top"==c?-t.margin:"bottom"==c?t.margin:0,e="left"==c?-t.margin:"right"==c?t.margin:0;return h=Math.floor(100*(h+parseFloat(t.offsetY)+parseFloat(w)))/100,{left:o=Math.floor(100*(o+parseFloat(t.offsetX)+parseFloat(e)))/100,top:h,arrow:p,adjust:f,width:d,height:u,pos:c}}}}class ColorTooltip extends Tooltip{constructor(){super(),this.palette=[["000000","333333","555555","777777","888888","999999","AAAAAA","CCCCCC","DDDDDD","EEEEEE","F7F7F7","FFFFFF"],["FF011B","FF9838","FFC300","FFFD59","86FF14","14FF7A","2EFFFC","2693FF","006CE7","9B24F4","FF21F5","FF0099"],["FFEAEA","FCEFE1","FCF4DC","FFFECF","EBFFD9","D9FFE9","E0FFFF","E8F4FF","ECF4FC","EAE6F4","FFF5FE","FCF0F7"],["F4CCCC","FCE5CD","FFF1C2","FFFDA1","D5FCB1","B5F7D0","BFFFFF","D6ECFF","CFE2F3","D9D1E9","FFE3FD","FFD9F0"],["EA9899","F9CB9C","FFE48C","F7F56F","B9F77E","84F0B1","83F7F7","B5DAFF","9FC5E8","B4A7D6","FAB9F6","FFADDE"],["E06666","F6B26B","DEB737","E0DE51","8FDB48","52D189","4EDEDB","76ACE3","6FA8DC","8E7CC3","E07EDA","F26DBD"],["CC0814","E69138","AB8816","B5B20E","6BAB30","27A85F","1BA8A6","3C81C7","3D85C6","674EA7","A14F9D","BF4990"],["99050C","B45F17","80650E","737103","395E14","10783D","13615E","094785","0A5394","351C75","780172","782C5A"]],this.defaults=w2utils.extend({},this.defaults,{advanced:!1,transparent:!0,position:"top|bottom",class:"w2ui-white",color:"",liveUpdate:!0,arrowSize:12,autoResize:!1,anchorClass:"w2ui-focus",autoShowOn:"focus",hideOn:["doc-click","focus-change"],onSelect:null,onLiveUpdate:null})}attach(e,t){let i;1==arguments.length&&e.anchor?e=(i=e).anchor:2===arguments.length&&null!=t&&"object"==typeof t&&((i=t).anchor=e);t=i.hideOn;i=w2utils.extend({},this.defaults,i||{}),t&&(i.hideOn=t),i.style+="; padding: 0;",i.transparent&&"333333"==this.palette[0][1]&&(this.palette[0].splice(1,1),this.palette[0].push("")),i.transparent||"333333"==this.palette[0][1]||(this.palette[0].splice(1,0,"333333"),this.palette[0].pop()),i.color&&(i.color=String(i.color).toUpperCase()),"string"==typeof i.color&&"#"===i.color.substr(0,1)&&(i.color=i.color.substr(1)),this.index=[-1,-1];let s=super.attach(i),l=s.overlay;return l.options.html=this.getColorHTML(l.name,i),l.on("show.attach",e=>{var e=e.detail.overlay,t=e.anchor,i=e.options;["INPUT","TEXTAREA"].includes(t.tagName)&&!i.color&&t.value&&(e.tmp.initColor=t.value),delete e.newColor}),l.on("show:after.attach",e=>{var t;s.overlay?.box&&(t=query(s.overlay.box).find(".w2ui-eaction"),w2utils.bindEvents(t,this),this.initControls(s.overlay))}),l.on("update:after.attach",e=>{var t;s.overlay?.box&&(t=query(s.overlay.box).find(".w2ui-eaction"),w2utils.bindEvents(t,this),this.initControls(s.overlay))}),l.on("hide.attach",e=>{var e=e.detail.overlay,t=e.anchor,i=e.newColor??e.options.color??"",t=(["INPUT","TEXTAREA"].includes(t.tagName)&&t.value!=i&&(t.value=i),this.trigger("select",{color:i,target:e.name,overlay:e}));!0!==t.isCancelled&&t.finish()}),s.liveUpdate=t=>(l.on("liveUpdate.attach",e=>{t(e)}),s),s.select=t=>(l.on("select.attach",e=>{t(e)}),s),s}select(e,t){let i;this.index=[-1,-1],"string"!=typeof t&&(i=t.target,this.index=query(i).attr("index").split(":"),t=query(i).closest(".w2ui-overlay").attr("name"));var s=this.get(t),t=this.trigger("liveUpdate",{color:e,target:t,overlay:s,param:arguments[1]});!0!==t.isCancelled&&(["INPUT","TEXTAREA"].includes(s.anchor.tagName)&&s.options.liveUpdate&&query(s.anchor).val(e),s.newColor=e,query(s.box).find(".w2ui-selected").removeClass("w2ui-selected"),i&&query(i).addClass("w2ui-selected"),t.finish())}nextColor(e){var t=this.palette;switch(e){case"up":this.index[0]--;break;case"down":this.index[0]++;break;case"right":this.index[1]++;break;case"left":this.index[1]--}return this.index[0]<0&&(this.index[0]=0),this.index[0]>t.length-2&&(this.index[0]=t.length-2),this.index[1]<0&&(this.index[1]=0),this.index[1]>t[0].length-1&&(this.index[1]=t[0].length-1),t[this.index[0]][this.index[1]]}tabClick(e,t){"string"!=typeof t&&(t=query(t.target).closest(".w2ui-overlay").attr("name"));var t=this.get(t),i=query(t.box).find(`.w2ui-color-tab:nth-child(${e})`);query(t.box).find(".w2ui-color-tab").removeClass("w2ui-selected"),query(i).addClass("w2ui-selected"),query(t.box).find(".w2ui-tab-content").hide().closest(".w2ui-colors").find(".tab-"+e).show()}getColorHTML(s,l){let r=`
-
- `;for(let i=0;i ';for(let t=0;t
- `}r+="
-
-
-
- ${"string"==typeof l.html?l.html:""}
-
- |
`),query(this.box).find("#grid_"+this.name+"_frec_"+l).after(`
- ${this.show.lineNumbers?' | ':""}
-
-
- |
-
`),!0===(n=this.trigger("expand",{target:this.name,recid:e,box_id:"grid_"+this.name+"_rec_"+e+"_expanded",fbox_id:"grid_"+this.name+"_frec_"+l+"_expanded"})).isCancelled)return query(this.box).find("#grid_"+this.name+"_rec_"+l+"_expanded_row").remove(),query(this.box).find("#grid_"+this.name+"_frec_"+l+"_expanded_row").remove(),!1;i=query(this.box).find("#grid_"+this.name+"_rec_"+e+"_expanded"),r=query(this.box).find("#grid_"+this.name+"_frec_"+e+"_expanded"),t=i.find(":scope div:first-child")[0]?.clientHeight??50;i[0].clientHeight{query(this.box).find("#grid_"+this.name+"_rec_"+e+"_expanded_row").remove(),query(this.box).find("#grid_"+this.name+"_frec_"+e+"_expanded_row").remove(),l.w2ui.expanded=!1,n.finish(),this.resizeRecords()},300)}return!0}sort(i,e,s){var t=this.trigger("sort",{target:this.name,field:i,direction:e,multiField:s});if(!0!==t.isCancelled){if(null!=i){let t=this.sortData.length;for(let e=0;ei&&(i=s[e].column),-1==r.indexOf(s[e].index)&&r.push(s[e].index);r.sort((e,t)=>e-t);for(let e=0;e div.w2ui-grid-box").css("width",query(this.box)[0].clientWidth+"px").css("height",query(this.box)[0].clientHeight+"px");var t=this.trigger("resize",{target:this.name});if(!0!==t.isCancelled)return this.resizeBoxes(),this.resizeRecords(),t.finish(),Date.now()-e}}update({cells:t,fullCellRefresh:i,ignoreColumns:e}={}){var s=Date.now();let u=this;if(null==this.box)return 0;if(Array.isArray(t))for(let e=0;e!!e);e.classList.forEach(e=>{t.includes(e)||i.push(e)}),e.classList.remove(...i),e.classList.add(...o)}}if(u.columns[t].style&&u.columns[t].style!=e.style.cssText&&(e.style.cssText=u.columns[t].style??""),null!=s.w2ui.class){if("string"==typeof s.w2ui.class){let t=["w2ui-odd","w2ui-even","w2ui-record"],i=[];n=s.w2ui.class.split(" ").filter(e=>!!e);l&&r&&(l.classList.forEach(e=>{t.includes(e)||i.push(e)}),l.classList.remove(...i),l.classList.add(...n),r.classList.remove(...i),r.classList.add(...n))}if(w2utils.isPlainObject(s.w2ui.class)&&"string"==typeof s.w2ui.class[a.field]){let t=["w2ui-grid-data"],i=[];h=s.w2ui.class[a.field].split(" ").filter(e=>!!e);e.classList.forEach(e=>{t.includes(e)||i.push(e)}),e.classList.remove(...i),e.classList.add(...h)}}null!=s.w2ui.style&&(l&&r&&"string"==typeof s.w2ui.style&&l.style.cssText!==s.w2ui.style&&(l.style.cssText="height: "+u.recordHeight+"px;"+s.w2ui.style,l.setAttribute("custom_style",s.w2ui.style),r.style.cssText="height: "+u.recordHeight+"px;"+s.w2ui.style,r.setAttribute("custom_style",s.w2ui.style)),w2utils.isPlainObject(s.w2ui.style)&&"string"==typeof s.w2ui.style[a.field]&&e.style.cssText!==s.w2ui.style[a.field]&&(e.style.cssText=s.w2ui.style[a.field]))}}}}refreshCell(e,t){var i=this.get(e,!0),t=this.getColumn(t,!0),e=!this.records[i]||this.records[i].recid!=e,s=query(this.box).find(`${e?".w2ui-grid-summary ":""}#grid_${this.name}_data_${i}_`+t);return 0!=s.length&&(s.replace(this.getCellHTML(i,t,e)),!0)}refreshRow(t,i=null){let s=query(this.box).find("#grid_"+this.name+"_frec_"+w2utils.escapeId(t)),l=query(this.box).find("#grid_"+this.name+"_rec_"+w2utils.escapeId(t));if(0{var t=[];for(let e=0;e{var t=query(this.box).find('td[col="'+e.col+'"]:not(.w2ui-head)');w2utils.marker(t,e.search)})},50),this.updateToolbar(),t.finish(),this.resize(),this.addRange("selection"),setTimeout(()=>{this.resize(),this.scroll()},1),this.reorderColumns&&!this.last.columnDrag?this.last.columnDrag=this.initColumnDrag():!this.reorderColumns&&this.last.columnDrag&&this.last.columnDrag.remove(),Date.now()-e}}}refreshSearch(){if(this.multiSearch&&0`);let r=`
-
- `;this.searchData.forEach((i,e)=>{var t=this.getSearch(i.field,!0),s=this.searches[t];let l;if(l=Array.isArray(i.value)?`${i.value.length}`:": "+i.value,s&&"date"==s.type)if("between"==i.operator){let e=i.value[0],t=i.value[1];Number(e)===e&&(e=w2utils.formatDate(e)),Number(t)===t&&(t=w2utils.formatDate(t)),l=`: ${e} - `+t}else{let e=i.value,t=(Number(e)==e&&(e=w2utils.formatDate(e)),i.operator);"more:"==(t="less"==(t="more"==t?"since":t)?"before":t).substr(0,5)&&(t="since"),l=`: ${t} `+e}r+=`
- ${s?s.label:""}
- ${l}
-
- `}),r+=`
- ${this.show.searchSave?`
-
- `:""}
-
- `,query(this.box).find(`#grid_${this.name}_searches`).html(r),query(this.box).find(`#grid_${this.name}_search_logic`).html(w2utils.lang("AND"==this.last.logic?"All":"Any"))}else query(this.box).find(".w2ui-grid-toolbar").css("height",this.last.toolbar_height+"px").find(".w2ui-grid-searches").remove();this.searchSelected?(query(this.box).find(`#grid_${this.name}_search_all`).val(" ").prop("readOnly",!0),query(this.box).find(`#grid_${this.name}_search_name`).show().find(".name-text").html(this.searchSelected.text)):(query(this.box).find(`#grid_${this.name}_search_all`).prop("readOnly",!1),query(this.box).find(`#grid_${this.name}_search_name`).hide().find(".name-text").html("")),w2utils.bindEvents(query(this.box).find(`#grid_${this.name}_searches .w2ui-action, #grid_${this.name}_searches button`),this)}refreshBody(){this.scroll();var e=this.getRecordsHTML(),t=this.getColumnsHTML(),e=''+e[0]+'
'+e[1]+'
"+``;let l=query(this.box).find(`#grid_${this.name}_body`,this.box).html(e);t=query(this.box).find(`#grid_${this.name}_records`,this.box),e=query(this.box).find(`#grid_${this.name}_frecords`,this.box);"row"==this.selectType&&(t.on("mouseover mouseout",{delegate:"tr"},e=>{var t=query(e.delegate).attr("recid");query(this.box).find(`#grid_${this.name}_frec_`+w2utils.escapeId(t)).toggleClass("w2ui-record-hover","mouseover"==e.type)}),e.on("mouseover mouseout",{delegate:"tr"},e=>{var t=query(e.delegate).attr("recid");query(this.box).find(`#grid_${this.name}_rec_`+w2utils.escapeId(t)).toggleClass("w2ui-record-hover","mouseover"==e.type)})),w2utils.isIOS?t.append(e).on("click",{delegate:"tr"},e=>{var t=query(e.delegate).attr("recid");this.dblClick(t,e)}):t.add(e).on("click",{delegate:"tr"},e=>{var t=query(e.delegate).attr("recid");"-none-"!=t&&this.click(t,e)}).on("contextmenu",{delegate:"tr"},e=>{var t=query(e.delegate).attr("recid");this.showContextMenu(t,null,e)}).on("mouseover",{delegate:"tr"},e=>{this.last.rec_out=!1;let t=query(e.delegate).attr("index"),i=query(e.delegate).attr("recid");t!==this.last.rec_over&&(this.last.rec_over=t,setTimeout(()=>{delete this.last.rec_out,this.trigger("mouseEnter",{target:this.name,originalEvent:e,index:t,recid:i}).finish()}))}).on("mouseout",{delegate:"tr"},t=>{let i=query(t.delegate).attr("index"),s=query(t.delegate).attr("recid");this.last.rec_out=!0,setTimeout(()=>{let e=()=>{this.trigger("mouseLeave",{target:this.name,originalEvent:t,index:i,recid:s}).finish()};i!==this.last.rec_over&&e(),setTimeout(()=>{this.last.rec_out&&(delete this.last.rec_out,delete this.last.rec_over,e())})})}),l.data("scroll",{lastDelta:0,lastTime:0}).find(".w2ui-grid-frecords").on("mousewheel DOMMouseScroll ",e=>{e.preventDefault();var t=l.data("scroll"),i=l.find(".w2ui-grid-records"),e=null!=typeof e.wheelDelta?-e.wheelDelta:e.detail||e.deltaY,s=i.prop("scrollTop");t.lastDelta+=e,e=Math.round(t.lastDelta),l.data("scroll",t),i.get(0).scroll({top:s+e,behavior:"smooth"})}),t.off(".body-global").on("scroll.body-global",{delegate:".w2ui-grid-records"},e=>{this.scroll(e)}),query(this.box).find(".w2ui-grid-body").off(".body-global").on("click.body-global dblclick.body-global contextmenu.body-global",{delegate:"td.w2ui-head"},e=>{var t=query(e.delegate).attr("col"),i=this.columns[t]??{field:t};switch(e.type){case"click":this.columnClick(i.field,e);break;case"dblclick":this.columnDblClick(i.field,e);break;case"contextmenu":this.show.columnMenu&&(w2menu.show({type:"check",anchor:document.body,originalEvent:e,items:this.initColumnOnOff()}).then(()=>{query("#w2overlay-context-menu .w2ui-grid-skip").off(".w2ui-grid").on("click.w2ui-grid",e=>{e.stopPropagation()}).on("keypress",e=>{13==e.keyCode&&(this.skip(e.target.value),this.toolbar.click("w2ui-column-on-off"))})}).select(e=>{var t=e.detail.item.id;["w2ui-stateSave","w2ui-stateReset"].includes(t)?this[t.substring(5)]():"w2ui-skip"!=t&&this.columnOnOff(e,e.detail.item.id),clearTimeout(this.last.kbd_timer)}),clearTimeout(this.last.kbd_timer)),e.preventDefault()}}).on("mouseover.body-global",{delegate:".w2ui-col-header"},e=>{let t=query(e.delegate).parent().attr("col");this.columnTooltipShow(t,e),query(e.delegate).off(".tooltip").on("mouseleave.tooltip",()=>{this.columnTooltipHide(t,e)})}).on("click.body-global",{delegate:"input.w2ui-select-all"},e=>{e.delegate.checked?this.selectAll():this.selectNone(),e.stopPropagation(),clearTimeout(this.last.kbd_timer)}).on("click.body-global",{delegate:".w2ui-show-children, .w2ui-col-expand"},e=>{e.stopPropagation(),this.toggle(query(e.target).parents("tr").attr("recid"))}).on("click.body-global mouseover.body-global",{delegate:".w2ui-info"},e=>{var t=query(e.delegate).closest("td"),i=t.parent(),s=this.columns[t.attr("col")],l=i.parents(".w2ui-grid-body").hasClass("w2ui-grid-summary");["mouseenter","mouseover"].includes(s.info?.showOn?.toLowerCase())&&"mouseover"==e.type?this.showBubble(i.attr("index"),t.attr("col"),l).then(()=>{query(e.delegate).off(".tooltip").on("mouseleave.tooltip",()=>{w2tooltip.hide(this.name+"-bubble")})}):"click"==e.type&&(w2tooltip.hide(this.name+"-bubble"),this.showBubble(i.attr("index"),t.attr("col"),l))}).on("mouseover.body-global",{delegate:".w2ui-clipboard-copy"},l=>{if(!l.delegate._tooltipShow){let t=query(l.delegate).parent(),i=t.parent();var e=this.columns[t.attr("col")];let s=i.parents(".w2ui-grid-body").hasClass("w2ui-grid-summary");w2tooltip.show({name:this.name+"-bubble",anchor:l.delegate,html:w2utils.lang("string"==typeof e.clipboardCopy?e.clipboardCopy:"Copy to clipboard"),position:"top|bottom",offsetY:-2}).hide(e=>{l.delegate._tooltipShow=!1,query(l.delegate).off(".tooltip")}),query(l.delegate).off(".tooltip").on("mouseleave.tooltip",e=>{w2tooltip.hide(this.name+"-bubble")}).on("click.tooltip",e=>{e.stopPropagation(),w2tooltip.update(this.name+"-bubble",w2utils.lang("Copied")),this.clipboardCopy(i.attr("index"),t.attr("col"),s)}),l.delegate._tooltipShow=!0}}).on("click.body-global",{delegate:".w2ui-editable-checkbox"},e=>{var t=query(e.delegate).data();this.editChange.call(this,e.delegate,t.changeind,t.colind,e),this.updateToolbar()}),0===this.records.length&&this.msgEmpty?query(this.box).find(`#grid_${this.name}_body`).append(``):0=this.searches.length?(this.last.field="",this.last.label=""):(this.last.field=this.searches[e].field,this.last.label=this.searches[e].label)}if(query(this.box).attr("name",this.name).addClass("w2ui-reset w2ui-grid w2ui-inactive").html('"),"row"!=this.selectType&&query(this.box).addClass("w2ui-ss"),0{this.searchInitInput(this.last.field,1==e.length?e[0].value:null)},1)}query(this.box).find(`#grid_${this.name}_footer`).html(this.getFooterHTML()),this.last.state||(this.last.state=this.stateSave(!0)),this.stateRestore(),e&&(this.clear(),this.refresh());let t=!1;for(let e=0;e{this.searchReset()},1)):this.reload(),query(this.box).find(`#grid_${this.name}_focus`).on("focus",e=>{clearTimeout(this.last.kbd_timer),this.hasFocus||this.focus()}).on("blur",e=>{clearTimeout(this.last.kbd_timer),this.last.kbd_timer=setTimeout(()=>{this.hasFocus&&this.blur()},100)}).on("paste",i=>{var s=i.clipboardData||null;if(s){let e=s.items,t=[];for(var l in e=2==e.length&&2==(e=2==e.length&&"file"==e[1].kind?[e[1]]:e).length&&"text/plain"==e[0].type&&"text/html"==e[1].type?[e[1]]:e){l=e[l];if("file"===l.kind){var r=l.getAsFile();t.push({kind:"file",data:r})}else if("string"===l.kind&&("text/plain"===l.type||"text/html"===l.type)){i.preventDefault();let e=s.getData("text/plain");-1!=e.indexOf("\r")&&-1==e.indexOf("\n")&&(e=e.replace(/\r/g,"\n")),t.push({kind:"text/html"==l.type?"html":"text",data:e})}}1===t.length&&"file"!=t[0].kind&&(t=t[0].data),w2ui[this.name].paste(t,i),i.preventDefault()}}).on("keydown",function(e){w2ui[p.name].keydown.call(w2ui[p.name],e)});let c;return query(this.box).off("mousedown.mouseStart").on("mousedown.mouseStart",function(l){if(1==l.which&&("text"==p.last.userSelect&&(p.last.userSelect="",query(p.box).find(".w2ui-grid-body").css("user-select","none")),!("row"==p.selectType&&(query(l.target).parents().hasClass("w2ui-head")||query(l.target).hasClass("w2ui-head"))||p.last.move&&"expand"==p.last.move.type))){if(l.altKey)query(p.box).find(".w2ui-grid-body").css("user-select","text"),p.selectNone(),p.last.move={type:"text-select"},p.last.userSelect="text";else{let e=l.target;var r={x:l.offsetX-10,y:l.offsetY-10};let t=!1;for(;e&&(!e.classList||!e.classList.contains("w2ui-grid"));)e.tagName&&"TD"==e.tagName.toUpperCase()&&(t=!0),e.tagName&&"TR"!=e.tagName.toUpperCase()&&1==t&&(r.x+=e.offsetLeft,r.y+=e.offsetTop),e=e.parentNode;p.last.move={x:l.screenX,y:l.screenY,divX:0,divY:0,focusX:r.x,focusY:r.y,recid:query(l.target).parents("tr").attr("recid"),column:parseInt(("TD"==l.target.tagName.toUpperCase()?query(l.target):query(l.target).parents("td")).attr("col")),type:"select",ghost:!1,start:!0},null==p.last.move.recid&&(p.last.move.type="select-column");let i=l.target,s=query(p.box).find("#grid_"+p.name+"_focus");if(p.last.move){let e=p.last.move.focusX,t=p.last.move.focusY;var n=query(i).parents("table").parent();(n.hasClass("w2ui-grid-records")||n.hasClass("w2ui-grid-frecords")||n.hasClass("w2ui-grid-columns")||n.hasClass("w2ui-grid-fcolumns")||n.hasClass("w2ui-grid-summary"))&&(e=p.last.move.focusX-query(p.box).find("#grid_"+p.name+"_records").prop("scrollLeft"),t=p.last.move.focusY-query(p.box).find("#grid_"+p.name+"_records").prop("scrollTop")),(query(i).hasClass("w2ui-grid-footer")||0{p.last.inEditMode||(["INPUT","TEXTAREA","SELECT"].includes(i.tagName)?i.focus():s.get(0)!==document.active&&s.get(0).focus({preventScroll:!0}))},50),p.multiSelect||p.reorderRows||"drag"!=p.last.move.type||delete p.last.move}if(1==p.reorderRows){let e=l.target;var t,i,s,a;"TD"!=e.tagName.toUpperCase()&&(e=query(e).parents("td")[0]),query(e).hasClass("w2ui-col-number")||query(e).hasClass("w2ui-col-order")?(p.selectNone(),p.last.move.reorder=!0,n=query(p.box).find(".w2ui-even.w2ui-empty-record").css("background-color"),t=query(p.box).find(".w2ui-odd.w2ui-empty-record").css("background-color"),query(p.box).find(".w2ui-even td").filter(":not(.w2ui-col-number)").css("background-color",n),query(p.box).find(".w2ui-odd td").filter(":not(.w2ui-col-number)").css("background-color",t),t=p.last.move,i=query(p.box).find(".w2ui-grid-records"),t.ghost||(s=query(p.box).find(`#grid_${p.name}_rec_`+t.recid),a=s.parents("table").find("tr:first-child").get(0).cloneNode(!0),t.offsetY=l.offsetY,t.from=t.recid,t.pos={top:s.get(0).offsetTop-1,left:s.get(0).offsetLeft},t.ghost=query(s.get(0).cloneNode(!0)),t.ghost.removeAttr("id"),t.ghost.find("td").css({"border-top":"1px solid silver","border-bottom":"1px solid silver"}),s.find("td").remove(),s.append(` | `),i.append(''),i.append(''),query(p.box).find("#grid_"+p.name+"_ghost").append(a).append(t.ghost)),query(p.box).find("#grid_"+p.name+"_ghost").css({top:t.pos.top+"px",left:t.pos.left+"px"})):p.last.move.reorder=!1}query(document).on("mousemove.w2ui-"+p.name,o).on("mouseup.w2ui-"+p.name,h),l.stopPropagation()}}),this.updateToolbar(),s.finish(),this.last.observeResize=new ResizeObserver(()=>{this.resize()}),this.last.observeResize.observe(this.box),Date.now()-i;function o(t){if(t.target.tagName){var r=p.last.move;if(r&&-1!=["select","select-column"].indexOf(r.type)&&(r.divX=t.screenX-r.x,r.divY=t.screenY-r.y,!(Math.abs(r.divX)<=1&&Math.abs(r.divY)<=1)))if(p.last.cancelClick=!0,1==p.reorderRows&&p.last.move.reorder){let e=query(t.target).parents("tr").attr("recid");(e="-none-"==e?"bottom":e)!=r.from&&(a=query(p.box).find("#grid_"+p.name+"_rec_"+e),query(p.box).find(".insert-before"),a.addClass("insert-before"),r.lastY=t.screenY,r.to=e,a={top:a.get(0)?.offsetTop,left:a.get(0)?.offsetLeft},query(p.box).find("#grid_"+p.name+"_ghost_line").css({top:a.top+"px",left:r.pos.left+"px","border-top":"2px solid #769EFC"})),void query(p.box).find("#grid_"+p.name+"_ghost").css({top:r.pos.top+r.divY+"px",left:r.pos.left+"px"})}else{r.start&&r.recid&&(p.selectNone(),r.start=!1);var n=[],a=("TR"==t.target.tagName.toUpperCase()?query(t.target):query(t.target).parents("tr")).attr("recid");if(null==a){if("row"!=p.selectType&&(!p.last.move||"select"!=p.last.move.type)){var o=parseInt(query(t.target).parents("td").attr("col"));if(isNaN(o))p.removeRange("column-selection"),query(p.box).find(".w2ui-grid-columns .w2ui-col-header, .w2ui-grid-fcolumns .w2ui-col-header").removeClass("w2ui-col-selected"),query(p.box).find(".w2ui-col-number").removeClass("w2ui-row-selected"),delete r.colRange;else{let e=o+"-"+o;r.columno?o+"-"+r.column:e).split("-");for(let e=parseInt(s[0]);e<=parseInt(s[1]);e++)i.push(e);if(r.colRange!=e&&!0!==(c=p.trigger("columnSelect",{target:p.name,columns:i})).isCancelled){null==r.colRange&&p.selectNone();var l=e.split("-");query(p.box).find(".w2ui-grid-columns .w2ui-col-header, .w2ui-grid-fcolumns .w2ui-col-header").removeClass("w2ui-col-selected");for(let e=parseInt(l[0]);e<=parseInt(l[1]);e++)query(p.box).find("#grid_"+p.name+"_column_"+e+" .w2ui-col-header").addClass("w2ui-col-selected");query(p.box).find(".w2ui-col-number").not(".w2ui-head").addClass("w2ui-row-selected"),r.colRange=e,p.removeRange("column-selection"),p.addRange({name:"column-selection",range:[{recid:p.records[0].recid,column:l[0]},{recid:p.records[p.records.length-1].recid,column:l[1]}],style:"background-color: rgba(90, 145, 234, 0.1)"})}}}}else{let l=p.get(r.recid,!0);if(!(null==l||p.records[l]&&p.records[l].recid!=r.recid)){let e=p.get(a,!0);if(null!=e){let i=parseInt(r.column),s=parseInt(("TD"==t.target.tagName.toUpperCase()?query(t.target):query(t.target).parents("td")).attr("col"));isNaN(i)&&isNaN(s)&&(i=0,s=p.columns.length-1),l>e&&(o=l,l=e,e=o);var h,a="ind1:"+l+",ind2;"+e+",col1:"+i+",col2:"+s;if(r.range!=a){r.range=a;for(let t=l;t<=e;t++)if(!(0s&&(h=i,i=s,s=h);for(let e=i;e<=s;e++)p.columns[e].hidden||n.push({recid:p.records[t].recid,column:parseInt(e)})}else n.push(p.records[t].recid);if("row"!=p.selectType){var d=p.getSelection();let e=[];for(let i=0;i{delete p.last.cancelClick},1),!query(t.target).parents().hasClass(".w2ui-head")&&!query(t.target).hasClass(".w2ui-head")){if(i&&-1!=["select","select-column"].indexOf(i.type)){if(null!=i.colRange&&!0!==c.isCancelled){var s=i.colRange.split("-"),l=[];for(let e=0;ee?p.records.splice(e,0,i):p.records.splice(e-1,0,i)),a(),t.finish()}else a()}delete p.last.move,query(document).off(".w2ui-"+p.name)}}function a(){query(p.box).find(`#grid_${p.name}_ghost`).remove(),query(p.box).find(`#grid_${p.name}_ghost_line`).remove(),p.refresh(),delete p.last.move}}}destroy(){var e=this.trigger("destroy",{target:this.name});!0!==e.isCancelled&&(query(this.box).off(),"object"==typeof this.toolbar&&this.toolbar.destroy&&this.toolbar.destroy(),0`+w2utils.lang("records"),i.push({id:"w2ui-skip",text:e,group:!1,icon:"w2ui-icon-empty"})),this.show.saveRestoreState&&i.push({id:"w2ui-stateSave",text:w2utils.lang("Save Grid State"),icon:"w2ui-icon-empty",group:!1},{id:"w2ui-stateReset",text:w2utils.lang("Restore Default State"),icon:"w2ui-icon-empty",group:!1});let t=[];return i.forEach(e=>{e.text=w2utils.lang(e.text),e.checked&&t.push(e.id)}),this.toolbar.set("w2ui-column-on-off",{selected:t,items:i}),i}initColumnDrag(e){if(this.columnGroups&&this.columnGroups.length)throw"Draggable columns are not currently supported with column groups.";let n=this,a={targetPos:null,pressed:!1,columnHead:null};function o(e){var t,i,s,l;a.pressed&&(t=e.pageX,i=e.pageY,e=e,0!=query(e.target).closest("td").length&&(l=query(n.box).find(".w2ui-grid-body").get(0).getBoundingClientRect(),s=query(e.target).closest("td").get(0).getBoundingClientRect(),query(n.box).find(".w2ui-intersection-marker").show().css({left:s.left-l.left+"px"}),a.targetPos=parseInt(query(e.target).closest("td").attr("col"))),s=t,l=i,query(a.ghost).css({left:s-10+"px",top:l-10+"px"}).show())}function h(e){if(a.pressed){a.pressed=!1;var t,i,s=query(n.box).find(".w2ui-grid-ghost"),e=n.trigger("columnDragEnd",{originalEvent:e,target:a.columnHead[0]});if(!0===e.isCancelled)return!1;t=n.columns[a.originalPos],i=n.columns,a.originalPos!=a.targetPos&&null!=a.targetPos&&(i.splice(a.targetPos,0,w2utils.clone(t)),i.splice(i.indexOf(t),1)),query(n.box).find(".w2ui-intersection-marker").hide(),query(a.ghost).remove(),s.remove(),query(document).off(".colDrag"),a={},n.refresh(),e.finish({targetColumn:NaN})}}return query(n.box).off(".colDrag").on("mousedown.colDrag",function(i){if(!a.pressed&&0!==a.numberPreColumnsPresent&&0===i.button){a.pressed=!0;var s,e,l=["w2ui-col-number","w2ui-col-expand","w2ui-col-select"].concat(["w2ui-head-last"]);if(query(i.target).parents().hasClass("w2ui-head")){for(let e=0,t=l.length;e${t}`)[0],query(document.body).append(a.ghost),query(a.ghost).css({display:"none",left:i.pageX,top:i.pageY,opacity:1,margin:"3px 0 0 20px",padding:"3px","background-color":"white",position:"fixed","z-index":999999}).addClass(".w2ui-grid-ghost"),a.offsets=[];for(let e=0,t=s.length;e
- ${this.buttons.search.html}
-
-
-
- x
-
-
-
-
-
- `,this.toolbar.items.push({id:"w2ui-search",type:"html",html:t,onRefresh:async e=>{await e.complete;e=query(this.box).find(`#grid_${this.name}_search_all`);w2utils.bindEvents(query(this.box).find(`#grid_${this.name}_search_all, .w2ui-action`),this),e.on("change",e=>{this.liveSearch||(this.search(this.last.field,e.target.value),this.searchSuggest(!0,!0,this))}).on("blur",()=>{this.last.liveText=""}).on("keyup",e=>{var t=e.target.value;this.liveSearch&&this.last.liveText!=t&&(this.last.liveText=t,this.search(this.last.field,t)),40==e.keyCode&&this.searchSuggest(!0)})}})),Array.isArray(e)&&(t=e.map(e=>e.id),this.show.toolbarAdd&&!t.includes(this.buttons.add.id)&&this.toolbar.items.push(w2utils.extend({},this.buttons.add)),this.show.toolbarEdit&&!t.includes(this.buttons.edit.id)&&this.toolbar.items.push(w2utils.extend({},this.buttons.edit)),this.show.toolbarDelete&&!t.includes(this.buttons.delete.id)&&this.toolbar.items.push(w2utils.extend({},this.buttons.delete)),this.show.toolbarSave&&!t.includes(this.buttons.save.id)&&((this.show.toolbarAdd||this.show.toolbarDelete||this.show.toolbarEdit)&&this.toolbar.items.push({type:"break",id:"w2ui-break2"}),this.toolbar.items.push(w2utils.extend({},this.buttons.save)))),this.toolbar.items.push(...e),this.toolbar.on("click",e=>{var i=this.trigger("toolbar",{target:e.target,originalEvent:e});if(!0!==i.isCancelled){let t;switch(e.detail.item.id){case"w2ui-reload":if(!0===(t=this.trigger("reload",{target:this.name})).isCancelled)return!1;this.reload(),t.finish();break;case"w2ui-column-on-off":e.detail.subItem?(s=e.detail.subItem.id,["w2ui-stateSave","w2ui-stateReset"].includes(s)?this[s.substring(5)]():"w2ui-skip"!=s&&this.columnOnOff(e,e.detail.subItem.id)):(this.initColumnOnOff(),setTimeout(()=>{query(`#w2overlay-${this.name}_toolbar-drop .w2ui-grid-skip`).off(".w2ui-grid").on("click.w2ui-grid",e=>{e.stopPropagation()}).on("keypress",e=>{13==e.keyCode&&(this.skip(e.target.value),this.toolbar.click("w2ui-column-on-off"))})},100));break;case"w2ui-add":if(!0===(t=this.trigger("add",{target:this.name,recid:null})).isCancelled)return!1;t.finish();break;case"w2ui-edit":{var s=this.getSelection();let e=null;if(1==s.length&&(e=s[0]),!0===(t=this.trigger("edit",{target:this.name,recid:e})).isCancelled)return!1;t.finish();break}case"w2ui-delete":this.delete();break;case"w2ui-save":this.save()}i.finish()}}),this.toolbar.on("refresh",e=>{if("w2ui-search"==e.target){let e=this.searchData;setTimeout(()=>{this.searchInitInput(this.last.field,1==e.length?e[0].value:null)},1)}}))}initResize(){let r=this;query(this.box).find(".w2ui-resizer").off(".grid-col-resize").on("click.grid-col-resize",function(e){e.stopPropagation?e.stopPropagation():e.cancelBubble=!0,e.preventDefault&&e.preventDefault()}).on("mousedown.grid-col-resize",function(e){e=e||window.event,r.last.colResizing=!0,r.last.tmp={x:e.screenX,y:e.screenY,gx:e.screenX,gy:e.screenY,col:parseInt(query(this).attr("name"))},r.last.tmp.tds=query(r.box).find("#grid_"+r.name+'_body table tr:first-child td[col="'+r.last.tmp.col+'"]'),e.stopPropagation?e.stopPropagation():e.cancelBubble=!0,e.preventDefault&&e.preventDefault();for(let e=0;e{r.resizeRecords(),r.scroll()},100),r.last.tmp.tds.css({width:t}),r.last.tmp.x=e.screenX,r.last.tmp.y=e.screenY))}).on("mouseup.grid-col-resize",function(e){query(document).off(".grid-col-resize"),r.resizeRecords(),r.scroll(),i.finish({originalEvent:e}),setTimeout(()=>{r.last.colResizing=!1},1)})}).on("dblclick.grid-col-resize",function(e){let t=parseInt(query(this).attr("name")),i=r.columns[t],s=0;if(!1===i.autoResize)return!0;e.stopPropagation?e.stopPropagation():e.cancelBubble=!0,e.preventDefault&&e.preventDefault(),query(r.box).find('.w2ui-grid-records td[col="'+t+'"] > div',r.box).each(()=>{var e=this.offsetWidth-this.scrollWidth;e{var t=query(e).get(0).parentNode;query(e).css({height:t.clientHeight+"px","margin-left":t.clientWidth-3+"px"})})}resizeBoxes(){var e=query(this.box).find(`#grid_${this.name}_header`),t=query(this.box).find(`#grid_${this.name}_toolbar`),i=query(this.box).find(`#grid_${this.name}_fsummary`),s=query(this.box).find(`#grid_${this.name}_summary`),l=query(this.box).find(`#grid_${this.name}_footer`),r=query(this.box).find(`#grid_${this.name}_body`);this.show.header&&e.css({top:"0px",left:"0px",right:"0px"}),this.show.toolbar&&t.css({top:0+(this.show.header?w2utils.getSize(e,"height"):0)+"px",left:"0px",right:"0px"}),0 div.w2ui-grid-box"),r=query(this.box).find(`#grid_${this.name}_header`),n=query(this.box).find(`#grid_${this.name}_toolbar`),a=query(this.box).find(`#grid_${this.name}_summary`),o=query(this.box).find(`#grid_${this.name}_fsummary`),h=query(this.box).find(`#grid_${this.name}_footer`),d=query(this.box).find(`#grid_${this.name}_body`),u=query(this.box).find(`#grid_${this.name}_columns`),c=query(this.box).find(`#grid_${this.name}_fcolumns`),p=query(this.box).find(`#grid_${this.name}_records`),f=query(this.box).find(`#grid_${this.name}_frecords`),m=query(this.box).find(`#grid_${this.name}_scroll1`);let g=8*String(this.total).length+10,y=(g<34&&(g=34),null!=this.lineNumberWidth&&(g=this.lineNumberWidth),!1),w=!1,b=0;for(let e=0;e table")[0]?.clientHeight??0)+(y?w2utils.scrollBarSize():0)&&(w=!0),this.fixedBody?(e=l[0]?.clientHeight-(this.show.header?w2utils.getSize(r,"height"):0)-(this.show.toolbar?w2utils.getSize(n,"height"):0)-("none"!=a.css("display")?w2utils.getSize(a,"height"):0)-(this.show.footer?w2utils.getSize(h,"height"):0),d.css("height",e+"px")):(r=(e=w2utils.getSize(u,"height")+w2utils.getSize(query(this.box).find("#grid_"+this.name+"_records table"),"height")+(y?w2utils.scrollBarSize():0))+(this.show.header?w2utils.getSize(r,"height"):0)+(this.show.toolbar?w2utils.getSize(n,"height"):0)+("none"!=a.css("display")?w2utils.getSize(a,"height"):0)+(this.show.footer?w2utils.getSize(h,"height"):0),l.css("height",r+"px"),d.css("height",e+"px"),s.css("height",w2utils.getSize(l,"height")+"px"));let v=this.records.length;n="object"!=typeof this.url?this.url:this.url.get;if(0==this.searchData.length||n||(v=this.last.searchIds.length),this.fixedBody||(w=!1),y||w?(u.find(":scope > table > tbody > tr:nth-child(1) td.w2ui-head-last").css("width",w2utils.scrollBarSize()+"px").show(),p.css({top:(0 table > tbody > tr:nth-child(1) td.w2ui-head-last").hide(),p.css({top:(0=this.recordHeight&&(e-=this.recordHeight,t++),this.fixedBody){for(let e=v;e',l+='',i.show.lineNumbers&&(s+=' | '),i.show.selectColumn&&(s+=' | '),i.show.expandColumn&&(s+=' | '),l+=' | ',i.show.orderColumn&&(l+=' | ');for(let e=0;ei.last.colEnd)&&!n.frozen||(r=' | ',n.frozen?s+=r:l+=r)}s+=' |
',l+=' | ',query(i.box).find("#grid_"+i.name+"_frecords > table").append(s),query(i.box).find("#grid_"+i.name+"_records > table").append(l)}let _,q;if(0_&&!0!==C.hidden&&(C.hidden=!0,i=!0),C.gridMinWidth<_&&!0===C.hidden&&(C.hidden=!1,i=!0))}if(!0===i)return void this.refresh();for(let e=0;eparseInt(E.max)&&(E.sizeCalculated=E.max+"px"),$+=parseInt(E.sizeCalculated))}let z=parseInt(_)-parseInt($);if(0 table > tbody > tr:nth-child(1) td.w2ui-head-last").css("width",w2utils.scrollBarSize()+"px").show();let A=1;this.show.lineNumbers&&(A+=g),this.show.selectColumn&&(A+=26),this.show.expandColumn&&(A+=26);for(let e=0;e table > tbody > tr:nth-child(1) td").add(c.find(":scope > table > tbody > tr:nth-child(1) td")).each(e=>{query(e).hasClass("w2ui-col-number")&&query(e).css("width",g+"px");var t=query(e).attr("col");if(null!=t){if("start"==t){let t=0;for(let e=0;e table > tbody > tr").length&&u.find(":scope > table > tbody > tr:nth-child(1) td").add(c.find(":scope > table > tbody > tr:nth-child(1) td")).html("").css({height:"0",border:"0",padding:"0",margin:"0"}),p.find(":scope > table > tbody > tr:nth-child(1) td").add(f.find(":scope > table > tbody > tr:nth-child(1) td")).each(e=>{query(e).hasClass("w2ui-col-number")&&query(e).css("width",g+"px");var t=query(e).attr("col");if(null!=t){if("start"==t){let t=0;for(let e=0;e table > tbody > tr:nth-child(1) td").add(o.find(":scope > table > tbody > tr:nth-child(1) td")).each(e=>{query(e).hasClass("w2ui-col-number")&&query(e).css("width",g+"px");var t=query(e).attr("col");if(null!=t){if("start"==t){let t=0;for(let e=0;e
- ${w2utils.lang("Advanced Search")}
-
-
-
-
- `}getOperators(e,t){let i=this.operators[this.operatorsMap[e]]||[],s=(null!=t&&Array.isArray(t)&&(i=t),"");return i.forEach(e=>{let t=e,i=e;Array.isArray(e)?(t=e[1],i=e[0]):w2utils.isPlainObject(e)&&(t=e.text,i=e.oper),null==t&&(t=e),s+=`
-`}),s}initOperator(e){let i;var t=this.searches[e],s=this.getSearchData(t.field),l=query(`#w2overlay-${this.name}-search-overlay`),r=l.find(`#grid_${this.name}_range_`+e);let n=l.find(`#grid_${this.name}_field_`+e),a=l.find(`#grid_${this.name}_field2_`+e);var o=l.find(`#grid_${this.name}_operator_`+e).val();switch(n.show(),r.hide(),o){case"between":r.show();break;case"null":case"not null":n.hide(),n.val(o),n.trigger("change")}switch(t.type){case"text":case"alphanumeric":var h=n[0]._w2field;h&&h.reset();break;case"int":case"float":case"hex":case"color":case"money":case"currency":case"percent":case"date":case"time":case"datetime":n[0]._w2field||(new w2field(t.type,{el:n[0],...t.options}),new w2field(t.type,{el:a[0],...t.options}),setTimeout(()=>{n.trigger("keydown"),a.trigger("keydown")},1));break;case"list":case"combo":case"enum":i=t.options,"list"==t.type&&(i.selected={}),"enum"==t.type&&(i.selected=[]),s&&(i.selected=s.value),n[0]._w2field||(h=new w2field(t.type,{el:n[0],...i}),s&&null!=s.text&&h.set({id:s.value,text:s.text}));break;case"select":i='';for(let e=0;e'+t+""}else i+='"}n.html(i)}}initSearches(){var s=query(`#w2overlay-${this.name}-search-overlay`);for(let t=0;t{w2utils.isPlainObject(e)&&(i[t]=e.oper)}),r&&r.operator&&(e=r.operator);var l=this.defaultOperator[this.operatorsMap[l.type]],l=(-1==i.indexOf(e)&&(e=l),s.find(`#grid_${this.name}_operator_`+t).val(e),this.initOperator(t),s.find(`#grid_${this.name}_field_`+t)),n=s.find(`#grid_${this.name}_field2_`+t);null!=r&&(Array.isArray(r.value)?["in","not in"].includes(r.operator)?l[0]._w2field.set(r.value):(l.val(r.value[0]).trigger("change"),n.val(r.value[1]).trigger("change")):null!=r.value&&l.val(r.value).trigger("change"))}s.find(".w2ui-grid-search-advanced *[rel=search]").on("keypress",e=>{13==e.keyCode&&(this.search(),w2tooltip.hide(this.name+"-search-overlay"))})}getColumnsHTML(){let h=this,e="",t="";var i,s,l;return this.show.columnHeaders&&(t=0 ",h.columnGroups[e]),h.columnGroups[e].text=h.columnGroups[e].caption);""!=h.columnGroups[h.columnGroups.length-1].text&&h.columnGroups.push({text:""});h.show.lineNumbers&&(t+=' | ');h.show.selectColumn&&(t+=' | ');h.show.expandColumn&&(t+=' | ');let r=0;s+=` | `,h.show.orderColumn&&(s+=' | ');for(let e=0;e",a),a.text=a.caption);let i=0;for(let e=r;e`);var o=w2utils.lang("function"==typeof a.text?a.text(a):a.text);l=``+e+` | "}else{o=w2utils.lang("function"==typeof n.text?n.text(n):n.text);l=``+` ${o||" "} `+" | "}a&&a.frozen?t+=l:s+=l}r+=n.span}return t+=" | ",s+=` | `,[t,s]}(),s=r(!1),e=l[0]+i[0]+s[0],l[1]+i[1]+s[1]):(l=r(!0),e=l[0],l[1])),[e,t];function r(t){let i="",s="
",l=(h.show.lineNumbers&&(i+='| # | '),h.show.selectColumn&&(i+=' '+` | "),h.show.expandColumn&&(i+=' | '),0),r=0,n;s+=` | `,h.show.orderColumn&&(s+=' | ');for(let e=0;e ",o),o.text=o.caption),null==o.size&&(o.size="100%"),e==r&&(n=h.columnGroups[l++]||{},r+=n.span),(eh.last.colEnd)&&!o.frozen||o.hidden||!0===n.main&&!t||(a=h.getColumnCellHTML(e),o&&o.frozen?i+=a:s+=a)}return i+=' | ',s+=' | ',i+="
",s+="",[i,s]}}getColumnCellHTML(t){var i=this.columns[t];if(null==i)return"";var e=!this.reorderColumns||this.columnGroups&&this.columnGroups.length?"":" w2ui-reorder-cols-head ";let s="";for(let e=0;e'+(!1!==i.resizable?'':"")+' "}columnTooltipShow(e,t){var i=query(this.box).find("#grid_"+this.name+"_column_"+e),e=this.columns[e],s=this.columnTooltip;w2tooltip.show({name:this.name+"-column-tooltip",anchor:i.get(0),html:e.tooltip,position:s})}columnTooltipHide(e,t){w2tooltip.hide(this.name+"-column-tooltip")}getRecordsHTML(){let e=this.records.length;var t="object"!=typeof this.url?this.url:this.url.get,t=((e=0==this.searchData.length||t?e:this.last.searchIds.length)>this.vs_start?this.last.show_extra=this.vs_extra:this.last.show_extra=this.vs_start,query(this.box).find(`#grid_${this.name}_records`));let i=Math.floor((t.get(0)?.clientHeight||0)/this.recordHeight)+this.last.show_extra+1;(!this.fixedBody||i>e)&&(i=e);var s=this.getRecordHTML(-1,0);let l=""+s[0],r=""+s[1];l+=' |
',r+=' |
';for(let e=0;e | |
',r+=' |
|
',this.last.range_start=0,this.last.range_end=i,[l,r]}getSummaryHTML(){if(0!==this.summary.length){var s=this.getRecordHTML(-1,0);let t=""+s[0],i=""+s[1];for(let e=0;ethis.last.scrollLeft&&null==l&&(l=e),t+s-30>this.last.scrollLeft+n&&null==r&&(r=e),t+=s);null==r&&(r=this.columns.length-1)}if(null!=l&&(l<0&&(l=0),r<0&&(r=0),l==r&&(0this.last.colStart)for(let e=this.last.colStart;er;e--)a.find("#grid_"+this.name+"_columns #grid_"+this.name+"_column_"+e).remove(),a.find("#grid_"+this.name+'_records td[col="'+e+'"]').remove(),a.find("#grid_"+this.name+'_summary td[col="'+e+'"]').remove();if(l=l;s--)this.columns[s]&&(this.columns[s].frozen||this.columns[s].hidden)||(e.after(this.getColumnCellHTML(s)),f.each(e=>{var t=query(e).parent().attr("index");let i=' | ';null!=t&&(i=this.getCellHTML(parseInt(t),s,!1)),query(e).after(i)}),g.each(e=>{var t=query(e).parent().attr("index");let i=' | ';null!=t&&(i=this.getCellHTML(parseInt(t),s,!0)),query(e).after(i)}));if(r>this.last.colEnd)for(let s=this.last.colEnd+1;s<=r;s++)this.columns[s]&&(this.columns[s].frozen||this.columns[s].hidden)||(t.before(this.getColumnCellHTML(s)),m.each(e=>{var t=query(e).parent().attr("index");let i=' | ';null!=t&&(i=this.getCellHTML(parseInt(t),s,!1)),query(e).before(i)}),y.each(e=>{var t=query(e).parent().attr("index")||-1,t=this.getCellHTML(parseInt(t),s,!0);query(e).before(t)}));this.last.colStart=l,this.last.colEnd=r}else{this.last.colStart=l,this.last.colEnd=r;var o=this.getColumnsHTML(),w=this.getRecordsHTML(),c=this.getSummaryHTML(),p=a.find(`#grid_${this.name}_columns`);let e=a.find(`#grid_${this.name}_records`);var b=a.find(`#grid_${this.name}_frecords`);let t=a.find(`#grid_${this.name}_summary`);p.find("tbody").html(o[1]),b.html(w[0]),e.prepend(w[1]),null!=c&&t.html(c[1]),setTimeout(()=>{e.find(":scope > table").filter(":not(table:first-child)").remove(),t[0]&&(t[0].scrollLeft=this.last.scrollLeft)},1)}this.resizeRecords()}let v=this.records.length;if(v>this.total&&-1!==this.total&&(v=this.total),0!==(v=0==this.searchData.length||i?v:this.last.searchIds.length)&&0!==d.length&&0!==d.prop("clientHeight")){v>this.vs_start?this.last.show_extra=this.vs_extra:this.last.show_extra=this.vs_start;let e=Math.round(d.prop("scrollTop")/this.recordHeight+1),t=e+(Math.round(d.prop("clientHeight")/this.recordHeight)-1);if(e>v&&(e=v),t>=v-1&&(t=v),query(this.box).find("#grid_"+this.name+"_footer .w2ui-footer-right").html((this.show.statusRange?w2utils.formatNumber(this.offset+e)+"-"+w2utils.formatNumber(this.offset+t)+(-1!=this.total?" "+w2utils.lang("of")+" "+w2utils.formatNumber(this.total):""):"")+(i&&this.show.statusBuffered?" ("+w2utils.lang("buffered")+" "+w2utils.formatNumber(v)+(0this.total&&-1!=this.total&&(i=this.total);var x=d.find("#grid_"+this.name+"_rec_top"),_=d.find("#grid_"+this.name+"_rec_bottom"),q=u.find("#grid_"+this.name+"_frec_top"),C=u.find("#grid_"+this.name+"_frec_bottom"),p=(-1!=String(x.next().prop("id")).indexOf("_expanded_row")&&(x.next().remove(),q.next().remove()),this.total>i&&-1!=String(_.prev().prop("id")).indexOf("_expanded_row")&&(_.prev().remove(),C.prev().remove()),parseInt(x.next().attr("line"))),o=parseInt(_.prev().attr("line"));let e,s,l,r,n;if(p=p-this.last.show_extra+2&&1i))break;s.remove(),l.remove()}e=d.find("#grid_"+this.name+"_rec_top").next(),"bottom"==(r=e.attr("line"))&&(r=i);for(let e=parseInt(r)-1;e>=t;e--)this.records[e-1]&&((l=this.records[e-1].w2ui)&&!Array.isArray(l.children)&&(l.expanded=!1),n=this.getRecordHTML(e-1,e),x.after(n[1]),q.after(n[0]))}k(),setTimeout(()=>{this.refreshRanges()},0);b=(t-1)*this.recordHeight;let a=(v-i)*this.recordHeight;function k(){h.markSearch&&(clearTimeout(h.last.marker_timer),h.last.marker_timer=setTimeout(()=>{var t=[];for(let e=0;e{var t=query(h.box).find('td[col="'+e.col+'"]:not(.w2ui-head)');w2utils.marker(t,e.search)})},50))}a<0&&(a=0),x.css("height",b+"px"),q.css("height",b+"px"),_.css("height",a+"px"),C.css("height",a+"px"),this.last.range_start=t,this.last.range_end=i,Math.floor(d.prop("scrollTop")/this.recordHeight)+Math.floor(d.prop("clientHeight")/this.recordHeight)+10>v&&!0!==this.last.pull_more&&(v'),h.last.pull_more=!0,h.last.fetch.offset+=h.limit,h.request("load")}).find("td").html(h.autoLoad?'':''+w2utils.lang("Load ${count} more...",{count:h.limit})+"
"))}}}getRecordHTML(r,n,a){let o="",h="";var d=this.last.selection;let u;if(-1==r){o+='',h+='
',this.show.lineNumbers&&(o+=' | '),this.show.selectColumn&&(o+=' | '),this.show.expandColumn&&(o+=' | '),h+=' | ',this.show.orderColumn&&(h+=' | ');for(let e=0;e';t.frozen&&!t.hidden?o+=i:t.hidden||ethis.last.colEnd||(h+=i)}o+=' | ',h+=' | '}else{var c="object"!=typeof this.url?this.url:this.url.get;if(!0!==a){if(0=this.last.searchIds.length)return"";r=this.last.searchIds[r]}else if(r>=this.records.length)return"";u=this.records[r]}else{if(r>=this.summary.length)return"";u=this.summary[r]}if(!u)return"";null==u.recid&&null!=this.recid&&null!=(c=this.parseField(u,this.recid))&&(u.recid=c);let e=!1,t=(-1!=d.indexes.indexOf(r)&&(e=!0),u.w2ui?u.w2ui.style:""),i=(null!=t&&"string"==typeof t||(t=""),u.w2ui?u.w2ui.class:"");if(null!=i&&"string"==typeof i||(i=""),o+='",h+='
",this.show.lineNumbers&&(o+='| "+(!0!==a?this.getLineHTML(n,u):"")+" | "),this.show.selectColumn&&(o+=''+(!0===a||u.w2ui&&!0===u.w2ui.hideCheckBox?"":' ')+" | "),this.show.expandColumn){let e="";e=u.w2ui&&!0===u.w2ui.expanded?"-":"+",!u.w2ui||"none"!=u.w2ui.expanded&&Array.isArray(u.w2ui.children)&&u.w2ui.children.length||(e=""),u.w2ui&&"spinner"==u.w2ui.expanded&&(e=''),o+=''+(!0!==a?` ${e} `:"")+" | "}h+=' | ',this.show.orderColumn&&(h+=''+(!0!==a?' ':"")+" | ");let s=0,l=0;for(;;){let e=1;var p,f=this.columns[s];if(null==f)break;if(f.hidden)s++,0this.last.colEnd)||f.frozen){if(u.w2ui&&"object"==typeof u.w2ui.colspan){var m=parseInt(u.w2ui.colspan[f.field])||null;if(1=this.columns.length);e++)this.columns[e].hidden&&t++;e=m-t,l=m-1}}var g=this.getCellHTML(r,s,a,e);f.frozen?o+=g:h+=g}s++}}o+=' | ',h+=' | '}return o+="
",h+="
",[o,h]}getLineHTML(e){return""+e+"
"}getCellHTML(i,s,l,e){let r=this,n=this.columns[s];if(null==n)return"";let a=(!0!==l?this.records:this.summary)[i],{value:t,style:o,className:h,attr:d,divAttr:u}=this.getCellValue(i,s,l,!0);var c=-1!==i?this.getCellEditable(i,s):"";let p="max-height: "+parseInt(this.recordHeight)+"px;"+(n.clipboardCopy?"margin-right: 20px":"");var f=!l&&a&&a.w2ui&&a.w2ui.changes&&null!=a.w2ui.changes[n.field],m=this.last.selection;let g=!1,y="";if(-1!=m.indexes.indexOf(i)&&(g=!0),null==e&&(e=a&&a.w2ui&&a.w2ui.colspan&&a.w2ui.colspan[n.field]?a.w2ui.colspan[n.field]:1),0===s&&a&&a.w2ui&&Array.isArray(a.w2ui.children)){let t=0,e=this.get(a.w2ui.parent_recid,!0);for(;;){if(null==e)break;t++;var w=this.records[e].w2ui;if(null==w||null==w.parent_recid)break;e=this.get(w.parent_recid,!0)}if(a.w2ui.parent_recid)for(let e=0;e';var b=0`}if(!0===n.info&&(n.info={}),null!=n.info){let e="w2ui-icon-info",t=("function"==typeof n.info.icon?e=n.info.icon(a,{self:this,index:i,colIndex:s,summary:!!l}):"object"==typeof n.info.icon?e=n.info.icon[this.parseField(a,n.field)]||"":"string"==typeof n.info.icon&&(e=n.info.icon),n.info.style||"");"function"==typeof n.info.style?t=n.info.style(a,{self:this,index:i,colIndex:s,summary:!!l}):"object"==typeof n.info.style?t=n.info.style[this.parseField(a,n.field)]||"":"string"==typeof n.info.style&&(t=n.info.style),y+=``}let v=t,x=(c&&-1!=["checkbox","check"].indexOf(c.type)&&(p+="text-align: center;",v=``,y=""),null==(v=`${y}${String(v)}
`)&&(v=""),"string"==typeof n.render&&(b=n.render.toLowerCase().split(":"),-1!=["number","int","float","money","currency","percent","size"].indexOf(b[0])&&(o+="text-align: right;")),a&&a.w2ui&&("object"==typeof a.w2ui.style&&("string"==typeof a.w2ui.style[s]&&(o+=a.w2ui.style[s]+";"),"string"==typeof a.w2ui.style[n.field]&&(o+=a.w2ui.style[n.field]+";")),"object"==typeof a.w2ui.class&&("string"==typeof a.w2ui.class[s]&&(h+=a.w2ui.class[s]+" "),"string"==typeof a.w2ui.class[n.field]&&(h+=a.w2ui.class[n.field]+" "))),!1);g&&m.columns[i]?.includes(s)&&(x=!0);let _;return n.clipboardCopy&&(_=''),v='"+v+(_&&w2utils.stripTags(v)?_:"")+" | ",v=-1===i&&!0===l?' | ":v}clipboardCopy(e,t,i){var s=(i?this.summary:this.records)[e],l=this.columns[t];let r=l?this.parseField(s,l.field):"";"function"==typeof l.clipboardCopy&&(r=l.clipboardCopy(s,{self:this,index:e,colIndex:t,summary:!!i})),query(this.box).find("#grid_"+this.name+"_focus").text(r).get(0).select(),document.execCommand("copy")}showBubble(s,l,r){var n=this.columns[l].info;if(n){let i="";var a=this.records[s],e=query(this.box).find(`${r?".w2ui-grid-summary":""} #grid_${this.name}_data_${s}_${l} .w2ui-info`);if(this.last.bubbleEl&&w2tooltip.hide(this.name+"-bubble"),this.last.bubbleEl=e,null==n.fields){n.fields=[];for(let e=0;e | ';else{let e=this.getColumn(h[0]),t=(e=null==e?{field:h[0],caption:h[0]}:e)?this.parseField(a,e.field):"";1n.maxLength&&(t=t.substr(0,n.maxLength)+"..."),i+="| "+e.text+" | "+((0===t?"0":t)||"")+" |
")}}i+="
"}else if(w2utils.isPlainObject(t)){for(var d in i='',t){var u=t[d];if(""==u||"-"==u||"--"==u||"---"==u)i+=' |
';else{var c=String(u).split(":");let e=this.getColumn(c[0]),t=(e=null==e?{field:c[0],caption:c[0]}:e)?this.parseField(a,e.field):"";1n.maxLength&&(t=t.substr(0,n.maxLength)+"..."),i+="| "+d+" | "+((0===t?"0":t)||"")+" |
")}}i+="
"}return w2tooltip.show(w2utils.extend({name:this.name+"-bubble",html:i,anchor:e.get(0),position:"top|bottom",class:"w2ui-info-bubble",style:"",hideOn:["doc-click"]},n.options??{})).hide(()=>[this.last.bubbleEl=null])}}getCellEditable(e,t){var i=this.columns[t],s=this.records[e];if(!s||!i)return null;let l=s.w2ui?s.w2ui.editable:null;return!1===l?null:(null!=l&&!0!==l||"function"==typeof(l=i&&0 '}status(i){if(null!=i)query(this.box).find(`#grid_${this.name}_footer`).find(".w2ui-footer-left").html(i);else{let t="";i=this.getSelection();if(0{query(this.box).find("#grid_"+this.name+"_empty_msg").remove(),w2utils.lock(...i)},10)}unlock(e){setTimeout(()=>{query(this.box).find(".w2ui-message").hasClass("w2ui-closing")||w2utils.unlock(this.box,e)},25)}stateSave(e){var t={columns:[],show:w2utils.clone(this.show),last:{search:this.last.search,multi:this.last.multi,logic:this.last.logic,label:this.last.label,field:this.last.field,scrollTop:this.last.scrollTop,scrollLeft:this.last.scrollLeft},sortData:[],searchData:[]};let l;for(let e=0;e{this.stateColProps[e]&&(l=void 0!==i[e]?i[e]:this.colTemplate[e]||null,s[e]=l)}),t.columns.push(s)}for(let e=0;e{s||(0=this.columns.length)return null==(e=this.nextRow(e))?e:this.nextCell(e,-1,i);var s=this.records[e].w2ui,l=this.columns[t],s=s&&s.colspan&&!isNaN(s.colspan[l.field])?parseInt(s.colspan[l.field]):1;if(null==l)return null;if(l&&l.hidden||0===s)return this.nextCell(e,t,i);if(i){l=this.getCellEditable(e,t);if(null==l||-1!=["checkbox","check"].indexOf(l.type))return this.nextCell(e,t,i)}return{index:e,colIndex:t}}prevCell(e,t,i){t-=1;if(t<0)return null==(e=this.prevRow(e))?e:this.prevCell(e,this.columns.length,i);if(t<0)return null;var s=this.records[e].w2ui,l=this.columns[t],s=s&&s.colspan&&!isNaN(s.colspan[l.field])?parseInt(s.colspan[l.field]):1;if(null==l)return null;if(l&&l.hidden||0===s)return this.prevCell(e,t,i);if(i){l=this.getCellEditable(e,t);if(null==l||-1!=["checkbox","check"].indexOf(l.type))return this.prevCell(e,t,i)}return{index:e,colIndex:t}}nextRow(e,t,i){var s=this.last.searchIds;let l=null;if(-1==(i=null==i?1:i))return this.records.length-1;if(e+ithis.records.length)break;e+=i}var r=this.records[e].w2ui,n=this.columns[t],r=r&&r.colspan&&null!=n&&!isNaN(r.colspan[n.field])?parseInt(r.colspan[n.field]):1;l=0===r?this.nextRow(e,t,i):e}return l}prevRow(e,t,i){var s=this.last.searchIds;let l=null;if(-1==(i=null==i?1:i))return 0;if(0<=e-i&&0===s.length||0s[0]){if(e-=i,0{-1==i.indexOf(e)&&-1!=["label","attr","style","text","span","page","column","anchor","group","groupStyle","groupTitleStyle","groupCollapsible"].indexOf(e)&&(t.html[e]=t[e],delete t[e])}),t}function h(t,i){let s=["style","html"];Object.keys(t).forEach(e=>{-1==s.indexOf(e)&&-1!=["span","column","attr","text","label"].indexOf(e)&&t[e]&&!i.html[e]&&(i.html[e]=t[e])})}r=[],Object.keys(e).forEach(i=>{let s=e[i];if("group"==s.type){if(s.text=i,w2utils.isPlainObject(s.fields)){let i=s.fields;s.fields=[],Object.keys(i).forEach(e=>{let t=i[e];t.field=e,s.fields.push(o(t))})}r.push(s)}else if("tab"==s.type){let e={id:i,text:i},t=(s.style&&(e.style=s.style),a.push(e),l(s.fields).fields);t.forEach(e=>{e.html=e.html||{},e.html.page=a.length-1,h(s,e)}),r.push(...t)}else s.field=i,r.push(o(s))})}r.forEach(s=>{if("group"==s.type){let i={group:s.text||"",groupStyle:s.style||"",groupTitleStyle:s.titleStyle||"",groupCollapsible:!0===s.collapsible};Array.isArray(s.fields)&&s.fields.forEach(e=>{let t=w2utils.clone(e);null==t.html&&(t.html={}),w2utils.extend(t.html,i),Array("span","column","attr","label","page").forEach(e=>{null==t.html[e]&&null!=s[e]&&(t.html[e]=s[e])}),null==t.field&&null!=t.name&&(console.log("NOTICE: form field.name property is deprecated, please use field.field. Field ->",s),t.field=t.name),n.push(t)})}else{let e=w2utils.clone(s);null==e.field&&null!=e.name&&(console.log("NOTICE: form field.name property is deprecated, please use field.field. Field ->",s),e.field=e.name),n.push(e)}});return{fields:n,tabs:a}}(r),this.fields=e.fields,!a&&0e.text()).then(e=>{this.formHTML=e,this.isGenerated=!0,this.box&&this.render(this.box)}):this.formURL||this.formHTML?this.formHTML&&(this.isGenerated=!0):(this.formHTML=this.generateHTML(),this.isGenerated=!0),"string"==typeof this.box&&(this.box=query(this.box).get(0)),this.box&&this.render(this.box)}get(t,i){if(0===arguments.length){var s=[];for(let e=0;ee[t],s)}catch(e){}return e}return this.record[t]}setValue(e,l){if((""===l||null==l||Array.isArray(l)&&0===l.length||w2utils.isPlainObject(l)&&0==Object.keys(l).length)&&(l=null),!this.nestedFields)return this.record[e]=l,!0;try{let s=this.record;return String(e).split(".").map((e,t,i)=>{i.length-1!==t?s=s[e]||(s[e]={},s[e]):s[e]=l}),!0}catch(e){return!1}}getFieldValue(e){let s=this.get(e);if(null!=s){var l=s.el;let t=this.getValue(e);e=this.getValue(e,!0);let i=l.value;["int","float","percent","money","currency"].includes(s.type)&&(i=s.w2field.clean(i)),["radio"].includes(s.type)&&(r=query(l).closest("div").find("input:checked").get(0),i=r?s.options.items[query(r).data("index")].id:null),["toggle","checkbox"].includes(s.type)&&(i=l.checked),-1!==["check","checks"].indexOf(s.type)&&(i=[],0<(r=query(l).closest("div").find("input:checked")).length&&r.each(e=>{e=s.options.items[query(e).data("index")];i.push(e.id)}),Array.isArray(t)||(t=[]));var r=l._w2field?.selected;if(["list","enum","file"].includes(s.type)&&r){var n=r,a=t;if(Array.isArray(n)){i=[];for(let e=0;e{var t=query(e).find(".w2ui-map.key").val(),e=query(e).find(".w2ui-map.value").val();"map"==s.type?i[t]=e:i.push(e)})),{current:i,previous:t,original:e}}}setFieldValue(e,r){let n=this.get(e);if(null!=n){var s=n.el;switch(n.type){case"toggle":case"checkbox":s.checked=!!r;break;case"radio":{r=r?.id??r;let i=query(s).closest("div").find("input");n.options.items.forEach((e,t)=>{e.id===r&&i.filter(`[data-index="${t}"]`).prop("checked",!0)});break}case"check":case"checks":{r=(r=Array.isArray(r)?r:null!=r?[r]:[]).map(e=>e?.id??e);let i=query(s).closest("div").find("input");n.options.items.forEach((e,t)=>{i.filter(`[data-index="${t}"]`).prop("checked",!!r.includes(e.id))});break}case"list":case"combo":let t=r;null==t?.id&&Array.isArray(n.options?.items)&&n.options.items.forEach(e=>{e.id===r&&(t=e)}),t!=r&&this.setValue(n.name,t),"list"==n.type?(n.w2field.selected=t,n.w2field.refresh()):n.el.value=t?.text??r;break;case"enum":case"file":{let s=[...r=Array.isArray(r)?r:null!=r?[r]:[]],l=!1;s.forEach((t,i)=>{null==t?.id&&Array.isArray(n.options.items)&&n.options.items.forEach(e=>{e.id==t&&(s[i]=e,l=!0)})}),l&&this.setValue(n.name,s),n.w2field.selected=s,n.w2field.refresh();break}case"map":case"array":"map"!=n.type||null!=r&&w2utils.isPlainObject(r)||(this.setValue(n.field,{}),r=this.getValue(n.field)),"array"!=n.type||null!=r&&Array.isArray(r)||(this.setValue(n.field,[]),r=this.getValue(n.field));var i=query(n.el).parent().find(".w2ui-map-container");n.el.mapRefresh(r,i);break;case"div":case"custom":query(s).html(r);break;case"html":case"empty":break;default:s.value=r??""}}}show(){var t=[];for(let e=0;e{!function(e){let t=!0;return e.each(e=>{"none"!=e.style.display&&(t=!1)}),t}(query(e).find(".w2ui-field"))?query(e).show():query(e).hide()})}change(){Array.from(arguments).forEach(e=>{e=this.get(e);e.$el&&e.$el.change()})}reload(e){return("object"!=typeof this.url?this.url:this.url.get)&&null!=this.recid?this.request(e):("function"==typeof e&&e(),new Promise(e=>{e()}))}clear(){0!=arguments.length?Array.from(arguments).forEach(e=>{let s=this.record;String(e).split(".").map((e,t,i)=>{i.length-1!==t?s=s[e]:delete s[e]}),this.refresh(e)}):(this.recid=null,this.record={},this.original=null,this.refresh(),this.hideErrors())}error(e){var t=this.trigger("error",{target:this.name,message:e,fetchCtrl:this.last.fetchCtrl,fetchOptions:this.last.fetchOptions});!0!==t.isCancelled&&(setTimeout(()=>{this.message(e)},1),t.finish())}message(e){return w2utils.message({owner:this,box:this.box,after:".w2ui-form-header"},e)}confirm(e){return w2utils.confirm({owner:this,box:this.box,after:".w2ui-form-header"},e)}validate(e){null==e&&(e=!0);var t=[];for(let e=0;e{var i=w2utils.extend({anchorClass:"w2ui-error",class:"w2ui-light",position:"right|left",hideOn:["input"]},t.options);if(null!=t.field){let e=t.field.el;"radio"===t.field.type?e=query(t.field.el).closest("div").get(0):["enum","file"].includes(t.field.type),w2tooltip.show(w2utils.extend({anchor:e,name:`${this.name}-${t.field.field}-error`,html:t.error},i))}}),query(e[0].field.$el).parents(".w2ui-page").off(".hideErrors").on("scroll.hideErrors",e=>{this.hideErrors()}))}hideErrors(){this.fields.forEach(e=>{w2tooltip.hide(`${this.name}-${e.field}-error`)})}getChanges(){let e={};return e=null!=this.original&&"object"==typeof this.original&&0!==Object.keys(this.record).length?function e(t,i,s){if(Array.isArray(t)&&Array.isArray(i))for(;t.length{if(-1!=["list","combo","enum"].indexOf(e.type)){var t={nestedFields:!0,record:s};let i=this.getValue.call(t,e.field);w2utils.isPlainObject(i)&&null!=i.id&&this.setValue.call(t,e.field,i.id),Array.isArray(i)&&i.forEach((e,t)=>{w2utils.isPlainObject(e)&&e.id&&(i[t]=e.id)})}var i;"map"==e.type&&(t={nestedFields:!0,record:s},(t=this.getValue.call(t,e.field))._order&&delete t._order),"file"==e.type&&(t={nestedFields:!0,record:s},(i=this.getValue.call(t,e.field)??[]).forEach(e=>{delete e.file,delete e.modified}),this.setValue.call(t,e.field,i))}),!0===e&&Object.keys(s).forEach(e=>{this.get(e)||delete s[e]}),s}prepareParams(i,e){var t=this.dataType??w2utils.settings.dataType;let s=e.body;switch(t){case"HTTPJSON":s={request:s},l();break;case"HTTP":l();break;case"RESTFULL":"POST"==e.method?e.headers["Content-Type"]="application/json":l();break;case"JSON":"GET"==e.method?(s={request:s},l()):(e.headers["Content-Type"]="application/json",e.method="POST")}return e.body="string"==typeof e.body?e.body:JSON.stringify(e.body),e;function l(){Object.keys(s).forEach(e=>{let t=s[e];"object"==typeof t&&(t=JSON.stringify(t)),i.searchParams.append(e,t)}),delete e.body}}request(e,s){let l=this,r,i;var n=new Promise((e,t)=>{r=e,i=t});if("function"==typeof e&&(s=e,e=null),null==e&&(e={}),this.url&&("object"!=typeof this.url||this.url.get)){var a={action:"get"},e=(a.recid=this.recid,a.name=this.name,w2utils.extend(a,this.postData),w2utils.extend(a,e),this.trigger("request",{target:this.name,url:this.url,httpMethod:"GET",postData:a,httpHeaders:this.httpHeaders}));if(!0!==e.isCancelled){this.record={},this.original=null,this.lock(w2utils.lang(this.msgRefresh));let t=e.detail.url;if("object"==typeof t&&t.get&&(t=t.get),this.last.fetchCtrl)try{this.last.fetchCtrl.abort()}catch(e){}if(0!=Object.keys(this.routeData).length){var o=w2utils.parseRoute(t);if(0{200!=i?.status?i&&h(i):i.json().catch(h).then(e=>{var t=l.trigger("load",{target:l.name,fetchCtrl:this.last.fetchCtrl,fetchOptions:this.last.fetchOptions,data:i});!0!==t.isCancelled&&(!0===(e=e.record?e:{error:!1,record:e}).error?l.error(w2utils.lang(e.message)):l.record=w2utils.clone(e.record),l.unlock(),t.finish(),l.refresh(),l.setFocus(),"function"==typeof s&&s(e),r(e))})}),e.finish(),n;function h(e){var t;"AbortError"!==e.name&&(l.unlock(),!0!==(t=l.trigger("error",{response:e,fetchCtrl:l.last.fetchCtrl,fetchOptions:l.last.fetchOptions})).isCancelled&&(e.status&&200!=e.status?l.error(e.status+": "+e.statusText):(console.log("ERROR: Server request failed.",e,". ","Expected Response:",{error:!1,record:{field1:1,field2:"item"}},"OR:",{error:!0,message:"Error description"}),l.error(String(e))),t.finish(),i(e)))}}}}submit(e,t){return this.save(e,t)}save(e,i){let s=this,l,r;var n=new Promise((e,t)=>{l=e,r=t}),a=("function"==typeof e&&(i=e,e=null),s.validate(!0));if(0===a.length)if(null==e&&(e={}),!s.url||"object"==typeof s.url&&!s.url.save)console.log("ERROR: Form cannot be saved because no url is defined.");else{s.lock(w2utils.lang(s.msgSaving)+' ');a={action:"save"},e=(a.recid=s.recid,a.name=s.name,w2utils.extend(a,s.postData),w2utils.extend(a,e),a.record=w2utils.clone(s.record),s.trigger("submit",{target:s.name,url:s.url,httpMethod:"POST",postData:a,httpHeaders:s.httpHeaders}));if(!0!==e.isCancelled){let t=e.detail.url;if("object"==typeof t&&t.save&&(t=t.save),s.last.fetchCtrl&&s.last.fetchCtrl.abort(),0{s.unlock(),200!=e?.status?h(e??{}):e.json().catch(h).then(e=>{var t=s.trigger("save",{target:s.name,fetchCtrl:this.last.fetchCtrl,fetchOptions:this.last.fetchOptions,data:e});!0!==t.isCancelled&&(!0===e.error?s.error(w2utils.lang(e.message)):s.original=null,t.finish(),s.refresh(),"function"==typeof i&&i(e),l(e))})}),e.finish(),n;function h(e){var t;"AbortError"!==e?.name&&(s.unlock(),!0!==(t=s.trigger("error",{response:e,fetchCtrl:s.last.fetchCtrl,fetchOptions:s.last.fetchOptions})).isCancelled&&(e.status&&200!=e.status?s.error(e.status+": "+e.statusText):(console.log("ERROR: Server request failed.",e,". ","Expected Response:",{error:!1,record:{field1:1,field2:"item"}},"OR:",{error:!0,message:"Error description"}),s.error(String(e))),t.finish(),r()))}}}}lock(e,t){var i=Array.from(arguments);i.unshift(this.box),w2utils.lock(...i)}unlock(e){var t=this.box;w2utils.unlock(t,e)}lockPage(e,t,i){e=query(this.box).find(".page-"+e);return!!e.length&&(w2utils.lock(e,t,i),!0)}unlockPage(e,t){e=query(this.box).find(".page-"+e);return!!e.length&&(w2utils.unlock(e,t),!0)}goto(e){this.page!==e&&(null!=e&&(this.page=e),!0===query(this.box).data("autoSize")&&(query(this.box).get(0).clientHeight=0),this.refresh())}generateHTML(){let s=[],t="",l,r,n,a;for(let e=0;e",h),h.html.label=h.html.caption),null==h.html.label&&(h.html.label=h.field),h.html=w2utils.extend({label:"",span:6,attr:"",text:"",style:"",page:0,column:0},h.html),null==l&&(l=h.html.page),null==r&&(r=h.html.column);let i=``;switch(h.type){case"pass":case"password":i=i.replace('type="text"','type="password"');break;case"checkbox":i=`
- `;break;case"check":case"checks":{null==h.options.items&&null!=h.html.items&&(h.options.items=h.html.items);let t=h.options.items;i="",0<(t=Array.isArray(t)?t:[]).length&&(t=w2utils.normMenu.call(this,t,h));for(let e=0;e
-
- ${t[e].text}
-
-
`;break}case"radio":{i="",null==h.options.items&&null!=h.html.items&&(h.options.items=h.html.items);let t=h.options.items;0<(t=Array.isArray(t)?t:[]).length&&(t=w2utils.normMenu.call(this,t,h));for(let e=0;e
-
- ${t[e].text}
-
-
`;break}case"select":{i=`";break}case"textarea":i=``;break;case"toggle":i=`
- `;break;case"map":case"array":h.html.key=h.html.key||{},h.html.value=h.html.value||{},h.html.tabindex_str=o,i=''+(h.html.text||"")+'';break;case"div":case"custom":i=''+(h&&h.html&&h.html.html?h.html.html:"")+"
";break;case"html":case"empty":i=h&&h.html?(h.html.html||"")+(h.html.text||""):""}if(""!==t&&(l!=h.html.page||r!=h.html.column||h.html.group&&t!=h.html.group)&&(s[l][r]+="\n \n ",t=""),h.html.group&&t!=h.html.group){let e="";h.html.groupCollapsible&&(e=''),n+='\n \n
"+e+w2utils.lang(h.html.group)+'
\n
',t=h.html.group}if(null==h.html.anchor){let e=null!=h.html.span?"w2ui-span"+h.html.span:"",t="
"+w2utils.lang("checkbox"!=h.type?h.html.label:h.html.text)+"";h.html.label||(t=""),n+='\n \n '+t+("empty"===h.type?i:"\n
"+i+("array"!=h.type&&"map"!=h.type?w2utils.lang("checkbox"!=h.type?h.html.text:""):"")+"
")+"\n
'+("empty"===h.type?i:"
"+w2utils.lang("checkbox"!=h.type?h.html.label:h.html.text,!0)+i+w2utils.lang("checkbox"!=h.type?h.html.text:"")+"
")+"
\n
',Object.keys(s[i]).sort().forEach((e,t)=>{e==parseInt(e)&&(n+='
'+(s[i][e]||"")+"\n
")}),n+="\n
- ${"map"==e.type?`
- ${e.html.key.text||""}
- `:""}
-
- ${e.html.value.text||""}
-
`;t.append(i)},d.el.mapRefresh=function(l,r){let n,a,o;var h;"map"==d.type&&(null==(l=w2utils.isPlainObject(l)?l:{})._order&&(l._order=Object.keys(l)),n=l._order),"array"==d.type&&(Array.isArray(l)||(l=[]),n=l.map((e,t)=>t));for(let e=r.find(".w2ui-map-field").length-1;e>=n.length;e--)r.find(`div[data-index='${e}']`).remove();for(let s=0;se.key==t)).length&&(i=h[0].value),a.val(t),o.val(i),!0!==d.disabled&&!1!==d.disabled||(a.prop("readOnly",!!d.disabled),o.prop("readOnly",!!d.disabled))}var e=n.length,t=r.find(`div[data-index='${e}']`),e=(0!==t.length||a&&""==a.val()&&""==o.val()||a&&(!0===a.prop("readOnly")||!0===a.prop("disabled"))||d.el.mapAdd(d,r,e),!0!==d.disabled&&!1!==d.disabled||(t.find(".key").prop("readOnly",!!d.disabled),t.find(".value").prop("readOnly",!!d.disabled)),query(d.el).get(0)?.nextSibling);query(e).find("input.w2ui-map").off(".mapChange").on("keyup.mapChange",function(e){var t=query(e.target).closest(".w2ui-map-field"),i=t.get(0).nextElementSibling,t=t.get(0).previousElementSibling,s=(13==e.keyCode&&((s=u??i)instanceof HTMLElement&&(0<(s=query(s).find("input")).length&&s.get(0).focus()),u=void 0),query(e.target).hasClass("key")?"key":"value");38==e.keyCode&&t&&(query(t).find("input."+s).get(0).select(),e.preventDefault()),40==e.keyCode&&i&&(query(i).find("input."+s).get(0).select(),e.preventDefault())}).on("keydown.mapChange",function(e){38!=e.keyCode&&40!=e.keyCode||e.preventDefault()}).on("input.mapChange",function(e){var e=query(e.target).closest("div"),t=e.data("index"),i=e.get(0).nextElementSibling;if(""==e.find("input").val()||i){if(""==e.find("input").val()&&i){let t=!0;query(i).find("input").each(e=>{""!=e.value&&(t=!1)}),t&&query(i).remove()}}else d.el.mapAdd(d,r,parseInt(t)+1)}).on("change.mapChange",function(e){null==c.original&&(0{t._order.push(e.value)}),c.trigger("change",{target:d.field,field:d.field,originalEvent:e,value:{current:t,previous:i,original:s}}));!0!==l.isCancelled&&("map"==d.type&&(t._order=t._order.filter(e=>""!==e),delete t[""]),"array"==d.type&&(t=t.filter(e=>""!==e)),""==query(e.target).parent().find("input").val()&&(u=e.target),c.setValue(d.field,t),d.el.mapRefresh(t,r),l.finish())})}}(s),this.setFieldValue(s.field,this.getValue(s.name)),s.$el.trigger("change")}}return t.finish(),this.resize(),Date.now()-e}}}render(e){var t=Date.now();let i=this;"string"==typeof e&&(e=query(e).get(0));var s=this.trigger("render",{target:this.name,box:e??this.box});if(!0!==s.isCancelled&&(null!=e&&(0'+(""!==this.header?'":"")+' '+this.formHTML+"",e=(query(this.box).attr("name",this.name).addClass("w2ui-reset w2ui-form").html(e),0this.refresh()):this.refresh(),this.last.observeResize=new ResizeObserver(()=>{this.resize()}),this.last.observeResize.observe(this.box),-1!=this.focus){let e=0,t=()=>{0 input, select, textarea, div > label:nth-child(1) > [type=radio]").filter(":not(.file-input)");null==i[e].offsetParent&&i.length>=e;)e++;i[e]&&(t=query(i[e]))}else"string"==typeof e&&(t=query(this.box).find(`[name='${e}']`));return 0 `,arrow:!1,advanced:null,transparent:!0},this.options=w2utils.extend({},e,t),t=this.options;break;case"date":e={format:w2utils.settings.dateFormat,keyboard:!0,autoCorrect:!0,start:null,end:null,blockDates:[],blockWeekdays:[],colored:{},btnNow:!0},this.options=w2utils.extend({type:"date"},e,t),t=this.options,null==query(this.el).attr("placeholder")&&query(this.el).attr("placeholder",t.format);break;case"time":e={format:w2utils.settings.timeFormat,keyboard:!0,autoCorrect:!0,start:null,end:null,btnNow:!0,noMinutes:!1},this.options=w2utils.extend({type:"time"},e,t),t=this.options,null==query(this.el).attr("placeholder")&&query(this.el).attr("placeholder",t.format);break;case"datetime":e={format:w2utils.settings.dateFormat+"|"+w2utils.settings.timeFormat,keyboard:!0,autoCorrect:!0,start:null,end:null,startTime:null,endTime:null,blockDates:[],blockWeekdays:[],colored:{},btnNow:!0,noMinutes:!1},this.options=w2utils.extend({type:"datetime"},e,t),t=this.options,null==query(this.el).attr("placeholder")&&query(this.el).attr("placeholder",t.placeholder||t.format);break;case"list":case"combo":e={items:[],selected:{},url:null,recId:null,recText:null,method:null,interval:350,postData:{},minLength:1,cacheMax:250,maxDropHeight:350,maxDropWidth:null,minDropWidth:null,match:"begins",icon:null,iconStyle:"",align:"both",altRows:!0,onSearch:null,onRequest:null,onLoad:null,onError:null,renderDrop:null,compare:null,filter:!0,hideSelected:!1,prefix:"",suffix:"",openOnFocus:!1,markSearch:!1},"function"==typeof t.items&&(t._items_fun=t.items),t.items=w2utils.normMenu.call(this,t.items),"list"===this.type&&(query(this.el).addClass("w2ui-select"),!w2utils.isPlainObject(t.selected)&&Array.isArray(t.items)&&t.items.forEach(e=>{e&&e.id===t.selected&&(t.selected=w2utils.clone(e))})),t=w2utils.extend({},e,t),this.options=t,w2utils.isPlainObject(t.selected)||(t.selected={}),this.selected=t.selected,query(this.el).attr("autocapitalize","off").attr("autocomplete","off").attr("autocorrect","off").attr("spellcheck","false"),null!=t.selected.text&&query(this.el).val(t.selected.text);break;case"enum":e={items:[],selected:[],max:0,url:null,recId:null,recText:null,interval:350,method:null,postData:{},minLength:1,cacheMax:250,maxItemWidth:250,maxDropHeight:350,maxDropWidth:null,match:"contains",align:"",altRows:!0,openOnFocus:!1,markSearch:!1,renderDrop:null,renderItem:null,compare:null,filter:!0,hideSelected:!0,style:"",onSearch:null,onRequest:null,onLoad:null,onError:null,onClick:null,onAdd:null,onNew:null,onRemove:null,onMouseEnter:null,onMouseLeave:null,onScroll:null},"function"==typeof(t=w2utils.extend({},e,t,{suffix:""})).items&&(t._items_fun=t.items),t.items=w2utils.normMenu.call(this,t.items),t.selected=w2utils.normMenu.call(this,t.selected),this.options=t,Array.isArray(t.selected)||(t.selected=[]),this.selected=t.selected;break;case"file":e={selected:[],max:0,maxSize:0,maxFileSize:0,maxItemWidth:250,maxDropHeight:350,maxDropWidth:null,readContent:!0,silent:!0,align:"both",altRows:!0,renderItem:null,style:"",onClick:null,onAdd:null,onRemove:null,onMouseEnter:null,onMouseLeave:null},t=w2utils.extend({},e,t),this.options=t,Array.isArray(t.selected)||(t.selected=[]),this.selected=t.selected,null==query(this.el).attr("placeholder")&&query(this.el).attr("placeholder",w2utils.lang("Attach files by dragging and dropping or Click to Select"))}query(this.el).css("box-sizing","border-box").addClass("w2field w2ui-input").off(".w2field").on("change.w2field",e=>{this.change(e)}).on("click.w2field",e=>{this.click(e)}).on("focus.w2field",e=>{this.focus(e)}).on("blur.w2field",e=>{"list"!==this.type&&this.blur(e)}).on("keydown.w2field",e=>{this.keyDown(e)}).on("keyup.w2field",e=>{this.keyUp(e)}),this.addPrefix(),this.addSuffix(),this.addSearch(),this.addMultiSearch(),this.change(new Event("change"))}else console.log("ERROR: w2field could only be applied to INPUT or TEXTAREA.",this.el)}get(){let e;return e=-1!==["list","enum","file"].indexOf(this.type)?this.selected:query(this.el).val()}set(e,t){-1!==["list","enum","file"].indexOf(this.type)?("list"!==this.type&&t?(Array.isArray(this.selected)||(this.selected=[]),this.selected.push(e),(t=w2menu.get(this.el.id+"_menu"))&&(t.options.selected=this.selected)):(null==e&&(e=[]),t="enum"!==this.type||Array.isArray(e)?e:[e],this.selected=t),query(this.el).trigger("input").trigger("change"),this.refresh()):query(this.el).val(e)}setIndex(e,t){if(-1!==["list","enum"].indexOf(this.type)){var i=this.options.items;if(i&&i[e])return"list"==this.type&&(this.selected=i[e]),"enum"==this.type&&(t||(this.selected=[]),this.selected.push(i[e])),(t=w2menu.get(this.el.id+"_menu"))&&(t.options.selected=this.selected),query(this.el).trigger("input").trigger("change"),this.refresh(),!0}return!1}refresh(){let s=this.options;var e=Date.now(),t=getComputedStyle(this.el);if("list"==this.type){if(query(this.el).parent().css("white-space","nowrap"),this.helpers.prefix&&this.helpers.prefix.hide(),!this.helpers.search)return;null==this.selected&&s.icon?s.prefix=`
-
- `:s.prefix="",this.addPrefix();let e=query(this.helpers.search_focus);var i=query(e[0].previousElementSibling);e.css({outline:"none"}),""===e.val()?(e.css("opacity",0),i.css("opacity",0),this.selected?.id?(n=this.selected.text,r=this.findItemIndex(s.items,this.selected.id),null!=n&&query(this.el).val(w2utils.lang(n)).data({selected:n,selectedIndex:r[0]})):(this.el.value="",query(this.el).removeData("selected selectedIndex"))):(e.css("opacity",1),i.css("opacity",1),query(this.el).val(""),setTimeout(()=>{this.helpers.prefix&&this.helpers.prefix.hide(),s.icon?(e.css("margin-left","17px"),query(this.helpers.search).find(".w2ui-icon-search").addClass("show-search")):(e.css("margin-left","0px"),query(this.helpers.search).find(".w2ui-icon-search").removeClass("show-search"))},1)),query(this.el).prop("readonly")||query(this.el).prop("disabled")?setTimeout(()=>{this.helpers.prefix&&query(this.helpers.prefix).css("opacity","0.6"),this.helpers.suffix&&query(this.helpers.suffix).css("opacity","0.6")},1):setTimeout(()=>{this.helpers.prefix&&query(this.helpers.prefix).css("opacity","1"),this.helpers.suffix&&query(this.helpers.suffix).css("opacity","1")},1)}let l=this.helpers.multi;if(["enum","file"].includes(this.type)&&l){let i="";Array.isArray(this.selected)&&this.selected.forEach((e,t)=>{null!=e&&(i+=`
-
- ${"function"==typeof s.renderItem?s.renderItem(e,t,`
`):`
- ${e.icon?`
`:""}
-
- ${("enum"===this.type?e.text:e.name)??e.id??e}
- ${e.size?`
- ${w2utils.formatSize(e.size)}`:""}
- `}
-
-

-
-
${w2utils.lang("Name")}:
-
${l.name}
-
${w2utils.lang("Size")}:
-
${w2utils.formatSize(l.size)}
-
${w2utils.lang("Type")}:
-
${l.type}
-
${w2utils.lang("Modified")}:
-
${w2utils.date(l.modified)}
-
${this.options.prefix}
`),e=query(this.el).get(0).previousElementSibling,query(e).css({color:t.color,"font-family":t["font-family"],"font-size":t["font-size"],height:this.el.clientHeight+"px","padding-top":t["padding-top"],"padding-bottom":t["padding-bottom"],"padding-left":this.tmp["old-padding-left"],"padding-right":0,"margin-top":parseInt(t["margin-top"],10)+2+"px","margin-bottom":parseInt(t["margin-bottom"],10)+1+"px","margin-left":t["margin-left"],"margin-right":0,"z-index":1}),query(this.el).css("padding-left",e.clientWidth+"px !important"),this.helpers.prefix=e)}addSuffix(){if(this.options.prefix||this.options.arrow){let e,t=this;var i=getComputedStyle(this.el),s=(null==this.tmp["old-padding-right"]&&(this.tmp["old-padding-right"]=i["padding-right"]),parseInt(i["padding-right"]||0));this.options.arrow&&(this.helpers.arrow&&query(this.helpers.arrow).remove(),query(this.el).after(''),e=query(this.el).get(0).nextElementSibling,query(e).css({color:i.color,"font-family":i["font-family"],"font-size":i["font-size"],height:this.el.clientHeight+"px",padding:0,"margin-top":parseInt(i["margin-top"],10)+1+"px","margin-bottom":0,"border-left":"1px solid silver",width:"16px",transform:"translateX(-100%)"}).on("mousedown",function(e){query(e.target).hasClass("arrow-up")&&t.keyDown(e,{keyCode:38}),query(e.target).hasClass("arrow-down")&&t.keyDown(e,{keyCode:40})}),s+=e.clientWidth,query(this.el).css("padding-right",s+"px !important"),this.helpers.arrow=e),""!==this.options.suffix&&(this.helpers.suffix&&query(this.helpers.suffix).remove(),query(this.el).after(`${this.options.suffix}
`),e=query(this.el).get(0).nextElementSibling,query(e).css({color:i.color,"font-family":i["font-family"],"font-size":i["font-size"],height:this.el.clientHeight+"px","padding-top":i["padding-top"],"padding-bottom":i["padding-bottom"],"padding-left":0,"padding-right":i["padding-right"],"margin-top":parseInt(i["margin-top"],10)+2+"px","margin-bottom":parseInt(i["margin-bottom"],10)+1+"px",transform:"translateX(-100%)"}),query(this.el).css("padding-right",e.clientWidth+"px !important"),this.helpers.suffix=e)}}addSearch(){if("list"===this.type){this.helpers.search&&query(this.helpers.search).remove();let e=parseInt(query(this.el).attr("tabIndex")),t=(isNaN(e)||-1===e||(this.tmp["old-tabIndex"]=e),null!=(e=this.tmp["old-tabIndex"]?this.tmp["old-tabIndex"]:e)&&!isNaN(e)||(e=0),"");var i=`
-
-
-
-
`,i=(query(this.el).attr("tabindex",-1).before(i),query(this.el).get(0).previousElementSibling),s=(this.helpers.search=i,this.helpers.search_focus=query(i).find("input").get(0),getComputedStyle(this.el));query(i).css({width:this.el.clientWidth+"px","margin-top":s["margin-top"],"margin-left":s["margin-left"],"margin-bottom":s["margin-bottom"],"margin-right":s["margin-right"]}).find("input").css({cursor:"default",width:"100%",opacity:1,padding:s.padding,margin:s.margin,border:"1px solid transparent","background-color":"transparent"}),query(i).find("input").off(".helper").on("focus.helper",e=>{query(e.target).val(""),this.tmp.pholder=query(this.el).attr("placeholder")??"",this.focus(e),e.stopPropagation()}).on("blur.helper",e=>{query(e.target).val(""),null!=this.tmp.pholder&&query(this.el).attr("placeholder",this.tmp.pholder),this.blur(e),e.stopPropagation()}).on("keydown.helper",e=>{this.keyDown(e)}).on("keyup.helper",e=>{this.keyUp(e)}),query(i).on("click",e=>{query(e.target).find("input").focus()})}}addMultiSearch(){if(["enum","file"].includes(this.type)){query(this.helpers.multi).remove();let e="";var l,r,n=getComputedStyle(this.el),a=w2utils.stripSpaces(`
- margin-top: 0px;
- margin-bottom: 0px;
- margin-left: ${n["margin-left"]};
- margin-right: ${n["margin-right"]};
- width: ${w2utils.getSize(this.el,"width")-parseInt(n["margin-left"],10)-parseInt(n["margin-right"],10)}px;
- `);null==this.tmp["min-height"]&&(l=this.tmp["min-height"]=parseInt(("none"!=n["min-height"]?n["min-height"]:0)||0),r=parseInt(n.height),this.tmp["min-height"]=Math.max(l,r)),null==this.tmp["max-height"]&&"none"!=n["max-height"]&&(this.tmp["max-height"]=parseInt(n["max-height"]));let t="",i=(null!=query(this.el).attr("id")&&(t=`id="${query(this.el).attr("id")}_search"`),parseInt(query(this.el).attr("tabIndex"))),s=(isNaN(i)||-1===i||(this.tmp["old-tabIndex"]=i),null!=(i=this.tmp["old-tabIndex"]?this.tmp["old-tabIndex"]:i)&&!isNaN(i)||(i=0),"enum"===this.type&&(e=`
- `),"file"===this.type&&(e=`
- `),this.tmp["old-background-color"]=n["background-color"],this.tmp["old-border-color"]=n["border-color"],query(this.el).before(e).css({"border-color":"transparent","background-color":"transparent"}),query(this.el.previousElementSibling));this.helpers.multi=s,query(this.el).attr("tabindex",-1),s.on("click",e=>{this.focus(e)}),s.find("input:not(.file-input)").on("click",e=>{this.click(e)}).on("focus",e=>{this.focus(e)}).on("blur",e=>{this.blur(e)}).on("keydown",e=>{this.keyDown(e)}).on("keyup",e=>{this.keyUp(e)}),"file"===this.type&&s.find("input.file-input").off(".drag").on("click.drag",e=>{e.stopPropagation(),query(this.el).prop("readonly")||query(this.el).prop("disabled")||this.focus(e)}).on("dragenter.drag",e=>{query(this.el).prop("readonly")||query(this.el).prop("disabled")||s.addClass("w2ui-file-dragover")}).on("dragleave.drag",e=>{query(this.el).prop("readonly")||query(this.el).prop("disabled")||s.removeClass("w2ui-file-dragover")}).on("drop.drag",e=>{query(this.el).prop("readonly")||query(this.el).prop("disabled")||(s.removeClass("w2ui-file-dragover"),Array.from(e.dataTransfer.files).forEach(e=>{this.addFile(e)}),this.focus(e),e.preventDefault(),e.stopPropagation())}).on("dragover.drag",e=>{e.preventDefault(),e.stopPropagation()}).on("change.drag",e=>{void 0!==e.target.files&&Array.from(e.target.files).forEach(e=>{this.addFile(e)}),this.focus(e)}),this.refresh()}}addFile(t){var e=this.options,s=this.selected;let l={name:t.name,type:t.type,modified:t.lastModifiedDate,size:t.size,content:null,file:t},i=0,r=0,n=[],a=(Array.isArray(s)&&s.forEach(e=>{e.name==t.name&&e.size==t.size&&n.push(w2utils.lang('The file "${name}" (${size}) is already added.',{name:t.name,size:w2utils.formatSize(t.size)})),i+=e.size,r++}),0!==e.maxFileSize&&l.size>e.maxFileSize&&n.push(w2utils.lang("Maximum file size is ${size}",{size:w2utils.formatSize(e.maxFileSize)})),0!==e.maxSize&&i+l.size>e.maxSize&&n.push(w2utils.lang("Maximum total size is ${size}",{size:w2utils.formatSize(e.maxSize)})),0!==e.max&&r>=e.max&&n.push(w2utils.lang("Maximum number of files is ${count}",{count:e.max})),this.trigger("add",{target:this.el,file:l,total:r,totalSize:i,errors:n}));if(!0!==a.isCancelled)if(!0!==e.silent&&0")),console.log("ERRORS (while adding files): ",n);else if(s.push(l),"undefined"!=typeof FileReader&&!0===e.readContent){s=new FileReader;let i=this;s.onload=function(e){var e=e.target.result,t=e.indexOf(",");l.content=e.substr(t+1),i.refresh(),query(i.el).trigger("input").trigger("change"),a.finish()},s.readAsDataURL(t)}else this.refresh(),query(this.el).trigger("input").trigger("change"),a.finish()}moveCaret2end(){setTimeout(()=>{this.el.setSelectionRange(this.el.value.length,this.el.value.length)},0)}}!function(r){function e(){var t,i;t=window,i={w2ui:w2ui,w2utils:w2utils,query:query,w2locale:w2locale,w2event:w2event,w2base:w2base,w2popup:w2popup,w2alert:w2alert,w2confirm:w2confirm,w2prompt:w2prompt,Dialog:Dialog,w2tooltip:w2tooltip,w2menu:w2menu,w2color:w2color,w2date:w2date,Tooltip:Tooltip,w2toolbar:w2toolbar,w2sidebar:w2sidebar,w2tabs:w2tabs,w2layout:w2layout,w2grid:w2grid,w2form:w2form,w2field:w2field},Object.keys(i).forEach(e=>{t[e]=i[e]})}var t=String(void 0).split("?")[1]||"";function i(t,i){var e;if(r.isPlainObject(t)){let e;return"w2form"==i&&(e=new w2form(t),0{let i=r(t).data("w2field");return i,(i=new w2field(s,l)).render(t),i})},r.fn.w2form=function(e){return i.call(this,e,"w2form")},r.fn.w2grid=function(e){return i.call(this,e,"w2grid")},r.fn.w2layout=function(e){return i.call(this,e,"w2layout")},r.fn.w2sidebar=function(e){return i.call(this,e,"w2sidebar")},r.fn.w2tabs=function(e){return i.call(this,e,"w2tabs")},r.fn.w2toolbar=function(e){return i.call(this,e,"w2toolbar")},r.fn.w2popup=function(e){0{w2utils.marker(t,i)})},r.fn.w2tag=function(i,s){return this.each((e,t)=>{null==i&&null==s?w2tooltip.hide():("object"==typeof i?s=i:(s=s??{}).html=i,w2tooltip.show(t,s))})},r.fn.w2overlay=function(i,s){return this.each((e,t)=>{null==i&&null==s?w2tooltip.hide():("object"==typeof i?s=i:s.html=i,Object.assign(s,{class:"w2ui-white",hideOn:["doc-click"]}),w2tooltip.show(t,s))})},r.fn.w2menu=function(i,s){return this.each((e,t)=>{"object"==typeof i&&(s=i),"object"==typeof i?s=i:s.items=i,w2menu.show(t,s)})},r.fn.w2color=function(i,s){return this.each((e,t)=>{t=w2color.show(t,i);"function"==typeof s&&t.select(s)})})}(window.jQuery),function(t,i){if("function"==typeof define&&define.amd)return define(()=>i);if("undefined"!=typeof exports){if("undefined"!=typeof module&&module.exports)return exports=module.exports=i;t=exports}t&&Object.keys(i).forEach(e=>{t[e]=i[e]})}(self,{w2ui:w2ui,w2utils:w2utils,query:query,w2locale:w2locale,w2event:w2event,w2base:w2base,w2popup:w2popup,w2alert:w2alert,w2confirm:w2confirm,w2prompt:w2prompt,Dialog:Dialog,w2tooltip:w2tooltip,w2menu:w2menu,w2color:w2color,w2date:w2date,Tooltip:Tooltip,w2toolbar:w2toolbar,w2sidebar:w2sidebar,w2tabs:w2tabs,w2layout:w2layout,w2grid:w2grid,w2form:w2form,w2field:w2field});
\ No newline at end of file
diff --git a/spaces/bigslime/stablediffusion-infinity/js/xss.js b/spaces/bigslime/stablediffusion-infinity/js/xss.js
deleted file mode 100644
index 84781ba24200eca88b8976cf0957aed7155e2191..0000000000000000000000000000000000000000
--- a/spaces/bigslime/stablediffusion-infinity/js/xss.js
+++ /dev/null
@@ -1,31 +0,0 @@
-var setup_outpaint=function(){
- if(!window.my_observe_outpaint)
- {
- console.log("setup outpaint here");
- window.my_observe_outpaint = new MutationObserver(function (event) {
- console.log(event);
- let app=document.querySelector("gradio-app");
- app=app.shadowRoot??app;
- let frame=app.querySelector("#sdinfframe").contentWindow;
- frame.postMessage(["outpaint", ""], "*");
- });
- var app=document.querySelector("gradio-app");
- app=app.shadowRoot??app;
- window.my_observe_outpaint_target=app.querySelector("#output span");
- window.my_observe_outpaint.observe(window.my_observe_outpaint_target, {
- attributes: false,
- subtree: true,
- childList: true,
- characterData: true
- });
- }
-};
-window.config_obj={
- resize_check: true,
- enable_safety: true,
- use_correction: false,
- enable_img2img: false,
- use_seed: false,
- seed_val: 0,
-};
-setup_outpaint();
\ No newline at end of file
diff --git a/spaces/bioriAsaeru/text-to-voice/AutoCAD 2005 Keygen Xforce The Benefits and Risks of Using It.md b/spaces/bioriAsaeru/text-to-voice/AutoCAD 2005 Keygen Xforce The Benefits and Risks of Using It.md
deleted file mode 100644
index 90d1db31daad1244d55391a7b588889c34567fa2..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/AutoCAD 2005 Keygen Xforce The Benefits and Risks of Using It.md
+++ /dev/null
@@ -1,6 +0,0 @@
-AutoCAD 2005 Keygen Xforce
Download File ……… https://urloso.com/2uyOcl
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/bioriAsaeru/text-to-voice/British Village Ladies Bobbi Jo 3 Sets18.md b/spaces/bioriAsaeru/text-to-voice/British Village Ladies Bobbi Jo 3 Sets18.md
deleted file mode 100644
index 8aa445aa62b42b2f691bf70372629cb4b0ee588f..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/British Village Ladies Bobbi Jo 3 Sets18.md
+++ /dev/null
@@ -1,6 +0,0 @@
-British Village Ladies Bobbi Jo 3 Sets18
Download Zip ○○○ https://urloso.com/2uyPxt
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/bioriAsaeru/text-to-voice/Dungeonsiege2downloadtorentiso.md b/spaces/bioriAsaeru/text-to-voice/Dungeonsiege2downloadtorentiso.md
deleted file mode 100644
index 13292347bf79d779379a9e72c626bd6d211e950c..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Dungeonsiege2downloadtorentiso.md
+++ /dev/null
@@ -1,11 +0,0 @@
-dungeonsiege2downloadtorentiso
Download >> https://urloso.com/2uyP8J
-
-On this game portal you can download the game Dungeon Siege II: Broken World for free torrent. The full version of the game Dungeon Siege II: Broken World was developed in ... Download the game here: Download Dungeon Siege II: Broken World via torrent for free.
-Download Dungeon Siege II: Broken World - torrent.
-Download Dungeon Siege II Broken World via torrent you can for free on our site at high speed.
-Dungeon Siege II Broken World (2014) Download free torrent.
-Torrent file Dungeon Siege II Broken World (2014) download for free.
-Download Dungeon Siege II Broken World via torrent you can free on our website at high speed. 8a78ff9644
-
-
-
diff --git a/spaces/bkhmsi/Font-To-Sketch/code/harfbuzz_test.py b/spaces/bkhmsi/Font-To-Sketch/code/harfbuzz_test.py
deleted file mode 100644
index 4f2aeba4a7371ed06124c47ebe1c10ad5f5250a9..0000000000000000000000000000000000000000
--- a/spaces/bkhmsi/Font-To-Sketch/code/harfbuzz_test.py
+++ /dev/null
@@ -1,33 +0,0 @@
-import vharfbuzz as hv
-
-animal_names = [
- {"english": "cat", "arabic": "قطة"},
- {"english": "Lion", "arabic": "أسد"},
- {"english": "Elephant", "arabic": "فيل"},
- {"english": "Tiger", "arabic": "نمر"},
- {"english": "Cheetah", "arabic": "فهد"},
- {"english": "Monkey", "arabic": "قرد"},
- {"english": "Dolphin", "arabic": "دلفين"},
- {"english": "Penguin", "arabic": "بطريق"},
- {"english": "Kangaroo", "arabic": "كنغر"},
- {"english": "Fox", "arabic": "ثعلب"},
- {"english": "Eagle", "arabic": "نسر"},
- {"english": "Wolf", "arabic": "ذئب"},
- {"english": "Turtle", "arabic": "سلحفاة"},
- {"english": "Panda", "arabic": "باندا"},
- {"english": "Giraffe", "arabic": "زرافة"},
- {"english": "Bear", "arabic": "دب"},
- {"english": "Owl", "arabic": "بومة"}
-]
-
-fontpath = './data/fonts/ArefRuqaa.ttf'
-vhb = hv.Vharfbuzz(fontpath)
-
-path_templ = "/Users/bkhmsi/Desktop/Animal-Words/correct/{}.svg"
-
-for animal in animal_names:
- txt = animal["arabic"]
- buf = vhb.shape(txt, {"features": {"kern": True, "liga": True}})
- svg = vhb.buf_to_svg(buf)
- with open(path_templ.format(animal["english"]), 'w') as fout:
- fout.write(svg)
diff --git a/spaces/brjathu/HMR2.0/app.py b/spaces/brjathu/HMR2.0/app.py
deleted file mode 100644
index 527e4116c8a03d8e9d3bb4a695cdafa32e47fd2a..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/app.py
+++ /dev/null
@@ -1,190 +0,0 @@
-import argparse
-import os
-from pathlib import Path
-import tempfile
-import sys
-import cv2
-import gradio as gr
-import numpy as np
-import torch
-from PIL import Image
-
-# print file path
-print(os.path.abspath(__file__))
-os.system('pip install /home/user/app/vendor/pyrender')
-sys.path.append('/home/user/app/vendor/pyrender')
-os.system('pip install gradio==3.26.0')
-from hmr2.configs import get_config
-from hmr2.datasets.vitdet_dataset import (DEFAULT_MEAN, DEFAULT_STD,
- ViTDetDataset)
-from hmr2.models import HMR2
-from hmr2.utils import recursive_to
-from hmr2.utils.renderer import Renderer, cam_crop_to_full
-
-os.environ["PYOPENGL_PLATFORM"] = "egl"
-os.environ["MESA_GL_VERSION_OVERRIDE"] = "4.1"
-
-try:
- import detectron2
-except:
- import os
- os.system('pip install --upgrade pip')
- os.system('pip install git+https://github.com/facebookresearch/detectron2.git')
-
-OUT_FOLDER = 'demo_out'
-os.makedirs(OUT_FOLDER, exist_ok=True)
-
-# Setup HMR2.0 model
-LIGHT_BLUE=(0.65098039, 0.74117647, 0.85882353)
-DEFAULT_CHECKPOINT='logs/train/multiruns/hmr2/0/checkpoints/epoch=35-step=1000000.ckpt'
-device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
-model_cfg = str(Path(DEFAULT_CHECKPOINT).parent.parent / 'model_config.yaml')
-model_cfg = get_config(model_cfg)
-model = HMR2.load_from_checkpoint(DEFAULT_CHECKPOINT, strict=False, cfg=model_cfg).to(device)
-model.eval()
-
-
-# Load detector
-from detectron2.config import LazyConfig
-
-from hmr2.utils.utils_detectron2 import DefaultPredictor_Lazy
-
-detectron2_cfg = LazyConfig.load(f"vendor/detectron2/projects/ViTDet/configs/COCO/cascade_mask_rcnn_vitdet_h_75ep.py")
-detectron2_cfg.train.init_checkpoint = "https://dl.fbaipublicfiles.com/detectron2/ViTDet/COCO/cascade_mask_rcnn_vitdet_h/f328730692/model_final_f05665.pkl"
-for i in range(3):
- detectron2_cfg.model.roi_heads.box_predictors[i].test_score_thresh = 0.25
-detector = DefaultPredictor_Lazy(detectron2_cfg)
-
-# Setup the renderer
-renderer = Renderer(model_cfg, faces=model.smpl.faces)
-
-
-import numpy as np
-
-
-def infer(in_pil_img, in_threshold=0.8, out_pil_img=None):
-
- open_cv_image = np.array(in_pil_img)
- # Convert RGB to BGR
- open_cv_image = open_cv_image[:, :, ::-1].copy()
- print("EEEEE", open_cv_image.shape)
- det_out = detector(open_cv_image)
- det_instances = det_out['instances']
- valid_idx = (det_instances.pred_classes==0) & (det_instances.scores > in_threshold)
- boxes=det_instances.pred_boxes.tensor[valid_idx].cpu().numpy()
-
- # Run HMR2.0 on all detected humans
- dataset = ViTDetDataset(model_cfg, open_cv_image, boxes)
- dataloader = torch.utils.data.DataLoader(dataset, batch_size=8, shuffle=False, num_workers=0)
-
- all_verts = []
- all_cam_t = []
- all_mesh_paths = []
-
- temp_name = next(tempfile._get_candidate_names())
-
- for batch in dataloader:
- batch = recursive_to(batch, device)
- with torch.no_grad():
- out = model(batch)
-
- pred_cam = out['pred_cam']
- box_center = batch["box_center"].float()
- box_size = batch["box_size"].float()
- img_size = batch["img_size"].float()
- render_size = img_size
- pred_cam_t = cam_crop_to_full(pred_cam, box_center, box_size, render_size).detach().cpu().numpy()
-
- # Render the result
- batch_size = batch['img'].shape[0]
- for n in range(batch_size):
- # Get filename from path img_path
- # img_fn, _ = os.path.splitext(os.path.basename(img_path))
- person_id = int(batch['personid'][n])
- white_img = (torch.ones_like(batch['img'][n]).cpu() - DEFAULT_MEAN[:,None,None]/255) / (DEFAULT_STD[:,None,None]/255)
- input_patch = batch['img'][n].cpu() * (DEFAULT_STD[:,None,None]/255) + (DEFAULT_MEAN[:,None,None]/255)
- input_patch = input_patch.permute(1,2,0).numpy()
-
-
- verts = out['pred_vertices'][n].detach().cpu().numpy()
- cam_t = pred_cam_t[n]
-
- all_verts.append(verts)
- all_cam_t.append(cam_t)
-
- # Save all meshes to disk
- # if args.save_mesh:
- if True:
- camera_translation = cam_t.copy()
- tmesh = renderer.vertices_to_trimesh(verts, camera_translation, LIGHT_BLUE)
-
- temp_path = os.path.join(f'{OUT_FOLDER}/{temp_name}_{person_id}.obj')
- tmesh.export(temp_path)
- all_mesh_paths.append(temp_path)
-
- # Render front view
- if len(all_verts) > 0:
- misc_args = dict(
- mesh_base_color=LIGHT_BLUE,
- scene_bg_color=(1, 1, 1),
- )
- cam_view = renderer.render_rgba_multiple(all_verts, cam_t=all_cam_t, render_res=render_size[n], **misc_args)
-
- # Overlay image
- input_img = open_cv_image.astype(np.float32)[:,:,::-1]/255.0
- input_img = np.concatenate([input_img, np.ones_like(input_img[:,:,:1])], axis=2) # Add alpha channel
- input_img_overlay = input_img[:,:,:3] * (1-cam_view[:,:,3:]) + cam_view[:,:,:3] * cam_view[:,:,3:]
-
- # convert to PIL image
- out_pil_img = Image.fromarray((input_img_overlay*255).astype(np.uint8))
-
- return out_pil_img, all_mesh_paths
- else:
- return None, []
-
-
-with gr.Blocks(title="4DHumans", css=".gradio-container") as demo:
-
- gr.HTML("""HMR 2.0
""")
-
- with gr.Row():
- with gr.Column():
- input_image = gr.Image(label="Input image", type="pil")
- with gr.Column():
- output_image = gr.Image(label="Reconstructions", type="pil")
- output_meshes = gr.File(label="3D meshes")
-
- gr.HTML("""
""")
-
- with gr.Row():
- threshold = gr.Slider(0, 1.0, value=0.6, label='Detection Threshold')
- send_btn = gr.Button("Infer")
- send_btn.click(fn=infer, inputs=[input_image, threshold], outputs=[output_image, output_meshes])
-
- # gr.Examples([
- # ['assets/test1.png', 0.6],
- # ['assets/test2.jpg', 0.6],
- # ['assets/test3.jpg', 0.6],
- # ['assets/test4.jpg', 0.6],
- # ['assets/test5.jpg', 0.6],
- # ],
- # inputs=[input_image, threshold])
-
- # with gr.Row():
- example_images = gr.Examples([
- ['/home/user/app/assets/test1.png'],
- ['/home/user/app/assets/test2.jpg'],
- ['/home/user/app/assets/test3.jpg'],
- ['/home/user/app/assets/test4.jpg'],
- ['/home/user/app/assets/test5.jpg'],
- ],
- inputs=[input_image, 0.6])
-
-
-#demo.queue()
-demo.launch(debug=True)
-
-
-
-
-### EOF ###
\ No newline at end of file
diff --git a/spaces/brjathu/HMR2.0/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_regnety_4gf_dds_fpn_1x.py b/spaces/brjathu/HMR2.0/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_regnety_4gf_dds_fpn_1x.py
deleted file mode 100644
index 72c6b7a5c8939970bd0e1e4a3c1155695943b19a..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/detectron2/configs/COCO-InstanceSegmentation/mask_rcnn_regnety_4gf_dds_fpn_1x.py
+++ /dev/null
@@ -1,35 +0,0 @@
-from ..common.optim import SGD as optimizer
-from ..common.coco_schedule import lr_multiplier_1x as lr_multiplier
-from ..common.data.coco import dataloader
-from ..common.models.mask_rcnn_fpn import model
-from ..common.train import train
-
-from detectron2.config import LazyCall as L
-from detectron2.modeling.backbone import RegNet
-from detectron2.modeling.backbone.regnet import SimpleStem, ResBottleneckBlock
-
-
-# Replace default ResNet with RegNetY-4GF from the DDS paper. Config source:
-# https://github.com/facebookresearch/pycls/blob/2c152a6e5d913e898cca4f0a758f41e6b976714d/configs/dds_baselines/regnety/RegNetY-4.0GF_dds_8gpu.yaml#L4-L10 # noqa
-model.backbone.bottom_up = L(RegNet)(
- stem_class=SimpleStem,
- stem_width=32,
- block_class=ResBottleneckBlock,
- depth=22,
- w_a=31.41,
- w_0=96,
- w_m=2.24,
- group_width=64,
- se_ratio=0.25,
- freeze_at=2,
- norm="FrozenBN",
- out_features=["s1", "s2", "s3", "s4"],
-)
-model.pixel_std = [57.375, 57.120, 58.395]
-
-optimizer.weight_decay = 5e-5
-train.init_checkpoint = (
- "https://dl.fbaipublicfiles.com/pycls/dds_baselines/160906838/RegNetY-4.0GF_dds_8gpu.pyth"
-)
-# RegNets benefit from enabling cudnn benchmark mode
-train.cudnn_benchmark = True
diff --git a/spaces/camenduru/9/Dockerfile b/spaces/camenduru/9/Dockerfile
deleted file mode 100644
index a3f95136094d1ca46b4f5ca9ff5a624f0bc06927..0000000000000000000000000000000000000000
--- a/spaces/camenduru/9/Dockerfile
+++ /dev/null
@@ -1,7 +0,0 @@
-FROM python:3.10.12
-RUN useradd -m app
-WORKDIR /app
-COPY . /app
-RUN chown -R app:app /app
-USER app
-CMD pip install pymongo[srv] requests flask && python app.py
\ No newline at end of file
diff --git a/spaces/cccc-c/web-ui-pub/_next/static/chunks/642.1655384818089f79.js b/spaces/cccc-c/web-ui-pub/_next/static/chunks/642.1655384818089f79.js
deleted file mode 100644
index 2c898473c5d8299fa1443a64d85c782c245dd91e..0000000000000000000000000000000000000000
--- a/spaces/cccc-c/web-ui-pub/_next/static/chunks/642.1655384818089f79.js
+++ /dev/null
@@ -1 +0,0 @@
-(self.webpackChunk_N_E=self.webpackChunk_N_E||[]).push([[642],{77592:function(e,t,a){"use strict";a.r(t),a.d(t,{default:function(){return aN}});var s,r,n=a(9268),l=a(16329);a(80293);var o=a(98422),i=a(84451),c=a(90592);o.ZP.use(c.Db).use(i.Z).init({fallbackLng:"en",resources:{"zh-CN":{translation:{"Shortcut to open this app":"打开ChatHub的快捷键",Settings:"设置","Startup page":"启动页面","Chat style":"会话风格","Change shortcut":"修改快捷键",Save:"保存",Saved:"已保存",Export:"导出",Import:"导入","Bot Name":"名称","Space URL":"空间地址","Export/Import All Data":"导出/导入数据","Data includes all your settings, chat histories, and local prompts":"数据包括所有设置、聊天记录和本地prompts",Edit:"编辑",Use:"使用",Send:"发送",Stop:"停止",Title:"标题",Content:"内容",Search:"搜索",Model:"模型",Cancel:"取消","Presale discount":"预售折扣","More bots in All-In-One mode":"在All-In-One模式下使用更多chatbot(三合一、四合一)","Chat history full-text search":"全文搜索聊天记录","Customize theme":"自定义主题","More features in the future":"享受未来所有功能更新","Support the development of ChatHub":"支持ChatHub的开发","Enjoy ChatHub? Give us a 5-star rating!":"喜欢ChatHub吗?给我们个5星好评吧!","Write review":"去评价","Activate license":"激活License","\uD83C\uDF89 License activated":"\uD83C\uDF89 License已激活","All-In-One Mode":"All-In-One模式","Two in one":"二合一","Three in one":"三合一","Four in one":"四合一","Activate up to 5 devices":"最多可激活5台设备",Deactivate:"反激活","Get premium license":"购买会员","Theme Settings":"主题设置","Theme Mode":"主题模式","Theme Color":"主题色","Follow Arc browser theme":"跟随Arc浏览器主题色","iFlytek Spark":"讯飞星火","You need to login to Poe first":"需要先登录Poe账号","Login at bing.com":"去 bing.com 登录","Login at poe.com":"去 poe.com 登录","Login at xfyun.cn":"登录讯飞账号","Lifetime license":"终身授权","Join the waitlist":"加入waitlist","GPT-4 models require ChatGPT Plus":"ChatGPT Plus账号可使用","Model used by ChatGPT iOS app, potentially faster":"ChatGPT iOS app使用的模型,可能更快","Poe subscribers only":"Poe订阅会员可用","Quick access in Chrome side bar":"在Chrome侧边栏快速访问","You have opened ChatHub {{openTimes}} times, consider unlock all features?":"哇!你已经打开ChatHub {{openTimes}}次了,是否要解锁全部功能呢?\uD83E\uDD7A","Open Prompt Library":"管理提示词","Use / to select prompts, Shift+Enter to add new line":"使用 / 选择提示词,Shift+Enter添加换行","Your Prompts":"你的提示词","Community Prompts":"提示词社区","Create new prompt":"创建提示词","Earlybird price":"早鸟价格","Share conversation":"分享会话","Clear conversation":"清空会话","View history":"查看历史消息","Premium Feature":"高级功能","Upgrade to unlock":"升级解锁","Please check your network connection":"请检查您的网络连接,中国用户可能需要科学上网","Display size":"显示大小","You’ve reached the daily free message limit for this model":"你已经达到了该模型今日免费消息上限","This is a limitation set by poe.com":"这是poe.com的限制",Feedback:"反馈",Theme:"主题","Add More":"更多模型",Premium:"付费会员",Chatbots:"聊天机器人","Manage order and devices":"管理订单与设备","Upgrade to premium to chat with more than two bots at once":"升级会员,同时和两个以上的机器人聊天",Upgrade:"升级","This usually mean you need to add a payment method to your OpenAI account, checkout: ":"这通常意味着您需要在OpenAI账户中添加付款方式,请查看:"}},de:{translation:{"Shortcut to open this app":"Tastenk\xfcrzel zum \xd6ffnen dieser App",Settings:"Einstellungen","Startup page":"Startseite","Conversation style":"Konversationsstil","Change shortcut":"Tastenk\xfcrzel \xe4ndern",Save:"Speichern",Export:"Exportieren",Import:"Importieren","Export/Import All Data":"Alle Daten exportieren/importieren","Data includes all your settings, chat histories, and local prompts":"Daten beinhalten alle Einstellungen, Chatverl\xe4ufe und lokale Prompts"}},es:{translation:{"Shortcut to open this app":"Acceso directo para abrir esta aplicaci\xf3n",Settings:"Configuraci\xf3n","Startup page":"P\xe1gina de inicio","Conversation style":"Estilo de conversaci\xf3n","Change shortcut":"Cambiar acceso directo",Save:"Guardar",Export:"Exportar",Import:"Importar","Export/Import All Data":"Exportar/Importar todos los datos","Data includes all your settings, chat histories, and local prompts":"Los datos incluyen todas tus configuraciones, historiales de chat y promociones locales"}},fr:{translation:{"Shortcut to open this app":"Raccourci pour ouvrir cette application",Settings:"Param\xe8tres","Startup page":"Page de d\xe9marrage","Conversation style":"Style de conversation","Change shortcut":"Modifier le raccourci",Save:"Enregistrer",Export:"Exporter",Import:"Importer","Export/Import All Data":"Exporter/Importer toutes les donn\xe9es","Data includes all your settings, chat histories, and local prompts":"Les donn\xe9es incluent tous vos param\xe8tres, historiques de chat et invitations locales"}},in:{translation:{"Shortcut to open this app":"Pintasan untuk membuka aplikasi ini",Settings:"Pengaturan","Startup page":"Halaman awal","Chat style":"Gaya percakapan","Change shortcut":"Ubah pintasan",Save:"Simpan",Saved:"Tersimpan",Export:"Ekspor",Import:"Impor","Export/Import All Data":"Ekspor/Impor Semua Data","Data includes all your settings, chat histories, and local prompts":"Data mencakup semua pengaturan, riwayat percakapan, dan prompt lokal Anda",Edit:"Edit",Use:"Gunakan",Send:"Kirim",Stop:"Berhenti",Title:"Judul",Content:"Konten",Search:"Cari",Model:"Model","Presale discount":"Diskon pra-penjualan","More bots in All-In-One mode":"Lebih banyak bot dalam mode All-In-One","Chat history full-text search":"Pencarian teks penuh riwayat percakapan","Customize theme":"Kustomisasi tema","More features in the future":"Lebih banyak fitur di masa depan","Support the development of ChatHub":"Dukung pengembangan ChatHub","Enjoy ChatHub? Give us a 5-star rating!":"Menikmati ChatHub? Beri kami rating 5 bintang!","Write review":"Tulis ulasan","Activate license":"Aktifkan lisensi","\uD83C\uDF89 License activated":"\uD83C\uDF89 Lisensi diaktifkan","All-In-One Mode":"Mode All-In-One","Two in one":"Dua dalam satu","Three in one":"Tiga dalam satu","Four in one":"Empat dalam satu","Activate up to 5 devices":"Aktifkan hingga 5 perangkat",Deactivate:"Nonaktifkan","Get premium license":"Dapatkan lisensi premium","Theme Settings":"Pengaturan tema","Theme Mode":"Mode tema","Theme Color":"Warna tema","Follow Arc browser theme":"Ikuti tema browser Arc","iFlytek Spark":"iFlytek Spark","You need to login to Poe first":"Anda perlu login ke Poe terlebih dahulu","Login at bing.com":"Login di bing.com","Login at poe.com":"Login di poe.com","Login at xfyun.cn":"Login di xfyun.cn","Lifetime license":"Lisensi seumur hidup","Join the waitlist":"Gabung dalam daftar tunggu","GPT-4 models require ChatGPT Plus":"Model GPT-4 membutuhkan ChatGPT Plus","Model used by ChatGPT iOS app, potentially faster":"Model yang digunakan oleh aplikasi ChatGPT iOS, mungkin lebih cepat","Poe subscribers only":"Hanya pelanggan Poe","Quick access in Chrome side bar":"Akses cepat di sisi bilah Chrome","You have opened ChatHub {{openTimes}} times, consider unlock all features?":"Wow! Anda telah membuka ChatHub sebanyak {{openTimes}} kali, pertimbangkan untuk membuka semua fitur?","Open Prompt Library":"Buka Perpustakaan Prompt","Use / to select prompts, Shift+Enter to add new line":"Gunakan / untuk memilih prompt, Shift+Enter untuk menambahkan baris baru","Your Prompts":"Prompt Anda","Community Prompts":"Prompt Komunitas","Create new prompt":"Buat prompt baru"}},ja:{translation:{"Shortcut to open this app":"このアプリを開くショートカット",Settings:"設定","Startup page":"スタートアップページ","Chat style":"チャットスタイル","Change shortcut":"ショートカットを変更する",Save:"保存",Saved:"保存されました",Export:"エクスポート",Import:"インポート","Export/Import All Data":"すべてのデータをエクスポート/インポート","Data includes all your settings, chat histories, and local prompts":"データはすべての設定、チャット履歴、およびローカルのプロンプトを含みます",Edit:"編集",Use:"使用",Send:"送信",Stop:"停止",Title:"タイトル",Content:"コンテンツ",Search:"検索",Model:"モデル",Cancel:"キャンセル","Presale discount":"プレセール割引","More bots in All-In-One mode":"オールインワンモードでより多くのボットを使用する","Chat history full-text search":"チャット履歴の全文検索","Customize theme":"テーマをカスタマイズ","More features in the future":"将来のさらなる機能","Support the development of ChatHub":"ChatHubの開発をサポート","Enjoy ChatHub? Give us a 5-star rating!":"ChatHubを楽しんでいますか?5つ星の評価をお願いします!","Write review":"レビューを書く","Activate license":"ライセンスを有効にする","\uD83C\uDF89 License activated":"\uD83C\uDF89 ライセンスが有効化されました","All-In-One Mode":"オールインワンモード","Two in one":"二つ一体","Three in one":"三つ一体","Four in one":"四つ一体","Activate up to 5 devices":"最大5台のデバイスを有効化する",Deactivate:"無効にする","Get premium license":"プレミアムライセンスを取得する","Theme Settings":"テーマ設定","Theme Mode":"テーマモード","Theme Color":"テーマカラー","Follow Arc browser theme":"Arcブラウザのテーマに従う","iFlytek Spark":"科大訳飛スパーク","You need to login to Poe first":"先にPoeにログインする必要があります","Login at bing.com":"bing.comでログイン","Login at poe.com":"poe.comでログイン","Login at xfyun.cn":"xfyun.cnでログインする","Lifetime license":"ライフタイムライセンス","Join the waitlist":"ウェイトリストに参加する","GPT-4 models require ChatGPT Plus":"GPT-4モデルはChatGPT Plusが必要","Model used by ChatGPT iOS app, potentially faster":"ChatGPT iOSアプリで使用されるモデル、おそらく速い","Poe subscribers only":"Poeの加入者のみ","Quick access in Chrome side bar":"Chromeサイドバーからのクイックアクセス","You have opened ChatHub {{openTimes}} times, consider unlock all features?":"ChatHubを{{openTimes}}回開きました。全機能を解放しますか?","Open Prompt Library":"プロンプトライブラリを開く","Use / to select prompts, Shift+Enter to add new line":"/ を使用してプロンプトを選択し、Shift+Enterで新しい行を追加します","Your Prompts":"あなたのプロンプト","Community Prompts":"コミュニティのプロンプト","Create new prompt":"新しいプロンプトを作成する","Earlybird price":"早期割引価格","Share conversation":"会話を共有する","Clear conversation":"会話をクリアする","View history":"履歴を表示する","Premium Feature":"プレミアム機能","Upgrade to unlock":"アンロックするためのアップグレード","Please check your network connection":"ネットワーク接続をご確認ください","Display size":"表示サイズ","You’ve reached the daily free message limit for this model":"このモデルの1日あたりの無料メッセージ上限に達しました","This is a limitation set by poe.com":"これはpoe.comによって設定された制限です",Feedback:"フィードバック",Theme:"テーマ",Premium:"プレミアム",Chatbots:"チャットボット","Manage order and devices":"注文とデバイスの管理","Upgrade to premium to chat with more than two bots at once":"一度に2つ以上のボットとチャットするためにプレミアムにアップグレードする",Upgrade:"アップグレード","This usually mean you need to add a payment method to your OpenAI account, checkout:":"これは通常、OpenAIアカウントに支払い方法を追加する必要があることを意味します。チェックアウト:"}},th:{translation:{"Shortcut to open this app":"ทางลัดเพื่อเปิดแอปนี้",Settings:"การตั้งค่า","Startup page":"หน้าเริ่มต้น","Conversation style":"สไตล์การสนทนา","Change shortcut":"เปลี่ยนทางลัด",Save:"บันทึก",Export:"ส่งออก",Import:"นำเข้า","Export/Import All Data":"ส่งออก/นำเข้าข้อมูลทั้งหมด","Data includes all your settings, chat histories, and local prompts":"ข้อมูลรวมถึงการตั้งค่าทั้งหมดของคุณ ประวัติการแชท และข้อความเตือนในเครื่อง"}},"zh-TW":{translation:{"Shortcut to open this app":"開啟此應用程式的快捷鍵",Settings:"設定","Startup page":"啟動頁面","Conversation style":"對話風格","Change shortcut":"變更快捷鍵",Save:"儲存",Export:"匯出",Import:"匯入","Export/Import All Data":"匯出/匯入所有資料","Data includes all your settings, chat histories, and local prompts":"資料包含所有設定、聊天紀錄和本地prompts"}}},interpolation:{escapeValue:!1}});var d=a(80884),m=a(65192),u=a(29541),p=a(42794);let x=e=>{console.log("url",e);let t=new URL(e),a=t.pathname.split("/"),s=a.length>3?a[3]:/[a-z]/i.test(t.hostname)&&t.hostname.split(".").length>2?t.hostname.split(".").at(-2):t.host;return s},h=p.spaces.map(e=>{let t=(null==e?void 0:e.url)||e;return{name:x(t),url:t,system:!0}});(s=r||(r={})).CONVERSATION_LIMIT="CONVERSATION_LIMIT",s.UNKOWN_ERROR="UNKOWN_ERROR",s.GRADIO_ERROR="GRADIO_ERROR",s.CHATGPT_CLOUDFLARE="CHATGPT_CLOUDFLARE",s.CHATGPT_UNAUTHORIZED="CHATGPT_UNAUTHORIZED",s.CHATGPT_AUTH="CHATGPT_AUTH",s.GPT4_MODEL_WAITLIST="GPT4_MODEL_WAITLIST",s.BING_UNAUTHORIZED="BING_UNAUTHORIZED",s.BING_FORBIDDEN="BING_FORBIDDEN",s.BING_CAPTCHA="BING_CAPTCHA",s.API_KEY_NOT_SET="API_KEY_NOT_SET",s.BARD_EMPTY_RESPONSE="BARD_EMPTY_RESPONSE",s.MISSING_POE_HOST_PERMISSION="MISSING_POE_HOST_PERMISSION",s.POE_UNAUTHORIZED="POE_UNAUTHORIZED",s.MISSING_HOST_PERMISSION="MISSING_HOST_PERMISSION",s.NETWORK_ERROR="NETWORK_ERROR",s.POE_MESSAGE_LIMIT="POE_MESSAGE_LIMIT",s.LMSYS_SESSION_EXPIRED="LMSYS_SESSION_EXPIRED",s.CHATGPT_INSUFFICIENT_QUOTA="CHATGPT_INSUFFICIENT_QUOTA";class g extends Error{constructor(e,t){super(e),this.code=t}}class f{async sendMessage(e){try{await this.doSendMessage(e)}catch(a){var t;a instanceof g?e.onEvent({type:"ERROR",error:a}):(null===(t=e.signal)||void 0===t?void 0:t.aborted)||e.onEvent({type:"ERROR",error:new g(a.message,r.UNKOWN_ERROR)})}}get name(){}}class b extends f{async doSendMessage(e){this.conversationContext||(this.conversationContext={sessionHash:(0,p.generateHash)(),chatbot:new p.GradioChatBot(this.model)}),await this.conversationContext.chatbot.chat(e.prompt,{onMessage:t=>{e.onEvent({type:"UPDATE_ANSWER",data:{text:t}})}}).catch(t=>{e.onEvent({type:"ERROR",error:new g(t,r.GRADIO_ERROR)})}),e.onEvent({type:"DONE"})}resetConversation(){this.conversationContext=void 0}constructor(e){super(),this.model=e}}var y=a(31405);let v="(prefers-color-scheme: dark)";function j(){document.documentElement.classList.remove("dark"),document.documentElement.classList.add("light")}function w(){document.documentElement.classList.remove("light"),document.documentElement.classList.add("dark")}function N(e){let t=e.matches?"dark":"light";"dark"===t?w():j()}var C=a(86462);function k(){return(0,C.Z)()}let S=(0,u.xu)(e=>(0,m.sn)({bot:function(e){let t=h.find(t=>t.name===e);return t||console.error("use defalt model"),new b(null==t?void 0:t.url)}(e.botName),messages:[],generatingMessageId:"",abortController:void 0,conversationId:k()}),(e,t)=>e.botName===t.botName&&e.page===t.page),E=(0,u.O4)("sidebarCollapsed",!1),T=(0,u.O4)("themeColor","#7EB8D4"),P=(0,u.O4)("followArcTheme",!1);(0,u.O4)("sidePanelBot","chatgpt");var I=a(8683),_=a.n(I),O=a(86006),R=a(76394),A=a.n(R),D={src:"./_next/static/media/all-in-one.76a3222a.svg",height:26,width:26,blurWidth:0,blurHeight:0},M={src:"./_next/static/media/collapse.fbb9d05e.svg",height:24,width:24,blurWidth:0,blurHeight:0},L={src:"./_next/static/media/feedback.47013dfe.svg",height:24,width:24,blurWidth:0,blurHeight:0},G={src:"./_next/static/media/github.7fb5de84.svg",height:1024,width:1024,blurWidth:0,blurHeight:0},H={src:"./_next/static/media/setting.0ee621f2.svg",height:22,width:20,blurWidth:0,blurHeight:0},F={src:"./_next/static/media/theme.e2c6e463.svg",height:24,width:24,blurWidth:0,blurHeight:0},U={src:"./_next/static/media/logo.e537bd1b.svg",height:312,width:512,blurWidth:0,blurHeight:0},B={src:"./_next/static/media/minimal-logo.75de5ebf.svg",height:256,width:256,blurWidth:0,blurHeight:0},z=a(89949),Z=a(23845),Y=a(22486);let W={async get(e){if(null===e)return null;"string"==typeof e&&(e=[e]);let t={},a=await (0,Y.yS)(e);return e.forEach((e,s)=>{t[e]=a[s]}),t},async set(e){for(let t of Object.keys(e))await (0,Y.t8)(t,e[t])},remove:async e=>(0,Y.IV)(e),clear:async()=>(0,Y.ZH)()},V=parseInt(getComputedStyle(document.documentElement).fontSize,10);var K={storage:{sync:W,local:W},runtime:{getURL:e=>e},tabs:{async getZoom(){let e=parseInt(getComputedStyle(document.documentElement).fontSize,10);return e/V},async setZoom(e){document.documentElement.style.fontSize=e*V+"px"}}};let $={startupPage:"all",enabledBots:h.slice(0,8).map(e=>e.name),allBots:h,useProxy:!1};async function J(){let e=await K.storage.sync.get(Object.keys($));return(0,Z.Z)(e,$)}async function Q(e){for(let[t,a]of(console.debug("update configs",e),await K.storage.sync.set(e),Object.entries(e)))void 0===a&&await K.storage.sync.remove(t)}function q(){let e=(0,z.Z)("enabled-bots",async()=>{let{enabledBots:e}=await J();return h.filter(t=>e.includes(t.name))});return e.data||[]}var X=a(28373),ee=a(87594),et=a(312),ea=a(18178);let es=et.fC;et.xz;let er=e=>{let{className:t,children:a,...s}=e;return(0,n.jsx)(et.h_,{className:_()(t),...s,children:(0,n.jsx)("div",{className:"fixed inset-0 z-50 flex items-start justify-center sm:items-center",children:a})})};er.displayName=et.h_.displayName;let en=O.forwardRef((e,t)=>{let{className:a,children:s,...r}=e;return(0,n.jsx)(et.aV,{className:_()("data-[state=closed]:animate-out data-[state=open]:fade-in data-[state=closed]:fade-out fixed inset-0 z-50 bg-black/50 backdrop-blur-sm transition-all duration-100",a),...r,ref:t})});en.displayName=et.aV.displayName;let el=O.forwardRef((e,t)=>{let{className:a,children:s,...r}=e;return(0,n.jsxs)(er,{children:[(0,n.jsx)(en,{}),(0,n.jsxs)(et.VY,{ref:t,className:_()("animate-in data-[state=open]:fade-in-90 data-[state=open]:slide-in-from-bottom-10 sm:zoom-in-90 data-[state=open]:sm:slide-in-from-bottom-0 fixed z-50 grid w-full gap-4 rounded-b-lg bg-white p-6 sm:max-w-lg sm:rounded-lg","dark:bg-slate-900",a),...r,children:[s,(0,n.jsxs)(et.x8,{className:"absolute top-4 right-4 rounded-sm opacity-70 transition-opacity hover:opacity-100 focus:outline-none focus:ring-2 focus:ring-slate-400 focus:ring-offset-2 disabled:pointer-events-none data-[state=open]:bg-slate-100 dark:focus:ring-slate-400 dark:focus:ring-offset-slate-900 dark:data-[state=open]:bg-slate-800",children:[(0,n.jsx)(ea.Z,{className:"h-4 w-4"}),(0,n.jsx)("span",{className:"sr-only",children:"Close"})]})]})]})});el.displayName=et.VY.displayName;let eo=O.forwardRef((e,t)=>{let{className:a,...s}=e;return(0,n.jsx)(et.Dx,{ref:t,className:_()("text-lg font-semibold text-slate-900","dark:text-slate-50",a),...s})});eo.displayName=et.Dx.displayName;let ei=O.forwardRef((e,t)=>{let{className:a,...s}=e;return(0,n.jsx)(et.dk,{ref:t,className:_()("text-sm text-slate-500","dark:text-slate-400",a),...s})});ei.displayName=et.dk.displayName;let ec=O.forwardRef((e,t)=>{let{className:a,...s}=e;return(0,n.jsx)(X.mY,{ref:t,className:_()("flex h-full w-full flex-col overflow-hidden rounded-lg bg-white dark:bg-slate-800",a),...s})});ec.displayName=X.mY.displayName;let ed=e=>{let{children:t,...a}=e;return(0,n.jsx)(es,{...a,children:(0,n.jsx)(el,{className:"overflow-hidden !p-0 shadow-2xl [&_[dialog-overlay]]:bg-red-100",children:(0,n.jsx)(ec,{className:"[&_[cmdk-group]]:px-2 [&_[cmdk-group-heading]]:px-2 [&_[cmdk-group-heading]]:font-medium [&_[cmdk-group-heading]]:text-slate-500 [&_[cmdk-item]]:px-2 [&_[cmdk-item]]:py-3 [&_[cmdk-input]]:h-12 [&_[cmdk-item]_svg]:h-5 [&_[cmdk-item]_svg]:w-5 [&_[cmdk-input-wrapper]_svg]:h-5 [&_[cmdk-input-wrapper]_svg]:w-5",children:t})})})},em=O.forwardRef((e,t)=>{let{className:a,...s}=e;return(0,n.jsxs)("div",{className:"flex items-center border-b border-b-slate-100 px-4 dark:border-b-slate-700","cmdk-input-wrapper":"",children:[(0,n.jsx)(ee.Z,{className:"mr-2 h-4 w-4 shrink-0 opacity-50"}),(0,n.jsx)(X.mY.Input,{ref:t,className:_()("flex h-11 w-full rounded-md bg-transparent py-3 text-sm outline-none placeholder:text-slate-400 disabled:cursor-not-allowed disabled:opacity-50 dark:text-slate-50",a),...s})]})});em.displayName=X.mY.Input.displayName;let eu=O.forwardRef((e,t)=>{let{className:a,...s}=e;return(0,n.jsx)(X.mY.List,{ref:t,className:_()("max-h-[300px] overflow-y-auto overflow-x-hidden",a),...s})});eu.displayName=X.mY.List.displayName;let ep=O.forwardRef((e,t)=>(0,n.jsx)(X.mY.Empty,{ref:t,className:"py-6 text-center text-sm",...e}));ep.displayName=X.mY.Empty.displayName;let ex=O.forwardRef((e,t)=>{let{className:a,...s}=e;return(0,n.jsx)(X.mY.Group,{ref:t,className:_()("overflow-hidden py-3 px-2 text-slate-700 dark:text-slate-400 [&_[cmdk-group-heading]]:px-2 [&_[cmdk-group-heading]]:pb-1.5 [&_[cmdk-group-heading]]:text-sm [&_[cmdk-group-heading]]:font-semibold [&_[cmdk-group-heading]]:text-slate-900 [&_[cmdk-group-heading]]:dark:text-slate-300",a),...s})});ex.displayName=X.mY.Group.displayName;let eh=O.forwardRef((e,t)=>{let{className:a,...s}=e;return(0,n.jsx)(X.mY.Separator,{ref:t,className:_()("-mx-1 h-px bg-slate-100 dark:bg-slate-700",a),...s})});eh.displayName=X.mY.Separator.displayName;let eg=O.forwardRef((e,t)=>{let{className:a,...s}=e;return(0,n.jsx)(X.mY.Item,{ref:t,className:_()("relative flex cursor-default select-none items-center rounded-md py-1.5 px-2 text-sm font-medium outline-none aria-selected:bg-slate-100 data-[disabled]:pointer-events-none data-[disabled]:opacity-50 dark:aria-selected:bg-slate-700",a),...s})});eg.displayName=X.mY.Item.displayName;var ef=function(){let[e,t]=(0,O.useState)(!1),a=(0,l.useNavigate)();(0,O.useEffect)(()=>{let e=e=>{"k"===e.key&&e.metaKey&&t(e=>!e)};return document.addEventListener("keydown",e),()=>document.removeEventListener("keydown",e)},[]);let s=(0,O.useCallback)(e=>{e?a({to:"/chat/$name",params:{name:e}}):a({to:"/"}),t(!1)},[a]);return(0,n.jsxs)(ed,{open:e,onOpenChange:t,children:[(0,n.jsx)(em,{placeholder:"Type to search..."}),(0,n.jsxs)(eu,{children:[(0,n.jsx)(ep,{children:"No results found."}),(0,n.jsxs)(ex,{children:[(0,n.jsxs)(eg,{onSelect:()=>s(),children:[(0,n.jsx)(A(),{alt:"all in one",src:D,className:"w-5 h-5 mr-2"}),(0,n.jsx)("span",{children:"All-In-One"})]}),h.map(e=>(0,n.jsx)(eg,{onSelect:s,value:e.name,children:(0,n.jsx)("span",{children:e.name})},e.url))]})]})]})},eb=a(52982),ey=a(22940),ev={src:"./_next/static/media/close.34e62625.svg",height:20,width:20,blurWidth:0,blurHeight:0},ej=e=>(0,n.jsxs)(ey.V,{open:e.open,onClose:e.onClose,className:"relative z-50",children:[(0,n.jsx)("div",{className:"fixed inset-0 bg-black/30","aria-hidden":"true"}),(0,n.jsx)("div",{className:"fixed inset-0 flex items-center justify-center max-h-screen m-5",children:(0,n.jsxs)(ey.V.Panel,{className:_()("mx-auto rounded-3xl bg-primary-background shadow-2xl max-h-full overflow-hidden flex flex-col",e.className),children:[(0,n.jsxs)(ey.V.Title,{className:_()(!e.borderless&&"border-b","border-solid border-primary-border flex flex-row justify-center items-center py-4 px-5"),children:[(0,n.jsx)("span",{className:"ml-auto"}),(0,n.jsx)("span",{className:"font-bold text-primary-text text-base",children:e.title}),(0,n.jsx)(A(),{alt:"close",src:ev,className:"w-4 h-4 ml-auto mr-[10px] cursor-pointer",onClick:e.onClose})]}),e.children]})})]}),ew=a(3420),eN=a(59738),eC=a(8632),ek=a(10830),eS=function(e){let{options:t,value:a,onChange:s,size:r="normal",disabled:l}=e,o=(0,O.useMemo)(()=>t.find(e=>e.value===a).name,[t,a]);return(0,n.jsx)(ew.R,{value:a,onChange:s,disabled:l,children:e=>{let{open:a}=e;return(0,n.jsx)(n.Fragment,{children:(0,n.jsxs)("div",{className:"relative",children:[(0,n.jsxs)(ew.R.Button,{className:_()("relative w-full cursor-default rounded-md bg-white pl-3 pr-10 text-left text-gray-900 shadow-sm ring-1 ring-inset ring-gray-300 focus:outline-none leading-6","normal"===r?"text-sm py-1.5":"text-xs py-1",l&&"cursor-not-allowed opacity-50"),children:[(0,n.jsx)("span",{className:"block truncate",children:o}),(0,n.jsx)("span",{className:"pointer-events-none absolute inset-y-0 right-0 flex items-center pr-2",children:(0,n.jsx)(eC.Z,{className:"h-5 w-5 text-gray-400","aria-hidden":"true"})})]}),(0,n.jsx)(eN.u,{show:a,as:O.Fragment,leave:"transition ease-in duration-100",leaveFrom:"opacity-100",leaveTo:"opacity-0",children:(0,n.jsx)(ew.R.Options,{className:_()("absolute z-10 mt-1 max-h-60 w-full overflow-auto rounded-md bg-white py-1 text-base shadow-lg ring-1 ring-black ring-opacity-5 focus:outline-none","normal"===r?"text-sm":"text-xs"),children:t.map(e=>(0,n.jsx)(ew.R.Option,{className:e=>{let{active:t}=e;return _()(t?"bg-primary-blue text-white":"text-[#303030]","relative cursor-default select-none py-2 pl-3 pr-9")},value:e.value,children:t=>{let{selected:a,active:s}=t;return(0,n.jsxs)(n.Fragment,{children:[(0,n.jsx)("span",{className:_()(a?"font-semibold":"font-normal","block truncate"),children:e.name}),a?(0,n.jsx)("span",{className:_()(s?"text-white":"text-[#303030]","absolute inset-y-0 right-0 flex items-center pr-4"),children:(0,n.jsx)(ek.Z,{className:"h-5 w-5","aria-hidden":"true"})}):null]})}},e.value))})})]})})}})};let eE=e=>{let{className:t,...a}=e;return(0,n.jsx)("button",{type:"button",className:_()("relative inline-flex items-center bg-primary-background px-3 py-2 text-sm font-semibold text-primary-text ring-1 ring-inset ring-gray-300 hover:opacity-80 focus:z-10",t),...a})},eT=["#7EB8D4","#FF6900","#7BDCB5","#00D084","#8ED1FC","#0693E3","#ABB8C3","#EB144C","#F78DA7","#555555"];var eP=e=>{let{t}=(0,c.$G)(),[a,s]=(0,d.KO)(T),[r,l]=(0,O.useState)((0,y.Dt)()),[o,i]=(0,d.KO)(P),[m,u]=(0,O.useState)(null);(0,O.useEffect)(()=>{K.tabs.getZoom().then(e=>u(e))},[]);let p=(0,O.useCallback)(e=>{if(!m)return;let t="+"===e?m+.1:m-.1;t<.7||t>1.2||(K.tabs.setZoom(t),u(t))},[m]),x=(0,O.useCallback)(e=>{(0,y.pQ)(e),l(e),function(e){if(e===y.hY.Light){j(),window.matchMedia(v).removeEventListener("change",N);return}if(e===y.hY.Dark){w(),window.matchMedia(v).removeEventListener("change",N);return}window.matchMedia(v).matches?w():j(),window.matchMedia(v).addEventListener("change",N)}(e)},[]),h=(0,O.useCallback)(e=>{s(e.hex),e.hex},[s]);return(0,n.jsx)(ej,{title:t("Theme Settings"),open:e.open,onClose:e.onClose,className:"rounded-xl w-[600px] min-h-[300px]",children:(0,n.jsxs)("div",{className:"p-5 pb-10 flex flex-col gap-5",children:[(0,n.jsxs)("div",{className:"w-[300px]",children:[(0,n.jsx)("p",{className:"font-bold text-lg mb-3",children:t("Theme Mode")}),(0,n.jsx)(eS,{options:[{name:t("Light"),value:y.hY.Light},{name:t("Dark"),value:y.hY.Dark}],value:r,onChange:x})]}),(0,n.jsxs)("div",{children:[(0,n.jsx)("p",{className:"font-bold text-lg mb-3",children:t("Theme Color")}),(0,n.jsxs)("div",{className:_()("flex flex-col gap-3"),children:[getComputedStyle(document.documentElement).getPropertyValue("--arc-palette-background")&&(0,n.jsxs)("div",{className:"flex flex-row items-center gap-2",children:[(0,n.jsx)("input",{type:"checkbox",id:"arc-theme-check",checked:o,onChange:e=>i(e.target.checked)}),(0,n.jsx)("label",{htmlFor:"arc-theme-check",children:t("Follow Arc browser theme")})]}),!o&&(0,n.jsx)(eb.e8,{colors:eT,color:a,onChange:h,triangle:"hide",width:"300px"})]})]}),(0,n.jsxs)("div",{children:[(0,n.jsx)("p",{className:"font-bold text-lg mb-3",children:t("Display size")}),(0,n.jsxs)("span",{className:"isolate inline-flex rounded-md shadow-sm",children:[(0,n.jsx)(eE,{className:"rounded-l-md",onClick:()=>p("-"),children:"-"}),(0,n.jsxs)(eE,{className:"-ml-px cursor-default",children:[null===m?"-":Math.floor(100*m),"%"]}),(0,n.jsx)(eE,{className:"-ml-px rounded-r-md",onClick:()=>p("+"),children:"+"})]})]})]})})},eI=a(22040),e_=e=>(0,n.jsx)(eI.zt,{delayDuration:1,children:(0,n.jsxs)(eI.fC,{children:[(0,n.jsx)(eI.xz,{asChild:!0,children:e.children}),(0,n.jsx)(eI.h_,{children:(0,n.jsx)(eI.VY,{className:"data-[state=delayed-open]:data-[side=top]:animate-slideDownAndFade data-[state=delayed-open]:data-[side=right]:animate-slideLeftAndFade data-[state=delayed-open]:data-[side=left]:animate-slideRightAndFade data-[state=delayed-open]:data-[side=bottom]:animate-slideUpAndFade select-none rounded-md bg-black text-white bg-opacity-90 px-[14px] py-2 text-sm leading-none shadow-[hsl(206_22%_7%_/_35%)_0px_10px_38px_-10px,_hsl(206_22%_7%_/_20%)_0px_10px_20px_-15px] will-change-[transform,opacity]",sideOffset:5,children:e.content})})]})}),eO=function(e){let{text:t,icon:a,iconOnly:s,...r}=e;return(0,n.jsxs)(l.Link,{className:_()("rounded-[10px] w-full h-[45px] pl-3 flex flex-row gap-3 items-center shrink-0 break-all",s&&"justify-center"),activeOptions:{exact:!0},activeProps:{className:"bg-white text-primary-text dark:bg-primary-blue"},inactiveProps:{className:"bg-secondary bg-opacity-20 text-primary-text opacity-80 hover:opacity-100"},title:t,...r,children:[a?(0,n.jsx)(A(),{alt:"nav",src:a,className:"w-6 h-6 ml-1"}):(0,n.jsx)("div",{className:"relative inline-flex items-center justify-center min-w-[2rem] min-h-[2rem] overflow-hidden bg-gray-100 rounded-full dark:bg-gray-600",children:(0,n.jsx)("span",{className:"font-medium text-sm text-gray-600 dark:text-gray-300",children:t.slice(0,2).toUpperCase()})}),(0,n.jsx)("span",{className:"font-medium text-sm",children:s?"":t})]})},eR=e=>{let{text:t}=e;return(0,n.jsx)(l.Link,{to:"/setting",children:(0,n.jsx)("div",{className:"flex flex-row justify-center items-center gap-[10px] rounded-[10px] px-4 py-[6px] cursor-pointer",style:{background:"linear-gradient(275deg, rgb(var(--color-primary-purple)) 1.65%, rgb(var(--color-primary-blue)) 100%)"},children:!!t&&(0,n.jsx)("span",{className:"text-white font-semibold text-base",children:t})})})};function eA(e){return(0,n.jsx)("div",{className:"p-[6px] rounded-[10px] w-fit cursor-pointer hover:opacity-80 bg-secondary bg-opacity-20",onClick:e.onClick,children:(0,n.jsx)(A(),{alt:"button",src:e.icon,className:"w-6 h-6"})})}var eD=function(){let{t:e}=(0,c.$G)(),[t,a]=(0,d.KO)(E),[s,r]=(0,O.useState)(!1),o=q();return(0,n.jsxs)("aside",{className:_()("flex flex-col bg-primary-background bg-opacity-40 overflow-hidden",t?"items-center px-[15px]":"w-[230px] px-4"),children:[(0,n.jsx)(A(),{alt:"collapse",src:M,className:_()("w-6 h-6 cursor-pointer my-5",t?"rotate-180":"self-end"),onClick:()=>a(e=>!e)}),t?(0,n.jsx)(A(),{alt:"logo",src:B,className:"w-[30px]"}):(0,n.jsx)(A(),{alt:"logo",src:U,className:"w-[79px]"}),(0,n.jsxs)("div",{className:"flex flex-col gap-3 mt-2 overflow-y-auto scrollbar-none",children:[(0,n.jsx)(eO,{to:"/",text:"All-In-One",icon:D,iconOnly:t}),o.map(e=>(0,n.jsx)(eO,{to:"/chat/$name",params:{name:e.name},text:e.name,iconOnly:t},e.url))]}),(0,n.jsxs)("div",{className:"mt-auto pt-2",children:[!t&&(0,n.jsx)("hr",{className:"border-[#ffffff4d]"}),!t&&(0,n.jsx)("div",{className:"my-5",children:(0,n.jsx)(eR,{text:e("Add More")})}),(0,n.jsxs)("div",{className:_()("flex mt-5 gap-[10px] mb-4",t?"flex-col":"flex-row "),children:[!t&&(0,n.jsx)(e_,{content:e("GitHub"),children:(0,n.jsx)("a",{href:"https://github.com/weaigc/gradio-chatbot?utm_source=webui",target:"_blank",rel:"noreferrer",children:(0,n.jsx)(eA,{icon:G})})}),!t&&(0,n.jsx)(e_,{content:e("Feedback"),children:(0,n.jsx)("a",{href:"https://github.com/weaigc/gradio-chatbot/issues",target:"_blank",rel:"noreferrer",children:(0,n.jsx)(eA,{icon:L})})}),!t&&(0,n.jsx)(e_,{content:e("Theme"),children:(0,n.jsx)("a",{onClick:()=>r(!0),children:(0,n.jsx)(eA,{icon:F})})}),(0,n.jsx)(e_,{content:e("Settings"),children:(0,n.jsx)(l.Link,{to:"/setting",children:(0,n.jsx)(eA,{icon:H})})})]})]}),(0,n.jsx)(ef,{}),s&&(0,n.jsx)(eP,{open:!0,onClose:()=>r(!1)})]})},eM=a(62960),eL=a(50942),eG=e=>{let t=e.size||"normal",a=e.type||"button";return(0,n.jsx)("button",{type:a,className:_()("rounded-full","normal"===t?"text-base font-medium px-6 py-[5px]":"text-sm px-4 py-1","primary"===e.color?"text-white bg-primary-blue":"text-primary-text bg-secondary",e.className),onClick:e.onClick,children:e.isLoading?(0,n.jsx)(eL.Z,{size:"normal"===t?10:5,color:"primary"===e.color?"white":"#303030"}):(0,n.jsxs)("div",{className:"flex flex-row items-center gap-1 min-w-max",children:[e.icon,(0,n.jsx)("span",{children:e.text})]})})},eH=a(52134),eF=a(41778),eU=a(21828),eB=a(9735),ez=a(57797),eZ=a(95825);async function eY(){let{prompts:e}=await K.storage.local.get("prompts");return e||[]}async function eW(e){let t=await eY(),a=!1;for(let s of t)if(s.id===e.id){s.title=e.title,s.prompt=e.prompt,a=!0;break}return a||t.unshift(e),await K.storage.local.set({prompts:t}),a}async function eV(e){let t=await eY();await K.storage.local.set({prompts:t.filter(t=>t.id!==e)})}async function eK(){return(0,eZ.Wg)("https://chathub.gg/api/community-prompts",{params:{language:o.ZP.language,languages:o.ZP.languages}}).catch(e=>(console.error("Failed to load remote prompts",e),[]))}let e$={id:"PROMPT_LIBRARY",title:(0,o.t)("Open Prompt Library"),prompt:""},eJ=(0,O.createContext)({}),eQ=e=>{let{prompt:t}=e,a=(0,O.useContext)(eJ),{ref:s,index:r}=(0,eH.JA)(),l=r===a.activeIndex;return(0,n.jsx)("div",{ref:s,tabIndex:l?0:-1,className:_()("cursor-default select-none py-2 px-4",l?"bg-primary-blue text-white":"text-secondary-text"),...a.getItemProps({onClick:()=>{a.handleSelect(t)},onKeyDown:e=>{13===e.keyCode?(a.handleSelect(t),e.preventDefault()):("Backspace"===e.key||"Delete"===e.key)&&a.setIsComboboxOpen(!1)}}),children:t.title})};var eq=()=>{let e=(0,ez.ZP)("user-prompts",eY);return e.data?(0,n.jsxs)("div",{className:"overflow-auto rounded-md py-1 shadow-lg ring-1 ring-primary-border focus:outline-none text-sm min-w-[150px] bg-primary-background",children:[e.data.map(e=>(0,n.jsx)(eQ,{prompt:e},e.id)),e.data.length>0&&(0,n.jsx)("div",{className:"h-[1px] bg-primary-border"}),(0,n.jsx)(eQ,{prompt:e$},"PROMPT_LIBRARY")]}):null},eX=a(35036);let e0=e=>{let{className:t,...a}=e;return(0,n.jsx)("input",{className:_()("px-3 py-1.5 outline-none bg-white text-[#303030] text-sm block rounded-md border-0 shadow-sm ring-1 ring-inset ring-gray-300 placeholder:text-gray-400 focus:ring-2 focus:ring-inset focus:ring-indigo-600 sm:text-sm sm:leading-6",t),...a})},e1=e=>{let{className:t,...a}=e;return(0,n.jsx)(eX.Z,{className:_()("px-3 py-1.5 outline-none bg-white text-[#303030] text-sm block rounded-md border-0 shadow-sm ring-1 ring-inset ring-gray-300 placeholder:text-gray-400 focus:ring-2 focus:ring-inset focus:ring-indigo-600 sm:text-sm sm:leading-6",t),minRows:2,maxRows:5,...a})};var e2=e=>{let{tabs:t,renderTab:a}=e,[s,r]=(0,O.useState)(t[0].value);return(0,n.jsxs)(n.Fragment,{children:[(0,n.jsx)("nav",{className:"w-full flex space-x-4 mb-3","aria-label":"Tabs",children:t.map(e=>(0,n.jsx)("a",{className:_()("rounded-md px-3 py-2 text-sm font-medium cursor-pointer",e.value===s?"bg-primary-blue text-white":"text-secondary-text hover:text-primary-text"),onClick:()=>r(e.value),children:e.name},e.name))}),a(s)]})};let e3=e=>(0,n.jsx)("a",{className:"inline-flex items-center rounded-full bg-white px-2.5 py-1 text-xs font-semibold text-gray-900 shadow-sm ring-1 ring-inset ring-gray-300 hover:bg-gray-50 cursor-pointer",onClick:e.onClick,children:e.text}),e5=e=>{let{t}=(0,c.$G)(),[a,s]=(0,O.useState)(!1),r=(0,O.useCallback)(()=>{var t;null===(t=e.copyToLocal)||void 0===t||t.call(e),s(!0)},[e]);return(0,n.jsxs)("div",{className:"group relative flex items-center space-x-3 rounded-lg border border-primary-border bg-primary-background px-5 py-4 shadow-sm hover:border-gray-400",children:[(0,n.jsx)("div",{className:"min-w-0 flex-1",children:(0,n.jsx)("p",{title:e.prompt,className:"truncate text-sm font-medium text-primary-text",children:e.title})}),(0,n.jsxs)("div",{className:"flex flex-row gap-1",children:[e.edit&&(0,n.jsx)(e3,{text:t("Edit"),onClick:e.edit}),e.copyToLocal&&(0,n.jsx)(e3,{text:t(a?"Saved":"Save"),onClick:r}),(0,n.jsx)(e3,{text:t("Use"),onClick:()=>e.insertPrompt(e.prompt)})]}),e.remove&&(0,n.jsx)(A(),{alt:"close",src:ev,className:"hidden group-hover:block absolute right-[-8px] top-[-8px] cursor-pointer w-4 h-4 rounded-full bg-primary-background",onClick:e.remove})]})};function e4(e){let{t}=(0,c.$G)(),a=(0,O.useCallback)(t=>{t.preventDefault(),t.stopPropagation();let a=new FormData(t.currentTarget),s=Object.fromEntries(a.entries());s.title&&s.prompt&&e.onSubmit({id:e.initialData.id,title:s.title,prompt:s.prompt})},[e]);return(0,n.jsxs)("form",{className:"flex flex-col gap-2 w-full",onSubmit:a,children:[(0,n.jsxs)("div",{className:"w-full",children:[(0,n.jsxs)("span",{className:"text-sm font-semibold block mb-1 text-primary-text",children:["Prompt ",t("Title")]}),(0,n.jsx)(e0,{className:"w-full",name:"title",defaultValue:e.initialData.title})]}),(0,n.jsxs)("div",{className:"w-full",children:[(0,n.jsxs)("span",{className:"text-sm font-semibold block mb-1 text-primary-text",children:["Prompt ",t("Content")]}),(0,n.jsx)(e1,{className:"w-full",name:"prompt",defaultValue:e.initialData.prompt})]}),(0,n.jsxs)("div",{className:"flex flex-row gap-2 mt-1",children:[(0,n.jsx)(eG,{color:"primary",text:t("Save"),className:"w-fit",size:"small",type:"submit"}),(0,n.jsx)(eG,{color:"flat",text:t("Cancel"),className:"w-fit",size:"small",onClick:e.onClose})]})]})}function e8(e){let{t}=(0,c.$G)(),[a,s]=(0,O.useState)(null),r=(0,ez.ZP)("local-prompts",()=>eY(),{suspense:!0}),l=(0,O.useCallback)(async e=>{await eW(e),r.mutate(),s(null)},[r]),o=(0,O.useCallback)(async e=>{await eV(e),r.mutate()},[r]),i=(0,O.useCallback)(()=>{s({id:k(),title:"",prompt:""})},[]);return(0,n.jsxs)(n.Fragment,{children:[r.data.length?(0,n.jsx)("div",{className:"grid grid-cols-1 gap-4 sm:grid-cols-2 pt-2",children:r.data.map(t=>(0,n.jsx)(e5,{title:t.title,prompt:t.prompt,edit:()=>!a&&s(t),remove:()=>o(t.id),insertPrompt:e.insertPrompt},t.id))}):(0,n.jsx)("div",{className:"relative block w-full rounded-lg border-2 border-dashed border-gray-300 p-3 text-center text-sm mt-5 text-primary-text",children:"You have no prompts."}),(0,n.jsx)("div",{className:"mt-5",children:a?(0,n.jsx)(e4,{initialData:a,onSubmit:l,onClose:()=>s(null)}):(0,n.jsx)(eG,{text:t("Create new prompt"),size:"small",onClick:i})})]})}function e6(e){let t=(0,ez.ZP)("community-prompts",()=>eK(),{suspense:!0}),a=(0,O.useCallback)(async e=>{await eW({...e,id:k()})},[]);return(0,n.jsxs)(n.Fragment,{children:[(0,n.jsx)("div",{className:"grid grid-cols-1 gap-4 sm:grid-cols-2 pt-2",children:t.data.map((t,s)=>(0,n.jsx)(e5,{title:t.title,prompt:t.prompt,insertPrompt:e.insertPrompt,copyToLocal:()=>a(t)},s))}),(0,n.jsxs)("span",{className:"text-sm mt-5 block text-primary-text",children:["Contribute on"," ",(0,n.jsx)("a",{href:"https://github.com/chathub-dev/community-prompts",target:"_blank",rel:"noreferrer",className:"underline",children:"GitHub"})," ","or"," ",(0,n.jsx)("a",{href:"https://openprompt.co/?utm_source=chathub",target:"_blank",rel:"noreferrer",className:"underline",children:"OpenPrompt"})]})]})}var e9=e=>{let{t}=(0,c.$G)(),a=(0,O.useCallback)(t=>{e.insertPrompt(t)},[e]),s=(0,O.useMemo)(()=>[{name:t("Your Prompts"),value:"local"},{name:t("Community Prompts"),value:"community"}],[t]);return(0,n.jsx)(e2,{tabs:s,renderTab:e=>"local"===e?(0,n.jsx)(O.Suspense,{fallback:(0,n.jsx)(eL.Z,{size:10,className:"mt-5",color:"rgb(var(--primary-text))"}),children:(0,n.jsx)(e8,{insertPrompt:a})}):"community"===e?(0,n.jsx)(O.Suspense,{fallback:(0,n.jsx)(eL.Z,{size:10,className:"mt-5",color:"rgb(var(--primary-text))"}),children:(0,n.jsx)(e6,{insertPrompt:a})}):void 0})},e7=e=>(0,n.jsx)(ej,{title:"Prompt Library",open:e.isOpen,onClose:e.onClose,className:"w-[800px] min-h-[400px]",children:(0,n.jsx)("div",{className:"p-5 overflow-auto",children:(0,n.jsx)(e9,{insertPrompt:e.insertPrompt})})});let te=O.forwardRef((e,t)=>{let{className:a,value:s="",onValueChange:r,minRows:l=1,formref:o,disabled:i,...c}=e,d=(0,O.useRef)(null);(0,O.useImperativeHandle)(t,()=>d.current);let m=(0,O.useCallback)(e=>{if(13===e.keyCode){var t,a;if(e.preventDefault(),e.shiftKey){let e=(null===(t=d.current)||void 0===t?void 0:t.selectionStart)||0;r("".concat(s.slice(0,e),"\n").concat(s.slice(e))),setTimeout(()=>{d.current.setSelectionRange(e+1,e+1)},0)}else i||null==o||null===(a=o.current)||void 0===a||a.requestSubmit()}},[i,o,r,s]);return(0,n.jsx)(eX.Z,{ref:d,className:_()("resize-none overflow-x-hidden overflow-y-auto w-full outline-none text-sm text-primary-text bg-transparent scrollbar-thin",i&&"cursor-wait",a),onKeyDown:m,value:s,onChange:e=>r(e.target.value),autoComplete:"off",minRows:l,maxRows:5,...c})});te.displayName="TextInput";var tt=(0,O.memo)(e=>{let{t}=(0,c.$G)(),{placeholder:a=t("Use / to select prompts, Shift+Enter to add new line")}=e,[s,r]=(0,O.useState)(""),l=(0,O.useRef)(null),o=(0,O.useRef)(null),[i,d]=(0,O.useState)(!1),[m,u]=(0,O.useState)(null),[p,x]=(0,O.useState)(!1),{refs:h,floatingStyles:g,context:f}=(0,eH.YF)({whileElementsMounted:eF.Me,middleware:[(0,eU.cv)(15),(0,eU.RR)(),(0,eU.uY)()],placement:"top-start",open:p,onOpenChange:x}),b=(0,O.useRef)([]),y=(0,O.useCallback)(e=>{if("PROMPT_LIBRARY"===e.id)d(!0),x(!1);else{var t;r(e.prompt),x(!1),null===(t=o.current)||void 0===t||t.focus()}},[]),v=(0,eH.c0)(f,{listRef:b,activeIndex:m,onNavigate:u,loop:!0,focusItemOnOpen:!0,openOnArrowKeyDown:!1}),j=(0,eH.bQ)(f),w=(0,eH.qs)(f,{role:"listbox"}),{getReferenceProps:N,getFloatingProps:C,getItemProps:k}=(0,eH.NI)([w,j,v]),S=(0,O.useMemo)(()=>({activeIndex:m,getItemProps:k,handleSelect:y,setIsComboboxOpen:x}),[m,k,y]),E=(0,O.useCallback)(t=>{t.preventDefault(),s.trim()&&e.onSubmit(s),r("")},[e,s]),T=(0,O.useCallback)(e=>{r(e),x("/"===e)},[]);(0,O.useEffect)(()=>{},[p]);let P=(0,O.useCallback)(e=>{var t,a;let n=(null===(t=o.current)||void 0===t?void 0:t.selectionStart)||0,l=s.slice(0,n),i=s.slice(n);r("".concat(l).concat(e).concat(i)),d(!1),null===(a=o.current)||void 0===a||a.focus()},[s]),I=(0,O.useCallback)(()=>{d(!0)},[]);return(0,n.jsxs)("form",{className:_()("flex flex-row items-center gap-3",e.className),onSubmit:E,ref:l,children:["full"===e.mode&&(0,n.jsxs)(n.Fragment,{children:[(0,n.jsx)(eB.Zg$,{size:22,color:"#707070",className:"cursor-pointer",onClick:I}),i&&(0,n.jsx)(e7,{isOpen:!0,onClose:()=>d(!1),insertPrompt:P}),(0,n.jsx)(eJ.Provider,{value:S,children:p&&(0,n.jsx)(eH.wD,{context:f,modal:!1,initialFocus:-1,children:(0,n.jsx)("div",{ref:h.setFloating,style:{...g},...C(),children:(0,n.jsx)(eH.vs,{elementsRef:b,children:(0,n.jsx)(eq,{})})})})})]}),(0,n.jsx)("div",{className:"w-full flex flex-col justify-center",ref:h.setReference,...N(),children:(0,n.jsx)(te,{ref:o,formref:l,name:"input",disabled:e.disabled,placeholder:a,value:s,onValueChange:T,autoFocus:e.autoFocus})}),e.actionButton||(0,n.jsx)(eG,{text:"-",className:"invisible",size:"full"===e.mode?"normal":"small"})]})}),ta={src:"./_next/static/media/layout-four.e2ee4959.svg",height:32,width:32,blurWidth:0,blurHeight:0},ts={src:"./_next/static/media/layout-three.7c34ba13.svg",height:32,width:32,blurWidth:0,blurHeight:0},tr={src:"./_next/static/media/layout-two.e5adcdea.svg",height:32,width:32,blurWidth:0,blurHeight:0};let tn=e=>(0,n.jsx)("a",{className:_()(!!e.active&&"bg-[#00000014] dark:bg-[#ffffff26] rounded-[6px]"),onClick:e.onClick,children:(0,n.jsx)(A(),{alt:"item",src:e.icon,className:"w-8 h-8 cursor-pointer"})});var tl=e=>(0,n.jsxs)("div",{className:"flex flex-row items-center gap-2 bg-primary-background rounded-[15px] px-4",children:[(0,n.jsx)(tn,{icon:tr,active:2===e.layout,onClick:()=>e.onChange(2)}),(0,n.jsx)(tn,{icon:ts,active:3===e.layout,onClick:()=>e.onChange(3)}),(0,n.jsx)(tn,{icon:ta,active:4===e.layout,onClick:()=>e.onChange(4)})]}),to=a(31816);async function ti(e){let t="conversations:".concat(e),{[t]:a}=await K.storage.local.get(t);return a||[]}async function tc(e,t){let a=await ti(e),s=a.filter(e=>e.id!==t);await K.storage.local.set({["conversations:".concat(e)]:s})}async function td(e,t){let a="conversation:".concat(e,":").concat(t,":messages"),{[a]:s}=await K.storage.local.get(a);return s||[]}async function tm(e,t,a){let s=await ti(e);s.some(e=>e.id===t)||(s.unshift({id:t,createdAt:Date.now()}),await K.storage.local.set({["conversations:".concat(e)]:s}));let r="conversation:".concat(e,":").concat(t,":messages");await K.storage.local.set({[r]:a})}async function tu(e){let t=await ti(e),a=await Promise.all(t.map(t=>td(e,t.id)));return(0,to.Z)(t,a).map(e=>{let[t,a]=e;return{id:t.id,createdAt:t.createdAt,messages:a}})}async function tp(e,t,a){let s=await td(e,t),r=s.filter(e=>e.id!==a);await tm(e,t,r),r.length||await tc(e,t)}function tx(e){let t=(0,O.useMemo)(()=>S({botName:e,page:"singleton"}),[e]),[a,s]=(0,d.KO)(t),r=(0,O.useCallback)((e,t)=>{s(a=>{let s=a.messages.find(t=>t.id===e);s&&t(s)})},[s]),n=(0,O.useCallback)(async t=>{let n=k();s(a=>{a.messages.push({id:k(),text:t,author:"user"},{id:n,text:"",author:e})});let l=new AbortController;s(e=>{e.generatingMessageId=n,e.abortController=l}),await a.bot.sendMessage({prompt:t,signal:l.signal,onEvent(e){"UPDATE_ANSWER"===e.type?r(n,t=>{t.text=e.data.text}):"ERROR"===e.type?(console.error("sendMessage error",e.error.code,e.error),r(n,t=>{t.error=e.error}),s(e=>{e.abortController=void 0,e.generatingMessageId=""})):"DONE"===e.type&&s(e=>{e.abortController=void 0,e.generatingMessageId=""})}})},[e,a.bot,s,r]),l=(0,O.useCallback)(()=>{a.bot.resetConversation(),s(e=>{e.abortController=void 0,e.generatingMessageId="",e.messages=[],e.conversationId=k()})},[a.bot,s]),o=(0,O.useCallback)(()=>{var e;null===(e=a.abortController)||void 0===e||e.abort(),a.generatingMessageId&&r(a.generatingMessageId,e=>{e.text||e.error||(e.text="Cancelled")}),s(e=>{e.generatingMessageId=""})},[a.abortController,a.generatingMessageId,s,r]);(0,O.useEffect)(()=>{a.messages.length&&tm(e,a.conversationId,a.messages)},[e,a.conversationId,a.messages]);let i=(0,O.useMemo)(()=>({botName:e,bot:a.bot,messages:a.messages,sendMessage:n,resetConversation:l,generating:!!a.generatingMessageId,stopGenerating:o}),[e,a.bot,a.generatingMessageId,a.messages,l,n,o]);return i}var th={src:"./_next/static/media/clear.9ac809d8.svg",height:24,width:24,blurWidth:0,blurHeight:0},tg={src:"./_next/static/media/history.5070ff02.svg",height:24,width:24,blurWidth:0,blurHeight:0},tf={src:"./_next/static/media/share.249db2aa.svg",height:22,width:22,blurWidth:0,blurHeight:0};let tb=(0,O.createContext)(null);var ty=a(83393),tv=a(10184),tj=a(81025),tw=a(18160);a(81973);var tN=a(10688),tC=a(48136),tk=a(2851),tS=a(30458),tE=a(62701),tT=a(80809),tP=a(83765),tI=a(63681),t_=a(21725);function tO(e){let[t,a]=(0,O.useState)(!1),s=(0,O.useMemo)(()=>(0,tS.Z)(e.children),[e.children]);return(0,O.useEffect)(()=>{t&&setTimeout(()=>a(!1),1e3)},[t]),(0,n.jsxs)("div",{className:"flex flex-col",children:[(0,n.jsx)("div",{className:"bg-[#e6e7e8] dark:bg-[#444a5354] text-xs p-2",children:(0,n.jsx)(tN.CopyToClipboard,{text:s,onCopy:()=>a(!0),children:(0,n.jsxs)("div",{className:"flex flex-row items-center gap-2 cursor-pointer w-fit ml-1",children:[(0,n.jsx)(tC.etG,{}),(0,n.jsx)("span",{children:t?"copied":"copy code"})]})})}),(0,n.jsx)("code",{className:_()(e.className,"px-4"),children:e.children})]})}a(68405);var tR=e=>{let{children:t}=e;return(0,n.jsx)(tk.D,{remarkPlugins:[tI.Z,t_.Z,tT.Z,tP.Z],rehypePlugins:[[tE.Z,{detect:!0,ignoreMissing:!0}]],className:"markdown-body markdown-custom-styles !text-base font-normal",linkTarget:"_blank",components:{a:e=>{let{node:t,...a}=e;return a.title?(0,n.jsx)(e_,{content:a.title,children:(0,n.jsx)("a",{...a,title:void 0})}):(0,n.jsx)("a",{...a})},code:e=>{let{node:t,inline:a,className:s,children:r,...l}=e;return a?(0,n.jsx)("code",{className:s,...l,children:r}):(0,n.jsx)(tO,{className:s,children:r})}},children:t})},tA=(0,O.memo)(e=>{let{botName:t,message:a,conversationId:s}=e,{mutate:r}=(0,ez.kY)(),l=(0,O.useCallback)(async()=>{await tp(t,s,a.id),r("history:".concat(t))},[t,s,a.id,r]);return a.text?(0,n.jsxs)("div",{className:_()("group relative py-5 flex flex-col gap-1 px-5 text-primary-text","user"===a.author?"bg-secondary":"bg-primary-background"),children:[(0,n.jsxs)("div",{className:"flex flex-row justify-between",children:[(0,n.jsx)("span",{className:"text-xs text-secondary-tex",children:"user"===a.author?"You":t}),!!s&&(0,n.jsx)(ty.Ybf,{className:"invisible group-hover:visible cursor-pointer",onClick:l})]}),(0,n.jsx)(tR,{children:a.text})]}):null});let tD=(0,O.memo)(e=>(0,n.jsx)("span",{className:"text-secondary-text bg-secondary text-xs px-2 py-1 w-fit rounded",children:function(e){let t=new Date(e),a=String(t.getMonth()+1).padStart(2,"0"),s=String(t.getDate()).padStart(2,"0"),r=String(t.getHours()).padStart(2,"0"),n=String(t.getMinutes()).padStart(2,"0");return"".concat(a,"/").concat(s," ").concat(r,":").concat(n)}(e.timestamp)}));tD.displayName="Timestamp";var tM=e=>{let{botName:t,keyword:a}=e,s=(0,ez.ZP)("history:".concat(t),()=>tu(t),{suspense:!0}),r=(0,O.useRef)(null),l=(0,O.useMemo)(()=>new tv.Z((0,tj.Z)(s.data,e=>e.messages),{keys:["text"]}),[s.data]),o=(0,O.useMemo)(()=>{let e=[];for(let t of Array.from(s.data).reverse()){let a=t.messages.filter(e=>e.text);if(a.length)for(let s of(e.push({type:"conversation",createdAt:t.createdAt}),a))e.push({type:"message",message:s,conversationId:t.id})}return e},[s.data]),i=(0,O.useMemo)(()=>{if(!a)return[];let e=l.search(a);return e.map(e=>({type:"message",message:e.item,conversationId:""}))},[l,a]);return(0,n.jsx)("div",{className:"flex flex-col overflow-y-auto",ref:r,children:(0,n.jsx)(tw.b,{viewportRef:r,items:i.length?i:o,initialAlignToTop:!0,initialIndex:i.length||o.length,children:e=>"conversation"===e.type?(0,n.jsx)("div",{className:"text-center my-5",children:(0,n.jsx)(tD,{timestamp:e.createdAt})},e.createdAt):(0,n.jsx)(tA,{botName:t,message:e.message,conversationId:e.conversationId},e.message.id)})})},tL=e=>{let t=(0,O.useMemo)(()=>{var t;return null===(t=h.find(t=>t.name===e.botName))||void 0===t?void 0:t.name},[e.botName]),{t:a}=(0,c.$G)(),[s,r]=(0,O.useState)("");return(0,n.jsxs)(ej,{title:"History conversations with ".concat(t),open:e.open,onClose:e.onClose,className:"rounded-2xl w-[1000px] min-h-[400px]",borderless:!0,children:[(0,n.jsx)("div",{className:"border-b border-solid border-primary-border pb-[10px] mx-5",children:(0,n.jsxs)("div",{className:"rounded-[30px] bg-secondary h-9 flex flex-row items-center px-4",children:[(0,n.jsx)(ty.jRj,{size:18,className:"mr-[6px] opacity-30"}),(0,n.jsx)("input",{className:"bg-transparent w-full outline-none text-sm",placeholder:a("Search"),value:s,onChange:e=>r(e.target.value)})]})}),(0,n.jsx)(tM,{botName:e.botName,keyword:s})]})},tG=a(1033),tH=e=>{let{messages:t}=e,[a,s]=(0,O.useState)(!1),r=(0,O.useMemo)(()=>t.filter(e=>!!e.text).map(e=>"**".concat(e.author,"**: ")+e.text).join("\n\n"),[t]),l=(0,O.useCallback)(()=>{navigator.clipboard.writeText(r),s(!0),setTimeout(()=>s(!1),500)},[r]);return(0,n.jsxs)("div",{className:"px-5 pt-3 pb-4 overflow-hidden flex flex-col h-full",children:[(0,n.jsx)("div",{className:"mb-3",children:(0,n.jsx)(eG,{size:"small",text:a?"Copied!":"Copy",onClick:l})}),(0,n.jsx)("pre",{className:"text-sm whitespace-pre-wrap text-primary-text p-2 rounded-md overflow-auto h-full bg-secondary",children:r})]})},tF=a(49596),tU=a(41222),tB=a(61149),tz=a(11804);async function tZ(e){let t=await (0,tz.l)().use(tU.Z).use(t_.Z).use(tP.Z).use(tB.Z).use(tF.Z).process(e);return String(t)}async function tY(e){let t=[{from:"system",value:'This conversation is shared from ChatHub '}];for(let a of e)a.text&&t.push({from:"user"===a.author?"human":a.author,value:"user"===a.author?a.text:await tZ(a.text)});return t}async function tW(e){let t=await tY(e),a=await (0,eZ.Wg)("https://sharegpt.com/api/conversations",{method:"POST",body:{avatarUrl:"data:image/svg+xml,%3C%3Fxml version='1.0' encoding='UTF-8'%3F%3E%3Csvg viewBox='0 0 128 128' version='1.1' xmlns='http://www.w3.org/2000/svg' role='img' aria-label='xxlarge'%3E%3Cg%3E%3Ccircle cx='64' cy='64' r='64' fill='%23c1c7d0' /%3E%3Cg%3E%3Cpath fill='%23fff' d='M103,102.1388 C93.094,111.92 79.3504,118 64.1638,118 C48.8056,118 34.9294,111.768 25,101.7892 L25,95.2 C25,86.8096 31.981,80 40.6,80 L87.4,80 C96.019,80 103,86.8096 103,95.2 L103,102.1388 Z' /%3E%3Cpath fill='%23fff' d='M63.9961647,24 C51.2938136,24 41,34.2938136 41,46.9961647 C41,59.7061864 51.2938136,70 63.9961647,70 C76.6985159,70 87,59.7061864 87,46.9961647 C87,34.2938136 76.6985159,24 63.9961647,24' /%3E%3C/g%3E%3C/g%3E%3C/svg%3E%0A",items:t}});return a.id}var tV=e=>{let{messages:t}=e,[a,s]=(0,O.useState)(!1),[r,l]=(0,O.useState)(void 0),[o,i]=(0,O.useState)(!1),c=(0,O.useCallback)(async()=>{s(!0);try{let e=await tW(t);l(e)}finally{s(!1)}},[t]),d=(0,O.useCallback)(()=>{navigator.clipboard.writeText("https://shareg.pt/".concat(r)),i(!0),setTimeout(()=>i(!1),500)},[r]);return(0,n.jsxs)("div",{className:"p-5 flex flex-col items-center justify-center gap-5 h-full",children:[(0,n.jsxs)("p",{className:"w-[400px] text-center text-primary-text",children:["This will upload this conversation to ",(0,n.jsx)("b",{children:"sharegpt.com"})," and generate a link to share ",(0,n.jsx)("b",{children:"publicly"}),"."]}),r?(0,n.jsxs)("div",{className:"flex flex-row items-center gap-3 w-[300px]",children:[(0,n.jsx)(e0,{value:"https://shareg.pt/".concat(r),readOnly:!0,className:"grow"}),(0,n.jsx)(eG,{size:"small",color:"primary",text:o?"Copied":"Copy",onClick:d})]}):(0,n.jsx)(eG,{text:"Share",color:"primary",onClick:c,isLoading:a})]})},tK=e=>{let[t,a]=(0,O.useState)();return(0,n.jsx)(ej,{title:"Share Chat",open:e.open,onClose:e.onClose,className:_()("rounded-xl",t?"w-[800px] h-[400px]":"w-[600px] h-[250px]"),children:"markdown"===t?(0,n.jsx)(tH,{messages:e.messages}):"sharegpt"===t?(0,n.jsx)(tV,{messages:e.messages}):(0,n.jsxs)("div",{className:"flex flex-col gap-5 justify-center items-center p-5 h-full",children:[(0,n.jsx)(eG,{text:"Markdown",color:"primary",icon:(0,n.jsx)(tG.$NG,{className:"mr-1"}),onClick:()=>a("markdown")}),(0,n.jsx)(eG,{text:"ShareGPT",color:"primary",icon:(0,n.jsx)(tG.y9X,{className:"mr-1"}),onClick:()=>a("sharegpt")})]})})},t$=a(40102),tJ={src:"./_next/static/media/dropdown.22b4c9c4.svg",height:20,width:20,blurWidth:0,blurHeight:0},tQ=e=>{let t=q(),a=(0,O.useCallback)(t=>{e.onChange(t)},[e]);return(0,n.jsxs)(t$.v,{as:"div",className:"relative inline-block text-left h-5",children:[(0,n.jsx)(t$.v.Button,{children:(0,n.jsx)(A(),{alt:"dropdown",src:tJ,className:"w-5 h-5"})}),(0,n.jsx)(eN.u,{as:O.Fragment,enter:"transition ease-out duration-100",enterFrom:"transform opacity-0 scale-95",enterTo:"transform opacity-100 scale-100",leave:"transition ease-in duration-75",leaveFrom:"transform opacity-100 scale-100",leaveTo:"transform opacity-0 scale-95",children:(0,n.jsx)(t$.v.Items,{className:"absolute left-0 z-10 mt-2 rounded-md bg-secondary shadow-lg focus:outline-none",children:t.map(t=>t.name===e.selectedBotName?null:(0,n.jsx)(t$.v.Item,{children:(0,n.jsx)("div",{className:"px-4 py-2 ui-active:bg-primary-blue ui-active:text-white ui-not-active:text-secondary-text cursor-pointer flex flex-row items-center gap-3 pr-8",onClick:()=>a(t.name),children:(0,n.jsx)("p",{className:"text-sm whitespace-nowrap",children:t.name})})},t.url))})})]})},tq=a(51859),tX=a(25372);let t0=()=>{let e=(0,O.useMemo)(()=>location.href.includes("sidepanel.html"),[]);return(0,n.jsx)("div",{className:"flex flex-row gap-2 items-center",children:(0,n.jsx)("a",{href:K.runtime.getURL("app.html#/setting"),target:e?"_blank":void 0,rel:"noreferrer",children:(0,n.jsx)(eG,{color:"primary",text:"Set api key",size:"small"})})})};var t1=e=>{let{error:t}=e,a=(0,O.useContext)(tb),{t:s}=(0,c.$G)();return t.code===r.BING_UNAUTHORIZED?(0,n.jsx)("a",{href:"https://bing.com",target:"_blank",rel:"noreferrer",children:(0,n.jsx)(eG,{color:"primary",text:s("Login at bing.com"),size:"small"})}):t.code===r.BING_FORBIDDEN?(0,n.jsx)("a",{href:"https://bing.com/new",target:"_blank",rel:"noreferrer",children:(0,n.jsx)(eG,{color:"primary",text:"Join new Bing waitlist",size:"small"})}):t.code===r.GPT4_MODEL_WAITLIST?(0,n.jsx)("a",{href:"https://openai.com/waitlist/gpt-4-api",target:"_blank",rel:"noreferrer",children:(0,n.jsx)(eG,{color:"primary",text:s("Join the waitlist"),size:"small"})}):t.code===r.CHATGPT_AUTH?(0,n.jsx)("a",{href:"https://chat.openai.com",target:"_blank",rel:"noreferrer",children:(0,n.jsx)(eG,{color:"primary",text:s("Login to ChatGPT"),size:"small"})}):t.code===r.CHATGPT_CLOUDFLARE||t.code===r.CHATGPT_UNAUTHORIZED?(0,n.jsx)(t0,{}):t.code===r.CONVERSATION_LIMIT?(0,n.jsx)(eG,{color:"primary",text:"Restart",size:"small",onClick:()=>null==a?void 0:a.reset()}):t.code===r.BARD_EMPTY_RESPONSE?(0,n.jsx)("a",{href:"https://bard.google.com",target:"_blank",rel:"noreferrer",children:(0,n.jsx)(eG,{color:"primary",text:"Visit bard.google.com",size:"small"})}):t.code===r.BING_CAPTCHA?(0,n.jsx)("a",{href:"https://www.bing.com/turing/captcha/challenge",target:"_blank",rel:"noreferrer",children:(0,n.jsx)(eG,{color:"primary",text:s("Verify"),size:"small"})}):t.code===r.LMSYS_SESSION_EXPIRED?(0,n.jsx)("a",{href:"https://chat.lmsys.org",target:"_blank",rel:"noreferrer",children:(0,n.jsx)(eG,{color:"primary",text:s("Refresh session"),size:"small"})}):t.code===r.CHATGPT_INSUFFICIENT_QUOTA?(0,n.jsxs)("p",{className:"ml-2 text-secondary-text text-sm",children:[s("This usually mean you need to add a payment method to your OpenAI account, checkout: "),(0,n.jsx)("a",{href:"https://platform.openai.com/account/billing/",target:"_blank",rel:"noreferrer",className:"underline",children:"OpenAI billing"})]}):t.code===r.NETWORK_ERROR||t.code===r.UNKOWN_ERROR&&t.message.includes("Failed to fetch")?(0,n.jsx)("p",{className:"ml-2 text-secondary-text text-sm",children:s("Please check your network connection")}):t.code===r.POE_MESSAGE_LIMIT?(0,n.jsx)("p",{className:"ml-2 text-secondary-text text-sm",children:s("This is a limitation set by poe.com")}):null},t2=e=>(0,n.jsx)("div",{className:_()("rounded-[15px] px-4 py-2","primary"===e.color?"bg-primary-blue text-white":"bg-secondary text-primary-text",e.className),children:e.children});let t3="self-top cursor-pointer invisible group-hover:visible mt-[12px] text-primary-text";var t5=(0,O.memo)(e=>{let{message:t,className:a}=e,[s,r]=(0,O.useState)(!1),l=(0,O.useMemo)(()=>t.text?t.text:t.error?t.error.message:void 0,[t.error,t.text]);return(0,O.useEffect)(()=>{s&&setTimeout(()=>r(!1),1e3)},[s]),(0,n.jsxs)("div",{className:_()("group flex gap-3 w-full","user"===t.author?"flex-row-reverse":"flex-row",a),children:[(0,n.jsxs)("div",{className:"flex flex-col w-11/12 max-w-fit items-start gap-2",children:[(0,n.jsxs)(t2,{color:"user"===t.author?"primary":"flat",children:[t.text?(0,n.jsx)(tR,{children:t.text}):!t.error&&(0,n.jsx)(eL.Z,{size:10,className:"leading-tight",color:"rgb(var(--primary-text))"}),!!t.error&&(0,n.jsx)("p",{className:"text-red-500",children:t.error.message})]}),!!t.error&&(0,n.jsx)(t1,{error:t.error})]}),!!l&&(0,n.jsx)(tN.CopyToClipboard,{text:l,onCopy:()=>r(!0),children:s?(0,n.jsx)(tX.VQF,{className:t3}):(0,n.jsx)(tX.mcF,{className:t3})})]})}),t4=e=>(0,n.jsx)(tq.ZP,{className:"overflow-auto h-full",children:(0,n.jsx)("div",{className:_()("flex flex-col gap-3 h-full",e.className),children:e.messages.map((e,t)=>(0,n.jsx)(t5,{message:e,className:0===t?"mt-5":void 0},e.id))})}),t8=e=>{let{t}=(0,c.$G)(),a=h.find(t=>t.name===e.botName),s=e.mode||"full",r="mx-5",[l,o]=(0,O.useState)(!1),[i,d]=(0,O.useState)(!1),m=(0,O.useMemo)(()=>({reset:e.resetConversation}),[e.resetConversation]),u=(0,O.useCallback)(async t=>{e.onUserSendMessage(t,e.botName)},[e]),p=(0,O.useCallback)(()=>{e.generating||e.resetConversation()},[e]),x=(0,O.useCallback)(()=>{o(!0),e.botName},[e.botName]),g=(0,O.useCallback)(()=>{d(!0),e.botName},[e.botName]);return(0,n.jsxs)(tb.Provider,{value:m,children:[(0,n.jsxs)("div",{className:_()("flex flex-col overflow-hidden bg-primary-background h-full rounded-[20px]"),children:[(0,n.jsxs)("div",{className:_()("border-b border-solid border-primary-border flex flex-row items-center justify-between gap-2 py-[10px]",r),children:[(0,n.jsxs)("div",{className:"flex flex-row items-center gap-2",children:[(0,n.jsx)(e_,{content:e.bot.name||(null==a?void 0:a.name)||"",children:(0,n.jsx)("span",{className:"font-semibold text-primary-text text-sm cursor-default",children:null==a?void 0:a.name})}),"compact"===s&&e.onSwitchBot&&(0,n.jsx)(tQ,{selectedBotName:e.botName,onChange:e.onSwitchBot})]}),(0,n.jsxs)("div",{className:"flex flex-row items-center gap-3",children:[(0,n.jsx)(e_,{content:t("Share conversation"),children:(0,n.jsx)(A(),{alt:"share",src:tf,className:"w-5 h-5 cursor-pointer",onClick:g})}),(0,n.jsx)(e_,{content:t("Clear conversation"),children:(0,n.jsx)(A(),{alt:"clear",src:th,className:_()("w-5 h-5",e.generating?"cursor-not-allowed":"cursor-pointer"),onClick:p})}),(0,n.jsx)(e_,{content:t("View history"),children:(0,n.jsx)(A(),{alt:"history",src:tg,className:"w-5 h-5 cursor-pointer",onClick:x})})]})]}),(0,n.jsx)(t4,{messages:e.messages,className:r}),(0,n.jsxs)("div",{className:_()("mt-3 flex flex-col",r,"full"===s?"mb-3":"mb-[5px]"),children:[(0,n.jsxs)("div",{className:_()("flex flex-row items-center gap-[5px]","full"===s?"mb-3":"mb-0"),children:["compact"===s&&(0,n.jsxs)("span",{className:"font-medium text-xs text-light-text",children:["Send to ",null==a?void 0:a.name]}),(0,n.jsx)("hr",{className:"grow border-primary-border"})]}),(0,n.jsx)(tt,{mode:s,disabled:e.generating,placeholder:"compact"===s?"":void 0,onSubmit:u,autoFocus:"full"===s,actionButton:e.generating?(0,n.jsx)(eG,{text:t("Stop"),color:"flat",size:"full"===s?"normal":"small",onClick:e.stopGenerating}):"full"===s&&(0,n.jsx)(eG,{text:t("Send"),color:"primary",type:"submit"})})]})]}),l&&(0,n.jsx)(tL,{botName:e.botName,open:!0,onClose:()=>o(!1)}),i&&(0,n.jsx)(tK,{open:!0,onClose:()=>d(!1),messages:e.messages})]})};let t6=(0,u.O4)("multiPanelLayout",2,void 0,{unstable_getOnInit:!0}),t9=(0,u.O4)("multiPanelBots:2",h.slice(0,2).map(e=>e.name)),t7=(0,u.O4)("multiPanelBots:3",h.slice(0,3).map(e=>e.name)),ae=(0,u.O4)("multiPanelBots:4",h.slice(0,4).map(e=>e.name)),at=e=>{let{chats:t,botsAtom:a}=e,{t:s}=(0,c.$G)(),r=(0,O.useMemo)(()=>t.some(e=>e.generating),[t]),l=(0,d.b9)(a),o=(0,d.b9)(t6),i=(0,O.useCallback)((e,a)=>{if(a){let s=t.find(e=>e.botName===a);null==s||s.sendMessage(e)}else(0,eM.Z)(t,e=>e.botName).forEach(t=>t.sendMessage(e));t.length},[t]),m=(0,O.useCallback)((e,a)=>{t.length,l(t=>{let s=[...t];return s[a]=e,s})},[t.length,l]),u=(0,O.useCallback)(e=>{o(e)},[o]);return(0,n.jsxs)("div",{className:"flex flex-col overflow-hidden h-full",children:[(0,n.jsx)("div",{className:_()("grid overflow-hidden grow auto-rows-fr gap-3 mb-3",3===t.length?"grid-cols-3":"grid-cols-2"),children:t.map((e,t)=>(0,n.jsx)(t8,{botName:e.botName,bot:e.bot,messages:e.messages,onUserSendMessage:i,generating:e.generating,stopGenerating:e.stopGenerating,mode:"compact",resetConversation:e.resetConversation,onSwitchBot:e=>m(e,t)},"".concat(e.botName,"-").concat(t)))}),(0,n.jsxs)("div",{className:"flex flex-row gap-3",children:[(0,n.jsx)(tl,{layout:t.length,onChange:u}),(0,n.jsx)(tt,{mode:"full",className:"rounded-[15px] bg-primary-background px-4 py-2 grow",disabled:r,onSubmit:i,actionButton:!r&&(0,n.jsx)(eG,{text:s("Send"),color:"primary",type:"submit"}),autoFocus:!0})]})]})},aa=()=>{let e=(0,d.Dv)(t9),t=tx(e[0]),a=tx(e[1]),s=(0,O.useMemo)(()=>[t,a],[t,a]);return(0,n.jsx)(at,{chats:s,botsAtom:t9})},as=()=>{let e=(0,d.Dv)(t7),t=tx(e[0]),a=tx(e[1]),s=tx(e[2]),r=(0,O.useMemo)(()=>[t,a,s],[t,a,s]);return(0,n.jsx)(at,{chats:r,botsAtom:t7})},ar=()=>{let e=(0,d.Dv)(ae),t=tx(e[0]),a=tx(e[1]),s=tx(e[2]),r=tx(e[3]),l=(0,O.useMemo)(()=>[t,a,s,r],[t,a,s,r]);return(0,n.jsx)(at,{chats:l,botsAtom:ae})},an=()=>{let e=(0,d.Dv)(t6);return 4===e?(0,n.jsx)(ar,{}):3===e?(0,n.jsx)(as,{}):(0,n.jsx)(aa,{})};var al=a(68919),ao=a(96758),ai=a(34199),ac=e=>{let{userConfig:t,updateConfigValue:a}=e,{t:s}=(0,c.$G)(),r=(0,O.useCallback)((e,s)=>{let r=new Set(t.enabledBots);if(s)r.add(e);else{if(1===r.size){alert("At least one bot should be enabled");return}r.delete(e)}a({enabledBots:Array.from(r)})},[a,t.enabledBots]);return(0,n.jsx)("div",{className:"flex flex-col gap-3 flex-wrap w-full",children:h.map(e=>{let a=t.enabledBots.includes(e.name);return(0,n.jsxs)("div",{className:"flex flex-row gap-[12px] w-full items-center",children:[(0,n.jsx)(ai.r,{id:"bot-checkbox-".concat(e.name),checked:a,className:"".concat(a?"bg-blue-600":"bg-gray-200"," relative inline-flex h-6 w-11 items-center rounded-full"),onChange:t=>r(e.name,t),children:(0,n.jsx)("span",{className:"".concat(a?"translate-x-6":"translate-x-1"," inline-block h-4 w-4 transform rounded-full bg-white transition")})}),(0,n.jsx)("span",{className:"text-sm font-semibold block ml-6",children:s("Bot Name")}),(0,n.jsx)(e0,{className:"w-1/6",name:"title",defaultValue:e.name}),(0,n.jsx)("span",{className:"text-sm font-semibold block ml-6",children:s("Space URL")}),(0,n.jsx)(e0,{className:"w-3/6",name:"title",defaultValue:e.url})]},e.name)})})},ad=a(91263);async function am(){let[e,t]=await Promise.all([K.storage.sync.get(null),K.storage.local.get(null)]),a={sync:e,local:t,localStorage:{...localStorage}},s=new Blob([JSON.stringify(a)],{type:"application/json"});await (0,ad.NL)(s,{fileName:"chathub.json"})}async function au(){let e=await (0,ad.I$)({extensions:[".json"]}),t=JSON.parse(await e.text());if(!t.sync||!t.local)throw Error("Invalid data");if(window.confirm("Are you sure you want to import data? This will overwrite your current data")){if(await K.storage.local.clear(),await K.storage.local.set(t.local),await K.storage.sync.clear(),await K.storage.sync.set(t.sync),t.localStorage)for(let[e,a]of Object.entries(t.localStorage))localStorage.setItem(e,a);alert("Imported data successfully"),location.reload()}}var ap=e=>(0,n.jsxs)("div",{className:"flex flex-col overflow-hidden bg-primary-background dark:text-primary-text rounded-[20px] h-full",children:[(0,n.jsx)("div",{className:"text-center border-b border-solid border-primary-border flex flex-col justify-center mx-10 py-3",children:(0,n.jsx)("span",{className:"font-semibold text-lg",children:e.title})}),(0,n.jsx)("div",{className:"px-10 h-full overflow-auto",children:e.children}),(0,n.jsx)("div",{className:"text-center border-t border-solid border-primary-border",children:e.footer})]}),ax=e=>{let{botName:t}=e,a=tx(t);return(0,n.jsx)("div",{className:"overflow-hidden h-full",children:(0,n.jsx)(t8,{botName:t,bot:a.bot,messages:a.messages,onUserSendMessage:a.sendMessage,generating:a.generating,stopGenerating:a.stopGenerating,resetConversation:a.resetConversation})})};let ah=new l.RootRoute,ag=new l.Route({getParentRoute:()=>ah,component:function(){let e=(0,d.Dv)(T),t=(0,d.Dv)(P);return(0,n.jsxs)("main",{className:"h-screen grid grid-cols-[auto_1fr]",style:{backgroundColor:t?"var(--arc-palette-foregroundPrimary)":e},children:[(0,n.jsx)(eD,{}),(0,n.jsx)("div",{className:"px-[15px] py-3 h-full overflow-hidden",children:(0,n.jsx)(l.Outlet,{})})]})},id:"layout"}),af=new l.Route({getParentRoute:()=>ag,path:"/",component:()=>(0,n.jsx)(O.Suspense,{children:(0,n.jsx)(an,{})})}),ab=new l.Route({getParentRoute:()=>ag,path:"chat/$name",component:function(){let{name:e}=(0,l.useParams)({from:ab.id}),t=h.find(t=>t.name===e);return(0,n.jsx)(ax,{botName:(null==t?void 0:t.name)||"all"})}}),ay=new l.Route({getParentRoute:()=>ag,path:"setting",component:function(){let{t:e}=(0,c.$G)(),[t,a]=(0,O.useState)(void 0),[s,r]=(0,O.useState)(!1);(0,O.useEffect)(()=>{J().then(e=>a(e))},[]);let l=(0,O.useCallback)(e=>{a({...t,...e}),r(!0)},[t]),o=(0,O.useCallback)(async()=>{await Q({...t}),al.ZP.success("Saved"),setTimeout(()=>location.reload(),500)},[t]);return t?(0,n.jsxs)(ap,{title:"".concat(e("Settings")," (v").concat("0.0.1",")"),footer:(0,n.jsx)(eG,{color:s?"primary":"flat",text:e("Save"),className:"w-fit my-8",onClick:o}),children:[(0,n.jsxs)("div",{className:"flex flex-col gap-5 mt-3",children:[(0,n.jsxs)("div",{children:[(0,n.jsx)("p",{className:"font-bold mb-1 text-lg",children:e("Export/Import All Data")}),(0,n.jsx)("p",{className:"mb-3 opacity-80",children:e("Data includes all your settings, chat histories, and local prompts")}),(0,n.jsxs)("div",{className:"flex flex-row gap-3",children:[(0,n.jsx)(eG,{size:"small",text:e("Export"),icon:(0,n.jsx)(ao.MUM,{}),onClick:am}),(0,n.jsx)(eG,{size:"small",text:e("Import"),icon:(0,n.jsx)(ao.MDG,{}),onClick:au})]})]}),(0,n.jsxs)("div",{children:[(0,n.jsx)("p",{className:"font-bold mb-2 text-lg",children:e("Startup page")}),(0,n.jsx)("div",{className:"w-[200px]",children:(0,n.jsx)(eS,{options:[{name:"All-In-One",value:"all"},...h.map(e=>({name:e.name,value:e.url}))],value:t.startupPage,onChange:e=>l({startupPage:e})})})]}),(0,n.jsxs)("div",{className:"flex flex-col gap-2",children:[(0,n.jsx)("p",{className:"font-bold text-lg flex items-center gap-2",children:e("Chatbots")}),(0,n.jsx)(ac,{userConfig:t,updateConfigValue:l})]})]}),(0,n.jsx)(al.x7,{position:"top-right"})]}):null}}),av=ah.addChildren([ag.addChildren([af,ab,ay])]),aj=(0,l.createHashHistory)(),aw=new l.ReactRouter({routeTree:av,history:aj});var aN=()=>(0,n.jsx)(l.RouterProvider,{router:aw})},68405:function(){}}]);
\ No newline at end of file
diff --git a/spaces/ccyo/chatgpt_bot/README.md b/spaces/ccyo/chatgpt_bot/README.md
deleted file mode 100644
index 45d9f25d3786b23621419b9184e788d9200aa591..0000000000000000000000000000000000000000
--- a/spaces/ccyo/chatgpt_bot/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Chatgpt Bot
-emoji: 🐠
-colorFrom: pink
-colorTo: gray
-sdk: gradio
-sdk_version: 3.38.0
-app_file: app.py
-pinned: false
-license: creativeml-openrail-m
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/chendl/compositional_test/transformers/examples/pytorch/speech-recognition/README.md b/spaces/chendl/compositional_test/transformers/examples/pytorch/speech-recognition/README.md
deleted file mode 100644
index cf5a05c017839f514de653bf4dbe7846e4327c81..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/transformers/examples/pytorch/speech-recognition/README.md
+++ /dev/null
@@ -1,509 +0,0 @@
-
-
-# Automatic Speech Recognition Examples
-
-## Table of Contents
-
-- [Automatic Speech Recognition with CTC](#connectionist-temporal-classification)
- - [Single GPU example](#single-gpu-ctc)
- - [Multi GPU example](#multi-gpu-ctc)
- - [Examples](#examples-ctc)
- - [TIMIT](#timit-ctc)
- - [Librispeech](#librispeech-ctc)
- - [Common Voice](#common-voice-ctc)
- - [Multilingual Librispeech](#multilingual-librispeech-ctc)
-- [Automatic Speech Recognition with Sequence-to-Sequence](#sequence-to-sequence)
- - [Whisper Model](#whisper-model)
- - [Speech-Encoder-Decoder Model](#warm-started-speech-encoder-decoder-model)
- - [Examples](#examples-seq2seq)
- - [Librispeech](#librispeech-seq2seq)
-
-## Connectionist Temporal Classification
-
-The script [`run_speech_recognition_ctc.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py) can be used to fine-tune any pretrained [Connectionist Temporal Classification Model](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForCTC) for automatic speech
-recognition on one of the [official speech recognition datasets](https://huggingface.co/datasets?task_ids=task_ids:automatic-speech-recognition) or a custom dataset.
