How to Download Music Playlists from Different Platforms
-How to download music playlists from YouTube Music
-YouTube Music is a music streaming service that allows you to access millions of songs, albums, and playlists from YouTube and other sources. You can also create your own playlists and upload your own music to the service.
-To download music playlists from YouTube Music, you need to have a YouTube Music Premium or YouTube Premium subscription, which costs $9.99 or $11.99 per month respectively. With these subscriptions, you can download up to 100,000 songs and listen to them offline for up to 30 days.
-Here are the steps to download music playlists from YouTube Music:
-Step 1: Get a YouTube Music Premium or YouTube Premium subscription
-To get a YouTube Music Premium or YouTube Premium subscription, you need to sign in to your Google account and go to the YouTube Music or YouTube website or app. Then, you need to click on the profile icon and select "Get YouTube Premium" or "Get YouTube Music Premium". You can then choose your payment method and confirm your purchase.
-Step 2: Choose the songs, albums, or playlists that you want to download
-To choose the songs, albums, or playlists that you want to download, you need to browse or search for them on the YouTube Music website or app. You can also access your own playlists and uploads by clicking on the library icon.
-Step 3: Tap the download button and wait for the process to finish
-To download the songs, albums, or playlists that you have chosen, you need to tap on the download button that appears next to them. You can also tap on the menu icon and select "Download" from the options. You will see a progress bar that shows how much of the download is completed. Once the download is finished, you will see a checkmark icon that indicates that the songs, albums, or playlists are available offline.
-How to download music playlists from Spotify
-Spotify is another popular music streaming service that offers over 70 million songs, podcasts, and playlists. You can also create your own playlists and follow other users and artists on the service.
-To download music playlists from Spotify, you need to have a Spotify Premium subscription, which costs $9.99 per month. With this subscription, you can download up to 10,000 songs and listen to them offline for up to 30 days.
-Here are the steps to download music playlists from Spotify:
-Step 1: Get a Spotify Premium subscription
-To get a Spotify Premium subscription, you need to sign up for a Spotify account and go to the Spotify website or app. Then, you need to click on the profile icon and select "Upgrade". You can then choose your payment method and confirm your purchase.
-Step 2: Create or find the playlists that you want to download
-To create or find the playlists that you want to download, you need to use the search function or browse through the categories on the Spotify website or app. You can also access your own playlists and followings by clicking on the library icon.
-Step 3: Toggle the download switch and wait for the process to finish
-To download the playlists that you have created or found, you need to toggle the download switch that appears at the top of each playlist. You will see a green arrow icon that shows that the playlist is being downloaded. Once the download is finished, you will see a green checkmark icon that indicates that the playlist is available offline.
Summarize the main points of the article
-In this article, we have learned how to download music playlists and enjoy your favorite songs offline. We have covered the following topics:
--
-
- What is a music playlist and why you should download it. -
- How to choose the best music streaming service for your needs. -
- How to download music playlists from different platforms, such as YouTube Music, Spotify, Apple Music, Amazon Music, Deezer, Tidal, and more. -
- How to manage and play your downloaded music playlists on your device. -
Provide some tips and recommendations for downloading music playlists
-Here are some tips and recommendations for downloading music playlists:
--
-
- Make sure you have enough space on your device before downloading music playlists. You can check your storage settings or use a memory card to expand your capacity. -
- Make sure you have a stable and fast internet connection before downloading music playlists. You can use Wi-Fi or a mobile hotspot to avoid interruptions or errors. -
- Make sure you have a valid and active subscription to the music streaming service that you want to download music playlists from. You can check your subscription status or renew it if necessary. -
- Make sure you download music playlists that you really like and listen to frequently. You can create your own playlists or explore the curated ones on the music streaming service. -
- Make sure you update your downloaded music playlists regularly. You can add new songs, remove old ones, or sync them with the online version. -
Include a call-to-action and invite the readers to share their feedback
-We hope you have found this article helpful and informative. Now you know how to download music playlists and enjoy your favorite songs offline. You can use this skill to create the perfect soundtrack for any occasion or mood.
-If you have any questions, comments, or suggestions, please feel free to share them with us. We would love to hear from you and learn from your experience. You can also share this article with your friends and family who might be interested in downloading music playlists.
-Thank you for reading and happy listening!
-Frequently Asked Questions
-Q: How do I download music playlists from YouTube without YouTube Music Premium or YouTube Premium?
-A: There are some third-party apps or websites that claim to allow you to download music playlists from YouTube without YouTube Music Premium or YouTube Premium. However, these methods are not authorized by YouTube and may violate its terms of service or infringe on the rights of the content owners. Therefore, we do not recommend using them and we advise you to respect the law and the creators.
-Q: How do I download music playlists from Spotify without Spotify Premium?
-A: There is no official way to download music playlists from Spotify without Spotify Premium. However, there are some alternatives that you can try, such as:
--
-
- Using the free trial of Spotify Premium for 30 days. -
- Using a family plan or a student discount to get Spotify Premium for a lower price. -
- Using a VPN or a proxy to access Spotify Premium in a different country where it is cheaper. -
However, these methods may not work for everyone and may have some risks or limitations. Therefore, we do not guarantee their effectiveness and we advise you to be careful and responsible.
-Q: How do I transfer my downloaded music playlists from one device to another?
-A: To transfer your downloaded music playlists from one device to another, you need to use the same music streaming service and account on both devices. Then, you need to sync your downloads or offline library on both devices. You may also need to connect both devices to the same Wi-Fi network or use a USB cable or Bluetooth connection.
-Q: How do I edit my downloaded music playlists?
-A: To edit your downloaded music playlists, you need to go to the music streaming app that you used to download them. Then, you need to find the playlist that you want to edit and tap on the menu icon or the edit button. You can then add or remove songs, change the order, rename the playlist, or change the cover image.
-Q: How do I share my downloaded music playlists with others?
-A: To share your downloaded music playlists with others, you need to go to the music streaming app that you used to download them. Then, you need to find the playlist that you want to share and tap on the menu icon or the share button. You can then choose the method or platform that you want to use to share your playlist, such as email , text message, social media, etc. You can also copy the link or the code of your playlist and paste it wherever you want. However, keep in mind that the people who receive your playlist may not be able to listen to it offline unless they have the same music streaming service and subscription as you.
401be4b1e0-
-
\ No newline at end of file diff --git a/spaces/1toTree/lora_test/ppdiffusers/schedulers/scheduling_lms_discrete.py b/spaces/1toTree/lora_test/ppdiffusers/schedulers/scheduling_lms_discrete.py deleted file mode 100644 index f8830b9157259a638d873a085cc8e035054d1b21..0000000000000000000000000000000000000000 --- a/spaces/1toTree/lora_test/ppdiffusers/schedulers/scheduling_lms_discrete.py +++ /dev/null @@ -1,257 +0,0 @@ -# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved. -# Copyright 2022 Katherine Crowson and The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -import warnings -from dataclasses import dataclass -from typing import List, Optional, Tuple, Union - -import numpy as np -import paddle -from scipy import integrate - -from ..configuration_utils import ConfigMixin, register_to_config -from ..utils import _COMPATIBLE_STABLE_DIFFUSION_SCHEDULERS, BaseOutput -from .scheduling_utils import SchedulerMixin - - -@dataclass -# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->LMSDiscrete -class LMSDiscreteSchedulerOutput(BaseOutput): - """ - Output class for the scheduler's step function output. - - Args: - prev_sample (`paddle.Tensor` of shape `(batch_size, num_channels, height, width)` for images): - Computed sample (x_{t-1}) of previous timestep. `prev_sample` should be used as next model input in the - denoising loop. - pred_original_sample (`paddle.Tensor` of shape `(batch_size, num_channels, height, width)` for images): - The predicted denoised sample (x_{0}) based on the model output from the current timestep. - `pred_original_sample` can be used to preview progress or for guidance. - """ - - prev_sample: paddle.Tensor - pred_original_sample: Optional[paddle.Tensor] = None - - -class LMSDiscreteScheduler(SchedulerMixin, ConfigMixin): - """ - Linear Multistep Scheduler for discrete beta schedules. Based on the original k-diffusion implementation by - Katherine Crowson: - https://github.com/crowsonkb/k-diffusion/blob/481677d114f6ea445aa009cf5bd7a9cdee909e47/k_diffusion/sampling.py#L181 - - [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__` - function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`. - [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and - [`~SchedulerMixin.from_pretrained`] functions. - - Args: - num_train_timesteps (`int`): number of diffusion steps used to train the model. - beta_start (`float`): the starting `beta` value of inference. - beta_end (`float`): the final `beta` value. - beta_schedule (`str`): - the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from - `linear` or `scaled_linear`. - trained_betas (`np.ndarray`, optional): - option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc. - prediction_type (`str`, default `epsilon`, optional): - prediction type of the scheduler function, one of `epsilon` (predicting the noise of the diffusion - process), `sample` (directly predicting the noisy sample`) or `v_prediction` (see section 2.4 - https://imagen.research.google/video/paper.pdf) - """ - - _compatibles = _COMPATIBLE_STABLE_DIFFUSION_SCHEDULERS.copy() - order = 1 - - @register_to_config - def __init__( - self, - num_train_timesteps: int = 1000, - beta_start: float = 0.0001, - beta_end: float = 0.02, - beta_schedule: str = "linear", - trained_betas: Optional[Union[np.ndarray, List[float]]] = None, - prediction_type: str = "epsilon", - ): - if trained_betas is not None: - self.betas = paddle.to_tensor(trained_betas, dtype="float32") - elif beta_schedule == "linear": - self.betas = paddle.linspace(beta_start, beta_end, num_train_timesteps, dtype="float32") - elif beta_schedule == "scaled_linear": - # this schedule is very specific to the latent diffusion model. - self.betas = paddle.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype="float32") ** 2 - else: - raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}") - - self.alphas = 1.0 - self.betas - self.alphas_cumprod = paddle.cumprod(self.alphas, 0) - - sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5) - sigmas = np.concatenate([sigmas[::-1], [0.0]]).astype(np.float32) - self.sigmas = paddle.to_tensor(sigmas) - - # standard deviation of the initial noise distribution - self.init_noise_sigma = self.sigmas.max() - - # setable values - self.num_inference_steps = None - timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=float)[::-1].copy() - self.timesteps = paddle.to_tensor(timesteps, dtype="float32") - self.derivatives = [] - self.is_scale_input_called = False - - def scale_model_input(self, sample: paddle.Tensor, timestep: Union[float, paddle.Tensor]) -> paddle.Tensor: - """ - Scales the denoising model input by `(sigma**2 + 1) ** 0.5` to match the K-LMS algorithm. - - Args: - sample (`paddle.Tensor`): input sample - timestep (`float` or `paddle.Tensor`): the current timestep in the diffusion chain - - Returns: - `paddle.Tensor`: scaled input sample - """ - step_index = (self.timesteps == timestep).nonzero().item() - sigma = self.sigmas[step_index] - sample = sample / ((sigma**2 + 1) ** 0.5) - self.is_scale_input_called = True - return sample - - def get_lms_coefficient(self, order, t, current_order): - """ - Compute a linear multistep coefficient. - - Args: - order (TODO): - t (TODO): - current_order (TODO): - """ - - def lms_derivative(tau): - prod = 1.0 - for k in range(order): - if current_order == k: - continue - prod *= (tau - self.sigmas[t - k]) / (self.sigmas[t - current_order] - self.sigmas[t - k]) - return prod - - integrated_coeff = integrate.quad(lms_derivative, self.sigmas[t], self.sigmas[t + 1], epsrel=1e-4)[0] - - return integrated_coeff - - def set_timesteps(self, num_inference_steps: int): - """ - Sets the timesteps used for the diffusion chain. Supporting function to be run before inference. - - Args: - num_inference_steps (`int`): - the number of diffusion steps used when generating samples with a pre-trained model. - """ - self.num_inference_steps = num_inference_steps - - timesteps = np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps, dtype=float)[::-1].copy() - sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5) - sigmas = np.interp(timesteps, np.arange(0, len(sigmas)), sigmas) - sigmas = np.concatenate([sigmas, [0.0]]).astype(np.float32) - self.sigmas = paddle.to_tensor(sigmas) - self.timesteps = paddle.to_tensor(timesteps, dtype="float32") - - self.derivatives = [] - - def step( - self, - model_output: paddle.Tensor, - timestep: Union[float, paddle.Tensor], - sample: paddle.Tensor, - order: int = 4, - return_dict: bool = True, - ) -> Union[LMSDiscreteSchedulerOutput, Tuple]: - """ - Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion - process from the learned model outputs (most often the predicted noise). - - Args: - model_output (`paddle.Tensor`): direct output from learned diffusion model. - timestep (`float`): current timestep in the diffusion chain. - sample (`paddle.Tensor`): - current instance of sample being created by diffusion process. - order: coefficient for multi-step inference. - return_dict (`bool`): option for returning tuple rather than LMSDiscreteSchedulerOutput class - - Returns: - [`~schedulers.scheduling_utils.LMSDiscreteSchedulerOutput`] or `tuple`: - [`~schedulers.scheduling_utils.LMSDiscreteSchedulerOutput`] if `return_dict` is True, otherwise a `tuple`. - When returning a tuple, the first element is the sample tensor. - - """ - if not self.is_scale_input_called: - warnings.warn( - "The `scale_model_input` function should be called before `step` to ensure correct denoising. " - "See `StableDiffusionPipeline` for a usage example." - ) - - step_index = (self.timesteps == timestep).nonzero().item() - sigma = self.sigmas[step_index] - - # 1. compute predicted original sample (x_0) from sigma-scaled predicted noise - if self.config.prediction_type == "epsilon": - pred_original_sample = sample - sigma * model_output - elif self.config.prediction_type == "v_prediction": - # * c_out + input * c_skip - pred_original_sample = model_output * (-sigma / (sigma**2 + 1) ** 0.5) + (sample / (sigma**2 + 1)) - else: - raise ValueError( - f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`" - ) - - # 2. Convert to an ODE derivative - derivative = (sample - pred_original_sample) / sigma - self.derivatives.append(derivative) - if len(self.derivatives) > order: - self.derivatives.pop(0) - - # 3. Compute linear multistep coefficients - order = min(step_index + 1, order) - lms_coeffs = [self.get_lms_coefficient(order, step_index, curr_order) for curr_order in range(order)] - - # 4. Compute previous sample based on the derivatives path - prev_sample = sample + sum( - coeff * derivative for coeff, derivative in zip(lms_coeffs, reversed(self.derivatives)) - ) - - if not return_dict: - return (prev_sample,) - - return LMSDiscreteSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample) - - def add_noise( - self, - original_samples: paddle.Tensor, - noise: paddle.Tensor, - timesteps: paddle.Tensor, - ) -> paddle.Tensor: - # Make sure sigmas and timesteps have the same dtype as original_samples - sigmas = self.sigmas.cast(original_samples.dtype) - schedule_timesteps = self.timesteps - - step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps] - - sigma = sigmas[step_indices].flatten() - while len(sigma.shape) < len(original_samples.shape): - sigma = sigma.unsqueeze(-1) - - noisy_samples = original_samples + noise * sigma - return noisy_samples - - def __len__(self): - return self.config.num_train_timesteps diff --git a/spaces/4f20/text_generator/README.md b/spaces/4f20/text_generator/README.md deleted file mode 100644 index 31821062ccb680b6797bf722a711bfa433da8f8e..0000000000000000000000000000000000000000 --- a/spaces/4f20/text_generator/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Text Generator -emoji: 👀 -colorFrom: gray -colorTo: pink -sdk: gradio -sdk_version: 3.12.0 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/AIGC-Audio/Make_An_Audio/wav_evaluation/models/utils.py b/spaces/AIGC-Audio/Make_An_Audio/wav_evaluation/models/utils.py deleted file mode 100644 index f95931fb1c422cbd8349b88e1effb9323f170b2b..0000000000000000000000000000000000000000 --- a/spaces/AIGC-Audio/Make_An_Audio/wav_evaluation/models/utils.py +++ /dev/null @@ -1,26 +0,0 @@ -import argparse -import yaml -import sys - -def read_config_as_args(config_path,args=None,is_config_str=False): - return_dict = {} - - if config_path is not None: - if is_config_str: - yml_config = yaml.load(config_path, Loader=yaml.FullLoader) - else: - with open(config_path, "r") as f: - yml_config = yaml.load(f, Loader=yaml.FullLoader) - - if args != None: - for k, v in yml_config.items(): - if k in args.__dict__: - args.__dict__[k] = v - else: - sys.stderr.write("Ignored unknown parameter {} in yaml.\n".format(k)) - else: - for k, v in yml_config.items(): - return_dict[k] = v - - args = args if args != None else return_dict - return argparse.Namespace(**args) diff --git a/spaces/AIGC-Audio/Make_An_Audio_inpaint/ldm/modules/encoders/open_clap/__init__.py b/spaces/AIGC-Audio/Make_An_Audio_inpaint/ldm/modules/encoders/open_clap/__init__.py deleted file mode 100644 index 96ccf3e709b62e0548572ea424bb03a1a67a4b2e..0000000000000000000000000000000000000000 --- a/spaces/AIGC-Audio/Make_An_Audio_inpaint/ldm/modules/encoders/open_clap/__init__.py +++ /dev/null @@ -1,8 +0,0 @@ -from .factory import list_models, create_model, create_model_and_transforms, add_model_config -from .loss import ClipLoss, gather_features, LPLoss, lp_gather_features, LPMetrics -from .model import CLAP, CLAPTextCfg, CLAPVisionCfg, CLAPAudioCfp, convert_weights_to_fp16, trace_model -from .openai import load_openai_model, list_openai_models -from .pretrained import list_pretrained, list_pretrained_tag_models, list_pretrained_model_tags,\ - get_pretrained_url, download_pretrained -from .tokenizer import SimpleTokenizer, tokenize -from .transform import image_transform diff --git a/spaces/AIZero2Hero4Health/9-Seq2SeqQAGenerator-GR/qasrl_model_pipeline.py b/spaces/AIZero2Hero4Health/9-Seq2SeqQAGenerator-GR/qasrl_model_pipeline.py deleted file mode 100644 index 50135f76849bc8537fcae83b72532da661487da6..0000000000000000000000000000000000000000 --- a/spaces/AIZero2Hero4Health/9-Seq2SeqQAGenerator-GR/qasrl_model_pipeline.py +++ /dev/null @@ -1,183 +0,0 @@ -from typing import Optional -import json -from argparse import Namespace -from pathlib import Path -from transformers import Text2TextGenerationPipeline, AutoModelForSeq2SeqLM, AutoTokenizer - -def get_markers_for_model(is_t5_model: bool) -> Namespace: - special_tokens_constants = Namespace() - if is_t5_model: - # T5 model have 100 special tokens by default - special_tokens_constants.separator_input_question_predicate = "
Cinco noches en Freddy’s 6 Descargar: Cómo jugar la última entrega de la serie de juegos de terror
-Si eres un fan de los juegos de terror, probablemente hayas oído hablar de Five Nights at Freddy’s, una popular serie que cuenta con personajes animatrónicos que intentan matarte en una pizzería. La serie ha generado varias secuelas, spin-offs, novelas e incluso una película en desarrollo. Pero ¿qué pasa con la última entrega, Five Nights at Freddy’s 6? ¿Cómo se puede descargar y jugar? En este artículo, te contaremos todo lo que necesitas saber sobre Five Nights at Freddy’s 6, también conocido como Five Nights at Freddy’s: Security Breach.
-cinco noches en freddy 39;s 6 descarga
Download Zip · https://bltlly.com/2v6LPJ
-
¿Qué es Cinco Noches en Freddy’s 6?
-Five Nights at Freddy’s 6 es el sexto juego principal de la serie Five Nights at Freddy’s, creado por Scott Cawthon y desarrollado por Steel Wool Studios. Fue lanzado el 16 de diciembre de 2021 para Windows, PlayStation 4 y PlayStation 5. También está planeado para Xbox One, Xbox Series X/S, Nintendo Switch, iOS y Android en 2022.
-La trama y la configuración del juego
-El juego tiene lugar en Mega Pizzaplex de Freddy Fazbear, un centro de diversión familiar de tres pisos que cuenta con personajes animatrónicos como Freddy Fazbear, Chica, Monty Gator y Roxanne Wolf. Usted juega como Gregory, un joven que está atrapado dentro de la Pizzaplex durante la noche. Con la ayuda del propio Freddy, Gregory debe descubrir los secretos del Pizzaplex, aprender la verdad sobre su pasado y sobrevivir hasta el amanecer. Sin embargo, no está solo. El Pizzaplex es también el hogar de Vanessa, un guardia de seguridad que tiene una agenda oscura, y otros animatrónicos hostiles que no se detendrán ante nada para atraparlo.
-La jugabilidad y características del juego
- -El juego también ofrece una variedad de atracciones y actividades para disfrutar en el Pizzaplex. Puedes jugar juegos de árcade como Monty Golf, Roxy Raceway, Bonnie Bowl o Fazbear Blast. También puede explorar diferentes áreas, como las alcantarillas o la arena láser tag. También puede recoger monedas y fichas para comprar artículos o desbloquear secretos.
- -Cómo descargar Five Nights at Freddy’s 6?
-Las plataformas oficiales y los precios del juego
-El juego está disponible para su compra en Steam para usuarios de Windows por $39.99. También puedes comprarlo en PlayStation Store para usuarios de PlayStation 4 o PlayStation 5 por $39.99. El juego admite la compra cruzada entre las versiones de PS4 y PS5.
-El juego aún no está disponible para otras plataformas como Xbox One, Xbox Series X/S, Nintendo Switch, iOS o Android. Sin embargo, se espera que sean liberados en algún momento de 2022.
-Los requisitos del sistema y la compatibilidad del juego
-Antes de descargar el juego, usted debe asegurarse de que su dispositivo cumple con los requisitos mínimos del sistema para el juego. Estos son los requisitos del sistema para los usuarios de Windows y PlayStation:
--
-
- OS: Windows 10 64-bit -
- Procesador: Intel Core i5-2500K o AMD FX-8350 -
- Memoria: 8 GB RAM -
- Gráficos: NVIDIA GeForce GTX 960 o AMD Radeon R9 280X -
- DirectX: Versión 11 -
- Almacenamiento: 20 GB de espacio disponible -
-
-
- OS: Windows 10 64-bit -
- Procesador: Intel Core i7-6700K o AMD Ryzen 5 2600X -
- Memoria: 16 GB RAM -
- Gráficos: NVIDIA GeForce GTX 1070 o AMD Radeon RX Vega 56 -
- DirectX: Versión 12 -
- Almacenamiento: 20 GB de espacio disponible -
-
-
- OS: software de sistema PlayStation 4 o PlayStation 5 -
- Procesador: N/A - -
- Gráficos: N/A -
- DirectX: N/A -
- Almacenamiento: 20 GB de espacio disponible -
Nota: El juego admite funciones mejoradas de PS4 Pro y PS5, como una resolución más alta, tiempos de carga más rápidos y trazado de rayos.
-Si tu dispositivo cumple con los requisitos del sistema, puedes descargar el juego desde las plataformas oficiales siguiendo estos pasos:
--
-
- Crear una cuenta o iniciar sesión en Steam o PlayStation Store. -
- Búsqueda de cinco noches en Freddy’s 6 o cinco noches en Freddy’s: Violación de seguridad en la tienda. -
- Seleccione el juego y haga clic en Comprar o Añadir al carrito. -
- Complete el proceso de pago y confirme su compra. -
- El juego comenzará a descargarse automáticamente a su dispositivo. -
- Una vez completada la descarga, puedes lanzar el juego y disfrutarlo. -
- Utilice las cámaras de seguridad para monitorear su entorno y planificar su ruta. Puede cambiar entre diferentes cámaras usando el ratón o el controlador. También puede acercar o alejar usando la rueda de desplazamiento o los disparadores. Las cámaras te mostrarán dónde están Vanessa y los otros animatrónicos, así como dónde puedes encontrar objetos, herramientas, escondites o salidas. - -
- Escóndete en diferentes lugares o huye del peligro. Puede esconderse en varios lugares, como casilleros, gabinetes, rejillas de ventilación o botes de basura presionando F o A en su teclado o controlador. También puede huir del peligro pulsando Shift o L3 en su teclado o controlador. Sin embargo, debe tener cuidado con su resistencia, potencia de la batería, nivel de ruido y límite de tiempo. Su resistencia disminuirá si corre demasiado, su potencia de la batería disminuirá si usa demasiados artículos o herramientas, su nivel de ruido aumentará si hace demasiado ruido, y su límite de tiempo disminuirá si toma demasiado tiempo para completar sus objetivos. Si cualquiera de estos factores llega a cero, usted será más vulnerable a ser atrapado. -
- Recoge monedas y fichas para comprar objetos o desbloquear secretos. Puedes encontrar monedas y fichas en todo el Pizzaplex. Puede utilizarlos para comprar artículos en máquinas expendedoras o en contadores de premios. También puedes usarlos para desbloquear secretos como juegos de árcade ocultos, habitaciones secretas o finales secretos. -
- Jugar juegos de árcade para ganar recompensas o acceder a mini-juegos. Puedes jugar juegos de árcade como Monty Golf, Roxy Raceway, Bonnie Bowl o Fazbear Blast in the Pizzaplex. Puedes ganar recompensas como monedas, fichas u objetos al jugarlos. También puedes acceder a minijuegos como Princess Quest, Freddy in Space 2 o Corn Maze jugando ciertos juegos de árcade. -
- Explora diferentes áreas para encontrar pistas o huevos de Pascua. Puedes explorar diferentes áreas como las alcantarillas o la arena láser tag en el Pizzaplex. Puedes encontrar pistas o huevos de Pascua como carteles, notas, cintas o referencias a juegos anteriores u otros medios. -
- Q: ¿Cinco noches en Freddy’s 6 da miedo? -
- A: Sí, Five Nights at Freddy’s 6 es un juego de terror que presenta sustos de salto, gore, violencia y temas oscuros. No es adecuado para niños o personas que se asustan fácilmente. -
- Q: ¿Son cinco noches en el 6 canon de Freddy? -
- A: Sí, Five Nights at Freddy’s 6 es canon y parte de la línea de tiempo principal de la serie Five Nights at Freddy’s. Tiene lugar después de los eventos de Five Nights at Freddy’s: Help Wanted y Five Nights at Freddy’s: Special Delivery. -
- Q: ¿Cinco noches en Freddy’s 6 es gratis? -
- A: No, Five Nights at Freddy’s 6 no es gratis. Cuesta $39.99 en Steam y PlayStation Store. Sin embargo, puede estar disponible de forma gratuita o con descuento en ciertas ocasiones o plataformas. -
- Q: ¿Son cinco noches en el multijugador de Freddy’s 6? -
- A: No, Five Nights at Freddy’s 6 no es multijugador. Es un juego para un solo jugador que no admite modos cooperativos o versus en línea o locales. -
- Q: ¿Cinco noches en Freddy’s 6 es el juego final de la serie? -
- A: No, Five Nights at Freddy’s 6 no es el juego final de la serie. Scott Cawthon, el creador de la serie, ha confirmado que hay más juegos en desarrollo, como Five Nights at Freddy’s: Into Madness y Five Nights at Freddy’s: The Movie. -
Cómo jugar cinco noches en Freddy’s 6?
-Ahora que ha descargado el juego, es posible que se pregunte cómo jugarlo. Estos son algunos consejos y trucos para sobrevivir la noche y descubrir los secretos de la Pizzaplex.
-Los consejos y trucos para sobrevivir la noche
-El objetivo principal del juego es sobrevivir hasta las 6 a.m. sin ser atrapado por Vanessa o los otros animatrónicos. Aquí hay algunos consejos y trucos para ayudarte a hacerlo:
--
-
Los secretos y huevos de Pascua para descubrir en el juego
-El juego también ofrece muchos secretos y huevos de Pascua para que los descubras en el juego. Estos son algunos de ellos:
--
-
Conclusión
- -Preguntas frecuentes
-Aquí hay algunas preguntas frecuentes sobre Five Nights at Freddy’s 6:
--
-
-
-
\ No newline at end of file diff --git a/spaces/CVPR/Bamboo_ViT-B16_demo/README.md b/spaces/CVPR/Bamboo_ViT-B16_demo/README.md deleted file mode 100644 index 74a1caa7498f2c89cde79a3f031ec6a77758e45f..0000000000000000000000000000000000000000 --- a/spaces/CVPR/Bamboo_ViT-B16_demo/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Bamboo ViT-B16 Demo -emoji: 🎋 -colorFrom: blue -colorTo: blue -sdk: gradio -sdk_version: 3.0.17 -app_file: app.py -pinned: false -license: cc-by-4.0 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference \ No newline at end of file diff --git a/spaces/CVPR/GFPGAN-example/setup.py b/spaces/CVPR/GFPGAN-example/setup.py deleted file mode 100644 index 474e9188aa2dc5c19614921760ce4ad99bd19c13..0000000000000000000000000000000000000000 --- a/spaces/CVPR/GFPGAN-example/setup.py +++ /dev/null @@ -1,107 +0,0 @@ -#!/usr/bin/env python - -from setuptools import find_packages, setup - -import os -import subprocess -import time - -version_file = 'gfpgan/version.py' - - -def readme(): - with open('README.md', encoding='utf-8') as f: - content = f.read() - return content - - -def get_git_hash(): - - def _minimal_ext_cmd(cmd): - # construct minimal environment - env = {} - for k in ['SYSTEMROOT', 'PATH', 'HOME']: - v = os.environ.get(k) - if v is not None: - env[k] = v - # LANGUAGE is used on win32 - env['LANGUAGE'] = 'C' - env['LANG'] = 'C' - env['LC_ALL'] = 'C' - out = subprocess.Popen(cmd, stdout=subprocess.PIPE, env=env).communicate()[0] - return out - - try: - out = _minimal_ext_cmd(['git', 'rev-parse', 'HEAD']) - sha = out.strip().decode('ascii') - except OSError: - sha = 'unknown' - - return sha - - -def get_hash(): - if os.path.exists('.git'): - sha = get_git_hash()[:7] - else: - sha = 'unknown' - - return sha - - -def write_version_py(): - content = """# GENERATED VERSION FILE -# TIME: {} -__version__ = '{}' -__gitsha__ = '{}' -version_info = ({}) -""" - sha = get_hash() - with open('VERSION', 'r') as f: - SHORT_VERSION = f.read().strip() - VERSION_INFO = ', '.join([x if x.isdigit() else f'"{x}"' for x in SHORT_VERSION.split('.')]) - - version_file_str = content.format(time.asctime(), SHORT_VERSION, sha, VERSION_INFO) - with open(version_file, 'w') as f: - f.write(version_file_str) - - -def get_version(): - with open(version_file, 'r') as f: - exec(compile(f.read(), version_file, 'exec')) - return locals()['__version__'] - - -def get_requirements(filename='requirements.txt'): - here = os.path.dirname(os.path.realpath(__file__)) - with open(os.path.join(here, filename), 'r') as f: - requires = [line.replace('\n', '') for line in f.readlines()] - return requires - - -if __name__ == '__main__': - write_version_py() - setup( - name='gfpgan', - version=get_version(), - description='GFPGAN aims at developing Practical Algorithms for Real-world Face Restoration', - long_description=readme(), - long_description_content_type='text/markdown', - author='Xintao Wang', - author_email='xintao.wang@outlook.com', - keywords='computer vision, pytorch, image restoration, super-resolution, face restoration, gan, gfpgan', - url='https://github.com/TencentARC/GFPGAN', - include_package_data=True, - packages=find_packages(exclude=('options', 'datasets', 'experiments', 'results', 'tb_logger', 'wandb')), - classifiers=[ - 'Development Status :: 4 - Beta', - 'License :: OSI Approved :: Apache Software License', - 'Operating System :: OS Independent', - 'Programming Language :: Python :: 3', - 'Programming Language :: Python :: 3.7', - 'Programming Language :: Python :: 3.8', - ], - license='Apache License Version 2.0', - setup_requires=['cython', 'numpy'], - install_requires=get_requirements(), - zip_safe=False) diff --git a/spaces/CVPR/LIVE/thrust/thrust/detail/allocator_aware_execution_policy.h b/spaces/CVPR/LIVE/thrust/thrust/detail/allocator_aware_execution_policy.h deleted file mode 100644 index 28fd54f9b73d45ba01e10797e392151e70de690c..0000000000000000000000000000000000000000 --- a/spaces/CVPR/LIVE/thrust/thrust/detail/allocator_aware_execution_policy.h +++ /dev/null @@ -1,101 +0,0 @@ -/* - * Copyright 2018 NVIDIA Corporation - * - * Licensed under the Apache License, Version 2.0 (the "License"); - * you may not use this file except in compliance with the License. - * You may obtain a copy of the License at - * - * http://www.apache.org/licenses/LICENSE-2.0 - * - * Unless required by applicable law or agreed to in writing, software - * distributed under the License is distributed on an "AS IS" BASIS, - * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - * See the License for the specific language governing permissions and - * limitations under the License. - */ - -#pragma once - -#include
Traceback:
\n{tb}"
- message = (
- ""
- "{title}
" - "\n{msg}\n\n" - ).format(title=title, msg=msg) - ct = "text/html" - else: - if tb: - msg = tb - message = title + "\n\n" + msg - - resp = Response(status=status, text=message, content_type=ct) - resp.force_close() - - return resp - - def _make_error_handler( - self, err_info: _ErrInfo - ) -> Callable[[BaseRequest], Awaitable[StreamResponse]]: - async def handler(request: BaseRequest) -> StreamResponse: - return self.handle_error( - request, err_info.status, err_info.exc, err_info.message - ) - - return handler diff --git a/spaces/Dachus/Realfee/Dockerfile b/spaces/Dachus/Realfee/Dockerfile deleted file mode 100644 index 8673c32e47d0e6700f24404e933dac777d2abe83..0000000000000000000000000000000000000000 --- a/spaces/Dachus/Realfee/Dockerfile +++ /dev/null @@ -1,15 +0,0 @@ -FROM ghcr.io/livebook-dev/livebook:latest-cuda11.8 - -ENV LIVEBOOK_APP_SERVICE_NAME "🐳 Hugging Face - $SPACE_TITLE" -ENV LIVEBOOK_APP_SERVICE_URL "https://huggingface.co/spaces/$SPACE_AUTHOR_NAME/$SPACE_REPO_NAME" -ENV LIVEBOOK_UPDATE_INSTRUCTIONS_URL "https://livebook.dev" -ENV LIVEBOOK_WITHIN_IFRAME "true" -ENV LIVEBOOK_APPS_PATH "/public-apps" -ENV LIVEBOOK_DATA_PATH "/data" -ENV LIVEBOOK_PORT 7860 - -EXPOSE 7860 -USER root -COPY public-apps/ /public-apps -RUN mkdir -p /data -RUN chmod 777 /data diff --git a/spaces/Dauzy/whisper-webui/src/utils.py b/spaces/Dauzy/whisper-webui/src/utils.py deleted file mode 100644 index 576244c9cf8b8e8aa888b0a51312ddf56db928ce..0000000000000000000000000000000000000000 --- a/spaces/Dauzy/whisper-webui/src/utils.py +++ /dev/null @@ -1,245 +0,0 @@ -import textwrap -import unicodedata -import re - -import zlib -from typing import Iterator, TextIO, Union -import tqdm - -import urllib3 - - -def exact_div(x, y): - assert x % y == 0 - return x // y - - -def str2bool(string): - str2val = {"True": True, "False": False} - if string in str2val: - return str2val[string] - else: - raise ValueError(f"Expected one of {set(str2val.keys())}, got {string}") - - -def optional_int(string): - return None if string == "None" else int(string) - - -def optional_float(string): - return None if string == "None" else float(string) - - -def compression_ratio(text) -> float: - return len(text) / len(zlib.compress(text.encode("utf-8"))) - - -def format_timestamp(seconds: float, always_include_hours: bool = False, fractionalSeperator: str = '.'): - assert seconds >= 0, "non-negative timestamp expected" - milliseconds = round(seconds * 1000.0) - - hours = milliseconds // 3_600_000 - milliseconds -= hours * 3_600_000 - - minutes = milliseconds // 60_000 - milliseconds -= minutes * 60_000 - - seconds = milliseconds // 1_000 - milliseconds -= seconds * 1_000 - - hours_marker = f"{hours:02d}:" if always_include_hours or hours > 0 else "" - return f"{hours_marker}{minutes:02d}:{seconds:02d}{fractionalSeperator}{milliseconds:03d}" - - -def write_txt(transcript: Iterator[dict], file: TextIO): - for segment in transcript: - print(segment['text'].strip(), file=file, flush=True) - - -def write_vtt(transcript: Iterator[dict], file: TextIO, - maxLineWidth=None, highlight_words: bool = False): - iterator = __subtitle_preprocessor_iterator(transcript, maxLineWidth, highlight_words) - - print("WEBVTT\n", file=file) - - for segment in iterator: - text = segment['text'].replace('-->', '->') - - print( - f"{format_timestamp(segment['start'])} --> {format_timestamp(segment['end'])}\n" - f"{text}\n", - file=file, - flush=True, - ) - -def write_srt(transcript: Iterator[dict], file: TextIO, - maxLineWidth=None, highlight_words: bool = False): - """ - Write a transcript to a file in SRT format. - Example usage: - from pathlib import Path - from whisper.utils import write_srt - result = transcribe(model, audio_path, temperature=temperature, **args) - # save SRT - audio_basename = Path(audio_path).stem - with open(Path(output_dir) / (audio_basename + ".srt"), "w", encoding="utf-8") as srt: - write_srt(result["segments"], file=srt) - """ - iterator = __subtitle_preprocessor_iterator(transcript, maxLineWidth, highlight_words) - - for i, segment in enumerate(iterator, start=1): - text = segment['text'].replace('-->', '->') - - # write srt lines - print( - f"{i}\n" - f"{format_timestamp(segment['start'], always_include_hours=True, fractionalSeperator=',')} --> " - f"{format_timestamp(segment['end'], always_include_hours=True, fractionalSeperator=',')}\n" - f"{text}\n", - file=file, - flush=True, - ) - -def __subtitle_preprocessor_iterator(transcript: Iterator[dict], maxLineWidth: int = None, highlight_words: bool = False): - for segment in transcript: - words = segment.get('words', []) - - if len(words) == 0: - # Yield the segment as-is or processed - if maxLineWidth is None or maxLineWidth < 0: - yield segment - else: - yield { - 'start': segment['start'], - 'end': segment['end'], - 'text': process_text(segment['text'].strip(), maxLineWidth) - } - # We are done - continue - - subtitle_start = segment['start'] - subtitle_end = segment['end'] - - text_words = [ this_word["word"] for this_word in words ] - subtitle_text = __join_words(text_words, maxLineWidth) - - # Iterate over the words in the segment - if highlight_words: - last = subtitle_start - - for i, this_word in enumerate(words): - start = this_word['start'] - end = this_word['end'] - - if last != start: - # Display the text up to this point - yield { - 'start': last, - 'end': start, - 'text': subtitle_text - } - - # Display the text with the current word highlighted - yield { - 'start': start, - 'end': end, - 'text': __join_words( - [ - { - "word": re.sub(r"^(\s*)(.