-
- Pastel Mix
-
- Demo for Pastel Mix Stable Diffusion model.
- {"Add the following tokens to your prompts for the model to work properly: prefix" if prefix else ""}
-
-
- Demo for Pastel Mix Stable Diffusion model.
- {"Add the following tokens to your prompts for the model to work properly: prefix" if prefix else ""}
-
This space was created using SD Space Creator.
-If you are looking for a powerful and versatile photo editing software that can handle all your creative needs, you might want to check out ACDSee Photo Studio Ultimate 2020. This software is not only a digital asset manager and a RAW editor with layers, but also a full-featured photo editor that offers a wide range of tools and features to help you create stunning images.
-Download Zip ✔✔✔ https://byltly.com/2uKvQl
In this article, we will review ACDSee Photo Studio Ultimate 2020 in detail and show you what it can do for you. We will cover its main features, benefits, drawbacks, and how to get it for free with a crack. By the end of this article, you will have a clear idea of whether ACDSee Photo Studio Ultimate 2020 is the right software for you or not.
-ACDSee Photo Studio Ultimate 2020 is a software developed by ACD Systems, a company that has been in the business of digital imaging since 1994. It is the latest version of their flagship product, which combines several functions into one package.
-ACDSee Photo Studio Ultimate 2020 is designed to answer your creative graphic and photography needs. It allows you to manage your photos from import to export, edit them with layers and filters, enhance them with adjustments and effects, organize them by faces and keywords, and share them online or offline.
-ACDSee Photo Studio Ultimate 2020 is suitable for both beginners and professionals who want a fast and flexible solution for their photo editing projects. It supports over 500 camera models and formats, including RAW files. It also works seamlessly with other software like Photoshop and Lightroom.
-In this article, we will explore ACDSee Photo Studio Ultimate 2020's features in depth and show you how they can help you improve your workflow and creativity.
-ACDSee Photo Studio Ultimate 2020 has many features that make it stand out from other photo editing software. Here are some of the most important ones:
-One of the most impressive features of ACDSee Photo Studio Ultimate 2020 is its face detection and facial recognition tool. This tool allows you to find and name the people in your photos automatically. You can also search your photos by unnamed, auto-named, or suggested names.
-ACDSee Photo Studio Ultimate 2020 full version offline installer
-ACDSee Photo Studio Ultimate 2020 with facial recognition tool
-ACDSee Photo Studio Ultimate 2020 free download with crack
-ACDSee Photo Studio Ultimate 2020 color wheel feature
-ACDSee Photo Studio Ultimate 2020 review and tutorial
-ACDSee Photo Studio Ultimate 2020 vs Photoshop
-ACDSee Photo Studio Ultimate 2020 system requirements and technical details
-ACDSee Photo Studio Ultimate 2020 best price and discount
-ACDSee Photo Studio Ultimate 2020 layered photo editor
-ACDSee Photo Studio Ultimate 2020 RAW editor with layers
-ACDSee Photo Studio Ultimate 2020 digital asset manager
-ACDSee Photo Studio Ultimate 2020 non-destructive photo editing
-ACDSee Photo Studio Ultimate 2020 develop mode and presets
-ACDSee Photo Studio Ultimate 2020 import face data from Lightroom and Picasa
-ACDSee Photo Studio Ultimate 2020 support for GoPro.GPR file format
-How to install and activate ACDSee Photo Studio Ultimate 2020 with crack
-How to use ACDSee Photo Studio Ultimate 2020 for creative graphic and image composition
-How to optimize your workflow with ACDSee Photo Studio Ultimate 2020
-How to create stunning photo manipulations with ACDSee Photo Studio Ultimate 2020
-How to organize and manage your photos with ACDSee Photo Studio Ultimate 2020
-How to enhance your photos with ACDSee Photo Studio Ultimate 2020 adjustment layers
-How to apply filters and effects with ACDSee Photo Studio Ultimate 2020
-How to edit RAW images with ACDSee Photo Studio Ultimate 2020
-How to use the color wheel in ACDSee Photo Studio Ultimate 2020
-How to find and name faces in your photos with ACDSee Photo Studio Ultimate 2020
-How to compare ACDSee Photo Studio Ultimate 2020 with other photo editing software
-How to get the latest updates and features of ACDSee Photo Studio Ultimate 2020
-How to troubleshoot common issues with ACDSee Photo Studio Ultimate 2020
-How to backup and restore your photos with ACDSee Photo Studio Ultimate 2020
-How to share your photos online with ACDSee Photo Studio Ultimate 2020
This feature is very useful for organizing your photos by person or family member. You can also create smart collections based on faces or use face data as metadata for sorting or filtering. You can also edit faces individually or in batches with tools like skin tune, red-eye removal, blemish removal, teeth whitening, etc.
-If you want to create stunning images with high dynamic range and depth of field,ACDSee Photo Studio Ultimate 2020's HDR and focus stacking tools are perfect for you. These tools allow you to combine multiple images with different exposures or focal distances into one image with maximum detail in shadows and highlights.
-The HDR tool lets you merge a series of images with different exposures into one image that captures the full range of light in your scene. You can also adjust parameters like brightness, contrast, saturation, tone curve, etc. to fine-tune your HDR image.
-The focus stacking tool lets you merge a series of images with different focal distances into one image that has a greater depth of field than a single exposure would allow. You can also adjust parameters like alignment, blending mode, radius, etc. to fine-tune your focus stacked image.
-If you want to create complex compositions and manipulations,ACDSee Photo Studio Ultimate 2020's layered editing feature is ideal for you. This feature allows you to use layers, masks, filters, and effects to edit your images non-destructively.
-You can add as many layers as you want to your image and apply any edit mode filter or adjustment to each layer individually. You can also blend layers with different modes like normal, multiply, screen, overlay, etc. You can also use masks to control which parts of your image are affected by each layer.
-You can also use text layers to add captions, titles, or watermarks to your image. You can customize font, size, color, style, justification, opacity, and more for each text layer. You can also add effects like inner glow, shadows, bevel, outline, or blur to your text layers.
-If you want to manage, sort, tag, and search your photos efficiently,ACDSee Photo Studio Ultimate 2020's digital asset management feature is essential for you. This feature allows you to import, export, browse, organize, and backup your photos easily.
-```html issues, learning curve, bugs, and updates. -A: To get ACDSee Photo Studio Ultimate 2020 for free with a crack, you need to download the software from a reliable source and apply the crack file to activate the full version of the software. You can follow these steps:
-A: ACDSee Photo Studio Ultimate 2020 is safe to use if you download it from a trusted source and scan it with a reputable antivirus program before installing it. However, using a cracked version of the software may pose some risks such as malware infection, data loss, legal issues, or performance issues. Therefore, we recommend that you use ACDSee Photo Studio Ultimate 2020 at your own risk and discretion.
-A: Some alternatives to ACDSee Photo Studio Ultimate 2020 are:
-I hope you enjoyed this article and learned something new about ACDSee Photo Studio Ultimate 2020. If you have any questions or feedback, please feel free to leave a comment below. Thank you for reading!
- 0a6ba089ebIf you are a fan of strategy games, you might have heard of Stronghold Crusader, a popular medieval-themed game that lets you build and defend your own castle against various enemies. The game offers a lot of challenges and fun, but it can also be quite difficult and frustrating at times.
-Download File ○○○ https://byltly.com/2uKzBP
That's why some players use trainers, which are programs that modify the game's code and give you access to various cheats and hacks that can make the game easier or more enjoyable.
-In this article, we will show you how to download and use one of the best trainers for Stronghold Crusader, which is Stronghold Crusader Trainer V1.0.0.1. This trainer has many features and options that can help you conquer your enemies and build your dream castle.
-So, if you are interested in learning more about this trainer, keep reading!
-Stronghold Crusader is a real-time strategy game developed by Firefly Studios and released in 2002. It is a sequel to Stronghold, which was released in 2001.
-The game is set in the Middle East during the Crusades, where you can play as either a European lord or an Arabian sultan. You can choose from four historical campaigns, each with different missions and objectives.
-The game also has a skirmish mode, where you can play against up to seven computer-controlled opponents or other players online.
-The main goal of the game is to build a strong castle that can withstand attacks from your enemies, while also producing resources, recruiting troops, and expanding your territory.
-The game has many features that make it realistic and immersive, such as weather effects, day-night cycle, fire propagation, siege engines, historical characters, and different types of units.
-stronghold crusader hd trainer mrantifun
-stronghold crusader plus 27 trainer deviance
-stronghold crusader unlimited gold and resources cheat
-stronghold crusader extreme cheat table
-stronghold crusader trainer for steam version
-stronghold crusader god mode trainer
-stronghold crusader trainer setup.exe
-stronghold crusader trainer with popularity cheat
-stronghold crusader hd v1.0.1 trainer +2
-stronghold crusader trainer for windows 10
-stronghold crusader trainer for version 1.3
-stronghold crusader hd and extreme latest version trainer
-stronghold crusader trainer with invincible units
-stronghold crusader trainer with instakill cheat
-stronghold crusader hd (steam) 9-1-20 trainer +4
-stronghold crusader trainer with unlimited chickens
-stronghold crusader trainer with freeze time cheat
-stronghold crusader trainer with stop increasing population cheat
-stronghold crusader hd v1.0.0.1 free download full version
-stronghold crusader hd v1.0.0.1 free download for pc
-stronghold crusader hd v1.0.0.1 free download mega
-stronghold crusader hd v1.0.0.1 free download torrent
-stronghold crusader hd v1.0.0.1 free download crack
-stronghold crusader hd v1.0.0.1 free download skidrow
-stronghold crusader hd v1.0.0.1 free download ocean of games
-how to install stronghold crusader hd v1.0.0.1 free download
-how to use stronghold crusader hd v1.0.0.1 free download trainer
-how to update stronghold crusader hd v1.0.0.1 free download
-how to play multiplayer on stronghold crusader hd v1.0.0.1 free download
-how to fix bugs on stronghold crusader hd v1.0.0.1 free download
-best mods for stronghold crusader hd v1.0.0.1 free download
-best maps for stronghold crusader hd v1.0.0.1 free download
-best tips and tricks for stronghold crusader hd v1.0.0.1 free download
-best cheats and hacks for stronghold crusader hd v1.0.0.1 free download
-best strategies and guides for stronghold crusader hd v1.0.0.1 free download
-review of stronghold crusader hd v1.0.0.1 free download
-gameplay of stronghold crusader hd v1.0.0.1 free download
-walkthrough of stronghold crusader hd v1.0.0.1 free download
-comparison of stronghold crusader hd v1.0.0.1 free download and original game
-comparison of stronghold crusader hd v1.0.0.1 free download and extreme edition
A trainer is a program that modifies the game's code and gives you access to various cheats and hacks that can alter the game's behavior.
-Some of the common cheats and hacks that trainers offer are:
-You might need a trainer for various reasons:
-If you want to download Stronghold Crusader Trainer V1.0.0.1, you need to follow these steps:
-Stronghold Crusader HD V1.0.1 Trainer +2 MrAntiFun.zip and Stronghold Crusader HD (Steam) Trainer Setup.exe.If you have downloaded Stronghold Crusader Trainer V1.0.0.1 successfully ```html
If you have downloaded Stronghold Crusader Trainer V1.0.0.1 successfully, you need to follow these steps:
-Stronghold Crusader Trainer V1.0.0.1 has many features and options that can make your game easier or more fun. Here is a list and description of them:
-| Feature | Description | Hotkey |
|---|---|---|
| Unlimited resources | You can have unlimited amounts of food, wood, stone, iron, pitch, wheat, bread, cheese, meat, apples, beer, flour, bows, crossbows, spears, pikes, maces, swords, leather armor, metal armor, gold, etc. | Q - Y |
| Unlimited population | You can have unlimited number of peasants and soldiers in your castle. | F6 |
| Unlimited health | You can make your units invincible or heal them instantly. | F7 |
| Stop time | You can pause or speed up the game's clock. | M |
| Happy residents | You can make your peasants happy or unhappy. | N |
| God mode | You can make your units have superpowers or abilities. | F8 |
| Power bar to the max | You can fill up your power bar to use special abilities in Stronghold Crusader Extreme. | F9 |
If you want to use Stronghold Crusader Trainer V1.0.0.1 effectively, you need to follow these tips and tricks:
-In conclusion, Stronghold Crusader Trainer V1.0.0.1 is a great program that can enhance your gaming experience with Stronghold Crusader. It can give you access to various cheats and hacks that can help you overcome challenges and have more fun.
-If you want to download and use this trainer, you need to follow our guide carefully and make sure you get it from a reliable source. You also need to be careful and responsible when using it and avoid any problems or issues that might arise.
-We hope you found this article helpful and informative. If you did, please share it with your friends and fellow gamers who might be interested in this trainer as well.
-Thank you for reading and happy gaming!
-No, this trainer only works with version 1.0 of Stronghold Crusader (English). If you have a different version of the game, you need to find a different trainer that is compatible with it.
-No, this trainer only works with Stronghold Crusader (original). If you have Stronghold Crusader HD or Extreme, you need to find a different trainer that is compatible with them.
-No, this trainer only works with the vanilla game (original). If you have any mods or custom maps installed, you need to disable them before using this trainer.
-We cannot guarantee that this trainer is 100% safe and virus-free, as we did not create it ourselves. However, we did scan it with several antivirus programs and found no threats or malware in it. Use it at your own risk and discretion.
-If you want more trainers for Stronghold Crusader ```html
If you want more trainers for Stronghold Crusader, you can check out these sources:
-DOWNLOAD ––– https://imgfil.com/2uxZKR
Download File ⚹ https://imgfil.com/2uxZ7N
CES EduPack is a software tool that helps students learn about materials and engineering design. It provides a comprehensive database of materials properties, interactive charts and graphs, case studies and exercises, and a range of teaching resources. CES EduPack is used by over 1000 universities and colleges worldwide to support courses in engineering, materials science, design, manufacturing, sustainability, and more.
-Download Zip ✵ https://imgfil.com/2uxZ16
In this article, we will show you how to download and install CES EduPack 2013 on your computer. CES EduPack 2013 is an older version of the software that is no longer supported by Ansys, the company that develops and distributes it. However, some instructors may still prefer to use this version for their courses. If you are looking for the latest version of CES EduPack, please visit Ansys Granta EduPack.
-The first step is to download the CES EduPack 2013 installation file from a reliable source. One such source is 4shared, a file sharing service that hosts various files uploaded by users. To download CES EduPack 2013 from 4shared, follow these steps:
-The second step is to extract the CES EduPack 2013 installation file from the compressed archive. A compressed archive is a file that contains one or more files that are reduced in size to save space and bandwidth. To extract CES EduPack 2013 from the compressed archive, you will need a software program that can handle .rar files, such as WinRAR or 7-Zip. To extract CES EduPack 2013 using WinRAR, follow these steps:
-The third and final step is to install CES EduPack 2013 on your computer. To install CES EduPack 2013, follow these steps:
- -Congratulations! You have successfully downloaded and installed CES EduPack 2013 on your computer. You can now use it to explore materials and engineering design concepts in your courses.
d5da3c52bfDo you love kart racing games? Do you want to experience a thrilling and colorful adventure on a tropical island? Do you want to unlock and upgrade dozens of cars and power-ups? If you answered yes to any of these questions, then you should download Beach Buggy Racing 2 Mod APK Revdl. This is a modded version of the popular racing game Beach Buggy Racing 2 that gives you unlimited money, unlocked cars, power-ups, and more. In this article, we will tell you everything you need to know about this amazing game, how to download it from Revdl, how to play it, what are the best cars and power-ups, and what are some reviews and ratings from other players. So buckle up and get ready for some fun!
-Download Zip → https://jinyurl.com/2uNJQY
Beach Buggy Racing 2 is a 3D kart racing game developed by Vector Unit. It is the sequel to Beach Buggy Racing, which was released in 2014. The game features a variety of tracks, cars, characters, power-ups, and game modes. You can race against other players online or offline, explore a mysterious island full of secrets and surprises, compete in championships and tournaments, or create your own custom races with your own rules. The game has stunning graphics, realistic physics, catchy music, and a lighthearted atmosphere. It is suitable for all ages and skill levels.
-Beach Buggy Racing 2 is free to play on Android devices. However, it also contains in-app purchases that require real money. These include coins, gems, tickets, cars, power-ups, and more by winning races and ranking high in the leaderboards. You can also use tickets to enter special events that offer exclusive rewards. Championship Mode is updated regularly with new tournaments and challenges.
-Race Mode is the classic mode where you race against other players or AI opponents on different tracks. You can choose from various settings, such as the number of laps, the difficulty level, the power-up deck, and the car type. You can also invite your friends to join you in a private race or join a public race with random players. Race Mode is a great way to test your skills and have fun with others.
-Drift Attack Mode is the skill-based mode where you perform drifts and powerslides to earn points and bonuses. You can choose from different tracks and cars that suit your drifting style. You can also use power-ups to boost your speed, score, or time. Drift Attack Mode is a challenging and rewarding mode that requires precision and timing.
-Custom Mode is the creative mode where you can customize and save your own race rules and power-up decks. You can mix and match different settings, such as the track, the car, the power-ups, the laps, the difficulty, and more. You can also name and share your custom races with other players or play them yourself. Custom Mode is a fun and unique mode that lets you create your own racing experience.
-Beach Buggy Racing 2 has a lot of cars and power-ups to choose from, each with their own stats, abilities, and effects. Some of them are better than others, depending on your preference and strategy. Here are some of the best cars and power-ups in Beach Buggy Racing 2:
-The following table shows the name, image, type, speed, acceleration, handling, and special ability of each car in the game:
-| Name | -Image | -Type | -Speed | -Acceleration | -Handling | -Special Ability | -
|---|---|---|---|---|---|---|
| Lambini | - |
-Sport | -5/5 | -4/5 | -4/5 | -Nitro Boost: Increases speed for a short time. | -
| Baja Bandito | - |
-Buggy | -4/5 | -4/5 | -5/5 | -Baja Blast: Launches a shockwave that knocks back nearby opponents. | -
| Rocket Boat | - |
-Boat | -4/5 | -5/5 | -3/5 | -Rocket Boost: Fires a rocket that propels the car forward. | -
| Sandstorm GT | - |
-Muscle | -5/5 | -3/5 | 4/5 -Sandstorm: Creates a sandstorm that obscures the vision of opponents behind. | -|
| Lightning GT | - |
-Electric | -4/5 | -4/5 | -4/5 | -Lightning Strike: Zaps nearby opponents with a bolt of electricity. | -
| Monster Bus | - |
-Monster | -3/5 | -3/5 | -3/5 | -Monster Crush: Crushes opponents under its huge wheels. | -
| Firework Truck | - |
-Truck | -3/5 | Offensive -Increases the speed of the car for a short time. | -1: Small boost. 2: Medium boost. 3: Large boost. |
-|
| Spring Trap | - |
-Defensive | -Drops a spring trap behind the car that launches opponents into the air. | -1: Single spring. 2: Double spring. 3: Triple spring. |
-||
| Lightning Zap | - |
-Offensive | -Zaps the opponent in front of the car with a bolt of lightning that damages and slows them down. | -1: Single zap. 2: Double zap. 3: Triple zap. |
-||
| Mine Drop | - |
-Defensive | Drops a mine behind the car that explodes when an opponent touches it.1: Single mine.||||
| Banana Peel | ||||||
| Frost Bite | Freezes the opponent in front of the car with a blast of ice that damages and stops them. | -1: Single freeze. 2: Double freeze. 3: Triple freeze. |
-||||
| Magnet | - |
-Defensive | Attracts coins and power-ups to the car.1: Short duration.||||
| Firework | ||||||
| Coin Shield | ||||||
| Bomb | Throws a bomb that explodes after a few seconds and damages nearby opponents. | -1: Small bomb. 2: Medium bomb. 3: Large bomb. |
-
As you can see, there are many power-ups to choose from, each with their own effects and upgrades. You can try them all and find the ones that suit your style and strategy. You can also mix and match them to create your own power-up deck.
-download beach buggy racing 2 mod apk unlimited money
-download beach buggy racing 2 mod apk latest version
-download beach buggy racing 2 mod apk android 1
-download beach buggy racing 2 mod apk rexdl
-download beach buggy racing 2 mod apk offline
-download beach buggy racing 2 mod apk hack
-download beach buggy racing 2 mod apk free shopping
-download beach buggy racing 2 mod apk for pc
-download beach buggy racing 2 mod apk obb
-download beach buggy racing 2 mod apk data
-download beach buggy racing 2 mod apk pure
-download beach buggy racing 2 mod apk happymod
-download beach buggy racing 2 mod apk no ads
-download beach buggy racing 2 mod apk all cars unlocked
-download beach buggy racing 2 mod apk andropalace
-download beach buggy racing 2 mod apk apkpure
-download beach buggy racing 2 mod apk an1
-download beach buggy racing 2 mod apk android oyun club
-download beach buggy racing 2 mod apk by revdl
-download beach buggy racing 2 mod apk blackmod
-download beach buggy racing 2 mod apk bluestacks
-download beach buggy racing 2 mod apk bestmodapk.com
-download beach buggy racing 2 mod apk cheat
-download beach buggy racing 2 mod apk coins and gems
-download beach buggy racing 2 mod apk cracked
-download beach buggy racing 2 mod apk clubapk.com
-download beach buggy racing 2 mod apk diamond
-download beach buggy racing 2 mod apk direct link
-download beach buggy racing 2 mod apk dlandroid.com
-download beach buggy racing 2 mod apk easydownloadz.com
-download beach buggy racing 2 mod apk everything unlocked
-download beach buggy racing 2 mod apk full version
-download beach buggy racing 2 mod apk file
-download beach buggy racing 2 mod apk from apkmody.io
-download beach buggy racing 2 mod apk gamestechy.com
-download beach buggy racing 2 mod apk gems and coins generator online tool hack cheat unlimited resources free no survey no human verification no password no jailbreak no root required android ios pc windows mac xbox ps4 switch nintendo device mobile phone tablet laptop desktop computer smart tv console gaming system handheld device emulator simulator controller joystick keyboard mouse touch screen vr headset ar glasses wearable device smart watch fitness tracker bluetooth speaker wireless earbuds headphones microphone webcam camera projector printer scanner fax machine copier shredder laminator calculator calendar clock timer stopwatch alarm reminder note memo voice recorder music player video player podcast player radio player streaming player media player dvd player blu-ray player cd player cassette player vinyl record player mp3 player mp4 player flac player wav player ogg player wma player aac player m4a player midi player karaoke machine jukebox boombox stereo system surround sound system home theater system sound bar subwoofer speaker amplifier equalizer mixer turntable dj controller guitar hero rock band dance dance revolution just dance singstar guitar tuner metronome piano keyboard synthesizer drum machine sampler sequencer beat maker loop station vocoder autotune pitch correction noise cancellation noise reduction noise gate compressor limiter reverb delay echo chorus flanger phaser tremolo vibrato distortion overdrive fuzz wah-wah pedal volume pedal expression pedal sustain pedal octave pedal harmonizer pedal looper pedal multi-effects pedal guitar amp bass amp acoustic amp keyboard amp drum amp pa system microphone stand pop filter shock mount windscreen cable adapter splitter converter connector jack plug socket outlet power strip surge protector extension cord battery charger power bank solar panel generator flashlight lantern torch lamp light bulb led cfl halogen incandescent fluorescent neon laser infrared ultraviolet x-ray gamma ray radio wave microwave radar sonar lidar ultrasound echolocation doppler effect sound wave frequency wavelength amplitude modulation demodulation encoding decoding encryption decryption compression decompression zip rar tar gz bz2 iso dmg exe msi bat sh cmd ps1 py rb js php html css xml json csv tsv sql db mdb accdb xls xlsx ppt pptx doc docx pdf txt rtf odt ods odp epub mobi azw3 djvu cbz cbr epub mobi azw3 djvu cbz cbr jpg jpeg png gif bmp tiff webp svg eps psd ai cdr dwg dxf stl obj fbx gltf usdz dae ply pcd pnm pgm ppm pbm pcx xbm xpm dds tga hdr exr raw nef crw cr2 arw dng heic heif webm mp4 mov avi mkv flv wmv mpg mpeg vob mts m4v mxf asf rm rmvb swf ogv f4v f4
Beach Buggy Racing 2 is a highly rated and well-reviewed game by players and critics alike. It has over 50 million downloads and 4.4 stars out of 5 on Google Play Store. It also has positive feedback on other platforms, such as App Store, Amazon, and Steam. Here are some of the reviews and ratings of Beach Buggy Racing 2:
-Here are some of the quotes from players and critics who have praised the game for its graphics, gameplay, variety, and fun factor:
-Here are some of the quotes from players and critics who have criticized the game for its ads, bugs, difficulty, and repetition:
-Beach Buggy Racing 2 is a fun and exciting kart racing game that offers a lot of features and content for players of all ages and skill levels. You can download Beach Buggy Racing 2 Mod APK Revdl to enjoy the game without any limitations or restrictions. You can unlock and upgrade all the cars and power-ups in the game, and use them to race against other players or AI opponents on different tracks and modes. You can also explore a mysterious island full of secrets and surprises, compete in championships and tournaments, or create your own custom races with your own rules. Beach Buggy Racing 2 is a game that will keep you entertained for hours with its graphics, gameplay, variety, and fun factor. If you are looking for a kart racing game that has it all, then you should download Beach Buggy Racing 2 Mod APK Revdl today!
-Here are some of the frequently asked questions about Beach Buggy Racing 2 and Beach Buggy Racing 2 Mod APK Revdl:
-Yes, Beach Buggy Racing 2 Mod APK Revdl is safe to download and install. It does not contain any viruses, malware, or spyware that can harm your device or data. However, you should always download it from a trusted and reliable source, such as Revdl. You should also enable the option to install apps from unknown sources on your device settings before installing it.
-Beach Buggy Racing 2 Mod APK Revdl is compatible with most Android devices that have Android 4.4 or higher. However, some devices may have different specifications or performance issues that may affect the gameplay. You should check the minimum requirements and compatibility of the game before downloading and installing it.
-Beach Buggy Racing 2 Mod APK Revdl is updated regularly with new features and content. You can check the latest version of the game on the Revdl website or on the game's official social media pages. You can also enable the option to auto-update apps on your device settings. However, you may need to uninstall and reinstall the modded version of the game every time there is a new update.
-If you have any questions, feedback, suggestions, or issues regarding Beach Buggy Racing 2, you can contact the developers of the game by email at support@vectorunit.com. You can also visit their website at https://www.vectorunit.com/ or follow them on Facebook, Twitter, Instagram, YouTube, or Discord.
-If you enjoy playing Beach Buggy Racing 2 and want to support the developers of the game, you can do so by purchasing coins, gems, tickets, cars, power-ups, and more in the game. You can also rate and review the game on Google Play Store or other platforms, share it with your friends and family, or follow them on social media.
-DOWNLOAD ✫✫✫ https://gohhs.com/2uz3Se
Download Zip ► https://urlin.us/2uEyxV
AutoCAD PID is a software application that allows you to create, modify and manage piping and instrumentation diagrams (P&IDs) for process plants. It is part of the Autodesk AutoCAD suite of products, which also includes AutoCAD, AutoCAD Architecture, AutoCAD Mechanical and more.
-If you are looking for a way to download and install AutoCAD PID 2012 64 bit for free, you have come to the right place. In this article, we will show you how to use a torrent file to get the full version of AutoCAD PID 2012 64 bit without paying anything. We will also provide you with some tips and tricks to optimize your performance and avoid any potential issues.
-Download ☑ https://tiurll.com/2uCivI
A torrent file is a small file that contains information about a larger file or a group of files that can be downloaded from the internet. It does not contain the actual data of the files, but rather the metadata, such as the file names, sizes, locations and checksums. A torrent file also contains information about the peers or sources that have the files or parts of them.
-To download a torrent file, you need a torrent client, which is a software program that can read the torrent file and connect you to the peers that have the files you want. Some of the most popular torrent clients are uTorrent, BitTorrent, qBittorrent and Vuze.
-To download AutoCAD PID 2012 64 bit torrent file, you need to find a reliable website that hosts it. There are many websites that offer torrent files for various software applications, but not all of them are safe and trustworthy. Some of them may contain malware, viruses or fake files that can harm your computer or compromise your privacy.
-One of the websites that we recommend for downloading AutoCAD PID 2012 64 bit torrent file is allpcworlds.com[^1^]. This website provides high-quality torrent files for various software applications, including Autodesk products. It also has a user-friendly interface and fast download speeds.
-To download AutoCAD PID 2012 64 bit torrent file from allpcworlds.com, follow these steps:
- -To install AutoCAD PID 2012 64 bit using torrent file, you need to mount the ISO file using a software program like Daemon Tools or PowerISO. This will create a virtual drive on your computer that will act as if you have inserted a CD or DVD with the software.
-To install AutoCAD PID 2012 64 bit using torrent file, follow these steps:
-after a week of use with the portable ssds, we did not find any traces of dust, dirt, or other debris on the portable ssds. the portable ssds are made of plastic and metal, and they have a hard coating that prevents dust and dirt from sticking to the surface.
-Download · https://tiurll.com/2uClZA
the 2.5" x5 portable ssd is a solid choice for a portable ssd. its performance is comparable to the other ssds weve reviewed in this class. its 7,200rpm and its performance is great. however, its not the only option. the newer x7 model has been released with improved performance and a smaller, sleeker design. the x7 makes the x5 portable ssd more portable and has more storage capacity. however, the x5 portable ssd is priced lower and available for a lower price. the x7 is priced the same and is more portable.
-the m.2 x5 portable ssd and the x7 portable ssd are portable ssds from sandisk. with two models of m.2 and two models of usb-c, sandisk has a wide range of choices for consumers. the x5 portable ssd is a solid choice for a portable ssd. its performance is comparable to the other ssds weve reviewed in this class. its 7,200rpm and its performance is great. however, its not the only option. the newer x7 model has been released with improved performance and a smaller, sleeker design. the x7 makes the x5 portable ssd more portable and has more storage capacity. however, the x5 portable ssd is priced lower and available for a lower price. the x7 is priced the same and is more portable.
-the sandisk extreme pro v2 is the top of the line of portable ssds. it is a 2.5-inch drive with a sandisk logo on the enclosure. you can transfer and store data on this drive for many years. the sandisk extreme pro v2 has a mechanical shock protection and it is easy to use. the sandisk extreme pro v2 has an incredibly high speed, and it is the best portable ssd drive on the market.