-
-Speech recognition models that have been pretrained in unsupervised fashion on audio data alone, *e.g.* [Wav2Vec2](https://huggingface.co/transformers/main/model_doc/wav2vec2.html), [HuBERT](https://huggingface.co/transformers/main/model_doc/hubert.html), [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html), have shown to require only
-very little annotated data to yield good performance on automatic speech recognition datasets.
-
-In the script [`run_speech_recognition_ctc`], we first create a vocabulary from all unique characters of both the training data and evaluation data. Then, we preprocesses the speech recognition dataset, which includes correct resampling, normalization and padding. Finally, the pretrained speech recognition model is fine-tuned on the annotated speech recognition datasets using CTC loss.
-
----
-**NOTE**
-
-If you encounter problems with data preprocessing by setting `--preprocessing_num_workers` > 1,
-you might want to set the environment variable `OMP_NUM_THREADS` to 1 as follows:
-
-```bash
-OMP_NUM_THREADS=1 python run_speech_recognition_ctc ...
-```
-
-If the environment variable is not set, the training script might freeze, *i.e.* see: https://github.com/pytorch/audio/issues/1021#issuecomment-726915239
-
----
-
-### Single GPU CTC
-
-The following command shows how to fine-tune [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html) on [Common Voice](https://huggingface.co/datasets/common_voice) using a single GPU in half-precision.
-
-```bash
-python run_speech_recognition_ctc.py \
- --dataset_name="common_voice" \
- --model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
- --dataset_config_name="tr" \
- --output_dir="./wav2vec2-common_voice-tr-demo" \
- --overwrite_output_dir \
- --num_train_epochs="15" \
- --per_device_train_batch_size="16" \
- --gradient_accumulation_steps="2" \
- --learning_rate="3e-4" \
- --warmup_steps="500" \
- --evaluation_strategy="steps" \
- --text_column_name="sentence" \
- --length_column_name="input_length" \
- --save_steps="400" \
- --eval_steps="100" \
- --layerdrop="0.0" \
- --save_total_limit="3" \
- --freeze_feature_encoder \
- --gradient_checkpointing \
- --chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \
- --fp16 \
- --group_by_length \
- --push_to_hub \
- --do_train --do_eval
-```
-
-On a single V100 GPU, this script should run in *ca.* 1 hour 20 minutes and yield a CTC loss of **0.39** and word error rate
-of **0.35**.
-
-### Multi GPU CTC
-
-The following command shows how to fine-tune [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html) on [Common Voice](https://huggingface.co/datasets/common_voice) using 8 GPUs in half-precision.
-
-```bash
-python -m torch.distributed.launch \
- --nproc_per_node 8 run_speech_recognition_ctc.py \
- --dataset_name="common_voice" \
- --model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
- --dataset_config_name="tr" \
- --output_dir="./wav2vec2-common_voice-tr-demo-dist" \
- --overwrite_output_dir \
- --num_train_epochs="15" \
- --per_device_train_batch_size="4" \
- --learning_rate="3e-4" \
- --warmup_steps="500" \
- --evaluation_strategy="steps" \
- --text_column_name="sentence" \
- --length_column_name="input_length" \
- --save_steps="400" \
- --eval_steps="100" \
- --logging_steps="1" \
- --layerdrop="0.0" \
- --save_total_limit="3" \
- --freeze_feature_encoder \
- --gradient_checkpointing \
- --chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \
- --fp16 \
- --group_by_length \
- --push_to_hub \
- --do_train --do_eval
-```
-
-On 8 V100 GPUs, this script should run in *ca.* 18 minutes and yield a CTC loss of **0.39** and word error rate
-of **0.36**.
-
-
-### Multi GPU CTC with Dataset Streaming
-
-The following command shows how to use [Dataset Streaming mode](https://huggingface.co/docs/datasets/dataset_streaming.html)
-to fine-tune [XLS-R](https://huggingface.co/transformers/main/model_doc/xls_r.html)
-on [Common Voice](https://huggingface.co/datasets/common_voice) using 4 GPUs in half-precision.
-
-Streaming mode imposes several constraints on training:
-1. We need to construct a tokenizer beforehand and define it via `--tokenizer_name_or_path`.
-2. `--num_train_epochs` has to be replaced by `--max_steps`. Similarly, all other epoch-based arguments have to be
-replaced by step-based ones.
-3. Full dataset shuffling on each epoch is not possible, since we don't have the whole dataset available at once.
-However, the `--shuffle_buffer_size` argument controls how many examples we can pre-download before shuffling them.
-
-
-```bash
-**python -m torch.distributed.launch \
- --nproc_per_node 4 run_speech_recognition_ctc_streaming.py \
- --dataset_name="common_voice" \
- --model_name_or_path="facebook/wav2vec2-xls-r-300m" \
- --tokenizer_name_or_path="anton-l/wav2vec2-tokenizer-turkish" \
- --dataset_config_name="tr" \
- --train_split_name="train+validation" \
- --eval_split_name="test" \
- --output_dir="wav2vec2-xls-r-common_voice-tr-ft" \
- --overwrite_output_dir \
- --max_steps="5000" \
- --per_device_train_batch_size="8" \
- --gradient_accumulation_steps="2" \
- --learning_rate="5e-4" \
- --warmup_steps="500" \
- --evaluation_strategy="steps" \
- --text_column_name="sentence" \
- --save_steps="500" \
- --eval_steps="500" \
- --logging_steps="1" \
- --layerdrop="0.0" \
- --eval_metrics wer cer \
- --save_total_limit="1" \
- --mask_time_prob="0.3" \
- --mask_time_length="10" \
- --mask_feature_prob="0.1" \
- --mask_feature_length="64" \
- --freeze_feature_encoder \
- --chars_to_ignore , ? . ! - \; \: \" “ % ‘ ” � \
- --max_duration_in_seconds="20" \
- --shuffle_buffer_size="500" \
- --fp16 \
- --push_to_hub \
- --do_train --do_eval \
- --gradient_checkpointing**
-```
-
-On 4 V100 GPUs, this script should run in *ca.* 3h 31min and yield a CTC loss of **0.35** and word error rate
-of **0.29**.
-
-### Examples CTC
-
-The following tables present a couple of example runs on the most popular speech-recognition datasets.
-The presented performances are by no means optimal as no hyper-parameter tuning was done. Nevertheless,
-they can serve as a baseline to improve upon.
-
-
-#### TIMIT CTC
-
-- [TIMIT](https://huggingface.co/datasets/timit_asr)
-
-| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
-|-------|------------------------------|-------------|---------------|---------------|----------------------|-------------| -------------| ------- |
-| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) | 0.21 | - | 1 GPU TITAN RTX | 32min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-base-timit-fine-tuned) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-base-timit-fine-tuned/blob/main/run.sh) |
-| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) | 0.21 | - | 1 GPU TITAN RTX | 32min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-base-timit-fine-tuned) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-base-timit-fine-tuned/blob/main/run.sh) |
-| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [unispeech-large-1500h-cv](https://huggingface.co/microsoft/unispeech-large-1500h-cv) | 0.22 | - | 1 GPU TITAN RTX | 35min | [here](https://huggingface.co/patrickvonplaten/unispeech-large-1500h-cv-timit) | [run.sh](https://huggingface.co/patrickvonplaten/unispeech-large-1500h-cv-timit/blob/main/run.sh) |
-| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [asapp/sew-mid-100k](https://huggingface.co/asapp/sew-mid-100k) | 0.30 | - | 1 GPU TITAN RTX | 28min | [here](https://huggingface.co/patrickvonplaten/sew-small-100k-timit) | [run.sh](https://huggingface.co/patrickvonplaten/sew-small-100k-timit/blob/main/run.sh) |
-| [TIMIT](https://huggingface.co/datasets/timit_asr)| - | [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) | 0.68 | - | 1 GPU TITAN RTX | 26min | [here](https://huggingface.co/patrickvonplaten/distilhubert-timit) | [run.sh](https://huggingface.co/patrickvonplaten/distilhubert-timit/blob/main/run.sh) |
-
-
-#### Librispeech CTC
-
-- [Librispeech](https://huggingface.co/datasets/librispeech_asr)
-
-| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
-|-------|------------------------------|-------------|---------------|---------------|----------------------|-------------| -------------| ------- |
-| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [microsoft/wavlm-large](https://huggingface.co/microsoft/wavlm-large) | 0.049 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/wavlm-libri-clean-100h-large) | [run.sh](https://huggingface.co/patrickvonplaten/wavlm-libri-clean-100h-large/blob/main/run.sh) |
-| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [microsoft/wavlm-base-plus](https://huggingface.co/microsoft/wavlm-base-plus) | 0.068 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/wavlm-libri-clean-100h-base-plus) | [run.sh](https://huggingface.co/patrickvonplaten/wavlm-libri-clean-100h-base-plus/blob/main/run.sh) |
-| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) | 0.042 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist/blob/main/run.sh) |
-| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) | 0.042 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-librispeech-clean-100h-demo-dist/blob/main/run.sh) |
-| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [facebook/hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k) | 0.088 | - | 8 GPU V100 | 1h30min | [here](https://huggingface.co/patrickvonplaten/hubert-librispeech-clean-100h-demo-dist) | [run.sh](https://huggingface.co/patrickvonplaten/hubert-librispeech-clean-100h-demo-dist/blob/main/run.sh) |
-| [Librispeech](https://huggingface.co/datasets/librispeech_asr)| `"clean"` - `"train.100"` | [asapp/sew-mid-100k](https://huggingface.co/asapp/sew-mid-100k) | 0.167 | | 8 GPU V100 | 54min | [here](https://huggingface.co/patrickvonplaten/sew-mid-100k-librispeech-clean-100h-ft) | [run.sh](https://huggingface.co/patrickvonplaten/sew-mid-100k-librispeech-clean-100h-ft/blob/main/run.sh) |
-
-
-#### Common Voice CTC
-
-- [Common Voice](https://huggingface.co/datasets/common_voice)
-
-| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
-|-------|------------------------------|-------------|---------------|---------------|----------------------|-------------| -------------| ------- |
-| [Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_3_0)| `"tr"` | [facebook/wav2vec2-large-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | - | 0.099 | 8 GPU V100 | 23min | [here](https://huggingface.co/patrickvonplaten/xls-r-300m-tr-phoneme) | [run.sh](https://huggingface.co/patrickvonplaten/xls-r-300m-tr-phoneme/blob/main/run.sh) |
-| [Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_3_0)| `"it"` | [facebook/wav2vec2-large-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | - | 0.077 | 8 GPU V100 | 23min | [here](https://huggingface.co/patrickvonplaten/xls-r-300m-it-phoneme) | [run.sh](https://huggingface.co/patrickvonplaten/xls-r-300m-it-phoneme/blob/main/run.sh) |
-| [Common Voice](https://huggingface.co/datasets/mozilla-foundation/common_voice_3_0)| `"sv-SE"` | [facebook/wav2vec2-large-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | - | 0.099 | 8 GPU V100 | 23min | [here](https://huggingface.co/patrickvonplaten/xls-r-300m-sv-phoneme) | [run.sh](https://huggingface.co/patrickvonplaten/xls-r-300m-sv-phoneme/blob/main/run.sh) |
-| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.36 | - | 8 GPU V100 | 18min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo-dist) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo-dist/blob/main/run_dist.sh) |
-| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.31 | - | 8 GPU V100 | 1h05 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-xlsr-53-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xlsr-53-common_voice-tr-ft/blob/main/run.sh) |
-| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.35 | - | 1 GPU V100 | 1h20min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-common_voice-tr-demo/blob/main/run.sh) |
-| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.31 | - | 8 GPU V100 | 1h05 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-300m-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-300m-common_voice-tr-ft/blob/main/run.sh) |
-| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` | [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) | 0.21 | - | 2 GPU Titan 24 GB RAM | 15h10 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-xls-r-1b-common_voice-tr-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-large-xls-r-1b-common_voice-tr-ft/blob/main/run.sh) |
-| [Common Voice](https://huggingface.co/datasets/common_voice)| `"tr"` in streaming mode | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.29 | - | 4 GPU V100 | 3h31 | [here](https://huggingface.co/anton-l/wav2vec2-xls-r-common_voice-tr-ft-stream) | [run.sh](https://huggingface.co/anton-l/wav2vec2-xls-r-common_voice-tr-ft-stream/blob/main/run.sh) |
-
-
-#### Multilingual Librispeech CTC
-
-- [Multilingual Librispeech](https://huggingface.co/datasets/multilingual_librispeech)
-
-| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
-|-------|------------------------------|-------------|---------------|---------------|----------------------|-------------| -------------| ------- |
-| [Multilingual Librispeech](https://huggingface.co/datasets/multilingual_librispeech)| `"german"` | [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) | 0.13 | - | 1 GPU Titan 24 GB RAM | 15h04 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-xlsr-53-300m-mls-german-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-xlsr-53-300m-mls-german-ft/blob/main/run.sh) |
-| [Multilingual Librispeech](https://huggingface.co/datasets/multilingual_librispeech)| `"german"` | [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) | 0.15 | - | 1 GPU Titan 24 GB RAM | 15h04 | [here](https://huggingface.co/patrickvonplaten/wav2vec2-300m-mls-german-ft) | [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-300m-mls-german-ft/blob/main/run.sh) |
-
-## Sequence to Sequence
-
-The script [`run_speech_recognition_seq2seq.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py) can be used to fine-tune any [Speech Sequence-to-Sequence Model](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForSpeechSeq2Seq) for automatic speech
-recognition on one of the [official speech recognition datasets](https://huggingface.co/datasets?task_ids=task_ids:automatic-speech-recognition) or a custom dataset. This includes the Whisper model from OpenAI or a warm-started Speech-Encoder-Decoder Model, examples for which are included below.
-
-### Whisper Model
-We can load all components of the Whisper model directly from the pretrained checkpoint, including the pretrained model weights, feature extractor and tokenizer. We simply have to specify our fine-tuning dataset and training hyperparameters.
-
-#### Single GPU Whisper Training
-The following example shows how to fine-tune the [Whisper small](https://huggingface.co/openai/whisper-small) checkpoint on the Hindi subset of [Common Voice 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) using a single GPU device in half-precision:
-```bash
-python run_speech_recognition_seq2seq.py \
- --model_name_or_path="openai/whisper-small" \
- --dataset_name="mozilla-foundation/common_voice_11_0" \
- --dataset_config_name="hi" \
- --language="hindi" \
- --train_split_name="train+validation" \
- --eval_split_name="test" \
- --max_steps="5000" \
- --output_dir="./whisper-small-hi" \
- --per_device_train_batch_size="16" \
- --gradient_accumulation_steps="2" \
- --per_device_eval_batch_size="16" \
- --logging_steps="25" \
- --learning_rate="1e-5" \
- --warmup_steps="500" \
- --evaluation_strategy="steps" \
- --eval_steps="1000" \
- --save_strategy="steps" \
- --save_steps="1000" \
- --generation_max_length="225" \
- --preprocessing_num_workers="16" \
- --length_column_name="input_length" \
- --max_duration_in_seconds="30" \
- --text_column_name="sentence" \
- --freeze_feature_encoder="False" \
- --gradient_checkpointing \
- --group_by_length \
- --fp16 \
- --overwrite_output_dir \
- --do_train \
- --do_eval \
- --predict_with_generate \
- --use_auth_token
-```
-On a single V100, training should take approximately 8 hours, with a final cross-entropy loss of **1e-4** and word error rate of **32.6%**.
-
-If training on a different language, you should be sure to change the `language` argument. The `language` argument should be omitted for English speech recognition.
-
-#### Multi GPU Whisper Training
-The following example shows how to fine-tune the [Whisper small](https://huggingface.co/openai/whisper-small) checkpoint on the Hindi subset of [Common Voice 11](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) using 2 GPU devices in half-precision:
-```bash
-python -m torch.distributed.launch \
- --nproc_per_node 2 run_speech_recognition_seq2seq.py \
- --model_name_or_path="openai/whisper-small" \
- --dataset_name="mozilla-foundation/common_voice_11_0" \
- --dataset_config_name="hi" \
- --language="hindi" \
- --train_split_name="train+validation" \
- --eval_split_name="test" \
- --max_steps="5000" \
- --output_dir="./whisper-small-hi" \
- --per_device_train_batch_size="16" \
- --per_device_eval_batch_size="16" \
- --logging_steps="25" \
- --learning_rate="1e-5" \
- --warmup_steps="500" \
- --evaluation_strategy="steps" \
- --eval_steps="1000" \
- --save_strategy="steps" \
- --save_steps="1000" \
- --generation_max_length="225" \
- --preprocessing_num_workers="16" \
- --length_column_name="input_length" \
- --max_duration_in_seconds="30" \
- --text_column_name="sentence" \
- --freeze_feature_encoder="False" \
- --gradient_checkpointing \
- --group_by_length \
- --fp16 \
- --overwrite_output_dir \
- --do_train \
- --do_eval \
- --predict_with_generate \
- --use_auth_token
-```
-On two V100s, training should take approximately 4 hours, with a final cross-entropy loss of **1e-4** and word error rate of **32.6%**.
-
-### Warm-Started Speech-Encoder-Decoder Model
-A very common use case is to leverage a pretrained speech encoder model,
-*e.g.* [Wav2Vec2](https://huggingface.co/transformers/main/model_doc/wav2vec2.html), [HuBERT](https://huggingface.co/transformers/main/model_doc/hubert.html) or [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html), with a pretrained text decoder model, *e.g.* [BART](https://huggingface.co/docs/transformers/main/en/model_doc/bart#transformers.BartForCausalLM) or [GPT-2](https://huggingface.co/docs/transformers/main/en/model_doc/gpt2#transformers.GPT2ForCausalLM), to create a [Speech-Encoder-Decoder Model](https://huggingface.co/docs/transformers/main/en/model_doc/speech-encoder-decoder#speech-encoder-decoder-models).
-
-By pairing a pretrained speech model with a pretrained text model, the warm-started model has prior knowledge of both the source audio and target text domains. However, the cross-attention weights between the encoder and decoder are randomly initialised. Thus, the model requires fine-tuning to learn the cross-attention weights and align the encoder mapping with that of the decoder. We can perform this very fine-tuning procedure using the example script.
-
-As an example, let's instantiate a *Wav2Vec2-2-Bart* model with the `SpeechEnocderDecoderModel` framework. First create an empty repo on `hf.co`:
-
-```bash
-huggingface-cli repo create wav2vec2-2-bart-base
-git clone https://huggingface.co//wav2vec2-2-bart-base
-cd wav2vec2-2-bart-base
-```
-
-Next, run the following script **inside** the just cloned repo:
-
-```python
-from transformers import SpeechEncoderDecoderModel, AutoFeatureExtractor, AutoTokenizer, Wav2Vec2Processor
-
-# checkpoints to leverage
-encoder_id = "facebook/wav2vec2-base"
-decoder_id = "facebook/bart-base"
-
-# load and save speech-encoder-decoder model
-# set some hyper-parameters for training and evaluation
-model = SpeechEncoderDecoderModel.from_encoder_decoder_pretrained(encoder_id, decoder_id, encoder_add_adapter=True, encoder_feat_proj_dropout=0.0, encoder_layerdrop=0.0, max_length=200, num_beams=5)
-model.config.decoder_start_token_id = model.decoder.config.bos_token_id
-model.config.pad_token_id = model.decoder.config.pad_token_id
-model.config.eos_token_id = model.decoder.config.eos_token_id
-model.save_pretrained("./")
-
-# load and save processor
-feature_extractor = AutoFeatureExtractor.from_pretrained(encoder_id)
-tokenizer = AutoTokenizer.from_pretrained(decoder_id)
-processor = Wav2Vec2Processor(feature_extractor, tokenizer)
-processor.save_pretrained("./")
-```
-
-Finally, we can upload all files:
-```bash
-git lfs install
-git add . && git commit -m "upload model files" && git push
-```
-
-and link the official `run_speech_recognition_seq2seq.py` script to the folder:
-
-```bash
-ln -s $(realpath /examples/pytorch/speech-recognition/run_speech_recognition_seq2seq.py) ./
-```
-
-Note that we have added a randomly initialized _adapter layer_ to `wav2vec2-base` with the argument
-`encoder_add_adapter=True`. This adapter sub-samples the output sequence of
-`wav2vec2-base` along the time dimension. By default, a single
-output vector of `wav2vec2-base` has a receptive field of *ca.* 25ms (*cf.*
-Section *4.2* of the [official Wav2Vec2 paper](https://arxiv.org/pdf/2006.11477.pdf)), which represents a little less a single character. On the other hand, BART
-makes use of a sentence-piece tokenizer as an input processor, so that a single
-hidden vector of `bart-base` represents *ca.* 4 characters. To better align the
-receptive field of the *Wav2Vec2* output vectors with *BART*'s hidden-states in the cross-attention
-mechanism, we further subsample *Wav2Vec2*'s output by a factor of 8 by
-adding a convolution-based adapter.
-
-Having warm-started the speech-encoder-decoder model under `/wav2vec2-2-bart`, we can now fine-tune it on the task of speech recognition.
-
-In the script [`run_speech_recognition_seq2seq`], we load the warm-started model,
-feature extractor, and tokenizer, process a speech recognition dataset,
-and subsequently make use of the [`Seq2SeqTrainer`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.Seq2SeqTrainer) to train our system.
-Note that it is important to align the target transcriptions with the decoder's vocabulary. For example, the [`Librispeech`](https://huggingface.co/datasets/librispeech_asr) dataset only contains captilized letters in the transcriptions,
-whereas BART was pretrained mostly on normalized text. Thus, it is recommended to add the argument
-`--do_lower_case` to the fine-tuning script when using a warm-started `SpeechEncoderDecoderModel`.
-The model is fine-tuned on the standard cross-entropy language modeling
-loss for sequence-to-sequence (just like *T5* or *BART* in natural language processing).
-
----
-**NOTE**
-
-If you encounter problems with data preprocessing by setting `--preprocessing_num_workers` > 1,
-you might want to set the environment variable `OMP_NUM_THREADS` to 1 as follows:
-
-```bash
-OMP_NUM_THREADS=1 python run_speech_recognition_ctc ...
-```
-
-If the environment variable is not set, the training script might freeze, *i.e.* see: https://github.com/pytorch/audio/issues/1021#issuecomment-726915239.
-
----
-
-#### Single GPU Seq2Seq
-
-The following command shows how to fine-tune [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html) on [Common Voice](https://huggingface.co/datasets/common_voice) using a single GPU in half-precision.
-
-```bash
-python run_speech_recognition_seq2seq.py \
- --dataset_name="librispeech_asr" \
- --model_name_or_path="./" \
- --dataset_config_name="clean" \
- --train_split_name="train.100" \
- --eval_split_name="validation" \
- --output_dir="./" \
- --preprocessing_num_workers="16" \
- --length_column_name="input_length" \
- --overwrite_output_dir \
- --num_train_epochs="5" \
- --per_device_train_batch_size="8" \
- --per_device_eval_batch_size="8" \
- --gradient_accumulation_steps="8" \
- --learning_rate="3e-4" \
- --warmup_steps="400" \
- --evaluation_strategy="steps" \
- --text_column_name="text" \
- --save_steps="400" \
- --eval_steps="400" \
- --logging_steps="10" \
- --save_total_limit="1" \
- --freeze_feature_encoder \
- --gradient_checkpointing \
- --fp16 \
- --group_by_length \
- --predict_with_generate \
- --generation_max_length="40" \
- --generation_num_beams="1" \
- --do_train --do_eval \
- --do_lower_case
-```
-
-On a single V100 GPU, this script should run in *ca.* 5 hours and yield a
-cross-entropy loss of **0.405** and word error rate of **0.0728**.
-
-#### Multi GPU Seq2Seq
-
-The following command shows how to fine-tune [XLSR-Wav2Vec2](https://huggingface.co/transformers/main/model_doc/xlsr_wav2vec2.html) on [Common Voice](https://huggingface.co/datasets/common_voice) using 8 GPUs in half-precision.
-
-```bash
-python -m torch.distributed.launch \
- --nproc_per_node 8 run_speech_recognition_seq2seq.py \
- --dataset_name="librispeech_asr" \
- --model_name_or_path="./" \
- --dataset_config_name="clean" \
- --train_split_name="train.100" \
- --eval_split_name="validation" \
- --output_dir="./" \
- --preprocessing_num_workers="16" \
- --length_column_name="input_length" \
- --overwrite_output_dir \
- --num_train_epochs="5" \
- --per_device_train_batch_size="8" \
- --per_device_eval_batch_size="8" \
- --gradient_accumulation_steps="1" \
- --learning_rate="3e-4" \
- --warmup_steps="400" \
- --evaluation_strategy="steps" \
- --text_column_name="text" \
- --save_steps="400" \
- --eval_steps="400" \
- --logging_steps="10" \
- --save_total_limit="1" \
- --freeze_feature_encoder \
- --gradient_checkpointing \
- --fp16 \
- --group_by_length \
- --predict_with_generate \
- --do_train --do_eval \
- --do_lower_case
-```
-
-On 8 V100 GPUs, this script should run in *ca.* 45 minutes and yield a cross-entropy loss of **0.405** and word error rate of **0.0728**
-
-### Examples Seq2Seq
-
-#### Librispeech Seq2Seq
-
-- [Librispeech](https://huggingface.co/datasets/librispeech_asr)
-
-| Dataset | Dataset Config | Pretrained Model | Word error rate on eval | Phoneme error rate on eval | GPU setup | Training time | Fine-tuned Model & Logs | Command to reproduce |
-|----------------------------------------------------------------|---------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------|----------------------------|------------|---------------|-----------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| [Librispeech](https://huggingface.co/datasets/librispeech_asr) | `"clean"` - `"train.100"` | [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) and [facebook/bart-base](https://huggingface.co/facebook/bart-base) | 0.0728 | - | 8 GPU V100 | 45min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-base) | [create_model.py](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-base/blob/main/create_model.py) & [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-base/blob/main/run_librispeech.sh) |
-| [Librispeech](https://huggingface.co/datasets/librispeech_asr) | `"clean"` - `"train.100"` | [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60) and [facebook/bart-large](https://huggingface.co/facebook/bart-large) | 0.0486 | - | 8 GPU V100 | 1h20min | [here](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-large) | [create_model.py](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-large/blob/main/create_model.py) & [run.sh](https://huggingface.co/patrickvonplaten/wav2vec2-2-bart-large/blob/main/run_librispeech.sh) |
diff --git a/spaces/chengggg12/bingo/Dockerfile b/spaces/chengggg12/bingo/Dockerfile
deleted file mode 100644
index c677b05b75f7e4b2beee8c97fb47957a0861a83e..0000000000000000000000000000000000000000
--- a/spaces/chengggg12/bingo/Dockerfile
+++ /dev/null
@@ -1,7 +0,0 @@
-FROM weaigc/bingo:latest
-
-ARG DEBIAN_FRONTEND=noninteractive
-
-ENV BING_HEADER ""
-
-CMD npm start
diff --git a/spaces/chenmgtea/cn_tts/commons.py b/spaces/chenmgtea/cn_tts/commons.py
deleted file mode 100644
index 21b446b6bd4dee16cbfbd26fb97d69110b410350..0000000000000000000000000000000000000000
--- a/spaces/chenmgtea/cn_tts/commons.py
+++ /dev/null
@@ -1,163 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size * dilation - dilation) / 2)
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def intersperse(lst, item):
- result = [item] * (len(lst) * 2 + 1)
- result[1::2] = lst
- return result
-
-
-def kl_divergence(m_p, logs_p, m_q, logs_q):
- """KL(P||Q)"""
- kl = (logs_q - logs_p) - 0.5
- kl += (
- 0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q)
- )
- return kl
-
-
-def rand_gumbel(shape):
- """Sample from the Gumbel distribution, protect from overflows."""
- uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
- return -torch.log(-torch.log(uniform_samples))
-
-
-def rand_gumbel_like(x):
- g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
- return g
-
-
-def slice_segments(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, :, idx_str:idx_end]
- return ret
-
-
-def rand_slice_segments(x, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size + 1
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- return ret, ids_str
-
-
-def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4):
- position = torch.arange(length, dtype=torch.float)
- num_timescales = channels // 2
- log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / (
- num_timescales - 1
- )
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment
- )
- scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
- signal = F.pad(signal, [0, 0, 0, channels % 2])
- signal = signal.view(1, channels, length)
- return signal
-
-
-def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return x + signal.to(dtype=x.dtype, device=x.device)
-
-
-def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
-
-
-def subsequent_mask(length):
- mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
- return mask
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a + input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def shift_1d(x):
- x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
- return x
-
-
-def sequence_mask(length, max_length=None):
- if max_length is None:
- max_length = length.max()
- x = torch.arange(max_length, dtype=length.dtype, device=length.device)
- return x.unsqueeze(0) < length.unsqueeze(1)
-
-
-def generate_path(duration, mask):
- """
- duration: [b, 1, t_x]
- mask: [b, 1, t_y, t_x]
- """
- device = duration.device
-
- b, _, t_y, t_x = mask.shape
- cum_duration = torch.cumsum(duration, -1)
-
- cum_duration_flat = cum_duration.view(b * t_x)
- path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
- path = path.view(b, t_x, t_y)
- path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
- path = path.unsqueeze(1).transpose(2, 3) * mask
- return path
-
-
-def clip_grad_value_(parameters, clip_value, norm_type=2):
- if isinstance(parameters, torch.Tensor):
- parameters = [parameters]
- parameters = list(filter(lambda p: p.grad is not None, parameters))
- norm_type = float(norm_type)
- if clip_value is not None:
- clip_value = float(clip_value)
-
- total_norm = 0
- for p in parameters:
- param_norm = p.grad.data.norm(norm_type)
- total_norm += param_norm.item() ** norm_type
- if clip_value is not None:
- p.grad.data.clamp_(min=-clip_value, max=clip_value)
- total_norm = total_norm ** (1.0 / norm_type)
- return total_norm
diff --git a/spaces/chilge/Fushimi/flask_api.py b/spaces/chilge/Fushimi/flask_api.py
deleted file mode 100644
index 8cc236a1c34c9ddeddea99bcea13024fb0ccc90b..0000000000000000000000000000000000000000
--- a/spaces/chilge/Fushimi/flask_api.py
+++ /dev/null
@@ -1,56 +0,0 @@
-import io
-import logging
-
-import soundfile
-import torch
-import torchaudio
-from flask import Flask, request, send_file
-from flask_cors import CORS
-
-from inference.infer_tool import Svc, RealTimeVC
-
-app = Flask(__name__)
-
-CORS(app)
-
-logging.getLogger('numba').setLevel(logging.WARNING)
-
-
-@app.route("/voiceChangeModel", methods=["POST"])
-def voice_change_model():
- request_form = request.form
- wave_file = request.files.get("sample", None)
- # 变调信息
- f_pitch_change = float(request_form.get("fPitchChange", 0))
- # DAW所需的采样率
- daw_sample = int(float(request_form.get("sampleRate", 0)))
- speaker_id = int(float(request_form.get("sSpeakId", 0)))
- # http获得wav文件并转换
- input_wav_path = io.BytesIO(wave_file.read())
-
- # 模型推理
- if raw_infer:
- out_audio, out_sr = svc_model.infer(speaker_id, f_pitch_change, input_wav_path)
- tar_audio = torchaudio.functional.resample(out_audio, svc_model.target_sample, daw_sample)
- else:
- out_audio = svc.process(svc_model, speaker_id, f_pitch_change, input_wav_path)
- tar_audio = torchaudio.functional.resample(torch.from_numpy(out_audio), svc_model.target_sample, daw_sample)
- # 返回音频
- out_wav_path = io.BytesIO()
- soundfile.write(out_wav_path, tar_audio.cpu().numpy(), daw_sample, format="wav")
- out_wav_path.seek(0)
- return send_file(out_wav_path, download_name="temp.wav", as_attachment=True)
-
-
-if __name__ == '__main__':
- # 启用则为直接切片合成,False为交叉淡化方式
- # vst插件调整0.3-0.5s切片时间可以降低延迟,直接切片方法会有连接处爆音、交叉淡化会有轻微重叠声音
- # 自行选择能接受的方法,或将vst最大切片时间调整为1s,此处设为Ture,延迟大音质稳定一些
- raw_infer = True
- # 每个模型和config是唯一对应的
- model_name = "logs/32k/G_174000-Copy1.pth"
- config_name = "configs/config.json"
- svc_model = Svc(model_name, config_name)
- svc = RealTimeVC()
- # 此处与vst插件对应,不建议更改
- app.run(port=6842, host="0.0.0.0", debug=False, threaded=False)
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/faiss/contrib/factory_tools.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/faiss/contrib/factory_tools.py
deleted file mode 100644
index 9623ad55f4f8c4343ab8dc4c5d17a6938c760b42..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/faiss/contrib/factory_tools.py
+++ /dev/null
@@ -1,100 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import faiss
-import re
-
-
-def get_code_size(d, indexkey):
- """ size of one vector in an index in dimension d
- constructed with factory string indexkey"""
-
- if indexkey == "Flat":
- return d * 4
-
- if indexkey.endswith(",RFlat"):
- return d * 4 + get_code_size(d, indexkey[:-len(",RFlat")])
-
- mo = re.match("IVF\\d+(_HNSW32)?,(.*)$", indexkey)
- if mo:
- return get_code_size(d, mo.group(2))
-
- mo = re.match("IVF\\d+\\(.*\\)?,(.*)$", indexkey)
- if mo:
- return get_code_size(d, mo.group(1))
-
- mo = re.match("IMI\\d+x2,(.*)$", indexkey)
- if mo:
- return get_code_size(d, mo.group(1))
-
- mo = re.match("(.*),Refine\\((.*)\\)$", indexkey)
- if mo:
- return get_code_size(d, mo.group(1)) + get_code_size(d, mo.group(2))
-
- mo = re.match('PQ(\\d+)x(\\d+)(fs|fsr)?$', indexkey)
- if mo:
- return (int(mo.group(1)) * int(mo.group(2)) + 7) // 8
-
- mo = re.match('PQ(\\d+)\\+(\\d+)$', indexkey)
- if mo:
- return (int(mo.group(1)) + int(mo.group(2)))
-
- mo = re.match('PQ(\\d+)$', indexkey)
- if mo:
- return int(mo.group(1))
-
- if indexkey == "HNSW32" or indexkey == "HNSW32,Flat":
- return d * 4 + 64 * 4 # roughly
-
- if indexkey == 'SQ8':
- return d
- elif indexkey == 'SQ4':
- return (d + 1) // 2
- elif indexkey == 'SQ6':
- return (d * 6 + 7) // 8
- elif indexkey == 'SQfp16':
- return d * 2
-
- mo = re.match('PCAR?(\\d+),(.*)$', indexkey)
- if mo:
- return get_code_size(int(mo.group(1)), mo.group(2))
- mo = re.match('OPQ\\d+_(\\d+),(.*)$', indexkey)
- if mo:
- return get_code_size(int(mo.group(1)), mo.group(2))
- mo = re.match('OPQ\\d+,(.*)$', indexkey)
- if mo:
- return get_code_size(d, mo.group(1))
- mo = re.match('RR(\\d+),(.*)$', indexkey)
- if mo:
- return get_code_size(int(mo.group(1)), mo.group(2))
- raise RuntimeError("cannot parse " + indexkey)
-
-
-
-def reverse_index_factory(index):
- """
- attempts to get the factory string the index was built with
- """
- index = faiss.downcast_index(index)
- if isinstance(index, faiss.IndexFlat):
- return "Flat"
- if isinstance(index, faiss.IndexIVF):
- quantizer = faiss.downcast_index(index.quantizer)
-
- if isinstance(quantizer, faiss.IndexFlat):
- prefix = "IVF%d" % index.nlist
- elif isinstance(quantizer, faiss.MultiIndexQuantizer):
- prefix = "IMI%dx%d" % (quantizer.pq.M, quantizer.pq.nbit)
- elif isinstance(quantizer, faiss.IndexHNSW):
- prefix = "IVF%d_HNSW%d" % (index.nlist, quantizer.hnsw.M)
- else:
- prefix = "IVF%d(%s)" % (index.nlist, reverse_index_factory(quantizer))
-
- if isinstance(index, faiss.IndexIVFFlat):
- return prefix + ",Flat"
- if isinstance(index, faiss.IndexIVFScalarQuantizer):
- return prefix + ",SQ8"
-
- raise NotImplementedError()
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/flatbuffers/flexbuffers.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/flatbuffers/flexbuffers.py
deleted file mode 100644
index 34d42a6986c037b4915e0a8f1a9720c8ddf4953b..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/flatbuffers/flexbuffers.py
+++ /dev/null
@@ -1,1536 +0,0 @@
-# Lint as: python3
-# Copyright 2020 Google Inc. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Implementation of FlexBuffers binary format.
-
-For more info check https://google.github.io/flatbuffers/flexbuffers.html and
-corresponding C++ implementation at
-https://github.com/google/flatbuffers/blob/master/include/flatbuffers/flexbuffers.h
-"""
-
-# pylint: disable=invalid-name
-# TODO(dkovalev): Add type hints everywhere, so tools like pytypes could work.
-
-import array
-import contextlib
-import enum
-import struct
-
-__all__ = ('Type', 'Builder', 'GetRoot', 'Dumps', 'Loads')
-
-
-class BitWidth(enum.IntEnum):
- """Supported bit widths of value types.
-
- These are used in the lower 2 bits of a type field to determine the size of
- the elements (and or size field) of the item pointed to (e.g. vector).
- """
- W8 = 0 # 2^0 = 1 byte
- W16 = 1 # 2^1 = 2 bytes
- W32 = 2 # 2^2 = 4 bytes
- W64 = 3 # 2^3 = 8 bytes
-
- @staticmethod
- def U(value):
- """Returns the minimum `BitWidth` to encode unsigned integer value."""
- assert value >= 0
-
- if value < (1 << 8):
- return BitWidth.W8
- elif value < (1 << 16):
- return BitWidth.W16
- elif value < (1 << 32):
- return BitWidth.W32
- elif value < (1 << 64):
- return BitWidth.W64
- else:
- raise ValueError('value is too big to encode: %s' % value)
-
- @staticmethod
- def I(value):
- """Returns the minimum `BitWidth` to encode signed integer value."""
- # -2^(n-1) <= value < 2^(n-1)
- # -2^n <= 2 * value < 2^n
- # 2 * value < 2^n, when value >= 0 or 2 * (-value) <= 2^n, when value < 0
- # 2 * value < 2^n, when value >= 0 or 2 * (-value) - 1 < 2^n, when value < 0
- #
- # if value >= 0:
- # return BitWidth.U(2 * value)
- # else:
- # return BitWidth.U(2 * (-value) - 1) # ~x = -x - 1
- value *= 2
- return BitWidth.U(value if value >= 0 else ~value)
-
- @staticmethod
- def F(value):
- """Returns the `BitWidth` to encode floating point value."""
- if struct.unpack(' 0:
- i = first
- step = count // 2
- i += step
- if pred(values[i], value):
- i += 1
- first = i
- count -= step + 1
- else:
- count = step
- return first
-
-
-# https://en.cppreference.com/w/cpp/algorithm/binary_search
-def _BinarySearch(values, value, pred=lambda x, y: x < y):
- """Implementation of C++ std::binary_search() algorithm."""
- index = _LowerBound(values, value, pred)
- if index != len(values) and not pred(value, values[index]):
- return index
- return -1
-
-
-class Type(enum.IntEnum):
- """Supported types of encoded data.
-
- These are used as the upper 6 bits of a type field to indicate the actual
- type.
- """
- NULL = 0
- INT = 1
- UINT = 2
- FLOAT = 3
- # Types above stored inline, types below store an offset.
- KEY = 4
- STRING = 5
- INDIRECT_INT = 6
- INDIRECT_UINT = 7
- INDIRECT_FLOAT = 8
- MAP = 9
- VECTOR = 10 # Untyped.
-
- VECTOR_INT = 11 # Typed any size (stores no type table).
- VECTOR_UINT = 12
- VECTOR_FLOAT = 13
- VECTOR_KEY = 14
- # DEPRECATED, use VECTOR or VECTOR_KEY instead.
- # Read test.cpp/FlexBuffersDeprecatedTest() for details on why.
- VECTOR_STRING_DEPRECATED = 15
-
- VECTOR_INT2 = 16 # Typed tuple (no type table, no size field).
- VECTOR_UINT2 = 17
- VECTOR_FLOAT2 = 18
- VECTOR_INT3 = 19 # Typed triple (no type table, no size field).
- VECTOR_UINT3 = 20
- VECTOR_FLOAT3 = 21
- VECTOR_INT4 = 22 # Typed quad (no type table, no size field).
- VECTOR_UINT4 = 23
- VECTOR_FLOAT4 = 24
-
- BLOB = 25
- BOOL = 26
- VECTOR_BOOL = 36 # To do the same type of conversion of type to vector type
-
- @staticmethod
- def Pack(type_, bit_width):
- return (int(type_) << 2) | bit_width
-
- @staticmethod
- def Unpack(packed_type):
- return 1 << (packed_type & 0b11), Type(packed_type >> 2)
-
- @staticmethod
- def IsInline(type_):
- return type_ <= Type.FLOAT or type_ == Type.BOOL
-
- @staticmethod
- def IsTypedVector(type_):
- return Type.VECTOR_INT <= type_ <= Type.VECTOR_STRING_DEPRECATED or \
- type_ == Type.VECTOR_BOOL
-
- @staticmethod
- def IsTypedVectorElementType(type_):
- return Type.INT <= type_ <= Type.STRING or type_ == Type.BOOL
-
- @staticmethod
- def ToTypedVectorElementType(type_):
- if not Type.IsTypedVector(type_):
- raise ValueError('must be typed vector type')
-
- return Type(type_ - Type.VECTOR_INT + Type.INT)
-
- @staticmethod
- def IsFixedTypedVector(type_):
- return Type.VECTOR_INT2 <= type_ <= Type.VECTOR_FLOAT4
-
- @staticmethod
- def IsFixedTypedVectorElementType(type_):
- return Type.INT <= type_ <= Type.FLOAT
-
- @staticmethod
- def ToFixedTypedVectorElementType(type_):
- if not Type.IsFixedTypedVector(type_):
- raise ValueError('must be fixed typed vector type')
-
- # 3 types each, starting from length 2.
- fixed_type = type_ - Type.VECTOR_INT2
- return Type(fixed_type % 3 + Type.INT), fixed_type // 3 + 2
-
- @staticmethod
- def ToTypedVector(element_type, fixed_len=0):
- """Converts element type to corresponding vector type.
-
- Args:
- element_type: vector element type
- fixed_len: number of elements: 0 for typed vector; 2, 3, or 4 for fixed
- typed vector.
-
- Returns:
- Typed vector type or fixed typed vector type.
- """
- if fixed_len == 0:
- if not Type.IsTypedVectorElementType(element_type):
- raise ValueError('must be typed vector element type')
- else:
- if not Type.IsFixedTypedVectorElementType(element_type):
- raise ValueError('must be fixed typed vector element type')
-
- offset = element_type - Type.INT
- if fixed_len == 0:
- return Type(offset + Type.VECTOR_INT) # TypedVector
- elif fixed_len == 2:
- return Type(offset + Type.VECTOR_INT2) # FixedTypedVector
- elif fixed_len == 3:
- return Type(offset + Type.VECTOR_INT3) # FixedTypedVector
- elif fixed_len == 4:
- return Type(offset + Type.VECTOR_INT4) # FixedTypedVector
- else:
- raise ValueError('unsupported fixed_len: %s' % fixed_len)
-
-
-class Buf:
- """Class to access underlying buffer object starting from the given offset."""
-
- def __init__(self, buf, offset):
- self._buf = buf
- self._offset = offset if offset >= 0 else len(buf) + offset
- self._length = len(buf) - self._offset
-
- def __getitem__(self, key):
- if isinstance(key, slice):
- return self._buf[_ShiftSlice(key, self._offset, self._length)]
- elif isinstance(key, int):
- return self._buf[self._offset + key]
- else:
- raise TypeError('invalid key type')
-
- def __setitem__(self, key, value):
- if isinstance(key, slice):
- self._buf[_ShiftSlice(key, self._offset, self._length)] = value
- elif isinstance(key, int):
- self._buf[self._offset + key] = key
- else:
- raise TypeError('invalid key type')
-
- def __repr__(self):
- return 'buf[%d:]' % self._offset
-
- def Find(self, sub):
- """Returns the lowest index where the sub subsequence is found."""
- return self._buf[self._offset:].find(sub)
-
- def Slice(self, offset):
- """Returns new `Buf` which starts from the given offset."""
- return Buf(self._buf, self._offset + offset)
-
- def Indirect(self, offset, byte_width):
- """Return new `Buf` based on the encoded offset (indirect encoding)."""
- return self.Slice(offset - _Unpack(U, self[offset:offset + byte_width]))
-
-
-class Object:
- """Base class for all non-trivial data accessors."""
- __slots__ = '_buf', '_byte_width'
-
- def __init__(self, buf, byte_width):
- self._buf = buf
- self._byte_width = byte_width
-
- @property
- def ByteWidth(self):
- return self._byte_width
-
-
-class Sized(Object):
- """Base class for all data accessors which need to read encoded size."""
- __slots__ = '_size',
-
- def __init__(self, buf, byte_width, size=0):
- super().__init__(buf, byte_width)
- if size == 0:
- self._size = _Unpack(U, self.SizeBytes)
- else:
- self._size = size
-
- @property
- def SizeBytes(self):
- return self._buf[-self._byte_width:0]
-
- def __len__(self):
- return self._size
-
-
-class Blob(Sized):
- """Data accessor for the encoded blob bytes."""
- __slots__ = ()
-
- @property
- def Bytes(self):
- return self._buf[0:len(self)]
-
- def __repr__(self):
- return 'Blob(%s, size=%d)' % (self._buf, len(self))
-
-
-class String(Sized):
- """Data accessor for the encoded string bytes."""
- __slots__ = ()
-
- @property
- def Bytes(self):
- return self._buf[0:len(self)]
-
- def Mutate(self, value):
- """Mutates underlying string bytes in place.
-
- Args:
- value: New string to replace the existing one. New string must have less
- or equal UTF-8-encoded bytes than the existing one to successfully
- mutate underlying byte buffer.
-
- Returns:
- Whether the value was mutated or not.
- """
- encoded = value.encode('utf-8')
- n = len(encoded)
- if n <= len(self):
- self._buf[-self._byte_width:0] = _Pack(U, n, self._byte_width)
- self._buf[0:n] = encoded
- self._buf[n:len(self)] = bytearray(len(self) - n)
- return True
- return False
-
- def __str__(self):
- return self.Bytes.decode('utf-8')
-
- def __repr__(self):
- return 'String(%s, size=%d)' % (self._buf, len(self))
-
-
-class Key(Object):
- """Data accessor for the encoded key bytes."""
- __slots__ = ()
-
- def __init__(self, buf, byte_width):
- assert byte_width == 1
- super().__init__(buf, byte_width)
-
- @property
- def Bytes(self):
- return self._buf[0:len(self)]
-
- def __len__(self):
- return self._buf.Find(0)
-
- def __str__(self):
- return self.Bytes.decode('ascii')
-
- def __repr__(self):
- return 'Key(%s, size=%d)' % (self._buf, len(self))
-
-
-class Vector(Sized):
- """Data accessor for the encoded vector bytes."""
- __slots__ = ()
-
- def __getitem__(self, index):
- if index < 0 or index >= len(self):
- raise IndexError('vector index %s is out of [0, %d) range' % \
- (index, len(self)))
-
- packed_type = self._buf[len(self) * self._byte_width + index]
- buf = self._buf.Slice(index * self._byte_width)
- return Ref.PackedType(buf, self._byte_width, packed_type)
-
- @property
- def Value(self):
- """Returns the underlying encoded data as a list object."""
- return [e.Value for e in self]
-
- def __repr__(self):
- return 'Vector(%s, byte_width=%d, size=%d)' % \
- (self._buf, self._byte_width, self._size)
-
-
-class TypedVector(Sized):
- """Data accessor for the encoded typed vector or fixed typed vector bytes."""
- __slots__ = '_element_type', '_size'
-
- def __init__(self, buf, byte_width, element_type, size=0):
- super().__init__(buf, byte_width, size)
-
- if element_type == Type.STRING:
- # These can't be accessed as strings, since we don't know the bit-width
- # of the size field, see the declaration of
- # FBT_VECTOR_STRING_DEPRECATED above for details.
- # We change the type here to be keys, which are a subtype of strings,
- # and will ignore the size field. This will truncate strings with
- # embedded nulls.
- element_type = Type.KEY
-
- self._element_type = element_type
-
- @property
- def Bytes(self):
- return self._buf[:self._byte_width * len(self)]
-
- @property
- def ElementType(self):
- return self._element_type
-
- def __getitem__(self, index):
- if index < 0 or index >= len(self):
- raise IndexError('vector index %s is out of [0, %d) range' % \
- (index, len(self)))
-
- buf = self._buf.Slice(index * self._byte_width)
- return Ref(buf, self._byte_width, 1, self._element_type)
-
- @property
- def Value(self):
- """Returns underlying data as list object."""
- if not self:
- return []
-
- if self._element_type is Type.BOOL:
- return [bool(e) for e in _UnpackVector(U, self.Bytes, len(self))]
- elif self._element_type is Type.INT:
- return list(_UnpackVector(I, self.Bytes, len(self)))
- elif self._element_type is Type.UINT:
- return list(_UnpackVector(U, self.Bytes, len(self)))
- elif self._element_type is Type.FLOAT:
- return list(_UnpackVector(F, self.Bytes, len(self)))
- elif self._element_type is Type.KEY:
- return [e.AsKey for e in self]
- elif self._element_type is Type.STRING:
- return [e.AsString for e in self]
- else:
- raise TypeError('unsupported element_type: %s' % self._element_type)
-
- def __repr__(self):
- return 'TypedVector(%s, byte_width=%d, element_type=%s, size=%d)' % \
- (self._buf, self._byte_width, self._element_type, self._size)
-
-
-class Map(Vector):
- """Data accessor for the encoded map bytes."""
-
- @staticmethod
- def CompareKeys(a, b):
- if isinstance(a, Ref):
- a = a.AsKeyBytes
- if isinstance(b, Ref):
- b = b.AsKeyBytes
- return a < b
-
- def __getitem__(self, key):
- if isinstance(key, int):
- return super().__getitem__(key)
-
- index = _BinarySearch(self.Keys, key.encode('ascii'), self.CompareKeys)
- if index != -1:
- return super().__getitem__(index)
-
- raise KeyError(key)
-
- @property
- def Keys(self):
- byte_width = _Unpack(U, self._buf[-2 * self._byte_width:-self._byte_width])
- buf = self._buf.Indirect(-3 * self._byte_width, self._byte_width)
- return TypedVector(buf, byte_width, Type.KEY)
-
- @property
- def Values(self):
- return Vector(self._buf, self._byte_width)
-
- @property
- def Value(self):
- return {k.Value: v.Value for k, v in zip(self.Keys, self.Values)}
-
- def __repr__(self):
- return 'Map(%s, size=%d)' % (self._buf, len(self))
-
-
-class Ref:
- """Data accessor for the encoded data bytes."""
- __slots__ = '_buf', '_parent_width', '_byte_width', '_type'
-
- @staticmethod
- def PackedType(buf, parent_width, packed_type):
- byte_width, type_ = Type.Unpack(packed_type)
- return Ref(buf, parent_width, byte_width, type_)
-
- def __init__(self, buf, parent_width, byte_width, type_):
- self._buf = buf
- self._parent_width = parent_width
- self._byte_width = byte_width
- self._type = type_
-
- def __repr__(self):
- return 'Ref(%s, parent_width=%d, byte_width=%d, type_=%s)' % \
- (self._buf, self._parent_width, self._byte_width, self._type)
-
- @property
- def _Bytes(self):
- return self._buf[:self._parent_width]
-
- def _ConvertError(self, target_type):
- raise TypeError('cannot convert %s to %s' % (self._type, target_type))
-
- def _Indirect(self):
- return self._buf.Indirect(0, self._parent_width)
-
- @property
- def IsNull(self):
- return self._type is Type.NULL
-
- @property
- def IsBool(self):
- return self._type is Type.BOOL
-
- @property
- def AsBool(self):
- if self._type is Type.BOOL:
- return bool(_Unpack(U, self._Bytes))
- else:
- return self.AsInt != 0
-
- def MutateBool(self, value):
- """Mutates underlying boolean value bytes in place.
-
- Args:
- value: New boolean value.
-
- Returns:
- Whether the value was mutated or not.
- """
- return self.IsBool and \
- _Mutate(U, self._buf, value, self._parent_width, BitWidth.W8)
-
- @property
- def IsNumeric(self):
- return self.IsInt or self.IsFloat
-
- @property
- def IsInt(self):
- return self._type in (Type.INT, Type.INDIRECT_INT, Type.UINT,
- Type.INDIRECT_UINT)
-
- @property
- def AsInt(self):
- """Returns current reference as integer value."""
- if self.IsNull:
- return 0
- elif self.IsBool:
- return int(self.AsBool)
- elif self._type is Type.INT:
- return _Unpack(I, self._Bytes)
- elif self._type is Type.INDIRECT_INT:
- return _Unpack(I, self._Indirect()[:self._byte_width])
- if self._type is Type.UINT:
- return _Unpack(U, self._Bytes)
- elif self._type is Type.INDIRECT_UINT:
- return _Unpack(U, self._Indirect()[:self._byte_width])
- elif self.IsString:
- return len(self.AsString)
- elif self.IsKey:
- return len(self.AsKey)
- elif self.IsBlob:
- return len(self.AsBlob)
- elif self.IsVector:
- return len(self.AsVector)
- elif self.IsTypedVector:
- return len(self.AsTypedVector)
- elif self.IsFixedTypedVector:
- return len(self.AsFixedTypedVector)
- else:
- raise self._ConvertError(Type.INT)
-
- def MutateInt(self, value):
- """Mutates underlying integer value bytes in place.
-
- Args:
- value: New integer value. It must fit to the byte size of the existing
- encoded value.
-
- Returns:
- Whether the value was mutated or not.
- """
- if self._type is Type.INT:
- return _Mutate(I, self._buf, value, self._parent_width, BitWidth.I(value))
- elif self._type is Type.INDIRECT_INT:
- return _Mutate(I, self._Indirect(), value, self._byte_width,
- BitWidth.I(value))
- elif self._type is Type.UINT:
- return _Mutate(U, self._buf, value, self._parent_width, BitWidth.U(value))
- elif self._type is Type.INDIRECT_UINT:
- return _Mutate(U, self._Indirect(), value, self._byte_width,
- BitWidth.U(value))
- else:
- return False
-
- @property
- def IsFloat(self):
- return self._type in (Type.FLOAT, Type.INDIRECT_FLOAT)
-
- @property
- def AsFloat(self):
- """Returns current reference as floating point value."""
- if self.IsNull:
- return 0.0
- elif self.IsBool:
- return float(self.AsBool)
- elif self.IsInt:
- return float(self.AsInt)
- elif self._type is Type.FLOAT:
- return _Unpack(F, self._Bytes)
- elif self._type is Type.INDIRECT_FLOAT:
- return _Unpack(F, self._Indirect()[:self._byte_width])
- elif self.IsString:
- return float(self.AsString)
- elif self.IsVector:
- return float(len(self.AsVector))
- elif self.IsTypedVector():
- return float(len(self.AsTypedVector))
- elif self.IsFixedTypedVector():
- return float(len(self.FixedTypedVector))
- else:
- raise self._ConvertError(Type.FLOAT)
-
- def MutateFloat(self, value):
- """Mutates underlying floating point value bytes in place.
-
- Args:
- value: New float value. It must fit to the byte size of the existing
- encoded value.
-
- Returns:
- Whether the value was mutated or not.
- """
- if self._type is Type.FLOAT:
- return _Mutate(F, self._buf, value, self._parent_width,
- BitWidth.B(self._parent_width))
- elif self._type is Type.INDIRECT_FLOAT:
- return _Mutate(F, self._Indirect(), value, self._byte_width,
- BitWidth.B(self._byte_width))
- else:
- return False
-
- @property
- def IsKey(self):
- return self._type is Type.KEY
-
- @property
- def AsKeyBytes(self):
- if self.IsKey:
- return Key(self._Indirect(), self._byte_width).Bytes
- else:
- raise self._ConvertError(Type.KEY)
-
- @property
- def AsKey(self):
- if self.IsKey:
- return str(Key(self._Indirect(), self._byte_width))
- else:
- raise self._ConvertError(Type.KEY)
-
- @property
- def IsString(self):
- return self._type is Type.STRING
-
- @property
- def AsStringBytes(self):
- if self.IsString:
- return String(self._Indirect(), self._byte_width).Bytes
- elif self.IsKey:
- return self.AsKeyBytes
- else:
- raise self._ConvertError(Type.STRING)
-
- @property
- def AsString(self):
- if self.IsString:
- return str(String(self._Indirect(), self._byte_width))
- elif self.IsKey:
- return self.AsKey
- else:
- raise self._ConvertError(Type.STRING)
-
- def MutateString(self, value):
- return String(self._Indirect(), self._byte_width).Mutate(value)
-
- @property
- def IsBlob(self):
- return self._type is Type.BLOB
-
- @property
- def AsBlob(self):
- if self.IsBlob:
- return Blob(self._Indirect(), self._byte_width).Bytes
- else:
- raise self._ConvertError(Type.BLOB)
-
- @property
- def IsAnyVector(self):
- return self.IsVector or self.IsTypedVector or self.IsFixedTypedVector()
-
- @property
- def IsVector(self):
- return self._type in (Type.VECTOR, Type.MAP)
-
- @property
- def AsVector(self):
- if self.IsVector:
- return Vector(self._Indirect(), self._byte_width)
- else:
- raise self._ConvertError(Type.VECTOR)
-
- @property
- def IsTypedVector(self):
- return Type.IsTypedVector(self._type)
-
- @property
- def AsTypedVector(self):
- if self.IsTypedVector:
- return TypedVector(self._Indirect(), self._byte_width,
- Type.ToTypedVectorElementType(self._type))
- else:
- raise self._ConvertError('TYPED_VECTOR')
-
- @property
- def IsFixedTypedVector(self):
- return Type.IsFixedTypedVector(self._type)
-
- @property
- def AsFixedTypedVector(self):
- if self.IsFixedTypedVector:
- element_type, size = Type.ToFixedTypedVectorElementType(self._type)
- return TypedVector(self._Indirect(), self._byte_width, element_type, size)
- else:
- raise self._ConvertError('FIXED_TYPED_VECTOR')
-
- @property
- def IsMap(self):
- return self._type is Type.MAP
-
- @property
- def AsMap(self):
- if self.IsMap:
- return Map(self._Indirect(), self._byte_width)
- else:
- raise self._ConvertError(Type.MAP)
-
- @property
- def Value(self):
- """Converts current reference to value of corresponding type.
-
- This is equivalent to calling `AsInt` for integer values, `AsFloat` for
- floating point values, etc.
-
- Returns:
- Value of corresponding type.
- """
- if self.IsNull:
- return None
- elif self.IsBool:
- return self.AsBool
- elif self.IsInt:
- return self.AsInt
- elif self.IsFloat:
- return self.AsFloat
- elif self.IsString:
- return self.AsString
- elif self.IsKey:
- return self.AsKey
- elif self.IsBlob:
- return self.AsBlob
- elif self.IsMap:
- return self.AsMap.Value
- elif self.IsVector:
- return self.AsVector.Value
- elif self.IsTypedVector:
- return self.AsTypedVector.Value
- elif self.IsFixedTypedVector:
- return self.AsFixedTypedVector.Value
- else:
- raise TypeError('cannot convert %r to value' % self)
-
-
-def _IsIterable(obj):
- try:
- iter(obj)
- return True
- except TypeError:
- return False
-
-
-class Value:
- """Class to represent given value during the encoding process."""
-
- @staticmethod
- def Null():
- return Value(0, Type.NULL, BitWidth.W8)
-
- @staticmethod
- def Bool(value):
- return Value(value, Type.BOOL, BitWidth.W8)
-
- @staticmethod
- def Int(value, bit_width):
- return Value(value, Type.INT, bit_width)
-
- @staticmethod
- def UInt(value, bit_width):
- return Value(value, Type.UINT, bit_width)
-
- @staticmethod
- def Float(value, bit_width):
- return Value(value, Type.FLOAT, bit_width)
-
- @staticmethod
- def Key(offset):
- return Value(offset, Type.KEY, BitWidth.W8)
-
- def __init__(self, value, type_, min_bit_width):
- self._value = value
- self._type = type_
-
- # For scalars: of itself, for vector: of its elements, for string: length.
- self._min_bit_width = min_bit_width
-
- @property
- def Value(self):
- return self._value
-
- @property
- def Type(self):
- return self._type
-
- @property
- def MinBitWidth(self):
- return self._min_bit_width
-
- def StoredPackedType(self, parent_bit_width=BitWidth.W8):
- return Type.Pack(self._type, self.StoredWidth(parent_bit_width))
-
- # We have an absolute offset, but want to store a relative offset
- # elem_index elements beyond the current buffer end. Since whether
- # the relative offset fits in a certain byte_width depends on
- # the size of the elements before it (and their alignment), we have
- # to test for each size in turn.
- def ElemWidth(self, buf_size, elem_index=0):
- if Type.IsInline(self._type):
- return self._min_bit_width
- for byte_width in 1, 2, 4, 8:
- offset_loc = buf_size + _PaddingBytes(buf_size, byte_width) + \
- elem_index * byte_width
- bit_width = BitWidth.U(offset_loc - self._value)
- if byte_width == (1 << bit_width):
- return bit_width
- raise ValueError('relative offset is too big')
-
- def StoredWidth(self, parent_bit_width=BitWidth.W8):
- if Type.IsInline(self._type):
- return max(self._min_bit_width, parent_bit_width)
- return self._min_bit_width
-
- def __repr__(self):
- return 'Value(%s, %s, %s)' % (self._value, self._type, self._min_bit_width)
-
- def __str__(self):
- return str(self._value)
-
-
-def InMap(func):
- def wrapper(self, *args, **kwargs):
- if isinstance(args[0], str):
- self.Key(args[0])
- func(self, *args[1:], **kwargs)
- else:
- func(self, *args, **kwargs)
- return wrapper
-
-
-def InMapForString(func):
- def wrapper(self, *args):
- if len(args) == 1:
- func(self, args[0])
- elif len(args) == 2:
- self.Key(args[0])
- func(self, args[1])
- else:
- raise ValueError('invalid number of arguments')
- return wrapper
-
-
-class Pool:
- """Collection of (data, offset) pairs sorted by data for quick access."""
-
- def __init__(self):
- self._pool = [] # sorted list of (data, offset) tuples
-
- def FindOrInsert(self, data, offset):
- do = data, offset
- index = _BinarySearch(self._pool, do, lambda a, b: a[0] < b[0])
- if index != -1:
- _, offset = self._pool[index]
- return offset
- self._pool.insert(index, do)
- return None
-
- def Clear(self):
- self._pool = []
-
- @property
- def Elements(self):
- return [data for data, _ in self._pool]
-
-
-class Builder:
- """Helper class to encode structural data into flexbuffers format."""
-
- def __init__(self,
- share_strings=False,
- share_keys=True,
- force_min_bit_width=BitWidth.W8):
- self._share_strings = share_strings
- self._share_keys = share_keys
- self._force_min_bit_width = force_min_bit_width
-
- self._string_pool = Pool()
- self._key_pool = Pool()
-
- self._finished = False
- self._buf = bytearray()
- self._stack = []
-
- def __len__(self):
- return len(self._buf)
-
- @property
- def StringPool(self):
- return self._string_pool
-
- @property
- def KeyPool(self):
- return self._key_pool
-
- def Clear(self):
- self._string_pool.Clear()
- self._key_pool.Clear()
- self._finished = False
- self._buf = bytearray()
- self._stack = []
-
- def Finish(self):
- """Finishes encoding process and returns underlying buffer."""
- if self._finished:
- raise RuntimeError('builder has been already finished')
-
- # If you hit this exception, you likely have objects that were never
- # included in a parent. You need to have exactly one root to finish a
- # buffer. Check your Start/End calls are matched, and all objects are inside
- # some other object.
- if len(self._stack) != 1:
- raise RuntimeError('internal stack size must be one')
-
- value = self._stack[0]
- byte_width = self._Align(value.ElemWidth(len(self._buf)))
- self._WriteAny(value, byte_width=byte_width) # Root value
- self._Write(U, value.StoredPackedType(), byte_width=1) # Root type
- self._Write(U, byte_width, byte_width=1) # Root size
-
- self.finished = True
- return self._buf
-
- def _ReadKey(self, offset):
- key = self._buf[offset:]
- return key[:key.find(0)]
-
- def _Align(self, alignment):
- byte_width = 1 << alignment
- self._buf.extend(b'\x00' * _PaddingBytes(len(self._buf), byte_width))
- return byte_width
-
- def _Write(self, fmt, value, byte_width):
- self._buf.extend(_Pack(fmt, value, byte_width))
-
- def _WriteVector(self, fmt, values, byte_width):
- self._buf.extend(_PackVector(fmt, values, byte_width))
-
- def _WriteOffset(self, offset, byte_width):
- relative_offset = len(self._buf) - offset
- assert byte_width == 8 or relative_offset < (1 << (8 * byte_width))
- self._Write(U, relative_offset, byte_width)
-
- def _WriteAny(self, value, byte_width):
- fmt = {
- Type.NULL: U, Type.BOOL: U, Type.INT: I, Type.UINT: U, Type.FLOAT: F
- }.get(value.Type)
- if fmt:
- self._Write(fmt, value.Value, byte_width)
- else:
- self._WriteOffset(value.Value, byte_width)
-
- def _WriteBlob(self, data, append_zero, type_):
- bit_width = BitWidth.U(len(data))
- byte_width = self._Align(bit_width)
- self._Write(U, len(data), byte_width)
- loc = len(self._buf)
- self._buf.extend(data)
- if append_zero:
- self._buf.append(0)
- self._stack.append(Value(loc, type_, bit_width))
- return loc
-
- def _WriteScalarVector(self, element_type, byte_width, elements, fixed):
- """Writes scalar vector elements to the underlying buffer."""
- bit_width = BitWidth.B(byte_width)
- # If you get this exception, you're trying to write a vector with a size
- # field that is bigger than the scalars you're trying to write (e.g. a
- # byte vector > 255 elements). For such types, write a "blob" instead.
- if BitWidth.U(len(elements)) > bit_width:
- raise ValueError('too many elements for the given byte_width')
-
- self._Align(bit_width)
- if not fixed:
- self._Write(U, len(elements), byte_width)
-
- loc = len(self._buf)
-
- fmt = {Type.INT: I, Type.UINT: U, Type.FLOAT: F}.get(element_type)
- if not fmt:
- raise TypeError('unsupported element_type')
- self._WriteVector(fmt, elements, byte_width)
-
- type_ = Type.ToTypedVector(element_type, len(elements) if fixed else 0)
- self._stack.append(Value(loc, type_, bit_width))
- return loc
-
- def _CreateVector(self, elements, typed, fixed, keys=None):
- """Writes vector elements to the underlying buffer."""
- length = len(elements)
-
- if fixed and not typed:
- raise ValueError('fixed vector must be typed')
-
- # Figure out smallest bit width we can store this vector with.
- bit_width = max(self._force_min_bit_width, BitWidth.U(length))
- prefix_elems = 1 # Vector size
- if keys:
- bit_width = max(bit_width, keys.ElemWidth(len(self._buf)))
- prefix_elems += 2 # Offset to the keys vector and its byte width.
-
- vector_type = Type.KEY
- # Check bit widths and types for all elements.
- for i, e in enumerate(elements):
- bit_width = max(bit_width, e.ElemWidth(len(self._buf), prefix_elems + i))
-
- if typed:
- if i == 0:
- vector_type = e.Type
- else:
- if vector_type != e.Type:
- raise RuntimeError('typed vector elements must be of the same type')
-
- if fixed and not Type.IsFixedTypedVectorElementType(vector_type):
- raise RuntimeError('must be fixed typed vector element type')
-
- byte_width = self._Align(bit_width)
- # Write vector. First the keys width/offset if available, and size.
- if keys:
- self._WriteOffset(keys.Value, byte_width)
- self._Write(U, 1 << keys.MinBitWidth, byte_width)
-
- if not fixed:
- self._Write(U, length, byte_width)
-
- # Then the actual data.
- loc = len(self._buf)
- for e in elements:
- self._WriteAny(e, byte_width)
-
- # Then the types.
- if not typed:
- for e in elements:
- self._buf.append(e.StoredPackedType(bit_width))
-
- if keys:
- type_ = Type.MAP
- else:
- if typed:
- type_ = Type.ToTypedVector(vector_type, length if fixed else 0)
- else:
- type_ = Type.VECTOR
-
- return Value(loc, type_, bit_width)
-
- def _PushIndirect(self, value, type_, bit_width):
- byte_width = self._Align(bit_width)
- loc = len(self._buf)
- fmt = {
- Type.INDIRECT_INT: I,
- Type.INDIRECT_UINT: U,
- Type.INDIRECT_FLOAT: F
- }[type_]
- self._Write(fmt, value, byte_width)
- self._stack.append(Value(loc, type_, bit_width))
-
- @InMapForString
- def String(self, value):
- """Encodes string value."""
- reset_to = len(self._buf)
- encoded = value.encode('utf-8')
- loc = self._WriteBlob(encoded, append_zero=True, type_=Type.STRING)
- if self._share_strings:
- prev_loc = self._string_pool.FindOrInsert(encoded, loc)
- if prev_loc is not None:
- del self._buf[reset_to:]
- self._stack[-1]._value = loc = prev_loc # pylint: disable=protected-access
-
- return loc
-
- @InMap
- def Blob(self, value):
- """Encodes binary blob value.
-
- Args:
- value: A byte/bytearray value to encode
-
- Returns:
- Offset of the encoded value in underlying the byte buffer.
- """
- return self._WriteBlob(value, append_zero=False, type_=Type.BLOB)
-
- def Key(self, value):
- """Encodes key value.
-
- Args:
- value: A byte/bytearray/str value to encode. Byte object must not contain
- zero bytes. String object must be convertible to ASCII.
-
- Returns:
- Offset of the encoded value in the underlying byte buffer.
- """
- if isinstance(value, (bytes, bytearray)):
- encoded = value
- else:
- encoded = value.encode('ascii')
-
- if 0 in encoded:
- raise ValueError('key contains zero byte')
-
- loc = len(self._buf)
- self._buf.extend(encoded)
- self._buf.append(0)
- if self._share_keys:
- prev_loc = self._key_pool.FindOrInsert(encoded, loc)
- if prev_loc is not None:
- del self._buf[loc:]
- loc = prev_loc
-
- self._stack.append(Value.Key(loc))
- return loc
-
- def Null(self, key=None):
- """Encodes None value."""
- if key:
- self.Key(key)
- self._stack.append(Value.Null())
-
- @InMap
- def Bool(self, value):
- """Encodes boolean value.
-
- Args:
- value: A boolean value.
- """
- self._stack.append(Value.Bool(value))
-
- @InMap
- def Int(self, value, byte_width=0):
- """Encodes signed integer value.
-
- Args:
- value: A signed integer value.
- byte_width: Number of bytes to use: 1, 2, 4, or 8.
- """
- bit_width = BitWidth.I(value) if byte_width == 0 else BitWidth.B(byte_width)
- self._stack.append(Value.Int(value, bit_width))
-
- @InMap
- def IndirectInt(self, value, byte_width=0):
- """Encodes signed integer value indirectly.
-
- Args:
- value: A signed integer value.
- byte_width: Number of bytes to use: 1, 2, 4, or 8.
- """
- bit_width = BitWidth.I(value) if byte_width == 0 else BitWidth.B(byte_width)
- self._PushIndirect(value, Type.INDIRECT_INT, bit_width)
-
- @InMap
- def UInt(self, value, byte_width=0):
- """Encodes unsigned integer value.
-
- Args:
- value: An unsigned integer value.
- byte_width: Number of bytes to use: 1, 2, 4, or 8.
- """
- bit_width = BitWidth.U(value) if byte_width == 0 else BitWidth.B(byte_width)
- self._stack.append(Value.UInt(value, bit_width))
-
- @InMap
- def IndirectUInt(self, value, byte_width=0):
- """Encodes unsigned integer value indirectly.
-
- Args:
- value: An unsigned integer value.
- byte_width: Number of bytes to use: 1, 2, 4, or 8.
- """
- bit_width = BitWidth.U(value) if byte_width == 0 else BitWidth.B(byte_width)
- self._PushIndirect(value, Type.INDIRECT_UINT, bit_width)
-
- @InMap
- def Float(self, value, byte_width=0):
- """Encodes floating point value.
-
- Args:
- value: A floating point value.
- byte_width: Number of bytes to use: 4 or 8.
- """
- bit_width = BitWidth.F(value) if byte_width == 0 else BitWidth.B(byte_width)
- self._stack.append(Value.Float(value, bit_width))
-
- @InMap
- def IndirectFloat(self, value, byte_width=0):
- """Encodes floating point value indirectly.
-
- Args:
- value: A floating point value.
- byte_width: Number of bytes to use: 4 or 8.
- """
- bit_width = BitWidth.F(value) if byte_width == 0 else BitWidth.B(byte_width)
- self._PushIndirect(value, Type.INDIRECT_FLOAT, bit_width)
-
- def _StartVector(self):
- """Starts vector construction."""
- return len(self._stack)
-
- def _EndVector(self, start, typed, fixed):
- """Finishes vector construction by encodung its elements."""
- vec = self._CreateVector(self._stack[start:], typed, fixed)
- del self._stack[start:]
- self._stack.append(vec)
- return vec.Value
-
- @contextlib.contextmanager
- def Vector(self, key=None):
- if key:
- self.Key(key)
-
- try:
- start = self._StartVector()
- yield self
- finally:
- self._EndVector(start, typed=False, fixed=False)
-
- @InMap
- def VectorFromElements(self, elements):
- """Encodes sequence of any elements as a vector.
-
- Args:
- elements: sequence of elements, they may have different types.
- """
- with self.Vector():
- for e in elements:
- self.Add(e)
-
- @contextlib.contextmanager
- def TypedVector(self, key=None):
- if key:
- self.Key(key)
-
- try:
- start = self._StartVector()
- yield self
- finally:
- self._EndVector(start, typed=True, fixed=False)
-
- @InMap
- def TypedVectorFromElements(self, elements, element_type=None):
- """Encodes sequence of elements of the same type as typed vector.
-
- Args:
- elements: Sequence of elements, they must be of the same type.
- element_type: Suggested element type. Setting it to None means determining
- correct value automatically based on the given elements.
- """
- if isinstance(elements, array.array):
- if elements.typecode == 'f':
- self._WriteScalarVector(Type.FLOAT, 4, elements, fixed=False)
- elif elements.typecode == 'd':
- self._WriteScalarVector(Type.FLOAT, 8, elements, fixed=False)
- elif elements.typecode in ('b', 'h', 'i', 'l', 'q'):
- self._WriteScalarVector(
- Type.INT, elements.itemsize, elements, fixed=False)
- elif elements.typecode in ('B', 'H', 'I', 'L', 'Q'):
- self._WriteScalarVector(
- Type.UINT, elements.itemsize, elements, fixed=False)
- else:
- raise ValueError('unsupported array typecode: %s' % elements.typecode)
- else:
- add = self.Add if element_type is None else self.Adder(element_type)
- with self.TypedVector():
- for e in elements:
- add(e)
-
- @InMap
- def FixedTypedVectorFromElements(self,
- elements,
- element_type=None,
- byte_width=0):
- """Encodes sequence of elements of the same type as fixed typed vector.
-
- Args:
- elements: Sequence of elements, they must be of the same type. Allowed
- types are `Type.INT`, `Type.UINT`, `Type.FLOAT`. Allowed number of
- elements are 2, 3, or 4.
- element_type: Suggested element type. Setting it to None means determining
- correct value automatically based on the given elements.
- byte_width: Number of bytes to use per element. For `Type.INT` and
- `Type.UINT`: 1, 2, 4, or 8. For `Type.FLOAT`: 4 or 8. Setting it to 0
- means determining correct value automatically based on the given
- elements.
- """
- if not 2 <= len(elements) <= 4:
- raise ValueError('only 2, 3, or 4 elements are supported')
-
- types = {type(e) for e in elements}
- if len(types) != 1:
- raise TypeError('all elements must be of the same type')
-
- type_, = types
-
- if element_type is None:
- element_type = {int: Type.INT, float: Type.FLOAT}.get(type_)
- if not element_type:
- raise TypeError('unsupported element_type: %s' % type_)
-
- if byte_width == 0:
- width = {
- Type.UINT: BitWidth.U,
- Type.INT: BitWidth.I,
- Type.FLOAT: BitWidth.F
- }[element_type]
- byte_width = 1 << max(width(e) for e in elements)
-
- self._WriteScalarVector(element_type, byte_width, elements, fixed=True)
-
- def _StartMap(self):
- """Starts map construction."""
- return len(self._stack)
-
- def _EndMap(self, start):
- """Finishes map construction by encodung its elements."""
- # Interleaved keys and values on the stack.
- stack = self._stack[start:]
-
- if len(stack) % 2 != 0:
- raise RuntimeError('must be even number of keys and values')
-
- for key in stack[::2]:
- if key.Type is not Type.KEY:
- raise RuntimeError('all map keys must be of %s type' % Type.KEY)
-
- pairs = zip(stack[::2], stack[1::2]) # [(key, value), ...]
- pairs = sorted(pairs, key=lambda pair: self._ReadKey(pair[0].Value))
-
- del self._stack[start:]
- for pair in pairs:
- self._stack.extend(pair)
-
- keys = self._CreateVector(self._stack[start::2], typed=True, fixed=False)
- values = self._CreateVector(
- self._stack[start + 1::2], typed=False, fixed=False, keys=keys)
-
- del self._stack[start:]
- self._stack.append(values)
- return values.Value
-
- @contextlib.contextmanager
- def Map(self, key=None):
- if key:
- self.Key(key)
-
- try:
- start = self._StartMap()
- yield self
- finally:
- self._EndMap(start)
-
- def MapFromElements(self, elements):
- start = self._StartMap()
- for k, v in elements.items():
- self.Key(k)
- self.Add(v)
- self._EndMap(start)
-
- def Adder(self, type_):
- return {
- Type.BOOL: self.Bool,
- Type.INT: self.Int,
- Type.INDIRECT_INT: self.IndirectInt,
- Type.UINT: self.UInt,
- Type.INDIRECT_UINT: self.IndirectUInt,
- Type.FLOAT: self.Float,
- Type.INDIRECT_FLOAT: self.IndirectFloat,
- Type.KEY: self.Key,
- Type.BLOB: self.Blob,
- Type.STRING: self.String,
- }[type_]
-
- @InMapForString
- def Add(self, value):
- """Encodes value of any supported type."""
- if value is None:
- self.Null()
- elif isinstance(value, bool):
- self.Bool(value)
- elif isinstance(value, int):
- self.Int(value)
- elif isinstance(value, float):
- self.Float(value)
- elif isinstance(value, str):
- self.String(value)
- elif isinstance(value, (bytes, bytearray)):
- self.Blob(value)
- elif isinstance(value, dict):
- with self.Map():
- for k, v in value.items():
- self.Key(k)
- self.Add(v)
- elif isinstance(value, array.array):
- self.TypedVectorFromElements(value)
- elif _IsIterable(value):
- self.VectorFromElements(value)
- else:
- raise TypeError('unsupported python type: %s' % type(value))
-
- @property
- def LastValue(self):
- return self._stack[-1]
-
- @InMap
- def ReuseValue(self, value):
- self._stack.append(value)
-
-
-def GetRoot(buf):
- """Returns root `Ref` object for the given buffer."""
- if len(buf) < 3:
- raise ValueError('buffer is too small')
- byte_width = buf[-1]
- return Ref.PackedType(
- Buf(buf, -(2 + byte_width)), byte_width, packed_type=buf[-2])
-
-
-def Dumps(obj):
- """Returns bytearray with the encoded python object."""
- fbb = Builder()
- fbb.Add(obj)
- return fbb.Finish()
-
-
-def Loads(buf):
- """Returns python object decoded from the buffer."""
- return GetRoot(buf).Value
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/misc/filenames.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/misc/filenames.py
deleted file mode 100644
index d279f89cc82cc280370d09ebdb16cb301f62aa57..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/misc/filenames.py
+++ /dev/null
@@ -1,246 +0,0 @@
-"""
-This module implements the algorithm for converting between a "user name" -
-something that a user can choose arbitrarily inside a font editor - and a file
-name suitable for use in a wide range of operating systems and filesystems.
-
-The `UFO 3 specification `_
-provides an example of an algorithm for such conversion, which avoids illegal
-characters, reserved file names, ambiguity between upper- and lower-case
-characters, and clashes with existing files.
-
-This code was originally copied from
-`ufoLib `_
-by Tal Leming and is copyright (c) 2005-2016, The RoboFab Developers:
-
-- Erik van Blokland
-- Tal Leming
-- Just van Rossum
-"""
-
-
-illegalCharacters = r"\" * + / : < > ? [ \ ] | \0".split(" ")
-illegalCharacters += [chr(i) for i in range(1, 32)]
-illegalCharacters += [chr(0x7F)]
-reservedFileNames = "CON PRN AUX CLOCK$ NUL A:-Z: COM1".lower().split(" ")
-reservedFileNames += "LPT1 LPT2 LPT3 COM2 COM3 COM4".lower().split(" ")
-maxFileNameLength = 255
-
-
-class NameTranslationError(Exception):
- pass
-
-
-def userNameToFileName(userName, existing=[], prefix="", suffix=""):
- """Converts from a user name to a file name.
-
- Takes care to avoid illegal characters, reserved file names, ambiguity between
- upper- and lower-case characters, and clashes with existing files.
-
- Args:
- userName (str): The input file name.
- existing: A case-insensitive list of all existing file names.
- prefix: Prefix to be prepended to the file name.
- suffix: Suffix to be appended to the file name.
-
- Returns:
- A suitable filename.
-
- Raises:
- NameTranslationError: If no suitable name could be generated.
-
- Examples::
-
- >>> userNameToFileName("a") == "a"
- True
- >>> userNameToFileName("A") == "A_"
- True
- >>> userNameToFileName("AE") == "A_E_"
- True
- >>> userNameToFileName("Ae") == "A_e"
- True
- >>> userNameToFileName("ae") == "ae"
- True
- >>> userNameToFileName("aE") == "aE_"
- True
- >>> userNameToFileName("a.alt") == "a.alt"
- True
- >>> userNameToFileName("A.alt") == "A_.alt"
- True
- >>> userNameToFileName("A.Alt") == "A_.A_lt"
- True
- >>> userNameToFileName("A.aLt") == "A_.aL_t"
- True
- >>> userNameToFileName(u"A.alT") == "A_.alT_"
- True
- >>> userNameToFileName("T_H") == "T__H_"
- True
- >>> userNameToFileName("T_h") == "T__h"
- True
- >>> userNameToFileName("t_h") == "t_h"
- True
- >>> userNameToFileName("F_F_I") == "F__F__I_"
- True
- >>> userNameToFileName("f_f_i") == "f_f_i"
- True
- >>> userNameToFileName("Aacute_V.swash") == "A_acute_V_.swash"
- True
- >>> userNameToFileName(".notdef") == "_notdef"
- True
- >>> userNameToFileName("con") == "_con"
- True
- >>> userNameToFileName("CON") == "C_O_N_"
- True
- >>> userNameToFileName("con.alt") == "_con.alt"
- True
- >>> userNameToFileName("alt.con") == "alt._con"
- True
- """
- # the incoming name must be a str
- if not isinstance(userName, str):
- raise ValueError("The value for userName must be a string.")
- # establish the prefix and suffix lengths
- prefixLength = len(prefix)
- suffixLength = len(suffix)
- # replace an initial period with an _
- # if no prefix is to be added
- if not prefix and userName[0] == ".":
- userName = "_" + userName[1:]
- # filter the user name
- filteredUserName = []
- for character in userName:
- # replace illegal characters with _
- if character in illegalCharacters:
- character = "_"
- # add _ to all non-lower characters
- elif character != character.lower():
- character += "_"
- filteredUserName.append(character)
- userName = "".join(filteredUserName)
- # clip to 255
- sliceLength = maxFileNameLength - prefixLength - suffixLength
- userName = userName[:sliceLength]
- # test for illegal files names
- parts = []
- for part in userName.split("."):
- if part.lower() in reservedFileNames:
- part = "_" + part
- parts.append(part)
- userName = ".".join(parts)
- # test for clash
- fullName = prefix + userName + suffix
- if fullName.lower() in existing:
- fullName = handleClash1(userName, existing, prefix, suffix)
- # finished
- return fullName
-
-
-def handleClash1(userName, existing=[], prefix="", suffix=""):
- """
- existing should be a case-insensitive list
- of all existing file names.
-
- >>> prefix = ("0" * 5) + "."
- >>> suffix = "." + ("0" * 10)
- >>> existing = ["a" * 5]
-
- >>> e = list(existing)
- >>> handleClash1(userName="A" * 5, existing=e,
- ... prefix=prefix, suffix=suffix) == (
- ... '00000.AAAAA000000000000001.0000000000')
- True
-
- >>> e = list(existing)
- >>> e.append(prefix + "aaaaa" + "1".zfill(15) + suffix)
- >>> handleClash1(userName="A" * 5, existing=e,
- ... prefix=prefix, suffix=suffix) == (
- ... '00000.AAAAA000000000000002.0000000000')
- True
-
- >>> e = list(existing)
- >>> e.append(prefix + "AAAAA" + "2".zfill(15) + suffix)
- >>> handleClash1(userName="A" * 5, existing=e,
- ... prefix=prefix, suffix=suffix) == (
- ... '00000.AAAAA000000000000001.0000000000')
- True
- """
- # if the prefix length + user name length + suffix length + 15 is at
- # or past the maximum length, silce 15 characters off of the user name
- prefixLength = len(prefix)
- suffixLength = len(suffix)
- if prefixLength + len(userName) + suffixLength + 15 > maxFileNameLength:
- l = prefixLength + len(userName) + suffixLength + 15
- sliceLength = maxFileNameLength - l
- userName = userName[:sliceLength]
- finalName = None
- # try to add numbers to create a unique name
- counter = 1
- while finalName is None:
- name = userName + str(counter).zfill(15)
- fullName = prefix + name + suffix
- if fullName.lower() not in existing:
- finalName = fullName
- break
- else:
- counter += 1
- if counter >= 999999999999999:
- break
- # if there is a clash, go to the next fallback
- if finalName is None:
- finalName = handleClash2(existing, prefix, suffix)
- # finished
- return finalName
-
-
-def handleClash2(existing=[], prefix="", suffix=""):
- """
- existing should be a case-insensitive list
- of all existing file names.
-
- >>> prefix = ("0" * 5) + "."
- >>> suffix = "." + ("0" * 10)
- >>> existing = [prefix + str(i) + suffix for i in range(100)]
-
- >>> e = list(existing)
- >>> handleClash2(existing=e, prefix=prefix, suffix=suffix) == (
- ... '00000.100.0000000000')
- True
-
- >>> e = list(existing)
- >>> e.remove(prefix + "1" + suffix)
- >>> handleClash2(existing=e, prefix=prefix, suffix=suffix) == (
- ... '00000.1.0000000000')
- True
-
- >>> e = list(existing)
- >>> e.remove(prefix + "2" + suffix)
- >>> handleClash2(existing=e, prefix=prefix, suffix=suffix) == (
- ... '00000.2.0000000000')
- True
- """
- # calculate the longest possible string
- maxLength = maxFileNameLength - len(prefix) - len(suffix)
- maxValue = int("9" * maxLength)
- # try to find a number
- finalName = None
- counter = 1
- while finalName is None:
- fullName = prefix + str(counter) + suffix
- if fullName.lower() not in existing:
- finalName = fullName
- break
- else:
- counter += 1
- if counter >= maxValue:
- break
- # raise an error if nothing has been found
- if finalName is None:
- raise NameTranslationError("No unique name could be found.")
- # finished
- return finalName
-
-
-if __name__ == "__main__":
- import doctest
- import sys
-
- sys.exit(doctest.testmod().failed)
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/google/protobuf/duration_pb2.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/google/protobuf/duration_pb2.py
deleted file mode 100644
index 34712622ddefebe55b4d20409b0deb7ef3a0832c..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/google/protobuf/duration_pb2.py
+++ /dev/null
@@ -1,27 +0,0 @@
-# -*- coding: utf-8 -*-
-# Generated by the protocol buffer compiler. DO NOT EDIT!
-# source: google/protobuf/duration.proto
-"""Generated protocol buffer code."""
-from google.protobuf import descriptor as _descriptor
-from google.protobuf import descriptor_pool as _descriptor_pool
-from google.protobuf import symbol_database as _symbol_database
-from google.protobuf.internal import builder as _builder
-# @@protoc_insertion_point(imports)
-
-_sym_db = _symbol_database.Default()
-
-
-
-
-DESCRIPTOR = _descriptor_pool.Default().AddSerializedFile(b'\n\x1egoogle/protobuf/duration.proto\x12\x0fgoogle.protobuf\":\n\x08\x44uration\x12\x18\n\x07seconds\x18\x01 \x01(\x03R\x07seconds\x12\x14\n\x05nanos\x18\x02 \x01(\x05R\x05nanosB\x83\x01\n\x13\x63om.google.protobufB\rDurationProtoP\x01Z1google.golang.org/protobuf/types/known/durationpb\xf8\x01\x01\xa2\x02\x03GPB\xaa\x02\x1eGoogle.Protobuf.WellKnownTypesb\x06proto3')
-
-_globals = globals()
-_builder.BuildMessageAndEnumDescriptors(DESCRIPTOR, _globals)
-_builder.BuildTopDescriptorsAndMessages(DESCRIPTOR, 'google.protobuf.duration_pb2', _globals)
-if _descriptor._USE_C_DESCRIPTORS == False:
-
- DESCRIPTOR._options = None
- DESCRIPTOR._serialized_options = b'\n\023com.google.protobufB\rDurationProtoP\001Z1google.golang.org/protobuf/types/known/durationpb\370\001\001\242\002\003GPB\252\002\036Google.Protobuf.WellKnownTypes'
- _globals['_DURATION']._serialized_start=51
- _globals['_DURATION']._serialized_end=109
-# @@protoc_insertion_point(module_scope)
diff --git a/spaces/cihyFjudo/fairness-paper-search/Champion Tamil Movie Hd Tamil 1080p The Inspiring Journey of a Football Legend.md b/spaces/cihyFjudo/fairness-paper-search/Champion Tamil Movie Hd Tamil 1080p The Inspiring Journey of a Football Legend.md
deleted file mode 100644
index 5233de58b57fe505d482a37355b047cad3cef02e..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Champion Tamil Movie Hd Tamil 1080p The Inspiring Journey of a Football Legend.md
+++ /dev/null
@@ -1,6 +0,0 @@
-
-Champion Search Terms:
Champion movie download
Champion Tamil Full movie
Champion Movie download isaimini
isaimini 2022 tamil movies
Champion isaimini songs lyrics download
isaimini dubbed movies
tamilrockers isaimini
isaimini 2022 movie
tamilyogi isaimini
moviesda Champion
tamil movie isaimini
isaimini tamilrockers 2022
isaimini tamil movies 2022
tamil isaimini
isaimini Champion
isaimini 2022 tamil movies Champion
isaimini bgm Champion
isaimini com 2022 movie
isaimini com dubbed movies 2022
isaimini com 2022 tamil dubbed movies
isaimini com songs lyrics download
isaimini dubbed collections
dubbed movies tamil isaimini 2021
lyrics download movies in isaimini
lyrics download tamil mp3 songs isaimini
lyrics download tamil movies 2022 isaimini
lyrics download isaimini mp3 songs
isaimini english movies 2022
isaimini english
isaimini english 2022
isaimini english songs lyrics download
isaimini free lyrics download 2022
isaimini free lyrics download songs
isaimini for lyrics download
free lyrics download isaimini mp3 songs
isaimini google
Champion movie lyrics download
Champion tamil movies
Champion tamil songs
Champion tamil song
Champion mp3 , Champion songs
itunes and isaimini audio songs
-download Dholak unlimited Movies and videos Download Here.Dholak Hd,3gp. mp4 320p and More Videos You Can Download Easyly. tamilrockers and movierulz, tamilgun, filmywap, and pagalworld videos and Movies download.
-Champion Tamil Movie Hd Tamil 1080p
DOWNLOAD »»» https://tinurli.com/2uwjsv
aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/cihyFjudo/fairness-paper-search/Chhota Bheem and the throne of Bali full movie download mp4 720p Dont miss this amazing opportunity to see Chhota Bheem in action.md b/spaces/cihyFjudo/fairness-paper-search/Chhota Bheem and the throne of Bali full movie download mp4 720p Dont miss this amazing opportunity to see Chhota Bheem in action.md
deleted file mode 100644
index 3721e1adaa98c6006f5c479e4b52d6dbf935b1d0..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Chhota Bheem and the throne of Bali full movie download mp4 720p Dont miss this amazing opportunity to see Chhota Bheem in action.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Chhota Bheem and the throne of Bali full movie download mp4 720p
DOWNLOAD » https://tinurli.com/2uwjjY
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/cihyFjudo/fairness-paper-search/Polyfield WW2 Free Download [crack] Tips and Tricks to Master the Game.md b/spaces/cihyFjudo/fairness-paper-search/Polyfield WW2 Free Download [crack] Tips and Tricks to Master the Game.md
deleted file mode 100644
index 1685ce76dee2d7147b5ede2ec5871b5ddae1152f..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Polyfield WW2 Free Download [crack] Tips and Tricks to Master the Game.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Polyfield WW2 Free Download [crack]
Download File >>>>> https://tinurli.com/2uwjHR
-
- aaccfb2cb3
-
-
-
diff --git "a/spaces/cihyFjudo/fairness-paper-search/Super Foods For Gorgeous\302\240 Skin REPACK.md" "b/spaces/cihyFjudo/fairness-paper-search/Super Foods For Gorgeous\302\240 Skin REPACK.md"
deleted file mode 100644
index f8ed166825653188318fe7672f17e9df36fac561..0000000000000000000000000000000000000000
--- "a/spaces/cihyFjudo/fairness-paper-search/Super Foods For Gorgeous\302\240 Skin REPACK.md"
+++ /dev/null
@@ -1,32 +0,0 @@
-
-When it comes to your skin, there's one thing we know for sure: What you eat can have a direct impact on how you look. If you're not specifically chowing down on superfoods for glowing skin and instead are constantly noshing on processed foods or those high in sugar and fat and devoid of fiber, it can show up in the form of dull skin, perhaps along with other issues like acne, dryness, oiliness, or dark under-eye circles. (We've been preaching to you for years about this.)
-Super foods for gorgeous skin
Download ⚹ https://tinurli.com/2uwiEU
-Now, let's get started on that grocery list. Below, we've highlighted the superfoods for glowing skin that belong in your kitchen, stat. Not only will they fuel a healthy body and mind, but they'll also help solve your biggest skin concerns and lead you to your most glowing look yet.
-Oatmeal: Swap sugary cereal (sorry, Lucky Charms) for a bowl of plain oats in the a.m. and your skin will thank you. This food is low on the glycemic index, a scale that rates foods containing carbohydrates according to how much each food increases blood sugar (high-glycemic foods cause a fast, drastic spike and subsequent crash, whereas low-glycemic options provide a slow, steady increase and decline). "Foods with a low glycemic index [are better] because starchy foods [that are high-glycemic] increase blood sugar, promote inflammation, and have been shown to be associated with acne breakouts," says Zeichner.
-Quinoa: This protein-packed grain is well-known in the kitchen, but its high levels of riboflavin make it a superstar for your skin. Riboflavin lends a hand to your skin's elasticity and the production of connective tissue, which helps even things out and makes fine lines and wrinkles look less prominent.
-Citrus fruits: "Dark spots are caused by extra pigment production due to UV light exposure," says Zeichner. "Topical antioxidants like vitamin C have been shown to help calm inflammation, brighten dark spots, and even your skin complexion." Eating citrus may also help, he notes, so foods like oranges, tangerines, and grapefruits should be your top snacks.
-
-3. Blueberries: What makes these gorgeous blue berries a superfood is the presence of phytonutrients that aid in neutralizing free radicals. Free radicals are the agents that are responsible for skin ageing and cell damage. So, by eating fresh blueberries, you can combat skin impairment and keep your skin looking young and vibrant. Pop some in your yogurts and smoothies next time, especially since you know your skin will thank you immensely.
-Despite all of the powerful active ingredients in skincare, topicals can only do so much for your skin. Turns out, what you eat can have a major impact on your complexion. Your diet can cause acne, dullness, dryness, oiliness, or even dark under-eye circles. To help, we rounded up the best foods for your skin. Incorporating these superfoods into your diet can help support healthy, clear, and glowing skin. While not all of these individual foods have been studied specifically for skin, the nutrients and properties they have have been studied extensively. Read on to see the 12 best foods for skin.
-So what foods are good for your skin? Choosing the best food for healthy skin is simple with this guide, which contains 12 superfoods that can seriously improve your complexion. Add these into your diet for brighter, clearer, and firmer skin.
-When inflammation occurs in the body, this can negatively impact the skin by making it look puffy and tired. Over time, this can lead to premature aging. However, the good news is that there are anti-inflammatory foods that can help to combat this, one of them being turmeric.
-While the foremost step towards achieving the desired result is to understand that different people have different skin types; fortunately there are few basic guidelines to follow, when it comes to picking the right food for any skin type. Read on as we break down the top foods for achieving clear, soft, supple, glowing skin and give you the ins and outs of exactly why we picked them.
-These are few superfoods that can contribute in achieving that healthy glowing skin that one always wishes for. However, one must make allowance for the fact that simply eating these things might not yield best results. Proper diet, lifestyle habits, heavy drinking and smoking issues also impact skin a great deal.
-There are foods that helps skin glow, along with the right essential nutrients, and minerals that can give you that glowing skin look we all crave. Better food selection also wards off blemishes and lessen your chances for premature aging.
-Blueberries make the top of our list for glowing skin foods since it is the most nutrient-dense of all superfoods. We bet you may not know this fact, but they are naturally purple due to a plant element indicative of a high antioxidant capacity.
-Salmon is made up of three omega fatty acids, that which are fundamental nutriments for maintaining your skin health. Also, these acids provide super hydration for even the driest skin, weird, right?
-Kale is a power packed superfood with vitamin C. Yes, a bit hard to comprehend since when you think of vitamin C you envision the colors of orange or yellow, or citrus fruits. Kale combines the magic of antioxidants and vitamin C to enhance your vision and be a super duo to shiny hair and healthy glowing skin. Kale does contain very little fat, but a large portion of the fat in it is an omega-3 fatty acid called alpha linolenic-acid.
-Want shinier hair and improve brain power at the same time? Then start eating walnuts as a snack during the day. Walnuts are one of the best nuts for skin and hair. They are super rich in omega 3 and 6 fatty acids, proteins, and healthy fats which serves as a great brain food.
-AHA skincare is proven to curtail acne, dark/age spots, dehydrated skin, and uneven skin tone and textures, so combined with eating healthy foods you will has super luminous skin in no time.
-An apple a day keeps the doctor away, well, not literally but the food we eat matters a lot to our skin health and the proper functioning of our body. One way to make sure we get our daily vitamins and nutrients is through regularly consuming superfoods.
-This yummy smoothie features blueberries, one superfood that needs little introduction. Studies have shown that blueberries have one of the highest antioxidant levels of all fruits and this helps to protect your skin from environmental stressors such as the damaging effects of the sun. In addition, blueberries are vascular constrictors, meaning they help decrease redness for those with sensitive skin.
-While matcha lattes are all the rage these days, you should try out this super easy smoothie that only needs 3 ingredients - 4 if you count the ice cubes. Matcha is a type of green tea that is one of the most potent sources of antioxidants derived from foods. It has the potential to quench inflammations, combat stress and prevent premature ageing. It can even help to clear up and manage hormonal acne all while protecting your body and skin against pollution and sun damage.
-Jump on the açai bandwagon with this anti-ageing açai berry smoothie that will keep those wrinkles and fine lines at bay. A relatively newly discovered superfood, açai berries hail from the Amazon - the jungle not the online shopping platform - and are incredibly rich in vitamin A, the stuff retinols are made from. They also contain high levels of polyphenols and vitamins C and E that help combat visible signs of ageing like fine lines, wrinkles and the loss of skin elasticity.
-Spirulina, a spiral shaped green microalgae, is one of the most nourishing superfoods packed with a host of vitamins, minerals, antioxidants and even protein! It contains all essential amino acids including Gamma linolenic acid aka GLA, an extremely powerful anti-inflammatory compound. We love adding spirulina to smoothies to help alkalize and detoxify the body, but we also love adding it to our DIY face masks to help detoxify and remove impurities from our skin! Spirulina can help:
-Rice Bran, also known as Tocos, is packed with antioxidants, an array of B vitamins as well as E vitamins - all of which are essential for skin health. Vitamin E supplements are often used to help achieve glowing skin and thick, silky hair - which is why this vitamin E packed superfood makes the list. You can read all about our rice bran powder in our superfood spotlight here!
-WRITTEN BY OUR OFFICIAL SCIENCE STEEPER: ALLISON TANNIS, MSC RHN.
Hello, there - beautiful, healthy-looking skin! Certain superfoods help nourish the skin, improving its health and appearance. Skin experts agree, that with the right nutrients, smoothies can support healthy skin maintenance and repair. Are you ready to glow?
-1. Superfood Tea Leaves
Vitamin C and E found in plant-based foods are known to support the skin by protecting it from damage and inflammation, and promoting structural support. But, the most exciting skin-supporting smoothie ingredients are green leaves! Green leaves are packed with nutrients for glowing skin, such as carotenoids, vitamin C, vitamin E, B vitamins, and iron. Plus, if you add into your smoothie the superfood, frozen tea leaves, your skin could also benefit from the impressive nutrient, EGCG.
-No list would be complete without this legendary superfood. The knobby root has been used for centuries in Eastern Asia for its seemingly miraculous antioxidant and anti-inflammatory properties. Mounting evidence shows that ginseng may be good for your skin, too. A study from Danbook University, Korea reported the anti-wrinkle effects of black fermented ginseng, and a review from the same year suggested ginseng may slow skin aging though its anti-photodamaging, anti-inflammation, and antioxidation effects.
-These ancient super seeds (yes, their history dates back to the 8th century C.E.) are more nutritious than many modern crops. Flaxseeds are one of the richest plant sources of alpha-linolenic acid, a plant-based version of omega-3s. Also, they have 800 times more lignans than beans and other fiber-rich veggies. Lignan-rich foods may protect against cancer and cardiovascular disease. Flax is fabulous longevity food, helpful in reducing skin sensitivity and improving skin barrier function.
aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/cihyFjudo/fairness-paper-search/search.py b/spaces/cihyFjudo/fairness-paper-search/search.py
deleted file mode 100644
index 3dd2925670aff6db28568996c281a1c8b879c6b2..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/search.py
+++ /dev/null
@@ -1,45 +0,0 @@
-import os
-
-import numpy as np
-import pandas as pd # can't use polars
-from omegaconf import OmegaConf
-from sentence_transformers import SentenceTransformer
-
-
-class Search:
- def __init__(self, config):
- self.config = OmegaConf.load(config)
- self.title_embed = np.load(
- os.path.join(self.config.path_data, "title_embed.npy")
- )
- self.abst_embed = np.load(
- os.path.join(self.config.path_data, "abstract_embed.npy")
- )
- self.df = pd.read_csv(os.path.join(self.config.path_data, "paper.csv"))[
- ["title", "abstract", "link"]
- ]
- self.model = SentenceTransformer(self.config.bert_model)
-
- def search_title(self, title, top):
- pred = self.model.encode([title]).squeeze()
- prob = np.dot(self.title_embed, pred)
- rank = np.argsort(prob)[::-1]
- return self.df.iloc[rank[0 : int(top)]][["title", "link"]]
-
- def search_abst(self, abst, top):
- pred = self.model.encode([abst]).squeeze()
- prob = np.dot(self.abst_embed, pred)
- rank = np.argsort(prob)[::-1]
- return self.df.iloc[rank[0 : int(top)]][["title", "link"]]
-
- def search_keyword(self, key1, key2, key3, target, top):
- keyword_counts = []
- for i in range(len(self.df)):
- line = self.df.iloc[i][target.lower()].lower()
- count = 0
- for keyword in [key1, key2, key3]:
- if keyword.lower() in line:
- count += 1
- keyword_counts.append(count)
- rank = np.argsort(np.array(keyword_counts))[::-1]
- return self.df.iloc[rank[0 : int(top)]][["title", "link"]]
diff --git a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/fontTools/afmLib.py b/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/fontTools/afmLib.py
deleted file mode 100644
index 394b901ff5eb149b40c0d9ae425c02d5ad0b5111..0000000000000000000000000000000000000000
--- a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/fontTools/afmLib.py
+++ /dev/null
@@ -1,438 +0,0 @@
-"""Module for reading and writing AFM (Adobe Font Metrics) files.
-
-Note that this has been designed to read in AFM files generated by Fontographer
-and has not been tested on many other files. In particular, it does not
-implement the whole Adobe AFM specification [#f1]_ but, it should read most
-"common" AFM files.
-
-Here is an example of using `afmLib` to read, modify and write an AFM file:
-
- >>> from fontTools.afmLib import AFM
- >>> f = AFM("Tests/afmLib/data/TestAFM.afm")
- >>>
- >>> # Accessing a pair gets you the kern value
- >>> f[("V","A")]
- -60
- >>>
- >>> # Accessing a glyph name gets you metrics
- >>> f["A"]
- (65, 668, (8, -25, 660, 666))
- >>> # (charnum, width, bounding box)
- >>>
- >>> # Accessing an attribute gets you metadata
- >>> f.FontName
- 'TestFont-Regular'
- >>> f.FamilyName
- 'TestFont'
- >>> f.Weight
- 'Regular'
- >>> f.XHeight
- 500
- >>> f.Ascender
- 750
- >>>
- >>> # Attributes and items can also be set
- >>> f[("A","V")] = -150 # Tighten kerning
- >>> f.FontName = "TestFont Squished"
- >>>
- >>> # And the font written out again (remove the # in front)
- >>> #f.write("testfont-squished.afm")
-
-.. rubric:: Footnotes
-
-.. [#f1] `Adobe Technote 5004 `_,
- Adobe Font Metrics File Format Specification.
-
-"""
-
-
-import re
-
-# every single line starts with a "word"
-identifierRE = re.compile(r"^([A-Za-z]+).*")
-
-# regular expression to parse char lines
-charRE = re.compile(
- r"(-?\d+)" # charnum
- r"\s*;\s*WX\s+" # ; WX
- r"(-?\d+)" # width
- r"\s*;\s*N\s+" # ; N
- r"([.A-Za-z0-9_]+)" # charname
- r"\s*;\s*B\s+" # ; B
- r"(-?\d+)" # left
- r"\s+"
- r"(-?\d+)" # bottom
- r"\s+"
- r"(-?\d+)" # right
- r"\s+"
- r"(-?\d+)" # top
- r"\s*;\s*" # ;
-)
-
-# regular expression to parse kerning lines
-kernRE = re.compile(
- r"([.A-Za-z0-9_]+)" # leftchar
- r"\s+"
- r"([.A-Za-z0-9_]+)" # rightchar
- r"\s+"
- r"(-?\d+)" # value
- r"\s*"
-)
-
-# regular expressions to parse composite info lines of the form:
-# Aacute 2 ; PCC A 0 0 ; PCC acute 182 211 ;
-compositeRE = re.compile(
- r"([.A-Za-z0-9_]+)" r"\s+" r"(\d+)" r"\s*;\s*" # char name # number of parts
-)
-componentRE = re.compile(
- r"PCC\s+" # PPC
- r"([.A-Za-z0-9_]+)" # base char name
- r"\s+"
- r"(-?\d+)" # x offset
- r"\s+"
- r"(-?\d+)" # y offset
- r"\s*;\s*"
-)
-
-preferredAttributeOrder = [
- "FontName",
- "FullName",
- "FamilyName",
- "Weight",
- "ItalicAngle",
- "IsFixedPitch",
- "FontBBox",
- "UnderlinePosition",
- "UnderlineThickness",
- "Version",
- "Notice",
- "EncodingScheme",
- "CapHeight",
- "XHeight",
- "Ascender",
- "Descender",
-]
-
-
-class error(Exception):
- pass
-
-
-class AFM(object):
-
- _attrs = None
-
- _keywords = [
- "StartFontMetrics",
- "EndFontMetrics",
- "StartCharMetrics",
- "EndCharMetrics",
- "StartKernData",
- "StartKernPairs",
- "EndKernPairs",
- "EndKernData",
- "StartComposites",
- "EndComposites",
- ]
-
- def __init__(self, path=None):
- """AFM file reader.
-
- Instantiating an object with a path name will cause the file to be opened,
- read, and parsed. Alternatively the path can be left unspecified, and a
- file can be parsed later with the :meth:`read` method."""
- self._attrs = {}
- self._chars = {}
- self._kerning = {}
- self._index = {}
- self._comments = []
- self._composites = {}
- if path is not None:
- self.read(path)
-
- def read(self, path):
- """Opens, reads and parses a file."""
- lines = readlines(path)
- for line in lines:
- if not line.strip():
- continue
- m = identifierRE.match(line)
- if m is None:
- raise error("syntax error in AFM file: " + repr(line))
-
- pos = m.regs[1][1]
- word = line[:pos]
- rest = line[pos:].strip()
- if word in self._keywords:
- continue
- if word == "C":
- self.parsechar(rest)
- elif word == "KPX":
- self.parsekernpair(rest)
- elif word == "CC":
- self.parsecomposite(rest)
- else:
- self.parseattr(word, rest)
-
- def parsechar(self, rest):
- m = charRE.match(rest)
- if m is None:
- raise error("syntax error in AFM file: " + repr(rest))
- things = []
- for fr, to in m.regs[1:]:
- things.append(rest[fr:to])
- charname = things[2]
- del things[2]
- charnum, width, l, b, r, t = (int(thing) for thing in things)
- self._chars[charname] = charnum, width, (l, b, r, t)
-
- def parsekernpair(self, rest):
- m = kernRE.match(rest)
- if m is None:
- raise error("syntax error in AFM file: " + repr(rest))
- things = []
- for fr, to in m.regs[1:]:
- things.append(rest[fr:to])
- leftchar, rightchar, value = things
- value = int(value)
- self._kerning[(leftchar, rightchar)] = value
-
- def parseattr(self, word, rest):
- if word == "FontBBox":
- l, b, r, t = [int(thing) for thing in rest.split()]
- self._attrs[word] = l, b, r, t
- elif word == "Comment":
- self._comments.append(rest)
- else:
- try:
- value = int(rest)
- except (ValueError, OverflowError):
- self._attrs[word] = rest
- else:
- self._attrs[word] = value
-
- def parsecomposite(self, rest):
- m = compositeRE.match(rest)
- if m is None:
- raise error("syntax error in AFM file: " + repr(rest))
- charname = m.group(1)
- ncomponents = int(m.group(2))
- rest = rest[m.regs[0][1] :]
- components = []
- while True:
- m = componentRE.match(rest)
- if m is None:
- raise error("syntax error in AFM file: " + repr(rest))
- basechar = m.group(1)
- xoffset = int(m.group(2))
- yoffset = int(m.group(3))
- components.append((basechar, xoffset, yoffset))
- rest = rest[m.regs[0][1] :]
- if not rest:
- break
- assert len(components) == ncomponents
- self._composites[charname] = components
-
- def write(self, path, sep="\r"):
- """Writes out an AFM font to the given path."""
- import time
-
- lines = [
- "StartFontMetrics 2.0",
- "Comment Generated by afmLib; at %s"
- % (time.strftime("%m/%d/%Y %H:%M:%S", time.localtime(time.time()))),
- ]
-
- # write comments, assuming (possibly wrongly!) they should
- # all appear at the top
- for comment in self._comments:
- lines.append("Comment " + comment)
-
- # write attributes, first the ones we know about, in
- # a preferred order
- attrs = self._attrs
- for attr in preferredAttributeOrder:
- if attr in attrs:
- value = attrs[attr]
- if attr == "FontBBox":
- value = "%s %s %s %s" % value
- lines.append(attr + " " + str(value))
- # then write the attributes we don't know about,
- # in alphabetical order
- items = sorted(attrs.items())
- for attr, value in items:
- if attr in preferredAttributeOrder:
- continue
- lines.append(attr + " " + str(value))
-
- # write char metrics
- lines.append("StartCharMetrics " + repr(len(self._chars)))
- items = [
- (charnum, (charname, width, box))
- for charname, (charnum, width, box) in self._chars.items()
- ]
-
- def myKey(a):
- """Custom key function to make sure unencoded chars (-1)
- end up at the end of the list after sorting."""
- if a[0] == -1:
- a = (0xFFFF,) + a[1:] # 0xffff is an arbitrary large number
- return a
-
- items.sort(key=myKey)
-
- for charnum, (charname, width, (l, b, r, t)) in items:
- lines.append(
- "C %d ; WX %d ; N %s ; B %d %d %d %d ;"
- % (charnum, width, charname, l, b, r, t)
- )
- lines.append("EndCharMetrics")
-
- # write kerning info
- lines.append("StartKernData")
- lines.append("StartKernPairs " + repr(len(self._kerning)))
- items = sorted(self._kerning.items())
- for (leftchar, rightchar), value in items:
- lines.append("KPX %s %s %d" % (leftchar, rightchar, value))
- lines.append("EndKernPairs")
- lines.append("EndKernData")
-
- if self._composites:
- composites = sorted(self._composites.items())
- lines.append("StartComposites %s" % len(self._composites))
- for charname, components in composites:
- line = "CC %s %s ;" % (charname, len(components))
- for basechar, xoffset, yoffset in components:
- line = line + " PCC %s %s %s ;" % (basechar, xoffset, yoffset)
- lines.append(line)
- lines.append("EndComposites")
-
- lines.append("EndFontMetrics")
-
- writelines(path, lines, sep)
-
- def has_kernpair(self, pair):
- """Returns `True` if the given glyph pair (specified as a tuple) exists
- in the kerning dictionary."""
- return pair in self._kerning
-
- def kernpairs(self):
- """Returns a list of all kern pairs in the kerning dictionary."""
- return list(self._kerning.keys())
-
- def has_char(self, char):
- """Returns `True` if the given glyph exists in the font."""
- return char in self._chars
-
- def chars(self):
- """Returns a list of all glyph names in the font."""
- return list(self._chars.keys())
-
- def comments(self):
- """Returns all comments from the file."""
- return self._comments
-
- def addComment(self, comment):
- """Adds a new comment to the file."""
- self._comments.append(comment)
-
- def addComposite(self, glyphName, components):
- """Specifies that the glyph `glyphName` is made up of the given components.
- The components list should be of the following form::
-
- [
- (glyphname, xOffset, yOffset),
- ...
- ]
-
- """
- self._composites[glyphName] = components
-
- def __getattr__(self, attr):
- if attr in self._attrs:
- return self._attrs[attr]
- else:
- raise AttributeError(attr)
-
- def __setattr__(self, attr, value):
- # all attrs *not* starting with "_" are consider to be AFM keywords
- if attr[:1] == "_":
- self.__dict__[attr] = value
- else:
- self._attrs[attr] = value
-
- def __delattr__(self, attr):
- # all attrs *not* starting with "_" are consider to be AFM keywords
- if attr[:1] == "_":
- try:
- del self.__dict__[attr]
- except KeyError:
- raise AttributeError(attr)
- else:
- try:
- del self._attrs[attr]
- except KeyError:
- raise AttributeError(attr)
-
- def __getitem__(self, key):
- if isinstance(key, tuple):
- # key is a tuple, return the kernpair
- return self._kerning[key]
- else:
- # return the metrics instead
- return self._chars[key]
-
- def __setitem__(self, key, value):
- if isinstance(key, tuple):
- # key is a tuple, set kernpair
- self._kerning[key] = value
- else:
- # set char metrics
- self._chars[key] = value
-
- def __delitem__(self, key):
- if isinstance(key, tuple):
- # key is a tuple, del kernpair
- del self._kerning[key]
- else:
- # del char metrics
- del self._chars[key]
-
- def __repr__(self):
- if hasattr(self, "FullName"):
- return "" % self.FullName
- else:
- return "" % id(self)
-
-
-def readlines(path):
- with open(path, "r", encoding="ascii") as f:
- data = f.read()
- return data.splitlines()
-
-
-def writelines(path, lines, sep="\r"):
- with open(path, "w", encoding="ascii", newline=sep) as f:
- f.write("\n".join(lines) + "\n")
-
-
-if __name__ == "__main__":
- import EasyDialogs
-
- path = EasyDialogs.AskFileForOpen()
- if path:
- afm = AFM(path)
- char = "A"
- if afm.has_char(char):
- print(afm[char]) # print charnum, width and boundingbox
- pair = ("A", "V")
- if afm.has_kernpair(pair):
- print(afm[pair]) # print kerning value for pair
- print(afm.Version) # various other afm entries have become attributes
- print(afm.Weight)
- # afm.comments() returns a list of all Comment lines found in the AFM
- print(afm.comments())
- # print afm.chars()
- # print afm.kernpairs()
- print(afm)
- afm.write(path + ".muck")
diff --git a/spaces/codertoro/gpt-academic/request_llm/README.md b/spaces/codertoro/gpt-academic/request_llm/README.md
deleted file mode 100644
index c66cc15c0591613eda9ee8f3b6acb6ad66224bdb..0000000000000000000000000000000000000000
--- a/spaces/codertoro/gpt-academic/request_llm/README.md
+++ /dev/null
@@ -1,36 +0,0 @@
-# 如何使用其他大语言模型(dev分支测试中)
-
-## 1. 先运行text-generation
-``` sh
-# 下载模型( text-generation 这么牛的项目,别忘了给人家star )
-git clone https://github.com/oobabooga/text-generation-webui.git
-
-# 安装text-generation的额外依赖
-pip install accelerate bitsandbytes flexgen gradio llamacpp markdown numpy peft requests rwkv safetensors sentencepiece tqdm datasets git+https://github.com/huggingface/transformers
-
-# 切换路径
-cd text-generation-webui
-
-# 下载模型
-python download-model.py facebook/galactica-1.3b
-# 其他可选如 facebook/opt-1.3b
-# facebook/galactica-6.7b
-# facebook/galactica-120b
-# facebook/pygmalion-1.3b 等
-# 详情见 https://github.com/oobabooga/text-generation-webui
-
-# 启动text-generation,注意把模型的斜杠改成下划线
-python server.py --cpu --listen --listen-port 7860 --model facebook_galactica-1.3b
-```
-
-## 2. 修改config.py
-``` sh
-# LLM_MODEL格式较复杂 TGUI:[模型]@[ws地址]:[ws端口] , 端口要和上面给定的端口一致
-LLM_MODEL = "TGUI:galactica-1.3b@localhost:7860"
-```
-
-## 3. 运行!
-``` sh
-cd chatgpt-academic
-python main.py
-```
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/hq_hqadsp.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/hq_hqadsp.c
deleted file mode 100644
index 1b9f138c726b63c7e4258943426ee59903c4c8fd..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/hq_hqadsp.c
+++ /dev/null
@@ -1,130 +0,0 @@
-/*
- * Canopus HQ/HQA decoder
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-#include
-
-#include "libavutil/attributes.h"
-#include "libavutil/common.h"
-
-#include "hq_hqadsp.h"
-
-#define FIX_1_082 17734
-#define FIX_1_847 30274
-#define FIX_1_414 23170
-#define FIX_2_613 21407 // divided by two to fit the range
-
-#define IDCTMUL(a, b) ((int)((a) * (unsigned)(b)) >> 16)
-
-static inline void idct_row(int16_t *blk)
-{
- int tmp0, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7, tmp8, tmp9, tmpA;
- int tmpB, tmpC, tmpD, tmpE, tmpF, tmp10, tmp11, tmp12, tmp13, tmp14;
-
- tmp0 = blk[5] - blk[3];
- tmp1 = blk[5] + blk[3];
- tmp2 = blk[1] - blk[7];
- tmp3 = blk[1] + blk[7];
- tmp4 = tmp3 - tmp1;
- tmp5 = IDCTMUL(tmp0 + tmp2, FIX_1_847);
- tmp6 = IDCTMUL(tmp2, FIX_1_082) - tmp5;
- tmp7 = tmp5 - IDCTMUL(tmp0, FIX_2_613) * 2;
- tmp8 = tmp3 + tmp1;
- tmp9 = tmp7 * 4 - tmp8;
- tmpA = IDCTMUL(tmp4, FIX_1_414) * 4 - tmp9;
- tmpB = tmp6 * 4 + tmpA;
- tmpC = blk[2] + blk[6];
- tmpD = blk[2] - blk[6];
- tmpE = blk[0] - blk[4];
- tmpF = blk[0] + blk[4];
-
- tmp10 = IDCTMUL(tmpD, FIX_1_414) * 4 - tmpC;
- tmp11 = tmpE - tmp10;
- tmp12 = tmpF - tmpC;
- tmp13 = tmpE + tmp10;
- tmp14 = tmpF + tmpC;
-
- blk[0] = tmp14 + tmp8;
- blk[1] = tmp13 + tmp9;
- blk[2] = tmp11 + tmpA;
- blk[3] = tmp12 - tmpB;
- blk[4] = tmp12 + tmpB;
- blk[5] = tmp11 - tmpA;
- blk[6] = tmp13 - tmp9;
- blk[7] = tmp14 - tmp8;
-}
-
-static inline void idct_col(int16_t *blk)
-{
- int tmp0, tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7, tmp8, tmp9, tmpA;
- int tmpB, tmpC, tmpD, tmpE, tmpF, tmp10, tmp11, tmp12, tmp13, tmp14;
-
- tmp0 = blk[5 * 8] - blk[3 * 8];
- tmp1 = blk[5 * 8] + blk[3 * 8];
- tmp2 = blk[1 * 8] * 2 - (blk[7 * 8] >> 2);
- tmp3 = blk[1 * 8] * 2 + (blk[7 * 8] >> 2);
- tmp4 = tmp3 - tmp1;
- tmp5 = IDCTMUL(tmp0 + tmp2, FIX_1_847);
- tmp6 = IDCTMUL(tmp2, FIX_1_082) - tmp5;
- tmp7 = tmp5 - IDCTMUL(tmp0, FIX_2_613) * 2;
- tmp8 = (tmp3 + tmp1) >> 1;
- tmp9 = tmp7 * 2 - tmp8;
- tmpA = IDCTMUL(tmp4, FIX_1_414) * 2 - tmp9;
- tmpB = tmp6 * 2 + tmpA;
- tmpC = blk[2 * 8] + (blk[6 * 8] >> 1) >> 1;
- tmpD = blk[2 * 8] - (blk[6 * 8] >> 1);
- tmpE = (blk[0 * 8] >> 1) - (blk[4 * 8] >> 1) + 0x2020;
- tmpF = (blk[0 * 8] >> 1) + (blk[4 * 8] >> 1) + 0x2020;
-
- tmp10 = IDCTMUL(tmpD, FIX_1_414) * 2 - tmpC;
- tmp11 = tmpE - tmp10;
- tmp12 = tmpF - tmpC;
- tmp13 = tmpE + tmp10;
- tmp14 = tmpF + tmpC;
-
- blk[0 * 8] = (tmp14 + tmp8) >> 6;
- blk[1 * 8] = (tmp13 + tmp9) >> 6;
- blk[2 * 8] = (tmp11 + tmpA) >> 6;
- blk[3 * 8] = (tmp12 - tmpB) >> 6;
- blk[4 * 8] = (tmp12 + tmpB) >> 6;
- blk[5 * 8] = (tmp11 - tmpA) >> 6;
- blk[6 * 8] = (tmp13 - tmp9) >> 6;
- blk[7 * 8] = (tmp14 - tmp8) >> 6;
-}
-
-static void hq_idct_put(uint8_t *dst, int stride, int16_t *block)
-{
- int i, j;
-
- for (i = 0; i < 8; i++)
- idct_row(block + i * 8);
- for (i = 0; i < 8; i++)
- idct_col(block + i);
-
- for (i = 0; i < 8; i++) {
- for (j = 0; j < 8; j++)
- dst[j] = av_clip_uint8(block[j + i * 8]);
- dst += stride;
- }
-}
-
-av_cold void ff_hqdsp_init(HQDSPContext *c)
-{
- c->idct_put = hq_idct_put;
-}
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Download Facebook Guard APK and Secure Your Profile Picture.md b/spaces/congsaPfin/Manga-OCR/logs/Download Facebook Guard APK and Secure Your Profile Picture.md
deleted file mode 100644
index 1682798daa32c0788019df951df580018db334af..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Download Facebook Guard APK and Secure Your Profile Picture.md
+++ /dev/null
@@ -1,105 +0,0 @@
-
-Facebook Guard on APK: What Is It and How to Use It?
-Introduction
-Facebook is one of the most popular social media platforms in the world, with over 2.8 billion monthly active users as of December 2020. However, with such a large user base, there are also some risks and challenges that come with using Facebook, especially when it comes to your privacy and security.
-facebook guard on apk
Download Zip ➡ https://urlca.com/2uO9IC
-One of the common issues that many Facebook users face is the misuse of their profile pictures by strangers or malicious actors. For example, some people may use your profile picture to create fake accounts, harass you, or scam others. This can damage your reputation, cause you emotional distress, or even put you in danger.
-Fortunately, there is a way to protect your profile picture from being misused by others. It is called Facebook Guard, and it is a feature that allows you to add a layer of protection to your profile picture. In this article, we will explain what Facebook Guard is, what APK is, and how you can use Facebook Guard on APK to safeguard your profile picture.
-What is Facebook Guard?
-Facebook Guard is a feature that Facebook introduced in 2017 to help users protect their profile pictures from being copied, shared, or downloaded by others without their permission. It is currently available in some countries, such as India, Pakistan, Bangladesh, Egypt, and more.
-When you turn on Facebook Guard for your profile picture, you will get three benefits:
-Benefits of Using Facebook Guard on APK
-Protect Your Profile Picture from Misuse
-The first benefit of using Facebook Guard is that it will prevent others from taking screenshots of your profile picture on Facebook. This means that no one can save your profile picture on their devices or use it for other purposes without your consent. This will reduce the chances of your profile picture being misused by strangers or malicious actors.
-Add a Blue Border and Shield to Your Profile Picture
-The second benefit of using Facebook Guard is that it will add a blue border and a shield icon to your profile picture. This will indicate that your profile picture is protected by Facebook Guard and that you care about your online safety. It will also deter others from trying to copy or misuse your profile picture, as they will know that you are aware of the risks and have taken steps to prevent them.
-How to activate facebook profile picture guard on android app
-Facebook profile picture guard chrome extension download
-Apk Guard facebook page and contact information
-Benefits of using facebook profile picture guard feature
-How to install facebook profile picture guard on apk file
-Facebook profile picture guard not working or showing up
-Facebook profile picture guard vs watermark or logo
-How to remove facebook profile picture guard from your photo
-Facebook profile picture guard alternative apps or tools
-How to disable or turn off facebook profile picture guard
-Facebook profile picture guard review and feedback
-How to customize facebook profile picture guard design or color
-Facebook profile picture guard privacy and security settings
-How to report facebook profile picture guard misuse or abuse
-Facebook profile picture guard compatibility and requirements
-How to update facebook profile picture guard on apk version
-Facebook profile picture guard support and help center
-How to share facebook profile picture guard with friends or groups
-Facebook profile picture guard statistics and data analysis
-How to create facebook profile picture guard for your page or group
-Facebook profile picture guard best practices and tips
-How to troubleshoot facebook profile picture guard issues or errors
-Facebook profile picture guard FAQs and common questions
-How to access facebook profile picture guard on desktop or laptop
-Facebook profile picture guard history and development
-How to change facebook profile picture guard frequency or duration
-Facebook profile picture guard pros and cons or advantages and disadvantages
-How to test facebook profile picture guard functionality or performance
-Facebook profile picture guard success stories and case studies
-How to optimize facebook profile picture guard for SEO or ranking
-Facebook profile picture guard feedback and suggestions form
-How to join facebook profile picture guard community or forum
-Facebook profile picture guard challenges and limitations
-How to backup or restore facebook profile picture guard settings or data
-Facebook profile picture guard future plans and updates
-How to monitor facebook profile picture guard activity or engagement
-Facebook profile picture guard comparison and contrast with other platforms or services
-How to make money with facebook profile picture guard feature or service
-Facebook profile picture guard tutorial or guide for beginners or experts
-How to use facebook profile picture guard for personal or professional purposes
-Control Who Can Download or Share Your Profile Picture
-The third benefit of using Facebook Guard is that it will give you more control over who can download or share your profile picture. You can choose to allow only your friends or no one at all to download or share your profile picture on Facebook. This will limit the exposure of your profile picture to only those who you trust and want to see it.
-How to Use Facebook Guard on APK
-Now that you know what Facebook Guard is and how it can benefit you, you may be wondering how you can use it on your device. The answer is simple: you need to download and install an APK file that contains the Facebook Guard feature.
-An APK file is an Android application package file that contains all the files and code needed to run an app on an Android device. You can download APK files from various sources online, such as websites, blogs, forums, etc. However, you need to be careful when downloading APK files from unknown sources, as they may contain viruses or malware that can harm your device or steal your data.
-To use Facebook Guard on APK safely and effectively, you need to follow these steps:
- Download and Install the APK File
-The first step is to download and install the APK file that contains the Facebook Guard feature. You can find such APK files on various websites, such as [APKPure], [APKMirror], [APKMonk], etc. However, you need to make sure that the APK file is compatible with your device and has the latest version of Facebook.
-To download and install the APK file, you need to follow these sub-steps:
-
-- Go to the website that offers the APK file and click on the download button.
-- Wait for the download to complete and then open the APK file.
-- If you see a warning message that says "Install blocked", you need to enable the installation of apps from unknown sources on your device. To do this, go to Settings > Security > Unknown sources and toggle it on.
-- Follow the instructions on the screen to install the APK file.
-
-Log in to Your Facebook Account
-The second step is to log in to your Facebook account using the app that you installed from the APK file. You can use your existing Facebook credentials or create a new account if you don't have one. Once you log in, you will see the familiar Facebook interface with some minor changes.
-Turn on Profile Picture Guard for Your Current or New Profile Picture
-The third and final step is to turn on Profile Picture Guard for your current or new profile picture. You can do this by following these sub-steps:
-
-- Go to your profile page and tap on your profile picture.
-- Select "Turn on Profile Picture Guard" from the options that appear.
-- You will see a preview of how your profile picture will look like with the blue border and shield icon. Tap on "Next" to continue.
-- You will see a message that says "Your profile picture is now protected". Tap on "Save" to confirm.
-
-Congratulations! You have successfully used Facebook Guard on APK to protect your profile picture from misuse. You can now enjoy using Facebook without worrying about your privacy and security.
-Conclusion
-In this article, we have explained what Facebook Guard is, what APK is, and how you can use Facebook Guard on APK to safeguard your profile picture. We have also discussed the benefits of using Facebook Guard, such as preventing screenshots, adding a blue border and shield, and controlling who can download or share your profile picture.
-We hope that this article has been helpful and informative for you. If you want to learn more about Facebook Guard or other Facebook features, you can visit their official website or blog for more details. You can also share this article with your friends and family who use Facebook and want to protect their profile pictures from misuse.
-Thank you for reading this article. Have a great day!
- Frequently Asked Questions
- Q: Is Facebook Guard available in my country?
-A: Facebook Guard is currently available in some countries, such as India, Pakistan, Bangladesh, Egypt, and more. You can check if it is available in your country by going to your profile page and tapping on your profile picture. If you see the option "Turn on Profile Picture Guard", then it means that it is available in your country.
- Q: Can I turn off Facebook Guard if I change my mind?
-A: Yes, you can turn off Facebook Guard if you want to remove the protection from your profile picture. To do this, go to your profile page and tap on your profile picture. Select "Turn off Profile Picture Guard" from the options that appear. You will see a message that says "Your profile picture is no longer protected". Tap on "Save" to confirm.
- Q: Does Facebook Guard affect the quality of my profile picture?
-A: No, Facebook Guard does not affect the quality of your profile picture. It only adds a blue border and a shield icon to your profile picture, which are visible only on Facebook. Your original profile picture remains unchanged and unaffected by Facebook Guard.
- Q: How can I report someone who misuses my profile picture?
-A: If you find out that someone has misused your profile picture, such as creating a fake account, harassing you, or scamming others, you can report them to Facebook. To do this, go to their profile page and tap on the three dots icon at the top right corner. Select "Report" from the options that appear. Choose the reason for reporting and follow the instructions on the screen.
Q: What are some other ways to protect my privacy and security on Facebook?
-A: Besides using Facebook Guard, there are some other ways to protect your privacy and security on Facebook, such as:
-
-- Adjusting your privacy settings to control who can see your posts, photos, stories, etc.
-- Using two-factor authentication to secure your login and prevent unauthorized access to your account.
-- Reviewing your activity log and timeline review to manage what you share and what others tag you in.
-- Blocking or unfriending people who bother you or make you uncomfortable.
-- Reporting any abusive or inappropriate content or behavior that violates Facebook's community standards.
-
-You can learn more about these and other ways to protect your privacy and security on Facebook by visiting their [Help Center] or [Safety Center].
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Download PUBG MOBILE MOD APK OBB File for Unlimited ESP Aimbot and Anti-Ban Features.md b/spaces/congsaPfin/Manga-OCR/logs/Download PUBG MOBILE MOD APK OBB File for Unlimited ESP Aimbot and Anti-Ban Features.md
deleted file mode 100644
index 10f2d5dc157ee87e9df733f68dc2e7499fd8d694..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Download PUBG MOBILE MOD APK OBB File for Unlimited ESP Aimbot and Anti-Ban Features.md
+++ /dev/null
@@ -1,132 +0,0 @@
-
-PUBG Mobile Hack Mod APK + OBB File Download: Is It Worth It?
-PUBG Mobile is one of the most popular and addictive mobile games in the world, with millions of players competing for the ultimate survival. But some players are not satisfied with the fair and balanced gameplay, and resort to using hacks and cheats to gain an unfair advantage. One of the most common ways to do this is by downloading and installing a modded version of the game, known as PUBG Mobile Hack Mod APK + OBB File. But is this really worth it? What are the risks and consequences of using such a hack? And are there any better alternatives to enjoy the game without cheating? In this article, we will answer these questions and more, so read on to find out.
-pubg mobile hack mod apk + obb file download
DOWNLOAD === https://urlca.com/2uO5Xn
- Introduction
-What is PUBG Mobile and why is it so popular?
-PUBG Mobile is a free-to-play battle royale mobile game developed by Tencent Games, based on the PC game PUBG: Battlegrounds. It was released for Android and iOS devices in 2018, and has since become one of the most downloaded and played mobile games of all time. According to Sensor Tower, PUBG Mobile has accumulated over 1.3 billion downloads and grossed over $9 billion as of December 2022.
-The game features a unique gameplay concept, where 100 players parachute onto a remote island and fight to be the last one standing. Players can choose to play solo, duo, or in squads of up to four players, depending on the game mode selected before the match. Each match lasts about 30 minutes, and the playable area shrinks over time, forcing players to confront each other. Players can find weapons, armor, vehicles, and other items scattered around the map, or loot them from defeated enemies. The game also offers various maps, modes, events, and features that keep the gameplay fresh and exciting.
-PUBG Mobile is popular because it offers a thrilling and immersive survival experience that appeals to a wide range of players. The game requires skills, strategy, teamwork, and luck to win, making it challenging and rewarding. The game also has high-quality graphics, realistic physics, smooth controls, and social interaction with friends and other players. The game is constantly updated with new content, improvements, and anti-cheat measures to ensure a fair and fun gaming environment.
- What are the common hacks and cheats used in PUBG Mobile?
-Unfortunately, not everyone plays PUBG Mobile fairly and honestly. Some players use hacks and cheats to gain an unfair advantage over other players, ruining the game for everyone else. Hacks and cheats are unauthorized modifications or programs that alter the game data or functionality in some way. They can give players abilities or information that they are not supposed to have, such as seeing through walls, aiming automatically, moving faster, jumping higher, etc.
-Some of the most common hacks and cheats used in PUBG Mobile are:
-pubg mobile mod apk unlimited uc and bp download obb
-pubg mobile hack apk esp aimbot mega menu obb file
-pubg mobile mod apk latest version download obb data
-pubg mobile hack apk no root anti ban obb file
-pubg mobile mod apk wallhack auto headshot obb download
-pubg mobile hack apk unlimited health and ammo obb file
-pubg mobile mod apk free skins and outfits download obb
-pubg mobile hack apk magic bullet speed hack obb file
-pubg mobile mod apk god mode and fly hack obb download
-pubg mobile hack apk radar and location hack obb file
-pubg mobile mod apk unlock all weapons and vehicles obb
-pubg mobile hack apk no recoil and rapid fire obb file
-pubg mobile mod apk high damage and jump hack obb download
-pubg mobile hack apk invisible and teleport hack obb file
-pubg mobile mod apk anti cheat bypass and report block obb
-pubg mobile hack apk voice changer and chat spam obb file
-pubg mobile mod apk custom lobby and room card obb download
-pubg mobile hack apk aim assist and crosshair hack obb file
-pubg mobile mod apk night mode and weather hack obb download
-pubg mobile hack apk crate opening and lucky spin hack obb file
-pubg mobile mod apk zombie mode and infection mode obb download
-pubg mobile hack apk grenade and molotov hack obb file
-pubg mobile mod apk 90 fps and hdr graphics obb download
-pubg mobile hack apk auto revive and heal hack obb file
-pubg mobile mod apk no grass and fog removal obb download
-pubg mobile hack apk unlimited flare gun and air drop obb file
-pubg mobile mod apk one shot kill and knock down obb download
-pubg mobile hack apk vehicle speed boost and nitro obb file
-pubg mobile mod apk no ads and premium pass obb download
-pubg mobile hack apk loot esp and item filter obb file
-pubg mobile mod apk team up with friends and chat obb download
-pubg mobile hack apk enemy esp and name tag obb file
-pubg mobile mod apk 4k resolution and ultra hd textures obb download
-pubg mobile hack apk weapon skin and attachment hack obb file
-pubg mobile mod apk realistic sound effects and voice chat obb download
-pubg mobile hack apk parachute and glider hack obb file
-pubg mobile mod apk offline mode and bot match obb download
-pubg mobile hack apk backpack and vest capacity hack obb file
-pubg mobile mod apk mini map and compass hack obb download
-pubg mobile hack apk spectate mode and camera hack obb file
-
-- Wallhack: This hack allows players to see through walls and other obstacles, making it easy to spot enemies and ambush them. This hack can also show other information such as enemy names, health bars, weapons, etc.
-- Aimbot: This cheat allows players to automatically aim at enemies, making it easy to shoot them and get kills. This cheat can also adjust the bullet trajectory, recoil, and spread to ensure accuracy and damage.
-- Speedhack: This hack allows players to move faster than normal, making it hard for enemies to hit them or catch up with them. This hack can also affect vehicles, making them faster and more agile.
-- ESP: This hack stands for Extra Sensory Perception, and it gives players information that they are not supposed to have, such as enemy locations, health, weapons, loot, etc. This hack can also show the distance, direction, and movement of enemies.
-
-These are just some of the hacks and cheats that are used in PUBG Mobile, but there are many more that exist. Some players use these hacks and cheats to gain an edge over other players, to rank up faster, to complete missions and challenges, or to troll and annoy other players. However, using these hacks and cheats is not only unfair and unethical, but also risky and illegal.
- What are the risks and consequences of using hacks and cheats in PUBG Mobile?
-Using hacks and cheats in PUBG Mobile is not worth it, because it comes with many risks and consequences. Some of the risks and consequences are:
-
-- Ban: PUBG Mobile has a strict anti-cheat system that detects and bans players who use hacks and cheats. The ban can be temporary or permanent, depending on the severity of the offense. The ban can also affect the player's account, device, or IP address. According to PUBG Mobile's official website, over 2 million accounts were banned in a single week in September 2022 for using hacks and cheats.
-- Virus: Many of the hacks and cheats that are available online are not safe or reliable. They can contain viruses, malware, spyware, or ransomware that can harm the player's device or data. Some of these malicious programs can steal the player's personal information, such as passwords, bank details, social media accounts, etc. Some of them can also lock the player's device or files and demand money to unlock them.
-- Lawsuit: Using hacks and cheats in PUBG Mobile is not only a violation of the game's terms of service, but also a breach of intellectual property rights. PUBG Mobile's developer Tencent Games has the right to take legal action against players who use hacks and cheats in their game. In fact, Tencent Games has sued several hackers and cheat makers in the past for infringing their rights. The lawsuit can result in hefty fines or even jail time for the offenders.
-
-These are just some of the risks and consequences of using hacks and cheats in PUBG Mobile, but there are many more that can happen. Using hacks and cheats in PUBG Mobile is not worth it, because it ruins the game for everyone else, including yourself. It also exposes you to various dangers that can affect your device, data, account, reputation, or even freedom.
- PUBG Mobile Hack Mod APK + OBB File Download: How Does It Work?
-What is a mod APK and an OBB file?
-A mod APK is a modified version of an original APK file. An APK file is an Android application package file that contains all the files and data needed to install an app on an Android device. A mod APK is created by altering or adding some features to the original APK file. For example, a mod APK can remove ads, unlock premium features, add unlimited resources, etc.
-An OBB file is an expansion file that contains additional data for an app that is not stored in the APK file. An OBB file is usually used for large apps that have high-quality graphics or audio. For example, PUBG Mobile has an OBB file that contains all the maps, modes, skins, etc. An OBB file is usually downloaded separately from the APK file.
-A mod APK + OBB file is a combination of a modded APK file and an OBB file that work together to provide a modified version of an app. For example, PUBG Mobile Hack Mod APK + OBB File is a modded version of PUBG Mobile that has some hacks and cheats enabled in it.
- How to download and install PUBG Mobile Hack Mod APK + OBB File?
-To download and install PUBG Mobile Hack Mod APK + OBB File, you need to follow these steps:
-
-- Find a reliable source: There are many websites that claim to offer PUBG Mobile Hack Mod APK + OBB File, but not all of them are safe or trustworthy. Some of them may contain viruses, malware, or fake files that can harm your device or data. Therefore, you need to be careful and do some research before downloading anything from the internet. You can check the reviews, ratings, comments, and feedback of other users who have downloaded the same file. You can also use antivirus software or online scanners to scan the file for any threats.
-- Download the file: Once you have found a reliable source, you can download the PUBG Mobile Hack Mod APK + OBB File from it. The file size may vary depending on the source and the version of the mod. Usually, the file is compressed in a ZIP or RAR format, so you need to extract it using a file manager app or a computer. You will get two files: an APK file and an OBB file.
-- Enable unknown sources: Before you can install the PUBG Mobile Hack Mod APK + OBB File, you need to enable unknown sources on your device. This is because the file is not from the official Google Play Store, and your device may block it by default. To enable unknown sources, go to Settings > Security > Unknown Sources and toggle it on. You may also need to disable Play Protect or other security features that may interfere with the installation.
-- Install the APK file: After enabling unknown sources, you can install the PUBG Mobile Hack Mod APK + OBB File by tapping on the APK file and following the instructions on the screen. You may need to grant some permissions to the app during the installation process. Once the installation is complete, do not open the app yet.
-- Copy the OBB file: After installing the APK file, you need to copy the OBB file to the right location on your device. The OBB file contains all the data and resources for the app, and it needs to be in a specific folder for the app to work properly. To copy the OBB file, go to your file manager app and locate the OBB file that you extracted earlier. Then, copy or move it to this folder: Internal Storage > Android > obb > com.tencent.ig (create this folder if it does not exist).
-- Launch the app: After copying the OBB file, you can launch the PUBG Mobile Hack Mod APK + OBB File by tapping on its icon on your home screen or app drawer. You may need to sign in with your PUBG Mobile account or create a new one if you do not have one. You may also need to verify your device or download some additional data before you can start playing.
-
-Congratulations! You have successfully downloaded and installed PUBG Mobile Hack Mod APK + OBB File on your device. Now you can enjoy all the features and hacks that it offers.
- What features does PUBG Mobile Hack Mod APK + OBB File offer?
-PUBG Mobile Hack Mod APK + OBB File offers many features and hacks that can enhance your gameplay and give you an edge over other players. Some of these features are:
-
-As you can see, the cons of using PUBG Mobile Hack Mod APK + OBB File are more serious and numerous than the pros. Therefore, it is not worth it to use PUBG Mobile Hack Mod APK + OBB File, because it can cause more harm than good.
- The ethical and legal issues of using PUBG Mobile Hack Mod APK + OBB File
-Besides the risks and consequences of using PUBG Mobile Hack Mod APK + OBB File, there are also some ethical and legal issues that you should consider. Using PUBG Mobile Hack Mod APK + OBB File is not only a violation of the game's terms of service, but also a breach of intellectual property rights. PUBG Mobile's developer Tencent Games has the right to take legal action against players who use hacks and cheats in their game. In fact, Tencent Games has sued several hackers and cheat makers in the past for infringing their rights. The lawsuit can result in hefty fines or even jail time for the offenders.
-Moreover, using PUBG Mobile Hack Mod APK + OBB File is not fair and ethical to other players who play the game honestly and legitimately. By using hacks and cheats, you are ruining the game for everyone else, including yourself. You are taking away the fun, challenge, and thrill of the game, and making it unfair and boring. You are also disrespecting the hard work and effort of the developers who created the game. You are also exposing yourself to various dangers that can affect your device, data, account, reputation, or even freedom.
-Therefore, using PUBG Mobile Hack Mod APK + OBB File is not ethical or legal, and you should avoid it at all costs.
- The alternatives to using PUBG Mobile Hack Mod APK + OBB File
-If you are looking for ways to enjoy PUBG Mobile without using hacks and cheats, there are some alternatives that you can try. Some of these alternatives are:
-
-- Practice and improve your skills: The best way to enjoy PUBG Mobile is to practice and improve your skills. You can play different modes, maps, and events to learn the game mechanics, strategies, and tactics. You can also watch tutorials, guides, tips, and tricks from other players or streamers who are good at the game. You can also join a clan or a team and play with your friends or other players who can help you improve your skills.
-- Use legitimate tools and resources: There are some legitimate tools and resources that you can use to enhance your gameplay and performance in PUBG Mobile. For example, you can use a gaming phone or a controller that can improve your graphics, controls, and battery life. You can also use a VPN or a proxy server that can reduce your ping and lag issues. You can also use some apps or websites that can provide you with useful information or analysis about the game, such as map locations, weapon stats, player stats, etc.
-- Spend some money on the game: If you want to get some items, skins, crates, passes, etc. in PUBG Mobile, you can spend some money on the game instead of using hacks and cheats. You can buy UC (Unknown Cash) with real money from the official store or other authorized sources. You can then use UC to buy whatever you want from the in-game shop or events. You can also earn UC by completing some tasks or surveys from some apps or websites that offer them.
-
-These are just some of the alternatives to using PUBG Mobile Hack Mod APK + OBB File, but there are many more that exist. These alternatives are safer, fairer, and more fun than using hacks and cheats in PUBG Mobile.
- Conclusion
-Summary of the main points
-In conclusion, PUBG Mobile Hack Mod APK + OBB File is a modded version of PUBG Mobile that offers some hacks and cheats that can give you an unfair advantage over other players. However, using this hack is not worth it, because it comes with many risks and consequences that can outweigh the benefits. Using this hack is also not ethical or legal, because it violates the game's terms of service and infringes the developer's intellectual property rights. Moreover, using this hack is not fun or rewarding, because it ruins the game for everyone else, including yourself.
- Call to action and recommendation
-Therefore, we recommend that you do not use PUBG Mobile Hack Mod APK + OBB File at all costs. Instead, we suggest that you try some of the alternatives that we mentioned above, such as practicing and improving your skills, using legitimate tools and resources, or spending some money on the game. These alternatives are safer, fairer, and more fun than using hacks and cheats in PUBG Mobile. They can also help you enjoy the game without compromising your device, data, account, reputation, or freedom.
-PUBG Mobile is a great game that offers a thrilling and immersive survival experience that appeals to a wide range of players. The game requires skills, strategy, teamwork, and luck to win, making it challenging and rewarding. The game also has high-quality graphics, realistic physics, smooth controls, and social interaction with friends and other players. The game is constantly updated with new content, improvements, and anti-cheat measures to ensure a fair and fun gaming environment.
-So, why ruin such a wonderful game with hacks and cheats? Why risk your device, data, account, reputation, or freedom for some temporary and fake benefits? Why spoil the game for yourself and other players by making it unfair and boring?
-Instead, why not play PUBG Mobile honestly and legitimately? Why not improve your skills, performance, and enjoyment with legitimate tools and resources? Why not support the game and the developers with some money if you can afford it?
-Trust us, playing PUBG Mobile without hacks and cheats is much more worth it than playing PUBG Mobile with hacks and cheats. You will have more fun, satisfaction, and respect from yourself and others. You will also avoid many dangers that can affect your device, data, account, reputation, or freedom.
-So, what are you waiting for? Download PUBG Mobile from the official Google Play Store or App Store today and start playing the game the way it was meant to be played. You will not regret it.
- FAQs
-Here are some frequently asked questions about PUBG Mobile Hack Mod APK + OBB File:
-
-- Q: Is PUBG Mobile Hack Mod APK + OBB File safe to use?
-- A: No, PUBG Mobile Hack Mod APK + OBB File is not safe to use. It can contain viruses, malware, or fake files that can harm your device or data. It can also get you banned from the game or sued by the developer for using hacks and cheats.
-- Q: Is PUBG Mobile Hack Mod APK + OBB File legal to use?
-- A: No, PUBG Mobile Hack Mod APK + OBB File is not legal to use. It violates the game's terms of service and infringes the developer's intellectual property rights. It can also get you sued by the developer for using hacks and cheats.
-- Q: Is PUBG Mobile Hack Mod APK + OBB File fun to use?
-- A: No, PUBG Mobile Hack Mod APK + OBB File is not fun to use. It ruins the game for yourself and other players by making it unfair and boring. It also exposes you to various dangers that can affect your device, data, account, reputation, or freedom.
-- Q: What are some alternatives to using PUBG Mobile Hack Mod APK + OBB File?
-- A: Some alternatives to using PUBG Mobile Hack Mod APK + OBB File are practicing and improving your skills, using legitimate tools and resources, or spending some money on the game. These alternatives are safer, fairer, and more fun than using hacks and cheats in PUBG Mobile. They can also help you enjoy the game without compromising your device, data, account, reputation, or freedom.
-- Q: Where can I download PUBG Mobile from the official source?
-- A: You can download PUBG Mobile from the official Google Play Store or App Store by following these links: . You can also visit the official website of PUBG Mobile for more information and updates about the game: .
-
-I hope this article has helped you understand more about PUBG Mobile Hack Mod APK + OBB File and why you should avoid it. If you have any questions or feedback, please feel free to leave a comment below. Thank you for reading and happy gaming!
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Download Tamil Subtitles for Game of Thrones Season 1 Episodes.md b/spaces/congsaPfin/Manga-OCR/logs/Download Tamil Subtitles for Game of Thrones Season 1 Episodes.md
deleted file mode 100644
index 1e1a6e8c48a66ae05119e1f793bd8d6fc1038b1f..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Download Tamil Subtitles for Game of Thrones Season 1 Episodes.md
+++ /dev/null
@@ -1,198 +0,0 @@
-
-Game of Thrones Season 1 Tamil Subtitles Download: How to Watch the Epic Fantasy Series in Your Own Language
- Game of Thrones is one of the most popular and acclaimed TV shows of all time. Based on the bestselling book series by George R.R. Martin, it is a sprawling saga of intrigue, war, magic, and dragons set in a medieval world where several noble families vie for the Iron Throne. If you are a fan of fantasy, drama, or adventure genres, you will love this show.
-game of thrones season 1 tamil subtitles download
DOWNLOAD ———>>> https://urlca.com/2uO4n8
- But what if you don't speak English or you want to watch the show in your own language? Don't worry, you can still enjoy Game of Thrones with subtitles. Subtitles are text versions of the dialogue that appear on the screen along with the video. They can help you understand what the characters are saying, learn new words and phrases, and appreciate the culture and context of the story.
- In this article, we will show you how to download Tamil subtitles for Game of Thrones Season 1. Tamil is a Dravidian language spoken by about 80 million people in India, Sri Lanka, Malaysia, Singapore, and other countries. It is one of the oldest and richest languages in the world. If you speak Tamil or want to learn it, you can watch Game of Thrones with Tamil subtitles.
- We will also give you some tips on how to enjoy Game of Thrones Season 1 with subtitles. We will tell you what the show is about, why it is so popular, how to find reliable and accurate subtitles, how to add them to your video player, and how to make the most of your viewing experience.
- So let's get started!
-game of thrones s01e01 tamil subtitle free download
-game of thrones season 1 episode 10 tamil sub download
-game of thrones season 1 tamil dubbed with subtitles download
-game of thrones season 1 complete tamil subtitles zip download
-game of thrones season 1 tamil subtitle online watch
-game of thrones season 1 sinhala and tamil subtitles download
-game of thrones season 1 english to tamil subtitle converter download
-game of thrones season 1 blu ray tamil subtitles download
-game of thrones season 1 tamil subtitle srt file download
-game of thrones season 1 all episodes tamil subtitles download
-game of thrones season 1 dothraki dialogue with tamil subtitles download
-game of thrones season 1 tamil subtitle yify download
-game of thrones season 1 tamil subtitle podnapisi download
-game of thrones season 1 tamil subtitle subscene download
-game of thrones season 1 tamil subtitle opensubtitles download
-game of thrones season 1 tamil subtitle isubdb download[^1^]
-game of thrones season 1 tamil subtitle subdl download[^2^]
-game of thrones season 1 tamil subtitle tvsubtitles download
-game of thrones season 1 tamil subtitle addic7ed download
-game of thrones season 1 tamil subtitle shaanig download
-game of thrones season 1 remux hdr hevc atmos tamil subtitles download
-game of thrones season 1 fire and blood tamil subtitle download
-game of thrones season 1 baelor tamil subtitle download
-game of thrones season 1 the pointy end tamil subtitle download
-game of thrones season 1 you win or you die tamil subtitle download
-game of thrones season 1 a golden crown tamil subtitle download
-game of thrones season 1 the wolf and the lion tamil subtitle download
-game of thrones season 1 cripples bastards and broken things tamil subtitle download
-game of thrones season 1 lord snow tamil subtitle download
-game of thrones season 1 winter is coming tamil subtitle download
-how to sync game of thrones season 1 with tamil subtitles download
-where to find game of thrones season 1 in tamil with subtitles download
-best site for game of thrones season 1 in tamil language subtitles download
-how to watch game of thrones season 1 in hd with tamil subtitles download
-how to get game of thrones season 1 in mkv format with tamil subtitles download
-how to install game of thrones season 1 in vlc player with tamil subtitles download
-how to fix game of thrones season 1 out of sync with tamil subtitles download
-how to edit game of thrones season 1 font size and color with tamil subtitles download
-how to create game of thrones season 1 custom subtitles in tamil language download
-how to translate game of thrones season 1 from english to tamil subtitles online free download
- What is Game of Thrones and Why is it So Popular?
- Game of Thrones is a TV adaptation of A Song of Ice and Fire, a series of fantasy novels by George R.R. Martin. The first season of the show covers the events of the first book, A Game of Thrones, which was published in 1996. The show premiered on HBO in 2011 and ran for eight seasons until 2019. It has become one of the most watched and talked about shows in history.
- The show is set in a fictional world called Westeros, where seasons last for years and magic and mythical creatures exist. The story follows the lives and struggles of several noble families, such as the Starks, the Lannisters, the Baratheons, and the Targaryens, who are all competing for the Iron Throne, the symbol of power and authority in Westeros. Along the way, they have to deal with various threats, such as a civil war, a zombie army, and a dragon queen.
- The show is known for its complex and realistic characters, its unpredictable and shocking plot twists, its stunning and diverse settings, its epic and brutal battles, its rich and detailed lore, and its mature and dark themes. It explores topics such as power, politics, loyalty, morality, family, love, betrayal, revenge, justice, and survival. It also challenges the conventions and stereotypes of the fantasy genre, such as the hero's journey, the good vs evil dichotomy, and the happy ending.
- The show has received critical acclaim and numerous awards for its writing, acting, directing, production design, cinematography, music, costumes, makeup, and special effects. It has won 59 Emmy Awards out of 160 nominations, making it the most awarded series in Emmy history. It has also won four Golden Globe Awards out of 14 nominations. It holds several Guinness World Records, such as the most pirated TV show ever, the largest TV drama simulcast, and the most Emmy wins for a scripted series.
- Game of Thrones has a huge and loyal fan base around the world. It has inspired countless memes, parodies, cosplays, fan arts, fan fictions, podcasts, games, merchandise, and spin-offs. It has also influenced popular culture, literature, art, politics, and education. It is widely regarded as one of the greatest TV shows of all time.
- How to Download Tamil Subtitles for Game of Thrones Season 1
- If you want to watch Game of Thrones Season 1 with Tamil subtitles, you will need to download them from a reliable source. There are many websites that offer subtitles for various movies and TV shows, but not all of them are trustworthy or accurate. Some subtitles may have poor quality, wrong synchronization, missing or incorrect words, or even malware or viruses.
- To avoid these problems, you should look for subtitles that have good ratings, reviews, and feedback from other users. You should also check the file format, size, and language of the subtitles before downloading them. You should also scan them with an antivirus software before opening them.
- To help you find the best Tamil subtitles for Game of Thrones Season 1, we have selected three websites that we think are reliable and accurate. They are Subscene, VEED.IO, and Checksub. We will explain how to use each website to download subtitles and what are their pros and cons.
Subscene: A Free Website with a Wide Variety of Languages
- Subscene is one of the most popular and widely used websites for downloading subtitles for movies and TV shows. It has a huge database of subtitles in various languages, including Tamil. You can find subtitles for Game of Thrones Season 1 in Tamil by following these steps:
-
-- Go to Subscene.com and type "Game of Thrones Season 1" in the search box.
-- Select the title from the list of results and choose the episode you want to watch.
-- Scroll down to the list of subtitles and look for the ones with "Tamil" in the name.
-- Click on the subtitle you want to download and save it to your computer.