*)$", r"\1\2", word) - if j == i - else word, - # The HTML tags and are not displayed, - # # so they should not be counted in the word length - "length": len(word) - } for j, word in enumerate(text_words) - ], maxLineWidth) - } - last = end - - if last != subtitle_end: - # Display the last part of the text - yield { - 'start': last, - 'end': subtitle_end, - 'text': subtitle_text - } - - # Just return the subtitle text - else: - yield { - 'start': subtitle_start, - 'end': subtitle_end, - 'text': subtitle_text - } - -def __join_words(words: Iterator[Union[str, dict]], maxLineWidth: int = None): - if maxLineWidth is None or maxLineWidth < 0: - return " ".join(words) - - lines = [] - current_line = "" - current_length = 0 - - for entry in words: - # Either accept a string or a dict with a 'word' and 'length' field - if isinstance(entry, dict): - word = entry['word'] - word_length = entry['length'] - else: - word = entry - word_length = len(word) - - if current_length > 0 and current_length + word_length > maxLineWidth: - lines.append(current_line) - current_line = "" - current_length = 0 - - current_length += word_length - # The word will be prefixed with a space by Whisper, so we don't need to add one here - current_line += word - - if len(current_line) > 0: - lines.append(current_line) - - return "\n".join(lines) - -def process_text(text: str, maxLineWidth=None): - if (maxLineWidth is None or maxLineWidth < 0): - return text - - lines = textwrap.wrap(text, width=maxLineWidth, tabsize=4) - return '\n'.join(lines) - -def slugify(value, allow_unicode=False): - """ - Taken from https://github.com/django/django/blob/master/django/utils/text.py - Convert to ASCII if 'allow_unicode' is False. Convert spaces or repeated - dashes to single dashes. Remove characters that aren't alphanumerics, - underscores, or hyphens. Convert to lowercase. Also strip leading and - trailing whitespace, dashes, and underscores. - """ - value = str(value) - if allow_unicode: - value = unicodedata.normalize('NFKC', value) - else: - value = unicodedata.normalize('NFKD', value).encode('ascii', 'ignore').decode('ascii') - value = re.sub(r'[^\w\s-]', '', value.lower()) - return re.sub(r'[-\s]+', '-', value).strip('-_') - -def download_file(url: str, destination: str): - with urllib3.request.urlopen(url) as source, open(destination, "wb") as output: - with tqdm( - total=int(source.info().get("Content-Length")), - ncols=80, - unit="iB", - unit_scale=True, - unit_divisor=1024, - ) as loop: - while True: - buffer = source.read(8192) - if not buffer: - break - - output.write(buffer) - loop.update(len(buffer)) \ No newline at end of file diff --git a/spaces/DemoLou/moe-tts/text/mandarin.py b/spaces/DemoLou/moe-tts/text/mandarin.py deleted file mode 100644 index ff71de9788e4f20c897b971a775d1ecfbfe1c7b7..0000000000000000000000000000000000000000 --- a/spaces/DemoLou/moe-tts/text/mandarin.py +++ /dev/null @@ -1,329 +0,0 @@ -import os -import sys -import re -from pypinyin import lazy_pinyin, BOPOMOFO -import jieba -import cn2an -import logging - -logging.getLogger('jieba').setLevel(logging.WARNING) -jieba.initialize() - - -# List of (Latin alphabet, bopomofo) pairs: -_latin_to_bopomofo = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [ - ('a', 'ㄟˉ'), - ('b', 'ㄅㄧˋ'), - ('c', 'ㄙㄧˉ'), - ('d', 'ㄉㄧˋ'), - ('e', 'ㄧˋ'), - ('f', 'ㄝˊㄈㄨˋ'), - ('g', 'ㄐㄧˋ'), - ('h', 'ㄝˇㄑㄩˋ'), - ('i', 'ㄞˋ'), - ('j', 'ㄐㄟˋ'), - ('k', 'ㄎㄟˋ'), - ('l', 'ㄝˊㄛˋ'), - ('m', 'ㄝˊㄇㄨˋ'), - ('n', 'ㄣˉ'), - ('o', 'ㄡˉ'), - ('p', 'ㄆㄧˉ'), - ('q', 'ㄎㄧㄡˉ'), - ('r', 'ㄚˋ'), - ('s', 'ㄝˊㄙˋ'), - ('t', 'ㄊㄧˋ'), - ('u', 'ㄧㄡˉ'), - ('v', 'ㄨㄧˉ'), - ('w', 'ㄉㄚˋㄅㄨˋㄌㄧㄡˋ'), - ('x', 'ㄝˉㄎㄨˋㄙˋ'), - ('y', 'ㄨㄞˋ'), - ('z', 'ㄗㄟˋ') -]] - -# List of (bopomofo, romaji) pairs: -_bopomofo_to_romaji = [(re.compile('%s' % x[0]), x[1]) for x in [ - ('ㄅㄛ', 'p⁼wo'), - ('ㄆㄛ', 'pʰwo'), - ('ㄇㄛ', 'mwo'), - ('ㄈㄛ', 'fwo'), - ('ㄅ', 'p⁼'), - ('ㄆ', 'pʰ'), - ('ㄇ', 'm'), - ('ㄈ', 'f'), - ('ㄉ', 't⁼'), - ('ㄊ', 'tʰ'), - ('ㄋ', 'n'), - ('ㄌ', 'l'), - ('ㄍ', 'k⁼'), - ('ㄎ', 'kʰ'), - ('ㄏ', 'h'), - ('ㄐ', 'ʧ⁼'), - ('ㄑ', 'ʧʰ'), - ('ㄒ', 'ʃ'), - ('ㄓ', 'ʦ`⁼'), - ('ㄔ', 'ʦ`ʰ'), - ('ㄕ', 's`'), - ('ㄖ', 'ɹ`'), - ('ㄗ', 'ʦ⁼'), - ('ㄘ', 'ʦʰ'), - ('ㄙ', 's'), - ('ㄚ', 'a'), - ('ㄛ', 'o'), - ('ㄜ', 'ə'), - ('ㄝ', 'e'), - ('ㄞ', 'ai'), - ('ㄟ', 'ei'), - ('ㄠ', 'au'), - ('ㄡ', 'ou'), - ('ㄧㄢ', 'yeNN'), - ('ㄢ', 'aNN'), - ('ㄧㄣ', 'iNN'), - ('ㄣ', 'əNN'), - ('ㄤ', 'aNg'), - ('ㄧㄥ', 'iNg'), - ('ㄨㄥ', 'uNg'), - ('ㄩㄥ', 'yuNg'), - ('ㄥ', 'əNg'), - ('ㄦ', 'əɻ'), - ('ㄧ', 'i'), - ('ㄨ', 'u'), - ('ㄩ', 'ɥ'), - ('ˉ', '→'), - ('ˊ', '↑'), - ('ˇ', '↓↑'), - ('ˋ', '↓'), - ('˙', ''), - (',', ','), - ('。', '.'), - ('!', '!'), - ('?', '?'), - ('—', '-') -]] - -# List of (romaji, ipa) pairs: -_romaji_to_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [ - ('ʃy', 'ʃ'), - ('ʧʰy', 'ʧʰ'), - ('ʧ⁼y', 'ʧ⁼'), - ('NN', 'n'), - ('Ng', 'ŋ'), - ('y', 'j'), - ('h', 'x') -]] - -# List of (bopomofo, ipa) pairs: -_bopomofo_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [ - ('ㄅㄛ', 'p⁼wo'), - ('ㄆㄛ', 'pʰwo'), - ('ㄇㄛ', 'mwo'), - ('ㄈㄛ', 'fwo'), - ('ㄅ', 'p⁼'), - ('ㄆ', 'pʰ'), - ('ㄇ', 'm'), - ('ㄈ', 'f'), - ('ㄉ', 't⁼'), - ('ㄊ', 'tʰ'), - ('ㄋ', 'n'), - ('ㄌ', 'l'), - ('ㄍ', 'k⁼'), - ('ㄎ', 'kʰ'), - ('ㄏ', 'x'), - ('ㄐ', 'tʃ⁼'), - ('ㄑ', 'tʃʰ'), - ('ㄒ', 'ʃ'), - ('ㄓ', 'ts`⁼'), - ('ㄔ', 'ts`ʰ'), - ('ㄕ', 's`'), - ('ㄖ', 'ɹ`'), - ('ㄗ', 'ts⁼'), - ('ㄘ', 'tsʰ'), - ('ㄙ', 's'), - ('ㄚ', 'a'), - ('ㄛ', 'o'), - ('ㄜ', 'ə'), - ('ㄝ', 'ɛ'), - ('ㄞ', 'aɪ'), - ('ㄟ', 'eɪ'), - ('ㄠ', 'ɑʊ'), - ('ㄡ', 'oʊ'), - ('ㄧㄢ', 'jɛn'), - ('ㄩㄢ', 'ɥæn'), - ('ㄢ', 'an'), - ('ㄧㄣ', 'in'), - ('ㄩㄣ', 'ɥn'), - ('ㄣ', 'ən'), - ('ㄤ', 'ɑŋ'), - ('ㄧㄥ', 'iŋ'), - ('ㄨㄥ', 'ʊŋ'), - ('ㄩㄥ', 'jʊŋ'), - ('ㄥ', 'əŋ'), - ('ㄦ', 'əɻ'), - ('ㄧ', 'i'), - ('ㄨ', 'u'), - ('ㄩ', 'ɥ'), - ('ˉ', '→'), - ('ˊ', '↑'), - ('ˇ', '↓↑'), - ('ˋ', '↓'), - ('˙', ''), - (',', ','), - ('。', '.'), - ('!', '!'), - ('?', '?'), - ('—', '-') -]] - -# List of (bopomofo, ipa2) pairs: -_bopomofo_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [ - ('ㄅㄛ', 'pwo'), - ('ㄆㄛ', 'pʰwo'), - ('ㄇㄛ', 'mwo'), - ('ㄈㄛ', 'fwo'), - ('ㄅ', 'p'), - ('ㄆ', 'pʰ'), - ('ㄇ', 'm'), - ('ㄈ', 'f'), - ('ㄉ', 't'), - ('ㄊ', 'tʰ'), - ('ㄋ', 'n'), - ('ㄌ', 'l'), - ('ㄍ', 'k'), - ('ㄎ', 'kʰ'), - ('ㄏ', 'h'), - ('ㄐ', 'tɕ'), - ('ㄑ', 'tɕʰ'), - ('ㄒ', 'ɕ'), - ('ㄓ', 'tʂ'), - ('ㄔ', 'tʂʰ'), - ('ㄕ', 'ʂ'), - ('ㄖ', 'ɻ'), - ('ㄗ', 'ts'), - ('ㄘ', 'tsʰ'), - ('ㄙ', 's'), - ('ㄚ', 'a'), - ('ㄛ', 'o'), - ('ㄜ', 'ɤ'), - ('ㄝ', 'ɛ'), - ('ㄞ', 'aɪ'), - ('ㄟ', 'eɪ'), - ('ㄠ', 'ɑʊ'), - ('ㄡ', 'oʊ'), - ('ㄧㄢ', 'jɛn'), - ('ㄩㄢ', 'yæn'), - ('ㄢ', 'an'), - ('ㄧㄣ', 'in'), - ('ㄩㄣ', 'yn'), - ('ㄣ', 'ən'), - ('ㄤ', 'ɑŋ'), - ('ㄧㄥ', 'iŋ'), - ('ㄨㄥ', 'ʊŋ'), - ('ㄩㄥ', 'jʊŋ'), - ('ㄥ', 'ɤŋ'), - ('ㄦ', 'əɻ'), - ('ㄧ', 'i'), - ('ㄨ', 'u'), - ('ㄩ', 'y'), - ('ˉ', '˥'), - ('ˊ', '˧˥'), - ('ˇ', '˨˩˦'), - ('ˋ', '˥˩'), - ('˙', ''), - (',', ','), - ('。', '.'), - ('!', '!'), - ('?', '?'), - ('—', '-') -]] - - -def number_to_chinese(text): - numbers = re.findall(r'\d+(?:\.?\d+)?', text) - for number in numbers: - text = text.replace(number, cn2an.an2cn(number), 1) - return text - - -def chinese_to_bopomofo(text): - text = text.replace('、', ',').replace(';', ',').replace(':', ',') - words = jieba.lcut(text, cut_all=False) - text = '' - for word in words: - bopomofos = lazy_pinyin(word, BOPOMOFO) - if not re.search('[\u4e00-\u9fff]', word): - text += word - continue - for i in range(len(bopomofos)): - bopomofos[i] = re.sub(r'([\u3105-\u3129])$', r'\1ˉ', bopomofos[i]) - if text != '': - text += ' ' - text += ''.join(bopomofos) - return text - - -def latin_to_bopomofo(text): - for regex, replacement in _latin_to_bopomofo: - text = re.sub(regex, replacement, text) - return text - - -def bopomofo_to_romaji(text): - for regex, replacement in _bopomofo_to_romaji: - text = re.sub(regex, replacement, text) - return text - - -def bopomofo_to_ipa(text): - for regex, replacement in _bopomofo_to_ipa: - text = re.sub(regex, replacement, text) - return text - - -def bopomofo_to_ipa2(text): - for regex, replacement in _bopomofo_to_ipa2: - text = re.sub(regex, replacement, text) - return text - - -def chinese_to_romaji(text): - text = number_to_chinese(text) - text = chinese_to_bopomofo(text) - text = latin_to_bopomofo(text) - text = bopomofo_to_romaji(text) - text = re.sub('i([aoe])', r'y\1', text) - text = re.sub('u([aoəe])', r'w\1', text) - text = re.sub('([ʦsɹ]`[⁼ʰ]?)([→↓↑ ]+|$)', - r'\1ɹ`\2', text).replace('ɻ', 'ɹ`') - text = re.sub('([ʦs][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text) - return text - - -def chinese_to_lazy_ipa(text): - text = chinese_to_romaji(text) - for regex, replacement in _romaji_to_ipa: - text = re.sub(regex, replacement, text) - return text - - -def chinese_to_ipa(text): - text = number_to_chinese(text) - text = chinese_to_bopomofo(text) - text = latin_to_bopomofo(text) - text = bopomofo_to_ipa(text) - text = re.sub('i([aoe])', r'j\1', text) - text = re.sub('u([aoəe])', r'w\1', text) - text = re.sub('([sɹ]`[⁼ʰ]?)([→↓↑ ]+|$)', - r'\1ɹ`\2', text).replace('ɻ', 'ɹ`') - text = re.sub('([s][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text) - return text - - -def chinese_to_ipa2(text): - text = number_to_chinese(text) - text = chinese_to_bopomofo(text) - text = latin_to_bopomofo(text) - text = bopomofo_to_ipa2(text) - text = re.sub(r'i([aoe])', r'j\1', text) - text = re.sub(r'u([aoəe])', r'w\1', text) - text = re.sub(r'([ʂɹ]ʰ?)([˩˨˧˦˥ ]+|$)', r'\1ʅ\2', text) - text = re.sub(r'(sʰ?)([˩˨˧˦˥ ]+|$)', r'\1ɿ\2', text) - return text diff --git a/spaces/Dharshinijayakumar/Dharshujayakumaraiapp/app.py b/spaces/Dharshinijayakumar/Dharshujayakumaraiapp/app.py deleted file mode 100644 index ca8b6d40b4ab898c70da92f4a4298de2baf703dc..0000000000000000000000000000000000000000 --- a/spaces/Dharshinijayakumar/Dharshujayakumaraiapp/app.py +++ /dev/null @@ -1,164 +0,0 @@ -import os -import re -import requests -import json -import gradio as gr -from langchain.chat_models import ChatOpenAI -from langchain import LLMChain, PromptTemplate -from langchain.memory import ConversationBufferMemory - -OPENAI_API_KEY=os.getenv('OPENAI_API_KEY') -PLAY_HT_API_KEY=os.getenv('PLAY_HT_API_KEY') -PLAY_HT_USER_ID=os.getenv('PLAY_HT_USER_ID') - -PLAY_HT_VOICE_ID=os.getenv('PLAY_HT_VOICE_ID') -play_ht_api_get_audio_url = "https://play.ht/api/v2/tts" - - -template = """You are a helpful assistant to answer user queries. -{chat_history} -User: {user_message} -Chatbot:""" - -prompt = PromptTemplate( - input_variables=["chat_history", "user_message"], template=template -) - -memory = ConversationBufferMemory(memory_key="chat_history") - -llm_chain = LLMChain( - llm=ChatOpenAI(temperature='0.5', model_name="gpt-3.5-turbo"), - prompt=prompt, - verbose=True, - memory=memory, -) - -headers = { - "accept": "text/event-stream", - "content-type": "application/json", - "AUTHORIZATION": "Bearer "+ PLAY_HT_API_KEY, - "X-USER-ID": PLAY_HT_USER_ID -} - - -def get_payload(text): - return { - "text": text, - "voice": PLAY_HT_VOICE_ID, - "quality": "medium", - "output_format": "mp3", - "speed": 1, - "sample_rate": 24000, - "seed": None, - "temperature": None - } - -def get_generated_audio(text): - payload = get_payload(text) - generated_response = {} - try: - response = requests.post(play_ht_api_get_audio_url, json=payload, headers=headers) - response.raise_for_status() - generated_response["type"]= 'SUCCESS' - generated_response["response"] = response.text - except requests.exceptions.RequestException as e: - generated_response["type"]= 'ERROR' - try: - response_text = json.loads(response.text) - if response_text['error_message']: - generated_response["response"] = response_text['error_message'] - else: - generated_response["response"] = response.text - except Exception as e: - generated_response["response"] = response.text - except Exception as e: - generated_response["type"]= 'ERROR' - generated_response["response"] = response.text - return generated_response - -def extract_urls(text): - # Define the regex pattern for URLs - url_pattern = r'https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+[/\w\.-]*' - - # Find all occurrences of URLs in the text - urls = re.findall(url_pattern, text) - - return urls - -def get_audio_reply_for_question(text): - generated_audio_event = get_generated_audio(text) - #From get_generated_audio, you will get events in a string format, from that we need to extract the url - final_response = { - "audio_url": '', - "message": '' - } - if generated_audio_event["type"] == 'SUCCESS': - audio_urls = extract_urls(generated_audio_event["response"]) - if len(audio_urls) == 0: - final_response['message'] = "No audio file link found in generated event" - else: - final_response['audio_url'] = audio_urls[-1] - else: - final_response['message'] = generated_audio_event['response'] - return final_response - -def download_url(url): - try: - # Send a GET request to the URL to fetch the content - final_response = { - 'content':'', - 'error':'' - } - response = requests.get(url) - # Check if the request was successful (status code 200) - if response.status_code == 200: - final_response['content'] = response.content - else: - final_response['error'] = f"Failed to download the URL. Status code: {response.status_code}" - except Exception as e: - final_response['error'] = f"Failed to download the URL. Error: {e}" - return final_response - -def get_filename_from_url(url): - # Use os.path.basename() to extract the file name from the URL - file_name = os.path.basename(url) - return file_name - -def get_text_response(user_message): - response = llm_chain.predict(user_message = user_message) - return response - -def get_text_response_and_audio_response(user_message): - response = get_text_response(user_message) # Getting the reply from Open AI - audio_reply_for_question_response = get_audio_reply_for_question(response) - final_response = { - 'output_file_path': '', - 'message':'' - } - audio_url = audio_reply_for_question_response['audio_url'] - if audio_url: - output_file_path=get_filename_from_url(audio_url) - download_url_response = download_url(audio_url) - audio_content = download_url_response['content'] - if audio_content: - with open(output_file_path, "wb") as audio_file: - audio_file.write(audio_content) - final_response['output_file_path'] = output_file_path - else: - final_response['message'] = download_url_response['error'] - else: - final_response['message'] = audio_reply_for_question_response['message'] - return final_response - -def chat_bot_response(message, history): - text_and_audio_response = get_text_response_and_audio_response(message) - output_file_path = text_and_audio_response['output_file_path'] - if output_file_path: - return (text_and_audio_response['output_file_path'],) - else: - return text_and_audio_response['message'] - -demo = gr.ChatInterface(chat_bot_response,examples=["How are you doing?","What are your interests?","Which places do you like to visit?"]) - -if __name__ == "__main__": - demo.launch() #To create a public link, set `share=True` in `launch()`. To enable errors and logs, set `debug=True` in `launch()`. diff --git a/spaces/DragGan/DragGan-Inversion/gui_utils/glfw_window.py b/spaces/DragGan/DragGan-Inversion/gui_utils/glfw_window.py deleted file mode 100644 index 69c96ff72ccff6a42bcf6ab1dbdbb8cfb8005921..0000000000000000000000000000000000000000 --- a/spaces/DragGan/DragGan-Inversion/gui_utils/glfw_window.py +++ /dev/null @@ -1,239 +0,0 @@ -# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved. -# -# NVIDIA CORPORATION and its licensors retain all intellectual property -# and proprietary rights in and to this software, related documentation -# and any modifications thereto. Any use, reproduction, disclosure or -# distribution of this software and related documentation without an express -# license agreement from NVIDIA CORPORATION is strictly prohibited. - -import time -import glfw -import OpenGL.GL as gl -from . import gl_utils - -# ---------------------------------------------------------------------------- - - -class GlfwWindow: # pylint: disable=too-many-public-methods - def __init__(self, *, title='GlfwWindow', window_width=1920, window_height=1080, deferred_show=True, close_on_esc=True): - self._glfw_window = None - self._drawing_frame = False - self._frame_start_time = None - self._frame_delta = 0 - self._fps_limit = None - self._vsync = None - self._skip_frames = 0 - self._deferred_show = deferred_show - self._close_on_esc = close_on_esc - self._esc_pressed = False - self._drag_and_drop_paths = None - self._capture_next_frame = False - self._captured_frame = None - - # Create window. - glfw.init() - glfw.window_hint(glfw.VISIBLE, False) - self._glfw_window = glfw.create_window( - width=window_width, height=window_height, title=title, monitor=None, share=None) - self._attach_glfw_callbacks() - self.make_context_current() - - # Adjust window. - self.set_vsync(False) - self.set_window_size(window_width, window_height) - if not self._deferred_show: - glfw.show_window(self._glfw_window) - - def close(self): - if self._drawing_frame: - self.end_frame() - if self._glfw_window is not None: - glfw.destroy_window(self._glfw_window) - self._glfw_window = None - # glfw.terminate() # Commented out to play it nice with other glfw clients. - - def __del__(self): - try: - self.close() - except: - pass - - @property - def window_width(self): - return self.content_width - - @property - def window_height(self): - return self.content_height + self.title_bar_height - - @property - def content_width(self): - width, _height = glfw.get_window_size(self._glfw_window) - return width - - @property - def content_height(self): - _width, height = glfw.get_window_size(self._glfw_window) - return height - - @property - def title_bar_height(self): - _left, top, _right, _bottom = glfw.get_window_frame_size( - self._glfw_window) - return top - - @property - def monitor_width(self): - _, _, width, _height = glfw.get_monitor_workarea( - glfw.get_primary_monitor()) - return width - - @property - def monitor_height(self): - _, _, _width, height = glfw.get_monitor_workarea( - glfw.get_primary_monitor()) - return height - - @property - def frame_delta(self): - return self._frame_delta - - def set_title(self, title): - glfw.set_window_title(self._glfw_window, title) - - def set_window_size(self, width, height): - width = min(width, self.monitor_width) - height = min(height, self.monitor_height) - glfw.set_window_size(self._glfw_window, width, max( - height - self.title_bar_height, 0)) - if width == self.monitor_width and height == self.monitor_height: - self.maximize() - - def set_content_size(self, width, height): - self.set_window_size(width, height + self.title_bar_height) - - def maximize(self): - glfw.maximize_window(self._glfw_window) - - def set_position(self, x, y): - glfw.set_window_pos(self._glfw_window, x, y + self.title_bar_height) - - def center(self): - self.set_position((self.monitor_width - self.window_width) // - 2, (self.monitor_height - self.window_height) // 2) - - def set_vsync(self, vsync): - vsync = bool(vsync) - if vsync != self._vsync: - glfw.swap_interval(1 if vsync else 0) - self._vsync = vsync - - def set_fps_limit(self, fps_limit): - self._fps_limit = int(fps_limit) - - def should_close(self): - return glfw.window_should_close(self._glfw_window) or (self._close_on_esc and self._esc_pressed) - - def skip_frame(self): - self.skip_frames(1) - - def skip_frames(self, num): # Do not update window for the next N frames. - self._skip_frames = max(self._skip_frames, int(num)) - - def is_skipping_frames(self): - return self._skip_frames > 0 - - def capture_next_frame(self): - self._capture_next_frame = True - - def pop_captured_frame(self): - frame = self._captured_frame - self._captured_frame = None - return frame - - def pop_drag_and_drop_paths(self): - paths = self._drag_and_drop_paths - self._drag_and_drop_paths = None - return paths - - def draw_frame(self): # To be overridden by subclass. - self.begin_frame() - # Rendering code goes here. - self.end_frame() - - def make_context_current(self): - if self._glfw_window is not None: - glfw.make_context_current(self._glfw_window) - - def begin_frame(self): - # End previous frame. - if self._drawing_frame: - self.end_frame() - - # Apply FPS limit. - if self._frame_start_time is not None and self._fps_limit is not None: - delay = self._frame_start_time - time.perf_counter() + 1 / self._fps_limit - if delay > 0: - time.sleep(delay) - cur_time = time.perf_counter() - if self._frame_start_time is not None: - self._frame_delta = cur_time - self._frame_start_time - self._frame_start_time = cur_time - - # Process events. - glfw.poll_events() - - # Begin frame. - self._drawing_frame = True - self.make_context_current() - - # Initialize GL state. - gl.glViewport(0, 0, self.content_width, self.content_height) - gl.glMatrixMode(gl.GL_PROJECTION) - gl.glLoadIdentity() - gl.glTranslate(-1, 1, 0) - gl.glScale(2 / max(self.content_width, 1), - - 2 / max(self.content_height, 1), 1) - gl.glMatrixMode(gl.GL_MODELVIEW) - gl.glLoadIdentity() - gl.glEnable(gl.GL_BLEND) - # Pre-multiplied alpha. - gl.glBlendFunc(gl.GL_ONE, gl.GL_ONE_MINUS_SRC_ALPHA) - - # Clear. - gl.glClearColor(0, 0, 0, 1) - gl.glClear(gl.GL_COLOR_BUFFER_BIT | gl.GL_DEPTH_BUFFER_BIT) - - def end_frame(self): - assert self._drawing_frame - self._drawing_frame = False - - # Skip frames if requested. - if self._skip_frames > 0: - self._skip_frames -= 1 - return - - # Capture frame if requested. - if self._capture_next_frame: - self._captured_frame = gl_utils.read_pixels( - self.content_width, self.content_height) - self._capture_next_frame = False - - # Update window. - if self._deferred_show: - glfw.show_window(self._glfw_window) - self._deferred_show = False - glfw.swap_buffers(self._glfw_window) - - def _attach_glfw_callbacks(self): - glfw.set_key_callback(self._glfw_window, self._glfw_key_callback) - glfw.set_drop_callback(self._glfw_window, self._glfw_drop_callback) - - def _glfw_key_callback(self, _window, key, _scancode, action, _mods): - if action == glfw.PRESS and key == glfw.KEY_ESCAPE: - self._esc_pressed = True - - def _glfw_drop_callback(self, _window, paths): - self._drag_and_drop_paths = paths - -# ---------------------------------------------------------------------------- diff --git a/spaces/ECCV2022/bytetrack/tutorials/trades/README.md b/spaces/ECCV2022/bytetrack/tutorials/trades/README.md deleted file mode 100644 index 95afad0195f6230b7ca593dfd088ea7953ff2ed6..0000000000000000000000000000000000000000 --- a/spaces/ECCV2022/bytetrack/tutorials/trades/README.md +++ /dev/null @@ -1,41 +0,0 @@ -# TraDeS - -Step1. git clone https://github.com/JialianW/TraDeS.git - - -Step2. - -replace https://github.com/JialianW/TraDeS/blob/master/src/lib/utils/tracker.py - -replace https://github.com/JialianW/TraDeS/blob/master/src/lib/opts.py - - -Step3. run -``` -python3 test.py tracking --exp_id mot17_half --dataset mot --dataset_version 17halfval --pre_hm --ltrb_amodal --inference --load_model ../models/mot_half.pth --gpus 0 --clip_len 3 --trades --track_thresh 0.4 --new_thresh 0.4 --out_thresh 0.2 --pre_thresh 0.5 -``` - - -# TraDeS_BYTE - -Step1. git clone https://github.com/JialianW/TraDeS.git - - -Step2. - -replace https://github.com/JialianW/TraDeS/blob/master/src/lib/utils/tracker.py by byte_tracker.py - -replace https://github.com/JialianW/TraDeS/blob/master/src/lib/opts.py - -add mot_online to https://github.com/JialianW/TraDeS/blob/master/src/lib/utils - -Step3. run -``` -python3 test.py tracking --exp_id mot17_half --dataset mot --dataset_version 17halfval --pre_hm --ltrb_amodal --inference --load_model ../models/mot_half.pth --gpus 0 --clip_len 3 --trades --track_thresh 0.4 --new_thresh 0.5 --out_thresh 0.1 --pre_thresh 0.5 -``` - - -## Notes -tracker.py: motion + reid - -byte_tracker.py: motion with kalman filter diff --git a/spaces/Eddycrack864/Applio-Inference/demucs/repitch.py b/spaces/Eddycrack864/Applio-Inference/demucs/repitch.py deleted file mode 100644 index 8846ab2d951a024c95067f66a113968500442828..0000000000000000000000000000000000000000 --- a/spaces/Eddycrack864/Applio-Inference/demucs/repitch.py +++ /dev/null @@ -1,96 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -import io -import random -import subprocess as sp -import tempfile - -import numpy as np -import torch -from scipy.io import wavfile - - -def i16_pcm(wav): - if wav.dtype == np.int16: - return wav - return (wav * 2**15).clamp_(-2**15, 2**15 - 1).short() - - -def f32_pcm(wav): - if wav.dtype == np.float: - return wav - return wav.float() / 2**15 - - -class RepitchedWrapper: - """ - Wrap a dataset to apply online change of pitch / tempo. - """ - def __init__(self, dataset, proba=0.2, max_pitch=2, max_tempo=12, tempo_std=5, vocals=[3]): - self.dataset = dataset - self.proba = proba - self.max_pitch = max_pitch - self.max_tempo = max_tempo - self.tempo_std = tempo_std - self.vocals = vocals - - def __len__(self): - return len(self.dataset) - - def __getitem__(self, index): - streams = self.dataset[index] - in_length = streams.shape[-1] - out_length = int((1 - 0.01 * self.max_tempo) * in_length) - - if random.random() < self.proba: - delta_pitch = random.randint(-self.max_pitch, self.max_pitch) - delta_tempo = random.gauss(0, self.tempo_std) - delta_tempo = min(max(-self.max_tempo, delta_tempo), self.max_tempo) - outs = [] - for idx, stream in enumerate(streams): - stream = repitch( - stream, - delta_pitch, - delta_tempo, - voice=idx in self.vocals) - outs.append(stream[:, :out_length]) - streams = torch.stack(outs) - else: - streams = streams[..., :out_length] - return streams - - -def repitch(wav, pitch, tempo, voice=False, quick=False, samplerate=44100): - """ - tempo is a relative delta in percentage, so tempo=10 means tempo at 110%! - pitch is in semi tones. - Requires `soundstretch` to be installed, see - https://www.surina.net/soundtouch/soundstretch.html - """ - outfile = tempfile.NamedTemporaryFile(suffix=".wav") - in_ = io.BytesIO() - wavfile.write(in_, samplerate, i16_pcm(wav).t().numpy()) - command = [ - "soundstretch", - "stdin", - outfile.name, - f"-pitch={pitch}", - f"-tempo={tempo:.6f}", - ] - if quick: - command += ["-quick"] - if voice: - command += ["-speech"] - try: - sp.run(command, capture_output=True, input=in_.getvalue(), check=True) - except sp.CalledProcessError as error: - raise RuntimeError(f"Could not change bpm because {error.stderr.decode('utf-8')}") - sr, wav = wavfile.read(outfile.name) - wav = wav.copy() - wav = f32_pcm(torch.from_numpy(wav).t()) - assert sr == samplerate - return wav diff --git a/spaces/Epoching/GLIDE_Inpaint/glide_text2im/clip/encoders.py b/spaces/Epoching/GLIDE_Inpaint/glide_text2im/clip/encoders.py deleted file mode 100644 index ee72773c2c891d2dda6d02933e88599b5330b052..0000000000000000000000000000000000000000 --- a/spaces/Epoching/GLIDE_Inpaint/glide_text2im/clip/encoders.py +++ /dev/null @@ -1,497 +0,0 @@ -import math -from collections import OrderedDict -from typing import List, Optional, Tuple, cast - -import attr -import numpy as np -import torch -import torch.nn as nn -import torch.nn.functional as F - -from .attention import ( - AttentionInfo, - DenseAttentionMask, - DenseCausalAttentionMask, - make_full_layout, - to_attention_info, -) -from .utils import Affine, LayerNorm, zero_key_bias_grad - -# Constants used in the original CLIP implementation. -image_channel_means = [122.77093945, 116.74601272, 104.09373519] -image_channel_stds = [68.50053285, 66.63215831, 70.32316309] - - -@attr.s(eq=False, repr=False) -class TextEmbedding(nn.Module): - n_vocab: int = attr.ib() - n_context: int = attr.ib() - n_state: int = attr.ib() - device: torch.device = attr.ib(default=torch.device("cuda")) - - def __attrs_post_init__(self) -> None: - super().__init__() - - w_voc = torch.empty((self.n_vocab, self.n_state), dtype=torch.float32, device=self.device) - w_pos = torch.empty((self.n_context, self.n_state), dtype=torch.float32, device=self.device) - - with torch.no_grad(): - w_voc.normal_(std=0.02) - w_pos.normal_(std=0.01) - - self.w_voc = nn.Parameter(w_voc) - self.w_pos = nn.Parameter(w_pos) - - def forward(self, x: torch.Tensor) -> torch.Tensor: - if len(x.shape) != 2: - raise ValueError() - - return F.embedding(x, self.w_voc) + self.w_pos[None, :, :] - - -@attr.s(eq=False, repr=False) -class ImageEmbedding(nn.Module): - image_size: int = attr.ib() - patch_size: int = attr.ib() - n_state: int = attr.ib() - n_timestep: int = attr.ib(default=0) - device: torch.device = attr.ib(default=torch.device("cuda")) - - def __attrs_post_init__(self) -> None: - super().__init__() - - if self.image_size % self.patch_size != 0: - raise ValueError() - - n_patch = self.image_size // self.patch_size - patch_proj = torch.empty( - (self.n_state, 3) + 2 * (self.patch_size,), dtype=torch.float32, device=self.device - ) - w_pos = torch.empty( - (1 + n_patch ** 2, self.n_state), dtype=torch.float32, device=self.device - ) - - with torch.no_grad(): - if self.n_timestep == 0: - pred_state = torch.empty((self.n_state,), dtype=torch.float32, device=self.device) - pred_state.normal_(std=1 / np.sqrt(self.n_state)) - self.pred_state = nn.Parameter(pred_state) - else: - w_t = torch.empty( - (self.n_timestep, self.n_state), dtype=torch.float32, device=self.device - ) - w_t.normal_(std=1 / np.sqrt(self.n_state)) - self.w_t = nn.Parameter(w_t) - - patch_proj.normal_(std=np.sqrt(2 / (self.n_state * self.patch_size ** 2))) - w_pos.normal_(std=1 / np.sqrt(self.n_state)) - - self.patch_proj = nn.Parameter(patch_proj) - self.w_pos = nn.Parameter(w_pos) - - self.channel_means = torch.tensor( - image_channel_means, dtype=torch.float32, device=self.device - )[None, :, None, None] - self.channel_stds = torch.tensor( - image_channel_stds, dtype=torch.float32, device=self.device - )[None, :, None, None] - self.ln = LayerNorm(self.n_state, eps=1e-5, device=self.device) - - def forward(self, x: torch.Tensor, t: Optional[torch.Tensor] = None) -> torch.Tensor: - if len(x.shape) != 4: - raise ValueError("input should be 4d") - if x.shape[1] != 3: - raise ValueError("input should have 3 channels") - if not (x.shape[2] == self.image_size and x.shape[3] == self.image_size): - raise ValueError(f"input is not {self.image_size} x {self.image_size}") - - if (self.n_timestep == 0 and t is not None) or (self.n_timestep != 0 and t is None): - raise ValueError() - if self.n_timestep != 0: - assert t is not None - if len(t.shape) != 1: - raise ValueError() - if t.shape[0] != x.shape[0]: - raise ValueError() - - x = (x - self.channel_means) / self.channel_stds - x = F.conv2d(x, self.patch_proj, stride=self.patch_size) - x = x.reshape(x.shape[0], self.n_state, (self.image_size // self.patch_size) ** 2).permute( - 0, 2, 1 - ) - - sot = ( - self.pred_state[None, None].expand(x.shape[0], -1, -1) - if self.n_timestep == 0 - else F.embedding(cast(torch.Tensor, t), self.w_t)[:, None] - ) - x = torch.cat((sot, x), dim=1) + self.w_pos[None] - return self.ln(x) - - -@attr.s(eq=False, repr=False) -class AttentionResblock(nn.Module): - n_state: int = attr.ib() - n_resblocks: int = attr.ib() - attn_fn: AttentionInfo = attr.ib() - device: torch.device = attr.ib(default=torch.device("cuda")) - - def __attrs_post_init__(self) -> None: - super().__init__() - - self.n_head_state = self.n_state // self.attn_fn.n_heads - self.qk_scale = 1 / np.sqrt(self.n_head_state) - - self.ln = LayerNorm(self.n_state, eps=1e-5, device=self.device) - self.f_q = Affine( - self.n_state, - self.n_state, - std=1 / math.sqrt(self.n_state), - use_bias=True, - bias_filter_fn=zero_key_bias_grad, - device=self.device, - ) - self.f_k = Affine( - self.n_state, - self.n_state, - std=1 / math.sqrt(self.n_state), - use_bias=False, - bias_filter_fn=zero_key_bias_grad, - device=self.device, - ) - self.f_v = Affine( - self.n_state, - self.n_state, - std=1 / math.sqrt(self.n_state), - use_bias=True, - bias_filter_fn=zero_key_bias_grad, - device=self.device, - ) - self.f_c = Affine( - self.n_state, - self.n_state, - use_bias=True, - std=1 / np.sqrt(self.n_state * self.n_resblocks ** 2), - device=self.device, - ) # XXX - - def forward(self, m: torch.Tensor) -> torch.Tensor: - n_context = m.shape[1] - n_query_pad = self.attn_fn.ctx_blks_q * self.attn_fn.block_size - n_context - n_key_pad = self.attn_fn.ctx_blks_k * self.attn_fn.block_size - n_context - assert n_query_pad >= 0 - assert n_key_pad >= 0 - - r = m - r = self.ln(r) - q, k, v = self.f_q(r), self.f_k(r), self.f_v(r) - - if n_query_pad != 0: - q = F.pad(q, (0, 0, 0, n_query_pad)) - - if n_key_pad != 0: - k = F.pad(k, (0, 0, 0, n_key_pad)) - v = F.pad(v, (0, 0, 0, n_key_pad)) - - q = q.view([q.shape[0], -1, self.attn_fn.n_heads, self.n_head_state]).permute((0, 2, 1, 3)) - k = k.view([k.shape[0], -1, self.attn_fn.n_heads, self.n_head_state]).permute((0, 2, 1, 3)) - v = v.view([v.shape[0], -1, self.attn_fn.n_heads, self.n_head_state]).permute((0, 2, 1, 3)) - w = torch.einsum( - "bhcd,bhkd->bhck", q * math.sqrt(self.qk_scale), k * math.sqrt(self.qk_scale) - ) - - if hasattr(self.attn_fn, "pytorch_attn_bias"): - bias = self.attn_fn.pytorch_attn_bias - assert len(bias.shape) in {2, 3} - - if len(bias.shape) == 2: - w = torch.softmax(w + self.attn_fn.pytorch_attn_bias[None, None], dim=-1) - elif len(bias.shape) == 3: - w = torch.softmax(w + self.attn_fn.pytorch_attn_bias[None], dim=-1) - else: - w = torch.softmax(w, dim=-1) - - r = torch.einsum("bhck,bhkd->bhcd", w, v) - r = r.permute((0, 2, 1, 3)).reshape((r.shape[0], -1, self.n_state)) - - if n_query_pad != 0: - r = r[:, :-n_query_pad] - - assert r.shape[1] == n_context - - r = self.f_c(r) - return m + r - - -@attr.s(eq=False, repr=False) -class FullyConnectedResblock(nn.Module): - """ - Not imported from other files because we retain Alec's original inits. - """ - - n_state: int = attr.ib() - n_resblocks: int = attr.ib() - device: torch.device = attr.ib(default=torch.device("cuda")) - - def __attrs_post_init__(self) -> None: - super().__init__() - - self.ln = LayerNorm(self.n_state, eps=1e-5, device=self.device) - self.f_1 = Affine( - self.n_state, - 4 * self.n_state, - use_bias=True, - std=np.sqrt(2 / (4 * self.n_state)), - device=self.device, - ) - self.f_2 = Affine( - 4 * self.n_state, - self.n_state, - use_bias=True, - std=1 / np.sqrt(self.n_state * self.n_resblocks ** 2), - device=self.device, - ) # XXX - - def forward(self, m: torch.Tensor) -> torch.Tensor: - r = m - r = self.ln(r) - - r = self.f_2(F.gelu(self.f_1(r))) - return m + r - - -@attr.s(eq=False, repr=False) -class TransformerBlock(nn.Module): - n_state: int = attr.ib() - n_resblocks: int = attr.ib() - attn_fn: AttentionInfo = attr.ib() - device: torch.device = attr.ib(default=torch.device("cuda")) - - def __attrs_post_init__(self) -> None: - super().__init__() - - self.f_attn = AttentionResblock( - self.n_state, - self.n_resblocks, - self.attn_fn, - self.device, - ) - self.f_mlp = FullyConnectedResblock(self.n_state, self.n_resblocks, self.device) - - def forward(self, x: torch.Tensor) -> torch.Tensor: - return self.f_mlp(self.f_attn(x)) - - -@attr.s(eq=False, repr=False) -class TextFeatureExtractor(nn.Module): - n_state: int = attr.ib() - n_embd: int = attr.ib() - device: torch.device = attr.ib(default=torch.device("cuda")) - - def __attrs_post_init__(self) -> None: - super().__init__() - - self.ln = LayerNorm(self.n_state, eps=1e-5, device=self.device) - self.f = Affine(self.n_state, self.n_embd, use_bias=False, device=self.device) - - def forward( - self, text: torch.Tensor, text_len: torch.Tensor, return_probe_features: bool = False - ) -> torch.Tensor: - if len(text.shape) != 3: - raise ValueError("expected text to be 3d") - if len(text_len.shape) != 1: - raise ValueError("expected text length to be 1d") - if text.shape[0] != text_len.shape[0]: - raise ValueError("text and text_len have inconsistent batch dimensions") - - index = (text_len - 1)[:, None, None].expand(-1, 1, text.shape[2]) - x = torch.gather(text, dim=1, index=index) - assert list(x.shape) == [text.shape[0], 1, text.shape[2]] - - if return_probe_features: - return x[:, 0] - - x = self.ln(x) - return self.f(x[:, 0]) - - -@attr.s(eq=False, repr=False) -class ImageFeatureExtractor(nn.Module): - n_state: int = attr.ib() - n_embd: int = attr.ib() - device: torch.device = attr.ib(default=torch.device("cuda")) - - def __attrs_post_init__(self) -> None: - super().__init__() - - self.ln = LayerNorm(self.n_state, eps=1e-5, device=self.device) - self.f = Affine(self.n_state, self.n_embd, use_bias=False, device=self.device) - - def forward(self, x: torch.Tensor, return_probe_features: bool = False) -> torch.Tensor: - if return_probe_features: - return x[:, 0] - - x = self.ln(x[:, :1]) - return self.f(x[:, 0]) - - -@attr.s(eq=False, repr=False) -class TextEncoder(nn.Module): - n_bpe_vocab: int = attr.ib() - max_text_len: int = attr.ib() - n_embd: int = attr.ib() - n_head: int = attr.ib() - n_xf_blocks: int = attr.ib() - n_head_state: int = attr.ib(default=64) - device: torch.device = attr.ib(default=torch.device("cuda")) - block_size: int = attr.ib(init=False, default=32) - - def __attrs_post_init__(self) -> None: - super().__init__() - - self.n_state = self.n_head * self.n_head_state - n_rounded_context = self.block_size * int(math.ceil(self.max_text_len / self.block_size)) - n_pad = n_rounded_context - self.max_text_len - - args = ( - n_rounded_context, - n_rounded_context, - self.block_size, - self.n_head, - False, - n_pad, - n_pad, - ) - mask = DenseCausalAttentionMask(*args) - attn_fn = to_attention_info(mask) - - m = 1 - make_full_layout(mask).astype(np.float32) - m[m == 1] = -1e10 - attn_fn.pytorch_attn_bias = torch.from_numpy(m).to(self.device) - - blocks: List[Tuple[str, nn.Module]] = [ - ( - "input", - TextEmbedding( - self.n_bpe_vocab, self.max_text_len, self.n_state, device=self.device - ), - ) - ] - - for i in range(self.n_xf_blocks): - blocks.append( - ( - f"block_{i}", - TransformerBlock(self.n_state, 2 * self.n_xf_blocks, attn_fn, self.device), - ) - ) - - blocks.append( - ("output", TextFeatureExtractor(self.n_state, self.n_embd, device=self.device)) - ) - - self.blocks = nn.ModuleDict(OrderedDict(blocks)) - - def forward( - self, - text: torch.Tensor, - text_len: torch.Tensor, - return_probe_features: bool = False, - ) -> torch.Tensor: - - n_batch = text.shape[0] - h = self.blocks["input"](text) - - for i in range(self.n_xf_blocks): - h = self.blocks[f"block_{i}"](h) - - h = self.blocks["output"](h, text_len, return_probe_features=return_probe_features) - - assert list(h.shape) == [ - n_batch, - self.n_embd if not return_probe_features else self.n_state, - ] - return h - - -@attr.s(eq=False, repr=False) -class ImageEncoder(nn.Module): - image_size: int = attr.ib() - patch_size: int = attr.ib() - n_embd: int = attr.ib() - n_head: int = attr.ib() - n_xf_blocks: int = attr.ib() - n_head_state: int = attr.ib(default=64) - n_timestep: int = attr.ib(default=0) - device: torch.device = attr.ib(default=torch.device("cuda")) - block_size: int = attr.ib(init=False, default=32) - - def __attrs_post_init__(self) -> None: - super().__init__() - - self.n_state = self.n_head * self.n_head_state - self.n_context = 1 + (self.image_size // self.patch_size) ** 2 - n_rounded_context = self.block_size * int(math.ceil(self.n_context / self.block_size)) - n_pad = n_rounded_context - self.n_context - - args = ( - n_rounded_context, - n_rounded_context, - self.block_size, - self.n_head, - False, - n_pad, - n_pad, - ) - mask = DenseAttentionMask(*args) - attn_fn = to_attention_info(mask) - - m = 1 - make_full_layout(mask).astype(np.float32) - m[m == 1] = -1e10 - attn_fn.pytorch_attn_bias = torch.from_numpy(m).to(self.device) - - blocks: List[Tuple[str, nn.Module]] = [ - ( - "input", - ImageEmbedding( - self.image_size, - self.patch_size, - self.n_state, - n_timestep=self.n_timestep, - device=self.device, - ), - ) - ] - - for i in range(self.n_xf_blocks): - blocks.append( - ( - f"block_{i}", - TransformerBlock(self.n_state, 2 * self.n_xf_blocks, attn_fn, self.device), - ) - ) - - blocks.append(("output", ImageFeatureExtractor(self.n_state, self.n_embd, self.device))) - - self.blocks = nn.ModuleDict(OrderedDict(blocks)) - - def forward( - self, - image: torch.Tensor, - timesteps: Optional[torch.Tensor] = None, - return_probe_features: bool = False, - ) -> torch.Tensor: - n_batch = image.shape[0] - h = self.blocks["input"](image, t=timesteps) - - for i in range(self.n_xf_blocks): - h = self.blocks[f"block_{i}"](h) - - h = self.blocks["output"](h, return_probe_features=return_probe_features) - - assert list(h.shape) == [ - n_batch, - self.n_embd if not return_probe_features else self.n_state, - ] - - return h diff --git a/spaces/EronSamez/RVC_HFmeu/go-applio.bat b/spaces/EronSamez/RVC_HFmeu/go-applio.bat deleted file mode 100644 index 60c0c41d34a8aee5e14e744accb33d028d807245..0000000000000000000000000000000000000000 --- a/spaces/EronSamez/RVC_HFmeu/go-applio.bat +++ /dev/null @@ -1,92 +0,0 @@ -@echo off -setlocal -title Start Applio - -::: -::: _ _ -::: /\ | (_) -::: / \ _ __ _ __ | |_ ___ -::: / /\ \ | '_ \| '_ \| | |/ _ \ -::: / ____ \| |_) | |_) | | | (_) | -::: /_/ \_\ .__/| .__/|_|_|\___/ -::: | | | | -::: |_| |_| -::: -::: - -:menu -for /f "delims=: tokens=*" %%A in ('findstr /b ":::" "%~f0"') do @echo(%%A - -echo [1] Start Applio -echo [2] Start Applio (DML) -echo [3] Start Realtime GUI (DML) -echo [4] Start Realtime GUI (V0) -echo [5] Start Realtime GUI (V1) -echo. - -set /p choice=Select an option: -set choice=%choice: =% - -cls -echo WARNING: It's recommended to disable antivirus or firewall, as errors might occur when starting the ssl. -pause - -if "%choice%"=="1" ( - cls - echo WARNING: At this point, it's recommended to disable antivirus or firewall, as errors might occur when downloading pretrained models. - pause>null - echo Starting Applio... - echo. - runtime\python.exe infer-web.py --pycmd runtime\python.exe --port 7897 - pause - cls - goto menu -) - -if "%choice%"=="2" ( - cls - echo Starting Applio ^(DML^)... - echo. - runtime\python.exe infer-web.py --pycmd runtime\python.exe --port 7897 --dml - pause - cls - goto menu -) - -if "%choice%"=="3" ( - cls - echo Starting Realtime GUI ^(DML^)... - echo. - runtime\python.exe gui_v1.py --pycmd runtime\python.exe --dml - pause - cls - goto menu -) - -if "%choice%"=="4" ( - cls - echo Starting Realtime GUI ^(V0^)... - echo. - runtime\python.exe gui_v0.py - pause - cls - goto menu -) - -if "%choice%"=="5" ( - cls - echo Starting Realtime GUI ^(V1^)... - echo. - runtime\python.exe gui_v1.py - pause - cls - goto menu -) - -cls -echo Invalid option. Please enter a number from 1 to 5. -echo. -echo Press 'Enter' to access the main menu... -pause>nul -cls -goto menu diff --git a/spaces/FrankZxShen/so-vits-svc-models-pcr/diffusion/diffusion_onnx.py b/spaces/FrankZxShen/so-vits-svc-models-pcr/diffusion/diffusion_onnx.py deleted file mode 100644 index 1c1e80321de162b5233801efa3423739f7f92bdc..0000000000000000000000000000000000000000 --- a/spaces/FrankZxShen/so-vits-svc-models-pcr/diffusion/diffusion_onnx.py +++ /dev/null @@ -1,612 +0,0 @@ -from collections import deque -from functools import partial -from inspect import isfunction -import torch.nn.functional as F -import librosa.sequence -import numpy as np -from torch.nn import Conv1d -from torch.nn import Mish -import torch -from torch import nn -from tqdm import tqdm -import math - - -def exists(x): - return x is not None - - -def default(val, d): - if exists(val): - return val - return d() if isfunction(d) else d - - -def extract(a, t): - return a[t].reshape((1, 1, 1, 1)) - - -def noise_like(shape, device, repeat=False): - repeat_noise = lambda: torch.randn((1, *shape[1:]), device=device).repeat(shape[0], *((1,) * (len(shape) - 1))) - noise = lambda: torch.randn(shape, device=device) - return repeat_noise() if repeat else noise() - - -def linear_beta_schedule(timesteps, max_beta=0.02): - """ - linear schedule - """ - betas = np.linspace(1e-4, max_beta, timesteps) - return betas - - -def cosine_beta_schedule(timesteps, s=0.008): - """ - cosine schedule - as proposed in https://openreview.net/forum?id=-NEXDKk8gZ - """ - steps = timesteps + 1 - x = np.linspace(0, steps, steps) - alphas_cumprod = np.cos(((x / steps) + s) / (1 + s) * np.pi * 0.5) ** 2 - alphas_cumprod = alphas_cumprod / alphas_cumprod[0] - betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1]) - return np.clip(betas, a_min=0, a_max=0.999) - - -beta_schedule = { - "cosine": cosine_beta_schedule, - "linear": linear_beta_schedule, -} - - -def extract_1(a, t): - return a[t].reshape((1, 1, 1, 1)) - - -def predict_stage0(noise_pred, noise_pred_prev): - return (noise_pred + noise_pred_prev) / 2 - - -def predict_stage1(noise_pred, noise_list): - return (noise_pred * 3 - - noise_list[-1]) / 2 - - -def predict_stage2(noise_pred, noise_list): - return (noise_pred * 23 - - noise_list[-1] * 16 - + noise_list[-2] * 5) / 12 - - -def predict_stage3(noise_pred, noise_list): - return (noise_pred * 55 - - noise_list[-1] * 59 - + noise_list[-2] * 37 - - noise_list[-3] * 9) / 24 - - -class SinusoidalPosEmb(nn.Module): - def __init__(self, dim): - super().__init__() - self.dim = dim - self.half_dim = dim // 2 - self.emb = 9.21034037 / (self.half_dim - 1) - self.emb = torch.exp(torch.arange(self.half_dim) * torch.tensor(-self.emb)).unsqueeze(0) - self.emb = self.emb.cpu() - - def forward(self, x): - emb = self.emb * x - emb = torch.cat((emb.sin(), emb.cos()), dim=-1) - return emb - - -class ResidualBlock(nn.Module): - def __init__(self, encoder_hidden, residual_channels, dilation): - super().