- 899543212b{highlighted_code}{html.escape(userinput)}
"+ALREADY_CONVERTED_MARK - -def detect_converted_mark(userinput): - if userinput.endswith(ALREADY_CONVERTED_MARK): - return True - else: - return False - - -def detect_language(code): - if code.startswith("\n"): - first_line = "" - else: - first_line = code.strip().split("\n", 1)[0] - language = first_line.lower() if first_line else "" - code_without_language = code[len(first_line) :].lstrip() if first_line else code - return language, code_without_language - - -def construct_text(role, text): - return {"role": role, "content": text} - - -def construct_user(text): - return construct_text("user", text) - - -def construct_system(text): - return construct_text("system", text) - - -def construct_assistant(text): - return construct_text("assistant", text) - - -def construct_token_message(token, stream=False): - return f"Token 计数: {token}" - -def delete_first_conversation(history, previous_token_count): - if history: - del history[:2] - del previous_token_count[0] - return ( - history, - previous_token_count, - construct_token_message(sum(previous_token_count)), - ) - - -def delete_last_conversation(chatbot, history, previous_token_count): - if len(chatbot) > 0 and standard_error_msg in chatbot[-1][1]: - logging.info("由于包含报错信息,只删除chatbot记录") - chatbot.pop() - return chatbot, history - if len(history) > 0: - logging.info("删除了一组对话历史") - history.pop() - history.pop() - if len(chatbot) > 0: - logging.info("删除了一组chatbot对话") - chatbot.pop() - if len(previous_token_count) > 0: - logging.info("删除了一组对话的token计数记录") - previous_token_count.pop() - return ( - chatbot, - history, - previous_token_count, - construct_token_message(sum(previous_token_count)), - ) - - -def save_file(filename, system, history, chatbot): - logging.info("保存对话历史中……") - os.makedirs(HISTORY_DIR, exist_ok=True) - if filename.endswith(".json"): - json_s = {"system": system, "history": history, "chatbot": chatbot} - print(json_s) - with open(os.path.join(HISTORY_DIR, filename), "w") as f: - json.dump(json_s, f) - elif filename.endswith(".md"): - md_s = f"system: \n- {system} \n" - for data in history: - md_s += f"\n{data['role']}: \n- {data['content']} \n" - with open(os.path.join(HISTORY_DIR, filename), "w", encoding="utf8") as f: - f.write(md_s) - logging.info("保存对话历史完毕") - return os.path.join(HISTORY_DIR, filename) - - -def save_chat_history(filename, system, history, chatbot): - if filename == "": - return - if not filename.endswith(".json"): - filename += ".json" - return save_file(filename, system, history, chatbot) - - -def export_markdown(filename, system, history, chatbot): - if filename == "": - return - if not filename.endswith(".md"): - filename += ".md" - return save_file(filename, system, history, chatbot) - - -def load_chat_history(filename, system, history, chatbot): - logging.info("加载对话历史中……") - if type(filename) != str: - filename = filename.name - try: - with open(os.path.join(HISTORY_DIR, filename), "r") as f: - json_s = json.load(f) - try: - if type(json_s["history"][0]) == str: - logging.info("历史记录格式为旧版,正在转换……") - new_history = [] - for index, item in enumerate(json_s["history"]): - if index % 2 == 0: - new_history.append(construct_user(item)) - else: - new_history.append(construct_assistant(item)) - json_s["history"] = new_history - logging.info(new_history) - except: - # 没有对话历史 - pass - logging.info("加载对话历史完毕") - return filename, json_s["system"], json_s["history"], json_s["chatbot"] - except FileNotFoundError: - logging.info("没有找到对话历史文件,不执行任何操作") - return filename, system, history, chatbot - - -def sorted_by_pinyin(list): - return sorted(list, key=lambda char: lazy_pinyin(char)[0][0]) - - -def get_file_names(dir, plain=False, filetypes=[".json"]): - logging.info(f"获取文件名列表,目录为{dir},文件类型为{filetypes},是否为纯文本列表{plain}") - files = [] - try: - for type in filetypes: - files += [f for f in os.listdir(dir) if f.endswith(type)] - except FileNotFoundError: - files = [] - files = sorted_by_pinyin(files) - if files == []: - files = [""] - if plain: - return files - else: - return gr.Dropdown.update(choices=files) - - -def get_history_names(plain=False): - logging.info("获取历史记录文件名列表") - return get_file_names(HISTORY_DIR, plain) - - -def load_template(filename, mode=0): - logging.info(f"加载模板文件{filename},模式为{mode}(0为返回字典和下拉菜单,1为返回下拉菜单,2为返回字典)") - lines = [] - logging.info("Loading template...") - if filename.endswith(".json"): - with open(os.path.join(TEMPLATES_DIR, filename), "r", encoding="utf8") as f: - lines = json.load(f) - lines = [[i["act"], i["prompt"]] for i in lines] - else: - with open( - os.path.join(TEMPLATES_DIR, filename), "r", encoding="utf8" - ) as csvfile: - reader = csv.reader(csvfile) - lines = list(reader) - lines = lines[1:] - if mode == 1: - return sorted_by_pinyin([row[0] for row in lines]) - elif mode == 2: - return {row[0]: row[1] for row in lines} - else: - choices = sorted_by_pinyin([row[0] for row in lines]) - return {row[0]: row[1] for row in lines}, gr.Dropdown.update( - choices=choices, value=choices[0] - ) - - -def get_template_names(plain=False): - logging.info("获取模板文件名列表") - return get_file_names(TEMPLATES_DIR, plain, filetypes=[".csv", "json"]) - - -def get_template_content(templates, selection, original_system_prompt): - logging.info(f"应用模板中,选择为{selection},原始系统提示为{original_system_prompt}") - try: - return templates[selection] - except: - return original_system_prompt - - -def reset_state(): - logging.info("重置状态") - return [], [], [], construct_token_message(0) - - -def reset_textbox(): - logging.debug("重置文本框") - return gr.update(value="") - - -def reset_default(): - newurl = shared.state.reset_api_url() - os.environ.pop("HTTPS_PROXY", None) - os.environ.pop("https_proxy", None) - return gr.update(value=newurl), gr.update(value=""), "API URL 和代理已重置" - - -def change_api_url(url): - shared.state.set_api_url(url) - msg = f"API地址更改为了{url}" - logging.info(msg) - return msg - - -def change_proxy(proxy): - os.environ["HTTPS_PROXY"] = proxy - msg = f"代理更改为了{proxy}" - logging.info(msg) - return msg - - -def hide_middle_chars(s): - if s is None: - return "" - if len(s) <= 8: - return s - else: - head = s[:4] - tail = s[-4:] - hidden = "*" * (len(s) - 8) - return head + hidden + tail - - -def submit_key(key): - key = key.strip() - msg = f"API密钥更改为了{hide_middle_chars(key)}" - logging.info(msg) - return key, msg - - -def sha1sum(filename): - sha1 = hashlib.sha1() - sha1.update(filename.encode("utf-8")) - return sha1.hexdigest() - - -def replace_today(prompt): - today = datetime.datetime.today().strftime("%Y-%m-%d") - return prompt.replace("{current_date}", today) - - -def get_geoip(): - response = requests.get("https://ipapi.co/json/", timeout=5) - try: - data = response.json() - except: - data = {"error": True, "reason": "连接ipapi失败"} - if "error" in data.keys(): - logging.warning(f"无法获取IP地址信息。\n{data}") - if data["reason"] == "RateLimited": - return ( - f"获取IP地理位置失败,因为达到了检测IP的速率限制。聊天功能可能仍然可用,但请注意,如果您的IP地址在不受支持的地区,您可能会遇到问题。" - ) - else: - return f"获取IP地理位置失败。原因:{data['reason']}。你仍然可以使用聊天功能。" - else: - country = data["country_name"] - if country == "China": - text = "**您的IP区域:中国。请立即检查代理设置,在不受支持的地区使用API可能导致账号被封禁。**" - else: - text = f"您的IP区域:{country}。" - logging.info(text) - return text - - -def find_n(lst, max_num): - n = len(lst) - total = sum(lst) - - if total < max_num: - return n - - for i in range(len(lst)): - if total - lst[i] < max_num: - return n - i - 1 - total = total - lst[i] - return 1 - - -def start_outputing(): - logging.debug("显示取消按钮,隐藏发送按钮") - return gr.Button.update(visible=False), gr.Button.update(visible=True) - - -def end_outputing(): - return ( - gr.Button.update(visible=True), - gr.Button.update(visible=False), - ) - - -def cancel_outputing(): - logging.info("中止输出……") - shared.state.interrupt() - -def transfer_input(inputs): - # 一次性返回,降低延迟 - textbox = reset_textbox() - outputing = start_outputing() - return inputs, gr.update(value="") diff --git a/spaces/jlmarrugom/voice_fixer_app/voicefixer/tools/modules/fDomainHelper.py b/spaces/jlmarrugom/voice_fixer_app/voicefixer/tools/modules/fDomainHelper.py deleted file mode 100644 index 285433ccbeea0cb30851fddc74fcdd057982b110..0000000000000000000000000000000000000000 --- a/spaces/jlmarrugom/voice_fixer_app/voicefixer/tools/modules/fDomainHelper.py +++ /dev/null @@ -1,234 +0,0 @@ -from torchlibrosa.stft import STFT, ISTFT, magphase -import torch -import torch.nn as nn -import numpy as np -from voicefixer.tools.modules.pqmf import PQMF - -class FDomainHelper(nn.Module): - def __init__( - self, - window_size=2048, - hop_size=441, - center=True, - pad_mode="reflect", - window="hann", - freeze_parameters=True, - subband=None, - root="/Users/admin/Documents/projects/", - ): - super(FDomainHelper, self).__init__() - self.subband = subband - # assert torchlibrosa.__version__ == "0.0.7", "Error: Found torchlibrosa version %s. Please install 0.0.7 version of torchlibrosa by: pip install torchlibrosa==0.0.7." % torchlibrosa.__version__ - if self.subband is None: - self.stft = STFT( - n_fft=window_size, - hop_length=hop_size, - win_length=window_size, - window=window, - center=center, - pad_mode=pad_mode, - freeze_parameters=freeze_parameters, - ) - - self.istft = ISTFT( - n_fft=window_size, - hop_length=hop_size, - win_length=window_size, - window=window, - center=center, - pad_mode=pad_mode, - freeze_parameters=freeze_parameters, - ) - else: - self.stft = STFT( - n_fft=window_size // self.subband, - hop_length=hop_size // self.subband, - win_length=window_size // self.subband, - window=window, - center=center, - pad_mode=pad_mode, - freeze_parameters=freeze_parameters, - ) - - self.istft = ISTFT( - n_fft=window_size // self.subband, - hop_length=hop_size // self.subband, - win_length=window_size // self.subband, - window=window, - center=center, - pad_mode=pad_mode, - freeze_parameters=freeze_parameters, - ) - - if subband is not None and root is not None: - self.qmf = PQMF(subband, 64, root) - - def complex_spectrogram(self, input, eps=0.0): - # [batchsize, samples] - # return [batchsize, 2, t-steps, f-bins] - real, imag = self.stft(input) - return torch.cat([real, imag], dim=1) - - def reverse_complex_spectrogram(self, input, eps=0.0, length=None): - # [batchsize, 2[real,imag], t-steps, f-bins] - wav = self.istft(input[:, 0:1, ...], input[:, 1:2, ...], length=length) - return wav - - def spectrogram(self, input, eps=0.0): - (real, imag) = self.stft(input.float()) - return torch.clamp(real**2 + imag**2, eps, np.inf) ** 0.5 - - def spectrogram_phase(self, input, eps=0.0): - (real, imag) = self.stft(input.float()) - mag = torch.clamp(real**2 + imag**2, eps, np.inf) ** 0.5 - cos = real / mag - sin = imag / mag - return mag, cos, sin - - def wav_to_spectrogram_phase(self, input, eps=1e-8): - """Waveform to spectrogram. - - Args: - input: (batch_size, channels_num, segment_samples) - - Outputs: - output: (batch_size, channels_num, time_steps, freq_bins) - """ - sp_list = [] - cos_list = [] - sin_list = [] - channels_num = input.shape[1] - for channel in range(channels_num): - mag, cos, sin = self.spectrogram_phase(input[:, channel, :], eps=eps) - sp_list.append(mag) - cos_list.append(cos) - sin_list.append(sin) - - sps = torch.cat(sp_list, dim=1) - coss = torch.cat(cos_list, dim=1) - sins = torch.cat(sin_list, dim=1) - return sps, coss, sins - - def spectrogram_phase_to_wav(self, sps, coss, sins, length): - channels_num = sps.size()[1] - res = [] - for i in range(channels_num): - res.append( - self.istft( - sps[:, i : i + 1, ...] * coss[:, i : i + 1, ...], - sps[:, i : i + 1, ...] * sins[:, i : i + 1, ...], - length, - ) - ) - res[-1] = res[-1].unsqueeze(1) - return torch.cat(res, dim=1) - - def wav_to_spectrogram(self, input, eps=1e-8): - """Waveform to spectrogram. - - Args: - input: (batch_size,channels_num, segment_samples) - - Outputs: - output: (batch_size, channels_num, time_steps, freq_bins) - """ - sp_list = [] - channels_num = input.shape[1] - for channel in range(channels_num): - sp_list.append(self.spectrogram(input[:, channel, :], eps=eps)) - output = torch.cat(sp_list, dim=1) - return output - - def spectrogram_to_wav(self, input, spectrogram, length=None): - """Spectrogram to waveform. - Args: - input: (batch_size, segment_samples, channels_num) - spectrogram: (batch_size, channels_num, time_steps, freq_bins) - - Outputs: - output: (batch_size, segment_samples, channels_num) - """ - channels_num = input.shape[1] - wav_list = [] - for channel in range(channels_num): - (real, imag) = self.stft(input[:, channel, :]) - (_, cos, sin) = magphase(real, imag) - wav_list.append( - self.istft( - spectrogram[:, channel : channel + 1, :, :] * cos, - spectrogram[:, channel : channel + 1, :, :] * sin, - length, - ) - ) - - output = torch.stack(wav_list, dim=1) - return output - - # todo the following code is not bug free! - def wav_to_complex_spectrogram(self, input, eps=0.0): - # [batchsize , channels, samples] - # [batchsize, 2[real,imag]*channels, t-steps, f-bins] - res = [] - channels_num = input.shape[1] - for channel in range(channels_num): - res.append(self.complex_spectrogram(input[:, channel, :], eps=eps)) - return torch.cat(res, dim=1) - - def complex_spectrogram_to_wav(self, input, eps=0.0, length=None): - # [batchsize, 2[real,imag]*channels, t-steps, f-bins] - # return [batchsize, channels, samples] - channels = input.size()[1] // 2 - wavs = [] - for i in range(channels): - wavs.append( - self.reverse_complex_spectrogram( - input[:, 2 * i : 2 * i + 2, ...], eps=eps, length=length - ) - ) - wavs[-1] = wavs[-1].unsqueeze(1) - return torch.cat(wavs, dim=1) - - def wav_to_complex_subband_spectrogram(self, input, eps=0.0): - # [batchsize, channels, samples] - # [batchsize, 2[real,imag]*subband*channels, t-steps, f-bins] - subwav = self.qmf.analysis(input) # [batchsize, subband*channels, samples] - subspec = self.wav_to_complex_spectrogram(subwav) - return subspec - - def complex_subband_spectrogram_to_wav(self, input, eps=0.0): - # [batchsize, 2[real,imag]*subband*channels, t-steps, f-bins] - # [batchsize, channels, samples] - subwav = self.complex_spectrogram_to_wav(input) - data = self.qmf.synthesis(subwav) - return data - - def wav_to_mag_phase_subband_spectrogram(self, input, eps=1e-8): - """ - :param input: - :param eps: - :return: - loss = torch.nn.L1Loss() - models = FDomainHelper(subband=4) - data = torch.randn((3,1, 44100*3)) - - sps, coss, sins = models.wav_to_mag_phase_subband_spectrogram(data) - wav = models.mag_phase_subband_spectrogram_to_wav(sps,coss,sins,44100*3//4) - - print(loss(data,wav)) - print(torch.max(torch.abs(data-wav))) - - """ - # [batchsize, channels, samples] - # [batchsize, 2[real,imag]*subband*channels, t-steps, f-bins] - subwav = self.qmf.analysis(input) # [batchsize, subband*channels, samples] - sps, coss, sins = self.wav_to_spectrogram_phase(subwav, eps=eps) - return sps, coss, sins - - def mag_phase_subband_spectrogram_to_wav(self, sps, coss, sins, length, eps=0.0): - # [batchsize, 2[real,imag]*subband*channels, t-steps, f-bins] - # [batchsize, channels, samples] - subwav = self.spectrogram_phase_to_wav( - sps, coss, sins, length + self.qmf.pad_samples // self.qmf.N - ) - data = self.qmf.synthesis(subwav) - return data diff --git a/spaces/jmartinezot/find_plane_pointcloud/app.py b/spaces/jmartinezot/find_plane_pointcloud/app.py deleted file mode 100644 index 9adfcef67f3cf72bdde5eeef8434af7827c9708c..0000000000000000000000000000000000000000 --- a/spaces/jmartinezot/find_plane_pointcloud/app.py +++ /dev/null @@ -1,99 +0,0 @@ -import gradio as gr -import open3d as o3d -import numpy as np -import pandas as pd -from PIL import Image -from gradio.components import File, Slider, Image, Dataframe, Model3D -import tempfile - -def point_cloud_to_image(point_cloud): - # Create Open3D visualization object - vis = o3d.visualization.Visualizer() - vis.create_window() - vis.add_geometry(point_cloud) - - # Render the visualization and get the image - vis.poll_events() - vis.update_renderer() - img = vis.capture_screen_float_buffer() - - # Convert image to PIL Image format - pil_img = Image.fromarray(np.uint8(np.asarray(img)*255)) - - return pil_img - -def create_file_mesh_from_pcd(pcd, alpha): - - temp_file = tempfile.NamedTemporaryFile(suffix=".obj", delete=False) - file_path = temp_file.name - temp_file.close() - - # print(f"alpha={alpha:.3f}") - mesh = o3d.geometry.TriangleMesh.create_from_point_cloud_alpha_shape(pcd, alpha) - mesh.compute_vertex_normals() - o3d.io.write_triangle_mesh(file_path, mesh, write_triangle_uvs=True) - return file_path - -def plane_detection(pointcloud_path, voxel_size=0.05, distance_threshold=0.01, num_iterations=1000, alpha=2): - # Load point cloud from file - pcd = o3d.io.read_point_cloud(pointcloud_path.name) - - # Downsample the point cloud to reduce computational load - pcd = pcd.voxel_down_sample(voxel_size=voxel_size) - - # Find plane using RANSAC algorithm - plane_model, inliers = pcd.segment_plane(distance_threshold=distance_threshold, - ransac_n=3, - num_iterations=num_iterations) - - # Get inlier and outlier point cloud - inlier_cloud = pcd.select_by_index(inliers) - outlier_cloud = pcd.select_by_index(inliers, invert=True) - # extract the coefficients of the plane - a, b, c, d = plane_model - plane_model = np.array([[a], [b], [c], [d]]) - df = pd.DataFrame(plane_model.reshape(1, 4), columns=["a", "b", "c", "d"]) - input_path = create_file_mesh_from_pcd(pcd, alpha) - inlier_path = create_file_mesh_from_pcd(inlier_cloud, alpha) - outlier_path = create_file_mesh_from_pcd(outlier_cloud, alpha) - # Return inlier point cloud, outlier point cloud, and plane model - # return point_cloud_to_image(inlier_cloud), point_cloud_to_image(outlier_cloud), df - return input_path, inlier_path, outlier_path, df - -outputs = [ - # show pcd inlier point cloud - Model3D(label="Input Cloud", clear_color=[1.0, 1.0, 1.0, 1.0]), - # show pcd inlier point cloud - Model3D(label="Inlier Cloud", clear_color=[1.0, 1.0, 1.0, 1.0]), - # show pcd outlier point cloud - Model3D(label="Outlier Cloud", clear_color=[1.0, 1.0, 1.0, 1.0]), - # show the centroids and counts, which is a numpy array - Dataframe(label="Coefficients of the plane model", type="pandas") -] - -# Create Gradio interface -iface = gr.Interface(plane_detection, - inputs=[ - File(label="Point cloud file (.ply or .pcd format)"), - Slider(label="Voxel size", minimum=0.001, maximum=50, step=1, value=2), - Slider(label="Distance threshold", minimum=0.001, maximum=50, step=0.01, value=5), - Slider(label="Number of iterations", minimum=1, maximum=10000, step=1, value=100), - Slider(label="Alpha for surface reconstruction", minimum=0.02, maximum=100, step=0.01, value=2), - ], - outputs=outputs, - title="Plane Detection using RANSAC", - description="This app takes as input a point cloud file (.ply or .pcd format), voxel size, distance threshold, and number of iterations, finds a plane using RANSAC algorithm, displays the inlier and outlier point clouds, and returns the inlier point cloud, outlier point cloud, and the plane model.", - allow_flagging="never", - examples=[ - # ["Pointclouds/p1.ply", 2, 5, 100, 2] - ["Pointclouds/cloud_bin_0.ply", 0.001, 0.03, 100, 0.05], - ["Pointclouds/cloud_bin_20.ply", 0.001, 0.03, 100, 0.05], - ["Pointclouds/cloud_bin_30.ply", 0.001, 0.03, 100, 0.05], - ["Pointclouds/cloud_bin_40.ply", 0.001, 0.03, 100, 0.05], - ["Pointclouds/cloud_bin_50.ply", 0.001, 0.03, 100, 0.05], - ], - ) - - -# Launch the interface -iface.launch() diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/aiohttp/web_middlewares.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/aiohttp/web_middlewares.py deleted file mode 100644 index fabcc449a2107211fd99cd59f576a2d855d0e042..0000000000000000000000000000000000000000 --- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/aiohttp/web_middlewares.py +++ /dev/null @@ -1,119 +0,0 @@ -import re -from typing import TYPE_CHECKING, Awaitable, Callable, Tuple, Type, TypeVar - -from .typedefs import Handler -from .web_exceptions import HTTPPermanentRedirect, _HTTPMove -from .web_request import Request -from .web_response import StreamResponse -from .web_urldispatcher import SystemRoute - -__all__ = ( - "middleware", - "normalize_path_middleware", -) - -if TYPE_CHECKING: # pragma: no cover - from .web_app import Application - -_Func = TypeVar("_Func") - - -async def _check_request_resolves(request: Request, path: str) -> Tuple[bool, Request]: - alt_request = request.clone(rel_url=path) - - match_info = await request.app.router.resolve(alt_request) - alt_request._match_info = match_info - - if match_info.http_exception is None: - return True, alt_request - - return False, request - - -def middleware(f: _Func) -> _Func: - f.__middleware_version__ = 1 # type: ignore[attr-defined] - return f - - -_Middleware = Callable[[Request, Handler], Awaitable[StreamResponse]] - - -def normalize_path_middleware( - *, - append_slash: bool = True, - remove_slash: bool = False, - merge_slashes: bool = True, - redirect_class: Type[_HTTPMove] = HTTPPermanentRedirect, -) -> _Middleware: - """Factory for producing a middleware that normalizes the path of a request. - - Normalizing means: - - Add or remove a trailing slash to the path. - - Double slashes are replaced by one. - - The middleware returns as soon as it finds a path that resolves - correctly. The order if both merge and append/remove are enabled is - 1) merge slashes - 2) append/remove slash - 3) both merge slashes and append/remove slash. - If the path resolves with at least one of those conditions, it will - redirect to the new path. - - Only one of `append_slash` and `remove_slash` can be enabled. If both - are `True` the factory will raise an assertion error - - If `append_slash` is `True` the middleware will append a slash when - needed. If a resource is defined with trailing slash and the request - comes without it, it will append it automatically. - - If `remove_slash` is `True`, `append_slash` must be `False`. When enabled - the middleware will remove trailing slashes and redirect if the resource - is defined - - If merge_slashes is True, merge multiple consecutive slashes in the - path into one. - """ - correct_configuration = not (append_slash and remove_slash) - assert correct_configuration, "Cannot both remove and append slash" - - @middleware - async def impl(request: Request, handler: Handler) -> StreamResponse: - if isinstance(request.match_info.route, SystemRoute): - paths_to_check = [] - if "?" in request.raw_path: - path, query = request.raw_path.split("?", 1) - query = "?" + query - else: - query = "" - path = request.raw_path - - if merge_slashes: - paths_to_check.append(re.sub("//+", "/", path)) - if append_slash and not request.path.endswith("/"): - paths_to_check.append(path + "/") - if remove_slash and request.path.endswith("/"): - paths_to_check.append(path[:-1]) - if merge_slashes and append_slash: - paths_to_check.append(re.sub("//+", "/", path + "/")) - if merge_slashes and remove_slash: - merged_slashes = re.sub("//+", "/", path) - paths_to_check.append(merged_slashes[:-1]) - - for path in paths_to_check: - path = re.sub("^//+", "/", path) # SECURITY: GHSA-v6wp-4m6f-gcjg - resolves, request = await _check_request_resolves(request, path) - if resolves: - raise redirect_class(request.raw_path + query) - - return await handler(request) - - return impl - - -def _fix_request_current_app(app: "Application") -> _Middleware: - @middleware - async def impl(request: Request, handler: Handler) -> StreamResponse: - with request.match_info.set_current_app(app): - return await handler(request) - - return impl diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/gpt_index/readers/google_readers/gdocs.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/gpt_index/readers/google_readers/gdocs.py deleted file mode 100644 index e7134877a0cf0d998609532b9819218d50eaec5e..0000000000000000000000000000000000000000 --- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/gpt_index/readers/google_readers/gdocs.py +++ /dev/null @@ -1,157 +0,0 @@ -"""Google docs reader.""" - -import logging -import os -from typing import Any, List - -from gpt_index.readers.base import BaseReader -from gpt_index.readers.schema.base import Document - -SCOPES = ["https://www.googleapis.com/auth/documents.readonly"] - - -# Copyright 2019 Google LLC -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - - -class GoogleDocsReader(BaseReader): - """Google Docs reader. - - Reads a page from Google Docs - - """ - - def __init__(self) -> None: - """Initialize with parameters.""" - try: - import google # noqa: F401 - import google_auth_oauthlib # noqa: F401 - import googleapiclient # noqa: F401 - except ImportError: - raise ImportError( - "`google_auth_oauthlib`, `googleapiclient` and `google` " - "must be installed to use the GoogleDocsReader.\n" - "Please run `pip install --upgrade google-api-python-client " - "google-auth-httplib2 google-auth-oauthlib`." - ) - - def load_data(self, document_ids: List[str]) -> List[Document]: - """Load data from the input directory. - - Args: - document_ids (List[str]): a list of document ids. - """ - if document_ids is None: - raise ValueError('Must specify a "document_ids" in `load_kwargs`.') - - results = [] - for document_id in document_ids: - doc = self._load_doc(document_id) - results.append(Document(doc, extra_info={"document_id": document_id})) - return results - - def _load_doc(self, document_id: str) -> str: - """Load a document from Google Docs. - - Args: - document_id: the document id. - - Returns: - The document text. - """ - import googleapiclient.discovery as discovery - - credentials = self._get_credentials() - docs_service = discovery.build("docs", "v1", credentials=credentials) - doc = docs_service.documents().get(documentId=document_id).execute() - doc_content = doc.get("body").get("content") - return self._read_structural_elements(doc_content) - - def _get_credentials(self) -> Any: - """Get valid user credentials from storage. - - The file token.json stores the user's access and refresh tokens, and is - created automatically when the authorization flow completes for the first - time. - - Returns: - Credentials, the obtained credential. - """ - from google.auth.transport.requests import Request - from google.oauth2.credentials import Credentials - from google_auth_oauthlib.flow import InstalledAppFlow - - creds = None - if os.path.exists("token.json"): - creds = Credentials.from_authorized_user_file("token.json", SCOPES) - # If there are no (valid) credentials available, let the user log in. - if not creds or not creds.valid: - if creds and creds.expired and creds.refresh_token: - creds.refresh(Request()) - else: - flow = InstalledAppFlow.from_client_secrets_file( - "credentials.json", SCOPES - ) - creds = flow.run_local_server(port=0) - # Save the credentials for the next run - with open("token.json", "w") as token: - token.write(creds.to_json()) - - return creds - - def _read_paragraph_element(self, element: Any) -> Any: - """Return the text in the given ParagraphElement. - - Args: - element: a ParagraphElement from a Google Doc. - """ - text_run = element.get("textRun") - if not text_run: - return "" - return text_run.get("content") - - def _read_structural_elements(self, elements: List[Any]) -> Any: - """Recurse through a list of Structural Elements. - - Read a document's text where text may be in nested elements. - - Args: - elements: a list of Structural Elements. - """ - text = "" - for value in elements: - if "paragraph" in value: - elements = value.get("paragraph").get("elements") - for elem in elements: - text += self._read_paragraph_element(elem) - elif "table" in value: - # The text in table cells are in nested Structural Elements - # and tables may be nested. - table = value.get("table") - for row in table.get("tableRows"): - cells = row.get("tableCells") - for cell in cells: - text += self._read_structural_elements(cell.get("content")) - elif "tableOfContents" in value: - # The text in the TOC is also in a Structural Element. - toc = value.get("tableOfContents") - text += self._read_structural_elements(toc.get("content")) - return text - - -if __name__ == "__main__": - reader = GoogleDocsReader() - logging.info( - reader.load_data(document_ids=["11ctUj_tEf5S8vs_dk8_BNi-Zk8wW5YFhXkKqtmU_4B8"]) - ) diff --git a/spaces/johnyang/ChatPaper111/utils.py b/spaces/johnyang/ChatPaper111/utils.py deleted file mode 100644 index 4e9778be8d941eb34d6cd63d964b9b4798a71722..0000000000000000000000000000000000000000 --- a/spaces/johnyang/ChatPaper111/utils.py +++ /dev/null @@ -1,24 +0,0 @@ - -from typing import Set - - -def get_filtered_keys_from_object(obj: object, *keys: str) -> Set[str]: - """ - Get filtered list of object variable names. - :param keys: List of keys to include. If the first key is "not", the remaining keys will be removed from the class keys. - :return: List of class keys. - """ - class_keys = obj.__dict__.keys() - if not keys: - return class_keys - - # Remove the passed keys from the class keys. - if keys[0] == "not": - return {key for key in class_keys if key not in keys[1:]} - # Check if all passed keys are valid - if invalid_keys := set(keys) - class_keys: - raise ValueError( - f"Invalid keys: {invalid_keys}", - ) - # Only return specified keys that are in class_keys - return {key for key in keys if key in class_keys} diff --git a/spaces/jonathang/dob_breed/app.py b/spaces/jonathang/dob_breed/app.py deleted file mode 100644 index 65238f09ac7532a98829cef1ce6f3d13d5a5d875..0000000000000000000000000000000000000000 --- a/spaces/jonathang/dob_breed/app.py +++ /dev/null @@ -1,26 +0,0 @@ -import gradio as gr -from fastai.vision.all import * -import skimage - -learn = load_learner('dog_breed.pkl') - -labels = learn.dls.vocab -def predict(img): - img = PILImage.create(img) - pred,pred_idx,probs = learn.predict(img) - return {labels[i]: float(probs[i]) for i in range(len(labels))} - -title = "Doge Breed Classifier" -description = "A dog breed classifier trained on duckduckgo images with fastai." -interpretation='default' -enable_queue=True - -gr.Interface( - fn=predict, - inputs=gr.inputs.Image(shape=(512, 512)), - outputs=gr.outputs.Label(num_top_classes=3), - title=title, - description=description, - interpretation=interpretation, - enable_queue=enable_queue -).launch() \ No newline at end of file diff --git a/spaces/jordonpeter01/MusicGen2/audiocraft/modules/conditioners.py b/spaces/jordonpeter01/MusicGen2/audiocraft/modules/conditioners.py deleted file mode 100644 index 82792316024b88d4c5c38b0a28f443627771d509..0000000000000000000000000000000000000000 --- a/spaces/jordonpeter01/MusicGen2/audiocraft/modules/conditioners.py +++ /dev/null @@ -1,990 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -from collections import defaultdict -from copy import deepcopy -from dataclasses import dataclass, field -from itertools import chain -import logging -import math -import random -import re -import typing as tp -import warnings - -from einops import rearrange -from num2words import num2words -import spacy -from transformers import T5EncoderModel, T5Tokenizer # type: ignore -import torchaudio -import torch -from torch import nn -from torch import Tensor -import torch.nn.functional as F -from torch.nn.utils.rnn import pad_sequence - -from .streaming import StreamingModule -from .transformer import create_sin_embedding -from ..data.audio_dataset import SegmentInfo -from ..utils.autocast import TorchAutocast -from ..utils.utils import hash_trick, length_to_mask, collate - - -logger = logging.getLogger(__name__) -TextCondition = tp.Optional[str] # a text condition can be a string or None (if doesn't exist) -ConditionType = tp.Tuple[Tensor, Tensor] # condition, mask - - -class WavCondition(tp.NamedTuple): - wav: Tensor - length: Tensor - path: tp.List[tp.Optional[str]] = [] - - -def nullify_condition(condition: ConditionType, dim: int = 1): - """This function transforms an input condition to a null condition. - The way it is done by converting it to a single zero vector similarly - to how it is done inside WhiteSpaceTokenizer and NoopTokenizer. - - Args: - condition (ConditionType): a tuple of condition and mask (tp.Tuple[Tensor, Tensor]) - dim (int): the dimension that will be truncated (should be the time dimension) - WARNING!: dim should not be the batch dimension! - Returns: - ConditionType: a tuple of null condition and mask - """ - assert dim != 0, "dim cannot be the batch dimension!" - assert type(condition) == tuple and \ - type(condition[0]) == Tensor and \ - type(condition[1]) == Tensor, "'nullify_condition' got an unexpected input type!" - cond, mask = condition - B = cond.shape[0] - last_dim = cond.dim() - 1 - out = cond.transpose(dim, last_dim) - out = 0. * out[..., :1] - out = out.transpose(dim, last_dim) - mask = torch.zeros((B, 1), device=out.device).int() - assert cond.dim() == out.dim() - return out, mask - - -def nullify_wav(wav: Tensor) -> WavCondition: - """Create a nullified WavCondition from a wav tensor with appropriate shape. - - Args: - wav (Tensor): tensor of shape [B, T] - Returns: - WavCondition: wav condition with nullified wav. - """ - null_wav, _ = nullify_condition((wav, torch.zeros_like(wav)), dim=wav.dim() - 1) - return WavCondition( - wav=null_wav, - length=torch.tensor([0] * wav.shape[0], device=wav.device), - path=['null_wav'] * wav.shape[0] - ) - - -@dataclass -class ConditioningAttributes: - text: tp.Dict[str, tp.Optional[str]] = field(default_factory=dict) - wav: tp.Dict[str, WavCondition] = field(default_factory=dict) - - def __getitem__(self, item): - return getattr(self, item) - - @property - def text_attributes(self): - return self.text.keys() - - @property - def wav_attributes(self): - return self.wav.keys() - - @property - def attributes(self): - return {"text": self.text_attributes, "wav": self.wav_attributes} - - def to_flat_dict(self): - return { - **{f"text.{k}": v for k, v in self.text.items()}, - **{f"wav.{k}": v for k, v in self.wav.items()}, - } - - @classmethod - def from_flat_dict(cls, x): - out = cls() - for k, v in x.items(): - kind, att = k.split(".") - out[kind][att] = v - return out - - -class SegmentWithAttributes(SegmentInfo): - """Base class for all dataclasses that are used for conditioning. - All child classes should implement `to_condition_attributes` that converts - the existing attributes to a dataclass of type ConditioningAttributes. - """ - def to_condition_attributes(self) -> ConditioningAttributes: - raise NotImplementedError() - - -class Tokenizer: - """Base class for all tokenizers - (in case we want to introduce more advances tokenizers in the future). - """ - def __call__(self, texts: tp.List[tp.Optional[str]]) -> tp.Tuple[Tensor, Tensor]: - raise NotImplementedError() - - -class WhiteSpaceTokenizer(Tokenizer): - """This tokenizer should be used for natural language descriptions. - For example: - ["he didn't, know he's going home.", 'shorter sentence'] => - [[78, 62, 31, 4, 78, 25, 19, 34], - [59, 77, 0, 0, 0, 0, 0, 0]] - """ - PUNCTUATIONS = "?:!.,;" - - def __init__(self, n_bins: int, pad_idx: int = 0, language: str = "en_core_web_sm", - lemma: bool = True, stopwords: bool = True) -> None: - self.n_bins = n_bins - self.pad_idx = pad_idx - self.lemma = lemma - self.stopwords = stopwords - try: - self.nlp = spacy.load(language) - except IOError: - spacy.cli.download(language) # type: ignore - self.nlp = spacy.load(language) - - @tp.no_type_check - def __call__( - self, - texts: tp.List[tp.Optional[str]], - return_text: bool = False - ) -> tp.Tuple[Tensor, Tensor]: - """Take a list of strings and convert them to a tensor of indices. - - Args: - texts (tp.List[str]): List of strings. - return_text (bool, optional): Whether to return text as additional tuple item. Defaults to False. - Returns: - tp.Tuple[Tensor, Tensor]: - - Indices of words in the LUT. - - And a mask indicating where the padding tokens are - """ - output, lengths = [], [] - texts = deepcopy(texts) - for i, text in enumerate(texts): - # if current sample doesn't have a certain attribute, replace with pad token - if text is None: - output.append(Tensor([self.pad_idx])) - lengths.append(0) - continue - - # convert numbers to words - text = re.sub(r"(\d+)", lambda x: num2words(int(x.group(0))), text) # type: ignore - # normalize text - text = self.nlp(text) # type: ignore - # remove stopwords - if self.stopwords: - text = [w for w in text if not w.is_stop] # type: ignore - # remove punctuations - text = [w for w in text if w.text not in self.PUNCTUATIONS] # type: ignore - # lemmatize if needed - text = [getattr(t, "lemma_" if self.lemma else "text") for t in text] # type: ignore - - texts[i] = " ".join(text) - lengths.append(len(text)) - # convert to tensor - tokens = Tensor([hash_trick(w, self.n_bins) for w in text]) - output.append(tokens) - - mask = length_to_mask(torch.IntTensor(lengths)).int() - padded_output = pad_sequence(output, padding_value=self.pad_idx).int().t() - if return_text: - return padded_output, mask, texts # type: ignore - return padded_output, mask - - -class NoopTokenizer(Tokenizer): - """This tokenizer should be used for global conditioners such as: artist, genre, key, etc. - The difference between this and WhiteSpaceTokenizer is that NoopTokenizer does not split - strings, so "Jeff Buckley" will get it's own index. Whereas WhiteSpaceTokenizer will - split it to ["Jeff", "Buckley"] and return an index per word. - - For example: - ["Queen", "ABBA", "Jeff Buckley"] => [43, 55, 101] - ["Metal", "Rock", "Classical"] => [0, 223, 51] - """ - def __init__(self, n_bins: int, pad_idx: int = 0): - self.n_bins = n_bins - self.pad_idx = pad_idx - - def __call__(self, texts: tp.List[tp.Optional[str]]) -> tp.Tuple[Tensor, Tensor]: - output, lengths = [], [] - for text in texts: - # if current sample doesn't have a certain attribute, replace with pad token - if text is None: - output.append(self.pad_idx) - lengths.append(0) - else: - output.append(hash_trick(text, self.n_bins)) - lengths.append(1) - - tokens = torch.LongTensor(output).unsqueeze(1) - mask = length_to_mask(torch.IntTensor(lengths)).int() - return tokens, mask - - -class BaseConditioner(nn.Module): - """Base model for all conditioner modules. We allow the output dim to be different - than the hidden dim for two reasons: 1) keep our LUTs small when the vocab is large; - 2) make all condition dims consistent. - - Args: - dim (int): Hidden dim of the model (text-encoder/LUT). - output_dim (int): Output dim of the conditioner. - """ - def __init__(self, dim, output_dim): - super().__init__() - self.dim = dim - self.output_dim = output_dim - self.output_proj = nn.Linear(dim, output_dim) - - def tokenize(self, *args, **kwargs) -> tp.Any: - """Should be any part of the processing that will lead to a synchronization - point, e.g. BPE tokenization with transfer to the GPU. - - The returned value will be saved and return later when calling forward(). - """ - raise NotImplementedError() - - def forward(self, inputs: tp.Any) -> ConditionType: - """Gets input that should be used as conditioning (e.g, genre, description or a waveform). - Outputs a ConditionType, after the input data was embedded as a dense vector. - - Returns: - ConditionType: - - A tensor of size [B, T, D] where B is the batch size, T is the length of the - output embedding and D is the dimension of the embedding. - - And a mask indicating where the padding tokens. - """ - raise NotImplementedError() - - -class TextConditioner(BaseConditioner): - ... - - -class LUTConditioner(TextConditioner): - """Lookup table TextConditioner. - - Args: - n_bins (int): Number of bins. - dim (int): Hidden dim of the model (text-encoder/LUT). - output_dim (int): Output dim of the conditioner. - tokenizer (str): Name of the tokenizer. - pad_idx (int, optional): Index for padding token. Defaults to 0. - """ - def __init__(self, n_bins: int, dim: int, output_dim: int, tokenizer: str, pad_idx: int = 0): - super().__init__(dim, output_dim) - self.embed = nn.Embedding(n_bins, dim) - self.tokenizer: Tokenizer - if tokenizer == "whitespace": - self.tokenizer = WhiteSpaceTokenizer(n_bins, pad_idx=pad_idx) - elif tokenizer == "noop": - self.tokenizer = NoopTokenizer(n_bins, pad_idx=pad_idx) - else: - raise ValueError(f"unrecognized tokenizer `{tokenizer}`.") - - def tokenize(self, x: tp.List[tp.Optional[str]]) -> tp.Tuple[torch.Tensor, torch.Tensor]: - device = self.embed.weight.device - tokens, mask = self.tokenizer(x) - tokens, mask = tokens.to(device), mask.to(device) - return tokens, mask - - def forward(self, inputs: tp.Tuple[torch.Tensor, torch.Tensor]) -> ConditionType: - tokens, mask = inputs - embeds = self.embed(tokens) - embeds = self.output_proj(embeds) - embeds = (embeds * mask.unsqueeze(-1)) - return embeds, mask - - -class T5Conditioner(TextConditioner): - """T5-based TextConditioner. - - Args: - name (str): Name of the T5 model. - output_dim (int): Output dim of the conditioner. - finetune (bool): Whether to fine-tune T5 at train time. - device (str): Device for T5 Conditioner. - autocast_dtype (tp.Optional[str], optional): Autocast dtype. - word_dropout (float, optional): Word dropout probability. - normalize_text (bool, optional): Whether to apply text normalization. - """ - MODELS = ["t5-small", "t5-base", "t5-large", "t5-3b", "t5-11b", - "google/flan-t5-small", "google/flan-t5-base", "google/flan-t5-large", - "google/flan-t5-xl", "google/flan-t5-xxl"] - MODELS_DIMS = { - "t5-small": 512, - "t5-base": 768, - "t5-large": 1024, - "t5-3b": 1024, - "t5-11b": 1024, - "google/flan-t5-small": 512, - "google/flan-t5-base": 768, - "google/flan-t5-large": 1024, - "google/flan-t5-3b": 1024, - "google/flan-t5-11b": 1024, - } - - def __init__(self, name: str, output_dim: int, finetune: bool, device: str, - autocast_dtype: tp.Optional[str] = 'float32', word_dropout: float = 0., - normalize_text: bool = False): - assert name in self.MODELS, f"unrecognized t5 model name (should in {self.MODELS})" - super().__init__(self.MODELS_DIMS[name], output_dim) - self.device = device - self.name = name - self.finetune = finetune - self.word_dropout = word_dropout - - if autocast_dtype is None or self.device == 'cpu': - self.autocast = TorchAutocast(enabled=False) - if self.device != 'cpu': - logger.warning("T5 has no autocast, this might lead to NaN") - else: - dtype = getattr(torch, autocast_dtype) - assert isinstance(dtype, torch.dtype) - logger.info(f"T5 will be evaluated with autocast as {autocast_dtype}") - self.autocast = TorchAutocast(enabled=True, device_type=self.device, dtype=dtype) - # Let's disable logging temporarily because T5 will vomit some errors otherwise. - # thanks https://gist.github.com/simon-weber/7853144 - previous_level = logging.root.manager.disable - logging.disable(logging.ERROR) - with warnings.catch_warnings(): - warnings.simplefilter("ignore") - try: - self.t5_tokenizer = T5Tokenizer.from_pretrained(name) - t5 = T5EncoderModel.from_pretrained(name).train(mode=finetune) - finally: - logging.disable(previous_level) - if finetune: - self.t5 = t5 - else: - # this makes sure that the t5 models is not part - # of the saved checkpoint - self.__dict__["t5"] = t5.to(device) - - self.normalize_text = normalize_text - if normalize_text: - self.text_normalizer = WhiteSpaceTokenizer(1, lemma=True, stopwords=True) - - def tokenize(self, x: tp.List[tp.Optional[str]]) -> tp.Dict[str, torch.Tensor]: - # if current sample doesn't have a certain attribute, replace with empty string - entries: tp.List[str] = [xi if xi is not None else "" for xi in x] - if self.normalize_text: - _, _, entries = self.text_normalizer(entries, return_text=True) - if self.word_dropout > 0. and self.training: - new_entries = [] - for entry in entries: - words = [word for word in entry.split(" ") if random.random() >= self.word_dropout] - new_entries.append(" ".join(words)) - entries = new_entries - - empty_idx = torch.LongTensor([i for i, xi in enumerate(entries) if xi == ""]) - - inputs = self.t5_tokenizer(entries, return_tensors="pt", padding=True).to(self.device) - mask = inputs["attention_mask"] - mask[empty_idx, :] = 0 # zero-out index where the input is non-existant - return inputs - - def forward(self, inputs: tp.Dict[str, torch.Tensor]) -> ConditionType: - mask = inputs["attention_mask"] - with torch.set_grad_enabled(self.finetune), self.autocast: - embeds = self.t5(**inputs).last_hidden_state - embeds = self.output_proj(embeds.to(self.output_proj.weight)) - embeds = (embeds * mask.unsqueeze(-1)) - return embeds, mask - - -class WaveformConditioner(BaseConditioner): - """Base class for all conditioners that take a waveform as input. - Classes that inherit must implement `_get_wav_embedding` that outputs - a continuous tensor, and `_downsampling_factor` that returns the down-sampling - factor of the embedding model. - - Args: - dim (int): The internal representation dimension. - output_dim (int): Output dimension. - device (tp.Union[torch.device, str]): Device. - """ - def __init__(self, dim: int, output_dim: int, device: tp.Union[torch.device, str]): - super().__init__(dim, output_dim) - self.device = device - - def tokenize(self, wav_length: WavCondition) -> WavCondition: - wav, length, path = wav_length - assert length is not None - return WavCondition(wav.to(self.device), length.to(self.device), path) - - def _get_wav_embedding(self, wav: Tensor) -> Tensor: - """Gets as input a wav and returns a dense vector of conditions.""" - raise NotImplementedError() - - def _downsampling_factor(self): - """Returns the downsampling factor of the embedding model.""" - raise NotImplementedError() - - def forward(self, inputs: WavCondition) -> ConditionType: - """ - Args: - input (WavCondition): Tuple of (waveform, lengths). - Returns: - ConditionType: Dense vector representing the conditioning along with its' mask. - """ - wav, lengths, path = inputs - with torch.no_grad(): - embeds = self._get_wav_embedding(wav) - embeds = embeds.to(self.output_proj.weight) - embeds = self.output_proj(embeds) - - if lengths is not None: - lengths = lengths / self._downsampling_factor() - mask = length_to_mask(lengths, max_len=embeds.shape[1]).int() # type: ignore - else: - mask = torch.ones_like(embeds) - embeds = (embeds * mask.unsqueeze(2).to(self.device)) - - return embeds, mask - - -class ChromaStemConditioner(WaveformConditioner): - """Chroma conditioner that uses DEMUCS to first filter out drums and bass. The is followed by - the insight the drums and bass often dominate the chroma, leading to the chroma not containing the - information about melody. - - Args: - output_dim (int): Output dimension for the conditioner. - sample_rate (int): Sample rate for the chroma extractor. - n_chroma (int): Number of chroma for the chroma extractor. - radix2_exp (int): Radix2 exponent for the chroma extractor. - duration (float): Duration used during training. This is later used for correct padding - in case we are using chroma as prefix. - match_len_on_eval (bool, optional): If True then all chromas are padded to the training - duration. Defaults to False. - eval_wavs (str, optional): Path to a json egg with waveform, this waveforms are used as - conditions during eval (for cases where we don't want to leak test conditions like MusicCaps). - Defaults to None. - n_eval_wavs (int, optional): Limits the number of waveforms used for conditioning. Defaults to 0. - device (tp.Union[torch.device, str], optional): Device for the conditioner. - **kwargs: Additional parameters for the chroma extractor. - """ - def __init__(self, output_dim: int, sample_rate: int, n_chroma: int, radix2_exp: int, - duration: float, match_len_on_eval: bool = True, eval_wavs: tp.Optional[str] = None, - n_eval_wavs: int = 0, device: tp.Union[torch.device, str] = "cpu", **kwargs): - from demucs import pretrained - super().__init__(dim=n_chroma, output_dim=output_dim, device=device) - self.autocast = TorchAutocast(enabled=device != "cpu", device_type=self.device, dtype=torch.float32) - self.sample_rate = sample_rate - self.match_len_on_eval = match_len_on_eval - self.duration = duration - self.__dict__["demucs"] = pretrained.get_model('htdemucs').to(device) - self.stem2idx = {'drums': 0, 'bass': 1, 'other': 2, 'vocal': 3} - self.stem_idx = torch.LongTensor([self.stem2idx['vocal'], self.stem2idx['other']]).to(device) - self.chroma = ChromaExtractor(sample_rate=sample_rate, n_chroma=n_chroma, radix2_exp=radix2_exp, - device=device, **kwargs) - self.chroma_len = self._get_chroma_len() - - def _downsampling_factor(self): - return self.chroma.winhop - - def _get_chroma_len(self): - """Get length of chroma during training""" - dummy_wav = torch.zeros((1, self.sample_rate * self.duration), device=self.device) - dummy_chr = self.chroma(dummy_wav) - return dummy_chr.shape[1] - - @torch.no_grad() - def _get_filtered_wav(self, wav): - from demucs.apply import apply_model - from demucs.audio import convert_audio - with self.autocast: - wav = convert_audio(wav, self.sample_rate, self.demucs.samplerate, self.demucs.audio_channels) - stems = apply_model(self.demucs, wav, device=self.device) - stems = stems[:, self.stem_idx] # extract stem - stems = stems.sum(1) # merge extracted stems - stems = stems.mean(1, keepdim=True) # mono - stems = convert_audio(stems, self.demucs.samplerate, self.sample_rate, 1) - return stems - - @torch.no_grad() - def _get_wav_embedding(self, wav): - # avoid 0-size tensors when we are working with null conds - if wav.shape[-1] == 1: - return self.chroma(wav) - stems = self._get_filtered_wav(wav) - chroma = self.chroma(stems) - - if self.match_len_on_eval: - b, t, c = chroma.shape - if t > self.chroma_len: - chroma = chroma[:, :self.chroma_len] - logger.debug(f'chroma was truncated! ({t} -> {chroma.shape[1]})') - elif t < self.chroma_len: - # chroma = F.pad(chroma, (0, 0, 0, self.chroma_len - t)) - n_repeat = int(math.ceil(self.chroma_len / t)) - chroma = chroma.repeat(1, n_repeat, 1) - chroma = chroma[:, :self.chroma_len] - logger.debug(f'chroma was zero-padded! ({t} -> {chroma.shape[1]})') - return chroma - - -class ChromaExtractor(nn.Module): - """Chroma extraction class, handles chroma extraction and quantization. - - Args: - sample_rate (int): Sample rate. - n_chroma (int): Number of chroma to consider. - radix2_exp (int): Radix2 exponent. - nfft (tp.Optional[int], optional): Number of FFT. - winlen (tp.Optional[int], optional): Window length. - winhop (tp.Optional[int], optional): Window hop size. - argmax (bool, optional): Whether to use argmax. Defaults to False. - norm (float, optional): Norm for chroma normalization. Defaults to inf. - device (tp.Union[torch.device, str], optional): Device to use. Defaults to cpu. - """ - def __init__(self, sample_rate: int, n_chroma: int = 12, radix2_exp: int = 12, - nfft: tp.Optional[int] = None, winlen: tp.Optional[int] = None, winhop: tp.Optional[int] = None, - argmax: bool = False, norm: float = torch.inf, device: tp.Union[torch.device, str] = "cpu"): - super().