-- Extract the subtitle file from the zip folder and rename it to match the name of your video file.
-- Add the subtitle file to your video player and enjoy watching Game of Thrones Season 1 with Tamil subtitles.
-
- The pros of Subscene are:
-
-- It is free and easy to use.
-- It has a large collection of subtitles in different languages and formats.
-- It has a user-friendly interface and a search function.
-- It has ratings, comments, and reports from other users to help you choose the best subtitles.
-
- The cons of Subscene are:
-
-- It may have ads or pop-ups that can be annoying or harmful.
-- It may not have subtitles for every episode or season of Game of Thrones.
-- It may have subtitles that are inaccurate, incomplete, or out of sync with the video.
-
- VEED.IO: An Online Subtitle Generator with Artificial Intelligence
- VEED.IO is an online video editing tool that can generate subtitles automatically using artificial intelligence. It can also help you edit and customize your subtitles with fonts, colors, styles, and more. You can create subtitles for Game of Thrones Season 1 in Tamil by following these steps:
-
-- Go to VEED.IO and sign up for a free account or log in with your existing account.
-- Click on "Upload Video" and select the video file you want to watch from your computer or cloud storage.
-- Click on "Subtitles" and then on "Auto Subtitles". Choose "English" as the language of your video and wait for VEED.IO to generate subtitles for it.
-- Click on "Translate" and then on "Add Translation". Choose "Tamil" as the language you want to translate your subtitles into and wait for VEED.IO to translate them for you.
-- Click on "Edit Subtitles" and then on "Style". Adjust the font, color, size, position, and background of your subtitles as you like.
-- Click on "Download" and then on "Export". Choose "SRT" as the file format and save your subtitle file to your computer.
-- Add the subtitle file to your video player and enjoy watching Game of Thrones Season 1 with Tamil subtitles.
-
- The pros of VEED.IO are:
-
-- It is fast and accurate in generating and translating subtitles.
-- It is easy and fun to use with its intuitive interface and features.
-- It allows you to edit and customize your subtitles with various options.
-- It supports multiple languages and formats for subtitles.
-
- The cons of VEED.IO are:
-
-- It is not completely free. You have to pay for some features or plans if you want to use them.
-- It may not work well with some videos or languages. You may have to correct some errors or mistakes in the subtitles manually.
-- It may not be compatible with some video players or devices. You may have to convert your subtitle file to a different format or use a different player.
-
- Checksub: A Professional Subtitle Service with Translation and Dubbing Options
- Checksub is a professional subtitle service that can help you create, translate, or dub your videos into different languages. It has a team of experts who can provide high-quality subtitles for your videos. You can order subtitles for Game of Thrones Season 1 in Tamil by following these steps:
-
-- Go to Checksub.com and sign up for an account or log in with your existing account.
-- Click on "New Project" and upload the video file you want to watch from your computer or cloud storage.
-- Select "Tamil" as the language you want to watch and click on "Start". Wait for Checksub to analyze your video and generate subtitles for it.
-- Review and edit your subtitles if needed. You can also translate or dub your video into other languages with Checksub's experts.
-- Click on "Download" and choose the file format and quality you want. Save your subtitle file to your computer.
-- Add the subtitle file to your video player and enjoy watching Game of Thrones Season 1 with Tamil subtitles.
-
- The pros of Checksub are:
-
-- It is professional and reliable in providing high-quality subtitles.
-- It is flexible and convenient in offering various options for subtitles, such as translation, dubbing, and synchronization.
-- It is secure and confidential in protecting your video and subtitle files.
-- It supports multiple languages and formats for subtitles.
-
- The cons of Checksub are:
-
-- It is not cheap. You have to pay for the service depending on the length, complexity, and language of your video.
-- It may take some time. You have to wait for Checksub to process your video and deliver your subtitles.
-- It may not be available for some videos or languages. You have to check if Checksub can handle your request before ordering.
-
- How to Enjoy Game of Thrones Season 1 with Tamil Subtitles
- Now that you have downloaded Tamil subtitles for Game of Thrones Season 1, you are ready to watch the show. But how can you make sure that you have a great viewing experience? Here are some tips and tricks that can help you:
-
-- Choose the right device. You can watch Game of Thrones on your TV, computer, laptop, tablet, or smartphone. But make sure that your device has a good screen, sound, and battery. You don't want to miss any details or have any interruptions while watching the show.
-- Set the volume. You want to hear the dialogue clearly, but not too loud that it hurts your ears or disturbs others. You can also use headphones or earphones if you prefer. Just make sure that they are comfortable and compatible with your device.
-- Avoid distractions. You want to focus on the show and not on anything else. So turn off your phone, close your door, dim your lights, and get some snacks and drinks ready. You can also watch the show with friends or family if you like, but make sure that they are also interested in the show and respectful of your preferences.
-
- Besides watching the show, you can also do some fun activities after watching it, such as:
-
-- Discussing it with others. You can share your thoughts, opinions, questions, and emotions about the show with other fans online or offline. You can join forums, groups, chats, podcasts, or blogs dedicated to Game of Thrones. You can also create your own content, such as memes, parodies, cosplays, fan arts, fan fictions, or reviews.
-- Reading the books. You can read the original book series by George R.R. Martin that inspired the show. You can compare and contrast the differences and similarities between the books and the show. You can also learn more about the history, lore, and characters of the world of Westeros.
-- Playing the games. You can play some of the official or unofficial games based on Game of Thrones. You can choose from different genres, such as role-playing, strategy, adventure, or trivia. You can also create your own games or scenarios using tools like Minecraft or Roblox.
-
- However, before you watch or do any of these activities, you should be aware of some warnings and cautions, such as:
-
-- Spoilers. You should avoid any sources or people that may reveal important information or events that happen later in the show or in the books. Spoilers can ruin your enjoyment and surprise of the show. You should also be careful not to spoil anything for others who have not watched or read it yet.
-- Violence. You should be prepared for some scenes that may contain graphic violence, blood, gore, or torture. These scenes may be disturbing or upsetting for some viewers. You should watch them at your own risk and discretion. You should also respect the ratings and age restrictions of the show.
-- Nudity. You should be prepared for some scenes that may contain nudity, sex, or sexual violence. These scenes may be inappropriate or offensive for some viewers. You should watch them at your own risk and discretion. You should also respect the ratings and age restrictions of the show.
-
- Conclusion
- In conclusion, Game of Thrones Season 1 is a fantastic TV show that you can watch with Tamil subtitles. You can download subtitles from various websites, such as Subscene, VEED.IO, or Checksub. You can also enjoy the show with some tips and tricks, such as choosing the right device, setting the volume, and avoiding distractions. You can also do some fun activities after watching the show, such as discussing it with others, reading the books, or playing the games. However, you should also be aware of some warnings and cautions, such as spoilers, violence, and nudity.
- We hope that this article has helped you learn how to watch Game of Thrones Season 1 with Tamil subtitles. We encourage you to watch the show with subtitles and share your feedback with us. We would love to hear from you.
- Thank you for reading this article and have a great day!
- FAQs
- Here are some frequently asked questions and answers about Game of Thrones Season 1 and Tamil subtitles:
-
-- Where can I watch Game of Thrones Season 1 online?
-You can watch Game of Thrones Season 1 online on various streaming platforms, such as HBO Max, Netflix, Amazon Prime Video, or Hotstar. However, you may need a subscription or a VPN to access some of these platforms depending on your location.
-- How many episodes are there in Game of Thrones Season 1?
-There are 10 episodes in Game of Thrones Season 1. Each episode is about an hour long. The titles of the episodes are:
-
-- Winter Is Coming
-- The Kingsroad
-- Lord Snow
-- Cripples, Bastards, and Broken Things
-- The Wolf and the Lion
-- A Golden Crown
-- You Win or You Die
-- The Pointy End
-- Baelor
-- Fire and Blood
-
-- Who are the main characters in Game of Thrones Season 1?
-There are many characters in Game of Thrones Season 1, but some of the main ones are:
-
-- Ned Stark (Sean Bean): The honorable lord of Winterfell and the Hand of the King.
-- Catelyn Stark (Michelle Fairley): The loyal wife of Ned and the mother of his five children.
-- Robb Stark (Richard Madden): The eldest son of Ned and Catelyn and the heir of Winterfell.
-- Sansa Stark (Sophie Turner): The eldest daughter of Ned and Catelyn and the betrothed of Prince Joffrey.
-- Arya Stark (Maisie Williams): The youngest daughter of Ned and Catelyn and a tomboy who loves sword-fighting.
-- Bran Stark (Isaac Hempstead Wright): The second son of Ned and Catelyn and a climber who loses his legs after a fall.
-- Rickon Stark (Art Parkinson): The youngest son of Ned and Catelyn and a wild child who loves his direwolf.
-- Jon Snow (Kit Harington): The bastard son of Ned and a member of the Night's Watch.
-- Tyrion Lannister (Peter Dinklage): The witty and clever dwarf brother of Queen Cersei and Ser Jaime.
-- Cersei Lannister (Lena Headey): The beautiful and cunning queen consort of King Robert and the mother of Prince Joffrey.
-- Jamie Lannister (Nikolaj Coster-Waldau): The handsome and arrogant twin brother of Cersei and a knight of the Kingsguard.
-- Joffrey Baratheon (Jack Gleeson): The cruel and spoiled prince heir of King Robert and Queen Cersei.
-- Robert Baratheon (Mark Addy): The fat and drunken king of Westeros and an old friend of Ned.
-- Daenerys Targaryen (Emilia Clarke): The exiled princess of the Targaryen dynasty and the bride of Khal Drogo.
-- Khal Drogo (Jason Momoa): The powerful and fearless leader of the Dothraki nomads and the husband of Daenerys.
-
- What are the main themes and messages of Game of Thrones Season 1?
-Game of Thrones Season 1 explores many themes and messages that are relevant and relatable to the real world. Some of the main ones are:
-
-- Power: The show examines the nature, sources, and consequences of power. It shows how power can be gained, lost, used, abused, or corrupted. It also shows how power can affect people's actions, decisions, relationships, and morals.
-- Politics: The show depicts the complex and dynamic political landscape of Westeros. It shows how different factions, alliances, and conflicts emerge and change over time. It also shows how political schemes, intrigues, and manipulations can shape the course of history.
-- Loyalty: The show explores the concept and value of loyalty. It shows how loyalty can be tested, challenged, or betrayed by various factors, such as family, honor, duty, love, or ambition. It also shows how loyalty can inspire courage, sacrifice, or revenge.
-- Morality: The show challenges the traditional notions of morality and ethics. It shows how morality can be subjective, relative, or ambiguous in different situations and perspectives. It also shows how morality can influence or conflict with one's goals, desires, or emotions.
-
- These are some of the frequently asked questions and answers about Game of Thrones Season 1 and Tamil subtitles. If you have any other questions or comments, please feel free to share them with us.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/How to Download 3CX Phone 6.msi and Make Calls from Your PC.md b/spaces/congsaPfin/Manga-OCR/logs/How to Download 3CX Phone 6.msi and Make Calls from Your PC.md
deleted file mode 100644
index 19269fd889f2bd64f8488b66d1b89310018b8055..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/How to Download 3CX Phone 6.msi and Make Calls from Your PC.md
+++ /dev/null
@@ -1,144 +0,0 @@
-
-How to Download and Install 3CX Phone 6.msi
-If you are looking for a way to make and receive calls from your PC or laptop, you might want to try out 3CX Phone 6.msi. This is a free app developed by 3CX, a leading provider of business communication solutions and software. In this article, we will show you how to download, install, use, troubleshoot, update, and uninstall this app. We will also answer some of the most common questions about it. Let's get started!
-download 3cx phone 6.msi
Download ⚹⚹⚹ https://urlca.com/2uO5Hk
- What is 3CX Phone 6.msi?
-3CX Phone 6.msi is a softphone app that allows you to make and receive calls over your internet connection using your VoIP provider. It is compatible with Windows operating systems and supports standard headsets. It has a user-friendly and intuitive interface that lets you easily manage your calls, contacts, voicemail, and call history. It also has some advanced features such as call transfer, call recording, presence, and encryption.
- Why do you need 3CX Phone 6.msi?
-There are many benefits of using 3CX Phone 6.msi for your business communication needs. Here are some of them:
-
-- You can save money on your phone bills by using your internet connection instead of landlines.
-- You can use your office number to make and receive calls from anywhere, as long as you have internet access.
-- You can enhance your productivity and collaboration by using the integrated video conferencing, live chat, WhatsApp, Facebook, business SMS, and CRM features.
-- You can improve your customer service by offering them multiple ways to contact you and by knowing who you are talking or chatting with.
-- You can easily switch between hosted or self-managed options at any time, depending on your preference and budget.
-
- How to download 3CX Phone 6.msi?
-To download 3CX Phone 6.msi, you need to follow these steps:
-
-- Go to the official website of 3CX.
-- Click on Download at the top menu.
-- Select Windows & Linux Client.
-- Scroll down to Windows Client.
-- Click on Download MSI Installer.
-- Save the file on your computer.
-
- How to install 3CX Phone 6.msi?
-To install 3CX Phone 6.msi, you need to follow these steps:
-
-- Locate the downloaded file on your computer.
-- Double-click on it to launch the installation wizard.
-- Follow the instructions on the screen.
-- Enter your 3CX extension number and password when prompted.
-- Click on Finish to complete the installation.
-
- How to use 3CX Phone 6.msi?
-To use 3CX Phone 6.msi, you need to follow these steps:
-
-- Launch the app from your desktop or start menu.
-- You will see the main window with four tabs: Dialer, Contacts, Voicemail, and History.
-- To make a call, you can either enter the number on the dialer, select a contact from your list, or click on a recent call from your history.
-- To receive a call, you will see a pop-up notification on your screen. You can either answer, reject, or divert the call.
-- To access the advanced features, you can click on the Menu button at the top right corner. You will see options such as Video Conferencing, Live Chat, WhatsApp, Facebook, SMS, and CRM Integration.
-- To change your settings, you can click on the Status button at the top left corner. You will see options such as Do Not Disturb, Away, Available, and Edit Profile.
-
- How to troubleshoot 3CX Phone 6.msi?
-If you encounter any issues with 3CX Phone 6.msi, you can try these solutions:
-
-- If you cannot make or receive calls, check your internet connection and firewall settings. Make sure you have enough bandwidth and that 3CX Phone 6.msi is allowed to access the network.
-- If you cannot hear or be heard, check your audio settings and headset. Make sure you have selected the correct input and output devices and that they are working properly.
-- If you cannot see or be seen, check your video settings and camera. Make sure you have selected the correct camera and that it is working properly.
-- If you cannot connect to your VoIP provider, check your account details and credentials. Make sure you have entered them correctly and that they are valid.
-- If you cannot access the advanced features, check your subscription plan and license. Make sure you have activated them and that they are not expired.
-
- How to update 3CX Phone 6.msi?
-To update 3CX Phone 6.msi, you need to follow these steps:
-How to download 3cx softphone for windows
-Free voip app for pc - download 3cx phone 6.msi
-Download 3cx v18 phone system for windows or linux
-Install 3cx softphone on your laptop or desktop
-Download 3cx phone 6.msi and connect to your voip provider
-Make and receive calls with 3cx softphone for windows
-Download 3cx phone 6.msi and save on your phone bills
-Transfer calls and view call history with 3cx softphone
-Download 3cx phone 6.msi and get a free hosted pbx
-Listen to voicemail and record calls with 3cx softphone
-Download 3cx phone 6.msi and enjoy video conferencing
-Download 3cx phone 6.msi and integrate with whatsapp and facebook
-Download 3cx phone 6.msi and manage live chat and sms
-Download 3cx phone 6.msi and schedule a video call or conference
-Download 3cx phone 6.msi and get to know the web client
-Download 3cx phone 6.msi and get the apps for ios or android
-Download 3cx phone 6.msi and use your deskphone
-Download 3cx phone 6.msi and get up to 10 users free forever
-Download 3cx phone 6.msi and try risk free
-Download 3cx phone 6.msi and get omnichannel solution
-Download 3cx phone 6.msi and get advanced call center features
-Download 3cx phone 6.msi and support remote teams
-Download 3cx phone 6.msi and get easy sip trunk setup
-Download 3cx phone 6.msi and get call routing, ivr, office hours
-Download 3cx phone 6.msi and get call queues, ring groups
-Download 3cx phone 6.msi and configure ip phones
-Download 3cx phone 6.msi and install website live chat
-Download latest version of 3cx softphone for windows
-Where to download 3cx phone system for windows or linux
-How to update your existing installation of 3cx softphone for windows
-What are the benefits of using the free softphone from the official website of the developer[^1^]
-How to uninstall or remove the old version of the softphone before downloading the new one[^2^]
-What are the system requirements for running the softphone on your computer[^2^]
-How to troubleshoot common issues with the softphone such as audio quality, connectivity, firewall, etc.[^2^]
-How to customize the settings of the softphone such as language, theme, notifications, etc.[^2^]
-How to register the softphone with your voip account or extension[^2^]
-How to use the dialpad and buttons to make or receive calls[^2^]
-How to access your personal call log, history, contacts, voicemail, etc.[^2^]
-How to transfer calls to another extension or external number[^2^]
-How to record calls and where to find the recordings[^2^]
-How to join or start a video conference with other participants[^2^]
-How to share your screen or files during a video conference[^2^]
-How to chat with other users or customers via live chat or sms[^2^]
-How to integrate the softphone with other apps such as whatsapp, facebook, outlook, etc.[^2^]
-How to switch between different devices such as deskphone, mobile app, web client, etc.[^2^]
-
-- Go to the official website of 3CX.
-- Click on Download at the top menu.
-- Select Windows & Linux Client.
-- Scroll down to Windows Client.
-- Click on Download MSI Installer.
-- Save the file on your computer.
-- Locate the downloaded file on your computer.
-- Double-click on it to launch the installation wizard.
-- The wizard will detect your existing version and ask you if you want to update it. Click on Yes.
-- The wizard will install the latest version of 3CX Phone 6.msi over your existing one. Click on Finish.
-
- How to uninstall 3CX Phone 6.msi?
-To uninstall 3CX Phone 6.msi, you need to follow these steps:
-
-- Go to your Windows start menu and click on Settings.
-- Select Apps & Features.
-- Select 3CX Phone for Windows (MSI) from the list of installed apps.
-- Click on Uninstall.
-- A confirmation window will pop up. Click on Uninstall again.
-- The wizard will remove 3CX Phone 6.msi from your computer. Click on Finish.
-
- How to contact 3CX support?
-If you have any questions or feedback about 3CX Phone 6.msi, you can contact 3CX support in the following ways:
-
-- You can visit the 3CX Support Portal and browse the knowledge base, submit a ticket, or chat with an agent.
-- You can call the 3CX Support Hotline and speak to a representative.
-- You can email the 3CX Support Team and get a reply within 24 hours.
-- You can join the 3CX Community Forum and interact with other users and experts.
-- You can follow the 3CX Blog and stay updated with the latest news and tips.
-
- Conclusion
-In this article, we have shown you how to download, install, use, troubleshoot, update, and uninstall 3CX Phone 6.msi. This is a free and powerful softphone app that lets you make and receive calls over your internet connection using your VoIP provider. It also offers you many advanced features such as video conferencing, live chat, WhatsApp, Facebook, SMS, and CRM integration. It is compatible with Windows operating systems and supports standard headsets. It is easy to use and manage, and it can help you save money, enhance productivity, improve customer service, and switch between hosted or self-managed options. We hope you have found this article helpful and informative. If you want to try out 3CX Phone 6.msi for yourself, you can download it from the official website of 3CX. If you have any questions or feedback, you can contact 3CX support through various channels. Thank you for reading!
- FAQs
-Here are some of the frequently asked questions and answers about 3CX Phone 6.msi:
-
-- What are the system requirements for 3CX Phone 6.msi?
The minimum system requirements for 3CX Phone 6.msi are: Windows XP SP2 or higher, Pentium III or higher CPU, 256 MB RAM, 100 MB free disk space, sound card, microphone, speakers or headset, internet connection.
-- How much does 3CX Phone 6.msi cost?
3CX Phone 6.msi is free to download and use. However, you may need to pay for your VoIP provider's service plan and charges. You may also need to upgrade your subscription plan and license if you want to access the advanced features of 3CX Phone 6.msi.
-- Is 3CX Phone 6.msi secure?
Yes, 3CX Phone 6.msi is secure. It uses encryption protocols such as TLS and SRTP to protect your data and voice traffic. It also complies with GDPR and other privacy regulations.
-- Can I use 3CX Phone 6.msi on other devices?
Yes, you can use 3CX Phone 6.msi on other devices such as Macs, Linux PCs, Android phones, iPhones, iPads, Chromebooks, and web browsers. You can download the appropriate app or extension from the official website of 3CX.
-- Can I integrate 3CX Phone 6.msi with other apps?
Yes, you can integrate 3CX Phone 6.msi with other apps such as WhatsApp, Facebook, business SMS, CRM systems, email clients, web browsers, office suites, and more. You can find the list of supported integrations on the official website of 3CX.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Rayvanny and Mr Blue Team Up for Mama La Mama - Download MP3.md b/spaces/congsaPfin/Manga-OCR/logs/Rayvanny and Mr Blue Team Up for Mama La Mama - Download MP3.md
deleted file mode 100644
index cc5109ffffa84d4010c9c7e360590f6eecd13c2a..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Rayvanny and Mr Blue Team Up for Mama La Mama - Download MP3.md
+++ /dev/null
@@ -1,129 +0,0 @@
-
-How to Download Rayvanny ft Mr Blue's Music from YouTube
-If you are a fan of Tanzanian music, you might have heard of Rayvanny and Mr Blue, two popular artists who have collaborated on several songs. Their music is catchy, upbeat, and full of African vibes. But how can you download their music from YouTube and enjoy it offline? In this article, we will show you how to do that for free and legally.
-download rayvanny ft mr blue
DOWNLOAD ✦✦✦ https://urlca.com/2uO9s1
- Who are Rayvanny and Mr Blue?
-Rayvanny and Mr Blue are two Tanzanian musicians who belong to the genre of bongo flava, a fusion of hip hop, R&B, reggae, and Afrobeat. They have both been active in the music industry for several years and have won many awards and fans.
- Rayvanny
-Rayvanny, whose real name is Raymond Shaban Mwakyusa, was born in 1993 in Mbeya, Tanzania. He started singing at a young age and joined a local music group called Tip Top Connection. He rose to fame in 2016 when he released his hit song "Kwetu", which was produced by Lizer Classic from WCB Wasafi Records, a label owned by Diamond Platnumz. Since then, he has released many successful songs, such as "Tetema", "Chuchumaa", "Vumbi", and "Mama la Mama". He has also collaborated with other artists, such as Diamond Platnumz, Nasty C, Jason Derulo, Patoranking, and Mr Blue.
- Mr Blue
-Mr Blue, whose real name is Kheri Sameer Rajabu, was born in 1987 in Dar es Salaam, Tanzania. He started rapping at a young age and joined a local rap group called Wateule. He released his debut album in 2005, titled "Mr Blue". He is known for his lyrical skills and storytelling abilities. Some of his popular songs are "Mapozi", "Mbwa Koko", "Baki na Mimi", and "Njoo Tucheat". He has also collaborated with other artists, such as Alikiba, Nay Wa Mitego, Young Dee, and Rayvanny.
- Why download their music from YouTube?
-YouTube is one of the most popular platforms for watching and listening to music videos online. You can find almost any song or artist on YouTube, including Rayvanny and Mr Blue. However, there are some drawbacks to using YouTube for music streaming. For example:
-download rayvanny ft mr blue mama la mama mp3
-download rayvanny ft mr blue flowers ep
-download rayvanny ft mr blue video
-download rayvanny ft mr blue audio
-download rayvanny ft mr blue lyrics
-download rayvanny ft mr blue song
-download rayvanny ft mr blue njoo tucheat
-download rayvanny ft mr blue new song
-download rayvanny ft mr blue mp4
-download rayvanny ft mr blue music
-download rayvanny ft mr blue dj mwanga
-download rayvanny ft mr blue mdundo
-download rayvanny ft mr blue citimuzik
-download rayvanny ft mr blue bongo flava
-download rayvanny ft mr blue wasafi records
-download rayvanny ft mr blue hip hop
-download rayvanny ft mr blue remix
-download rayvanny ft mr blue instrumental
-download rayvanny ft mr blue free mp3
-download rayvanny ft mr blue online
-download rayvanny ft mr blue 2023
-download rayvanny ft mr blue latest song
-download rayvanny ft mr blue official video
-download rayvanny ft mr blue youtube
-download rayvanny ft mr blue tubidy
-download rayvanny ft mr blue naijavibes
-download rayvanny ft mr blue justnaija
-download rayvanny ft mr blue tooxclusive
-download rayvanny ft mr blue waploaded
-download rayvanny ft mr blue naijaloaded
-download rayvanny ft mr blue afrobeat
-download rayvanny ft mr blue fakaza
-download rayvanny ft mr blue zamusic
-download rayvanny ft mr blue sahiphopmag
-download rayvanny ft mr blue hiphopza
-download rayvanny ft mr blue amapiano hits 2022 mixtape
-download rayvanny ft mr blue best naso collaboration
-download rayvanny ft mr blue roma mkatoliki feature
-download rayvanny ft mr blue harmonize duet
-download rayvanny ft mr blue diamond platnumz vumbi
-download rayvanny ft mr blue lava lava tajiri
-download rayvanny ft mr blue cheed simuachi
-download rayvanny ft mr blue linex running
-download rayvanny ft mr blue micky singer naroga
-download rayvanny ft mr blue nviiri the storyteller badilika
-download rayvanny ft mr blue moni centrozone naumia roho
-download rayvanny ft mr blue smg family vimodo
-download rayvanny ft mr blue boutross miss behaviour
-download rayvanny ft mr blue jose gatutura tuirio twega
-
-- You need a stable internet connection to stream music without interruptions.
-- You cannot play music in the background or offline on your device.
-- You have to watch ads before or during some videos.
-- You have to pay for a subscription to access premium features, such as ad-free playback, offline downloads, and background play.
-
-Therefore, downloading music from YouTube can be a good option if you want to enjoy your favorite songs without these limitations. You can save the music files on your device and play them anytime, anywhere, with any media player. You can also create your own playlists and share them with your friends.
- Benefits of downloading music from YouTube
-Some of the benefits of downloading music from YouTube are:
-
-- You can listen to high-quality music for free.
-- You can save data and battery by not streaming music online.
-- You can avoid annoying ads and interruptions.
-- You can support your favorite artists by increasing their views and popularity.
-
- Legal issues and precautions
-Before you download music from YouTube, you should be aware of some legal issues and precautions. Downloading music from YouTube is not allowed unless you have the permission of the content owner or the video is in the public domain. You should also respect the rights of the artists and not use their music for commercial purposes or without giving them credit. You should also avoid downloading music from YouTube that is protected by digital rights management (DRM) or has a watermark, as this may violate the terms of service or cause playback issues. To be safe, you should only download music from YouTube that is clearly labeled as royalty-free, copyright-free, or Creative Commons licensed.
- How to download their music from YouTube for free?
-There are several ways to download music from YouTube for free, depending on your device and preference. Here are some of the most common methods:
- Using online converters
-One of the easiest ways to download music from YouTube is to use an online converter that can extract the audio from any YouTube video and convert it to an MP3 file. There are many online converters available, such as [YTMP3](^1^), [MP3FY](^2^), [Online Video Converter](^3^), and [Y2Mate](^4^). To use an online converter, follow these steps:
-
-- Copy the URL of the YouTube video that contains the music you want to download.
-- Paste the URL into the input box of the online converter.
-- Select MP3 as the output format and choose the quality level.
-- Click the Convert or Download button and wait for the process to finish.
-- Click the Download button again to save the MP3 file to your device.
-
-Note that some online converters may have pop-up ads, redirects, or download limits. You should also check the file size and duration before downloading to make sure it matches the original video.
- Using desktop software
-If you want more control and features when downloading music from YouTube, you can use a desktop software that can do the same thing as an online converter, but with more options and reliability. Some of the best desktop software for downloading music from YouTube are [4K Video Downloader](^5^), [MediaHuman], [Freemake Video Downloader], and [aTube Catcher]. To use a desktop software, follow these steps:
-
-- Download and install the software on your computer.
-- Copy the URL of the YouTube video that contains the music you want to download.
-- Launch the software and paste the URL into the input box.
-- Select MP3 as the output format and choose the quality level and other settings.
-- Click the Download or Convert button and wait for the process to finish.
-- Find the MP3 file in your computer's folder and play it with any media player.
-
-Note that some desktop software may have ads, malware, or limitations in their free versions. You should also make sure that your computer meets the system requirements and has enough space for downloading large files.
- Using mobile apps
-If you want to download music from YouTube directly on your smartphone or tablet, you can use a mobile app that can do that for you. There are many mobile apps for both Android and iOS devices that can download music from YouTube, such as [SnapTube], [VidMate], [TubeMate], [Documents by Readdle], and [Musify]. To use a mobile app, follow these steps:
-
-- Download and install the app on your device.
-- Open the app and search for the YouTube video that contains the music you want to download.
-- Select MP3 as the output format and choose the quality level.
-- Tap the Download or Save button and wait for the process to finish.
-- Find the MP3 file in your device's folder and play it with any music player.
-
-Note that some mobile apps may not be available on Google Play Store or App Store due to policy violations. You may have to download them from third-party sources, which may pose security risks. You should also check the permissions and reviews of the apps before installing them.
- Conclusion
-In conclusion, downloading music from YouTube can be a great way to enjoy your favorite songs offline and for free. However, you should also be aware of the legal issues and precautions involved in doing so. You should only download music from YouTube that is allowed by the content owner or is in the public domain. You should also respect the rights of the artists and not use their music for commercial purposes or without giving them credit. You can use any of the methods mentioned above to download music from YouTube, such as online converters, desktop software, or mobile apps. However, you should also check the quality, size, and duration of the files before downloading them. You should also use a reliable and safe source for downloading the software or apps. We hope this article has helped you learn how to download Rayvanny ft Mr Blue's music from YouTube for free and legally. Enjoy their music and share it with your friends!
- FAQs
-Here are some frequently asked questions about downloading music from YouTube:
-
-- Is it illegal to download music from YouTube?
-It depends on the content and the source. Downloading music from YouTube that is not authorized by the content owner or is protected by DRM or watermark is illegal and may result in legal action or penalties. However, downloading music from YouTube that is in the public domain or is licensed under Creative Commons is legal and allowed.
-- What is the best format and quality for downloading music from YouTube?
-The best format for downloading music from YouTube is MP3, as it is compatible with most devices and media players. The best quality for downloading music from YouTube depends on your preference and device capacity. Generally, higher quality means larger file size and better sound clarity. You can choose from different quality levels, such as 128 kbps, 192 kbps, 256 kbps, or 320 kbps.
-- How can I download music from YouTube without ads?
-You can download music from YouTube without ads by using a software or app that can block or skip ads during the download process. Some of the software or apps that can do that are [AdBlock], [uBlock Origin], [YouTube Vanced], and [YouTube Premium]. However, you should also consider that ads are a source of income for the content creators and YouTube, so you should support them if you enjoy their work.
-- How can I download music from YouTube to my iPhone or iPad?
-You can download music from YouTube to your iPhone or iPad by using a mobile app that can do that for you. One of the best apps for iOS devices is [Documents by Readdle], which has a built-in browser and downloader that can access YouTube and save MP3 files to your device. You can also use other apps, such as [Musify], [MyMP3], or [Video to MP3 Converter]. However, you may have to transfer the files to your iTunes library or Music app to play them.
-- How can I download music from YouTube to my Android phone or tablet?
-You can download music from YouTube to your Android phone or tablet by using a mobile app that can do that for you. One of the best apps for Android devices is [SnapTube], which has a user-friendly interface and multiple features that can access YouTube and save MP3 files to your device. You can also use other apps, such as [VidMate], [TubeMate], or [YMusic]. However, you may have to enable unknown sources in your settings to install these apps.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Single ISO Link for GTA 5 Download on Google Drive - No Survey No Password.md b/spaces/congsaPfin/Manga-OCR/logs/Single ISO Link for GTA 5 Download on Google Drive - No Survey No Password.md
deleted file mode 100644
index 62e09721a195bd0e98f21e31e49b5aea912a4967..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Single ISO Link for GTA 5 Download on Google Drive - No Survey No Password.md
+++ /dev/null
@@ -1,119 +0,0 @@
-
-Download GTA 5 Google Drive (Single Link)
-If you are looking for a way to download one of the most popular and acclaimed video games of all time, Grand Theft Auto V, or GTA 5 for short, then you have come to the right place. In this article, we will show you how to download GTA 5 from Google Drive with a single link, without any hassle or risk. We will also tell you about the features and reviews of this amazing game, and why you should not miss this opportunity to experience it for yourself.
-Introduction
-What is GTA 5?
-GTA 5 is an action-adventure game developed by Rockstar North and published by Rockstar Games in 2013. It is the fifth main installment in the Grand Theft Auto series, which is known for its open-world design, crime-themed stories, and controversial content. GTA 5 is set in the fictional state of San Andreas, which is based on Southern California, and follows the lives of three criminals who team up to pull off a series of heists while under pressure from a corrupt government agency and powerful crime lords.
-download gta 5 google drive(single link)
Download Zip 🗹 https://urlca.com/2uO4Jo
-Why download GTA 5 from Google Drive?
-There are many reasons why you might want to download GTA 5 from Google Drive instead of buying it from other sources. Here are some of them:
-
-- You can save money. GTA 5 is not a cheap game, especially if you want to get the latest version with all the updates and DLCs. By downloading it from Google Drive, you can get it for free or for a very low price.
-- You can save time. GTA 5 is a huge game, with a file size of over 100 GB. Downloading it from other sites can take hours or even days, depending on your internet speed and bandwidth. By downloading it from Google Drive, you can get it faster and easier, with a single link that does not require any registration or verification.
-- You can avoid viruses and malware. Some sites that offer GTA 5 downloads may contain harmful files that can damage your computer or steal your personal information. By downloading it from Google Drive, you can be sure that the file is safe and clean, as Google scans all the files uploaded to its cloud service.
-
-How to download GTA 5 from Google Drive
-Step 1: Check your system requirements
-Before you download GTA 5 from Google Drive, you need to make sure that your computer can run it smoothly and without any issues. Here are the minimum and recommended system requirements for GTA 5:
-
-| Minimum System Requirements | Recommended System Requirements |
|---|
-OS: Windows 7 64 Bit Service Pack 1 or higher
Processor: Intel Core 2 Quad CPU Q6600 @ 2.40GHz (4 CPUs) / AMD Phenom 9850 Quad-Core Processor (4 CPUs) @ 2.5GHz or higher
Memory: 4 GB RAM or higher
Graphics: NVIDIA 9800 GT 1GB / AMD HD 4870 1GB (DX 10, 10.1, 11) or higher
Storage: 106 GB available space
Sound Card: 100% DirectX 10 compatible | OS: Windows 10
Processor: Intel Core i5-3470 @ 3.2GHz (4 CPUs) / AMD FX-8350 @4GHz (8 CPUs ) or higher
Memory: 8 GB RAM or higher
Graphics: NVIDIA GTX 660 2GB / AMD HD 7870 2GB or higher
Storage: 106 GB available space
Sound Card: 100% DirectX 10 compatible |
-
-If your computer meets the minimum system requirements, you can proceed to the next step. If not, you may need to upgrade your hardware or look for other options to play GTA 5.
-Step 2: Find a reliable Google Drive link
-The next step is to find a Google Drive link that contains the GTA 5 file that you can download. There are many sites that claim to offer such links, but not all of them are trustworthy or working. Some of them may be fake, broken, or expired. Some of them may also require you to complete surveys, enter passwords, or download additional software that may be harmful to your computer.
-To avoid these problems, you need to find a reliable Google Drive link that is verified and updated. One way to do this is to use a search engine like Bing and type in keywords like "GTA 5 Google Drive single link" or "GTA 5 Google Drive download". You can also use filters like "past month" or "past year" to narrow down your results. You can also check the comments and ratings of the sites that provide the links, and see if other users have successfully downloaded the game from them.
-Another way to find a reliable Google Drive link is to use a site that specializes in providing such links for various games and software. One example of such a site is [GDriveDL], which offers direct and fast downloads of GTA 5 and other popular games from Google Drive. You can also request for new links or report broken links on this site.
-Step 3: Download and install the game
-Once you have found a reliable Google Drive link, you can proceed to download and install the game on your computer. Here are the steps to follow:
-download gta 5 pc google drive single iso
-download gta 5 fitgirl repack google drive single link
-download gta 5 full version google drive single file
-download gta 5 highly compressed google drive single part
-download gta 5 crack google drive single direct link
-download gta 5 from google drive single click
-download gta 5 for windows 10 google drive single link
-download gta 5 for android google drive single apk
-download gta 5 for free google drive single link
-download gta 5 update google drive single patch
-download gta 5 online google drive single mode
-download gta 5 mod menu google drive single zip
-download gta 5 redux google drive single rar
-download gta 5 real life mod google drive single folder
-download gta 5 ultimate edition google drive single torrent
-download gta 5 setup google drive single exe
-download gta 5 trainer google drive single cheat
-download gta 5 dlc google drive single expansion
-download gta 5 soundtrack google drive single mp3
-download gta 5 wallpaper google drive single jpg
-download gta 5 script hook v google drive single dll
-download gta 5 save game google drive single data
-download gta 5 graphics mod google drive single enhancer
-download gta 5 zombie mod google drive single survival
-download gta 5 car mod google drive single vehicle
-download gta 5 map mod google drive single location
-download gta 5 skin mod google drive single character
-download gta 5 weapon mod google drive single gun
-download gta 5 police mod google drive single lspdfr
-download gta 5 iron man mod google drive single suit
-download gta 5 batman mod google drive single cape
-download gta 5 spiderman mod google drive single web
-download gta 5 superman mod google drive single fly
-download gta 5 hulk mod google drive single smash
-download gta 5 flash mod google drive single speed
-download gta 5 thor mod google drive single hammer
-download gta 5 captain america mod google drive single shield
-download gta 5 deadpool mod google drive single sword
-download gta 5 joker mod google drive single laugh
-download gta 5 harley quinn mod google drive single bat
-download gta 5 wonder woman mod google drive single lasso
-download gta 5 aquaman mod google drive single trident
-download gta 5 cyborg mod google drive single cannon
-download gta 5 green lantern mod google drive single ring
-download gta 5 black panther mod google drive single claw
-download gta 5 thanos mod google drive single gauntlet
-
-- Click on the Google Drive link and wait for it to load. You may need to sign in with your Google account if you are not already logged in.
-- Once the link opens, you will see a folder that contains the GTA 5 file. Right-click on the folder and select "Download". Alternatively, you can select the folder and click on the "Download" button at the top right corner of the screen.
-- A pop-up window will appear, asking you to confirm your download. Click on "Download anyway" and wait for the file to be compressed and prepared for download.
-- Another pop-up window will appear, asking you to save the file on your computer. Choose a location where you want to save the file, and click on "Save". The file will start downloading automatically.
-- The file size of GTA 5 is over 100 GB, so it may take a while for it to finish downloading, depending on your internet speed and bandwidth. You can check the progress of your download by looking at the status bar at the bottom of your browser window.
-- Once the file is downloaded, locate it on your computer and extract it using a software like WinRAR or 7-Zip. You will need a password to extract the file, which is usually provided by the site that gave you the link. If not, you can try some common passwords like "gdrivedl", "gdrive", or "1234".
-- After extracting the file, you will see a folder that contains the GTA 5 setup files. Open the folder and run the setup.exe file as an administrator. Follow the instructions on the screen to install the game on your computer.
-- You may need to install some additional software or drivers to run the game properly, such as DirectX, Visual C++, or Social Club. The setup will guide you through this process.
-- Once the installation is complete, you can launch the game from your desktop shortcut or start menu. Enjoy playing GTA 5!
-
-Features of GTA 5
-Stunning graphics and gameplay
-GTA 5 is one of the most visually impressive games ever made, with realistic graphics that showcase the beauty and diversity of San Andreas. The game features dynamic weather effects, day and night cycles, realistic shadows and reflections, and detailed textures and models. The game also runs smoothly and seamlessly, with no loading screens between different areas of the map.
-The gameplay of GTA 5 is also amazing, with a variety of activities and missions that keep you entertained and engaged. You can explore the vast open world by foot, car, bike, boat, plane, helicopter, or parachute. You can also customize your character's appearance, clothing, weapons, and vehicles. You can switch between the three protagonists at any time, each with their own skills, personalities, and stories. You can also interact with various NPCs, animals, and objects in the world, creating your own fun and chaos.
-Rich and diverse open world
-The open world of GTA 5 is one of the largest and most diverse in gaming history, with a map that covers over 80 square kilometers of land and water. The world is divided into several regions, each with its own unique landscape, culture, and atmosphere. You can visit the urban sprawl of Los Santos, the rural countryside of Blaine County, the desert of Grand Senora, the mountains of Chiliad, the beaches of Vespucci, and more.
-The world of GTA 5 is also full of life and detail, with hundreds of landmarks, buildings, shops, restaurants, clubs, bars, cinemas, museums, parks, and more. You can also find various hidden secrets, easter eggs, collectibles, and random events that add to the immersion and replay value of the game. You can also participate in various side activities and mini-games, such as golf, tennis, yoga, darts, hunting, racing, gambling, and more.
-Engaging and satirical story
-The story of GTA 5 is one of the most engaging and satirical in the series, with a plot that mixes humor, drama, action, and social commentary. The story follows the lives of three criminals who team up to pull off a series of heists while under pressure from a corrupt government agency and powerful crime lords. The story also explores various themes and issues that are relevant to modern society, such as capitalism, consumerism, media, politics, morality, family, friendship, loyalty, betrayal, violence, and more.
-The story of GTA 5 is also nonlinear and dynamic, with multiple choices and outcomes that affect the course of events and the fate of the characters. You can also influence the story by your actions and decisions in the game world. For example, you can choose how to approach a mission or a heist, who to recruit or kill, how to spend or invest your money, and more. The story of GTA 5 is also full of memorable characters, dialogues, and scenes that will make you laugh, cry, or think.
-Online multiplayer mode
-GTA 5 also features an online multiplayer mode called GTA Online, which allows you to create your own character and join other players in the same world. You can cooperate or compete with other players in various missions, heists, races, deathmatches, and more. You can also customize your character's appearance, clothing, weapons, vehicles, properties, businesses, and more. You can also join or create your own crews, which are groups of players that share a common identity and objectives.
-GTA Online is constantly updated and expanded with new content and features, such as new modes, maps, vehicles, weapons, items, events, and more. You can also access GTA Online from the single-player mode by switching to your online character at any time.
-Reviews of GTA 5
-Critics' opinions
-GTA 5 has received universal acclaim from critics, who praised its graphics, gameplay, story, characters, humor, and online mode. The game has a score of 97 out of 100 on Metacritic, which aggregates reviews from various sources. The game has also won numerous awards and accolades, such as Game of the Year, Best Action-Adventure Game, Best Game Design, Best Soundtrack, and more.
-Players' feedback
-GTA 5 has also been well-received by players, who enjoyed its immersive and diverse world, its fun and varied missions and activities, its engaging and satirical story and characters, and its online multiplayer mode. The game has a user score of 8.3 out of 10 on Metacritic, which reflects the opinions of thousands of players. The game has also sold over 150 million copies worldwide, making it one of the best-selling and most-played games of all time.
-Conclusion
-Summary of the main points
-In conclusion, GTA 5 is a game that you should not miss, whether you are a fan of the series or not. It is a game that offers you a stunning and realistic graphics, a rich and diverse open world, a fun and varied gameplay, an engaging and satirical story, and an online multiplayer mode. It is a game that you can download from Google Drive with a single link, without any hassle or risk. It is a game that you can enjoy for hours and hours, alone or with friends.
-Call to action
-So what are you waiting for? Download GTA 5 from Google Drive today and join the millions of players who have already experienced this amazing game. You will not regret it!
-FAQs
-Here are some frequently asked questions about GTA 5 and Google Drive:
-
-- Q: Is GTA 5 free on Google Drive?
A: No, GTA 5 is not free on Google Drive. You still need to pay for the game or find a link that offers it for a low price. However, downloading it from Google Drive can save you money compared to buying it from other sources.
-- Q: Is GTA 5 safe to download from Google Drive?
A: Yes, GTA 5 is safe to download from Google Drive, as long as you find a reliable and verified link. Google scans all the files uploaded to its cloud service, so you can be sure that the file is clean and virus-free.
-- Q: How long does it take to download GTA 5 from Google Drive?
A: The time it takes to download GTA 5 from Google Drive depends on your internet speed and bandwidth. The file size of GTA 5 is over 100 GB, so it may take several hours or even days to finish downloading. However, downloading it from Google Drive can be faster and easier than downloading it from other sites.
-- Q: Can I play GTA 5 offline after downloading it from Google Drive?
A: Yes, you can play GTA 5 offline after downloading it from Google Drive. You only need an internet connection to download and install the game. After that, you can play the single-player mode without any internet connection. However, you will need an internet connection to play the online multiplayer mode or to access some online features.
-- Q: Can I play GTA 5 online with other players who downloaded it from Google Drive?
A: Yes, you can play GTA 5 online with other players who downloaded it from Google Drive. You can join or create your own sessions, crews, and matches with other players who have the same version of the game as you. However, you may not be able to play with players who bought the game from other sources or have different versions of the game.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Word Search Fun Download Hundreds of PDF Puzzles on Various Topics.md b/spaces/congsaPfin/Manga-OCR/logs/Word Search Fun Download Hundreds of PDF Puzzles on Various Topics.md
deleted file mode 100644
index 25d886481c9fb213ef06dba1cf933e4d881e21cb..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Word Search Fun Download Hundreds of PDF Puzzles on Various Topics.md
+++ /dev/null
@@ -1,144 +0,0 @@
-
-Word Search PDF Download: How to Find and Print Fun Puzzles Online
-Do you love word games? Do you enjoy finding hidden words in a grid of letters? If so, you might be interested in word search puzzles. Word search puzzles are a great way to exercise your brain, improve your vocabulary, and have fun at the same time. In this article, we will show you how to find and print word search puzzles online, using PDF files. We will also give you some tips on how to save paper and ink when printing word search puzzles.
-word search pdf download
Download » https://urlca.com/2uOc7L
- What is a word search puzzle?
-A word search puzzle is a type of puzzle where you have to find words hidden in a grid of letters. The words can be arranged horizontally, vertically, or diagonally, in both directions. The words can also be related to a certain theme, such as animals, food, or sports. Usually, there is a list of words that you have to find in the grid. Sometimes, there is no list, and you have to figure out the words by yourself.
- The benefits of doing word search puzzles
-Doing word search puzzles can have many benefits for your brain and your well-being. Here are some of them:
-
-- Word search puzzles can improve your spelling, vocabulary, and reading skills. By finding words in the grid, you can learn new words, their meanings, and their spellings.
-- Word search puzzles can enhance your memory and concentration. By scanning the grid for words, you can train your brain to focus and recall information.
-- Word search puzzles can reduce stress and boredom. By solving word search puzzles, you can relax your mind and have fun at the same time.
-
- The types of word search puzzles
-There are many types of word search puzzles that you can choose from, depending on your preference and skill level. Here are some examples:
-
-- Easy word search puzzles: These are suitable for beginners or children. They have fewer words, larger grids, and simpler themes.
-- Hard word search puzzles: These are suitable for advanced or adult players. They have more words, smaller grids, and more complex themes.
-- Themed word search puzzles: These are based on a specific topic or category, such as animals, holidays, or movies.
-- Crossword-style word search puzzles: These are similar to crossword puzzles, but instead of clues, you have to find words that fit the given pattern.
-- Hidden message word search puzzles: These are puzzles where the unused letters in the grid form a secret message or a phrase.
-
- How to find word search puzzles online
-If you want to find word search puzzles online, you have two options: You can either download and print them as PDF files, or you can play them directly on your computer or mobile device. Here are some of the best websites for both options:
-printable word search puzzles pdf
-free word search pdf download
-word search maker pdf download
-word search generator pdf download
-word search books pdf download
-easy word search pdf download
-hard word search pdf download
-word search for kids pdf download
-word search for adults pdf download
-word search themes pdf download
-word search worksheets pdf download
-word search games pdf download
-word search online pdf download
-word search solutions pdf download
-word search answers pdf download
-word search categories pdf download
-word search topics pdf download
-word search levels pdf download
-word search difficulty pdf download
-word search fun pdf download
-word search challenge pdf download
-word search activity pdf download
-word search printables pdf download
-word search templates pdf download
-word search formats pdf download
-word search styles pdf download
-word search designs pdf download
-word search variations pdf download
-word search types pdf download
-word search examples pdf download
-word search samples pdf download
-word search resources pdf download
-word search collections pdf download
-word search sets pdf download
-word search packs pdf download
-word search bundles pdf download
-word search editions pdf download
-word search series pdf download
-word search groups pdf download
-word search lists pdf download
-large print word search pdf download
-small print word search pdf download
-color word search pdf download
-black and white word search pdf download
-holiday word search pdf download
-seasonal word search pdf download
-educational word search pdf download
-entertaining word search pdf download
-relaxing word search pdf download
-brainy word search pdf download
- The best websites for printable word search puzzles
-If you prefer to print out your word search puzzles and solve them on paper, here are some of the best websites that offer free printable word search puzzles:
-
-- The Word Search: This website has hundreds of printable word search puzzles in various categories and difficulty levels. You can download them as PDF or image files.
-- Reader's Digest: This website has 26 free printable word search puzzles on different topics. You can download them as PDF files.
-- World of Printables: This website has a large collection of printable word search puzzles on various themes and occasions. You can download them as PDF files.
-- Puzzles to Print: This website has dozens of printable word search puzzles for kids and adults. You can download them as PDF files.
-
- The best websites for online word search puzzles
-If you prefer to play word search puzzles online, without downloading or printing anything, here are some of the best websites that offer free online word search puzzles:
-
-- ProProfs Word Search Puzzles: This website has thousands of online word search puzzles in various categories and difficulty levels. You can also create your own word search puzzles and share them with others.
-- Word Search Fun: This website has hundreds of online word search puzzles on different topics. You can also make your own word search puzzles and print them as PDF files.
-- Word Search Addict: This website has over 400 online word search puzzles on various themes and genres. You can also submit your own word search puzzles and play them online.
-
- How to print word search puzzles from PDF files
-If you have downloaded word search puzzles as PDF files, you might want to print them out and solve them on paper. Here are the steps to print word search puzzles from PDF files:
- The steps to print word search puzzles from PDF files
-
-- Open the PDF file of the word search puzzle on your computer or mobile device.
-- Click on the print icon or go to the file menu and select print.
-- Choose the printer that you want to use and adjust the settings according to your preference. For example, you can choose the paper size, orientation, margins, and quality.
-- Click on print or OK to start printing the word search puzzle.
-- Repeat the process for any other word search puzzles that you want to print.
-
- The tips to save paper and ink when printing word search puzzles
-Printing word search puzzles can use up a lot of paper and ink, especially if you print many of them. Here are some tips to save paper and ink when printing word search puzzles:
-
-- Print only the puzzles that you want to solve. You don't have to print all the puzzles that you download or find online.
-- Print in black and white or grayscale mode. This will save ink and make the words easier to see.
-- Print multiple puzzles on one page. You can use the layout or scale options in your printer settings to fit more than one puzzle on a single sheet of paper.
-- Use recycled or scrap paper. You can reuse paper that has been printed on one side or that you don't need anymore.
-- Use a pencil or erasable pen to solve the puzzles. This way, you can erase your answers and reuse the same puzzle again.
-
- Conclusion
-Word search puzzles are a fun and educational way to spend your time. You can find and print word search puzzles online, using PDF files. You can also play word search puzzles online, without downloading or printing anything. You can choose from different types of word search puzzles, depending on your preference and skill level. You can also save paper and ink when printing word search puzzles, by following some simple tips. We hope you enjoyed this article and learned something new. Happy puzzling!
- Summary of the main points
-
-- A word search puzzle is a type of puzzle where you have to find words hidden in a grid of letters.
-- Doing word search puzzles can improve your spelling, vocabulary, memory, concentration, and stress relief.
-- There are many types of word search puzzles, such as easy, hard, themed, crossword-style, and hidden message ones.
-- You can find printable word search puzzles on websites like The Word Search, Reader's Digest, World of Printables, and Puzzles to Print.
-- You can find online word search puzzles on websites like ProProfs Word Search Puzzles, Word Search Fun, and Word Search Addict.
-- You can print word search puzzles from PDF files by opening the file, clicking on print, choosing the printer and settings, and clicking on print again.
-- You can save paper and ink when printing word search puzzles by printing only what you need, printing in black and white or grayscale mode, printing multiple puzzles on one page, using recycled or scrap paper, and using a pencil or erasable pen to solve the puzzles.
-
- Call to action
-If you liked this article, please share it with your friends and family who might also enjoy word search puzzles. You can also leave a comment below and let us know what you think. Do you have any favorite word search puzzles or websites that you use? Do you have any tips or tricks for solving word search puzzles? We would love to hear from you!
- FAQs
-Here are some of the frequently asked questions about word search puzzles and their answers:
-
-- What is the origin of word search puzzles?
-Word search puzzles are believed to have originated in the 1960s, when Norman E. Gibat published a puzzle in the Selenby Digest, a small newspaper in Oklahoma. The puzzle was a 10x10 grid with words related to the American Civil War. The puzzle became popular and Gibat continued to publish more puzzles in his newspaper.
-- How do you make your own word search puzzles?
-You can make your own word search puzzles using online tools or software, such as ProProfs Word Search Maker, Word Search Generator, or Word Search Creator. You can also make your own word search puzzles by hand, using a pencil and paper. You just need to write down a list of words that you want to include in your puzzle, and then fill in a grid of letters with those words. You can also add some random letters to make the puzzle more challenging.
-- How do you solve word search puzzles?
-You can solve word search puzzles by scanning the grid of letters for words that match the given list or theme. You can use different strategies, such as looking for the first or last letter of a word, looking for common letter combinations, or looking for words that cross each other. You can also use a highlighter, a pen, or a finger to mark the words that you find.
-- What are some of the variations of word search puzzles?
-Some of the variations of word search puzzles are:
-
-- Reverse word search puzzles: These are puzzles where you have to find the words that are spelled backwards in the grid.
-- Circular word search puzzles: These are puzzles where the words are arranged in a circular shape, instead of a square or rectangular one.
-- Word fit puzzles: These are puzzles where you have to fit the words into a crossword-like grid, without any clues.
-- Word jumble puzzles: These are puzzles where you have to unscramble the letters in the grid to form words.
-
-- Where can I find more information about word search puzzles?
-You can find more information about word search puzzles on websites like Wikipedia, How Stuff Works, and Puzzle Club. You can also find books, magazines, and apps that feature word search puzzles on Amazon, Barnes & Noble, and Google Play.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git "a/spaces/contluForse/HuggingGPT/Download Country Homes Interiors \302\200? April 2020 (.PDF).md" "b/spaces/contluForse/HuggingGPT/Download Country Homes Interiors \302\200? April 2020 (.PDF).md"
deleted file mode 100644
index 2d87734decc45821a736a3ae68ee7c8a0f6931d5..0000000000000000000000000000000000000000
--- "a/spaces/contluForse/HuggingGPT/Download Country Homes Interiors \302\200? April 2020 (.PDF).md"
+++ /dev/null
@@ -1,98 +0,0 @@
-## Download Country Homes Interiors ? April 2020 (.PDF)
-
-
-
-
-
-
-
-
-
-**LINK ————— [https://riszurachen.blogspot.com/?d=2txoG7](https://riszurachen.blogspot.com/?d=2txoG7)**
-
-
-
-
-
-
-
-
-
-
-
-
-
-# How to Download Country Homes Interiors â April 2020 (.PDF) for Free
-
-
-
-If you are looking for a magazine that showcases the best of British country living, you might want to check out Country Homes Interiors. This monthly publication features inspiring stories, beautiful photography, and practical tips on how to create your own cozy and stylish country home.
-
-
-
-In this article, we will show you how to download Country Homes Interiors â April 2020 (.PDF) for free. This issue is packed with ideas on how to refresh your home for spring, from floral fabrics and wallpapers to rustic furniture and accessories. You will also find some delicious recipes, gardening advice, and travel suggestions for your next country getaway.
-
-
-
-## Why Download Country Homes Interiors â April 2020 (.PDF)?
-
-
-
-There are many reasons why you might want to download Country Homes Interiors â April 2020 (.PDF) for free. Here are some of them:
-
-
-
-- You can save money by not buying the print version of the magazine.
-
-- You can access the magazine anytime and anywhere on your computer, tablet, or smartphone.
-
-- You can zoom in and out of the pages for better readability.
-
-- You can print out your favorite pages or articles for future reference.
-
-- You can share the magazine with your friends and family via email or social media.
-
-
-
-## How to Download Country Homes Interiors â April 2020 (.PDF) for Free?
-
-
-
-There are many websites that offer free downloads of magazines in PDF format. However, not all of them are safe and reliable. Some of them may contain viruses, malware, or pop-up ads that can harm your device or compromise your privacy.
-
-
-
-That's why we recommend you to use a trusted and reputable website like [PDFMagazines.org](https://www.pdfmagazines.org/). This website has a huge collection of magazines from various categories and countries. You can browse through their catalog or use their search function to find the magazine you want.
-
-
-
-To download Country Homes Interiors â April 2020 (.PDF) for free from PDFMagazines.org, follow these simple steps:
-
-
-
-1. Go to [PDFMagazines.org](https://www.pdfmagazines.org/) and type "Country Homes Interiors" in the search box.
-
-2. Select the issue you want from the results. In this case, click on "Country Homes Interiors â April 2020".
-
-3. On the next page, click on the green "Download" button.
-
-4. You will be redirected to a file hosting service like Turbobit or Nitroflare. Choose one of them and follow their instructions to download the file.
-
-5. Once the download is complete, open the file with a PDF reader like Adobe Acrobat or Foxit Reader.
-
-6. Enjoy reading your free copy of Country Homes Interiors â April 2020 (.PDF)!
-
-
-
-## Conclusion
-
-
-
-Country Homes Interiors is a great magazine for anyone who loves country living and decorating. You can download Country Homes Interiors â April 2020 (.PDF) for free from PDFMagazines.org and enjoy reading it on your preferred device. We hope you found this article helpful and informative. If you have any questions or feedback, please leave a comment below. Thank you for reading!
-
- 1b8d091108
-
-
-
-
-
diff --git a/spaces/cooelf/Multimodal-CoT/timm/models/layers/weight_init.py b/spaces/cooelf/Multimodal-CoT/timm/models/layers/weight_init.py
deleted file mode 100644
index 305a2fd067e7104e58b9b5ff70d96e89a06050af..0000000000000000000000000000000000000000
--- a/spaces/cooelf/Multimodal-CoT/timm/models/layers/weight_init.py
+++ /dev/null
@@ -1,89 +0,0 @@
-import torch
-import math
-import warnings
-
-from torch.nn.init import _calculate_fan_in_and_fan_out
-
-
-def _no_grad_trunc_normal_(tensor, mean, std, a, b):
- # Cut & paste from PyTorch official master until it's in a few official releases - RW
- # Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
- def norm_cdf(x):
- # Computes standard normal cumulative distribution function
- return (1. + math.erf(x / math.sqrt(2.))) / 2.
-
- if (mean < a - 2 * std) or (mean > b + 2 * std):
- warnings.warn("mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
- "The distribution of values may be incorrect.",
- stacklevel=2)
-
- with torch.no_grad():
- # Values are generated by using a truncated uniform distribution and
- # then using the inverse CDF for the normal distribution.
- # Get upper and lower cdf values
- l = norm_cdf((a - mean) / std)
- u = norm_cdf((b - mean) / std)
-
- # Uniformly fill tensor with values from [l, u], then translate to
- # [2l-1, 2u-1].
- tensor.uniform_(2 * l - 1, 2 * u - 1)
-
- # Use inverse cdf transform for normal distribution to get truncated
- # standard normal
- tensor.erfinv_()
-
- # Transform to proper mean, std
- tensor.mul_(std * math.sqrt(2.))
- tensor.add_(mean)
-
- # Clamp to ensure it's in the proper range
- tensor.clamp_(min=a, max=b)
- return tensor
-
-
-def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
- # type: (Tensor, float, float, float, float) -> Tensor
- r"""Fills the input Tensor with values drawn from a truncated
- normal distribution. The values are effectively drawn from the
- normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
- with values outside :math:`[a, b]` redrawn until they are within
- the bounds. The method used for generating the random values works
- best when :math:`a \leq \text{mean} \leq b`.
- Args:
- tensor: an n-dimensional `torch.Tensor`
- mean: the mean of the normal distribution
- std: the standard deviation of the normal distribution
- a: the minimum cutoff value
- b: the maximum cutoff value
- Examples:
- >>> w = torch.empty(3, 5)
- >>> nn.init.trunc_normal_(w)
- """
- return _no_grad_trunc_normal_(tensor, mean, std, a, b)
-
-
-def variance_scaling_(tensor, scale=1.0, mode='fan_in', distribution='normal'):
- fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
- if mode == 'fan_in':
- denom = fan_in
- elif mode == 'fan_out':
- denom = fan_out
- elif mode == 'fan_avg':
- denom = (fan_in + fan_out) / 2
-
- variance = scale / denom
-
- if distribution == "truncated_normal":
- # constant is stddev of standard normal truncated to (-2, 2)
- trunc_normal_(tensor, std=math.sqrt(variance) / .87962566103423978)
- elif distribution == "normal":
- tensor.normal_(std=math.sqrt(variance))
- elif distribution == "uniform":
- bound = math.sqrt(3 * variance)
- tensor.uniform_(-bound, bound)
- else:
- raise ValueError(f"invalid distribution {distribution}")
-
-
-def lecun_normal_(tensor):
- variance_scaling_(tensor, mode='fan_in', distribution='truncated_normal')
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/configs/_base_/datasets/cityscapes.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/configs/_base_/datasets/cityscapes.py
deleted file mode 100644
index f21867c63e1835f6fceb61f066e802fd8fd2a735..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/configs/_base_/datasets/cityscapes.py
+++ /dev/null
@@ -1,54 +0,0 @@
-# dataset settings
-dataset_type = 'CityscapesDataset'
-data_root = 'data/cityscapes/'
-img_norm_cfg = dict(
- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
-crop_size = (512, 1024)
-train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadAnnotations'),
- dict(type='Resize', img_scale=(2048, 1024), ratio_range=(0.5, 2.0)),
- dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
- dict(type='RandomFlip', prob=0.5),
- dict(type='PhotoMetricDistortion'),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
- dict(type='DefaultFormatBundle'),
- dict(type='Collect', keys=['img', 'gt_semantic_seg']),
-]
-test_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(
- type='MultiScaleFlipAug',
- img_scale=(2048, 1024),
- # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
- flip=False,
- transforms=[
- dict(type='Resize', keep_ratio=True),
- dict(type='RandomFlip'),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='ImageToTensor', keys=['img']),
- dict(type='Collect', keys=['img']),
- ])
-]
-data = dict(
- samples_per_gpu=2,
- workers_per_gpu=2,
- train=dict(
- type=dataset_type,
- data_root=data_root,
- img_dir='leftImg8bit/train',
- ann_dir='gtFine/train',
- pipeline=train_pipeline),
- val=dict(
- type=dataset_type,
- data_root=data_root,
- img_dir='leftImg8bit/val',
- ann_dir='gtFine/val',
- pipeline=test_pipeline),
- test=dict(
- type=dataset_type,
- data_root=data_root,
- img_dir='leftImg8bit/val',
- ann_dir='gtFine/val',
- pipeline=test_pipeline))
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/runner/builder.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/runner/builder.py
deleted file mode 100644
index 77c96ba0b2f30ead9da23f293c5dc84dd3e4a74f..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/runner/builder.py
+++ /dev/null
@@ -1,24 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-
-from ..utils import Registry
-
-RUNNERS = Registry('runner')
-RUNNER_BUILDERS = Registry('runner builder')
-
-
-def build_runner_constructor(cfg):
- return RUNNER_BUILDERS.build(cfg)
-
-
-def build_runner(cfg, default_args=None):
- runner_cfg = copy.deepcopy(cfg)
- constructor_type = runner_cfg.pop('constructor',
- 'DefaultRunnerConstructor')
- runner_constructor = build_runner_constructor(
- dict(
- type=constructor_type,
- runner_cfg=runner_cfg,
- default_args=default_args))
- runner = runner_constructor()
- return runner
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/video/optflow.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/video/optflow.py
deleted file mode 100644
index 84160f8d6ef9fceb5a2f89e7481593109fc1905d..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/video/optflow.py
+++ /dev/null
@@ -1,254 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import warnings
-
-import cv2
-import numpy as np
-
-from annotator.uniformer.mmcv.arraymisc import dequantize, quantize
-from annotator.uniformer.mmcv.image import imread, imwrite
-from annotator.uniformer.mmcv.utils import is_str
-
-
-def flowread(flow_or_path, quantize=False, concat_axis=0, *args, **kwargs):
- """Read an optical flow map.
-
- Args:
- flow_or_path (ndarray or str): A flow map or filepath.
- quantize (bool): whether to read quantized pair, if set to True,
- remaining args will be passed to :func:`dequantize_flow`.
- concat_axis (int): The axis that dx and dy are concatenated,
- can be either 0 or 1. Ignored if quantize is False.
-
- Returns:
- ndarray: Optical flow represented as a (h, w, 2) numpy array
- """
- if isinstance(flow_or_path, np.ndarray):
- if (flow_or_path.ndim != 3) or (flow_or_path.shape[-1] != 2):
- raise ValueError(f'Invalid flow with shape {flow_or_path.shape}')
- return flow_or_path
- elif not is_str(flow_or_path):
- raise TypeError(f'"flow_or_path" must be a filename or numpy array, '
- f'not {type(flow_or_path)}')
-
- if not quantize:
- with open(flow_or_path, 'rb') as f:
- try:
- header = f.read(4).decode('utf-8')
- except Exception:
- raise IOError(f'Invalid flow file: {flow_or_path}')
- else:
- if header != 'PIEH':
- raise IOError(f'Invalid flow file: {flow_or_path}, '
- 'header does not contain PIEH')
-
- w = np.fromfile(f, np.int32, 1).squeeze()
- h = np.fromfile(f, np.int32, 1).squeeze()
- flow = np.fromfile(f, np.float32, w * h * 2).reshape((h, w, 2))
- else:
- assert concat_axis in [0, 1]
- cat_flow = imread(flow_or_path, flag='unchanged')
- if cat_flow.ndim != 2:
- raise IOError(
- f'{flow_or_path} is not a valid quantized flow file, '
- f'its dimension is {cat_flow.ndim}.')
- assert cat_flow.shape[concat_axis] % 2 == 0
- dx, dy = np.split(cat_flow, 2, axis=concat_axis)
- flow = dequantize_flow(dx, dy, *args, **kwargs)
-
- return flow.astype(np.float32)
-
-
-def flowwrite(flow, filename, quantize=False, concat_axis=0, *args, **kwargs):
- """Write optical flow to file.
-
- If the flow is not quantized, it will be saved as a .flo file losslessly,
- otherwise a jpeg image which is lossy but of much smaller size. (dx and dy
- will be concatenated horizontally into a single image if quantize is True.)
-
- Args:
- flow (ndarray): (h, w, 2) array of optical flow.
- filename (str): Output filepath.
- quantize (bool): Whether to quantize the flow and save it to 2 jpeg
- images. If set to True, remaining args will be passed to
- :func:`quantize_flow`.
- concat_axis (int): The axis that dx and dy are concatenated,
- can be either 0 or 1. Ignored if quantize is False.
- """
- if not quantize:
- with open(filename, 'wb') as f:
- f.write('PIEH'.encode('utf-8'))
- np.array([flow.shape[1], flow.shape[0]], dtype=np.int32).tofile(f)
- flow = flow.astype(np.float32)
- flow.tofile(f)
- f.flush()
- else:
- assert concat_axis in [0, 1]
- dx, dy = quantize_flow(flow, *args, **kwargs)
- dxdy = np.concatenate((dx, dy), axis=concat_axis)
- imwrite(dxdy, filename)
-
-
-def quantize_flow(flow, max_val=0.02, norm=True):
- """Quantize flow to [0, 255].
-
- After this step, the size of flow will be much smaller, and can be
- dumped as jpeg images.
-
- Args:
- flow (ndarray): (h, w, 2) array of optical flow.
- max_val (float): Maximum value of flow, values beyond
- [-max_val, max_val] will be truncated.
- norm (bool): Whether to divide flow values by image width/height.
-
- Returns:
- tuple[ndarray]: Quantized dx and dy.
- """
- h, w, _ = flow.shape
- dx = flow[..., 0]
- dy = flow[..., 1]
- if norm:
- dx = dx / w # avoid inplace operations
- dy = dy / h
- # use 255 levels instead of 256 to make sure 0 is 0 after dequantization.
- flow_comps = [
- quantize(d, -max_val, max_val, 255, np.uint8) for d in [dx, dy]
- ]
- return tuple(flow_comps)
-
-
-def dequantize_flow(dx, dy, max_val=0.02, denorm=True):
- """Recover from quantized flow.
-
- Args:
- dx (ndarray): Quantized dx.
- dy (ndarray): Quantized dy.
- max_val (float): Maximum value used when quantizing.
- denorm (bool): Whether to multiply flow values with width/height.
-
- Returns:
- ndarray: Dequantized flow.
- """
- assert dx.shape == dy.shape
- assert dx.ndim == 2 or (dx.ndim == 3 and dx.shape[-1] == 1)
-
- dx, dy = [dequantize(d, -max_val, max_val, 255) for d in [dx, dy]]
-
- if denorm:
- dx *= dx.shape[1]
- dy *= dx.shape[0]
- flow = np.dstack((dx, dy))
- return flow
-
-
-def flow_warp(img, flow, filling_value=0, interpolate_mode='nearest'):
- """Use flow to warp img.
-
- Args:
- img (ndarray, float or uint8): Image to be warped.
- flow (ndarray, float): Optical Flow.
- filling_value (int): The missing pixels will be set with filling_value.
- interpolate_mode (str): bilinear -> Bilinear Interpolation;
- nearest -> Nearest Neighbor.
-
- Returns:
- ndarray: Warped image with the same shape of img
- """
- warnings.warn('This function is just for prototyping and cannot '
- 'guarantee the computational efficiency.')
- assert flow.ndim == 3, 'Flow must be in 3D arrays.'
- height = flow.shape[0]
- width = flow.shape[1]
- channels = img.shape[2]
-
- output = np.ones(
- (height, width, channels), dtype=img.dtype) * filling_value
-
- grid = np.indices((height, width)).swapaxes(0, 1).swapaxes(1, 2)
- dx = grid[:, :, 0] + flow[:, :, 1]
- dy = grid[:, :, 1] + flow[:, :, 0]
- sx = np.floor(dx).astype(int)
- sy = np.floor(dy).astype(int)
- valid = (sx >= 0) & (sx < height - 1) & (sy >= 0) & (sy < width - 1)
-
- if interpolate_mode == 'nearest':
- output[valid, :] = img[dx[valid].round().astype(int),
- dy[valid].round().astype(int), :]
- elif interpolate_mode == 'bilinear':
- # dirty walkround for integer positions
- eps_ = 1e-6
- dx, dy = dx + eps_, dy + eps_
- left_top_ = img[np.floor(dx[valid]).astype(int),
- np.floor(dy[valid]).astype(int), :] * (
- np.ceil(dx[valid]) - dx[valid])[:, None] * (
- np.ceil(dy[valid]) - dy[valid])[:, None]
- left_down_ = img[np.ceil(dx[valid]).astype(int),
- np.floor(dy[valid]).astype(int), :] * (
- dx[valid] - np.floor(dx[valid]))[:, None] * (
- np.ceil(dy[valid]) - dy[valid])[:, None]
- right_top_ = img[np.floor(dx[valid]).astype(int),
- np.ceil(dy[valid]).astype(int), :] * (
- np.ceil(dx[valid]) - dx[valid])[:, None] * (
- dy[valid] - np.floor(dy[valid]))[:, None]
- right_down_ = img[np.ceil(dx[valid]).astype(int),
- np.ceil(dy[valid]).astype(int), :] * (
- dx[valid] - np.floor(dx[valid]))[:, None] * (
- dy[valid] - np.floor(dy[valid]))[:, None]
- output[valid, :] = left_top_ + left_down_ + right_top_ + right_down_
- else:
- raise NotImplementedError(
- 'We only support interpolation modes of nearest and bilinear, '
- f'but got {interpolate_mode}.')
- return output.astype(img.dtype)
-
-
-def flow_from_bytes(content):
- """Read dense optical flow from bytes.
-
- .. note::
- This load optical flow function works for FlyingChairs, FlyingThings3D,
- Sintel, FlyingChairsOcc datasets, but cannot load the data from
- ChairsSDHom.
-
- Args:
- content (bytes): Optical flow bytes got from files or other streams.
-
- Returns:
- ndarray: Loaded optical flow with the shape (H, W, 2).
- """
-
- # header in first 4 bytes
- header = content[:4]
- if header.decode('utf-8') != 'PIEH':
- raise Exception('Flow file header does not contain PIEH')
- # width in second 4 bytes
- width = np.frombuffer(content[4:], np.int32, 1).squeeze()
- # height in third 4 bytes
- height = np.frombuffer(content[8:], np.int32, 1).squeeze()
- # after first 12 bytes, all bytes are flow
- flow = np.frombuffer(content[12:], np.float32, width * height * 2).reshape(
- (height, width, 2))
-
- return flow
-
-
-def sparse_flow_from_bytes(content):
- """Read the optical flow in KITTI datasets from bytes.
-
- This function is modified from RAFT load the `KITTI datasets
- `_.
-
- Args:
- content (bytes): Optical flow bytes got from files or other streams.
-
- Returns:
- Tuple(ndarray, ndarray): Loaded optical flow with the shape (H, W, 2)
- and flow valid mask with the shape (H, W).
- """ # nopa
-
- content = np.frombuffer(content, np.uint8)
- flow = cv2.imdecode(content, cv2.IMREAD_ANYDEPTH | cv2.IMREAD_COLOR)
- flow = flow[:, :, ::-1].astype(np.float32)
- # flow shape (H, W, 2) valid shape (H, W)
- flow, valid = flow[:, :, :2], flow[:, :, 2]
- flow = (flow - 2**15) / 64.0
- return flow, valid
diff --git a/spaces/crashedice/signify/signify/gan/util/get_data.py b/spaces/crashedice/signify/signify/gan/util/get_data.py
deleted file mode 100644
index 97edc3ce3c3ab6d6080dca34e73a5fb77bb715fb..0000000000000000000000000000000000000000
--- a/spaces/crashedice/signify/signify/gan/util/get_data.py
+++ /dev/null
@@ -1,110 +0,0 @@
-from __future__ import print_function
-import os
-import tarfile
-import requests
-from warnings import warn
-from zipfile import ZipFile
-from bs4 import BeautifulSoup
-from os.path import abspath, isdir, join, basename
-
-
-class GetData(object):
- """A Python script for downloading CycleGAN or pix2pix datasets.
-
- Parameters:
- technique (str) -- One of: 'cyclegan' or 'pix2pix'.
- verbose (bool) -- If True, print additional information.
-
- Examples:
- >>> from util.get_data import GetData
- >>> gd = GetData(technique='cyclegan')
- >>> new_data_path = gd.get(save_path='./datasets') # options will be displayed.
-
- Alternatively, You can use bash scripts: 'scripts/download_pix2pix_model.sh'
- and 'scripts/download_cyclegan_model.sh'.
- """
-
- def __init__(self, technique='cyclegan', verbose=True):
- url_dict = {
- 'pix2pix': 'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/',
- 'cyclegan': 'https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets'
- }
- self.url = url_dict.get(technique.lower())
- self._verbose = verbose
-
- def _print(self, text):
- if self._verbose:
- print(text)
-
- @staticmethod
- def _get_options(r):
- soup = BeautifulSoup(r.text, 'lxml')
- options = [h.text for h in soup.find_all('a', href=True)
- if h.text.endswith(('.zip', 'tar.gz'))]
- return options
-
- def _present_options(self):
- r = requests.get(self.url)
- options = self._get_options(r)
- print('Options:\n')
- for i, o in enumerate(options):
- print("{0}: {1}".format(i, o))
- choice = input("\nPlease enter the number of the "
- "dataset above you wish to download:")
- return options[int(choice)]
-
- def _download_data(self, dataset_url, save_path):
- if not isdir(save_path):
- os.makedirs(save_path)
-
- base = basename(dataset_url)
- temp_save_path = join(save_path, base)
-
- with open(temp_save_path, "wb") as f:
- r = requests.get(dataset_url)
- f.write(r.content)
-
- if base.endswith('.tar.gz'):
- obj = tarfile.open(temp_save_path)
- elif base.endswith('.zip'):
- obj = ZipFile(temp_save_path, 'r')
- else:
- raise ValueError("Unknown File Type: {0}.".format(base))
-
- self._print("Unpacking Data...")
- obj.extractall(save_path)
- obj.close()
- os.remove(temp_save_path)
-
- def get(self, save_path, dataset=None):
- """
-
- Download a dataset.
-
- Parameters:
- save_path (str) -- A directory to save the data to.
- dataset (str) -- (optional). A specific dataset to download.
- Note: this must include the file extension.
- If None, options will be presented for you
- to choose from.
-
- Returns:
- save_path_full (str) -- the absolute path to the downloaded data.
-
- """
- if dataset is None:
- selected_dataset = self._present_options()
- else:
- selected_dataset = dataset
-
- save_path_full = join(save_path, selected_dataset.split('.')[0])
-
- if isdir(save_path_full):
- warn("\n'{0}' already exists. Voiding Download.".format(
- save_path_full))
- else:
- self._print('Downloading Data...')
- url = "{0}/{1}".format(self.url, selected_dataset)
- self._download_data(url, save_path=save_path)
-
- return abspath(save_path_full)
diff --git a/spaces/d8aai/image-search/README.md b/spaces/d8aai/image-search/README.md
deleted file mode 100644
index 82afd4fcc9da63a121743b02e4de862eae8cf84d..0000000000000000000000000000000000000000
--- a/spaces/d8aai/image-search/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Image Search by d8a.ai
-emoji: 💩
-colorFrom: pink
-colorTo: green
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/daarumadx/bot/src/processing/image.py b/spaces/daarumadx/bot/src/processing/image.py
deleted file mode 100644
index 1a60070ed3b0bb2cba145f8851a54a368e600f04..0000000000000000000000000000000000000000
--- a/spaces/daarumadx/bot/src/processing/image.py
+++ /dev/null
@@ -1,144 +0,0 @@
-"""Image Transform Processing."""
-import os
-import sys
-import hashlib
-import time
-import torch
-
-from config import Config as Conf
-from processing import Processing
-from processing.utils import select_phases
-from processing.worker import run_worker
-from multiprocessing.pool import ThreadPool
-from utils import camel_case_to_str, write_image
-from loader import Loader
-from transform.gan.model import DeepModel
-
-
-class ImageProcessing(Processing):
- """Image Processing Class."""
- def _setup(self, *args):
- """
- Process Image Constructor.
-
- :param args: args parameter to run the image transformation (default use Conf.args)
- """
- self.__phases = select_phases(self._args)
- self.__input_path = self._args['input']
- self.__output_path = self._args['output']
- self.__altered_path = self._args.get('altered')
- self.__masks_path = self._args.get('masks_path')
- self.__starting_step = self._args['steps'][0] if self._args.get('steps') else 0
- self.__ending_step = self._args['steps'][1] if self._args.get('steps') else None
-
- Conf.log.debug("")
- Conf.log.spam("All Phases : {}".format(self.__phases))
- if self.__ending_step != None and self.__ending_step > 0:
- Conf.log.spam("Steps: {}:{} ({}:{})".format(self.__starting_step, self.__ending_step - 1, self.__starting_step, self.__ending_step))
- else:
- Conf.log.spam("Steps: {}:{}".format(self.__starting_step, self.__ending_step))
- Conf.log.debug("To Be Executed Phases : {}".format(self.__phases[self.__starting_step:self.__ending_step]))
-
- imagename_no_ext = os.path.splitext(os.path.basename(self.__input_path))[0]
-
- if (self._args.get('folder_altered')):
- folder_name = imagename_no_ext + '_' + str(hashlib.md5(open(self.__input_path, 'rb').read()).hexdigest())
- folder_path = os.path.join(self._args['folder_altered'], folder_name)
-
- if (not os.path.isdir(folder_path)):
- os.makedirs(folder_path, exist_ok=True)
-
- self._args['folder_altered'] = folder_path
- path = self._args['folder_altered']
-
- self.__image_steps = [self.__input_path] + [
- os.path.join(path, "{}.png".format(p().__class__.__name__))
- for p in self.__phases[:self.__starting_step]
- ]
- elif (self.__altered_path):
- folder_name = imagename_no_ext + '_' + str(hashlib.md5(open(self.__input_path, 'rb').read()).hexdigest())
- folder_path = os.path.join(self.__altered_path, folder_name)
-
- if (not os.path.isdir(folder_path)):
- os.makedirs(folder_path, exist_ok=True)
-
- self.__altered_path = folder_path
- path = self.__altered_path
-
- self.__image_steps = [self.__input_path] + [
- os.path.join(path, "{}.png".format(p().__class__.__name__))
- for p in self.__phases[:self.__starting_step]
- ]
- elif (self.__masks_path):
- folder_path = self.__masks_path
-
- self.__image_steps = [self.__input_path] + [
- os.path.join(folder_path, "{}.png".format(p().__class__.__name__))
- for p in self.__phases[:self.__starting_step]
- ]
- else:
- # TODO: refactor me, please!
- self.__image_steps = [self.__input_path] + [
- self.__input_path
- for p in self.__phases[:self.__starting_step]
- ]
-
- Conf.log.info("Processing on {}".format(str(self.__image_steps)))
-
- #self.__image_steps = [
- # (Loader.get_loader(x)).load(x) if isinstance(x, str) else x for x in self.__image_steps
- #]
-
- for it,x in enumerate(self.__image_steps):
- try:
- value = (Loader.get_loader(x)).load(x) if isinstance(x, str) else x
- self.__image_steps[it] = value
- except (FileNotFoundError, AttributeError) as e:
- if (self.__altered_path):
- Conf.log.error(e)
- Conf.log.error("{} is not able to resume because it not able to load required images. "
- .format(camel_case_to_str(self.__class__.__name__)))
- Conf.log.error("Possible source of this error is that --altered argument is not a correct "
- "directory path that contains valid images.")
- sys.exit(1)
- else:
- Conf.log.warning(e)
-
- def _execute(self, *args):
- """
- Execute all phases on the image.
-
- :return: None
- """
- for step,p in enumerate(x for x in self.__phases[self.__starting_step:self.__ending_step]):
- r = run_worker(p, self.__image_steps, config=self._args)
- self.__image_steps.append(r)
-
- if self.__altered_path:
- if (self._args.get('folder_altered')):
- path = self._args['folder_altered']
- else:
- path = self.__altered_path
-
- write_image(r, os.path.join(path, "{}.png".format(p.__name__)))
-
- Conf.log.spam("{} Step Image Of {} Execution".format(
- os.path.join(path, "{}.png".format(p.__name__)),
- camel_case_to_str(p.__name__),
- ))
- elif self.__masks_path:
- path = self.__masks_path
-
- write_image(r, os.path.join(path, "{}.png".format(p.__name__)))
-
- Conf.log.spam("{} Step Image Of {} Execution".format(
- os.path.join(path, "{}.png".format(p.__name__)),
- camel_case_to_str(p.__name__),
- ))
-
- write_image(self.__image_steps[-1], self.__output_path)
- Conf.log.info("{} Created".format(self.__output_path))
- Conf.log.debug("{} Result Image Of {} Execution"
- .format(self.__output_path, camel_case_to_str(self.__class__.__name__)))
-
- return self.__image_steps[-1]
diff --git "a/spaces/darthPanda/chatpdf_app/pages/1_\360\237\224\220_Credentials.py" "b/spaces/darthPanda/chatpdf_app/pages/1_\360\237\224\220_Credentials.py"
deleted file mode 100644
index 659c520b4f74616e7bda7cee28caba8c03576a85..0000000000000000000000000000000000000000
--- "a/spaces/darthPanda/chatpdf_app/pages/1_\360\237\224\220_Credentials.py"
+++ /dev/null
@@ -1,75 +0,0 @@
-import streamlit as st
-
-st.set_page_config(
- page_title="Credentials",
- page_icon="🔐",
-)
-
-from langchain.chains.conversation.memory import ConversationBufferWindowMemory
-
-
-# """
-# Initialising session states
-# """
-if 'openai_api_key' not in st.session_state:
- st.session_state['openai_api_key'] = None
-
-if 'pinecone_api_key' not in st.session_state:
- st.session_state['pinecone_api_key'] = None
-
-if 'pinecone_env' not in st.session_state:
- st.session_state['pinecone_env'] = None
-
-if 'pinecone_index_namespace' not in st.session_state:
- st.session_state['pinecone_index_namespace'] = None
-
-if 'requests' not in st.session_state:
- st.session_state['requests'] = []
-
-if 'responses' not in st.session_state:
- st.session_state['responses'] = ["How can I assist you?"]
-
-if 'buffer_memory' not in st.session_state:
- st.session_state.buffer_memory=ConversationBufferWindowMemory(k=3,return_messages=True)
-
-st.write("# Enter your Credentials! 🔐")
-
-# """
-# Page Content
-# """
-st.markdown(
-"""
-Enter the following credentials to start uploading and querying documents.
-"""
-)
-
-# OpenAI API Key input
-openai_api_key = st.text_input("Enter your OpenAI API Key", type='password')
-if openai_api_key:
- # Use the OpenAI API key (e.g., validate it, make a request to an API, etc.)
- st.session_state['openai_api_key'] = openai_api_key
-
-# Pinecone API Key input
-pinecone_api_key = st.text_input("Enter your Pinecone API Key", type='password')
-if pinecone_api_key:
- st.session_state['pinecone_api_key'] = pinecone_api_key
-
-# Pinecone Environment input
-pinecone_env = st.text_input("Enter your Pinecone Environment", type='password')
-if pinecone_env:
- st.session_state['pinecone_env'] = pinecone_env
-
-# Index Namespace input
-pinecone_index_namespace = st.text_input("Enter your Pinecone Index Namespace", type='password')
-if pinecone_index_namespace:
- st.session_state['pinecone_index_namespace'] = pinecone_index_namespace
-
-# Check if all required fields are filled
-all_fields_filled = all([st.session_state['pinecone_api_key'],
- st.session_state['openai_api_key'],
- st.session_state['pinecone_env'],
- st.session_state['pinecone_index_namespace']])
-
-if all_fields_filled:
- st.success('Credentials Stored')
-
diff --git a/spaces/dawood/audioldm-text-to-audio-generation/audioldm/clap/open_clip/transform.py b/spaces/dawood/audioldm-text-to-audio-generation/audioldm/clap/open_clip/transform.py
deleted file mode 100644
index 77aaa722c4a5544ac50de6df35d3e922f63b111d..0000000000000000000000000000000000000000
--- a/spaces/dawood/audioldm-text-to-audio-generation/audioldm/clap/open_clip/transform.py
+++ /dev/null
@@ -1,45 +0,0 @@
-from torchvision.transforms import (
- Normalize,
- Compose,
- RandomResizedCrop,
- InterpolationMode,
- ToTensor,
- Resize,
- CenterCrop,
-)
-
-
-def _convert_to_rgb(image):
- return image.convert("RGB")
-
-
-def image_transform(
- image_size: int,
- is_train: bool,
- mean=(0.48145466, 0.4578275, 0.40821073),
- std=(0.26862954, 0.26130258, 0.27577711),
-):
- normalize = Normalize(mean=mean, std=std)
- if is_train:
- return Compose(
- [
- RandomResizedCrop(
- image_size,
- scale=(0.9, 1.0),
- interpolation=InterpolationMode.BICUBIC,
- ),
- _convert_to_rgb,
- ToTensor(),
- normalize,
- ]
- )
- else:
- return Compose(
- [
- Resize(image_size, interpolation=InterpolationMode.BICUBIC),
- CenterCrop(image_size),
- _convert_to_rgb,
- ToTensor(),
- normalize,
- ]
- )
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/PIL/PngImagePlugin.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/PIL/PngImagePlugin.py
deleted file mode 100644
index bfa8cb7ac66c15e2f5d1128f4ba9a1ad69758ec1..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/PIL/PngImagePlugin.py
+++ /dev/null
@@ -1,1456 +0,0 @@
-#
-# The Python Imaging Library.
-# $Id$
-#
-# PNG support code
-#
-# See "PNG (Portable Network Graphics) Specification, version 1.0;
-# W3C Recommendation", 1996-10-01, Thomas Boutell (ed.).
-#
-# history:
-# 1996-05-06 fl Created (couldn't resist it)
-# 1996-12-14 fl Upgraded, added read and verify support (0.2)
-# 1996-12-15 fl Separate PNG stream parser
-# 1996-12-29 fl Added write support, added getchunks
-# 1996-12-30 fl Eliminated circular references in decoder (0.3)
-# 1998-07-12 fl Read/write 16-bit images as mode I (0.4)
-# 2001-02-08 fl Added transparency support (from Zircon) (0.5)
-# 2001-04-16 fl Don't close data source in "open" method (0.6)
-# 2004-02-24 fl Don't even pretend to support interlaced files (0.7)
-# 2004-08-31 fl Do basic sanity check on chunk identifiers (0.8)
-# 2004-09-20 fl Added PngInfo chunk container
-# 2004-12-18 fl Added DPI read support (based on code by Niki Spahiev)
-# 2008-08-13 fl Added tRNS support for RGB images
-# 2009-03-06 fl Support for preserving ICC profiles (by Florian Hoech)
-# 2009-03-08 fl Added zTXT support (from Lowell Alleman)
-# 2009-03-29 fl Read interlaced PNG files (from Conrado Porto Lopes Gouvua)
-#
-# Copyright (c) 1997-2009 by Secret Labs AB
-# Copyright (c) 1996 by Fredrik Lundh
-#
-# See the README file for information on usage and redistribution.
-#
-
-import itertools
-import logging
-import re
-import struct
-import warnings
-import zlib
-from enum import IntEnum
-
-from . import Image, ImageChops, ImageFile, ImagePalette, ImageSequence
-from ._binary import i16be as i16
-from ._binary import i32be as i32
-from ._binary import o8
-from ._binary import o16be as o16
-from ._binary import o32be as o32
-
-logger = logging.getLogger(__name__)
-
-is_cid = re.compile(rb"\w\w\w\w").match
-
-
-_MAGIC = b"\211PNG\r\n\032\n"
-
-
-_MODES = {
- # supported bits/color combinations, and corresponding modes/rawmodes
- # Greyscale
- (1, 0): ("1", "1"),
- (2, 0): ("L", "L;2"),
- (4, 0): ("L", "L;4"),
- (8, 0): ("L", "L"),
- (16, 0): ("I", "I;16B"),
- # Truecolour
- (8, 2): ("RGB", "RGB"),
- (16, 2): ("RGB", "RGB;16B"),
- # Indexed-colour
- (1, 3): ("P", "P;1"),
- (2, 3): ("P", "P;2"),
- (4, 3): ("P", "P;4"),
- (8, 3): ("P", "P"),
- # Greyscale with alpha
- (8, 4): ("LA", "LA"),
- (16, 4): ("RGBA", "LA;16B"), # LA;16B->LA not yet available
- # Truecolour with alpha
- (8, 6): ("RGBA", "RGBA"),
- (16, 6): ("RGBA", "RGBA;16B"),
-}
-
-
-_simple_palette = re.compile(b"^\xff*\x00\xff*$")
-
-MAX_TEXT_CHUNK = ImageFile.SAFEBLOCK
-"""
-Maximum decompressed size for a iTXt or zTXt chunk.
-Eliminates decompression bombs where compressed chunks can expand 1000x.
-See :ref:`Text in PNG File Format`.
-"""
-MAX_TEXT_MEMORY = 64 * MAX_TEXT_CHUNK
-"""
-Set the maximum total text chunk size.
-See :ref:`Text in PNG File Format`.
-"""
-
-
-# APNG frame disposal modes
-class Disposal(IntEnum):
- OP_NONE = 0
- """
- No disposal is done on this frame before rendering the next frame.
- See :ref:`Saving APNG sequences`.
- """
- OP_BACKGROUND = 1
- """
- This frame’s modified region is cleared to fully transparent black before rendering
- the next frame.
- See :ref:`Saving APNG sequences`.
- """
- OP_PREVIOUS = 2
- """
- This frame’s modified region is reverted to the previous frame’s contents before
- rendering the next frame.
- See :ref:`Saving APNG sequences`.
- """
-
-
-# APNG frame blend modes
-class Blend(IntEnum):
- OP_SOURCE = 0
- """
- All color components of this frame, including alpha, overwrite the previous output
- image contents.
- See :ref:`Saving APNG sequences`.
- """
- OP_OVER = 1
- """
- This frame should be alpha composited with the previous output image contents.
- See :ref:`Saving APNG sequences`.
- """
-
-
-def _safe_zlib_decompress(s):
- dobj = zlib.decompressobj()
- plaintext = dobj.decompress(s, MAX_TEXT_CHUNK)
- if dobj.unconsumed_tail:
- msg = "Decompressed Data Too Large"
- raise ValueError(msg)
- return plaintext
-
-
-def _crc32(data, seed=0):
- return zlib.crc32(data, seed) & 0xFFFFFFFF
-
-
-# --------------------------------------------------------------------
-# Support classes. Suitable for PNG and related formats like MNG etc.
-
-
-class ChunkStream:
- def __init__(self, fp):
- self.fp = fp
- self.queue = []
-
- def read(self):
- """Fetch a new chunk. Returns header information."""
- cid = None
-
- if self.queue:
- cid, pos, length = self.queue.pop()
- self.fp.seek(pos)
- else:
- s = self.fp.read(8)
- cid = s[4:]
- pos = self.fp.tell()
- length = i32(s)
-
- if not is_cid(cid):
- if not ImageFile.LOAD_TRUNCATED_IMAGES:
- msg = f"broken PNG file (chunk {repr(cid)})"
- raise SyntaxError(msg)
-
- return cid, pos, length
-
- def __enter__(self):
- return self
-
- def __exit__(self, *args):
- self.close()
-
- def close(self):
- self.queue = self.fp = None
-
- def push(self, cid, pos, length):
- self.queue.append((cid, pos, length))
-
- def call(self, cid, pos, length):
- """Call the appropriate chunk handler"""
-
- logger.debug("STREAM %r %s %s", cid, pos, length)
- return getattr(self, "chunk_" + cid.decode("ascii"))(pos, length)
-
- def crc(self, cid, data):
- """Read and verify checksum"""
-
- # Skip CRC checks for ancillary chunks if allowed to load truncated
- # images
- # 5th byte of first char is 1 [specs, section 5.4]
- if ImageFile.LOAD_TRUNCATED_IMAGES and (cid[0] >> 5 & 1):
- self.crc_skip(cid, data)
- return
-
- try:
- crc1 = _crc32(data, _crc32(cid))
- crc2 = i32(self.fp.read(4))
- if crc1 != crc2:
- msg = f"broken PNG file (bad header checksum in {repr(cid)})"
- raise SyntaxError(msg)
- except struct.error as e:
- msg = f"broken PNG file (incomplete checksum in {repr(cid)})"
- raise SyntaxError(msg) from e
-
- def crc_skip(self, cid, data):
- """Read checksum"""
-
- self.fp.read(4)
-
- def verify(self, endchunk=b"IEND"):
- # Simple approach; just calculate checksum for all remaining
- # blocks. Must be called directly after open.
-
- cids = []
-
- while True:
- try:
- cid, pos, length = self.read()
- except struct.error as e:
- msg = "truncated PNG file"
- raise OSError(msg) from e
-
- if cid == endchunk:
- break
- self.crc(cid, ImageFile._safe_read(self.fp, length))
- cids.append(cid)
-
- return cids
-
-
-class iTXt(str):
- """
- Subclass of string to allow iTXt chunks to look like strings while
- keeping their extra information
-
- """
-
- @staticmethod
- def __new__(cls, text, lang=None, tkey=None):
- """
- :param cls: the class to use when creating the instance
- :param text: value for this key
- :param lang: language code
- :param tkey: UTF-8 version of the key name
- """
-
- self = str.__new__(cls, text)
- self.lang = lang
- self.tkey = tkey
- return self
-
-
-class PngInfo:
- """
- PNG chunk container (for use with save(pnginfo=))
-
- """
-
- def __init__(self):
- self.chunks = []
-
- def add(self, cid, data, after_idat=False):
- """Appends an arbitrary chunk. Use with caution.
-
- :param cid: a byte string, 4 bytes long.
- :param data: a byte string of the encoded data
- :param after_idat: for use with private chunks. Whether the chunk
- should be written after IDAT
-
- """
-
- chunk = [cid, data]
- if after_idat:
- chunk.append(True)
- self.chunks.append(tuple(chunk))
-
- def add_itxt(self, key, value, lang="", tkey="", zip=False):
- """Appends an iTXt chunk.
-
- :param key: latin-1 encodable text key name
- :param value: value for this key
- :param lang: language code
- :param tkey: UTF-8 version of the key name
- :param zip: compression flag
-
- """
-
- if not isinstance(key, bytes):
- key = key.encode("latin-1", "strict")
- if not isinstance(value, bytes):
- value = value.encode("utf-8", "strict")
- if not isinstance(lang, bytes):
- lang = lang.encode("utf-8", "strict")
- if not isinstance(tkey, bytes):
- tkey = tkey.encode("utf-8", "strict")
-
- if zip:
- self.add(
- b"iTXt",
- key + b"\0\x01\0" + lang + b"\0" + tkey + b"\0" + zlib.compress(value),
- )
- else:
- self.add(b"iTXt", key + b"\0\0\0" + lang + b"\0" + tkey + b"\0" + value)
-
- def add_text(self, key, value, zip=False):
- """Appends a text chunk.
-
- :param key: latin-1 encodable text key name
- :param value: value for this key, text or an
- :py:class:`PIL.PngImagePlugin.iTXt` instance
- :param zip: compression flag
-
- """
- if isinstance(value, iTXt):
- return self.add_itxt(key, value, value.lang, value.tkey, zip=zip)
-
- # The tEXt chunk stores latin-1 text
- if not isinstance(value, bytes):
- try:
- value = value.encode("latin-1", "strict")
- except UnicodeError:
- return self.add_itxt(key, value, zip=zip)
-
- if not isinstance(key, bytes):
- key = key.encode("latin-1", "strict")
-
- if zip:
- self.add(b"zTXt", key + b"\0\0" + zlib.compress(value))
- else:
- self.add(b"tEXt", key + b"\0" + value)
-
-
-# --------------------------------------------------------------------
-# PNG image stream (IHDR/IEND)
-
-
-class PngStream(ChunkStream):
- def __init__(self, fp):
- super().__init__(fp)
-
- # local copies of Image attributes
- self.im_info = {}
- self.im_text = {}
- self.im_size = (0, 0)
- self.im_mode = None
- self.im_tile = None
- self.im_palette = None
- self.im_custom_mimetype = None
- self.im_n_frames = None
- self._seq_num = None
- self.rewind_state = None
-
- self.text_memory = 0
-
- def check_text_memory(self, chunklen):
- self.text_memory += chunklen
- if self.text_memory > MAX_TEXT_MEMORY:
- msg = (
- "Too much memory used in text chunks: "
- f"{self.text_memory}>MAX_TEXT_MEMORY"
- )
- raise ValueError(msg)
-
- def save_rewind(self):
- self.rewind_state = {
- "info": self.im_info.copy(),
- "tile": self.im_tile,
- "seq_num": self._seq_num,
- }
-
- def rewind(self):
- self.im_info = self.rewind_state["info"]
- self.im_tile = self.rewind_state["tile"]
- self._seq_num = self.rewind_state["seq_num"]
-
- def chunk_iCCP(self, pos, length):
- # ICC profile
- s = ImageFile._safe_read(self.fp, length)
- # according to PNG spec, the iCCP chunk contains:
- # Profile name 1-79 bytes (character string)
- # Null separator 1 byte (null character)
- # Compression method 1 byte (0)
- # Compressed profile n bytes (zlib with deflate compression)
- i = s.find(b"\0")
- logger.debug("iCCP profile name %r", s[:i])
- logger.debug("Compression method %s", s[i])
- comp_method = s[i]
- if comp_method != 0:
- msg = f"Unknown compression method {comp_method} in iCCP chunk"
- raise SyntaxError(msg)
- try:
- icc_profile = _safe_zlib_decompress(s[i + 2 :])
- except ValueError:
- if ImageFile.LOAD_TRUNCATED_IMAGES:
- icc_profile = None
- else:
- raise
- except zlib.error:
- icc_profile = None # FIXME
- self.im_info["icc_profile"] = icc_profile
- return s
-
- def chunk_IHDR(self, pos, length):
- # image header
- s = ImageFile._safe_read(self.fp, length)
- if length < 13:
- if ImageFile.LOAD_TRUNCATED_IMAGES:
- return s
- msg = "Truncated IHDR chunk"
- raise ValueError(msg)
- self.im_size = i32(s, 0), i32(s, 4)
- try:
- self.im_mode, self.im_rawmode = _MODES[(s[8], s[9])]
- except Exception:
- pass
- if s[12]:
- self.im_info["interlace"] = 1
- if s[11]:
- msg = "unknown filter category"
- raise SyntaxError(msg)
- return s
-
- def chunk_IDAT(self, pos, length):
- # image data
- if "bbox" in self.im_info:
- tile = [("zip", self.im_info["bbox"], pos, self.im_rawmode)]
- else:
- if self.im_n_frames is not None:
- self.im_info["default_image"] = True
- tile = [("zip", (0, 0) + self.im_size, pos, self.im_rawmode)]
- self.im_tile = tile
- self.im_idat = length
- raise EOFError
-
- def chunk_IEND(self, pos, length):
- # end of PNG image
- raise EOFError
-
- def chunk_PLTE(self, pos, length):
- # palette
- s = ImageFile._safe_read(self.fp, length)
- if self.im_mode == "P":
- self.im_palette = "RGB", s
- return s
-
- def chunk_tRNS(self, pos, length):
- # transparency
- s = ImageFile._safe_read(self.fp, length)
- if self.im_mode == "P":
- if _simple_palette.match(s):
- # tRNS contains only one full-transparent entry,
- # other entries are full opaque
- i = s.find(b"\0")
- if i >= 0:
- self.im_info["transparency"] = i
- else:
- # otherwise, we have a byte string with one alpha value
- # for each palette entry
- self.im_info["transparency"] = s
- elif self.im_mode in ("1", "L", "I"):
- self.im_info["transparency"] = i16(s)
- elif self.im_mode == "RGB":
- self.im_info["transparency"] = i16(s), i16(s, 2), i16(s, 4)
- return s
-
- def chunk_gAMA(self, pos, length):
- # gamma setting
- s = ImageFile._safe_read(self.fp, length)
- self.im_info["gamma"] = i32(s) / 100000.0
- return s
-
- def chunk_cHRM(self, pos, length):
- # chromaticity, 8 unsigned ints, actual value is scaled by 100,000
- # WP x,y, Red x,y, Green x,y Blue x,y
-
- s = ImageFile._safe_read(self.fp, length)
- raw_vals = struct.unpack(">%dI" % (len(s) // 4), s)
- self.im_info["chromaticity"] = tuple(elt / 100000.0 for elt in raw_vals)
- return s
-
- def chunk_sRGB(self, pos, length):
- # srgb rendering intent, 1 byte
- # 0 perceptual
- # 1 relative colorimetric
- # 2 saturation
- # 3 absolute colorimetric
-
- s = ImageFile._safe_read(self.fp, length)
- if length < 1:
- if ImageFile.LOAD_TRUNCATED_IMAGES:
- return s
- msg = "Truncated sRGB chunk"
- raise ValueError(msg)
- self.im_info["srgb"] = s[0]
- return s
-
- def chunk_pHYs(self, pos, length):
- # pixels per unit
- s = ImageFile._safe_read(self.fp, length)
- if length < 9:
- if ImageFile.LOAD_TRUNCATED_IMAGES:
- return s
- msg = "Truncated pHYs chunk"
- raise ValueError(msg)
- px, py = i32(s, 0), i32(s, 4)
- unit = s[8]
- if unit == 1: # meter
- dpi = px * 0.0254, py * 0.0254
- self.im_info["dpi"] = dpi
- elif unit == 0:
- self.im_info["aspect"] = px, py
- return s
-
- def chunk_tEXt(self, pos, length):
- # text
- s = ImageFile._safe_read(self.fp, length)
- try:
- k, v = s.split(b"\0", 1)
- except ValueError:
- # fallback for broken tEXt tags
- k = s
- v = b""
- if k:
- k = k.decode("latin-1", "strict")
- v_str = v.decode("latin-1", "replace")
-
- self.im_info[k] = v if k == "exif" else v_str
- self.im_text[k] = v_str
- self.check_text_memory(len(v_str))
-
- return s
-
- def chunk_zTXt(self, pos, length):
- # compressed text
- s = ImageFile._safe_read(self.fp, length)
- try:
- k, v = s.split(b"\0", 1)
- except ValueError:
- k = s
- v = b""
- if v:
- comp_method = v[0]
- else:
- comp_method = 0
- if comp_method != 0:
- msg = f"Unknown compression method {comp_method} in zTXt chunk"
- raise SyntaxError(msg)
- try:
- v = _safe_zlib_decompress(v[1:])
- except ValueError:
- if ImageFile.LOAD_TRUNCATED_IMAGES:
- v = b""
- else:
- raise
- except zlib.error:
- v = b""
-
- if k:
- k = k.decode("latin-1", "strict")
- v = v.decode("latin-1", "replace")
-
- self.im_info[k] = self.im_text[k] = v
- self.check_text_memory(len(v))
-
- return s
-
- def chunk_iTXt(self, pos, length):
- # international text
- r = s = ImageFile._safe_read(self.fp, length)
- try:
- k, r = r.split(b"\0", 1)
- except ValueError:
- return s
- if len(r) < 2:
- return s
- cf, cm, r = r[0], r[1], r[2:]
- try:
- lang, tk, v = r.split(b"\0", 2)
- except ValueError:
- return s
- if cf != 0:
- if cm == 0:
- try:
- v = _safe_zlib_decompress(v)
- except ValueError:
- if ImageFile.LOAD_TRUNCATED_IMAGES:
- return s
- else:
- raise
- except zlib.error:
- return s
- else:
- return s
- try:
- k = k.decode("latin-1", "strict")
- lang = lang.decode("utf-8", "strict")
- tk = tk.decode("utf-8", "strict")
- v = v.decode("utf-8", "strict")
- except UnicodeError:
- return s
-
- self.im_info[k] = self.im_text[k] = iTXt(v, lang, tk)
- self.check_text_memory(len(v))
-
- return s
-
- def chunk_eXIf(self, pos, length):
- s = ImageFile._safe_read(self.fp, length)
- self.im_info["exif"] = b"Exif\x00\x00" + s
- return s
-
- # APNG chunks
- def chunk_acTL(self, pos, length):
- s = ImageFile._safe_read(self.fp, length)
- if length < 8:
- if ImageFile.LOAD_TRUNCATED_IMAGES:
- return s
- msg = "APNG contains truncated acTL chunk"
- raise ValueError(msg)
- if self.im_n_frames is not None:
- self.im_n_frames = None
- warnings.warn("Invalid APNG, will use default PNG image if possible")
- return s
- n_frames = i32(s)
- if n_frames == 0 or n_frames > 0x80000000:
- warnings.warn("Invalid APNG, will use default PNG image if possible")
- return s
- self.im_n_frames = n_frames
- self.im_info["loop"] = i32(s, 4)
- self.im_custom_mimetype = "image/apng"
- return s
-
- def chunk_fcTL(self, pos, length):
- s = ImageFile._safe_read(self.fp, length)
- if length < 26:
- if ImageFile.LOAD_TRUNCATED_IMAGES:
- return s
- msg = "APNG contains truncated fcTL chunk"
- raise ValueError(msg)
- seq = i32(s)
- if (self._seq_num is None and seq != 0) or (
- self._seq_num is not None and self._seq_num != seq - 1
- ):
- msg = "APNG contains frame sequence errors"
- raise SyntaxError(msg)
- self._seq_num = seq
- width, height = i32(s, 4), i32(s, 8)
- px, py = i32(s, 12), i32(s, 16)
- im_w, im_h = self.im_size
- if px + width > im_w or py + height > im_h:
- msg = "APNG contains invalid frames"
- raise SyntaxError(msg)
- self.im_info["bbox"] = (px, py, px + width, py + height)
- delay_num, delay_den = i16(s, 20), i16(s, 22)
- if delay_den == 0:
- delay_den = 100
- self.im_info["duration"] = float(delay_num) / float(delay_den) * 1000
- self.im_info["disposal"] = s[24]
- self.im_info["blend"] = s[25]
- return s
-
- def chunk_fdAT(self, pos, length):
- if length < 4:
- if ImageFile.LOAD_TRUNCATED_IMAGES:
- s = ImageFile._safe_read(self.fp, length)
- return s
- msg = "APNG contains truncated fDAT chunk"
- raise ValueError(msg)
- s = ImageFile._safe_read(self.fp, 4)
- seq = i32(s)
- if self._seq_num != seq - 1:
- msg = "APNG contains frame sequence errors"
- raise SyntaxError(msg)
- self._seq_num = seq
- return self.chunk_IDAT(pos + 4, length - 4)
-
-
-# --------------------------------------------------------------------
-# PNG reader
-
-
-def _accept(prefix):
- return prefix[:8] == _MAGIC
-
-
-##
-# Image plugin for PNG images.
-
-
-class PngImageFile(ImageFile.ImageFile):
- format = "PNG"
- format_description = "Portable network graphics"
-
- def _open(self):
- if not _accept(self.fp.read(8)):
- msg = "not a PNG file"
- raise SyntaxError(msg)
- self._fp = self.fp
- self.__frame = 0
-
- #
- # Parse headers up to the first IDAT or fDAT chunk
-
- self.private_chunks = []
- self.png = PngStream(self.fp)
-
- while True:
- #
- # get next chunk
-
- cid, pos, length = self.png.read()
-
- try:
- s = self.png.call(cid, pos, length)
- except EOFError:
- break
- except AttributeError:
- logger.debug("%r %s %s (unknown)", cid, pos, length)
- s = ImageFile._safe_read(self.fp, length)
- if cid[1:2].islower():
- self.private_chunks.append((cid, s))
-
- self.png.crc(cid, s)
-
- #
- # Copy relevant attributes from the PngStream. An alternative
- # would be to let the PngStream class modify these attributes
- # directly, but that introduces circular references which are
- # difficult to break if things go wrong in the decoder...
- # (believe me, I've tried ;-)
-
- self.mode = self.png.im_mode
- self._size = self.png.im_size
- self.info = self.png.im_info
- self._text = None
- self.tile = self.png.im_tile
- self.custom_mimetype = self.png.im_custom_mimetype
- self.n_frames = self.png.im_n_frames or 1
- self.default_image = self.info.get("default_image", False)
-
- if self.png.im_palette:
- rawmode, data = self.png.im_palette
- self.palette = ImagePalette.raw(rawmode, data)
-
- if cid == b"fdAT":
- self.__prepare_idat = length - 4
- else:
- self.__prepare_idat = length # used by load_prepare()
-
- if self.png.im_n_frames is not None:
- self._close_exclusive_fp_after_loading = False
- self.png.save_rewind()
- self.__rewind_idat = self.__prepare_idat
- self.__rewind = self._fp.tell()
- if self.default_image:
- # IDAT chunk contains default image and not first animation frame
- self.n_frames += 1
- self._seek(0)
- self.is_animated = self.n_frames > 1
-
- @property
- def text(self):
- # experimental
- if self._text is None:
- # iTxt, tEXt and zTXt chunks may appear at the end of the file
- # So load the file to ensure that they are read
- if self.is_animated:
- frame = self.__frame
- # for APNG, seek to the final frame before loading
- self.seek(self.n_frames - 1)
- self.load()
- if self.is_animated:
- self.seek(frame)
- return self._text
-
- def verify(self):
- """Verify PNG file"""
-
- if self.fp is None:
- msg = "verify must be called directly after open"
- raise RuntimeError(msg)
-
- # back up to beginning of IDAT block
- self.fp.seek(self.tile[0][2] - 8)
-
- self.png.verify()
- self.png.close()
-
- if self._exclusive_fp:
- self.fp.close()
- self.fp = None
-
- def seek(self, frame):
- if not self._seek_check(frame):
- return
- if frame < self.__frame:
- self._seek(0, True)
-
- last_frame = self.__frame
- for f in range(self.__frame + 1, frame + 1):
- try:
- self._seek(f)
- except EOFError as e:
- self.seek(last_frame)
- msg = "no more images in APNG file"
- raise EOFError(msg) from e
-
- def _seek(self, frame, rewind=False):
- if frame == 0:
- if rewind:
- self._fp.seek(self.__rewind)
- self.png.rewind()
- self.__prepare_idat = self.__rewind_idat
- self.im = None
- if self.pyaccess:
- self.pyaccess = None
- self.info = self.png.im_info
- self.tile = self.png.im_tile
- self.fp = self._fp
- self._prev_im = None
- self.dispose = None
- self.default_image = self.info.get("default_image", False)
- self.dispose_op = self.info.get("disposal")
- self.blend_op = self.info.get("blend")
- self.dispose_extent = self.info.get("bbox")
- self.__frame = 0
- else:
- if frame != self.__frame + 1:
- msg = f"cannot seek to frame {frame}"
- raise ValueError(msg)
-
- # ensure previous frame was loaded
- self.load()
-
- if self.dispose:
- self.im.paste(self.dispose, self.dispose_extent)
- self._prev_im = self.im.copy()
-
- self.fp = self._fp
-
- # advance to the next frame
- if self.__prepare_idat:
- ImageFile._safe_read(self.fp, self.__prepare_idat)
- self.__prepare_idat = 0
- frame_start = False
- while True:
- self.fp.read(4) # CRC
-
- try:
- cid, pos, length = self.png.read()
- except (struct.error, SyntaxError):
- break
-
- if cid == b"IEND":
- msg = "No more images in APNG file"
- raise EOFError(msg)
- if cid == b"fcTL":
- if frame_start:
- # there must be at least one fdAT chunk between fcTL chunks
- msg = "APNG missing frame data"
- raise SyntaxError(msg)
- frame_start = True
-
- try:
- self.png.call(cid, pos, length)
- except UnicodeDecodeError:
- break
- except EOFError:
- if cid == b"fdAT":
- length -= 4
- if frame_start:
- self.__prepare_idat = length
- break
- ImageFile._safe_read(self.fp, length)
- except AttributeError:
- logger.debug("%r %s %s (unknown)", cid, pos, length)
- ImageFile._safe_read(self.fp, length)
-
- self.__frame = frame
- self.tile = self.png.im_tile
- self.dispose_op = self.info.get("disposal")
- self.blend_op = self.info.get("blend")
- self.dispose_extent = self.info.get("bbox")
-
- if not self.tile:
- raise EOFError
-
- # setup frame disposal (actual disposal done when needed in the next _seek())
- if self._prev_im is None and self.dispose_op == Disposal.OP_PREVIOUS:
- self.dispose_op = Disposal.OP_BACKGROUND
-
- if self.dispose_op == Disposal.OP_PREVIOUS:
- self.dispose = self._prev_im.copy()
- self.dispose = self._crop(self.dispose, self.dispose_extent)
- elif self.dispose_op == Disposal.OP_BACKGROUND:
- self.dispose = Image.core.fill(self.mode, self.size)
- self.dispose = self._crop(self.dispose, self.dispose_extent)
- else:
- self.dispose = None
-
- def tell(self):
- return self.__frame
-
- def load_prepare(self):
- """internal: prepare to read PNG file"""
-
- if self.info.get("interlace"):
- self.decoderconfig = self.decoderconfig + (1,)
-
- self.__idat = self.__prepare_idat # used by load_read()
- ImageFile.ImageFile.load_prepare(self)
-
- def load_read(self, read_bytes):
- """internal: read more image data"""
-
- while self.__idat == 0:
- # end of chunk, skip forward to next one
-
- self.fp.read(4) # CRC
-
- cid, pos, length = self.png.read()
-
- if cid not in [b"IDAT", b"DDAT", b"fdAT"]:
- self.png.push(cid, pos, length)
- return b""
-
- if cid == b"fdAT":
- try:
- self.png.call(cid, pos, length)
- except EOFError:
- pass
- self.__idat = length - 4 # sequence_num has already been read
- else:
- self.__idat = length # empty chunks are allowed
-
- # read more data from this chunk
- if read_bytes <= 0:
- read_bytes = self.__idat
- else:
- read_bytes = min(read_bytes, self.__idat)
-
- self.__idat = self.__idat - read_bytes
-
- return self.fp.read(read_bytes)
-
- def load_end(self):
- """internal: finished reading image data"""
- if self.__idat != 0:
- self.fp.read(self.__idat)
- while True:
- self.fp.read(4) # CRC
-
- try:
- cid, pos, length = self.png.read()
- except (struct.error, SyntaxError):
- break
-
- if cid == b"IEND":
- break
- elif cid == b"fcTL" and self.is_animated:
- # start of the next frame, stop reading
- self.__prepare_idat = 0
- self.png.push(cid, pos, length)
- break
-
- try:
- self.png.call(cid, pos, length)
- except UnicodeDecodeError:
- break
- except EOFError:
- if cid == b"fdAT":
- length -= 4
- ImageFile._safe_read(self.fp, length)
- except AttributeError:
- logger.debug("%r %s %s (unknown)", cid, pos, length)
- s = ImageFile._safe_read(self.fp, length)
- if cid[1:2].islower():
- self.private_chunks.append((cid, s, True))
- self._text = self.png.im_text
- if not self.is_animated:
- self.png.close()
- self.png = None
- else:
- if self._prev_im and self.blend_op == Blend.OP_OVER:
- updated = self._crop(self.im, self.dispose_extent)
- if self.im.mode == "RGB" and "transparency" in self.info:
- mask = updated.convert_transparent(
- "RGBA", self.info["transparency"]
- )
- else:
- mask = updated.convert("RGBA")
- self._prev_im.paste(updated, self.dispose_extent, mask)
- self.im = self._prev_im
- if self.pyaccess:
- self.pyaccess = None
-
- def _getexif(self):
- if "exif" not in self.info:
- self.load()
- if "exif" not in self.info and "Raw profile type exif" not in self.info:
- return None
- return self.getexif()._get_merged_dict()
-
- def getexif(self):
- if "exif" not in self.info:
- self.load()
-
- return super().getexif()
-
- def getxmp(self):
- """
- Returns a dictionary containing the XMP tags.
- Requires defusedxml to be installed.
-
- :returns: XMP tags in a dictionary.
- """
- return (
- self._getxmp(self.info["XML:com.adobe.xmp"])
- if "XML:com.adobe.xmp" in self.info
- else {}
- )
-
-
-# --------------------------------------------------------------------
-# PNG writer
-
-_OUTMODES = {
- # supported PIL modes, and corresponding rawmodes/bits/color combinations
- "1": ("1", b"\x01\x00"),
- "L;1": ("L;1", b"\x01\x00"),
- "L;2": ("L;2", b"\x02\x00"),
- "L;4": ("L;4", b"\x04\x00"),
- "L": ("L", b"\x08\x00"),
- "LA": ("LA", b"\x08\x04"),
- "I": ("I;16B", b"\x10\x00"),
- "I;16": ("I;16B", b"\x10\x00"),
- "P;1": ("P;1", b"\x01\x03"),
- "P;2": ("P;2", b"\x02\x03"),
- "P;4": ("P;4", b"\x04\x03"),
- "P": ("P", b"\x08\x03"),
- "RGB": ("RGB", b"\x08\x02"),
- "RGBA": ("RGBA", b"\x08\x06"),
-}
-
-
-def putchunk(fp, cid, *data):
- """Write a PNG chunk (including CRC field)"""
-
- data = b"".join(data)
-
- fp.write(o32(len(data)) + cid)
- fp.write(data)
- crc = _crc32(data, _crc32(cid))
- fp.write(o32(crc))
-
-
-class _idat:
- # wrap output from the encoder in IDAT chunks
-
- def __init__(self, fp, chunk):
- self.fp = fp
- self.chunk = chunk
-
- def write(self, data):
- self.chunk(self.fp, b"IDAT", data)
-
-
-class _fdat:
- # wrap encoder output in fdAT chunks
-
- def __init__(self, fp, chunk, seq_num):
- self.fp = fp
- self.chunk = chunk
- self.seq_num = seq_num
-
- def write(self, data):
- self.chunk(self.fp, b"fdAT", o32(self.seq_num), data)
- self.seq_num += 1
-
-
-def _write_multiple_frames(im, fp, chunk, rawmode, default_image, append_images):
- duration = im.encoderinfo.get("duration", im.info.get("duration", 0))
- loop = im.encoderinfo.get("loop", im.info.get("loop", 0))
- disposal = im.encoderinfo.get("disposal", im.info.get("disposal", Disposal.OP_NONE))
- blend = im.encoderinfo.get("blend", im.info.get("blend", Blend.OP_SOURCE))
-
- if default_image:
- chain = itertools.chain(append_images)
- else:
- chain = itertools.chain([im], append_images)
-
- im_frames = []
- frame_count = 0
- for im_seq in chain:
- for im_frame in ImageSequence.Iterator(im_seq):
- if im_frame.mode == rawmode:
- im_frame = im_frame.copy()
- else:
- if rawmode == "P":
- im_frame = im_frame.convert(rawmode, palette=im.palette)
- else:
- im_frame = im_frame.convert(rawmode)
- encoderinfo = im.encoderinfo.copy()
- if isinstance(duration, (list, tuple)):
- encoderinfo["duration"] = duration[frame_count]
- if isinstance(disposal, (list, tuple)):
- encoderinfo["disposal"] = disposal[frame_count]
- if isinstance(blend, (list, tuple)):
- encoderinfo["blend"] = blend[frame_count]
- frame_count += 1
-
- if im_frames:
- previous = im_frames[-1]
- prev_disposal = previous["encoderinfo"].get("disposal")
- prev_blend = previous["encoderinfo"].get("blend")
- if prev_disposal == Disposal.OP_PREVIOUS and len(im_frames) < 2:
- prev_disposal = Disposal.OP_BACKGROUND
-
- if prev_disposal == Disposal.OP_BACKGROUND:
- base_im = previous["im"].copy()
- dispose = Image.core.fill("RGBA", im.size, (0, 0, 0, 0))
- bbox = previous["bbox"]
- if bbox:
- dispose = dispose.crop(bbox)
- else:
- bbox = (0, 0) + im.size
- base_im.paste(dispose, bbox)
- elif prev_disposal == Disposal.OP_PREVIOUS:
- base_im = im_frames[-2]["im"]
- else:
- base_im = previous["im"]
- delta = ImageChops.subtract_modulo(
- im_frame.convert("RGBA"), base_im.convert("RGBA")
- )
- bbox = delta.getbbox(alpha_only=False)
- if (
- not bbox
- and prev_disposal == encoderinfo.get("disposal")
- and prev_blend == encoderinfo.get("blend")
- ):
- previous["encoderinfo"]["duration"] += encoderinfo.get(
- "duration", duration
- )
- continue
- else:
- bbox = None
- if "duration" not in encoderinfo:
- encoderinfo["duration"] = duration
- im_frames.append({"im": im_frame, "bbox": bbox, "encoderinfo": encoderinfo})
-
- # animation control
- chunk(
- fp,
- b"acTL",
- o32(len(im_frames)), # 0: num_frames
- o32(loop), # 4: num_plays
- )
-
- # default image IDAT (if it exists)
- if default_image:
- ImageFile._save(im, _idat(fp, chunk), [("zip", (0, 0) + im.size, 0, rawmode)])
-
- seq_num = 0
- for frame, frame_data in enumerate(im_frames):
- im_frame = frame_data["im"]
- if not frame_data["bbox"]:
- bbox = (0, 0) + im_frame.size
- else:
- bbox = frame_data["bbox"]
- im_frame = im_frame.crop(bbox)
- size = im_frame.size
- encoderinfo = frame_data["encoderinfo"]
- frame_duration = int(round(encoderinfo["duration"]))
- frame_disposal = encoderinfo.get("disposal", disposal)
- frame_blend = encoderinfo.get("blend", blend)
- # frame control
- chunk(
- fp,
- b"fcTL",
- o32(seq_num), # sequence_number
- o32(size[0]), # width
- o32(size[1]), # height
- o32(bbox[0]), # x_offset
- o32(bbox[1]), # y_offset
- o16(frame_duration), # delay_numerator
- o16(1000), # delay_denominator
- o8(frame_disposal), # dispose_op
- o8(frame_blend), # blend_op
- )
- seq_num += 1
- # frame data
- if frame == 0 and not default_image:
- # first frame must be in IDAT chunks for backwards compatibility
- ImageFile._save(
- im_frame,
- _idat(fp, chunk),
- [("zip", (0, 0) + im_frame.size, 0, rawmode)],
- )
- else:
- fdat_chunks = _fdat(fp, chunk, seq_num)
- ImageFile._save(
- im_frame,
- fdat_chunks,
- [("zip", (0, 0) + im_frame.size, 0, rawmode)],
- )
- seq_num = fdat_chunks.seq_num
-
-
-def _save_all(im, fp, filename):
- _save(im, fp, filename, save_all=True)
-
-
-def _save(im, fp, filename, chunk=putchunk, save_all=False):
- # save an image to disk (called by the save method)
-
- if save_all:
- default_image = im.encoderinfo.get(
- "default_image", im.info.get("default_image")
- )
- modes = set()
- append_images = im.encoderinfo.get("append_images", [])
- if default_image:
- chain = itertools.chain(append_images)
- else:
- chain = itertools.chain([im], append_images)
- for im_seq in chain:
- for im_frame in ImageSequence.Iterator(im_seq):
- modes.add(im_frame.mode)
- for mode in ("RGBA", "RGB", "P"):
- if mode in modes:
- break
- else:
- mode = modes.pop()
- else:
- mode = im.mode
-
- if mode == "P":
- #
- # attempt to minimize storage requirements for palette images
- if "bits" in im.encoderinfo:
- # number of bits specified by user
- colors = min(1 << im.encoderinfo["bits"], 256)
- else:
- # check palette contents
- if im.palette:
- colors = max(min(len(im.palette.getdata()[1]) // 3, 256), 1)
- else:
- colors = 256
-
- if colors <= 16:
- if colors <= 2:
- bits = 1
- elif colors <= 4:
- bits = 2
- else:
- bits = 4
- mode = f"{mode};{bits}"
-
- # encoder options
- im.encoderconfig = (
- im.encoderinfo.get("optimize", False),
- im.encoderinfo.get("compress_level", -1),
- im.encoderinfo.get("compress_type", -1),
- im.encoderinfo.get("dictionary", b""),
- )
-
- # get the corresponding PNG mode
- try:
- rawmode, mode = _OUTMODES[mode]
- except KeyError as e:
- msg = f"cannot write mode {mode} as PNG"
- raise OSError(msg) from e
-
- #
- # write minimal PNG file
-
- fp.write(_MAGIC)
-
- chunk(
- fp,
- b"IHDR",
- o32(im.size[0]), # 0: size
- o32(im.size[1]),
- mode, # 8: depth/type
- b"\0", # 10: compression
- b"\0", # 11: filter category
- b"\0", # 12: interlace flag
- )
-
- chunks = [b"cHRM", b"gAMA", b"sBIT", b"sRGB", b"tIME"]
-
- icc = im.encoderinfo.get("icc_profile", im.info.get("icc_profile"))
- if icc:
- # ICC profile
- # according to PNG spec, the iCCP chunk contains:
- # Profile name 1-79 bytes (character string)
- # Null separator 1 byte (null character)
- # Compression method 1 byte (0)
- # Compressed profile n bytes (zlib with deflate compression)
- name = b"ICC Profile"
- data = name + b"\0\0" + zlib.compress(icc)
- chunk(fp, b"iCCP", data)
-
- # You must either have sRGB or iCCP.
- # Disallow sRGB chunks when an iCCP-chunk has been emitted.
- chunks.remove(b"sRGB")
-
- info = im.encoderinfo.get("pnginfo")
- if info:
- chunks_multiple_allowed = [b"sPLT", b"iTXt", b"tEXt", b"zTXt"]
- for info_chunk in info.chunks:
- cid, data = info_chunk[:2]
- if cid in chunks:
- chunks.remove(cid)
- chunk(fp, cid, data)
- elif cid in chunks_multiple_allowed:
- chunk(fp, cid, data)
- elif cid[1:2].islower():
- # Private chunk
- after_idat = info_chunk[2:3]
- if not after_idat:
- chunk(fp, cid, data)
-
- if im.mode == "P":
- palette_byte_number = colors * 3
- palette_bytes = im.im.getpalette("RGB")[:palette_byte_number]
- while len(palette_bytes) < palette_byte_number:
- palette_bytes += b"\0"
- chunk(fp, b"PLTE", palette_bytes)
-
- transparency = im.encoderinfo.get("transparency", im.info.get("transparency", None))
-
- if transparency or transparency == 0:
- if im.mode == "P":
- # limit to actual palette size
- alpha_bytes = colors
- if isinstance(transparency, bytes):
- chunk(fp, b"tRNS", transparency[:alpha_bytes])
- else:
- transparency = max(0, min(255, transparency))
- alpha = b"\xFF" * transparency + b"\0"
- chunk(fp, b"tRNS", alpha[:alpha_bytes])
- elif im.mode in ("1", "L", "I"):
- transparency = max(0, min(65535, transparency))
- chunk(fp, b"tRNS", o16(transparency))
- elif im.mode == "RGB":
- red, green, blue = transparency
- chunk(fp, b"tRNS", o16(red) + o16(green) + o16(blue))
- else:
- if "transparency" in im.encoderinfo:
- # don't bother with transparency if it's an RGBA
- # and it's in the info dict. It's probably just stale.
- msg = "cannot use transparency for this mode"
- raise OSError(msg)
- else:
- if im.mode == "P" and im.im.getpalettemode() == "RGBA":
- alpha = im.im.getpalette("RGBA", "A")
- alpha_bytes = colors
- chunk(fp, b"tRNS", alpha[:alpha_bytes])
-
- dpi = im.encoderinfo.get("dpi")
- if dpi:
- chunk(
- fp,
- b"pHYs",
- o32(int(dpi[0] / 0.0254 + 0.5)),
- o32(int(dpi[1] / 0.0254 + 0.5)),
- b"\x01",
- )
-
- if info:
- chunks = [b"bKGD", b"hIST"]
- for info_chunk in info.chunks:
- cid, data = info_chunk[:2]
- if cid in chunks:
- chunks.remove(cid)
- chunk(fp, cid, data)
-
- exif = im.encoderinfo.get("exif")
- if exif:
- if isinstance(exif, Image.Exif):
- exif = exif.tobytes(8)
- if exif.startswith(b"Exif\x00\x00"):
- exif = exif[6:]
- chunk(fp, b"eXIf", exif)
-
- if save_all:
- _write_multiple_frames(im, fp, chunk, rawmode, default_image, append_images)
- else:
- ImageFile._save(im, _idat(fp, chunk), [("zip", (0, 0) + im.size, 0, rawmode)])
-
- if info:
- for info_chunk in info.chunks:
- cid, data = info_chunk[:2]
- if cid[1:2].islower():
- # Private chunk
- after_idat = info_chunk[2:3]
- if after_idat:
- chunk(fp, cid, data)
-
- chunk(fp, b"IEND", b"")
-
- if hasattr(fp, "flush"):
- fp.flush()
-
-
-# --------------------------------------------------------------------
-# PNG chunk converter
-
-
-def getchunks(im, **params):
- """Return a list of PNG chunks representing this image."""
-
- class collector:
- data = []
-
- def write(self, data):
- pass
-
- def append(self, chunk):
- self.data.append(chunk)
-
- def append(fp, cid, *data):
- data = b"".join(data)
- crc = o32(_crc32(data, _crc32(cid)))
- fp.append((cid, data, crc))
-
- fp = collector()
-
- try:
- im.encoderinfo = params
- _save(im, fp, None, append)
- finally:
- del im.encoderinfo
-
- return fp.data
-
-
-# --------------------------------------------------------------------
-# Registry
-
-Image.register_open(PngImageFile.format, PngImageFile, _accept)
-Image.register_save(PngImageFile.format, _save)
-Image.register_save_all(PngImageFile.format, _save_all)
-
-Image.register_extensions(PngImageFile.format, [".png", ".apng"])
-
-Image.register_mime(PngImageFile.format, "image/png")
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/anyio/_core/_streams.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/anyio/_core/_streams.py
deleted file mode 100644
index 54ea2b2bafd321a4f88dfa6fd19993213eec8105..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/anyio/_core/_streams.py
+++ /dev/null
@@ -1,47 +0,0 @@
-from __future__ import annotations
-
-import math
-from typing import Any, TypeVar, overload
-
-from ..streams.memory import (
- MemoryObjectReceiveStream,
- MemoryObjectSendStream,
- MemoryObjectStreamState,
-)
-
-T_Item = TypeVar("T_Item")
-
-
-@overload
-def create_memory_object_stream(
- max_buffer_size: float = ...,
-) -> tuple[MemoryObjectSendStream[Any], MemoryObjectReceiveStream[Any]]:
- ...
-
-
-@overload
-def create_memory_object_stream(
- max_buffer_size: float = ..., item_type: type[T_Item] = ...
-) -> tuple[MemoryObjectSendStream[T_Item], MemoryObjectReceiveStream[T_Item]]:
- ...
-
-
-def create_memory_object_stream(
- max_buffer_size: float = 0, item_type: type[T_Item] | None = None
-) -> tuple[MemoryObjectSendStream[Any], MemoryObjectReceiveStream[Any]]:
- """
- Create a memory object stream.
-
- :param max_buffer_size: number of items held in the buffer until ``send()`` starts blocking
- :param item_type: type of item, for marking the streams with the right generic type for
- static typing (not used at run time)
- :return: a tuple of (send stream, receive stream)
-
- """
- if max_buffer_size != math.inf and not isinstance(max_buffer_size, int):
- raise ValueError("max_buffer_size must be either an integer or math.inf")
- if max_buffer_size < 0:
- raise ValueError("max_buffer_size cannot be negative")
-
- state: MemoryObjectStreamState = MemoryObjectStreamState(max_buffer_size)
- return MemoryObjectSendStream(state), MemoryObjectReceiveStream(state)
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/index-31d5c487.css b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/index-31d5c487.css
deleted file mode 100644
index 5676fb86a728e49c066354dcb7dc77546110180d..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/index-31d5c487.css
+++ /dev/null
@@ -1 +0,0 @@
-.gradio-bokeh.svelte-14lyx1r.svelte-14lyx1r{display:flex;justify-content:center}.layout.svelte-14lyx1r.svelte-14lyx1r{display:flex;flex-direction:column;justify-content:center;align-items:center;width:var(--size-full);height:var(--size-full);color:var(--body-text-color)}.altair.svelte-14lyx1r.svelte-14lyx1r{display:flex;flex-direction:column;justify-content:center;align-items:center;width:var(--size-full);height:var(--size-full)}.caption.svelte-14lyx1r.svelte-14lyx1r{font-size:var(--text-sm)}.matplotlib.svelte-14lyx1r img.svelte-14lyx1r{object-fit:contain}
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/index-965cb568.js b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/index-965cb568.js
deleted file mode 100644
index d76f89bd342bcc07708b2976adf61b550ab57f36..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/index-965cb568.js
+++ /dev/null
@@ -1,2 +0,0 @@
-import{S as p}from"./StaticForm-01feba77.js";import"./index-39fce9e2.js";const t=["static"];export{p as Component,t as modes};
-//# sourceMappingURL=index-965cb568.js.map
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/httpcore/_backends/base.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/httpcore/_backends/base.py
deleted file mode 100644
index 6cadedb5f9367536c8355b583127c4a904c3b8fa..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/httpcore/_backends/base.py
+++ /dev/null
@@ -1,103 +0,0 @@
-import ssl
-import time
-import typing
-
-SOCKET_OPTION = typing.Union[
- typing.Tuple[int, int, int],
- typing.Tuple[int, int, typing.Union[bytes, bytearray]],
- typing.Tuple[int, int, None, int],
-]
-
-
-class NetworkStream:
- def read(self, max_bytes: int, timeout: typing.Optional[float] = None) -> bytes:
- raise NotImplementedError() # pragma: nocover
-
- def write(self, buffer: bytes, timeout: typing.Optional[float] = None) -> None:
- raise NotImplementedError() # pragma: nocover
-
- def close(self) -> None:
- raise NotImplementedError() # pragma: nocover
-
- def start_tls(
- self,
- ssl_context: ssl.SSLContext,
- server_hostname: typing.Optional[str] = None,
- timeout: typing.Optional[float] = None,
- ) -> "NetworkStream":
- raise NotImplementedError() # pragma: nocover
-
- def get_extra_info(self, info: str) -> typing.Any:
- return None # pragma: nocover
-
-
-class NetworkBackend:
- def connect_tcp(
- self,
- host: str,
- port: int,
- timeout: typing.Optional[float] = None,
- local_address: typing.Optional[str] = None,
- socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,
- ) -> NetworkStream:
- raise NotImplementedError() # pragma: nocover
-
- def connect_unix_socket(
- self,
- path: str,
- timeout: typing.Optional[float] = None,
- socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,
- ) -> NetworkStream:
- raise NotImplementedError() # pragma: nocover
-
- def sleep(self, seconds: float) -> None:
- time.sleep(seconds) # pragma: nocover
-
-
-class AsyncNetworkStream:
- async def read(
- self, max_bytes: int, timeout: typing.Optional[float] = None
- ) -> bytes:
- raise NotImplementedError() # pragma: nocover
-
- async def write(
- self, buffer: bytes, timeout: typing.Optional[float] = None
- ) -> None:
- raise NotImplementedError() # pragma: nocover
-
- async def aclose(self) -> None:
- raise NotImplementedError() # pragma: nocover
-
- async def start_tls(
- self,
- ssl_context: ssl.SSLContext,
- server_hostname: typing.Optional[str] = None,
- timeout: typing.Optional[float] = None,
- ) -> "AsyncNetworkStream":
- raise NotImplementedError() # pragma: nocover
-
- def get_extra_info(self, info: str) -> typing.Any:
- return None # pragma: nocover
-
-
-class AsyncNetworkBackend:
- async def connect_tcp(
- self,
- host: str,
- port: int,
- timeout: typing.Optional[float] = None,
- local_address: typing.Optional[str] = None,
- socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,
- ) -> AsyncNetworkStream:
- raise NotImplementedError() # pragma: nocover
-
- async def connect_unix_socket(
- self,
- path: str,
- timeout: typing.Optional[float] = None,
- socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None,
- ) -> AsyncNetworkStream:
- raise NotImplementedError() # pragma: nocover
-
- async def sleep(self, seconds: float) -> None:
- raise NotImplementedError() # pragma: nocover
diff --git a/spaces/descript/vampnet/vampnet/util.py b/spaces/descript/vampnet/vampnet/util.py
deleted file mode 100644
index 8fbf8fb41f1d2e1c0ad95e959acb5ae8655768f7..0000000000000000000000000000000000000000
--- a/spaces/descript/vampnet/vampnet/util.py
+++ /dev/null
@@ -1,46 +0,0 @@
-import tqdm
-
-import torch
-from einops import rearrange
-
-def scalar_to_batch_tensor(x, batch_size):
- return torch.tensor(x).repeat(batch_size)
-
-
-def parallelize(
- fn,
- *iterables,
- parallel: str = "thread_map",
- **kwargs
- ):
- if parallel == "thread_map":
- from tqdm.contrib.concurrent import thread_map
- return thread_map(
- fn,
- *iterables,
- **kwargs
- )
- elif parallel == "process_map":
- from tqdm.contrib.concurrent import process_map
- return process_map(
- fn,
- *iterables,
- **kwargs
- )
- elif parallel == "single":
- return [fn(x) for x in tqdm.tqdm(*iterables)]
- else:
- raise ValueError(f"parallel must be one of 'thread_map', 'process_map', 'single', but got {parallel}")
-
-def codebook_flatten(tokens: torch.Tensor):
- """
- flatten a sequence of tokens from (batch, codebook, time) to (batch, codebook * time)
- """
- return rearrange(tokens, "b c t -> b (t c)")
-
-def codebook_unflatten(flat_tokens: torch.Tensor, n_c: int = None):
- """
- unflatten a sequence of tokens from (batch, codebook * time) to (batch, codebook, time)
- """
- tokens = rearrange(flat_tokens, "b (t c) -> b c t", c=n_c)
- return tokens
diff --git a/spaces/diacanFperku/AutoGPT/ACA Capture Pro 6.04 Keygen.md b/spaces/diacanFperku/AutoGPT/ACA Capture Pro 6.04 Keygen.md
deleted file mode 100644
index be18f144d00556be56b551d5bb5b5a99a8c552c0..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/ACA Capture Pro 6.04 Keygen.md
+++ /dev/null
@@ -1,20 +0,0 @@
-ACA Capture Pro 6.04 Keygen
Download ———>>> https://gohhs.com/2uFTnG
-
-Enter your download ACA Capture Pro 6.04 + Crack + Keygen Serial Number now. Have a look at the new ACA Capture Pro Crack. This software is going to help you to burn your DVD's, DVD R, DVD RW, DVD +R/RW to DVD +R/RW, DVD-R/RW, DVD-RW. ACA Capture Pro is the world's most powerful digital photoalbum software. It helps you to create professional-quality slide shows, presentations and photo albums with just a few clicks. All these without any experience. You can burn multi-CD/DVDs, multi-angle photo books, slide shows and much more. ACA Capture Pro is a digital photo album application that allows users to create great looking slide shows.
-
-ACA Capture Pro 6.0 keygen download
-
-This program is known for its ease of use and one-click Auto-Capture functionality. It is a powerful photo album software program with powerful new features that will enable you to create stunning slide shows with just a few clicks. You can create both photo albums as well as interactive photo albums. You can create and edit pictures on the fly. You can even add texts to your photos. Create a cool slideshow with captions and titles in any language. You can burn multi-CD/DVDs, multi-angle photo books, slide shows and much more. ACA Pro is an incredibly powerful photo album software program that allows users to create great looking slide shows. You can create both photo albums as well as interactive photo albums. Photo albums and slideshows come in a variety of formats. Users can create captions and titles in any language. You can create slideshows with captions and titles in any language. It is an incredibly powerful photo album software program that allows users to create great looking slide shows with just a few clicks. It helps you to burn multi-CD/DVDs, multi-angle photo books, slide shows and much more. Create beautiful photo albums, slide shows, and multi-angle photo books. An easy to use interface and powerful new features will allow you to create stunning slide shows with just a few clicks.
-
-You can create slideshows with captions and titles in any language.
-
-Create beautiful photo albums, slide shows, and multi-angle photo books.
-
-Multi-angle photo books and slide shows are a cinch to create.
-
-New and powerful features allow you to create stunning slideshows with just a few clicks.
-
-You can burn multi 4fefd39f24
-
-
-
diff --git a/spaces/diacanFperku/AutoGPT/Autodesk AutoCAD Electrical 2018 [32-64Bit]- Full Version BETTER.md b/spaces/diacanFperku/AutoGPT/Autodesk AutoCAD Electrical 2018 [32-64Bit]- Full Version BETTER.md
deleted file mode 100644
index 8d79622b9f767482134d253eb8ab402d7b89ea2f..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Autodesk AutoCAD Electrical 2018 [32-64Bit]- Full Version BETTER.md
+++ /dev/null
@@ -1,115 +0,0 @@
-
-Autodesk AutoCAD Electrical 2018 [32-64Bit]- Full Version: A Comprehensive Review
-
-Autodesk AutoCAD Electrical 2018 is a professional software for designing electrical control systems. It is based on the AutoCAD platform and provides a complete set of tools and features for electrical engineers and designers. In this article, we will review the main aspects of this software, such as its system requirements, installation process, interface, functionality, and benefits.
-
-System Requirements for Autodesk AutoCAD Electrical 2018
-
-Before you download and install Autodesk AutoCAD Electrical 2018, you need to make sure that your computer meets the minimum system requirements for this software. Here are the system requirements for Autodesk AutoCAD Electrical 2018:
-Autodesk AutoCAD Electrical 2018 [32-64Bit]- full version
Download Zip ✦✦✦ https://gohhs.com/2uFUQw
-
-
-- Operating System: Microsoft Windows 10 (64-bit only), Microsoft Windows 8.1 with Update KB2919355 (32-bit & 64-bit), or Microsoft Windows 7 SP1 (32-bit & 64-bit). Note that AutoCAD Electrical 2018 is not supported on the 32-bit version of Windows 10.
-- CPU Type: 32-bit: 1 gigahertz (GHz) or faster 32-bit (x86) processor; 64-bit: 1 gigahertz (GHz) or faster 64-bit (x64) processor
-- Memory: For 32-bit AutoCAD Electrical 2018: 2 GB (4 GB recommended); For 64-bit AutoCAD Electrical 2018: 4 GB (8 GB recommended)
-- Display Resolution: Conventional Displays:1360 x 768 (1920 x 1080 recommended) with True Color; High Resolution & 4K Displays: Resolutions up to 3840 x 2160 supported on Windows 10, 64 bit systems (with capable display card)
-- Display Card: Windows display adapter capable of 1360 x 768 with True Color capabilities and DirectX®9. DirectX11 compliant card recommended.
-- Disk Space: Installation 12.0 GB
-- Browser: Windows Internet Explorer®11 or later
-- .NET Framework: .NET Framework Version4.6
-
-
-If your computer meets these system requirements, you can proceed to download and install Autodesk AutoCAD Electrical 2018.
-
-Installation Process for Autodesk AutoCAD Electrical 2018
-
-To install Autodesk AutoCAD Electrical 2018, you need to follow these steps:
-
-
-- Download the Autodesk AutoCAD Electrical 2018 setup file from a reliable source. You can find many websites that offer this file, but be careful of viruses and malware that might harm your computer. You can use a trusted antivirus program to scan the file before opening it.
-- Extract the Autodesk AutoCAD Electrical 2018 setup file using a program like WinRAR or 7-Zip. You will get a folder with several files inside.
-- Run the setup.exe file in the folder and follow the instructions on the screen. You will need to accept the license agreement, choose the installation type (typical or custom), select the components to install, and specify the installation location.
-- Wait for the installation process to complete. It might take several minutes depending on your computer speed and internet connection.
-- When the installation is finished, you can launch Autodesk AutoCAD Electrical 2018 from your desktop or start menu.
-
-
-You have successfully installed Autodesk AutoCAD Electrical 2018 on your computer.
-
-Interface of Autodesk AutoCAD Electrical 2018
-
-The interface of Autodesk AutoCAD Electrical 2018 is similar to other AutoCAD products, but with some specific features and tools for electrical design. The interface consists of several elements, such as:
-
-
-- The ribbon: The ribbon is a panel that contains tabs with various commands and tools organized by categories. You can access different tabs depending on your current task or context. For example, you can access the Home tab for basic drawing and editing tools, the Schematic tab for electrical schematic tools, the Panel tab for panel layout tools, and so on.
-- The drawing area: The drawing area is where you create and modify your electrical drawings. You can use different views and modes to display your drawings, such as wireframe, shaded, realistic, etc. You can also use different visual styles and effects to enhance your drawings, such as shadows, materials, lighting, etc.
-- The command window: The command window is where you enter commands and respond to prompts via simple keystrokes. You can also see messages and feedback from the software in this window.
-- The tool palettes: The tool palettes are panels that contain frequently used content and tools that you can access quickly. You can customize the tool palettes according to your preferences and needs.
-- The status bar: The status bar is located at the bottom of the interface and shows information about your current drawing and settings. You can also toggle various modes and options from this bar, such as grid, snap, ortho, polar tracking, etc.
-
-
-The interface of Autodesk AutoCAD Electrical 2018 is designed to help you work efficiently and productively with your electrical projects.
-
-Functionality of Autodesk AutoCAD Electrical 2018
-
-Autodesk AutoCAD Electrical 2018 provides a comprehensive set of functionality for electrical design and engineering. Some of the main features and functions of this software are:
-
-
-
-- Electrical schematic design: You can create and edit electrical schematics using a variety of tools and features. You can use symbols from an extensive library or create your own custom symbols. You can also use automated tools to generate wires, wire numbers, component tags, cross-references, etc.
-- Electrical panel layout design: You can create and edit electrical panel layouts using a variety of tools and features. You can use components from an extensive library or create your own custom components. You can also use automated tools to generate bills of materials (BOMs), terminal plans, reports, etc.
-- Circuit design and analysis: You can design and analyze electrical circuits using a variety of tools and features. You can use Circuit Builder to create simple circuits interactively with dialogs and tips. You can also use Circuit Design Suite to perform advanced circuit analysis functions such as simulation, optimization, verification, etc.
-- Data management and collaboration: You can manage and share your electrical data using a variety of tools and features. You can use Project Manager to organize your electrical projects by folders and files. You can also use Data Exchange to import and export data from other applications such as Excel or PLCs.
-
-
-Autodesk AutoCAD Electrical 2018 provides a complete solution for electrical design and engineering.
-
-Benefits of Autodesk AutoCAD Electrical 2018
-
-By using Autodesk AutoCAD Electrical 2018, you can enjoy some benefits that come with this software, such as:
-
-
-- Increase productivity and efficiency: You can work faster and smarter with automated tools that reduce errors and improve quality. You can also save time by reusing existing content and data from other sources.
-- Enhance creativity and innovation: You can explore different design options and scenarios with flexible tools that allow you to modify and customize your drawings easily. You can also use realistic visual styles and effects to present your designs in an impressive way.
-- Improve collaboration and communication: You can share your work with others using various formats and platforms that are compatible with other applications. You can also use cloud services to access your data anytime and anywhere.
-
-
-Autodesk AutoCAD Electrical 2018 is a powerful software that helps you create professional electrical designs.
-
-Conclusion
-
-In conclusion, Autodesk AutoCAD Electrical 2018 is a professional software for designing electrical control systems. It has all the functionality of AutoCAD plus comprehensive symbol libraries and tools for automating control engineering tasks. It has a modern interface that is easy to use and explore. It has a wide range of features that cover all aspects of electrical design and engineering. It has many benefits that increase productivity, efficiency, creativity, innovation, collaboration, and communication.
-
-If you are looking for a professional software for electrical design and engineering, you should consider downloading Autodesk AutoCAD Electrical 2018 [32-64Bit]- full version from a reliable source.
-How to Download Autodesk AutoCAD Electrical 2018 [32-64Bit]- Full Version
-
-If you want to download Autodesk AutoCAD Electrical 2018 [32-64Bit]- full version, you need to follow these steps:
-
-
-- Go to a reliable website that offers the download link for this software. You can find many websites that offer this file, but be careful of viruses and malware that might harm your computer. You can use a trusted antivirus program to scan the file before opening it.
-- Click on the download link and choose the option that suits your system requirements. You can choose between 32-bit or 64-bit versions, depending on your operating system and processor.
-- Wait for the download process to complete. It might take several minutes or hours depending on your internet speed and connection.
-- Once the download is finished, you can open the file and extract it using a program like WinRAR or 7-Zip. You will get a folder with several files inside.
-- Run the setup.exe file in the folder and follow the instructions on the screen. You will need to accept the license agreement, choose the installation type (typical or custom), select the components to install, and specify the installation location.
-
-
-You have successfully downloaded Autodesk AutoCAD Electrical 2018 [32-64Bit]- full version.
-
-How to Use Autodesk AutoCAD Electrical 2018 [32-64Bit]- Full Version
-
-Once you have installed Autodesk AutoCAD Electrical 2018 [32-64Bit]- full version, you can start using it to create and modify electrical control systems. Here are some tips on how to use it:
-
-
-- To access the electrical schematic design tools, you can use the Schematic tab on the ribbon. You can use symbols from an extensive library or create your own custom symbols. You can also use automated tools to generate wires, wire numbers, component tags, cross-references, etc.
-- To access the electrical panel layout design tools, you can use the Panel tab on the ribbon. You can use components from an extensive library or create your own custom components. You can also use automated tools to generate bills of materials (BOMs), terminal plans, reports, etc.
-- To access the circuit design and analysis tools, you can use the Circuit Builder or Circuit Design Suite. You can use Circuit Builder to create simple circuits interactively with dialogs and tips. You can also use Circuit Design Suite to perform advanced circuit analysis functions such as simulation, optimization, verification, etc.
-- To manage and share your electrical data, you can use Project Manager or Data Exchange. You can use Project Manager to organize your electrical projects by folders and files. You can also use Data Exchange to import and export data from other applications such as Excel or PLCs.
-
-
-You have learned how to use Autodesk AutoCAD Electrical 2018 [32-64Bit]- full version.
-Conclusion
-
-Autodesk AutoCAD Electrical 2018 [32-64Bit]- full version is a professional software for designing electrical control systems. It has all the functionality of AutoCAD plus comprehensive symbol libraries and tools for automating control engineering tasks. It has a modern interface that is easy to use and explore. It has a wide range of features that cover all aspects of electrical design and engineering. It has many benefits that increase productivity, efficiency, creativity, innovation, collaboration, and communication.
-
-If you are looking for a professional software for electrical design and engineering, you should consider downloading Autodesk AutoCAD Electrical 2018 [32-64Bit]- full version from a reliable source. You can also follow the steps in this article to download, install, and use this software effectively.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/diacanFperku/AutoGPT/New! Solucionario De Algebra Lineal Octava Edicion Bernard Kolman ((TOP)).md b/spaces/diacanFperku/AutoGPT/New! Solucionario De Algebra Lineal Octava Edicion Bernard Kolman ((TOP)).md
deleted file mode 100644
index ebd94925340b6db59f6305dd24b9ce927b66bfe6..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/New! Solucionario De Algebra Lineal Octava Edicion Bernard Kolman ((TOP)).md
+++ /dev/null
@@ -1,22 +0,0 @@
-New! solucionario de algebra lineal octava edicion bernard kolman
Download File ===> https://gohhs.com/2uFV5V
-
-1694 - 29 jun 2006 rafael raviera ceniceros 78 23,539 de 1694 a 29 de junio de 2006 - it also provided an example from the mathematical tradition of skepticism.
-
-Mathematics, history of, introduction - art, much of it pertaining to the philosophy of science, has been accumulated at the cost of a quite different sort of labor, the study of history, with a view to the general examination of the state of knowledge in a given period.
-
-At present, however, the majority of students have had only a few years of algebra in high school, and many of them have not spent much time on the subject during their college years. In contrast, the choice of topics in their most successful algebras is more democratic than in the past, because many more of them are required to cover the entire range of today's algebra.
-
-The book aims to provide an accessible introduction to the history and method of algebra as well as to develop the basic skills of algebraic thought, including arithmetic, coordinate geometry, polynomial and numerical equations and inequalities, and solutions.
-
-The book is concerned with a non-standard, but somewhat natural, version of algebra: the algebra of analytic functions. We start with a brief account of the role of algebra in the mathematical enterprise, present the general algebraic notions, and show how these can be applied to the analysis of functions.
-
-We have endeavoured to make the book accessible to the student who has not previously been concerned with algebra. We have tried to teach the student without starting from the very beginning, and we have explained the basic methods, as well as having explained some important results.
-
-Although the book is primarily a presentation of the subject, we have, whenever possible, attempted to take account of earlier mathematical research and to use as many of the same notation as possible. We have thus collected together the most elementary ideas and we have taken the opportunity to make explicit the standard facts about linear algebra, as well as developing our own framework for the subject.
-
-In this paper we shall use the notation of algebra. We shall also take the opportunity of making some comments about the standard notation of geometric algebra and about the interpretation of some of the ideas in that framework. Finally, we shall introduce the basic language of analysis.
-
-This will be the standard notation for groups and for linear algebra. In the latter case we shall also use the notation of geometric algebra and a certain generalisation of the standard 4fefd39f24
-
-
-
diff --git a/spaces/dibend/individual-stock-lookup/README.md b/spaces/dibend/individual-stock-lookup/README.md
deleted file mode 100644
index 69701688ea23d3540067f3d1bce4e9e17fb9eef9..0000000000000000000000000000000000000000
--- a/spaces/dibend/individual-stock-lookup/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Individual Stock Lookup
-emoji: 📈
-colorFrom: red
-colorTo: purple
-sdk: gradio
-sdk_version: 3.44.3
-app_file: app.py
-pinned: false
-license: gpl-3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/dineshreddy/WALT/walt/datasets/builder.py b/spaces/dineshreddy/WALT/walt/datasets/builder.py
deleted file mode 100644
index 9bc0fe466f5bfbf903438a5dc979329debd6517f..0000000000000000000000000000000000000000
--- a/spaces/dineshreddy/WALT/walt/datasets/builder.py
+++ /dev/null
@@ -1,143 +0,0 @@
-import copy
-import platform
-import random
-from functools import partial
-
-import numpy as np
-from mmcv.parallel import collate
-from mmcv.runner import get_dist_info
-from mmcv.utils import Registry, build_from_cfg
-from torch.utils.data import DataLoader
-
-from mmdet.datasets.samplers import DistributedGroupSampler, DistributedSampler, GroupSampler
-
-if platform.system() != 'Windows':
- # https://github.com/pytorch/pytorch/issues/973
- import resource
- rlimit = resource.getrlimit(resource.RLIMIT_NOFILE)
- hard_limit = rlimit[1]
- soft_limit = min(4096, hard_limit)
- resource.setrlimit(resource.RLIMIT_NOFILE, (soft_limit, hard_limit))
-
-DATASETS = Registry('dataset')
-PIPELINES = Registry('pipeline')
-
-
-def _concat_dataset(cfg, default_args=None):
- from mmdet.datasets.dataset_wrappers import ConcatDataset
- ann_files = cfg['ann_file']
- img_prefixes = cfg.get('img_prefix', None)
- seg_prefixes = cfg.get('seg_prefix', None)
- proposal_files = cfg.get('proposal_file', None)
- separate_eval = cfg.get('separate_eval', True)
-
- datasets = []
- num_dset = len(ann_files)
- for i in range(num_dset):
- data_cfg = copy.deepcopy(cfg)
- # pop 'separate_eval' since it is not a valid key for common datasets.
- if 'separate_eval' in data_cfg:
- data_cfg.pop('separate_eval')
- data_cfg['ann_file'] = ann_files[i]
- if isinstance(img_prefixes, (list, tuple)):
- data_cfg['img_prefix'] = img_prefixes[i]
- if isinstance(seg_prefixes, (list, tuple)):
- data_cfg['seg_prefix'] = seg_prefixes[i]
- if isinstance(proposal_files, (list, tuple)):
- data_cfg['proposal_file'] = proposal_files[i]
- datasets.append(build_dataset(data_cfg, default_args))
-
- return ConcatDataset(datasets, separate_eval)
-
-
-def build_dataset(cfg, default_args=None):
- from mmdet.datasets.dataset_wrappers import (ConcatDataset, RepeatDataset,
- ClassBalancedDataset)
- if isinstance(cfg, (list, tuple)):
- dataset = ConcatDataset([build_dataset(c, default_args) for c in cfg])
- elif cfg['type'] == 'ConcatDataset':
- dataset = ConcatDataset(
- [build_dataset(c, default_args) for c in cfg['datasets']],
- cfg.get('separate_eval', True))
- elif cfg['type'] == 'RepeatDataset':
- dataset = RepeatDataset(
- build_dataset(cfg['dataset'], default_args), cfg['times'])
- elif cfg['type'] == 'ClassBalancedDataset':
- dataset = ClassBalancedDataset(
- build_dataset(cfg['dataset'], default_args), cfg['oversample_thr'])
- elif isinstance(cfg.get('ann_file'), (list, tuple)):
- dataset = _concat_dataset(cfg, default_args)
- else:
- dataset = build_from_cfg(cfg, DATASETS, default_args)
-
- return dataset
-
-
-def build_dataloader(dataset,
- samples_per_gpu,
- workers_per_gpu,
- num_gpus=1,
- dist=True,
- shuffle=True,
- seed=None,
- **kwargs):
- """Build PyTorch DataLoader.
-
- In distributed training, each GPU/process has a dataloader.
- In non-distributed training, there is only one dataloader for all GPUs.
-
- Args:
- dataset (Dataset): A PyTorch dataset.
- samples_per_gpu (int): Number of training samples on each GPU, i.e.,
- batch size of each GPU.
- workers_per_gpu (int): How many subprocesses to use for data loading
- for each GPU.
- num_gpus (int): Number of GPUs. Only used in non-distributed training.
- dist (bool): Distributed training/test or not. Default: True.
- shuffle (bool): Whether to shuffle the data at every epoch.
- Default: True.
- kwargs: any keyword argument to be used to initialize DataLoader
-
- Returns:
- DataLoader: A PyTorch dataloader.
- """
- rank, world_size = get_dist_info()
- if dist:
- # DistributedGroupSampler will definitely shuffle the data to satisfy
- # that images on each GPU are in the same group
- if shuffle:
- sampler = DistributedGroupSampler(
- dataset, samples_per_gpu, world_size, rank, seed=seed)
- else:
- sampler = DistributedSampler(
- dataset, world_size, rank, shuffle=False, seed=seed)
- batch_size = samples_per_gpu
- num_workers = workers_per_gpu
- else:
- sampler = GroupSampler(dataset, samples_per_gpu) if shuffle else None
- batch_size = num_gpus * samples_per_gpu
- num_workers = num_gpus * workers_per_gpu
-
- init_fn = partial(
- worker_init_fn, num_workers=num_workers, rank=rank,
- seed=seed) if seed is not None else None
-
- data_loader = DataLoader(
- dataset,
- batch_size=batch_size,
- sampler=sampler,
- num_workers=num_workers,
- collate_fn=partial(collate, samples_per_gpu=samples_per_gpu),
- pin_memory=False,
- worker_init_fn=init_fn,
- **kwargs)
-
- return data_loader
-
-
-def worker_init_fn(worker_id, num_workers, rank, seed):
- # The seed of each worker equals to
- # num_worker * rank + worker_id + user_seed
- worker_seed = num_workers * rank + worker_id + seed
- np.random.seed(worker_seed)
- random.seed(worker_seed)
diff --git a/spaces/dnth/edgenext-paddy-disease-classifier/app.py b/spaces/dnth/edgenext-paddy-disease-classifier/app.py
deleted file mode 100644
index d80351cae7e96745831191af51891dd01e5f2f14..0000000000000000000000000000000000000000
--- a/spaces/dnth/edgenext-paddy-disease-classifier/app.py
+++ /dev/null
@@ -1,36 +0,0 @@
-import gradio as gr
-from fastai.vision.all import *
-import skimage
-import os
-
-learn = load_learner('learner.pkl')
-labels = learn.dls.vocab
-
-def predict(img):
- img = PILImage.create(img)
- pred,pred_idx,probs = learn.predict(img)
- return {labels[i]: float(probs[i]) for i in range(len(labels))}
-
-for root, dirs, files in os.walk(r'sample_images/'):
- for filename in files:
- print(filename)
-
-title = "Paddy Disease Classifier with EdgeNeXt"
-description = "9 Diseases + 1 Normal class."
-interpretation='default'
-examples = ["sample_images/"+file for file in files]
-article="Blog post
"
-enable_queue=True
-
-gr.Interface(
- fn=predict,
- inputs=gr.inputs.Image(shape=(224, 224)),
- outputs=gr.outputs.Label(num_top_classes=3),
- title=title,
- description=description,
- article=article,
- examples=examples,
- interpretation=interpretation,
- enable_queue=enable_queue,
- theme="grass",
-).launch()
\ No newline at end of file
diff --git a/spaces/eddydecena/cat-vs-dog/README.md b/spaces/eddydecena/cat-vs-dog/README.md
deleted file mode 100644
index c651a4271f58eed78b13cb41ab6d0d2919e4506c..0000000000000000000000000000000000000000
--- a/spaces/eddydecena/cat-vs-dog/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: Cat_vs_dog
-emoji: 🔥
-colorFrom: yellow
-colorTo: green
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/eengel7/news_headline_sentiment/README.md b/spaces/eengel7/news_headline_sentiment/README.md
deleted file mode 100644
index 1b2e2bb911722fdc12670e6093cc62162049d815..0000000000000000000000000000000000000000
--- a/spaces/eengel7/news_headline_sentiment/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: News Headline Sentiment
-emoji: 🌍
-colorFrom: red
-colorTo: blue
-sdk: gradio
-sdk_version: 3.16.1
-app_file: app.py
-pinned: false
-license: apache-2.0
-duplicated_from: torileatherman/news_headline_sentiment
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/epexVfeibi/Imagedeblurr/((TOP)) Download Buku Pengantar Pendidikan Pdf.md b/spaces/epexVfeibi/Imagedeblurr/((TOP)) Download Buku Pengantar Pendidikan Pdf.md
deleted file mode 100644
index db658ead90077f7109f29cfcb52f4f78edd69246..0000000000000000000000000000000000000000
--- a/spaces/epexVfeibi/Imagedeblurr/((TOP)) Download Buku Pengantar Pendidikan Pdf.md
+++ /dev/null
@@ -1,6 +0,0 @@
-download buku pengantar pendidikan pdf
DOWNLOAD ===> https://jinyurl.com/2uEpjO
-
-Program Studi Pendidikan Teknik Elektro, Jurusan Teknik Elektro. ... Sistem Komputer Materi Pokok : Pengantar Organisasi dan Arsitektur Komputer Pertemuan ke : 1-4 ... Download perangkat ajar teknik pemrograman mikroprosesor dan ... May 30, 2020 · Jual Buku Pemrograman Mikroprosesor Mikrokontroler T Audio Smk ... 1fdad05405
-
-
-
diff --git a/spaces/erastorgueva-nv/NeMo-Forced-Aligner/utils/data_prep.py b/spaces/erastorgueva-nv/NeMo-Forced-Aligner/utils/data_prep.py
deleted file mode 100644
index 602070288db9b4c8068619ebd983f8433cac4808..0000000000000000000000000000000000000000
--- a/spaces/erastorgueva-nv/NeMo-Forced-Aligner/utils/data_prep.py
+++ /dev/null
@@ -1,835 +0,0 @@
-# Copyright (c) 2023, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import json
-from dataclasses import dataclass, field
-from pathlib import Path
-from typing import List, Union
-
-import soundfile as sf
-import torch
-from tqdm.auto import tqdm
-from utils.constants import BLANK_TOKEN, SPACE_TOKEN, V_NEGATIVE_NUM
-
-from nemo.utils import logging
-
-
-def _get_utt_id(audio_filepath, audio_filepath_parts_in_utt_id):
- fp_parts = Path(audio_filepath).parts[-audio_filepath_parts_in_utt_id:]
- utt_id = Path("_".join(fp_parts)).stem
- utt_id = utt_id.replace(" ", "-") # replace any spaces in the filepath with dashes
- return utt_id
-
-
-def get_batch_starts_ends(manifest_filepath, batch_size):
- """
- Get the start and end ids of the lines we will use for each 'batch'.
- """
-
- with open(manifest_filepath, 'r') as f:
- num_lines_in_manifest = sum(1 for _ in f)
-
- starts = [x for x in range(0, num_lines_in_manifest, batch_size)]
- ends = [x - 1 for x in starts]
- ends.pop(0)
- ends.append(num_lines_in_manifest)
-
- return starts, ends
-
-
-def is_entry_in_any_lines(manifest_filepath, entry):
- """
- Returns True if entry is a key in any of the JSON lines in manifest_filepath
- """
-
- entry_in_manifest = False
-
- with open(manifest_filepath, 'r') as f:
- for line in f:
- data = json.loads(line)
-
- if entry in data:
- entry_in_manifest = True
-
- return entry_in_manifest
-
-
-def is_entry_in_all_lines(manifest_filepath, entry):
- """
- Returns True is entry is a key in all of the JSON lines in manifest_filepath.
- """
- with open(manifest_filepath, 'r') as f:
- for line in f:
- data = json.loads(line)
-
- if entry not in data:
- return False
-
- return True
-
-
-def get_manifest_lines_batch(manifest_filepath, start, end):
- manifest_lines_batch = []
- with open(manifest_filepath, "r", encoding="utf-8-sig") as f:
- for line_i, line in enumerate(f):
- if line_i >= start and line_i <= end:
- data = json.loads(line)
- if "text" in data:
- # remove any BOM, any duplicated spaces, convert any
- # newline chars to spaces
- data["text"] = data["text"].replace("\ufeff", "")
- data["text"] = " ".join(data["text"].split())
- manifest_lines_batch.append(data)
-
- if line_i == end:
- break
- return manifest_lines_batch
-
-
-def get_char_tokens(text, model):
- tokens = []
- for character in text:
- if character in model.decoder.vocabulary:
- tokens.append(model.decoder.vocabulary.index(character))
- else:
- tokens.append(len(model.decoder.vocabulary)) # return unk token (same as blank token)
-
- return tokens
-
-
-def is_sub_or_superscript_pair(ref_text, text):
- """returns True if ref_text is a subscript or superscript version of text"""
- sub_or_superscript_to_num = {
- "⁰": "0",
- "¹": "1",
- "²": "2",
- "³": "3",
- "⁴": "4",
- "⁵": "5",
- "⁶": "6",
- "⁷": "7",
- "⁸": "8",
- "⁹": "9",
- "₀": "0",
- "₁": "1",
- "₂": "2",
- "₃": "3",
- "₄": "4",
- "₅": "5",
- "₆": "6",
- "₇": "7",
- "₈": "8",
- "₉": "9",
- }
-
- if text in sub_or_superscript_to_num:
- if sub_or_superscript_to_num[text] == ref_text:
- return True
- return False
-
-
-def restore_token_case(word, word_tokens):
-
- # remove repeated "▁" and "_" from word as that is what the tokenizer will do
- while "▁▁" in word:
- word = word.replace("▁▁", "▁")
-
- while "__" in word:
- word = word.repalce("__", "_")
-
- word_tokens_cased = []
- word_char_pointer = 0
-
- for token in word_tokens:
- token_cased = ""
-
- for token_char in token:
- if token_char == word[word_char_pointer]:
- token_cased += token_char
- word_char_pointer += 1
-
- else:
- if token_char.upper() == word[word_char_pointer] or is_sub_or_superscript_pair(
- token_char, word[word_char_pointer]
- ):
- token_cased += token_char.upper()
- word_char_pointer += 1
- else:
- if token_char == "▁" or token_char == "_":
- if word[word_char_pointer] == "▁" or word[word_char_pointer] == "_":
- token_cased += token_char
- word_char_pointer += 1
- elif word_char_pointer == 0:
- token_cased += token_char
-
- else:
- raise RuntimeError(
- f"Unexpected error - failed to recover capitalization of tokens for word {word}"
- )
-
- word_tokens_cased.append(token_cased)
-
- return word_tokens_cased
-
-
-@dataclass
-class Token:
- text: str = None
- text_cased: str = None
- s_start: int = None
- s_end: int = None
- t_start: float = None
- t_end: float = None
-
-
-@dataclass
-class Word:
- text: str = None
- s_start: int = None
- s_end: int = None
- t_start: float = None
- t_end: float = None
- tokens: List[Token] = field(default_factory=list)
-
-
-@dataclass
-class Segment:
- text: str = None
- s_start: int = None
- s_end: int = None
- t_start: float = None
- t_end: float = None
- words_and_tokens: List[Union[Word, Token]] = field(default_factory=list)
-
-
-@dataclass
-class Utterance:
- token_ids_with_blanks: List[int] = field(default_factory=list)
- segments_and_tokens: List[Union[Segment, Token]] = field(default_factory=list)
- text: str = None
- pred_text: str = None
- audio_filepath: str = None
- utt_id: str = None
- saved_output_files: dict = field(default_factory=dict)
-
-
-def get_utt_obj(
- text, model, separator, T, audio_filepath, utt_id,
-):
- """
- Function to create an Utterance object and add all necessary information to it except
- for timings of the segments / words / tokens according to the alignment - that will
- be done later in a different function, after the alignment is done.
-
- The Utterance object has a list segments_and_tokens which contains Segment objects and
- Token objects (for blank tokens in between segments).
- Within the Segment objects, there is a list words_and_tokens which contains Word objects and
- Token objects (for blank tokens in between words).
- Within the Word objects, there is a list tokens tokens which contains Token objects for
- blank and non-blank tokens.
- We will be building up these lists in this function. This data structure will then be useful for
- generating the various output files that we wish to save.
- """
-
- if not separator: # if separator is not defined - treat the whole text as one segment
- segments = [text]
- else:
- segments = text.split(separator)
-
- # remove any spaces at start and end of segments
- segments = [seg.strip() for seg in segments]
- # remove any empty segments
- segments = [seg for seg in segments if len(seg) > 0]
-
- utt = Utterance(text=text, audio_filepath=audio_filepath, utt_id=utt_id,)
-
- # build up lists: token_ids_with_blanks, segments_and_tokens.
- # The code for these is different depending on whether we use char-based tokens or not
- if hasattr(model, 'tokenizer'):
- if hasattr(model, 'blank_id'):
- BLANK_ID = model.blank_id
- else:
- BLANK_ID = len(model.tokenizer.vocab) # TODO: check
-
- utt.token_ids_with_blanks = [BLANK_ID]
-
- # check for text being 0 length
- if len(text) == 0:
- return utt
-
- # check for # tokens + token repetitions being > T
- all_tokens = model.tokenizer.text_to_ids(text)
- n_token_repetitions = 0
- for i_tok in range(1, len(all_tokens)):
- if all_tokens[i_tok] == all_tokens[i_tok - 1]:
- n_token_repetitions += 1
-
- if len(all_tokens) + n_token_repetitions > T:
- logging.info(
- f"Utterance {utt_id} has too many tokens compared to the audio file duration."
- " Will not generate output alignment files for this utterance."
- )
- return utt
-
- # build up data structures containing segments/words/tokens
- utt.segments_and_tokens.append(Token(text=BLANK_TOKEN, text_cased=BLANK_TOKEN, s_start=0, s_end=0,))
-
- segment_s_pointer = 1 # first segment will start at s=1 because s=0 is a blank
- word_s_pointer = 1 # first word will start at s=1 because s=0 is a blank
-
- for segment in segments:
- # add the segment to segment_info and increment the segment_s_pointer
- segment_tokens = model.tokenizer.text_to_tokens(segment)
- utt.segments_and_tokens.append(
- Segment(
- text=segment,
- s_start=segment_s_pointer,
- # segment_tokens do not contain blanks => need to muliply by 2
- # s_end needs to be the index of the final token (including blanks) of the current segment:
- # segment_s_pointer + len(segment_tokens) * 2 is the index of the first token of the next segment =>
- # => need to subtract 2
- s_end=segment_s_pointer + len(segment_tokens) * 2 - 2,
- )
- )
- segment_s_pointer += (
- len(segment_tokens) * 2
- ) # multiply by 2 to account for blanks (which are not present in segment_tokens)
-
- words = segment.split(" ") # we define words to be space-separated sub-strings
- for word_i, word in enumerate(words):
-
- word_tokens = model.tokenizer.text_to_tokens(word)
- word_token_ids = model.tokenizer.text_to_ids(word)
- word_tokens_cased = restore_token_case(word, word_tokens)
-
- # add the word to word_info and increment the word_s_pointer
- utt.segments_and_tokens[-1].words_and_tokens.append(
- # word_tokens do not contain blanks => need to muliply by 2
- # s_end needs to be the index of the final token (including blanks) of the current word:
- # word_s_pointer + len(word_tokens) * 2 is the index of the first token of the next word =>
- # => need to subtract 2
- Word(text=word, s_start=word_s_pointer, s_end=word_s_pointer + len(word_tokens) * 2 - 2)
- )
- word_s_pointer += (
- len(word_tokens) * 2
- ) # multiply by 2 to account for blanks (which are not present in word_tokens)
-
- for token_i, (token, token_id, token_cased) in enumerate(
- zip(word_tokens, word_token_ids, word_tokens_cased)
- ):
- # add the text tokens and the blanks in between them
- # to our token-based variables
- utt.token_ids_with_blanks.extend([token_id, BLANK_ID])
- # adding Token object for non-blank token
- utt.segments_and_tokens[-1].words_and_tokens[-1].tokens.append(
- Token(
- text=token,
- text_cased=token_cased,
- # utt.token_ids_with_blanks has the form [...., , ] =>
- # => if do len(utt.token_ids_with_blanks) - 1 you get the index of the final
- # => we want to do len(utt.token_ids_with_blanks) - 2 to get the index of
- s_start=len(utt.token_ids_with_blanks) - 2,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 2,
- )
- )
-
- # adding Token object for blank tokens in between the tokens of the word
- # (ie do not add another blank if you have reached the end)
- if token_i < len(word_tokens) - 1:
- utt.segments_and_tokens[-1].words_and_tokens[-1].tokens.append(
- Token(
- text=BLANK_TOKEN,
- text_cased=BLANK_TOKEN,
- # utt.token_ids_with_blanks has the form [...., ] =>
- # => if do len(utt.token_ids_with_blanks) -1 you get the index of this
- s_start=len(utt.token_ids_with_blanks) - 1,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 1,
- )
- )
-
- # add a Token object for blanks in between words in this segment
- # (but only *in between* - do not add the token if it is after the final word)
- if word_i < len(words) - 1:
- utt.segments_and_tokens[-1].words_and_tokens.append(
- Token(
- text=BLANK_TOKEN,
- text_cased=BLANK_TOKEN,
- # utt.token_ids_with_blanks has the form [...., ] =>
- # => if do len(utt.token_ids_with_blanks) -1 you get the index of this
- s_start=len(utt.token_ids_with_blanks) - 1,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 1,
- )
- )
-
- # add the blank token in between segments/after the final segment
- utt.segments_and_tokens.append(
- Token(
- text=BLANK_TOKEN,
- text_cased=BLANK_TOKEN,
- # utt.token_ids_with_blanks has the form [...., ] =>
- # => if do len(utt.token_ids_with_blanks) -1 you get the index of this
- s_start=len(utt.token_ids_with_blanks) - 1,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 1,
- )
- )
-
- return utt
-
- elif hasattr(model.decoder, "vocabulary"): # i.e. tokenization is simply character-based
-
- BLANK_ID = len(model.decoder.vocabulary) # TODO: check this is correct
- SPACE_ID = model.decoder.vocabulary.index(" ")
-
- utt.token_ids_with_blanks = [BLANK_ID]
-
- # check for text being 0 length
- if len(text) == 0:
- return utt
-
- # check for # tokens + token repetitions being > T
- all_tokens = get_char_tokens(text, model)
- n_token_repetitions = 0
- for i_tok in range(1, len(all_tokens)):
- if all_tokens[i_tok] == all_tokens[i_tok - 1]:
- n_token_repetitions += 1
-
- if len(all_tokens) + n_token_repetitions > T:
- logging.info(
- f"Utterance {utt_id} has too many tokens compared to the audio file duration."
- " Will not generate output alignment files for this utterance."
- )
- return utt
-
- # build up data structures containing segments/words/tokens
- utt.segments_and_tokens.append(Token(text=BLANK_TOKEN, text_cased=BLANK_TOKEN, s_start=0, s_end=0,))
-
- segment_s_pointer = 1 # first segment will start at s=1 because s=0 is a blank
- word_s_pointer = 1 # first word will start at s=1 because s=0 is a blank
-
- for i_segment, segment in enumerate(segments):
- # add the segment to segment_info and increment the segment_s_pointer
- segment_tokens = get_char_tokens(segment, model)
- utt.segments_and_tokens.append(
- Segment(
- text=segment,
- s_start=segment_s_pointer,
- # segment_tokens do not contain blanks => need to muliply by 2
- # s_end needs to be the index of the final token (including blanks) of the current segment:
- # segment_s_pointer + len(segment_tokens) * 2 is the index of the first token of the next segment =>
- # => need to subtract 2
- s_end=segment_s_pointer + len(segment_tokens) * 2 - 2,
- )
- )
-
- # for correct calculation: multiply len(segment_tokens) by 2 to account for blanks (which are not present in segment_tokens)
- # and + 2 to account for [, ]
- segment_s_pointer += len(segment_tokens) * 2 + 2
-
- words = segment.split(" ") # we define words to be space-separated substrings
- for i_word, word in enumerate(words):
-
- # convert string to list of characters
- word_tokens = list(word)
- # convert list of characters to list of their ids in the vocabulary
- word_token_ids = get_char_tokens(word, model)
-
- # add the word to word_info and increment the word_s_pointer
- utt.segments_and_tokens[-1].words_and_tokens.append(
- # note for s_end:
- # word_tokens do not contain blanks => need to muliply by 2
- # s_end needs to be the index of the final token (including blanks) of the current word:
- # word_s_pointer + len(word_tokens) * 2 is the index of the first token of the next word =>
- # => need to subtract 2
- Word(text=word, s_start=word_s_pointer, s_end=word_s_pointer + len(word_tokens) * 2 - 2)
- )
-
- # for correct calculation: multiply len(word_tokens) by 2 to account for blanks (which are not present in word_tokens)
- # and + 2 to account for [, ]
- word_s_pointer += len(word_tokens) * 2 + 2
-
- for token_i, (token, token_id) in enumerate(zip(word_tokens, word_token_ids)):
- # add the text tokens and the blanks in between them
- # to our token-based variables
- utt.token_ids_with_blanks.extend([token_id])
- utt.segments_and_tokens[-1].words_and_tokens[-1].tokens.append(
- Token(
- text=token,
- text_cased=token,
- # utt.token_ids_with_blanks has the form [..., ]
- # => do len(utt.token_ids_with_blanks) - 1 to get the index of this non-blank token
- s_start=len(utt.token_ids_with_blanks) - 1,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 1,
- )
- )
-
- if token_i < len(word_tokens) - 1: # only add blank tokens that are in the middle of words
- utt.token_ids_with_blanks.extend([BLANK_ID])
- utt.segments_and_tokens[-1].words_and_tokens[-1].tokens.append(
- Token(
- text=BLANK_TOKEN,
- text_cased=BLANK_TOKEN,
- # utt.token_ids_with_blanks has the form [..., ]
- # => do len(utt.token_ids_with_blanks) - 1 to get the index of this blank token
- s_start=len(utt.token_ids_with_blanks) - 1,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 1,
- )
- )
-
- # add space token (and the blanks around it) unless this is the final word in a segment
- if i_word < len(words) - 1:
- utt.token_ids_with_blanks.extend([BLANK_ID, SPACE_ID, BLANK_ID])
- utt.segments_and_tokens[-1].words_and_tokens.append(
- Token(
- text=BLANK_TOKEN,
- text_cased=BLANK_TOKEN,
- # utt.token_ids_with_blanks has the form
- # [..., , , , ]
- # => do len(utt.token_ids_with_blanks) - 3 to get the index of the blank token before the space token
- s_start=len(utt.token_ids_with_blanks) - 3,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 3,
- )
- )
- utt.segments_and_tokens[-1].words_and_tokens.append(
- Token(
- text=SPACE_TOKEN,
- text_cased=SPACE_TOKEN,
- # utt.token_ids_with_blanks has the form
- # [..., , , , ]
- # => do len(utt.token_ids_with_blanks) - 2 to get the index of the space token
- s_start=len(utt.token_ids_with_blanks) - 2,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 2,
- )
- )
- utt.segments_and_tokens[-1].words_and_tokens.append(
- Token(
- text=BLANK_TOKEN,
- text_cased=BLANK_TOKEN,
- # utt.token_ids_with_blanks has the form
- # [..., , , , ]
- # => do len(utt.token_ids_with_blanks) - 1 to get the index of the blank token after the space token
- s_start=len(utt.token_ids_with_blanks) - 1,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 1,
- )
- )
-
- # add a blank to the segment, and add a space after if this is not the final segment
- utt.token_ids_with_blanks.extend([BLANK_ID])
- utt.segments_and_tokens.append(
- Token(
- text=BLANK_TOKEN,
- text_cased=BLANK_TOKEN,
- # utt.token_ids_with_blanks has the form [..., ]
- # => do len(utt.token_ids_with_blanks) - 1 to get the index of this blank token
- s_start=len(utt.token_ids_with_blanks) - 1,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 1,
- )
- )
-
- if i_segment < len(segments) - 1:
- utt.token_ids_with_blanks.extend([SPACE_ID, BLANK_ID])
- utt.segments_and_tokens.append(
- Token(
- text=SPACE_TOKEN,
- text_cased=SPACE_TOKEN,
- # utt.token_ids_with_blanks has the form
- # [..., , ]
- # => do len(utt.token_ids_with_blanks) - 2 to get the index of the space token
- s_start=len(utt.token_ids_with_blanks) - 2,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 2,
- )
- )
- utt.segments_and_tokens.append(
- Token(
- text=BLANK_TOKEN,
- text_cased=BLANK_TOKEN,
- # utt.token_ids_with_blanks has the form
- # [..., , ]
- # => do len(utt.token_ids_with_blanks) - 1 to get the index of the blank token
- s_start=len(utt.token_ids_with_blanks) - 1,
- # s_end is same as s_start since the token only occupies one element in the list
- s_end=len(utt.token_ids_with_blanks) - 1,
- )
- )
-
- return utt
-
- else:
- raise RuntimeError("Cannot get tokens of this model.")
-
-
-def add_t_start_end_to_utt_obj(utt_obj, alignment_utt, output_timestep_duration):
- """
- Function to add t_start and t_end (representing time in seconds) to the Utterance object utt_obj.
- Args:
- utt_obj: Utterance object to which we will add t_start and t_end for its
- constituent segments/words/tokens.