__init__() - self.residual_channels = residual_channels - self.dilated_conv = Conv1d(residual_channels, 2 * residual_channels, 3, padding=dilation, dilation=dilation) - self.diffusion_projection = nn.Linear(residual_channels, residual_channels) - self.conditioner_projection = Conv1d(encoder_hidden, 2 * residual_channels, 1) - self.output_projection = Conv1d(residual_channels, 2 * residual_channels, 1) - - def forward(self, x, conditioner, diffusion_step): - diffusion_step = self.diffusion_projection(diffusion_step).unsqueeze(-1) - conditioner = self.conditioner_projection(conditioner) - y = x + diffusion_step - y = self.dilated_conv(y) + conditioner - - gate, filter_1 = torch.split(y, [self.residual_channels, self.residual_channels], dim=1) - - y = torch.sigmoid(gate) * torch.tanh(filter_1) - y = self.output_projection(y) - - residual, skip = torch.split(y, [self.residual_channels, self.residual_channels], dim=1) - - return (x + residual) / 1.41421356, skip - - -class DiffNet(nn.Module): - def __init__(self, in_dims, n_layers, n_chans, n_hidden): - super().__init__() - self.encoder_hidden = n_hidden - self.residual_layers = n_layers - self.residual_channels = n_chans - self.input_projection = Conv1d(in_dims, self.residual_channels, 1) - self.diffusion_embedding = SinusoidalPosEmb(self.residual_channels) - dim = self.residual_channels - self.mlp = nn.Sequential( - nn.Linear(dim, dim * 4), - Mish(), - nn.Linear(dim * 4, dim) - ) - self.residual_layers = nn.ModuleList([ - ResidualBlock(self.encoder_hidden, self.residual_channels, 1) - for i in range(self.residual_layers) - ]) - self.skip_projection = Conv1d(self.residual_channels, self.residual_channels, 1) - self.output_projection = Conv1d(self.residual_channels, in_dims, 1) - nn.init.zeros_(self.output_projection.weight) - - def forward(self, spec, diffusion_step, cond): - x = spec.squeeze(0) - x = self.input_projection(x) # x [B, residual_channel, T] - x = F.relu(x) - # skip = torch.randn_like(x) - diffusion_step = diffusion_step.float() - diffusion_step = self.diffusion_embedding(diffusion_step) - diffusion_step = self.mlp(diffusion_step) - - x, skip = self.residual_layers[0](x, cond, diffusion_step) - # noinspection PyTypeChecker - for layer in self.residual_layers[1:]: - x, skip_connection = layer.forward(x, cond, diffusion_step) - skip = skip + skip_connection - x = skip / math.sqrt(len(self.residual_layers)) - x = self.skip_projection(x) - x = F.relu(x) - x = self.output_projection(x) # [B, 80, T] - return x.unsqueeze(1) - - -class AfterDiffusion(nn.Module): - def __init__(self, spec_max, spec_min, v_type='a'): - super().__init__() - self.spec_max = spec_max - self.spec_min = spec_min - self.type = v_type - - def forward(self, x): - x = x.squeeze(1).permute(0, 2, 1) - mel_out = (x + 1) / 2 * (self.spec_max - self.spec_min) + self.spec_min - if self.type == 'nsf-hifigan-log10': - mel_out = mel_out * 0.434294 - return mel_out.transpose(2, 1) - - -class Pred(nn.Module): - def __init__(self, alphas_cumprod): - super().__init__() - self.alphas_cumprod = alphas_cumprod - - def forward(self, x_1, noise_t, t_1, t_prev): - a_t = extract(self.alphas_cumprod, t_1).cpu() - a_prev = extract(self.alphas_cumprod, t_prev).cpu() - a_t_sq, a_prev_sq = a_t.sqrt().cpu(), a_prev.sqrt().cpu() - x_delta = (a_prev - a_t) * ((1 / (a_t_sq * (a_t_sq + a_prev_sq))) * x_1 - 1 / ( - a_t_sq * (((1 - a_prev) * a_t).sqrt() + ((1 - a_t) * a_prev).sqrt())) * noise_t) - x_pred = x_1 + x_delta.cpu() - - return x_pred - - -class GaussianDiffusion(nn.Module): - def __init__(self, - out_dims=128, - n_layers=20, - n_chans=384, - n_hidden=256, - timesteps=1000, - k_step=1000, - max_beta=0.02, - spec_min=-12, - spec_max=2): - super().__init__() - self.denoise_fn = DiffNet(out_dims, n_layers, n_chans, n_hidden) - self.out_dims = out_dims - self.mel_bins = out_dims - self.n_hidden = n_hidden - betas = beta_schedule['linear'](timesteps, max_beta=max_beta) - - alphas = 1. - betas - alphas_cumprod = np.cumprod(alphas, axis=0) - alphas_cumprod_prev = np.append(1., alphas_cumprod[:-1]) - timesteps, = betas.shape - self.num_timesteps = int(timesteps) - self.k_step = k_step - - self.noise_list = deque(maxlen=4) - - to_torch = partial(torch.tensor, dtype=torch.float32) - - self.register_buffer('betas', to_torch(betas)) - self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod)) - self.register_buffer('alphas_cumprod_prev', to_torch(alphas_cumprod_prev)) - - # calculations for diffusion q(x_t | x_{t-1}) and others - self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod))) - self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod))) - self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod))) - self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod))) - self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod - 1))) - - # calculations for posterior q(x_{t-1} | x_t, x_0) - posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod) - # above: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t) - self.register_buffer('posterior_variance', to_torch(posterior_variance)) - # below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain - self.register_buffer('posterior_log_variance_clipped', to_torch(np.log(np.maximum(posterior_variance, 1e-20)))) - self.register_buffer('posterior_mean_coef1', to_torch( - betas * np.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod))) - self.register_buffer('posterior_mean_coef2', to_torch( - (1. - alphas_cumprod_prev) * np.sqrt(alphas) / (1. - alphas_cumprod))) - - self.register_buffer('spec_min', torch.FloatTensor([spec_min])[None, None, :out_dims]) - self.register_buffer('spec_max', torch.FloatTensor([spec_max])[None, None, :out_dims]) - self.ad = AfterDiffusion(self.spec_max, self.spec_min) - self.xp = Pred(self.alphas_cumprod) - - def q_mean_variance(self, x_start, t): - mean = extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start - variance = extract(1. - self.alphas_cumprod, t, x_start.shape) - log_variance = extract(self.log_one_minus_alphas_cumprod, t, x_start.shape) - return mean, variance, log_variance - - def predict_start_from_noise(self, x_t, t, noise): - return ( - extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t - - extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise - ) - - def q_posterior(self, x_start, x_t, t): - posterior_mean = ( - extract(self.posterior_mean_coef1, t, x_t.shape) * x_start + - extract(self.posterior_mean_coef2, t, x_t.shape) * x_t - ) - posterior_variance = extract(self.posterior_variance, t, x_t.shape) - posterior_log_variance_clipped = extract(self.posterior_log_variance_clipped, t, x_t.shape) - return posterior_mean, posterior_variance, posterior_log_variance_clipped - - def p_mean_variance(self, x, t, cond): - noise_pred = self.denoise_fn(x, t, cond=cond) - x_recon = self.predict_start_from_noise(x, t=t, noise=noise_pred) - - x_recon.clamp_(-1., 1.) - - model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start=x_recon, x_t=x, t=t) - return model_mean, posterior_variance, posterior_log_variance - - @torch.no_grad() - def p_sample(self, x, t, cond, clip_denoised=True, repeat_noise=False): - b, *_, device = *x.shape, x.device - model_mean, _, model_log_variance = self.p_mean_variance(x=x, t=t, cond=cond) - noise = noise_like(x.shape, device, repeat_noise) - # no noise when t == 0 - nonzero_mask = (1 - (t == 0).float()).reshape(b, *((1,) * (len(x.shape) - 1))) - return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise - - @torch.no_grad() - def p_sample_plms(self, x, t, interval, cond, clip_denoised=True, repeat_noise=False): - """ - Use the PLMS method from - [Pseudo Numerical Methods for Diffusion Models on Manifolds](https://arxiv.org/abs/2202.09778). - """ - - def get_x_pred(x, noise_t, t): - a_t = extract(self.alphas_cumprod, t) - a_prev = extract(self.alphas_cumprod, torch.max(t - interval, torch.zeros_like(t))) - a_t_sq, a_prev_sq = a_t.sqrt(), a_prev.sqrt() - - x_delta = (a_prev - a_t) * ((1 / (a_t_sq * (a_t_sq + a_prev_sq))) * x - 1 / ( - a_t_sq * (((1 - a_prev) * a_t).sqrt() + ((1 - a_t) * a_prev).sqrt())) * noise_t) - x_pred = x + x_delta - - return x_pred - - noise_list = self.noise_list - noise_pred = self.denoise_fn(x, t, cond=cond) - - if len(noise_list) == 0: - x_pred = get_x_pred(x, noise_pred, t) - noise_pred_prev = self.denoise_fn(x_pred, max(t - interval, 0), cond=cond) - noise_pred_prime = (noise_pred + noise_pred_prev) / 2 - elif len(noise_list) == 1: - noise_pred_prime = (3 * noise_pred - noise_list[-1]) / 2 - elif len(noise_list) == 2: - noise_pred_prime = (23 * noise_pred - 16 * noise_list[-1] + 5 * noise_list[-2]) / 12 - else: - noise_pred_prime = (55 * noise_pred - 59 * noise_list[-1] + 37 * noise_list[-2] - 9 * noise_list[-3]) / 24 - - x_prev = get_x_pred(x, noise_pred_prime, t) - noise_list.append(noise_pred) - - return x_prev - - def q_sample(self, x_start, t, noise=None): - noise = default(noise, lambda: torch.randn_like(x_start)) - return ( - extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start + - extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise - ) - - def p_losses(self, x_start, t, cond, noise=None, loss_type='l2'): - noise = default(noise, lambda: torch.randn_like(x_start)) - - x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise) - x_recon = self.denoise_fn(x_noisy, t, cond) - - if loss_type == 'l1': - loss = (noise - x_recon).abs().mean() - elif loss_type == 'l2': - loss = F.mse_loss(noise, x_recon) - else: - raise NotImplementedError() - - return loss - - def org_forward(self, - condition, - init_noise=None, - gt_spec=None, - infer=True, - infer_speedup=100, - method='pndm', - k_step=1000, - use_tqdm=True): - """ - conditioning diffusion, use fastspeech2 encoder output as the condition - """ - cond = condition - b, device = condition.shape[0], condition.device - if not infer: - spec = self.norm_spec(gt_spec) - t = torch.randint(0, self.k_step, (b,), device=device).long() - norm_spec = spec.transpose(1, 2)[:, None, :, :] # [B, 1, M, T] - return self.p_losses(norm_spec, t, cond=cond) - else: - shape = (cond.shape[0], 1, self.out_dims, cond.shape[2]) - - if gt_spec is None: - t = self.k_step - if init_noise is None: - x = torch.randn(shape, device=device) - else: - x = init_noise - else: - t = k_step - norm_spec = self.norm_spec(gt_spec) - norm_spec = norm_spec.transpose(1, 2)[:, None, :, :] - x = self.q_sample(x_start=norm_spec, t=torch.tensor([t - 1], device=device).long()) - - if method is not None and infer_speedup > 1: - if method == 'dpm-solver': - from .dpm_solver_pytorch import NoiseScheduleVP, model_wrapper, DPM_Solver - # 1. Define the noise schedule. - noise_schedule = NoiseScheduleVP(schedule='discrete', betas=self.betas[:t]) - - # 2. Convert your discrete-time `model` to the continuous-time - # noise prediction model. Here is an example for a diffusion model - # `model` with the noise prediction type ("noise") . - def my_wrapper(fn): - def wrapped(x, t, **kwargs): - ret = fn(x, t, **kwargs) - if use_tqdm: - self.bar.update(1) - return ret - - return wrapped - - model_fn = model_wrapper( - my_wrapper(self.denoise_fn), - noise_schedule, - model_type="noise", # or "x_start" or "v" or "score" - model_kwargs={"cond": cond} - ) - - # 3. Define dpm-solver and sample by singlestep DPM-Solver. - # (We recommend singlestep DPM-Solver for unconditional sampling) - # You can adjust the `steps` to balance the computation - # costs and the sample quality. - dpm_solver = DPM_Solver(model_fn, noise_schedule) - - steps = t // infer_speedup - if use_tqdm: - self.bar = tqdm(desc="sample time step", total=steps) - x = dpm_solver.sample( - x, - steps=steps, - order=3, - skip_type="time_uniform", - method="singlestep", - ) - if use_tqdm: - self.bar.close() - elif method == 'pndm': - self.noise_list = deque(maxlen=4) - if use_tqdm: - for i in tqdm( - reversed(range(0, t, infer_speedup)), desc='sample time step', - total=t // infer_speedup, - ): - x = self.p_sample_plms( - x, torch.full((b,), i, device=device, dtype=torch.long), - infer_speedup, cond=cond - ) - else: - for i in reversed(range(0, t, infer_speedup)): - x = self.p_sample_plms( - x, torch.full((b,), i, device=device, dtype=torch.long), - infer_speedup, cond=cond - ) - else: - raise NotImplementedError(method) - else: - if use_tqdm: - for i in tqdm(reversed(range(0, t)), desc='sample time step', total=t): - x = self.p_sample(x, torch.full((b,), i, device=device, dtype=torch.long), cond) - else: - for i in reversed(range(0, t)): - x = self.p_sample(x, torch.full((b,), i, device=device, dtype=torch.long), cond) - x = x.squeeze(1).transpose(1, 2) # [B, T, M] - return self.denorm_spec(x).transpose(2, 1) - - def norm_spec(self, x): - return (x - self.spec_min) / (self.spec_max - self.spec_min) * 2 - 1 - - def denorm_spec(self, x): - return (x + 1) / 2 * (self.spec_max - self.spec_min) + self.spec_min - - def get_x_pred(self, x_1, noise_t, t_1, t_prev): - a_t = extract(self.alphas_cumprod, t_1) - a_prev = extract(self.alphas_cumprod, t_prev) - a_t_sq, a_prev_sq = a_t.sqrt(), a_prev.sqrt() - x_delta = (a_prev - a_t) * ((1 / (a_t_sq * (a_t_sq + a_prev_sq))) * x_1 - 1 / ( - a_t_sq * (((1 - a_prev) * a_t).sqrt() + ((1 - a_t) * a_prev).sqrt())) * noise_t) - x_pred = x_1 + x_delta - return x_pred - - def OnnxExport(self, project_name=None, init_noise=None, hidden_channels=256, export_denoise=True, export_pred=True, export_after=True): - cond = torch.randn([1, self.n_hidden, 10]).cpu() - if init_noise is None: - x = torch.randn((1, 1, self.mel_bins, cond.shape[2]), dtype=torch.float32).cpu() - else: - x = init_noise - pndms = 100 - - org_y_x = self.org_forward(cond, init_noise=x) - - device = cond.device - n_frames = cond.shape[2] - step_range = torch.arange(0, self.k_step, pndms, dtype=torch.long, device=device).flip(0) - plms_noise_stage = torch.tensor(0, dtype=torch.long, device=device) - noise_list = torch.zeros((0, 1, 1, self.mel_bins, n_frames), device=device) - - ot = step_range[0] - ot_1 = torch.full((1,), ot, device=device, dtype=torch.long) - if export_denoise: - torch.onnx.export( - self.denoise_fn, - (x.cpu(), ot_1.cpu(), cond.cpu()), - f"{project_name}_denoise.onnx", - input_names=["noise", "time", "condition"], - output_names=["noise_pred"], - dynamic_axes={ - "noise": [3], - "condition": [2] - }, - opset_version=16 - ) - - for t in step_range: - t_1 = torch.full((1,), t, device=device, dtype=torch.long) - noise_pred = self.denoise_fn(x, t_1, cond) - t_prev = t_1 - pndms - t_prev = t_prev * (t_prev > 0) - if plms_noise_stage == 0: - if export_pred: - torch.onnx.export( - self.xp, - (x.cpu(), noise_pred.cpu(), t_1.cpu(), t_prev.cpu()), - f"{project_name}_pred.onnx", - input_names=["noise", "noise_pred", "time", "time_prev"], - output_names=["noise_pred_o"], - dynamic_axes={ - "noise": [3], - "noise_pred": [3] - }, - opset_version=16 - ) - - x_pred = self.get_x_pred(x, noise_pred, t_1, t_prev) - noise_pred_prev = self.denoise_fn(x_pred, t_prev, cond=cond) - noise_pred_prime = predict_stage0(noise_pred, noise_pred_prev) - - elif plms_noise_stage == 1: - noise_pred_prime = predict_stage1(noise_pred, noise_list) - - elif plms_noise_stage == 2: - noise_pred_prime = predict_stage2(noise_pred, noise_list) - - else: - noise_pred_prime = predict_stage3(noise_pred, noise_list) - - noise_pred = noise_pred.unsqueeze(0) - - if plms_noise_stage < 3: - noise_list = torch.cat((noise_list, noise_pred), dim=0) - plms_noise_stage = plms_noise_stage + 1 - - else: - noise_list = torch.cat((noise_list[-2:], noise_pred), dim=0) - - x = self.get_x_pred(x, noise_pred_prime, t_1, t_prev) - if export_after: - torch.onnx.export( - self.ad, - x.cpu(), - f"{project_name}_after.onnx", - input_names=["x"], - output_names=["mel_out"], - dynamic_axes={ - "x": [3] - }, - opset_version=16 - ) - x = self.ad(x) - - print((x == org_y_x).all()) - return x - - def forward(self, condition=None, init_noise=None, pndms=None, k_step=None): - cond = condition - x = init_noise - - device = cond.device - n_frames = cond.shape[2] - step_range = torch.arange(0, k_step.item(), pndms.item(), dtype=torch.long, device=device).flip(0) - plms_noise_stage = torch.tensor(0, dtype=torch.long, device=device) - noise_list = torch.zeros((0, 1, 1, self.mel_bins, n_frames), device=device) - - ot = step_range[0] - ot_1 = torch.full((1,), ot, device=device, dtype=torch.long) - - for t in step_range: - t_1 = torch.full((1,), t, device=device, dtype=torch.long) - noise_pred = self.denoise_fn(x, t_1, cond) - t_prev = t_1 - pndms - t_prev = t_prev * (t_prev > 0) - if plms_noise_stage == 0: - x_pred = self.get_x_pred(x, noise_pred, t_1, t_prev) - noise_pred_prev = self.denoise_fn(x_pred, t_prev, cond=cond) - noise_pred_prime = predict_stage0(noise_pred, noise_pred_prev) - - elif plms_noise_stage == 1: - noise_pred_prime = predict_stage1(noise_pred, noise_list) - - elif plms_noise_stage == 2: - noise_pred_prime = predict_stage2(noise_pred, noise_list) - - else: - noise_pred_prime = predict_stage3(noise_pred, noise_list) - - noise_pred = noise_pred.unsqueeze(0) - - if plms_noise_stage < 3: - noise_list = torch.cat((noise_list, noise_pred), dim=0) - plms_noise_stage = plms_noise_stage + 1 - - else: - noise_list = torch.cat((noise_list[-2:], noise_pred), dim=0) - - x = self.get_x_pred(x, noise_pred_prime, t_1, t_prev) - x = self.ad(x) - return x diff --git a/spaces/GT4SD/PatentToolkit/Model_bert/train_script.py b/spaces/GT4SD/PatentToolkit/Model_bert/train_script.py deleted file mode 100644 index 82b47b6277499b8f17d139d0c651a6f961c06124..0000000000000000000000000000000000000000 --- a/spaces/GT4SD/PatentToolkit/Model_bert/train_script.py +++ /dev/null @@ -1,344 +0,0 @@ -""" -Train script for a single file - -Need to set the TPU address first: -export XRT_TPU_CONFIG="localservice;0;localhost:51011" -""" - -import torch.multiprocessing as mp -import threading -import time -import random -import sys -import argparse -import gzip -import json -import logging -import tqdm -import torch -from torch import nn -from torch.utils.data import DataLoader -import torch -import torch_xla -import torch_xla.core -import torch_xla.core.functions -import torch_xla.core.xla_model as xm -import torch_xla.distributed.xla_multiprocessing as xmp -import torch_xla.distributed.parallel_loader as pl -import os -from shutil import copyfile - - -from transformers import ( - AdamW, - AutoModel, - AutoTokenizer, - get_linear_schedule_with_warmup, - set_seed, -) - -class AutoModelForSentenceEmbedding(nn.Module): - def __init__(self, model_name, tokenizer, normalize=True): - super(AutoModelForSentenceEmbedding, self).__init__() - - self.model = AutoModel.from_pretrained(model_name) - self.normalize = normalize - self.tokenizer = tokenizer - - def forward(self, **kwargs): - model_output = self.model(**kwargs) - embeddings = self.mean_pooling(model_output, kwargs['attention_mask']) - if self.normalize: - embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1) - - return embeddings - - def mean_pooling(self, model_output, attention_mask): - token_embeddings = model_output[0] # First element of model_output contains all token embeddings - input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float() - return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9) - - def save_pretrained(self, output_path): - if xm.is_master_ordinal(): - self.tokenizer.save_pretrained(output_path) - self.model.config.save_pretrained(output_path) - - xm.save(self.model.state_dict(), os.path.join(output_path, "pytorch_model.bin")) - - - - -def train_function(index, args, queue): - tokenizer = AutoTokenizer.from_pretrained(args.model) - model = AutoModelForSentenceEmbedding(args.model, tokenizer) - - - ### Train Loop - device = xm.xla_device() - model = model.to(device) - - # Instantiate optimizer - optimizer = AdamW(params=model.parameters(), lr=2e-5, correct_bias=True) - - lr_scheduler = get_linear_schedule_with_warmup( - optimizer=optimizer, - num_warmup_steps=500, - num_training_steps=args.steps, - ) - - # Now we train the model - cross_entropy_loss = nn.CrossEntropyLoss() - max_grad_norm = 1 - - model.train() - - for global_step in tqdm.trange(args.steps, disable=not xm.is_master_ordinal()): - #### Get the batch data - batch = queue.get() - #print(index, "batch {}x{}".format(len(batch), ",".join([str(len(b)) for b in batch]))) - - - if len(batch[0]) == 2: #(anchor, positive) - text1 = tokenizer([b[0] for b in batch], return_tensors="pt", max_length=args.max_length, truncation=True, padding="max_length") - text2 = tokenizer([b[1] for b in batch], return_tensors="pt", max_length=args.max_length, truncation=True, padding="max_length") - - ### Compute embeddings - embeddings_a = model(**text1.to(device)) - embeddings_b = model(**text2.to(device)) - - ### Gather all embedings - embeddings_a = torch_xla.core.functions.all_gather(embeddings_a) - embeddings_b = torch_xla.core.functions.all_gather(embeddings_b) - - ### Compute similarity scores 512 x 512 - scores = torch.mm(embeddings_a, embeddings_b.transpose(0, 1)) * args.scale - - ### Compute cross-entropy loss - labels = torch.tensor(range(len(scores)), dtype=torch.long, device=embeddings_a.device) # Example a[i] should match with b[i] - - ## Symmetric loss as in CLIP - loss = (cross_entropy_loss(scores, labels) + cross_entropy_loss(scores.transpose(0, 1), labels)) / 2 - - else: #(anchor, positive, negative) - text1 = tokenizer([b[0] for b in batch], return_tensors="pt", max_length=args.max_length, truncation=True, padding="max_length") - text2 = tokenizer([b[1] for b in batch], return_tensors="pt", max_length=args.max_length, truncation=True, padding="max_length") - text3 = tokenizer([b[2] for b in batch], return_tensors="pt", max_length=args.max_length, truncation=True, padding="max_length") - - embeddings_a = model(**text1.to(device)) - embeddings_b1 = model(**text2.to(device)) - embeddings_b2 = model(**text3.to(device)) - - embeddings_a = torch_xla.core.functions.all_gather(embeddings_a) - embeddings_b1 = torch_xla.core.functions.all_gather(embeddings_b1) - embeddings_b2 = torch_xla.core.functions.all_gather(embeddings_b2) - - embeddings_b = torch.cat([embeddings_b1, embeddings_b2]) - - ### Compute similarity scores 512 x 1024 - scores = torch.mm(embeddings_a, embeddings_b.transpose(0, 1)) * args.scale - - ### Compute cross-entropy loss - labels = torch.tensor(range(len(scores)), dtype=torch.long, device=embeddings_a.device) # Example a[i] should match with b[i] - - ## One-way loss - loss = cross_entropy_loss(scores, labels) - - - # Backward pass - optimizer.zero_grad() - loss.backward() - torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm) - - xm.optimizer_step(optimizer, barrier=True) - lr_scheduler.step() - - - #Save model - if (global_step+1) % args.save_steps == 0: - output_path = os.path.join(args.output, str(global_step+1)) - xm.master_print("save model: "+output_path) - model.save_pretrained(output_path) - - - output_path = os.path.join(args.output, "final") - xm.master_print("save model final: "+ output_path) - model.save_pretrained(output_path) - - -def produce_data(args, queue, filepaths, dataset_indices): - global_batch_size = args.batch_size*args.nprocs #Global batch size - size_per_dataset = int(global_batch_size / args.datasets_per_batch) #How many datasets per batch - num_same_dataset = int(size_per_dataset / args.batch_size) - print("producer", "global_batch_size", global_batch_size) - print("producer", "size_per_dataset", size_per_dataset) - print("producer", "num_same_dataset", num_same_dataset) - - datasets = [] - for filepath in filepaths: - if "reddit_" in filepath: #Special dataset class for Reddit files - data_obj = RedditDataset(filepath) - else: - data_obj = Dataset(filepath) - datasets.append(iter(data_obj)) - - # Store if dataset is in a 2 col or 3 col format - num_cols = {idx: len(next(dataset)) for idx, dataset in enumerate(datasets)} - - while True: - texts_in_batch = set() - batch_format = None #2 vs 3 col format for this batch - - #Add data from several sub datasets - for _ in range(args.datasets_per_batch): - valid_dataset = False #Check that datasets have the same 2/3 col format - while not valid_dataset: - data_idx = random.choice(dataset_indices) - if batch_format is None: - batch_format = num_cols[data_idx] - valid_dataset = True - else: #Check that this dataset has the same format - valid_dataset = (batch_format == num_cols[data_idx]) - - #Get data from this dataset - dataset = datasets[data_idx] - for _ in range(num_same_dataset): - for _ in range(args.nprocs): - batch_device = [] #A batch for one device - while len(batch_device) < args.batch_size: - sample = next(dataset) - in_batch = False - for text in sample: - if text in texts_in_batch: - in_batch = True - break - - if not in_batch: - for text in sample: - texts_in_batch.add(text) - batch_device.append(sample) - - queue.put(batch_device) - - -class RedditDataset: - """ - A class that handles the reddit data files - """ - def __init__(self, filepath): - self.filepath = filepath - - def __iter__(self): - while True: - with gzip.open(self.filepath, "rt") as fIn: - for line in fIn: - data = json.loads(line) - - if "response" in data and "context" in data: - yield [data["response"], data["context"]] - -class Dataset: - """ - A class that handles one dataset - """ - def __init__(self, filepath): - self.filepath = filepath - - def __iter__(self): - max_dataset_size = 10*1000*1000 #Cache small datasets in memory - dataset = [] - data_format = None - - while dataset is None or len(dataset) == 0: - with gzip.open(self.filepath, "rt") as fIn: - for line in fIn: - data = json.loads(line) - if isinstance(data, dict): - data = data['texts'] - - if data_format is None: - data_format = len(data) - - #Ensure that all entries are of the same 2/3 col format - assert len(data) == data_format - - if dataset is not None: - dataset.append(data) - if len(dataset) >= max_dataset_size: - dataset = None - - yield data - - # Data loaded. Now stream to the queue - # Shuffle for each epoch - while True: - random.shuffle(dataset) - for data in dataset: - yield data - - - -if __name__ == "__main__": - parser = argparse.ArgumentParser() - parser.add_argument('--model', default='nreimers/MiniLM-L6-H384-uncased') - parser.add_argument('--steps', type=int, default=2000) - parser.add_argument('--save_steps', type=int, default=10000) - parser.add_argument('--batch_size', type=int, default=64) - parser.add_argument('--max_length', type=int, default=128) - parser.add_argument('--nprocs', type=int, default=8) - parser.add_argument('--datasets_per_batch', type=int, default=2, help="Number of datasets per batch") - parser.add_argument('--scale', type=float, default=20, help="Use 20 for cossim, and 1 when you work with unnormalized embeddings with dot product") - parser.add_argument('--data_folder', default="/data", help="Folder with your dataset files") - parser.add_argument('data_config', help="A data_config.json file") - parser.add_argument('output') - args = parser.parse_args() - - # Ensure global batch size is divisble by data_sample_size - assert (args.batch_size*args.nprocs) % args.datasets_per_batch == 0 - - logging.info("Output: "+args.output) - if os.path.exists(args.output): - print("Output folder already exists.") - input("Continue?") - - # Write train script to output path - os.makedirs(args.output, exist_ok=True) - - data_config_path = os.path.join(args.output, 'data_config.json') - copyfile(args.data_config, data_config_path) - - train_script_path = os.path.join(args.output, 'train_script.py') - copyfile(__file__, train_script_path) - with open(train_script_path, 'a') as fOut: - fOut.write("\n\n# Script was called via:\n#python " + " ".join(sys.argv)) - - - - #Load data config - with open(args.data_config) as fIn: - data_config = json.load(fIn) - - queue = mp.Queue(maxsize=100*args.nprocs) - - filepaths = [] - dataset_indices = [] - for idx, data in enumerate(data_config): - filepaths.append(os.path.join(os.path.expanduser(args.data_folder), data['name'])) - dataset_indices.extend([idx]*data['weight']) - - # Start producer - p = mp.Process(target=produce_data, args=(args, queue, filepaths, dataset_indices)) - p.start() - - # Run training - print("Start processes:", args.nprocs) - xmp.spawn(train_function, args=(args, queue), nprocs=args.nprocs, start_method='fork') - print("Training done") - print("It might be that not all processes exit automatically. In that case you must manually kill this process.") - print("With 'pkill python' you can kill all remaining python processes") - p.kill() - exit() - - - -# Script was called via: -#python train_many_data_files_v2.py --steps 1000000 --batch_size 128 --model nreimers/MiniLM-L6-H384-uncased train_data_configs/all_datasets_v4.json output/all_datasets_v4_MiniLM-L6-H384-uncased-batch128 \ No newline at end of file diff --git a/spaces/GastonMazzei/escher-inpaint-project/README.md b/spaces/GastonMazzei/escher-inpaint-project/README.md deleted file mode 100644 index 451a2b1776856f62c12d95537905856ec62e6431..0000000000000000000000000000000000000000 --- a/spaces/GastonMazzei/escher-inpaint-project/README.md +++ /dev/null @@ -1,37 +0,0 @@ ---- -title: GLIDE_Inpaint -emoji: 💻 -colorFrom: green -colorTo: purple -sdk: gradio -app_file: app.py -pinned: false ---- - -# Configuration - -`title`: _string_ -Display title for the Space - -`emoji`: _string_ -Space emoji (emoji-only character allowed) - -`colorFrom`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`colorTo`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`sdk`: _string_ -Can be either `gradio` or `streamlit` - -`sdk_version` : _string_ -Only applicable for `streamlit` SDK. -See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions. - -`app_file`: _string_ -Path to your main application file (which contains either `gradio` or `streamlit` Python code). -Path is relative to the root of the repository. - -`pinned`: _boolean_ -Whether the Space stays on top of your list. diff --git a/spaces/Gen-Sim/Gen-Sim/cliport/generated_tasks/color_sequenced_pyramid_packing.py b/spaces/Gen-Sim/Gen-Sim/cliport/generated_tasks/color_sequenced_pyramid_packing.py deleted file mode 100644 index c2a2dea351a5b7a978c8a7763e5e0e687a0bdb1e..0000000000000000000000000000000000000000 --- a/spaces/Gen-Sim/Gen-Sim/cliport/generated_tasks/color_sequenced_pyramid_packing.py +++ /dev/null @@ -1,63 +0,0 @@ -import numpy as np -import os -import pybullet as p -import random -from cliport.tasks import primitives -from cliport.tasks.grippers import Spatula -from cliport.tasks.task import Task -from cliport.utils import utils -import numpy as np -from cliport.tasks.task import Task -from cliport.utils import utils -import pybullet as p - -class ColorSequencedPyramidPacking(Task): - """Sort cubes by color into four pallets and stack them in each pallet as a pyramid""" - - def __init__(self): - super().__init__() - self.max_steps = 12 - self.lang_template = "sort the {color} cubes into the pallet and stack them as a pyramid" - self.task_completed_desc = "done sorting and stacking cubes." - self.additional_reset() - - def reset(self, env): - super().reset(env) - - # Add pallets. - # x, y, z dimensions for the asset size - pallet_size = (0.15, 0.15, 0.02) - pallet_urdf = 'pallet/pallet.urdf' - pallet_poses = [] - for _ in range(4): - pallet_pose = self.get_random_pose(env, pallet_size) - env.add_object(pallet_urdf, pallet_pose, category='fixed') - pallet_poses.append(pallet_pose) - - # Cube colors. - colors = [ - utils.COLORS['red'], utils.COLORS['green'], utils.COLORS['blue'], utils.COLORS['yellow'] - ] - - # Add cubes. - # x, y, z dimensions for the asset size - cube_size = (0.04, 0.04, 0.04) - cube_urdf = 'block/block.urdf' - - objs = [] - for i in range(12): - cube_pose = self.get_random_pose(env, cube_size) - cube_id = env.add_object(cube_urdf, cube_pose, color=colors[i%4]) - objs.append(cube_id) - - # Associate placement locations for goals. - place_pos = [(0, -0.05, 0.03), (0, 0, 0.03), - (0, 0.05, 0.03), (0, -0.025, 0.08), - (0, 0.025, 0.08), (0, 0, 0.13)] - targs = [(utils.apply(pallet_pose, i), pallet_pose[1]) for i in place_pos for pallet_pose in pallet_poses] - - # Goal: cubes are sorted by color and stacked in a pyramid in each pallet. - for i in range(4): - self.add_goal(objs=objs[i*3:(i+1)*3], matches=np.ones((3, 3)), targ_poses=targs[i*3:(i+1)*3], replace=False, - rotations=True, metric='pose', params=None, step_max_reward=1 / 4, symmetries=[np.pi/2]*3, - language_goal=self.lang_template.format(color=list(utils.COLORS.keys())[i])) \ No newline at end of file diff --git a/spaces/Gmq-x/gpt-academic/request_llm/README.md b/spaces/Gmq-x/gpt-academic/request_llm/README.md deleted file mode 100644 index 973adea1ed6ca1f027e5d84dc2e7b3e92ee8a5ba..0000000000000000000000000000000000000000 --- a/spaces/Gmq-x/gpt-academic/request_llm/README.md +++ /dev/null @@ -1,54 +0,0 @@ -# 如何使用其他大语言模型(v3.0分支测试中) - -## ChatGLM - -- 安装依赖 `pip install -r request_llm/requirements_chatglm.txt` -- 修改配置,在config.py中将LLM_MODEL的值改为"chatglm" - -``` sh -LLM_MODEL = "chatglm" -``` -- 运行! -``` sh -`python main.py` -``` - - ---- -## Text-Generation-UI (TGUI) - -### 1. 部署TGUI -``` sh -# 1 下载模型 -git clone https://github.com/oobabooga/text-generation-webui.git -# 2 这个仓库的最新代码有问题,回滚到几周之前 -git reset --hard fcda3f87767e642d1c0411776e549e1d3894843d -# 3 切换路径 -cd text-generation-webui -# 4 安装text-generation的额外依赖 -pip install accelerate bitsandbytes flexgen gradio llamacpp markdown numpy peft requests rwkv safetensors sentencepiece tqdm datasets git+https://github.com/huggingface/transformers -# 5 下载模型 -python download-model.py facebook/galactica-1.3b -# 其他可选如 facebook/opt-1.3b -# facebook/galactica-1.3b -# facebook/galactica-6.7b -# facebook/galactica-120b -# facebook/pygmalion-1.3b 等 -# 详情见 https://github.com/oobabooga/text-generation-webui - -# 6 启动text-generation -python server.py --cpu --listen --listen-port 7865 --model facebook_galactica-1.3b -``` - -### 2. 修改config.py - -``` sh -# LLM_MODEL格式: tgui:[模型]@[ws地址]:[ws端口] , 端口要和上面给定的端口一致 -LLM_MODEL = "tgui:galactica-1.3b@localhost:7860" -``` - -### 3. 运行! -``` sh -cd chatgpt-academic -python main.py -``` diff --git a/spaces/Gradio-Blocks/StyleGAN-NADA/op/fused_act_cpu.py b/spaces/Gradio-Blocks/StyleGAN-NADA/op/fused_act_cpu.py deleted file mode 100644 index f997dafdd53aa9f4bbe07af6746c67a2c6dcb4c7..0000000000000000000000000000000000000000 --- a/spaces/Gradio-Blocks/StyleGAN-NADA/op/fused_act_cpu.py +++ /dev/null @@ -1,41 +0,0 @@ -import os - -import torch -from torch import nn -from torch.autograd import Function -from torch.nn import functional as F - - -module_path = os.path.dirname(__file__) - - -class FusedLeakyReLU(nn.Module): - def __init__(self, channel, negative_slope=0.2, scale=2 ** 0.5): - super().__init__() - - self.bias = nn.Parameter(torch.zeros(channel)) - self.negative_slope = negative_slope - self.scale = scale - - def forward(self, input): - return fused_leaky_relu(input, self.bias, self.negative_slope, self.scale) - -def fused_leaky_relu(input, bias=None, negative_slope=0.2, scale=2 ** 0.5): - if input.device.type == "cpu": - if bias is not None: - rest_dim = [1] * (input.ndim - bias.ndim - 1) - return ( - F.leaky_relu( - input + bias.view(1, bias.shape[0], *rest_dim), negative_slope=0.2 - ) - * scale - ) - - else: - return F.leaky_relu(input, negative_slope=0.2) * scale - - else: - return FusedLeakyReLUFunction.apply( - input.contiguous(), bias, negative_slope, scale - ) - diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/configs/gn+ws/faster_rcnn_x50_32x4d_fpn_gn_ws-all_1x_coco.py b/spaces/Gradio-Blocks/uniformer_image_detection/configs/gn+ws/faster_rcnn_x50_32x4d_fpn_gn_ws-all_1x_coco.py deleted file mode 100644 index 1268980615b69009a33b785eeb59322372633d10..0000000000000000000000000000000000000000 --- a/spaces/Gradio-Blocks/uniformer_image_detection/configs/gn+ws/faster_rcnn_x50_32x4d_fpn_gn_ws-all_1x_coco.py +++ /dev/null @@ -1,16 +0,0 @@ -_base_ = './faster_rcnn_r50_fpn_gn_ws-all_1x_coco.py' -conv_cfg = dict(type='ConvWS') -norm_cfg = dict(type='GN', num_groups=32, requires_grad=True) -model = dict( - pretrained='open-mmlab://jhu/resnext50_32x4d_gn_ws', - backbone=dict( - type='ResNeXt', - depth=50, - groups=32, - base_width=4, - num_stages=4, - out_indices=(0, 1, 2, 3), - frozen_stages=1, - style='pytorch', - conv_cfg=conv_cfg, - norm_cfg=norm_cfg)) diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/detectors/mask_rcnn.py b/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/detectors/mask_rcnn.py deleted file mode 100644 index c15a7733170e059d2825138b3812319915b7cad6..0000000000000000000000000000000000000000 --- a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/detectors/mask_rcnn.py +++ /dev/null @@ -1,24 +0,0 @@ -from ..builder import DETECTORS -from .two_stage import TwoStageDetector - - -@DETECTORS.register_module() -class MaskRCNN(TwoStageDetector): - """Implementation of `Mask R-CNN', unsafe_allow_html=True) - # try: - def main(): - db = {} - - # cap = cv2.VideoCapture('//home//anas//PersonTracking//WebUI//movement.mp4') - path='/usr/local/lib/python3.10/dist-packages/yolo0vs5/yolov5s-int8.tflite' - #count=0 - custom = 'yolov5s' - - model = torch.hub.load('/usr/local/lib/python3.10/dist-packages/yolovs5', custom, path,source='local',force_reload=True) - - b=model.names[0] = 'person' - mobile = model.names[67] = 'cell phone' - watch = model.names[75] = 'clock' - - fps_start_time = datetime.datetime.now() - fps = 0 - size=416 - - count=0 - counter=0 - - - color=(0,0,255) - - cy1=250 - offset=6 - - - pt1 = (120, 100) - pt2 = (980, 1150) - color = (0, 255, 0) - - pt3 = (283, 103) - pt4 = (1500, 1150) - - cy2 = 500 - color = (0, 255, 0) - total_frames = 0 - prevTime = 0 - cur_frame = 0 - count=0 - counter=0 - fps_start_time = datetime.datetime.now() - fps = 0 - total_frames = 0 - lpc_count = 0 - opc_count = 0 - object_id_list = [] - # success = True - if st.button("Detect"): - try: - while video.isOpened(): - - ret, frame = video.read() - frame = imutils.resize(frame, width=600) - total_frames = total_frames + 1 - - (H, W) = frame.shape[:2] - - blob = cv2.dnn.blobFromImage(frame, 0.007843, (W, H), 127.5) - - detector.setInput(blob) - person_detections = detector.forward() - rects = [] - for i in np.arange(0, person_detections.shape[2]): - confidence = person_detections[0, 0, i, 2] - if confidence > 0.5: - idx = int(person_detections[0, 0, i, 1]) - - if CLASSES[idx] != "person": - continue - - person_box = person_detections[0, 0, i, 3:7] * np.array([W, H, W, H]) - (startX, startY, endX, endY) = person_box.astype("int") - rects.append(person_box) - - boundingboxes = np.array(rects) - boundingboxes = boundingboxes.astype(int) - rects = non_max_suppression_fast(boundingboxes, 0.3) - - objects = tracker.update(rects) - for (objectId, bbox) in objects.items(): - x1, y1, x2, y2 = bbox - x1 = int(x1) - y1 = int(y1) - x2 = int(x2) - y2 = int(y2) - - cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 0, 255), 2) - text = "ID: {}".format(objectId) - # print(text) - cv2.putText(frame, text, (x1, y1-5), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 0, 255), 1) - if objectId not in object_id_list: - object_id_list.append(objectId) - fps_end_time = datetime.datetime.now() - time_diff = fps_end_time - fps_start_time - if time_diff.seconds == 0: - fps = 0.0 - else: - fps = (total_frames / time_diff.seconds) - - fps_text = "FPS: {:.2f}".format(fps) - - cv2.putText(frame, fps_text, (5, 30), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 0, 255), 1) - lpc_count = len(objects) - opc_count = len(object_id_list) - - lpc_txt = "LPC: {}".format(lpc_count) - opc_txt = "OPC: {}".format(opc_count) - - count += 1 - if count % 4 != 0: - continue - # frame=cv.resize(frame, (600,500)) - # cv2.line(frame, pt1, pt2,color,2) - # cv2.line(frame, pt3, pt4,color,2) - results = model(frame,size) - components = results.pandas().xyxy[0] - for index, row in results.pandas().xyxy[0].iterrows(): - x1 = int(row['xmin']) - y1 = int(row['ymin']) - x2 = int(row['xmax']) - y2 = int(row['ymax']) - confidence = (row['confidence']) - obj = (row['class']) - - - # min':x1,'ymin':y1,'xmax':x2,'ymax':y2,'confidence':confidence,'Object':obj} - # if lpc_txt is not None: - # try: - # db["student Count"] = [lpc_txt] - # except: - # db["student Count"] = ['N/A'] - if obj == 0: - cv2.rectangle(frame,(x1,y1),(x2,y2),(0,0,255),2) - rectx1,recty1 = ((x1+x2)/2,(y1+y2)/2) - rectcenter = int(rectx1),int(recty1) - cx = rectcenter[0] - cy = rectcenter[1] - cv2.circle(frame,(cx,cy),3,(0,255,0),-1) - cv2.putText(frame,str(b), (x1,y1), cv2.FONT_HERSHEY_PLAIN,2,(255,255,255),2) - - db["student Count"] = [lpc_txt] - db['Date'] = [date_time] - db['id'] = ['N/A'] - db['Mobile']=['N/A'] - db['Watch'] = ['N/A'] - if cy<(cy1+offset) and cy>(cy1-offset): - DB = [] - counter+=1 - DB.append(counter) - - ff = DB[-1] - fx = str(ff) - # cv2.line(frame, pt1, pt2,(0, 0, 255),2) - # if cy<(cy2+offset) and cy>(cy2-offset): - - # cv2.line(frame, pt3, pt4,(0, 0, 255),2) - font = cv2.FONT_HERSHEY_TRIPLEX - cv2.putText(frame,fx,(50, 50),font, 1,(0, 0, 255),2,cv2.LINE_4) - cv2.putText(frame,"Movement",(70, 70),font, 1,(0, 0, 255),2,cv2.LINE_4) - kpil2_text.write(f"
{text}
", unsafe_allow_html=True) - - - db['id'] = [text] - - - - if obj == 67: - cv2.rectangle(frame,(x1,y1),(x2,y2),(0,0,255),2) - rectx1,recty1 = ((x1+x2)/2,(y1+y2)/2) - rectcenter = int(rectx1),int(recty1) - cx = rectcenter[0] - cy = rectcenter[1] - cv2.circle(frame,(cx,cy),3,(0,255,0),-1) - cv2.putText(frame,str(mobile), (x1,y1), cv2.FONT_HERSHEY_PLAIN,2,(255,255,255),2) - cv2.putText(frame,'Mobile',(50, 50),cv2.FONT_HERSHEY_PLAIN, 1,(0, 0, 255),2,cv2.LINE_4) - kpil3_text.write(f"{mobile}{text}
", unsafe_allow_html=True) - - db['Mobile']=mobile+' '+text - - - - if obj == 75: - cv2.rectangle(frame,(x1,y1),(x2,y2),(0,0,255),2) - rectx1,recty1 = ((x1+x2)/2,(y1+y2)/2) - rectcenter = int(rectx1),int(recty1) - cx = rectcenter[0] - cy = rectcenter[1] - cv2.circle(frame,(cx,cy),3,(0,255,0),-1) - cv2.putText(frame,str(watch), (x1,y1), cv2.FONT_HERSHEY_PLAIN,2,(255,255,255),2) - cv2.putText(frame,'Watch',(50, 50),cv2.FONT_HERSHEY_PLAIN, 1,(0, 0, 255),2,cv2.LINE_4) - kpil6_text.write(f"{watch}
", unsafe_allow_html=True) - - - db['Watch']=watch - - - - kpil_text.write(f"{int(fps)}
", unsafe_allow_html=True) - kpil5_text.write(f"{lpc_txt}
", unsafe_allow_html=True) - kpil6_text.write(f"{width*height}
", - unsafe_allow_html=True) - - - frame = cv.resize(frame,(0,0), fx=0.8, fy=0.8) - frame = image_resize(image=frame, width=640) - stframe.image(frame,channels='BGR', use_column_width=True) - df = pd.DataFrame(db) - df.to_csv('final.csv',mode='a',header=False,index=False) - except: - pass - with open('final.csv') as f: - st.download_button(label = 'Download Cheating Report',data=f,file_name='data.csv') - - os.remove("final.csv") - main() diff --git a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/README.md b/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/README.md deleted file mode 100644 index 0fa95f40411765cf5b2b3acfa93a75c159c1bb71..0000000000000000000000000000000000000000 --- a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/README.md +++ /dev/null @@ -1,381 +0,0 @@ -
-
-  -
-
-
 -
- -
 -
- -
- YOLOv5 🚀 is the world's most loved vision AI, representing Ultralytics
- open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development.