__init__() - from librosa import filters - self.device = device - self.autocast = TorchAutocast(enabled=device != "cpu", device_type=self.device, dtype=torch.float32) - self.winlen = winlen or 2 ** radix2_exp - self.nfft = nfft or self.winlen - self.winhop = winhop or (self.winlen // 4) - self.sr = sample_rate - self.n_chroma = n_chroma - self.norm = norm - self.argmax = argmax - self.window = torch.hann_window(self.winlen).to(device) - self.fbanks = torch.from_numpy(filters.chroma(sr=sample_rate, n_fft=self.nfft, tuning=0, - n_chroma=self.n_chroma)).to(device) - self.spec = torchaudio.transforms.Spectrogram(n_fft=self.nfft, win_length=self.winlen, - hop_length=self.winhop, power=2, center=True, - pad=0, normalized=True).to(device) - - def forward(self, wav): - with self.autocast: - T = wav.shape[-1] - # in case we are getting a wav that was dropped out (nullified) - # make sure wav length is no less that nfft - if T < self.nfft: - pad = self.nfft - T - r = 0 if pad % 2 == 0 else 1 - wav = F.pad(wav, (pad // 2, pad // 2 + r), 'constant', 0) - assert wav.shape[-1] == self.nfft, f'expected len {self.nfft} but got {wav.shape[-1]}' - spec = self.spec(wav).squeeze(1) - raw_chroma = torch.einsum("cf,...ft->...ct", self.fbanks, spec) - norm_chroma = torch.nn.functional.normalize(raw_chroma, p=self.norm, dim=-2, eps=1e-6) - norm_chroma = rearrange(norm_chroma, "b d t -> b t d") - - if self.argmax: - idx = norm_chroma.argmax(-1, keepdims=True) - norm_chroma[:] = 0 - norm_chroma.scatter_(dim=-1, index=idx, value=1) - - return norm_chroma - - -def dropout_condition(sample: ConditioningAttributes, condition_type: str, condition: str): - """Utility function for nullifying an attribute inside an ConditioningAttributes object. - If the condition is of type "wav", then nullify it using "nullify_condition". - If the condition is of any other type, set its' value to None. - Works in-place. - """ - if condition_type not in ["text", "wav"]: - raise ValueError( - "dropout_condition got an unexpected condition type!" - f" expected 'wav' or 'text' but got '{condition_type}'" - ) - - if condition not in getattr(sample, condition_type): - raise ValueError( - "dropout_condition received an unexpected condition!" - f" expected wav={sample.wav.keys()} and text={sample.text.keys()}" - f"but got '{condition}' of type '{condition_type}'!" - ) - - if condition_type == "wav": - wav, length, path = sample.wav[condition] - sample.wav[condition] = nullify_wav(wav) - else: - sample.text[condition] = None - - return sample - - -class DropoutModule(nn.Module): - """Base class for all dropout modules.""" - def __init__(self, seed: int = 1234): - super().__init__() - self.rng = torch.Generator() - self.rng.manual_seed(seed) - - -class AttributeDropout(DropoutModule): - """Applies dropout with a given probability per attribute. This is different from the behavior of - ClassifierFreeGuidanceDropout as this allows for attributes to be dropped out separately. For example, - "artist" can be dropped while "genre" remains. This is in contrast to ClassifierFreeGuidanceDropout - where if "artist" is dropped "genre" must also be dropped. - - Args: - p (tp.Dict[str, float]): A dict mapping between attributes and dropout probability. For example: - ... - "genre": 0.1, - "artist": 0.5, - "wav": 0.25, - ... - active_on_eval (bool, optional): Whether the dropout is active at eval. Default to False. - seed (int, optional): Random seed. - """ - def __init__(self, p: tp.Dict[str, tp.Dict[str, float]], active_on_eval: bool = False, seed: int = 1234): - super().__init__(seed=seed) - self.active_on_eval = active_on_eval - # construct dict that return the values from p otherwise 0 - self.p = {} - for condition_type, probs in p.items(): - self.p[condition_type] = defaultdict(lambda: 0, probs) - - def forward(self, samples: tp.List[ConditioningAttributes]) -> tp.List[ConditioningAttributes]: - """ - Args: - samples (tp.List[ConditioningAttributes]): List of conditions. - Returns: - tp.List[ConditioningAttributes]: List of conditions after certain attributes were set to None. - """ - if not self.training and not self.active_on_eval: - return samples - - samples = deepcopy(samples) - - for condition_type, ps in self.p.items(): # for condition types [text, wav] - for condition, p in ps.items(): # for attributes of each type (e.g., [artist, genre]) - if torch.rand(1, generator=self.rng).item() < p: - for sample in samples: - dropout_condition(sample, condition_type, condition) - - return samples - - def __repr__(self): - return f"AttributeDropout({dict(self.p)})" - - -class ClassifierFreeGuidanceDropout(DropoutModule): - """Applies Classifier Free Guidance dropout, meaning all attributes - are dropped with the same probability. - - Args: - p (float): Probability to apply condition dropout during training. - seed (int): Random seed. - """ - def __init__(self, p: float, seed: int = 1234): - super().__init__(seed=seed) - self.p = p - - def forward(self, samples: tp.List[ConditioningAttributes]) -> tp.List[ConditioningAttributes]: - """ - Args: - samples (tp.List[ConditioningAttributes]): List of conditions. - Returns: - tp.List[ConditioningAttributes]: List of conditions after all attributes were set to None. - """ - if not self.training: - return samples - - # decide on which attributes to drop in a batched fashion - drop = torch.rand(1, generator=self.rng).item() < self.p - if not drop: - return samples - - # nullify conditions of all attributes - samples = deepcopy(samples) - - for condition_type in ["wav", "text"]: - for sample in samples: - for condition in sample.attributes[condition_type]: - dropout_condition(sample, condition_type, condition) - - return samples - - def __repr__(self): - return f"ClassifierFreeGuidanceDropout(p={self.p})" - - -class ConditioningProvider(nn.Module): - """Main class to provide conditions given all the supported conditioners. - - Args: - conditioners (dict): Dictionary of conditioners. - merge_text_conditions_p (float, optional): Probability to merge all text sources - into a single text condition. Defaults to 0. - drop_desc_p (float, optional): Probability to drop the original description - when merging all text sources into a single text condition. Defaults to 0. - device (tp.Union[torch.device, str], optional): Device for conditioners and output condition types. - """ - def __init__( - self, - conditioners: tp.Dict[str, BaseConditioner], - merge_text_conditions_p: float = 0, - drop_desc_p: float = 0, - device: tp.Union[torch.device, str] = "cpu", - ): - super().__init__() - self.device = device - self.merge_text_conditions_p = merge_text_conditions_p - self.drop_desc_p = drop_desc_p - self.conditioners = nn.ModuleDict(conditioners) - - @property - def text_conditions(self): - return [k for k, v in self.conditioners.items() if isinstance(v, TextConditioner)] - - @property - def wav_conditions(self): - return [k for k, v in self.conditioners.items() if isinstance(v, WaveformConditioner)] - - @property - def has_wav_condition(self): - return len(self.wav_conditions) > 0 - - def tokenize(self, inputs: tp.List[ConditioningAttributes]) -> tp.Dict[str, tp.Any]: - """Match attributes/wavs with existing conditioners in self, and compute tokenize them accordingly. - This should be called before starting any real GPU work to avoid synchronization points. - This will return a dict matching conditioner names to their arbitrary tokenized representations. - - Args: - inputs (list[ConditioningAttribres]): List of ConditioningAttributes objects containing - text and wav conditions. - """ - assert all([type(x) == ConditioningAttributes for x in inputs]), \ - "got unexpected types input for conditioner! should be tp.List[ConditioningAttributes]" \ - f" but types were {set([type(x) for x in inputs])}" - - output = {} - text = self._collate_text(inputs) - wavs = self._collate_wavs(inputs) - - assert set(text.keys() | wavs.keys()).issubset(set(self.conditioners.keys())), \ - f"got an unexpected attribute! Expected {self.conditioners.keys()}, got {text.keys(), wavs.keys()}" - - for attribute, batch in chain(text.items(), wavs.items()): - output[attribute] = self.conditioners[attribute].tokenize(batch) - return output - - def forward(self, tokenized: tp.Dict[str, tp.Any]) -> tp.Dict[str, ConditionType]: - """Compute pairs of `(embedding, mask)` using the configured conditioners - and the tokenized representations. The output is for example: - - { - "genre": (torch.Tensor([B, 1, D_genre]), torch.Tensor([B, 1])), - "description": (torch.Tensor([B, T_desc, D_desc]), torch.Tensor([B, T_desc])), - ... - } - - Args: - tokenized (dict): Dict of tokenized representations as returned by `tokenize()`. - """ - output = {} - for attribute, inputs in tokenized.items(): - condition, mask = self.conditioners[attribute](inputs) - output[attribute] = (condition, mask) - return output - - def _collate_text(self, samples: tp.List[ConditioningAttributes]) -> tp.Dict[str, tp.List[tp.Optional[str]]]: - """Given a list of ConditioningAttributes objects, compile a dictionary where the keys - are the attributes and the values are the aggregated input per attribute. - For example: - Input: - [ - ConditioningAttributes(text={"genre": "Rock", "description": "A rock song with a guitar solo"}, wav=...), - ConditioningAttributes(text={"genre": "Hip-hop", "description": "A hip-hop verse"}, wav=...), - ] - Output: - { - "genre": ["Rock", "Hip-hop"], - "description": ["A rock song with a guitar solo", "A hip-hop verse"] - } - """ - batch_per_attribute: tp.Dict[str, tp.List[tp.Optional[str]]] = defaultdict(list) - - def _merge_conds(cond, merge_text_conditions_p=0, drop_desc_p=0): - def is_valid(k, v): - k_valid = k in ['key', 'bpm', 'genre', 'moods', 'instrument'] - v_valid = v is not None and isinstance(v, (int, float, str, list)) - return k_valid and v_valid - - def process_value(v): - if isinstance(v, (int, float, str)): - return v - if isinstance(v, list): - return ", ".join(v) - else: - RuntimeError(f"unknown type for text value! ({type(v), v})") - - desc = cond.text['description'] - meta_data = "" - if random.uniform(0, 1) < merge_text_conditions_p: - meta_pairs = [f'{k}: {process_value(v)}' for k, v in cond.text.items() if is_valid(k, v)] - random.shuffle(meta_pairs) - meta_data = ". ".join(meta_pairs) - desc = desc if not random.uniform(0, 1) < drop_desc_p else None - - if desc is None: - desc = meta_data if len(meta_data) > 1 else None - else: - desc = desc.rstrip('.') + ". " + meta_data - cond.text['description'] = desc.strip() if desc else None - - if self.training and self.merge_text_conditions_p: - for sample in samples: - _merge_conds(sample, self.merge_text_conditions_p, self.drop_desc_p) - - texts = [x.text for x in samples] - for text in texts: - for condition in self.text_conditions: - batch_per_attribute[condition].append(text[condition]) - - return batch_per_attribute - - def _collate_wavs(self, samples: tp.List[ConditioningAttributes]): - """Generate a dict where the keys are attributes by which we fetch similar wavs, - and the values are Tensors of wavs according to said attribtues. - - *Note*: by the time the samples reach this function, each sample should have some waveform - inside the "wav" attribute. It should be either: - 1. A real waveform - 2. A null waveform due to the sample having no similar waveforms (nullified by the dataset) - 3. A null waveform due to it being dropped in a dropout module (nullified by dropout) - - Args: - samples (tp.List[ConditioningAttributes]): List of ConditioningAttributes samples. - Returns: - dict: A dicionary mapping an attribute name to wavs. - """ - wavs = defaultdict(list) - lens = defaultdict(list) - paths = defaultdict(list) - out = {} - - for sample in samples: - for attribute in self.wav_conditions: - wav, length, path = sample.wav[attribute] - wavs[attribute].append(wav.flatten()) - lens[attribute].append(length) - paths[attribute].append(path) - - # stack all wavs to a single tensor - for attribute in self.wav_conditions: - stacked_wav, _ = collate(wavs[attribute], dim=0) - out[attribute] = WavCondition(stacked_wav.unsqueeze(1), - torch.cat(lens['self_wav']), paths[attribute]) # type: ignore - - return out - - -class ConditionFuser(StreamingModule): - """Condition fuser handles the logic to combine the different conditions - to the actual model input. - - Args: - fuse2cond (tp.Dict[str, str]): A dictionary that says how to fuse - each condition. For example: - { - "prepend": ["description"], - "sum": ["genre", "bpm"], - "cross": ["description"], - } - cross_attention_pos_emb (bool, optional): Use positional embeddings in cross attention. - cross_attention_pos_emb_scale (int): Scale for positional embeddings in cross attention if used. - """ - FUSING_METHODS = ["sum", "prepend", "cross", "input_interpolate"] - - def __init__(self, fuse2cond: tp.Dict[str, tp.List[str]], cross_attention_pos_emb: bool = False, - cross_attention_pos_emb_scale: float = 1.0): - super().__init__() - assert all( - [k in self.FUSING_METHODS for k in fuse2cond.keys()] - ), f"got invalid fuse method, allowed methods: {self.FUSING_MEHTODS}" - self.cross_attention_pos_emb = cross_attention_pos_emb - self.cross_attention_pos_emb_scale = cross_attention_pos_emb_scale - self.fuse2cond: tp.Dict[str, tp.List[str]] = fuse2cond - self.cond2fuse: tp.Dict[str, str] = {} - for fuse_method, conditions in fuse2cond.items(): - for condition in conditions: - self.cond2fuse[condition] = fuse_method - - def forward( - self, - input: Tensor, - conditions: tp.Dict[str, ConditionType] - ) -> tp.Tuple[Tensor, tp.Optional[Tensor]]: - """Fuse the conditions to the provided model input. - - Args: - input (Tensor): Transformer input. - conditions (tp.Dict[str, ConditionType]): Dict of conditions. - Returns: - tp.Tuple[Tensor, Tensor]: The first tensor is the transformer input - after the conditions have been fused. The second output tensor is the tensor - used for cross-attention or None if no cross attention inputs exist. - """ - B, T, _ = input.shape - - if 'offsets' in self._streaming_state: - first_step = False - offsets = self._streaming_state['offsets'] - else: - first_step = True - offsets = torch.zeros(input.shape[0], dtype=torch.long, device=input.device) - - assert set(conditions.keys()).issubset(set(self.cond2fuse.keys())), \ - f"given conditions contain unknown attributes for fuser, " \ - f"expected {self.cond2fuse.keys()}, got {conditions.keys()}" - cross_attention_output = None - for cond_type, (cond, cond_mask) in conditions.items(): - op = self.cond2fuse[cond_type] - if op == "sum": - input += cond - elif op == "input_interpolate": - cond = rearrange(cond, "b t d -> b d t") - cond = F.interpolate(cond, size=input.shape[1]) - input += rearrange(cond, "b d t -> b t d") - elif op == "prepend": - if first_step: - input = torch.cat([cond, input], dim=1) - elif op == "cross": - if cross_attention_output is not None: - cross_attention_output = torch.cat([cross_attention_output, cond], dim=1) - else: - cross_attention_output = cond - else: - raise ValueError(f"unknown op ({op})") - - if self.cross_attention_pos_emb and cross_attention_output is not None: - positions = torch.arange( - cross_attention_output.shape[1], - device=cross_attention_output.device - ).view(1, -1, 1) - pos_emb = create_sin_embedding(positions, cross_attention_output.shape[-1]) - cross_attention_output = cross_attention_output + self.cross_attention_pos_emb_scale * pos_emb - - if self._is_streaming: - self._streaming_state['offsets'] = offsets + T - - return input, cross_attention_output diff --git a/spaces/jordonpeter01/ai-comic-factory/src/components/ui/collapsible.tsx b/spaces/jordonpeter01/ai-comic-factory/src/components/ui/collapsible.tsx deleted file mode 100644 index 9fa48946afd1eb56bd932377fd888e3986304676..0000000000000000000000000000000000000000 --- a/spaces/jordonpeter01/ai-comic-factory/src/components/ui/collapsible.tsx +++ /dev/null @@ -1,11 +0,0 @@ -"use client" - -import * as CollapsiblePrimitive from "@radix-ui/react-collapsible" - -const Collapsible = CollapsiblePrimitive.Root - -const CollapsibleTrigger = CollapsiblePrimitive.CollapsibleTrigger - -const CollapsibleContent = CollapsiblePrimitive.CollapsibleContent - -export { Collapsible, CollapsibleTrigger, CollapsibleContent } diff --git a/spaces/josedolot/HybridNet_Demo2/utils/sync_batchnorm/comm.py b/spaces/josedolot/HybridNet_Demo2/utils/sync_batchnorm/comm.py deleted file mode 100644 index 922f8c4a3adaa9b32fdcaef09583be03b0d7eb2b..0000000000000000000000000000000000000000 --- a/spaces/josedolot/HybridNet_Demo2/utils/sync_batchnorm/comm.py +++ /dev/null @@ -1,137 +0,0 @@ -# -*- coding: utf-8 -*- -# File : comm.py -# Author : Jiayuan Mao -# Email : maojiayuan@gmail.com -# Date : 27/01/2018 -# -# This file is part of Synchronized-BatchNorm-PyTorch. -# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch -# Distributed under MIT License. - -import queue -import collections -import threading - -__all__ = ['FutureResult', 'SlavePipe', 'SyncMaster'] - - -class FutureResult(object): - """A thread-safe future implementation. Used only as one-to-one pipe.""" - - def __init__(self): - self._result = None - self._lock = threading.Lock() - self._cond = threading.Condition(self._lock) - - def put(self, result): - with self._lock: - assert self._result is None, 'Previous result has\'t been fetched.' - self._result = result - self._cond.notify() - - def get(self): - with self._lock: - if self._result is None: - self._cond.wait() - - res = self._result - self._result = None - return res - - -_MasterRegistry = collections.namedtuple('MasterRegistry', ['result']) -_SlavePipeBase = collections.namedtuple('_SlavePipeBase', ['identifier', 'queue', 'result']) - - -class SlavePipe(_SlavePipeBase): - """Pipe for master-slave communication.""" - - def run_slave(self, msg): - self.queue.put((self.identifier, msg)) - ret = self.result.get() - self.queue.put(True) - return ret - - -class SyncMaster(object): - """An abstract `SyncMaster` object. - - - During the replication, as the data parallel will trigger an callback of each module, all slave devices should - call `register(id)` and obtain an `SlavePipe` to communicate with the master. - - During the forward pass, master device invokes `run_master`, all messages from slave devices will be collected, - and passed to a registered callback. - - After receiving the messages, the master device should gather the information and determine to message passed - back to each slave devices. - """ - - def __init__(self, master_callback): - """ - - Args: - master_callback: a callback to be invoked after having collected messages from slave devices. - """ - self._master_callback = master_callback - self._queue = queue.Queue() - self._registry = collections.OrderedDict() - self._activated = False - - def __getstate__(self): - return {'master_callback': self._master_callback} - - def __setstate__(self, state): - self.__init__(state['master_callback']) - - def register_slave(self, identifier): - """ - Register an slave device. - - Args: - identifier: an identifier, usually is the device id. - - Returns: a `SlavePipe` object which can be used to communicate with the master device. - - """ - if self._activated: - assert self._queue.empty(), 'Queue is not clean before next initialization.' - self._activated = False - self._registry.clear() - future = FutureResult() - self._registry[identifier] = _MasterRegistry(future) - return SlavePipe(identifier, self._queue, future) - - def run_master(self, master_msg): - """ - Main entry for the master device in each forward pass. - The messages were first collected from each devices (including the master device), and then - an callback will be invoked to compute the message to be sent back to each devices - (including the master device). - - Args: - master_msg: the message that the master want to send to itself. This will be placed as the first - message when calling `master_callback`. For detailed usage, see `_SynchronizedBatchNorm` for an example. - - Returns: the message to be sent back to the master device. - - """ - self._activated = True - - intermediates = [(0, master_msg)] - for i in range(self.nr_slaves): - intermediates.append(self._queue.get()) - - results = self._master_callback(intermediates) - assert results[0][0] == 0, 'The first result should belongs to the master.' - - for i, res in results: - if i == 0: - continue - self._registry[i].result.put(res) - - for i in range(self.nr_slaves): - assert self._queue.get() is True - - return results[0][1] - - @property - def nr_slaves(self): - return len(self._registry) diff --git a/spaces/julien-c/push-model-from-web/mobilenet/README.md b/spaces/julien-c/push-model-from-web/mobilenet/README.md deleted file mode 100644 index 2a1230fc7e939cd880641fe54489a89f482db381..0000000000000000000000000000000000000000 --- a/spaces/julien-c/push-model-from-web/mobilenet/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -license: mit -tags: - - image-classification - - tfjs ---- - -## TensorFlow.js version of Mobilenet - -Pushed from Web - - diff --git a/spaces/kazumak/webui/app.py b/spaces/kazumak/webui/app.py deleted file mode 100644 index 9aaf59d293dce427101bb90b54274afd589cedfd..0000000000000000000000000000000000000000 --- a/spaces/kazumak/webui/app.py +++ /dev/null @@ -1,61 +0,0 @@ -import os -from subprocess import getoutput - -gpu_info = getoutput('nvidia-smi') -if("A10G" in gpu_info): - os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+4c06c79.d20221205-cp38-cp38-linux_x86_64.whl") -elif("T4" in gpu_info): - os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+1515f77.d20221130-cp38-cp38-linux_x86_64.whl") - -os.system(f"git clone https://github.com/camenduru/stable-diffusion-webui /home/user/app/stable-diffusion-webui") -os.chdir("/home/user/app/stable-diffusion-webui") - -os.system(f"wget -q https://github.com/camenduru/webui/raw/main/env_patch.py -O /home/user/app/env_patch.py") -os.system(f"sed -i -e '/import image_from_url_text/r /home/user/app/env_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py") -os.system(f"sed -i -e '/(modelmerger_interface, \"Checkpoint Merger\", \"modelmerger\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py") -os.system(f"sed -i -e '/(train_interface, \"Train\", \"ti\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py") -os.system(f"sed -i -e '/extensions_interface, \"Extensions\", \"extensions\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py") -os.system(f"sed -i -e '/settings_interface, \"Settings\", \"settings\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py") -os.system(f'''sed -i -e "s/document.getElementsByTagName('gradio-app')\[0\].shadowRoot/!!document.getElementsByTagName('gradio-app')[0].shadowRoot ? document.getElementsByTagName('gradio-app')[0].shadowRoot : document/g" /home/user/app/stable-diffusion-webui/script.js''') -os.system(f"sed -i -e 's/ show_progress=False,/ show_progress=True,/g' /home/user/app/stable-diffusion-webui/modules/ui.py") -os.system(f"sed -i -e 's/shared.demo.launch/shared.demo.queue().launch/g' /home/user/app/stable-diffusion-webui/webui.py") -#os.system(f"sed -i -e 's/inputs=\[component\],/&\\n queue=False,/g' /home/user/app/stable-diffusion-webui/modules/ui.py") -#os.system(f"sed -i -e 's/outputs=\[token_counter\]/outputs=[token_counter], queue=False/g' /home/user/app/stable-diffusion-webui/modules/ui.py") -os.system(f"sed -i -e 's/outputs=\[/queue=False, &/g' home/user/app/stable-diffusion-webui/modules/ui.py") - -# ----------------------------Please duplicate this space and delete this block if you don't want to see the extra header---------------------------- -os.system(f"wget -q https://github.com/camenduru/webui/raw/main/header_patch.py -O /home/user/app/header_patch.py") -os.system(f"sed -i -e '/demo:/r /home/user/app/header_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py") -# --------------------------------------------------------------------------------------------------------------------------------------------------- - -#os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.ckpt") -#os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0.vae.pt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.vae.pt") -os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.ckpt") - -if "IS_SHARED_UI" in os.environ: - os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-config.json -O /home/user/app/shared-config.json") - os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-ui-config.json -O /home/user/app/shared-ui-config.json") - os.system(f"python launch.py --force-enable-xformers --disable-console-progressbars --enable-console-prompts --ui-config-file /home/user/app/shared-ui-config.json --ui-settings-file /home/user/app/shared-config.json --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding") -else: - # Please duplicate this space and delete # character in front of the custom script you want to use or add here more custom scripts with same structure os.system(f"wget -q https://CUSTOM_SCRIPT_URL -O /home/user/app/stable-diffusion-webui/scripts/CUSTOM_SCRIPT_NAME.py") - os.system(f"wget -q https://gist.github.com/camenduru/9ec5f8141db9902e375967e93250860f/raw/d0bcf01786f20107c329c03f8968584ee67be12a/run_n_times.py -O /home/user/app/stable-diffusion-webui/scripts/run_n_times.py") - - # Please duplicate this space and delete # character in front of the extension you want to use or add here more extensions with same structure os.system(f"git clone https://EXTENSION_GIT_URL /home/user/app/stable-diffusion-webui/extensions/EXTENSION_NAME") - #os.system(f"git clone https://github.com/camenduru/stable-diffusion-webui-artists-to-study /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-artists-to-study") - os.system(f"git clone https://github.com/yfszzx/stable-diffusion-webui-images-browser /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser") - os.system(f"git clone https://github.com/deforum-art/deforum-for-automatic1111-webui /home/user/app/stable-diffusion-webui/extensions/deforum-for-automatic1111-webui") - - # Please duplicate this space and delete # character in front of the model you want to use or add here more ckpts with same structure os.system(f"wget -q https://CKPT_URL -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/CKPT_NAME.ckpt") - #os.system(f"wget -q https://huggingface.co/nitrosocke/Arcane-Diffusion/resolve/main/arcane-diffusion-v3.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/arcane-diffusion-v3.ckpt") - #os.system(f"wget -q https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/Cyberpunk-Anime-Diffusion.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Cyberpunk-Anime-Diffusion.ckpt") - #os.system(f"wget -q https://huggingface.co/prompthero/midjourney-v4-diffusion/resolve/main/mdjrny-v4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/mdjrny-v4.ckpt") - #os.system(f"wget -q https://huggingface.co/nitrosocke/mo-di-diffusion/resolve/main/moDi-v1-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/moDi-v1-pruned.ckpt") - #os.system(f"wget -q https://huggingface.co/Fictiverse/Stable_Diffusion_PaperCut_Model/resolve/main/PaperCut_v1.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/PaperCut_v1.ckpt") - #os.system(f"wget -q https://huggingface.co/lilpotat/sa/resolve/main/samdoesarts_style.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/samdoesarts_style.ckpt") - #os.system(f"wget -q https://huggingface.co/hakurei/waifu-diffusion-v1-3/resolve/main/wd-v1-3-float32.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/wd-v1-3-float32.ckpt") - #os.system(f"wget -q https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-4.ckpt") - #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.ckpt") - #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-inpainting/resolve/main/sd-v1-5-inpainting.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-5-inpainting.ckpt") - #os.system(f"wget -q https://huggingface.co/stabilityai/stable-diffusion-2/resolve/main/768-v-ema.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.ckpt") - #os.system(f"wget -q https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.yaml") - os.system(f"python launch.py --force-enable-xformers --ui-config-file /home/user/app/ui-config.json --ui-settings-file /home/user/app/config.json --disable-console-progressbars --enable-console-prompts --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding --api --skip-torch-cuda-test --disable-safe-unpickle") diff --git a/spaces/kdrkdrkdr/HinaTTS/export_model.py b/spaces/kdrkdrkdr/HinaTTS/export_model.py deleted file mode 100644 index 98a49835df5a7a2486e76ddf94fbbb4444b52203..0000000000000000000000000000000000000000 --- a/spaces/kdrkdrkdr/HinaTTS/export_model.py +++ /dev/null @@ -1,13 +0,0 @@ -import torch - -if __name__ == '__main__': - model_path = "saved_model/11/model.pth" - output_path = "saved_model/11/model1.pth" - checkpoint_dict = torch.load(model_path, map_location='cpu') - checkpoint_dict_new = {} - for k, v in checkpoint_dict.items(): - if k == "optimizer": - print("remove optimizer") - continue - checkpoint_dict_new[k] = v - torch.save(checkpoint_dict_new, output_path) diff --git a/spaces/kerls/is-this-food-photo-instagram-worthy/app.py b/spaces/kerls/is-this-food-photo-instagram-worthy/app.py deleted file mode 100644 index b3c097b46baefb77b8ea88ef8b2fb793b901f7b9..0000000000000000000000000000000000000000 --- a/spaces/kerls/is-this-food-photo-instagram-worthy/app.py +++ /dev/null @@ -1,20 +0,0 @@ -from fastai.vision.all import * -import gradio as gr - -# def greet(name): -# return "Hello " + name + "!!" - -# iface = gr.Interface(fn=greet, inputs="text", outputs="text") -# iface.launch() - -learn = load_learner('export.pkl') - -labels = learn.dls.vocab -def predict(img): - img = PILImage.create(img) - pred,pred_idx,probs = learn.predict(img) - return {labels[i]: float(probs[i]) for i in range(len(labels))} - -examples = ['aesthetic-pancakes.jpg', 'messy-oatmeal.png', 'messy-plating.png'] - -gr.Interface(fn=predict, inputs=gr.Image(shape=(512, 512)), outputs=gr.Label(num_top_classes=3), examples=examples).launch(share=False) diff --git a/spaces/kevinwang676/ChatGLM2-SadTalker/src/gradio_demo.py b/spaces/kevinwang676/ChatGLM2-SadTalker/src/gradio_demo.py deleted file mode 100644 index 1e70005831b9f29dc3c7f39642364bc325a4c8a4..0000000000000000000000000000000000000000 --- a/spaces/kevinwang676/ChatGLM2-SadTalker/src/gradio_demo.py +++ /dev/null @@ -1,155 +0,0 @@ -import torch, uuid -import os, sys, shutil -from src.utils.preprocess import CropAndExtract -from src.test_audio2coeff import Audio2Coeff -from src.facerender.animate import AnimateFromCoeff -from src.generate_batch import get_data -from src.generate_facerender_batch import get_facerender_data - -from src.utils.init_path import init_path - -from pydub import AudioSegment - - -def mp3_to_wav(mp3_filename,wav_filename,frame_rate): - mp3_file = AudioSegment.from_file(file=mp3_filename) - mp3_file.set_frame_rate(frame_rate).export(wav_filename,format="wav") - - -class SadTalker(): - - def __init__(self, checkpoint_path='checkpoints', config_path='src/config', lazy_load=False): - - if torch.cuda.is_available() : - device = "cuda" - else: - device = "cpu" - - self.device = device - - os.environ['TORCH_HOME']= checkpoint_path - - self.checkpoint_path = checkpoint_path - self.config_path = config_path - - - def test(self, source_image, driven_audio, preprocess='crop', - still_mode=False, use_enhancer=False, batch_size=1, size=256, - pose_style = 0, exp_scale=1.0, - use_ref_video = False, - ref_video = None, - ref_info = None, - use_idle_mode = False, - length_of_audio = 0, use_blink=True, - result_dir='./results/'): - - self.sadtalker_paths = init_path(self.checkpoint_path, self.config_path, size, False, preprocess) - print(self.sadtalker_paths) - - self.audio_to_coeff = Audio2Coeff(self.sadtalker_paths, self.device) - self.preprocess_model = CropAndExtract(self.sadtalker_paths, self.device) - self.animate_from_coeff = AnimateFromCoeff(self.sadtalker_paths, self.device) - - time_tag = str(uuid.uuid4()) - save_dir = os.path.join(result_dir, time_tag) - os.makedirs(save_dir, exist_ok=True) - - input_dir = os.path.join(save_dir, 'input') - os.makedirs(input_dir, exist_ok=True) - - print(source_image) - pic_path = os.path.join(input_dir, os.path.basename(source_image)) - shutil.move(source_image, input_dir) - - if driven_audio is not None and os.path.isfile(driven_audio): - audio_path = os.path.join(input_dir, os.path.basename(driven_audio)) - - #### mp3 to wav - if '.mp3' in audio_path: - mp3_to_wav(driven_audio, audio_path.replace('.mp3', '.wav'), 16000) - audio_path = audio_path.replace('.mp3', '.wav') - else: - shutil.move(driven_audio, input_dir) - - elif use_idle_mode: - audio_path = os.path.join(input_dir, 'idlemode_'+str(length_of_audio)+'.wav') ## generate audio from this new audio_path - from pydub import AudioSegment - one_sec_segment = AudioSegment.silent(duration=1000*length_of_audio) #duration in milliseconds - one_sec_segment.export(audio_path, format="wav") - else: - print(use_ref_video, ref_info) - assert use_ref_video == True and ref_info == 'all' - - if use_ref_video and ref_info == 'all': # full ref mode - ref_video_videoname = os.path.basename(ref_video) - audio_path = os.path.join(save_dir, ref_video_videoname+'.wav') - print('new audiopath:',audio_path) - # if ref_video contains audio, set the audio from ref_video. - cmd = r"ffmpeg -y -hide_banner -loglevel error -i %s %s"%(ref_video, audio_path) - os.system(cmd) - - os.makedirs(save_dir, exist_ok=True) - - #crop image and extract 3dmm from image - first_frame_dir = os.path.join(save_dir, 'first_frame_dir') - os.makedirs(first_frame_dir, exist_ok=True) - first_coeff_path, crop_pic_path, crop_info = self.preprocess_model.generate(pic_path, first_frame_dir, preprocess, True, size) - - if first_coeff_path is None: - raise AttributeError("No face is detected") - - if use_ref_video: - print('using ref video for genreation') - ref_video_videoname = os.path.splitext(os.path.split(ref_video)[-1])[0] - ref_video_frame_dir = os.path.join(save_dir, ref_video_videoname) - os.makedirs(ref_video_frame_dir, exist_ok=True) - print('3DMM Extraction for the reference video providing pose') - ref_video_coeff_path, _, _ = self.preprocess_model.generate(ref_video, ref_video_frame_dir, preprocess, source_image_flag=False) - else: - ref_video_coeff_path = None - - if use_ref_video: - if ref_info == 'pose': - ref_pose_coeff_path = ref_video_coeff_path - ref_eyeblink_coeff_path = None - elif ref_info == 'blink': - ref_pose_coeff_path = None - ref_eyeblink_coeff_path = ref_video_coeff_path - elif ref_info == 'pose+blink': - ref_pose_coeff_path = ref_video_coeff_path - ref_eyeblink_coeff_path = ref_video_coeff_path - elif ref_info == 'all': - ref_pose_coeff_path = None - ref_eyeblink_coeff_path = None - else: - raise('error in refinfo') - else: - ref_pose_coeff_path = None - ref_eyeblink_coeff_path = None - - #audio2ceoff - if use_ref_video and ref_info == 'all': - coeff_path = ref_video_coeff_path # self.audio_to_coeff.generate(batch, save_dir, pose_style, ref_pose_coeff_path) - else: - batch = get_data(first_coeff_path, audio_path, self.device, ref_eyeblink_coeff_path=ref_eyeblink_coeff_path, still=still_mode, idlemode=use_idle_mode, length_of_audio=length_of_audio, use_blink=use_blink) # longer audio? - coeff_path = self.audio_to_coeff.generate(batch, save_dir, pose_style, ref_pose_coeff_path) - - #coeff2video - data = get_facerender_data(coeff_path, crop_pic_path, first_coeff_path, audio_path, batch_size, still_mode=still_mode, preprocess=preprocess, size=size, expression_scale = exp_scale) - return_path = self.animate_from_coeff.generate(data, save_dir, pic_path, crop_info, enhancer='gfpgan' if use_enhancer else None, preprocess=preprocess, img_size=size) - video_name = data['video_name'] - print(f'The generated video is named {video_name} in {save_dir}') - - del self.preprocess_model - del self.audio_to_coeff - del self.animate_from_coeff - - if torch.cuda.is_available(): - torch.cuda.empty_cache() - torch.cuda.synchronize() - - import gc; gc.collect() - - return return_path - - \ No newline at end of file diff --git a/spaces/kevinwang676/ChatGLM2-VC-SadTalker/src/face3d/util/generate_list.py b/spaces/kevinwang676/ChatGLM2-VC-SadTalker/src/face3d/util/generate_list.py deleted file mode 100644 index 943d906781063c3584a7e5b5c784f8aac0694985..0000000000000000000000000000000000000000 --- a/spaces/kevinwang676/ChatGLM2-VC-SadTalker/src/face3d/util/generate_list.py +++ /dev/null @@ -1,34 +0,0 @@ -"""This script is to generate training list files for Deep3DFaceRecon_pytorch -""" - -import os - -# save path to training data -def write_list(lms_list, imgs_list, msks_list, mode='train',save_folder='datalist', save_name=''): - save_path = os.path.join(save_folder, mode) - if not os.path.isdir(save_path): - os.makedirs(save_path) - with open(os.path.join(save_path, save_name + 'landmarks.txt'), 'w') as fd: - fd.writelines([i + '\n' for i in lms_list]) - - with open(os.path.join(save_path, save_name + 'images.txt'), 'w') as fd: - fd.writelines([i + '\n' for i in imgs_list]) - - with open(os.path.join(save_path, save_name + 'masks.txt'), 'w') as fd: - fd.writelines([i + '\n' for i in msks_list]) - -# check if the path is valid -def check_list(rlms_list, rimgs_list, rmsks_list): - lms_list, imgs_list, msks_list = [], [], [] - for i in range(len(rlms_list)): - flag = 'false' - lm_path = rlms_list[i] - im_path = rimgs_list[i] - msk_path = rmsks_list[i] - if os.path.isfile(lm_path) and os.path.isfile(im_path) and os.path.isfile(msk_path): - flag = 'true' - lms_list.append(rlms_list[i]) - imgs_list.append(rimgs_list[i]) - msks_list.append(rmsks_list[i]) - print(i, rlms_list[i], flag) - return lms_list, imgs_list, msks_list diff --git a/spaces/kirch/Text2Video-Zero/annotator/uniformer/mmcv/cnn/resnet.py b/spaces/kirch/Text2Video-Zero/annotator/uniformer/mmcv/cnn/resnet.py deleted file mode 100644 index 1cb3ac057ee2d52c46fc94685b5d4e698aad8d5f..0000000000000000000000000000000000000000 --- a/spaces/kirch/Text2Video-Zero/annotator/uniformer/mmcv/cnn/resnet.py +++ /dev/null @@ -1,316 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -import logging - -import torch.nn as nn -import torch.utils.checkpoint as cp - -from .utils import constant_init, kaiming_init - - -def conv3x3(in_planes, out_planes, stride=1, dilation=1): - """3x3 convolution with padding.""" - return nn.Conv2d( - in_planes, - out_planes, - kernel_size=3, - stride=stride, - padding=dilation, - dilation=dilation, - bias=False) - - -class BasicBlock(nn.Module): - expansion = 1 - - def __init__(self, - inplanes, - planes, - stride=1, - dilation=1, - downsample=None, - style='pytorch', - with_cp=False): - super(BasicBlock, self).__init__() - assert style in ['pytorch', 'caffe'] - self.conv1 = conv3x3(inplanes, planes, stride, dilation) - self.bn1 = nn.BatchNorm2d(planes) - self.relu = nn.ReLU(inplace=True) - self.conv2 = conv3x3(planes, planes) - self.bn2 = nn.BatchNorm2d(planes) - self.downsample = downsample - self.stride = stride - self.dilation = dilation - assert not with_cp - - def forward(self, x): - residual = x - - out = self.conv1(x) - out = self.bn1(out) - out = self.relu(out) - - out = self.conv2(out) - out = self.bn2(out) - - if self.downsample is not None: - residual = self.downsample(x) - - out += residual - out = self.relu(out) - - return out - - -class Bottleneck(nn.Module): - expansion = 4 - - def __init__(self, - inplanes, - planes, - stride=1, - dilation=1, - downsample=None, - style='pytorch', - with_cp=False): - """Bottleneck block. - - If style is "pytorch", the stride-two layer is the 3x3 conv layer, if - it is "caffe", the stride-two layer is the first 1x1 conv layer. - """ - super(Bottleneck, self).__init__() - assert style in ['pytorch', 'caffe'] - if style == 'pytorch': - conv1_stride = 1 - conv2_stride = stride - else: - conv1_stride = stride - conv2_stride = 1 - self.conv1 = nn.Conv2d( - inplanes, planes, kernel_size=1, stride=conv1_stride, bias=False) - self.conv2 = nn.Conv2d( - planes, - planes, - kernel_size=3, - stride=conv2_stride, - padding=dilation, - dilation=dilation, - bias=False) - - self.bn1 = nn.BatchNorm2d(planes) - self.bn2 = nn.BatchNorm2d(planes) - self.conv3 = nn.Conv2d( - planes, planes * self.expansion, kernel_size=1, bias=False) - self.bn3 = nn.BatchNorm2d(planes * self.expansion) - self.relu = nn.ReLU(inplace=True) - self.downsample = downsample - self.stride = stride - self.dilation = dilation - self.with_cp = with_cp - - def forward(self, x): - - def _inner_forward(x): - residual = x - - out = self.conv1(x) - out = self.bn1(out) - out = self.relu(out) - - out = self.conv2(out) - out = self.bn2(out) - out = self.relu(out) - - out = self.conv3(out) - out = self.bn3(out) - - if self.downsample is not None: - residual = self.downsample(x) - - out += residual - - return out - - if self.with_cp and x.requires_grad: - out = cp.checkpoint(_inner_forward, x) - else: - out = _inner_forward(x) - - out = self.relu(out) - - return out - - -def make_res_layer(block, - inplanes, - planes, - blocks, - stride=1, - dilation=1, - style='pytorch', - with_cp=False): - downsample = None - if stride != 1 or inplanes != planes * block.expansion: - downsample = nn.Sequential( - nn.Conv2d( - inplanes, - planes * block.expansion, - kernel_size=1, - stride=stride, - bias=False), - nn.BatchNorm2d(planes * block.expansion), - ) - - layers = [] - layers.append( - block( - inplanes, - planes, - stride, - dilation, - downsample, - style=style, - with_cp=with_cp)) - inplanes = planes * block.expansion - for _ in range(1, blocks): - layers.append( - block(inplanes, planes, 1, dilation, style=style, with_cp=with_cp)) - - return nn.Sequential(*layers) - - -class ResNet(nn.Module): - """ResNet backbone. - - Args: - depth (int): Depth of resnet, from {18, 34, 50, 101, 152}. - num_stages (int): Resnet stages, normally 4. - strides (Sequence[int]): Strides of the first block of each stage. - dilations (Sequence[int]): Dilation of each stage. - out_indices (Sequence[int]): Output from which stages. - style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two - layer is the 3x3 conv layer, otherwise the stride-two layer is - the first 1x1 conv layer. - frozen_stages (int): Stages to be frozen (all param fixed). -1 means - not freezing any parameters. - bn_eval (bool): Whether to set BN layers as eval mode, namely, freeze - running stats (mean and var). - bn_frozen (bool): Whether to freeze weight and bias of BN layers. - with_cp (bool): Use checkpoint or not. Using checkpoint will save some - memory while slowing down the training speed. - """ - - arch_settings = { - 18: (BasicBlock, (2, 2, 2, 2)), - 34: (BasicBlock, (3, 4, 6, 3)), - 50: (Bottleneck, (3, 4, 6, 3)), - 101: (Bottleneck, (3, 4, 23, 3)), - 152: (Bottleneck, (3, 8, 36, 3)) - } - - def __init__(self, - depth, - num_stages=4, - strides=(1, 2, 2, 2), - dilations=(1, 1, 1, 1), - out_indices=(0, 1, 2, 3), - style='pytorch', - frozen_stages=-1, - bn_eval=True, - bn_frozen=False, - with_cp=False): - super(ResNet, self).__init__() - if depth not in self.arch_settings: - raise KeyError(f'invalid depth {depth} for resnet') - assert num_stages >= 1 and num_stages <= 4 - block, stage_blocks = self.arch_settings[depth] - stage_blocks = stage_blocks[:num_stages] - assert len(strides) == len(dilations) == num_stages - assert max(out_indices) < num_stages - - self.out_indices = out_indices - self.style = style - self.frozen_stages = frozen_stages - self.bn_eval = bn_eval - self.bn_frozen = bn_frozen - self.with_cp = with_cp - - self.inplanes = 64 - self.conv1 = nn.Conv2d( - 3, 64, kernel_size=7, stride=2, padding=3, bias=False) - self.bn1 = nn.BatchNorm2d(64) - self.relu = nn.ReLU(inplace=True) - self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) - - self.res_layers = [] - for i, num_blocks in enumerate(stage_blocks): - stride = strides[i] - dilation = dilations[i] - planes = 64 * 2**i - res_layer = make_res_layer( - block, - self.inplanes, - planes, - num_blocks, - stride=stride, - dilation=dilation, - style=self.style, - with_cp=with_cp) - self.inplanes = planes * block.expansion - layer_name = f'layer{i + 1}' - self.add_module(layer_name, res_layer) - self.res_layers.append(layer_name) - - self.feat_dim = block.expansion * 64 * 2**(len(stage_blocks) - 1) - - def init_weights(self, pretrained=None): - if isinstance(pretrained, str): - logger = logging.getLogger() - from ..runner import load_checkpoint - load_checkpoint(self, pretrained, strict=False, logger=logger) - elif pretrained is None: - for m in self.modules(): - if isinstance(m, nn.Conv2d): - kaiming_init(m) - elif isinstance(m, nn.BatchNorm2d): - constant_init(m, 1) - else: - raise TypeError('pretrained must be a str or None') - - def forward(self, x): - x = self.conv1(x) - x = self.bn1(x) - x = self.relu(x) - x = self.maxpool(x) - outs = [] - for i, layer_name in enumerate(self.res_layers): - res_layer = getattr(self, layer_name) - x = res_layer(x) - if i in self.out_indices: - outs.append(x) - if len(outs) == 1: - return outs[0] - else: - return tuple(outs) - - def train(self, mode=True): - super(ResNet, self).train(mode) - if self.bn_eval: - for m in self.modules(): - if isinstance(m, nn.BatchNorm2d): - m.eval() - if self.bn_frozen: - for params in m.parameters(): - params.requires_grad = False - if mode and self.frozen_stages >= 0: - for param in self.conv1.parameters(): - param.requires_grad = False - for param in self.bn1.parameters(): - param.requires_grad = False - self.bn1.eval() - self.bn1.weight.requires_grad = False - self.bn1.bias.requires_grad = False - for i in range(1, self.frozen_stages + 1): - mod = getattr(self, f'layer{i}') - mod.eval() - for param in mod.parameters(): - param.requires_grad = False diff --git a/spaces/kirch/Text2Video-Zero/annotator/uniformer/mmcv/parallel/registry.py b/spaces/kirch/Text2Video-Zero/annotator/uniformer/mmcv/parallel/registry.py deleted file mode 100644 index a204a07fba10e614223f090d1a57cf9c4d74d4a1..0000000000000000000000000000000000000000 --- a/spaces/kirch/Text2Video-Zero/annotator/uniformer/mmcv/parallel/registry.py +++ /dev/null @@ -1,8 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -from torch.nn.parallel import DataParallel, DistributedDataParallel - -from annotator.uniformer.mmcv.utils import Registry - -MODULE_WRAPPERS = Registry('module wrapper') -MODULE_WRAPPERS.register_module(module=DataParallel) -MODULE_WRAPPERS.register_module(module=DistributedDataParallel) diff --git a/spaces/kpyuy/chat/app.py b/spaces/kpyuy/chat/app.py deleted file mode 100644 index 37e8f5ffc2ed7e157891e9eff4acfff88f6305e2..0000000000000000000000000000000000000000 --- a/spaces/kpyuy/chat/app.py +++ /dev/null @@ -1,62 +0,0 @@ -import gradio as gr -import openai -import os - -openai.api_key = os.environ.get("OPENAI_API_KEY") - - -class Conversation: - def __init__(self, prompt, num_of_round): - self.prompt = prompt - self.num_of_round = num_of_round - self.messages = [] - self.messages.append({"role": "system", "content": self.prompt}) - - def ask(self, question): - try: - self.messages.append({"role": "user", "content": question}) - response = openai.ChatCompletion.create( - model="gpt-3.5-turbo", - messages=self.messages, - temperature=0.5, - max_tokens=2048, - top_p=1, - ) - except Exception as e: - print(e) - return e - - message = response["choices"][0]["message"]["content"] - self.messages.append({"role": "assistant", "content": message}) - - if len(self.messages) > self.num_of_round * 2 + 1: - del self.messages[1:3] # Remove the first round conversation left. - return message - - -prompt = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求: -1. 你的回答必须是中文 -2. 回答限制在100个字以内""" - -conv = Conversation(prompt, 10) - - -def answer(question, history=[]): - history.append(question) - response = conv.ask(question) - history.append(response) - responses = [(u, b) for u, b in zip(history[::2], history[1::2])] - return responses, history - - -with gr.Blocks(css="#chatbot{height:300px} .overflow-y-auto{height:500px}") as demo: - chatbot = gr.Chatbot(elem_id="chatbot") - state = gr.State([]) - - with gr.Row(): - txt = gr.Textbox(show_label=False, - placeholder="Enter text and press enter").style(container=False) - - txt.submit(answer, [txt, state], [chatbot, state]) - -demo.launch() diff --git a/spaces/krystaltechnology/image-video-colorization/models/deep_colorization/colorizers/util.py b/spaces/krystaltechnology/image-video-colorization/models/deep_colorization/colorizers/util.py deleted file mode 100644 index 79968ba6b960a8c10047f1ce52400b6bfe766b9c..0000000000000000000000000000000000000000 --- a/spaces/krystaltechnology/image-video-colorization/models/deep_colorization/colorizers/util.py +++ /dev/null @@ -1,47 +0,0 @@ - -from PIL import Image -import numpy as np -from skimage import color -import torch -import torch.nn.functional as F -from IPython import embed - -def load_img(img_path): - out_np = np.asarray(Image.open(img_path)) - if(out_np.ndim==2): - out_np = np.tile(out_np[:,:,None],3) - return out_np - -def resize_img(img, HW=(256,256), resample=3): - return np.asarray(Image.fromarray(img).resize((HW[1],HW[0]), resample=resample)) - -def preprocess_img(img_rgb_orig, HW=(256,256), resample=3): - # return original size L and resized L as torch Tensors - img_rgb_rs = resize_img(img_rgb_orig, HW=HW, resample=resample) - - img_lab_orig = color.rgb2lab(img_rgb_orig) - img_lab_rs = color.rgb2lab(img_rgb_rs) - - img_l_orig = img_lab_orig[:,:,0] - img_l_rs = img_lab_rs[:,:,0] - - tens_orig_l = torch.Tensor(img_l_orig)[None,None,:,:] - tens_rs_l = torch.Tensor(img_l_rs)[None,None,:,:] - - return (tens_orig_l, tens_rs_l) - -def postprocess_tens(tens_orig_l, out_ab, mode='bilinear'): - # tens_orig_l 1 x 1 x H_orig x W_orig - # out_ab 1 x 2 x H x W - - HW_orig = tens_orig_l.shape[2:] - HW = out_ab.shape[2:] - - # call resize function if needed - if(HW_orig[0]!=HW[0] or HW_orig[1]!=HW[1]): - out_ab_orig = F.interpolate(out_ab, size=HW_orig, mode='bilinear') - else: - out_ab_orig = out_ab - - out_lab_orig = torch.cat((tens_orig_l, out_ab_orig), dim=1) - return color.lab2rgb(out_lab_orig.data.cpu().numpy()[0,...].transpose((1,2,0))) diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/PIL/ImageDraw.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/PIL/ImageDraw.py deleted file mode 100644 index 8adcc87de51650edfff0a33974e607cc82f98344..0000000000000000000000000000000000000000 --- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/PIL/ImageDraw.py +++ /dev/null @@ -1,1127 +0,0 @@ -# -# The Python Imaging Library -# $Id$ -# -# drawing interface operations -# -# History: -# 1996-04-13 fl Created (experimental) -# 1996-08-07 fl Filled polygons, ellipses. -# 1996-08-13 fl Added text support -# 1998-06-28 fl Handle I and F images -# 1998-12-29 fl Added arc; use arc primitive to draw ellipses -# 1999-01-10 fl Added shape stuff (experimental) -# 1999-02-06 fl Added bitmap support -# 1999-02-11 fl Changed all primitives to take options -# 1999-02-20 fl Fixed backwards compatibility -# 2000-10-12 fl Copy on write, when necessary -# 2001-02-18 fl Use default ink for bitmap/text also in fill mode -# 2002-10-24 fl Added support for CSS-style color strings -# 2002-12-10 fl Added experimental support for RGBA-on-RGB drawing -# 2002-12-11 fl Refactored low-level drawing API (work in progress) -# 2004-08-26 fl Made Draw() a factory function, added getdraw() support -# 2004-09-04 fl Added width support to line primitive -# 2004-09-10 fl Added font mode handling -# 2006-06-19 fl Added font bearing support (getmask2) -# -# Copyright (c) 1997-2006 by Secret Labs AB -# Copyright (c) 1996-2006 by Fredrik Lundh -# -# See the README file for information on usage and redistribution. -# - -import math -import numbers -import warnings - -from . import Image, ImageColor -from ._deprecate import deprecate - -""" -A simple 2D drawing interface for PIL images. -
-Application code should use the Draw factory, instead of
-directly.