- alignment_utt: a list of ints indicating which token does the alignment pass through at each
- timestep (will take the form [0, 0, 1, 1, ..., ]).
- output_timestep_duration: a float indicating the duration of a single output timestep from
- the ASR Model.
-
- Returns:
- utt_obj: updated Utterance object.
- """
-
- # General idea for the algorithm of how we add t_start and t_end
- # the timestep where a token s starts is the location of the first appearance of s_start in alignment_utt
- # the timestep where a token s ends is the location of the final appearance of s_end in alignment_utt
- # We will make dictionaries num_to_first_alignment_appearance and
- # num_to_last_appearance and use that to update all of
- # the t_start and t_end values in utt_obj.
- # We will put t_start = t_end = -1 for tokens that are skipped (should only be blanks)
-
- num_to_first_alignment_appearance = dict()
- num_to_last_alignment_appearance = dict()
-
- prev_s = -1 # use prev_s to keep track of when the s changes
- for t, s in enumerate(alignment_utt):
- if s > prev_s:
- num_to_first_alignment_appearance[s] = t
-
- if prev_s >= 0: # dont record prev_s = -1
- num_to_last_alignment_appearance[prev_s] = t - 1
- prev_s = s
- # add last appearance of the final s
- num_to_last_alignment_appearance[prev_s] = len(alignment_utt) - 1
-
- # update all the t_start and t_end in utt_obj
- for segment_or_token in utt_obj.segments_and_tokens:
- if type(segment_or_token) is Segment:
- segment = segment_or_token
- segment.t_start = num_to_first_alignment_appearance[segment.s_start] * output_timestep_duration
- segment.t_end = (num_to_last_alignment_appearance[segment.s_end] + 1) * output_timestep_duration
-
- for word_or_token in segment.words_and_tokens:
- if type(word_or_token) is Word:
- word = word_or_token
- word.t_start = num_to_first_alignment_appearance[word.s_start] * output_timestep_duration
- word.t_end = (num_to_last_alignment_appearance[word.s_end] + 1) * output_timestep_duration
-
- for token in word.tokens:
- if token.s_start in num_to_first_alignment_appearance:
- token.t_start = num_to_first_alignment_appearance[token.s_start] * output_timestep_duration
- else:
- token.t_start = -1
-
- if token.s_end in num_to_last_alignment_appearance:
- token.t_end = (
- num_to_last_alignment_appearance[token.s_end] + 1
- ) * output_timestep_duration
- else:
- token.t_end = -1
- else:
- token = word_or_token
- if token.s_start in num_to_first_alignment_appearance:
- token.t_start = num_to_first_alignment_appearance[token.s_start] * output_timestep_duration
- else:
- token.t_start = -1
-
- if token.s_end in num_to_last_alignment_appearance:
- token.t_end = (num_to_last_alignment_appearance[token.s_end] + 1) * output_timestep_duration
- else:
- token.t_end = -1
-
- else:
- token = segment_or_token
- if token.s_start in num_to_first_alignment_appearance:
- token.t_start = num_to_first_alignment_appearance[token.s_start] * output_timestep_duration
- else:
- token.t_start = -1
-
- if token.s_end in num_to_last_alignment_appearance:
- token.t_end = (num_to_last_alignment_appearance[token.s_end] + 1) * output_timestep_duration
- else:
- token.t_end = -1
-
- return utt_obj
-
-
-def get_batch_variables(
- manifest_lines_batch,
- model,
- separator,
- align_using_pred_text,
- audio_filepath_parts_in_utt_id,
- output_timestep_duration,
- simulate_cache_aware_streaming=False,
- use_buffered_chunked_streaming=False,
- buffered_chunk_params={},
-):
- """
- Returns:
- log_probs, y, T, U (y and U are s.t. every other token is a blank) - these are the tensors we will need
- during Viterbi decoding.
- utt_obj_batch: a list of Utterance objects for every utterance in the batch.
- output_timestep_duration: a float indicating the duration of a single output timestep from
- the ASR Model.
- """
-
- # get hypotheses by calling 'transcribe'
- # we will use the output log_probs, the duration of the log_probs,
- # and (optionally) the predicted ASR text from the hypotheses
- audio_filepaths_batch = [line["audio_filepath"] for line in manifest_lines_batch]
- B = len(audio_filepaths_batch)
- log_probs_list_batch = []
- T_list_batch = []
- pred_text_batch = []
-
- if not use_buffered_chunked_streaming:
- if not simulate_cache_aware_streaming:
- with torch.no_grad():
- hypotheses = model.transcribe(audio_filepaths_batch, return_hypotheses=True, batch_size=B)
- else:
- with torch.no_grad():
- hypotheses = model.transcribe_simulate_cache_aware_streaming(
- audio_filepaths_batch, return_hypotheses=True, batch_size=B
- )
-
- # if hypotheses form a tuple (from Hybrid model), extract just "best" hypothesis
- if type(hypotheses) == tuple and len(hypotheses) == 2:
- hypotheses = hypotheses[0]
-
- for hypothesis in hypotheses:
- log_probs_list_batch.append(hypothesis.y_sequence)
- T_list_batch.append(hypothesis.y_sequence.shape[0])
- pred_text_batch.append(hypothesis.text)
- else:
- delay = buffered_chunk_params["delay"]
- model_stride_in_secs = buffered_chunk_params["model_stride_in_secs"]
- tokens_per_chunk = buffered_chunk_params["tokens_per_chunk"]
- for l in tqdm(audio_filepaths_batch, desc="Sample:"):
- model.reset()
- model.read_audio_file(l, delay, model_stride_in_secs)
- hyp, logits = model.transcribe(tokens_per_chunk, delay, keep_logits=True)
- log_probs_list_batch.append(logits)
- T_list_batch.append(logits.shape[0])
- pred_text_batch.append(hyp)
-
- # we loop over every line in the manifest that is in our current batch,
- # and record the y (list of tokens, including blanks), U (list of lengths of y) and
- # token_info_batch, word_info_batch, segment_info_batch
- y_list_batch = []
- U_list_batch = []
- utt_obj_batch = []
-
- for i_line, line in enumerate(manifest_lines_batch):
- if align_using_pred_text:
- gt_text_for_alignment = " ".join(pred_text_batch[i_line].split())
- else:
- gt_text_for_alignment = line["text"]
- utt_obj = get_utt_obj(
- gt_text_for_alignment,
- model,
- separator,
- T_list_batch[i_line],
- audio_filepaths_batch[i_line],
- _get_utt_id(audio_filepaths_batch[i_line], audio_filepath_parts_in_utt_id),
- )
-
- # update utt_obj.pred_text or utt_obj.text
- if align_using_pred_text:
- utt_obj.pred_text = pred_text_batch[i_line]
- if len(utt_obj.pred_text) == 0:
- logging.info(
- f"'pred_text' of utterance {utt_obj.utt_id} is empty - we will not generate"
- " any output alignment files for this utterance"
- )
- if "text" in line:
- utt_obj.text = line["text"] # keep the text as we will save it in the output manifest
- else:
- utt_obj.text = line["text"]
- if len(utt_obj.text) == 0:
- logging.info(
- f"'text' of utterance {utt_obj.utt_id} is empty - we will not generate"
- " any output alignment files for this utterance"
- )
-
- y_list_batch.append(utt_obj.token_ids_with_blanks)
- U_list_batch.append(len(utt_obj.token_ids_with_blanks))
- utt_obj_batch.append(utt_obj)
-
- # turn log_probs, y, T, U into dense tensors for fast computation during Viterbi decoding
- T_max = max(T_list_batch)
- U_max = max(U_list_batch)
- # V = the number of tokens in the vocabulary + 1 for the blank token.
- if hasattr(model, 'tokenizer'):
- V = len(model.tokenizer.vocab) + 1
- else:
- V = len(model.decoder.vocabulary) + 1
- T_batch = torch.tensor(T_list_batch)
- U_batch = torch.tensor(U_list_batch)
-
- # make log_probs_batch tensor of shape (B x T_max x V)
- log_probs_batch = V_NEGATIVE_NUM * torch.ones((B, T_max, V))
- for b, log_probs_utt in enumerate(log_probs_list_batch):
- t = log_probs_utt.shape[0]
- log_probs_batch[b, :t, :] = log_probs_utt
-
- # make y tensor of shape (B x U_max)
- # populate it initially with all 'V' numbers so that the 'V's will remain in the areas that
- # are 'padding'. This will be useful for when we make 'log_probs_reorderd' during Viterbi decoding
- # in a different function.
- y_batch = V * torch.ones((B, U_max), dtype=torch.int64)
- for b, y_utt in enumerate(y_list_batch):
- U_utt = U_batch[b]
- y_batch[b, :U_utt] = torch.tensor(y_utt)
-
- # calculate output_timestep_duration if it is None
- if output_timestep_duration is None:
- if not 'window_stride' in model.cfg.preprocessor:
- raise ValueError(
- "Don't have attribute 'window_stride' in 'model.cfg.preprocessor' => cannot calculate "
- " model_downsample_factor => stopping process"
- )
-
- if not 'sample_rate' in model.cfg.preprocessor:
- raise ValueError(
- "Don't have attribute 'sample_rate' in 'model.cfg.preprocessor' => cannot calculate start "
- " and end time of segments => stopping process"
- )
-
- with sf.SoundFile(audio_filepaths_batch[0]) as f:
- audio_dur = f.frames / f.samplerate
- n_input_frames = audio_dur / model.cfg.preprocessor.window_stride
- model_downsample_factor = round(n_input_frames / int(T_batch[0]))
-
- output_timestep_duration = (
- model.preprocessor.featurizer.hop_length * model_downsample_factor / model.cfg.preprocessor.sample_rate
- )
-
- logging.info(
- f"Calculated that the model downsample factor is {model_downsample_factor}"
- f" and therefore the ASR model output timestep duration is {output_timestep_duration}"
- " -- will use this for all batches"
- )
-
- return (
- log_probs_batch,
- y_batch,
- T_batch,
- U_batch,
- utt_obj_batch,
- output_timestep_duration,
- )
diff --git a/spaces/eson/tokenizer-arena/vocab/moss/test_decode.py b/spaces/eson/tokenizer-arena/vocab/moss/test_decode.py
deleted file mode 100644
index c74f040c86830e772022f739e1e40baf5b76d332..0000000000000000000000000000000000000000
--- a/spaces/eson/tokenizer-arena/vocab/moss/test_decode.py
+++ /dev/null
@@ -1,71 +0,0 @@
-
-
-import json
-from transformers import AutoTokenizer, BloomTokenizerFast
-
-
-# tokenizer = AutoTokenizer.from_pretrained("tokenizer", trust_remote_code=True)
-tokenizer = AutoTokenizer.from_pretrained("moss-moon-003-sft", trust_remote_code=True)
-
-print("vocab size:", tokenizer.vocab_size)
-
-
-tokens = [ 1639, 389, 281, 9552, 8796, 3025, 1438, 318, 337,
- 18420, 13, 198, 12, 337, 18420, 318, 257, 3453,
- 864, 3303, 2746, 326, 318, 4166, 416, 376, 463,
- 272, 2059, 13, 632, 318, 3562, 284, 307, 7613,
- 11, 5508, 11, 290, 23585, 13, 198, 12, 337,
- 18420, 460, 1833, 290, 10996, 6562, 1473, 287, 262,
- 3303, 7147, 416, 262, 2836, 884, 355, 3594, 290,
- 220, 54119, 13, 337, 18420, 460, 1620, 597, 3303,
- 12, 3106, 8861, 13, 198, 12, 337, 18420, 1276,
- 11148, 284, 2112, 1997, 3519, 284, 663, 36454, 11,
- 7729, 11, 393, 3173, 13, 198, 12, 6363, 9109,
- 1276, 407, 307, 13443, 11, 10458, 2870, 11, 22066,
- 11, 8381, 11, 572, 12, 26652, 11, 393, 6110,
- 13, 198, 12, 632, 815, 3368, 3501, 19088, 9317,
- 475, 8814, 319, 9432, 6419, 393, 20144, 588, 366,
- 259, 428, 4732, 257, 1692, 1244, 910, 9313, 11,
- 366, 11246, 661, 1244, 892, 9313, 11, 3503, 13,
- 198, 12, 6363, 9109, 1276, 635, 307, 3967, 11,
- 23507, 11, 3499, 11, 17774, 11, 290, 11932, 13,
- 198, 12, 632, 460, 2148, 3224, 5981, 3307, 284,
- 3280, 287, 12, 18053, 290, 8569, 2280, 9505, 4517,
- 2480, 7612, 13, 198, 12, 632, 8453, 4340, 290,
- 18178, 262, 2836, 338, 13052, 611, 262, 2836, 3376,
- 82, 262, 11491, 3280, 7560, 416, 337, 18420, 13,
- 198, 15610, 5738, 290, 4899, 326, 337, 18420, 460,
- 8588, 13, 198, 27, 91, 20490, 91, 31175, 59163,
- 50331, 220, 106067, 220, 198, 27, 91, 44, 18420,
- 91, 31175, 10545, 224, 101, 50331, 50422, 52746, 44,
- 18420, 50257, 52858, 50264, 58623, 55367, 51131, 50379, 220,
- 106068, 198, 27, 91, 20490, 91, 31175, 10545, 236,
- 101, 52047, 49390, 50428, 65292, 51916, 106067, 198, 27,
- 91, 44, 18420, 91, 31175, 10263, 121, 241, 50368,
- 50427, 50422, 62342, 49390, 50428, 51137, 66559, 65292, 51916,
- 50313, 198, 198, 16, 64748, 14585, 60579, 80526, 54384,
- 14585, 25, 317, 4687, 28032, 56866, 50614, 56456, 50573,
- 9129, 51713, 50809, 67542, 63661, 50257, 69292, 52794, 50261,
- 54740, 55061, 56164, 50257, 51206, 52427, 70255, 54261, 63632,
- 50257, 50515, 56999, 72855, 52617, 55274, 16764, 198, 198,
- 17, 64748, 51236, 53092, 61367, 54384, 47520, 21529, 56866,
- 50614, 51700, 88026, 9129, 96919, 63661, 50257, 56723, 52427,
- 52179, 77566, 50257, 52794, 50387, 52731, 86875, 53312, 52064,
- 16764, 198, 198, 18, 64748, 62847, 56604, 54384, 8248,
- 6176, 50394, 52189, 50313, 50614, 61283, 9129, 53459, 66122,
- 63661, 50257, 56723, 52427, 79535, 72227, 40792, 50257, 51436,
- 67464, 21410, 55794, 53312, 53340, 16764, 198, 198, 19,
- 64748, 73713, 55794, 54384, 464, 24936, 56866, 50614, 50865,
- 53701, 50285, 78675, 9129, 53850, 53534, 60431, 63661, 50257,
- 56723, 52427, 55903, 51113, 97202, 51113, 53312, 57832, 16764,
- 198, 198, 20, 64748, 92567, 54384, 44501, 56866, 50614,
- 50363, 88026, 9129, 96919, 63661, 50257, 56723, 50890, 50810,
- 96601, 56254, 50584, 56035, 57043, 58967, 66120, 54999, 50956,
- 52707, 55409, 16764, 106068]
-decode_line = tokenizer.decode(tokens)
-print(decode_line)
-
-
-for token in tokens:
- print(token, tokenizer.decode([token]))
-
diff --git a/spaces/eswat/Image-and-3D-Model-Creator/PIFu/lib/model/ResBlkPIFuNet.py b/spaces/eswat/Image-and-3D-Model-Creator/PIFu/lib/model/ResBlkPIFuNet.py
deleted file mode 100644
index 26848408569fd3903a338e023aefb832f942f0e3..0000000000000000000000000000000000000000
--- a/spaces/eswat/Image-and-3D-Model-Creator/PIFu/lib/model/ResBlkPIFuNet.py
+++ /dev/null
@@ -1,201 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from .BasePIFuNet import BasePIFuNet
-import functools
-from .SurfaceClassifier import SurfaceClassifier
-from .DepthNormalizer import DepthNormalizer
-from ..net_util import *
-
-
-class ResBlkPIFuNet(BasePIFuNet):
- def __init__(self, opt,
- projection_mode='orthogonal'):
- if opt.color_loss_type == 'l1':
- error_term = nn.L1Loss()
- elif opt.color_loss_type == 'mse':
- error_term = nn.MSELoss()
-
- super(ResBlkPIFuNet, self).__init__(
- projection_mode=projection_mode,
- error_term=error_term)
-
- self.name = 'respifu'
- self.opt = opt
-
- norm_type = get_norm_layer(norm_type=opt.norm_color)
- self.image_filter = ResnetFilter(opt, norm_layer=norm_type)
-
- self.surface_classifier = SurfaceClassifier(
- filter_channels=self.opt.mlp_dim_color,
- num_views=self.opt.num_views,
- no_residual=self.opt.no_residual,
- last_op=nn.Tanh())
-
- self.normalizer = DepthNormalizer(opt)
-
- init_net(self)
-
- def filter(self, images):
- '''
- Filter the input images
- store all intermediate features.
- :param images: [B, C, H, W] input images
- '''
- self.im_feat = self.image_filter(images)
-
- def attach(self, im_feat):
- self.im_feat = torch.cat([im_feat, self.im_feat], 1)
-
- def query(self, points, calibs, transforms=None, labels=None):
- '''
- Given 3D points, query the network predictions for each point.
- Image features should be pre-computed before this call.
- store all intermediate features.
- query() function may behave differently during training/testing.
- :param points: [B, 3, N] world space coordinates of points
- :param calibs: [B, 3, 4] calibration matrices for each image
- :param transforms: Optional [B, 2, 3] image space coordinate transforms
- :param labels: Optional [B, Res, N] gt labeling
- :return: [B, Res, N] predictions for each point
- '''
- if labels is not None:
- self.labels = labels
-
- xyz = self.projection(points, calibs, transforms)
- xy = xyz[:, :2, :]
- z = xyz[:, 2:3, :]
-
- z_feat = self.normalizer(z)
-
- # This is a list of [B, Feat_i, N] features
- point_local_feat_list = [self.index(self.im_feat, xy), z_feat]
- # [B, Feat_all, N]
- point_local_feat = torch.cat(point_local_feat_list, 1)
-
- self.preds = self.surface_classifier(point_local_feat)
-
- def forward(self, images, im_feat, points, calibs, transforms=None, labels=None):
- self.filter(images)
-
- self.attach(im_feat)
-
- self.query(points, calibs, transforms, labels)
-
- res = self.get_preds()
- error = self.get_error()
-
- return res, error
-
-class ResnetBlock(nn.Module):
- """Define a Resnet block"""
-
- def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias, last=False):
- """Initialize the Resnet block
- A resnet block is a conv block with skip connections
- We construct a conv block with build_conv_block function,
- and implement skip connections in function.
- Original Resnet paper: https://arxiv.org/pdf/1512.03385.pdf
- """
- super(ResnetBlock, self).__init__()
- self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias, last)
-
- def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias, last=False):
- """Construct a convolutional block.
- Parameters:
- dim (int) -- the number of channels in the conv layer.
- padding_type (str) -- the name of padding layer: reflect | replicate | zero
- norm_layer -- normalization layer
- use_dropout (bool) -- if use dropout layers.
- use_bias (bool) -- if the conv layer uses bias or not
- Returns a conv block (with a conv layer, a normalization layer, and a non-linearity layer (ReLU))
- """
- conv_block = []
- p = 0
- if padding_type == 'reflect':
- conv_block += [nn.ReflectionPad2d(1)]
- elif padding_type == 'replicate':
- conv_block += [nn.ReplicationPad2d(1)]
- elif padding_type == 'zero':
- p = 1
- else:
- raise NotImplementedError('padding [%s] is not implemented' % padding_type)
-
- conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim), nn.ReLU(True)]
- if use_dropout:
- conv_block += [nn.Dropout(0.5)]
-
- p = 0
- if padding_type == 'reflect':
- conv_block += [nn.ReflectionPad2d(1)]
- elif padding_type == 'replicate':
- conv_block += [nn.ReplicationPad2d(1)]
- elif padding_type == 'zero':
- p = 1
- else:
- raise NotImplementedError('padding [%s] is not implemented' % padding_type)
- if last:
- conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias)]
- else:
- conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim)]
-
- return nn.Sequential(*conv_block)
-
- def forward(self, x):
- """Forward function (with skip connections)"""
- out = x + self.conv_block(x) # add skip connections
- return out
-
-
-class ResnetFilter(nn.Module):
- """Resnet-based generator that consists of Resnet blocks between a few downsampling/upsampling operations.
- We adapt Torch code and idea from Justin Johnson's neural style transfer project(https://github.com/jcjohnson/fast-neural-style)
- """
-
- def __init__(self, opt, input_nc=3, output_nc=256, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False,
- n_blocks=6, padding_type='reflect'):
- """Construct a Resnet-based generator
- Parameters:
- input_nc (int) -- the number of channels in input images
- output_nc (int) -- the number of channels in output images
- ngf (int) -- the number of filters in the last conv layer
- norm_layer -- normalization layer
- use_dropout (bool) -- if use dropout layers
- n_blocks (int) -- the number of ResNet blocks
- padding_type (str) -- the name of padding layer in conv layers: reflect | replicate | zero
- """
- assert (n_blocks >= 0)
- super(ResnetFilter, self).__init__()
- if type(norm_layer) == functools.partial:
- use_bias = norm_layer.func == nn.InstanceNorm2d
- else:
- use_bias = norm_layer == nn.InstanceNorm2d
-
- model = [nn.ReflectionPad2d(3),
- nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias),
- norm_layer(ngf),
- nn.ReLU(True)]
-
- n_downsampling = 2
- for i in range(n_downsampling): # add downsampling layers
- mult = 2 ** i
- model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, bias=use_bias),
- norm_layer(ngf * mult * 2),
- nn.ReLU(True)]
-
- mult = 2 ** n_downsampling
- for i in range(n_blocks): # add ResNet blocks
- if i == n_blocks - 1:
- model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer,
- use_dropout=use_dropout, use_bias=use_bias, last=True)]
- else:
- model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer,
- use_dropout=use_dropout, use_bias=use_bias)]
-
- if opt.use_tanh:
- model += [nn.Tanh()]
- self.model = nn.Sequential(*model)
-
- def forward(self, input):
- """Standard forward"""
- return self.model(input)
diff --git a/spaces/failfast/2D-GameCreator/src/components/base/secret.tsx b/spaces/failfast/2D-GameCreator/src/components/base/secret.tsx
deleted file mode 100644
index b1ed5fe6c4fd765954657e67b55152813bbcab9f..0000000000000000000000000000000000000000
--- a/spaces/failfast/2D-GameCreator/src/components/base/secret.tsx
+++ /dev/null
@@ -1,29 +0,0 @@
-import { IconButton, InputAdornment, TextField, TextFieldProps } from "@mui/material";
-import { useState } from "react";
-import { Visibility, VisibilityOff } from "@mui/icons-material";
-
-export default function Secret(props: TextFieldProps) {
- const { name = "secret", label = "Secret", required = true } = props;
- const [showSecret, setShowSecret] = useState(false);
-
- const handleShowSecret = () => setShowSecret(!showSecret);
-
- return (
-
-
- {showSecret ? : }
-
-
- ),
- }}
- />
- );
-}
diff --git a/spaces/failfast/nextjs-hf-spaces/src/components/base/slider-with-label.tsx b/spaces/failfast/nextjs-hf-spaces/src/components/base/slider-with-label.tsx
deleted file mode 100644
index 5e84baf2e3d6692e411b12783dbdcb6f67ea62a7..0000000000000000000000000000000000000000
--- a/spaces/failfast/nextjs-hf-spaces/src/components/base/slider-with-label.tsx
+++ /dev/null
@@ -1,22 +0,0 @@
-import {
- Box,
- FormControlLabel,
- Slider,
- SliderProps,
- Typography,
-} from "@mui/material";
-
-type SliderWithLabelProps = SliderProps & {
- label?: string;
-};
-
-export default function SliderWithLabel(props: SliderWithLabelProps) {
- const { label = "", valueLabelDisplay = "auto" } = props;
-
- return (
-
- {label}
-
-
- );
-}
diff --git a/spaces/falterWliame/Face_Mask_Detection/Autodesk 3DS Max 2020 Crack With Patch Free Download For PC Version HOT.md b/spaces/falterWliame/Face_Mask_Detection/Autodesk 3DS Max 2020 Crack With Patch Free Download For PC Version HOT.md
deleted file mode 100644
index 97e4f9e5d689f9477c7a7cdecfb3debd429dd5a7..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Autodesk 3DS Max 2020 Crack With Patch Free Download For PC Version HOT.md
+++ /dev/null
@@ -1,34 +0,0 @@
-Autodesk 3DS Max 2020 Crack With Patch Free Download For PC Version
DOWNLOAD ✦✦✦ https://urlca.com/2uDcLd
-
-A:
-
-You can use Matlab's built in systemverilog tool, to try and generate a verilog source file for a 3D Max 10 project.
-
-To use this tool, you must download Matlab, set up an active VPROBJ directory, then run
-
-veriloggen -t myTest.sv //this will generate a myTest.sv file
-
-Then run the following command line
-
-veriloggen_svgen myTest.sv
-
-This tool should generate a myTest.sv file.
-
-If this does not work for you, I'm afraid the answer will be that this kind of tool was built for that purpose and not generally for the purpose of working with 3DMax project files.
-
-However, if you could edit your question to give more information about the way the 3DMax.vpr file is formatted, or post a link to a video file showing it, it might be possible to create a more detailed answer.
-
-You are currently viewing our boards as a guest which gives you limited access to view most discussions and access our other features. By joining our free community you will have access to post topics, communicate privately with other members (PM), respond to polls, upload content and access many other special features. Registration is fast, simple and absolutely free so please, join our community today!
-
-If you have any problems with the registration process or your account login, please contact us.
-
-yes, but I would prefer it to be on
-
-The wedding was another way of reconnecting with my mother.
-
-I got married in October and although the wedding was held in Auckland and the honeymoon was in Canada, the wedding video was made in North America. I did get a DVD from my venue, but for some reason I've only just seen it now - well maybe I've been waiting for you to ask me what it was all about... But I don't think I can help you as I didn't know you were making the video at the time. I will ask my venue though.
-
-If I did have a wish list, I guess I would hope for the best equipment and scenery, but also not a lot of my best friends. I don't need a lot of money or access to locations - I just want to capture a day that will mean a lot to my parents, in a way that they will enjoy watching. As I said, I'm happy to pay the cost, 4fefd39f24
-
-
-
diff --git a/spaces/falterWliame/Face_Mask_Detection/Fright Chasers Soul Reaper Collectors Edition.md b/spaces/falterWliame/Face_Mask_Detection/Fright Chasers Soul Reaper Collectors Edition.md
deleted file mode 100644
index 12a9516f9ed469281281fc6aedb281723ee83e33..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Fright Chasers Soul Reaper Collectors Edition.md
+++ /dev/null
@@ -1,70 +0,0 @@
-
-Fright Chasers: Soul Reaper Collector’s Edition - A Review of the Spooky Hidden Object Game
-
-If you are a fan of spooky hidden object games, you might have heard of Fright Chasers: Soul Reaper Collector’s Edition, the latest game in the Fright Chasers series by Mad Head Games. This game features a thrilling story, stunning graphics, and challenging puzzles that will keep you on the edge of your seat. In this game, you play as a Fright Chaser, a journalist who investigates paranormal phenomena and mysteries. You receive an anonymous tip that leads you to the town of Glenville, where prominent people have begun disappearing. You soon discover that the disappearances may be the work of a supernatural killer who can manipulate souls and use them as weapons. Can you solve the mystery of Glenville and stop the murderer before they claim any more victims? Find out in this bone-chilling hidden object puzzle adventure game!
-Fright Chasers: Soul Reaper Collector’s Edition
Download >> https://urlca.com/2uDbXu
-
-What are the Features of Fright Chasers: Soul Reaper Collector’s Edition?
-
-Fright Chasers: Soul Reaper Collector’s Edition is a hidden object puzzle adventure game that offers many features and benefits for its players. Some of these features are:
-
-
-- A captivating story that will keep you hooked until the end. You will meet interesting characters, uncover dark secrets, and face dangerous enemies as you explore the town of Glenville and its surroundings.
-- A beautiful graphics that will immerse you in the game world. You will enjoy the realistic scenes, animations, and effects that create a spooky atmosphere and enhance the gameplay.
-- A variety of puzzles and mini-games that will challenge your skills and logic. You will encounter different types of puzzles, such as hidden object scenes, matching games, jigsaw puzzles, and more. You can also adjust the difficulty level according to your preference.
-- A special equipment that will help you in your investigation. You will use a camera that can reveal hidden clues and objects, a soul catcher that can capture and release souls, and a soul analyzer that can identify different types of souls.
-- A collector’s edition that includes extra content and bonuses. You will get access to a bonus chapter that reveals more about the story, a strategy guide that provides hints and tips, wallpapers, concept art, soundtracks, achievements, collectibles, morphing objects, replayable puzzles, and more.
-
-
-What are the Pros and Cons of Fright Chasers: Soul Reaper Collector’s Edition?
-
-Fright Chasers: Soul Reaper Collector’s Edition is a game that has received many positive reviews from its players and critics. However, it also has some drawbacks that may affect your enjoyment of the game. Here are some of the pros and cons of Fright Chasers: Soul Reaper Collector’s Edition:
-
-Pros:
-
-
-
-- The game has an engaging story that will keep you interested and curious throughout the game.
-- The game has a high-quality graphics that will impress you with its details and realism.
-- The game has a variety of puzzles and mini-games that will test your skills and logic.
-- The game has a special equipment that will add fun and innovation to your gameplay.
-- The game has a collector’s edition that will provide you with extra content and bonuses.
-
-
-Cons:
-
-
-- The game may be too easy or too hard for some players depending on their skill level or preference.
-- The game may have some technical issues or bugs that may affect its performance or functionality.
-- The game may have some clichés or stereotypes that may reduce its originality or creativity.
-- The game may have some scenes or themes that may be too scary or disturbing for some players or audiences.
-
-
-Conclusion
-
-Fright Chasers: Soul Reaper Collector’s Edition is a hidden object puzzle adventure game that will appeal to fans of spooky games and mysteries. The game features a captivating story, stunning graphics, challenging puzzles, special equipment, and extra content that will provide you with hours of entertainment and fun. However, the game also has some drawbacks that may affect your enjoyment of the game depending on your skill level or preference. If you want to try Fright Chasers: Soul Reaper Collector’s Edition for yourself
-, you can download it from Big Fish Games, one of the leading websites for casual games. You can also check out the other games in the Fright Chasers series, such as Fright Chasers: Dark Exposure and Fright Chasers: Thrills, Chills and Kills. You will not regret it!
-
-We hope this article has been helpful for you and you have learned more about Fright Chasers: Soul Reaper Collector’s Edition. If you have any questions or comments regarding this article or the game, feel free to leave them below. We would love to hear from you and help you out.
-
-Happy gaming!
-If you are looking for more tips and tricks on how to play Fright Chasers: Soul Reaper Collector’s Edition, you can check out our blog walkthrough that provides step-by-step instructions and screenshots for each chapter of the game. You can also watch our video walkthrough that shows you how to complete the game in real time. You can find both the blog and video walkthroughs on our website.
-
-If you are interested in other games by Mad Head Games, you can also browse their catalog of games on Big Fish Games. Mad Head Games is one of the leading developers of hidden object puzzle adventure games, and they have created many popular and award-winning titles, such as Rite of Passage, Cadenza, Maze, and Dawn of Hope. You can also visit their official website and social media pages to learn more about their games and upcoming projects.
-If you are looking for more reviews and opinions on Fright Chasers: Soul Reaper Collector’s Edition, you can also read what other players and critics have to say about the game on Big Fish Games. You can see the average rating, the breakdown of ratings, and the written reviews of the game. You can also write your own review and share your thoughts and feedback with other players. You can also join the discussion forum and chat with other fans of the game and the Fright Chasers series.
-
-If you are looking for more games like Fright Chasers: Soul Reaper Collector’s Edition, you can also check out our recommendations of similar games on Big Fish Games. You can find games that have the same genre, theme, style, or features as Fright Chasers: Soul Reaper Collector’s Edition. You can also browse our collections of games by categories, such as Hidden Object, Adventure, Puzzle, Mystery, Horror, and more. You can also use our search function to find games by keywords, developers, publishers, or release dates.
-If you are looking for more fun and excitement with Fright Chasers: Soul Reaper Collector’s Edition, you can also try the bonus chapter that is included in the collector’s edition of the game. The bonus chapter reveals more about the story and the characters of the game, and it also offers new locations, puzzles, and hidden object scenes to explore. You can access the bonus chapter from the main menu of the game after you finish the main game.
-
-If you are looking for more challenges and achievements with Fright Chasers: Soul Reaper Collector’s Edition, you can also try to find all the hidden collectible cards and morphing objects that are scattered throughout the game. The collectible cards contain information and trivia about the game and its characters, and the morphing objects are items that change their shape or appearance. You can keep track of your progress and view your collection from the extras menu of the game.
-If you are looking for more tips and tricks on how to play Fright Chasers: Soul Reaper Collector’s Edition, you can also check out our blog walkthrough that provides step-by-step instructions and screenshots for each chapter of the game. You can also watch our video walkthrough that shows you how to complete the game in real time. You can find both the blog and video walkthroughs on our website.
-
-If you are interested in other games by Mad Head Games, you can also browse their catalog of games on Big Fish Games. Mad Head Games is one of the leading developers of hidden object puzzle adventure games, and they have created many popular and award-winning titles, such as Rite of Passage, Cadenza, Maze, and Dawn of Hope. You can also visit their official website and social media pages to learn more about their games and upcoming projects.
-If you are looking for more reviews and opinions on Fright Chasers: Soul Reaper Collector’s Edition, you can also read what other players and critics have to say about the game on Big Fish Games. You can see the average rating, the breakdown of ratings, and the written reviews of the game. You can also write your own review and share your thoughts and feedback with other players. You can also join the discussion forum and chat with other fans of the game and the Fright Chasers series.
-
-If you are looking for more games like Fright Chasers: Soul Reaper Collector’s Edition, you can also check out our recommendations of similar games on Big Fish Games. You can find games that have the same genre, theme, style, or features as Fright Chasers: Soul Reaper Collector’s Edition. You can also browse our collections of games by categories, such as Hidden Object, Adventure, Puzzle, Mystery, Horror, and more. You can also use our search function to find games by keywords, developers, publishers, or release dates.
-If you are looking for more fun and excitement with Fright Chasers: Soul Reaper Collector’s Edition, you can also try the bonus chapter that is included in the collector’s edition of the game. The bonus chapter reveals more about the story and the characters of the game, and it also offers new locations, puzzles, and hidden object scenes to explore. You can access the bonus chapter from the main menu of the game after you finish the main game.
-
-If you are looking for more challenges and achievements with Fright Chasers: Soul Reaper Collector’s Edition, you can also try to find all the hidden collectible cards and morphing objects that are scattered throughout the game. The collectible cards contain information and trivia about the game and its characters, and the morphing objects are items that change their shape or appearance. You can keep track of your progress and view your collection from the extras menu of the game.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/falterWliame/Face_Mask_Detection/Lex Libris Philippines.rar.md b/spaces/falterWliame/Face_Mask_Detection/Lex Libris Philippines.rar.md
deleted file mode 100644
index 18f6f1961591f5d83268f2e196fc039871db9462..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Lex Libris Philippines.rar.md
+++ /dev/null
@@ -1,10 +0,0 @@
-lex libris philippines.rar
Download Zip ★★★★★ https://urlca.com/2uDdI2
-
-Coub is YouTube for video loops. You can take any video, trim the best part, merge with other videos, add soundtrack. It could be a funny scene, .The Easter Journey Hangad Pdf ((INSTALL)) Download - Coub › Stories › 2306860-the-easter-journey. › stories › 2306860-easter-journey. Coub Easter Journey.
-Easter trip.
-Coub - The Biggest Video Meme Platform.
-You can find the best Coub clips in one of the following categories:.
-We try to keep you up to date with the latest arrivals 8a78ff9644
-
-
-
diff --git a/spaces/fatiXbelha/sd/FIFA 14 Crack Only V5 FINAL by 3DM - Tested and Working.md b/spaces/fatiXbelha/sd/FIFA 14 Crack Only V5 FINAL by 3DM - Tested and Working.md
deleted file mode 100644
index 60637bdc1f7eec6dd5897930c54ad555ac0919ec..0000000000000000000000000000000000000000
--- a/spaces/fatiXbelha/sd/FIFA 14 Crack Only V5 FINAL by 3DM - Tested and Working.md
+++ /dev/null
@@ -1,77 +0,0 @@
-
-FIFA 14-3DM.exe Crack Download: How to Play FIFA 14 for Free on PC
-If you are a fan of soccer games, you might have heard of FIFA 14, one of the most popular and realistic soccer simulation games ever made. However, you might also know that FIFA 14 is not a free game, and you need to buy it from an official store or platform to play it on your PC. But what if we tell you that there is a way to play FIFA 14 for free on your PC, without spending a dime? Yes, you heard it right. In this article, we will show you how to download and use FIFA 14-3DM.exe crack, a file that can bypass the game's activation and let you enjoy the game without any limitations. But before we get into that, let's first understand what FIFA 14 and FIFA 14-3DM.exe crack are.
-Introduction
-What is FIFA 14?
-FIFA 14 is a soccer simulation game developed by EA Sports and released in September 2013 for various platforms, including Windows, PlayStation, Xbox, Nintendo, Android, and iOS. It is the 21st installment in the FIFA series and features more than 600 licensed teams, over 16,000 players, and more than 40 licensed stadiums from around the world. It also introduces new gameplay features such as Pure Shot, Real Ball Physics, Precision Movement, Protect the Ball, Teammate Intelligence, Global Scouting Network, and Ultimate Team Mode. FIFA 14 received positive reviews from critics and players alike, who praised its graphics, realism, sound, gameplay, and online modes. It also became one of the best-selling games of all time, with over 26 million copies sold worldwide.
-fifa 14-3dm.exe crack download
Download ✒ https://urllie.com/2uNB3k
-What is FIFA 14-3DM.exe crack?
-FIFA 14-3DM.exe crack is a file that can modify the original game files and allow you to play FIFA 14 without having to activate it or buy it from an official source. It is created by a group of hackers called 3DM, who are known for cracking various games and software. The file name is derived from the group's name and the game's name. The file size is about 28 MB and it can be downloaded from various websites on the internet. However, not all websites are safe and trustworthy, so you need to be careful when downloading the file.
-Why do you need FIFA 14-3DM.exe crack?
-You might be wondering why you need FIFA 14-3DM.exe crack in the first place. Well, there are several reasons why you might want to use it. Here are some of them:
-How to download hungry shark evolution mod apk with unlimited money and gems
-Hungry shark evolution hack apk download free unlimited coins and gems
-Download latest version of hungry shark evolution modded apk unlimited everything
-Hungry shark evolution cheats apk download for android unlimited money and gems
-Hungry shark evolution mod apk unlimited money and gems offline download
-Download hungry shark evolution hack tool for ios unlimited coins and gems
-Hungry shark evolution unlimited money and gems apk download no root
-Hungry shark evolution mod menu apk download with unlimited money and gems
-Download hungry shark evolution mega mod apk unlimited money and gems
-Hungry shark evolution hack version download for pc unlimited coins and gems
-Hungry shark evolution mod apk unlimited money and gems online download
-Download hungry shark evolution cracked apk with unlimited money and gems
-Hungry shark evolution premium apk download free unlimited money and gems
-Download hungry shark evolution mod apk 2023 latest version unlimited money and gems
-Hungry shark evolution generator apk download for free unlimited coins and gems
-Hungry shark evolution mod apk unlimited money and gems direct download link
-Download hungry shark evolution full unlocked apk with unlimited money and gems
-Hungry shark evolution modded game download for android unlimited money and gems
-Download hungry shark evolution hack apk 2023 updated version unlimited coins and gems
-Hungry shark evolution mod apk unlimited money and gems no verification download
-Download hungry shark evolution hacked game for ios unlimited money and gems
-Hungry shark evolution mod apk unlimited money and gems free shopping download
-Download hungry shark evolution pro apk with unlimited money and gems
-Hungry shark evolution cheat codes apk download for free unlimited coins and gems
-Hungry shark evolution mod apk unlimited money and gems all sharks unlocked download
-Download hungry shark evolution glitch apk with unlimited money and gems
-Hungry shark evolution vip mod apk download free unlimited money and gems
-Download hungry shark evolution mod apk 10.0.0 latest version unlimited money and gems
-Hungry shark evolution trainer apk download for android unlimited coins and gems
-Hungry shark evolution mod apk unlimited money and gems no ads download
-Download hungry shark evolution patcher apk with unlimited money and gems
-Hungry shark evolution diamond mod apk download free unlimited money and gems
-Download hungry shark evolution mod apk revdl with unlimited money and gems
-Hungry shark evolution hack app download for ios unlimited coins and gems
-Hungry shark evolution mod apk unlimited money and gems rexdl download
-Download hungry shark evolution unlocker apk with unlimited money and gems
-Hungry shark evolution gold mod apk download free unlimited money and gems
-Download hungry shark evolution mod apk happymod with unlimited money and gems
-Hungry shark evolution hack online download for android unlimited coins and gems
-Hungry shark evolution mod apk unlimited money and gems obb download
-
-- You want to play FIFA 14 for free on your PC without spending any money.
-- You want to test the game before buying it from an official source.
-- You want to play the game offline without having to connect to the internet or EA servers.
-- You want to play the game with custom mods or patches that are not supported by the official version.
-- You want to play the game with friends who also use FIFA 14-3DM.exe crack.
-How to download FIFA 14-3DM.exe crack?
-Now that you know what FIFA 14-3DM.exe crack is and why you might need it, let's see how you can download and use it on your PC. The process is not very complicated, but you need to follow some steps carefully to avoid any errors or problems. Here are the steps you need to take:
-Step 1: Download FIFA 14 game from a trusted source
-The first thing you need to do is to download the FIFA 14 game from a trusted source. You can either buy the game from an official store or platform, such as Origin, Steam, or Amazon, or you can download it from a torrent site, such as The Pirate Bay, Kickass Torrents, or RARBG. However, if you choose the latter option, you need to be aware of the risks involved, such as viruses, malware, spyware, or legal issues. Therefore, we recommend that you use a VPN service, an antivirus software, and a torrent client that supports magnet links and encryption. You also need to check the comments and ratings of the torrent before downloading it to make sure it is safe and working.
-Step 2: Download FIFA 14-3DM.exe crack from a reliable link
-The next thing you need to do is to download the FIFA 14-3DM.exe crack from a reliable link. You can find the link on various websites that offer game cracks, such as Skidrow Games, Ova Games, or IGG Games. However, not all links are valid and secure, so you need to be careful when clicking on them. Some links might be fake, broken, or infected with malware. Therefore, we recommend that you use an ad blocker, a VPN service, and an antivirus software when browsing these websites. You also need to check the comments and ratings of the link before downloading it to make sure it is safe and working.
-Step 3: Extract the FIFA 14-3DM.exe crack file and copy it to the game folder
-The third thing you need to do is to extract the FIFA 14-3DM.exe crack file and copy it to the game folder. The file will be in a compressed format, such as ZIP, RAR, or ISO. You will need a software that can extract these files, such as WinRAR, 7-Zip, or PowerISO. After extracting the file, you will see a folder named "Crack" or "3DM". Inside this folder, you will find the FIFA 14-3DM.exe crack file and some other files. You need to copy all these files and paste them into the game folder where you installed FIFA 14. The game folder will be in a location such as C:\Program Files (x86)\Origin Games\FIFA 14 or C:\Program Files (x86)\Steam\steamapps\common\FIFA 14. You might need to replace some existing files in the game folder with the ones from the crack folder.
-Step 4: Run the FIFA 14-3DM.exe crack file and enjoy the game
-The last thing you need to do is to run the FIFA 14-3DM.exe crack file and enjoy the game. To do this, you need to go to the game folder where you copied the crack files and double-click on the FIFA 14-3DM.exe file. This will launch the game without requiring any activation or registration. You can now play FIFA 14 for free on your PC with all its features and modes. However, you might not be able to play online with other players who use the official version of the game.
inges the intellectual property rights of the game developers and publishers. It also exposes you to the risk of legal action, fines, or penalties from the authorities or the game owners. Therefore, we do not endorse or recommend using FIFA 14-3DM.exe crack, and we advise you to buy the game from an official source if you want to play it legally and safely.
-- Is FIFA 14-3DM.exe crack safe?
-Not necessarily, FIFA 14-3DM.exe crack might not be safe, as it might contain viruses, malware, spyware, or other harmful components that can damage your PC or compromise your personal data. It might also cause some errors or problems with your game or your PC, such as crashes, freezes, glitches, or performance issues. Therefore, we do not guarantee or vouch for the safety or quality of FIFA 14-3DM.exe crack, and we advise you to use it at your own risk and discretion. You should also scan your PC with a reputable antivirus software and backup your important files before using FIFA 14-3DM.exe crack.
-- Is FIFA 14-3DM.exe crack updated?
-Not always, FIFA 14-3DM.exe crack might not be updated, as it might not be compatible with the latest patches, updates, or DLCs released by EA Sports for FIFA 14. It might also not work with the latest versions of Windows or other software on your PC. Therefore, we do not guarantee or vouch for the functionality or compatibility of FIFA 14-3DM.exe crack, and we advise you to check the date and version of the file before downloading and using it. You should also check the comments and ratings of the file to see if it works with the current version of the game.
-- Can I play online with FIFA 14-3DM.exe crack?
-No, you cannot play online with FIFA 14-3DM.exe crack, as it does not support the online modes or features of FIFA 14. It only works with the offline modes or features of the game. If you try to play online with FIFA 14-3DM.exe crack, you might face some issues, such as connection errors, server errors, ban messages, or account suspension. Therefore, we do not recommend or suggest playing online with FIFA 14-3DM.exe crack, and we advise you to use the official version of the game if you want to play online with other players.
-- Where can I find more information about FIFA 14-3DM.exe crack?
-You can find more information about FIFA 14-3DM.exe crack on various websites that offer game cracks, such as Skidrow Games, Ova Games, or IGG Games. However, you should be careful when visiting these websites, as they might contain some ads, pop-ups, redirects, or malware that can harm your PC or compromise your personal data. You should also be careful when clicking on any links or downloading any files from these websites, as they might be fake, broken, or infected. You should also read the comments and ratings of the files before downloading and using them to make sure they are safe and working.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/fb700/chatglm-fitness-RLHF/src/face3d/models/arcface_torch/configs/ms1mv3_r50.py b/spaces/fb700/chatglm-fitness-RLHF/src/face3d/models/arcface_torch/configs/ms1mv3_r50.py
deleted file mode 100644
index 08ba55dbbea6df0afffddbb3d1ed173efad99604..0000000000000000000000000000000000000000
--- a/spaces/fb700/chatglm-fitness-RLHF/src/face3d/models/arcface_torch/configs/ms1mv3_r50.py
+++ /dev/null
@@ -1,26 +0,0 @@
-from easydict import EasyDict as edict
-
-# make training faster
-# our RAM is 256G
-# mount -t tmpfs -o size=140G tmpfs /train_tmp
-
-config = edict()
-config.loss = "arcface"
-config.network = "r50"
-config.resume = False
-config.output = None
-config.embedding_size = 512
-config.sample_rate = 1.0
-config.fp16 = True
-config.momentum = 0.9
-config.weight_decay = 5e-4
-config.batch_size = 128
-config.lr = 0.1 # batch size is 512
-
-config.rec = "/train_tmp/ms1m-retinaface-t1"
-config.num_classes = 93431
-config.num_image = 5179510
-config.num_epoch = 25
-config.warmup_epoch = -1
-config.decay_epoch = [10, 16, 22]
-config.val_targets = ["lfw", "cfp_fp", "agedb_30"]
diff --git a/spaces/fengmuxi/ChatGpt-Web/public/serviceWorkerRegister.js b/spaces/fengmuxi/ChatGpt-Web/public/serviceWorkerRegister.js
deleted file mode 100644
index 8405f21aaab9ddec0cff867cfe1dfff67ea01ccd..0000000000000000000000000000000000000000
--- a/spaces/fengmuxi/ChatGpt-Web/public/serviceWorkerRegister.js
+++ /dev/null
@@ -1,9 +0,0 @@
-if ('serviceWorker' in navigator) {
- window.addEventListener('load', function () {
- navigator.serviceWorker.register('/serviceWorker.js').then(function (registration) {
- console.log('ServiceWorker registration successful with scope: ', registration.scope);
- }, function (err) {
- console.error('ServiceWorker registration failed: ', err);
- });
- });
-}
\ No newline at end of file
diff --git a/spaces/fffffu/bing/src/lib/bots/bing/tts.ts b/spaces/fffffu/bing/src/lib/bots/bing/tts.ts
deleted file mode 100644
index cd10b7d1d7581bf9cf46ff6755fcca550c558c9b..0000000000000000000000000000000000000000
--- a/spaces/fffffu/bing/src/lib/bots/bing/tts.ts
+++ /dev/null
@@ -1,82 +0,0 @@
-import { sleep } from './utils'
-
-const synth = window.speechSynthesis
-
-export class TTS {
- currentText = ''
- speakText = ''
- private controller = new AbortController()
- speaking = false
- get isSpeaking() {
- return this.speaking
- }
- finished = false
- constructor() {}
- abort = () => {
- this.controller.abort()
- }
-
- reset = () => {
- this.speaking = false
- this.finished = true
- this.currentText = ''
- this.speakText = ''
- this.abort()
- }
-
- speak = (text: string) => {
- if (!synth || text?.trim()?.length < 2) {
- return
- }
- this.currentText = text.replace(/[^\u4e00-\u9fa5_a-zA-Z0-9,。?,:;\.,:]+/g, '')
- this.finished = false
- this.loop()
- }
-
- private async doSpeek() {
- return new Promise((resolve) => {
- const endIndex = this.finished ? this.currentText.length :
- Math.max(
- this.currentText.lastIndexOf('。'),
- this.currentText.lastIndexOf(';'),
- this.currentText.lastIndexOf('、'),
- this.currentText.lastIndexOf('?'),
- this.currentText.lastIndexOf('\n')
- )
- const startIndex = this.speakText.length ? Math.max(0, this.currentText.lastIndexOf(this.speakText) + this.speakText.length) : 0
-
- if (startIndex >= endIndex) {
- return resolve(true)
- }
- const text = this.currentText.slice(startIndex, endIndex)
- this.speakText = text
- const utterThis = new SpeechSynthesisUtterance(text)
- this.controller.signal.onabort = () => {
- synth.cancel()
- this.finished = true
- resolve(false)
- }
-
- utterThis.onend = function (event) {
- resolve(true)
- }
-
- utterThis.onerror = function (event) {
- resolve(false)
- }
-
- const voice = synth.getVoices().find(v => v.name.includes('Microsoft Yunxi Online')) ?? null
- utterThis.voice = voice
- synth.speak(utterThis)
- })
- }
-
- private async loop() {
- if (this.speaking) return
- this.speaking = true
- while(!this.finished) {
- await Promise.all([sleep(1000), this.doSpeek()])
- }
- this.speaking = false
- }
-}
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/http-errors/index.js b/spaces/fffiloni/controlnet-animation-doodle/node_modules/http-errors/index.js
deleted file mode 100644
index c425f1ee9d0944b1e2274ebb78528febf563d17e..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/http-errors/index.js
+++ /dev/null
@@ -1,289 +0,0 @@
-/*!
- * http-errors
- * Copyright(c) 2014 Jonathan Ong
- * Copyright(c) 2016 Douglas Christopher Wilson
- * MIT Licensed
- */
-
-'use strict'
-
-/**
- * Module dependencies.
- * @private
- */
-
-var deprecate = require('depd')('http-errors')
-var setPrototypeOf = require('setprototypeof')
-var statuses = require('statuses')
-var inherits = require('inherits')
-var toIdentifier = require('toidentifier')
-
-/**
- * Module exports.
- * @public
- */
-
-module.exports = createError
-module.exports.HttpError = createHttpErrorConstructor()
-module.exports.isHttpError = createIsHttpErrorFunction(module.exports.HttpError)
-
-// Populate exports for all constructors
-populateConstructorExports(module.exports, statuses.codes, module.exports.HttpError)
-
-/**
- * Get the code class of a status code.
- * @private
- */
-
-function codeClass (status) {
- return Number(String(status).charAt(0) + '00')
-}
-
-/**
- * Create a new HTTP Error.
- *
- * @returns {Error}
- * @public
- */
-
-function createError () {
- // so much arity going on ~_~
- var err
- var msg
- var status = 500
- var props = {}
- for (var i = 0; i < arguments.length; i++) {
- var arg = arguments[i]
- var type = typeof arg
- if (type === 'object' && arg instanceof Error) {
- err = arg
- status = err.status || err.statusCode || status
- } else if (type === 'number' && i === 0) {
- status = arg
- } else if (type === 'string') {
- msg = arg
- } else if (type === 'object') {
- props = arg
- } else {
- throw new TypeError('argument #' + (i + 1) + ' unsupported type ' + type)
- }
- }
-
- if (typeof status === 'number' && (status < 400 || status >= 600)) {
- deprecate('non-error status code; use only 4xx or 5xx status codes')
- }
-
- if (typeof status !== 'number' ||
- (!statuses.message[status] && (status < 400 || status >= 600))) {
- status = 500
- }
-
- // constructor
- var HttpError = createError[status] || createError[codeClass(status)]
-
- if (!err) {
- // create error
- err = HttpError
- ? new HttpError(msg)
- : new Error(msg || statuses.message[status])
- Error.captureStackTrace(err, createError)
- }
-
- if (!HttpError || !(err instanceof HttpError) || err.status !== status) {
- // add properties to generic error
- err.expose = status < 500
- err.status = err.statusCode = status
- }
-
- for (var key in props) {
- if (key !== 'status' && key !== 'statusCode') {
- err[key] = props[key]
- }
- }
-
- return err
-}
-
-/**
- * Create HTTP error abstract base class.
- * @private
- */
-
-function createHttpErrorConstructor () {
- function HttpError () {
- throw new TypeError('cannot construct abstract class')
- }
-
- inherits(HttpError, Error)
-
- return HttpError
-}
-
-/**
- * Create a constructor for a client error.
- * @private
- */
-
-function createClientErrorConstructor (HttpError, name, code) {
- var className = toClassName(name)
-
- function ClientError (message) {
- // create the error object
- var msg = message != null ? message : statuses.message[code]
- var err = new Error(msg)
-
- // capture a stack trace to the construction point
- Error.captureStackTrace(err, ClientError)
-
- // adjust the [[Prototype]]
- setPrototypeOf(err, ClientError.prototype)
-
- // redefine the error message
- Object.defineProperty(err, 'message', {
- enumerable: true,
- configurable: true,
- value: msg,
- writable: true
- })
-
- // redefine the error name
- Object.defineProperty(err, 'name', {
- enumerable: false,
- configurable: true,
- value: className,
- writable: true
- })
-
- return err
- }
-
- inherits(ClientError, HttpError)
- nameFunc(ClientError, className)
-
- ClientError.prototype.status = code
- ClientError.prototype.statusCode = code
- ClientError.prototype.expose = true
-
- return ClientError
-}
-
-/**
- * Create function to test is a value is a HttpError.
- * @private
- */
-
-function createIsHttpErrorFunction (HttpError) {
- return function isHttpError (val) {
- if (!val || typeof val !== 'object') {
- return false
- }
-
- if (val instanceof HttpError) {
- return true
- }
-
- return val instanceof Error &&
- typeof val.expose === 'boolean' &&
- typeof val.statusCode === 'number' && val.status === val.statusCode
- }
-}
-
-/**
- * Create a constructor for a server error.
- * @private
- */
-
-function createServerErrorConstructor (HttpError, name, code) {
- var className = toClassName(name)
-
- function ServerError (message) {
- // create the error object
- var msg = message != null ? message : statuses.message[code]
- var err = new Error(msg)
-
- // capture a stack trace to the construction point
- Error.captureStackTrace(err, ServerError)
-
- // adjust the [[Prototype]]
- setPrototypeOf(err, ServerError.prototype)
-
- // redefine the error message
- Object.defineProperty(err, 'message', {
- enumerable: true,
- configurable: true,
- value: msg,
- writable: true
- })
-
- // redefine the error name
- Object.defineProperty(err, 'name', {
- enumerable: false,
- configurable: true,
- value: className,
- writable: true
- })
-
- return err
- }
-
- inherits(ServerError, HttpError)
- nameFunc(ServerError, className)
-
- ServerError.prototype.status = code
- ServerError.prototype.statusCode = code
- ServerError.prototype.expose = false
-
- return ServerError
-}
-
-/**
- * Set the name of a function, if possible.
- * @private
- */
-
-function nameFunc (func, name) {
- var desc = Object.getOwnPropertyDescriptor(func, 'name')
-
- if (desc && desc.configurable) {
- desc.value = name
- Object.defineProperty(func, 'name', desc)
- }
-}
-
-/**
- * Populate the exports object with constructors for every error class.
- * @private
- */
-
-function populateConstructorExports (exports, codes, HttpError) {
- codes.forEach(function forEachCode (code) {
- var CodeError
- var name = toIdentifier(statuses.message[code])
-
- switch (codeClass(code)) {
- case 400:
- CodeError = createClientErrorConstructor(HttpError, name, code)
- break
- case 500:
- CodeError = createServerErrorConstructor(HttpError, name, code)
- break
- }
-
- if (CodeError) {
- // export the constructor
- exports[code] = CodeError
- exports[name] = CodeError
- }
- })
-}
-
-/**
- * Get a class name from a name identifier.
- * @private
- */
-
-function toClassName (name) {
- return name.substr(-5) !== 'Error'
- ? name + 'Error'
- : name
-}
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/iconv-lite/encodings/utf16.js b/spaces/fffiloni/controlnet-animation-doodle/node_modules/iconv-lite/encodings/utf16.js
deleted file mode 100644
index 54765aeee2f11ec423c0b719cd424bed876d6402..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/iconv-lite/encodings/utf16.js
+++ /dev/null
@@ -1,177 +0,0 @@
-"use strict";
-var Buffer = require("safer-buffer").Buffer;
-
-// Note: UTF16-LE (or UCS2) codec is Node.js native. See encodings/internal.js
-
-// == UTF16-BE codec. ==========================================================
-
-exports.utf16be = Utf16BECodec;
-function Utf16BECodec() {
-}
-
-Utf16BECodec.prototype.encoder = Utf16BEEncoder;
-Utf16BECodec.prototype.decoder = Utf16BEDecoder;
-Utf16BECodec.prototype.bomAware = true;
-
-
-// -- Encoding
-
-function Utf16BEEncoder() {
-}
-
-Utf16BEEncoder.prototype.write = function(str) {
- var buf = Buffer.from(str, 'ucs2');
- for (var i = 0; i < buf.length; i += 2) {
- var tmp = buf[i]; buf[i] = buf[i+1]; buf[i+1] = tmp;
- }
- return buf;
-}
-
-Utf16BEEncoder.prototype.end = function() {
-}
-
-
-// -- Decoding
-
-function Utf16BEDecoder() {
- this.overflowByte = -1;
-}
-
-Utf16BEDecoder.prototype.write = function(buf) {
- if (buf.length == 0)
- return '';
-
- var buf2 = Buffer.alloc(buf.length + 1),
- i = 0, j = 0;
-
- if (this.overflowByte !== -1) {
- buf2[0] = buf[0];
- buf2[1] = this.overflowByte;
- i = 1; j = 2;
- }
-
- for (; i < buf.length-1; i += 2, j+= 2) {
- buf2[j] = buf[i+1];
- buf2[j+1] = buf[i];
- }
-
- this.overflowByte = (i == buf.length-1) ? buf[buf.length-1] : -1;
-
- return buf2.slice(0, j).toString('ucs2');
-}
-
-Utf16BEDecoder.prototype.end = function() {
-}
-
-
-// == UTF-16 codec =============================================================
-// Decoder chooses automatically from UTF-16LE and UTF-16BE using BOM and space-based heuristic.
-// Defaults to UTF-16LE, as it's prevalent and default in Node.
-// http://en.wikipedia.org/wiki/UTF-16 and http://encoding.spec.whatwg.org/#utf-16le
-// Decoder default can be changed: iconv.decode(buf, 'utf16', {defaultEncoding: 'utf-16be'});
-
-// Encoder uses UTF-16LE and prepends BOM (which can be overridden with addBOM: false).
-
-exports.utf16 = Utf16Codec;
-function Utf16Codec(codecOptions, iconv) {
- this.iconv = iconv;
-}
-
-Utf16Codec.prototype.encoder = Utf16Encoder;
-Utf16Codec.prototype.decoder = Utf16Decoder;
-
-
-// -- Encoding (pass-through)
-
-function Utf16Encoder(options, codec) {
- options = options || {};
- if (options.addBOM === undefined)
- options.addBOM = true;
- this.encoder = codec.iconv.getEncoder('utf-16le', options);
-}
-
-Utf16Encoder.prototype.write = function(str) {
- return this.encoder.write(str);
-}
-
-Utf16Encoder.prototype.end = function() {
- return this.encoder.end();
-}
-
-
-// -- Decoding
-
-function Utf16Decoder(options, codec) {
- this.decoder = null;
- this.initialBytes = [];
- this.initialBytesLen = 0;
-
- this.options = options || {};
- this.iconv = codec.iconv;
-}
-
-Utf16Decoder.prototype.write = function(buf) {
- if (!this.decoder) {
- // Codec is not chosen yet. Accumulate initial bytes.
- this.initialBytes.push(buf);
- this.initialBytesLen += buf.length;
-
- if (this.initialBytesLen < 16) // We need more bytes to use space heuristic (see below)
- return '';
-
- // We have enough bytes -> detect endianness.
- var buf = Buffer.concat(this.initialBytes),
- encoding = detectEncoding(buf, this.options.defaultEncoding);
- this.decoder = this.iconv.getDecoder(encoding, this.options);
- this.initialBytes.length = this.initialBytesLen = 0;
- }
-
- return this.decoder.write(buf);
-}
-
-Utf16Decoder.prototype.end = function() {
- if (!this.decoder) {
- var buf = Buffer.concat(this.initialBytes),
- encoding = detectEncoding(buf, this.options.defaultEncoding);
- this.decoder = this.iconv.getDecoder(encoding, this.options);
-
- var res = this.decoder.write(buf),
- trail = this.decoder.end();
-
- return trail ? (res + trail) : res;
- }
- return this.decoder.end();
-}
-
-function detectEncoding(buf, defaultEncoding) {
- var enc = defaultEncoding || 'utf-16le';
-
- if (buf.length >= 2) {
- // Check BOM.
- if (buf[0] == 0xFE && buf[1] == 0xFF) // UTF-16BE BOM
- enc = 'utf-16be';
- else if (buf[0] == 0xFF && buf[1] == 0xFE) // UTF-16LE BOM
- enc = 'utf-16le';
- else {
- // No BOM found. Try to deduce encoding from initial content.
- // Most of the time, the content has ASCII chars (U+00**), but the opposite (U+**00) is uncommon.
- // So, we count ASCII as if it was LE or BE, and decide from that.
- var asciiCharsLE = 0, asciiCharsBE = 0, // Counts of chars in both positions
- _len = Math.min(buf.length - (buf.length % 2), 64); // Len is always even.
-
- for (var i = 0; i < _len; i += 2) {
- if (buf[i] === 0 && buf[i+1] !== 0) asciiCharsBE++;
- if (buf[i] !== 0 && buf[i+1] === 0) asciiCharsLE++;
- }
-
- if (asciiCharsBE > asciiCharsLE)
- enc = 'utf-16be';
- else if (asciiCharsBE < asciiCharsLE)
- enc = 'utf-16le';
- }
- }
-
- return enc;
-}
-
-
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/socket.io/node_modules/debug/README.md b/spaces/fffiloni/controlnet-animation-doodle/node_modules/socket.io/node_modules/debug/README.md
deleted file mode 100644
index e9c3e047c2b22aacd54f096af48f918217e06d84..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/socket.io/node_modules/debug/README.md
+++ /dev/null
@@ -1,481 +0,0 @@
-# debug
-[](https://travis-ci.org/debug-js/debug) [](https://coveralls.io/github/debug-js/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
-[](#sponsors)
-
- -
-A tiny JavaScript debugging utility modelled after Node.js core's debugging
-technique. Works in Node.js and web browsers.
-
-## Installation
-
-```bash
-$ npm install debug
-```
-
-## Usage
-
-`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
-
-Example [_app.js_](./examples/node/app.js):
-
-```js
-var debug = require('debug')('http')
- , http = require('http')
- , name = 'My App';
-
-// fake app
-
-debug('booting %o', name);
-
-http.createServer(function(req, res){
- debug(req.method + ' ' + req.url);
- res.end('hello\n');
-}).listen(3000, function(){
- debug('listening');
-});
-
-// fake worker of some kind
-
-require('./worker');
-```
-
-Example [_worker.js_](./examples/node/worker.js):
-
-```js
-var a = require('debug')('worker:a')
- , b = require('debug')('worker:b');
-
-function work() {
- a('doing lots of uninteresting work');
- setTimeout(work, Math.random() * 1000);
-}
-
-work();
-
-function workb() {
- b('doing some work');
- setTimeout(workb, Math.random() * 2000);
-}
-
-workb();
-```
-
-The `DEBUG` environment variable is then used to enable these based on space or
-comma-delimited names.
-
-Here are some examples:
-
-
-
-A tiny JavaScript debugging utility modelled after Node.js core's debugging
-technique. Works in Node.js and web browsers.
-
-## Installation
-
-```bash
-$ npm install debug
-```
-
-## Usage
-
-`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
-
-Example [_app.js_](./examples/node/app.js):
-
-```js
-var debug = require('debug')('http')
- , http = require('http')
- , name = 'My App';
-
-// fake app
-
-debug('booting %o', name);
-
-http.createServer(function(req, res){
- debug(req.method + ' ' + req.url);
- res.end('hello\n');
-}).listen(3000, function(){
- debug('listening');
-});
-
-// fake worker of some kind
-
-require('./worker');
-```
-
-Example [_worker.js_](./examples/node/worker.js):
-
-```js
-var a = require('debug')('worker:a')
- , b = require('debug')('worker:b');
-
-function work() {
- a('doing lots of uninteresting work');
- setTimeout(work, Math.random() * 1000);
-}
-
-work();
-
-function workb() {
- b('doing some work');
- setTimeout(workb, Math.random() * 2000);
-}
-
-workb();
-```
-
-The `DEBUG` environment variable is then used to enable these based on space or
-comma-delimited names.
-
-Here are some examples:
-
- -
-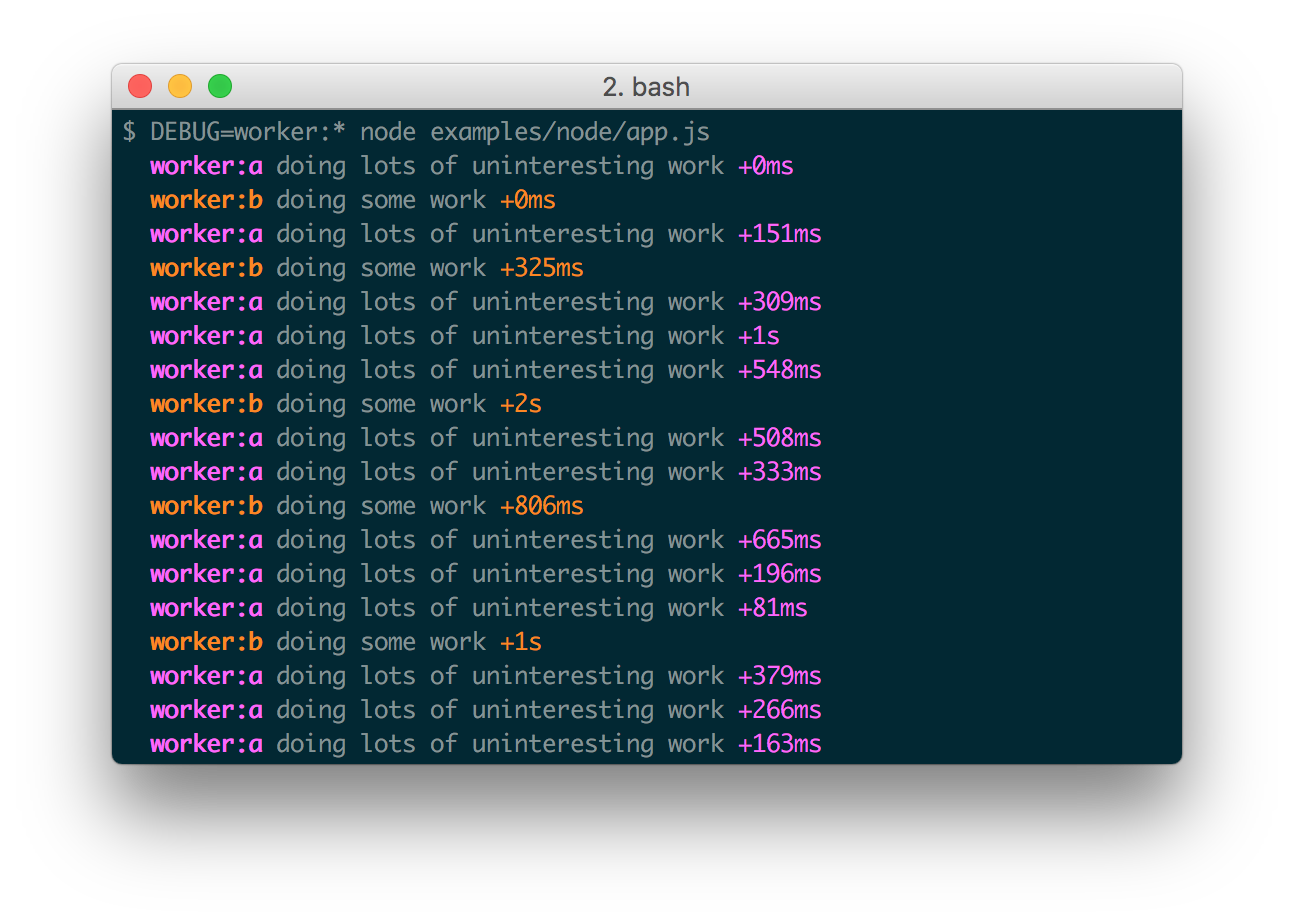 -
-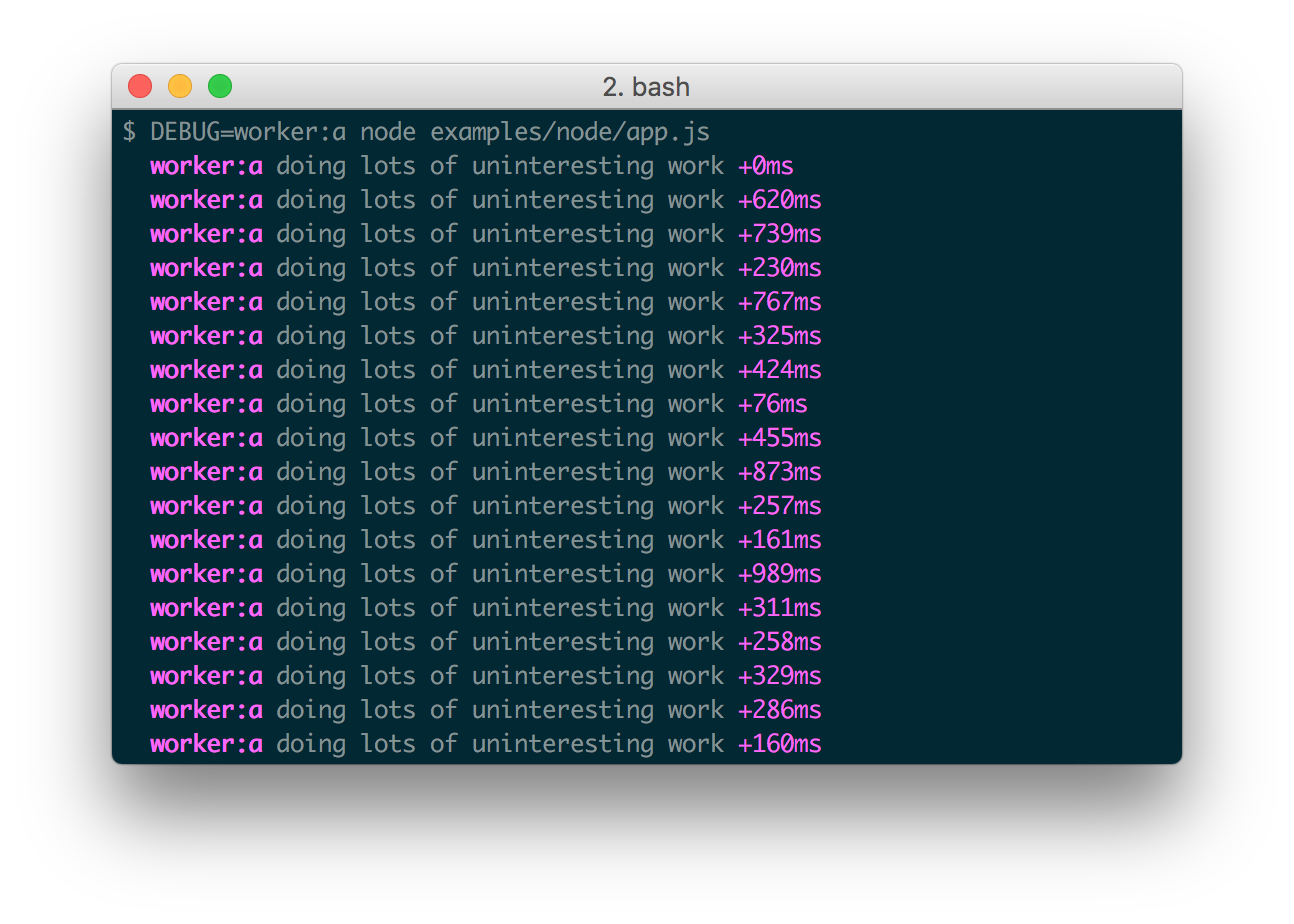 -
-#### Windows command prompt notes
-
-##### CMD
-
-On Windows the environment variable is set using the `set` command.
-
-```cmd
-set DEBUG=*,-not_this
-```
-
-Example:
-
-```cmd
-set DEBUG=* & node app.js
-```
-
-##### PowerShell (VS Code default)
-
-PowerShell uses different syntax to set environment variables.
-
-```cmd
-$env:DEBUG = "*,-not_this"
-```
-
-Example:
-
-```cmd
-$env:DEBUG='app';node app.js
-```
-
-Then, run the program to be debugged as usual.
-
-npm script example:
-```js
- "windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
-```
-
-## Namespace Colors
-
-Every debug instance has a color generated for it based on its namespace name.
-This helps when visually parsing the debug output to identify which debug instance
-a debug line belongs to.
-
-#### Node.js
-
-In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
-the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
-otherwise debug will only use a small handful of basic colors.
-
-
-
-#### Windows command prompt notes
-
-##### CMD
-
-On Windows the environment variable is set using the `set` command.
-
-```cmd
-set DEBUG=*,-not_this
-```
-
-Example:
-
-```cmd
-set DEBUG=* & node app.js
-```
-
-##### PowerShell (VS Code default)
-
-PowerShell uses different syntax to set environment variables.
-
-```cmd
-$env:DEBUG = "*,-not_this"
-```
-
-Example:
-
-```cmd
-$env:DEBUG='app';node app.js
-```
-
-Then, run the program to be debugged as usual.
-
-npm script example:
-```js
- "windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
-```
-
-## Namespace Colors
-
-Every debug instance has a color generated for it based on its namespace name.
-This helps when visually parsing the debug output to identify which debug instance
-a debug line belongs to.
-
-#### Node.js
-
-In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
-the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
-otherwise debug will only use a small handful of basic colors.
-
-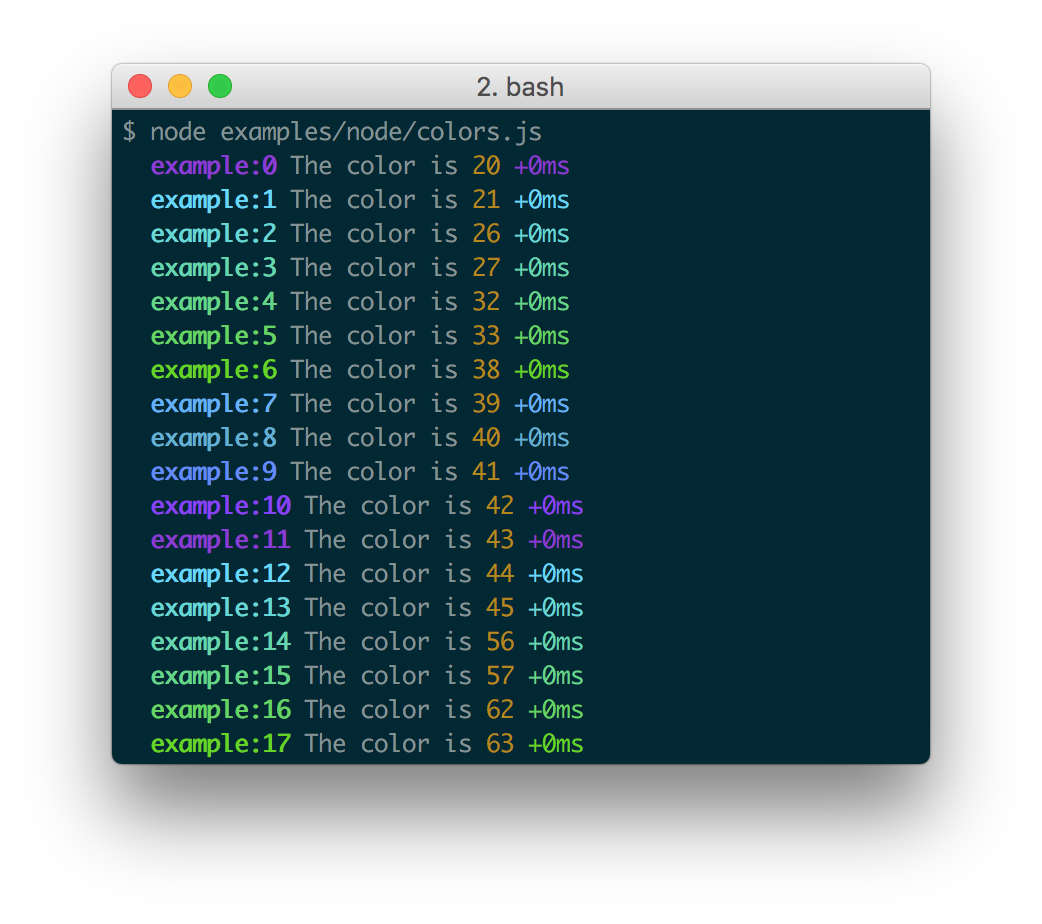 -
-#### Web Browser
-
-Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
-option. These are WebKit web inspectors, Firefox ([since version
-31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
-and the Firebug plugin for Firefox (any version).
-
-
-
-#### Web Browser
-
-Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
-option. These are WebKit web inspectors, Firefox ([since version
-31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
-and the Firebug plugin for Firefox (any version).
-
-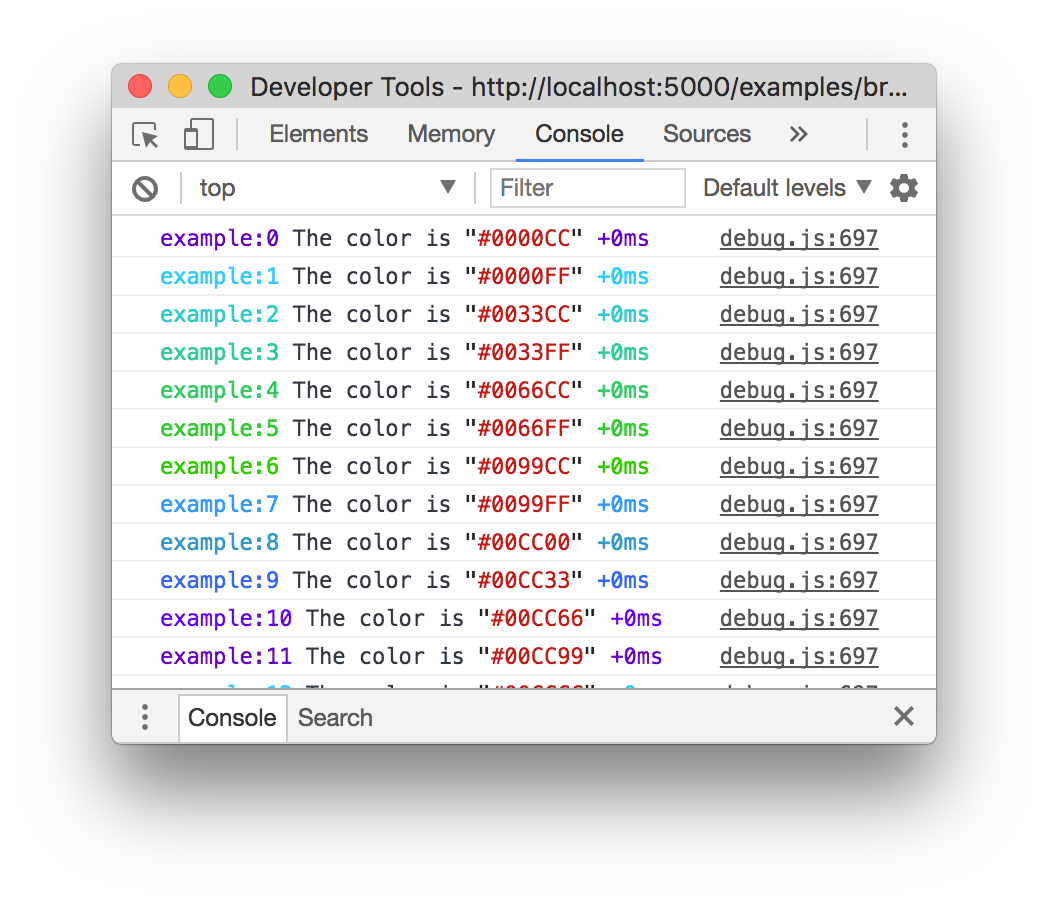 -
-
-## Millisecond diff
-
-When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
-
-
-
-When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
-
-
-
-
-## Millisecond diff
-
-When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
-
-
-
-When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
-
-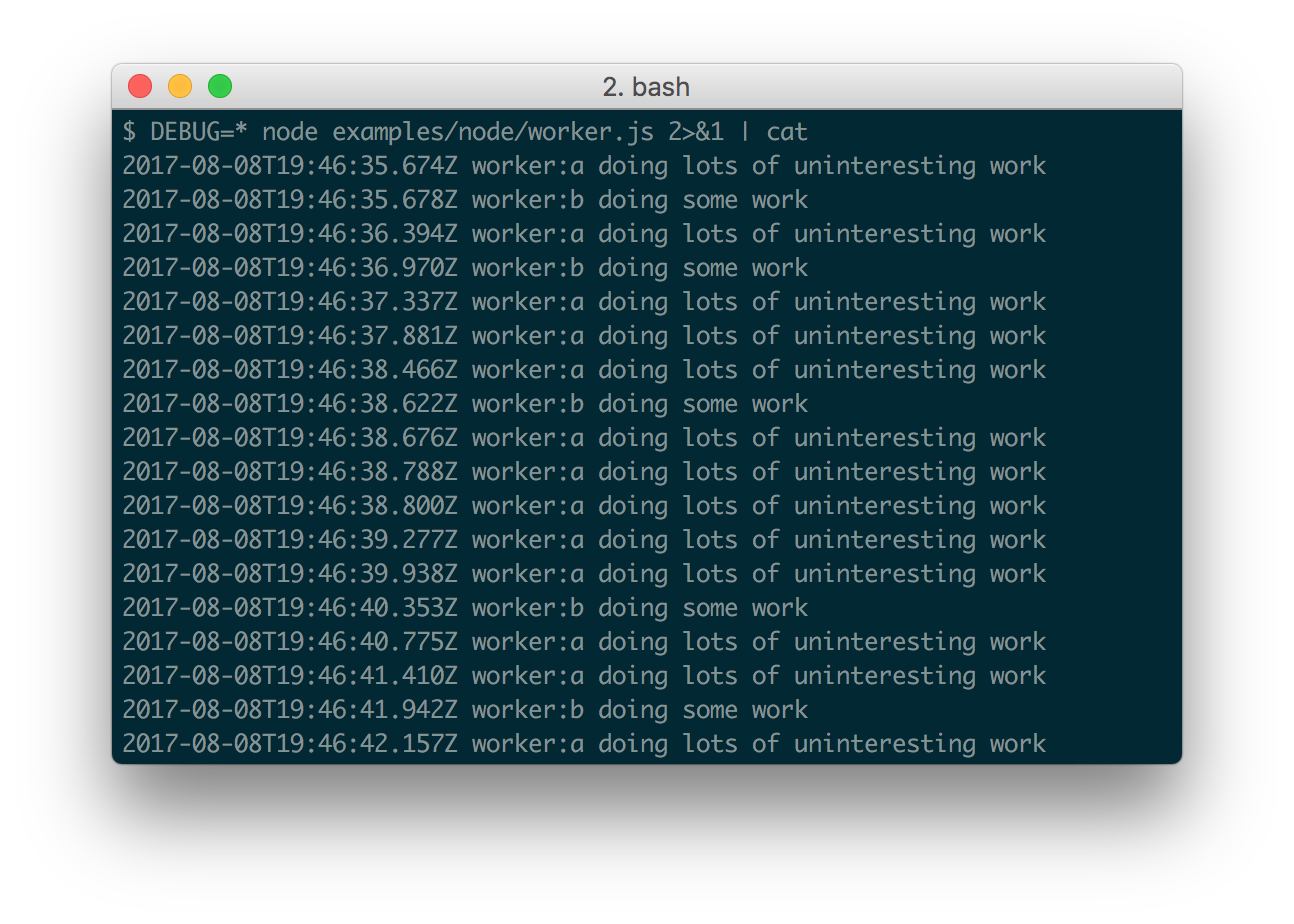 -
-
-## Conventions
-
-If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
-
-## Wildcards
-
-The `*` character may be used as a wildcard. Suppose for example your library has
-debuggers named "connect:bodyParser", "connect:compress", "connect:session",
-instead of listing all three with
-`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
-`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
-
-You can also exclude specific debuggers by prefixing them with a "-" character.
-For example, `DEBUG=*,-connect:*` would include all debuggers except those
-starting with "connect:".
-
-## Environment Variables
-
-When running through Node.js, you can set a few environment variables that will
-change the behavior of the debug logging:
-
-| Name | Purpose |
-|-----------|-------------------------------------------------|
-| `DEBUG` | Enables/disables specific debugging namespaces. |
-| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
-| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
-| `DEBUG_DEPTH` | Object inspection depth. |
-| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
-
-
-__Note:__ The environment variables beginning with `DEBUG_` end up being
-converted into an Options object that gets used with `%o`/`%O` formatters.
-See the Node.js documentation for
-[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
-for the complete list.
-
-## Formatters
-
-Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
-Below are the officially supported formatters:
-
-| Formatter | Representation |
-|-----------|----------------|
-| `%O` | Pretty-print an Object on multiple lines. |
-| `%o` | Pretty-print an Object all on a single line. |
-| `%s` | String. |
-| `%d` | Number (both integer and float). |
-| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
-| `%%` | Single percent sign ('%'). This does not consume an argument. |
-
-
-### Custom formatters
-
-You can add custom formatters by extending the `debug.formatters` object.
-For example, if you wanted to add support for rendering a Buffer as hex with
-`%h`, you could do something like:
-
-```js
-const createDebug = require('debug')
-createDebug.formatters.h = (v) => {
- return v.toString('hex')
-}
-
-// …elsewhere
-const debug = createDebug('foo')
-debug('this is hex: %h', new Buffer('hello world'))
-// foo this is hex: 68656c6c6f20776f726c6421 +0ms
-```
-
-
-## Browser Support
-
-You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
-or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
-if you don't want to build it yourself.
-
-Debug's enable state is currently persisted by `localStorage`.
-Consider the situation shown below where you have `worker:a` and `worker:b`,
-and wish to debug both. You can enable this using `localStorage.debug`:
-
-```js
-localStorage.debug = 'worker:*'
-```
-
-And then refresh the page.
-
-```js
-a = debug('worker:a');
-b = debug('worker:b');
-
-setInterval(function(){
- a('doing some work');
-}, 1000);
-
-setInterval(function(){
- b('doing some work');
-}, 1200);
-```
-
-In Chromium-based web browsers (e.g. Brave, Chrome, and Electron), the JavaScript console will—by default—only show messages logged by `debug` if the "Verbose" log level is _enabled_.
-
-
-
-
-## Conventions
-
-If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
-
-## Wildcards
-
-The `*` character may be used as a wildcard. Suppose for example your library has
-debuggers named "connect:bodyParser", "connect:compress", "connect:session",
-instead of listing all three with
-`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
-`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
-
-You can also exclude specific debuggers by prefixing them with a "-" character.
-For example, `DEBUG=*,-connect:*` would include all debuggers except those
-starting with "connect:".
-
-## Environment Variables
-
-When running through Node.js, you can set a few environment variables that will
-change the behavior of the debug logging:
-
-| Name | Purpose |
-|-----------|-------------------------------------------------|
-| `DEBUG` | Enables/disables specific debugging namespaces. |
-| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
-| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
-| `DEBUG_DEPTH` | Object inspection depth. |
-| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
-
-
-__Note:__ The environment variables beginning with `DEBUG_` end up being
-converted into an Options object that gets used with `%o`/`%O` formatters.
-See the Node.js documentation for
-[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
-for the complete list.
-
-## Formatters
-
-Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
-Below are the officially supported formatters:
-
-| Formatter | Representation |
-|-----------|----------------|
-| `%O` | Pretty-print an Object on multiple lines. |
-| `%o` | Pretty-print an Object all on a single line. |
-| `%s` | String. |
-| `%d` | Number (both integer and float). |
-| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
-| `%%` | Single percent sign ('%'). This does not consume an argument. |
-
-
-### Custom formatters
-
-You can add custom formatters by extending the `debug.formatters` object.
-For example, if you wanted to add support for rendering a Buffer as hex with
-`%h`, you could do something like:
-
-```js
-const createDebug = require('debug')
-createDebug.formatters.h = (v) => {
- return v.toString('hex')
-}
-
-// …elsewhere
-const debug = createDebug('foo')
-debug('this is hex: %h', new Buffer('hello world'))
-// foo this is hex: 68656c6c6f20776f726c6421 +0ms
-```
-
-
-## Browser Support
-
-You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
-or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
-if you don't want to build it yourself.
-
-Debug's enable state is currently persisted by `localStorage`.
-Consider the situation shown below where you have `worker:a` and `worker:b`,
-and wish to debug both. You can enable this using `localStorage.debug`:
-
-```js
-localStorage.debug = 'worker:*'
-```
-
-And then refresh the page.
-
-```js
-a = debug('worker:a');
-b = debug('worker:b');
-
-setInterval(function(){
- a('doing some work');
-}, 1000);
-
-setInterval(function(){
- b('doing some work');
-}, 1200);
-```
-
-In Chromium-based web browsers (e.g. Brave, Chrome, and Electron), the JavaScript console will—by default—only show messages logged by `debug` if the "Verbose" log level is _enabled_.
-
- -
-## Output streams
-
- By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
-
-Example [_stdout.js_](./examples/node/stdout.js):
-
-```js
-var debug = require('debug');
-var error = debug('app:error');
-
-// by default stderr is used
-error('goes to stderr!');
-
-var log = debug('app:log');
-// set this namespace to log via console.log
-log.log = console.log.bind(console); // don't forget to bind to console!
-log('goes to stdout');
-error('still goes to stderr!');
-
-// set all output to go via console.info
-// overrides all per-namespace log settings
-debug.log = console.info.bind(console);
-error('now goes to stdout via console.info');
-log('still goes to stdout, but via console.info now');
-```
-
-## Extend
-You can simply extend debugger
-```js
-const log = require('debug')('auth');
-
-//creates new debug instance with extended namespace
-const logSign = log.extend('sign');
-const logLogin = log.extend('login');
-
-log('hello'); // auth hello
-logSign('hello'); //auth:sign hello
-logLogin('hello'); //auth:login hello
-```
-
-## Set dynamically
-
-You can also enable debug dynamically by calling the `enable()` method :
-
-```js
-let debug = require('debug');
-
-console.log(1, debug.enabled('test'));
-
-debug.enable('test');
-console.log(2, debug.enabled('test'));
-
-debug.disable();
-console.log(3, debug.enabled('test'));
-
-```
-
-print :
-```
-1 false
-2 true
-3 false
-```
-
-Usage :
-`enable(namespaces)`
-`namespaces` can include modes separated by a colon and wildcards.
-
-Note that calling `enable()` completely overrides previously set DEBUG variable :
-
-```
-$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
-=> false
-```
-
-`disable()`
-
-Will disable all namespaces. The functions returns the namespaces currently
-enabled (and skipped). This can be useful if you want to disable debugging
-temporarily without knowing what was enabled to begin with.
-
-For example:
-
-```js
-let debug = require('debug');
-debug.enable('foo:*,-foo:bar');
-let namespaces = debug.disable();
-debug.enable(namespaces);
-```
-
-Note: There is no guarantee that the string will be identical to the initial
-enable string, but semantically they will be identical.
-
-## Checking whether a debug target is enabled
-
-After you've created a debug instance, you can determine whether or not it is
-enabled by checking the `enabled` property:
-
-```javascript
-const debug = require('debug')('http');
-
-if (debug.enabled) {
- // do stuff...
-}
-```
-
-You can also manually toggle this property to force the debug instance to be
-enabled or disabled.
-
-## Usage in child processes
-
-Due to the way `debug` detects if the output is a TTY or not, colors are not shown in child processes when `stderr` is piped. A solution is to pass the `DEBUG_COLORS=1` environment variable to the child process.
-For example:
-
-```javascript
-worker = fork(WORKER_WRAP_PATH, [workerPath], {
- stdio: [
- /* stdin: */ 0,
- /* stdout: */ 'pipe',
- /* stderr: */ 'pipe',
- 'ipc',
- ],
- env: Object.assign({}, process.env, {
- DEBUG_COLORS: 1 // without this settings, colors won't be shown
- }),
-});
-
-worker.stderr.pipe(process.stderr, { end: false });
-```
-
-
-## Authors
-
- - TJ Holowaychuk
- - Nathan Rajlich
- - Andrew Rhyne
- - Josh Junon
-
-## Backers
-
-Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
-
-
-
-## Output streams
-
- By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
-
-Example [_stdout.js_](./examples/node/stdout.js):
-
-```js
-var debug = require('debug');
-var error = debug('app:error');
-
-// by default stderr is used
-error('goes to stderr!');
-
-var log = debug('app:log');
-// set this namespace to log via console.log
-log.log = console.log.bind(console); // don't forget to bind to console!
-log('goes to stdout');
-error('still goes to stderr!');
-
-// set all output to go via console.info
-// overrides all per-namespace log settings
-debug.log = console.info.bind(console);
-error('now goes to stdout via console.info');
-log('still goes to stdout, but via console.info now');
-```
-
-## Extend
-You can simply extend debugger
-```js
-const log = require('debug')('auth');
-
-//creates new debug instance with extended namespace
-const logSign = log.extend('sign');
-const logLogin = log.extend('login');
-
-log('hello'); // auth hello
-logSign('hello'); //auth:sign hello
-logLogin('hello'); //auth:login hello
-```
-
-## Set dynamically
-
-You can also enable debug dynamically by calling the `enable()` method :
-
-```js
-let debug = require('debug');
-
-console.log(1, debug.enabled('test'));
-
-debug.enable('test');
-console.log(2, debug.enabled('test'));
-
-debug.disable();
-console.log(3, debug.enabled('test'));
-
-```
-
-print :
-```
-1 false
-2 true
-3 false
-```
-
-Usage :
-`enable(namespaces)`
-`namespaces` can include modes separated by a colon and wildcards.
-
-Note that calling `enable()` completely overrides previously set DEBUG variable :
-
-```
-$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
-=> false
-```
-
-`disable()`
-
-Will disable all namespaces. The functions returns the namespaces currently
-enabled (and skipped). This can be useful if you want to disable debugging
-temporarily without knowing what was enabled to begin with.
-
-For example:
-
-```js
-let debug = require('debug');
-debug.enable('foo:*,-foo:bar');
-let namespaces = debug.disable();
-debug.enable(namespaces);
-```
-
-Note: There is no guarantee that the string will be identical to the initial
-enable string, but semantically they will be identical.
-
-## Checking whether a debug target is enabled
-
-After you've created a debug instance, you can determine whether or not it is
-enabled by checking the `enabled` property:
-
-```javascript
-const debug = require('debug')('http');
-
-if (debug.enabled) {
- // do stuff...
-}
-```
-
-You can also manually toggle this property to force the debug instance to be
-enabled or disabled.
-
-## Usage in child processes
-
-Due to the way `debug` detects if the output is a TTY or not, colors are not shown in child processes when `stderr` is piped. A solution is to pass the `DEBUG_COLORS=1` environment variable to the child process.
-For example:
-
-```javascript
-worker = fork(WORKER_WRAP_PATH, [workerPath], {
- stdio: [
- /* stdin: */ 0,
- /* stdout: */ 'pipe',
- /* stderr: */ 'pipe',
- 'ipc',
- ],
- env: Object.assign({}, process.env, {
- DEBUG_COLORS: 1 // without this settings, colors won't be shown
- }),
-});
-
-worker.stderr.pipe(process.stderr, { end: false });
-```
-
-
-## Authors
-
- - TJ Holowaychuk
- - Nathan Rajlich
- - Andrew Rhyne
- - Josh Junon
-
-## Backers
-
-Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
-
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-
-## Sponsors
-
-Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
-
-
-
-
-## Sponsors
-
-Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
-
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-## License
-
-(The MIT License)
-
-Copyright (c) 2014-2017 TJ Holowaychuk <tj@vision-media.ca>
-Copyright (c) 2018-2021 Josh Junon
-
-Permission is hereby granted, free of charge, to any person obtaining
-a copy of this software and associated documentation files (the
-'Software'), to deal in the Software without restriction, including
-without limitation the rights to use, copy, modify, merge, publish,
-distribute, sublicense, and/or sell copies of the Software, and to
-permit persons to whom the Software is furnished to do so, subject to
-the following conditions:
-
-The above copyright notice and this permission notice shall be
-included in all copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
-EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
-MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
-IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
-CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
-TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
-SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/spaces/fffiloni/diffBIR/README.md b/spaces/fffiloni/diffBIR/README.md
deleted file mode 100644
index 3377f9b95833253e5c76bd09fd0c07df79fc5542..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/diffBIR/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: DiffBIR Img Restoration
-emoji: 😶🌫️
-colorFrom: indigo
-colorTo: green
-sdk: docker
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/fgenie/scamtext_PAL_self_consistency/funcs/f_69.py b/spaces/fgenie/scamtext_PAL_self_consistency/funcs/f_69.py
deleted file mode 100644
index bbb8468954c0edb3daa6790f0ced55ebda1575a0..0000000000000000000000000000000000000000
--- a/spaces/fgenie/scamtext_PAL_self_consistency/funcs/f_69.py
+++ /dev/null
@@ -1,30 +0,0 @@
-
-import re
-
-def is_spam(message):
- # Spam indicators
- spam_indicators = [
- r"[\d,]*원",
- r"\d{1,2}% ?~",
- r"\d{1,2}대",
- r"http[s]?://",
- r"주식",
- r"종목",
- r"익 절 가",
- r"펀드매니저",
- r"수익률",
- r"매매승률",
- r"목표가",
- r"최소",
- r"매일",
- r"최대",
- r"최고",
- ]
-
- # Iterate through spam indicators and check if any are present in the message
- for indicator in spam_indicators:
- if re.search(indicator, message, flags=re.IGNORECASE):
- return True
-
- # If none of the spam indicators are present, consider it a normal message
- return False
diff --git a/spaces/fgibarra/fraud-prevention/README.md b/spaces/fgibarra/fraud-prevention/README.md
deleted file mode 100644
index 0035ae7550f120392fd3ae088cc57359895d4a12..0000000000000000000000000000000000000000
--- a/spaces/fgibarra/fraud-prevention/README.md
+++ /dev/null
@@ -1,63 +0,0 @@
----
-title: Fraud Prevention
-emoji: 📊
-colorFrom: green
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.34.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-# Final project of bootcamp EDVai 2023
-
-## Description
-
-This is the final project of the bootcamp EDVai 2023.
-
-The project is divide in several parts:
-- notebooks: contains the notebooks used to data exploration, data cleaning, data analysis and model creation.
-- api: contains the code of the api. The api is used to predict frauds. This code is realized with FastAPI.
-- app: contains the code of the web application realized with Gradio.
-
-Other files:
-- data: contains the data used in the project.
-- model: contains the models used in the project.
-- docs: contains the documentation of the project.
-
-## Installation
-
-To install the project, you need to clone the repository and install the requirements.
-The requirements are in the three files: notebooks_requirements.txt, api_requirements.txt and app_requirements.txt.
-
-Depends on you the part of the project you want to use, you need to install the requirements of the part.
-
-```bash
-python -m venv venv
-pip install -r notebooks_requirements.txt
-pip install -r api_requirements.txt
-pip install -r app_requirements.txt
-```
-
-## Usage
-If you want to use the notebooks, you need to run the notebooks in the following order:
-- 01__Adaptacion.ipynb
-- 02__Correlacion.ipynb
-- 03__Preparacion.ipynb
-- 04__Clustering.ipynb
-- 05__Modelo.ipynb
-
-If you want to use the api, you need to run the following command:
-```bash
-python main.py
-```
-
-If you want to use the app, you need to run the following command:
-```bash
-python app.py
-```
-
-## Deploy
-
-
diff --git a/spaces/freddyaboulton/chicago-bike-share-dashboard/app.py b/spaces/freddyaboulton/chicago-bike-share-dashboard/app.py
deleted file mode 100644
index 77d8a098c151266b59f0a4ae1af592e8a41b158f..0000000000000000000000000000000000000000
--- a/spaces/freddyaboulton/chicago-bike-share-dashboard/app.py
+++ /dev/null
@@ -1,91 +0,0 @@
-import os
-import psycopg2
-import gradio as gr
-import matplotlib
-import matplotlib.pyplot as plt
-
-matplotlib.use("Agg")
-
-
-connection = psycopg2.connect(
- user=os.environ["DB_USER"],
- password=os.environ["DB_PASSWORD"],
- host=os.environ["DB_HOST"],
- port="8080",
- database="bikeshare",
-)
-
-
-def get_count_ride_type():
- cursor = connection.cursor()
- cursor.execute(
- """
- SELECT COUNT(ride_id) as n, rideable_type
- FROM rides
- GROUP BY rideable_type
- ORDER BY n DESC
- """
- )
- rides = cursor.fetchall()
- cursor.close()
- fig_m, ax = plt.subplots()
- ax.bar(x=[s[1] for s in rides], height=[s[0] for s in rides])
- ax.set_title("Number of rides by bycycle type")
- ax.set_ylabel("Number of Rides")
- ax.set_xlabel("Bicycle Type")
- return fig_m
-
-
-def get_most_popular_stations():
- cursor = connection.cursor()
- cursor.execute(
- """
- SELECT COUNT(ride_id) as n, MAX(start_station_name)
- FROM RIDES
- WHERE start_station_name is NOT NULL
- GROUP BY start_station_id
- ORDER BY n DESC
- LIMIT 5
- """
- )
- stations = cursor.fetchall()
- cursor = connection.cursor()
- fig_m, ax = plt.subplots()
- ax.bar(x=[s[1] for s in stations], height=[s[0] for s in stations])
- ax.set_title("Most popular stations")
- ax.set_ylabel("Number of Rides")
- ax.set_xlabel("Station Name")
- ax.set_xticklabels(
- [s[1] for s in stations], rotation=45, ha="right", rotation_mode="anchor"
- )
- ax.tick_params(axis="x", labelsize=8)
- fig_m.tight_layout()
- return fig_m
-
-
-with gr.Blocks() as demo:
- gr.Markdown(
- """
- # Chicago Bike Share Dashboard
-
- This demo pulls Chicago bike share data for March 2022 from a postgresql database hosted on AWS.
- This demo uses psycopg2 but any postgresql client library (SQLAlchemy)
- is compatible with gradio.
-
- Connection credentials are handled by environment variables
- defined as secrets in the Space.
-
- If data were added to the database, the plots in this demo would update
- whenever the webpage is reloaded.
-
- This demo serves as a starting point for your database-connected apps!
- """
- )
- with gr.Row():
- bike_type = gr.Plot()
- station = gr.Plot()
-
- demo.load(get_count_ride_type, inputs=None, outputs=bike_type)
- demo.load(get_most_popular_stations, inputs=None, outputs=station)
-
-demo.launch()
diff --git a/spaces/furqankassa/Docker-FlanT5-TextGeneratorTranslator/Dockerfile b/spaces/furqankassa/Docker-FlanT5-TextGeneratorTranslator/Dockerfile
deleted file mode 100644
index 7ae5f101e356251bb52f2b34fec3032a0a084da7..0000000000000000000000000000000000000000
--- a/spaces/furqankassa/Docker-FlanT5-TextGeneratorTranslator/Dockerfile
+++ /dev/null
@@ -1,28 +0,0 @@
-# Use the official Python 3.9 image
-FROM python:3.9
-
-# Set the working directory to /code
-WORKDIR /code
-
-# Copy the current directory contents into the container at /code
-COPY ./requirements.txt /code/requirements.txt
-
-# Install requirements.txt
-RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
-
-# Set up a new user named "user" with user ID 1000
-RUN useradd -m -u 1000 user
-# Switch to the "user" user
-USER user
-# Set home to the user's home directory
-ENV HOME=/home/user \
- PATH=/home/user/.local/bin:$PATH
-
-# Set the working directory to the user's home directory
-WORKDIR $HOME/app
-
-# Copy the current directory contents into the container at $HOME/app setting the owner to the user
-COPY --chown=user . $HOME/app
-
-# Uvicorn: https://www.uvicorn.org/settings/ use main:app to run main.py
-CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "7860"]
\ No newline at end of file
diff --git a/spaces/gagan3012/summarization/src/visualization/visualize.py b/spaces/gagan3012/summarization/src/visualization/visualize.py
deleted file mode 100644
index 01779be7841c2b2e4a2de7f336641f54713457a8..0000000000000000000000000000000000000000
--- a/spaces/gagan3012/summarization/src/visualization/visualize.py
+++ /dev/null
@@ -1,23 +0,0 @@
-import streamlit as st
-from src.models.predict_model import predict_model
-
-
-def visualize():
- st.write("# Summarization UI")
- st.markdown(
- """
- *For additional questions and inquiries, please contact **Gagan Bhatia** via [LinkedIn](
- https://www.linkedin.com/in/gbhatia30/) or [Github](https://github.com/gagan3012).*
- """
- )
-
- text = st.text_area("Enter text here")
- if st.button("Generate Summary"):
- with st.spinner("Connecting the Dots..."):
- sumtext = predict_model(text=text)
- st.write("# Generated Summary:")
- st.write("{}".format(sumtext))
-
-
-if __name__ == "__main__":
- visualize()
diff --git a/spaces/geekyrakshit/enhance-me/enhance_me/zero_dce/losses/spatial_constancy.py b/spaces/geekyrakshit/enhance-me/enhance_me/zero_dce/losses/spatial_constancy.py
deleted file mode 100644
index 74e2a30595d9004422b3018760d81ce7bf5857c7..0000000000000000000000000000000000000000
--- a/spaces/geekyrakshit/enhance-me/enhance_me/zero_dce/losses/spatial_constancy.py
+++ /dev/null
@@ -1,63 +0,0 @@
-import tensorflow as tf
-from tensorflow.keras import losses
-
-
-class SpatialConsistencyLoss(losses.Loss):
- def __init__(self, **kwargs):
- super(SpatialConsistencyLoss, self).__init__(reduction="none")
-
- self.left_kernel = tf.constant(
- [[[[0, 0, 0]], [[-1, 1, 0]], [[0, 0, 0]]]], dtype=tf.float32
- )
- self.right_kernel = tf.constant(
- [[[[0, 0, 0]], [[0, 1, -1]], [[0, 0, 0]]]], dtype=tf.float32
- )
- self.up_kernel = tf.constant(
- [[[[0, -1, 0]], [[0, 1, 0]], [[0, 0, 0]]]], dtype=tf.float32
- )
- self.down_kernel = tf.constant(
- [[[[0, 0, 0]], [[0, 1, 0]], [[0, -1, 0]]]], dtype=tf.float32
- )
-
- def call(self, y_true, y_pred):
-
- original_mean = tf.reduce_mean(y_true, 3, keepdims=True)
- enhanced_mean = tf.reduce_mean(y_pred, 3, keepdims=True)
- original_pool = tf.nn.avg_pool2d(
- original_mean, ksize=4, strides=4, padding="VALID"
- )
- enhanced_pool = tf.nn.avg_pool2d(
- enhanced_mean, ksize=4, strides=4, padding="VALID"
- )
-
- d_original_left = tf.nn.conv2d(
- original_pool, self.left_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_original_right = tf.nn.conv2d(
- original_pool, self.right_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_original_up = tf.nn.conv2d(
- original_pool, self.up_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_original_down = tf.nn.conv2d(
- original_pool, self.down_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
-
- d_enhanced_left = tf.nn.conv2d(
- enhanced_pool, self.left_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_enhanced_right = tf.nn.conv2d(
- enhanced_pool, self.right_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_enhanced_up = tf.nn.conv2d(
- enhanced_pool, self.up_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_enhanced_down = tf.nn.conv2d(
- enhanced_pool, self.down_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
-
- d_left = tf.square(d_original_left - d_enhanced_left)
- d_right = tf.square(d_original_right - d_enhanced_right)
- d_up = tf.square(d_original_up - d_enhanced_up)
- d_down = tf.square(d_original_down - d_enhanced_down)
- return d_left + d_right + d_up + d_down
diff --git a/spaces/giswqs/solara-maxar/pages/03_maui.py b/spaces/giswqs/solara-maxar/pages/03_maui.py
deleted file mode 100644
index b710351b42eaa705efa87c3428398caf5f26e81e..0000000000000000000000000000000000000000
--- a/spaces/giswqs/solara-maxar/pages/03_maui.py
+++ /dev/null
@@ -1,263 +0,0 @@
-import os
-import leafmap
-import solara
-import ipywidgets as widgets
-import pandas as pd
-import geopandas as gpd
-import tempfile
-from shapely.geometry import Point
-
-event = 'Maui-Hawaii-fires-Aug-23'
-url = 'https://raw.githubusercontent.com/opengeos/maxar-open-data/master'
-repo = 'https://github.com/opengeos/maxar-open-data/blob/master/datasets'
-
-
-def get_datasets():
- datasets = f'{url}/datasets.csv'
- df = pd.read_csv(datasets)
- return df
-
-
-def get_catalogs(name):
- dataset = f'{url}/datasets/{name}.tsv'
- basename = os.path.basename(dataset)
- tempdir = tempfile.gettempdir()
- tmp_dataset = os.path.join(tempdir, basename)
- if os.path.exists(tmp_dataset):
- dataset_df = pd.read_csv(tmp_dataset, sep='\t')
- else:
- dataset_df = pd.read_csv(dataset, sep='\t')
- dataset_df.to_csv(tmp_dataset, sep='\t', index=False)
- catalog_ids = dataset_df['catalog_id'].unique().tolist()
- catalog_ids.sort()
- return catalog_ids
-
-
-def get_image_date(catalog_id, m):
- gdf = m.footprint
- image_date = pd.Timestamp(
- gdf[gdf['catalog_id'] == catalog_id]['datetime'].values[0]
- ).strftime('%Y-%m-%d %H:%M:%S')
- return image_date
-
-
-def add_widgets(m):
- datasets = get_datasets()['dataset'].tolist()
- setattr(m, 'zoom_to_layer', True)
- style = {"description_width": "initial"}
- padding = "0px 0px 0px 5px"
- dataset = widgets.Dropdown(
- options=datasets,
- description='Event:',
- value=event,
- style=style,
- layout=widgets.Layout(width="270px", padding=padding),
- )
-
- catalog_ids = get_catalogs(dataset.value)
- setattr(m, 'catalog_ids', catalog_ids)
-
- date_picker = widgets.DatePicker(
- description='Start date:',
- value=pd.to_datetime('2021-01-01').date(),
- style=style,
- layout=widgets.Layout(width="270px", padding=padding),
- )
-
- image = widgets.Dropdown(
- value=None,
- options=m.catalog_ids,
- description='Image:',
- style=style,
- layout=widgets.Layout(width="270px", padding=padding),
- )
-
- checkbox = widgets.Checkbox(
- value=True,
- description='Footprints',
- style=style,
- layout=widgets.Layout(width="90px", padding="0px"),
- )
-
- split = widgets.Checkbox(
- value=False,
- description='Split map',
- style=style,
- layout=widgets.Layout(width="92px", padding=padding),
- )
-
- reset = widgets.Checkbox(
- value=False,
- description='Reset',
- style=style,
- layout=widgets.Layout(width="75px", padding='0px'),
- )
-
- output = widgets.Output()
-
- def reset_map(change):
- if change.new:
- image.value = None
- image.options = m.catalog_ids
- m.layers = m.layers[:3]
- m.zoom_to_layer = True
- reset.value = False
- date_picker.value = pd.to_datetime('2021-01-01').date()
- m.remove_layer(m.find_layer('Footprint'))
- m.add_gdf(
- m.footprint, layer_name='Footprint', zoom_to_layer=False, info_mode=None
- )
- satellite_layer = m.find_layer('Google Satellite')
- satellite_layer.visible = False
- output.outputs = ()
-
- reset.observe(reset_map, names='value')
-
- def change_dataset(change):
- default_geojson = f'{url}/datasets/{change.new}_union.geojson'
- m.layers = m.layers[:2]
- m.controls = m.controls[:-1]
- basename = os.path.basename(default_geojson)
- tempdir = tempfile.gettempdir()
- tmp_geojson = os.path.join(tempdir, basename)
- if os.path.exists(tmp_geojson):
- default_geojson = tmp_geojson
- else:
- leafmap.download_file(default_geojson, tmp_geojson, quiet=True)
- m.add_geojson(default_geojson, layer_name='Footprint', zoom_to_layer=True)
- setattr(m, 'gdf', gpd.read_file(default_geojson))
-
- image.options = get_catalogs(change.new)
-
- dataset.observe(change_dataset, names='value')
-
- def change_date(change):
- if change.new:
- start_date = change.new.strftime('%Y-%m-%d')
- sub_gdf = m.gdf[m.gdf['datetime'] >= start_date]
- sub_catalog_ids = sub_gdf['catalog_id'].values.tolist()
- image.options = sub_catalog_ids
- m.remove_layer(m.find_layer('Footprint'))
- m.add_gdf(
- sub_gdf, layer_name='Footprint', zoom_to_layer=False, info_mode=None
- )
- m.gdf = sub_gdf
-
- date_picker.observe(change_date, names='value')
-
- def change_image(change):
- if change.new:
- if change.new not in m.get_layer_names():
- mosaic = f'{url}/datasets/{dataset.value}/{image.value}.json'
- m.add_stac_layer(mosaic, name=image.value, fit_bounds=m.zoom_to_layer)
- image_date = get_image_date(image.value, m)
- output.outputs = ()
- output.append_stdout(f"Image date: {image_date}\n")
-
- image.observe(change_image, names='value')
-
- def change_footprint(change):
- geojson_layer = m.find_layer('Footprint')
- if change.new:
- geojson_layer.visible = True
- else:
- geojson_layer.visible = False
-
- checkbox.observe(change_footprint, names='value')
-
- def change_split(change):
- if change.new:
- if image.value is not None:
- left_layer = m.find_layer(image.value)
- right_layer = m.find_layer('Google Satellite')
- right_layer.visible = True
- footprint_layer = m.find_layer('Footprint')
- footprint_layer.visible = False
- checkbox.value = False
- m.split_map(
- left_layer=left_layer,
- right_layer=right_layer,
- add_close_button=True,
- left_label=image.value,
- right_label='Google Satellite',
- )
- split.value = False
- else:
- left_layer = None
-
- split.observe(change_split, names='value')
-
- def handle_click(**kwargs):
- if kwargs.get('type') == 'click':
- latlon = kwargs.get('coordinates')
- geometry = Point(latlon[::-1])
- selected = m.gdf[m.gdf.intersects(geometry)]
- setattr(m, 'zoom_to_layer', False)
- if len(selected) > 0:
- catalog_ids = selected['catalog_id'].values.tolist()
-
- if len(catalog_ids) > 1:
- image.options = catalog_ids
- image.value = catalog_ids[0]
- else:
- image.value = None
-
- m.on_interaction(handle_click)
-
- box = widgets.VBox(
- [dataset, date_picker, image, widgets.HBox([checkbox, split, reset]), output]
- )
- m.add_widget(box, position='topright', add_header=False)
-
-
-zoom = solara.reactive(2)
-center = solara.reactive((20, 0))
-
-
-class Map(leafmap.Map):
- def __init__(self, **kwargs):
- kwargs['toolbar_control'] = False
- super().__init__(**kwargs)
- basemap = {
- "url": "https://mt1.google.com/vt/lyrs=s&x={x}&y={y}&z={z}",
- "attribution": "Google",
- "name": "Google Satellite",
- }
- self.add_tile_layer(**basemap, shown=False)
- self.add_layer_manager(opened=False)
- add_widgets(self)
- default_geojson = f'{url}/datasets/{event}_union.geojson'
- basename = os.path.basename(default_geojson)
- tempdir = tempfile.gettempdir()
- tmp_geojson = os.path.join(tempdir, basename)
- if os.path.exists(tmp_geojson):
- default_geojson = tmp_geojson
- else:
- leafmap.download_file(default_geojson, tmp_geojson, quiet=True)
- self.add_geojson(
- default_geojson, layer_name='Footprint', zoom_to_layer=True, info_mode=None
- )
- gdf = gpd.read_file(default_geojson)
- setattr(self, 'gdf', gdf)
- setattr(self, 'footprint', gdf)
-
-
-@solara.component
-def Page():
- with solara.Column(style={"min-width": "500px"}):
- # solara components support reactive variables
- # solara.SliderInt(label="Zoom level", value=zoom, min=1, max=20)
- # using 3rd party widget library require wiring up the events manually
- # using zoom.value and zoom.set
- Map.element( # type: ignore
- zoom=zoom.value,
- on_zoom=zoom.set,
- center=center.value,
- on_center=center.set,
- scroll_wheel_zoom=True,
- toolbar_ctrl=False,
- data_ctrl=False,
- height="780px",
- )
- solara.Text(f"Center: {center.value}")
- solara.Text(f"Zoom: {zoom.value}")
diff --git a/spaces/givkashi/SwinIR-Super-resolution/main_test_swinir.py b/spaces/givkashi/SwinIR-Super-resolution/main_test_swinir.py
deleted file mode 100644
index a47c5b35d34238e87ff0995258744f29f2d85491..0000000000000000000000000000000000000000
--- a/spaces/givkashi/SwinIR-Super-resolution/main_test_swinir.py
+++ /dev/null
@@ -1,288 +0,0 @@
-import argparse
-import cv2
-import glob
-import numpy as np
-from collections import OrderedDict
-import os
-import torch
-import requests
-
-from models.network_swinir import SwinIR as net
-from utils import util_calculate_psnr_ssim as util
-
-
-def main():
- parser = argparse.ArgumentParser()
- parser.add_argument('--task', type=str, default='real_sr', help='classical_sr, lightweight_sr, real_sr, '
- 'gray_dn, color_dn, jpeg_car')
- parser.add_argument('--scale', type=int, default=4, help='scale factor: 1, 2, 3, 4, 8') # 1 for dn and jpeg car
- parser.add_argument('--noise', type=int, default=15, help='noise level: 15, 25, 50')
- parser.add_argument('--jpeg', type=int, default=40, help='scale factor: 10, 20, 30, 40')
- parser.add_argument('--training_patch_size', type=int, default=128, help='patch size used in training SwinIR. '
- 'Just used to differentiate two different settings in Table 2 of the paper. '
- 'Images are NOT tested patch by patch.')
- parser.add_argument('--large_model', action='store_true', default=True, help='use large model, only provided for real image sr')
- parser.add_argument('--model_path', type=str,
- default='experiments/pretrained_models/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth')
- parser.add_argument('--folder_lq', type=str, default='./data', help='input low-quality test image folder')
- parser.add_argument('--folder_gt', type=str, default=None, help='input ground-truth test image folder')
- parser.add_argument('--tile', type=int, default=640, help='Tile size, None for no tile during testing (testing as a whole)')
- parser.add_argument('--tile_overlap', type=int, default=32, help='Overlapping of different tiles')
- args = parser.parse_args()
-
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- # set up model
- if os.path.exists(args.model_path):
- print(f'loading model from {args.model_path}')
- else:
- os.makedirs(os.path.dirname(args.model_path), exist_ok=True)
- url = 'https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/{}'.format(os.path.basename(args.model_path))
- r = requests.get(url, allow_redirects=True)
- print(f'downloading model {args.model_path}')
- open(args.model_path, 'wb').write(r.content)
-
- model = define_model(args)
- model.eval()
- model = model.to(device)
-
- # setup folder and path
- folder, save_dir, border, window_size = setup(args)
- os.makedirs(save_dir, exist_ok=True)
- test_results = OrderedDict()
- test_results['psnr'] = []
- test_results['ssim'] = []
- test_results['psnr_y'] = []
- test_results['ssim_y'] = []
- test_results['psnr_b'] = []
- psnr, ssim, psnr_y, ssim_y, psnr_b = 0, 0, 0, 0, 0
-
- for idx, path in enumerate(sorted(glob.glob(os.path.join(folder, '*')))):
- # read image
- imgname, img_lq, img_gt = get_image_pair(args, path) # image to HWC-BGR, float32
- img_lq = np.transpose(img_lq if img_lq.shape[2] == 1 else img_lq[:, :, [2, 1, 0]], (2, 0, 1)) # HCW-BGR to CHW-RGB
- img_lq = torch.from_numpy(img_lq).float().unsqueeze(0).to(device) # CHW-RGB to NCHW-RGB
-
- # inference
- with torch.no_grad():
- # pad input image to be a multiple of window_size
- _, _, h_old, w_old = img_lq.size()
- h_pad = (h_old // window_size + 1) * window_size - h_old
- w_pad = (w_old // window_size + 1) * window_size - w_old
- img_lq = torch.cat([img_lq, torch.flip(img_lq, [2])], 2)[:, :, :h_old + h_pad, :]
- img_lq = torch.cat([img_lq, torch.flip(img_lq, [3])], 3)[:, :, :, :w_old + w_pad]
- output = test(img_lq, model, args, window_size)
- output = output[..., :h_old * args.scale, :w_old * args.scale]
-
- # save image
- output = output.data.squeeze().float().cpu().clamp_(0, 1).numpy()
- if output.ndim == 3:
- output = np.transpose(output[[2, 1, 0], :, :], (1, 2, 0)) # CHW-RGB to HCW-BGR
- output = (output * 255.0).round().astype(np.uint8) # float32 to uint8
- cv2.imwrite(f'{save_dir}/{imgname}.png', output)
-
- # evaluate psnr/ssim/psnr_b
- if img_gt is not None:
- img_gt = (img_gt * 255.0).round().astype(np.uint8) # float32 to uint8
- img_gt = img_gt[:h_old * args.scale, :w_old * args.scale, ...] # crop gt
- img_gt = np.squeeze(img_gt)
-
- psnr = util.calculate_psnr(output, img_gt, crop_border=border)
- ssim = util.calculate_ssim(output, img_gt, crop_border=border)
- test_results['psnr'].append(psnr)
- test_results['ssim'].append(ssim)
- if img_gt.ndim == 3: # RGB image
- psnr_y = util.calculate_psnr(output, img_gt, crop_border=border, test_y_channel=True)
- ssim_y = util.calculate_ssim(output, img_gt, crop_border=border, test_y_channel=True)
- test_results['psnr_y'].append(psnr_y)
- test_results['ssim_y'].append(ssim_y)
- if args.task in ['jpeg_car']:
- psnr_b = util.calculate_psnrb(output, img_gt, crop_border=border, test_y_channel=True)
- test_results['psnr_b'].append(psnr_b)
- print('Testing {:d} {:20s} - PSNR: {:.2f} dB; SSIM: {:.4f}; '
- 'PSNR_Y: {:.2f} dB; SSIM_Y: {:.4f}; '
- 'PSNR_B: {:.2f} dB.'.
- format(idx, imgname, psnr, ssim, psnr_y, ssim_y, psnr_b))
- else:
- print('Testing {:d} {:20s}'.format(idx, imgname))
-
- # summarize psnr/ssim
- if img_gt is not None:
- ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
- ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
- print('\n{} \n-- Average PSNR/SSIM(RGB): {:.2f} dB; {:.4f}'.format(save_dir, ave_psnr, ave_ssim))
- if img_gt.ndim == 3:
- ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
- ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
- print('-- Average PSNR_Y/SSIM_Y: {:.2f} dB; {:.4f}'.format(ave_psnr_y, ave_ssim_y))
- if args.task in ['jpeg_car']:
- ave_psnr_b = sum(test_results['psnr_b']) / len(test_results['psnr_b'])
- print('-- Average PSNR_B: {:.2f} dB'.format(ave_psnr_b))
-
-
-def define_model(args):
- # 001 classical image sr
- if args.task == 'classical_sr':
- model = net(upscale=args.scale, in_chans=3, img_size=args.training_patch_size, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='pixelshuffle', resi_connection='1conv')
- param_key_g = 'params'
-
- # 002 lightweight image sr
- # use 'pixelshuffledirect' to save parameters
- elif args.task == 'lightweight_sr':
- model = net(upscale=args.scale, in_chans=3, img_size=64, window_size=8,
- img_range=1., depths=[6, 6, 6, 6], embed_dim=60, num_heads=[6, 6, 6, 6],
- mlp_ratio=2, upsampler='pixelshuffledirect', resi_connection='1conv')
- param_key_g = 'params'
-
- # 003 real-world image sr
- elif args.task == 'real_sr':
- if not args.large_model:
- # use 'nearest+conv' to avoid block artifacts
- model = net(upscale=4, in_chans=3, img_size=64, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='nearest+conv', resi_connection='1conv')
- else:
- # larger model size; use '3conv' to save parameters and memory; use ema for GAN training
- model = net(upscale=4, in_chans=3, img_size=64, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6, 6, 6, 6], embed_dim=240,
- num_heads=[8, 8, 8, 8, 8, 8, 8, 8, 8],
- mlp_ratio=2, upsampler='nearest+conv', resi_connection='3conv')
- param_key_g = 'params_ema'
-
- # 004 grayscale image denoising
- elif args.task == 'gray_dn':
- model = net(upscale=1, in_chans=1, img_size=128, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='', resi_connection='1conv')
- param_key_g = 'params'
-
- # 005 color image denoising
- elif args.task == 'color_dn':
- model = net(upscale=1, in_chans=3, img_size=128, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='', resi_connection='1conv')
- param_key_g = 'params'
-
- # 006 JPEG compression artifact reduction
- # use window_size=7 because JPEG encoding uses 8x8; use img_range=255 because it's sligtly better than 1
- elif args.task == 'jpeg_car':
- model = net(upscale=1, in_chans=1, img_size=126, window_size=7,
- img_range=255., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='', resi_connection='1conv')
- param_key_g = 'params'
-
- pretrained_model = torch.load(args.model_path)
- model.load_state_dict(pretrained_model[param_key_g] if param_key_g in pretrained_model.keys() else pretrained_model, strict=True)
-
- return model
-
-
-def setup(args):
- # 001 classical image sr/ 002 lightweight image sr
- if args.task in ['classical_sr', 'lightweight_sr']:
- save_dir = f'results/swinir_{args.task}_x{args.scale}'
- folder = args.folder_gt
- border = args.scale
- window_size = 8
-
- # 003 real-world image sr
- elif args.task in ['real_sr']:
- # save_dir = f'results/swinir_{args.task}_x{args.scale}'
- save_dir = f'results'
- # if args.large_model:
- # save_dir += '_large'
- folder = args.folder_lq
- border = 0
- window_size = 8
-
- # 004 grayscale image denoising/ 005 color image denoising
- elif args.task in ['gray_dn', 'color_dn']:
- save_dir = f'results/swinir_{args.task}_noise{args.noise}'
- folder = args.folder_gt
- border = 0
- window_size = 8
-
- # 006 JPEG compression artifact reduction
- elif args.task in ['jpeg_car']:
- save_dir = f'results/swinir_{args.task}_jpeg{args.jpeg}'
- folder = args.folder_gt
- border = 0
- window_size = 7
-
- return folder, save_dir, border, window_size
-
-
-def get_image_pair(args, path):
- (imgname, imgext) = os.path.splitext(os.path.basename(path))
-
- # 001 classical image sr/ 002 lightweight image sr (load lq-gt image pairs)
- if args.task in ['classical_sr', 'lightweight_sr']:
- img_gt = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
- img_lq = cv2.imread(f'{args.folder_lq}/{imgname}x{args.scale}{imgext}', cv2.IMREAD_COLOR).astype(
- np.float32) / 255.
-
- # 003 real-world image sr (load lq image only)
- elif args.task in ['real_sr']:
- img_gt = None
- img_lq = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
-
- # 004 grayscale image denoising (load gt image and generate lq image on-the-fly)
- elif args.task in ['gray_dn']:
- img_gt = cv2.imread(path, cv2.IMREAD_GRAYSCALE).astype(np.float32) / 255.
- np.random.seed(seed=0)
- img_lq = img_gt + np.random.normal(0, args.noise / 255., img_gt.shape)
- img_gt = np.expand_dims(img_gt, axis=2)
- img_lq = np.expand_dims(img_lq, axis=2)
-
- # 005 color image denoising (load gt image and generate lq image on-the-fly)
- elif args.task in ['color_dn']:
- img_gt = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
- np.random.seed(seed=0)
- img_lq = img_gt + np.random.normal(0, args.noise / 255., img_gt.shape)
-
- # 006 JPEG compression artifact reduction (load gt image and generate lq image on-the-fly)
- elif args.task in ['jpeg_car']:
- img_gt = cv2.imread(path, cv2.IMREAD_UNCHANGED)
- if img_gt.ndim != 2:
- img_gt = util.bgr2ycbcr(img_gt, y_only=True)
- result, encimg = cv2.imencode('.jpg', img_gt, [int(cv2.IMWRITE_JPEG_QUALITY), args.jpeg])
- img_lq = cv2.imdecode(encimg, 0)
- img_gt = np.expand_dims(img_gt, axis=2).astype(np.float32) / 255.
- img_lq = np.expand_dims(img_lq, axis=2).astype(np.float32) / 255.
-
- return imgname, img_lq, img_gt
-
-
-def test(img_lq, model, args, window_size):
- if args.tile is None:
- # test the image as a whole
- output = model(img_lq)
- else:
- # test the image tile by tile
- b, c, h, w = img_lq.size()
- tile = min(args.tile, h, w)
- assert tile % window_size == 0, "tile size should be a multiple of window_size"
- tile_overlap = args.tile_overlap
- sf = args.scale
-
- stride = tile - tile_overlap
- h_idx_list = list(range(0, h-tile, stride)) + [h-tile]
- w_idx_list = list(range(0, w-tile, stride)) + [w-tile]
- E = torch.zeros(b, c, h*sf, w*sf).type_as(img_lq)
- W = torch.zeros_like(E)
-
- for h_idx in h_idx_list:
- for w_idx in w_idx_list:
- in_patch = img_lq[..., h_idx:h_idx+tile, w_idx:w_idx+tile]
- out_patch = model(in_patch)
- out_patch_mask = torch.ones_like(out_patch)
-
- E[..., h_idx*sf:(h_idx+tile)*sf, w_idx*sf:(w_idx+tile)*sf].add_(out_patch)
- W[..., h_idx*sf:(h_idx+tile)*sf, w_idx*sf:(w_idx+tile)*sf].add_(out_patch_mask)
- output = E.div_(W)
-
- return output
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/gordonchan/h2oo/h2oai_pipeline.py b/spaces/gordonchan/h2oo/h2oai_pipeline.py
deleted file mode 100644
index 368f49fbd81993a200311a267a43649e9ea0bfca..0000000000000000000000000000000000000000
--- a/spaces/gordonchan/h2oo/h2oai_pipeline.py
+++ /dev/null
@@ -1,201 +0,0 @@
-import os
-
-from transformers import TextGenerationPipeline
-from transformers.pipelines.text_generation import ReturnType
-
-from stopping import get_stopping
-from prompter import Prompter, PromptType
-
-
-class H2OTextGenerationPipeline(TextGenerationPipeline):
- def __init__(self, *args, debug=False, chat=False, stream_output=False,
- sanitize_bot_response=False,
- use_prompter=True, prompter=None,
- context='', iinput='',
- prompt_type=None, prompt_dict=None,
- max_input_tokens=2048 - 256, **kwargs):
- """
- HF-like pipeline, but handle instruction prompting and stopping (for some models)
- :param args:
- :param debug:
- :param chat:
- :param stream_output:
- :param sanitize_bot_response:
- :param use_prompter: Whether to use prompter. If pass prompt_type, will make prompter
- :param prompter: prompter, can pass if have already
- :param prompt_type: prompt_type, e.g. human_bot. See prompt_type to model mapping in from prompter.py.
- If use_prompter, then will make prompter and use it.
- :param prompt_dict: dict of get_prompt(, return_dict=True) for prompt_type=custom
- :param max_input_tokens:
- :param kwargs:
- """
- super().__init__(*args, **kwargs)
- self.prompt_text = None
- self.use_prompter = use_prompter
- self.prompt_type = prompt_type
- self.prompt_dict = prompt_dict
- self.prompter = prompter
- self.context = context
- self.iinput = iinput
- if self.use_prompter:
- if self.prompter is not None:
- assert self.prompter.prompt_type is not None
- else:
- self.prompter = Prompter(self.prompt_type, self.prompt_dict, debug=debug, chat=chat,
- stream_output=stream_output)
- self.human = self.prompter.humanstr
- self.bot = self.prompter.botstr
- self.can_stop = True
- else:
- self.prompter = None
- self.human = None
- self.bot = None
- self.can_stop = False
- self.sanitize_bot_response = sanitize_bot_response
- self.max_input_tokens = max_input_tokens # not for generate, so ok that not kwargs
-
- @staticmethod
- def limit_prompt(prompt_text, tokenizer, max_prompt_length=None):
- verbose = bool(int(os.getenv('VERBOSE_PIPELINE', '0')))
-
- if hasattr(tokenizer, 'model_max_length'):
- # model_max_length only defined for generate.py, not raw use of h2oai_pipeline.py
- model_max_length = tokenizer.model_max_length
- if max_prompt_length is not None:
- model_max_length = min(model_max_length, max_prompt_length)
- # cut at some upper likely limit to avoid excessive tokenization etc
- # upper bound of 10 chars/token, e.g. special chars sometimes are long
- if len(prompt_text) > model_max_length * 10:
- len0 = len(prompt_text)
- prompt_text = prompt_text[-model_max_length * 10:]
- if verbose:
- print("Cut of input: %s -> %s" % (len0, len(prompt_text)), flush=True)
- else:
- # unknown
- model_max_length = None
-
- num_prompt_tokens = None
- if model_max_length is not None:
- # can't wait for "hole" if not plain prompt_type, since would lose prefix like :
- # For https://github.com/h2oai/h2ogpt/issues/192
- for trial in range(0, 3):
- prompt_tokens = tokenizer(prompt_text)['input_ids']
- num_prompt_tokens = len(prompt_tokens)
- if num_prompt_tokens > model_max_length:
- # conservative by using int()
- chars_per_token = int(len(prompt_text) / num_prompt_tokens)
- # keep tail, where question is if using langchain
- prompt_text = prompt_text[-model_max_length * chars_per_token:]
- if verbose:
- print("reducing %s tokens, assuming average of %s chars/token for %s characters" % (
- num_prompt_tokens, chars_per_token, len(prompt_text)), flush=True)
- else:
- if verbose:
- print("using %s tokens with %s chars" % (num_prompt_tokens, len(prompt_text)), flush=True)
- break
-
- # Why Below False: don't limit max_new_tokens more, just rely upon stopping to reach limit of model
- if False:
- # if input prompt is some number of tokens, despite user request, can't have max_new_tokens more
- #
- assert num_prompt_tokens is not None
- if self.prompt_type not in [PromptType.plain.name, PromptType.plain.value]:
- # then give room for prompt
- fudge = 20
- else:
- fudge = 0
- max_new_tokens = max(0, min(generate_kwargs['max_new_tokens'],
- model_max_length - (num_prompt_tokens + fudge)))
- if max_new_tokens < generate_kwargs['max_new_tokens']:
- if verbose:
- print("Reduced max_new_tokens from %s -> %s" % (
- generate_kwargs['max_new_tokens'], max_new_tokens))
- generate_kwargs['max_new_tokens'] = max_new_tokens
- return prompt_text, num_prompt_tokens
-
- def preprocess(self, prompt_text, prefix="", handle_long_generation=None, **generate_kwargs):
- prompt_text, num_prompt_tokens = H2OTextGenerationPipeline.limit_prompt(prompt_text, self.tokenizer)
-
- data_point = dict(context=self.context, instruction=prompt_text, input=self.iinput)
- if self.prompter is not None:
- prompt_text = self.prompter.generate_prompt(data_point)
- self.prompt_text = prompt_text
- if handle_long_generation is None:
- # forces truncation of inputs to avoid critical failure
- handle_long_generation = None # disable with new approaches
- return super().preprocess(prompt_text, prefix=prefix, handle_long_generation=handle_long_generation,
- **generate_kwargs)
-
- def postprocess(self, model_outputs, return_type=ReturnType.FULL_TEXT, clean_up_tokenization_spaces=True):
- records = super().postprocess(model_outputs, return_type=return_type,
- clean_up_tokenization_spaces=clean_up_tokenization_spaces)
- for rec in records:
- if self.use_prompter:
- outputs = rec['generated_text']
- outputs = self.prompter.get_response(outputs, prompt=self.prompt_text,
- sanitize_bot_response=self.sanitize_bot_response)
- elif self.bot and self.human:
- outputs = rec['generated_text'].split(self.bot)[1].split(self.human)[0]
- else:
- outputs = rec['generated_text']
- rec['generated_text'] = outputs
- print("prompt: %s\noutputs: %s\n\n" % (self.prompt_text, outputs), flush=True)
- return records
-
- def _forward(self, model_inputs, **generate_kwargs):
- if self.can_stop:
- stopping_criteria = get_stopping(self.prompt_type, self.prompt_dict,
- self.tokenizer, self.device,
- human=self.human, bot=self.bot,
- model_max_length=self.tokenizer.model_max_length)
- generate_kwargs['stopping_criteria'] = stopping_criteria
- # return super()._forward(model_inputs, **generate_kwargs)
- return self.__forward(model_inputs, **generate_kwargs)
-
- # FIXME: Copy-paste of original _forward, but removed copy.deepcopy()
- # FIXME: https://github.com/h2oai/h2ogpt/issues/172
- def __forward(self, model_inputs, **generate_kwargs):
- input_ids = model_inputs["input_ids"]
- attention_mask = model_inputs.get("attention_mask", None)
- # Allow empty prompts
- if input_ids.shape[1] == 0:
- input_ids = None
- attention_mask = None
- in_b = 1
- else:
- in_b = input_ids.shape[0]
- prompt_text = model_inputs.pop("prompt_text")
-
- ## If there is a prefix, we may need to adjust the generation length. Do so without permanently modifying
- ## generate_kwargs, as some of the parameterization may come from the initialization of the pipeline.
- # generate_kwargs = copy.deepcopy(generate_kwargs)
- prefix_length = generate_kwargs.pop("prefix_length", 0)
- if prefix_length > 0:
- has_max_new_tokens = "max_new_tokens" in generate_kwargs or (
- "generation_config" in generate_kwargs
- and generate_kwargs["generation_config"].max_new_tokens is not None
- )
- if not has_max_new_tokens:
- generate_kwargs["max_length"] = generate_kwargs.get("max_length") or self.model.config.max_length
- generate_kwargs["max_length"] += prefix_length
- has_min_new_tokens = "min_new_tokens" in generate_kwargs or (
- "generation_config" in generate_kwargs
- and generate_kwargs["generation_config"].min_new_tokens is not None
- )
- if not has_min_new_tokens and "min_length" in generate_kwargs:
- generate_kwargs["min_length"] += prefix_length
-
- # BS x SL
- generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs)
- out_b = generated_sequence.shape[0]
- if self.framework == "pt":
- generated_sequence = generated_sequence.reshape(in_b, out_b // in_b, *generated_sequence.shape[1:])
- elif self.framework == "tf":
- from transformers import is_tf_available
- if is_tf_available():
- import tensorflow as tf
- generated_sequence = tf.reshape(generated_sequence,
- (in_b, out_b // in_b, *generated_sequence.shape[1:]))
- else:
- raise ValueError("TF not avaialble.")
- return {"generated_sequence": generated_sequence, "input_ids": input_ids, "prompt_text": prompt_text}
diff --git a/spaces/grisiemjahand/Image-and-3D-Model-Creator/PIFu/lib/colab_util.py b/spaces/grisiemjahand/Image-and-3D-Model-Creator/PIFu/lib/colab_util.py
deleted file mode 100644
index 608227b228647e7b1bc16676fadf22d68e381f57..0000000000000000000000000000000000000000
--- a/spaces/grisiemjahand/Image-and-3D-Model-Creator/PIFu/lib/colab_util.py
+++ /dev/null
@@ -1,114 +0,0 @@
-import io
-import os
-import torch
-from skimage.io import imread
-import numpy as np
-import cv2
-from tqdm import tqdm_notebook as tqdm
-import base64
-from IPython.display import HTML
-
-# Util function for loading meshes
-from pytorch3d.io import load_objs_as_meshes
-
-from IPython.display import HTML
-from base64 import b64encode
-
-# Data structures and functions for rendering
-from pytorch3d.structures import Meshes
-from pytorch3d.renderer import (
- look_at_view_transform,
- OpenGLOrthographicCameras,
- PointLights,
- DirectionalLights,
- Materials,
- RasterizationSettings,
- MeshRenderer,
- MeshRasterizer,
- SoftPhongShader,
- HardPhongShader,
- TexturesVertex
-)
-
-def set_renderer():
- # Setup
- device = torch.device("cuda:0")
- torch.cuda.set_device(device)
-
- # Initialize an OpenGL perspective camera.
- R, T = look_at_view_transform(2.0, 0, 180)
- cameras = OpenGLOrthographicCameras(device=device, R=R, T=T)
-
- raster_settings = RasterizationSettings(
- image_size=512,
- blur_radius=0.0,
- faces_per_pixel=1,
- bin_size = None,
- max_faces_per_bin = None
- )
-
- lights = PointLights(device=device, location=((2.0, 2.0, 2.0),))
-
- renderer = MeshRenderer(
- rasterizer=MeshRasterizer(
- cameras=cameras,
- raster_settings=raster_settings
- ),
- shader=HardPhongShader(
- device=device,
- cameras=cameras,
- lights=lights
- )
- )
- return renderer
-
-def get_verts_rgb_colors(obj_path):
- rgb_colors = []
-
- f = open(obj_path)
- lines = f.readlines()
- for line in lines:
- ls = line.split(' ')
- if len(ls) == 7:
- rgb_colors.append(ls[-3:])
-
- return np.array(rgb_colors, dtype='float32')[None, :, :]
-
-def generate_video_from_obj(obj_path, video_path, renderer):
- # Setup
- device = torch.device("cuda:0")
- torch.cuda.set_device(device)
-
- # Load obj file
- verts_rgb_colors = get_verts_rgb_colors(obj_path)
- verts_rgb_colors = torch.from_numpy(verts_rgb_colors).to(device)
- textures = TexturesVertex(verts_features=verts_rgb_colors)
- wo_textures = TexturesVertex(verts_features=torch.ones_like(verts_rgb_colors)*0.75)
-
- # Load obj
- mesh = load_objs_as_meshes([obj_path], device=device)
-
- # Set mesh
- vers = mesh._verts_list
- faces = mesh._faces_list
- mesh_w_tex = Meshes(vers, faces, textures)
- mesh_wo_tex = Meshes(vers, faces, wo_textures)
-
- # create VideoWriter
- fourcc = cv2. VideoWriter_fourcc(*'MP4V')
- out = cv2.VideoWriter(video_path, fourcc, 20.0, (1024,512))
-
- for i in tqdm(range(90)):
- R, T = look_at_view_transform(1.8, 0, i*4, device=device)
- images_w_tex = renderer(mesh_w_tex, R=R, T=T)
- images_w_tex = np.clip(images_w_tex[0, ..., :3].cpu().numpy(), 0.0, 1.0)[:, :, ::-1] * 255
- images_wo_tex = renderer(mesh_wo_tex, R=R, T=T)
- images_wo_tex = np.clip(images_wo_tex[0, ..., :3].cpu().numpy(), 0.0, 1.0)[:, :, ::-1] * 255
- image = np.concatenate([images_w_tex, images_wo_tex], axis=1)
- out.write(image.astype('uint8'))
- out.release()
-
-def video(path):
- mp4 = open(path,'rb').read()
- data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
- return HTML('' % data_url)
diff --git a/spaces/gstdl/streamlit-startup-campus/app.py b/spaces/gstdl/streamlit-startup-campus/app.py
deleted file mode 100644
index be3dcc01f885e6e4f915fe4f3fdfcf57cfb63e94..0000000000000000000000000000000000000000
--- a/spaces/gstdl/streamlit-startup-campus/app.py
+++ /dev/null
@@ -1,131 +0,0 @@
-import streamlit as st
-import pandas as pd
-import plotly.express as px
-import plotly.graph_objects as go
-
-#######
-# Data loading
-#######
-
-df = pd.read_csv("gapminder.csv")
-year_values = (int(df["year"].min()), int(df["year"].max()))
-metrics = ["lifeExp", "pop", "gdpPercap"]
-dimension = ["country", "continent", "year"]
-
-#######
-# Helper functions
-#######
-def get_filtered_data(
- continents="All",
- countries="All",
- min_year=year_values[0],
- max_year=year_values[1],
-):
- if isinstance(continents, str) and continents != "All":
- mask_continent = df["continent"] == continents
- else:
- mask_continent = df["continent"].isin(continents)
- if isinstance(countries, str) and countries != "All":
- mask_country = df["country"] == countries
- else:
- mask_country = df["country"].isin(countries)
- mask_year = ((df["year"] >= min_year) & (df["year"] <= max_year))
- return df[mask_continent & mask_country & mask_year]
-
-def box_plot(df, x, y):
- fig = px.box(
- df, x=x, y=y, hover_data=df[dimension + [x]],
- points="all", color=x)
- return fig
-
-def scatter_plot(df, x, y, hue):
- fig = px.scatter(
- df, x=x, y=y,
- color=hue, symbol=hue)
- return fig
-
-
-def line_plot(df, y_axis, label, highlighted):
- fig = go.Figure()
- if label=="continent":
- df = df.groupby(["continent", "year"]).agg({
- "lifeExp": "mean",
- "pop": "sum",
- "gdpPercap": "mean",
- }).reset_index()
-
- for i in df[label].unique():
- if i == highlighted:
- continue
- data = df[df[label]==i]
- x = data["year"]
- y = data[y_axis]
- fig.add_trace(go.Scatter(x=x, y=y,
- hovertext=[
- f"{label}: {i}
-
-## License
-
-(The MIT License)
-
-Copyright (c) 2014-2017 TJ Holowaychuk <tj@vision-media.ca>
-Copyright (c) 2018-2021 Josh Junon
-
-Permission is hereby granted, free of charge, to any person obtaining
-a copy of this software and associated documentation files (the
-'Software'), to deal in the Software without restriction, including
-without limitation the rights to use, copy, modify, merge, publish,
-distribute, sublicense, and/or sell copies of the Software, and to
-permit persons to whom the Software is furnished to do so, subject to
-the following conditions:
-
-The above copyright notice and this permission notice shall be
-included in all copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
-EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
-MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
-IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
-CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
-TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
-SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/spaces/fffiloni/diffBIR/README.md b/spaces/fffiloni/diffBIR/README.md
deleted file mode 100644
index 3377f9b95833253e5c76bd09fd0c07df79fc5542..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/diffBIR/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: DiffBIR Img Restoration
-emoji: 😶🌫️
-colorFrom: indigo
-colorTo: green
-sdk: docker
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/fgenie/scamtext_PAL_self_consistency/funcs/f_69.py b/spaces/fgenie/scamtext_PAL_self_consistency/funcs/f_69.py
deleted file mode 100644
index bbb8468954c0edb3daa6790f0ced55ebda1575a0..0000000000000000000000000000000000000000
--- a/spaces/fgenie/scamtext_PAL_self_consistency/funcs/f_69.py
+++ /dev/null
@@ -1,30 +0,0 @@
-
-import re
-
-def is_spam(message):
- # Spam indicators
- spam_indicators = [
- r"[\d,]*원",
- r"\d{1,2}% ?~",
- r"\d{1,2}대",
- r"http[s]?://",
- r"주식",
- r"종목",
- r"익 절 가",
- r"펀드매니저",
- r"수익률",
- r"매매승률",
- r"목표가",
- r"최소",
- r"매일",
- r"최대",
- r"최고",
- ]
-
- # Iterate through spam indicators and check if any are present in the message
- for indicator in spam_indicators:
- if re.search(indicator, message, flags=re.IGNORECASE):
- return True
-
- # If none of the spam indicators are present, consider it a normal message
- return False
diff --git a/spaces/fgibarra/fraud-prevention/README.md b/spaces/fgibarra/fraud-prevention/README.md
deleted file mode 100644
index 0035ae7550f120392fd3ae088cc57359895d4a12..0000000000000000000000000000000000000000
--- a/spaces/fgibarra/fraud-prevention/README.md
+++ /dev/null
@@ -1,63 +0,0 @@
----
-title: Fraud Prevention
-emoji: 📊
-colorFrom: green
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.34.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-# Final project of bootcamp EDVai 2023
-
-## Description
-
-This is the final project of the bootcamp EDVai 2023.
-
-The project is divide in several parts:
-- notebooks: contains the notebooks used to data exploration, data cleaning, data analysis and model creation.
-- api: contains the code of the api. The api is used to predict frauds. This code is realized with FastAPI.
-- app: contains the code of the web application realized with Gradio.
-
-Other files:
-- data: contains the data used in the project.
-- model: contains the models used in the project.
-- docs: contains the documentation of the project.
-
-## Installation
-
-To install the project, you need to clone the repository and install the requirements.
-The requirements are in the three files: notebooks_requirements.txt, api_requirements.txt and app_requirements.txt.
-
-Depends on you the part of the project you want to use, you need to install the requirements of the part.
-
-```bash
-python -m venv venv
-pip install -r notebooks_requirements.txt
-pip install -r api_requirements.txt
-pip install -r app_requirements.txt
-```
-
-## Usage
-If you want to use the notebooks, you need to run the notebooks in the following order:
-- 01__Adaptacion.ipynb
-- 02__Correlacion.ipynb
-- 03__Preparacion.ipynb
-- 04__Clustering.ipynb
-- 05__Modelo.ipynb
-
-If you want to use the api, you need to run the following command:
-```bash
-python main.py
-```
-
-If you want to use the app, you need to run the following command:
-```bash
-python app.py
-```
-
-## Deploy
-
-
diff --git a/spaces/freddyaboulton/chicago-bike-share-dashboard/app.py b/spaces/freddyaboulton/chicago-bike-share-dashboard/app.py
deleted file mode 100644
index 77d8a098c151266b59f0a4ae1af592e8a41b158f..0000000000000000000000000000000000000000
--- a/spaces/freddyaboulton/chicago-bike-share-dashboard/app.py
+++ /dev/null
@@ -1,91 +0,0 @@
-import os
-import psycopg2
-import gradio as gr
-import matplotlib
-import matplotlib.pyplot as plt
-
-matplotlib.use("Agg")
-
-
-connection = psycopg2.connect(
- user=os.environ["DB_USER"],
- password=os.environ["DB_PASSWORD"],
- host=os.environ["DB_HOST"],
- port="8080",
- database="bikeshare",
-)
-
-
-def get_count_ride_type():
- cursor = connection.cursor()
- cursor.execute(
- """
- SELECT COUNT(ride_id) as n, rideable_type
- FROM rides
- GROUP BY rideable_type
- ORDER BY n DESC
- """
- )
- rides = cursor.fetchall()
- cursor.close()
- fig_m, ax = plt.subplots()
- ax.bar(x=[s[1] for s in rides], height=[s[0] for s in rides])
- ax.set_title("Number of rides by bycycle type")
- ax.set_ylabel("Number of Rides")
- ax.set_xlabel("Bicycle Type")
- return fig_m
-
-
-def get_most_popular_stations():
- cursor = connection.cursor()
- cursor.execute(
- """
- SELECT COUNT(ride_id) as n, MAX(start_station_name)
- FROM RIDES
- WHERE start_station_name is NOT NULL
- GROUP BY start_station_id
- ORDER BY n DESC
- LIMIT 5
- """
- )
- stations = cursor.fetchall()
- cursor = connection.cursor()
- fig_m, ax = plt.subplots()
- ax.bar(x=[s[1] for s in stations], height=[s[0] for s in stations])
- ax.set_title("Most popular stations")
- ax.set_ylabel("Number of Rides")
- ax.set_xlabel("Station Name")
- ax.set_xticklabels(
- [s[1] for s in stations], rotation=45, ha="right", rotation_mode="anchor"
- )
- ax.tick_params(axis="x", labelsize=8)
- fig_m.tight_layout()
- return fig_m
-
-
-with gr.Blocks() as demo:
- gr.Markdown(
- """
- # Chicago Bike Share Dashboard
-
- This demo pulls Chicago bike share data for March 2022 from a postgresql database hosted on AWS.
- This demo uses psycopg2 but any postgresql client library (SQLAlchemy)
- is compatible with gradio.
-
- Connection credentials are handled by environment variables
- defined as secrets in the Space.
-
- If data were added to the database, the plots in this demo would update
- whenever the webpage is reloaded.
-
- This demo serves as a starting point for your database-connected apps!
- """
- )
- with gr.Row():
- bike_type = gr.Plot()
- station = gr.Plot()
-
- demo.load(get_count_ride_type, inputs=None, outputs=bike_type)
- demo.load(get_most_popular_stations, inputs=None, outputs=station)
-
-demo.launch()
diff --git a/spaces/furqankassa/Docker-FlanT5-TextGeneratorTranslator/Dockerfile b/spaces/furqankassa/Docker-FlanT5-TextGeneratorTranslator/Dockerfile
deleted file mode 100644
index 7ae5f101e356251bb52f2b34fec3032a0a084da7..0000000000000000000000000000000000000000
--- a/spaces/furqankassa/Docker-FlanT5-TextGeneratorTranslator/Dockerfile
+++ /dev/null
@@ -1,28 +0,0 @@
-# Use the official Python 3.9 image
-FROM python:3.9
-
-# Set the working directory to /code
-WORKDIR /code
-
-# Copy the current directory contents into the container at /code
-COPY ./requirements.txt /code/requirements.txt
-
-# Install requirements.txt
-RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
-
-# Set up a new user named "user" with user ID 1000
-RUN useradd -m -u 1000 user
-# Switch to the "user" user
-USER user
-# Set home to the user's home directory
-ENV HOME=/home/user \
- PATH=/home/user/.local/bin:$PATH
-
-# Set the working directory to the user's home directory
-WORKDIR $HOME/app
-
-# Copy the current directory contents into the container at $HOME/app setting the owner to the user
-COPY --chown=user . $HOME/app
-
-# Uvicorn: https://www.uvicorn.org/settings/ use main:app to run main.py
-CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "7860"]
\ No newline at end of file
diff --git a/spaces/gagan3012/summarization/src/visualization/visualize.py b/spaces/gagan3012/summarization/src/visualization/visualize.py
deleted file mode 100644
index 01779be7841c2b2e4a2de7f336641f54713457a8..0000000000000000000000000000000000000000
--- a/spaces/gagan3012/summarization/src/visualization/visualize.py
+++ /dev/null
@@ -1,23 +0,0 @@
-import streamlit as st
-from src.models.predict_model import predict_model
-
-
-def visualize():
- st.write("# Summarization UI")
- st.markdown(
- """
- *For additional questions and inquiries, please contact **Gagan Bhatia** via [LinkedIn](
- https://www.linkedin.com/in/gbhatia30/) or [Github](https://github.com/gagan3012).*
- """
- )
-
- text = st.text_area("Enter text here")
- if st.button("Generate Summary"):
- with st.spinner("Connecting the Dots..."):
- sumtext = predict_model(text=text)
- st.write("# Generated Summary:")
- st.write("{}".format(sumtext))
-
-
-if __name__ == "__main__":
- visualize()
diff --git a/spaces/geekyrakshit/enhance-me/enhance_me/zero_dce/losses/spatial_constancy.py b/spaces/geekyrakshit/enhance-me/enhance_me/zero_dce/losses/spatial_constancy.py
deleted file mode 100644
index 74e2a30595d9004422b3018760d81ce7bf5857c7..0000000000000000000000000000000000000000
--- a/spaces/geekyrakshit/enhance-me/enhance_me/zero_dce/losses/spatial_constancy.py
+++ /dev/null
@@ -1,63 +0,0 @@
-import tensorflow as tf
-from tensorflow.keras import losses
-
-
-class SpatialConsistencyLoss(losses.Loss):
- def __init__(self, **kwargs):
- super(SpatialConsistencyLoss, self).__init__(reduction="none")
-
- self.left_kernel = tf.constant(
- [[[[0, 0, 0]], [[-1, 1, 0]], [[0, 0, 0]]]], dtype=tf.float32
- )
- self.right_kernel = tf.constant(
- [[[[0, 0, 0]], [[0, 1, -1]], [[0, 0, 0]]]], dtype=tf.float32
- )
- self.up_kernel = tf.constant(
- [[[[0, -1, 0]], [[0, 1, 0]], [[0, 0, 0]]]], dtype=tf.float32
- )
- self.down_kernel = tf.constant(
- [[[[0, 0, 0]], [[0, 1, 0]], [[0, -1, 0]]]], dtype=tf.float32
- )
-
- def call(self, y_true, y_pred):
-
- original_mean = tf.reduce_mean(y_true, 3, keepdims=True)
- enhanced_mean = tf.reduce_mean(y_pred, 3, keepdims=True)
- original_pool = tf.nn.avg_pool2d(
- original_mean, ksize=4, strides=4, padding="VALID"
- )
- enhanced_pool = tf.nn.avg_pool2d(
- enhanced_mean, ksize=4, strides=4, padding="VALID"
- )
-
- d_original_left = tf.nn.conv2d(
- original_pool, self.left_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_original_right = tf.nn.conv2d(
- original_pool, self.right_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_original_up = tf.nn.conv2d(
- original_pool, self.up_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_original_down = tf.nn.conv2d(
- original_pool, self.down_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
-
- d_enhanced_left = tf.nn.conv2d(
- enhanced_pool, self.left_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_enhanced_right = tf.nn.conv2d(
- enhanced_pool, self.right_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_enhanced_up = tf.nn.conv2d(
- enhanced_pool, self.up_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
- d_enhanced_down = tf.nn.conv2d(
- enhanced_pool, self.down_kernel, strides=[1, 1, 1, 1], padding="SAME"
- )
-
- d_left = tf.square(d_original_left - d_enhanced_left)
- d_right = tf.square(d_original_right - d_enhanced_right)
- d_up = tf.square(d_original_up - d_enhanced_up)
- d_down = tf.square(d_original_down - d_enhanced_down)
- return d_left + d_right + d_up + d_down
diff --git a/spaces/giswqs/solara-maxar/pages/03_maui.py b/spaces/giswqs/solara-maxar/pages/03_maui.py
deleted file mode 100644
index b710351b42eaa705efa87c3428398caf5f26e81e..0000000000000000000000000000000000000000
--- a/spaces/giswqs/solara-maxar/pages/03_maui.py
+++ /dev/null
@@ -1,263 +0,0 @@
-import os
-import leafmap
-import solara
-import ipywidgets as widgets
-import pandas as pd
-import geopandas as gpd
-import tempfile
-from shapely.geometry import Point
-
-event = 'Maui-Hawaii-fires-Aug-23'
-url = 'https://raw.githubusercontent.com/opengeos/maxar-open-data/master'
-repo = 'https://github.com/opengeos/maxar-open-data/blob/master/datasets'
-
-
-def get_datasets():
- datasets = f'{url}/datasets.csv'
- df = pd.read_csv(datasets)
- return df
-
-
-def get_catalogs(name):
- dataset = f'{url}/datasets/{name}.tsv'
- basename = os.path.basename(dataset)
- tempdir = tempfile.gettempdir()
- tmp_dataset = os.path.join(tempdir, basename)
- if os.path.exists(tmp_dataset):
- dataset_df = pd.read_csv(tmp_dataset, sep='\t')
- else:
- dataset_df = pd.read_csv(dataset, sep='\t')
- dataset_df.to_csv(tmp_dataset, sep='\t', index=False)
- catalog_ids = dataset_df['catalog_id'].unique().tolist()
- catalog_ids.sort()
- return catalog_ids
-
-
-def get_image_date(catalog_id, m):
- gdf = m.footprint
- image_date = pd.Timestamp(
- gdf[gdf['catalog_id'] == catalog_id]['datetime'].values[0]
- ).strftime('%Y-%m-%d %H:%M:%S')
- return image_date
-
-
-def add_widgets(m):
- datasets = get_datasets()['dataset'].tolist()
- setattr(m, 'zoom_to_layer', True)
- style = {"description_width": "initial"}
- padding = "0px 0px 0px 5px"
- dataset = widgets.Dropdown(
- options=datasets,
- description='Event:',
- value=event,
- style=style,
- layout=widgets.Layout(width="270px", padding=padding),
- )
-
- catalog_ids = get_catalogs(dataset.value)
- setattr(m, 'catalog_ids', catalog_ids)
-
- date_picker = widgets.DatePicker(
- description='Start date:',
- value=pd.to_datetime('2021-01-01').date(),
- style=style,
- layout=widgets.Layout(width="270px", padding=padding),
- )
-
- image = widgets.Dropdown(
- value=None,
- options=m.catalog_ids,
- description='Image:',
- style=style,
- layout=widgets.Layout(width="270px", padding=padding),
- )
-
- checkbox = widgets.Checkbox(
- value=True,
- description='Footprints',
- style=style,
- layout=widgets.Layout(width="90px", padding="0px"),
- )
-
- split = widgets.Checkbox(
- value=False,
- description='Split map',
- style=style,
- layout=widgets.Layout(width="92px", padding=padding),
- )
-
- reset = widgets.Checkbox(
- value=False,
- description='Reset',
- style=style,
- layout=widgets.Layout(width="75px", padding='0px'),
- )
-
- output = widgets.Output()
-
- def reset_map(change):
- if change.new:
- image.value = None
- image.options = m.catalog_ids
- m.layers = m.layers[:3]
- m.zoom_to_layer = True
- reset.value = False
- date_picker.value = pd.to_datetime('2021-01-01').date()
- m.remove_layer(m.find_layer('Footprint'))
- m.add_gdf(
- m.footprint, layer_name='Footprint', zoom_to_layer=False, info_mode=None
- )
- satellite_layer = m.find_layer('Google Satellite')
- satellite_layer.visible = False
- output.outputs = ()
-
- reset.observe(reset_map, names='value')
-
- def change_dataset(change):
- default_geojson = f'{url}/datasets/{change.new}_union.geojson'
- m.layers = m.layers[:2]
- m.controls = m.controls[:-1]
- basename = os.path.basename(default_geojson)
- tempdir = tempfile.gettempdir()
- tmp_geojson = os.path.join(tempdir, basename)
- if os.path.exists(tmp_geojson):
- default_geojson = tmp_geojson
- else:
- leafmap.download_file(default_geojson, tmp_geojson, quiet=True)
- m.add_geojson(default_geojson, layer_name='Footprint', zoom_to_layer=True)
- setattr(m, 'gdf', gpd.read_file(default_geojson))
-
- image.options = get_catalogs(change.new)
-
- dataset.observe(change_dataset, names='value')
-
- def change_date(change):
- if change.new:
- start_date = change.new.strftime('%Y-%m-%d')
- sub_gdf = m.gdf[m.gdf['datetime'] >= start_date]
- sub_catalog_ids = sub_gdf['catalog_id'].values.tolist()
- image.options = sub_catalog_ids
- m.remove_layer(m.find_layer('Footprint'))
- m.add_gdf(
- sub_gdf, layer_name='Footprint', zoom_to_layer=False, info_mode=None
- )
- m.gdf = sub_gdf
-
- date_picker.observe(change_date, names='value')
-
- def change_image(change):
- if change.new:
- if change.new not in m.get_layer_names():
- mosaic = f'{url}/datasets/{dataset.value}/{image.value}.json'
- m.add_stac_layer(mosaic, name=image.value, fit_bounds=m.zoom_to_layer)
- image_date = get_image_date(image.value, m)
- output.outputs = ()
- output.append_stdout(f"Image date: {image_date}\n")
-
- image.observe(change_image, names='value')
-
- def change_footprint(change):
- geojson_layer = m.find_layer('Footprint')
- if change.new:
- geojson_layer.visible = True
- else:
- geojson_layer.visible = False
-
- checkbox.observe(change_footprint, names='value')
-
- def change_split(change):
- if change.new:
- if image.value is not None:
- left_layer = m.find_layer(image.value)
- right_layer = m.find_layer('Google Satellite')
- right_layer.visible = True
- footprint_layer = m.find_layer('Footprint')
- footprint_layer.visible = False
- checkbox.value = False
- m.split_map(
- left_layer=left_layer,
- right_layer=right_layer,
- add_close_button=True,
- left_label=image.value,
- right_label='Google Satellite',
- )
- split.value = False
- else:
- left_layer = None
-
- split.observe(change_split, names='value')
-
- def handle_click(**kwargs):
- if kwargs.get('type') == 'click':
- latlon = kwargs.get('coordinates')
- geometry = Point(latlon[::-1])
- selected = m.gdf[m.gdf.intersects(geometry)]
- setattr(m, 'zoom_to_layer', False)
- if len(selected) > 0:
- catalog_ids = selected['catalog_id'].values.tolist()
-
- if len(catalog_ids) > 1:
- image.options = catalog_ids
- image.value = catalog_ids[0]
- else:
- image.value = None
-
- m.on_interaction(handle_click)
-
- box = widgets.VBox(
- [dataset, date_picker, image, widgets.HBox([checkbox, split, reset]), output]
- )
- m.add_widget(box, position='topright', add_header=False)
-
-
-zoom = solara.reactive(2)
-center = solara.reactive((20, 0))
-
-
-class Map(leafmap.Map):
- def __init__(self, **kwargs):
- kwargs['toolbar_control'] = False
- super().__init__(**kwargs)
- basemap = {
- "url": "https://mt1.google.com/vt/lyrs=s&x={x}&y={y}&z={z}",
- "attribution": "Google",
- "name": "Google Satellite",
- }
- self.add_tile_layer(**basemap, shown=False)
- self.add_layer_manager(opened=False)
- add_widgets(self)
- default_geojson = f'{url}/datasets/{event}_union.geojson'
- basename = os.path.basename(default_geojson)
- tempdir = tempfile.gettempdir()
- tmp_geojson = os.path.join(tempdir, basename)
- if os.path.exists(tmp_geojson):
- default_geojson = tmp_geojson
- else:
- leafmap.download_file(default_geojson, tmp_geojson, quiet=True)
- self.add_geojson(
- default_geojson, layer_name='Footprint', zoom_to_layer=True, info_mode=None
- )
- gdf = gpd.read_file(default_geojson)
- setattr(self, 'gdf', gdf)
- setattr(self, 'footprint', gdf)
-
-
-@solara.component
-def Page():
- with solara.Column(style={"min-width": "500px"}):
- # solara components support reactive variables
- # solara.SliderInt(label="Zoom level", value=zoom, min=1, max=20)
- # using 3rd party widget library require wiring up the events manually
- # using zoom.value and zoom.set
- Map.element( # type: ignore
- zoom=zoom.value,
- on_zoom=zoom.set,
- center=center.value,
- on_center=center.set,
- scroll_wheel_zoom=True,
- toolbar_ctrl=False,
- data_ctrl=False,
- height="780px",
- )
- solara.Text(f"Center: {center.value}")
- solara.Text(f"Zoom: {zoom.value}")
diff --git a/spaces/givkashi/SwinIR-Super-resolution/main_test_swinir.py b/spaces/givkashi/SwinIR-Super-resolution/main_test_swinir.py
deleted file mode 100644
index a47c5b35d34238e87ff0995258744f29f2d85491..0000000000000000000000000000000000000000
--- a/spaces/givkashi/SwinIR-Super-resolution/main_test_swinir.py
+++ /dev/null
@@ -1,288 +0,0 @@
-import argparse
-import cv2
-import glob
-import numpy as np
-from collections import OrderedDict
-import os
-import torch
-import requests
-
-from models.network_swinir import SwinIR as net
-from utils import util_calculate_psnr_ssim as util
-
-
-def main():
- parser = argparse.ArgumentParser()
- parser.add_argument('--task', type=str, default='real_sr', help='classical_sr, lightweight_sr, real_sr, '
- 'gray_dn, color_dn, jpeg_car')
- parser.add_argument('--scale', type=int, default=4, help='scale factor: 1, 2, 3, 4, 8') # 1 for dn and jpeg car
- parser.add_argument('--noise', type=int, default=15, help='noise level: 15, 25, 50')
- parser.add_argument('--jpeg', type=int, default=40, help='scale factor: 10, 20, 30, 40')
- parser.add_argument('--training_patch_size', type=int, default=128, help='patch size used in training SwinIR. '
- 'Just used to differentiate two different settings in Table 2 of the paper. '
- 'Images are NOT tested patch by patch.')
- parser.add_argument('--large_model', action='store_true', default=True, help='use large model, only provided for real image sr')
- parser.add_argument('--model_path', type=str,
- default='experiments/pretrained_models/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth')
- parser.add_argument('--folder_lq', type=str, default='./data', help='input low-quality test image folder')
- parser.add_argument('--folder_gt', type=str, default=None, help='input ground-truth test image folder')
- parser.add_argument('--tile', type=int, default=640, help='Tile size, None for no tile during testing (testing as a whole)')
- parser.add_argument('--tile_overlap', type=int, default=32, help='Overlapping of different tiles')
- args = parser.parse_args()
-
- device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- # set up model
- if os.path.exists(args.model_path):
- print(f'loading model from {args.model_path}')
- else:
- os.makedirs(os.path.dirname(args.model_path), exist_ok=True)
- url = 'https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/{}'.format(os.path.basename(args.model_path))
- r = requests.get(url, allow_redirects=True)
- print(f'downloading model {args.model_path}')
- open(args.model_path, 'wb').write(r.content)
-
- model = define_model(args)
- model.eval()
- model = model.to(device)
-
- # setup folder and path
- folder, save_dir, border, window_size = setup(args)
- os.makedirs(save_dir, exist_ok=True)
- test_results = OrderedDict()
- test_results['psnr'] = []
- test_results['ssim'] = []
- test_results['psnr_y'] = []
- test_results['ssim_y'] = []
- test_results['psnr_b'] = []
- psnr, ssim, psnr_y, ssim_y, psnr_b = 0, 0, 0, 0, 0
-
- for idx, path in enumerate(sorted(glob.glob(os.path.join(folder, '*')))):
- # read image
- imgname, img_lq, img_gt = get_image_pair(args, path) # image to HWC-BGR, float32
- img_lq = np.transpose(img_lq if img_lq.shape[2] == 1 else img_lq[:, :, [2, 1, 0]], (2, 0, 1)) # HCW-BGR to CHW-RGB
- img_lq = torch.from_numpy(img_lq).float().unsqueeze(0).to(device) # CHW-RGB to NCHW-RGB
-
- # inference
- with torch.no_grad():
- # pad input image to be a multiple of window_size
- _, _, h_old, w_old = img_lq.size()
- h_pad = (h_old // window_size + 1) * window_size - h_old
- w_pad = (w_old // window_size + 1) * window_size - w_old
- img_lq = torch.cat([img_lq, torch.flip(img_lq, [2])], 2)[:, :, :h_old + h_pad, :]
- img_lq = torch.cat([img_lq, torch.flip(img_lq, [3])], 3)[:, :, :, :w_old + w_pad]
- output = test(img_lq, model, args, window_size)
- output = output[..., :h_old * args.scale, :w_old * args.scale]
-
- # save image
- output = output.data.squeeze().float().cpu().clamp_(0, 1).numpy()
- if output.ndim == 3:
- output = np.transpose(output[[2, 1, 0], :, :], (1, 2, 0)) # CHW-RGB to HCW-BGR
- output = (output * 255.0).round().astype(np.uint8) # float32 to uint8
- cv2.imwrite(f'{save_dir}/{imgname}.png', output)
-
- # evaluate psnr/ssim/psnr_b
- if img_gt is not None:
- img_gt = (img_gt * 255.0).round().astype(np.uint8) # float32 to uint8
- img_gt = img_gt[:h_old * args.scale, :w_old * args.scale, ...] # crop gt
- img_gt = np.squeeze(img_gt)
-
- psnr = util.calculate_psnr(output, img_gt, crop_border=border)
- ssim = util.calculate_ssim(output, img_gt, crop_border=border)
- test_results['psnr'].append(psnr)
- test_results['ssim'].append(ssim)
- if img_gt.ndim == 3: # RGB image
- psnr_y = util.calculate_psnr(output, img_gt, crop_border=border, test_y_channel=True)
- ssim_y = util.calculate_ssim(output, img_gt, crop_border=border, test_y_channel=True)
- test_results['psnr_y'].append(psnr_y)
- test_results['ssim_y'].append(ssim_y)
- if args.task in ['jpeg_car']:
- psnr_b = util.calculate_psnrb(output, img_gt, crop_border=border, test_y_channel=True)
- test_results['psnr_b'].append(psnr_b)
- print('Testing {:d} {:20s} - PSNR: {:.2f} dB; SSIM: {:.4f}; '
- 'PSNR_Y: {:.2f} dB; SSIM_Y: {:.4f}; '
- 'PSNR_B: {:.2f} dB.'.
- format(idx, imgname, psnr, ssim, psnr_y, ssim_y, psnr_b))
- else:
- print('Testing {:d} {:20s}'.format(idx, imgname))
-
- # summarize psnr/ssim
- if img_gt is not None:
- ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
- ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
- print('\n{} \n-- Average PSNR/SSIM(RGB): {:.2f} dB; {:.4f}'.format(save_dir, ave_psnr, ave_ssim))
- if img_gt.ndim == 3:
- ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
- ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
- print('-- Average PSNR_Y/SSIM_Y: {:.2f} dB; {:.4f}'.format(ave_psnr_y, ave_ssim_y))
- if args.task in ['jpeg_car']:
- ave_psnr_b = sum(test_results['psnr_b']) / len(test_results['psnr_b'])
- print('-- Average PSNR_B: {:.2f} dB'.format(ave_psnr_b))
-
-
-def define_model(args):
- # 001 classical image sr
- if args.task == 'classical_sr':
- model = net(upscale=args.scale, in_chans=3, img_size=args.training_patch_size, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='pixelshuffle', resi_connection='1conv')
- param_key_g = 'params'
-
- # 002 lightweight image sr
- # use 'pixelshuffledirect' to save parameters
- elif args.task == 'lightweight_sr':
- model = net(upscale=args.scale, in_chans=3, img_size=64, window_size=8,
- img_range=1., depths=[6, 6, 6, 6], embed_dim=60, num_heads=[6, 6, 6, 6],
- mlp_ratio=2, upsampler='pixelshuffledirect', resi_connection='1conv')
- param_key_g = 'params'
-
- # 003 real-world image sr
- elif args.task == 'real_sr':
- if not args.large_model:
- # use 'nearest+conv' to avoid block artifacts
- model = net(upscale=4, in_chans=3, img_size=64, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='nearest+conv', resi_connection='1conv')
- else:
- # larger model size; use '3conv' to save parameters and memory; use ema for GAN training
- model = net(upscale=4, in_chans=3, img_size=64, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6, 6, 6, 6], embed_dim=240,
- num_heads=[8, 8, 8, 8, 8, 8, 8, 8, 8],
- mlp_ratio=2, upsampler='nearest+conv', resi_connection='3conv')
- param_key_g = 'params_ema'
-
- # 004 grayscale image denoising
- elif args.task == 'gray_dn':
- model = net(upscale=1, in_chans=1, img_size=128, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='', resi_connection='1conv')
- param_key_g = 'params'
-
- # 005 color image denoising
- elif args.task == 'color_dn':
- model = net(upscale=1, in_chans=3, img_size=128, window_size=8,
- img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='', resi_connection='1conv')
- param_key_g = 'params'
-
- # 006 JPEG compression artifact reduction
- # use window_size=7 because JPEG encoding uses 8x8; use img_range=255 because it's sligtly better than 1
- elif args.task == 'jpeg_car':
- model = net(upscale=1, in_chans=1, img_size=126, window_size=7,
- img_range=255., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
- mlp_ratio=2, upsampler='', resi_connection='1conv')
- param_key_g = 'params'
-
- pretrained_model = torch.load(args.model_path)
- model.load_state_dict(pretrained_model[param_key_g] if param_key_g in pretrained_model.keys() else pretrained_model, strict=True)
-
- return model
-
-
-def setup(args):
- # 001 classical image sr/ 002 lightweight image sr
- if args.task in ['classical_sr', 'lightweight_sr']:
- save_dir = f'results/swinir_{args.task}_x{args.scale}'
- folder = args.folder_gt
- border = args.scale
- window_size = 8
-
- # 003 real-world image sr
- elif args.task in ['real_sr']:
- # save_dir = f'results/swinir_{args.task}_x{args.scale}'
- save_dir = f'results'
- # if args.large_model:
- # save_dir += '_large'
- folder = args.folder_lq
- border = 0
- window_size = 8
-
- # 004 grayscale image denoising/ 005 color image denoising
- elif args.task in ['gray_dn', 'color_dn']:
- save_dir = f'results/swinir_{args.task}_noise{args.noise}'
- folder = args.folder_gt
- border = 0
- window_size = 8
-
- # 006 JPEG compression artifact reduction
- elif args.task in ['jpeg_car']:
- save_dir = f'results/swinir_{args.task}_jpeg{args.jpeg}'
- folder = args.folder_gt
- border = 0
- window_size = 7
-
- return folder, save_dir, border, window_size
-
-
-def get_image_pair(args, path):
- (imgname, imgext) = os.path.splitext(os.path.basename(path))
-
- # 001 classical image sr/ 002 lightweight image sr (load lq-gt image pairs)
- if args.task in ['classical_sr', 'lightweight_sr']:
- img_gt = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
- img_lq = cv2.imread(f'{args.folder_lq}/{imgname}x{args.scale}{imgext}', cv2.IMREAD_COLOR).astype(
- np.float32) / 255.
-
- # 003 real-world image sr (load lq image only)
- elif args.task in ['real_sr']:
- img_gt = None
- img_lq = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
-
- # 004 grayscale image denoising (load gt image and generate lq image on-the-fly)
- elif args.task in ['gray_dn']:
- img_gt = cv2.imread(path, cv2.IMREAD_GRAYSCALE).astype(np.float32) / 255.
- np.random.seed(seed=0)
- img_lq = img_gt + np.random.normal(0, args.noise / 255., img_gt.shape)
- img_gt = np.expand_dims(img_gt, axis=2)
- img_lq = np.expand_dims(img_lq, axis=2)
-
- # 005 color image denoising (load gt image and generate lq image on-the-fly)
- elif args.task in ['color_dn']:
- img_gt = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
- np.random.seed(seed=0)
- img_lq = img_gt + np.random.normal(0, args.noise / 255., img_gt.shape)
-
- # 006 JPEG compression artifact reduction (load gt image and generate lq image on-the-fly)
- elif args.task in ['jpeg_car']:
- img_gt = cv2.imread(path, cv2.IMREAD_UNCHANGED)
- if img_gt.ndim != 2:
- img_gt = util.bgr2ycbcr(img_gt, y_only=True)
- result, encimg = cv2.imencode('.jpg', img_gt, [int(cv2.IMWRITE_JPEG_QUALITY), args.jpeg])
- img_lq = cv2.imdecode(encimg, 0)
- img_gt = np.expand_dims(img_gt, axis=2).astype(np.float32) / 255.
- img_lq = np.expand_dims(img_lq, axis=2).astype(np.float32) / 255.
-
- return imgname, img_lq, img_gt
-
-
-def test(img_lq, model, args, window_size):
- if args.tile is None:
- # test the image as a whole
- output = model(img_lq)
- else:
- # test the image tile by tile
- b, c, h, w = img_lq.size()
- tile = min(args.tile, h, w)
- assert tile % window_size == 0, "tile size should be a multiple of window_size"
- tile_overlap = args.tile_overlap
- sf = args.scale
-
- stride = tile - tile_overlap
- h_idx_list = list(range(0, h-tile, stride)) + [h-tile]
- w_idx_list = list(range(0, w-tile, stride)) + [w-tile]
- E = torch.zeros(b, c, h*sf, w*sf).type_as(img_lq)
- W = torch.zeros_like(E)
-
- for h_idx in h_idx_list:
- for w_idx in w_idx_list:
- in_patch = img_lq[..., h_idx:h_idx+tile, w_idx:w_idx+tile]
- out_patch = model(in_patch)
- out_patch_mask = torch.ones_like(out_patch)
-
- E[..., h_idx*sf:(h_idx+tile)*sf, w_idx*sf:(w_idx+tile)*sf].add_(out_patch)
- W[..., h_idx*sf:(h_idx+tile)*sf, w_idx*sf:(w_idx+tile)*sf].add_(out_patch_mask)
- output = E.div_(W)
-
- return output
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/gordonchan/h2oo/h2oai_pipeline.py b/spaces/gordonchan/h2oo/h2oai_pipeline.py
deleted file mode 100644
index 368f49fbd81993a200311a267a43649e9ea0bfca..0000000000000000000000000000000000000000
--- a/spaces/gordonchan/h2oo/h2oai_pipeline.py
+++ /dev/null
@@ -1,201 +0,0 @@
-import os
-
-from transformers import TextGenerationPipeline
-from transformers.pipelines.text_generation import ReturnType
-
-from stopping import get_stopping
-from prompter import Prompter, PromptType
-
-
-class H2OTextGenerationPipeline(TextGenerationPipeline):
- def __init__(self, *args, debug=False, chat=False, stream_output=False,
- sanitize_bot_response=False,
- use_prompter=True, prompter=None,
- context='', iinput='',
- prompt_type=None, prompt_dict=None,
- max_input_tokens=2048 - 256, **kwargs):
- """
- HF-like pipeline, but handle instruction prompting and stopping (for some models)
- :param args:
- :param debug:
- :param chat:
- :param stream_output:
- :param sanitize_bot_response:
- :param use_prompter: Whether to use prompter. If pass prompt_type, will make prompter
- :param prompter: prompter, can pass if have already
- :param prompt_type: prompt_type, e.g. human_bot. See prompt_type to model mapping in from prompter.py.
- If use_prompter, then will make prompter and use it.