-
- To request a commercial license please complete the form at Ultralytics Licensing.
-
-
Install
- -Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a -[**Python>=3.7.0**](https://www.python.org/) environment, including -[**PyTorch>=1.7**](https://pytorch.org/get-started/locally/). - -```bash -git clone https://github.com/ultralytics/yolov5 # clone -cd yolov5 -pip install -r requirements.txt # install -``` - -Inference
- -YOLOv5 [PyTorch Hub](https://github.com/ultralytics/yolov5/issues/36) inference. [Models](https://github.com/ultralytics/yolov5/tree/master/models) download automatically from the latest -YOLOv5 [release](https://github.com/ultralytics/yolov5/releases). - -```python -import torch - -# Model -model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom - -# Images -img = 'https://ultralytics.com/images/zidane.jpg' # or file, Path, PIL, OpenCV, numpy, list - -# Inference -results = model(img) - -# Results -results.print() # or .show(), .save(), .crop(), .pandas(), etc. -``` - -Inference with detect.py
- -`detect.py` runs inference on a variety of sources, downloading [models](https://github.com/ultralytics/yolov5/tree/master/models) automatically from -the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) and saving results to `runs/detect`. - -```bash -python detect.py --source 0 # webcam - img.jpg # image - vid.mp4 # video - screen # screenshot - path/ # directory - 'path/*.jpg' # glob - 'https://youtu.be/Zgi9g1ksQHc' # YouTube - 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream -``` - -Training
- -The commands below reproduce YOLOv5 [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) -results. [Models](https://github.com/ultralytics/yolov5/tree/master/models) -and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest -YOLOv5 [release](https://github.com/ultralytics/yolov5/releases). Training times for YOLOv5n/s/m/l/x are -1/2/4/6/8 days on a V100 GPU ([Multi-GPU](https://github.com/ultralytics/yolov5/issues/475) times faster). Use the -largest `--batch-size` possible, or pass `--batch-size -1` for -YOLOv5 [AutoBatch](https://github.com/ultralytics/yolov5/pull/5092). Batch sizes shown for V100-16GB. - -```bash -python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128 - yolov5s 64 - yolov5m 40 - yolov5l 24 - yolov5x 16 -``` - - -
-
-
-Tutorials
- -- [Train Custom Data](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data) 🚀 RECOMMENDED -- [Tips for Best Training Results](https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results) ☘️ - RECOMMENDED -- [Multi-GPU Training](https://github.com/ultralytics/yolov5/issues/475) -- [PyTorch Hub](https://github.com/ultralytics/yolov5/issues/36) 🌟 NEW -- [TFLite, ONNX, CoreML, TensorRT Export](https://github.com/ultralytics/yolov5/issues/251) 🚀 -- [NVIDIA Jetson Nano Deployment](https://github.com/ultralytics/yolov5/issues/9627) 🌟 NEW -- [Test-Time Augmentation (TTA)](https://github.com/ultralytics/yolov5/issues/303) -- [Model Ensembling](https://github.com/ultralytics/yolov5/issues/318) -- [Model Pruning/Sparsity](https://github.com/ultralytics/yolov5/issues/304) -- [Hyperparameter Evolution](https://github.com/ultralytics/yolov5/issues/607) -- [Transfer Learning with Frozen Layers](https://github.com/ultralytics/yolov5/issues/1314) -- [Architecture Summary](https://github.com/ultralytics/yolov5/issues/6998) 🌟 NEW -- [Roboflow for Datasets, Labeling, and Active Learning](https://github.com/ultralytics/yolov5/issues/4975) 🌟 NEW -- [ClearML Logging](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/clearml) 🌟 NEW -- [Deci Platform](https://github.com/ultralytics/yolov5/wiki/Deci-Platform) 🌟 NEW -- [Comet Logging](https://github.com/ultralytics/yolov5/tree/master/utils/loggers/comet) 🌟 NEW - -- -
 -
--
- - - -|Roboflow|ClearML ⭐ NEW|Comet ⭐ NEW|Deci ⭐ NEW| -|:-:|:-:|:-:|:-:| -|Label and export your custom datasets directly to YOLOv5 for training with [Roboflow](https://roboflow.com/?ref=ultralytics)|Automatically track, visualize and even remotely train YOLOv5 using [ClearML](https://cutt.ly/yolov5-readme-clearml) (open-source!)|Free forever, [Comet](https://bit.ly/yolov5-readme-comet) lets you save YOLOv5 models, resume training, and interactively visualise and debug predictions|Automatically compile and quantize YOLOv5 for better inference performance in one click at [Deci](https://bit.ly/yolov5-deci-platform)| - - -##
 -
-
-##
-
-
-## 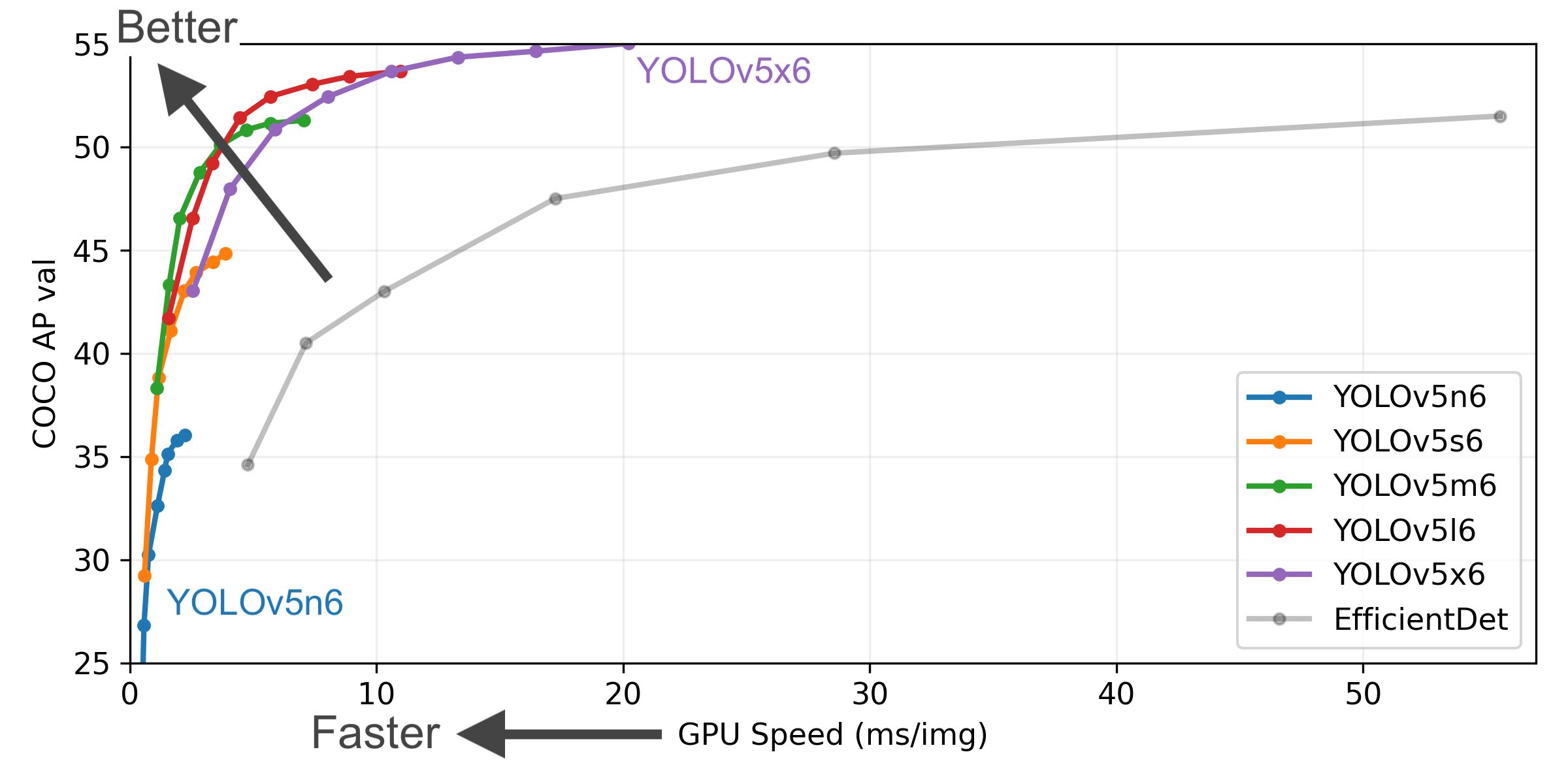
YOLOv5-P5 640 Figure (click to expand)
- -
Figure Notes (click to expand)
- -- **COCO AP val** denotes mAP@0.5:0.95 metric measured on the 5000-image [COCO val2017](http://cocodataset.org) dataset over various inference sizes from 256 to 1536. -- **GPU Speed** measures average inference time per image on [COCO val2017](http://cocodataset.org) dataset using a [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) V100 instance at batch-size 32. -- **EfficientDet** data from [google/automl](https://github.com/google/automl) at batch size 8. -- **Reproduce** by `python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt` - -(pixels) | mAPval
0.5:0.95 | mAPval
0.5 | Speed
CPU b1
(ms) | Speed
V100 b1
(ms) | Speed
V100 b32
(ms) | params
(M) | FLOPs
@640 (B) | -|------------------------------------------------------------------------------------------------------|-----------------------|-------------------------|--------------------|------------------------------|-------------------------------|--------------------------------|--------------------|------------------------| -| [YOLOv5n](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n.pt) | 640 | 28.0 | 45.7 | **45** | **6.3** | **0.6** | **1.9** | **4.5** | -| [YOLOv5s](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt) | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 | -| [YOLOv5m](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m.pt) | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 | -| [YOLOv5l](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l.pt) | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 | -| [YOLOv5x](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x.pt) | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 | -| | | | | | | | | | -| [YOLOv5n6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n6.pt) | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 | -| [YOLOv5s6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s6.pt) | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 | -| [YOLOv5m6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m6.pt) | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 | -| [YOLOv5l6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l6.pt) | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 | -| [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x6.pt)
+ [TTA][TTA] | 1280
1536 | 55.0
**55.8** | 72.7
**72.7** | 3136
- | 26.2
- | 19.4
- | 140.7
- | 209.8
- | - -
Table Notes (click to expand)
- -- All checkpoints are trained to 300 epochs with default settings. Nano and Small models use [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml) hyps, all others use [hyp.scratch-high.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-high.yaml). -- **mAPval** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.Reproduce by `python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65` -- **Speed** averaged over COCO val images using a [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) instance. NMS times (~1 ms/img) not included.
Reproduce by `python val.py --data coco.yaml --img 640 --task speed --batch 1` -- **TTA** [Test Time Augmentation](https://github.com/ultralytics/yolov5/issues/303) includes reflection and scale augmentations.
Reproduce by `python val.py --data coco.yaml --img 1536 --iou 0.7 --augment` - -
Classification Checkpoints (click to expand)
- -- -We trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4xA100 instance, and we trained ResNet and EfficientNet models alongside with the same default training settings to compare. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google [Colab Pro](https://colab.research.google.com/signup) for easy reproducibility. - -| Model | size
(pixels) | acc
top1 | acc
top5 | Training
90 epochs
4xA100 (hours) | Speed
ONNX CPU
(ms) | Speed
TensorRT V100
(ms) | params
(M) | FLOPs
@224 (B) | -|----------------------------------------------------------------------------------------------------|-----------------------|------------------|------------------|----------------------------------------------|--------------------------------|-------------------------------------|--------------------|------------------------| -| [YOLOv5n-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5n-cls.pt) | 224 | 64.6 | 85.4 | 7:59 | **3.3** | **0.5** | **2.5** | **0.5** | -| [YOLOv5s-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s-cls.pt) | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 | -| [YOLOv5m-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5m-cls.pt) | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 | -| [YOLOv5l-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5l-cls.pt) | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 | -| [YOLOv5x-cls](https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5x-cls.pt) | 224 | **79.0** | **94.4** | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 | -| | -| [ResNet18](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet18.pt) | 224 | 70.3 | 89.5 | **6:47** | 11.2 | 0.5 | 11.7 | 3.7 | -| [ResNet34](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet34.pt) | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 | -| [ResNet50](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet50.pt) | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 | -| [ResNet101](https://github.com/ultralytics/yolov5/releases/download/v6.2/resnet101.pt) | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 | -| | -| [EfficientNet_b0](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b0.pt) | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 | -| [EfficientNet_b1](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b1.pt) | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 | -| [EfficientNet_b2](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b2.pt) | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 | -| [EfficientNet_b3](https://github.com/ultralytics/yolov5/releases/download/v6.2/efficientnet_b3.pt) | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 | - -
Table Notes (click to expand)
- -- All checkpoints are trained to 90 epochs with SGD optimizer with `lr0=0.001` and `weight_decay=5e-5` at image size 224 and all default settings.Runs logged to https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2 -- **Accuracy** values are for single-model single-scale on [ImageNet-1k](https://www.image-net.org/index.php) dataset.
Reproduce by `python classify/val.py --data ../datasets/imagenet --img 224` -- **Speed** averaged over 100 inference images using a Google [Colab Pro](https://colab.research.google.com/signup) V100 High-RAM instance.
Reproduce by `python classify/val.py --data ../datasets/imagenet --img 224 --batch 1` -- **Export** to ONNX at FP32 and TensorRT at FP16 done with `export.py`.
Reproduce by `python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224` -
Classification Usage Examples (click to expand)
- -### Train -YOLOv5 classification training supports auto-download of MNIST, Fashion-MNIST, CIFAR10, CIFAR100, Imagenette, Imagewoof, and ImageNet datasets with the `--data` argument. To start training on MNIST for example use `--data mnist`. - -```bash -# Single-GPU -python classify/train.py --model yolov5s-cls.pt --data cifar100 --epochs 5 --img 224 --batch 128 - -# Multi-GPU DDP -python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3 -``` - -### Val -Validate YOLOv5m-cls accuracy on ImageNet-1k dataset: -```bash -bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images) -python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate -``` - -### Predict -Use pretrained YOLOv5s-cls.pt to predict bus.jpg: -```bash -python classify/predict.py --weights yolov5s-cls.pt --data data/images/bus.jpg -``` -```python -model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s-cls.pt') # load from PyTorch Hub -``` - -### Export -Export a group of trained YOLOv5s-cls, ResNet and EfficientNet models to ONNX and TensorRT: -```bash -python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224 -``` - -
-##
-
-## - - -[assets]: https://github.com/ultralytics/yolov5/releases -[tta]: https://github.com/ultralytics/yolov5/issues/303 diff --git a/spaces/Ibtehaj10/cheating-detection/draw_tracking_line.py b/spaces/Ibtehaj10/cheating-detection/draw_tracking_line.py deleted file mode 100644 index 25feefac898e230f2265f145b4b6631156c3cd69..0000000000000000000000000000000000000000 --- a/spaces/Ibtehaj10/cheating-detection/draw_tracking_line.py +++ /dev/null @@ -1,152 +0,0 @@ -import cv2 -import datetime -import imutils -import numpy as np -from centroidtracker import CentroidTracker -from collections import defaultdict - -protopath = "MobileNetSSD_deploy.prototxt" -modelpath = "MobileNetSSD_deploy.caffemodel" -detector = cv2.dnn.readNetFromCaffe(prototxt=protopath, caffeModel=modelpath) - -# Only enable it if you are using OpenVino environment -# detector.setPreferableBackend(cv2.dnn.DNN_BACKEND_INFERENCE_ENGINE) -# detector.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU) - - -CLASSES = ["background", "aeroplane", "bicycle", "bird", "boat", - "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", - "dog", "horse", "motorbike", "person", "pottedplant", "sheep", - "sofa", "train", "tvmonitor"] - -tracker = CentroidTracker(maxDisappeared=80, maxDistance=90) - - -def non_max_suppression_fast(boxes, overlapThresh): - try: - if len(boxes) == 0: - return [] - - if boxes.dtype.kind == "i": - boxes = boxes.astype("float") - - pick = [] - - x1 = boxes[:, 0] - y1 = boxes[:, 1] - x2 = boxes[:, 2] - y2 = boxes[:, 3] - - area = (x2 - x1 + 1) * (y2 - y1 + 1) - idxs = np.argsort(y2) - - while len(idxs) > 0: - last = len(idxs) - 1 - i = idxs[last] - pick.append(i) - - xx1 = np.maximum(x1[i], x1[idxs[:last]]) - yy1 = np.maximum(y1[i], y1[idxs[:last]]) - xx2 = np.minimum(x2[i], x2[idxs[:last]]) - yy2 = np.minimum(y2[i], y2[idxs[:last]]) - - w = np.maximum(0, xx2 - xx1 + 1) - h = np.maximum(0, yy2 - yy1 + 1) - - overlap = (w * h) / area[idxs[:last]] - - idxs = np.delete(idxs, np.concatenate(([last], - np.where(overlap > overlapThresh)[0]))) - - return boxes[pick].astype("int") - except Exception as e: - print("Exception occurred in non_max_suppression : {}".format(e)) - - -def main(): - cap = cv2.VideoCapture('test_video.mp4') - - fps_start_time = datetime.datetime.now() - fps = 0 - total_frames = 0 - centroid_dict = defaultdict(list) - object_id_list = [] - - while True: - ret, frame = cap.read() - frame = imutils.resize(frame, width=600) - total_frames = total_frames + 1 - - (H, W) = frame.shape[:2] - - blob = cv2.dnn.blobFromImage(frame, 0.007843, (W, H), 127.5) - - detector.setInput(blob) - person_detections = detector.forward() - rects = [] - for i in np.arange(0, person_detections.shape[2]): - confidence = person_detections[0, 0, i, 2] - if confidence > 0.5: - idx = int(person_detections[0, 0, i, 1]) - - if CLASSES[idx] != "person": - continue - - person_box = person_detections[0, 0, i, 3:7] * np.array([W, H, W, H]) - (startX, startY, endX, endY) = person_box.astype("int") - rects.append(person_box) - - boundingboxes = np.array(rects) - boundingboxes = boundingboxes.astype(int) - rects = non_max_suppression_fast(boundingboxes, 0.3) - - objects = tracker.update(rects) - for (objectId, bbox) in objects.items(): - x1, y1, x2, y2 = bbox - x1 = int(x1) - y1 = int(y1) - x2 = int(x2) - y2 = int(y2) - - cX = int((x1 + x2) / 2.0) - cY = int((y1 + y2) / 2.0) - cv2.circle(frame, (cX, cY), 4, (0, 255, 0), -1) - - centroid_dict[objectId].append((cX, cY)) - if objectId not in object_id_list: - object_id_list.append(objectId) - start_pt = (cX, cY) - end_pt = (cX, cY) - cv2.line(frame, start_pt, end_pt, (0, 255, 0), 2) - else: - l = len(centroid_dict[objectId]) - for pt in range(len(centroid_dict[objectId])): - if not pt + 1 == l: - start_pt = (centroid_dict[objectId][pt][0], centroid_dict[objectId][pt][1]) - end_pt = (centroid_dict[objectId][pt + 1][0], centroid_dict[objectId][pt + 1][1]) - cv2.line(frame, start_pt, end_pt, (0, 255, 0), 2) - - cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 0, 255), 2) - text = "ID: {}".format(objectId) - cv2.putText(frame, text, (x1, y1-5), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 0, 255), 1) - - fps_end_time = datetime.datetime.now() - time_diff = fps_end_time - fps_start_time - if time_diff.seconds == 0: - fps = 0.0 - else: - fps = (total_frames / time_diff.seconds) - - fps_text = "FPS: {:.2f}".format(fps) - - cv2.putText(frame, fps_text, (5, 30), cv2.FONT_HERSHEY_COMPLEX_SMALL, 1, (0, 0, 255), 1) - - cv2.imshow("Application", frame) - key = cv2.waitKey(1) - if key == ord('q'): - break - - cv2.destroyAllWindows() - - -main() diff --git a/spaces/Iceclear/StableSR/StableSR/basicsr/utils/plot_util.py b/spaces/Iceclear/StableSR/StableSR/basicsr/utils/plot_util.py deleted file mode 100644 index 1e6da5bc29e706da87ab83af6d5367176fe78763..0000000000000000000000000000000000000000 --- a/spaces/Iceclear/StableSR/StableSR/basicsr/utils/plot_util.py +++ /dev/null @@ -1,83 +0,0 @@ -import re - - -def read_data_from_tensorboard(log_path, tag): - """Get raw data (steps and values) from tensorboard events. - - Args: - log_path (str): Path to the tensorboard log. - tag (str): tag to be read. - """ - from tensorboard.backend.event_processing.event_accumulator import EventAccumulator - - # tensorboard event - event_acc = EventAccumulator(log_path) - event_acc.Reload() - scalar_list = event_acc.Tags()['scalars'] - print('tag list: ', scalar_list) - steps = [int(s.step) for s in event_acc.Scalars(tag)] - values = [s.value for s in event_acc.Scalars(tag)] - return steps, values - - -def read_data_from_txt_2v(path, pattern, step_one=False): - """Read data from txt with 2 returned values (usually [step, value]). - - Args: - path (str): path to the txt file. - pattern (str): re (regular expression) pattern. - step_one (bool): add 1 to steps. Default: False. - """ - with open(path) as f: - lines = f.readlines() - lines = [line.strip() for line in lines] - steps = [] - values = [] - - pattern = re.compile(pattern) - for line in lines: - match = pattern.match(line) - if match: - steps.append(int(match.group(1))) - values.append(float(match.group(2))) - if step_one: - steps = [v + 1 for v in steps] - return steps, values - - -def read_data_from_txt_1v(path, pattern): - """Read data from txt with 1 returned values. - - Args: - path (str): path to the txt file. - pattern (str): re (regular expression) pattern. - """ - with open(path) as f: - lines = f.readlines() - lines = [line.strip() for line in lines] - data = [] - - pattern = re.compile(pattern) - for line in lines: - match = pattern.match(line) - if match: - data.append(float(match.group(1))) - return data - - -def smooth_data(values, smooth_weight): - """ Smooth data using 1st-order IIR low-pass filter (what tensorflow does). - - Reference: https://github.com/tensorflow/tensorboard/blob/f801ebf1f9fbfe2baee1ddd65714d0bccc640fb1/tensorboard/plugins/scalar/vz_line_chart/vz-line-chart.ts#L704 # noqa: E501 - - Args: - values (list): A list of values to be smoothed. - smooth_weight (float): Smooth weight. - """ - values_sm = [] - last_sm_value = values[0] - for value in values: - value_sm = last_sm_value * smooth_weight + (1 - smooth_weight) * value - values_sm.append(value_sm) - last_sm_value = value_sm - return values_sm diff --git a/spaces/Iceclear/StableSR/StableSR/ldm/models/diffusion/plms.py b/spaces/Iceclear/StableSR/StableSR/ldm/models/diffusion/plms.py deleted file mode 100644 index 78eeb1003aa45d27bdbfc6b4a1d7ccbff57cd2e3..0000000000000000000000000000000000000000 --- a/spaces/Iceclear/StableSR/StableSR/ldm/models/diffusion/plms.py +++ /dev/null @@ -1,236 +0,0 @@ -"""SAMPLING ONLY.""" - -import torch -import numpy as np -from tqdm import tqdm -from functools import partial - -from ldm.modules.diffusionmodules.util import make_ddim_sampling_parameters, make_ddim_timesteps, noise_like - - -class PLMSSampler(object): - def __init__(self, model, schedule="linear", **kwargs): - super().__init__() - self.model = model - self.ddpm_num_timesteps = model.num_timesteps - self.schedule = schedule - - def register_buffer(self, name, attr): - if type(attr) == torch.Tensor: - if attr.device != torch.device("cuda"): - attr = attr.to(torch.device("cuda")) - setattr(self, name, attr) - - def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True): - if ddim_eta != 0: - raise ValueError('ddim_eta must be 0 for PLMS') - self.ddim_timesteps = make_ddim_timesteps(ddim_discr_method=ddim_discretize, num_ddim_timesteps=ddim_num_steps, - num_ddpm_timesteps=self.ddpm_num_timesteps,verbose=verbose) - alphas_cumprod = self.model.alphas_cumprod - assert alphas_cumprod.shape[0] == self.ddpm_num_timesteps, 'alphas have to be defined for each timestep' - to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device) - - self.register_buffer('betas', to_torch(self.model.betas)) - self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod)) - self.register_buffer('alphas_cumprod_prev', to_torch(self.model.alphas_cumprod_prev)) - - # calculations for diffusion q(x_t | x_{t-1}) and others - self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod.cpu()))) - self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod.cpu()))) - self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod.cpu()))) - self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu()))) - self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu() - 1))) - - # ddim sampling parameters - ddim_sigmas, ddim_alphas, ddim_alphas_prev = make_ddim_sampling_parameters(alphacums=alphas_cumprod.cpu(), - ddim_timesteps=self.ddim_timesteps, - eta=ddim_eta,verbose=verbose) - self.register_buffer('ddim_sigmas', ddim_sigmas) - self.register_buffer('ddim_alphas', ddim_alphas) - self.register_buffer('ddim_alphas_prev', ddim_alphas_prev) - self.register_buffer('ddim_sqrt_one_minus_alphas', np.sqrt(1. - ddim_alphas)) - sigmas_for_original_sampling_steps = ddim_eta * torch.sqrt( - (1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod) * ( - 1 - self.alphas_cumprod / self.alphas_cumprod_prev)) - self.register_buffer('ddim_sigmas_for_original_num_steps', sigmas_for_original_sampling_steps) - - @torch.no_grad() - def sample(self, - S, - batch_size, - shape, - conditioning=None, - callback=None, - normals_sequence=None, - img_callback=None, - quantize_x0=False, - eta=0., - mask=None, - x0=None, - temperature=1., - noise_dropout=0., - score_corrector=None, - corrector_kwargs=None, - verbose=True, - x_T=None, - log_every_t=100, - unconditional_guidance_scale=1., - unconditional_conditioning=None, - # this has to come in the same format as the conditioning, # e.g. as encoded tokens, ... - **kwargs - ): - if conditioning is not None: - if isinstance(conditioning, dict): - cbs = conditioning[list(conditioning.keys())[0]].shape[0] - if cbs != batch_size: - print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}") - else: - if conditioning.shape[0] != batch_size: - print(f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}") - - self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose) - # sampling - C, H, W = shape - size = (batch_size, C, H, W) - print(f'Data shape for PLMS sampling is {size}') - - samples, intermediates = self.plms_sampling(conditioning, size, - callback=callback, - img_callback=img_callback, - quantize_denoised=quantize_x0, - mask=mask, x0=x0, - ddim_use_original_steps=False, - noise_dropout=noise_dropout, - temperature=temperature, - score_corrector=score_corrector, - corrector_kwargs=corrector_kwargs, - x_T=x_T, - log_every_t=log_every_t, - unconditional_guidance_scale=unconditional_guidance_scale, - unconditional_conditioning=unconditional_conditioning, - ) - return samples, intermediates - - @torch.no_grad() - def plms_sampling(self, cond, shape, - x_T=None, ddim_use_original_steps=False, - callback=None, timesteps=None, quantize_denoised=False, - mask=None, x0=None, img_callback=None, log_every_t=100, - temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None, - unconditional_guidance_scale=1., unconditional_conditioning=None,): - device = self.model.betas.device - b = shape[0] - if x_T is None: - img = torch.randn(shape, device=device) - else: - img = x_T - - if timesteps is None: - timesteps = self.ddpm_num_timesteps if ddim_use_original_steps else self.ddim_timesteps - elif timesteps is not None and not ddim_use_original_steps: - subset_end = int(min(timesteps / self.ddim_timesteps.shape[0], 1) * self.ddim_timesteps.shape[0]) - 1 - timesteps = self.ddim_timesteps[:subset_end] - - intermediates = {'x_inter': [img], 'pred_x0': [img]} - time_range = list(reversed(range(0,timesteps))) if ddim_use_original_steps else np.flip(timesteps) - total_steps = timesteps if ddim_use_original_steps else timesteps.shape[0] - print(f"Running PLMS Sampling with {total_steps} timesteps") - - iterator = tqdm(time_range, desc='PLMS Sampler', total=total_steps) - old_eps = [] - - for i, step in enumerate(iterator): - index = total_steps - i - 1 - ts = torch.full((b,), step, device=device, dtype=torch.long) - ts_next = torch.full((b,), time_range[min(i + 1, len(time_range) - 1)], device=device, dtype=torch.long) - - if mask is not None: - assert x0 is not None - img_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass? - img = img_orig * mask + (1. - mask) * img - - outs = self.p_sample_plms(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps, - quantize_denoised=quantize_denoised, temperature=temperature, - noise_dropout=noise_dropout, score_corrector=score_corrector, - corrector_kwargs=corrector_kwargs, - unconditional_guidance_scale=unconditional_guidance_scale, - unconditional_conditioning=unconditional_conditioning, - old_eps=old_eps, t_next=ts_next) - img, pred_x0, e_t = outs - old_eps.append(e_t) - if len(old_eps) >= 4: - old_eps.pop(0) - if callback: callback(i) - if img_callback: img_callback(pred_x0, i) - - if index % log_every_t == 0 or index == total_steps - 1: - intermediates['x_inter'].append(img) - intermediates['pred_x0'].append(pred_x0) - - return img, intermediates - - @torch.no_grad() - def p_sample_plms(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False, - temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None, - unconditional_guidance_scale=1., unconditional_conditioning=None, old_eps=None, t_next=None): - b, *_, device = *x.shape, x.device - - def get_model_output(x, t): - if unconditional_conditioning is None or unconditional_guidance_scale == 1.: - e_t = self.model.apply_model(x, t, c) - else: - x_in = torch.cat([x] * 2) - t_in = torch.cat([t] * 2) - c_in = torch.cat([unconditional_conditioning, c]) - e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2) - e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond) - - if score_corrector is not None: - assert self.model.parameterization == "eps" - e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs) - - return e_t - - alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas - alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev - sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas - sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas - - def get_x_prev_and_pred_x0(e_t, index): - # select parameters corresponding to the currently considered timestep - a_t = torch.full((b, 1, 1, 1), alphas[index], device=device) - a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device) - sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device) - sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device) - - # current prediction for x_0 - pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt() - if quantize_denoised: - pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0) - # direction pointing to x_t - dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t - noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature - if noise_dropout > 0.: - noise = torch.nn.functional.dropout(noise, p=noise_dropout) - x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise - return x_prev, pred_x0 - - e_t = get_model_output(x, t) - if len(old_eps) == 0: - # Pseudo Improved Euler (2nd order) - x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t, index) - e_t_next = get_model_output(x_prev, t_next) - e_t_prime = (e_t + e_t_next) / 2 - elif len(old_eps) == 1: - # 2nd order Pseudo Linear Multistep (Adams-Bashforth) - e_t_prime = (3 * e_t - old_eps[-1]) / 2 - elif len(old_eps) == 2: - # 3nd order Pseudo Linear Multistep (Adams-Bashforth) - e_t_prime = (23 * e_t - 16 * old_eps[-1] + 5 * old_eps[-2]) / 12 - elif len(old_eps) >= 3: - # 4nd order Pseudo Linear Multistep (Adams-Bashforth) - e_t_prime = (55 * e_t - 59 * old_eps[-1] + 37 * old_eps[-2] - 9 * old_eps[-3]) / 24 - - x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t_prime, index) - - return x_prev, pred_x0, e_t diff --git a/spaces/Ikaros521/so-vits-svc-4.0-ikaros2/utils.py b/spaces/Ikaros521/so-vits-svc-4.0-ikaros2/utils.py deleted file mode 100644 index f13d3526d514be71c77bebb17a5af8831b9c6a36..0000000000000000000000000000000000000000 --- a/spaces/Ikaros521/so-vits-svc-4.0-ikaros2/utils.py +++ /dev/null @@ -1,508 +0,0 @@ -import os -import glob -import re -import sys -import argparse -import logging -import json -import subprocess -import random - -import librosa -import numpy as np -from scipy.io.wavfile import read -import torch -from torch.nn import functional as F -from modules.commons import sequence_mask -from hubert import hubert_model -MATPLOTLIB_FLAG = False - -logging.basicConfig(stream=sys.stdout, level=logging.DEBUG) -logger = logging - -f0_bin = 256 -f0_max = 1100.0 -f0_min = 50.0 -f0_mel_min = 1127 * np.log(1 + f0_min / 700) -f0_mel_max = 1127 * np.log(1 + f0_max / 700) - - -# def normalize_f0(f0, random_scale=True): -# f0_norm = f0.clone() # create a copy of the input Tensor -# batch_size, _, frame_length = f0_norm.shape -# for i in range(batch_size): -# means = torch.mean(f0_norm[i, 0, :]) -# if random_scale: -# factor = random.uniform(0.8, 1.2) -# else: -# factor = 1 -# f0_norm[i, 0, :] = (f0_norm[i, 0, :] - means) * factor -# return f0_norm -# def normalize_f0(f0, random_scale=True): -# means = torch.mean(f0[:, 0, :], dim=1, keepdim=True) -# if random_scale: -# factor = torch.Tensor(f0.shape[0],1).uniform_(0.8, 1.2).to(f0.device) -# else: -# factor = torch.ones(f0.shape[0], 1, 1).to(f0.device) -# f0_norm = (f0 - means.unsqueeze(-1)) * factor.unsqueeze(-1) -# return f0_norm -def normalize_f0(f0, x_mask, uv, random_scale=True): - # calculate means based on x_mask - uv_sum = torch.sum(uv, dim=1, keepdim=True) - uv_sum[uv_sum == 0] = 9999 - means = torch.sum(f0[:, 0, :] * uv, dim=1, keepdim=True) / uv_sum - - if random_scale: - factor = torch.Tensor(f0.shape[0], 1).uniform_(0.8, 1.2).to(f0.device) - else: - factor = torch.ones(f0.shape[0], 1).to(f0.device) - # normalize f0 based on means and factor - f0_norm = (f0 - means.unsqueeze(-1)) * factor.unsqueeze(-1) - if torch.isnan(f0_norm).any(): - exit(0) - return f0_norm * x_mask - - -def plot_data_to_numpy(x, y): - global MATPLOTLIB_FLAG - if not MATPLOTLIB_FLAG: - import matplotlib - matplotlib.use("Agg") - MATPLOTLIB_FLAG = True - mpl_logger = logging.getLogger('matplotlib') - mpl_logger.setLevel(logging.WARNING) - import matplotlib.pylab as plt - import numpy as np - - fig, ax = plt.subplots(figsize=(10, 2)) - plt.plot(x) - plt.plot(y) - plt.tight_layout() - - fig.canvas.draw() - data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='') - data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,)) - plt.close() - return data - - - -def interpolate_f0(f0): - ''' - 对F0进行插值处理 - ''' - - data = np.reshape(f0, (f0.size, 1)) - - vuv_vector = np.zeros((data.size, 1), dtype=np.float32) - vuv_vector[data > 0.0] = 1.0 - vuv_vector[data <= 0.0] = 0.0 - - ip_data = data - - frame_number = data.size - last_value = 0.0 - for i in range(frame_number): - if data[i] <= 0.0: - j = i + 1 - for j in range(i + 1, frame_number): - if data[j] > 0.0: - break - if j < frame_number - 1: - if last_value > 0.0: - step = (data[j] - data[i - 1]) / float(j - i) - for k in range(i, j): - ip_data[k] = data[i - 1] + step * (k - i + 1) - else: - for k in range(i, j): - ip_data[k] = data[j] - else: - for k in range(i, frame_number): - ip_data[k] = last_value - else: - ip_data[i] = data[i] - last_value = data[i] - - return ip_data[:,0], vuv_vector[:,0] - - -def compute_f0_parselmouth(wav_numpy, p_len=None, sampling_rate=44100, hop_length=512): - import parselmouth - x = wav_numpy - if p_len is None: - p_len = x.shape[0]//hop_length - else: - assert abs(p_len-x.shape[0]//hop_length) < 4, "pad length error" - time_step = hop_length / sampling_rate * 1000 - f0_min = 50 - f0_max = 1100 - f0 = parselmouth.Sound(x, sampling_rate).to_pitch_ac( - time_step=time_step / 1000, voicing_threshold=0.6, - pitch_floor=f0_min, pitch_ceiling=f0_max).selected_array['frequency'] - - pad_size=(p_len - len(f0) + 1) // 2 - if(pad_size>0 or p_len - len(f0) - pad_size>0): - f0 = np.pad(f0,[[pad_size,p_len - len(f0) - pad_size]], mode='constant') - return f0 - -def resize_f0(x, target_len): - source = np.array(x) - source[source<0.001] = np.nan - target = np.interp(np.arange(0, len(source)*target_len, len(source))/ target_len, np.arange(0, len(source)), source) - res = np.nan_to_num(target) - return res - -def compute_f0_dio(wav_numpy, p_len=None, sampling_rate=44100, hop_length=512): - import pyworld - if p_len is None: - p_len = wav_numpy.shape[0]//hop_length - f0, t = pyworld.dio( - wav_numpy.astype(np.double), - fs=sampling_rate, - f0_ceil=800, - frame_period=1000 * hop_length / sampling_rate, - ) - f0 = pyworld.stonemask(wav_numpy.astype(np.double), f0, t, sampling_rate) - for index, pitch in enumerate(f0): - f0[index] = round(pitch, 1) - return resize_f0(f0, p_len) - -def f0_to_coarse(f0): - is_torch = isinstance(f0, torch.Tensor) - f0_mel = 1127 * (1 + f0 / 700).log() if is_torch else 1127 * np.log(1 + f0 / 700) - f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * (f0_bin - 2) / (f0_mel_max - f0_mel_min) + 1 - - f0_mel[f0_mel <= 1] = 1 - f0_mel[f0_mel > f0_bin - 1] = f0_bin - 1 - f0_coarse = (f0_mel + 0.5).long() if is_torch else np.rint(f0_mel).astype(np.int) - assert f0_coarse.max() <= 255 and f0_coarse.min() >= 1, (f0_coarse.max(), f0_coarse.min()) - return f0_coarse - - -def get_hubert_model(): - vec_path = "hubert/checkpoint_best_legacy_500.pt" - print("load model(s) from {}".format(vec_path)) - from fairseq import checkpoint_utils - models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task( - [vec_path], - suffix="", - ) - model = models[0] - model.eval() - return model - -def get_hubert_content(hmodel, wav_16k_tensor): - feats = wav_16k_tensor - if feats.dim() == 2: # double channels - feats = feats.mean(-1) - assert feats.dim() == 1, feats.dim() - feats = feats.view(1, -1) - padding_mask = torch.BoolTensor(feats.shape).fill_(False) - inputs = { - "source": feats.to(wav_16k_tensor.device), - "padding_mask": padding_mask.to(wav_16k_tensor.device), - "output_layer": 9, # layer 9 - } - with torch.no_grad(): - logits = hmodel.extract_features(**inputs) - feats = hmodel.final_proj(logits[0]) - return feats.transpose(1, 2) - - -def get_content(cmodel, y): - with torch.no_grad(): - c = cmodel.extract_features(y.squeeze(1))[0] - c = c.transpose(1, 2) - return c - - - -def load_checkpoint(checkpoint_path, model, optimizer=None, skip_optimizer=False): - assert os.path.isfile(checkpoint_path) - checkpoint_dict = torch.load(checkpoint_path, map_location='cpu') - iteration = checkpoint_dict['iteration'] - learning_rate = checkpoint_dict['learning_rate'] - if optimizer is not None and not skip_optimizer: - optimizer.load_state_dict(checkpoint_dict['optimizer']) - saved_state_dict = checkpoint_dict['model'] - if hasattr(model, 'module'): - state_dict = model.module.state_dict() - else: - state_dict = model.state_dict() - new_state_dict = {} - for k, v in state_dict.items(): - try: - # assert "dec" in k or "disc" in k - # print("load", k) - new_state_dict[k] = saved_state_dict[k] - assert saved_state_dict[k].shape == v.shape, (saved_state_dict[k].shape, v.shape) - except: - print("error, %s is not in the checkpoint" % k) - logger.info("%s is not in the checkpoint" % k) - new_state_dict[k] = v - if hasattr(model, 'module'): - model.module.load_state_dict(new_state_dict) - else: - model.load_state_dict(new_state_dict) - print("load ") - logger.info("Loaded checkpoint '{}' (iteration {})".format( - checkpoint_path, iteration)) - return model, optimizer, learning_rate, iteration - - -def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path, val_steps, current_step): - logger.info("Saving model and optimizer state at iteration {} to {}".format( - iteration, checkpoint_path)) - if hasattr(model, 'module'): - state_dict = model.module.state_dict() - else: - state_dict = model.state_dict() - torch.save({'model': state_dict, - 