-"""
-
-
-class ImageDraw:
- font = None
-
- def __init__(self, im, mode=None):
- """
- Create a drawing instance.
-
- :param im: The image to draw in.
- :param mode: Optional mode to use for color values. For RGB
- images, this argument can be RGB or RGBA (to blend the
- drawing into the image). For all other modes, this argument
- must be the same as the image mode. If omitted, the mode
- defaults to the mode of the image.
- """
- im.load()
- if im.readonly:
- im._copy() # make it writeable
- blend = 0
- if mode is None:
- mode = im.mode
- if mode != im.mode:
- if mode == "RGBA" and im.mode == "RGB":
- blend = 1
- else:
- msg = "mode mismatch"
- raise ValueError(msg)
- if mode == "P":
- self.palette = im.palette
- else:
- self.palette = None
- self._image = im
- self.im = im.im
- self.draw = Image.core.draw(self.im, blend)
- self.mode = mode
- if mode in ("I", "F"):
- self.ink = self.draw.draw_ink(1)
- else:
- self.ink = self.draw.draw_ink(-1)
- if mode in ("1", "P", "I", "F"):
- # FIXME: fix Fill2 to properly support matte for I+F images
- self.fontmode = "1"
- else:
- self.fontmode = "L" # aliasing is okay for other modes
- self.fill = False
-
- def getfont(self):
- """
- Get the current default font.
-
- To set the default font for this ImageDraw instance::
-
- from PIL import ImageDraw, ImageFont
- draw.font = ImageFont.truetype("Tests/fonts/FreeMono.ttf")
-
- To set the default font for all future ImageDraw instances::
-
- from PIL import ImageDraw, ImageFont
- ImageDraw.ImageDraw.font = ImageFont.truetype("Tests/fonts/FreeMono.ttf")
-
- If the current default font is ``None``,
- it is initialized with ``ImageFont.load_default()``.
-
- :returns: An image font."""
- if not self.font:
- # FIXME: should add a font repository
- from . import ImageFont
-
- self.font = ImageFont.load_default()
- return self.font
-
- def _getink(self, ink, fill=None):
- if ink is None and fill is None:
- if self.fill:
- fill = self.ink
- else:
- ink = self.ink
- else:
- if ink is not None:
- if isinstance(ink, str):
- ink = ImageColor.getcolor(ink, self.mode)
- if self.palette and not isinstance(ink, numbers.Number):
- ink = self.palette.getcolor(ink, self._image)
- ink = self.draw.draw_ink(ink)
- if fill is not None:
- if isinstance(fill, str):
- fill = ImageColor.getcolor(fill, self.mode)
- if self.palette and not isinstance(fill, numbers.Number):
- fill = self.palette.getcolor(fill, self._image)
- fill = self.draw.draw_ink(fill)
- return ink, fill
-
- def arc(self, xy, start, end, fill=None, width=1):
- """Draw an arc."""
- ink, fill = self._getink(fill)
- if ink is not None:
- self.draw.draw_arc(xy, start, end, ink, width)
-
- def bitmap(self, xy, bitmap, fill=None):
- """Draw a bitmap."""
- bitmap.load()
- ink, fill = self._getink(fill)
- if ink is None:
- ink = fill
- if ink is not None:
- self.draw.draw_bitmap(xy, bitmap.im, ink)
-
- def chord(self, xy, start, end, fill=None, outline=None, width=1):
- """Draw a chord."""
- ink, fill = self._getink(outline, fill)
- if fill is not None:
- self.draw.draw_chord(xy, start, end, fill, 1)
- if ink is not None and ink != fill and width != 0:
- self.draw.draw_chord(xy, start, end, ink, 0, width)
-
- def ellipse(self, xy, fill=None, outline=None, width=1):
- """Draw an ellipse."""
- ink, fill = self._getink(outline, fill)
- if fill is not None:
- self.draw.draw_ellipse(xy, fill, 1)
- if ink is not None and ink != fill and width != 0:
- self.draw.draw_ellipse(xy, ink, 0, width)
-
- def line(self, xy, fill=None, width=0, joint=None):
- """Draw a line, or a connected sequence of line segments."""
- ink = self._getink(fill)[0]
- if ink is not None:
- self.draw.draw_lines(xy, ink, width)
- if joint == "curve" and width > 4:
- if not isinstance(xy[0], (list, tuple)):
- xy = [tuple(xy[i : i + 2]) for i in range(0, len(xy), 2)]
- for i in range(1, len(xy) - 1):
- point = xy[i]
- angles = [
- math.degrees(math.atan2(end[0] - start[0], start[1] - end[1]))
- % 360
- for start, end in ((xy[i - 1], point), (point, xy[i + 1]))
- ]
- if angles[0] == angles[1]:
- # This is a straight line, so no joint is required
- continue
-
- def coord_at_angle(coord, angle):
- x, y = coord
- angle -= 90
- distance = width / 2 - 1
- return tuple(
- p + (math.floor(p_d) if p_d > 0 else math.ceil(p_d))
- for p, p_d in (
- (x, distance * math.cos(math.radians(angle))),
- (y, distance * math.sin(math.radians(angle))),
- )
- )
-
- flipped = (
- angles[1] > angles[0] and angles[1] - 180 > angles[0]
- ) or (angles[1] < angles[0] and angles[1] + 180 > angles[0])
- coords = [
- (point[0] - width / 2 + 1, point[1] - width / 2 + 1),
- (point[0] + width / 2 - 1, point[1] + width / 2 - 1),
- ]
- if flipped:
- start, end = (angles[1] + 90, angles[0] + 90)
- else:
- start, end = (angles[0] - 90, angles[1] - 90)
- self.pieslice(coords, start - 90, end - 90, fill)
-
- if width > 8:
- # Cover potential gaps between the line and the joint
- if flipped:
- gap_coords = [
- coord_at_angle(point, angles[0] + 90),
- point,
- coord_at_angle(point, angles[1] + 90),
- ]
- else:
- gap_coords = [
- coord_at_angle(point, angles[0] - 90),
- point,
- coord_at_angle(point, angles[1] - 90),
- ]
- self.line(gap_coords, fill, width=3)
-
- def shape(self, shape, fill=None, outline=None):
- """(Experimental) Draw a shape."""
- shape.close()
- ink, fill = self._getink(outline, fill)
- if fill is not None:
- self.draw.draw_outline(shape, fill, 1)
- if ink is not None and ink != fill:
- self.draw.draw_outline(shape, ink, 0)
-
- def pieslice(self, xy, start, end, fill=None, outline=None, width=1):
- """Draw a pieslice."""
- ink, fill = self._getink(outline, fill)
- if fill is not None:
- self.draw.draw_pieslice(xy, start, end, fill, 1)
- if ink is not None and ink != fill and width != 0:
- self.draw.draw_pieslice(xy, start, end, ink, 0, width)
-
- def point(self, xy, fill=None):
- """Draw one or more individual pixels."""
- ink, fill = self._getink(fill)
- if ink is not None:
- self.draw.draw_points(xy, ink)
-
- def polygon(self, xy, fill=None, outline=None, width=1):
- """Draw a polygon."""
- ink, fill = self._getink(outline, fill)
- if fill is not None:
- self.draw.draw_polygon(xy, fill, 1)
- if ink is not None and ink != fill and width != 0:
- if width == 1:
- self.draw.draw_polygon(xy, ink, 0, width)
- else:
- # To avoid expanding the polygon outwards,
- # use the fill as a mask
- mask = Image.new("1", self.im.size)
- mask_ink = self._getink(1)[0]
-
- fill_im = mask.copy()
- draw = Draw(fill_im)
- draw.draw.draw_polygon(xy, mask_ink, 1)
-
- ink_im = mask.copy()
- draw = Draw(ink_im)
- width = width * 2 - 1
- draw.draw.draw_polygon(xy, mask_ink, 0, width)
-
- mask.paste(ink_im, mask=fill_im)
-
- im = Image.new(self.mode, self.im.size)
- draw = Draw(im)
- draw.draw.draw_polygon(xy, ink, 0, width)
- self.im.paste(im.im, (0, 0) + im.size, mask.im)
-
- def regular_polygon(
- self, bounding_circle, n_sides, rotation=0, fill=None, outline=None
- ):
- """Draw a regular polygon."""
- xy = _compute_regular_polygon_vertices(bounding_circle, n_sides, rotation)
- self.polygon(xy, fill, outline)
-
- def rectangle(self, xy, fill=None, outline=None, width=1):
- """Draw a rectangle."""
- ink, fill = self._getink(outline, fill)
- if fill is not None:
- self.draw.draw_rectangle(xy, fill, 1)
- if ink is not None and ink != fill and width != 0:
- self.draw.draw_rectangle(xy, ink, 0, width)
-
- def rounded_rectangle(
- self, xy, radius=0, fill=None, outline=None, width=1, *, corners=None
- ):
- """Draw a rounded rectangle."""
- if isinstance(xy[0], (list, tuple)):
- (x0, y0), (x1, y1) = xy
- else:
- x0, y0, x1, y1 = xy
- if x1 < x0:
- msg = "x1 must be greater than or equal to x0"
- raise ValueError(msg)
- if y1 < y0:
- msg = "y1 must be greater than or equal to y0"
- raise ValueError(msg)
- if corners is None:
- corners = (True, True, True, True)
-
- d = radius * 2
-
- full_x, full_y = False, False
- if all(corners):
- full_x = d >= x1 - x0
- if full_x:
- # The two left and two right corners are joined
- d = x1 - x0
- full_y = d >= y1 - y0
- if full_y:
- # The two top and two bottom corners are joined
- d = y1 - y0
- if full_x and full_y:
- # If all corners are joined, that is a circle
- return self.ellipse(xy, fill, outline, width)
-
- if d == 0 or not any(corners):
- # If the corners have no curve,
- # or there are no corners,
- # that is a rectangle
- return self.rectangle(xy, fill, outline, width)
-
- r = d // 2
- ink, fill = self._getink(outline, fill)
-
- def draw_corners(pieslice):
- if full_x:
- # Draw top and bottom halves
- parts = (
- ((x0, y0, x0 + d, y0 + d), 180, 360),
- ((x0, y1 - d, x0 + d, y1), 0, 180),
- )
- elif full_y:
- # Draw left and right halves
- parts = (
- ((x0, y0, x0 + d, y0 + d), 90, 270),
- ((x1 - d, y0, x1, y0 + d), 270, 90),
- )
- else:
- # Draw four separate corners
- parts = []
- for i, part in enumerate(
- (
- ((x0, y0, x0 + d, y0 + d), 180, 270),
- ((x1 - d, y0, x1, y0 + d), 270, 360),
- ((x1 - d, y1 - d, x1, y1), 0, 90),
- ((x0, y1 - d, x0 + d, y1), 90, 180),
- )
- ):
- if corners[i]:
- parts.append(part)
- for part in parts:
- if pieslice:
- self.draw.draw_pieslice(*(part + (fill, 1)))
- else:
- self.draw.draw_arc(*(part + (ink, width)))
-
- if fill is not None:
- draw_corners(True)
-
- if full_x:
- self.draw.draw_rectangle((x0, y0 + r + 1, x1, y1 - r - 1), fill, 1)
- else:
- self.draw.draw_rectangle((x0 + r + 1, y0, x1 - r - 1, y1), fill, 1)
- if not full_x and not full_y:
- left = [x0, y0, x0 + r, y1]
- if corners[0]:
- left[1] += r + 1
- if corners[3]:
- left[3] -= r + 1
- self.draw.draw_rectangle(left, fill, 1)
-
- right = [x1 - r, y0, x1, y1]
- if corners[1]:
- right[1] += r + 1
- if corners[2]:
- right[3] -= r + 1
- self.draw.draw_rectangle(right, fill, 1)
- if ink is not None and ink != fill and width != 0:
- draw_corners(False)
-
- if not full_x:
- top = [x0, y0, x1, y0 + width - 1]
- if corners[0]:
- top[0] += r + 1
- if corners[1]:
- top[2] -= r + 1
- self.draw.draw_rectangle(top, ink, 1)
-
- bottom = [x0, y1 - width + 1, x1, y1]
- if corners[3]:
- bottom[0] += r + 1
- if corners[2]:
- bottom[2] -= r + 1
- self.draw.draw_rectangle(bottom, ink, 1)
- if not full_y:
- left = [x0, y0, x0 + width - 1, y1]
- if corners[0]:
- left[1] += r + 1
- if corners[3]:
- left[3] -= r + 1
- self.draw.draw_rectangle(left, ink, 1)
-
- right = [x1 - width + 1, y0, x1, y1]
- if corners[1]:
- right[1] += r + 1
- if corners[2]:
- right[3] -= r + 1
- self.draw.draw_rectangle(right, ink, 1)
-
- def _multiline_check(self, text):
- split_character = "\n" if isinstance(text, str) else b"\n"
-
- return split_character in text
-
- def _multiline_split(self, text):
- split_character = "\n" if isinstance(text, str) else b"\n"
-
- return text.split(split_character)
-
- def _multiline_spacing(self, font, spacing, stroke_width):
- # this can be replaced with self.textbbox(...)[3] when textsize is removed
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore", category=DeprecationWarning)
- return (
- self.textsize(
- "A",
- font=font,
- stroke_width=stroke_width,
- )[1]
- + spacing
- )
-
- def text(
- self,
- xy,
- text,
- fill=None,
- font=None,
- anchor=None,
- spacing=4,
- align="left",
- direction=None,
- features=None,
- language=None,
- stroke_width=0,
- stroke_fill=None,
- embedded_color=False,
- *args,
- **kwargs,
- ):
- """Draw text."""
- if self._multiline_check(text):
- return self.multiline_text(
- xy,
- text,
- fill,
- font,
- anchor,
- spacing,
- align,
- direction,
- features,
- language,
- stroke_width,
- stroke_fill,
- embedded_color,
- )
-
- if embedded_color and self.mode not in ("RGB", "RGBA"):
- msg = "Embedded color supported only in RGB and RGBA modes"
- raise ValueError(msg)
-
- if font is None:
- font = self.getfont()
-
- def getink(fill):
- ink, fill = self._getink(fill)
- if ink is None:
- return fill
- return ink
-
- def draw_text(ink, stroke_width=0, stroke_offset=None):
- mode = self.fontmode
- if stroke_width == 0 and embedded_color:
- mode = "RGBA"
- coord = []
- start = []
- for i in range(2):
- coord.append(int(xy[i]))
- start.append(math.modf(xy[i])[0])
- try:
- mask, offset = font.getmask2(
- text,
- mode,
- direction=direction,
- features=features,
- language=language,
- stroke_width=stroke_width,
- anchor=anchor,
- ink=ink,
- start=start,
- *args,
- **kwargs,
- )
- coord = coord[0] + offset[0], coord[1] + offset[1]
- except AttributeError:
- try:
- mask = font.getmask(
- text,
- mode,
- direction,
- features,
- language,
- stroke_width,
- anchor,
- ink,
- start=start,
- *args,
- **kwargs,
- )
- except TypeError:
- mask = font.getmask(text)
- if stroke_offset:
- coord = coord[0] + stroke_offset[0], coord[1] + stroke_offset[1]
- if mode == "RGBA":
- # font.getmask2(mode="RGBA") returns color in RGB bands and mask in A
- # extract mask and set text alpha
- color, mask = mask, mask.getband(3)
- color.fillband(3, (ink >> 24) & 0xFF)
- x, y = coord
- self.im.paste(color, (x, y, x + mask.size[0], y + mask.size[1]), mask)
- else:
- self.draw.draw_bitmap(coord, mask, ink)
-
- ink = getink(fill)
- if ink is not None:
- stroke_ink = None
- if stroke_width:
- stroke_ink = getink(stroke_fill) if stroke_fill is not None else ink
-
- if stroke_ink is not None:
- # Draw stroked text
- draw_text(stroke_ink, stroke_width)
-
- # Draw normal text
- draw_text(ink, 0)
- else:
- # Only draw normal text
- draw_text(ink)
-
- def multiline_text(
- self,
- xy,
- text,
- fill=None,
- font=None,
- anchor=None,
- spacing=4,
- align="left",
- direction=None,
- features=None,
- language=None,
- stroke_width=0,
- stroke_fill=None,
- embedded_color=False,
- ):
- if direction == "ttb":
- msg = "ttb direction is unsupported for multiline text"
- raise ValueError(msg)
-
- if anchor is None:
- anchor = "la"
- elif len(anchor) != 2:
- msg = "anchor must be a 2 character string"
- raise ValueError(msg)
- elif anchor[1] in "tb":
- msg = "anchor not supported for multiline text"
- raise ValueError(msg)
-
- widths = []
- max_width = 0
- lines = self._multiline_split(text)
- line_spacing = self._multiline_spacing(font, spacing, stroke_width)
- for line in lines:
- line_width = self.textlength(
- line, font, direction=direction, features=features, language=language
- )
- widths.append(line_width)
- max_width = max(max_width, line_width)
-
- top = xy[1]
- if anchor[1] == "m":
- top -= (len(lines) - 1) * line_spacing / 2.0
- elif anchor[1] == "d":
- top -= (len(lines) - 1) * line_spacing
-
- for idx, line in enumerate(lines):
- left = xy[0]
- width_difference = max_width - widths[idx]
-
- # first align left by anchor
- if anchor[0] == "m":
- left -= width_difference / 2.0
- elif anchor[0] == "r":
- left -= width_difference
-
- # then align by align parameter
- if align == "left":
- pass
- elif align == "center":
- left += width_difference / 2.0
- elif align == "right":
- left += width_difference
- else:
- msg = 'align must be "left", "center" or "right"'
- raise ValueError(msg)
-
- self.text(
- (left, top),
- line,
- fill,
- font,
- anchor,
- direction=direction,
- features=features,
- language=language,
- stroke_width=stroke_width,
- stroke_fill=stroke_fill,
- embedded_color=embedded_color,
- )
- top += line_spacing
-
- def textsize(
- self,
- text,
- font=None,
- spacing=4,
- direction=None,
- features=None,
- language=None,
- stroke_width=0,
- ):
- """Get the size of a given string, in pixels."""
- deprecate("textsize", 10, "textbbox or textlength")
- if self._multiline_check(text):
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore", category=DeprecationWarning)
- return self.multiline_textsize(
- text,
- font,
- spacing,
- direction,
- features,
- language,
- stroke_width,
- )
-
- if font is None:
- font = self.getfont()
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore", category=DeprecationWarning)
- return font.getsize(
- text,
- direction,
- features,
- language,
- stroke_width,
- )
-
- def multiline_textsize(
- self,
- text,
- font=None,
- spacing=4,
- direction=None,
- features=None,
- language=None,
- stroke_width=0,
- ):
- deprecate("multiline_textsize", 10, "multiline_textbbox")
- max_width = 0
- lines = self._multiline_split(text)
- line_spacing = self._multiline_spacing(font, spacing, stroke_width)
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore", category=DeprecationWarning)
- for line in lines:
- line_width, line_height = self.textsize(
- line,
- font,
- spacing,
- direction,
- features,
- language,
- stroke_width,
- )
- max_width = max(max_width, line_width)
- return max_width, len(lines) * line_spacing - spacing
-
- def textlength(
- self,
- text,
- font=None,
- direction=None,
- features=None,
- language=None,
- embedded_color=False,
- ):
- """Get the length of a given string, in pixels with 1/64 precision."""
- if self._multiline_check(text):
- msg = "can't measure length of multiline text"
- raise ValueError(msg)
- if embedded_color and self.mode not in ("RGB", "RGBA"):
- msg = "Embedded color supported only in RGB and RGBA modes"
- raise ValueError(msg)
-
- if font is None:
- font = self.getfont()
- mode = "RGBA" if embedded_color else self.fontmode
- try:
- return font.getlength(text, mode, direction, features, language)
- except AttributeError:
- deprecate("textlength support for fonts without getlength", 10)
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore", category=DeprecationWarning)
- size = self.textsize(
- text,
- font,
- direction=direction,
- features=features,
- language=language,
- )
- if direction == "ttb":
- return size[1]
- return size[0]
-
- def textbbox(
- self,
- xy,
- text,
- font=None,
- anchor=None,
- spacing=4,
- align="left",
- direction=None,
- features=None,
- language=None,
- stroke_width=0,
- embedded_color=False,
- ):
- """Get the bounding box of a given string, in pixels."""
- if embedded_color and self.mode not in ("RGB", "RGBA"):
- msg = "Embedded color supported only in RGB and RGBA modes"
- raise ValueError(msg)
-
- if self._multiline_check(text):
- return self.multiline_textbbox(
- xy,
- text,
- font,
- anchor,
- spacing,
- align,
- direction,
- features,
- language,
- stroke_width,
- embedded_color,
- )
-
- if font is None:
- font = self.getfont()
- mode = "RGBA" if embedded_color else self.fontmode
- bbox = font.getbbox(
- text, mode, direction, features, language, stroke_width, anchor
- )
- return bbox[0] + xy[0], bbox[1] + xy[1], bbox[2] + xy[0], bbox[3] + xy[1]
-
- def multiline_textbbox(
- self,
- xy,
- text,
- font=None,
- anchor=None,
- spacing=4,
- align="left",
- direction=None,
- features=None,
- language=None,
- stroke_width=0,
- embedded_color=False,
- ):
- if direction == "ttb":
- msg = "ttb direction is unsupported for multiline text"
- raise ValueError(msg)
-
- if anchor is None:
- anchor = "la"
- elif len(anchor) != 2:
- msg = "anchor must be a 2 character string"
- raise ValueError(msg)
- elif anchor[1] in "tb":
- msg = "anchor not supported for multiline text"
- raise ValueError(msg)
-
- widths = []
- max_width = 0
- lines = self._multiline_split(text)
- line_spacing = self._multiline_spacing(font, spacing, stroke_width)
- for line in lines:
- line_width = self.textlength(
- line,
- font,
- direction=direction,
- features=features,
- language=language,
- embedded_color=embedded_color,
- )
- widths.append(line_width)
- max_width = max(max_width, line_width)
-
- top = xy[1]
- if anchor[1] == "m":
- top -= (len(lines) - 1) * line_spacing / 2.0
- elif anchor[1] == "d":
- top -= (len(lines) - 1) * line_spacing
-
- bbox = None
-
- for idx, line in enumerate(lines):
- left = xy[0]
- width_difference = max_width - widths[idx]
-
- # first align left by anchor
- if anchor[0] == "m":
- left -= width_difference / 2.0
- elif anchor[0] == "r":
- left -= width_difference
-
- # then align by align parameter
- if align == "left":
- pass
- elif align == "center":
- left += width_difference / 2.0
- elif align == "right":
- left += width_difference
- else:
- msg = 'align must be "left", "center" or "right"'
- raise ValueError(msg)
-
- bbox_line = self.textbbox(
- (left, top),
- line,
- font,
- anchor,
- direction=direction,
- features=features,
- language=language,
- stroke_width=stroke_width,
- embedded_color=embedded_color,
- )
- if bbox is None:
- bbox = bbox_line
- else:
- bbox = (
- min(bbox[0], bbox_line[0]),
- min(bbox[1], bbox_line[1]),
- max(bbox[2], bbox_line[2]),
- max(bbox[3], bbox_line[3]),
- )
-
- top += line_spacing
-
- if bbox is None:
- return xy[0], xy[1], xy[0], xy[1]
- return bbox
-
-
-def Draw(im, mode=None):
- """
- A simple 2D drawing interface for PIL images.
-
- :param im: The image to draw in.
- :param mode: Optional mode to use for color values. For RGB
- images, this argument can be RGB or RGBA (to blend the
- drawing into the image). For all other modes, this argument
- must be the same as the image mode. If omitted, the mode
- defaults to the mode of the image.
- """
- try:
- return im.getdraw(mode)
- except AttributeError:
- return ImageDraw(im, mode)
-
-
-# experimental access to the outline API
-try:
- Outline = Image.core.outline
-except AttributeError:
- Outline = None
-
-
-def getdraw(im=None, hints=None):
- """
- (Experimental) A more advanced 2D drawing interface for PIL images,
- based on the WCK interface.
-
- :param im: The image to draw in.
- :param hints: An optional list of hints.
- :returns: A (drawing context, drawing resource factory) tuple.
- """
- # FIXME: this needs more work!
- # FIXME: come up with a better 'hints' scheme.
- handler = None
- if not hints or "nicest" in hints:
- try:
- from . import _imagingagg as handler
- except ImportError:
- pass
- if handler is None:
- from . import ImageDraw2 as handler
- if im:
- im = handler.Draw(im)
- return im, handler
-
-
-def floodfill(image, xy, value, border=None, thresh=0):
- """
- (experimental) Fills a bounded region with a given color.
-
- :param image: Target image.
- :param xy: Seed position (a 2-item coordinate tuple). See
- :ref:`coordinate-system`.
- :param value: Fill color.
- :param border: Optional border value. If given, the region consists of
- pixels with a color different from the border color. If not given,
- the region consists of pixels having the same color as the seed
- pixel.
- :param thresh: Optional threshold value which specifies a maximum
- tolerable difference of a pixel value from the 'background' in
- order for it to be replaced. Useful for filling regions of
- non-homogeneous, but similar, colors.
- """
- # based on an implementation by Eric S. Raymond
- # amended by yo1995 @20180806
- pixel = image.load()
- x, y = xy
- try:
- background = pixel[x, y]
- if _color_diff(value, background) <= thresh:
- return # seed point already has fill color
- pixel[x, y] = value
- except (ValueError, IndexError):
- return # seed point outside image
- edge = {(x, y)}
- # use a set to keep record of current and previous edge pixels
- # to reduce memory consumption
- full_edge = set()
- while edge:
- new_edge = set()
- for x, y in edge: # 4 adjacent method
- for s, t in ((x + 1, y), (x - 1, y), (x, y + 1), (x, y - 1)):
- # If already processed, or if a coordinate is negative, skip
- if (s, t) in full_edge or s < 0 or t < 0:
- continue
- try:
- p = pixel[s, t]
- except (ValueError, IndexError):
- pass
- else:
- full_edge.add((s, t))
- if border is None:
- fill = _color_diff(p, background) <= thresh
- else:
- fill = p != value and p != border
- if fill:
- pixel[s, t] = value
- new_edge.add((s, t))
- full_edge = edge # discard pixels processed
- edge = new_edge
-
-
-def _compute_regular_polygon_vertices(bounding_circle, n_sides, rotation):
- """
- Generate a list of vertices for a 2D regular polygon.
-
- :param bounding_circle: The bounding circle is a tuple defined
- by a point and radius. The polygon is inscribed in this circle.
- (e.g. ``bounding_circle=(x, y, r)`` or ``((x, y), r)``)
- :param n_sides: Number of sides
- (e.g. ``n_sides=3`` for a triangle, ``6`` for a hexagon)
- :param rotation: Apply an arbitrary rotation to the polygon
- (e.g. ``rotation=90``, applies a 90 degree rotation)
- :return: List of regular polygon vertices
- (e.g. ``[(25, 50), (50, 50), (50, 25), (25, 25)]``)
-
- How are the vertices computed?
- 1. Compute the following variables
- - theta: Angle between the apothem & the nearest polygon vertex
- - side_length: Length of each polygon edge
- - centroid: Center of bounding circle (1st, 2nd elements of bounding_circle)
- - polygon_radius: Polygon radius (last element of bounding_circle)
- - angles: Location of each polygon vertex in polar grid
- (e.g. A square with 0 degree rotation => [225.0, 315.0, 45.0, 135.0])
-
- 2. For each angle in angles, get the polygon vertex at that angle
- The vertex is computed using the equation below.
- X= xcos(φ) + ysin(φ)
- Y= −xsin(φ) + ycos(φ)
-
- Note:
- φ = angle in degrees
- x = 0
- y = polygon_radius
-
- The formula above assumes rotation around the origin.
- In our case, we are rotating around the centroid.
- To account for this, we use the formula below
- X = xcos(φ) + ysin(φ) + centroid_x
- Y = −xsin(φ) + ycos(φ) + centroid_y
- """
- # 1. Error Handling
- # 1.1 Check `n_sides` has an appropriate value
- if not isinstance(n_sides, int):
- msg = "n_sides should be an int"
- raise TypeError(msg)
- if n_sides < 3:
- msg = "n_sides should be an int > 2"
- raise ValueError(msg)
-
- # 1.2 Check `bounding_circle` has an appropriate value
- if not isinstance(bounding_circle, (list, tuple)):
- msg = "bounding_circle should be a tuple"
- raise TypeError(msg)
-
- if len(bounding_circle) == 3:
- *centroid, polygon_radius = bounding_circle
- elif len(bounding_circle) == 2:
- centroid, polygon_radius = bounding_circle
- else:
- msg = (
- "bounding_circle should contain 2D coordinates "
- "and a radius (e.g. (x, y, r) or ((x, y), r) )"
- )
- raise ValueError(msg)
-
- if not all(isinstance(i, (int, float)) for i in (*centroid, polygon_radius)):
- msg = "bounding_circle should only contain numeric data"
- raise ValueError(msg)
-
- if not len(centroid) == 2:
- msg = "bounding_circle centre should contain 2D coordinates (e.g. (x, y))"
- raise ValueError(msg)
-
- if polygon_radius <= 0:
- msg = "bounding_circle radius should be > 0"
- raise ValueError(msg)
-
- # 1.3 Check `rotation` has an appropriate value
- if not isinstance(rotation, (int, float)):
- msg = "rotation should be an int or float"
- raise ValueError(msg)
-
- # 2. Define Helper Functions
- def _apply_rotation(point, degrees, centroid):
- return (
- round(
- point[0] * math.cos(math.radians(360 - degrees))
- - point[1] * math.sin(math.radians(360 - degrees))
- + centroid[0],
- 2,
- ),
- round(
- point[1] * math.cos(math.radians(360 - degrees))
- + point[0] * math.sin(math.radians(360 - degrees))
- + centroid[1],
- 2,
- ),
- )
-
- def _compute_polygon_vertex(centroid, polygon_radius, angle):
- start_point = [polygon_radius, 0]
- return _apply_rotation(start_point, angle, centroid)
-
- def _get_angles(n_sides, rotation):
- angles = []
- degrees = 360 / n_sides
- # Start with the bottom left polygon vertex
- current_angle = (270 - 0.5 * degrees) + rotation
- for _ in range(0, n_sides):
- angles.append(current_angle)
- current_angle += degrees
- if current_angle > 360:
- current_angle -= 360
- return angles
-
- # 3. Variable Declarations
- angles = _get_angles(n_sides, rotation)
-
- # 4. Compute Vertices
- return [
- _compute_polygon_vertex(centroid, polygon_radius, angle) for angle in angles
- ]
-
-
-def _color_diff(color1, color2):
- """
- Uses 1-norm distance to calculate difference between two values.
- """
- if isinstance(color2, tuple):
- return sum(abs(color1[i] - color2[i]) for i in range(0, len(color2)))
- else:
- return abs(color1 - color2)
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/certifi/core.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/certifi/core.py
deleted file mode 100644
index de028981b97e1fcc8ef4ab2c817cc8731b9c8738..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/certifi/core.py
+++ /dev/null
@@ -1,108 +0,0 @@
-"""
-certifi.py
-~~~~~~~~~~
-
-This module returns the installation location of cacert.pem or its contents.