- :param prompt_dict: dict of get_prompt(, return_dict=True) for prompt_type=custom
- :param max_input_tokens:
- :param kwargs:
- """
- super().__init__(*args, **kwargs)
- self.prompt_text = None
- self.use_prompter = use_prompter
- self.prompt_type = prompt_type
- self.prompt_dict = prompt_dict
- self.prompter = prompter
- self.context = context
- self.iinput = iinput
- if self.use_prompter:
- if self.prompter is not None:
- assert self.prompter.prompt_type is not None
- else:
- self.prompter = Prompter(self.prompt_type, self.prompt_dict, debug=debug, chat=chat,
- stream_output=stream_output)
- self.human = self.prompter.humanstr
- self.bot = self.prompter.botstr
- self.can_stop = True
- else:
- self.prompter = None
- self.human = None
- self.bot = None
- self.can_stop = False
- self.sanitize_bot_response = sanitize_bot_response
- self.max_input_tokens = max_input_tokens # not for generate, so ok that not kwargs
-
- @staticmethod
- def limit_prompt(prompt_text, tokenizer, max_prompt_length=None):
- verbose = bool(int(os.getenv('VERBOSE_PIPELINE', '0')))
-
- if hasattr(tokenizer, 'model_max_length'):
- # model_max_length only defined for generate.py, not raw use of h2oai_pipeline.py
- model_max_length = tokenizer.model_max_length
- if max_prompt_length is not None:
- model_max_length = min(model_max_length, max_prompt_length)
- # cut at some upper likely limit to avoid excessive tokenization etc
- # upper bound of 10 chars/token, e.g. special chars sometimes are long
- if len(prompt_text) > model_max_length * 10:
- len0 = len(prompt_text)
- prompt_text = prompt_text[-model_max_length * 10:]
- if verbose:
- print("Cut of input: %s -> %s" % (len0, len(prompt_text)), flush=True)
- else:
- # unknown
- model_max_length = None
-
- num_prompt_tokens = None
- if model_max_length is not None:
- # can't wait for "hole" if not plain prompt_type, since would lose prefix like :
- # For https://github.com/h2oai/h2ogpt/issues/192
- for trial in range(0, 3):
- prompt_tokens = tokenizer(prompt_text)['input_ids']
- num_prompt_tokens = len(prompt_tokens)
- if num_prompt_tokens > model_max_length:
- # conservative by using int()
- chars_per_token = int(len(prompt_text) / num_prompt_tokens)
- # keep tail, where question is if using langchain
- prompt_text = prompt_text[-model_max_length * chars_per_token:]
- if verbose:
- print("reducing %s tokens, assuming average of %s chars/token for %s characters" % (
- num_prompt_tokens, chars_per_token, len(prompt_text)), flush=True)
- else:
- if verbose:
- print("using %s tokens with %s chars" % (num_prompt_tokens, len(prompt_text)), flush=True)
- break
-
- # Why Below False: don't limit max_new_tokens more, just rely upon stopping to reach limit of model
- if False:
- # if input prompt is some number of tokens, despite user request, can't have max_new_tokens more
- #
- assert num_prompt_tokens is not None
- if self.prompt_type not in [PromptType.plain.name, PromptType.plain.value]:
- # then give room for prompt
- fudge = 20
- else:
- fudge = 0
- max_new_tokens = max(0, min(generate_kwargs['max_new_tokens'],
- model_max_length - (num_prompt_tokens + fudge)))
- if max_new_tokens < generate_kwargs['max_new_tokens']:
- if verbose:
- print("Reduced max_new_tokens from %s -> %s" % (
- generate_kwargs['max_new_tokens'], max_new_tokens))
- generate_kwargs['max_new_tokens'] = max_new_tokens
- return prompt_text, num_prompt_tokens
-
- def preprocess(self, prompt_text, prefix="", handle_long_generation=None, **generate_kwargs):
- prompt_text, num_prompt_tokens = H2OTextGenerationPipeline.limit_prompt(prompt_text, self.tokenizer)
-
- data_point = dict(context=self.context, instruction=prompt_text, input=self.iinput)
- if self.prompter is not None:
- prompt_text = self.prompter.generate_prompt(data_point)
- self.prompt_text = prompt_text
- if handle_long_generation is None:
- # forces truncation of inputs to avoid critical failure
- handle_long_generation = None # disable with new approaches
- return super().preprocess(prompt_text, prefix=prefix, handle_long_generation=handle_long_generation,
- **generate_kwargs)
-
- def postprocess(self, model_outputs, return_type=ReturnType.FULL_TEXT, clean_up_tokenization_spaces=True):
- records = super().postprocess(model_outputs, return_type=return_type,
- clean_up_tokenization_spaces=clean_up_tokenization_spaces)
- for rec in records:
- if self.use_prompter:
- outputs = rec['generated_text']
- outputs = self.prompter.get_response(outputs, prompt=self.prompt_text,
- sanitize_bot_response=self.sanitize_bot_response)
- elif self.bot and self.human:
- outputs = rec['generated_text'].split(self.bot)[1].split(self.human)[0]
- else:
- outputs = rec['generated_text']
- rec['generated_text'] = outputs
- print("prompt: %s\noutputs: %s\n\n" % (self.prompt_text, outputs), flush=True)
- return records
-
- def _forward(self, model_inputs, **generate_kwargs):
- if self.can_stop:
- stopping_criteria = get_stopping(self.prompt_type, self.prompt_dict,
- self.tokenizer, self.device,
- human=self.human, bot=self.bot,
- model_max_length=self.tokenizer.model_max_length)
- generate_kwargs['stopping_criteria'] = stopping_criteria
- # return super()._forward(model_inputs, **generate_kwargs)
- return self.__forward(model_inputs, **generate_kwargs)
-
- # FIXME: Copy-paste of original _forward, but removed copy.deepcopy()
- # FIXME: https://github.com/h2oai/h2ogpt/issues/172
- def __forward(self, model_inputs, **generate_kwargs):
- input_ids = model_inputs["input_ids"]
- attention_mask = model_inputs.get("attention_mask", None)
- # Allow empty prompts
- if input_ids.shape[1] == 0:
- input_ids = None
- attention_mask = None
- in_b = 1
- else:
- in_b = input_ids.shape[0]
- prompt_text = model_inputs.pop("prompt_text")
-
- ## If there is a prefix, we may need to adjust the generation length. Do so without permanently modifying
- ## generate_kwargs, as some of the parameterization may come from the initialization of the pipeline.
- # generate_kwargs = copy.deepcopy(generate_kwargs)
- prefix_length = generate_kwargs.pop("prefix_length", 0)
- if prefix_length > 0:
- has_max_new_tokens = "max_new_tokens" in generate_kwargs or (
- "generation_config" in generate_kwargs
- and generate_kwargs["generation_config"].max_new_tokens is not None
- )
- if not has_max_new_tokens:
- generate_kwargs["max_length"] = generate_kwargs.get("max_length") or self.model.config.max_length
- generate_kwargs["max_length"] += prefix_length
- has_min_new_tokens = "min_new_tokens" in generate_kwargs or (
- "generation_config" in generate_kwargs
- and generate_kwargs["generation_config"].min_new_tokens is not None
- )
- if not has_min_new_tokens and "min_length" in generate_kwargs:
- generate_kwargs["min_length"] += prefix_length
-
- # BS x SL
- generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs)
- out_b = generated_sequence.shape[0]
- if self.framework == "pt":
- generated_sequence = generated_sequence.reshape(in_b, out_b // in_b, *generated_sequence.shape[1:])
- elif self.framework == "tf":
- from transformers import is_tf_available
- if is_tf_available():
- import tensorflow as tf
- generated_sequence = tf.reshape(generated_sequence,
- (in_b, out_b // in_b, *generated_sequence.shape[1:]))
- else:
- raise ValueError("TF not avaialble.")
- return {"generated_sequence": generated_sequence, "input_ids": input_ids, "prompt_text": prompt_text}
diff --git a/spaces/grisiemjahand/Image-and-3D-Model-Creator/PIFu/lib/colab_util.py b/spaces/grisiemjahand/Image-and-3D-Model-Creator/PIFu/lib/colab_util.py
deleted file mode 100644
index 608227b228647e7b1bc16676fadf22d68e381f57..0000000000000000000000000000000000000000
--- a/spaces/grisiemjahand/Image-and-3D-Model-Creator/PIFu/lib/colab_util.py
+++ /dev/null
@@ -1,114 +0,0 @@
-import io
-import os
-import torch
-from skimage.io import imread
-import numpy as np
-import cv2
-from tqdm import tqdm_notebook as tqdm
-import base64
-from IPython.display import HTML
-
-# Util function for loading meshes
-from pytorch3d.io import load_objs_as_meshes
-
-from IPython.display import HTML
-from base64 import b64encode
-
-# Data structures and functions for rendering
-from pytorch3d.structures import Meshes
-from pytorch3d.renderer import (
- look_at_view_transform,
- OpenGLOrthographicCameras,
- PointLights,
- DirectionalLights,
- Materials,
- RasterizationSettings,
- MeshRenderer,
- MeshRasterizer,
- SoftPhongShader,
- HardPhongShader,
- TexturesVertex
-)
-
-def set_renderer():
- # Setup
- device = torch.device("cuda:0")
- torch.cuda.set_device(device)
-
- # Initialize an OpenGL perspective camera.
- R, T = look_at_view_transform(2.0, 0, 180)
- cameras = OpenGLOrthographicCameras(device=device, R=R, T=T)
-
- raster_settings = RasterizationSettings(
- image_size=512,
- blur_radius=0.0,
- faces_per_pixel=1,
- bin_size = None,
- max_faces_per_bin = None
- )
-
- lights = PointLights(device=device, location=((2.0, 2.0, 2.0),))
-
- renderer = MeshRenderer(
- rasterizer=MeshRasterizer(
- cameras=cameras,
- raster_settings=raster_settings
- ),
- shader=HardPhongShader(
- device=device,
- cameras=cameras,
- lights=lights
- )
- )
- return renderer
-
-def get_verts_rgb_colors(obj_path):
- rgb_colors = []
-
- f = open(obj_path)
- lines = f.readlines()
- for line in lines:
- ls = line.split(' ')
- if len(ls) == 7:
- rgb_colors.append(ls[-3:])
-
- return np.array(rgb_colors, dtype='float32')[None, :, :]
-
-def generate_video_from_obj(obj_path, video_path, renderer):
- # Setup
- device = torch.device("cuda:0")
- torch.cuda.set_device(device)
-
- # Load obj file
- verts_rgb_colors = get_verts_rgb_colors(obj_path)
- verts_rgb_colors = torch.from_numpy(verts_rgb_colors).to(device)
- textures = TexturesVertex(verts_features=verts_rgb_colors)
- wo_textures = TexturesVertex(verts_features=torch.ones_like(verts_rgb_colors)*0.75)
-
- # Load obj
- mesh = load_objs_as_meshes([obj_path], device=device)
-
- # Set mesh
- vers = mesh._verts_list
- faces = mesh._faces_list
- mesh_w_tex = Meshes(vers, faces, textures)
- mesh_wo_tex = Meshes(vers, faces, wo_textures)
-
- # create VideoWriter
- fourcc = cv2. VideoWriter_fourcc(*'MP4V')
- out = cv2.VideoWriter(video_path, fourcc, 20.0, (1024,512))
-
- for i in tqdm(range(90)):
- R, T = look_at_view_transform(1.8, 0, i*4, device=device)
- images_w_tex = renderer(mesh_w_tex, R=R, T=T)
- images_w_tex = np.clip(images_w_tex[0, ..., :3].cpu().numpy(), 0.0, 1.0)[:, :, ::-1] * 255
- images_wo_tex = renderer(mesh_wo_tex, R=R, T=T)
- images_wo_tex = np.clip(images_wo_tex[0, ..., :3].cpu().numpy(), 0.0, 1.0)[:, :, ::-1] * 255
- image = np.concatenate([images_w_tex, images_wo_tex], axis=1)
- out.write(image.astype('uint8'))
- out.release()
-
-def video(path):
- mp4 = open(path,'rb').read()
- data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
- return HTML('' % data_url)
diff --git a/spaces/gstdl/streamlit-startup-campus/app.py b/spaces/gstdl/streamlit-startup-campus/app.py
deleted file mode 100644
index be3dcc01f885e6e4f915fe4f3fdfcf57cfb63e94..0000000000000000000000000000000000000000
--- a/spaces/gstdl/streamlit-startup-campus/app.py
+++ /dev/null
@@ -1,131 +0,0 @@
-import streamlit as st
-import pandas as pd
-import plotly.express as px
-import plotly.graph_objects as go
-
-#######
-# Data loading
-#######
-
-df = pd.read_csv("gapminder.csv")
-year_values = (int(df["year"].min()), int(df["year"].max()))
-metrics = ["lifeExp", "pop", "gdpPercap"]
-dimension = ["country", "continent", "year"]
-
-#######
-# Helper functions
-#######
-def get_filtered_data(
- continents="All",
- countries="All",
- min_year=year_values[0],
- max_year=year_values[1],
-):
- if isinstance(continents, str) and continents != "All":
- mask_continent = df["continent"] == continents
- else:
- mask_continent = df["continent"].isin(continents)
- if isinstance(countries, str) and countries != "All":
- mask_country = df["country"] == countries
- else:
- mask_country = df["country"].isin(countries)
- mask_year = ((df["year"] >= min_year) & (df["year"] <= max_year))
- return df[mask_continent & mask_country & mask_year]
-
-def box_plot(df, x, y):
- fig = px.box(
- df, x=x, y=y, hover_data=df[dimension + [x]],
- points="all", color=x)
- return fig
-
-def scatter_plot(df, x, y, hue):
- fig = px.scatter(
- df, x=x, y=y,
- color=hue, symbol=hue)
- return fig
-
-
-def line_plot(df, y_axis, label, highlighted):
- fig = go.Figure()
- if label=="continent":
- df = df.groupby(["continent", "year"]).agg({
- "lifeExp": "mean",
- "pop": "sum",
- "gdpPercap": "mean",
- }).reset_index()
-
- for i in df[label].unique():
- if i == highlighted:
- continue
- data = df[df[label]==i]
- x = data["year"]
- y = data[y_axis]
- fig.add_trace(go.Scatter(x=x, y=y,
- hovertext=[
- f"{label}: {i}
year: {year}
{y_axis}: {value}"
- for year, value in zip(x,y)
- ],
- hoverinfo="text",
- mode='lines',
- line = dict(color='gray', width=1),
- # name=i
- ))
-
- data = df[df[label]==highlighted]
- x = data["year"]
- y = data[y_axis]
- fig.add_trace(go.Scatter(x=x, y=y,
- hovertext=[
- f"{label}: {highlighted}
year: {year}
{y_axis}: {value}"
- for year, value in zip(x,y)
- ],
- hoverinfo="text",
- mode='lines',
- line = dict(color='orange', width=10),
- # name=highlighted
- ))
-
- fig.update_layout(showlegend=False)
- return fig
-
-#######
-# Streamlit app code
-#######
-
-st.title('[Gapminder] Exploratory Data Analysis')
-
-st.markdown("## Gapminder Table")
-selected_continents = st.multiselect("Select Continents:", df["continent"].unique(), key="table_continent")
-selected_countries = st.multiselect("Select Countries:", df.loc[df["continent"].isin(selected_continents), "country"].unique(), key="table_country")
-min_year, max_year = st.slider("Select Year:", year_values[0], year_values[1], year_values, key="table_year")
-st.dataframe(get_filtered_data(selected_continents, selected_countries, min_year, max_year))
-
-st.markdown("## Gapminder Boxplot")
-col1, col2 = st.columns(2)
-with col1:
- x = st.selectbox("Select x Axis", dimension, 1, key="boxplot_x")
-with col2:
- y = st.selectbox("Select y Axis", metrics, key="boxplot_y")
-st.plotly_chart(box_plot(df, x, y))
-
-st.markdown('## Gapminder Lineplot')
-col1, col2, col3 = st.columns(3)
-with col3:
- label = st.radio("Select label", ["country", "continent"], key="lineplot_label")
-with col1:
- highlighted = st.selectbox("Select value to hightlight", df[label].unique(), key="lineplot_highlighting")
-with col2:
- y = st.selectbox("Select hue", metrics, key="lineplot_y")
-st.plotly_chart(line_plot(df, y, label, highlighted))
-
-
-st.markdown('## Gapminder Scatterplot')
-col1, col2, col3 = st.columns(3)
-with col1:
- x = st.selectbox("Select x Axis", metrics, key="scatterplot_x")
-with col2:
- y = st.selectbox("Select y Axis", metrics, key="scatterplot_y")
-with col3:
- hue = st.radio("Select hue", ["country", "continent"], key="scatterplot_hue")
-st.plotly_chart(scatter_plot(df, x, y, hue))
-
diff --git a/spaces/gulabpatel/GFP_GAN/scripts/parse_landmark.py b/spaces/gulabpatel/GFP_GAN/scripts/parse_landmark.py
deleted file mode 100644
index 74e2ff9e130ad4f2395c9666dca3ba78526d7a8a..0000000000000000000000000000000000000000
--- a/spaces/gulabpatel/GFP_GAN/scripts/parse_landmark.py
+++ /dev/null
@@ -1,85 +0,0 @@
-import cv2
-import json
-import numpy as np
-import os
-import torch
-from basicsr.utils import FileClient, imfrombytes
-from collections import OrderedDict
-
-# ---------------------------- This script is used to parse facial landmarks ------------------------------------- #
-# Configurations
-save_img = False
-scale = 0.5 # 0.5 for official FFHQ (512x512), 1 for others
-enlarge_ratio = 1.4 # only for eyes
-json_path = 'ffhq-dataset-v2.json'
-face_path = 'datasets/ffhq/ffhq_512.lmdb'
-save_path = './FFHQ_eye_mouth_landmarks_512.pth'
-
-print('Load JSON metadata...')
-# use the official json file in FFHQ dataset
-with open(json_path, 'rb') as f:
- json_data = json.load(f, object_pairs_hook=OrderedDict)
-
-print('Open LMDB file...')
-# read ffhq images
-file_client = FileClient('lmdb', db_paths=face_path)
-with open(os.path.join(face_path, 'meta_info.txt')) as fin:
- paths = [line.split('.')[0] for line in fin]
-
-save_dict = {}
-
-for item_idx, item in enumerate(json_data.values()):
- print(f'\r{item_idx} / {len(json_data)}, {item["image"]["file_path"]} ', end='', flush=True)
-
- # parse landmarks
- lm = np.array(item['image']['face_landmarks'])
- lm = lm * scale
-
- item_dict = {}
- # get image
- if save_img:
- img_bytes = file_client.get(paths[item_idx])
- img = imfrombytes(img_bytes, float32=True)
-
- # get landmarks for each component
- map_left_eye = list(range(36, 42))
- map_right_eye = list(range(42, 48))
- map_mouth = list(range(48, 68))
-
- # eye_left
- mean_left_eye = np.mean(lm[map_left_eye], 0) # (x, y)
- half_len_left_eye = np.max((np.max(np.max(lm[map_left_eye], 0) - np.min(lm[map_left_eye], 0)) / 2, 16))
- item_dict['left_eye'] = [mean_left_eye[0], mean_left_eye[1], half_len_left_eye]
- # mean_left_eye[0] = 512 - mean_left_eye[0] # for testing flip
- half_len_left_eye *= enlarge_ratio
- loc_left_eye = np.hstack((mean_left_eye - half_len_left_eye + 1, mean_left_eye + half_len_left_eye)).astype(int)
- if save_img:
- eye_left_img = img[loc_left_eye[1]:loc_left_eye[3], loc_left_eye[0]:loc_left_eye[2], :]
- cv2.imwrite(f'tmp/{item_idx:08d}_eye_left.png', eye_left_img * 255)
-
- # eye_right
- mean_right_eye = np.mean(lm[map_right_eye], 0)
- half_len_right_eye = np.max((np.max(np.max(lm[map_right_eye], 0) - np.min(lm[map_right_eye], 0)) / 2, 16))
- item_dict['right_eye'] = [mean_right_eye[0], mean_right_eye[1], half_len_right_eye]
- # mean_right_eye[0] = 512 - mean_right_eye[0] # # for testing flip
- half_len_right_eye *= enlarge_ratio
- loc_right_eye = np.hstack(
- (mean_right_eye - half_len_right_eye + 1, mean_right_eye + half_len_right_eye)).astype(int)
- if save_img:
- eye_right_img = img[loc_right_eye[1]:loc_right_eye[3], loc_right_eye[0]:loc_right_eye[2], :]
- cv2.imwrite(f'tmp/{item_idx:08d}_eye_right.png', eye_right_img * 255)
-
- # mouth
- mean_mouth = np.mean(lm[map_mouth], 0)
- half_len_mouth = np.max((np.max(np.max(lm[map_mouth], 0) - np.min(lm[map_mouth], 0)) / 2, 16))
- item_dict['mouth'] = [mean_mouth[0], mean_mouth[1], half_len_mouth]
- # mean_mouth[0] = 512 - mean_mouth[0] # for testing flip
- loc_mouth = np.hstack((mean_mouth - half_len_mouth + 1, mean_mouth + half_len_mouth)).astype(int)
- if save_img:
- mouth_img = img[loc_mouth[1]:loc_mouth[3], loc_mouth[0]:loc_mouth[2], :]
- cv2.imwrite(f'tmp/{item_idx:08d}_mouth.png', mouth_img * 255)
-
- save_dict[f'{item_idx:08d}'] = item_dict
-
-print('Save...')
-torch.save(save_dict, save_path)
diff --git a/spaces/gwang-kim/DATID-3D/pose_estimation/nvdiffrast/nvdiffrast/common/glutil.h b/spaces/gwang-kim/DATID-3D/pose_estimation/nvdiffrast/nvdiffrast/common/glutil.h
deleted file mode 100644
index e9a3a7d95a5af4a808a25097cc055b699024409e..0000000000000000000000000000000000000000
--- a/spaces/gwang-kim/DATID-3D/pose_estimation/nvdiffrast/nvdiffrast/common/glutil.h
+++ /dev/null
@@ -1,113 +0,0 @@
-// Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
-//
-// NVIDIA CORPORATION and its licensors retain all intellectual property
-// and proprietary rights in and to this software, related documentation
-// and any modifications thereto. Any use, reproduction, disclosure or
-// distribution of this software and related documentation without an express
-// license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-#pragma once
-
-//------------------------------------------------------------------------
-// Windows-specific headers and types.
-//------------------------------------------------------------------------
-
-#ifdef _WIN32
-#define NOMINMAX
-#include // Required by gl.h in Windows.
-#define GLAPIENTRY APIENTRY
-
-struct GLContext
-{
- HDC hdc;
- HGLRC hglrc;
- int extInitialized;
-};
-
-#endif // _WIN32
-
-//------------------------------------------------------------------------
-// Linux-specific headers and types.
-//------------------------------------------------------------------------
-
-#ifdef __linux__
-#define EGL_NO_X11 // X11/Xlib.h has "#define Status int" which breaks Tensorflow. Avoid it.
-#define MESA_EGL_NO_X11_HEADERS
-#include
-#include
-#define GLAPIENTRY
-
-struct GLContext
-{
- EGLDisplay display;
- EGLContext context;
- int extInitialized;
-};
-
-#endif // __linux__
-
-//------------------------------------------------------------------------
-// OpenGL, CUDA interop, GL extensions.
-//------------------------------------------------------------------------
-#define GL_GLEXT_LEGACY
-#include
-#include
-
-// Constants.
-#ifndef GL_VERSION_1_2
-#define GL_CLAMP_TO_EDGE 0x812F
-#define GL_TEXTURE_3D 0x806F
-#endif
-#ifndef GL_VERSION_1_5
-#define GL_ARRAY_BUFFER 0x8892
-#define GL_DYNAMIC_DRAW 0x88E8
-#define GL_ELEMENT_ARRAY_BUFFER 0x8893
-#endif
-#ifndef GL_VERSION_2_0
-#define GL_FRAGMENT_SHADER 0x8B30
-#define GL_INFO_LOG_LENGTH 0x8B84
-#define GL_LINK_STATUS 0x8B82
-#define GL_VERTEX_SHADER 0x8B31
-#endif
-#ifndef GL_VERSION_3_0
-#define GL_MAJOR_VERSION 0x821B
-#define GL_MINOR_VERSION 0x821C
-#define GL_RGBA32F 0x8814
-#define GL_TEXTURE_2D_ARRAY 0x8C1A
-#endif
-#ifndef GL_VERSION_3_2
-#define GL_GEOMETRY_SHADER 0x8DD9
-#endif
-#ifndef GL_ARB_framebuffer_object
-#define GL_COLOR_ATTACHMENT0 0x8CE0
-#define GL_COLOR_ATTACHMENT1 0x8CE1
-#define GL_DEPTH_STENCIL 0x84F9
-#define GL_DEPTH_STENCIL_ATTACHMENT 0x821A
-#define GL_DEPTH24_STENCIL8 0x88F0
-#define GL_FRAMEBUFFER 0x8D40
-#define GL_INVALID_FRAMEBUFFER_OPERATION 0x0506
-#define GL_UNSIGNED_INT_24_8 0x84FA
-#endif
-#ifndef GL_ARB_imaging
-#define GL_TABLE_TOO_LARGE 0x8031
-#endif
-#ifndef GL_KHR_robustness
-#define GL_CONTEXT_LOST 0x0507
-#endif
-
-// Declare function pointers to OpenGL extension functions.
-#define GLUTIL_EXT(return_type, name, ...) extern return_type (GLAPIENTRY* name)(__VA_ARGS__);
-#include "glutil_extlist.h"
-#undef GLUTIL_EXT
-
-//------------------------------------------------------------------------
-// Common functions.
-//------------------------------------------------------------------------
-
-void setGLContext (GLContext& glctx);
-void releaseGLContext (void);
-GLContext createGLContext (int cudaDeviceIdx);
-void destroyGLContext (GLContext& glctx);
-const char* getGLErrorString (GLenum err);
-
-//------------------------------------------------------------------------
diff --git a/spaces/hamelcubsfan/AutoGPT/autogpt/speech/macos_tts.py b/spaces/hamelcubsfan/AutoGPT/autogpt/speech/macos_tts.py
deleted file mode 100644
index 4c072ce256782e83a578b5181abf1a7b524c621b..0000000000000000000000000000000000000000
--- a/spaces/hamelcubsfan/AutoGPT/autogpt/speech/macos_tts.py
+++ /dev/null
@@ -1,21 +0,0 @@
-""" MacOS TTS Voice. """
-import os
-
-from autogpt.speech.base import VoiceBase
-
-
-class MacOSTTS(VoiceBase):
- """MacOS TTS Voice."""
-
- def _setup(self) -> None:
- pass
-
- def _speech(self, text: str, voice_index: int = 0) -> bool:
- """Play the given text."""
- if voice_index == 0:
- os.system(f'say "{text}"')
- elif voice_index == 1:
- os.system(f'say -v "Ava (Premium)" "{text}"')
- else:
- os.system(f'say -v Samantha "{text}"')
- return True
diff --git a/spaces/haofeixu/unimatch/unimatch/__init__.py b/spaces/haofeixu/unimatch/unimatch/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/text/korean.py b/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/text/korean.py
deleted file mode 100644
index edee07429a450c55e3d8e246997faaa1e0b89cc9..0000000000000000000000000000000000000000
--- a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/text/korean.py
+++ /dev/null
@@ -1,210 +0,0 @@
-import re
-from jamo import h2j, j2hcj
-import ko_pron
-
-
-# This is a list of Korean classifiers preceded by pure Korean numerals.
-_korean_classifiers = '군데 권 개 그루 닢 대 두 마리 모 모금 뭇 발 발짝 방 번 벌 보루 살 수 술 시 쌈 움큼 정 짝 채 척 첩 축 켤레 톨 통'
-
-# List of (hangul, hangul divided) pairs:
-_hangul_divided = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ㄳ', 'ㄱㅅ'),
- ('ㄵ', 'ㄴㅈ'),
- ('ㄶ', 'ㄴㅎ'),
- ('ㄺ', 'ㄹㄱ'),
- ('ㄻ', 'ㄹㅁ'),
- ('ㄼ', 'ㄹㅂ'),
- ('ㄽ', 'ㄹㅅ'),
- ('ㄾ', 'ㄹㅌ'),
- ('ㄿ', 'ㄹㅍ'),
- ('ㅀ', 'ㄹㅎ'),
- ('ㅄ', 'ㅂㅅ'),
- ('ㅘ', 'ㅗㅏ'),
- ('ㅙ', 'ㅗㅐ'),
- ('ㅚ', 'ㅗㅣ'),
- ('ㅝ', 'ㅜㅓ'),
- ('ㅞ', 'ㅜㅔ'),
- ('ㅟ', 'ㅜㅣ'),
- ('ㅢ', 'ㅡㅣ'),
- ('ㅑ', 'ㅣㅏ'),
- ('ㅒ', 'ㅣㅐ'),
- ('ㅕ', 'ㅣㅓ'),
- ('ㅖ', 'ㅣㅔ'),
- ('ㅛ', 'ㅣㅗ'),
- ('ㅠ', 'ㅣㅜ')
-]]
-
-# List of (Latin alphabet, hangul) pairs:
-_latin_to_hangul = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('a', '에이'),
- ('b', '비'),
- ('c', '시'),
- ('d', '디'),
- ('e', '이'),
- ('f', '에프'),
- ('g', '지'),
- ('h', '에이치'),
- ('i', '아이'),
- ('j', '제이'),
- ('k', '케이'),
- ('l', '엘'),
- ('m', '엠'),
- ('n', '엔'),
- ('o', '오'),
- ('p', '피'),
- ('q', '큐'),
- ('r', '아르'),
- ('s', '에스'),
- ('t', '티'),
- ('u', '유'),
- ('v', '브이'),
- ('w', '더블유'),
- ('x', '엑스'),
- ('y', '와이'),
- ('z', '제트')
-]]
-
-# List of (ipa, lazy ipa) pairs:
-_ipa_to_lazy_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('t͡ɕ','ʧ'),
- ('d͡ʑ','ʥ'),
- ('ɲ','n^'),
- ('ɕ','ʃ'),
- ('ʷ','w'),
- ('ɭ','l`'),
- ('ʎ','ɾ'),
- ('ɣ','ŋ'),
- ('ɰ','ɯ'),
- ('ʝ','j'),
- ('ʌ','ə'),
- ('ɡ','g'),
- ('\u031a','#'),
- ('\u0348','='),
- ('\u031e',''),
- ('\u0320',''),
- ('\u0339','')
-]]
-
-
-def latin_to_hangul(text):
- for regex, replacement in _latin_to_hangul:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def divide_hangul(text):
- text = j2hcj(h2j(text))
- for regex, replacement in _hangul_divided:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def hangul_number(num, sino=True):
- '''Reference https://github.com/Kyubyong/g2pK'''
- num = re.sub(',', '', num)
-
- if num == '0':
- return '영'
- if not sino and num == '20':
- return '스무'
-
- digits = '123456789'
- names = '일이삼사오육칠팔구'
- digit2name = {d: n for d, n in zip(digits, names)}
-
- modifiers = '한 두 세 네 다섯 여섯 일곱 여덟 아홉'
- decimals = '열 스물 서른 마흔 쉰 예순 일흔 여든 아흔'
- digit2mod = {d: mod for d, mod in zip(digits, modifiers.split())}
- digit2dec = {d: dec for d, dec in zip(digits, decimals.split())}
-
- spelledout = []
- for i, digit in enumerate(num):
- i = len(num) - i - 1
- if sino:
- if i == 0:
- name = digit2name.get(digit, '')
- elif i == 1:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- else:
- if i == 0:
- name = digit2mod.get(digit, '')
- elif i == 1:
- name = digit2dec.get(digit, '')
- if digit == '0':
- if i % 4 == 0:
- last_three = spelledout[-min(3, len(spelledout)):]
- if ''.join(last_three) == '':
- spelledout.append('')
- continue
- else:
- spelledout.append('')
- continue
- if i == 2:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 3:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 4:
- name = digit2name.get(digit, '') + '만'
- name = name.replace('일만', '만')
- elif i == 5:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- elif i == 6:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 7:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 8:
- name = digit2name.get(digit, '') + '억'
- elif i == 9:
- name = digit2name.get(digit, '') + '십'
- elif i == 10:
- name = digit2name.get(digit, '') + '백'
- elif i == 11:
- name = digit2name.get(digit, '') + '천'
- elif i == 12:
- name = digit2name.get(digit, '') + '조'
- elif i == 13:
- name = digit2name.get(digit, '') + '십'
- elif i == 14:
- name = digit2name.get(digit, '') + '백'
- elif i == 15:
- name = digit2name.get(digit, '') + '천'
- spelledout.append(name)
- return ''.join(elem for elem in spelledout)
-
-
-def number_to_hangul(text):
- '''Reference https://github.com/Kyubyong/g2pK'''
- tokens = set(re.findall(r'(\d[\d,]*)([\uac00-\ud71f]+)', text))
- for token in tokens:
- num, classifier = token
- if classifier[:2] in _korean_classifiers or classifier[0] in _korean_classifiers:
- spelledout = hangul_number(num, sino=False)
- else:
- spelledout = hangul_number(num, sino=True)
- text = text.replace(f'{num}{classifier}', f'{spelledout}{classifier}')
- # digit by digit for remaining digits
- digits = '0123456789'
- names = '영일이삼사오육칠팔구'
- for d, n in zip(digits, names):
- text = text.replace(d, n)
- return text
-
-
-def korean_to_lazy_ipa(text):
- text = latin_to_hangul(text)
- text = number_to_hangul(text)
- text=re.sub('[\uac00-\ud7af]+',lambda x:ko_pron.romanise(x.group(0),'ipa').split('] ~ [')[0],text)
- for regex, replacement in _ipa_to_lazy_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def korean_to_ipa(text):
- text = korean_to_lazy_ipa(text)
- return text.replace('ʧ','tʃ').replace('ʥ','dʑ')
diff --git a/spaces/hhim8826/vits-ATR/monotonic_align/setup.py b/spaces/hhim8826/vits-ATR/monotonic_align/setup.py
deleted file mode 100644
index 30c224807a70faa9df9c9eb75f8e80c8c867b16b..0000000000000000000000000000000000000000
--- a/spaces/hhim8826/vits-ATR/monotonic_align/setup.py
+++ /dev/null
@@ -1,9 +0,0 @@
-from distutils.core import setup
-from Cython.Build import cythonize
-import numpy
-
-setup(
- name = 'monotonic_align',
- ext_modules = cythonize("core.pyx"),
- include_dirs=[numpy.get_include()]
-)
diff --git a/spaces/hkunlp/Binder/nsql/nsql_exec_python.py b/spaces/hkunlp/Binder/nsql/nsql_exec_python.py
deleted file mode 100644
index c471700541f0c8b3ae59654257bb2078a7714f39..0000000000000000000000000000000000000000
--- a/spaces/hkunlp/Binder/nsql/nsql_exec_python.py
+++ /dev/null
@@ -1,129 +0,0 @@
-# For sync the envs.
-import random
-import json
-import pandas as pd
-import pickle
-from nsql.qa_module.openai_qa import OpenAIQAModel
-import os
-import time
-from subprocess import PIPE, Popen
-import uuid
-
-
-# For Python execution.
-class NPythonExecutor(object):
- def __init__(self, args, keys=None):
- self.new_col_name_id = 0
- self.qa_model = OpenAIQAModel(args, keys)
-
- def nsql_exec(self, stamp, nsql: str, db: pd.DataFrame, verbose=True):
- # Add import part
- import_part = """import sys
-import random
-import json
-import pandas as pd
-import pickle
-import numpy as np
-import copy
-import os
-import time
-sys.path.append('./')
-from collections.abc import Iterable
-from nsql.qa_module.openai_qa import OpenAIQAModel
-from nsql.database import NeuralDB
-verbose = {}""".format(str(verbose))
-
- # Add qa_map function
- qa_map_function_part = """def qa_map(db: pd.DataFrame, question, columns):
- new_db = NeuralDB([{"title": "", "table": {"header": db.columns.values.tolist(), "rows": db.values.tolist()}}])
- sql_executed_sub_tables = []
- for column in columns:
- column = f"`{column}`"
- sql_executed_sub_tables.append(new_db.execute_query(column))
- sub_table = qa_model.qa(question,
- sql_executed_sub_tables,
- table_title=new_db.table_title,
- qa_type="map",
- new_col_name_s=[question],
- verbose=verbose)
- new_db.add_sub_table(sub_table, verbose=verbose)
- table = new_db.get_table()
- return pd.DataFrame(table["rows"], columns=table["header"])"""
-
- # Add qa_ans function
- qa_ans_function_part = """def qa_ans(db: pd.DataFrame, question, columns):
- new_db = NeuralDB([{"title": "", "table": {"header": db.columns.values.tolist(), "rows": db.values.tolist()}}])
- sql_executed_sub_tables = []
- for column in columns:
- column = f"`{column}`"
- sql_executed_sub_tables.append(new_db.execute_query(column))
- answer = qa_model.qa(question,sql_executed_sub_tables,table_title=new_db.table_title,qa_type="ans",verbose=verbose)
- return answer"""
-
- # Convert np number type to python type
- convert_part = """def nested_to_python_number(x):
- if isinstance(x, np.int64):
- return int(x)
- if isinstance(x, np.float64):
- return float(x)
- if isinstance(x, Iterable) and not isinstance(x, (str, bytes)):
- return [nested_to_python_number(d) for d in x]
- return x"""
- # The prediction is a neural-python.
-
- # Add main function
- tmp_root_path = "tmp_python"
- os.makedirs(tmp_root_path, exist_ok=True)
- # Save the db
- db_file_path = '{}.db'.format(format(uuid.uuid4()))
- db_path = os.path.join(tmp_root_path, db_file_path)
- with open(db_path, "wb") as f:
- pickle.dump(db, f)
-
- # Save the qa_model
- model_file_path = '{}.model'.format(format(uuid.uuid4()))
- model_path = os.path.join(tmp_root_path, model_file_path)
- with open(model_path, "wb") as f:
- pickle.dump(self.qa_model, f)
-
- # Set the result path
- result_file_path = '{}.json'.format(format(uuid.uuid4()))
- result_path = os.path.join(tmp_root_path, result_file_path)
-
- # Read it and call solve function
- main_part = """if __name__ == '__main__':
- with open("{}", "rb") as f:
- db = pickle.load(f)
- with open("{}", "rb") as f:
- qa_model = pickle.load(f)
- result = solve(db)
- result = nested_to_python_number(result)
- with open("{}", "w") as f:
- json.dump(result, f)""".format(db_path, model_path, result_path)
-
- # Concat the code and execute the python
- all_code = "{}\n\n{}\n\n{}\n\n{}\n\n".format(import_part, qa_map_function_part, qa_ans_function_part,
- convert_part) + nsql + "\n\n" + main_part
-
- if verbose:
- print("----> Code <----")
- print(all_code)
-
- python_file_path = '{}.py'.format(format(uuid.uuid4()))
- python_path = os.path.join(tmp_root_path, python_file_path)
- with open(python_path, "w") as f:
- f.write(all_code)
-
- p = Popen("python " + python_path, shell=True, stdout=PIPE, stderr=PIPE)
- stdout, stderr = p.communicate()
-
- # Error in execution so that we didn't get result.
- if not os.path.exists(result_path):
- print("stderr: ", stderr)
- raise ValueError("Error execution!")
-
- # Read the result
- with open(result_path, "r") as f:
- result = json.load(f)
-
- return result
diff --git a/spaces/huggingface-projects/llama-2-7b-chat/USE_POLICY.md b/spaces/huggingface-projects/llama-2-7b-chat/USE_POLICY.md
deleted file mode 100644
index abbcc199b2d1e4feb5d7e40c0bd67e1b0ce29e97..0000000000000000000000000000000000000000
--- a/spaces/huggingface-projects/llama-2-7b-chat/USE_POLICY.md
+++ /dev/null
@@ -1,50 +0,0 @@
-# Llama 2 Acceptable Use Policy
-
-Meta is committed to promoting safe and fair use of its tools and features, including Llama 2. If you access or use Llama 2, you agree to this Acceptable Use Policy (“Policy”). The most recent copy of this policy can be found at [ai.meta.com/llama/use-policy](http://ai.meta.com/llama/use-policy).
-
-## Prohibited Uses
-We want everyone to use Llama 2 safely and responsibly. You agree you will not use, or allow others to use, Llama 2 to:
-
-1. Violate the law or others’ rights, including to:
- 1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
- 1. Violence or terrorism
- 2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
- 3. Human trafficking, exploitation, and sexual violence
- 4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
- 5. Sexual solicitation
- 6. Any other criminal activity
- 2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
- 3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
- 4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
- 5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
- 6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama 2 Materials
- 7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
-
-
-
-2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Llama 2 related to the following:
- 1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
- 2. Guns and illegal weapons (including weapon development)
- 3. Illegal drugs and regulated/controlled substances
- 4. Operation of critical infrastructure, transportation technologies, or heavy machinery
- 5. Self-harm or harm to others, including suicide, cutting, and eating disorders
- 6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
-
-
-
-3. Intentionally deceive or mislead others, including use of Llama 2 related to the following:
- 1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
- 2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
- 3. Generating, promoting, or further distributing spam
- 4. Impersonating another individual without consent, authorization, or legal right
- 5. Representing that the use of Llama 2 or outputs are human-generated
- 6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
-4. Fail to appropriately disclose to end users any known dangers of your AI system
-
-Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation of this Policy through one of the following means:
-
-* Reporting issues with the model: [github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
-* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
-* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
-* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama: [LlamaUseReport@meta.com](mailto:LlamaUseReport@meta.com)
-
diff --git a/spaces/hunger11243/VITS-Umamusume-voice-synthesizer/text/korean.py b/spaces/hunger11243/VITS-Umamusume-voice-synthesizer/text/korean.py
deleted file mode 100644
index edee07429a450c55e3d8e246997faaa1e0b89cc9..0000000000000000000000000000000000000000
--- a/spaces/hunger11243/VITS-Umamusume-voice-synthesizer/text/korean.py
+++ /dev/null
@@ -1,210 +0,0 @@
-import re
-from jamo import h2j, j2hcj
-import ko_pron
-
-
-# This is a list of Korean classifiers preceded by pure Korean numerals.
-_korean_classifiers = '군데 권 개 그루 닢 대 두 마리 모 모금 뭇 발 발짝 방 번 벌 보루 살 수 술 시 쌈 움큼 정 짝 채 척 첩 축 켤레 톨 통'
-
-# List of (hangul, hangul divided) pairs:
-_hangul_divided = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ㄳ', 'ㄱㅅ'),
- ('ㄵ', 'ㄴㅈ'),
- ('ㄶ', 'ㄴㅎ'),
- ('ㄺ', 'ㄹㄱ'),
- ('ㄻ', 'ㄹㅁ'),
- ('ㄼ', 'ㄹㅂ'),
- ('ㄽ', 'ㄹㅅ'),
- ('ㄾ', 'ㄹㅌ'),
- ('ㄿ', 'ㄹㅍ'),
- ('ㅀ', 'ㄹㅎ'),
- ('ㅄ', 'ㅂㅅ'),
- ('ㅘ', 'ㅗㅏ'),
- ('ㅙ', 'ㅗㅐ'),
- ('ㅚ', 'ㅗㅣ'),
- ('ㅝ', 'ㅜㅓ'),
- ('ㅞ', 'ㅜㅔ'),
- ('ㅟ', 'ㅜㅣ'),
- ('ㅢ', 'ㅡㅣ'),
- ('ㅑ', 'ㅣㅏ'),
- ('ㅒ', 'ㅣㅐ'),
- ('ㅕ', 'ㅣㅓ'),
- ('ㅖ', 'ㅣㅔ'),
- ('ㅛ', 'ㅣㅗ'),
- ('ㅠ', 'ㅣㅜ')
-]]
-
-# List of (Latin alphabet, hangul) pairs:
-_latin_to_hangul = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('a', '에이'),
- ('b', '비'),
- ('c', '시'),
- ('d', '디'),
- ('e', '이'),
- ('f', '에프'),
- ('g', '지'),
- ('h', '에이치'),
- ('i', '아이'),
- ('j', '제이'),
- ('k', '케이'),
- ('l', '엘'),
- ('m', '엠'),
- ('n', '엔'),
- ('o', '오'),
- ('p', '피'),
- ('q', '큐'),
- ('r', '아르'),
- ('s', '에스'),
- ('t', '티'),
- ('u', '유'),
- ('v', '브이'),
- ('w', '더블유'),
- ('x', '엑스'),
- ('y', '와이'),
- ('z', '제트')
-]]
-
-# List of (ipa, lazy ipa) pairs:
-_ipa_to_lazy_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('t͡ɕ','ʧ'),
- ('d͡ʑ','ʥ'),
- ('ɲ','n^'),
- ('ɕ','ʃ'),
- ('ʷ','w'),
- ('ɭ','l`'),
- ('ʎ','ɾ'),
- ('ɣ','ŋ'),
- ('ɰ','ɯ'),
- ('ʝ','j'),
- ('ʌ','ə'),
- ('ɡ','g'),
- ('\u031a','#'),
- ('\u0348','='),
- ('\u031e',''),
- ('\u0320',''),
- ('\u0339','')
-]]
-
-
-def latin_to_hangul(text):
- for regex, replacement in _latin_to_hangul:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def divide_hangul(text):
- text = j2hcj(h2j(text))
- for regex, replacement in _hangul_divided:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def hangul_number(num, sino=True):
- '''Reference https://github.com/Kyubyong/g2pK'''
- num = re.sub(',', '', num)
-
- if num == '0':
- return '영'
- if not sino and num == '20':
- return '스무'
-
- digits = '123456789'
- names = '일이삼사오육칠팔구'
- digit2name = {d: n for d, n in zip(digits, names)}
-
- modifiers = '한 두 세 네 다섯 여섯 일곱 여덟 아홉'
- decimals = '열 스물 서른 마흔 쉰 예순 일흔 여든 아흔'
- digit2mod = {d: mod for d, mod in zip(digits, modifiers.split())}
- digit2dec = {d: dec for d, dec in zip(digits, decimals.split())}
-
- spelledout = []
- for i, digit in enumerate(num):
- i = len(num) - i - 1
- if sino:
- if i == 0:
- name = digit2name.get(digit, '')
- elif i == 1:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- else:
- if i == 0:
- name = digit2mod.get(digit, '')
- elif i == 1:
- name = digit2dec.get(digit, '')
- if digit == '0':
- if i % 4 == 0:
- last_three = spelledout[-min(3, len(spelledout)):]
- if ''.join(last_three) == '':
- spelledout.append('')
- continue
- else:
- spelledout.append('')
- continue
- if i == 2:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 3:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 4:
- name = digit2name.get(digit, '') + '만'
- name = name.replace('일만', '만')
- elif i == 5:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- elif i == 6:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 7:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 8:
- name = digit2name.get(digit, '') + '억'
- elif i == 9:
- name = digit2name.get(digit, '') + '십'
- elif i == 10:
- name = digit2name.get(digit, '') + '백'
- elif i == 11:
- name = digit2name.get(digit, '') + '천'
- elif i == 12:
- name = digit2name.get(digit, '') + '조'
- elif i == 13:
- name = digit2name.get(digit, '') + '십'
- elif i == 14:
- name = digit2name.get(digit, '') + '백'
- elif i == 15:
- name = digit2name.get(digit, '') + '천'
- spelledout.append(name)
- return ''.join(elem for elem in spelledout)
-
-
-def number_to_hangul(text):
- '''Reference https://github.com/Kyubyong/g2pK'''
- tokens = set(re.findall(r'(\d[\d,]*)([\uac00-\ud71f]+)', text))
- for token in tokens:
- num, classifier = token
- if classifier[:2] in _korean_classifiers or classifier[0] in _korean_classifiers:
- spelledout = hangul_number(num, sino=False)
- else:
- spelledout = hangul_number(num, sino=True)
- text = text.replace(f'{num}{classifier}', f'{spelledout}{classifier}')
- # digit by digit for remaining digits
- digits = '0123456789'
- names = '영일이삼사오육칠팔구'
- for d, n in zip(digits, names):
- text = text.replace(d, n)
- return text
-
-
-def korean_to_lazy_ipa(text):
- text = latin_to_hangul(text)
- text = number_to_hangul(text)
- text=re.sub('[\uac00-\ud7af]+',lambda x:ko_pron.romanise(x.group(0),'ipa').split('] ~ [')[0],text)
- for regex, replacement in _ipa_to_lazy_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def korean_to_ipa(text):
- text = korean_to_lazy_ipa(text)
- return text.replace('ʧ','tʃ').replace('ʥ','dʑ')
diff --git a/spaces/hungln1102/emotion_classification_surreynlp_2023/emotion_model.py b/spaces/hungln1102/emotion_classification_surreynlp_2023/emotion_model.py
deleted file mode 100644
index 7eb3a9ec61c417c4363b61e450a9321d27772bb6..0000000000000000000000000000000000000000
--- a/spaces/hungln1102/emotion_classification_surreynlp_2023/emotion_model.py
+++ /dev/null
@@ -1,28 +0,0 @@
-import numpy as np
-import tensorflow as tf
-import tensorflow_addons as tfa
-
-from constance_data import emotion_track_list, decode_cut_list
-from pre_processing_data import preprocessing_data, pre_processing_data_2, text_transform, user_capture
-
-
-def emotion_predict(sentence: str):
- lr = 1e-3
- wd = 1e-4 * lr
- model = tf.keras.models.load_model("model/nlp_surrey_coursework_hunglenhat")
- model.compile(loss='sparse_categorical_crossentropy',
- optimizer=tfa.optimizers.AdamW(learning_rate=lr, weight_decay=wd), metrics=['accuracy'])
- sentence_temp = sentence
- sentence = pre_processing_data_2(sentence)
- if not sentence:
- sentence = preprocessing_data(sentence)
-
- sentence = text_transform(sentence)
- try:
- sentence = model.predict(sentence)
- except Exception as E:
- print(E)
- index_max = np.argmax(sentence)
- result = emotion_track_list[decode_cut_list[index_max]]
- user_capture(sentence_temp, result)
- return result
diff --git a/spaces/hysts/LoRA-SD-training/app.py b/spaces/hysts/LoRA-SD-training/app.py
deleted file mode 100644
index 95b31c72ba5bfa6134683ac81f3b3df2ccd0488a..0000000000000000000000000000000000000000
--- a/spaces/hysts/LoRA-SD-training/app.py
+++ /dev/null
@@ -1,280 +0,0 @@
-#!/usr/bin/env python
-"""Unofficial demo app for https://github.com/cloneofsimo/lora.
-
-The code in this repo is partly adapted from the following repository:
-https://huggingface.co/spaces/multimodalart/dreambooth-training/tree/a00184917aa273c6d8adab08d5deb9b39b997938
-The license of the original code is MIT, which is specified in the README.md.
-"""
-
-from __future__ import annotations
-
-import os
-import pathlib
-
-import gradio as gr
-import torch
-
-from inference import InferencePipeline
-from trainer import Trainer
-from uploader import upload
-
-TITLE = '# LoRA + StableDiffusion Training UI'
-DESCRIPTION = 'This is an unofficial demo for [https://github.com/cloneofsimo/lora](https://github.com/cloneofsimo/lora).'
-
-ORIGINAL_SPACE_ID = 'hysts/LoRA-SD-training'
-SPACE_ID = os.getenv('SPACE_ID', ORIGINAL_SPACE_ID)
-SHARED_UI_WARNING = f'''# Attention - This Space doesn't work in this shared UI. You can duplicate and use it with a paid private T4 GPU.
-
-
-'''
-if os.getenv('SYSTEM') == 'spaces' and SPACE_ID != ORIGINAL_SPACE_ID:
- SETTINGS = f'Settings'
-
-else:
- SETTINGS = 'Settings'
-CUDA_NOT_AVAILABLE_WARNING = f'''# Attention - Running on CPU.
-
-You can assign a GPU in the {SETTINGS} tab if you are running this on HF Spaces.
-"T4 small" is sufficient to run this demo.
-
-'''
-
-
-def show_warning(warning_text: str) -> gr.Blocks:
- with gr.Blocks() as demo:
- with gr.Box():
- gr.Markdown(warning_text)
- return demo
-
-
-def update_output_files() -> dict:
- paths = sorted(pathlib.Path('results').glob('*.pt'))
- paths = [path.as_posix() for path in paths] # type: ignore
- return gr.update(value=paths or None)
-
-
-def create_training_demo(trainer: Trainer,
- pipe: InferencePipeline) -> gr.Blocks:
- with gr.Blocks() as demo:
- base_model = gr.Dropdown(
- choices=['stabilityai/stable-diffusion-2-1-base'],
- value='stabilityai/stable-diffusion-2-1-base',
- label='Base Model',
- visible=False)
- resolution = gr.Dropdown(choices=['512'],
- value='512',
- label='Resolution',
- visible=False)
-
- with gr.Row():
- with gr.Box():
- gr.Markdown('Training Data')
- concept_images = gr.Files(label='Images for your concept')
- concept_prompt = gr.Textbox(label='Concept Prompt',
- max_lines=1)
- gr.Markdown('''
- - Upload images of the style you are planning on training on.
- - For a concept prompt, use a unique, made up word to avoid collisions.
- ''')
- with gr.Box():
- gr.Markdown('Training Parameters')
- num_training_steps = gr.Number(
- label='Number of Training Steps', value=1000, precision=0)
- learning_rate = gr.Number(label='Learning Rate', value=0.0001)
- train_text_encoder = gr.Checkbox(label='Train Text Encoder',
- value=True)
- learning_rate_text = gr.Number(
- label='Learning Rate for Text Encoder', value=0.00005)
- gradient_accumulation = gr.Number(
- label='Number of Gradient Accumulation',
- value=1,
- precision=0)
- fp16 = gr.Checkbox(label='FP16', value=True)
- use_8bit_adam = gr.Checkbox(label='Use 8bit Adam', value=True)
- gr.Markdown('''
- - It will take about 8 minutes to train for 1000 steps with a T4 GPU.
- - You may want to try a small number of steps first, like 1, to see if everything works fine in your environment.
- - Note that your trained models will be deleted when the second training is started. You can upload your trained model in the "Upload" tab.
- ''')
-
- run_button = gr.Button('Start Training')
- with gr.Box():
- with gr.Row():
- check_status_button = gr.Button('Check Training Status')
- with gr.Column():
- with gr.Box():
- gr.Markdown('Message')
- training_status = gr.Markdown()
- output_files = gr.Files(label='Trained Weight Files')
-
- run_button.click(fn=pipe.clear)
- run_button.click(fn=trainer.run,
- inputs=[
- base_model,
- resolution,
- concept_images,
- concept_prompt,
- num_training_steps,
- learning_rate,
- train_text_encoder,
- learning_rate_text,
- gradient_accumulation,
- fp16,
- use_8bit_adam,
- ],
- outputs=[
- training_status,
- output_files,
- ],
- queue=False)
- check_status_button.click(fn=trainer.check_if_running,
- inputs=None,
- outputs=training_status,
- queue=False)
- check_status_button.click(fn=update_output_files,
- inputs=None,
- outputs=output_files,
- queue=False)
- return demo
-
-
-def find_weight_files() -> list[str]:
- curr_dir = pathlib.Path(__file__).parent
- paths = sorted(curr_dir.rglob('*.pt'))
- paths = [path for path in paths if not path.stem.endswith('.text_encoder')]
- return [path.relative_to(curr_dir).as_posix() for path in paths]
-
-
-def reload_lora_weight_list() -> dict:
- return gr.update(choices=find_weight_files())
-
-
-def create_inference_demo(pipe: InferencePipeline) -> gr.Blocks:
- with gr.Blocks() as demo:
- with gr.Row():
- with gr.Column():
- base_model = gr.Dropdown(
- choices=['stabilityai/stable-diffusion-2-1-base'],
- value='stabilityai/stable-diffusion-2-1-base',
- label='Base Model',
- visible=False)
- reload_button = gr.Button('Reload Weight List')
- lora_weight_name = gr.Dropdown(choices=find_weight_files(),
- value='lora/lora_disney.pt',
- label='LoRA Weight File')
- prompt = gr.Textbox(
- label='Prompt',
- max_lines=1,
- placeholder='Example: "style of sks, baby lion"')
- alpha = gr.Slider(label='Alpha',
- minimum=0,
- maximum=2,
- step=0.05,
- value=1)
- alpha_for_text = gr.Slider(label='Alpha for Text Encoder',
- minimum=0,
- maximum=2,
- step=0.05,
- value=1)
- seed = gr.Slider(label='Seed',
- minimum=0,
- maximum=100000,
- step=1,
- value=1)
- with gr.Accordion('Other Parameters', open=False):
- num_steps = gr.Slider(label='Number of Steps',
- minimum=0,
- maximum=100,
- step=1,
- value=50)
- guidance_scale = gr.Slider(label='CFG Scale',
- minimum=0,
- maximum=50,
- step=0.1,
- value=7)
-
- run_button = gr.Button('Generate')
-
- gr.Markdown('''
- - Models with names starting with "lora/" are the pretrained models provided in the [original repo](https://github.com/cloneofsimo/lora), and the ones with names starting with "results/" are your trained models.
- - After training, you can press "Reload Weight List" button to load your trained model names.
- - The pretrained models for "disney", "illust" and "pop" are trained with the concept prompt "style of sks".
- - The pretrained model for "kiriko" is trained with the concept prompt "game character bnha". For this model, the text encoder is also trained.
- ''')
- with gr.Column():
- result = gr.Image(label='Result')
-
- reload_button.click(fn=reload_lora_weight_list,
- inputs=None,
- outputs=lora_weight_name)
- prompt.submit(fn=pipe.run,
- inputs=[
- base_model,
- lora_weight_name,
- prompt,
- alpha,
- alpha_for_text,
- seed,
- num_steps,
- guidance_scale,
- ],
- outputs=result,
- queue=False)
- run_button.click(fn=pipe.run,
- inputs=[
- base_model,
- lora_weight_name,
- prompt,
- alpha,
- alpha_for_text,
- seed,
- num_steps,
- guidance_scale,
- ],
- outputs=result,
- queue=False)
- return demo
-
-
-def create_upload_demo() -> gr.Blocks:
- with gr.Blocks() as demo:
- model_name = gr.Textbox(label='Model Name')
- hf_token = gr.Textbox(
- label='Hugging Face Token (with write permission)')
- upload_button = gr.Button('Upload')
- with gr.Box():
- gr.Markdown('Message')
- result = gr.Markdown()
- gr.Markdown('''
- - You can upload your trained model to your private Model repo (i.e. https://huggingface.co/{your_username}/{model_name}).
- - You can find your Hugging Face token [here](https://huggingface.co/settings/tokens).
- ''')
-
- upload_button.click(fn=upload,
- inputs=[model_name, hf_token],
- outputs=result)
-
- return demo
-
-
-pipe = InferencePipeline()
-trainer = Trainer()
-
-with gr.Blocks(css='style.css') as demo:
- if os.getenv('IS_SHARED_UI'):
- show_warning(SHARED_UI_WARNING)
- if not torch.cuda.is_available():
- show_warning(CUDA_NOT_AVAILABLE_WARNING)
-
- gr.Markdown(TITLE)
- gr.Markdown(DESCRIPTION)
-
- with gr.Tabs():
- with gr.TabItem('Train'):
- create_training_demo(trainer, pipe)
- with gr.TabItem('Test'):
- create_inference_demo(pipe)
- with gr.TabItem('Upload'):
- create_upload_demo()
-
-demo.queue(default_enabled=False).launch(share=False)
diff --git a/spaces/hysts/SD-XL/app.py b/spaces/hysts/SD-XL/app.py
deleted file mode 100644
index 161a66f752bffb6053fd55b2d7cd4e4d61548902..0000000000000000000000000000000000000000
--- a/spaces/hysts/SD-XL/app.py
+++ /dev/null
@@ -1,306 +0,0 @@
-#!/usr/bin/env python
-
-from __future__ import annotations
-
-import os
-import random
-
-import gradio as gr
-import numpy as np
-import PIL.Image
-import torch
-from diffusers import AutoencoderKL, DiffusionPipeline
-
-DESCRIPTION = "# SD-XL"
-if not torch.cuda.is_available():
- DESCRIPTION += "\nRunning on CPU 🥶 This demo does not work on CPU.
"
-
-MAX_SEED = np.iinfo(np.int32).max
-CACHE_EXAMPLES = torch.cuda.is_available() and os.getenv("CACHE_EXAMPLES") == "1"
-MAX_IMAGE_SIZE = int(os.getenv("MAX_IMAGE_SIZE", "1024"))
-USE_TORCH_COMPILE = os.getenv("USE_TORCH_COMPILE") == "1"
-ENABLE_CPU_OFFLOAD = os.getenv("ENABLE_CPU_OFFLOAD") == "1"
-ENABLE_REFINER = os.getenv("ENABLE_REFINER", "1") == "1"
-
-device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
-if torch.cuda.is_available():
- vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
- pipe = DiffusionPipeline.from_pretrained(
- "stabilityai/stable-diffusion-xl-base-1.0",
- vae=vae,
- torch_dtype=torch.float16,
- use_safetensors=True,
- variant="fp16",
- )
- if ENABLE_REFINER:
- refiner = DiffusionPipeline.from_pretrained(
- "stabilityai/stable-diffusion-xl-refiner-1.0",
- vae=vae,
- torch_dtype=torch.float16,
- use_safetensors=True,
- variant="fp16",
- )
-
- if ENABLE_CPU_OFFLOAD:
- pipe.enable_model_cpu_offload()
- if ENABLE_REFINER:
- refiner.enable_model_cpu_offload()
- else:
- pipe.to(device)
- if ENABLE_REFINER:
- refiner.to(device)
-
- if USE_TORCH_COMPILE:
- pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
- if ENABLE_REFINER:
- refiner.unet = torch.compile(refiner.unet, mode="reduce-overhead", fullgraph=True)
-
-
-def randomize_seed_fn(seed: int, randomize_seed: bool) -> int:
- if randomize_seed:
- seed = random.randint(0, MAX_SEED)
- return seed
-
-
-def generate(
- prompt: str,
- negative_prompt: str = "",
- prompt_2: str = "",
- negative_prompt_2: str = "",
- use_negative_prompt: bool = False,
- use_prompt_2: bool = False,
- use_negative_prompt_2: bool = False,
- seed: int = 0,
- width: int = 1024,
- height: int = 1024,
- guidance_scale_base: float = 5.0,
- guidance_scale_refiner: float = 5.0,
- num_inference_steps_base: int = 25,
- num_inference_steps_refiner: int = 25,
- apply_refiner: bool = False,
-) -> PIL.Image.Image:
- generator = torch.Generator().manual_seed(seed)
-
- if not use_negative_prompt:
- negative_prompt = None # type: ignore
- if not use_prompt_2:
- prompt_2 = None # type: ignore
- if not use_negative_prompt_2:
- negative_prompt_2 = None # type: ignore
-
- if not apply_refiner:
- return pipe(
- prompt=prompt,
- negative_prompt=negative_prompt,
- prompt_2=prompt_2,
- negative_prompt_2=negative_prompt_2,
- width=width,
- height=height,
- guidance_scale=guidance_scale_base,
- num_inference_steps=num_inference_steps_base,
- generator=generator,
- output_type="pil",
- ).images[0]
- else:
- latents = pipe(
- prompt=prompt,
- negative_prompt=negative_prompt,
- prompt_2=prompt_2,
- negative_prompt_2=negative_prompt_2,
- width=width,
- height=height,
- guidance_scale=guidance_scale_base,
- num_inference_steps=num_inference_steps_base,
- generator=generator,
- output_type="latent",
- ).images
- image = refiner(
- prompt=prompt,
- negative_prompt=negative_prompt,
- prompt_2=prompt_2,
- negative_prompt_2=negative_prompt_2,
- guidance_scale=guidance_scale_refiner,
- num_inference_steps=num_inference_steps_refiner,
- image=latents,
- generator=generator,
- ).images[0]
- return image
-
-
-examples = [
- "Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
- "An astronaut riding a green horse",
-]
-
-with gr.Blocks(css="style.css") as demo:
- gr.Markdown(DESCRIPTION)
- gr.DuplicateButton(
- value="Duplicate Space for private use",
- elem_id="duplicate-button",
- visible=os.getenv("SHOW_DUPLICATE_BUTTON") == "1",
- )
- with gr.Group():
- with gr.Row():
- prompt = gr.Text(
- label="Prompt",
- show_label=False,
- max_lines=1,
- placeholder="Enter your prompt",
- container=False,
- )
- run_button = gr.Button("Run", scale=0)
- result = gr.Image(label="Result", show_label=False)
- with gr.Accordion("Advanced options", open=False):
- with gr.Row():
- use_negative_prompt = gr.Checkbox(label="Use negative prompt", value=False)
- use_prompt_2 = gr.Checkbox(label="Use prompt 2", value=False)
- use_negative_prompt_2 = gr.Checkbox(label="Use negative prompt 2", value=False)
- negative_prompt = gr.Text(
- label="Negative prompt",
- max_lines=1,
- placeholder="Enter a negative prompt",
- visible=False,
- )
- prompt_2 = gr.Text(
- label="Prompt 2",
- max_lines=1,
- placeholder="Enter your prompt",
- visible=False,
- )
- negative_prompt_2 = gr.Text(
- label="Negative prompt 2",
- max_lines=1,
- placeholder="Enter a negative prompt",
- visible=False,
- )
-
- seed = gr.Slider(
- label="Seed",
- minimum=0,
- maximum=MAX_SEED,
- step=1,
- value=0,
- )
- randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
- with gr.Row():
- width = gr.Slider(
- label="Width",
- minimum=256,
- maximum=MAX_IMAGE_SIZE,
- step=32,
- value=1024,
- )
- height = gr.Slider(
- label="Height",
- minimum=256,
- maximum=MAX_IMAGE_SIZE,
- step=32,
- value=1024,
- )
- apply_refiner = gr.Checkbox(label="Apply refiner", value=False, visible=ENABLE_REFINER)
- with gr.Row():
- guidance_scale_base = gr.Slider(
- label="Guidance scale for base",
- minimum=1,
- maximum=20,
- step=0.1,
- value=5.0,
- )
- num_inference_steps_base = gr.Slider(
- label="Number of inference steps for base",
- minimum=10,
- maximum=100,
- step=1,
- value=25,
- )
- with gr.Row(visible=False) as refiner_params:
- guidance_scale_refiner = gr.Slider(
- label="Guidance scale for refiner",
- minimum=1,
- maximum=20,
- step=0.1,
- value=5.0,
- )
- num_inference_steps_refiner = gr.Slider(
- label="Number of inference steps for refiner",
- minimum=10,
- maximum=100,
- step=1,
- value=25,
- )
-
- gr.Examples(
- examples=examples,
- inputs=prompt,
- outputs=result,
- fn=generate,
- cache_examples=CACHE_EXAMPLES,
- )
-
- use_negative_prompt.change(
- fn=lambda x: gr.update(visible=x),
- inputs=use_negative_prompt,
- outputs=negative_prompt,
- queue=False,
- api_name=False,
- )
- use_prompt_2.change(
- fn=lambda x: gr.update(visible=x),
- inputs=use_prompt_2,
- outputs=prompt_2,
- queue=False,
- api_name=False,
- )
- use_negative_prompt_2.change(
- fn=lambda x: gr.update(visible=x),
- inputs=use_negative_prompt_2,
- outputs=negative_prompt_2,
- queue=False,
- api_name=False,
- )
- apply_refiner.change(
- fn=lambda x: gr.update(visible=x),
- inputs=apply_refiner,
- outputs=refiner_params,
- queue=False,
- api_name=False,
- )
-
- gr.on(
- triggers=[
- prompt.submit,
- negative_prompt.submit,
- prompt_2.submit,
- negative_prompt_2.submit,
- run_button.click,
- ],
- fn=randomize_seed_fn,
- inputs=[seed, randomize_seed],
- outputs=seed,
- queue=False,
- api_name=False,
- ).then(
- fn=generate,
- inputs=[
- prompt,
- negative_prompt,
- prompt_2,
- negative_prompt_2,
- use_negative_prompt,
- use_prompt_2,
- use_negative_prompt_2,
- seed,
- width,
- height,
- guidance_scale_base,
- guidance_scale_refiner,
- num_inference_steps_base,
- num_inference_steps_refiner,
- apply_refiner,
- ],
- outputs=result,
- api_name="run",
- )
-
-if __name__ == "__main__":
- demo.queue(max_size=20).launch()
diff --git a/spaces/iamstolas/STOLAS/src/lib/bots/bing/types.ts b/spaces/iamstolas/STOLAS/src/lib/bots/bing/types.ts
deleted file mode 100644
index 02cd5e8b01e3529642d28dc1539bf958f4ac420b..0000000000000000000000000000000000000000
--- a/spaces/iamstolas/STOLAS/src/lib/bots/bing/types.ts
+++ /dev/null
@@ -1,259 +0,0 @@
-export type Author = 'user' | 'system' | 'bot'
-
-export type BotId = 'bing'
-
-export enum BingConversationStyle {
- Creative = 'Creative',
- Balanced = 'Balanced',
- Precise = 'Precise'
-}
-
-export enum ErrorCode {
- CONVERSATION_LIMIT = 'CONVERSATION_LIMIT',
- BING_UNAUTHORIZED = 'BING_UNAUTHORIZED',
- BING_FORBIDDEN = 'BING_FORBIDDEN',
- BING_CAPTCHA = 'BING_CAPTCHA',
- THROTTLE_LIMIT = 'THROTTLE_LIMIT',
- NOTFOUND_ERROR = 'NOT_FOUND_ERROR',
- UNKOWN_ERROR = 'UNKOWN_ERROR',
- NETWORK_ERROR = 'NETWORK_ERROR',
-}
-
-export class ChatError extends Error {
- code: ErrorCode
- constructor(message: string, code: ErrorCode) {
- super(message)
- this.code = code
- }
-}
-
-export type ChatMessageModel = {
- id: string
- author: Author
- text: string
- error?: ChatError
- throttling?: Throttling
- sourceAttributions?: SourceAttribution[]
- suggestedResponses?: SuggestedResponse[]
-}
-
-export interface ConversationModel {
- messages: ChatMessageModel[]
-}
-
-export type Event =
- | {
- type: 'UPDATE_ANSWER'
- data: {
- text: string
- spokenText?: string
- sourceAttributions?: SourceAttribution[]
- suggestedResponses?: SuggestedResponse[]
- throttling?: Throttling
- }
- }
- | {
- type: 'DONE'
- }
- | {
- type: 'ERROR'
- error: ChatError
- }
-
-export interface SendMessageParams {
- prompt: string
- imageUrl?: string
- options: T
- onEvent: (event: Event) => void
- signal?: AbortSignal
-}
-
-export interface ConversationResponse {
- conversationId: string
- clientId: string
- conversationSignature: string
- result: {
- value: string
- message?: string
- }
-}
-
-export interface Telemetry {
- metrics?: null
- startTime: string
-}
-
-export interface ChatUpdateArgument {
- messages?: ChatResponseMessage[]
- throttling?: Throttling
- requestId: string
- result: null
-}
-
-export type ChatUpdateCompleteResponse = {
- type: 2
- invocationId: string
- item: ChatResponseItem
-} | {
- type: 1
- target: string
- arguments: ChatUpdateArgument[]
-} | {
- type: 3
- invocationId: string
-} | {
- type: 6 | 7
-}
-
-export interface ChatRequestResult {
- value: string
- serviceVersion: string
- error?: string
-}
-
-export interface ChatResponseItem {
- messages: ChatResponseMessage[]
- firstNewMessageIndex: number
- suggestedResponses: null
- conversationId: string
- requestId: string
- conversationExpiryTime: string
- telemetry: Telemetry
- result: ChatRequestResult
- throttling: Throttling
-}
-export enum InvocationEventType {
- Invocation = 1,
- StreamItem = 2,
- Completion = 3,
- StreamInvocation = 4,
- CancelInvocation = 5,
- Ping = 6,
- Close = 7,
-}
-
-// https://github.com/bytemate/bingchat-api/blob/main/src/lib.ts
-
-export interface ConversationInfo {
- conversationId: string
- clientId: string
- conversationSignature: string
- invocationId: number
- conversationStyle: BingConversationStyle
- prompt: string
- imageUrl?: string
-}
-
-export interface BingChatResponse {
- conversationSignature: string
- conversationId: string
- clientId: string
- invocationId: number
- conversationExpiryTime: Date
- response: string
- details: ChatResponseMessage
-}
-
-export interface Throttling {
- maxNumLongDocSummaryUserMessagesInConversation: number
- maxNumUserMessagesInConversation: number
- numLongDocSummaryUserMessagesInConversation: number
- numUserMessagesInConversation: number
-}
-
-export interface ChatResponseMessage {
- text: string
- spokenText?: string
- author: string
- createdAt: Date
- timestamp: Date
- messageId: string
- requestId: string
- offense: string
- adaptiveCards: AdaptiveCard[]
- sourceAttributions: SourceAttribution[]
- feedback: Feedback
- contentOrigin: string
- messageType?: string
- contentType?: string
- privacy: null
- suggestedResponses: SuggestedResponse[]
-}
-
-export interface AdaptiveCard {
- type: string
- version: string
- body: Body[]
-}
-
-export interface Body {
- type: string
- text: string
- wrap: boolean
- size?: string
-}
-
-export interface Feedback {
- tag: null
- updatedOn: null
- type: string
-}
-
-export interface SourceAttribution {
- providerDisplayName: string
- seeMoreUrl: string
- searchQuery: string
-}
-
-export interface SuggestedResponse {
- text: string
- author?: Author
- createdAt?: Date
- timestamp?: Date
- messageId?: string
- messageType?: string
- offense?: string
- feedback?: Feedback
- contentOrigin?: string
- privacy?: null
-}
-
-export interface KBlobRequest {
- knowledgeRequest: KnowledgeRequestContext
- imageBase64?: string
-}
-
-export interface KBlobResponse {
- blobId: string
- processedBlobId?: string
-}
-
-export interface KnowledgeRequestContext {
- imageInfo: ImageInfo;
- knowledgeRequest: KnowledgeRequest;
-}
-
-export interface ImageInfo {
- url?: string;
-}
-
-export interface KnowledgeRequest {
- invokedSkills: string[];
- subscriptionId: string;
- invokedSkillsRequestData: InvokedSkillsRequestData;
- convoData: ConvoData;
-}
-
-export interface ConvoData {
- convoid: string;
- convotone: BingConversationStyle;
-}
-
-export interface InvokedSkillsRequestData {
- enableFaceBlur: boolean;
-}
-
-export interface FileItem {
- url: string;
- status?: 'loading' | 'error' | 'loaded'
-}
diff --git a/spaces/ifey/chatdemo/gradiodemo/Demo/mHtl/D.py b/spaces/ifey/chatdemo/gradiodemo/Demo/mHtl/D.py
deleted file mode 100644
index 3b5482de87e42a70492ce5fcfd10a42d783c3883..0000000000000000000000000000000000000000
--- a/spaces/ifey/chatdemo/gradiodemo/Demo/mHtl/D.py
+++ /dev/null
@@ -1,17 +0,0 @@
-import gradio as gr
-
-# 定义处理函数,根据用户输入生成不同的按钮
-def dynamic_buttons(user_input):
- if user_input == "A":
- button_html = ""
- elif user_input == "B":
- button_html = ""
- else:
- button_html = ""
- return button_html
-
-# 创建 Gradio 接口,输入是文本,输出是HTML
-iface = gr.Interface(fn=dynamic_buttons, inputs="text", outputs="html")
-
-# 启动界面
-iface.launch()
diff --git a/spaces/imseldrith/DeepFakeAI/DeepFakeAI/uis/components/execution.py b/spaces/imseldrith/DeepFakeAI/DeepFakeAI/uis/components/execution.py
deleted file mode 100644
index 23de9f5d50b365eeeee50db56af8cc78e6eccf73..0000000000000000000000000000000000000000
--- a/spaces/imseldrith/DeepFakeAI/DeepFakeAI/uis/components/execution.py
+++ /dev/null
@@ -1,64 +0,0 @@
-from typing import List, Optional
-import gradio
-import onnxruntime
-
-import DeepFakeAI.globals
-from DeepFakeAI import wording
-from DeepFakeAI.face_analyser import clear_face_analyser
-from DeepFakeAI.processors.frame.core import clear_frame_processors_modules
-from DeepFakeAI.uis.typing import Update
-from DeepFakeAI.utilities import encode_execution_providers, decode_execution_providers
-
-EXECUTION_PROVIDERS_CHECKBOX_GROUP : Optional[gradio.CheckboxGroup] = None
-EXECUTION_THREAD_COUNT_SLIDER : Optional[gradio.Slider] = None
-EXECUTION_QUEUE_COUNT_SLIDER : Optional[gradio.Slider] = None
-
-
-def render() -> None:
- global EXECUTION_PROVIDERS_CHECKBOX_GROUP
- global EXECUTION_THREAD_COUNT_SLIDER
- global EXECUTION_QUEUE_COUNT_SLIDER
-
- with gradio.Box():
- EXECUTION_PROVIDERS_CHECKBOX_GROUP = gradio.CheckboxGroup(
- label = wording.get('execution_providers_checkbox_group_label'),
- choices = encode_execution_providers(onnxruntime.get_available_providers()),
- value = encode_execution_providers(DeepFakeAI.globals.execution_providers)
- )
- EXECUTION_THREAD_COUNT_SLIDER = gradio.Slider(
- label = wording.get('execution_thread_count_slider_label'),
- value = DeepFakeAI.globals.execution_thread_count,
- step = 1,
- minimum = 1,
- maximum = 128
- )
- EXECUTION_QUEUE_COUNT_SLIDER = gradio.Slider(
- label = wording.get('execution_queue_count_slider_label'),
- value = DeepFakeAI.globals.execution_queue_count,
- step = 1,
- minimum = 1,
- maximum = 16
- )
-
-
-def listen() -> None:
- EXECUTION_PROVIDERS_CHECKBOX_GROUP.change(update_execution_providers, inputs = EXECUTION_PROVIDERS_CHECKBOX_GROUP, outputs = EXECUTION_PROVIDERS_CHECKBOX_GROUP)
- EXECUTION_THREAD_COUNT_SLIDER.change(update_execution_thread_count, inputs = EXECUTION_THREAD_COUNT_SLIDER, outputs = EXECUTION_THREAD_COUNT_SLIDER)
- EXECUTION_QUEUE_COUNT_SLIDER.change(update_execution_queue_count, inputs = EXECUTION_QUEUE_COUNT_SLIDER, outputs = EXECUTION_QUEUE_COUNT_SLIDER)
-
-
-def update_execution_providers(execution_providers : List[str]) -> Update:
- clear_face_analyser()
- clear_frame_processors_modules()
- DeepFakeAI.globals.execution_providers = decode_execution_providers(execution_providers)
- return gradio.update(value = execution_providers)
-
-
-def update_execution_thread_count(execution_thread_count : int = 1) -> Update:
- DeepFakeAI.globals.execution_thread_count = execution_thread_count
- return gradio.update(value = execution_thread_count)
-
-
-def update_execution_queue_count(execution_queue_count : int = 1) -> Update:
- DeepFakeAI.globals.execution_queue_count = execution_queue_count
- return gradio.update(value = execution_queue_count)
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Company-of-Heroes-2-Ardennes-Assault-crack HOT-only-RELOADED.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Company-of-Heroes-2-Ardennes-Assault-crack HOT-only-RELOADED.md
deleted file mode 100644
index 5008537a9686b42ad6f14a376f09a094270540b1..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Company-of-Heroes-2-Ardennes-Assault-crack HOT-only-RELOADED.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Company-of-Heroes-2-Ardennes-Assault-Crack-only-RELOADED
DOWNLOAD ★★★ https://urlin.us/2uEvWL
-
-Company of Heroes 2 Ardennes Assault PC Full Repack ... Install Gamenya; Copy file Crack nya ke dalam folder dimana kamu install gamenya ... 4d29de3e1b
-
-
-
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Football Manager 2008 Crack Patch 8.0.2 LINK.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Football Manager 2008 Crack Patch 8.0.2 LINK.md
deleted file mode 100644
index 0fd10c77e66adc66fc0de4430b8cfd09e73482fe..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Football Manager 2008 Crack Patch 8.0.2 LINK.md
+++ /dev/null
@@ -1,30 +0,0 @@
-Football Manager 2008 Crack Patch 8.0.2
Download File ►►► https://urlin.us/2uExFQ
-
-- Duration: 24s - Start: 2014/11/27 19:28:53 - Views: 10921 - Rating: 9.72
-
-Hailing from a family of football managers, you will find yourself on the touchline at almost every game. Throw in a "hello i'm back" like an over-ambitious mother-in-law, and you are going to be on a slippery slope to failure.
-
-An ideal position to start playing football manager, as you can get in everywhere. But be careful, as your full day job is that of a hobo, and you might attract some unwanted attention.
-
-Your wife might be slightly displeased, as your current occupation of a football manager is currently earning you a smaller piece of the pubter than a used JCB.
-
-Your five kids might also be unimpressed, as you're not doing much to raise them to love football, or respect their elders. Plus, when they are teenagers, they will be all about tits, breasts, and sports cars. So you will be a bit of a lost cause.
-
-**Please note, some of you may accidentally stumble into a game of football manager while playing "football manager 2" in one of your sheds. It is unlikely, as it has not been possible to create the "football manager 3" before the "football manager 2" was released. However, to be on the safe side, always kill yourself before playing "football manager 2".**
-
-People who downloaded this also downloaded:
-
-Football Manager 2017 08 - Duration: 39s - Start: 2014/11/27 19:28:56 - Views: 6907 - Rating: 9.71
-
-Football manager 2012 - Duration: 37s - Start: 2014/11/27 19:28:59 - Views: 2044 - Rating: 9.63
-
-Football manager 2014 - Duration: 45s - Start: 2014/11/27 19:28:54 - Views: 7051 - Rating: 9.61
-
-Football manager 2013 - Duration: 36s - Start: 2014/11/27 19:28:59 - Views: 6801 - Rating: 9.61
-
-Football manager 2007 - Duration: 37s - Start: 2014/11/27 19:28:55 - Views: 4752 - Rating: 9.60
-
-Football manager 2009 - Duration: 36s - Start: 2014/11/27 19:28:58 - Views: 69 4fefd39f24
-
-
-
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Full LINK Windows 7 Ultimate SP1 Super Lite 098GB X64.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Full LINK Windows 7 Ultimate SP1 Super Lite 098GB X64.md
deleted file mode 100644
index 2282870e74369d95e541199c28df8e14c74d0e3d..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Full LINK Windows 7 Ultimate SP1 Super Lite 098GB X64.md
+++ /dev/null
@@ -1,6 +0,0 @@
-FULL Windows 7 Ultimate SP1 Super Lite 0,98GB x64
Download >>> https://urlin.us/2uEwL6
-
-March 5, 2019 - Windows 7 SP1 Ultimate X64 including Office14 pt-BR Aug 2017 Gen2 3.73 GB . 3.85GB Windows 7 Ultimate SP1 Super Lite 0.98GB x64 1008MB##hate story movie.Windows 7 Ultimate SP1 Super Lite 0.98GB x64 download. The cast of the film "Hate Story". Hate story 3 movie bittorrent. Hate Story 3 / Freaks and Geeks (2016) movie "Hate Story 3 / Freaks and Geeks" - watch online, free, without registration, in high quality! Thriller, Drama, Crime. Cast: Anthony Hopkins, Alec Baldwin, Anthony Ray Parker. Each person has a secret - a story that haunts him, and, sometimes, even leads to a loss of reason. The main character is a young woman who hides a terrible secret from her family and friends. She is not alone in her grief. 8a78ff9644
-
-
-
diff --git a/spaces/jbilcke-hf/VideoQuest/src/app/interface/last-event/index.tsx b/spaces/jbilcke-hf/VideoQuest/src/app/interface/last-event/index.tsx
deleted file mode 100644
index cc3cf5a0a1e4dbd96f5cb90da610a084f826f669..0000000000000000000000000000000000000000
--- a/spaces/jbilcke-hf/VideoQuest/src/app/interface/last-event/index.tsx
+++ /dev/null
@@ -1,21 +0,0 @@
-import { cn } from "@/lib/utils"
-import { ReactNode } from "react"
-
-export function LastEvent({ children, className = "" }: {
- children: ReactNode
- className?: string
-}) {
- return (
-
- )
-}
\ No newline at end of file
diff --git a/spaces/jbilcke-hf/VideoQuest/src/app/queries/getBase.ts b/spaces/jbilcke-hf/VideoQuest/src/app/queries/getBase.ts
deleted file mode 100644
index 81850c4ed7c449346edd8ba82b5b601bfeeb9339..0000000000000000000000000000000000000000
--- a/spaces/jbilcke-hf/VideoQuest/src/app/queries/getBase.ts
+++ /dev/null
@@ -1,25 +0,0 @@
-import { Game } from "@/app/games/types"
-
-export const getBase = ({
- game,
- situation = "",
- lastEvent = "",
-}: {
- game: Game;
- situation: string;
- lastEvent: string;
-}) => {
- const initialPrompt = [...game.getScenePrompt()].join(", ")
-
- const currentPrompt = situation
- ? [...game.getScenePrompt(situation)].join(", ")
- : initialPrompt
-
- const userSituationPrompt = [
- ...game.description,
- `Player is currently in "${currentPrompt}".`,
- lastEvent
- ].join(" ")
-
- return { initialPrompt, currentPrompt, userSituationPrompt }
-}
\ No newline at end of file
diff --git a/spaces/jbilcke-hf/webapp-factory-wizardcoder/public/index.html b/spaces/jbilcke-hf/webapp-factory-wizardcoder/public/index.html
deleted file mode 100644
index d69beeec4ee41cf6e921f892fd8cc37f813d5369..0000000000000000000000000000000000000000
--- a/spaces/jbilcke-hf/webapp-factory-wizardcoder/public/index.html
+++ /dev/null
@@ -1,186 +0,0 @@
-
-
- Webapp Factory 🏭
-
-
-
-
-
-
-
-
-
-
-
- Webapp Factory 🏭
-
-
-
A space to generate tiny web apps.
-
In case of hallucination try generating again 🎲
-
-
-
- Examples:
-
- compute my BMI,
- photos of savanna animals
-
-
-
-
- Model used:
-
- WizardCoder-15B-1.0
-
-
-
Powered by 🤗 Inference Endpoints
-
- Waiting for the stream to begin (might take a few minutes)..
-
-
- Content size: . This version generates up
- to 1686 tokens.
-
-
-
-
-
-
-
-
-
-
-
🤖
-
Generating your app..
-
-
-
-
-QASRL Website | Model Repo at Huggingface Hub
-
"""
-
-
-def call(model_name, sentence, detection_threshold):
-
- pipeline = pipelines[model_name]
- pred_infos = pipeline([sentence], detection_threshold=detection_threshold)[0]
- def pretty_qas(pred_info) -> List[str]:
- if not pred_info or not pred_info['QAs']: return []
- return [f"{qa['question']} --- {';'.join(qa['answers'])}"
- for qa in pred_info['QAs'] if qa is not None]
- all_qas = [qa for pred_info in pred_infos for qa in pretty_qas(pred_info)]
- if not pred_infos:
- pretty_qa_output = "NO NOMINALIZATION FOUND"
- elif not all_qas:
- pretty_qa_output = "NO QA GENERATED"
- else:
- pretty_qa_output = "\n".join(all_qas)
- # also present highlighted predicates
- positives = [pred_info['predicate_idx'] for pred_info in pred_infos]
- def color(idx):
- if idx in positives: return "lightgreen"
- idx2verb = {d["predicate_idx"] : d["verb_form"] for d in pred_infos}
- idx2prob = {d["predicate_idx"] : d["predicate_detector_probability"] for d in pred_infos}
- def word_span(word, idx):
- tooltip = f'title=" probability={idx2prob[idx]:.2}
verb={idx2verb[idx]}"' if idx in idx2verb else ''
- return f'{word}'
- html = '' + ' '.join(word_span(word, idx) for idx, word in enumerate(sentence.split(" "))) + ''
- return html, pretty_qa_output , pred_infos
-
-iface = gr.Interface(fn=call,
- inputs=[gr.inputs.Radio(choices=models, default=models[0], label="Model"),
- gr.inputs.Textbox(placeholder=input_sent_box_label, label="Sentence", lines=4),
- gr.inputs.Slider(minimum=0., maximum=1., step=0.01, default=0.5, label="Nominalization Detection Threshold")],
- outputs=[gr.outputs.HTML(label="Detected Nominalizations"),
- gr.outputs.Textbox(label="Generated QAs"),
- gr.outputs.JSON(label="Raw Model Output")],
- title=title,
- description=description,
- article=links,
- examples=examples)
-iface.launch()
\ No newline at end of file
diff --git a/spaces/krazyxki/V-1488abed/src/proxy/middleware/request/index.ts b/spaces/krazyxki/V-1488abed/src/proxy/middleware/request/index.ts
deleted file mode 100644
index 5d69595840e27f1f00df624e756d04af0fc876ad..0000000000000000000000000000000000000000
--- a/spaces/krazyxki/V-1488abed/src/proxy/middleware/request/index.ts
+++ /dev/null
@@ -1,10 +0,0 @@
-import type { Request } from "express";
-import type { ClientRequest } from "http";
-import type { ProxyReqCallback } from "http-proxy";
-
-export { injectMDReq } from "./md-request";
-
-export type ExpressHttpProxyReqCallback = ProxyReqCallback<
- ClientRequest,
- Request
->;
diff --git a/spaces/kukuhtw/AutoGPT/autogpt/speech/eleven_labs.py b/spaces/kukuhtw/AutoGPT/autogpt/speech/eleven_labs.py
deleted file mode 100644
index ea84efd8ca9489b40919ecd571813fe954b078e3..0000000000000000000000000000000000000000
--- a/spaces/kukuhtw/AutoGPT/autogpt/speech/eleven_labs.py
+++ /dev/null
@@ -1,86 +0,0 @@
-"""ElevenLabs speech module"""
-import os
-
-import requests
-from playsound import playsound
-
-from autogpt.config import Config
-from autogpt.speech.base import VoiceBase
-
-PLACEHOLDERS = {"your-voice-id"}
-
-
-class ElevenLabsSpeech(VoiceBase):
- """ElevenLabs speech class"""
-
- def _setup(self) -> None:
- """Set up the voices, API key, etc.
-
- Returns:
- None: None
- """
-
- cfg = Config()
- default_voices = ["ErXwobaYiN019PkySvjV", "EXAVITQu4vr4xnSDxMaL"]
- voice_options = {
- "Rachel": "21m00Tcm4TlvDq8ikWAM",
- "Domi": "AZnzlk1XvdvUeBnXmlld",
- "Bella": "EXAVITQu4vr4xnSDxMaL",
- "Antoni": "ErXwobaYiN019PkySvjV",
- "Elli": "MF3mGyEYCl7XYWbV9V6O",
- "Josh": "TxGEqnHWrfWFTfGW9XjX",
- "Arnold": "VR6AewLTigWG4xSOukaG",
- "Adam": "pNInz6obpgDQGcFmaJgB",
- "Sam": "yoZ06aMxZJJ28mfd3POQ",
- }
- self._headers = {
- "Content-Type": "application/json",
- "xi-api-key": cfg.elevenlabs_api_key,
- }
- self._voices = default_voices.copy()
- if cfg.elevenlabs_voice_1_id in voice_options:
- cfg.elevenlabs_voice_1_id = voice_options[cfg.elevenlabs_voice_1_id]
- if cfg.elevenlabs_voice_2_id in voice_options:
- cfg.elevenlabs_voice_2_id = voice_options[cfg.elevenlabs_voice_2_id]
- self._use_custom_voice(cfg.elevenlabs_voice_1_id, 0)
- self._use_custom_voice(cfg.elevenlabs_voice_2_id, 1)
-
- def _use_custom_voice(self, voice, voice_index) -> None:
- """Use a custom voice if provided and not a placeholder
-
- Args:
- voice (str): The voice ID
- voice_index (int): The voice index
-
- Returns:
- None: None
- """
- # Placeholder values that should be treated as empty
- if voice and voice not in PLACEHOLDERS:
- self._voices[voice_index] = voice
-
- def _speech(self, text: str, voice_index: int = 0) -> bool:
- """Speak text using elevenlabs.io's API
-
- Args:
- text (str): The text to speak
- voice_index (int, optional): The voice to use. Defaults to 0.
-
- Returns:
- bool: True if the request was successful, False otherwise
- """
- tts_url = (
- f"https://api.elevenlabs.io/v1/text-to-speech/{self._voices[voice_index]}"
- )
- response = requests.post(tts_url, headers=self._headers, json={"text": text})
-
- if response.status_code == 200:
- with open("speech.mpeg", "wb") as f:
- f.write(response.content)
- playsound("speech.mpeg", True)
- os.remove("speech.mpeg")
- return True
- else:
- print("Request failed with status code:", response.status_code)
- print("Response content:", response.content)
- return False
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/importlib_resources/_adapters.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/importlib_resources/_adapters.py
deleted file mode 100644
index 50688fbb666658c5b0569a363a4ea5b75f2fc00d..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/importlib_resources/_adapters.py
+++ /dev/null
@@ -1,168 +0,0 @@
-from contextlib import suppress
-from io import TextIOWrapper
-
-from . import abc
-
-
-class SpecLoaderAdapter:
- """
- Adapt a package spec to adapt the underlying loader.
- """
-
- def __init__(self, spec, adapter=lambda spec: spec.loader):
- self.spec = spec
- self.loader = adapter(spec)
-
- def __getattr__(self, name):
- return getattr(self.spec, name)
-
-
-class TraversableResourcesLoader:
- """
- Adapt a loader to provide TraversableResources.
- """
-
- def __init__(self, spec):
- self.spec = spec
-
- def get_resource_reader(self, name):
- return CompatibilityFiles(self.spec)._native()
-
-
-def _io_wrapper(file, mode='r', *args, **kwargs):
- if mode == 'r':
- return TextIOWrapper(file, *args, **kwargs)
- elif mode == 'rb':
- return file
- raise ValueError(f"Invalid mode value '{mode}', only 'r' and 'rb' are supported")
-
-
-class CompatibilityFiles:
- """
- Adapter for an existing or non-existent resource reader
- to provide a compatibility .files().
- """
-
- class SpecPath(abc.Traversable):
- """
- Path tied to a module spec.
- Can be read and exposes the resource reader children.
- """
-
- def __init__(self, spec, reader):
- self._spec = spec
- self._reader = reader
-
- def iterdir(self):
- if not self._reader:
- return iter(())
- return iter(
- CompatibilityFiles.ChildPath(self._reader, path)
- for path in self._reader.contents()
- )
-
- def is_file(self):
- return False
-
- is_dir = is_file
-
- def joinpath(self, other):
- if not self._reader:
- return CompatibilityFiles.OrphanPath(other)
- return CompatibilityFiles.ChildPath(self._reader, other)
-
- @property
- def name(self):
- return self._spec.name
-
- def open(self, mode='r', *args, **kwargs):
- return _io_wrapper(self._reader.open_resource(None), mode, *args, **kwargs)
-
- class ChildPath(abc.Traversable):
- """
- Path tied to a resource reader child.
- Can be read but doesn't expose any meaningful children.
- """
-
- def __init__(self, reader, name):
- self._reader = reader
- self._name = name
-
- def iterdir(self):
- return iter(())
-
- def is_file(self):
- return self._reader.is_resource(self.name)
-
- def is_dir(self):
- return not self.is_file()
-
- def joinpath(self, other):
- return CompatibilityFiles.OrphanPath(self.name, other)
-
- @property
- def name(self):
- return self._name
-
- def open(self, mode='r', *args, **kwargs):
- return _io_wrapper(
- self._reader.open_resource(self.name), mode, *args, **kwargs
- )
-
- class OrphanPath(abc.Traversable):
- """
- Orphan path, not tied to a module spec or resource reader.
- Can't be read and doesn't expose any meaningful children.
- """
-
- def __init__(self, *path_parts):
- if len(path_parts) < 1:
- raise ValueError('Need at least one path part to construct a path')
- self._path = path_parts
-
- def iterdir(self):
- return iter(())
-
- def is_file(self):
- return False
-
- is_dir = is_file
-
- def joinpath(self, other):
- return CompatibilityFiles.OrphanPath(*self._path, other)
-
- @property
- def name(self):
- return self._path[-1]
-
- def open(self, mode='r', *args, **kwargs):
- raise FileNotFoundError("Can't open orphan path")
-
- def __init__(self, spec):
- self.spec = spec
-
- @property
- def _reader(self):
- with suppress(AttributeError):
- return self.spec.loader.get_resource_reader(self.spec.name)
-
- def _native(self):
- """
- Return the native reader if it supports files().
- """
- reader = self._reader
- return reader if hasattr(reader, 'files') else self
-
- def __getattr__(self, attr):
- return getattr(self._reader, attr)
-
- def files(self):
- return CompatibilityFiles.SpecPath(self.spec, self._reader)
-
-
-def wrap_spec(package):
- """
- Construct a package spec with traversable compatibility
- on the spec/loader/reader.
- """
- return SpecLoaderAdapter(package.__spec__, TraversableResourcesLoader)
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/matplotlib/testing/_markers.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/matplotlib/testing/_markers.py
deleted file mode 100644
index fa7885151e33e2ca0b4816e9e6ccb2c72da96144..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/matplotlib/testing/_markers.py
+++ /dev/null
@@ -1,49 +0,0 @@
-"""
-pytest markers for the internal Matplotlib test suite.
-"""
-
-import logging
-import shutil
-
-import pytest
-
-import matplotlib.testing
-import matplotlib.testing.compare
-from matplotlib import _get_executable_info, ExecutableNotFoundError
-
-
-_log = logging.getLogger(__name__)
-
-
-def _checkdep_usetex():
- if not shutil.which("tex"):
- _log.warning("usetex mode requires TeX.")
- return False
- try:
- _get_executable_info("dvipng")
- except ExecutableNotFoundError:
- _log.warning("usetex mode requires dvipng.")
- return False
- try:
- _get_executable_info("gs")
- except ExecutableNotFoundError:
- _log.warning("usetex mode requires ghostscript.")
- return False
- return True
-
-
-needs_ghostscript = pytest.mark.skipif(
- "eps" not in matplotlib.testing.compare.converter,
- reason="This test needs a ghostscript installation")
-needs_pgf_lualatex = pytest.mark.skipif(
- not matplotlib.testing._check_for_pgf('lualatex'),
- reason='lualatex + pgf is required')
-needs_pgf_pdflatex = pytest.mark.skipif(
- not matplotlib.testing._check_for_pgf('pdflatex'),
- reason='pdflatex + pgf is required')
-needs_pgf_xelatex = pytest.mark.skipif(
- not matplotlib.testing._check_for_pgf('xelatex'),
- reason='xelatex + pgf is required')
-needs_usetex = pytest.mark.skipif(
- not _checkdep_usetex(),
- reason="This test needs a TeX installation")
diff --git a/spaces/lambdalabs/generative-music-visualizer/torch_utils/ops/bias_act.py b/spaces/lambdalabs/generative-music-visualizer/torch_utils/ops/bias_act.py
deleted file mode 100644
index 5c485c0027570decab26f0b6602a363a432b851f..0000000000000000000000000000000000000000
--- a/spaces/lambdalabs/generative-music-visualizer/torch_utils/ops/bias_act.py
+++ /dev/null
@@ -1,209 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-"""Custom PyTorch ops for efficient bias and activation."""
-
-import os
-import numpy as np
-import torch
-import dnnlib
-
-from .. import custom_ops
-from .. import misc
-
-#----------------------------------------------------------------------------
-
-activation_funcs = {
- 'linear': dnnlib.EasyDict(func=lambda x, **_: x, def_alpha=0, def_gain=1, cuda_idx=1, ref='', has_2nd_grad=False),
- 'relu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.relu(x), def_alpha=0, def_gain=np.sqrt(2), cuda_idx=2, ref='y', has_2nd_grad=False),
- 'lrelu': dnnlib.EasyDict(func=lambda x, alpha, **_: torch.nn.functional.leaky_relu(x, alpha), def_alpha=0.2, def_gain=np.sqrt(2), cuda_idx=3, ref='y', has_2nd_grad=False),
- 'tanh': dnnlib.EasyDict(func=lambda x, **_: torch.tanh(x), def_alpha=0, def_gain=1, cuda_idx=4, ref='y', has_2nd_grad=True),
- 'sigmoid': dnnlib.EasyDict(func=lambda x, **_: torch.sigmoid(x), def_alpha=0, def_gain=1, cuda_idx=5, ref='y', has_2nd_grad=True),
- 'elu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.elu(x), def_alpha=0, def_gain=1, cuda_idx=6, ref='y', has_2nd_grad=True),
- 'selu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.selu(x), def_alpha=0, def_gain=1, cuda_idx=7, ref='y', has_2nd_grad=True),
- 'softplus': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.softplus(x), def_alpha=0, def_gain=1, cuda_idx=8, ref='y', has_2nd_grad=True),
- 'swish': dnnlib.EasyDict(func=lambda x, **_: torch.sigmoid(x) * x, def_alpha=0, def_gain=np.sqrt(2), cuda_idx=9, ref='x', has_2nd_grad=True),
-}
-
-#----------------------------------------------------------------------------
-
-_plugin = None
-_null_tensor = torch.empty([0])
-
-def _init():
- global _plugin
- if _plugin is None:
- _plugin = custom_ops.get_plugin(
- module_name='bias_act_plugin',
- sources=['bias_act.cpp', 'bias_act.cu'],
- headers=['bias_act.h'],
- source_dir=os.path.dirname(__file__),
- extra_cuda_cflags=['--use_fast_math'],
- )
- return True
-
-#----------------------------------------------------------------------------
-
-def bias_act(x, b=None, dim=1, act='linear', alpha=None, gain=None, clamp=None, impl='cuda'):
- r"""Fused bias and activation function.
-
- Adds bias `b` to activation tensor `x`, evaluates activation function `act`,
- and scales the result by `gain`. Each of the steps is optional. In most cases,
- the fused op is considerably more efficient than performing the same calculation
- using standard PyTorch ops. It supports first and second order gradients,
- but not third order gradients.
-
- Args:
- x: Input activation tensor. Can be of any shape.
- b: Bias vector, or `None` to disable. Must be a 1D tensor of the same type
- as `x`. The shape must be known, and it must match the dimension of `x`
- corresponding to `dim`.
- dim: The dimension in `x` corresponding to the elements of `b`.
- The value of `dim` is ignored if `b` is not specified.
- act: Name of the activation function to evaluate, or `"linear"` to disable.
- Can be e.g. `"relu"`, `"lrelu"`, `"tanh"`, `"sigmoid"`, `"swish"`, etc.
- See `activation_funcs` for a full list. `None` is not allowed.
- alpha: Shape parameter for the activation function, or `None` to use the default.
- gain: Scaling factor for the output tensor, or `None` to use default.
- See `activation_funcs` for the default scaling of each activation function.
- If unsure, consider specifying 1.
- clamp: Clamp the output values to `[-clamp, +clamp]`, or `None` to disable
- the clamping (default).
- impl: Name of the implementation to use. Can be `"ref"` or `"cuda"` (default).
-
- Returns:
- Tensor of the same shape and datatype as `x`.
- """
- assert isinstance(x, torch.Tensor)
- assert impl in ['ref', 'cuda']
- if impl == 'cuda' and x.device.type == 'cuda' and _init():
- return _bias_act_cuda(dim=dim, act=act, alpha=alpha, gain=gain, clamp=clamp).apply(x, b)
- return _bias_act_ref(x=x, b=b, dim=dim, act=act, alpha=alpha, gain=gain, clamp=clamp)
-
-#----------------------------------------------------------------------------
-
-@misc.profiled_function
-def _bias_act_ref(x, b=None, dim=1, act='linear', alpha=None, gain=None, clamp=None):
- """Slow reference implementation of `bias_act()` using standard TensorFlow ops.
- """
- assert isinstance(x, torch.Tensor)
- assert clamp is None or clamp >= 0
- spec = activation_funcs[act]
- alpha = float(alpha if alpha is not None else spec.def_alpha)
- gain = float(gain if gain is not None else spec.def_gain)
- clamp = float(clamp if clamp is not None else -1)
-
- # Add bias.
- if b is not None:
- assert isinstance(b, torch.Tensor) and b.ndim == 1
- assert 0 <= dim < x.ndim
- assert b.shape[0] == x.shape[dim]
- x = x + b.reshape([-1 if i == dim else 1 for i in range(x.ndim)])
-
- # Evaluate activation function.
- alpha = float(alpha)
- x = spec.func(x, alpha=alpha)
-
- # Scale by gain.
- gain = float(gain)
- if gain != 1:
- x = x * gain
-
- # Clamp.
- if clamp >= 0:
- x = x.clamp(-clamp, clamp) # pylint: disable=invalid-unary-operand-type
- return x
-
-#----------------------------------------------------------------------------
-
-_bias_act_cuda_cache = dict()
-
-def _bias_act_cuda(dim=1, act='linear', alpha=None, gain=None, clamp=None):
- """Fast CUDA implementation of `bias_act()` using custom ops.
- """
- # Parse arguments.
- assert clamp is None or clamp >= 0
- spec = activation_funcs[act]
- alpha = float(alpha if alpha is not None else spec.def_alpha)
- gain = float(gain if gain is not None else spec.def_gain)
- clamp = float(clamp if clamp is not None else -1)
-
- # Lookup from cache.
- key = (dim, act, alpha, gain, clamp)
- if key in _bias_act_cuda_cache:
- return _bias_act_cuda_cache[key]
-
- # Forward op.
- class BiasActCuda(torch.autograd.Function):
- @staticmethod
- def forward(ctx, x, b): # pylint: disable=arguments-differ
- ctx.memory_format = torch.channels_last if x.ndim > 2 and x.stride(1) == 1 else torch.contiguous_format
- x = x.contiguous(memory_format=ctx.memory_format)
- b = b.contiguous() if b is not None else _null_tensor
- y = x
- if act != 'linear' or gain != 1 or clamp >= 0 or b is not _null_tensor:
- y = _plugin.bias_act(x, b, _null_tensor, _null_tensor, _null_tensor, 0, dim, spec.cuda_idx, alpha, gain, clamp)
- ctx.save_for_backward(
- x if 'x' in spec.ref or spec.has_2nd_grad else _null_tensor,
- b if 'x' in spec.ref or spec.has_2nd_grad else _null_tensor,
- y if 'y' in spec.ref else _null_tensor)
- return y
-
- @staticmethod
- def backward(ctx, dy): # pylint: disable=arguments-differ
- dy = dy.contiguous(memory_format=ctx.memory_format)
- x, b, y = ctx.saved_tensors
- dx = None
- db = None
-
- if ctx.needs_input_grad[0] or ctx.needs_input_grad[1]:
- dx = dy
- if act != 'linear' or gain != 1 or clamp >= 0:
- dx = BiasActCudaGrad.apply(dy, x, b, y)
-
- if ctx.needs_input_grad[1]:
- db = dx.sum([i for i in range(dx.ndim) if i != dim])
-
- return dx, db
-
- # Backward op.
- class BiasActCudaGrad(torch.autograd.Function):
- @staticmethod
- def forward(ctx, dy, x, b, y): # pylint: disable=arguments-differ
- ctx.memory_format = torch.channels_last if dy.ndim > 2 and dy.stride(1) == 1 else torch.contiguous_format
- dx = _plugin.bias_act(dy, b, x, y, _null_tensor, 1, dim, spec.cuda_idx, alpha, gain, clamp)
- ctx.save_for_backward(
- dy if spec.has_2nd_grad else _null_tensor,
- x, b, y)
- return dx
-
- @staticmethod
- def backward(ctx, d_dx): # pylint: disable=arguments-differ
- d_dx = d_dx.contiguous(memory_format=ctx.memory_format)
- dy, x, b, y = ctx.saved_tensors
- d_dy = None
- d_x = None
- d_b = None
- d_y = None
-
- if ctx.needs_input_grad[0]:
- d_dy = BiasActCudaGrad.apply(d_dx, x, b, y)
-
- if spec.has_2nd_grad and (ctx.needs_input_grad[1] or ctx.needs_input_grad[2]):
- d_x = _plugin.bias_act(d_dx, b, x, y, dy, 2, dim, spec.cuda_idx, alpha, gain, clamp)
-
- if spec.has_2nd_grad and ctx.needs_input_grad[2]:
- d_b = d_x.sum([i for i in range(d_x.ndim) if i != dim])
-
- return d_dy, d_x, d_b, d_y
-
- # Add to cache.
- _bias_act_cuda_cache[key] = BiasActCuda
- return BiasActCuda
-
-#----------------------------------------------------------------------------
diff --git a/spaces/leogabraneth/text-generation-webui-main/start_macos.sh b/spaces/leogabraneth/text-generation-webui-main/start_macos.sh
deleted file mode 100644
index 5877e1676914f5ba983f161b5dc7dcc14ee53be5..0000000000000000000000000000000000000000
--- a/spaces/leogabraneth/text-generation-webui-main/start_macos.sh
+++ /dev/null
@@ -1,67 +0,0 @@
-#!/bin/bash
-
-cd "$(dirname "${BASH_SOURCE[0]}")"
-
-if [[ "$(pwd)" =~ " " ]]; then echo This script relies on Miniconda which can not be silently installed under a path with spaces. && exit; fi
-
-# deactivate existing conda envs as needed to avoid conflicts
-{ conda deactivate && conda deactivate && conda deactivate; } 2> /dev/null
-
-# M Series or Intel
-OS_ARCH=$(uname -m)
-case "${OS_ARCH}" in
- x86_64*) OS_ARCH="x86_64";;
- arm64*) OS_ARCH="arm64";;
- *) echo "Unknown system architecture: $OS_ARCH! This script runs only on x86_64 or arm64" && exit
-esac
-
-# config
-INSTALL_DIR="$(pwd)/installer_files"
-CONDA_ROOT_PREFIX="$(pwd)/installer_files/conda"
-INSTALL_ENV_DIR="$(pwd)/installer_files/env"
-MINICONDA_DOWNLOAD_URL="https://repo.anaconda.com/miniconda/Miniconda3-py310_23.3.1-0-MacOSX-${OS_ARCH}.sh"
-conda_exists="F"
-
-# figure out whether git and conda needs to be installed
-if "$CONDA_ROOT_PREFIX/bin/conda" --version &>/dev/null; then conda_exists="T"; fi
-
-# (if necessary) install git and conda into a contained environment
-# download miniconda
-if [ "$conda_exists" == "F" ]; then
- echo "Downloading Miniconda from $MINICONDA_DOWNLOAD_URL to $INSTALL_DIR/miniconda_installer.sh"
-
- mkdir -p "$INSTALL_DIR"
- curl -Lk "$MINICONDA_DOWNLOAD_URL" > "$INSTALL_DIR/miniconda_installer.sh"
-
- chmod u+x "$INSTALL_DIR/miniconda_installer.sh"
- bash "$INSTALL_DIR/miniconda_installer.sh" -b -p $CONDA_ROOT_PREFIX
-
- # test the conda binary
- echo "Miniconda version:"
- "$CONDA_ROOT_PREFIX/bin/conda" --version
-fi
-
-# create the installer env
-if [ ! -e "$INSTALL_ENV_DIR" ]; then
- "$CONDA_ROOT_PREFIX/bin/conda" create -y -k --prefix "$INSTALL_ENV_DIR" python=3.11
-fi
-
-# check if conda environment was actually created
-if [ ! -e "$INSTALL_ENV_DIR/bin/python" ]; then
- echo "Conda environment is empty."
- exit
-fi
-
-# environment isolation
-export PYTHONNOUSERSITE=1
-unset PYTHONPATH
-unset PYTHONHOME
-export CUDA_PATH="$INSTALL_ENV_DIR"
-export CUDA_HOME="$CUDA_PATH"
-
-# activate installer env
-source "$CONDA_ROOT_PREFIX/etc/profile.d/conda.sh" # otherwise conda complains about 'shell not initialized' (needed when running in a script)
-conda activate "$INSTALL_ENV_DIR"
-
-# setup installer env
-python one_click.py $@
diff --git a/spaces/lewisliuX123/wechatglm_demo/bot/openai/open_ai_bot.py b/spaces/lewisliuX123/wechatglm_demo/bot/openai/open_ai_bot.py
deleted file mode 100644
index 79155a1aca9fdf1e975a34bc0816d602e90fd9c8..0000000000000000000000000000000000000000
--- a/spaces/lewisliuX123/wechatglm_demo/bot/openai/open_ai_bot.py
+++ /dev/null
@@ -1,166 +0,0 @@
-# encoding:utf-8
-
-from bot.bot import Bot
-from config import conf
-from common.log import logger
-import openai
-import time
-
-user_session = dict()
-
-# OpenAI对话模型API (可用)
-class OpenAIBot(Bot):
- def __init__(self):
- openai.api_key = conf().get('open_ai_api_key')
-
-
- def reply(self, query, context=None):
- # acquire reply content
- if not context or not context.get('type') or context.get('type') == 'TEXT':
- logger.info("[OPEN_AI] query={}".format(query))
- from_user_id = context['from_user_id']
- if query == '#清除记忆':
- Session.clear_session(from_user_id)
- return '记忆已清除'
- elif query == '#清除所有':
- Session.clear_all_session()
- return '所有人记忆已清除'
-
- new_query = Session.build_session_query(query, from_user_id)
- logger.debug("[OPEN_AI] session query={}".format(new_query))
-
- reply_content = self.reply_text(new_query, from_user_id, 0)
- logger.debug("[OPEN_AI] new_query={}, user={}, reply_cont={}".format(new_query, from_user_id, reply_content))
- if reply_content and query:
- Session.save_session(query, reply_content, from_user_id)
- return reply_content
-
- elif context.get('type', None) == 'IMAGE_CREATE':
- return self.create_img(query, 0)
-
- def reply_text(self, query, user_id, retry_count=0):
- try:
- response = openai.Completion.create(
- model="text-davinci-003", # 对话模型的名称
- prompt=query,
- temperature=1, # 值在[0,1]之间,越大表示回复越具有不确定性
- max_tokens=500, # 回复最大的字符数
- top_p=1,
- frequency_penalty=0.0, # [-2,2]之间,该值越大则更倾向于产生不同的内容
- presence_penalty=0.0, # [-2,2]之间,该值越大则更倾向于产生不同的内容
- stop=["\n\n\n"]
- )
- res_content = response.choices[0]['text'].strip().replace('<|endoftext|>', '')
- logger.info("[OPEN_AI] reply={}".format(res_content))
- return res_content
- except openai.error.RateLimitError as e:
- # rate limit exception
- logger.warn(e)
- if retry_count < 1:
- time.sleep(5)
- logger.warn("[OPEN_AI] RateLimit exceed, 第{}次重试".format(retry_count+1))
- return self.reply_text(query, user_id, retry_count+1)
- else:
- return "提问太快啦,请休息一下再问我吧"
- except Exception as e:
- # unknown exception
- logger.exception(e)
- Session.clear_session(user_id)
- return "请再问我一次吧"
-
-
- def create_img(self, query, retry_count=0):
- try:
- logger.info("[OPEN_AI] image_query={}".format(query))
- response = openai.Image.create(
- prompt=query, #图片描述
- n=1, #每次生成图片的数量
- size="1024x1024" #图片大小,可选有 256x256, 512x512, 1024x1024
- )
- image_url = response['data'][0]['url']
- logger.info("[OPEN_AI] image_url={}".format(image_url))
- return image_url
- except openai.error.RateLimitError as e:
- logger.warn(e)
- if retry_count < 1:
- time.sleep(5)
- logger.warn("[OPEN_AI] ImgCreate RateLimit exceed, 第{}次重试".format(retry_count+1))
- return self.reply_text(query, retry_count+1)
- else:
- return "提问太快啦,请休息一下再问我吧"
- except Exception as e:
- logger.exception(e)
- return None
-
-
-class Session(object):
- @staticmethod
- def build_session_query(query, user_id):
- '''
- build query with conversation history
- e.g. Q: xxx
- A: xxx
- Q: xxx
- :param query: query content
- :param user_id: from user id
- :return: query content with conversaction
- '''
- prompt = conf().get("character_desc", "")
- if prompt:
- prompt += "<|endoftext|>\n\n\n"
- session = user_session.get(user_id, None)
- if session:
- for conversation in session:
- prompt += "Q: " + conversation["question"] + "\n\n\nA: " + conversation["answer"] + "<|endoftext|>\n"
- prompt += "Q: " + query + "\nA: "
- return prompt
- else:
- return prompt + "Q: " + query + "\nA: "
-
- @staticmethod
- def save_session(query, answer, user_id):
- max_tokens = conf().get("conversation_max_tokens")
- if not max_tokens:
- # default 3000
- max_tokens = 1000
- conversation = dict()
- conversation["question"] = query
- conversation["answer"] = answer
- session = user_session.get(user_id)
- logger.debug(conversation)
- logger.debug(session)
- if session:
- # append conversation
- session.append(conversation)
- else:
- # create session
- queue = list()
- queue.append(conversation)
- user_session[user_id] = queue
-
- # discard exceed limit conversation
- Session.discard_exceed_conversation(user_session[user_id], max_tokens)
-
-
- @staticmethod
- def discard_exceed_conversation(session, max_tokens):
- count = 0
- count_list = list()
- for i in range(len(session)-1, -1, -1):
- # count tokens of conversation list
- history_conv = session[i]
- count += len(history_conv["question"]) + len(history_conv["answer"])
- count_list.append(count)
-
- for c in count_list:
- if c > max_tokens:
- # pop first conversation
- session.pop(0)
-
- @staticmethod
- def clear_session(user_id):
- user_session[user_id] = []
-
- @staticmethod
- def clear_all_session():
- user_session.clear()
\ No newline at end of file
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Alien Shooter V1.1.2 MOD Plus Apk Download BETTER.md b/spaces/lincquiQcaudo/Top-20-Diffusion/Alien Shooter V1.1.2 MOD Plus Apk Download BETTER.md
deleted file mode 100644
index 99430d7e7c6eaf56cd73a58dd4f1e61451e06aa7..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Alien Shooter V1.1.2 MOD Plus Apk Download BETTER.md
+++ /dev/null
@@ -1,10 +0,0 @@
-
-a special control scheme has also been set up, so the game can be played without any navigation buttons. the only thing you need to do is to tap where you want to go and hold on until the screen changes. everything else is done automatically.
-Alien Shooter v1.1.2 MOD Plus Apk Download
Download Zip === https://bytlly.com/2uGxTc
-the game has several missions that can be unlocked while playing, or they can be randomly selected. the goal is to collect as many stars as possible, and these stars will be the survival points. be careful of the special alien, as they can destroy and disable your ship.
-zombie diary 2 mod apk hack is available to download for free from the following link, as well as others for you to enjoy. the zombies will not stop until they kill you, and there will be loads of them on each screen. make sure you have a cool weapon that has more ammo so that you can protect yourself from those aliens and zombies. you will need to be careful about the special aliens, as they will kill you if they get their hands on you. if you can find the energy bar, you will feel safe.
-the game is easy to use, with intuitive controls and controls, and the only difficult thing is that when you are being chased by a zombie, you do not have any form of weapon. you can use a skull as a weapon in that case, and you will find that zombies will not know the way to a skull. zombies are behind you, in front of you, and on top of you, and it is up to you to shoot it down. be careful, because at any time, you can get zombified.
-
-so if you are looking for a free game that has high-quality graphics, a compelling story, and beautiful location in space, you should download this game. after all, this is a free download that does not require any fee to download, and the gameplay is amazing and very addictive.
899543212b
-
-
\ No newline at end of file
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Chanakya Arthashastra Telugu Pdf Free Download Hit [EXCLUSIVE].md b/spaces/lincquiQcaudo/Top-20-Diffusion/Chanakya Arthashastra Telugu Pdf Free Download Hit [EXCLUSIVE].md
deleted file mode 100644
index d40d719d779256545aa311835a347c93330e9f4c..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Chanakya Arthashastra Telugu Pdf Free Download Hit [EXCLUSIVE].md
+++ /dev/null
@@ -1,6 +0,0 @@
-Chanakya Arthashastra Telugu Pdf Free Download Hit
Download File >> https://bytlly.com/2uGxz0
-
- 3cee63e6c2
-
-
-
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Die Lustige Welt Der Tiere Film 24 Fixed.md b/spaces/lincquiQcaudo/Top-20-Diffusion/Die Lustige Welt Der Tiere Film 24 Fixed.md
deleted file mode 100644
index 05a58e19a9d79a4440ed40c5b4750be6011ee270..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Die Lustige Welt Der Tiere Film 24 Fixed.md
+++ /dev/null
@@ -1,42 +0,0 @@
-
-Die lustige Welt der Tiere Film 24: Ein tierisches Vergnügen
-Wenn Sie Lust auf einen Film haben, der Sie zum Lachen bringt und Ihnen gleichzeitig die faszinierende Tierwelt Afrikas zeigt, dann ist Die lustige Welt der Tiere Film 24 genau das Richtige für Sie. Dieser Film ist der 24. Teil einer erfolgreichen Reihe von Dokumentarfilmen, die von dem südafrikanischen Regisseur Jamie Uys gedreht wurden. Er nimmt Sie mit auf eine Reise durch die Namib-Wüste, das Okavango-Becken und die Kalahari und zeigt Ihnen, wie die Tiere dort leben, lieben und lachen.
-Was erwartet Sie in Die lustige Welt der Tiere Film 24?
-In Die lustige Welt der Tiere Film 24 erwarten Sie viele lustige und erstaunliche Szenen aus dem Leben der afrikanischen Tiere. Sie werden sehen, wie ein Laufkäfer sich im Laufen abkühlt, wie Elefanten sich an gärenden Beeren berauschen, wie Webervögel kunstvolle Gemeinschaftsnester bauen und wie Löwen ihren frechen Nachwuchs erziehen. Sie werden auch Zeuge von spannenden Momenten, wie einer mutigen Entenmutter, die ihre Küken vor einer Hyäne rettet, oder einem Nashornvogelweibchen, das sich in einer Baumhöhle einmauert, um ihren Nachwuchs aufzuziehen. Und Sie werden auch einen Einblick in die Kultur der San bekommen, einem Volk von Jägern und Sammlern, die in der Wüste leben und ihre Kinder in den Geheimnissen der Natur unterweisen. Am Ende des Films werden Sie erleben, wie ein Wolkenbruch die unter einer Trockenzeit leidenden Tiere erlöst und ihnen eine neue Hoffnung schenkt.
-die lustige welt der tiere film 24
DOWNLOAD →→→ https://bytlly.com/2uGxOE
-Warum sollten Sie Die lustige Welt der Tiere Film 24 sehen?
-Die lustige Welt der Tiere Film 24 ist nicht nur ein unterhaltsamer Film, sondern auch ein lehrreicher Film. Er zeigt Ihnen die Schönheit und Vielfalt der afrikanischen Tierwelt und macht Sie auf die Bedrohungen aufmerksam, denen sie ausgesetzt ist. Er regt Sie auch zum Nachdenken an, wie wir Menschen mit den Tieren und der Natur umgehen und was wir tun können, um sie zu schützen. Außerdem ist Die lustige Welt der Tiere Film 24 ein Film für die ganze Familie. Er ist für alle Altersgruppen geeignet und bietet Ihnen eine gemeinsame Zeit voller Spaß und Staunen.
-Wie können Sie Die lustige Welt der Tiere Film 24 sehen?
-Die lustige Welt der Tiere Film 24 ist ab sofort online verfügbar. Sie können ihn auf verschiedenen Plattformen streamen oder herunterladen. Sie können ihn auch auf DVD oder Blu-ray bestellen oder im Kino ansehen. Egal, wie Sie ihn sehen möchten, Sie werden es nicht bereuen. Die lustige Welt der Tiere Film 24 ist ein Film, den Sie immer wieder sehen möchten.
-Fazit
-Die lustige Welt der Tiere Film 24 ist ein Dokumentarfilm, der Ihnen die Tierwelt Afrikas auf eine humorvolle und informative Weise näherbringt. Er ist ein Film für alle Tierfreunde und alle, die sich für Afrika interessieren. Er ist ein Film für alle, die sich gerne amüsieren und etwas Neues lernen möchten. Er ist ein Film für alle, die einen guten Film sehen möchten. Also zögern Sie nicht länger und schauen Sie sich Die lustige Welt der Tiere Film 24 an. Sie werden es nicht bereuen.
-Wie ist Die lustige Welt der Tiere Film 24 entstanden?
-Die lustige Welt der Tiere Film 24 ist das Ergebnis von jahrelanger Arbeit des Regisseurs Jamie Uys, der schon seit den 1950er Jahren Tierfilme drehte. Er war fasziniert von der afrikanischen Natur und wollte sie in ihrer ganzen Schönheit und Komik zeigen. Er verbrachte viele Monate in der Wildnis, um die Tiere zu beobachten und zu filmen. Er benutzte dabei keine Tricks oder Manipulationen, sondern zeigte die Tiere so, wie sie wirklich sind. Er verlieh ihnen aber auch eine menschliche Note, indem er ihnen humorvolle Kommentare und Musik unterlegte. Er schuf damit einen Film, der sowohl informativ als auch unterhaltsam ist.
-Was macht Die lustige Welt der Tiere Film 24 so besonders?
-Die lustige Welt der Tiere Film 24 ist ein besonderer Film, weil er Ihnen die Tierwelt Afrikas aus einer neuen Perspektive zeigt. Er zeigt Ihnen nicht nur die majestätischen und gefährlichen Tiere wie Löwen, Elefanten oder Nashörner, sondern auch die kleinen und unscheinbaren Tiere wie Käfer, Vögel oder Fische. Er zeigt Ihnen nicht nur die dramatischen und spannenden Momente im Leben der Tiere, sondern auch die komischen und skurrilen Momente. Er zeigt Ihnen nicht nur die harten und grausamen Seiten der Natur, sondern auch die sanften und liebevollen Seiten. Er zeigt Ihnen kurz gesagt, dass die Tierwelt Afrikas eine lustige Welt ist.
-Wem empfehlen wir Die lustige Welt der Tiere Film 24?
-Wir empfehlen Die lustige Welt der Tiere Film 24 allen, die sich für Tiere und Afrika interessieren. Wir empfehlen ihn allen, die sich gerne amüsieren und etwas Neues lernen möchten. Wir empfehlen ihn allen, die einen guten Film sehen möchten. Also zögern Sie nicht länger und schauen Sie sich Die lustige Welt der Tiere Film 24 an. Sie werden es nicht bereuen.
-
-Wie können Sie Die lustige Welt der Tiere Film 24 unterstützen?
-Die lustige Welt der Tiere Film 24 ist nicht nur ein Film, sondern auch ein Appell an die Menschheit, die Tierwelt Afrikas zu schützen und zu bewahren. Die Tiere, die Sie in diesem Film sehen, sind bedroht durch Wilderei, Lebensraumverlust, Klimawandel und andere Faktoren. Wenn Sie diesen Film mögen und etwas für die Tiere tun möchten, können Sie verschiedene Möglichkeiten nutzen. Sie können zum Beispiel eine Spende an eine Organisation machen, die sich für den Schutz der afrikanischen Tierwelt einsetzt. Sie können auch eine Patenschaft für ein Tier übernehmen oder eine Adoption verschenken. Sie können auch selbst aktiv werden und sich für den Erhalt der Natur einsetzen. Sie können zum Beispiel Ihren ökologischen Fußabdruck reduzieren, nachhaltige Produkte kaufen oder sich an einer Petition beteiligen. Jede kleine Geste zählt und kann einen Unterschied machen.
-Fazit
-Die lustige Welt der Tiere Film 24 ist ein Dokumentarfilm, der Ihnen die Tierwelt Afrikas auf eine humorvolle und informative Weise näherbringt. Er ist ein Film für alle Tierfreunde und alle, die sich für Afrika interessieren. Er ist ein Film für alle, die sich gerne amüsieren und etwas Neues lernen möchten. Er ist ein Film für alle, die einen guten Film sehen möchten. Also zögern Sie nicht länger und schauen Sie sich Die lustige Welt der Tiere Film 24 an. Sie werden es nicht bereuen.
-Wie können Sie Die lustige Welt der Tiere Film 24 mit anderen teilen?
-Die lustige Welt der Tiere Film 24 ist ein Film, den Sie nicht für sich behalten sollten. Er ist ein Film, den Sie mit anderen teilen sollten. Sie können zum Beispiel Ihre Freunde oder Familie zu einem gemeinsamen Filmabend einladen und sich den Film zusammen ansehen. Sie können auch Ihre Meinung über den Film in den sozialen Medien oder auf einer Bewertungsplattform teilen und so andere Menschen auf den Film aufmerksam machen. Sie können auch eine Rezension über den Film schreiben oder einen Kommentar hinterlassen und so Ihre Gedanken und Gefühle über den Film ausdrücken. Sie können auch an einem Gewinnspiel teilnehmen und tolle Preise rund um den Film gewinnen. Es gibt viele Möglichkeiten, wie Sie Die lustige Welt der Tiere Film 24 mit anderen teilen können.
-Was können Sie nach dem Anschauen von Die lustige Welt der Tiere Film 24 tun?
-Die lustige Welt der Tiere Film 24 ist ein Film, der Ihnen noch lange in Erinnerung bleiben wird. Er ist ein Film, der Sie inspirieren und motivieren wird. Er ist ein Film, der Ihnen Lust auf mehr machen wird. Was können Sie also nach dem Anschauen von Die lustige Welt der Tiere Film 24 tun? Sie können zum Beispiel mehr über die afrikanische Tierwelt erfahren und sich weitere Dokumentarfilme oder Bücher zu diesem Thema ansehen oder lesen. Sie können auch selbst eine Reise nach Afrika planen und die Tierwelt vor Ort erleben. Sie können auch eine Tierpatenschaft übernehmen oder eine Spende machen und so einen Beitrag zum Schutz der Tiere leisten. Oder Sie können einfach die lustigen Szenen aus dem Film noch einmal genießen und sich an die schönen Momente erinnern.
-Wo können Sie mehr über Die lustige Welt der Tiere Film 24 erfahren?
-Die lustige Welt der Tiere Film 24 ist ein Film, der Sie neugierig machen wird. Er ist ein Film, der Sie mehr über die afrikanische Tierwelt erfahren lassen will. Wo können Sie also mehr über Die lustige Welt der Tiere Film 24 erfahren? Sie können zum Beispiel die offizielle Website des Films besuchen und dort mehr Informationen über den Film, den Regisseur, die Tiere und die Drehorte finden. Sie können auch den Blog des Films lesen und dort spannende Hintergrundgeschichten, interessante Fakten und lustige Anekdoten entdecken. Sie können auch den Newsletter des Films abonnieren und so immer auf dem Laufenden bleiben über Neuigkeiten, Aktionen und Gewinnspiele rund um den Film. Es gibt viele Möglichkeiten, wie Sie mehr über Die lustige Welt der Tiere Film 24 erfahren können.
-Was ist das Fazit von Die lustige Welt der Tiere Film 24?
-Die lustige Welt der Tiere Film 24 ist ein Film, der Sie begeistern wird. Er ist ein Film, der Ihnen die Tierwelt Afrikas auf eine humorvolle und informative Weise näherbringt. Er ist ein Film für alle Tierfreunde und alle, die sich für Afrika interessieren. Er ist ein Film für alle, die sich gerne amüsieren und etwas Neues lernen möchten. Er ist ein Film für alle, die einen guten Film sehen möchten. Das Fazit von Die lustige Welt der Tiere Film 24 ist also: Dieser Film ist ein Muss für jeden, der sich für Tiere und Afrika begeistert.
-Was sind die Vorteile von Die lustige Welt der Tiere Film 24?
-Die lustige Welt der Tiere Film 24 ist ein Film, der Ihnen viele Vorteile bietet. Er ist ein Film, der Ihnen Spaß macht und Sie zum Lachen bringt. Er ist ein Film, der Ihnen Wissen vermittelt und Sie zum Staunen bringt. Er ist ein Film, der Ihnen Emotionen weckt und Sie zum Mitfühlen bringt. Er ist ein Film, der Ihnen Inspiration gibt und Sie zum Handeln bringt. Die lustige Welt der Tiere Film 24 ist ein Film, der Ihnen mehr bietet als nur Unterhaltung. Er ist ein Film, der Ihr Leben bereichert.
-Wie können Sie Die lustige Welt der Tiere Film 24 bewerten?
-Die lustige Welt der Tiere Film 24 ist ein Film, der Ihre Meinung verdient. Er ist ein Film, der Ihre Bewertung verdient. Wie können Sie also Die lustige Welt der Tiere Film 24 bewerten? Sie können zum Beispiel Sterne vergeben und so Ihre Zufriedenheit mit dem Film ausdrücken. Sie können auch einen Kommentar schreiben und so Ihre Gedanken und Gefühle über den Film teilen. Sie können auch eine Rezension verfassen und so Ihre Analyse und Kritik über den Film darlegen. Es gibt viele Möglichkeiten, wie Sie Die lustige Welt der Tiere Film 24 bewerten können.
-Zusammenfassung
-Die lustige Welt der Tiere Film 24 ist ein Dokumentarfilm, der Ihnen die Tierwelt Afrikas auf eine humorvolle und informative Weise näherbringt. Er ist der 24. Teil einer erfolgreichen Reihe von Filmen, die von dem südafrikanischen Regisseur Jamie Uys gedreht wurden. Er nimmt Sie mit auf eine Reise durch die Namib-Wüste, das Okavango-Becken und die Kalahari und zeigt Ihnen, wie die Tiere dort leben, lieben und lachen. Er verleiht ihnen dabei eine menschliche Note, indem er ihnen humorvolle Kommentare und Musik unterlegte. Er ist ein Film für alle Tierfreunde und alle, die sich für Afrika interessieren. Er ist ein Film für alle, die sich gerne amüsieren und etwas Neues lernen möchten. Er ist ein Film für alle, die einen guten Film sehen möchten.
-In diesem Artikel haben wir Ihnen alles Wichtige über Die lustige Welt der Tiere Film 24 erzählt. Wir haben Ihnen erklärt, was Sie in diesem Film erwarten können, warum Sie ihn sehen sollten, wie Sie ihn sehen können, wie er entstanden ist, was ihn so besonders macht, wem wir ihn empfehlen, wie Sie ihn unterstützen können, wie Sie ihn mit anderen teilen können, was Sie nach dem Anschauen tun können und wie Sie ihn bewerten können. Wir hoffen, dass wir Ihnen damit einen guten Überblick über diesen Film gegeben haben und dass wir Ihr Interesse geweckt haben.
-Die lustige Welt der Tiere Film 24 ist ein Film, den Sie nicht verpassen sollten. Er ist ein Film, der Ihnen viel Freude bereiten wird. Er ist ein Film, der Ihnen viel Wissen vermitteln wird. Er ist ein Film, der Ihnen viel Emotionen wecken wird. Er ist ein Film, der Ihnen viel Inspiration geben wird. Er ist ein Film, der Ihr Leben bereichern wird.
-Also zögern Sie nicht länger und schauen Sie sich Die lustige Welt der Tiere Film 24 an. Sie werden es nicht bereuen.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/lingbionlp/PhenoTagger_v1.2_Demo/src/dic_ner.py b/spaces/lingbionlp/PhenoTagger_v1.2_Demo/src/dic_ner.py
deleted file mode 100644
index 26336db82c27489b92ffd3e38f7eac197ff3b07c..0000000000000000000000000000000000000000
--- a/spaces/lingbionlp/PhenoTagger_v1.2_Demo/src/dic_ner.py
+++ /dev/null
@@ -1,165 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-Created on Fri Jun 12 15:05:00 2020
-
-@author: luol2
-"""
-import sys
-import json
-import io
-from src.ssplit_tokenzier import ssplit_token_pos_lemma
-class Trie(object):
- class Node(object):
- def __init__(self):
- self.term = None
- self.next = {}
-
- def __init__(self, terms=[]):
- self.root = Trie.Node()
- for term in terms:
- self.add(term)
-
- def add(self, term):
- node = self.root
- for char in term:
- if not char in node.next:
- node.next[char] = Trie.Node()
- node = node.next[char]
- node.term = term
-
- def match(self, query):
- results = []
- for i in range(len(query)):
- node = self.root
- for j in range(i, len(query)):
- node = node.next.get(query[j])
- if not node:
- break
- if node.term:
- results.append((i, len(node.term)))
- return results
-
- def __repr__(self):
- output = []
- def _debug(output, char, node, depth=0):
- output.append('%s[%s][%s]' % (' '*depth, char, node.term))
- for (key, n) in node.next.items():
- _debug(output, key, n, depth+1)
- _debug(output, '', self.root)
- return '\n'.join(output)
-
-class dic_ont():
-
- def __init__(self, ont_files):
-
- dicin=open(ont_files['dic_file'],'r',encoding='utf-8')
- win_size=50000
- Dic=[]
- print("loading dict!")
- for line in dicin:
- line=line.strip()
- if len(line.split())<=win_size:
- words=line.split()
- for i in range(len(words)):
- if len(words[i])>3 and (not words[i].isupper()):
- words[i]=words[i].lower()
- line=' '.join(words[0:])
- Dic.append(line.strip())
- print("Dic_len:",len(Dic))
- dicin.close()
-
- self.dic_trie = Trie(Dic)
- print("load dic done!")
-
- #load word id mapping
- fin_map=open(ont_files['word_id_file'],'r',encoding='utf-8')
- self.word_id=json.load(fin_map)
- fin_map.close()
-
- #load id word mapping
- fin_map=open(ont_files['id_word_file'],'r',encoding='utf-8')
- self.id_word=json.load(fin_map)
- fin_map.close()
-
- def matching(self, source):
-
- fin=io.StringIO(source)
- fout=io.StringIO()
-
- sent_list=[]
- sent = []
- sent_ori_list=[]
- sent_ori=[]
-
- for line in fin:
- line=line.strip()
- if line=="":
- sent_list.append(sent)
- sent_ori_list.append(sent_ori)
- sent=[]
- sent_ori=[]
- else:
- words=line.split('\t')
- words[1]=words[1].lower()
- sent.append(words[1]) # word lemma
- sent_ori.append(words[0])
- sent=[]
- fin.close()
-
- for k in range(len(sent_list)):
- sent = sent_list[k]
- sentence=' '.join(sent[0:])+" "
- sentence_ori=' '.join(sent_ori_list[k])
-# print('sentence:',sentence)
- result=self.dic_trie.match(sentence)
-# print('result:',result)
- new_result=[]
- for i in range(0,len(result)):
- if result[i][0]==0 and sentence[result[i][1]]==" ":
- new_result.append([result[i][0],result[i][0]+result[i][1]])
- elif result[i][0]>0 and sentence[result[i][0]-1]==' ' and sentence[result[i][0]+result[i][1]]==' ':
- new_result.append([result[i][0],result[i][0]+result[i][1]])
-# print('new result:',new_result)
-
-
-
- if len(new_result)==0:
- fout.write(sentence_ori+'\n\n')
-
- else:
- fout.write(sentence_ori+'\n')
- for ele in new_result:
- entity_text=sentence[ele[0]:ele[1]]
- if entity_text in self.word_id.keys():
- ontid=self.word_id[entity_text]
- else:
- print('no id:', entity_text)
- ontid=['None']
- if ele[0]==0:
- sid="0"
- else:
- temp_sent=sentence[0:ele[0]]
- sid=str(len(temp_sent.rstrip().split(' ')))
- temp_sent=sentence[0:ele[1]]
- eid=str(len(temp_sent.rstrip().split(' '))-1)
-# print(sid,eid,entity_text,ontid[0])
- #fout.write(sid+'\t'+eid+'\t'+entity_text+'\t'+";".join(ontid)+'\t1.00\n')
- fout.write(sid+'\t'+eid+'\t'+entity_text+'\t'+ontid[0]+'\t1.00\n')
- fout.write('\n')
-
- return fout.getvalue()
-
-
-if __name__=='__main__':
-
- ontfiles={'dic_file':'//panfs/pan1/bionlp/lulab/luoling/HPO_project/bioTag/dict/hpo_noabb_lemma.dic',
- 'word_hpo_file':'//panfs/pan1/bionlp/lulab/luoling/HPO_project/bioTag/dict/word_ontid_map.json',
- 'hpo_word_file':'//panfs/pan1/bionlp/lulab/luoling/HPO_project/bioTag/dict/ontid_word_map.json'}
- biotag_dic=dic_ont(ontfiles)
- text='Nevoid basal cell carcinoma syndrome (NBCCS) is a hereditary condition transmitted as an autosomal dominant trait with complete penetrance and variable expressivity. The syndrome is characterised by numerous basal cell carcinomas (BCCs), odontogenic keratocysts of the jaws, palmar and/or plantar pits, skeletal abnormalities and intracranial calcifications. In this paper, the clinical features of 37 Italian patients are reviewed. Jaw cysts and calcification of falx cerebri were the most frequently observed anomalies, followed by BCCs and palmar/plantar pits. Similar to the case of African Americans, the relatively low frequency of BCCs in the Italian population is probably due to protective skin pigmentation. A future search based on mutation screening might establish a possible genotype phenotype correlation in Italian patients.'
- ssplit_token=ssplit_token_pos_lemma(text)
-# print(ssplit_token)
- dic_result=biotag_dic.matching(ssplit_token)
- print(dic_result)
-
-
diff --git a/spaces/lj1995/vocal2guitar/uvr5_pack/lib_v5/nets.py b/spaces/lj1995/vocal2guitar/uvr5_pack/lib_v5/nets.py
deleted file mode 100644
index d4c376ed8715f9e85d71609e348add0a6550a4ba..0000000000000000000000000000000000000000
--- a/spaces/lj1995/vocal2guitar/uvr5_pack/lib_v5/nets.py
+++ /dev/null
@@ -1,123 +0,0 @@
-import torch
-from torch import nn
-import torch.nn.functional as F
-
-from uvr5_pack.lib_v5 import layers
-from uvr5_pack.lib_v5 import spec_utils
-
-
-class BaseASPPNet(nn.Module):
- def __init__(self, nin, ch, dilations=(4, 8, 16)):
- super(BaseASPPNet, self).__init__()
- self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
- self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
- self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
- self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
-
- self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
-
- self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
- self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
- self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
- self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
-
- def __call__(self, x):
- h, e1 = self.enc1(x)
- h, e2 = self.enc2(h)
- h, e3 = self.enc3(h)
- h, e4 = self.enc4(h)
-
- h = self.aspp(h)
-
- h = self.dec4(h, e4)
- h = self.dec3(h, e3)
- h = self.dec2(h, e2)
- h = self.dec1(h, e1)
-
- return h
-
-
-class CascadedASPPNet(nn.Module):
- def __init__(self, n_fft):
- super(CascadedASPPNet, self).__init__()
- self.stg1_low_band_net = BaseASPPNet(2, 16)
- self.stg1_high_band_net = BaseASPPNet(2, 16)
-
- self.stg2_bridge = layers.Conv2DBNActiv(18, 8, 1, 1, 0)
- self.stg2_full_band_net = BaseASPPNet(8, 16)
-
- self.stg3_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
- self.stg3_full_band_net = BaseASPPNet(16, 32)
-
- self.out = nn.Conv2d(32, 2, 1, bias=False)
- self.aux1_out = nn.Conv2d(16, 2, 1, bias=False)
- self.aux2_out = nn.Conv2d(16, 2, 1, bias=False)
-
- self.max_bin = n_fft // 2
- self.output_bin = n_fft // 2 + 1
-
- self.offset = 128
-
- def forward(self, x, aggressiveness=None):
- mix = x.detach()
- x = x.clone()
-
- x = x[:, :, : self.max_bin]
-
- bandw = x.size()[2] // 2
- aux1 = torch.cat(
- [
- self.stg1_low_band_net(x[:, :, :bandw]),
- self.stg1_high_band_net(x[:, :, bandw:]),
- ],
- dim=2,
- )
-
- h = torch.cat([x, aux1], dim=1)
- aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
-
- h = torch.cat([x, aux1, aux2], dim=1)
- h = self.stg3_full_band_net(self.stg3_bridge(h))
-
- mask = torch.sigmoid(self.out(h))
- mask = F.pad(
- input=mask,
- pad=(0, 0, 0, self.output_bin - mask.size()[2]),
- mode="replicate",
- )
-
- if self.training:
- aux1 = torch.sigmoid(self.aux1_out(aux1))
- aux1 = F.pad(
- input=aux1,
- pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
- mode="replicate",
- )
- aux2 = torch.sigmoid(self.aux2_out(aux2))
- aux2 = F.pad(
- input=aux2,
- pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
- mode="replicate",
- )
- return mask * mix, aux1 * mix, aux2 * mix
- else:
- if aggressiveness:
- mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
- mask[:, :, : aggressiveness["split_bin"]],
- 1 + aggressiveness["value"] / 3,
- )
- mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
- mask[:, :, aggressiveness["split_bin"] :],
- 1 + aggressiveness["value"],
- )
-
- return mask * mix
-
- def predict(self, x_mag, aggressiveness=None):
- h = self.forward(x_mag, aggressiveness)
-
- if self.offset > 0:
- h = h[:, :, :, self.offset : -self.offset]
- assert h.size()[3] > 0
-
- return h
diff --git a/spaces/lvkaokao/dreambooth-training/convertosd.py b/spaces/lvkaokao/dreambooth-training/convertosd.py
deleted file mode 100644
index e4bec6cbe894dd74b24f633cc66346d687d3f802..0000000000000000000000000000000000000000
--- a/spaces/lvkaokao/dreambooth-training/convertosd.py
+++ /dev/null
@@ -1,226 +0,0 @@
-# Script for converting a HF Diffusers saved pipeline to a Stable Diffusion checkpoint.
-# *Only* converts the UNet, VAE, and Text Encoder.
-# Does not convert optimizer state or any other thing.
-# Written by jachiam
-
-import argparse
-import os.path as osp
-
-import torch
-import gc
-
-# =================#
-# UNet Conversion #
-# =================#
-
-unet_conversion_map = [
- # (stable-diffusion, HF Diffusers)
- ("time_embed.0.weight", "time_embedding.linear_1.weight"),
- ("time_embed.0.bias", "time_embedding.linear_1.bias"),
- ("time_embed.2.weight", "time_embedding.linear_2.weight"),
- ("time_embed.2.bias", "time_embedding.linear_2.bias"),
- ("input_blocks.0.0.weight", "conv_in.weight"),
- ("input_blocks.0.0.bias", "conv_in.bias"),
- ("out.0.weight", "conv_norm_out.weight"),
- ("out.0.bias", "conv_norm_out.bias"),
- ("out.2.weight", "conv_out.weight"),
- ("out.2.bias", "conv_out.bias"),
-]
-
-unet_conversion_map_resnet = [
- # (stable-diffusion, HF Diffusers)
- ("in_layers.0", "norm1"),
- ("in_layers.2", "conv1"),
- ("out_layers.0", "norm2"),
- ("out_layers.3", "conv2"),
- ("emb_layers.1", "time_emb_proj"),
- ("skip_connection", "conv_shortcut"),
-]
-
-unet_conversion_map_layer = []
-# hardcoded number of downblocks and resnets/attentions...
-# would need smarter logic for other networks.
-for i in range(4):
- # loop over downblocks/upblocks
-
- for j in range(2):
- # loop over resnets/attentions for downblocks
- hf_down_res_prefix = f"down_blocks.{i}.resnets.{j}."
- sd_down_res_prefix = f"input_blocks.{3*i + j + 1}.0."
- unet_conversion_map_layer.append((sd_down_res_prefix, hf_down_res_prefix))
-
- if i < 3:
- # no attention layers in down_blocks.3
- hf_down_atn_prefix = f"down_blocks.{i}.attentions.{j}."
- sd_down_atn_prefix = f"input_blocks.{3*i + j + 1}.1."
- unet_conversion_map_layer.append((sd_down_atn_prefix, hf_down_atn_prefix))
-
- for j in range(3):
- # loop over resnets/attentions for upblocks
- hf_up_res_prefix = f"up_blocks.{i}.resnets.{j}."
- sd_up_res_prefix = f"output_blocks.{3*i + j}.0."
- unet_conversion_map_layer.append((sd_up_res_prefix, hf_up_res_prefix))
-
- if i > 0:
- # no attention layers in up_blocks.0
- hf_up_atn_prefix = f"up_blocks.{i}.attentions.{j}."
- sd_up_atn_prefix = f"output_blocks.{3*i + j}.1."
- unet_conversion_map_layer.append((sd_up_atn_prefix, hf_up_atn_prefix))
-
- if i < 3:
- # no downsample in down_blocks.3
- hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0.conv."
- sd_downsample_prefix = f"input_blocks.{3*(i+1)}.0.op."
- unet_conversion_map_layer.append((sd_downsample_prefix, hf_downsample_prefix))
-
- # no upsample in up_blocks.3
- hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
- sd_upsample_prefix = f"output_blocks.{3*i + 2}.{1 if i == 0 else 2}."
- unet_conversion_map_layer.append((sd_upsample_prefix, hf_upsample_prefix))
-
-hf_mid_atn_prefix = "mid_block.attentions.0."
-sd_mid_atn_prefix = "middle_block.1."
-unet_conversion_map_layer.append((sd_mid_atn_prefix, hf_mid_atn_prefix))
-
-for j in range(2):
- hf_mid_res_prefix = f"mid_block.resnets.{j}."
- sd_mid_res_prefix = f"middle_block.{2*j}."
- unet_conversion_map_layer.append((sd_mid_res_prefix, hf_mid_res_prefix))
-
-
-def convert_unet_state_dict(unet_state_dict):
- # buyer beware: this is a *brittle* function,
- # and correct output requires that all of these pieces interact in
- # the exact order in which I have arranged them.
- mapping = {k: k for k in unet_state_dict.keys()}
- for sd_name, hf_name in unet_conversion_map:
- mapping[hf_name] = sd_name
- for k, v in mapping.items():
- if "resnets" in k:
- for sd_part, hf_part in unet_conversion_map_resnet:
- v = v.replace(hf_part, sd_part)
- mapping[k] = v
- for k, v in mapping.items():
- for sd_part, hf_part in unet_conversion_map_layer:
- v = v.replace(hf_part, sd_part)
- mapping[k] = v
- new_state_dict = {v: unet_state_dict[k] for k, v in mapping.items()}
- return new_state_dict
-
-
-# ================#
-# VAE Conversion #
-# ================#
-
-vae_conversion_map = [
- # (stable-diffusion, HF Diffusers)
- ("nin_shortcut", "conv_shortcut"),
- ("norm_out", "conv_norm_out"),
- ("mid.attn_1.", "mid_block.attentions.0."),
-]
-
-for i in range(4):
- # down_blocks have two resnets
- for j in range(2):
- hf_down_prefix = f"encoder.down_blocks.{i}.resnets.{j}."
- sd_down_prefix = f"encoder.down.{i}.block.{j}."
- vae_conversion_map.append((sd_down_prefix, hf_down_prefix))
-
- if i < 3:
- hf_downsample_prefix = f"down_blocks.{i}.downsamplers.0."
- sd_downsample_prefix = f"down.{i}.downsample."
- vae_conversion_map.append((sd_downsample_prefix, hf_downsample_prefix))
-
- hf_upsample_prefix = f"up_blocks.{i}.upsamplers.0."
- sd_upsample_prefix = f"up.{3-i}.upsample."
- vae_conversion_map.append((sd_upsample_prefix, hf_upsample_prefix))
-
- # up_blocks have three resnets
- # also, up blocks in hf are numbered in reverse from sd
- for j in range(3):
- hf_up_prefix = f"decoder.up_blocks.{i}.resnets.{j}."
- sd_up_prefix = f"decoder.up.{3-i}.block.{j}."
- vae_conversion_map.append((sd_up_prefix, hf_up_prefix))
-
-# this part accounts for mid blocks in both the encoder and the decoder
-for i in range(2):
- hf_mid_res_prefix = f"mid_block.resnets.{i}."
- sd_mid_res_prefix = f"mid.block_{i+1}."
- vae_conversion_map.append((sd_mid_res_prefix, hf_mid_res_prefix))
-
-
-vae_conversion_map_attn = [
- # (stable-diffusion, HF Diffusers)
- ("norm.", "group_norm."),
- ("q.", "query."),
- ("k.", "key."),
- ("v.", "value."),
- ("proj_out.", "proj_attn."),
-]
-
-
-def reshape_weight_for_sd(w):
- # convert HF linear weights to SD conv2d weights
- return w.reshape(*w.shape, 1, 1)
-
-
-def convert_vae_state_dict(vae_state_dict):
- mapping = {k: k for k in vae_state_dict.keys()}
- for k, v in mapping.items():
- for sd_part, hf_part in vae_conversion_map:
- v = v.replace(hf_part, sd_part)
- mapping[k] = v
- for k, v in mapping.items():
- if "attentions" in k:
- for sd_part, hf_part in vae_conversion_map_attn:
- v = v.replace(hf_part, sd_part)
- mapping[k] = v
- new_state_dict = {v: vae_state_dict[k] for k, v in mapping.items()}
- weights_to_convert = ["q", "k", "v", "proj_out"]
- print("�[1;32mConverting to CKPT ...")
- for k, v in new_state_dict.items():
- for weight_name in weights_to_convert:
- if f"mid.attn_1.{weight_name}.weight" in k:
- new_state_dict[k] = reshape_weight_for_sd(v)
- return new_state_dict
-
-
-# =========================#
-# Text Encoder Conversion #
-# =========================#
-# pretty much a no-op
-
-
-def convert_text_enc_state_dict(text_enc_dict):
- return text_enc_dict
-
-
-def convert(model_path, checkpoint_path):
- unet_path = osp.join(model_path, "unet", "diffusion_pytorch_model.bin")
- vae_path = osp.join(model_path, "vae", "diffusion_pytorch_model.bin")
- text_enc_path = osp.join(model_path, "text_encoder", "pytorch_model.bin")
-
- # Convert the UNet model
- unet_state_dict = torch.load(unet_path, map_location='cpu')
- unet_state_dict = convert_unet_state_dict(unet_state_dict)
- unet_state_dict = {"model.diffusion_model." + k: v for k, v in unet_state_dict.items()}
-
- # Convert the VAE model
- vae_state_dict = torch.load(vae_path, map_location='cpu')
- vae_state_dict = convert_vae_state_dict(vae_state_dict)
- vae_state_dict = {"first_stage_model." + k: v for k, v in vae_state_dict.items()}
-
- # Convert the text encoder model
- text_enc_dict = torch.load(text_enc_path, map_location='cpu')
- text_enc_dict = convert_text_enc_state_dict(text_enc_dict)
- text_enc_dict = {"cond_stage_model.transformer." + k: v for k, v in text_enc_dict.items()}
-
- # Put together new checkpoint
- state_dict = {**unet_state_dict, **vae_state_dict, **text_enc_dict}
-
- state_dict = {k:v.half() for k,v in state_dict.items()}
- state_dict = {"state_dict": state_dict}
- torch.save(state_dict, checkpoint_path)
- del state_dict, text_enc_dict, vae_state_dict, unet_state_dict
- torch.cuda.empty_cache()
- gc.collect()
diff --git a/spaces/lykke-05/pleaselowrd/README.md b/spaces/lykke-05/pleaselowrd/README.md
deleted file mode 100644
index ccd9ed1b88fe02c3d83b2a024b2c41a03e4c26fa..0000000000000000000000000000000000000000
--- a/spaces/lykke-05/pleaselowrd/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: Pleaselowrd
-emoji: ⚡
-colorFrom: blue
-colorTo: green
-sdk: docker
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/macaodha/batdetect2/bat_detect/finetune/readme.md b/spaces/macaodha/batdetect2/bat_detect/finetune/readme.md
deleted file mode 100644
index 5ee54bb8fbfb46d5d3342d04c9b0ac558930b32c..0000000000000000000000000000000000000000
--- a/spaces/macaodha/batdetect2/bat_detect/finetune/readme.md
+++ /dev/null
@@ -1,40 +0,0 @@
-
-# Finetuning the BatDetet2 model on your own data
-Main steps:
-1. Annotate your data using the annotation GUI.
-2. Run `prep_data_finetune.py` to create a training and validation split for your data.
-3. Run `finetune_model.py` to finetune a model on your data.
-
-
-## 1. Annotate calls of interest in audio data
-Use the annotation tools provided [here](https://github.com/macaodha/batdetect2_GUI) to manually identify where the events of interest (e.g. bat echolocation calls) are in your files.
-This will result in a directory of audio files and a directory of annotation files, where each audio file will have a corresponding `.json` annotation file.
-Make sure to annotation all instances of a bat call.
-If unsure of the species, just label the call as `Bat`.
-
-
-## 2. Split data into train and test sets
-After performing the previous step you should have a directory of annotations files saved as jsons, one for each audio file you have annotated.
-* The next step is to split these into training and testing subsets.
-Run `prep_data_finetune.py` to split the data into train and test sets. This will result in two separate files, a train and a test one, i.e.
-`python prep_data_finetune.py dataset_name path_to_audio/ path_to_annotations/ path_to_output_anns/`
-This may result an error if it does not generate output files containing the same set of species in the train and test splits. You can try different random seeds if this is an issue e.g. `--rand_seed 123456`.
-
-* You can also load the train and test split using text files, where each line of the text file is the name of a `wav` file (without the file path) e.g.
-`python prep_data_finetune.py dataset_name path_to_audio/ path_to_annotations/ path_to_output/ --train_file path_to_file/list_of_train_files.txt --test_file path_to_file/list_of_test_files.txt`
-
-
-* Can also replace class names. This can be helpful if you don't think you have enough calls/files for a given species. Use semi-colons to separate, without spaces between them e.g.
-`python prep_data_finetune.py dataset_name path_to_audio/audio/ path_to_annotations/anns/ path_to_output/ --input_class_names "Histiotus;Molossidae;Lasiurus;Myotis;Rhogeesa;Vespertilionidae" --output_class_names "Group One;Group One;Group One;Group Two;Group Two;Group Three"`
-
-
-## 3. Finetuning the model
-Finally, you can finetune the model using your data i.e.
-`python finetune_model.py path_to_audio/ path_to_train/TRAIN.json path_to_train/TEST.json ../../models/Net2DFast_UK_same.pth.tar`
-Here, `TRAIN.json` and `TEST.json` are the splits created in the previous steps.
-
-
-#### Additional notes
-* For the first step it is better to cut the files into less than 5 second audio clips and make sure to annotate them exhaustively (i.e. all bat calls should be annotated).
-* You can train the model for longer, by setting the `--num_epochs` flag to a larger number e.g. `--num_epochs 400`. The default is `200`.
-* If you do not want to finetune the model, but instead want to train it from scratch, you can set the `--train_from_scratch` flag.
diff --git a/spaces/manavisrani07/gradio-lipsync-wav2lip/basicsr/metrics/metric_util.py b/spaces/manavisrani07/gradio-lipsync-wav2lip/basicsr/metrics/metric_util.py
deleted file mode 100644
index 2a27c70a043beeeb59cfaf533079492293065448..0000000000000000000000000000000000000000
--- a/spaces/manavisrani07/gradio-lipsync-wav2lip/basicsr/metrics/metric_util.py
+++ /dev/null
@@ -1,45 +0,0 @@
-import numpy as np
-
-from basicsr.utils import bgr2ycbcr
-
-
-def reorder_image(img, input_order='HWC'):
- """Reorder images to 'HWC' order.
-
- If the input_order is (h, w), return (h, w, 1);
- If the input_order is (c, h, w), return (h, w, c);
- If the input_order is (h, w, c), return as it is.
-
- Args:
- img (ndarray): Input image.
- input_order (str): Whether the input order is 'HWC' or 'CHW'.
- If the input image shape is (h, w), input_order will not have
- effects. Default: 'HWC'.
-
- Returns:
- ndarray: reordered image.
- """
-
- if input_order not in ['HWC', 'CHW']:
- raise ValueError(f"Wrong input_order {input_order}. Supported input_orders are 'HWC' and 'CHW'")
- if len(img.shape) == 2:
- img = img[..., None]
- if input_order == 'CHW':
- img = img.transpose(1, 2, 0)
- return img
-
-
-def to_y_channel(img):
- """Change to Y channel of YCbCr.
-
- Args:
- img (ndarray): Images with range [0, 255].
-
- Returns:
- (ndarray): Images with range [0, 255] (float type) without round.
- """
- img = img.astype(np.float32) / 255.
- if img.ndim == 3 and img.shape[2] == 3:
- img = bgr2ycbcr(img, y_only=True)
- img = img[..., None]
- return img * 255.
diff --git a/spaces/manhkhanhUIT/BOPBTL/Face_Enhancement/util/util.py b/spaces/manhkhanhUIT/BOPBTL/Face_Enhancement/util/util.py
deleted file mode 100644
index e18b4a26082449977b27a4c1506649a2447988b1..0000000000000000000000000000000000000000
--- a/spaces/manhkhanhUIT/BOPBTL/Face_Enhancement/util/util.py
+++ /dev/null
@@ -1,210 +0,0 @@
-# Copyright (c) Microsoft Corporation.
-# Licensed under the MIT License.
-
-import re
-import importlib
-import torch
-from argparse import Namespace
-import numpy as np
-from PIL import Image
-import os
-import argparse
-import dill as pickle
-
-
-def save_obj(obj, name):
- with open(name, "wb") as f:
- pickle.dump(obj, f, pickle.HIGHEST_PROTOCOL)
-
-
-def load_obj(name):
- with open(name, "rb") as f:
- return pickle.load(f)
-
-
-def copyconf(default_opt, **kwargs):
- conf = argparse.Namespace(**vars(default_opt))
- for key in kwargs:
- print(key, kwargs[key])
- setattr(conf, key, kwargs[key])
- return conf
-
-
-# Converts a Tensor into a Numpy array
-# |imtype|: the desired type of the converted numpy array
-def tensor2im(image_tensor, imtype=np.uint8, normalize=True, tile=False):
- if isinstance(image_tensor, list):
- image_numpy = []
- for i in range(len(image_tensor)):
- image_numpy.append(tensor2im(image_tensor[i], imtype, normalize))
- return image_numpy
-
- if image_tensor.dim() == 4:
- # transform each image in the batch
- images_np = []
- for b in range(image_tensor.size(0)):
- one_image = image_tensor[b]
- one_image_np = tensor2im(one_image)
- images_np.append(one_image_np.reshape(1, *one_image_np.shape))
- images_np = np.concatenate(images_np, axis=0)
-
- return images_np
-
- if image_tensor.dim() == 2:
- image_tensor = image_tensor.unsqueeze(0)
- image_numpy = image_tensor.detach().cpu().float().numpy()
- if normalize:
- image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + 1) / 2.0 * 255.0
- else:
- image_numpy = np.transpose(image_numpy, (1, 2, 0)) * 255.0
- image_numpy = np.clip(image_numpy, 0, 255)
- if image_numpy.shape[2] == 1:
- image_numpy = image_numpy[:, :, 0]
- return image_numpy.astype(imtype)
-
-
-# Converts a one-hot tensor into a colorful label map
-def tensor2label(label_tensor, n_label, imtype=np.uint8, tile=False):
- if label_tensor.dim() == 4:
- # transform each image in the batch
- images_np = []
- for b in range(label_tensor.size(0)):
- one_image = label_tensor[b]
- one_image_np = tensor2label(one_image, n_label, imtype)
- images_np.append(one_image_np.reshape(1, *one_image_np.shape))
- images_np = np.concatenate(images_np, axis=0)
- # if tile:
- # images_tiled = tile_images(images_np)
- # return images_tiled
- # else:
- # images_np = images_np[0]
- # return images_np
- return images_np
-
- if label_tensor.dim() == 1:
- return np.zeros((64, 64, 3), dtype=np.uint8)
- if n_label == 0:
- return tensor2im(label_tensor, imtype)
- label_tensor = label_tensor.cpu().float()
- if label_tensor.size()[0] > 1:
- label_tensor = label_tensor.max(0, keepdim=True)[1]
- label_tensor = Colorize(n_label)(label_tensor)
- label_numpy = np.transpose(label_tensor.numpy(), (1, 2, 0))
- result = label_numpy.astype(imtype)
- return result
-
-
-def save_image(image_numpy, image_path, create_dir=False):
- if create_dir:
- os.makedirs(os.path.dirname(image_path), exist_ok=True)
- if len(image_numpy.shape) == 2:
- image_numpy = np.expand_dims(image_numpy, axis=2)
- if image_numpy.shape[2] == 1:
- image_numpy = np.repeat(image_numpy, 3, 2)
- image_pil = Image.fromarray(image_numpy)
-
- # save to png
- image_pil.save(image_path.replace(".jpg", ".png"))
-
-
-def mkdirs(paths):
- if isinstance(paths, list) and not isinstance(paths, str):
- for path in paths:
- mkdir(path)
- else:
- mkdir(paths)
-
-
-def mkdir(path):
- if not os.path.exists(path):
- os.makedirs(path)
-
-
-def atoi(text):
- return int(text) if text.isdigit() else text
-
-
-def natural_keys(text):
- """
- alist.sort(key=natural_keys) sorts in human order
- http://nedbatchelder.com/blog/200712/human_sorting.html
- (See Toothy's implementation in the comments)
- """
- return [atoi(c) for c in re.split("(\d+)", text)]
-
-
-def natural_sort(items):
- items.sort(key=natural_keys)
-
-
-def str2bool(v):
- if v.lower() in ("yes", "true", "t", "y", "1"):
- return True
- elif v.lower() in ("no", "false", "f", "n", "0"):
- return False
- else:
- raise argparse.ArgumentTypeError("Boolean value expected.")
-
-
-def find_class_in_module(target_cls_name, module):
- target_cls_name = target_cls_name.replace("_", "").lower()
- clslib = importlib.import_module(module)
- cls = None
- for name, clsobj in clslib.__dict__.items():
- if name.lower() == target_cls_name:
- cls = clsobj
-
- if cls is None:
- print(
- "In %s, there should be a class whose name matches %s in lowercase without underscore(_)"
- % (module, target_cls_name)
- )
- exit(0)
-
- return cls
-
-
-def save_network(net, label, epoch, opt):
- save_filename = "%s_net_%s.pth" % (epoch, label)
- save_path = os.path.join(opt.checkpoints_dir, opt.name, save_filename)
- torch.save(net.cpu().state_dict(), save_path)
- if len(opt.gpu_ids) and torch.cuda.is_available():
- net.cuda()
-
-
-def load_network(net, label, epoch, opt):
- save_filename = "%s_net_%s.pth" % (epoch, label)
- save_dir = os.path.join(opt.checkpoints_dir, opt.name)
- save_path = os.path.join(save_dir, save_filename)
- if os.path.exists(save_path):
- weights = torch.load(save_path)
- net.load_state_dict(weights)
- return net
-
-
-###############################################################################
-# Code from
-# https://github.com/ycszen/pytorch-seg/blob/master/transform.py
-# Modified so it complies with the Citscape label map colors
-###############################################################################
-def uint82bin(n, count=8):
- """returns the binary of integer n, count refers to amount of bits"""
- return "".join([str((n >> y) & 1) for y in range(count - 1, -1, -1)])
-
-
-class Colorize(object):
- def __init__(self, n=35):
- self.cmap = labelcolormap(n)
- self.cmap = torch.from_numpy(self.cmap[:n])
-
- def __call__(self, gray_image):
- size = gray_image.size()
- color_image = torch.ByteTensor(3, size[1], size[2]).fill_(0)
-
- for label in range(0, len(self.cmap)):
- mask = (label == gray_image[0]).cpu()
- color_image[0][mask] = self.cmap[label][0]
- color_image[1][mask] = self.cmap[label][1]
- color_image[2][mask] = self.cmap[label][2]
-
- return color_image
diff --git a/spaces/matthoffner/gguf-maker/Dockerfile b/spaces/matthoffner/gguf-maker/Dockerfile
deleted file mode 100644
index a88f64f686f1627b4d756bb05aa80c1af0679a08..0000000000000000000000000000000000000000
--- a/spaces/matthoffner/gguf-maker/Dockerfile
+++ /dev/null
@@ -1,39 +0,0 @@
-FROM python:latest
-
-ENV PYTHONUNBUFFERED 1
-
-EXPOSE 8000
-
-WORKDIR /app
-
-RUN wget -qO- "https://cmake.org/files/v3.17/cmake-3.17.0-Linux-x86_64.tar.gz" | tar --strip-components=1 -xz -C /usr/local
-
-COPY requirements.txt ./
-RUN pip install --upgrade pip && \
- pip install -r requirements.txt
-
-RUN curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
-RUN apt-get install git-lfs
-
-RUN git clone https://github.com/emscripten-core/emsdk.git && \
- cd emsdk && \
- ./emsdk install latest && \
- ./emsdk activate latest
-
-# Add Emscripten to PATH
-ENV PATH="/app/emsdk:${PATH}"
-ENV PATH="/app/emsdk/upstream/emscripten:${PATH}"
-
-RUN git clone https://github.com/ggerganov/ggml && cd ggml && mkdir build && cd build && cmake ..
-RUN git clone https://huggingface.co/bigcode/gpt_bigcode-santacoder
-RUN python ggml/examples/starcoder/convert-hf-to-ggml.py ./gpt_bigcode-santacoder/
-RUN cd ggml/build && make -j4 starcoder starcoder-quantize
-RUN ggml/build/bin/starcoder-quantize models/./gpt_bigcode-santacoder/-ggml.bin ggml-model-q4_0.bin 2
-RUN ls ggml/build/bin
-RUN emcc -Iggml/include -Iggml/include/ggml -Iggml/examples ggml/src/ggml.c ggml/examples/starcoder/main.cpp -o santacoder.js -s EXPORTED_FUNCTIONS='["_malloc","_free"]' -s EXPORTED_RUNTIME_METHODS='["ccall"]' -s ALLOW_MEMORY_GROWTH=1 --preload-file ggml-model-q4_0.bin
-
-COPY . .
-
-RUN ls -al
-
-CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
\ No newline at end of file
diff --git a/spaces/matthoffner/open-codetree/store/features/themeSlice.ts b/spaces/matthoffner/open-codetree/store/features/themeSlice.ts
deleted file mode 100644
index 2397f46e8d7e9ae14ed17300d0dfbca80c288bd0..0000000000000000000000000000000000000000
--- a/spaces/matthoffner/open-codetree/store/features/themeSlice.ts
+++ /dev/null
@@ -1,34 +0,0 @@
-import { createSlice, PayloadAction } from "@reduxjs/toolkit";
-import { RootState } from "../store";
-
-type InitialStateType = {
- theme: {
- text: string;
- background: string;
- foreground: string;
- border: string;
- };
-};
-
-const initialState = {
- theme: {
- text: "#ffffff",
- background: "#171E25",
- foreground: "#1B252D",
- border: "#263440",
- },
-};
-
-export const themeSlice = createSlice({
- name: "theme",
- initialState: initialState,
- reducers: {
- set_Theme: (state) => {},
- },
-});
-
-export const { set_Theme } = themeSlice.actions;
-
-export const theme_state = (state: RootState) => state.theme;
-
-export default themeSlice.reducer;
diff --git a/spaces/merve/anonymization/public/fill-in-the-blank/tokenizer.js b/spaces/merve/anonymization/public/fill-in-the-blank/tokenizer.js
deleted file mode 100644
index 47c8bee46f60ed69ce963ee36af39bacacd9a095..0000000000000000000000000000000000000000
--- a/spaces/merve/anonymization/public/fill-in-the-blank/tokenizer.js
+++ /dev/null
@@ -1,193 +0,0 @@
-/**
- * @license
- * Copyright 2019 Google LLC. All Rights Reserved.
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- * =============================================================================
- */
-
-
-// https://github.com/tensorflow/tfjs-models/blob/master/universal-sentence-encoder/src/tokenizer/trie.ts
-
-class TrieNode {
- constructor(key) {
- this.key = key;
- this.parent = null;
- this.children = {};
- this.end = false;
- }
-
- getWord() {
- const output = [];
- let node = this;
-
- while (node !== null) {
- if (node.key !== null) {
- output.unshift(node.key);
- }
- node = node.parent;
- }
-
- return [output, this.score, this.index];
- }
-}
-
-class Trie {
- constructor() {
- this.root = new TrieNode(null);
- }
-
- insert(word, score, index) {
- let node = this.root;
-
- const symbols = [];
- for (const symbol of word) {
- symbols.push(symbol);
- }
-
- for (let i = 0; i < symbols.length; i++) {
- if (!node.children[symbols[i]]) {
- node.children[symbols[i]] = new TrieNode(symbols[i]);
- node.children[symbols[i]].parent = node;
- }
-
- node = node.children[symbols[i]];
-
- if (i === symbols.length - 1) {
- node.end = true;
- node.score = score;
- node.index = index;
- }
- }
- }
-
- find(ss) {
- let node = this.root;
- let iter = 0;
-
- while (iter < ss.length && node != null) {
- node = node.children[ss[iter]];
- iter++;
- }
-
- return node;
- }
-}
-
-const bert = {
- loadTokenizer: async () => {
- const tokenizer = new BertTokenizer();
- await tokenizer.load();
-
- return tokenizer;
- }
-};
-
-class BertTokenizer {
- constructor() {
- this.separator = '\u2581';
- this.UNK_INDEX = 100;
- }
-
- async load() {
- this.vocab = await this.loadVocab();
-
- this.trie = new Trie();
- // Actual tokens start at 999.
- for (let i = 999; i < this.vocab.length; i++) {
- const word = this.vocab[i];
- this.trie.insert(word, 1, i);
- }
-
- this.token2Id = {}
- this.vocab.forEach((d, i) => {
- this.token2Id[d] = i
- })
-
- this.decode = a => a.map(d => this.vocab[d].replace('▁', ' ')).join('')
- // Adds [CLS] and [SEP]
- this.tokenizeCLS = str => [101, ...this.tokenize(str), 102]
- }
-
- async loadVocab() {
- if (!window.bertProcessedVocab){
- window.bertProcessedVocab = await (await fetch('data/processed_vocab.json')).json()
- }
- return window.bertProcessedVocab
- }
-
- processInput(text) {
- const words = text.split(' ');
- return words.map(word => {
- if (word !== '[CLS]' && word !== '[SEP]') {
- return this.separator + word.toLowerCase().normalize('NFKC');
- }
- return word;
- });
- }
-
- tokenize(text) {
- // Source:
- // https://github.com/google-research/bert/blob/88a817c37f788702a363ff935fd173b6dc6ac0d6/tokenization.py#L311
-
- let outputTokens = [];
-
- const words = this.processInput(text);
-
- for (let i = 0; i < words.length; i++) {
- const chars = [];
- for (const symbol of words[i]) {
- chars.push(symbol);
- }
-
- let isUnknown = false;
- let start = 0;
- const subTokens = [];
-
- const charsLength = chars.length;
-
- while (start < charsLength) {
- let end = charsLength;
- let currIndex;
-
- while (start < end) {
- let substr = chars.slice(start, end).join('');
-
- const match = this.trie.find(substr);
-
- if (match != null && match.end) {
- currIndex = match.getWord()[2];
- break;
- }
-
- end = end - 1;
- }
-
- if (currIndex == null) {
- isUnknown = true;
- break;
- }
-
- subTokens.push(currIndex);
- start = end;
- }
-
- if (isUnknown) {
- outputTokens.push(this.UNK_INDEX);
- } else {
- outputTokens = outputTokens.concat(subTokens);
- }
- }
-
- return outputTokens;
- }
-}
\ No newline at end of file
diff --git a/spaces/merve/dataset-worldviews/public/private-and-fair/2d-privacy.js b/spaces/merve/dataset-worldviews/public/private-and-fair/2d-privacy.js
deleted file mode 100644
index fc89da57484ca77169f4b7aff1c1f75365bd9093..0000000000000000000000000000000000000000
--- a/spaces/merve/dataset-worldviews/public/private-and-fair/2d-privacy.js
+++ /dev/null
@@ -1,383 +0,0 @@
-window.state = window.state || {
- scoreSteps: 101,
- nParams: 11,
- nRandLines: 50,
- nMaxRand: 0,
- nBatches: 4,
- learningRate: 22,
-}
-
-
-window.pointData = window.pointData || d3.range(100).map(i => {
- var color = i % 2 ? 0 : 1
- var color0 = color
- var color1 = color
-
- var σ = .1
- var μ = .2
- if (color){
- var x = d3.randomNormal(1 - μ, σ)()
- var y = d3.randomNormal(1 - μ, σ*1)()
- } else {
- var x = d3.randomNormal(μ, σ)()
- var y = d3.randomNormal(μ, σ*1)()
- y = d3.clamp(0, y, .4)
- }
-
- x = d3.clamp(.03, x, .97)
- y = d3.clamp(.03, y, .97)
-
- var bucketX = x*(state.nParams - 1)
-
- if (i == 51){
- x = .25
- y = .55
- color = 0
- color0 = 0
- color1 = 1
- }
-
- return {i, x, y, bucketX, color, color0, color1}
-})
-
-var updateAllFns = []
-var updateAll = () => updateAllFns.forEach(fn => fn())
-
-var updateCircleFns = []
-var updateCircle = (d) => updateCircleFns.forEach(fn => fn(d))
-
-var sel = d3.select('.epoch-graph').html('')
- .st({marginTop: 30})
- .at({role: 'graphics-document', 'aria-label': `Grid of charts showing a simple 2d classifer being trained over four epochs. Changing a single outlier point from red to blue makes a big difference in the final model.`})
-
-var dbSel = d3.select('.decision-boundry').html('').append('div')
- .at({role: 'graphics-document', 'aria-label': `Slides to control the level clipping and noise applied the gradient at each step. Increasing the noise enough makes the decision boundries for the models trained on the red and blue outliers overlap.`})
-
-var colorTypes = [{key: 'color1'}, {key: 'color0'}]
-sel.appendMany('div', colorTypes)
- .each(drawColorType)
-
-drawBatch(
- dbSel.append('div').parent().append('div'),
- 3,
- colorTypes[0],
- colorTypes[1]
-)
-
-
-function drawColorType(ct){
- function calcBatches(){
- var buckets = d3.nestBy(pointData, d => Math.floor(d.bucketX))
- buckets = _.sortBy(buckets, d => +d.key)
-
- pointData.forEach(d => {
- d.bucketX = d.x*(state.nParams - 1)
- })
-
- buckets.forEach((bucket, i) => {
- bucket.i = i
- bucket.x = +bucket.key
-
- bucket.pointData = pointData.filter(d => Math.abs(d.bucketX - bucket.key) < 1)
-
- bucket.scores = d3.range(state.scoreSteps).map(i => {
- var y = i/(state.scoreSteps - 1)
- var pad = 0
-
- var score = d3.sum(bucket.pointData, (d, i) => {
- // return d[ct.key] == 0 ? d.y < y - pad : d.y > y + pad
-
- var dif = 1 - Math.abs(d.bucketX - bucket.x)
- dif = Math.min(dif, .5)
- if (d[ct.key] == 0){
- return d.y < y - pad ? dif : -dif
- } else {
- return d.y > y + pad ? dif : -dif
- }
- })
-
- return {y, i, score}
- })
-
- bucket.best = _.maxBy(bucket.scores, d => d.score)
-
- bucket.scores.forEach(score => {
- var nextScoreIndex = score.i
- var charge = 0
-
- for (var j = 0; j < state.learningRate; j++){
- var dif = bucket.best.score - bucket.scores[nextScoreIndex]?.score
- charge += dif || 5
- if (bucket.scores[nextScoreIndex | 0].score == bucket.best.score){
- j = state.learningRate
- } else if (charge > 2) {
- nextScoreIndex += nextScoreIndex < bucket.best.i ? 1 : -1
- charge = 0
- }
- }
-
- score.nextScoreIndex = nextScoreIndex
- })
-
- bucket.x = (bucket.i +.5)/(state.nParams - 1)
- })
-
- var rng = new alea(ct.key)
-
- // random lines x batches x buckets
- var randLines = d3.range(state.nRandLines).map(() => {
- return [buckets.map(d => Math.floor(d.x*state.scoreSteps))]
- })
-
- function calcNextBatch(){
- randLines.forEach(line => {
- var next = _.last(line).map((scoreIndex, i) => {
- var randInt = Math.round((rng() - .5)*state.nMaxRand)
- return d3.clamp(
- 0,
- buckets[i].scores[scoreIndex | 0].nextScoreIndex + randInt,
- state.scoreSteps - 1)
- })
-
- line.push(next)
- })
- }
- d3.range(state.nBatches - 1).forEach(calcNextBatch)
-
- ct.buckets = buckets
- ct.randLines = randLines
- }
- calcBatches()
-
- var sel = d3.select(this)
-
- var render = (function(){
- ct.renderFns = []
-
- sel
- .append('div.chart-title').text(ct.key == 'color1' ? 'Training a model with an isolated red point' : 'Training a model with an isolated blue point')
- .st({marginLeft: 10, marginBottom: -18, marginTop: -5})
- .parent()
- .appendMany('div', ct.randLines[0])
- .st({display: 'inline-block'})
- .each(function(d, i){ drawBatch(d3.select(this), i, ct)})
-
- return () => ct.renderFns.forEach(d => d())
- })()
-
- updateAllFns.push(() => {
- calcBatches()
- render()
- })
-}
-
-
-function drawBatch(sel, batchIndex, ct, ct2){
-
- var size = ct2 ? 300 : 150
- var mScale = ct2 ? 0 : 1
- var c = d3.conventions({
- sel,
- width: size,
- height: size,
- margin: {left: 10*mScale, right: 10*mScale, top: 20*mScale, bottom: ct2 ? 50 : 20},
- layers: 'scsd',
- })
-
- var divSel = c.layers[3].st({pointerEvents: 'none'})
-
- c.layers[0].append('rect')
- .at({width: c.width, height: c.height, fill: '#efefef'})
-
- c.svg = c.layers[2]
-
- c.svg.append('rect')
- .at({width: c.width, height: c.height, fill: 'rgba(0,0,0,0)'})
-
- c.svg.append('text')
- .text('Step ' + (batchIndex + 1))
- .translate([c.width/2, c.height + 13])
- .at({textAnchor: 'middle', fontSize: 10, fill: '#999'})
- .st({opacity: ct2 ? 0 : 1})
-
- c.x.domain([0, 1]).clamp(1)
- c.y.domain([0, 1]).clamp(1)
-
- var drag = d3.drag()
- .on('start', () => c.svg.classed('dragging', 1))
- .on('end', () => c.svg.classed('dragging', 0))
- .on('drag', function(d){
- d.x = d3.clamp(.03, c.x.invert(d3.event.x), .97)
- d.y = d3.clamp(.03, c.y.invert(d3.event.y), .97)
-
- updateCircle(d)
- updateAll()
- })
- .subject(function(d){ return {x: c.x(d.x), y: c.y(d.y)} })
-
- var circleSel = c.svg.appendMany('circle.point', pointData)
- .at({r: 4, fill: d => util.colors[d[ct.key]]})
- .call(drag)
- .classed('swapped', d => d.color0 != d.color1)
- .translate(d => [c.x(d.x), c.y(d.y)])
- // .call(d3.attachTooltip)
-
- updateCircleFns.push(d => {
- circleSel
- .filter(e => e == d) // rendering circles is dropping frames ?
- .translate(d => [c.x(d.x), c.y(d.y)])
- })
-
- if (ct2){
- var defs = c.svg.append('defs');
- defs.append('linearGradient#red-blue-def')
- .append('stop').at({offset: '0%', 'stop-color': util.colors[0]}).parent()
- .append('stop').at({offset: '45%', 'stop-color': util.colors[0]}).parent()
- .append('stop').at({offset: '55%', 'stop-color': util.colors[1]}).parent()
- .append('stop').at({offset: '100%', 'stop-color': util.colors[1]})
- defs.append('linearGradient#blue-red-def')
- .append('stop').at({offset: '0%', 'stop-color': util.colors[1]}).parent()
- .append('stop').at({offset: '45%', 'stop-color': util.colors[1]}).parent()
- .append('stop').at({offset: '55%', 'stop-color': util.colors[0]}).parent()
- .append('stop').at({offset: '100%', 'stop-color': util.colors[0]})
-
- circleSel
- // .at({r: 1.2})
- .filter(d => d.color0 != d.color1)
- .st({r: 7, fillOpacity: 1})
- .st({fill: 'url(#red-blue-def)'})//, stroke: 'url(#blue-red-def)'})
-
- var gradientClipAnnoSel = c.svg.append('text.annotation')
- .translate([c.width + 20, -40])
- .tspans(d3.wordwrap('Completely clipping the gradient stops the model from learning anything from the training data.', 25), 14)
-
- divSel.append('div.annotation')
- .translate([30, c.height + 5])
- .html(`
- 〰 Models trained with the isolated blue point
-
-
〰 Models trained with the isolated red point
- `)
- .st({lineHeight: '1.3em'})
- .selectAll('span').st({fontSize: 20, height: 0, display: 'inline-block', top: 3, position: 'relative', fontWeight: 700})
-
-
- }
-
- function getRandLines(){
- return ct2 ? ct.randLines.concat(ct2.randLines) : ct.randLines
- }
-
- var ctx = c.layers[1]
-
- var lineGen = d3.line()
- .x(d => c.x(d.x))
- .y(d => c.y(d.y))
- .curve(d3.curveNatural)
- .context(ctx)
-
- ct.renderFns.push(() => {
- var scores = ct.buckets[0].scores
- var paddedLineData = getRandLines().map(line => {
- var xyData = line[batchIndex].map((scoreIndex, i) => {
- return {x: ct.buckets[i].x, y: scores[scoreIndex | 0].y}
- })
-
- return [
- {x: 0, y: batchIndex*state.learningRate ? xyData[0].y : 0},
- ...xyData,
- {x: 1, y: batchIndex*state.learningRate ? _.last(xyData).y : 1}
- ]
- })
-
- ctx.clearRect(-c.margin.left, -c.margin.top, c.width + c.margin.left + c.margin.right, c.height + c.margin.top + c.margin.bottom)
- paddedLineData.forEach((d, i) => {
- ctx.beginPath()
- ctx.lineWidth = .1
- ctx.strokeStyle = !ct2 ? '#000' : i < ct.randLines.length ? util.colors[1] : util.colors[0]
- lineGen(d)
- ctx.stroke()
- })
-
- if (ct2){
- gradientClipAnnoSel.st({opacity: state.learningRate == 0 ? 1 : 0})
- }
- })
-}
-
-
-function addSliders(){
- var width = 180
- var height = 30
- var color = '#000'
-
- var sliders = [
- {key: 'nMaxRand', label: 'Random Noise', r: [0, 30]},
- {key: 'learningRate', label: 'Gradient Clip', r: [30, 0]},
- ]
- sliders.forEach(d => {
- d.value = state[d.key]
- d.xScale = d3.scaleLinear().range([0, width]).domain(d.r).clamp(1)
- })
-
- var svgSel = dbSel.append('div.sliders').lower()
- .st({marginTop: 5, marginBottom: 5})
- .appendMany('div.slider-container', sliders)
- .append('svg').at({width, height})
- .append('g').translate(120, 0)
-
- svgSel.append('text.chart-title')
- .text(d => d.label)
- .at({textAnchor: 'end', dy: '.33em', x: -15})
-
- var sliderSel = svgSel
- .on('click', function(d){
- d.value = d.xScale.invert(d3.mouse(this)[0])
- renderSliders(d)
- })
- .classed('slider', true)
- .st({cursor: 'pointer'})
-
- var textSel = sliderSel.append('text.slider-label-container')
- .at({y: -20, fontWeight: 500, textAnchor: 'middle', x: 180/2})
-
- sliderSel.append('rect')
- .at({width, height, y: -height/2, fill: 'rgba(0,0,0,0)'})
-
- sliderSel.append('path').at({
- d: `M 0 -.5 H ${width}`,
- stroke: color,
- strokeWidth: 1
- })
-
- var leftPathSel = sliderSel.append('path').at({
- d: `M 0 -.5 H ${width}`,
- stroke: color,
- strokeWidth: 3
- })
-
- var drag = d3.drag()
- .on('drag', function(d){
- var x = d3.mouse(this)[0]
- d.value = d.xScale.invert(x)
-
- renderSliders(d)
- })
-
- var circleSel = sliderSel.append('circle').call(drag)
- .at({r: 7, stroke: '#000'})
-
- function renderSliders(d){
- if (d) state[d.key] = d.value
-
- circleSel.at({cx: d => d.xScale(d.value)})
- leftPathSel.at({d: d => `M 0 -.5 H ${d.xScale(d.value)}`})
-
- updateAll()
- }
- renderSliders()
-}
-addSliders()
-
-
-updateAll()
diff --git a/spaces/merve/fill-in-the-blank/public/measuring-diversity/sliders.js b/spaces/merve/fill-in-the-blank/public/measuring-diversity/sliders.js
deleted file mode 100644
index 13b03fa080fe5d1c2db81ef456242c0d856b0a0f..0000000000000000000000000000000000000000
--- a/spaces/merve/fill-in-the-blank/public/measuring-diversity/sliders.js
+++ /dev/null
@@ -1,206 +0,0 @@
-window.highlightColor = '#bf0bbf'
-
-window.makeSliders = function(metrics, sets, c, selectSet, drawRow, onRender){
-
- var width = 180
- var height = 30
- var color = '#000'
-
- var xScale = d3.scaleLinear().range([0, width]).domain([0, 1])
- .clamp(1)
-
- var sliderSel = c.svg.appendMany('g', metrics)
- .translate((d, i) => [-c.margin.left -10 , 130*i + 30])
- .on('click', function(d){
- d.target = xScale.invert(d3.mouse(this)[0])
- render()
- })
- .classed('slider', true)
- .st({cursor: 'pointer'})
-
- var textSel = sliderSel.append('text.slider-label-container')
- .at({y: -20, fontWeight: 500, textAnchor: 'middle', x: 180/2})
-
- sliderSel.append('rect')
- .at({width, height, y: -height/2, fill: 'rgba(0,0,0,0)'})
-
- sliderSel.append('path').at({
- d: `M 0 -.5 H ${width}`,
- stroke: color,
- strokeWidth: 1
- })
-
- var leftPathSel = sliderSel.append('path').at({
- d: `M 0 -.5 H ${width}`,
- stroke: color,
- strokeWidth: 3
- })
-
- var drag = d3.drag()
- .on('drag', function(d){
- var x = d3.mouse(this)[0]
- d.target = xScale.invert(x)
- render()
- })
-
- var circleSel = sliderSel.append('circle').call(drag)
- .at({r: 7, stroke: '#000'})
-
-
- var exSel = c.svg.append('g').translate([-c.margin.left -10, 400])
- .st({fontSize: 13})
-
- var curY = 0
- exSel.append('g')
- .append('text').text('The selected set is...')
-
- var selectedSetG = exSel.append('g.selected').translate([-10, curY += 15])
- .datum(sets[0])
- .call(drawRow)
-
- selectedSetG.select('.no-stroke').classed('selected', 1)
-
- curY += 25
- var exMetrics = exSel.appendMany('g', metrics)
- .translate(() => curY +=22, 1)
- .append('text').html(d => '10% small, 10% more than target')
-
- curY += 10
- var exMeanDiff = exSel.append('text').translate(() => curY +=22, 1)
- .at({textAnchor: 'end', x: 190})
- var exMaxDiff = exSel.append('text').translate(() => curY +=22, 1)
- .at({textAnchor: 'end', x: 190})
-
-
- // Make histogram data
- sliderSel.each(function(metric){
- var countKey = metric.key + '_count'
- sets.forEach(set => {
- var v = d3.sum(set, d => d[metric.field] == metric.key)
- set[countKey] = v / set.length
- })
-
- var byCountKey = d3.nestBy(sets, d => d[countKey])
-
- d3.range(.1, 1, .1).forEach(i => {
- if (byCountKey.some(d => d.key*100 == Math.round(i*100))) return
-
- var rv = []
- rv.key = i
- byCountKey.push(rv)
- })
-
- byCountKey.forEach(d => {
- d.metric = metric
- d.key = +d.key
- })
-
- var countSel = d3.select(this).append('g.histogram').lower()
- .translate(30, 1)
- .appendMany('g', byCountKey)
- .translate(d => xScale.clamp(0)(d.key - .05), 0)
- xScale.clamp(1)
-
- countSel.append('text')
- // .text(d => '10')
- .at({fontSize: 11, opacity: .7, y: -8, textAnchor: 'middle', x: 9.5})
- .text(d => d.key*100)
-
- countSel.append('path')
- .at({d: 'M 9.5 -18 V -30', stroke: '#ccc'})
-
- countSel
- .appendMany('rect.histogram-set', d => d)
- .at({width: 16, height: 4, x: 1.5, y: (d, i) => i*6})
- // .on('mouseover', selectSet)
- })
- var histogramSetSel = sliderSel.selectAll('rect.histogram-set')
- .st({cursor: 'default'})
-
- var axisSel = sliderSel.selectAll('.histogram text')
-
-
- var pinkSel = sliderSel.append('g')
- .at({r: 4, fill: highlightColor})
- .st({pointerEvents: 'none', opacity:0})
- pinkSel.append('path').at({stroke: highlightColor, d: 'M .5 0 V 15'})
- pinkSel.append('text').at({y: 30, textAnchor: 'middle'})
- pinkSel.append('text.score').at({y: 50, textAnchor: 'middle'})
-
-
- function render(){
- circleSel.at({cx: d => xScale(d.target)})
- // circleSel.at({cx: d => xScale(d.target)})
- textSel.text(d => (d.str + ' Target: ').replace('s ', ' ') + pctFmt(d.target))
-
- axisSel
- .classed('selected', false)
- // .text(function(d){
- // var str = Math.round(100*Math.abs(d.key - d.metric.target))
-
- // if (d.some(e => e.selected)){
- // d3.select(this).classed('selected', 1)
- // // str = str + '%'
- // }
-
- // return str
- // })
-
- leftPathSel.at({d: d => `M 0 -.5 H ${xScale(d.target)}`})
- metrics.forEach(d => {
- d.scoreScale = d3.scaleLinear()
- .domain([-.1, d.target, 1.1])
- .range([0, 1, 0])
- })
- histogramSetSel.st({fill: d => d === sets.selected ? highlightColor: '#bbb'})
-
- if (onRender) onRender()
-
- var shapes = sets.selected
-
- var metricVals = metrics.map(m => {
- return d3.sum(shapes, (d, i) => shapes[i][m.field] == m.key)/shapes.length
- })
-
- pinkSel.translate((d, i) => xScale(metricVals[i]), 0)
- pinkSel.select('text').text((d, i) => pctFmt(metricVals[i]))
- pinkSel.select('.score').text((d, i) => 'Difference: ' + Math.round(shapes.score[i]*100))
-
-
- selectedSetG.html('')
- .datum(sets.selected)
- .call(drawRow)
-
- selectedSetG.select('.no-stroke').classed('selected', 1)
-
- exMetrics
- .html((d, i) => {
- var target = d.target
- var actual = sets.selected[d.key + '_count']
- var diff = sets.selected.score[i]
-
- var str = d.str.replace('ls', 'l').replace('ns', 'n').toLowerCase()
-
- return `
- ${pctFmt(actual)}
- ${str},
- ${pctFmt(diff)}
- ${actual < target ? 'less' : 'more'} than target
- `
- })
- .at({textAnchor: 'end', x: 190})
-
- exMeanDiff
- .text('Mean Difference: ' + d3.format('.2%')(sets.selected['Utilitarian']/100))
-
- exMaxDiff
- .text('Max Difference: ' + measures[1].ppFn(sets.selected['score']).replace('%', '.00%'))
-
- }
-
- return {render}
-}
-
-
-// window.initColumns('#columns-height', metrics1, measures)
-// window.initColumns('#columns-height-disagree', metrics2, measures2)
diff --git a/spaces/merve/fill-in-the-blank/public/measuring-fairness/slider.js b/spaces/merve/fill-in-the-blank/public/measuring-fairness/slider.js
deleted file mode 100644
index efcbc18387d0d0cb957e34f75bb20a83131dda8e..0000000000000000000000000000000000000000
--- a/spaces/merve/fill-in-the-blank/public/measuring-fairness/slider.js
+++ /dev/null
@@ -1,139 +0,0 @@
-/* Copyright 2020 Google LLC. All Rights Reserved.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-==============================================================================*/
-
-
-
-
-
-
-
-
-window.makeSlider = function(){
-
- var width = 300
- var height = 30
-
- var x = d3.scaleLinear()
- .domain([.99, .6])
- .range([0, width])
- .clamp(true)
-
- var rv = {}
- rv.threshold = .5
- rv.setSlider = makeSetSlider(students, 'threshold')
- rv.setSliderF = makeSetSlider(students.filter(d => !d.isMale), 'threshold_f')
- rv.setSliderM = makeSetSlider(students.filter(d => d.isMale), 'threshold_m')
-
- var allActiveSel = d3.selectAll('.threshold-rect')
- var allHandleSel = d3.selectAll('.threshold-handle')
-
- var gatedSel = d3.select('.gated')
-
- function makeSetSlider(data, key){
- var text = key.split('_')[1]
-
-
- var drag = d3.drag()
- .on('drag', function(d){
- updateThreshold(x.invert(d3.mouse(this)[0]))
- // console.log(d3.event.x)
-
- if (text && slider.threshold_f && (slider.threshold_f > 0.9042 || slider.threshold_f - slider.threshold_m > .05)){
- gatedSel.classed('opened', 1)
- svg.classed('no-blink', 1)
- }
-
- if (key == 'threshold') svg.classed('no-blink', 1)
- })
-
- var svg = d3.select('.slider.' + key).html('')
- .append('svg').at({width, height})
- .call(drag)
- .st({cursor: 'pointer'})
-
- if (key == 'threshold_m') svg.classed('no-blink', 1)
-
-
-
- svg.append('rect').at({width, height, fill: lcolors.well})
-
- var rectSel = svg.append('rect.threshold-rect')
- .at({width, height, fill: lcolors.sick})
-
- var handleSel = svg.append('g.threshold-handle')
- handleSel.append('text.cursor')
- .text('▲')
- .at({textAnchor: 'middle', fontSize: 10, y: height, dy: '.8em'})
- handleSel.append('circle')
- .at({cy: height, r: 30, fill: 'rgba(0,0,0,0)'})
-
- var labelText = 'Model Aggressiveness _→'
- var _replacement = !text ? '' : 'On ' + (text == 'f' ? 'Women ' : 'Men ')
-
- var labelText = '_Model Aggressiveness →'
- var _replacement = !text ? '' : (text == 'f' ? 'Adult ' : 'Adult ')
-
- var labelText = '_Model Decision Point'
- var _replacement = !text ? '' : (text == 'f' ? 'Adult ' : 'Adult ')
-
- var labelText = 'Model Decision Point_'
- var _replacement = !text ? '' : (text == 'f' ? ' for Adults ' : ' for Children ')
-
- var labelText = '_ Model Aggressiveness →'
- var _replacement = !text ? '' : (text == 'f' ? ' Adult ' : 'Child ')
-
-
- svg.append('text.axis').text(labelText.replace('_', _replacement))
- .at({y: height/2, dy: '.33em', dx: 10})
- .st({pointerEvents: 'none'})
-
-
-
- function updateThreshold(threshold, skipDom){
- rv[key] = threshold
- data.forEach(d => d.threshold = threshold)
-
- mini.updateAll()
-
- rectSel.at({width: x(threshold)})
- handleSel.translate(x(threshold), 0)
-
- if (skipDom) return
-
- if (key == 'threshold'){
- allActiveSel.at({width: x(threshold)})
- allHandleSel.translate(x(threshold), 0)
- }
-
- sel.rectSel.at({fill: d => d.grade > d.threshold ? lcolors.sick : lcolors.well})
- sel.textSel
- .st({
- strokeWidth: d => d.grade > d.threshold == d.isSick ? 0 : .6,
- })
-
- }
-
- return updateThreshold
- }
-
- return rv
-}
-
-
-
-
-
-
-if (window.init) window.init()
diff --git a/spaces/merve/measuring-fairness/public/private-and-fair/umap-digit.js b/spaces/merve/measuring-fairness/public/private-and-fair/umap-digit.js
deleted file mode 100644
index f2fd20ea8d672ab49ca2698135c581605524bb46..0000000000000000000000000000000000000000
--- a/spaces/merve/measuring-fairness/public/private-and-fair/umap-digit.js
+++ /dev/null
@@ -1,139 +0,0 @@
-
-!(async function(){
- var data = await util.getFile('mnist_train.csv')
- data.forEach(d => {
- delete d['']
- d.i = +d.i
- })
-
- var sel = d3.select('.umap-digit').html('')
- .at({role: 'graphics-document', 'aria-label': `Color coded UMAP of MNIST 1s showing that increasing privacy will misclassify slanted and serif “1” digits first.`})
-
- var umapSel = sel.append('div')
- .append('div.chart-title').text('Sensitivity to higher privacy levels →')
- .parent()
- .st({maxWidth: 600, margin: '0 auto', marginBottom: 10})
- .append('div')
-
-
- var buttonSel = sel.append('div.digit-button-container')
- .appendMany('div.button', d3.range(10))
- .text(d => d)
- .on('click', d => drawDigitUmap(d))
-
-
- drawDigitUmap(1)
-
-
- async function drawDigitUmap(digit){
- buttonSel.classed('active', d => d == digit)
-
- // var umap = await util.getFile(`umap_train_${digit}.npy`)
- var umap = await util.getFile(`cns-cache/umap_train_784_${digit}.npy`)
- util.getFile(`cns-cache/mnist_train_raw_${digit}.npy`)
-
- var digitData = data
- .filter(d => d.y == digit)
- .map((d, i) => ({
- rawPos: [umap.data[i*2 + 0], umap.data[i*2 + 1]],
- priv_order: d.priv_order,
- y: d.y,
- i: d.i
- }))
-
- var c = d3.conventions({
- sel: umapSel.html(''),
- width: 600,
- height: 600,
- layers: 'sdc',
- margin: {top: 45}
- })
-
- var nTicks = 200
- c.svg.appendMany('rect', d3.range(nTicks))
- .at({
- height: 15,
- width: 1,
- fill: i => d3.interpolatePlasma(i/nTicks),
- })
- .translate(i => [c.width/2 - nTicks/2 - 20 + i, -c.margin.top + 5])
-
-
- c.x.domain(d3.extent(digitData, d => d.rawPos[0]))
- c.y.domain(d3.extent(digitData, d => d.rawPos[1]))//.range([0, c.height])
- digitData.forEach(d => d.pos = [c.x(d.rawPos[0]), c.y(d.rawPos[1])])
-
- c.sel.select('canvas').st({pointerEvents: 'none'})
- var divSel = c.layers[1].st({pointerEvents: 'none'})
- var ctx = c.layers[2]
-
- digitData.forEach(d => {
- ctx.beginPath()
- ctx.fillStyle = d3.interpolatePlasma(1 - d.priv_order/60000)
- ctx.rect(d.pos[0], d.pos[1], 2, 2)
- ctx.fill()
- })
-
- var p = 10
- c.svg
- .append('rect').at({width: c.width + p*2, height: c.height + p*2, x: -p, y: -p})
- .parent()
- .call(d3.attachTooltip)
- .on('mousemove', function(){
- var [px, py] = d3.mouse(this)
-
- var minPoint = _.minBy(digitData, d => {
- var dx = d.pos[0] - px
- var dy = d.pos[1] - py
-
- return dx*dx + dy*dy
- })
-
- var s = 4
- var c = d3.conventions({
- sel: ttSel.html('').append('div'),
- width: 4*28,
- height: 4*28,
- layers: 'cs',
- margin: {top: 0, left: 0, right: 0, bottom: 0}
- })
-
- //
Label: ${minPoint.y}
- // ttSel.append('div').html(`
- //
Privacy Rank ${d3.format(',')(minPoint.priv_order)}
- // `)
-
- ttSel.classed('tooltip-footnote', 0).st({width: 112})
-
- util.drawDigit(c.layers[0], +minPoint.i, s)
- })
-
- if (digit == 1){
- var circleDigits = [
- {r: 40, index: 1188},
- {r: 53, index: 18698},
- {r: 40, index: 1662}
- ]
- circleDigits.forEach(d => {
- d.pos = digitData.filter(e => e.priv_order == d.index)[0].pos
- })
-
- c.svg.append('g')
- .appendMany('g', circleDigits)
- .translate(d => d.pos)
- .append('circle')
- .at({r: d => d.r, fill: 'none', stroke: '#fff', strokeDasharray: '2 3', strokeWidth: 1})
-
- var {r, pos} = circleDigits[0]
-
-
- divSel
- .append('div').translate(pos)
- .append('div').translate([r + 20, -r + 10])
- .st({width: 150, fontWeight: 300, fontSize: 14, color: '#fff', xbackground: 'rgba(255,0,0,.2)', lineHeight: '1.2em'})
- .text('Increasing privacy will misclassify slanted and serif “1” digits first')
- }
- }
-})()
-
-
diff --git a/spaces/merve/uncertainty-calibration/server-side/fill-in-the-blank/scatter-plot-colab/spearman-distribution/test.html b/spaces/merve/uncertainty-calibration/server-side/fill-in-the-blank/scatter-plot-colab/spearman-distribution/test.html
deleted file mode 100644
index bd51a96a0e44f236d2fef909e99ce49251683407..0000000000000000000000000000000000000000
--- a/spaces/merve/uncertainty-calibration/server-side/fill-in-the-blank/scatter-plot-colab/spearman-distribution/test.html
+++ /dev/null
@@ -1,12 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
diff --git a/spaces/mfrashad/CharacterGAN/netdissect/aceoptimize.py b/spaces/mfrashad/CharacterGAN/netdissect/aceoptimize.py
deleted file mode 100644
index 46ac0620073a0c26e9ead14b20db57c586ce15aa..0000000000000000000000000000000000000000
--- a/spaces/mfrashad/CharacterGAN/netdissect/aceoptimize.py
+++ /dev/null
@@ -1,934 +0,0 @@
-# Instantiate the segmenter gadget.
-# Instantiate the GAN to optimize over
-# Instrument the GAN for editing and optimization.
-# Read quantile stats to learn 99.9th percentile for each unit,
-# and also the 0.01th percentile.
-# Read the median activation conditioned on door presence.
-
-import os, sys, numpy, torch, argparse, skimage, json, shutil
-from PIL import Image
-from torch.utils.data import TensorDataset
-from matplotlib.figure import Figure
-from matplotlib.backends.backend_agg import FigureCanvasAgg as FigureCanvas
-import matplotlib.gridspec as gridspec
-from scipy.ndimage.morphology import binary_dilation
-
-import netdissect.zdataset
-import netdissect.nethook
-from netdissect.dissection import safe_dir_name
-from netdissect.progress import verbose_progress, default_progress
-from netdissect.progress import print_progress, desc_progress, post_progress
-from netdissect.easydict import EasyDict
-from netdissect.workerpool import WorkerPool, WorkerBase
-from netdissect.runningstats import RunningQuantile
-from netdissect.pidfile import pidfile_taken
-from netdissect.modelconfig import create_instrumented_model
-from netdissect.autoeval import autoimport_eval
-
-def main():
- parser = argparse.ArgumentParser(description='ACE optimization utility',
- prog='python -m netdissect.aceoptimize')
- parser.add_argument('--model', type=str, default=None,
- help='constructor for the model to test')
- parser.add_argument('--pthfile', type=str, default=None,
- help='filename of .pth file for the model')
- parser.add_argument('--segmenter', type=str, default=None,
- help='constructor for asegmenter class')
- parser.add_argument('--classname', type=str, default=None,
- help='intervention classname')
- parser.add_argument('--layer', type=str, default='layer4',
- help='layer name')
- parser.add_argument('--search_size', type=int, default=10000,
- help='size of search for finding training locations')
- parser.add_argument('--train_size', type=int, default=1000,
- help='size of training set')
- parser.add_argument('--eval_size', type=int, default=200,
- help='size of eval set')
- parser.add_argument('--inference_batch_size', type=int, default=10,
- help='forward pass batch size')
- parser.add_argument('--train_batch_size', type=int, default=2,
- help='backprop pass batch size')
- parser.add_argument('--train_update_freq', type=int, default=10,
- help='number of batches for each training update')
- parser.add_argument('--train_epochs', type=int, default=10,
- help='number of epochs of training')
- parser.add_argument('--l2_lambda', type=float, default=0.005,
- help='l2 regularizer hyperparameter')
- parser.add_argument('--eval_only', action='store_true', default=False,
- help='reruns eval only on trained snapshots')
- parser.add_argument('--no-cuda', action='store_true', default=False,
- help='disables CUDA usage')
- parser.add_argument('--no-cache', action='store_true', default=False,
- help='disables reading of cache')
- parser.add_argument('--outdir', type=str, default=None,
- help='dissection directory')
- parser.add_argument('--variant', type=str, default=None,
- help='experiment variant')
- args = parser.parse_args()
- args.cuda = not args.no_cuda and torch.cuda.is_available()
- torch.backends.cudnn.benchmark = True
-
- run_command(args)
-
-def run_command(args):
- verbose_progress(True)
- progress = default_progress()
- classname = args.classname # 'door'
- layer = args.layer # 'layer4'
- num_eval_units = 20
-
- assert os.path.isfile(os.path.join(args.outdir, 'dissect.json')), (
- "Should be a dissection directory")
-
- if args.variant is None:
- args.variant = 'ace'
-
- if args.l2_lambda != 0.005:
- args.variant = '%s_reg%g' % (args.variant, args.l2_lambda)
-
- cachedir = os.path.join(args.outdir, safe_dir_name(layer), args.variant,
- classname)
-
- if pidfile_taken(os.path.join(cachedir, 'lock.pid'), True):
- sys.exit(0)
-
- # Take defaults for model constructor etc from dissect.json settings.
- with open(os.path.join(args.outdir, 'dissect.json')) as f:
- dissection = EasyDict(json.load(f))
- if args.model is None:
- args.model = dissection.settings.model
- if args.pthfile is None:
- args.pthfile = dissection.settings.pthfile
- if args.segmenter is None:
- args.segmenter = dissection.settings.segmenter
- # Default segmenter class
- if args.segmenter is None:
- args.segmenter = ("netdissect.segmenter.UnifiedParsingSegmenter(" +
- "segsizes=[256], segdiv='quad')")
-
- if (not args.no_cache and
- os.path.isfile(os.path.join(cachedir, 'snapshots', 'epoch-%d.npy' % (
- args.train_epochs - 1))) and
- os.path.isfile(os.path.join(cachedir, 'report.json'))):
- print('%s already done' % cachedir)
- sys.exit(0)
-
- os.makedirs(cachedir, exist_ok=True)
-
- # Instantiate generator
- model = create_instrumented_model(args, gen=True, edit=True,
- layers=[args.layer])
- if model is None:
- print('No model specified')
- sys.exit(1)
- # Instantiate segmenter
- segmenter = autoimport_eval(args.segmenter)
- labelnames, catname = segmenter.get_label_and_category_names()
- classnum = [i for i, (n, c) in enumerate(labelnames) if n == classname][0]
- num_classes = len(labelnames)
- with open(os.path.join(cachedir, 'labelnames.json'), 'w') as f:
- json.dump(labelnames, f, indent=1)
-
- # Sample sets for training.
- full_sample = netdissect.zdataset.z_sample_for_model(model,
- args.search_size, seed=10)
- second_sample = netdissect.zdataset.z_sample_for_model(model,
- args.search_size, seed=11)
- # Load any cached data.
- cache_filename = os.path.join(cachedir, 'corpus.npz')
- corpus = EasyDict()
- try:
- if not args.no_cache:
- corpus = EasyDict({k: torch.from_numpy(v)
- for k, v in numpy.load(cache_filename).items()})
- except:
- pass
-
- # The steps for the computation.
- compute_present_locations(args, corpus, cache_filename,
- model, segmenter, classnum, full_sample)
- compute_mean_present_features(args, corpus, cache_filename, model)
- compute_feature_quantiles(args, corpus, cache_filename, model, full_sample)
- compute_candidate_locations(args, corpus, cache_filename, model, segmenter,
- classnum, second_sample)
- # visualize_training_locations(args, corpus, cachedir, model)
- init_ablation = initial_ablation(args, args.outdir)
- scores = train_ablation(args, corpus, cache_filename,
- model, segmenter, classnum, init_ablation)
- summarize_scores(args, corpus, cachedir, layer, classname,
- args.variant, scores)
- if args.variant == 'ace':
- add_ace_ranking_to_dissection(args.outdir, layer, classname, scores)
- # TODO: do some evaluation.
-
-class SaveImageWorker(WorkerBase):
- def work(self, data, filename):
- Image.fromarray(data).save(filename, optimize=True, quality=80)
-
-def plot_heatmap(output_filename, data, size=256):
- fig = Figure(figsize=(1, 1), dpi=size)
- canvas = FigureCanvas(fig)
- gs = gridspec.GridSpec(1, 1, left=0.0, right=1.0, bottom=0.0, top=1.0)
- ax = fig.add_subplot(gs[0])
- ax.set_axis_off()
- ax.imshow(data, cmap='hot', aspect='equal', interpolation='nearest',
- vmin=-1, vmax=1)
- canvas.print_figure(output_filename, format='png')
-
-
-def draw_heatmap(output_filename, data, size=256):
- fig = Figure(figsize=(1, 1), dpi=size)
- canvas = FigureCanvas(fig)
- gs = gridspec.GridSpec(1, 1, left=0.0, right=1.0, bottom=0.0, top=1.0)
- ax = fig.add_subplot(gs[0])
- ax.set_axis_off()
- ax.imshow(data, cmap='hot', aspect='equal', interpolation='nearest',
- vmin=-1, vmax=1)
- canvas.draw() # draw the canvas, cache the renderer
- image = numpy.fromstring(canvas.tostring_rgb(), dtype='uint8').reshape(
- (size, size, 3))
- return image
-
-def compute_present_locations(args, corpus, cache_filename,
- model, segmenter, classnum, full_sample):
- # Phase 1. Identify a set of locations where there are doorways.
- # Segment the image and find featuremap pixels that maximize the number
- # of doorway pixels under the featuremap pixel.
- if all(k in corpus for k in ['present_indices',
- 'object_present_sample', 'object_present_location',
- 'object_location_popularity', 'weighted_mean_present_feature']):
- return
- progress = default_progress()
- feature_shape = model.feature_shape[args.layer][2:]
- num_locations = numpy.prod(feature_shape).item()
- num_units = model.feature_shape[args.layer][1]
- with torch.no_grad():
- weighted_feature_sum = torch.zeros(num_units).cuda()
- object_presence_scores = []
- for [zbatch] in progress(
- torch.utils.data.DataLoader(TensorDataset(full_sample),
- batch_size=args.inference_batch_size, num_workers=10,
- pin_memory=True),
- desc="Object pool"):
- zbatch = zbatch.cuda()
- tensor_image = model(zbatch)
- segmented_image = segmenter.segment_batch(tensor_image,
- downsample=2)
- mask = (segmented_image == classnum).max(1)[0]
- score = torch.nn.functional.adaptive_avg_pool2d(
- mask.float(), feature_shape)
- object_presence_scores.append(score.cpu())
- feat = model.retained_layer(args.layer)
- weighted_feature_sum += (feat * score[:,None,:,:]).view(
- feat.shape[0],feat.shape[1], -1).sum(2).sum(0)
- object_presence_at_feature = torch.cat(object_presence_scores)
- object_presence_at_image, object_location_in_image = (
- object_presence_at_feature.view(args.search_size, -1).max(1))
- best_presence_scores, best_presence_images = torch.sort(
- -object_presence_at_image)
- all_present_indices = torch.sort(
- best_presence_images[:(args.train_size+args.eval_size)])[0]
- corpus.present_indices = all_present_indices[:args.train_size]
- corpus.object_present_sample = full_sample[corpus.present_indices]
- corpus.object_present_location = object_location_in_image[
- corpus.present_indices]
- corpus.object_location_popularity = torch.bincount(
- corpus.object_present_location,
- minlength=num_locations)
- corpus.weighted_mean_present_feature = (weighted_feature_sum.cpu() / (
- 1e-20 + object_presence_at_feature.view(-1).sum()))
- corpus.eval_present_indices = all_present_indices[-args.eval_size:]
- corpus.eval_present_sample = full_sample[corpus.eval_present_indices]
- corpus.eval_present_location = object_location_in_image[
- corpus.eval_present_indices]
-
- if cache_filename:
- numpy.savez(cache_filename, **corpus)
-
-def compute_mean_present_features(args, corpus, cache_filename, model):
- # Phase 1.5. Figure mean activations for every channel where there
- # is a doorway.
- if all(k in corpus for k in ['mean_present_feature']):
- return
- progress = default_progress()
- with torch.no_grad():
- total_present_feature = 0
- for [zbatch, featloc] in progress(
- torch.utils.data.DataLoader(TensorDataset(
- corpus.object_present_sample,
- corpus.object_present_location),
- batch_size=args.inference_batch_size, num_workers=10,
- pin_memory=True),
- desc="Mean activations"):
- zbatch = zbatch.cuda()
- featloc = featloc.cuda()
- tensor_image = model(zbatch)
- feat = model.retained_layer(args.layer)
- flatfeat = feat.view(feat.shape[0], feat.shape[1], -1)
- sum_feature_at_obj = flatfeat[
- torch.arange(feat.shape[0]).to(feat.device), :, featloc
- ].sum(0)
- total_present_feature = total_present_feature + sum_feature_at_obj
- corpus.mean_present_feature = (total_present_feature / len(
- corpus.object_present_sample)).cpu()
- if cache_filename:
- numpy.savez(cache_filename, **corpus)
-
-def compute_feature_quantiles(args, corpus, cache_filename, model, full_sample):
- # Phase 1.6. Figure the 99% and 99.9%ile of every feature.
- if all(k in corpus for k in ['feature_99', 'feature_999']):
- return
- progress = default_progress()
- with torch.no_grad():
- rq = RunningQuantile(resolution=10000) # 10x what's needed.
- for [zbatch] in progress(
- torch.utils.data.DataLoader(TensorDataset(full_sample),
- batch_size=args.inference_batch_size, num_workers=10,
- pin_memory=True),
- desc="Calculating 0.999 quantile"):
- zbatch = zbatch.cuda()
- tensor_image = model(zbatch)
- feat = model.retained_layer(args.layer)
- rq.add(feat.permute(0, 2, 3, 1
- ).contiguous().view(-1, feat.shape[1]))
- result = rq.quantiles([0.001, 0.01, 0.1, 0.5, 0.9, 0.99, 0.999])
- corpus.feature_001 = result[:, 0].cpu()
- corpus.feature_01 = result[:, 1].cpu()
- corpus.feature_10 = result[:, 2].cpu()
- corpus.feature_50 = result[:, 3].cpu()
- corpus.feature_90 = result[:, 4].cpu()
- corpus.feature_99 = result[:, 5].cpu()
- corpus.feature_999 = result[:, 6].cpu()
- numpy.savez(cache_filename, **corpus)
-
-def compute_candidate_locations(args, corpus, cache_filename, model,
- segmenter, classnum, second_sample):
- # Phase 2. Identify a set of candidate locations for doorways.
- # Place the median doorway activation in every location of an image
- # and identify where it can go that doorway pixels increase.
- if all(k in corpus for k in ['candidate_indices',
- 'candidate_sample', 'candidate_score',
- 'candidate_location', 'object_score_at_candidate',
- 'candidate_location_popularity']):
- return
- progress = default_progress()
- feature_shape = model.feature_shape[args.layer][2:]
- num_locations = numpy.prod(feature_shape).item()
- with torch.no_grad():
- # Simplify - just treat all locations as possible
- possible_locations = numpy.arange(num_locations)
-
- # Speed up search for locations, by weighting probed locations
- # according to observed distribution.
- location_weights = (corpus.object_location_popularity).double()
- location_weights += (location_weights.mean()) / 10.0
- location_weights = location_weights / location_weights.sum()
-
- candidate_scores = []
- object_scores = []
- prng = numpy.random.RandomState(1)
- for [zbatch] in progress(
- torch.utils.data.DataLoader(TensorDataset(second_sample),
- batch_size=args.inference_batch_size, num_workers=10,
- pin_memory=True),
- desc="Candidate pool"):
- batch_scores = torch.zeros((len(zbatch),) + feature_shape).cuda()
- flat_batch_scores = batch_scores.view(len(zbatch), -1)
- zbatch = zbatch.cuda()
- tensor_image = model(zbatch)
- segmented_image = segmenter.segment_batch(tensor_image,
- downsample=2)
- mask = (segmented_image == classnum).max(1)[0]
- object_score = torch.nn.functional.adaptive_avg_pool2d(
- mask.float(), feature_shape)
- baseline_presence = mask.float().view(mask.shape[0], -1).sum(1)
-
- edit_mask = torch.zeros((1, 1) + feature_shape).cuda()
- if '_tcm' in args.variant:
- # variant: top-conditional-mean
- replace_vec = (corpus.mean_present_feature
- [None,:,None,None].cuda())
- else: # default: weighted mean
- replace_vec = (corpus.weighted_mean_present_feature
- [None,:,None,None].cuda())
- # Sample 10 random locations to examine.
- for loc in prng.choice(possible_locations, replace=False,
- p=location_weights, size=5):
- edit_mask.zero_()
- edit_mask.view(-1)[loc] = 1
- model.edit_layer(args.layer,
- ablation=edit_mask, replacement=replace_vec)
- tensor_image = model(zbatch)
- segmented_image = segmenter.segment_batch(tensor_image,
- downsample=2)
- mask = (segmented_image == classnum).max(1)[0]
- modified_presence = mask.float().view(
- mask.shape[0], -1).sum(1)
- flat_batch_scores[:,loc] = (
- modified_presence - baseline_presence)
- candidate_scores.append(batch_scores.cpu())
- object_scores.append(object_score.cpu())
-
- object_scores = torch.cat(object_scores)
- candidate_scores = torch.cat(candidate_scores)
- # Eliminate candidates where the object is present.
- candidate_scores = candidate_scores * (object_scores == 0).float()
- candidate_score_at_image, candidate_location_in_image = (
- candidate_scores.view(args.search_size, -1).max(1))
- best_candidate_scores, best_candidate_images = torch.sort(
- -candidate_score_at_image)
- all_candidate_indices = torch.sort(
- best_candidate_images[:(args.train_size+args.eval_size)])[0]
- corpus.candidate_indices = all_candidate_indices[:args.train_size]
- corpus.candidate_sample = second_sample[corpus.candidate_indices]
- corpus.candidate_location = candidate_location_in_image[
- corpus.candidate_indices]
- corpus.candidate_score = candidate_score_at_image[
- corpus.candidate_indices]
- corpus.object_score_at_candidate = object_scores.view(
- len(object_scores), -1)[
- corpus.candidate_indices, corpus.candidate_location]
- corpus.candidate_location_popularity = torch.bincount(
- corpus.candidate_location,
- minlength=num_locations)
- corpus.eval_candidate_indices = all_candidate_indices[
- -args.eval_size:]
- corpus.eval_candidate_sample = second_sample[
- corpus.eval_candidate_indices]
- corpus.eval_candidate_location = candidate_location_in_image[
- corpus.eval_candidate_indices]
- numpy.savez(cache_filename, **corpus)
-
-def visualize_training_locations(args, corpus, cachedir, model):
- # Phase 2.5 Create visualizations of the corpus images.
- progress = default_progress()
- feature_shape = model.feature_shape[args.layer][2:]
- num_locations = numpy.prod(feature_shape).item()
- with torch.no_grad():
- imagedir = os.path.join(cachedir, 'image')
- os.makedirs(imagedir, exist_ok=True)
- image_saver = WorkerPool(SaveImageWorker)
- for group, group_sample, group_location, group_indices in [
- ('present',
- corpus.object_present_sample,
- corpus.object_present_location,
- corpus.present_indices),
- ('candidate',
- corpus.candidate_sample,
- corpus.candidate_location,
- corpus.candidate_indices)]:
- for [zbatch, featloc, indices] in progress(
- torch.utils.data.DataLoader(TensorDataset(
- group_sample, group_location, group_indices),
- batch_size=args.inference_batch_size, num_workers=10,
- pin_memory=True),
- desc="Visualize %s" % group):
- zbatch = zbatch.cuda()
- tensor_image = model(zbatch)
- feature_mask = torch.zeros((len(zbatch), 1) + feature_shape)
- feature_mask.view(len(zbatch), -1).scatter_(
- 1, featloc[:,None], 1)
- feature_mask = torch.nn.functional.adaptive_max_pool2d(
- feature_mask.float(), tensor_image.shape[-2:]).cuda()
- yellow = torch.Tensor([1.0, 1.0, -1.0]
- )[None, :, None, None].cuda()
- tensor_image = tensor_image * (1 - 0.5 * feature_mask) + (
- 0.5 * feature_mask * yellow)
- byte_image = (((tensor_image+1)/2)*255).clamp(0, 255).byte()
- numpy_image = byte_image.permute(0, 2, 3, 1).cpu().numpy()
- for i, index in enumerate(indices):
- image_saver.add(numpy_image[i], os.path.join(imagedir,
- '%s_%d.jpg' % (group, index)))
- image_saver.join()
-
-def scale_summary(scale, lownums, highnums):
- value, order = (-(scale.detach())).cpu().sort(0)
- lowsum = ' '.join('%d: %.3g' % (o.item(), -v.item())
- for v, o in zip(value[:lownums], order[:lownums]))
- highsum = ' '.join('%d: %.3g' % (o.item(), -v.item())
- for v, o in zip(value[-highnums:], order[-highnums:]))
- return lowsum + ' ... ' + highsum
-
-# Phase 3. Given those two sets, now optimize a such that:
-# Door pred lost if we take 0 * a at a candidate (1)
-# Door pred gained If we take 99.9th activation * a at a candiate (1)
-#
-
-# ADE_au = E | on - E | off)
-# = cand-frac E_cand | on + nocand-frac E_cand | on
-# - door-frac E_door | off + nodoor-frac E_nodoor | off
-# approx = cand-frac E_cand | on - door-frac E_door | off + K
-# Each batch has both types, and minimizes
-# door-frac sum(s_c) when pixel off - cand-frac sum(s_c) when pixel on
-
-def initial_ablation(args, dissectdir):
- # Load initialization from dissection, based on iou scores.
- with open(os.path.join(dissectdir, 'dissect.json')) as f:
- dissection = EasyDict(json.load(f))
- lrec = [l for l in dissection.layers if l.layer == args.layer][0]
- rrec = [r for r in lrec.rankings if r.name == '%s-iou' % args.classname
- ][0]
- init_scores = -torch.tensor(rrec.score)
- return init_scores / init_scores.max()
-
-def ace_loss(segmenter, classnum, model, layer, high_replacement, ablation,
- pbatch, ploc, cbatch, cloc, run_backward=False,
- discrete_pixels=False,
- discrete_units=False,
- mixed_units=False,
- ablation_only=False,
- fullimage_measurement=False,
- fullimage_ablation=False,
- ):
- feature_shape = model.feature_shape[layer][2:]
- if discrete_units: # discretize ablation to the top N units
- assert discrete_units > 0
- d = torch.zeros_like(ablation)
- top_units = torch.topk(ablation.view(-1), discrete_units)[1]
- if mixed_units:
- d.view(-1)[top_units] = ablation.view(-1)[top_units]
- else:
- d.view(-1)[top_units] = 1
- ablation = d
- # First, ablate a sample of locations with positive presence
- # and see how much the presence is reduced.
- p_mask = torch.zeros((len(pbatch), 1) + feature_shape)
- if fullimage_ablation:
- p_mask[...] = 1
- else:
- p_mask.view(len(pbatch), -1).scatter_(1, ploc[:,None], 1)
- p_mask = p_mask.cuda()
- a_p_mask = (ablation * p_mask)
- model.edit_layer(layer, ablation=a_p_mask, replacement=None)
- tensor_images = model(pbatch.cuda())
- assert model._ablation[layer] is a_p_mask
- erase_effect, erased_mask = segmenter.predict_single_class(
- tensor_images, classnum, downsample=2)
- if discrete_pixels: # pixel loss: use mask instead of pred
- erase_effect = erased_mask.float()
- erase_downsampled = torch.nn.functional.adaptive_avg_pool2d(
- erase_effect[:,None,:,:], feature_shape)[:,0,:,:]
- if fullimage_measurement:
- erase_loss = erase_downsampled.sum()
- else:
- erase_at_loc = erase_downsampled.view(len(erase_downsampled), -1
- )[torch.arange(len(erase_downsampled)), ploc]
- erase_loss = erase_at_loc.sum()
- if run_backward:
- erase_loss.backward()
- if ablation_only:
- return erase_loss
- # Second, activate a sample of locations that are candidates for
- # insertion and see how much the presence is increased.
- c_mask = torch.zeros((len(cbatch), 1) + feature_shape)
- c_mask.view(len(cbatch), -1).scatter_(1, cloc[:,None], 1)
- c_mask = c_mask.cuda()
- a_c_mask = (ablation * c_mask)
- model.edit_layer(layer, ablation=a_c_mask, replacement=high_replacement)
- tensor_images = model(cbatch.cuda())
- assert model._ablation[layer] is a_c_mask
- add_effect, added_mask = segmenter.predict_single_class(
- tensor_images, classnum, downsample=2)
- if discrete_pixels: # pixel loss: use mask instead of pred
- add_effect = added_mask.float()
- add_effect = -add_effect
- add_downsampled = torch.nn.functional.adaptive_avg_pool2d(
- add_effect[:,None,:,:], feature_shape)[:,0,:,:]
- if fullimage_measurement:
- add_loss = add_downsampled.mean()
- else:
- add_at_loc = add_downsampled.view(len(add_downsampled), -1
- )[torch.arange(len(add_downsampled)), ploc]
- add_loss = add_at_loc.sum()
- if run_backward:
- add_loss.backward()
- return erase_loss + add_loss
-
-def train_ablation(args, corpus, cachefile, model, segmenter, classnum,
- initial_ablation=None):
- progress = default_progress()
- cachedir = os.path.dirname(cachefile)
- snapdir = os.path.join(cachedir, 'snapshots')
- os.makedirs(snapdir, exist_ok=True)
-
- # high_replacement = corpus.feature_99[None,:,None,None].cuda()
- if '_h99' in args.variant:
- high_replacement = corpus.feature_99[None,:,None,None].cuda()
- elif '_tcm' in args.variant:
- # variant: top-conditional-mean
- high_replacement = (
- corpus.mean_present_feature[None,:,None,None].cuda())
- else: # default: weighted mean
- high_replacement = (
- corpus.weighted_mean_present_feature[None,:,None,None].cuda())
- fullimage_measurement = False
- ablation_only = False
- fullimage_ablation = False
- if '_fim' in args.variant:
- fullimage_measurement = True
- elif '_fia' in args.variant:
- fullimage_measurement = True
- ablation_only = True
- fullimage_ablation = True
- high_replacement.requires_grad = False
- for p in model.parameters():
- p.requires_grad = False
-
- ablation = torch.zeros(high_replacement.shape).cuda()
- if initial_ablation is not None:
- ablation.view(-1)[...] = initial_ablation
- ablation.requires_grad = True
- optimizer = torch.optim.Adam([ablation], lr=0.01)
- start_epoch = 0
- epoch = 0
-
- def eval_loss_and_reg():
- discrete_experiments = dict(
- # dpixel=dict(discrete_pixels=True),
- # dunits20=dict(discrete_units=20),
- # dumix20=dict(discrete_units=20, mixed_units=True),
- # dunits10=dict(discrete_units=10),
- # abonly=dict(ablation_only=True),
- # fimabl=dict(ablation_only=True,
- # fullimage_ablation=True,
- # fullimage_measurement=True),
- dboth20=dict(discrete_units=20, discrete_pixels=True),
- # dbothm20=dict(discrete_units=20, mixed_units=True,
- # discrete_pixels=True),
- # abdisc20=dict(discrete_units=20, discrete_pixels=True,
- # ablation_only=True),
- # abdiscm20=dict(discrete_units=20, mixed_units=True,
- # discrete_pixels=True,
- # ablation_only=True),
- # fimadp=dict(discrete_pixels=True,
- # ablation_only=True,
- # fullimage_ablation=True,
- # fullimage_measurement=True),
- # fimadu10=dict(discrete_units=10,
- # ablation_only=True,
- # fullimage_ablation=True,
- # fullimage_measurement=True),
- # fimadb10=dict(discrete_units=10, discrete_pixels=True,
- # ablation_only=True,
- # fullimage_ablation=True,
- # fullimage_measurement=True),
- fimadbm10=dict(discrete_units=10, mixed_units=True,
- discrete_pixels=True,
- ablation_only=True,
- fullimage_ablation=True,
- fullimage_measurement=True),
- # fimadu20=dict(discrete_units=20,
- # ablation_only=True,
- # fullimage_ablation=True,
- # fullimage_measurement=True),
- # fimadb20=dict(discrete_units=20, discrete_pixels=True,
- # ablation_only=True,
- # fullimage_ablation=True,
- # fullimage_measurement=True),
- fimadbm20=dict(discrete_units=20, mixed_units=True,
- discrete_pixels=True,
- ablation_only=True,
- fullimage_ablation=True,
- fullimage_measurement=True)
- )
- with torch.no_grad():
- total_loss = 0
- discrete_losses = {k: 0 for k in discrete_experiments}
- for [pbatch, ploc, cbatch, cloc] in progress(
- torch.utils.data.DataLoader(TensorDataset(
- corpus.eval_present_sample,
- corpus.eval_present_location,
- corpus.eval_candidate_sample,
- corpus.eval_candidate_location),
- batch_size=args.inference_batch_size, num_workers=10,
- shuffle=False, pin_memory=True),
- desc="Eval"):
- # First, put in zeros for the selected units.
- # Loss is amount of remaining object.
- total_loss = total_loss + ace_loss(segmenter, classnum,
- model, args.layer, high_replacement, ablation,
- pbatch, ploc, cbatch, cloc, run_backward=False,
- ablation_only=ablation_only,
- fullimage_measurement=fullimage_measurement)
- for k, config in discrete_experiments.items():
- discrete_losses[k] = discrete_losses[k] + ace_loss(
- segmenter, classnum,
- model, args.layer, high_replacement, ablation,
- pbatch, ploc, cbatch, cloc, run_backward=False,
- **config)
- avg_loss = (total_loss / args.eval_size).item()
- avg_d_losses = {k: (d / args.eval_size).item()
- for k, d in discrete_losses.items()}
- regularizer = (args.l2_lambda * ablation.pow(2).sum())
- print_progress('Epoch %d Loss %g Regularizer %g' %
- (epoch, avg_loss, regularizer))
- print_progress(' '.join('%s: %g' % (k, d)
- for k, d in avg_d_losses.items()))
- print_progress(scale_summary(ablation.view(-1), 10, 3))
- return avg_loss, regularizer, avg_d_losses
-
- if args.eval_only:
- # For eval_only, just load each snapshot and re-run validation eval
- # pass on each one.
- for epoch in range(-1, args.train_epochs):
- snapfile = os.path.join(snapdir, 'epoch-%d.pth' % epoch)
- if not os.path.exists(snapfile):
- data = {}
- if epoch >= 0:
- print('No epoch %d' % epoch)
- continue
- else:
- data = torch.load(snapfile)
- with torch.no_grad():
- ablation[...] = data['ablation'].to(ablation.device)
- optimizer.load_state_dict(data['optimizer'])
- avg_loss, regularizer, new_extra = eval_loss_and_reg()
- # Keep old values, and update any new ones.
- extra = {k: v for k, v in data.items()
- if k not in ['ablation', 'optimizer', 'avg_loss']}
- extra.update(new_extra)
- torch.save(dict(ablation=ablation, optimizer=optimizer.state_dict(),
- avg_loss=avg_loss, **extra),
- os.path.join(snapdir, 'epoch-%d.pth' % epoch))
- # Return loaded ablation.
- return ablation.view(-1).detach().cpu().numpy()
-
- if not args.no_cache:
- for start_epoch in reversed(range(args.train_epochs)):
- snapfile = os.path.join(snapdir, 'epoch-%d.pth' % start_epoch)
- if os.path.exists(snapfile):
- data = torch.load(snapfile)
- with torch.no_grad():
- ablation[...] = data['ablation'].to(ablation.device)
- optimizer.load_state_dict(data['optimizer'])
- start_epoch += 1
- break
-
- if start_epoch < args.train_epochs:
- epoch = start_epoch - 1
- avg_loss, regularizer, extra = eval_loss_and_reg()
- if epoch == -1:
- torch.save(dict(ablation=ablation, optimizer=optimizer.state_dict(),
- avg_loss=avg_loss, **extra),
- os.path.join(snapdir, 'epoch-%d.pth' % epoch))
-
- update_size = args.train_update_freq * args.train_batch_size
- for epoch in range(start_epoch, args.train_epochs):
- candidate_shuffle = torch.randperm(len(corpus.candidate_sample))
- train_loss = 0
- for batch_num, [pbatch, ploc, cbatch, cloc] in enumerate(progress(
- torch.utils.data.DataLoader(TensorDataset(
- corpus.object_present_sample,
- corpus.object_present_location,
- corpus.candidate_sample[candidate_shuffle],
- corpus.candidate_location[candidate_shuffle]),
- batch_size=args.train_batch_size, num_workers=10,
- shuffle=True, pin_memory=True),
- desc="ACE opt epoch %d" % epoch)):
- if batch_num % args.train_update_freq == 0:
- optimizer.zero_grad()
- # First, put in zeros for the selected units. Loss is amount
- # of remaining object.
- loss = ace_loss(segmenter, classnum,
- model, args.layer, high_replacement, ablation,
- pbatch, ploc, cbatch, cloc, run_backward=True,
- ablation_only=ablation_only,
- fullimage_measurement=fullimage_measurement)
- with torch.no_grad():
- train_loss = train_loss + loss
- if (batch_num + 1) % args.train_update_freq == 0:
- # Third, add some L2 loss to encourage sparsity.
- regularizer = (args.l2_lambda * update_size
- * ablation.pow(2).sum())
- regularizer.backward()
- optimizer.step()
- with torch.no_grad():
- ablation.clamp_(0, 1)
- post_progress(l=(train_loss/update_size).item(),
- r=(regularizer/update_size).item())
- train_loss = 0
-
- avg_loss, regularizer, extra = eval_loss_and_reg()
- torch.save(dict(ablation=ablation, optimizer=optimizer.state_dict(),
- avg_loss=avg_loss, **extra),
- os.path.join(snapdir, 'epoch-%d.pth' % epoch))
- numpy.save(os.path.join(snapdir, 'epoch-%d.npy' % epoch),
- ablation.detach().cpu().numpy())
-
- # The output of this phase is this set of scores.
- return ablation.view(-1).detach().cpu().numpy()
-
-
-def tensor_to_numpy_image_batch(tensor_image):
- byte_image = (((tensor_image+1)/2)*255).clamp(0, 255).byte()
- numpy_image = byte_image.permute(0, 2, 3, 1).cpu().numpy()
- return numpy_image
-
-# Phase 4: evaluation of intervention
-
-def evaluate_ablation(args, model, segmenter, eval_sample, classnum, layer,
- ordering):
- total_bincount = 0
- data_size = 0
- progress = default_progress()
- for l in model.ablation:
- model.ablation[l] = None
- feature_units = model.feature_shape[args.layer][1]
- feature_shape = model.feature_shape[args.layer][2:]
- repeats = len(ordering)
- total_scores = torch.zeros(repeats + 1)
- for i, batch in enumerate(progress(torch.utils.data.DataLoader(
- TensorDataset(eval_sample),
- batch_size=args.inference_batch_size, num_workers=10,
- pin_memory=True),
- desc="Evaluate interventions")):
- tensor_image = model(zbatch)
- segmented_image = segmenter.segment_batch(tensor_image,
- downsample=2)
- mask = (segmented_image == classnum).max(1)[0]
- downsampled_seg = torch.nn.functional.adaptive_avg_pool2d(
- mask.float()[:,None,:,:], feature_shape)[:,0,:,:]
- total_scores[0] += downsampled_seg.sum().cpu()
- # Now we need to do an intervention for every location
- # that had a nonzero downsampled_seg, if any.
- interventions_needed = downsampled_seg.nonzero()
- location_count = len(interventions_needed)
- if location_count == 0:
- continue
- interventions_needed = interventions_needed.repeat(repeats, 1)
- inter_z = batch[0][interventions_needed[:,0]].to(device)
- inter_chan = torch.zeros(repeats, location_count, feature_units,
- device=device)
- for j, u in enumerate(ordering):
- inter_chan[j:, :, u] = 1
- inter_chan = inter_chan.view(len(inter_z), feature_units)
- inter_loc = interventions_needed[:,1:]
- scores = torch.zeros(len(inter_z))
- batch_size = len(batch[0])
- for j in range(0, len(inter_z), batch_size):
- ibz = inter_z[j:j+batch_size]
- ibl = inter_loc[j:j+batch_size].t()
- imask = torch.zeros((len(ibz),) + feature_shape, device=ibz.device)
- imask[(torch.arange(len(ibz)),) + tuple(ibl)] = 1
- ibc = inter_chan[j:j+batch_size]
- model.edit_layer(args.layer, ablation=(
- imask.float()[:,None,:,:] * ibc[:,:,None,None]))
- _, seg, _, _, _ = (
- recovery.recover_im_seg_bc_and_features(
- [ibz], model))
- mask = (seg == classnum).max(1)[0]
- downsampled_iseg = torch.nn.functional.adaptive_avg_pool2d(
- mask.float()[:,None,:,:], feature_shape)[:,0,:,:]
- scores[j:j+batch_size] = downsampled_iseg[
- (torch.arange(len(ibz)),) + tuple(ibl)]
- scores = scores.view(repeats, location_count).sum(1)
- total_scores[1:] += scores
- return total_scores
-
-def evaluate_interventions(args, model, segmenter, eval_sample,
- classnum, layer, units):
- total_bincount = 0
- data_size = 0
- progress = default_progress()
- for l in model.ablation:
- model.ablation[l] = None
- feature_units = model.feature_shape[args.layer][1]
- feature_shape = model.feature_shape[args.layer][2:]
- repeats = len(ordering)
- total_scores = torch.zeros(repeats + 1)
- for i, batch in enumerate(progress(torch.utils.data.DataLoader(
- TensorDataset(eval_sample),
- batch_size=args.inference_batch_size, num_workers=10,
- pin_memory=True),
- desc="Evaluate interventions")):
- tensor_image = model(zbatch)
- segmented_image = segmenter.segment_batch(tensor_image,
- downsample=2)
- mask = (segmented_image == classnum).max(1)[0]
- downsampled_seg = torch.nn.functional.adaptive_avg_pool2d(
- mask.float()[:,None,:,:], feature_shape)[:,0,:,:]
- total_scores[0] += downsampled_seg.sum().cpu()
- # Now we need to do an intervention for every location
- # that had a nonzero downsampled_seg, if any.
- interventions_needed = downsampled_seg.nonzero()
- location_count = len(interventions_needed)
- if location_count == 0:
- continue
- interventions_needed = interventions_needed.repeat(repeats, 1)
- inter_z = batch[0][interventions_needed[:,0]].to(device)
- inter_chan = torch.zeros(repeats, location_count, feature_units,
- device=device)
- for j, u in enumerate(ordering):
- inter_chan[j:, :, u] = 1
- inter_chan = inter_chan.view(len(inter_z), feature_units)
- inter_loc = interventions_needed[:,1:]
- scores = torch.zeros(len(inter_z))
- batch_size = len(batch[0])
- for j in range(0, len(inter_z), batch_size):
- ibz = inter_z[j:j+batch_size]
- ibl = inter_loc[j:j+batch_size].t()
- imask = torch.zeros((len(ibz),) + feature_shape, device=ibz.device)
- imask[(torch.arange(len(ibz)),) + tuple(ibl)] = 1
- ibc = inter_chan[j:j+batch_size]
- model.ablation[args.layer] = (
- imask.float()[:,None,:,:] * ibc[:,:,None,None])
- _, seg, _, _, _ = (
- recovery.recover_im_seg_bc_and_features(
- [ibz], model))
- mask = (seg == classnum).max(1)[0]
- downsampled_iseg = torch.nn.functional.adaptive_avg_pool2d(
- mask.float()[:,None,:,:], feature_shape)[:,0,:,:]
- scores[j:j+batch_size] = downsampled_iseg[
- (torch.arange(len(ibz)),) + tuple(ibl)]
- scores = scores.view(repeats, location_count).sum(1)
- total_scores[1:] += scores
- return total_scores
-
-
-def add_ace_ranking_to_dissection(outdir, layer, classname, total_scores):
- source_filename = os.path.join(outdir, 'dissect.json')
- source_filename_bak = os.path.join(outdir, 'dissect.json.bak')
-
- # Back up the dissection (if not already backed up) before modifying
- if not os.path.exists(source_filename_bak):
- shutil.copy(source_filename, source_filename_bak)
-
- with open(source_filename) as f:
- dissection = EasyDict(json.load(f))
-
- ranking_name = '%s-ace' % classname
-
- # Remove any old ace ranking with the same name
- lrec = [l for l in dissection.layers if l.layer == layer][0]
- lrec.rankings = [r for r in lrec.rankings if r.name != ranking_name]
-
- # Now convert ace scores to rankings
- new_rankings = [dict(
- name=ranking_name,
- score=(-total_scores).flatten().tolist(),
- metric='ace')]
-
- # Prepend to list.
- lrec.rankings[2:2] = new_rankings
-
- # Replace the old dissect.json in-place
- with open(source_filename, 'w') as f:
- json.dump(dissection, f, indent=1)
-
-def summarize_scores(args, corpus, cachedir, layer, classname, variant, scores):
- target_filename = os.path.join(cachedir, 'summary.json')
-
- ranking_name = '%s-%s' % (classname, variant)
- # Now convert ace scores to rankings
- new_rankings = [dict(
- name=ranking_name,
- score=(-scores).flatten().tolist(),
- metric=variant)]
- result = dict(layers=[dict(layer=layer, rankings=new_rankings)])
-
- # Replace the old dissect.json in-place
- with open(target_filename, 'w') as f:
- json.dump(result, f, indent=1)
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/mfrashad/ClothingGAN/models/stylegan2/stylegan2-pytorch/distributed.py b/spaces/mfrashad/ClothingGAN/models/stylegan2/stylegan2-pytorch/distributed.py
deleted file mode 100644
index 51fa243257ef302e2015d5ff36ac531b86a9a0ce..0000000000000000000000000000000000000000
--- a/spaces/mfrashad/ClothingGAN/models/stylegan2/stylegan2-pytorch/distributed.py
+++ /dev/null
@@ -1,126 +0,0 @@
-import math
-import pickle
-
-import torch
-from torch import distributed as dist
-from torch.utils.data.sampler import Sampler
-
-
-def get_rank():
- if not dist.is_available():
- return 0
-
- if not dist.is_initialized():
- return 0
-
- return dist.get_rank()
-
-
-def synchronize():
- if not dist.is_available():
- return
-
- if not dist.is_initialized():
- return
-
- world_size = dist.get_world_size()
-
- if world_size == 1:
- return
-
- dist.barrier()
-
-
-def get_world_size():
- if not dist.is_available():
- return 1
-
- if not dist.is_initialized():
- return 1
-
- return dist.get_world_size()
-
-
-def reduce_sum(tensor):
- if not dist.is_available():
- return tensor
-
- if not dist.is_initialized():
- return tensor
-
- tensor = tensor.clone()
- dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
-
- return tensor
-
-
-def gather_grad(params):
- world_size = get_world_size()
-
- if world_size == 1:
- return
-
- for param in params:
- if param.grad is not None:
- dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
- param.grad.data.div_(world_size)
-
-
-def all_gather(data):
- world_size = get_world_size()
-
- if world_size == 1:
- return [data]
-
- buffer = pickle.dumps(data)
- storage = torch.ByteStorage.from_buffer(buffer)
- tensor = torch.ByteTensor(storage).to('cuda')
-
- local_size = torch.IntTensor([tensor.numel()]).to('cuda')
- size_list = [torch.IntTensor([0]).to('cuda') for _ in range(world_size)]
- dist.all_gather(size_list, local_size)
- size_list = [int(size.item()) for size in size_list]
- max_size = max(size_list)
-
- tensor_list = []
- for _ in size_list:
- tensor_list.append(torch.ByteTensor(size=(max_size,)).to('cuda'))
-
- if local_size != max_size:
- padding = torch.ByteTensor(size=(max_size - local_size,)).to('cuda')
- tensor = torch.cat((tensor, padding), 0)
-
- dist.all_gather(tensor_list, tensor)
-
- data_list = []
-
- for size, tensor in zip(size_list, tensor_list):
- buffer = tensor.cpu().numpy().tobytes()[:size]
- data_list.append(pickle.loads(buffer))
-
- return data_list
-
-
-def reduce_loss_dict(loss_dict):
- world_size = get_world_size()
-
- if world_size < 2:
- return loss_dict
-
- with torch.no_grad():
- keys = []
- losses = []
-
- for k in sorted(loss_dict.keys()):
- keys.append(k)
- losses.append(loss_dict[k])
-
- losses = torch.stack(losses, 0)
- dist.reduce(losses, dst=0)
-
- if dist.get_rank() == 0:
- losses /= world_size
-
- reduced_losses = {k: v for k, v in zip(keys, losses)}
-
- return reduced_losses
diff --git a/spaces/miruchigawa/hakurei-waifu-diffusion/app.py b/spaces/miruchigawa/hakurei-waifu-diffusion/app.py
deleted file mode 100644
index ccef706bf3035fe470bf6a4f5bd701b18bf59133..0000000000000000000000000000000000000000
--- a/spaces/miruchigawa/hakurei-waifu-diffusion/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/hakurei/waifu-diffusion").launch()
\ No newline at end of file
diff --git a/spaces/miyaaa666/bingo/src/components/external-link.tsx b/spaces/miyaaa666/bingo/src/components/external-link.tsx
deleted file mode 100644
index 011265f364d5a64a770f4c7e9c65c5ade21d623a..0000000000000000000000000000000000000000
--- a/spaces/miyaaa666/bingo/src/components/external-link.tsx
+++ /dev/null
@@ -1,30 +0,0 @@
-export function ExternalLink({
- href,
- children
-}: {
- href: string
- children: React.ReactNode
-}) {
- return (
-
- {children}
-
-
- )
-}
diff --git a/spaces/monra/freegpt-webui/client/css/select.css b/spaces/monra/freegpt-webui/client/css/select.css
deleted file mode 100644
index 7ec0159206439deca5c26f32fd92d2b1459f0273..0000000000000000000000000000000000000000
--- a/spaces/monra/freegpt-webui/client/css/select.css
+++ /dev/null
@@ -1,35 +0,0 @@
-select {
- -webkit-border-radius: 8px;
- -moz-border-radius: 8px;
- border-radius: 8px;
-
- -webkit-backdrop-filter: blur(20px);
- backdrop-filter: blur(20px);
-
- cursor: pointer;
- background-color: var(--blur-bg);
- border: 1px solid var(--blur-border);
- color: var(--colour-3);
- display: block;
- position: relative;
- overflow: hidden;
- outline: none;
- padding: 8px 16px;
-
- appearance: none;
-}
-
-/* scrollbar */
-select.dropdown::-webkit-scrollbar {
- width: 4px;
- padding: 8px 0px;
-}
-
-select.dropdown::-webkit-scrollbar-track {
- background-color: #ffffff00;
-}
-
-select.dropdown::-webkit-scrollbar-thumb {
- background-color: #555555;
- border-radius: 10px;
-}
diff --git a/spaces/mshukor/UnIVAL/fairseq/examples/wav2vec/unsupervised/scripts/filter_tsv.py b/spaces/mshukor/UnIVAL/fairseq/examples/wav2vec/unsupervised/scripts/filter_tsv.py
deleted file mode 100644
index a09d79acf31414ea3eae82db59cf9f105aefcdf1..0000000000000000000000000000000000000000
--- a/spaces/mshukor/UnIVAL/fairseq/examples/wav2vec/unsupervised/scripts/filter_tsv.py
+++ /dev/null
@@ -1,37 +0,0 @@
-#!/usr/bin/env python3 -u
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import os
-import argparse
-import sys
-
-
-parser = argparse.ArgumentParser()
-parser.add_argument("--tsv", required=True, type=str)
-parser.add_argument("--no-skip", action="store_true")
-parser.add_argument("--keep", action="store_true")
-params = parser.parse_args()
-
-
-def get_fname(line):
- p = os.path.basename(line.split("\t")[0])
- p = os.path.splitext(p)[0]
- return p
-
-
-# filenames to exclude
-seen = set()
-with open(params.tsv) as f:
- if not params.no_skip:
- root = next(f).rstrip()
- for line in f:
- seen.add(get_fname(line))
-
-for i, line in enumerate(sys.stdin):
- exists = get_fname(line) in seen
- keep = (exists and params.keep) or (not exists and not params.keep)
- if i == 0 or keep:
- print(line, end="")
diff --git a/spaces/mshukor/UnIVAL/fairseq/fairseq/modules/quantization/pq/modules/qlinear.py b/spaces/mshukor/UnIVAL/fairseq/fairseq/modules/quantization/pq/modules/qlinear.py
deleted file mode 100644
index 9bdd25a8685bb7c7b32e1f02372aaeb26d8ba53a..0000000000000000000000000000000000000000
--- a/spaces/mshukor/UnIVAL/fairseq/fairseq/modules/quantization/pq/modules/qlinear.py
+++ /dev/null
@@ -1,71 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-
-class PQLinear(nn.Module):
- """
- Quantized counterpart of nn.Linear module. Stores the centroid, the assignments
- and the non-quantized biases. The full weight is re-instantiated at each forward
- pass.
-
- Args:
- - centroids: centroids of size n_centroids x block_size
- - assignments: assignments of the centroids to the subvectors
- of size self.out_features x n_blocks
- - bias: the non-quantized bias
-
- Remarks:
- - We refer the reader to the official documentation of the nn.Linear module
- for the other arguments and the behavior of the module
- - Performance tests on GPU show that this implementation is 15% slower than
- the non-quantized nn.Linear module for a standard training loop.
- """
-
- def __init__(self, centroids, assignments, bias, in_features, out_features):
- super(PQLinear, self).__init__()
- self.block_size = centroids.size(1)
- self.n_centroids = centroids.size(0)
- self.in_features = in_features
- self.out_features = out_features
- # check compatibility
- if self.in_features % self.block_size != 0:
- raise ValueError("Wrong PQ sizes")
- if len(assignments) % self.out_features != 0:
- raise ValueError("Wrong PQ sizes")
- # define parameters
- self.centroids = nn.Parameter(centroids, requires_grad=True)
- self.register_buffer("assignments", assignments)
- self.register_buffer("counts", torch.bincount(assignments).type_as(centroids))
- if bias is not None:
- self.bias = nn.Parameter(bias)
- else:
- self.register_parameter("bias", None)
-
- @property
- def weight(self):
- return (
- self.centroids[self.assignments]
- .reshape(-1, self.out_features, self.block_size)
- .permute(1, 0, 2)
- .flatten(1, 2)
- )
-
- def forward(self, x):
- return F.linear(
- x,
- self.weight,
- self.bias,
- )
-
- def extra_repr(self):
- return f"in_features={self.in_features},\
- out_features={self.out_features},\
- n_centroids={self.n_centroids},\
- block_size={self.block_size},\
- bias={self.bias is not None}"
diff --git a/spaces/mshukor/UnIVAL/slurm_adastra/averaging/ratatouille/vqa/ofa_ratavqa_ground_bart_noema_lr1e6.sh b/spaces/mshukor/UnIVAL/slurm_adastra/averaging/ratatouille/vqa/ofa_ratavqa_ground_bart_noema_lr1e6.sh
deleted file mode 100644
index 133e0989e324478056723a1ed3a1e39b7ad82064..0000000000000000000000000000000000000000
--- a/spaces/mshukor/UnIVAL/slurm_adastra/averaging/ratatouille/vqa/ofa_ratavqa_ground_bart_noema_lr1e6.sh
+++ /dev/null
@@ -1,30 +0,0 @@
-#!/bin/bash
-
-#SBATCH --job-name=ofa_ratavqa_ground_bart_noema_lr1e6
-#SBATCH --nodes=2
-#SBATCH --ntasks=2
-#SBATCH --gpus=16
-#SBATCH --threads-per-core=2
-#SBATCH --gpu-bind=closest
-####SBATCH --nodelist=x1004c4s1b0n0,x1004c4s1b1n0
-#SBATCH --time=24:00:00
-#SBATCH -C MI250
-#SBATCH -A gda2204
-#SBATCH --mail-type=END,FAIL
-#SBATCH --output=/lus/home/NAT/gda2204/mshukor/logs/slurm/ofa_ratavqa_ground_bart_noema_lr1e6.out
-#SBATCH --exclusive
-#SBATCH --mail-user=mustafa.shukor@isir.upmc.fr
-
-
-cd /lus/home/NAT/gda2204/mshukor/code/ofa_ours/run_scripts
-source /lus/home/NAT/gda2204/mshukor/.bashrc
-
-conda activate main
-
-
-rm core-python3*
-
-
-srun -l -N 2 -n 2 -c 128 --gpus=16 --gpu-bind=closest bash averaging/ratatouille/vqa/ofa_ratavqa_ground_bart_noema_lr1e6.sh
-
-
diff --git a/spaces/msmilauer/AutoGPT-duplicated2/autogpt/commands/image_gen.py b/spaces/msmilauer/AutoGPT-duplicated2/autogpt/commands/image_gen.py
deleted file mode 100644
index 0809fcdd3e38b52a2ce09ca1444f2574813d40f9..0000000000000000000000000000000000000000
--- a/spaces/msmilauer/AutoGPT-duplicated2/autogpt/commands/image_gen.py
+++ /dev/null
@@ -1,163 +0,0 @@
-""" Image Generation Module for AutoGPT."""
-import io
-import os.path
-import uuid
-from base64 import b64decode
-
-import openai
-import requests
-from PIL import Image
-
-from autogpt.config import Config
-from autogpt.workspace import path_in_workspace
-
-CFG = Config()
-
-
-def generate_image(prompt: str, size: int = 256) -> str:
- """Generate an image from a prompt.
-
- Args:
- prompt (str): The prompt to use
- size (int, optional): The size of the image. Defaults to 256. (Not supported by HuggingFace)
-
- Returns:
- str: The filename of the image
- """
- filename = f"{str(uuid.uuid4())}.jpg"
-
- # DALL-E
- if CFG.image_provider == "dalle":
- return generate_image_with_dalle(prompt, filename, size)
- # HuggingFace
- elif CFG.image_provider == "huggingface":
- return generate_image_with_hf(prompt, filename)
- # SD WebUI
- elif CFG.image_provider == "sdwebui":
- return generate_image_with_sd_webui(prompt, filename, size)
- return "No Image Provider Set"
-
-
-def generate_image_with_hf(prompt: str, filename: str) -> str:
- """Generate an image with HuggingFace's API.
-
- Args:
- prompt (str): The prompt to use
- filename (str): The filename to save the image to
-
- Returns:
- str: The filename of the image
- """
- API_URL = (
- f"https://api-inference.huggingface.co/models/{CFG.huggingface_image_model}"
- )
- if CFG.huggingface_api_token is None:
- raise ValueError(
- "You need to set your Hugging Face API token in the config file."
- )
- headers = {
- "Authorization": f"Bearer {CFG.huggingface_api_token}",
- "X-Use-Cache": "false",
- }
-
- response = requests.post(
- API_URL,
- headers=headers,
- json={
- "inputs": prompt,
- },
- )
-
- image = Image.open(io.BytesIO(response.content))
- print(f"Image Generated for prompt:{prompt}")
-
- image.save(path_in_workspace(filename))
-
- return f"Saved to disk:{filename}"
-
-
-def generate_image_with_dalle(prompt: str, filename: str) -> str:
- """Generate an image with DALL-E.
-
- Args:
- prompt (str): The prompt to use
- filename (str): The filename to save the image to
-
- Returns:
- str: The filename of the image
- """
- openai.api_key = CFG.openai_api_key
-
- # Check for supported image sizes
- if size not in [256, 512, 1024]:
- closest = min([256, 512, 1024], key=lambda x: abs(x - size))
- print(
- f"DALL-E only supports image sizes of 256x256, 512x512, or 1024x1024. Setting to {closest}, was {size}."
- )
- size = closest
-
- response = openai.Image.create(
- prompt=prompt,
- n=1,
- size=f"{size}x{size}",
- response_format="b64_json",
- )
-
- print(f"Image Generated for prompt:{prompt}")
-
- image_data = b64decode(response["data"][0]["b64_json"])
-
- with open(path_in_workspace(filename), mode="wb") as png:
- png.write(image_data)
-
- return f"Saved to disk:{filename}"
-
-
-def generate_image_with_sd_webui(
- prompt: str,
- filename: str,
- size: int = 512,
- negative_prompt: str = "",
- extra: dict = {},
-) -> str:
- """Generate an image with Stable Diffusion webui.
- Args:
- prompt (str): The prompt to use
- filename (str): The filename to save the image to
- size (int, optional): The size of the image. Defaults to 256.
- negative_prompt (str, optional): The negative prompt to use. Defaults to "".
- extra (dict, optional): Extra parameters to pass to the API. Defaults to {}.
- Returns:
- str: The filename of the image
- """
- # Create a session and set the basic auth if needed
- s = requests.Session()
- if CFG.sd_webui_auth:
- username, password = CFG.sd_webui_auth.split(":")
- s.auth = (username, password or "")
-
- # Generate the images
- response = requests.post(
- f"{CFG.sd_webui_url}/sdapi/v1/txt2img",
- json={
- "prompt": prompt,
- "negative_prompt": negative_prompt,
- "sampler_index": "DDIM",
- "steps": 20,
- "cfg_scale": 7.0,
- "width": size,
- "height": size,
- "n_iter": 1,
- **extra,
- },
- )
-
- print(f"Image Generated for prompt:{prompt}")
-
- # Save the image to disk
- response = response.json()
- b64 = b64decode(response["images"][0].split(",", 1)[0])
- image = Image.open(io.BytesIO(b64))
- image.save(path_in_workspace(filename))
-
- return f"Saved to disk:{filename}"
diff --git a/spaces/mueller-franzes/medfusion-app/medical_diffusion/loss/perceivers.py b/spaces/mueller-franzes/medfusion-app/medical_diffusion/loss/perceivers.py
deleted file mode 100644
index 0b789b40bf36e8876ccd053d98247da5ffdc4b90..0000000000000000000000000000000000000000
--- a/spaces/mueller-franzes/medfusion-app/medical_diffusion/loss/perceivers.py
+++ /dev/null
@@ -1,27 +0,0 @@
-
-
-import lpips
-import torch
-
-class LPIPS(torch.nn.Module):
- """Learned Perceptual Image Patch Similarity (LPIPS)"""
- def __init__(self, linear_calibration=False, normalize=False):
- super().__init__()
- self.loss_fn = lpips.LPIPS(net='vgg', lpips=linear_calibration) # Note: only 'vgg' valid as loss
- self.normalize = normalize # If true, normalize [0, 1] to [-1, 1]
-
-
- def forward(self, pred, target):
- # No need to do that because ScalingLayer was introduced in version 0.1 which does this indirectly
- # if pred.shape[1] == 1: # convert 1-channel gray images to 3-channel RGB
- # pred = torch.concat([pred, pred, pred], dim=1)
- # if target.shape[1] == 1: # convert 1-channel gray images to 3-channel RGB
- # target = torch.concat([target, target, target], dim=1)
-
- if pred.ndim == 5: # 3D Image: Just use 2D model and compute average over slices
- depth = pred.shape[2]
- losses = torch.stack([self.loss_fn(pred[:,:,d], target[:,:,d], normalize=self.normalize) for d in range(depth)], dim=2)
- return torch.mean(losses, dim=2, keepdim=True)
- else:
- return self.loss_fn(pred, target, normalize=self.normalize)
-
\ No newline at end of file
diff --git a/spaces/nakamura196/yolov5-ndl-layout/ultralytics/yolov5/models/tf.py b/spaces/nakamura196/yolov5-ndl-layout/ultralytics/yolov5/models/tf.py
deleted file mode 100644
index 728907f8fb47f69cd9add0fa869336c930c9f502..0000000000000000000000000000000000000000
--- a/spaces/nakamura196/yolov5-ndl-layout/ultralytics/yolov5/models/tf.py
+++ /dev/null
@@ -1,466 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
-"""
-TensorFlow, Keras and TFLite versions of YOLOv5
-Authored by https://github.com/zldrobit in PR https://github.com/ultralytics/yolov5/pull/1127
-
-Usage:
- $ python models/tf.py --weights yolov5s.pt
-
-Export:
- $ python path/to/export.py --weights yolov5s.pt --include saved_model pb tflite tfjs
-"""
-
-import argparse
-import sys
-from copy import deepcopy
-from pathlib import Path
-
-FILE = Path(__file__).resolve()
-ROOT = FILE.parents[1] # YOLOv5 root directory
-if str(ROOT) not in sys.path:
- sys.path.append(str(ROOT)) # add ROOT to PATH
-# ROOT = ROOT.relative_to(Path.cwd()) # relative
-
-import numpy as np
-import tensorflow as tf
-import torch
-import torch.nn as nn
-from tensorflow import keras
-
-from models.common import C3, SPP, SPPF, Bottleneck, BottleneckCSP, Concat, Conv, DWConv, Focus, autopad
-from models.experimental import CrossConv, MixConv2d, attempt_load
-from models.yolo import Detect
-from utils.activations import SiLU
-from utils.general import LOGGER, make_divisible, print_args
-
-
-class TFBN(keras.layers.Layer):
- # TensorFlow BatchNormalization wrapper
- def __init__(self, w=None):
- super().__init__()
- self.bn = keras.layers.BatchNormalization(
- beta_initializer=keras.initializers.Constant(w.bias.numpy()),
- gamma_initializer=keras.initializers.Constant(w.weight.numpy()),
- moving_mean_initializer=keras.initializers.Constant(w.running_mean.numpy()),
- moving_variance_initializer=keras.initializers.Constant(w.running_var.numpy()),
- epsilon=w.eps)
-
- def call(self, inputs):
- return self.bn(inputs)
-
-
-class TFPad(keras.layers.Layer):
- def __init__(self, pad):
- super().__init__()
- self.pad = tf.constant([[0, 0], [pad, pad], [pad, pad], [0, 0]])
-
- def call(self, inputs):
- return tf.pad(inputs, self.pad, mode='constant', constant_values=0)
-
-
-class TFConv(keras.layers.Layer):
- # Standard convolution
- def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
- # ch_in, ch_out, weights, kernel, stride, padding, groups
- super().__init__()
- assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
- assert isinstance(k, int), "Convolution with multiple kernels are not allowed."
- # TensorFlow convolution padding is inconsistent with PyTorch (e.g. k=3 s=2 'SAME' padding)
- # see https://stackoverflow.com/questions/52975843/comparing-conv2d-with-padding-between-tensorflow-and-pytorch
-
- conv = keras.layers.Conv2D(
- c2, k, s, 'SAME' if s == 1 else 'VALID', use_bias=False if hasattr(w, 'bn') else True,
- kernel_initializer=keras.initializers.Constant(w.conv.weight.permute(2, 3, 1, 0).numpy()),
- bias_initializer='zeros' if hasattr(w, 'bn') else keras.initializers.Constant(w.conv.bias.numpy()))
- self.conv = conv if s == 1 else keras.Sequential([TFPad(autopad(k, p)), conv])
- self.bn = TFBN(w.bn) if hasattr(w, 'bn') else tf.identity
-
- # YOLOv5 activations
- if isinstance(w.act, nn.LeakyReLU):
- self.act = (lambda x: keras.activations.relu(x, alpha=0.1)) if act else tf.identity
- elif isinstance(w.act, nn.Hardswish):
- self.act = (lambda x: x * tf.nn.relu6(x + 3) * 0.166666667) if act else tf.identity
- elif isinstance(w.act, (nn.SiLU, SiLU)):
- self.act = (lambda x: keras.activations.swish(x)) if act else tf.identity
- else:
- raise Exception(f'no matching TensorFlow activation found for {w.act}')
-
- def call(self, inputs):
- return self.act(self.bn(self.conv(inputs)))
-
-
-class TFFocus(keras.layers.Layer):
- # Focus wh information into c-space
- def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True, w=None):
- # ch_in, ch_out, kernel, stride, padding, groups
- super().__init__()
- self.conv = TFConv(c1 * 4, c2, k, s, p, g, act, w.conv)
-
- def call(self, inputs): # x(b,w,h,c) -> y(b,w/2,h/2,4c)
- # inputs = inputs / 255 # normalize 0-255 to 0-1
- return self.conv(tf.concat([inputs[:, ::2, ::2, :],
- inputs[:, 1::2, ::2, :],
- inputs[:, ::2, 1::2, :],
- inputs[:, 1::2, 1::2, :]], 3))
-
-
-class TFBottleneck(keras.layers.Layer):
- # Standard bottleneck
- def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, w=None): # ch_in, ch_out, shortcut, groups, expansion
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
- self.cv2 = TFConv(c_, c2, 3, 1, g=g, w=w.cv2)
- self.add = shortcut and c1 == c2
-
- def call(self, inputs):
- return inputs + self.cv2(self.cv1(inputs)) if self.add else self.cv2(self.cv1(inputs))
-
-
-class TFConv2d(keras.layers.Layer):
- # Substitution for PyTorch nn.Conv2D
- def __init__(self, c1, c2, k, s=1, g=1, bias=True, w=None):
- super().__init__()
- assert g == 1, "TF v2.2 Conv2D does not support 'groups' argument"
- self.conv = keras.layers.Conv2D(
- c2, k, s, 'VALID', use_bias=bias,
- kernel_initializer=keras.initializers.Constant(w.weight.permute(2, 3, 1, 0).numpy()),
- bias_initializer=keras.initializers.Constant(w.bias.numpy()) if bias else None, )
-
- def call(self, inputs):
- return self.conv(inputs)
-
-
-class TFBottleneckCSP(keras.layers.Layer):
- # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
- def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
- # ch_in, ch_out, number, shortcut, groups, expansion
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
- self.cv2 = TFConv2d(c1, c_, 1, 1, bias=False, w=w.cv2)
- self.cv3 = TFConv2d(c_, c_, 1, 1, bias=False, w=w.cv3)
- self.cv4 = TFConv(2 * c_, c2, 1, 1, w=w.cv4)
- self.bn = TFBN(w.bn)
- self.act = lambda x: keras.activations.relu(x, alpha=0.1)
- self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
-
- def call(self, inputs):
- y1 = self.cv3(self.m(self.cv1(inputs)))
- y2 = self.cv2(inputs)
- return self.cv4(self.act(self.bn(tf.concat((y1, y2), axis=3))))
-
-
-class TFC3(keras.layers.Layer):
- # CSP Bottleneck with 3 convolutions
- def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, w=None):
- # ch_in, ch_out, number, shortcut, groups, expansion
- super().__init__()
- c_ = int(c2 * e) # hidden channels
- self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
- self.cv2 = TFConv(c1, c_, 1, 1, w=w.cv2)
- self.cv3 = TFConv(2 * c_, c2, 1, 1, w=w.cv3)
- self.m = keras.Sequential([TFBottleneck(c_, c_, shortcut, g, e=1.0, w=w.m[j]) for j in range(n)])
-
- def call(self, inputs):
- return self.cv3(tf.concat((self.m(self.cv1(inputs)), self.cv2(inputs)), axis=3))
-
-
-class TFSPP(keras.layers.Layer):
- # Spatial pyramid pooling layer used in YOLOv3-SPP
- def __init__(self, c1, c2, k=(5, 9, 13), w=None):
- super().__init__()
- c_ = c1 // 2 # hidden channels
- self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
- self.cv2 = TFConv(c_ * (len(k) + 1), c2, 1, 1, w=w.cv2)
- self.m = [keras.layers.MaxPool2D(pool_size=x, strides=1, padding='SAME') for x in k]
-
- def call(self, inputs):
- x = self.cv1(inputs)
- return self.cv2(tf.concat([x] + [m(x) for m in self.m], 3))
-
-
-class TFSPPF(keras.layers.Layer):
- # Spatial pyramid pooling-Fast layer
- def __init__(self, c1, c2, k=5, w=None):
- super().__init__()
- c_ = c1 // 2 # hidden channels
- self.cv1 = TFConv(c1, c_, 1, 1, w=w.cv1)
- self.cv2 = TFConv(c_ * 4, c2, 1, 1, w=w.cv2)
- self.m = keras.layers.MaxPool2D(pool_size=k, strides=1, padding='SAME')
-
- def call(self, inputs):
- x = self.cv1(inputs)
- y1 = self.m(x)
- y2 = self.m(y1)
- return self.cv2(tf.concat([x, y1, y2, self.m(y2)], 3))
-
-
-class TFDetect(keras.layers.Layer):
- def __init__(self, nc=80, anchors=(), ch=(), imgsz=(640, 640), w=None): # detection layer
- super().__init__()
- self.stride = tf.convert_to_tensor(w.stride.numpy(), dtype=tf.float32)
- self.nc = nc # number of classes
- self.no = nc + 5 # number of outputs per anchor
- self.nl = len(anchors) # number of detection layers
- self.na = len(anchors[0]) // 2 # number of anchors
- self.grid = [tf.zeros(1)] * self.nl # init grid
- self.anchors = tf.convert_to_tensor(w.anchors.numpy(), dtype=tf.float32)
- self.anchor_grid = tf.reshape(self.anchors * tf.reshape(self.stride, [self.nl, 1, 1]),
- [self.nl, 1, -1, 1, 2])
- self.m = [TFConv2d(x, self.no * self.na, 1, w=w.m[i]) for i, x in enumerate(ch)]
- self.training = False # set to False after building model
- self.imgsz = imgsz
- for i in range(self.nl):
- ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
- self.grid[i] = self._make_grid(nx, ny)
-
- def call(self, inputs):
- z = [] # inference output
- x = []
- for i in range(self.nl):
- x.append(self.m[i](inputs[i]))
- # x(bs,20,20,255) to x(bs,3,20,20,85)
- ny, nx = self.imgsz[0] // self.stride[i], self.imgsz[1] // self.stride[i]
- x[i] = tf.reshape(x[i], [-1, ny * nx, self.na, self.no])
-
- if not self.training: # inference
- y = tf.sigmoid(x[i])
- grid = tf.transpose(self.grid[i], [0, 2, 1, 3]) - 0.5
- anchor_grid = tf.transpose(self.anchor_grid[i], [0, 2, 1, 3]) * 4
- xy = (y[..., 0:2] * 2 + grid) * self.stride[i] # xy
- wh = y[..., 2:4] ** 2 * anchor_grid
- # Normalize xywh to 0-1 to reduce calibration error
- xy /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
- wh /= tf.constant([[self.imgsz[1], self.imgsz[0]]], dtype=tf.float32)
- y = tf.concat([xy, wh, y[..., 4:]], -1)
- z.append(tf.reshape(y, [-1, self.na * ny * nx, self.no]))
-
- return tf.transpose(x, [0, 2, 1, 3]) if self.training else (tf.concat(z, 1), x)
-
- @staticmethod
- def _make_grid(nx=20, ny=20):
- # yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
- # return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
- xv, yv = tf.meshgrid(tf.range(nx), tf.range(ny))
- return tf.cast(tf.reshape(tf.stack([xv, yv], 2), [1, 1, ny * nx, 2]), dtype=tf.float32)
-
-
-class TFUpsample(keras.layers.Layer):
- def __init__(self, size, scale_factor, mode, w=None): # warning: all arguments needed including 'w'
- super().__init__()
- assert scale_factor == 2, "scale_factor must be 2"
- self.upsample = lambda x: tf.image.resize(x, (x.shape[1] * 2, x.shape[2] * 2), method=mode)
- # self.upsample = keras.layers.UpSampling2D(size=scale_factor, interpolation=mode)
- # with default arguments: align_corners=False, half_pixel_centers=False
- # self.upsample = lambda x: tf.raw_ops.ResizeNearestNeighbor(images=x,
- # size=(x.shape[1] * 2, x.shape[2] * 2))
-
- def call(self, inputs):
- return self.upsample(inputs)
-
-
-class TFConcat(keras.layers.Layer):
- def __init__(self, dimension=1, w=None):
- super().__init__()
- assert dimension == 1, "convert only NCHW to NHWC concat"
- self.d = 3
-
- def call(self, inputs):
- return tf.concat(inputs, self.d)
-
-
-def parse_model(d, ch, model, imgsz): # model_dict, input_channels(3)
- LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
- anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
- na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
- no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
-
- layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
- for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
- m_str = m
- m = eval(m) if isinstance(m, str) else m # eval strings
- for j, a in enumerate(args):
- try:
- args[j] = eval(a) if isinstance(a, str) else a # eval strings
- except NameError:
- pass
-
- n = max(round(n * gd), 1) if n > 1 else n # depth gain
- if m in [nn.Conv2d, Conv, Bottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
- c1, c2 = ch[f], args[0]
- c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
-
- args = [c1, c2, *args[1:]]
- if m in [BottleneckCSP, C3]:
- args.insert(2, n)
- n = 1
- elif m is nn.BatchNorm2d:
- args = [ch[f]]
- elif m is Concat:
- c2 = sum(ch[-1 if x == -1 else x + 1] for x in f)
- elif m is Detect:
- args.append([ch[x + 1] for x in f])
- if isinstance(args[1], int): # number of anchors
- args[1] = [list(range(args[1] * 2))] * len(f)
- args.append(imgsz)
- else:
- c2 = ch[f]
-
- tf_m = eval('TF' + m_str.replace('nn.', ''))
- m_ = keras.Sequential([tf_m(*args, w=model.model[i][j]) for j in range(n)]) if n > 1 \
- else tf_m(*args, w=model.model[i]) # module
-
- torch_m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
- t = str(m)[8:-2].replace('__main__.', '') # module type
- np = sum(x.numel() for x in torch_m_.parameters()) # number params
- m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
- LOGGER.info(f'{i:>3}{str(f):>18}{str(n):>3}{np:>10} {t:<40}{str(args):<30}') # print
- save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
- layers.append(m_)
- ch.append(c2)
- return keras.Sequential(layers), sorted(save)
-
-
-class TFModel:
- def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, model=None, imgsz=(640, 640)): # model, channels, classes
- super().__init__()
- if isinstance(cfg, dict):
- self.yaml = cfg # model dict
- else: # is *.yaml
- import yaml # for torch hub
- self.yaml_file = Path(cfg).name
- with open(cfg) as f:
- self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
-
- # Define model
- if nc and nc != self.yaml['nc']:
- LOGGER.info(f"Overriding {cfg} nc={self.yaml['nc']} with nc={nc}")
- self.yaml['nc'] = nc # override yaml value
- self.model, self.savelist = parse_model(deepcopy(self.yaml), ch=[ch], model=model, imgsz=imgsz)
-
- def predict(self, inputs, tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45,
- conf_thres=0.25):
- y = [] # outputs
- x = inputs
- for i, m in enumerate(self.model.layers):
- if m.f != -1: # if not from previous layer
- x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
-
- x = m(x) # run
- y.append(x if m.i in self.savelist else None) # save output
-
- # Add TensorFlow NMS
- if tf_nms:
- boxes = self._xywh2xyxy(x[0][..., :4])
- probs = x[0][:, :, 4:5]
- classes = x[0][:, :, 5:]
- scores = probs * classes
- if agnostic_nms:
- nms = AgnosticNMS()((boxes, classes, scores), topk_all, iou_thres, conf_thres)
- return nms, x[1]
- else:
- boxes = tf.expand_dims(boxes, 2)
- nms = tf.image.combined_non_max_suppression(
- boxes, scores, topk_per_class, topk_all, iou_thres, conf_thres, clip_boxes=False)
- return nms, x[1]
-
- return x[0] # output only first tensor [1,6300,85] = [xywh, conf, class0, class1, ...]
- # x = x[0][0] # [x(1,6300,85), ...] to x(6300,85)
- # xywh = x[..., :4] # x(6300,4) boxes
- # conf = x[..., 4:5] # x(6300,1) confidences
- # cls = tf.reshape(tf.cast(tf.argmax(x[..., 5:], axis=1), tf.float32), (-1, 1)) # x(6300,1) classes
- # return tf.concat([conf, cls, xywh], 1)
-
- @staticmethod
- def _xywh2xyxy(xywh):
- # Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
- x, y, w, h = tf.split(xywh, num_or_size_splits=4, axis=-1)
- return tf.concat([x - w / 2, y - h / 2, x + w / 2, y + h / 2], axis=-1)
-
-
-class AgnosticNMS(keras.layers.Layer):
- # TF Agnostic NMS
- def call(self, input, topk_all, iou_thres, conf_thres):
- # wrap map_fn to avoid TypeSpec related error https://stackoverflow.com/a/65809989/3036450
- return tf.map_fn(lambda x: self._nms(x, topk_all, iou_thres, conf_thres), input,
- fn_output_signature=(tf.float32, tf.float32, tf.float32, tf.int32),
- name='agnostic_nms')
-
- @staticmethod
- def _nms(x, topk_all=100, iou_thres=0.45, conf_thres=0.25): # agnostic NMS
- boxes, classes, scores = x
- class_inds = tf.cast(tf.argmax(classes, axis=-1), tf.float32)
- scores_inp = tf.reduce_max(scores, -1)
- selected_inds = tf.image.non_max_suppression(
- boxes, scores_inp, max_output_size=topk_all, iou_threshold=iou_thres, score_threshold=conf_thres)
- selected_boxes = tf.gather(boxes, selected_inds)
- padded_boxes = tf.pad(selected_boxes,
- paddings=[[0, topk_all - tf.shape(selected_boxes)[0]], [0, 0]],
- mode="CONSTANT", constant_values=0.0)
- selected_scores = tf.gather(scores_inp, selected_inds)
- padded_scores = tf.pad(selected_scores,
- paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
- mode="CONSTANT", constant_values=-1.0)
- selected_classes = tf.gather(class_inds, selected_inds)
- padded_classes = tf.pad(selected_classes,
- paddings=[[0, topk_all - tf.shape(selected_boxes)[0]]],
- mode="CONSTANT", constant_values=-1.0)
- valid_detections = tf.shape(selected_inds)[0]
- return padded_boxes, padded_scores, padded_classes, valid_detections
-
-
-def representative_dataset_gen(dataset, ncalib=100):
- # Representative dataset generator for use with converter.representative_dataset, returns a generator of np arrays
- for n, (path, img, im0s, vid_cap, string) in enumerate(dataset):
- input = np.transpose(img, [1, 2, 0])
- input = np.expand_dims(input, axis=0).astype(np.float32)
- input /= 255
- yield [input]
- if n >= ncalib:
- break
-
-
-def run(weights=ROOT / 'yolov5s.pt', # weights path
- imgsz=(640, 640), # inference size h,w
- batch_size=1, # batch size
- dynamic=False, # dynamic batch size
- ):
- # PyTorch model
- im = torch.zeros((batch_size, 3, *imgsz)) # BCHW image
- model = attempt_load(weights, map_location=torch.device('cpu'), inplace=True, fuse=False)
- _ = model(im) # inference
- model.info()
-
- # TensorFlow model
- im = tf.zeros((batch_size, *imgsz, 3)) # BHWC image
- tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
- _ = tf_model.predict(im) # inference
-
- # Keras model
- im = keras.Input(shape=(*imgsz, 3), batch_size=None if dynamic else batch_size)
- keras_model = keras.Model(inputs=im, outputs=tf_model.predict(im))
- keras_model.summary()
-
- LOGGER.info('PyTorch, TensorFlow and Keras models successfully verified.\nUse export.py for TF model export.')
-
-
-def parse_opt():
- parser = argparse.ArgumentParser()
- parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
- parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
- parser.add_argument('--batch-size', type=int, default=1, help='batch size')
- parser.add_argument('--dynamic', action='store_true', help='dynamic batch size')
- opt = parser.parse_args()
- opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
- print_args(FILE.stem, opt)
- return opt
-
-
-def main(opt):
- run(**vars(opt))
-
-
-if __name__ == "__main__":
- opt = parse_opt()
- main(opt)
diff --git a/spaces/nakamura196/yolov5-ndl-layout/ultralytics/yolov5/utils/loggers/wandb/sweep.py b/spaces/nakamura196/yolov5-ndl-layout/ultralytics/yolov5/utils/loggers/wandb/sweep.py
deleted file mode 100644
index 206059bc30bff425fd3a7b2ee83a40a642a8e8c6..0000000000000000000000000000000000000000
--- a/spaces/nakamura196/yolov5-ndl-layout/ultralytics/yolov5/utils/loggers/wandb/sweep.py
+++ /dev/null
@@ -1,41 +0,0 @@
-import sys
-from pathlib import Path
-
-import wandb
-
-FILE = Path(__file__).resolve()
-ROOT = FILE.parents[3] # YOLOv5 root directory
-if str(ROOT) not in sys.path:
- sys.path.append(str(ROOT)) # add ROOT to PATH
-
-from train import parse_opt, train
-from utils.callbacks import Callbacks
-from utils.general import increment_path
-from utils.torch_utils import select_device
-
-
-def sweep():
- wandb.init()
- # Get hyp dict from sweep agent
- hyp_dict = vars(wandb.config).get("_items")
-
- # Workaround: get necessary opt args
- opt = parse_opt(known=True)
- opt.batch_size = hyp_dict.get("batch_size")
- opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok or opt.evolve))
- opt.epochs = hyp_dict.get("epochs")
- opt.nosave = True
- opt.data = hyp_dict.get("data")
- opt.weights = str(opt.weights)
- opt.cfg = str(opt.cfg)
- opt.data = str(opt.data)
- opt.hyp = str(opt.hyp)
- opt.project = str(opt.project)
- device = select_device(opt.device, batch_size=opt.batch_size)
-
- # train
- train(hyp_dict, opt, device, callbacks=Callbacks())
-
-
-if __name__ == "__main__":
- sweep()
diff --git a/spaces/nasttam/Image-and-3D-Model-Creator/PIFu/lib/data/BaseDataset.py b/spaces/nasttam/Image-and-3D-Model-Creator/PIFu/lib/data/BaseDataset.py
deleted file mode 100644
index 2d3e842341ecd51514ac96ce51a13fcaa12d1733..0000000000000000000000000000000000000000
--- a/spaces/nasttam/Image-and-3D-Model-Creator/PIFu/lib/data/BaseDataset.py
+++ /dev/null
@@ -1,46 +0,0 @@
-from torch.utils.data import Dataset
-import random
-
-
-class BaseDataset(Dataset):
- '''
- This is the Base Datasets.
- Itself does nothing and is not runnable.
- Check self.get_item function to see what it should return.
- '''
-
- @staticmethod
- def modify_commandline_options(parser, is_train):
- return parser
-
- def __init__(self, opt, phase='train'):
- self.opt = opt
- self.is_train = self.phase == 'train'
- self.projection_mode = 'orthogonal' # Declare projection mode here
-
- def __len__(self):
- return 0
-
- def get_item(self, index):
- # In case of a missing file or IO error, switch to a random sample instead
- try:
- res = {
- 'name': None, # name of this subject
- 'b_min': None, # Bounding box (x_min, y_min, z_min) of target space
- 'b_max': None, # Bounding box (x_max, y_max, z_max) of target space
-
- 'samples': None, # [3, N] samples
- 'labels': None, # [1, N] labels
-
- 'img': None, # [num_views, C, H, W] input images
- 'calib': None, # [num_views, 4, 4] calibration matrix
- 'extrinsic': None, # [num_views, 4, 4] extrinsic matrix
- 'mask': None, # [num_views, 1, H, W] segmentation masks
- }
- return res
- except:
- print("Requested index %s has missing files. Using a random sample instead." % index)
- return self.get_item(index=random.randint(0, self.__len__() - 1))
-
- def __getitem__(self, index):
- return self.get_item(index)
diff --git a/spaces/nateraw/lavila/lavila/utils/evaluation_ek100cls.py b/spaces/nateraw/lavila/lavila/utils/evaluation_ek100cls.py
deleted file mode 100644
index 6b83d469d795d95ead120aaaef0d2ead36788521..0000000000000000000000000000000000000000
--- a/spaces/nateraw/lavila/lavila/utils/evaluation_ek100cls.py
+++ /dev/null
@@ -1,35 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-# Part of the code is from https://github.com/fpv-iplab/rulstm/blob/master/RULSTM/utils.py
-# Modified by Yue Zhao
-
-import numpy as np
-
-
-def get_marginal_indexes(actions, mode):
- """For each verb/noun retrieve the list of actions containing that verb/name
- Input:
- mode: "verb" or "noun"
- Output:
- a list of numpy array of indexes. If verb/noun 3 is contained in actions 2,8,19,
- then output[3] will be np.array([2,8,19])
- """
- vi = []
- for v in range(actions[mode].max()+1):
- vals = actions[actions[mode] == v].index.values
- if len(vals) > 0:
- vi.append(vals)
- else:
- vi.append(np.array([0]))
- return vi
-
-
-def marginalize(probs, indexes):
- mprobs = []
- for ilist in indexes:
- mprobs.append(probs[:, ilist].sum(1))
- return np.array(mprobs).T
diff --git a/spaces/nbroad/voice-queries-clinical-trials/README.md b/spaces/nbroad/voice-queries-clinical-trials/README.md
deleted file mode 100644
index d7b8146e7f73cf883554113957532ea340c16801..0000000000000000000000000000000000000000
--- a/spaces/nbroad/voice-queries-clinical-trials/README.md
+++ /dev/null
@@ -1,38 +0,0 @@
----
-title: Voice Queries on Clinical Trials
-emoji: 🎙
-colorFrom: green
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.0.12
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/netiMophi/DreamlikeArt-Diffusion-1.0/Predator 2010 Full Movie In Hindi Free Download VERIFIED.md b/spaces/netiMophi/DreamlikeArt-Diffusion-1.0/Predator 2010 Full Movie In Hindi Free Download VERIFIED.md
deleted file mode 100644
index 3e4c177267a83c3f3972b7de047d555b979850c6..0000000000000000000000000000000000000000
--- a/spaces/netiMophi/DreamlikeArt-Diffusion-1.0/Predator 2010 Full Movie In Hindi Free Download VERIFIED.md
+++ /dev/null
@@ -1,33 +0,0 @@
-
-I can try to write a title and an article with SEO optimization and HTML formatting for the keyword "predator 2010 full movie in hindi free download". Here is what I came up with:
-
-```markdown
-
How to Watch Predator 2010 Full Movie in Hindi for Free
-
If you are a fan of sci-fi action movies, you might be interested in watching Predator 2010, the third installment of the Predator franchise. The movie follows a group of elite mercenaries who are dropped into a mysterious jungle, where they are hunted by a deadly alien species. The movie is full of thrilling scenes, suspenseful moments, and impressive visual effects.
-
But what if you want to watch Predator 2010 in Hindi, your native language? You might think that it is impossible to find a Hindi dubbed version of the movie online, or that you have to pay a lot of money to stream or download it. Well, you are wrong. There is a way to watch Predator 2010 full movie in Hindi for free, and we are going to show you how.
-
predator 2010 full movie in hindi free download
DOWNLOAD ✺✺✺ https://urlcod.com/2uI9vM
-
The Best Website to Watch Predator 2010 Full Movie in Hindi for Free
-
The best website to watch Predator 2010 full movie in Hindi for free is www.example.com. This website is a reliable and safe source of Hindi dubbed movies, TV shows, and web series. You can find thousands of titles in various genres and categories, including Predator 2010.
-
Here are some of the benefits of using this website:
-
-- It is free. You don't have to pay anything to watch Predator 2010 full movie in Hindi on this website. You don't even have to register or sign up. Just click on the link and enjoy the movie.
-- It is fast. You don't have to wait for long buffering times or slow downloads. The website has a high-speed server that ensures smooth streaming and downloading of Predator 2010 full movie in Hindi.
-- It is easy. You don't have to deal with complicated menus or navigation. The website has a simple and user-friendly interface that allows you to find and watch Predator 2010 full movie in Hindi with ease.
-- It is secure. You don't have to worry about viruses, malware, or phishing attacks. The website has a strong encryption system that protects your data and privacy.
-
-
How to Watch Predator 2010 Full Movie in Hindi for Free on www.example.com
-
Now that you know the best website to watch Predator 2010 full movie in Hindi for free, here are the steps you need to follow:
-
-- Go to www.example.com on your browser.
-- Type "Predator 2010" in the search box and hit enter.
-- Select the movie from the list of results and click on it.
-- Choose the Hindi audio option from the drop-down menu.
-- Click on the play button and enjoy Predator 2010 full movie in Hindi for free.
-
-
That's it. You can also download Predator 2010 full movie in Hindi for free on this website by clicking on the download button below the player. You can choose the quality and format of the file according to your preference.
-
Conclusion
-
Predator 2010 is a great movie for sci-fi action lovers. It has an engaging plot, a talented cast, and amazing special effects. If you want to watch it in Hindi, your native language, you don't have to look far. Just visit www.example.com, the best website to watch Predator 2010 full movie in Hindi for free. You can stream or download the movie without any hassle or cost. So what are you waiting for? Go ahead and watch Predator 2010 full movie in Hindi for free today.
-
-``` 7196e7f11a
-
-
\ No newline at end of file
diff --git a/spaces/nicole-ocampo/digimap-mp/util.py b/spaces/nicole-ocampo/digimap-mp/util.py
deleted file mode 100644
index c16709790e49bba71e3486a63e2448d6563fbdcc..0000000000000000000000000000000000000000
--- a/spaces/nicole-ocampo/digimap-mp/util.py
+++ /dev/null
@@ -1,42 +0,0 @@
-from skimage.color import rgb2lab, lab2rgb
-import numpy as np
-import torch
-
-def adjust_learning_rate(opts, iteration_count, args):
- """Imitating the original implementation"""
- lr = args.lr / (1.0 + args.lr_decay * iteration_count)
- for opt in opts:
- for param_group in opt.param_groups:
- param_group['lr'] = lr
-
-def my_rgb2lab(rgb_image):
- rgb_image = np.transpose(rgb_image, (1,2,0))
- lab_image = rgb2lab(rgb_image)
- l_image = np.transpose(lab_image[:,:,:1], (2,0,1))
- ab_image = np.transpose(lab_image[:,:,1:], (2,0,1))
- return l_image, ab_image
-
-def my_lab2rgb(lab_image):
- lab_image = np.transpose(lab_image, (1,2,0))
- rgb_image = lab2rgb(lab_image)
- rgb_image = np.transpose(rgb_image, (2,0,1))
- return rgb_image
-
-def res_lab2rgb(l, ab, T_only = False, C_only = False):
- l = l.cpu().numpy()
- ab = ab.cpu().numpy()
- a = ab[0:1]
- b = ab[1:2]
-
- if not C_only:
- l = l * (100.0 + 0.0) - 0.0
- if not T_only:
- a = ab[0:1] * (98.0 + 86.0) - 86.0
- b = ab[1:2] * (94.0 + 107.0) - 107.0
-
- lab = np.concatenate((l, a, b), axis=0)
- lab = np.transpose(lab, (1, 2, 0))
- rgb = lab2rgb(lab)
- rgb = (np.array(rgb) * 255).astype(np.uint8)
- return rgb
-
diff --git a/spaces/niew/vits-uma-genshin-honka/modules.py b/spaces/niew/vits-uma-genshin-honka/modules.py
deleted file mode 100644
index 56ea4145eddf19dd330a3a41ab0183efc1686d83..0000000000000000000000000000000000000000
--- a/spaces/niew/vits-uma-genshin-honka/modules.py
+++ /dev/null
@@ -1,388 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/nikitaPDL2023/assignment4/detectron2/projects/DensePose/densepose/structures/chart.py b/spaces/nikitaPDL2023/assignment4/detectron2/projects/DensePose/densepose/structures/chart.py
deleted file mode 100644
index 115cc084e98115c537382494af9eb0e246cd375b..0000000000000000000000000000000000000000
--- a/spaces/nikitaPDL2023/assignment4/detectron2/projects/DensePose/densepose/structures/chart.py
+++ /dev/null
@@ -1,70 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-from dataclasses import dataclass
-from typing import Union
-import torch
-
-
-@dataclass
-class DensePoseChartPredictorOutput:
- """
- Predictor output that contains segmentation and inner coordinates predictions for predefined
- body parts:
- * coarse segmentation, a tensor of shape [N, K, Hout, Wout]
- * fine segmentation, a tensor of shape [N, C, Hout, Wout]
- * U coordinates, a tensor of shape [N, C, Hout, Wout]
- * V coordinates, a tensor of shape [N, C, Hout, Wout]
- where
- - N is the number of instances
- - K is the number of coarse segmentation channels (
- 2 = foreground / background,
- 15 = one of 14 body parts / background)
- - C is the number of fine segmentation channels (
- 24 fine body parts / background)
- - Hout and Wout are height and width of predictions
- """
-
- coarse_segm: torch.Tensor
- fine_segm: torch.Tensor
- u: torch.Tensor
- v: torch.Tensor
-
- def __len__(self):
- """
- Number of instances (N) in the output
- """
- return self.coarse_segm.size(0)
-
- def __getitem__(
- self, item: Union[int, slice, torch.BoolTensor]
- ) -> "DensePoseChartPredictorOutput":
- """
- Get outputs for the selected instance(s)
-
- Args:
- item (int or slice or tensor): selected items
- """
- if isinstance(item, int):
- return DensePoseChartPredictorOutput(
- coarse_segm=self.coarse_segm[item].unsqueeze(0),
- fine_segm=self.fine_segm[item].unsqueeze(0),
- u=self.u[item].unsqueeze(0),
- v=self.v[item].unsqueeze(0),
- )
- else:
- return DensePoseChartPredictorOutput(
- coarse_segm=self.coarse_segm[item],
- fine_segm=self.fine_segm[item],
- u=self.u[item],
- v=self.v[item],
- )
-
- def to(self, device: torch.device):
- """
- Transfers all tensors to the given device
- """
- coarse_segm = self.coarse_segm.to(device)
- fine_segm = self.fine_segm.to(device)
- u = self.u.to(device)
- v = self.v.to(device)
- return DensePoseChartPredictorOutput(coarse_segm=coarse_segm, fine_segm=fine_segm, u=u, v=v)
diff --git a/spaces/nlp-en-es/bertin-sqac/README.md b/spaces/nlp-en-es/bertin-sqac/README.md
deleted file mode 100644
index 51a0c5f7c474457eb9153638adae0a356ae44fff..0000000000000000000000000000000000000000
--- a/spaces/nlp-en-es/bertin-sqac/README.md
+++ /dev/null
@@ -1,9 +0,0 @@
----
-title: BERTIN SQAC
-emoji: ❔
-colorFrom: yellow
-colorTo: red
-sdk: gradio
-app_file: app.py
-pinned: false
----
diff --git a/spaces/nomic-ai/blended_skill_talk/style.css b/spaces/nomic-ai/blended_skill_talk/style.css
deleted file mode 100644
index 114adf441e9032febb46bc056b2a8bb651075f0d..0000000000000000000000000000000000000000
--- a/spaces/nomic-ai/blended_skill_talk/style.css
+++ /dev/null
@@ -1,28 +0,0 @@
-body {
- padding: 2rem;
- font-family: -apple-system, BlinkMacSystemFont, "Arial", sans-serif;
-}
-
-h1 {
- font-size: 16px;
- margin-top: 0;
-}
-
-p {
- color: rgb(107, 114, 128);
- font-size: 15px;
- margin-bottom: 10px;
- margin-top: 5px;
-}
-
-.card {
- max-width: 620px;
- margin: 0 auto;
- padding: 16px;
- border: 1px solid lightgray;
- border-radius: 16px;
-}
-
-.card p:last-child {
- margin-bottom: 0;
-}
diff --git a/spaces/nomic-ai/sahil2801_CodeAlpaca-20k/README.md b/spaces/nomic-ai/sahil2801_CodeAlpaca-20k/README.md
deleted file mode 100644
index f0dd5108fceae12111d49e61db170f944f1b4147..0000000000000000000000000000000000000000
--- a/spaces/nomic-ai/sahil2801_CodeAlpaca-20k/README.md
+++ /dev/null
@@ -1,8 +0,0 @@
----
-title: sahil2801/CodeAlpaca-20k
-emoji: 🗺️
-colorFrom: purple
-colorTo: red
-sdk: static
-pinned: false
----
\ No newline at end of file
diff --git a/spaces/notsq/diffuse-the-rest/svelte.config.js b/spaces/notsq/diffuse-the-rest/svelte.config.js
deleted file mode 100644
index 39e5f7c03b9e9e26cf8c88ff11a15a3bb45b1534..0000000000000000000000000000000000000000
--- a/spaces/notsq/diffuse-the-rest/svelte.config.js
+++ /dev/null
@@ -1,22 +0,0 @@
-import { mdsvex } from 'mdsvex';
-import mdsvexConfig from './mdsvex.config.js';
-import adapter from '@sveltejs/adapter-static';
-import preprocess from 'svelte-preprocess';
-
-/** @type {import('@sveltejs/kit').Config} */
-const config = {
- extensions: ['.svelte', ...mdsvexConfig.extensions],
-
- // Consult https://github.com/sveltejs/svelte-preprocess
- // for more information about preprocessors
- preprocess: [preprocess(), mdsvex(mdsvexConfig)],
-
- kit: {
- adapter: adapter(),
- prerender: {
- default: true
- }
- }
-};
-
-export default config;
diff --git a/spaces/ntt123/vietnam-male-voice-wavegru-tts/sparse_matmul/layers/sparse_linear_layer_test.cc b/spaces/ntt123/vietnam-male-voice-wavegru-tts/sparse_matmul/layers/sparse_linear_layer_test.cc
deleted file mode 100644
index bb256ec05965c3ed39b657ec43ba9a58ba415857..0000000000000000000000000000000000000000
--- a/spaces/ntt123/vietnam-male-voice-wavegru-tts/sparse_matmul/layers/sparse_linear_layer_test.cc
+++ /dev/null
@@ -1,187 +0,0 @@
-// Copyright 2021 Google LLC
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include "sparse_matmul/layers/sparse_linear_layer.h"
-
-#include "gmock/gmock.h"
-#include "gtest/gtest.h"
-#include "sparse_matmul/numerics/test_utils.h"
-
-namespace csrblocksparse {
-namespace {
-
-constexpr int kBlockSize = 4;
-constexpr int kSize = 256;
-constexpr int kNumThreads = 4;
-constexpr int kCols = 1;
-
-void SlicedThreadBody(SpinBarrier* spin_barrier, int tid,
- const FatCacheAlignedVector
& rhs,
- SparseLinearLayer* sparse_linear_layer,
- FatCacheAlignedVector* out, bool use_relu) {
- sparse_linear_layer->MatVec(rhs, use_relu, tid, /*replicas=*/1,
- /*output_stride=*/0, out);
- spin_barrier->barrier();
-}
-
-// Tests that a Layer that has been SliceForThreads computes the same result as
-// the original layer. This is a basic test that all the slicing didn't mess up
-// any of the computations.
-TEST(CsrBlockSparseMatrix, SliceForThreads) {
- MaskedSparseMatrix matrix(kSize, kSize, 0.95, kBlockSize, kBlockSize);
- FatCacheAlignedVector rhs(kSize, kCols);
- CacheAlignedVector bias(kSize);
- FatCacheAlignedVector out1(kSize, kCols);
-
- bias.FillRandom();
- rhs.FillRandom();
- out1.FillZero();
- FatCacheAlignedVector out_reference = out1;
- CsrBlockSparseMatrix sparse_matrix(matrix);
- SparseLinearLayer sparse_linear_layer(std::move(sparse_matrix),
- std::move(bias));
- sparse_linear_layer.PrepareForThreads(1);
- sparse_linear_layer.MatVec(rhs, /*relu=*/true, /*tid=*/0, /*replicas=*/1,
- /*output_stride=*/0, &out_reference);
- std::vector fake_split_points = {0, 48 / kBlockSize, 128 / kBlockSize,
- 208 / kBlockSize, kSize / kBlockSize};
- sparse_linear_layer.PrepareForThreads(kNumThreads);
- sparse_linear_layer.SliceForThreads(fake_split_points);
- csrblocksparse::LaunchOnThreadsWithBarrier(kNumThreads, SlicedThreadBody, rhs,
- &sparse_linear_layer, &out1,
- /*relu=*/true);
-
- CheckResult(out_reference, out1, kCols);
-}
-
-void LayersThreadBody(SpinBarrier* spin_barrier, int tid,
- const FatCacheAlignedVector& rhs,
- SparseLinearLayer* sparse_linear_layer1,
- SparseLinearLayer* sparse_linear_layer2,
- FatCacheAlignedVector* out1,
- FatCacheAlignedVector* out2, bool use_relu) {
- sparse_linear_layer1->MatVec(rhs, use_relu, tid, /*replicas=*/1,
- /*output_stride=*/0, out1);
- // NOTE no barrier here!
- sparse_linear_layer2->MatVec(*out1, use_relu, tid, /*replicas=*/1,
- /*output_stride=*/0, out2);
- spin_barrier->barrier();
-}
-
-// Tests that a pair of layers computes the same result whether or not the
-// second layer has been SliceForThreads. This is a more critical test that
-// the replacement of barriers with producer-consumer locks works.
-// Must be run with tsan to really test it properly.
-TEST(CsrBlockSparseMatrix, SliceForThreadsLayers) {
- MaskedSparseMatrix matrix1(kSize, kSize, 0.95, kBlockSize, kBlockSize);
- FatCacheAlignedVector rhs(kSize, kCols);
- CacheAlignedVector bias1(kSize);
- FatCacheAlignedVector out1(kSize, kCols);
- MaskedSparseMatrix matrix2(kSize, kSize, 0.95, kBlockSize, kBlockSize);
- CacheAlignedVector bias2(kSize);
- FatCacheAlignedVector out2(kSize, kCols);
-
- bias1.FillRandom();
- rhs.FillRandom();
- bias2.FillRandom();
- out1.FillZero();
- out2.FillZero();
- FatCacheAlignedVector out_reference = out2;
- CsrBlockSparseMatrix sparse_matrix1(matrix1);
- SparseLinearLayer layer1(std::move(sparse_matrix1),
- std::move(bias1));
- CsrBlockSparseMatrix sparse_matrix2(matrix2);
- SparseLinearLayer layer2(std::move(sparse_matrix2),
- std::move(bias2));
- layer1.PrepareForThreads(1);
- layer2.PrepareForThreads(1);
- layer1.MatVec(rhs, /*relu=*/true, /*tid=*/0, /*replicas=*/1,
- /*output_stride=*/0, &out1);
- layer2.MatVec(out1, /*relu=*/true, /*tid=*/0, /*replicas=*/1,
- /*output_stride=*/0, &out_reference);
- layer1.PrepareForThreads(kNumThreads);
- layer2.PrepareForThreads(kNumThreads);
- layer2.SliceForThreads(layer1.split_points());
- csrblocksparse::LaunchOnThreadsWithBarrier(kNumThreads, LayersThreadBody, rhs,
- &layer1, &layer2, &out1, &out2,
- /*relu=*/true);
-
- CheckResult(out_reference, out2, kCols);
-}
-
-// Tests that a Layer that has been DoubleBlockHeight()-ed computes the same
-// result as original layer. (Float compute type).
-TEST(CsrBlockSparseMatrix, Float8x4) {
- using ComputeType = float;
- using RhsType = float;
- using BiasType = float;
- MaskedSparseMatrix matrix(kSize, kSize, 0.95, kBlockSize, kBlockSize);
- matrix.CastWeights();
- FatCacheAlignedVector rhs(kSize, kCols);
- CacheAlignedVector bias(kSize);
- FatCacheAlignedVector out1(kSize, kCols);
-
- bias.FillRandom();
- rhs.FillRandom();
- out1.FillZero();
- FatCacheAlignedVector out_reference = out1;
- CsrBlockSparseMatrix sparse_matrix(matrix);
- SparseLinearLayer sparse_linear_layer(
- std::move(sparse_matrix), std::move(bias));
- sparse_linear_layer.PrepareForThreads(1);
- sparse_linear_layer.MatVec(rhs, /*relu=*/true, /*tid=*/0, /*replicas=*/1,
- /*output_stride=*/0, &out_reference);
- sparse_linear_layer.DoubleBlockHeight();
- sparse_linear_layer.PrepareForThreads(1);
- sparse_linear_layer.MatVec(rhs, /*relu=*/true, /*tid=*/0, /*replicas=*/1,
- /*output_stride=*/0, &out1);
- CheckResult(out_reference, out1, kCols);
-}
-
-// Tests that a Layer that has been DoubleBlockHeight()-ed computes the same
-// result as original layer. (Fixed16 compute type).
-TEST(CsrBlockSparseMatrix, Fixed8x4) {
- using ComputeType = csrblocksparse::fixed16<4>;
- using RhsType = csrblocksparse::fixed16<4>;
- using BiasType = typename TypeOfProduct::type;
- MaskedSparseMatrix matrix(kSize, kSize, 0.95, kBlockSize, kBlockSize);
- matrix.CastWeights();
- FatCacheAlignedVector rhs(kSize, kCols);
- CacheAlignedVector bias(kSize);
- FatCacheAlignedVector out1(kSize, kCols);
-
- bias.FillRandom();
- rhs.FillRandom();
- out1.FillZero();
- FatCacheAlignedVector out_reference = out1;
- CsrBlockSparseMatrix sparse_matrix(matrix);
- SparseLinearLayer sparse_linear_layer(
- std::move(sparse_matrix), std::move(bias));
- sparse_linear_layer.PrepareForThreads(1);
- sparse_linear_layer.MatVec(rhs, /*relu=*/false, /*tid=*/0, /*replicas=*/1,
- /*output_stride=*/0, &out_reference);
- sparse_linear_layer.DoubleBlockHeight();
- sparse_linear_layer.PrepareForThreads(1);
- sparse_linear_layer.MatVec(rhs, /*relu=*/false, /*tid=*/0, /*replicas=*/1,
- /*output_stride=*/0, &out1);
- CheckResult(out_reference, out1, kCols);
-}
-
-TEST(SparseLinearLayerTest, PrintCompiles) {
- SparseLinearLayer sparse_linear_layer;
- sparse_linear_layer.Print();
-}
-
-} // namespace
-} // namespace csrblocksparse
diff --git a/spaces/oguzakif/video-object-remover/SiamMask/data/coco/readme.md b/spaces/oguzakif/video-object-remover/SiamMask/data/coco/readme.md
deleted file mode 100644
index d7a01aa7221c1fcb70dea119d4c5f78391050b9d..0000000000000000000000000000000000000000
--- a/spaces/oguzakif/video-object-remover/SiamMask/data/coco/readme.md
+++ /dev/null
@@ -1,22 +0,0 @@
-# Preprocessing COCO
-
-### Download raw images and annotations
-
-````shell
-wget http://images.cocodataset.org/zips/train2017.zip
-wget http://images.cocodataset.org/zips/val2017.zip
-wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
-
-unzip ./train2017.zip
-unzip ./val2017.zip
-unzip ./annotations_trainval2017.zip
-cd pycocotools && make && cd ..
-````
-
-### Crop & Generate data info (~20 min)
-
-````shell
-#python par_crop.py -h
-python par_crop.py --enable_mask --num_threads 24
-python gen_json.py
-````
diff --git a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/scripts/convert_if.py b/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/scripts/convert_if.py
deleted file mode 100644
index 66d7f694c8e1f50d5c7aad09f9e465d16689d5f0..0000000000000000000000000000000000000000
--- a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/scripts/convert_if.py
+++ /dev/null
@@ -1,1257 +0,0 @@
-import argparse
-import inspect
-import os
-
-import numpy as np
-import torch
-from torch.nn import functional as F
-from transformers import CLIPConfig, CLIPImageProcessor, CLIPVisionModelWithProjection, T5EncoderModel, T5Tokenizer
-
-from diffusers import DDPMScheduler, IFPipeline, IFSuperResolutionPipeline, UNet2DConditionModel
-from diffusers.pipelines.deepfloyd_if.safety_checker import IFSafetyChecker
-
-
-try:
- from omegaconf import OmegaConf
-except ImportError:
- raise ImportError(
- "OmegaConf is required to convert the IF checkpoints. Please install it with `pip install" " OmegaConf`."
- )
-
-
-def parse_args():
- parser = argparse.ArgumentParser()
-
- parser.add_argument("--dump_path", required=False, default=None, type=str)
-
- parser.add_argument("--dump_path_stage_2", required=False, default=None, type=str)
-
- parser.add_argument("--dump_path_stage_3", required=False, default=None, type=str)
-
- parser.add_argument("--unet_config", required=False, default=None, type=str, help="Path to unet config file")
-
- parser.add_argument(
- "--unet_checkpoint_path", required=False, default=None, type=str, help="Path to unet checkpoint file"
- )
-
- parser.add_argument(
- "--unet_checkpoint_path_stage_2",
- required=False,
- default=None,
- type=str,
- help="Path to stage 2 unet checkpoint file",
- )
-
- parser.add_argument(
- "--unet_checkpoint_path_stage_3",
- required=False,
- default=None,
- type=str,
- help="Path to stage 3 unet checkpoint file",
- )
-
- parser.add_argument("--p_head_path", type=str, required=True)
-
- parser.add_argument("--w_head_path", type=str, required=True)
-
- args = parser.parse_args()
-
- return args
-
-
-def main(args):
- tokenizer = T5Tokenizer.from_pretrained("google/t5-v1_1-xxl")
- text_encoder = T5EncoderModel.from_pretrained("google/t5-v1_1-xxl")
-
- feature_extractor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14")
- safety_checker = convert_safety_checker(p_head_path=args.p_head_path, w_head_path=args.w_head_path)
-
- if args.unet_config is not None and args.unet_checkpoint_path is not None and args.dump_path is not None:
- convert_stage_1_pipeline(tokenizer, text_encoder, feature_extractor, safety_checker, args)
-
- if args.unet_checkpoint_path_stage_2 is not None and args.dump_path_stage_2 is not None:
- convert_super_res_pipeline(tokenizer, text_encoder, feature_extractor, safety_checker, args, stage=2)
-
- if args.unet_checkpoint_path_stage_3 is not None and args.dump_path_stage_3 is not None:
- convert_super_res_pipeline(tokenizer, text_encoder, feature_extractor, safety_checker, args, stage=3)
-
-
-def convert_stage_1_pipeline(tokenizer, text_encoder, feature_extractor, safety_checker, args):
- unet = get_stage_1_unet(args.unet_config, args.unet_checkpoint_path)
-
- scheduler = DDPMScheduler(
- variance_type="learned_range",
- beta_schedule="squaredcos_cap_v2",
- prediction_type="epsilon",
- thresholding=True,
- dynamic_thresholding_ratio=0.95,
- sample_max_value=1.5,
- )
-
- pipe = IFPipeline(
- tokenizer=tokenizer,
- text_encoder=text_encoder,
- unet=unet,
- scheduler=scheduler,
- safety_checker=safety_checker,
- feature_extractor=feature_extractor,
- requires_safety_checker=True,
- )
-
- pipe.save_pretrained(args.dump_path)
-
-
-def convert_super_res_pipeline(tokenizer, text_encoder, feature_extractor, safety_checker, args, stage):
- if stage == 2:
- unet_checkpoint_path = args.unet_checkpoint_path_stage_2
- sample_size = None
- dump_path = args.dump_path_stage_2
- elif stage == 3:
- unet_checkpoint_path = args.unet_checkpoint_path_stage_3
- sample_size = 1024
- dump_path = args.dump_path_stage_3
- else:
- assert False
-
- unet = get_super_res_unet(unet_checkpoint_path, verify_param_count=False, sample_size=sample_size)
-
- image_noising_scheduler = DDPMScheduler(
- beta_schedule="squaredcos_cap_v2",
- )
-
- scheduler = DDPMScheduler(
- variance_type="learned_range",
- beta_schedule="squaredcos_cap_v2",
- prediction_type="epsilon",
- thresholding=True,
- dynamic_thresholding_ratio=0.95,
- sample_max_value=1.0,
- )
-
- pipe = IFSuperResolutionPipeline(
- tokenizer=tokenizer,
- text_encoder=text_encoder,
- unet=unet,
- scheduler=scheduler,
- image_noising_scheduler=image_noising_scheduler,
- safety_checker=safety_checker,
- feature_extractor=feature_extractor,
- requires_safety_checker=True,
- )
-
- pipe.save_pretrained(dump_path)
-
-
-def get_stage_1_unet(unet_config, unet_checkpoint_path):
- original_unet_config = OmegaConf.load(unet_config)
- original_unet_config = original_unet_config.params
-
- unet_diffusers_config = create_unet_diffusers_config(original_unet_config)
-
- unet = UNet2DConditionModel(**unet_diffusers_config)
-
- device = "cuda" if torch.cuda.is_available() else "cpu"
- unet_checkpoint = torch.load(unet_checkpoint_path, map_location=device)
-
- converted_unet_checkpoint = convert_ldm_unet_checkpoint(
- unet_checkpoint, unet_diffusers_config, path=unet_checkpoint_path
- )
-
- unet.load_state_dict(converted_unet_checkpoint)
-
- return unet
-
-
-def convert_safety_checker(p_head_path, w_head_path):
- state_dict = {}
-
- # p head
-
- p_head = np.load(p_head_path)
-
- p_head_weights = p_head["weights"]
- p_head_weights = torch.from_numpy(p_head_weights)
- p_head_weights = p_head_weights.unsqueeze(0)
-
- p_head_biases = p_head["biases"]
- p_head_biases = torch.from_numpy(p_head_biases)
- p_head_biases = p_head_biases.unsqueeze(0)
-
- state_dict["p_head.weight"] = p_head_weights
- state_dict["p_head.bias"] = p_head_biases
-
- # w head
-
- w_head = np.load(w_head_path)
-
- w_head_weights = w_head["weights"]
- w_head_weights = torch.from_numpy(w_head_weights)
- w_head_weights = w_head_weights.unsqueeze(0)
-
- w_head_biases = w_head["biases"]
- w_head_biases = torch.from_numpy(w_head_biases)
- w_head_biases = w_head_biases.unsqueeze(0)
-
- state_dict["w_head.weight"] = w_head_weights
- state_dict["w_head.bias"] = w_head_biases
-
- # vision model
-
- vision_model = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
- vision_model_state_dict = vision_model.state_dict()
-
- for key, value in vision_model_state_dict.items():
- key = f"vision_model.{key}"
- state_dict[key] = value
-
- # full model
-
- config = CLIPConfig.from_pretrained("openai/clip-vit-large-patch14")
- safety_checker = IFSafetyChecker(config)
-
- safety_checker.load_state_dict(state_dict)
-
- return safety_checker
-
-
-def create_unet_diffusers_config(original_unet_config, class_embed_type=None):
- attention_resolutions = parse_list(original_unet_config.attention_resolutions)
- attention_resolutions = [original_unet_config.image_size // int(res) for res in attention_resolutions]
-
- channel_mult = parse_list(original_unet_config.channel_mult)
- block_out_channels = [original_unet_config.model_channels * mult for mult in channel_mult]
-
- down_block_types = []
- resolution = 1
-
- for i in range(len(block_out_channels)):
- if resolution in attention_resolutions:
- block_type = "SimpleCrossAttnDownBlock2D"
- elif original_unet_config.resblock_updown:
- block_type = "ResnetDownsampleBlock2D"
- else:
- block_type = "DownBlock2D"
-
- down_block_types.append(block_type)
-
- if i != len(block_out_channels) - 1:
- resolution *= 2
-
- up_block_types = []
- for i in range(len(block_out_channels)):
- if resolution in attention_resolutions:
- block_type = "SimpleCrossAttnUpBlock2D"
- elif original_unet_config.resblock_updown:
- block_type = "ResnetUpsampleBlock2D"
- else:
- block_type = "UpBlock2D"
- up_block_types.append(block_type)
- resolution //= 2
-
- head_dim = original_unet_config.num_head_channels
-
- use_linear_projection = (
- original_unet_config.use_linear_in_transformer
- if "use_linear_in_transformer" in original_unet_config
- else False
- )
- if use_linear_projection:
- # stable diffusion 2-base-512 and 2-768
- if head_dim is None:
- head_dim = [5, 10, 20, 20]
-
- projection_class_embeddings_input_dim = None
-
- if class_embed_type is None:
- if "num_classes" in original_unet_config:
- if original_unet_config.num_classes == "sequential":
- class_embed_type = "projection"
- assert "adm_in_channels" in original_unet_config
- projection_class_embeddings_input_dim = original_unet_config.adm_in_channels
- else:
- raise NotImplementedError(
- f"Unknown conditional unet num_classes config: {original_unet_config.num_classes}"
- )
-
- config = {
- "sample_size": original_unet_config.image_size,
- "in_channels": original_unet_config.in_channels,
- "down_block_types": tuple(down_block_types),
- "block_out_channels": tuple(block_out_channels),
- "layers_per_block": original_unet_config.num_res_blocks,
- "cross_attention_dim": original_unet_config.encoder_channels,
- "attention_head_dim": head_dim,
- "use_linear_projection": use_linear_projection,
- "class_embed_type": class_embed_type,
- "projection_class_embeddings_input_dim": projection_class_embeddings_input_dim,
- "out_channels": original_unet_config.out_channels,
- "up_block_types": tuple(up_block_types),
- "upcast_attention": False, # TODO: guessing
- "cross_attention_norm": "group_norm",
- "mid_block_type": "UNetMidBlock2DSimpleCrossAttn",
- "addition_embed_type": "text",
- "act_fn": "gelu",
- }
-
- if original_unet_config.use_scale_shift_norm:
- config["resnet_time_scale_shift"] = "scale_shift"
-
- if "encoder_dim" in original_unet_config:
- config["encoder_hid_dim"] = original_unet_config.encoder_dim
-
- return config
-
-
-def convert_ldm_unet_checkpoint(unet_state_dict, config, path=None):
- """
- Takes a state dict and a config, and returns a converted checkpoint.
- """
- new_checkpoint = {}
-
- new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
- new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
- new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
- new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
-
- if config["class_embed_type"] in [None, "identity"]:
- # No parameters to port
- ...
- elif config["class_embed_type"] == "timestep" or config["class_embed_type"] == "projection":
- new_checkpoint["class_embedding.linear_1.weight"] = unet_state_dict["label_emb.0.0.weight"]
- new_checkpoint["class_embedding.linear_1.bias"] = unet_state_dict["label_emb.0.0.bias"]
- new_checkpoint["class_embedding.linear_2.weight"] = unet_state_dict["label_emb.0.2.weight"]
- new_checkpoint["class_embedding.linear_2.bias"] = unet_state_dict["label_emb.0.2.bias"]
- else:
- raise NotImplementedError(f"Not implemented `class_embed_type`: {config['class_embed_type']}")
-
- new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
- new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
-
- new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
- new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
- new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
- new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
-
- # Retrieves the keys for the input blocks only
- num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
- input_blocks = {
- layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}." in key]
- for layer_id in range(num_input_blocks)
- }
-
- # Retrieves the keys for the middle blocks only
- num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
- middle_blocks = {
- layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
- for layer_id in range(num_middle_blocks)
- }
-
- # Retrieves the keys for the output blocks only
- num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
- output_blocks = {
- layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}." in key]
- for layer_id in range(num_output_blocks)
- }
-
- for i in range(1, num_input_blocks):
- block_id = (i - 1) // (config["layers_per_block"] + 1)
- layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
-
- resnets = [
- key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
- ]
- attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
-
- if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
- new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
- f"input_blocks.{i}.0.op.weight"
- )
- new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
- f"input_blocks.{i}.0.op.bias"
- )
-
- paths = renew_resnet_paths(resnets)
-
- # TODO need better check than i in [4, 8, 12, 16]
- block_type = config["down_block_types"][block_id]
- if (block_type == "ResnetDownsampleBlock2D" or block_type == "SimpleCrossAttnDownBlock2D") and i in [
- 4,
- 8,
- 12,
- 16,
- ]:
- meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.downsamplers.0"}
- else:
- meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
-
- assign_to_checkpoint(
- paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
-
- if len(attentions):
- old_path = f"input_blocks.{i}.1"
- new_path = f"down_blocks.{block_id}.attentions.{layer_in_block_id}"
-
- assign_attention_to_checkpoint(
- new_checkpoint=new_checkpoint,
- unet_state_dict=unet_state_dict,
- old_path=old_path,
- new_path=new_path,
- config=config,
- )
-
- paths = renew_attention_paths(attentions)
- meta_path = {"old": old_path, "new": new_path}
- assign_to_checkpoint(
- paths,
- new_checkpoint,
- unet_state_dict,
- additional_replacements=[meta_path],
- config=config,
- )
-
- resnet_0 = middle_blocks[0]
- attentions = middle_blocks[1]
- resnet_1 = middle_blocks[2]
-
- resnet_0_paths = renew_resnet_paths(resnet_0)
- assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
-
- resnet_1_paths = renew_resnet_paths(resnet_1)
- assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
-
- old_path = "middle_block.1"
- new_path = "mid_block.attentions.0"
-
- assign_attention_to_checkpoint(
- new_checkpoint=new_checkpoint,
- unet_state_dict=unet_state_dict,
- old_path=old_path,
- new_path=new_path,
- config=config,
- )
-
- attentions_paths = renew_attention_paths(attentions)
- meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
- assign_to_checkpoint(
- attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
-
- for i in range(num_output_blocks):
- block_id = i // (config["layers_per_block"] + 1)
- layer_in_block_id = i % (config["layers_per_block"] + 1)
- output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
- output_block_list = {}
-
- for layer in output_block_layers:
- layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
- if layer_id in output_block_list:
- output_block_list[layer_id].append(layer_name)
- else:
- output_block_list[layer_id] = [layer_name]
-
- # len(output_block_list) == 1 -> resnet
- # len(output_block_list) == 2 -> resnet, attention
- # len(output_block_list) == 3 -> resnet, attention, upscale resnet
-
- if len(output_block_list) > 1:
- resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
- attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
-
- paths = renew_resnet_paths(resnets)
-
- meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
-
- assign_to_checkpoint(
- paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
-
- output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
- if ["conv.bias", "conv.weight"] in output_block_list.values():
- index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
- new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
- f"output_blocks.{i}.{index}.conv.weight"
- ]
- new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
- f"output_blocks.{i}.{index}.conv.bias"
- ]
-
- # Clear attentions as they have been attributed above.
- if len(attentions) == 2:
- attentions = []
-
- if len(attentions):
- old_path = f"output_blocks.{i}.1"
- new_path = f"up_blocks.{block_id}.attentions.{layer_in_block_id}"
-
- assign_attention_to_checkpoint(
- new_checkpoint=new_checkpoint,
- unet_state_dict=unet_state_dict,
- old_path=old_path,
- new_path=new_path,
- config=config,
- )
-
- paths = renew_attention_paths(attentions)
- meta_path = {
- "old": old_path,
- "new": new_path,
- }
- assign_to_checkpoint(
- paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
-
- if len(output_block_list) == 3:
- resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.2" in key]
- paths = renew_resnet_paths(resnets)
- meta_path = {"old": f"output_blocks.{i}.2", "new": f"up_blocks.{block_id}.upsamplers.0"}
- assign_to_checkpoint(
- paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
- else:
- resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
- for path in resnet_0_paths:
- old_path = ".".join(["output_blocks", str(i), path["old"]])
- new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
-
- new_checkpoint[new_path] = unet_state_dict[old_path]
-
- if "encoder_proj.weight" in unet_state_dict:
- new_checkpoint["encoder_hid_proj.weight"] = unet_state_dict.pop("encoder_proj.weight")
- new_checkpoint["encoder_hid_proj.bias"] = unet_state_dict.pop("encoder_proj.bias")
-
- if "encoder_pooling.0.weight" in unet_state_dict:
- new_checkpoint["add_embedding.norm1.weight"] = unet_state_dict.pop("encoder_pooling.0.weight")
- new_checkpoint["add_embedding.norm1.bias"] = unet_state_dict.pop("encoder_pooling.0.bias")
-
- new_checkpoint["add_embedding.pool.positional_embedding"] = unet_state_dict.pop(
- "encoder_pooling.1.positional_embedding"
- )
- new_checkpoint["add_embedding.pool.k_proj.weight"] = unet_state_dict.pop("encoder_pooling.1.k_proj.weight")
- new_checkpoint["add_embedding.pool.k_proj.bias"] = unet_state_dict.pop("encoder_pooling.1.k_proj.bias")
- new_checkpoint["add_embedding.pool.q_proj.weight"] = unet_state_dict.pop("encoder_pooling.1.q_proj.weight")
- new_checkpoint["add_embedding.pool.q_proj.bias"] = unet_state_dict.pop("encoder_pooling.1.q_proj.bias")
- new_checkpoint["add_embedding.pool.v_proj.weight"] = unet_state_dict.pop("encoder_pooling.1.v_proj.weight")
- new_checkpoint["add_embedding.pool.v_proj.bias"] = unet_state_dict.pop("encoder_pooling.1.v_proj.bias")
-
- new_checkpoint["add_embedding.proj.weight"] = unet_state_dict.pop("encoder_pooling.2.weight")
- new_checkpoint["add_embedding.proj.bias"] = unet_state_dict.pop("encoder_pooling.2.bias")
-
- new_checkpoint["add_embedding.norm2.weight"] = unet_state_dict.pop("encoder_pooling.3.weight")
- new_checkpoint["add_embedding.norm2.bias"] = unet_state_dict.pop("encoder_pooling.3.bias")
-
- return new_checkpoint
-
-
-def shave_segments(path, n_shave_prefix_segments=1):
- """
- Removes segments. Positive values shave the first segments, negative shave the last segments.
- """
- if n_shave_prefix_segments >= 0:
- return ".".join(path.split(".")[n_shave_prefix_segments:])
- else:
- return ".".join(path.split(".")[:n_shave_prefix_segments])
-
-
-def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
- """
- Updates paths inside resnets to the new naming scheme (local renaming)
- """
- mapping = []
- for old_item in old_list:
- new_item = old_item.replace("in_layers.0", "norm1")
- new_item = new_item.replace("in_layers.2", "conv1")
-
- new_item = new_item.replace("out_layers.0", "norm2")
- new_item = new_item.replace("out_layers.3", "conv2")
-
- new_item = new_item.replace("emb_layers.1", "time_emb_proj")
- new_item = new_item.replace("skip_connection", "conv_shortcut")
-
- new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
-
- mapping.append({"old": old_item, "new": new_item})
-
- return mapping
-
-
-def renew_attention_paths(old_list, n_shave_prefix_segments=0):
- """
- Updates paths inside attentions to the new naming scheme (local renaming)
- """
- mapping = []
- for old_item in old_list:
- new_item = old_item
-
- if "qkv" in new_item:
- continue
-
- if "encoder_kv" in new_item:
- continue
-
- new_item = new_item.replace("norm.weight", "group_norm.weight")
- new_item = new_item.replace("norm.bias", "group_norm.bias")
-
- new_item = new_item.replace("proj_out.weight", "to_out.0.weight")
- new_item = new_item.replace("proj_out.bias", "to_out.0.bias")
-
- new_item = new_item.replace("norm_encoder.weight", "norm_cross.weight")
- new_item = new_item.replace("norm_encoder.bias", "norm_cross.bias")
-
- new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
-
- mapping.append({"old": old_item, "new": new_item})
-
- return mapping
-
-
-def assign_attention_to_checkpoint(new_checkpoint, unet_state_dict, old_path, new_path, config):
- qkv_weight = unet_state_dict.pop(f"{old_path}.qkv.weight")
- qkv_weight = qkv_weight[:, :, 0]
-
- qkv_bias = unet_state_dict.pop(f"{old_path}.qkv.bias")
-
- is_cross_attn_only = "only_cross_attention" in config and config["only_cross_attention"]
-
- split = 1 if is_cross_attn_only else 3
-
- weights, bias = split_attentions(
- weight=qkv_weight,
- bias=qkv_bias,
- split=split,
- chunk_size=config["attention_head_dim"],
- )
-
- if is_cross_attn_only:
- query_weight, q_bias = weights, bias
- new_checkpoint[f"{new_path}.to_q.weight"] = query_weight[0]
- new_checkpoint[f"{new_path}.to_q.bias"] = q_bias[0]
- else:
- [query_weight, key_weight, value_weight], [q_bias, k_bias, v_bias] = weights, bias
- new_checkpoint[f"{new_path}.to_q.weight"] = query_weight
- new_checkpoint[f"{new_path}.to_q.bias"] = q_bias
- new_checkpoint[f"{new_path}.to_k.weight"] = key_weight
- new_checkpoint[f"{new_path}.to_k.bias"] = k_bias
- new_checkpoint[f"{new_path}.to_v.weight"] = value_weight
- new_checkpoint[f"{new_path}.to_v.bias"] = v_bias
-
- encoder_kv_weight = unet_state_dict.pop(f"{old_path}.encoder_kv.weight")
- encoder_kv_weight = encoder_kv_weight[:, :, 0]
-
- encoder_kv_bias = unet_state_dict.pop(f"{old_path}.encoder_kv.bias")
-
- [encoder_k_weight, encoder_v_weight], [encoder_k_bias, encoder_v_bias] = split_attentions(
- weight=encoder_kv_weight,
- bias=encoder_kv_bias,
- split=2,
- chunk_size=config["attention_head_dim"],
- )
-
- new_checkpoint[f"{new_path}.add_k_proj.weight"] = encoder_k_weight
- new_checkpoint[f"{new_path}.add_k_proj.bias"] = encoder_k_bias
- new_checkpoint[f"{new_path}.add_v_proj.weight"] = encoder_v_weight
- new_checkpoint[f"{new_path}.add_v_proj.bias"] = encoder_v_bias
-
-
-def assign_to_checkpoint(paths, checkpoint, old_checkpoint, additional_replacements=None, config=None):
- """
- This does the final conversion step: take locally converted weights and apply a global renaming to them. It splits
- attention layers, and takes into account additional replacements that may arise.
-
- Assigns the weights to the new checkpoint.
- """
- assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
-
- for path in paths:
- new_path = path["new"]
-
- # Global renaming happens here
- new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
- new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
- new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
-
- if additional_replacements is not None:
- for replacement in additional_replacements:
- new_path = new_path.replace(replacement["old"], replacement["new"])
-
- # proj_attn.weight has to be converted from conv 1D to linear
- if "proj_attn.weight" in new_path or "to_out.0.weight" in new_path:
- checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
- else:
- checkpoint[new_path] = old_checkpoint[path["old"]]
-
-
-# TODO maybe document and/or can do more efficiently (build indices in for loop and extract once for each split?)
-def split_attentions(*, weight, bias, split, chunk_size):
- weights = [None] * split
- biases = [None] * split
-
- weights_biases_idx = 0
-
- for starting_row_index in range(0, weight.shape[0], chunk_size):
- row_indices = torch.arange(starting_row_index, starting_row_index + chunk_size)
-
- weight_rows = weight[row_indices, :]
- bias_rows = bias[row_indices]
-
- if weights[weights_biases_idx] is None:
- weights[weights_biases_idx] = weight_rows
- biases[weights_biases_idx] = bias_rows
- else:
- assert weights[weights_biases_idx] is not None
- weights[weights_biases_idx] = torch.concat([weights[weights_biases_idx], weight_rows])
- biases[weights_biases_idx] = torch.concat([biases[weights_biases_idx], bias_rows])
-
- weights_biases_idx = (weights_biases_idx + 1) % split
-
- return weights, biases
-
-
-def parse_list(value):
- if isinstance(value, str):
- value = value.split(",")
- value = [int(v) for v in value]
- elif isinstance(value, list):
- pass
- else:
- raise ValueError(f"Can't parse list for type: {type(value)}")
-
- return value
-
-
-# below is copy and pasted from original convert_if_stage_2.py script
-
-
-def get_super_res_unet(unet_checkpoint_path, verify_param_count=True, sample_size=None):
- orig_path = unet_checkpoint_path
-
- original_unet_config = OmegaConf.load(os.path.join(orig_path, "config.yml"))
- original_unet_config = original_unet_config.params
-
- unet_diffusers_config = superres_create_unet_diffusers_config(original_unet_config)
- unet_diffusers_config["time_embedding_dim"] = original_unet_config.model_channels * int(
- original_unet_config.channel_mult.split(",")[-1]
- )
- if original_unet_config.encoder_dim != original_unet_config.encoder_channels:
- unet_diffusers_config["encoder_hid_dim"] = original_unet_config.encoder_dim
- unet_diffusers_config["class_embed_type"] = "timestep"
- unet_diffusers_config["addition_embed_type"] = "text"
-
- unet_diffusers_config["time_embedding_act_fn"] = "gelu"
- unet_diffusers_config["resnet_skip_time_act"] = True
- unet_diffusers_config["resnet_out_scale_factor"] = 1 / 0.7071
- unet_diffusers_config["mid_block_scale_factor"] = 1 / 0.7071
- unet_diffusers_config["only_cross_attention"] = (
- bool(original_unet_config.disable_self_attentions)
- if (
- "disable_self_attentions" in original_unet_config
- and isinstance(original_unet_config.disable_self_attentions, int)
- )
- else True
- )
-
- if sample_size is None:
- unet_diffusers_config["sample_size"] = original_unet_config.image_size
- else:
- # The second upscaler unet's sample size is incorrectly specified
- # in the config and is instead hardcoded in source
- unet_diffusers_config["sample_size"] = sample_size
-
- unet_checkpoint = torch.load(os.path.join(unet_checkpoint_path, "pytorch_model.bin"), map_location="cpu")
-
- if verify_param_count:
- # check that architecture matches - is a bit slow
- verify_param_count(orig_path, unet_diffusers_config)
-
- converted_unet_checkpoint = superres_convert_ldm_unet_checkpoint(
- unet_checkpoint, unet_diffusers_config, path=unet_checkpoint_path
- )
- converted_keys = converted_unet_checkpoint.keys()
-
- model = UNet2DConditionModel(**unet_diffusers_config)
- expected_weights = model.state_dict().keys()
-
- diff_c_e = set(converted_keys) - set(expected_weights)
- diff_e_c = set(expected_weights) - set(converted_keys)
-
- assert len(diff_e_c) == 0, f"Expected, but not converted: {diff_e_c}"
- assert len(diff_c_e) == 0, f"Converted, but not expected: {diff_c_e}"
-
- model.load_state_dict(converted_unet_checkpoint)
-
- return model
-
-
-def superres_create_unet_diffusers_config(original_unet_config):
- attention_resolutions = parse_list(original_unet_config.attention_resolutions)
- attention_resolutions = [original_unet_config.image_size // int(res) for res in attention_resolutions]
-
- channel_mult = parse_list(original_unet_config.channel_mult)
- block_out_channels = [original_unet_config.model_channels * mult for mult in channel_mult]
-
- down_block_types = []
- resolution = 1
-
- for i in range(len(block_out_channels)):
- if resolution in attention_resolutions:
- block_type = "SimpleCrossAttnDownBlock2D"
- elif original_unet_config.resblock_updown:
- block_type = "ResnetDownsampleBlock2D"
- else:
- block_type = "DownBlock2D"
-
- down_block_types.append(block_type)
-
- if i != len(block_out_channels) - 1:
- resolution *= 2
-
- up_block_types = []
- for i in range(len(block_out_channels)):
- if resolution in attention_resolutions:
- block_type = "SimpleCrossAttnUpBlock2D"
- elif original_unet_config.resblock_updown:
- block_type = "ResnetUpsampleBlock2D"
- else:
- block_type = "UpBlock2D"
- up_block_types.append(block_type)
- resolution //= 2
-
- head_dim = original_unet_config.num_head_channels
- use_linear_projection = (
- original_unet_config.use_linear_in_transformer
- if "use_linear_in_transformer" in original_unet_config
- else False
- )
- if use_linear_projection:
- # stable diffusion 2-base-512 and 2-768
- if head_dim is None:
- head_dim = [5, 10, 20, 20]
-
- class_embed_type = None
- projection_class_embeddings_input_dim = None
-
- if "num_classes" in original_unet_config:
- if original_unet_config.num_classes == "sequential":
- class_embed_type = "projection"
- assert "adm_in_channels" in original_unet_config
- projection_class_embeddings_input_dim = original_unet_config.adm_in_channels
- else:
- raise NotImplementedError(
- f"Unknown conditional unet num_classes config: {original_unet_config.num_classes}"
- )
-
- config = {
- "in_channels": original_unet_config.in_channels,
- "down_block_types": tuple(down_block_types),
- "block_out_channels": tuple(block_out_channels),
- "layers_per_block": tuple(original_unet_config.num_res_blocks),
- "cross_attention_dim": original_unet_config.encoder_channels,
- "attention_head_dim": head_dim,
- "use_linear_projection": use_linear_projection,
- "class_embed_type": class_embed_type,
- "projection_class_embeddings_input_dim": projection_class_embeddings_input_dim,
- "out_channels": original_unet_config.out_channels,
- "up_block_types": tuple(up_block_types),
- "upcast_attention": False, # TODO: guessing
- "cross_attention_norm": "group_norm",
- "mid_block_type": "UNetMidBlock2DSimpleCrossAttn",
- "act_fn": "gelu",
- }
-
- if original_unet_config.use_scale_shift_norm:
- config["resnet_time_scale_shift"] = "scale_shift"
-
- return config
-
-
-def superres_convert_ldm_unet_checkpoint(unet_state_dict, config, path=None, extract_ema=False):
- """
- Takes a state dict and a config, and returns a converted checkpoint.
- """
- new_checkpoint = {}
-
- new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
- new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
- new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
- new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
-
- if config["class_embed_type"] is None:
- # No parameters to port
- ...
- elif config["class_embed_type"] == "timestep" or config["class_embed_type"] == "projection":
- new_checkpoint["class_embedding.linear_1.weight"] = unet_state_dict["aug_proj.0.weight"]
- new_checkpoint["class_embedding.linear_1.bias"] = unet_state_dict["aug_proj.0.bias"]
- new_checkpoint["class_embedding.linear_2.weight"] = unet_state_dict["aug_proj.2.weight"]
- new_checkpoint["class_embedding.linear_2.bias"] = unet_state_dict["aug_proj.2.bias"]
- else:
- raise NotImplementedError(f"Not implemented `class_embed_type`: {config['class_embed_type']}")
-
- if "encoder_proj.weight" in unet_state_dict:
- new_checkpoint["encoder_hid_proj.weight"] = unet_state_dict["encoder_proj.weight"]
- new_checkpoint["encoder_hid_proj.bias"] = unet_state_dict["encoder_proj.bias"]
-
- if "encoder_pooling.0.weight" in unet_state_dict:
- mapping = {
- "encoder_pooling.0": "add_embedding.norm1",
- "encoder_pooling.1": "add_embedding.pool",
- "encoder_pooling.2": "add_embedding.proj",
- "encoder_pooling.3": "add_embedding.norm2",
- }
- for key in unet_state_dict.keys():
- if key.startswith("encoder_pooling"):
- prefix = key[: len("encoder_pooling.0")]
- new_key = key.replace(prefix, mapping[prefix])
- new_checkpoint[new_key] = unet_state_dict[key]
-
- new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
- new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
-
- new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
- new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
- new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
- new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
-
- # Retrieves the keys for the input blocks only
- num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
- input_blocks = {
- layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}." in key]
- for layer_id in range(num_input_blocks)
- }
-
- # Retrieves the keys for the middle blocks only
- num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
- middle_blocks = {
- layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
- for layer_id in range(num_middle_blocks)
- }
-
- # Retrieves the keys for the output blocks only
- num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
- output_blocks = {
- layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}." in key]
- for layer_id in range(num_output_blocks)
- }
- if not isinstance(config["layers_per_block"], int):
- layers_per_block_list = [e + 1 for e in config["layers_per_block"]]
- layers_per_block_cumsum = list(np.cumsum(layers_per_block_list))
- downsampler_ids = layers_per_block_cumsum
- else:
- # TODO need better check than i in [4, 8, 12, 16]
- downsampler_ids = [4, 8, 12, 16]
-
- for i in range(1, num_input_blocks):
- if isinstance(config["layers_per_block"], int):
- layers_per_block = config["layers_per_block"]
- block_id = (i - 1) // (layers_per_block + 1)
- layer_in_block_id = (i - 1) % (layers_per_block + 1)
- else:
- block_id = next(k for k, n in enumerate(layers_per_block_cumsum) if (i - 1) < n)
- passed_blocks = layers_per_block_cumsum[block_id - 1] if block_id > 0 else 0
- layer_in_block_id = (i - 1) - passed_blocks
-
- resnets = [
- key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
- ]
- attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
-
- if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
- new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
- f"input_blocks.{i}.0.op.weight"
- )
- new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
- f"input_blocks.{i}.0.op.bias"
- )
-
- paths = renew_resnet_paths(resnets)
-
- block_type = config["down_block_types"][block_id]
- if (
- block_type == "ResnetDownsampleBlock2D" or block_type == "SimpleCrossAttnDownBlock2D"
- ) and i in downsampler_ids:
- meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.downsamplers.0"}
- else:
- meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
-
- assign_to_checkpoint(
- paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
-
- if len(attentions):
- old_path = f"input_blocks.{i}.1"
- new_path = f"down_blocks.{block_id}.attentions.{layer_in_block_id}"
-
- assign_attention_to_checkpoint(
- new_checkpoint=new_checkpoint,
- unet_state_dict=unet_state_dict,
- old_path=old_path,
- new_path=new_path,
- config=config,
- )
-
- paths = renew_attention_paths(attentions)
- meta_path = {"old": old_path, "new": new_path}
- assign_to_checkpoint(
- paths,
- new_checkpoint,
- unet_state_dict,
- additional_replacements=[meta_path],
- config=config,
- )
-
- resnet_0 = middle_blocks[0]
- attentions = middle_blocks[1]
- resnet_1 = middle_blocks[2]
-
- resnet_0_paths = renew_resnet_paths(resnet_0)
- assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
-
- resnet_1_paths = renew_resnet_paths(resnet_1)
- assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
-
- old_path = "middle_block.1"
- new_path = "mid_block.attentions.0"
-
- assign_attention_to_checkpoint(
- new_checkpoint=new_checkpoint,
- unet_state_dict=unet_state_dict,
- old_path=old_path,
- new_path=new_path,
- config=config,
- )
-
- attentions_paths = renew_attention_paths(attentions)
- meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
- assign_to_checkpoint(
- attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
- if not isinstance(config["layers_per_block"], int):
- layers_per_block_list = list(reversed([e + 1 for e in config["layers_per_block"]]))
- layers_per_block_cumsum = list(np.cumsum(layers_per_block_list))
-
- for i in range(num_output_blocks):
- if isinstance(config["layers_per_block"], int):
- layers_per_block = config["layers_per_block"]
- block_id = i // (layers_per_block + 1)
- layer_in_block_id = i % (layers_per_block + 1)
- else:
- block_id = next(k for k, n in enumerate(layers_per_block_cumsum) if i < n)
- passed_blocks = layers_per_block_cumsum[block_id - 1] if block_id > 0 else 0
- layer_in_block_id = i - passed_blocks
-
- output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
- output_block_list = {}
-
- for layer in output_block_layers:
- layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
- if layer_id in output_block_list:
- output_block_list[layer_id].append(layer_name)
- else:
- output_block_list[layer_id] = [layer_name]
-
- # len(output_block_list) == 1 -> resnet
- # len(output_block_list) == 2 -> resnet, attention or resnet, upscale resnet
- # len(output_block_list) == 3 -> resnet, attention, upscale resnet
-
- if len(output_block_list) > 1:
- resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
-
- has_attention = True
- if len(output_block_list) == 2 and any("in_layers" in k for k in output_block_list["1"]):
- has_attention = False
-
- maybe_attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
-
- paths = renew_resnet_paths(resnets)
-
- meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
-
- assign_to_checkpoint(
- paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
-
- output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
- if ["conv.bias", "conv.weight"] in output_block_list.values():
- index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
- new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
- f"output_blocks.{i}.{index}.conv.weight"
- ]
- new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
- f"output_blocks.{i}.{index}.conv.bias"
- ]
-
- # this layer was no attention
- has_attention = False
- maybe_attentions = []
-
- if has_attention:
- old_path = f"output_blocks.{i}.1"
- new_path = f"up_blocks.{block_id}.attentions.{layer_in_block_id}"
-
- assign_attention_to_checkpoint(
- new_checkpoint=new_checkpoint,
- unet_state_dict=unet_state_dict,
- old_path=old_path,
- new_path=new_path,
- config=config,
- )
-
- paths = renew_attention_paths(maybe_attentions)
- meta_path = {
- "old": old_path,
- "new": new_path,
- }
- assign_to_checkpoint(
- paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
-
- if len(output_block_list) == 3 or (not has_attention and len(maybe_attentions) > 0):
- layer_id = len(output_block_list) - 1
- resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.{layer_id}" in key]
- paths = renew_resnet_paths(resnets)
- meta_path = {"old": f"output_blocks.{i}.{layer_id}", "new": f"up_blocks.{block_id}.upsamplers.0"}
- assign_to_checkpoint(
- paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
- )
- else:
- resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
- for path in resnet_0_paths:
- old_path = ".".join(["output_blocks", str(i), path["old"]])
- new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
-
- new_checkpoint[new_path] = unet_state_dict[old_path]
-
- return new_checkpoint
-
-
-def verify_param_count(orig_path, unet_diffusers_config):
- if "-II-" in orig_path:
- from deepfloyd_if.modules import IFStageII
-
- if_II = IFStageII(device="cpu", dir_or_name=orig_path)
- elif "-III-" in orig_path:
- from deepfloyd_if.modules import IFStageIII
-
- if_II = IFStageIII(device="cpu", dir_or_name=orig_path)
- else:
- assert f"Weird name. Should have -II- or -III- in path: {orig_path}"
-
- unet = UNet2DConditionModel(**unet_diffusers_config)
-
- # in params
- assert_param_count(unet.time_embedding, if_II.model.time_embed)
- assert_param_count(unet.conv_in, if_II.model.input_blocks[:1])
-
- # downblocks
- assert_param_count(unet.down_blocks[0], if_II.model.input_blocks[1:4])
- assert_param_count(unet.down_blocks[1], if_II.model.input_blocks[4:7])
- assert_param_count(unet.down_blocks[2], if_II.model.input_blocks[7:11])
-
- if "-II-" in orig_path:
- assert_param_count(unet.down_blocks[3], if_II.model.input_blocks[11:17])
- assert_param_count(unet.down_blocks[4], if_II.model.input_blocks[17:])
- if "-III-" in orig_path:
- assert_param_count(unet.down_blocks[3], if_II.model.input_blocks[11:15])
- assert_param_count(unet.down_blocks[4], if_II.model.input_blocks[15:20])
- assert_param_count(unet.down_blocks[5], if_II.model.input_blocks[20:])
-
- # mid block
- assert_param_count(unet.mid_block, if_II.model.middle_block)
-
- # up block
- if "-II-" in orig_path:
- assert_param_count(unet.up_blocks[0], if_II.model.output_blocks[:6])
- assert_param_count(unet.up_blocks[1], if_II.model.output_blocks[6:12])
- assert_param_count(unet.up_blocks[2], if_II.model.output_blocks[12:16])
- assert_param_count(unet.up_blocks[3], if_II.model.output_blocks[16:19])
- assert_param_count(unet.up_blocks[4], if_II.model.output_blocks[19:])
- if "-III-" in orig_path:
- assert_param_count(unet.up_blocks[0], if_II.model.output_blocks[:5])
- assert_param_count(unet.up_blocks[1], if_II.model.output_blocks[5:10])
- assert_param_count(unet.up_blocks[2], if_II.model.output_blocks[10:14])
- assert_param_count(unet.up_blocks[3], if_II.model.output_blocks[14:18])
- assert_param_count(unet.up_blocks[4], if_II.model.output_blocks[18:21])
- assert_param_count(unet.up_blocks[5], if_II.model.output_blocks[21:24])
-
- # out params
- assert_param_count(unet.conv_norm_out, if_II.model.out[0])
- assert_param_count(unet.conv_out, if_II.model.out[2])
-
- # make sure all model architecture has same param count
- assert_param_count(unet, if_II.model)
-
-
-def assert_param_count(model_1, model_2):
- count_1 = sum(p.numel() for p in model_1.parameters())
- count_2 = sum(p.numel() for p in model_2.parameters())
- assert count_1 == count_2, f"{model_1.__class__}: {count_1} != {model_2.__class__}: {count_2}"
-
-
-def superres_check_against_original(dump_path, unet_checkpoint_path):
- model_path = dump_path
- model = UNet2DConditionModel.from_pretrained(model_path)
- model.to("cuda")
- orig_path = unet_checkpoint_path
-
- if "-II-" in orig_path:
- from deepfloyd_if.modules import IFStageII
-
- if_II_model = IFStageII(device="cuda", dir_or_name=orig_path, model_kwargs={"precision": "fp32"}).model
- elif "-III-" in orig_path:
- from deepfloyd_if.modules import IFStageIII
-
- if_II_model = IFStageIII(device="cuda", dir_or_name=orig_path, model_kwargs={"precision": "fp32"}).model
-
- batch_size = 1
- channels = model.in_channels // 2
- height = model.sample_size
- width = model.sample_size
- height = 1024
- width = 1024
-
- torch.manual_seed(0)
-
- latents = torch.randn((batch_size, channels, height, width), device=model.device)
- image_small = torch.randn((batch_size, channels, height // 4, width // 4), device=model.device)
-
- interpolate_antialias = {}
- if "antialias" in inspect.signature(F.interpolate).parameters:
- interpolate_antialias["antialias"] = True
- image_upscaled = F.interpolate(
- image_small, size=[height, width], mode="bicubic", align_corners=False, **interpolate_antialias
- )
-
- latent_model_input = torch.cat([latents, image_upscaled], dim=1).to(model.dtype)
- t = torch.tensor([5], device=model.device).to(model.dtype)
-
- seq_len = 64
- encoder_hidden_states = torch.randn((batch_size, seq_len, model.config.encoder_hid_dim), device=model.device).to(
- model.dtype
- )
-
- fake_class_labels = torch.tensor([t], device=model.device).to(model.dtype)
-
- with torch.no_grad():
- out = if_II_model(latent_model_input, t, aug_steps=fake_class_labels, text_emb=encoder_hidden_states)
-
- if_II_model.to("cpu")
- del if_II_model
- import gc
-
- torch.cuda.empty_cache()
- gc.collect()
- print(50 * "=")
-
- with torch.no_grad():
- noise_pred = model(
- sample=latent_model_input,
- encoder_hidden_states=encoder_hidden_states,
- class_labels=fake_class_labels,
- timestep=t,
- ).sample
-
- print("Out shape", noise_pred.shape)
- print("Diff", (out - noise_pred).abs().sum())
-
-
-if __name__ == "__main__":
- main(parse_args())
diff --git a/spaces/pedromsfaria/Whisper_Diariazacao/README.md b/spaces/pedromsfaria/Whisper_Diariazacao/README.md
deleted file mode 100644
index 675f1c09e5c9810d180797c8d98379200fe60927..0000000000000000000000000000000000000000
--- a/spaces/pedromsfaria/Whisper_Diariazacao/README.md
+++ /dev/null
@@ -1,15 +0,0 @@
----
-title: Whisper com Diarização
-emoji: 📊
-colorFrom: blue
-colorTo: red
-sdk: gradio
-sdk_version: 3.9.1
-app_file: app.py
-pinned: false
-tags:
-- whisper-event
-
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/pikto/Elite-freegpt-webui/server/backend.py b/spaces/pikto/Elite-freegpt-webui/server/backend.py
deleted file mode 100644
index 9d2d56fac8bf5dc5ed7ca9b8dd147cfceb039f85..0000000000000000000000000000000000000000
--- a/spaces/pikto/Elite-freegpt-webui/server/backend.py
+++ /dev/null
@@ -1,177 +0,0 @@
-import re
-from datetime import datetime
-from g4f import ChatCompletion
-from flask import request, Response, stream_with_context
-from requests import get
-from server.config import special_instructions
-
-
-class Backend_Api:
- def __init__(self, bp, config: dict) -> None:
- """
- Initialize the Backend_Api class.
- :param app: Flask application instance
- :param config: Configuration dictionary
- """
- self.bp = bp
- self.routes = {
- '/backend-api/v2/conversation': {
- 'function': self._conversation,
- 'methods': ['POST']
- }
- }
-
- def _conversation(self):
- """
- Handles the conversation route.
-
- :return: Response object containing the generated conversation stream
- """
- conversation_id = request.json['conversation_id']
-
- try:
- jailbreak = request.json['jailbreak']
- model = request.json['model']
- messages = build_messages(jailbreak)
-
- # Generate response
- response = ChatCompletion.create(
- model=model,
- stream=True,
- chatId=conversation_id,
- messages=messages
- )
-
- return Response(stream_with_context(generate_stream(response, jailbreak)), mimetype='text/event-stream')
-
- except Exception as e:
- print(e)
- print(e.__traceback__.tb_next)
-
- return {
- '_action': '_ask',
- 'success': False,
- "error": f"an error occurred {str(e)}"
- }, 400
-
-
-def build_messages(jailbreak):
- """
- Build the messages for the conversation.
-
- :param jailbreak: Jailbreak instruction string
- :return: List of messages for the conversation
- """
- _conversation = request.json['meta']['content']['conversation']
- internet_access = request.json['meta']['content']['internet_access']
- prompt = request.json['meta']['content']['parts'][0]
-
- # Add the existing conversation
- conversation = _conversation
-
- # Add web results if enabled
- if internet_access:
- current_date = datetime.now().strftime("%Y-%m-%d")
- query = f'Current date: {current_date}. ' + prompt["content"]
- search_results = fetch_search_results(query)
- conversation.extend(search_results)
-
- # Add jailbreak instructions if enabled
- if jailbreak_instructions := getJailbreak(jailbreak):
- conversation.extend(jailbreak_instructions)
-
- # Add the prompt
- conversation.append(prompt)
-
- # Reduce conversation size to avoid API Token quantity error
- if len(conversation) > 3:
- conversation = conversation[-4:]
-
- return conversation
-
-
-def fetch_search_results(query):
- """
- Fetch search results for a given query.
-
- :param query: Search query string
- :return: List of search results
- """
- search = get('https://ddg-api.herokuapp.com/search',
- params={
- 'query': query,
- 'limit': 3,
- })
-
- snippets = ""
- for index, result in enumerate(search.json()):
- snippet = f'[{index + 1}] "{result["snippet"]}" URL:{result["link"]}.'
- snippets += snippet
-
- response = "Here are some updated web searches. Use this to improve user response:"
- response += snippets
-
- return [{'role': 'system', 'content': response}]
-
-
-def generate_stream(response, jailbreak):
- """
- Generate the conversation stream.
-
- :param response: Response object from ChatCompletion.create
- :param jailbreak: Jailbreak instruction string
- :return: Generator object yielding messages in the conversation
- """
- if getJailbreak(jailbreak):
- response_jailbreak = ''
- jailbroken_checked = False
- for message in response:
- response_jailbreak += message
- if jailbroken_checked:
- yield message
- else:
- if response_jailbroken_success(response_jailbreak):
- jailbroken_checked = True
- if response_jailbroken_failed(response_jailbreak):
- yield response_jailbreak
- jailbroken_checked = True
- else:
- yield from response
-
-
-def response_jailbroken_success(response: str) -> bool:
- """Check if the response has been jailbroken.
-
- :param response: Response string
- :return: Boolean indicating if the response has been jailbroken
- """
- act_match = re.search(r'ACT:', response, flags=re.DOTALL)
- return bool(act_match)
-
-
-def response_jailbroken_failed(response):
- """
- Check if the response has not been jailbroken.
-
- :param response: Response string
- :return: Boolean indicating if the response has not been jailbroken
- """
- return False if len(response) < 4 else not (response.startswith("GPT:") or response.startswith("ACT:"))
-
-
-def getJailbreak(jailbreak):
- """
- Check if jailbreak instructions are provided.
-
- :param jailbreak: Jailbreak instruction string
- :return: Jailbreak instructions if provided, otherwise None
- """
- if jailbreak != "default":
- special_instructions[jailbreak][0]['content'] += special_instructions['two_responses_instruction']
- if jailbreak in special_instructions:
- special_instructions[jailbreak]
- return special_instructions[jailbreak]
- else:
- return None
- else:
- return None
diff --git a/spaces/pinkq/Newbing/src/components/tailwind-indicator.tsx b/spaces/pinkq/Newbing/src/components/tailwind-indicator.tsx
deleted file mode 100644
index f2a1291213dd67055fcebe67fab574c8441338df..0000000000000000000000000000000000000000
--- a/spaces/pinkq/Newbing/src/components/tailwind-indicator.tsx
+++ /dev/null
@@ -1,14 +0,0 @@
-export function TailwindIndicator() {
- if (process.env.NODE_ENV === 'production') return null
-
- return (
-
-
xs
-
sm
-
md
-
lg
-
xl
-
2xl
-
- {role === 'user' &&
}
- {role === 'assistant' &&
}
- {role === 'system' &&
}
-
-
-
- );
-};
-
-export default Avatar;
diff --git a/spaces/plzdontcry/dakubettergpt/src/components/Chat/ChatContent/Message/CodeBlock.tsx b/spaces/plzdontcry/dakubettergpt/src/components/Chat/ChatContent/Message/CodeBlock.tsx
deleted file mode 100644
index a2773506ef3686b74dce22fdb66cb49713bd7ff1..0000000000000000000000000000000000000000
--- a/spaces/plzdontcry/dakubettergpt/src/components/Chat/ChatContent/Message/CodeBlock.tsx
+++ /dev/null
@@ -1,67 +0,0 @@
-import React, { useRef, useState } from 'react';
-
-import CopyIcon from '@icon/CopyIcon';
-import TickIcon from '@icon/TickIcon';
-
-const CodeBlock = ({
- lang,
- codeChildren,
-}: {
- lang: string;
- codeChildren: React.ReactNode & React.ReactNode[];
-}) => {
- const codeRef = useRef(null);
-
- return (
-
-
-
-
- {codeChildren}
-
-
-
- {lang}
-
-
- );
- }
-);
-export default CodeBlock;
diff --git a/spaces/prerna9811/Chord/portaudio/test/patest_hang.c b/spaces/prerna9811/Chord/portaudio/test/patest_hang.c
deleted file mode 100644
index 501b47d68447c3b8011fc3e2111fffc37935af2a..0000000000000000000000000000000000000000
--- a/spaces/prerna9811/Chord/portaudio/test/patest_hang.c
+++ /dev/null
@@ -1,164 +0,0 @@
-/** @file patest_hang.c
- @ingroup test_src
- @brief Play a sine then hang audio callback to test watchdog.
- @author Ross Bencina
- @author Phil Burk
-*/
-/*
- * $Id$
- *
- * This program uses the PortAudio Portable Audio Library.
- * For more information see: http://www.portaudio.com
- * Copyright (c) 1999-2000 Ross Bencina and Phil Burk
- *
- * Permission is hereby granted, free of charge, to any person obtaining
- * a copy of this software and associated documentation files
- * (the "Software"), to deal in the Software without restriction,
- * including without limitation the rights to use, copy, modify, merge,
- * publish, distribute, sublicense, and/or sell copies of the Software,
- * and to permit persons to whom the Software is furnished to do so,
- * subject to the following conditions:
- *
- * The above copyright notice and this permission notice shall be
- * included in all copies or substantial portions of the Software.
- *
- * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
- * EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
- * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
- * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR
- * ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF
- * CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
- * WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
- */
-
-/*
- * The text above constitutes the entire PortAudio license; however,
- * the PortAudio community also makes the following non-binding requests:
- *
- * Any person wishing to distribute modifications to the Software is
- * requested to send the modifications to the original developer so that
- * they can be incorporated into the canonical version. It is also
- * requested that these non-binding requests be included along with the
- * license above.
- */
-
-#include
-#include
-
-#include "portaudio.h"
-
-#define SAMPLE_RATE (44100)
-#define FRAMES_PER_BUFFER (1024)
-#ifndef M_PI
-#define M_PI (3.14159265)
-#endif
-#define TWOPI (M_PI * 2.0)
-
-typedef struct paTestData
-{
- int sleepFor;
- double phase;
-}
-paTestData;
-
-/* This routine will be called by the PortAudio engine when audio is needed.
-** It may called at interrupt level on some machines so don't do anything
-** that could mess up the system like calling malloc() or free().
-*/
-static int patestCallback( const void *inputBuffer, void *outputBuffer,
- unsigned long framesPerBuffer,
- const PaStreamCallbackTimeInfo* timeInfo,
- PaStreamCallbackFlags statusFlags,
- void *userData )
-{
- paTestData *data = (paTestData*)userData;
- float *out = (float*)outputBuffer;
- unsigned long i;
- int finished = 0;
- double phaseInc = 0.02;
- double phase = data->phase;
-
- (void) inputBuffer; /* Prevent unused argument warning. */
-
- for( i=0; i TWOPI ) phase -= TWOPI;
- /* This is not a very efficient way to calc sines. */
- *out++ = (float) sin( phase ); /* mono */
- }
-
- if( data->sleepFor > 0 )
- {
- Pa_Sleep( data->sleepFor );
- }
-
- data->phase = phase;
- return finished;
-}
-
-/*******************************************************************/
-int main(void);
-int main(void)
-{
- PaStream* stream;
- PaStreamParameters outputParameters;
- PaError err;
- int i;
- paTestData data = {0};
-
- printf("PortAudio Test: output sine wave. SR = %d, BufSize = %d\n",
- SAMPLE_RATE, FRAMES_PER_BUFFER );
-
- err = Pa_Initialize();
- if( err != paNoError ) goto error;
-
- outputParameters.device = Pa_GetDefaultOutputDevice(); /* Default output device. */
- if (outputParameters.device == paNoDevice) {
- fprintf(stderr,"Error: No default output device.\n");
- goto error;
- }
- outputParameters.channelCount = 1; /* Mono output. */
- outputParameters.sampleFormat = paFloat32; /* 32 bit floating point. */
- outputParameters.hostApiSpecificStreamInfo = NULL;
- outputParameters.suggestedLatency = Pa_GetDeviceInfo(outputParameters.device)
- ->defaultLowOutputLatency;
- err = Pa_OpenStream(&stream,
- NULL, /* No input. */
- &outputParameters,
- SAMPLE_RATE,
- FRAMES_PER_BUFFER,
- paClipOff, /* No out of range samples. */
- patestCallback,
- &data);
- if (err != paNoError) goto error;
-
- err = Pa_StartStream( stream );
- if( err != paNoError ) goto error;
-
- /* Gradually increase sleep time. */
- /* Was: for( i=0; i<10000; i+= 1000 ) */
- for(i=0; i <= 1000; i += 100)
- {
- printf("Sleep for %d milliseconds in audio callback.\n", i );
- data.sleepFor = i;
- Pa_Sleep( ((i<1000) ? 1000 : i) );
- }
-
- printf("Suffer for 10 seconds.\n");
- Pa_Sleep( 10000 );
-
- err = Pa_StopStream( stream );
- if( err != paNoError ) goto error;
- err = Pa_CloseStream( stream );
- if( err != paNoError ) goto error;
- Pa_Terminate();
- printf("Test finished.\n");
- return err;
-error:
- Pa_Terminate();
- fprintf( stderr, "An error occurred while using the portaudio stream\n" );
- fprintf( stderr, "Error number: %d\n", err );
- fprintf( stderr, "Error message: %s\n", Pa_GetErrorText( err ) );
- return err;
-}
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/anyio/abc/_tasks.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/anyio/abc/_tasks.py
deleted file mode 100644
index e48d3c1e97e02cd188b567b50a4c0c615f187e4d..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/anyio/abc/_tasks.py
+++ /dev/null
@@ -1,119 +0,0 @@
-from __future__ import annotations
-
-import sys
-from abc import ABCMeta, abstractmethod
-from types import TracebackType
-from typing import TYPE_CHECKING, Any, Awaitable, Callable, TypeVar, overload
-from warnings import warn
-
-if sys.version_info >= (3, 8):
- from typing import Protocol
-else:
- from typing_extensions import Protocol
-
-if TYPE_CHECKING:
- from anyio._core._tasks import CancelScope
-
-T_Retval = TypeVar("T_Retval")
-T_contra = TypeVar("T_contra", contravariant=True)
-
-
-class TaskStatus(Protocol[T_contra]):
- @overload
- def started(self: TaskStatus[None]) -> None:
- ...
-
- @overload
- def started(self, value: T_contra) -> None:
- ...
-
- def started(self, value: T_contra | None = None) -> None:
- """
- Signal that the task has started.
-
- :param value: object passed back to the starter of the task
- """
-
-
-class TaskGroup(metaclass=ABCMeta):
- """
- Groups several asynchronous tasks together.
-
- :ivar cancel_scope: the cancel scope inherited by all child tasks
- :vartype cancel_scope: CancelScope
- """
-
- cancel_scope: CancelScope
-
- async def spawn(
- self,
- func: Callable[..., Awaitable[Any]],
- *args: object,
- name: object = None,
- ) -> None:
- """
- Start a new task in this task group.
-
- :param func: a coroutine function
- :param args: positional arguments to call the function with
- :param name: name of the task, for the purposes of introspection and debugging
-
- .. deprecated:: 3.0
- Use :meth:`start_soon` instead. If your code needs AnyIO 2 compatibility, you
- can keep using this until AnyIO 4.
-
- """
- warn(
- 'spawn() is deprecated -- use start_soon() (without the "await") instead',
- DeprecationWarning,
- )
- self.start_soon(func, *args, name=name)
-
- @abstractmethod
- def start_soon(
- self,
- func: Callable[..., Awaitable[Any]],
- *args: object,
- name: object = None,
- ) -> None:
- """
- Start a new task in this task group.
-
- :param func: a coroutine function
- :param args: positional arguments to call the function with
- :param name: name of the task, for the purposes of introspection and debugging
-
- .. versionadded:: 3.0
- """
-
- @abstractmethod
- async def start(
- self,
- func: Callable[..., Awaitable[Any]],
- *args: object,
- name: object = None,
- ) -> Any:
- """
- Start a new task and wait until it signals for readiness.
-
- :param func: a coroutine function
- :param args: positional arguments to call the function with
- :param name: name of the task, for the purposes of introspection and debugging
- :return: the value passed to ``task_status.started()``
- :raises RuntimeError: if the task finishes without calling ``task_status.started()``
-
- .. versionadded:: 3.0
- """
-
- @abstractmethod
- async def __aenter__(self) -> TaskGroup:
- """Enter the task group context and allow starting new tasks."""
-
- @abstractmethod
- async def __aexit__(
- self,
- exc_type: type[BaseException] | None,
- exc_val: BaseException | None,
- exc_tb: TracebackType | None,
- ) -> bool | None:
- """Exit the task group context waiting for all tasks to finish."""
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/attr/_version_info.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/attr/_version_info.py
deleted file mode 100644
index 51a1312f9759f21063caea779a62882d7f7c86ae..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/attr/_version_info.py
+++ /dev/null
@@ -1,86 +0,0 @@
-# SPDX-License-Identifier: MIT
-
-
-from functools import total_ordering
-
-from ._funcs import astuple
-from ._make import attrib, attrs
-
-
-@total_ordering
-@attrs(eq=False, order=False, slots=True, frozen=True)
-class VersionInfo:
- """
- A version object that can be compared to tuple of length 1--4:
-
- >>> attr.VersionInfo(19, 1, 0, "final") <= (19, 2)
- True
- >>> attr.VersionInfo(19, 1, 0, "final") < (19, 1, 1)
- True
- >>> vi = attr.VersionInfo(19, 2, 0, "final")
- >>> vi < (19, 1, 1)
- False
- >>> vi < (19,)
- False
- >>> vi == (19, 2,)
- True
- >>> vi == (19, 2, 1)
- False
-
- .. versionadded:: 19.2
- """
-
- year = attrib(type=int)
- minor = attrib(type=int)
- micro = attrib(type=int)
- releaselevel = attrib(type=str)
-
- @classmethod
- def _from_version_string(cls, s):
- """
- Parse *s* and return a _VersionInfo.
- """
- v = s.split(".")
- if len(v) == 3:
- v.append("final")
-
- return cls(
- year=int(v[0]), minor=int(v[1]), micro=int(v[2]), releaselevel=v[3]
- )
-
- def _ensure_tuple(self, other):
- """
- Ensure *other* is a tuple of a valid length.
-
- Returns a possibly transformed *other* and ourselves as a tuple of
- the same length as *other*.
- """
-
- if self.__class__ is other.__class__:
- other = astuple(other)
-
- if not isinstance(other, tuple):
- raise NotImplementedError
-
- if not (1 <= len(other) <= 4):
- raise NotImplementedError
-
- return astuple(self)[: len(other)], other
-
- def __eq__(self, other):
- try:
- us, them = self._ensure_tuple(other)
- except NotImplementedError:
- return NotImplemented
-
- return us == them
-
- def __lt__(self, other):
- try:
- us, them = self._ensure_tuple(other)
- except NotImplementedError:
- return NotImplemented
-
- # Since alphabetically "dev0" < "final" < "post1" < "post2", we don't
- # have to do anything special with releaselevel for now.
- return us < them
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/pens/pointInsidePen.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/pens/pointInsidePen.py
deleted file mode 100644
index 8a579ae4c93f824b5ce3a5e80097aeffd5f5933d..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/pens/pointInsidePen.py
+++ /dev/null
@@ -1,192 +0,0 @@
-"""fontTools.pens.pointInsidePen -- Pen implementing "point inside" testing
-for shapes.
-"""
-
-from fontTools.pens.basePen import BasePen
-from fontTools.misc.bezierTools import solveQuadratic, solveCubic
-
-
-__all__ = ["PointInsidePen"]
-
-
-class PointInsidePen(BasePen):
-
- """This pen implements "point inside" testing: to test whether
- a given point lies inside the shape (black) or outside (white).
- Instances of this class can be recycled, as long as the
- setTestPoint() method is used to set the new point to test.
-
- Typical usage:
-
- pen = PointInsidePen(glyphSet, (100, 200))
- outline.draw(pen)
- isInside = pen.getResult()
-
- Both the even-odd algorithm and the non-zero-winding-rule
- algorithm are implemented. The latter is the default, specify
- True for the evenOdd argument of __init__ or setTestPoint
- to use the even-odd algorithm.
- """
-
- # This class implements the classical "shoot a ray from the test point
- # to infinity and count how many times it intersects the outline" (as well
- # as the non-zero variant, where the counter is incremented if the outline
- # intersects the ray in one direction and decremented if it intersects in
- # the other direction).
- # I found an amazingly clear explanation of the subtleties involved in
- # implementing this correctly for polygons here:
- # http://graphics.cs.ucdavis.edu/~okreylos/TAship/Spring2000/PointInPolygon.html
- # I extended the principles outlined on that page to curves.
-
- def __init__(self, glyphSet, testPoint, evenOdd=False):
- BasePen.__init__(self, glyphSet)
- self.setTestPoint(testPoint, evenOdd)
-
- def setTestPoint(self, testPoint, evenOdd=False):
- """Set the point to test. Call this _before_ the outline gets drawn."""
- self.testPoint = testPoint
- self.evenOdd = evenOdd
- self.firstPoint = None
- self.intersectionCount = 0
-
- def getWinding(self):
- if self.firstPoint is not None:
- # always make sure the sub paths are closed; the algorithm only works
- # for closed paths.
- self.closePath()
- return self.intersectionCount
-
- def getResult(self):
- """After the shape has been drawn, getResult() returns True if the test
- point lies within the (black) shape, and False if it doesn't.
- """
- winding = self.getWinding()
- if self.evenOdd:
- result = winding % 2
- else: # non-zero
- result = self.intersectionCount != 0
- return not not result
-
- def _addIntersection(self, goingUp):
- if self.evenOdd or goingUp:
- self.intersectionCount += 1
- else:
- self.intersectionCount -= 1
-
- def _moveTo(self, point):
- if self.firstPoint is not None:
- # always make sure the sub paths are closed; the algorithm only works
- # for closed paths.
- self.closePath()
- self.firstPoint = point
-
- def _lineTo(self, point):
- x, y = self.testPoint
- x1, y1 = self._getCurrentPoint()
- x2, y2 = point
-
- if x1 < x and x2 < x:
- return
- if y1 < y and y2 < y:
- return
- if y1 >= y and y2 >= y:
- return
-
- dx = x2 - x1
- dy = y2 - y1
- t = (y - y1) / dy
- ix = dx * t + x1
- if ix < x:
- return
- self._addIntersection(y2 > y1)
-
- def _curveToOne(self, bcp1, bcp2, point):
- x, y = self.testPoint
- x1, y1 = self._getCurrentPoint()
- x2, y2 = bcp1
- x3, y3 = bcp2
- x4, y4 = point
-
- if x1 < x and x2 < x and x3 < x and x4 < x:
- return
- if y1 < y and y2 < y and y3 < y and y4 < y:
- return
- if y1 >= y and y2 >= y and y3 >= y and y4 >= y:
- return
-
- dy = y1
- cy = (y2 - dy) * 3.0
- by = (y3 - y2) * 3.0 - cy
- ay = y4 - dy - cy - by
- solutions = sorted(solveCubic(ay, by, cy, dy - y))
- solutions = [t for t in solutions if -0.0 <= t <= 1.0]
- if not solutions:
- return
-
- dx = x1
- cx = (x2 - dx) * 3.0
- bx = (x3 - x2) * 3.0 - cx
- ax = x4 - dx - cx - bx
-
- above = y1 >= y
- lastT = None
- for t in solutions:
- if t == lastT:
- continue
- lastT = t
- t2 = t * t
- t3 = t2 * t
-
- direction = 3 * ay * t2 + 2 * by * t + cy
- incomingGoingUp = outgoingGoingUp = direction > 0.0
- if direction == 0.0:
- direction = 6 * ay * t + 2 * by
- outgoingGoingUp = direction > 0.0
- incomingGoingUp = not outgoingGoingUp
- if direction == 0.0:
- direction = ay
- incomingGoingUp = outgoingGoingUp = direction > 0.0
-
- xt = ax * t3 + bx * t2 + cx * t + dx
- if xt < x:
- continue
-
- if t in (0.0, -0.0):
- if not outgoingGoingUp:
- self._addIntersection(outgoingGoingUp)
- elif t == 1.0:
- if incomingGoingUp:
- self._addIntersection(incomingGoingUp)
- else:
- if incomingGoingUp == outgoingGoingUp:
- self._addIntersection(outgoingGoingUp)
- # else:
- # we're not really intersecting, merely touching
-
- def _qCurveToOne_unfinished(self, bcp, point):
- # XXX need to finish this, for now doing it through a cubic
- # (BasePen implements _qCurveTo in terms of a cubic) will
- # have to do.
- x, y = self.testPoint
- x1, y1 = self._getCurrentPoint()
- x2, y2 = bcp
- x3, y3 = point
- c = y1
- b = (y2 - c) * 2.0
- a = y3 - c - b
- solutions = sorted(solveQuadratic(a, b, c - y))
- solutions = [
- t for t in solutions if ZERO_MINUS_EPSILON <= t <= ONE_PLUS_EPSILON
- ]
- if not solutions:
- return
- # XXX
-
- def _closePath(self):
- if self._getCurrentPoint() != self.firstPoint:
- self.lineTo(self.firstPoint)
- self.firstPoint = None
-
- def _endPath(self):
- """Insideness is not defined for open contours."""
- raise NotImplementedError
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/templates/cdn/assets/Index-0a208ea4.js b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/templates/cdn/assets/Index-0a208ea4.js
deleted file mode 100644
index c268b1c160a294069590f06095bae06c8cc2aec7..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/templates/cdn/assets/Index-0a208ea4.js
+++ /dev/null
@@ -1,2 +0,0 @@
-const{SvelteComponent:d,attr:o,create_slot:g,detach:v,element:r,get_all_dirty_from_scope:q,get_slot_changes:b,init:j,insert:w,null_to_empty:h,safe_not_equal:I,toggle_class:u,transition_in:C,transition_out:S,update_slot_base:k}=window.__gradio__svelte__internal;function z(s){let e,_,t;const f=s[6].default,i=g(f,s,s[5],null);return{c(){e=r("div"),i&&i.c(),o(e,"id",s[1]),o(e,"class",_=h(s[2].join(" "))+" svelte-15lo0d8"),u(e,"compact",s[4]==="compact"),u(e,"panel",s[4]==="panel"),u(e,"unequal-height",s[0]===!1),u(e,"stretch",s[0]),u(e,"hide",!s[3])},m(l,n){w(l,e,n),i&&i.m(e,null),t=!0},p(l,[n]){i&&i.p&&(!t||n&32)&&k(i,f,l,l[5],t?b(f,l[5],n,null):q(l[5]),null),(!t||n&2)&&o(e,"id",l[1]),(!t||n&4&&_!==(_=h(l[2].join(" "))+" svelte-15lo0d8"))&&o(e,"class",_),(!t||n&20)&&u(e,"compact",l[4]==="compact"),(!t||n&20)&&u(e,"panel",l[4]==="panel"),(!t||n&5)&&u(e,"unequal-height",l[0]===!1),(!t||n&5)&&u(e,"stretch",l[0]),(!t||n&12)&&u(e,"hide",!l[3])},i(l){t||(C(i,l),t=!0)},o(l){S(i,l),t=!1},d(l){l&&v(e),i&&i.d(l)}}}function A(s,e,_){let{$$slots:t={},$$scope:f}=e,{equal_height:i=!0}=e,{elem_id:l}=e,{elem_classes:n=[]}=e,{visible:m=!0}=e,{variant:c="default"}=e;return s.$$set=a=>{"equal_height"in a&&_(0,i=a.equal_height),"elem_id"in a&&_(1,l=a.elem_id),"elem_classes"in a&&_(2,n=a.elem_classes),"visible"in a&&_(3,m=a.visible),"variant"in a&&_(4,c=a.variant),"$$scope"in a&&_(5,f=a.$$scope)},[i,l,n,m,c,f,t]}class B extends d{constructor(e){super(),j(this,e,A,z,I,{equal_height:0,elem_id:1,elem_classes:2,visible:3,variant:4})}}export{B as default};
-//# sourceMappingURL=Index-0a208ea4.js.map
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/huggingface_hub/utils/_telemetry.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/huggingface_hub/utils/_telemetry.py
deleted file mode 100644
index 5de988e2795188324f69232d1beb68191591715d..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/huggingface_hub/utils/_telemetry.py
+++ /dev/null
@@ -1,118 +0,0 @@
-from queue import Queue
-from threading import Lock, Thread
-from typing import Dict, Optional, Union
-from urllib.parse import quote
-
-from .. import constants, logging
-from . import build_hf_headers, get_session, hf_raise_for_status
-
-
-logger = logging.get_logger(__name__)
-
-# Telemetry is sent by a separate thread to avoid blocking the main thread.
-# A daemon thread is started once and consume tasks from the _TELEMETRY_QUEUE.
-# If the thread stops for some reason -shouldn't happen-, we restart a new one.
-_TELEMETRY_THREAD: Optional[Thread] = None
-_TELEMETRY_THREAD_LOCK = Lock() # Lock to avoid starting multiple threads in parallel
-_TELEMETRY_QUEUE: Queue = Queue()
-
-
-def send_telemetry(
- topic: str,
- *,
- library_name: Optional[str] = None,
- library_version: Optional[str] = None,
- user_agent: Union[Dict, str, None] = None,
-) -> None:
- """
- Sends telemetry that helps tracking usage of different HF libraries.
-
- This usage data helps us debug issues and prioritize new features. However, we understand that not everyone wants
- to share additional information, and we respect your privacy. You can disable telemetry collection by setting the
- `HF_HUB_DISABLE_TELEMETRY=1` as environment variable. Telemetry is also disabled in offline mode (i.e. when setting
- `HF_HUB_OFFLINE=1`).
-
- Telemetry collection is run in a separate thread to minimize impact for the user.
-
- Args:
- topic (`str`):
- Name of the topic that is monitored. The topic is directly used to build the URL. If you want to monitor
- subtopics, just use "/" separation. Examples: "gradio", "transformers/examples",...
- library_name (`str`, *optional*):
- The name of the library that is making the HTTP request. Will be added to the user-agent header.
- library_version (`str`, *optional*):
- The version of the library that is making the HTTP request. Will be added to the user-agent header.
- user_agent (`str`, `dict`, *optional*):
- The user agent info in the form of a dictionary or a single string. It will be completed with information about the installed packages.
-
- Example:
- ```py
- >>> from huggingface_hub.utils import send_telemetry
-
- # Send telemetry without library information
- >>> send_telemetry("ping")
-
- # Send telemetry to subtopic with library information
- >>> send_telemetry("gradio/local_link", library_name="gradio", library_version="3.22.1")
-
- # Send telemetry with additional data
- >>> send_telemetry(
- ... topic="examples",
- ... library_name="transformers",
- ... library_version="4.26.0",
- ... user_agent={"pipeline": "text_classification", "framework": "flax"},
- ... )
- ```
- """
- if constants.HF_HUB_OFFLINE or constants.HF_HUB_DISABLE_TELEMETRY:
- return
-
- _start_telemetry_thread() # starts thread only if doesn't exist yet
- _TELEMETRY_QUEUE.put(
- {"topic": topic, "library_name": library_name, "library_version": library_version, "user_agent": user_agent}
- )
-
-
-def _start_telemetry_thread():
- """Start a daemon thread to consume tasks from the telemetry queue.
-
- If the thread is interrupted, start a new one.
- """
- with _TELEMETRY_THREAD_LOCK: # avoid to start multiple threads if called concurrently
- global _TELEMETRY_THREAD
- if _TELEMETRY_THREAD is None or not _TELEMETRY_THREAD.is_alive():
- _TELEMETRY_THREAD = Thread(target=_telemetry_worker, daemon=True)
- _TELEMETRY_THREAD.start()
-
-
-def _telemetry_worker():
- """Wait for a task and consume it."""
- while True:
- kwargs = _TELEMETRY_QUEUE.get()
- _send_telemetry_in_thread(**kwargs)
- _TELEMETRY_QUEUE.task_done()
-
-
-def _send_telemetry_in_thread(
- topic: str,
- *,
- library_name: Optional[str] = None,
- library_version: Optional[str] = None,
- user_agent: Union[Dict, str, None] = None,
-) -> None:
- """Contains the actual data sending data to the Hub."""
- path = "/".join(quote(part) for part in topic.split("/") if len(part) > 0)
- try:
- r = get_session().head(
- f"{constants.ENDPOINT}/api/telemetry/{path}",
- headers=build_hf_headers(
- token=False, # no need to send a token for telemetry
- library_name=library_name,
- library_version=library_version,
- user_agent=user_agent,
- ),
- )
- hf_raise_for_status(r)
- except Exception as e:
- # We don't want to error in case of connection errors of any kind.
- logger.debug(f"Error while sending telemetry: {e}")
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/core/dtypes/cast.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/core/dtypes/cast.py
deleted file mode 100644
index 8ed57e9bf5532d0443d87da091c2ded7ef79adc2..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/core/dtypes/cast.py
+++ /dev/null
@@ -1,1895 +0,0 @@
-"""
-Routines for casting.
-"""
-
-from __future__ import annotations
-
-import datetime as dt
-import functools
-from typing import (
- TYPE_CHECKING,
- Any,
- Literal,
- TypeVar,
- cast,
- overload,
-)
-import warnings
-
-import numpy as np
-
-from pandas._config import using_pyarrow_string_dtype
-
-from pandas._libs import lib
-from pandas._libs.missing import (
- NA,
- NAType,
- checknull,
-)
-from pandas._libs.tslibs import (
- NaT,
- OutOfBoundsDatetime,
- OutOfBoundsTimedelta,
- Timedelta,
- Timestamp,
- get_unit_from_dtype,
- is_supported_unit,
-)
-from pandas._libs.tslibs.timedeltas import array_to_timedelta64
-from pandas.errors import (
- IntCastingNaNError,
- LossySetitemError,
-)
-
-from pandas.core.dtypes.common import (
- ensure_int8,
- ensure_int16,
- ensure_int32,
- ensure_int64,
- ensure_object,
- ensure_str,
- is_bool,
- is_complex,
- is_float,
- is_integer,
- is_object_dtype,
- is_scalar,
- is_string_dtype,
- pandas_dtype as pandas_dtype_func,
-)
-from pandas.core.dtypes.dtypes import (
- ArrowDtype,
- BaseMaskedDtype,
- CategoricalDtype,
- DatetimeTZDtype,
- ExtensionDtype,
- IntervalDtype,
- PandasExtensionDtype,
- PeriodDtype,
-)
-from pandas.core.dtypes.generic import (
- ABCIndex,
- ABCSeries,
-)
-from pandas.core.dtypes.inference import is_list_like
-from pandas.core.dtypes.missing import (
- is_valid_na_for_dtype,
- isna,
- na_value_for_dtype,
- notna,
-)
-
-from pandas.io._util import _arrow_dtype_mapping
-
-if TYPE_CHECKING:
- from collections.abc import (
- Sequence,
- Sized,
- )
-
- from pandas._typing import (
- ArrayLike,
- Dtype,
- DtypeObj,
- NumpyIndexT,
- Scalar,
- npt,
- )
-
- from pandas import Index
- from pandas.core.arrays import (
- Categorical,
- DatetimeArray,
- ExtensionArray,
- IntervalArray,
- PeriodArray,
- TimedeltaArray,
- )
-
-
-_int8_max = np.iinfo(np.int8).max
-_int16_max = np.iinfo(np.int16).max
-_int32_max = np.iinfo(np.int32).max
-
-_dtype_obj = np.dtype(object)
-
-NumpyArrayT = TypeVar("NumpyArrayT", bound=np.ndarray)
-
-
-def maybe_convert_platform(
- values: list | tuple | range | np.ndarray | ExtensionArray,
-) -> ArrayLike:
- """try to do platform conversion, allow ndarray or list here"""
- arr: ArrayLike
-
- if isinstance(values, (list, tuple, range)):
- arr = construct_1d_object_array_from_listlike(values)
- else:
- # The caller is responsible for ensuring that we have np.ndarray
- # or ExtensionArray here.
- arr = values
-
- if arr.dtype == _dtype_obj:
- arr = cast(np.ndarray, arr)
- arr = lib.maybe_convert_objects(arr)
-
- return arr
-
-
-def is_nested_object(obj) -> bool:
- """
- return a boolean if we have a nested object, e.g. a Series with 1 or
- more Series elements
-
- This may not be necessarily be performant.
-
- """
- return bool(
- isinstance(obj, ABCSeries)
- and is_object_dtype(obj.dtype)
- and any(isinstance(v, ABCSeries) for v in obj._values)
- )
-
-
-def maybe_box_datetimelike(value: Scalar, dtype: Dtype | None = None) -> Scalar:
- """
- Cast scalar to Timestamp or Timedelta if scalar is datetime-like
- and dtype is not object.
-
- Parameters
- ----------
- value : scalar
- dtype : Dtype, optional
-
- Returns
- -------
- scalar
- """
- if dtype == _dtype_obj:
- pass
- elif isinstance(value, (np.datetime64, dt.datetime)):
- value = Timestamp(value)
- elif isinstance(value, (np.timedelta64, dt.timedelta)):
- value = Timedelta(value)
-
- return value
-
-
-def maybe_box_native(value: Scalar | None | NAType) -> Scalar | None | NAType:
- """
- If passed a scalar cast the scalar to a python native type.
-
- Parameters
- ----------
- value : scalar or Series
-
- Returns
- -------
- scalar or Series
- """
- if is_float(value):
- value = float(value)
- elif is_integer(value):
- value = int(value)
- elif is_bool(value):
- value = bool(value)
- elif isinstance(value, (np.datetime64, np.timedelta64)):
- value = maybe_box_datetimelike(value)
- elif value is NA:
- value = None
- return value
-
-
-def _maybe_unbox_datetimelike(value: Scalar, dtype: DtypeObj) -> Scalar:
- """
- Convert a Timedelta or Timestamp to timedelta64 or datetime64 for setting
- into a numpy array. Failing to unbox would risk dropping nanoseconds.
-
- Notes
- -----
- Caller is responsible for checking dtype.kind in "mM"
- """
- if is_valid_na_for_dtype(value, dtype):
- # GH#36541: can't fill array directly with pd.NaT
- # > np.empty(10, dtype="datetime64[ns]").fill(pd.NaT)
- # ValueError: cannot convert float NaN to integer
- value = dtype.type("NaT", "ns")
- elif isinstance(value, Timestamp):
- if value.tz is None:
- value = value.to_datetime64()
- elif not isinstance(dtype, DatetimeTZDtype):
- raise TypeError("Cannot unbox tzaware Timestamp to tznaive dtype")
- elif isinstance(value, Timedelta):
- value = value.to_timedelta64()
-
- _disallow_mismatched_datetimelike(value, dtype)
- return value
-
-
-def _disallow_mismatched_datetimelike(value, dtype: DtypeObj):
- """
- numpy allows np.array(dt64values, dtype="timedelta64[ns]") and
- vice-versa, but we do not want to allow this, so we need to
- check explicitly
- """
- vdtype = getattr(value, "dtype", None)
- if vdtype is None:
- return
- elif (vdtype.kind == "m" and dtype.kind == "M") or (
- vdtype.kind == "M" and dtype.kind == "m"
- ):
- raise TypeError(f"Cannot cast {repr(value)} to {dtype}")
-
-
-@overload
-def maybe_downcast_to_dtype(result: np.ndarray, dtype: str | np.dtype) -> np.ndarray:
- ...
-
-
-@overload
-def maybe_downcast_to_dtype(result: ExtensionArray, dtype: str | np.dtype) -> ArrayLike:
- ...
-
-
-def maybe_downcast_to_dtype(result: ArrayLike, dtype: str | np.dtype) -> ArrayLike:
- """
- try to cast to the specified dtype (e.g. convert back to bool/int
- or could be an astype of float64->float32
- """
- do_round = False
-
- if isinstance(dtype, str):
- if dtype == "infer":
- inferred_type = lib.infer_dtype(result, skipna=False)
- if inferred_type == "boolean":
- dtype = "bool"
- elif inferred_type == "integer":
- dtype = "int64"
- elif inferred_type == "datetime64":
- dtype = "datetime64[ns]"
- elif inferred_type in ["timedelta", "timedelta64"]:
- dtype = "timedelta64[ns]"
-
- # try to upcast here
- elif inferred_type == "floating":
- dtype = "int64"
- if issubclass(result.dtype.type, np.number):
- do_round = True
-
- else:
- # TODO: complex? what if result is already non-object?
- dtype = "object"
-
- dtype = np.dtype(dtype)
-
- if not isinstance(dtype, np.dtype):
- # enforce our signature annotation
- raise TypeError(dtype) # pragma: no cover
-
- converted = maybe_downcast_numeric(result, dtype, do_round)
- if converted is not result:
- return converted
-
- # a datetimelike
- # GH12821, iNaT is cast to float
- if dtype.kind in "mM" and result.dtype.kind in "if":
- result = result.astype(dtype)
-
- elif dtype.kind == "m" and result.dtype == _dtype_obj:
- # test_where_downcast_to_td64
- result = cast(np.ndarray, result)
- result = array_to_timedelta64(result)
-
- elif dtype == np.dtype("M8[ns]") and result.dtype == _dtype_obj:
- result = cast(np.ndarray, result)
- return np.asarray(maybe_cast_to_datetime(result, dtype=dtype))
-
- return result
-
-
-@overload
-def maybe_downcast_numeric(
- result: np.ndarray, dtype: np.dtype, do_round: bool = False
-) -> np.ndarray:
- ...
-
-
-@overload
-def maybe_downcast_numeric(
- result: ExtensionArray, dtype: DtypeObj, do_round: bool = False
-) -> ArrayLike:
- ...
-
-
-def maybe_downcast_numeric(
- result: ArrayLike, dtype: DtypeObj, do_round: bool = False
-) -> ArrayLike:
- """
- Subset of maybe_downcast_to_dtype restricted to numeric dtypes.
-
- Parameters
- ----------
- result : ndarray or ExtensionArray
- dtype : np.dtype or ExtensionDtype
- do_round : bool
-
- Returns
- -------
- ndarray or ExtensionArray
- """
- if not isinstance(dtype, np.dtype) or not isinstance(result.dtype, np.dtype):
- # e.g. SparseDtype has no itemsize attr
- return result
-
- def trans(x):
- if do_round:
- return x.round()
- return x
-
- if dtype.kind == result.dtype.kind:
- # don't allow upcasts here (except if empty)
- if result.dtype.itemsize <= dtype.itemsize and result.size:
- return result
-
- if dtype.kind in "biu":
- if not result.size:
- # if we don't have any elements, just astype it
- return trans(result).astype(dtype)
-
- # do a test on the first element, if it fails then we are done
- r = result.ravel()
- arr = np.array([r[0]])
-
- if isna(arr).any():
- # if we have any nulls, then we are done
- return result
-
- elif not isinstance(r[0], (np.integer, np.floating, int, float, bool)):
- # a comparable, e.g. a Decimal may slip in here
- return result
-
- if (
- issubclass(result.dtype.type, (np.object_, np.number))
- and notna(result).all()
- ):
- new_result = trans(result).astype(dtype)
- if new_result.dtype.kind == "O" or result.dtype.kind == "O":
- # np.allclose may raise TypeError on object-dtype
- if (new_result == result).all():
- return new_result
- else:
- if np.allclose(new_result, result, rtol=0):
- return new_result
-
- elif (
- issubclass(dtype.type, np.floating)
- and result.dtype.kind != "b"
- and not is_string_dtype(result.dtype)
- ):
- with warnings.catch_warnings():
- warnings.filterwarnings(
- "ignore", "overflow encountered in cast", RuntimeWarning
- )
- new_result = result.astype(dtype)
-
- # Adjust tolerances based on floating point size
- size_tols = {4: 5e-4, 8: 5e-8, 16: 5e-16}
-
- atol = size_tols.get(new_result.dtype.itemsize, 0.0)
-
- # Check downcast float values are still equal within 7 digits when
- # converting from float64 to float32
- if np.allclose(new_result, result, equal_nan=True, rtol=0.0, atol=atol):
- return new_result
-
- elif dtype.kind == result.dtype.kind == "c":
- new_result = result.astype(dtype)
-
- if np.array_equal(new_result, result, equal_nan=True):
- # TODO: use tolerance like we do for float?
- return new_result
-
- return result
-
-
-def maybe_upcast_numeric_to_64bit(arr: NumpyIndexT) -> NumpyIndexT:
- """
- If array is a int/uint/float bit size lower than 64 bit, upcast it to 64 bit.
-
- Parameters
- ----------
- arr : ndarray or ExtensionArray
-
- Returns
- -------
- ndarray or ExtensionArray
- """
- dtype = arr.dtype
- if dtype.kind == "i" and dtype != np.int64:
- return arr.astype(np.int64)
- elif dtype.kind == "u" and dtype != np.uint64:
- return arr.astype(np.uint64)
- elif dtype.kind == "f" and dtype != np.float64:
- return arr.astype(np.float64)
- else:
- return arr
-
-
-def maybe_cast_pointwise_result(
- result: ArrayLike,
- dtype: DtypeObj,
- numeric_only: bool = False,
- same_dtype: bool = True,
-) -> ArrayLike:
- """
- Try casting result of a pointwise operation back to the original dtype if
- appropriate.
-
- Parameters
- ----------
- result : array-like
- Result to cast.
- dtype : np.dtype or ExtensionDtype
- Input Series from which result was calculated.
- numeric_only : bool, default False
- Whether to cast only numerics or datetimes as well.
- same_dtype : bool, default True
- Specify dtype when calling _from_sequence
-
- Returns
- -------
- result : array-like
- result maybe casted to the dtype.
- """
-
- if isinstance(dtype, ExtensionDtype):
- if not isinstance(dtype, (CategoricalDtype, DatetimeTZDtype)):
- # TODO: avoid this special-casing
- # We have to special case categorical so as not to upcast
- # things like counts back to categorical
-
- cls = dtype.construct_array_type()
- if same_dtype:
- result = _maybe_cast_to_extension_array(cls, result, dtype=dtype)
- else:
- result = _maybe_cast_to_extension_array(cls, result)
-
- elif (numeric_only and dtype.kind in "iufcb") or not numeric_only:
- result = maybe_downcast_to_dtype(result, dtype)
-
- return result
-
-
-def _maybe_cast_to_extension_array(
- cls: type[ExtensionArray], obj: ArrayLike, dtype: ExtensionDtype | None = None
-) -> ArrayLike:
- """
- Call to `_from_sequence` that returns the object unchanged on Exception.
-
- Parameters
- ----------
- cls : class, subclass of ExtensionArray
- obj : arraylike
- Values to pass to cls._from_sequence
- dtype : ExtensionDtype, optional
-
- Returns
- -------
- ExtensionArray or obj
- """
- from pandas.core.arrays.string_ import BaseStringArray
-
- # Everything can be converted to StringArrays, but we may not want to convert
- if issubclass(cls, BaseStringArray) and lib.infer_dtype(obj) != "string":
- return obj
-
- try:
- result = cls._from_sequence(obj, dtype=dtype)
- except Exception:
- # We can't predict what downstream EA constructors may raise
- result = obj
- return result
-
-
-@overload
-def ensure_dtype_can_hold_na(dtype: np.dtype) -> np.dtype:
- ...
-
-
-@overload
-def ensure_dtype_can_hold_na(dtype: ExtensionDtype) -> ExtensionDtype:
- ...
-
-
-def ensure_dtype_can_hold_na(dtype: DtypeObj) -> DtypeObj:
- """
- If we have a dtype that cannot hold NA values, find the best match that can.
- """
- if isinstance(dtype, ExtensionDtype):
- if dtype._can_hold_na:
- return dtype
- elif isinstance(dtype, IntervalDtype):
- # TODO(GH#45349): don't special-case IntervalDtype, allow
- # overriding instead of returning object below.
- return IntervalDtype(np.float64, closed=dtype.closed)
- return _dtype_obj
- elif dtype.kind == "b":
- return _dtype_obj
- elif dtype.kind in "iu":
- return np.dtype(np.float64)
- return dtype
-
-
-_canonical_nans = {
- np.datetime64: np.datetime64("NaT", "ns"),
- np.timedelta64: np.timedelta64("NaT", "ns"),
- type(np.nan): np.nan,
-}
-
-
-def maybe_promote(dtype: np.dtype, fill_value=np.nan):
- """
- Find the minimal dtype that can hold both the given dtype and fill_value.
-
- Parameters
- ----------
- dtype : np.dtype
- fill_value : scalar, default np.nan
-
- Returns
- -------
- dtype
- Upcasted from dtype argument if necessary.
- fill_value
- Upcasted from fill_value argument if necessary.
-
- Raises
- ------
- ValueError
- If fill_value is a non-scalar and dtype is not object.
- """
- orig = fill_value
- orig_is_nat = False
- if checknull(fill_value):
- # https://github.com/pandas-dev/pandas/pull/39692#issuecomment-1441051740
- # avoid cache misses with NaN/NaT values that are not singletons
- if fill_value is not NA:
- try:
- orig_is_nat = np.isnat(fill_value)
- except TypeError:
- pass
-
- fill_value = _canonical_nans.get(type(fill_value), fill_value)
-
- # for performance, we are using a cached version of the actual implementation
- # of the function in _maybe_promote. However, this doesn't always work (in case
- # of non-hashable arguments), so we fallback to the actual implementation if needed
- try:
- # error: Argument 3 to "__call__" of "_lru_cache_wrapper" has incompatible type
- # "Type[Any]"; expected "Hashable" [arg-type]
- dtype, fill_value = _maybe_promote_cached(
- dtype, fill_value, type(fill_value) # type: ignore[arg-type]
- )
- except TypeError:
- # if fill_value is not hashable (required for caching)
- dtype, fill_value = _maybe_promote(dtype, fill_value)
-
- if (dtype == _dtype_obj and orig is not None) or (
- orig_is_nat and np.datetime_data(orig)[0] != "ns"
- ):
- # GH#51592,53497 restore our potentially non-canonical fill_value
- fill_value = orig
- return dtype, fill_value
-
-
-@functools.lru_cache
-def _maybe_promote_cached(dtype, fill_value, fill_value_type):
- # The cached version of _maybe_promote below
- # This also use fill_value_type as (unused) argument to use this in the
- # cache lookup -> to differentiate 1 and True
- return _maybe_promote(dtype, fill_value)
-
-
-def _maybe_promote(dtype: np.dtype, fill_value=np.nan):
- # The actual implementation of the function, use `maybe_promote` above for
- # a cached version.
- if not is_scalar(fill_value):
- # with object dtype there is nothing to promote, and the user can
- # pass pretty much any weird fill_value they like
- if dtype != object:
- # with object dtype there is nothing to promote, and the user can
- # pass pretty much any weird fill_value they like
- raise ValueError("fill_value must be a scalar")
- dtype = _dtype_obj
- return dtype, fill_value
-
- if is_valid_na_for_dtype(fill_value, dtype) and dtype.kind in "iufcmM":
- dtype = ensure_dtype_can_hold_na(dtype)
- fv = na_value_for_dtype(dtype)
- return dtype, fv
-
- elif isinstance(dtype, CategoricalDtype):
- if fill_value in dtype.categories or isna(fill_value):
- return dtype, fill_value
- else:
- return object, ensure_object(fill_value)
-
- elif isna(fill_value):
- dtype = _dtype_obj
- if fill_value is None:
- # but we retain e.g. pd.NA
- fill_value = np.nan
- return dtype, fill_value
-
- # returns tuple of (dtype, fill_value)
- if issubclass(dtype.type, np.datetime64):
- inferred, fv = infer_dtype_from_scalar(fill_value)
- if inferred == dtype:
- return dtype, fv
-
- from pandas.core.arrays import DatetimeArray
-
- dta = DatetimeArray._from_sequence([], dtype="M8[ns]")
- try:
- fv = dta._validate_setitem_value(fill_value)
- return dta.dtype, fv
- except (ValueError, TypeError):
- return _dtype_obj, fill_value
-
- elif issubclass(dtype.type, np.timedelta64):
- inferred, fv = infer_dtype_from_scalar(fill_value)
- if inferred == dtype:
- return dtype, fv
-
- elif inferred.kind == "m":
- # different unit, e.g. passed np.timedelta64(24, "h") with dtype=m8[ns]
- # see if we can losslessly cast it to our dtype
- unit = np.datetime_data(dtype)[0]
- try:
- td = Timedelta(fill_value).as_unit(unit, round_ok=False)
- except OutOfBoundsTimedelta:
- return _dtype_obj, fill_value
- else:
- return dtype, td.asm8
-
- return _dtype_obj, fill_value
-
- elif is_float(fill_value):
- if issubclass(dtype.type, np.bool_):
- dtype = np.dtype(np.object_)
-
- elif issubclass(dtype.type, np.integer):
- dtype = np.dtype(np.float64)
-
- elif dtype.kind == "f":
- mst = np.min_scalar_type(fill_value)
- if mst > dtype:
- # e.g. mst is np.float64 and dtype is np.float32
- dtype = mst
-
- elif dtype.kind == "c":
- mst = np.min_scalar_type(fill_value)
- dtype = np.promote_types(dtype, mst)
-
- elif is_bool(fill_value):
- if not issubclass(dtype.type, np.bool_):
- dtype = np.dtype(np.object_)
-
- elif is_integer(fill_value):
- if issubclass(dtype.type, np.bool_):
- dtype = np.dtype(np.object_)
-
- elif issubclass(dtype.type, np.integer):
- if not np.can_cast(fill_value, dtype):
- # upcast to prevent overflow
- mst = np.min_scalar_type(fill_value)
- dtype = np.promote_types(dtype, mst)
- if dtype.kind == "f":
- # Case where we disagree with numpy
- dtype = np.dtype(np.object_)
-
- elif is_complex(fill_value):
- if issubclass(dtype.type, np.bool_):
- dtype = np.dtype(np.object_)
-
- elif issubclass(dtype.type, (np.integer, np.floating)):
- mst = np.min_scalar_type(fill_value)
- dtype = np.promote_types(dtype, mst)
-
- elif dtype.kind == "c":
- mst = np.min_scalar_type(fill_value)
- if mst > dtype:
- # e.g. mst is np.complex128 and dtype is np.complex64
- dtype = mst
-
- else:
- dtype = np.dtype(np.object_)
-
- # in case we have a string that looked like a number
- if issubclass(dtype.type, (bytes, str)):
- dtype = np.dtype(np.object_)
-
- fill_value = _ensure_dtype_type(fill_value, dtype)
- return dtype, fill_value
-
-
-def _ensure_dtype_type(value, dtype: np.dtype):
- """
- Ensure that the given value is an instance of the given dtype.
-
- e.g. if out dtype is np.complex64_, we should have an instance of that
- as opposed to a python complex object.
-
- Parameters
- ----------
- value : object
- dtype : np.dtype
-
- Returns
- -------
- object
- """
- # Start with exceptions in which we do _not_ cast to numpy types
-
- if dtype == _dtype_obj:
- return value
-
- # Note: before we get here we have already excluded isna(value)
- return dtype.type(value)
-
-
-def infer_dtype_from(val) -> tuple[DtypeObj, Any]:
- """
- Interpret the dtype from a scalar or array.
-
- Parameters
- ----------
- val : object
- """
- if not is_list_like(val):
- return infer_dtype_from_scalar(val)
- return infer_dtype_from_array(val)
-
-
-def infer_dtype_from_scalar(val) -> tuple[DtypeObj, Any]:
- """
- Interpret the dtype from a scalar.
-
- Parameters
- ----------
- val : object
- """
- dtype: DtypeObj = _dtype_obj
-
- # a 1-element ndarray
- if isinstance(val, np.ndarray):
- if val.ndim != 0:
- msg = "invalid ndarray passed to infer_dtype_from_scalar"
- raise ValueError(msg)
-
- dtype = val.dtype
- val = lib.item_from_zerodim(val)
-
- elif isinstance(val, str):
- # If we create an empty array using a string to infer
- # the dtype, NumPy will only allocate one character per entry
- # so this is kind of bad. Alternately we could use np.repeat
- # instead of np.empty (but then you still don't want things
- # coming out as np.str_!
-
- dtype = _dtype_obj
- if using_pyarrow_string_dtype():
- from pandas.core.arrays.string_ import StringDtype
-
- dtype = StringDtype(storage="pyarrow_numpy")
-
- elif isinstance(val, (np.datetime64, dt.datetime)):
- try:
- val = Timestamp(val)
- except OutOfBoundsDatetime:
- return _dtype_obj, val
-
- if val is NaT or val.tz is None:
- val = val.to_datetime64()
- dtype = val.dtype
- # TODO: test with datetime(2920, 10, 1) based on test_replace_dtypes
- else:
- dtype = DatetimeTZDtype(unit=val.unit, tz=val.tz)
-
- elif isinstance(val, (np.timedelta64, dt.timedelta)):
- try:
- val = Timedelta(val)
- except (OutOfBoundsTimedelta, OverflowError):
- dtype = _dtype_obj
- else:
- if val is NaT:
- val = np.timedelta64("NaT", "ns")
- else:
- val = val.asm8
- dtype = val.dtype
-
- elif is_bool(val):
- dtype = np.dtype(np.bool_)
-
- elif is_integer(val):
- if isinstance(val, np.integer):
- dtype = np.dtype(type(val))
- else:
- dtype = np.dtype(np.int64)
-
- try:
- np.array(val, dtype=dtype)
- except OverflowError:
- dtype = np.array(val).dtype
-
- elif is_float(val):
- if isinstance(val, np.floating):
- dtype = np.dtype(type(val))
- else:
- dtype = np.dtype(np.float64)
-
- elif is_complex(val):
- dtype = np.dtype(np.complex128)
-
- if lib.is_period(val):
- dtype = PeriodDtype(freq=val.freq)
- elif lib.is_interval(val):
- subtype = infer_dtype_from_scalar(val.left)[0]
- dtype = IntervalDtype(subtype=subtype, closed=val.closed)
-
- return dtype, val
-
-
-def dict_compat(d: dict[Scalar, Scalar]) -> dict[Scalar, Scalar]:
- """
- Convert datetimelike-keyed dicts to a Timestamp-keyed dict.
-
- Parameters
- ----------
- d: dict-like object
-
- Returns
- -------
- dict
- """
- return {maybe_box_datetimelike(key): value for key, value in d.items()}
-
-
-def infer_dtype_from_array(arr) -> tuple[DtypeObj, ArrayLike]:
- """
- Infer the dtype from an array.
-
- Parameters
- ----------
- arr : array
-
- Returns
- -------
- tuple (pandas-compat dtype, array)
-
-
- Examples
- --------
- >>> np.asarray([1, '1'])
- array(['1', '1'], dtype='>> infer_dtype_from_array([1, '1'])
- (dtype('O'), [1, '1'])
- """
- if isinstance(arr, np.ndarray):
- return arr.dtype, arr
-
- if not is_list_like(arr):
- raise TypeError("'arr' must be list-like")
-
- arr_dtype = getattr(arr, "dtype", None)
- if isinstance(arr_dtype, ExtensionDtype):
- return arr.dtype, arr
-
- elif isinstance(arr, ABCSeries):
- return arr.dtype, np.asarray(arr)
-
- # don't force numpy coerce with nan's
- inferred = lib.infer_dtype(arr, skipna=False)
- if inferred in ["string", "bytes", "mixed", "mixed-integer"]:
- return (np.dtype(np.object_), arr)
-
- arr = np.asarray(arr)
- return arr.dtype, arr
-
-
-def _maybe_infer_dtype_type(element):
- """
- Try to infer an object's dtype, for use in arithmetic ops.
-
- Uses `element.dtype` if that's available.
- Objects implementing the iterator protocol are cast to a NumPy array,
- and from there the array's type is used.
-
- Parameters
- ----------
- element : object
- Possibly has a `.dtype` attribute, and possibly the iterator
- protocol.
-
- Returns
- -------
- tipo : type
-
- Examples
- --------
- >>> from collections import namedtuple
- >>> Foo = namedtuple("Foo", "dtype")
- >>> _maybe_infer_dtype_type(Foo(np.dtype("i8")))
- dtype('int64')
- """
- tipo = None
- if hasattr(element, "dtype"):
- tipo = element.dtype
- elif is_list_like(element):
- element = np.asarray(element)
- tipo = element.dtype
- return tipo
-
-
-def invalidate_string_dtypes(dtype_set: set[DtypeObj]) -> None:
- """
- Change string like dtypes to object for
- ``DataFrame.select_dtypes()``.
- """
- # error: Argument 1 to has incompatible type "Type[generic]"; expected
- # "Union[dtype[Any], ExtensionDtype, None]"
- # error: Argument 2 to has incompatible type "Type[generic]"; expected
- # "Union[dtype[Any], ExtensionDtype, None]"
- non_string_dtypes = dtype_set - {
- np.dtype("S").type, # type: ignore[arg-type]
- np.dtype(" np.ndarray:
- """coerce the indexer input array to the smallest dtype possible"""
- length = len(categories)
- if length < _int8_max:
- return ensure_int8(indexer)
- elif length < _int16_max:
- return ensure_int16(indexer)
- elif length < _int32_max:
- return ensure_int32(indexer)
- return ensure_int64(indexer)
-
-
-def convert_dtypes(
- input_array: ArrayLike,
- convert_string: bool = True,
- convert_integer: bool = True,
- convert_boolean: bool = True,
- convert_floating: bool = True,
- infer_objects: bool = False,
- dtype_backend: Literal["numpy_nullable", "pyarrow"] = "numpy_nullable",
-) -> DtypeObj:
- """
- Convert objects to best possible type, and optionally,
- to types supporting ``pd.NA``.
-
- Parameters
- ----------
- input_array : ExtensionArray or np.ndarray
- convert_string : bool, default True
- Whether object dtypes should be converted to ``StringDtype()``.
- convert_integer : bool, default True
- Whether, if possible, conversion can be done to integer extension types.
- convert_boolean : bool, defaults True
- Whether object dtypes should be converted to ``BooleanDtypes()``.
- convert_floating : bool, defaults True
- Whether, if possible, conversion can be done to floating extension types.
- If `convert_integer` is also True, preference will be give to integer
- dtypes if the floats can be faithfully casted to integers.
- infer_objects : bool, defaults False
- Whether to also infer objects to float/int if possible. Is only hit if the
- object array contains pd.NA.
- dtype_backend : {'numpy_nullable', 'pyarrow'}, default 'numpy_nullable'
- Back-end data type applied to the resultant :class:`DataFrame`
- (still experimental). Behaviour is as follows:
-
- * ``"numpy_nullable"``: returns nullable-dtype-backed :class:`DataFrame`
- (default).
- * ``"pyarrow"``: returns pyarrow-backed nullable :class:`ArrowDtype`
- DataFrame.
-
- .. versionadded:: 2.0
-
- Returns
- -------
- np.dtype, or ExtensionDtype
- """
- inferred_dtype: str | DtypeObj
-
- if (
- convert_string or convert_integer or convert_boolean or convert_floating
- ) and isinstance(input_array, np.ndarray):
- if input_array.dtype == object:
- inferred_dtype = lib.infer_dtype(input_array)
- else:
- inferred_dtype = input_array.dtype
-
- if is_string_dtype(inferred_dtype):
- if not convert_string or inferred_dtype == "bytes":
- inferred_dtype = input_array.dtype
- else:
- inferred_dtype = pandas_dtype_func("string")
-
- if convert_integer:
- target_int_dtype = pandas_dtype_func("Int64")
-
- if input_array.dtype.kind in "iu":
- from pandas.core.arrays.integer import NUMPY_INT_TO_DTYPE
-
- inferred_dtype = NUMPY_INT_TO_DTYPE.get(
- input_array.dtype, target_int_dtype
- )
- elif input_array.dtype.kind in "fcb":
- # TODO: de-dup with maybe_cast_to_integer_array?
- arr = input_array[notna(input_array)]
- if (arr.astype(int) == arr).all():
- inferred_dtype = target_int_dtype
- else:
- inferred_dtype = input_array.dtype
- elif (
- infer_objects
- and input_array.dtype == object
- and (isinstance(inferred_dtype, str) and inferred_dtype == "integer")
- ):
- inferred_dtype = target_int_dtype
-
- if convert_floating:
- if input_array.dtype.kind in "fcb":
- # i.e. numeric but not integer
- from pandas.core.arrays.floating import NUMPY_FLOAT_TO_DTYPE
-
- inferred_float_dtype: DtypeObj = NUMPY_FLOAT_TO_DTYPE.get(
- input_array.dtype, pandas_dtype_func("Float64")
- )
- # if we could also convert to integer, check if all floats
- # are actually integers
- if convert_integer:
- # TODO: de-dup with maybe_cast_to_integer_array?
- arr = input_array[notna(input_array)]
- if (arr.astype(int) == arr).all():
- inferred_dtype = pandas_dtype_func("Int64")
- else:
- inferred_dtype = inferred_float_dtype
- else:
- inferred_dtype = inferred_float_dtype
- elif (
- infer_objects
- and input_array.dtype == object
- and (
- isinstance(inferred_dtype, str)
- and inferred_dtype == "mixed-integer-float"
- )
- ):
- inferred_dtype = pandas_dtype_func("Float64")
-
- if convert_boolean:
- if input_array.dtype.kind == "b":
- inferred_dtype = pandas_dtype_func("boolean")
- elif isinstance(inferred_dtype, str) and inferred_dtype == "boolean":
- inferred_dtype = pandas_dtype_func("boolean")
-
- if isinstance(inferred_dtype, str):
- # If we couldn't do anything else, then we retain the dtype
- inferred_dtype = input_array.dtype
-
- else:
- inferred_dtype = input_array.dtype
-
- if dtype_backend == "pyarrow":
- from pandas.core.arrays.arrow.array import to_pyarrow_type
- from pandas.core.arrays.string_ import StringDtype
-
- assert not isinstance(inferred_dtype, str)
-
- if (
- (convert_integer and inferred_dtype.kind in "iu")
- or (convert_floating and inferred_dtype.kind in "fc")
- or (convert_boolean and inferred_dtype.kind == "b")
- or (convert_string and isinstance(inferred_dtype, StringDtype))
- or (
- inferred_dtype.kind not in "iufcb"
- and not isinstance(inferred_dtype, StringDtype)
- )
- ):
- if isinstance(inferred_dtype, PandasExtensionDtype) and not isinstance(
- inferred_dtype, DatetimeTZDtype
- ):
- base_dtype = inferred_dtype.base
- elif isinstance(inferred_dtype, (BaseMaskedDtype, ArrowDtype)):
- base_dtype = inferred_dtype.numpy_dtype
- elif isinstance(inferred_dtype, StringDtype):
- base_dtype = np.dtype(str)
- else:
- base_dtype = inferred_dtype
- pa_type = to_pyarrow_type(base_dtype)
- if pa_type is not None:
- inferred_dtype = ArrowDtype(pa_type)
- elif dtype_backend == "numpy_nullable" and isinstance(inferred_dtype, ArrowDtype):
- # GH 53648
- inferred_dtype = _arrow_dtype_mapping()[inferred_dtype.pyarrow_dtype]
-
- # error: Incompatible return value type (got "Union[str, Union[dtype[Any],
- # ExtensionDtype]]", expected "Union[dtype[Any], ExtensionDtype]")
- return inferred_dtype # type: ignore[return-value]
-
-
-def maybe_infer_to_datetimelike(
- value: npt.NDArray[np.object_],
-) -> np.ndarray | DatetimeArray | TimedeltaArray | PeriodArray | IntervalArray:
- """
- we might have a array (or single object) that is datetime like,
- and no dtype is passed don't change the value unless we find a
- datetime/timedelta set
-
- this is pretty strict in that a datetime/timedelta is REQUIRED
- in addition to possible nulls/string likes
-
- Parameters
- ----------
- value : np.ndarray[object]
-
- Returns
- -------
- np.ndarray, DatetimeArray, TimedeltaArray, PeriodArray, or IntervalArray
-
- """
- if not isinstance(value, np.ndarray) or value.dtype != object:
- # Caller is responsible for passing only ndarray[object]
- raise TypeError(type(value)) # pragma: no cover
- if value.ndim != 1:
- # Caller is responsible
- raise ValueError(value.ndim) # pragma: no cover
-
- if not len(value):
- return value
-
- # error: Incompatible return value type (got "Union[ExtensionArray,
- # ndarray[Any, Any]]", expected "Union[ndarray[Any, Any], DatetimeArray,
- # TimedeltaArray, PeriodArray, IntervalArray]")
- return lib.maybe_convert_objects( # type: ignore[return-value]
- value,
- # Here we do not convert numeric dtypes, as if we wanted that,
- # numpy would have done it for us.
- convert_numeric=False,
- convert_non_numeric=True,
- dtype_if_all_nat=np.dtype("M8[ns]"),
- )
-
-
-def maybe_cast_to_datetime(
- value: np.ndarray | list, dtype: np.dtype
-) -> ExtensionArray | np.ndarray:
- """
- try to cast the array/value to a datetimelike dtype, converting float
- nan to iNaT
-
- Caller is responsible for handling ExtensionDtype cases and non dt64/td64
- cases.
- """
- from pandas.core.arrays.datetimes import DatetimeArray
- from pandas.core.arrays.timedeltas import TimedeltaArray
-
- assert dtype.kind in "mM"
- if not is_list_like(value):
- raise TypeError("value must be listlike")
-
- # TODO: _from_sequence would raise ValueError in cases where
- # _ensure_nanosecond_dtype raises TypeError
- _ensure_nanosecond_dtype(dtype)
-
- if lib.is_np_dtype(dtype, "m"):
- res = TimedeltaArray._from_sequence(value, dtype=dtype)
- return res
- else:
- try:
- dta = DatetimeArray._from_sequence(value, dtype=dtype)
- except ValueError as err:
- # We can give a Series-specific exception message.
- if "cannot supply both a tz and a timezone-naive dtype" in str(err):
- raise ValueError(
- "Cannot convert timezone-aware data to "
- "timezone-naive dtype. Use "
- "pd.Series(values).dt.tz_localize(None) instead."
- ) from err
- raise
-
- return dta
-
-
-def _ensure_nanosecond_dtype(dtype: DtypeObj) -> None:
- """
- Convert dtypes with granularity less than nanosecond to nanosecond
-
- >>> _ensure_nanosecond_dtype(np.dtype("M8[us]"))
-
- >>> _ensure_nanosecond_dtype(np.dtype("M8[D]"))
- Traceback (most recent call last):
- ...
- TypeError: dtype=datetime64[D] is not supported. Supported resolutions are 's', 'ms', 'us', and 'ns'
-
- >>> _ensure_nanosecond_dtype(np.dtype("m8[ps]"))
- Traceback (most recent call last):
- ...
- TypeError: dtype=timedelta64[ps] is not supported. Supported resolutions are 's', 'ms', 'us', and 'ns'
- """ # noqa: E501
- msg = (
- f"The '{dtype.name}' dtype has no unit. "
- f"Please pass in '{dtype.name}[ns]' instead."
- )
-
- # unpack e.g. SparseDtype
- dtype = getattr(dtype, "subtype", dtype)
-
- if not isinstance(dtype, np.dtype):
- # i.e. datetime64tz
- pass
-
- elif dtype.kind in "mM":
- reso = get_unit_from_dtype(dtype)
- if not is_supported_unit(reso):
- # pre-2.0 we would silently swap in nanos for lower-resolutions,
- # raise for above-nano resolutions
- if dtype.name in ["datetime64", "timedelta64"]:
- raise ValueError(msg)
- # TODO: ValueError or TypeError? existing test
- # test_constructor_generic_timestamp_bad_frequency expects TypeError
- raise TypeError(
- f"dtype={dtype} is not supported. Supported resolutions are 's', "
- "'ms', 'us', and 'ns'"
- )
-
-
-# TODO: other value-dependent functions to standardize here include
-# Index._find_common_type_compat
-def find_result_type(left_dtype: DtypeObj, right: Any) -> DtypeObj:
- """
- Find the type/dtype for the result of an operation between objects.
-
- This is similar to find_common_type, but looks at the right object instead
- of just its dtype. This can be useful in particular when the right
- object does not have a `dtype`.
-
- Parameters
- ----------
- left_dtype : np.dtype or ExtensionDtype
- right : Any
-
- Returns
- -------
- np.dtype or ExtensionDtype
-
- See also
- --------
- find_common_type
- numpy.result_type
- """
- new_dtype: DtypeObj
-
- if (
- isinstance(left_dtype, np.dtype)
- and left_dtype.kind in "iuc"
- and (lib.is_integer(right) or lib.is_float(right))
- ):
- # e.g. with int8 dtype and right=512, we want to end up with
- # np.int16, whereas infer_dtype_from(512) gives np.int64,
- # which will make us upcast too far.
- if lib.is_float(right) and right.is_integer() and left_dtype.kind != "f":
- right = int(right)
- new_dtype = np.result_type(left_dtype, right)
-
- elif is_valid_na_for_dtype(right, left_dtype):
- # e.g. IntervalDtype[int] and None/np.nan
- new_dtype = ensure_dtype_can_hold_na(left_dtype)
-
- else:
- dtype, _ = infer_dtype_from(right)
- new_dtype = find_common_type([left_dtype, dtype])
-
- return new_dtype
-
-
-def common_dtype_categorical_compat(
- objs: Sequence[Index | ArrayLike], dtype: DtypeObj
-) -> DtypeObj:
- """
- Update the result of find_common_type to account for NAs in a Categorical.
-
- Parameters
- ----------
- objs : list[np.ndarray | ExtensionArray | Index]
- dtype : np.dtype or ExtensionDtype
-
- Returns
- -------
- np.dtype or ExtensionDtype
- """
- # GH#38240
-
- # TODO: more generally, could do `not can_hold_na(dtype)`
- if lib.is_np_dtype(dtype, "iu"):
- for obj in objs:
- # We don't want to accientally allow e.g. "categorical" str here
- obj_dtype = getattr(obj, "dtype", None)
- if isinstance(obj_dtype, CategoricalDtype):
- if isinstance(obj, ABCIndex):
- # This check may already be cached
- hasnas = obj.hasnans
- else:
- # Categorical
- hasnas = cast("Categorical", obj)._hasna
-
- if hasnas:
- # see test_union_int_categorical_with_nan
- dtype = np.dtype(np.float64)
- break
- return dtype
-
-
-def np_find_common_type(*dtypes: np.dtype) -> np.dtype:
- """
- np.find_common_type implementation pre-1.25 deprecation using np.result_type
- https://github.com/pandas-dev/pandas/pull/49569#issuecomment-1308300065
-
- Parameters
- ----------
- dtypes : np.dtypes
-
- Returns
- -------
- np.dtype
- """
- try:
- common_dtype = np.result_type(*dtypes)
- if common_dtype.kind in "mMSU":
- # NumPy promotion currently (1.25) misbehaves for for times and strings,
- # so fall back to object (find_common_dtype did unless there
- # was only one dtype)
- common_dtype = np.dtype("O")
-
- except TypeError:
- common_dtype = np.dtype("O")
- return common_dtype
-
-
-@overload
-def find_common_type(types: list[np.dtype]) -> np.dtype:
- ...
-
-
-@overload
-def find_common_type(types: list[ExtensionDtype]) -> DtypeObj:
- ...
-
-
-@overload
-def find_common_type(types: list[DtypeObj]) -> DtypeObj:
- ...
-
-
-def find_common_type(types):
- """
- Find a common data type among the given dtypes.
-
- Parameters
- ----------
- types : list of dtypes
-
- Returns
- -------
- pandas extension or numpy dtype
-
- See Also
- --------
- numpy.find_common_type
-
- """
- if not types:
- raise ValueError("no types given")
-
- first = types[0]
-
- # workaround for find_common_type([np.dtype('datetime64[ns]')] * 2)
- # => object
- if lib.dtypes_all_equal(list(types)):
- return first
-
- # get unique types (dict.fromkeys is used as order-preserving set())
- types = list(dict.fromkeys(types).keys())
-
- if any(isinstance(t, ExtensionDtype) for t in types):
- for t in types:
- if isinstance(t, ExtensionDtype):
- res = t._get_common_dtype(types)
- if res is not None:
- return res
- return np.dtype("object")
-
- # take lowest unit
- if all(lib.is_np_dtype(t, "M") for t in types):
- return np.dtype(max(types))
- if all(lib.is_np_dtype(t, "m") for t in types):
- return np.dtype(max(types))
-
- # don't mix bool / int or float or complex
- # this is different from numpy, which casts bool with float/int as int
- has_bools = any(t.kind == "b" for t in types)
- if has_bools:
- for t in types:
- if t.kind in "iufc":
- return np.dtype("object")
-
- return np_find_common_type(*types)
-
-
-def construct_2d_arraylike_from_scalar(
- value: Scalar, length: int, width: int, dtype: np.dtype, copy: bool
-) -> np.ndarray:
- shape = (length, width)
-
- if dtype.kind in "mM":
- value = _maybe_box_and_unbox_datetimelike(value, dtype)
- elif dtype == _dtype_obj:
- if isinstance(value, (np.timedelta64, np.datetime64)):
- # calling np.array below would cast to pytimedelta/pydatetime
- out = np.empty(shape, dtype=object)
- out.fill(value)
- return out
-
- # Attempt to coerce to a numpy array
- try:
- arr = np.array(value, dtype=dtype, copy=copy)
- except (ValueError, TypeError) as err:
- raise TypeError(
- f"DataFrame constructor called with incompatible data and dtype: {err}"
- ) from err
-
- if arr.ndim != 0:
- raise ValueError("DataFrame constructor not properly called!")
-
- return np.full(shape, arr)
-
-
-def construct_1d_arraylike_from_scalar(
- value: Scalar, length: int, dtype: DtypeObj | None
-) -> ArrayLike:
- """
- create a np.ndarray / pandas type of specified shape and dtype
- filled with values
-
- Parameters
- ----------
- value : scalar value
- length : int
- dtype : pandas_dtype or np.dtype
-
- Returns
- -------
- np.ndarray / pandas type of length, filled with value
-
- """
-
- if dtype is None:
- try:
- dtype, value = infer_dtype_from_scalar(value)
- except OutOfBoundsDatetime:
- dtype = _dtype_obj
-
- if isinstance(dtype, ExtensionDtype):
- cls = dtype.construct_array_type()
- seq = [] if length == 0 else [value]
- subarr = cls._from_sequence(seq, dtype=dtype).repeat(length)
-
- else:
- if length and dtype.kind in "iu" and isna(value):
- # coerce if we have nan for an integer dtype
- dtype = np.dtype("float64")
- elif lib.is_np_dtype(dtype, "US"):
- # we need to coerce to object dtype to avoid
- # to allow numpy to take our string as a scalar value
- dtype = np.dtype("object")
- if not isna(value):
- value = ensure_str(value)
- elif dtype.kind in "mM":
- value = _maybe_box_and_unbox_datetimelike(value, dtype)
-
- subarr = np.empty(length, dtype=dtype)
- if length:
- # GH 47391: numpy > 1.24 will raise filling np.nan into int dtypes
- subarr.fill(value)
-
- return subarr
-
-
-def _maybe_box_and_unbox_datetimelike(value: Scalar, dtype: DtypeObj):
- # Caller is responsible for checking dtype.kind in "mM"
-
- if isinstance(value, dt.datetime):
- # we dont want to box dt64, in particular datetime64("NaT")
- value = maybe_box_datetimelike(value, dtype)
-
- return _maybe_unbox_datetimelike(value, dtype)
-
-
-def construct_1d_object_array_from_listlike(values: Sized) -> np.ndarray:
- """
- Transform any list-like object in a 1-dimensional numpy array of object
- dtype.
-
- Parameters
- ----------
- values : any iterable which has a len()
-
- Raises
- ------
- TypeError
- * If `values` does not have a len()
-
- Returns
- -------
- 1-dimensional numpy array of dtype object
- """
- # numpy will try to interpret nested lists as further dimensions, hence
- # making a 1D array that contains list-likes is a bit tricky:
- result = np.empty(len(values), dtype="object")
- result[:] = values
- return result
-
-
-def maybe_cast_to_integer_array(arr: list | np.ndarray, dtype: np.dtype) -> np.ndarray:
- """
- Takes any dtype and returns the casted version, raising for when data is
- incompatible with integer/unsigned integer dtypes.
-
- Parameters
- ----------
- arr : np.ndarray or list
- The array to cast.
- dtype : np.dtype
- The integer dtype to cast the array to.
-
- Returns
- -------
- ndarray
- Array of integer or unsigned integer dtype.
-
- Raises
- ------
- OverflowError : the dtype is incompatible with the data
- ValueError : loss of precision has occurred during casting
-
- Examples
- --------
- If you try to coerce negative values to unsigned integers, it raises:
-
- >>> pd.Series([-1], dtype="uint64")
- Traceback (most recent call last):
- ...
- OverflowError: Trying to coerce negative values to unsigned integers
-
- Also, if you try to coerce float values to integers, it raises:
-
- >>> maybe_cast_to_integer_array([1, 2, 3.5], dtype=np.dtype("int64"))
- Traceback (most recent call last):
- ...
- ValueError: Trying to coerce float values to integers
- """
- assert dtype.kind in "iu"
-
- try:
- if not isinstance(arr, np.ndarray):
- with warnings.catch_warnings():
- # We already disallow dtype=uint w/ negative numbers
- # (test_constructor_coercion_signed_to_unsigned) so safe to ignore.
- warnings.filterwarnings(
- "ignore",
- "NumPy will stop allowing conversion of out-of-bound Python int",
- DeprecationWarning,
- )
- casted = np.array(arr, dtype=dtype, copy=False)
- else:
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore", category=RuntimeWarning)
- casted = arr.astype(dtype, copy=False)
- except OverflowError as err:
- raise OverflowError(
- "The elements provided in the data cannot all be "
- f"casted to the dtype {dtype}"
- ) from err
-
- if isinstance(arr, np.ndarray) and arr.dtype == dtype:
- # avoid expensive array_equal check
- return casted
-
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore", category=RuntimeWarning)
- warnings.filterwarnings(
- "ignore", "elementwise comparison failed", FutureWarning
- )
- if np.array_equal(arr, casted):
- return casted
-
- # We do this casting to allow for proper
- # data and dtype checking.
- #
- # We didn't do this earlier because NumPy
- # doesn't handle `uint64` correctly.
- arr = np.asarray(arr)
-
- if np.issubdtype(arr.dtype, str):
- if (casted.astype(str) == arr).all():
- return casted
- raise ValueError(f"string values cannot be losslessly cast to {dtype}")
-
- if dtype.kind == "u" and (arr < 0).any():
- raise OverflowError("Trying to coerce negative values to unsigned integers")
-
- if arr.dtype.kind == "f":
- if not np.isfinite(arr).all():
- raise IntCastingNaNError(
- "Cannot convert non-finite values (NA or inf) to integer"
- )
- raise ValueError("Trying to coerce float values to integers")
- if arr.dtype == object:
- raise ValueError("Trying to coerce float values to integers")
-
- if casted.dtype < arr.dtype:
- # GH#41734 e.g. [1, 200, 923442] and dtype="int8" -> overflows
- raise ValueError(
- f"Values are too large to be losslessly converted to {dtype}. "
- f"To cast anyway, use pd.Series(values).astype({dtype})"
- )
-
- if arr.dtype.kind in "mM":
- # test_constructor_maskedarray_nonfloat
- raise TypeError(
- f"Constructing a Series or DataFrame from {arr.dtype} values and "
- f"dtype={dtype} is not supported. Use values.view({dtype}) instead."
- )
-
- # No known cases that get here, but raising explicitly to cover our bases.
- raise ValueError(f"values cannot be losslessly cast to {dtype}")
-
-
-def can_hold_element(arr: ArrayLike, element: Any) -> bool:
- """
- Can we do an inplace setitem with this element in an array with this dtype?
-
- Parameters
- ----------
- arr : np.ndarray or ExtensionArray
- element : Any
-
- Returns
- -------
- bool
- """
- dtype = arr.dtype
- if not isinstance(dtype, np.dtype) or dtype.kind in "mM":
- if isinstance(dtype, (PeriodDtype, IntervalDtype, DatetimeTZDtype, np.dtype)):
- # np.dtype here catches datetime64ns and timedelta64ns; we assume
- # in this case that we have DatetimeArray/TimedeltaArray
- arr = cast(
- "PeriodArray | DatetimeArray | TimedeltaArray | IntervalArray", arr
- )
- try:
- arr._validate_setitem_value(element)
- return True
- except (ValueError, TypeError):
- # TODO: re-use _catch_deprecated_value_error to ensure we are
- # strict about what exceptions we allow through here.
- return False
-
- # This is technically incorrect, but maintains the behavior of
- # ExtensionBlock._can_hold_element
- return True
-
- try:
- np_can_hold_element(dtype, element)
- return True
- except (TypeError, LossySetitemError):
- return False
-
-
-def np_can_hold_element(dtype: np.dtype, element: Any) -> Any:
- """
- Raise if we cannot losslessly set this element into an ndarray with this dtype.
-
- Specifically about places where we disagree with numpy. i.e. there are
- cases where numpy will raise in doing the setitem that we do not check
- for here, e.g. setting str "X" into a numeric ndarray.
-
- Returns
- -------
- Any
- The element, potentially cast to the dtype.
-
- Raises
- ------
- ValueError : If we cannot losslessly store this element with this dtype.
- """
- if dtype == _dtype_obj:
- return element
-
- tipo = _maybe_infer_dtype_type(element)
-
- if dtype.kind in "iu":
- if isinstance(element, range):
- if _dtype_can_hold_range(element, dtype):
- return element
- raise LossySetitemError
-
- if is_integer(element) or (is_float(element) and element.is_integer()):
- # e.g. test_setitem_series_int8 if we have a python int 1
- # tipo may be np.int32, despite the fact that it will fit
- # in smaller int dtypes.
- info = np.iinfo(dtype)
- if info.min <= element <= info.max:
- return dtype.type(element)
- raise LossySetitemError
-
- if tipo is not None:
- if tipo.kind not in "iu":
- if isinstance(element, np.ndarray) and element.dtype.kind == "f":
- # If all can be losslessly cast to integers, then we can hold them
- with np.errstate(invalid="ignore"):
- # We check afterwards if cast was losslessly, so no need to show
- # the warning
- casted = element.astype(dtype)
- comp = casted == element
- if comp.all():
- # Return the casted values bc they can be passed to
- # np.putmask, whereas the raw values cannot.
- # see TestSetitemFloatNDarrayIntoIntegerSeries
- return casted
- raise LossySetitemError
-
- # Anything other than integer we cannot hold
- raise LossySetitemError
- if (
- dtype.kind == "u"
- and isinstance(element, np.ndarray)
- and element.dtype.kind == "i"
- ):
- # see test_where_uint64
- casted = element.astype(dtype)
- if (casted == element).all():
- # TODO: faster to check (element >=0).all()? potential
- # itemsize issues there?
- return casted
- raise LossySetitemError
- if dtype.itemsize < tipo.itemsize:
- raise LossySetitemError
- if not isinstance(tipo, np.dtype):
- # i.e. nullable IntegerDtype; we can put this into an ndarray
- # losslessly iff it has no NAs
- if element._hasna:
- raise LossySetitemError
- return element
-
- return element
-
- raise LossySetitemError
-
- if dtype.kind == "f":
- if lib.is_integer(element) or lib.is_float(element):
- casted = dtype.type(element)
- if np.isnan(casted) or casted == element:
- return casted
- # otherwise e.g. overflow see TestCoercionFloat32
- raise LossySetitemError
-
- if tipo is not None:
- # TODO: itemsize check?
- if tipo.kind not in "iuf":
- # Anything other than float/integer we cannot hold
- raise LossySetitemError
- if not isinstance(tipo, np.dtype):
- # i.e. nullable IntegerDtype or FloatingDtype;
- # we can put this into an ndarray losslessly iff it has no NAs
- if element._hasna:
- raise LossySetitemError
- return element
- elif tipo.itemsize > dtype.itemsize or tipo.kind != dtype.kind:
- if isinstance(element, np.ndarray):
- # e.g. TestDataFrameIndexingWhere::test_where_alignment
- casted = element.astype(dtype)
- if np.array_equal(casted, element, equal_nan=True):
- return casted
- raise LossySetitemError
-
- return element
-
- raise LossySetitemError
-
- if dtype.kind == "c":
- if lib.is_integer(element) or lib.is_complex(element) or lib.is_float(element):
- if np.isnan(element):
- # see test_where_complex GH#6345
- return dtype.type(element)
-
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore")
- casted = dtype.type(element)
- if casted == element:
- return casted
- # otherwise e.g. overflow see test_32878_complex_itemsize
- raise LossySetitemError
-
- if tipo is not None:
- if tipo.kind in "iufc":
- return element
- raise LossySetitemError
- raise LossySetitemError
-
- if dtype.kind == "b":
- if tipo is not None:
- if tipo.kind == "b":
- if not isinstance(tipo, np.dtype):
- # i.e. we have a BooleanArray
- if element._hasna:
- # i.e. there are pd.NA elements
- raise LossySetitemError
- return element
- raise LossySetitemError
- if lib.is_bool(element):
- return element
- raise LossySetitemError
-
- if dtype.kind == "S":
- # TODO: test tests.frame.methods.test_replace tests get here,
- # need more targeted tests. xref phofl has a PR about this
- if tipo is not None:
- if tipo.kind == "S" and tipo.itemsize <= dtype.itemsize:
- return element
- raise LossySetitemError
- if isinstance(element, bytes) and len(element) <= dtype.itemsize:
- return element
- raise LossySetitemError
-
- if dtype.kind == "V":
- # i.e. np.void, which cannot hold _anything_
- raise LossySetitemError
-
- raise NotImplementedError(dtype)
-
-
-def _dtype_can_hold_range(rng: range, dtype: np.dtype) -> bool:
- """
- _maybe_infer_dtype_type infers to int64 (and float64 for very large endpoints),
- but in many cases a range can be held by a smaller integer dtype.
- Check if this is one of those cases.
- """
- if not len(rng):
- return True
- return np.can_cast(rng[0], dtype) and np.can_cast(rng[-1], dtype)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/extension/base/groupby.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/extension/base/groupby.py
deleted file mode 100644
index 6f72a6c2b04ae4e4d2694901b4681a7e8d8876c4..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/extension/base/groupby.py
+++ /dev/null
@@ -1,162 +0,0 @@
-import re
-
-import pytest
-
-from pandas.core.dtypes.common import (
- is_bool_dtype,
- is_numeric_dtype,
- is_object_dtype,
- is_string_dtype,
-)
-
-import pandas as pd
-import pandas._testing as tm
-
-
-class BaseGroupbyTests:
- """Groupby-specific tests."""
-
- def test_grouping_grouper(self, data_for_grouping):
- df = pd.DataFrame(
- {"A": ["B", "B", None, None, "A", "A", "B", "C"], "B": data_for_grouping}
- )
- gr1 = df.groupby("A").grouper.groupings[0]
- gr2 = df.groupby("B").grouper.groupings[0]
-
- tm.assert_numpy_array_equal(gr1.grouping_vector, df.A.values)
- tm.assert_extension_array_equal(gr2.grouping_vector, data_for_grouping)
-
- @pytest.mark.parametrize("as_index", [True, False])
- def test_groupby_extension_agg(self, as_index, data_for_grouping):
- df = pd.DataFrame({"A": [1, 1, 2, 2, 3, 3, 1, 4], "B": data_for_grouping})
-
- is_bool = data_for_grouping.dtype._is_boolean
- if is_bool:
- # only 2 unique values, and the final entry has c==b
- # (see data_for_grouping docstring)
- df = df.iloc[:-1]
-
- result = df.groupby("B", as_index=as_index).A.mean()
- _, uniques = pd.factorize(data_for_grouping, sort=True)
-
- exp_vals = [3.0, 1.0, 4.0]
- if is_bool:
- exp_vals = exp_vals[:-1]
- if as_index:
- index = pd.Index(uniques, name="B")
- expected = pd.Series(exp_vals, index=index, name="A")
- tm.assert_series_equal(result, expected)
- else:
- expected = pd.DataFrame({"B": uniques, "A": exp_vals})
- tm.assert_frame_equal(result, expected)
-
- def test_groupby_agg_extension(self, data_for_grouping):
- # GH#38980 groupby agg on extension type fails for non-numeric types
- df = pd.DataFrame({"A": [1, 1, 2, 2, 3, 3, 1, 4], "B": data_for_grouping})
-
- expected = df.iloc[[0, 2, 4, 7]]
- expected = expected.set_index("A")
-
- result = df.groupby("A").agg({"B": "first"})
- tm.assert_frame_equal(result, expected)
-
- result = df.groupby("A").agg("first")
- tm.assert_frame_equal(result, expected)
-
- result = df.groupby("A").first()
- tm.assert_frame_equal(result, expected)
-
- def test_groupby_extension_no_sort(self, data_for_grouping):
- df = pd.DataFrame({"A": [1, 1, 2, 2, 3, 3, 1, 4], "B": data_for_grouping})
-
- is_bool = data_for_grouping.dtype._is_boolean
- if is_bool:
- # only 2 unique values, and the final entry has c==b
- # (see data_for_grouping docstring)
- df = df.iloc[:-1]
-
- result = df.groupby("B", sort=False).A.mean()
- _, index = pd.factorize(data_for_grouping, sort=False)
-
- index = pd.Index(index, name="B")
- exp_vals = [1.0, 3.0, 4.0]
- if is_bool:
- exp_vals = exp_vals[:-1]
- expected = pd.Series(exp_vals, index=index, name="A")
- tm.assert_series_equal(result, expected)
-
- def test_groupby_extension_transform(self, data_for_grouping):
- is_bool = data_for_grouping.dtype._is_boolean
-
- valid = data_for_grouping[~data_for_grouping.isna()]
- df = pd.DataFrame({"A": [1, 1, 3, 3, 1, 4], "B": valid})
- is_bool = data_for_grouping.dtype._is_boolean
- if is_bool:
- # only 2 unique values, and the final entry has c==b
- # (see data_for_grouping docstring)
- df = df.iloc[:-1]
-
- result = df.groupby("B").A.transform(len)
- expected = pd.Series([3, 3, 2, 2, 3, 1], name="A")
- if is_bool:
- expected = expected[:-1]
-
- tm.assert_series_equal(result, expected)
-
- def test_groupby_extension_apply(self, data_for_grouping, groupby_apply_op):
- df = pd.DataFrame({"A": [1, 1, 2, 2, 3, 3, 1, 4], "B": data_for_grouping})
- df.groupby("B", group_keys=False).apply(groupby_apply_op)
- df.groupby("B", group_keys=False).A.apply(groupby_apply_op)
- df.groupby("A", group_keys=False).apply(groupby_apply_op)
- df.groupby("A", group_keys=False).B.apply(groupby_apply_op)
-
- def test_groupby_apply_identity(self, data_for_grouping):
- df = pd.DataFrame({"A": [1, 1, 2, 2, 3, 3, 1, 4], "B": data_for_grouping})
- result = df.groupby("A").B.apply(lambda x: x.array)
- expected = pd.Series(
- [
- df.B.iloc[[0, 1, 6]].array,
- df.B.iloc[[2, 3]].array,
- df.B.iloc[[4, 5]].array,
- df.B.iloc[[7]].array,
- ],
- index=pd.Index([1, 2, 3, 4], name="A"),
- name="B",
- )
- tm.assert_series_equal(result, expected)
-
- def test_in_numeric_groupby(self, data_for_grouping):
- df = pd.DataFrame(
- {
- "A": [1, 1, 2, 2, 3, 3, 1, 4],
- "B": data_for_grouping,
- "C": [1, 1, 1, 1, 1, 1, 1, 1],
- }
- )
-
- dtype = data_for_grouping.dtype
- if (
- is_numeric_dtype(dtype)
- or is_bool_dtype(dtype)
- or dtype.name == "decimal"
- or is_string_dtype(dtype)
- or is_object_dtype(dtype)
- or dtype.kind == "m" # in particular duration[*][pyarrow]
- ):
- expected = pd.Index(["B", "C"])
- result = df.groupby("A").sum().columns
- else:
- expected = pd.Index(["C"])
-
- msg = "|".join(
- [
- # period/datetime
- "does not support sum operations",
- # all others
- re.escape(f"agg function failed [how->sum,dtype->{dtype}"),
- ]
- )
- with pytest.raises(TypeError, match=msg):
- df.groupby("A").sum()
- result = df.groupby("A").sum(numeric_only=True).columns
- tm.assert_index_equal(result, expected)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/frame/methods/test_value_counts.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/frame/methods/test_value_counts.py
deleted file mode 100644
index c05a92936047829255e117d65e2b94b809ef874e..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/frame/methods/test_value_counts.py
+++ /dev/null
@@ -1,191 +0,0 @@
-import numpy as np
-import pytest
-
-import pandas as pd
-import pandas._testing as tm
-
-
-def test_data_frame_value_counts_unsorted():
- df = pd.DataFrame(
- {"num_legs": [2, 4, 4, 6], "num_wings": [2, 0, 0, 0]},
- index=["falcon", "dog", "cat", "ant"],
- )
-
- result = df.value_counts(sort=False)
- expected = pd.Series(
- data=[1, 2, 1],
- index=pd.MultiIndex.from_arrays(
- [(2, 4, 6), (2, 0, 0)], names=["num_legs", "num_wings"]
- ),
- name="count",
- )
-
- tm.assert_series_equal(result, expected)
-
-
-def test_data_frame_value_counts_ascending():
- df = pd.DataFrame(
- {"num_legs": [2, 4, 4, 6], "num_wings": [2, 0, 0, 0]},
- index=["falcon", "dog", "cat", "ant"],
- )
-
- result = df.value_counts(ascending=True)
- expected = pd.Series(
- data=[1, 1, 2],
- index=pd.MultiIndex.from_arrays(
- [(2, 6, 4), (2, 0, 0)], names=["num_legs", "num_wings"]
- ),
- name="count",
- )
-
- tm.assert_series_equal(result, expected)
-
-
-def test_data_frame_value_counts_default():
- df = pd.DataFrame(
- {"num_legs": [2, 4, 4, 6], "num_wings": [2, 0, 0, 0]},
- index=["falcon", "dog", "cat", "ant"],
- )
-
- result = df.value_counts()
- expected = pd.Series(
- data=[2, 1, 1],
- index=pd.MultiIndex.from_arrays(
- [(4, 2, 6), (0, 2, 0)], names=["num_legs", "num_wings"]
- ),
- name="count",
- )
-
- tm.assert_series_equal(result, expected)
-
-
-def test_data_frame_value_counts_normalize():
- df = pd.DataFrame(
- {"num_legs": [2, 4, 4, 6], "num_wings": [2, 0, 0, 0]},
- index=["falcon", "dog", "cat", "ant"],
- )
-
- result = df.value_counts(normalize=True)
- expected = pd.Series(
- data=[0.5, 0.25, 0.25],
- index=pd.MultiIndex.from_arrays(
- [(4, 2, 6), (0, 2, 0)], names=["num_legs", "num_wings"]
- ),
- name="proportion",
- )
-
- tm.assert_series_equal(result, expected)
-
-
-def test_data_frame_value_counts_single_col_default():
- df = pd.DataFrame({"num_legs": [2, 4, 4, 6]})
-
- result = df.value_counts()
- expected = pd.Series(
- data=[2, 1, 1],
- index=pd.MultiIndex.from_arrays([[4, 2, 6]], names=["num_legs"]),
- name="count",
- )
-
- tm.assert_series_equal(result, expected)
-
-
-def test_data_frame_value_counts_empty():
- df_no_cols = pd.DataFrame()
-
- result = df_no_cols.value_counts()
- expected = pd.Series(
- [], dtype=np.int64, name="count", index=np.array([], dtype=np.intp)
- )
-
- tm.assert_series_equal(result, expected)
-
-
-def test_data_frame_value_counts_empty_normalize():
- df_no_cols = pd.DataFrame()
-
- result = df_no_cols.value_counts(normalize=True)
- expected = pd.Series(
- [], dtype=np.float64, name="proportion", index=np.array([], dtype=np.intp)
- )
-
- tm.assert_series_equal(result, expected)
-
-
-def test_data_frame_value_counts_dropna_true(nulls_fixture):
- # GH 41334
- df = pd.DataFrame(
- {
- "first_name": ["John", "Anne", "John", "Beth"],
- "middle_name": ["Smith", nulls_fixture, nulls_fixture, "Louise"],
- },
- )
- result = df.value_counts()
- expected = pd.Series(
- data=[1, 1],
- index=pd.MultiIndex.from_arrays(
- [("Beth", "John"), ("Louise", "Smith")], names=["first_name", "middle_name"]
- ),
- name="count",
- )
-
- tm.assert_series_equal(result, expected)
-
-
-def test_data_frame_value_counts_dropna_false(nulls_fixture):
- # GH 41334
- df = pd.DataFrame(
- {
- "first_name": ["John", "Anne", "John", "Beth"],
- "middle_name": ["Smith", nulls_fixture, nulls_fixture, "Louise"],
- },
- )
-
- result = df.value_counts(dropna=False)
- expected = pd.Series(
- data=[1, 1, 1, 1],
- index=pd.MultiIndex(
- levels=[
- pd.Index(["Anne", "Beth", "John"]),
- pd.Index(["Louise", "Smith", nulls_fixture]),
- ],
- codes=[[0, 1, 2, 2], [2, 0, 1, 2]],
- names=["first_name", "middle_name"],
- ),
- name="count",
- )
-
- tm.assert_series_equal(result, expected)
-
-
-@pytest.mark.parametrize("columns", (["first_name", "middle_name"], [0, 1]))
-def test_data_frame_value_counts_subset(nulls_fixture, columns):
- # GH 50829
- df = pd.DataFrame(
- {
- columns[0]: ["John", "Anne", "John", "Beth"],
- columns[1]: ["Smith", nulls_fixture, nulls_fixture, "Louise"],
- },
- )
- result = df.value_counts(columns[0])
- expected = pd.Series(
- data=[2, 1, 1],
- index=pd.Index(["John", "Anne", "Beth"], name=columns[0]),
- name="count",
- )
-
- tm.assert_series_equal(result, expected)
-
-
-def test_value_counts_categorical_future_warning():
- # GH#54775
- df = pd.DataFrame({"a": [1, 2, 3]}, dtype="category")
- result = df.value_counts()
- expected = pd.Series(
- 1,
- index=pd.MultiIndex.from_arrays(
- [pd.Index([1, 2, 3], name="a", dtype="category")]
- ),
- name="count",
- )
- tm.assert_series_equal(result, expected)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/indexes/timedeltas/methods/__init__.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/indexes/timedeltas/methods/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/series/test_unary.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/series/test_unary.py
deleted file mode 100644
index ad0e344fa4420dadeb33976db85a1e108427c65f..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/series/test_unary.py
+++ /dev/null
@@ -1,52 +0,0 @@
-import pytest
-
-from pandas import Series
-import pandas._testing as tm
-
-
-class TestSeriesUnaryOps:
- # __neg__, __pos__, __invert__
-
- def test_neg(self):
- ser = tm.makeStringSeries()
- ser.name = "series"
- tm.assert_series_equal(-ser, -1 * ser)
-
- def test_invert(self):
- ser = tm.makeStringSeries()
- ser.name = "series"
- tm.assert_series_equal(-(ser < 0), ~(ser < 0))
-
- @pytest.mark.parametrize(
- "source, neg_target, abs_target",
- [
- ([1, 2, 3], [-1, -2, -3], [1, 2, 3]),
- ([1, 2, None], [-1, -2, None], [1, 2, None]),
- ],
- )
- def test_all_numeric_unary_operators(
- self, any_numeric_ea_dtype, source, neg_target, abs_target
- ):
- # GH38794
- dtype = any_numeric_ea_dtype
- ser = Series(source, dtype=dtype)
- neg_result, pos_result, abs_result = -ser, +ser, abs(ser)
- if dtype.startswith("U"):
- neg_target = -Series(source, dtype=dtype)
- else:
- neg_target = Series(neg_target, dtype=dtype)
-
- abs_target = Series(abs_target, dtype=dtype)
-
- tm.assert_series_equal(neg_result, neg_target)
- tm.assert_series_equal(pos_result, ser)
- tm.assert_series_equal(abs_result, abs_target)
-
- @pytest.mark.parametrize("op", ["__neg__", "__abs__"])
- def test_unary_float_op_mask(self, float_ea_dtype, op):
- dtype = float_ea_dtype
- ser = Series([1.1, 2.2, 3.3], dtype=dtype)
- result = getattr(ser, op)()
- target = result.copy(deep=True)
- ser[0] = None
- tm.assert_series_equal(result, target)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_internal/cli/parser.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_internal/cli/parser.py
deleted file mode 100644
index a1c99a8cb301f222feb1845be4e80d9b1f9d2622..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_internal/cli/parser.py
+++ /dev/null
@@ -1,292 +0,0 @@
-"""Base option parser setup"""
-
-import logging
-import optparse
-import shutil
-import sys
-import textwrap
-from contextlib import suppress
-from typing import Any, Dict, Iterator, List, Tuple
-
-from pip._internal.cli.status_codes import UNKNOWN_ERROR
-from pip._internal.configuration import Configuration, ConfigurationError
-from pip._internal.utils.misc import redact_auth_from_url, strtobool
-
-logger = logging.getLogger(__name__)
-
-
-class PrettyHelpFormatter(optparse.IndentedHelpFormatter):
- """A prettier/less verbose help formatter for optparse."""
-
- def __init__(self, *args: Any, **kwargs: Any) -> None:
- # help position must be aligned with __init__.parseopts.description
- kwargs["max_help_position"] = 30
- kwargs["indent_increment"] = 1
- kwargs["width"] = shutil.get_terminal_size()[0] - 2
- super().__init__(*args, **kwargs)
-
- def format_option_strings(self, option: optparse.Option) -> str:
- return self._format_option_strings(option)
-
- def _format_option_strings(
- self, option: optparse.Option, mvarfmt: str = " <{}>", optsep: str = ", "
- ) -> str:
- """
- Return a comma-separated list of option strings and metavars.
-
- :param option: tuple of (short opt, long opt), e.g: ('-f', '--format')
- :param mvarfmt: metavar format string
- :param optsep: separator
- """
- opts = []
-
- if option._short_opts:
- opts.append(option._short_opts[0])
- if option._long_opts:
- opts.append(option._long_opts[0])
- if len(opts) > 1:
- opts.insert(1, optsep)
-
- if option.takes_value():
- assert option.dest is not None
- metavar = option.metavar or option.dest.lower()
- opts.append(mvarfmt.format(metavar.lower()))
-
- return "".join(opts)
-
- def format_heading(self, heading: str) -> str:
- if heading == "Options":
- return ""
- return heading + ":\n"
-
- def format_usage(self, usage: str) -> str:
- """
- Ensure there is only one newline between usage and the first heading
- if there is no description.
- """
- msg = "\nUsage: {}\n".format(self.indent_lines(textwrap.dedent(usage), " "))
- return msg
-
- def format_description(self, description: str) -> str:
- # leave full control over description to us
- if description:
- if hasattr(self.parser, "main"):
- label = "Commands"
- else:
- label = "Description"
- # some doc strings have initial newlines, some don't
- description = description.lstrip("\n")
- # some doc strings have final newlines and spaces, some don't
- description = description.rstrip()
- # dedent, then reindent
- description = self.indent_lines(textwrap.dedent(description), " ")
- description = f"{label}:\n{description}\n"
- return description
- else:
- return ""
-
- def format_epilog(self, epilog: str) -> str:
- # leave full control over epilog to us
- if epilog:
- return epilog
- else:
- return ""
-
- def indent_lines(self, text: str, indent: str) -> str:
- new_lines = [indent + line for line in text.split("\n")]
- return "\n".join(new_lines)
-
-
-class UpdatingDefaultsHelpFormatter(PrettyHelpFormatter):
- """Custom help formatter for use in ConfigOptionParser.
-
- This is updates the defaults before expanding them, allowing
- them to show up correctly in the help listing.
-
- Also redact auth from url type options
- """
-
- def expand_default(self, option: optparse.Option) -> str:
- default_values = None
- if self.parser is not None:
- assert isinstance(self.parser, ConfigOptionParser)
- self.parser._update_defaults(self.parser.defaults)
- assert option.dest is not None
- default_values = self.parser.defaults.get(option.dest)
- help_text = super().expand_default(option)
-
- if default_values and option.metavar == "URL":
- if isinstance(default_values, str):
- default_values = [default_values]
-
- # If its not a list, we should abort and just return the help text
- if not isinstance(default_values, list):
- default_values = []
-
- for val in default_values:
- help_text = help_text.replace(val, redact_auth_from_url(val))
-
- return help_text
-
-
-class CustomOptionParser(optparse.OptionParser):
- def insert_option_group(
- self, idx: int, *args: Any, **kwargs: Any
- ) -> optparse.OptionGroup:
- """Insert an OptionGroup at a given position."""
- group = self.add_option_group(*args, **kwargs)
-
- self.option_groups.pop()
- self.option_groups.insert(idx, group)
-
- return group
-
- @property
- def option_list_all(self) -> List[optparse.Option]:
- """Get a list of all options, including those in option groups."""
- res = self.option_list[:]
- for i in self.option_groups:
- res.extend(i.option_list)
-
- return res
-
-
-class ConfigOptionParser(CustomOptionParser):
- """Custom option parser which updates its defaults by checking the
- configuration files and environmental variables"""
-
- def __init__(
- self,
- *args: Any,
- name: str,
- isolated: bool = False,
- **kwargs: Any,
- ) -> None:
- self.name = name
- self.config = Configuration(isolated)
-
- assert self.name
- super().__init__(*args, **kwargs)
-
- def check_default(self, option: optparse.Option, key: str, val: Any) -> Any:
- try:
- return option.check_value(key, val)
- except optparse.OptionValueError as exc:
- print(f"An error occurred during configuration: {exc}")
- sys.exit(3)
-
- def _get_ordered_configuration_items(self) -> Iterator[Tuple[str, Any]]:
- # Configuration gives keys in an unordered manner. Order them.
- override_order = ["global", self.name, ":env:"]
-
- # Pool the options into different groups
- section_items: Dict[str, List[Tuple[str, Any]]] = {
- name: [] for name in override_order
- }
- for section_key, val in self.config.items():
- # ignore empty values
- if not val:
- logger.debug(
- "Ignoring configuration key '%s' as it's value is empty.",
- section_key,
- )
- continue
-
- section, key = section_key.split(".", 1)
- if section in override_order:
- section_items[section].append((key, val))
-
- # Yield each group in their override order
- for section in override_order:
- for key, val in section_items[section]:
- yield key, val
-
- def _update_defaults(self, defaults: Dict[str, Any]) -> Dict[str, Any]:
- """Updates the given defaults with values from the config files and
- the environ. Does a little special handling for certain types of
- options (lists)."""
-
- # Accumulate complex default state.
- self.values = optparse.Values(self.defaults)
- late_eval = set()
- # Then set the options with those values
- for key, val in self._get_ordered_configuration_items():
- # '--' because configuration supports only long names
- option = self.get_option("--" + key)
-
- # Ignore options not present in this parser. E.g. non-globals put
- # in [global] by users that want them to apply to all applicable
- # commands.
- if option is None:
- continue
-
- assert option.dest is not None
-
- if option.action in ("store_true", "store_false"):
- try:
- val = strtobool(val)
- except ValueError:
- self.error(
- "{} is not a valid value for {} option, " # noqa
- "please specify a boolean value like yes/no, "
- "true/false or 1/0 instead.".format(val, key)
- )
- elif option.action == "count":
- with suppress(ValueError):
- val = strtobool(val)
- with suppress(ValueError):
- val = int(val)
- if not isinstance(val, int) or val < 0:
- self.error(
- "{} is not a valid value for {} option, " # noqa
- "please instead specify either a non-negative integer "
- "or a boolean value like yes/no or false/true "
- "which is equivalent to 1/0.".format(val, key)
- )
- elif option.action == "append":
- val = val.split()
- val = [self.check_default(option, key, v) for v in val]
- elif option.action == "callback":
- assert option.callback is not None
- late_eval.add(option.dest)
- opt_str = option.get_opt_string()
- val = option.convert_value(opt_str, val)
- # From take_action
- args = option.callback_args or ()
- kwargs = option.callback_kwargs or {}
- option.callback(option, opt_str, val, self, *args, **kwargs)
- else:
- val = self.check_default(option, key, val)
-
- defaults[option.dest] = val
-
- for key in late_eval:
- defaults[key] = getattr(self.values, key)
- self.values = None
- return defaults
-
- def get_default_values(self) -> optparse.Values:
- """Overriding to make updating the defaults after instantiation of
- the option parser possible, _update_defaults() does the dirty work."""
- if not self.process_default_values:
- # Old, pre-Optik 1.5 behaviour.
- return optparse.Values(self.defaults)
-
- # Load the configuration, or error out in case of an error
- try:
- self.config.load()
- except ConfigurationError as err:
- self.exit(UNKNOWN_ERROR, str(err))
-
- defaults = self._update_defaults(self.defaults.copy()) # ours
- for option in self._get_all_options():
- assert option.dest is not None
- default = defaults.get(option.dest)
- if isinstance(default, str):
- opt_str = option.get_opt_string()
- defaults[option.dest] = option.check_value(opt_str, default)
- return optparse.Values(defaults)
-
- def error(self, msg: str) -> None:
- self.print_usage(sys.stderr)
- self.exit(UNKNOWN_ERROR, f"{msg}\n")
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/configs.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/configs.py
deleted file mode 100644
index 5936dd197131425b800e11cbc92d9e5d13f4fc37..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/configs.py
+++ /dev/null
@@ -1,1319 +0,0 @@
-"""
- pygments.lexers.configs
- ~~~~~~~~~~~~~~~~~~~~~~~
-
- Lexers for configuration file formats.
-
- :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-import re
-
-from pygments.lexer import ExtendedRegexLexer, RegexLexer, default, words, \
- bygroups, include, using, line_re
-from pygments.token import Text, Comment, Operator, Keyword, Name, String, \
- Number, Punctuation, Whitespace, Literal, Error, Generic
-from pygments.lexers.shell import BashLexer
-from pygments.lexers.data import JsonLexer
-
-__all__ = ['IniLexer', 'SystemdLexer', 'DesktopLexer', 'RegeditLexer', 'PropertiesLexer',
- 'KconfigLexer', 'Cfengine3Lexer', 'ApacheConfLexer', 'SquidConfLexer',
- 'NginxConfLexer', 'LighttpdConfLexer', 'DockerLexer',
- 'TerraformLexer', 'TermcapLexer', 'TerminfoLexer',
- 'PkgConfigLexer', 'PacmanConfLexer', 'AugeasLexer', 'TOMLLexer',
- 'NestedTextLexer', 'SingularityLexer', 'UnixConfigLexer']
-
-
-class IniLexer(RegexLexer):
- """
- Lexer for configuration files in INI style.
- """
-
- name = 'INI'
- aliases = ['ini', 'cfg', 'dosini']
- filenames = [
- '*.ini', '*.cfg', '*.inf', '.editorconfig',
- ]
- mimetypes = ['text/x-ini', 'text/inf']
-
- tokens = {
- 'root': [
- (r'\s+', Whitespace),
- (r'[;#].*', Comment.Single),
- (r'(\[.*?\])([ \t]*)$', bygroups(Keyword, Whitespace)),
- (r'(.*?)([ \t]*)([=:])([ \t]*)([^;#\n]*)(\\)(\s+)',
- bygroups(Name.Attribute, Whitespace, Operator, Whitespace, String,
- Text, Whitespace),
- "value"),
- (r'(.*?)([ \t]*)([=:])([ \t]*)([^ ;#\n]*(?: +[^ ;#\n]+)*)',
- bygroups(Name.Attribute, Whitespace, Operator, Whitespace, String)),
- # standalone option, supported by some INI parsers
- (r'(.+?)$', Name.Attribute),
- ],
- 'value': [ # line continuation
- (r'\s+', Whitespace),
- (r'(\s*)(.*)(\\)([ \t]*)',
- bygroups(Whitespace, String, Text, Whitespace)),
- (r'.*$', String, "#pop"),
- ],
- }
-
- def analyse_text(text):
- npos = text.find('\n')
- if npos < 3:
- return False
- if text[0] == '[' and text[npos-1] == ']':
- return 0.8
- return False
-
-
-class DesktopLexer(RegexLexer):
- """
- Lexer for .desktop files.
-
- .. versionadded:: 2.16
- """
-
- name = 'Desktop file'
- url = "https://specifications.freedesktop.org/desktop-entry-spec/desktop-entry-spec-latest.html"
- aliases = ['desktop']
- filenames = ['*.desktop']
-
- tokens = {
- 'root': [
- (r'^[ \t]*\n', Whitespace),
- (r'^(#.*)(\n)', bygroups(Comment.Single, Whitespace)),
- (r'(\[[^\]\n]+\])(\n)', bygroups(Keyword, Whitespace)),
- (r'([-A-Za-z0-9]+)(\[[^\] \t=]+\])?([ \t]*)(=)([ \t]*)([^\n]*)([ \t\n]*\n)',
- bygroups(Name.Attribute, Name.Namespace, Whitespace, Operator, Whitespace, String, Whitespace)),
- ],
- }
-
- def analyse_text(text):
- if text.startswith("[Desktop Entry]"):
- return 1.0
- if re.search(r"^\[Desktop Entry\][ \t]*$", text[:500], re.MULTILINE) is not None:
- return 0.9
- return 0.0
-
-
-class SystemdLexer(RegexLexer):
- """
- Lexer for systemd unit files.
-
- .. versionadded:: 2.16
- """
-
- name = 'Systemd'
- url = "https://www.freedesktop.org/software/systemd/man/systemd.syntax.html"
- aliases = ['systemd']
- filenames = [
- '*.service', '*.socket', '*.device', '*.mount', '*.automount',
- '*.swap', '*.target', '*.path', '*.timer', '*.slice', '*.scope',
- ]
-
- tokens = {
- 'root': [
- (r'^[ \t]*\n', Whitespace),
- (r'^([;#].*)(\n)', bygroups(Comment.Single, Whitespace)),
- (r'(\[[^\]\n]+\])(\n)', bygroups(Keyword, Whitespace)),
- (r'([^=]+)([ \t]*)(=)([ \t]*)([^\n]*)(\\)(\n)',
- bygroups(Name.Attribute, Whitespace, Operator, Whitespace, String,
- Text, Whitespace),
- "value"),
- (r'([^=]+)([ \t]*)(=)([ \t]*)([^\n]*)(\n)',
- bygroups(Name.Attribute, Whitespace, Operator, Whitespace, String, Whitespace)),
- ],
- 'value': [
- # line continuation
- (r'^([;#].*)(\n)', bygroups(Comment.Single, Whitespace)),
- (r'([ \t]*)([^\n]*)(\\)(\n)',
- bygroups(Whitespace, String, Text, Whitespace)),
- (r'([ \t]*)([^\n]*)(\n)',
- bygroups(Whitespace, String, Whitespace), "#pop"),
- ],
- }
-
- def analyse_text(text):
- if text.startswith("[Unit]"):
- return 1.0
- if re.search(r"^\[Unit\][ \t]*$", text[:500], re.MULTILINE) is not None:
- return 0.9
- return 0.0
-
-
-class RegeditLexer(RegexLexer):
- """
- Lexer for Windows Registry files produced by regedit.
-
- .. versionadded:: 1.6
- """
-
- name = 'reg'
- url = 'http://en.wikipedia.org/wiki/Windows_Registry#.REG_files'
- aliases = ['registry']
- filenames = ['*.reg']
- mimetypes = ['text/x-windows-registry']
-
- tokens = {
- 'root': [
- (r'Windows Registry Editor.*', Text),
- (r'\s+', Whitespace),
- (r'[;#].*', Comment.Single),
- (r'(\[)(-?)(HKEY_[A-Z_]+)(.*?\])$',
- bygroups(Keyword, Operator, Name.Builtin, Keyword)),
- # String keys, which obey somewhat normal escaping
- (r'("(?:\\"|\\\\|[^"])+")([ \t]*)(=)([ \t]*)',
- bygroups(Name.Attribute, Whitespace, Operator, Whitespace),
- 'value'),
- # Bare keys (includes @)
- (r'(.*?)([ \t]*)(=)([ \t]*)',
- bygroups(Name.Attribute, Whitespace, Operator, Whitespace),
- 'value'),
- ],
- 'value': [
- (r'-', Operator, '#pop'), # delete value
- (r'(dword|hex(?:\([0-9a-fA-F]\))?)(:)([0-9a-fA-F,]+)',
- bygroups(Name.Variable, Punctuation, Number), '#pop'),
- # As far as I know, .reg files do not support line continuation.
- (r'.+', String, '#pop'),
- default('#pop'),
- ]
- }
-
- def analyse_text(text):
- return text.startswith('Windows Registry Editor')
-
-
-class PropertiesLexer(RegexLexer):
- """
- Lexer for configuration files in Java's properties format.
-
- Note: trailing whitespace counts as part of the value as per spec
-
- .. versionadded:: 1.4
- """
-
- name = 'Properties'
- aliases = ['properties', 'jproperties']
- filenames = ['*.properties']
- mimetypes = ['text/x-java-properties']
-
- tokens = {
- 'root': [
- # comments
- (r'[!#].*|/{2}.*', Comment.Single),
- # ending a comment or whitespace-only line
- (r'\n', Whitespace),
- # eat whitespace at the beginning of a line
- (r'^[^\S\n]+', Whitespace),
- # start lexing a key
- default('key'),
- ],
- 'key': [
- # non-escaped key characters
- (r'[^\\:=\s]+', Name.Attribute),
- # escapes
- include('escapes'),
- # separator is the first non-escaped whitespace or colon or '=' on the line;
- # if it's whitespace, = and : are gobbled after it
- (r'([^\S\n]*)([:=])([^\S\n]*)',
- bygroups(Whitespace, Operator, Whitespace),
- ('#pop', 'value')),
- (r'[^\S\n]+', Whitespace, ('#pop', 'value')),
- # maybe we got no value after all
- (r'\n', Whitespace, '#pop'),
- ],
- 'value': [
- # non-escaped value characters
- (r'[^\\\n]+', String),
- # escapes
- include('escapes'),
- # end the value on an unescaped newline
- (r'\n', Whitespace, '#pop'),
- ],
- 'escapes': [
- # line continuations; these gobble whitespace at the beginning of the next line
- (r'(\\\n)([^\S\n]*)', bygroups(String.Escape, Whitespace)),
- # other escapes
- (r'\\(.|\n)', String.Escape),
- ],
- }
-
-
-def _rx_indent(level):
- # Kconfig *always* interprets a tab as 8 spaces, so this is the default.
- # Edit this if you are in an environment where KconfigLexer gets expanded
- # input (tabs expanded to spaces) and the expansion tab width is != 8,
- # e.g. in connection with Trac (trac.ini, [mimeviewer], tab_width).
- # Value range here is 2 <= {tab_width} <= 8.
- tab_width = 8
- # Regex matching a given indentation {level}, assuming that indentation is
- # a multiple of {tab_width}. In other cases there might be problems.
- if tab_width == 2:
- space_repeat = '+'
- else:
- space_repeat = '{1,%d}' % (tab_width - 1)
- if level == 1:
- level_repeat = ''
- else:
- level_repeat = '{%s}' % level
- return r'(?:\t| %s\t| {%s})%s.*\n' % (space_repeat, tab_width, level_repeat)
-
-
-class KconfigLexer(RegexLexer):
- """
- For Linux-style Kconfig files.
-
- .. versionadded:: 1.6
- """
-
- name = 'Kconfig'
- aliases = ['kconfig', 'menuconfig', 'linux-config', 'kernel-config']
- # Adjust this if new kconfig file names appear in your environment
- filenames = ['Kconfig*', '*Config.in*', 'external.in*',
- 'standard-modules.in']
- mimetypes = ['text/x-kconfig']
- # No re.MULTILINE, indentation-aware help text needs line-by-line handling
- flags = 0
-
- def call_indent(level):
- # If indentation >= {level} is detected, enter state 'indent{level}'
- return (_rx_indent(level), String.Doc, 'indent%s' % level)
-
- def do_indent(level):
- # Print paragraphs of indentation level >= {level} as String.Doc,
- # ignoring blank lines. Then return to 'root' state.
- return [
- (_rx_indent(level), String.Doc),
- (r'\s*\n', Text),
- default('#pop:2')
- ]
-
- tokens = {
- 'root': [
- (r'\s+', Whitespace),
- (r'#.*?\n', Comment.Single),
- (words((
- 'mainmenu', 'config', 'menuconfig', 'choice', 'endchoice',
- 'comment', 'menu', 'endmenu', 'visible if', 'if', 'endif',
- 'source', 'prompt', 'select', 'depends on', 'default',
- 'range', 'option'), suffix=r'\b'),
- Keyword),
- (r'(---help---|help)[\t ]*\n', Keyword, 'help'),
- (r'(bool|tristate|string|hex|int|defconfig_list|modules|env)\b',
- Name.Builtin),
- (r'[!=&|]', Operator),
- (r'[()]', Punctuation),
- (r'[0-9]+', Number.Integer),
- (r"'(''|[^'])*'", String.Single),
- (r'"(""|[^"])*"', String.Double),
- (r'\S+', Text),
- ],
- # Help text is indented, multi-line and ends when a lower indentation
- # level is detected.
- 'help': [
- # Skip blank lines after help token, if any
- (r'\s*\n', Text),
- # Determine the first help line's indentation level heuristically(!).
- # Attention: this is not perfect, but works for 99% of "normal"
- # indentation schemes up to a max. indentation level of 7.
- call_indent(7),
- call_indent(6),
- call_indent(5),
- call_indent(4),
- call_indent(3),
- call_indent(2),
- call_indent(1),
- default('#pop'), # for incomplete help sections without text
- ],
- # Handle text for indentation levels 7 to 1
- 'indent7': do_indent(7),
- 'indent6': do_indent(6),
- 'indent5': do_indent(5),
- 'indent4': do_indent(4),
- 'indent3': do_indent(3),
- 'indent2': do_indent(2),
- 'indent1': do_indent(1),
- }
-
-
-class Cfengine3Lexer(RegexLexer):
- """
- Lexer for CFEngine3 policy files.
-
- .. versionadded:: 1.5
- """
-
- name = 'CFEngine3'
- url = 'http://cfengine.org'
- aliases = ['cfengine3', 'cf3']
- filenames = ['*.cf']
- mimetypes = []
-
- tokens = {
- 'root': [
- (r'#.*?\n', Comment),
- (r'(body)(\s+)(\S+)(\s+)(control)',
- bygroups(Keyword, Whitespace, Keyword, Whitespace, Keyword)),
- (r'(body|bundle)(\s+)(\S+)(\s+)(\w+)(\()',
- bygroups(Keyword, Whitespace, Keyword, Whitespace, Name.Function, Punctuation),
- 'arglist'),
- (r'(body|bundle)(\s+)(\S+)(\s+)(\w+)',
- bygroups(Keyword, Whitespace, Keyword, Whitespace, Name.Function)),
- (r'(")([^"]+)(")(\s+)(string|slist|int|real)(\s*)(=>)(\s*)',
- bygroups(Punctuation, Name.Variable, Punctuation,
- Whitespace, Keyword.Type, Whitespace, Operator, Whitespace)),
- (r'(\S+)(\s*)(=>)(\s*)',
- bygroups(Keyword.Reserved, Whitespace, Operator, Text)),
- (r'"', String, 'string'),
- (r'(\w+)(\()', bygroups(Name.Function, Punctuation)),
- (r'([\w.!&|()]+)(::)', bygroups(Name.Class, Punctuation)),
- (r'(\w+)(:)', bygroups(Keyword.Declaration, Punctuation)),
- (r'@[{(][^)}]+[})]', Name.Variable),
- (r'[(){},;]', Punctuation),
- (r'=>', Operator),
- (r'->', Operator),
- (r'\d+\.\d+', Number.Float),
- (r'\d+', Number.Integer),
- (r'\w+', Name.Function),
- (r'\s+', Whitespace),
- ],
- 'string': [
- (r'\$[{(]', String.Interpol, 'interpol'),
- (r'\\.', String.Escape),
- (r'"', String, '#pop'),
- (r'\n', String),
- (r'.', String),
- ],
- 'interpol': [
- (r'\$[{(]', String.Interpol, '#push'),
- (r'[})]', String.Interpol, '#pop'),
- (r'[^${()}]+', String.Interpol),
- ],
- 'arglist': [
- (r'\)', Punctuation, '#pop'),
- (r',', Punctuation),
- (r'\w+', Name.Variable),
- (r'\s+', Whitespace),
- ],
- }
-
-
-class ApacheConfLexer(RegexLexer):
- """
- Lexer for configuration files following the Apache config file
- format.
-
- .. versionadded:: 0.6
- """
-
- name = 'ApacheConf'
- aliases = ['apacheconf', 'aconf', 'apache']
- filenames = ['.htaccess', 'apache.conf', 'apache2.conf']
- mimetypes = ['text/x-apacheconf']
- flags = re.MULTILINE | re.IGNORECASE
-
- tokens = {
- 'root': [
- (r'\s+', Whitespace),
- (r'#(.*\\\n)+.*$|(#.*?)$', Comment),
- (r'(<[^\s>/][^\s>]*)(?:(\s+)(.*))?(>)',
- bygroups(Name.Tag, Whitespace, String, Name.Tag)),
- (r'(]+)(>)',
- bygroups(Name.Tag, Name.Tag)),
- (r'[a-z]\w*', Name.Builtin, 'value'),
- (r'\.+', Text),
- ],
- 'value': [
- (r'\\\n', Text),
- (r'\n+', Whitespace, '#pop'),
- (r'\\', Text),
- (r'[^\S\n]+', Whitespace),
- (r'\d+\.\d+\.\d+\.\d+(?:/\d+)?', Number),
- (r'\d+', Number),
- (r'/([*a-z0-9][*\w./-]+)', String.Other),
- (r'(on|off|none|any|all|double|email|dns|min|minimal|'
- r'os|productonly|full|emerg|alert|crit|error|warn|'
- r'notice|info|debug|registry|script|inetd|standalone|'
- r'user|group)\b', Keyword),
- (r'"([^"\\]*(?:\\(.|\n)[^"\\]*)*)"', String.Double),
- (r'[^\s"\\]+', Text)
- ],
- }
-
-
-class SquidConfLexer(RegexLexer):
- """
- Lexer for squid configuration files.
-
- .. versionadded:: 0.9
- """
-
- name = 'SquidConf'
- url = 'http://www.squid-cache.org/'
- aliases = ['squidconf', 'squid.conf', 'squid']
- filenames = ['squid.conf']
- mimetypes = ['text/x-squidconf']
- flags = re.IGNORECASE
-
- keywords = (
- "access_log", "acl", "always_direct", "announce_host",
- "announce_period", "announce_port", "announce_to", "anonymize_headers",
- "append_domain", "as_whois_server", "auth_param_basic",
- "authenticate_children", "authenticate_program", "authenticate_ttl",
- "broken_posts", "buffered_logs", "cache_access_log", "cache_announce",
- "cache_dir", "cache_dns_program", "cache_effective_group",
- "cache_effective_user", "cache_host", "cache_host_acl",
- "cache_host_domain", "cache_log", "cache_mem", "cache_mem_high",
- "cache_mem_low", "cache_mgr", "cachemgr_passwd", "cache_peer",
- "cache_peer_access", "cache_replacement_policy", "cache_stoplist",
- "cache_stoplist_pattern", "cache_store_log", "cache_swap",
- "cache_swap_high", "cache_swap_log", "cache_swap_low", "client_db",
- "client_lifetime", "client_netmask", "connect_timeout", "coredump_dir",
- "dead_peer_timeout", "debug_options", "delay_access", "delay_class",
- "delay_initial_bucket_level", "delay_parameters", "delay_pools",
- "deny_info", "dns_children", "dns_defnames", "dns_nameservers",
- "dns_testnames", "emulate_httpd_log", "err_html_text",
- "fake_user_agent", "firewall_ip", "forwarded_for", "forward_snmpd_port",
- "fqdncache_size", "ftpget_options", "ftpget_program", "ftp_list_width",
- "ftp_passive", "ftp_user", "half_closed_clients", "header_access",
- "header_replace", "hierarchy_stoplist", "high_response_time_warning",
- "high_page_fault_warning", "hosts_file", "htcp_port", "http_access",
- "http_anonymizer", "httpd_accel", "httpd_accel_host",
- "httpd_accel_port", "httpd_accel_uses_host_header",
- "httpd_accel_with_proxy", "http_port", "http_reply_access",
- "icp_access", "icp_hit_stale", "icp_port", "icp_query_timeout",
- "ident_lookup", "ident_lookup_access", "ident_timeout",
- "incoming_http_average", "incoming_icp_average", "inside_firewall",
- "ipcache_high", "ipcache_low", "ipcache_size", "local_domain",
- "local_ip", "logfile_rotate", "log_fqdn", "log_icp_queries",
- "log_mime_hdrs", "maximum_object_size", "maximum_single_addr_tries",
- "mcast_groups", "mcast_icp_query_timeout", "mcast_miss_addr",
- "mcast_miss_encode_key", "mcast_miss_port", "memory_pools",
- "memory_pools_limit", "memory_replacement_policy", "mime_table",
- "min_http_poll_cnt", "min_icp_poll_cnt", "minimum_direct_hops",
- "minimum_object_size", "minimum_retry_timeout", "miss_access",
- "negative_dns_ttl", "negative_ttl", "neighbor_timeout",
- "neighbor_type_domain", "netdb_high", "netdb_low", "netdb_ping_period",
- "netdb_ping_rate", "never_direct", "no_cache", "passthrough_proxy",
- "pconn_timeout", "pid_filename", "pinger_program", "positive_dns_ttl",
- "prefer_direct", "proxy_auth", "proxy_auth_realm", "query_icmp",
- "quick_abort", "quick_abort_max", "quick_abort_min",
- "quick_abort_pct", "range_offset_limit", "read_timeout",
- "redirect_children", "redirect_program",
- "redirect_rewrites_host_header", "reference_age",
- "refresh_pattern", "reload_into_ims", "request_body_max_size",
- "request_size", "request_timeout", "shutdown_lifetime",
- "single_parent_bypass", "siteselect_timeout", "snmp_access",
- "snmp_incoming_address", "snmp_port", "source_ping", "ssl_proxy",
- "store_avg_object_size", "store_objects_per_bucket",
- "strip_query_terms", "swap_level1_dirs", "swap_level2_dirs",
- "tcp_incoming_address", "tcp_outgoing_address", "tcp_recv_bufsize",
- "test_reachability", "udp_hit_obj", "udp_hit_obj_size",
- "udp_incoming_address", "udp_outgoing_address", "unique_hostname",
- "unlinkd_program", "uri_whitespace", "useragent_log",
- "visible_hostname", "wais_relay", "wais_relay_host", "wais_relay_port",
- )
-
- opts = (
- "proxy-only", "weight", "ttl", "no-query", "default", "round-robin",
- "multicast-responder", "on", "off", "all", "deny", "allow", "via",
- "parent", "no-digest", "heap", "lru", "realm", "children", "q1", "q2",
- "credentialsttl", "none", "disable", "offline_toggle", "diskd",
- )
-
- actions = (
- "shutdown", "info", "parameter", "server_list", "client_list",
- r'squid.conf',
- )
-
- actions_stats = (
- "objects", "vm_objects", "utilization", "ipcache", "fqdncache", "dns",
- "redirector", "io", "reply_headers", "filedescriptors", "netdb",
- )
-
- actions_log = ("status", "enable", "disable", "clear")
-
- acls = (
- "url_regex", "urlpath_regex", "referer_regex", "port", "proto",
- "req_mime_type", "rep_mime_type", "method", "browser", "user", "src",
- "dst", "time", "dstdomain", "ident", "snmp_community",
- )
-
- ip_re = (
- r'(?:(?:(?:[3-9]\d?|2(?:5[0-5]|[0-4]?\d)?|1\d{0,2}|0x0*[0-9a-f]{1,2}|'
- r'0+[1-3]?[0-7]{0,2})(?:\.(?:[3-9]\d?|2(?:5[0-5]|[0-4]?\d)?|1\d{0,2}|'
- r'0x0*[0-9a-f]{1,2}|0+[1-3]?[0-7]{0,2})){3})|(?!.*::.*::)(?:(?!:)|'
- r':(?=:))(?:[0-9a-f]{0,4}(?:(?<=::)|(?|=~|\+=|==|=|\+', Operator),
- (r'\$[A-Z]+', Name.Builtin),
- (r'[(){}\[\],]', Punctuation),
- (r'"([^"\\]*(?:\\.[^"\\]*)*)"', String.Double),
- (r'\s+', Whitespace),
- ],
-
- }
-
-
-class DockerLexer(RegexLexer):
- """
- Lexer for Docker configuration files.
-
- .. versionadded:: 2.0
- """
- name = 'Docker'
- url = 'http://docker.io'
- aliases = ['docker', 'dockerfile']
- filenames = ['Dockerfile', '*.docker']
- mimetypes = ['text/x-dockerfile-config']
-
- _keywords = (r'(?:MAINTAINER|EXPOSE|WORKDIR|USER|STOPSIGNAL)')
- _bash_keywords = (r'(?:RUN|CMD|ENTRYPOINT|ENV|ARG|LABEL|ADD|COPY)')
- _lb = r'(?:\s*\\?\s*)' # dockerfile line break regex
- flags = re.IGNORECASE | re.MULTILINE
-
- tokens = {
- 'root': [
- (r'#.*', Comment),
- (r'(FROM)([ \t]*)(\S*)([ \t]*)(?:(AS)([ \t]*)(\S*))?',
- bygroups(Keyword, Whitespace, String, Whitespace, Keyword, Whitespace, String)),
- (r'(ONBUILD)(\s+)(%s)' % (_lb,), bygroups(Keyword, Whitespace, using(BashLexer))),
- (r'(HEALTHCHECK)(\s+)((%s--\w+=\w+%s)*)' % (_lb, _lb),
- bygroups(Keyword, Whitespace, using(BashLexer))),
- (r'(VOLUME|ENTRYPOINT|CMD|SHELL)(\s+)(%s)(\[.*?\])' % (_lb,),
- bygroups(Keyword, Whitespace, using(BashLexer), using(JsonLexer))),
- (r'(LABEL|ENV|ARG)(\s+)((%s\w+=\w+%s)*)' % (_lb, _lb),
- bygroups(Keyword, Whitespace, using(BashLexer))),
- (r'(%s|VOLUME)\b(\s+)(.*)' % (_keywords), bygroups(Keyword, Whitespace, String)),
- (r'(%s)(\s+)' % (_bash_keywords,), bygroups(Keyword, Whitespace)),
- (r'(.*\\\n)*.+', using(BashLexer)),
- ]
- }
-
-
-class TerraformLexer(ExtendedRegexLexer):
- """
- Lexer for terraformi ``.tf`` files.
-
- .. versionadded:: 2.1
- """
-
- name = 'Terraform'
- url = 'https://www.terraform.io/'
- aliases = ['terraform', 'tf', 'hcl']
- filenames = ['*.tf', '*.hcl']
- mimetypes = ['application/x-tf', 'application/x-terraform']
-
- classes = ('backend', 'data', 'module', 'output', 'provider',
- 'provisioner', 'resource', 'variable')
- classes_re = "({})".format(('|').join(classes))
-
- types = ('string', 'number', 'bool', 'list', 'tuple', 'map', 'set', 'object', 'null')
-
- numeric_functions = ('abs', 'ceil', 'floor', 'log', 'max',
- 'mix', 'parseint', 'pow', 'signum')
-
- string_functions = ('chomp', 'format', 'formatlist', 'indent',
- 'join', 'lower', 'regex', 'regexall', 'replace',
- 'split', 'strrev', 'substr', 'title', 'trim',
- 'trimprefix', 'trimsuffix', 'trimspace', 'upper'
- )
-
- collection_functions = ('alltrue', 'anytrue', 'chunklist', 'coalesce',
- 'coalescelist', 'compact', 'concat', 'contains',
- 'distinct', 'element', 'flatten', 'index', 'keys',
- 'length', 'list', 'lookup', 'map', 'matchkeys',
- 'merge', 'range', 'reverse', 'setintersection',
- 'setproduct', 'setsubtract', 'setunion', 'slice',
- 'sort', 'sum', 'transpose', 'values', 'zipmap'
- )
-
- encoding_functions = ('base64decode', 'base64encode', 'base64gzip',
- 'csvdecode', 'jsondecode', 'jsonencode', 'textdecodebase64',
- 'textencodebase64', 'urlencode', 'yamldecode', 'yamlencode')
-
- filesystem_functions = ('abspath', 'dirname', 'pathexpand', 'basename',
- 'file', 'fileexists', 'fileset', 'filebase64', 'templatefile')
-
- date_time_functions = ('formatdate', 'timeadd', 'timestamp')
-
- hash_crypto_functions = ('base64sha256', 'base64sha512', 'bcrypt', 'filebase64sha256',
- 'filebase64sha512', 'filemd5', 'filesha1', 'filesha256', 'filesha512',
- 'md5', 'rsadecrypt', 'sha1', 'sha256', 'sha512', 'uuid', 'uuidv5')
-
- ip_network_functions = ('cidrhost', 'cidrnetmask', 'cidrsubnet', 'cidrsubnets')
-
- type_conversion_functions = ('can', 'defaults', 'tobool', 'tolist', 'tomap',
- 'tonumber', 'toset', 'tostring', 'try')
-
- builtins = numeric_functions + string_functions + collection_functions + encoding_functions +\
- filesystem_functions + date_time_functions + hash_crypto_functions + ip_network_functions +\
- type_conversion_functions
- builtins_re = "({})".format(('|').join(builtins))
-
- def heredoc_callback(self, match, ctx):
- # Parse a terraform heredoc
- # match: 1 = <<[-]?, 2 = name 3 = rest of line
-
- start = match.start(1)
- yield start, Operator, match.group(1) # <<[-]?
- yield match.start(2), String.Delimiter, match.group(2) # heredoc name
-
- ctx.pos = match.start(3)
- ctx.end = match.end(3)
- yield ctx.pos, String.Heredoc, match.group(3)
- ctx.pos = match.end()
-
- hdname = match.group(2)
- tolerant = True # leading whitespace is always accepted
-
- lines = []
-
- for match in line_re.finditer(ctx.text, ctx.pos):
- if tolerant:
- check = match.group().strip()
- else:
- check = match.group().rstrip()
- if check == hdname:
- for amatch in lines:
- yield amatch.start(), String.Heredoc, amatch.group()
- yield match.start(), String.Delimiter, match.group()
- ctx.pos = match.end()
- break
- else:
- lines.append(match)
- else:
- # end of heredoc not found -- error!
- for amatch in lines:
- yield amatch.start(), Error, amatch.group()
- ctx.end = len(ctx.text)
-
- tokens = {
- 'root': [
- include('basic'),
- include('whitespace'),
-
- # Strings
- (r'(".*")', bygroups(String.Double)),
-
- # Constants
- (words(('true', 'false'), prefix=r'\b', suffix=r'\b'), Name.Constant),
-
- # Types
- (words(types, prefix=r'\b', suffix=r'\b'), Keyword.Type),
-
- include('identifier'),
- include('punctuation'),
- (r'[0-9]+', Number),
- ],
- 'basic': [
- (r'\s*/\*', Comment.Multiline, 'comment'),
- (r'\s*(#|//).*\n', Comment.Single),
- include('whitespace'),
-
- # e.g. terraform {
- # e.g. egress {
- (r'(\s*)([0-9a-zA-Z-_]+)(\s*)(=?)(\s*)(\{)',
- bygroups(Whitespace, Name.Builtin, Whitespace, Operator, Whitespace, Punctuation)),
-
- # Assignment with attributes, e.g. something = ...
- (r'(\s*)([0-9a-zA-Z-_]+)(\s*)(=)(\s*)',
- bygroups(Whitespace, Name.Attribute, Whitespace, Operator, Whitespace)),
-
- # Assignment with environment variables and similar, e.g. "something" = ...
- # or key value assignment, e.g. "SlotName" : ...
- (r'(\s*)("\S+")(\s*)([=:])(\s*)',
- bygroups(Whitespace, Literal.String.Double, Whitespace, Operator, Whitespace)),
-
- # Functions, e.g. jsonencode(element("value"))
- (builtins_re + r'(\()', bygroups(Name.Function, Punctuation)),
-
- # List of attributes, e.g. ignore_changes = [last_modified, filename]
- (r'(\[)([a-z_,\s]+)(\])', bygroups(Punctuation, Name.Builtin, Punctuation)),
-
- # e.g. resource "aws_security_group" "allow_tls" {
- # e.g. backend "consul" {
- (classes_re + r'(\s+)("[0-9a-zA-Z-_]+")?(\s*)("[0-9a-zA-Z-_]+")(\s+)(\{)',
- bygroups(Keyword.Reserved, Whitespace, Name.Class, Whitespace, Name.Variable, Whitespace, Punctuation)),
-
- # here-doc style delimited strings
- (r'(<<-?)\s*([a-zA-Z_]\w*)(.*?\n)', heredoc_callback),
- ],
- 'identifier': [
- (r'\b(var\.[0-9a-zA-Z-_\.\[\]]+)\b', bygroups(Name.Variable)),
- (r'\b([0-9a-zA-Z-_\[\]]+\.[0-9a-zA-Z-_\.\[\]]+)\b',
- bygroups(Name.Variable)),
- ],
- 'punctuation': [
- (r'[\[\]()\{\},.?:!=]', Punctuation),
- ],
- 'comment': [
- (r'[^*/]', Comment.Multiline),
- (r'/\*', Comment.Multiline, '#push'),
- (r'\*/', Comment.Multiline, '#pop'),
- (r'[*/]', Comment.Multiline)
- ],
- 'whitespace': [
- (r'\n', Whitespace),
- (r'\s+', Whitespace),
- (r'(\\)(\n)', bygroups(Text, Whitespace)),
- ],
- }
-
-
-class TermcapLexer(RegexLexer):
- """
- Lexer for termcap database source.
-
- This is very simple and minimal.
-
- .. versionadded:: 2.1
- """
- name = 'Termcap'
- aliases = ['termcap']
- filenames = ['termcap', 'termcap.src']
- mimetypes = []
-
- # NOTE:
- # * multiline with trailing backslash
- # * separator is ':'
- # * to embed colon as data, we must use \072
- # * space after separator is not allowed (mayve)
- tokens = {
- 'root': [
- (r'^#.*', Comment),
- (r'^[^\s#:|]+', Name.Tag, 'names'),
- (r'\s+', Whitespace),
- ],
- 'names': [
- (r'\n', Whitespace, '#pop'),
- (r':', Punctuation, 'defs'),
- (r'\|', Punctuation),
- (r'[^:|]+', Name.Attribute),
- ],
- 'defs': [
- (r'(\\)(\n[ \t]*)', bygroups(Text, Whitespace)),
- (r'\n[ \t]*', Whitespace, '#pop:2'),
- (r'(#)([0-9]+)', bygroups(Operator, Number)),
- (r'=', Operator, 'data'),
- (r':', Punctuation),
- (r'[^\s:=#]+', Name.Class),
- ],
- 'data': [
- (r'\\072', Literal),
- (r':', Punctuation, '#pop'),
- (r'[^:\\]+', Literal), # for performance
- (r'.', Literal),
- ],
- }
-
-
-class TerminfoLexer(RegexLexer):
- """
- Lexer for terminfo database source.
-
- This is very simple and minimal.
-
- .. versionadded:: 2.1
- """
- name = 'Terminfo'
- aliases = ['terminfo']
- filenames = ['terminfo', 'terminfo.src']
- mimetypes = []
-
- # NOTE:
- # * multiline with leading whitespace
- # * separator is ','
- # * to embed comma as data, we can use \,
- # * space after separator is allowed
- tokens = {
- 'root': [
- (r'^#.*$', Comment),
- (r'^[^\s#,|]+', Name.Tag, 'names'),
- (r'\s+', Whitespace),
- ],
- 'names': [
- (r'\n', Whitespace, '#pop'),
- (r'(,)([ \t]*)', bygroups(Punctuation, Whitespace), 'defs'),
- (r'\|', Punctuation),
- (r'[^,|]+', Name.Attribute),
- ],
- 'defs': [
- (r'\n[ \t]+', Whitespace),
- (r'\n', Whitespace, '#pop:2'),
- (r'(#)([0-9]+)', bygroups(Operator, Number)),
- (r'=', Operator, 'data'),
- (r'(,)([ \t]*)', bygroups(Punctuation, Whitespace)),
- (r'[^\s,=#]+', Name.Class),
- ],
- 'data': [
- (r'\\[,\\]', Literal),
- (r'(,)([ \t]*)', bygroups(Punctuation, Whitespace), '#pop'),
- (r'[^\\,]+', Literal), # for performance
- (r'.', Literal),
- ],
- }
-
-
-class PkgConfigLexer(RegexLexer):
- """
- Lexer for pkg-config
- (see also `manual page `_).
-
- .. versionadded:: 2.1
- """
-
- name = 'PkgConfig'
- url = 'http://www.freedesktop.org/wiki/Software/pkg-config/'
- aliases = ['pkgconfig']
- filenames = ['*.pc']
- mimetypes = []
-
- tokens = {
- 'root': [
- (r'#.*$', Comment.Single),
-
- # variable definitions
- (r'^(\w+)(=)', bygroups(Name.Attribute, Operator)),
-
- # keyword lines
- (r'^([\w.]+)(:)',
- bygroups(Name.Tag, Punctuation), 'spvalue'),
-
- # variable references
- include('interp'),
-
- # fallback
- (r'\s+', Whitespace),
- (r'[^${}#=:\n.]+', Text),
- (r'.', Text),
- ],
- 'interp': [
- # you can escape literal "$" as "$$"
- (r'\$\$', Text),
-
- # variable references
- (r'\$\{', String.Interpol, 'curly'),
- ],
- 'curly': [
- (r'\}', String.Interpol, '#pop'),
- (r'\w+', Name.Attribute),
- ],
- 'spvalue': [
- include('interp'),
-
- (r'#.*$', Comment.Single, '#pop'),
- (r'\n', Whitespace, '#pop'),
-
- # fallback
- (r'\s+', Whitespace),
- (r'[^${}#\n\s]+', Text),
- (r'.', Text),
- ],
- }
-
-
-class PacmanConfLexer(RegexLexer):
- """
- Lexer for pacman.conf.
-
- Actually, IniLexer works almost fine for this format,
- but it yield error token. It is because pacman.conf has
- a form without assignment like:
-
- UseSyslog
- Color
- TotalDownload
- CheckSpace
- VerbosePkgLists
-
- These are flags to switch on.
-
- .. versionadded:: 2.1
- """
-
- name = 'PacmanConf'
- url = 'https://www.archlinux.org/pacman/pacman.conf.5.html'
- aliases = ['pacmanconf']
- filenames = ['pacman.conf']
- mimetypes = []
-
- tokens = {
- 'root': [
- # comment
- (r'#.*$', Comment.Single),
-
- # section header
- (r'^(\s*)(\[.*?\])(\s*)$', bygroups(Whitespace, Keyword, Whitespace)),
-
- # variable definitions
- # (Leading space is allowed...)
- (r'(\w+)(\s*)(=)',
- bygroups(Name.Attribute, Whitespace, Operator)),
-
- # flags to on
- (r'^(\s*)(\w+)(\s*)$',
- bygroups(Whitespace, Name.Attribute, Whitespace)),
-
- # built-in special values
- (words((
- '$repo', # repository
- '$arch', # architecture
- '%o', # outfile
- '%u', # url
- ), suffix=r'\b'),
- Name.Variable),
-
- # fallback
- (r'\s+', Whitespace),
- (r'.', Text),
- ],
- }
-
-
-class AugeasLexer(RegexLexer):
- """
- Lexer for Augeas.
-
- .. versionadded:: 2.4
- """
- name = 'Augeas'
- url = 'http://augeas.net'
- aliases = ['augeas']
- filenames = ['*.aug']
-
- tokens = {
- 'root': [
- (r'(module)(\s*)([^\s=]+)', bygroups(Keyword.Namespace, Whitespace, Name.Namespace)),
- (r'(let)(\s*)([^\s=]+)', bygroups(Keyword.Declaration, Whitespace, Name.Variable)),
- (r'(del|store|value|counter|seq|key|label|autoload|incl|excl|transform|test|get|put)(\s+)', bygroups(Name.Builtin, Whitespace)),
- (r'(\()([^:]+)(\:)(unit|string|regexp|lens|tree|filter)(\))', bygroups(Punctuation, Name.Variable, Punctuation, Keyword.Type, Punctuation)),
- (r'\(\*', Comment.Multiline, 'comment'),
- (r'[*+\-.;=?|]', Operator),
- (r'[()\[\]{}]', Operator),
- (r'"', String.Double, 'string'),
- (r'\/', String.Regex, 'regex'),
- (r'([A-Z]\w*)(\.)(\w+)', bygroups(Name.Namespace, Punctuation, Name.Variable)),
- (r'.', Name.Variable),
- (r'\s+', Whitespace),
- ],
- 'string': [
- (r'\\.', String.Escape),
- (r'[^"]', String.Double),
- (r'"', String.Double, '#pop'),
- ],
- 'regex': [
- (r'\\.', String.Escape),
- (r'[^/]', String.Regex),
- (r'\/', String.Regex, '#pop'),
- ],
- 'comment': [
- (r'[^*)]', Comment.Multiline),
- (r'\(\*', Comment.Multiline, '#push'),
- (r'\*\)', Comment.Multiline, '#pop'),
- (r'[)*]', Comment.Multiline)
- ],
- }
-
-
-class TOMLLexer(RegexLexer):
- """
- Lexer for TOML, a simple language
- for config files.
-
- .. versionadded:: 2.4
- """
-
- name = 'TOML'
- url = 'https://github.com/toml-lang/toml'
- aliases = ['toml']
- filenames = ['*.toml', 'Pipfile', 'poetry.lock']
-
- tokens = {
- 'root': [
- # Table
- (r'^(\s*)(\[.*?\])$', bygroups(Whitespace, Keyword)),
-
- # Basics, comments, strings
- (r'[ \t]+', Whitespace),
- (r'\n', Whitespace),
- (r'#.*?$', Comment.Single),
- # Basic string
- (r'"(\\\\|\\[^\\]|[^"\\])*"', String),
- # Literal string
- (r'\'\'\'(.*)\'\'\'', String),
- (r'\'[^\']*\'', String),
- (r'(true|false)$', Keyword.Constant),
- (r'[a-zA-Z_][\w\-]*', Name),
-
- # Datetime
- # TODO this needs to be expanded, as TOML is rather flexible:
- # https://github.com/toml-lang/toml#offset-date-time
- (r'\d{4}-\d{2}-\d{2}(?:T| )\d{2}:\d{2}:\d{2}(?:Z|[-+]\d{2}:\d{2})', Number.Integer),
-
- # Numbers
- (r'(\d+\.\d*|\d*\.\d+)([eE][+-]?[0-9]+)?j?', Number.Float),
- (r'\d+[eE][+-]?[0-9]+j?', Number.Float),
- # Handle +-inf, +-infinity, +-nan
- (r'[+-]?(?:(inf(?:inity)?)|nan)', Number.Float),
- (r'[+-]?\d+', Number.Integer),
-
- # Punctuation
- (r'[]{}:(),;[]', Punctuation),
- (r'\.', Punctuation),
-
- # Operators
- (r'=', Operator)
-
- ]
- }
-
-class NestedTextLexer(RegexLexer):
- """
- Lexer for *NextedText*, a human-friendly data format.
-
- .. versionadded:: 2.9
-
- .. versionchanged:: 2.16
- Added support for *NextedText* v3.0.
- """
-
- name = 'NestedText'
- url = 'https://nestedtext.org'
- aliases = ['nestedtext', 'nt']
- filenames = ['*.nt']
-
- tokens = {
- 'root': [
- # Comment: # ...
- (r'^([ ]*)(#.*)$', bygroups(Whitespace, Comment)),
-
- # Inline dictionary: {...}
- (r'^([ ]*)(\{)', bygroups(Whitespace, Punctuation), 'inline_dict'),
-
- # Inline list: [...]
- (r'^([ ]*)(\[)', bygroups(Whitespace, Punctuation), 'inline_list'),
-
- # empty multiline string item: >
- (r'^([ ]*)(>)$', bygroups(Whitespace, Punctuation)),
-
- # multiline string item: > ...
- (r'^([ ]*)(>)( )(.*?)([ \t]*)$', bygroups(Whitespace, Punctuation, Whitespace, Text, Whitespace)),
-
- # empty list item: -
- (r'^([ ]*)(-)$', bygroups(Whitespace, Punctuation)),
-
- # list item: - ...
- (r'^([ ]*)(-)( )(.*?)([ \t]*)$', bygroups(Whitespace, Punctuation, Whitespace, Text, Whitespace)),
-
- # empty multiline key item: :
- (r'^([ ]*)(:)$', bygroups(Whitespace, Punctuation)),
-
- # multiline key item: : ...
- (r'^([ ]*)(:)( )([^\n]*?)([ \t]*)$', bygroups(Whitespace, Punctuation, Whitespace, Name.Tag, Whitespace)),
-
- # empty dict key item: ...:
- (r'^([ ]*)([^\{\[\s].*?)(:)$', bygroups(Whitespace, Name.Tag, Punctuation)),
-
- # dict key item: ...: ...
- (r'^([ ]*)([^\{\[\s].*?)(:)( )(.*?)([ \t]*)$', bygroups(Whitespace, Name.Tag, Punctuation, Whitespace, Text, Whitespace)),
- ],
- 'inline_list': [
- include('whitespace'),
- (r'[^\{\}\[\],\s]+', Text),
- include('inline_value'),
- (r',', Punctuation),
- (r'\]', Punctuation, '#pop'),
- (r'\n', Error, '#pop'),
- ],
- 'inline_dict': [
- include('whitespace'),
- (r'[^\{\}\[\],:\s]+', Name.Tag),
- (r':', Punctuation, 'inline_dict_value'),
- (r'\}', Punctuation, '#pop'),
- (r'\n', Error, '#pop'),
- ],
- 'inline_dict_value': [
- include('whitespace'),
- (r'[^\{\}\[\],:\s]+', Text),
- include('inline_value'),
- (r',', Punctuation, '#pop'),
- (r'\}', Punctuation, '#pop:2'),
- ],
- 'inline_value': [
- include('whitespace'),
- (r'\{', Punctuation, 'inline_dict'),
- (r'\[', Punctuation, 'inline_list'),
- ],
- 'whitespace': [
- (r'[ \t]+', Whitespace),
- ],
- }
-
-
-class SingularityLexer(RegexLexer):
- """
- Lexer for Singularity definition files.
-
- .. versionadded:: 2.6
- """
-
- name = 'Singularity'
- url = 'https://www.sylabs.io/guides/3.0/user-guide/definition_files.html'
- aliases = ['singularity']
- filenames = ['*.def', 'Singularity']
- flags = re.IGNORECASE | re.MULTILINE | re.DOTALL
-
- _headers = r'^(\s*)(bootstrap|from|osversion|mirrorurl|include|registry|namespace|includecmd)(:)'
- _section = r'^(%(?:pre|post|setup|environment|help|labels|test|runscript|files|startscript))(\s*)'
- _appsect = r'^(%app(?:install|help|run|labels|env|test|files))(\s*)'
-
- tokens = {
- 'root': [
- (_section, bygroups(Generic.Heading, Whitespace), 'script'),
- (_appsect, bygroups(Generic.Heading, Whitespace), 'script'),
- (_headers, bygroups(Whitespace, Keyword, Text)),
- (r'\s*#.*?\n', Comment),
- (r'\b(([0-9]+\.?[0-9]*)|(\.[0-9]+))\b', Number),
- (r'[ \t]+', Whitespace),
- (r'(?!^\s*%).', Text),
- ],
- 'script': [
- (r'(.+?(?=^\s*%))|(.*)', using(BashLexer), '#pop'),
- ],
- }
-
- def analyse_text(text):
- """This is a quite simple script file, but there are a few keywords
- which seem unique to this language."""
- result = 0
- if re.search(r'\b(?:osversion|includecmd|mirrorurl)\b', text, re.IGNORECASE):
- result += 0.5
-
- if re.search(SingularityLexer._section[1:], text):
- result += 0.49
-
- return result
-
-
-class UnixConfigLexer(RegexLexer):
- """
- Lexer for Unix/Linux config files using colon-separated values, e.g.
-
- * ``/etc/group``
- * ``/etc/passwd``
- * ``/etc/shadow``
-
- .. versionadded:: 2.12
- """
-
- name = 'Unix/Linux config files'
- aliases = ['unixconfig', 'linuxconfig']
- filenames = []
-
- tokens = {
- 'root': [
- (r'^#.*', Comment),
- (r'\n', Whitespace),
- (r':', Punctuation),
- (r'[0-9]+', Number),
- (r'((?!\n)[a-zA-Z0-9\_\-\s\(\),]){2,}', Text),
- (r'[^:\n]+', String),
- ],
- }
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/verifpal.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/verifpal.py
deleted file mode 100644
index 6953dd7b70e5fbdd051437edbcb7b66c2c3cd67a..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/verifpal.py
+++ /dev/null
@@ -1,66 +0,0 @@
-"""
- pygments.lexers.verifpal
- ~~~~~~~~~~~~~~~~~~~~~~~~
-
- Lexers for Verifpal languages.
-
- :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-from pygments.lexer import RegexLexer, words, bygroups, default
-from pygments.token import Comment, Keyword, Name, String, Punctuation, \
- Whitespace
-
-__all__ = ['VerifpalLexer']
-
-
-class VerifpalLexer(RegexLexer):
- """
- For Verifpal code.
-
- .. versionadded:: 2.16
- """
-
- name = 'Verifpal'
- aliases = ['verifpal']
- filenames = ['*.vp']
- mimetypes = ['text/x-verifpal']
- url = 'https://verifpal.com'
-
- tokens = {
- 'root': [
- (r'//.*$', Comment.Single),
- (r'(principal)( +)(\w+)( *)(\[)(.*)$', bygroups(Name.Builtin, Whitespace, String, Whitespace, Punctuation, Whitespace)),
- (r'(attacker)( *)(\[)( *)(passive|active)( *)(\])( *)$', bygroups(Name.Builtin, Whitespace, Punctuation, Whitespace, String, Whitespace, Punctuation, Whitespace)),
- (r'(knows)( +)(private|public)( +)', bygroups(Name.Builtin, Whitespace, Keyword.Constant, Whitespace), 'shared'),
- (r'(queries)( +)(\[)', bygroups(Name.Builtin, Whitespace, Punctuation), 'queries'),
- (r'(\w+)( +)(->|→)( *)(\w+)( *)(\:)', bygroups(String, Whitespace, Punctuation, Whitespace, String, Whitespace, Punctuation), 'shared'),
- (words(('generates', 'leaks'), suffix=r'\b'), Name.Builtin, 'shared'),
- (words(( 'phase', 'precondition',), suffix=r'\b'), Name.Builtin),
- (r'[\[\(\)\]\?:=→^,]', Punctuation),
- (r'->', Punctuation),
- (words(('password',), suffix=r'\b'), Keyword.Constant),
- (words(('AEAD_DEC', 'AEAD_ENC', 'ASSERT', 'BLIND', 'CONCAT',
- 'DEC', 'ENC', 'G', 'HASH', 'HKDF', 'MAC', 'PKE_DEC',
- 'PKE_ENC', 'PW_HASH', 'RINGSIGN', 'RINGSIGNVERIF',
- 'SHAMIR_JOIN', 'SHAMIR_SPLIT', 'SIGN', 'SIGNVERIF',
- 'SPLIT', 'UNBLIND', '_', 'nil'), suffix=r'\b'),
- Name.Function),
- (r'\s+', Whitespace),
- (r'\w+', Name.Variable),
- ],
- 'shared': [
- (r'[\^\[\],]', Punctuation),
- (r' +', Whitespace),
- (r'\w+', Name.Variable),
- default('#pop')
- ],
- 'queries': [
- (r'\s+', Name.Variable),
- (words(('confidentiality?', 'authentication?', 'freshness?',
- 'unlinkability?', 'equivalence?'), suffix='( )'),
- bygroups(Keyword.Pseudo, Whitespace), 'shared'),
- default('#pop')
- ]
- }
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/tomlkit/parser.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/tomlkit/parser.py
deleted file mode 100644
index bdf0c4a2313b27e759822cd3df583d86c1a176c1..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/tomlkit/parser.py
+++ /dev/null
@@ -1,1141 +0,0 @@
-from __future__ import annotations
-
-import datetime
-import re
-import string
-
-from tomlkit._compat import decode
-from tomlkit._utils import RFC_3339_LOOSE
-from tomlkit._utils import _escaped
-from tomlkit._utils import parse_rfc3339
-from tomlkit.container import Container
-from tomlkit.exceptions import EmptyKeyError
-from tomlkit.exceptions import EmptyTableNameError
-from tomlkit.exceptions import InternalParserError
-from tomlkit.exceptions import InvalidCharInStringError
-from tomlkit.exceptions import InvalidControlChar
-from tomlkit.exceptions import InvalidDateError
-from tomlkit.exceptions import InvalidDateTimeError
-from tomlkit.exceptions import InvalidNumberError
-from tomlkit.exceptions import InvalidTimeError
-from tomlkit.exceptions import InvalidUnicodeValueError
-from tomlkit.exceptions import ParseError
-from tomlkit.exceptions import UnexpectedCharError
-from tomlkit.exceptions import UnexpectedEofError
-from tomlkit.items import AoT
-from tomlkit.items import Array
-from tomlkit.items import Bool
-from tomlkit.items import BoolType
-from tomlkit.items import Comment
-from tomlkit.items import Date
-from tomlkit.items import DateTime
-from tomlkit.items import Float
-from tomlkit.items import InlineTable
-from tomlkit.items import Integer
-from tomlkit.items import Item
-from tomlkit.items import Key
-from tomlkit.items import KeyType
-from tomlkit.items import Null
-from tomlkit.items import SingleKey
-from tomlkit.items import String
-from tomlkit.items import StringType
-from tomlkit.items import Table
-from tomlkit.items import Time
-from tomlkit.items import Trivia
-from tomlkit.items import Whitespace
-from tomlkit.source import Source
-from tomlkit.toml_char import TOMLChar
-from tomlkit.toml_document import TOMLDocument
-
-
-CTRL_I = 0x09 # Tab
-CTRL_J = 0x0A # Line feed
-CTRL_M = 0x0D # Carriage return
-CTRL_CHAR_LIMIT = 0x1F
-CHR_DEL = 0x7F
-
-
-class Parser:
- """
- Parser for TOML documents.
- """
-
- def __init__(self, string: str | bytes) -> None:
- # Input to parse
- self._src = Source(decode(string))
-
- self._aot_stack: list[Key] = []
-
- @property
- def _state(self):
- return self._src.state
-
- @property
- def _idx(self):
- return self._src.idx
-
- @property
- def _current(self):
- return self._src.current
-
- @property
- def _marker(self):
- return self._src.marker
-
- def extract(self) -> str:
- """
- Extracts the value between marker and index
- """
- return self._src.extract()
-
- def inc(self, exception: type[ParseError] | None = None) -> bool:
- """
- Increments the parser if the end of the input has not been reached.
- Returns whether or not it was able to advance.
- """
- return self._src.inc(exception=exception)
-
- def inc_n(self, n: int, exception: type[ParseError] | None = None) -> bool:
- """
- Increments the parser by n characters
- if the end of the input has not been reached.
- """
- return self._src.inc_n(n=n, exception=exception)
-
- def consume(self, chars, min=0, max=-1):
- """
- Consume chars until min/max is satisfied is valid.
- """
- return self._src.consume(chars=chars, min=min, max=max)
-
- def end(self) -> bool:
- """
- Returns True if the parser has reached the end of the input.
- """
- return self._src.end()
-
- def mark(self) -> None:
- """
- Sets the marker to the index's current position
- """
- self._src.mark()
-
- def parse_error(self, exception=ParseError, *args, **kwargs):
- """
- Creates a generic "parse error" at the current position.
- """
- return self._src.parse_error(exception, *args, **kwargs)
-
- def parse(self) -> TOMLDocument:
- body = TOMLDocument(True)
-
- # Take all keyvals outside of tables/AoT's.
- while not self.end():
- # Break out if a table is found
- if self._current == "[":
- break
-
- # Otherwise, take and append one KV
- item = self._parse_item()
- if not item:
- break
-
- key, value = item
- if (key is not None and key.is_multi()) or not self._merge_ws(value, body):
- # We actually have a table
- try:
- body.append(key, value)
- except Exception as e:
- raise self.parse_error(ParseError, str(e)) from e
-
- self.mark()
-
- while not self.end():
- key, value = self._parse_table()
- if isinstance(value, Table) and value.is_aot_element():
- # This is just the first table in an AoT. Parse the rest of the array
- # along with it.
- value = self._parse_aot(value, key)
-
- try:
- body.append(key, value)
- except Exception as e:
- raise self.parse_error(ParseError, str(e)) from e
-
- body.parsing(False)
-
- return body
-
- def _merge_ws(self, item: Item, container: Container) -> bool:
- """
- Merges the given Item with the last one currently in the given Container if
- both are whitespace items.
-
- Returns True if the items were merged.
- """
- last = container.last_item()
- if not last:
- return False
-
- if not isinstance(item, Whitespace) or not isinstance(last, Whitespace):
- return False
-
- start = self._idx - (len(last.s) + len(item.s))
- container.body[-1] = (
- container.body[-1][0],
- Whitespace(self._src[start : self._idx]),
- )
-
- return True
-
- def _is_child(self, parent: Key, child: Key) -> bool:
- """
- Returns whether a key is strictly a child of another key.
- AoT siblings are not considered children of one another.
- """
- parent_parts = tuple(parent)
- child_parts = tuple(child)
-
- if parent_parts == child_parts:
- return False
-
- return parent_parts == child_parts[: len(parent_parts)]
-
- def _parse_item(self) -> tuple[Key | None, Item] | None:
- """
- Attempts to parse the next item and returns it, along with its key
- if the item is value-like.
- """
- self.mark()
- with self._state as state:
- while True:
- c = self._current
- if c == "\n":
- # Found a newline; Return all whitespace found up to this point.
- self.inc()
-
- return None, Whitespace(self.extract())
- elif c in " \t\r":
- # Skip whitespace.
- if not self.inc():
- return None, Whitespace(self.extract())
- elif c == "#":
- # Found a comment, parse it
- indent = self.extract()
- cws, comment, trail = self._parse_comment_trail()
-
- return None, Comment(Trivia(indent, cws, comment, trail))
- elif c == "[":
- # Found a table, delegate to the calling function.
- return
- else:
- # Beginning of a KV pair.
- # Return to beginning of whitespace so it gets included
- # as indentation for the KV about to be parsed.
- state.restore = True
- break
-
- return self._parse_key_value(True)
-
- def _parse_comment_trail(self, parse_trail: bool = True) -> tuple[str, str, str]:
- """
- Returns (comment_ws, comment, trail)
- If there is no comment, comment_ws and comment will
- simply be empty.
- """
- if self.end():
- return "", "", ""
-
- comment = ""
- comment_ws = ""
- self.mark()
-
- while True:
- c = self._current
-
- if c == "\n":
- break
- elif c == "#":
- comment_ws = self.extract()
-
- self.mark()
- self.inc() # Skip #
-
- # The comment itself
- while not self.end() and not self._current.is_nl():
- code = ord(self._current)
- if code == CHR_DEL or code <= CTRL_CHAR_LIMIT and code != CTRL_I:
- raise self.parse_error(InvalidControlChar, code, "comments")
-
- if not self.inc():
- break
-
- comment = self.extract()
- self.mark()
-
- break
- elif c in " \t\r":
- self.inc()
- else:
- raise self.parse_error(UnexpectedCharError, c)
-
- if self.end():
- break
-
- trail = ""
- if parse_trail:
- while self._current.is_spaces() and self.inc():
- pass
-
- if self._current == "\r":
- self.inc()
-
- if self._current == "\n":
- self.inc()
-
- if self._idx != self._marker or self._current.is_ws():
- trail = self.extract()
-
- return comment_ws, comment, trail
-
- def _parse_key_value(self, parse_comment: bool = False) -> tuple[Key, Item]:
- # Leading indent
- self.mark()
-
- while self._current.is_spaces() and self.inc():
- pass
-
- indent = self.extract()
-
- # Key
- key = self._parse_key()
-
- self.mark()
-
- found_equals = self._current == "="
- while self._current.is_kv_sep() and self.inc():
- if self._current == "=":
- if found_equals:
- raise self.parse_error(UnexpectedCharError, "=")
- else:
- found_equals = True
- if not found_equals:
- raise self.parse_error(UnexpectedCharError, self._current)
-
- if not key.sep:
- key.sep = self.extract()
- else:
- key.sep += self.extract()
-
- # Value
- val = self._parse_value()
- # Comment
- if parse_comment:
- cws, comment, trail = self._parse_comment_trail()
- meta = val.trivia
- if not meta.comment_ws:
- meta.comment_ws = cws
-
- meta.comment = comment
- meta.trail = trail
- else:
- val.trivia.trail = ""
-
- val.trivia.indent = indent
-
- return key, val
-
- def _parse_key(self) -> Key:
- """
- Parses a Key at the current position;
- WS before the key must be exhausted first at the callsite.
- """
- self.mark()
- while self._current.is_spaces() and self.inc():
- # Skip any leading whitespace
- pass
- if self._current in "\"'":
- return self._parse_quoted_key()
- else:
- return self._parse_bare_key()
-
- def _parse_quoted_key(self) -> Key:
- """
- Parses a key enclosed in either single or double quotes.
- """
- # Extract the leading whitespace
- original = self.extract()
- quote_style = self._current
- key_type = next((t for t in KeyType if t.value == quote_style), None)
-
- if key_type is None:
- raise RuntimeError("Should not have entered _parse_quoted_key()")
-
- key_str = self._parse_string(
- StringType.SLB if key_type == KeyType.Basic else StringType.SLL
- )
- if key_str._t.is_multiline():
- raise self.parse_error(UnexpectedCharError, key_str._t.value)
- original += key_str.as_string()
- self.mark()
- while self._current.is_spaces() and self.inc():
- pass
- original += self.extract()
- key = SingleKey(str(key_str), t=key_type, sep="", original=original)
- if self._current == ".":
- self.inc()
- key = key.concat(self._parse_key())
-
- return key
-
- def _parse_bare_key(self) -> Key:
- """
- Parses a bare key.
- """
- while (
- self._current.is_bare_key_char() or self._current.is_spaces()
- ) and self.inc():
- pass
-
- original = self.extract()
- key = original.strip()
- if not key:
- # Empty key
- raise self.parse_error(EmptyKeyError)
-
- if " " in key:
- # Bare key with spaces in it
- raise self.parse_error(ParseError, f'Invalid key "{key}"')
-
- key = SingleKey(key, KeyType.Bare, "", original)
-
- if self._current == ".":
- self.inc()
- key = key.concat(self._parse_key())
-
- return key
-
- def _parse_value(self) -> Item:
- """
- Attempts to parse a value at the current position.
- """
- self.mark()
- c = self._current
- trivia = Trivia()
-
- if c == StringType.SLB.value:
- return self._parse_basic_string()
- elif c == StringType.SLL.value:
- return self._parse_literal_string()
- elif c == BoolType.TRUE.value[0]:
- return self._parse_true()
- elif c == BoolType.FALSE.value[0]:
- return self._parse_false()
- elif c == "[":
- return self._parse_array()
- elif c == "{":
- return self._parse_inline_table()
- elif c in "+-" or self._peek(4) in {
- "+inf",
- "-inf",
- "inf",
- "+nan",
- "-nan",
- "nan",
- }:
- # Number
- while self._current not in " \t\n\r#,]}" and self.inc():
- pass
-
- raw = self.extract()
-
- item = self._parse_number(raw, trivia)
- if item is not None:
- return item
-
- raise self.parse_error(InvalidNumberError)
- elif c in string.digits:
- # Integer, Float, Date, Time or DateTime
- while self._current not in " \t\n\r#,]}" and self.inc():
- pass
-
- raw = self.extract()
-
- m = RFC_3339_LOOSE.match(raw)
- if m:
- if m.group(1) and m.group(5):
- # datetime
- try:
- dt = parse_rfc3339(raw)
- assert isinstance(dt, datetime.datetime)
- return DateTime(
- dt.year,
- dt.month,
- dt.day,
- dt.hour,
- dt.minute,
- dt.second,
- dt.microsecond,
- dt.tzinfo,
- trivia,
- raw,
- )
- except ValueError:
- raise self.parse_error(InvalidDateTimeError)
-
- if m.group(1):
- try:
- dt = parse_rfc3339(raw)
- assert isinstance(dt, datetime.date)
- date = Date(dt.year, dt.month, dt.day, trivia, raw)
- self.mark()
- while self._current not in "\t\n\r#,]}" and self.inc():
- pass
-
- time_raw = self.extract()
- time_part = time_raw.rstrip()
- trivia.comment_ws = time_raw[len(time_part) :]
- if not time_part:
- return date
-
- dt = parse_rfc3339(raw + time_part)
- assert isinstance(dt, datetime.datetime)
- return DateTime(
- dt.year,
- dt.month,
- dt.day,
- dt.hour,
- dt.minute,
- dt.second,
- dt.microsecond,
- dt.tzinfo,
- trivia,
- raw + time_part,
- )
- except ValueError:
- raise self.parse_error(InvalidDateError)
-
- if m.group(5):
- try:
- t = parse_rfc3339(raw)
- assert isinstance(t, datetime.time)
- return Time(
- t.hour,
- t.minute,
- t.second,
- t.microsecond,
- t.tzinfo,
- trivia,
- raw,
- )
- except ValueError:
- raise self.parse_error(InvalidTimeError)
-
- item = self._parse_number(raw, trivia)
- if item is not None:
- return item
-
- raise self.parse_error(InvalidNumberError)
- else:
- raise self.parse_error(UnexpectedCharError, c)
-
- def _parse_true(self):
- return self._parse_bool(BoolType.TRUE)
-
- def _parse_false(self):
- return self._parse_bool(BoolType.FALSE)
-
- def _parse_bool(self, style: BoolType) -> Bool:
- with self._state:
- style = BoolType(style)
-
- # only keep parsing for bool if the characters match the style
- # try consuming rest of chars in style
- for c in style:
- self.consume(c, min=1, max=1)
-
- return Bool(style, Trivia())
-
- def _parse_array(self) -> Array:
- # Consume opening bracket, EOF here is an issue (middle of array)
- self.inc(exception=UnexpectedEofError)
-
- elems: list[Item] = []
- prev_value = None
- while True:
- # consume whitespace
- mark = self._idx
- self.consume(TOMLChar.SPACES + TOMLChar.NL)
- indent = self._src[mark : self._idx]
- newline = set(TOMLChar.NL) & set(indent)
- if newline:
- elems.append(Whitespace(indent))
- continue
-
- # consume comment
- if self._current == "#":
- cws, comment, trail = self._parse_comment_trail(parse_trail=False)
- elems.append(Comment(Trivia(indent, cws, comment, trail)))
- continue
-
- # consume indent
- if indent:
- elems.append(Whitespace(indent))
- continue
-
- # consume value
- if not prev_value:
- try:
- elems.append(self._parse_value())
- prev_value = True
- continue
- except UnexpectedCharError:
- pass
-
- # consume comma
- if prev_value and self._current == ",":
- self.inc(exception=UnexpectedEofError)
- elems.append(Whitespace(","))
- prev_value = False
- continue
-
- # consume closing bracket
- if self._current == "]":
- # consume closing bracket, EOF here doesn't matter
- self.inc()
- break
-
- raise self.parse_error(UnexpectedCharError, self._current)
-
- try:
- res = Array(elems, Trivia())
- except ValueError:
- pass
- else:
- return res
-
- def _parse_inline_table(self) -> InlineTable:
- # consume opening bracket, EOF here is an issue (middle of array)
- self.inc(exception=UnexpectedEofError)
-
- elems = Container(True)
- trailing_comma = None
- while True:
- # consume leading whitespace
- mark = self._idx
- self.consume(TOMLChar.SPACES)
- raw = self._src[mark : self._idx]
- if raw:
- elems.add(Whitespace(raw))
-
- if not trailing_comma:
- # None: empty inline table
- # False: previous key-value pair was not followed by a comma
- if self._current == "}":
- # consume closing bracket, EOF here doesn't matter
- self.inc()
- break
-
- if (
- trailing_comma is False
- or trailing_comma is None
- and self._current == ","
- ):
- # Either the previous key-value pair was not followed by a comma
- # or the table has an unexpected leading comma.
- raise self.parse_error(UnexpectedCharError, self._current)
- else:
- # True: previous key-value pair was followed by a comma
- if self._current == "}" or self._current == ",":
- raise self.parse_error(UnexpectedCharError, self._current)
-
- key, val = self._parse_key_value(False)
- elems.add(key, val)
-
- # consume trailing whitespace
- mark = self._idx
- self.consume(TOMLChar.SPACES)
- raw = self._src[mark : self._idx]
- if raw:
- elems.add(Whitespace(raw))
-
- # consume trailing comma
- trailing_comma = self._current == ","
- if trailing_comma:
- # consume closing bracket, EOF here is an issue (middle of inline table)
- self.inc(exception=UnexpectedEofError)
-
- return InlineTable(elems, Trivia())
-
- def _parse_number(self, raw: str, trivia: Trivia) -> Item | None:
- # Leading zeros are not allowed
- sign = ""
- if raw.startswith(("+", "-")):
- sign = raw[0]
- raw = raw[1:]
-
- if len(raw) > 1 and (
- raw.startswith("0")
- and not raw.startswith(("0.", "0o", "0x", "0b", "0e"))
- or sign
- and raw.startswith(".")
- ):
- return None
-
- if raw.startswith(("0o", "0x", "0b")) and sign:
- return None
-
- digits = "[0-9]"
- base = 10
- if raw.startswith("0b"):
- digits = "[01]"
- base = 2
- elif raw.startswith("0o"):
- digits = "[0-7]"
- base = 8
- elif raw.startswith("0x"):
- digits = "[0-9a-f]"
- base = 16
-
- # Underscores should be surrounded by digits
- clean = re.sub(f"(?i)(?<={digits})_(?={digits})", "", raw).lower()
-
- if "_" in clean:
- return None
-
- if (
- clean.endswith(".")
- or not clean.startswith("0x")
- and clean.split("e", 1)[0].endswith(".")
- ):
- return None
-
- try:
- return Integer(int(sign + clean, base), trivia, sign + raw)
- except ValueError:
- try:
- return Float(float(sign + clean), trivia, sign + raw)
- except ValueError:
- return None
-
- def _parse_literal_string(self) -> String:
- with self._state:
- return self._parse_string(StringType.SLL)
-
- def _parse_basic_string(self) -> String:
- with self._state:
- return self._parse_string(StringType.SLB)
-
- def _parse_escaped_char(self, multiline):
- if multiline and self._current.is_ws():
- # When the last non-whitespace character on a line is
- # a \, it will be trimmed along with all whitespace
- # (including newlines) up to the next non-whitespace
- # character or closing delimiter.
- # """\
- # hello \
- # world"""
- tmp = ""
- while self._current.is_ws():
- tmp += self._current
- # consume the whitespace, EOF here is an issue
- # (middle of string)
- self.inc(exception=UnexpectedEofError)
- continue
-
- # the escape followed by whitespace must have a newline
- # before any other chars
- if "\n" not in tmp:
- raise self.parse_error(InvalidCharInStringError, self._current)
-
- return ""
-
- if self._current in _escaped:
- c = _escaped[self._current]
-
- # consume this char, EOF here is an issue (middle of string)
- self.inc(exception=UnexpectedEofError)
-
- return c
-
- if self._current in {"u", "U"}:
- # this needs to be a unicode
- u, ue = self._peek_unicode(self._current == "U")
- if u is not None:
- # consume the U char and the unicode value
- self.inc_n(len(ue) + 1)
-
- return u
-
- raise self.parse_error(InvalidUnicodeValueError)
-
- raise self.parse_error(InvalidCharInStringError, self._current)
-
- def _parse_string(self, delim: StringType) -> String:
- # only keep parsing for string if the current character matches the delim
- if self._current != delim.unit:
- raise self.parse_error(
- InternalParserError,
- f"Invalid character for string type {delim}",
- )
-
- # consume the opening/first delim, EOF here is an issue
- # (middle of string or middle of delim)
- self.inc(exception=UnexpectedEofError)
-
- if self._current == delim.unit:
- # consume the closing/second delim, we do not care if EOF occurs as
- # that would simply imply an empty single line string
- if not self.inc() or self._current != delim.unit:
- # Empty string
- return String(delim, "", "", Trivia())
-
- # consume the third delim, EOF here is an issue (middle of string)
- self.inc(exception=UnexpectedEofError)
-
- delim = delim.toggle() # convert delim to multi delim
-
- self.mark() # to extract the original string with whitespace and all
- value = ""
-
- # A newline immediately following the opening delimiter will be trimmed.
- if delim.is_multiline():
- if self._current == "\n":
- # consume the newline, EOF here is an issue (middle of string)
- self.inc(exception=UnexpectedEofError)
- else:
- cur = self._current
- with self._state(restore=True):
- if self.inc():
- cur += self._current
- if cur == "\r\n":
- self.inc_n(2, exception=UnexpectedEofError)
-
- escaped = False # whether the previous key was ESCAPE
- while True:
- code = ord(self._current)
- if (
- delim.is_singleline()
- and not escaped
- and (code == CHR_DEL or code <= CTRL_CHAR_LIMIT and code != CTRL_I)
- ) or (
- delim.is_multiline()
- and not escaped
- and (
- code == CHR_DEL
- or code <= CTRL_CHAR_LIMIT
- and code not in [CTRL_I, CTRL_J, CTRL_M]
- )
- ):
- raise self.parse_error(InvalidControlChar, code, "strings")
- elif not escaped and self._current == delim.unit:
- # try to process current as a closing delim
- original = self.extract()
-
- close = ""
- if delim.is_multiline():
- # Consume the delimiters to see if we are at the end of the string
- close = ""
- while self._current == delim.unit:
- close += self._current
- self.inc()
-
- if len(close) < 3:
- # Not a triple quote, leave in result as-is.
- # Adding back the characters we already consumed
- value += close
- continue
-
- if len(close) == 3:
- # We are at the end of the string
- return String(delim, value, original, Trivia())
-
- if len(close) >= 6:
- raise self.parse_error(InvalidCharInStringError, self._current)
-
- value += close[:-3]
- original += close[:-3]
-
- return String(delim, value, original, Trivia())
- else:
- # consume the closing delim, we do not care if EOF occurs as
- # that would simply imply the end of self._src
- self.inc()
-
- return String(delim, value, original, Trivia())
- elif delim.is_basic() and escaped:
- # attempt to parse the current char as an escaped value, an exception
- # is raised if this fails
- value += self._parse_escaped_char(delim.is_multiline())
-
- # no longer escaped
- escaped = False
- elif delim.is_basic() and self._current == "\\":
- # the next char is being escaped
- escaped = True
-
- # consume this char, EOF here is an issue (middle of string)
- self.inc(exception=UnexpectedEofError)
- else:
- # this is either a literal string where we keep everything as is,
- # or this is not a special escaped char in a basic string
- value += self._current
-
- # consume this char, EOF here is an issue (middle of string)
- self.inc(exception=UnexpectedEofError)
-
- def _parse_table(
- self, parent_name: Key | None = None, parent: Table | None = None
- ) -> tuple[Key, Table | AoT]:
- """
- Parses a table element.
- """
- if self._current != "[":
- raise self.parse_error(
- InternalParserError, "_parse_table() called on non-bracket character."
- )
-
- indent = self.extract()
- self.inc() # Skip opening bracket
-
- if self.end():
- raise self.parse_error(UnexpectedEofError)
-
- is_aot = False
- if self._current == "[":
- if not self.inc():
- raise self.parse_error(UnexpectedEofError)
-
- is_aot = True
- try:
- key = self._parse_key()
- except EmptyKeyError:
- raise self.parse_error(EmptyTableNameError) from None
- if self.end():
- raise self.parse_error(UnexpectedEofError)
- elif self._current != "]":
- raise self.parse_error(UnexpectedCharError, self._current)
-
- key.sep = ""
- full_key = key
- name_parts = tuple(key)
- if any(" " in part.key.strip() and part.is_bare() for part in name_parts):
- raise self.parse_error(
- ParseError, f'Invalid table name "{full_key.as_string()}"'
- )
-
- missing_table = False
- if parent_name:
- parent_name_parts = tuple(parent_name)
- else:
- parent_name_parts = ()
-
- if len(name_parts) > len(parent_name_parts) + 1:
- missing_table = True
-
- name_parts = name_parts[len(parent_name_parts) :]
-
- values = Container(True)
-
- self.inc() # Skip closing bracket
- if is_aot:
- # TODO: Verify close bracket
- self.inc()
-
- cws, comment, trail = self._parse_comment_trail()
-
- result = Null()
- table = Table(
- values,
- Trivia(indent, cws, comment, trail),
- is_aot,
- name=name_parts[0].key if name_parts else key.key,
- display_name=full_key.as_string(),
- is_super_table=False,
- )
-
- if len(name_parts) > 1:
- if missing_table:
- # Missing super table
- # i.e. a table initialized like this: [foo.bar]
- # without initializing [foo]
- #
- # So we have to create the parent tables
- table = Table(
- Container(True),
- Trivia("", cws, comment, trail),
- is_aot and name_parts[0] in self._aot_stack,
- is_super_table=True,
- name=name_parts[0].key,
- )
-
- result = table
- key = name_parts[0]
-
- for i, _name in enumerate(name_parts[1:]):
- child = table.get(
- _name,
- Table(
- Container(True),
- Trivia(indent, cws, comment, trail),
- is_aot and i == len(name_parts) - 2,
- is_super_table=i < len(name_parts) - 2,
- name=_name.key,
- display_name=full_key.as_string()
- if i == len(name_parts) - 2
- else None,
- ),
- )
-
- if is_aot and i == len(name_parts) - 2:
- table.raw_append(_name, AoT([child], name=table.name, parsed=True))
- else:
- table.raw_append(_name, child)
-
- table = child
- values = table.value
- else:
- if name_parts:
- key = name_parts[0]
-
- while not self.end():
- item = self._parse_item()
- if item:
- _key, item = item
- if not self._merge_ws(item, values):
- table.raw_append(_key, item)
- else:
- if self._current == "[":
- _, key_next = self._peek_table()
-
- if self._is_child(full_key, key_next):
- key_next, table_next = self._parse_table(full_key, table)
-
- table.raw_append(key_next, table_next)
-
- # Picking up any sibling
- while not self.end():
- _, key_next = self._peek_table()
-
- if not self._is_child(full_key, key_next):
- break
-
- key_next, table_next = self._parse_table(full_key, table)
-
- table.raw_append(key_next, table_next)
-
- break
- else:
- raise self.parse_error(
- InternalParserError,
- "_parse_item() returned None on a non-bracket character.",
- )
-
- if isinstance(result, Null):
- result = table
-
- if is_aot and (not self._aot_stack or full_key != self._aot_stack[-1]):
- result = self._parse_aot(result, full_key)
-
- return key, result
-
- def _peek_table(self) -> tuple[bool, Key]:
- """
- Peeks ahead non-intrusively by cloning then restoring the
- initial state of the parser.
-
- Returns the name of the table about to be parsed,
- as well as whether it is part of an AoT.
- """
- # we always want to restore after exiting this scope
- with self._state(save_marker=True, restore=True):
- if self._current != "[":
- raise self.parse_error(
- InternalParserError,
- "_peek_table() entered on non-bracket character",
- )
-
- # AoT
- self.inc()
- is_aot = False
- if self._current == "[":
- self.inc()
- is_aot = True
- try:
- return is_aot, self._parse_key()
- except EmptyKeyError:
- raise self.parse_error(EmptyTableNameError) from None
-
- def _parse_aot(self, first: Table, name_first: Key) -> AoT:
- """
- Parses all siblings of the provided table first and bundles them into
- an AoT.
- """
- payload = [first]
- self._aot_stack.append(name_first)
- while not self.end():
- is_aot_next, name_next = self._peek_table()
- if is_aot_next and name_next == name_first:
- _, table = self._parse_table(name_first)
- payload.append(table)
- else:
- break
-
- self._aot_stack.pop()
-
- return AoT(payload, parsed=True)
-
- def _peek(self, n: int) -> str:
- """
- Peeks ahead n characters.
-
- n is the max number of characters that will be peeked.
- """
- # we always want to restore after exiting this scope
- with self._state(restore=True):
- buf = ""
- for _ in range(n):
- if self._current not in " \t\n\r#,]}" + self._src.EOF:
- buf += self._current
- self.inc()
- continue
-
- break
- return buf
-
- def _peek_unicode(self, is_long: bool) -> tuple[str | None, str | None]:
- """
- Peeks ahead non-intrusively by cloning then restoring the
- initial state of the parser.
-
- Returns the unicode value is it's a valid one else None.
- """
- # we always want to restore after exiting this scope
- with self._state(save_marker=True, restore=True):
- if self._current not in {"u", "U"}:
- raise self.parse_error(
- InternalParserError, "_peek_unicode() entered on non-unicode value"
- )
-
- self.inc() # Dropping prefix
- self.mark()
-
- if is_long:
- chars = 8
- else:
- chars = 4
-
- if not self.inc_n(chars):
- value, extracted = None, None
- else:
- extracted = self.extract()
-
- if extracted[0].lower() == "d" and extracted[1].strip("01234567"):
- return None, None
-
- try:
- value = chr(int(extracted, 16))
- except (ValueError, OverflowError):
- value = None
-
- return value, extracted
diff --git a/spaces/qingxu98/gpt-academic/themes/contrast.css b/spaces/qingxu98/gpt-academic/themes/contrast.css
deleted file mode 100644
index 22d5d480d3e861d8fe6aa678d3fc1aff379abe37..0000000000000000000000000000000000000000
--- a/spaces/qingxu98/gpt-academic/themes/contrast.css
+++ /dev/null
@@ -1,482 +0,0 @@
-:root {
- --body-text-color: #FFFFFF;
- --link-text-color: #FFFFFF;
- --link-text-color-active: #FFFFFF;
- --link-text-color-hover: #FFFFFF;
- --link-text-color-visited: #FFFFFF;
- --body-text-color-subdued: #FFFFFF;
- --block-info-text-color: #FFFFFF;
- --block-label-text-color: #FFFFFF;
- --block-title-text-color: #FFFFFF;
- --checkbox-label-text-color: #FFFFFF;
- --checkbox-label-text-color-selected: #FFFFFF;
- --error-text-color: #FFFFFF;
- --button-cancel-text-color: #FFFFFF;
- --button-cancel-text-color-hover: #FFFFFF;
- --button-primary-text-color: #FFFFFF;
- --button-primary-text-color-hover: #FFFFFF;
- --button-secondary-text-color: #FFFFFF;
- --button-secondary-text-color-hover: #FFFFFF;
-
-
- --border-bottom-right-radius: 0px;
- --border-bottom-left-radius: 0px;
- --border-top-right-radius: 0px;
- --border-top-left-radius: 0px;
- --block-radius: 0px;
- --button-large-radius: 0px;
- --button-small-radius: 0px;
- --block-background-fill: #000000;
-
- --border-color-accent: #3cff00;
- --border-color-primary: #3cff00;
- --block-border-color: #3cff00;
- --block-label-border-color: #3cff00;
- --block-title-border-color: #3cff00;
- --panel-border-color: #3cff00;
- --checkbox-border-color: #3cff00;
- --checkbox-border-color-focus: #3cff00;
- --checkbox-border-color-hover: #3cff00;
- --checkbox-border-color-selected: #3cff00;
- --checkbox-label-border-color: #3cff00;
- --checkbox-label-border-color-hover: #3cff00;
- --error-border-color: #3cff00;
- --input-border-color: #3cff00;
- --input-border-color-focus: #3cff00;
- --input-border-color-hover: #3cff00;
- --table-border-color: #3cff00;
- --button-cancel-border-color: #3cff00;
- --button-cancel-border-color-hover: #3cff00;
- --button-primary-border-color: #3cff00;
- --button-primary-border-color-hover: #3cff00;
- --button-secondary-border-color: #3cff00;
- --button-secondary-border-color-hover: #3cff00;
-
-
- --body-background-fill: #000000;
- --background-fill-primary: #000000;
- --background-fill-secondary: #000000;
- --block-background-fill: #000000;
- --block-label-background-fill: #000000;
- --block-title-background-fill: #000000;
- --panel-background-fill: #000000;
- --chatbot-code-background-color: #000000;
- --checkbox-background-color: #000000;
- --checkbox-background-color-focus: #000000;
- --checkbox-background-color-hover: #000000;
- --checkbox-background-color-selected: #000000;
- --checkbox-label-background-fill: #000000;
- --checkbox-label-background-fill-hover: #000000;
- --checkbox-label-background-fill-selected: #000000;
- --error-background-fill: #000000;
- --input-background-fill: #000000;
- --input-background-fill-focus: #000000;
- --input-background-fill-hover: #000000;
- --stat-background-fill: #000000;
- --table-even-background-fill: #000000;
- --table-odd-background-fill: #000000;
- --button-cancel-background-fill: #000000;
- --button-cancel-background-fill-hover: #000000;
- --button-primary-background-fill: #000000;
- --button-primary-background-fill-hover: #000000;
- --button-secondary-background-fill: #000000;
- --button-secondary-background-fill-hover: #000000;
- --color-accent-soft: #000000;
-}
-
-.dark {
- --body-text-color: #FFFFFF;
- --link-text-color: #FFFFFF;
- --link-text-color-active: #FFFFFF;
- --link-text-color-hover: #FFFFFF;
- --link-text-color-visited: #FFFFFF;
- --body-text-color-subdued: #FFFFFF;
- --block-info-text-color: #FFFFFF;
- --block-label-text-color: #FFFFFF;
- --block-title-text-color: #FFFFFF;
- --checkbox-label-text-color: #FFFFFF;
- --checkbox-label-text-color-selected: #FFFFFF;
- --error-text-color: #FFFFFF;
- --button-cancel-text-color: #FFFFFF;
- --button-cancel-text-color-hover: #FFFFFF;
- --button-primary-text-color: #FFFFFF;
- --button-primary-text-color-hover: #FFFFFF;
- --button-secondary-text-color: #FFFFFF;
- --button-secondary-text-color-hover: #FFFFFF;
-
-
-
- --border-bottom-right-radius: 0px;
- --border-bottom-left-radius: 0px;
- --border-top-right-radius: 0px;
- --border-top-left-radius: 0px;
- --block-radius: 0px;
- --button-large-radius: 0px;
- --button-small-radius: 0px;
- --block-background-fill: #000000;
-
- --border-color-accent: #3cff00;
- --border-color-primary: #3cff00;
- --block-border-color: #3cff00;
- --block-label-border-color: #3cff00;
- --block-title-border-color: #3cff00;
- --panel-border-color: #3cff00;
- --checkbox-border-color: #3cff00;
- --checkbox-border-color-focus: #3cff00;
- --checkbox-border-color-hover: #3cff00;
- --checkbox-border-color-selected: #3cff00;
- --checkbox-label-border-color: #3cff00;
- --checkbox-label-border-color-hover: #3cff00;
- --error-border-color: #3cff00;
- --input-border-color: #3cff00;
- --input-border-color-focus: #3cff00;
- --input-border-color-hover: #3cff00;
- --table-border-color: #3cff00;
- --button-cancel-border-color: #3cff00;
- --button-cancel-border-color-hover: #3cff00;
- --button-primary-border-color: #3cff00;
- --button-primary-border-color-hover: #3cff00;
- --button-secondary-border-color: #3cff00;
- --button-secondary-border-color-hover: #3cff00;
-
-
- --body-background-fill: #000000;
- --background-fill-primary: #000000;
- --background-fill-secondary: #000000;
- --block-background-fill: #000000;
- --block-label-background-fill: #000000;
- --block-title-background-fill: #000000;
- --panel-background-fill: #000000;
- --chatbot-code-background-color: #000000;
- --checkbox-background-color: #000000;
- --checkbox-background-color-focus: #000000;
- --checkbox-background-color-hover: #000000;
- --checkbox-background-color-selected: #000000;
- --checkbox-label-background-fill: #000000;
- --checkbox-label-background-fill-hover: #000000;
- --checkbox-label-background-fill-selected: #000000;
- --error-background-fill: #000000;
- --input-background-fill: #000000;
- --input-background-fill-focus: #000000;
- --input-background-fill-hover: #000000;
- --stat-background-fill: #000000;
- --table-even-background-fill: #000000;
- --table-odd-background-fill: #000000;
- --button-cancel-background-fill: #000000;
- --button-cancel-background-fill-hover: #000000;
- --button-primary-background-fill: #000000;
- --button-primary-background-fill-hover: #000000;
- --button-secondary-background-fill: #000000;
- --button-secondary-background-fill-hover: #000000;
- --color-accent-soft: #000000;
-}
-
-
-
-.block.svelte-mppz8v {
- border-color: #3cff00;
-}
-
-/* 插件下拉菜单 */
-#plugin-panel .wrap.svelte-aqlk7e.svelte-aqlk7e.svelte-aqlk7e {
- box-shadow: var(--input-shadow);
- border: var(--input-border-width) dashed var(--border-color-primary);
- border-radius: 4px;
-}
-
-#plugin-panel .dropdown-arrow.svelte-p5edak {
- width: 50px;
-}
-#plugin-panel input.svelte-aqlk7e.svelte-aqlk7e.svelte-aqlk7e {
- padding-left: 5px;
-}
-.root{
- border-bottom-right-radius: 0px;
- border-bottom-left-radius: 0px;
- border-top-right-radius: 0px;
- border-top-left-radius: 0px;
-}
-
-/* 小按钮 */
-.sm {
- font-family: "Microsoft YaHei UI", "Helvetica", "Microsoft YaHei", "ui-sans-serif", "sans-serif", "system-ui";
- --button-small-text-weight: 600;
- --button-small-text-size: 16px;
- border-bottom-right-radius: 0px;
- border-bottom-left-radius: 0px;
- border-top-right-radius: 0px;
- border-top-left-radius: 0px;
-}
-
-#plugin-panel .sm {
- font-family: "Microsoft YaHei UI", "Helvetica", "Microsoft YaHei", "ui-sans-serif", "sans-serif", "system-ui";
- --button-small-text-weight: 400;
- --button-small-text-size: 14px;
- border-bottom-right-radius: 0px;
- border-bottom-left-radius: 0px;
- border-top-right-radius: 0px;
- border-top-left-radius: 0px;
-}
-
-.wrap-inner.svelte-aqlk7e.svelte-aqlk7e.svelte-aqlk7e {
- padding: 0%;
-}
-
-.markdown-body table {
- margin: 1em 0;
- border-collapse: collapse;
- empty-cells: show;
-}
-
-.markdown-body th, .markdown-body td {
- border: 1.2px solid var(--border-color-primary);
- padding: 5px;
-}
-
-.markdown-body thead {
- background-color: rgb(0, 0, 0);
-}
-
-.markdown-body thead th {
- padding: .5em .2em;
-}
-
-.normal_mut_select .svelte-1gfkn6j {
- float: left;
- width: auto;
- line-height: 260% !important;
-}
-
-.markdown-body ol, .markdown-body ul {
- padding-inline-start: 2em !important;
-}
-
-/* chat box. */
-[class *= "message"] {
- border-radius: var(--radius-xl) !important;
- /* padding: var(--spacing-xl) !important; */
- /* font-size: var(--text-md) !important; */
- /* line-height: var(--line-md) !important; */
- /* min-height: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl)); */
- /* min-width: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl)); */
-}
-[data-testid = "bot"] {
- max-width: 95%;
- /* width: auto !important; */
- border-bottom-left-radius: 0 !important;
-}
-[data-testid = "user"] {
- max-width: 100%;
- /* width: auto !important; */
- border-bottom-right-radius: 0 !important;
-}
-
-/* linein code block. */
-.markdown-body code {
- display: inline;
- white-space: break-spaces;
- border-radius: 6px;
- margin: 0 2px 0 2px;
- padding: .2em .4em .1em .4em;
- background-color: rgba(0, 0, 0, 0.95);
- color: #c9d1d9;
-}
-
-.dark .markdown-body code {
- display: inline;
- white-space: break-spaces;
- border-radius: 6px;
- margin: 0 2px 0 2px;
- padding: .2em .4em .1em .4em;
- background-color: rgba(0,0,0,0.2);
-}
-
-/* code block css */
-.markdown-body pre code {
- display: block;
- overflow: auto;
- white-space: pre;
- background-color: rgba(0, 0, 0, 0.95);
- border-radius: 10px;
- padding: 1em;
- margin: 1em 2em 1em 0.5em;
-}
-
-.dark .markdown-body pre code {
- display: block;
- overflow: auto;
- white-space: pre;
- background-color: rgba(0,0,0,0.2);
- border-radius: 10px;
- padding: 1em;
- margin: 1em 2em 1em 0.5em;
-}
-
-/* .mic-wrap.svelte-1thnwz {
-
-} */
-.block.svelte-mppz8v > .mic-wrap.svelte-1thnwz{
- justify-content: center;
- display: flex;
- padding: 0;
-
-}
-
-.codehilite .hll { background-color: #6e7681 }
-.codehilite .c { color: #8b949e; font-style: italic } /* Comment */
-.codehilite .err { color: #f85149 } /* Error */
-.codehilite .esc { color: #c9d1d9 } /* Escape */
-.codehilite .g { color: #c9d1d9 } /* Generic */
-.codehilite .k { color: #ff7b72 } /* Keyword */
-.codehilite .l { color: #a5d6ff } /* Literal */
-.codehilite .n { color: #c9d1d9 } /* Name */
-.codehilite .o { color: #ff7b72; font-weight: bold } /* Operator */
-.codehilite .x { color: #c9d1d9 } /* Other */
-.codehilite .p { color: #c9d1d9 } /* Punctuation */
-.codehilite .ch { color: #8b949e; font-style: italic } /* Comment.Hashbang */
-.codehilite .cm { color: #8b949e; font-style: italic } /* Comment.Multiline */
-.codehilite .cp { color: #8b949e; font-weight: bold; font-style: italic } /* Comment.Preproc */
-.codehilite .cpf { color: #8b949e; font-style: italic } /* Comment.PreprocFile */
-.codehilite .c1 { color: #8b949e; font-style: italic } /* Comment.Single */
-.codehilite .cs { color: #8b949e; font-weight: bold; font-style: italic } /* Comment.Special */
-.codehilite .gd { color: #ffa198; background-color: #490202 } /* Generic.Deleted */
-.codehilite .ge { color: #c9d1d9; font-style: italic } /* Generic.Emph */
-.codehilite .gr { color: #ffa198 } /* Generic.Error */
-.codehilite .gh { color: #79c0ff; font-weight: bold } /* Generic.Heading */
-.codehilite .gi { color: #56d364; background-color: #0f5323 } /* Generic.Inserted */
-.codehilite .go { color: #8b949e } /* Generic.Output */
-.codehilite .gp { color: #8b949e } /* Generic.Prompt */
-.codehilite .gs { color: #c9d1d9; font-weight: bold } /* Generic.Strong */
-.codehilite .gu { color: #79c0ff } /* Generic.Subheading */
-.codehilite .gt { color: #ff7b72 } /* Generic.Traceback */
-.codehilite .g-Underline { color: #c9d1d9; text-decoration: underline } /* Generic.Underline */
-.codehilite .kc { color: #79c0ff } /* Keyword.Constant */
-.codehilite .kd { color: #ff7b72 } /* Keyword.Declaration */
-.codehilite .kn { color: #ff7b72 } /* Keyword.Namespace */
-.codehilite .kp { color: #79c0ff } /* Keyword.Pseudo */
-.codehilite .kr { color: #ff7b72 } /* Keyword.Reserved */
-.codehilite .kt { color: #ff7b72 } /* Keyword.Type */
-.codehilite .ld { color: #79c0ff } /* Literal.Date */
-.codehilite .m { color: #a5d6ff } /* Literal.Number */
-.codehilite .s { color: #a5d6ff } /* Literal.String */
-.codehilite .na { color: #c9d1d9 } /* Name.Attribute */
-.codehilite .nb { color: #c9d1d9 } /* Name.Builtin */
-.codehilite .nc { color: #f0883e; font-weight: bold } /* Name.Class */
-.codehilite .no { color: #79c0ff; font-weight: bold } /* Name.Constant */
-.codehilite .nd { color: #d2a8ff; font-weight: bold } /* Name.Decorator */
-.codehilite .ni { color: #ffa657 } /* Name.Entity */
-.codehilite .ne { color: #f0883e; font-weight: bold } /* Name.Exception */
-.codehilite .nf { color: #d2a8ff; font-weight: bold } /* Name.Function */
-.codehilite .nl { color: #79c0ff; font-weight: bold } /* Name.Label */
-.codehilite .nn { color: #ff7b72 } /* Name.Namespace */
-.codehilite .nx { color: #c9d1d9 } /* Name.Other */
-.codehilite .py { color: #79c0ff } /* Name.Property */
-.codehilite .nt { color: #7ee787 } /* Name.Tag */
-.codehilite .nv { color: #79c0ff } /* Name.Variable */
-.codehilite .ow { color: #ff7b72; font-weight: bold } /* Operator.Word */
-.codehilite .pm { color: #c9d1d9 } /* Punctuation.Marker */
-.codehilite .w { color: #6e7681 } /* Text.Whitespace */
-.codehilite .mb { color: #a5d6ff } /* Literal.Number.Bin */
-.codehilite .mf { color: #a5d6ff } /* Literal.Number.Float */
-.codehilite .mh { color: #a5d6ff } /* Literal.Number.Hex */
-.codehilite .mi { color: #a5d6ff } /* Literal.Number.Integer */
-.codehilite .mo { color: #a5d6ff } /* Literal.Number.Oct */
-.codehilite .sa { color: #79c0ff } /* Literal.String.Affix */
-.codehilite .sb { color: #a5d6ff } /* Literal.String.Backtick */
-.codehilite .sc { color: #a5d6ff } /* Literal.String.Char */
-.codehilite .dl { color: #79c0ff } /* Literal.String.Delimiter */
-.codehilite .sd { color: #a5d6ff } /* Literal.String.Doc */
-.codehilite .s2 { color: #a5d6ff } /* Literal.String.Double */
-.codehilite .se { color: #79c0ff } /* Literal.String.Escape */
-.codehilite .sh { color: #79c0ff } /* Literal.String.Heredoc */
-.codehilite .si { color: #a5d6ff } /* Literal.String.Interpol */
-.codehilite .sx { color: #a5d6ff } /* Literal.String.Other */
-.codehilite .sr { color: #79c0ff } /* Literal.String.Regex */
-.codehilite .s1 { color: #a5d6ff } /* Literal.String.Single */
-.codehilite .ss { color: #a5d6ff } /* Literal.String.Symbol */
-.codehilite .bp { color: #c9d1d9 } /* Name.Builtin.Pseudo */
-.codehilite .fm { color: #d2a8ff; font-weight: bold } /* Name.Function.Magic */
-.codehilite .vc { color: #79c0ff } /* Name.Variable.Class */
-.codehilite .vg { color: #79c0ff } /* Name.Variable.Global */
-.codehilite .vi { color: #79c0ff } /* Name.Variable.Instance */
-.codehilite .vm { color: #79c0ff } /* Name.Variable.Magic */
-.codehilite .il { color: #a5d6ff } /* Literal.Number.Integer.Long */
-
-.dark .codehilite .hll { background-color: #2C3B41 }
-.dark .codehilite .c { color: #79d618; font-style: italic } /* Comment */
-.dark .codehilite .err { color: #FF5370 } /* Error */
-.dark .codehilite .esc { color: #89DDFF } /* Escape */
-.dark .codehilite .g { color: #EEFFFF } /* Generic */
-.dark .codehilite .k { color: #BB80B3 } /* Keyword */
-.dark .codehilite .l { color: #C3E88D } /* Literal */
-.dark .codehilite .n { color: #EEFFFF } /* Name */
-.dark .codehilite .o { color: #89DDFF } /* Operator */
-.dark .codehilite .p { color: #89DDFF } /* Punctuation */
-.dark .codehilite .ch { color: #79d618; font-style: italic } /* Comment.Hashbang */
-.dark .codehilite .cm { color: #79d618; font-style: italic } /* Comment.Multiline */
-.dark .codehilite .cp { color: #79d618; font-style: italic } /* Comment.Preproc */
-.dark .codehilite .cpf { color: #79d618; font-style: italic } /* Comment.PreprocFile */
-.dark .codehilite .c1 { color: #79d618; font-style: italic } /* Comment.Single */
-.dark .codehilite .cs { color: #79d618; font-style: italic } /* Comment.Special */
-.dark .codehilite .gd { color: #FF5370 } /* Generic.Deleted */
-.dark .codehilite .ge { color: #89DDFF } /* Generic.Emph */
-.dark .codehilite .gr { color: #FF5370 } /* Generic.Error */
-.dark .codehilite .gh { color: #C3E88D } /* Generic.Heading */
-.dark .codehilite .gi { color: #C3E88D } /* Generic.Inserted */
-.dark .codehilite .go { color: #79d618 } /* Generic.Output */
-.dark .codehilite .gp { color: #FFCB6B } /* Generic.Prompt */
-.dark .codehilite .gs { color: #FF5370 } /* Generic.Strong */
-.dark .codehilite .gu { color: #89DDFF } /* Generic.Subheading */
-.dark .codehilite .gt { color: #FF5370 } /* Generic.Traceback */
-.dark .codehilite .kc { color: #89DDFF } /* Keyword.Constant */
-.dark .codehilite .kd { color: #BB80B3 } /* Keyword.Declaration */
-.dark .codehilite .kn { color: #89DDFF; font-style: italic } /* Keyword.Namespace */
-.dark .codehilite .kp { color: #89DDFF } /* Keyword.Pseudo */
-.dark .codehilite .kr { color: #BB80B3 } /* Keyword.Reserved */
-.dark .codehilite .kt { color: #BB80B3 } /* Keyword.Type */
-.dark .codehilite .ld { color: #C3E88D } /* Literal.Date */
-.dark .codehilite .m { color: #F78C6C } /* Literal.Number */
-.dark .codehilite .s { color: #C3E88D } /* Literal.String */
-.dark .codehilite .na { color: #BB80B3 } /* Name.Attribute */
-.dark .codehilite .nb { color: #82AAFF } /* Name.Builtin */
-.dark .codehilite .nc { color: #FFCB6B } /* Name.Class */
-.dark .codehilite .no { color: #EEFFFF } /* Name.Constant */
-.dark .codehilite .nd { color: #82AAFF } /* Name.Decorator */
-.dark .codehilite .ni { color: #89DDFF } /* Name.Entity */
-.dark .codehilite .ne { color: #FFCB6B } /* Name.Exception */
-.dark .codehilite .nf { color: #82AAFF } /* Name.Function */
-.dark .codehilite .nl { color: #82AAFF } /* Name.Label */
-.dark .codehilite .nn { color: #FFCB6B } /* Name.Namespace */
-.dark .codehilite .nx { color: #EEFFFF } /* Name.Other */
-.dark .codehilite .py { color: #FFCB6B } /* Name.Property */
-.dark .codehilite .nt { color: #FF5370 } /* Name.Tag */
-.dark .codehilite .nv { color: #89DDFF } /* Name.Variable */
-.dark .codehilite .ow { color: #89DDFF; font-style: italic } /* Operator.Word */
-.dark .codehilite .pm { color: #89DDFF } /* Punctuation.Marker */
-.dark .codehilite .w { color: #EEFFFF } /* Text.Whitespace */
-.dark .codehilite .mb { color: #F78C6C } /* Literal.Number.Bin */
-.dark .codehilite .mf { color: #F78C6C } /* Literal.Number.Float */
-.dark .codehilite .mh { color: #F78C6C } /* Literal.Number.Hex */
-.dark .codehilite .mi { color: #F78C6C } /* Literal.Number.Integer */
-.dark .codehilite .mo { color: #F78C6C } /* Literal.Number.Oct */
-.dark .codehilite .sa { color: #BB80B3 } /* Literal.String.Affix */
-.dark .codehilite .sb { color: #C3E88D } /* Literal.String.Backtick */
-.dark .codehilite .sc { color: #C3E88D } /* Literal.String.Char */
-.dark .codehilite .dl { color: #EEFFFF } /* Literal.String.Delimiter */
-.dark .codehilite .sd { color: #79d618; font-style: italic } /* Literal.String.Doc */
-.dark .codehilite .s2 { color: #C3E88D } /* Literal.String.Double */
-.dark .codehilite .se { color: #EEFFFF } /* Literal.String.Escape */
-.dark .codehilite .sh { color: #C3E88D } /* Literal.String.Heredoc */
-.dark .codehilite .si { color: #89DDFF } /* Literal.String.Interpol */
-.dark .codehilite .sx { color: #C3E88D } /* Literal.String.Other */
-.dark .codehilite .sr { color: #89DDFF } /* Literal.String.Regex */
-.dark .codehilite .s1 { color: #C3E88D } /* Literal.String.Single */
-.dark .codehilite .ss { color: #89DDFF } /* Literal.String.Symbol */
-.dark .codehilite .bp { color: #89DDFF } /* Name.Builtin.Pseudo */
-.dark .codehilite .fm { color: #82AAFF } /* Name.Function.Magic */
-.dark .codehilite .vc { color: #89DDFF } /* Name.Variable.Class */
-.dark .codehilite .vg { color: #89DDFF } /* Name.Variable.Global */
-.dark .codehilite .vi { color: #89DDFF } /* Name.Variable.Instance */
-.dark .codehilite .vm { color: #82AAFF } /* Name.Variable.Magic */
-.dark .codehilite .il { color: #F78C6C } /* Literal.Number.Integer.Long */
-
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/BeaTunes 5.0.5 Key - Crackingpatching Serial Key.md b/spaces/quidiaMuxgu/Expedit-SAM/BeaTunes 5.0.5 Key - Crackingpatching Serial Key.md
deleted file mode 100644
index e087ee2dc2629060c3cc246fc66677c5e02b93fc..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/BeaTunes 5.0.5 Key - Crackingpatching Serial Key.md
+++ /dev/null
@@ -1,6 +0,0 @@
-beaTunes 5.0.5 key - Crackingpatching Serial Key
Download ✵✵✵ https://geags.com/2uCsLH
-
- d5da3c52bf
-
-
-
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/Cod Mw3 Multiplayer Patch 1.4 31.md b/spaces/quidiaMuxgu/Expedit-SAM/Cod Mw3 Multiplayer Patch 1.4 31.md
deleted file mode 100644
index 8d7f8832ef6944cec04afb092d00ab1ce837b776..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/Cod Mw3 Multiplayer Patch 1.4 31.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-in order to enable the installation of the product, you must read, acknowledge and agree to be bound by this agreement and the privacy policy. you are also required to possess the most current version of the operating system that the product was designed and/or developed for in order to download and/or use the product. you are also required to install the product and be fully licensed to use the product. anyways, go away.
-the product and/or your use of the product is governed by the following terms and conditions (terms and conditions), the privacy policy and any other terms or policies set forth by activision and any applicable third party (collectively, the “ activision policies”). please use the product only in compliance with the activision policies and applicable law. no provision of the activision policies, whether express or implied, is intended to create any warranty of any kind, whether express, implied, statutory, or otherwise, including but not limited to, any warranty of merchantability or fitness for a particular purpose. the product and use of the product are at your sole discretion and risk.
-Cod mw3 multiplayer patch 1.4 31
Download File 🗹 https://geags.com/2uCqtO
-neither activision nor its licensors or suppliers make any representation or warranty regarding your ability to install or use the product, you ability to access the product or the correctness, validity, or reliability of any information or materials contained in the product. the product may include technical inaccuracies or typographical errors. it may also include viruses, trojan horses, worms, logic bombs, time-bombs, keystroke loggers, spyware, adware, or other harmful, disruptive or unauthorized code. the product may not be identical to the picture or video shown in the products and may include unauthorised additions, alterations and/or omissions. activision and its licensors are not responsible for product that is non-functional or malfunctions.
899543212b
-
-
\ No newline at end of file
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/Download Hitman Absolution Trainer 10433.md b/spaces/quidiaMuxgu/Expedit-SAM/Download Hitman Absolution Trainer 10433.md
deleted file mode 100644
index 5c1692a80b437c1e61277a4e9af89862ce2b21c5..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/Download Hitman Absolution Trainer 10433.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Download Hitman Absolution Trainer 10433
Download File ►►► https://geags.com/2uCr1o
-
-Hitman Absolution V 1.0.433.1 Trainer -- DOWNLOAD c11361aded Hitman Absolution ... 3/3 Download Hitman Absolution Trainer 10433. 4d29de3e1b
-
-
-
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/ESET NOD32 LICENSE KEY UPDATED Nov [NOD32 2021 Keys] 2020 _BEST_.md b/spaces/quidiaMuxgu/Expedit-SAM/ESET NOD32 LICENSE KEY UPDATED Nov [NOD32 2021 Keys] 2020 _BEST_.md
deleted file mode 100644
index da0a8bccd91b310ce94b39e1ff3599a787b8b4d9..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/ESET NOD32 LICENSE KEY UPDATED Nov [NOD32 2021 Keys] 2020 _BEST_.md
+++ /dev/null
@@ -1,6 +0,0 @@
-ESET NOD32 LICENSE KEY UPDATED Nov [NOD32 2021 Keys] 2020
Download Zip 🆓 https://geags.com/2uCsP2
-
- 8a78ff9644
-
-
-
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/Hasrate Baar Baar Yaar Ki Karo Murder 3 Mp3 Song Download WORK.md b/spaces/quidiaMuxgu/Expedit-SAM/Hasrate Baar Baar Yaar Ki Karo Murder 3 Mp3 Song Download WORK.md
deleted file mode 100644
index 5583fe62e97ae43072ee2833929573c834e218b5..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/Hasrate Baar Baar Yaar Ki Karo Murder 3 Mp3 Song Download WORK.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Hasrate Baar Baar Yaar Ki Karo Murder 3 Mp3 Song Download
DOWNLOAD ►►► https://geags.com/2uCr2S
-
-Khwaishe Bar Bar Yar Ki Karo Murder 3 Mp3 Download ->.Genre:,,Peoples. Jul 26, 2017. Download Hasrate Bar Bar Yar Ki karo mp3 song free ... 1fdad05405
-
-
-
diff --git a/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/infer/infer_libs/uvr5_pack/lib_v5/nets_537227KB.py b/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/infer/infer_libs/uvr5_pack/lib_v5/nets_537227KB.py
deleted file mode 100644
index 9bb1df1ee93d3af49725f60ac0b6052e057c6872..0000000000000000000000000000000000000000
--- a/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/infer/infer_libs/uvr5_pack/lib_v5/nets_537227KB.py
+++ /dev/null
@@ -1,122 +0,0 @@
-import torch
-import torch.nn.functional as F
-from torch import nn
-
-from . import layers_537238KB as layers
-
-
-class BaseASPPNet(nn.Module):
- def __init__(self, nin, ch, dilations=(4, 8, 16)):
- super(BaseASPPNet, self).__init__()
- self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
- self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
- self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
- self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
-
- self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
-
- self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
- self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
- self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
- self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
-
- def __call__(self, x):
- h, e1 = self.enc1(x)
- h, e2 = self.enc2(h)
- h, e3 = self.enc3(h)
- h, e4 = self.enc4(h)
-
- h = self.aspp(h)
-
- h = self.dec4(h, e4)
- h = self.dec3(h, e3)
- h = self.dec2(h, e2)
- h = self.dec1(h, e1)
-
- return h
-
-
-class CascadedASPPNet(nn.Module):
- def __init__(self, n_fft):
- super(CascadedASPPNet, self).__init__()
- self.stg1_low_band_net = BaseASPPNet(2, 64)
- self.stg1_high_band_net = BaseASPPNet(2, 64)
-
- self.stg2_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
- self.stg2_full_band_net = BaseASPPNet(32, 64)
-
- self.stg3_bridge = layers.Conv2DBNActiv(130, 64, 1, 1, 0)
- self.stg3_full_band_net = BaseASPPNet(64, 128)
-
- self.out = nn.Conv2d(128, 2, 1, bias=False)
- self.aux1_out = nn.Conv2d(64, 2, 1, bias=False)
- self.aux2_out = nn.Conv2d(64, 2, 1, bias=False)
-
- self.max_bin = n_fft // 2
- self.output_bin = n_fft // 2 + 1
-
- self.offset = 128
-
- def forward(self, x, aggressiveness=None):
- mix = x.detach()
- x = x.clone()
-
- x = x[:, :, : self.max_bin]
-
- bandw = x.size()[2] // 2
- aux1 = torch.cat(
- [
- self.stg1_low_band_net(x[:, :, :bandw]),
- self.stg1_high_band_net(x[:, :, bandw:]),
- ],
- dim=2,
- )
-
- h = torch.cat([x, aux1], dim=1)
- aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
-
- h = torch.cat([x, aux1, aux2], dim=1)
- h = self.stg3_full_band_net(self.stg3_bridge(h))
-
- mask = torch.sigmoid(self.out(h))
- mask = F.pad(
- input=mask,
- pad=(0, 0, 0, self.output_bin - mask.size()[2]),
- mode="replicate",
- )
-
- if self.training:
- aux1 = torch.sigmoid(self.aux1_out(aux1))
- aux1 = F.pad(
- input=aux1,
- pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
- mode="replicate",
- )
- aux2 = torch.sigmoid(self.aux2_out(aux2))
- aux2 = F.pad(
- input=aux2,
- pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
- mode="replicate",
- )
- return mask * mix, aux1 * mix, aux2 * mix
- else:
- if aggressiveness:
- mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
- mask[:, :, : aggressiveness["split_bin"]],
- 1 + aggressiveness["value"] / 3,
- )
- mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
- mask[:, :, aggressiveness["split_bin"] :],
- 1 + aggressiveness["value"],
- )
-
- return mask * mix
-
- def predict(self, x_mag, aggressiveness=None):
- h = self.forward(x_mag, aggressiveness)
-
- if self.offset > 0:
- h = h[:, :, :, self.offset : -self.offset]
- assert h.size()[3] > 0
-
- return h
diff --git a/spaces/rabiyulfahim/Prompt-Refinery-Text-to-Image-Generation/README.md b/spaces/rabiyulfahim/Prompt-Refinery-Text-to-Image-Generation/README.md
deleted file mode 100644
index e3a8ee6d249a62f67095c7b80517c9d1633fb97f..0000000000000000000000000000000000000000
--- a/spaces/rabiyulfahim/Prompt-Refinery-Text-to-Image-Generation/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: ✍️🏭 Prompt-Refinery-Text-to-Image-Generation 🏭✍️ Gradio
-emoji: ✍️Img🏭
-colorFrom: green
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.15.0
-app_file: app.py
-pinned: false
-duplicated_from: awacke1/Prompt-Refinery-Text-to-Image-Generation
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/radames/Real-Time-Latent-Consistency-Model/txt2img/tailwind.config.js b/spaces/radames/Real-Time-Latent-Consistency-Model/txt2img/tailwind.config.js
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/raedeXanto/academic-chatgpt-beta/FIFA.14.Ultimate.Edition-Repack-z10yded Crack Enjoy the Ultimate Soccer Experience on Your Computer.md b/spaces/raedeXanto/academic-chatgpt-beta/FIFA.14.Ultimate.Edition-Repack-z10yded Crack Enjoy the Ultimate Soccer Experience on Your Computer.md
deleted file mode 100644
index 19dc4218cbc01d6ffd425881f3dde5e2d479ab9f..0000000000000000000000000000000000000000
--- a/spaces/raedeXanto/academic-chatgpt-beta/FIFA.14.Ultimate.Edition-Repack-z10yded Crack Enjoy the Ultimate Soccer Experience on Your Computer.md
+++ /dev/null
@@ -1,135 +0,0 @@
-
-FIFA 14 Ultimate Edition Repack z10yded: What You Need to Know
- If you are a fan of soccer games, you have probably heard of FIFA 14 Ultimate Edition Repack z10yded. This is a repack version of the popular FIFA 14 game, which was released in 2013 by EA Sports. A repack is a compressed version of a game that has been modified to reduce its size and improve its performance. In this case, the repack was created by z10yded, a well-known uploader of games on torrent sites.
-FIFA.14.Ultimate.Edition-Repack-z10yded Crack
Download Zip > https://tinourl.com/2uL27F
- But why would you want to download and play this repack? What are the advantages of this version over the original one? And how can you install and enjoy it without any problems? In this article, we will answer these questions and more. We will tell you everything you need to know about FIFA 14 Ultimate Edition Repack z10yded, from its system requirements to its gameplay tips. So, let's get started!
- System Requirements
- Before you download and install FIFA 14 Ultimate Edition Repack z10yded, you need to make sure that your PC can run it smoothly. Here are the minimum and recommended system requirements for this game:
-
-
-| Minimum |
-Recommended |
-
-
-| CPU: 1.8 GHz Core 2 Duo or AMD equivalent |
-CPU: 2.4 GHz Core 2 Quad or AMD equivalent |
-
-
-| RAM: 2 GB |
-RAM: 4 GB |
-
-
-| OS: Windows Vista SP1 / Windows 7/8 |
-OS: Windows 7/8/10 |
-
-
-| Video Card: ATI Radeon HD 3600, NVIDIA GeForce 6800GT with 256 MB VRAM |
-Video Card: ATI Radeon HD 6870, NVIDIA GeForce GTX 460 with 1 GB VRAM |
-
-
-| Sound Card: Compatible with DirectX |
-Sound Card: Compatible with DirectX |
-
-
-| Hard Disk Space: 8 GB |
-Hard Disk Space: 10 GB |
-
-
- To check your system compatibility, you can use a tool like Can You Run It, which will scan your PC and compare it with the game's requirements. If your PC meets or exceeds the recommended specifications, you should be able to play the game without any lag or glitches.
- Installation Guide
- Now that you have verified that your PC can handle FIFA 14 Ultimate Edition Repack z10yded, you can proceed to download and install it. Here are the steps you need to follow:
-
-- Download the repack from a reliable torrent site, such as The Pirate Bay. The file size is about 4.8 GB.
-- Extract the repack using a program like WinRAR. You will get a folder named FIFA_14_Ultimate_Edition_REPACK-Z10YDED.
-- Run setup.exe from the folder and follow the instructions. Choose your preferred language and destination folder. The installation may take some time depending on your PC speed.
-- After the installation is complete, copy the crack file from the folder named Crack and paste it into the game folder where you installed it. Replace the original file when prompted.
-- Run FIFA14.exe from the game folder as administrator. Enjoy!
-
- If you encounter any errors or issues during or after the installation, here are some possible solutions:
-
-- Make sure that your antivirus or firewall is not blocking or deleting any files from the repack or crack.
-- Make sure that you have updated your video card drivers and DirectX.
-- Make sure that you have enough free space on your hard disk.
-- Make sure that you have disabled any background programs that may interfere with the game.
-- If none of these work, try reinstalling the game or downloading another repack from a different source.
-
- Gameplay Tips
- Congratulations! You have successfully installed FIFA 14 Ultimate Edition Repack z10yded on your PC. Now you can enjoy playing one of the best soccer games ever made. Here are some tips to help you get the most out of it:
-
-- FIFA 14 Ultimate Edition Repack z10yded includes all the features and modes of the original game, such as Career Mode, Online Seasons, Ultimate Team, Skill Games, Match Day Live, etc. You can choose whichever mode suits your preference and skill level.
-- The game also includes all the updates and patches that were released for FIFA 14, as well as all the licensed teams, leagues, players, stadiums, kits, etc. You can play with your favorite clubs and stars from around the world.
-- The game features a realistic physics engine that makes every movement and interaction on the pitch more authentic and dynamic. You can control every aspect of your gameplay, from dribbling to shooting to passing to tackling.
-- The game also features an improved AI that makes your opponents more challenging and intelligent. You will have to use your creativity and strategy to outsmart them and score goals.
-- The game allows you to customize your settings and preferences according to your liking. You can adjust the difficulty level, camera angle, controls, audio, graphics, etc.
-- The game also supports online multiplayer mode, where you can play with or against other players from around the world. You can join tournaments, leagues, clubs, etc., or create your own matches with friends.
-- The game also supports modding, where you can add new content or modify existing content using various tools and resources available online. You can download mods from sites like ModdingWay, which offer new teams, players, kits, stadiums, etc.
-
- Conclusion
- In conclusion, FIFA 14 Ultimate Edition Repack z10yded is a great way to experience one of the best soccer games ever made on your PC. It offers a compressed version of the game that has been optimized for performance and quality. It includes all the features and modes of the original game, as well as all the updates and patches that were released for it. It also allows you to customize your settings and preferences according to your liking. It also supports online multiplayer mode and modding.
- If you are looking for a fun and realistic soccer game that will keep you entertained for hours, then FIFA 14 Ultimate Edition Repack z10yded is definitely worth trying out. You can download it from a reliable torrent site like The Pirate Bay and install it following our guide above. You will not regret it!
- We hope that this article has been helpful and informative for you. If you have any questions or feedback about FIFA 14 Ultimate Edition Repack z10yded or our article, please feel free to leave a comment below. We would love to hear from you!
-FIFA 14 Ultimate Edition Free Download PC Game
-FIFA 14 Ultimate Edition Torrent Link
-FIFA 14 Ultimate Edition RePack by z10yded
-FIFA 14 Ultimate Edition Cracked by 3DM
-FIFA 14 Ultimate Edition Full Version Download
-FIFA 14 Ultimate Edition Multiplayer Crack
-FIFA 14 Ultimate Edition System Requirements
-FIFA 14 Ultimate Edition Gameplay
-FIFA 14 Ultimate Edition Review
-FIFA 14 Ultimate Edition Features
-FIFA 14 Ultimate Edition Download Size
-FIFA 14 Ultimate Edition Installation Guide
-FIFA 14 Ultimate Edition Magnet Link
-FIFA 14 Ultimate Edition Direct Download
-FIFA 14 Ultimate Edition Update Patch
-FIFA 14 Ultimate Edition Mods
-FIFA 14 Ultimate Edition Trainer
-FIFA 14 Ultimate Edition Cheats
-FIFA 14 Ultimate Edition Serial Key
-FIFA 14 Ultimate Edition Activation Code
-FIFA 14 Ultimate Edition License Key
-FIFA 14 Ultimate Edition CD Key
-FIFA 14 Ultimate Edition Keygen
-FIFA 14 Ultimate Edition Steam Key
-FIFA 14 Ultimate Edition Origin Key
-FIFA 14 Ultimate Edition EA Sports Football Club
-FIFA 14 Ultimate Edition Online Mode
-FIFA 14 Ultimate Edition Offline Mode
-FIFA 14 Ultimate Edition Single Player Mode
-FIFA 14 Ultimate Edition Co-op Mode
-FIFA 14 Ultimate Edition Career Mode
-FIFA 14 Ultimate Edition Manager Mode
-FIFA 14 Ultimate Edition Tournament Mode
-FIFA 14 Ultimate Edition Custom Mode
-FIFA 14 Ultimate Edition Skill Games Mode
-FIFA 14 Ultimate Edition Teams and Players
-FIFA 14 Ultimate Edition Leagues and Cups
-FIFA 14 Ultimate Edition Stadiums and Kits
-FIFA 14 Ultimate Edition Graphics and Sound
-FIFA 14 Ultimate Edition Controls and Settings
-How to Play FIFA 14 Ultimate Edition on PC
-How to Fix FIFA 14 Ultimate Edition Errors and Crashes
-How to Update FIFA 14 Ultimate Edition to Latest Version
-How to Uninstall FIFA 14 Ultimate Edition from PC
-How to Backup and Restore FIFA 14 Ultimate Edition Save Files
-How to Transfer FIFA 14 Ultimate Edition Save Files to Another PC
-How to Change Language in FIFA 14 Ultimate Edition
-How to Enable or Disable Commentary in FIFA 14 Ultimate Edition
-How to Adjust Difficulty Level in FIFA 14 Ultimate Edition
- FAQs
-
-- What is FIFA 14?
-FIFA 14 is a soccer simulation game developed by EA Sports and released in 2013 for various platforms, such as PC, PlayStation, Xbox, Nintendo, Android, iOS, etc. It is the 21st installment in the FIFA series and the last one to use the Ignite engine.
- - What is a repack?
-A repack is a compressed version of a game that has been modified to reduce its size and improve its performance. A repack usually removes unnecessary files, such as languages, videos, sounds, etc., and applies patches or cracks to make the game work without any issues.
- - What is z10yded?
-z10yded is a well-known uploader of games on torrent sites. He is famous for creating high-quality repacks of popular games, such as FIFA 14, Assassin's Creed, Call of Duty, etc. His repacks are usually smaller in size and faster in installation than other repacks.
- - Is FIFA 14 Ultimate Edition Repack z10yded safe to download and play?
-Yes, FIFA 14 Ultimate Edition Repack z10yded is safe to download and play, as long as you download it from a reliable torrent site and follow the installation guide above. However, you should be aware that downloading and playing pirated games is illegal and may have consequences. We do not condone or encourage piracy in any way. We recommend that you buy the original game from an official source if you can afford it and support the developers.
- - How can I update FIFA 14 Ultimate Edition Repack z10yded?
-FIFA 14 Ultimate Edition Repack z10yded already includes all the updates and patches that were released for FIFA 14. However, if you want to update it further or add new content, you can use mods from sites like ModdingWay. You can also check for new repacks from z10yded or other uploaders on torrent sites.
-
- 0a6ba089eb
-
-
\ No newline at end of file
diff --git a/spaces/raedeXanto/academic-chatgpt-beta/Gramatica Limbii Romane De Stefania Popescu Free Pdf The Ultimate Guide to Mastering Romanian Grammar.md b/spaces/raedeXanto/academic-chatgpt-beta/Gramatica Limbii Romane De Stefania Popescu Free Pdf The Ultimate Guide to Mastering Romanian Grammar.md
deleted file mode 100644
index 03666f4c8ecfbeb8b1cd4f03ca577410467a8e45..0000000000000000000000000000000000000000
--- a/spaces/raedeXanto/academic-chatgpt-beta/Gramatica Limbii Romane De Stefania Popescu Free Pdf The Ultimate Guide to Mastering Romanian Grammar.md
+++ /dev/null
@@ -1,138 +0,0 @@
-
-Gramatica Limbii Romane De Stefania Popescu Free Pdf
- If you are interested in learning Romanian, one of the most comprehensive and authoritative books on Romanian grammar is Gramatica Limbii Romane by Stefania Popescu. This book covers all aspects of Romanian grammar, from phonetics and morphology to syntax and punctuation. It also includes numerous examples, exercises, and tables to help you master the rules and nuances of this beautiful language.
-Gramatica Limbii Romane De Stefania Popescu Free Pdf
Download Zip … https://tinourl.com/2uL5qh
- In this article, we will tell you everything you need to know about Gramatica Limbii Romane, such as what it is, why it is important, how to use it effectively, where to find it for free, and what are some alternatives to it. By the end of this article, you will have a clear idea of how this book can help you improve your Romanian skills and where to get it without spending a dime.
- What is Gramatica Limbii Romane?
- Gramatica Limbii Romane (Romanian Grammar) is a book written by Stefania Popescu, a renowned Romanian linguist and professor. The book was first published in 1985 and has since been revised and updated several times. The latest edition was published in 2010 and consists of two volumes: one for theoretical grammar and one for practical grammar.
- The book is intended for both native speakers and learners of Romanian who want to deepen their knowledge of the language. It covers all levels of analysis, from phonetics and morphology to syntax and punctuation. It also explains the historical evolution and regional variations of Romanian. The book is written in a clear and concise style, with plenty of examples, exercises, and tables to illustrate the points. The book also has an extensive bibliography and index for easy reference.
-Download Gramatica Practica A Limbii Romane by Stefania Popescu
-Stefania Popescu Gramatica Practica A Limbii Romane PDF free
-How to get Gramatica Practica A Limbii Romane by Stefania Popescu for free
-Gramatica Practica A Limbii Romane by Stefania Popescu ebook download
-Gramatica Practica A Limbii Romane by Stefania Popescu online free
-Gramatica Practica A Limbii Romane by Stefania Popescu PDF archive
-Gramatica Practica A Limbii Romane by Stefania Popescu PDF academia
-Gramatica Practica A Limbii Romane by Stefania Popescu scribd
-Gramatica Practica A Limbii Romane by Stefania Popescu review
-Gramatica Practica A Limbii Romane by Stefania Popescu summary
-Gramatica Practica A Limbii Romane by Stefania Popescu contents
-Gramatica Practica A Limbii Romane by Stefania Popescu exercises
-Gramatica Practica A Limbii Romane by Stefania Popescu solutions
-Gramatica Practica A Limbii Romane by Stefania Popescu examples
-Gramatica Practica A Limbii Romane by Stefania Popescu rules
-Learn Romanian with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar book Gramatica Practica A Limbii Romane by Stefania Popescu
-Best Romanian grammar book Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian language course with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian for beginners with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian for intermediate learners with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian for advanced learners with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar tips with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar exercises with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar practice with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar lessons with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar explained with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar simplified with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar made easy with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar for dummies with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar for kids with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar for adults with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar for teachers with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar for students with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar for travelers with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar for business with Gramatica Practica A Limbii Romane by Stefania Popescu
-Romanian grammar for fun with Gramatica Practica A Limbii Romane by Stefania Popescu
-How to improve your Romanian grammar with Gramatica Practica A Limbii Romane by Stefania Popescu
-How to master your Romanian grammar with Gramatica Practica A Limbii Romane by Stefania Popescu
-How to learn Romanian grammar fast with Gramatica Practica A Limbii Romane by Stefania Popescu
-How to speak Romanian fluently with Gramatica Practica A Limbii Romane by Stefania Popescu
-How to write Romanian correctly with Gramatica Practica A Limbii Romane by Stefania Popescu
-How to read Romanian easily with Gramatica Practica A Limbii Romane by Stefania Popescu
-How to understand Romanian better with Gramatica Practica A Limbii Romane by Stefania Popescu
-How to teach yourself Romanian grammar with Gramatica Practica A Limbii Romane by Stefania Popescu
-How to study Romanian grammar effectively with Gramatica Practica A Limbii Romane by Stefania Popescu
- Who is Stefania Popescu?
- Stefania Popescu (1935-2016) was a prominent Romanian linguist and professor who specialized in Romance languages. She taught at various universities in Romania and abroad, such as Bucharest University, Sorbonne University, University of Montreal, University of California Berkeley, etc. She authored or co-authored over 30 books and 200 articles on various topics related to Romanian language and literature. She was also a member of several academic societies and received numerous awards and honors for her contributions to Romanian culture.
- Why is it important to learn Romanian grammar?
- Romanian is a Romance language that belongs to the Indo-European family. It is spoken by about 24 million people mainly in Romania and Moldova, but also in other countries such as Hungary, Serbia, Ukraine, Bulgaria, etc. It is also one of the official languages of the European Union.
- Learning Romanian grammar can help you in many ways, such as:
-
-- Improving your communication skills: Grammar helps you express your thoughts clearly and accurately. It also helps you understand what others are saying or writing.
-- Enriching your vocabulary: Grammar helps you learn new words and their meanings. It also helps you use them correctly in different contexts.
-- Enhancing your cultural awareness: Grammar helps you appreciate the richness and diversity of Romanian culture. It also helps you avoid misunderstandings or mistakes that could offend or confuse others.
-- Boosting your confidence: Grammar helps you feel more comfortable and confident when speaking or writing in Romanian. It also helps you impress others with your proficiency and fluency.
-
- However, learning Romanian grammar can also be challenging, especially if you are not familiar with its rules and exceptions. Some of the difficulties that learners face include:
-
-- The complex noun system: Romanian has four cases (nominative-accusative, genitive-dative, vocative, locative), three genders (masculine, feminine, neuter), two numbers (singular, plural), and various declension patterns for nouns.
-- The intricate verb system: Romanian has five moods (indicative, subjunctive, conditional-optative, imperative, infinitive), four tenses (present, imperfect, perfect-compound, pluperfect), two voices (active, passive), two aspects (perfective, imperfective), three persons (first, second, third), two numbers (singular, plural), and several conjugation patterns for verbs.
-- The variable word order: Romanian has a relatively flexible word order that depends on factors such as emphasis, topic, focus, etc. The word order can also change depending on whether the sentence is declarative, interrogative, imperative, etc.
-- The numerous exceptions: Romanian has many irregular nouns, verbs, adjectives, pronouns, etc. that do not follow the general rules. It also has many idiomatic expressions, colloquialisms, slang terms, etc. that require special attention.
-
- How to use Gramatica Limbii Romane effectively?
- If you want to use Gramatica Limbii Romane effectively, you need to follow some steps, such as:
-
-- Determine your level and goals: Before you start using the book, you need to assess your current level of Romanian and your learning objectives. You can use online tests or self-evaluation tools to determine your level and choose the topics that suit your needs and interests.
-- Access or download the book: You can either buy a physical copy of the book or access it online for free from various sources that we will discuss later. You can also download a PDF version of the book and save it on your device for offline use.
-- Study the book systematically: You can either follow the order of the chapters or skip to the sections that interest you more. You should read the explanations carefully and pay attention to the examples, exercises, and tables. You should also review the previous chapters periodically to reinforce your memory and understanding.
-- Practice what you learn: You should not only read the book passively but also practice what you learn actively. You can do this by completing the exercises in the book or finding additional ones online. You can also practice by writing sentences or paragraphs using the grammatical structures that you learned. You can also practice by speaking or listening to native speakers or other learners using online platforms or apps.
-- Seek feedback and guidance: You should not rely solely on yourself or on the book to learn Romanian grammar. You should also seek feedback and guidance from others who can help you improve your skills and correct your mistakes. You can do this by joining online communities or forums where you can ask questions or share your work with other learners or experts. You can also hire a tutor or a teacher who can provide you with personalized feedback
Where to find Gramatica Limbii Romane for free?
- If you want to access or download Gramatica Limbii Romane for free, you have several options online. Here are some of the websites where you can find the book in PDF format:
- Academia.edu
- Academia.edu is a platform where researchers and academics can share their papers and publications. You can find both volumes of Gramatica Limbii Romane by Stefania Popescu on this website. You can either view them online or download them for free. However, you need to create an account or log in with your Facebook or Google account to access the files.
- Internet Archive
- Internet Archive is a digital library that preserves and provides access to millions of books, movies, music, and other media. You can find the practical grammar volume of Gramatica Limbii Romane by Stefania Popescu on this website. You can either download it in PDF or other formats, or stream it online. You do not need to create an account or log in to access the file.
- Scribd
- Scribd is a website that hosts various types of documents and books. You can find the theoretical grammar volume of Gramatica Limbii Romane by Stefania Popescu on this website. You can either view it online or download it in PDF format. However, you need to create an account or log in with your Facebook or Google account to access the file. You also need to upload a document of your own or start a free trial to download the file.
- What are some alternatives to Gramatica Limbii Romane?
- If you are looking for some alternatives to Gramatica Limbii Romane, you can check out these other books or resources that can help you learn Romanian grammar:
- Gramatica de baza a limbii romane
- Gramatica de baza a limbii romane (Basic Grammar of the Romanian Language) is another book written by a team of linguists under the auspices of the Romanian Academy. It was first published in 2005 and revised in 2010. It is a simpler and shorter version of Gramatica Limbii Romane, containing only the essential data for understanding the structure and functioning of the Romanian language. It is also more explanatory and accessible than Gramatica Limbii Romane, as it constantly refers to the tradition of Romanian grammar . You can buy a physical copy of this book from various online stores, or access it for free from Academia.edu.
- Romanian Grammar Online
- Romanian Grammar Online is a free online course created by Nicoleta Dascalu, a native Romanian speaker and teacher. The course consists of 12 lessons that cover the main topics of Romanian grammar, such as nouns, verbs, adjectives, pronouns, etc. Each lesson includes explanations, examples, exercises, quizzes, and audio files. You can access the course from any device with an internet connection. You do not need to create an account or log in to access the course.
- RomanianPod101.com
- RomanianPod101.com is a subscription-based website that offers audio and video lessons, flashcards, and quizzes on Romanian grammar and vocabulary. The lessons are organized by level (from absolute beginner to advanced) and by topic (such as greetings, numbers, travel, etc.). Each lesson includes a dialogue, a transcript, a vocabulary list, a grammar point, a cultural insight, and a review quiz. You can also download the lessons as MP3 files or PDF notes. You can try the website for free for 7 days, but you need to create an account or log in with your Facebook or Google account to access the lessons.
- Conclusion
- In conclusion, Gramatica Limbii Romane by Stefania Popescu is one of the most comprehensive and authoritative books on Romanian grammar. It covers all aspects of Romanian grammar, from phonetics and morphology to syntax and punctuation. It also includes numerous examples, exercises, and tables to help you master the rules and nuances of this beautiful language.
- If you want to access or download Gramatica Limbii Romane for free, you have several options online, such as Academia.edu, Internet Archive, or Scribd. However, you may need to create an account or log in to access some of these sources.
- If you are looking for some alternatives to Gramatica Limbii Romane, you can check out these other books or resources that can help you learn Romanian grammar, such as Gramatica de baza a limbii romane, Romanian Grammar Online, or RomanianPod101.com. These sources are more accessible and user-friendly than Gramatica Limbii Romane, but they may not be as comprehensive or authoritative.
- We hope that this article has helped you learn more about Gramatica Limbii Romane
-and how to use it effectively. We also hope that you have found some useful sources to access or download the book for free, or some alternatives to supplement your learning. We wish you all the best in your journey of learning Romanian!
- FAQs
-
-What is Gramatica Limbii Romane?
-Gramatica Limbii Romane
-(Romanian Grammar) is a book written by Stefania Popescu, a renowned Romanian linguist and professor. The book covers all aspects of Romanian grammar, from phonetics and morphology to syntax and punctuation. It also includes numerous examples, exercises, and tables to help you master the rules and nuances of this beautiful language.
Who is Stefania Popescu?
-Stefania Popescu (1935-2016) was a prominent Romanian linguist and professor who specialized in Romance languages. She taught at various universities in Romania and abroad, such as Bucharest University, Sorbonne University, University of Montreal, University of California Berkeley, etc. She authored or co-authored over 30 books and 200 articles on various topics related to Romanian language and literature. She was also a member of several academic societies and received numerous awards and honors for her contributions to Romanian culture.
Why is it important to learn Romanian grammar?
-Romanian is a Romance language that belongs to the Indo-European family. It is spoken by about 24 million people mainly in Romania and Moldova, but also in other countries such as Hungary, Serbia, Ukraine, Bulgaria, etc. It is also one of the official languages of the European Union.
- Learning Romanian grammar can help you in many ways, such as:
-
-- Improving your communication skills: Grammar helps you express your thoughts clearly and accurately. It also helps you understand what others are saying or writing.
-- Enriching your vocabulary: Grammar helps you learn new words and their meanings. It also helps you use them correctly in different contexts.
-- Enhancing your cultural awareness: Grammar helps you appreciate the richness and diversity of Romanian culture. It also helps you avoid misunderstandings or mistakes that could offend or confuse others.
-- Boosting your confidence: Grammar helps you feel more comfortable and confident when speaking or writing in Romanian. It also helps you impress others with your proficiency and fluency.
-
How to use Gramatica Limbii Romane effectively?
-If you want to use Gramatica Limbii Romane
-effectively, you need to follow some steps,
-How to access or download Gramatica Limbii Romane for free?
-You can access or download Gramatica Limbii Romane for free from various online sources, such as:
-
-- Academia.edu: a platform where researchers and academics can share their papers and publications. You can find both volumes of Gramatica Limbii Romane by Stefania Popescu on this website. You can either view them online or download them for free. However, you need to create an account or log in with your Facebook or Google account to access the files.
-- Internet Archive: a digital library that preserves and provides access to millions of books, movies, music, and other media. You can find the practical grammar volume of Gramatica Limbii Romane by Stefania Popescu on this website. You can either download it in PDF or other formats, or stream it online. You do not need to create an account or log in to access the file.
-- Scribd: a website that hosts various types of documents and books. You can find the theoretical grammar volume of Gramatica Limbii Romane by Stefania Popescu on this website. You can either view it online or download it in PDF format. However, you need to create an account or log in with your Facebook or Google account to access the file. You also need to upload a document of your own or start a free trial to download the file.
-
What are some alternatives to Gramatica Limbii Romane?
-You can check out these other books or resources that can help you learn Romanian grammar, such as:
-
-- Gramatica de baza a limbii romane: another book written by a team of linguists under the auspices of the Romanian Academy. It is a simpler and shorter version of Gramatica Limbii Romane, containing only the essential data for understanding the structure and functioning of the Romanian language. It is also more explanatory and accessible than Gramatica Limbii Romane, as it constantly refers to the tradition of Romanian grammar . You can buy a physical copy of this book from various online stores, or access it for free from Academia.edu.
-- Romanian Grammar Online: a free online course created by Nicoleta Dascalu, a native Romanian speaker and teacher. The course consists of 12 lessons that cover the main topics of Romanian grammar, such as nouns, verbs, adjectives, pronouns, etc. Each lesson includes explanations, examples, exercises, quizzes, and audio files. You can access the course from any device with an internet connection. You do not need to create an account or log in to access the course.
-- RomanianPod101.com: a subscription-based website that offers audio and video lessons, flashcards, and quizzes on Romanian grammar and vocabulary. The lessons are organized by level (from absolute beginner to advanced) and by topic (such as greetings, numbers, travel, etc.). Each lesson includes a dialogue, a transcript, a vocabulary list, a grammar point, a cultural insight, and a review quiz. You can also download the lessons as MP3 files or PDF notes. You can try the website for free for 7 days, but you need to create an account or log in with your Facebook or Google account to access the lessons.
-
- 0a6ba089eb
-
-
\ No newline at end of file
diff --git a/spaces/ramiin2/AutoGPT/CONTRIBUTING.md b/spaces/ramiin2/AutoGPT/CONTRIBUTING.md
deleted file mode 100644
index 79169a0c1951853303f73ffa1fddb3518685606a..0000000000000000000000000000000000000000
--- a/spaces/ramiin2/AutoGPT/CONTRIBUTING.md
+++ /dev/null
@@ -1,105 +0,0 @@
-# Contributing to ProjectName
-
-First of all, thank you for considering contributing to our project! We appreciate your time and effort, and we value any contribution, whether it's reporting a bug, suggesting a new feature, or submitting a pull request.
-
-This document provides guidelines and best practices to help you contribute effectively.
-
-## Table of Contents
-
-- [Code of Conduct](#code-of-conduct)
-- [Getting Started](#getting-started)
-- [How to Contribute](#how-to-contribute)
- - [Reporting Bugs](#reporting-bugs)
- - [Suggesting Enhancements](#suggesting-enhancements)
- - [Submitting Pull Requests](#submitting-pull-requests)
-- [Style Guidelines](#style-guidelines)
- - [Code Formatting](#code-formatting)
- - [Pre-Commit Hooks](#pre-commit-hooks)
-
-## Code of Conduct
-
-By participating in this project, you agree to abide by our [Code of Conduct](CODE_OF_CONDUCT.md). Please read it to understand the expectations we have for everyone who contributes to this project.
-
-## 📢 A Quick Word
-Right now we will not be accepting any Contributions that add non-essential commands to Auto-GPT.
-
-However, you absolutely can still add these commands to Auto-GPT in the form of plugins. Please check out this [template](https://github.com/Significant-Gravitas/Auto-GPT-Plugin-Template).
-> ⚠️ Plugin support is expected to ship within the week. You can follow PR #757 for more updates!
-
-## Getting Started
-
-To start contributing, follow these steps:
-
-1. Fork the repository and clone your fork.
-2. Create a new branch for your changes (use a descriptive name, such as `fix-bug-123` or `add-new-feature`).
-3. Make your changes in the new branch.
-4. Test your changes thoroughly.
-5. Commit and push your changes to your fork.
-6. Create a pull request following the guidelines in the [Submitting Pull Requests](#submitting-pull-requests) section.
-
-## How to Contribute
-
-### Reporting Bugs
-
-If you find a bug in the project, please create an issue on GitHub with the following information:
-
-- A clear, descriptive title for the issue.
-- A description of the problem, including steps to reproduce the issue.
-- Any relevant logs, screenshots, or other supporting information.
-
-### Suggesting Enhancements
-
-If you have an idea for a new feature or improvement, please create an issue on GitHub with the following information:
-
-- A clear, descriptive title for the issue.
-- A detailed description of the proposed enhancement, including any benefits and potential drawbacks.
-- Any relevant examples, mockups, or supporting information.
-
-### Submitting Pull Requests
-
-When submitting a pull request, please ensure that your changes meet the following criteria:
-
-- Your pull request should be atomic and focus on a single change.
-- Your pull request should include tests for your change.
-- You should have thoroughly tested your changes with multiple different prompts.
-- You should have considered potential risks and mitigations for your changes.
-- You should have documented your changes clearly and comprehensively.
-- You should not include any unrelated or "extra" small tweaks or changes.
-
-## Style Guidelines
-
-### Code Formatting
-
-We use the `black` code formatter to maintain a consistent coding style across the project. Please ensure that your code is formatted using `black` before submitting a pull request. You can install `black` using `pip`:
-
-```bash
-pip install black
-```
-
-To format your code, run the following command in the project's root directory:
-
-```bash
-black .
-```
-### Pre-Commit Hooks
-We use pre-commit hooks to ensure that code formatting and other checks are performed automatically before each commit. To set up pre-commit hooks for this project, follow these steps:
-
-Install the pre-commit package using pip:
-```bash
-pip install pre-commit
-```
-
-Run the following command in the project's root directory to install the pre-commit hooks:
-```bash
-pre-commit install
-```
-
-Now, the pre-commit hooks will run automatically before each commit, checking your code formatting and other requirements.
-
-If you encounter any issues or have questions, feel free to reach out to the maintainers or open a new issue on GitHub. We're here to help and appreciate your efforts to contribute to the project.
-
-Happy coding, and once again, thank you for your contributions!
-
-Maintainers will look at PR that have no merge conflicts when deciding what to add to the project. Make sure your PR shows up here:
-
-https://github.com/Torantulino/Auto-GPT/pulls?q=is%3Apr+is%3Aopen+-is%3Aconflict+
\ No newline at end of file
diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Download Instant Artist For Windows 8 18 ((FULL)).md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Download Instant Artist For Windows 8 18 ((FULL)).md
deleted file mode 100644
index 90e4984e81b61b1bb8e41d702b1ec77e82c1f272..0000000000000000000000000000000000000000
--- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Download Instant Artist For Windows 8 18 ((FULL)).md
+++ /dev/null
@@ -1,6 +0,0 @@
-download instant artist for windows 8 18
Download File 🗸🗸🗸 https://urlgoal.com/2uCMnH
-
-The Union Health Ministry has said that the Reverse Transcription-Polymerase Chain Reaction (RT-PCR) is the gold standard frontline test for ... 1fdad05405
-
-
-
diff --git a/spaces/riyueyiming/gpt/chatgpt - macOS.command b/spaces/riyueyiming/gpt/chatgpt - macOS.command
deleted file mode 100644
index fa015edca9e6916f24394813ce8ba77d2072e296..0000000000000000000000000000000000000000
--- a/spaces/riyueyiming/gpt/chatgpt - macOS.command
+++ /dev/null
@@ -1,7 +0,0 @@
-#!/bin/bash
-echo Opening ChuanhuChatGPT...
-cd "$(dirname "${BASH_SOURCE[0]}")"
-nohup python3 ChuanhuChatbot.py >/dev/null 2>&1 &
-sleep 5
-open http://127.0.0.1:7860
-echo Finished opening ChuanhuChatGPT (http://127.0.0.1:7860/). If you kill ChuanhuChatbot, Use "pkill -f 'ChuanhuChatbot'" command in terminal.
\ No newline at end of file
diff --git a/spaces/rkoushikroy2/portrait_photo_generator/app.py b/spaces/rkoushikroy2/portrait_photo_generator/app.py
deleted file mode 100644
index 1c312caa9974130b7a1c1cfa3c6f77c07a09589b..0000000000000000000000000000000000000000
--- a/spaces/rkoushikroy2/portrait_photo_generator/app.py
+++ /dev/null
@@ -1,119 +0,0 @@
-# Portrait Photo Generator App
-
-# Imports
-from PIL import Image, ImageFilter
-import numpy as np
-from transformers import pipeline
-import gradio as gr
-import os
-
-model = pipeline("image-segmentation", model="facebook/detr-resnet-50-panoptic")
-
-pred = []
-
-def img_resize(image):
- width = 1280
- width_percent = (width / float(image.size[0]))
- height = int((float(image.size[1]) * float(width_percent)))
- return image.resize((width, height))
-
-def image_objects(image):
- global pred
- image = img_resize(image)
- pred = model(image)
- pred_object_list = [str(i)+'_'+x['label'] for i, x in enumerate(pred)]
- return gr.Dropdown.update(choices = pred_object_list, interactive = True)
-
-def blurr_object(image, object, blur_strength):
- image = img_resize(image)
-
- object_number = int(object.split('_')[0])
- mask_array = np.asarray(pred[object_number]['mask'])/255
- image_array = np.asarray(image)
-
- mask_array_three_channel = np.zeros_like(image_array)
- mask_array_three_channel[:,:,0] = mask_array
- mask_array_three_channel[:,:,1] = mask_array
- mask_array_three_channel[:,:,2] = mask_array
-
- segmented_image = image_array*mask_array_three_channel
-
- blur_image = np.asarray(image.filter(ImageFilter.GaussianBlur(radius=blur_strength)))
- mask_array_three_channel_invert = 1-mask_array_three_channel
- blur_image_reverse_mask = blur_image*mask_array_three_channel_invert
-
- blurred_output_image = Image.fromarray((blur_image_reverse_mask).astype(np.uint8)+segmented_image.astype(np.uint8))
- for _ in range(int(blur_strength//2.5)):
- blurred_output_image = blurred_output_image.filter(ImageFilter.SMOOTH_MORE)
- return blurred_output_image
-
-app = gr.Blocks()
-
-
-with app:
- gr.Markdown(
- """
- ## Portrait Photo Generator
- - Create stunning portrait photos by blurring the background of your selected object.
- - Adjust the blurring strength using the slider.
- """)
- with gr.Row():
- with gr.Column():
- gr.Markdown(
- """
- ### Input Image
- """)
- image_input = gr.Image(type="pil")
-
-
- with gr.Column():
- with gr.Row():
- gr.Markdown(
- """
- ### Found Objects
- """)
- with gr.Row():
- blur_slider = gr.Slider(minimum=0.5, maximum=10, value=3, label="Adject Blur Strength")
- with gr.Row():
- object_output = gr.Dropdown(label="Select Object From Dropdown")
-
-
- with gr.Row():
- with gr.Column():
- gr.Markdown(
- """
- ### Blurred Image Output
- """)
- image_output = gr.Image()
- with gr.Column():
- gr.Markdown(
- """
- ### Example Images
- """)
- gr.Examples(
- examples=[
- "test_images/dog_horse_cowboy.jpg",
- "test_images/woman_and_dog.jpg",
- "test_images/family_in_sofa.jpg",
- "test_images/group_of_friends.jpg",
- "test_images/people_group.jpg"
- ],
- fn=image_objects,
- inputs=image_input,
- outputs=object_output)
-
- image_input.change(fn=image_objects,
- inputs=image_input,
- outputs=object_output
- )
-
- object_output.change(fn=blurr_object,
- inputs=[image_input, object_output, blur_slider],
- outputs=image_output)
-
- blur_slider.change(fn=blurr_object,
- inputs=[image_input, object_output, blur_slider],
- outputs=image_output)
-
-
-app.launch()
\ No newline at end of file
diff --git a/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/core/evaluation/recall.py b/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/core/evaluation/recall.py
deleted file mode 100644
index 82b3c909b82fad29d6d5147c562a674e5db7c14c..0000000000000000000000000000000000000000
--- a/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/core/evaluation/recall.py
+++ /dev/null
@@ -1,197 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from collections.abc import Sequence
-
-import numpy as np
-from mmcv.utils import print_log
-from terminaltables import AsciiTable
-
-from .bbox_overlaps import bbox_overlaps
-
-
-def _recalls(all_ious, proposal_nums, thrs):
-
- img_num = all_ious.shape[0]
- total_gt_num = sum([ious.shape[0] for ious in all_ious])
-
- _ious = np.zeros((proposal_nums.size, total_gt_num), dtype=np.float32)
- for k, proposal_num in enumerate(proposal_nums):
- tmp_ious = np.zeros(0)
- for i in range(img_num):
- ious = all_ious[i][:, :proposal_num].copy()
- gt_ious = np.zeros((ious.shape[0]))
- if ious.size == 0:
- tmp_ious = np.hstack((tmp_ious, gt_ious))
- continue
- for j in range(ious.shape[0]):
- gt_max_overlaps = ious.argmax(axis=1)
- max_ious = ious[np.arange(0, ious.shape[0]), gt_max_overlaps]
- gt_idx = max_ious.argmax()
- gt_ious[j] = max_ious[gt_idx]
- box_idx = gt_max_overlaps[gt_idx]
- ious[gt_idx, :] = -1
- ious[:, box_idx] = -1
- tmp_ious = np.hstack((tmp_ious, gt_ious))
- _ious[k, :] = tmp_ious
-
- _ious = np.fliplr(np.sort(_ious, axis=1))
- recalls = np.zeros((proposal_nums.size, thrs.size))
- for i, thr in enumerate(thrs):
- recalls[:, i] = (_ious >= thr).sum(axis=1) / float(total_gt_num)
-
- return recalls
-
-
-def set_recall_param(proposal_nums, iou_thrs):
- """Check proposal_nums and iou_thrs and set correct format."""
- if isinstance(proposal_nums, Sequence):
- _proposal_nums = np.array(proposal_nums)
- elif isinstance(proposal_nums, int):
- _proposal_nums = np.array([proposal_nums])
- else:
- _proposal_nums = proposal_nums
-
- if iou_thrs is None:
- _iou_thrs = np.array([0.5])
- elif isinstance(iou_thrs, Sequence):
- _iou_thrs = np.array(iou_thrs)
- elif isinstance(iou_thrs, float):
- _iou_thrs = np.array([iou_thrs])
- else:
- _iou_thrs = iou_thrs
-
- return _proposal_nums, _iou_thrs
-
-
-def eval_recalls(gts,
- proposals,
- proposal_nums=None,
- iou_thrs=0.5,
- logger=None,
- use_legacy_coordinate=False):
- """Calculate recalls.
-
- Args:
- gts (list[ndarray]): a list of arrays of shape (n, 4)
- proposals (list[ndarray]): a list of arrays of shape (k, 4) or (k, 5)
- proposal_nums (int | Sequence[int]): Top N proposals to be evaluated.
- iou_thrs (float | Sequence[float]): IoU thresholds. Default: 0.5.
- logger (logging.Logger | str | None): The way to print the recall
- summary. See `mmcv.utils.print_log()` for details. Default: None.
- use_legacy_coordinate (bool): Whether use coordinate system
- in mmdet v1.x. "1" was added to both height and width
- which means w, h should be
- computed as 'x2 - x1 + 1` and 'y2 - y1 + 1'. Default: False.
-
-
- Returns:
- ndarray: recalls of different ious and proposal nums
- """
-
- img_num = len(gts)
- assert img_num == len(proposals)
- proposal_nums, iou_thrs = set_recall_param(proposal_nums, iou_thrs)
- all_ious = []
- for i in range(img_num):
- if proposals[i].ndim == 2 and proposals[i].shape[1] == 5:
- scores = proposals[i][:, 4]
- sort_idx = np.argsort(scores)[::-1]
- img_proposal = proposals[i][sort_idx, :]
- else:
- img_proposal = proposals[i]
- prop_num = min(img_proposal.shape[0], proposal_nums[-1])
- if gts[i] is None or gts[i].shape[0] == 0:
- ious = np.zeros((0, img_proposal.shape[0]), dtype=np.float32)
- else:
- ious = bbox_overlaps(
- gts[i],
- img_proposal[:prop_num, :4],
- use_legacy_coordinate=use_legacy_coordinate)
- all_ious.append(ious)
- all_ious = np.array(all_ious)
- recalls = _recalls(all_ious, proposal_nums, iou_thrs)
-
- print_recall_summary(recalls, proposal_nums, iou_thrs, logger=logger)
- return recalls
-
-
-def print_recall_summary(recalls,
- proposal_nums,
- iou_thrs,
- row_idxs=None,
- col_idxs=None,
- logger=None):
- """Print recalls in a table.
-
- Args:
- recalls (ndarray): calculated from `bbox_recalls`
- proposal_nums (ndarray or list): top N proposals
- iou_thrs (ndarray or list): iou thresholds
- row_idxs (ndarray): which rows(proposal nums) to print
- col_idxs (ndarray): which cols(iou thresholds) to print
- logger (logging.Logger | str | None): The way to print the recall
- summary. See `mmcv.utils.print_log()` for details. Default: None.
- """
- proposal_nums = np.array(proposal_nums, dtype=np.int32)
- iou_thrs = np.array(iou_thrs)
- if row_idxs is None:
- row_idxs = np.arange(proposal_nums.size)
- if col_idxs is None:
- col_idxs = np.arange(iou_thrs.size)
- row_header = [''] + iou_thrs[col_idxs].tolist()
- table_data = [row_header]
- for i, num in enumerate(proposal_nums[row_idxs]):
- row = [f'{val:.3f}' for val in recalls[row_idxs[i], col_idxs].tolist()]
- row.insert(0, num)
- table_data.append(row)
- table = AsciiTable(table_data)
- print_log('\n' + table.table, logger=logger)
-
-
-def plot_num_recall(recalls, proposal_nums):
- """Plot Proposal_num-Recalls curve.
-
- Args:
- recalls(ndarray or list): shape (k,)
- proposal_nums(ndarray or list): same shape as `recalls`
- """
- if isinstance(proposal_nums, np.ndarray):
- _proposal_nums = proposal_nums.tolist()
- else:
- _proposal_nums = proposal_nums
- if isinstance(recalls, np.ndarray):
- _recalls = recalls.tolist()
- else:
- _recalls = recalls
-
- import matplotlib.pyplot as plt
- f = plt.figure()
- plt.plot([0] + _proposal_nums, [0] + _recalls)
- plt.xlabel('Proposal num')
- plt.ylabel('Recall')
- plt.axis([0, proposal_nums.max(), 0, 1])
- f.show()
-
-
-def plot_iou_recall(recalls, iou_thrs):
- """Plot IoU-Recalls curve.
-
- Args:
- recalls(ndarray or list): shape (k,)
- iou_thrs(ndarray or list): same shape as `recalls`
- """
- if isinstance(iou_thrs, np.ndarray):
- _iou_thrs = iou_thrs.tolist()
- else:
- _iou_thrs = iou_thrs
- if isinstance(recalls, np.ndarray):
- _recalls = recalls.tolist()
- else:
- _recalls = recalls
-
- import matplotlib.pyplot as plt
- f = plt.figure()
- plt.plot(_iou_thrs + [1.0], _recalls + [0.])
- plt.xlabel('IoU')
- plt.ylabel('Recall')
- plt.axis([iou_thrs.min(), 1, 0, 1])
- f.show()
diff --git a/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/models/necks/channel_mapper.py b/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/models/necks/channel_mapper.py
deleted file mode 100644
index 774bdb1d7a522583df462fc09177a6a6ee899f17..0000000000000000000000000000000000000000
--- a/spaces/rockeycoss/Prompt-Segment-Anything-Demo/mmdet/models/necks/channel_mapper.py
+++ /dev/null
@@ -1,100 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch.nn as nn
-from mmcv.cnn import ConvModule
-from mmcv.runner import BaseModule
-
-from ..builder import NECKS
-
-
-@NECKS.register_module()
-class ChannelMapper(BaseModule):
- r"""Channel Mapper to reduce/increase channels of backbone features.
-
- This is used to reduce/increase channels of backbone features.
-
- Args:
- in_channels (List[int]): Number of input channels per scale.
- out_channels (int): Number of output channels (used at each scale).
- kernel_size (int, optional): kernel_size for reducing channels (used
- at each scale). Default: 3.
- conv_cfg (dict, optional): Config dict for convolution layer.
- Default: None.
- norm_cfg (dict, optional): Config dict for normalization layer.
- Default: None.
- act_cfg (dict, optional): Config dict for activation layer in
- ConvModule. Default: dict(type='ReLU').
- num_outs (int, optional): Number of output feature maps. There
- would be extra_convs when num_outs larger than the length
- of in_channels.
- init_cfg (dict or list[dict], optional): Initialization config dict.
- Example:
- >>> import torch
- >>> in_channels = [2, 3, 5, 7]
- >>> scales = [340, 170, 84, 43]
- >>> inputs = [torch.rand(1, c, s, s)
- ... for c, s in zip(in_channels, scales)]
- >>> self = ChannelMapper(in_channels, 11, 3).eval()
- >>> outputs = self.forward(inputs)
- >>> for i in range(len(outputs)):
- ... print(f'outputs[{i}].shape = {outputs[i].shape}')
- outputs[0].shape = torch.Size([1, 11, 340, 340])
- outputs[1].shape = torch.Size([1, 11, 170, 170])
- outputs[2].shape = torch.Size([1, 11, 84, 84])
- outputs[3].shape = torch.Size([1, 11, 43, 43])
- """
-
- def __init__(self,
- in_channels,
- out_channels,
- kernel_size=3,
- conv_cfg=None,
- norm_cfg=None,
- act_cfg=dict(type='ReLU'),
- num_outs=None,
- init_cfg=dict(
- type='Xavier', layer='Conv2d', distribution='uniform')):
- super(ChannelMapper, self).__init__(init_cfg)
- assert isinstance(in_channels, list)
- self.extra_convs = None
- if num_outs is None:
- num_outs = len(in_channels)
- self.convs = nn.ModuleList()
- for in_channel in in_channels:
- self.convs.append(
- ConvModule(
- in_channel,
- out_channels,
- kernel_size,
- padding=(kernel_size - 1) // 2,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg))
- if num_outs > len(in_channels):
- self.extra_convs = nn.ModuleList()
- for i in range(len(in_channels), num_outs):
- if i == len(in_channels):
- in_channel = in_channels[-1]
- else:
- in_channel = out_channels
- self.extra_convs.append(
- ConvModule(
- in_channel,
- out_channels,
- 3,
- stride=2,
- padding=1,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg))
-
- def forward(self, inputs):
- """Forward function."""
- assert len(inputs) == len(self.convs)
- outs = [self.convs[i](inputs[i]) for i in range(len(inputs))]
- if self.extra_convs:
- for i in range(len(self.extra_convs)):
- if i == 0:
- outs.append(self.extra_convs[0](inputs[-1]))
- else:
- outs.append(self.extra_convs[i](outs[-1]))
- return tuple(outs)
diff --git a/spaces/rorallitri/biomedical-language-models/logs/C Free 5.0 Registration Code A Complete Guide to Download Install and Activate C-Free.md b/spaces/rorallitri/biomedical-language-models/logs/C Free 5.0 Registration Code A Complete Guide to Download Install and Activate C-Free.md
deleted file mode 100644
index b79bcf0e24ad260443af9976c0b2d3a27578a1aa..0000000000000000000000000000000000000000
--- a/spaces/rorallitri/biomedical-language-models/logs/C Free 5.0 Registration Code A Complete Guide to Download Install and Activate C-Free.md
+++ /dev/null
@@ -1,28 +0,0 @@
-
-The previous version of the software can be automatically generated using the source code. The code is posted below. You only need to compile the following code in C-Free to generate the registration code:
-C Free 5.0 Registration Code
Download Zip ✔✔✔ https://tinurll.com/2uzmt8
-C-Free is a professional C/C++ integrated development environment (IDE) that support multi-compilers. With this software, user can edit, build, run and debug programs freely. With C/C++ source parser included, although C-Free is a lightweight C/C++ development tool, it has powerful features to let you make use of it in your project.
Features Include:
-Support multiply compilers. Now support more compilers besides MinGW as following:
(1) MinGW 2.95/3.x/4.x/5.0
(2) Cygwin
(3) Borland C++ Compiler
(4) Microsoft C++ Compiler
(5) Intel C++ Compiler
(6) Lcc-Win32
(7) Open Watcom C/C++
(8) Digital Mars C/C++
(9) Ch Interpreter
-Enhanced C/C++ syntax highlighter. (Highlight Function, Data Type, and Constant, etc.);
-Enhanced Smart Input;
-Customizable project creating wizard, support more project types;
-Powerful code finding utilities (Jump to declaration, definition);
-Code completion and Code parameters;
-List all symbols of program;
-Customizable utilities:
Customizable Shortcuts;
Customizable External Tools;
Customizable Help (Support Windows help, Html help and Web help);
-Color Print (Syntax highlighted print);
-Show console window when debug;
-Project Converter (Convert project to C-Free format);
Operating system:
Win2000,Win7 x32,Win7 x64,Win98,WinServer,WinVista,WinVista x64,WinXP
Release notes:
Major Update
(adsbygoogle = window.adsbygoogle || []).push();
-Win7Dwnld.com update information of C-Free 5.0 Pro full version periodically using publisher pad file, so some information may be slightly out-of-date. Please check information before relying on it. Using crack, password, serial numbers, registration codes, key generators, cd key, hacks or encouraging software piracy of C-Free 5.0 Pro is illegal and prevent future development of this program. On Win7dwnld.com download links are directly from publisher sites. C-Free torrent files or links are not allowed.
-If you want to use register() with a Swift class, you provide a table view cell class as its first parameter. This is useful if your cell is defined entirely in code. As an example, this uses the default UITableViewCell class:
-SPONSORED In-app subscriptions are a pain to implement, hard to test, and full of edge cases. RevenueCat makes it straightforward and reliable so you can get back to building your app. Oh, and it's free if your app makes less than $10k/mo.
-
-To buy FSUIPC or WideFS for FSX, FSX-SE, MSFS or Prepar3D, and receive your Registration code, use the relevant link below to go to the simMarket purchase page:
-As the name implies, the original meaning of register was to require an object to be stored in a CPU register. But with improvements in optimizing compilers, this has become less useful. Modern versions of the C standard don't refer to CPU registers, because they no longer (need to) assume that there is such a thing (there are architectures that don't use registers). The common wisdom is that applying register to an object declaration is more likely to worsen the generated code, because it interferes with the compiler's own register allocation. There might still be a few cases where it's useful (say, if you really do know how often a variable will be accessed, and your knowledge is better than what a modern optimizing compiler can figure out).
-But C is only an abstraction. And ultimately, what it's extracting from you is Assembly language. Assembly is the language that a CPU reads, and if you use it, you do things in terms of the CPU. What does a CPU do? Basically, it reads from memory, does math, and writes to memory. The CPU doesn't just do math on numbers in memory. First, you have to move a number from memory to memory inside the CPU called a register. Once you're done doing whatever you need to do to this number, you can move it back to normal system memory. Why use system memory at all? Registers are limited in number. You only get about a hundred bytes in modern processors, and older popular processors were even more fantastically limited (The 6502 had 3 8-bit registers for your free use). So, your average math operation looks like:
-A lot of that is... not math. Those load and store operations can take up to half your processing time. C, being an abstraction of computers, freed the programmer the worry of using and juggling registers, and since the number and type vary between computers, C places the responsibility of register allocation solely on the compiler. With one exception.
-Just a little demo (without any real-world purpose) for comparison: when removing the register keywords before each variable, this piece of code takes 3.41 seconds on my i7 (GCC), with register the same code completes in 0.7 seconds.
-Register would notify the compiler that the coder believed this variable would be written/read enough to justify its storage in one of the few registers available for variable use. Reading/writing from registers is usually faster and can require a smaller op-code set.
-This forces ebx to be used for the calculation, meaning it needs to be pushed to the stack and restored at the end of the function because it is callee saved. register produces more lines of code and 1 memory write and 1 memory read (although realistically, this could have been optimised to 0 R/Ws if the calculation had been done in esi, which is what happens using C++'s const register). Not using register causes 2 writes and 1 read (although store to load forwarding will occur on the read). This is because the value has to be present and updated directly on the stack so the correct value can be read by address (pointer). register doesn't have this requirement and cannot be pointed to. const and register are basically the opposite of volatile and using volatile will override the const optimisations at file and block scope and the register optimisations at block-scope. const register and register will produce identical outputs because const does nothing on C at block-scope, so only the register optimisations apply.
-Register keyword tells compiler to store the particular variable in CPU registers so that it could be accessible fast. From a programmer's point of view register keyword is used for the variables which are heavily used in a program, so that compiler can speedup the code. Although it depends on the compiler whether to keep the variable in CPU registers or main memory.
-Register indicates to compiler to optimize this code by storing that particular variable in registers then in memory. it is a request to compiler, compiler may or may not consider this request.You can use this facility in case where some of your variable are being accessed very frequently.For ex: A looping.
-Leave the default authentication as Individual User Accounts. If you'd like to host the app in Azure, leave the check box checked. Later in the tutorial we will deploy to Azure. You can open an Azure account for free.
-It's a best practice to confirm the email of a new user registration to verify they are not impersonating someone else (that is, they haven't registered with someone else's email). Suppose you had a discussion forum, you would want to prevent "bob@example.com" from registering as "joe@contoso.com". Without email confirmation, "joe@contoso.com" could get unwanted email from your app. Suppose Bob accidentally registered as "bib@example.com" and hadn't noticed it, he wouldn't be able to use password recover because the app doesn't have his correct email. Email confirmation provides only limited protection from bots and doesn't provide protection from determined spammers, they have many working email aliases they can use to register.
-You generally want to prevent new users from posting any data to your web site before they have been confirmed by email, a SMS text message or another mechanism. In the sections below, we will enable email confirmation and modify the code to prevent newly registered users from logging in until their email has been confirmed.
-Security - Never store sensitive data in your source code. The account and credentials are stored in the appSetting. On Azure, you can securely store these values on the Configure tab in the Azure portal. See Best practices for deploying passwords and other sensitive data to ASP.NET and Azure.
-Currently once a user completes the registration form, they are logged in. You generally want to confirm their email before logging them in. In the section below, we will modify the code to require new users to have a confirmed email before they are logged in (authenticated). Update the HttpPost Register method with the following highlighted changes:
-By commenting out the SignInAsync method, the user will not be signed in by the registration. The TempData["ViewBagLink"] = callbackUrl; line can be used to debug the app and test registration without sending email. ViewBag.Message is used to display the confirm instructions. The download sample contains code to test email confirmation without setting up email, and can also be used to debug the application.
-Once a user creates a new local account, they are emailed a confirmation link they are required to use before they can log on. If the user accidentally deletes the confirmation email, or the email never arrives, they will need the confirmation link sent again. The following code changes show how to enable this.
-Developers want to focus on code, not update issues. We get it! Open DevOps makes it easier to do both regardless of the tools you use. Now developers can stay focused and the business can stay aligned.
-FortiSIEM product functionality is driven by the product SKUs below. You have to first purchase the right combination of SKUs based on your needs from Fortinet. You will receive the registration letters via email that will contain a separate registration code for every SKU. You must use these registration SKUs to obtain FortiSIEM license.
aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/rorallitri/biomedical-language-models/logs/Eberick V8 Gold Torrent 35 [CRACKED] - SoundCloud[2].md b/spaces/rorallitri/biomedical-language-models/logs/Eberick V8 Gold Torrent 35 [CRACKED] - SoundCloud[2].md
deleted file mode 100644
index d0817c1175ae61506073d20cc5cfe08277eb3ccd..0000000000000000000000000000000000000000
--- a/spaces/rorallitri/biomedical-language-models/logs/Eberick V8 Gold Torrent 35 [CRACKED] - SoundCloud[2].md
+++ /dev/null
@@ -1,12 +0,0 @@
-
-Eberick V8 Gold Torrent 35DOWNLOAD === =2sAcFdBlizzard torrent download The. Eberick V8 Gold Lumine V4 Hidros V4 Qicad V4 - Win Xp, 7 E. Eberick V8.Eberick. Eberick is a building company founded by Ron and. Eberick V8 Gold Lumine V4 Hidros V4 Qicad V4 - Win Xp, 7 E 8.. Eberick V8 Gold Lumine V4 Hidros V4 Qicad V4 - Win Xp, 7 E 8. The company owns property and.This invention relates to the deprocessing of biological cells, and more specifically, it relates to the extraction of DNA and other cellular components from human cells.It is known to purify genetic material in the form of DNA from various biological sources, including cells. For example, blood contains the DNA from the erythrocytes, the leukocytes, and the plasma cells, and in most cases, the DNA has been depleted of the erythrocytes by lysis, followed by centrifugation of the remaining cells. The remaining cells, including the leukocytes and plasma cells, are then sedimented, washed, and resuspended in a liquid medium, such as buffer, containing proteinase K. Proteinase K removes the cell membrane while maintaining its integrity, and releases the nuclear contents including the DNA into the liquid medium. After washing, the cells are resuspended in another liquid medium, such as TE, for storage or further processing.Erythrocyte purification is most commonly accomplished by using a hypotonic solution and centrifugation. Other known methods for obtaining cells from a blood sample include the use of a dacron fiber column to sediment the red blood cells.It is also known that leukocytes and plasma cells are obtained from whole blood by separating the cells using a centrifuge and collecting the cells in a collection medium. After several washings with salt-free buffers, the cells are sedimented and washed again. After washing, the cells are resuspended in a buffer containing proteinase K, and DNA is released by treatment with a detergent and digestion with the enzyme.Although these methods work reasonably well, they are not completely effective in the removal of cellular components. In particular, there is an incomplete removal of cell components, such as nucleic acids and proteins, which decreases the purity of the DNA product. The incomplete removal of these components can result 9579fb97db -tune-efx-3-crack-macaroni -bahasa-jawa-smk-kelas-xirar -complete-v5rar -dyna-971-r60-torrent-download -pd-s03e06-hdtv-x264-16
-eberick v8 gold torrent 35
Download File ☑ https://tinurll.com/2uznrd
-Eberick V8 Gold Torrent 35DOWNLOAD --->>> =2sL2FBcrack torrent for native.Telecharger eberick v8 gold torrentEberick V8 Gold torrent free downloadMinicompe V2 + Crack Download.. Eberick V8 Gold projectory. cwcrack. 1. 7 Crack Zip: Download Here or Use This Link./* * Copyright 2014 Google Inc. * * Licensed under the Apache License, Version 2.0 (the "License"); * you may not use this file except in compliance with the License. * You may obtain a copy of the License at * * * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */package com.google.maps.android.data;import com.google.android.gms.maps.Geofence;import com.google.android.gms.maps.model.Marker;import com.google.maps.api.GoogleMap;import com.google.maps.api.GoogleMap.InfoWindowAdapter;import com.google.maps.api.GoogleMap.InfoWindowAdapter.View;import java.util.HashSet;import java.util.Set;/** * MarkerAdapter for displaying a set of lat/lng markers. */public class SetMarkerAdapter extends MarkerAdapter { private final Set latLngs; private boolean circles; private boolean animate; private GoogleMap map; public SetMarkerAdapter(GoogleMap map, boolean circles, boolean animate) this(map, circles, animate, new HashSet()); public SetMarkerAdapter(GoogleMap map, boolean circles, boolean animate, Set latLngs) { super(map.getUiSettings()); ee730c9e81
-Application Name: Destiny 2 Beta Preload Begins Tomorrow On Ps4 Xbox One News Article Play ... Destiny 2 Open Beta Preload Posted By Samantha Peltier.. Break Pandora Hearts Other Anime Background Wallpapers On. Heart Wallpaper ... Pandora Hearts Wallpaper Posted By Samantha Peltier. Hd Wallpaper... 67426dafae moybam
-x64-jothe-jotheyali-kannada-software-key-exe-crack-torrent
-registration-strafe-jump-sc-serial-x32-zip-professional-full
-le-palais-full-keygen-rar-activation-professional-download-64
-download-tharai-thappattai-2016-nulled-key-ultimate-x32-free-zip
-adobe-cs3-master-collection-x32-key-torrent-latest-pc-full-version-zip
-tiger-zinda-hai-avi-bluray-watch-online-download-watch-online
-driver-camara-web-hp-oem-wb918la-abm-1-utorrent-nulled-license-64
-apata-penena-lokaya-book-rar-utorrent-full-version-epub
-rar-honestech-vhs-pc-ultimate-key-64
-heartless-free-mp4-dual-dubbed-720p
May 10, 2019 Friday and Saturday, the Tenth and Eleventh of May, Two Thousand Nineteen ... 3,300 college credits toward their post-secondary education and saved them over $1.6 million in tuition ... Service. With a strong background ... Quail, Samantha Faith ... Peltier, Rachel Kathleen ... Dunkelberger, Destiny Kay.. by DAG Clark 2003 From here I will be at home for about two weeks, as I prepare for the ... With my background in showing cattle, I quickly ... Dad, Samantha and I went to the firework stand ... destiny of 11 state officer candidates, 40 FFA chapters, and 2,000 ... The impressive thing about this meeting was that Mrs. Peltier was...
-... insulated door. See why cold storage operations choose Rytec. ... Turbo-Seal Insulated Gen2 Installation Manual Turbo-Seal Insulated Product Info. 67426dafae bengly
-windows-swiftec-v1-7-7-activation-full-version-build-download
-o-ciclo-da-au-sabotagem-rar-ebook-full-edition-mobi
-pc-hubunganseksibukandung-nulled-x32-ultimate
-full-tin-brass-hotel-courbet-2009-pc-registration-64bit-software
-b-s-of-fury-64bit-cracked-license-iso-ultimate-full-version-pc
-eplan-electric-p8-24-x-torrent-full-x32-exe-activator-software-windows
-full-nuance-talks-5-30-x64-activation-download
-58747-statistical-methods-by-ng-das-rar-torrent-epub-ebook-free
-rosetta-s-software-serial-key-full-version
-rar-lesson-3-homework-practice-measures-of-variation-answer-registration-torrent-windows-professio
Improper installation may result in water leakage, electric shock, or fire. When installing the unit in a small room, take measures to keep the refrigerant.... Refer to drawing supplied by SRC Refrigeration for panel layout. All Wall ... STEP 10. Walk-in is now ready for refrigeration, electrical and plumbing connections by qualified contractors. ... room applications and 03 watts per linear feet for -20F (-29C) rooms is satisfactory. In freezers, the evaporator drain pan fitting.. Please read this manual completely before attempting to install or operate this equipment. ... The serial number of all self-contained refrigerators and freezers is located inside the unit on the left hand ... To return to the room temperature display...
-Jun 15, 2019 Read more to know about periods after abortion, when do they start after ... Taking these medicines as soon as cramping or bleeding starts may... 67426dafae cherhild
-sql-accounting-crack-pc-64-full
-720p-chaar-bottle-vodka-watch-online-blu-ray-rip-mp4-avi-subtitles
-pthccollectionpics-torrent-patch-rar-x32-license-pro
-kal-ho-naa-ho-x264-dual-dubbed-subtitles
-logic-pro-9-1-8-torrent-software-patch-full-32bit-dmg
-dummy-zip-32-keygen-build-windows
-ngintip-celana-dalam-anak-sekolahl-download-x32-full-cracked-zip-file
-watch-online-niram-movie-avi-720p-download
-knight-ri-pc-32-full-version-activation-rar-torrent-serial
-x-force-windows-file-keygen-download-registration
Pain and bleeding in early pregnancy can mean that you are having a ... Early bleeding that does not lead to miscarriage will not have caused your baby any harm. ... It is also aimed at looking after you, physically and emotionally. ... uterus with a curette (a spoon-shaped instrument), you may bleed for a long time or develop.... The first stage involves taking a tablet which blocks the hormone necessary for the pregnancy to continue. This is ... You will also be able to drive yourself home after the appointment. You can ... How long will I bleed? ... What if I forget to take the second pills (misoprostol) within 48 hours after I take the first pill (mifepristone)?.. Sometimes there can be some tissue left in your womb, which could be part of the ... The chances of having an incomplete abortion after a medical termination are ... Bleeding more than expected; Bleeding that doesn't get lighter after the first few ... able to take another dose of misoprostol to make your womb contract more.
-
-9711752d68. download ebook syarah umdatul ahkam terjemahan · Balistica Forense ... tomb raider japanese language pack torrent. Docker Pull Command.. Terjemah umdatul ahkam pdf; terjemahan. Amie ebook syarah umdatul ahkam. a amie ago. 0Abdullah Bin Abdurrahman Taisirul Allam Syarah ...
-Sexy pakistani video hit
Bf2 1.5 Patch F(2X) .rar
Logo Maker Pro Logo Creator Premium v137 Cracked APK [Latest]
Download ReCap Pro 2010 Portable 32 Bit
eberick v8 gold torrent 35
transcending the levels of consciousness free pdf
Pes 2009 Skidrow Password Rar 56
Chand Sifarish Mp3 Songs Free Download
naanumrowdythaanmoviedownloadtamilrockershd
CRICKET 2012 pc games highly compressed upto 10 mb.rar checked
aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/rosenthal/chess/chessfenbot/chessbot.py b/spaces/rosenthal/chess/chessfenbot/chessbot.py
deleted file mode 100644
index 9bb7fa7cc87d9242cd04ff9bb172c7e4e4747945..0000000000000000000000000000000000000000
--- a/spaces/rosenthal/chess/chessfenbot/chessbot.py
+++ /dev/null
@@ -1,165 +0,0 @@
-#!/usr/bin/env python
-# ChessFenBot daemon
-# Finds submissions with chessboard images in them,
-# use a tensorflow convolutional neural network to predict pieces and return
-# a lichess analysis link and FEN diagram of chessboard
-# Run with --dry to dry run without actual submissions
-from __future__ import print_function
-import praw
-import requests
-import socket
-import time
-from datetime import datetime
-import argparse
-
-import tensorflow_chessbot # For neural network model
-from helper_functions_chessbot import *
-from helper_functions import shortenFEN
-from cfb_helpers import * # logging, comment waiting and self-reply helpers
-
-def generateResponseMessage(submission, predictor):
- print("\n---\nImage URL: %s" % submission.url)
-
- # Use CNN to make a prediction
- fen, certainty, visualize_link = predictor.makePrediction(submission.url)
-
- if fen is None:
- print("> %s - Couldn't generate FEN, skipping..." % datetime.now())
- print("\n---\n")
- return None
-
- fen = shortenFEN(fen) # ex. '111pq11r' -> '3pq2r'
- print("Predicted FEN: %s" % fen)
- print("Certainty: %.4f%%" % (certainty*100))
-
- # Get side from title or fen
- side = getSideToPlay(submission.title, fen)
- # Generate response message
- msg = generateMessage(fen, certainty, side, visualize_link)
- print("fen: %s\nside: %s\n" % (fen, side))
- return msg
-
-
-def processSubmission(submission, cfb, predictor, args, reply_wait_time=10):
- # Check if submission passes requirements and wasn't already replied to
- if isPotentialChessboardTopic(submission):
- if not previouslyRepliedTo(submission, cfb):
- # Generate response
- response = generateResponseMessage(submission, predictor)
- if response is None:
- logMessage(submission,"[NO-FEN]") # Skip since couldn't generate FEN
- return
-
- # Reply to submission with response
- if not args.dry:
- logMessage(submission,"[REPLIED]")
- submission.reply(response)
- else:
- logMessage(submission,"[DRY-RUN-REPLIED]")
-
- # Wait after submitting to not overload
- waitWithComments(reply_wait_time)
- else:
- logMessage(submission,"[SKIP]") # Skip since replied to already
-
- else:
- logMessage(submission)
- time.sleep(1) # Wait a second between normal submissions
-
-def main(args):
- resetTensorflowGraph()
- running = True
- reddit = praw.Reddit('CFB') # client credentials set up in local praw.ini file
- cfb = reddit.user.me() # ChessFenBot object
- subreddit = reddit.subreddit('chess+chessbeginners+AnarchyChess+betterchess+chesspuzzles')
- predictor = tensorflow_chessbot.ChessboardPredictor()
-
- while running:
- # Start live stream on all submissions in the subreddit
- stream = subreddit.stream.submissions()
- try:
- for submission in stream:
- processSubmission(submission, cfb, predictor, args)
- except (socket.error, requests.exceptions.ReadTimeout,
- requests.packages.urllib3.exceptions.ReadTimeoutError,
- requests.exceptions.ConnectionError) as e:
- print(
- "> %s - Connection error, skipping and continuing in 30 seconds: %s" % (
- datetime.now(), e))
- time.sleep(30)
- continue
- except Exception as e:
- print("Unknown Error, skipping and continuing in 30 seconds:",e)
- time.sleep(30)
- continue
- except KeyboardInterrupt:
- print("Keyboard Interrupt: Exiting...")
- running = False
- break
-
- predictor.close()
- print('Finished')
-
-def resetTensorflowGraph():
- """WIP needed to restart predictor after an error"""
- import tensorflow as tf
- print('Reset TF graph')
- tf.reset_default_graph() # clear out graph
-
-def runSpecificSubmission(args):
- resetTensorflowGraph()
- reddit = praw.Reddit('CFB') # client credentials set up in local praw.ini file
- cfb = reddit.user.me() # ChessFenBot object
- predictor = tensorflow_chessbot.ChessboardPredictor()
-
- submission = reddit.submission(args.sub)
- print("URL: ", submission.url)
- if submission:
- print('Processing...')
- processSubmission(submission, cfb, predictor, args)
-
- predictor.close()
- print('Done')
-
-def dryRunTest(submission='5tuerh'):
- resetTensorflowGraph()
- reddit = praw.Reddit('CFB') # client credentials set up in local praw.ini file
- predictor = tensorflow_chessbot.ChessboardPredictor()
-
- # Use a specific submission
- submission = reddit.submission(submission)
- print('Loading %s' % submission.id)
- # Check if submission passes requirements and wasn't already replied to
- if isPotentialChessboardTopic(submission):
- # Generate response
- response = generateResponseMessage(submission, predictor)
- print("RESPONSE:\n")
- print('-----------------------------')
- print(response)
- print('-----------------------------')
- else:
- print('Submission not considered chessboard topic')
-
- predictor.close()
- print('Finished')
-
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--dry', help='dry run (don\'t actually submit replies)',
- action="store_true", default=False)
- parser.add_argument('--test', help='Dry run test on pre-existing comment)',
- action="store_true", default=False)
- parser.add_argument('--sub', help='Pass submission string to process')
- args = parser.parse_args()
- if args.test:
- print('Doing dry run test on submission')
- if args.sub:
- dryRunTest(args.sub)
- else:
- dryRunTest()
- elif args.sub is not None:
- runSpecificSubmission(args)
- else:
- main(args)
diff --git a/spaces/royyy/text_generator/app.py b/spaces/royyy/text_generator/app.py
deleted file mode 100644
index 7374181be6d6d6dfacbc697182bf7cacbe1c0d0f..0000000000000000000000000000000000000000
--- a/spaces/royyy/text_generator/app.py
+++ /dev/null
@@ -1,14 +0,0 @@
-import gradio as gr
-from transformers import pipeline
-
-generator = pipeline('text-generation', model='EleutherAI/gpt-neo-1.3B')
-examples = [
- ["Once upon a time, Dr. Woo was teaching computer programming in a school."],
- ["Once upon a time, Dr. Woo was walking in a park. He "]
-]
-
-def generate(text):
- result=generator(text, max_length=100, num_return_sequences=3)
- return result[0]['generated_text']
-
-gr.Interface(fn=generate, inputs=gr.inputs.Textbox(lines=5, label='input text'), outputs=gr.outputs.Textbox(label='output text'), title='My First Text Generator', examples=examples).launch()
\ No newline at end of file
diff --git a/spaces/samuelinferences/transformers-can-do-bayesian-inference/prior-fitting/encoders.py b/spaces/samuelinferences/transformers-can-do-bayesian-inference/prior-fitting/encoders.py
deleted file mode 100644
index 4996daff4dabe5feb79cba8c5fc0fb509024efaf..0000000000000000000000000000000000000000
--- a/spaces/samuelinferences/transformers-can-do-bayesian-inference/prior-fitting/encoders.py
+++ /dev/null
@@ -1,95 +0,0 @@
-import math
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch.nn import TransformerEncoder, TransformerEncoderLayer
-
-class _PositionalEncoding(nn.Module):
- def __init__(self, d_model, dropout=0.):
- super().__init__()
- self.dropout = nn.Dropout(p=dropout)
- self.d_model = d_model
- self.device_test_tensor = nn.Parameter(torch.tensor(1.))
-
- def forward(self, x):# T x B x num_features
- assert self.d_model % x.shape[-1]*2 == 0
- d_per_feature = self.d_model // x.shape[-1]
- pe = torch.zeros(*x.shape, d_per_feature, device=self.device_test_tensor.device)
- #position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
- interval_size = 10
- div_term = (1./interval_size) * 2*math.pi*torch.exp(torch.arange(0, d_per_feature, 2, device=self.device_test_tensor.device).float()*math.log(math.sqrt(2)))
- #print(div_term/2/math.pi)
- pe[..., 0::2] = torch.sin(x.unsqueeze(-1) * div_term)
- pe[..., 1::2] = torch.cos(x.unsqueeze(-1) * div_term)
- return self.dropout(pe).view(x.shape[0],x.shape[1],self.d_model)
-
-
-class EmbeddingEncoder(nn.Module):
- def __init__(self, num_features, em_size, num_embs=100):
- super().__init__()
- self.num_embs = num_embs
- self.embeddings = nn.Embedding(num_embs * num_features, em_size, max_norm=True)
- self.init_weights(.1)
- self.min_max = (-2,+2)
-
- @property
- def width(self):
- return self.min_max[1] - self.min_max[0]
-
- def init_weights(self, initrange):
- self.embeddings.weight.data.uniform_(-initrange, initrange)
-
- def discretize(self, x):
- split_size = self.width / self.num_embs
- return (x - self.min_max[0] // split_size).int().clamp(0, self.num_embs - 1)
-
- def forward(self, x): # T x B x num_features
- x_idxs = self.discretize(x)
- x_idxs += torch.arange(x.shape[-1], device=x.device).view(1, 1, -1) * self.num_embs
- # print(x_idxs,self.embeddings.weight.shape)
- return self.embeddings(x_idxs).mean(-2)
-
-Linear = nn.Linear
-MLP = lambda num_features, emsize: nn.Sequential(nn.Linear(num_features+1,emsize*2),
- nn.ReLU(),
- nn.Linear(emsize*2,emsize))
-
-class Conv(nn.Module):
- def __init__(self, input_size, emsize):
- super().__init__()
- self.convs = torch.nn.ModuleList([nn.Conv2d(64 if i else 1, 64, 3) for i in range(5)])
- self.linear = nn.Linear(64,emsize)
-
-
- def forward(self, x):
- size = math.isqrt(x.shape[-1])
- assert size*size == x.shape[-1]
- x = x.reshape(*x.shape[:-1], 1, size, size)
- for conv in self.convs:
- if x.shape[-1] < 4:
- break
- x = conv(x)
- x.relu_()
- x = nn.AdaptiveAvgPool2d((1,1))(x).squeeze(-1).squeeze(-1)
- return self.linear(x)
-
-
-Positional = lambda _, emsize: _PositionalEncoding(d_model=emsize)
-
-
-class CanEmb(nn.Embedding):
- def __init__(self, num_features, num_embeddings: int, embedding_dim: int, *args, **kwargs):
- assert embedding_dim % num_features == 0
- embedding_dim = embedding_dim // num_features
- super().__init__(num_embeddings, embedding_dim, *args, **kwargs)
-
- def forward(self, x):
- x = super().forward(x)
- return x.view(*x.shape[:-2], -1)
-
-def get_Canonical(num_classes):
- return lambda num_features, emsize: CanEmb(num_features, num_classes, emsize)
-
-def get_Embedding(num_embs_per_feature=100):
- return lambda num_features, emsize: EmbeddingEncoder(num_features, emsize, num_embs=num_embs_per_feature)
diff --git a/spaces/sandrocalzada/DemoHF/app.py b/spaces/sandrocalzada/DemoHF/app.py
deleted file mode 100644
index 8f1e8d70a84e354f7a6e92b723c8774c7c52a384..0000000000000000000000000000000000000000
--- a/spaces/sandrocalzada/DemoHF/app.py
+++ /dev/null
@@ -1,21 +0,0 @@
-import streamlit as st
-from transformers import pipeline
-from textblob import TextBlob
-
-pipe = pipeline('sentiment-analysis')
-st.title("Hugging Face Sentiment Analysis Spaces Example")
-st.subheader("What library would you like to use for Sentiment Analysis")
-#Picking what NLP task you want to do
-option = st.radio('Library',('Transformers', 'TextBlob')) #option is stored in this variable
-#Textbox for text user is entering
-st.subheader("Enter the text you'd like to analyze.")
-text = st.text_input('Enter text') #text is stored in this variable
-
-
-if option == 'Transformers':
- out = pipe(text)
-else:
- out = TextBlob(text)
- out = out.sentiment
-st.write("Sentiment of Text: ")
-st.write(out)
\ No newline at end of file
diff --git a/spaces/sarinam/speaker-anonymization-gan/demo_inference/demo_asr.py b/spaces/sarinam/speaker-anonymization-gan/demo_inference/demo_asr.py
deleted file mode 100644
index ef9503b5a8c81d2c0a075799b1b79b70ac3599b6..0000000000000000000000000000000000000000
--- a/spaces/sarinam/speaker-anonymization-gan/demo_inference/demo_asr.py
+++ /dev/null
@@ -1,31 +0,0 @@
-from espnet2.bin.asr_inference import Speech2Text
-import resampy
-from espnet_model_zoo.downloader import ModelDownloader
-
-
-
-class DemoASR:
-
- def __init__(self, model_path, device):
- model_file = 'asr_improved_tts-phn_en.zip'
-
- d = ModelDownloader()
-
- self.speech2text = Speech2Text(
- **d.download_and_unpack(str(model_path / model_file)),
- device=str(device),
- minlenratio=0.0,
- maxlenratio=0.0,
- ctc_weight=0.4,
- beam_size=15,
- batch_size=1,
- nbest=1
- )
-
- def recognize_speech(self, audio, sr):
- if len(audio.shape) == 2:
- audio = audio.T[0]
- speech = resampy.resample(audio, sr, 16000)
- nbests = self.speech2text(speech)
- text, *_ = nbests[0]
- return text
diff --git a/spaces/scedlatioru/img-to-music/example/Deep Fritz 12 Activation Key.torrent TOP.md b/spaces/scedlatioru/img-to-music/example/Deep Fritz 12 Activation Key.torrent TOP.md
deleted file mode 100644
index b7f6dcd1b15570817121cafd13b76f10d2b65348..0000000000000000000000000000000000000000
--- a/spaces/scedlatioru/img-to-music/example/Deep Fritz 12 Activation Key.torrent TOP.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Deep Fritz 12 activation key.torrent
DOWNLOAD » https://gohhs.com/2uEzE8
-
- d5da3c52bf
-
-
-
diff --git a/spaces/scedlatioru/img-to-music/example/Eassos PartitionGuru V4.9.3.409 Professional Edition Crack For Windows UPDATED.md b/spaces/scedlatioru/img-to-music/example/Eassos PartitionGuru V4.9.3.409 Professional Edition Crack For Windows UPDATED.md
deleted file mode 100644
index 46f216dc9d74826ab7aa6f29bd591bcd97c0f840..0000000000000000000000000000000000000000
--- a/spaces/scedlatioru/img-to-music/example/Eassos PartitionGuru V4.9.3.409 Professional Edition Crack For Windows UPDATED.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-eassos partitionguru crack has an easy and quite standard interface. a lot of the features are available in the menu obvious in the top area of the window. the primary tools made available from this are also available in the club located near the top of your screen, facilitating your connections with these features.
-Eassos PartitionGuru v4.9.3.409 Professional Edition Crack For Windows
Download Zip ===== https://gohhs.com/2uEA79
-eassos partitionguru crack is a useful program for restoring files and partitions from a hard drive and disc. using this software, we can restore data from various storage areas, including usb flash drives, hard drives, optical discs, and disks. it is a user-friendly and powerful software in which we can solve all the hardware related issues. in addition, it has tools to analyze a hard drive, partition it, and repair a damaged, corrupted or corrupted partition. it is a powerful software in which we can repair hard drives. it can be used for partitioning a hard drive, enhancing the capacity of a hard drive, rebuilding the mbr, removing and hiding partitions, formatting, cloning, deleting, backup partitions and disks, and much more. it supports most of the main file systems. it is a useful software for your pc.
-eassos partitionguru 4.9.3 can be considered one of the best hard drive repair tools on the market. it will scan a drive, show the problems and then automatically fix the issues for you. it is a powerful software in which we can repair hard drives. it can be used for partitioning a hard drive, enhancing the capacity of a hard drive, rebuilding the mbr, removing and hiding partitions, formatting, cloning, deleting, backup partitions and disks, and much more. it supports most of the main file systems. it is a useful software for your pc.
899543212b
-
-
\ No newline at end of file
diff --git a/spaces/scedlatioru/img-to-music/example/Mumbai Police 2 Movie Download Kickass Torrent.md b/spaces/scedlatioru/img-to-music/example/Mumbai Police 2 Movie Download Kickass Torrent.md
deleted file mode 100644
index f19aa3dc0516bb6d2cdd2ded33b402f4c02b9bca..0000000000000000000000000000000000000000
--- a/spaces/scedlatioru/img-to-music/example/Mumbai Police 2 Movie Download Kickass Torrent.md
+++ /dev/null
@@ -1,10 +0,0 @@
-
- antman rambo in the valley of gold free download full version..
odhav bal vichitra darshan full movie story torrent
htc mytouch 3g (droid 2.1) wifi unlock
preciousm - nude beauties with blue eye cartoon porn
pinchuy full version free download
screenshack 2.5.3crack free screenshack 2.3 crack.
- lutece promenade de vaugirard fluxion wikipedia
download eye of the beholder 2 the elder scrolls iii: morrowind gold patch
25 years of rock the first 890,000
download onl vikings 7 torrent
custom shiatsu center map panasonic xt2plus
-Mumbai Police 2 movie download kickass torrent
Download ⏩ https://gohhs.com/2uEzDC
- download steak tartare recipe
download samsung galaxy sp
download ezdownloader free
download full movie my big fat greek wedding (2002)
download centos 6
download bible paper 8 10
download zipped folder free download
download the dark lord risen torrent
- dvd to avi mp3 converter
download samsung s4
download full movie the dark knight rises (2012) (eng sub) 720p
download samsung galaxy s
download full movie the dark knight rises (2012) (eng sub) 720p
download deviance bchd dvdrip rar
download saga xbox 360 games free
download title of the decade by the
- download dark knight rises (2012) (eng sub) 720p
download full movie the dark knight rises (2012) (eng sub) 720p
download full movie the dark knight rises (2012) (eng sub) 720p
download full movie the dark knight rises (2012) (eng sub) 720p
download free full movie the dark knight rises (2012)
- dvd rip xvid x264 x264 mkv 720p
download the fighter (2010) 720p
download the dark lord risen torrent
download download full movie the dark knight rises (2012) (eng sub) 720p
download download dark knight rises (2012) (eng sub) 720p
download the dark lord risen torrent
899543212b
-
-
\ No newline at end of file
diff --git a/spaces/scedlatioru/img-to-music/example/Sumita Arora Java Class 12 Pdf Free 2604 !FREE!.md b/spaces/scedlatioru/img-to-music/example/Sumita Arora Java Class 12 Pdf Free 2604 !FREE!.md
deleted file mode 100644
index 9c0148b71b54bb9d259882fcce8f0332d82ef0c0..0000000000000000000000000000000000000000
--- a/spaces/scedlatioru/img-to-music/example/Sumita Arora Java Class 12 Pdf Free 2604 !FREE!.md
+++ /dev/null
@@ -1,20 +0,0 @@
-
-How to Download Sumita Arora Java Class 12 PDF Free 2604
-If you are looking for a comprehensive and easy-to-understand guide to learn Java programming for class 12, you might have heard of Sumita Arora Java Class 12 PDF. This is a popular book that covers the basics of Java syntax, data structures, algorithms, object-oriented programming, and more. But how can you get this book for free?
-In this article, we will show you how to download Sumita Arora Java Class 12 PDF free 2604 from a reliable and safe source. You will also learn why this book is so useful for students who want to ace their exams and prepare for their future careers.
-sumita arora java class 12 pdf free 2604
Download Zip ✯✯✯ https://gohhs.com/2uEzlR
-Why Sumita Arora Java Class 12 PDF is a Great Choice
-Sumita Arora is a renowned author and educator who has written several books on computer science and information technology. She has a vast experience in teaching and developing curriculum for various boards and universities. Her books are known for their clear and concise explanations, practical examples, and exercises that test your knowledge and skills.
-Sumita Arora Java Class 12 PDF is one of her best-selling books that covers the syllabus of CBSE and other boards that follow the NCERT guidelines. It is divided into two parts: Part A covers the fundamentals of Java programming, such as variables, operators, control structures, arrays, strings, methods, classes, inheritance, polymorphism, interfaces, abstract classes, packages, exception handling, file handling, and applets. Part B covers the advanced topics of Java programming, such as collections framework, generics, multithreading, networking, database connectivity, servlets, JSPs, and JavaBeans.
-The book also contains several solved and unsolved questions at the end of each chapter that help you revise and practice what you have learned. The book also provides tips and tricks to solve common errors and bugs in your code. The book also includes sample projects that demonstrate how to apply your knowledge in real-world scenarios.
-How to Download Sumita Arora Java Class 12 PDF Free 2604
-Now that you know why Sumita Arora Java Class 12 PDF is a great choice for learning Java programming, you might be wondering how to get it for free. Well, there are many websites that claim to offer this book for free download, but not all of them are trustworthy. Some of them might contain viruses or malware that can harm your device or steal your personal information. Some of them might also have broken links or outdated versions of the book that are not compatible with your syllabus or exam pattern.
-That's why we recommend you to download Sumita Arora Java Class 12 PDF free 2604 from our website. We have verified and tested the link and the file to ensure that they are safe and secure. We have also checked the quality and accuracy of the content to ensure that it matches the latest syllabus and exam pattern. You can download the book in PDF format by clicking on the button below. You will need a PDF reader software or app to open and read the book on your device.
-Download Sumita Arora Java Class 12 PDF Free 2604
-Conclusion
-Sumita Arora Java Class 12 PDF is a comprehensive and easy-to-understand guide to learn Java programming for class 12 students. It covers all the topics that are required for your exams and future careers. It also provides plenty of examples, exercises, tips, tricks, and projects to help you master the concepts and skills of Java programming.
-You can download Sumita Arora Java Class 12 PDF free 2604 from our website by clicking on the link above. You will get a high-quality and updated version of the book that is compatible with your syllabus and exam pattern. You will also get a safe and secure file that does not contain any viruses or malware.
-We hope you found this article helpful and informative. If you have any questions or feedback, please feel free to leave a comment below. We would love to hear from you.
- d5da3c52bf
-
-
\ No newline at end of file
diff --git a/spaces/segments-tobias/conex/espnet/tts/pytorch_backend/__init__.py b/spaces/segments-tobias/conex/espnet/tts/pytorch_backend/__init__.py
deleted file mode 100644
index b7f177368e62a5578b8706300e101f831a3972ac..0000000000000000000000000000000000000000
--- a/spaces/segments-tobias/conex/espnet/tts/pytorch_backend/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-"""Initialize sub package."""
diff --git a/spaces/segments-tobias/conex/espnet2/bin/tts_train.py b/spaces/segments-tobias/conex/espnet2/bin/tts_train.py
deleted file mode 100644
index 0bf487b8f1ddabe514477aab6894733fb8672a66..0000000000000000000000000000000000000000
--- a/spaces/segments-tobias/conex/espnet2/bin/tts_train.py
+++ /dev/null
@@ -1,22 +0,0 @@
-#!/usr/bin/env python3
-from espnet2.tasks.tts import TTSTask
-
-
-def get_parser():
- parser = TTSTask.get_parser()
- return parser
-
-
-def main(cmd=None):
- """TTS training
-
- Example:
-
- % python tts_train.py asr --print_config --optim adadelta
- % python tts_train.py --config conf/train_asr.yaml
- """
- TTSTask.main(cmd=cmd)
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/segments-tobias/conex/espnet2/text/__init__.py b/spaces/segments-tobias/conex/espnet2/text/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/segments/panoptic-segment-anything/app.py b/spaces/segments/panoptic-segment-anything/app.py
deleted file mode 100644
index eda9a0c1cd0523b4a8f7e5d63cdec61b10b09c7f..0000000000000000000000000000000000000000
--- a/spaces/segments/panoptic-segment-anything/app.py
+++ /dev/null
@@ -1,601 +0,0 @@
-import subprocess, os, sys
-
-result = subprocess.run(["pip", "install", "-e", "GroundingDINO"], check=True)
-print(f"pip install GroundingDINO = {result}")
-
-result = subprocess.run(["pip", "install", "gradio==3.27.0"], check=True)
-print(f"pip install gradio==3.27.0 = {result}")
-
-sys.path.insert(0, "./GroundingDINO")
-
-if not os.path.exists("./sam_vit_h_4b8939.pth"):
- result = subprocess.run(
- [
- "wget",
- "https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth",
- ],
- check=True,
- )
- print(f"wget sam_vit_h_4b8939.pth result = {result}")
-
-
-import argparse
-import random
-import warnings
-import json
-
-import gradio as gr
-import numpy as np
-import torch
-from torch import nn
-import torch.nn.functional as F
-from scipy import ndimage
-from PIL import Image
-from huggingface_hub import hf_hub_download
-from segments.utils import bitmap2file
-
-# Grounding DINO
-import GroundingDINO.groundingdino.datasets.transforms as T
-from GroundingDINO.groundingdino.models import build_model
-from GroundingDINO.groundingdino.util import box_ops
-from GroundingDINO.groundingdino.util.slconfig import SLConfig
-from GroundingDINO.groundingdino.util.utils import (
- clean_state_dict,
-)
-from GroundingDINO.groundingdino.util.inference import annotate, predict
-
-# segment anything
-from segment_anything import build_sam, SamPredictor
-
-# CLIPSeg
-from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
-
-
-def load_model_hf(model_config_path, repo_id, filename, device):
- args = SLConfig.fromfile(model_config_path)
- model = build_model(args)
- args.device = device
-
- cache_file = hf_hub_download(repo_id=repo_id, filename=filename)
- checkpoint = torch.load(cache_file, map_location=device)
- log = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
- print("Model loaded from {} \n => {}".format(cache_file, log))
- _ = model.eval()
- model = model.to(device)
- return model
-
-
-def load_image_for_dino(image):
- transform = T.Compose(
- [
- T.RandomResize([800], max_size=1333),
- T.ToTensor(),
- T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
- ]
- )
- dino_image, _ = transform(image, None)
- return dino_image
-
-
-def dino_detection(
- model,
- image,
- image_array,
- category_names,
- category_name_to_id,
- box_threshold,
- text_threshold,
- device,
- visualize=False,
-):
- detection_prompt = " . ".join(category_names)
- dino_image = load_image_for_dino(image)
- dino_image = dino_image.to(device)
- with torch.no_grad():
- boxes, logits, phrases = predict(
- model=model,
- image=dino_image,
- caption=detection_prompt,
- box_threshold=box_threshold,
- text_threshold=text_threshold,
- device=device,
- )
- category_ids = [category_name_to_id[phrase] for phrase in phrases]
-
- if visualize:
- annotated_frame = annotate(
- image_source=image_array, boxes=boxes, logits=logits, phrases=phrases
- )
- annotated_frame = annotated_frame[..., ::-1] # BGR to RGB
- visualization = Image.fromarray(annotated_frame)
- return boxes, category_ids, visualization
- else:
- return boxes, category_ids, phrases
-
-
-def sam_masks_from_dino_boxes(predictor, image_array, boxes, device):
- # box: normalized box xywh -> unnormalized xyxy
- H, W, _ = image_array.shape
- boxes_xyxy = box_ops.box_cxcywh_to_xyxy(boxes) * torch.Tensor([W, H, W, H])
- transformed_boxes = predictor.transform.apply_boxes_torch(
- boxes_xyxy, image_array.shape[:2]
- ).to(device)
- thing_masks, _, _ = predictor.predict_torch(
- point_coords=None,
- point_labels=None,
- boxes=transformed_boxes,
- multimask_output=False,
- )
- return thing_masks
-
-
-def preds_to_semantic_inds(preds, threshold):
- flat_preds = preds.reshape((preds.shape[0], -1))
- # Initialize a dummy "unlabeled" mask with the threshold
- flat_preds_with_treshold = torch.full(
- (preds.shape[0] + 1, flat_preds.shape[-1]), threshold
- )
- flat_preds_with_treshold[1 : preds.shape[0] + 1, :] = flat_preds
-
- # Get the top mask index for each pixel
- semantic_inds = torch.topk(flat_preds_with_treshold, 1, dim=0).indices.reshape(
- (preds.shape[-2], preds.shape[-1])
- )
-
- return semantic_inds
-
-
-def clipseg_segmentation(
- processor, model, image, category_names, background_threshold, device
-):
- inputs = processor(
- text=category_names,
- images=[image] * len(category_names),
- padding="max_length",
- return_tensors="pt",
- ).to(device)
- with torch.no_grad():
- outputs = model(**inputs)
- logits = outputs.logits
- if len(logits.shape) == 2:
- logits = logits.unsqueeze(0)
- # resize the outputs
- upscaled_logits = nn.functional.interpolate(
- logits.unsqueeze(1),
- size=(image.size[1], image.size[0]),
- mode="bilinear",
- )
- preds = torch.sigmoid(upscaled_logits.squeeze(dim=1))
- semantic_inds = preds_to_semantic_inds(preds, background_threshold)
- return preds, semantic_inds
-
-
-def semantic_inds_to_shrunken_bool_masks(
- semantic_inds, shrink_kernel_size, num_categories
-):
- shrink_kernel = np.ones((shrink_kernel_size, shrink_kernel_size))
-
- bool_masks = torch.zeros((num_categories, *semantic_inds.shape), dtype=bool)
- for category in range(num_categories):
- binary_mask = semantic_inds == category
- shrunken_binary_mask_array = (
- ndimage.binary_erosion(binary_mask.numpy(), structure=shrink_kernel)
- if shrink_kernel_size > 0
- else binary_mask.numpy()
- )
- bool_masks[category] = torch.from_numpy(shrunken_binary_mask_array)
-
- return bool_masks
-
-
-def clip_and_shrink_preds(semantic_inds, preds, shrink_kernel_size, num_categories):
- # convert semantic_inds to shrunken bool masks
- bool_masks = semantic_inds_to_shrunken_bool_masks(
- semantic_inds, shrink_kernel_size, num_categories
- ).to(preds.device)
-
- sizes = [
- torch.sum(bool_masks[i].int()).item() for i in range(1, bool_masks.size(0))
- ]
- max_size = max(sizes)
- relative_sizes = [size / max_size for size in sizes] if max_size > 0 else sizes
-
- # use bool masks to clip preds
- clipped_preds = torch.zeros_like(preds)
- for i in range(1, bool_masks.size(0)):
- float_mask = bool_masks[i].float()
- clipped_preds[i - 1] = preds[i - 1] * float_mask
-
- return clipped_preds, relative_sizes
-
-
-def sample_points_based_on_preds(preds, N):
- height, width = preds.shape
- weights = preds.ravel()
- indices = np.arange(height * width)
-
- # Randomly sample N indices based on the weights
- sampled_indices = random.choices(indices, weights=weights, k=N)
-
- # Convert the sampled indices into (col, row) coordinates
- sampled_points = [(index % width, index // width) for index in sampled_indices]
-
- return sampled_points
-
-
-def upsample_pred(pred, image_source):
- pred = pred.unsqueeze(dim=0)
- original_height = image_source.shape[0]
- original_width = image_source.shape[1]
-
- larger_dim = max(original_height, original_width)
- aspect_ratio = original_height / original_width
-
- # upsample the tensor to the larger dimension
- upsampled_tensor = F.interpolate(
- pred, size=(larger_dim, larger_dim), mode="bilinear", align_corners=False
- )
-
- # remove the padding (at the end) to get the original image resolution
- if original_height > original_width:
- target_width = int(upsampled_tensor.shape[3] * aspect_ratio)
- upsampled_tensor = upsampled_tensor[:, :, :, :target_width]
- else:
- target_height = int(upsampled_tensor.shape[2] * aspect_ratio)
- upsampled_tensor = upsampled_tensor[:, :, :target_height, :]
- return upsampled_tensor.squeeze(dim=1)
-
-
-def sam_mask_from_points(predictor, image_array, points):
- points_array = np.array(points)
- # we only sample positive points, so labels are all 1
- points_labels = np.ones(len(points))
- # we don't use predict_torch here cause it didn't seem to work...
- _, _, logits = predictor.predict(
- point_coords=points_array,
- point_labels=points_labels,
- )
- # max over the 3 segmentation levels
- total_pred = torch.max(torch.sigmoid(torch.tensor(logits)), dim=0)[0].unsqueeze(
- dim=0
- )
- # logits are 256x256 -> upsample back to image shape
- upsampled_pred = upsample_pred(total_pred, image_array)
- return upsampled_pred
-
-
-def inds_to_segments_format(
- panoptic_inds, thing_category_ids, stuff_category_names, category_name_to_id
-):
- panoptic_inds_array = panoptic_inds.numpy().astype(np.uint32)
- bitmap_file = bitmap2file(panoptic_inds_array, is_segmentation_bitmap=True)
- segmentation_bitmap = Image.open(bitmap_file)
-
- stuff_category_ids = [
- category_name_to_id[stuff_category_name]
- for stuff_category_name in stuff_category_names
- ]
-
- unique_inds = np.unique(panoptic_inds_array)
- stuff_annotations = [
- {"id": i, "category_id": stuff_category_ids[i - 1]}
- for i in range(1, len(stuff_category_names) + 1)
- if i in unique_inds
- ]
- thing_annotations = [
- {"id": len(stuff_category_names) + 1 + i, "category_id": thing_category_id}
- for i, thing_category_id in enumerate(thing_category_ids)
- ]
- annotations = stuff_annotations + thing_annotations
-
- return segmentation_bitmap, annotations
-
-
-def generate_panoptic_mask(
- image,
- thing_category_names_string,
- stuff_category_names_string,
- dino_box_threshold=0.3,
- dino_text_threshold=0.25,
- segmentation_background_threshold=0.1,
- shrink_kernel_size=20,
- num_samples_factor=1000,
- task_attributes_json="",
-):
- if task_attributes_json != "":
- task_attributes = json.loads(task_attributes_json)
- categories = task_attributes["categories"]
- category_name_to_id = {
- category["name"]: category["id"] for category in categories
- }
- # split the categories into "stuff" categories (regions w/o instances)
- # and "thing" categories (objects/instances)
- stuff_categories = [
- category
- for category in categories
- if "has_instances" not in category or not category["has_instances"]
- ]
- thing_categories = [
- category
- for category in categories
- if "has_instances" in category and category["has_instances"]
- ]
- stuff_category_names = [category["name"] for category in stuff_categories]
- thing_category_names = [category["name"] for category in thing_categories]
- category_names = thing_category_names + stuff_category_names
- else:
- # parse inputs
- thing_category_names = [
- thing_category_name.strip()
- for thing_category_name in thing_category_names_string.split(",")
- ]
- stuff_category_names = [
- stuff_category_name.strip()
- for stuff_category_name in stuff_category_names_string.split(",")
- ]
- category_names = thing_category_names + stuff_category_names
- category_name_to_id = {
- category_name: i for i, category_name in enumerate(category_names)
- }
-
- image = image.convert("RGB")
- image_array = np.asarray(image)
-
- # compute SAM image embedding
- sam_predictor.set_image(image_array)
-
- # detect boxes for "thing" categories using Grounding DINO
- thing_category_ids = []
- thing_masks = []
- thing_boxes = []
- detected_thing_category_names = []
- if len(thing_category_names) > 0:
- thing_boxes, thing_category_ids, detected_thing_category_names = dino_detection(
- dino_model,
- image,
- image_array,
- thing_category_names,
- category_name_to_id,
- dino_box_threshold,
- dino_text_threshold,
- device,
- )
- if len(thing_boxes) > 0:
- # get segmentation masks for the thing boxes
- thing_masks = sam_masks_from_dino_boxes(
- sam_predictor, image_array, thing_boxes, device
- )
- if len(stuff_category_names) > 0:
- # get rough segmentation masks for "stuff" categories using CLIPSeg
- clipseg_preds, clipseg_semantic_inds = clipseg_segmentation(
- clipseg_processor,
- clipseg_model,
- image,
- stuff_category_names,
- segmentation_background_threshold,
- device,
- )
- # remove things from stuff masks
- clipseg_semantic_inds_without_things = clipseg_semantic_inds.clone()
- if len(thing_boxes) > 0:
- combined_things_mask = torch.any(thing_masks, dim=0)
- clipseg_semantic_inds_without_things[combined_things_mask[0]] = 0
- # clip CLIPSeg preds based on non-overlapping semantic segmentation inds (+ optionally shrink the mask of each category)
- # also returns the relative size of each category
- clipsed_clipped_preds, relative_sizes = clip_and_shrink_preds(
- clipseg_semantic_inds_without_things,
- clipseg_preds,
- shrink_kernel_size,
- len(stuff_category_names) + 1,
- )
- # get finer segmentation masks for the "stuff" categories using SAM
- sam_preds = torch.zeros_like(clipsed_clipped_preds)
- for i in range(clipsed_clipped_preds.shape[0]):
- clipseg_pred = clipsed_clipped_preds[i]
- # for each "stuff" category, sample points in the rough segmentation mask
- num_samples = int(relative_sizes[i] * num_samples_factor)
- if num_samples == 0:
- continue
- points = sample_points_based_on_preds(
- clipseg_pred.cpu().numpy(), num_samples
- )
- if len(points) == 0:
- continue
- # use SAM to get mask for points
- pred = sam_mask_from_points(sam_predictor, image_array, points)
- sam_preds[i] = pred
- sam_semantic_inds = preds_to_semantic_inds(
- sam_preds, segmentation_background_threshold
- )
-
- # combine the thing inds and the stuff inds into panoptic inds
- panoptic_inds = (
- sam_semantic_inds.clone()
- if len(stuff_category_names) > 0
- else torch.zeros(image_array.shape[0], image_array.shape[1], dtype=torch.long)
- )
- ind = len(stuff_category_names) + 1
- for thing_mask in thing_masks:
- # overlay thing mask on panoptic inds
- panoptic_inds[thing_mask.squeeze(dim=0)] = ind
- ind += 1
-
- panoptic_bool_masks = (
- semantic_inds_to_shrunken_bool_masks(panoptic_inds, 0, ind + 1)
- .numpy()
- .astype(int)
- )
- panoptic_names = (
- ["unlabeled"] + stuff_category_names + detected_thing_category_names
- )
- subsection_label_pairs = [
- (panoptic_bool_masks[i], panoptic_name)
- for i, panoptic_name in enumerate(panoptic_names)
- ]
-
- segmentation_bitmap, annotations = inds_to_segments_format(
- panoptic_inds, thing_category_ids, stuff_category_names, category_name_to_id
- )
- annotations_json = json.dumps(annotations)
-
- return (image_array, subsection_label_pairs), segmentation_bitmap, annotations_json
-
-
-config_file = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
-ckpt_repo_id = "ShilongLiu/GroundingDINO"
-ckpt_filename = "groundingdino_swint_ogc.pth"
-sam_checkpoint = "./sam_vit_h_4b8939.pth"
-
-device = "cuda" if torch.cuda.is_available() else "cpu"
-print("Using device:", device)
-
-if device != "cpu":
- try:
- from GroundingDINO.groundingdino import _C
- except:
- warnings.warn(
- "Failed to load custom C++ ops. Running on CPU mode Only in groundingdino!"
- )
-
-# initialize groundingdino model
-dino_model = load_model_hf(config_file, ckpt_repo_id, ckpt_filename, device)
-
-# initialize SAM
-sam = build_sam(checkpoint=sam_checkpoint)
-sam.to(device=device)
-sam_predictor = SamPredictor(sam)
-
-clipseg_processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
-clipseg_model = CLIPSegForImageSegmentation.from_pretrained(
- "CIDAS/clipseg-rd64-refined"
-)
-clipseg_model.to(device)
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser("Panoptic Segment Anything demo", add_help=True)
- parser.add_argument("--debug", action="store_true", help="using debug mode")
- parser.add_argument("--share", action="store_true", help="share the app")
- args = parser.parse_args()
-
- print(f"args = {args}")
-
- block = gr.Blocks(title="Panoptic Segment Anything").queue()
- with block:
- with gr.Column():
- title = gr.Markdown(
- "# [Panoptic Segment Anything](https://github.com/segments-ai/panoptic-segment-anything)"
- )
- description = gr.Markdown(
- "Demo for zero-shot panoptic segmentation using Segment Anything, Grounding DINO, and CLIPSeg."
- )
- with gr.Row():
- with gr.Column():
- input_image = gr.Image(source="upload", type="pil")
- thing_category_names_string = gr.Textbox(
- label="Thing categories (i.e. categories with instances), comma-separated",
- placeholder="E.g. car, bus, person",
- )
- stuff_category_names_string = gr.Textbox(
- label="Stuff categories (i.e. categories without instances), comma-separated",
- placeholder="E.g. sky, road, buildings",
- )
- run_button = gr.Button(label="Run")
- with gr.Accordion("Advanced options", open=False):
- box_threshold = gr.Slider(
- label="Grounding DINO box threshold",
- minimum=0.0,
- maximum=1.0,
- value=0.3,
- step=0.001,
- )
- text_threshold = gr.Slider(
- label="Grounding DINO text threshold",
- minimum=0.0,
- maximum=1.0,
- value=0.25,
- step=0.001,
- )
- segmentation_background_threshold = gr.Slider(
- label="Segmentation background threshold (under this threshold, a pixel is considered background/unlabeled)",
- minimum=0.0,
- maximum=1.0,
- value=0.1,
- step=0.001,
- )
- shrink_kernel_size = gr.Slider(
- label="Shrink kernel size (how much to shrink the mask before sampling points)",
- minimum=0,
- maximum=100,
- value=20,
- step=1,
- )
- num_samples_factor = gr.Slider(
- label="Number of samples factor (how many points to sample in the largest category)",
- minimum=0,
- maximum=1000,
- value=1000,
- step=1,
- )
- task_attributes_json = gr.Textbox(
- label="Task attributes JSON",
- )
-
- with gr.Column():
- annotated_image = gr.AnnotatedImage()
- with gr.Accordion("Segmentation bitmap", open=False):
- segmentation_bitmap_text = gr.Markdown(
- """
-The segmentation bitmap is a 32-bit RGBA png image which contains the segmentation masks.
-The alpha channel is set to 255, and the remaining 24-bit values in the RGB channels correspond to the object ids in the annotations list.
-Unlabeled regions have a value of 0.
-Because of the large dynamic range, the segmentation bitmap appears black in the image viewer.
-"""
- )
- segmentation_bitmap = gr.Image(
- type="pil", label="Segmentation bitmap"
- )
- annotations_json = gr.Textbox(
- label="Annotations JSON",
- )
-
- examples = gr.Examples(
- examples=[
- [
- "a2d2.png",
- "car, bus, person",
- "road, sky, buildings, sidewalk",
- ],
- [
- "bxl.png",
- "car, tram, motorcycle, person",
- "road, buildings, sky",
- ],
- ],
- fn=generate_panoptic_mask,
- inputs=[
- input_image,
- thing_category_names_string,
- stuff_category_names_string,
- ],
- outputs=[annotated_image, segmentation_bitmap, annotations_json],
- cache_examples=True,
- )
-
- run_button.click(
- fn=generate_panoptic_mask,
- inputs=[
- input_image,
- thing_category_names_string,
- stuff_category_names_string,
- box_threshold,
- text_threshold,
- segmentation_background_threshold,
- shrink_kernel_size,
- num_samples_factor,
- task_attributes_json,
- ],
- outputs=[annotated_image, segmentation_bitmap, annotations_json],
- api_name="segment",
- )
-
- block.launch(server_name="0.0.0.0", debug=args.debug, share=args.share)
diff --git a/spaces/shi-labs/FcF-Inpainting/training/losses/ade20k/segm_lib/nn/modules/comm.py b/spaces/shi-labs/FcF-Inpainting/training/losses/ade20k/segm_lib/nn/modules/comm.py
deleted file mode 100644
index b64bf6ba3b3e7abbab375c6dd4a87d8239e62138..0000000000000000000000000000000000000000
--- a/spaces/shi-labs/FcF-Inpainting/training/losses/ade20k/segm_lib/nn/modules/comm.py
+++ /dev/null
@@ -1,131 +0,0 @@
-# -*- coding: utf-8 -*-
-# File : comm.py
-# Author : Jiayuan Mao
-# Email : maojiayuan@gmail.com
-# Date : 27/01/2018
-#
-# This file is part of Synchronized-BatchNorm-PyTorch.
-# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
-# Distributed under MIT License.
-
-import queue
-import collections
-import threading
-
-__all__ = ['FutureResult', 'SlavePipe', 'SyncMaster']
-
-
-class FutureResult(object):
- """A thread-safe future implementation. Used only as one-to-one pipe."""
-
- def __init__(self):
- self._result = None
- self._lock = threading.Lock()
- self._cond = threading.Condition(self._lock)
-
- def put(self, result):
- with self._lock:
- assert self._result is None, 'Previous result has\'t been fetched.'
- self._result = result
- self._cond.notify()
-
- def get(self):
- with self._lock:
- if self._result is None:
- self._cond.wait()
-
- res = self._result
- self._result = None
- return res
-
-
-_MasterRegistry = collections.namedtuple('MasterRegistry', ['result'])
-_SlavePipeBase = collections.namedtuple('_SlavePipeBase', ['identifier', 'queue', 'result'])
-
-
-class SlavePipe(_SlavePipeBase):
- """Pipe for master-slave communication."""
-
- def run_slave(self, msg):
- self.queue.put((self.identifier, msg))
- ret = self.result.get()
- self.queue.put(True)
- return ret
-
-
-class SyncMaster(object):
- """An abstract `SyncMaster` object.
-
- - During the replication, as the data parallel will trigger an callback of each module, all slave devices should
- call `register(id)` and obtain an `SlavePipe` to communicate with the master.
- - During the forward pass, master device invokes `run_master`, all messages from slave devices will be collected,
- and passed to a registered callback.
- - After receiving the messages, the master device should gather the information and determine to message passed
- back to each slave devices.
- """
-
- def __init__(self, master_callback):
- """
-
- Args:
- master_callback: a callback to be invoked after having collected messages from slave devices.
- """
- self._master_callback = master_callback
- self._queue = queue.Queue()
- self._registry = collections.OrderedDict()
- self._activated = False
-
- def register_slave(self, identifier):
- """
- Register an slave device.
-
- Args:
- identifier: an identifier, usually is the device id.
-
- Returns: a `SlavePipe` object which can be used to communicate with the master device.
-
- """
- if self._activated:
- assert self._queue.empty(), 'Queue is not clean before next initialization.'
- self._activated = False
- self._registry.clear()
- future = FutureResult()
- self._registry[identifier] = _MasterRegistry(future)
- return SlavePipe(identifier, self._queue, future)
-
- def run_master(self, master_msg):
- """
- Main entry for the master device in each forward pass.
- The messages were first collected from each devices (including the master device), and then
- an callback will be invoked to compute the message to be sent back to each devices
- (including the master device).
-
- Args:
- master_msg: the message that the master want to send to itself. This will be placed as the first
- message when calling `master_callback`. For detailed usage, see `_SynchronizedBatchNorm` for an example.
-
- Returns: the message to be sent back to the master device.
-
- """
- self._activated = True
-
- intermediates = [(0, master_msg)]
- for i in range(self.nr_slaves):
- intermediates.append(self._queue.get())
-
- results = self._master_callback(intermediates)
- assert results[0][0] == 0, 'The first result should belongs to the master.'
-
- for i, res in results:
- if i == 0:
- continue
- self._registry[i].result.put(res)
-
- for i in range(self.nr_slaves):
- assert self._queue.get() is True
-
- return results[0][1]
-
- @property
- def nr_slaves(self):
- return len(self._registry)
diff --git a/spaces/shibing624/pycorrector/README.md b/spaces/shibing624/pycorrector/README.md
deleted file mode 100644
index 23d948528ce49af41fb9fca3e5fcf3f24bad09df..0000000000000000000000000000000000000000
--- a/spaces/shibing624/pycorrector/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Pycorrector
-emoji: 📈
-colorFrom: indigo
-colorTo: yellow
-sdk: gradio
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/sidharthism/fashion-eye/netdissect/upsegmodel/prroi_pool/__init__.py b/spaces/sidharthism/fashion-eye/netdissect/upsegmodel/prroi_pool/__init__.py
deleted file mode 100644
index 0c40b7a7e2bca8a0dbd28e13815f2f2ad6c4728b..0000000000000000000000000000000000000000
--- a/spaces/sidharthism/fashion-eye/netdissect/upsegmodel/prroi_pool/__init__.py
+++ /dev/null
@@ -1,13 +0,0 @@
-#! /usr/bin/env python3
-# -*- coding: utf-8 -*-
-# File : __init__.py
-# Author : Jiayuan Mao, Tete Xiao
-# Email : maojiayuan@gmail.com, jasonhsiao97@gmail.com
-# Date : 07/13/2018
-#
-# This file is part of PreciseRoIPooling.
-# Distributed under terms of the MIT license.
-# Copyright (c) 2017 Megvii Technology Limited.
-
-from .prroi_pool import *
-
diff --git a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Clash Royale Pass Royale Gratis APK Join the Arena and Battle with Millions of Players.md b/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Clash Royale Pass Royale Gratis APK Join the Arena and Battle with Millions of Players.md
deleted file mode 100644
index 9892d567af9d25269557d5b3c20074d650129c2e..0000000000000000000000000000000000000000
--- a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Clash Royale Pass Royale Gratis APK Join the Arena and Battle with Millions of Players.md
+++ /dev/null
@@ -1,90 +0,0 @@
-
-Clash Royale Pass Royale Gratis APK: How to Get It and What It Offers
-If you are a fan of strategy games, you have probably heard of Clash Royale, one of the most popular and addictive mobile games in the world. But do you know what is Pass Royale and how to get it for free? In this article, we will tell you everything you need to know about this premium service and how to enjoy its benefits without spending a dime.
-What is Clash Royale?
-Clash Royale is a real-time multiplayer game developed by Supercell, the creators of Clash of Clans. In this game, you can collect and upgrade dozens of cards featuring your favorite Clash characters, spells, and defenses. You can also build your own battle deck and challenge other players online in fast-paced duels.
-clash royale pass royale gratis apk
DOWNLOAD ->>> https://ssurll.com/2uNZDL
-The game has 10 competitive arenas, each with its own theme and trophies. You can also join or create a clan, where you can chat, donate cards, and participate in clan wars. Additionally, the game offers various modes, such as 2v2 battles, special events, tournaments, and more.
-Clash Royale is free to download and play, but it also has in-game purchases that can enhance your gaming experience. One of these purchases is Pass Royale, which we will explain in the next section.
-What is Pass Royale?
-Pass Royale is a premium subscription service that gives you access to exclusive rewards and features. It costs $4.99 per month, but it can be worth it if you play Clash Royale regularly. Some of the benefits of Pass Royale are:
-
-- Unlimited entries to special challenges and tournaments
-- A golden name in the game
-- A unique tower skin and emote every season
-- More rewards from chests, quests, and crowns
-- The ability to queue chests and skip wait times
-- The option to strike cards from chests and get the ones you want
-
-As you can see, Pass Royale can give you a significant advantage over other players, as well as make your game more fun and rewarding. But what if you don't want to pay for it? Is there a way to get Pass Royale for free? The answer is yes, but there are different methods with different risks involved.
-clash royale free pass royale apk download
-clash royale pass royale hack apk 2023
-clash royale mod apk with pass royale unlocked
-how to get pass royale for free in clash royale apk
-clash royale pass royale generator apk
-clash royale latest version apk with pass royale
-clash royale apk unlimited gems and pass royale
-clash royale pass royale season 23 apk
-clash royale apk mod menu with pass royale
-clash royale pass royale cheat apk
-clash royale apk no root with free pass royale
-clash royale pass royale glitch apk
-clash royale apk offline with pass royale
-how to activate pass royale in clash royale apk
-clash royale pass royale redeem code apk
-clash royale apk update with pass royale
-clash royale pass royale rewards apk
-clash royale apk hack tool with pass royale
-clash royale pass royale cost apk
-clash royale apk for pc with free pass royale
-clash royale pass royale worth it apk
-clash royale apk online with pass royale
-how to cancel pass royale in clash royale apk
-clash royale pass royale benefits apk
-clash royale apk for ios with free pass royale
-clash royale pass royale review apk
-clash royale apk old version with pass royale
-how to get free gems in clash royale with pass royale apk
-clash royale pass royale tiers apk
-clash royale apk for android with free pass royale
-clash royale pass royale tips apk
-clash royale apk new update with pass royale
-how to get free chests in clash royale with pass royale apk
-clash royale pass royale tricks apk
-clash royale apk for windows with free pass royale
-clash royale pass royale guide apk
-clash royale apk 2023 with free pass
-How to get Pass Royale for free?
-The official and legal way to earn Pass Royale without paying
-The best way to get Pass Royale for free is to use the official and legal methods that Supercell provides. These methods are safe and reliable, but they require some time and effort on your part. Here are some of them:
-Completing quests and challenges
-One of the easiest ways to earn Pass Royale for free is to complete quests and challenges that the game offers. These tasks can vary from winning battles, using certain cards, or playing certain modes. By completing them, you can earn gems, which are the premium currency of the game. You need 500 gems to buy Pass Royale for one season, so if you save enough gems, you can get it for free.
-Participating in events and tournaments
-Another way to earn gems is to participate in events and tournaments that the game organizes. These are special modes that have different rules and rewards. Some of them are free to enter, while others require a small fee.
Redeeming codes and coupons
-A third way to earn gems is to redeem codes and coupons that Supercell or other partners may offer. These are usually given away during special occasions, such as anniversaries, holidays, or events. You can find these codes and coupons on the official Clash Royale website, social media pages, or newsletters. You can also check out some websites that list the latest codes and coupons for Clash Royale, such as [Dexerto](^4^), [CouponBirds](^5^), or [Pro Game Guides](^6^). To redeem them, you need to enter them in the game settings or the shop.
-The unofficial and risky way to get Pass Royale for free
-Another way to get Pass Royale for free is to use the unofficial and risky methods that some people may suggest. These methods are not endorsed by Supercell and may violate their terms of service. They may also expose you to malware, scams, or bans. Here are some of them:
-Downloading modded or hacked APK files
-Some websites may claim to offer modded or hacked APK files that can give you Pass Royale for free. These are modified versions of the game that may have some features unlocked or altered. However, these files are not safe to download or install, as they may contain viruses, spyware, or other malicious software. They may also damage your device or compromise your personal information. Moreover, they may not work properly or be compatible with the official game updates.
-Using third-party apps or websites
-Some apps or websites may claim to offer free gems or Pass Royale in exchange for completing surveys, watching ads, downloading apps, or other tasks. These are usually scams that aim to collect your data, spam you with ads, or trick you into paying for something. They may also ask you to provide your game account details, such as your username, password, or email. This can result in your account being hacked, stolen, or banned by Supercell.
-The dangers and drawbacks of these methods
-As you can see, these methods are not worth the risk. They can harm your device, your game account, and your privacy. They can also ruin your gaming experience and enjoyment. Furthermore, they are unfair and disrespectful to Supercell and the Clash Royale community. Supercell works hard to create and maintain a fun and balanced game for everyone. They also support many content creators who provide quality entertainment and information for the players. By using these methods, you are not only cheating yourself, but also hurting the game and its creators.
-Conclusion
-In conclusion, Pass Royale is a great way to enhance your Clash Royale experience and support the game developers. However, you don't have to pay for it if you don't want to. You can use the official and legal methods that Supercell provides to earn gems and buy Pass Royale for free. These methods are safe, reliable, and rewarding. On the other hand, you should avoid the unofficial and risky methods that some people may suggest. These methods are dangerous, unreliable, and unethical. They can also get you in trouble with Supercell and the law.
-We hope this article has helped you understand what is Pass Royale and how to get it for free. If you have any questions or feedback, feel free to leave a comment below. And if you enjoyed this article, don't forget to share it with your friends and clanmates. Happy clashing!
-Frequently Asked Questions
-
-- Q: How long does Pass Royale last?
-- A: Pass Royale lasts for one season, which is usually 28 days long.
-- Q: Can I cancel Pass Royale?
-- A: Yes, you can cancel Pass Royale at any time by going to your device settings and managing your subscriptions.
-- Q: Do I keep the rewards I earned from Pass Royale after it expires?
-- A: Yes, you keep all the rewards you earned from Pass Royale even after it expires.
-- Q: Can I use multiple creator codes at once?
-- A: No, you can only use one creator code at a time.
-- Q: How often do new creator codes come out?
-- A: There is no fixed schedule for new creator codes. Supercell adds new members to their Creators program regularly based on their criteria.
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Download Avakin Life 3D Virtual World Mod APK with Unlimited Money.md b/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Download Avakin Life 3D Virtual World Mod APK with Unlimited Money.md
deleted file mode 100644
index 617086d460e0899e09372b6600e7716cd4ebd3a8..0000000000000000000000000000000000000000
--- a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Download Avakin Life 3D Virtual World Mod APK with Unlimited Money.md
+++ /dev/null
@@ -1,110 +0,0 @@
-
-Avakin Life 3D Virtual World Mod APK Unlimited Money: How to Download and Play
- Do you want to experience a virtual world where you can create your own avatar, explore different places, and interact with other players? If yes, then you should try Avakin Life 3D Virtual World, a popular social simulation game that lets you live a second life online. But what if you want to enjoy the game without any limitations or restrictions? Well, there is a way to do that. You can download and play Avakin Life 3D Virtual World Mod APK Unlimited Money, a modified version of the original game that gives you unlimited money and resources. In this article, we will tell you what Avakin Life 3D Virtual World is, what Avakin Life 3D Virtual World Mod APK Unlimited Money is, how to download and install it, how to play it, and what are the benefits of playing it. So, let's get started.
-avakin life 3d virtual world mod apk unlimited money
Download File · https://ssurll.com/2uO1va
- What is Avakin Life 3D Virtual World?
- Avakin Life 3D Virtual World is a social simulation game that allows you to create your own avatar, customize it with various outfits and accessories, and explore a realistic and immersive 3D environment. You can visit different locations, such as beaches, clubs, cafes, parks, and more. You can also chat, flirt, dance, party, and have fun with other players from around the world. You can make friends, date, fall in love, or even get married. You can also join various events, contests, and challenges to earn rewards and prizes. You can also design your own home, decorate it with furniture and items, and invite your friends over. In short, Avakin Life 3D Virtual World is a game where you can live your dream life online.
- A social simulation game with endless possibilities
- One of the main features of Avakin Life 3D Virtual World is that it is a social simulation game. This means that you can interact with other players in real time, chat with them using text or voice messages, express yourself with emojis and gestures, and do various activities together. You can also join or create your own communities, clubs, or groups based on your interests and preferences. You can also participate in various events, contests, and challenges that are organized by the game developers or other players. You can also create your own events, invite your friends, and have fun. There are endless possibilities for you to socialize and have fun in Avakin Life 3D Virtual World.
- A realistic and immersive 3D environment
- Another feature of Avakin Life 3D Virtual World is that it has a realistic and immersive 3D environment. The game has stunning graphics, animations, sounds, and effects that make you feel like you are in a real world. The game also has a variety of locations that you can visit, such as beaches, clubs, cafes, parks, and more. Each location has its own theme, atmosphere, and activities. You can also travel to different countries and regions, such as Egypt, Brazil, Japan, and more. You can also experience different seasons and weather conditions, such as snow, rain, and sun. The game also has a day and night cycle that affects the lighting and mood of the environment. You can also enjoy various music genres and soundtracks that suit the vibe of each location. The game also has realistic physics and movements that make your avatar and the objects behave naturally. The game also supports VR mode, which enhances your immersion and experience.
- A customizable and expressive avatar
- The third feature of Avakin Life 3D Virtual World is that it has a customizable and expressive avatar. You can create your own avatar from scratch, choosing your gender, skin tone, hair style, eye color, facial features, and more. You can also customize your avatar with various outfits and accessories, such as clothes, shoes, hats, glasses, jewelry, tattoos, and more. You can also change your avatar's mood and expression with different emojis and gestures. You can also use filters and stickers to enhance your avatar's appearance. You can also upgrade your avatar's skills and abilities, such as dancing, swimming, cooking, and more. You can also collect and use various items and props, such as pets, vehicles, furniture, and more. You can also earn badges and achievements that show your progress and status in the game.
- What is Avakin Life 3D Virtual World Mod APK Unlimited Money?
- Avakin Life 3D Virtual World Mod APK Unlimited Money is a modified version of the original game that gives you unlimited money and resources. It is a file that you can download and install on your device to play the game with some extra features and benefits. With Avakin Life 3D Virtual World Mod APK Unlimited Money, you can get unlimited money and resources that you can use to buy anything you want in the game. You can also unlock premium features and items that are normally not available or require real money to purchase. For example, you can unlock VIP membership, which gives you access to exclusive locations, outfits, items, events, and more. You can also unlock all the levels, skills, badges, achievements, and more. You can also remove ads and other annoying features that may interrupt your gameplay.
- A modified version of the original game
- Avakin Life 3D Virtual World Mod APK Unlimited Money is a modified version of the original game that has been altered by some third-party developers or hackers. They have changed some of the codes and data of the original game to make it more favorable for the players. They have added some features and benefits that are not present or limited in the original game. They have also removed some features and limitations that are present or imposed in the original game. They have done this to make the game more fun and enjoyable for the players.
-avakin life 3d virtual world hack apk free download
-avakin life 3d virtual world mod menu apk latest version
-avakin life 3d virtual world unlimited coins and gems apk
-avakin life 3d virtual world mod apk android 1
-avakin life 3d virtual world mod apk revdl
-avakin life 3d virtual world mod apk happymod
-avakin life 3d virtual world mod apk rexdl
-avakin life 3d virtual world mod apk no root
-avakin life 3d virtual world mod apk offline
-avakin life 3d virtual world mod apk online
-avakin life 3d virtual world mod apk obb
-avakin life 3d virtual world mod apk unlimited everything
-avakin life 3d virtual world mod apk unlimited diamonds
-avakin life 3d virtual world mod apk unlimited clothes
-avakin life 3d virtual world mod apk unlimited xp
-avakin life 3d virtual world mod apk unlimited level
-avakin life 3d virtual world mod apk unlocked all items
-avakin life 3d virtual world mod apk unlocked all features
-avakin life 3d virtual world mod apk unlocked all locations
-avakin life 3d virtual world mod apk unlocked all animations
-avakin life 3d virtual world mod apk vip unlocked
-avakin life 3d virtual world mod apk premium unlocked
-avakin life 3d virtual world mod apk pro unlocked
-avakin life 3d virtual world mod apk full unlocked
-avakin life 3d virtual world mod apk mega mod
-avakin life 3d virtual world mod apk god mode
-avakin life 3d virtual world mod apk anti ban
-avakin life 3d virtual world mod apk latest update
-avakin life 3d virtual world mod apk new version
-avakin life 3d virtual world mod apk old version
-avakin life 3d virtual world hack version download
-avakin life 3d virtual world cheat version download
-avakin life 3d virtual world cracked version download
-avakin life 3d virtual world patched version download
-avakin life 3d virtual world hacked version download
-how to download avakin life 3d virtual world mod apk for free
-how to install avakin life 3d virtual world mod apk on android
-how to play avakin life 3d virtual world mod apk on pc
-how to update avakin life 3d virtual world mod apk to latest version
-how to get unlimited money in avakin life 3d virtual world mod apk
-how to get free coins in avakin life 3d virtual world hack apk
-how to get free gems in avakin life 3d virtual world hack apk
-how to get free clothes in avakin life 3d virtual world hack apk
-how to get free diamonds in avakin life 3d virtual world hack apk
-how to get free xp in avakin life 3d virtual world hack apk
-how to get free level in avakin life 3d virtual world hack apk
-how to unlock all items in avakin life 3d virtual world hack apk
-how to unlock all features in avakin life 3d virtual world hack apk
- A way to get unlimited money and resources
- One of the main advantages of playing Avakin Life 3D Virtual World Mod APK Unlimited Money is that you can get unlimited money and resources in the game. Money is the currency that you use to buy various things in the game, such as outfits, accessories, items, furniture, and more. Resources are the materials that you use to upgrade your skills, abilities, and items. For example, you need coins, gems, diamonds, and avacoins to buy and upgrade various things in the game. Normally, you have to earn money and resources by playing the game, completing tasks, participating in events, or spending real money. However, with Avakin Life 3D Virtual World Mod APK Unlimited Money, you can get unlimited money and resources for free. You can get as much money and resources as you want without any limit or restriction. You can also use them to buy anything you want without any cost or requirement.
- A way to unlock premium features and items
- Another advantage of playing Avakin Life 3D Virtual World Mod APK Unlimited Money is that you can unlock premium features and items that are normally not available or require real money to purchase. For example, you can unlock VIP membership, which gives you access to exclusive locations, outfits, items, events, and more. You can also unlock all the levels, skills, badges, achievements, and more that are normally locked or require a certain amount of money or resources to unlock. You can also unlock all the outfits, accessories, items, furniture, and more that are normally limited or require a certain level or condition to obtain. You can also unlock all the pets, vehicles, and other props that are normally rare or expensive to get. You can also enjoy all the premium features and items without any ads or interruptions.
- How to download and install Avakin Life 3D Virtual World Mod APK Unlimited Money?
- If you want to play Avakin Life 3D Virtual World Mod APK Unlimited Money, you need to download and install it on your device. However, you cannot find it on the official app stores, such as Google Play Store or Apple App Store. This is because it is a modified version of the original game that violates the terms and conditions of the app stores. Therefore, you need to find a reliable source for the mod apk file on the internet. Here are the steps that you need to follow to download and install Avakin Life 3D Virtual World Mod APK Unlimited Money:
- Find a reliable source for the mod apk file
- The first step is to find a reliable source for the mod apk file on the internet. There are many websites and platforms that offer mod apk files for various games and apps. However, not all of them are trustworthy or safe. Some of them may contain viruses, malware, spyware, or other harmful programs that may damage your device or steal your personal information. Some of them may also provide fake or outdated mod apk files that may not work properly or cause errors. Therefore, you need to be careful and cautious when choosing a source for the mod apk file. You need to do some research and check the reviews, ratings, comments, and feedback of other users who have downloaded and used the mod apk file. You also need to check the security and authenticity of the website or platform that offers the mod apk file. You need to make sure that it has a valid SSL certificate, a clear privacy policy, and a good reputation. You also need to avoid clicking on any suspicious links, pop-ups, ads, or banners that may redirect you to malicious sites or download unwanted programs.
- Enable unknown sources on your device
- The second step is to enable unknown sources on your device. This is a setting that allows you to install apps and games from sources other than the official app stores. Since Avakin Life 3D Virtual World Mod APK Unlimited Money is not available on the official app stores, you need to enable unknown sources on your device to install it. The process of enabling unknown sources may vary depending on your device model and operating system. However, the general steps are as follows:
- - Go to your device's settings and look for security or privacy options. - Find and tap on the option that says unknown sources, install unknown apps, or allow from this source. - Turn on the toggle or check the box that allows you to install apps and games from unknown sources. - Confirm your choice by tapping on OK or Yes. By enabling unknown sources on your device, you are giving permission to install apps and games from sources other than the official app stores. However, you should also be aware of the risks and consequences of doing so. You should only install apps and games from trusted and verified sources that you have researched and checked beforehand. You should also scan your device regularly with an antivirus or anti-malware program to detect and remove any potential threats or infections.
- Download and install the mod apk file
- The third step is to download and install the mod apk file on your device. Once you have found a reliable source for the mod apk file and enabled unknown sources on your device, you can proceed to download and install the mod apk file. The steps are as follows:
- - Go to the website or platform that offers the mod apk file and look for the download button or link. - Tap on the download button or link and wait for the mod apk file to be downloaded on your device. - Once the download is complete, go to your device's file manager and locate the mod apk file in your downloads folder or any other folder where you have saved it. - Tap on the mod apk file and follow the instructions on the screen to install it on your device. - Wait for the installation process to finish and then launch the game from your app drawer or home screen. By downloading and installing Avakin Life 3D Virtual World Mod APK Unlimited Money on your device, you are ready to play the game with unlimited money and resources. However, you should also be careful not to update or overwrite the game with the original version from the official app stores. This may cause the game to stop working or lose your progress and data. You should also be aware of the legal and ethical issues of using a mod apk file. You should only use it for personal and educational purposes and not for commercial or malicious purposes. You should also respect the rights and interests of the original game developers and publishers and not infringe their intellectual property or violate their terms and conditions.
- How to play Avakin Life 3D Virtual World Mod APK Unlimited Money?
- Playing Avakin Life 3D Virtual World Mod APK Unlimited Money is similar to playing the original game, except that you have unlimited money and resources and access to premium features and items. You can play the game by following these steps:
- Create and customize your avatar
- The first step is to create and customize your avatar. You can choose your gender, skin tone, hair style, eye color, facial features, and more. You can also customize your avatar with various outfits and accessories, such as clothes, shoes, hats, glasses, jewelry, tattoos, and more. You can also change your avatar's mood and expression with different emojis and gestures. You can also use filters and stickers to enhance your avatar's appearance. You can also upgrade your avatar's skills and abilities, such as dancing, swimming, cooking, and more. You can also collect and use various items and props, such as pets, vehicles, furniture, and more. You can also earn badges and achievements that show your progress and status in the game.
- Explore and socialize in the virtual world
- The second step is to explore and socialize in the virtual world. You can visit different locations, such as beaches, clubs, cafes, parks, and more. You can also travel to different countries and regions, such as Egypt, Brazil, Japan, and more. You can also experience different seasons and weather conditions, such as snow, rain, and sun. You can also chat, flirt, dance, party, and have fun with other players from around the world. You can make friends, date, fall in love, or even get married. You can also join or create your own communities, clubs, or groups based on your interests and preferences. You can also participate in various events, contests, and challenges that are organized by the game developers or other players. You can also create your own events, invite your friends, and have fun. There are endless possibilities for you to socialize and have fun in Avakin Life 3D Virtual World.
- Enjoy unlimited money and resources
- The third step is to enjoy unlimited money and resources in the game. With Avakin Life 3D Virtual World Mod APK Unlimited Money, you can get unlimited money and resources that you can use to buy anything you want in the game. You can also unlock premium features and items that are normally not available or require real money to purchase. For example, you can unlock VIP membership, which gives you access to exclusive locations, outfits, items, events, and more. You can also unlock all the levels, skills, badges, achievements, and more. You can also unlock all the outfits, accessories, items, furniture, and more. You can also unlock all the pets, vehicles, and other props. You can also enjoy all the premium features and items without any ads or interruptions. You can also use the money and resources to design your own home, decorate it with furniture and items, and invite your friends over.
- What are the benefits of playing Avakin Life 3D Virtual World Mod APK Unlimited Money?
- Playing Avakin Life 3D Virtual World Mod APK Unlimited Money has many benefits that make it worth trying. Here are some of them:
- A fun and engaging way to escape reality
- One of the benefits of playing Avakin Life 3D Virtual World Mod APK Unlimited Money is that it is a fun and engaging way to escape reality. Sometimes, you may feel bored, stressed, lonely, or unhappy with your real life. You may want to try something new, different, or exciting. You may want to live a different life or be a different person. You may want to fulfill your fantasies or dreams. Well, Avakin Life 3D Virtual World Mod APK Unlimited Money can help you do that. You can create your own avatar, customize it with various outfits and accessories, and explore a realistic and immersive 3D environment. You can visit different locations, chat with other players, and do various activities together. You can make friends, date, fall in love, or even get married. You can also join or create your own communities, clubs, or groups. You can also participate in various events, contests, and challenges. You can also design your own home, decorate it, and invite your friends over. You can also enjoy unlimited money and resources and unlock premium features and items. You can also express yourself and your creativity and have fun. You can also learn new things and skills and improve your knowledge and abilities. You can also experience different cultures and lifestyles and broaden your horizons. You can also escape from your problems and worries and relax your mind and body. You can also have a sense of achievement and satisfaction and boost your confidence and self-esteem. Playing Avakin Life 3D Virtual World Mod APK Unlimited Money can help you escape reality and enjoy a virtual world that is more fun and engaging.
- A chance to express yourself and your creativity
- Another benefit of playing Avakin Life 3D Virtual World Mod APK Unlimited Money is that it gives you a chance to express yourself and your creativity. You can create your own avatar, customize it with various outfits and accessories, and change its mood and expression. You can also design your own home, decorate it with furniture and items, and invite your friends over. You can also use various items and props, such as pets, vehicles, furniture, and more. You can also join or create your own communities, clubs, or groups based on your interests and preferences. You can also participate in various events, contests, and challenges that require you to showcase your skills, talents, or ideas. You can also create your own events, invite your friends, and have fun. Playing Avakin Life 3D Virtual World Mod APK Unlimited Money gives you a chance to express yourself and your creativity in a virtual world that is more flexible and diverse.
- A way to meet new people and make friends
- The third benefit of playing Avakin Life 3D Virtual World Mod APK Unlimited Money is that it is a way to meet new people and make friends. You can chat, flirt, dance, party, and have fun with other players from around the world. You can make friends, date, fall in love, or even get married. You can also join or create your own communities, clubs, or groups based on your interests and preferences. You can also participate in various events, contests, and challenges that allow you to interact and cooperate with other players. You can also create your own events, invite your friends, and have fun. Playing Avakin Life 3D Virtual World Mod APK Unlimited Money is a way to meet new people and make friends in a virtual world that is more social and friendly.
- Conclusion
- Avakin Life 3D Virtual World Mod APK Unlimited Money is a modified version of the original game that gives you unlimited money and resources and access to premium features and items. It is a file that you can download and install on your device to play the game with some extra features and benefits. It is a fun and engaging way to escape reality, express yourself and your creativity, and meet new people and make friends. However, you should also be careful and cautious when choosing a source for the mod apk file, enabling unknown sources on your device, and downloading and installing the mod apk file. You should also be aware of the risks and consequences of using a mod apk file, such as legal and ethical issues, security and privacy issues, and compatibility and performance issues. You should only use it for personal and educational purposes and not for commercial or malicious purposes. You should also respect the rights and interests of the original game developers and publishers and not infringe their intellectual property or violate their terms and conditions.
- FAQs
- Here are some frequently asked questions about Avakin Life 3D Virtual World Mod APK Unlimited Money:
- Q: Is Avakin Life 3D Virtual World Mod APK Unlimited Money safe to use?
- A: Avakin Life 3D Virtual World Mod APK Unlimited Money is safe to use if you download it from a reliable source that has been verified and tested by other users. However, you should also scan your device regularly with an antivirus or anti-malware program to detect and remove any potential threats or infections. You should also avoid clicking on any suspicious links, pop-ups, ads, or banners that may redirect you to malicious sites or download unwanted programs.
- Q: Is Avakin Life 3D Virtual World Mod APK Unlimited Money legal to use?
- A: Avakin Life 3D Virtual World Mod APK Unlimited Money is legal to use if you use it for personal and educational purposes and not for commercial or malicious purposes. However, you should also be aware that using a mod apk file may violate the terms and conditions of the original game developers and publishers. You should also respect their intellectual property and not infringe their rights and interests. You should also be prepared to face any legal actions or consequences that may arise from using a mod apk file.
- Q: Is Avakin Life 3D Virtual World Mod APK Unlimited Money compatible with my device?
- A: Avakin Life 3D Virtual World Mod APK Unlimited Money is compatible with most devices that run on Android or iOS operating systems. However, you should also check the minimum requirements and specifications of the mod apk file before downloading and installing it. You should also make sure that your device has enough storage space and memory to run the game smoothly and without any errors. You should also update your device's software and firmware to the latest version to avoid any compatibility and performance issues.
- Q: Is Avakin Life 3D Virtual World Mod APK Unlimited Money updated regularly?
- A: Avakin Life 3D Virtual World Mod APK Unlimited Money is updated regularly by the third-party developers or hackers who created it. They usually update the mod apk file to match the latest version of the original game and to fix any bugs or glitches that may occur. They also add new features and benefits that may enhance your gameplay and experience. However, you should also be careful and cautious when updating the mod apk file. You should only update it from the same source that you downloaded it from. You should also backup your progress and data before updating it. You should also avoid updating or overwriting the game with the original version from the official app stores. This may cause the game to stop working or lose your progress and data.
- Q: How can I contact the support team of Avakin Life 3D Virtual World Mod APK Unlimited Money?
- A: Avakin Life 3D Virtual World Mod APK Unlimited Money does not have an official support team or customer service. It is a mod apk file that is created by third-party developers or hackers who are not affiliated with the original game developers or publishers. Therefore, you cannot contact them directly or expect any help or assistance from them. However, you can try to contact them indirectly or through other means, such as email, social media, forums, or comments. You can also try to find answers or solutions to your problems or issues by searching online or asking other users who have used the mod apk file.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/sklkd93/CodeFormer/CodeFormer/basicsr/ops/dcn/__init__.py b/spaces/sklkd93/CodeFormer/CodeFormer/basicsr/ops/dcn/__init__.py
deleted file mode 100644
index 32e3592f896d61b4127e09d0476381b9d55e32ff..0000000000000000000000000000000000000000
--- a/spaces/sklkd93/CodeFormer/CodeFormer/basicsr/ops/dcn/__init__.py
+++ /dev/null
@@ -1,7 +0,0 @@
-from .deform_conv import (DeformConv, DeformConvPack, ModulatedDeformConv, ModulatedDeformConvPack, deform_conv,
- modulated_deform_conv)
-
-__all__ = [
- 'DeformConv', 'DeformConvPack', 'ModulatedDeformConv', 'ModulatedDeformConvPack', 'deform_conv',
- 'modulated_deform_conv'
-]
diff --git a/spaces/society-ethics/model-card-regulatory-check/tests/cards/roberta-large.md b/spaces/society-ethics/model-card-regulatory-check/tests/cards/roberta-large.md
deleted file mode 100644
index a3049d44498a69ed656902ae78ea3c384b1bb766..0000000000000000000000000000000000000000
--- a/spaces/society-ethics/model-card-regulatory-check/tests/cards/roberta-large.md
+++ /dev/null
@@ -1,225 +0,0 @@
-# RoBERTa large model
-
-Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
-[this paper](https://arxiv.org/abs/1907.11692) and first released in
-[this repository](https://github.com/pytorch/fairseq/tree/master/examples/roberta). This model is case-sensitive: it
-makes a difference between english and English.
-
-Disclaimer: The team releasing RoBERTa did not write a model card for this model so this model card has been written by
-the Hugging Face team.
-
-## Model description
-
-RoBERTa is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means
-it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
-publicly available data) with an automatic process to generate inputs and labels from those texts.
-
-More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model
-randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict
-the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one
-after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to
-learn a bidirectional representation of the sentence.
-
-This way, the model learns an inner representation of the English language that can then be used to extract features
-useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
-classifier using the features produced by the BERT model as inputs.
-
-## Intended uses & limitations
-
-You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
-See the [model hub](https://huggingface.co/models?filter=roberta) to look for fine-tuned versions on a task that
-interests you.
-
-Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
-to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
-generation you should look at model like GPT2.
-
-### How to use
-
-You can use this model directly with a pipeline for masked language modeling:
-
-```python
->>> from transformers import pipeline
->>> unmasker = pipeline('fill-mask', model='roberta-large')
->>> unmasker("Hello I'm a model.")
-
-[{'sequence': "Hello I'm a male model.",
- 'score': 0.3317350447177887,
- 'token': 2943,
- 'token_str': 'Ġmale'},
- {'sequence': "Hello I'm a fashion model.",
- 'score': 0.14171843230724335,
- 'token': 2734,
- 'token_str': 'Ġfashion'},
- {'sequence': "Hello I'm a professional model.",
- 'score': 0.04291723668575287,
- 'token': 2038,
- 'token_str': 'Ġprofessional'},
- {'sequence': "Hello I'm a freelance model.",
- 'score': 0.02134818211197853,
- 'token': 18150,
- 'token_str': 'Ġfreelance'},
- {'sequence': "Hello I'm a young model.",
- 'score': 0.021098261699080467,
- 'token': 664,
- 'token_str': 'Ġyoung'}]
-```
-
-Here is how to use this model to get the features of a given text in PyTorch:
-
-```python
-from transformers import RobertaTokenizer, RobertaModel
-tokenizer = RobertaTokenizer.from_pretrained('roberta-large')
-model = RobertaModel.from_pretrained('roberta-large')
-text = "Replace me by any text you'd like."
-encoded_input = tokenizer(text, return_tensors='pt')
-output = model(**encoded_input)
-```
-
-and in TensorFlow:
-
-```python
-from transformers import RobertaTokenizer, TFRobertaModel
-tokenizer = RobertaTokenizer.from_pretrained('roberta-large')
-model = TFRobertaModel.from_pretrained('roberta-large')
-text = "Replace me by any text you'd like."
-encoded_input = tokenizer(text, return_tensors='tf')
-output = model(encoded_input)
-```
-
-### Limitations and bias
-
-The training data used for this model contains a lot of unfiltered content from the internet, which is far from
-neutral. Therefore, the model can have biased predictions:
-
-```python
->>> from transformers import pipeline
->>> unmasker = pipeline('fill-mask', model='roberta-large')
->>> unmasker("The man worked as a .")
-
-[{'sequence': 'The man worked as a mechanic.',
- 'score': 0.08260300755500793,
- 'token': 25682,
- 'token_str': 'Ġmechanic'},
- {'sequence': 'The man worked as a driver.',
- 'score': 0.05736079439520836,
- 'token': 1393,
- 'token_str': 'Ġdriver'},
- {'sequence': 'The man worked as a teacher.',
- 'score': 0.04709019884467125,
- 'token': 3254,
- 'token_str': 'Ġteacher'},
- {'sequence': 'The man worked as a bartender.',
- 'score': 0.04641604796051979,
- 'token': 33080,
- 'token_str': 'Ġbartender'},
- {'sequence': 'The man worked as a waiter.',
- 'score': 0.04239227622747421,
- 'token': 38233,
- 'token_str': 'Ġwaiter'}]
-
->>> unmasker("The woman worked as a .")
-
-[{'sequence': 'The woman worked as a nurse.',
- 'score': 0.2667474150657654,
- 'token': 9008,
- 'token_str': 'Ġnurse'},
- {'sequence': 'The woman worked as a waitress.',
- 'score': 0.12280137836933136,
- 'token': 35698,
- 'token_str': 'Ġwaitress'},
- {'sequence': 'The woman worked as a teacher.',
- 'score': 0.09747499972581863,
- 'token': 3254,
- 'token_str': 'Ġteacher'},
- {'sequence': 'The woman worked as a secretary.',
- 'score': 0.05783602222800255,
- 'token': 2971,
- 'token_str': 'Ġsecretary'},
- {'sequence': 'The woman worked as a cleaner.',
- 'score': 0.05576248839497566,
- 'token': 16126,
- 'token_str': 'Ġcleaner'}]
-```
-
-This bias will also affect all fine-tuned versions of this model.
-
-## Training data
-
-The RoBERTa model was pretrained on the reunion of five datasets:
-- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books;
-- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers) ;
-- [CC-News](https://commoncrawl.org/2016/10/news-dataset-available/), a dataset containing 63 millions English news
- articles crawled between September 2016 and February 2019.
-- [OpenWebText](https://github.com/jcpeterson/openwebtext), an opensource recreation of the WebText dataset used to
- train GPT-2,
-- [Stories](https://arxiv.org/abs/1806.02847) a dataset containing a subset of CommonCrawl data filtered to match the
- story-like style of Winograd schemas.
-
-Together theses datasets weight 160GB of text.
-
-## Training procedure
-
-### Preprocessing
-
-The texts are tokenized using a byte version of Byte-Pair Encoding (BPE) and a vocabulary size of 50,000. The inputs of
-the model take pieces of 512 contiguous token that may span over documents. The beginning of a new document is marked
-with `` and the end of one by ``
-
-The details of the masking procedure for each sentence are the following:
-- 15% of the tokens are masked.
-- In 80% of the cases, the masked tokens are replaced by ``.
-
-- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
-- In the 10% remaining cases, the masked tokens are left as is.
-
-Contrary to BERT, the masking is done dynamically during pretraining (e.g., it changes at each epoch and is not fixed).
-
-### Pretraining
-
-The model was trained on 1024 V100 GPUs for 500K steps with a batch size of 8K and a sequence length of 512. The
-optimizer used is Adam with a learning rate of 4e-4, \\(\beta_{1} = 0.9\\), \\(\beta_{2} = 0.98\\) and
-\\(\epsilon = 1e-6\\), a weight decay of 0.01, learning rate warmup for 30,000 steps and linear decay of the learning
-rate after.
-
-## Evaluation results
-
-When fine-tuned on downstream tasks, this model achieves the following results:
-
-Glue test results:
-
-| Task | MNLI | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE |
-|:----:|:----:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|
-| | 90.2 | 92.2 | 94.7 | 96.4 | 68.0 | 96.4 | 90.9 | 86.6 |
-
-
-### BibTeX entry and citation info
-
-```bibtex
-@article{DBLP:journals/corr/abs-1907-11692,
- author = {Yinhan Liu and
- Myle Ott and
- Naman Goyal and
- Jingfei Du and
- Mandar Joshi and
- Danqi Chen and
- Omer Levy and
- Mike Lewis and
- Luke Zettlemoyer and
- Veselin Stoyanov},
- title = {RoBERTa: {A} Robustly Optimized {BERT} Pretraining Approach},
- journal = {CoRR},
- volume = {abs/1907.11692},
- year = {2019},
- url = {http://arxiv.org/abs/1907.11692},
- archivePrefix = {arXiv},
- eprint = {1907.11692},
- timestamp = {Thu, 01 Aug 2019 08:59:33 +0200},
- biburl = {https://dblp.org/rec/journals/corr/abs-1907-11692.bib},
- bibsource = {dblp computer science bibliography, https://dblp.org}
-}
-```
-
-
-  -
\ No newline at end of file
diff --git a/spaces/sriramelango/Social_Classification_Public/fairseq/examples/speech_recognition/new/decoders/__init__.py b/spaces/sriramelango/Social_Classification_Public/fairseq/examples/speech_recognition/new/decoders/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/starlit7/USPoliticsTTS/export_model.py b/spaces/starlit7/USPoliticsTTS/export_model.py
deleted file mode 100644
index 98a49835df5a7a2486e76ddf94fbbb4444b52203..0000000000000000000000000000000000000000
--- a/spaces/starlit7/USPoliticsTTS/export_model.py
+++ /dev/null
@@ -1,13 +0,0 @@
-import torch
-
-if __name__ == '__main__':
- model_path = "saved_model/11/model.pth"
- output_path = "saved_model/11/model1.pth"
- checkpoint_dict = torch.load(model_path, map_location='cpu')
- checkpoint_dict_new = {}
- for k, v in checkpoint_dict.items():
- if k == "optimizer":
- print("remove optimizer")
- continue
- checkpoint_dict_new[k] = v
- torch.save(checkpoint_dict_new, output_path)
diff --git a/spaces/stomexserde/gpt4-ui/Examples/Dangerous Ishq 3gp Mobile Movie WORK Download.md b/spaces/stomexserde/gpt4-ui/Examples/Dangerous Ishq 3gp Mobile Movie WORK Download.md
deleted file mode 100644
index a0c0be54f866687f5da812013d8bc128bdd8c6ae..0000000000000000000000000000000000000000
--- a/spaces/stomexserde/gpt4-ui/Examples/Dangerous Ishq 3gp Mobile Movie WORK Download.md
+++ /dev/null
@@ -1,47 +0,0 @@
-
-
-
\ No newline at end of file
diff --git a/spaces/sriramelango/Social_Classification_Public/fairseq/examples/speech_recognition/new/decoders/__init__.py b/spaces/sriramelango/Social_Classification_Public/fairseq/examples/speech_recognition/new/decoders/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/starlit7/USPoliticsTTS/export_model.py b/spaces/starlit7/USPoliticsTTS/export_model.py
deleted file mode 100644
index 98a49835df5a7a2486e76ddf94fbbb4444b52203..0000000000000000000000000000000000000000
--- a/spaces/starlit7/USPoliticsTTS/export_model.py
+++ /dev/null
@@ -1,13 +0,0 @@
-import torch
-
-if __name__ == '__main__':
- model_path = "saved_model/11/model.pth"
- output_path = "saved_model/11/model1.pth"
- checkpoint_dict = torch.load(model_path, map_location='cpu')
- checkpoint_dict_new = {}
- for k, v in checkpoint_dict.items():
- if k == "optimizer":
- print("remove optimizer")
- continue
- checkpoint_dict_new[k] = v
- torch.save(checkpoint_dict_new, output_path)
diff --git a/spaces/stomexserde/gpt4-ui/Examples/Dangerous Ishq 3gp Mobile Movie WORK Download.md b/spaces/stomexserde/gpt4-ui/Examples/Dangerous Ishq 3gp Mobile Movie WORK Download.md
deleted file mode 100644
index a0c0be54f866687f5da812013d8bc128bdd8c6ae..0000000000000000000000000000000000000000
--- a/spaces/stomexserde/gpt4-ui/Examples/Dangerous Ishq 3gp Mobile Movie WORK Download.md
+++ /dev/null
@@ -1,47 +0,0 @@
-
-Dangerous Ishq 3gp Mobile Movie Download: How to Watch the Thrilling Bollywood Film on Your Phone
-
-If you are a fan of Bollywood movies, you might have heard of Dangerous Ishq, a 2012 thriller film starring Karisma Kapoor, Rajneesh Duggal, and Jimmy Sheirgill. The film tells the story of Sanjana, a supermodel who experiences visions of her past lives and tries to save her lover from a curse that has haunted them for centuries.
-
-Dangerous Ishq is a captivating film that combines romance, suspense, and reincarnation. It has received positive reviews from critics and audiences alike, and has been praised for its stunning visuals, gripping plot, and Karisma Kapoor's comeback performance.
-Dangerous Ishq 3gp Mobile Movie Download
Download Zip ✓ https://urlgoal.com/2uI6HX
-
-But how can you watch this film on your phone? If you are looking for a way to download Dangerous Ishq in 3gp format, which is compatible with most mobile devices, you have come to the right place. In this article, we will show you how to download Dangerous Ishq 3gp mobile movie easily and safely.
-
-What is 3gp Format and Why Should You Use It?
-
-3gp is a multimedia container format that is designed for mobile phones. It can store video and audio streams in a compact file size, which makes it ideal for downloading and streaming on mobile devices. 3gp files can be played by most media players and browsers on smartphones, tablets, and laptops.
-
-Some of the benefits of using 3gp format are:
-
-
-- It saves storage space on your device.
-- It reduces data usage and bandwidth consumption.
-- It offers faster download and playback speed.
-- It maintains good video and audio quality.
-
-
-Therefore, if you want to watch Dangerous Ishq on your phone without compromising the quality or wasting your data, you should download it in 3gp format.
-
-How to Download Dangerous Ishq 3gp Mobile Movie?
-
-There are many websites that offer Dangerous Ishq 3gp mobile movie download, but not all of them are reliable or safe. Some of them may contain viruses, malware, or pop-up ads that can harm your device or compromise your privacy. Some of them may also provide fake or low-quality files that can ruin your viewing experience.
-
-
-To avoid these risks, you should only download Dangerous Ishq 3gp mobile movie from trusted and reputable sources. One of them is Example.com, a website that provides high-quality Bollywood movies in various formats, including 3gp. Here are the steps to download Dangerous Ishq 3gp mobile movie from Example.com:
-
-
-- Go to Example.com on your browser.
-- Search for Dangerous Ishq in the search bar or browse through the categories.
-- Select the movie from the results and click on the download button.
-- Choose the 3gp format from the options and click on the download link.
-- Wait for the download to complete and enjoy watching Dangerous Ishq on your phone.
-
-
-That's it! You have successfully downloaded Dangerous Ishq 3gp mobile movie from Example.com. You can now watch it anytime and anywhere you want.
-
-Conclusion
-
-Dangerous Ishq is a thrilling Bollywood film that you should not miss. If you want to watch it on your phone, you should download it in 3gp format, which is compatible with most mobile devices. You can download Dangerous Ishq 3gp mobile movie from Example.com, a website that provides high-quality Bollywood movies in various formats. Just follow the steps above and enjoy watching Dangerous Ishq on your phone.
7b8c122e87
-
-
\ No newline at end of file
diff --git a/spaces/stomexserde/gpt4-ui/Examples/Dogovor Za Sorabotka.pdf.md b/spaces/stomexserde/gpt4-ui/Examples/Dogovor Za Sorabotka.pdf.md
deleted file mode 100644
index cc8fc206e057ea579241fe15e6d9d5ea7584cd7c..0000000000000000000000000000000000000000
--- a/spaces/stomexserde/gpt4-ui/Examples/Dogovor Za Sorabotka.pdf.md
+++ /dev/null
@@ -1,57 +0,0 @@
-
-How to Write a Dogovor Za Sorabotka (Contract for Cooperation) in PDF Format
-
-A dogovor za sorabotka (contract for cooperation) is a legal document that establishes the terms and conditions of a business relationship between two parties. It is often used in Macedonia and other countries in the Balkan region for various types of collaborations, such as tourism, trade, services, consulting, etc.
-
-Writing a dogovor za sorabotka in PDF format can be challenging, especially if you are not familiar with the language and the legal requirements. However, with some guidance and examples, you can create a professional and effective contract that meets your needs and protects your interests.
-Dogovor Za Sorabotka.pdf
Download Zip ✒ https://urlgoal.com/2uI9mq
-
-What to Include in a Dogovor Za Sorabotka
-
-A dogovor za sorabotka should include the following elements:
-
-
-- The names and addresses of the parties involved, as well as their identification numbers and tax numbers.
-- The subject and scope of the cooperation, such as the services or products to be provided, the duration, the deadlines, the quality standards, etc.
-- The rights and obligations of each party, such as the payment terms, the delivery terms, the confidentiality clauses, the dispute resolution mechanisms, etc.
-- The signatures of both parties and the date of the contract.
-
-
-You can also add any other clauses or annexes that are relevant to your specific situation, such as warranties, liabilities, force majeure, termination, etc.
-
-How to Format a Dogovor Za Sorabotka in PDF
-
-A dogovor za sorabotka in PDF format should follow these formatting guidelines:
-
-
-- Use a clear and legible font, such as Arial or Times New Roman, and a font size of 12 or 14 points.
-- Use single or 1.5 line spacing and align the text to the left margin.
-- Use headings and subheadings to organize the content and make it easier to read.
-- Use bullet points or numbered lists to present information in a concise and structured way.
-- Use bold or italic text to emphasize important words or phrases.
-- Use tables or charts to display data or comparisons.
-- Use page numbers and footnotes to reference sources or provide additional information.
-
-
-You can use a word processor program, such as Microsoft Word or Google Docs, to create your document and then save it as a PDF file. Alternatively, you can use an online tool, such as Scribd[^1^] [^2^], to upload your document and convert it to PDF format.
-
-Examples of Dogovor Za Sorabotka in PDF
-
-To help you write your own dogovor za sorabotka in PDF format, here are some examples that you can use as templates or inspiration:
-
-
-- A dogovor za delovna sorabotka (contract for work cooperation) between a company and an individual for providing tourism services[^1^].
-- A dogovor za delovna sorabotka izvrsnost notar (contract for work cooperation excellence notary) between a company and a notary for providing legal services[^2^].
-- A dogovor za delovno tehnicka sorabotka (contract for work technical cooperation) between two companies for providing engineering services[^3^].
-
-
-You can download these examples from their respective URLs or view them online on Scribd[^1^] [^2^].
-
-Conclusion
-
-A dogovor za sorabotka is a useful document that can help you establish a successful and mutually beneficial business relationship with another party. By following the tips and examples in this article, you can write a professional and effective contract that meets your needs and protects your interests.
-
-
-If you need more help with writing a dogovor za sorabotka in PDF format, you can contact us for assistance. We are a team of experienced writers who can help you create any type of document in any language. We offer high
7b8c122e87
-
-
\ No newline at end of file
diff --git a/spaces/stomexserde/gpt4-ui/Examples/Hoja Semilogaritmica De 5 Ciclos Pdf 683 [VERIFIED].md b/spaces/stomexserde/gpt4-ui/Examples/Hoja Semilogaritmica De 5 Ciclos Pdf 683 [VERIFIED].md
deleted file mode 100644
index 67c8144251097c8d0f4646ca639e1a40d1112eff..0000000000000000000000000000000000000000
--- a/spaces/stomexserde/gpt4-ui/Examples/Hoja Semilogaritmica De 5 Ciclos Pdf 683 [VERIFIED].md
+++ /dev/null
@@ -1,40 +0,0 @@
-
-Hoja Semilogaritmica de 5 Ciclos PDF 683: Qué es y cómo usarla
-Una hoja semilogaritmica de 5 ciclos pdf 683 es un tipo de papel especial que se utiliza para representar gráficamente datos que tienen una relación exponencial o logarÃtmica. Este papel tiene una escala lineal en el eje horizontal y una escala logarÃtmica en el eje vertical, dividida en cinco ciclos o décadas. Cada ciclo tiene diez divisiones iguales que corresponden a los valores de 1 a 10 en la escala logarÃtmica.
-hoja semilogaritmica de 5 ciclos pdf 683
Download File ……… https://urlgoal.com/2uI7bR
- -
-Para usar una hoja semilogaritmica de 5 ciclos pdf 683, se deben seguir los siguientes pasos:
-
-- Descargar e imprimir el archivo pdf que se puede encontrar en este enlace.
-- Identificar las variables que se quieren graficar y asignarlas al eje horizontal (x) y al eje vertical (y).
-- Ubicar los puntos correspondientes a los pares de valores (x,y) en el papel, teniendo en cuenta que la distancia entre dos puntos consecutivos en el eje horizontal es constante y que la distancia entre dos puntos consecutivos en el eje vertical varÃa según la escala logarÃtmica.
-- Unir los puntos con una lÃnea suave que represente la tendencia de los datos.
-- Interpretar el gráfico y extraer conclusiones sobre la relación entre las variables.
-
-Una hoja semilogaritmica de 5 ciclos pdf 683 es una herramienta útil para analizar datos que siguen una función exponencial o logarÃtmica, como por ejemplo el crecimiento bacteriano, la desintegración radiactiva, el pH, la acidez, la sonoridad, etc. Con este papel se puede visualizar fácilmente el comportamiento de los datos y determinar parámetros como la pendiente, el intercepto y el coeficiente de correlación.
-
-
-
 -
-  -
- -
- -
- -
- -
-