'iteration': iteration, - 'optimizer': optimizer.state_dict(), - 'learning_rate': learning_rate}, checkpoint_path) - if current_step >= val_steps * 3: - to_del_ckptname = checkpoint_path.replace(str(current_step), str(current_step - val_steps * 3)) - if os.path.exists(to_del_ckptname): - os.remove(to_del_ckptname) - print("Removing ", to_del_ckptname) - - -def clean_checkpoints(path_to_models='logs/48k/', n_ckpts_to_keep=2, sort_by_time=True): - """Freeing up space by deleting saved ckpts - - Arguments: - path_to_models -- Path to the model directory - n_ckpts_to_keep -- Number of ckpts to keep, excluding G_0.pth and D_0.pth - sort_by_time -- True -> chronologically delete ckpts - False -> lexicographically delete ckpts - """ - ckpts_files = [f for f in os.listdir(path_to_models) if os.path.isfile(os.path.join(path_to_models, f))] - name_key = (lambda _f: int(re.compile('._(\d+)\.pth').match(_f).group(1))) - time_key = (lambda _f: os.path.getmtime(os.path.join(path_to_models, _f))) - sort_key = time_key if sort_by_time else name_key - x_sorted = lambda _x: sorted([f for f in ckpts_files if f.startswith(_x) and not f.endswith('_0.pth')], key=sort_key) - to_del = [os.path.join(path_to_models, fn) for fn in - (x_sorted('G')[:-n_ckpts_to_keep] + x_sorted('D')[:-n_ckpts_to_keep])] - del_info = lambda fn: logger.info(f".. Free up space by deleting ckpt {fn}") - del_routine = lambda x: [os.remove(x), del_info(x)] - rs = [del_routine(fn) for fn in to_del] - -def summarize(writer, global_step, scalars={}, histograms={}, images={}, audios={}, audio_sampling_rate=22050): - for k, v in scalars.items(): - writer.add_scalar(k, v, global_step) - for k, v in histograms.items(): - writer.add_histogram(k, v, global_step) - for k, v in images.items(): - writer.add_image(k, v, global_step, dataformats='HWC') - for k, v in audios.items(): - writer.add_audio(k, v, global_step, audio_sampling_rate) - - -def latest_checkpoint_path(dir_path, regex="G_*.pth"): - f_list = glob.glob(os.path.join(dir_path, regex)) - f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f)))) - x = f_list[-1] - print(x) - return x - - -def plot_spectrogram_to_numpy(spectrogram): - global MATPLOTLIB_FLAG - if not MATPLOTLIB_FLAG: - import matplotlib - matplotlib.use("Agg") - MATPLOTLIB_FLAG = True - mpl_logger = logging.getLogger('matplotlib') - mpl_logger.setLevel(logging.WARNING) - import matplotlib.pylab as plt - import numpy as np - - fig, ax = plt.subplots(figsize=(10,2)) - im = ax.imshow(spectrogram, aspect="auto", origin="lower", - interpolation='none') - plt.colorbar(im, ax=ax) - plt.xlabel("Frames") - plt.ylabel("Channels") - plt.tight_layout() - - fig.canvas.draw() - data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='') - data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,)) - plt.close() - return data - - -def plot_alignment_to_numpy(alignment, info=None): - global MATPLOTLIB_FLAG - if not MATPLOTLIB_FLAG: - import matplotlib - matplotlib.use("Agg") - MATPLOTLIB_FLAG = True - mpl_logger = logging.getLogger('matplotlib') - mpl_logger.setLevel(logging.WARNING) - import matplotlib.pylab as plt - import numpy as np - - fig, ax = plt.subplots(figsize=(6, 4)) - im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower', - interpolation='none') - fig.colorbar(im, ax=ax) - xlabel = 'Decoder timestep' - if info is not None: - xlabel += '\n\n' + info - plt.xlabel(xlabel) - plt.ylabel('Encoder timestep') - plt.tight_layout() - - fig.canvas.draw() - data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='') - data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,)) - plt.close() - return data - - -def load_wav_to_torch(full_path): - sampling_rate, data = read(full_path) - return torch.FloatTensor(data.astype(np.float32)), sampling_rate - - -def load_filepaths_and_text(filename, split="|"): - with open(filename, encoding='utf-8') as f: - filepaths_and_text = [line.strip().split(split) for line in f] - return filepaths_and_text - - -def get_hparams(init=True): - parser = argparse.ArgumentParser() - parser.add_argument('-c', '--config', type=str, default="./configs/base.json", - help='JSON file for configuration') - parser.add_argument('-m', '--model', type=str, required=True, - help='Model name') - - args = parser.parse_args() - model_dir = os.path.join("./logs", args.model) - - if not os.path.exists(model_dir): - os.makedirs(model_dir) - - config_path = args.config - config_save_path = os.path.join(model_dir, "config.json") - if init: - with open(config_path, "r") as f: - data = f.read() - with open(config_save_path, "w") as f: - f.write(data) - else: - with open(config_save_path, "r") as f: - data = f.read() - config = json.loads(data) - - hparams = HParams(**config) - hparams.model_dir = model_dir - return hparams - - -def get_hparams_from_dir(model_dir): - config_save_path = os.path.join(model_dir, "config.json") - with open(config_save_path, "r") as f: - data = f.read() - config = json.loads(data) - - hparams =HParams(**config) - hparams.model_dir = model_dir - return hparams - - -def get_hparams_from_file(config_path): - with open(config_path, "r") as f: - data = f.read() - config = json.loads(data) - - hparams =HParams(**config) - return hparams - - -def check_git_hash(model_dir): - source_dir = os.path.dirname(os.path.realpath(__file__)) - if not os.path.exists(os.path.join(source_dir, ".git")): - logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format( - source_dir - )) - return - - cur_hash = subprocess.getoutput("git rev-parse HEAD") - - path = os.path.join(model_dir, "githash") - if os.path.exists(path): - saved_hash = open(path).read() - if saved_hash != cur_hash: - logger.warn("git hash values are different. {}(saved) != {}(current)".format( - saved_hash[:8], cur_hash[:8])) - else: - open(path, "w").write(cur_hash) - - -def get_logger(model_dir, filename="train.log"): - global logger - logger = logging.getLogger(os.path.basename(model_dir)) - logger.setLevel(logging.DEBUG) - - formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s") - if not os.path.exists(model_dir): - os.makedirs(model_dir) - h = logging.FileHandler(os.path.join(model_dir, filename)) - h.setLevel(logging.DEBUG) - h.setFormatter(formatter) - logger.addHandler(h) - return logger - - -def repeat_expand_2d(content, target_len): - # content : [h, t] - - src_len = content.shape[-1] - target = torch.zeros([content.shape[0], target_len], dtype=torch.float).to(content.device) - temp = torch.arange(src_len+1) * target_len / src_len - current_pos = 0 - for i in range(target_len): - if i < temp[current_pos+1]: - target[:, i] = content[:, current_pos] - else: - current_pos += 1 - target[:, i] = content[:, current_pos] - - return target - - -class HParams(): - def __init__(self, **kwargs): - for k, v in kwargs.items(): - if type(v) == dict: - v = HParams(**v) - self[k] = v - - def keys(self): - return self.__dict__.keys() - - def items(self): - return self.__dict__.items() - - def values(self): - return self.__dict__.values() - - def __len__(self): - return len(self.__dict__) - - def __getitem__(self, key): - return getattr(self, key) - - def __setitem__(self, key, value): - return setattr(self, key, value) - - def __contains__(self, key): - return key in self.__dict__ - - def __repr__(self): - return self.__dict__.__repr__() - diff --git a/spaces/Jaehan/Text2Text-Question-Generation-1/app.py b/spaces/Jaehan/Text2Text-Question-Generation-1/app.py deleted file mode 100644 index 2ba9b0ef840a4d0baf746c89c39110c9a2b30c0e..0000000000000000000000000000000000000000 --- a/spaces/Jaehan/Text2Text-Question-Generation-1/app.py +++ /dev/null @@ -1,19 +0,0 @@ -from transformers import AutoModelWithLMHead, AutoTokenizer -import gradio as gr - -model_name = "mrm8488/t5-base-finetuned-question-generation-ap" -text2text_tokenizer = AutoTokenizer.from_pretrained(model_name) -model = AutoModelWithLMHead.from_pretrained(model_name) - -def text2text(context, answer): - input_text = f"answer: {answer} context: <{context}>" - features = text2text_tokenizer([input_text], return_tensors="pt") - output = model.generate(input_ids=features["input_ids"], attention_mask=features["attention_mask"], max_length=100) - response = text2text_tokenizer.decode(output[0]) - return response - -context = gr.Textbox(lines=10, label="English", placeholder="Context") -answer = gr.Textbox(lines=1, label="Answer") -out = gr.Textbox(lines=1, label="Generated question") - -gr.Interface(text2text, inputs=[context, answer], outputs=out).launch() \ No newline at end of file diff --git a/spaces/Jasonyoyo/CodeFormer/CodeFormer/facelib/utils/face_restoration_helper.py b/spaces/Jasonyoyo/CodeFormer/CodeFormer/facelib/utils/face_restoration_helper.py deleted file mode 100644 index 5d3fb8f3b95ed9959610e64f6d7373ea8a56ece8..0000000000000000000000000000000000000000 --- a/spaces/Jasonyoyo/CodeFormer/CodeFormer/facelib/utils/face_restoration_helper.py +++ /dev/null @@ -1,460 +0,0 @@ -import cv2 -import numpy as np -import os -import torch -from torchvision.transforms.functional import normalize - -from facelib.detection import init_detection_model -from facelib.parsing import init_parsing_model -from facelib.utils.misc import img2tensor, imwrite, is_gray, bgr2gray - - -def get_largest_face(det_faces, h, w): - - def get_location(val, length): - if val < 0: - return 0 - elif val > length: - return length - else: - return val - - face_areas = [] - for det_face in det_faces: - left = get_location(det_face[0], w) - right = get_location(det_face[2], w) - top = get_location(det_face[1], h) - bottom = get_location(det_face[3], h) - face_area = (right - left) * (bottom - top) - face_areas.append(face_area) - largest_idx = face_areas.index(max(face_areas)) - return det_faces[largest_idx], largest_idx - - -def get_center_face(det_faces, h=0, w=0, center=None): - if center is not None: - center = np.array(center) - else: - center = np.array([w / 2, h / 2]) - center_dist = [] - for det_face in det_faces: - face_center = np.array([(det_face[0] + det_face[2]) / 2, (det_face[1] + det_face[3]) / 2]) - dist = np.linalg.norm(face_center - center) - center_dist.append(dist) - center_idx = center_dist.index(min(center_dist)) - return det_faces[center_idx], center_idx - - -class FaceRestoreHelper(object): - """Helper for the face restoration pipeline (base class).""" - - def __init__(self, - upscale_factor, - face_size=512, - crop_ratio=(1, 1), - det_model='retinaface_resnet50', - save_ext='png', - template_3points=False, - pad_blur=False, - use_parse=False, - device=None): - self.template_3points = template_3points # improve robustness - self.upscale_factor = int(upscale_factor) - # the cropped face ratio based on the square face - self.crop_ratio = crop_ratio # (h, w) - assert (self.crop_ratio[0] >= 1 and self.crop_ratio[1] >= 1), 'crop ration only supports >=1' - self.face_size = (int(face_size * self.crop_ratio[1]), int(face_size * self.crop_ratio[0])) - - if self.template_3points: - self.face_template = np.array([[192, 240], [319, 240], [257, 371]]) - else: - # standard 5 landmarks for FFHQ faces with 512 x 512 - # facexlib - self.face_template = np.array([[192.98138, 239.94708], [318.90277, 240.1936], [256.63416, 314.01935], - [201.26117, 371.41043], [313.08905, 371.15118]]) - - # dlib: left_eye: 36:41 right_eye: 42:47 nose: 30,32,33,34 left mouth corner: 48 right mouth corner: 54 - # self.face_template = np.array([[193.65928, 242.98541], [318.32558, 243.06108], [255.67984, 328.82894], - # [198.22603, 372.82502], [313.91018, 372.75659]]) - - - self.face_template = self.face_template * (face_size / 512.0) - if self.crop_ratio[0] > 1: - self.face_template[:, 1] += face_size * (self.crop_ratio[0] - 1) / 2 - if self.crop_ratio[1] > 1: - self.face_template[:, 0] += face_size * (self.crop_ratio[1] - 1) / 2 - self.save_ext = save_ext - self.pad_blur = pad_blur - if self.pad_blur is True: - self.template_3points = False - - self.all_landmarks_5 = [] - self.det_faces = [] - self.affine_matrices = [] - self.inverse_affine_matrices = [] - self.cropped_faces = [] - self.restored_faces = [] - self.pad_input_imgs = [] - - if device is None: - self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') - else: - self.device = device - - # init face detection model - self.face_det = init_detection_model(det_model, half=False, device=self.device) - - # init face parsing model - self.use_parse = use_parse - self.face_parse = init_parsing_model(model_name='parsenet', device=self.device) - - def set_upscale_factor(self, upscale_factor): - self.upscale_factor = upscale_factor - - def read_image(self, img): - """img can be image path or cv2 loaded image.""" - # self.input_img is Numpy array, (h, w, c), BGR, uint8, [0, 255] - if isinstance(img, str): - img = cv2.imread(img) - - if np.max(img) > 256: # 16-bit image - img = img / 65535 * 255 - if len(img.shape) == 2: # gray image - img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) - elif img.shape[2] == 4: # BGRA image with alpha channel - img = img[:, :, 0:3] - - self.input_img = img - self.is_gray = is_gray(img, threshold=5) - if self.is_gray: - print('Grayscale input: True') - - if min(self.input_img.shape[:2])<512: - f = 512.0/min(self.input_img.shape[:2]) - self.input_img = cv2.resize(self.input_img, (0,0), fx=f, fy=f, interpolation=cv2.INTER_LINEAR) - - def get_face_landmarks_5(self, - only_keep_largest=False, - only_center_face=False, - resize=None, - blur_ratio=0.01, - eye_dist_threshold=None): - if resize is None: - scale = 1 - input_img = self.input_img - else: - h, w = self.input_img.shape[0:2] - scale = resize / min(h, w) - scale = max(1, scale) # always scale up - h, w = int(h * scale), int(w * scale) - interp = cv2.INTER_AREA if scale < 1 else cv2.INTER_LINEAR - input_img = cv2.resize(self.input_img, (w, h), interpolation=interp) - - with torch.no_grad(): - bboxes = self.face_det.detect_faces(input_img) - - if bboxes is None or bboxes.shape[0] == 0: - return 0 - else: - bboxes = bboxes / scale - - for bbox in bboxes: - # remove faces with too small eye distance: side faces or too small faces - eye_dist = np.linalg.norm([bbox[6] - bbox[8], bbox[7] - bbox[9]]) - if eye_dist_threshold is not None and (eye_dist < eye_dist_threshold): - continue - - if self.template_3points: - landmark = np.array([[bbox[i], bbox[i + 1]] for i in range(5, 11, 2)]) - else: - landmark = np.array([[bbox[i], bbox[i + 1]] for i in range(5, 15, 2)]) - self.all_landmarks_5.append(landmark) - self.det_faces.append(bbox[0:5]) - - if len(self.det_faces) == 0: - return 0 - if only_keep_largest: - h, w, _ = self.input_img.shape - self.det_faces, largest_idx = get_largest_face(self.det_faces, h, w) - self.all_landmarks_5 = [self.all_landmarks_5[largest_idx]] - elif only_center_face: - h, w, _ = self.input_img.shape - self.det_faces, center_idx = get_center_face(self.det_faces, h, w) - self.all_landmarks_5 = [self.all_landmarks_5[center_idx]] - - # pad blurry images - if self.pad_blur: - self.pad_input_imgs = [] - for landmarks in self.all_landmarks_5: - # get landmarks - eye_left = landmarks[0, :] - eye_right = landmarks[1, :] - eye_avg = (eye_left + eye_right) * 0.5 - mouth_avg = (landmarks[3, :] + landmarks[4, :]) * 0.5 - eye_to_eye = eye_right - eye_left - eye_to_mouth = mouth_avg - eye_avg - - # Get the oriented crop rectangle - # x: half width of the oriented crop rectangle - x = eye_to_eye - np.flipud(eye_to_mouth) * [-1, 1] - # - np.flipud(eye_to_mouth) * [-1, 1]: rotate 90 clockwise - # norm with the hypotenuse: get the direction - x /= np.hypot(*x) # get the hypotenuse of a right triangle - rect_scale = 1.5 - x *= max(np.hypot(*eye_to_eye) * 2.0 * rect_scale, np.hypot(*eye_to_mouth) * 1.8 * rect_scale) - # y: half height of the oriented crop rectangle - y = np.flipud(x) * [-1, 1] - - # c: center - c = eye_avg + eye_to_mouth * 0.1 - # quad: (left_top, left_bottom, right_bottom, right_top) - quad = np.stack([c - x - y, c - x + y, c + x + y, c + x - y]) - # qsize: side length of the square - qsize = np.hypot(*x) * 2 - border = max(int(np.rint(qsize * 0.1)), 3) - - # get pad - # pad: (width_left, height_top, width_right, height_bottom) - pad = (int(np.floor(min(quad[:, 0]))), int(np.floor(min(quad[:, 1]))), int(np.ceil(max(quad[:, 0]))), - int(np.ceil(max(quad[:, 1])))) - pad = [ - max(-pad[0] + border, 1), - max(-pad[1] + border, 1), - max(pad[2] - self.input_img.shape[0] + border, 1), - max(pad[3] - self.input_img.shape[1] + border, 1) - ] - - if max(pad) > 1: - # pad image - pad_img = np.pad(self.input_img, ((pad[1], pad[3]), (pad[0], pad[2]), (0, 0)), 'reflect') - # modify landmark coords - landmarks[:, 0] += pad[0] - landmarks[:, 1] += pad[1] - # blur pad images - h, w, _ = pad_img.shape - y, x, _ = np.ogrid[:h, :w, :1] - mask = np.maximum(1.0 - np.minimum(np.float32(x) / pad[0], - np.float32(w - 1 - x) / pad[2]), - 1.0 - np.minimum(np.float32(y) / pad[1], - np.float32(h - 1 - y) / pad[3])) - blur = int(qsize * blur_ratio) - if blur % 2 == 0: - blur += 1 - blur_img = cv2.boxFilter(pad_img, 0, ksize=(blur, blur)) - # blur_img = cv2.GaussianBlur(pad_img, (blur, blur), 0) - - pad_img = pad_img.astype('float32') - pad_img += (blur_img - pad_img) * np.clip(mask * 3.0 + 1.0, 0.0, 1.0) - pad_img += (np.median(pad_img, axis=(0, 1)) - pad_img) * np.clip(mask, 0.0, 1.0) - pad_img = np.clip(pad_img, 0, 255) # float32, [0, 255] - self.pad_input_imgs.append(pad_img) - else: - self.pad_input_imgs.append(np.copy(self.input_img)) - - return len(self.all_landmarks_5) - - def align_warp_face(self, save_cropped_path=None, border_mode='constant'): - """Align and warp faces with face template. - """ - if self.pad_blur: - assert len(self.pad_input_imgs) == len( - self.all_landmarks_5), f'Mismatched samples: {len(self.pad_input_imgs)} and {len(self.all_landmarks_5)}' - for idx, landmark in enumerate(self.all_landmarks_5): - # use 5 landmarks to get affine matrix - # use cv2.LMEDS method for the equivalence to skimage transform - # ref: https://blog.csdn.net/yichxi/article/details/115827338 - affine_matrix = cv2.estimateAffinePartial2D(landmark, self.face_template, method=cv2.LMEDS)[0] - self.affine_matrices.append(affine_matrix) - # warp and crop faces - if border_mode == 'constant': - border_mode = cv2.BORDER_CONSTANT - elif border_mode == 'reflect101': - border_mode = cv2.BORDER_REFLECT101 - elif border_mode == 'reflect': - border_mode = cv2.BORDER_REFLECT - if self.pad_blur: - input_img = self.pad_input_imgs[idx] - else: - input_img = self.input_img - cropped_face = cv2.warpAffine( - input_img, affine_matrix, self.face_size, borderMode=border_mode, borderValue=(135, 133, 132)) # gray - self.cropped_faces.append(cropped_face) - # save the cropped face - if save_cropped_path is not None: - path = os.path.splitext(save_cropped_path)[0] - save_path = f'{path}_{idx:02d}.{self.save_ext}' - imwrite(cropped_face, save_path) - - def get_inverse_affine(self, save_inverse_affine_path=None): - """Get inverse affine matrix.""" - for idx, affine_matrix in enumerate(self.affine_matrices): - inverse_affine = cv2.invertAffineTransform(affine_matrix) - inverse_affine *= self.upscale_factor - self.inverse_affine_matrices.append(inverse_affine) - # save inverse affine matrices - if save_inverse_affine_path is not None: - path, _ = os.path.splitext(save_inverse_affine_path) - save_path = f'{path}_{idx:02d}.pth' - torch.save(inverse_affine, save_path) - - - def add_restored_face(self, face): - if self.is_gray: - face = bgr2gray(face) # convert img into grayscale - self.restored_faces.append(face) - - - def paste_faces_to_input_image(self, save_path=None, upsample_img=None, draw_box=False, face_upsampler=None): - h, w, _ = self.input_img.shape - h_up, w_up = int(h * self.upscale_factor), int(w * self.upscale_factor) - - if upsample_img is None: - # simply resize the background - # upsample_img = cv2.resize(self.input_img, (w_up, h_up), interpolation=cv2.INTER_LANCZOS4) - upsample_img = cv2.resize(self.input_img, (w_up, h_up), interpolation=cv2.INTER_LINEAR) - else: - upsample_img = cv2.resize(upsample_img, (w_up, h_up), interpolation=cv2.INTER_LANCZOS4) - - assert len(self.restored_faces) == len( - self.inverse_affine_matrices), ('length of restored_faces and affine_matrices are different.') - - inv_mask_borders = [] - for restored_face, inverse_affine in zip(self.restored_faces, self.inverse_affine_matrices): - if face_upsampler is not None: - restored_face = face_upsampler.enhance(restored_face, outscale=self.upscale_factor)[0] - inverse_affine /= self.upscale_factor - inverse_affine[:, 2] *= self.upscale_factor - face_size = (self.face_size[0]*self.upscale_factor, self.face_size[1]*self.upscale_factor) - else: - # Add an offset to inverse affine matrix, for more precise back alignment - if self.upscale_factor > 1: - extra_offset = 0.5 * self.upscale_factor - else: - extra_offset = 0 - inverse_affine[:, 2] += extra_offset - face_size = self.face_size - inv_restored = cv2.warpAffine(restored_face, inverse_affine, (w_up, h_up)) - - # if draw_box or not self.use_parse: # use square parse maps - # mask = np.ones(face_size, dtype=np.float32) - # inv_mask = cv2.warpAffine(mask, inverse_affine, (w_up, h_up)) - # # remove the black borders - # inv_mask_erosion = cv2.erode( - # inv_mask, np.ones((int(2 * self.upscale_factor), int(2 * self.upscale_factor)), np.uint8)) - # pasted_face = inv_mask_erosion[:, :, None] * inv_restored - # total_face_area = np.sum(inv_mask_erosion) # // 3 - # # add border - # if draw_box: - # h, w = face_size - # mask_border = np.ones((h, w, 3), dtype=np.float32) - # border = int(1400/np.sqrt(total_face_area)) - # mask_border[border:h-border, border:w-border,:] = 0 - # inv_mask_border = cv2.warpAffine(mask_border, inverse_affine, (w_up, h_up)) - # inv_mask_borders.append(inv_mask_border) - # if not self.use_parse: - # # compute the fusion edge based on the area of face - # w_edge = int(total_face_area**0.5) // 20 - # erosion_radius = w_edge * 2 - # inv_mask_center = cv2.erode(inv_mask_erosion, np.ones((erosion_radius, erosion_radius), np.uint8)) - # blur_size = w_edge * 2 - # inv_soft_mask = cv2.GaussianBlur(inv_mask_center, (blur_size + 1, blur_size + 1), 0) - # if len(upsample_img.shape) == 2: # upsample_img is gray image - # upsample_img = upsample_img[:, :, None] - # inv_soft_mask = inv_soft_mask[:, :, None] - - # always use square mask - mask = np.ones(face_size, dtype=np.float32) - inv_mask = cv2.warpAffine(mask, inverse_affine, (w_up, h_up)) - # remove the black borders - inv_mask_erosion = cv2.erode( - inv_mask, np.ones((int(2 * self.upscale_factor), int(2 * self.upscale_factor)), np.uint8)) - pasted_face = inv_mask_erosion[:, :, None] * inv_restored - total_face_area = np.sum(inv_mask_erosion) # // 3 - # add border - if draw_box: - h, w = face_size - mask_border = np.ones((h, w, 3), dtype=np.float32) - border = int(1400/np.sqrt(total_face_area)) - mask_border[border:h-border, border:w-border,:] = 0 - inv_mask_border = cv2.warpAffine(mask_border, inverse_affine, (w_up, h_up)) - inv_mask_borders.append(inv_mask_border) - # compute the fusion edge based on the area of face - w_edge = int(total_face_area**0.5) // 20 - erosion_radius = w_edge * 2 - inv_mask_center = cv2.erode(inv_mask_erosion, np.ones((erosion_radius, erosion_radius), np.uint8)) - blur_size = w_edge * 2 - inv_soft_mask = cv2.GaussianBlur(inv_mask_center, (blur_size + 1, blur_size + 1), 0) - if len(upsample_img.shape) == 2: # upsample_img is gray image - upsample_img = upsample_img[:, :, None] - inv_soft_mask = inv_soft_mask[:, :, None] - - # parse mask - if self.use_parse: - # inference - face_input = cv2.resize(restored_face, (512, 512), interpolation=cv2.INTER_LINEAR) - face_input = img2tensor(face_input.astype('float32') / 255., bgr2rgb=True, float32=True) - normalize(face_input, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True) - face_input = torch.unsqueeze(face_input, 0).to(self.device) - with torch.no_grad(): - out = self.face_parse(face_input)[0] - out = out.argmax(dim=1).squeeze().cpu().numpy() - - parse_mask = np.zeros(out.shape) - MASK_COLORMAP = [0, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 0, 255, 0, 0, 0] - for idx, color in enumerate(MASK_COLORMAP): - parse_mask[out == idx] = color - # blur the mask - parse_mask = cv2.GaussianBlur(parse_mask, (101, 101), 11) - parse_mask = cv2.GaussianBlur(parse_mask, (101, 101), 11) - # remove the black borders - thres = 10 - parse_mask[:thres, :] = 0 - parse_mask[-thres:, :] = 0 - parse_mask[:, :thres] = 0 - parse_mask[:, -thres:] = 0 - parse_mask = parse_mask / 255. - - parse_mask = cv2.resize(parse_mask, face_size) - parse_mask = cv2.warpAffine(parse_mask, inverse_affine, (w_up, h_up), flags=3) - inv_soft_parse_mask = parse_mask[:, :, None] - # pasted_face = inv_restored - fuse_mask = (inv_soft_parse_mask
", " ") - examples.append( - InputExample( - guid="unused_id", text_a=text, text_b=None, label=label)) - return examples - - -class MnliMatchedProcessor(GLUEProcessor): - """MnliMatchedProcessor.""" - - def __init__(self): - super(MnliMatchedProcessor, self).__init__() - self.dev_file = "dev_matched.tsv" - self.test_file = "test_matched.tsv" - self.label_column = -1 - self.text_a_column = 8 - self.text_b_column = 9 - - def get_labels(self): - return ["contradiction", "entailment", "neutral"] - - -class MnliMismatchedProcessor(MnliMatchedProcessor): - - def __init__(self): - super(MnliMismatchedProcessor, self).__init__() - self.dev_file = "dev_mismatched.tsv" - self.test_file = "test_mismatched.tsv" - - -class StsbProcessor(GLUEProcessor): - """StsbProcessor.""" - - def __init__(self): - super(StsbProcessor, self).__init__() - self.label_column = 9 - self.text_a_column = 7 - self.text_b_column = 8 - - def get_labels(self): - return [0.0] - - def _create_examples(self, lines, set_type): - """Creates examples for the training and dev sets.""" - examples = [] - for (i, line) in enumerate(lines): - if i == 0 and self.contains_header and set_type != "test": - continue - if i == 0 and self.test_contains_header and set_type == "test": - continue - guid = "%s-%s" % (set_type, i) - - a_column = ( - self.text_a_column if set_type != "test" else self.test_text_a_column) - b_column = ( - self.text_b_column if set_type != "test" else self.test_text_b_column) - - # there are some incomplete lines in QNLI - if len(line) <= a_column: - logging.warning("Incomplete line, ignored.") - continue - text_a = line[a_column] - - if b_column is not None: - if len(line) <= b_column: - logging.warning("Incomplete line, ignored.") - continue - text_b = line[b_column] - else: - text_b = None - - if set_type == "test": - label = self.get_labels()[0] - else: - if len(line) <= self.label_column: - logging.warning("Incomplete line, ignored.") - continue - label = float(line[self.label_column]) - examples.append( - InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label)) - - return examples - - -def file_based_convert_examples_to_features(examples, - label_list, - max_seq_length, - tokenize_fn, - output_file, - num_passes=1): - """Convert a set of `InputExample`s to a TFRecord file.""" - - # do not create duplicated records - if tf.io.gfile.exists(output_file) and not FLAGS.overwrite_data: - logging.info("Do not overwrite tfrecord %s exists.", output_file) - return - - logging.info("Create new tfrecord %s.", output_file) - - writer = tf.io.TFRecordWriter(output_file) - - examples *= num_passes - - for (ex_index, example) in enumerate(examples): - if ex_index % 10000 == 0: - logging.info("Writing example %d of %d", ex_index, len(examples)) - - feature = classifier_utils.convert_single_example(ex_index, example, - label_list, - max_seq_length, - tokenize_fn, - FLAGS.use_bert_format) - - def create_int_feature(values): - f = tf.train.Feature(int64_list=tf.train.Int64List(value=list(values))) - return f - - def create_float_feature(values): - f = tf.train.Feature(float_list=tf.train.FloatList(value=list(values))) - return f - - features = collections.OrderedDict() - features["input_ids"] = create_int_feature(feature.input_ids) - features["input_mask"] = create_float_feature(feature.input_mask) - features["segment_ids"] = create_int_feature(feature.segment_ids) - if label_list is not None: - features["label_ids"] = create_int_feature([feature.label_id]) - else: - features["label_ids"] = create_float_feature([float(feature.label_id)]) - features["is_real_example"] = create_int_feature( - [int(feature.is_real_example)]) - - tf_example = tf.train.Example(features=tf.train.Features(feature=features)) - writer.write(tf_example.SerializeToString()) - writer.close() - - -def main(_): - logging.set_verbosity(logging.INFO) - processors = { - "mnli_matched": MnliMatchedProcessor, - "mnli_mismatched": MnliMismatchedProcessor, - "sts-b": StsbProcessor, - "imdb": ImdbProcessor, - "yelp5": Yelp5Processor - } - - task_name = FLAGS.task_name.lower() - - if task_name not in processors: - raise ValueError("Task not found: %s" % (task_name)) - - processor = processors[task_name]() - label_list = processor.get_labels() if not FLAGS.is_regression else None - - sp = spm.SentencePieceProcessor() - sp.Load(FLAGS.spiece_model_file) - - def tokenize_fn(text): - text = preprocess_utils.preprocess_text(text, lower=FLAGS.uncased) - return preprocess_utils.encode_ids(sp, text) - - spm_basename = os.path.basename(FLAGS.spiece_model_file) - - train_file_base = "{}.len-{}.train.tf_record".format(spm_basename, - FLAGS.max_seq_length) - train_file = os.path.join(FLAGS.output_dir, train_file_base) - logging.info("Use tfrecord file %s", train_file) - - train_examples = processor.get_train_examples(FLAGS.data_dir) - np.random.shuffle(train_examples) - logging.info("Num of train samples: %d", len(train_examples)) - - file_based_convert_examples_to_features(train_examples, label_list, - FLAGS.max_seq_length, tokenize_fn, - train_file, FLAGS.num_passes) - if FLAGS.eval_split == "dev": - eval_examples = processor.get_dev_examples(FLAGS.data_dir) - else: - eval_examples = processor.get_test_examples(FLAGS.data_dir) - - logging.info("Num of eval samples: %d", len(eval_examples)) - - # TPU requires a fixed batch size for all batches, therefore the number - # of examples must be a multiple of the batch size, or else examples - # will get dropped. So we pad with fake examples which are ignored - # later on. These do NOT count towards the metric (all tf.metrics - # support a per-instance weight, and these get a weight of 0.0). - # - # Modified in XL: We also adopt the same mechanism for GPUs. - while len(eval_examples) % FLAGS.eval_batch_size != 0: - eval_examples.append(classifier_utils.PaddingInputExample()) - - eval_file_base = "{}.len-{}.{}.eval.tf_record".format(spm_basename, - FLAGS.max_seq_length, - FLAGS.eval_split) - eval_file = os.path.join(FLAGS.output_dir, eval_file_base) - - file_based_convert_examples_to_features(eval_examples, label_list, - FLAGS.max_seq_length, tokenize_fn, - eval_file) - - -if __name__ == "__main__": - app.run(main) diff --git a/spaces/NCTCMumbai/NCTC/models/official/vision/image_classification/efficientnet/efficientnet_model.py b/spaces/NCTCMumbai/NCTC/models/official/vision/image_classification/efficientnet/efficientnet_model.py deleted file mode 100644 index ab81fc25d1200557c99f77424d34c74cf8774d84..0000000000000000000000000000000000000000 --- a/spaces/NCTCMumbai/NCTC/models/official/vision/image_classification/efficientnet/efficientnet_model.py +++ /dev/null @@ -1,505 +0,0 @@ -# Lint as: python3 -# Copyright 2019 The TensorFlow Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ============================================================================== -"""Contains definitions for EfficientNet model. - -[1] Mingxing Tan, Quoc V. Le - EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. - ICML'19, https://arxiv.org/abs/1905.11946 -""" - -from __future__ import absolute_import -from __future__ import division -from __future__ import print_function - -import math -import os -from typing import Any, Dict, Optional, Text, Tuple - -from absl import logging -from dataclasses import dataclass -import tensorflow as tf - -from official.modeling import tf_utils -from official.modeling.hyperparams import base_config -from official.vision.image_classification import preprocessing -from official.vision.image_classification.efficientnet import common_modules - - -@dataclass -class BlockConfig(base_config.Config): - """Config for a single MB Conv Block.""" - input_filters: int = 0 - output_filters: int = 0 - kernel_size: int = 3 - num_repeat: int = 1 - expand_ratio: int = 1 - strides: Tuple[int, int] = (1, 1) - se_ratio: Optional[float] = None - id_skip: bool = True - fused_conv: bool = False - conv_type: str = 'depthwise' - - -@dataclass -class ModelConfig(base_config.Config): - """Default Config for Efficientnet-B0.""" - width_coefficient: float = 1.0 - depth_coefficient: float = 1.0 - resolution: int = 224 - dropout_rate: float = 0.2 - blocks: Tuple[BlockConfig, ...] = ( - # (input_filters, output_filters, kernel_size, num_repeat, - # expand_ratio, strides, se_ratio) - # pylint: disable=bad-whitespace - BlockConfig.from_args(32, 16, 3, 1, 1, (1, 1), 0.25), - BlockConfig.from_args(16, 24, 3, 2, 6, (2, 2), 0.25), - BlockConfig.from_args(24, 40, 5, 2, 6, (2, 2), 0.25), - BlockConfig.from_args(40, 80, 3, 3, 6, (2, 2), 0.25), - BlockConfig.from_args(80, 112, 5, 3, 6, (1, 1), 0.25), - BlockConfig.from_args(112, 192, 5, 4, 6, (2, 2), 0.25), - BlockConfig.from_args(192, 320, 3, 1, 6, (1, 1), 0.25), - # pylint: enable=bad-whitespace - ) - stem_base_filters: int = 32 - top_base_filters: int = 1280 - activation: str = 'simple_swish' - batch_norm: str = 'default' - bn_momentum: float = 0.99 - bn_epsilon: float = 1e-3 - # While the original implementation used a weight decay of 1e-5, - # tf.nn.l2_loss divides it by 2, so we halve this to compensate in Keras - weight_decay: float = 5e-6 - drop_connect_rate: float = 0.2 - depth_divisor: int = 8 - min_depth: Optional[int] = None - use_se: bool = True - input_channels: int = 3 - num_classes: int = 1000 - model_name: str = 'efficientnet' - rescale_input: bool = True - data_format: str = 'channels_last' - dtype: str = 'float32' - - -MODEL_CONFIGS = { - # (width, depth, resolution, dropout) - 'efficientnet-b0': ModelConfig.from_args(1.0, 1.0, 224, 0.2), - 'efficientnet-b1': ModelConfig.from_args(1.0, 1.1, 240, 0.2), - 'efficientnet-b2': ModelConfig.from_args(1.1, 1.2, 260, 0.3), - 'efficientnet-b3': ModelConfig.from_args(1.2, 1.4, 300, 0.3), - 'efficientnet-b4': ModelConfig.from_args(1.4, 1.8, 380, 0.4), - 'efficientnet-b5': ModelConfig.from_args(1.6, 2.2, 456, 0.4), - 'efficientnet-b6': ModelConfig.from_args(1.8, 2.6, 528, 0.5), - 'efficientnet-b7': ModelConfig.from_args(2.0, 3.1, 600, 0.5), - 'efficientnet-b8': ModelConfig.from_args(2.2, 3.6, 672, 0.5), - 'efficientnet-l2': ModelConfig.from_args(4.3, 5.3, 800, 0.5), -} - -CONV_KERNEL_INITIALIZER = { - 'class_name': 'VarianceScaling', - 'config': { - 'scale': 2.0, - 'mode': 'fan_out', - # Note: this is a truncated normal distribution - 'distribution': 'normal' - } -} - -DENSE_KERNEL_INITIALIZER = { - 'class_name': 'VarianceScaling', - 'config': { - 'scale': 1 / 3.0, - 'mode': 'fan_out', - 'distribution': 'uniform' - } -} - - -def round_filters(filters: int, - config: ModelConfig) -> int: - """Round number of filters based on width coefficient.""" - width_coefficient = config.width_coefficient - min_depth = config.min_depth - divisor = config.depth_divisor - orig_filters = filters - - if not width_coefficient: - return filters - - filters *= width_coefficient - min_depth = min_depth or divisor - new_filters = max(min_depth, int(filters + divisor / 2) // divisor * divisor) - # Make sure that round down does not go down by more than 10%. - if new_filters < 0.9 * filters: - new_filters += divisor - logging.info('round_filter input=%s output=%s', orig_filters, new_filters) - return int(new_filters) - - -def round_repeats(repeats: int, depth_coefficient: float) -> int: - """Round number of repeats based on depth coefficient.""" - return int(math.ceil(depth_coefficient * repeats)) - - -def conv2d_block(inputs: tf.Tensor, - conv_filters: Optional[int], - config: ModelConfig, - kernel_size: Any = (1, 1), - strides: Any = (1, 1), - use_batch_norm: bool = True, - use_bias: bool = False, - activation: Any = None, - depthwise: bool = False, - name: Text = None): - """A conv2d followed by batch norm and an activation.""" - batch_norm = common_modules.get_batch_norm(config.batch_norm) - bn_momentum = config.bn_momentum - bn_epsilon = config.bn_epsilon - data_format = tf.keras.backend.image_data_format() - weight_decay = config.weight_decay - - name = name or '' - - # Collect args based on what kind of conv2d block is desired - init_kwargs = { - 'kernel_size': kernel_size, - 'strides': strides, - 'use_bias': use_bias, - 'padding': 'same', - 'name': name + '_conv2d', - 'kernel_regularizer': tf.keras.regularizers.l2(weight_decay), - 'bias_regularizer': tf.keras.regularizers.l2(weight_decay), - } - - if depthwise: - conv2d = tf.keras.layers.DepthwiseConv2D - init_kwargs.update({'depthwise_initializer': CONV_KERNEL_INITIALIZER}) - else: - conv2d = tf.keras.layers.Conv2D - init_kwargs.update({'filters': conv_filters, - 'kernel_initializer': CONV_KERNEL_INITIALIZER}) - - x = conv2d(**init_kwargs)(inputs) - - if use_batch_norm: - bn_axis = 1 if data_format == 'channels_first' else -1 - x = batch_norm(axis=bn_axis, - momentum=bn_momentum, - epsilon=bn_epsilon, - name=name + '_bn')(x) - - if activation is not None: - x = tf.keras.layers.Activation(activation, - name=name + '_activation')(x) - return x - - -def mb_conv_block(inputs: tf.Tensor, - block: BlockConfig, - config: ModelConfig, - prefix: Text = None): - """Mobile Inverted Residual Bottleneck. - - Args: - inputs: the Keras input to the block - block: BlockConfig, arguments to create a Block - config: ModelConfig, a set of model parameters - prefix: prefix for naming all layers - - Returns: - the output of the block - """ - use_se = config.use_se - activation = tf_utils.get_activation(config.activation) - drop_connect_rate = config.drop_connect_rate - data_format = tf.keras.backend.image_data_format() - use_depthwise = block.conv_type != 'no_depthwise' - prefix = prefix or '' - - filters = block.input_filters * block.expand_ratio - - x = inputs - - if block.fused_conv: - # If we use fused mbconv, skip expansion and use regular conv. - x = conv2d_block(x, - filters, - config, - kernel_size=block.kernel_size, - strides=block.strides, - activation=activation, - name=prefix + 'fused') - else: - if block.expand_ratio != 1: - # Expansion phase - kernel_size = (1, 1) if use_depthwise else (3, 3) - x = conv2d_block(x, - filters, - config, - kernel_size=kernel_size, - activation=activation, - name=prefix + 'expand') - - # Depthwise Convolution - if use_depthwise: - x = conv2d_block(x, - conv_filters=None, - config=config, - kernel_size=block.kernel_size, - strides=block.strides, - activation=activation, - depthwise=True, - name=prefix + 'depthwise') - - # Squeeze and Excitation phase - if use_se: - assert block.se_ratio is not None - assert 0 < block.se_ratio <= 1 - num_reduced_filters = max(1, int( - block.input_filters * block.se_ratio - )) - - if data_format == 'channels_first': - se_shape = (filters, 1, 1) - else: - se_shape = (1, 1, filters) - - se = tf.keras.layers.GlobalAveragePooling2D(name=prefix + 'se_squeeze')(x) - se = tf.keras.layers.Reshape(se_shape, name=prefix + 'se_reshape')(se) - - se = conv2d_block(se, - num_reduced_filters, - config, - use_bias=True, - use_batch_norm=False, - activation=activation, - name=prefix + 'se_reduce') - se = conv2d_block(se, - filters, - config, - use_bias=True, - use_batch_norm=False, - activation='sigmoid', - name=prefix + 'se_expand') - x = tf.keras.layers.multiply([x, se], name=prefix + 'se_excite') - - # Output phase - x = conv2d_block(x, - block.output_filters, - config, - activation=None, - name=prefix + 'project') - - # Add identity so that quantization-aware training can insert quantization - # ops correctly. - x = tf.keras.layers.Activation(tf_utils.get_activation('identity'), - name=prefix + 'id')(x) - - if (block.id_skip - and all(s == 1 for s in block.strides) - and block.input_filters == block.output_filters): - if drop_connect_rate and drop_connect_rate > 0: - # Apply dropconnect - # The only difference between dropout and dropconnect in TF is scaling by - # drop_connect_rate during training. See: - # https://github.com/keras-team/keras/pull/9898#issuecomment-380577612 - x = tf.keras.layers.Dropout(drop_connect_rate, - noise_shape=(None, 1, 1, 1), - name=prefix + 'drop')(x) - - x = tf.keras.layers.add([x, inputs], name=prefix + 'add') - - return x - - -def efficientnet(image_input: tf.keras.layers.Input, - config: ModelConfig): - """Creates an EfficientNet graph given the model parameters. - - This function is wrapped by the `EfficientNet` class to make a tf.keras.Model. - - Args: - image_input: the input batch of images - config: the model config - - Returns: - the output of efficientnet - """ - depth_coefficient = config.depth_coefficient - blocks = config.blocks - stem_base_filters = config.stem_base_filters - top_base_filters = config.top_base_filters - activation = tf_utils.get_activation(config.activation) - dropout_rate = config.dropout_rate - drop_connect_rate = config.drop_connect_rate - num_classes = config.num_classes - input_channels = config.input_channels - rescale_input = config.rescale_input - data_format = tf.keras.backend.image_data_format() - dtype = config.dtype - weight_decay = config.weight_decay - - x = image_input - if data_format == 'channels_first': - # Happens on GPU/TPU if available. - x = tf.keras.layers.Permute((3, 1, 2))(x) - if rescale_input: - x = preprocessing.normalize_images(x, - num_channels=input_channels, - dtype=dtype, - data_format=data_format) - - # Build stem - x = conv2d_block(x, - round_filters(stem_base_filters, config), - config, - kernel_size=[3, 3], - strides=[2, 2], - activation=activation, - name='stem') - - # Build blocks - num_blocks_total = sum( - round_repeats(block.num_repeat, depth_coefficient) for block in blocks) - block_num = 0 - - for stack_idx, block in enumerate(blocks): - assert block.num_repeat > 0 - # Update block input and output filters based on depth multiplier - block = block.replace( - input_filters=round_filters(block.input_filters, config), - output_filters=round_filters(block.output_filters, config), - num_repeat=round_repeats(block.num_repeat, depth_coefficient)) - - # The first block needs to take care of stride and filter size increase - drop_rate = drop_connect_rate * float(block_num) / num_blocks_total - config = config.replace(drop_connect_rate=drop_rate) - block_prefix = 'stack_{}/block_0/'.format(stack_idx) - x = mb_conv_block(x, block, config, block_prefix) - block_num += 1 - if block.num_repeat > 1: - block = block.replace( - input_filters=block.output_filters, - strides=[1, 1] - ) - - for block_idx in range(block.num_repeat - 1): - drop_rate = drop_connect_rate * float(block_num) / num_blocks_total - config = config.replace(drop_connect_rate=drop_rate) - block_prefix = 'stack_{}/block_{}/'.format(stack_idx, block_idx + 1) - x = mb_conv_block(x, block, config, prefix=block_prefix) - block_num += 1 - - # Build top - x = conv2d_block(x, - round_filters(top_base_filters, config), - config, - activation=activation, - name='top') - - # Build classifier - x = tf.keras.layers.GlobalAveragePooling2D(name='top_pool')(x) - if dropout_rate and dropout_rate > 0: - x = tf.keras.layers.Dropout(dropout_rate, name='top_dropout')(x) - x = tf.keras.layers.Dense( - num_classes, - kernel_initializer=DENSE_KERNEL_INITIALIZER, - kernel_regularizer=tf.keras.regularizers.l2(weight_decay), - bias_regularizer=tf.keras.regularizers.l2(weight_decay), - name='logits')(x) - x = tf.keras.layers.Activation('softmax', name='probs')(x) - - return x - - -@tf.keras.utils.register_keras_serializable(package='Vision') -class EfficientNet(tf.keras.Model): - """Wrapper class for an EfficientNet Keras model. - - Contains helper methods to build, manage, and save metadata about the model. - """ - - def __init__(self, - config: ModelConfig = None, - overrides: Dict[Text, Any] = None): - """Create an EfficientNet model. - - Args: - config: (optional) the main model parameters to create the model - overrides: (optional) a dict containing keys that can override - config - """ - overrides = overrides or {} - config = config or ModelConfig() - - self.config = config.replace(**overrides) - - input_channels = self.config.input_channels - model_name = self.config.model_name - input_shape = (None, None, input_channels) # Should handle any size image - image_input = tf.keras.layers.Input(shape=input_shape) - - output = efficientnet(image_input, self.config) - - # Cast to float32 in case we have a different model dtype - output = tf.cast(output, tf.float32) - - logging.info('Building model %s with params %s', - model_name, - self.config) - - super(EfficientNet, self).__init__( - inputs=image_input, outputs=output, name=model_name) - - @classmethod - def from_name(cls, - model_name: Text, - model_weights_path: Text = None, - weights_format: Text = 'saved_model', - overrides: Dict[Text, Any] = None): - """Construct an EfficientNet model from a predefined model name. - - E.g., `EfficientNet.from_name('efficientnet-b0')`. - - Args: - model_name: the predefined model name - model_weights_path: the path to the weights (h5 file or saved model dir) - weights_format: the model weights format. One of 'saved_model', 'h5', - or 'checkpoint'. - overrides: (optional) a dict containing keys that can override config - - Returns: - A constructed EfficientNet instance. - """ - model_configs = dict(MODEL_CONFIGS) - overrides = dict(overrides) if overrides else {} - - # One can define their own custom models if necessary - model_configs.update(overrides.pop('model_config', {})) - - if model_name not in model_configs: - raise ValueError('Unknown model name {}'.format(model_name)) - - config = model_configs[model_name] - - model = cls(config=config, overrides=overrides) - - if model_weights_path: - common_modules.load_weights(model, - model_weights_path, - weights_format=weights_format) - - return model diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/speech2unit/pretrained/logmel_feature_reader.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/speech2unit/pretrained/logmel_feature_reader.py deleted file mode 100644 index 106f50247622deca688b223f1ad63275d5b65e58..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/speech2unit/pretrained/logmel_feature_reader.py +++ /dev/null @@ -1,30 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import soundfile as sf -import torch -import torchaudio.compliance.kaldi as kaldi - - -class LogMelFeatureReader: - """ - Wrapper class to run inference on HuBERT model. - Helps extract features for a given audio file. - """ - - def __init__(self, *args, **kwargs): - self.num_mel_bins = kwargs.get("num_mel_bins", 80) - self.frame_length = kwargs.get("frame_length", 25.0) - - def get_feats(self, file_path): - wav, sr = sf.read(file_path) - feats = torch.from_numpy(wav).float() - feats = kaldi.fbank( - feats.unsqueeze(0), - num_mel_bins=self.num_mel_bins, - frame_length=self.frame_length, - sample_frequency=sr, - ) - return feats diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/speech2unit/pretrained/utils.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/speech2unit/pretrained/utils.py deleted file mode 100644 index 5aaddf6421ab7fa417af508005671a0ed821c701..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/examples/textless_nlp/gslm/speech2unit/pretrained/utils.py +++ /dev/null @@ -1,126 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import gc -import os -import random -import shutil -import numpy as np - -import torch -import tqdm -from examples.textless_nlp.gslm.speech2unit.pretrained.cpc_feature_reader import ( - CpcFeatureReader, -) -from examples.textless_nlp.gslm.speech2unit.pretrained.hubert_feature_reader import ( - HubertFeatureReader, -) -from examples.textless_nlp.gslm.speech2unit.pretrained.logmel_feature_reader import ( - LogMelFeatureReader, -) -from examples.textless_nlp.gslm.speech2unit.pretrained.w2v2_feature_reader import ( - Wav2VecFeatureReader, -) - - -def get_feature_reader(feature_type): - if feature_type == "logmel": - return LogMelFeatureReader - elif feature_type == "hubert": - return HubertFeatureReader - elif feature_type == "w2v2": - return Wav2VecFeatureReader - elif feature_type == "cpc": - return CpcFeatureReader - else: - raise NotImplementedError(f"{feature_type} is not supported.") - - -def get_feature_iterator( - feature_type, checkpoint_path, layer, manifest_path, sample_pct -): - feature_reader_cls = get_feature_reader(feature_type) - with open(manifest_path, "r") as fp: - lines = fp.read().split("\n") - root = lines.pop(0).strip() - file_path_list = [ - os.path.join(root, line.split("\t")[0]) - for line in lines - if len(line) > 0 - ] - if sample_pct < 1.0: - file_path_list = random.sample( - file_path_list, int(sample_pct * len(file_path_list)) - ) - num_files = len(file_path_list) - reader = feature_reader_cls( - checkpoint_path=checkpoint_path, layer=layer - ) - - def iterate(): - for file_path in file_path_list: - feats = reader.get_feats(file_path) - yield feats.cpu().numpy() - - return iterate, num_files - - -def get_features( - feature_type, checkpoint_path, layer, manifest_path, sample_pct, flatten -): - generator, num_files = get_feature_iterator( - feature_type=feature_type, - checkpoint_path=checkpoint_path, - layer=layer, - manifest_path=manifest_path, - sample_pct=sample_pct, - ) - iterator = generator() - - features_list = [] - for features in tqdm.tqdm(iterator, total=num_files): - features_list.append(features) - - # Explicit clean up - del iterator - del generator - gc.collect() - torch.cuda.empty_cache() - - if flatten: - return np.concatenate(features_list) - - return features_list - - -def get_and_dump_features( - feature_type, - checkpoint_path, - layer, - manifest_path, - sample_pct, - flatten, - out_features_path, -): - # Feature extraction - features_batch = get_features( - feature_type=feature_type, - checkpoint_path=checkpoint_path, - layer=layer, - manifest_path=manifest_path, - sample_pct=sample_pct, - flatten=flatten, - ) - - # Save features - out_dir_path = os.path.dirname(out_features_path) - os.makedirs(out_dir_path, exist_ok=True) - shutil.copyfile( - manifest_path, - os.path.join(out_dir_path, os.path.basename(manifest_path)), - ) - np.save(out_features_path, features_batch) - - return features_batch diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/iterative_refinement_generator.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/iterative_refinement_generator.py deleted file mode 100644 index 4fb0946f499329ceb130761b59675d761df1c158..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/iterative_refinement_generator.py +++ /dev/null @@ -1,359 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -from collections import namedtuple - -import numpy as np -import torch -from fairseq import utils - - -DecoderOut = namedtuple( - "IterativeRefinementDecoderOut", - ["output_tokens", "output_scores", "attn", "step", "max_step", "history"], -) - - -class IterativeRefinementGenerator(object): - def __init__( - self, - tgt_dict, - models=None, - eos_penalty=0.0, - max_iter=10, - max_ratio=2, - beam_size=1, - decoding_format=None, - retain_dropout=False, - adaptive=True, - retain_history=False, - reranking=False, - ): - """ - Generates translations based on iterative refinement. - - Args: - tgt_dict: target dictionary - eos_penalty: if > 0.0, it penalized early-stopping in decoding - max_iter: maximum number of refinement iterations - max_ratio: generate sequences of maximum length ax, where x is the source length - decoding_format: decoding mode in {'unigram', 'ensemble', 'vote', 'dp', 'bs'} - retain_dropout: retaining dropout in the inference - adaptive: decoding with early stop - """ - self.bos = tgt_dict.bos() - self.pad = tgt_dict.pad() - self.unk = tgt_dict.unk() - self.eos = tgt_dict.eos() - self.vocab_size = len(tgt_dict) - self.eos_penalty = eos_penalty - self.max_iter = max_iter - self.max_ratio = max_ratio - self.beam_size = beam_size - self.reranking = reranking - self.decoding_format = decoding_format - self.retain_dropout = retain_dropout - self.retain_history = retain_history - self.adaptive = adaptive - self.models = models - - def generate_batched_itr( - self, - data_itr, - maxlen_a=None, - maxlen_b=None, - cuda=False, - timer=None, - prefix_size=0, - ): - """Iterate over a batched dataset and yield individual translations. - - Args: - maxlen_a/b: generate sequences of maximum length ax + b, - where x is the source sentence length. - cuda: use GPU for generation - timer: StopwatchMeter for timing generations. - """ - - for sample in data_itr: - if "net_input" not in sample: - continue - if timer is not None: - timer.start() - with torch.no_grad(): - hypos = self.generate( - self.models, - sample, - prefix_tokens=sample["target"][:, :prefix_size] - if prefix_size > 0 - else None, - ) - if timer is not None: - timer.stop(sample["ntokens"]) - for i, id in enumerate(sample["id"]): - # remove padding - src = utils.strip_pad(sample["net_input"]["src_tokens"][i, :], self.pad) - ref = utils.strip_pad(sample["target"][i, :], self.pad) - yield id, src, ref, hypos[i] - - @torch.no_grad() - def generate(self, models, sample, prefix_tokens=None, constraints=None): - if constraints is not None: - raise NotImplementedError( - "Constrained decoding with the IterativeRefinementGenerator is not supported" - ) - - # TODO: iterative refinement generator does not support ensemble for now. - if not self.retain_dropout: - for model in models: - model.eval() - - model, reranker = models[0], None - if self.reranking: - assert len(models) > 1, "Assuming the last checkpoint is the reranker" - assert ( - self.beam_size > 1 - ), "Reranking requires multiple translation for each example" - - reranker = models[-1] - models = models[:-1] - - if len(models) > 1 and hasattr(model, "enable_ensemble"): - assert model.allow_ensemble, "{} does not support ensembling".format( - model.__class__.__name__ - ) - model.enable_ensemble(models) - - # TODO: better encoder inputs? - src_tokens = sample["net_input"]["src_tokens"] - src_lengths = sample["net_input"]["src_lengths"] - bsz, src_len = src_tokens.size() - - # initialize - encoder_out = model.forward_encoder([src_tokens, src_lengths]) - prev_decoder_out = model.initialize_output_tokens(encoder_out, src_tokens) - - if self.beam_size > 1: - assert ( - model.allow_length_beam - ), "{} does not support decoding with length beam.".format( - model.__class__.__name__ - ) - - # regenerate data based on length-beam - length_beam_order = ( - utils.new_arange(src_tokens, self.beam_size, bsz).t().reshape(-1) - ) - encoder_out = model.encoder.reorder_encoder_out( - encoder_out, length_beam_order - ) - prev_decoder_out = model.regenerate_length_beam( - prev_decoder_out, self.beam_size - ) - bsz = bsz * self.beam_size - - sent_idxs = torch.arange(bsz) - prev_output_tokens = prev_decoder_out.output_tokens.clone() - - if self.retain_history: - prev_decoder_out = prev_decoder_out._replace(history=[prev_output_tokens]) - - finalized = [[] for _ in range(bsz)] - - def is_a_loop(x, y, s, a): - b, l_x, l_y = x.size(0), x.size(1), y.size(1) - if l_x > l_y: - y = torch.cat([y, x.new_zeros(b, l_x - l_y).fill_(self.pad)], 1) - s = torch.cat([s, s.new_zeros(b, l_x - l_y)], 1) - if a is not None: - a = torch.cat([a, a.new_zeros(b, l_x - l_y, a.size(2))], 1) - elif l_x < l_y: - x = torch.cat([x, y.new_zeros(b, l_y - l_x).fill_(self.pad)], 1) - return (x == y).all(1), y, s, a - - def finalized_hypos(step, prev_out_token, prev_out_score, prev_out_attn): - cutoff = prev_out_token.ne(self.pad) - tokens = prev_out_token[cutoff] - if prev_out_score is None: - scores, score = None, None - else: - scores = prev_out_score[cutoff] - score = scores.mean() - - if prev_out_attn is None: - hypo_attn, alignment = None, None - else: - hypo_attn = prev_out_attn[cutoff] - alignment = hypo_attn.max(dim=1)[1] - return { - "steps": step, - "tokens": tokens, - "positional_scores": scores, - "score": score, - "hypo_attn": hypo_attn, - "alignment": alignment, - } - - for step in range(self.max_iter + 1): - - decoder_options = { - "eos_penalty": self.eos_penalty, - "max_ratio": self.max_ratio, - "decoding_format": self.decoding_format, - } - prev_decoder_out = prev_decoder_out._replace( - step=step, - max_step=self.max_iter + 1, - ) - - decoder_out = model.forward_decoder( - prev_decoder_out, encoder_out, **decoder_options - ) - - if self.adaptive: - # terminate if there is a loop - terminated, out_tokens, out_scores, out_attn = is_a_loop( - prev_output_tokens, - decoder_out.output_tokens, - decoder_out.output_scores, - decoder_out.attn, - ) - decoder_out = decoder_out._replace( - output_tokens=out_tokens, - output_scores=out_scores, - attn=out_attn, - ) - - else: - terminated = decoder_out.output_tokens.new_zeros( - decoder_out.output_tokens.size(0) - ).bool() - - if step == self.max_iter: # reach last iteration, terminate - terminated.fill_(1) - - # collect finalized sentences - finalized_idxs = sent_idxs[terminated] - finalized_tokens = decoder_out.output_tokens[terminated] - finalized_scores = decoder_out.output_scores[terminated] - finalized_attn = ( - None - if (decoder_out.attn is None or decoder_out.attn.size(0) == 0) - else decoder_out.attn[terminated] - ) - - if self.retain_history: - finalized_history_tokens = [h[terminated] for h in decoder_out.history] - - for i in range(finalized_idxs.size(0)): - finalized[finalized_idxs[i]] = [ - finalized_hypos( - step, - finalized_tokens[i], - finalized_scores[i], - None if finalized_attn is None else finalized_attn[i], - ) - ] - - if self.retain_history: - finalized[finalized_idxs[i]][0]["history"] = [] - for j in range(len(finalized_history_tokens)): - finalized[finalized_idxs[i]][0]["history"].append( - finalized_hypos( - step, finalized_history_tokens[j][i], None, None - ) - ) - - # check if all terminated - if terminated.sum() == terminated.size(0): - break - - # for next step - not_terminated = ~terminated - prev_decoder_out = decoder_out._replace( - output_tokens=decoder_out.output_tokens[not_terminated], - output_scores=decoder_out.output_scores[not_terminated], - attn=decoder_out.attn[not_terminated] - if (decoder_out.attn is not None and decoder_out.attn.size(0) > 0) - else None, - history=[h[not_terminated] for h in decoder_out.history] - if decoder_out.history is not None - else None, - ) - encoder_out = model.encoder.reorder_encoder_out( - encoder_out, not_terminated.nonzero(as_tuple=False).squeeze() - ) - sent_idxs = sent_idxs[not_terminated] - prev_output_tokens = prev_decoder_out.output_tokens.clone() - - if self.beam_size > 1: - if reranker is not None: - finalized = self.rerank( - reranker, finalized, [src_tokens, src_lengths], self.beam_size - ) - - # aggregate information from length beam - finalized = [ - finalized[ - np.argmax( - [ - finalized[self.beam_size * i + j][0]["score"] - for j in range(self.beam_size) - ] - ) - + self.beam_size * i - ] - for i in range(len(finalized) // self.beam_size) - ] - - return finalized - - def rerank(self, reranker, finalized, encoder_input, beam_size): - def rebuild_batch(finalized): - finalized_tokens = [f[0]["tokens"] for f in finalized] - finalized_maxlen = max(f.size(0) for f in finalized_tokens) - final_output_tokens = ( - finalized_tokens[0] - .new_zeros(len(finalized_tokens), finalized_maxlen) - .fill_(self.pad) - ) - for i, f in enumerate(finalized_tokens): - final_output_tokens[i, : f.size(0)] = f - return final_output_tokens - - final_output_tokens = rebuild_batch(finalized) - final_output_tokens[ - :, 0 - ] = self.eos # autoregressive model assumes starting with EOS - - reranker_encoder_out = reranker.encoder(*encoder_input) - length_beam_order = ( - utils.new_arange( - final_output_tokens, beam_size, reranker_encoder_out.encoder_out.size(1) - ) - .t() - .reshape(-1) - ) - reranker_encoder_out = reranker.encoder.reorder_encoder_out( - reranker_encoder_out, length_beam_order - ) - reranking_scores = reranker.get_normalized_probs( - reranker.decoder(final_output_tokens[:, :-1], reranker_encoder_out), - True, - None, - ) - reranking_scores = reranking_scores.gather(2, final_output_tokens[:, 1:, None]) - reranking_masks = final_output_tokens[:, 1:].ne(self.pad) - reranking_scores = ( - reranking_scores[:, :, 0].masked_fill_(~reranking_masks, 0).sum(1) - ) - reranking_scores = reranking_scores / reranking_masks.sum(1).type_as( - reranking_scores - ) - - for i in range(len(finalized)): - finalized[i][0]["score"] = reranking_scores[i] - - return finalized diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/translation_moe/translation_moe_src/logsumexp_moe.py b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/translation_moe/translation_moe_src/logsumexp_moe.py deleted file mode 100644 index fb299daecbc2b15fb66555bbfb8d1d983e481518..0000000000000000000000000000000000000000 --- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/translation_moe/translation_moe_src/logsumexp_moe.py +++ /dev/null @@ -1,26 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import torch - - -class LogSumExpMoE(torch.autograd.Function): - """Standard LogSumExp forward pass, but use *posterior* for the backward. - - See `"Mixture Models for Diverse Machine Translation: Tricks of the Trade" - (Shen et al., 2019)
-* [Non-Autoregressive Neural Machine Translation (Gu et al., 2017)](https://arxiv.org/abs/1711.02281)
-* [Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement (Lee et al., 2018)](https://arxiv.org/abs/1802.06901)
-* [Insertion Transformer: Flexible Sequence Generation via Insertion Operations (Stern et al., 2019)](https://arxiv.org/abs/1902.03249)
-* [Mask-Predict: Parallel Decoding of Conditional Masked Language Models (Ghazvininejad et al., 2019)](https://arxiv.org/abs/1904.09324v2)
-* [Fast Structured Decoding for Sequence Models (Sun et al., 2019)](https://arxiv.org/abs/1910.11555) - -## Dataset - -First, follow the [instructions to download and preprocess the WMT'14 En-De dataset](../translation#wmt14-english-to-german-convolutional). -Make sure to learn a joint vocabulary by passing the `--joined-dictionary` option to `fairseq-preprocess`. - -### Knowledge Distillation -Following [Gu et al. 2019](https://arxiv.org/abs/1905.11006), [knowledge distillation](https://arxiv.org/abs/1606.07947) from an autoregressive model can effectively simplify the training data distribution, which is sometimes essential for NAT-based models to learn good translations. -The easiest way of performing distillation is to follow the [instructions of training a standard transformer model](../translation) on the same data, and then decode the training set to produce a distillation dataset for NAT. - -### Download -We also provided the preprocessed [original](http://dl.fbaipublicfiles.com/nat/original_dataset.zip) and [distillation](http://dl.fbaipublicfiles.com/nat/distill_dataset.zip) datasets. Please build the binarized dataset on your own. - - -## Train a model - -Then we can train a nonautoregressive model using the `translation_lev` task and a new criterion `nat_loss`. -Use the `--noise` flag to specify the input noise used on the target sentences. -In default, we run the task for *Levenshtein Transformer*, with `--noise='random_delete'`. Full scripts to run other models can also be found [here](./scripts.md). - -The following command will train a *Levenshtein Transformer* on the binarized dataset. - -```bash -fairseq-train \ - data-bin/wmt14_en_de_distill \ - --save-dir checkpoints \ - --ddp-backend=legacy_ddp \ - --task translation_lev \ - --criterion nat_loss \ - --arch levenshtein_transformer \ - --noise random_delete \ - --share-all-embeddings \ - --optimizer adam --adam-betas '(0.9,0.98)' \ - --lr 0.0005 --lr-scheduler inverse_sqrt \ - --stop-min-lr '1e-09' --warmup-updates 10000 \ - --warmup-init-lr '1e-07' --label-smoothing 0.1 \ - --dropout 0.3 --weight-decay 0.01 \ - --decoder-learned-pos \ - --encoder-learned-pos \ - --apply-bert-init \ - --log-format 'simple' --log-interval 100 \ - --fixed-validation-seed 7 \ - --max-tokens 8000 \ - --save-interval-updates 10000 \ - --max-update 300000 -``` - -## Translate - -Once a model is trained, we can generate translations using an `iterative_refinement_generator` which will based on the model's initial output and iteratively read and greedily refine the translation until (1) the model predicts the same translations for two consecutive iterations; or (2) the generator reaches the maximum iterations (`--iter-decode-max-iter`). Use `--print-step` to check the actual # of iteration for each sentence. - -For *Levenshtein Transformer*, it sometimes helps to apply a `--iter-decode-eos-penalty` (typically, 0~3) to penalize the model finishing generation too early and generating too short translations. - -For example, to generate with `--iter-decode-max-iter=9`: -```bash -fairseq-generate \ - data-bin/wmt14_en_de_distill \ - --gen-subset test \ - --task translation_lev \ - --path checkpoints/checkpoint_best.pt \ - --iter-decode-max-iter 9 \ - --iter-decode-eos-penalty 0 \ - --beam 1 --remove-bpe \ - --print-step \ - --batch-size 400 -``` -In the end of the generation, we can see the tokenized BLEU score for the translation. - -## Advanced Decoding Methods -### Ensemble -The NAT models use special implementations of [ensembling](https://github.com/fairinternal/fairseq-py/blob/b98d88da52f2f21f1b169bab8c70c1c4ca19a768/fairseq/sequence_generator.py#L522) to support iterative refinement and a variety of parallel operations in different models, while it shares the same API as standard autoregressive models as follows: -```bash -fairseq-generate \ - data-bin/wmt14_en_de_distill \ - --gen-subset test \ - --task translation_lev \ - --path checkpoint_1.pt:checkpoint_2.pt:checkpoint_3.pt \ - --iter-decode-max-iter 9 \ - --iter-decode-eos-penalty 0 \ - --beam 1 --remove-bpe \ - --print-step \ - --batch-size 400 -``` -We use ``:`` to split multiple models. Note that, not all NAT models support ensembling for now. - - -### Length-beam -For models that predict lengths before decoding (e.g. the vanilla NAT, Mask-Predict, etc), it is possible to improve the translation quality by varying the target lengths around the predicted value, and translating the same example multiple times in parallel. We can select the best translation with the highest scores defined by your model's output. - -Note that, not all models support length beams. For models which dynamically change the lengths (e.g. *Insertion Transformer*, *Levenshtein Transformer*), the same trick does not apply. - -### Re-ranking -If the model generates multiple translations with length beam, we can also introduce an autoregressive model to rerank the translations considering scoring from an autoregressive model is much faster than decoding from that. - -For example, to generate translations with length beam and reranking, -```bash -fairseq-generate \ - data-bin/wmt14_en_de_distill \ - --gen-subset test \ - --task translation_lev \ - --path checkpoints/checkpoint_best.pt:at_checkpoints/checkpoint_best.pt \ - --iter-decode-max-iter 9 \ - --iter-decode-eos-penalty 0 \ - --iter-decode-with-beam 9 \ - --iter-decode-with-external-reranker \ - --beam 1 --remove-bpe \ - --print-step \ - --batch-size 100 -``` -Note that we need to make sure the autoregressive model shares the same vocabulary as our target non-autoregressive model. - - -## Citation - -```bibtex -@incollection{NIPS2019_9297, - title = {Levenshtein Transformer}, - author = {Gu, Jiatao and Wang, Changhan and Zhao, Junbo}, - booktitle = {Advances in Neural Information Processing Systems 32}, - editor = {H. Wallach and H. Larochelle and A. Beygelzimer and F. d\textquotesingle Alch\'{e}-Buc and E. Fox and R. Garnett}, - pages = {11179--11189}, - year = {2019}, - publisher = {Curran Associates, Inc.}, - url = {http://papers.nips.cc/paper/9297-levenshtein-transformer.pdf} -} -``` -```bibtex -@article{zhou2019understanding, - title={Understanding Knowledge Distillation in Non-autoregressive Machine Translation}, - author={Zhou, Chunting and Neubig, Graham and Gu, Jiatao}, - journal={arXiv preprint arXiv:1911.02727}, - year={2019} -} -``` diff --git a/spaces/OlaWod/FreeVC/app.py b/spaces/OlaWod/FreeVC/app.py deleted file mode 100644 index 390198b05bcdad1a96cb2f5e3795c620a5856cfd..0000000000000000000000000000000000000000 --- a/spaces/OlaWod/FreeVC/app.py +++ /dev/null @@ -1,103 +0,0 @@ -import os -import torch -import librosa -import gradio as gr -from scipy.io.wavfile import write -from transformers import WavLMModel - -import utils -from models import SynthesizerTrn -from mel_processing import mel_spectrogram_torch -from speaker_encoder.voice_encoder import SpeakerEncoder - -''' -def get_wavlm(): - os.system('gdown https://drive.google.com/uc?id=12-cB34qCTvByWT-QtOcZaqwwO21FLSqU') - shutil.move('WavLM-Large.pt', 'wavlm') -''' - -device = torch.device("cuda" if torch.cuda.is_available() else "cpu") - -print("Loading FreeVC...") -hps = utils.get_hparams_from_file("configs/freevc.json") -freevc = SynthesizerTrn( - hps.data.filter_length // 2 + 1, - hps.train.segment_size // hps.data.hop_length, - **hps.model).to(device) -_ = freevc.eval() -_ = utils.load_checkpoint("checkpoints/freevc.pth", freevc, None) -smodel = SpeakerEncoder('speaker_encoder/ckpt/pretrained_bak_5805000.pt') - -print("Loading FreeVC(24k)...") -hps = utils.get_hparams_from_file("configs/freevc-24.json") -freevc_24 = SynthesizerTrn( - hps.data.filter_length // 2 + 1, - hps.train.segment_size // hps.data.hop_length, - **hps.model).to(device) -_ = freevc_24.eval() -_ = utils.load_checkpoint("checkpoints/freevc-24.pth", freevc_24, None) - -print("Loading FreeVC-s...") -hps = utils.get_hparams_from_file("configs/freevc-s.json") -freevc_s = SynthesizerTrn( - hps.data.filter_length // 2 + 1, - hps.train.segment_size // hps.data.hop_length, - **hps.model).to(device) -_ = freevc_s.eval() -_ = utils.load_checkpoint("checkpoints/freevc-s.pth", freevc_s, None) - -print("Loading WavLM for content...") -cmodel = WavLMModel.from_pretrained("microsoft/wavlm-large").to(device) - -def convert(model, src, tgt): - with torch.no_grad(): - # tgt - wav_tgt, _ = librosa.load(tgt, sr=hps.data.sampling_rate) - wav_tgt, _ = librosa.effects.trim(wav_tgt, top_db=20) - if model == "FreeVC" or model == "FreeVC (24kHz)": - g_tgt = smodel.embed_utterance(wav_tgt) - g_tgt = torch.from_numpy(g_tgt).unsqueeze(0).to(device) - else: - wav_tgt = torch.from_numpy(wav_tgt).unsqueeze(0).to(device) - mel_tgt = mel_spectrogram_torch( - wav_tgt, - hps.data.filter_length, - hps.data.n_mel_channels, - hps.data.sampling_rate, - hps.data.hop_length, - hps.data.win_length, - hps.data.mel_fmin, - hps.data.mel_fmax - ) - # src - wav_src, _ = librosa.load(src, sr=hps.data.sampling_rate) - wav_src = torch.from_numpy(wav_src).unsqueeze(0).to(device) - c = cmodel(wav_src).last_hidden_state.transpose(1, 2).to(device) - # infer - if model == "FreeVC": - audio = freevc.infer(c, g=g_tgt) - elif model == "FreeVC-s": - audio = freevc_s.infer(c, mel=mel_tgt) - else: - audio = freevc_24.infer(c, g=g_tgt) - audio = audio[0][0].data.cpu().float().numpy() - if model == "FreeVC" or model == "FreeVC-s": - write("out.wav", hps.data.sampling_rate, audio) - else: - write("out.wav", 24000, audio) - out = "out.wav" - return out - -model = gr.Dropdown(choices=["FreeVC", "FreeVC-s", "FreeVC (24kHz)"], value="FreeVC",type="value", label="Model") -audio1 = gr.inputs.Audio(label="Source Audio", type='filepath') -audio2 = gr.inputs.Audio(label="Reference Audio", type='filepath') -inputs = [model, audio1, audio2] -outputs = gr.outputs.Audio(label="Output Audio", type='filepath') - -title = "FreeVC" -description = "Gradio Demo for FreeVC: Towards High-Quality Text-Free One-Shot Voice Conversion. To use it, simply upload your audio, or click the example to load. Read more at the links below. Note: It seems that the WavLM checkpoint in HuggingFace is a little different from the one used to train FreeVC, which may degrade the performance a bit. In addition, speaker similarity can be largely affected if there are too much silence in the reference audio, so please trim it before submitting." -article = "" - -examples=[["FreeVC", 'p225_001.wav', 'p226_002.wav'], ["FreeVC-s", 'p226_002.wav', 'p225_001.wav'], ["FreeVC (24kHz)", 'p225_001.wav', 'p226_002.wav']] - -gr.Interface(convert, inputs, outputs, title=title, description=description, article=article, examples=examples, enable_queue=True).launch() diff --git a/spaces/OpenGVLab/InternGPT/iGPT/models/grit_src/third_party/CenterNet2/detectron2/layers/csrc/vision.cpp b/spaces/OpenGVLab/InternGPT/iGPT/models/grit_src/third_party/CenterNet2/detectron2/layers/csrc/vision.cpp deleted file mode 100644 index c9a2cd4f20e6f58be1c5783d67c64232dd59b560..0000000000000000000000000000000000000000 --- a/spaces/OpenGVLab/InternGPT/iGPT/models/grit_src/third_party/CenterNet2/detectron2/layers/csrc/vision.cpp +++ /dev/null @@ -1,117 +0,0 @@ -// Copyright (c) Facebook, Inc. and its affiliates. - -#include
" - "⭐ Star me on GitHub: [Spico197/writing-comrade](https://github.com/Spico197/writing-comrade)