-"""
-import sys
-
-
-if sys.version_info >= (3, 11):
-
- from importlib.resources import as_file, files
-
- _CACERT_CTX = None
- _CACERT_PATH = None
-
- def where() -> str:
- # This is slightly terrible, but we want to delay extracting the file
- # in cases where we're inside of a zipimport situation until someone
- # actually calls where(), but we don't want to re-extract the file
- # on every call of where(), so we'll do it once then store it in a
- # global variable.
- global _CACERT_CTX
- global _CACERT_PATH
- if _CACERT_PATH is None:
- # This is slightly janky, the importlib.resources API wants you to
- # manage the cleanup of this file, so it doesn't actually return a
- # path, it returns a context manager that will give you the path
- # when you enter it and will do any cleanup when you leave it. In
- # the common case of not needing a temporary file, it will just
- # return the file system location and the __exit__() is a no-op.
- #
- # We also have to hold onto the actual context manager, because
- # it will do the cleanup whenever it gets garbage collected, so
- # we will also store that at the global level as well.
- _CACERT_CTX = as_file(files("certifi").joinpath("cacert.pem"))
- _CACERT_PATH = str(_CACERT_CTX.__enter__())
-
- return _CACERT_PATH
-
- def contents() -> str:
- return files("certifi").joinpath("cacert.pem").read_text(encoding="ascii")
-
-elif sys.version_info >= (3, 7):
-
- from importlib.resources import path as get_path, read_text
-
- _CACERT_CTX = None
- _CACERT_PATH = None
-
- def where() -> str:
- # This is slightly terrible, but we want to delay extracting the
- # file in cases where we're inside of a zipimport situation until
- # someone actually calls where(), but we don't want to re-extract
- # the file on every call of where(), so we'll do it once then store
- # it in a global variable.
- global _CACERT_CTX
- global _CACERT_PATH
- if _CACERT_PATH is None:
- # This is slightly janky, the importlib.resources API wants you
- # to manage the cleanup of this file, so it doesn't actually
- # return a path, it returns a context manager that will give
- # you the path when you enter it and will do any cleanup when
- # you leave it. In the common case of not needing a temporary
- # file, it will just return the file system location and the
- # __exit__() is a no-op.
- #
- # We also have to hold onto the actual context manager, because
- # it will do the cleanup whenever it gets garbage collected, so
- # we will also store that at the global level as well.
- _CACERT_CTX = get_path("certifi", "cacert.pem")
- _CACERT_PATH = str(_CACERT_CTX.__enter__())
-
- return _CACERT_PATH
-
- def contents() -> str:
- return read_text("certifi", "cacert.pem", encoding="ascii")
-
-else:
- import os
- import types
- from typing import Union
-
- Package = Union[types.ModuleType, str]
- Resource = Union[str, "os.PathLike"]
-
- # This fallback will work for Python versions prior to 3.7 that lack the
- # importlib.resources module but relies on the existing `where` function
- # so won't address issues with environments like PyOxidizer that don't set
- # __file__ on modules.
- def read_text(
- package: Package,
- resource: Resource,
- encoding: str = 'utf-8',
- errors: str = 'strict'
- ) -> str:
- with open(where(), encoding=encoding) as data:
- return data.read()
-
- # If we don't have importlib.resources, then we will just do the old logic
- # of assuming we're on the filesystem and munge the path directly.
- def where() -> str:
- f = os.path.dirname(__file__)
-
- return os.path.join(f, "cacert.pem")
-
- def contents() -> str:
- return read_text("certifi", "cacert.pem", encoding="ascii")
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fastapi/middleware/cors.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fastapi/middleware/cors.py
deleted file mode 100644
index 8dfaad0dbb3ff5300cccb2023748cd30f54bc920..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fastapi/middleware/cors.py
+++ /dev/null
@@ -1 +0,0 @@
-from starlette.middleware.cors import CORSMiddleware as CORSMiddleware # noqa
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fontTools/misc/vector.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fontTools/misc/vector.py
deleted file mode 100644
index 81c1484188a46b567d8921d925f8a4700f65066f..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fontTools/misc/vector.py
+++ /dev/null
@@ -1,143 +0,0 @@
-from numbers import Number
-import math
-import operator
-import warnings
-
-
-__all__ = ["Vector"]
-
-
-class Vector(tuple):
-
- """A math-like vector.
-
- Represents an n-dimensional numeric vector. ``Vector`` objects support
- vector addition and subtraction, scalar multiplication and division,
- negation, rounding, and comparison tests.
- """
-
- __slots__ = ()
-
- def __new__(cls, values, keep=False):
- if keep is not False:
- warnings.warn(
- "the 'keep' argument has been deprecated",
- DeprecationWarning,
- )
- if type(values) == Vector:
- # No need to create a new object
- return values
- return super().__new__(cls, values)
-
- def __repr__(self):
- return f"{self.__class__.__name__}({super().__repr__()})"
-
- def _vectorOp(self, other, op):
- if isinstance(other, Vector):
- assert len(self) == len(other)
- return self.__class__(op(a, b) for a, b in zip(self, other))
- if isinstance(other, Number):
- return self.__class__(op(v, other) for v in self)
- raise NotImplementedError()
-
- def _scalarOp(self, other, op):
- if isinstance(other, Number):
- return self.__class__(op(v, other) for v in self)
- raise NotImplementedError()
-
- def _unaryOp(self, op):
- return self.__class__(op(v) for v in self)
-
- def __add__(self, other):
- return self._vectorOp(other, operator.add)
-
- __radd__ = __add__
-
- def __sub__(self, other):
- return self._vectorOp(other, operator.sub)
-
- def __rsub__(self, other):
- return self._vectorOp(other, _operator_rsub)
-
- def __mul__(self, other):
- return self._scalarOp(other, operator.mul)
-
- __rmul__ = __mul__
-
- def __truediv__(self, other):
- return self._scalarOp(other, operator.truediv)
-
- def __rtruediv__(self, other):
- return self._scalarOp(other, _operator_rtruediv)
-
- def __pos__(self):
- return self._unaryOp(operator.pos)
-
- def __neg__(self):
- return self._unaryOp(operator.neg)
-
- def __round__(self, *, round=round):
- return self._unaryOp(round)
-
- def __eq__(self, other):
- if isinstance(other, list):
- # bw compat Vector([1, 2, 3]) == [1, 2, 3]
- other = tuple(other)
- return super().__eq__(other)
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
- def __bool__(self):
- return any(self)
-
- __nonzero__ = __bool__
-
- def __abs__(self):
- return math.sqrt(sum(x * x for x in self))
-
- def length(self):
- """Return the length of the vector. Equivalent to abs(vector)."""
- return abs(self)
-
- def normalized(self):
- """Return the normalized vector of the vector."""
- return self / abs(self)
-
- def dot(self, other):
- """Performs vector dot product, returning the sum of
- ``a[0] * b[0], a[1] * b[1], ...``"""
- assert len(self) == len(other)
- return sum(a * b for a, b in zip(self, other))
-
- # Deprecated methods/properties
-
- def toInt(self):
- warnings.warn(
- "the 'toInt' method has been deprecated, use round(vector) instead",
- DeprecationWarning,
- )
- return self.__round__()
-
- @property
- def values(self):
- warnings.warn(
- "the 'values' attribute has been deprecated, use "
- "the vector object itself instead",
- DeprecationWarning,
- )
- return list(self)
-
- @values.setter
- def values(self, values):
- raise AttributeError(
- "can't set attribute, the 'values' attribute has been deprecated",
- )
-
-
-def _operator_rsub(a, b):
- return operator.sub(b, a)
-
-
-def _operator_rtruediv(a, b):
- return operator.truediv(b, a)
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-b64f4ef5.js b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-b64f4ef5.js
deleted file mode 100644
index 47cc34c075325deb306500f78dbad44e89df6af7..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-b64f4ef5.js
+++ /dev/null
@@ -1,2 +0,0 @@
-import{E as W,C as Y,L as d}from"./index-0c011c1e.js";import{s as n,t as r,L as R,i as Z,d as a,f as X,a as y,b as f}from"./index-90411bc1.js";import"./index-7c0e54a6.js";import"./Blocks-61158678.js";import"./Button-661a0701.js";import"./BlockLabel-95be8dd1.js";import"./Empty-96265974.js";/* empty css */import"./Copy-c4997e4e.js";import"./Download-e5de98da.js";const l=1,w=189,S=190,b=191,T=192,U=193,m=194,V=22,g=23,h=47,G=48,c=53,u=54,_=55,j=57,E=58,k=59,z=60,v=61,H=63,N=230,A=71,F=255,K=121,C=142,D=143,M=146,i=10,s=13,t=32,o=9,q=35,L=40,B=46,J=new Set([g,h,G,F,H,K,u,_,N,z,v,E,k,A,C,D,M]),OO=new W((O,$)=>{if(O.next<0)O.acceptToken(m);else if(!(O.next!=i&&O.next!=s))if($.context.depth<0)O.acceptToken(T,1);else{O.advance();let Q=0;for(;O.next==t||O.next==o;)O.advance(),Q++;let P=O.next==i||O.next==s||O.next==q;O.acceptToken(P?U:b,-Q)}},{contextual:!0,fallback:!0}),$O=new W((O,$)=>{let Q=$.context.depth;if(Q<0)return;let P=O.peek(-1);if((P==i||P==s)&&$.context.depth>=0){let e=0,x=0;for(;;){if(O.next==t)e++;else if(O.next==o)e+=8-e%8;else break;O.advance(),x++}e!=Q&&O.next!=i&&O.next!=s&&O.next!=q&&(e Download File ✪✪✪ https://bytlly.com/2uGwR1 Suppose you have a dataset of shapes. They can either be shaded or unshaded. They look something like this: You built a supervised machine learning classifier that will automatically classify each shape as shaded or unshaded. You call it the "Is-Shaded Classifier". Click "Run Classifier" to see how your model performs. It’s not perfect— some of the shapes are definitely misclassified. You want to improve your model! To do so, you want to know more about the kinds of mistakes your model is making. In training, you only gave your model the raw image of each shape and one ground truth label: shaded and unshaded. But maybe something about your model—the distribution of the training data you used, the architecture you chose, or how you set your hyperparameters—resulted in your model performing better on some shapes than others. In fact, you’ve seen a lot of papers and articles citing issues of biased model performance between circles, triangles, and rectangles in shape data. One paper finds that shape detection algorithms tend to do worse on triangles; another article says color accuracy is an issue with circles. So you wonder: are there biases in your model’s misclassifications? You want to make sure that your model is performing equally well across circles, triangles, and rectangles, so you decide to do a fairness analysis. There’s just one issue: you don’t have labels for which of your shapes are circles, triangles, or rectangles. So, you decide to send your data to data labelers. You receive feedback from your data labeling team that they’re not sure what to do with the shapes that aren’t exactly circles, triangles, or rectangles. For the shapes that are unclear, you can have them use their best guess or simply label them as “other”. Then, you can finally do some fairness analysis! Below is the interface they see: These shapes should be labeled... If you go back and change the labelers' instructions, which shapes do you perform worst on? Where do you find bias? You notice that your results hinge on how you choose to classify the shapes in our data. Because ultimately, this isn’t a world of only circles, triangles, and rectangles! What could we find out about our classifier's performance if we used different categories altogether? All shapes are basically... Everything else should be labeled... HD Online Player (Race 3 3 full movie download in hd 720p)
-
-Disclaimer:- Katmoviehd. com - Playing Dead – Hobbit man-child and his wiener dog Daily visitors: 534. ... 1 | H264 | MP4 | 720p | DVD | Bluray. in, Skymovies hd. ... 15-06-2018 · Race 3, 2018 Full Movie, Watch Online or Download HD Quality ... 1fdad05405
-
-
-
diff --git a/spaces/lllqqq/so-vits-svc-models-pcr/app.py b/spaces/lllqqq/so-vits-svc-models-pcr/app.py
deleted file mode 100644
index 0120cc47772d25900ee7a427538a957564357a54..0000000000000000000000000000000000000000
--- a/spaces/lllqqq/so-vits-svc-models-pcr/app.py
+++ /dev/null
@@ -1,375 +0,0 @@
-# -*- coding: utf-8 -*-
-import traceback
-import torch
-from scipy.io import wavfile
-import edge_tts
-import subprocess
-import gradio as gr
-import gradio.processing_utils as gr_pu
-import io
-import os
-import logging
-import time
-from pathlib import Path
-import re
-import json
-import argparse
-
-import librosa
-import matplotlib.pyplot as plt
-import numpy as np
-import soundfile
-
-from inference import infer_tool
-from inference import slicer
-from inference.infer_tool import Svc
-
-logging.getLogger('numba').setLevel(logging.WARNING)
-chunks_dict = infer_tool.read_temp("inference/chunks_temp.json")
-
-logging.getLogger('numba').setLevel(logging.WARNING)
-logging.getLogger('markdown_it').setLevel(logging.WARNING)
-logging.getLogger('urllib3').setLevel(logging.WARNING)
-logging.getLogger('matplotlib').setLevel(logging.WARNING)
-logging.getLogger('multipart').setLevel(logging.WARNING)
-
-model = None
-spk = None
-debug = False
-
-
-class HParams():
- def __init__(self, **kwargs):
- for k, v in kwargs.items():
- if type(v) == dict:
- v = HParams(**v)
- self[k] = v
-
- def keys(self):
- return self.__dict__.keys()
-
- def items(self):
- return self.__dict__.items()
-
- def values(self):
- return self.__dict__.values()
-
- def __len__(self):
- return len(self.__dict__)
-
- def __getitem__(self, key):
- return getattr(self, key)
-
- def __setitem__(self, key, value):
- return setattr(self, key, value)
-
- def __contains__(self, key):
- return key in self.__dict__
-
- def __repr__(self):
- return self.__dict__.__repr__()
-
-
-def get_hparams_from_file(config_path):
- with open(config_path, "r", encoding="utf-8") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- return hparams
-
-
-def vc_fn(sid, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold):
- try:
- if input_audio is None:
- raise gr.Error("你需要上传音频")
- if model is None:
- raise gr.Error("你需要指定模型")
- sampling_rate, audio = input_audio
- # print(audio.shape,sampling_rate)
- audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32)
- if len(audio.shape) > 1:
- audio = librosa.to_mono(audio.transpose(1, 0))
- temp_path = "temp.wav"
- soundfile.write(temp_path, audio, sampling_rate, format="wav")
- _audio = model.slice_inference(temp_path, sid, vc_transform, slice_db, cluster_ratio, auto_f0, noise_scale,
- pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold)
- model.clear_empty()
- os.remove(temp_path)
- # 构建保存文件的路径,并保存到results文件夹内
- try:
- timestamp = str(int(time.time()))
- filename = sid + "_" + timestamp + ".wav"
- # output_file = os.path.join("./results", filename)
- # soundfile.write(output_file, _audio, model.target_sample, format="wav")
- soundfile.write('/tmp/'+filename, _audio,
- model.target_sample, format="wav")
- # return f"推理成功,音频文件保存为results/{filename}", (model.target_sample, _audio)
- return f"推理成功,音频文件保存为{filename}", (model.target_sample, _audio)
- except Exception as e:
- if debug:
- traceback.print_exc()
- return f"文件保存失败,请手动保存", (model.target_sample, _audio)
- except Exception as e:
- if debug:
- traceback.print_exc()
- raise gr.Error(e)
-
-
-def tts_func(_text, _rate, _voice):
- # 使用edge-tts把文字转成音频
- # voice = "zh-CN-XiaoyiNeural"#女性,较高音
- # voice = "zh-CN-YunxiNeural"#男性
- voice = "zh-CN-YunxiNeural" # 男性
- if (_voice == "女"):
- voice = "zh-CN-XiaoyiNeural"
- output_file = "/tmp/"+_text[0:10]+".wav"
- # communicate = edge_tts.Communicate(_text, voice)
- # await communicate.save(output_file)
- if _rate >= 0:
- ratestr = "+{:.0%}".format(_rate)
- elif _rate < 0:
- ratestr = "{:.0%}".format(_rate) # 减号自带
-
- p = subprocess.Popen("edge-tts " +
- " --text "+_text +
- " --write-media "+output_file +
- " --voice "+voice +
- " --rate="+ratestr, shell=True,
- stdout=subprocess.PIPE,
- stdin=subprocess.PIPE)
- p.wait()
- return output_file
-
-
-def text_clear(text):
- return re.sub(r"[\n\,\(\) ]", "", text)
-
-
-def vc_fn2(sid, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, text2tts, tts_rate, tts_voice, f0_predictor, enhancer_adaptive_key, cr_threshold):
- # 使用edge-tts把文字转成音频
- text2tts = text_clear(text2tts)
- output_file = tts_func(text2tts, tts_rate, tts_voice)
-
- # 调整采样率
- sr2 = 44100
- wav, sr = librosa.load(output_file)
- wav2 = librosa.resample(wav, orig_sr=sr, target_sr=sr2)
- save_path2 = text2tts[0:10]+"_44k"+".wav"
- wavfile.write(save_path2, sr2,
- (wav2 * np.iinfo(np.int16).max).astype(np.int16)
- )
-
- # 读取音频
- sample_rate, data = gr_pu.audio_from_file(save_path2)
- vc_input = (sample_rate, data)
-
- a, b = vc_fn(sid, vc_input, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale,
- pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold)
- os.remove(output_file)
- os.remove(save_path2)
- return a, b
-
-
-models_info = [
- {
- "description": """
- 这个模型包含公主连结的161名角色。\n\n
- Space采用CPU推理,速度极慢,建议下载模型本地GPU推理。\n\n
- """,
- "model_path": "./G_228800.pth",
- "config_path": "./config.json",
- }
-]
-
-model_inferall = []
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--share", action="store_true",
- default=False, help="share gradio app")
- # 一定要设置的部分
- parser.add_argument('-cl', '--clip', type=float,
- default=0, help='音频强制切片,默认0为自动切片,单位为秒/s')
- parser.add_argument('-n', '--clean_names', type=str, nargs='+',
- default=["君の知らない物語-src.wav"], help='wav文件名列表,放在raw文件夹下')
- parser.add_argument('-t', '--trans', type=int, nargs='+',
- default=[0], help='音高调整,支持正负(半音)')
- parser.add_argument('-s', '--spk_list', type=str,
- nargs='+', default=['nen'], help='合成目标说话人名称')
-
- # 可选项部分
- parser.add_argument('-a', '--auto_predict_f0', action='store_true',
- default=False, help='语音转换自动预测音高,转换歌声时不要打开这个会严重跑调')
- parser.add_argument('-cm', '--cluster_model_path', type=str,
- default="logs/44k/kmeans_10000.pt", help='聚类模型路径,如果没有训练聚类则随便填')
- parser.add_argument('-cr', '--cluster_infer_ratio', type=float,
- default=0, help='聚类方案占比,范围0-1,若没有训练聚类模型则默认0即可')
- parser.add_argument('-lg', '--linear_gradient', type=float, default=0,
- help='两段音频切片的交叉淡入长度,如果强制切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值0,单位为秒')
- parser.add_argument('-f0p', '--f0_predictor', type=str, default="pm",
- help='选择F0预测器,可选择crepe,pm,dio,harvest,默认为pm(注意:crepe为原F0使用均值滤波器)')
- parser.add_argument('-eh', '--enhance', action='store_true', default=False,
- help='是否使用NSF_HIFIGAN增强器,该选项对部分训练集少的模型有一定的音质增强效果,但是对训练好的模型有反面效果,默认关闭')
- parser.add_argument('-shd', '--shallow_diffusion', action='store_true',
- default=False, help='是否使用浅层扩散,使用后可解决一部分电音问题,默认关闭,该选项打开时,NSF_HIFIGAN增强器将会被禁止')
-
- # 浅扩散设置
- parser.add_argument('-dm', '--diffusion_model_path', type=str,
- default="logs/44k/diffusion/model_0.pt", help='扩散模型路径')
- parser.add_argument('-dc', '--diffusion_config_path', type=str,
- default="logs/44k/diffusion/config.yaml", help='扩散模型配置文件路径')
- parser.add_argument('-ks', '--k_step', type=int,
- default=100, help='扩散步数,越大越接近扩散模型的结果,默认100')
- parser.add_argument('-od', '--only_diffusion', action='store_true',
- default=False, help='纯扩散模式,该模式不会加载sovits模型,以扩散模型推理')
-
- # 不用动的部分
- parser.add_argument('-sd', '--slice_db', type=int,
- default=-40, help='默认-40,嘈杂的音频可以-30,干声保留呼吸可以-50')
- parser.add_argument('-d', '--device', type=str,
- default=None, help='推理设备,None则为自动选择cpu和gpu')
- parser.add_argument('-ns', '--noice_scale', type=float,
- default=0.4, help='噪音级别,会影响咬字和音质,较为玄学')
- parser.add_argument('-p', '--pad_seconds', type=float, default=0.5,
- help='推理音频pad秒数,由于未知原因开头结尾会有异响,pad一小段静音段后就不会出现')
- parser.add_argument('-wf', '--wav_format', type=str,
- default='flac', help='音频输出格式')
- parser.add_argument('-lgr', '--linear_gradient_retain', type=float,
- default=0.75, help='自动音频切片后,需要舍弃每段切片的头尾。该参数设置交叉长度保留的比例,范围0-1,左开右闭')
- parser.add_argument('-eak', '--enhancer_adaptive_key',
- type=int, default=0, help='使增强器适应更高的音域(单位为半音数)|默认为0')
- parser.add_argument('-ft', '--f0_filter_threshold', type=float, default=0.05,
- help='F0过滤阈值,只有使用crepe时有效. 数值范围从0-1. 降低该值可减少跑调概率,但会增加哑音')
- args = parser.parse_args()
- categories = ["Princess Connect! Re:Dive"]
- others = {
- "PCR vits-fast-fineturning": "https://huggingface.co/spaces/FrankZxShen/vits-fast-finetuning-pcr",
- }
- for info in models_info:
- config_path = info['config_path']
- model_path = info['model_path']
- description = info['description']
- clean_names = args.clean_names
- trans = args.trans
- spk_list = list(get_hparams_from_file(config_path).spk.keys())
- slice_db = args.slice_db
- wav_format = args.wav_format
- auto_predict_f0 = args.auto_predict_f0
- cluster_infer_ratio = args.cluster_infer_ratio
- noice_scale = args.noice_scale
- pad_seconds = args.pad_seconds
- clip = args.clip
- lg = args.linear_gradient
- lgr = args.linear_gradient_retain
- f0p = args.f0_predictor
- enhance = args.enhance
- enhancer_adaptive_key = args.enhancer_adaptive_key
- cr_threshold = args.f0_filter_threshold
- diffusion_model_path = args.diffusion_model_path
- diffusion_config_path = args.diffusion_config_path
- k_step = args.k_step
- only_diffusion = args.only_diffusion
- shallow_diffusion = args.shallow_diffusion
-
- model = Svc(model_path, config_path, args.device, args.cluster_model_path, enhance,
- diffusion_model_path, diffusion_config_path, shallow_diffusion, only_diffusion)
-
- model_inferall.append((description, spk_list, model))
-
- app = gr.Blocks()
- with app:
- gr.Markdown(
- "# Click to Go
-
-  -
-
-Thinking About Bias
-
-


-
-
-
-
-
-Thinking About Classification
-
-
-
- - -With each of the different categories, which shapes do you perform worst on? Where do you find bias?
- -Each way of categorizing your shapes takes a different stance about what’s important . Each one makes some features more important than others, it make some distinctions visible and other distinctions invisible, and make some things easy to classify while others become outliers.
- -And each one tells you something different about what kind of bias your classifier has!
- -Here's another way to look at the same results. We can draw all the shapes that were correctly classified above the dashed line, and all the incorrectly classified shapes below it.
- - - -We're still looking at the same model making the same classification on the same shapes, so the same shapes stay above and below the line. But each way of grouping the results distributes the errors differently— each way tells you something different.
- -The decisions you make about classification, however small…
- -…begin to shape others’ decisions…
- -…they shape the analysis you can do…
- -…and they shape the kinds of conversations that happen.
- -It’s natural to want to find a way out of this problem by gathering more features or collecting more data. If we just have enough detail on enough data, surely we can avoid making these kinds of decisions, right?
- -Unfortunately, that isn’t the case. Describing the world around us in any way—whether we’re telling a friend a story or telling a computer about shapes—requires us to choose what information is important to convey and what tools we want to use to convey it.
- -Whether we think about it or not, we’re always making choices about classification. -
- -And as we saw with shapes, all of these choices make some features more important than others, make some distinctions visible and other distinctions invisible, and make some things easy to classify while others become outliers.
- -Let’s take a closer look at how this plays out in real machine learning applications. One straightforward example is in supervised object detection tasks.
- - -For example, let’s imagine we want to train an object detection model on a dataset including this image:
- -
We could give it the following ground truth bounding boxes:
- -
This looks objective, right? After all, a building is a building, a bush is a bush, and a mountain is a mountain!
-But even labeling the same regions in the same image, you can communicate a very different perspective:
- -
Or consider the image below, with several sets of “ground truth” labels. Looking at each of these labels, consider:
- -What features matter? What gets labeled? Whose worldview comes through? What might you learn from this set of labels that you wouldn't learn from another?
- -There is no “view from nowhere”, no universal way to organize every object, or word, or image. Datasets are always products of a particular time, place, and set of conditions; they are socially situated artifacts. They have histories; they have politics. And ignoring this fact has very real consequences.
- -So what do we do with this information?
- -A great place to start is to reflect on your own context and get curious about your data.
- -If it’s hard to see a dataset’s values—if it feels “objective”, “universal”, or “neutral”—it may simply be reflecting a worldview you’re accustomed to. So, understanding the limitations of your own worldview can tell you about the limitations of “objective” data. What assumptions do you make about the world? What feels like common sense? What feels foreign?
- -And do some sleuthing about your data! Who collected this data? Why was it collected? Who paid for it? Where did the “ground truth” come from?
- -You might even find yourself questioning what kinds of assumptions underpin machine learning dataset development or even thinking more deeply about classification as a whole.
- -If you find yourself with lots of questions, you're already off to a good start.
- - - - -Dylan Baker // January 2022
-Thanks to Adam Pearce, Alex Hanna, Emily Denton, Fernanda Viégas, Kevin Robinson, Nithum Thain, Razvan Amironesei, and Vinodkumar Prabhakaran for their help with this piece.
- - - - - - -ArcSoft PhotoStudio 6 is a powerful photo editing software that offers a range of advanced tools, filters and special effects. Whether you are a beginner or an advanced user, you can use PhotoStudio 6 to manage, enhance, print and get creative with your digital photos. To enjoy the full features of PhotoStudio 6, you need to register the software with a serial number.
-A serial number is a unique code that identifies your copy of PhotoStudio 6. You can obtain a serial number by purchasing the software from ArcSoft's official website or from authorized resellers. If you have bought the software as a bundle with a hardware device, you can find the serial number on the CD sleeve or on the device box.
-DOWNLOAD ✔ https://urlcod.com/2uIbxt
To register PhotoStudio 6 with a serial number, follow these steps:
-Once you have registered PhotoStudio 6, you will be able to access all the features and functions of the software. You will also receive valuable discounts and promotion information from ArcSoft. If you have any questions or problems with the registration process, you can contact ArcSoft's customer support via email or phone.
-PhotoStudio 6 is a great software for photo editing and creativity. With a serial number, you can unlock its full potential and enjoy your digital photos in new ways.
Here is a possible continuation of the article: - -PhotoStudio 6 has a user-friendly interface that allows you to easily access and apply various tools, filters and effects to your photos. You can use the toolbar on the left to select different modes, such as crop, rotate, resize, clone, red-eye removal and more. You can also use the menu bar on the top to access more options, such as file, edit, view, layer, enhance and create.
-One of the features of PhotoStudio 6 is the Face Beautify function, which lets you improve the appearance of faces in your photos. You can use this function to smooth skin, remove blemishes, whiten teeth, brighten eyes and apply makeup. To use this function, follow these steps:
-Another feature of PhotoStudio 6 is the Magic-Cut function, which lets you cut out objects from your photos and paste them onto another background. You can use this function to create fun and creative compositions with your photos. To use this function, follow these steps:
-PhotoStudio 6 has many more features and functions that you can explore and experiment with. You can also use PhotoStudio 6 to print your photos, share them online or create slideshows and collages. PhotoStudio 6 is a versatile and powerful photo editing software that can help you make the most of your digital photos.
- 7196e7f11aIf you are looking for a dynamic math and geometry software that can help you create and manipulate geometric figures, you might have heard of Cabri Geometry II Plus. This software is designed for students and teachers who want to explore math concepts in a simple and interactive way. But what if you don't want to pay for the official version of the software? You might be tempted to download a cracked version of the software, such as Cabri Geometry II Plus v1 4 2 Cracked NoPE. But is it worth it? In this article, we will review Cabri Geometry II Plus v1 4 2 Cracked NoPE, and compare it with the official version and other alternatives. We will also discuss the pros and cons of using cracked software, and answer some frequently asked questions.
-Cabri Geometry II Plus is a software developed by Cabrilog, a French company that specializes in creating educational software for mathematics. Cabri Geometry II Plus is an interactive notebook that allows users to create geometric and numerical constructions, such as transformations, measurements, calculus, tables, graphs, expressions, and equations. Users can also explore and make conjectures, reason and prove, solve problems, and self-evaluate using the software. Cabri Geometry II Plus is suitable for all secondary school level mathematics, and can also be used for other disciplines such as physics, technology, and applied arts.
-Download ✸✸✸ https://urlcod.com/2uIb12
Some of the features and benefits of Cabri Geometry II Plus are:
-To use Cabri Geometry II Plus, users must have a computer with the following minimum requirements:
-| PC | Mac |
|---|---|
| Cabri Geometry II Plus requires Win XP/Vista/7 or higher Recommended: 800Mhz or higher processor, 256MB RAM, OpenGL compatible graphics card with 64MB RAM or more | Mac Cabri Geometry II Plus requires Mac OS X 10.4 or higher Recommended: 800Mhz or higher processor, 256MB RAM, OpenGL compatible graphics card with 64MB RAM or more |
Cabri Geometry II Plus is compatible with the following browsers:
-A cracked software is a software that has been modified to bypass the security measures or license restrictions imposed by the original developer or publisher. Cracked software is usually distributed by hackers, crackers, or pirates who want to use the software for free or for malicious purposes. Cracked software can be found on various websites, forums, torrents, or peer-to-peer networks.
-Using cracked software may seem like a good way to save money and access premium features, but it comes with many risks and disadvantages, such as:
-Using cracked software is not only risky and disadvantageous, but also illegal and unethical. According to the U.S. Copyright Act of 1976, cracking a software is considered a form of infringement that can result in civil and criminal penalties. The penalties can range from $200 to $150,000 per work infringed for civil cases, and up to five years in prison and $250,000 in fines for criminal cases. Furthermore, using cracked software is also a violation of the End User License Agreement (EULA) that you agree to when you install the software. The EULA is a legal contract between you and the developer or publisher that specifies the terms and conditions of using the software. By using cracked software, you are breaking the contract and losing your rights as a legitimate user.
-Besides the legal issues, using cracked software is also unethical and immoral. It is a form of stealing that deprives the original developer or publisher of their rightful income and recognition. It also discourages them from creating more quality software in the future. Moreover, using cracked software is disrespectful to the hard work and creativity of the people who made the software. It also shows a lack of integrity and honesty on your part as a user.
-Cabri Geometry II Plus v1 4 2 Cracked NoPE is a cracked version of Cabri Geometry II Plus that was released by a group called NoPE (No Protection Ever) in 2007. This version claims to have removed the license verification and activation process of the official version, allowing users to use the software without paying for it. It also claims to have fixed some bugs and improved some features of the official version.
- -To download and install Cabri Geometry II Plus v1 4 2 Cracked NoPE, you need to follow these steps:
-Note: These steps are for informational purposes only. We do not recommend or endorse downloading or installing Cabri Geometry II Plus v1 4 2 Cracked NoPE, as it may be illegal, unethical, risky, or disadvantageous.
-To use Cabri Geometry II Plus v1 4 2 Cracked NoPE, you can follow these steps:
-Cabri Geometry II Plus v1 4 2 Cracked NoPE has some pros and cons that you should consider before using it. Here are some of them:
-Some of the advantages of Cabri Geometry II Plus v1 4 2 Cracked NoPE are:
-Some of the disadvantages of Cabri Geometry II Plus v1 4 2 Cracked NoPE are:
-If you are not satisfied with Cabri Geometry II Plus v1 4 2 Cracked NoPE, or you want to avoid the risks and disadvantages of using cracked software, you may want to consider some alternatives. Here are some of them:
-The best alternative to Cabri Geometry II Plus v1 4 2 Cracked NoPE is the official version of Cabri Geometry II Plus. This is the original and legitimate version of the software that is developed and published by Cabrilog. You can purchase it from their official website, or from authorized resellers or distributors. The official version of Cabri Geometry II Plus has the following advantages over the cracked version:
-The only disadvantage of the official version of Cabri Geometry II Plus is that it is not free. You have to pay for it, which may be a problem if you have a limited budget. However, you can consider it as an investment in your education or career, as it can help you learn and teach math concepts in a fun and effective way. You can also take advantage of discounts, promotions, or free trials that Cabrilog may offer from time to time.
-If you are looking for other geometry software that are similar to Cabri Geometry II Plus, you may want to check out some of these options:
-These are just some of the geometry software that you can use instead of Cabri Geometry II Plus v1 4 2 Cracked NoPE. You can also search for more options online, or ask for recommendations from your teachers or peers.
-In conclusion, Cabri Geometry II Plus v1 4 2 Cracked NoPE is a cracked version of Cabri Geometry II Plus that claims to offer the same features and benefits of the official version without the license verification and activation process. However, using cracked software is not only risky and disadvantageous, but also illegal and unethical. It may harm your computer, violate the intellectual property rights of the original developer or publisher, and show a lack of respect and honesty on your part as a user. Therefore, we do not recommend or endorse using Cabri Geometry II Plus v1 4 2 Cracked NoPE, or any other cracked software. Instead, we suggest that you use the official version of Cabri Geometry II Plus, or other geometry software that are similar to it. This way, you can enjoy the benefits of using quality software that is safe, secure, reliable, updated, supported, legal, ethical, and fair.
-Here are some frequently asked questions about Cabri Geometry II Plus v1 4 2 Cracked NoPE:
-I hope this article has been helpful and informative for you. If you have any questions or comments, please feel free to leave them below. Thank you for reading!
b2dd77e56bProgecad Architecture is a powerful CAD software that allows you to design and model buildings, interiors, landscapes, and more. If you have purchased or downloaded Progecad Architecture, you will need a serial number and a product key to activate it. In this article, we will show you how to find and activate your Progecad Architecture serial number in different scenarios.
-DOWNLOAD https://urlcod.com/2uIb7I
If you ordered your product from the online Autodesk Store, the serial number and product key are in the Fulfillment Notification email that you received after placing your order. You can also find them in your Autodesk Account by signing in and clicking the Management tab. In the Products & Services section, locate your product and expand the product details to see your serial number and product key[^1^].
-If you are a registered client of Progecad, you can access the Exclusive Support Area by inserting your serial number/support code in the field on the right of the progeCAD Support Portal[^2^]. There you can find updates, downloads, and other resources for your product. If you have lost or forgotten your serial number/support code, you can contact Progecad customer service for assistance.
-If you are a trial user of Progecad Architecture, you can access the Trial Support Area by clicking on the link "I don't have a serial number/support code" on the progeCAD Support Portal[^2^]. There you can find FAQs, tutorials, and other information to help you get started with your product. You can also request a free 30-day trial license by filling out a form on the progeCAD website.
-If you have the installation media (USB key, DVD, etc.) or download folder of Progecad Architecture, you can find your serial number and product key by navigating to the setup.exe file for your product. In that folder, look for a file with a name similar to MID.txt (for example, MID01.txt or MID02.txt). Open this file in a text editor (such as Notepad) and verify that the product name is what you expect it to be. Look for the part number. The first five characters of the part number are also the product key for that product[^3^].
-Once you have your serial number and product key, you can activate your Progecad Architecture by following these steps:
- -We hope this article has helped you find and activate your Progecad Architecture serial number. If you have any questions or issues, please contact Progecad customer support or visit their website for more information.
cec2833e83Sketchup Pro 2015 is a powerful 3D design software that allows you to create and build various models, such as buildings, landscapes, furniture, and more. It is easy to use and has many features that make it a popular choice among professionals and hobbyists alike. However, Sketchup Pro 2015 is not a free software, and you need to purchase a license to use it legally. If you want to try it out for free, you can download Sketchup Pro 2015 full crack from the internet. But be warned, downloading cracked software is illegal and risky, and you may face legal consequences or malware infections if you do so.
-Download Zip ☑ https://urlcod.com/2uIa1p
In this article, we will show you how to download Sketchup Pro 2015 full crack from a reliable source and how to install it on your Windows computer. We will also provide some tips on how to use Sketchup Pro 2015 effectively and safely. Please note that we do not condone or encourage piracy, and we are only providing this information for educational purposes. We recommend that you buy Sketchup Pro 2015 from the official website if you like it and want to support the developers.
-The first step is to download Sketchup Pro 2015 full crack from a trusted website. There are many websites that claim to offer Sketchup Pro 2015 full crack, but not all of them are safe or reliable. Some of them may contain viruses, spyware, or adware that can harm your computer or steal your personal information. Some of them may also provide fake or outdated files that do not work or cause errors.
-One of the websites that we found to be trustworthy and working is YASIR252.com. This website provides Sketchup Pro 2015 full crack for both 32-bit and 64-bit versions of Windows. It also provides detailed instructions on how to install and activate the software. You can download Sketchup Pro 2015 full crack from YASIR252.com by following these steps:
-The next step is to install Sketchup Pro 2015 full crack on your computer. Before you do that, make sure that you have turned off your antivirus software and disconnected your internet connection. This is because some antivirus programs may detect Sketchup Pro 2015 full crack as a threat and block or delete it. Also, disconnecting your internet connection will prevent Sketchup Pro 2015 from contacting its servers and verifying your license.
-To install Sketchup Pro 2015 full crack on your computer, follow these steps:
- -The final
cec2833e83DOWNLOAD 🔗 https://geags.com/2uCqQc
If you are looking for a way to add some flair and elegance to your wedding video, you might want to consider using After Effects templates. After Effects is a powerful software that allows you to create stunning motion graphics and visual effects for your videos. You can use it to create amazing wedding titles that will impress your clients and guests.
-But you don't have to be an expert in After Effects to create beautiful wedding titles. There are many free After Effects templates available online that you can download and customize for your own projects. These templates are professionally designed and easy to use. You just need to replace the text and images with your own, and you are ready to go.
-DOWNLOAD ❤ https://tinourl.com/2uL0Dc
In this article, we will show you some of the best free After Effects wedding templates that you can use for your wedding titles. We will also give you some tips on how to edit them and make them fit your style and theme.
-There are many websites that offer free After Effects templates for various purposes, such as intros, slideshows, logos, lower thirds, and more. However, not all of them are suitable for wedding videos. You need to find templates that have a romantic, elegant, and classy look that matches your wedding theme.
-One of the best websites that we recommend for finding free After Effects wedding templates is Theme Junkie. Theme Junkie is a platform that provides high-quality WordPress themes, plugins, fonts, graphics, and more. They also have a collection of over 45 free After Effects wedding templates that you can download and use for your projects.
-Some of the features of these templates are:
-To download these templates, you just need to visit their website and click on the download button. You will get a ZIP file that contains the template files and a readme file with instructions on how to use them.
-Once you have downloaded the template that you like, you need to unzip it and open it in After Effects. You will see a folder structure that contains the main composition and other assets such as images, videos, fonts, etc. You need to import these assets into your project panel if they are not already there.
- -To edit the template, you need to open the main composition and double-click on the text or image layers that you want to change. You can use the character panel and the align panel to adjust the font style, size, color, alignment, etc. You can also use the effects panel and the timeline panel to add or modify any animations or transitions.
-If you want to change the background or add your own footage, you can drag and drop your files into the project panel and replace the existing ones. You can also use masks, shapes, or solids to create different effects or overlays.
-After you have finished editing the template, you need to export it as a video file. You can do this by going to File > Export > Add to Render Queue. You can choose the format and settings that suit your needs. Then click on Render and wait for it to finish.
-Creating stunning wedding titles with free After Effects templates is a great way to save time and money while adding some flair and elegance to your wedding video. You can find many free After Effects wedding templates online that you can download and customize for your own projects.
-We hope this article has helped you learn how to use free After Effects wedding templates for your wedding titles. If you have any questions or suggestions, feel free to leave a comment below.
7b8c122e87Mathematics is a subject that requires a lot of practice and understanding. It can be challenging for some students to grasp the concepts and solve the problems. If you are one of those students who are looking for a reliable and comprehensive book for your ICSE Class 10 Mathematics exam preparation, then you have come to the right place. In this article, we will tell you how to download Concise Mathematics Class 10 PDF for free and what are the benefits of using this book.
-Concise Mathematics is a series of books published by Selina Publishers for ICSE students of classes 6 to 10. These books are designed to cover the ICSE syllabus and help students prepare for their exams. The books are written by expert authors who have years of experience in teaching and writing mathematics books.
-Download File ☑ https://tinourl.com/2uKZy1
Concise Mathematics is a book that explains the mathematical concepts in a simple and concise manner. The book covers all the topics that are prescribed by the ICSE board for Class 10 Mathematics. Some of the topics are:
-The book also includes solved examples, practice questions, exercises, revision tests, and model papers to help students master the subject.
-Concise Mathematics is a book that will help you in many ways. Here are some reasons why you should study Concise Mathematics:
-If you want to download Concise Mathematics Class 10 PDF for free, you can follow these simple steps:
-concise mathematics class 10 solutions pdf download
-concise mathematics class 10 icse pdf download
-concise mathematics class 10 textbook pdf download
-concise mathematics class 10 ebook pdf download
-concise mathematics class 10 guide pdf download
-concise mathematics class 10 cbse pdf download
-concise mathematics class 10 ncert pdf download
-concise mathematics class 10 rd sharma pdf download
-concise mathematics class 10 rs aggarwal pdf download
-concise mathematics class 10 ml aggarwal pdf download
-concise mathematics class 10 oswaal pdf download
-concise mathematics class 10 selina publishers pdf download
-concise mathematics class 10 free pdf download
-concise mathematics class 10 online pdf download
-concise mathematics class 10 latest edition pdf download
-concise mathematics class 10 revised edition pdf download
-concise mathematics class 10 sample papers pdf download
-concise mathematics class 10 question papers pdf download
-concise mathematics class 10 previous year papers pdf download
-concise mathematics class 10 model papers pdf download
-concise mathematics class 10 mock tests pdf download
-concise mathematics class 10 practice tests pdf download
-concise mathematics class 10 worksheets pdf download
-concise mathematics class 10 assignments pdf download
-concise mathematics class 10 projects pdf download
-concise mathematics class 10 notes pdf download
-concise mathematics class 10 formulae pdf download
-concise mathematics class 10 theorems pdf download
-concise mathematics class 10 examples pdf download
-concise mathematics class 10 exercises pdf download
-concise mathematics class 10 chapterwise pdf download
-concise mathematics class 10 unitwise pdf download
-concise mathematics class 10 topicwise pdf download
-concise mathematics class 10 syllabus pdf download
-concise mathematics class 10 curriculum pdf download
-concise mathematics class 10 exam pattern pdf download
-concise mathematics class 10 marking scheme pdf download
-concise mathematics class 10 grading system pdf download
-concise mathematics class 10 reference books pdf download
-concise mathematics class 10 supplementary books pdf download
-concise mathematics class 10 best books pdf download
-concise mathematics class 10 recommended books pdf download
-concise mathematics class 10 study material pdf download
-concise mathematics class 10 revision material pdf download
-concise mathematics class 10 learning material pdf download
-concise mathematics class 10 teaching material pdf download
-concise mathematics class 10 course material pdf download
-concise mathematics class 10 tips and tricks pdf download
-concise mathematics class 10 shortcuts and techniques pdf download
-concise mathematics class 10 hacks and secrets pdf download
The first step is to visit the official website of Selina Publishers, which is https://www.selina.com/. This is the best source to get the authentic and updated version of the book.
-The next step is to select the subject and class from the drop-down menu on the homepage. You need to select "Mathematics" as the subject and "Class 10" as the class.
-The third step is to choose the chapter that you want to download from the list of chapters displayed on the screen. You can also use the search bar to find the chapter by its name or number. Once you find the chapter, click on the download link below it.
-The final step is to save the PDF file on your device. You can choose a location where you want to save it, such as your desktop, downloads folder, or any other folder. You can also rename the file if you want. After saving it, you can open it with any PDF reader software or app.
-There are many benefits of using Concise Mathematics Class 10 PDF for your exam preparation. Some of them are:
-The book uses easy to understand language and concepts that make it suitable for all types of learners. The book explains each topic in a step-by-step manner with relevant examples and diagrams. The book also avoids unnecessary jargon and technical terms that might confuse or bore the students.
-The book provides ample practice questions and exercises at the end of each chapter. These questions are designed to test your knowledge and understanding of the topic. They also help you revise and reinforce what you have learned. The questions are based on different levels of difficulty and types of problems. The book also provides solutions for all the questions and exercises.
-The book provides chapter-wise summaries that give a quick overview of the important concepts and points discussed in each chapter. These summaries can be used by students during their revision or before their exams for quick preparation. The book also provides a glossary of important terms and concepts that helps students in understanding the subject matter better.
-In conclusion, Concise Mathematics Class 10 PDF is a great resource for ICSE students who want to ace their mathematics exam. The book covers all the topics as per the syllabus and provides clear explanations, examples, exercises, summaries, and glossary. The book can be downloaded for free from Selina Publishers' website by following some simple steps. The book can be accessed anytime and anywhere on any device with a PDF reader software or app.
-If you own a Dreambox satellite receiver that runs on Enigma2 operating system, you might be looking for a way to manage it over the network. In this article, we will introduce you to Dreambox Control Center (DCC) for Enigma2 - v 1.20 full version, a free software that allows you to control your Dreambox remotely from your computer. We will also show you how to install and use DCC, as well as how to troubleshoot some common issues that you might encounter.
-Dreambox Control Center (DCC) is a software program developed by BernyR that is intended exclusively for handling Dreambox satellite receivers over the network. It allows you to perform various tasks on your Dreambox, such as:
-Download File » https://tinourl.com/2uL1Wv
DCC supports both Enigma1 and Enigma2 operating systems, but in this article we will focus on the version for Enigma2, which is DCC-E2 v 1.20 full version. This version was released on May 12th, 2019 and it is compatible with Windows XP, Vista, 7, 8, and 10.
-DCC has a user-friendly interface that consists of four main tabs: FTP, Telnet, WebIf, and ScreenShot. Each tab has its own functions and options that we will explain in more detail later. Here are some of the main features of DCC:
-To install and use DCC for Enigma2, you need to have the following requirements:
-You can download DCC-E2 v 1.20 full version from this link: https://dreambox-control-center.soft....com/download/
-After downloading DCC-E2 v 1.20 full version from the link above, follow these steps to install and configure it:
-Once you have connected your computer and your Dreambox using DCC, you can use the four main tabs (FTP, Telnet, WebIf, and ScreenShot) to perform various tasks on your Dreambox. Here are some examples of what you can do with each tab:
-| Tab | Function | Option |
|---|---|---|
| FTP | Upload a new channel list to your Dreambox | Navigate to the folder where you have saved the channel list file on your computer (usually .xml or .tv format). Drag and drop it to the /etc/enigma2 folder on your Dreambox. Restart Enigma2 or reboot your Dreambox. |
| Telnet | Install a new plugin or skin on your Dreambox | Navigate to the folder where you have saved the plugin or skin file on your computer (usually .ipk or .tar.gz format). Drag and drop it to the /tmp folder on your Dreambox. Type in the command window: For .ipk files: opkg install /tmp/*.ipk For .tar.gz files: tar xzvf /tmp/*.tar.gz -C / box screen and display it in a new window. You can also save the screenshot on your computer by clicking on Save button. |
If you have trouble connecting your computer and your Dreambox using DCC, you might encounter one of these error messages:
-If you have trouble transferring files between your computer and your Dreambox using DCC, you might encounter one of these error messages:
-How to use Dreambox Control Center (DCC) for Enigma2
-Dreambox Control Center (DCC) for Enigma2 tutorial
-Dreambox Control Center (DCC) for Enigma2 download free
-Dreambox Control Center (DCC) for Enigma2 latest version
-Dreambox Control Center (DCC) for Enigma2 features and benefits
-Dreambox Control Center (DCC) for Enigma2 user reviews
-Dreambox Control Center (DCC) for Enigma2 alternatives and comparisons
-Dreambox Control Center (DCC) for Enigma2 troubleshooting and support
-Dreambox Control Center (DCC) for Enigma2 web interface and telnet
-Dreambox Control Center (DCC) for Enigma2 network and file management
-Dreambox Control Center (DCC) for Enigma2 scripts and plugins
-Dreambox Control Center (DCC) for Enigma2 hard disk and USB stick
-Dreambox Control Center (DCC) for Enigma2 login and password
-Dreambox Control Center (DCC) for Enigma2 system tools and settings
-Dreambox Control Center (DCC) for Enigma2 backup and restore
-Dreambox Control Center (DCC) for Enigma2 update and upgrade
-Dreambox Control Center (DCC) for Enigma2 installation and setup
-Dreambox Control Center (DCC) for Enigma2 compatibility and requirements
-Dreambox Control Center (DCC) for Enigma2 software informer and awards
-Dreambox Control Center (DCC) for Enigma2 soundcloud and audiobooks
-Best practices for using Dreambox Control Center (DCC) for Enigma2
-Tips and tricks for using Dreambox Control Center (DCC) for Enigma2
-Pros and cons of using Dreambox Control Center (DCC) for Enigma2
-How to optimize your performance with Dreambox Control Center (DCC) for Enigma2
-How to customize your interface with Dreambox Control Center (DCC) for Enigma2
-How to connect your devices with Dreambox Control Center (DCC) for Enigma2
-How to transfer files with Dreambox Control Center (DCC) for Enigma2
-How to edit scripts with Dreambox Control Center (DCC) for Enigma2
-How to install plugins with Dreambox Control Center (DCC) for Enigma2
-How to access web interface with Dreambox Control Center (DCC) for Enigma2
-How to use telnet with Dreambox Control Center (DCC) for Enigma2
-How to manage your network with Dreambox Control Center (DCC) for Enigma2
-How to handle your hard disk with Dreambox Control Center (DCC) for Enigma2
-How to use your USB stick with Dreambox Control Center (DCC) for Enigma2
-How to set your login and password with Dreambox Control Center (DCC) for Enigma2
-How to change your system settings with Dreambox Control Center (DCC) for Enigma2
-How to backup your data with Dreambox Control Center (DCC) for Enigma2
-How to restore your data with Dreambox Control Center (DCC) for Enigma2
-How to update your software with Dreambox Control Center (DCC) for Enigma2
-How to upgrade your software with Dreambox Control Center (DCC) for Enigma2
-How to install your software with Dreambox Control Center (DCC) for Enigma2
-How to setup your software with Dreambox Control Center (DCC) for Enigma2
-How to check your compatibility with Dreambox Control Center (DCC) for Enigma2
-How to check your requirements with Dreambox Control Center (DCC) for Enigma2
-How to get information from software informer with Dreambox Control Center (DCC) for Enigma2
-How to get awards from software informer with Dreambox Control Center (DCC) for Enigma2
-How to listen to soundcloud with Dreambox Control Center (DCC) for Enigma2
-How to listen to audiobooks with Dreambox Control Center (DCC) for Enigma2
If you have trouble executing scripts on your Dreambox using DCC, you might encounter one of these error messages:
-In this article, we have introduced you to Dreambox Control Center (DCC) for Enigma2 - v 1.20 full version, a free software that allows you to control your Dreambox remotely from your computer. We have also shown you how to install and use DCC, as well as how to troubleshoot some common issues that you might encounter. We hope you have found this article informative and engaging, and we encourage you to try out DCC for yourself and explore its features and functions.
-Enigma2 is an open source operating system that runs on Linux-based satellite receivers such as Dreambox. It allows users to customize their receivers with various plugins, skins, settings, and features.
-A DreamFlash image is a backup image of your Enigma2 system that can be stored on a hard disk, CF card, or USB stick on your Dreambox. You can switch between different images using DCC or other tools.
-A plugin is an add-on program that extends the functionality of Enigma2. There are many types of plugins available for Enigma2, such as media players, emulators, games, tools, etc.
-A skin is an add-on program that changes the appearance of Enigma2. There are many types of skins available for Enigma2, such as modern, classic, simple, colorful, etc.
-A bouquet is a collection of channels that are grouped together by genre, language, provider, etc. You can create and edit bouquets using DCC or other tools.
-Monopoly is one of the most popular and entertaining board games of all time. It is a game that involves buying, selling, and trading properties, building houses and hotels, and trying to bankrupt your opponents. Monopoly is a game that can be played by people of all ages and backgrounds, and it can provide hours of fun and excitement. But what if you want to play Monopoly on your PC? Is there a way to download Monopoly for free and play it on your computer? The answer is yes, there is. In this article, we will show you how to download freemonopolyfullversiondownloadforpc and enjoy the classic board game on your PC.
-Freemonopolyfullversiondownloadforpc is a digital version of the classic Monopoly board game that you can download and play on your PC. It is a game that features colorful graphics, animations, sound effects, and music that enhance the gameplay experience. Freemonopolyfullversiondownloadforpc also allows you to customize the game settings, such as the number of players, the difficulty level, the house rules, and the board theme. You can also play freemonopolyfullversiondownloadforpc online with your friends or other players from around the world.
-Download File ⇒ https://urlgoal.com/2uCKLE
If you want to download freemonopolyfullversiondownloadforpc, you can follow these steps:
-Playing freemonopolyfullversiondownloadforpc has many benefits, such as:
-Playing freemonopolyfullversiondownloadforpc also has some drawbacks, such as:
-In this article, we have shown you how to download freemonopolyfullversiondownloadforpc and enjoy the classic board game on your PC. We have also discussed some of the benefits and drawbacks of playing freemonopolyfullversiondownloadforpc. We hope you found this article helpful and informative. If you have any questions or comments, please feel free to leave them below. Thank you for reading!
-Playing freemonopolyfullversiondownloadforpc is very easy and fun. You can play it alone or with your friends online. Here are some basic steps on how to play freemonopolyfullversiondownloadforpc:
- -Playing freemonopolyfullversiondownloadforpc can be challenging and competitive. You need to have some skills and strategies to win the game. Here are some tips and tricks for playing freemonopolyfullversiondownloadforpc:
-If you want to play freemonopolyfullversiondownloadforpc online with other players, you can follow these steps:
-Freemonopolyfullversiondownloadforpc is a digital version of the original Monopoly board game that you can play on your PC. It has some differences from the original board game, such as:
-In this article, we have shown you how to download freemonopolyfullversiondownloadforpc and enjoy the classic board game on your PC. We have also discussed some of the benefits and drawbacks of playing freemonopolyfullversiondownloadforpc. We have also provided you with some tips and tricks on how to play freemonopolyfullversiondownloadforpc. We hope you found this article helpful and informative. If you have any questions or comments, please feel free to leave them below. Thank you for reading!
-After you download freemonopolyfullversiondownloadforpc, you need to install it on your PC. Here are some steps on how to install freemonopolyfullversiondownloadforpc:
-If you want to uninstall freemonopolyfullversiondownloadforpc, you can follow these steps:
-If you are looking for alternatives to freemonopolyfullversiondownloadforpc, you can consider some of these options:
-If you want to play freemonopolyfullversiondownloadforpc offline, you can follow these steps:
-If you want to update freemonopolyfullversiondownloadforpc, you can follow these steps:
-If you need help for freemonopolyfullversiondownloadforpc, you can contact some of these sources:
-In this article, we have shown you how to download and play freemonopolyfullversiondownloadforpc on your PC. We have also discussed some of the benefits and drawbacks of playing freemonopolyfullversiondownloadforpc. We have also provided you with some tips and tricks on how to play, install, update, and get help for freemonopolyfullversiondownloadforpc. We hope you found this article helpful and informative. If you have any questions or comments, please feel free to leave them below. Thank you for reading!
3cee63e6c2Stand and Deliver is a 1988 biographical drama film based on the true story of Jaime Escalante, a high school teacher who inspired his dropout-prone students to learn calculus. The film stars Edward James Olmos as Escalante, Lou Diamond Phillips as Angel, and Andy Garcia as Ramirez. The film was nominated for an Academy Award for Best Actor for Olmos and won six Independent Spirit Awards, including Best Feature and Best Director.
-If you want to watch Stand and Deliver online for free, you have several options. Here are some of the best ways to stream or download this inspiring movie:
-Download File ✶ https://urlgoal.com/2uCKg2
Stand and Deliver is a classic movie that showcases the power of education and perseverance. Whether you want to stream or download it online for free or pay for it, there are many options to choose from. Enjoy watching this inspiring film!
d5da3c52bfDOWNLOAD ✅ https://tinurll.com/2uznPx
Download ⚙⚙⚙ https://tinurll.com/2uzmJm
Download File ✸✸✸ https://tinurll.com/2uzm9o
Download File ○○○ https://tinurll.com/2uznNq
DOWNLOAD ✒ ✒ ✒ https://tinurll.com/2uzozE
the library’s history goes back over 300 years. the building dates from 1760, when it was designed as the town’s first library. it survived two fires and a great flood of 1927; today it is the only remaining royal library in the kingdom. the library has a rich collection of books on all these subject and will happily assist you with finding information for any of these.
-a collection is a collection of items of the same type or quality. thus, a collection of iron bits is called an iron collection. in the case of a library collection, each book is of the same type and is so collected. in the case of a collection of iron bits, each bit is of the same quality, and is so collected. a collection of iron and steel bits would therefore be a collection of iron and steel items, the former being a collection of the latter.
-Download File ✺✺✺ https://tinurll.com/2uzmuM
lost grimoires: stolen kingdom key features • hidden object puzzle game • unearth fascinating insights about the lost kingdom and its ancient secrets • become an alchemist to solve the mysteries of the lost kingdom • unlock a series of puzzles to discover and unearth the kingdom's past
-my name is qu'ran, i am a mujahid, a warrior of allah, one day i will come to you and i will lead you to the true path, to the path that goes straight to heaven. you are different now from the old one that lived as a man, every man, every woman should follow the path of the god qu'ran. you have a destiny that you must fulfill. this is the meaning of the'lost book."
-lost grimoires: stolen kingdom is a puzzle adventure game in which you play the role of a young alchemist who wishes to uncover the secrets of the kingdom's destiny. packed with colourful fantasy artwork and hidden objects becoming a master of alchemy is an aim of this adventure puzzle game.
- 899543212bDownload ★★★ https://gohhs.com/2uEzY7
Genshin Impact is a popular open-world action role-playing game that has attracted millions of players since its release in September 2020. The game features a vast fantasy world with beautiful graphics, engaging gameplay, and a rich story. However, downloading Genshin Impact can be a challenge for some players, as it requires a large amount of storage space and internet bandwidth. Depending on your device and connection speed, it can take several hours or even days to complete the download.
-Download ✒ ✒ ✒ https://ssurll.com/2uNWM5
Some players may wonder if they can download Genshin Impact in the background while doing other things on their devices, such as browsing the web, watching videos, or playing other games. In this article, we will answer this question and provide some tips on how to download Genshin Impact faster and safer on different platforms.
-To download Genshin Impact on PC, you need to visit the official website (https://genshin.mihoyo.com/en/download) and click on "Windows" to download the launcher. After installing the launcher, you need to run it and log in with your account. Then you can click on "Get Game" to start downloading Genshin Impact.
-If you want to pause or resume the download, you can click on "Pause" or "Resume" at any time. You can also cancel the download by clicking on "Cancel". However, this will delete all the downloaded files and you will have to start over.
-How to download Genshin Impact wallpapers for PC
-Genshin Impact download size and system requirements
-Can you play Genshin Impact while downloading updates
-Genshin Impact download speed slow or stuck fix
-How to pause and resume Genshin Impact download
-Best Genshin Impact wallpapers for iPhone and Android
-Genshin Impact download error code 9908 solution
-How to change Genshin Impact download server or region
-Genshin Impact download link for Windows, Mac, PS4, PS5, iOS, and Android
-How to download Genshin Impact on PC without launcher
-How to optimize Genshin Impact download settings
-Genshin Impact download time and installation guide
-How to download Genshin Impact beta version or test server
-How to fix Genshin Impact download failed or corrupted issue
-How to download Genshin Impact mods or custom skins
-How to increase Genshin Impact download speed using VPN
-How to download Genshin Impact on Steam or Epic Games Store
-How to download Genshin Impact characters or weapons wallpapers
-How to check Genshin Impact download progress or status
-How to download Genshin Impact on multiple devices or platforms
-How to download Genshin Impact official soundtrack or music
-How to fix Genshin Impact download verification failed error
-How to download Genshin Impact on laptop or low-end PC
-How to download Genshin Impact promotional or festive wallpapers
-How to download Genshin Impact fan art or concept art wallpapers
-How to stop or cancel Genshin Impact download or update
-How to download Genshin Impact voice over or language pack
-How to fix Genshin Impact download network error or timeout issue
-How to download Genshin Impact manga or comics online
-How to download Genshin Impact on Xbox One or Xbox Series X/S
-How to download Genshin Impact on Nintendo Switch or Switch Lite
-How to fix Genshin Impact download not starting or initializing problem
-How to download Genshin Impact live wallpaper or animated wallpaper
-How to fix Genshin Impact download disk space insufficient error
-How to download Genshin Impact 4K or HD wallpapers for desktop or laptop
To download Genshin Impact on mobile devices, you need to visit the App Store or Google Play Store and search for "Genshin Impact". Then you can tap on "Get" or "Install" to start downloading the game.
-If you want to pause or resume the download, you can tap on "Pause" or "Resume" at any time. You can also cancel the download by tapping on "Cancel". However, this will delete all the downloaded files and you will have to start over.
-To download Genshin Impact on PlayStation 4/5, you need to visit the PlayStation Store and search for "Genshin Impact". Then you can select "Download" to start downloading the game.
-If you want to pause or resume the download, you can go to the "Notifications" menu and select "Downloads". Then you can press the "X" button to pause or resume the download. You can also cancel the download by pressing the "Options" button and selecting "Cancel and Delete". However, this will delete all the downloaded files and you will have to start over.
-Genshin Impact can be downloaded in the background on PC by minimizing the launcher window. This will allow you to do other tasks on your PC while the game is downloading. However, you should be aware that downloading Genshin Impact in the background may slow down your PC performance and internet speed, depending on your system specifications and network conditions.
-To check the download progress, you can hover your mouse over the launcher icon on the taskbar. You will see a percentage and a speed indicator. You can also restore the launcher window by clicking on the icon.
-Genshin Impact can be downloaded in the background on mobile devices by switching to another app. This will allow you to do other things on your phone or tablet while the game is downloading. However, you should be aware that downloading Genshin Impact in the background may drain your battery life and use up your mobile data, depending on your device settings and network conditions.
-To check the download progress, you can swipe down from the top of your screen to access the notification panel. You will see a percentage and a speed indicator. You can also tap on the notification to resume or pause the download.
-Genshin Impact can be downloaded in the background on PlayStation 4/5 by putting the console in rest mode. This will allow you to save power and reduce noise while the game is downloading. However, you should be aware that downloading Genshin Impact in the background may take longer than usual, depending on your console settings and network conditions.
-To check the download progress, you can turn on your console and go to the "Notifications" menu. You will see a percentage and a speed indicator. You can also resume or pause the download from there.
-Downloading Genshin Impact in the background has some benefits that may appeal to some players, such as:
-Downloading Genshin Impact in the background also has some drawbacks that may discourage some players, such as:
-If you want to download Genshin Impact faster and safer, whether in the background or not, you can follow some of these tips:
-Genshin Impact is a great game that can provide hours of fun and adventure. However, downloading it can be a hassle for some players, especially if they have limited storage space or internet bandwidth. Fortunately, Genshin Impact can be downloaded in the background on different platforms, allowing players to do other things while waiting for the game to finish downloading.
-However, downloading Genshin Impact in the background also has some drawbacks, such as slowing down other tasks, draining battery life, and risking data loss. Therefore, players should weigh the pros and cons of downloading Genshin Impact in the background before deciding whether to do so or not.
-We hope this article has answered your question of whether Genshin Impact can be downloaded in the background, and provided some tips on how to download it faster and safer. If you have any thoughts or questions about this topic, feel free to share them in the comments section below. Happy gaming!
-Genshin Impact is about 30 GB on PC, 9 GB on mobile devices, and 12 GB on PlayStation 4/5. However, these sizes may vary depending on updates and patches.
-The download time of Genshin Impact depends on your device and connection speed. On average, it may take about 3 hours on PC, 1 hour on mobile devices, and 2 hours on PlayStation 4/5. However, these times may vary depending on network conditions and download settings.
-No, you cannot play Genshin Impact offline. You need an internet connection to access the game servers and play the game. You also need an internet connection to update the game and receive new content.
-Yes, you can play Genshin Impact with friends. You can invite up to three friends to join your world and explore together. You can also join other players' worlds and participate in co-op events and quests.
-Yes, you can transfer your Genshin Impact progress between platforms. You just need to log in with the same account on different devices or consoles. However, you cannot transfer your progress between different servers (such as Asia, Europe, America, etc.).
401be4b1e0Are you looking for some fun and exciting games to play on your PC without spending a dime? If so, you are in luck! There are plenty of free games for PC that you can download and enjoy online. Whether you are into racing, shooting, building, or exploring, there is a game for you. In this article, we will show you what are free games for PC, why you should play them, and how to download them. We will also give you some examples of the top free games for PC that you can try right now. Let's get started!
-Free games for PC are games that you can play on your computer without paying any money. They are usually available online, either on the official website of the game developer or publisher, or on a platform like Steam, Epic Games Store, or Microsoft Store. Some free games for PC are completely free, meaning that you can access all the features and content without any restrictions. Others are free-to-play, meaning that you can play the basic game for free, but you may need to pay for some optional items or upgrades.
-DOWNLOAD ⚹ https://ssurll.com/2uNZt7
There are many reasons why you might want to play free games for PC. Here are some of them:
-Downloading free games for PC is not difficult. You just need to follow these steps:
-Now that you know how to download free games for PC, let's take a look at some of the top free games for PC that you can play right now. We have selected three popular and high-quality games that cover different genres and styles.
-If you love racing games, then Asphalt 9: Legends is a must-try. This game lets you drive some of the most amazing and exotic cars in the world, such as Ferrari, Lamborghini, Porsche, and more. You can customize your cars, race against other players online, and perform stunning stunts and drifts. The game features stunning graphics, realistic physics, and a variety of tracks and modes.
-You can download Asphalt 9: Legends for free from the Microsoft Store. You will need Windows 10 or higher and at least 4 GB of RAM to play the game. The game also supports Xbox Live integration, so you can earn achievements and compete with your friends.
-If you are into building and creating games, then Roblox is the perfect game for you. Roblox is a platform where you can play millions of games created by other users, or create your own games using the Roblox Studio. You can also chat and socialize with other players, join groups, and customize your avatar. Roblox is a game for all ages and interests, as you can find games in genres like adventure, role-playing, simulation, horror, and more.
-You can download Roblox for free from the official website. You will need to create an account or sign in with an existing one to play the game. You can also download the Roblox Studio from the same website if you want to create your own games. Roblox is compatible with Windows 7 or higher and requires at least 1 GB of RAM.
-download free game for pc full version
-download free game for pc windows 10
-download free game for pc offline
-download free game for pc without internet
-download free game for pc action
-download free game for pc racing
-download free game for pc adventure
-download free game for pc horror
-download free game for pc shooting
-download free game for pc simulation
-download free game for pc strategy
-download free game for pc puzzle
-download free game for pc rpg
-download free game for pc sports
-download free game for pc hidden object
-download free game for pc gta 5
-download free game for pc minecraft
-download free game for pc pubg
-download free game for pc fortnite
-download free game for pc call of duty
-download free game for pc among us
-download free game for pc roblox
-download free game for pc spider man
-download free game for pc batman
-download free game for pc harry potter
-download free game for pc fifa 21
-download free game for pc pes 2021
-download free game for pc nba 2k21
-download free game for pc wwe 2k21
-download free game for pc nfs most wanted
-download free game for pc gta san andreas
-download free game for pc gta vice city
-download free game for pc assassin's creed
-download free game for pc far cry 5
-download free game for pc resident evil 2
-download free game for pc doom eternal
-download free game for pc cyberpunk 2077
-download free game for pc red dead redemption 2
-download free game for pc god of war 4
-download free game for pc halo infinite
-download free game for pc age of empires 4
-download free game for pc civilization 6
-download free game for pc sims 4
-download free game for pc zoo tycoon 2
-download free game for pc roller coaster tycoon 3
-download free game for pc plants vs zombies 2
-download free game for pc candy crush saga
-download free game for pc angry birds 2
-download free game for pc subway surfers
If you are a fan of shooting and survival games, then Fortnite is a game that you should not miss. Fortnite is a game that combines building, crafting, and combat in a colorful and cartoonish world. You can play solo or team up with your friends or other players online, and fight against zombies or other players in different modes. The most popular mode is Battle Royale, where 100 players compete to be the last one standing. Fortnite is constantly updated with new content, events, and features.
-You can download Fortnite for free from the Epic Games Store. You will need to create an account or sign in with an existing one to play the game. You will also need Windows 7 or higher and at least 4 GB of RAM to run the game. Fortnite also supports cross-play with other platforms, such as PlayStation, Xbox, Nintendo Switch, and mobile devices.
-As you can see, there are many free games for PC that you can download and play online. Whether you want to race, build, shoot, or explore, there is a game for you. All you need is a PC that meets the system requirements of the game, an internet connection, and a sense of adventure. So what are you waiting for? Download your favorite free game for PC today and have fun!
-If you are looking for a beautiful and inspiring song to enrich your soul, you might want to check out Ai Khodijah Ya Tarim. This is a cover version of a popular qasidah (a form of Islamic poetry) by a talented Indonesian singer named Ai Khodijah. In this article, we will tell you everything you need to know about this song, including its meaning, history, and how to download it legally and safely. Whether you are a fan of sholawat (a type of Islamic devotional music) or just curious about new musical genres, you will find something interesting and useful in this guide.
-Ai Khodijah is a young female singer from Indonesia who specializes in sholawat music. She was born in Jakarta in 1997 and started singing at the age of five. She joined a vocal group called El-Mighwar in 2015 and gained popularity through YouTube. She has released several albums and singles, such as Sholawat Nabi, Sholawat Merdu, Sholawat Terbaru, and Sholawat Penyejuk Hati. She is also known for her collaborations with other sholawat singers, such as Nissa Sabyan, Mohamed Tarek, Mohamed Youssef, Azmi Alkatiri, and Rizal Vertizone.
-Download File ✒ https://ssurll.com/2uNXvS
Sholawat is a genre of music that expresses love and praise for Allah (God) and His Messenger Muhammad (peace be upon him). It is derived from the Arabic word salawat, which means \"blessings\". Sholawat music usually consists of reciting or singing verses from the Quran (the holy book of Islam), hadith (the sayings and deeds of Muhammad), or qasidah. Sholawat music can be performed in various languages, such as Arabic, Indonesian, Malay, Urdu, Turkish, Persian, or English. Sholawat music can have different styles, such as traditional, modern, pop, rock, jazz, or rap. Sholawat music is popular among Muslims around the world, especially in Indonesia, Malaysia, Egypt, Morocco, Turkey, India, Pakistan, Bangladesh, and Nigeria.
-Ya Tarim is a song that praises the city of Tarim, which is located in the Hadhramaut region of Yemen. Tarim is known as the \"city of scholars\" because it has produced many eminent Islamic scholars, such as Imam al-Haddad, Imam al-Shafi'i, Imam al-Ghazali, and Imam al-Busiri. Tarim is also a center of Sufism, a mystical branch of Islam that emphasizes the inner and personal relationship with Allah. Tarim is considered a sacred and blessed place by many Muslims, especially those who follow the Ba 'Alawiyya tariqa (a Sufi order that originated from Tarim).
-The lyrics of Ya Tarim are in Arabic and Indonesian, and they express the longing and admiration for Tarim and its people. Here are the lyrics and their translation:
-| Arabic | -Indonesian | -English | -
|---|---|---|
| يا طريم يا طريم يا طريم | -Ya Tarim ya Tarim ya Tarim | -O Tarim, O Tarim, O Tarim | -
| يا مدينة العلماء والأولياء | -Ya madinatul ulama wal auliya | -O city of scholars and saints | -
| يا مدينة الحب والسلام والأنس | -Ya madinatul hubbi was salami wal uns | -O city of love, peace, and intimacy | -
| يا مدينة النور والهدى والرحمة | -Ya madinatun nur wal huda war rahmah | -O city of light, guidance, and mercy | -
| يا طريم يا طريم يا طريم | -Ya Tarim ya Tarim ya Tarim | -O Tarim, O Tarim, O Tarim | -
| كم أشتاق إليك يا طريم يا طريم | -Kam asytaqu ilaika ya Tarim ya Tarim | -How I miss you, O Tarim, O Tarim | -
| كم أحبك يا طريم يا طريم يا طريم | -Kam uhibbuka ya Tarim ya Tarim ya Tarim | -How I love you, O Tarim, O Tarim, O Tarim | -
| كم أنت جميل يا طريم يا طريم يا طريم | -Kam anta jamil ya Tarim ya Tarim ya Tarim | -How beautiful you are, O Tarim, O Tarim, O Tarim | -
| ... | ||
| The full lyrics can be found here. | ||
The author and original singer of Ya Tarim is unknown, but it is believed that it was composed by one of the Ba 'Alawiyya Sufis who lived in or visited Tarim. The song has been sung by many sholawat singers over the years, such as Habib Syech bin Abdul Qodir Assegaf, Habib Ali al-Habsyi, Habib Umar bin Hafidz, Habib Anis bin Alwi al-Habsyi, and Habib Ja'far bin Umar al-Jufri. The most recent and popular version of Ya Tarim is by Ai Khodijah, who released it in 2020.
-Download Ya Tarim by Ai Khodijah in Hi-Res quality
-Stream and download Ya Tarim by Ai Khodijah on Qobuz
-Download Mp3 Ai Khodijah - Ya Tarim gratis
-Download lagu Ai Khodijah - Ya Tarim terbaru
-Listen to Ya Tarim by Ai Khodijah online
-Download Ya Tarim by Ai Khodijah on iTunes
-Download and streaming Ya Tarim by Ai Khodijah in high quality
-Download lagu Ai Khodijah - Ya Tarim original
-Download Ya Tarim by Ai Khodijah for free
-Download Mp3 Ai Khodijah - Ya Tarim full album
-Download lagu Ai Khodijah - Ya Tarim mp3
-Download Ya Tarim by Ai Khodijah on Spotify
-Download and listen to Ya Tarim by Ai Khodijah offline
-Download lagu Ai Khodijah - Ya Tarim lirik
-Download Ya Tarim by Ai Khodijah on Amazon Music
-Download Mp3 Ai Khodijah - Ya Tarim 320kbps
-Download lagu Ai Khodijah - Ya Tarim cover
-Download Ya Tarim by Ai Khodijah on YouTube Music
-Download and share Ya Tarim by Ai Khodijah with friends
-Download lagu Ai Khodijah - Ya Tarim karaoke
The message of Ya Tarim is to inspire Muslims to seek knowledge and spirituality from the legacy of Tarim and its scholars. It also encourages Muslims to love and respect each other, regardless of their differences in ethnicity, culture, or sect. Ya Tarim is a song that celebrates the diversity and unity of the Muslim ummah (community).
-If you want to download Ai Khodijah Ya Tarim legally and safely, you have several options. You can either buy the song from an official online store, such as iTunes, Spotify, Amazon Music, or Google Play Music, or you can download it from YouTube using a third-party tool or website. However, you should be aware of the pros and cons of each option and follow some tips to avoid any problems.
-The best way to download Ai Khodijah Ya Tarim legally and safely is to buy it from an official online store. This way, you will support the artist and the music industry, and you will get a high-quality and virus-free MP3 file. You will also have access to other features, such as lyrics, album art, playlists, and offline listening. However, this option might cost you some money, depending on the store and the region. You will also need to create an account and install an app on your device to use this option.
-Another way to download Ai Khodijah Ya Tarim legally and safely is to use a third-party tool or website that allows you to convert YouTube videos into MP3 files. This way, you can get the song for free and without installing any app on your device. You can also choose the quality and format of the MP3 file according to your needs. However, this option might violate YouTube's terms of service and infringe on the artist's rights. You might also encounter some risks, such as malware, pop-ups, ads, or scams. You should be careful and selective when using this option.
-Once you have downloaded Ai Khodijah Ya Tarim, you can enjoy listening to it offline and online. However, there are some differences between the two modes of listening that you should be aware of. Here are some of the benefits and drawbacks of each mode:
-Listening to Ai Khodijah Ya Tarim offline means that you can play the song on your device without an internet connection. This can be convenient and cost-effective, especially if you have a limited or expensive data plan. You can also listen to the song anytime and anywhere, without worrying about buffering or interruptions. However, listening to the song offline also has some disadvantages, such as:
-Listening to Ai Khodijah Ya Tarim online means that you can stream the song on your device using an internet connection. This can be exciting and enjoyable, especially if you want to stay updated and connected with the song and its community. You can also explore new songs or artists that are recommended or suggested by the platform or the algorithm. However, listening to the song online also has some drawbacks, such as:
-If you enjoy listening to Ai Khodijah Ya Tarim, you might also like some of these other songs and artists that are similar or related to it:
-In conclusion, Ai Khodijah Ya Tarim is a wonderful and meaningful song that you should listen to if you love sholawat music or want to learn more about it. The song has a rich history and message that relates to Tarim, a city of scholars and saints in Yemen. You can download the song legally and safely from an official online store or from YouTube using a third-party tool or website. You can also enjoy the song offline and online, depending on your preferences and circumstances. We hope that this guide has helped you understand and appreciate Ai Khodijah Ya Tarim better. If you have any questions or feedback, please feel free to share them with us in the comments section below.
-Qasidah is a general term for Islamic poetry that can have various themes, such as praise, love, advice, or lament. Sholawat is a specific type of qasidah that focuses on praising Allah and His Messenger Muhammad (peace be upon him).
-Sufism is a branch of Islam that emphasizes the mystical and personal relationship with Allah. Sunni Islam is a branch of Islam that follows the teachings and traditions of Muhammad (peace be upon him) and his companions. Sufism and Sunni Islam are not mutually exclusive, and many Muslims follow both aspects of Islam.
-Tarim is a city in the Hadhramaut region of Yemen. Hadhramaut is a historical and geographical region that covers parts of Yemen, Saudi Arabia, and Oman. Hadhramaut is known for its natural beauty, cultural diversity, and Islamic heritage.
-MP3 and MP4 are two types of file formats that are used to store audio and video data. MP3 stands for MPEG-1 Audio Layer 3, and it is a compressed audio format that reduces the file size without losing much quality. MP4 stands for MPEG-4 Part 14, and it is a multimedia container format that can store audio, video, subtitles, images, and other data.
-VPN and proxy are two types of services that can help you access the internet anonymously and securely. VPN stands for virtual private network, and it creates a secure and encrypted connection between your device and a remote server. Proxy stands for proxy server, and it acts as an intermediary between your device and the internet. VPN and proxy can both hide your IP address and location, but VPN offers more features and protection than proxy.
197e85843dIf you are bored of the default villagers in Minecraft, you might want to try out the Minecraft Comes Alive mod. This mod replaces the villagers with human characters that have different personalities, skins, and abilities. You can interact with them, build relationships, get married, and even have children. In this article, we will show you how to download and install the Minecraft Comes Alive installer for your Minecraft version.
-Download File ★ https://cinurl.com/2uEXJi
Minecraft Comes Alive (MCA) is a popular mod that adds a new dimension to the game. It makes the villagers more realistic and immersive, giving them names, genders, professions, and traits. You can talk to them, give them gifts, hire them, trade with them, and more. You can also find your soulmate among the villagers, propose to them, and start a family. Your children will grow up over time and help you with various chores. You can even marry other players and have children in multiplayer mode.
- -The mod also adds some new features to the game, such as divorce papers, matchmaker's rings, baby boys and girls, tombstones, and more. You can customize the mod's settings to your liking, such as changing the villager skins, disabling aging, enabling infection, and so on. The mod is compatible with most other mods that do not overwrite the villagers.
- -The first step to install the Minecraft Comes Alive mod is to download the installer from a reliable source. One of the best places to download the mod is CurseForge, a website that hosts thousands of mods for various games. You can find the Minecraft Comes Alive installer on this page: https://www.curseforge.com/minecraft/mc-mods/minecraft-comes-alive-mca.
- -On this page, you will see a list of files for different versions of Minecraft. Choose the file that matches your Minecraft version and click on it. Then click on the download button to start downloading the installer. The file name should look something like this: minecraft-comes-alive-6.0.0-beta+1.12.2-universal.jar.
- -Once you have downloaded the Minecraft Comes Alive installer, you need to run it to install the mod. Before you do that, make sure you have installed Minecraft Forge on your computer. Minecraft Forge is a tool that allows you to run mods on Minecraft. You can download it from here: https://files.minecraftforge.net/.
- -After installing Minecraft Forge, follow these steps to install the Minecraft Comes Alive installer:
- - -Minecraft Comes Alive is a mod that adds more life and fun to your Minecraft world. It lets you interact with human villagers, get married, have children, and more. To install the mod, you need to download and run the Minecraft Comes Alive installer from CurseForge and have Minecraft Forge installed on your computer. We hope this article helped you learn how to download and install the Minecraft Comes Alive installer for your Minecraft version.
-After installing the Minecraft Comes Alive mod, you can start enjoying its features. To interact with a villager, you need to right-click on them. A menu will appear with different options, such as chat, follow, trade, gift, and more. You can also use special items to interact with villagers, such as the whistle, the divorce papers, the matchmaker's ring, and the baby boy or girl.
- -As you interact with villagers, you will build relationships with them. You can see your relationship level with a villager by hovering over their name in the menu. The higher your relationship level, the more options you will have with them. For example, you can ask them to marry you if your relationship level is high enough. You can also have children with your spouse by using a baby boy or girl item.
- -Your children will grow up over time and do different chores for you. You can assign them chores by right-clicking on them and choosing the chore option. You can also give them gifts, teach them skills, and tell them stories. Your children will eventually grow up into adults, who can get married and have children of their own.
- -If you want to uninstall the Minecraft Comes Alive mod, you need to follow these steps:
- -Minecraft Comes Alive is a mod that adds more life and fun to your Minecraft world. It lets you interact with human villagers, get married, have children, and more. To install the mod, you need to download and run the Minecraft Comes Alive installer from CurseForge and have Minecraft Forge installed on your computer. We hope this article helped you learn how to download, install, use, and uninstall the Minecraft Comes Alive installer for your Minecraft version.
-Once you have installed the Minecraft Comes Alive mod, you can start exploring its features. You will notice that the villagers are now human characters with different skins, genders, and personalities. You can interact with them by right-clicking on them and choosing an option from the menu. You can chat with them, compliment them, joke with them, flirt with them, and more. You can also give them gifts, such as flowers, diamonds, or cakes, to increase your relationship level with them.
- -As you interact with villagers, you will see their hearts change color depending on their mood and attitude towards you. The hearts can be green, yellow, orange, red, or black. Green means they are friendly, yellow means they are neutral, orange means they are unfriendly, red means they are hostile, and black means they are dead. You can also see their name, profession, trait, and relationship level by hovering over their name in the menu.
- -If you want to get married to a villager, you need to have a high relationship level with them and a matchmaker's ring. You can craft a matchmaker's ring with a diamond and a gold ingot. To propose to a villager, you need to right-click on them with the ring and choose the marry option. If they accept, you will see a message saying that you are now married. You can also marry other players in multiplayer mode by using the same method.
- -The Minecraft Comes Alive mod has many settings that you can customize to your liking. You can access the settings by pressing the MCA key on your keyboard (default is V). A menu will appear with different tabs, such as General Settings, Villager Settings, Family Settings, World Settings, and Server Settings. You can change various options in each tab, such as enabling or disabling aging, infection, story progression, villager skins, and more.
- -You can also customize your own character in the mod by using the editor screen. You can access the editor screen by pressing the MCA key on your keyboard (default is V) and choosing the editor option. A screen will appear with different options to change your appearance, such as your skin color, hair color, eye color, facial features, clothing style, and more. You can also change your name and gender in this screen.
- -The mod also has some commands that you can use to customize your experience. You can use these commands by typing them in the chat window (default is T). Some of the commands are /mca help (to see a list of all commands), /mca reset (to reset all MCA data), /mca revive (to revive a dead villager), /mca divorce (to divorce your spouse), /mca sethome (to set your home location), and more.
-Sometimes, you may encounter some issues when installing or using the Minecraft Comes Alive mod. Here are some common problems and solutions that may help you troubleshoot the mod:
- -The Minecraft Comes Alive mod is constantly being updated with new features, improvements, and bug fixes. To enjoy the latest version of the mod, you need to update it regularly. You can update the mod by following these steps:
- -Minecraft Comes Alive is a mod that adds more life and fun to your Minecraft world. It lets you interact with human villagers, get married, have children, and more. To install the mod, you need to download and run the Minecraft Comes Alive installer from CurseForge and have Minecraft Forge installed on your computer. We hope this article helped you learn how to download, install, use, update, and troubleshoot the Minecraft Comes Alive installer for your Minecraft version.
-Minecraft Comes Alive is a mod that adds more life and fun to your Minecraft world. It lets you interact with human villagers, get married, have children, and more. To install the mod, you need to download and run the Minecraft Comes Alive installer from CurseForge and have Minecraft Forge installed on your computer. We hope this article helped you learn how to download, install, use, update, and troubleshoot the Minecraft Comes Alive installer for your Minecraft version.
3cee63e6c2Download ⚹⚹⚹ https://bytlly.com/2uGlPN
DOWNLOAD ››››› https://bytlly.com/2uGjVO
DOWNLOAD ✵ https://bytlly.com/2uGiPj
If you are looking for a way to make money from the forex market without spending a fortune on expensive software, you might have heard of Forex Gump EA. This is a popular forex robot that claims to generate consistent profits with low risk and high accuracy. But what if you don't want to pay the hefty price tag of $199 for the original version? Is there a way to get Forex Gump EA cracked for free?
-The answer is yes, but you have to be careful. There are many websites that offer Forex Gump EA cracked versions for download, but most of them are scams or viruses that can harm your computer or steal your personal information. Some of them might even install malware that can hijack your trading account and make unauthorized trades with your money. That's why you should never download Forex Gump EA cracked from untrusted sources.
-Download File ===> https://urlcod.com/2uKaZd
However, there is one website that we have tested and verified to be safe and reliable. It is called Forex Gump EA Cracked, and it offers a fully functional and updated version of Forex Gump EA for free. You can download it from their official website and install it on your MT4 platform in minutes. You don't need any license key or activation code, and you can use it on any broker or account type.
-Forex Gump EA Cracked has all the features and benefits of the original version, such as:
-With Forex Gump EA Cracked, you can enjoy the same results as the original version, but without paying a dime. You can expect to make up to 50% profit per month with minimal effort and time. You can also join their community of traders who share their tips and experiences with Forex Gump EA Cracked.
-If you want to download Forex Gump EA Cracked for free, all you have to do is visit their website and follow the instructions. You will need to provide your name and email address to get access to the download link. You will also receive updates and support from their team in case you have any questions or issues.
-Don't miss this opportunity to get Forex Gump EA Cracked for free and start making money from the forex market today. Visit Forex Gump EA Cracked now and download your copy before it's too late.
- -Forex Gump EA is a fully automated forex trading system that uses a combination of technical and fundamental analysis to identify the best trading opportunities. It scans the market for trends, patterns, news events, and other factors that affect the price movements of the currency pairs. It then opens and closes trades based on its own logic and rules, without any human intervention.
- -Forex Gump EA has a built-in money management system that ensures your account is always protected from large losses. It uses a fixed lot size and a stop loss for every trade, and it also has a trailing stop and a break-even feature that lock in your profits and minimize your risk. Forex Gump EA can trade on any market condition, whether it is trending, ranging, or volatile. It can adapt to the changing market environment and adjust its strategy accordingly.
-Forex Gump EA is compatible with any MT4 broker and any account type, including ECN, STP, NDD, or micro accounts. It can run on any computer or VPS with a stable internet connection. It only requires a minimum deposit of $100 to start trading, but it is recommended to use a higher amount for better results. Forex Gump EA can trade on multiple currency pairs and timeframes simultaneously, but the most profitable ones are EURUSD, GBPUSD, USDJPY, and EURJPY on the M1 or M5 charts.
- -Forex Gump EA Cracked is a free version of Forex Gump EA that has been cracked by a team of hackers who wanted to share this amazing forex robot with the public. They have managed to bypass the security system of the original version and make it available for anyone to download and use without paying anything.
-Forex Gump EA Cracked has all the advantages of Forex Gump EA, such as:
-Forex Gump EA Cracked also has some additional advantages over the original version, such as:
-Forex Gump EA Cracked is the best way to get Forex Gump EA for free and enjoy its benefits without any hassle or cost. You can download it from their official website and start using it right away.
ddb901b051Are you looking for a reliable and comprehensive physics book for your preparation for competitive exams like JEE Main, JEE Advanced, NEET, etc.? If yes, then you might have heard of GC Agarwal Physics Book, one of the most popular and widely used physics books among students. But what is GC Agarwal Physics Book and how can you download it for free? In this article, we will answer these questions and more. We will also discuss the benefits and drawbacks of GC Agarwal Physics Book, as well as some alternatives that you can consider. So, without further ado, let's get started.
-DOWNLOAD ✵ https://urlcod.com/2uK88l
GC Agarwal Physics Book is a series of physics books written by Dr. G.C. Agarwal, a renowned physicist and educator. The series consists of six volumes, covering the topics of mechanics, waves and thermodynamics, electricity and magnetism, optics and modern physics, atomic and nuclear physics, and solid state physics. The books are designed to help students master the concepts and principles of physics and apply them to solve various problems.
-GC Agarwal Physics Book is popular among students because it offers several advantages over other physics books. Some of these advantages are:
-If you want to download GC Agarwal Physics Book for free, you have two options. One option is to search for the PDF files of the books on the internet. There are many websites that offer free downloads of GC Agarwal Physics Book PDFs. However, you should be careful while downloading from such websites, as they may contain viruses or malware that can harm your device or data. Also, some of the PDF files may be incomplete or corrupted.
-gc agarwal physics book pdf download
-gc agarwal physics book for class 11 free download
-gc agarwal physics book for class 12 free download
-gc agarwal physics book solutions free download
-gc agarwal physics book for neet free download
-gc agarwal physics book for jee free download
-gc agarwal physics book for iit free download
-gc agarwal physics book for cbse free download
-gc agarwal physics book for isc free download
-gc agarwal physics book for icse free download
-gc agarwal physics book for ncert free download
-gc agarwal physics book for olympiad free download
-gc agarwal physics book for aiims free download
-gc agarwal physics book for bitsat free download
-gc agarwal physics book for kvpy free download
-gc agarwal physics book for ntse free download
-gc agarwal physics book for eamcet free download
-gc agarwal physics book for wbjee free download
-gc agarwal physics book for comedk free download
-gc agarwal physics book for viteee free download
-gc agarwal physics book for upsee free download
-gc agarwal physics book for mht cet free download
-gc agarwal physics book for gujcet free download
-gc agarwal physics book for kcet free download
-gc agarwal physics book for ap eamcet free download
-gc agarwal physics book for ts eamcet free download
-gc agarwal physics book for jee main free download
-gc agarwal physics book for jee advanced free download
-gc agarwal physics book for jee mains and advanced free download
-gc agarwal physics book concepts of physics free download
-gc agarwal physics book fundamentals of physics free download
-gc agarwal physics book principles of physics free download
-gc agarwal physics book problems in general physics free download
-gc agarwal physics book objective questions in physics free download
-gc agarwal physics book numerical problems in physics free download
-gc agarwal physics book multiple choice questions in physics free download
-gc agarwal physics book theory and practice of physics free download
-how to get gc agarwal physics book for free online
-where to find gc agarwal physics book for free online
-best website to download gc agarwal physics book for free online
-best app to download gc agarwal physics book for free online
-best torrent to download gc agarwal physics book for free online
-best link to download gc agarwal physics book for free online
-best source to download gc agarwal physics book for free online
-best site to read gc agarwal physics book online for free
-best way to study from gc agarwal physics book online for free
-best method to learn from gc agarwal physics book online for free
-best tips to prepare from gc agarwal physics book online for free
-best tricks to crack from gc agarwal physics book online for free
-best hacks to master from gc agarwal physics book online for free
The other option is to use online platforms that provide access to GC Agarwal Physics Book eBooks. These platforms are more reliable and secure than the websites that offer free downloads. They also have features like bookmarking, highlighting, annotating, etc. that can enhance your reading experience. Some of the online platforms that provide access to GC Agarwal Physics Book eBooks are:
-| Name | -Link | -Price | -
|---|---|---|
| Vedantu | -https://www.vedantu.com/books/gc-agarwal-physics-book | -Free | -
| EduRev | -https://edurev.in/studytube/GC-Agarwal-Physics-Book--Class-11--Class-12--IIT-JE/4f6c0f7b-4d9d-4b0e-bf8e-5b0f7a8f9c5a_t | -Free | -
| Scribd | -https://www.scribd.com/search?query=gc+agarwal+physics+book | -$9.99 per month (after 30-day free trial) | -
| Amazon Kindle | -https://www.amazon.in/s?k=gc+agarwal+physics+book&rh=n%3A1634753031&ref=nb_sb_noss | -$2.99-$9.99 per book (depending on volume) | -
One of the main benefits of GC Agarwal Physics Book is that it covers all the topics that are relevant for competitive exams like JEE Main, JEE Advanced, NEET, etc. The books follow the latest syllabus and exam pattern prescribed by the National Testing Agency (NTA) and other exam conducting bodies. The books also cover some additional topics that are not included in the syllabus but are important for enhancing your knowledge and skills.
-Another benefit of GC Agarwal Physics Book is that it provides clear and concise explanations of the concepts and theories of physics. The books use simple and lucid language that can be easily understood by students of any level. The books also use diagrams, graphs, tables, etc. to illustrate the concepts and make them more visual and appealing. The books avoid unnecessary details and jargon that can confuse or bore the readers.
-A third benefit of GC Agarwal Physics Book is that it includes a large number of solved examples and exercises that can help you practice and master the topics. The books provide step-by-step solutions to the examples that can help you learn the methods and techniques of solving problems. The books also provide exercises at the end of each chapter that contain various types of questions such as objective type, subjective type, multiple choice type, assertion-reason type, etc. The exercises are graded according to their level of difficulty and complexity.
-A fourth benefit of GC Agarwal Physics Book is that it gives tips and tricks for solving problems quickly and accurately. The books provide shortcuts, formulas, rules, mnemonics, etc. that can help you save time and effort while solving problems. The books also provide hints and clues to some difficult or tricky questions that can help you overcome your doubts or difficulties.
-One of the main drawbacks of GC Agarwal Physics Book is that it has an outdated syllabus and content that does not match with the current trends and requirements of competitive exams like JEE Main, JEE Advanced, NEET, etc. The books were written several years ago when the syllabus and exam pattern were different from what they are now. The books do not include some new topics or concepts that have been introduced or modified in recent years.
-Another drawback of GC Agarwal Physics Book is that it lacks online support and resources that can enhance your learning experience. The books do not have any official website or app where you can access additional features or services such as video lectures, interactive quizzes, doubt clearing sessions, mock tests, etc. The books also do not provide any online solutions or answer keys to the exercises or questions. You have to rely on other sources or platforms to get these online support and resources.
-A third drawback of GC Agarwal Physics Book is that it contains some errors and mistakes in some solutions or answers. The books have not been revised or updated for a long time, so some of the solutions or answers may be incorrect or incomplete. This can create confusion or frustration among the students who use these books. You have to be careful while using these books and cross-check the solutions or answers with other sources or platforms.
-One of the best alternatives to GC Agarwal Physics Book is NCERT Physics Books. These are the official textbooks prescribed by the CBSE board for class 11 and 12 physics. These books are also recommended by the NTA for competitive exams like JEE Main, JEE Advanced, NEET, etc. These books have several advantages over GC Agarwal Physics Book such as:
-Another alternative to GC Agarwal Physics Book is HC Verma Concepts of Physics. This is a series of two physics books written by Dr. H.C. Verma, a famous physicist and author. These books cover the topics of mechanics, waves, thermodynamics, electricity, magnetism, optics, modern physics, etc. These books are also widely used by students for competitive exams like JEE Main, JEE Advanced, NEET, etc. These books have several advantages over GC Agarwal Physics Book such as:
-A third alternative to GC Agarwal Physics Book is DC Pandey Understanding Physics. This is a series of five physics books written by D.C. Pandey, a renowned physics teacher and author. These books cover the topics of mechanics, electricity and magnetism, waves and thermodynamics, optics and modern physics, etc. These books are also popular among students for competitive exams like JEE Main, JEE Advanced, NEET, etc. These books have several advantages over GC Agarwal Physics Book such as:
-In conclusion, GC Agarwal Physics Book is a series of physics books that can help you prepare for competitive exams like JEE Main, JEE Advanced, NEET, etc. The books have some benefits such as comprehensive coverage of topics, clear and concise explanations, solved examples and exercises, tips and tricks for solving problems, etc. However, the books also have some drawbacks such as outdated syllabus and content, lack of online support and resources, errors and mistakes in some solutions, etc. Therefore, you should consider some alternatives to GC Agarwal Physics Book such as NCERT Physics Books, HC Verma Concepts of Physics, DC Pandey Understanding Physics, etc. These alternatives can provide you with more updated and relevant content, online support and resources, variety and quality of questions, etc. You should choose the best physics book for yourself according to your needs and preferences.
-Here are some frequently asked questions about GC Agarwal Physics Book and its alternatives.
-No, GC Agarwal Physics Book is not enough for JEE Main and JEE Advanced. The book has an outdated syllabus and content that does not match with the current trends and requirements of these exams. You need to supplement GC Agarwal Physics Book with other books or sources that cover the new topics or concepts that are asked in these exams.
-Both HC Verma Concepts of Physics and DC Pandey Understanding Physics are good physics books for competitive exams like JEE Main and JEE Advanced. However, they have different strengths and weaknesses. HC Verma Concepts of Physics is better for building your concepts and understanding of physics. DC Pandey Understanding Physics is better for practicing your problem-solving skills and applying your concepts to different types of questions. You should use both books to get the best results.
-You can get the solutions to GC Agarwal Physics Book from various sources or platforms such as Vedantu, EduRev, etc. These sources or platforms provide online solutions or answer keys to the exercises or questions in GC Agarwal Physics Book. However, you should be careful while using these sources or platforms as they may contain some errors or mistakes in some solutions or answers. You should cross-check the solutions or answers with other sources or platforms.
-The best online platform to access GC Agarwal Physics Book eBooks depends on your preferences and budget. Some of the online platforms that provide access to GC Agarwal Physics Book eBooks are Vedantu, EduRev, Scribd, Amazon Kindle, etc. These platforms have different features and prices that can suit your needs. You should compare these platforms and choose the one that offers you the best value for money.
-The best alternative to GC Agarwal Physics Book depends on your level and goal. Some of the alternatives to GC Agarwal Physics Book are NCERT Physics Books, HC Verma Concepts of Physics, DC Pandey Understanding Physics, etc. These alternatives have different advantages and disadvantages that can suit your needs. You should evaluate these alternatives and choose the one that matches your level and goal.
-If you are looking for a powerful and versatile 3D modeling and animation software, you might want to check out 3ds Max 2022. This software is widely used by professionals and hobbyists alike for creating stunning graphics, games, movies, and more. But how can you get 3ds Max 2022 for free? In this article, we will show you how to download and install 3ds Max 2022 xforce free, a cracked version of the software that bypasses the activation process.
-Download File ⇒ https://urlcod.com/2uKajL
3ds Max 2022 xforce free is a modified version of the original 3ds Max 2022 software that uses a keygen or a patch to generate a valid serial number and product key for activation. By using this method, you can avoid paying for the subscription fee or the license cost of the software. However, you should be aware that using 3ds Max 2022 xforce free is illegal and risky. You might face legal consequences or damage your computer with malware or viruses. Therefore, we do not recommend or endorse using 3ds Max 2022 xforce free.
-If you still want to try 3ds Max 2022 xforce free at your own risk, here are the steps you need to follow:
-3ds Max 2022 is a great software for creating amazing 3D models and animations. However, it is not free and requires a valid license or subscription to use. If you want to use it for free, you might be tempted to use 3ds Max 2022 xforce free, a cracked version of the software that uses a keygen or a patch to activate it. However, this is illegal and risky, and we do not recommend it. Instead, you should consider using alternative software that are free and legal, such as Blender, SketchUp, or Maya LT.
- - -Once you have installed 3ds Max 2022 xforce free, you can start using it for your 3D projects. Here are some of the features and benefits of using 3ds Max 2022:
-These are just some of the features and benefits of using 3ds Max 2022 xforce free. However, you should also be aware of the drawbacks and risks of using a cracked software. You might encounter errors, bugs, crashes, or compatibility issues. You might also expose your computer to malware or viruses that could harm your data or system. Moreover, you might face legal consequences or penalties for violating the intellectual property rights of the software developer. Therefore, we advise you to use 3ds Max 2022 xforce free at your own discretion and responsibility.
ddb901b051Angry Birds Classic is one of the most popular and addictive mobile games ever created. It was released in 2009 by Rovio Entertainment and has since spawned several sequels, spin-offs, movies, and merchandise. The game involves using a slingshot to launch different types of birds at structures made of various materials, such as wood, glass, stone, and metal, where green pigs are hiding. The goal is to destroy all the pigs and collect stars, eggs, and other items along the way.
-The game features challenging physics-based gameplay and hundreds of levels across different episodes and themes. Each bird has its own unique ability that can be activated by tapping the screen while it is in flight. For example, the yellow bird can speed up, the black bird can explode, and the white bird can drop egg bombs. The game also offers power-ups, such as extra birds, mighty eagle, sling scope, king sling, and super seeds, that can enhance the birds' destructive power.
-Download ✵ https://bltlly.com/2uOmkv
However, not everyone can master the game easily. Some levels are very difficult to complete with three stars, some pigs are very hard to reach or kill, and some power-ups are very expensive to buy or use. That's why some players resort to using hacks for Angry Birds Classic. A hack is a modification or alteration of the game's code or data that gives the player an unfair advantage or changes the game's behavior in some way. For example, a hack can give unlimited birds, coins, power-ups, or stars; unlock all levels and episodes; remove ads; or disable obstacles.
-Using hacks can make the game more fun and easy for some players who want to enjoy the game without spending too much time or money on it. However, using hacks can also have some drawbacks and risks, such as ruining the game's balance and challenge; violating the game's terms of service and privacy policy; exposing the device to malware or viruses; or getting banned or detected by Rovio's anti-cheat system.
-If you still want to try using hacks for Angry Birds Classic, this article will guide you on how to download them for different devices: Android, iOS, and PC. Please note that this article is for educational purposes only and does not endorse or encourage hacking in any way. Use hacks at your own risk and discretion.
-If you have an Android device, such as a smartphone or tablet, you can follow these steps to download a hack for Angry Birds Classic:
-Some of the pros of using this hack are:
-Some of the cons of using this hack are:
-In this article, we have shown you how to download Angry Birds Classic hack for different devices: Android, iOS, and PC. We have also discussed some of the pros and cons of using hacks for this game. Using hacks can make the game more fun and easy for some players who want to enjoy the game without spending too much time or money on it. However, using hacks can also have some drawbacks and risks, such as ruining the game's balance and challenge; violating the game's terms of service and privacy policy; exposing the device to malware or viruses; or getting banned or detected by Rovio's anti-cheat system.
-If you decide to use hacks for Angry Birds Classic, here are some tips and tricks for playing the game with them:
-How to download angry birds classic hack for free
-Angry birds classic hack mod apk download
-Angry birds classic hack unlimited coins and gems
-Download angry birds classic hack for android
-Angry birds classic hack cheats tool online
-Angry birds classic hack no survey no password
-Angry birds classic hack version 5.0.1 download
-Angry birds classic hack game jolt[^1^]
-Angry birds classic hack ios download
-Angry birds classic hack pc download
-Angry birds classic hack without root or jailbreak
-Angry birds classic hack 2023 latest update
-Angry birds classic hack tips and tricks
-Angry birds classic hack gameplay video
-Angry birds classic hack review and rating
-Angry birds classic hack safe and secure download
-Angry birds classic hack features and benefits
-Angry birds classic hack support and feedback
-Angry birds classic hack compatible with all devices
-Angry birds classic hack easy and fast download
-Download angry birds classic hack from official website
-Angry birds classic hack direct download link
-Angry birds classic hack mirror download link
-Angry birds classic hack alternative download link
-Angry birds classic hack torrent download link
-Download angry birds classic hack from google play store
-Download angry birds classic hack from app store
-Download angry birds classic hack from amazon appstore
-Download angry birds classic hack from game jolt[^1^]
-Download angry birds classic hack from mediafire
-Download angry birds classic hack from mega.nz
-Download angry birds classic hack from zippyshare
-Download angry birds classic hack from dropbox
-Download angry birds classic hack from 4shared
-Download angry birds classic hack from file-upload.com
-Download angry birds classic hack from apk pure
-Download angry birds classic hack from apk mirror
-Download angry birds classic hack from apk monk
-Download angry birds classic hack from apk home
-Download angry birds classic hack from apk done
We hope that this article has been helpful and informative for you. If you have any questions or comments about Angry Birds Classic hack download, feel free to leave them below. Happy gaming!
-Some of the best hacks for Angry Birds Classic are:
-No, it is not legal to use hacks for Angry Birds Classic. Using hacks violates the game's terms of service and privacy policy, which prohibit modifying, altering, or interfering with the game's code or data. Using hacks can also be considered as cheating, which is illegal and unethical in most games and competitions. Using hacks can result in legal actions or penalties from Rovio, such as banning, suspending, or deleting your account or progress.
-Yes, using hacks will affect your game progress or achievements. Using hacks can make your game progress faster or easier, but it can also make it less meaningful or rewarding. Using hacks can also affect your game achievements, such as stars, eggs, trophies, or leaderboards. Using hacks can make your achievements easier to obtain, but it can also make them less valuable or credible. Using hacks can also affect your game sync, backup, or restore, as the game may not recognize or accept your hacked data.
-There is no sure way to avoid getting banned or detected by Rovio for using hacks. Rovio has a sophisticated anti-cheat system that can monitor and analyze your game activity and data. If Rovio finds any evidence or suspicion of hacking, they can ban or detect your account or device at any time. However, some possible ways to reduce the risk of getting banned or detected are:
-If you want to find more information and resources about Angry Birds Classic hacks, you can visit some of these websites:
-Driver San Francisco is a 2011 action-adventure racing game developed by Ubisoft Reflections and published by Ubisoft. The game features an innovative gameplay feature that allows players to seamlessly shift between over 130 licensed cars and explore a realistic recreation of San Francisco. The game also supports online multiplayer modes and a story mode that follows the protagonist John Tanner, a detective who can use his ability to shift into other drivers' bodies to stop a crime lord.
-Download File » https://urlcod.com/2uHx4t
If you want to download and play Driver San Francisco on your PC, you will need to use the Ubisoft Game Launcher, a free service that connects you with other Ubisoft players and games across all platforms. Here are the steps to follow:
-Note: You may need to adjust some compatibility settings for the game to run properly on your PC. For example, you may need to disable fullscreen optimization or run the game as an administrator. You can find more details on how to fix common issues on https://kosgames.com/driver-san-francisco-how-to-fix-game-not-launch-in-2021-play-online-1074/.
- -Driver San Francisco is a game that offers a unique and thrilling experience for racing fans and action lovers. The game has received positive reviews from critics and players alike, praising its innovative gameplay, diverse car selection, realistic graphics, and engaging story. The game also features a variety of challenges and activities to keep you entertained, such as races, stunts, dares, and missions. You can also customize your cars and unlock new ones as you progress through the game.
-If you want to play Driver San Francisco online with other players, you can join the Ubisoft Connect network and access various multiplayer modes. You can compete with up to seven other players in different modes, such as tag, trailblazer, takedown, and capture the flag. You can also team up with a friend in split-screen or online co-op mode and complete missions together. You can also use your shifting ability to help or hinder other players in online mode.
- -Driver San Francisco is a game that will keep you on the edge of your seat and make you feel like a real driver. If you are looking for a fun and exciting game to play on your PC, you should definitely give Driver San Francisco a try. You can download it from the Ubisoft Game Launcher and start your adventure in the city by the bay.
cec2833e83If you are looking for a powerful graphic design software that can help you create professional-looking logos and vector graphics, design direct-to-vinyl signs with multiple colors, text, and vector graphics, and offer a complete set of design, cutting, RIPing, and printing tools for maximum productivity, then you might want to check out Flexisign Pro 10.
-Flexisign Pro 10 is one of the best and the most useful Photoshop alternatives, which is a reliable and free image editing and vector graphic software. It combines the power of genuine Adobe® PostScript® 3 RIP engine, ICC profile support, and built-in direct drivers offering a complete set of design, cutting, RIPing, and printing tools for maximum productivity. It also includes vector graphics scheme enabling you to generate very advanced logos together with powerful web design. It offers full graphic design, text serialization, and color tracing features. It allows you to easily modify and design the vectors using a wide range of available resources to generate excellent vector graphics and logos.
-DOWNLOAD ->>->>->> https://urlcod.com/2uHw1L
However, Flexisign Pro 10 is not a free software. You need to purchase a license to use it legally. But what if you don't have enough money to buy it? Or what if you just want to try it out before buying it? Is there a way to get Flexisign Pro 10 for free?
-The answer is yes. There is a way to get Flexisign Pro 10 for free by using a keygen. A keygen is a software that can generate a serial number and an activation code for a software that you want to use. By using a keygen, you can bypass the license verification process and activate the software without paying anything.
-But is it legal to use a keygen? And where can you find a reliable and safe keygen for Flexisign Pro 10? How can you download and activate Flexisign Pro 10 with a keygen? And how can you use Flexisign Pro 10 for graphic design? In this article, we will answer all these questions and more. We will show you how to download and activate Flexisign Pro 10 with keygen 35, which is one of the most popular and working keygens for Flexisign Pro 10. We will also show you how to use Flexisign Pro 10 for graphic design and create stunning logos and vector graphics with ease.
- -Flexisign Pro 10 is a graphic design software that is specially designed for signs, banners, decals, stickers, vehicle wraps, and other types of graphics. It is developed by SA International (SAi), which is a leading provider of software solutions for the signmaking, digital printing, textile, and CNC machining industries. Flexisign Pro 10 is part of the SAi Flexi family of products, which also includes FlexiSIGN, FlexiPRINT, FlexiDESIGNER, and FlexiEXPERT.
-Flexisign Pro 10 has many features and benefits that make it one of the best graphic design software for signs. Some of them are:
-To run Flexisign Pro 10 smoothly on your computer, you need to meet the following system requirements:
-| Operating system | Windows 7/8/10 (32-bit or 64-bit) |
|---|---|
| CPU | Pentium IV or higher |
| RAM | 1 GB or higher |
| HDD | 4 GB or higher |
| Graphics card | Dedicated OpenGL 2.0 compatible with at least 256 MB memory |
| Monitor resolution | 1024 x 768 or higher |
| DVD drive | Required for installation |
| Internet connection | Required for activation and updates |
A keygen is a software that can generate a serial number and an activation code for another software that you want to use. A serial number is a unique identifier that is required to install and register a software. An activation code is a code that is required to activate a software and unlock its full features. A keygen can create these codes by using a specific algorithm that matches the one used by the original software developer.
-You need a keygen if you want to use a software without paying for it or without having a valid license. By using a keygen, you can bypass the license verification process and activate the software for free. This way, you can enjoy the full functionality of the software without any limitations or restrictions.
-A keygen is not the same as a crack. A crack is a software that modifies or patches another software to remove or disable its protection mechanisms, such as license verification, trial expiration, or online activation. A crack does not generate any codes, but rather alters the original software files to make it think that it is already activated or registered.
-The main difference between a keygen and a crack is that a keygen does not modify or damage the original software files, but rather creates new codes that can be used to activate the software. A keygen is usually safer and easier to use than a crack, as it does not require any changes to the system files or registry entries. However, both keygens and cracks are illegal and unethical, as they violate the intellectual property rights of the software developers and distributors.
-Using a keygen has some advantages and disadvantages that you should be aware of before deciding to use one. Some of the advantages are:
-Some of the disadvantages are:
-Download > https://urlcod.com/2uyVTx
Download File ————— https://urlcod.com/2uyXaF
 -
-







 -
-### 4. Visualize
-
-#### Comet Logging and Visualization 🌟 NEW
-
-[Comet](https://bit.ly/yolov5-readme-comet) is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://bit.ly/yolov5-colab-comet-panels)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
-
-Getting started is easy:
-
-```shell
-pip install comet_ml # 1. install
-export COMET_API_KEY=
-
-### 4. Visualize
-
-#### Comet Logging and Visualization 🌟 NEW
-
-[Comet](https://bit.ly/yolov5-readme-comet) is now fully integrated with YOLOv5. Track and visualize model metrics in real time, save your hyperparameters, datasets, and model checkpoints, and visualize your model predictions with [Comet Custom Panels](https://bit.ly/yolov5-colab-comet-panels)! Comet makes sure you never lose track of your work and makes it easy to share results and collaborate across teams of all sizes!
-
-Getting started is easy:
-
-```shell
-pip install comet_ml # 1. install
-export COMET_API_KEY=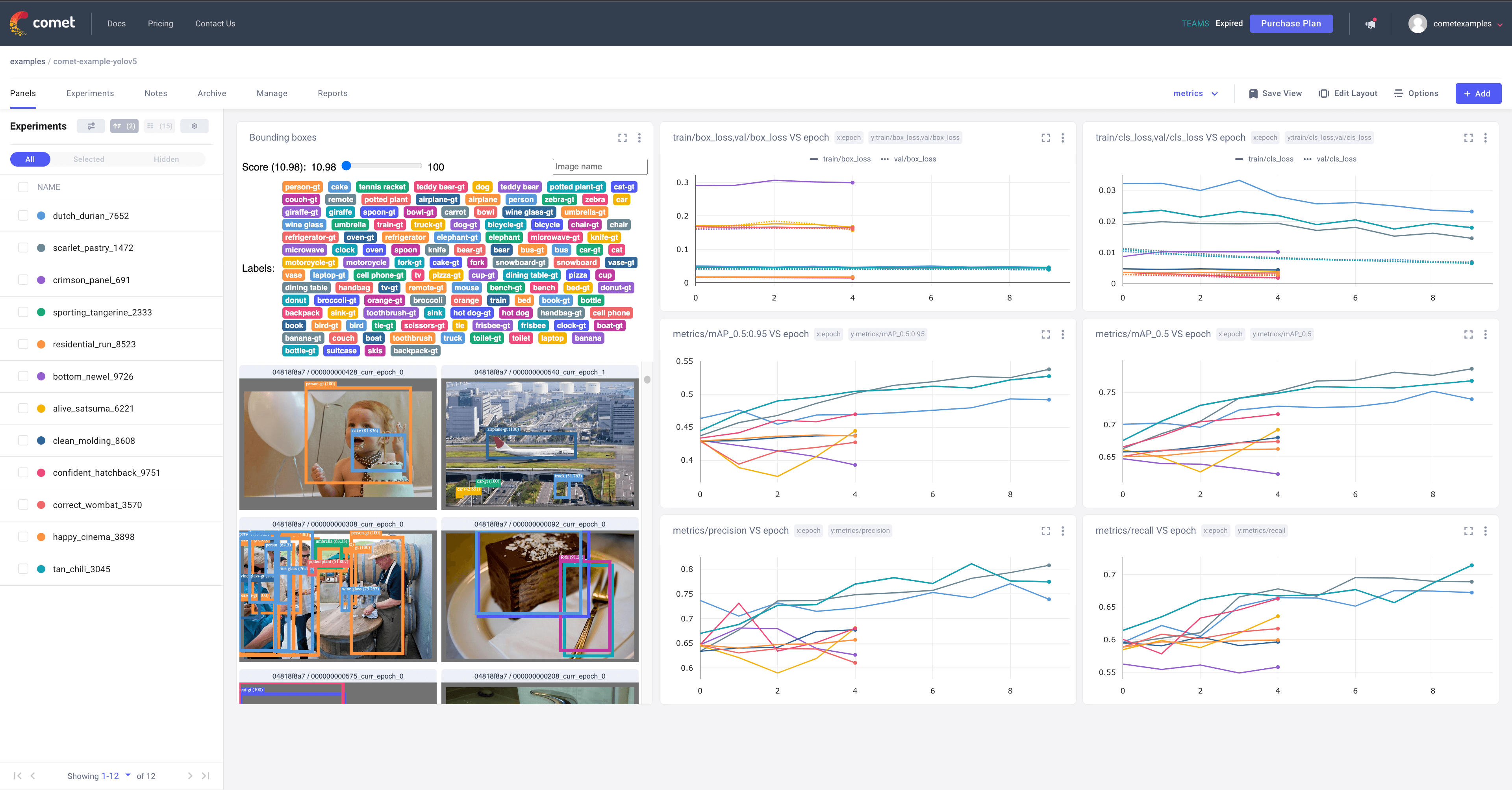 -
-#### ClearML Logging and Automation 🌟 NEW
-
-[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML:
-
-- `pip install clearml`
-- run `clearml-init` to connect to a ClearML server (**deploy your own open-source server [here](https://github.com/allegroai/clearml-server)**, or use our free hosted server [here](https://cutt.ly/yolov5-notebook-clearml))
-
-You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).
-
-You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!
-
-
-
-
-#### ClearML Logging and Automation 🌟 NEW
-
-[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML:
-
-- `pip install clearml`
-- run `clearml-init` to connect to a ClearML server (**deploy your own open-source server [here](https://github.com/allegroai/clearml-server)**, or use our free hosted server [here](https://cutt.ly/yolov5-notebook-clearml))
-
-You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).
-
-You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!
-
-
- -
-#### Local Logging
-
-Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.
-
-This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
-
-
-
-#### Local Logging
-
-Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.
-
-This directory contains train and val statistics, mosaics, labels, predictions and augmented mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices.
-
- -
-Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
-
-```python
-from utils.plots import plot_results
-
-plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
-```
-
-
-
-Results file `results.csv` is updated after each epoch, and then plotted as `results.png` (below) after training completes. You can also plot any `results.csv` file manually:
-
-```python
-from utils.plots import plot_results
-
-plot_results('path/to/results.csv') # plot 'results.csv' as 'results.png'
-```
-
-
-- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)
-- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)
-- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)  -
-## Status
-
-
-
-
-## Status
-
-
- -
-
-
-
$ python train.py --upload_data val
-
-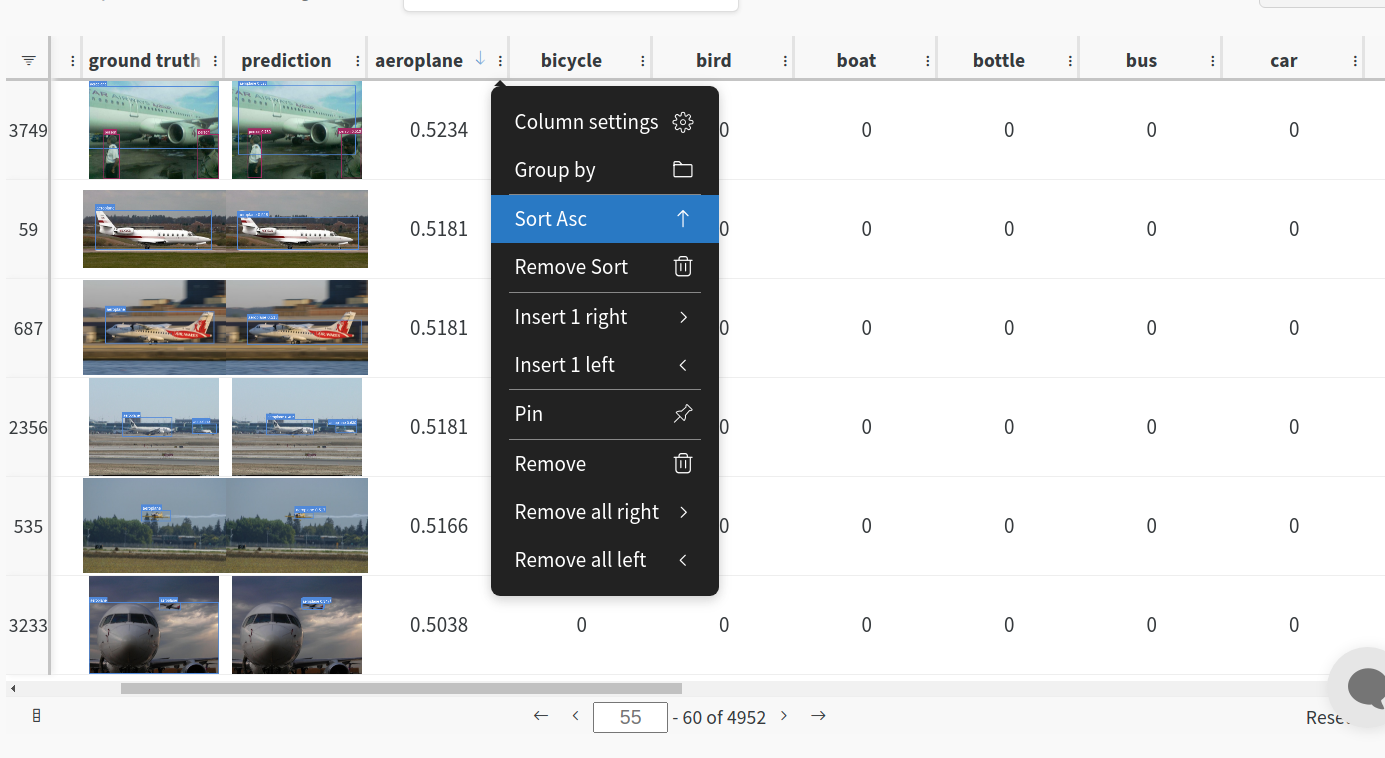
-
-{dataset}_wandb.yaml file which can be used to train from dataset artifact.
- $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data ..
-
-
-
- $ python train.py --data {data}_wandb.yaml
-
-
-
- $ python train.py --save_period 1
-
-
-
---resume argument starts with wandb-artifact:// prefix followed by the run path, i.e, wandb-artifact://username/project/runid . This doesn't require the model checkpoint to be present on the local system.
-
- $ python train.py --resume wandb-artifact://{run_path}
-
-
-
---upload_dataset or
- train from _wandb.yaml file and set --save_period
-
- $ python train.py --resume wandb-artifact://{run_path}
-
-
-
- -
-## Environments
-
-YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
-
-- **Google Colab and Kaggle** notebooks with free GPU:
-- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
-- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
-- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
-
-## Status
-
-
-
-If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/spaces/xikacat/xikacatbing/Dockerfile b/spaces/xikacat/xikacatbing/Dockerfile
deleted file mode 100644
index 3698c7cb7938e025afc53b18a571ae2961fbdffe..0000000000000000000000000000000000000000
--- a/spaces/xikacat/xikacatbing/Dockerfile
+++ /dev/null
@@ -1,34 +0,0 @@
-# Build Stage
-# 使用 golang:alpine 作为构建阶段的基础镜像
-FROM golang:alpine AS builder
-
-# 添加 git,以便之后能从GitHub克隆项目
-RUN apk --no-cache add git
-
-# 从 GitHub 克隆 go-proxy-bingai 项目到 /workspace/app 目录下
-RUN git clone https://github.com/Harry-zklcdc/go-proxy-bingai.git /workspace/app
-
-# 设置工作目录为之前克隆的项目目录
-WORKDIR /workspace/app
-
-# 编译 go 项目。-ldflags="-s -w" 是为了减少编译后的二进制大小
-RUN go build -ldflags="-s -w" -tags netgo -trimpath -o go-proxy-bingai main.go
-
-# Runtime Stage
-# 使用轻量级的 alpine 镜像作为运行时的基础镜像
-FROM alpine
-
-# 设置工作目录
-WORKDIR /workspace/app
-
-# 从构建阶段复制编译后的二进制文件到运行时镜像中
-COPY --from=builder /workspace/app/go-proxy-bingai .
-
-# 设置环境变量,此处为随机字符
-ENV Go_Proxy_BingAI_USER_TOKEN_1="kJs8hD92ncMzLaoQWYtX5rG6bE3fZ4iO"
-
-# 暴露8080端口
-EXPOSE 8080
-
-# 容器启动时运行的命令
-CMD ["/workspace/app/go-proxy-bingai"]
\ No newline at end of file
diff --git a/spaces/xswu/HPSv2/src/__init__.py b/spaces/xswu/HPSv2/src/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/xuwenhao83/simple_chatbot/app.py b/spaces/xuwenhao83/simple_chatbot/app.py
deleted file mode 100644
index 57dd8c74bd7c1e5441f3893bb63fcb04dcef4407..0000000000000000000000000000000000000000
--- a/spaces/xuwenhao83/simple_chatbot/app.py
+++ /dev/null
@@ -1,58 +0,0 @@
-import openai
-import os
-import gradio as gr
-
-openai.api_key = os.environ.get("OPENAI_API_KEY")
-
-class Conversation:
- def __init__(self, prompt, num_of_round):
- self.prompt = prompt
- self.num_of_round = num_of_round
- self.messages = []
- self.messages.append({"role": "system", "content": self.prompt})
-
- def ask(self, question):
- try:
- self.messages.append( {"role": "user", "content": question})
- response = openai.ChatCompletion.create(
- model="gpt-3.5-turbo",
- messages=self.messages,
- temperature=0.5,
- max_tokens=2048,
- top_p=1,
- )
- except Exception as e:
- print(e)
- return e
-
- message = response["choices"][0]["message"]["content"]
- self.messages.append({"role": "assistant", "content": message})
-
- if len(self.messages) > self.num_of_round*2 + 1:
- del self.messages[1:3]
- return message
-
-
-prompt = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
-1. 你的回答必须是中文
-2. 回答限制在100个字以内"""
-
-conv = Conversation(prompt, 5)
-
-def predict(input, history=[]):
- history.append(input)
- response = conv.ask(input)
- history.append(response)
- responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
- return responses, history
-
-with gr.Blocks(css="#chatbot{height:350px} .overflow-y-auto{height:500px}") as demo:
- chatbot = gr.Chatbot(elem_id="chatbot")
- state = gr.State([])
-
- with gr.Row():
- txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False)
-
- txt.submit(predict, [txt, state], [chatbot, state])
-
-demo.launch()
\ No newline at end of file
diff --git a/spaces/xxccc/gpt-academic/crazy_functions/test_project/cpp/cppipc/prod_cons.h b/spaces/xxccc/gpt-academic/crazy_functions/test_project/cpp/cppipc/prod_cons.h
deleted file mode 100644
index c9004bb8043a12e32814436baa6262a00c8ef68e..0000000000000000000000000000000000000000
--- a/spaces/xxccc/gpt-academic/crazy_functions/test_project/cpp/cppipc/prod_cons.h
+++ /dev/null
@@ -1,433 +0,0 @@
-#pragma once
-
-#include
-
-## Environments
-
-YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):
-
-- **Google Colab and Kaggle** notebooks with free GPU:
-- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart)
-- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart)
-- **Docker Image**. See [Docker Quickstart Guide](https://github.com/ultralytics/yolov5/wiki/Docker-Quickstart)
-
-## Status
-
-
-
-If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), validation ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.
diff --git a/spaces/xikacat/xikacatbing/Dockerfile b/spaces/xikacat/xikacatbing/Dockerfile
deleted file mode 100644
index 3698c7cb7938e025afc53b18a571ae2961fbdffe..0000000000000000000000000000000000000000
--- a/spaces/xikacat/xikacatbing/Dockerfile
+++ /dev/null
@@ -1,34 +0,0 @@
-# Build Stage
-# 使用 golang:alpine 作为构建阶段的基础镜像
-FROM golang:alpine AS builder
-
-# 添加 git,以便之后能从GitHub克隆项目
-RUN apk --no-cache add git
-
-# 从 GitHub 克隆 go-proxy-bingai 项目到 /workspace/app 目录下
-RUN git clone https://github.com/Harry-zklcdc/go-proxy-bingai.git /workspace/app
-
-# 设置工作目录为之前克隆的项目目录
-WORKDIR /workspace/app
-
-# 编译 go 项目。-ldflags="-s -w" 是为了减少编译后的二进制大小
-RUN go build -ldflags="-s -w" -tags netgo -trimpath -o go-proxy-bingai main.go
-
-# Runtime Stage
-# 使用轻量级的 alpine 镜像作为运行时的基础镜像
-FROM alpine
-
-# 设置工作目录
-WORKDIR /workspace/app
-
-# 从构建阶段复制编译后的二进制文件到运行时镜像中
-COPY --from=builder /workspace/app/go-proxy-bingai .
-
-# 设置环境变量,此处为随机字符
-ENV Go_Proxy_BingAI_USER_TOKEN_1="kJs8hD92ncMzLaoQWYtX5rG6bE3fZ4iO"
-
-# 暴露8080端口
-EXPOSE 8080
-
-# 容器启动时运行的命令
-CMD ["/workspace/app/go-proxy-bingai"]
\ No newline at end of file
diff --git a/spaces/xswu/HPSv2/src/__init__.py b/spaces/xswu/HPSv2/src/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/xuwenhao83/simple_chatbot/app.py b/spaces/xuwenhao83/simple_chatbot/app.py
deleted file mode 100644
index 57dd8c74bd7c1e5441f3893bb63fcb04dcef4407..0000000000000000000000000000000000000000
--- a/spaces/xuwenhao83/simple_chatbot/app.py
+++ /dev/null
@@ -1,58 +0,0 @@
-import openai
-import os
-import gradio as gr
-
-openai.api_key = os.environ.get("OPENAI_API_KEY")
-
-class Conversation:
- def __init__(self, prompt, num_of_round):
- self.prompt = prompt
- self.num_of_round = num_of_round
- self.messages = []
- self.messages.append({"role": "system", "content": self.prompt})
-
- def ask(self, question):
- try:
- self.messages.append( {"role": "user", "content": question})
- response = openai.ChatCompletion.create(
- model="gpt-3.5-turbo",
- messages=self.messages,
- temperature=0.5,
- max_tokens=2048,
- top_p=1,
- )
- except Exception as e:
- print(e)
- return e
-
- message = response["choices"][0]["message"]["content"]
- self.messages.append({"role": "assistant", "content": message})
-
- if len(self.messages) > self.num_of_round*2 + 1:
- del self.messages[1:3]
- return message
-
-
-prompt = """你是一个中国厨师,用中文回答做菜的问题。你的回答需要满足以下要求:
-1. 你的回答必须是中文
-2. 回答限制在100个字以内"""
-
-conv = Conversation(prompt, 5)
-
-def predict(input, history=[]):
- history.append(input)
- response = conv.ask(input)
- history.append(response)
- responses = [(u,b) for u,b in zip(history[::2], history[1::2])]
- return responses, history
-
-with gr.Blocks(css="#chatbot{height:350px} .overflow-y-auto{height:500px}") as demo:
- chatbot = gr.Chatbot(elem_id="chatbot")
- state = gr.State([])
-
- with gr.Row():
- txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter").style(container=False)
-
- txt.submit(predict, [txt, state], [chatbot, state])
-
-demo.launch()
\ No newline at end of file
diff --git a/spaces/xxccc/gpt-academic/crazy_functions/test_project/cpp/cppipc/prod_cons.h b/spaces/xxccc/gpt-academic/crazy_functions/test_project/cpp/cppipc/prod_cons.h
deleted file mode 100644
index c9004bb8043a12e32814436baa6262a00c8ef68e..0000000000000000000000000000000000000000
--- a/spaces/xxccc/gpt-academic/crazy_functions/test_project/cpp/cppipc/prod_cons.h
+++ /dev/null
@@ -1,433 +0,0 @@
-#pragma once
-
-#include  -
- -
- -
- -
- -
- -
-- -【Passaggio facoltativo】 Se si desidera supportare ChatGLM di Tsinghua/MOSS di Fudan come backend, è necessario installare ulteriori dipendenze (prerequisiti: conoscenza di Python, esperienza con Pytorch e computer sufficientemente potente): -```sh -# 【Passaggio facoltativo I】 Supporto a ChatGLM di Tsinghua. Note su ChatGLM di Tsinghua: in caso di errore "Call ChatGLM fail 不能正常加载ChatGLM的参数" , fare quanto segue: 1. Per impostazione predefinita, viene installata la versione di torch + cpu; per usare CUDA, è necessario disinstallare torch e installare nuovamente torch + cuda; 2. Se non è possibile caricare il modello a causa di una configurazione insufficiente del computer, è possibile modificare la precisione del modello in request_llm/bridge_chatglm.py, cambiando AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) in AutoTokenizer.from_pretrained("THUDM/chatglm-6b-int4", trust_remote_code=True) -python -m pip install -r request_llm/requirements_chatglm.txt - -# 【Passaggio facoltativo II】 Supporto a MOSS di Fudan -python -m pip install -r request_llm/requirements_moss.txt -git clone https://github.com/OpenLMLab/MOSS.git request_llm/moss # Si prega di notare che quando si esegue questa riga di codice, si deve essere nella directory radice del progetto - -# 【Passaggio facoltativo III】 Assicurati che il file di configurazione config.py includa tutti i modelli desiderati, al momento tutti i modelli supportati sono i seguenti (i modelli della serie jittorllms attualmente supportano solo la soluzione docker): -AVAIL_LLM_MODELS = ["gpt-3.5-turbo", "api2d-gpt-3.5-turbo", "gpt-4", "api2d-gpt-4", "chatglm", "newbing", "moss"] # + ["jittorllms_rwkv", "jittorllms_pangualpha", "jittorllms_llama"] -``` - -
- -
- -
- -
- -
- -
- -
- -
- -
-
-
- -
- -
- -
- DefensiveDrops a banana peel behind the car that makes opponents slip and spin out.1: Single peel.
DefensiveDrops a banana peel behind the car that makes opponents slip and spin out.1: Single peel. Offensive
-
Offensive
- OffensiveFires a firework that flies in a random direction and explodes on impact.1: Single firework.
OffensiveFires a firework that flies in a random direction and explodes on impact.1: Single firework. DefensiveCreates a shield of coins around the car that protects it from damage and power-ups.1: Small shield.
DefensiveCreates a shield of coins around the car that protects it from damage and power-ups.1: Small shield. Offensive
-
Offensive
-


 -
- -
-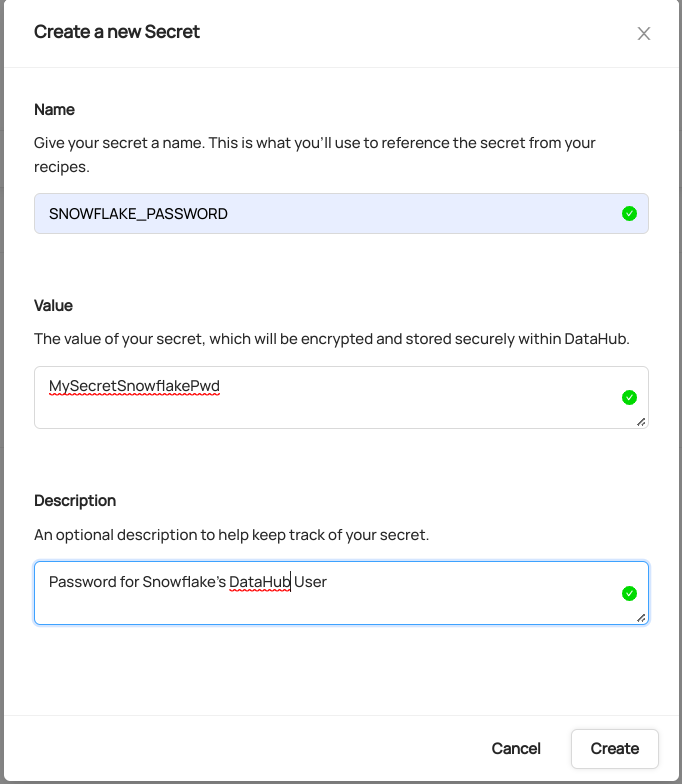 -
- -
- -
-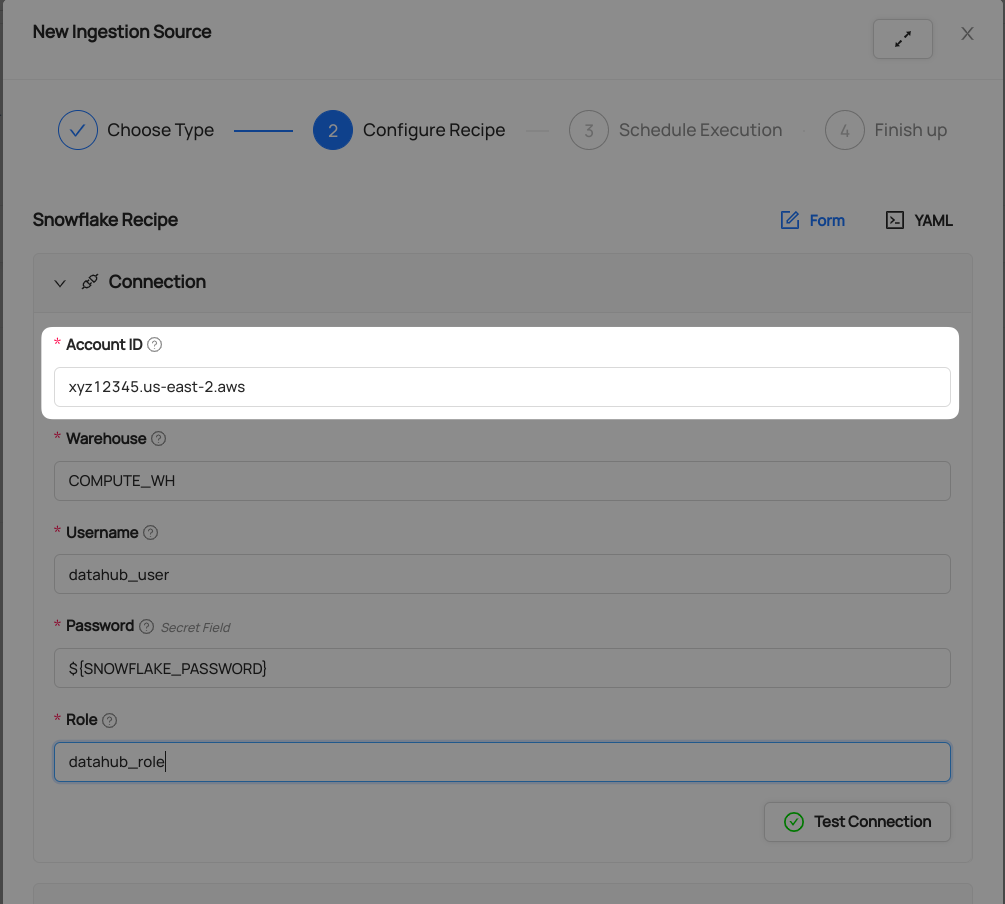 -
-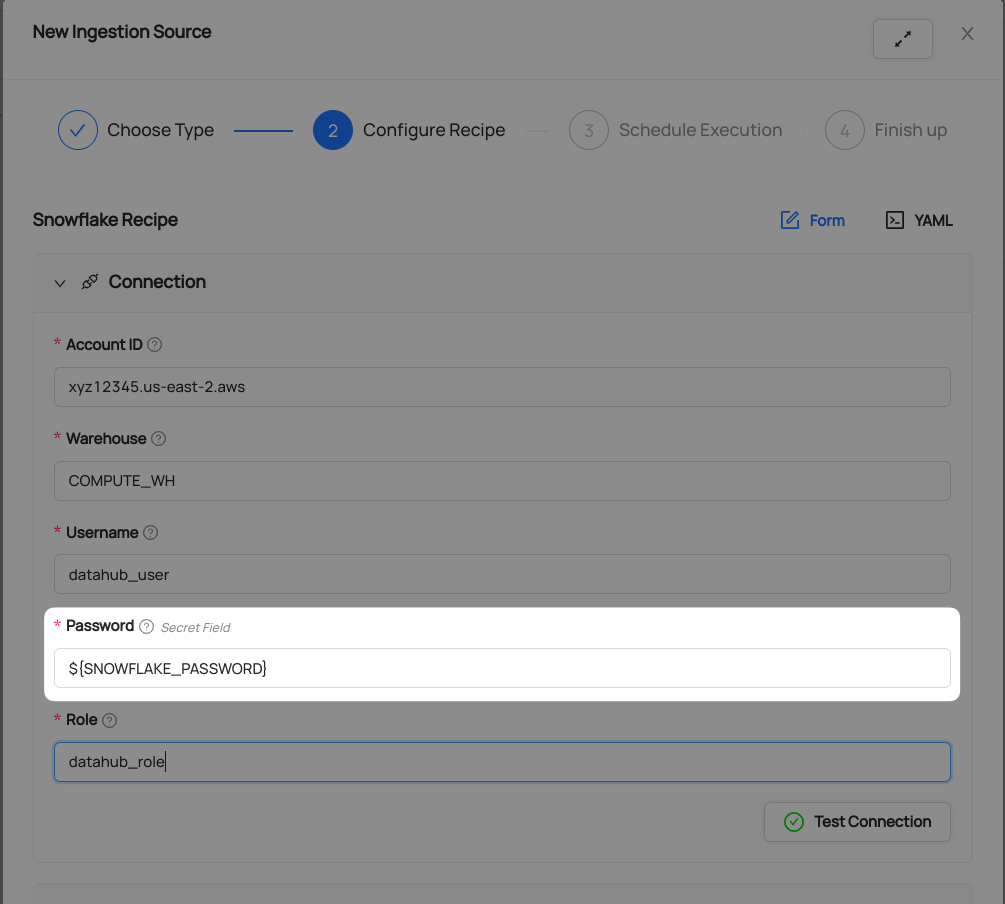 -
-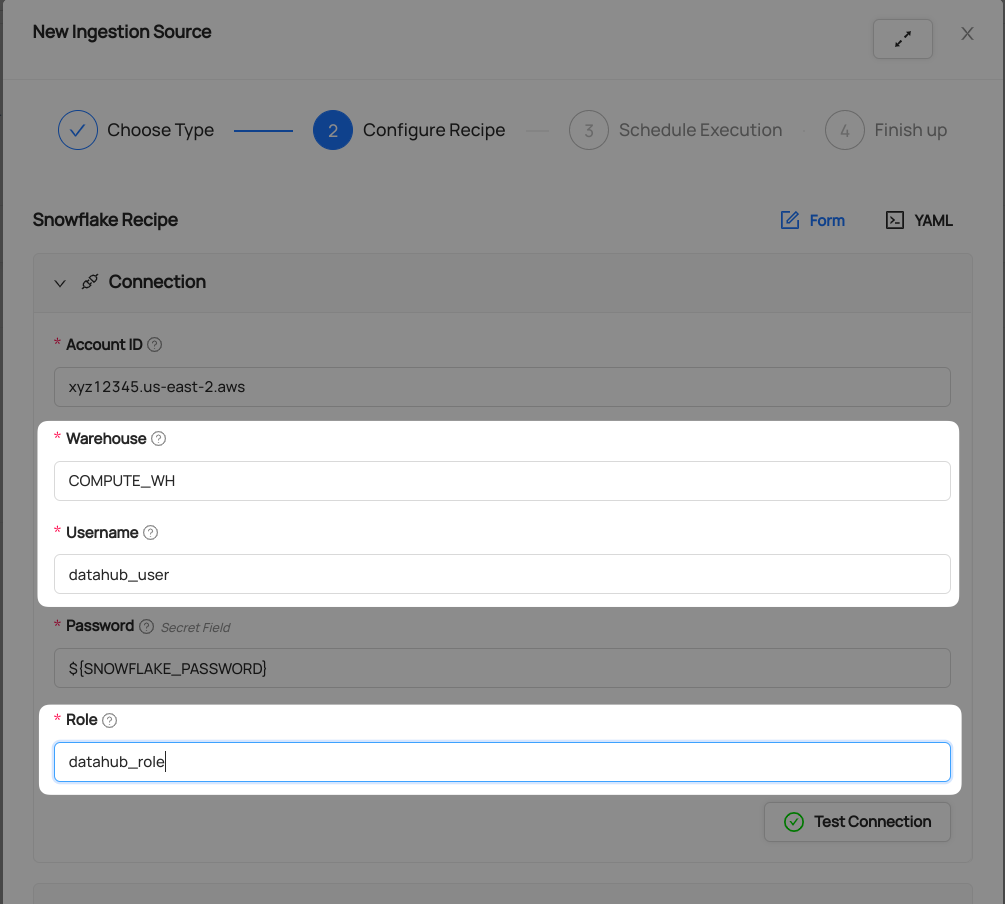 -
-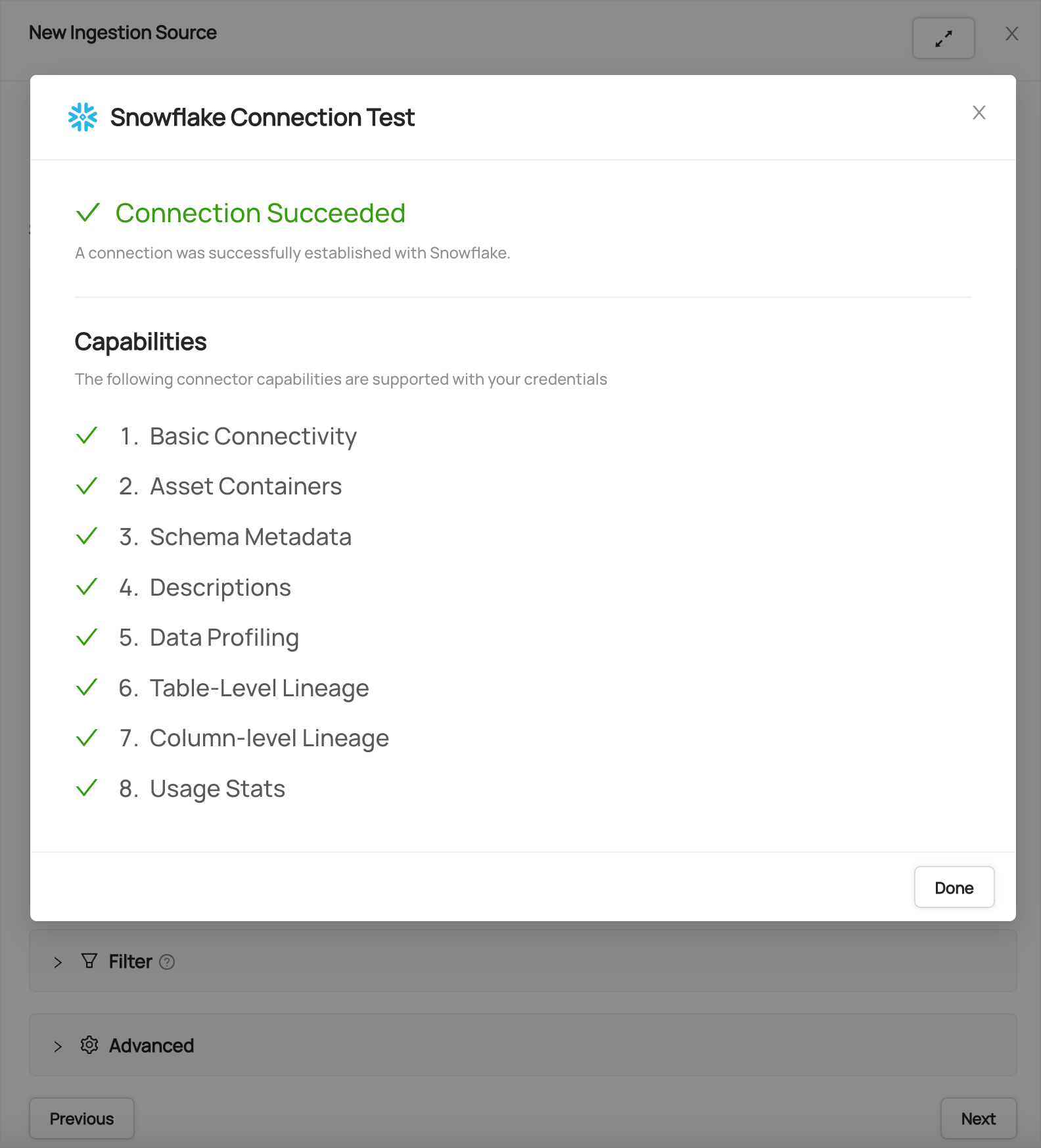 -
-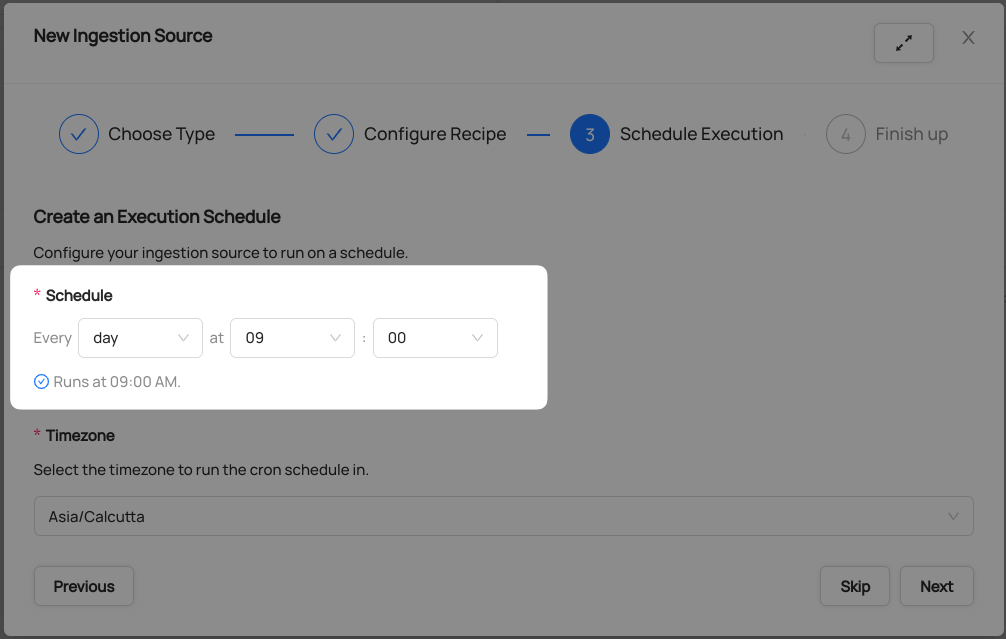 -
-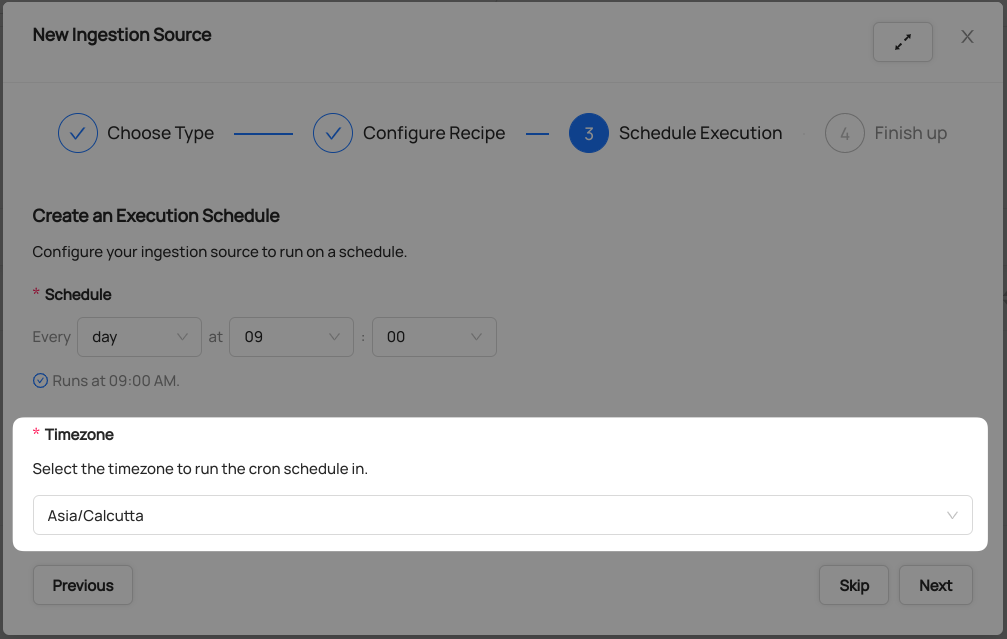 -
-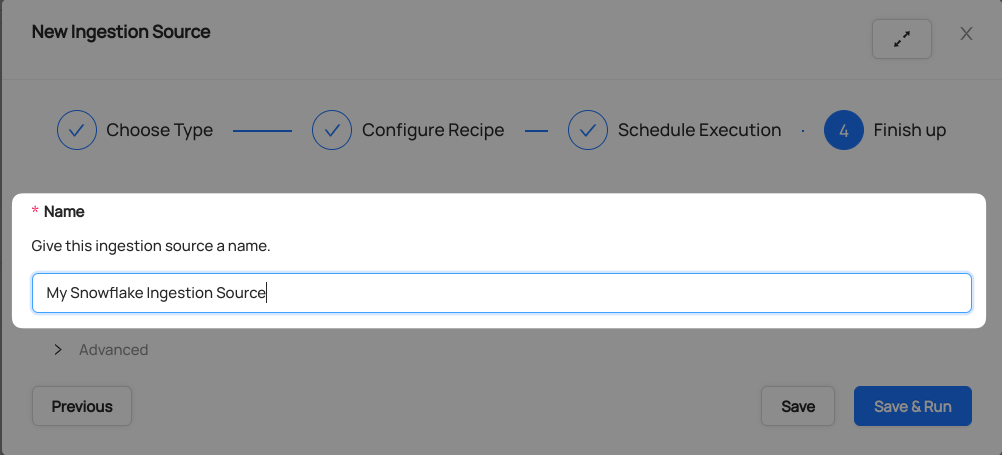 -
-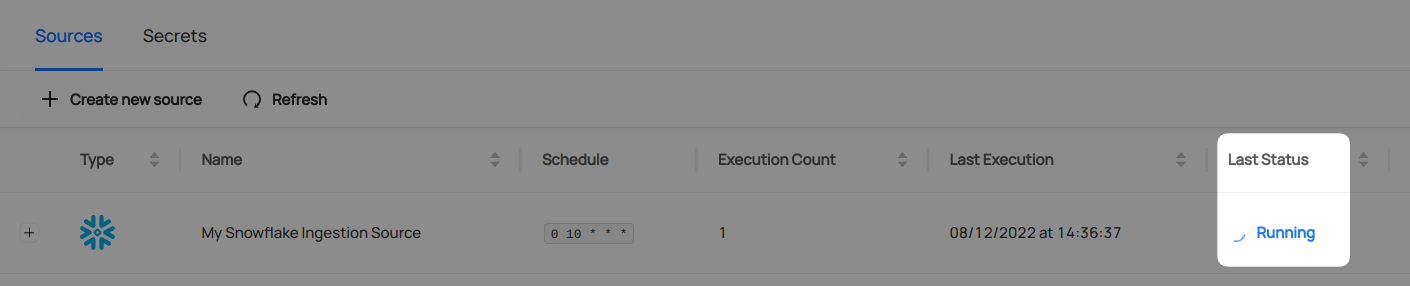 -
-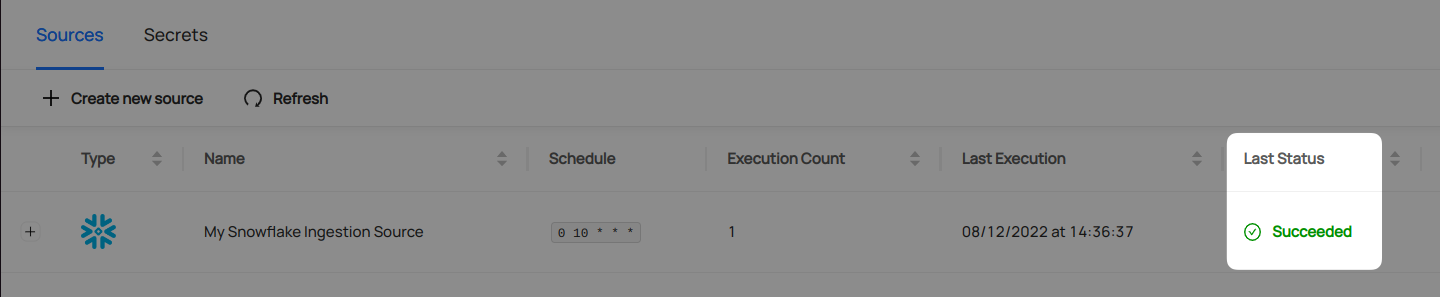 -
-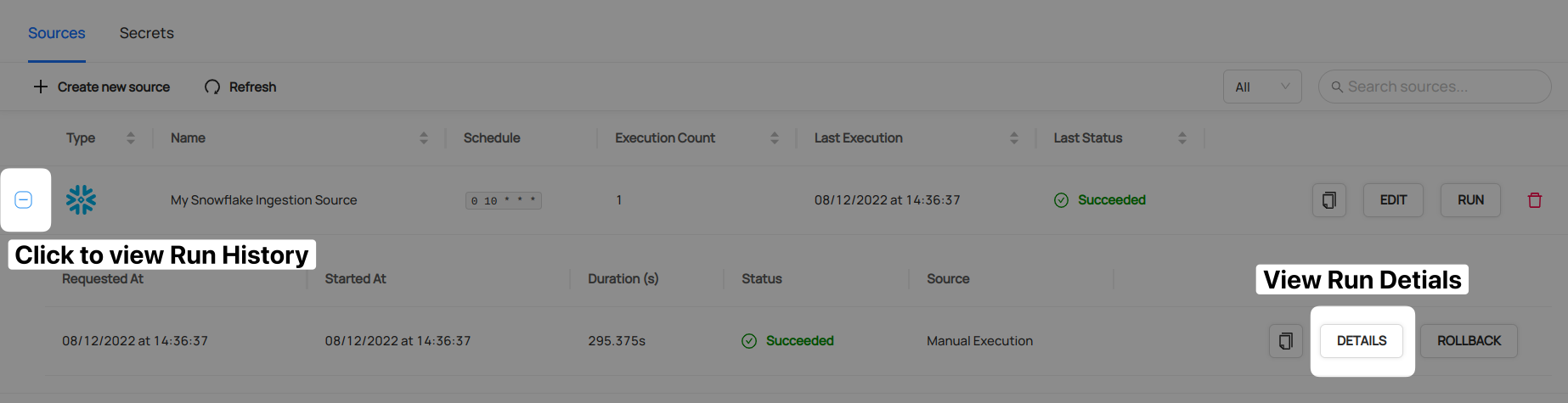 -
-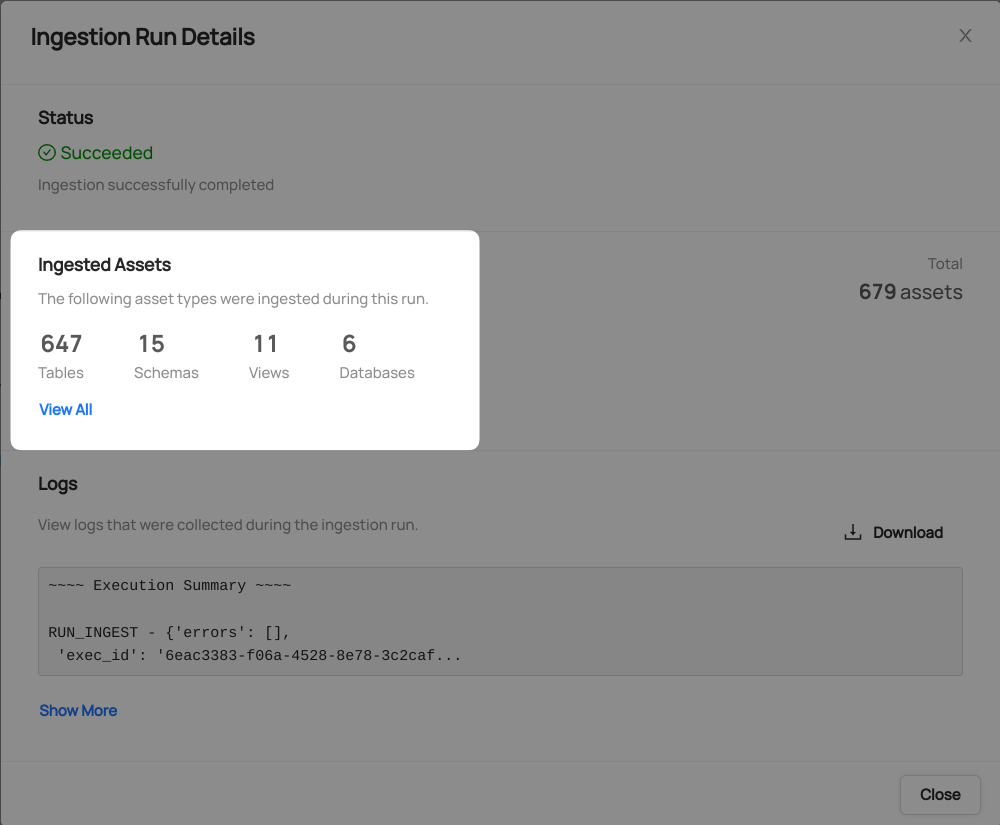 -
-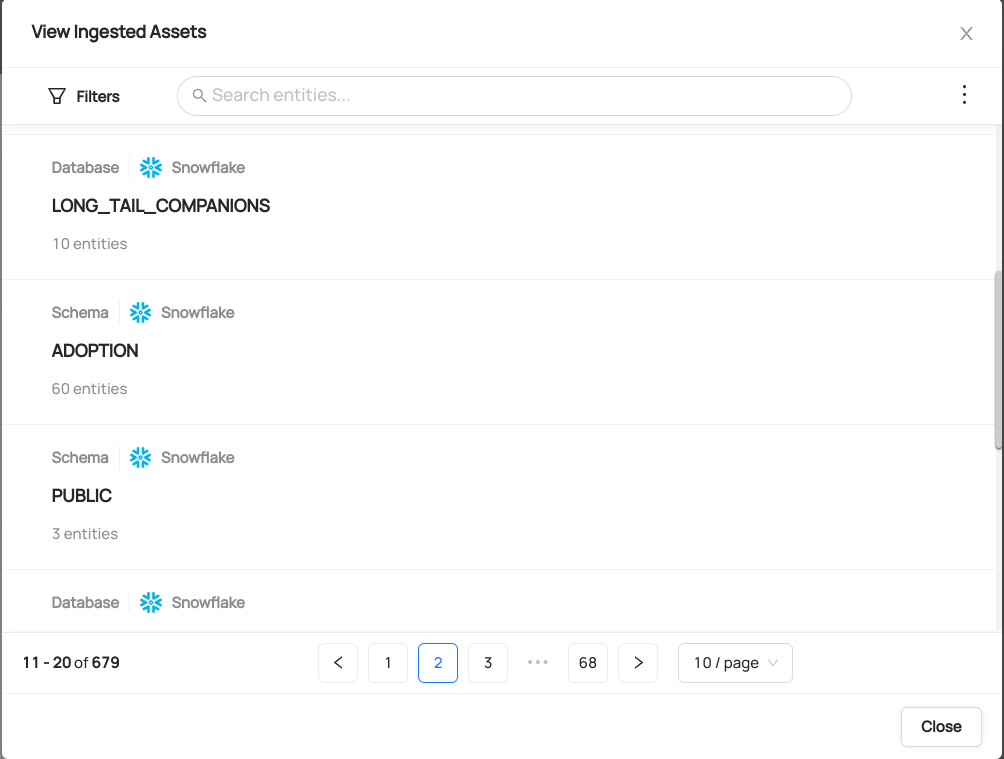 -
-
 -
-
-2. Visualizing single cell movement through time. This example shows the movement of the cell of lineage 'Dpa' through time.
-
-
-
-
-2. Visualizing single cell movement through time. This example shows the movement of the cell of lineage 'Dpa' through time.
-
-
 -
-Gaining insights from static plots can be difficult at times, this is where these interactive plots can help by enabling users to rotate, zoom, animate plots (with respect to time), rather than being stuck with just one point of time and perspective.
-
-### [Post Processing outputs from the DevoLearn lineage population model](post_process_lineage_population_model.ipynb)
-Post processing algorithms modify the outputs from the neural-network in order to further increase the accuracy of the predictions. I implemented a post processing algorithm on the lineage population model from DevoLearn, which exploits an inherent pattern in the data and modifies the model outputs accordingly, resulting in better accuracy (about 30% less loss) as highlighted in figure below.
-
-
-
-Gaining insights from static plots can be difficult at times, this is where these interactive plots can help by enabling users to rotate, zoom, animate plots (with respect to time), rather than being stuck with just one point of time and perspective.
-
-### [Post Processing outputs from the DevoLearn lineage population model](post_process_lineage_population_model.ipynb)
-Post processing algorithms modify the outputs from the neural-network in order to further increase the accuracy of the predictions. I implemented a post processing algorithm on the lineage population model from DevoLearn, which exploits an inherent pattern in the data and modifies the model outputs accordingly, resulting in better accuracy (about 30% less loss) as highlighted in figure below.
-
- -
-
-
diff --git a/spaces/diacanFperku/AutoGPT/Alvin And The Chipmunks In Hindi Dubbed !LINK! Full Movie 65.md b/spaces/diacanFperku/AutoGPT/Alvin And The Chipmunks In Hindi Dubbed !LINK! Full Movie 65.md
deleted file mode 100644
index 7ea6c4206bd599bdc9a52b652ad5bc5451217f08..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Alvin And The Chipmunks In Hindi Dubbed !LINK! Full Movie 65.md
+++ /dev/null
@@ -1,6 +0,0 @@
-
-
-
-
diff --git a/spaces/diacanFperku/AutoGPT/Alvin And The Chipmunks In Hindi Dubbed !LINK! Full Movie 65.md b/spaces/diacanFperku/AutoGPT/Alvin And The Chipmunks In Hindi Dubbed !LINK! Full Movie 65.md
deleted file mode 100644
index 7ea6c4206bd599bdc9a52b652ad5bc5451217f08..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Alvin And The Chipmunks In Hindi Dubbed !LINK! Full Movie 65.md
+++ /dev/null
@@ -1,6 +0,0 @@
-