" - "You may want to follow [this instruction](https://help.openai.com/en/articles/4936850-where-do-i-find-my-secret-api-key) to get an API key." - ) - - with gr.Row(): - api_key = gr.Textbox(label='OpenAI API Key', type="password") - - with gr.Row().style(equal_height=True): - with gr.Column(scale=3): - emojis = "📝🥊💎🍦🚌🎤" - task_type = gr.Radio([f"{emojis[i]}{k.title()}" for i, k in enumerate(instructions.keys())], label="Task") - with gr.Column(min_width=100): - tgt_lang = gr.Textbox(label="Target language in translation") - with gr.Column(): - text_button = gr.Button("Can~ do!", variant="primary") - - with gr.Row(): - with gr.Column(): - text_input = gr.TextArea(lines=15, label="Input") - with gr.Column(): - text_output = gr.TextArea(lines=15, label="Output") - - text_button.click( - chat, inputs=[task_type, text_input, api_key, tgt_lang], outputs=text_output - ) - -demo.launch(show_error=True) diff --git a/spaces/SuYuanS/AudioCraft_Plus/docs/METRICS.md b/spaces/SuYuanS/AudioCraft_Plus/docs/METRICS.md deleted file mode 100644 index e2ae9a184cbccb8bfefb4ce77afa5ddab743a051..0000000000000000000000000000000000000000 --- a/spaces/SuYuanS/AudioCraft_Plus/docs/METRICS.md +++ /dev/null @@ -1,127 +0,0 @@ -# AudioCraft objective metrics - -In addition to training losses, AudioCraft provides a set of objective metrics -for audio synthesis and audio generation. As these metrics may require -extra dependencies and can be costly to train, they are often disabled by default. -This section provides guidance for setting up and using these metrics in -the AudioCraft training pipelines. - -## Available metrics - -### Audio synthesis quality metrics - -#### SI-SNR - -We provide an implementation of the Scale-Invariant Signal-to-Noise Ratio in PyTorch. -No specific requirement is needed for this metric. Please activate the metric at the -evaluation stage with the appropriate flag: - -```shell -dora run <...> evaluate.metrics.sisnr=true -``` - -#### ViSQOL - -We provide a Python wrapper around the ViSQOL [official implementation](https://github.com/google/visqol) -to conveniently run ViSQOL within the training pipelines. - -One must specify the path to the ViSQOL installation through the configuration in order -to enable ViSQOL computations in AudioCraft: - -```shell -# the first parameter is used to activate visqol computation while the second specify -# the path to visqol's library to be used by our python wrapper -dora run <...> evaluate.metrics.visqol=true metrics.visqol.bin=
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models | Github Repo
" -examples =[["image_0.png"]] - -iface = gr.Interface(fn=hand_written, - inputs=gr.inputs.Image(type="pil"), - outputs=gr.outputs.Textbox(), - title=title, - description=description, - article=article, - examples=examples) - -iface.launch(debug=True,share=True) \ No newline at end of file diff --git a/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/models/blip2.py b/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/models/blip2.py deleted file mode 100644 index ee4a9dc3e2544033139841032ebb7b35168ac8fa..0000000000000000000000000000000000000000 --- a/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/models/blip2.py +++ /dev/null @@ -1,221 +0,0 @@ -""" - Copyright (c) 2023, salesforce.com, inc. - All rights reserved. - SPDX-License-Identifier: BSD-3-Clause - For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause -""" -import contextlib -import logging -import os -import time -import datetime - -import torch -import torch.nn as nn -import torch.distributed as dist -import torch.nn.functional as F - -import minigpt4.common.dist_utils as dist_utils -from minigpt4.common.dist_utils import download_cached_file -from minigpt4.common.utils import is_url -from minigpt4.common.logger import MetricLogger -from minigpt4.models.base_model import BaseModel -from minigpt4.models.Qformer import BertConfig, BertLMHeadModel -from minigpt4.models.eva_vit import create_eva_vit_g -from transformers import BertTokenizer - - -class Blip2Base(BaseModel): - @classmethod - def init_tokenizer(cls): - tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") - tokenizer.add_special_tokens({"bos_token": "[DEC]"}) - return tokenizer - - def maybe_autocast(self, dtype=torch.float16): - # if on cpu, don't use autocast - # if on gpu, use autocast with dtype if provided, otherwise use torch.float16 - enable_autocast = self.device != torch.device("cpu") - - if enable_autocast: - return torch.cuda.amp.autocast(dtype=dtype) - else: - return contextlib.nullcontext() - - @classmethod - def init_Qformer(cls, num_query_token, vision_width, cross_attention_freq=2): - encoder_config = BertConfig.from_pretrained("bert-base-uncased") - encoder_config.encoder_width = vision_width - # insert cross-attention layer every other block - encoder_config.add_cross_attention = True - encoder_config.cross_attention_freq = cross_attention_freq - encoder_config.query_length = num_query_token - Qformer = BertLMHeadModel(config=encoder_config) - query_tokens = nn.Parameter( - torch.zeros(1, num_query_token, encoder_config.hidden_size) - ) - query_tokens.data.normal_(mean=0.0, std=encoder_config.initializer_range) - return Qformer, query_tokens - - @classmethod - def init_vision_encoder( - cls, model_name, img_size, drop_path_rate, use_grad_checkpoint, precision - ): - assert model_name == "eva_clip_g", "vit model must be eva_clip_g for current version of MiniGPT-4" - visual_encoder = create_eva_vit_g( - img_size, drop_path_rate, use_grad_checkpoint, precision - ) - - ln_vision = LayerNorm(visual_encoder.num_features) - return visual_encoder, ln_vision - - def load_from_pretrained(self, url_or_filename): - if is_url(url_or_filename): - cached_file = download_cached_file( - url_or_filename, check_hash=False, progress=True - ) - checkpoint = torch.load(cached_file, map_location="cpu") - elif os.path.isfile(url_or_filename): - checkpoint = torch.load(url_or_filename, map_location="cpu") - else: - raise RuntimeError("checkpoint url or path is invalid") - - state_dict = checkpoint["model"] - - msg = self.load_state_dict(state_dict, strict=False) - - # logging.info("Missing keys {}".format(msg.missing_keys)) - logging.info("load checkpoint from %s" % url_or_filename) - - return msg - - -def disabled_train(self, mode=True): - """Overwrite model.train with this function to make sure train/eval mode - does not change anymore.""" - return self - - -class LayerNorm(nn.LayerNorm): - """Subclass torch's LayerNorm to handle fp16.""" - - def forward(self, x: torch.Tensor): - orig_type = x.dtype - ret = super().forward(x.type(torch.float32)) - return ret.type(orig_type) - - -def compute_sim_matrix(model, data_loader, **kwargs): - k_test = kwargs.pop("k_test") - - metric_logger = MetricLogger(delimiter=" ") - header = "Evaluation:" - - logging.info("Computing features for evaluation...") - start_time = time.time() - - texts = data_loader.dataset.text - num_text = len(texts) - text_bs = 256 - text_ids = [] - text_embeds = [] - text_atts = [] - for i in range(0, num_text, text_bs): - text = texts[i : min(num_text, i + text_bs)] - text_input = model.tokenizer( - text, - padding="max_length", - truncation=True, - max_length=35, - return_tensors="pt", - ).to(model.device) - text_feat = model.forward_text(text_input) - text_embed = F.normalize(model.text_proj(text_feat)) - text_embeds.append(text_embed) - text_ids.append(text_input.input_ids) - text_atts.append(text_input.attention_mask) - - text_embeds = torch.cat(text_embeds, dim=0) - text_ids = torch.cat(text_ids, dim=0) - text_atts = torch.cat(text_atts, dim=0) - - vit_feats = [] - image_embeds = [] - for samples in data_loader: - image = samples["image"] - - image = image.to(model.device) - image_feat, vit_feat = model.forward_image(image) - image_embed = model.vision_proj(image_feat) - image_embed = F.normalize(image_embed, dim=-1) - - vit_feats.append(vit_feat.cpu()) - image_embeds.append(image_embed) - - vit_feats = torch.cat(vit_feats, dim=0) - image_embeds = torch.cat(image_embeds, dim=0) - - sims_matrix = [] - for image_embed in image_embeds: - sim_q2t = image_embed @ text_embeds.t() - sim_i2t, _ = sim_q2t.max(0) - sims_matrix.append(sim_i2t) - sims_matrix = torch.stack(sims_matrix, dim=0) - - score_matrix_i2t = torch.full( - (len(data_loader.dataset.image), len(texts)), -100.0 - ).to(model.device) - - num_tasks = dist_utils.get_world_size() - rank = dist_utils.get_rank() - step = sims_matrix.size(0) // num_tasks + 1 - start = rank * step - end = min(sims_matrix.size(0), start + step) - - for i, sims in enumerate( - metric_logger.log_every(sims_matrix[start:end], 50, header) - ): - topk_sim, topk_idx = sims.topk(k=k_test, dim=0) - image_inputs = vit_feats[start + i].repeat(k_test, 1, 1).to(model.device) - score = model.compute_itm( - image_inputs=image_inputs, - text_ids=text_ids[topk_idx], - text_atts=text_atts[topk_idx], - ).float() - score_matrix_i2t[start + i, topk_idx] = score + topk_sim - - sims_matrix = sims_matrix.t() - score_matrix_t2i = torch.full( - (len(texts), len(data_loader.dataset.image)), -100.0 - ).to(model.device) - - step = sims_matrix.size(0) // num_tasks + 1 - start = rank * step - end = min(sims_matrix.size(0), start + step) - - for i, sims in enumerate( - metric_logger.log_every(sims_matrix[start:end], 50, header) - ): - topk_sim, topk_idx = sims.topk(k=k_test, dim=0) - image_inputs = vit_feats[topk_idx.cpu()].to(model.device) - score = model.compute_itm( - image_inputs=image_inputs, - text_ids=text_ids[start + i].repeat(k_test, 1), - text_atts=text_atts[start + i].repeat(k_test, 1), - ).float() - score_matrix_t2i[start + i, topk_idx] = score + topk_sim - - if dist_utils.is_dist_avail_and_initialized(): - dist.barrier() - torch.distributed.all_reduce( - score_matrix_i2t, op=torch.distributed.ReduceOp.SUM - ) - torch.distributed.all_reduce( - score_matrix_t2i, op=torch.distributed.ReduceOp.SUM - ) - - total_time = time.time() - start_time - total_time_str = str(datetime.timedelta(seconds=int(total_time))) - logging.info("Evaluation time {}".format(total_time_str)) - - return score_matrix_i2t.cpu().numpy(), score_matrix_t2i.cpu().numpy() diff --git a/spaces/VoiceHero69/changer/webui/modules/implementations/rvc/infer_pack/onnx_inference.py b/spaces/VoiceHero69/changer/webui/modules/implementations/rvc/infer_pack/onnx_inference.py deleted file mode 100644 index 322572820dfc75d789e40ce5bbd9415066a03979..0000000000000000000000000000000000000000 --- a/spaces/VoiceHero69/changer/webui/modules/implementations/rvc/infer_pack/onnx_inference.py +++ /dev/null @@ -1,139 +0,0 @@ -import onnxruntime -import librosa -import numpy as np -import soundfile - - -class ContentVec: - def __init__(self, vec_path="pretrained/vec-768-layer-12.onnx", device=None): - print("load model(s) from {}".format(vec_path)) - if device == "cpu" or device is None: - providers = ["CPUExecutionProvider"] - elif device == "cuda": - providers = ["CUDAExecutionProvider", "CPUExecutionProvider"] - else: - raise RuntimeError("Unsportted Device") - self.model = onnxruntime.InferenceSession(vec_path, providers=providers) - - def __call__(self, wav): - return self.forward(wav) - - def forward(self, wav): - feats = wav - if feats.ndim == 2: # double channels - feats = feats.mean(-1) - assert feats.ndim == 1, feats.ndim - feats = np.expand_dims(np.expand_dims(feats, 0), 0) - onnx_input = {self.model.get_inputs()[0].name: feats} - logits = self.model.run(None, onnx_input)[0] - return logits.transpose(0, 2, 1) - - -def get_f0_predictor(f0_predictor, hop_length, sampling_rate, **kargs): - if f0_predictor == "pm": - from infer_pack.modules.F0Predictor.PMF0Predictor import PMF0Predictor - - f0_predictor_object = PMF0Predictor( - hop_length=hop_length, sampling_rate=sampling_rate - ) - elif f0_predictor == "harvest": - from infer_pack.modules.F0Predictor.HarvestF0Predictor import HarvestF0Predictor - - f0_predictor_object = HarvestF0Predictor( - hop_length=hop_length, sampling_rate=sampling_rate - ) - elif f0_predictor == "dio": - from infer_pack.modules.F0Predictor.DioF0Predictor import DioF0Predictor - - f0_predictor_object = DioF0Predictor( - hop_length=hop_length, sampling_rate=sampling_rate - ) - else: - raise Exception("Unknown f0 predictor") - return f0_predictor_object - - -class OnnxRVC: - def __init__( - self, - model_path, - sr=40000, - hop_size=512, - vec_path="vec-768-layer-12", - device="cpu", - ): - vec_path = f"pretrained/{vec_path}.onnx" - self.vec_model = ContentVec(vec_path, device) - if device == "cpu" or device is None: - providers = ["CPUExecutionProvider"] - elif device == "cuda": - providers = ["CUDAExecutionProvider", "CPUExecutionProvider"] - else: - raise RuntimeError("Unsportted Device") - self.model = onnxruntime.InferenceSession(model_path, providers=providers) - self.sampling_rate = sr - self.hop_size = hop_size - - def forward(self, hubert, hubert_length, pitch, pitchf, ds, rnd): - onnx_input = { - self.model.get_inputs()[0].name: hubert, - self.model.get_inputs()[1].name: hubert_length, - self.model.get_inputs()[2].name: pitch, - self.model.get_inputs()[3].name: pitchf, - self.model.get_inputs()[4].name: ds, - self.model.get_inputs()[5].name: rnd, - } - return (self.model.run(None, onnx_input)[0] * 32767).astype(np.int16) - - def inference( - self, - raw_path, - sid, - f0_method="dio", - f0_up_key=0, - pad_time=0.5, - cr_threshold=0.02, - ): - f0_min = 50 - f0_max = 1100 - f0_mel_min = 1127 * np.log(1 + f0_min / 700) - f0_mel_max = 1127 * np.log(1 + f0_max / 700) - f0_predictor = get_f0_predictor( - f0_method, - hop_length=self.hop_size, - sampling_rate=self.sampling_rate, - threshold=cr_threshold, - ) - wav, sr = librosa.load(raw_path, sr=self.sampling_rate) - org_length = len(wav) - if org_length / sr > 50.0: - raise RuntimeError("Reached Max Length") - - wav16k = librosa.resample(wav, orig_sr=self.sampling_rate, target_sr=16000) - wav16k = wav16k - - hubert = self.vec_model(wav16k) - hubert = np.repeat(hubert, 2, axis=2).transpose(0, 2, 1).astype(np.float32) - hubert_length = hubert.shape[1] - - pitchf = f0_predictor.compute_f0(wav, hubert_length) - pitchf = pitchf * 2 ** (f0_up_key / 12) - pitch = pitchf.copy() - f0_mel = 1127 * np.log(1 + pitch / 700) - f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / ( - f0_mel_max - f0_mel_min - ) + 1 - f0_mel[f0_mel <= 1] = 1 - f0_mel[f0_mel > 255] = 255 - pitch = np.rint(f0_mel).astype(np.int64) - - pitchf = pitchf.reshape(1, len(pitchf)).astype(np.float32) - pitch = pitch.reshape(1, len(pitch)) - ds = np.array([sid]).astype(np.int64) - - rnd = np.random.randn(1, 192, hubert_length).astype(np.float32) - hubert_length = np.array([hubert_length]).astype(np.int64) - - out_wav = self.forward(hubert, hubert_length, pitch, pitchf, ds, rnd).squeeze() - out_wav = np.pad(out_wav, (0, 2 * self.hop_size), "constant") - return out_wav[0:org_length] diff --git a/spaces/XzJosh/Azusa-Bert-VITS2/text/chinese.py b/spaces/XzJosh/Azusa-Bert-VITS2/text/chinese.py deleted file mode 100644 index 276753880b73de2e8889dcb2101cd98c09e0710b..0000000000000000000000000000000000000000 --- a/spaces/XzJosh/Azusa-Bert-VITS2/text/chinese.py +++ /dev/null @@ -1,193 +0,0 @@ -import os -import re - -import cn2an -from pypinyin import lazy_pinyin, Style - -from text import symbols -from text.symbols import punctuation -from text.tone_sandhi import ToneSandhi - -current_file_path = os.path.dirname(__file__) -pinyin_to_symbol_map = {line.split("\t")[0]: line.strip().split("\t")[1] for line in - open(os.path.join(current_file_path, 'opencpop-strict.txt')).readlines()} - -import jieba.posseg as psg - - -rep_map = { - ':': ',', - ';': ',', - ',': ',', - '。': '.', - '!': '!', - '?': '?', - '\n': '.', - "·": ",", - '、': ",", - '...': '…', - '$': '.', - '“': "'", - '”': "'", - '‘': "'", - '’': "'", - '(': "'", - ')': "'", - '(': "'", - ')': "'", - '《': "'", - '》': "'", - '【': "'", - '】': "'", - '[': "'", - ']': "'", - '—': "-", - '~': "-", - '~': "-", - '「': "'", - '」': "'", - -} - -tone_modifier = ToneSandhi() - -def replace_punctuation(text): - text = text.replace("嗯", "恩").replace("呣","母") - pattern = re.compile('|'.join(re.escape(p) for p in rep_map.keys())) - - replaced_text = pattern.sub(lambda x: rep_map[x.group()], text) - - replaced_text = re.sub(r'[^\u4e00-\u9fa5'+"".join(punctuation)+r']+', '', replaced_text) - - return replaced_text - -def g2p(text): - pattern = r'(?<=[{0}])\s*'.format(''.join(punctuation)) - sentences = [i for i in re.split(pattern, text) if i.strip()!=''] - phones, tones, word2ph = _g2p(sentences) - assert sum(word2ph) == len(phones) - assert len(word2ph) == len(text) #Sometimes it will crash,you can add a try-catch. - phones = ['_'] + phones + ["_"] - tones = [0] + tones + [0] - word2ph = [1] + word2ph + [1] - return phones, tones, word2ph - - -def _get_initials_finals(word): - initials = [] - finals = [] - orig_initials = lazy_pinyin( - word, neutral_tone_with_five=True, style=Style.INITIALS) - orig_finals = lazy_pinyin( - word, neutral_tone_with_five=True, style=Style.FINALS_TONE3) - for c, v in zip(orig_initials, orig_finals): - initials.append(c) - finals.append(v) - return initials, finals - - -def _g2p(segments): - phones_list = [] - tones_list = [] - word2ph = [] - for seg in segments: - pinyins = [] - # Replace all English words in the sentence - seg = re.sub('[a-zA-Z]+', '', seg) - seg_cut = psg.lcut(seg) - initials = [] - finals = [] - seg_cut = tone_modifier.pre_merge_for_modify(seg_cut) - for word, pos in seg_cut: - if pos == 'eng': - continue - sub_initials, sub_finals = _get_initials_finals(word) - sub_finals = tone_modifier.modified_tone(word, pos, - sub_finals) - initials.append(sub_initials) - finals.append(sub_finals) - - # assert len(sub_initials) == len(sub_finals) == len(word) - initials = sum(initials, []) - finals = sum(finals, []) - # - for c, v in zip(initials, finals): - raw_pinyin = c+v - # NOTE: post process for pypinyin outputs - # we discriminate i, ii and iii - if c == v: - assert c in punctuation - phone = [c] - tone = '0' - word2ph.append(1) - else: - v_without_tone = v[:-1] - tone = v[-1] - - pinyin = c+v_without_tone - assert tone in '12345' - - if c: - # 多音节 - v_rep_map = { - "uei": 'ui', - 'iou': 'iu', - 'uen': 'un', - } - if v_without_tone in v_rep_map.keys(): - pinyin = c+v_rep_map[v_without_tone] - else: - # 单音节 - pinyin_rep_map = { - 'ing': 'ying', - 'i': 'yi', - 'in': 'yin', - 'u': 'wu', - } - if pinyin in pinyin_rep_map.keys(): - pinyin = pinyin_rep_map[pinyin] - else: - single_rep_map = { - 'v': 'yu', - 'e': 'e', - 'i': 'y', - 'u': 'w', - } - if pinyin[0] in single_rep_map.keys(): - pinyin = single_rep_map[pinyin[0]]+pinyin[1:] - - assert pinyin in pinyin_to_symbol_map.keys(), (pinyin, seg, raw_pinyin) - phone = pinyin_to_symbol_map[pinyin].split(' ') - word2ph.append(len(phone)) - - phones_list += phone - tones_list += [int(tone)] * len(phone) - return phones_list, tones_list, word2ph - - - -def text_normalize(text): - numbers = re.findall(r'\d+(?:\.?\d+)?', text) - for number in numbers: - text = text.replace(number, cn2an.an2cn(number), 1) - text = replace_punctuation(text) - return text - -def get_bert_feature(text, word2ph): - from text import chinese_bert - return chinese_bert.get_bert_feature(text, word2ph) - -if __name__ == '__main__': - from text.chinese_bert import get_bert_feature - text = "啊!但是《原神》是由,米哈\游自主, [研发]的一款全.新开放世界.冒险游戏" - text = text_normalize(text) - print(text) - phones, tones, word2ph = g2p(text) - bert = get_bert_feature(text, word2ph) - - print(phones, tones, word2ph, bert.shape) - - -# # 示例用法 -# text = "这是一个示例文本:,你好!这是一个测试...." -# print(g2p_paddle(text)) # 输出: 这是一个示例文本你好这是一个测试 diff --git a/spaces/XzJosh/Lumi-Bert-VITS2/text/tone_sandhi.py b/spaces/XzJosh/Lumi-Bert-VITS2/text/tone_sandhi.py deleted file mode 100644 index 0f45b7a72c5d858bcaab19ac85cfa686bf9a74da..0000000000000000000000000000000000000000 --- a/spaces/XzJosh/Lumi-Bert-VITS2/text/tone_sandhi.py +++ /dev/null @@ -1,351 +0,0 @@ -# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -from typing import List -from typing import Tuple - -import jieba -from pypinyin import lazy_pinyin -from pypinyin import Style - - -class ToneSandhi(): - def __init__(self): - self.must_neural_tone_words = { - '麻烦', '麻利', '鸳鸯', '高粱', '骨头', '骆驼', '马虎', '首饰', '馒头', '馄饨', '风筝', - '难为', '队伍', '阔气', '闺女', '门道', '锄头', '铺盖', '铃铛', '铁匠', '钥匙', '里脊', - '里头', '部分', '那么', '道士', '造化', '迷糊', '连累', '这么', '这个', '运气', '过去', - '软和', '转悠', '踏实', '跳蚤', '跟头', '趔趄', '财主', '豆腐', '讲究', '记性', '记号', - '认识', '规矩', '见识', '裁缝', '补丁', '衣裳', '衣服', '衙门', '街坊', '行李', '行当', - '蛤蟆', '蘑菇', '薄荷', '葫芦', '葡萄', '萝卜', '荸荠', '苗条', '苗头', '苍蝇', '芝麻', - '舒服', '舒坦', '舌头', '自在', '膏药', '脾气', '脑袋', '脊梁', '能耐', '胳膊', '胭脂', - '胡萝', '胡琴', '胡同', '聪明', '耽误', '耽搁', '耷拉', '耳朵', '老爷', '老实', '老婆', - '老头', '老太', '翻腾', '罗嗦', '罐头', '编辑', '结实', '红火', '累赘', '糨糊', '糊涂', - '精神', '粮食', '簸箕', '篱笆', '算计', '算盘', '答应', '笤帚', '笑语', '笑话', '窟窿', - '窝囊', '窗户', '稳当', '稀罕', '称呼', '秧歌', '秀气', '秀才', '福气', '祖宗', '砚台', - '码头', '石榴', '石头', '石匠', '知识', '眼睛', '眯缝', '眨巴', '眉毛', '相声', '盘算', - '白净', '痢疾', '痛快', '疟疾', '疙瘩', '疏忽', '畜生', '生意', '甘蔗', '琵琶', '琢磨', - '琉璃', '玻璃', '玫瑰', '玄乎', '狐狸', '状元', '特务', '牲口', '牙碜', '牌楼', '爽快', - '爱人', '热闹', '烧饼', '烟筒', '烂糊', '点心', '炊帚', '灯笼', '火候', '漂亮', '滑溜', - '溜达', '温和', '清楚', '消息', '浪头', '活泼', '比方', '正经', '欺负', '模糊', '槟榔', - '棺材', '棒槌', '棉花', '核桃', '栅栏', '柴火', '架势', '枕头', '枇杷', '机灵', '本事', - '木头', '木匠', '朋友', '月饼', '月亮', '暖和', '明白', '时候', '新鲜', '故事', '收拾', - '收成', '提防', '挖苦', '挑剔', '指甲', '指头', '拾掇', '拳头', '拨弄', '招牌', '招呼', - '抬举', '护士', '折腾', '扫帚', '打量', '打算', '打点', '打扮', '打听', '打发', '扎实', - '扁担', '戒指', '懒得', '意识', '意思', '情形', '悟性', '怪物', '思量', '怎么', '念头', - '念叨', '快活', '忙活', '志气', '心思', '得罪', '张罗', '弟兄', '开通', '应酬', '庄稼', - '干事', '帮手', '帐篷', '希罕', '师父', '师傅', '巴结', '巴掌', '差事', '工夫', '岁数', - '屁股', '尾巴', '少爷', '小气', '小伙', '将就', '对头', '对付', '寡妇', '家伙', '客气', - '实在', '官司', '学问', '学生', '字号', '嫁妆', '媳妇', '媒人', '婆家', '娘家', '委屈', - '姑娘', '姐夫', '妯娌', '妥当', '妖精', '奴才', '女婿', '头发', '太阳', '大爷', '大方', - '大意', '大夫', '多少', '多么', '外甥', '壮实', '地道', '地方', '在乎', '困难', '嘴巴', - '嘱咐', '嘟囔', '嘀咕', '喜欢', '喇嘛', '喇叭', '商量', '唾沫', '哑巴', '哈欠', '哆嗦', - '咳嗽', '和尚', '告诉', '告示', '含糊', '吓唬', '后头', '名字', '名堂', '合同', '吆喝', - '叫唤', '口袋', '厚道', '厉害', '千斤', '包袱', '包涵', '匀称', '勤快', '动静', '动弹', - '功夫', '力气', '前头', '刺猬', '刺激', '别扭', '利落', '利索', '利害', '分析', '出息', - '凑合', '凉快', '冷战', '冤枉', '冒失', '养活', '关系', '先生', '兄弟', '便宜', '使唤', - '佩服', '作坊', '体面', '位置', '似的', '伙计', '休息', '什么', '人家', '亲戚', '亲家', - '交情', '云彩', '事情', '买卖', '主意', '丫头', '丧气', '两口', '东西', '东家', '世故', - '不由', '不在', '下水', '下巴', '上头', '上司', '丈夫', '丈人', '一辈', '那个', '菩萨', - '父亲', '母亲', '咕噜', '邋遢', '费用', '冤家', '甜头', '介绍', '荒唐', '大人', '泥鳅', - '幸福', '熟悉', '计划', '扑腾', '蜡烛', '姥爷', '照顾', '喉咙', '吉他', '弄堂', '蚂蚱', - '凤凰', '拖沓', '寒碜', '糟蹋', '倒腾', '报复', '逻辑', '盘缠', '喽啰', '牢骚', '咖喱', - '扫把', '惦记' - } - self.must_not_neural_tone_words = { - "男子", "女子", "分子", "原子", "量子", "莲子", "石子", "瓜子", "电子", "人人", "虎虎" - } - self.punc = ":,;。?!“”‘’':,;.?!" - - # the meaning of jieba pos tag: https://blog.csdn.net/weixin_44174352/article/details/113731041 - # e.g. - # word: "家里" - # pos: "s" - # finals: ['ia1', 'i3'] - def _neural_sandhi(self, word: str, pos: str, - finals: List[str]) -> List[str]: - - # reduplication words for n. and v. e.g. 奶奶, 试试, 旺旺 - for j, item in enumerate(word): - if j - 1 >= 0 and item == word[j - 1] and pos[0] in { - "n", "v", "a" - } and word not in self.must_not_neural_tone_words: - finals[j] = finals[j][:-1] + "5" - ge_idx = word.find("个") - if len(word) >= 1 and word[-1] in "吧呢啊呐噻嘛吖嗨呐哦哒额滴哩哟喽啰耶喔诶": - finals[-1] = finals[-1][:-1] + "5" - elif len(word) >= 1 and word[-1] in "的地得": - finals[-1] = finals[-1][:-1] + "5" - # e.g. 走了, 看着, 去过 - # elif len(word) == 1 and word in "了着过" and pos in {"ul", "uz", "ug"}: - # finals[-1] = finals[-1][:-1] + "5" - elif len(word) > 1 and word[-1] in "们子" and pos in { - "r", "n" - } and word not in self.must_not_neural_tone_words: - finals[-1] = finals[-1][:-1] + "5" - # e.g. 桌上, 地下, 家里 - elif len(word) > 1 and word[-1] in "上下里" and pos in {"s", "l", "f"}: - finals[-1] = finals[-1][:-1] + "5" - # e.g. 上来, 下去 - elif len(word) > 1 and word[-1] in "来去" and word[-2] in "上下进出回过起开": - finals[-1] = finals[-1][:-1] + "5" - # 个做量词 - elif (ge_idx >= 1 and - (word[ge_idx - 1].isnumeric() or - word[ge_idx - 1] in "几有两半多各整每做是")) or word == '个': - finals[ge_idx] = finals[ge_idx][:-1] + "5" - else: - if word in self.must_neural_tone_words or word[ - -2:] in self.must_neural_tone_words: - finals[-1] = finals[-1][:-1] + "5" - - word_list = self._split_word(word) - finals_list = [finals[:len(word_list[0])], finals[len(word_list[0]):]] - for i, word in enumerate(word_list): - # conventional neural in Chinese - if word in self.must_neural_tone_words or word[ - -2:] in self.must_neural_tone_words: - finals_list[i][-1] = finals_list[i][-1][:-1] + "5" - finals = sum(finals_list, []) - return finals - - def _bu_sandhi(self, word: str, finals: List[str]) -> List[str]: - # e.g. 看不懂 - if len(word) == 3 and word[1] == "不": - finals[1] = finals[1][:-1] + "5" - else: - for i, char in enumerate(word): - # "不" before tone4 should be bu2, e.g. 不怕 - if char == "不" and i + 1 < len(word) and finals[i + - 1][-1] == "4": - finals[i] = finals[i][:-1] + "2" - return finals - - def _yi_sandhi(self, word: str, finals: List[str]) -> List[str]: - # "一" in number sequences, e.g. 一零零, 二一零 - if word.find("一") != -1 and all( - [item.isnumeric() for item in word if item != "一"]): - return finals - # "一" between reduplication words shold be yi5, e.g. 看一看 - elif len(word) == 3 and word[1] == "一" and word[0] == word[-1]: - finals[1] = finals[1][:-1] + "5" - # when "一" is ordinal word, it should be yi1 - elif word.startswith("第一"): - finals[1] = finals[1][:-1] + "1" - else: - for i, char in enumerate(word): - if char == "一" and i + 1 < len(word): - # "一" before tone4 should be yi2, e.g. 一段 - if finals[i + 1][-1] == "4": - finals[i] = finals[i][:-1] + "2" - # "一" before non-tone4 should be yi4, e.g. 一天 - else: - # "一" 后面如果是标点,还读一声 - if word[i + 1] not in self.punc: - finals[i] = finals[i][:-1] + "4" - return finals - - def _split_word(self, word: str) -> List[str]: - word_list = jieba.cut_for_search(word) - word_list = sorted(word_list, key=lambda i: len(i), reverse=False) - first_subword = word_list[0] - first_begin_idx = word.find(first_subword) - if first_begin_idx == 0: - second_subword = word[len(first_subword):] - new_word_list = [first_subword, second_subword] - else: - second_subword = word[:-len(first_subword)] - new_word_list = [second_subword, first_subword] - return new_word_list - - def _three_sandhi(self, word: str, finals: List[str]) -> List[str]: - if len(word) == 2 and self._all_tone_three(finals): - finals[0] = finals[0][:-1] + "2" - elif len(word) == 3: - word_list = self._split_word(word) - if self._all_tone_three(finals): - # disyllabic + monosyllabic, e.g. 蒙古/包 - if len(word_list[0]) == 2: - finals[0] = finals[0][:-1] + "2" - finals[1] = finals[1][:-1] + "2" - # monosyllabic + disyllabic, e.g. 纸/老虎 - elif len(word_list[0]) == 1: - finals[1] = finals[1][:-1] + "2" - else: - finals_list = [ - finals[:len(word_list[0])], finals[len(word_list[0]):] - ] - if len(finals_list) == 2: - for i, sub in enumerate(finals_list): - # e.g. 所有/人 - if self._all_tone_three(sub) and len(sub) == 2: - finals_list[i][0] = finals_list[i][0][:-1] + "2" - # e.g. 好/喜欢 - elif i == 1 and not self._all_tone_three(sub) and finals_list[i][0][-1] == "3" and \ - finals_list[0][-1][-1] == "3": - - finals_list[0][-1] = finals_list[0][-1][:-1] + "2" - finals = sum(finals_list, []) - # split idiom into two words who's length is 2 - elif len(word) == 4: - finals_list = [finals[:2], finals[2:]] - finals = [] - for sub in finals_list: - if self._all_tone_three(sub): - sub[0] = sub[0][:-1] + "2" - finals += sub - - return finals - - def _all_tone_three(self, finals: List[str]) -> bool: - return all(x[-1] == "3" for x in finals) - - # merge "不" and the word behind it - # if don't merge, "不" sometimes appears alone according to jieba, which may occur sandhi error - def _merge_bu(self, seg: List[Tuple[str, str]]) -> List[Tuple[str, str]]: - new_seg = [] - last_word = "" - for word, pos in seg: - if last_word == "不": - word = last_word + word - if word != "不": - new_seg.append((word, pos)) - last_word = word[:] - if last_word == "不": - new_seg.append((last_word, 'd')) - last_word = "" - return new_seg - - # function 1: merge "一" and reduplication words in it's left and right, e.g. "听","一","听" ->"听一听" - # function 2: merge single "一" and the word behind it - # if don't merge, "一" sometimes appears alone according to jieba, which may occur sandhi error - # e.g. - # input seg: [('听', 'v'), ('一', 'm'), ('听', 'v')] - # output seg: [['听一听', 'v']] - def _merge_yi(self, seg: List[Tuple[str, str]]) -> List[Tuple[str, str]]: - new_seg = [] - # function 1 - for i, (word, pos) in enumerate(seg): - if i - 1 >= 0 and word == "一" and i + 1 < len(seg) and seg[i - 1][ - 0] == seg[i + 1][0] and seg[i - 1][1] == "v": - new_seg[i - 1][0] = new_seg[i - 1][0] + "一" + new_seg[i - 1][0] - else: - if i - 2 >= 0 and seg[i - 1][0] == "一" and seg[i - 2][ - 0] == word and pos == "v": - continue - else: - new_seg.append([word, pos]) - seg = new_seg - new_seg = [] - # function 2 - for i, (word, pos) in enumerate(seg): - if new_seg and new_seg[-1][0] == "一": - new_seg[-1][0] = new_seg[-1][0] + word - else: - new_seg.append([word, pos]) - return new_seg - - # the first and the second words are all_tone_three - def _merge_continuous_three_tones( - self, seg: List[Tuple[str, str]]) -> List[Tuple[str, str]]: - new_seg = [] - sub_finals_list = [ - lazy_pinyin( - word, neutral_tone_with_five=True, style=Style.FINALS_TONE3) - for (word, pos) in seg - ] - assert len(sub_finals_list) == len(seg) - merge_last = [False] * len(seg) - for i, (word, pos) in enumerate(seg): - if i - 1 >= 0 and self._all_tone_three( - sub_finals_list[i - 1]) and self._all_tone_three( - sub_finals_list[i]) and not merge_last[i - 1]: - # if the last word is reduplication, not merge, because reduplication need to be _neural_sandhi - if not self._is_reduplication(seg[i - 1][0]) and len( - seg[i - 1][0]) + len(seg[i][0]) <= 3: - new_seg[-1][0] = new_seg[-1][0] + seg[i][0] - merge_last[i] = True - else: - new_seg.append([word, pos]) - else: - new_seg.append([word, pos]) - - return new_seg - - def _is_reduplication(self, word: str) -> bool: - return len(word) == 2 and word[0] == word[1] - - # the last char of first word and the first char of second word is tone_three - def _merge_continuous_three_tones_2( - self, seg: List[Tuple[str, str]]) -> List[Tuple[str, str]]: - new_seg = [] - sub_finals_list = [ - lazy_pinyin( - word, neutral_tone_with_five=True, style=Style.FINALS_TONE3) - for (word, pos) in seg - ] - assert len(sub_finals_list) == len(seg) - merge_last = [False] * len(seg) - for i, (word, pos) in enumerate(seg): - if i - 1 >= 0 and sub_finals_list[i - 1][-1][-1] == "3" and sub_finals_list[i][0][-1] == "3" and not \ - merge_last[i - 1]: - # if the last word is reduplication, not merge, because reduplication need to be _neural_sandhi - if not self._is_reduplication(seg[i - 1][0]) and len( - seg[i - 1][0]) + len(seg[i][0]) <= 3: - new_seg[-1][0] = new_seg[-1][0] + seg[i][0] - merge_last[i] = True - else: - new_seg.append([word, pos]) - else: - new_seg.append([word, pos]) - return new_seg - - def _merge_er(self, seg: List[Tuple[str, str]]) -> List[Tuple[str, str]]: - new_seg = [] - for i, (word, pos) in enumerate(seg): - if i - 1 >= 0 and word == "儿" and seg[i-1][0] != "#": - new_seg[-1][0] = new_seg[-1][0] + seg[i][0] - else: - new_seg.append([word, pos]) - return new_seg - - def _merge_reduplication( - self, seg: List[Tuple[str, str]]) -> List[Tuple[str, str]]: - new_seg = [] - for i, (word, pos) in enumerate(seg): - if new_seg and word == new_seg[-1][0]: - new_seg[-1][0] = new_seg[-1][0] + seg[i][0] - else: - new_seg.append([word, pos]) - return new_seg - - def pre_merge_for_modify( - self, seg: List[Tuple[str, str]]) -> List[Tuple[str, str]]: - seg = self._merge_bu(seg) - try: - seg = self._merge_yi(seg) - except: - print("_merge_yi failed") - seg = self._merge_reduplication(seg) - seg = self._merge_continuous_three_tones(seg) - seg = self._merge_continuous_three_tones_2(seg) - seg = self._merge_er(seg) - return seg - - def modified_tone(self, word: str, pos: str, - finals: List[str]) -> List[str]: - finals = self._bu_sandhi(word, finals) - finals = self._yi_sandhi(word, finals) - finals = self._neural_sandhi(word, pos, finals) - finals = self._three_sandhi(word, finals) - return finals diff --git a/spaces/Yiqin/ChatVID/model/fastchat/data/sample.py b/spaces/Yiqin/ChatVID/model/fastchat/data/sample.py deleted file mode 100644 index b53df6a67d575e8a6e91261d5468dee193292eb2..0000000000000000000000000000000000000000 --- a/spaces/Yiqin/ChatVID/model/fastchat/data/sample.py +++ /dev/null @@ -1,33 +0,0 @@ -""" -Sample some conversations from a file. - -Usage: python3 -m fastchat.data.sample --in sharegpt.json --out sampled.json -""" -import argparse -import json -from typing import Dict, Sequence, Optional - - -if __name__ == "__main__": - parser = argparse.ArgumentParser() - parser.add_argument("--in-file", type=str, required=True) - parser.add_argument("--out-file", type=str, default="sampled.json") - parser.add_argument("--begin", type=int, default=0) - parser.add_argument("--end", type=int, default=100) - parser.add_argument("--max-length", type=int, default=128) - args = parser.parse_args() - - content = json.load(open(args.in_file, "r")) - new_content = [] - for i in range(args.begin, args.end): - sample = content[i] - concat = "" - for s in sample["conversations"]: - concat += s["value"] - - if len(concat) > args.max_length: - continue - - new_content.append(sample) - - json.dump(new_content, open(args.out_file, "w"), indent=2) diff --git a/spaces/YuAnthony/Audio-Caption/processes/dataset_multiprocess.py b/spaces/YuAnthony/Audio-Caption/processes/dataset_multiprocess.py deleted file mode 100644 index 9aade85e2926b382e6919113b879cdefa187a32f..0000000000000000000000000000000000000000 --- a/spaces/YuAnthony/Audio-Caption/processes/dataset_multiprocess.py +++ /dev/null @@ -1,306 +0,0 @@ -#!/usr/bin/env python -# -*- coding: utf-8 -*- - -import sys - -sys.path.append('..') - -from typing import MutableMapping, Any -from datetime import datetime -from pathlib import Path -from functools import partial -from itertools import chain - -import numpy as np -from loguru import logger - -from tools.printing import init_loggers -from tools.argument_parsing import get_argument_parser -from tools.dataset_creation import get_annotations_files, \ - get_amount_of_file_in_dir, check_data_for_split, \ - create_split_data, create_lists_and_frequencies -from tools.file_io import load_settings_file, load_yaml_file, \ - load_numpy_object, dump_numpy_object -from tools.features_log_mel_bands import feature_extraction - -from concurrent.futures import ProcessPoolExecutor -from multiprocessing import cpu_count -from tqdm import tqdm - -executor = ProcessPoolExecutor(max_workers=cpu_count()) - -__author__ = 'Konstantinos Drossos -- Tampere University' -__docformat__ = 'reStructuredText' -__all__ = ['create_dataset', 'extract_features'] - - -def create_dataset(settings_dataset: MutableMapping[str, Any], - settings_dirs_and_files: MutableMapping[str, Any]) \ - -> None: - """Creates the dataset. - - Gets the dictionary with the settings and creates - the files of the dataset. - - :param settings_dataset: Settings to be used for dataset\ - creation. - :type settings_dataset: dict - :param settings_dirs_and_files: Settings to be used for\ - handling directories and\ - files. - :type settings_dirs_and_files: dict - """ - # Get logger - inner_logger = logger.bind( - indent=2, is_caption=False) - - # Get root dir - dir_root = Path(settings_dirs_and_files[ - 'root_dirs']['data']) - - # Read the annotation files - inner_logger.info('Reading annotations files') - csv_dev, csv_eva = get_annotations_files( - settings_ann=settings_dataset['annotations'], - dir_ann=dir_root.joinpath( - settings_dirs_and_files['dataset'][ - 'annotations_dir'])) - inner_logger.info('Done') - - # Get all captions - inner_logger.info('Getting the captions') - captions_development = [ - csv_field.get( - settings_dataset['annotations'][ - 'captions_fields_prefix'].format(c_ind)) - for csv_field in csv_dev - for c_ind in range(1, 6)] - inner_logger.info('Done') - - # Create lists of indices and frequencies for words and\ - # characters. - inner_logger.info('Creating and saving words and chars ' - 'lists and frequencies') - words_list, chars_list = create_lists_and_frequencies( - captions=captions_development, dir_root=dir_root, - settings_ann=settings_dataset['annotations'], - settings_cntr=settings_dirs_and_files['dataset']) - inner_logger.info('Done') - - # Aux partial function for convenience. - split_func = partial( - create_split_data, - words_list=words_list, chars_list=chars_list, - settings_ann=settings_dataset['annotations'], - settings_audio=settings_dataset['audio'], - settings_output=settings_dirs_and_files['dataset']) - - settings_audio_dirs = settings_dirs_and_files[ - 'dataset']['audio_dirs'] - - # For each data split (i.e. development and evaluation) - futures = [] - for split_data in [(csv_dev, 'development')]: - futures.append(executor.submit( - partial(_split, split_data, split_func, settings_dataset, settings_dirs_and_files, - inner_logger, dir_root, settings_audio_dirs))) - [future.result() for future in tqdm(futures)] - - futures = [] - for split_data in [(csv_eva, 'evaluation')]: - futures.append(executor.submit( - partial(_split, split_data, split_func, settings_dataset, settings_dirs_and_files, - inner_logger, dir_root, settings_audio_dirs))) - [future.result() for future in tqdm(futures)] - - -def _split(split_data, split_func, settings_dataset, settings_dirs_and_files, - inner_logger, dir_root, settings_audio_dirs): - # Get helper variables. - split_name = split_data[1] - split_csv = split_data[0] - - dir_split = dir_root.joinpath( - settings_audio_dirs['output'], - settings_audio_dirs[f'{split_name}']) - - dir_downloaded_audio = dir_root.joinpath( - settings_audio_dirs['downloaded'], - settings_audio_dirs[f'{split_name}']) - - # Create the data for the split. - inner_logger.info(f'Creating the {split_name} ' - f'split data') - split_func(split_csv, dir_split, - dir_downloaded_audio) - inner_logger.info('Done') - - # Count and print the amount of initial and resulting\ - # files. - nb_files_audio = get_amount_of_file_in_dir( - dir_downloaded_audio) - nb_files_data = get_amount_of_file_in_dir(dir_split) - - inner_logger.info(f'Amount of {split_name} ' - f'audio files: {nb_files_audio}') - inner_logger.info(f'Amount of {split_name} ' - f'data files: {nb_files_data}') - inner_logger.info(f'Amount of {split_name} data ' - f'files per audio: ' - f'{nb_files_data / nb_files_audio}') - - if settings_dataset['workflow']['validate_dataset']: - # Check the created lists of indices for words and characters. - inner_logger.info(f'Checking the {split_name} split') - check_data_for_split( - dir_audio=dir_downloaded_audio, - dir_data=Path(settings_audio_dirs['output'], - settings_audio_dirs[f'{split_name}']), - dir_root=dir_root, csv_split=split_csv, - settings_ann=settings_dataset['annotations'], - settings_audio=settings_dataset['audio'], - settings_cntr=settings_dirs_and_files['dataset']) - inner_logger.info('Done') - else: - inner_logger.info(f'Skipping validation of {split_name} split') - - -def extract_features(root_dir: str, - settings_data: MutableMapping[str, Any], - settings_features: MutableMapping[str, Any]) \ - -> None: - """Extracts features from the audio data of Clotho. - - :param root_dir: Root dir for the data. - :type root_dir: str - :param settings_data: Settings for creating data files. - :type settings_data: dict[str, T] - :param settings_features: Settings for feature extraction. - :type settings_features: dict[str, T] - """ - # Get the root directory. - dir_root = Path(root_dir) - - # Get the directories of files. - dir_output = dir_root.joinpath(settings_data['audio_dirs']['output']) - - dir_dev = dir_output.joinpath( - settings_data['audio_dirs']['development']) - dir_eva = dir_output.joinpath( - settings_data['audio_dirs']['evaluation']) - - # Get the directories for output. - dir_output_dev = dir_root.joinpath( - settings_data['features_dirs']['output'], - settings_data['features_dirs']['development']) - dir_output_eva = dir_root.joinpath( - settings_data['features_dirs']['output'], - settings_data['features_dirs']['evaluation']) - - # Create the directories. - dir_output_dev.mkdir(parents=True, exist_ok=True) - dir_output_eva.mkdir(parents=True, exist_ok=True) - - # Apply the function to each file and save the result. - futures = [] - for data_file_name in filter( - lambda _x: _x.suffix == '.npy', - chain(dir_dev.iterdir(), dir_eva.iterdir())): - futures.append(executor.submit( - partial(_extract, data_file_name, settings_features, settings_data, dir_output_dev, dir_output_eva))) - [future.result() for future in tqdm(futures)] - - -def _extract(data_file_name, settings_features, settings_data, dir_output_dev, dir_output_eva): - # Load the data file. - data_file = load_numpy_object(data_file_name) - - # Extract the features. - features = feature_extraction( - data_file['audio_data'].item(), - **settings_features['process']) - - # Populate the recarray data and dtypes. - array_data = (data_file['file_name'].item(),) - dtypes = [('file_name', data_file['file_name'].dtype)] - - # Check if we keeping the raw audio data. - if settings_features['keep_raw_audio_data']: - # And add them to the recarray data and dtypes. - array_data += (data_file['audio_data'].item(),) - dtypes.append(('audio_data', data_file['audio_data'].dtype)) - - # Add the rest to the recarray. - array_data += ( - features, - data_file['caption'].item(), - data_file['caption_ind'].item(), - data_file['words_ind'].item(), - data_file['chars_ind'].item()) - dtypes.extend([ - ('features', np.dtype(object)), - ('caption', data_file['caption'].dtype), - ('caption_ind', data_file['caption_ind'].dtype), - ('words_ind', data_file['words_ind'].dtype), - ('chars_ind', data_file['chars_ind'].dtype) - ]) - - # Make the recarray - np_rec_array = np.rec.array([array_data], dtype=dtypes) - - # Make the path for serializing the recarray. - parent_path = dir_output_dev \ - if data_file_name.parent.name == settings_data['audio_dirs']['development'] \ - else dir_output_eva - - file_path = parent_path.joinpath(data_file_name.name) - - # Dump it. - dump_numpy_object(np_rec_array, file_path) - - -def main(): - args = get_argument_parser().parse_args() - - file_dir = args.file_dir - config_file = args.config_file - file_ext = args.file_ext - verbose = args.verbose - - # Load settings file. - settings = load_yaml_file(Path( - file_dir, f'{config_file}.{file_ext}')) - - init_loggers(verbose=verbose, - settings=settings['dirs_and_files']) - - logger_main = logger.bind(is_caption=False, indent=0) - logger_sec = logger.bind(is_caption=False, indent=1) - - logger_main.info(datetime.now().strftime('%Y-%m-%d %H:%M')) - - logger_main.info('Doing only dataset creation') - - # Create the dataset. - logger_main.info('Starting Clotho dataset creation') - - logger_sec.info('Creating examples') - create_dataset( - settings_dataset=settings['dataset_creation_settings'], - settings_dirs_and_files=settings['dirs_and_files']) - logger_sec.info('Examples created') - - logger_sec.info('Extracting features') - extract_features( - root_dir=settings['dirs_and_files']['root_dirs']['data'], - settings_data=settings['dirs_and_files']['dataset'], - settings_features=settings['feature_extraction_settings']) - logger_sec.info('Features extracted') - - logger_main.info('Dataset created') - - -if __name__ == '__main__': - main() - -# EOF diff --git a/spaces/YuAnthony/Voice-Recognition/README.md b/spaces/YuAnthony/Voice-Recognition/README.md deleted file mode 100644 index 1846611ca07a1709aa786e2933b0424a7473bc9c..0000000000000000000000000000000000000000 --- a/spaces/YuAnthony/Voice-Recognition/README.md +++ /dev/null @@ -1,37 +0,0 @@ ---- -title: Voice-Recognition (ResNet) -emoji: 💬 -colorFrom: blue -colorTo: blue -sdk: gradio -app_file: app.py -pinned: false ---- - -# Configuration - -`title`: _string_ -Display title for the Space - -`emoji`: _string_ -Space emoji (emoji-only character allowed) - -`colorFrom`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`colorTo`: _string_ -Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray) - -`sdk`: _string_ -Can be either `gradio` or `streamlit` - -`sdk_version` : _string_ -Only applicable for `streamlit` SDK. -See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions. - -`app_file`: _string_ -Path to your main application file (which contains either `gradio` or `streamlit` Python code). -Path is relative to the root of the repository. - -`pinned`: _boolean_ -Whether the Space stays on top of your list. diff --git a/spaces/Yudha515/Rvc-Models/tests/modules/test_transformer.py b/spaces/Yudha515/Rvc-Models/tests/modules/test_transformer.py deleted file mode 100644 index ff7dfe4c2de05112aec55ddea9c8fd978668f80b..0000000000000000000000000000000000000000 --- a/spaces/Yudha515/Rvc-Models/tests/modules/test_transformer.py +++ /dev/null @@ -1,253 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -from itertools import product - -import pytest -import torch - -from audiocraft.modules.transformer import ( - StreamingMultiheadAttention, StreamingTransformer, set_efficient_attention_backend) - - -def test_transformer_causal_streaming(): - torch.manual_seed(1234) - - for context, custom in product([None, 10], [False, True]): - # Test that causality and receptive fields are properly handled. - # looking at the gradients - tr = StreamingTransformer( - 16, 4, 1 if context else 2, - causal=True, past_context=context, custom=custom, - dropout=0.) - steps = 20 - for k in [0, 10, 15, 19]: - x = torch.randn(4, steps, 16, requires_grad=True) - y = tr(x) - y[:, k].abs().sum().backward() - if k + 1 < steps: - assert torch.allclose(x.grad[:, k + 1:], torch.tensor(0.)), x.grad[:, k + 1:].norm() - assert not torch.allclose(x.grad[:, :k + 1], torch.tensor(0.)), x.grad[:, :k + 1].norm() - if context is not None and k > context: - limit = k - context - 1 - assert torch.allclose(x.grad[:, :limit], - torch.tensor(0.)), x.grad[:, :limit].norm() - - # Now check that streaming gives the same result at batch eval. - x = torch.randn(4, steps, 16) - y = tr(x) - ys = [] - with tr.streaming(): - for k in range(steps): - chunk = x[:, k:k + 1, :] - ys.append(tr(chunk)) - y_stream = torch.cat(ys, dim=1) - delta = torch.norm(y_stream - y) / torch.norm(y) - assert delta < 1e-6, delta - - -def test_transformer_vs_pytorch(): - torch.manual_seed(1234) - # Check that in the non causal setting, we get the same result as - # PyTorch Transformer encoder. - for custom in [False, True]: - tr = StreamingTransformer( - 16, 4, 2, - causal=False, custom=custom, dropout=0., positional_scale=0.) - layer = torch.nn.TransformerEncoderLayer(16, 4, dropout=0., batch_first=True) - tr_ref = torch.nn.TransformerEncoder(layer, 2) - tr.load_state_dict(tr_ref.state_dict()) - - x = torch.randn(4, 20, 16) - y = tr(x) - y2 = tr_ref(x) - delta = torch.norm(y2 - y) / torch.norm(y) - assert delta < 1e-6, delta - - -def test_streaming_api(): - tr = StreamingTransformer(16, 4, 2, causal=True, dropout=0.) - tr.eval() - steps = 12 - x = torch.randn(1, steps, 16) - - with torch.no_grad(): - with tr.streaming(): - _ = tr(x[:, :1]) - state = {k: v.clone() for k, v in tr.get_streaming_state().items()} - y = tr(x[:, 1:2]) - tr.set_streaming_state(state) - y2 = tr(x[:, 1:2]) - assert torch.allclose(y, y2), (y - y2).norm() - assert tr.flush() is None - - -def test_memory_efficient(): - for backend in ['torch', 'xformers']: - torch.manual_seed(1234) - set_efficient_attention_backend(backend) - - tr = StreamingTransformer( - 16, 4, 2, custom=True, dropout=0., layer_scale=0.1) - tr_mem_efficient = StreamingTransformer( - 16, 4, 2, dropout=0., memory_efficient=True, layer_scale=0.1) - tr_mem_efficient.load_state_dict(tr.state_dict()) - tr.eval() - steps = 12 - x = torch.randn(3, steps, 16) - - with torch.no_grad(): - y = tr(x) - y2 = tr_mem_efficient(x) - assert torch.allclose(y, y2), ((y - y2).norm(), backend) - - -def test_attention_as_float32(): - torch.manual_seed(1234) - cases = [ - {'custom': True}, - {'custom': False}, - ] - for case in cases: - tr = StreamingTransformer(16, 4, 2, dropout=0., dtype=torch.bfloat16, **case) - tr_float32 = StreamingTransformer( - 16, 4, 2, dropout=0., attention_as_float32=True, dtype=torch.bfloat16, **case) - if not case['custom']: - # we are not using autocast here because it doesn't really - # work as expected on CPU, so we have to manually cast the weights of the MHA. - for layer in tr_float32.layers: - layer.self_attn.mha.to(torch.float32) - tr_float32.load_state_dict(tr.state_dict()) - steps = 12 - x = torch.randn(3, steps, 16, dtype=torch.bfloat16) - - with torch.no_grad(): - y = tr(x) - y2 = tr_float32(x) - assert not torch.allclose(y, y2), (y - y2).norm() - - -@torch.no_grad() -def test_streaming_memory_efficient(): - for backend in ['torch', 'xformers']: - torch.manual_seed(1234) - set_efficient_attention_backend(backend) - tr = StreamingTransformer(16, 4, 2, causal=True, dropout=0., custom=True) - tr_mem_efficient = StreamingTransformer( - 16, 4, 2, dropout=0., memory_efficient=True, causal=True) - tr.load_state_dict(tr_mem_efficient.state_dict()) - tr.eval() - tr_mem_efficient.eval() - steps = 12 - x = torch.randn(3, steps, 16) - - ref = tr(x) - - with tr_mem_efficient.streaming(): - outs = [] - # frame_sizes = [2] + [1] * (steps - 2) - frame_sizes = [1] * steps - - for frame_size in frame_sizes: - frame = x[:, :frame_size] - x = x[:, frame_size:] - outs.append(tr_mem_efficient(frame)) - - out = torch.cat(outs, dim=1) - delta = torch.norm(out - ref) / torch.norm(out) - assert delta < 1e-6, delta - - -def test_cross_attention(): - torch.manual_seed(1234) - for norm_first in [True, False]: - m = StreamingTransformer( - 16, 4, 2, cross_attention=False, norm_first=norm_first, dropout=0., custom=True) - m_cross = StreamingTransformer( - 16, 4, 2, cross_attention=True, norm_first=norm_first, dropout=0., custom=True) - m_cross.load_state_dict(m.state_dict(), strict=False) - x = torch.randn(2, 5, 16) - cross_x = torch.randn(2, 3, 16) - y_ref = m(x) - y_cross_zero = m_cross(x, cross_attention_src=0 * cross_x) - # With norm_first, the two should be exactly yhe same, - # but with norm_first=False, we get 2 normalization in a row - # and the epsilon value leads to a tiny change. - atol = 0. if norm_first else 1e-6 - print((y_ref - y_cross_zero).norm() / y_ref.norm()) - assert torch.allclose(y_ref, y_cross_zero, atol=atol) - - # We now expect a difference even with a generous atol of 1e-2. - y_cross = m_cross(x, cross_attention_src=cross_x) - assert not torch.allclose(y_cross, y_cross_zero, atol=1e-2) - - with pytest.raises(AssertionError): - _ = m_cross(x) - _ = m(x, cross_attention_src=cross_x) - - -def test_cross_attention_compat(): - torch.manual_seed(1234) - num_heads = 2 - dim = num_heads * 64 - with pytest.raises(AssertionError): - StreamingMultiheadAttention(dim, num_heads, causal=True, cross_attention=True) - - cross_attn = StreamingMultiheadAttention( - dim, num_heads, dropout=0, cross_attention=True, custom=True) - ref_attn = torch.nn.MultiheadAttention(dim, num_heads, dropout=0, batch_first=True) - - # We can load the regular attention state dict - # so we have compat when loading old checkpoints. - cross_attn.load_state_dict(ref_attn.state_dict()) - - queries = torch.randn(3, 7, dim) - keys = torch.randn(3, 9, dim) - values = torch.randn(3, 9, dim) - - y = cross_attn(queries, keys, values)[0] - y_ref = ref_attn(queries, keys, values)[0] - assert torch.allclose(y, y_ref, atol=1e-7), (y - y_ref).norm() / y_ref.norm() - - # Now let's check that streaming is working properly. - with cross_attn.streaming(): - ys = [] - for step in range(queries.shape[1]): - ys.append(cross_attn(queries[:, step: step + 1], keys, values)[0]) - y_streaming = torch.cat(ys, dim=1) - assert torch.allclose(y_streaming, y, atol=1e-7) - - -def test_repeat_kv(): - torch.manual_seed(1234) - num_heads = 8 - kv_repeat = 4 - dim = num_heads * 64 - with pytest.raises(AssertionError): - mha = StreamingMultiheadAttention( - dim, num_heads, causal=True, kv_repeat=kv_repeat, cross_attention=True) - mha = StreamingMultiheadAttention( - dim, num_heads, causal=True, kv_repeat=kv_repeat) - mha = StreamingMultiheadAttention( - dim, num_heads, causal=True, kv_repeat=kv_repeat, custom=True) - x = torch.randn(4, 18, dim) - y = mha(x, x, x)[0] - assert x.shape == y.shape - - -def test_qk_layer_norm(): - torch.manual_seed(1234) - tr = StreamingTransformer( - 16, 4, 2, custom=True, dropout=0., qk_layer_norm=True, bias_attn=False) - steps = 12 - x = torch.randn(3, steps, 16) - y = tr(x) - - tr = StreamingTransformer( - 16, 4, 2, custom=True, dropout=0., qk_layer_norm=True, cross_attention=True) - z = torch.randn(3, 21, 16) - y = tr(x, cross_attention_src=z) - assert y.shape == x.shape diff --git a/spaces/Zengyf-CVer/Streamlit_YOLOv5_Model2x/README.md b/spaces/Zengyf-CVer/Streamlit_YOLOv5_Model2x/README.md deleted file mode 100644 index 3b90498d3e73a62ffd41aa7146ff7d7991449ddb..0000000000000000000000000000000000000000 --- a/spaces/Zengyf-CVer/Streamlit_YOLOv5_Model2x/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Streamlit YOLOv5 Model2x -emoji: 🚀 -colorFrom: red -colorTo: pink -sdk: streamlit -sdk_version: 1.10.0 -app_file: app.py -pinned: false -license: gpl-3.0 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/abhishek/first-order-motion-model/frames_dataset.py b/spaces/abhishek/first-order-motion-model/frames_dataset.py deleted file mode 100644 index 7fd3400814708a8b31f05a624b0051e97c6573e1..0000000000000000000000000000000000000000 --- a/spaces/abhishek/first-order-motion-model/frames_dataset.py +++ /dev/null @@ -1,197 +0,0 @@ -import os -from skimage import io, img_as_float32 -from skimage.color import gray2rgb -from sklearn.model_selection import train_test_split -from imageio import mimread - -import numpy as np -from torch.utils.data import Dataset -import pandas as pd -from augmentation import AllAugmentationTransform -import glob - - -def read_video(name, frame_shape): - """ - Read video which can be: - - an image of concatenated frames - - '.mp4' and'.gif' - - folder with videos - """ - - if os.path.isdir(name): - frames = sorted(os.listdir(name)) - num_frames = len(frames) - video_array = np.array( - [img_as_float32(io.imread(os.path.join(name, frames[idx]))) for idx in range(num_frames)]) - elif name.lower().endswith('.png') or name.lower().endswith('.jpg'): - image = io.imread(name) - - if len(image.shape) == 2 or image.shape[2] == 1: - image = gray2rgb(image) - - if image.shape[2] == 4: - image = image[..., :3] - - image = img_as_float32(image) - - video_array = np.moveaxis(image, 1, 0) - - video_array = video_array.reshape((-1,) + frame_shape) - video_array = np.moveaxis(video_array, 1, 2) - elif name.lower().endswith('.gif') or name.lower().endswith('.mp4') or name.lower().endswith('.mov'): - video = np.array(mimread(name)) - if len(video.shape) == 3: - video = np.array([gray2rgb(frame) for frame in video]) - if video.shape[-1] == 4: - video = video[..., :3] - video_array = img_as_float32(video) - else: - raise Exception("Unknown file extensions %s" % name) - - return video_array - - -class FramesDataset(Dataset): - """ - Dataset of videos, each video can be represented as: - - an image of concatenated frames - - '.mp4' or '.gif' - - folder with all frames - """ - - def __init__(self, root_dir, frame_shape=(256, 256, 3), id_sampling=False, is_train=True, - random_seed=0, pairs_list=None, augmentation_params=None): - self.root_dir = root_dir - self.videos = os.listdir(root_dir) - self.frame_shape = tuple(frame_shape) - self.pairs_list = pairs_list - self.id_sampling = id_sampling - if os.path.exists(os.path.join(root_dir, 'train')): - assert os.path.exists(os.path.join(root_dir, 'test')) - print("Use predefined train-test split.") - if id_sampling: - train_videos = {os.path.basename(video).split('#')[0] for video in - os.listdir(os.path.join(root_dir, 'train'))} - train_videos = list(train_videos) - else: - train_videos = os.listdir(os.path.join(root_dir, 'train')) - test_videos = os.listdir(os.path.join(root_dir, 'test')) - self.root_dir = os.path.join(self.root_dir, 'train' if is_train else 'test') - else: - print("Use random train-test split.") - train_videos, test_videos = train_test_split(self.videos, random_state=random_seed, test_size=0.2) - - if is_train: - self.videos = train_videos - else: - self.videos = test_videos - - self.is_train = is_train - - if self.is_train: - self.transform = AllAugmentationTransform(**augmentation_params) - else: - self.transform = None - - def __len__(self): - return len(self.videos) - - def __getitem__(self, idx): - if self.is_train and self.id_sampling: - name = self.videos[idx] - path = np.random.choice(glob.glob(os.path.join(self.root_dir, name + '*.mp4'))) - else: - name = self.videos[idx] - path = os.path.join(self.root_dir, name) - - video_name = os.path.basename(path) - - if self.is_train and os.path.isdir(path): - frames = os.listdir(path) - num_frames = len(frames) - frame_idx = np.sort(np.random.choice(num_frames, replace=True, size=2)) - video_array = [img_as_float32(io.imread(os.path.join(path, frames[idx]))) for idx in frame_idx] - else: - video_array = read_video(path, frame_shape=self.frame_shape) - num_frames = len(video_array) - frame_idx = np.sort(np.random.choice(num_frames, replace=True, size=2)) if self.is_train else range( - num_frames) - video_array = video_array[frame_idx] - - if self.transform is not None: - video_array = self.transform(video_array) - - out = {} - if self.is_train: - source = np.array(video_array[0], dtype='float32') - driving = np.array(video_array[1], dtype='float32') - - out['driving'] = driving.transpose((2, 0, 1)) - out['source'] = source.transpose((2, 0, 1)) - else: - video = np.array(video_array, dtype='float32') - out['video'] = video.transpose((3, 0, 1, 2)) - - out['name'] = video_name - - return out - - -class DatasetRepeater(Dataset): - """ - Pass several times over the same dataset for better i/o performance - """ - - def __init__(self, dataset, num_repeats=100): - self.dataset = dataset - self.num_repeats = num_repeats - - def __len__(self): - return self.num_repeats * self.dataset.__len__() - - def __getitem__(self, idx): - return self.dataset[idx % self.dataset.__len__()] - - -class PairedDataset(Dataset): - """ - Dataset of pairs for animation. - """ - - def __init__(self, initial_dataset, number_of_pairs, seed=0): - self.initial_dataset = initial_dataset - pairs_list = self.initial_dataset.pairs_list - - np.random.seed(seed) - - if pairs_list is None: - max_idx = min(number_of_pairs, len(initial_dataset)) - nx, ny = max_idx, max_idx - xy = np.mgrid[:nx, :ny].reshape(2, -1).T - number_of_pairs = min(xy.shape[0], number_of_pairs) - self.pairs = xy.take(np.random.choice(xy.shape[0], number_of_pairs, replace=False), axis=0) - else: - videos = self.initial_dataset.videos - name_to_index = {name: index for index, name in enumerate(videos)} - pairs = pd.read_csv(pairs_list) - pairs = pairs[np.logical_and(pairs['source'].isin(videos), pairs['driving'].isin(videos))] - - number_of_pairs = min(pairs.shape[0], number_of_pairs) - self.pairs = [] - self.start_frames = [] - for ind in range(number_of_pairs): - self.pairs.append( - (name_to_index[pairs['driving'].iloc[ind]], name_to_index[pairs['source'].iloc[ind]])) - - def __len__(self): - return len(self.pairs) - - def __getitem__(self, idx): - pair = self.pairs[idx] - first = self.initial_dataset[pair[0]] - second = self.initial_dataset[pair[1]] - first = {'driving_' + key: value for key, value in first.items()} - second = {'source_' + key: value for key, value in second.items()} - - return {**first, **second} diff --git a/spaces/abhishek/first-order-motion-model/modules/generator.py b/spaces/abhishek/first-order-motion-model/modules/generator.py deleted file mode 100644 index ec665703efb1e67c561ab86e116cbb41198dfe51..0000000000000000000000000000000000000000 --- a/spaces/abhishek/first-order-motion-model/modules/generator.py +++ /dev/null @@ -1,97 +0,0 @@ -import torch -from torch import nn -import torch.nn.functional as F -from modules.util import ResBlock2d, SameBlock2d, UpBlock2d, DownBlock2d -from modules.dense_motion import DenseMotionNetwork - - -class OcclusionAwareGenerator(nn.Module): - """ - Generator that given source image and and keypoints try to transform image according to movement trajectories - induced by keypoints. Generator follows Johnson architecture. - """ - - def __init__(self, num_channels, num_kp, block_expansion, max_features, num_down_blocks, - num_bottleneck_blocks, estimate_occlusion_map=False, dense_motion_params=None, estimate_jacobian=False): - super(OcclusionAwareGenerator, self).__init__() - - if dense_motion_params is not None: - self.dense_motion_network = DenseMotionNetwork(num_kp=num_kp, num_channels=num_channels, - estimate_occlusion_map=estimate_occlusion_map, - **dense_motion_params) - else: - self.dense_motion_network = None - - self.first = SameBlock2d(num_channels, block_expansion, kernel_size=(7, 7), padding=(3, 3)) - - down_blocks = [] - for i in range(num_down_blocks): - in_features = min(max_features, block_expansion * (2 ** i)) - out_features = min(max_features, block_expansion * (2 ** (i + 1))) - down_blocks.append(DownBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1))) - self.down_blocks = nn.ModuleList(down_blocks) - - up_blocks = [] - for i in range(num_down_blocks): - in_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i))) - out_features = min(max_features, block_expansion * (2 ** (num_down_blocks - i - 1))) - up_blocks.append(UpBlock2d(in_features, out_features, kernel_size=(3, 3), padding=(1, 1))) - self.up_blocks = nn.ModuleList(up_blocks) - - self.bottleneck = torch.nn.Sequential() - in_features = min(max_features, block_expansion * (2 ** num_down_blocks)) - for i in range(num_bottleneck_blocks): - self.bottleneck.add_module('r' + str(i), ResBlock2d(in_features, kernel_size=(3, 3), padding=(1, 1))) - - self.final = nn.Conv2d(block_expansion, num_channels, kernel_size=(7, 7), padding=(3, 3)) - self.estimate_occlusion_map = estimate_occlusion_map - self.num_channels = num_channels - - def deform_input(self, inp, deformation): - _, h_old, w_old, _ = deformation.shape - _, _, h, w = inp.shape - if h_old != h or w_old != w: - deformation = deformation.permute(0, 3, 1, 2) - deformation = F.interpolate(deformation, size=(h, w), mode='bilinear') - deformation = deformation.permute(0, 2, 3, 1) - return F.grid_sample(inp, deformation) - - def forward(self, source_image, kp_driving, kp_source): - # Encoding (downsampling) part - out = self.first(source_image) - for i in range(len(self.down_blocks)): - out = self.down_blocks[i](out) - - # Transforming feature representation according to deformation and occlusion - output_dict = {} - if self.dense_motion_network is not None: - dense_motion = self.dense_motion_network(source_image=source_image, kp_driving=kp_driving, - kp_source=kp_source) - output_dict['mask'] = dense_motion['mask'] - output_dict['sparse_deformed'] = dense_motion['sparse_deformed'] - - if 'occlusion_map' in dense_motion: - occlusion_map = dense_motion['occlusion_map'] - output_dict['occlusion_map'] = occlusion_map - else: - occlusion_map = None - deformation = dense_motion['deformation'] - out = self.deform_input(out, deformation) - - if occlusion_map is not None: - if out.shape[2] != occlusion_map.shape[2] or out.shape[3] != occlusion_map.shape[3]: - occlusion_map = F.interpolate(occlusion_map, size=out.shape[2:], mode='bilinear') - out = out * occlusion_map - - output_dict["deformed"] = self.deform_input(source_image, deformation) - - # Decoding part - out = self.bottleneck(out) - for i in range(len(self.up_blocks)): - out = self.up_blocks[i](out) - out = self.final(out) - out = F.sigmoid(out) - - output_dict["prediction"] = out - - return output_dict diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/configs/_base_/datasets/drive.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/configs/_base_/datasets/drive.py deleted file mode 100644 index 06e8ff606e0d2a4514ec8b7d2c6c436a32efcbf4..0000000000000000000000000000000000000000 --- a/spaces/abhishek/sketch-to-image/annotator/uniformer/configs/_base_/datasets/drive.py +++ /dev/null @@ -1,59 +0,0 @@ -# dataset settings -dataset_type = 'DRIVEDataset' -data_root = 'data/DRIVE' -img_norm_cfg = dict( - mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) -img_scale = (584, 565) -crop_size = (64, 64) -train_pipeline = [ - dict(type='LoadImageFromFile'), - dict(type='LoadAnnotations'), - dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)), - dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75), - dict(type='RandomFlip', prob=0.5), - dict(type='PhotoMetricDistortion'), - dict(type='Normalize', **img_norm_cfg), - dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255), - dict(type='DefaultFormatBundle'), - dict(type='Collect', keys=['img', 'gt_semantic_seg']) -] -test_pipeline = [ - dict(type='LoadImageFromFile'), - dict( - type='MultiScaleFlipAug', - img_scale=img_scale, - # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0], - flip=False, - transforms=[ - dict(type='Resize', keep_ratio=True), - dict(type='RandomFlip'), - dict(type='Normalize', **img_norm_cfg), - dict(type='ImageToTensor', keys=['img']), - dict(type='Collect', keys=['img']) - ]) -] - -data = dict( - samples_per_gpu=4, - workers_per_gpu=4, - train=dict( - type='RepeatDataset', - times=40000, - dataset=dict( - type=dataset_type, - data_root=data_root, - img_dir='images/training', - ann_dir='annotations/training', - pipeline=train_pipeline)), - val=dict( - type=dataset_type, - data_root=data_root, - img_dir='images/validation', - ann_dir='annotations/validation', - pipeline=test_pipeline), - test=dict( - type=dataset_type, - data_root=data_root, - img_dir='images/validation', - ann_dir='annotations/validation', - pipeline=test_pipeline)) diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/fileio/handlers/json_handler.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/fileio/handlers/json_handler.py deleted file mode 100644 index 18d4f15f74139d20adff18b20be5529c592a66b6..0000000000000000000000000000000000000000 --- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/fileio/handlers/json_handler.py +++ /dev/null @@ -1,36 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -import json - -import numpy as np - -from .base import BaseFileHandler - - -def set_default(obj): - """Set default json values for non-serializable values. - - It helps convert ``set``, ``range`` and ``np.ndarray`` data types to list. - It also converts ``np.generic`` (including ``np.int32``, ``np.float32``, - etc.) into plain numbers of plain python built-in types. - """ - if isinstance(obj, (set, range)): - return list(obj) - elif isinstance(obj, np.ndarray): - return obj.tolist() - elif isinstance(obj, np.generic): - return obj.item() - raise TypeError(f'{type(obj)} is unsupported for json dump') - - -class JsonHandler(BaseFileHandler): - - def load_from_fileobj(self, file): - return json.load(file) - - def dump_to_fileobj(self, obj, file, **kwargs): - kwargs.setdefault('default', set_default) - json.dump(obj, file, **kwargs) - - def dump_to_str(self, obj, **kwargs): - kwargs.setdefault('default', set_default) - return json.dumps(obj, **kwargs) diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/runner/hooks/logger/tensorboard.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/runner/hooks/logger/tensorboard.py deleted file mode 100644 index 4dd5011dc08def6c09eef86d3ce5b124c9fc5372..0000000000000000000000000000000000000000 --- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/runner/hooks/logger/tensorboard.py +++ /dev/null @@ -1,57 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -import os.path as osp - -from annotator.uniformer.mmcv.utils import TORCH_VERSION, digit_version -from ...dist_utils import master_only -from ..hook import HOOKS -from .base import LoggerHook - - -@HOOKS.register_module() -class TensorboardLoggerHook(LoggerHook): - - def __init__(self, - log_dir=None, - interval=10, - ignore_last=True, - reset_flag=False, - by_epoch=True): - super(TensorboardLoggerHook, self).__init__(interval, ignore_last, - reset_flag, by_epoch) - self.log_dir = log_dir - - @master_only - def before_run(self, runner): - super(TensorboardLoggerHook, self).before_run(runner) - if (TORCH_VERSION == 'parrots' - or digit_version(TORCH_VERSION) < digit_version('1.1')): - try: - from tensorboardX import SummaryWriter - except ImportError: - raise ImportError('Please install tensorboardX to use ' - 'TensorboardLoggerHook.') - else: - try: - from torch.utils.tensorboard import SummaryWriter - except ImportError: - raise ImportError( - 'Please run "pip install future tensorboard" to install ' - 'the dependencies to use torch.utils.tensorboard ' - '(applicable to PyTorch 1.1 or higher)') - - if self.log_dir is None: - self.log_dir = osp.join(runner.work_dir, 'tf_logs') - self.writer = SummaryWriter(self.log_dir) - - @master_only - def log(self, runner): - tags = self.get_loggable_tags(runner, allow_text=True) - for tag, val in tags.items(): - if isinstance(val, str): - self.writer.add_text(tag, val, self.get_iter(runner)) - else: - self.writer.add_scalar(tag, val, self.get_iter(runner)) - - @master_only - def after_run(self, runner): - self.writer.close() diff --git a/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/libs/egl/lib.py b/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/libs/egl/lib.py deleted file mode 100644 index 0707518877e96b03c04a628614201f08270bac24..0000000000000000000000000000000000000000 --- a/spaces/abrar-lohia/text-2-character-anim/pyrender/.eggs/pyglet-2.0.5-py3.10.egg/pyglet/libs/egl/lib.py +++ /dev/null @@ -1,31 +0,0 @@ -from ctypes import * - -import pyglet -import pyglet.util - - -__all__ = ['link_EGL'] - -egl_lib = pyglet.lib.load_library('EGL') - -# Look for eglGetProcAddress -eglGetProcAddress = getattr(egl_lib, 'eglGetProcAddress') -eglGetProcAddress.restype = POINTER(CFUNCTYPE(None)) -eglGetProcAddress.argtypes = [POINTER(c_ubyte)] - - -def link_EGL(name, restype, argtypes, requires=None, suggestions=None): - try: - func = getattr(egl_lib, name) - func.restype = restype - func.argtypes = argtypes - return func - except AttributeError: - bname = cast(pointer(create_string_buffer(pyglet.util.asbytes(name))), POINTER(c_ubyte)) - addr = eglGetProcAddress(bname) - if addr: - ftype = CFUNCTYPE(*((restype,) + tuple(argtypes))) - func = cast(addr, ftype) - return func - - return pyglet.gl.lib.missing_function(name, requires, suggestions) diff --git a/spaces/abrar-lohia/text-2-character-anim/pyrender/pyrender/platforms/base.py b/spaces/abrar-lohia/text-2-character-anim/pyrender/pyrender/platforms/base.py deleted file mode 100644 index c9ecda906145e239737901809aa59db8d3e231c6..0000000000000000000000000000000000000000 --- a/spaces/abrar-lohia/text-2-character-anim/pyrender/pyrender/platforms/base.py +++ /dev/null @@ -1,76 +0,0 @@ -import abc - -import six - - -@six.add_metaclass(abc.ABCMeta) -class Platform(object): - """Base class for all OpenGL platforms. - - Parameters - ---------- - viewport_width : int - The width of the main viewport, in pixels. - viewport_height : int - The height of the main viewport, in pixels - """ - - def __init__(self, viewport_width, viewport_height): - self.viewport_width = viewport_width - self.viewport_height = viewport_height - - @property - def viewport_width(self): - """int : The width of the main viewport, in pixels. - """ - return self._viewport_width - - @viewport_width.setter - def viewport_width(self, value): - self._viewport_width = value - - @property - def viewport_height(self): - """int : The height of the main viewport, in pixels. - """ - return self._viewport_height - - @viewport_height.setter - def viewport_height(self, value): - self._viewport_height = value - - @abc.abstractmethod - def init_context(self): - """Create an OpenGL context. - """ - pass - - @abc.abstractmethod - def make_current(self): - """Make the OpenGL context current. - """ - pass - - @abc.abstractmethod - def make_uncurrent(self): - """Make the OpenGL context uncurrent. - """ - pass - - @abc.abstractmethod - def delete_context(self): - """Delete the OpenGL context. - """ - pass - - @abc.abstractmethod - def supports_framebuffers(self): - """Returns True if the method supports framebuffer rendering. - """ - pass - - def __del__(self): - try: - self.delete_context() - except Exception: - pass diff --git a/spaces/adirik/stylemc-demo/__init__.py b/spaces/adirik/stylemc-demo/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/adirik/stylemc-demo/encoder4editing/criteria/__init__.py b/spaces/adirik/stylemc-demo/encoder4editing/criteria/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/adirik/stylemc-demo/torch_utils/ops/__init__.py b/spaces/adirik/stylemc-demo/torch_utils/ops/__init__.py deleted file mode 100644 index ece0ea08fe2e939cc260a1dafc0ab5b391b773d9..0000000000000000000000000000000000000000 --- a/spaces/adirik/stylemc-demo/torch_utils/ops/__init__.py +++ /dev/null @@ -1,9 +0,0 @@ -# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved. -# -# NVIDIA CORPORATION and its licensors retain all intellectual property -# and proprietary rights in and to this software, related documentation -# and any modifications thereto. Any use, reproduction, disclosure or -# distribution of this software and related documentation without an express -# license agreement from NVIDIA CORPORATION is strictly prohibited. - -# empty diff --git a/spaces/ahiruguagua/aiemo/template.md b/spaces/ahiruguagua/aiemo/template.md deleted file mode 100644 index c40eb5b940d4bcb58ff527488f0cc0ead27d00e3..0000000000000000000000000000000000000000 --- a/spaces/ahiruguagua/aiemo/template.md +++ /dev/null @@ -1,5 +0,0 @@ -### AIアシスタントの返信 - -ここにユーザのメッセージに対する返信を書く(爆笑必須) - - diff --git a/spaces/akhaliq/Ghibli-Diffusion/app.py b/spaces/akhaliq/Ghibli-Diffusion/app.py deleted file mode 100644 index 25e4911d6481344a01f0ab7867dabd1f3d130e7a..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/Ghibli-Diffusion/app.py +++ /dev/null @@ -1,10 +0,0 @@ -import gradio as gr - -description = """ -
- Ghibli Diffusion -This is the fine-tuned Stable Diffusion model trained on images from modern anime feature films from Studio Ghibli. Use the tokens ghibli style in your prompts for the effect.
Revisiting Weakly Supervised Pre-Training of Visual Perception Models | Github Repo
" - - -gr.Interface(inference, inputs, outputs, title=title, description=description, article=article, examples=[['dog.jpg']]).launch(enable_queue=True,cache_examples=True) \ No newline at end of file diff --git a/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/ljspeech/voc1/cmd.sh b/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/ljspeech/voc1/cmd.sh deleted file mode 100644 index 19f342102fc4f3389157c48f1196b16b68eb1cf1..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/VQMIVC/ParallelWaveGAN/egs/ljspeech/voc1/cmd.sh +++ /dev/null @@ -1,91 +0,0 @@ -# ====== About run.pl, queue.pl, slurm.pl, and ssh.pl ====== -# Usage: