Settings
--
-
-
-
- {{> general_tab}} {{> user_interface_tab}} {{> engines_tab}} {{>
- cookies_tab}}
-
-
-
- If you have an old Creative sound card and you want to use it on your Windows 7 computer, you might need a special driver to make it work. In this article, we will show you how to download and install Creative Ct4810 Driver Windows 7.rar, a compressed file that contains the driver for your sound card. We will also give you some troubleshooting tips in case you encounter any problems.
-Creative is a well-known brand of sound cards and audio devices for computers. One of their popular products is the Creative Sound Blaster CT4810, a PCI sound card that was released in the late 1990s. This sound card has a 16-bit digital audio processor and supports various sound effects and features.
-Download https://byltly.com/2uKyvx
Creative Ct4810 Driver Windows 7.rar is a compressed file that contains the driver for the Creative Sound Blaster CT4810 sound card. A driver is a software that allows your computer to communicate with your hardware device. Without a driver, your sound card might not work properly or at all on your computer.
-If you have a Creative Sound Blaster CT4810 sound card and you want to use it on your Windows 7 computer, you might need Creative Ct4810 Driver Windows 7.rar because the original driver that came with your sound card might not be compatible with Windows 7. Windows 7 is a newer operating system than the one that your sound card was designed for, so you might need a newer driver to make it work.
-Creative Ct4810 Sound Card Driver for Windows 7
-How to Install Creative Ct4810 Driver on Windows 7
-Download Creative Ct4810 Driver for Windows 7 32-bit
-Creative Ct4810 Driver Windows 7 64-bit Free Download
-Creative Ct4810 Driver Windows 7.zip File
-Creative Ct4810 Driver Update for Windows 7
-Creative Ct4810 Driver Compatibility with Windows 7
-Creative Ct4810 Driver Error on Windows 7
-Creative Ct4810 Driver Not Working on Windows 7
-Creative Ct4810 Driver Missing on Windows 7
-Creative Ct4810 Driver Fix for Windows 7
-Creative Ct4810 Driver Software for Windows 7
-Creative Ct4810 Driver Setup for Windows 7
-Creative Ct4810 Driver Installation Guide for Windows 7
-Creative Ct4810 Driver Troubleshooting for Windows 7
-Creative Ct4810 Driver Support for Windows 7
-Creative Ct4810 Driver Features for Windows 7
-Creative Ct4810 Driver Review for Windows 7
-Creative Ct4810 Driver Alternatives for Windows 7
-Creative Ct4810 Driver Comparison for Windows 7
-Best Creative Ct4810 Driver for Windows 7
-Latest Creative Ct4810 Driver for Windows 7
-Old Creative Ct4810 Driver for Windows 7
-Original Creative Ct4810 Driver for Windows 7
-Official Creative Ct4810 Driver for Windows 7
-Unofficial Creative Ct4810 Driver for Windows 7
-Modified Creative Ct4810 Driver for Windows 7
-Customized Creative Ct4810 Driver for Windows 7
-Enhanced Creative Ct4810 Driver for Windows 7
-Improved Creative Ct4810 Driver for Windows 7
-Optimized Creative Ct4810 Driver for Windows 7
-Tested Creative Ct4810 Driver for Windows 7
-Verified Creative Ct4810 Driver for Windows 7
-Safe Creative Ct4810 Driver for Windows 7
-Secure Creative Ct4810 Driver for Windows 7
-Reliable Creative Ct4810 Driver for Windows 7
-Fast Creative Ct4810 Driver for Windows 7
-Easy Creative Ct4810 Driver for Windows 7
-Simple Creative Ct4810 Driver for Windows 7
-User-friendly Creative Ct4810 Driver for Windows 7
-Advanced Creative Ct4810 Driver for Windows 7
-Professional Creative Ct4810 Driver for Windows 7
-Premium Creative Ct4810 Driver for Windows 7
-Free Creative Ct4810 Driver for Windows 7
-Cheap Creative Ct4810 Driver for Windows 7
-Discounted Creative Ct4810 Driver for Windows 7
-Affordable Creative Ct4810 Driver for Windows 7
-Quality Creative Ct4810 Driver for Windows 7
-High-performance Creative Ct4810 Driver for Windows 7
-Low-latency Creative Ct4810 Driver for Windows 7
You can download Creative Ct4810 Driver Windows 7.rar from various online sources, such as file-sharing websites or forums. However, you should be careful when downloading files from unknown sources, as they might contain viruses or malware that can harm your computer. You should always scan the files with an antivirus program before opening them.
-One of the websites that offer Creative Ct4810 Driver Windows 7.rar is https://www.driverguide.com/driver/detail.php?driverid=133039. This website claims to have tested and verified the file for safety and compatibility. However, we cannot guarantee the accuracy or reliability of this website, so use it at your own risk.
-To download Creative Ct4810 Driver Windows 7.rar from this website, follow these steps:
-After downloading Creative Ct4810 Driver Windows 7.rar, you need to extract it and install it on your computer. Here are the steps to do that:
-To extract Creative Ct4810 Driver Windows 7.rar, you need a program that can open compressed files, such as WinRAR or 7-Zip. You can download these programs from their official websites for free.
-To extract Creative Ct4810 Driver Windows 7.rar using WinRAR, follow these steps:
-To install Creative Ct4810 Driver Windows 7.rar, you need to run the setup file and follow the instructions on the screen. Here are the steps to do that:
-Double-click on the ct-4810.exe file in the ct4810_wdm folder. A window should pop up asking for your permission to run the program. Click on "Yes" or "Run" to continue.
-The setup wizard should guide you through the installation process. You might need to agree to some terms and conditions, choose a destination folder, and select some options. Follow the instructions on the screen and click on "Next" or "Finish" when prompted.
-After completing the installation, you might need to restart your computer for the changes to take effect. Click on "Yes" or "Restart" when asked by the setup wizard or by your computer.
-If you have installed Creative Ct4810 Driver Windows 7.rar but your sound card still does not work properly or at all on your computer, you might need some troubleshooting tips. Here are some possible solutions:
-Sometimes, older drivers might not work well with newer operating systems unless they are run in compatibility mode. Compatibility mode is a feature that allows you to run programs as if they were running on an older version of Windows.
-To check if compatibility mode is enabled for Creative Ct4810 Driver Windows 7.rar, follow these steps:
-Sometimes, newer drivers might be available for your sound card that can improve its performance and compatibility with Windows 7. You can check for updates from Creative's official website or from other sources online.
-To check for updates from Creative's official website, follow these steps:
-In this article, we have shown you how to download and install Creative Ct4810 Driver Windows 7.rar, a compressed file that contains the driver for your Creative Sound Blaster CT4810 sound card. We have also given you some troubleshooting tips in case you encounter any problems. We hope that this article has helped you to make your sound card work on your Windows 7 computer.
-If you have any questions or feedback, please leave a comment below. We would love to hear from you!
-Here are some frequently asked questions about Creative Ct4810 Driver Windows 7.rar:
-The size of Creative Ct4810 Driver Windows 7.rar is about 4.8 MB.
-Creative Ct4810 Driver Windows 7.rar is safe to download and install if you get it from a trusted source, such as Creative's official website or a reputable file-sharing website. However, you should always scan the file with an antivirus program before opening it to make sure that it does not contain any viruses or malware.
-Creative Ct4810 Driver Windows 7.rar might work on other versions of Windows, such as Windows Vista or Windows 8, but it is not guaranteed. You might need to use compatibility mode or look for other drivers that are compatible with your operating system.
-Creative Ct4810 Driver Windows 7.rar is designed specifically for the Creative Sound Blaster CT4810 sound card. It might not work on other models of sound cards, even if they are from the same brand or series. You should look for the driver that matches your sound card model.
-You can find more information about Creative Ct4810 Driver Windows 7.rar on Creative's official website: https://support.creative.com/Products/ProductDetails.aspx?catID=1&subCatID=207&prodID=4851&prodName=Sound%20Blaster%20PCI%20128&subCatName=Others&CatName=Sound+Blaster&VARSET=prodfaq:PRODFAQ_4851,VARSET=CategoryID:1. You can also search online for reviews, tutorials, or forums that discuss this topic.
-Fritzing is a software application that allows you to create, simulate and document electronic circuits. Whether you are a beginner or a professional, Fritzing can help you turn your ideas into reality.
-In this article, we will introduce you to the latest version of Fritzing, 0.9.10, which was released on May 22, 2022. We will also show you some of the features and benefits of using Fritzing for your electronics projects.
-Download File –––––>>> https://byltly.com/2uKxoG
Fritzing 0.9.10 is a maintenance release that fixes several bugs and improves the performance and stability of the application. It also adds some new features and enhancements, such as:
-Fritzing 0.9.10 is available for Windows (32-bit and 64-bit), Mac OS X (High Sierra to Monterey) and Linux (64-bit). You can download it from the official website for a suggested donation of 8⬠(around US$10). This way you can support the development and maintenance of Fritzing.
-To install Fritzing on your computer, follow these steps:
-apt install libfuse2.If you have any problems with the installation, do not hesitate to contact the Fritzing team via the contact form on their website. You can also check the installation instructions and the known issues on their website for more information.
-Fritzing has three main views that allow you to design your circuits in different ways:
-To start using Fritzing, you can either create a new project or open an existing one from the file menu. You can also browse through hundreds of examples and tutorials from the welcome screen or the help menu.
- -To create a new project, follow these steps:
-Download ✯✯✯ https://imgfil.com/2uy1RY
DOWNLOAD ⚹ https://imgfil.com/2uy0Xq
DOWNLOAD ->->->-> https://imgfil.com/2uxZ04
the following releases are available for download:
-Download ⚙⚙⚙ https://imgfil.com/2uy1On
for those who don't know naruto shippuden theme is the first game of the heian story its about ninja from the village of the fox and wolf clan in the meiyuu village and the hokage of the village of the lightning and thunder clan in the nidaime village
-the gameplay is based on ninja games there are some action scenes and some fighting scenes but the best is the story of the game it's so interesting and there are so many endings that it's hard to figure out what's going on in the story. so download naruto shippuden 340 subtitle indonesia mkv here!
-download naruto shippuden 340 subtitle indonesia mkv: otoriyoku narutoraikoji 3: naruto the last: a year after the war: naruto's back in action, and something like a year has passed since the final battle in the valley of the end. the story starts in a hospital, where all the heroes were in a group. a professional ninja, naruto uzumaki, sits in a hospital bed, his leg bandaged with a black hand. next to him is sasuke, and a little farther, sai. that's it - four heroes. "do you mean?" asks naruto. "i can't believe it! naruto, come back alive! sasuke, my brother, alive! sai, my friend, alive!" "yes, i do. now everything is going to be different. now, we can live the dream of my life as a ninja.. and the dream of a ninja is to go around the world, naruto! the dream is to go around the world. and you're going to walk in the journey together with me! " "yeah! we can do it!" "i love you all! go! go!" naruto declares. a nurse smiles and gives naruto a special medicine for the wound. he also gives the hero a special potion that will make him able to continue the mission in just two days. but naruto begins to worry about the mission. "what if i can't go? what will happen to you all?" naruto asks. "just go, you will continue the mission. all i need is you. i don't need anyone else! " "the only place i am going is the hospital. i'm leaving tomorrow. so, you and the others, just let me go! " naruto got up from the bed and stepped on the ground. he was ready to leave for the hospital. but he didn't know he was not alone. "naruto! what's the matter with you? if it's about your leg, i'll help you. let me look at it. i'll help you, i'll help you! " naruto heard someone scream. but his leg is not the only reason he's there. "you're not going anywhere, naruto. you're here because of me, because i've made you like this. i'm going to protect you!" sasuke said. "you? protect me? but why? you're a criminal, sasuke! i'll take you to the police and you'll be captured. and i'll become the criminal! " "no, i won't. i'm going to protect you, naruto. i'm going to protect you, even if you don't deserve it. i won't let anyone hurt you, even if you don't deserve it. " "i'll die if you try to help me, sasuke! i'm going to die if you try to help me! i'll die if you try to help me. " "you don't have to die, naruto. i'll protect you, even if you don't deserve it. " naruto heard the girl's voice. but the hero didn't see who she was. "you're not going to leave me, naruto! i'll protect you, even if you don't deserve it. " "don't leave me, naruto! don't leave me, naruto! " she cried as she approached him.
- 899543212bIf you are a fan of Kamen Rider Build, the 19th season of the popular Japanese tokusatsu series, you might have wondered how it feels to transform into one of the riders and use their amazing powers and weapons. Well, wonder no more, because you can now experience it yourself with Kamen Rider Build Flash Belt, a simulation game that lets you play with the flash belts of the main characters and create your own combinations of fullbottles.
-Download File >>> https://jinyurl.com/2uNLfk
Kamen Rider Build Flash Belt is a fan-made game created by CometComics, a general artist who has made several flash games based on different Kamen Rider series. The game is inspired by the show's premise, where the protagonist, Kiryu Sento, uses various fullbottles to transform into different forms of Kamen Rider Build. The fullbottles are small containers that hold the essence of different animals, elements, or objects, and when paired together, they form a "best match" that grants Sento enhanced abilities and weapons.
-The game allows you to simulate the transformation process by using your mouse or keyboard to twist the lever of the flash belt, which is a device that activates the fullbottles. You can choose from over 40 fullbottles and mix and match them to create different forms. You can also use other flash belts from other characters, such as Cross-Z, Grease, Rogue, and Evol, who have their own unique fullbottles and evolbottles. Additionally, you can use various weapons that correspond to each form, such as the Drill Crusher, Hawk Gatlinger, Fullbottle Buster, and more.
-The game is very easy to play and does not require any installation or registration. You can simply access it online through Newgrounds or DeviantArt, or download it from Google Drive. The game has a simple interface that shows you the flash belt on the left side, the fullbottles on the right side, and the options on the bottom. You can drag and drop the fullbottles into the flash belt slots, or use the arrow keys to select them. Then, you can click and hold the mouse button or press spacebar to twist the lever and activate the transformation. You can also click on the weapon icons to use them.
-[Kamen Rider Build Flash Belt 1.6 - DeviantArt](^1^): This is a website where you can play with a flash simulation of the Kamen Rider Build belt and create your own combinations of bottles and forms[^1^].
-What is Kamen Rider Build?
-How do I download the flash simulation?
-Can you show me some images of Kamen Rider Build?
The game has several modes and options that you can access by clicking on the buttons on the bottom. You can switch between different flash belts by clicking on their icons. You can also change the background music by clicking on the music note icon. You can mute or unmute the sound effects by clicking on the speaker icon. You can also adjust the volume by clicking on the plus or minus icons. You can also view some information about the game by clicking on the question mark icon.
-If you want to download the game and play it offline, you can do so by following these steps:
-The game does not require any special requirements to run, but you need to have Adobe Flash Player installed on your computer. You can download it for free from [here]. The game is compatible with Windows, Mac, and Linux operating systems.
-Kamen Rider Build Flash Belt is a game that offers a lot of fun and interactivity for fans of the show. By playing the game, you can:
-The game is a great way to immerse yourself in the world of Kamen Rider Build, and to express your creativity and fandom.
-The game has received positive feedback and reviews from other players and critics, who have praised its quality and features. Here are some examples of what they have said:
-"This is one of the best flash games I have ever played. The graphics are amazing, the sound effects are realistic, and the gameplay is smooth and easy. I love how I can mix and match different fullbottles and weapons, and create my own rider. This game is a must-play for any Kamen Rider fan." - User review on Newgrounds-
"Kamen Rider Build Flash Belt is a game that captures the essence of the show perfectly. It is a simulation game that lets you experience the transformation process of Kamen Rider Build, as well as other characters from the show. The game has a lot of options and modes, and it is very interactive and engaging. The game is also updated regularly with new content and features, making it more enjoyable and exciting. If you are a fan of Kamen Rider Build, you should definitely check out this game." - Review by Tokusatsu Network-
"This game is awesome! I have been playing it for hours, and I still can't get enough of it. The game is very well-made, with high-quality graphics, sound effects, and animations. The game is also very accurate to the show, with all the fullbottles, evolbottles, weapons, and flash belts available. The game is also very fun to play, with different modes and options to choose from. I highly recommend this game to anyone who likes Kamen Rider Build or tokusatsu in general." - User review on DeviantArt-
If you are looking for more games like Kamen Rider Build Flash Belt, you can also try these alternatives:
-If you want to stay updated with the latest news and updates on Kamen Rider Build Flash Belt, you can follow these sources:
-Kamen Rider Build Flash Belt is a game that every fan of Kamen Rider Build should try. It is a simulation game that lets you play with the flash belts of the main characters and create your own combinations of fullbottles and evolbottles. The game is very fun and interactive, and it enhances your fan experience by letting you immerse yourself in the world of Kamen Rider Build. The game is also easy to play and access, and it has a lot of features and options to choose from. The game is also updated regularly with new content and features, making it more enjoyable and exciting. The game has also received positive feedback and reviews from other players and critics, who have praised its quality and features. If you are looking for more games like Kamen Rider Build Flash Belt, you can also try some alternatives that are based on other Kamen Rider series. If you want to stay updated with the latest news and updates on Kamen Rider Build Flash Belt, you can follow some sources that provide them.
-So what are you waiting for? Go ahead and try Kamen Rider Build Flash Belt today and have fun transforming into different forms of Kamen Rider Build and other characters. You will not regret it!
-A1: Kamen Rider Build is the 19th season of the popular Japanese tokusatsu series Kamen Rider, which aired from 2017 to 2018. The show follows the story of Kiryu Sento, a genius physicist who lost his memory and became a fugitive after being framed for a murder. He uses various fullbottles to transform into different forms of Kamen Rider Build, and fights against the evil organization Faust, who are behind a mysterious phenomenon called the Skywall that divided Japan into three regions.
-A2: The game has over 40 fullbottles and evolbottles that you can use to create different forms of Kamen Rider Build and other characters. The game also has over 20 weapons that correspond to each form, such as the Drill Crusher, Hawk Gatlinger, Fullbottle Buster, etc.
-A3: You can support the developer of the game by following their DeviantArt page, Twitter account, and Patreon page. You can also leave feedback and reviews on their game pages, share their games with other fans, and donate to their Patreon page.
-A4: Yes, the game is safe and virus-free. The game does not contain any malicious or harmful content or software. However, you should always scan any downloaded files with your antivirus software before opening them.
-A5: Yes, you can play the game offline or on mobile devices. To play the game offline, you need to download it from Google Drive and run it on your computer. To play the game on mobile devices, you need to use a browser that supports Adobe Flash Player, such as Puffin Browser.
197e85843d¿Te gustan los juegos de simulación y estrategia? ¿Te gustan las gallinas? Si la respuesta es sí, entonces te encantará Egg Inc APK Español, un juego divertido y adictivo que te reta a crear la granja de huevos más avanzada del mundo. En este artículo te contamos todo lo que necesitas saber sobre este juego, desde cómo se juega hasta por qué deberías descargarlo desde APKCombo.
-Download File 🌟 https://jinyurl.com/2uNULc
Egg Inc APK Español es un juego de simulación incremental (clicker) que utiliza muchos elementos de los juegos de estrategia que le dan un estilo único y original. El juego se ambienta en un futuro cercano donde los secretos del universo se desbloquearán en el huevo de gallina. Tú has decidido aprovechar la fiebre del oro y vender tantos huevos como puedas.
-El juego tiene una apariencia hermosa y colorida, con gráficos 3D y una deliciosa simulación de un enjambre de gallinas. Además de elegir tus inversiones sabiamente, también debes equilibrar tus recursos para asegurar un funcionamiento suave y eficiente de tu granja de huevos. Hay algo para todos aquí: los jugadores casuales disfrutarán del ambiente relajado y la simplicidad del juego. Tómate tu tiempo para construir una maravillosa granja de huevos y explorar todo el contenido. Los jugadores más experimentados en los juegos incrementales (clicker) amarán el juego emergente y la profundidad que ofrecen los diferentes estilos de juego que se necesitan a lo largo del juego. Para alcanzar el objetivo final de tener una granja de huevos gigantesca con un valor astronómico, tendrás que equilibrar estrategias a través de muchos prestigios para aprovechar mejor tu tiempo.
-El primer paso para jugar a Egg Inc APK Español es crear tu granja de huevos. Para ello, tendrás que tocar la pantalla para hacer que las gallinas salgan del gallinero y pongan huevos. Cuantas más gallinas tengas, más huevos producirás y más dinero ganarás.
-Pero no solo se trata de tocar la pantalla. También tendrás que construir y mejorar diferentes edificios para alojar a tus gallinas, transportar tus huevos, generar energía y más. Algunos de los edificios que podrás construir son:
-Además de construir y mejorar edificios, también podrás comprar mejoras que te ayudarán a aumentar la producción y el valor de tus huevos. Algunas de las mejoras que podrás comprar son:
-Otra forma de jugar a Egg Inc APK Español es invertir en investigación y exploración espacial. Estas son dos actividades que te permitirán descubrir nuevos secretos sobre los huevos y el universo, así como obtener beneficios adicionales para tu granja.
-egg inc apk español descargar
-egg inc apk español mod
-egg inc apk español ultima version
-egg inc apk español hack
-egg inc apk español gratis
-egg inc apk español mega
-egg inc apk español full
-egg inc apk español android
-egg inc apk español 2023
-egg inc apk español actualizado
-egg inc apk español sin internet
-egg inc apk español infinito
-egg inc apk español trucos
-egg inc apk español mediafire
-egg inc apk español online
-egg inc apk español premium
-egg inc apk español dinero ilimitado
-egg inc apk español sin anuncios
-egg inc apk español oro infinito
-egg inc apk español juego
-egg inc apk español simulador
-egg inc apk español descargar gratis
-egg inc apk español mod menu
-egg inc apk español 1.27.0
-egg inc apk español uptodown
-egg inc apk español para pc
-egg inc apk español descargar mega
-egg inc apk español hackeado
-egg inc apk español descargar mediafire
-egg inc apk español descargar ultima version
-egg inc apk español descargar hackeado
-egg inc apk español descargar mod
-egg inc apk español descargar android
-egg inc apk español descargar 2023
-egg inc apk español descargar actualizado
-egg inc apk español descargar sin internet
-egg inc apk español descargar infinito
-egg inc apk español descargar trucos
-egg inc apk español descargar online
-egg inc apk español descargar premium
-egg inc apk español descargar dinero ilimitado
-egg inc apk español descargar sin anuncios
-egg inc apk español descargar oro infinito
-egg inc apk español descargar juego
-egg inc apk español descargar simulador
-egg inc apk español mod dinero infinito
-egg inc apk español mod oro infinito
-egg inc apk español mod sin anuncios
-egg inc apk español mod hackeado
-egg inc apk español mod ultima version
La investigación se divide en dos categorías: común y épica. La investigación común se paga con el dinero que ganas vendiendo huevos, y te ofrece mejoras permanentes para tu granja, como aumentar la felicidad de las gallinas, reducir el costo de las mejoras, acelerar el tiempo de construcción, etc. La investigación épica se paga con huevos de oro, que son una moneda especial que puedes obtener de varias formas, como viendo anuncios, completando misiones, abriendo cajas misteriosas, etc. La investigación épica te ofrece mejoras especiales para tu granja, como aumentar el efecto de las mejoras comunes, multiplicar el valor de los huevos, aumentar el límite de habitabilidad, etc.
-La exploración espacial se realiza mediante cohetes que puedes construir y lanzar desde tu granja. Los cohetes te permiten enviar gallinas y huevos al espacio para realizar misiones y experimentos. Algunos de los beneficios que puedes obtener de la exploración espacial son:
-El último aspecto que te explicaremos sobre cómo se juega a Egg Inc APK Español es el prestigio y el desbloqueo de nuevos huevos. Estas son dos acciones que te permitirán reiniciar tu progreso y empezar de nuevo con ventajas y desafíos adicionales.
-El prestigio es una opción que puedes activar cuando alcanzas cierto nivel de alma de huevo, que es una medida de tu éxito en el juego. Al hacer prestigio, reinicias tu granja y pierdes todo lo que has construido e invertido, pero conservas tus huevos de oro, tus cartas, tus artefactos y tus almas de huevo. Las almas de huevo te dan un bono multiplicador al valor de tus huevos, lo que te ayuda a avanzar más rápido y más lejos en tu próxima granja.
-El desbloqueo de nuevos huevos es una recompensa que obtienes al alcanzar cierto valor de granja, que depende del tipo de huevo que estés produciendo. Al desbloquear un nuevo tipo de huevo, puedes cambiar tu producción y empezar a vender ese huevo en lugar del anterior. Cada tipo de huevo tiene un valor base diferente, así como propiedades especiales que afectan al juego. Por ejemplo, el huevo comestible es el más básico y tiene un valor de 0.25 dólares, mientras que el huevo de antimateria es el más avanzado y tiene un valor de 1.8 billones de dólares.
-Ahora que ya sabes cómo se juega a Egg Inc APK Español, te preguntarás por qué deberías descargarlo desde APKCombo. La respuesta es simple: porque APKCombo te ofrece la mejor experiencia de descarga y juego posible. Algunas de las ventajas de descargar Egg Inc APK Español desde APKCombo son:
-Egg Inc APK Español es un juego de simulación y estrategia con gallinas que te hará pasar horas de diversión y entretenimiento. Podrás crear tu propia granja de huevos, invertir en investigación y exploración espacial, prestigiar y desbloquear nuevos huevos, y mucho más. Además, si descargas el juego desde APKCombo, podrás disfrutar de todas las ventajas que te ofrece esta plataforma, como rapidez, seguridad, actualización y compatibilidad. ¿A qué esperas para probarlo? ¡Descarga Egg Inc APK Español hoy mismo y empieza a vivir la aventura!
-Sí, es seguro descargar Egg Inc APK Español desde APKCombo. APKCombo es una plataforma confiable que verifica todos los archivos que ofrece para asegurarse de que no contienen virus ni malware. Además, APKCombo respeta tu privacidad y no recopila ni comparte tus datos personales.
-Para jugar a Egg Inc APK Español necesitas tener un dispositivo con Android 7.0 o superior y 89 MB de espacio libre en tu almacenamiento interno o externo. El juego no requiere conexión a internet para funcionar, pero sí para acceder a algunas funciones opcionales como los anuncios o las misiones diarias.
-En Egg Inc APK Español hay 19 tipos de huevos diferentes, cada uno con un valor base y unas propiedades espec iales que afectan al juego. Por ejemplo, el huevo comestible es el más básico y tiene un valor de 0.25 dólares, mientras que el huevo de antimateria es el más avanzado y tiene un valor de 1.8 billones de dólares. La lista completa de los tipos de huevos es la siguiente:
-| Tipo de huevo | -Valor base | -Propiedad especial | -
|---|---|---|
| Comestible | -0.25 $ | -Ninguna | -
| Súper alimento | -1.25 $ | -Aumenta la felicidad de las gallinas en un 10% | -
| Médico | -6.25 $ | -Aumenta la habitabilidad en un 10% | -
| Cohete | -30 $ | -Aumenta la velocidad de eclosión en un 10% | -
| Súper material | -150 $ | -Aumenta la calidad del huevo en un 10% | -
| Fusión | -700 $ | -Aumenta la cantidad del huevo en un 10% | -
| 3,000 $ | -Aumenta el valor de los huevos en un 10% por cada gallina | -|
| Inmortalidad | -12,500 $ | -Aumenta la vida de las gallinas en un 10% | -
| Tachyon | -50,000 $ | -Aumenta la velocidad de eclosión en un 20% | -
| Gravitón | -175,000 $ | -Aumenta la gravedad en un 10% | -
| Dilithium | -525,000 $ | -Aumenta la potencia de los cohetes en un 10% | -
| Protophase | -1.5 M$ | -Aumenta la calidad del huevo en un 20% | -
| 4.5 M$ | -Aumenta el valor de los huevos en un 20% por cada gallina | -|
| AI | -15 M$ | -Aumenta la inteligencia de las gallinas en un 10% | -
| Neblina | -50 M$ | -Aumenta la habitabilidad en un 20% | -
| Terraformación | -150 M$ | -Aumenta la felicidad de las gallinas en un 20% | -
| Antimateria | -1.8 B$ | -Aumenta la cantidad del huevo en un 20% | -
Una forma de cooperar con otros jugadores en Egg Inc APK Español es participar en los contratos cooperativos. Estos son desafíos especiales que te proponen producir una cantidad determinada de huevos de un tipo específico en un tiempo limitado. Para lograrlo, puedes unirte a un equipo con otros jugadores o crear el tuyo propio e invitar a tus amigos. Al completar los contratos cooperativos, podrás obtener recompensas como huevos de propulsión, huevos de oro, artefactos y más.
-Las cartas son objetos coleccionables que te proporcionan mejoras y bonificaciones para tu juego. Puedes obtener cartas de varias formas, como comprándolas con huevos de oro, ganándolas en los contratos cooperativos, encontrándolas en las cajas misteriosas, etc. Hay cuatro tipos de cartas: comunes, raras, épicas y legendarias. Cada carta tiene un efecto diferente, como aumentar el valor de los huevos, reducir el costo de las mejoras, acelerar la producción, etc. Puedes usar las cartas activando sus efectos o combinándolas para crear cartas más poderosas.
197e85843dSelective Residual M-Net | Github Repo
Si usted está buscando un juego de puzzle divertido y adictivo que puede mantenerlo entretenido durante horas, usted debe probar juegos de disparos de burbujas. Los juegos de disparos de burbujas son juegos simples pero desafiantes que requieren que coincidas y hagas estallar burbujas coloridas en la pantalla. En este artículo, te contaremos todo lo que necesitas saber sobre los juegos de disparos de burbujas, cómo descargarlos en tu dispositivo, cómo jugarlos y ganar niveles, y por qué deberías jugarlos.
-Bubble shooter es un tipo de juego de puzzle que consiste en disparar burbujas desde un cañón o un lanzador en la parte inferior de la pantalla. El objetivo es hacer coincidir tres o más burbujas del mismo color para hacerlas estallar y limpiar el tablero. El juego termina cuando se borran todas las burbujas o cuando las burbujas llegan a la parte inferior de la pantalla.
-Download ✫ https://bltlly.com/2v6LZ8
Los juegos de disparos de burbujas tienen una larga historia que se remonta a la década de 1980. El primer juego de disparos de burbujas se llamó Puzzle Bobble, que fue lanzado por Taito en 1986. Fue un spin-off del popular juego de árcade Bubble Bobble, que contó con dos lindos dragones llamados Bub y Bob. Puzzle Bobble se convirtió en un gran éxito en Japón y más tarde en otros países, generando muchas secuelas y clones.
-Desde entonces, los juegos de disparos de burbujas han evolucionado y mejorado, añadiendo nuevas características, gráficos, sonidos y elementos de juego. Hoy en día, los juegos de disparos de burbujas son uno de los géneros más populares de los juegos casuales, con millones de jugadores en todo el mundo. Puedes encontrar cientos de juegos de disparos de burbujas en varias plataformas, como navegadores web, dispositivos móviles, consolas y computadoras.
-Los juegos de disparos de burbujas también tienen varias características que los hacen más divertidos y emocionantes. Por ejemplo, algunos juegos tienen diferentes niveles con diferentes diseños, obstáculos, metas y dificultades. Algunos juegos tienen diferentes modos de juego, como el modo puzzle, el modo árcade, el modo clásico, etc. Algunos juegos tienen potenciadores y potenciadores que pueden ayudarte a limpiar el tablero más rápido o superar desafíos. Algunos juegos tienen tablas de clasificación, logros, recompensas, bonos diarios, etc.
-Si quieres jugar juegos de disparos de burbujas en tu dispositivo, necesitas descargarlos desde la tienda de aplicaciones o el navegador web. Aquí hay algunos pasos sobre cómo descargar juegos de disparos de burbujas en su dispositivo:
-Ahora que has descargado juegos de disparos de burbujas en tu dispositivo, estás listo para jugar y divertirte. Pero, ¿cómo se juega juegos de burbujas tirador y ganar niveles? Aquí hay algunos consejos y trucos sobre cómo jugar juegos de burbujas tirador y ganar niveles:
-Los juegos de disparos de burbujas tienen diferentes modos de juego y desafíos que pueden hacer que el juego sea más interesante y desafiante. Algunos de los modos de juego y desafíos comunes son:
-Los juegos de disparos de burbujas también tienen potenciadores y potenciadores que pueden ayudarte a limpiar el tablero más rápido o superar desafíos. Algunos de los potenciadores y potenciadores comunes son:
-Los juegos de disparos de burbujas no solo son divertidos y entretenidos, sino también beneficiosos para su cerebro y estado de ánimo. Aquí hay algunas razones por las que debe jugar juegos de disparos de burbujas:
- -Los juegos de disparos de burbujas son uno de los mejores tipos de juegos de puzzle que puedes jugar en tu dispositivo. Son divertidos, adictivos, desafiantes, beneficiosos, relajantes, sociales y competitivos. Pueden mantenerte entretenido durante horas y hacerte feliz e inteligente. Si todavía no has probado los juegos de disparos de burbujas, deberías descargarlos ahora y disfrutar de este increíble juego.
-Si está buscando un software de modelado 3D potente y fácil de usar, es posible que desee probar SketchUp 2020. SketchUp es una herramienta popular para crear, editar y compartir modelos 3D para diversos fines, como arquitectura, diseño de interiores, ingeniería, paisajismo, juegos y más. En este artículo, te mostraremos cómo descargar SketchUp 2020 de forma gratuita e instalarlo en tu ordenador. También le daremos una visión general de las características y mejoras de SketchUp 2020, así como algunos consejos sobre cómo comenzar a usarlo y aprender más sobre él.
-SketchUp 2020 es la última versión de SketchUp Pro, la versión premium de SketchUp que ofrece características y capacidades más avanzadas que la versión gratuita basada en la web. SketchUp Pro es un software de suscripción que cuesta $299 por año o $41.66 por mes. Sin embargo, también puede descargar una versión de prueba gratuita de SketchUp Pro durante 30 días y utilizar todas sus funciones sin limitaciones.
-Download File ——— https://bltlly.com/2v6Lo9
SketchUp 2020 viene con muchas características y mejoras que lo hacen más intuitivo, eficiente y divertido de usar. Algunos de los aspectos más destacados son:
-Puede obtener más información sobre las nuevas características y mejoras de SketchUp 2020 de estas fuentes .
-Antes de descargar SketchUp 2020, debe asegurarse de que su computadora cumple con los requisitos mínimos o recomendados del sistema para su funcionamiento sin problemas. Estos son los requisitos del sistema para los sistemas operativos Windows y Mac :
-También debe comprobar la compatibilidad de SketchUp 2020 con otros programas y extensiones que utiliza, como motores de renderizado, programas CAD, herramientas BIM, etc. Puede encontrar una lista de software y extensiones compatibles aquí.
- -Ahora que sabes lo que es SketchUp 2020 y lo que puede hacer, es posible que se pregunte cómo descargarlo de forma gratuita. Hay dos formas de hacerlo: descargando la versión de prueba gratuita desde el sitio web oficial o descargando el instalador sin conexión para Windows.
- -La forma más fácil de descargar SketchUp 2020 gratis es obtener la prueba gratuita desde el sitio web oficial. Estos son los pasos para hacer eso:
-Tenga en cuenta que la prueba gratuita caducará después de 30 días y tendrá que comprar una suscripción o iniciar sesión con una cuenta existente para continuar usando SketchUp Pro.
-Si prefiere descargar el instalador sin conexión SketchUp 2020 para Windows, puede hacerlo siguiendo estos pasos:
-Tenga en cuenta que este método solo funciona para los usuarios de Windows y que todavía necesitará una conexión a Internet para activar su licencia o iniciar sesión con su cuenta.
-Si descargó la versión de prueba gratuita desde el sitio web oficial, tendrá un archivo llamado SketchUpPro-2020-en.exe. Si ha descargado el instalador sin conexión para Windows, tendrá un archivo llamado SketchUpPro-2020-2-172-22215-en-x64.exe. Haga doble clic en el archivo para ejecutar el instalador y siga las instrucciones en la pantalla. Es posible que necesite otorgar permiso o ingresar su contraseña si su sistema se lo solicita.
-El instalador le guiará a través del proceso de instalación, que puede tardar unos minutos dependiendo de su sistema. Puede elegir la carpeta de destino, el idioma, los componentes y los accesos directos para SketchUp 2020. También puede optar por instalar LayOut, Style Builder y Trimble Connect si lo desea.
-Cuando la instalación esté completa, haga clic en Finalizar.
-Después de haber instalado SketchUp 2020 en su computadora, necesitará activar su licencia o iniciar sesión con su cuenta para usarla. Estos son los pasos para hacerlo:
-Ahora que ha descargado e instalado SketchUp 2020 de forma gratuita, es posible que se pregunte cómo empezar a usarlo y aprender más sobre él. Aquí hay algunos consejos para ayudarle a empezar:
-Cuando inicie SketchUp 2020, verá un espacio de trabajo en blanco con un modelo 3D predeterminado de una persona. Puede utilizar el ratón y el teclado para navegar por el modelo y acercar y alejar. También puede cambiar la perspectiva y la vista desde diferentes ángulos.
-También verá una barra de herramientas en la parte superior de la pantalla con varias herramientas e iconos. Puede utilizar estas herramientas para crear, modificar, medir y anotar sus modelos 3D. También puede acceder a más herramientas desde los menús desplegables o haciendo clic derecho en el modelo.
-Puede personalizar la barra de herramientas agregando o quitando herramientas, cambiando su orden o acoplándolas a diferentes ubicaciones. También puede cambiar entre diferentes conjuntos de herramientas haciendo clic en el icono de flecha en el extremo derecho de la barra de herramientas.
-También puedes abrir otros paneles y ventanas desde el menú Window, como Outliner, Entity Info, Layers, Materials, Styles, Scenes, etc. Estos paneles y ventanas te ayudarán a organizar, editar y mejorar tus modelos 3D.
-Si necesita ayuda u orientación sobre cómo usar SketchUp 2020, puede acceder a varios recursos desde el menú Ayuda en SketchUp 2020. Algunos de los recursos son:
-También puedes encontrar más recursos de otras fuentes como blogs, podcasts, libros, revistas, etc. que cubren SketchUp y temas relacionados.
-En este artículo, le hemos mostrado cómo descargar SketchUp 2020 gratis e instalarlo en su computadora. También le hemos dado una visión general de las características y mejoras de SketchUp 2020, así como algunos consejos sobre cómo comenzar a usarlo y aprender más sobre él.
-Esperamos que este artículo haya sido útil y que haya disfrutado aprendiendo sobre SketchUp 2020. SketchUp 2020 es un software de modelado 3D potente y fácil de usar que puede usar para diversos fines, como arquitectura, diseño de interiores, ingeniería, paisajismo, juegos y más. Puedes descargar SketchUp 2020 gratis y usarlo durante 30 días sin limitaciones. También puedes acceder a varios recursos para ayudarte a aprender y mejorar tus habilidades en SketchUp 2020.
-Si tiene alguna pregunta o comentario sobre SketchUp 2020, no dude en dejar un comentario a continuación o en contacto con nosotros a través de nuestro sitio web. Nos encantaría saber de ti y ayudarte con tus necesidades de modelado 3D.
-Aquí hay algunas preguntas frecuentes que puedes encontrar útiles:
-A: Si desea desinstalar SketchUp 2020 desde su computadora, puede hacerlo siguiendo estos pasos:
-A: Si desea actualizar SketchUp 2020 a la última versión, puede hacerlo siguiendo estos pasos:
-A: Si desea exportar su modelo SketchUp 2020 a otros formatos, como PDF, DWG, STL, etc., puede hacerlo siguiendo estos pasos:
-A: Si desea importar otros modelos o archivos en SketchUp 2020, como imágenes, archivos CAD, modelos 3D, etc., puede hacerlo siguiendo estos pasos:
-A: Si desea compartir su modelo SketchUp 2020 con otros, puede hacerlo siguiendo estos pasos:
-Si eres un fan de los juegos de terror, es posible que hayas oído hablar de Five Nights at Freddy’s, una popular serie de juegos de terror de supervivencia desarrollados por Scott Cawthon. La tercera entrega de la serie, Five Nights at Freddy’s 3, fue lanzada en 2015 y recibió críticas positivas de críticos y jugadores por igual. En este artículo, te diremos qué es Five Nights at Freddy’s 3, qué es un archivo APK y cómo descargar e instalar Five Nights at Freddy’s 3 APK en tus dispositivos.
-Five Nights at Freddy’s 3 se desarrolla treinta años después de los eventos del primer juego, en una atracción de terror llamada "Fazbear’s Fright". El jugador toma el papel de un guardia de seguridad que debe sobrevivir cinco noches (y una sexta noche extra) mientras es perseguido por un animatrónico decrépito llamado Springtrap y varias versiones fantasma de los animatrónicos originales. El jugador debe monitorear dos juegos de cámaras, una para las habitaciones y pasillos, y otra para los conductos de ventilación, y usar varios dispositivos como señales de audio, controles de ventilación y un panel de reinicio para evitar que Springtrap llegue a la oficina. A diferencia de los juegos anteriores, solo hay un animatronic que puede matar al jugador, pero los fantasmas pueden asustar al jugador y causar fallos en los sistemas.
-Download File ✸✸✸ https://bltlly.com/2v6LNI
Five Nights at Freddy’s 3 tiene varias características que lo hacen diferente de sus predecesores, como:
-El juego requiere Android 4.1 o superior para dispositivos móviles, Windows XP o superior para dispositivos PC e iOS 8.0 o posterior para dispositivos Apple. El juego también requiere 250 MB de espacio de almacenamiento y 1 GB de RAM.
-Un archivo APK significa Paquete Android Kit o Paquete de aplicación Android. Es un formato de archivo utilizado por el sistema operativo Android para distribuir e instalar aplicaciones. Un archivo APK contiene todos los componentes de una aplicación, como código, recursos, activos, certificados y manifiesto. Un archivo APK se puede descargar de varias fuentes, como Google Play Store, sitios web de terceros, o directamente de los desarrolladores.
-La instalación de archivos APK puede tener algunas ventajas sobre la instalación de aplicaciones de Google Play Store, como:
-Sin embargo, la instalación de archivos APK también viene con algunos riesgos, como:
-Por lo tanto, es importante tener cuidado y precaución al descargar e instalar archivos APK. Siempre debe comprobar el origen, los permisos y las revisiones del archivo APK antes de instalarlo. También debe escanear el archivo APK con un software antivirus y hacer una copia de seguridad de sus datos antes de instalarlo.
-Una de las fuentes de confianza para descargar Five Nights at Freddy’s 3 APK es APKPure.com, un sitio web que proporciona archivos APK seguros y verificados para varias aplicaciones y juegos. Para descargar el archivo APK de APKPure.com, debe seguir estos pasos:
-Para instalar el archivo APK en su dispositivo Android, es necesario habilitar fuentes desconocidas, que le permite instalar aplicaciones de fuentes distintas de Google Play Store. Para habilitar fuentes desconocidas, debe seguir estos pasos:
- -Para instalar el archivo APK en tu dispositivo Android, debes seguir estos pasos:
-Para abrir el archivo APK en su dispositivo Windows, es necesario utilizar un emulador, que es un software que simula un entorno Android en su PC. Uno de los emuladores populares es BlueStacks, que puede descargar desde BlueStacks.com. Para usar BlueStacks y abrir el archivo APK en tu dispositivo Windows, debes seguir estos pasos:
- -En este artículo, hemos explicado qué es Five Nights at Freddy’s 3, qué es un archivo APK, y cómo descargar e instalar Five Nights at Freddy’s 3 APK en sus dispositivos. Esperamos que este artículo te haya ayudado a disfrutar de este emocionante juego de terror. Sin embargo, también le recordamos que sea cuidadoso y responsable al descargar e instalar archivos APK, ya que pueden plantear algunos riesgos para sus dispositivos o datos. Si tiene alguna pregunta o comentario, no dude en dejar un comentario a continuación.
-A: Cinco noches en Freddy’s 3 no es gratis. Cuesta $2.99 en Google Play Store, $4.99 en Steam y $7.99 en App Store. Sin embargo, puedes descargarlo gratis usando un archivo APK de una fuente confiable.
-A: Five Nights at Freddy’s 3 es un juego de terror que involucra sustos de salto, sonidos espeluznantes e imágenes perturbadoras. No es adecuado para niños o personas que se asustan fácilmente o tienen problemas cardíacos. Si estás buscando un desafío y una emoción, puedes disfrutar de este juego.
-A: Para desinstalar Five Nights at Freddy’s 3 APK, es necesario seguir estos pasos:
-A: Para actualizar Five Nights at Freddy’s 3 APK, debe seguir estos pasos:
-A: Five Nights at Freddy’s 3 es un juego para un solo jugador que no tiene un modo en línea. Sin embargo, puedes jugar online usando un emulador basado en el navegador, como Gamejolt.com. Para jugar online, debes seguir estos pasos:
- 64aa2da5cf- # The higher the scale, the closer the output will be to the original image - #
- # ''') - # To make it user friendly, we currently hide the following two options from the users and just assume that the input image has no human - # model and has plain white background. In the future when we figure out how to best process human models or background, we - # may turn these options back on - # has_human = gr.Checkbox(visible=False, label="Contains models?", value=False) - # has_background = gr.Checkbox(visible=False, label="Contains background?", value=False) - - # The model_name ('Technical drawings' or 'Inspiration images' as specified in the config file) will trigger an update of the app UI as described previously in the change_input_option function - model_name.change(fn=change_input_option, inputs=model_name, outputs=[category, image, scale]) - generate = gr.Button(value="Generate").style(full_width=True) - # this hidden tab contains 4 more parameters - guidance scale, number of steps in the inference, width and hiegh of the output, - # that we don't believe users will use often. The default values are what recommended by concensus on the internet - with gr.Tab("Options"): - with gr.Group(): - with gr.Row(): - guidance = gr.Slider(label="Guidance scale", value=7.5, maximum=15) - steps = gr.Slider(label="Steps", value=50, minimum=2, maximum=75, step=1) - - with gr.Row(): - #The default of 512*512 was chosen somewhat randomly for txt-to-img. For img-to-img, SD will simply preserve the size of the - # input as the size of the output, so these two parameters are not even used by the SD img-to-imge pipeline. - width = gr.Slider(label="Image width", value=512, minimum=64, maximum=1024, step=8) - height = gr.Slider(label="Image height", value=512, minimum=64, maximum=1024, step=8) - - seed = gr.Slider(0, MAX_SEED, label='Seed (0 = random)', value=0, step=1) #note: the uppder bound MAX_SEED is specified in the config file - with gr.Column(scale=55): - image_out = gr.Gallery( - label="Output", show_label=True, elem_id="gallery" - ).style(grid=[1], height='auto') - ## Rahgav's code## - error_output = gr.Markdown() - inference_execution_time = gr.Markdown(visible=False) # Do not remove - used for triggering data analytics. See comment below for details. - with gr.Row(): - download_button = gr.Button(value="Download", elem_id="download-btn") - convert_to_ai_button = gr.Button(value="Convert to .ai", elem_id="convert-to-ai") - ## end of Rahgav's code## - ## End of app design ## - - ## Execute the app with the given input and output format## - inputs = [model_name, prompt, category, guidance, steps, width, height, seed, image, scale, neg_prompt] - outputs = [image_out, error_output, inference_execution_time] - # The SD inference will be triggered (i.e. call the inference_master function) either by users pressing - # the Enter key when they complete typing the text prompt or by clicking the 'Generate' button - prompt.submit(inference_master, inputs=inputs, outputs=outputs) - generate.click(inference_master, inputs=inputs, outputs=outputs) - ## End of app execution ## - - # List of examples for Inspiration image - # Only the parameters specified below will be shown in the UI. Other parameters will use the default values specified in the app design section - ex_ii = gr.Examples([ - ["rubber rain boot, slip on", 3662441489, 'caterpillar_boot.jpg','Inspiration images'], - ["", 5214608943, 'high_heels.jpg','Inspiration images'], - ["leopard print", 5214608943, 'high_heels.jpg','Inspiration images'], - #["", 9659990480, 'strawberry_dress.jpg','Inspiration images'], - ["dress", 9275268464, 'green_fur_coat.jpg','Inspiration images'], - ["shirt", 4588852266, 'colorful_jacket.jpeg','Inspiration images'], - ["jeans with many cargo pockets", 4648864138, 'revolve_jeans.jpeg','Inspiration images'], - ["jeans with Frayed hem and distressed details", 7800241265, 'revolve_jeans.jpeg','Inspiration images'], - ["ruffle maxi dress", 3678929147, 'revolve_dress.jpeg','Inspiration images'], - ["oil painting floral and leaves design on the dress", 1243336480, 'revolve_dress.jpeg','Inspiration images'], - # ["punk leather jacket", 5237416518, 'punk_jacket.jpg','Inspiration images'], - # ["dress with gigantic puff sleeves and mock neck", 1558563429, "phillip_lim_dress.jpeg",'Inspiration images' ], - ["men's hiker work boots, waterproof, composite toe protection", 8011630240, None, 'Inspiration images'], - ["women's duck boot, premium quilted nylon upper with a vulcanized rubber shell", 8011630240, None, 'Inspiration images'], - ], inputs=[prompt, seed, image, model_name], outputs=outputs, fn=inference,label = "Examples of inspiration images", cache_examples=False) - - # List of examples for Technical drawings - # Only the parameters specified below will be shown in the UI. Other parameters will use the default values specified in the app design section - ex_td = gr.Examples([ - ["midi shirt dress with the classic point collar, short roll up sleeves, button down along the front, two chest pockets, tie waist", 2773414568, None, 'Technical drawings'], - ["maxi dress, short puff sleeves, a tiered construction with 4 tiers and tasseled necktie, splitneck, elasticised cuffs, button front with 3 buttons, waist spaghetti tie, embroidered hem", - 3153349073, None, 'Technical drawings'], - [" mini dress with a cross neck wrap, sharp lines, a slashed cut out at the waist. Finished with ruched sides, this sheath-silhouetted style drapes with a jersey fabrication", - 4715243121, None, 'Technical drawings'], - ["midi babydoll bralette dress, buckle belt with belt holes, button down under below the belt along the front, curved neckline band, shoulder straps, sleeveless", - 5687562474, None, 'Technical drawings'], - ], inputs=[prompt, seed, image, model_name], outputs=outputs, fn=inference,label = "Examples of technical drawings", cache_examples=False) - - ######### Data analytics and Download functionality below - Rahgav's code ######### - # data_for_logging = [model_name, prompt, category, guidance, steps, image, neg_prompt, image_out] - # print("data for logging:", data_for_logging) - # # This needs to be called at some point prior to the first call to callback.flag() - # hf_writer_callback.setup(data_for_logging, "flagged_data_points") - # Gradio does not automatically log output because it has no way of tracking when inference has completed. See https://github.com/gradio-app/gradio/pull/2695 - # An approach to solve for this is to manually log (i.e. call the flag()) using an output component with an event listener. - # inference_execution_time, a markdown component, is updated whenever the inference method is called, which means we log after inference. - # See https://github.com/gradio-app/gradio/issues/2560 for reference. - # inference_execution_time.change( - # lambda *args: hf_writer_callback.flag(args), - # data_for_logging, - # None, - # show_progress=False, - # preprocess=False # See https://gradio.app/using_flagging/#flagging-with-blocks - # ) - # Download button with injected javascript to force download a file when clicked. - # Note: Passing a python function with the _js parameter set breaks download functionality. Not sure why. - download_button.click( - None, - inputs=[], - outputs=[], - _js=download_primary_image_url_js) - # Convert the primary image in the gallery to .ai file - convert_to_ai_button.click( - None, - inputs=[], - outputs=[], - _js=convert_gallery_image_to_ai_js) - - -print(f"Space built in {time.time() - start_time:.2f} seconds") -## End of Rahgav's code - -####################################### -# Launch the Gradio app -####################################### -#concurrency_count = 1 is the default value used by Gradio that I've seen other HF spaces use so I copied. I did NOT experiment other values. -#It controls the number of worker threads that will be processing requests from the queue concurrently. -#Increasing this number will increase the rate at which requests are processed, but will also increase the memory usage of the queue. -demo.queue(concurrency_count=1) -demo.launch(debug=True, share=False) - - - -# \ No newline at end of file diff --git a/spaces/Ricecake123/RVC-demo/lib/infer_pack/onnx_inference.py b/spaces/Ricecake123/RVC-demo/lib/infer_pack/onnx_inference.py deleted file mode 100644 index 6517853be49e61c427cf7cd9b5ed203f6d5f367e..0000000000000000000000000000000000000000 --- a/spaces/Ricecake123/RVC-demo/lib/infer_pack/onnx_inference.py +++ /dev/null @@ -1,145 +0,0 @@ -import onnxruntime -import librosa -import numpy as np -import soundfile - - -class ContentVec: - def __init__(self, vec_path="pretrained/vec-768-layer-12.onnx", device=None): - print("load model(s) from {}".format(vec_path)) - if device == "cpu" or device is None: - providers = ["CPUExecutionProvider"] - elif device == "cuda": - providers = ["CUDAExecutionProvider", "CPUExecutionProvider"] - elif device == "dml": - providers = ["DmlExecutionProvider"] - else: - raise RuntimeError("Unsportted Device") - self.model = onnxruntime.InferenceSession(vec_path, providers=providers) - - def __call__(self, wav): - return self.forward(wav) - - def forward(self, wav): - feats = wav - if feats.ndim == 2: # double channels - feats = feats.mean(-1) - assert feats.ndim == 1, feats.ndim - feats = np.expand_dims(np.expand_dims(feats, 0), 0) - onnx_input = {self.model.get_inputs()[0].name: feats} - logits = self.model.run(None, onnx_input)[0] - return logits.transpose(0, 2, 1) - - -def get_f0_predictor(f0_predictor, hop_length, sampling_rate, **kargs): - if f0_predictor == "pm": - from lib.infer_pack.modules.F0Predictor.PMF0Predictor import PMF0Predictor - - f0_predictor_object = PMF0Predictor( - hop_length=hop_length, sampling_rate=sampling_rate - ) - elif f0_predictor == "harvest": - from lib.infer_pack.modules.F0Predictor.HarvestF0Predictor import ( - HarvestF0Predictor, - ) - - f0_predictor_object = HarvestF0Predictor( - hop_length=hop_length, sampling_rate=sampling_rate - ) - elif f0_predictor == "dio": - from lib.infer_pack.modules.F0Predictor.DioF0Predictor import DioF0Predictor - - f0_predictor_object = DioF0Predictor( - hop_length=hop_length, sampling_rate=sampling_rate - ) - else: - raise Exception("Unknown f0 predictor") - return f0_predictor_object - - -class OnnxRVC: - def __init__( - self, - model_path, - sr=40000, - hop_size=512, - vec_path="vec-768-layer-12", - device="cpu", - ): - vec_path = f"pretrained/{vec_path}.onnx" - self.vec_model = ContentVec(vec_path, device) - if device == "cpu" or device is None: - providers = ["CPUExecutionProvider"] - elif device == "cuda": - providers = ["CUDAExecutionProvider", "CPUExecutionProvider"] - elif device == "dml": - providers = ["DmlExecutionProvider"] - else: - raise RuntimeError("Unsportted Device") - self.model = onnxruntime.InferenceSession(model_path, providers=providers) - self.sampling_rate = sr - self.hop_size = hop_size - - def forward(self, hubert, hubert_length, pitch, pitchf, ds, rnd): - onnx_input = { - self.model.get_inputs()[0].name: hubert, - self.model.get_inputs()[1].name: hubert_length, - self.model.get_inputs()[2].name: pitch, - self.model.get_inputs()[3].name: pitchf, - self.model.get_inputs()[4].name: ds, - self.model.get_inputs()[5].name: rnd, - } - return (self.model.run(None, onnx_input)[0] * 32767).astype(np.int16) - - def inference( - self, - raw_path, - sid, - f0_method="dio", - f0_up_key=0, - pad_time=0.5, - cr_threshold=0.02, - ): - f0_min = 50 - f0_max = 1100 - f0_mel_min = 1127 * np.log(1 + f0_min / 700) - f0_mel_max = 1127 * np.log(1 + f0_max / 700) - f0_predictor = get_f0_predictor( - f0_method, - hop_length=self.hop_size, - sampling_rate=self.sampling_rate, - threshold=cr_threshold, - ) - wav, sr = librosa.load(raw_path, sr=self.sampling_rate) - org_length = len(wav) - if org_length / sr > 50.0: - raise RuntimeError("Reached Max Length") - - wav16k = librosa.resample(wav, orig_sr=self.sampling_rate, target_sr=16000) - wav16k = wav16k - - hubert = self.vec_model(wav16k) - hubert = np.repeat(hubert, 2, axis=2).transpose(0, 2, 1).astype(np.float32) - hubert_length = hubert.shape[1] - - pitchf = f0_predictor.compute_f0(wav, hubert_length) - pitchf = pitchf * 2 ** (f0_up_key / 12) - pitch = pitchf.copy() - f0_mel = 1127 * np.log(1 + pitch / 700) - f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / ( - f0_mel_max - f0_mel_min - ) + 1 - f0_mel[f0_mel <= 1] = 1 - f0_mel[f0_mel > 255] = 255 - pitch = np.rint(f0_mel).astype(np.int64) - - pitchf = pitchf.reshape(1, len(pitchf)).astype(np.float32) - pitch = pitch.reshape(1, len(pitch)) - ds = np.array([sid]).astype(np.int64) - - rnd = np.random.randn(1, 192, hubert_length).astype(np.float32) - hubert_length = np.array([hubert_length]).astype(np.int64) - - out_wav = self.forward(hubert, hubert_length, pitch, pitchf, ds, rnd).squeeze() - out_wav = np.pad(out_wav, (0, 2 * self.hop_size), "constant") - return out_wav[0:org_length] diff --git a/spaces/Riksarkivet/htr_demo/helper/text/overview/faq_discussion/faq.md b/spaces/Riksarkivet/htr_demo/helper/text/overview/faq_discussion/faq.md deleted file mode 100644 index d7d344e343b3aa530dfdd123aa7b39d3e3991287..0000000000000000000000000000000000000000 --- a/spaces/Riksarkivet/htr_demo/helper/text/overview/faq_discussion/faq.md +++ /dev/null @@ -1,13 +0,0 @@ -## Frequently Asked Questions - -**Q**: Is my data secure? Can I upload my own images? -**A**: Absolutely. Uploaded files are not saved or stored. - -**Q**: Why am I always in a queue? -**A**: This is due to hardware constraints and rate limits imposed by Hugging Face. For alternative ways to use the app, refer to the tab > **Documentation** under > **Duplication for Own Use & API**. - -**Q**: Why is Fast track so slow? -**A**: The current speed is due to hardware limitations and the present state of the code. However, we plan to update the application in future releases, which will significantly improve the performance of the application. - -**Q**: Is it possible to run Fast track or the API on image batches? -**A**: Not currently, but we plan to implement this feature in the future. diff --git a/spaces/Ritori/play_with_baby_llama2/README.md b/spaces/Ritori/play_with_baby_llama2/README.md deleted file mode 100644 index 35d5cd948be067fe4cce5182344521ba13adcf5c..0000000000000000000000000000000000000000 --- a/spaces/Ritori/play_with_baby_llama2/README.md +++ /dev/null @@ -1,158 +0,0 @@ ---- -title: play_with_baby_llama2 -app_file: baby_llama2.py -sdk: gradio -sdk_version: 3.38.0 ---- - -## llama2.c - -Have you ever wanted to inference a baby [Llama 2](https://ai.meta.com/llama/) model in pure C? No? Well, now you can! - - -
-With this code you can train the Llama 2 LLM architecture from scratch in PyTorch, then save the weights to a raw binary file, then load that into one ~simple 500-line C file ([run.c](run.c)) that inferences the model, simply in fp32 for now. On my cloud Linux devbox a dim 288 6-layer 6-head model (~15M params) inferences at ~100 tok/s in fp32, and about the same on my M1 MacBook Air. I was somewhat pleasantly surprised that one can run reasonably sized models (few ten million params) at highly interactive rates with an approach this simple.
-
-Please note that this is just a weekend project: I took nanoGPT, tuned it to implement the Llama-2 architecture instead of GPT-2, and the meat of it was writing the C inference engine in [run.c](run.c). As such, this is not really meant to be a production-grade library right now.
-
-Hat tip to [llama.cpp](https://github.com/ggerganov/llama.cpp) for inspiring this project. I wanted something super minimal so I chose to hard-code the llama-2 architecture, stick to fp32, and just roll one inference file of pure C with no dependencies.
-
-## feel the magic
-
-Let's just run a baby Llama 2 model in C. You need a model checkpoint. Download this 15M parameter model I trained on the [TinyStories](https://huggingface.co/datasets/roneneldan/TinyStories) dataset (~58MB download) and place it into the default checkpoint directory `out`:
-
-```bash
-wget https://karpathy.ai/llama2c/model.bin -P out
-```
-
-(if that doesn't work try [google drive](https://drive.google.com/file/d/1aTimLdx3JktDXxcHySNrZJOOk8Vb1qBR/view?usp=share_link)). Compile and run the C code:
-
-```bash
-gcc -O3 -o run run.c -lm
-./run out/model.bin
-```
-
-You'll see the text stream a sample. On my M1 MacBook Air this runs at ~100 tokens/s, not bad for super naive fp32 single-threaded C code. See [performance](#performance) for compile flags that can significantly speed this up. Sample output:
-
-*Once upon a time, there was a boy named Timmy. Timmy loved to play sports with his friends. He was very good at throwing and catching balls. One day, Timmy's mom gave him a new shirt to wear to a party. Timmy thought it was impressive and asked his mom to explain what a shirt could be for. "A shirt is like a special suit for a basketball game," his mom said. Timmy was happy to hear that and put on his new shirt. He felt like a soldier going to the army and shouting. From that day on, Timmy wore his new shirt every time he played sports with his friends at the party. Once upon a time, there was a little girl named Lily. She loved to play outside with her friends. One day, Lily and her friend Emma were playing with a ball. Emma threw the ball too hard and it hit Lily's face. Lily felt embarrassed and didn't want to play anymore.
-Emma asked Lily what was wrong, and Lily told her about her memory. Emma told Lily that she was embarrassed because she had thrown the ball too hard. Lily felt bad
-achieved tok/s: 98.746993347843922*
-
-**Update**: I've now also uploaded a bigger checkpoint. This one is dim 512, 8 layers, 8 heads and context length 1024, a ~44M param Transformer. It trained for 200K iterations batch size 32 on 4XA100 40GB GPUs in ~8 hours. You can use this bigger and more powerful checkpoint like so:
-
-```bash
-wget https://karpathy.ai/llama2c/model44m.bin -P out44m
-./run out44m/model44m.bin
-```
-
-On my MacBook Air compiled with $ gcc -Ofast -o run run.c -lm this ran at ~150 tok/s. Still way too fast! I have to train an even bigger checkpoint... This model samples more coherent and diverse stories:
-
-*Once upon a time, there was a little girl named Lily. She loved playing with her toys on top of her bed. One day, she decided to have a tea party with her stuffed animals. She poured some tea into a tiny teapot and put it on top of the teapot. Suddenly, her little brother Max came into the room and wanted to join the tea party too. Lily didn't want to share her tea and she told Max to go away. Max started to cry and Lily felt bad. She decided to yield her tea party to Max and they both shared the teapot. But then, something unexpected happened. The teapot started to shake and wiggle. Lily and Max were scared and didn't know what to do. Suddenly, the teapot started to fly towards the ceiling and landed on the top of the bed. Lily and Max were amazed and they hugged each other. They realized that sharing was much more fun than being selfish. From that day on, they always shared their tea parties and toys.*
-
-## howto
-
-It should be possible to load the weights released by Meta but I haven't tried because the inference speed, even of the 7B model, would probably be not great with this baby single-threaded C program. So in this repo we focus on more narrow applications, and train the same architecture but from scratch, in this case on the TinyStories dataset for fun.
-
-First let's download and pretokenize some source dataset, e.g. I like [TinyStories](https://huggingface.co/datasets/roneneldan/TinyStories) so this is the only example currently available in this repo. But it should be very easy to add datasets, see the code.
-
-```bash
-python tinystories.py download
-python tinystories.py pretokenize
-```
-
-Then train our model:
-
-```bash
-python train.py
-```
-
-See the train.py script for more exotic launches and hyperparameter overrides. I didn't tune the hyperparameters, I expect simple hyperparameter exploration should give better models. Totally understand if you want to skip model training, for simple demo just download my pretrained model and save it into the directory `out`:
-
-```bash
-wget https://karpathy.ai/llama2c/model.bin -P out
-```
-
-Once we have the model.bin file, we can inference in C. Compile the C code first:
-
-```bash
-gcc -O3 -o run run.c -lm
-```
-
-You can now run it simply as
-
-```bash
-./run out/model.bin
-```
-
-Watch the tokens stream by, fun! We can also run the PyTorch inference script for comparison (to run, add [model.ckpt](https://drive.google.com/file/d/1SM0rMxzy7babB-v4MfTg1GFqOCgWar5w/view?usp=share_link) to /out if you haven't already):
-
-```bash
-python sample.py
-```
-
-Which gives the same results. More detailed testing will be done in `test_all.py`, run as:
-
-```bash
-$ pytest
-```
-
-Currently you will need two files to test or sample: the [model.bin](https://drive.google.com/file/d/1aTimLdx3JktDXxcHySNrZJOOk8Vb1qBR/view?usp=share_link) file and the [model.ckpt](https://drive.google.com/file/d/1SM0rMxzy7babB-v4MfTg1GFqOCgWar5w/view?usp=share_link) file from PyTorch training I ran earlier. I have to think through running the tests without having to download 200MB of data.
-
-## performance
-
-*(NOTE: this guide is not great because I personally spend a lot of my time in Python land and don't have an amazing understanding of a lot of these features and flags. If someone does and is willing to help document and briefly describe some of these and their tradeoffs, I'd welcome a PR)*
-
-There are many ways to potentially speed up this code depending on your system. Here we document a few together with a high-level guide on what they do. Here's again the default way to compile, but using -O3:
-
-```bash
-gcc -O3 -o run run.c -lm
-```
-
--O3 includes optimizations that are expensive in terms of compile time and memory usage. Including vectorization, loop unrolling, and predicting branches. Here's a few more to try.
-
-`-Ofast` Run additional optimizations which may break compliance with the C/IEEE specifications, in addition to `-O3`. See [the GCC docs](https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html) for more information.
-
-`-ffast-math` breaks IEEE compliance, e.g. allowing reordering of operations, disables a bunch of checks for e.g. NaNs (assuming they don't happen), enables reciprocal approximations, disables signed zero, etc. However, there is a good reason to be suspicious of this setting, one good writeup is here: ["Beware of fast-math"](https://simonbyrne.github.io/notes/fastmath/).
-
-`-funsafe-math-optimizations` a more limited form of -ffast-math, that still breaks IEEE compliance but doesn't have all of the numeric/error handling changes from `-ffasth-math`. See [the GCC docs](https://gcc.gnu.org/wiki/FloatingPointMath) for more information.
-
-`-march=native` Compile the program to use the architecture of the machine you're compiling on rather than a more generic CPU. This may enable additional optimizations and hardware-specific tuning such as improved vector instructions/width.
-
-Putting a few of these together, the fastest throughput I saw so far on my MacBook Air (M1) is with:
-
-```bash
-gcc -Ofast -o run run.c -lm
-```
-
-Also, I saw someone report higher throughput replacing `gcc` with `clang`.
-
-**OpenMP** Big improvements can also be achieved by compiling with OpenMP, which "activates" the `#pragma omp parallel for` inside the matmul. You can compile e.g. like so:
-
-```bash
-clang -Ofast -fopenmp -march=native run.c -lm -o run
-```
-
-(I believe you can swap clang/gcc, and may try to leave out -march=native). Then when you run inference, make sure to use OpenMP flags to set the number of threads, e.g.:
-
-```bash
-OMP_NUM_THREADS=4 ./run out/model.bin
-```
-
-Depending on your system resources you may want to tweak these hyperparameters. (TODO: I am not intimitely familiar with OpenMP and its configuration, if someone would like to flesh out this section I would welcome a PR).
-
-## unsorted todos
-
-- why is there a leading space in C sampling code when we `./run`?
-- todo multiquery support? doesn't seem as useful for smaller models that run on CPU (?)
-- todo support inferencing beyond max_seq_len steps, have to think through the kv cache
-- why is MFU so low (~10%) on my A100 40GB for training?
-- weird errors with torch.compile and wandb when using DDP
-- make more better tests to decrease yolo
-
-## ack
-
-I trained the llama2.c storyteller models on a 4X A100 40GB box graciously provided by the excellent [Lambda labs](https://lambdalabs.com/service/gpu-cloud), thank you.
-
-## License
-
-MIT
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/roi_heads/double_roi_head.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/roi_heads/double_roi_head.py
deleted file mode 100644
index a1aa6c8244a889fbbed312a89574c3e11be294f0..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/roi_heads/double_roi_head.py
+++ /dev/null
@@ -1,33 +0,0 @@
-from ..builder import HEADS
-from .standard_roi_head import StandardRoIHead
-
-
-@HEADS.register_module()
-class DoubleHeadRoIHead(StandardRoIHead):
- """RoI head for Double Head RCNN.
-
- https://arxiv.org/abs/1904.06493
- """
-
- def __init__(self, reg_roi_scale_factor, **kwargs):
- super(DoubleHeadRoIHead, self).__init__(**kwargs)
- self.reg_roi_scale_factor = reg_roi_scale_factor
-
- def _bbox_forward(self, x, rois):
- """Box head forward function used in both training and testing time."""
- bbox_cls_feats = self.bbox_roi_extractor(
- x[:self.bbox_roi_extractor.num_inputs], rois)
- bbox_reg_feats = self.bbox_roi_extractor(
- x[:self.bbox_roi_extractor.num_inputs],
- rois,
- roi_scale_factor=self.reg_roi_scale_factor)
- if self.with_shared_head:
- bbox_cls_feats = self.shared_head(bbox_cls_feats)
- bbox_reg_feats = self.shared_head(bbox_reg_feats)
- cls_score, bbox_pred = self.bbox_head(bbox_cls_feats, bbox_reg_feats)
-
- bbox_results = dict(
- cls_score=cls_score,
- bbox_pred=bbox_pred,
- bbox_feats=bbox_cls_feats)
- return bbox_results
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/models/utils/up_conv_block.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/models/utils/up_conv_block.py
deleted file mode 100644
index 378469da76cb7bff6a639e7877b3c275d50490fb..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/models/utils/up_conv_block.py
+++ /dev/null
@@ -1,101 +0,0 @@
-import torch
-import torch.nn as nn
-from annotator.uniformer.mmcv.cnn import ConvModule, build_upsample_layer
-
-
-class UpConvBlock(nn.Module):
- """Upsample convolution block in decoder for UNet.
-
- This upsample convolution block consists of one upsample module
- followed by one convolution block. The upsample module expands the
- high-level low-resolution feature map and the convolution block fuses
- the upsampled high-level low-resolution feature map and the low-level
- high-resolution feature map from encoder.
-
- Args:
- conv_block (nn.Sequential): Sequential of convolutional layers.
- in_channels (int): Number of input channels of the high-level
- skip_channels (int): Number of input channels of the low-level
- high-resolution feature map from encoder.
- out_channels (int): Number of output channels.
- num_convs (int): Number of convolutional layers in the conv_block.
- Default: 2.
- stride (int): Stride of convolutional layer in conv_block. Default: 1.
- dilation (int): Dilation rate of convolutional layer in conv_block.
- Default: 1.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- conv_cfg (dict | None): Config dict for convolution layer.
- Default: None.
- norm_cfg (dict | None): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict | None): Config dict for activation layer in ConvModule.
- Default: dict(type='ReLU').
- upsample_cfg (dict): The upsample config of the upsample module in
- decoder. Default: dict(type='InterpConv'). If the size of
- high-level feature map is the same as that of skip feature map
- (low-level feature map from encoder), it does not need upsample the
- high-level feature map and the upsample_cfg is None.
- dcn (bool): Use deformable convolution in convolutional layer or not.
- Default: None.
- plugins (dict): plugins for convolutional layers. Default: None.
- """
-
- def __init__(self,
- conv_block,
- in_channels,
- skip_channels,
- out_channels,
- num_convs=2,
- stride=1,
- dilation=1,
- with_cp=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU'),
- upsample_cfg=dict(type='InterpConv'),
- dcn=None,
- plugins=None):
- super(UpConvBlock, self).__init__()
- assert dcn is None, 'Not implemented yet.'
- assert plugins is None, 'Not implemented yet.'
-
- self.conv_block = conv_block(
- in_channels=2 * skip_channels,
- out_channels=out_channels,
- num_convs=num_convs,
- stride=stride,
- dilation=dilation,
- with_cp=with_cp,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg,
- dcn=None,
- plugins=None)
- if upsample_cfg is not None:
- self.upsample = build_upsample_layer(
- cfg=upsample_cfg,
- in_channels=in_channels,
- out_channels=skip_channels,
- with_cp=with_cp,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
- else:
- self.upsample = ConvModule(
- in_channels,
- skip_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
-
- def forward(self, skip, x):
- """Forward function."""
-
- x = self.upsample(x)
- out = torch.cat([skip, x], dim=1)
- out = self.conv_block(out)
-
- return out
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmseg/core/utils/misc.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmseg/core/utils/misc.py
deleted file mode 100644
index eb862a82bd47c8624db3dd5c6fb6ad8a03b62466..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmseg/core/utils/misc.py
+++ /dev/null
@@ -1,17 +0,0 @@
-def add_prefix(inputs, prefix):
- """Add prefix for dict.
-
- Args:
- inputs (dict): The input dict with str keys.
- prefix (str): The prefix to add.
-
- Returns:
-
- dict: The dict with keys updated with ``prefix``.
- """
-
- outputs = dict()
- for name, value in inputs.items():
- outputs[f'{prefix}.{name}'] = value
-
- return outputs
diff --git a/spaces/Rongjiehuang/ProDiff/utils/audio.py b/spaces/Rongjiehuang/ProDiff/utils/audio.py
deleted file mode 100644
index aba7ab926cf793d085bbdc70c97f376001183fe1..0000000000000000000000000000000000000000
--- a/spaces/Rongjiehuang/ProDiff/utils/audio.py
+++ /dev/null
@@ -1,56 +0,0 @@
-import subprocess
-import matplotlib
-
-matplotlib.use('Agg')
-import librosa
-import librosa.filters
-import numpy as np
-from scipy import signal
-from scipy.io import wavfile
-
-
-def save_wav(wav, path, sr, norm=False):
- if norm:
- wav = wav / np.abs(wav).max()
- wav *= 32767
- # proposed by @dsmiller
- wavfile.write(path, sr, wav.astype(np.int16))
-
-
-def get_hop_size(hparams):
- hop_size = hparams['hop_size']
- if hop_size is None:
- assert hparams['frame_shift_ms'] is not None
- hop_size = int(hparams['frame_shift_ms'] / 1000 * hparams['audio_sample_rate'])
- return hop_size
-
-
-###########################################################################################
-def _stft(y, hparams):
- return librosa.stft(y=y, n_fft=hparams['fft_size'], hop_length=get_hop_size(hparams),
- win_length=hparams['win_size'], pad_mode='constant')
-
-
-def _istft(y, hparams):
- return librosa.istft(y, hop_length=get_hop_size(hparams), win_length=hparams['win_size'])
-
-
-def librosa_pad_lr(x, fsize, fshift, pad_sides=1):
- '''compute right padding (final frame) or both sides padding (first and final frames)
- '''
- assert pad_sides in (1, 2)
- # return int(fsize // 2)
- pad = (x.shape[0] // fshift + 1) * fshift - x.shape[0]
- if pad_sides == 1:
- return 0, pad
- else:
- return pad // 2, pad // 2 + pad % 2
-
-
-# Conversions
-def amp_to_db(x):
- return 20 * np.log10(np.maximum(1e-5, x))
-
-
-def normalize(S, hparams):
- return (S - hparams['min_level_db']) / -hparams['min_level_db']
diff --git a/spaces/Sense-X/uniformer_image_demo/imagenet_class_index.py b/spaces/Sense-X/uniformer_image_demo/imagenet_class_index.py
deleted file mode 100644
index 5407d1471197fd9bfa466c47d8dfb6683cb9f551..0000000000000000000000000000000000000000
--- a/spaces/Sense-X/uniformer_image_demo/imagenet_class_index.py
+++ /dev/null
@@ -1,1002 +0,0 @@
-imagenet_classnames = {
- "0": ["n01440764", "tench"],
- "1": ["n01443537", "goldfish"],
- "2": ["n01484850", "great_white_shark"],
- "3": ["n01491361", "tiger_shark"],
- "4": ["n01494475", "hammerhead"],
- "5": ["n01496331", "electric_ray"],
- "6": ["n01498041", "stingray"],
- "7": ["n01514668", "cock"],
- "8": ["n01514859", "hen"],
- "9": ["n01518878", "ostrich"],
- "10": ["n01530575", "brambling"],
- "11": ["n01531178", "goldfinch"],
- "12": ["n01532829", "house_finch"],
- "13": ["n01534433", "junco"],
- "14": ["n01537544", "indigo_bunting"],
- "15": ["n01558993", "robin"],
- "16": ["n01560419", "bulbul"],
- "17": ["n01580077", "jay"],
- "18": ["n01582220", "magpie"],
- "19": ["n01592084", "chickadee"],
- "20": ["n01601694", "water_ouzel"],
- "21": ["n01608432", "kite"],
- "22": ["n01614925", "bald_eagle"],
- "23": ["n01616318", "vulture"],
- "24": ["n01622779", "great_grey_owl"],
- "25": ["n01629819", "European_fire_salamander"],
- "26": ["n01630670", "common_newt"],
- "27": ["n01631663", "eft"],
- "28": ["n01632458", "spotted_salamander"],
- "29": ["n01632777", "axolotl"],
- "30": ["n01641577", "bullfrog"],
- "31": ["n01644373", "tree_frog"],
- "32": ["n01644900", "tailed_frog"],
- "33": ["n01664065", "loggerhead"],
- "34": ["n01665541", "leatherback_turtle"],
- "35": ["n01667114", "mud_turtle"],
- "36": ["n01667778", "terrapin"],
- "37": ["n01669191", "box_turtle"],
- "38": ["n01675722", "banded_gecko"],
- "39": ["n01677366", "common_iguana"],
- "40": ["n01682714", "American_chameleon"],
- "41": ["n01685808", "whiptail"],
- "42": ["n01687978", "agama"],
- "43": ["n01688243", "frilled_lizard"],
- "44": ["n01689811", "alligator_lizard"],
- "45": ["n01692333", "Gila_monster"],
- "46": ["n01693334", "green_lizard"],
- "47": ["n01694178", "African_chameleon"],
- "48": ["n01695060", "Komodo_dragon"],
- "49": ["n01697457", "African_crocodile"],
- "50": ["n01698640", "American_alligator"],
- "51": ["n01704323", "triceratops"],
- "52": ["n01728572", "thunder_snake"],
- "53": ["n01728920", "ringneck_snake"],
- "54": ["n01729322", "hognose_snake"],
- "55": ["n01729977", "green_snake"],
- "56": ["n01734418", "king_snake"],
- "57": ["n01735189", "garter_snake"],
- "58": ["n01737021", "water_snake"],
- "59": ["n01739381", "vine_snake"],
- "60": ["n01740131", "night_snake"],
- "61": ["n01742172", "boa_constrictor"],
- "62": ["n01744401", "rock_python"],
- "63": ["n01748264", "Indian_cobra"],
- "64": ["n01749939", "green_mamba"],
- "65": ["n01751748", "sea_snake"],
- "66": ["n01753488", "horned_viper"],
- "67": ["n01755581", "diamondback"],
- "68": ["n01756291", "sidewinder"],
- "69": ["n01768244", "trilobite"],
- "70": ["n01770081", "harvestman"],
- "71": ["n01770393", "scorpion"],
- "72": ["n01773157", "black_and_gold_garden_spider"],
- "73": ["n01773549", "barn_spider"],
- "74": ["n01773797", "garden_spider"],
- "75": ["n01774384", "black_widow"],
- "76": ["n01774750", "tarantula"],
- "77": ["n01775062", "wolf_spider"],
- "78": ["n01776313", "tick"],
- "79": ["n01784675", "centipede"],
- "80": ["n01795545", "black_grouse"],
- "81": ["n01796340", "ptarmigan"],
- "82": ["n01797886", "ruffed_grouse"],
- "83": ["n01798484", "prairie_chicken"],
- "84": ["n01806143", "peacock"],
- "85": ["n01806567", "quail"],
- "86": ["n01807496", "partridge"],
- "87": ["n01817953", "African_grey"],
- "88": ["n01818515", "macaw"],
- "89": ["n01819313", "sulphur-crested_cockatoo"],
- "90": ["n01820546", "lorikeet"],
- "91": ["n01824575", "coucal"],
- "92": ["n01828970", "bee_eater"],
- "93": ["n01829413", "hornbill"],
- "94": ["n01833805", "hummingbird"],
- "95": ["n01843065", "jacamar"],
- "96": ["n01843383", "toucan"],
- "97": ["n01847000", "drake"],
- "98": ["n01855032", "red-breasted_merganser"],
- "99": ["n01855672", "goose"],
- "100": ["n01860187", "black_swan"],
- "101": ["n01871265", "tusker"],
- "102": ["n01872401", "echidna"],
- "103": ["n01873310", "platypus"],
- "104": ["n01877812", "wallaby"],
- "105": ["n01882714", "koala"],
- "106": ["n01883070", "wombat"],
- "107": ["n01910747", "jellyfish"],
- "108": ["n01914609", "sea_anemone"],
- "109": ["n01917289", "brain_coral"],
- "110": ["n01924916", "flatworm"],
- "111": ["n01930112", "nematode"],
- "112": ["n01943899", "conch"],
- "113": ["n01944390", "snail"],
- "114": ["n01945685", "slug"],
- "115": ["n01950731", "sea_slug"],
- "116": ["n01955084", "chiton"],
- "117": ["n01968897", "chambered_nautilus"],
- "118": ["n01978287", "Dungeness_crab"],
- "119": ["n01978455", "rock_crab"],
- "120": ["n01980166", "fiddler_crab"],
- "121": ["n01981276", "king_crab"],
- "122": ["n01983481", "American_lobster"],
- "123": ["n01984695", "spiny_lobster"],
- "124": ["n01985128", "crayfish"],
- "125": ["n01986214", "hermit_crab"],
- "126": ["n01990800", "isopod"],
- "127": ["n02002556", "white_stork"],
- "128": ["n02002724", "black_stork"],
- "129": ["n02006656", "spoonbill"],
- "130": ["n02007558", "flamingo"],
- "131": ["n02009229", "little_blue_heron"],
- "132": ["n02009912", "American_egret"],
- "133": ["n02011460", "bittern"],
- "134": ["n02012849", "crane"],
- "135": ["n02013706", "limpkin"],
- "136": ["n02017213", "European_gallinule"],
- "137": ["n02018207", "American_coot"],
- "138": ["n02018795", "bustard"],
- "139": ["n02025239", "ruddy_turnstone"],
- "140": ["n02027492", "red-backed_sandpiper"],
- "141": ["n02028035", "redshank"],
- "142": ["n02033041", "dowitcher"],
- "143": ["n02037110", "oystercatcher"],
- "144": ["n02051845", "pelican"],
- "145": ["n02056570", "king_penguin"],
- "146": ["n02058221", "albatross"],
- "147": ["n02066245", "grey_whale"],
- "148": ["n02071294", "killer_whale"],
- "149": ["n02074367", "dugong"],
- "150": ["n02077923", "sea_lion"],
- "151": ["n02085620", "Chihuahua"],
- "152": ["n02085782", "Japanese_spaniel"],
- "153": ["n02085936", "Maltese_dog"],
- "154": ["n02086079", "Pekinese"],
- "155": ["n02086240", "Shih-Tzu"],
- "156": ["n02086646", "Blenheim_spaniel"],
- "157": ["n02086910", "papillon"],
- "158": ["n02087046", "toy_terrier"],
- "159": ["n02087394", "Rhodesian_ridgeback"],
- "160": ["n02088094", "Afghan_hound"],
- "161": ["n02088238", "basset"],
- "162": ["n02088364", "beagle"],
- "163": ["n02088466", "bloodhound"],
- "164": ["n02088632", "bluetick"],
- "165": ["n02089078", "black-and-tan_coonhound"],
- "166": ["n02089867", "Walker_hound"],
- "167": ["n02089973", "English_foxhound"],
- "168": ["n02090379", "redbone"],
- "169": ["n02090622", "borzoi"],
- "170": ["n02090721", "Irish_wolfhound"],
- "171": ["n02091032", "Italian_greyhound"],
- "172": ["n02091134", "whippet"],
- "173": ["n02091244", "Ibizan_hound"],
- "174": ["n02091467", "Norwegian_elkhound"],
- "175": ["n02091635", "otterhound"],
- "176": ["n02091831", "Saluki"],
- "177": ["n02092002", "Scottish_deerhound"],
- "178": ["n02092339", "Weimaraner"],
- "179": ["n02093256", "Staffordshire_bullterrier"],
- "180": ["n02093428", "American_Staffordshire_terrier"],
- "181": ["n02093647", "Bedlington_terrier"],
- "182": ["n02093754", "Border_terrier"],
- "183": ["n02093859", "Kerry_blue_terrier"],
- "184": ["n02093991", "Irish_terrier"],
- "185": ["n02094114", "Norfolk_terrier"],
- "186": ["n02094258", "Norwich_terrier"],
- "187": ["n02094433", "Yorkshire_terrier"],
- "188": ["n02095314", "wire-haired_fox_terrier"],
- "189": ["n02095570", "Lakeland_terrier"],
- "190": ["n02095889", "Sealyham_terrier"],
- "191": ["n02096051", "Airedale"],
- "192": ["n02096177", "cairn"],
- "193": ["n02096294", "Australian_terrier"],
- "194": ["n02096437", "Dandie_Dinmont"],
- "195": ["n02096585", "Boston_bull"],
- "196": ["n02097047", "miniature_schnauzer"],
- "197": ["n02097130", "giant_schnauzer"],
- "198": ["n02097209", "standard_schnauzer"],
- "199": ["n02097298", "Scotch_terrier"],
- "200": ["n02097474", "Tibetan_terrier"],
- "201": ["n02097658", "silky_terrier"],
- "202": ["n02098105", "soft-coated_wheaten_terrier"],
- "203": ["n02098286", "West_Highland_white_terrier"],
- "204": ["n02098413", "Lhasa"],
- "205": ["n02099267", "flat-coated_retriever"],
- "206": ["n02099429", "curly-coated_retriever"],
- "207": ["n02099601", "golden_retriever"],
- "208": ["n02099712", "Labrador_retriever"],
- "209": ["n02099849", "Chesapeake_Bay_retriever"],
- "210": ["n02100236", "German_short-haired_pointer"],
- "211": ["n02100583", "vizsla"],
- "212": ["n02100735", "English_setter"],
- "213": ["n02100877", "Irish_setter"],
- "214": ["n02101006", "Gordon_setter"],
- "215": ["n02101388", "Brittany_spaniel"],
- "216": ["n02101556", "clumber"],
- "217": ["n02102040", "English_springer"],
- "218": ["n02102177", "Welsh_springer_spaniel"],
- "219": ["n02102318", "cocker_spaniel"],
- "220": ["n02102480", "Sussex_spaniel"],
- "221": ["n02102973", "Irish_water_spaniel"],
- "222": ["n02104029", "kuvasz"],
- "223": ["n02104365", "schipperke"],
- "224": ["n02105056", "groenendael"],
- "225": ["n02105162", "malinois"],
- "226": ["n02105251", "briard"],
- "227": ["n02105412", "kelpie"],
- "228": ["n02105505", "komondor"],
- "229": ["n02105641", "Old_English_sheepdog"],
- "230": ["n02105855", "Shetland_sheepdog"],
- "231": ["n02106030", "collie"],
- "232": ["n02106166", "Border_collie"],
- "233": ["n02106382", "Bouvier_des_Flandres"],
- "234": ["n02106550", "Rottweiler"],
- "235": ["n02106662", "German_shepherd"],
- "236": ["n02107142", "Doberman"],
- "237": ["n02107312", "miniature_pinscher"],
- "238": ["n02107574", "Greater_Swiss_Mountain_dog"],
- "239": ["n02107683", "Bernese_mountain_dog"],
- "240": ["n02107908", "Appenzeller"],
- "241": ["n02108000", "EntleBucher"],
- "242": ["n02108089", "boxer"],
- "243": ["n02108422", "bull_mastiff"],
- "244": ["n02108551", "Tibetan_mastiff"],
- "245": ["n02108915", "French_bulldog"],
- "246": ["n02109047", "Great_Dane"],
- "247": ["n02109525", "Saint_Bernard"],
- "248": ["n02109961", "Eskimo_dog"],
- "249": ["n02110063", "malamute"],
- "250": ["n02110185", "Siberian_husky"],
- "251": ["n02110341", "dalmatian"],
- "252": ["n02110627", "affenpinscher"],
- "253": ["n02110806", "basenji"],
- "254": ["n02110958", "pug"],
- "255": ["n02111129", "Leonberg"],
- "256": ["n02111277", "Newfoundland"],
- "257": ["n02111500", "Great_Pyrenees"],
- "258": ["n02111889", "Samoyed"],
- "259": ["n02112018", "Pomeranian"],
- "260": ["n02112137", "chow"],
- "261": ["n02112350", "keeshond"],
- "262": ["n02112706", "Brabancon_griffon"],
- "263": ["n02113023", "Pembroke"],
- "264": ["n02113186", "Cardigan"],
- "265": ["n02113624", "toy_poodle"],
- "266": ["n02113712", "miniature_poodle"],
- "267": ["n02113799", "standard_poodle"],
- "268": ["n02113978", "Mexican_hairless"],
- "269": ["n02114367", "timber_wolf"],
- "270": ["n02114548", "white_wolf"],
- "271": ["n02114712", "red_wolf"],
- "272": ["n02114855", "coyote"],
- "273": ["n02115641", "dingo"],
- "274": ["n02115913", "dhole"],
- "275": ["n02116738", "African_hunting_dog"],
- "276": ["n02117135", "hyena"],
- "277": ["n02119022", "red_fox"],
- "278": ["n02119789", "kit_fox"],
- "279": ["n02120079", "Arctic_fox"],
- "280": ["n02120505", "grey_fox"],
- "281": ["n02123045", "tabby"],
- "282": ["n02123159", "tiger_cat"],
- "283": ["n02123394", "Persian_cat"],
- "284": ["n02123597", "Siamese_cat"],
- "285": ["n02124075", "Egyptian_cat"],
- "286": ["n02125311", "cougar"],
- "287": ["n02127052", "lynx"],
- "288": ["n02128385", "leopard"],
- "289": ["n02128757", "snow_leopard"],
- "290": ["n02128925", "jaguar"],
- "291": ["n02129165", "lion"],
- "292": ["n02129604", "tiger"],
- "293": ["n02130308", "cheetah"],
- "294": ["n02132136", "brown_bear"],
- "295": ["n02133161", "American_black_bear"],
- "296": ["n02134084", "ice_bear"],
- "297": ["n02134418", "sloth_bear"],
- "298": ["n02137549", "mongoose"],
- "299": ["n02138441", "meerkat"],
- "300": ["n02165105", "tiger_beetle"],
- "301": ["n02165456", "ladybug"],
- "302": ["n02167151", "ground_beetle"],
- "303": ["n02168699", "long-horned_beetle"],
- "304": ["n02169497", "leaf_beetle"],
- "305": ["n02172182", "dung_beetle"],
- "306": ["n02174001", "rhinoceros_beetle"],
- "307": ["n02177972", "weevil"],
- "308": ["n02190166", "fly"],
- "309": ["n02206856", "bee"],
- "310": ["n02219486", "ant"],
- "311": ["n02226429", "grasshopper"],
- "312": ["n02229544", "cricket"],
- "313": ["n02231487", "walking_stick"],
- "314": ["n02233338", "cockroach"],
- "315": ["n02236044", "mantis"],
- "316": ["n02256656", "cicada"],
- "317": ["n02259212", "leafhopper"],
- "318": ["n02264363", "lacewing"],
- "319": ["n02268443", "dragonfly"],
- "320": ["n02268853", "damselfly"],
- "321": ["n02276258", "admiral"],
- "322": ["n02277742", "ringlet"],
- "323": ["n02279972", "monarch"],
- "324": ["n02280649", "cabbage_butterfly"],
- "325": ["n02281406", "sulphur_butterfly"],
- "326": ["n02281787", "lycaenid"],
- "327": ["n02317335", "starfish"],
- "328": ["n02319095", "sea_urchin"],
- "329": ["n02321529", "sea_cucumber"],
- "330": ["n02325366", "wood_rabbit"],
- "331": ["n02326432", "hare"],
- "332": ["n02328150", "Angora"],
- "333": ["n02342885", "hamster"],
- "334": ["n02346627", "porcupine"],
- "335": ["n02356798", "fox_squirrel"],
- "336": ["n02361337", "marmot"],
- "337": ["n02363005", "beaver"],
- "338": ["n02364673", "guinea_pig"],
- "339": ["n02389026", "sorrel"],
- "340": ["n02391049", "zebra"],
- "341": ["n02395406", "hog"],
- "342": ["n02396427", "wild_boar"],
- "343": ["n02397096", "warthog"],
- "344": ["n02398521", "hippopotamus"],
- "345": ["n02403003", "ox"],
- "346": ["n02408429", "water_buffalo"],
- "347": ["n02410509", "bison"],
- "348": ["n02412080", "ram"],
- "349": ["n02415577", "bighorn"],
- "350": ["n02417914", "ibex"],
- "351": ["n02422106", "hartebeest"],
- "352": ["n02422699", "impala"],
- "353": ["n02423022", "gazelle"],
- "354": ["n02437312", "Arabian_camel"],
- "355": ["n02437616", "llama"],
- "356": ["n02441942", "weasel"],
- "357": ["n02442845", "mink"],
- "358": ["n02443114", "polecat"],
- "359": ["n02443484", "black-footed_ferret"],
- "360": ["n02444819", "otter"],
- "361": ["n02445715", "skunk"],
- "362": ["n02447366", "badger"],
- "363": ["n02454379", "armadillo"],
- "364": ["n02457408", "three-toed_sloth"],
- "365": ["n02480495", "orangutan"],
- "366": ["n02480855", "gorilla"],
- "367": ["n02481823", "chimpanzee"],
- "368": ["n02483362", "gibbon"],
- "369": ["n02483708", "siamang"],
- "370": ["n02484975", "guenon"],
- "371": ["n02486261", "patas"],
- "372": ["n02486410", "baboon"],
- "373": ["n02487347", "macaque"],
- "374": ["n02488291", "langur"],
- "375": ["n02488702", "colobus"],
- "376": ["n02489166", "proboscis_monkey"],
- "377": ["n02490219", "marmoset"],
- "378": ["n02492035", "capuchin"],
- "379": ["n02492660", "howler_monkey"],
- "380": ["n02493509", "titi"],
- "381": ["n02493793", "spider_monkey"],
- "382": ["n02494079", "squirrel_monkey"],
- "383": ["n02497673", "Madagascar_cat"],
- "384": ["n02500267", "indri"],
- "385": ["n02504013", "Indian_elephant"],
- "386": ["n02504458", "African_elephant"],
- "387": ["n02509815", "lesser_panda"],
- "388": ["n02510455", "giant_panda"],
- "389": ["n02514041", "barracouta"],
- "390": ["n02526121", "eel"],
- "391": ["n02536864", "coho"],
- "392": ["n02606052", "rock_beauty"],
- "393": ["n02607072", "anemone_fish"],
- "394": ["n02640242", "sturgeon"],
- "395": ["n02641379", "gar"],
- "396": ["n02643566", "lionfish"],
- "397": ["n02655020", "puffer"],
- "398": ["n02666196", "abacus"],
- "399": ["n02667093", "abaya"],
- "400": ["n02669723", "academic_gown"],
- "401": ["n02672831", "accordion"],
- "402": ["n02676566", "acoustic_guitar"],
- "403": ["n02687172", "aircraft_carrier"],
- "404": ["n02690373", "airliner"],
- "405": ["n02692877", "airship"],
- "406": ["n02699494", "altar"],
- "407": ["n02701002", "ambulance"],
- "408": ["n02704792", "amphibian"],
- "409": ["n02708093", "analog_clock"],
- "410": ["n02727426", "apiary"],
- "411": ["n02730930", "apron"],
- "412": ["n02747177", "ashcan"],
- "413": ["n02749479", "assault_rifle"],
- "414": ["n02769748", "backpack"],
- "415": ["n02776631", "bakery"],
- "416": ["n02777292", "balance_beam"],
- "417": ["n02782093", "balloon"],
- "418": ["n02783161", "ballpoint"],
- "419": ["n02786058", "Band_Aid"],
- "420": ["n02787622", "banjo"],
- "421": ["n02788148", "bannister"],
- "422": ["n02790996", "barbell"],
- "423": ["n02791124", "barber_chair"],
- "424": ["n02791270", "barbershop"],
- "425": ["n02793495", "barn"],
- "426": ["n02794156", "barometer"],
- "427": ["n02795169", "barrel"],
- "428": ["n02797295", "barrow"],
- "429": ["n02799071", "baseball"],
- "430": ["n02802426", "basketball"],
- "431": ["n02804414", "bassinet"],
- "432": ["n02804610", "bassoon"],
- "433": ["n02807133", "bathing_cap"],
- "434": ["n02808304", "bath_towel"],
- "435": ["n02808440", "bathtub"],
- "436": ["n02814533", "beach_wagon"],
- "437": ["n02814860", "beacon"],
- "438": ["n02815834", "beaker"],
- "439": ["n02817516", "bearskin"],
- "440": ["n02823428", "beer_bottle"],
- "441": ["n02823750", "beer_glass"],
- "442": ["n02825657", "bell_cote"],
- "443": ["n02834397", "bib"],
- "444": ["n02835271", "bicycle-built-for-two"],
- "445": ["n02837789", "bikini"],
- "446": ["n02840245", "binder"],
- "447": ["n02841315", "binoculars"],
- "448": ["n02843684", "birdhouse"],
- "449": ["n02859443", "boathouse"],
- "450": ["n02860847", "bobsled"],
- "451": ["n02865351", "bolo_tie"],
- "452": ["n02869837", "bonnet"],
- "453": ["n02870880", "bookcase"],
- "454": ["n02871525", "bookshop"],
- "455": ["n02877765", "bottlecap"],
- "456": ["n02879718", "bow"],
- "457": ["n02883205", "bow_tie"],
- "458": ["n02892201", "brass"],
- "459": ["n02892767", "brassiere"],
- "460": ["n02894605", "breakwater"],
- "461": ["n02895154", "breastplate"],
- "462": ["n02906734", "broom"],
- "463": ["n02909870", "bucket"],
- "464": ["n02910353", "buckle"],
- "465": ["n02916936", "bulletproof_vest"],
- "466": ["n02917067", "bullet_train"],
- "467": ["n02927161", "butcher_shop"],
- "468": ["n02930766", "cab"],
- "469": ["n02939185", "caldron"],
- "470": ["n02948072", "candle"],
- "471": ["n02950826", "cannon"],
- "472": ["n02951358", "canoe"],
- "473": ["n02951585", "can_opener"],
- "474": ["n02963159", "cardigan"],
- "475": ["n02965783", "car_mirror"],
- "476": ["n02966193", "carousel"],
- "477": ["n02966687", "carpenter's_kit"],
- "478": ["n02971356", "carton"],
- "479": ["n02974003", "car_wheel"],
- "480": ["n02977058", "cash_machine"],
- "481": ["n02978881", "cassette"],
- "482": ["n02979186", "cassette_player"],
- "483": ["n02980441", "castle"],
- "484": ["n02981792", "catamaran"],
- "485": ["n02988304", "CD_player"],
- "486": ["n02992211", "cello"],
- "487": ["n02992529", "cellular_telephone"],
- "488": ["n02999410", "chain"],
- "489": ["n03000134", "chainlink_fence"],
- "490": ["n03000247", "chain_mail"],
- "491": ["n03000684", "chain_saw"],
- "492": ["n03014705", "chest"],
- "493": ["n03016953", "chiffonier"],
- "494": ["n03017168", "chime"],
- "495": ["n03018349", "china_cabinet"],
- "496": ["n03026506", "Christmas_stocking"],
- "497": ["n03028079", "church"],
- "498": ["n03032252", "cinema"],
- "499": ["n03041632", "cleaver"],
- "500": ["n03042490", "cliff_dwelling"],
- "501": ["n03045698", "cloak"],
- "502": ["n03047690", "clog"],
- "503": ["n03062245", "cocktail_shaker"],
- "504": ["n03063599", "coffee_mug"],
- "505": ["n03063689", "coffeepot"],
- "506": ["n03065424", "coil"],
- "507": ["n03075370", "combination_lock"],
- "508": ["n03085013", "computer_keyboard"],
- "509": ["n03089624", "confectionery"],
- "510": ["n03095699", "container_ship"],
- "511": ["n03100240", "convertible"],
- "512": ["n03109150", "corkscrew"],
- "513": ["n03110669", "cornet"],
- "514": ["n03124043", "cowboy_boot"],
- "515": ["n03124170", "cowboy_hat"],
- "516": ["n03125729", "cradle"],
- "517": ["n03126707", "crane"],
- "518": ["n03127747", "crash_helmet"],
- "519": ["n03127925", "crate"],
- "520": ["n03131574", "crib"],
- "521": ["n03133878", "Crock_Pot"],
- "522": ["n03134739", "croquet_ball"],
- "523": ["n03141823", "crutch"],
- "524": ["n03146219", "cuirass"],
- "525": ["n03160309", "dam"],
- "526": ["n03179701", "desk"],
- "527": ["n03180011", "desktop_computer"],
- "528": ["n03187595", "dial_telephone"],
- "529": ["n03188531", "diaper"],
- "530": ["n03196217", "digital_clock"],
- "531": ["n03197337", "digital_watch"],
- "532": ["n03201208", "dining_table"],
- "533": ["n03207743", "dishrag"],
- "534": ["n03207941", "dishwasher"],
- "535": ["n03208938", "disk_brake"],
- "536": ["n03216828", "dock"],
- "537": ["n03218198", "dogsled"],
- "538": ["n03220513", "dome"],
- "539": ["n03223299", "doormat"],
- "540": ["n03240683", "drilling_platform"],
- "541": ["n03249569", "drum"],
- "542": ["n03250847", "drumstick"],
- "543": ["n03255030", "dumbbell"],
- "544": ["n03259280", "Dutch_oven"],
- "545": ["n03271574", "electric_fan"],
- "546": ["n03272010", "electric_guitar"],
- "547": ["n03272562", "electric_locomotive"],
- "548": ["n03290653", "entertainment_center"],
- "549": ["n03291819", "envelope"],
- "550": ["n03297495", "espresso_maker"],
- "551": ["n03314780", "face_powder"],
- "552": ["n03325584", "feather_boa"],
- "553": ["n03337140", "file"],
- "554": ["n03344393", "fireboat"],
- "555": ["n03345487", "fire_engine"],
- "556": ["n03347037", "fire_screen"],
- "557": ["n03355925", "flagpole"],
- "558": ["n03372029", "flute"],
- "559": ["n03376595", "folding_chair"],
- "560": ["n03379051", "football_helmet"],
- "561": ["n03384352", "forklift"],
- "562": ["n03388043", "fountain"],
- "563": ["n03388183", "fountain_pen"],
- "564": ["n03388549", "four-poster"],
- "565": ["n03393912", "freight_car"],
- "566": ["n03394916", "French_horn"],
- "567": ["n03400231", "frying_pan"],
- "568": ["n03404251", "fur_coat"],
- "569": ["n03417042", "garbage_truck"],
- "570": ["n03424325", "gasmask"],
- "571": ["n03425413", "gas_pump"],
- "572": ["n03443371", "goblet"],
- "573": ["n03444034", "go-kart"],
- "574": ["n03445777", "golf_ball"],
- "575": ["n03445924", "golfcart"],
- "576": ["n03447447", "gondola"],
- "577": ["n03447721", "gong"],
- "578": ["n03450230", "gown"],
- "579": ["n03452741", "grand_piano"],
- "580": ["n03457902", "greenhouse"],
- "581": ["n03459775", "grille"],
- "582": ["n03461385", "grocery_store"],
- "583": ["n03467068", "guillotine"],
- "584": ["n03476684", "hair_slide"],
- "585": ["n03476991", "hair_spray"],
- "586": ["n03478589", "half_track"],
- "587": ["n03481172", "hammer"],
- "588": ["n03482405", "hamper"],
- "589": ["n03483316", "hand_blower"],
- "590": ["n03485407", "hand-held_computer"],
- "591": ["n03485794", "handkerchief"],
- "592": ["n03492542", "hard_disc"],
- "593": ["n03494278", "harmonica"],
- "594": ["n03495258", "harp"],
- "595": ["n03496892", "harvester"],
- "596": ["n03498962", "hatchet"],
- "597": ["n03527444", "holster"],
- "598": ["n03529860", "home_theater"],
- "599": ["n03530642", "honeycomb"],
- "600": ["n03532672", "hook"],
- "601": ["n03534580", "hoopskirt"],
- "602": ["n03535780", "horizontal_bar"],
- "603": ["n03538406", "horse_cart"],
- "604": ["n03544143", "hourglass"],
- "605": ["n03584254", "iPod"],
- "606": ["n03584829", "iron"],
- "607": ["n03590841", "jack-o'-lantern"],
- "608": ["n03594734", "jean"],
- "609": ["n03594945", "jeep"],
- "610": ["n03595614", "jersey"],
- "611": ["n03598930", "jigsaw_puzzle"],
- "612": ["n03599486", "jinrikisha"],
- "613": ["n03602883", "joystick"],
- "614": ["n03617480", "kimono"],
- "615": ["n03623198", "knee_pad"],
- "616": ["n03627232", "knot"],
- "617": ["n03630383", "lab_coat"],
- "618": ["n03633091", "ladle"],
- "619": ["n03637318", "lampshade"],
- "620": ["n03642806", "laptop"],
- "621": ["n03649909", "lawn_mower"],
- "622": ["n03657121", "lens_cap"],
- "623": ["n03658185", "letter_opener"],
- "624": ["n03661043", "library"],
- "625": ["n03662601", "lifeboat"],
- "626": ["n03666591", "lighter"],
- "627": ["n03670208", "limousine"],
- "628": ["n03673027", "liner"],
- "629": ["n03676483", "lipstick"],
- "630": ["n03680355", "Loafer"],
- "631": ["n03690938", "lotion"],
- "632": ["n03691459", "loudspeaker"],
- "633": ["n03692522", "loupe"],
- "634": ["n03697007", "lumbermill"],
- "635": ["n03706229", "magnetic_compass"],
- "636": ["n03709823", "mailbag"],
- "637": ["n03710193", "mailbox"],
- "638": ["n03710637", "maillot"],
- "639": ["n03710721", "maillot"],
- "640": ["n03717622", "manhole_cover"],
- "641": ["n03720891", "maraca"],
- "642": ["n03721384", "marimba"],
- "643": ["n03724870", "mask"],
- "644": ["n03729826", "matchstick"],
- "645": ["n03733131", "maypole"],
- "646": ["n03733281", "maze"],
- "647": ["n03733805", "measuring_cup"],
- "648": ["n03742115", "medicine_chest"],
- "649": ["n03743016", "megalith"],
- "650": ["n03759954", "microphone"],
- "651": ["n03761084", "microwave"],
- "652": ["n03763968", "military_uniform"],
- "653": ["n03764736", "milk_can"],
- "654": ["n03769881", "minibus"],
- "655": ["n03770439", "miniskirt"],
- "656": ["n03770679", "minivan"],
- "657": ["n03773504", "missile"],
- "658": ["n03775071", "mitten"],
- "659": ["n03775546", "mixing_bowl"],
- "660": ["n03776460", "mobile_home"],
- "661": ["n03777568", "Model_T"],
- "662": ["n03777754", "modem"],
- "663": ["n03781244", "monastery"],
- "664": ["n03782006", "monitor"],
- "665": ["n03785016", "moped"],
- "666": ["n03786901", "mortar"],
- "667": ["n03787032", "mortarboard"],
- "668": ["n03788195", "mosque"],
- "669": ["n03788365", "mosquito_net"],
- "670": ["n03791053", "motor_scooter"],
- "671": ["n03792782", "mountain_bike"],
- "672": ["n03792972", "mountain_tent"],
- "673": ["n03793489", "mouse"],
- "674": ["n03794056", "mousetrap"],
- "675": ["n03796401", "moving_van"],
- "676": ["n03803284", "muzzle"],
- "677": ["n03804744", "nail"],
- "678": ["n03814639", "neck_brace"],
- "679": ["n03814906", "necklace"],
- "680": ["n03825788", "nipple"],
- "681": ["n03832673", "notebook"],
- "682": ["n03837869", "obelisk"],
- "683": ["n03838899", "oboe"],
- "684": ["n03840681", "ocarina"],
- "685": ["n03841143", "odometer"],
- "686": ["n03843555", "oil_filter"],
- "687": ["n03854065", "organ"],
- "688": ["n03857828", "oscilloscope"],
- "689": ["n03866082", "overskirt"],
- "690": ["n03868242", "oxcart"],
- "691": ["n03868863", "oxygen_mask"],
- "692": ["n03871628", "packet"],
- "693": ["n03873416", "paddle"],
- "694": ["n03874293", "paddlewheel"],
- "695": ["n03874599", "padlock"],
- "696": ["n03876231", "paintbrush"],
- "697": ["n03877472", "pajama"],
- "698": ["n03877845", "palace"],
- "699": ["n03884397", "panpipe"],
- "700": ["n03887697", "paper_towel"],
- "701": ["n03888257", "parachute"],
- "702": ["n03888605", "parallel_bars"],
- "703": ["n03891251", "park_bench"],
- "704": ["n03891332", "parking_meter"],
- "705": ["n03895866", "passenger_car"],
- "706": ["n03899768", "patio"],
- "707": ["n03902125", "pay-phone"],
- "708": ["n03903868", "pedestal"],
- "709": ["n03908618", "pencil_box"],
- "710": ["n03908714", "pencil_sharpener"],
- "711": ["n03916031", "perfume"],
- "712": ["n03920288", "Petri_dish"],
- "713": ["n03924679", "photocopier"],
- "714": ["n03929660", "pick"],
- "715": ["n03929855", "pickelhaube"],
- "716": ["n03930313", "picket_fence"],
- "717": ["n03930630", "pickup"],
- "718": ["n03933933", "pier"],
- "719": ["n03935335", "piggy_bank"],
- "720": ["n03937543", "pill_bottle"],
- "721": ["n03938244", "pillow"],
- "722": ["n03942813", "ping-pong_ball"],
- "723": ["n03944341", "pinwheel"],
- "724": ["n03947888", "pirate"],
- "725": ["n03950228", "pitcher"],
- "726": ["n03954731", "plane"],
- "727": ["n03956157", "planetarium"],
- "728": ["n03958227", "plastic_bag"],
- "729": ["n03961711", "plate_rack"],
- "730": ["n03967562", "plow"],
- "731": ["n03970156", "plunger"],
- "732": ["n03976467", "Polaroid_camera"],
- "733": ["n03976657", "pole"],
- "734": ["n03977966", "police_van"],
- "735": ["n03980874", "poncho"],
- "736": ["n03982430", "pool_table"],
- "737": ["n03983396", "pop_bottle"],
- "738": ["n03991062", "pot"],
- "739": ["n03992509", "potter's_wheel"],
- "740": ["n03995372", "power_drill"],
- "741": ["n03998194", "prayer_rug"],
- "742": ["n04004767", "printer"],
- "743": ["n04005630", "prison"],
- "744": ["n04008634", "projectile"],
- "745": ["n04009552", "projector"],
- "746": ["n04019541", "puck"],
- "747": ["n04023962", "punching_bag"],
- "748": ["n04026417", "purse"],
- "749": ["n04033901", "quill"],
- "750": ["n04033995", "quilt"],
- "751": ["n04037443", "racer"],
- "752": ["n04039381", "racket"],
- "753": ["n04040759", "radiator"],
- "754": ["n04041544", "radio"],
- "755": ["n04044716", "radio_telescope"],
- "756": ["n04049303", "rain_barrel"],
- "757": ["n04065272", "recreational_vehicle"],
- "758": ["n04067472", "reel"],
- "759": ["n04069434", "reflex_camera"],
- "760": ["n04070727", "refrigerator"],
- "761": ["n04074963", "remote_control"],
- "762": ["n04081281", "restaurant"],
- "763": ["n04086273", "revolver"],
- "764": ["n04090263", "rifle"],
- "765": ["n04099969", "rocking_chair"],
- "766": ["n04111531", "rotisserie"],
- "767": ["n04116512", "rubber_eraser"],
- "768": ["n04118538", "rugby_ball"],
- "769": ["n04118776", "rule"],
- "770": ["n04120489", "running_shoe"],
- "771": ["n04125021", "safe"],
- "772": ["n04127249", "safety_pin"],
- "773": ["n04131690", "saltshaker"],
- "774": ["n04133789", "sandal"],
- "775": ["n04136333", "sarong"],
- "776": ["n04141076", "sax"],
- "777": ["n04141327", "scabbard"],
- "778": ["n04141975", "scale"],
- "779": ["n04146614", "school_bus"],
- "780": ["n04147183", "schooner"],
- "781": ["n04149813", "scoreboard"],
- "782": ["n04152593", "screen"],
- "783": ["n04153751", "screw"],
- "784": ["n04154565", "screwdriver"],
- "785": ["n04162706", "seat_belt"],
- "786": ["n04179913", "sewing_machine"],
- "787": ["n04192698", "shield"],
- "788": ["n04200800", "shoe_shop"],
- "789": ["n04201297", "shoji"],
- "790": ["n04204238", "shopping_basket"],
- "791": ["n04204347", "shopping_cart"],
- "792": ["n04208210", "shovel"],
- "793": ["n04209133", "shower_cap"],
- "794": ["n04209239", "shower_curtain"],
- "795": ["n04228054", "ski"],
- "796": ["n04229816", "ski_mask"],
- "797": ["n04235860", "sleeping_bag"],
- "798": ["n04238763", "slide_rule"],
- "799": ["n04239074", "sliding_door"],
- "800": ["n04243546", "slot"],
- "801": ["n04251144", "snorkel"],
- "802": ["n04252077", "snowmobile"],
- "803": ["n04252225", "snowplow"],
- "804": ["n04254120", "soap_dispenser"],
- "805": ["n04254680", "soccer_ball"],
- "806": ["n04254777", "sock"],
- "807": ["n04258138", "solar_dish"],
- "808": ["n04259630", "sombrero"],
- "809": ["n04263257", "soup_bowl"],
- "810": ["n04264628", "space_bar"],
- "811": ["n04265275", "space_heater"],
- "812": ["n04266014", "space_shuttle"],
- "813": ["n04270147", "spatula"],
- "814": ["n04273569", "speedboat"],
- "815": ["n04275548", "spider_web"],
- "816": ["n04277352", "spindle"],
- "817": ["n04285008", "sports_car"],
- "818": ["n04286575", "spotlight"],
- "819": ["n04296562", "stage"],
- "820": ["n04310018", "steam_locomotive"],
- "821": ["n04311004", "steel_arch_bridge"],
- "822": ["n04311174", "steel_drum"],
- "823": ["n04317175", "stethoscope"],
- "824": ["n04325704", "stole"],
- "825": ["n04326547", "stone_wall"],
- "826": ["n04328186", "stopwatch"],
- "827": ["n04330267", "stove"],
- "828": ["n04332243", "strainer"],
- "829": ["n04335435", "streetcar"],
- "830": ["n04336792", "stretcher"],
- "831": ["n04344873", "studio_couch"],
- "832": ["n04346328", "stupa"],
- "833": ["n04347754", "submarine"],
- "834": ["n04350905", "suit"],
- "835": ["n04355338", "sundial"],
- "836": ["n04355933", "sunglass"],
- "837": ["n04356056", "sunglasses"],
- "838": ["n04357314", "sunscreen"],
- "839": ["n04366367", "suspension_bridge"],
- "840": ["n04367480", "swab"],
- "841": ["n04370456", "sweatshirt"],
- "842": ["n04371430", "swimming_trunks"],
- "843": ["n04371774", "swing"],
- "844": ["n04372370", "switch"],
- "845": ["n04376876", "syringe"],
- "846": ["n04380533", "table_lamp"],
- "847": ["n04389033", "tank"],
- "848": ["n04392985", "tape_player"],
- "849": ["n04398044", "teapot"],
- "850": ["n04399382", "teddy"],
- "851": ["n04404412", "television"],
- "852": ["n04409515", "tennis_ball"],
- "853": ["n04417672", "thatch"],
- "854": ["n04418357", "theater_curtain"],
- "855": ["n04423845", "thimble"],
- "856": ["n04428191", "thresher"],
- "857": ["n04429376", "throne"],
- "858": ["n04435653", "tile_roof"],
- "859": ["n04442312", "toaster"],
- "860": ["n04443257", "tobacco_shop"],
- "861": ["n04447861", "toilet_seat"],
- "862": ["n04456115", "torch"],
- "863": ["n04458633", "totem_pole"],
- "864": ["n04461696", "tow_truck"],
- "865": ["n04462240", "toyshop"],
- "866": ["n04465501", "tractor"],
- "867": ["n04467665", "trailer_truck"],
- "868": ["n04476259", "tray"],
- "869": ["n04479046", "trench_coat"],
- "870": ["n04482393", "tricycle"],
- "871": ["n04483307", "trimaran"],
- "872": ["n04485082", "tripod"],
- "873": ["n04486054", "triumphal_arch"],
- "874": ["n04487081", "trolleybus"],
- "875": ["n04487394", "trombone"],
- "876": ["n04493381", "tub"],
- "877": ["n04501370", "turnstile"],
- "878": ["n04505470", "typewriter_keyboard"],
- "879": ["n04507155", "umbrella"],
- "880": ["n04509417", "unicycle"],
- "881": ["n04515003", "upright"],
- "882": ["n04517823", "vacuum"],
- "883": ["n04522168", "vase"],
- "884": ["n04523525", "vault"],
- "885": ["n04525038", "velvet"],
- "886": ["n04525305", "vending_machine"],
- "887": ["n04532106", "vestment"],
- "888": ["n04532670", "viaduct"],
- "889": ["n04536866", "violin"],
- "890": ["n04540053", "volleyball"],
- "891": ["n04542943", "waffle_iron"],
- "892": ["n04548280", "wall_clock"],
- "893": ["n04548362", "wallet"],
- "894": ["n04550184", "wardrobe"],
- "895": ["n04552348", "warplane"],
- "896": ["n04553703", "washbasin"],
- "897": ["n04554684", "washer"],
- "898": ["n04557648", "water_bottle"],
- "899": ["n04560804", "water_jug"],
- "900": ["n04562935", "water_tower"],
- "901": ["n04579145", "whiskey_jug"],
- "902": ["n04579432", "whistle"],
- "903": ["n04584207", "wig"],
- "904": ["n04589890", "window_screen"],
- "905": ["n04590129", "window_shade"],
- "906": ["n04591157", "Windsor_tie"],
- "907": ["n04591713", "wine_bottle"],
- "908": ["n04592741", "wing"],
- "909": ["n04596742", "wok"],
- "910": ["n04597913", "wooden_spoon"],
- "911": ["n04599235", "wool"],
- "912": ["n04604644", "worm_fence"],
- "913": ["n04606251", "wreck"],
- "914": ["n04612504", "yawl"],
- "915": ["n04613696", "yurt"],
- "916": ["n06359193", "web_site"],
- "917": ["n06596364", "comic_book"],
- "918": ["n06785654", "crossword_puzzle"],
- "919": ["n06794110", "street_sign"],
- "920": ["n06874185", "traffic_light"],
- "921": ["n07248320", "book_jacket"],
- "922": ["n07565083", "menu"],
- "923": ["n07579787", "plate"],
- "924": ["n07583066", "guacamole"],
- "925": ["n07584110", "consomme"],
- "926": ["n07590611", "hot_pot"],
- "927": ["n07613480", "trifle"],
- "928": ["n07614500", "ice_cream"],
- "929": ["n07615774", "ice_lolly"],
- "930": ["n07684084", "French_loaf"],
- "931": ["n07693725", "bagel"],
- "932": ["n07695742", "pretzel"],
- "933": ["n07697313", "cheeseburger"],
- "934": ["n07697537", "hotdog"],
- "935": ["n07711569", "mashed_potato"],
- "936": ["n07714571", "head_cabbage"],
- "937": ["n07714990", "broccoli"],
- "938": ["n07715103", "cauliflower"],
- "939": ["n07716358", "zucchini"],
- "940": ["n07716906", "spaghetti_squash"],
- "941": ["n07717410", "acorn_squash"],
- "942": ["n07717556", "butternut_squash"],
- "943": ["n07718472", "cucumber"],
- "944": ["n07718747", "artichoke"],
- "945": ["n07720875", "bell_pepper"],
- "946": ["n07730033", "cardoon"],
- "947": ["n07734744", "mushroom"],
- "948": ["n07742313", "Granny_Smith"],
- "949": ["n07745940", "strawberry"],
- "950": ["n07747607", "orange"],
- "951": ["n07749582", "lemon"],
- "952": ["n07753113", "fig"],
- "953": ["n07753275", "pineapple"],
- "954": ["n07753592", "banana"],
- "955": ["n07754684", "jackfruit"],
- "956": ["n07760859", "custard_apple"],
- "957": ["n07768694", "pomegranate"],
- "958": ["n07802026", "hay"],
- "959": ["n07831146", "carbonara"],
- "960": ["n07836838", "chocolate_sauce"],
- "961": ["n07860988", "dough"],
- "962": ["n07871810", "meat_loaf"],
- "963": ["n07873807", "pizza"],
- "964": ["n07875152", "potpie"],
- "965": ["n07880968", "burrito"],
- "966": ["n07892512", "red_wine"],
- "967": ["n07920052", "espresso"],
- "968": ["n07930864", "cup"],
- "969": ["n07932039", "eggnog"],
- "970": ["n09193705", "alp"],
- "971": ["n09229709", "bubble"],
- "972": ["n09246464", "cliff"],
- "973": ["n09256479", "coral_reef"],
- "974": ["n09288635", "geyser"],
- "975": ["n09332890", "lakeside"],
- "976": ["n09399592", "promontory"],
- "977": ["n09421951", "sandbar"],
- "978": ["n09428293", "seashore"],
- "979": ["n09468604", "valley"],
- "980": ["n09472597", "volcano"],
- "981": ["n09835506", "ballplayer"],
- "982": ["n10148035", "groom"],
- "983": ["n10565667", "scuba_diver"],
- "984": ["n11879895", "rapeseed"],
- "985": ["n11939491", "daisy"],
- "986": ["n12057211", "yellow_lady's_slipper"],
- "987": ["n12144580", "corn"],
- "988": ["n12267677", "acorn"],
- "989": ["n12620546", "hip"],
- "990": ["n12768682", "buckeye"],
- "991": ["n12985857", "coral_fungus"],
- "992": ["n12998815", "agaric"],
- "993": ["n13037406", "gyromitra"],
- "994": ["n13040303", "stinkhorn"],
- "995": ["n13044778", "earthstar"],
- "996": ["n13052670", "hen-of-the-woods"],
- "997": ["n13054560", "bolete"],
- "998": ["n13133613", "ear"],
- "999": ["n15075141", "toilet_tissue"]
-}
\ No newline at end of file
diff --git a/spaces/ServerX/PorcoDiaz/infer_uvr5.py b/spaces/ServerX/PorcoDiaz/infer_uvr5.py
deleted file mode 100644
index 8c8c05429a1d65dd8b198f16a8ea8c6e68991c07..0000000000000000000000000000000000000000
--- a/spaces/ServerX/PorcoDiaz/infer_uvr5.py
+++ /dev/null
@@ -1,363 +0,0 @@
-import os, sys, torch, warnings, pdb
-
-now_dir = os.getcwd()
-sys.path.append(now_dir)
-from json import load as ll
-
-warnings.filterwarnings("ignore")
-import librosa
-import importlib
-import numpy as np
-import hashlib, math
-from tqdm import tqdm
-from lib.uvr5_pack.lib_v5 import spec_utils
-from lib.uvr5_pack.utils import _get_name_params, inference
-from lib.uvr5_pack.lib_v5.model_param_init import ModelParameters
-import soundfile as sf
-from lib.uvr5_pack.lib_v5.nets_new import CascadedNet
-from lib.uvr5_pack.lib_v5 import nets_61968KB as nets
-
-
-class _audio_pre_:
- def __init__(self, agg, model_path, device, is_half):
- self.model_path = model_path
- self.device = device
- self.data = {
- # Processing Options
- "postprocess": False,
- "tta": False,
- # Constants
- "window_size": 512,
- "agg": agg,
- "high_end_process": "mirroring",
- }
- mp = ModelParameters("lib/uvr5_pack/lib_v5/modelparams/4band_v2.json")
- model = nets.CascadedASPPNet(mp.param["bins"] * 2)
- cpk = torch.load(model_path, map_location="cpu")
- model.load_state_dict(cpk)
- model.eval()
- if is_half:
- model = model.half().to(device)
- else:
- model = model.to(device)
-
- self.mp = mp
- self.model = model
-
- def _path_audio_(self, music_file, ins_root=None, vocal_root=None, format="flac"):
- if ins_root is None and vocal_root is None:
- return "No save root."
- name = os.path.basename(music_file)
- if ins_root is not None:
- os.makedirs(ins_root, exist_ok=True)
- if vocal_root is not None:
- os.makedirs(vocal_root, exist_ok=True)
- X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
- bands_n = len(self.mp.param["band"])
- # print(bands_n)
- for d in range(bands_n, 0, -1):
- bp = self.mp.param["band"][d]
- if d == bands_n: # high-end band
- (
- X_wave[d],
- _,
- ) = librosa.core.load(
- music_file,
- bp["sr"],
- False,
- dtype=np.float32,
- res_type=bp["res_type"],
- )
- if X_wave[d].ndim == 1:
- X_wave[d] = np.asfortranarray([X_wave[d], X_wave[d]])
- else: # lower bands
- X_wave[d] = librosa.core.resample(
- X_wave[d + 1],
- self.mp.param["band"][d + 1]["sr"],
- bp["sr"],
- res_type=bp["res_type"],
- )
- # Stft of wave source
- X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(
- X_wave[d],
- bp["hl"],
- bp["n_fft"],
- self.mp.param["mid_side"],
- self.mp.param["mid_side_b2"],
- self.mp.param["reverse"],
- )
- # pdb.set_trace()
- if d == bands_n and self.data["high_end_process"] != "none":
- input_high_end_h = (bp["n_fft"] // 2 - bp["crop_stop"]) + (
- self.mp.param["pre_filter_stop"] - self.mp.param["pre_filter_start"]
- )
- input_high_end = X_spec_s[d][
- :, bp["n_fft"] // 2 - input_high_end_h : bp["n_fft"] // 2, :
- ]
-
- X_spec_m = spec_utils.combine_spectrograms(X_spec_s, self.mp)
- aggresive_set = float(self.data["agg"] / 100)
- aggressiveness = {
- "value": aggresive_set,
- "split_bin": self.mp.param["band"][1]["crop_stop"],
- }
- with torch.no_grad():
- pred, X_mag, X_phase = inference(
- X_spec_m, self.device, self.model, aggressiveness, self.data
- )
- # Postprocess
- if self.data["postprocess"]:
- pred_inv = np.clip(X_mag - pred, 0, np.inf)
- pred = spec_utils.mask_silence(pred, pred_inv)
- y_spec_m = pred * X_phase
- v_spec_m = X_spec_m - y_spec_m
-
- if ins_root is not None:
- if self.data["high_end_process"].startswith("mirroring"):
- input_high_end_ = spec_utils.mirroring(
- self.data["high_end_process"], y_spec_m, input_high_end, self.mp
- )
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(
- y_spec_m, self.mp, input_high_end_h, input_high_end_
- )
- else:
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, self.mp)
- print("%s instruments done" % name)
- if format in ["wav", "flac"]:
- sf.write(
- os.path.join(
- ins_root,
- "instrument_{}_{}.{}".format(name, self.data["agg"], format),
- ),
- (np.array(wav_instrument) * 32768).astype("int16"),
- self.mp.param["sr"],
- ) #
- else:
- path = os.path.join(
- ins_root, "instrument_{}_{}.wav".format(name, self.data["agg"])
- )
- sf.write(
- path,
- (np.array(wav_instrument) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- if os.path.exists(path):
- os.system(
- "ffmpeg -i %s -vn %s -q:a 2 -y"
- % (path, path[:-4] + ".%s" % format)
- )
- if vocal_root is not None:
- if self.data["high_end_process"].startswith("mirroring"):
- input_high_end_ = spec_utils.mirroring(
- self.data["high_end_process"], v_spec_m, input_high_end, self.mp
- )
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(
- v_spec_m, self.mp, input_high_end_h, input_high_end_
- )
- else:
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, self.mp)
- print("%s vocals done" % name)
- if format in ["wav", "flac"]:
- sf.write(
- os.path.join(
- vocal_root,
- "vocal_{}_{}.{}".format(name, self.data["agg"], format),
- ),
- (np.array(wav_vocals) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- else:
- path = os.path.join(
- vocal_root, "vocal_{}_{}.wav".format(name, self.data["agg"])
- )
- sf.write(
- path,
- (np.array(wav_vocals) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- if os.path.exists(path):
- os.system(
- "ffmpeg -i %s -vn %s -q:a 2 -y"
- % (path, path[:-4] + ".%s" % format)
- )
-
-
-class _audio_pre_new:
- def __init__(self, agg, model_path, device, is_half):
- self.model_path = model_path
- self.device = device
- self.data = {
- # Processing Options
- "postprocess": False,
- "tta": False,
- # Constants
- "window_size": 512,
- "agg": agg,
- "high_end_process": "mirroring",
- }
- mp = ModelParameters("lib/uvr5_pack/lib_v5/modelparams/4band_v3.json")
- nout = 64 if "DeReverb" in model_path else 48
- model = CascadedNet(mp.param["bins"] * 2, nout)
- cpk = torch.load(model_path, map_location="cpu")
- model.load_state_dict(cpk)
- model.eval()
- if is_half:
- model = model.half().to(device)
- else:
- model = model.to(device)
-
- self.mp = mp
- self.model = model
-
- def _path_audio_(
- self, music_file, vocal_root=None, ins_root=None, format="flac"
- ): # 3个VR模型vocal和ins是反的
- if ins_root is None and vocal_root is None:
- return "No save root."
- name = os.path.basename(music_file)
- if ins_root is not None:
- os.makedirs(ins_root, exist_ok=True)
- if vocal_root is not None:
- os.makedirs(vocal_root, exist_ok=True)
- X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
- bands_n = len(self.mp.param["band"])
- # print(bands_n)
- for d in range(bands_n, 0, -1):
- bp = self.mp.param["band"][d]
- if d == bands_n: # high-end band
- (
- X_wave[d],
- _,
- ) = librosa.core.load(
- music_file,
- bp["sr"],
- False,
- dtype=np.float32,
- res_type=bp["res_type"],
- )
- if X_wave[d].ndim == 1:
- X_wave[d] = np.asfortranarray([X_wave[d], X_wave[d]])
- else: # lower bands
- X_wave[d] = librosa.core.resample(
- X_wave[d + 1],
- self.mp.param["band"][d + 1]["sr"],
- bp["sr"],
- res_type=bp["res_type"],
- )
- # Stft of wave source
- X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(
- X_wave[d],
- bp["hl"],
- bp["n_fft"],
- self.mp.param["mid_side"],
- self.mp.param["mid_side_b2"],
- self.mp.param["reverse"],
- )
- # pdb.set_trace()
- if d == bands_n and self.data["high_end_process"] != "none":
- input_high_end_h = (bp["n_fft"] // 2 - bp["crop_stop"]) + (
- self.mp.param["pre_filter_stop"] - self.mp.param["pre_filter_start"]
- )
- input_high_end = X_spec_s[d][
- :, bp["n_fft"] // 2 - input_high_end_h : bp["n_fft"] // 2, :
- ]
-
- X_spec_m = spec_utils.combine_spectrograms(X_spec_s, self.mp)
- aggresive_set = float(self.data["agg"] / 100)
- aggressiveness = {
- "value": aggresive_set,
- "split_bin": self.mp.param["band"][1]["crop_stop"],
- }
- with torch.no_grad():
- pred, X_mag, X_phase = inference(
- X_spec_m, self.device, self.model, aggressiveness, self.data
- )
- # Postprocess
- if self.data["postprocess"]:
- pred_inv = np.clip(X_mag - pred, 0, np.inf)
- pred = spec_utils.mask_silence(pred, pred_inv)
- y_spec_m = pred * X_phase
- v_spec_m = X_spec_m - y_spec_m
-
- if ins_root is not None:
- if self.data["high_end_process"].startswith("mirroring"):
- input_high_end_ = spec_utils.mirroring(
- self.data["high_end_process"], y_spec_m, input_high_end, self.mp
- )
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(
- y_spec_m, self.mp, input_high_end_h, input_high_end_
- )
- else:
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, self.mp)
- print("%s instruments done" % name)
- if format in ["wav", "flac"]:
- sf.write(
- os.path.join(
- ins_root,
- "instrument_{}_{}.{}".format(name, self.data["agg"], format),
- ),
- (np.array(wav_instrument) * 32768).astype("int16"),
- self.mp.param["sr"],
- ) #
- else:
- path = os.path.join(
- ins_root, "instrument_{}_{}.wav".format(name, self.data["agg"])
- )
- sf.write(
- path,
- (np.array(wav_instrument) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- if os.path.exists(path):
- os.system(
- "ffmpeg -i %s -vn %s -q:a 2 -y"
- % (path, path[:-4] + ".%s" % format)
- )
- if vocal_root is not None:
- if self.data["high_end_process"].startswith("mirroring"):
- input_high_end_ = spec_utils.mirroring(
- self.data["high_end_process"], v_spec_m, input_high_end, self.mp
- )
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(
- v_spec_m, self.mp, input_high_end_h, input_high_end_
- )
- else:
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, self.mp)
- print("%s vocals done" % name)
- if format in ["wav", "flac"]:
- sf.write(
- os.path.join(
- vocal_root,
- "vocal_{}_{}.{}".format(name, self.data["agg"], format),
- ),
- (np.array(wav_vocals) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- else:
- path = os.path.join(
- vocal_root, "vocal_{}_{}.wav".format(name, self.data["agg"])
- )
- sf.write(
- path,
- (np.array(wav_vocals) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- if os.path.exists(path):
- os.system(
- "ffmpeg -i %s -vn %s -q:a 2 -y"
- % (path, path[:-4] + ".%s" % format)
- )
-
-
-if __name__ == "__main__":
- device = "cuda"
- is_half = True
- # model_path = "uvr5_weights/2_HP-UVR.pth"
- # model_path = "uvr5_weights/VR-DeEchoDeReverb.pth"
- # model_path = "uvr5_weights/VR-DeEchoNormal.pth"
- model_path = "uvr5_weights/DeEchoNormal.pth"
- # pre_fun = _audio_pre_(model_path=model_path, device=device, is_half=True,agg=10)
- pre_fun = _audio_pre_new(model_path=model_path, device=device, is_half=True, agg=10)
- audio_path = "雪雪伴奏对消HP5.wav"
- save_path = "opt"
- pre_fun._path_audio_(audio_path, save_path, save_path)
diff --git a/spaces/Silentlin/DiffSinger/modules/parallel_wavegan/utils/utils.py b/spaces/Silentlin/DiffSinger/modules/parallel_wavegan/utils/utils.py
deleted file mode 100644
index d48a5ed28e8555d4b8cfb15fdee86426bbb9e368..0000000000000000000000000000000000000000
--- a/spaces/Silentlin/DiffSinger/modules/parallel_wavegan/utils/utils.py
+++ /dev/null
@@ -1,169 +0,0 @@
-# -*- coding: utf-8 -*-
-
-# Copyright 2019 Tomoki Hayashi
-# MIT License (https://opensource.org/licenses/MIT)
-
-"""Utility functions."""
-
-import fnmatch
-import logging
-import os
-import sys
-
-import h5py
-import numpy as np
-
-
-def find_files(root_dir, query="*.wav", include_root_dir=True):
- """Find files recursively.
-
- Args:
- root_dir (str): Root root_dir to find.
- query (str): Query to find.
- include_root_dir (bool): If False, root_dir name is not included.
-
- Returns:
- list: List of found filenames.
-
- """
- files = []
- for root, dirnames, filenames in os.walk(root_dir, followlinks=True):
- for filename in fnmatch.filter(filenames, query):
- files.append(os.path.join(root, filename))
- if not include_root_dir:
- files = [file_.replace(root_dir + "/", "") for file_ in files]
-
- return files
-
-
-def read_hdf5(hdf5_name, hdf5_path):
- """Read hdf5 dataset.
-
- Args:
- hdf5_name (str): Filename of hdf5 file.
- hdf5_path (str): Dataset name in hdf5 file.
-
- Return:
- any: Dataset values.
-
- """
- if not os.path.exists(hdf5_name):
- logging.error(f"There is no such a hdf5 file ({hdf5_name}).")
- sys.exit(1)
-
- hdf5_file = h5py.File(hdf5_name, "r")
-
- if hdf5_path not in hdf5_file:
- logging.error(f"There is no such a data in hdf5 file. ({hdf5_path})")
- sys.exit(1)
-
- hdf5_data = hdf5_file[hdf5_path][()]
- hdf5_file.close()
-
- return hdf5_data
-
-
-def write_hdf5(hdf5_name, hdf5_path, write_data, is_overwrite=True):
- """Write dataset to hdf5.
-
- Args:
- hdf5_name (str): Hdf5 dataset filename.
- hdf5_path (str): Dataset path in hdf5.
- write_data (ndarray): Data to write.
- is_overwrite (bool): Whether to overwrite dataset.
-
- """
- # convert to numpy array
- write_data = np.array(write_data)
-
- # check folder existence
- folder_name, _ = os.path.split(hdf5_name)
- if not os.path.exists(folder_name) and len(folder_name) != 0:
- os.makedirs(folder_name)
-
- # check hdf5 existence
- if os.path.exists(hdf5_name):
- # if already exists, open with r+ mode
- hdf5_file = h5py.File(hdf5_name, "r+")
- # check dataset existence
- if hdf5_path in hdf5_file:
- if is_overwrite:
- logging.warning("Dataset in hdf5 file already exists. "
- "recreate dataset in hdf5.")
- hdf5_file.__delitem__(hdf5_path)
- else:
- logging.error("Dataset in hdf5 file already exists. "
- "if you want to overwrite, please set is_overwrite = True.")
- hdf5_file.close()
- sys.exit(1)
- else:
- # if not exists, open with w mode
- hdf5_file = h5py.File(hdf5_name, "w")
-
- # write data to hdf5
- hdf5_file.create_dataset(hdf5_path, data=write_data)
- hdf5_file.flush()
- hdf5_file.close()
-
-
-class HDF5ScpLoader(object):
- """Loader class for a fests.scp file of hdf5 file.
-
- Examples:
- key1 /some/path/a.h5:feats
- key2 /some/path/b.h5:feats
- key3 /some/path/c.h5:feats
- key4 /some/path/d.h5:feats
- ...
- >>> loader = HDF5ScpLoader("hdf5.scp")
- >>> array = loader["key1"]
-
- key1 /some/path/a.h5
- key2 /some/path/b.h5
- key3 /some/path/c.h5
- key4 /some/path/d.h5
- ...
- >>> loader = HDF5ScpLoader("hdf5.scp", "feats")
- >>> array = loader["key1"]
-
- """
-
- def __init__(self, feats_scp, default_hdf5_path="feats"):
- """Initialize HDF5 scp loader.
-
- Args:
- feats_scp (str): Kaldi-style feats.scp file with hdf5 format.
- default_hdf5_path (str): Path in hdf5 file. If the scp contain the info, not used.
-
- """
- self.default_hdf5_path = default_hdf5_path
- with open(feats_scp) as f:
- lines = [line.replace("\n", "") for line in f.readlines()]
- self.data = {}
- for line in lines:
- key, value = line.split()
- self.data[key] = value
-
- def get_path(self, key):
- """Get hdf5 file path for a given key."""
- return self.data[key]
-
- def __getitem__(self, key):
- """Get ndarray for a given key."""
- p = self.data[key]
- if ":" in p:
- return read_hdf5(*p.split(":"))
- else:
- return read_hdf5(p, self.default_hdf5_path)
-
- def __len__(self):
- """Return the length of the scp file."""
- return len(self.data)
-
- def __iter__(self):
- """Return the iterator of the scp file."""
- return iter(self.data)
-
- def keys(self):
- """Return the keys of the scp file."""
- return self.data.keys()
diff --git a/spaces/SuYuanS/AudioCraft_Plus/audiocraft/models/__init__.py b/spaces/SuYuanS/AudioCraft_Plus/audiocraft/models/__init__.py
deleted file mode 100644
index be6bfe4b787a132aeaabaed1c3437c9ecd5c656c..0000000000000000000000000000000000000000
--- a/spaces/SuYuanS/AudioCraft_Plus/audiocraft/models/__init__.py
+++ /dev/null
@@ -1,18 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-"""
-Models for EnCodec, AudioGen, MusicGen, as well as the generic LMModel.
-"""
-# flake8: noqa
-from . import builders, loaders
-from .encodec import (
- CompressionModel, EncodecModel, DAC,
- HFEncodecModel, HFEncodecCompressionModel)
-from .audiogen import AudioGen
-from .lm import LMModel
-from .multibanddiffusion import MultiBandDiffusion
-from .musicgen import MusicGen
-from .unet import DiffusionUnet
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/prompts.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/prompts.py
deleted file mode 100644
index 3f5c07b980ef0b65dae36bd2970836fb1d9d2769..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/prompts.py
+++ /dev/null
@@ -1,108 +0,0 @@
-"""Terminal input and output prompts."""
-
-from pygments.token import Token
-import sys
-
-from IPython.core.displayhook import DisplayHook
-
-from prompt_toolkit.formatted_text import fragment_list_width, PygmentsTokens
-from prompt_toolkit.shortcuts import print_formatted_text
-from prompt_toolkit.enums import EditingMode
-
-
-class Prompts(object):
- def __init__(self, shell):
- self.shell = shell
-
- def vi_mode(self):
- if (getattr(self.shell.pt_app, 'editing_mode', None) == EditingMode.VI
- and self.shell.prompt_includes_vi_mode):
- mode = str(self.shell.pt_app.app.vi_state.input_mode)
- if mode.startswith('InputMode.'):
- mode = mode[10:13].lower()
- elif mode.startswith('vi-'):
- mode = mode[3:6]
- return '['+mode+'] '
- return ''
-
-
- def in_prompt_tokens(self):
- return [
- (Token.Prompt, self.vi_mode() ),
- (Token.Prompt, 'In ['),
- (Token.PromptNum, str(self.shell.execution_count)),
- (Token.Prompt, ']: '),
- ]
-
- def _width(self):
- return fragment_list_width(self.in_prompt_tokens())
-
- def continuation_prompt_tokens(self, width=None):
- if width is None:
- width = self._width()
- return [
- (Token.Prompt, (' ' * (width - 5)) + '...: '),
- ]
-
- def rewrite_prompt_tokens(self):
- width = self._width()
- return [
- (Token.Prompt, ('-' * (width - 2)) + '> '),
- ]
-
- def out_prompt_tokens(self):
- return [
- (Token.OutPrompt, 'Out['),
- (Token.OutPromptNum, str(self.shell.execution_count)),
- (Token.OutPrompt, ']: '),
- ]
-
-class ClassicPrompts(Prompts):
- def in_prompt_tokens(self):
- return [
- (Token.Prompt, '>>> '),
- ]
-
- def continuation_prompt_tokens(self, width=None):
- return [
- (Token.Prompt, '... ')
- ]
-
- def rewrite_prompt_tokens(self):
- return []
-
- def out_prompt_tokens(self):
- return []
-
-class RichPromptDisplayHook(DisplayHook):
- """Subclass of base display hook using coloured prompt"""
- def write_output_prompt(self):
- sys.stdout.write(self.shell.separate_out)
- # If we're not displaying a prompt, it effectively ends with a newline,
- # because the output will be left-aligned.
- self.prompt_end_newline = True
-
- if self.do_full_cache:
- tokens = self.shell.prompts.out_prompt_tokens()
- prompt_txt = ''.join(s for t, s in tokens)
- if prompt_txt and not prompt_txt.endswith('\n'):
- # Ask for a newline before multiline output
- self.prompt_end_newline = False
-
- if self.shell.pt_app:
- print_formatted_text(PygmentsTokens(tokens),
- style=self.shell.pt_app.app.style, end='',
- )
- else:
- sys.stdout.write(prompt_txt)
-
- def write_format_data(self, format_dict, md_dict=None) -> None:
- if self.shell.mime_renderers:
-
- for mime, handler in self.shell.mime_renderers.items():
- if mime in format_dict:
- handler(format_dict[mime], None)
- return
-
- super().write_format_data(format_dict, md_dict)
-
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/tests/test_interactivshell.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/tests/test_interactivshell.py
deleted file mode 100644
index ae7da217f1dffde0133685ea50baeda1b7091c92..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/tests/test_interactivshell.py
+++ /dev/null
@@ -1,255 +0,0 @@
-# -*- coding: utf-8 -*-
-"""Tests for the TerminalInteractiveShell and related pieces."""
-# Copyright (c) IPython Development Team.
-# Distributed under the terms of the Modified BSD License.
-
-import sys
-import unittest
-import os
-
-from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
-
-
-from IPython.testing import tools as tt
-
-from IPython.terminal.ptutils import _elide, _adjust_completion_text_based_on_context
-from IPython.terminal.shortcuts.auto_suggest import NavigableAutoSuggestFromHistory
-
-
-class TestAutoSuggest(unittest.TestCase):
- def test_changing_provider(self):
- ip = get_ipython()
- ip.autosuggestions_provider = None
- self.assertEqual(ip.auto_suggest, None)
- ip.autosuggestions_provider = "AutoSuggestFromHistory"
- self.assertIsInstance(ip.auto_suggest, AutoSuggestFromHistory)
- ip.autosuggestions_provider = "NavigableAutoSuggestFromHistory"
- self.assertIsInstance(ip.auto_suggest, NavigableAutoSuggestFromHistory)
-
-
-class TestElide(unittest.TestCase):
- def test_elide(self):
- _elide("concatenate((a1, a2, ...), axis", "") # do not raise
- _elide("concatenate((a1, a2, ..), . axis", "") # do not raise
- self.assertEqual(
- _elide("aaaa.bbbb.ccccc.dddddd.eeeee.fffff.gggggg.hhhhhh", ""),
- "aaaa.b…g.hhhhhh",
- )
-
- test_string = os.sep.join(["", 10 * "a", 10 * "b", 10 * "c", ""])
- expect_string = (
- os.sep + "a" + "\N{HORIZONTAL ELLIPSIS}" + "b" + os.sep + 10 * "c"
- )
- self.assertEqual(_elide(test_string, ""), expect_string)
-
- def test_elide_typed_normal(self):
- self.assertEqual(
- _elide(
- "the quick brown fox jumped over the lazy dog",
- "the quick brown fox",
- min_elide=10,
- ),
- "the…fox jumped over the lazy dog",
- )
-
- def test_elide_typed_short_match(self):
- """
- if the match is too short we don't elide.
- avoid the "the...the"
- """
- self.assertEqual(
- _elide("the quick brown fox jumped over the lazy dog", "the", min_elide=10),
- "the quick brown fox jumped over the lazy dog",
- )
-
- def test_elide_typed_no_match(self):
- """
- if the match is too short we don't elide.
- avoid the "the...the"
- """
- # here we typed red instead of brown
- self.assertEqual(
- _elide(
- "the quick brown fox jumped over the lazy dog",
- "the quick red fox",
- min_elide=10,
- ),
- "the quick brown fox jumped over the lazy dog",
- )
-
-
-class TestContextAwareCompletion(unittest.TestCase):
- def test_adjust_completion_text_based_on_context(self):
- # Adjusted case
- self.assertEqual(
- _adjust_completion_text_based_on_context("arg1=", "func1(a=)", 7), "arg1"
- )
-
- # Untouched cases
- self.assertEqual(
- _adjust_completion_text_based_on_context("arg1=", "func1(a)", 7), "arg1="
- )
- self.assertEqual(
- _adjust_completion_text_based_on_context("arg1=", "func1(a", 7), "arg1="
- )
- self.assertEqual(
- _adjust_completion_text_based_on_context("%magic", "func1(a=)", 7), "%magic"
- )
- self.assertEqual(
- _adjust_completion_text_based_on_context("func2", "func1(a=)", 7), "func2"
- )
-
-
-# Decorator for interaction loop tests -----------------------------------------
-
-
-class mock_input_helper(object):
- """Machinery for tests of the main interact loop.
-
- Used by the mock_input decorator.
- """
- def __init__(self, testgen):
- self.testgen = testgen
- self.exception = None
- self.ip = get_ipython()
-
- def __enter__(self):
- self.orig_prompt_for_code = self.ip.prompt_for_code
- self.ip.prompt_for_code = self.fake_input
- return self
-
- def __exit__(self, etype, value, tb):
- self.ip.prompt_for_code = self.orig_prompt_for_code
-
- def fake_input(self):
- try:
- return next(self.testgen)
- except StopIteration:
- self.ip.keep_running = False
- return u''
- except:
- self.exception = sys.exc_info()
- self.ip.keep_running = False
- return u''
-
-def mock_input(testfunc):
- """Decorator for tests of the main interact loop.
-
- Write the test as a generator, yield-ing the input strings, which IPython
- will see as if they were typed in at the prompt.
- """
- def test_method(self):
- testgen = testfunc(self)
- with mock_input_helper(testgen) as mih:
- mih.ip.interact()
-
- if mih.exception is not None:
- # Re-raise captured exception
- etype, value, tb = mih.exception
- import traceback
- traceback.print_tb(tb, file=sys.stdout)
- del tb # Avoid reference loop
- raise value
-
- return test_method
-
-# Test classes -----------------------------------------------------------------
-
-class InteractiveShellTestCase(unittest.TestCase):
- def rl_hist_entries(self, rl, n):
- """Get last n readline history entries as a list"""
- return [rl.get_history_item(rl.get_current_history_length() - x)
- for x in range(n - 1, -1, -1)]
-
- @mock_input
- def test_inputtransformer_syntaxerror(self):
- ip = get_ipython()
- ip.input_transformers_post.append(syntax_error_transformer)
-
- try:
- #raise Exception
- with tt.AssertPrints('4', suppress=False):
- yield u'print(2*2)'
-
- with tt.AssertPrints('SyntaxError: input contains', suppress=False):
- yield u'print(2345) # syntaxerror'
-
- with tt.AssertPrints('16', suppress=False):
- yield u'print(4*4)'
-
- finally:
- ip.input_transformers_post.remove(syntax_error_transformer)
-
- def test_repl_not_plain_text(self):
- ip = get_ipython()
- formatter = ip.display_formatter
- assert formatter.active_types == ['text/plain']
-
- # terminal may have arbitrary mimetype handler to open external viewer
- # or inline images.
- assert formatter.ipython_display_formatter.enabled
-
- class Test(object):
- def __repr__(self):
- return "
-
-With this code you can train the Llama 2 LLM architecture from scratch in PyTorch, then save the weights to a raw binary file, then load that into one ~simple 500-line C file ([run.c](run.c)) that inferences the model, simply in fp32 for now. On my cloud Linux devbox a dim 288 6-layer 6-head model (~15M params) inferences at ~100 tok/s in fp32, and about the same on my M1 MacBook Air. I was somewhat pleasantly surprised that one can run reasonably sized models (few ten million params) at highly interactive rates with an approach this simple.
-
-Please note that this is just a weekend project: I took nanoGPT, tuned it to implement the Llama-2 architecture instead of GPT-2, and the meat of it was writing the C inference engine in [run.c](run.c). As such, this is not really meant to be a production-grade library right now.
-
-Hat tip to [llama.cpp](https://github.com/ggerganov/llama.cpp) for inspiring this project. I wanted something super minimal so I chose to hard-code the llama-2 architecture, stick to fp32, and just roll one inference file of pure C with no dependencies.
-
-## feel the magic
-
-Let's just run a baby Llama 2 model in C. You need a model checkpoint. Download this 15M parameter model I trained on the [TinyStories](https://huggingface.co/datasets/roneneldan/TinyStories) dataset (~58MB download) and place it into the default checkpoint directory `out`:
-
-```bash
-wget https://karpathy.ai/llama2c/model.bin -P out
-```
-
-(if that doesn't work try [google drive](https://drive.google.com/file/d/1aTimLdx3JktDXxcHySNrZJOOk8Vb1qBR/view?usp=share_link)). Compile and run the C code:
-
-```bash
-gcc -O3 -o run run.c -lm
-./run out/model.bin
-```
-
-You'll see the text stream a sample. On my M1 MacBook Air this runs at ~100 tokens/s, not bad for super naive fp32 single-threaded C code. See [performance](#performance) for compile flags that can significantly speed this up. Sample output:
-
-*Once upon a time, there was a boy named Timmy. Timmy loved to play sports with his friends. He was very good at throwing and catching balls. One day, Timmy's mom gave him a new shirt to wear to a party. Timmy thought it was impressive and asked his mom to explain what a shirt could be for. "A shirt is like a special suit for a basketball game," his mom said. Timmy was happy to hear that and put on his new shirt. He felt like a soldier going to the army and shouting. From that day on, Timmy wore his new shirt every time he played sports with his friends at the party. Once upon a time, there was a little girl named Lily. She loved to play outside with her friends. One day, Lily and her friend Emma were playing with a ball. Emma threw the ball too hard and it hit Lily's face. Lily felt embarrassed and didn't want to play anymore.
-Emma asked Lily what was wrong, and Lily told her about her memory. Emma told Lily that she was embarrassed because she had thrown the ball too hard. Lily felt bad
-achieved tok/s: 98.746993347843922*
-
-**Update**: I've now also uploaded a bigger checkpoint. This one is dim 512, 8 layers, 8 heads and context length 1024, a ~44M param Transformer. It trained for 200K iterations batch size 32 on 4XA100 40GB GPUs in ~8 hours. You can use this bigger and more powerful checkpoint like so:
-
-```bash
-wget https://karpathy.ai/llama2c/model44m.bin -P out44m
-./run out44m/model44m.bin
-```
-
-On my MacBook Air compiled with $ gcc -Ofast -o run run.c -lm this ran at ~150 tok/s. Still way too fast! I have to train an even bigger checkpoint... This model samples more coherent and diverse stories:
-
-*Once upon a time, there was a little girl named Lily. She loved playing with her toys on top of her bed. One day, she decided to have a tea party with her stuffed animals. She poured some tea into a tiny teapot and put it on top of the teapot. Suddenly, her little brother Max came into the room and wanted to join the tea party too. Lily didn't want to share her tea and she told Max to go away. Max started to cry and Lily felt bad. She decided to yield her tea party to Max and they both shared the teapot. But then, something unexpected happened. The teapot started to shake and wiggle. Lily and Max were scared and didn't know what to do. Suddenly, the teapot started to fly towards the ceiling and landed on the top of the bed. Lily and Max were amazed and they hugged each other. They realized that sharing was much more fun than being selfish. From that day on, they always shared their tea parties and toys.*
-
-## howto
-
-It should be possible to load the weights released by Meta but I haven't tried because the inference speed, even of the 7B model, would probably be not great with this baby single-threaded C program. So in this repo we focus on more narrow applications, and train the same architecture but from scratch, in this case on the TinyStories dataset for fun.
-
-First let's download and pretokenize some source dataset, e.g. I like [TinyStories](https://huggingface.co/datasets/roneneldan/TinyStories) so this is the only example currently available in this repo. But it should be very easy to add datasets, see the code.
-
-```bash
-python tinystories.py download
-python tinystories.py pretokenize
-```
-
-Then train our model:
-
-```bash
-python train.py
-```
-
-See the train.py script for more exotic launches and hyperparameter overrides. I didn't tune the hyperparameters, I expect simple hyperparameter exploration should give better models. Totally understand if you want to skip model training, for simple demo just download my pretrained model and save it into the directory `out`:
-
-```bash
-wget https://karpathy.ai/llama2c/model.bin -P out
-```
-
-Once we have the model.bin file, we can inference in C. Compile the C code first:
-
-```bash
-gcc -O3 -o run run.c -lm
-```
-
-You can now run it simply as
-
-```bash
-./run out/model.bin
-```
-
-Watch the tokens stream by, fun! We can also run the PyTorch inference script for comparison (to run, add [model.ckpt](https://drive.google.com/file/d/1SM0rMxzy7babB-v4MfTg1GFqOCgWar5w/view?usp=share_link) to /out if you haven't already):
-
-```bash
-python sample.py
-```
-
-Which gives the same results. More detailed testing will be done in `test_all.py`, run as:
-
-```bash
-$ pytest
-```
-
-Currently you will need two files to test or sample: the [model.bin](https://drive.google.com/file/d/1aTimLdx3JktDXxcHySNrZJOOk8Vb1qBR/view?usp=share_link) file and the [model.ckpt](https://drive.google.com/file/d/1SM0rMxzy7babB-v4MfTg1GFqOCgWar5w/view?usp=share_link) file from PyTorch training I ran earlier. I have to think through running the tests without having to download 200MB of data.
-
-## performance
-
-*(NOTE: this guide is not great because I personally spend a lot of my time in Python land and don't have an amazing understanding of a lot of these features and flags. If someone does and is willing to help document and briefly describe some of these and their tradeoffs, I'd welcome a PR)*
-
-There are many ways to potentially speed up this code depending on your system. Here we document a few together with a high-level guide on what they do. Here's again the default way to compile, but using -O3:
-
-```bash
-gcc -O3 -o run run.c -lm
-```
-
--O3 includes optimizations that are expensive in terms of compile time and memory usage. Including vectorization, loop unrolling, and predicting branches. Here's a few more to try.
-
-`-Ofast` Run additional optimizations which may break compliance with the C/IEEE specifications, in addition to `-O3`. See [the GCC docs](https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html) for more information.
-
-`-ffast-math` breaks IEEE compliance, e.g. allowing reordering of operations, disables a bunch of checks for e.g. NaNs (assuming they don't happen), enables reciprocal approximations, disables signed zero, etc. However, there is a good reason to be suspicious of this setting, one good writeup is here: ["Beware of fast-math"](https://simonbyrne.github.io/notes/fastmath/).
-
-`-funsafe-math-optimizations` a more limited form of -ffast-math, that still breaks IEEE compliance but doesn't have all of the numeric/error handling changes from `-ffasth-math`. See [the GCC docs](https://gcc.gnu.org/wiki/FloatingPointMath) for more information.
-
-`-march=native` Compile the program to use the architecture of the machine you're compiling on rather than a more generic CPU. This may enable additional optimizations and hardware-specific tuning such as improved vector instructions/width.
-
-Putting a few of these together, the fastest throughput I saw so far on my MacBook Air (M1) is with:
-
-```bash
-gcc -Ofast -o run run.c -lm
-```
-
-Also, I saw someone report higher throughput replacing `gcc` with `clang`.
-
-**OpenMP** Big improvements can also be achieved by compiling with OpenMP, which "activates" the `#pragma omp parallel for` inside the matmul. You can compile e.g. like so:
-
-```bash
-clang -Ofast -fopenmp -march=native run.c -lm -o run
-```
-
-(I believe you can swap clang/gcc, and may try to leave out -march=native). Then when you run inference, make sure to use OpenMP flags to set the number of threads, e.g.:
-
-```bash
-OMP_NUM_THREADS=4 ./run out/model.bin
-```
-
-Depending on your system resources you may want to tweak these hyperparameters. (TODO: I am not intimitely familiar with OpenMP and its configuration, if someone would like to flesh out this section I would welcome a PR).
-
-## unsorted todos
-
-- why is there a leading space in C sampling code when we `./run`?
-- todo multiquery support? doesn't seem as useful for smaller models that run on CPU (?)
-- todo support inferencing beyond max_seq_len steps, have to think through the kv cache
-- why is MFU so low (~10%) on my A100 40GB for training?
-- weird errors with torch.compile and wandb when using DDP
-- make more better tests to decrease yolo
-
-## ack
-
-I trained the llama2.c storyteller models on a 4X A100 40GB box graciously provided by the excellent [Lambda labs](https://lambdalabs.com/service/gpu-cloud), thank you.
-
-## License
-
-MIT
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/roi_heads/double_roi_head.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/roi_heads/double_roi_head.py
deleted file mode 100644
index a1aa6c8244a889fbbed312a89574c3e11be294f0..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet_null/models/roi_heads/double_roi_head.py
+++ /dev/null
@@ -1,33 +0,0 @@
-from ..builder import HEADS
-from .standard_roi_head import StandardRoIHead
-
-
-@HEADS.register_module()
-class DoubleHeadRoIHead(StandardRoIHead):
- """RoI head for Double Head RCNN.
-
- https://arxiv.org/abs/1904.06493
- """
-
- def __init__(self, reg_roi_scale_factor, **kwargs):
- super(DoubleHeadRoIHead, self).__init__(**kwargs)
- self.reg_roi_scale_factor = reg_roi_scale_factor
-
- def _bbox_forward(self, x, rois):
- """Box head forward function used in both training and testing time."""
- bbox_cls_feats = self.bbox_roi_extractor(
- x[:self.bbox_roi_extractor.num_inputs], rois)
- bbox_reg_feats = self.bbox_roi_extractor(
- x[:self.bbox_roi_extractor.num_inputs],
- rois,
- roi_scale_factor=self.reg_roi_scale_factor)
- if self.with_shared_head:
- bbox_cls_feats = self.shared_head(bbox_cls_feats)
- bbox_reg_feats = self.shared_head(bbox_reg_feats)
- cls_score, bbox_pred = self.bbox_head(bbox_cls_feats, bbox_reg_feats)
-
- bbox_results = dict(
- cls_score=cls_score,
- bbox_pred=bbox_pred,
- bbox_feats=bbox_cls_feats)
- return bbox_results
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/models/utils/up_conv_block.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/models/utils/up_conv_block.py
deleted file mode 100644
index 378469da76cb7bff6a639e7877b3c275d50490fb..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/models/utils/up_conv_block.py
+++ /dev/null
@@ -1,101 +0,0 @@
-import torch
-import torch.nn as nn
-from annotator.uniformer.mmcv.cnn import ConvModule, build_upsample_layer
-
-
-class UpConvBlock(nn.Module):
- """Upsample convolution block in decoder for UNet.
-
- This upsample convolution block consists of one upsample module
- followed by one convolution block. The upsample module expands the
- high-level low-resolution feature map and the convolution block fuses
- the upsampled high-level low-resolution feature map and the low-level
- high-resolution feature map from encoder.
-
- Args:
- conv_block (nn.Sequential): Sequential of convolutional layers.
- in_channels (int): Number of input channels of the high-level
- skip_channels (int): Number of input channels of the low-level
- high-resolution feature map from encoder.
- out_channels (int): Number of output channels.
- num_convs (int): Number of convolutional layers in the conv_block.
- Default: 2.
- stride (int): Stride of convolutional layer in conv_block. Default: 1.
- dilation (int): Dilation rate of convolutional layer in conv_block.
- Default: 1.
- with_cp (bool): Use checkpoint or not. Using checkpoint will save some
- memory while slowing down the training speed. Default: False.
- conv_cfg (dict | None): Config dict for convolution layer.
- Default: None.
- norm_cfg (dict | None): Config dict for normalization layer.
- Default: dict(type='BN').
- act_cfg (dict | None): Config dict for activation layer in ConvModule.
- Default: dict(type='ReLU').
- upsample_cfg (dict): The upsample config of the upsample module in
- decoder. Default: dict(type='InterpConv'). If the size of
- high-level feature map is the same as that of skip feature map
- (low-level feature map from encoder), it does not need upsample the
- high-level feature map and the upsample_cfg is None.
- dcn (bool): Use deformable convolution in convolutional layer or not.
- Default: None.
- plugins (dict): plugins for convolutional layers. Default: None.
- """
-
- def __init__(self,
- conv_block,
- in_channels,
- skip_channels,
- out_channels,
- num_convs=2,
- stride=1,
- dilation=1,
- with_cp=False,
- conv_cfg=None,
- norm_cfg=dict(type='BN'),
- act_cfg=dict(type='ReLU'),
- upsample_cfg=dict(type='InterpConv'),
- dcn=None,
- plugins=None):
- super(UpConvBlock, self).__init__()
- assert dcn is None, 'Not implemented yet.'
- assert plugins is None, 'Not implemented yet.'
-
- self.conv_block = conv_block(
- in_channels=2 * skip_channels,
- out_channels=out_channels,
- num_convs=num_convs,
- stride=stride,
- dilation=dilation,
- with_cp=with_cp,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg,
- dcn=None,
- plugins=None)
- if upsample_cfg is not None:
- self.upsample = build_upsample_layer(
- cfg=upsample_cfg,
- in_channels=in_channels,
- out_channels=skip_channels,
- with_cp=with_cp,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
- else:
- self.upsample = ConvModule(
- in_channels,
- skip_channels,
- kernel_size=1,
- stride=1,
- padding=0,
- conv_cfg=conv_cfg,
- norm_cfg=norm_cfg,
- act_cfg=act_cfg)
-
- def forward(self, skip, x):
- """Forward function."""
-
- x = self.upsample(x)
- out = torch.cat([skip, x], dim=1)
- out = self.conv_block(out)
-
- return out
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmseg/core/utils/misc.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmseg/core/utils/misc.py
deleted file mode 100644
index eb862a82bd47c8624db3dd5c6fb6ad8a03b62466..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmseg/core/utils/misc.py
+++ /dev/null
@@ -1,17 +0,0 @@
-def add_prefix(inputs, prefix):
- """Add prefix for dict.
-
- Args:
- inputs (dict): The input dict with str keys.
- prefix (str): The prefix to add.
-
- Returns:
-
- dict: The dict with keys updated with ``prefix``.
- """
-
- outputs = dict()
- for name, value in inputs.items():
- outputs[f'{prefix}.{name}'] = value
-
- return outputs
diff --git a/spaces/Rongjiehuang/ProDiff/utils/audio.py b/spaces/Rongjiehuang/ProDiff/utils/audio.py
deleted file mode 100644
index aba7ab926cf793d085bbdc70c97f376001183fe1..0000000000000000000000000000000000000000
--- a/spaces/Rongjiehuang/ProDiff/utils/audio.py
+++ /dev/null
@@ -1,56 +0,0 @@
-import subprocess
-import matplotlib
-
-matplotlib.use('Agg')
-import librosa
-import librosa.filters
-import numpy as np
-from scipy import signal
-from scipy.io import wavfile
-
-
-def save_wav(wav, path, sr, norm=False):
- if norm:
- wav = wav / np.abs(wav).max()
- wav *= 32767
- # proposed by @dsmiller
- wavfile.write(path, sr, wav.astype(np.int16))
-
-
-def get_hop_size(hparams):
- hop_size = hparams['hop_size']
- if hop_size is None:
- assert hparams['frame_shift_ms'] is not None
- hop_size = int(hparams['frame_shift_ms'] / 1000 * hparams['audio_sample_rate'])
- return hop_size
-
-
-###########################################################################################
-def _stft(y, hparams):
- return librosa.stft(y=y, n_fft=hparams['fft_size'], hop_length=get_hop_size(hparams),
- win_length=hparams['win_size'], pad_mode='constant')
-
-
-def _istft(y, hparams):
- return librosa.istft(y, hop_length=get_hop_size(hparams), win_length=hparams['win_size'])
-
-
-def librosa_pad_lr(x, fsize, fshift, pad_sides=1):
- '''compute right padding (final frame) or both sides padding (first and final frames)
- '''
- assert pad_sides in (1, 2)
- # return int(fsize // 2)
- pad = (x.shape[0] // fshift + 1) * fshift - x.shape[0]
- if pad_sides == 1:
- return 0, pad
- else:
- return pad // 2, pad // 2 + pad % 2
-
-
-# Conversions
-def amp_to_db(x):
- return 20 * np.log10(np.maximum(1e-5, x))
-
-
-def normalize(S, hparams):
- return (S - hparams['min_level_db']) / -hparams['min_level_db']
diff --git a/spaces/Sense-X/uniformer_image_demo/imagenet_class_index.py b/spaces/Sense-X/uniformer_image_demo/imagenet_class_index.py
deleted file mode 100644
index 5407d1471197fd9bfa466c47d8dfb6683cb9f551..0000000000000000000000000000000000000000
--- a/spaces/Sense-X/uniformer_image_demo/imagenet_class_index.py
+++ /dev/null
@@ -1,1002 +0,0 @@
-imagenet_classnames = {
- "0": ["n01440764", "tench"],
- "1": ["n01443537", "goldfish"],
- "2": ["n01484850", "great_white_shark"],
- "3": ["n01491361", "tiger_shark"],
- "4": ["n01494475", "hammerhead"],
- "5": ["n01496331", "electric_ray"],
- "6": ["n01498041", "stingray"],
- "7": ["n01514668", "cock"],
- "8": ["n01514859", "hen"],
- "9": ["n01518878", "ostrich"],
- "10": ["n01530575", "brambling"],
- "11": ["n01531178", "goldfinch"],
- "12": ["n01532829", "house_finch"],
- "13": ["n01534433", "junco"],
- "14": ["n01537544", "indigo_bunting"],
- "15": ["n01558993", "robin"],
- "16": ["n01560419", "bulbul"],
- "17": ["n01580077", "jay"],
- "18": ["n01582220", "magpie"],
- "19": ["n01592084", "chickadee"],
- "20": ["n01601694", "water_ouzel"],
- "21": ["n01608432", "kite"],
- "22": ["n01614925", "bald_eagle"],
- "23": ["n01616318", "vulture"],
- "24": ["n01622779", "great_grey_owl"],
- "25": ["n01629819", "European_fire_salamander"],
- "26": ["n01630670", "common_newt"],
- "27": ["n01631663", "eft"],
- "28": ["n01632458", "spotted_salamander"],
- "29": ["n01632777", "axolotl"],
- "30": ["n01641577", "bullfrog"],
- "31": ["n01644373", "tree_frog"],
- "32": ["n01644900", "tailed_frog"],
- "33": ["n01664065", "loggerhead"],
- "34": ["n01665541", "leatherback_turtle"],
- "35": ["n01667114", "mud_turtle"],
- "36": ["n01667778", "terrapin"],
- "37": ["n01669191", "box_turtle"],
- "38": ["n01675722", "banded_gecko"],
- "39": ["n01677366", "common_iguana"],
- "40": ["n01682714", "American_chameleon"],
- "41": ["n01685808", "whiptail"],
- "42": ["n01687978", "agama"],
- "43": ["n01688243", "frilled_lizard"],
- "44": ["n01689811", "alligator_lizard"],
- "45": ["n01692333", "Gila_monster"],
- "46": ["n01693334", "green_lizard"],
- "47": ["n01694178", "African_chameleon"],
- "48": ["n01695060", "Komodo_dragon"],
- "49": ["n01697457", "African_crocodile"],
- "50": ["n01698640", "American_alligator"],
- "51": ["n01704323", "triceratops"],
- "52": ["n01728572", "thunder_snake"],
- "53": ["n01728920", "ringneck_snake"],
- "54": ["n01729322", "hognose_snake"],
- "55": ["n01729977", "green_snake"],
- "56": ["n01734418", "king_snake"],
- "57": ["n01735189", "garter_snake"],
- "58": ["n01737021", "water_snake"],
- "59": ["n01739381", "vine_snake"],
- "60": ["n01740131", "night_snake"],
- "61": ["n01742172", "boa_constrictor"],
- "62": ["n01744401", "rock_python"],
- "63": ["n01748264", "Indian_cobra"],
- "64": ["n01749939", "green_mamba"],
- "65": ["n01751748", "sea_snake"],
- "66": ["n01753488", "horned_viper"],
- "67": ["n01755581", "diamondback"],
- "68": ["n01756291", "sidewinder"],
- "69": ["n01768244", "trilobite"],
- "70": ["n01770081", "harvestman"],
- "71": ["n01770393", "scorpion"],
- "72": ["n01773157", "black_and_gold_garden_spider"],
- "73": ["n01773549", "barn_spider"],
- "74": ["n01773797", "garden_spider"],
- "75": ["n01774384", "black_widow"],
- "76": ["n01774750", "tarantula"],
- "77": ["n01775062", "wolf_spider"],
- "78": ["n01776313", "tick"],
- "79": ["n01784675", "centipede"],
- "80": ["n01795545", "black_grouse"],
- "81": ["n01796340", "ptarmigan"],
- "82": ["n01797886", "ruffed_grouse"],
- "83": ["n01798484", "prairie_chicken"],
- "84": ["n01806143", "peacock"],
- "85": ["n01806567", "quail"],
- "86": ["n01807496", "partridge"],
- "87": ["n01817953", "African_grey"],
- "88": ["n01818515", "macaw"],
- "89": ["n01819313", "sulphur-crested_cockatoo"],
- "90": ["n01820546", "lorikeet"],
- "91": ["n01824575", "coucal"],
- "92": ["n01828970", "bee_eater"],
- "93": ["n01829413", "hornbill"],
- "94": ["n01833805", "hummingbird"],
- "95": ["n01843065", "jacamar"],
- "96": ["n01843383", "toucan"],
- "97": ["n01847000", "drake"],
- "98": ["n01855032", "red-breasted_merganser"],
- "99": ["n01855672", "goose"],
- "100": ["n01860187", "black_swan"],
- "101": ["n01871265", "tusker"],
- "102": ["n01872401", "echidna"],
- "103": ["n01873310", "platypus"],
- "104": ["n01877812", "wallaby"],
- "105": ["n01882714", "koala"],
- "106": ["n01883070", "wombat"],
- "107": ["n01910747", "jellyfish"],
- "108": ["n01914609", "sea_anemone"],
- "109": ["n01917289", "brain_coral"],
- "110": ["n01924916", "flatworm"],
- "111": ["n01930112", "nematode"],
- "112": ["n01943899", "conch"],
- "113": ["n01944390", "snail"],
- "114": ["n01945685", "slug"],
- "115": ["n01950731", "sea_slug"],
- "116": ["n01955084", "chiton"],
- "117": ["n01968897", "chambered_nautilus"],
- "118": ["n01978287", "Dungeness_crab"],
- "119": ["n01978455", "rock_crab"],
- "120": ["n01980166", "fiddler_crab"],
- "121": ["n01981276", "king_crab"],
- "122": ["n01983481", "American_lobster"],
- "123": ["n01984695", "spiny_lobster"],
- "124": ["n01985128", "crayfish"],
- "125": ["n01986214", "hermit_crab"],
- "126": ["n01990800", "isopod"],
- "127": ["n02002556", "white_stork"],
- "128": ["n02002724", "black_stork"],
- "129": ["n02006656", "spoonbill"],
- "130": ["n02007558", "flamingo"],
- "131": ["n02009229", "little_blue_heron"],
- "132": ["n02009912", "American_egret"],
- "133": ["n02011460", "bittern"],
- "134": ["n02012849", "crane"],
- "135": ["n02013706", "limpkin"],
- "136": ["n02017213", "European_gallinule"],
- "137": ["n02018207", "American_coot"],
- "138": ["n02018795", "bustard"],
- "139": ["n02025239", "ruddy_turnstone"],
- "140": ["n02027492", "red-backed_sandpiper"],
- "141": ["n02028035", "redshank"],
- "142": ["n02033041", "dowitcher"],
- "143": ["n02037110", "oystercatcher"],
- "144": ["n02051845", "pelican"],
- "145": ["n02056570", "king_penguin"],
- "146": ["n02058221", "albatross"],
- "147": ["n02066245", "grey_whale"],
- "148": ["n02071294", "killer_whale"],
- "149": ["n02074367", "dugong"],
- "150": ["n02077923", "sea_lion"],
- "151": ["n02085620", "Chihuahua"],
- "152": ["n02085782", "Japanese_spaniel"],
- "153": ["n02085936", "Maltese_dog"],
- "154": ["n02086079", "Pekinese"],
- "155": ["n02086240", "Shih-Tzu"],
- "156": ["n02086646", "Blenheim_spaniel"],
- "157": ["n02086910", "papillon"],
- "158": ["n02087046", "toy_terrier"],
- "159": ["n02087394", "Rhodesian_ridgeback"],
- "160": ["n02088094", "Afghan_hound"],
- "161": ["n02088238", "basset"],
- "162": ["n02088364", "beagle"],
- "163": ["n02088466", "bloodhound"],
- "164": ["n02088632", "bluetick"],
- "165": ["n02089078", "black-and-tan_coonhound"],
- "166": ["n02089867", "Walker_hound"],
- "167": ["n02089973", "English_foxhound"],
- "168": ["n02090379", "redbone"],
- "169": ["n02090622", "borzoi"],
- "170": ["n02090721", "Irish_wolfhound"],
- "171": ["n02091032", "Italian_greyhound"],
- "172": ["n02091134", "whippet"],
- "173": ["n02091244", "Ibizan_hound"],
- "174": ["n02091467", "Norwegian_elkhound"],
- "175": ["n02091635", "otterhound"],
- "176": ["n02091831", "Saluki"],
- "177": ["n02092002", "Scottish_deerhound"],
- "178": ["n02092339", "Weimaraner"],
- "179": ["n02093256", "Staffordshire_bullterrier"],
- "180": ["n02093428", "American_Staffordshire_terrier"],
- "181": ["n02093647", "Bedlington_terrier"],
- "182": ["n02093754", "Border_terrier"],
- "183": ["n02093859", "Kerry_blue_terrier"],
- "184": ["n02093991", "Irish_terrier"],
- "185": ["n02094114", "Norfolk_terrier"],
- "186": ["n02094258", "Norwich_terrier"],
- "187": ["n02094433", "Yorkshire_terrier"],
- "188": ["n02095314", "wire-haired_fox_terrier"],
- "189": ["n02095570", "Lakeland_terrier"],
- "190": ["n02095889", "Sealyham_terrier"],
- "191": ["n02096051", "Airedale"],
- "192": ["n02096177", "cairn"],
- "193": ["n02096294", "Australian_terrier"],
- "194": ["n02096437", "Dandie_Dinmont"],
- "195": ["n02096585", "Boston_bull"],
- "196": ["n02097047", "miniature_schnauzer"],
- "197": ["n02097130", "giant_schnauzer"],
- "198": ["n02097209", "standard_schnauzer"],
- "199": ["n02097298", "Scotch_terrier"],
- "200": ["n02097474", "Tibetan_terrier"],
- "201": ["n02097658", "silky_terrier"],
- "202": ["n02098105", "soft-coated_wheaten_terrier"],
- "203": ["n02098286", "West_Highland_white_terrier"],
- "204": ["n02098413", "Lhasa"],
- "205": ["n02099267", "flat-coated_retriever"],
- "206": ["n02099429", "curly-coated_retriever"],
- "207": ["n02099601", "golden_retriever"],
- "208": ["n02099712", "Labrador_retriever"],
- "209": ["n02099849", "Chesapeake_Bay_retriever"],
- "210": ["n02100236", "German_short-haired_pointer"],
- "211": ["n02100583", "vizsla"],
- "212": ["n02100735", "English_setter"],
- "213": ["n02100877", "Irish_setter"],
- "214": ["n02101006", "Gordon_setter"],
- "215": ["n02101388", "Brittany_spaniel"],
- "216": ["n02101556", "clumber"],
- "217": ["n02102040", "English_springer"],
- "218": ["n02102177", "Welsh_springer_spaniel"],
- "219": ["n02102318", "cocker_spaniel"],
- "220": ["n02102480", "Sussex_spaniel"],
- "221": ["n02102973", "Irish_water_spaniel"],
- "222": ["n02104029", "kuvasz"],
- "223": ["n02104365", "schipperke"],
- "224": ["n02105056", "groenendael"],
- "225": ["n02105162", "malinois"],
- "226": ["n02105251", "briard"],
- "227": ["n02105412", "kelpie"],
- "228": ["n02105505", "komondor"],
- "229": ["n02105641", "Old_English_sheepdog"],
- "230": ["n02105855", "Shetland_sheepdog"],
- "231": ["n02106030", "collie"],
- "232": ["n02106166", "Border_collie"],
- "233": ["n02106382", "Bouvier_des_Flandres"],
- "234": ["n02106550", "Rottweiler"],
- "235": ["n02106662", "German_shepherd"],
- "236": ["n02107142", "Doberman"],
- "237": ["n02107312", "miniature_pinscher"],
- "238": ["n02107574", "Greater_Swiss_Mountain_dog"],
- "239": ["n02107683", "Bernese_mountain_dog"],
- "240": ["n02107908", "Appenzeller"],
- "241": ["n02108000", "EntleBucher"],
- "242": ["n02108089", "boxer"],
- "243": ["n02108422", "bull_mastiff"],
- "244": ["n02108551", "Tibetan_mastiff"],
- "245": ["n02108915", "French_bulldog"],
- "246": ["n02109047", "Great_Dane"],
- "247": ["n02109525", "Saint_Bernard"],
- "248": ["n02109961", "Eskimo_dog"],
- "249": ["n02110063", "malamute"],
- "250": ["n02110185", "Siberian_husky"],
- "251": ["n02110341", "dalmatian"],
- "252": ["n02110627", "affenpinscher"],
- "253": ["n02110806", "basenji"],
- "254": ["n02110958", "pug"],
- "255": ["n02111129", "Leonberg"],
- "256": ["n02111277", "Newfoundland"],
- "257": ["n02111500", "Great_Pyrenees"],
- "258": ["n02111889", "Samoyed"],
- "259": ["n02112018", "Pomeranian"],
- "260": ["n02112137", "chow"],
- "261": ["n02112350", "keeshond"],
- "262": ["n02112706", "Brabancon_griffon"],
- "263": ["n02113023", "Pembroke"],
- "264": ["n02113186", "Cardigan"],
- "265": ["n02113624", "toy_poodle"],
- "266": ["n02113712", "miniature_poodle"],
- "267": ["n02113799", "standard_poodle"],
- "268": ["n02113978", "Mexican_hairless"],
- "269": ["n02114367", "timber_wolf"],
- "270": ["n02114548", "white_wolf"],
- "271": ["n02114712", "red_wolf"],
- "272": ["n02114855", "coyote"],
- "273": ["n02115641", "dingo"],
- "274": ["n02115913", "dhole"],
- "275": ["n02116738", "African_hunting_dog"],
- "276": ["n02117135", "hyena"],
- "277": ["n02119022", "red_fox"],
- "278": ["n02119789", "kit_fox"],
- "279": ["n02120079", "Arctic_fox"],
- "280": ["n02120505", "grey_fox"],
- "281": ["n02123045", "tabby"],
- "282": ["n02123159", "tiger_cat"],
- "283": ["n02123394", "Persian_cat"],
- "284": ["n02123597", "Siamese_cat"],
- "285": ["n02124075", "Egyptian_cat"],
- "286": ["n02125311", "cougar"],
- "287": ["n02127052", "lynx"],
- "288": ["n02128385", "leopard"],
- "289": ["n02128757", "snow_leopard"],
- "290": ["n02128925", "jaguar"],
- "291": ["n02129165", "lion"],
- "292": ["n02129604", "tiger"],
- "293": ["n02130308", "cheetah"],
- "294": ["n02132136", "brown_bear"],
- "295": ["n02133161", "American_black_bear"],
- "296": ["n02134084", "ice_bear"],
- "297": ["n02134418", "sloth_bear"],
- "298": ["n02137549", "mongoose"],
- "299": ["n02138441", "meerkat"],
- "300": ["n02165105", "tiger_beetle"],
- "301": ["n02165456", "ladybug"],
- "302": ["n02167151", "ground_beetle"],
- "303": ["n02168699", "long-horned_beetle"],
- "304": ["n02169497", "leaf_beetle"],
- "305": ["n02172182", "dung_beetle"],
- "306": ["n02174001", "rhinoceros_beetle"],
- "307": ["n02177972", "weevil"],
- "308": ["n02190166", "fly"],
- "309": ["n02206856", "bee"],
- "310": ["n02219486", "ant"],
- "311": ["n02226429", "grasshopper"],
- "312": ["n02229544", "cricket"],
- "313": ["n02231487", "walking_stick"],
- "314": ["n02233338", "cockroach"],
- "315": ["n02236044", "mantis"],
- "316": ["n02256656", "cicada"],
- "317": ["n02259212", "leafhopper"],
- "318": ["n02264363", "lacewing"],
- "319": ["n02268443", "dragonfly"],
- "320": ["n02268853", "damselfly"],
- "321": ["n02276258", "admiral"],
- "322": ["n02277742", "ringlet"],
- "323": ["n02279972", "monarch"],
- "324": ["n02280649", "cabbage_butterfly"],
- "325": ["n02281406", "sulphur_butterfly"],
- "326": ["n02281787", "lycaenid"],
- "327": ["n02317335", "starfish"],
- "328": ["n02319095", "sea_urchin"],
- "329": ["n02321529", "sea_cucumber"],
- "330": ["n02325366", "wood_rabbit"],
- "331": ["n02326432", "hare"],
- "332": ["n02328150", "Angora"],
- "333": ["n02342885", "hamster"],
- "334": ["n02346627", "porcupine"],
- "335": ["n02356798", "fox_squirrel"],
- "336": ["n02361337", "marmot"],
- "337": ["n02363005", "beaver"],
- "338": ["n02364673", "guinea_pig"],
- "339": ["n02389026", "sorrel"],
- "340": ["n02391049", "zebra"],
- "341": ["n02395406", "hog"],
- "342": ["n02396427", "wild_boar"],
- "343": ["n02397096", "warthog"],
- "344": ["n02398521", "hippopotamus"],
- "345": ["n02403003", "ox"],
- "346": ["n02408429", "water_buffalo"],
- "347": ["n02410509", "bison"],
- "348": ["n02412080", "ram"],
- "349": ["n02415577", "bighorn"],
- "350": ["n02417914", "ibex"],
- "351": ["n02422106", "hartebeest"],
- "352": ["n02422699", "impala"],
- "353": ["n02423022", "gazelle"],
- "354": ["n02437312", "Arabian_camel"],
- "355": ["n02437616", "llama"],
- "356": ["n02441942", "weasel"],
- "357": ["n02442845", "mink"],
- "358": ["n02443114", "polecat"],
- "359": ["n02443484", "black-footed_ferret"],
- "360": ["n02444819", "otter"],
- "361": ["n02445715", "skunk"],
- "362": ["n02447366", "badger"],
- "363": ["n02454379", "armadillo"],
- "364": ["n02457408", "three-toed_sloth"],
- "365": ["n02480495", "orangutan"],
- "366": ["n02480855", "gorilla"],
- "367": ["n02481823", "chimpanzee"],
- "368": ["n02483362", "gibbon"],
- "369": ["n02483708", "siamang"],
- "370": ["n02484975", "guenon"],
- "371": ["n02486261", "patas"],
- "372": ["n02486410", "baboon"],
- "373": ["n02487347", "macaque"],
- "374": ["n02488291", "langur"],
- "375": ["n02488702", "colobus"],
- "376": ["n02489166", "proboscis_monkey"],
- "377": ["n02490219", "marmoset"],
- "378": ["n02492035", "capuchin"],
- "379": ["n02492660", "howler_monkey"],
- "380": ["n02493509", "titi"],
- "381": ["n02493793", "spider_monkey"],
- "382": ["n02494079", "squirrel_monkey"],
- "383": ["n02497673", "Madagascar_cat"],
- "384": ["n02500267", "indri"],
- "385": ["n02504013", "Indian_elephant"],
- "386": ["n02504458", "African_elephant"],
- "387": ["n02509815", "lesser_panda"],
- "388": ["n02510455", "giant_panda"],
- "389": ["n02514041", "barracouta"],
- "390": ["n02526121", "eel"],
- "391": ["n02536864", "coho"],
- "392": ["n02606052", "rock_beauty"],
- "393": ["n02607072", "anemone_fish"],
- "394": ["n02640242", "sturgeon"],
- "395": ["n02641379", "gar"],
- "396": ["n02643566", "lionfish"],
- "397": ["n02655020", "puffer"],
- "398": ["n02666196", "abacus"],
- "399": ["n02667093", "abaya"],
- "400": ["n02669723", "academic_gown"],
- "401": ["n02672831", "accordion"],
- "402": ["n02676566", "acoustic_guitar"],
- "403": ["n02687172", "aircraft_carrier"],
- "404": ["n02690373", "airliner"],
- "405": ["n02692877", "airship"],
- "406": ["n02699494", "altar"],
- "407": ["n02701002", "ambulance"],
- "408": ["n02704792", "amphibian"],
- "409": ["n02708093", "analog_clock"],
- "410": ["n02727426", "apiary"],
- "411": ["n02730930", "apron"],
- "412": ["n02747177", "ashcan"],
- "413": ["n02749479", "assault_rifle"],
- "414": ["n02769748", "backpack"],
- "415": ["n02776631", "bakery"],
- "416": ["n02777292", "balance_beam"],
- "417": ["n02782093", "balloon"],
- "418": ["n02783161", "ballpoint"],
- "419": ["n02786058", "Band_Aid"],
- "420": ["n02787622", "banjo"],
- "421": ["n02788148", "bannister"],
- "422": ["n02790996", "barbell"],
- "423": ["n02791124", "barber_chair"],
- "424": ["n02791270", "barbershop"],
- "425": ["n02793495", "barn"],
- "426": ["n02794156", "barometer"],
- "427": ["n02795169", "barrel"],
- "428": ["n02797295", "barrow"],
- "429": ["n02799071", "baseball"],
- "430": ["n02802426", "basketball"],
- "431": ["n02804414", "bassinet"],
- "432": ["n02804610", "bassoon"],
- "433": ["n02807133", "bathing_cap"],
- "434": ["n02808304", "bath_towel"],
- "435": ["n02808440", "bathtub"],
- "436": ["n02814533", "beach_wagon"],
- "437": ["n02814860", "beacon"],
- "438": ["n02815834", "beaker"],
- "439": ["n02817516", "bearskin"],
- "440": ["n02823428", "beer_bottle"],
- "441": ["n02823750", "beer_glass"],
- "442": ["n02825657", "bell_cote"],
- "443": ["n02834397", "bib"],
- "444": ["n02835271", "bicycle-built-for-two"],
- "445": ["n02837789", "bikini"],
- "446": ["n02840245", "binder"],
- "447": ["n02841315", "binoculars"],
- "448": ["n02843684", "birdhouse"],
- "449": ["n02859443", "boathouse"],
- "450": ["n02860847", "bobsled"],
- "451": ["n02865351", "bolo_tie"],
- "452": ["n02869837", "bonnet"],
- "453": ["n02870880", "bookcase"],
- "454": ["n02871525", "bookshop"],
- "455": ["n02877765", "bottlecap"],
- "456": ["n02879718", "bow"],
- "457": ["n02883205", "bow_tie"],
- "458": ["n02892201", "brass"],
- "459": ["n02892767", "brassiere"],
- "460": ["n02894605", "breakwater"],
- "461": ["n02895154", "breastplate"],
- "462": ["n02906734", "broom"],
- "463": ["n02909870", "bucket"],
- "464": ["n02910353", "buckle"],
- "465": ["n02916936", "bulletproof_vest"],
- "466": ["n02917067", "bullet_train"],
- "467": ["n02927161", "butcher_shop"],
- "468": ["n02930766", "cab"],
- "469": ["n02939185", "caldron"],
- "470": ["n02948072", "candle"],
- "471": ["n02950826", "cannon"],
- "472": ["n02951358", "canoe"],
- "473": ["n02951585", "can_opener"],
- "474": ["n02963159", "cardigan"],
- "475": ["n02965783", "car_mirror"],
- "476": ["n02966193", "carousel"],
- "477": ["n02966687", "carpenter's_kit"],
- "478": ["n02971356", "carton"],
- "479": ["n02974003", "car_wheel"],
- "480": ["n02977058", "cash_machine"],
- "481": ["n02978881", "cassette"],
- "482": ["n02979186", "cassette_player"],
- "483": ["n02980441", "castle"],
- "484": ["n02981792", "catamaran"],
- "485": ["n02988304", "CD_player"],
- "486": ["n02992211", "cello"],
- "487": ["n02992529", "cellular_telephone"],
- "488": ["n02999410", "chain"],
- "489": ["n03000134", "chainlink_fence"],
- "490": ["n03000247", "chain_mail"],
- "491": ["n03000684", "chain_saw"],
- "492": ["n03014705", "chest"],
- "493": ["n03016953", "chiffonier"],
- "494": ["n03017168", "chime"],
- "495": ["n03018349", "china_cabinet"],
- "496": ["n03026506", "Christmas_stocking"],
- "497": ["n03028079", "church"],
- "498": ["n03032252", "cinema"],
- "499": ["n03041632", "cleaver"],
- "500": ["n03042490", "cliff_dwelling"],
- "501": ["n03045698", "cloak"],
- "502": ["n03047690", "clog"],
- "503": ["n03062245", "cocktail_shaker"],
- "504": ["n03063599", "coffee_mug"],
- "505": ["n03063689", "coffeepot"],
- "506": ["n03065424", "coil"],
- "507": ["n03075370", "combination_lock"],
- "508": ["n03085013", "computer_keyboard"],
- "509": ["n03089624", "confectionery"],
- "510": ["n03095699", "container_ship"],
- "511": ["n03100240", "convertible"],
- "512": ["n03109150", "corkscrew"],
- "513": ["n03110669", "cornet"],
- "514": ["n03124043", "cowboy_boot"],
- "515": ["n03124170", "cowboy_hat"],
- "516": ["n03125729", "cradle"],
- "517": ["n03126707", "crane"],
- "518": ["n03127747", "crash_helmet"],
- "519": ["n03127925", "crate"],
- "520": ["n03131574", "crib"],
- "521": ["n03133878", "Crock_Pot"],
- "522": ["n03134739", "croquet_ball"],
- "523": ["n03141823", "crutch"],
- "524": ["n03146219", "cuirass"],
- "525": ["n03160309", "dam"],
- "526": ["n03179701", "desk"],
- "527": ["n03180011", "desktop_computer"],
- "528": ["n03187595", "dial_telephone"],
- "529": ["n03188531", "diaper"],
- "530": ["n03196217", "digital_clock"],
- "531": ["n03197337", "digital_watch"],
- "532": ["n03201208", "dining_table"],
- "533": ["n03207743", "dishrag"],
- "534": ["n03207941", "dishwasher"],
- "535": ["n03208938", "disk_brake"],
- "536": ["n03216828", "dock"],
- "537": ["n03218198", "dogsled"],
- "538": ["n03220513", "dome"],
- "539": ["n03223299", "doormat"],
- "540": ["n03240683", "drilling_platform"],
- "541": ["n03249569", "drum"],
- "542": ["n03250847", "drumstick"],
- "543": ["n03255030", "dumbbell"],
- "544": ["n03259280", "Dutch_oven"],
- "545": ["n03271574", "electric_fan"],
- "546": ["n03272010", "electric_guitar"],
- "547": ["n03272562", "electric_locomotive"],
- "548": ["n03290653", "entertainment_center"],
- "549": ["n03291819", "envelope"],
- "550": ["n03297495", "espresso_maker"],
- "551": ["n03314780", "face_powder"],
- "552": ["n03325584", "feather_boa"],
- "553": ["n03337140", "file"],
- "554": ["n03344393", "fireboat"],
- "555": ["n03345487", "fire_engine"],
- "556": ["n03347037", "fire_screen"],
- "557": ["n03355925", "flagpole"],
- "558": ["n03372029", "flute"],
- "559": ["n03376595", "folding_chair"],
- "560": ["n03379051", "football_helmet"],
- "561": ["n03384352", "forklift"],
- "562": ["n03388043", "fountain"],
- "563": ["n03388183", "fountain_pen"],
- "564": ["n03388549", "four-poster"],
- "565": ["n03393912", "freight_car"],
- "566": ["n03394916", "French_horn"],
- "567": ["n03400231", "frying_pan"],
- "568": ["n03404251", "fur_coat"],
- "569": ["n03417042", "garbage_truck"],
- "570": ["n03424325", "gasmask"],
- "571": ["n03425413", "gas_pump"],
- "572": ["n03443371", "goblet"],
- "573": ["n03444034", "go-kart"],
- "574": ["n03445777", "golf_ball"],
- "575": ["n03445924", "golfcart"],
- "576": ["n03447447", "gondola"],
- "577": ["n03447721", "gong"],
- "578": ["n03450230", "gown"],
- "579": ["n03452741", "grand_piano"],
- "580": ["n03457902", "greenhouse"],
- "581": ["n03459775", "grille"],
- "582": ["n03461385", "grocery_store"],
- "583": ["n03467068", "guillotine"],
- "584": ["n03476684", "hair_slide"],
- "585": ["n03476991", "hair_spray"],
- "586": ["n03478589", "half_track"],
- "587": ["n03481172", "hammer"],
- "588": ["n03482405", "hamper"],
- "589": ["n03483316", "hand_blower"],
- "590": ["n03485407", "hand-held_computer"],
- "591": ["n03485794", "handkerchief"],
- "592": ["n03492542", "hard_disc"],
- "593": ["n03494278", "harmonica"],
- "594": ["n03495258", "harp"],
- "595": ["n03496892", "harvester"],
- "596": ["n03498962", "hatchet"],
- "597": ["n03527444", "holster"],
- "598": ["n03529860", "home_theater"],
- "599": ["n03530642", "honeycomb"],
- "600": ["n03532672", "hook"],
- "601": ["n03534580", "hoopskirt"],
- "602": ["n03535780", "horizontal_bar"],
- "603": ["n03538406", "horse_cart"],
- "604": ["n03544143", "hourglass"],
- "605": ["n03584254", "iPod"],
- "606": ["n03584829", "iron"],
- "607": ["n03590841", "jack-o'-lantern"],
- "608": ["n03594734", "jean"],
- "609": ["n03594945", "jeep"],
- "610": ["n03595614", "jersey"],
- "611": ["n03598930", "jigsaw_puzzle"],
- "612": ["n03599486", "jinrikisha"],
- "613": ["n03602883", "joystick"],
- "614": ["n03617480", "kimono"],
- "615": ["n03623198", "knee_pad"],
- "616": ["n03627232", "knot"],
- "617": ["n03630383", "lab_coat"],
- "618": ["n03633091", "ladle"],
- "619": ["n03637318", "lampshade"],
- "620": ["n03642806", "laptop"],
- "621": ["n03649909", "lawn_mower"],
- "622": ["n03657121", "lens_cap"],
- "623": ["n03658185", "letter_opener"],
- "624": ["n03661043", "library"],
- "625": ["n03662601", "lifeboat"],
- "626": ["n03666591", "lighter"],
- "627": ["n03670208", "limousine"],
- "628": ["n03673027", "liner"],
- "629": ["n03676483", "lipstick"],
- "630": ["n03680355", "Loafer"],
- "631": ["n03690938", "lotion"],
- "632": ["n03691459", "loudspeaker"],
- "633": ["n03692522", "loupe"],
- "634": ["n03697007", "lumbermill"],
- "635": ["n03706229", "magnetic_compass"],
- "636": ["n03709823", "mailbag"],
- "637": ["n03710193", "mailbox"],
- "638": ["n03710637", "maillot"],
- "639": ["n03710721", "maillot"],
- "640": ["n03717622", "manhole_cover"],
- "641": ["n03720891", "maraca"],
- "642": ["n03721384", "marimba"],
- "643": ["n03724870", "mask"],
- "644": ["n03729826", "matchstick"],
- "645": ["n03733131", "maypole"],
- "646": ["n03733281", "maze"],
- "647": ["n03733805", "measuring_cup"],
- "648": ["n03742115", "medicine_chest"],
- "649": ["n03743016", "megalith"],
- "650": ["n03759954", "microphone"],
- "651": ["n03761084", "microwave"],
- "652": ["n03763968", "military_uniform"],
- "653": ["n03764736", "milk_can"],
- "654": ["n03769881", "minibus"],
- "655": ["n03770439", "miniskirt"],
- "656": ["n03770679", "minivan"],
- "657": ["n03773504", "missile"],
- "658": ["n03775071", "mitten"],
- "659": ["n03775546", "mixing_bowl"],
- "660": ["n03776460", "mobile_home"],
- "661": ["n03777568", "Model_T"],
- "662": ["n03777754", "modem"],
- "663": ["n03781244", "monastery"],
- "664": ["n03782006", "monitor"],
- "665": ["n03785016", "moped"],
- "666": ["n03786901", "mortar"],
- "667": ["n03787032", "mortarboard"],
- "668": ["n03788195", "mosque"],
- "669": ["n03788365", "mosquito_net"],
- "670": ["n03791053", "motor_scooter"],
- "671": ["n03792782", "mountain_bike"],
- "672": ["n03792972", "mountain_tent"],
- "673": ["n03793489", "mouse"],
- "674": ["n03794056", "mousetrap"],
- "675": ["n03796401", "moving_van"],
- "676": ["n03803284", "muzzle"],
- "677": ["n03804744", "nail"],
- "678": ["n03814639", "neck_brace"],
- "679": ["n03814906", "necklace"],
- "680": ["n03825788", "nipple"],
- "681": ["n03832673", "notebook"],
- "682": ["n03837869", "obelisk"],
- "683": ["n03838899", "oboe"],
- "684": ["n03840681", "ocarina"],
- "685": ["n03841143", "odometer"],
- "686": ["n03843555", "oil_filter"],
- "687": ["n03854065", "organ"],
- "688": ["n03857828", "oscilloscope"],
- "689": ["n03866082", "overskirt"],
- "690": ["n03868242", "oxcart"],
- "691": ["n03868863", "oxygen_mask"],
- "692": ["n03871628", "packet"],
- "693": ["n03873416", "paddle"],
- "694": ["n03874293", "paddlewheel"],
- "695": ["n03874599", "padlock"],
- "696": ["n03876231", "paintbrush"],
- "697": ["n03877472", "pajama"],
- "698": ["n03877845", "palace"],
- "699": ["n03884397", "panpipe"],
- "700": ["n03887697", "paper_towel"],
- "701": ["n03888257", "parachute"],
- "702": ["n03888605", "parallel_bars"],
- "703": ["n03891251", "park_bench"],
- "704": ["n03891332", "parking_meter"],
- "705": ["n03895866", "passenger_car"],
- "706": ["n03899768", "patio"],
- "707": ["n03902125", "pay-phone"],
- "708": ["n03903868", "pedestal"],
- "709": ["n03908618", "pencil_box"],
- "710": ["n03908714", "pencil_sharpener"],
- "711": ["n03916031", "perfume"],
- "712": ["n03920288", "Petri_dish"],
- "713": ["n03924679", "photocopier"],
- "714": ["n03929660", "pick"],
- "715": ["n03929855", "pickelhaube"],
- "716": ["n03930313", "picket_fence"],
- "717": ["n03930630", "pickup"],
- "718": ["n03933933", "pier"],
- "719": ["n03935335", "piggy_bank"],
- "720": ["n03937543", "pill_bottle"],
- "721": ["n03938244", "pillow"],
- "722": ["n03942813", "ping-pong_ball"],
- "723": ["n03944341", "pinwheel"],
- "724": ["n03947888", "pirate"],
- "725": ["n03950228", "pitcher"],
- "726": ["n03954731", "plane"],
- "727": ["n03956157", "planetarium"],
- "728": ["n03958227", "plastic_bag"],
- "729": ["n03961711", "plate_rack"],
- "730": ["n03967562", "plow"],
- "731": ["n03970156", "plunger"],
- "732": ["n03976467", "Polaroid_camera"],
- "733": ["n03976657", "pole"],
- "734": ["n03977966", "police_van"],
- "735": ["n03980874", "poncho"],
- "736": ["n03982430", "pool_table"],
- "737": ["n03983396", "pop_bottle"],
- "738": ["n03991062", "pot"],
- "739": ["n03992509", "potter's_wheel"],
- "740": ["n03995372", "power_drill"],
- "741": ["n03998194", "prayer_rug"],
- "742": ["n04004767", "printer"],
- "743": ["n04005630", "prison"],
- "744": ["n04008634", "projectile"],
- "745": ["n04009552", "projector"],
- "746": ["n04019541", "puck"],
- "747": ["n04023962", "punching_bag"],
- "748": ["n04026417", "purse"],
- "749": ["n04033901", "quill"],
- "750": ["n04033995", "quilt"],
- "751": ["n04037443", "racer"],
- "752": ["n04039381", "racket"],
- "753": ["n04040759", "radiator"],
- "754": ["n04041544", "radio"],
- "755": ["n04044716", "radio_telescope"],
- "756": ["n04049303", "rain_barrel"],
- "757": ["n04065272", "recreational_vehicle"],
- "758": ["n04067472", "reel"],
- "759": ["n04069434", "reflex_camera"],
- "760": ["n04070727", "refrigerator"],
- "761": ["n04074963", "remote_control"],
- "762": ["n04081281", "restaurant"],
- "763": ["n04086273", "revolver"],
- "764": ["n04090263", "rifle"],
- "765": ["n04099969", "rocking_chair"],
- "766": ["n04111531", "rotisserie"],
- "767": ["n04116512", "rubber_eraser"],
- "768": ["n04118538", "rugby_ball"],
- "769": ["n04118776", "rule"],
- "770": ["n04120489", "running_shoe"],
- "771": ["n04125021", "safe"],
- "772": ["n04127249", "safety_pin"],
- "773": ["n04131690", "saltshaker"],
- "774": ["n04133789", "sandal"],
- "775": ["n04136333", "sarong"],
- "776": ["n04141076", "sax"],
- "777": ["n04141327", "scabbard"],
- "778": ["n04141975", "scale"],
- "779": ["n04146614", "school_bus"],
- "780": ["n04147183", "schooner"],
- "781": ["n04149813", "scoreboard"],
- "782": ["n04152593", "screen"],
- "783": ["n04153751", "screw"],
- "784": ["n04154565", "screwdriver"],
- "785": ["n04162706", "seat_belt"],
- "786": ["n04179913", "sewing_machine"],
- "787": ["n04192698", "shield"],
- "788": ["n04200800", "shoe_shop"],
- "789": ["n04201297", "shoji"],
- "790": ["n04204238", "shopping_basket"],
- "791": ["n04204347", "shopping_cart"],
- "792": ["n04208210", "shovel"],
- "793": ["n04209133", "shower_cap"],
- "794": ["n04209239", "shower_curtain"],
- "795": ["n04228054", "ski"],
- "796": ["n04229816", "ski_mask"],
- "797": ["n04235860", "sleeping_bag"],
- "798": ["n04238763", "slide_rule"],
- "799": ["n04239074", "sliding_door"],
- "800": ["n04243546", "slot"],
- "801": ["n04251144", "snorkel"],
- "802": ["n04252077", "snowmobile"],
- "803": ["n04252225", "snowplow"],
- "804": ["n04254120", "soap_dispenser"],
- "805": ["n04254680", "soccer_ball"],
- "806": ["n04254777", "sock"],
- "807": ["n04258138", "solar_dish"],
- "808": ["n04259630", "sombrero"],
- "809": ["n04263257", "soup_bowl"],
- "810": ["n04264628", "space_bar"],
- "811": ["n04265275", "space_heater"],
- "812": ["n04266014", "space_shuttle"],
- "813": ["n04270147", "spatula"],
- "814": ["n04273569", "speedboat"],
- "815": ["n04275548", "spider_web"],
- "816": ["n04277352", "spindle"],
- "817": ["n04285008", "sports_car"],
- "818": ["n04286575", "spotlight"],
- "819": ["n04296562", "stage"],
- "820": ["n04310018", "steam_locomotive"],
- "821": ["n04311004", "steel_arch_bridge"],
- "822": ["n04311174", "steel_drum"],
- "823": ["n04317175", "stethoscope"],
- "824": ["n04325704", "stole"],
- "825": ["n04326547", "stone_wall"],
- "826": ["n04328186", "stopwatch"],
- "827": ["n04330267", "stove"],
- "828": ["n04332243", "strainer"],
- "829": ["n04335435", "streetcar"],
- "830": ["n04336792", "stretcher"],
- "831": ["n04344873", "studio_couch"],
- "832": ["n04346328", "stupa"],
- "833": ["n04347754", "submarine"],
- "834": ["n04350905", "suit"],
- "835": ["n04355338", "sundial"],
- "836": ["n04355933", "sunglass"],
- "837": ["n04356056", "sunglasses"],
- "838": ["n04357314", "sunscreen"],
- "839": ["n04366367", "suspension_bridge"],
- "840": ["n04367480", "swab"],
- "841": ["n04370456", "sweatshirt"],
- "842": ["n04371430", "swimming_trunks"],
- "843": ["n04371774", "swing"],
- "844": ["n04372370", "switch"],
- "845": ["n04376876", "syringe"],
- "846": ["n04380533", "table_lamp"],
- "847": ["n04389033", "tank"],
- "848": ["n04392985", "tape_player"],
- "849": ["n04398044", "teapot"],
- "850": ["n04399382", "teddy"],
- "851": ["n04404412", "television"],
- "852": ["n04409515", "tennis_ball"],
- "853": ["n04417672", "thatch"],
- "854": ["n04418357", "theater_curtain"],
- "855": ["n04423845", "thimble"],
- "856": ["n04428191", "thresher"],
- "857": ["n04429376", "throne"],
- "858": ["n04435653", "tile_roof"],
- "859": ["n04442312", "toaster"],
- "860": ["n04443257", "tobacco_shop"],
- "861": ["n04447861", "toilet_seat"],
- "862": ["n04456115", "torch"],
- "863": ["n04458633", "totem_pole"],
- "864": ["n04461696", "tow_truck"],
- "865": ["n04462240", "toyshop"],
- "866": ["n04465501", "tractor"],
- "867": ["n04467665", "trailer_truck"],
- "868": ["n04476259", "tray"],
- "869": ["n04479046", "trench_coat"],
- "870": ["n04482393", "tricycle"],
- "871": ["n04483307", "trimaran"],
- "872": ["n04485082", "tripod"],
- "873": ["n04486054", "triumphal_arch"],
- "874": ["n04487081", "trolleybus"],
- "875": ["n04487394", "trombone"],
- "876": ["n04493381", "tub"],
- "877": ["n04501370", "turnstile"],
- "878": ["n04505470", "typewriter_keyboard"],
- "879": ["n04507155", "umbrella"],
- "880": ["n04509417", "unicycle"],
- "881": ["n04515003", "upright"],
- "882": ["n04517823", "vacuum"],
- "883": ["n04522168", "vase"],
- "884": ["n04523525", "vault"],
- "885": ["n04525038", "velvet"],
- "886": ["n04525305", "vending_machine"],
- "887": ["n04532106", "vestment"],
- "888": ["n04532670", "viaduct"],
- "889": ["n04536866", "violin"],
- "890": ["n04540053", "volleyball"],
- "891": ["n04542943", "waffle_iron"],
- "892": ["n04548280", "wall_clock"],
- "893": ["n04548362", "wallet"],
- "894": ["n04550184", "wardrobe"],
- "895": ["n04552348", "warplane"],
- "896": ["n04553703", "washbasin"],
- "897": ["n04554684", "washer"],
- "898": ["n04557648", "water_bottle"],
- "899": ["n04560804", "water_jug"],
- "900": ["n04562935", "water_tower"],
- "901": ["n04579145", "whiskey_jug"],
- "902": ["n04579432", "whistle"],
- "903": ["n04584207", "wig"],
- "904": ["n04589890", "window_screen"],
- "905": ["n04590129", "window_shade"],
- "906": ["n04591157", "Windsor_tie"],
- "907": ["n04591713", "wine_bottle"],
- "908": ["n04592741", "wing"],
- "909": ["n04596742", "wok"],
- "910": ["n04597913", "wooden_spoon"],
- "911": ["n04599235", "wool"],
- "912": ["n04604644", "worm_fence"],
- "913": ["n04606251", "wreck"],
- "914": ["n04612504", "yawl"],
- "915": ["n04613696", "yurt"],
- "916": ["n06359193", "web_site"],
- "917": ["n06596364", "comic_book"],
- "918": ["n06785654", "crossword_puzzle"],
- "919": ["n06794110", "street_sign"],
- "920": ["n06874185", "traffic_light"],
- "921": ["n07248320", "book_jacket"],
- "922": ["n07565083", "menu"],
- "923": ["n07579787", "plate"],
- "924": ["n07583066", "guacamole"],
- "925": ["n07584110", "consomme"],
- "926": ["n07590611", "hot_pot"],
- "927": ["n07613480", "trifle"],
- "928": ["n07614500", "ice_cream"],
- "929": ["n07615774", "ice_lolly"],
- "930": ["n07684084", "French_loaf"],
- "931": ["n07693725", "bagel"],
- "932": ["n07695742", "pretzel"],
- "933": ["n07697313", "cheeseburger"],
- "934": ["n07697537", "hotdog"],
- "935": ["n07711569", "mashed_potato"],
- "936": ["n07714571", "head_cabbage"],
- "937": ["n07714990", "broccoli"],
- "938": ["n07715103", "cauliflower"],
- "939": ["n07716358", "zucchini"],
- "940": ["n07716906", "spaghetti_squash"],
- "941": ["n07717410", "acorn_squash"],
- "942": ["n07717556", "butternut_squash"],
- "943": ["n07718472", "cucumber"],
- "944": ["n07718747", "artichoke"],
- "945": ["n07720875", "bell_pepper"],
- "946": ["n07730033", "cardoon"],
- "947": ["n07734744", "mushroom"],
- "948": ["n07742313", "Granny_Smith"],
- "949": ["n07745940", "strawberry"],
- "950": ["n07747607", "orange"],
- "951": ["n07749582", "lemon"],
- "952": ["n07753113", "fig"],
- "953": ["n07753275", "pineapple"],
- "954": ["n07753592", "banana"],
- "955": ["n07754684", "jackfruit"],
- "956": ["n07760859", "custard_apple"],
- "957": ["n07768694", "pomegranate"],
- "958": ["n07802026", "hay"],
- "959": ["n07831146", "carbonara"],
- "960": ["n07836838", "chocolate_sauce"],
- "961": ["n07860988", "dough"],
- "962": ["n07871810", "meat_loaf"],
- "963": ["n07873807", "pizza"],
- "964": ["n07875152", "potpie"],
- "965": ["n07880968", "burrito"],
- "966": ["n07892512", "red_wine"],
- "967": ["n07920052", "espresso"],
- "968": ["n07930864", "cup"],
- "969": ["n07932039", "eggnog"],
- "970": ["n09193705", "alp"],
- "971": ["n09229709", "bubble"],
- "972": ["n09246464", "cliff"],
- "973": ["n09256479", "coral_reef"],
- "974": ["n09288635", "geyser"],
- "975": ["n09332890", "lakeside"],
- "976": ["n09399592", "promontory"],
- "977": ["n09421951", "sandbar"],
- "978": ["n09428293", "seashore"],
- "979": ["n09468604", "valley"],
- "980": ["n09472597", "volcano"],
- "981": ["n09835506", "ballplayer"],
- "982": ["n10148035", "groom"],
- "983": ["n10565667", "scuba_diver"],
- "984": ["n11879895", "rapeseed"],
- "985": ["n11939491", "daisy"],
- "986": ["n12057211", "yellow_lady's_slipper"],
- "987": ["n12144580", "corn"],
- "988": ["n12267677", "acorn"],
- "989": ["n12620546", "hip"],
- "990": ["n12768682", "buckeye"],
- "991": ["n12985857", "coral_fungus"],
- "992": ["n12998815", "agaric"],
- "993": ["n13037406", "gyromitra"],
- "994": ["n13040303", "stinkhorn"],
- "995": ["n13044778", "earthstar"],
- "996": ["n13052670", "hen-of-the-woods"],
- "997": ["n13054560", "bolete"],
- "998": ["n13133613", "ear"],
- "999": ["n15075141", "toilet_tissue"]
-}
\ No newline at end of file
diff --git a/spaces/ServerX/PorcoDiaz/infer_uvr5.py b/spaces/ServerX/PorcoDiaz/infer_uvr5.py
deleted file mode 100644
index 8c8c05429a1d65dd8b198f16a8ea8c6e68991c07..0000000000000000000000000000000000000000
--- a/spaces/ServerX/PorcoDiaz/infer_uvr5.py
+++ /dev/null
@@ -1,363 +0,0 @@
-import os, sys, torch, warnings, pdb
-
-now_dir = os.getcwd()
-sys.path.append(now_dir)
-from json import load as ll
-
-warnings.filterwarnings("ignore")
-import librosa
-import importlib
-import numpy as np
-import hashlib, math
-from tqdm import tqdm
-from lib.uvr5_pack.lib_v5 import spec_utils
-from lib.uvr5_pack.utils import _get_name_params, inference
-from lib.uvr5_pack.lib_v5.model_param_init import ModelParameters
-import soundfile as sf
-from lib.uvr5_pack.lib_v5.nets_new import CascadedNet
-from lib.uvr5_pack.lib_v5 import nets_61968KB as nets
-
-
-class _audio_pre_:
- def __init__(self, agg, model_path, device, is_half):
- self.model_path = model_path
- self.device = device
- self.data = {
- # Processing Options
- "postprocess": False,
- "tta": False,
- # Constants
- "window_size": 512,
- "agg": agg,
- "high_end_process": "mirroring",
- }
- mp = ModelParameters("lib/uvr5_pack/lib_v5/modelparams/4band_v2.json")
- model = nets.CascadedASPPNet(mp.param["bins"] * 2)
- cpk = torch.load(model_path, map_location="cpu")
- model.load_state_dict(cpk)
- model.eval()
- if is_half:
- model = model.half().to(device)
- else:
- model = model.to(device)
-
- self.mp = mp
- self.model = model
-
- def _path_audio_(self, music_file, ins_root=None, vocal_root=None, format="flac"):
- if ins_root is None and vocal_root is None:
- return "No save root."
- name = os.path.basename(music_file)
- if ins_root is not None:
- os.makedirs(ins_root, exist_ok=True)
- if vocal_root is not None:
- os.makedirs(vocal_root, exist_ok=True)
- X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
- bands_n = len(self.mp.param["band"])
- # print(bands_n)
- for d in range(bands_n, 0, -1):
- bp = self.mp.param["band"][d]
- if d == bands_n: # high-end band
- (
- X_wave[d],
- _,
- ) = librosa.core.load(
- music_file,
- bp["sr"],
- False,
- dtype=np.float32,
- res_type=bp["res_type"],
- )
- if X_wave[d].ndim == 1:
- X_wave[d] = np.asfortranarray([X_wave[d], X_wave[d]])
- else: # lower bands
- X_wave[d] = librosa.core.resample(
- X_wave[d + 1],
- self.mp.param["band"][d + 1]["sr"],
- bp["sr"],
- res_type=bp["res_type"],
- )
- # Stft of wave source
- X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(
- X_wave[d],
- bp["hl"],
- bp["n_fft"],
- self.mp.param["mid_side"],
- self.mp.param["mid_side_b2"],
- self.mp.param["reverse"],
- )
- # pdb.set_trace()
- if d == bands_n and self.data["high_end_process"] != "none":
- input_high_end_h = (bp["n_fft"] // 2 - bp["crop_stop"]) + (
- self.mp.param["pre_filter_stop"] - self.mp.param["pre_filter_start"]
- )
- input_high_end = X_spec_s[d][
- :, bp["n_fft"] // 2 - input_high_end_h : bp["n_fft"] // 2, :
- ]
-
- X_spec_m = spec_utils.combine_spectrograms(X_spec_s, self.mp)
- aggresive_set = float(self.data["agg"] / 100)
- aggressiveness = {
- "value": aggresive_set,
- "split_bin": self.mp.param["band"][1]["crop_stop"],
- }
- with torch.no_grad():
- pred, X_mag, X_phase = inference(
- X_spec_m, self.device, self.model, aggressiveness, self.data
- )
- # Postprocess
- if self.data["postprocess"]:
- pred_inv = np.clip(X_mag - pred, 0, np.inf)
- pred = spec_utils.mask_silence(pred, pred_inv)
- y_spec_m = pred * X_phase
- v_spec_m = X_spec_m - y_spec_m
-
- if ins_root is not None:
- if self.data["high_end_process"].startswith("mirroring"):
- input_high_end_ = spec_utils.mirroring(
- self.data["high_end_process"], y_spec_m, input_high_end, self.mp
- )
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(
- y_spec_m, self.mp, input_high_end_h, input_high_end_
- )
- else:
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, self.mp)
- print("%s instruments done" % name)
- if format in ["wav", "flac"]:
- sf.write(
- os.path.join(
- ins_root,
- "instrument_{}_{}.{}".format(name, self.data["agg"], format),
- ),
- (np.array(wav_instrument) * 32768).astype("int16"),
- self.mp.param["sr"],
- ) #
- else:
- path = os.path.join(
- ins_root, "instrument_{}_{}.wav".format(name, self.data["agg"])
- )
- sf.write(
- path,
- (np.array(wav_instrument) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- if os.path.exists(path):
- os.system(
- "ffmpeg -i %s -vn %s -q:a 2 -y"
- % (path, path[:-4] + ".%s" % format)
- )
- if vocal_root is not None:
- if self.data["high_end_process"].startswith("mirroring"):
- input_high_end_ = spec_utils.mirroring(
- self.data["high_end_process"], v_spec_m, input_high_end, self.mp
- )
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(
- v_spec_m, self.mp, input_high_end_h, input_high_end_
- )
- else:
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, self.mp)
- print("%s vocals done" % name)
- if format in ["wav", "flac"]:
- sf.write(
- os.path.join(
- vocal_root,
- "vocal_{}_{}.{}".format(name, self.data["agg"], format),
- ),
- (np.array(wav_vocals) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- else:
- path = os.path.join(
- vocal_root, "vocal_{}_{}.wav".format(name, self.data["agg"])
- )
- sf.write(
- path,
- (np.array(wav_vocals) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- if os.path.exists(path):
- os.system(
- "ffmpeg -i %s -vn %s -q:a 2 -y"
- % (path, path[:-4] + ".%s" % format)
- )
-
-
-class _audio_pre_new:
- def __init__(self, agg, model_path, device, is_half):
- self.model_path = model_path
- self.device = device
- self.data = {
- # Processing Options
- "postprocess": False,
- "tta": False,
- # Constants
- "window_size": 512,
- "agg": agg,
- "high_end_process": "mirroring",
- }
- mp = ModelParameters("lib/uvr5_pack/lib_v5/modelparams/4band_v3.json")
- nout = 64 if "DeReverb" in model_path else 48
- model = CascadedNet(mp.param["bins"] * 2, nout)
- cpk = torch.load(model_path, map_location="cpu")
- model.load_state_dict(cpk)
- model.eval()
- if is_half:
- model = model.half().to(device)
- else:
- model = model.to(device)
-
- self.mp = mp
- self.model = model
-
- def _path_audio_(
- self, music_file, vocal_root=None, ins_root=None, format="flac"
- ): # 3个VR模型vocal和ins是反的
- if ins_root is None and vocal_root is None:
- return "No save root."
- name = os.path.basename(music_file)
- if ins_root is not None:
- os.makedirs(ins_root, exist_ok=True)
- if vocal_root is not None:
- os.makedirs(vocal_root, exist_ok=True)
- X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {}
- bands_n = len(self.mp.param["band"])
- # print(bands_n)
- for d in range(bands_n, 0, -1):
- bp = self.mp.param["band"][d]
- if d == bands_n: # high-end band
- (
- X_wave[d],
- _,
- ) = librosa.core.load(
- music_file,
- bp["sr"],
- False,
- dtype=np.float32,
- res_type=bp["res_type"],
- )
- if X_wave[d].ndim == 1:
- X_wave[d] = np.asfortranarray([X_wave[d], X_wave[d]])
- else: # lower bands
- X_wave[d] = librosa.core.resample(
- X_wave[d + 1],
- self.mp.param["band"][d + 1]["sr"],
- bp["sr"],
- res_type=bp["res_type"],
- )
- # Stft of wave source
- X_spec_s[d] = spec_utils.wave_to_spectrogram_mt(
- X_wave[d],
- bp["hl"],
- bp["n_fft"],
- self.mp.param["mid_side"],
- self.mp.param["mid_side_b2"],
- self.mp.param["reverse"],
- )
- # pdb.set_trace()
- if d == bands_n and self.data["high_end_process"] != "none":
- input_high_end_h = (bp["n_fft"] // 2 - bp["crop_stop"]) + (
- self.mp.param["pre_filter_stop"] - self.mp.param["pre_filter_start"]
- )
- input_high_end = X_spec_s[d][
- :, bp["n_fft"] // 2 - input_high_end_h : bp["n_fft"] // 2, :
- ]
-
- X_spec_m = spec_utils.combine_spectrograms(X_spec_s, self.mp)
- aggresive_set = float(self.data["agg"] / 100)
- aggressiveness = {
- "value": aggresive_set,
- "split_bin": self.mp.param["band"][1]["crop_stop"],
- }
- with torch.no_grad():
- pred, X_mag, X_phase = inference(
- X_spec_m, self.device, self.model, aggressiveness, self.data
- )
- # Postprocess
- if self.data["postprocess"]:
- pred_inv = np.clip(X_mag - pred, 0, np.inf)
- pred = spec_utils.mask_silence(pred, pred_inv)
- y_spec_m = pred * X_phase
- v_spec_m = X_spec_m - y_spec_m
-
- if ins_root is not None:
- if self.data["high_end_process"].startswith("mirroring"):
- input_high_end_ = spec_utils.mirroring(
- self.data["high_end_process"], y_spec_m, input_high_end, self.mp
- )
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(
- y_spec_m, self.mp, input_high_end_h, input_high_end_
- )
- else:
- wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, self.mp)
- print("%s instruments done" % name)
- if format in ["wav", "flac"]:
- sf.write(
- os.path.join(
- ins_root,
- "instrument_{}_{}.{}".format(name, self.data["agg"], format),
- ),
- (np.array(wav_instrument) * 32768).astype("int16"),
- self.mp.param["sr"],
- ) #
- else:
- path = os.path.join(
- ins_root, "instrument_{}_{}.wav".format(name, self.data["agg"])
- )
- sf.write(
- path,
- (np.array(wav_instrument) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- if os.path.exists(path):
- os.system(
- "ffmpeg -i %s -vn %s -q:a 2 -y"
- % (path, path[:-4] + ".%s" % format)
- )
- if vocal_root is not None:
- if self.data["high_end_process"].startswith("mirroring"):
- input_high_end_ = spec_utils.mirroring(
- self.data["high_end_process"], v_spec_m, input_high_end, self.mp
- )
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(
- v_spec_m, self.mp, input_high_end_h, input_high_end_
- )
- else:
- wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, self.mp)
- print("%s vocals done" % name)
- if format in ["wav", "flac"]:
- sf.write(
- os.path.join(
- vocal_root,
- "vocal_{}_{}.{}".format(name, self.data["agg"], format),
- ),
- (np.array(wav_vocals) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- else:
- path = os.path.join(
- vocal_root, "vocal_{}_{}.wav".format(name, self.data["agg"])
- )
- sf.write(
- path,
- (np.array(wav_vocals) * 32768).astype("int16"),
- self.mp.param["sr"],
- )
- if os.path.exists(path):
- os.system(
- "ffmpeg -i %s -vn %s -q:a 2 -y"
- % (path, path[:-4] + ".%s" % format)
- )
-
-
-if __name__ == "__main__":
- device = "cuda"
- is_half = True
- # model_path = "uvr5_weights/2_HP-UVR.pth"
- # model_path = "uvr5_weights/VR-DeEchoDeReverb.pth"
- # model_path = "uvr5_weights/VR-DeEchoNormal.pth"
- model_path = "uvr5_weights/DeEchoNormal.pth"
- # pre_fun = _audio_pre_(model_path=model_path, device=device, is_half=True,agg=10)
- pre_fun = _audio_pre_new(model_path=model_path, device=device, is_half=True, agg=10)
- audio_path = "雪雪伴奏对消HP5.wav"
- save_path = "opt"
- pre_fun._path_audio_(audio_path, save_path, save_path)
diff --git a/spaces/Silentlin/DiffSinger/modules/parallel_wavegan/utils/utils.py b/spaces/Silentlin/DiffSinger/modules/parallel_wavegan/utils/utils.py
deleted file mode 100644
index d48a5ed28e8555d4b8cfb15fdee86426bbb9e368..0000000000000000000000000000000000000000
--- a/spaces/Silentlin/DiffSinger/modules/parallel_wavegan/utils/utils.py
+++ /dev/null
@@ -1,169 +0,0 @@
-# -*- coding: utf-8 -*-
-
-# Copyright 2019 Tomoki Hayashi
-# MIT License (https://opensource.org/licenses/MIT)
-
-"""Utility functions."""
-
-import fnmatch
-import logging
-import os
-import sys
-
-import h5py
-import numpy as np
-
-
-def find_files(root_dir, query="*.wav", include_root_dir=True):
- """Find files recursively.
-
- Args:
- root_dir (str): Root root_dir to find.
- query (str): Query to find.
- include_root_dir (bool): If False, root_dir name is not included.
-
- Returns:
- list: List of found filenames.
-
- """
- files = []
- for root, dirnames, filenames in os.walk(root_dir, followlinks=True):
- for filename in fnmatch.filter(filenames, query):
- files.append(os.path.join(root, filename))
- if not include_root_dir:
- files = [file_.replace(root_dir + "/", "") for file_ in files]
-
- return files
-
-
-def read_hdf5(hdf5_name, hdf5_path):
- """Read hdf5 dataset.
-
- Args:
- hdf5_name (str): Filename of hdf5 file.
- hdf5_path (str): Dataset name in hdf5 file.
-
- Return:
- any: Dataset values.
-
- """
- if not os.path.exists(hdf5_name):
- logging.error(f"There is no such a hdf5 file ({hdf5_name}).")
- sys.exit(1)
-
- hdf5_file = h5py.File(hdf5_name, "r")
-
- if hdf5_path not in hdf5_file:
- logging.error(f"There is no such a data in hdf5 file. ({hdf5_path})")
- sys.exit(1)
-
- hdf5_data = hdf5_file[hdf5_path][()]
- hdf5_file.close()
-
- return hdf5_data
-
-
-def write_hdf5(hdf5_name, hdf5_path, write_data, is_overwrite=True):
- """Write dataset to hdf5.
-
- Args:
- hdf5_name (str): Hdf5 dataset filename.
- hdf5_path (str): Dataset path in hdf5.
- write_data (ndarray): Data to write.
- is_overwrite (bool): Whether to overwrite dataset.
-
- """
- # convert to numpy array
- write_data = np.array(write_data)
-
- # check folder existence
- folder_name, _ = os.path.split(hdf5_name)
- if not os.path.exists(folder_name) and len(folder_name) != 0:
- os.makedirs(folder_name)
-
- # check hdf5 existence
- if os.path.exists(hdf5_name):
- # if already exists, open with r+ mode
- hdf5_file = h5py.File(hdf5_name, "r+")
- # check dataset existence
- if hdf5_path in hdf5_file:
- if is_overwrite:
- logging.warning("Dataset in hdf5 file already exists. "
- "recreate dataset in hdf5.")
- hdf5_file.__delitem__(hdf5_path)
- else:
- logging.error("Dataset in hdf5 file already exists. "
- "if you want to overwrite, please set is_overwrite = True.")
- hdf5_file.close()
- sys.exit(1)
- else:
- # if not exists, open with w mode
- hdf5_file = h5py.File(hdf5_name, "w")
-
- # write data to hdf5
- hdf5_file.create_dataset(hdf5_path, data=write_data)
- hdf5_file.flush()
- hdf5_file.close()
-
-
-class HDF5ScpLoader(object):
- """Loader class for a fests.scp file of hdf5 file.
-
- Examples:
- key1 /some/path/a.h5:feats
- key2 /some/path/b.h5:feats
- key3 /some/path/c.h5:feats
- key4 /some/path/d.h5:feats
- ...
- >>> loader = HDF5ScpLoader("hdf5.scp")
- >>> array = loader["key1"]
-
- key1 /some/path/a.h5
- key2 /some/path/b.h5
- key3 /some/path/c.h5
- key4 /some/path/d.h5
- ...
- >>> loader = HDF5ScpLoader("hdf5.scp", "feats")
- >>> array = loader["key1"]
-
- """
-
- def __init__(self, feats_scp, default_hdf5_path="feats"):
- """Initialize HDF5 scp loader.
-
- Args:
- feats_scp (str): Kaldi-style feats.scp file with hdf5 format.
- default_hdf5_path (str): Path in hdf5 file. If the scp contain the info, not used.
-
- """
- self.default_hdf5_path = default_hdf5_path
- with open(feats_scp) as f:
- lines = [line.replace("\n", "") for line in f.readlines()]
- self.data = {}
- for line in lines:
- key, value = line.split()
- self.data[key] = value
-
- def get_path(self, key):
- """Get hdf5 file path for a given key."""
- return self.data[key]
-
- def __getitem__(self, key):
- """Get ndarray for a given key."""
- p = self.data[key]
- if ":" in p:
- return read_hdf5(*p.split(":"))
- else:
- return read_hdf5(p, self.default_hdf5_path)
-
- def __len__(self):
- """Return the length of the scp file."""
- return len(self.data)
-
- def __iter__(self):
- """Return the iterator of the scp file."""
- return iter(self.data)
-
- def keys(self):
- """Return the keys of the scp file."""
- return self.data.keys()
diff --git a/spaces/SuYuanS/AudioCraft_Plus/audiocraft/models/__init__.py b/spaces/SuYuanS/AudioCraft_Plus/audiocraft/models/__init__.py
deleted file mode 100644
index be6bfe4b787a132aeaabaed1c3437c9ecd5c656c..0000000000000000000000000000000000000000
--- a/spaces/SuYuanS/AudioCraft_Plus/audiocraft/models/__init__.py
+++ /dev/null
@@ -1,18 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-"""
-Models for EnCodec, AudioGen, MusicGen, as well as the generic LMModel.
-"""
-# flake8: noqa
-from . import builders, loaders
-from .encodec import (
- CompressionModel, EncodecModel, DAC,
- HFEncodecModel, HFEncodecCompressionModel)
-from .audiogen import AudioGen
-from .lm import LMModel
-from .multibanddiffusion import MultiBandDiffusion
-from .musicgen import MusicGen
-from .unet import DiffusionUnet
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/prompts.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/prompts.py
deleted file mode 100644
index 3f5c07b980ef0b65dae36bd2970836fb1d9d2769..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/prompts.py
+++ /dev/null
@@ -1,108 +0,0 @@
-"""Terminal input and output prompts."""
-
-from pygments.token import Token
-import sys
-
-from IPython.core.displayhook import DisplayHook
-
-from prompt_toolkit.formatted_text import fragment_list_width, PygmentsTokens
-from prompt_toolkit.shortcuts import print_formatted_text
-from prompt_toolkit.enums import EditingMode
-
-
-class Prompts(object):
- def __init__(self, shell):
- self.shell = shell
-
- def vi_mode(self):
- if (getattr(self.shell.pt_app, 'editing_mode', None) == EditingMode.VI
- and self.shell.prompt_includes_vi_mode):
- mode = str(self.shell.pt_app.app.vi_state.input_mode)
- if mode.startswith('InputMode.'):
- mode = mode[10:13].lower()
- elif mode.startswith('vi-'):
- mode = mode[3:6]
- return '['+mode+'] '
- return ''
-
-
- def in_prompt_tokens(self):
- return [
- (Token.Prompt, self.vi_mode() ),
- (Token.Prompt, 'In ['),
- (Token.PromptNum, str(self.shell.execution_count)),
- (Token.Prompt, ']: '),
- ]
-
- def _width(self):
- return fragment_list_width(self.in_prompt_tokens())
-
- def continuation_prompt_tokens(self, width=None):
- if width is None:
- width = self._width()
- return [
- (Token.Prompt, (' ' * (width - 5)) + '...: '),
- ]
-
- def rewrite_prompt_tokens(self):
- width = self._width()
- return [
- (Token.Prompt, ('-' * (width - 2)) + '> '),
- ]
-
- def out_prompt_tokens(self):
- return [
- (Token.OutPrompt, 'Out['),
- (Token.OutPromptNum, str(self.shell.execution_count)),
- (Token.OutPrompt, ']: '),
- ]
-
-class ClassicPrompts(Prompts):
- def in_prompt_tokens(self):
- return [
- (Token.Prompt, '>>> '),
- ]
-
- def continuation_prompt_tokens(self, width=None):
- return [
- (Token.Prompt, '... ')
- ]
-
- def rewrite_prompt_tokens(self):
- return []
-
- def out_prompt_tokens(self):
- return []
-
-class RichPromptDisplayHook(DisplayHook):
- """Subclass of base display hook using coloured prompt"""
- def write_output_prompt(self):
- sys.stdout.write(self.shell.separate_out)
- # If we're not displaying a prompt, it effectively ends with a newline,
- # because the output will be left-aligned.
- self.prompt_end_newline = True
-
- if self.do_full_cache:
- tokens = self.shell.prompts.out_prompt_tokens()
- prompt_txt = ''.join(s for t, s in tokens)
- if prompt_txt and not prompt_txt.endswith('\n'):
- # Ask for a newline before multiline output
- self.prompt_end_newline = False
-
- if self.shell.pt_app:
- print_formatted_text(PygmentsTokens(tokens),
- style=self.shell.pt_app.app.style, end='',
- )
- else:
- sys.stdout.write(prompt_txt)
-
- def write_format_data(self, format_dict, md_dict=None) -> None:
- if self.shell.mime_renderers:
-
- for mime, handler in self.shell.mime_renderers.items():
- if mime in format_dict:
- handler(format_dict[mime], None)
- return
-
- super().write_format_data(format_dict, md_dict)
-
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/tests/test_interactivshell.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/tests/test_interactivshell.py
deleted file mode 100644
index ae7da217f1dffde0133685ea50baeda1b7091c92..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/terminal/tests/test_interactivshell.py
+++ /dev/null
@@ -1,255 +0,0 @@
-# -*- coding: utf-8 -*-
-"""Tests for the TerminalInteractiveShell and related pieces."""
-# Copyright (c) IPython Development Team.
-# Distributed under the terms of the Modified BSD License.
-
-import sys
-import unittest
-import os
-
-from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
-
-
-from IPython.testing import tools as tt
-
-from IPython.terminal.ptutils import _elide, _adjust_completion_text_based_on_context
-from IPython.terminal.shortcuts.auto_suggest import NavigableAutoSuggestFromHistory
-
-
-class TestAutoSuggest(unittest.TestCase):
- def test_changing_provider(self):
- ip = get_ipython()
- ip.autosuggestions_provider = None
- self.assertEqual(ip.auto_suggest, None)
- ip.autosuggestions_provider = "AutoSuggestFromHistory"
- self.assertIsInstance(ip.auto_suggest, AutoSuggestFromHistory)
- ip.autosuggestions_provider = "NavigableAutoSuggestFromHistory"
- self.assertIsInstance(ip.auto_suggest, NavigableAutoSuggestFromHistory)
-
-
-class TestElide(unittest.TestCase):
- def test_elide(self):
- _elide("concatenate((a1, a2, ...), axis", "") # do not raise
- _elide("concatenate((a1, a2, ..), . axis", "") # do not raise
- self.assertEqual(
- _elide("aaaa.bbbb.ccccc.dddddd.eeeee.fffff.gggggg.hhhhhh", ""),
- "aaaa.b…g.hhhhhh",
- )
-
- test_string = os.sep.join(["", 10 * "a", 10 * "b", 10 * "c", ""])
- expect_string = (
- os.sep + "a" + "\N{HORIZONTAL ELLIPSIS}" + "b" + os.sep + 10 * "c"
- )
- self.assertEqual(_elide(test_string, ""), expect_string)
-
- def test_elide_typed_normal(self):
- self.assertEqual(
- _elide(
- "the quick brown fox jumped over the lazy dog",
- "the quick brown fox",
- min_elide=10,
- ),
- "the…fox jumped over the lazy dog",
- )
-
- def test_elide_typed_short_match(self):
- """
- if the match is too short we don't elide.
- avoid the "the...the"
- """
- self.assertEqual(
- _elide("the quick brown fox jumped over the lazy dog", "the", min_elide=10),
- "the quick brown fox jumped over the lazy dog",
- )
-
- def test_elide_typed_no_match(self):
- """
- if the match is too short we don't elide.
- avoid the "the...the"
- """
- # here we typed red instead of brown
- self.assertEqual(
- _elide(
- "the quick brown fox jumped over the lazy dog",
- "the quick red fox",
- min_elide=10,
- ),
- "the quick brown fox jumped over the lazy dog",
- )
-
-
-class TestContextAwareCompletion(unittest.TestCase):
- def test_adjust_completion_text_based_on_context(self):
- # Adjusted case
- self.assertEqual(
- _adjust_completion_text_based_on_context("arg1=", "func1(a=)", 7), "arg1"
- )
-
- # Untouched cases
- self.assertEqual(
- _adjust_completion_text_based_on_context("arg1=", "func1(a)", 7), "arg1="
- )
- self.assertEqual(
- _adjust_completion_text_based_on_context("arg1=", "func1(a", 7), "arg1="
- )
- self.assertEqual(
- _adjust_completion_text_based_on_context("%magic", "func1(a=)", 7), "%magic"
- )
- self.assertEqual(
- _adjust_completion_text_based_on_context("func2", "func1(a=)", 7), "func2"
- )
-
-
-# Decorator for interaction loop tests -----------------------------------------
-
-
-class mock_input_helper(object):
- """Machinery for tests of the main interact loop.
-
- Used by the mock_input decorator.
- """
- def __init__(self, testgen):
- self.testgen = testgen
- self.exception = None
- self.ip = get_ipython()
-
- def __enter__(self):
- self.orig_prompt_for_code = self.ip.prompt_for_code
- self.ip.prompt_for_code = self.fake_input
- return self
-
- def __exit__(self, etype, value, tb):
- self.ip.prompt_for_code = self.orig_prompt_for_code
-
- def fake_input(self):
- try:
- return next(self.testgen)
- except StopIteration:
- self.ip.keep_running = False
- return u''
- except:
- self.exception = sys.exc_info()
- self.ip.keep_running = False
- return u''
-
-def mock_input(testfunc):
- """Decorator for tests of the main interact loop.
-
- Write the test as a generator, yield-ing the input strings, which IPython
- will see as if they were typed in at the prompt.
- """
- def test_method(self):
- testgen = testfunc(self)
- with mock_input_helper(testgen) as mih:
- mih.ip.interact()
-
- if mih.exception is not None:
- # Re-raise captured exception
- etype, value, tb = mih.exception
- import traceback
- traceback.print_tb(tb, file=sys.stdout)
- del tb # Avoid reference loop
- raise value
-
- return test_method
-
-# Test classes -----------------------------------------------------------------
-
-class InteractiveShellTestCase(unittest.TestCase):
- def rl_hist_entries(self, rl, n):
- """Get last n readline history entries as a list"""
- return [rl.get_history_item(rl.get_current_history_length() - x)
- for x in range(n - 1, -1, -1)]
-
- @mock_input
- def test_inputtransformer_syntaxerror(self):
- ip = get_ipython()
- ip.input_transformers_post.append(syntax_error_transformer)
-
- try:
- #raise Exception
- with tt.AssertPrints('4', suppress=False):
- yield u'print(2*2)'
-
- with tt.AssertPrints('SyntaxError: input contains', suppress=False):
- yield u'print(2345) # syntaxerror'
-
- with tt.AssertPrints('16', suppress=False):
- yield u'print(4*4)'
-
- finally:
- ip.input_transformers_post.remove(syntax_error_transformer)
-
- def test_repl_not_plain_text(self):
- ip = get_ipython()
- formatter = ip.display_formatter
- assert formatter.active_types == ['text/plain']
-
- # terminal may have arbitrary mimetype handler to open external viewer
- # or inline images.
- assert formatter.ipython_display_formatter.enabled
-
- class Test(object):
- def __repr__(self):
- return "" + "
\n".join([f"{html.escape(x)}" for x in text.split("\n")]) + "
{plaintext_to_html(str(key))}
-{plaintext_to_html(str(text))}
-{message}
As preface, I met and worked with Jeremy Harris at TowardsDataScience.com (TDS) while building the youtube/podcast platform for Ludo Benistant, TDS founder. Edouard approached me many years ago about becoming a mentor. I resonated with this position then, since I was a person who broke into the data science industry after working as an English teacher at a public school. Since my career transition, I’ve been passionate about mentoring others on how to mirror my path to finding success in landing a data science job.
To dive deeper in my mentorship experience, I've mentored 5+ students from UC Berkeley (my alma mater) in the last 3 years in securing data science roles, hosted through the university’s internal data alumni program. Furthermore, I have written 5+ highly successful articles on TowardsDataScience (TDS) on finding a job as a Data Scientist (One of my articles has been read over 100,000 times).
I have also interviewed many leaders in data science (such as the head of Data Science at Patreon) on questions about landing a data science job while working as a project lead at TDS. Many readers/audience have reached out to me on how my content has played an important role in performing well during interviews.
To summarize, I have two reasons for wanting to become a mentor at SharpestMinds:
1. I have a deep passion and in-depth knowledge in data science mentorship. I have transitioned into Data Science from a non-data related field, and thus have a frontline experience in knowing how to break into the data industry. This goes from how to write resumes, how to perform well during interviews, pitfalls to avoid, etc.
2. I deeply align with the company’s mission about nurturing junior/aspiring Data Scientists and helping them succeed in landing a dream job. It’s what I have been doing on the side out of passion, especially at TDS and my alma mater programs.
I am very excited to take this passion to the next level by becoming a mentor at SharpestMinds.
Download →→→ https://urloso.com/2uyPnC
Download Zip 🗸 https://urloso.com/2uyRWH
There was a download of FlexiSTARTER 10.0 on the developer's website when we last checked. We cannot confirm if there is a free download of this software available. This program is a product of Cutterpros. You can set up FlexiSTARTER on Windows XP/Vista/7 32-bit.
-The program is included in Photo & Graphics Tools. The following versions: 10.0 and 1.0 are the most frequently downloaded ones by the program users. According to the results of the Google Safe Browsing check, the developer's site is safe. Despite this, we recommend checking the downloaded files with any free antivirus software. The program's installer file is commonly found as App.exe.
-Download Zip 🗸 https://urloso.com/2uyRet
i really appreciate all your help. seems like you are a veteran. is flexi starter 10 good, bad, ok? all i have messed with is signblazer which isn't terrible but its free and sure cuts alot pro which came with my cutter. which is the best in your opinion? a guy that i know is gonna give me corel draw or something like that if he can find the disk give me your opinion on that also if you don;t mind
-FlexiSIGNPRO 8.1v1.exe and App.exe are the most used setup packages for this program. The download link was found to be safe by our antivirus system. Flexisign pro software free download; Flexisign pro 8.1 free download; Flexisign 7.5 free download software. FlexiSign Pro 8.1 includes graphic design, color tracing, and text serialization.
-If you looking on the internet a FlexiSign Pro 10.5 Full Version Free Download latest version So, you come to the right place now a day shares with you an amazing application FlexiSign Pro 10.5 free for Windows of charge 32-bit and 64-bit Windows standalone offline download. FlexiSign Pro 10.5 is a robust tool to create logos and vector graphics. FlexiSign Pro is a versatile program that allows consumers to generate excellent vector graphics and logos. FlexiSign Pro 10.5 for Windows 10, 8, 8.1, 7 is a powerful application. This is a great tool for digital design fans.
aaccfb2cb3DOWNLOAD →→→ https://urloso.com/2uyP1T
Karvalo is a novel by Poornachandra Tejaswi, a renowned Kannada writer who wrote novels, short stories, non-fiction and poetry. The novel won the 'most creative novel of the year' award from the Sahitya Akademi in 1980. The novel is a blend of science, nature and philosophy, set in a rural village in Karnataka.
- -The novel revolves around a farmer who meets Karvalo, a scientist in search of a rare flying lizard. The farmer also befriends Mandanna, a local cowboy who has a keen interest in nature and wildlife. Together, they embark on an adventure to find the elusive lizard in the dense forests of the Western Ghats.
-Download File ✔ https://urloso.com/2uySbv
The novel is a masterpiece of Kannada literature that explores themes such as human curiosity, scientific discovery, environmental conservation and rural life. The novel also has a touch of humor and suspense that keeps the readers engaged.
- -If you want to download Karvalo Kannada book PDF for free, you have several options. You can either buy or borrow the book from online or offline stores. You can also read the book online from platforms like Goodreads or Archive.org. However, you may need to register or sign up to access the book online.
- -Another option is to download the book from torrent sites or other sources. However, this may be illegal and risky, as you may face legal issues or malware attacks. Therefore, it is advisable to download the book legally and safely from authorized sources.
- -Once you have downloaded the book, you need to open it on your device. You can use any device that supports PDF files, such as a computer, laptop, tablet or smartphone. You can also use any PDF reader application that allows you to read and adjust the settings of the book according to your preference.
- -There are many reasons why you should read Karvalo Kannada book. Here are some of them:
- - -So what are you waiting for? Download Karvalo Kannada book PDF for free today and enjoy reading this amazing novel!
- -Karvalo is a novel that deserves to be read by everyone who loves literature. The novel is a unique and innovative work that showcases the best of Kannada literature in terms of story, style, language and theme. The novel is also a timeless classic that remains relevant and entertaining even today.
- -If you want to read Karvalo Kannada book PDF for free, you can follow the steps mentioned above and find the best sources for the book. You can also share your views and opinions about the book with other readers and appreciate the book together.
- -So don't wait any longer and read Karvalo Kannada book PDF for free today!
3cee63e6c2DOWNLOAD — https://urloso.com/2uyOyI
Download ☆☆☆☆☆ https://tinurli.com/2uwkrD
(This will NOT work with 1.90 or earlier licenses unless you have an OtsAV DJ Pro-Classic+ license [with free upgrades to 2.0] - download 1.90 or other below instead or upgrade your license to OtsAV DJ version 1.94)
-Download File ★★★ https://tinurli.com/2uwjTL
(This will NOT work with 1.85 licenses unless you have an OtsAV DJ Pro-Classic+ license [with free upgrades to 2.0] - download 1.85 below instead or upgrade your license to OtsAV DJ version 1.90)
aaccfb2cb3The Most Competitive Prices in the Online Software License Market.
Easy to Order with Paypal and Immediate Delivery, No Wait!
Keeping 95% of our Customers Happy over the Last 3 Years!
SSL Secure Payment Data and Protecting Your Personal Information!
Email:sales@turbotax-shop.com
I have used H&R Block for the past few years because it was less expensive and did a fine job. I have used Turbo Tax previously. But last year my taxes were more complicated and the H&R Block help was poor. I remember how good the Turbo Tax help was so I bought Turbo Tax for 2018 taxes. I have not done much of my taxes yet this year but the little I have done shows me that the help should make my taxes easier to do. Turbo Tax is more expensive, but when I think of how much time I spent last year trying to find tax answers, the extra expense should more that pay for itself in time savings and less frustration.
-DOWNLOAD ⇒⇒⇒ https://tinurli.com/2uwjLa
I paid for Turbo Tax 2018 online and completed some returns on it for 2018. Now I am using a PC with Windows 10. How do I download the version I bought (MAC) to my PC Windows 10 and transfer my *.tax2018 individual returns to my PC?
-Intuit TurboTax Home And Business 2018 Free Download includes all the necessary files to run perfectly on your system, uploaded program contains all latest and updated files, it is full offline or standalone version of Intuit TurboTax Home And Business 2018 Free Download for compatible versions of windows, download link at the end of the post.
-Below are some amazing features you can experience after installation of Intuit TurboTax Home And Business 2018 Free Download please keep in mind features may vary and totally depends if your system support them.
-Click on below button to start Intuit TurboTax Home And Business 2018 Free Download. This is complete offline installer and standalone setup for Intuit TurboTax Home And Business 2018. This would be compatible with compatible version of windows.
-In 2018, over a million taxpayers didn't file their federal return, leaving $1.5 billion in unclaimed refund money. It's not too late for people to file and get their refund, but the deadline is soon.
-To claim a refund for 2018, taxpayers must mail returns to the IRS center listed on the Form 1040 instructionsPDF. While they must mail in a 2018 return, taxpayers can still e-file for 2019, 2020 and 2021.
-A professional application to deal with the tax matters along personal finance and accounting, Intuit TurboTax Business 2018 delivers one of the best solutions. It provides a friendly environment with simple options and self-explaining tools that enhance financial matters. This powerful program provides different administration operations as well as accounting solution for small businesses. This powerful application provides support for a variety of features like installments, dates, taxes and a lot of other financial matters. Determine different rules, generate reports and manage all the tasks relating to finance and business.
It provides a professional environment that helps the user to deal with the inventory and generate different reports. It provides a complete solution for generating different reports as well as perform numerous other financial operations.
With the above information in-hand - follow this How to get old versions of macOS and verify what version this computer Qualifies to install. For Best results use Safari to commence the download as Others may not work.
-Deleted TAX2018 files that cannot be found in the Windows Recycle Bin or Mac Trash can still be recovered using an effective data recovery program. Just make sure you stop using the drive they were in right away to avoid overwriting the deleted file. Alternatively, if you had File History enabled or created a System Restore point beforehand, you can use those methods.
-Check the software list above to confirm that your software is certified for the year you need. If you are using uncertified software or an older version of the software, you may need to update or download a certified version from the developer.
-Quicken products contain online services such as transaction download and online bill pay. A purchase of a Quicken product license includes the ability to use these online services until the discontinuation date (listed in the chart above).
-The NETFILE program is now open for the electronic filing of your 2015, 2016, 2017, and 2018 T1 private earnings tax and profit return. When tax laws change , TurboTax modifications with them, so that you might be positive your tax return includes the newest IRS and state tax kinds. This tax season has been a watch-opener for filers. It marks the first time people are submitting their returns below the Tax Cuts and Jobs Act, an overhaul of the tax code that went into effect in 2018.
-The Deluxe version is by far the preferred. After studying the opinions at Amazon and Costco I learned long time users, like myself, of TurboTax are leaping ship as a result of TT Deluxe now not helps small buyers and companies as it has in years previous, with out upgrading. Absent the Web I might have never identified. TurboTax Home & Enterprise could be downloaded or purchased on a CD for both PC and Mac computers. Select your choice when buying.
-The beta code is available to download from the Apple Developer Center and via over-the-air updates to devices, for developers registered into the testing program. Typically, public beta counterparts to the developer betas are released a few days later.
aaccfb2cb3Are you looking for a fun and exciting game to play with your friends at parties, sleepovers, or any occasion? Do you want to spice up your conversations and interactions with hilarious questions and dares? Do you want to have unlimited access to thousands of challenges that will make you laugh, blush, scream, and more? If you answered yes to any of these questions, then you need to try Truth or Dare Pro APK, the ultimate party game for Android devices.
-Download › https://urlca.com/2uOdhW
Truth or Dare Pro APK is a modified version of the popular game Truth or Dare, where you have to answer a question truthfully or perform a dare that is given to you by your friends. The game is simple but very fun and addictive. You can play it with anyone, anywhere, anytime. All you need is your Android device and some friends who are ready to have a blast.
-Truth or Dare Pro APK has many features that make it stand out from other similar games. Here are some of them:
-The game has over 10,000 questions and dares that are divided into different categories, such as funny, dirty, extreme, couples, kids, teens, adults, etc. You can choose the category that suits your mood and preference. You can also add your own questions and dares to make the game more personalized.
-The game has four game modes that you can customize according to your liking. You can choose between classic mode, where you spin a bottle and select truth or dare; random mode, where you get a random question or dare; custom mode, where you create your own questions and dares; and online mode, where you play with other players around the world.
-truth or dare pro apk download
-truth or dare pro apk mod
-truth or dare pro apk free
-truth or dare pro apk latest version
-truth or dare pro apk unlocked
-truth or dare pro apk premium
-truth or dare pro apk full
-truth or dare pro apk cracked
-truth or dare pro apk hack
-truth or dare pro apk android
-truth or dare pro apk for pc
-truth or dare pro apk online
-truth or dare pro apk no ads
-truth or dare pro apk dirty
-truth or dare pro apk 18+
-truth or dare pro apk couples
-truth or dare pro apk kids
-truth or dare pro apk teens
-truth or dare pro apk family
-truth or dare pro apk friends
-truth or dare pro apk party
-truth or dare pro apk game
-truth or dare pro apk fun
-truth or dare pro apk questions
-truth or dare pro apk challenges
-truth or dare pro apk generator
-truth or dare pro apk custom
-truth or dare pro apk editor
-truth or dare pro apk offline
-truth or dare pro apk best
-truth or dare pro apk review
-truth or dare pro apk rating
-truth or dare pro apk features
-truth or dare pro apk update
-truth or dare pro apk new
-truth or dare pro apk 2023
-truth or dare pro apk reddit
-truth or dare pro apk quora
-truth or dare pro apk youtube
-truth or dare pro apk facebook
-truth or dare pro apk instagram
-truth or dare pro apk twitter
-truth or dare pro apk tiktok
-truth or dare pro apk pinterest
-truth or dare pro apk blogspot
-truth or dare pro apk wordpress
-truth or dare pro apk medium
-truth or dare pro apk tumblr
-truth or dare pro apk app store
You can download the APK file from a trusted source that offers safe and secure downloads. You can use the link below to get the latest version of Truth or Dare Pro APK for free. The file size is about 25 MB and it does not require any root access or special permissions.
-Download Truth or Dare Pro APK
-Before you can install the APK file, you need to enable unknown sources on your device. This will allow you to install apps that are not from the Google Play Store. To do this, go to your device settings, then security, then toggle on the unknown sources option. You may see a warning message, but you can ignore it and proceed.
-Once you have enabled unknown sources, you can install the APK file by tapping on it and following the instructions. The installation process will take a few seconds and then you will see the app icon on your home screen. Tap on it and launch the app. You are now ready to play Truth or Dare Pro APK with your friends.
Playing Truth or Dare Pro APK is very easy and fun. You just need to follow these simple steps:
-You can choose between four game modes: classic, random, custom, and online. You can also choose how many players you want to play with, from 2 to 20. You can enter your names and select your avatars. You can also choose the category of questions and dares, from funny to extreme.
-Once you have chosen your game mode and players, you can start the game by spinning the bottle. The bottle will point to one of the players, who will have to choose between truth or dare. If they choose truth, they will have to answer a question honestly. If they choose dare, they will have to perform a dare that is given to them by their friends.
-The player who has chosen truth or dare will have to answer the question or perform the dare that is displayed on the screen. They will have a limited time to do so, otherwise they will lose a point. The other players can judge if they have completed the challenge successfully or not. If they fail, they will have to face a penalty that is decided by their friends.
-The game will continue until one of the players reaches a certain number of points or until you decide to stop. You can view the scores and statistics of each player at any time. You can also pause, resume, or restart the game whenever you want. The most important thing is to have fun and laugh with your friends as you discover new things about each other and challenge yourselves.
-Truth or Dare Pro APK is not just another game. It is a game that can bring you many benefits and advantages. Here are some of them:
Some of the benefits of Truth or Dare Pro APK are:
-Truth or Dare Pro APK is the perfect game to play at parties and gatherings. It can make your events more lively, fun, and memorable. You can play it with your friends, family, classmates, coworkers, or anyone you want. You can also use it as an icebreaker, a conversation starter, or a bonding activity.
-Truth or Dare Pro APK can help you break the ice and get to know each other better. You can learn new things about your friends, such as their secrets, preferences, opinions, experiences, etc. You can also share your own stories and reveal your true self. You can discover new sides of your friends and yourself that you never knew before.
-Truth or Dare Pro APK can challenge you and your friends to step out of your comfort zones and try new things. You can test your limits and face your fears. You can also dare your friends to do something they normally wouldn't do. You can have fun and laugh at each other's reactions and outcomes.
-Truth or Dare Pro APK can provide you with unlimited fun and entertainment. You can play it anytime, anywhere, with anyone. You can choose from thousands of questions and dares that will keep you entertained for hours. You can also create your own questions and dares to make the game more interesting and unique.
-Truth or Dare Pro APK is the ultimate party game for Android devices. It is a modified version of the popular game Truth or Dare, where you have to answer a question truthfully or perform a dare that is given to you by your friends. The game has many features that make it stand out from other similar games, such as thousands of questions and dares, customizable game modes, offline and online play, and fun and easy interface. The game also has many benefits that make it worth playing, such as spicing up your parties and gatherings, breaking the ice and getting to know each other better, challenging yourself and your friends, and enjoying unlimited fun and entertainment. If you are looking for a game that can make your events more lively, fun, and memorable, then you should download and install Truth or Dare Pro APK on your Android device today.
-Here are some FAQs that you may have about the game:
-Yes, Truth or Dare Pro APK is safe to download and install. The APK file is free from viruses, malware, spyware, or any other harmful elements. However, you should always download the APK file from a trusted source that offers safe and secure downloads.
-Yes, Truth or Dare Pro APK is legal to use. The game does not violate any laws or regulations. However, you should always respect the rules and guidelines of the game and play it responsibly. You should also respect the privacy and consent of your friends who are playing with you.
-You can play Truth or Dare Pro APK with as many players as you want, from 2 to 20. However, the ideal number of players is between 4 to 10. This will ensure that everyone gets a chance to participate and have fun.
-Some tips to make the game more fun are:
-You can get more information about Truth or Dare Pro APK by visiting the official website of the game. There you can find more details about the features, benefits, instructions, reviews, ratings, screenshots, videos, etc. of the game. You can also contact the developers of the game if you have any questions, feedback, suggestions, or issues regarding the game.
401be4b1e0If you are a fan of first-person shooter games, you might have heard of Standoff 2, a dynamic and realistic online multiplayer action FPS game that has over 200 million players worldwide . In this game, you can choose from more than 20 weapon models, customize them with skins, stickers, and charms, and join the standoff with your friends or other players in various maps and modes .
-Download Zip ———>>> https://urlca.com/2uO4QO
But what if you want to experience the thrill of opening cases and collecting skins without spending real money or risking your ranking? That's where case simulator for Standoff 2 comes in handy. Case simulator for Standoff 2 is a simulation application that allows you to open cases from the game and knock out expensive skins and knives. You can also play different game modes such as upgrade, jackpot, crash, quiz, tower, bomb defuse, and more . In this article, we will show you why you should download case simulator for Standoff 2, how to download it on different platforms, how to use it, and some tips and tricks for using it.
-There are many benefits of using case simulator for Standoff 2. Here are some of them:
-Downloading case simulator for Standoff 2 is easy and fast. Here are the step-by-step instructions for downloading it on different platforms:
-How to download case simulator for standoff 2 on PC
-Case simulator for standoff 2 online free play
-Case simulator for standoff 2 skins and knives
-Case simulator for standoff 2 game modes and features
-Case simulator for standoff 2 tips and tricks
-Best case simulator for standoff 2 app
-Case simulator for standoff 2 apk download
-Case simulator for standoff 2 mod apk unlimited money
-Case simulator for standoff 2 hack tool
-Case simulator for standoff 2 cheats and codes
-Case simulator for standoff 2 review and rating
-Case simulator for standoff 2 gameplay and walkthrough
-Case simulator for standoff 2 update and patch notes
-Case simulator for standoff 2 support and feedback
-Case simulator for standoff 2 community and forum
-Case simulator for standoff 2 yandex games
-Case simulator for standoff 2 bluestacks emulator
-Case simulator for standoff 2 car simulator games developer
-Case simulator for standoff 2 funspirit publisher
-Case simulator for standoff 2 license agreement and terms of service
-Download case simulator for standoff 2 android
-Download case simulator for standoff 2 ios
-Download case simulator for standoff 2 windows
-Download case simulator for standoff 2 mac
-Download case simulator for standoff 2 linux
-Download case simulator for standoff 2 chromebook
-Download case simulator for standoff 2 amazon fire tablet
-Download case simulator for standoff 2 samsung galaxy phone
-Download case simulator for standoff 2 iphone and ipad
-Download case simulator for standoff 2 huawei device
-Download case simulator for standoff 2 google play store
-Download case simulator for standoff 2 apple app store
-Download case simulator for standoff 2 microsoft store
-Download case simulator for standoff 2 steam platform
-Download case simulator for standoff 2 epic games launcher
-Download case simulator for standoff 2 origin client
-Download case simulator for standoff 2 uplay service
-Download case simulator for standoff 2 gog galaxy software
-Download case simulator for standoff 2 itch.io website
-Download case simulator for standoff 2 gamejolt site
-Download case simulator for standoff 2 kongregate portal
-Download case simulator for standoff 2 newgrounds page
-Download case simulator for standoff 2 armor games network
-Download case simulator for standoff 2 miniclip channel
-Download case simulator for standoff 2 crazy games collection
-Download case simulator for standoff 2 poki selection
-Download case simulator for standoff 2 friv series
-Download case simulator for standoff 2 coolmath games category
Using case simulator for Standoff 2 is simple and fun. Here are some of the basic features and functions of the app:
-To open cases, you need to have coins. You can earn coins by completing missions, watching ads, or playing game modes. You can also buy coins with real money if you want. Once you have enough coins, you can choose from different case collections, such as Origin, Gold, Elite, etc. Each case has a different price and a different chance of getting rare skins. Tap on the case you want to open and swipe to open it. You will see what skin you got and how much it is worth. You can also see the odds of getting each skin in each case. You can keep the skin or sell it for coins. You can also open multiple cases at once by tapping on the "Open 10" or "Open 100" buttons.
-To upgrade skins, you need to have skins. You can get skins by opening cases or buying them from the market. Once you have some skins, you can go to the upgrade section and choose a skin you want to upgrade. You will see a slider that shows the percentage of success and the amount of coins you need to pay for the upgrade. You can adjust the slider to increase or decrease the chance of success and the cost of the upgrade. Tap on the "Upgrade" button and see if you succeed or fail. If you succeed, you will get a higher tier skin. If you fail, you will lose your skin and your coins.
-To play game modes, you need to have coins or skins. You can earn coins or skins by opening cases, upgrading skins, or selling skins. Once you have some coins or skins, you can go to the game modes section and choose a game mode you want to play. There are many game modes available, such as jackpot, crash, quiz, tower, bomb defuse, etc. Each game mode has different rules and rewards. For example, in jackpot, you can bet your skins against other players and try to win their skins. In crash, you can bet your coins on a multiplier that goes up and down and try to cash out before it crashes. In quiz, you can answer questions about Standoff 2 or general knowledge and earn coins for correct answers. In tower, you can open cases or defuse bombs to climb up a tower and win prizes. In bomb defuse, you can try to defuse a bomb by cutting wires in a limited time and win coins.
-To get the most out of case simulator for Standoff 2, here are some tips and tricks that might help you:
-Case simulator for Standoff 2 is a great app for anyone who loves Standoff 2 and wants to open cases and collect skins without spending real money or risking their ranking. It is also a fun and educational app that teaches you about the skins, collections, and weapons in the game and tests your luck and skills in different game modes. You can download case simulator for Standoff 2 on Android, iOS, PC, or Mac and enjoy the realistic graphics and sounds of the app. You can also use some tips and tricks to save money, get rare skins, and win game modes. So what are you waiting for? Download case simulator for Standoff 2 today and enjoy the thrill of opening cases and collecting skins!
-Here are some frequently asked questions about case simulator for Standoff 2:
-A: No, you cannot transfer your skins from case simulator for Standoff 2 to the original game. Case simulator for Standoff 2 is a simulation app that is not affiliated with the original game or its developers. It is only for entertainment purposes and does not affect your account or inventory in the original game.
-A: Yes, you can play case simulator for Standoff 2 offline. However, some features and functions may not work properly or may require an internet connection to work. For example, you may not be able to watch ads, complete missions, or access the market without an internet connection.
-A: There are several ways to get more coins in case simulator for Standoff 2. You can earn coins by opening cases, selling skins, completing missions, watching ads, or playing game modes. You can also buy coins with real money if you want.
-A: You can get free stickers in case simulator for Standoff 2 by opening sticker capsules or buying them from the market. You can also get free stickers by completing missions or watching ads.
-A: You can contact the developer of case simulator for Standoff 2 by sending an email to fallonightgames@gmail.com or by visiting their website at [9](https://fallonight.com/). You can also follow them on social media platforms such as Facebook, Twitter, Instagram, YouTube, etc.
401be4b1e0Do you love strategy games that challenge your mind and test your skills? Do you enjoy shooting bricks and upgrading your cannons? Do you want to have unlimited money and gems to unlock new features and modes? If you answered yes to any of these questions, then you should download Idle Cannon Tycoon Mod Apk, a fun and addictive strategy game that will keep you entertained for hours.
-Download ⚙⚙⚙ https://urlca.com/2uOaK6
Idle Cannon Tycoon is a game where you shoot bricks and upgrade your cannons. You start with a simple cannon that can fire one bullet at a time. Your goal is to destroy as many bricks as possible before they reach the bottom of the screen. The more bricks you destroy, the more money you earn. You can use the money to buy more cannons, upgrade your existing ones, or unlock new features and modes.
-Idle Cannon Tycoon is also a game where you can go idle or active. You can choose to play the game manually, tapping the screen to fire your cannons, or you can let the game play itself, earning money even when you are offline. You can also switch between different modes, such as normal mode, boss mode, or challenge mode, to spice up your gameplay.
-Idle Cannon Tycoon is also a game where you can unlock new features and modes. As you progress in the game, you will be able to unlock new cannons with different abilities, such as laser cannons, rocket launchers, or plasma guns. You will also be able to unlock new levels with different themes, such as desert, forest, or space. You will also be able to unlock special events and rewards that will make your gaming experience more exciting.
-If you are a fan of Idle Cannon Tycoon, you might be wondering why you should download the mod apk version of the game. Well, there are many reasons why you should do so, such as:
-You can enjoy unlimited money and gems. With the mod apk version of the game, you will have access to unlimited money and gems that you can use to buy anything you want in the game. You can buy as many cannons as you want, upgrade them to the max level, or unlock all the features and modes without any restrictions.
-You can access all the cannons and levels. With the mod apk version of the game, you will be able to access all the cannons and levels that are normally locked or require real money to unlock. You can try out all the different cannons with their unique abilities and see which one suits your style best. You can also explore all the different levels with their different themes and challenges.
-You can remove ads and enjoy a smooth gameplay. With the mod apk version of the game, you will be able to remove all the annoying ads that pop up every now and then in the game. You will be able to enjoy a smooth gameplay without any interruptions or distractions.
-idle cannon tycoon mod apk unlimited money
-idle cannon tycoon mod apk download
-idle cannon tycoon mod apk latest version
-idle cannon tycoon mod apk android 1
-idle cannon tycoon mod apk free shopping
-idle cannon tycoon mod apk hack
-idle cannon tycoon mod apk revdl
-idle cannon tycoon mod apk offline
-idle cannon tycoon mod apk no ads
-idle cannon tycoon mod apk 1.0.0.19
-idle cannon tycoon mod apk 2023
-idle cannon tycoon mod apk rexdl
-idle cannon tycoon mod apk happymod
-idle cannon tycoon mod apk unlimited gems
-idle cannon tycoon mod apk unlocked
-idle cannon tycoon mod apk online
-idle cannon tycoon mod apk ios
-idle cannon tycoon mod apk 1.0.0.18
-idle cannon tycoon mod apk 1.0.0.17
-idle cannon tycoon mod apk 1.0.0.16
-idle cannon tycoon mod apk 1.0.0.15
-idle cannon tycoon mod apk 1.0.0.14
-idle cannon tycoon mod apk 1.0.0.13
-idle cannon tycoon mod apk 1.0.0.12
-idle cannon tycoon mod apk 1.0.0.11
-idle cannon tycoon mod apk 1.0.0.10
-idle cannon tycoon mod apk 1.0.0.9
-idle cannon tycoon mod apk 1.0.0.8
-idle cannon tycoon mod apk 1.0.0.7
-idle cannon tycoon mod apk 1.0.0.6
-idle cannon tycoon mod apk 1.0.0.5
-idle cannon tycoon mod apk 1.0.0.4
-idle cannon tycoon mod apk 1.0.0.3
-idle cannon tycoon mod apk 1.0.0.2
-idle cannon tycoon mod apk 1.0.0.1
-idle cannon shooting game mod apk
-idle brick breaker game mod apk
-idle tower defense game mod apk
-idle strategy game with cannons mod apk
-free download of idle cannon game mod apk
If you are interested in downloading and installing Idle Cannon Tycoon Mod Apk on your device, you can follow these simple steps:Step 1: Download the mod apk file from a trusted source. You can find the link to the mod apk file at the end of this article. Make sure you download the latest version of the game that is compatible with your device.
-Step 2: Enable unknown sources on your device settings. To install the mod apk file, you need to allow your device to install apps from unknown sources. To do this, go to your device settings, then security, then enable unknown sources. This will allow you to install the mod apk file without any problems.
-Step 3: Install the mod apk file and launch the game. Once you have downloaded the mod apk file, locate it on your device storage and tap on it to install it. Follow the instructions on the screen and wait for the installation to complete. After that, launch the game and enjoy the mod features.
-Step 4: Enjoy the game with unlimited resources and features. Now that you have installed Idle Cannon Tycoon Mod Apk, you can enjoy the game with unlimited money and gems, access to all the cannons and levels, and no ads. You can also switch between different modes and events and have fun shooting bricks and upgrading your cannons.
-Idle Cannon Tycoon Mod Apk is a fun and addictive strategy game that you should try if you love shooting bricks and upgrading your cannons. You can download the mod apk version of the game and enjoy unlimited money and gems, access to all the cannons and levels, and no ads. You can also go idle or active, switch between different modes and events, and unlock new features and rewards. Idle Cannon Tycoon Mod Apk is a game that will keep you entertained for hours.
-Here are some frequently asked questions about Idle Cannon Tycoon Mod Apk:
-Slots casino games are among the most popular and exciting forms of gambling. They offer a chance to win big prizes with a simple click of a button. But how do you play and win at slots casino games online? In this article, we will answer this question and give you some tips and tricks to improve your chances of winning.
-Slots casino games are games of chance that involve spinning reels with symbols on them. The goal is to match the symbols on the paylines to form winning combinations. Depending on the game, you can win different amounts of money or even hit a jackpot.
-DOWNLOAD › https://urlca.com/2uOewN
The first slot machine was invented by Charles Fey in 1895 in San Francisco. It was called the Liberty Bell and had three reels with five symbols: horseshoes, diamonds, spades, hearts, and a liberty bell. The machine paid out 50 cents for a three-bell combination. The popularity of the machine led to the development of more complex and diverse slot machines over the years.
-Today, there are many types of slots casino games available online. Some of the most common ones are:
-These are the traditional slot machines that have three or five reels and one or more paylines. They usually have simple graphics and sounds and feature classic symbols like fruits, bars, sevens, and bells. They are easy to play and offer low to medium payouts.
-These are the modern slot machines that have five or more reels and multiple paylines. They have advanced graphics and animations and feature various themes and characters. They also have special features like wilds, scatters, bonus rounds, free spins, and multipliers. They are more entertaining and offer higher payouts.
-These are the slot machines that have a jackpot that increases every time someone plays them. A percentage of each bet goes into the jackpot pool until someone hits it. The jackpot can be triggered randomly or by landing a specific combination of symbols. Progressive slots can offer life-changing payouts, but they are also very risky.
-free slots casino games
-online slots casino real money
-best slots casino app
-no deposit bonus slots casino
-vegas slots casino online
-slots casino jackpot mania
-slots casino party
-slots casino near me
-slots casino bonus codes
-slots casino free spins
-play slots casino games online
-slots casino reviews
-slots casino no download
-slots casino cheats
-slots casino hack
-slots casino tournaments
-slots casino tips and tricks
-slots casino strategy
-slots casino odds
-slots casino payout percentage
-new slots casino 2023
-mobile slots casino
-live slots casino
-penny slots casino
-high limit slots casino
-progressive slots casino
-video slots casino
-classic slots casino
-3d slots casino
-fruit slots casino
-mega win slots casino
-hot shot slots casino
-quick hit slots casino
-double down slots casino
-cashman slots casino
-gold fish slots casino
-house of fun slots casino
-caesars slots casino
-huuuge slots casino
-billionaire slots casino
-heart of vegas slots casino
-scatter slots casino
-pop slots casino
-myvegas slots casino
-tycoon slots casino
-zynga slots casino
-gsn slots casino
-big fish slots casino
-slotomania slots casino
-jackpot party slots casino
If you want to play slots casino games online, you need to follow these steps:
-The first step is to find a reliable and trustworthy online casino that offers a variety of slots casino games. You can use our website to compare and review different online casinos based on their reputation, security, bonuses, customer service, game selection, and more.
-The next step is to create an account at the online casino of your choice and make your first deposit. Most online casinos offer generous welcome bonuses for new players that can boost your bankroll and give you more chances to play and win. Make sure to read the terms and conditions of the bonus before claiming it.
-The third step is to browse through the online casino's game lobby and choose a slot game that appeals to you. You can filter the games by type, theme, provider, features, or jackpot. You can also try out the games for free in demo mode before playing for real money.Learn the rules and features of the game -
The fourth step is to familiarize yourself with the rules and features of the slot game you have chosen. You can do this by reading the game's paytable, which shows the symbols, payouts, paylines, and bonus features of the game. You can also check the game's RTP (return to player) and volatility, which indicate how often and how much the game pays out.
-The final step is to place your bets and spin the reels. You can adjust your bet size by changing the coin value and the number of coins per payline. You can also choose to bet on all or some of the paylines. Then, you can either click on the spin button or use the autoplay feature to spin the reels automatically for a set number of times. If you land a winning combination, you will receive a payout according to the paytable. If you trigger a bonus feature, you will have a chance to win extra prizes or free spins.
-While slots casino games are based on luck, there are some things you can do to increase your chances of winning. Here are some tips and tricks to help you win at slots casino games online:
-The RTP and volatility of a slot game are two important factors that affect your chances of winning. The RTP is the percentage of money that the game returns to the players over a long period of time. The higher the RTP, the more likely you are to win back some of your bets. The volatility is the level of risk and reward that the game offers. The higher the volatility, the more unpredictable the game is, but also the higher the potential payouts are.
-You should choose a slot game that has an RTP of at least 96% and a volatility that matches your risk appetite. For example, if you have a small budget and want to play for longer, you should choose a low-volatility slot that pays out frequently but in smaller amounts. If you have a larger budget and want to chase big wins, you should choose a high-volatility slot that pays out rarely but in larger amounts.
-Another tip is to use a betting strategy that fits your budget and goals. A betting strategy is a set of rules that tells you how much to bet on each spin, depending on your previous outcomes. There are many betting strategies that you can use, such as the Martingale, the Fibonacci, or the Paroli. However, you should be aware that no betting strategy can guarantee you a win or overcome the house edge.
-You should use a betting strategy that suits your budget and goals. For example, if you want to minimize your losses and play for longer, you should use a flat betting strategy that involves betting the same amount on each spin. If you want to maximize your wins and take advantage of winning streaks, you should use a progressive betting strategy that involves increasing your bet size after each win.
A third tip is to take advantage of free spins and other promotions that online casinos offer to their players. Free spins are spins that you can use on a slot game without risking your own money. They can be part of the welcome bonus, the loyalty program, or a special offer. Free spins can help you try out new games, extend your playtime, and increase your chances of winning.
-Other promotions that online casinos offer include cashback, reload bonuses, tournaments, and giveaways. These promotions can also boost your bankroll and give you more opportunities to play and win. However, you should always read the terms and conditions of the promotions before claiming them, as they may have wagering requirements, expiration dates, or other restrictions.
-The last tip is to manage your bankroll and limit your losses. Your bankroll is the amount of money that you have allocated for gambling. You should never gamble with money that you cannot afford to lose or that you need for other purposes. You should also set a budget for each session and stick to it.
-One way to manage your bankroll is to use the stop-loss technique. This means that you set a limit on how much you are willing to lose in a session and stop playing when you reach it. This way, you can avoid chasing your losses and losing more than you can afford. You should also set a win limit, which is the amount of money that you are happy to win in a session and stop playing when you reach it. This way, you can avoid losing your winnings and end on a high note.
-Slots casino games are fun and exciting ways to gamble online. They offer a variety of themes, features, and payouts that can suit any player's preferences. However, they are also games of chance that require luck and skill to win. By following the tips and tricks we have shared in this article, you can improve your chances of winning at slots casino games online.
-Remember to choose a reputable online casino, register and claim your bonus, select a slot game that suits your preferences, learn the rules and features of the game, place your bets and spin the reels, understand the RTP and volatility of the game, use a betting strategy that fits your budget, take advantage of free spins and other promotions, manage your bankroll and limit your losses.
-We hope you enjoyed this article and learned something new. If you have any questions or feedback, please feel free to contact us. We would love to hear from you. Happy spinning!
-Here are some frequently asked questions about slots casino games online:
-There is no definitive answer to this question, as different online casinos may offer different advantages and disadvantages for slots players. However, some of the factors that you should consider when choosing an online casino for slots are:
-You can use our website to compare and review different online casinos based on these factors and more.
-All slot games at reputable online casinos are fair and random. They use a software called a random number generator (RNG) that ensures that every spin is independent and unpredictable. The RNG is tested and certified by independent third-party agencies that verify its accuracy and integrity.
-You can check the fairness of a slot game by looking for its RTP (return to player) percentage. The RTP is the percentage of money that the game returns to the players over a long period of time. The higher the RTP, the more fair the game is.
-A jackpot is a large prize that can be won at some slot games. There are two types of jackpots: fixed and progressive. A fixed jackpot is a set amount of money that does not change regardless of how many times it is won or how many people play the game. A progressive jackpot is an amount of money that increases every time someone plays the game until someone wins it.
-To win a jackpot at slots, you need to play a slot game that offers one and meet the requirements to trigger it. For example, some slot games require you to bet the maximum amount or land a specific combination of symbols to win the jackpot. The chances of winning a jackpot are very low, but not impossible. You can increase your chances of winning a jackpot by playing slot games that have a high RTP, a low volatility, and a large number of paylines.
-Yes, you can play slots casino games for free at most online casinos. You can do this by using the demo mode or the free spins that the online casino offers. Playing slots casino games for free can help you learn the rules and features of the game, test different strategies, and have fun without risking your own money. However, you cannot win real money or jackpots when playing for free.
-Yes, you can play slots casino games on your mobile device at most online casinos. You can do this by using the mobile version of the online casino's website or by downloading the online casino's app. Playing slots casino games on your mobile device can give you more convenience, flexibility, and accessibility. You can play anytime and anywhere, as long as you have a stable internet connection and a compatible device.
197e85843dMinecraft is a sandbox game that allows players to create and explore infinite worlds made of blocks. However, some players might find the default graphics, physics, sounds, and animations of the game too simplistic or unrealistic for their taste. That's where realistic mods come in.
-Realistic mods are modifications that aim to make Minecraft more immersive by enhancing or changing various aspects of the game, such as terrain generation, lighting, shadows, water, fire, weather, animals, plants, items, etc. By using realistic mods, players can experience Minecraft in a whole new way.
-Download Zip ::: https://urlca.com/2uOfqZ
In this article, we will explain what are the benefits and drawbacks of using realistic mods, how to install them, and what are some of the best realistic mods available for Minecraft.
-Using realistic mods can have several advantages for players who want to make their game more immersive. Some of these benefits are:
-ancy, fluid dynamics, etc.
Using realistic mods can also have some disadvantages for players who want to make their game more immersive. Some of these drawbacks are:
-To install realistic mods, you will need a few things:
-A mod loader is a program that allows you to install and manage multiple mods for Minecraft. There are different mod loaders available for Minecraft, but the most popular ones are Forge and Fabric. You will need to install one of these mod loaders before installing any realistic mod.
-To find and download realistic mods, you will need to visit some websites that host and distribute mods for Minecraft. There are many websites that offer mods for Minecraft, but some of the most reliable and popular ones are CurseForge and Planet Minecraft. You can browse these websites by categories, tags, ratings, downloads, etc. to find the mods that suit your preferences.
-To install realistic mods, you will need to follow these steps:
-There are many realistic mods available for Minecraft, but some of them stand out for their quality and popularity. Here are some of the best realistic mods that you can try:
-minecraft realistic mod forge
-minecraft realistic mod fabric
-minecraft realistic mod 1.19.2
-minecraft realistic mod 1.18.2
-minecraft realistic mod 1.20
-minecraft realistic mod download
-minecraft realistic mod curseforge
-minecraft realistic mod planet minecraft
-minecraft realistic mod shaders
-minecraft realistic mod texture pack
-minecraft realistic mod physics
-minecraft realistic mod explosions
-minecraft realistic mod fire
-minecraft realistic mod water
-minecraft realistic mod weather
-minecraft realistic mod biomes
-minecraft realistic mod terrain
-minecraft realistic mod animals
-minecraft realistic mod mobs
-minecraft realistic mod horses
-minecraft realistic mod genetics
-minecraft realistic mod food
-minecraft realistic mod cooking
-minecraft realistic mod sleep
-minecraft realistic mod time
-minecraft realistic mod torches
-minecraft realistic mod lighting
-minecraft realistic mod sound
-minecraft realistic mod movement
-minecraft realistic mod animation
-minecraft realistic mod cars
-minecraft realistic mod furniture
-minecraft realistic mod architecture
-minecraft realistic mod interior design
-minecraft realistic mod exterior design
-minecraft realistic mod landscape design
-minecraft realistic mod sci-fi design
-minecraft realistic mod modern design
-minecraft realistic mod medieval design
-minecraft realistic mod fantasy design
-minecraft realistic mod military design
-minecraft realistic mod weapons design
-minecraft realistic mod missiles design
This mod changes the way Minecraft generates terrain by using real-world data and algorithms. It creates more realistic and diverse landscapes with mountains, valleys, rivers, lakes, islands, etc. It also adds new biomes and structures that fit the terrain. You can customize the terrain generation settings to suit your preferences.
-You can download Realistic Terrain Generation from [here].
-This mod changes the way Minecraft spawns and breeds horses, donkeys, and mules by using real-world genetics and colors. It makes these animals have realistic coat patterns, markings, eye colors, etc. It also adds new features such as foals, gender differences, fertility, aging, etc. You can learn more about horse genetics and breeding by using this mod.
-You can download Realistic Horse Genetics from [here].
-This mod changes the way Minecraft spreads fire by making it more realistic and dangerous. It makes fire spread faster and farther depending on the flammability of the blocks and the wind direction. It also makes fire consume oxygen and create smoke that can suffocate players and mobs. You will need to be more careful when dealing with fire by using this mod.
-You can download Realistic Fire Spread from [here].
-This mod changes the way Minecraft handles torches by making them burn out after a configurable amount of time. It makes torches require matches or flint and steel to light up, and makes them emit smoke particles when burning. It also adds new types of torches such as stone torches, glowstone torches, etc. You will need to manage your light sources more wisely by using this mod.
-You can download Realistic Torches from [here].
-This mod changes the way Minecraft drops items by making them drop flat on the ground and disabling auto-pickup. It makes items behave more realistically by being affected by gravity, water
You can download Realistic Item Drops from [here](^1^).
-This mod changes the way Minecraft spawns and breeds bees by using real-world genetics and colors. It makes bees tiny or big, spawn in bigger groups, and have more hive space. It also adds new features such as honeycomb blocks, bee nests, bee armor, etc. You can learn more about bee biology and ecology by using this mod.
-You can download Realistic Bees from [here](^4^).
-This mod changes the way Minecraft handles sleeping by making it speed up time instead of skipping to day. It makes sleeping more realistic and immersive by showing the night sky and the moon phases. It also adds new features such as insomnia, nightmares, sleepwalking, etc. You can customize the sleep settings to suit your preferences.
-You can download Realistic Sleep from [here](^7^).
-This mod changes the way Minecraft handles explosions by making them more realistic and destructive. It makes explosions create shockwaves, debris, dust, smoke, fire, etc. It also makes explosions affect entities and blocks differently depending on their distance, mass, resistance, etc. You can enjoy more spectacular and dynamic explosions by using this mod.
-You can download Realistic Explosion Physics from [here](^10^).
-Realistic mods are a great way to make your Minecraft game more immersive and fun. They can improve or change various aspects of the game, such as graphics, physics, sounds, animations, gameplay, etc. However, they can also have some drawbacks, such as performance issues, compatibility problems, bugs, etc. Therefore, you should always check the mod requirements, compatibility, and updates before installing them.
-To install realistic mods, you will need a computer that meets the system requirements, a copy of Minecraft that is compatible with the mod version, a backup of your files and worlds, a mod loader such as Forge or Fabric, and a mod source such as CurseForge or Planet Minecraft. You will also need to download and place the mod files in the mods folder in your .minecraft directory and launch Minecraft with the mod loader profile.
-There are many realistic mods available for Minecraft, but some of them stand out for their quality and popularity. We have listed some of the best realistic mods that you can try, such as Realistic Terrain Generation, Realistic Horse Genetics, Realistic Fire Spread, Realistic Torches, Realistic Item Drops, Realistic Bees, Realistic Sleep , and Realistic Explosion Physics. You can download them from the links provided and enjoy your realistic Minecraft experience.
-We hope you found this article helpful and informative. If you have any questions or feedback, please feel free to leave a comment below. Thank you for reading and happy gaming!
-Here are some of the frequently asked questions about realistic mods:
-Tic tac toe is a classic game that is fun and easy to play. But did you know that you can also build it with React Hooks, a new feature that lets you use state and other React features without writing a class component?
-In this tutorial, you will learn how to build a tic tac toe game with React Hooks from scratch. You will also learn how to add a time travel feature that allows you to go back to any previous move in the game. By the end of this tutorial, you will have a fully functional tic tac toe game that you can play with your friends or online.
-Download File ○○○ https://urlca.com/2uO72X
To follow this tutorial, you will need some basic knowledge of HTML, CSS, JavaScript, and React. You will also need a code editor, a web browser, and Node.js installed on your computer.
-React Hooks are a new addition in React 16.8 that let you use state and other React features without writing a class component. They are functions that let you "hook into" React state and lifecycle features from function components.
-Some of the benefits of using React Hooks are:
-For tic tac toe, using React Hooks will make our code simpler and cleaner. We will be able to manage the state of the game, such as the board, the player, and the winner, with just a few lines of code. We will also be able to add some extra features, such as time travel, with ease.
-In this tutorial, you will learn how to:
-To follow this tutorial, you will need the following tools and resources:
-npm install -g create-react-appThe first step in building our tic tac toe game is to decide how to represent the board and the squares. The board is a 3x3 grid of squares, where each square can be either empty, marked with an X, or marked with an O. We can use an array of nine elements to store the state of the board, where each element corresponds to a square. For example, the initial state of the board can be represented as:
-How to build a tic tac toe game with react hooks
-React tutorial: tic tac toe with state and effects
-Tic tac toe react app with custom hooks and reducer
-Learn react by making a tic tac toe game with typescript
-Tic tac toe game in react native with expo
-React testing library: tic tac toe game example
-Tic tac toe with react and firebase authentication
-React tic tac toe game with AI using minimax algorithm
-Tic tac toe game with react and socket.io for multiplayer
-React tic tac toe game with next.js and tailwind css
-Tic tac toe game with react and graphql using apollo client
-React tic tac toe game with redux and redux toolkit
-Tic tac toe game with react and styled components
-React tic tac toe game with animations using framer motion
-Tic tac toe game with react and web assembly
-React tic tac toe game with drag and drop using react dnd
-Tic tac toe game with react and material ui
-React tic tac toe game with dark mode using context api
-Tic tac toe game with react and svg
-React tic tac toe game with voice control using speech recognition api
-Tic tac toe game with react and web workers
-React tic tac toe game with undo and redo functionality
-Tic tac toe game with react and emotion css-in-js library
-React tic tac toe game with internationalization using i18next
-Tic tac toe game with react and service workers for offline support
-React tic tac toe game with accessibility features using aria attributes
-Tic tac toe game with react and d3.js for data visualization
-React tic tac toe game with code splitting and lazy loading
-Tic tac toe game with react and three.js for 3d graphics
-React tic tac toe game with progressive web app features
-Tic tac toe game with react and bootstrap 5
-React tic tac toe game with server-side rendering using next.js or gatsby.js
-Tic tac toe game with react and firebase firestore database
-React tic tac toe game with authentication using auth0 or firebase auth
-Tic tac toe game with react and aws amplify cloud services
-React tic tac toe game with deployment using netlify or vercel
-Tic tac toe game with react and github actions for continuous integration
-React tic toc toe game with eslint and prettier for code quality
-Tic toc toe game with react and jest for unit testing
-React tic toc toe game with cypress or puppeteer for end-to-end testing
[null, null, null, null, null, null, null, null, null]
-We can use the index of the array to identify each square, starting from 0 to 8. For example, the top-left square has index 0, the top-middle square has index 1, and so on. We can also use a table element to display the board on the web page, where each table cell contains a button element that represents a square.
-The next step is to decide how to check for a winner or a draw. A player wins if they mark three squares in a row, either horizontally, vertically, or diagonally. A draw occurs if all nine squares are marked and no player wins. We can use a function that takes the board array as an argument and returns either 'X', 'O', or null depending on the outcome of the game. For example:
-function calculateWinner(board) // Define the winning combinations const lines = [ [0, 1, 2], // Top row [3, 4, 5], // Middle row [6, 7, 8], // Bottom row [0, 3, 6], // Left column [1, 4, 7], // Middle column [2, 5, 8], // Right column [0, 4, 8], // Top-left to bottom-right diagonal [2, 4, 6], // Top-right to bottom-left diagonal ]; // Loop through the lines and check for a winner for (let i = 0; i < lines.length; i++) const [a, b, c] = lines[i]; // Destructure the line into three squares if (board[a] && board[a] === board[b] && board[a] === board[c]) return board[a]; // Return the winner ('X' or 'O') // Check for a draw if (board.every(square => square !== null)) return 'Draw'; // Return 'Draw' if all squares are marked // Return null if no winner or draw return null;
-The final step in the logic of tic tac toe is to decide how to switch between players. We can use a variable to store the current player ('X' or 'O'), and toggle it after each move. We can also use another variable to store the history of moves, which will be useful for implementing the time travel feature later. For example:
-// Initialize the state variables let board = [null, null, null, null, null, null, null,null,null]; // The current board state let player = 'X'; // The current player ('X' or 'O') let history = []; // The history of moves // Handle user actions function handleClick(i) board[i]) return; // Update the board state with the current player's mark board[i] = player; // Add the board state to the history array history.push(board.slice()); // Use slice to make a copy of the board // Switch the player player = player === 'X' ? 'O' : 'X';
-Now that we have the logic of tic tac toe, we can start building our React app. The easiest way to create a React app is to use create-react-app, a tool that sets up everything for us, such as the development server, the bundler, the transpiler, etc.
-To use create-react-app, open your terminal and run the following command:
-npx create-react-app tic-tac-toe-react
-This will create a new folder called tic-tac-toe-react in your current directory, and install all the dependencies and files needed for your React app. It may take a few minutes to complete.
-Once it is done, you can navigate to the tic-tac-toe-react folder and run the following command to start the development server:
-cd tic-tac-toe-react npm start
-This will open your web browser and display a default React page at http://localhost:3000/. You can edit the files in the src folder and see the changes reflected in the browser automatically.
-The next step is to scaffold our project by creating the components and styles files. We will use a simple file structure that consists of three components: Square, Board, and App. We will also use a separate file for the styles and another file for the game logic.
-To create the components and styles files, open your code editor and navigate to the src folder. Then, create the following files:
-After creating the files, we need to import and export the components so that we can use them in other files. To do this, we need to use the import and export statements at the top and bottom of each file.
-For example, in Square.js, we need to import React from 'react' and export Square as a default export:
-// Import React from 'react' import React from 'react'; // Define the Square component function Square(props) // Return JSX for a button element return (
- ); // Export Square as a default export export default Square;
-Similarly, in Board.js, we need to import React from 'react', import Square from './Square', and export Board as a default export:
-// Import React from 'react' import React from 'react'; // Import Square from './Square' import Square from './Square'; // Define the Board component function Board(props) // Return JSX for a table element return (
-
-
- props.onClick(0) /> props.onClick(1) /> props.onClick(2) />
-
- props.onClick(3) /> props.onClick(4) /> props.onClick(5) />
-
- props.onClick(6) /> props.onClick(7) /> props.onClick(8) />
-
-
- ); // Export Board as a default export export default Board;
-And in App.js, we need to import React from 'react', import useState and useEffect from 'react', import Board from './Board', import calculateWinner and jumpTo from './logic', and import './styles.css' for the styles:
-// Import React from 'react' import React from 'react'; // Import useState and useEffect from 'react' import useState, useEffect from 'react'; // Import Board from './Board' import Board from './Board'; // Import calculateWinner and jumpTo from './logic' import calculateWinner, jumpTo from './logic'; // Import './styles.css' for the styles import './styles.css'; // Define the App component function App() winner === 'O') status = `Winner: $winner`; else if (winner === 'Draw') status = `It's a draw!`; else status = `Next player: $player`; // Return JSX for the app element return (
- Tic Tac Toe with React Hooks
- status
-
-
- history.map((board, move) => ( -
-
-
- ))
-
-
- ); // Export App as a default export export default App; Congratulations! You have successfully built a tic tac toe game with React Hooks. You have learned how to use useState and useEffect hooks to manage state and side effects, how to create functional components with JSX, how to handle user actions with onClick handler, how to implement game logic with custom functions, and how to add a time travel feature with localStorage and map method.
-This is just a basic example of what you can do with React Hooks. There are many more features and possibilities that you can explore and experiment with. For example, you can:
-We hope you enjoyed this tutorial and learned something new. If you have any questions or feedback, feel free to leave a comment below. Happy coding!
-Some of the benefits of using React Hooks are:
-You can make the game responsive or mobile-friendly by using media queries or CSS frameworks. Media queries are a feature of CSS that let you apply different styles based on the screen size or device orientation. For example, you can use media queries to adjust the font size, the margin, or the layout of your app depending on the width of the screen. CSS frameworks are libraries that provide ready-made components and styles for building responsive web pages. For example, you can use Bootstrap, Material UI, or Tailwind CSS to create a grid system, a navbar, a button, etc. for your app.
-You can add animations or sound effects to the game by using CSS transitions or libraries. CSS transitions are a feature of CSS that let you create smooth changes from one state to another. For example, you can use CSS transitions to change the color, the opacity, or the transform of your elements when they are clicked or hovered over. Libraries are external resources that provide additional functionality for your app. For example, you can use React Transition Group, React Spring, or Anime.js to create complex animations for your elements. You can also use Howler.js, Tone.js, or Pizzicato.js to play sound effects for your app.
-You can make the game more challenging or add different modes by changing the board size or the rules. For example, you can increase the board size from 3x3 to 4x4 or 5x5 and require four or five marks in a row to win. You can also change the rules from tic tac toe to gomoku, connect four, or ultimate tic tac toe. These are variations of tic tac toe that have different board sizes, shapes, or layers.
-You can learn more about React Hooks or tic tac toe from the following resources:
-I hope you found these resources helpful and interesting. If you have any other questions or suggestions, feel free to leave a comment below.
401be4b1e0Download File ❤❤❤ https://ssurll.com/2uzvjl
Download Zip · https://gohhs.com/2uFVCU
DOWNLOAD ⚙⚙⚙ https://gohhs.com/2uFUy7
mac users have a limited access to the macos recovery which is a sort of a diagnostic tool. disk drill offers a way around that with the capability to access disk partitions by a direct path. this lets disk drill recover files from disk partitions even from those that are impossible to reach by the mac. the tool can also recover files even from mac systems that dont have access to the macos recovery.
-Download Zip ✔ https://gohhs.com/2uFV4q
disk drill for macos mac os x is the first app to offer users a native recovery solution for mac. other mobile data recovery apps come with a limited version of mac os x support, but disk drill works with all apple mac systems at full speed.
-disk drill for macos lets the users access their encrypted files and backup drive with a free tool, and also provides a facility to make good backups without installing any specialized software. the software is a simple tool that many people may consider to be very straightforward. it does not ask for any obscure settings, and anyone could use it without issues. this makes disk drill an ideal choice for people who want to back up important data.
-disk drill is a light-weight mobile data recovery tool for windows and macs. the ultimate goal of the tool is to recover the most powerful and select files for free. if you need to recover data from a partition or system disk, disk drill can do that for you. disk drill is convenient, easy to use, and affordable. the free tool works only with files that are stored on a storage device.
- -disk drill for macos gives users the most powerful tool to access data that is stored on encrypted volumes and external drives. the utility can also recover files from locked disks and disks that have not been opened for some time. apart from the mentioned features, disk drill also lets users browse files and folders within the finder and also lets them make good backups while accessing data without any hassles.
899543212bDownload Zip ❤❤❤ https://gohhs.com/2uFVwC
Do you want to improve your typing speed and accuracy? Do you want to learn touch typing in a fun and effective way? If yes, then you may be interested in Rapid Typing Tutor Crack. This is a cracked version of Rapid Typing Tutor, a popular and powerful software that can help you learn touch typing through a series of lessons and exercises. In this article, we will tell you what Rapid Typing Tutor Crack is, how to download it, and how to use it.
-Download Zip ★★★ https://gohhs.com/2uFUZS
Rapid Typing Tutor is a keyboard trainer that can help you improve your typing speed and reduce typos. It can teach you touch typing in a short time, by organizing its lessons around various keyboard groups. It can also help you learn individual letters, numbers, and symbols, as well as a series of text exercises.
- -Rapid Typing Tutor has a simple and colorful interface, and supports colorful skins library. It also has a game plot, where you can train in a virtual picturesque underwater world, and see various underwater creatures as you progress. It also has a keyboard emulator that can help you learn blind typing quickly.
- -Rapid Typing Tutor is suitable for children and adults, and supports multiple users with their personal settings. It also supports QWERTY, AZERTY, QWERTZ, and Dvorak keyboard layouts.
- -Rapid Typing Tutor Crack is a cracked version of Rapid Typing Tutor, which means that it has been modified to bypass the activation process and use the full version of the software for free. However, using Rapid Typing Tutor Crack may have some risks and disadvantages, such as:
- - -Therefore, we do not recommend using Rapid Typing Tutor Crack, and we advise you to download the official version of Rapid Typing Tutor from its website or other reputable sources.
- -If you still want to download Rapid Typing Tutor Crack, you need to be careful and selective when choosing where to download it from. There are many websites that offer Rapid Typing Tutor Crack for free or for a small fee, but not all of them are reliable or trustworthy. Some may have corrupted files, outdated versions, or malicious links.
- -Here are some tips to help you find a reputable website that offers Rapid Typing Tutor Crack:
- -By following these tips, you can find a trustworthy website that offers Rapid Typing Tutor Crack safely and securely.
- -Using Rapid Typing Tutor Crack is simple and straightforward. Here are some steps you can follow:
- -By following these steps, you can use Rapid Typing Tutor Crack to learn touch typing fast and easy.
- -In this article, we have discussed Rapid Typing Tutor Crack and how to download and use it. We have seen that it is a cracked version of Rapid Typing Tutor, a popular and powerful keyboard trainer that can help you improve your typing speed and accuracy. We have also seen that it has some risks and disadvantages, such as containing viruses, having errors, being outdated, or violating copyright laws.
- -We hope this article has given you some useful information about Rapid Typing Tutor Crack and how to use it. However, we do not recommend using Rapid Typing Tutor Crack, and we advise you to download the official version of Rapid Typing Tutor from its website or other reputable sources.
-Rapid Typing Tutor has many features that can help you learn touch typing fast and easy. Some of these features are:
- -By using these features, you can make the most of Rapid Typing Tutor and learn touch typing fast and easy.
- -Rapid Typing Tutor has many benefits that can help you improve your typing speed and accuracy. Some of these benefits are:
- -By using these benefits, you can enjoy Rapid Typing Tutor and improve your typing speed and accuracy.
-While Rapid Typing Tutor Crack may seem tempting and appealing, it also has some drawbacks that can outweigh its benefits. Some of these drawbacks are:
- -By using these drawbacks, you can avoid Rapid Typing Tutor Crack and use the official version of Rapid Typing Tutor instead.
- -If you want to download and use the official version of Rapid Typing Tutor, you can follow these steps:
- -By following these steps, you can download and use the official version of Rapid Typing Tutor and enjoy its features and benefits without any risks or drawbacks.
-In this article, we have discussed Rapid Typing Tutor Crack and how to download and use it. We have seen that it is a cracked version of Rapid Typing Tutor, a popular and powerful keyboard trainer that can help you improve your typing speed and accuracy. We have also seen that it has some features and benefits, such as being free and easy to download, portable and convenient, comprehensive and accurate, helpful and informative, and fun and entertaining.
- -However, we have also seen that it has some risks and disadvantages, such as harming your device or data, not working properly or having errors or bugs, violating the law and the terms of service, and not being ethical or fair. Therefore, we do not recommend using Rapid Typing Tutor Crack, and we advise you to download and use the official version of Rapid Typing Tutor from its website or other reputable sources.
- -We hope this article has given you some useful information and tips about Rapid Typing Tutor Crack and how to use it. However, we encourage you to try the official version of Rapid Typing Tutor and see how it can enhance your typing skills and enrich your learning experience.
3cee63e6c2Dense Passage Retrieval for Open-Domain Question Answering
" - -examples = [ - ["Hello, is my dog cute ?","dpr-question_encoder-bert-base-multilingual"] -] - -io1 = gr.Interface.load("huggingface/voidful/dpr-question_encoder-bert-base-multilingual") - -io2 = gr.Interface.load("huggingface/sivasankalpp/dpr-multidoc2dial-structure-question-encoder") - -def inference(inputtext, model): - if model == "dpr-question_encoder-bert-base-multilingual": - outlabel = io1(inputtext) - else: - outlabel = io2(inputtext) - return outlabel - - -gr.Interface( - inference, - [gr.inputs.Textbox(label="Context",lines=10),gr.inputs.Dropdown(choices=["dpr-question_encoder-bert-base-multilingual","dpr-multidoc2dial-structure-question-encoder"], type="value", default="dpr-question_encoder-bert-base-multilingual", label="model")], - [gr.outputs.Dataframe(type="pandas",label="Output")], - examples=examples, - article=article, - title=title, - description=description).launch(enable_queue=True) \ No newline at end of file diff --git a/spaces/doevent/3D_Photo_Inpainting/utils.py b/spaces/doevent/3D_Photo_Inpainting/utils.py deleted file mode 100644 index 808e48b1979d16f32c050f43f1f6c0ca36d8d18b..0000000000000000000000000000000000000000 --- a/spaces/doevent/3D_Photo_Inpainting/utils.py +++ /dev/null @@ -1,1416 +0,0 @@ -import os -import glob -import cv2 -import scipy.misc as misc -from skimage.transform import resize -import numpy as np -from functools import reduce -from operator import mul -import torch -from torch import nn -import matplotlib.pyplot as plt -import re -try: - import cynetworkx as netx -except ImportError: - import networkx as netx -from scipy.ndimage import gaussian_filter -from skimage.feature import canny -import collections -import shutil -import imageio -import copy -from matplotlib import pyplot as plt -from mpl_toolkits.mplot3d import Axes3D -import time -from scipy.interpolate import interp1d -from collections import namedtuple - -def path_planning(num_frames, x, y, z, path_type=''): - if path_type == 'straight-line': - corner_points = np.array([[0, 0, 0], [(0 + x) * 0.5, (0 + y) * 0.5, (0 + z) * 0.5], [x, y, z]]) - corner_t = np.linspace(0, 1, len(corner_points)) - t = np.linspace(0, 1, num_frames) - cs = interp1d(corner_t, corner_points, axis=0, kind='quadratic') - spline = cs(t) - xs, ys, zs = [xx.squeeze() for xx in np.split(spline, 3, 1)] - elif path_type == 'double-straight-line': - corner_points = np.array([[-x, -y, -z], [0, 0, 0], [x, y, z]]) - corner_t = np.linspace(0, 1, len(corner_points)) - t = np.linspace(0, 1, num_frames) - cs = interp1d(corner_t, corner_points, axis=0, kind='quadratic') - spline = cs(t) - xs, ys, zs = [xx.squeeze() for xx in np.split(spline, 3, 1)] - elif path_type == 'circle': - xs, ys, zs = [], [], [] - for frame_id, bs_shift_val in enumerate(np.arange(-2.0, 2.0, (4./num_frames))): - xs += [np.cos(bs_shift_val * np.pi) * 1 * x] - ys += [np.sin(bs_shift_val * np.pi) * 1 * y] - zs += [np.cos(bs_shift_val * np.pi/2.) * 1 * z] - xs, ys, zs = np.array(xs), np.array(ys), np.array(zs) - - return xs, ys, zs - -def open_small_mask(mask, context, open_iteration, kernel): - np_mask = mask.cpu().data.numpy().squeeze().astype(np.uint8) - raw_mask = np_mask.copy() - np_context = context.cpu().data.numpy().squeeze().astype(np.uint8) - np_input = np_mask + np_context - for _ in range(open_iteration): - np_input = cv2.erode(cv2.dilate(np_input, np.ones((kernel, kernel)), iterations=1), np.ones((kernel,kernel)), iterations=1) - np_mask[(np_input - np_context) > 0] = 1 - out_mask = torch.FloatTensor(np_mask).to(mask)[None, None, ...] - - return out_mask - -def filter_irrelevant_edge_new(self_edge, comp_edge, other_edges, other_edges_with_id, current_edge_id, context, depth, mesh, context_cc, spdb=False): - other_edges = other_edges.squeeze().astype(np.uint8) - other_edges_with_id = other_edges_with_id.squeeze() - self_edge = self_edge.squeeze() - dilate_bevel_self_edge = cv2.dilate((self_edge + comp_edge).astype(np.uint8), np.array([[1,1,1],[1,1,1],[1,1,1]]), iterations=1) - dilate_cross_self_edge = cv2.dilate((self_edge + comp_edge).astype(np.uint8), np.array([[0,1,0],[1,1,1],[0,1,0]]).astype(np.uint8), iterations=1) - edge_ids = np.unique(other_edges_with_id * context + (-1) * (1 - context)).astype(np.int) - end_depth_maps = np.zeros_like(self_edge) - self_edge_ids = np.sort(np.unique(other_edges_with_id[self_edge > 0]).astype(np.int)) - self_edge_ids = self_edge_ids[1:] if self_edge_ids.shape[0] > 0 and self_edge_ids[0] == -1 else self_edge_ids - self_comp_ids = np.sort(np.unique(other_edges_with_id[comp_edge > 0]).astype(np.int)) - self_comp_ids = self_comp_ids[1:] if self_comp_ids.shape[0] > 0 and self_comp_ids[0] == -1 else self_comp_ids - edge_ids = edge_ids[1:] if edge_ids[0] == -1 else edge_ids - other_edges_info = [] - extend_other_edges = np.zeros_like(other_edges) - if spdb is True: - f, ((ax1, ax2, ax3)) = plt.subplots(1, 3, sharex=True, sharey=True); ax1.imshow(self_edge); ax2.imshow(context); ax3.imshow(other_edges_with_id * context + (-1) * (1 - context)); plt.show() - import pdb; pdb.set_trace() - filter_self_edge = np.zeros_like(self_edge) - for self_edge_id in self_edge_ids: - filter_self_edge[other_edges_with_id == self_edge_id] = 1 - dilate_self_comp_edge = cv2.dilate(comp_edge, kernel=np.ones((3, 3)), iterations=2) - valid_self_comp_edge = np.zeros_like(comp_edge) - for self_comp_id in self_comp_ids: - valid_self_comp_edge[self_comp_id == other_edges_with_id] = 1 - self_comp_edge = dilate_self_comp_edge * valid_self_comp_edge - filter_self_edge = (filter_self_edge + self_comp_edge).clip(0, 1) - for edge_id in edge_ids: - other_edge_locs = (other_edges_with_id == edge_id).astype(np.uint8) - condition = (other_edge_locs * other_edges * context.astype(np.uint8)) - end_cross_point = dilate_cross_self_edge * condition * (1 - filter_self_edge) - end_bevel_point = dilate_bevel_self_edge * condition * (1 - filter_self_edge) - if end_bevel_point.max() != 0: - end_depth_maps[end_bevel_point != 0] = depth[end_bevel_point != 0] - if end_cross_point.max() == 0: - nxs, nys = np.where(end_bevel_point != 0) - for nx, ny in zip(nxs, nys): - bevel_node = [xx for xx in context_cc if xx[0] == nx and xx[1] == ny][0] - for ne in mesh.neighbors(bevel_node): - if other_edges_with_id[ne[0], ne[1]] > -1 and dilate_cross_self_edge[ne[0], ne[1]] > 0: - extend_other_edges[ne[0], ne[1]] = 1 - break - else: - other_edges[other_edges_with_id == edge_id] = 0 - other_edges = (other_edges + extend_other_edges).clip(0, 1) * context - - return other_edges, end_depth_maps, other_edges_info - -def clean_far_edge_new(input_edge, end_depth_maps, mask, context, global_mesh, info_on_pix, self_edge, inpaint_id, config): - mesh = netx.Graph() - hxs, hys = np.where(input_edge * mask > 0) - valid_near_edge = (input_edge != 0).astype(np.uint8) * context - valid_map = mask + context - invalid_edge_ids = [] - for hx, hy in zip(hxs, hys): - node = (hx ,hy) - mesh.add_node((hx, hy)) - eight_nes = [ne for ne in [(hx + 1, hy), (hx - 1, hy), (hx, hy + 1), (hx, hy - 1), \ - (hx + 1, hy + 1), (hx - 1, hy - 1), (hx - 1, hy + 1), (hx + 1, hy - 1)]\ - if 0 <= ne[0] < input_edge.shape[0] and 0 <= ne[1] < input_edge.shape[1] and 0 < input_edge[ne[0], ne[1]]] # or end_depth_maps[ne[0], ne[1]] != 0] - for ne in eight_nes: - mesh.add_edge(node, ne, length=np.hypot(ne[0] - hx, ne[1] - hy)) - if end_depth_maps[ne[0], ne[1]] != 0: - mesh.nodes[ne[0], ne[1]]['cnt'] = True - if end_depth_maps[ne[0], ne[1]] == 0: - import pdb; pdb.set_trace() - mesh.nodes[ne[0], ne[1]]['depth'] = end_depth_maps[ne[0], ne[1]] - elif mask[ne[0], ne[1]] != 1: - four_nes = [nne for nne in [(ne[0] + 1, ne[1]), (ne[0] - 1, ne[1]), (ne[0], ne[1] + 1), (ne[0], ne[1] - 1)]\ - if nne[0] < end_depth_maps.shape[0] and nne[0] >= 0 and nne[1] < end_depth_maps.shape[1] and nne[1] >= 0] - for nne in four_nes: - if end_depth_maps[nne[0], nne[1]] != 0: - mesh.add_edge(nne, ne, length=np.hypot(nne[0] - ne[0], nne[1] - ne[1])) - mesh.nodes[nne[0], nne[1]]['cnt'] = True - mesh.nodes[nne[0], nne[1]]['depth'] = end_depth_maps[nne[0], nne[1]] - ccs = [*netx.connected_components(mesh)] - end_pts = [] - for cc in ccs: - end_pts.append(set()) - for node in cc: - if mesh.nodes[node].get('cnt') is not None: - end_pts[-1].add((node[0], node[1], mesh.nodes[node]['depth'])) - predef_npaths = [None for _ in range(len(ccs))] - fpath_map = np.zeros_like(input_edge) - 1 - npath_map = np.zeros_like(input_edge) - 1 - npaths, fpaths = dict(), dict() - break_flag = False - end_idx = 0 - while end_idx < len(end_pts): - end_pt, cc = [*zip(end_pts, ccs)][end_idx] - end_idx += 1 - sorted_end_pt = [] - fpath = [] - iter_fpath = [] - if len(end_pt) > 2 or len(end_pt) == 0: - if len(end_pt) > 2: - continue - continue - if len(end_pt) == 2: - ravel_end = [*end_pt] - tmp_sub_mesh = mesh.subgraph(list(cc)).copy() - tmp_npath = [*netx.shortest_path(tmp_sub_mesh, (ravel_end[0][0], ravel_end[0][1]), (ravel_end[1][0], ravel_end[1][1]), weight='length')] - fpath_map1, npath_map1, disp_diff1 = plan_path(mesh, info_on_pix, cc, ravel_end[0:1], global_mesh, input_edge, mask, valid_map, inpaint_id, npath_map=None, fpath_map=None, npath=tmp_npath) - fpath_map2, npath_map2, disp_diff2 = plan_path(mesh, info_on_pix, cc, ravel_end[1:2], global_mesh, input_edge, mask, valid_map, inpaint_id, npath_map=None, fpath_map=None, npath=tmp_npath) - tmp_disp_diff = [disp_diff1, disp_diff2] - self_end = [] - edge_len = [] - ds_edge = cv2.dilate(self_edge.astype(np.uint8), np.ones((3, 3)), iterations=1) - if ds_edge[ravel_end[0][0], ravel_end[0][1]] > 0: - self_end.append(1) - else: - self_end.append(0) - if ds_edge[ravel_end[1][0], ravel_end[1][1]] > 0: - self_end.append(1) - else: - self_end.append(0) - edge_len = [np.count_nonzero(npath_map1), np.count_nonzero(npath_map2)] - sorted_end_pts = [xx[0] for xx in sorted(zip(ravel_end, self_end, edge_len, [disp_diff1, disp_diff2]), key=lambda x: (x[1], x[2]), reverse=True)] - re_npath_map1, re_fpath_map1 = (npath_map1 != -1).astype(np.uint8), (fpath_map1 != -1).astype(np.uint8) - re_npath_map2, re_fpath_map2 = (npath_map2 != -1).astype(np.uint8), (fpath_map2 != -1).astype(np.uint8) - if np.count_nonzero(re_npath_map1 * re_npath_map2 * mask) / \ - (np.count_nonzero((re_npath_map1 + re_npath_map2) * mask) + 1e-6) > 0.5\ - and np.count_nonzero(re_fpath_map1 * re_fpath_map2 * mask) / \ - (np.count_nonzero((re_fpath_map1 + re_fpath_map2) * mask) + 1e-6) > 0.5\ - and tmp_disp_diff[0] != -1 and tmp_disp_diff[1] != -1: - my_fpath_map, my_npath_map, npath, fpath = \ - plan_path_e2e(mesh, cc, sorted_end_pts, global_mesh, input_edge, mask, valid_map, inpaint_id, npath_map=None, fpath_map=None) - npath_map[my_npath_map != -1] = my_npath_map[my_npath_map != -1] - fpath_map[my_fpath_map != -1] = my_fpath_map[my_fpath_map != -1] - if len(fpath) > 0: - edge_id = global_mesh.nodes[[*sorted_end_pts][0]]['edge_id'] - fpaths[edge_id] = fpath - npaths[edge_id] = npath - invalid_edge_ids.append(edge_id) - else: - if tmp_disp_diff[0] != -1: - ratio_a = tmp_disp_diff[0] / (np.sum(tmp_disp_diff) + 1e-8) - else: - ratio_a = 0 - if tmp_disp_diff[1] != -1: - ratio_b = tmp_disp_diff[1] / (np.sum(tmp_disp_diff) + 1e-8) - else: - ratio_b = 0 - npath_len = len(tmp_npath) - if npath_len > config['depth_edge_dilate_2'] * 2: - npath_len = npath_len - (config['depth_edge_dilate_2'] * 1) - tmp_npath_a = tmp_npath[:int(np.floor(npath_len * ratio_a))] - tmp_npath_b = tmp_npath[::-1][:int(np.floor(npath_len * ratio_b))] - tmp_merge = [] - if len(tmp_npath_a) > 0 and sorted_end_pts[0][0] == tmp_npath_a[0][0] and sorted_end_pts[0][1] == tmp_npath_a[0][1]: - if len(tmp_npath_a) > 0 and mask[tmp_npath_a[-1][0], tmp_npath_a[-1][1]] > 0: - tmp_merge.append([sorted_end_pts[:1], tmp_npath_a]) - if len(tmp_npath_b) > 0 and mask[tmp_npath_b[-1][0], tmp_npath_b[-1][1]] > 0: - tmp_merge.append([sorted_end_pts[1:2], tmp_npath_b]) - elif len(tmp_npath_b) > 0 and sorted_end_pts[0][0] == tmp_npath_b[0][0] and sorted_end_pts[0][1] == tmp_npath_b[0][1]: - if len(tmp_npath_b) > 0 and mask[tmp_npath_b[-1][0], tmp_npath_b[-1][1]] > 0: - tmp_merge.append([sorted_end_pts[:1], tmp_npath_b]) - if len(tmp_npath_a) > 0 and mask[tmp_npath_a[-1][0], tmp_npath_a[-1][1]] > 0: - tmp_merge.append([sorted_end_pts[1:2], tmp_npath_a]) - for tmp_idx in range(len(tmp_merge)): - if len(tmp_merge[tmp_idx][1]) == 0: - continue - end_pts.append(tmp_merge[tmp_idx][0]) - ccs.append(set(tmp_merge[tmp_idx][1])) - if len(end_pt) == 1: - sub_mesh = mesh.subgraph(list(cc)).copy() - pnodes = netx.periphery(sub_mesh) - if len(end_pt) == 1: - ends = [*end_pt] - elif len(sorted_end_pt) == 1: - ends = [*sorted_end_pt] - else: - import pdb; pdb.set_trace() - try: - edge_id = global_mesh.nodes[ends[0]]['edge_id'] - except: - import pdb; pdb.set_trace() - pnodes = sorted(pnodes, - key=lambda x: np.hypot((x[0] - ends[0][0]), (x[1] - ends[0][1])), - reverse=True)[0] - npath = [*netx.shortest_path(sub_mesh, (ends[0][0], ends[0][1]), pnodes, weight='length')] - for np_node in npath: - npath_map[np_node[0], np_node[1]] = edge_id - fpath = [] - if global_mesh.nodes[ends[0]].get('far') is None: - print("None far") - else: - fnodes = global_mesh.nodes[ends[0]].get('far') - dmask = mask + 0 - did = 0 - while True: - did += 1 - dmask = cv2.dilate(dmask, np.ones((3, 3)), iterations=1) - if did > 3: - break - ffnode = [fnode for fnode in fnodes if (dmask[fnode[0], fnode[1]] > 0 and mask[fnode[0], fnode[1]] == 0 and\ - global_mesh.nodes[fnode].get('inpaint_id') != inpaint_id + 1)] - if len(ffnode) > 0: - fnode = ffnode[0] - break - if len(ffnode) == 0: - continue - fpath.append((fnode[0], fnode[1])) - barrel_dir = np.array([[1, 0], [1, 1], [0, 1], [-1, 1], [-1, 0], [-1, -1], [0, -1], [1, -1]]) - n2f_dir = (int(fnode[0] - npath[0][0]), int(fnode[1] - npath[0][1])) - while True: - if barrel_dir[0, 0] == n2f_dir[0] and barrel_dir[0, 1] == n2f_dir[1]: - n2f_barrel = barrel_dir.copy() - break - barrel_dir = np.roll(barrel_dir, 1, axis=0) - for step in range(0, len(npath)): - if step == 0: - continue - elif step == 1: - next_dir = (npath[step][0] - npath[step - 1][0], npath[step][1] - npath[step - 1][1]) - while True: - if barrel_dir[0, 0] == next_dir[0] and barrel_dir[0, 1] == next_dir[1]: - next_barrel = barrel_dir.copy() - break - barrel_dir = np.roll(barrel_dir, 1, axis=0) - barrel_pair = np.stack((n2f_barrel, next_barrel), axis=0) - n2f_dir = (barrel_pair[0, 0, 0], barrel_pair[0, 0, 1]) - elif step > 1: - next_dir = (npath[step][0] - npath[step - 1][0], npath[step][1] - npath[step - 1][1]) - while True: - if barrel_pair[1, 0, 0] == next_dir[0] and barrel_pair[1, 0, 1] == next_dir[1]: - next_barrel = barrel_pair.copy() - break - barrel_pair = np.roll(barrel_pair, 1, axis=1) - n2f_dir = (barrel_pair[0, 0, 0], barrel_pair[0, 0, 1]) - new_locs = [] - if abs(n2f_dir[0]) == 1: - new_locs.append((npath[step][0] + n2f_dir[0], npath[step][1])) - if abs(n2f_dir[1]) == 1: - new_locs.append((npath[step][0], npath[step][1] + n2f_dir[1])) - if len(new_locs) > 1: - new_locs = sorted(new_locs, key=lambda xx: np.hypot((xx[0] - fpath[-1][0]), (xx[1] - fpath[-1][1]))) - break_flag = False - for new_loc in new_locs: - new_loc_nes = [xx for xx in [(new_loc[0] + 1, new_loc[1]), (new_loc[0] - 1, new_loc[1]), - (new_loc[0], new_loc[1] + 1), (new_loc[0], new_loc[1] - 1)]\ - if xx[0] >= 0 and xx[0] < fpath_map.shape[0] and xx[1] >= 0 and xx[1] < fpath_map.shape[1]] - if np.all([(fpath_map[nlne[0], nlne[1]] == -1) for nlne in new_loc_nes]) != True: - break - if npath_map[new_loc[0], new_loc[1]] != -1: - if npath_map[new_loc[0], new_loc[1]] != edge_id: - break_flag = True - break - else: - continue - if valid_map[new_loc[0], new_loc[1]] == 0: - break_flag = True - break - fpath.append(new_loc) - if break_flag is True: - break - if step != len(npath) - 1: - for xx in npath[step:]: - if npath_map[xx[0], xx[1]] == edge_id: - npath_map[xx[0], xx[1]] = -1 - npath = npath[:step] - if len(fpath) > 0: - for fp_node in fpath: - fpath_map[fp_node[0], fp_node[1]] = edge_id - fpaths[edge_id] = fpath - npaths[edge_id] = npath - fpath_map[valid_near_edge != 0] = -1 - if len(fpath) > 0: - iter_fpath = copy.deepcopy(fpaths[edge_id]) - for node in iter_fpath: - if valid_near_edge[node[0], node[1]] != 0: - fpaths[edge_id].remove(node) - - return fpath_map, npath_map, False, npaths, fpaths, invalid_edge_ids - -def plan_path_e2e(mesh, cc, end_pts, global_mesh, input_edge, mask, valid_map, inpaint_id, npath_map=None, fpath_map=None): - my_npath_map = np.zeros_like(input_edge) - 1 - my_fpath_map = np.zeros_like(input_edge) - 1 - sub_mesh = mesh.subgraph(list(cc)).copy() - ends_1, ends_2 = end_pts[0], end_pts[1] - edge_id = global_mesh.nodes[ends_1]['edge_id'] - npath = [*netx.shortest_path(sub_mesh, (ends_1[0], ends_1[1]), (ends_2[0], ends_2[1]), weight='length')] - for np_node in npath: - my_npath_map[np_node[0], np_node[1]] = edge_id - fpath = [] - if global_mesh.nodes[ends_1].get('far') is None: - print("None far") - else: - fnodes = global_mesh.nodes[ends_1].get('far') - dmask = mask + 0 - while True: - dmask = cv2.dilate(dmask, np.ones((3, 3)), iterations=1) - ffnode = [fnode for fnode in fnodes if (dmask[fnode[0], fnode[1]] > 0 and mask[fnode[0], fnode[1]] == 0 and\ - global_mesh.nodes[fnode].get('inpaint_id') != inpaint_id + 1)] - if len(ffnode) > 0: - fnode = ffnode[0] - break - e_fnodes = global_mesh.nodes[ends_2].get('far') - dmask = mask + 0 - while True: - dmask = cv2.dilate(dmask, np.ones((3, 3)), iterations=1) - e_ffnode = [e_fnode for e_fnode in e_fnodes if (dmask[e_fnode[0], e_fnode[1]] > 0 and mask[e_fnode[0], e_fnode[1]] == 0 and\ - global_mesh.nodes[e_fnode].get('inpaint_id') != inpaint_id + 1)] - if len(e_ffnode) > 0: - e_fnode = e_ffnode[0] - break - fpath.append((fnode[0], fnode[1])) - if len(e_ffnode) == 0 or len(ffnode) == 0: - return my_npath_map, my_fpath_map, [], [] - barrel_dir = np.array([[1, 0], [1, 1], [0, 1], [-1, 1], [-1, 0], [-1, -1], [0, -1], [1, -1]]) - n2f_dir = (int(fnode[0] - npath[0][0]), int(fnode[1] - npath[0][1])) - while True: - if barrel_dir[0, 0] == n2f_dir[0] and barrel_dir[0, 1] == n2f_dir[1]: - n2f_barrel = barrel_dir.copy() - break - barrel_dir = np.roll(barrel_dir, 1, axis=0) - for step in range(0, len(npath)): - if step == 0: - continue - elif step == 1: - next_dir = (npath[step][0] - npath[step - 1][0], npath[step][1] - npath[step - 1][1]) - while True: - if barrel_dir[0, 0] == next_dir[0] and barrel_dir[0, 1] == next_dir[1]: - next_barrel = barrel_dir.copy() - break - barrel_dir = np.roll(barrel_dir, 1, axis=0) - barrel_pair = np.stack((n2f_barrel, next_barrel), axis=0) - n2f_dir = (barrel_pair[0, 0, 0], barrel_pair[0, 0, 1]) - elif step > 1: - next_dir = (npath[step][0] - npath[step - 1][0], npath[step][1] - npath[step - 1][1]) - while True: - if barrel_pair[1, 0, 0] == next_dir[0] and barrel_pair[1, 0, 1] == next_dir[1]: - next_barrel = barrel_pair.copy() - break - barrel_pair = np.roll(barrel_pair, 1, axis=1) - n2f_dir = (barrel_pair[0, 0, 0], barrel_pair[0, 0, 1]) - new_locs = [] - if abs(n2f_dir[0]) == 1: - new_locs.append((npath[step][0] + n2f_dir[0], npath[step][1])) - if abs(n2f_dir[1]) == 1: - new_locs.append((npath[step][0], npath[step][1] + n2f_dir[1])) - if len(new_locs) > 1: - new_locs = sorted(new_locs, key=lambda xx: np.hypot((xx[0] - fpath[-1][0]), (xx[1] - fpath[-1][1]))) - break_flag = False - for new_loc in new_locs: - new_loc_nes = [xx for xx in [(new_loc[0] + 1, new_loc[1]), (new_loc[0] - 1, new_loc[1]), - (new_loc[0], new_loc[1] + 1), (new_loc[0], new_loc[1] - 1)]\ - if xx[0] >= 0 and xx[0] < my_fpath_map.shape[0] and xx[1] >= 0 and xx[1] < my_fpath_map.shape[1]] - if fpath_map is not None and np.sum([fpath_map[nlne[0], nlne[1]] for nlne in new_loc_nes]) != 0: - break_flag = True - break - if my_npath_map[new_loc[0], new_loc[1]] != -1: - continue - if npath_map is not None and npath_map[new_loc[0], new_loc[1]] != edge_id: - break_flag = True - break - fpath.append(new_loc) - if break_flag is True: - break - if (e_fnode[0], e_fnode[1]) not in fpath: - fpath.append((e_fnode[0], e_fnode[1])) - if step != len(npath) - 1: - for xx in npath[step:]: - if my_npath_map[xx[0], xx[1]] == edge_id: - my_npath_map[xx[0], xx[1]] = -1 - npath = npath[:step] - if len(fpath) > 0: - for fp_node in fpath: - my_fpath_map[fp_node[0], fp_node[1]] = edge_id - - return my_fpath_map, my_npath_map, npath, fpath - -def plan_path(mesh, info_on_pix, cc, end_pt, global_mesh, input_edge, mask, valid_map, inpaint_id, npath_map=None, fpath_map=None, npath=None): - my_npath_map = np.zeros_like(input_edge) - 1 - my_fpath_map = np.zeros_like(input_edge) - 1 - sub_mesh = mesh.subgraph(list(cc)).copy() - pnodes = netx.periphery(sub_mesh) - ends = [*end_pt] - edge_id = global_mesh.nodes[ends[0]]['edge_id'] - pnodes = sorted(pnodes, - key=lambda x: np.hypot((x[0] - ends[0][0]), (x[1] - ends[0][1])), - reverse=True)[0] - if npath is None: - npath = [*netx.shortest_path(sub_mesh, (ends[0][0], ends[0][1]), pnodes, weight='length')] - else: - if (ends[0][0], ends[0][1]) == npath[0]: - npath = npath - elif (ends[0][0], ends[0][1]) == npath[-1]: - npath = npath[::-1] - else: - import pdb; pdb.set_trace() - for np_node in npath: - my_npath_map[np_node[0], np_node[1]] = edge_id - fpath = [] - if global_mesh.nodes[ends[0]].get('far') is None: - print("None far") - else: - fnodes = global_mesh.nodes[ends[0]].get('far') - dmask = mask + 0 - did = 0 - while True: - did += 1 - if did > 3: - return my_fpath_map, my_npath_map, -1 - dmask = cv2.dilate(dmask, np.ones((3, 3)), iterations=1) - ffnode = [fnode for fnode in fnodes if (dmask[fnode[0], fnode[1]] > 0 and mask[fnode[0], fnode[1]] == 0 and\ - global_mesh.nodes[fnode].get('inpaint_id') != inpaint_id + 1)] - if len(ffnode) > 0: - fnode = ffnode[0] - break - - fpath.append((fnode[0], fnode[1])) - disp_diff = 0. - for n_loc in npath: - if mask[n_loc[0], n_loc[1]] != 0: - disp_diff = abs(abs(1. / info_on_pix[(n_loc[0], n_loc[1])][0]['depth']) - abs(1. / ends[0][2])) - break - barrel_dir = np.array([[1, 0], [1, 1], [0, 1], [-1, 1], [-1, 0], [-1, -1], [0, -1], [1, -1]]) - n2f_dir = (int(fnode[0] - npath[0][0]), int(fnode[1] - npath[0][1])) - while True: - if barrel_dir[0, 0] == n2f_dir[0] and barrel_dir[0, 1] == n2f_dir[1]: - n2f_barrel = barrel_dir.copy() - break - barrel_dir = np.roll(barrel_dir, 1, axis=0) - for step in range(0, len(npath)): - if step == 0: - continue - elif step == 1: - next_dir = (npath[step][0] - npath[step - 1][0], npath[step][1] - npath[step - 1][1]) - while True: - if barrel_dir[0, 0] == next_dir[0] and barrel_dir[0, 1] == next_dir[1]: - next_barrel = barrel_dir.copy() - break - barrel_dir = np.roll(barrel_dir, 1, axis=0) - barrel_pair = np.stack((n2f_barrel, next_barrel), axis=0) - n2f_dir = (barrel_pair[0, 0, 0], barrel_pair[0, 0, 1]) - elif step > 1: - next_dir = (npath[step][0] - npath[step - 1][0], npath[step][1] - npath[step - 1][1]) - while True: - if barrel_pair[1, 0, 0] == next_dir[0] and barrel_pair[1, 0, 1] == next_dir[1]: - next_barrel = barrel_pair.copy() - break - barrel_pair = np.roll(barrel_pair, 1, axis=1) - n2f_dir = (barrel_pair[0, 0, 0], barrel_pair[0, 0, 1]) - new_locs = [] - if abs(n2f_dir[0]) == 1: - new_locs.append((npath[step][0] + n2f_dir[0], npath[step][1])) - if abs(n2f_dir[1]) == 1: - new_locs.append((npath[step][0], npath[step][1] + n2f_dir[1])) - if len(new_locs) > 1: - new_locs = sorted(new_locs, key=lambda xx: np.hypot((xx[0] - fpath[-1][0]), (xx[1] - fpath[-1][1]))) - break_flag = False - for new_loc in new_locs: - new_loc_nes = [xx for xx in [(new_loc[0] + 1, new_loc[1]), (new_loc[0] - 1, new_loc[1]), - (new_loc[0], new_loc[1] + 1), (new_loc[0], new_loc[1] - 1)]\ - if xx[0] >= 0 and xx[0] < my_fpath_map.shape[0] and xx[1] >= 0 and xx[1] < my_fpath_map.shape[1]] - if fpath_map is not None and np.all([(fpath_map[nlne[0], nlne[1]] == -1) for nlne in new_loc_nes]) != True: - break_flag = True - break - if np.all([(my_fpath_map[nlne[0], nlne[1]] == -1) for nlne in new_loc_nes]) != True: - break_flag = True - break - if my_npath_map[new_loc[0], new_loc[1]] != -1: - continue - if npath_map is not None and npath_map[new_loc[0], new_loc[1]] != edge_id: - break_flag = True - break - if valid_map[new_loc[0], new_loc[1]] == 0: - break_flag = True - break - fpath.append(new_loc) - if break_flag is True: - break - if step != len(npath) - 1: - for xx in npath[step:]: - if my_npath_map[xx[0], xx[1]] == edge_id: - my_npath_map[xx[0], xx[1]] = -1 - npath = npath[:step] - if len(fpath) > 0: - for fp_node in fpath: - my_fpath_map[fp_node[0], fp_node[1]] = edge_id - - return my_fpath_map, my_npath_map, disp_diff - -def refresh_node(old_node, old_feat, new_node, new_feat, mesh, stime=False): - mesh.add_node(new_node) - mesh.nodes[new_node].update(new_feat) - mesh.nodes[new_node].update(old_feat) - for ne in mesh.neighbors(old_node): - mesh.add_edge(new_node, ne) - if mesh.nodes[new_node].get('far') is not None: - tmp_far_nodes = mesh.nodes[new_node]['far'] - for far_node in tmp_far_nodes: - if mesh.has_node(far_node) is False: - mesh.nodes[new_node]['far'].remove(far_node) - continue - if mesh.nodes[far_node].get('near') is not None: - for idx in range(len(mesh.nodes[far_node].get('near'))): - if mesh.nodes[far_node]['near'][idx][0] == new_node[0] and mesh.nodes[far_node]['near'][idx][1] == new_node[1]: - if len(mesh.nodes[far_node]['near'][idx]) == len(old_node): - mesh.nodes[far_node]['near'][idx] = new_node - if mesh.nodes[new_node].get('near') is not None: - tmp_near_nodes = mesh.nodes[new_node]['near'] - for near_node in tmp_near_nodes: - if mesh.has_node(near_node) is False: - mesh.nodes[new_node]['near'].remove(near_node) - continue - if mesh.nodes[near_node].get('far') is not None: - for idx in range(len(mesh.nodes[near_node].get('far'))): - if mesh.nodes[near_node]['far'][idx][0] == new_node[0] and mesh.nodes[near_node]['far'][idx][1] == new_node[1]: - if len(mesh.nodes[near_node]['far'][idx]) == len(old_node): - mesh.nodes[near_node]['far'][idx] = new_node - if new_node != old_node: - mesh.remove_node(old_node) - if stime is False: - return mesh - else: - return mesh, None, None - - -def create_placeholder(context, mask, depth, fpath_map, npath_map, mesh, inpaint_id, edge_ccs, extend_edge_cc, all_edge_maps, self_edge_id): - add_node_time = 0 - add_edge_time = 0 - add_far_near_time = 0 - valid_area = context + mask - H, W = mesh.graph['H'], mesh.graph['W'] - edge_cc = edge_ccs[self_edge_id] - num_com = len(edge_cc) + len(extend_edge_cc) - hxs, hys = np.where(mask > 0) - for hx, hy in zip(hxs, hys): - mesh.add_node((hx, hy), inpaint_id=inpaint_id + 1, num_context=num_com) - for hx, hy in zip(hxs, hys): - four_nes = [(x, y) for x, y in [(hx + 1, hy), (hx - 1, hy), (hx, hy + 1), (hx, hy - 1)] if\ - 0 <= x < mesh.graph['H'] and 0 <= y < mesh.graph['W'] and valid_area[x, y] != 0] - for ne in four_nes: - if mask[ne[0], ne[1]] != 0: - if not mesh.has_edge((hx, hy), ne): - mesh.add_edge((hx, hy), ne) - elif depth[ne[0], ne[1]] != 0: - if mesh.has_node((ne[0], ne[1], depth[ne[0], ne[1]])) and\ - not mesh.has_edge((hx, hy), (ne[0], ne[1], depth[ne[0], ne[1]])): - mesh.add_edge((hx, hy), (ne[0], ne[1], depth[ne[0], ne[1]])) - else: - print("Undefined context node.") - import pdb; pdb.set_trace() - near_ids = np.unique(npath_map) - if near_ids[0] == -1: near_ids = near_ids[1:] - for near_id in near_ids: - hxs, hys = np.where((fpath_map == near_id) & (mask > 0)) - if hxs.shape[0] > 0: - mesh.graph['max_edge_id'] = mesh.graph['max_edge_id'] + 1 - else: - break - for hx, hy in zip(hxs, hys): - mesh.nodes[(hx, hy)]['edge_id'] = int(round(mesh.graph['max_edge_id'])) - four_nes = [(x, y) for x, y in [(hx + 1, hy), (hx - 1, hy), (hx, hy + 1), (hx, hy - 1)] if\ - x < mesh.graph['H'] and x >= 0 and y < mesh.graph['W'] and y >= 0 and npath_map[x, y] == near_id] - for xx in four_nes: - xx_n = copy.deepcopy(xx) - if not mesh.has_node(xx_n): - if mesh.has_node((xx_n[0], xx_n[1], depth[xx_n[0], xx_n[1]])): - xx_n = (xx_n[0], xx_n[1], depth[xx_n[0], xx_n[1]]) - if mesh.has_edge((hx, hy), xx_n): - # pass - mesh.remove_edge((hx, hy), xx_n) - if mesh.nodes[(hx, hy)].get('near') is None: - mesh.nodes[(hx, hy)]['near'] = [] - mesh.nodes[(hx, hy)]['near'].append(xx_n) - connect_point_exception = set() - hxs, hys = np.where((npath_map == near_id) & (all_edge_maps > -1)) - for hx, hy in zip(hxs, hys): - unknown_id = int(round(all_edge_maps[hx, hy])) - if unknown_id != near_id and unknown_id != self_edge_id: - unknown_node = set([xx for xx in edge_ccs[unknown_id] if xx[0] == hx and xx[1] == hy]) - connect_point_exception |= unknown_node - hxs, hys = np.where((npath_map == near_id) & (mask > 0)) - if hxs.shape[0] > 0: - mesh.graph['max_edge_id'] = mesh.graph['max_edge_id'] + 1 - else: - break - for hx, hy in zip(hxs, hys): - mesh.nodes[(hx, hy)]['edge_id'] = int(round(mesh.graph['max_edge_id'])) - mesh.nodes[(hx, hy)]['connect_point_id'] = int(round(near_id)) - mesh.nodes[(hx, hy)]['connect_point_exception'] = connect_point_exception - four_nes = [(x, y) for x, y in [(hx + 1, hy), (hx - 1, hy), (hx, hy + 1), (hx, hy - 1)] if\ - x < mesh.graph['H'] and x >= 0 and y < mesh.graph['W'] and y >= 0 and fpath_map[x, y] == near_id] - for xx in four_nes: - xx_n = copy.deepcopy(xx) - if not mesh.has_node(xx_n): - if mesh.has_node((xx_n[0], xx_n[1], depth[xx_n[0], xx_n[1]])): - xx_n = (xx_n[0], xx_n[1], depth[xx_n[0], xx_n[1]]) - if mesh.has_edge((hx, hy), xx_n): - mesh.remove_edge((hx, hy), xx_n) - if mesh.nodes[(hx, hy)].get('far') is None: - mesh.nodes[(hx, hy)]['far'] = [] - mesh.nodes[(hx, hy)]['far'].append(xx_n) - - return mesh, add_node_time, add_edge_time, add_far_near_time - -def clean_far_edge(mask_edge, mask_edge_with_id, context_edge, mask, info_on_pix, global_mesh, anchor): - if isinstance(mask_edge, torch.Tensor): - if mask_edge.is_cuda: - mask_edge = mask_edge.cpu() - mask_edge = mask_edge.data - mask_edge = mask_edge.numpy() - if isinstance(context_edge, torch.Tensor): - if context_edge.is_cuda: - context_edge = context_edge.cpu() - context_edge = context_edge.data - context_edge = context_edge.numpy() - if isinstance(mask, torch.Tensor): - if mask.is_cuda: - mask = mask.cpu() - mask = mask.data - mask = mask.numpy() - mask = mask.squeeze() - mask_edge = mask_edge.squeeze() - context_edge = context_edge.squeeze() - valid_near_edge = np.zeros_like(mask_edge) - far_edge = np.zeros_like(mask_edge) - far_edge_with_id = np.ones_like(mask_edge) * -1 - near_edge_with_id = np.ones_like(mask_edge) * -1 - uncleaned_far_edge = np.zeros_like(mask_edge) - # Detect if there is any valid pixel mask_edge, if not ==> return default value - if mask_edge.sum() == 0: - return far_edge, uncleaned_far_edge, far_edge_with_id, near_edge_with_id - mask_edge_ids = dict(collections.Counter(mask_edge_with_id.flatten())).keys() - for edge_id in mask_edge_ids: - if edge_id < 0: - continue - specific_edge_map = (mask_edge_with_id == edge_id).astype(np.uint8) - _, sub_specific_edge_maps = cv2.connectedComponents(specific_edge_map.astype(np.uint8), connectivity=8) - for sub_edge_id in range(1, sub_specific_edge_maps.max() + 1): - specific_edge_map = (sub_specific_edge_maps == sub_edge_id).astype(np.uint8) - edge_pxs, edge_pys = np.where(specific_edge_map > 0) - edge_mesh = netx.Graph() - for edge_px, edge_py in zip(edge_pxs, edge_pys): - edge_mesh.add_node((edge_px, edge_py)) - for ex in [edge_px-1, edge_px, edge_px+1]: - for ey in [edge_py-1, edge_py, edge_py+1]: - if edge_px == ex and edge_py == ey: - continue - if ex < 0 or ex >= specific_edge_map.shape[0] or ey < 0 or ey >= specific_edge_map.shape[1]: - continue - if specific_edge_map[ex, ey] == 1: - if edge_mesh.has_node((ex, ey)): - edge_mesh.add_edge((ex, ey), (edge_px, edge_py)) - periphery_nodes = netx.periphery(edge_mesh) - path_diameter = netx.diameter(edge_mesh) - start_near_node = None - for node_s in periphery_nodes: - for node_e in periphery_nodes: - if node_s != node_e: - if netx.shortest_path_length(edge_mesh, node_s, node_e) == path_diameter: - if np.any(context_edge[node_s[0]-1:node_s[0]+2, node_s[1]-1:node_s[1]+2].flatten()): - start_near_node = (node_s[0], node_s[1]) - end_near_node = (node_e[0], node_e[1]) - break - if np.any(context_edge[node_e[0]-1:node_e[0]+2, node_e[1]-1:node_e[1]+2].flatten()): - start_near_node = (node_e[0], node_e[1]) - end_near_node = (node_s[0], node_s[1]) - break - if start_near_node is not None: - break - if start_near_node is None: - continue - new_specific_edge_map = np.zeros_like(mask) - for path_node in netx.shortest_path(edge_mesh, start_near_node, end_near_node): - new_specific_edge_map[path_node[0], path_node[1]] = 1 - context_near_pxs, context_near_pys = np.where(context_edge[start_near_node[0]-1:start_near_node[0]+2, start_near_node[1]-1:start_near_node[1]+2] > 0) - distance = np.abs((context_near_pxs - 1)) + np.abs((context_near_pys - 1)) - if (np.where(distance == distance.min())[0].shape[0]) > 1: - closest_pxs = context_near_pxs[np.where(distance == distance.min())[0]] - closest_pys = context_near_pys[np.where(distance == distance.min())[0]] - closest_depths = [] - for closest_px, closest_py in zip(closest_pxs, closest_pys): - if info_on_pix.get((closest_px + start_near_node[0] - 1 + anchor[0], closest_py + start_near_node[1] - 1 + anchor[2])) is not None: - for info in info_on_pix.get((closest_px + start_near_node[0] - 1 + anchor[0], closest_py + start_near_node[1] - 1 + anchor[2])): - if info['synthesis'] is False: - closest_depths.append(abs(info['depth'])) - context_near_px, context_near_py = closest_pxs[np.array(closest_depths).argmax()], closest_pys[np.array(closest_depths).argmax()] - else: - context_near_px, context_near_py = context_near_pxs[distance.argmin()], context_near_pys[distance.argmin()] - context_near_node = (start_near_node[0]-1 + context_near_px, start_near_node[1]-1 + context_near_py) - far_node_list = [] - global_context_near_node = (context_near_node[0] + anchor[0], context_near_node[1] + anchor[2]) - if info_on_pix.get(global_context_near_node) is not None: - for info in info_on_pix[global_context_near_node]: - if info['synthesis'] is False: - context_near_node_3d = (global_context_near_node[0], global_context_near_node[1], info['depth']) - if global_mesh.nodes[context_near_node_3d].get('far') is not None: - for far_node in global_mesh.nodes[context_near_node_3d].get('far'): - far_node = (far_node[0] - anchor[0], far_node[1] - anchor[2], far_node[2]) - if mask[far_node[0], far_node[1]] == 0: - far_node_list.append([far_node[0], far_node[1]]) - if len(far_node_list) > 0: - far_nodes_dist = np.sum(np.abs(np.array(far_node_list) - np.array([[edge_px, edge_py]])), axis=1) - context_far_node = tuple(far_node_list[far_nodes_dist.argmin()]) - corresponding_far_edge = np.zeros_like(mask_edge) - corresponding_far_edge[context_far_node[0], context_far_node[1]] = 1 - surround_map = cv2.dilate(new_specific_edge_map.astype(np.uint8), - np.array([[1,1,1],[1,1,1],[1,1,1]]).astype(np.uint8), - iterations=1) - specific_edge_map_wo_end_pt = new_specific_edge_map.copy() - specific_edge_map_wo_end_pt[end_near_node[0], end_near_node[1]] = 0 - surround_map_wo_end_pt = cv2.dilate(specific_edge_map_wo_end_pt.astype(np.uint8), - np.array([[1,1,1],[1,1,1],[1,1,1]]).astype(np.uint8), - iterations=1) - surround_map_wo_end_pt[new_specific_edge_map > 0] = 0 - surround_map_wo_end_pt[context_near_node[0], context_near_node[1]] = 0 - surround_map = surround_map_wo_end_pt.copy() - _, far_edge_cc = cv2.connectedComponents(surround_map.astype(np.uint8), connectivity=4) - start_far_node = None - accompany_far_node = None - if surround_map[context_far_node[0], context_far_node[1]] == 1: - start_far_node = context_far_node - else: - four_nes = [(context_far_node[0] - 1, context_far_node[1]), - (context_far_node[0] + 1, context_far_node[1]), - (context_far_node[0], context_far_node[1] - 1), - (context_far_node[0], context_far_node[1] + 1)] - candidate_bevel = [] - for ne in four_nes: - if surround_map[ne[0], ne[1]] == 1: - start_far_node = (ne[0], ne[1]) - break - elif (ne[0] != context_near_node[0] or ne[1] != context_near_node[1]) and \ - (ne[0] != start_near_node[0] or ne[1] != start_near_node[1]): - candidate_bevel.append((ne[0], ne[1])) - if start_far_node is None: - for ne in candidate_bevel: - if ne[0] == context_far_node[0]: - bevel_xys = [[ne[0] + 1, ne[1]], [ne[0] - 1, ne[1]]] - if ne[1] == context_far_node[1]: - bevel_xys = [[ne[0], ne[1] + 1], [ne[0], ne[1] - 1]] - for bevel_x, bevel_y in bevel_xys: - if surround_map[bevel_x, bevel_y] == 1: - start_far_node = (bevel_x, bevel_y) - accompany_far_node = (ne[0], ne[1]) - break - if start_far_node is not None: - break - if start_far_node is not None: - for far_edge_id in range(1, far_edge_cc.max() + 1): - specific_far_edge = (far_edge_cc == far_edge_id).astype(np.uint8) - if specific_far_edge[start_far_node[0], start_far_node[1]] == 1: - if accompany_far_node is not None: - specific_far_edge[accompany_far_node] = 1 - far_edge[specific_far_edge > 0] = 1 - far_edge_with_id[specific_far_edge > 0] = edge_id - end_far_candidates = np.zeros_like(far_edge) - end_far_candidates[end_near_node[0], end_near_node[1]] = 1 - end_far_candidates = cv2.dilate(end_far_candidates.astype(np.uint8), - np.array([[0,1,0],[1,1,1],[0,1,0]]).astype(np.uint8), - iterations=1) - end_far_candidates[end_near_node[0], end_near_node[1]] = 0 - invalid_nodes = (((far_edge_cc != far_edge_id).astype(np.uint8) * \ - (far_edge_cc != 0).astype(np.uint8)).astype(np.uint8) + \ - (new_specific_edge_map).astype(np.uint8) + \ - (mask == 0).astype(np.uint8)).clip(0, 1) - end_far_candidates[invalid_nodes > 0] = 0 - far_edge[end_far_candidates > 0] = 1 - far_edge_with_id[end_far_candidates > 0] = edge_id - - far_edge[context_far_node[0], context_far_node[1]] = 1 - far_edge_with_id[context_far_node[0], context_far_node[1]] = edge_id - near_edge_with_id[(mask_edge_with_id == edge_id) > 0] = edge_id - uncleaned_far_edge = far_edge.copy() - far_edge[mask == 0] = 0 - - return far_edge, uncleaned_far_edge, far_edge_with_id, near_edge_with_id - -def get_MiDaS_samples(image_folder, depth_folder, config, specific=None, aft_certain=None): - lines = [os.path.splitext(os.path.basename(xx))[0] for xx in glob.glob(os.path.join(image_folder, '*' + config['img_format']))] - samples = [] - generic_pose = np.eye(4) - assert len(config['traj_types']) == len(config['x_shift_range']) ==\ - len(config['y_shift_range']) == len(config['z_shift_range']) == len(config['video_postfix']), \ - "The number of elements in 'traj_types', 'x_shift_range', 'y_shift_range', 'z_shift_range' and \ - 'video_postfix' should be equal." - tgt_pose = [[generic_pose * 1]] - tgts_poses = [] - for traj_idx in range(len(config['traj_types'])): - tgt_poses = [] - sx, sy, sz = path_planning(config['num_frames'], config['x_shift_range'][traj_idx], config['y_shift_range'][traj_idx], - config['z_shift_range'][traj_idx], path_type=config['traj_types'][traj_idx]) - for xx, yy, zz in zip(sx, sy, sz): - tgt_poses.append(generic_pose * 1.) - tgt_poses[-1][:3, -1] = np.array([xx, yy, zz]) - tgts_poses += [tgt_poses] - tgt_pose = generic_pose * 1 - - aft_flag = True - if aft_certain is not None and len(aft_certain) > 0: - aft_flag = False - for seq_dir in lines: - if specific is not None and len(specific) > 0: - if specific != seq_dir: - continue - if aft_certain is not None and len(aft_certain) > 0: - if aft_certain == seq_dir: - aft_flag = True - if aft_flag is False: - continue - samples.append({}) - sdict = samples[-1] - sdict['depth_fi'] = os.path.join(depth_folder, seq_dir + config['depth_format']) - sdict['ref_img_fi'] = os.path.join(image_folder, seq_dir + config['img_format']) - H, W = imageio.imread(sdict['ref_img_fi']).shape[:2] - sdict['int_mtx'] = np.array([[max(H, W), 0, W//2], [0, max(H, W), H//2], [0, 0, 1]]).astype(np.float32) - if sdict['int_mtx'].max() > 1: - sdict['int_mtx'][0, :] = sdict['int_mtx'][0, :] / float(W) - sdict['int_mtx'][1, :] = sdict['int_mtx'][1, :] / float(H) - sdict['ref_pose'] = np.eye(4) - sdict['tgt_pose'] = tgt_pose - sdict['tgts_poses'] = tgts_poses - sdict['video_postfix'] = config['video_postfix'] - sdict['tgt_name'] = [os.path.splitext(os.path.basename(sdict['depth_fi']))[0]] - sdict['src_pair_name'] = sdict['tgt_name'][0] - - return samples - -def get_valid_size(imap): - x_max = np.where(imap.sum(1).squeeze() > 0)[0].max() + 1 - x_min = np.where(imap.sum(1).squeeze() > 0)[0].min() - y_max = np.where(imap.sum(0).squeeze() > 0)[0].max() + 1 - y_min = np.where(imap.sum(0).squeeze() > 0)[0].min() - size_dict = {'x_max':x_max, 'y_max':y_max, 'x_min':x_min, 'y_min':y_min} - - return size_dict - -def dilate_valid_size(isize_dict, imap, dilate=[0, 0]): - osize_dict = copy.deepcopy(isize_dict) - osize_dict['x_min'] = max(0, osize_dict['x_min'] - dilate[0]) - osize_dict['x_max'] = min(imap.shape[0], osize_dict['x_max'] + dilate[0]) - osize_dict['y_min'] = max(0, osize_dict['y_min'] - dilate[0]) - osize_dict['y_max'] = min(imap.shape[1], osize_dict['y_max'] + dilate[1]) - - return osize_dict - -def crop_maps_by_size(size, *imaps): - omaps = [] - for imap in imaps: - omaps.append(imap[size['x_min']:size['x_max'], size['y_min']:size['y_max']].copy()) - - return omaps - -def smooth_cntsyn_gap(init_depth_map, mask_region, context_region, init_mask_region=None): - if init_mask_region is not None: - curr_mask_region = init_mask_region * 1 - else: - curr_mask_region = mask_region * 0 - depth_map = init_depth_map.copy() - for _ in range(2): - cm_mask = context_region + curr_mask_region - depth_s1 = np.roll(depth_map, 1, 0) - depth_s2 = np.roll(depth_map, -1, 0) - depth_s3 = np.roll(depth_map, 1, 1) - depth_s4 = np.roll(depth_map, -1, 1) - mask_s1 = np.roll(cm_mask, 1, 0) - mask_s2 = np.roll(cm_mask, -1, 0) - mask_s3 = np.roll(cm_mask, 1, 1) - mask_s4 = np.roll(cm_mask, -1, 1) - fluxin_depths = (depth_s1 * mask_s1 + depth_s2 * mask_s2 + depth_s3 * mask_s3 + depth_s4 * mask_s4) / \ - ((mask_s1 + mask_s2 + mask_s3 + mask_s4) + 1e-6) - fluxin_mask = (fluxin_depths != 0) * mask_region - init_mask = (fluxin_mask * (curr_mask_region >= 0).astype(np.float32) > 0).astype(np.uint8) - depth_map[init_mask > 0] = fluxin_depths[init_mask > 0] - if init_mask.shape[-1] > curr_mask_region.shape[-1]: - curr_mask_region[init_mask.sum(-1, keepdims=True) > 0] = 1 - else: - curr_mask_region[init_mask > 0] = 1 - depth_map[fluxin_mask > 0] = fluxin_depths[fluxin_mask > 0] - - return depth_map - -def read_MiDaS_depth(disp_fi, disp_rescale=10., h=None, w=None): - if 'npy' in os.path.splitext(disp_fi)[-1]: - disp = np.load(disp_fi) - else: - disp = imageio.imread(disp_fi).astype(np.float32) - disp = disp - disp.min() - disp = cv2.blur(disp / disp.max(), ksize=(3, 3)) * disp.max() - disp = (disp / disp.max()) * disp_rescale - if h is not None and w is not None: - disp = resize(disp / disp.max(), (h, w), order=1) * disp.max() - depth = 1. / np.maximum(disp, 0.05) - - return depth - -def follow_image_aspect_ratio(depth, image): - H, W = image.shape[:2] - image_aspect_ratio = H / W - dH, dW = depth.shape[:2] - depth_aspect_ratio = dH / dW - if depth_aspect_ratio > image_aspect_ratio: - resize_H = dH - resize_W = dH / image_aspect_ratio - else: - resize_W = dW - resize_H = dW * image_aspect_ratio - depth = resize(depth / depth.max(), - (int(resize_H), - int(resize_W)), - order=0) * depth.max() - - return depth - -def depth_resize(depth, origin_size, image_size): - if origin_size[0] is not 0: - max_depth = depth.max() - depth = depth / max_depth - depth = resize(depth, origin_size, order=1, mode='edge') - depth = depth * max_depth - else: - max_depth = depth.max() - depth = depth / max_depth - depth = resize(depth, image_size, order=1, mode='edge') - depth = depth * max_depth - - return depth - -def filter_irrelevant_edge(self_edge, other_edges, other_edges_with_id, current_edge_id, context, edge_ccs, mesh, anchor): - other_edges = other_edges.squeeze() - other_edges_with_id = other_edges_with_id.squeeze() - - self_edge = self_edge.squeeze() - dilate_self_edge = cv2.dilate(self_edge.astype(np.uint8), np.array([[1,1,1],[1,1,1],[1,1,1]]).astype(np.uint8), iterations=1) - edge_ids = collections.Counter(other_edges_with_id.flatten()).keys() - other_edges_info = [] - # import ipdb - # ipdb.set_trace() - for edge_id in edge_ids: - edge_id = int(edge_id) - if edge_id >= 0: - condition = ((other_edges_with_id == edge_id) * other_edges * context).astype(np.uint8) - if dilate_self_edge[condition > 0].sum() == 0: - other_edges[other_edges_with_id == edge_id] = 0 - else: - num_condition, condition_labels = cv2.connectedComponents(condition, connectivity=8) - for condition_id in range(1, num_condition): - isolate_condition = ((condition_labels == condition_id) > 0).astype(np.uint8) - num_end_group, end_group = cv2.connectedComponents(((dilate_self_edge * isolate_condition) > 0).astype(np.uint8), connectivity=8) - if num_end_group == 1: - continue - for end_id in range(1, num_end_group): - end_pxs, end_pys = np.where((end_group == end_id)) - end_px, end_py = end_pxs[0], end_pys[0] - other_edges_info.append({}) - other_edges_info[-1]['edge_id'] = edge_id - # other_edges_info[-1]['near_depth'] = None - other_edges_info[-1]['diff'] = None - other_edges_info[-1]['edge_map'] = np.zeros_like(self_edge) - other_edges_info[-1]['end_point_map'] = np.zeros_like(self_edge) - other_edges_info[-1]['end_point_map'][(end_group == end_id)] = 1 - other_edges_info[-1]['forbidden_point_map'] = np.zeros_like(self_edge) - other_edges_info[-1]['forbidden_point_map'][(end_group != end_id) * (end_group != 0)] = 1 - other_edges_info[-1]['forbidden_point_map'] = cv2.dilate(other_edges_info[-1]['forbidden_point_map'], kernel=np.array([[1,1,1],[1,1,1],[1,1,1]]), iterations=2) - for x in edge_ccs[edge_id]: - nx = x[0] - anchor[0] - ny = x[1] - anchor[1] - if nx == end_px and ny == end_py: - # other_edges_info[-1]['near_depth'] = abs(nx) - if mesh.nodes[x].get('far') is not None and len(mesh.nodes[x].get('far')) == 1: - other_edges_info[-1]['diff'] = abs(1./abs([*mesh.nodes[x].get('far')][0][2]) - 1./abs(x[2])) - else: - other_edges_info[-1]['diff'] = 0 - # if end_group[nx, ny] != end_id and end_group[nx, ny] > 0: - # continue - try: - if isolate_condition[nx, ny] == 1: - other_edges_info[-1]['edge_map'][nx, ny] = 1 - except: - pass - try: - other_edges_info = sorted(other_edges_info, key=lambda x : x['diff'], reverse=True) - except: - import pdb - pdb.set_trace() - # import pdb - # pdb.set_trace() - # other_edges = other_edges[..., None] - for other_edge in other_edges_info: - if other_edge['end_point_map'] is None: - import pdb - pdb.set_trace() - - other_edges = other_edges * context - - return other_edges, other_edges_info - -def require_depth_edge(context_edge, mask): - dilate_mask = cv2.dilate(mask, np.array([[1,1,1],[1,1,1],[1,1,1]]).astype(np.uint8), iterations=1) - if (dilate_mask * context_edge).max() == 0: - return False - else: - return True - -def refine_color_around_edge(mesh, info_on_pix, edge_ccs, config, spdb=False): - H, W = mesh.graph['H'], mesh.graph['W'] - tmp_edge_ccs = copy.deepcopy(edge_ccs) - for edge_id, edge_cc in enumerate(edge_ccs): - if len(edge_cc) == 0: - continue - near_maps = np.zeros((H, W)).astype(np.bool) - far_maps = np.zeros((H, W)).astype(np.bool) - tmp_far_nodes = set() - far_nodes = set() - near_nodes = set() - end_nodes = set() - for i in range(5): - if i == 0: - for edge_node in edge_cc: - if mesh.nodes[edge_node].get('depth_edge_dilate_2_color_flag') is not True: - break - if mesh.nodes[edge_node].get('inpaint_id') == 1: - near_nodes.add(edge_node) - tmp_node = mesh.nodes[edge_node].get('far') - tmp_node = set(tmp_node) if tmp_node is not None else set() - tmp_far_nodes |= tmp_node - rmv_tmp_far_nodes = set() - for far_node in tmp_far_nodes: - if not(mesh.has_node(far_node) and mesh.nodes[far_node].get('inpaint_id') == 1): - rmv_tmp_far_nodes.add(far_node) - if len(tmp_far_nodes - rmv_tmp_far_nodes) == 0: - break - else: - for near_node in near_nodes: - near_maps[near_node[0], near_node[1]] = True - mesh.nodes[near_node]['refine_rgbd'] = True - mesh.nodes[near_node]['backup_depth'] = near_node[2] \ - if mesh.nodes[near_node].get('real_depth') is None else mesh.nodes[near_node]['real_depth'] - mesh.nodes[near_node]['backup_color'] = mesh.nodes[near_node]['color'] - for far_node in tmp_far_nodes: - if mesh.has_node(far_node) and mesh.nodes[far_node].get('inpaint_id') == 1: - far_nodes.add(far_node) - far_maps[far_node[0], far_node[1]] = True - mesh.nodes[far_node]['refine_rgbd'] = True - mesh.nodes[far_node]['backup_depth'] = far_node[2] \ - if mesh.nodes[far_node].get('real_depth') is None else mesh.nodes[far_node]['real_depth'] - mesh.nodes[far_node]['backup_color'] = mesh.nodes[far_node]['color'] - tmp_far_nodes = far_nodes - tmp_near_nodes = near_nodes - else: - tmp_far_nodes = new_tmp_far_nodes - tmp_near_nodes = new_tmp_near_nodes - new_tmp_far_nodes = None - new_tmp_near_nodes = None - new_tmp_far_nodes = set() - new_tmp_near_nodes = set() - for node in tmp_near_nodes: - for ne_node in mesh.neighbors(node): - if far_maps[ne_node[0], ne_node[1]] == False and \ - near_maps[ne_node[0], ne_node[1]] == False: - if mesh.nodes[ne_node].get('inpaint_id') == 1: - new_tmp_near_nodes.add(ne_node) - near_maps[ne_node[0], ne_node[1]] = True - mesh.nodes[ne_node]['refine_rgbd'] = True - mesh.nodes[ne_node]['backup_depth'] = ne_node[2] \ - if mesh.nodes[ne_node].get('real_depth') is None else mesh.nodes[ne_node]['real_depth'] - mesh.nodes[ne_node]['backup_color'] = mesh.nodes[ne_node]['color'] - else: - mesh.nodes[ne_node]['backup_depth'] = ne_node[2] \ - if mesh.nodes[ne_node].get('real_depth') is None else mesh.nodes[ne_node]['real_depth'] - mesh.nodes[ne_node]['backup_color'] = mesh.nodes[ne_node]['color'] - end_nodes.add(node) - near_nodes.update(new_tmp_near_nodes) - for node in tmp_far_nodes: - for ne_node in mesh.neighbors(node): - if far_maps[ne_node[0], ne_node[1]] == False and \ - near_maps[ne_node[0], ne_node[1]] == False: - if mesh.nodes[ne_node].get('inpaint_id') == 1: - new_tmp_far_nodes.add(ne_node) - far_maps[ne_node[0], ne_node[1]] = True - mesh.nodes[ne_node]['refine_rgbd'] = True - mesh.nodes[ne_node]['backup_depth'] = ne_node[2] \ - if mesh.nodes[ne_node].get('real_depth') is None else mesh.nodes[ne_node]['real_depth'] - mesh.nodes[ne_node]['backup_color'] = mesh.nodes[ne_node]['color'] - else: - mesh.nodes[ne_node]['backup_depth'] = ne_node[2] \ - if mesh.nodes[ne_node].get('real_depth') is None else mesh.nodes[ne_node]['real_depth'] - mesh.nodes[ne_node]['backup_color'] = mesh.nodes[ne_node]['color'] - end_nodes.add(node) - far_nodes.update(new_tmp_far_nodes) - if len(far_nodes) == 0: - tmp_edge_ccs[edge_id] = set() - continue - for node in new_tmp_far_nodes | new_tmp_near_nodes: - for ne_node in mesh.neighbors(node): - if far_maps[ne_node[0], ne_node[1]] == False and near_maps[ne_node[0], ne_node[1]] == False: - end_nodes.add(node) - mesh.nodes[ne_node]['backup_depth'] = ne_node[2] \ - if mesh.nodes[ne_node].get('real_depth') is None else mesh.nodes[ne_node]['real_depth'] - mesh.nodes[ne_node]['backup_color'] = mesh.nodes[ne_node]['color'] - tmp_end_nodes = end_nodes - - refine_nodes = near_nodes | far_nodes - remain_refine_nodes = copy.deepcopy(refine_nodes) - accum_idx = 0 - while len(remain_refine_nodes) > 0: - accum_idx += 1 - if accum_idx > 100: - break - new_tmp_end_nodes = None - new_tmp_end_nodes = set() - survive_tmp_end_nodes = set() - for node in tmp_end_nodes: - re_depth, re_color, re_count = 0, np.array([0., 0., 0.]), 0 - for ne_node in mesh.neighbors(node): - if mesh.nodes[ne_node].get('refine_rgbd') is True: - if ne_node not in tmp_end_nodes: - new_tmp_end_nodes.add(ne_node) - else: - try: - re_depth += mesh.nodes[ne_node]['backup_depth'] - re_color += mesh.nodes[ne_node]['backup_color'].astype(np.float32) - re_count += 1. - except: - import pdb; pdb.set_trace() - if re_count > 0: - re_depth = re_depth / re_count - re_color = re_color / re_count - mesh.nodes[node]['backup_depth'] = re_depth - mesh.nodes[node]['backup_color'] = re_color - mesh.nodes[node]['refine_rgbd'] = False - else: - survive_tmp_end_nodes.add(node) - for node in tmp_end_nodes - survive_tmp_end_nodes: - if node in remain_refine_nodes: - remain_refine_nodes.remove(node) - tmp_end_nodes = new_tmp_end_nodes - if spdb == True: - bfrd_canvas = np.zeros((H, W)) - bfrc_canvas = np.zeros((H, W, 3)).astype(np.uint8) - aftd_canvas = np.zeros((H, W)) - aftc_canvas = np.zeros((H, W, 3)).astype(np.uint8) - for node in refine_nodes: - bfrd_canvas[node[0], node[1]] = abs(node[2]) - aftd_canvas[node[0], node[1]] = abs(mesh.nodes[node]['backup_depth']) - bfrc_canvas[node[0], node[1]] = mesh.nodes[node]['color'].astype(np.uint8) - aftc_canvas[node[0], node[1]] = mesh.nodes[node]['backup_color'].astype(np.uint8) - f, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, sharex=True, sharey=True); - ax1.imshow(bfrd_canvas); - ax2.imshow(aftd_canvas); - ax3.imshow(bfrc_canvas); - ax4.imshow(aftc_canvas); - plt.show() - import pdb; pdb.set_trace() - for node in refine_nodes: - if mesh.nodes[node].get('refine_rgbd') is not None: - mesh.nodes[node].pop('refine_rgbd') - mesh.nodes[node]['color'] = mesh.nodes[node]['backup_color'] - for info in info_on_pix[(node[0], node[1])]: - if info['depth'] == node[2]: - info['color'] = mesh.nodes[node]['backup_color'] - - return mesh, info_on_pix - -def refine_depth_around_edge(mask_depth, far_edge, uncleaned_far_edge, near_edge, mask, all_depth, config): - if isinstance(mask_depth, torch.Tensor): - if mask_depth.is_cuda: - mask_depth = mask_depth.cpu() - mask_depth = mask_depth.data - mask_depth = mask_depth.numpy() - if isinstance(far_edge, torch.Tensor): - if far_edge.is_cuda: - far_edge = far_edge.cpu() - far_edge = far_edge.data - far_edge = far_edge.numpy() - if isinstance(uncleaned_far_edge, torch.Tensor): - if uncleaned_far_edge.is_cuda: - uncleaned_far_edge = uncleaned_far_edge.cpu() - uncleaned_far_edge = uncleaned_far_edge.data - uncleaned_far_edge = uncleaned_far_edge.numpy() - if isinstance(near_edge, torch.Tensor): - if near_edge.is_cuda: - near_edge = near_edge.cpu() - near_edge = near_edge.data - near_edge = near_edge.numpy() - if isinstance(mask, torch.Tensor): - if mask.is_cuda: - mask = mask.cpu() - mask = mask.data - mask = mask.numpy() - mask = mask.squeeze() - uncleaned_far_edge = uncleaned_far_edge.squeeze() - far_edge = far_edge.squeeze() - near_edge = near_edge.squeeze() - mask_depth = mask_depth.squeeze() - dilate_far_edge = cv2.dilate(uncleaned_far_edge.astype(np.uint8), kernel=np.array([[0,1,0],[1,1,1],[0,1,0]]).astype(np.uint8), iterations=1) - near_edge[dilate_far_edge == 0] = 0 - dilate_near_edge = cv2.dilate(near_edge.astype(np.uint8), kernel=np.array([[0,1,0],[1,1,1],[0,1,0]]).astype(np.uint8), iterations=1) - far_edge[dilate_near_edge == 0] = 0 - init_far_edge = far_edge.copy() - init_near_edge = near_edge.copy() - for i in range(config['depth_edge_dilate_2']): - init_far_edge = cv2.dilate(init_far_edge, kernel=np.array([[0,1,0],[1,1,1],[0,1,0]]).astype(np.uint8), iterations=1) - init_far_edge[init_near_edge == 1] = 0 - init_near_edge = cv2.dilate(init_near_edge, kernel=np.array([[0,1,0],[1,1,1],[0,1,0]]).astype(np.uint8), iterations=1) - init_near_edge[init_far_edge == 1] = 0 - init_far_edge[mask == 0] = 0 - init_near_edge[mask == 0] = 0 - hole_far_edge = 1 - init_far_edge - hole_near_edge = 1 - init_near_edge - change = None - while True: - change = False - hole_far_edge[init_near_edge == 1] = 0 - hole_near_edge[init_far_edge == 1] = 0 - far_pxs, far_pys = np.where((hole_far_edge == 0) * (init_far_edge == 1) > 0) - current_hole_far_edge = hole_far_edge.copy() - for far_px, far_py in zip(far_pxs, far_pys): - min_px = max(far_px - 1, 0) - max_px = min(far_px + 2, mask.shape[0]-1) - min_py = max(far_py - 1, 0) - max_py = min(far_py + 2, mask.shape[1]-1) - hole_far = current_hole_far_edge[min_px: max_px, min_py: max_py] - tmp_mask = mask[min_px: max_px, min_py: max_py] - all_depth_patch = all_depth[min_px: max_px, min_py: max_py] * 0 - all_depth_mask = (all_depth_patch != 0).astype(np.uint8) - cross_element = np.array([[0,1,0],[1,1,1],[0,1,0]])[min_px - (far_px - 1): max_px - (far_px - 1), min_py - (far_py - 1): max_py - (far_py - 1)] - combine_mask = (tmp_mask + all_depth_mask).clip(0, 1) * hole_far * cross_element - tmp_patch = combine_mask * (mask_depth[min_px: max_px, min_py: max_py] + all_depth_patch) - number = np.count_nonzero(tmp_patch) - if number > 0: - mask_depth[far_px, far_py] = np.sum(tmp_patch).astype(np.float32) / max(number, 1e-6) - hole_far_edge[far_px, far_py] = 1 - change = True - near_pxs, near_pys = np.where((hole_near_edge == 0) * (init_near_edge == 1) > 0) - current_hole_near_edge = hole_near_edge.copy() - for near_px, near_py in zip(near_pxs, near_pys): - min_px = max(near_px - 1, 0) - max_px = min(near_px + 2, mask.shape[0]-1) - min_py = max(near_py - 1, 0) - max_py = min(near_py + 2, mask.shape[1]-1) - hole_near = current_hole_near_edge[min_px: max_px, min_py: max_py] - tmp_mask = mask[min_px: max_px, min_py: max_py] - all_depth_patch = all_depth[min_px: max_px, min_py: max_py] * 0 - all_depth_mask = (all_depth_patch != 0).astype(np.uint8) - cross_element = np.array([[0,1,0],[1,1,1],[0,1,0]])[min_px - near_px + 1:max_px - near_px + 1, min_py - near_py + 1:max_py - near_py + 1] - combine_mask = (tmp_mask + all_depth_mask).clip(0, 1) * hole_near * cross_element - tmp_patch = combine_mask * (mask_depth[min_px: max_px, min_py: max_py] + all_depth_patch) - number = np.count_nonzero(tmp_patch) - if number > 0: - mask_depth[near_px, near_py] = np.sum(tmp_patch) / max(number, 1e-6) - hole_near_edge[near_px, near_py] = 1 - change = True - if change is False: - break - - return mask_depth - - - -def vis_depth_edge_connectivity(depth, config): - disp = 1./depth - u_diff = (disp[1:, :] - disp[:-1, :])[:-1, 1:-1] - b_diff = (disp[:-1, :] - disp[1:, :])[1:, 1:-1] - l_diff = (disp[:, 1:] - disp[:, :-1])[1:-1, :-1] - r_diff = (disp[:, :-1] - disp[:, 1:])[1:-1, 1:] - u_over = (np.abs(u_diff) > config['depth_threshold']).astype(np.float32) - b_over = (np.abs(b_diff) > config['depth_threshold']).astype(np.float32) - l_over = (np.abs(l_diff) > config['depth_threshold']).astype(np.float32) - r_over = (np.abs(r_diff) > config['depth_threshold']).astype(np.float32) - concat_diff = np.stack([u_diff, b_diff, r_diff, l_diff], axis=-1) - concat_over = np.stack([u_over, b_over, r_over, l_over], axis=-1) - over_diff = concat_diff * concat_over - pos_over = (over_diff > 0).astype(np.float32).sum(-1).clip(0, 1) - neg_over = (over_diff < 0).astype(np.float32).sum(-1).clip(0, 1) - neg_over[(over_diff > 0).astype(np.float32).sum(-1) > 0] = 0 - _, edge_label = cv2.connectedComponents(pos_over.astype(np.uint8), connectivity=8) - T_junction_maps = np.zeros_like(pos_over) - for edge_id in range(1, edge_label.max() + 1): - edge_map = (edge_label == edge_id).astype(np.uint8) - edge_map = np.pad(edge_map, pad_width=((1,1),(1,1)), mode='constant') - four_direc = np.roll(edge_map, 1, 1) + np.roll(edge_map, -1, 1) + np.roll(edge_map, 1, 0) + np.roll(edge_map, -1, 0) - eight_direc = np.roll(np.roll(edge_map, 1, 1), 1, 0) + np.roll(np.roll(edge_map, 1, 1), -1, 0) + \ - np.roll(np.roll(edge_map, -1, 1), 1, 0) + np.roll(np.roll(edge_map, -1, 1), -1, 0) - eight_direc = (eight_direc + four_direc)[1:-1,1:-1] - pos_over[eight_direc > 2] = 0 - T_junction_maps[eight_direc > 2] = 1 - _, edge_label = cv2.connectedComponents(pos_over.astype(np.uint8), connectivity=8) - edge_label = np.pad(edge_label, 1, mode='constant') - - return edge_label - - - -def max_size(mat, value=0): - if not (mat and mat[0]): return (0, 0) - it = iter(mat) - prev = [(el==value) for el in next(it)] - max_size = max_rectangle_size(prev) - for row in it: - hist = [(1+h) if el == value else 0 for h, el in zip(prev, row)] - max_size = max(max_size, max_rectangle_size(hist), key=get_area) - prev = hist - return max_size - -def max_rectangle_size(histogram): - Info = namedtuple('Info', 'start height') - stack = [] - top = lambda: stack[-1] - max_size = (0, 0) # height, width of the largest rectangle - pos = 0 # current position in the histogram - for pos, height in enumerate(histogram): - start = pos # position where rectangle starts - while True: - if not stack or height > top().height: - stack.append(Info(start, height)) # push - if stack and height < top().height: - max_size = max(max_size, (top().height, (pos-top().start)), - key=get_area) - start, _ = stack.pop() - continue - break # height == top().height goes here - - pos += 1 - for start, height in stack: - max_size = max(max_size, (height, (pos-start)), - key=get_area) - - return max_size - -def get_area(size): - return reduce(mul, size) - -def find_anchors(matrix): - matrix = [[*x] for x in matrix] - mh, mw = max_size(matrix) - matrix = np.array(matrix) - # element = np.zeros((mh, mw)) - for i in range(matrix.shape[0] + 1 - mh): - for j in range(matrix.shape[1] + 1 - mw): - if matrix[i:i + mh, j:j + mw].max() == 0: - return i, i + mh, j, j + mw - -def find_largest_rect(dst_img, bg_color=(128, 128, 128)): - valid = np.any(dst_img[..., :3] != bg_color, axis=-1) - dst_h, dst_w = dst_img.shape[:2] - ret, labels = cv2.connectedComponents(np.uint8(valid == False)) - red_mat = np.zeros_like(labels) - # denoise - for i in range(1, np.max(labels)+1, 1): - x, y, w, h = cv2.boundingRect(np.uint8(labels==i)) - if x == 0 or (x+w) == dst_h or y == 0 or (y+h) == dst_w: - red_mat[labels==i] = 1 - # crop - t, b, l, r = find_anchors(red_mat) - - return t, b, l, r diff --git a/spaces/doevent/VintageStyle/README.md b/spaces/doevent/VintageStyle/README.md deleted file mode 100644 index 2cb5bab0ee3f0c2e65abdba9c3e4a35d26348381..0000000000000000000000000000000000000000 --- a/spaces/doevent/VintageStyle/README.md +++ /dev/null @@ -1,18 +0,0 @@ ---- -title: Vintage Style -emoji: 💁🏼♀️ -colorFrom: pink -colorTo: yellow -sdk: gradio -sdk_version: 3.1.4 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference - -# Configuration - -`title`: _string_ -Display title for the Space - diff --git a/spaces/dotku/fastapi-demo/main.py b/spaces/dotku/fastapi-demo/main.py deleted file mode 100644 index 722892d56d3c7d4042c35442792195ef890defd8..0000000000000000000000000000000000000000 --- a/spaces/dotku/fastapi-demo/main.py +++ /dev/null @@ -1,17 +0,0 @@ -from fastapi import FastAPI -from fastapi.middleware.cors import CORSMiddleware - -app = FastAPI() - -app.add_middleware( - CORSMiddleware, - allow_origins=['*'] -) - -@app.get("/") -def read_root(): - return {"message": "Hello World"} - -@app.get("/api/python") -def hello_python(): - return {"message": "Hello Python"} \ No newline at end of file diff --git a/spaces/dragonSwing/annotate-anything/GroundingDINO/groundingdino/util/get_tokenlizer.py b/spaces/dragonSwing/annotate-anything/GroundingDINO/groundingdino/util/get_tokenlizer.py deleted file mode 100644 index f7dcf7e95f03f95b20546b26442a94225924618b..0000000000000000000000000000000000000000 --- a/spaces/dragonSwing/annotate-anything/GroundingDINO/groundingdino/util/get_tokenlizer.py +++ /dev/null @@ -1,26 +0,0 @@ -from transformers import AutoTokenizer, BertModel, BertTokenizer, RobertaModel, RobertaTokenizerFast - - -def get_tokenlizer(text_encoder_type): - if not isinstance(text_encoder_type, str): - # print("text_encoder_type is not a str") - if hasattr(text_encoder_type, "text_encoder_type"): - text_encoder_type = text_encoder_type.text_encoder_type - elif text_encoder_type.get("text_encoder_type", False): - text_encoder_type = text_encoder_type.get("text_encoder_type") - else: - raise ValueError( - "Unknown type of text_encoder_type: {}".format(type(text_encoder_type)) - ) - print("final text_encoder_type: {}".format(text_encoder_type)) - - tokenizer = AutoTokenizer.from_pretrained(text_encoder_type) - return tokenizer - - -def get_pretrained_language_model(text_encoder_type): - if text_encoder_type == "bert-base-uncased": - return BertModel.from_pretrained(text_encoder_type) - if text_encoder_type == "roberta-base": - return RobertaModel.from_pretrained(text_encoder_type) - raise ValueError("Unknown text_encoder_type {}".format(text_encoder_type)) diff --git a/spaces/eIysia/VITS-Umamusume-voice-synthesizer/ONNXVITS_inference.py b/spaces/eIysia/VITS-Umamusume-voice-synthesizer/ONNXVITS_inference.py deleted file mode 100644 index 258b618cd338322365dfa25bec468a0a3f70ccd1..0000000000000000000000000000000000000000 --- a/spaces/eIysia/VITS-Umamusume-voice-synthesizer/ONNXVITS_inference.py +++ /dev/null @@ -1,36 +0,0 @@ -import logging -logging.getLogger('numba').setLevel(logging.WARNING) -import IPython.display as ipd -import torch -import commons -import utils -import ONNXVITS_infer -from text import text_to_sequence - -def get_text(text, hps): - text_norm = text_to_sequence(text, hps.symbols, hps.data.text_cleaners) - if hps.data.add_blank: - text_norm = commons.intersperse(text_norm, 0) - text_norm = torch.LongTensor(text_norm) - return text_norm - -hps = utils.get_hparams_from_file("../vits/pretrained_models/uma87.json") - -net_g = ONNXVITS_infer.SynthesizerTrn( - len(hps.symbols), - hps.data.filter_length // 2 + 1, - hps.train.segment_size // hps.data.hop_length, - n_speakers=hps.data.n_speakers, - **hps.model) -_ = net_g.eval() - -_ = utils.load_checkpoint("../vits/pretrained_models/uma_1153000.pth", net_g) - -text1 = get_text("おはようございます。", hps) -stn_tst = text1 -with torch.no_grad(): - x_tst = stn_tst.unsqueeze(0) - x_tst_lengths = torch.LongTensor([stn_tst.size(0)]) - sid = torch.LongTensor([0]) - audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=1)[0][0,0].data.cpu().float().numpy() -print(audio) \ No newline at end of file diff --git a/spaces/ec7719/Excel/app.py b/spaces/ec7719/Excel/app.py deleted file mode 100644 index 2d94b9d6e508d3de04e1c7855cfae62482ab853c..0000000000000000000000000000000000000000 --- a/spaces/ec7719/Excel/app.py +++ /dev/null @@ -1,138 +0,0 @@ -import streamlit as st -import pandas as pd -import math -import matplotlib.pyplot as plt - -# Function to read different file types -def read_file(file): - file_extension = file.name.split(".")[-1] - if file_extension == "csv": - data = pd.read_csv(file) - elif file_extension == "xlsx": - data = pd.read_excel(file, engine="openpyxl") - else: - st.error("Unsupported file format. Please upload a CSV or Excel file.") - return None - return data - -# Function to display the uploaded data -def display_data(data): - st.write("### Data Preview") - st.dataframe(data.head()) - -# Function to perform mathematical calculations and store results as separate columns -def perform_calculations(data): - st.write("### Calculations") - - # Get column names - columns = data.columns - - # Iterate over each column and perform calculations - for column in columns: - st.write("Calculations for column:", column) - - # Example calculations: sum, mean, median - column_sum = data[column].sum() - column_mean = data[column].mean() - column_median = data[column].median() - - # Create new column names - sum_column_name = f"{column}_sum" - mean_column_name = f"{column}_mean" - median_column_name = f"{column}_median" - - # Add the calculated values as new columns - data[sum_column_name] = column_sum - data[mean_column_name] = column_mean - data[median_column_name] = column_median - - # Display the calculated values - st.write("Sum:", column_sum) - st.write("Mean:", column_mean) - st.write("Median:", column_median) - - # Display the updated data with calculated columns - st.write("### Updated Data") - st.dataframe(data) - -# Function to perform mathematical calculations -def perform_math(df, selected_columns, operation): - result = None - - if operation == "sqrt": - result = df[selected_columns].applymap(math.sqrt) - elif operation == "log": - result = df[selected_columns].applymap(math.log) - elif operation == "exp": - result = df[selected_columns].applymap(math.exp) - elif operation == "sin": - result = df[selected_columns].applymap(math.sin) - elif operation == "cos": - result = df[selected_columns].applymap(math.cos) - elif operation == "tan": - result = df[selected_columns].applymap(math.tan) - elif operation == "multiply": - result = df[selected_columns].prod(axis=1) - elif operation == "add": - result = df[selected_columns].sum(axis=1) - elif operation == "subtract": - result = df[selected_columns[0]] - df[selected_columns[1]] - - if result is not None: - df[f"{operation}_result"] = result - - return df - -def plot_graph(data, graph_type, x_variables, y_variables): - plt.figure(figsize=(8, 6)) - - for x_var in x_variables: - for y_var in y_variables: - if graph_type == "Scatter": - plt.scatter(data[x_var], data[y_var], label=f"{x_var} vs {y_var}") - elif graph_type == "Line": - plt.plot(data[x_var], data[y_var], label=f"{x_var} vs {y_var}") - st.pyplot() - elif graph_type == "Bar": - x = range(len(data)) - plt.bar(x, data[y_var], label=y_var) - - plt.xlabel("X Values") - plt.ylabel("Y Values") - plt.title(f"{graph_type} Plot") - plt.legend() - - st.pyplot() - -def main(): - st.title("Excel-like Data Visualization and Calculations") - st.write("Upload a CSV or Excel file and visualize the data") - - file = st.file_uploader("Upload file", type=["csv", "xlsx"]) - - if file is not None: - data = read_file(file) - if data is not None: - display_data(data) - perform_calculations(data) - - st.write("### Graph Visualizer") - st.write("Select variables for visualization:") - - graph_type = st.selectbox("Graph Type", options=["Scatter", "Line", "Bar"]) - x_variables = st.multiselect("X Variables", options=data.columns) - y_variables = st.multiselect("Y Variables", options=data.columns) - - selected_columns = st.multiselect("Select columns:", options=data.columns) - operation = st.selectbox("Select an operation:", ["sqrt", "log", "exp", "sin", "cos", "tan", "multiply", "add", "subtract"]) - - if st.button("Calculate"): - data = perform_math(data, selected_columns, operation) - st.write(data) - if st.button("Plot"): - plot_graph(data, graph_type, x_variables, y_variables) - - -if __name__ == "__main__": - st.set_page_config(page_title="My Analytics App") - main() diff --git a/spaces/elun15/image-regression/dataset.py b/spaces/elun15/image-regression/dataset.py deleted file mode 100644 index 36168e1c3ef907db14fa86945fd0aae4c039c46b..0000000000000000000000000000000000000000 --- a/spaces/elun15/image-regression/dataset.py +++ /dev/null @@ -1,75 +0,0 @@ -import os - -import pandas as pd -import torch -import torchvision -from hydra.utils import get_original_cwd -from PIL import Image - - -# Define ImageRegressionDataset class as a PyTorch Dataset -class ImageRegressionDataset(torch.utils.data.Dataset): - def __init__(self, cfg, set): - self.data_path = os.path.join(get_original_cwd(), cfg.data_path) - self.set = set - - # Load annotation.txt file from self.data path as a dataframe ignoring first row and \t as delimiter - self.data = pd.read_csv(os.path.join(self.data_path, "annotation.txt"), sep="\t", header=None, skiprows=1) - - # Divide the dataset into train and test set randomly with random seed 1 - self.train_df = self.data.sample(frac=cfg.train_percentages, random_state=1) - self.test_df = self.data.drop(self.train_df.index) - - # Define train transformations from PyTorch - self.train_transforms = torchvision.transforms.Compose( - [ - torchvision.transforms.Resize(224), - torchvision.transforms.RandomHorizontalFlip(), - torchvision.transforms.RandomVerticalFlip(), - torchvision.transforms.ToTensor(), - torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), - ] - ) - - # Define validation transformations from PyTorch - self.val_transforms = torchvision.transforms.Compose( - [ - torchvision.transforms.Resize(224), - torchvision.transforms.ToTensor(), - torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), - ] - ) - - def __len__(self): - # If set is train, return length of train_df, else return length of test_df - if self.set == "train": - return len(self.train_df) - else: - return len(self.test_df) - - def __getitem__(self, idx): - - # If set is train, use train_df, else use test_df - if self.set == "train": - df = self.train_df - else: - df = self.test_df - - # Get image path from df - image_path = os.path.join(self.data_path, "images", df.iloc[idx, 0]) - - # Read image from image_path - image = Image.open(image_path) - - # Get label from df - label = df.iloc[idx, 1] - # As labels are in range 0-100, we divide them by 100 to get them in range 0-1 - label /= 100 - - # If set is train, apply train_transforms, else apply val_transforms - if self.set == "train": - image = self.train_transforms(image) - else: - image = self.val_transforms(image) - - return image, label diff --git a/spaces/emc348/faces-through-time/torch_utils/ops/fma.py b/spaces/emc348/faces-through-time/torch_utils/ops/fma.py deleted file mode 100644 index 2eeac58a626c49231e04122b93e321ada954c5d3..0000000000000000000000000000000000000000 --- a/spaces/emc348/faces-through-time/torch_utils/ops/fma.py +++ /dev/null @@ -1,60 +0,0 @@ -# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved. -# -# NVIDIA CORPORATION and its licensors retain all intellectual property -# and proprietary rights in and to this software, related documentation -# and any modifications thereto. Any use, reproduction, disclosure or -# distribution of this software and related documentation without an express -# license agreement from NVIDIA CORPORATION is strictly prohibited. - -"""Fused multiply-add, with slightly faster gradients than `torch.addcmul()`.""" - -import torch - -#---------------------------------------------------------------------------- - -def fma(a, b, c): # => a * b + c - return _FusedMultiplyAdd.apply(a, b, c) - -#---------------------------------------------------------------------------- - -class _FusedMultiplyAdd(torch.autograd.Function): # a * b + c - @staticmethod - def forward(ctx, a, b, c): # pylint: disable=arguments-differ - out = torch.addcmul(c, a, b) - ctx.save_for_backward(a, b) - ctx.c_shape = c.shape - return out - - @staticmethod - def backward(ctx, dout): # pylint: disable=arguments-differ - a, b = ctx.saved_tensors - c_shape = ctx.c_shape - da = None - db = None - dc = None - - if ctx.needs_input_grad[0]: - da = _unbroadcast(dout * b, a.shape) - - if ctx.needs_input_grad[1]: - db = _unbroadcast(dout * a, b.shape) - - if ctx.needs_input_grad[2]: - dc = _unbroadcast(dout, c_shape) - - return da, db, dc - -#---------------------------------------------------------------------------- - -def _unbroadcast(x, shape): - extra_dims = x.ndim - len(shape) - assert extra_dims >= 0 - dim = [i for i in range(x.ndim) if x.shape[i] > 1 and (i < extra_dims or shape[i - extra_dims] == 1)] - if len(dim): - x = x.sum(dim=dim, keepdim=True) - if extra_dims: - x = x.reshape(-1, *x.shape[extra_dims+1:]) - assert x.shape == shape - return x - -#---------------------------------------------------------------------------- diff --git a/spaces/eubinecto/idiomify/idiomify/pipeline.py b/spaces/eubinecto/idiomify/idiomify/pipeline.py deleted file mode 100644 index 36044df44e6bfc465b4b35139b07dcadfc824d5a..0000000000000000000000000000000000000000 --- a/spaces/eubinecto/idiomify/idiomify/pipeline.py +++ /dev/null @@ -1,30 +0,0 @@ -import re -import pandas as pd -from typing import List -from transformers import BartTokenizer -from idiomify.builders import SourcesBuilder -from idiomify.models import Idiomifier - - -class Pipeline: - - def __init__(self, model: Idiomifier, tokenizer: BartTokenizer, idioms: pd.DataFrame): - self.model = model - self.builder = SourcesBuilder(tokenizer) - self.idioms = idioms - - def __call__(self, sents: List[str], max_length=100) -> List[str]: - srcs = self.builder(literal2idiomatic=[(sent, "") for sent in sents]) - pred_ids = self.model.bart.generate( - inputs=srcs[:, 0], # (N, 2, L) -> (N, L) - attention_mask=srcs[:, 1], # (N, 2, L) -> (N, L) - decoder_start_token_id=self.model.hparams['bos_token_id'], - max_length=max_length, - ) # -> (N, L_t) - # we don't skip special tokens because we have to keepSi vous êtes un mécanicien professionnel ou amateur, vous avez sans doute besoin d'un logiciel qui vous aide à réparer et à entretenir les voitures. Un logiciel qui vous fournit des informations techniques précises et à jour sur les différents modèles de véhicules. Un logiciel qui vous permet d'analyser les paramètres de la voiture, de régler les problèmes de climatisation, de courroies, d'injection, de moteurs, etc. Un logiciel qui vous fait gagner du temps et de l'argent. Ce logiciel existe et il s'appelle Autodata 3 44 En Francais.
-Dans cet article, nous allons vous présenter Autodata 3 44 En Francais, ses caractéristiques, ses avantages et sa compatibilité avec les systèmes d'exploitation Windows.
-Download File ►►► https://urlca.com/2uDbVk
Autodata 3 44 En Francais est un logiciel Windows complet qui a été développé pour analyser les paramètres de la voiture. Il s'agit d'une base de données techniques pour la réparation automobile qui couvre pratiquement toutes les marques et tous les modèles de voitures. Il propose la seule source d'informations d'origine constructeurs, avec une qualité et une quantité de données en évolution permanente.
-Autodata 3 44 En Francais est rédigé dans un style concis, clair et cohérent, qui est facile à comprendre et à utiliser par les mécaniciens. Il dispose d'une interface intuitive qui permet de naviguer facilement entre les différentes rubriques et sous-rubriques du logiciel. Il offre également la possibilité d'imprimer ou d'exporter les informations en format PDF.
-Autodata 3 44 En Francais offre de nombreuses caractéristiques qui font de lui un logiciel indispensable pour la réparation automobile. Parmi ces caractéristiques, on peut citer:
-Autodata 3 44 En Francais présente de nombreux avantages pour le mécanicien qui l'utilise. Parmi ces avantages, on peut citer:
-Autodata 3 44 En Francais est compatible avec les systèmes d'exploitation Windows XP (32-64 bits), Vista (32 bits SP1), Windows 7 (32-64 bits) et Windows 8 (32-64 bits). Il nécessite un espace disque dur de 2,2 Go et une mémoire RAM de 1 Go. Il fonctionne avec un processeur Intel Dual Core ou supérieur.
-Autodata 3 44 En Francais est le logiciel technique pour l'automobile par excellence. Il fournit des informations techniques précises et à jour sur les différents modèles de voitures. Il explique pas à pas comment effectuer les opérations de réparation sur les voitures. Il propose des outils de diagnostic qui permettent de tester le fonctionnement des différents systèmes de la voiture. Il donne des conseils pratiques pour optimiser le travail du mécanicien. Il garantit l'exactitude, la fiabilité et l'efficacité des informations qu'il fournit. Il est compatible avec les systèmes d'exploitation Windows XP (32-64 bits), Vista (32 bits SP1), Windows 7 (32-64 bits) et Windows 8 (32-64 bits). Si vous êtes un mécanicien professionnel ou amateur, vous ne pouvez pas vous passer de Autodata 3 44 En Francais.
-Si vous êtes un mécanicien professionnel ou amateur, vous avez sans doute besoin d'un logiciel qui vous aide à réparer et à entretenir les voitures. Un logiciel qui vous fournit des informations techniques précises et à jour sur les différents modèles de véhicules. Un logiciel qui vous permet d'analyser les paramètres de la voiture, de régler les problèmes de climatisation, de courroies, d'injection, de moteurs, etc. Un logiciel qui vous fait gagner du temps et de l'argent. Ce logiciel existe et il s'appelle Autodata 3 44 En Francais.
- -Dans cet article, nous allons vous présenter Autodata 3 44 En Francais, ses caractéristiques, ses avantages et sa compatibilité avec les systèmes d'exploitation Windows.
-Autodata 3 44 En Francais est un logiciel Windows complet qui a été développé pour analyser les paramètres de la voiture. Il s'agit d'une base de données techniques pour la réparation automobile qui couvre pratiquement toutes les marques et tous les modèles de voitures. Il propose la seule source d'informations d'origine constructeurs, avec une qualité et une quantité de données en évolution permanente.
-Autodata 3 44 En Francais est rédigé dans un style concis, clair et cohérent, qui est facile à comprendre et à utiliser par les mécaniciens. Il dispose d'une interface intuitive qui permet de naviguer facilement entre les différentes rubriques et sous-rubriques du logiciel. Il offre également la possibilité d'imprimer ou d'exporter les informations en format PDF.
-Autodata 3 44 En Francais offre de nombreuses caractéristiques qui font de lui un logiciel indispensable pour la réparation automobile. Parmi ces caractéristiques, on peut citer:
-Autodata 3 44 En Francais présente de nombreux avantages pour le mécanicien qui l'utilise. Parmi ces avantages, on peut citer:
-Autodata 3 44 En Francais est compatible avec les systèmes d'exploitation Windows XP (32-64 bits), Vista (32 bits SP1), Windows 7 (32-64 bits) et Windows 8 (32-64 bits). Il nécessite un espace disque dur de 2,2 Go et une mémoire RAM de 1 Go. Il fonctionne avec un processeur Intel Dual Core ou supérieur.
-Autodata 3 44 En Francais est le logiciel technique pour l'automobile par excellence. Il fournit des informations techniques précises et à jour sur les différents modèles de voitures. Il explique pas à pas comment effectuer les opérations de réparation sur les voitures. Il propose des outils de diagnostic qui permettent de tester le fonctionnement des différents systèmes de la voiture. Il donne des conseils pratiques pour optimiser le travail du mécanicien. Il garantit l'exactitude, la fiabilité et l'efficacité des informations qu'il fournit. Il est compatible avec les systèmes d'exploitation Windows XP (32-64 bits), Vista (32 bits SP1), Windows 7 (32-64 bits) et Windows 8 (32-64 bits). Si vous êtes un mécanicien professionnel ou amateur, vous ne pouvez pas vous passer de Autodata 3 44 En Francais.
-Autodata 3 44 En Francais est le logiciel technique pour l'automobile par excellence. Il fournit des informations techniques précises et à jour sur les différents modèles de voitures. Il explique pas à pas comment effectuer les opérations de réparation sur les voitures. Il propose des outils de diagnostic qui permettent de tester le fonctionnement des différents systèmes de la voiture. Il donne des conseils pratiques pour optimiser le travail du mécanicien. Il garantit l'exactitude, la fiabilité et l'efficacité des informations qu'il fournit. Il est compatible avec les systèmes d'exploitation Windows XP (32-64 bits), Vista (32 bits SP1), Windows 7 (32-64 bits) et Windows 8 (32-64 bits). Si vous êtes un mécanicien professionnel ou amateur, vous ne pouvez pas vous passer de Autodata 3 44 En Francais.
3cee63e6c2If you are looking for a fun and addictive racing game that will challenge your skills and keep you entertained for hours, then you should try Hill Climb Racing. This game is one of the most popular and downloaded racing games on Android, with over 500 million downloads on Google Play. But what if you want to enjoy the game without any limitations or interruptions? Well, that's where Hill Climb Racing Mod APK comes in. In this article, we will tell you what Hill Climb Racing is, what features it has, why you should download Hill Climb Racing Mod APK, and how to do it. So, buckle up and get ready for some hill climbing action!
-Hill Climb Racing is a 2D physics-based racing game developed by Fingersoft, a Finnish game studio. The game was released in 2012 and has since become one of the most successful indie games of all time. The game features a simple but addictive gameplay, where you have to drive various vehicles across different terrains, such as hills, mountains, deserts, forests, and even the moon. The goal is to go as far as possible without running out of gas or crashing your vehicle. Along the way, you can collect coins and fuel cans, which you can use to upgrade your vehicles and unlock new ones. You can also perform stunts and tricks to earn bonus points and coins.
-Download ->>->>->> https://urllie.com/2uNvFd
Hill Climb Racing has many features that make it an enjoyable and diverse game. Here are some of them:
-The game offers a wide range of vehicles that you can choose from, each with its own characteristics and abilities. You can drive cars, bikes, trucks, buses, tanks, tractors, snowmobiles, and even a sleigh pulled by reindeer. Some vehicles are faster, some are more stable, some are more fuel-efficient, and some are more suitable for certain terrains. You can also customize your vehicles with different paints, wheels, engines, suspensions, roll cages, and more.
-The game also has a variety of tracks that you can explore, each with its own challenges and scenery. You can race on hills, mountains, deserts, forests, caves, beaches, cities, junkyards, volcanoes, and even the moon. Each track has its own obstacles, such as rocks, bridges, ramps, loops, tunnels, waterfalls, lava pools, and more. You have to be careful not to flip over or crash into them.
-As you play the game, you can earn coins that you can use to upgrade your vehicles and make them faster, stronger, and more efficient. You can upgrade four aspects of your vehicle: engine, suspension, tires, and 4WD. Each upgrade has 10 levels that you can unlock with coins. Upgrading your vehicle will help you go further and overcome more difficult terrains.
-The game also has a challenge mode where you can compete with other players online or offline. You can choose from different challenges such as distance challenge, time challenge, flip challenge , and air time challenge. You can also create your own challenges and share them with your friends. Challenges are a great way to test your skills and compete with others for the best scores and rankings.
-[Hill Climb Racing MOD APK 1.58.0 (Unlimited Money) - APKdone](^1^)
-While Hill Climb Racing is a fun and free game, it also has some limitations and drawbacks that can affect your gaming experience. For example, you have to watch ads to get extra coins or fuel, you have to grind for a long time to unlock and upgrade all the vehicles and tracks, and you have to deal with the game's difficulty curve that can be frustrating at times. That's why many players prefer to download Hill Climb Racing Mod APK, which is a modified version of the game that gives you unlimited money and other benefits. Here are some of the reasons why you should download Hill Climb Racing Mod APK:
-Hill Climb Racing Mod APK has many advantages over the original game. Here are some of them:
-The most obvious benefit of Hill Climb Racing Mod APK is that it gives you unlimited money that you can use to buy and upgrade anything you want in the game. You don't have to worry about running out of coins or fuel, or watching ads to get more. You can enjoy the game without any restrictions or interruptions.
-Another benefit of Hill Climb Racing Mod APK is that it unlocks all the vehicles and tracks in the game from the start. You don't have to play for hours or days to unlock them one by one. You can choose any vehicle or track you like and explore them at your own pace. You can also try different combinations of vehicles and tracks to see which ones suit your style and preference.
-A third benefit of Hill Climb Racing Mod APK is that it removes all the ads from the game. You don't have to watch annoying and repetitive ads that pop up every few minutes or interrupt your gameplay. You can play the game smoothly and without any distractions.
-If you are convinced by the benefits of Hill Climb Racing Mod APK and want to download it, then you need to follow these simple steps:
-The first step is to download the APK file of Hill Climb Racing Mod APK from a reliable and safe source. You can find many websites that offer this file, but you need to be careful not to download a fake or malicious file that can harm your device or steal your data. We recommend you to use this link to download the latest version of Hill Climb Racing Mod APK, which is 100% safe and tested.
-The second step is to enable unknown sources on your device, which will allow you to install apps from sources other than Google Play. To do this, go to your device's settings, then security, then unknown sources, and turn it on. This will enable you to install the APK file that you downloaded in step 1.
-The final step is to install the APK file that you downloaded in step 1 by tapping on it and following the instructions on the screen. Once the installation is complete, you can launch the game and enjoy Hill Climb Racing Mod APK with unlimited money and fun.
-Hill Climb Racing is one of the best racing games on Android, with millions of fans around the world. It has a simple but addictive gameplay, a wide range of vehicles and tracks, and a challenge mode that will test your skills. However, if you want to enjoy the game without any limitations or interruptions, then you should download Hill Climb Racing Mod APK, which gives you unlimited money, all vehicles and tracks unlocked, and no ads. This way, you can have more fun and excitement while playing Hill Climb Racing.
-If you liked this article, please share it with your friends who love racing games. Also, if you have any questions or feedback about Hill Climb Racing Mod APK, please leave them in the comments section below. We would love to hear from you!
-Here are some of the most common questions that people ask about Hill Climb Racing Mod APK:
-Yes, Hill Climb Racing Mod APK is safe to download and install, as long as you use a trusted source like the one we provided in this article. However, you should always be careful when downloading and installing any app from unknown sources, as they may contain viruses or malware that can harm your device or steal your data. You should also check the permissions that the app requests and only grant them if you trust the app.
-Hill Climb Racing Mod APK is not legal, as it violates the terms and conditions of the original game. By using Hill Climb Racing Mod APK, you are essentially hacking the game and getting an unfair advantage over other players. This can also result in your account being banned or suspended by the game developers. Therefore, we do not encourage or endorse the use of Hill Climb Racing Mod APK, and we are not responsible for any consequences that may arise from using it.
-Hill Climb Racing Mod APK should work on most Android devices that support the original game. However, some devices may not be compatible with Hill Climb Racing Mod APK, or may experience some issues or glitches while playing it. If you encounter any problems while using Hill Climb Racing Mod APK, you can try to uninstall and reinstall it, or contact the mod developer for support.
-Hill Climb Racing Mod APK can be played online, but only with other players who are also using the modded version of the game. You cannot play Hill Climb Racing Mod APK with players who are using the official version of the game, as they have different features and settings. You can also play Hill Climb Racing Mod APK offline, without an internet connection.
-Hill Climb Racing Mod APK can be updated, but only by downloading and installing the latest version of the modded file from the same source that you used before. You cannot update Hill Climb Racing Mod APK from Google Play or from the original game's settings, as they will overwrite the modded file and remove all the benefits that you had. You should also backup your game data before updating Hill Climb Racing Mod APK, in case something goes wrong during the process.
-Roblox es una plataforma de juegos en línea que te permite crear, compartir y jugar experiencias con millones de personas en todo el mundo. Es una forma divertida y creativa de expresar tu imaginación y aprender habilidades de programación, diseño y colaboración. En este artículo, te mostraremos cómo descargar Roblox APK para tu dispositivo Android, cómo instalarlo y lanzarlo, cómo crear una cuenta y acceder a los juegos, cómo crear y compartir tus propios juegos usando Roblox Studio, y cómo solucionar algunos problemas comunes con Roblox APK.
-Roblox es una plataforma de juegos en línea que te permite crear, compartir y jugar experiencias con millones de personas en todo el mundo. Puedes explorar una variedad infinita de mundos virtuales creados por la comunidad, desde aventuras épicas hasta competiciones deportivas, pasando por simulaciones realistas y juegos educativos. También puedes crear tus propios juegos usando Roblox Studio, una herramienta gratuita y fácil de usar que te permite diseñar y programar tus propias experiencias con bloques, scripts y recursos. Puedes publicar tus juegos en la plataforma para que otros los jueguen, o jugar a los juegos de otros usuarios y darles tu opinión.
-Download Zip ✔ https://urllie.com/2uNB7O
Roblox es popular porque ofrece una experiencia única y personalizada para cada usuario. Puedes ser lo que quieras ser, desde un astronauta hasta un superhéroe, pasando por un chef o un artista. Puedes personalizar tu avatar con miles de objetos, ropas, caras, accesorios y más. Puedes chatear con tus amigos en línea, usar mensajes privados y grupos, y hacer nuevos amigos con intereses similares. Puedes aprender habilidades útiles como programación, diseño gráfico, animación, sonido y música. Y lo mejor de todo, puedes divertirte y expresarte en un entorno seguro y amigable.
-Jugar a Roblox tiene muchos beneficios para los usuarios de todas las edades. Algunos de ellos son:
-Aunque Roblox es una plataforma segura y divertida, también tiene algunos inconvenientes que debes tener en cuenta. Algunos de ellos son:
-descargar roblox apk gratis
-descargar roblox apk ultima version
-descargar roblox apk para android
-descargar roblox apk mod
-descargar roblox apk sin internet
-descargar roblox apk 2023
-descargar roblox apk hackeado
-descargar roblox apk full
-descargar roblox apk mega
-descargar roblox apk mediafire
-descargar roblox apk uptodown
-descargar roblox apk para pc
-descargar roblox apk sin licencia
-descargar roblox apk premium
-descargar roblox apk actualizado
-descargar roblox apk por aptoide
-descargar roblox apk con todo desbloqueado
-descargar roblox apk para tablet
-descargar roblox apk sin play store
-descargar roblox apk con robux infinitos
-descargar roblox apk android 5.0+
-descargar roblox apk desde el sitio oficial
-descargar roblox apk compatible con todos los dispositivos
-descargar roblox apk en español
-descargar roblox apk facil y rapido
-descargar roblox apk sin virus
-descargar roblox apk con chat de voz
-descargar roblox apk para celular
-descargar roblox apk con juegos gratis
-descargar roblox apk sin anuncios
-descargar roblox apk 2.578.564
-descargar roblox apk por mega y mediafire
-descargar roblox apk para android 4.4.2
-descargar roblox apk con modo oscuro
-descargar roblox apk con graficos mejorados
-descargar roblox apk con acceso a todos los servidores
-descargar roblox apk sin errores ni bugs
-descargar roblox apk con skins personalizados
-descargar roblox apk para jugar online y offline
-descargar roblox apk con musica de fondo
-descargar roblox apk con soporte para gamepad
-descargar roblox apk con actualizaciones automaticas
-descargar roblox apk con funciones especiales
-descargar roblox apk con emojis y stickers
-descargar roblox apk con opciones de seguridad y privacidad
-descargar roblox apk con traductor integrado
-descargar roblox apk con editor de video y foto
-descargar roblox apk con efectos de sonido y animacion
-descargar roblox apk con tutoriales y consejos
Roblox APK es el archivo de instalación de la aplicación de Roblox para dispositivos Android. Puedes descargarlo desde la página oficial de Roblox o desde otras fuentes confiables como APKPure o Uptodown. A continuación te explicamos cómo descargar Roblox APK para tu dispositivo Android paso a paso.
-Lo primero que debes hacer es acceder a la página oficial de Roblox desde tu navegador web. Puedes hacerlo desde este enlace: https://www.roblox.com/
-En la página principal verás un botón verde que dice "Descargar ahora". Haz clic en él para ir a la página de descarga.
-En la página de descarga verás varias opciones para diferentes plataformas como Windows, Mac, iOS, Xbox One y Android. Haz clic en el icono de Android para descargar el archivo APK de Roblox.
-Al hacer clic en el icono de Android se abrirá una ventana emergente que te preguntará si quieres descargar el archivo APK de Roblox. Haz clic en "Aceptar" para confirmar la descarga.
-Una vez que hayas confirmado la descarga, el archivo APK se guardará en la carpeta de descargas de tu dispositivo. Puedes usar un explorador de archivos para buscarlo y abrirlo. El nombre del archivo será algo como "Roblox-2.578.564.apk".
-Antes de instalar el archivo APK, debes permitir que tu dispositivo instale aplicaciones de fuentes desconocidas. Esto significa que puedes instalar aplicaciones que no provienen de la tienda oficial de Google Play. Para hacerlo, sigue estos pasos:
-Estos pasos pueden variar según el modelo y la versión de tu dispositivo. Si no encuentras la opción, puedes buscarla en el buscador de ajustes o consultar el manual de tu dispositivo.
-Una vez que hayas permitido la instalación de fuentes desconocidas, puedes instalar y lanzar Roblox APK. Para hacerlo, sigue estos pasos:
-¡Ya está! Ya puedes disfrutar de Roblox en tu dispositivo Android.
-Para poder jugar a los juegos de Roblox, necesitas crear una cuenta y acceder a ella. Esto te permitirá guardar tu progreso, personalizar tu avatar, chatear con otros usuarios, comprar y vender objetos, y mucho más. Para crear una cuenta y acceder a los juegos de Roblox, sigue estos pasos:
-Abre la aplicación de Roblox que acabas de instalar en tu dispositivo Android. Verás una pantalla de inicio con dos opciones: "Iniciar sesión" y "Registrarse". Si ya tienes una cuenta de Roblox, puedes iniciar sesión con tu nombre de usuario y contraseña. Si no tienes una cuenta, puedes registrarte con tu correo electrónico, fecha de nacimiento y nombre de usuario.
-Si eliges la opción de registrarte, tendrás que rellenar un formulario con tus datos personales. Debes introducir tu correo electrónico, tu fecha de nacimiento y tu nombre de usuario. También debes elegir una contraseña segura y aceptar los términos y condiciones de Roblox. Luego, haz clic en el botón "Registrarse".
-Después de registrarte, recibirás un correo electrónico de Roblox para verificar tu cuenta. Abre el correo electrónico y haz clic en el enlace que te envían. Esto confirmará tu registro y te llevará a la página principal de Roblox.
-Una vez que hayas verificado tu cuenta, podrás explorar los juegos de Roblox desde la aplicación. Verás una lista de categorías como "Destacados", "Populares", "Recomendados", "Top ganadores" y más. Puedes deslizar la pantalla para ver más opciones o usar el buscador para encontrar un juego específico. Para jugar a un juego, solo tienes que hacer clic en él y esperar a que se cargue.
-A veces, al usar Roblox APK en tu dispositivo Android, puedes encontrarte con algunos problemas que afecten a tu experiencia de juego. Estos problemas pueden ser de conexión, de rendimiento, de compatibilidad o de actualización. A continuación te damos algunos consejos para solucionar los problemas más comunes con Roblox APK.
-Para asegurarte de que Roblox APK funcione correctamente y tenga las últimas funciones y mejoras, es importante que lo actualices a la última versión disponible. Para hacerlo, puedes seguir estos pasos:
-Si no ves el botón de actualizar, significa que ya tienes la última versión instalada. También puedes comprobar si hay actualizaciones disponibles desde la página oficial de Roblox o desde otras fuentes confiables como APKPure o Uptodown.
-Algunos dispositivos Android pueden tener problemas para ejecutar Roblox APK debido a sus especificaciones técnicas o a su sistema operativo. Esto puede causar que el juego se cierre inesperadamente, se congele, se ralentice o no cargue correctamente. Para solucionar estos problemas, puedes probar las siguientes soluciones:
-Si ninguna de las soluciones anteriores te funciona, o si tienes algún otro problema con Roblox APK, puedes contactar con el so Continuing the article:
Si ninguna de las soluciones anteriores te funciona, o si tienes algún otro problema con Roblox APK, puedes contactar con el soporte técnico de Roblox para pedir ayuda. Para hacerlo, sigue estos pasos:
-Al contactar con el soporte técnico de Roblox, debes proporcionar la mayor información posible sobre tu problema, como el modelo y la versión de tu dispositivo, la versión de Roblox APK que usas, el nombre del juego que intentas jugar, el mensaje de error que recibes y los pasos que has seguido para solucionarlo. Esto ayudará al equipo de soporte a identificar y resolver tu problema más rápidamente.
-Roblox es una plataforma de juegos en línea que te permite crear, compartir y jugar experiencias con millones de personas en todo el mundo. Es una forma divertida y creativa de expresar tu imaginación y aprender habilidades de programación, diseño y colaboración. En este artículo, te hemos mostrado cómo descargar Roblox APK para tu dispositivo Android, cómo instalarlo y lanzarlo, cómo crear una cuenta y acceder a los juegos, cómo crear y compartir tus propios juegos usando Roblox Studio, y cómo solucionar algunos problemas comunes con Roblox APK.
-Esperamos que este artículo te haya sido útil y que disfrutes de Roblox en tu dispositivo Android. Si tienes alguna pregunta o comentario sobre Roblox APK, no dudes en dejarnos un mensaje abajo. ¡Nos encantaría saber tu opinión!
-A continuación te presentamos algunas preguntas frecuentes sobre Roblox APK y sus respuestas.
-Sí, Roblox APK es seguro siempre y cuando lo descargues desde la página oficial de Roblox o desde otras fuentes confiables como APKPure o Uptodown. Estas fuentes verifican que el archivo APK no contenga virus ni malware que puedan dañar tu dispositivo o robar tu información. Además, Roblox tiene medidas de seguridad y privacidad para proteger tu cuenta y tus datos personales.
-Sí, Roblox APK es gratis y no tiene ningún costo por descargarlo o instalarlo. Sin embargo, algunos juegos o funciones dentro de la plataforma pueden requerir el uso de Robux, la moneda virtual de Roblox. Puedes comprar Robux con dinero real o ganarlos con tus juegos.
-No, Roblox APK necesita conexión a internet para funcionar correctamente. Sin internet no podrás acceder a los juegos ni a las funciones sociales de la plataforma. Además, necesitarás internet para actualizar la aplicación y recibir las últimas novedades y mejoras.
-No, Roblox APK no es compatible con todos los dispositivos Android. Algunos dispositivos pueden tener problemas para ejecutar la aplicación debido a sus especificaciones técnicas o a su sistema operativo. Para poder usar Roblox APK en tu dispositivo Android, necesitas al menos un procesador ARMv7, 1 GB de RAM y Android 4.4 o superior.
-Para crear tus propios juegos con Roblox Studio, necesitas descargar e instalar la aplicación de Roblox Studio en tu computadora. Puedes hacerlo desde este enlace: https://www.roblox.com/develop. Luego, puedes usar la herramienta para diseñar y programar tus propios juegos con bloques, scripts Continuing the article: y recursos. También puedes publicar tus juegos en la plataforma para que otros los jueguen, o jugar a los juegos de otros usuarios y modificarlos. Para aprender más sobre cómo usar Roblox Studio, puedes consultar los tutoriales, los foros y el blog de Roblox.
401be4b1e0Genshin Impact adalah salah satu game RPG (role-playing game) yang paling populer saat ini. Game ini menawarkan dunia terbuka yang luas, grafis yang indah, dan karakter-karakter yang menarik. Namun, untuk bisa memainkan game ini, Anda harus mengunduh data yang cukup besar, sekitar 30 GB untuk PC dan 8 GB untuk Android dan iOS. Lalu, berapa jam download data Genshin Impact? Apakah ada cara untuk mempercepat prosesnya?
-DOWNLOAD ✫ https://urllie.com/2uNGCX
Dalam artikel ini, kami akan menjelaskan apa itu Genshin Impact, mengapa download data Genshin Impact lama, dan bagaimana cara mempercepat download data Genshin Impact. Simak ulasan lengkapnya di bawah ini.
-Genshin Impact adalah game RPG yang dikembangkan oleh Hoyoverse, sebuah perusahaan asal China. Game ini dirilis pada September 2020 dan telah mendapatkan banyak penghargaan dan pujian dari para kritikus dan pemain. Game ini juga memiliki lebih dari 100 juta pengguna aktif di seluruh dunia.
-Genshin Impact termasuk dalam genre RPG aksi dengan elemen fantasi. Dalam game ini, Anda akan berperan sebagai seorang Traveler yang mencari saudaranya yang hilang di dunia bernama Teyvat. Anda bisa menjelajahi berbagai wilayah dengan tema berbeda, bertemu dengan karakter-karakter lain yang bisa bergabung dengan tim Anda, dan bertarung dengan musuh-musuh yang menggunakan kekuatan elemen.
-Game ini juga memiliki sistem gacha, yaitu sebuah mekanisme di mana Anda bisa mendapatkan karakter atau senjata baru dengan cara mengeluarkan mata uang dalam game atau uang sungguhan. Selain itu, game ini juga memiliki fitur multiplayer, di mana Anda bisa bermain bersama dengan teman-teman Anda secara online.
-Genshin Impact bisa dimainkan di berbagai platform, seperti PC, Android, iOS, PlayStation 4, PlayStation 5, dan Nintendo Switch (dalam pengembangan). Untuk PC, game ini membutuhkan sistem operasi Windows 7 SP1 64-bit, Windows 8.1 64-bit, atau Windows 10 64-bit. Untuk Android, game ini membutuhkan sistem operasi Android 7.0 atau lebih tinggi. Untuk iOS, game ini membutuhkan sistem operasi iOS 9.0 atau lebih tinggi.
-Berikut adalah spesifikasi minimum dan rekomendasi untuk PC:
-| Spesifikasi | Minimum | Rekomendasi |
|---|---|---|
| Prosesor | Intel Core i5 atau setara | Intel Core i7 atau setara |
| RAM | 8 GB | 16 GB |
| Kartu grafis | NVIDIA GeForce GT 1030 atau lebih tinggi | NVIDIA GeForce GTX 1060 6 GB atau lebih tinggi |
| Versi DirectX | 11 | 1111 |
| Ruang penyimpanan | 30 GB | 30 GB |
Download data Genshin Impact bisa memakan waktu yang lama, tergantung pada beberapa faktor, seperti ukuran file, koneksi internet, dan jumlah pengguna. Berikut adalah penjelasan lebih lengkapnya.
-Genshin Impact memiliki ukuran file yang besar, sekitar 30 GB untuk PC dan 8 GB untuk Android dan iOS. Ini karena game ini memiliki grafis yang berkualitas tinggi, suara yang imersif, dan konten yang beragam. Ukuran file yang besar ini tentu saja membutuhkan waktu yang lama untuk diunduh, terutama jika Anda menggunakan koneksi internet yang lambat atau tidak stabil.
-Koneksi internet yang lambat adalah salah satu penyebab utama download data Genshin Impact lama. Koneksi internet yang lambat bisa disebabkan oleh banyak hal, seperti jarak antara perangkat Anda dengan server game, gangguan pada jaringan internet Anda, atau kuota internet Anda yang habis. Koneksi internet yang lambat akan mengurangi kecepatan download data Genshin Impact, sehingga memakan waktu yang lebih lama.
-berapa lama download data genshin impact di pc
-berapa ukuran download data genshin impact di android
-berapa waktu download data genshin impact di ios
-berapa mb download data genshin impact di ps4
-berapa gb download data genshin impact di ps5
-berapa kecepatan download data genshin impact optimal
-berapa kuota download data genshin impact habis
-berapa persen download data genshin impact selesai
-berapa jam update data genshin impact terbaru
-berapa lama install data genshin impact setelah download
-cara mempercepat download data genshin impact di pc
-cara mengatasi download data genshin impact lambat di android
-cara melanjutkan download data genshin impact di ios
-cara menghapus download data genshin impact di ps4
-cara mengecek download data genshin impact di ps5
-cara mengoptimalkan download data genshin impact dengan vpn
-cara menghemat kuota download data genshin impact dengan wifi
-cara mengetahui persen download data genshin impact dengan launcher
-cara mengupdate data genshin impact tanpa download ulang
-cara menginstall data genshin impact tanpa error setelah download
-tips dan trik download data genshin impact cepat dan mudah
-solusi dan panduan download data genshin impact lemot dan macet
-review dan testimoni download data genshin impact lancar dan sukses
-syarat dan spesifikasi download data genshin impact minimal dan rekomendasi
-link dan situs download data genshin impact resmi dan aman
-alasan dan manfaat download data genshin impact sekarang juga
-diskon dan promo download data genshin impact gratis dan murah
-bonus dan hadiah download data genshin impact banyak dan menarik
-event dan kontes download data genshin impact seru dan menguntungkan
-kode dan kupon download data genshin impact valid dan terbaru
Jumlah pengguna yang banyak juga bisa mempengaruhi kecepatan download data Genshin Impact. Jika banyak pengguna yang mengunduh data game secara bersamaan, maka server game akan mengalami beban yang tinggi, sehingga kecepatan download data Genshin Impact akan menurun. Hal ini biasanya terjadi saat ada pembaruan atau event baru di game.
-Meskipun download data Genshin Impact bisa memakan waktu yang lama, ada beberapa cara yang bisa Anda lakukan untuk mempercepat prosesnya. Berikut adalah beberapa tips yang bisa Anda coba.
-Genshin Impact memiliki beberapa server yang bisa Anda pilih, seperti Asia, Amerika, Eropa, dan TW/HK/MO. Server ini berpengaruh pada kecepatan download data Genshin Impact, karena semakin dekat jarak antara perangkat Anda dengan server game, semakin cepat kecepatan download data Genshin Impact. Oleh karena itu, sebaiknya Anda memilih server yang sesuai dengan lokasi Anda.
-Jika Anda menggunakan PC untuk bermain Genshin Impact, maka Anda bisa menggunakan kabel LAN untuk menghubungkan perangkat Anda dengan router internet. Kabel LAN biasanya lebih stabil dan cepat daripada Wi-Fi. Namun, jika Anda tidak memiliki kabel LAN atau menggunakan perangkat seluler, maka Anda bisa menggunakan Wi-Fi 5 GHz jika tersedia. Wi-Fi 5 GHz memiliki frekuensi yang lebih tinggi dan bandwidth yang lebih lebar daripada Wi-Fi 2.4 GHz, sehingga bisa meningkatkan kecepatan download data Genshin Impact.
-Aplikasi lain yang menggunakan bandwidth internet juga bisa mengganggu kecepatan download data Genshin Impact. Aplikasi seperti browser, streaming video, atau download manager bisa memakan bandwidth internet Anda, sehingga mengurangi kecepatan download data Genshin Impact. Oleh karena itu, sebaiknya Anda menutup aplikasi lain yang tidak perlu saat mengunduh data game.
-Download manager adalah sebuah aplikasi atau ekstensi browser yang bisa membantu Anda mengunduh file dengan lebih cepat dan mudah. Download manager biasanya memiliki fitur seperti pause dan resume download, multiple connections, speed limit, dan lain-lain. Beberapa contoh download manager yang bisa Anda gunakan adalah IDM (Internet Download Manager), FDM (Free Download Manager), atau XDM (Xtreme Download Manager).
-Genshin Impact adalah game RPG aksi dengan elemen fantasi yang sangat populer saat ini. Game ini memiliki ukuran file yang besar, sekitar 30 GB untuk PC dan 8 GB untuk Android dan iOS. Download data Genshin Impact bisa memakan waktu yang lama, tergantung pada koneksi internet, server game, dan jumlah pengguna. Namun, Anda bisa mempercepat download data Genshin Impact dengan beberapa cara, seperti memilih server yang dekat, menggunakan kabel LAN atau Wi-Fi 5 GHz, menutup aplikasi lain yang menggunakan bandwidth, dan menggunakan download manager.
-Semoga artikel ini bermanfaat untuk Anda yang ingin bermain Genshin Impact. Selamat bermain dan jangan lupa untuk mengikuti pembaruan dan event terbaru di game ini.
-Berikut adalah beberapa pertanyaan yang sering diajukan tentang download data Genshin Impact.
-Ya, Genshin Impact adalah game yang gratis untuk dimainkan. Anda tidak perlu membayar apapun untuk mengunduh atau memainkan game ini. Namun, Anda bisa membeli mata uang dalam game atau item-item tertentu dengan uang sungguhan jika Anda mau.
-Tidak, Genshin Impact adalah game yang membutuhkan koneksi internet untuk dimainkan. Anda tidak bisa memainkan game ini secara offline. Anda juga harus selalu mengunduh pembaruan terbaru jika ada.
-Ya, Genshin Impact adalah game yang bisa cross-play, yaitu Anda bisa bermain bersama dengan pemain lain yang menggunakan platform yang berbeda. Misalnya, Anda bisa bermain bersama dengan teman Anda yang menggunakan PC, Android, iOS, PlayStation 4, atau PlayStation 5.
-Genshin Impact adalah game yang memiliki rating T (Teen) dari ESRB (Entertainment Software Rating Board), yaitu sebuah lembaga yang memberikan penilaian usia untuk game. Rating T berarti game ini cocok untuk usia 13 tahun ke atas. Game ini mengandung unsur-unsur seperti kekerasan, darah, bahasa kasar, dan tema dewasa.
-Tidak, Genshin Impact tidak ada di Steam, yaitu sebuah platform distribusi digital untuk game PC. Anda harus mengunduh game ini dari situs resmi Hoyoverse atau dari toko aplikasi seperti Google Play Store atau App Store.
401be4b1e0If you are looking for a way to help your child improve their math and spelling skills, you might want to consider downloading Sumdog. Sumdog is a games-based adaptive-learning app that tailors curriculum-aligned questions to each child's unique level. Used at home and in schools across the UK, it can help you inspire and motivate even your most disengaged learners to help build their confidence and enjoy learning.
-In this article, we will show you how to download Sumdog on Apple and Android devices, how to use it after downloading it, and what benefits it can offer for learning math and spelling. Let's get started!
-Download File ⚡ https://urllie.com/2uNDeZ
If you have an iPad or an iPhone, you can download Sumdog from the App Store. You will need minimum iOS 11.0 or later. Here are the steps you need to follow:
-You can also click here if you are viewing this page using an iPad or an iPhone to download the Sumdog app directly.
-how to install sumdog app on android
-how to get sumdog on ipad or iphone
-how to access sumdog games online
-how to download sumdog for windows 10
-how to update sumdog app on chromebook
-how to sign up for sumdog free trial
-how to create a sumdog account for students
-how to log in to sumdog as a teacher or parent
-how to use sumdog for maths and spelling practice
-how to set up sumdog challenges and assessments
-how to track progress and results on sumdog
-how to earn coins and rewards on sumdog
-how to customize your avatar and house on sumdog
-how to play sumdog with friends and classmates
-how to join a sumdog contest or competition
-how to contact sumdog support or feedback
-how to uninstall or delete sumdog app
-how to troubleshoot common issues with sumdog
-how to find out more about sumdog features and benefits
-how to subscribe or upgrade to sumdog premium
-how to cancel or change your sumdog subscription plan
-how to get a refund or discount from sumdog
-how to redeem a sumdog voucher or coupon code
-how to review or rate sumdog app on app store or google play
-how to share your experience or testimonial with sumdog
-how to learn more about sumdog curriculum and alignment
-how to compare sumdog with other learning apps or platforms
-how to integrate sumdog with other tools or systems
-how to download sumdog data or reports
-how to manage your privacy and security settings on sumdog
-how to reset your password or username on sumdog
-how to add or remove students from your class on sumdog
-how to switch between different subjects or levels on sumdog
-how to adjust the difficulty or speed of questions on sumdog
-how to enable or disable sound effects or music on sumdog
-how to play the latest games or activities on sumdog
-how to watch tutorials or videos on how to use sumdog
-how to follow sumdog on social media or blog
-how to request a demo or webinar from sumdog
-how to become a partner or affiliate of sumdog
-how to apply for a job or career at sumdog
-how to donate or support sumdog's mission and vision
-how to find out about the research and evidence behind sumdog's effectiveness
-how to join the community or forum of sumdog users
-how to invite others or refer friends to join sumdog
-how to get help or tips from other teachers or parents using sumdog
-how to give feedback or suggestions for improving sumdog
-how to report a bug or problem with sumdog
If you have an Android tablet or smartphone, you can download Sumdog from the Play Store. You will need a minimum Android v5.0 or later. Here are the steps you need to follow:
-You can also click here if you are viewing this page using an Android tablet or smartphone to download the Sumdog app directly.
-Once you have downloaded Sumdog on your device, you can start using it right away. You will need an internet connection to access the app. Here are the steps you need to follow:
-Sumdog is not just a fun and engaging app, but also a powerful and effective learning tool. Here are some of the benefits of using Sumdog for learning math and spelling:
-In conclusion, Sumdog is a games-based adaptive-learning app that can help your child learn math and spelling skills in a fun and effective way. You can download it on your Apple or Android device easily by following the steps we have outlined in this article. You can also use it after downloading it by signing in or creating an account, choosing your subject, grade level, and skill, playing games and answering questions, and earning coins, rewards, and badges.
-If you want to give Sumdog a try, you can download it today from the App Store or the Play Store. You can also visit www.sumdog.com for more information about the app and its features.
-If you have
If you have any questions about Sumdog, you might find the answers in the following FAQs. If not, you can always contact Sumdog support for more help.
-Sumdog is free to download and use for all children. However, if you want to access more features and games, you can upgrade to a premium subscription. A premium subscription costs £6 per month or £48 per year for one child, or £12 per month or £96 per year for a family of up to six children. You can also get a free trial of the premium subscription for 14 days.
-If you are a parent, you can monitor your child's progress on Sumdog by logging into your parent dashboard. You can see how much time your child has spent on Sumdog, what skills they have practiced, how many questions they have answered, and what coins and rewards they have earned. You can also see their diagnostic test results and their accuracy and speed scores.
-If you are a parent, you can set work for your child on Sumdog by using the parent dashboard. You can choose the subject, grade level, and skill that you want your child to practice. You can also set a target number of questions or minutes that you want your child to complete each day or week. You can also assign specific games or challenges for your child to play.
-If you have any issues with Sumdog, you can contact Sumdog support by emailing support@sumdog.com or calling 0131 226 1511. You can also visit www.sumdog.com/en/Help/ for more help and resources.
-Some other features of Sumdog that you should know about are:
-
- How to Download and Install Euro Truck Simulator 2 Bus Indonesia Mod for Android-If you are a fan of simulation games, especially driving games, you might have heard of Euro Truck Simulator 2, a popular game that lets you drive trucks across Europe. But did you know that you can also drive buses across Indonesia with a mod? Yes, you read that right. There is a mod for Euro Truck Simulator 2 that adds buses and routes from Indonesia, giving you a whole new experience of driving in a different country. -In this article, we will show you how to download and install Euro Truck Simulator 2 Bus Indonesia Mod for Android devices. This mod will allow you to play the game on your smartphone or tablet, without needing a PC or a console. You will be able to enjoy the realistic graphics, physics, and sounds of driving buses in Indonesia, as well as explore various cities and landmarks along the way. -download mod euro truck simulator 2 bus indonesia for apk androidDownload File ✪ https://urllie.com/2uNHTj - But before we get into the details, let's first understand what this mod is all about. -What is Euro Truck Simulator 2 Bus Indonesia Mod?-Euro Truck Simulator 2 Bus Indonesia Mod is a modification for Euro Truck Simulator 2, a game developed by SCS Software and released in 2012. The game allows you to drive various trucks across Europe, delivering cargo and earning money. You can customize your truck, buy new ones, hire drivers, and expand your business. -The mod, however, changes the game completely. It replaces the trucks with buses, and the European map with an Indonesian map. You can choose from different types of buses, such as SR2 ECE, and drive them across Indonesia, picking up and dropping off passengers. You can also visit famous places in Indonesia, such as Jakarta, Bali, Surabaya, Bandung, and more. -The mod was created by Indonesian modders who wanted to bring their country's culture and scenery to the game. They also added realistic features, such as traffic jams, toll booths, police checkpoints, speed limits, weather effects, and more. The mod is constantly updated with new buses, routes, and improvements. -Features of Euro Truck Simulator 2 Bus Indonesia Mod-Some of the features that make this mod stand out are: -
Requirements for Euro Truck Simulator 2 Bus Indonesia Mod-To play this mod on your Android device, you will need the following: -
How to Download Euro Truck Simulator 2 Bus Indonesia Mod APK File-Now that you know what this mod is and what you need to play it, let's see how you can download it on your Android device. Here are the steps you need to follow: -Find a reputable website that offers the mod-The first step is to find a website that provides the APK file of the mod. There are many websites that claim to offer this mod, but not all of them are trustworthy. Some of them may contain viruses, malware, or fake files that can harm your device or steal your data. -download ets2 mod apk unlimited money and all trucks To avoid such risks, you should look for a website that has positive reviews, ratings, and feedback from other users. You should also check the date and size of the file, and compare it with other sources. You can also use antivirus software or online scanners to scan the file before downloading it. -One of the websites that we recommend is [Euro Truck Simulator 2 Bus Indonesia Mod APK Download]. This website has been verified by us and has a good reputation among users. It also offers the latest version of the mod, which is updated regularly with new features and improvements. -Download the APK file using your browser-The next step is to download the APK file using your browser. To do this, you need to follow these steps: -
Allow unknown apps on your Android device-The last step before installing the mod is to allow unknown apps on your Android device. Unknown apps are apps that are not downloaded from the Google Play Store or other official sources. By default, Android devices do not allow unknown apps to be installed for security reasons. -To enable unknown apps on your device, you need to follow these steps: -
How to Install Euro Truck Simulator 2 Bus Indonesia Mod APK File-Now that you have downloaded and enabled unknown apps on your device, you can install the mod. To do this, you need to follow these steps: -Install a file manager app on your Android deviceA file manager app is an app that allows you to access and manage the files and folders on your device. You will need a file manager app to locate and install the APK file of the mod. You can use any file manager app that you like, but we recommend using [ES File Explorer]. This app is free, easy to use, and has many features. -To install a file manager app on your device, you need to follow these steps: -
Locate the APK file in your file explorer app and select it-The next step is to locate the APK file of the mod in your file explorer app and select it. To do this, you need to follow these steps: -
Tap Yes when prompted to install the APK file-The final step is to tap Yes when prompted to install the APK file of the mod. To do this, you need to follow these steps: -
How to Play Euro Truck Simulator 2 Bus Indonesia Mod on Android-Congratulations! You have successfully downloaded and installed Euro Truck Simulator 2 Bus Indonesia Mod on your Android device. Now, let's see how you can play it and enjoy driving buses across Indonesia. Here are some tips and tricks that will help you: -Launch the game from your app drawer-The first thing you need to do is to launch the game from your app drawer. To do this, you need to follow these steps: -
Choose your bus and destination-The next thing you need to do is to choose your bus and destination. To do this, you need to follow these steps: -
Enjoy driving across Indonesia with realistic graphics and physics-The last thing you need to do is to enjoy driving across Indonesia with realistic graphics and physics. To do this, you need to follow these steps: -
Conclusion-Euro Truck Simulator 2 Bus Indonesia Mod is a great mod that allows you to drive buses across Indonesia on your Android device. It is a fun and realistic way to experience the culture and scenery of Indonesia. It is also easy to download and install on your device with a few simple steps. -If you are looking for a new and exciting simulation game that will challenge your driving skills and entertain you for hours, you should definitely try Euro Truck Simulator 2 Bus Indonesia Mod. It is one of the best mods for Euro Truck Simulator 2 and one of the best simulation games for Android devices. -FAQs-Here are some frequently asked questions about Euro Truck Simulator 2 Bus Indonesia Mod: -Q: Is Euro Truck Simulator 2 Bus Indonesia Mod free?-A: Yes, Euro Truck Simulator 2 Bus Indonesia Mod is free to download and play. However, you will need to have Euro Truck Simulator 2 game installed on your device first, which may cost some money depending on where you get it from. -Q: Is Euro Truck Simulator 2 Bus Indonesia Mod safe?-A: Yes, Euro Truck Simulator 2 Bus Indonesia Mod is safe to download and play. However, you should always download it from a reputable website that has positive reviews and ratings from other users. You should also scan the APK file with antivirus software or online scanners before installing it on your device. -Q: Is Euro Truck Simulator 2 Bus Indonesia Mod compatible with other mods?-A: No, Euro Truck Simulator 2 Bus Indonesia Mod is not compatible with other mods for Euro Truck Simulator 2. It is a standalone mod that replaces the original game completely. If you want to use other mods for Euro Truck Simulator 2 , you will need to uninstall Euro Truck Simulator 2 Bus Indonesia Mod first and then install the other mods. -Q: How can I update Euro Truck Simulator 2 Bus Indonesia Mod?-A: To update Euro Truck Simulator 2 Bus Indonesia Mod, you will need to download the latest version of the APK file from the website that you got it from. You will then need to uninstall the previous version of the mod from your device and then install the new version. You may also need to update Euro Truck Simulator 2 game if there are any changes or patches. -Q: How can I contact the developers of Euro Truck Simulator 2 Bus Indonesia Mod?-A: To contact the developers of Euro Truck Simulator 2 Bus Indonesia Mod, you can visit their official website [Euro Truck Simulator 2 Bus Indonesia Mod]. There, you can find their contact information, such as their email, Facebook, Instagram, YouTube, etc. You can also leave your feedback, suggestions, or questions on their website or social media pages. 401be4b1e0- - \ No newline at end of file diff --git a/spaces/fatiXbelha/sd/Download shapez io level 20 save file and unlock logic mode.md b/spaces/fatiXbelha/sd/Download shapez io level 20 save file and unlock logic mode.md deleted file mode 100644 index 270a359cf7e8c7c6766d1653cdc580287599ea79..0000000000000000000000000000000000000000 --- a/spaces/fatiXbelha/sd/Download shapez io level 20 save file and unlock logic mode.md +++ /dev/null @@ -1,127 +0,0 @@ - - How to Download and Use Shapez.io Level 20 Save File-Shapez.io is a fun and relaxing game that challenges you to build factories and automate the production of complex shapes. But what if you want to skip the grind and jump right into the logic mode? In this article, we will show you how to download and use a level 20 save file for Shapez.io, as well as how to backup and restore your own save files. Let's get started! -shapez io level 20 save file downloadDownload File ★★★ https://urllie.com/2uNxPX - What is Shapez.io?-Shapez.io is a game developed by Tobias Springer that is available on Steam, itch.io, and as a web browser game. The game is inspired by Factorio, but with a minimalist and colorful aesthetic. The goal of the game is to create factories that can process shapes and colors, using conveyor belts, cutters, rotators, stackers, mixers, painters, and more. As you progress through the levels, the shapes become more complicated and require more steps to produce. You also have to deal with limited resources, space constraints, and scaling issues. -The game has two modes: normal mode and logic mode. In normal mode, you have to complete the objectives given by the hub, which usually involve delivering a certain amount of shapes or colors per second. In logic mode, you can use wires, switches, logic gates, displays, and sensors to create your own circuits and contraptions. Logic mode is unlocked after reaching level 20 in normal mode. -Why would you want to download a level 20 save file?-Some players may find the normal mode too tedious or repetitive, and may want to skip it entirely and go straight to the logic mode. Others may have lost their progress due to a corrupted or deleted save file, and may want to restore it quickly. Or maybe you just want to experiment with different factory designs without worrying about the objectives or resources. -Whatever your reason, downloading a level 20 save file can help you access the logic mode faster and easier. A level 20 save file is a binary file that contains all the information about your game state at level 20, such as your factory layout, your inventory, your upgrades, and your achievements. By importing this file into your game, you can resume playing from level 20 without having to start from scratch. -shapez io level 20 save file location How to backup and restore your save files-Before you download and use a level 20 save file, it is highly recommended that you backup your own save files first. This way, you can avoid losing your original progress or overwriting your current game state. You can also restore your own save files if you encounter any problems or errors with the downloaded file. -The importance of backing up your save files regularly-Backing up your save files is a good practice for any game that you play, especially for games like Shapez.io that involve a lot of time and effort. Save files can get corrupted or deleted due to various reasons, such as power outages, system crashes, viruses, accidental deletion, or updates. If you don't have a backup of your save files, you may lose all your progress and have to start over from the beginning. -Therefore, it is advisable that you backup your save files regularly, preferably after each session or each level. You can also backup your save files before making any major changes to your factory or before trying out new features or mods. This way, you can always revert to your previous state if something goes wrong or if you are not satisfied with the results. -The location of your save files on different platforms-The location of your save files depends on the platform that you are playing the game on. Here are the common locations for each platform: -
You can also export your save files from the game's settings menu, which will generate a .bin file that you can save anywhere on your computer. -The methods of backing up and restoring your save files-There are two main methods of backing up and restoring your save files: manually and automatically. Here is how they work: -
Both methods have their advantages and disadvantages, so you can choose the one that suits your preferences and needs. -How to download and use a level 20 save file-Now that you know how to backup and restore your save files, let's see how to download and use a level 20 save file for Shapez.io. Here are the steps that you need to follow: -The sources of level 20 save files online-There are many sources of level 20 save files online, such as forums, websites, blogs, YouTube videos, or Reddit posts. You can search for them using keywords like "shapez.io level 20 save file", "shapez.io logic mode unlock", or "shapez.io level 20 download". Some examples of sources are: -
However, not all sources are reliable or safe, so you need to be careful when downloading files from unknown or untrusted sources. You should always scan the files for viruses or malware before opening them, and read the comments or reviews from other users before downloading them. You should also backup your own save files before using any downloaded file, in case something goes wrong or if you want to switch back to your own progress. -The steps of downloading and using a level 20 save file-Once you have found a source of a level 20 save file that you trust, you can download it by clicking on the link or button provided by the source. The file should be a .bin file that contains the game state at level 20. After downloading it, you need to place it in the same location as your own save files (see above for the location on different platforms). You may need to rename it or overwrite an existing file if there is already a file with the same name in that location. -After placing the file in the correct location, you can launch the game and go to the settings menu. There, you should see a list of available save files that you can load. You should see the level 20 save file that you downloaded among them. You can select it and click on "Load" to load it into the game. You should then see a message that says "Welcome to logic mode!" and a new tab in the bottom left corner that says "Logic". You can click on it to access the logic mode features and start creating your own circuits and contraptions. -The benefits and drawbacks of using a level 20 save file-Using a level 20 save file has some benefits and drawbacks that you should be aware of before using it. Here are some of them: -Benefits-
Drawbacks-
Conclusion-In conclusion, downloading and using a level 20 save file for Shapez.io can be a quick and easy way to access the logic mode and enjoy its features. However, you should also be careful when choosing a source of a level 20 save file and backup your own save files before using it. You should also weigh the benefits and drawbacks of using a level 20 save file and decide if it is worth it for you. We hope this article has helped you learn how to download and use a level 20 save file for Shapez.io. Have fun! -FAQs-Q: How do I export my own save file from Shapez.io?-A: You can export your own save file from Shapez.io by going to the settings menu and clicking on "Export Savegame". This will generate a .bin file that you can save anywhere on your computer. You can also share this file with others if you want to. -Q: How do I import a save file into Shapez.io?-A: You can import a save file into Shapez.io by going to the settings menu and clicking on "Import Savegame". This will open a file browser where you can select the .bin file that you want to import. You can also drag and drop the .bin file into the game window to import it. -Q: How do I delete a save file from Shapez.io?-A: You can delete a save file from Shapez.io by going to the settings menu and clicking on "Delete Savegame". This will show you a list of available save files that you can delete. You can also delete a save file manually by going to its location (see above for the location on different platforms) and deleting it from there. -Q: How do I update my game version for Shapez.io?-A: You can update your game version for Shapez.io by following these steps: -
Q: How do I access the modding features for Shapez.io?-A: You can access the modding features for Shapez.io by going to the settings menu and clicking on "Modding". This will open a new tab where you can browse, install, enable, disable, or uninstall mods for the game. You can also create your own mods using the modding API provided by the developer. 401be4b1e0- - \ No newline at end of file diff --git a/spaces/fatiXbelha/sd/Dynast.io APK The Best Survival Game with RPG Elements for Android Devices.md b/spaces/fatiXbelha/sd/Dynast.io APK The Best Survival Game with RPG Elements for Android Devices.md deleted file mode 100644 index 09f3614b6d11d332df2ec1107738852f5b2f474b..0000000000000000000000000000000000000000 --- a/spaces/fatiXbelha/sd/Dynast.io APK The Best Survival Game with RPG Elements for Android Devices.md +++ /dev/null @@ -1,96 +0,0 @@ - - Dynast.io APK: A Survival Game with RPG Elements-Are you looking for a new and exciting game to play on your Android device? Do you enjoy games that test your skills, creativity, and strategy? If so, you might want to check out Dynast.io APK, a survival game with RPG elements that will keep you hooked for hours. -What is Dynast.io?-Dynast.io is an online survival game in which you build your dynasty in a ruthless world where all other players will try to kill you to take your resources. The game was developed by Whalebox Studio LLC, a small indie team that aims to create fun and original games for mobile platforms. The game is available for free on Google Play Store, but you can also download the APK file from other sources if you prefer. -dynast.io apkDOWNLOAD ->>> https://urllie.com/2uNEBe - A multiplayer online game set in a ruthless world-In Dynast.io, you can join or create a server with up to 100 players, each with their own base, inventory, and character. You can also chat with other players, form alliances, or declare war. The game features a dynamic day-night cycle, weather effects, and seasons that affect the gameplay. For example, at night, the visibility is reduced and more monsters appear, while in winter, the temperature drops and you need to keep warm. -A game that combines survival, building, crafting, and fighting-Dynast.io is not just a simple survival game. It also incorporates elements of building, crafting, and fighting that make it more engaging and diverse. You can build your base with different materials and structures, such as walls, doors, chests, furnaces, traps, and more. You can craft various items and equipment, such as weapons, armor, tools, potions, food, and more. You can fight against monsters and other players using melee or ranged attacks, as well as magic spells. You can also tame animals and use them as mounts or pets. -How to download and install Dynast.io APK?-If you want to play Dynast.io on your Android device, you need to download and install the APK file. Here are the steps to do so: -Download the APK file from a trusted source-You can download the APK file from Google Play Store, or from other websites that offer it. However, be careful when downloading files from unknown sources, as they may contain viruses or malware. One of the websites that you can trust is APKCombo, which provides safe and fast downloads of various APK files. -Enable unknown sources on your device-Before you can install the APK file, you need to enable unknown sources on your device. This will allow you to install apps that are not from Google Play Store. To do this, go to Settings > Security > Unknown Sources and toggle it on. You may also need to grant permission for your browser or file manager to install apps. -Install the APK file and launch the game-Once you have downloaded the APK file, locate it on your device using a file manager or your browser's downloads folder. Tap on it and follow the instructions to install it. After the installation is complete, you can launch the game by tapping on its icon on your home screen or app drawer. You can also create a shortcut for the game on your desktop for easier access. Enjoy playing Dynast.io and have fun! -dynast.io game download apk How to play Dynast.io?-Dynast.io is a game that requires skill, strategy, and creativity. You need to survive in a harsh environment, build your base, craft your equipment, and fight your enemies. Here are some tips on how to play the game: -Start your journey by building a base with wood and stones-When you enter the game, you will spawn in a random location on the map. The first thing you need to do is to gather some basic resources, such as wood and stones. You can find them scattered around the map, or you can chop down trees and break rocks with your fists. You can also use your map (M key) to locate nearby resources. Once you have enough wood and stones, you can start building your base. You can use the build menu (B key) to select different structures and place them on the ground. You can also rotate them with the R key and delete them with the X key. You should build a base that is secure, spacious, and functional. You should also place a flag near your base to claim it as your territory and prevent other players from building there. -Venture on the map looking for resources and components-After you have built your base, you need to explore the map and look for more resources and components. You will need them to craft more advanced items and equipment, such as metal, leather, cloth, gunpowder, bullets, etc. You can find them in various places, such as chests, barrels, crates, campsites, caves, etc. You can also loot them from dead monsters or players. However, be careful when venturing on the map, as you may encounter dangers and enemies along the way. -Beware of monsters and other players who will try to kill you-Dynast.io is a game where everyone is your enemy. You will face different kinds of monsters and other players who will try to kill you and take your loot. Monsters are creatures that spawn randomly on the map and attack you on sight. They vary in size, strength, and behavior. Some of them are passive and will only attack if provoked, while others are aggressive and will chase you down. Some of them are also nocturnal and will only appear at night. Some examples of monsters are wolves, bears, zombies, skeletons, spiders, etc. -Other players are human opponents who can join or create servers with you. They can be friendly or hostile depending on their mood and intention. They can chat with you, trade with you, ally with you, or betray you. They can also attack you with weapons or spells, raid your base, or steal your flag. You can also do the same to them if you want. -Upgrade your base and equipment by crafting and hunting-To survive longer and better in Dynast.io, you need to upgrade your base and equipment by crafting and hunting. Crafting is the process of making new items and equipment from existing resources and components. You can use the craft menu (C key) to select different recipes and craft them. You can also use furnaces, workbenches, anvils, etc. to craft more complex items. Some examples of items and equipment that you can craft are swords, axes, bows, guns, helmets, chestplates, boots, etc. -Hunting is the process of killing animals and monsters for their meat and skins. You can use weapons or spells to hunt them down. You can also use traps or bait to lure them in. Hunting is useful for obtaining food and leather that you can use for crafting or eating. Eating food will restore your health and hunger bars that deplete over time. -Gain levels and skills by completing quests and achievements-Dynast.io is also a game that has RPG elements that allow you to gain levels and skills by completing quests and achievements. Quests are tasks that are given by NPCs (non-player characters) that you can find in villages or campsites. They will ask you to do something for them in exchange for rewards such as gold coins or items. Some examples of quests are collecting resources, killing monsters, delivering items, etc. -Achievements are goals that are set by the game that challenge you to do something specific or remarkable. They will reward you with experience points or items when you complete them. Some examples of achievements are building a certain structure, crafting a certain item, killing a certain monster or player etc. -By completing quests and achievements, you will gain experience points that will increase your level and unlock new skills. Skills are abilities that enhance your performance in the game. You can use the skill menu (S key) to select different skills and activate them. You can also upgrade your skills by spending skill points that you earn by leveling up. Some examples of skills are speed, strength, stealth, fireball, heal, etc. -Why should you play Dynast.io?-Dynast.io is a game that offers a challenging and immersive experience for players who love survival games with RPG elements. Here are some reasons why you should play Dynast.io: -A game that offers a challenging and immersive experience-Dynast.io is a game that will test your skills, creativity, and strategy in a ruthless world where you have to survive against all odds. The game will keep you on your toes as you face different threats and challenges every day and night. The game will also immerse you in a realistic and dynamic environment where you have to adapt to the changing weather, seasons, and biomes. -A game that features a variety of biomes, items, and enemies-Dynast.io is a game that features a large and diverse map with different biomes, such as forest, desert, snow, swamp, etc. Each biome has its own characteristics, resources, and dangers. The game also features a wide range of items and equipment that you can craft and use for different purposes. The game also features a variety of enemies that you can encounter and fight, such as monsters, animals, and other players. -A game that supports cross-platform play and chat-Dynast.io is a game that supports cross-platform play and chat, meaning that you can play and communicate with other players who are using different devices, such as PC, Android, iOS, etc. This makes the game more accessible and social for everyone. You can also invite your friends to join your server or join theirs. -Conclusion-Dynast.io APK is a survival game with RPG elements that will provide you with hours of fun and excitement. You can download and install the APK file from various sources and enjoy playing the game on your Android device. You can also play the game on other platforms and chat with other players. You can build your base, craft your equipment, fight your enemies, and gain levels and skills in this game. If you are looking for a new and exciting game to play on your Android device, you should give Dynast.io APK a try. -FAQs-Here are some frequently asked questions about Dynast.io APK: -
- - \ No newline at end of file diff --git a/spaces/fatiXbelha/sd/Facebook Lite Old Version The Best Way to Stay Connected with Less Data and Battery Usage.md b/spaces/fatiXbelha/sd/Facebook Lite Old Version The Best Way to Stay Connected with Less Data and Battery Usage.md deleted file mode 100644 index 37dcf145fb8762b61ab14736b218d0846c948f69..0000000000000000000000000000000000000000 --- a/spaces/fatiXbelha/sd/Facebook Lite Old Version The Best Way to Stay Connected with Less Data and Battery Usage.md +++ /dev/null @@ -1,130 +0,0 @@ - - Download Facebook Lite Old Version: A Complete Guide-Facebook is one of the most popular social media platforms in the world, with billions of users and tons of features. However, not everyone can enjoy the full Facebook experience on their phones, especially if they have limited storage space, data plan, or network speed. That's why Facebook created Facebook Lite, a lighter and faster version of the regular Facebook app that works on almost any Android device. -But what if you want to use an even lighter and faster version of Facebook Lite? What if you want to go back to an older version of Facebook Lite that has fewer bugs, less ads, or more compatibility? In this article, we will show you how to download Facebook Lite old version and why you might want to do so. -download facebook lite old versionDownload File 🗸 https://urllie.com/2uNxrf - What is Facebook Lite?-Facebook Lite is a stripped-down version of the standard Facebook app for Android and iOS. It was launched in 2015 as a way to provide a better Facebook experience for users in developing countries where data connectivity is poor or expensive. However, it soon became popular among users who wanted to save space, data, and battery on their phones, or who had older devices that couldn't run the regular Facebook app smoothly. -Facebook Lite has all the basic features of Facebook, such as News Feed, Messenger, Notifications, Groups, Pages, Events, Marketplace, and more. However, it also has some differences from the regular Facebook app, such as: -download facebook lite apk old version
Why use Facebook Lite old version?-While Facebook Lite is already a great alternative to the regular Facebook app, some users might prefer to use an older version of it for various reasons. Some of the possible benefits of using Facebook Lite old version are: -
What are the drawbacks of using Facebook Lite old version?-Of course, using an older version of any app also comes with some drawbacks that you should be aware of before you decide to do so. Some of the possible drawbacks of using Facebook Lite old version are: -
Therefore, you should weigh the pros and cons of using Facebook Lite old version carefully before you proceed. You should also backup your data and device before you install any older version of Facebook Lite, just in case something goes wrong. -How to download Facebook Lite old version?-If you still want to download Facebook Lite old version, you will need to find a reliable source that offers the APK file of the version that you want. APK stands for Android Package Kit, and it is the file format that Android uses to distribute and install apps. You can't find older versions of Facebook Lite on the official Google Play Store, so you will have to look for alternative sources online. -However, not all sources are safe or trustworthy. Some websites might offer fake or modified APK files that contain viruses, spyware, or malware. Some websites might also require you to sign up, pay, or complete surveys before you can download the APK file. Therefore, you should be careful and do some research before you download any APK file from any website. -One of the most reputable and popular sources for downloading older versions of Android apps is APKMirror. APKMirror is a website that hosts thousands of APK files for various apps, including Facebook Lite. It also verifies the authenticity and integrity of the APK files that it offers, so you can be sure that they are safe and original. Here are the steps to download Facebook Lite old version from APKMirror: -
How to install Facebook Lite old version?-After you download the APK file of Facebook Lite old version, you will need to install it on your device. However, before you do that, you will need to enable the option to install apps from unknown sources on your device. This option allows you to install apps that are not from the Google Play Store, such as APK files. Here are the steps to enable this option: -
To install Facebook Lite old version, follow these steps: -
Conclusion-In this article, we have shown you how to download and install Facebook Lite old version on your Android device. We have also explained what Facebook Lite is, why some people prefer to use older versions of it, and what are the benefits and drawbacks of doing so. We hope that this article has been helpful and informative for you. If you have any questions or feedback, please feel free to leave a comment below. And if you liked this article, please share it with your friends and family who might also be interested in downloading Facebook Lite old version. -FAQs-Here are some of the frequently asked questions and answers about Facebook Lite old version: -Is Facebook Lite old version safe to use?-Facebook Lite old version is generally safe to use, as long as you download it from a trusted source like APKMirror. However, you should be aware that using an older version of any app might expose you to some security risks or vulnerabilities that have been fixed in newer versions. You should also make sure that your device has the latest security updates and antivirus software installed. -Can I use Facebook Lite old version and regular Facebook app at the same time?-No, you can't use both versions of Facebook on the same device. You will have to uninstall one of them before you can install the other. However, you can use Facebook Lite old version on one device and regular Facebook app on another device, as long as you log in with the same account. -How can I update Facebook Lite old version to the latest version?-If you want to update Facebook Lite old version to the latest version, you will have to uninstall the old version first and then download and install the new version from the Google Play Store or APKMirror. Alternatively, you can enable the auto-update option on your device's settings, so that your apps will be updated automatically whenever a new version is available. -How can I delete Facebook Lite old version from my device?-If you want to delete Facebook Lite old version from your device, you will have to uninstall it like any other app. You can do this by going to your device's settings, finding the app in the list of installed apps, and tapping on "Uninstall". You can also delete the APK file that you downloaded from your device's storage. -What are some alternatives to Facebook Lite old version?-If you are looking for other ways to use Facebook on your phone without using too much space, data, or battery, you might want to try some of these alternatives: -
- - \ No newline at end of file diff --git a/spaces/feiya/feiyaa/Dockerfile b/spaces/feiya/feiyaa/Dockerfile deleted file mode 100644 index 3698c7cb7938e025afc53b18a571ae2961fbdffe..0000000000000000000000000000000000000000 --- a/spaces/feiya/feiyaa/Dockerfile +++ /dev/null @@ -1,34 +0,0 @@ -# Build Stage -# 使用 golang:alpine 作为构建阶段的基础镜像 -FROM golang:alpine AS builder - -# 添加 git,以便之后能从GitHub克隆项目 -RUN apk --no-cache add git - -# 从 GitHub 克隆 go-proxy-bingai 项目到 /workspace/app 目录下 -RUN git clone https://github.com/Harry-zklcdc/go-proxy-bingai.git /workspace/app - -# 设置工作目录为之前克隆的项目目录 -WORKDIR /workspace/app - -# 编译 go 项目。-ldflags="-s -w" 是为了减少编译后的二进制大小 -RUN go build -ldflags="-s -w" -tags netgo -trimpath -o go-proxy-bingai main.go - -# Runtime Stage -# 使用轻量级的 alpine 镜像作为运行时的基础镜像 -FROM alpine - -# 设置工作目录 -WORKDIR /workspace/app - -# 从构建阶段复制编译后的二进制文件到运行时镜像中 -COPY --from=builder /workspace/app/go-proxy-bingai . - -# 设置环境变量,此处为随机字符 -ENV Go_Proxy_BingAI_USER_TOKEN_1="kJs8hD92ncMzLaoQWYtX5rG6bE3fZ4iO" - -# 暴露8080端口 -EXPOSE 8080 - -# 容器启动时运行的命令 -CMD ["/workspace/app/go-proxy-bingai"] \ No newline at end of file diff --git a/spaces/fengmuxi/ChatGpt-Web/app/api/auth.ts b/spaces/fengmuxi/ChatGpt-Web/app/api/auth.ts deleted file mode 100644 index 4e3b3f388c60c8f7d65790521dd9e40bd77360b0..0000000000000000000000000000000000000000 --- a/spaces/fengmuxi/ChatGpt-Web/app/api/auth.ts +++ /dev/null @@ -1,73 +0,0 @@ -import { NextRequest } from "next/server"; -import { getServerSideConfig } from "../config/server"; -import md5 from "spark-md5"; -import { ACCESS_CODE_PREFIX } from "../constant"; - -const serverConfig = getServerSideConfig(); - -export function getIP(req: NextRequest) { - let ip = req.ip ?? req.headers.get("x-real-ip"); - const forwardedFor = req.headers.get("x-forwarded-for"); - - if (!ip && forwardedFor) { - ip = forwardedFor.split(",").at(0) ?? ""; - } - - return ip; -} - -function parseApiKey(bearToken: string) { - const token = bearToken.trim().replaceAll("Bearer ", "").trim(); - const isOpenAiKey = !token.startsWith(ACCESS_CODE_PREFIX); - - return { - accessCode: isOpenAiKey ? "" : token.slice(ACCESS_CODE_PREFIX.length), - apiKey: isOpenAiKey ? token : "", - }; -} - -export function auth(req: NextRequest) { - const authToken = req.headers.get("Authorization") ?? ""; - const auth = req.headers.get("auth") ?? ""; - - // check if it is openai api key or user token - const { accessCode, apiKey: token } = parseApiKey(authToken); - - const hashedCode = md5.hash(accessCode ?? "").trim(); - - console.log("[Auth] allowed hashed codes: ", [...serverConfig.codes]); - console.log("[Auth] got access code:", accessCode); - console.log("[Auth] hashed access code:", hashedCode); - console.log("[Auth] get auth:",auth); - console.log("[User IP] ", getIP(req)); - console.log("[Time] ", new Date().toLocaleString()); - // serverConfig.needCode && !serverConfig.codes.has(hashedCode) && - if (!token && !auth) { - return { - error: true, - needAccessCode: true, - msg: "Please go login page to login.", - }; - } - - // if user does not provide an api key, inject system api key - if (!token) { - const apiKey = serverConfig.apiKey; - if (apiKey) { - console.log("[Auth] use system api key"); - req.headers.set("Authorization", `Bearer ${apiKey}`); - } else { - console.log("[Auth] admin did not provide an api key"); - return { - error: true, - msg: "Empty Api Key", - }; - } - } else { - console.log("[Auth] use user api key"); - } - - return { - error: false, - }; -} diff --git a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download Attack on Titan Part 2 Full Movie in Hindi 720p HD Quality.md b/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download Attack on Titan Part 2 Full Movie in Hindi 720p HD Quality.md deleted file mode 100644 index 7125942482ff44831b1096555f6278034cb46ada..0000000000000000000000000000000000000000 --- a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download Attack on Titan Part 2 Full Movie in Hindi 720p HD Quality.md +++ /dev/null @@ -1,69 +0,0 @@ - - Attack on Titan Part 2 Full Movie Download in Hindi 720p: How to Watch the Epic Finale of the Live-Action Adaptation-If you are a fan of anime, manga, or action movies, you have probably heard of Attack on Titan, one of the most popular and acclaimed series of the past decade. Attack on Titan is a dark fantasy story that follows a group of young soldiers who fight against giant humanoid creatures called titans that have nearly wiped out humanity. -In 2015, a live-action adaptation of Attack on Titan was released in two parts, directed by Shinji Higuchi and starring Haruma Miura, Kiko Mizuhara, Kanata Hongo, Hiroki Hasegawa, and more. The movies were based on the manga by Hajime Isayama, but they also made some significant changes to the characters, plot, and setting. -attack on titan part 2 full movie download in hindi 720pDownload File ○ https://gohhs.com/2uPuMr - The first part of the movie introduced us to the main protagonist, Eren Yeager, who witnessed his mother being eaten by a titan when he was a child. He joined the Scouting Regiment, an elite military force that ventures outside the walls that protect humanity from the titans. He also discovered that he had a mysterious ability to transform into a titan himself. -The second part of the movie, titled Attack on Titan Part 2: End of the World, continued the story from where the first part left off. Eren had to face his own identity as a titan, as well as the secrets behind the origin and purpose of the titans. He also had to deal with a new enemy, Shikishima, a mysterious leader who claimed to be humanity's savior. -If you want to watch this epic finale of the live-action adaptation of Attack on Titan, you might be wondering how to download it in Hindi 720p. Hindi is one of the most widely spoken languages in the world, and many fans prefer to watch movies in their native language. 720p is also a good quality for streaming or downloading movies, as it offers clear images and sound without taking up too much space or bandwidth. -In this article, we will show you how to download Attack on Titan Part 2 in Hindi 720p, as well as what to expect from this movie. We will also give you some legal and safe options, as well as some illegal and risky options, for downloading or streaming this movie online. Read on to find out more! -How to Download Attack on Titan Part 2 in Hindi 720p-There are many ways to download or stream movies online, but not all of them are legal or safe. Some websites or apps may offer free or cheap downloads or streams, but they may also expose you to malware, viruses , phishing, hacking, or legal issues. Therefore, it is always better to use legal and safe options, even if they may cost some money or require a subscription. Here are some of the best legal and safe options for downloading or streaming Attack on Titan Part 2 in Hindi 720p. -Legal and safe options-
Illegal and risky options-If you are looking for free or cheap options to download or stream Attack on Titan Part 2 in Hindi 720p, you may be tempted to use some illegal and risky options. However, we strongly advise you to avoid these options, as they may harm your device or your privacy. Here are some of the most common illegal and risky options for downloading or streaming movies online. -
What to Expect from Attack on Titan Part 2-Now that you know how to download or stream Attack on Titan Part 2 in Hindi 720p legally and safely, you may be wondering what to expect from this movie. Well, we can tell you that this movie is not for the faint of heart. It is a thrilling and intense ride that will keep you on the edge of your seat from start to finish. Here are some of the things that you can expect from Attack on Titan Part 2. -The action and special effects-One of the main attractions of Attack on Titan Part 2 is the action and special effects. The movie features some of the most impressive and terrifying titans ever seen on screen. The titans have different designs Part 2? - attack on titan part 2 hindi dubbed 720p download - - \ No newline at end of file diff --git a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download GApps mod apk now and get unlimited coins for free.md b/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download GApps mod apk now and get unlimited coins for free.md deleted file mode 100644 index 2991f09771863990918f8af2aa1f16daebe5e217..0000000000000000000000000000000000000000 --- a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download GApps mod apk now and get unlimited coins for free.md +++ /dev/null @@ -1,79 +0,0 @@ - - GApps Unlimited Coins Mod APK Download: What You Need to Know-If you are looking for a way to enjoy Google apps and services on your Android device without any restrictions or limitations, you might be interested in GApps Unlimited Coins Mod APK. This is a modified version of the official Google Apps package that claims to offer unlimited coins, gems, and other resources for various games and apps. But before you download and install this modded version of GApps, there are some things you need to know. In this article, we will explain what are GApps, why do you need them, what is GApps Unlimited Coins Mod APK, how does it work, how to download and install it, and what are the alternatives. Read on to find out more. -gapps unlimited coins mod apk downloadDownload Zip > https://gohhs.com/2uPo9a - What are GApps and why do you need them?-GApps, short for Google Apps, are a set of applications and services that are developed by Google and come pre-installed on most Android devices. These include the Play Store, Gmail, Maps, YouTube, Photos, Drive, Chrome, Assistant, and many more. These apps and services provide core functionality and features that enhance the user experience and performance of Android devices. They also allow users to access the vast ecosystem of Google products and services, such as cloud storage, music streaming, video calling, email, navigation, etc. -However, not all Android devices come with GApps pre-installed. Some device makers or custom ROM developers may not have a license or permission from Google to include GApps in their software. This means that users who buy these devices or flash these ROMs will not be able to use Google apps and services on their devices. This can be a problem for many users who rely on Google apps and services for their daily needs. For example, without the Play Store, users will not be able to download or update apps from the official source. Without Google Play Services, users will not be able to use features like location-based services, push notifications, in-app purchases, etc. -What is GApps Unlimited Coins Mod APK and how does it work?-GApps Unlimited Coins Mod APK is a modified version of the official Google Apps package that claims to offer unlimited coins, gems, and other resources for various games and apps that use Google Play Services. This means that users who install this modded version of GApps will be able to enjoy Google apps and services on their devices without any restrictions or limitations. They will also be able to get unlimited resources for games and apps that require Google Play Services. -How does it work? According to the developers of this modded version of GApps, they have modified some files and libraries in the original package to bypass the verification and authentication process of Google Play Services. This allows them to inject unlimited coins, gems, and other resources into games and apps that use Google Play Services. They also claim that they have optimized the package size and performance to make it faster and smoother than the original package. -gapps mod apk download with unlimited money and gems How to download and install GApps Unlimited Coins Mod APK on your device?-If you want to try out GApps Unlimited Coins Mod APK on your device, you will need to follow these steps: - First, you will need to download the GApps Unlimited Coins Mod APK file from a reliable source. You can search for it on the internet or use the link provided below. Make sure you download the file that matches your device's architecture and Android version. - Second, you will need to enable the installation of apps from unknown sources on your device. To do this, go to Settings > Security > Unknown Sources and toggle it on. This will allow you to install apps that are not from the Play Store. - Third, you will need to locate the downloaded GApps Unlimited Coins Mod APK file on your device using a file manager app. Tap on the file and follow the instructions to install it. You may need to grant some permissions and accept some terms and conditions. - Fourth, you will need to reboot your device after the installation is complete. This will ensure that the modded version of GApps is properly integrated with your device's system. - Fifth, you will need to launch the GApps Unlimited Coins Mod APK app from your app drawer and sign in with your Google account. You will then be able to access Google apps and services on your device without any restrictions or limitations. You will also be able to get unlimited resources for games and apps that use Google Play Services. What are the alternatives to GApps Unlimited Coins Mod APK?-While GApps Unlimited Coins Mod APK may sound tempting and appealing, it is not without its risks and drawbacks. Here are some of the potential issues that you may face if you use this modded version of GApps: - - It may not be compatible with all devices or ROMs. Some devices or ROMs may have different configurations or security measures that may prevent the modded version of GApps from working properly or at all. - It may not be updated regularly or at all. The developers of this modded version of GApps may not be able to keep up with the updates and changes that Google makes to its apps and services. This may result in bugs, errors, crashes, or missing features. - It may compromise your privacy and security. The modded version of GApps may contain malicious code or spyware that may collect your personal data or expose your device to hackers or viruses. You may also lose access to some of the security features that Google provides, such as encryption, backup, or anti-theft. - It may violate Google's terms of service and policies. The modded version of GApps may breach Google's terms of service and policies that govern the use of its apps and services. This may result in your account being suspended or banned by Google. Therefore, if you are looking for alternatives to GApps Unlimited Coins Mod APK, you may want to consider these options: - Use official GApps packages from reputable sources. If your device or ROM supports official GApps packages, you can download and install them from reputable sources such as OpenGApps or BiTGApps . These packages are based on the original Google Apps package but are customized and optimized for different devices and ROMs. They are also updated regularly and do not contain any modifications or alterations that may affect your privacy or security. - Use FOSS alternatives to Google apps. If you want to avoid using Google apps and services altogether, you can use FOSS (Free and Open Source Software) alternatives that offer similar functionality and features but respect your privacy and freedom. Some examples of FOSS alternatives to Google apps are F-Droid (an app store for FOSS apps), microG (a lightweight replacement for Google Play Services), Aurora Store (a client for accessing the Play Store without Google account), K-9 Mail (an email client), OsmAnd (a navigation app), NewPipe (a YouTube client), Simple Gallery (a photo gallery app), etc.Conclusion-GApps Unlimited Coins Mod APK is a modified version of the official Google Apps package that claims to offer unlimited coins, gems, and other resources for various games and apps that use Google Play Services. It also claims to offer unrestricted access to Google apps and services on Android devices that do not have them pre-installed. However, this modded version of GApps is not without its risks and drawbacks. It may not be compatible with all devices or ROMs, it may not be updated regularly or at all, it may compromise your privacy and security, and it may violate Google's terms of service and policies. -If you want to use Google apps and services on your Android device without any restrictions or limitations, you may want to consider using official GApps packages from reputable sources or FOSS alternatives to Google apps that respect your privacy and freedom. -We hope We hope this article has helped you understand what GApps Unlimited Coins Mod APK is, how it works, how to download and install it, and what are the alternatives. If you have any questions or feedback, please feel free to leave a comment below. We would love to hear from you. -FAQs-Here are some of the frequently asked questions about GApps Unlimited Coins Mod APK: -Q1: Is GApps Unlimited Coins Mod APK safe to use?-A1: There is no definitive answer to this question, as different sources may provide different versions of GApps Unlimited Coins Mod APK that may have different levels of safety and quality. However, as a general rule of thumb, you should always be careful and cautious when downloading and installing any modded or unofficial app or package on your device. You should always scan the file for viruses or malware, check the reviews and ratings of the source, and backup your data before proceeding. You should also be aware of the potential risks and drawbacks of using GApps Unlimited Coins Mod APK, as we have discussed in this article. -Q2: Will GApps Unlimited Coins Mod APK work on any Android device?-A2: No, GApps Unlimited Coins Mod APK will not work on any Android device. It will only work on devices that support the installation of GApps packages, such as devices that run custom ROMs or non-GMS devices. It will also depend on the compatibility of the modded version of GApps with your device's architecture and Android version. You should always check the compatibility and requirements of the modded version of GApps before downloading and installing it on your device. -Q3: What are some of the best FOSS alternatives to Google apps?-A3: There are many FOSS alternatives to Google apps that offer similar functionality and features but respect your privacy and freedom. Some examples of FOSS alternatives to Google apps are F-Droid (an app store for FOSS apps), microG (a lightweight replacement for Google Play Services), Aurora Store (a client for accessing the Play Store without Google account), K-9 Mail (an email client), OsmAnd (a navigation app), NewPipe (a YouTube client), Simple Gallery (a photo gallery app), etc. You can find more FOSS alternatives to Google apps on websites like AlternativeTo or Fossdroid . -Q4: How can I update GApps Unlimited Coins Mod APK to the latest version?-A4: The best way to update GApps Unlimited Coins Mod APK to the latest version is to download and install the latest version from the same source that you got the previous version from. You should always check for updates regularly and install them as soon as possible to avoid missing out on new features or fixes. However, you should also be careful and cautious when updating GApps Unlimited Coins Mod APK, as some updates may not be compatible with your device or ROM, or may contain bugs or errors. You should always backup your data before updating and follow the instructions carefully. -Q5: Where can I get support or report bugs for GApps Unlimited Coins Mod APK?-A5: The best place to get support or report bugs for GApps Unlimited Coins Mod APK is to contact the developers or the source that provided you with the modded version of GApps. They may be able to help you with your issues or fix the bugs that you encounter. However, you should not expect too much support or assistance from them, as they are not affiliated with Google or the official GApps team. They may also not respond to your queries or requests promptly or at all. 197e85843d- - \ No newline at end of file diff --git a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download MilkChoco Mod APK 1.32.1 and Unlock All the Features for Free.md b/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download MilkChoco Mod APK 1.32.1 and Unlock All the Features for Free.md deleted file mode 100644 index 5d24795f6d58e9b94e4873f9beaa668f8fb8e3da..0000000000000000000000000000000000000000 --- a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download MilkChoco Mod APK 1.32.1 and Unlock All the Features for Free.md +++ /dev/null @@ -1,79 +0,0 @@ - - MilkChoco Mod APK 1.32.1: A Premium Version of MilkChoco Online FPS-If you are a fan of multiplayer shooting games with cute graphics and voices, you might have heard of MilkChoco Online FPS. This is a popular game where you can play as various heroes with different abilities in different game modes and maps. But did you know that there is a premium version of this game that you can get for free? It's called MilkChoco Mod APK 1.32.1, and it offers many advantages over the original version. In this article, we will tell you everything you need to know about this modded version of MilkChoco Online FPS, including what it is, how to download and install it, tips and tricks for playing it, reviews and ratings from other users, and some FAQs. -milkchoco mod apk 1.32.1Download File ✪✪✪ https://gohhs.com/2uPrOK - What is MilkChoco Online FPS?-MilkChoco Online FPS is a third-person shooter game where two teams of five players each battle each other in various game modes and maps. The game is free and available on iOS, Android, Nintendo Switch, and PC. You can choose from 22 classes, each with their own unique ability, such as attacker, doctor, bomber, sniper, etc., and play various roles in battlefields such as 'Assault', 'Deathmatch', 'Escort', 'Capture the Milk', 'Kill Devil', 'Ice Bang', and 'Free for All'. You can also customize your character with different weapons and outfits. The game has low latency online FPS and simple controls, making it easy to play. -The game modes and maps are as follows: -
What is MilkChoco Mod APK 1.32.1?-MilkChoco Mod APK 1.32.1 is a modified version of MilkChoco Online FPS that you can download and install on your Android device for free. This version offers many benefits over the original version, such as: -
MilkChoco Mod APK 1.32.1 is a premium version of MilkChoco Online FPS that gives you more fun and freedom in playing the game. You can enjoy all the features of the game without any restrictions or costs. You can also have an edge over other players who are using the original version of the game. -MilkChoco MOD APK v1.34.0 (Unlimited Money/Gems) - Jojoy[^1^]: This is a website that offers a premium version of MilkChoco, a game where you can play as different characters with different abilities in a team-based shooter. The mod apk allows you to use all the features in MilkChoco without paying or watching ads. You can also download and install the latest version of the mod apk from this website. -However, there are also some drawbacks of using this modded version of the game, such as: -
How to download and install MilkChoco Mod APK 1.32.1?-If you want to try out this modded version of MilkChoco Online FPS, you can follow these steps to download and install it on your Android device: -
Here is a table showing the file size, compatibility, and requirements of MilkChoco Mod APK 1.32.1: - | File size | Compatibility | Requirements | | --------- | ------------- | ------------ | | 210 MB | Android 4.4 and up | Internet connection, unknown sources enabled |Tips and tricks for playing MilkChoco Mod APK 1.32.1-Now that you have downloaded and installed MilkChoco Mod APK 1.32.1, you might be wondering how to play it better and have more fun. Here are some tips and tricks that you can use when playing this modded version of MilkChoco Online FPS: -
Reviews and ratings of MilkChoco Mod APK 1.32.1-MilkChoco Mod APK 1.32.1 is a popular modded version of MilkChoco Online FPS that has received many positive reviews and ratings from users who have tried it. Here are some of them: -"This is a SUPER FUN game! I love it! However, sometimes it glitches when I try to go into the game. Even though it gltiches occasionally, if you're looking for a new game to try, it's definitely worth a shot!" - Summer Terry -"I'm gonna be frank. This new update has several bugs in it... For one, the game reloads mid-game, making it almost impossible to play efficiently. I've seen it in several modes (battle royale and star league included). Two, for some reason, I can't shoot the targets I'm aiming for, which is a bit annoying." - Electrolitez -"This game is amazing! It has cute graphics, voices, and characters. It also has many game modes and maps to choose from. The modded version gives me unlimited money and diamonds, which makes me happy." - Lila Rose -"This game is awesome! It's like Overwatch but with milk cartons instead of heroes. The modded version lets me access all the classes and abilities, which makes me powerful. The only problem is that sometimes the game crashes or lags, which makes me sad." - Ryan Lee -"This game is very fun and addictive. I like the graphics and the sounds. The modded version is very cool and easy to use. I can buy anything I want and play any class I want. The only thing I don't like is that some players are very rude and toxic. They insult me or cheat in the game. I wish there was a report or block feature." - Mia Smith -Based on these reviews and ratings, we can give MilkChoco Mod APK 1.32.1 a score of 4.5 out of 5 stars. This modded version of MilkChoco Online FPS is a great way to enjoy the game with more features and benefits, but it also has some drawbacks and risks that you should be aware of. -Conclusion-MilkChoco Mod APK 1.32.1 is a premium version of MilkChoco Online FPS that you can download and install on your Android device for free. This modded version of the game offers unlimited money, diamonds, classes, and no ads, which can enhance your gameplay and experience. However, this modded version of the game also has some disadvantages and dangers, such as potential malware, ban, or compatibility issues, which you should be careful of. -If you are looking for a fun and cute multiplayer shooting game with different game modes and maps, you should try out MilkChoco Online FPS. If you want to have more fun and freedom in playing the game, you should try out MilkChoco Mod APK 1.32.1. But remember to use it at your own risk and discretion, and don't abuse its features or cheat in online matches. -FAQs-Here are some frequently asked questions and answers about MilkChoco Mod APK 1.32.1: -
- - \ No newline at end of file diff --git a/spaces/fffiloni/audioldm-text-to-audio-generation-copy/app.py b/spaces/fffiloni/audioldm-text-to-audio-generation-copy/app.py deleted file mode 100644 index 629eab165af167483b3def8286581e7270b8e01c..0000000000000000000000000000000000000000 --- a/spaces/fffiloni/audioldm-text-to-audio-generation-copy/app.py +++ /dev/null @@ -1,309 +0,0 @@ -import gradio as gr -import numpy as np -from audioldm import text_to_audio, build_model -from share_btn import community_icon_html, loading_icon_html, share_js - -model_id="haoheliu/AudioLDM-S-Full" - -audioldm = None -current_model_name = None - -# def predict(input, history=[]): -# # tokenize the new input sentence -# new_user_input_ids = tokenizer.encode(input + tokenizer.eos_token, return_tensors='pt') - -# # append the new user input tokens to the chat history -# bot_input_ids = torch.cat([torch.LongTensor(history), new_user_input_ids], dim=-1) - -# # generate a response -# history = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id).tolist() - -# # convert the tokens to text, and then split the responses into lines -# response = tokenizer.decode(history[0]).split("<|endoftext|>") -# response = [(response[i], response[i+1]) for i in range(0, len(response)-1, 2)] # convert to tuples of list -# return response, history - -def text2audio(text, duration, guidance_scale, random_seed, n_candidates, model_name="audioldm-m-text-ft"): - global audioldm, current_model_name - - if audioldm is None or model_name != current_model_name: - audioldm=build_model(model_name=model_name) - current_model_name = model_name - - # print(text, length, guidance_scale) - waveform = text_to_audio( - latent_diffusion=audioldm, - text=text, - seed=random_seed, - duration=duration, - guidance_scale=guidance_scale, - n_candidate_gen_per_text=int(n_candidates), - ) # [bs, 1, samples] - waveform = [ - gr.make_waveform((16000, wave[0]), bg_image="bg.png") for wave in waveform - ] - # waveform = [(16000, np.random.randn(16000)), (16000, np.random.randn(16000))] - if(len(waveform) == 1): - waveform = waveform[0] - return waveform - -# iface = gr.Interface(fn=text2audio, inputs=[ -# gr.Textbox(value="A man is speaking in a huge room", max_lines=1), -# gr.Slider(2.5, 10, value=5, step=2.5), -# gr.Slider(0, 5, value=2.5, step=0.5), -# gr.Number(value=42) -# ], outputs=[gr.Audio(label="Output", type="numpy"), gr.Audio(label="Output", type="numpy")], -# allow_flagging="never" -# ) -# iface.launch(share=True) - - -css = """ - a { - color: inherit; - text-decoration: underline; - } - .gradio-container { - font-family: 'IBM Plex Sans', sans-serif; - } - .gr-button { - color: white; - border-color: #000000; - background: #000000; - } - input[type='range'] { - accent-color: #000000; - } - .dark input[type='range'] { - accent-color: #dfdfdf; - } - .container { - max-width: 730px; - margin: auto; - padding-top: 1.5rem; - } - #gallery { - min-height: 22rem; - margin-bottom: 15px; - margin-left: auto; - margin-right: auto; - border-bottom-right-radius: .5rem !important; - border-bottom-left-radius: .5rem !important; - } - #gallery>div>.h-full { - min-height: 20rem; - } - .details:hover { - text-decoration: underline; - } - .gr-button { - white-space: nowrap; - } - .gr-button:focus { - border-color: rgb(147 197 253 / var(--tw-border-opacity)); - outline: none; - box-shadow: var(--tw-ring-offset-shadow), var(--tw-ring-shadow), var(--tw-shadow, 0 0 #0000); - --tw-border-opacity: 1; - --tw-ring-offset-shadow: var(--tw-ring-inset) 0 0 0 var(--tw-ring-offset-width) var(--tw-ring-offset-color); - --tw-ring-shadow: var(--tw-ring-inset) 0 0 0 calc(3px var(--tw-ring-offset-width)) var(--tw-ring-color); - --tw-ring-color: rgb(191 219 254 / var(--tw-ring-opacity)); - --tw-ring-opacity: .5; - } - #advanced-btn { - font-size: .7rem !important; - line-height: 19px; - margin-top: 12px; - margin-bottom: 12px; - padding: 2px 8px; - border-radius: 14px !important; - } - #advanced-options { - margin-bottom: 20px; - } - .footer { - margin-bottom: 45px; - margin-top: 35px; - text-align: center; - border-bottom: 1px solid #e5e5e5; - } - .footer>p { - font-size: .8rem; - display: inline-block; - padding: 0 10px; - transform: translateY(10px); - background: white; - } - .dark .footer { - border-color: #303030; - } - .dark .footer>p { - background: #0b0f19; - } - .acknowledgments h4{ - margin: 1.25em 0 .25em 0; - font-weight: bold; - font-size: 115%; - } - #container-advanced-btns{ - display: flex; - flex-wrap: wrap; - justify-content: space-between; - align-items: center; - } - .animate-spin { - animation: spin 1s linear infinite; - } - @keyframes spin { - from { - transform: rotate(0deg); - } - to { - transform: rotate(360deg); - } - } - #share-btn-container { - display: flex; padding-left: 0.5rem !important; padding-right: 0.5rem !important; background-color: #000000; justify-content: center; align-items: center; border-radius: 9999px !important; width: 13rem; - margin-top: 10px; - margin-left: auto; - } - #share-btn { - all: initial; color: #ffffff;font-weight: 600; cursor:pointer; font-family: 'IBM Plex Sans', sans-serif; margin-left: 0.5rem !important; padding-top: 0.25rem !important; padding-bottom: 0.25rem !important;right:0; - } - #share-btn * { - all: unset; - } - #share-btn-container div:nth-child(-n+2){ - width: auto !important; - min-height: 0px !important; - } - #share-btn-container .wrap { - display: none !important; - } - .gr-form{ - flex: 1 1 50%; border-top-right-radius: 0; border-bottom-right-radius: 0; - } - #prompt-container{ - gap: 0; - } - #generated_id{ - min-height: 700px - } - #setting_id{ - margin-bottom: 12px; - text-align: center; - font-weight: 900; - } -""" -iface = gr.Blocks(css=css) - -with iface: - gr.HTML( - """ -
-
- """
- )
- gr.HTML("""
-
-
-
- - AudioLDM: Text-to-Audio Generation with Latent Diffusion Models --- AudioLDM: Text-to-Audio Generation with Latent Diffusion Models --For faster inference without waiting in queue, you may duplicate the space and upgrade to GPU in settings.
-
-
- ''')
- with gr.Accordion("Additional information", open=False):
- gr.HTML(
- """
- Essential Tricks for Enhancing the Quality of Your Generated Audio -1. Try to use more adjectives to describe your sound. For example: "A man is speaking clearly and slowly in a large room" is better than "A man is speaking". This can make sure AudioLDM understands what you want. -2. Try to use different random seeds, which can affect the generation quality significantly sometimes. -3. It's better to use general terms like 'man' or 'woman' instead of specific names for individuals or abstract objects that humans may not be familiar with, such as 'mummy'. -
-
- """
- )
-# We build the model with data from AudioSet, Freesound and BBC Sound Effect library. We share this demo based on the UK copyright exception of data for academic research. -This demo is strictly for research demo purpose only. For commercial use please contact us. - -iface.queue(max_size=10).launch(debug=True) -# iface.launch(debug=True, share=True) diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/content-type/README.md b/spaces/fffiloni/controlnet-animation-doodle/node_modules/content-type/README.md deleted file mode 100644 index c1a922a9afba84293f449dc4b661124fbac2fd5d..0000000000000000000000000000000000000000 --- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/content-type/README.md +++ /dev/null @@ -1,94 +0,0 @@ -# content-type - -[![NPM Version][npm-version-image]][npm-url] -[![NPM Downloads][npm-downloads-image]][npm-url] -[![Node.js Version][node-image]][node-url] -[![Build Status][ci-image]][ci-url] -[![Coverage Status][coveralls-image]][coveralls-url] - -Create and parse HTTP Content-Type header according to RFC 7231 - -## Installation - -```sh -$ npm install content-type -``` - -## API - -```js -var contentType = require('content-type') -``` - -### contentType.parse(string) - -```js -var obj = contentType.parse('image/svg+xml; charset=utf-8') -``` - -Parse a `Content-Type` header. This will return an object with the following -properties (examples are shown for the string `'image/svg+xml; charset=utf-8'`): - - - `type`: The media type (the type and subtype, always lower case). - Example: `'image/svg+xml'` - - - `parameters`: An object of the parameters in the media type (name of parameter - always lower case). Example: `{charset: 'utf-8'}` - -Throws a `TypeError` if the string is missing or invalid. - -### contentType.parse(req) - -```js -var obj = contentType.parse(req) -``` - -Parse the `Content-Type` header from the given `req`. Short-cut for -`contentType.parse(req.headers['content-type'])`. - -Throws a `TypeError` if the `Content-Type` header is missing or invalid. - -### contentType.parse(res) - -```js -var obj = contentType.parse(res) -``` - -Parse the `Content-Type` header set on the given `res`. Short-cut for -`contentType.parse(res.getHeader('content-type'))`. - -Throws a `TypeError` if the `Content-Type` header is missing or invalid. - -### contentType.format(obj) - -```js -var str = contentType.format({ - type: 'image/svg+xml', - parameters: { charset: 'utf-8' } -}) -``` - -Format an object into a `Content-Type` header. This will return a string of the -content type for the given object with the following properties (examples are -shown that produce the string `'image/svg+xml; charset=utf-8'`): - - - `type`: The media type (will be lower-cased). Example: `'image/svg+xml'` - - - `parameters`: An object of the parameters in the media type (name of the - parameter will be lower-cased). Example: `{charset: 'utf-8'}` - -Throws a `TypeError` if the object contains an invalid type or parameter names. - -## License - -[MIT](LICENSE) - -[ci-image]: https://badgen.net/github/checks/jshttp/content-type/master?label=ci -[ci-url]: https://github.com/jshttp/content-type/actions/workflows/ci.yml -[coveralls-image]: https://badgen.net/coveralls/c/github/jshttp/content-type/master -[coveralls-url]: https://coveralls.io/r/jshttp/content-type?branch=master -[node-image]: https://badgen.net/npm/node/content-type -[node-url]: https://nodejs.org/en/download -[npm-downloads-image]: https://badgen.net/npm/dm/content-type -[npm-url]: https://npmjs.org/package/content-type -[npm-version-image]: https://badgen.net/npm/v/content-type diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/engine.io-parser/build/cjs/encodePacket.browser.js b/spaces/fffiloni/controlnet-animation-doodle/node_modules/engine.io-parser/build/cjs/encodePacket.browser.js deleted file mode 100644 index ec2b08a33355d6d16994aff619a9cf921a6ab806..0000000000000000000000000000000000000000 --- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/engine.io-parser/build/cjs/encodePacket.browser.js +++ /dev/null @@ -1,43 +0,0 @@ -"use strict"; -Object.defineProperty(exports, "__esModule", { value: true }); -const commons_js_1 = require("./commons.js"); -const withNativeBlob = typeof Blob === "function" || - (typeof Blob !== "undefined" && - Object.prototype.toString.call(Blob) === "[object BlobConstructor]"); -const withNativeArrayBuffer = typeof ArrayBuffer === "function"; -// ArrayBuffer.isView method is not defined in IE10 -const isView = obj => { - return typeof ArrayBuffer.isView === "function" - ? ArrayBuffer.isView(obj) - : obj && obj.buffer instanceof ArrayBuffer; -}; -const encodePacket = ({ type, data }, supportsBinary, callback) => { - if (withNativeBlob && data instanceof Blob) { - if (supportsBinary) { - return callback(data); - } - else { - return encodeBlobAsBase64(data, callback); - } - } - else if (withNativeArrayBuffer && - (data instanceof ArrayBuffer || isView(data))) { - if (supportsBinary) { - return callback(data); - } - else { - return encodeBlobAsBase64(new Blob([data]), callback); - } - } - // plain string - return callback(commons_js_1.PACKET_TYPES[type] + (data || "")); -}; -const encodeBlobAsBase64 = (data, callback) => { - const fileReader = new FileReader(); - fileReader.onload = function () { - const content = fileReader.result.split(",")[1]; - callback("b" + (content || "")); - }; - return fileReader.readAsDataURL(data); -}; -exports.default = encodePacket; diff --git a/spaces/flowers-team/SocialAISchool/autocrop.sh b/spaces/flowers-team/SocialAISchool/autocrop.sh deleted file mode 100644 index e2fe2b143702fbfcf578e957fac7cf898ef3f475..0000000000000000000000000000000000000000 --- a/spaces/flowers-team/SocialAISchool/autocrop.sh +++ /dev/null @@ -1,14 +0,0 @@ -#!/bin/bash - - -# Loop through all files in the specified directory -for file in "$@" -do - # Check if the file is an image - if [[ $file == *.jpg || $file == *.png ]] - then - # Crop the image using the `convert` command from the ImageMagick suite - echo "Cropping $file" - convert $file -trim +repage $file - fi -done diff --git a/spaces/gaviego/mnist/README.md b/spaces/gaviego/mnist/README.md deleted file mode 100644 index 67cc0de485d92ab60b0851b6dad8dca14f9b8702..0000000000000000000000000000000000000000 --- a/spaces/gaviego/mnist/README.md +++ /dev/null @@ -1,18 +0,0 @@ ---- -title: MNIST Training + Gradio -emoji: 📝 - 2️⃣ -colorFrom: red -colorTo: purple -sdk: gradio -sdk_version: 3.20.1 -app_file: app.py -pinned: false -license: openrail ---- - -# MNIST Comparsion - -This repo contains two trainings for MNIST, one with just an MLP (`train.py`) and second with convolution(`train_conv.py`). - -See the live demo here (https://huggingface.co/spaces/gaviego/mnist) - diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/configs/_base_/models/dnl_r50-d8.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/configs/_base_/models/dnl_r50-d8.py deleted file mode 100644 index edb4c174c51e34c103737ba39bfc48bf831e561d..0000000000000000000000000000000000000000 --- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/configs/_base_/models/dnl_r50-d8.py +++ /dev/null @@ -1,46 +0,0 @@ -# model settings -norm_cfg = dict(type='SyncBN', requires_grad=True) -model = dict( - type='EncoderDecoder', - pretrained='open-mmlab://resnet50_v1c', - backbone=dict( - type='ResNetV1c', - depth=50, - num_stages=4, - out_indices=(0, 1, 2, 3), - dilations=(1, 1, 2, 4), - strides=(1, 2, 1, 1), - norm_cfg=norm_cfg, - norm_eval=False, - style='pytorch', - contract_dilation=True), - decode_head=dict( - type='DNLHead', - in_channels=2048, - in_index=3, - channels=512, - dropout_ratio=0.1, - reduction=2, - use_scale=True, - mode='embedded_gaussian', - num_classes=19, - norm_cfg=norm_cfg, - align_corners=False, - loss_decode=dict( - type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)), - auxiliary_head=dict( - type='FCNHead', - in_channels=1024, - in_index=2, - channels=256, - num_convs=1, - concat_input=False, - dropout_ratio=0.1, - num_classes=19, - norm_cfg=norm_cfg, - align_corners=False, - loss_decode=dict( - type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)), - # model training and testing settings - train_cfg=dict(), - test_cfg=dict(mode='whole')) diff --git a/spaces/gheng/belanjawan-2024-chatbot/search_embedding.py b/spaces/gheng/belanjawan-2024-chatbot/search_embedding.py deleted file mode 100644 index c5d4b6cb24a2cfe8fd1e0c65ff575c13ab6b0b72..0000000000000000000000000000000000000000 --- a/spaces/gheng/belanjawan-2024-chatbot/search_embedding.py +++ /dev/null @@ -1,86 +0,0 @@ -import numpy as np -import json -import openai -from sklearn.neighbors import NearestNeighbors -import os -from dataset_loader import load_dataset - -openai.api_key=os.environ['OPENAI_API_KEY'] - -class SearchEmbedding(): - def __init__(self,max_knowledge_intake=3,knowledge_score_threshold=0.8) -> None: - self.knowledge_base = None - self.knowledge_base_emb = None - self.load_knowledge_base() - - self.max_knowledge_intake = max_knowledge_intake - self.knowledge_score_threshold = knowledge_score_threshold - - def load_knowledge_base(self): - if not os.path.isdir('belanjawan-2024-speech'): - load_dataset() - - self.knowledge_base = json.load(open('belanjawan-2024-speech/knowledge.json','r')) - self.knowledge_base_emb = np.load('belanjawan-2024-speech/embedding.npy') - - - - - def search(self,question): - #question_emb = self.emb_model([question]) - question_emb = self.openai_create_embeddng(question) - - top_result = self.nn_search([question_emb]) - - context = [] - for result in top_result: - context.append(self.knowledge_base[str(result)]) - - return context - - def nn_search(self, question_emb, n_neighbors=3): - n_neighbors = min(n_neighbors, len(self.knowledge_base_emb)) - self.nn = NearestNeighbors(n_neighbors=n_neighbors) - self.nn.fit(self.knowledge_base_emb) - self.fitted = True - - neighbors = self.nn.kneighbors(question_emb, return_distance=True) - index = neighbors[1][0] - - return index - - - def knn_search(self,target): - target = np.array(target) - cosine_similarities = np.dot(self.knowledge_base_emb, target.T) / (np.linalg.norm(self.knowledge_base_emb, axis=1) * np.linalg.norm(target)) - top_result = [] - - - sorted_score = np.copy(cosine_similarities) - sorted_score[::-1].sort() - - score_intake = sorted_score[:self.max_knowledge_intake] - - - for score in score_intake: - if score >= self.knowledge_score_threshold: - - index = np.where(cosine_similarities == score) - - - top_result.append({ - 'index':str(index[0][0]), - 'score':score - }) - - return top_result - - - def openai_create_embeddng(self,question): - emb = openai.Embedding.create( - input=question, - model = 'text-embedding-ada-002', - ) - embedding = emb['data'][0]['embedding'] - - return embedding \ No newline at end of file diff --git a/spaces/gradio/HuBERT/fairseq/data/audio/raw_audio_dataset.py b/spaces/gradio/HuBERT/fairseq/data/audio/raw_audio_dataset.py deleted file mode 100644 index 9ce3f7e39d55860f38b3332fe79917c8d38724fe..0000000000000000000000000000000000000000 --- a/spaces/gradio/HuBERT/fairseq/data/audio/raw_audio_dataset.py +++ /dev/null @@ -1,386 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - - -import logging -import os -import sys -import io - -import numpy as np -import torch -import torch.nn.functional as F - -from .. import FairseqDataset -from ..data_utils import compute_mask_indices, get_buckets, get_bucketed_sizes -from fairseq.data.audio.audio_utils import ( - parse_path, - read_from_stored_zip, - is_sf_audio_data, -) - - -logger = logging.getLogger(__name__) - - -class RawAudioDataset(FairseqDataset): - def __init__( - self, - sample_rate, - max_sample_size=None, - min_sample_size=0, - shuffle=True, - pad=False, - normalize=False, - compute_mask_indices=False, - **mask_compute_kwargs, - ): - super().__init__() - - self.sample_rate = sample_rate - self.sizes = [] - self.max_sample_size = ( - max_sample_size if max_sample_size is not None else sys.maxsize - ) - self.min_sample_size = min_sample_size - self.pad = pad - self.shuffle = shuffle - self.normalize = normalize - self.compute_mask_indices = compute_mask_indices - if self.compute_mask_indices: - self.mask_compute_kwargs = mask_compute_kwargs - self._features_size_map = {} - self._C = mask_compute_kwargs["encoder_embed_dim"] - self._conv_feature_layers = eval(mask_compute_kwargs["conv_feature_layers"]) - - def __getitem__(self, index): - raise NotImplementedError() - - def __len__(self): - return len(self.sizes) - - def postprocess(self, feats, curr_sample_rate): - if feats.dim() == 2: - feats = feats.mean(-1) - - if curr_sample_rate != self.sample_rate: - raise Exception(f"sample rate: {curr_sample_rate}, need {self.sample_rate}") - - assert feats.dim() == 1, feats.dim() - - if self.normalize: - with torch.no_grad(): - feats = F.layer_norm(feats, feats.shape) - return feats - - def crop_to_max_size(self, wav, target_size): - size = len(wav) - diff = size - target_size - if diff <= 0: - return wav - - start = np.random.randint(0, diff + 1) - end = size - diff + start - return wav[start:end] - - def _compute_mask_indices(self, dims, padding_mask): - B, T, C = dims - mask_indices, mask_channel_indices = None, None - if self.mask_compute_kwargs["mask_prob"] > 0: - mask_indices = compute_mask_indices( - (B, T), - padding_mask, - self.mask_compute_kwargs["mask_prob"], - self.mask_compute_kwargs["mask_length"], - self.mask_compute_kwargs["mask_selection"], - self.mask_compute_kwargs["mask_other"], - min_masks=2, - no_overlap=self.mask_compute_kwargs["no_mask_overlap"], - min_space=self.mask_compute_kwargs["mask_min_space"], - ) - mask_indices = torch.from_numpy(mask_indices) - if self.mask_compute_kwargs["mask_channel_prob"] > 0: - mask_channel_indices = compute_mask_indices( - (B, C), - None, - self.mask_compute_kwargs["mask_channel_prob"], - self.mask_compute_kwargs["mask_channel_length"], - self.mask_compute_kwargs["mask_channel_selection"], - self.mask_compute_kwargs["mask_channel_other"], - no_overlap=self.mask_compute_kwargs["no_mask_channel_overlap"], - min_space=self.mask_compute_kwargs["mask_channel_min_space"], - ) - mask_channel_indices = ( - torch.from_numpy(mask_channel_indices).unsqueeze(1).expand(-1, T, -1) - ) - - return mask_indices, mask_channel_indices - - @staticmethod - def _bucket_tensor(tensor, num_pad, value): - return F.pad(tensor, (0, num_pad), value=value) - - def collater(self, samples): - samples = [s for s in samples if s["source"] is not None] - if len(samples) == 0: - return {} - - sources = [s["source"] for s in samples] - sizes = [len(s) for s in sources] - - if self.pad: - target_size = min(max(sizes), self.max_sample_size) - else: - target_size = min(min(sizes), self.max_sample_size) - - collated_sources = sources[0].new_zeros(len(sources), target_size) - padding_mask = ( - torch.BoolTensor(collated_sources.shape).fill_(False) if self.pad else None - ) - for i, (source, size) in enumerate(zip(sources, sizes)): - diff = size - target_size - if diff == 0: - collated_sources[i] = source - elif diff < 0: - assert self.pad - collated_sources[i] = torch.cat( - [source, source.new_full((-diff,), 0.0)] - ) - padding_mask[i, diff:] = True - else: - collated_sources[i] = self.crop_to_max_size(source, target_size) - - input = {"source": collated_sources} - out = {"id": torch.LongTensor([s["id"] for s in samples])} - if self.pad: - input["padding_mask"] = padding_mask - - if hasattr(self, "num_buckets") and self.num_buckets > 0: - assert self.pad, "Cannot bucket without padding first." - bucket = max(self._bucketed_sizes[s["id"]] for s in samples) - num_pad = bucket - collated_sources.size(-1) - if num_pad: - input["source"] = self._bucket_tensor(collated_sources, num_pad, 0) - input["padding_mask"] = self._bucket_tensor(padding_mask, num_pad, True) - - if self.compute_mask_indices: - B = input["source"].size(0) - T = self._get_mask_indices_dims(input["source"].size(-1)) - padding_mask_reshaped = input["padding_mask"].clone() - extra = padding_mask_reshaped.size(1) % T - if extra > 0: - padding_mask_reshaped = padding_mask_reshaped[:, :-extra] - padding_mask_reshaped = padding_mask_reshaped.view( - padding_mask_reshaped.size(0), T, -1 - ) - padding_mask_reshaped = padding_mask_reshaped.all(-1) - input["padding_count"] = padding_mask_reshaped.sum(-1).max().item() - mask_indices, mask_channel_indices = self._compute_mask_indices( - (B, T, self._C), - padding_mask_reshaped, - ) - input["mask_indices"] = mask_indices - input["mask_channel_indices"] = mask_channel_indices - out["sample_size"] = mask_indices.sum().item() - - out["net_input"] = input - return out - - def _get_mask_indices_dims(self, size, padding=0, dilation=1): - if size not in self._features_size_map: - L_in = size - for (_, kernel_size, stride) in self._conv_feature_layers: - L_out = L_in + 2 * padding - dilation * (kernel_size - 1) - 1 - L_out = 1 + L_out // stride - L_in = L_out - self._features_size_map[size] = L_out - return self._features_size_map[size] - - def num_tokens(self, index): - return self.size(index) - - def size(self, index): - """Return an example's size as a float or tuple. This value is used when - filtering a dataset with ``--max-positions``.""" - if self.pad: - return self.sizes[index] - return min(self.sizes[index], self.max_sample_size) - - def ordered_indices(self): - """Return an ordered list of indices. Batches will be constructed based - on this order.""" - - if self.shuffle: - order = [np.random.permutation(len(self))] - order.append( - np.minimum( - np.array(self.sizes), - self.max_sample_size, - ) - ) - return np.lexsort(order)[::-1] - else: - return np.arange(len(self)) - - def set_bucket_info(self, num_buckets): - self.num_buckets = num_buckets - if self.num_buckets > 0: - self._collated_sizes = np.minimum( - np.array(self.sizes), - self.max_sample_size, - ) - self.buckets = get_buckets( - self._collated_sizes, - self.num_buckets, - ) - self._bucketed_sizes = get_bucketed_sizes( - self._collated_sizes, self.buckets - ) - logger.info( - f"{len(self.buckets)} bucket(s) for the audio dataset: " - f"{self.buckets}" - ) - - -class FileAudioDataset(RawAudioDataset): - def __init__( - self, - manifest_path, - sample_rate, - max_sample_size=None, - min_sample_size=0, - shuffle=True, - pad=False, - normalize=False, - num_buckets=0, - compute_mask_indices=False, - **mask_compute_kwargs, - ): - super().__init__( - sample_rate=sample_rate, - max_sample_size=max_sample_size, - min_sample_size=min_sample_size, - shuffle=shuffle, - pad=pad, - normalize=normalize, - compute_mask_indices=compute_mask_indices, - **mask_compute_kwargs, - ) - - skipped = 0 - self.fnames = [] - sizes = [] - self.skipped_indices = set() - - with open(manifest_path, "r") as f: - self.root_dir = f.readline().strip() - for i, line in enumerate(f): - items = line.strip().split("\t") - assert len(items) == 2, line - sz = int(items[1]) - if min_sample_size is not None and sz < min_sample_size: - skipped += 1 - self.skipped_indices.add(i) - continue - self.fnames.append(items[0]) - sizes.append(sz) - logger.info(f"loaded {len(self.fnames)}, skipped {skipped} samples") - - self.sizes = np.array(sizes, dtype=np.int64) - - try: - import pyarrow - - self.fnames = pyarrow.array(self.fnames) - except: - logger.debug( - "Could not create a pyarrow array. Please install pyarrow for better performance" - ) - pass - - self.set_bucket_info(num_buckets) - - def __getitem__(self, index): - import soundfile as sf - - path_or_fp = os.path.join(self.root_dir, str(self.fnames[index])) - _path, slice_ptr = parse_path(path_or_fp) - if len(slice_ptr) == 2: - byte_data = read_from_stored_zip(_path, slice_ptr[0], slice_ptr[1]) - assert is_sf_audio_data(byte_data) - path_or_fp = io.BytesIO(byte_data) - - wav, curr_sample_rate = sf.read(path_or_fp, dtype="float32") - - feats = torch.from_numpy(wav).float() - feats = self.postprocess(feats, curr_sample_rate) - return {"id": index, "source": feats} - - -class BinarizedAudioDataset(RawAudioDataset): - def __init__( - self, - data_dir, - split, - sample_rate, - max_sample_size=None, - min_sample_size=0, - shuffle=True, - pad=False, - normalize=False, - num_buckets=0, - compute_mask_indices=False, - **mask_compute_kwargs, - ): - super().__init__( - sample_rate=sample_rate, - max_sample_size=max_sample_size, - min_sample_size=min_sample_size, - shuffle=shuffle, - pad=pad, - normalize=normalize, - compute_mask_indices=compute_mask_indices, - **mask_compute_kwargs, - ) - - from fairseq.data import data_utils, Dictionary - - self.fnames_dict = Dictionary.load(os.path.join(data_dir, "dict.txt")) - - root_path = os.path.join(data_dir, f"{split}.root") - if os.path.exists(root_path): - with open(root_path, "r") as f: - self.root_dir = next(f).strip() - else: - self.root_dir = None - - fnames_path = os.path.join(data_dir, split) - self.fnames = data_utils.load_indexed_dataset(fnames_path, self.fnames_dict) - lengths_path = os.path.join(data_dir, f"{split}.lengths") - - with open(lengths_path, "r") as f: - for line in f: - sz = int(line.rstrip()) - assert ( - sz >= min_sample_size - ), f"Min sample size is not supported for binarized dataset, but found a sample with size {sz}" - self.sizes.append(sz) - - self.sizes = np.array(self.sizes, dtype=np.int64) - - self.set_bucket_info(num_buckets) - logger.info(f"loaded {len(self.fnames)} samples") - - def __getitem__(self, index): - import soundfile as sf - - fname = self.fnames_dict.string(self.fnames[index], separator="") - if self.root_dir: - fname = os.path.join(self.root_dir, fname) - - wav, curr_sample_rate = sf.read(fname) - feats = torch.from_numpy(wav).float() - feats = self.postprocess(feats, curr_sample_rate) - return {"id": index, "source": feats} diff --git a/spaces/gsaivinay/open_llm_leaderboard/src/display_models/model_metadata_type.py b/spaces/gsaivinay/open_llm_leaderboard/src/display_models/model_metadata_type.py deleted file mode 100644 index 61dec0a30f758c9350f59d028f07b0a782a3f317..0000000000000000000000000000000000000000 --- a/spaces/gsaivinay/open_llm_leaderboard/src/display_models/model_metadata_type.py +++ /dev/null @@ -1,555 +0,0 @@ -from dataclasses import dataclass -from enum import Enum -from typing import Dict - - -@dataclass -class ModelInfo: - name: str - symbol: str # emoji - - -class ModelType(Enum): - PT = ModelInfo(name="pretrained", symbol="🟢") - FT = ModelInfo(name="fine-tuned", symbol="🔶") - IFT = ModelInfo(name="instruction-tuned", symbol="⭕") - RL = ModelInfo(name="RL-tuned", symbol="🟦") - Unknown = ModelInfo(name="Unknown", symbol="?") - - def to_str(self, separator=" "): - return f"{self.value.symbol}{separator}{self.value.name}" - - -MODEL_TYPE_METADATA: Dict[str, ModelType] = { - "tiiuae/falcon-180B": ModelType.PT, - "tiiuae/falcon-180B-chat": ModelType.RL, - "microsoft/phi-1_5": ModelType.PT, - "Qwen/Qwen-7B": ModelType.PT, - "Qwen/Qwen-7B-Chat": ModelType.RL, - "notstoic/PygmalionCoT-7b": ModelType.IFT, - "aisquared/dlite-v1-355m": ModelType.IFT, - "aisquared/dlite-v1-1_5b": ModelType.IFT, - "aisquared/dlite-v1-774m": ModelType.IFT, - "aisquared/dlite-v1-124m": ModelType.IFT, - "aisquared/chopt-2_7b": ModelType.IFT, - "aisquared/dlite-v2-124m": ModelType.IFT, - "aisquared/dlite-v2-774m": ModelType.IFT, - "aisquared/dlite-v2-1_5b": ModelType.IFT, - "aisquared/chopt-1_3b": ModelType.IFT, - "aisquared/dlite-v2-355m": ModelType.IFT, - "augtoma/qCammel-13": ModelType.IFT, - "Aspik101/Llama-2-7b-hf-instruct-pl-lora_unload": ModelType.IFT, - "Aspik101/vicuna-7b-v1.3-instruct-pl-lora_unload": ModelType.IFT, - "TheBloke/alpaca-lora-65B-HF": ModelType.FT, - "TheBloke/tulu-7B-fp16": ModelType.IFT, - "TheBloke/guanaco-7B-HF": ModelType.FT, - "TheBloke/koala-7B-HF": ModelType.FT, - "TheBloke/wizardLM-7B-HF": ModelType.IFT, - "TheBloke/airoboros-13B-HF": ModelType.IFT, - "TheBloke/koala-13B-HF": ModelType.FT, - "TheBloke/Wizard-Vicuna-7B-Uncensored-HF": ModelType.FT, - "TheBloke/dromedary-65b-lora-HF": ModelType.IFT, - "TheBloke/wizardLM-13B-1.0-fp16": ModelType.IFT, - "TheBloke/WizardLM-13B-V1-1-SuperHOT-8K-fp16": ModelType.FT, - "TheBloke/Wizard-Vicuna-30B-Uncensored-fp16": ModelType.FT, - "TheBloke/wizard-vicuna-13B-HF": ModelType.IFT, - "TheBloke/UltraLM-13B-fp16": ModelType.IFT, - "TheBloke/OpenAssistant-FT-7-Llama-30B-HF": ModelType.FT, - "TheBloke/vicuna-13B-1.1-HF": ModelType.IFT, - "TheBloke/guanaco-13B-HF": ModelType.FT, - "TheBloke/guanaco-65B-HF": ModelType.FT, - "TheBloke/airoboros-7b-gpt4-fp16": ModelType.IFT, - "TheBloke/llama-30b-supercot-SuperHOT-8K-fp16": ModelType.IFT, - "TheBloke/Llama-2-13B-fp16": ModelType.PT, - "TheBloke/llama-2-70b-Guanaco-QLoRA-fp16": ModelType.FT, - "TheBloke/landmark-attention-llama7b-fp16": ModelType.IFT, - "TheBloke/Planner-7B-fp16": ModelType.IFT, - "TheBloke/Wizard-Vicuna-13B-Uncensored-HF": ModelType.FT, - "TheBloke/gpt4-alpaca-lora-13B-HF": ModelType.IFT, - "TheBloke/gpt4-x-vicuna-13B-HF": ModelType.IFT, - "TheBloke/gpt4-alpaca-lora_mlp-65B-HF": ModelType.IFT, - "TheBloke/tulu-13B-fp16": ModelType.IFT, - "TheBloke/VicUnlocked-alpaca-65B-QLoRA-fp16": ModelType.IFT, - "TheBloke/Llama-2-70B-fp16": ModelType.IFT, - "TheBloke/WizardLM-30B-fp16": ModelType.IFT, - "TheBloke/robin-13B-v2-fp16": ModelType.FT, - "TheBloke/robin-33B-v2-fp16": ModelType.FT, - "TheBloke/Vicuna-13B-CoT-fp16": ModelType.IFT, - "TheBloke/Vicuna-33B-1-3-SuperHOT-8K-fp16": ModelType.IFT, - "TheBloke/Wizard-Vicuna-30B-Superhot-8K-fp16": ModelType.FT, - "TheBloke/Nous-Hermes-13B-SuperHOT-8K-fp16": ModelType.IFT, - "TheBloke/GPlatty-30B-SuperHOT-8K-fp16": ModelType.FT, - "TheBloke/CAMEL-33B-Combined-Data-SuperHOT-8K-fp16": ModelType.IFT, - "TheBloke/Chinese-Alpaca-33B-SuperHOT-8K-fp16": ModelType.IFT, - "jphme/orca_mini_v2_ger_7b": ModelType.IFT, - "Ejafa/vicuna_7B_vanilla_1.1": ModelType.FT, - "kevinpro/Vicuna-13B-CoT": ModelType.IFT, - "AlekseyKorshuk/pygmalion-6b-vicuna-chatml": ModelType.FT, - "AlekseyKorshuk/chatml-pyg-v1": ModelType.FT, - "concedo/Vicuzard-30B-Uncensored": ModelType.FT, - "concedo/OPT-19M-ChatSalad": ModelType.FT, - "concedo/Pythia-70M-ChatSalad": ModelType.FT, - "digitous/13B-HyperMantis": ModelType.IFT, - "digitous/Adventien-GPTJ": ModelType.FT, - "digitous/Alpacino13b": ModelType.IFT, - "digitous/GPT-R": ModelType.IFT, - "digitous/Javelin-R": ModelType.IFT, - "digitous/Javalion-GPTJ": ModelType.IFT, - "digitous/Javalion-R": ModelType.IFT, - "digitous/Skegma-GPTJ": ModelType.FT, - "digitous/Alpacino30b": ModelType.IFT, - "digitous/Janin-GPTJ": ModelType.FT, - "digitous/Janin-R": ModelType.FT, - "digitous/Javelin-GPTJ": ModelType.FT, - "SaylorTwift/gpt2_test": ModelType.PT, - "anton-l/gpt-j-tiny-random": ModelType.FT, - "Andron00e/YetAnother_Open-Llama-3B-LoRA-OpenOrca": ModelType.FT, - "Lazycuber/pyg-instruct-wizardlm": ModelType.FT, - "Lazycuber/Janemalion-6B": ModelType.FT, - "IDEA-CCNL/Ziya-LLaMA-13B-Pretrain-v1": ModelType.FT, - "IDEA-CCNL/Ziya-LLaMA-13B-v1": ModelType.IFT, - "dsvv-cair/alpaca-cleaned-llama-30b-bf16": ModelType.FT, - "gpt2-medium": ModelType.PT, - "camel-ai/CAMEL-13B-Combined-Data": ModelType.IFT, - "camel-ai/CAMEL-13B-Role-Playing-Data": ModelType.FT, - "camel-ai/CAMEL-33B-Combined-Data": ModelType.IFT, - "PygmalionAI/pygmalion-6b": ModelType.FT, - "PygmalionAI/metharme-1.3b": ModelType.IFT, - "PygmalionAI/pygmalion-1.3b": ModelType.FT, - "PygmalionAI/pygmalion-350m": ModelType.FT, - "PygmalionAI/pygmalion-2.7b": ModelType.FT, - "medalpaca/medalpaca-7b": ModelType.FT, - "lilloukas/Platypus-30B": ModelType.IFT, - "lilloukas/GPlatty-30B": ModelType.FT, - "mncai/chatdoctor": ModelType.FT, - "chaoyi-wu/MedLLaMA_13B": ModelType.FT, - "LoupGarou/WizardCoder-Guanaco-15B-V1.0": ModelType.IFT, - "LoupGarou/WizardCoder-Guanaco-15B-V1.1": ModelType.FT, - "hakurei/instruct-12b": ModelType.IFT, - "hakurei/lotus-12B": ModelType.FT, - "shibing624/chinese-llama-plus-13b-hf": ModelType.IFT, - "shibing624/chinese-alpaca-plus-7b-hf": ModelType.IFT, - "shibing624/chinese-alpaca-plus-13b-hf": ModelType.IFT, - "mosaicml/mpt-7b-instruct": ModelType.IFT, - "mosaicml/mpt-30b-chat": ModelType.IFT, - "mosaicml/mpt-7b-storywriter": ModelType.FT, - "mosaicml/mpt-30b-instruct": ModelType.IFT, - "mosaicml/mpt-7b-chat": ModelType.IFT, - "mosaicml/mpt-30b": ModelType.PT, - "Corianas/111m": ModelType.IFT, - "Corianas/Quokka_1.3b": ModelType.IFT, - "Corianas/256_5epoch": ModelType.FT, - "Corianas/Quokka_256m": ModelType.IFT, - "Corianas/Quokka_590m": ModelType.IFT, - "Corianas/gpt-j-6B-Dolly": ModelType.FT, - "Corianas/Quokka_2.7b": ModelType.IFT, - "cyberagent/open-calm-7b": ModelType.FT, - "Aspik101/Nous-Hermes-13b-pl-lora_unload": ModelType.IFT, - "THUDM/chatglm2-6b": ModelType.IFT, - "MetaIX/GPT4-X-Alpasta-30b": ModelType.IFT, - "NYTK/PULI-GPTrio": ModelType.PT, - "EleutherAI/pythia-1.3b": ModelType.PT, - "EleutherAI/pythia-2.8b-deduped": ModelType.PT, - "EleutherAI/gpt-neo-125m": ModelType.PT, - "EleutherAI/pythia-160m": ModelType.PT, - "EleutherAI/gpt-neo-2.7B": ModelType.PT, - "EleutherAI/pythia-1b-deduped": ModelType.PT, - "EleutherAI/pythia-6.7b": ModelType.PT, - "EleutherAI/pythia-70m-deduped": ModelType.PT, - "EleutherAI/gpt-neox-20b": ModelType.PT, - "EleutherAI/pythia-1.4b-deduped": ModelType.PT, - "EleutherAI/pythia-2.7b": ModelType.PT, - "EleutherAI/pythia-6.9b-deduped": ModelType.PT, - "EleutherAI/pythia-70m": ModelType.PT, - "EleutherAI/gpt-j-6b": ModelType.PT, - "EleutherAI/pythia-12b-deduped": ModelType.PT, - "EleutherAI/gpt-neo-1.3B": ModelType.PT, - "EleutherAI/pythia-410m-deduped": ModelType.PT, - "EleutherAI/pythia-160m-deduped": ModelType.PT, - "EleutherAI/polyglot-ko-12.8b": ModelType.PT, - "EleutherAI/pythia-12b": ModelType.PT, - "roneneldan/TinyStories-33M": ModelType.PT, - "roneneldan/TinyStories-28M": ModelType.PT, - "roneneldan/TinyStories-1M": ModelType.PT, - "roneneldan/TinyStories-8M": ModelType.PT, - "roneneldan/TinyStories-3M": ModelType.PT, - "jerryjalapeno/nart-100k-7b": ModelType.FT, - "lmsys/vicuna-13b-v1.3": ModelType.IFT, - "lmsys/vicuna-7b-v1.3": ModelType.IFT, - "lmsys/vicuna-13b-v1.1": ModelType.IFT, - "lmsys/vicuna-13b-delta-v1.1": ModelType.IFT, - "lmsys/vicuna-7b-delta-v1.1": ModelType.IFT, - "abhiramtirumala/DialoGPT-sarcastic-medium": ModelType.FT, - "haonan-li/bactrian-x-llama-13b-merged": ModelType.IFT, - "Gryphe/MythoLogic-13b": ModelType.IFT, - "Gryphe/MythoBoros-13b": ModelType.IFT, - "pillowtalks-ai/delta13b": ModelType.FT, - "wannaphong/openthaigpt-0.1.0-beta-full-model_for_open_llm_leaderboard": ModelType.FT, - "bigscience/bloom-7b1": ModelType.PT, - "bigcode/tiny_starcoder_py": ModelType.PT, - "bigcode/starcoderplus": ModelType.FT, - "bigcode/gpt_bigcode-santacoder": ModelType.PT, - "bigcode/starcoder": ModelType.PT, - "Open-Orca/OpenOrca-Preview1-13B": ModelType.IFT, - "microsoft/DialoGPT-large": ModelType.FT, - "microsoft/DialoGPT-small": ModelType.FT, - "microsoft/DialoGPT-medium": ModelType.FT, - "microsoft/CodeGPT-small-py": ModelType.FT, - "Tincando/fiction_story_generator": ModelType.FT, - "Pirr/pythia-13b-deduped-green_devil": ModelType.FT, - "Aeala/GPT4-x-AlpacaDente2-30b": ModelType.FT, - "Aeala/GPT4-x-AlpacaDente-30b": ModelType.FT, - "Aeala/GPT4-x-Alpasta-13b": ModelType.FT, - "Aeala/VicUnlocked-alpaca-30b": ModelType.IFT, - "Tap-M/Luna-AI-Llama2-Uncensored": ModelType.FT, - "illuin/test-custom-llama": ModelType.FT, - "dvruette/oasst-llama-13b-2-epochs": ModelType.FT, - "dvruette/oasst-gpt-neox-20b-1000-steps": ModelType.FT, - "dvruette/llama-13b-pretrained-dropout": ModelType.PT, - "dvruette/llama-13b-pretrained": ModelType.PT, - "dvruette/llama-13b-pretrained-sft-epoch-1": ModelType.FT, - "dvruette/llama-13b-pretrained-sft-do2": ModelType.FT, - "dvruette/oasst-gpt-neox-20b-3000-steps": ModelType.FT, - "dvruette/oasst-pythia-12b-pretrained-sft": ModelType.FT, - "dvruette/oasst-pythia-6.9b-4000-steps": ModelType.FT, - "dvruette/gpt-neox-20b-full-precision": ModelType.FT, - "dvruette/oasst-llama-13b-1000-steps": ModelType.FT, - "openlm-research/open_llama_7b_700bt_preview": ModelType.PT, - "openlm-research/open_llama_7b": ModelType.PT, - "openlm-research/open_llama_7b_v2": ModelType.PT, - "openlm-research/open_llama_3b": ModelType.PT, - "openlm-research/open_llama_13b": ModelType.PT, - "openlm-research/open_llama_3b_v2": ModelType.PT, - "PocketDoc/Dans-PileOfSets-Mk1-llama-13b-merged": ModelType.IFT, - "GeorgiaTechResearchInstitute/galpaca-30b": ModelType.IFT, - "GeorgiaTechResearchInstitute/starcoder-gpteacher-code-instruct": ModelType.IFT, - "databricks/dolly-v2-7b": ModelType.IFT, - "databricks/dolly-v2-3b": ModelType.IFT, - "databricks/dolly-v2-12b": ModelType.IFT, - "Rachneet/gpt2-xl-alpaca": ModelType.FT, - "Locutusque/gpt2-conversational-or-qa": ModelType.FT, - "psyche/kogpt": ModelType.FT, - "NbAiLab/nb-gpt-j-6B-alpaca": ModelType.IFT, - "Mikael110/llama-2-7b-guanaco-fp16": ModelType.FT, - "Mikael110/llama-2-13b-guanaco-fp16": ModelType.FT, - "Fredithefish/CrimsonPajama": ModelType.IFT, - "Fredithefish/RedPajama-INCITE-Chat-3B-ShareGPT-11K": ModelType.FT, - "Fredithefish/ScarletPajama-3B-HF": ModelType.FT, - "Fredithefish/RedPajama-INCITE-Chat-3B-Instruction-Tuning-with-GPT-4": ModelType.IFT, - "acrastt/RedPajama-INCITE-Chat-Instruct-3B-V1": ModelType.IFT, - "eachadea/vicuna-13b-1.1": ModelType.FT, - "eachadea/vicuna-7b-1.1": ModelType.FT, - "eachadea/vicuna-13b": ModelType.FT, - "openaccess-ai-collective/wizard-mega-13b": ModelType.IFT, - "openaccess-ai-collective/manticore-13b": ModelType.IFT, - "openaccess-ai-collective/manticore-30b-chat-pyg-alpha": ModelType.IFT, - "openaccess-ai-collective/minotaur-13b": ModelType.IFT, - "openaccess-ai-collective/minotaur-13b-fixed": ModelType.IFT, - "openaccess-ai-collective/hippogriff-30b-chat": ModelType.IFT, - "openaccess-ai-collective/manticore-13b-chat-pyg": ModelType.IFT, - "pythainlp/wangchanglm-7.5B-sft-enth": ModelType.IFT, - "pythainlp/wangchanglm-7.5B-sft-en-sharded": ModelType.IFT, - "euclaise/gpt-neox-122m-minipile-digits": ModelType.FT, - "stabilityai/StableBeluga1-Delta": ModelType.IFT, - "stabilityai/stablelm-tuned-alpha-7b": ModelType.IFT, - "stabilityai/StableBeluga2": ModelType.IFT, - "stabilityai/StableBeluga-13B": ModelType.IFT, - "stabilityai/StableBeluga-7B": ModelType.IFT, - "stabilityai/stablelm-base-alpha-7b": ModelType.PT, - "stabilityai/stablelm-base-alpha-3b": ModelType.PT, - "stabilityai/stablelm-tuned-alpha-3b": ModelType.IFT, - "alibidaran/medical_transcription_generator": ModelType.FT, - "CalderaAI/30B-Lazarus": ModelType.IFT, - "CalderaAI/13B-BlueMethod": ModelType.IFT, - "CalderaAI/13B-Ouroboros": ModelType.IFT, - "KoboldAI/OPT-13B-Erebus": ModelType.FT, - "KoboldAI/GPT-J-6B-Janeway": ModelType.FT, - "KoboldAI/GPT-J-6B-Shinen": ModelType.FT, - "KoboldAI/fairseq-dense-2.7B": ModelType.PT, - "KoboldAI/OPT-6B-nerys-v2": ModelType.FT, - "KoboldAI/GPT-NeoX-20B-Skein": ModelType.FT, - "KoboldAI/PPO_Pygway-6b-Mix": ModelType.FT, - "KoboldAI/fairseq-dense-6.7B": ModelType.PT, - "KoboldAI/fairseq-dense-125M": ModelType.PT, - "KoboldAI/OPT-13B-Nerybus-Mix": ModelType.FT, - "KoboldAI/OPT-2.7B-Erebus": ModelType.FT, - "KoboldAI/OPT-350M-Nerys-v2": ModelType.FT, - "KoboldAI/OPT-2.7B-Nerys-v2": ModelType.FT, - "KoboldAI/OPT-2.7B-Nerybus-Mix": ModelType.FT, - "KoboldAI/OPT-13B-Nerys-v2": ModelType.FT, - "KoboldAI/GPT-NeoX-20B-Erebus": ModelType.FT, - "KoboldAI/OPT-6.7B-Erebus": ModelType.FT, - "KoboldAI/fairseq-dense-355M": ModelType.PT, - "KoboldAI/OPT-6.7B-Nerybus-Mix": ModelType.FT, - "KoboldAI/GPT-J-6B-Adventure": ModelType.FT, - "KoboldAI/OPT-350M-Erebus": ModelType.FT, - "KoboldAI/GPT-J-6B-Skein": ModelType.FT, - "KoboldAI/OPT-30B-Erebus": ModelType.FT, - "klosax/pythia-160m-deduped-step92k-193bt": ModelType.PT, - "klosax/open_llama_3b_350bt_preview": ModelType.PT, - "klosax/openllama-3b-350bt": ModelType.PT, - "klosax/pythia-70m-deduped-step44k-92bt": ModelType.PT, - "klosax/open_llama_13b_600bt_preview": ModelType.PT, - "klosax/open_llama_7b_400bt_preview": ModelType.PT, - "kfkas/Llama-2-ko-7b-Chat": ModelType.IFT, - "WeOpenML/Alpaca-7B-v1": ModelType.IFT, - "WeOpenML/PandaLM-Alpaca-7B-v1": ModelType.IFT, - "TFLai/gpt2-turkish-uncased": ModelType.FT, - "ehartford/WizardLM-13B-Uncensored": ModelType.IFT, - "ehartford/dolphin-llama-13b": ModelType.IFT, - "ehartford/Wizard-Vicuna-30B-Uncensored": ModelType.FT, - "ehartford/WizardLM-30B-Uncensored": ModelType.IFT, - "ehartford/Wizard-Vicuna-13B-Uncensored": ModelType.FT, - "ehartford/WizardLM-7B-Uncensored": ModelType.IFT, - "ehartford/based-30b": ModelType.FT, - "ehartford/Wizard-Vicuna-7B-Uncensored": ModelType.FT, - "wahaha1987/llama_7b_sharegpt94k_fastchat": ModelType.FT, - "wahaha1987/llama_13b_sharegpt94k_fastchat": ModelType.FT, - "OpenAssistant/oasst-sft-1-pythia-12b": ModelType.FT, - "OpenAssistant/stablelm-7b-sft-v7-epoch-3": ModelType.IFT, - "OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5": ModelType.FT, - "OpenAssistant/pythia-12b-sft-v8-2.5k-steps": ModelType.IFT, - "OpenAssistant/pythia-12b-sft-v8-7k-steps": ModelType.IFT, - "OpenAssistant/pythia-12b-pre-v8-12.5k-steps": ModelType.IFT, - "OpenAssistant/llama2-13b-orca-8k-3319": ModelType.IFT, - "junelee/wizard-vicuna-13b": ModelType.FT, - "BreadAi/gpt-YA-1-1_160M": ModelType.PT, - "BreadAi/MuseCan": ModelType.PT, - "BreadAi/MusePy-1-2": ModelType.PT, - "BreadAi/DiscordPy": ModelType.PT, - "BreadAi/PM_modelV2": ModelType.PT, - "BreadAi/gpt-Youtube": ModelType.PT, - "BreadAi/StoryPy": ModelType.FT, - "julianweng/Llama-2-7b-chat-orcah": ModelType.FT, - "AGI-inc/lora_moe_7b_baseline": ModelType.FT, - "AGI-inc/lora_moe_7b": ModelType.FT, - "togethercomputer/GPT-NeoXT-Chat-Base-20B": ModelType.IFT, - "togethercomputer/RedPajama-INCITE-Chat-7B-v0.1": ModelType.IFT, - "togethercomputer/RedPajama-INCITE-Instruct-7B-v0.1": ModelType.IFT, - "togethercomputer/RedPajama-INCITE-7B-Base": ModelType.PT, - "togethercomputer/RedPajama-INCITE-7B-Instruct": ModelType.IFT, - "togethercomputer/RedPajama-INCITE-Base-3B-v1": ModelType.PT, - "togethercomputer/Pythia-Chat-Base-7B": ModelType.IFT, - "togethercomputer/RedPajama-INCITE-Base-7B-v0.1": ModelType.PT, - "togethercomputer/GPT-JT-6B-v1": ModelType.IFT, - "togethercomputer/GPT-JT-6B-v0": ModelType.IFT, - "togethercomputer/RedPajama-INCITE-Chat-3B-v1": ModelType.IFT, - "togethercomputer/RedPajama-INCITE-7B-Chat": ModelType.IFT, - "togethercomputer/RedPajama-INCITE-Instruct-3B-v1": ModelType.IFT, - "Writer/camel-5b-hf": ModelType.IFT, - "Writer/palmyra-base": ModelType.PT, - "MBZUAI/LaMini-GPT-1.5B": ModelType.IFT, - "MBZUAI/lamini-cerebras-111m": ModelType.IFT, - "MBZUAI/lamini-neo-1.3b": ModelType.IFT, - "MBZUAI/lamini-cerebras-1.3b": ModelType.IFT, - "MBZUAI/lamini-cerebras-256m": ModelType.IFT, - "MBZUAI/LaMini-GPT-124M": ModelType.IFT, - "MBZUAI/lamini-neo-125m": ModelType.IFT, - "TehVenom/DiffMerge-DollyGPT-Pygmalion": ModelType.FT, - "TehVenom/PPO_Shygmalion-6b": ModelType.FT, - "TehVenom/Dolly_Shygmalion-6b-Dev_V8P2": ModelType.FT, - "TehVenom/Pygmalion_AlpacaLora-7b": ModelType.FT, - "TehVenom/PPO_Pygway-V8p4_Dev-6b": ModelType.FT, - "TehVenom/Dolly_Malion-6b": ModelType.FT, - "TehVenom/PPO_Shygmalion-V8p4_Dev-6b": ModelType.FT, - "TehVenom/ChanMalion": ModelType.FT, - "TehVenom/GPT-J-Pyg_PPO-6B": ModelType.IFT, - "TehVenom/Pygmalion-13b-Merged": ModelType.FT, - "TehVenom/Metharme-13b-Merged": ModelType.IFT, - "TehVenom/Dolly_Shygmalion-6b": ModelType.FT, - "TehVenom/GPT-J-Pyg_PPO-6B-Dev-V8p4": ModelType.IFT, - "georgesung/llama2_7b_chat_uncensored": ModelType.FT, - "vicgalle/gpt2-alpaca": ModelType.IFT, - "vicgalle/alpaca-7b": ModelType.FT, - "vicgalle/gpt2-alpaca-gpt4": ModelType.IFT, - "facebook/opt-350m": ModelType.PT, - "facebook/opt-125m": ModelType.PT, - "facebook/xglm-4.5B": ModelType.PT, - "facebook/opt-2.7b": ModelType.PT, - "facebook/opt-6.7b": ModelType.PT, - "facebook/galactica-30b": ModelType.PT, - "facebook/opt-13b": ModelType.PT, - "facebook/opt-66b": ModelType.PT, - "facebook/xglm-7.5B": ModelType.PT, - "facebook/xglm-564M": ModelType.PT, - "facebook/opt-30b": ModelType.PT, - "golaxy/gogpt-7b": ModelType.FT, - "golaxy/gogpt2-7b": ModelType.FT, - "golaxy/gogpt-7b-bloom": ModelType.FT, - "golaxy/gogpt-3b-bloom": ModelType.FT, - "psmathur/orca_mini_v2_7b": ModelType.IFT, - "psmathur/orca_mini_7b": ModelType.IFT, - "psmathur/orca_mini_3b": ModelType.IFT, - "psmathur/orca_mini_v2_13b": ModelType.IFT, - "gpt2-xl": ModelType.PT, - "lxe/Cerebras-GPT-2.7B-Alpaca-SP": ModelType.FT, - "Monero/Manticore-13b-Chat-Pyg-Guanaco": ModelType.FT, - "Monero/WizardLM-Uncensored-SuperCOT-StoryTelling-30b": ModelType.IFT, - "Monero/WizardLM-13b-OpenAssistant-Uncensored": ModelType.IFT, - "Monero/WizardLM-30B-Uncensored-Guanaco-SuperCOT-30b": ModelType.IFT, - "jzjiao/opt-1.3b-rlhf": ModelType.FT, - "HuggingFaceH4/starchat-beta": ModelType.IFT, - "KnutJaegersberg/gpt-2-xl-EvolInstruct": ModelType.IFT, - "KnutJaegersberg/megatron-GPT-2-345m-EvolInstruct": ModelType.IFT, - "KnutJaegersberg/galactica-orca-wizardlm-1.3b": ModelType.IFT, - "openchat/openchat_8192": ModelType.IFT, - "openchat/openchat_v2": ModelType.IFT, - "openchat/openchat_v2_w": ModelType.IFT, - "ausboss/llama-13b-supercot": ModelType.IFT, - "ausboss/llama-30b-supercot": ModelType.IFT, - "Neko-Institute-of-Science/metharme-7b": ModelType.IFT, - "Neko-Institute-of-Science/pygmalion-7b": ModelType.FT, - "SebastianSchramm/Cerebras-GPT-111M-instruction": ModelType.IFT, - "victor123/WizardLM-13B-1.0": ModelType.IFT, - "OpenBuddy/openbuddy-openllama-13b-v7-fp16": ModelType.FT, - "OpenBuddy/openbuddy-llama2-13b-v8.1-fp16": ModelType.FT, - "OpenBuddyEA/openbuddy-llama-30b-v7.1-bf16": ModelType.FT, - "baichuan-inc/Baichuan-7B": ModelType.PT, - "tiiuae/falcon-40b-instruct": ModelType.IFT, - "tiiuae/falcon-40b": ModelType.PT, - "tiiuae/falcon-7b": ModelType.PT, - "YeungNLP/firefly-llama-13b": ModelType.FT, - "YeungNLP/firefly-llama-13b-v1.2": ModelType.FT, - "YeungNLP/firefly-llama2-13b": ModelType.FT, - "YeungNLP/firefly-ziya-13b": ModelType.FT, - "shaohang/Sparse0.5_OPT-1.3": ModelType.FT, - "xzuyn/Alpacino-SuperCOT-13B": ModelType.IFT, - "xzuyn/MedicWizard-7B": ModelType.FT, - "xDAN-AI/xDAN_13b_l2_lora": ModelType.FT, - "beomi/KoAlpaca-Polyglot-5.8B": ModelType.FT, - "beomi/llama-2-ko-7b": ModelType.IFT, - "Salesforce/codegen-6B-multi": ModelType.PT, - "Salesforce/codegen-16B-nl": ModelType.PT, - "Salesforce/codegen-6B-nl": ModelType.PT, - "ai-forever/rugpt3large_based_on_gpt2": ModelType.FT, - "gpt2-large": ModelType.PT, - "frank098/orca_mini_3b_juniper": ModelType.FT, - "frank098/WizardLM_13B_juniper": ModelType.FT, - "FPHam/Free_Sydney_13b_HF": ModelType.FT, - "huggingface/llama-13b": ModelType.PT, - "huggingface/llama-7b": ModelType.PT, - "huggingface/llama-65b": ModelType.PT, - "huggingface/llama-30b": ModelType.PT, - "Henk717/chronoboros-33B": ModelType.IFT, - "jondurbin/airoboros-13b-gpt4-1.4": ModelType.IFT, - "jondurbin/airoboros-7b": ModelType.IFT, - "jondurbin/airoboros-7b-gpt4": ModelType.IFT, - "jondurbin/airoboros-7b-gpt4-1.1": ModelType.IFT, - "jondurbin/airoboros-7b-gpt4-1.2": ModelType.IFT, - "jondurbin/airoboros-7b-gpt4-1.3": ModelType.IFT, - "jondurbin/airoboros-7b-gpt4-1.4": ModelType.IFT, - "jondurbin/airoboros-l2-7b-gpt4-1.4.1": ModelType.IFT, - "jondurbin/airoboros-l2-13b-gpt4-1.4.1": ModelType.IFT, - "jondurbin/airoboros-l2-70b-gpt4-1.4.1": ModelType.IFT, - "jondurbin/airoboros-13b": ModelType.IFT, - "jondurbin/airoboros-33b-gpt4-1.4": ModelType.IFT, - "jondurbin/airoboros-33b-gpt4-1.2": ModelType.IFT, - "jondurbin/airoboros-65b-gpt4-1.2": ModelType.IFT, - "ariellee/SuperPlatty-30B": ModelType.IFT, - "danielhanchen/open_llama_3b_600bt_preview": ModelType.FT, - "cerebras/Cerebras-GPT-256M": ModelType.PT, - "cerebras/Cerebras-GPT-1.3B": ModelType.PT, - "cerebras/Cerebras-GPT-13B": ModelType.PT, - "cerebras/Cerebras-GPT-2.7B": ModelType.PT, - "cerebras/Cerebras-GPT-111M": ModelType.PT, - "cerebras/Cerebras-GPT-6.7B": ModelType.PT, - "Yhyu13/oasst-rlhf-2-llama-30b-7k-steps-hf": ModelType.RL, - "Yhyu13/llama-30B-hf-openassitant": ModelType.FT, - "NousResearch/Nous-Hermes-Llama2-13b": ModelType.IFT, - "NousResearch/Nous-Hermes-llama-2-7b": ModelType.IFT, - "NousResearch/Redmond-Puffin-13B": ModelType.IFT, - "NousResearch/Nous-Hermes-13b": ModelType.IFT, - "project-baize/baize-v2-7b": ModelType.IFT, - "project-baize/baize-v2-13b": ModelType.IFT, - "LLMs/WizardLM-13B-V1.0": ModelType.FT, - "LLMs/AlpacaGPT4-7B-elina": ModelType.FT, - "wenge-research/yayi-7b": ModelType.FT, - "wenge-research/yayi-7b-llama2": ModelType.FT, - "wenge-research/yayi-13b-llama2": ModelType.FT, - "yhyhy3/open_llama_7b_v2_med_instruct": ModelType.IFT, - "llama-anon/instruct-13b": ModelType.IFT, - "huggingtweets/jerma985": ModelType.FT, - "huggingtweets/gladosystem": ModelType.FT, - "huggingtweets/bladeecity-jerma985": ModelType.FT, - "huggyllama/llama-13b": ModelType.PT, - "huggyllama/llama-65b": ModelType.PT, - "FabbriSimo01/Facebook_opt_1.3b_Quantized": ModelType.PT, - "upstage/Llama-2-70b-instruct": ModelType.IFT, - "upstage/Llama-2-70b-instruct-1024": ModelType.IFT, - "upstage/llama-65b-instruct": ModelType.IFT, - "upstage/llama-30b-instruct-2048": ModelType.IFT, - "upstage/llama-30b-instruct": ModelType.IFT, - "WizardLM/WizardLM-13B-1.0": ModelType.IFT, - "WizardLM/WizardLM-13B-V1.1": ModelType.IFT, - "WizardLM/WizardLM-13B-V1.2": ModelType.IFT, - "WizardLM/WizardLM-30B-V1.0": ModelType.IFT, - "WizardLM/WizardCoder-15B-V1.0": ModelType.IFT, - "gpt2": ModelType.PT, - "keyfan/vicuna-chinese-replication-v1.1": ModelType.IFT, - "nthngdy/pythia-owt2-70m-100k": ModelType.FT, - "nthngdy/pythia-owt2-70m-50k": ModelType.FT, - "quantumaikr/KoreanLM-hf": ModelType.FT, - "quantumaikr/open_llama_7b_hf": ModelType.FT, - "quantumaikr/QuantumLM-70B-hf": ModelType.IFT, - "MayaPH/FinOPT-Lincoln": ModelType.FT, - "MayaPH/FinOPT-Franklin": ModelType.FT, - "MayaPH/GodziLLa-30B": ModelType.IFT, - "MayaPH/GodziLLa-30B-plus": ModelType.IFT, - "MayaPH/FinOPT-Washington": ModelType.FT, - "ogimgio/gpt-neo-125m-neurallinguisticpioneers": ModelType.FT, - "layoric/llama-2-13b-code-alpaca": ModelType.FT, - "CobraMamba/mamba-gpt-3b": ModelType.FT, - "CobraMamba/mamba-gpt-3b-v2": ModelType.FT, - "CobraMamba/mamba-gpt-3b-v3": ModelType.FT, - "timdettmers/guanaco-33b-merged": ModelType.FT, - "elinas/chronos-33b": ModelType.IFT, - "heegyu/RedTulu-Uncensored-3B-0719": ModelType.IFT, - "heegyu/WizardVicuna-Uncensored-3B-0719": ModelType.IFT, - "heegyu/WizardVicuna-3B-0719": ModelType.IFT, - "meta-llama/Llama-2-7b-chat-hf": ModelType.RL, - "meta-llama/Llama-2-7b-hf": ModelType.PT, - "meta-llama/Llama-2-13b-chat-hf": ModelType.RL, - "meta-llama/Llama-2-13b-hf": ModelType.PT, - "meta-llama/Llama-2-70b-chat-hf": ModelType.RL, - "meta-llama/Llama-2-70b-hf": ModelType.PT, - "xhyi/PT_GPTNEO350_ATG": ModelType.FT, - "h2oai/h2ogpt-gm-oasst1-en-1024-20b": ModelType.FT, - "h2oai/h2ogpt-gm-oasst1-en-1024-open-llama-7b-preview-400bt": ModelType.FT, - "h2oai/h2ogpt-oig-oasst1-512-6_9b": ModelType.IFT, - "h2oai/h2ogpt-oasst1-512-12b": ModelType.IFT, - "h2oai/h2ogpt-oig-oasst1-256-6_9b": ModelType.IFT, - "h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b-preview-300bt": ModelType.FT, - "h2oai/h2ogpt-oasst1-512-20b": ModelType.IFT, - "h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b-preview-300bt-v2": ModelType.FT, - "h2oai/h2ogpt-gm-oasst1-en-1024-12b": ModelType.FT, - "h2oai/h2ogpt-gm-oasst1-multilang-1024-20b": ModelType.FT, - "bofenghuang/vigogne-13b-instruct": ModelType.IFT, - "bofenghuang/vigogne-13b-chat": ModelType.FT, - "bofenghuang/vigogne-2-7b-instruct": ModelType.IFT, - "bofenghuang/vigogne-7b-instruct": ModelType.IFT, - "bofenghuang/vigogne-7b-chat": ModelType.FT, - "Vmware/open-llama-7b-v2-open-instruct": ModelType.IFT, - "VMware/open-llama-0.7T-7B-open-instruct-v1.1": ModelType.IFT, - "ewof/koishi-instruct-3b": ModelType.IFT, - "gywy/llama2-13b-chinese-v1": ModelType.FT, - "GOAT-AI/GOAT-7B-Community": ModelType.FT, - "psyche/kollama2-7b": ModelType.FT, - "TheTravellingEngineer/llama2-7b-hf-guanaco": ModelType.FT, - "beaugogh/pythia-1.4b-deduped-sharegpt": ModelType.FT, - "augtoma/qCammel-70-x": ModelType.IFT, - "Lajonbot/Llama-2-7b-chat-hf-instruct-pl-lora_unload": ModelType.IFT, - "anhnv125/pygmalion-6b-roleplay": ModelType.FT, - "64bits/LexPodLM-13B": ModelType.FT, -} - - -def model_type_from_str(type): - if "fine-tuned" in type or "🔶" in type: - return ModelType.FT - if "pretrained" in type or "🟢" in type: - return ModelType.PT - if "RL-tuned" in type or "🟦" in type: - return ModelType.RL - if "instruction-tuned" in type or "⭕" in type: - return ModelType.IFT - return ModelType.Unknown diff --git a/spaces/guymorlan/Arabic2Taatik/README.md b/spaces/guymorlan/Arabic2Taatik/README.md deleted file mode 100644 index 367054309a3d7173ed712f938d975b01ded5c535..0000000000000000000000000000000000000000 --- a/spaces/guymorlan/Arabic2Taatik/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Arabic2Taatik -emoji: 📈 -colorFrom: green -colorTo: red -sdk: gradio -sdk_version: 3.35.2 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/h2oai/wave-tour/examples/file_upload_compact.py b/spaces/h2oai/wave-tour/examples/file_upload_compact.py deleted file mode 100644 index 7090652ecb29e20447036146457d6c097f85bccf..0000000000000000000000000000000000000000 --- a/spaces/h2oai/wave-tour/examples/file_upload_compact.py +++ /dev/null @@ -1,24 +0,0 @@ -# Form / File Upload / Compact -# Use a compact file #upload component to take less form space. -# #form #file_upload #compact -# --- -from h2o_wave import main, app, Q, ui - - -@app('/demo') -async def serve(q: Q): - if 'file_upload' in q.args: - q.page['example'] = ui.form_card(box='1 1 4 10', items=[ - ui.text(f'file_upload={q.args.file_upload}'), - ui.button(name='show_upload', label='Back', primary=True), - ]) - else: - q.page['example'] = ui.form_card( - box='1 1 4 7', - items=[ - ui.file_upload(name='file_upload', label='Select one or more files to upload', compact=True, - multiple=True, file_extensions=['jpg', 'png'], max_file_size=1, max_size=15), - ui.button(name='submit', label='Submit', primary=True) - ] - ) - await q.page.save() diff --git a/spaces/h2oai/wave-tour/examples/plot_line.py b/spaces/h2oai/wave-tour/examples/plot_line.py deleted file mode 100644 index 68c5a701e726213796ea6ebf5c0c624995fa2615..0000000000000000000000000000000000000000 --- a/spaces/h2oai/wave-tour/examples/plot_line.py +++ /dev/null @@ -1,25 +0,0 @@ -# Plot / Line -# Make a line #plot. -# --- -from h2o_wave import site, data, ui - -page = site['/demo'] - -page.add('example', ui.plot_card( - box='1 1 4 5', - title='Line', - data=data('year value', 8, rows=[ - ('1991', 3), - ('1992', 4), - ('1993', 3.5), - ('1994', 5), - ('1995', 4.9), - ('1996', 6), - ('1997', 7), - ('1998', 9), - ('1999', 13), - ]), - plot=ui.plot([ui.mark(type='line', x_scale='time', x='=year', y='=value', y_min=0)]) -)) - -page.save() diff --git a/spaces/haakohu/deep_privacy2_face/sg3_torch_utils/ops/conv2d_gradfix.py b/spaces/haakohu/deep_privacy2_face/sg3_torch_utils/ops/conv2d_gradfix.py deleted file mode 100644 index e66591f19fad68760d3df7c9737a14574b70ee83..0000000000000000000000000000000000000000 --- a/spaces/haakohu/deep_privacy2_face/sg3_torch_utils/ops/conv2d_gradfix.py +++ /dev/null @@ -1,175 +0,0 @@ -# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved. -# -# NVIDIA CORPORATION and its licensors retain all intellectual property -# and proprietary rights in and to this software, related documentation -# and any modifications thereto. Any use, reproduction, disclosure or -# distribution of this software and related documentation without an express -# license agreement from NVIDIA CORPORATION is strictly prohibited. - -"""Custom replacement for `torch.nn.functional.conv2d` that supports -arbitrarily high order gradients with zero performance penalty.""" - -import warnings -import contextlib -import torch -from torch.cuda.amp import custom_bwd, custom_fwd - -# pylint: disable=redefined-builtin -# pylint: disable=arguments-differ -# pylint: disable=protected-access - -#---------------------------------------------------------------------------- - -enabled = False # Enable the custom op by setting this to true. -weight_gradients_disabled = False # Forcefully disable computation of gradients with respect to the weights. - -@contextlib.contextmanager -def no_weight_gradients(): - global weight_gradients_disabled - old = weight_gradients_disabled - weight_gradients_disabled = True - yield - weight_gradients_disabled = old - -#---------------------------------------------------------------------------- - -def conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1): - if _should_use_custom_op(input): - return _conv2d_gradfix(transpose=False, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=0, dilation=dilation, groups=groups).apply(input, weight, bias) - return torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, dilation=dilation, groups=groups) - -def conv_transpose2d(input, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1): - if _should_use_custom_op(input): - return _conv2d_gradfix(transpose=True, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation).apply(input, weight, bias) - return torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation) - -#---------------------------------------------------------------------------- - -def _should_use_custom_op(input): - assert isinstance(input, torch.Tensor) - if (not enabled) or (not torch.backends.cudnn.enabled): - return False - if input.device.type != 'cuda': - return False - if any(torch.__version__.startswith(x) for x in ['1.7.', '1.8.', '1.9', '1.10']): - return True - warnings.warn(f'conv2d_gradfix not supported on PyTorch {torch.__version__}. Falling back to torch.nn.functional.conv2d().') - return False - -def _tuple_of_ints(xs, ndim): - xs = tuple(xs) if isinstance(xs, (tuple, list)) else (xs,) * ndim - assert len(xs) == ndim - assert all(isinstance(x, int) for x in xs) - return xs - -#---------------------------------------------------------------------------- - -_conv2d_gradfix_cache = dict() - -def _conv2d_gradfix(transpose, weight_shape, stride, padding, output_padding, dilation, groups): - # Parse arguments. - ndim = 2 - weight_shape = tuple(weight_shape) - stride = _tuple_of_ints(stride, ndim) - padding = _tuple_of_ints(padding, ndim) - output_padding = _tuple_of_ints(output_padding, ndim) - dilation = _tuple_of_ints(dilation, ndim) - - # Lookup from cache. - key = (transpose, weight_shape, stride, padding, output_padding, dilation, groups) - if key in _conv2d_gradfix_cache: - return _conv2d_gradfix_cache[key] - - # Validate arguments. - assert groups >= 1 - assert len(weight_shape) == ndim + 2 - assert all(stride[i] >= 1 for i in range(ndim)) - assert all(padding[i] >= 0 for i in range(ndim)) - assert all(dilation[i] >= 0 for i in range(ndim)) - if not transpose: - assert all(output_padding[i] == 0 for i in range(ndim)) - else: # transpose - assert all(0 <= output_padding[i] < max(stride[i], dilation[i]) for i in range(ndim)) - - # Helpers. - common_kwargs = dict(stride=stride, padding=padding, dilation=dilation, groups=groups) - def calc_output_padding(input_shape, output_shape): - if transpose: - return [0, 0] - return [ - input_shape[i + 2] - - (output_shape[i + 2] - 1) * stride[i] - - (1 - 2 * padding[i]) - - dilation[i] * (weight_shape[i + 2] - 1) - for i in range(ndim) - ] - - # Forward & backward. - class Conv2d(torch.autograd.Function): - @staticmethod - @custom_fwd(cast_inputs=torch.float16) - def forward(ctx, input, weight, bias): - assert weight.shape == weight_shape - if not transpose: - output = torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, **common_kwargs) - else: # transpose - output = torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, output_padding=output_padding, **common_kwargs) - ctx.save_for_backward(input, weight) - return output - - @staticmethod - @custom_bwd - def backward(ctx, grad_output): - input, weight = ctx.saved_tensors - grad_input = None - grad_weight = None - grad_bias = None - - if ctx.needs_input_grad[0]: - p = calc_output_padding(input_shape=input.shape, output_shape=grad_output.shape) - grad_input = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs).apply(grad_output.float(), weight.float(), None) - assert grad_input.shape == input.shape - - if ctx.needs_input_grad[1] and not weight_gradients_disabled: - grad_weight = Conv2dGradWeight.apply(grad_output.float(), input.float()) - assert grad_weight.shape == weight_shape - - if ctx.needs_input_grad[2]: - grad_bias = grad_output.float().sum([0, 2, 3]) - - return grad_input, grad_weight, grad_bias - - # Gradient with respect to the weights. - class Conv2dGradWeight(torch.autograd.Function): - @staticmethod - @custom_fwd(cast_inputs=torch.float16) - def forward(ctx, grad_output, input): - op = torch._C._jit_get_operation('aten::cudnn_convolution_backward_weight' if not transpose else 'aten::cudnn_convolution_transpose_backward_weight') - flags = [torch.backends.cudnn.benchmark, torch.backends.cudnn.deterministic, torch.backends.cudnn.allow_tf32] - grad_weight = op(weight_shape, grad_output, input, padding, stride, dilation, groups, *flags) - assert grad_weight.shape == weight_shape - ctx.save_for_backward(grad_output, input) - return grad_weight - - @staticmethod - @custom_bwd - def backward(ctx, grad2_grad_weight): - grad_output, input = ctx.saved_tensors - grad2_grad_output = None - grad2_input = None - - if ctx.needs_input_grad[0]: - grad2_grad_output = Conv2d.apply(input, grad2_grad_weight, None) - assert grad2_grad_output.shape == grad_output.shape - - if ctx.needs_input_grad[1]: - p = calc_output_padding(input_shape=input.shape, output_shape=grad_output.shape) - grad2_input = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs).apply(grad_output, grad2_grad_weight, None) - assert grad2_input.shape == input.shape - - return grad2_grad_output, grad2_input - - _conv2d_gradfix_cache[key] = Conv2d - return Conv2d - -#---------------------------------------------------------------------------- diff --git a/spaces/hamelcubsfan/AutoGPT/autogpt/memory/__init__.py b/spaces/hamelcubsfan/AutoGPT/autogpt/memory/__init__.py deleted file mode 100644 index 3d18704c70dfc287642b1923e6f2e1f72a5f2a62..0000000000000000000000000000000000000000 --- a/spaces/hamelcubsfan/AutoGPT/autogpt/memory/__init__.py +++ /dev/null @@ -1,99 +0,0 @@ -from autogpt.memory.local import LocalCache -from autogpt.memory.no_memory import NoMemory - -# List of supported memory backends -# Add a backend to this list if the import attempt is successful -supported_memory = ["local", "no_memory"] - -try: - from autogpt.memory.redismem import RedisMemory - - supported_memory.append("redis") -except ImportError: - # print("Redis not installed. Skipping import.") - RedisMemory = None - -try: - from autogpt.memory.pinecone import PineconeMemory - - supported_memory.append("pinecone") -except ImportError: - # print("Pinecone not installed. Skipping import.") - PineconeMemory = None - -try: - from autogpt.memory.weaviate import WeaviateMemory - - supported_memory.append("weaviate") -except ImportError: - # print("Weaviate not installed. Skipping import.") - WeaviateMemory = None - -try: - from autogpt.memory.milvus import MilvusMemory - - supported_memory.append("milvus") -except ImportError: - # print("pymilvus not installed. Skipping import.") - MilvusMemory = None - - -def get_memory(cfg, init=False): - memory = None - if cfg.memory_backend == "pinecone": - if not PineconeMemory: - print( - "Error: Pinecone is not installed. Please install pinecone" - " to use Pinecone as a memory backend." - ) - else: - memory = PineconeMemory(cfg) - if init: - memory.clear() - elif cfg.memory_backend == "redis": - if not RedisMemory: - print( - "Error: Redis is not installed. Please install redis-py to" - " use Redis as a memory backend." - ) - else: - memory = RedisMemory(cfg) - elif cfg.memory_backend == "weaviate": - if not WeaviateMemory: - print( - "Error: Weaviate is not installed. Please install weaviate-client to" - " use Weaviate as a memory backend." - ) - else: - memory = WeaviateMemory(cfg) - elif cfg.memory_backend == "milvus": - if not MilvusMemory: - print( - "Error: Milvus sdk is not installed." - "Please install pymilvus to use Milvus as memory backend." - ) - else: - memory = MilvusMemory(cfg) - elif cfg.memory_backend == "no_memory": - memory = NoMemory(cfg) - - if memory is None: - memory = LocalCache(cfg) - if init: - memory.clear() - return memory - - -def get_supported_memory_backends(): - return supported_memory - - -__all__ = [ - "get_memory", - "LocalCache", - "RedisMemory", - "PineconeMemory", - "NoMemory", - "MilvusMemory", - "WeaviateMemory", -] diff --git a/spaces/hanzportgas/rvc-models/vc_infer_pipeline.py b/spaces/hanzportgas/rvc-models/vc_infer_pipeline.py deleted file mode 100644 index c26d45068f9b6bf2b194b13c3c89f8a06347c124..0000000000000000000000000000000000000000 --- a/spaces/hanzportgas/rvc-models/vc_infer_pipeline.py +++ /dev/null @@ -1,306 +0,0 @@ -import numpy as np, parselmouth, torch, pdb -from time import time as ttime -import torch.nn.functional as F -from config import x_pad, x_query, x_center, x_max -import scipy.signal as signal -import pyworld, os, traceback, faiss -from scipy import signal - -bh, ah = signal.butter(N=5, Wn=48, btype="high", fs=16000) - - -class VC(object): - def __init__(self, tgt_sr, device, is_half): - self.sr = 16000 # hubert输入采样率 - self.window = 160 # 每帧点数 - self.t_pad = self.sr * x_pad # 每条前后pad时间 - self.t_pad_tgt = tgt_sr * x_pad - self.t_pad2 = self.t_pad * 2 - self.t_query = self.sr * x_query # 查询切点前后查询时间 - self.t_center = self.sr * x_center # 查询切点位置 - self.t_max = self.sr * x_max # 免查询时长阈值 - self.device = device - self.is_half = is_half - - def get_f0(self, x, p_len, f0_up_key, f0_method, inp_f0=None): - time_step = self.window / self.sr * 1000 - f0_min = 50 - f0_max = 1100 - f0_mel_min = 1127 * np.log(1 + f0_min / 700) - f0_mel_max = 1127 * np.log(1 + f0_max / 700) - if f0_method == "pm": - f0 = ( - parselmouth.Sound(x, self.sr) - .to_pitch_ac( - time_step=time_step / 1000, - voicing_threshold=0.6, - pitch_floor=f0_min, - pitch_ceiling=f0_max, - ) - .selected_array["frequency"] - ) - pad_size = (p_len - len(f0) + 1) // 2 - if pad_size > 0 or p_len - len(f0) - pad_size > 0: - f0 = np.pad( - f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant" - ) - elif f0_method == "harvest": - f0, t = pyworld.harvest( - x.astype(np.double), - fs=self.sr, - f0_ceil=f0_max, - f0_floor=f0_min, - frame_period=10, - ) - f0 = pyworld.stonemask(x.astype(np.double), f0, t, self.sr) - f0 = signal.medfilt(f0, 3) - f0 *= pow(2, f0_up_key / 12) - # with open("test.txt","w")as f:f.write("\n".join([str(i)for i in f0.tolist()])) - tf0 = self.sr // self.window # 每秒f0点数 - if inp_f0 is not None: - delta_t = np.round( - (inp_f0[:, 0].max() - inp_f0[:, 0].min()) * tf0 + 1 - ).astype("int16") - replace_f0 = np.interp( - list(range(delta_t)), inp_f0[:, 0] * 100, inp_f0[:, 1] - ) - shape = f0[x_pad * tf0 : x_pad * tf0 + len(replace_f0)].shape[0] - f0[x_pad * tf0 : x_pad * tf0 + len(replace_f0)] = replace_f0[:shape] - # with open("test_opt.txt","w")as f:f.write("\n".join([str(i)for i in f0.tolist()])) - f0bak = f0.copy() - f0_mel = 1127 * np.log(1 + f0 / 700) - f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * 254 / ( - f0_mel_max - f0_mel_min - ) + 1 - f0_mel[f0_mel <= 1] = 1 - f0_mel[f0_mel > 255] = 255 - f0_coarse = np.rint(f0_mel).astype(np.int) - return f0_coarse, f0bak # 1-0 - - def vc( - self, - model, - net_g, - sid, - audio0, - pitch, - pitchf, - times, - index, - big_npy, - index_rate, - ): # ,file_index,file_big_npy - feats = torch.from_numpy(audio0) - if self.is_half: - feats = feats.half() - else: - feats = feats.float() - if feats.dim() == 2: # double channels - feats = feats.mean(-1) - assert feats.dim() == 1, feats.dim() - feats = feats.view(1, -1) - padding_mask = torch.BoolTensor(feats.shape).to(self.device).fill_(False) - - inputs = { - "source": feats.to(self.device), - "padding_mask": padding_mask, - "output_layer": 9, # layer 9 - } - t0 = ttime() - with torch.no_grad(): - logits = model.extract_features(**inputs) - feats = model.final_proj(logits[0]) - - if ( - isinstance(index, type(None)) == False - and isinstance(big_npy, type(None)) == False - and index_rate != 0 - ): - npy = feats[0].cpu().numpy() - if self.is_half: - npy = npy.astype("float32") - _, I = index.search(npy, 1) - npy = big_npy[I.squeeze()] - if self.is_half: - npy = npy.astype("float16") - feats = ( - torch.from_numpy(npy).unsqueeze(0).to(self.device) * index_rate - + (1 - index_rate) * feats - ) - - feats = F.interpolate(feats.permute(0, 2, 1), scale_factor=2).permute(0, 2, 1) - t1 = ttime() - p_len = audio0.shape[0] // self.window - if feats.shape[1] < p_len: - p_len = feats.shape[1] - if pitch != None and pitchf != None: - pitch = pitch[:, :p_len] - pitchf = pitchf[:, :p_len] - p_len = torch.tensor([p_len], device=self.device).long() - with torch.no_grad(): - if pitch != None and pitchf != None: - audio1 = ( - (net_g.infer(feats, p_len, pitch, pitchf, sid)[0][0, 0] * 32768) - .data.cpu() - .float() - .numpy() - .astype(np.int16) - ) - else: - audio1 = ( - (net_g.infer(feats, p_len, sid)[0][0, 0] * 32768) - .data.cpu() - .float() - .numpy() - .astype(np.int16) - ) - del feats, p_len, padding_mask - if torch.cuda.is_available(): - torch.cuda.empty_cache() - t2 = ttime() - times[0] += t1 - t0 - times[2] += t2 - t1 - return audio1 - - def pipeline( - self, - model, - net_g, - sid, - audio, - times, - f0_up_key, - f0_method, - file_index, - file_big_npy, - index_rate, - if_f0, - f0_file=None, - ): - if ( - file_big_npy != "" - and file_index != "" - and os.path.exists(file_big_npy) == True - and os.path.exists(file_index) == True - and index_rate != 0 - ): - try: - index = faiss.read_index(file_index) - big_npy = np.load(file_big_npy) - except: - traceback.print_exc() - index = big_npy = None - else: - index = big_npy = None - print("Feature retrieval library doesn't exist or ratio is 0") - audio = signal.filtfilt(bh, ah, audio) - audio_pad = np.pad(audio, (self.window // 2, self.window // 2), mode="reflect") - opt_ts = [] - if audio_pad.shape[0] > self.t_max: - audio_sum = np.zeros_like(audio) - for i in range(self.window): - audio_sum += audio_pad[i : i - self.window] - for t in range(self.t_center, audio.shape[0], self.t_center): - opt_ts.append( - t - - self.t_query - + np.where( - np.abs(audio_sum[t - self.t_query : t + self.t_query]) - == np.abs(audio_sum[t - self.t_query : t + self.t_query]).min() - )[0][0] - ) - s = 0 - audio_opt = [] - t = None - t1 = ttime() - audio_pad = np.pad(audio, (self.t_pad, self.t_pad), mode="reflect") - p_len = audio_pad.shape[0] // self.window - inp_f0 = None - if hasattr(f0_file, "name") == True: - try: - with open(f0_file.name, "r") as f: - lines = f.read().strip("\n").split("\n") - inp_f0 = [] - for line in lines: - inp_f0.append([float(i) for i in line.split(",")]) - inp_f0 = np.array(inp_f0, dtype="float32") - except: - traceback.print_exc() - sid = torch.tensor(sid, device=self.device).unsqueeze(0).long() - pitch, pitchf = None, None - if if_f0 == 1: - pitch, pitchf = self.get_f0(audio_pad, p_len, f0_up_key, f0_method, inp_f0) - pitch = pitch[:p_len] - pitchf = pitchf[:p_len] - pitch = torch.tensor(pitch, device=self.device).unsqueeze(0).long() - pitchf = torch.tensor(pitchf, device=self.device).unsqueeze(0).float() - t2 = ttime() - times[1] += t2 - t1 - for t in opt_ts: - t = t // self.window * self.window - if if_f0 == 1: - audio_opt.append( - self.vc( - model, - net_g, - sid, - audio_pad[s : t + self.t_pad2 + self.window], - pitch[:, s // self.window : (t + self.t_pad2) // self.window], - pitchf[:, s // self.window : (t + self.t_pad2) // self.window], - times, - index, - big_npy, - index_rate, - )[self.t_pad_tgt : -self.t_pad_tgt] - ) - else: - audio_opt.append( - self.vc( - model, - net_g, - sid, - audio_pad[s : t + self.t_pad2 + self.window], - None, - None, - times, - index, - big_npy, - index_rate, - )[self.t_pad_tgt : -self.t_pad_tgt] - ) - s = t - if if_f0 == 1: - audio_opt.append( - self.vc( - model, - net_g, - sid, - audio_pad[t:], - pitch[:, t // self.window :] if t is not None else pitch, - pitchf[:, t // self.window :] if t is not None else pitchf, - times, - index, - big_npy, - index_rate, - )[self.t_pad_tgt : -self.t_pad_tgt] - ) - else: - audio_opt.append( - self.vc( - model, - net_g, - sid, - audio_pad[t:], - None, - None, - times, - index, - big_npy, - index_rate, - )[self.t_pad_tgt : -self.t_pad_tgt] - ) - audio_opt = np.concatenate(audio_opt) - del pitch, pitchf, sid - if torch.cuda.is_available(): - torch.cuda.empty_cache() - return audio_opt diff --git a/spaces/haryoaw/id-recigen/app.py b/spaces/haryoaw/id-recigen/app.py deleted file mode 100644 index e92aa7fa1b570dc16fdc9b76059498a94cc7bfeb..0000000000000000000000000000000000000000 --- a/spaces/haryoaw/id-recigen/app.py +++ /dev/null @@ -1,78 +0,0 @@ -""" -Main App -""" - -import streamlit as st -from transformers import AutoModelForSeq2SeqLM - -from src.tokenizers import IndoNLGTokenizer - - -@st.cache(allow_output_mutation=True) -def fetch_tokenizer_model(): - """ - Fetch tokenizer and model - """ - tokenizer = IndoNLGTokenizer.from_pretrained("indobenchmark/indobart-v2") - model = AutoModelForSeq2SeqLM.from_pretrained("haryoaw/id-recigen-bart") - return tokenizer, model - - -tokenizer, model = fetch_tokenizer_model() - - -def predict_recipe(food: str) -> str: - """ - Predict Ingredients Here! - - Parameters - ---------- - food: str - The food that will be used - - Returns - ------- - str - Return the model here - """ - inp = tokenizer(food.lower(), return_tensors="pt")["input_ids"] - generated = model.generate( - inp, max_length=500, do_sample=False, num_beams=10, num_beam_groups=2 - ) - returned_input: str = tokenizer.decode(generated[0], skip_special_tokens=True) - returned_input = "\n".join([x.strip() for x in returned_input.split("||")]) - return returned_input - - -def create_frontend() -> None: - """ - Create front end streamlit here - """ - st.markdown("# Food Ingredients Generator Indonesia Showcase!") - st.write("🥑Generate your ingredients here!") - - with st.form("my_form"): - food_name = st.text_input( - "Food", value="Nasi Goreng Ayam", help="Input your food here!" - ) - submitted = st.form_submit_button("Submit") - if submitted: - predicted = predict_recipe(food_name) - st.markdown(f"## Bahan ( Ingredients ) `{food_name}`:") - st.text(predicted) - st.markdown("## Additional Note") - st.write( - "❗Please note that the model is trained with the food that use:" - ) - for i, ingr in enumerate(("ayam", "tempe", "ikan", "kambing", "telur", "tahu", "sapi")): - st.write(f"{i+1}. {ingr}") - - st.markdown("## Models") - st.markdown( - "🤗 Huggingface Model: [Link](https://huggingface.co/haryoaw/id-recigen-bart)" - ) - st.write("Thank you 😊") - - -if __name__ == "__main__": - create_frontend() diff --git a/spaces/haseeb-heaven/AutoBard-Coder/CHANGELOGS.md b/spaces/haseeb-heaven/AutoBard-Coder/CHANGELOGS.md deleted file mode 100644 index f558dcdab061c136fc481dd009d1bd1e82eaeb9b..0000000000000000000000000000000000000000 --- a/spaces/haseeb-heaven/AutoBard-Coder/CHANGELOGS.md +++ /dev/null @@ -1,27 +0,0 @@ -# Changelog 📝 - -All notable changes to this project will be documented in this file. -## [1.3] - 2023-05-2 -### Added -- **Updated** with totaly new _UI_ and _UX_. 🎨 -- Updated security for code checking and prompt checking. 🔒 -- Added new Help section. 🆘 -- Fix API Key bugs. 🛠 - -## [1.2] - 2023-05-28 -### Added -- **Advanced security** for code checking and prompt checking. 🔒 -- Support for graphs, charts, and tables. 📊 -- More libraries for data science. 🧬 - -## [1.1] - 2023-05-22 -### Added -- Upload files option. 📤 -- API key settings. 🔑 -### Fixed -- Error handling from server. 🛠 - -## [1.0] - 2023-05-21 -### Added -- Auto barcode generator. 🏷 -- Auto barcode interpreter. 🔎 diff --git a/spaces/hasibzunair/fifa-tryon-demo/rembg/session_factory.py b/spaces/hasibzunair/fifa-tryon-demo/rembg/session_factory.py deleted file mode 100644 index 0f96a0580e6877f449a58bb0e7b19e64c28c609b..0000000000000000000000000000000000000000 --- a/spaces/hasibzunair/fifa-tryon-demo/rembg/session_factory.py +++ /dev/null @@ -1,63 +0,0 @@ -import hashlib -import os -import sys -from contextlib import redirect_stdout -from pathlib import Path -from typing import Type - -import gdown -import onnxruntime as ort - -from .session_base import BaseSession -from .session_cloth import ClothSession -from .session_simple import SimpleSession - - -def new_session(model_name: str) -> BaseSession: - session_class: Type[BaseSession] - - if model_name == "u2netp": - md5 = "8e83ca70e441ab06c318d82300c84806" - url = "https://drive.google.com/uc?id=1tNuFmLv0TSNDjYIkjEdeH1IWKQdUA4HR" - session_class = SimpleSession - elif model_name == "u2net": - md5 = "60024c5c889badc19c04ad937298a77b" - url = "https://drive.google.com/uc?id=1tCU5MM1LhRgGou5OpmpjBQbSrYIUoYab" - session_class = SimpleSession - elif model_name == "u2net_human_seg": - md5 = "c09ddc2e0104f800e3e1bb4652583d1f" - url = "https://drive.google.com/uc?id=1ZfqwVxu-1XWC1xU1GHIP-FM_Knd_AX5j" - session_class = SimpleSession - elif model_name == "u2net_cloth_seg": - md5 = "2434d1f3cb744e0e49386c906e5a08bb" - url = "https://drive.google.com/uc?id=15rKbQSXQzrKCQurUjZFg8HqzZad8bcyz" - session_class = ClothSession - else: - assert AssertionError( - "Choose between u2net, u2netp, u2net_human_seg or u2net_cloth_seg" - ) - - home = os.getenv("U2NET_HOME", os.path.join("~", ".u2net")) - path = Path(home).expanduser() / f"{model_name}.onnx" - path.parents[0].mkdir(parents=True, exist_ok=True) - - if not path.exists(): - with redirect_stdout(sys.stderr): - gdown.download(url, str(path), use_cookies=False) - else: - hashing = hashlib.new("md5", path.read_bytes(), usedforsecurity=False) - if hashing.hexdigest() != md5: - with redirect_stdout(sys.stderr): - gdown.download(url, str(path), use_cookies=False) - - sess_opts = ort.SessionOptions() - - if "OMP_NUM_THREADS" in os.environ: - sess_opts.inter_op_num_threads = int(os.environ["OMP_NUM_THREADS"]) - - return session_class( - model_name, - ort.InferenceSession( - str(path), providers=ort.get_available_providers(), sess_options=sess_opts - ), - ) diff --git a/spaces/hca97/Mosquito-Detection/my_models/yolov5_clip_model.py b/spaces/hca97/Mosquito-Detection/my_models/yolov5_clip_model.py deleted file mode 100644 index 22b62bc50261667f0bfc2a3a5f3b0893b607792b..0000000000000000000000000000000000000000 --- a/spaces/hca97/Mosquito-Detection/my_models/yolov5_clip_model.py +++ /dev/null @@ -1,101 +0,0 @@ -import logging -import time - -import torch -import numpy as np - -torch.set_num_threads(2) - -from my_models.clip_model.data_loader import pre_process_foo -from my_models.clip_model.classification import MosquitoClassifier - -IMG_SIZE = (224, 224) -USE_CHANNEL_LAST = False -DATASET = "laion" -DEVICE = "cpu" -PRESERVE_ASPECT_RATIO = False -SHIFT = 0 - - -@torch.no_grad() -def detect_image(model, image: np.ndarray) -> dict: - image_information = {} - result = model(image) - result_df = result.pandas().xyxy[0] - if result_df.empty: - print("No results from yolov5 model!") - else: - image_information = result_df.to_dict() - return image_information - - -@torch.no_grad() -def classify_image(model: MosquitoClassifier, image: np.ndarray, bbox: list) -> tuple: - labels = [ - "albopictus", - "culex", - "japonicus-koreicus", - "culiseta", - "anopheles", - "aegypti", - ] - - image_cropped = image[bbox[1] : bbox[3], bbox[0] : bbox[2], :] - x = torch.unsqueeze(pre_process_foo(IMG_SIZE, DATASET)(image_cropped), 0) - x = x.to(device=DEVICE) - p: torch.Tensor = model(x) - ind = torch.argmax(p).item() - label = labels[ind] - return label, p.max().item() - - -def extract_predicted_mosquito_bbox(extractedInformation): - bbox = [] - if extractedInformation is not None: - xmin = int(extractedInformation.get("xmin").get(0)) - ymin = int(extractedInformation.get("ymin").get(0)) - xmax = int(extractedInformation.get("xmax").get(0)) - ymax = int(extractedInformation.get("ymax").get(0)) - bbox = [xmin, ymin, xmax, ymax] - return bbox - - -class YOLOV5CLIPModel: - def __init__(self): - trained_model_path = "my_models/yolo_weights/mosquitoalert-yolov5-baseline.pt" - repo_path = "my_models/torch_hub_cache/yolov5" - self.det = torch.hub.load( - repo_path, - "custom", - path=trained_model_path, - force_reload=True, - source="local", - ) - - clip_model_path = f"my_models/clip_weights/best_clf.ckpt" - self.cls = MosquitoClassifier.load_from_checkpoint( - clip_model_path, head_version=7, map_location=torch.device(DEVICE) - ).eval() - - def predict(self, image: np.ndarray): - s = time.time() - predictedInformation = detect_image(self.det, image) - mosquito_class_name_predicted = "albopictus" - mosquito_class_confidence = 0.0 - mosquito_class_bbox = [0, 0, image.shape[0], image.shape[1]] - - if predictedInformation: - mosquito_class_bbox = extract_predicted_mosquito_bbox(predictedInformation) - - mosquito_class_name_predicted, mosquito_class_confidence = classify_image( - self.cls, image, mosquito_class_bbox - ) - - e = time.time() - - logging.info(f"[PREDICTION] Total time passed {e - s}ms") - return ( - mosquito_class_name_predicted, - mosquito_class_confidence, - mosquito_class_bbox, - ) diff --git a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/text/shanghainese.py b/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/text/shanghainese.py deleted file mode 100644 index cb29c24a08d2e406e8399cf7bc9fe5cb43cb9c61..0000000000000000000000000000000000000000 --- a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/text/shanghainese.py +++ /dev/null @@ -1,64 +0,0 @@ -import re -import cn2an -import opencc - - -converter = opencc.OpenCC('zaonhe') - -# List of (Latin alphabet, ipa) pairs: -_latin_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [ - ('A', 'ᴇ'), - ('B', 'bi'), - ('C', 'si'), - ('D', 'di'), - ('E', 'i'), - ('F', 'ᴇf'), - ('G', 'dʑi'), - ('H', 'ᴇtɕʰ'), - ('I', 'ᴀi'), - ('J', 'dʑᴇ'), - ('K', 'kʰᴇ'), - ('L', 'ᴇl'), - ('M', 'ᴇm'), - ('N', 'ᴇn'), - ('O', 'o'), - ('P', 'pʰi'), - ('Q', 'kʰiu'), - ('R', 'ᴀl'), - ('S', 'ᴇs'), - ('T', 'tʰi'), - ('U', 'ɦiu'), - ('V', 'vi'), - ('W', 'dᴀbɤliu'), - ('X', 'ᴇks'), - ('Y', 'uᴀi'), - ('Z', 'zᴇ') -]] - - -def _number_to_shanghainese(num): - num = cn2an.an2cn(num).replace('一十','十').replace('二十', '廿').replace('二', '两') - return re.sub(r'((?:^|[^三四五六七八九])十|廿)两', r'\1二', num) - - -def number_to_shanghainese(text): - return re.sub(r'\d+(?:\.?\d+)?', lambda x: _number_to_shanghainese(x.group()), text) - - -def latin_to_ipa(text): - for regex, replacement in _latin_to_ipa: - text = re.sub(regex, replacement, text) - return text - - -def shanghainese_to_ipa(text): - text = number_to_shanghainese(text.upper()) - text = converter.convert(text).replace('-','').replace('$',' ') - text = re.sub(r'[A-Z]', lambda x: latin_to_ipa(x.group())+' ', text) - text = re.sub(r'[、;:]', ',', text) - text = re.sub(r'\s*,\s*', ', ', text) - text = re.sub(r'\s*。\s*', '. ', text) - text = re.sub(r'\s*?\s*', '? ', text) - text = re.sub(r'\s*!\s*', '! ', text) - text = re.sub(r'\s*$', '', text) - return text diff --git a/spaces/ho11laqe/nnUNet_calvingfront_detection/nnunet/training/network_training/nnUNet_variants/architectural_variants/nnUNetTrainerV2_lReLU_convlReLUIN.py b/spaces/ho11laqe/nnUNet_calvingfront_detection/nnunet/training/network_training/nnUNet_variants/architectural_variants/nnUNetTrainerV2_lReLU_convlReLUIN.py deleted file mode 100644 index 198f9ef43eedeaa0db5d673e77407d65738fcb9c..0000000000000000000000000000000000000000 --- a/spaces/ho11laqe/nnUNet_calvingfront_detection/nnunet/training/network_training/nnUNet_variants/architectural_variants/nnUNetTrainerV2_lReLU_convlReLUIN.py +++ /dev/null @@ -1,46 +0,0 @@ -# Copyright 2020 Division of Medical Image Computing, German Cancer Research Center (DKFZ), Heidelberg, Germany -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -import torch -from nnunet.network_architecture.generic_UNet import Generic_UNet, ConvDropoutNonlinNorm -from nnunet.network_architecture.initialization import InitWeights_He -from nnunet.training.network_training.nnUNetTrainerV2 import nnUNetTrainerV2 -from nnunet.utilities.nd_softmax import softmax_helper -from torch import nn - - -class nnUNetTrainerV2_lReLU_convReLUIN(nnUNetTrainerV2): - def initialize_network(self): - if self.threeD: - conv_op = nn.Conv3d - dropout_op = nn.Dropout3d - norm_op = nn.InstanceNorm3d - - else: - conv_op = nn.Conv2d - dropout_op = nn.Dropout2d - norm_op = nn.InstanceNorm2d - - norm_op_kwargs = {'eps': 1e-5, 'affine': True} - dropout_op_kwargs = {'p': 0, 'inplace': True} - net_nonlin = nn.LeakyReLU - net_nonlin_kwargs = {'inplace': True, 'negative_slope': 1e-2} - self.network = Generic_UNet(self.num_input_channels, self.base_num_features, self.num_classes, - len(self.net_num_pool_op_kernel_sizes), - self.conv_per_stage, 2, conv_op, norm_op, norm_op_kwargs, dropout_op, dropout_op_kwargs, - net_nonlin, net_nonlin_kwargs, True, False, lambda x: x, InitWeights_He(1e-2), - self.net_num_pool_op_kernel_sizes, self.net_conv_kernel_sizes, False, True, True, - basic_block=ConvDropoutNonlinNorm) - if torch.cuda.is_available(): - self.network.cuda() - self.network.inference_apply_nonlin = softmax_helper diff --git a/spaces/ho11laqe/nnUNet_calvingfront_detection/nnunet/training/network_training/nnUNet_variants/miscellaneous/__init__.py b/spaces/ho11laqe/nnUNet_calvingfront_detection/nnunet/training/network_training/nnUNet_variants/miscellaneous/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/hysts/ControlNet/app_hough.py b/spaces/hysts/ControlNet/app_hough.py deleted file mode 100644 index ef87a73ca6c757eea4352aeafbd45fdad0189599..0000000000000000000000000000000000000000 --- a/spaces/hysts/ControlNet/app_hough.py +++ /dev/null @@ -1,97 +0,0 @@ -# This file is adapted from https://github.com/lllyasviel/ControlNet/blob/f4748e3630d8141d7765e2bd9b1e348f47847707/gradio_hough2image.py -# The original license file is LICENSE.ControlNet in this repo. -import gradio as gr - - -def create_demo(process, max_images=12, default_num_images=3): - with gr.Blocks() as demo: - with gr.Row(): - gr.Markdown('## Control Stable Diffusion with Hough Line Maps') - with gr.Row(): - with gr.Column(): - input_image = gr.Image(source='upload', type='numpy') - prompt = gr.Textbox(label='Prompt') - run_button = gr.Button(label='Run') - with gr.Accordion('Advanced options', open=False): - num_samples = gr.Slider(label='Images', - minimum=1, - maximum=max_images, - value=default_num_images, - step=1) - image_resolution = gr.Slider(label='Image Resolution', - minimum=256, - maximum=512, - value=512, - step=256) - detect_resolution = gr.Slider(label='Hough Resolution', - minimum=128, - maximum=512, - value=512, - step=1) - mlsd_value_threshold = gr.Slider( - label='Hough value threshold (MLSD)', - minimum=0.01, - maximum=2.0, - value=0.1, - step=0.01) - mlsd_distance_threshold = gr.Slider( - label='Hough distance threshold (MLSD)', - minimum=0.01, - maximum=20.0, - value=0.1, - step=0.01) - num_steps = gr.Slider(label='Steps', - minimum=1, - maximum=100, - value=20, - step=1) - guidance_scale = gr.Slider(label='Guidance Scale', - minimum=0.1, - maximum=30.0, - value=9.0, - step=0.1) - seed = gr.Slider(label='Seed', - minimum=-1, - maximum=2147483647, - step=1, - randomize=True) - a_prompt = gr.Textbox( - label='Added Prompt', - value='best quality, extremely detailed') - n_prompt = gr.Textbox( - label='Negative Prompt', - value= - 'longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality' - ) - with gr.Column(): - result = gr.Gallery(label='Output', - show_label=False, - elem_id='gallery').style(grid=2, - height='auto') - inputs = [ - input_image, - prompt, - a_prompt, - n_prompt, - num_samples, - image_resolution, - detect_resolution, - num_steps, - guidance_scale, - seed, - mlsd_value_threshold, - mlsd_distance_threshold, - ] - prompt.submit(fn=process, inputs=inputs, outputs=result) - run_button.click(fn=process, - inputs=inputs, - outputs=result, - api_name='hough') - return demo - - -if __name__ == '__main__': - from model import Model - model = Model() - demo = create_demo(model.process_hough) - demo.queue().launch() diff --git a/spaces/innovatorved/whisper.api/app/utils/constant.py b/spaces/innovatorved/whisper.api/app/utils/constant.py deleted file mode 100644 index 89ef6ce5ae9093e9609b202c35751d87f69546c8..0000000000000000000000000000000000000000 --- a/spaces/innovatorved/whisper.api/app/utils/constant.py +++ /dev/null @@ -1,11 +0,0 @@ -model_names = { - "tiny.en": "ggml-tiny.en.bin", - "tiny.en.q5": "ggml-model-whisper-tiny.en-q5_1.bin", - "base.en.q5": "ggml-model-whisper-base.en-q5_1.bin", -} - -model_urls = { - "tiny.en": "https://firebasestorage.googleapis.com/v0/b/model-innovatorved.appspot.com/o/ggml-model-whisper-base.en-q5_1.bin?alt=media", - "tiny.en.q5": "https://firebasestorage.googleapis.com/v0/b/model-innovatorved.appspot.com/o/ggml-model-whisper-tiny.en-q5_1.bin?alt=media", - "base.en.q5": "https://firebasestorage.googleapis.com/v0/b/model-innovatorved.appspot.com/o/ggml-model-whisper-base.en-q5_1.bin?alt=media", -} diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Dhoom 2 Full Movie Download Filmywap Bollywood UPDATED.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Dhoom 2 Full Movie Download Filmywap Bollywood UPDATED.md deleted file mode 100644 index 5c933d575ea325bc1eb2083efc54ad90e99f768f..0000000000000000000000000000000000000000 --- a/spaces/inplisQlawa/anything-midjourney-v4-1/Dhoom 2 Full Movie Download Filmywap Bollywood UPDATED.md +++ /dev/null @@ -1,6 +0,0 @@ -dhoom 2 full movie download filmywap bollywoodDOWNLOAD ✑ ✑ ✑ https://urlin.us/2uEwKK - -Ltd. Genre: Action; Released: 2006; Run Time: 2 hr 31 min; Rated: PG. © 2006 Yash Raj Films Pvt. Ltd ... 4d29de3e1b - - - diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/FULL Galcott Super Text Search V3.0 Serial TOP.md b/spaces/inplisQlawa/anything-midjourney-v4-1/FULL Galcott Super Text Search V3.0 Serial TOP.md deleted file mode 100644 index 91b8d558c79cfd707f22bf429ce2696a4521df31..0000000000000000000000000000000000000000 --- a/spaces/inplisQlawa/anything-midjourney-v4-1/FULL Galcott Super Text Search V3.0 Serial TOP.md +++ /dev/null @@ -1,12 +0,0 @@ - - 137 records. x1 search serial numbers are presented here. no registration.. galcott super text search v3.12. suncross power file search v2.1.0. the trial versions are fully functional for 15 days after installation,. super text search, search files for any text, including powerful wildcard. -FULL Galcott Super Text Search V3.0 SerialDownload Zip ⇒ https://urlin.us/2uExKj - serialnews - serials - g1. galcott directory printer v4.0-bean :: 43 b :: 20.04.09. galcott super text search v3.0-bean :: 44 b :: 14.05.10 . ://xn--80aagyardii6h.xn--p1ai/full-galcott-super-text-search-v3-0-serial/ -1477 records. find all steam key stores and prices to download jagged alliance 2 wildfire and play at the. full galcott super text search v3.0-bean :: 44 b :: 14.05.10 . ://xn--80aagyardii6h.xn--p1ai/full-galcott-super-text-search-v3-0-serial/ -00 eldiego90 applications > windowsgalcott super text search v3.0 + serial 2010-08-26 2.24 mib galcott super text search v3.0 :: 44 b :: 20.06.10. ://xn--80aagyardii6h.xn--p1ai/full-galcott-super-text-search-v3-0-serial/ -full galcott super text search v3.12. suncross power file search v2.1.0. the trial versions are fully functional for 15 days after installation,. super text search, search files for any text, including powerful wildcard. -find all steam key stores and prices to download jagged alliance 2 wildfire and play at the. full galcott super text search v3.0 serial -serial/. cs-pack-icons-crack-with-license-code-x64-updated-2022 - -galcott directory printer v4.1-bean :: 43 b :: 10.02.11. galcott pdf converter v3.0-bean :: 43 b :: 19.04.09. galcott super text search v3.0-bean :: 44 b. ze converter with license key pc/windows [updated-2022]. ://xn--80aagyardii6h.xn--p1ai/full-galcott-super-text-search-v3-0-serial/ 899543212b- - \ No newline at end of file diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Fable 3 Guild Seals Cheat Engine Table.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Fable 3 Guild Seals Cheat Engine Table.md deleted file mode 100644 index aac44d741db1aa3e1458b8df647d5c094ed8c638..0000000000000000000000000000000000000000 --- a/spaces/inplisQlawa/anything-midjourney-v4-1/Fable 3 Guild Seals Cheat Engine Table.md +++ /dev/null @@ -1,6 +0,0 @@ - Fable 3 Guild Seals Cheat Engine TableDOWNLOAD ===> https://urlin.us/2uEw6F - -... charr charred charring chars chart chart's charted charter charter's chartered ... cheapo cheapskate cheapskate's cheapskates cheat cheat's cheated cheater ... coders codes codeword codewords codex codex's codfish codfish's codfishes ... f fa fa's fab fabaceous fable fable's fabled fables fabliau fabliaux fabric fabric's ... 1fdad05405 - - - diff --git a/spaces/isabel/anime-project/reader.py b/spaces/isabel/anime-project/reader.py deleted file mode 100644 index 2089f121665bf06f1c4d8a54d78df7b435b01ae9..0000000000000000000000000000000000000000 --- a/spaces/isabel/anime-project/reader.py +++ /dev/null @@ -1,161 +0,0 @@ -import os -from yattag import Doc -## --------------------------------- ### -### reading: info.txt ### -### -------------------------------- ### -# placeholders in case info.txt does not exist -def get_article(acc, most_imp_feat): - filename = "info.txt" - placeholder = "please create an info.txt to customize this text" - note = "**Note that model accuracy is based on the uploaded data.csv and reflects how well the AI model can give correct recommendations for that dataset. An accuracy of 50% means that half of the model's predictions for that dataset were accurate. Model accuracy and most important feature can be helpful for understanding how the model works, but should not be considered absolute facts about the real world." - - title = bkgd = data_collection = priv_cons = bias_cons = img_src = membs = description = placeholder - # check if info.txt is present - if os.path.isfile(filename): - # open info.txt in read mode - info = open(filename, "r") - - # read each line to a string - description = "An AI project created by " + info.readline() - title = info.readline() - bkgd = info.readline() - data_collection = info.readline() - priv_cons = info.readline() - bias_cons = info.readline() - img_src = info.readline() - membs = info.readline() - - # close file - info.close() - - # use yattag library to generate html - doc, tag, text, line = Doc().ttl() - # create html based on info.txt - with tag('div'): - with tag('div', klass='box model-container'): - with tag('div', klass='spacer'): - with tag('div', klass='box model-div'): - line('h2', "Model Accuracy", klass='acc') - line('p', acc) - with tag('div', klass='box model-div'): - line('h2', "Most Important Feature", klass='feat') - line('p', most_imp_feat) - with tag('div', klass='spacer'): - line('p', note) - with tag('div', klass='box'): - line('h2', 'Problem Statement and Research Summary', klass='prj') - line('p', bkgd) - with tag('div', klass='box'): - line('h2', 'Data Collection Plan', klass='data') - line('p', data_collection) - with tag('div', klass='box'): - line('h2', 'Ethical Considerations (Data Privacy and Bias)', klass='ethics') - with tag('ul'): - line('li', priv_cons) - line('li', bias_cons) - with tag('div', klass='box'): - line('h2', 'Our Team', klass='team') - line('p', membs) - doc.stag('img', src=img_src) - - css = ''' - .box { - border: 2px solid black; - text-align: center; - margin: 10px; - padding: 5%; - } - ul { - display: inline-block; - text-align: left; - } - img { - display: block; - margin: auto; - } - .description { - text-align: center; - } - .panel_button { - display: block !important; - width: 100% !important; - background-color: #00EACD !important; - color: #000; - transition: all .2s ease-out 0s !important; - box-shadow: 0 10px #00AEAB !important; - border-radius: 10px !important; - } - .panel_button:hover { - box-shadow: 0 5px #00AEAB; - transform: translateY(5px); - } - .submit { - color: black !important; - } - .selected { - background-color: #656bd6 !important; - } - .radio_item { - border-radius: 10px; - padding-left: 10px !important; - padding-right: 10px !important; - } - .radio_item:hover { - color: #656bd6 !important; - } - .title { - background-image: url(https://media.giphy.com/media/26BROrSHlmyzzHf3i/giphy.gif); - background-size: cover; - color: transparent; - -moz-background-clip: text; - -webkit-background-clip: text; - text-transform: uppercase; - font-size: 60px; - line-height: .75; - margin: 10px 0; - } - .panel_header { - color: black !important; - } - input { - background-color: #efeffa !important; - } - .acc, .feat { - background-color: #FF3399 !important - } - .prj { - background-color: #FFCE3B !important; - } - .data { - background-color: #ED6800 !important; - } - .ethics { - background-color: #3EE6F9 !important; - } - .team { - background-color: #9581EF !important; - } - .model-container { - display: flex; - flex-direction: column; - justify-content: center; - } - .spacer { - display: flex; - justify-content: center; - } - .model-div { - width: 45%; - } - @media screen and (max-width: 700px) { - .model-container { - flex-wrap: wrap; - } - } - ''' - return { - 'article': doc.getvalue(), - 'css': css, - 'title': title, - 'description': description, - } \ No newline at end of file diff --git a/spaces/jacinthes/PubMed-fact-checker/app.py b/spaces/jacinthes/PubMed-fact-checker/app.py deleted file mode 100644 index 8a7eca30e871c78f6e7fd563dbe62edb8fc5bd00..0000000000000000000000000000000000000000 --- a/spaces/jacinthes/PubMed-fact-checker/app.py +++ /dev/null @@ -1,216 +0,0 @@ -import streamlit as st -import GPTHelper -from sentence_transformers import CrossEncoder -from pymed import PubMed -import pandas as pd -import plotly.express as px -import logging -from langdetect import detect -from typing import Dict, List - - -if 'valid_inputs_received' not in st.session_state: - st.session_state['valid_inputs_received'] = False - - -def get_articles(query, fetcher) -> Dict[List[str], List[str]]: - # Fetches articles using pymed. Increasing max_results results in longer loading times. - results = fetcher.query(query, max_results=50) - conclusions = [] - titles = [] - links = [] - for article in results: - article_id = 0 # If PubMed search fails to return anything - try: - article_id = article.pubmed_id[:8] # Sometimes pymed wrongly returns a long list of ids. Use only the first - # [] can cause the cross-encoder to misinterpret string as a list - title = article.title.replace('[', '(').replace(']', ')') - conclusion = article.conclusions - abstract = article.abstract - article_url = f'https://pubmed.ncbi.nlm.nih.gov/{article_id}/' - article_link = f'PubMed ID: {article_id}' # Injects a link to plotly - if conclusion: - # Not all articles come with the provided conclusions. Abstract is used alternatively. - conclusion = conclusion.replace('[', '(').replace(']', ')') - conclusions.append(title+'\n'+conclusion) - titles.append(title) # Title is added to the conclusion to improve relevance ranking. - links.append(article_link) - elif abstract: - abstract = abstract.replace('[', '(').replace(']', ')') - conclusions.append(title + '\n' + abstract) - titles.append(title) - links.append(article_link) - except Exception as e: - logging.warning(f'Error reading article: {article_id}: ', exc_info=e) - - return { - 'Conclusions': conclusions, - 'Links': links - } - - -@st.cache_resource -def load_cross_encoder(): - # The pretrained cross-encoder model used for reranking. Can be substituted with a different one. - cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2') - return cross_encoder - - -@st.cache_resource -def load_pubmed_fetcher(): - pubmed = PubMed(tool='PubmedFactChecker', email='stihec.jan@gmail.com') - return pubmed - - -def run_ui(): - # This function controls the whole app flow. - st.set_page_config(page_title='PUBMED FACT-CHECKER', page_icon='📖') - - sidebar = st.sidebar - sidebar.title('ABOUT') - sidebar.write(''' - The PubMed fact-checker app enables users to verify biomedical claims by comparing them against - research papers available on PubMed. \n - As the number of self-proclaimed experts continues to rise, - so does the risk of harmful misinformation. This app showcases the potential of Large Language Models - to provide accurate and valuable information to people. - ''') - sidebar.title('EXAMPLES') - sidebar.write('Try one of the below examples to see PubMed fact-checker in action.') - - st.title('PubMed FACT CHECKER') - with st.form(key='fact_form'): - fact = st.text_input('Fact:', placeholder='Enter your fact', key='form_input') - submitted = st.form_submit_button('Fact-Check') - - if sidebar.button('Mediterranean diet helps with weight loss.', use_container_width=250): - submitted = True - fact = 'Mediterranean diet helps with weight loss.' - - if sidebar.button('Low Carb High Fat diet is healthy in long term.', use_container_width=250): - submitted = True - fact = 'Low Carb High Fat diet is healthy in long term.' - - if sidebar.button('Vaccines are a cause of autism.', use_container_width=250): - submitted = True - fact = 'Vaccines are a cause of autism.' - - sidebar.title('HOW IT WORKS') - sidebar.write('Source code and an in-depth app description available at:') - sidebar.info('**GitHub: [@jacinthes](https://github.com/jacinthes/PubMed-fact-checker)**', icon="💻") - sidebar.title('DISCLAIMER') - sidebar.write('This project is meant for educational and research purposes. \n' - 'PubMed fact-checker may provide inaccurate information.') - - if not submitted and not st.session_state.valid_inputs_received: - st.stop() - - elif submitted and not fact: - st.warning('Please enter your fact before fact-checking.') - st.session_state.valid_inputs_received = False - st.stop() - - elif submitted and not detect(fact) == 'en': - st.warning('Please enter valid text in English. For short inputs, language detection is sometimes inaccurate.' - ' Try making the fact more verbose.') - st.session_state.valid_inputs_received = False - st.stop() - - elif submitted and not len(fact) < 75: - st.warning('To ensure accurate searching, please keep your fact under 75 characters.') - st.session_state.valid_inputs_received = False - st.stop() - - elif submitted and '?' in fact: - st.warning('Please state a fact. PubMed Fact Checker is good at verifying facts, ' - 'it is not meant to answer questions.') - st.session_state.valid_inputs_received = False - st.stop() - - elif submitted or st.session_state.valid_inputs_received: - pubmed_query = GPTHelper.gpt35_rephrase(fact) # Call gpt3.5 to rephrase the fact as a PubMed query. - pubmed = load_pubmed_fetcher() - - with st.spinner('Fetching articles...'): - articles = get_articles(pubmed_query, pubmed) - - article_conclusions = articles['Conclusions'] - article_links = articles['Links'] - if len(article_conclusions) == 0: - # If nothing is returned by pymed, inform user. - st.info( - "Unfortunately, I couldn't find anything for your search.\n" - "Don't let that discourage you, I have over 35 million citations in my database.\n" - "I am sure your next search will be more successful." - ) - st.stop() - - cross_inp = [[fact, conclusions] for conclusions in article_conclusions] - - with st.spinner('Assessing article relevancy...'): - cross_encoder = load_cross_encoder() - cross_scores = cross_encoder.predict(cross_inp) # Calculate relevancy using the defined cross-encoder. - - df = pd.DataFrame({ - 'Link': article_links, - 'Conclusion': article_conclusions, - 'Score': cross_scores - }) - df.sort_values(by=['Score'], ascending=False, inplace=True) - df = df[df['Score'] > 0] # Only keep articles with relevancy score above 0. - if df.shape[0] == 0: # If no relevant article is found, inform the user. - st.info( - "Unfortunately, I couldn't find anything for your search.\n" - "Don't let that discourage you, I have over 35 million citations in my database.\n" - "I am sure your next search will be more successful." - ) - st.stop() - - df = df.head(10) # Keep only 10 most relevant articles. This is done to control OpenAI costs and load time. - progress_text = 'Assessing the validity of the fact based on relevant research papers.' - fact_checking_bar = st.progress(0, text=progress_text) - step = 100/df.shape[0] - percent_complete = 0 - predictions = [] - for index, row in df.iterrows(): - prediction = GPTHelper.gpt35_check_fact(row['Conclusion'], fact) # Prompt to GPT3.5 to fact-check - # For output purposes I use True, False and Undetermined as labels. - if prediction == 'Entails': - predictions.append('True') - elif prediction == 'Contradicts': - predictions.append('False') - elif prediction == 'Undetermined': - predictions.append(prediction) - else: - # If GPT3.5 returns an invalid response. Has not happened during testing. - predictions.append('Invalid') - logging.warning(f'Unexpected prediction: {prediction}') - - percent_complete += step/100 - fact_checking_bar.progress(round(percent_complete, 2), text=progress_text) - fact_checking_bar.empty() - df['Prediction'] = predictions - df = df[df.Prediction != 'Invalid'] # Drop rows with invalid prediction. - # Prepare DataFrame for plotly sunburst chart. - totals = df.groupby('Prediction').size().to_dict() - df['Total'] = df['Prediction'].map(totals) - - fig = px.sunburst(df, path=['Prediction', 'Link'], values='Total', height=600, width=600, color='Prediction', - color_discrete_map={ - 'False': "#FF8384", - 'True': "#A5D46A", - 'Undetermined': "#FFDF80" - } - ) - fig.update_layout( - margin=dict(l=20, r=20, t=20, b=20), - font_size=32, - font_color='#000000' - ) - st.write(f'According to PubMed "{fact}" is:') - st.plotly_chart(fig, use_container_width=True) - - -if __name__ == "__main__": - run_ui() diff --git a/spaces/jason9693/KoreanHateSpeechClassifier/app.py b/spaces/jason9693/KoreanHateSpeechClassifier/app.py deleted file mode 100644 index 7728349ce03a91836c91a4e93584d0928257514d..0000000000000000000000000000000000000000 --- a/spaces/jason9693/KoreanHateSpeechClassifier/app.py +++ /dev/null @@ -1,116 +0,0 @@ -from transformers import AutoTokenizer, AutoModelForSequenceClassification, AutoConfig -import gradio as gr -from torch.nn import functional as F -import seaborn - -import matplotlib -import platform - -from transformers.file_utils import ModelOutput - -if platform.system() == "Darwin": - print("MacOS") - matplotlib.use('Agg') -import matplotlib.pyplot as plt -import io -from PIL import Image - -import matplotlib.font_manager as fm -import util - - -# global var -MODEL_NAME = 'jason9693/SoongsilBERT-base-beep' -tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) -model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME) -config = AutoConfig.from_pretrained(MODEL_NAME) - -MODEL_BUF = { - "name": MODEL_NAME, - "tokenizer": tokenizer, - "model": model, - "config": config -} - - -font_dir = ['./'] -for font in fm.findSystemFonts(font_dir): - print(font) - fm.fontManager.addfont(font) -plt.rcParams["font.family"] = 'NanumGothicCoding' - - -def visualize_attention(sent, attention_matrix, n_words=10): - def draw(data, x, y, ax): - - seaborn.heatmap(data, - xticklabels=x, square=True, yticklabels=y, vmin=0.0, vmax=1.0, - cbar=False, ax=ax) - - # make plt figure with 1x6 subplots - fig = plt.figure(figsize=(16, 8)) - # fig.subplots_adjust(hspace=0.7, wspace=0.2) - for i, layer in enumerate(range(1, 12, 2)): - ax = fig.add_subplot(2, 3, i+1) - ax.set_title("Layer {}".format(layer)) - draw(attention_matrix[layer], sent if layer > 6 else [], sent if layer in [1,7] else [], ax=ax) - - fig.tight_layout() - plt.close() - return fig - - -def change_model_name(name): - MODEL_BUF["name"] = name - MODEL_BUF["tokenizer"] = AutoTokenizer.from_pretrained(name) - MODEL_BUF["model"] = AutoModelForSequenceClassification.from_pretrained(name) - MODEL_BUF["config"] = AutoConfig.from_pretrained(name) - - -def predict(model_name, text): - if model_name != MODEL_BUF["name"]: - change_model_name(model_name) - - tokenizer = MODEL_BUF["tokenizer"] - model = MODEL_BUF["model"] - config = MODEL_BUF["config"] - - tokenized_text = tokenizer([text], return_tensors='pt') - - input_tokens = tokenizer.convert_ids_to_tokens(tokenized_text.input_ids[0]) - try: - input_tokens = util.bytetokens_to_unicdode(input_tokens) if config.model_type in ['roberta', 'gpt', 'gpt2'] else input_tokens - except KeyError: - input_tokens = input_tokens - - model.eval() - output, attention = model(**tokenized_text, output_attentions=True, return_dict=False) - output = F.softmax(output, dim=-1) - result = {} - - for idx, label in enumerate(output[0].detach().numpy()): - result[config.id2label[idx]] = float(label) - - fig = visualize_attention(input_tokens, attention[0][0].detach().numpy()) - return result, fig#.logits.detach()#.numpy()#, output.attentions.detach().numpy() - - -if __name__ == '__main__': - text = '읿딴걸 홍볿글 읿랉곭 쌑젩낄고 앉앟있냩' - - model_name_list = [ - 'jason9693/SoongsilBERT-base-beep', - "beomi/beep-klue-roberta-base-hate", - "beomi/beep-koelectra-base-v3-discriminator-hate", - "beomi/beep-KcELECTRA-base-hate" - ] - - #Create a gradio app with a button that calls predict() - app = gr.Interface( - fn=predict, - inputs=[gr.inputs.Dropdown(model_name_list, label="Model Name"), 'text'], outputs=['label', 'plot'], - examples = [[MODEL_BUF["name"], text], [MODEL_BUF["name"], "4=🦀 4≠🦀"]], - title="한국어 혐오성 발화 분류기 (Korean Hate Speech Classifier)", - description="Korean Hate Speech Classifier with Several Pretrained LM\nCurrent Supported Model:\n1. SoongsilBERT\n2. KcBERT(+KLUE)\n3. KcELECTRA\n4.KoELECTRA." - ) - app.launch(inline=False) diff --git a/spaces/jbilcke-hf/LifeSim/scripts/test.js b/spaces/jbilcke-hf/LifeSim/scripts/test.js deleted file mode 100644 index 67a07d8e5fdac589d574c227500bf8a08b23c92b..0000000000000000000000000000000000000000 --- a/spaces/jbilcke-hf/LifeSim/scripts/test.js +++ /dev/null @@ -1,23 +0,0 @@ -const { promises: fs } = require("node:fs") - -const main = async () => { - console.log('generating shot..') - const response = await fetch("http://localhost:3000/api/shot", { - method: "POST", - headers: { - "Accept": "application/json", - "Content-Type": "application/json" - }, - body: JSON.stringify({ - token: process.env.VC_SECRET_ACCESS_TOKEN, - shotPrompt: "video of a dancing cat" - }) - }); - - console.log('response:', response) - const buffer = await response.buffer() - - fs.writeFile(`./test-juju.mp4`, buffer) -} - -main() \ No newline at end of file diff --git a/spaces/jbilcke-hf/ai-comic-factory/src/lib/computePercentage.ts b/spaces/jbilcke-hf/ai-comic-factory/src/lib/computePercentage.ts deleted file mode 100644 index eaf8c1645451d44bf97a417d04e098e51ec167bb..0000000000000000000000000000000000000000 --- a/spaces/jbilcke-hf/ai-comic-factory/src/lib/computePercentage.ts +++ /dev/null @@ -1,4 +0,0 @@ -export function computePercentage(input: string | number) { - // TODO something - return 0 -} \ No newline at end of file diff --git a/spaces/jbilcke-hf/template-node-wizardcoder-express/public/css/tailwind-typography@0.1.2.css b/spaces/jbilcke-hf/template-node-wizardcoder-express/public/css/tailwind-typography@0.1.2.css deleted file mode 100644 index 6824ef97438023939b62642ce3a28a69cc9e1176..0000000000000000000000000000000000000000 --- a/spaces/jbilcke-hf/template-node-wizardcoder-express/public/css/tailwind-typography@0.1.2.css +++ /dev/null @@ -1 +0,0 @@ -.prose{color:#4a5568;max-width:65ch;font-size:1rem;line-height:1.75}.prose .lead{color:#4a5568;font-size:1.25em;line-height:1.6;margin-top:1.2em;margin-bottom:1.2em}.prose a{color:#1a202c;text-decoration:underline}.prose strong{color:#1a202c;font-weight:600}.prose ol{counter-reset:list-counter;margin-top:1.25em;margin-bottom:1.25em}.prose ol>li{position:relative;counter-increment:list-counter;padding-left:1.75em}.prose ol>li::before{content:counter(list-counter) ".";position:absolute;font-weight:400;color:#718096}.prose ul>li{position:relative;padding-left:1.75em}.prose ul>li::before{content:"";position:absolute;background-color:#cbd5e0;border-radius:50%;width:.375em;height:.375em;top:calc(.875em - .1875em);left:.25em}.prose hr{border-color:#e2e8f0;border-top-width:1px;margin-top:3em;margin-bottom:3em}.prose blockquote{font-weight:500;font-style:italic;color:#1a202c;border-left-width:.25rem;border-left-color:#e2e8f0;quotes:"\201C""\201D""\2018""\2019";margin-top:1.6em;margin-bottom:1.6em;padding-left:1em}.prose blockquote p:first-of-type::before{content:open-quote}.prose blockquote p:last-of-type::after{content:close-quote}.prose h1{color:#1a202c;font-weight:800;font-size:2.25em;margin-top:0;margin-bottom:.8888889em;line-height:1.1111111}.prose h2{color:#1a202c;font-weight:700;font-size:1.5em;margin-top:2em;margin-bottom:1em;line-height:1.3333333}.prose h3{color:#1a202c;font-weight:600;font-size:1.25em;margin-top:1.6em;margin-bottom:.6em;line-height:1.6}.prose h4{color:#1a202c;font-weight:600;margin-top:1.5em;margin-bottom:.5em;line-height:1.5}.prose figure figcaption{color:#718096;font-size:.875em;line-height:1.4285714;margin-top:.8571429em}.prose code{font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;color:#1a202c;font-weight:600;font-size:.875em}.prose code::before{content:"`"}.prose code::after{content:"`"}.prose pre{color:#e2e8f0;font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;background-color:#2d3748;overflow-x:auto;font-size:.875em;line-height:1.7142857;margin-top:1.7142857em;margin-bottom:1.7142857em;border-radius:.375rem;padding-top:.8571429em;padding-right:1.1428571em;padding-bottom:.8571429em;padding-left:1.1428571em}.prose pre code{background-color:transparent;border-width:0;border-radius:0;padding:0;font-weight:400;color:inherit;font-size:inherit;font-family:inherit;line-height:inherit}.prose pre code::before{content:""}.prose pre code::after{content:""}.prose table{width:100%;table-layout:auto;text-align:left;margin-top:2em;margin-bottom:2em;font-size:.875em;line-height:1.7142857}.prose thead{color:#1a202c;font-weight:600;border-bottom-width:1px;border-bottom-color:#cbd5e0}.prose thead th{vertical-align:bottom;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.prose tbody tr{border-bottom-width:1px;border-bottom-color:#e2e8f0}.prose tbody tr:last-child{border-bottom-width:0}.prose tbody td{vertical-align:top;padding-top:.5714286em;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.prose p{margin-top:1.25em;margin-bottom:1.25em}.prose img{margin-top:2em;margin-bottom:2em}.prose video{margin-top:2em;margin-bottom:2em}.prose figure{margin-top:2em;margin-bottom:2em}.prose figure>*{margin-top:0;margin-bottom:0}.prose h2 code{font-size:.875em}.prose h3 code{font-size:.9em}.prose ul{margin-top:1.25em;margin-bottom:1.25em}.prose li{margin-top:.5em;margin-bottom:.5em}.prose ol>li:before{left:0}.prose>ul>li p{margin-top:.75em;margin-bottom:.75em}.prose>ul>li>:first-child{margin-top:1.25em}.prose>ul>li>:last-child{margin-bottom:1.25em}.prose>ol>li>:first-child{margin-top:1.25em}.prose>ol>li>:last-child{margin-bottom:1.25em}.prose ol ol,.prose ol ul,.prose ul ol,.prose ul ul{margin-top:.75em;margin-bottom:.75em}.prose hr+*{margin-top:0}.prose h2+*{margin-top:0}.prose h3+*{margin-top:0}.prose h4+*{margin-top:0}.prose thead th:first-child{padding-left:0}.prose thead th:last-child{padding-right:0}.prose tbody td:first-child{padding-left:0}.prose tbody td:last-child{padding-right:0}.prose>:first-child{margin-top:0}.prose>:last-child{margin-bottom:0}.prose-sm{font-size:.875rem;line-height:1.7142857}.prose-sm p{margin-top:1.1428571em;margin-bottom:1.1428571em}.prose-sm .lead{font-size:1.2857143em;line-height:1.5555556;margin-top:.8888889em;margin-bottom:.8888889em}.prose-sm blockquote{margin-top:1.3333333em;margin-bottom:1.3333333em;padding-left:1.1111111em}.prose-sm h1{font-size:2.1428571em;margin-top:0;margin-bottom:.8em;line-height:1.2}.prose-sm h2{font-size:1.4285714em;margin-top:1.6em;margin-bottom:.8em;line-height:1.4}.prose-sm h3{font-size:1.2857143em;margin-top:1.5555556em;margin-bottom:.4444444em;line-height:1.5555556}.prose-sm h4{margin-top:1.4285714em;margin-bottom:.5714286em;line-height:1.4285714}.prose-sm img{margin-top:1.7142857em;margin-bottom:1.7142857em}.prose-sm video{margin-top:1.7142857em;margin-bottom:1.7142857em}.prose-sm figure{margin-top:1.7142857em;margin-bottom:1.7142857em}.prose-sm figure>*{margin-top:0;margin-bottom:0}.prose-sm figure figcaption{font-size:.8571429em;line-height:1.3333333;margin-top:.6666667em}.prose-sm code{font-size:.8571429em}.prose-sm h2 code{font-size:.9em}.prose-sm h3 code{font-size:.8888889em}.prose-sm pre{font-size:.8571429em;line-height:1.6666667;margin-top:1.6666667em;margin-bottom:1.6666667em;border-radius:.25rem;padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.prose-sm ol{margin-top:1.1428571em;margin-bottom:1.1428571em}.prose-sm ul{margin-top:1.1428571em;margin-bottom:1.1428571em}.prose-sm li{margin-top:.2857143em;margin-bottom:.2857143em}.prose-sm ol>li{padding-left:1.5714286em}.prose-sm ol>li:before{left:0}.prose-sm ul>li{padding-left:1.5714286em}.prose-sm ul>li::before{height:.3571429em;width:.3571429em;top:calc(.8571429em - .1785714em);left:.2142857em}.prose-sm>ul>li p{margin-top:.5714286em;margin-bottom:.5714286em}.prose-sm>ul>li>:first-child{margin-top:1.1428571em}.prose-sm>ul>li>:last-child{margin-bottom:1.1428571em}.prose-sm>ol>li>:first-child{margin-top:1.1428571em}.prose-sm>ol>li>:last-child{margin-bottom:1.1428571em}.prose-sm ol ol,.prose-sm ol ul,.prose-sm ul ol,.prose-sm ul ul{margin-top:.5714286em;margin-bottom:.5714286em}.prose-sm hr{margin-top:2.8571429em;margin-bottom:2.8571429em}.prose-sm hr+*{margin-top:0}.prose-sm h2+*{margin-top:0}.prose-sm h3+*{margin-top:0}.prose-sm h4+*{margin-top:0}.prose-sm table{font-size:.8571429em;line-height:1.5}.prose-sm thead th{padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.prose-sm thead th:first-child{padding-left:0}.prose-sm thead th:last-child{padding-right:0}.prose-sm tbody td{padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.prose-sm tbody td:first-child{padding-left:0}.prose-sm tbody td:last-child{padding-right:0}.prose-sm>:first-child{margin-top:0}.prose-sm>:last-child{margin-bottom:0}.prose-lg{font-size:1.125rem;line-height:1.7777778}.prose-lg p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-lg .lead{font-size:1.2222222em;line-height:1.4545455;margin-top:1.0909091em;margin-bottom:1.0909091em}.prose-lg blockquote{margin-top:1.6666667em;margin-bottom:1.6666667em;padding-left:1em}.prose-lg h1{font-size:2.6666667em;margin-top:0;margin-bottom:.8333333em;line-height:1}.prose-lg h2{font-size:1.6666667em;margin-top:1.8666667em;margin-bottom:1.0666667em;line-height:1.3333333}.prose-lg h3{font-size:1.3333333em;margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.prose-lg h4{margin-top:1.7777778em;margin-bottom:.4444444em;line-height:1.5555556}.prose-lg img{margin-top:1.7777778em;margin-bottom:1.7777778em}.prose-lg video{margin-top:1.7777778em;margin-bottom:1.7777778em}.prose-lg figure{margin-top:1.7777778em;margin-bottom:1.7777778em}.prose-lg figure>*{margin-top:0;margin-bottom:0}.prose-lg figure figcaption{font-size:.8888889em;line-height:1.5;margin-top:1em}.prose-lg code{font-size:.8888889em}.prose-lg h2 code{font-size:.8666667em}.prose-lg h3 code{font-size:.875em}.prose-lg pre{font-size:.8888889em;line-height:1.75;margin-top:2em;margin-bottom:2em;border-radius:.375rem;padding-top:1em;padding-right:1.5em;padding-bottom:1em;padding-left:1.5em}.prose-lg ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-lg ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-lg li{margin-top:.6666667em;margin-bottom:.6666667em}.prose-lg ol>li{padding-left:1.6666667em}.prose-lg ol>li:before{left:0}.prose-lg ul>li{padding-left:1.6666667em}.prose-lg ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8888889em - .1666667em);left:.2222222em}.prose-lg>ul>li p{margin-top:.8888889em;margin-bottom:.8888889em}.prose-lg>ul>li>:first-child{margin-top:1.3333333em}.prose-lg>ul>li>:last-child{margin-bottom:1.3333333em}.prose-lg>ol>li>:first-child{margin-top:1.3333333em}.prose-lg>ol>li>:last-child{margin-bottom:1.3333333em}.prose-lg ol ol,.prose-lg ol ul,.prose-lg ul ol,.prose-lg ul ul{margin-top:.8888889em;margin-bottom:.8888889em}.prose-lg hr{margin-top:3.1111111em;margin-bottom:3.1111111em}.prose-lg hr+*{margin-top:0}.prose-lg h2+*{margin-top:0}.prose-lg h3+*{margin-top:0}.prose-lg h4+*{margin-top:0}.prose-lg table{font-size:.8888889em;line-height:1.5}.prose-lg thead th{padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.prose-lg thead th:first-child{padding-left:0}.prose-lg thead th:last-child{padding-right:0}.prose-lg tbody td{padding-top:.75em;padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.prose-lg tbody td:first-child{padding-left:0}.prose-lg tbody td:last-child{padding-right:0}.prose-lg>:first-child{margin-top:0}.prose-lg>:last-child{margin-bottom:0}.prose-xl{font-size:1.25rem;line-height:1.8}.prose-xl p{margin-top:1.2em;margin-bottom:1.2em}.prose-xl .lead{font-size:1.2em;line-height:1.5;margin-top:1em;margin-bottom:1em}.prose-xl blockquote{margin-top:1.6em;margin-bottom:1.6em;padding-left:1.0666667em}.prose-xl h1{font-size:2.8em;margin-top:0;margin-bottom:.8571429em;line-height:1}.prose-xl h2{font-size:1.8em;margin-top:1.5555556em;margin-bottom:.8888889em;line-height:1.1111111}.prose-xl h3{font-size:1.5em;margin-top:1.6em;margin-bottom:.6666667em;line-height:1.3333333}.prose-xl h4{margin-top:1.8em;margin-bottom:.6em;line-height:1.6}.prose-xl img{margin-top:2em;margin-bottom:2em}.prose-xl video{margin-top:2em;margin-bottom:2em}.prose-xl figure{margin-top:2em;margin-bottom:2em}.prose-xl figure>*{margin-top:0;margin-bottom:0}.prose-xl figure figcaption{font-size:.9em;line-height:1.5555556;margin-top:1em}.prose-xl code{font-size:.9em}.prose-xl h2 code{font-size:.8611111em}.prose-xl h3 code{font-size:.9em}.prose-xl pre{font-size:.9em;line-height:1.7777778;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.1111111em;padding-right:1.3333333em;padding-bottom:1.1111111em;padding-left:1.3333333em}.prose-xl ol{margin-top:1.2em;margin-bottom:1.2em}.prose-xl ul{margin-top:1.2em;margin-bottom:1.2em}.prose-xl li{margin-top:.6em;margin-bottom:.6em}.prose-xl ol>li{padding-left:1.8em}.prose-xl ol>li:before{left:0}.prose-xl ul>li{padding-left:1.8em}.prose-xl ul>li::before{width:.35em;height:.35em;top:calc(.9em - .175em);left:.25em}.prose-xl>ul>li p{margin-top:.8em;margin-bottom:.8em}.prose-xl>ul>li>:first-child{margin-top:1.2em}.prose-xl>ul>li>:last-child{margin-bottom:1.2em}.prose-xl>ol>li>:first-child{margin-top:1.2em}.prose-xl>ol>li>:last-child{margin-bottom:1.2em}.prose-xl ol ol,.prose-xl ol ul,.prose-xl ul ol,.prose-xl ul ul{margin-top:.8em;margin-bottom:.8em}.prose-xl hr{margin-top:2.8em;margin-bottom:2.8em}.prose-xl hr+*{margin-top:0}.prose-xl h2+*{margin-top:0}.prose-xl h3+*{margin-top:0}.prose-xl h4+*{margin-top:0}.prose-xl table{font-size:.9em;line-height:1.5555556}.prose-xl thead th{padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.prose-xl thead th:first-child{padding-left:0}.prose-xl thead th:last-child{padding-right:0}.prose-xl tbody td{padding-top:.8888889em;padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.prose-xl tbody td:first-child{padding-left:0}.prose-xl tbody td:last-child{padding-right:0}.prose-xl>:first-child{margin-top:0}.prose-xl>:last-child{margin-bottom:0}.prose-2xl{font-size:1.5rem;line-height:1.6666667}.prose-2xl p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-2xl .lead{font-size:1.25em;line-height:1.4666667;margin-top:1.0666667em;margin-bottom:1.0666667em}.prose-2xl blockquote{margin-top:1.7777778em;margin-bottom:1.7777778em;padding-left:1.1111111em}.prose-2xl h1{font-size:2.6666667em;margin-top:0;margin-bottom:.875em;line-height:1}.prose-2xl h2{font-size:2em;margin-top:1.5em;margin-bottom:.8333333em;line-height:1.0833333}.prose-2xl h3{font-size:1.5em;margin-top:1.5555556em;margin-bottom:.6666667em;line-height:1.2222222}.prose-2xl h4{margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.prose-2xl img{margin-top:2em;margin-bottom:2em}.prose-2xl video{margin-top:2em;margin-bottom:2em}.prose-2xl figure{margin-top:2em;margin-bottom:2em}.prose-2xl figure>*{margin-top:0;margin-bottom:0}.prose-2xl figure figcaption{font-size:.8333333em;line-height:1.6;margin-top:1em}.prose-2xl code{font-size:.8333333em}.prose-2xl h2 code{font-size:.875em}.prose-2xl h3 code{font-size:.8888889em}.prose-2xl pre{font-size:.8333333em;line-height:1.8;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.2em;padding-right:1.6em;padding-bottom:1.2em;padding-left:1.6em}.prose-2xl ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-2xl ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-2xl li{margin-top:.5em;margin-bottom:.5em}.prose-2xl ol>li{padding-left:1.6666667em}.prose-2xl ol>li:before{left:0}.prose-2xl ul>li{padding-left:1.6666667em}.prose-2xl ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8333333em - .1666667em);left:.25em}.prose-2xl>ul>li p{margin-top:.8333333em;margin-bottom:.8333333em}.prose-2xl>ul>li>:first-child{margin-top:1.3333333em}.prose-2xl>ul>li>:last-child{margin-bottom:1.3333333em}.prose-2xl>ol>li>:first-child{margin-top:1.3333333em}.prose-2xl>ol>li>:last-child{margin-bottom:1.3333333em}.prose-2xl ol ol,.prose-2xl ol ul,.prose-2xl ul ol,.prose-2xl ul ul{margin-top:.6666667em;margin-bottom:.6666667em}.prose-2xl hr{margin-top:3em;margin-bottom:3em}.prose-2xl hr+*{margin-top:0}.prose-2xl h2+*{margin-top:0}.prose-2xl h3+*{margin-top:0}.prose-2xl h4+*{margin-top:0}.prose-2xl table{font-size:.8333333em;line-height:1.4}.prose-2xl thead th{padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.prose-2xl thead th:first-child{padding-left:0}.prose-2xl thead th:last-child{padding-right:0}.prose-2xl tbody td{padding-top:.8em;padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.prose-2xl tbody td:first-child{padding-left:0}.prose-2xl tbody td:last-child{padding-right:0}.prose-2xl>:first-child{margin-top:0}.prose-2xl>:last-child{margin-bottom:0}@media (min-width:640px){.sm\:prose{color:#4a5568;max-width:65ch;font-size:1rem;line-height:1.75}.prose .sm\:lead{color:#4a5568;font-size:1.25em;line-height:1.6;margin-top:1.2em;margin-bottom:1.2em}.sm\:prose a{color:#1a202c;text-decoration:underline}.sm\:prose strong{color:#1a202c;font-weight:600}.sm\:prose ol{counter-reset:list-counter;margin-top:1.25em;margin-bottom:1.25em}.sm\:prose ol>li{position:relative;counter-increment:list-counter;padding-left:1.75em}.sm\:prose ol>li::before{content:counter(list-counter) ".";position:absolute;font-weight:400;color:#718096}.sm\:prose ul>li{position:relative;padding-left:1.75em}.sm\:prose ul>li::before{content:"";position:absolute;background-color:#cbd5e0;border-radius:50%;width:.375em;height:.375em;top:calc(.875em - .1875em);left:.25em}.sm\:prose hr{border-color:#e2e8f0;border-top-width:1px;margin-top:3em;margin-bottom:3em}.sm\:prose blockquote{font-weight:500;font-style:italic;color:#1a202c;border-left-width:.25rem;border-left-color:#e2e8f0;quotes:"\201C""\201D""\2018""\2019";margin-top:1.6em;margin-bottom:1.6em;padding-left:1em}.sm\:prose blockquote p:first-of-type::before{content:open-quote}.sm\:prose blockquote p:last-of-type::after{content:close-quote}.sm\:prose h1{color:#1a202c;font-weight:800;font-size:2.25em;margin-top:0;margin-bottom:.8888889em;line-height:1.1111111}.sm\:prose h2{color:#1a202c;font-weight:700;font-size:1.5em;margin-top:2em;margin-bottom:1em;line-height:1.3333333}.sm\:prose h3{color:#1a202c;font-weight:600;font-size:1.25em;margin-top:1.6em;margin-bottom:.6em;line-height:1.6}.sm\:prose h4{color:#1a202c;font-weight:600;margin-top:1.5em;margin-bottom:.5em;line-height:1.5}.sm\:prose figure figcaption{color:#718096;font-size:.875em;line-height:1.4285714;margin-top:.8571429em}.sm\:prose code{font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;color:#1a202c;font-weight:600;font-size:.875em}.sm\:prose code::before{content:"`"}.sm\:prose code::after{content:"`"}.sm\:prose pre{color:#e2e8f0;font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;background-color:#2d3748;overflow-x:auto;font-size:.875em;line-height:1.7142857;margin-top:1.7142857em;margin-bottom:1.7142857em;border-radius:.375rem;padding-top:.8571429em;padding-right:1.1428571em;padding-bottom:.8571429em;padding-left:1.1428571em}.sm\:prose pre code{background-color:transparent;border-width:0;border-radius:0;padding:0;font-weight:400;color:inherit;font-size:inherit;font-family:inherit;line-height:inherit}.sm\:prose pre code::before{content:""}.sm\:prose pre code::after{content:""}.sm\:prose table{width:100%;table-layout:auto;text-align:left;margin-top:2em;margin-bottom:2em;font-size:.875em;line-height:1.7142857}.sm\:prose thead{color:#1a202c;font-weight:600;border-bottom-width:1px;border-bottom-color:#cbd5e0}.sm\:prose thead th{vertical-align:bottom;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.sm\:prose tbody tr{border-bottom-width:1px;border-bottom-color:#e2e8f0}.sm\:prose tbody tr:last-child{border-bottom-width:0}.sm\:prose tbody td{vertical-align:top;padding-top:.5714286em;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.sm\:prose p{margin-top:1.25em;margin-bottom:1.25em}.sm\:prose img{margin-top:2em;margin-bottom:2em}.sm\:prose video{margin-top:2em;margin-bottom:2em}.sm\:prose figure{margin-top:2em;margin-bottom:2em}.sm\:prose figure>*{margin-top:0;margin-bottom:0}.sm\:prose h2 code{font-size:.875em}.sm\:prose h3 code{font-size:.9em}.sm\:prose ul{margin-top:1.25em;margin-bottom:1.25em}.sm\:prose li{margin-top:.5em;margin-bottom:.5em}.sm\:prose ol>li:before{left:0}.sm\:prose>ul>li p{margin-top:.75em;margin-bottom:.75em}.sm\:prose>ul>li>:first-child{margin-top:1.25em}.sm\:prose>ul>li>:last-child{margin-bottom:1.25em}.sm\:prose>ol>li>:first-child{margin-top:1.25em}.sm\:prose>ol>li>:last-child{margin-bottom:1.25em}.sm\:prose ol ol,.sm\:prose ol ul,.sm\:prose ul ol,.sm\:prose ul ul{margin-top:.75em;margin-bottom:.75em}.sm\:prose hr+*{margin-top:0}.sm\:prose h2+*{margin-top:0}.sm\:prose h3+*{margin-top:0}.sm\:prose h4+*{margin-top:0}.sm\:prose thead th:first-child{padding-left:0}.sm\:prose thead th:last-child{padding-right:0}.sm\:prose tbody td:first-child{padding-left:0}.sm\:prose tbody td:last-child{padding-right:0}.sm\:prose>:first-child{margin-top:0}.sm\:prose>:last-child{margin-bottom:0}.sm\:prose-sm{font-size:.875rem;line-height:1.7142857}.sm\:prose-sm p{margin-top:1.1428571em;margin-bottom:1.1428571em}.prose-sm .sm\:lead{font-size:1.2857143em;line-height:1.5555556;margin-top:.8888889em;margin-bottom:.8888889em}.sm\:prose-sm blockquote{margin-top:1.3333333em;margin-bottom:1.3333333em;padding-left:1.1111111em}.sm\:prose-sm h1{font-size:2.1428571em;margin-top:0;margin-bottom:.8em;line-height:1.2}.sm\:prose-sm h2{font-size:1.4285714em;margin-top:1.6em;margin-bottom:.8em;line-height:1.4}.sm\:prose-sm h3{font-size:1.2857143em;margin-top:1.5555556em;margin-bottom:.4444444em;line-height:1.5555556}.sm\:prose-sm h4{margin-top:1.4285714em;margin-bottom:.5714286em;line-height:1.4285714}.sm\:prose-sm img{margin-top:1.7142857em;margin-bottom:1.7142857em}.sm\:prose-sm video{margin-top:1.7142857em;margin-bottom:1.7142857em}.sm\:prose-sm figure{margin-top:1.7142857em;margin-bottom:1.7142857em}.sm\:prose-sm figure>*{margin-top:0;margin-bottom:0}.sm\:prose-sm figure figcaption{font-size:.8571429em;line-height:1.3333333;margin-top:.6666667em}.sm\:prose-sm code{font-size:.8571429em}.sm\:prose-sm h2 code{font-size:.9em}.sm\:prose-sm h3 code{font-size:.8888889em}.sm\:prose-sm pre{font-size:.8571429em;line-height:1.6666667;margin-top:1.6666667em;margin-bottom:1.6666667em;border-radius:.25rem;padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.sm\:prose-sm ol{margin-top:1.1428571em;margin-bottom:1.1428571em}.sm\:prose-sm ul{margin-top:1.1428571em;margin-bottom:1.1428571em}.sm\:prose-sm li{margin-top:.2857143em;margin-bottom:.2857143em}.sm\:prose-sm ol>li{padding-left:1.5714286em}.sm\:prose-sm ol>li:before{left:0}.sm\:prose-sm ul>li{padding-left:1.5714286em}.sm\:prose-sm ul>li::before{height:.3571429em;width:.3571429em;top:calc(.8571429em - .1785714em);left:.2142857em}.sm\:prose-sm>ul>li p{margin-top:.5714286em;margin-bottom:.5714286em}.sm\:prose-sm>ul>li>:first-child{margin-top:1.1428571em}.sm\:prose-sm>ul>li>:last-child{margin-bottom:1.1428571em}.sm\:prose-sm>ol>li>:first-child{margin-top:1.1428571em}.sm\:prose-sm>ol>li>:last-child{margin-bottom:1.1428571em}.sm\:prose-sm ol ol,.sm\:prose-sm ol ul,.sm\:prose-sm ul ol,.sm\:prose-sm ul ul{margin-top:.5714286em;margin-bottom:.5714286em}.sm\:prose-sm hr{margin-top:2.8571429em;margin-bottom:2.8571429em}.sm\:prose-sm hr+*{margin-top:0}.sm\:prose-sm h2+*{margin-top:0}.sm\:prose-sm h3+*{margin-top:0}.sm\:prose-sm h4+*{margin-top:0}.sm\:prose-sm table{font-size:.8571429em;line-height:1.5}.sm\:prose-sm thead th{padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.sm\:prose-sm thead th:first-child{padding-left:0}.sm\:prose-sm thead th:last-child{padding-right:0}.sm\:prose-sm tbody td{padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.sm\:prose-sm tbody td:first-child{padding-left:0}.sm\:prose-sm tbody td:last-child{padding-right:0}.sm\:prose-sm>:first-child{margin-top:0}.sm\:prose-sm>:last-child{margin-bottom:0}.sm\:prose-lg{font-size:1.125rem;line-height:1.7777778}.sm\:prose-lg p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-lg .sm\:lead{font-size:1.2222222em;line-height:1.4545455;margin-top:1.0909091em;margin-bottom:1.0909091em}.sm\:prose-lg blockquote{margin-top:1.6666667em;margin-bottom:1.6666667em;padding-left:1em}.sm\:prose-lg h1{font-size:2.6666667em;margin-top:0;margin-bottom:.8333333em;line-height:1}.sm\:prose-lg h2{font-size:1.6666667em;margin-top:1.8666667em;margin-bottom:1.0666667em;line-height:1.3333333}.sm\:prose-lg h3{font-size:1.3333333em;margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.sm\:prose-lg h4{margin-top:1.7777778em;margin-bottom:.4444444em;line-height:1.5555556}.sm\:prose-lg img{margin-top:1.7777778em;margin-bottom:1.7777778em}.sm\:prose-lg video{margin-top:1.7777778em;margin-bottom:1.7777778em}.sm\:prose-lg figure{margin-top:1.7777778em;margin-bottom:1.7777778em}.sm\:prose-lg figure>*{margin-top:0;margin-bottom:0}.sm\:prose-lg figure figcaption{font-size:.8888889em;line-height:1.5;margin-top:1em}.sm\:prose-lg code{font-size:.8888889em}.sm\:prose-lg h2 code{font-size:.8666667em}.sm\:prose-lg h3 code{font-size:.875em}.sm\:prose-lg pre{font-size:.8888889em;line-height:1.75;margin-top:2em;margin-bottom:2em;border-radius:.375rem;padding-top:1em;padding-right:1.5em;padding-bottom:1em;padding-left:1.5em}.sm\:prose-lg ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.sm\:prose-lg ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.sm\:prose-lg li{margin-top:.6666667em;margin-bottom:.6666667em}.sm\:prose-lg ol>li{padding-left:1.6666667em}.sm\:prose-lg ol>li:before{left:0}.sm\:prose-lg ul>li{padding-left:1.6666667em}.sm\:prose-lg ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8888889em - .1666667em);left:.2222222em}.sm\:prose-lg>ul>li p{margin-top:.8888889em;margin-bottom:.8888889em}.sm\:prose-lg>ul>li>:first-child{margin-top:1.3333333em}.sm\:prose-lg>ul>li>:last-child{margin-bottom:1.3333333em}.sm\:prose-lg>ol>li>:first-child{margin-top:1.3333333em}.sm\:prose-lg>ol>li>:last-child{margin-bottom:1.3333333em}.sm\:prose-lg ol ol,.sm\:prose-lg ol ul,.sm\:prose-lg ul ol,.sm\:prose-lg ul ul{margin-top:.8888889em;margin-bottom:.8888889em}.sm\:prose-lg hr{margin-top:3.1111111em;margin-bottom:3.1111111em}.sm\:prose-lg hr+*{margin-top:0}.sm\:prose-lg h2+*{margin-top:0}.sm\:prose-lg h3+*{margin-top:0}.sm\:prose-lg h4+*{margin-top:0}.sm\:prose-lg table{font-size:.8888889em;line-height:1.5}.sm\:prose-lg thead th{padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.sm\:prose-lg thead th:first-child{padding-left:0}.sm\:prose-lg thead th:last-child{padding-right:0}.sm\:prose-lg tbody td{padding-top:.75em;padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.sm\:prose-lg tbody td:first-child{padding-left:0}.sm\:prose-lg tbody td:last-child{padding-right:0}.sm\:prose-lg>:first-child{margin-top:0}.sm\:prose-lg>:last-child{margin-bottom:0}.sm\:prose-xl{font-size:1.25rem;line-height:1.8}.sm\:prose-xl p{margin-top:1.2em;margin-bottom:1.2em}.prose-xl .sm\:lead{font-size:1.2em;line-height:1.5;margin-top:1em;margin-bottom:1em}.sm\:prose-xl blockquote{margin-top:1.6em;margin-bottom:1.6em;padding-left:1.0666667em}.sm\:prose-xl h1{font-size:2.8em;margin-top:0;margin-bottom:.8571429em;line-height:1}.sm\:prose-xl h2{font-size:1.8em;margin-top:1.5555556em;margin-bottom:.8888889em;line-height:1.1111111}.sm\:prose-xl h3{font-size:1.5em;margin-top:1.6em;margin-bottom:.6666667em;line-height:1.3333333}.sm\:prose-xl h4{margin-top:1.8em;margin-bottom:.6em;line-height:1.6}.sm\:prose-xl img{margin-top:2em;margin-bottom:2em}.sm\:prose-xl video{margin-top:2em;margin-bottom:2em}.sm\:prose-xl figure{margin-top:2em;margin-bottom:2em}.sm\:prose-xl figure>*{margin-top:0;margin-bottom:0}.sm\:prose-xl figure figcaption{font-size:.9em;line-height:1.5555556;margin-top:1em}.sm\:prose-xl code{font-size:.9em}.sm\:prose-xl h2 code{font-size:.8611111em}.sm\:prose-xl h3 code{font-size:.9em}.sm\:prose-xl pre{font-size:.9em;line-height:1.7777778;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.1111111em;padding-right:1.3333333em;padding-bottom:1.1111111em;padding-left:1.3333333em}.sm\:prose-xl ol{margin-top:1.2em;margin-bottom:1.2em}.sm\:prose-xl ul{margin-top:1.2em;margin-bottom:1.2em}.sm\:prose-xl li{margin-top:.6em;margin-bottom:.6em}.sm\:prose-xl ol>li{padding-left:1.8em}.sm\:prose-xl ol>li:before{left:0}.sm\:prose-xl ul>li{padding-left:1.8em}.sm\:prose-xl ul>li::before{width:.35em;height:.35em;top:calc(.9em - .175em);left:.25em}.sm\:prose-xl>ul>li p{margin-top:.8em;margin-bottom:.8em}.sm\:prose-xl>ul>li>:first-child{margin-top:1.2em}.sm\:prose-xl>ul>li>:last-child{margin-bottom:1.2em}.sm\:prose-xl>ol>li>:first-child{margin-top:1.2em}.sm\:prose-xl>ol>li>:last-child{margin-bottom:1.2em}.sm\:prose-xl ol ol,.sm\:prose-xl ol ul,.sm\:prose-xl ul ol,.sm\:prose-xl ul ul{margin-top:.8em;margin-bottom:.8em}.sm\:prose-xl hr{margin-top:2.8em;margin-bottom:2.8em}.sm\:prose-xl hr+*{margin-top:0}.sm\:prose-xl h2+*{margin-top:0}.sm\:prose-xl h3+*{margin-top:0}.sm\:prose-xl h4+*{margin-top:0}.sm\:prose-xl table{font-size:.9em;line-height:1.5555556}.sm\:prose-xl thead th{padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.sm\:prose-xl thead th:first-child{padding-left:0}.sm\:prose-xl thead th:last-child{padding-right:0}.sm\:prose-xl tbody td{padding-top:.8888889em;padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.sm\:prose-xl tbody td:first-child{padding-left:0}.sm\:prose-xl tbody td:last-child{padding-right:0}.sm\:prose-xl>:first-child{margin-top:0}.sm\:prose-xl>:last-child{margin-bottom:0}.sm\:prose-2xl{font-size:1.5rem;line-height:1.6666667}.sm\:prose-2xl p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-2xl .sm\:lead{font-size:1.25em;line-height:1.4666667;margin-top:1.0666667em;margin-bottom:1.0666667em}.sm\:prose-2xl blockquote{margin-top:1.7777778em;margin-bottom:1.7777778em;padding-left:1.1111111em}.sm\:prose-2xl h1{font-size:2.6666667em;margin-top:0;margin-bottom:.875em;line-height:1}.sm\:prose-2xl h2{font-size:2em;margin-top:1.5em;margin-bottom:.8333333em;line-height:1.0833333}.sm\:prose-2xl h3{font-size:1.5em;margin-top:1.5555556em;margin-bottom:.6666667em;line-height:1.2222222}.sm\:prose-2xl h4{margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.sm\:prose-2xl img{margin-top:2em;margin-bottom:2em}.sm\:prose-2xl video{margin-top:2em;margin-bottom:2em}.sm\:prose-2xl figure{margin-top:2em;margin-bottom:2em}.sm\:prose-2xl figure>*{margin-top:0;margin-bottom:0}.sm\:prose-2xl figure figcaption{font-size:.8333333em;line-height:1.6;margin-top:1em}.sm\:prose-2xl code{font-size:.8333333em}.sm\:prose-2xl h2 code{font-size:.875em}.sm\:prose-2xl h3 code{font-size:.8888889em}.sm\:prose-2xl pre{font-size:.8333333em;line-height:1.8;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.2em;padding-right:1.6em;padding-bottom:1.2em;padding-left:1.6em}.sm\:prose-2xl ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.sm\:prose-2xl ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.sm\:prose-2xl li{margin-top:.5em;margin-bottom:.5em}.sm\:prose-2xl ol>li{padding-left:1.6666667em}.sm\:prose-2xl ol>li:before{left:0}.sm\:prose-2xl ul>li{padding-left:1.6666667em}.sm\:prose-2xl ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8333333em - .1666667em);left:.25em}.sm\:prose-2xl>ul>li p{margin-top:.8333333em;margin-bottom:.8333333em}.sm\:prose-2xl>ul>li>:first-child{margin-top:1.3333333em}.sm\:prose-2xl>ul>li>:last-child{margin-bottom:1.3333333em}.sm\:prose-2xl>ol>li>:first-child{margin-top:1.3333333em}.sm\:prose-2xl>ol>li>:last-child{margin-bottom:1.3333333em}.sm\:prose-2xl ol ol,.sm\:prose-2xl ol ul,.sm\:prose-2xl ul ol,.sm\:prose-2xl ul ul{margin-top:.6666667em;margin-bottom:.6666667em}.sm\:prose-2xl hr{margin-top:3em;margin-bottom:3em}.sm\:prose-2xl hr+*{margin-top:0}.sm\:prose-2xl h2+*{margin-top:0}.sm\:prose-2xl h3+*{margin-top:0}.sm\:prose-2xl h4+*{margin-top:0}.sm\:prose-2xl table{font-size:.8333333em;line-height:1.4}.sm\:prose-2xl thead th{padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.sm\:prose-2xl thead th:first-child{padding-left:0}.sm\:prose-2xl thead th:last-child{padding-right:0}.sm\:prose-2xl tbody td{padding-top:.8em;padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.sm\:prose-2xl tbody td:first-child{padding-left:0}.sm\:prose-2xl tbody td:last-child{padding-right:0}.sm\:prose-2xl>:first-child{margin-top:0}.sm\:prose-2xl>:last-child{margin-bottom:0}}@media (min-width:768px){.md\:prose{color:#4a5568;max-width:65ch;font-size:1rem;line-height:1.75}.prose .md\:lead{color:#4a5568;font-size:1.25em;line-height:1.6;margin-top:1.2em;margin-bottom:1.2em}.md\:prose a{color:#1a202c;text-decoration:underline}.md\:prose strong{color:#1a202c;font-weight:600}.md\:prose ol{counter-reset:list-counter;margin-top:1.25em;margin-bottom:1.25em}.md\:prose ol>li{position:relative;counter-increment:list-counter;padding-left:1.75em}.md\:prose ol>li::before{content:counter(list-counter) ".";position:absolute;font-weight:400;color:#718096}.md\:prose ul>li{position:relative;padding-left:1.75em}.md\:prose ul>li::before{content:"";position:absolute;background-color:#cbd5e0;border-radius:50%;width:.375em;height:.375em;top:calc(.875em - .1875em);left:.25em}.md\:prose hr{border-color:#e2e8f0;border-top-width:1px;margin-top:3em;margin-bottom:3em}.md\:prose blockquote{font-weight:500;font-style:italic;color:#1a202c;border-left-width:.25rem;border-left-color:#e2e8f0;quotes:"\201C""\201D""\2018""\2019";margin-top:1.6em;margin-bottom:1.6em;padding-left:1em}.md\:prose blockquote p:first-of-type::before{content:open-quote}.md\:prose blockquote p:last-of-type::after{content:close-quote}.md\:prose h1{color:#1a202c;font-weight:800;font-size:2.25em;margin-top:0;margin-bottom:.8888889em;line-height:1.1111111}.md\:prose h2{color:#1a202c;font-weight:700;font-size:1.5em;margin-top:2em;margin-bottom:1em;line-height:1.3333333}.md\:prose h3{color:#1a202c;font-weight:600;font-size:1.25em;margin-top:1.6em;margin-bottom:.6em;line-height:1.6}.md\:prose h4{color:#1a202c;font-weight:600;margin-top:1.5em;margin-bottom:.5em;line-height:1.5}.md\:prose figure figcaption{color:#718096;font-size:.875em;line-height:1.4285714;margin-top:.8571429em}.md\:prose code{font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;color:#1a202c;font-weight:600;font-size:.875em}.md\:prose code::before{content:"`"}.md\:prose code::after{content:"`"}.md\:prose pre{color:#e2e8f0;font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;background-color:#2d3748;overflow-x:auto;font-size:.875em;line-height:1.7142857;margin-top:1.7142857em;margin-bottom:1.7142857em;border-radius:.375rem;padding-top:.8571429em;padding-right:1.1428571em;padding-bottom:.8571429em;padding-left:1.1428571em}.md\:prose pre code{background-color:transparent;border-width:0;border-radius:0;padding:0;font-weight:400;color:inherit;font-size:inherit;font-family:inherit;line-height:inherit}.md\:prose pre code::before{content:""}.md\:prose pre code::after{content:""}.md\:prose table{width:100%;table-layout:auto;text-align:left;margin-top:2em;margin-bottom:2em;font-size:.875em;line-height:1.7142857}.md\:prose thead{color:#1a202c;font-weight:600;border-bottom-width:1px;border-bottom-color:#cbd5e0}.md\:prose thead th{vertical-align:bottom;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.md\:prose tbody tr{border-bottom-width:1px;border-bottom-color:#e2e8f0}.md\:prose tbody tr:last-child{border-bottom-width:0}.md\:prose tbody td{vertical-align:top;padding-top:.5714286em;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.md\:prose p{margin-top:1.25em;margin-bottom:1.25em}.md\:prose img{margin-top:2em;margin-bottom:2em}.md\:prose video{margin-top:2em;margin-bottom:2em}.md\:prose figure{margin-top:2em;margin-bottom:2em}.md\:prose figure>*{margin-top:0;margin-bottom:0}.md\:prose h2 code{font-size:.875em}.md\:prose h3 code{font-size:.9em}.md\:prose ul{margin-top:1.25em;margin-bottom:1.25em}.md\:prose li{margin-top:.5em;margin-bottom:.5em}.md\:prose ol>li:before{left:0}.md\:prose>ul>li p{margin-top:.75em;margin-bottom:.75em}.md\:prose>ul>li>:first-child{margin-top:1.25em}.md\:prose>ul>li>:last-child{margin-bottom:1.25em}.md\:prose>ol>li>:first-child{margin-top:1.25em}.md\:prose>ol>li>:last-child{margin-bottom:1.25em}.md\:prose ol ol,.md\:prose ol ul,.md\:prose ul ol,.md\:prose ul ul{margin-top:.75em;margin-bottom:.75em}.md\:prose hr+*{margin-top:0}.md\:prose h2+*{margin-top:0}.md\:prose h3+*{margin-top:0}.md\:prose h4+*{margin-top:0}.md\:prose thead th:first-child{padding-left:0}.md\:prose thead th:last-child{padding-right:0}.md\:prose tbody td:first-child{padding-left:0}.md\:prose tbody td:last-child{padding-right:0}.md\:prose>:first-child{margin-top:0}.md\:prose>:last-child{margin-bottom:0}.md\:prose-sm{font-size:.875rem;line-height:1.7142857}.md\:prose-sm p{margin-top:1.1428571em;margin-bottom:1.1428571em}.prose-sm .md\:lead{font-size:1.2857143em;line-height:1.5555556;margin-top:.8888889em;margin-bottom:.8888889em}.md\:prose-sm blockquote{margin-top:1.3333333em;margin-bottom:1.3333333em;padding-left:1.1111111em}.md\:prose-sm h1{font-size:2.1428571em;margin-top:0;margin-bottom:.8em;line-height:1.2}.md\:prose-sm h2{font-size:1.4285714em;margin-top:1.6em;margin-bottom:.8em;line-height:1.4}.md\:prose-sm h3{font-size:1.2857143em;margin-top:1.5555556em;margin-bottom:.4444444em;line-height:1.5555556}.md\:prose-sm h4{margin-top:1.4285714em;margin-bottom:.5714286em;line-height:1.4285714}.md\:prose-sm img{margin-top:1.7142857em;margin-bottom:1.7142857em}.md\:prose-sm video{margin-top:1.7142857em;margin-bottom:1.7142857em}.md\:prose-sm figure{margin-top:1.7142857em;margin-bottom:1.7142857em}.md\:prose-sm figure>*{margin-top:0;margin-bottom:0}.md\:prose-sm figure figcaption{font-size:.8571429em;line-height:1.3333333;margin-top:.6666667em}.md\:prose-sm code{font-size:.8571429em}.md\:prose-sm h2 code{font-size:.9em}.md\:prose-sm h3 code{font-size:.8888889em}.md\:prose-sm pre{font-size:.8571429em;line-height:1.6666667;margin-top:1.6666667em;margin-bottom:1.6666667em;border-radius:.25rem;padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.md\:prose-sm ol{margin-top:1.1428571em;margin-bottom:1.1428571em}.md\:prose-sm ul{margin-top:1.1428571em;margin-bottom:1.1428571em}.md\:prose-sm li{margin-top:.2857143em;margin-bottom:.2857143em}.md\:prose-sm ol>li{padding-left:1.5714286em}.md\:prose-sm ol>li:before{left:0}.md\:prose-sm ul>li{padding-left:1.5714286em}.md\:prose-sm ul>li::before{height:.3571429em;width:.3571429em;top:calc(.8571429em - .1785714em);left:.2142857em}.md\:prose-sm>ul>li p{margin-top:.5714286em;margin-bottom:.5714286em}.md\:prose-sm>ul>li>:first-child{margin-top:1.1428571em}.md\:prose-sm>ul>li>:last-child{margin-bottom:1.1428571em}.md\:prose-sm>ol>li>:first-child{margin-top:1.1428571em}.md\:prose-sm>ol>li>:last-child{margin-bottom:1.1428571em}.md\:prose-sm ol ol,.md\:prose-sm ol ul,.md\:prose-sm ul ol,.md\:prose-sm ul ul{margin-top:.5714286em;margin-bottom:.5714286em}.md\:prose-sm hr{margin-top:2.8571429em;margin-bottom:2.8571429em}.md\:prose-sm hr+*{margin-top:0}.md\:prose-sm h2+*{margin-top:0}.md\:prose-sm h3+*{margin-top:0}.md\:prose-sm h4+*{margin-top:0}.md\:prose-sm table{font-size:.8571429em;line-height:1.5}.md\:prose-sm thead th{padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.md\:prose-sm thead th:first-child{padding-left:0}.md\:prose-sm thead th:last-child{padding-right:0}.md\:prose-sm tbody td{padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.md\:prose-sm tbody td:first-child{padding-left:0}.md\:prose-sm tbody td:last-child{padding-right:0}.md\:prose-sm>:first-child{margin-top:0}.md\:prose-sm>:last-child{margin-bottom:0}.md\:prose-lg{font-size:1.125rem;line-height:1.7777778}.md\:prose-lg p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-lg .md\:lead{font-size:1.2222222em;line-height:1.4545455;margin-top:1.0909091em;margin-bottom:1.0909091em}.md\:prose-lg blockquote{margin-top:1.6666667em;margin-bottom:1.6666667em;padding-left:1em}.md\:prose-lg h1{font-size:2.6666667em;margin-top:0;margin-bottom:.8333333em;line-height:1}.md\:prose-lg h2{font-size:1.6666667em;margin-top:1.8666667em;margin-bottom:1.0666667em;line-height:1.3333333}.md\:prose-lg h3{font-size:1.3333333em;margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.md\:prose-lg h4{margin-top:1.7777778em;margin-bottom:.4444444em;line-height:1.5555556}.md\:prose-lg img{margin-top:1.7777778em;margin-bottom:1.7777778em}.md\:prose-lg video{margin-top:1.7777778em;margin-bottom:1.7777778em}.md\:prose-lg figure{margin-top:1.7777778em;margin-bottom:1.7777778em}.md\:prose-lg figure>*{margin-top:0;margin-bottom:0}.md\:prose-lg figure figcaption{font-size:.8888889em;line-height:1.5;margin-top:1em}.md\:prose-lg code{font-size:.8888889em}.md\:prose-lg h2 code{font-size:.8666667em}.md\:prose-lg h3 code{font-size:.875em}.md\:prose-lg pre{font-size:.8888889em;line-height:1.75;margin-top:2em;margin-bottom:2em;border-radius:.375rem;padding-top:1em;padding-right:1.5em;padding-bottom:1em;padding-left:1.5em}.md\:prose-lg ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.md\:prose-lg ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.md\:prose-lg li{margin-top:.6666667em;margin-bottom:.6666667em}.md\:prose-lg ol>li{padding-left:1.6666667em}.md\:prose-lg ol>li:before{left:0}.md\:prose-lg ul>li{padding-left:1.6666667em}.md\:prose-lg ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8888889em - .1666667em);left:.2222222em}.md\:prose-lg>ul>li p{margin-top:.8888889em;margin-bottom:.8888889em}.md\:prose-lg>ul>li>:first-child{margin-top:1.3333333em}.md\:prose-lg>ul>li>:last-child{margin-bottom:1.3333333em}.md\:prose-lg>ol>li>:first-child{margin-top:1.3333333em}.md\:prose-lg>ol>li>:last-child{margin-bottom:1.3333333em}.md\:prose-lg ol ol,.md\:prose-lg ol ul,.md\:prose-lg ul ol,.md\:prose-lg ul ul{margin-top:.8888889em;margin-bottom:.8888889em}.md\:prose-lg hr{margin-top:3.1111111em;margin-bottom:3.1111111em}.md\:prose-lg hr+*{margin-top:0}.md\:prose-lg h2+*{margin-top:0}.md\:prose-lg h3+*{margin-top:0}.md\:prose-lg h4+*{margin-top:0}.md\:prose-lg table{font-size:.8888889em;line-height:1.5}.md\:prose-lg thead th{padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.md\:prose-lg thead th:first-child{padding-left:0}.md\:prose-lg thead th:last-child{padding-right:0}.md\:prose-lg tbody td{padding-top:.75em;padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.md\:prose-lg tbody td:first-child{padding-left:0}.md\:prose-lg tbody td:last-child{padding-right:0}.md\:prose-lg>:first-child{margin-top:0}.md\:prose-lg>:last-child{margin-bottom:0}.md\:prose-xl{font-size:1.25rem;line-height:1.8}.md\:prose-xl p{margin-top:1.2em;margin-bottom:1.2em}.prose-xl .md\:lead{font-size:1.2em;line-height:1.5;margin-top:1em;margin-bottom:1em}.md\:prose-xl blockquote{margin-top:1.6em;margin-bottom:1.6em;padding-left:1.0666667em}.md\:prose-xl h1{font-size:2.8em;margin-top:0;margin-bottom:.8571429em;line-height:1}.md\:prose-xl h2{font-size:1.8em;margin-top:1.5555556em;margin-bottom:.8888889em;line-height:1.1111111}.md\:prose-xl h3{font-size:1.5em;margin-top:1.6em;margin-bottom:.6666667em;line-height:1.3333333}.md\:prose-xl h4{margin-top:1.8em;margin-bottom:.6em;line-height:1.6}.md\:prose-xl img{margin-top:2em;margin-bottom:2em}.md\:prose-xl video{margin-top:2em;margin-bottom:2em}.md\:prose-xl figure{margin-top:2em;margin-bottom:2em}.md\:prose-xl figure>*{margin-top:0;margin-bottom:0}.md\:prose-xl figure figcaption{font-size:.9em;line-height:1.5555556;margin-top:1em}.md\:prose-xl code{font-size:.9em}.md\:prose-xl h2 code{font-size:.8611111em}.md\:prose-xl h3 code{font-size:.9em}.md\:prose-xl pre{font-size:.9em;line-height:1.7777778;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.1111111em;padding-right:1.3333333em;padding-bottom:1.1111111em;padding-left:1.3333333em}.md\:prose-xl ol{margin-top:1.2em;margin-bottom:1.2em}.md\:prose-xl ul{margin-top:1.2em;margin-bottom:1.2em}.md\:prose-xl li{margin-top:.6em;margin-bottom:.6em}.md\:prose-xl ol>li{padding-left:1.8em}.md\:prose-xl ol>li:before{left:0}.md\:prose-xl ul>li{padding-left:1.8em}.md\:prose-xl ul>li::before{width:.35em;height:.35em;top:calc(.9em - .175em);left:.25em}.md\:prose-xl>ul>li p{margin-top:.8em;margin-bottom:.8em}.md\:prose-xl>ul>li>:first-child{margin-top:1.2em}.md\:prose-xl>ul>li>:last-child{margin-bottom:1.2em}.md\:prose-xl>ol>li>:first-child{margin-top:1.2em}.md\:prose-xl>ol>li>:last-child{margin-bottom:1.2em}.md\:prose-xl ol ol,.md\:prose-xl ol ul,.md\:prose-xl ul ol,.md\:prose-xl ul ul{margin-top:.8em;margin-bottom:.8em}.md\:prose-xl hr{margin-top:2.8em;margin-bottom:2.8em}.md\:prose-xl hr+*{margin-top:0}.md\:prose-xl h2+*{margin-top:0}.md\:prose-xl h3+*{margin-top:0}.md\:prose-xl h4+*{margin-top:0}.md\:prose-xl table{font-size:.9em;line-height:1.5555556}.md\:prose-xl thead th{padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.md\:prose-xl thead th:first-child{padding-left:0}.md\:prose-xl thead th:last-child{padding-right:0}.md\:prose-xl tbody td{padding-top:.8888889em;padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.md\:prose-xl tbody td:first-child{padding-left:0}.md\:prose-xl tbody td:last-child{padding-right:0}.md\:prose-xl>:first-child{margin-top:0}.md\:prose-xl>:last-child{margin-bottom:0}.md\:prose-2xl{font-size:1.5rem;line-height:1.6666667}.md\:prose-2xl p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-2xl .md\:lead{font-size:1.25em;line-height:1.4666667;margin-top:1.0666667em;margin-bottom:1.0666667em}.md\:prose-2xl blockquote{margin-top:1.7777778em;margin-bottom:1.7777778em;padding-left:1.1111111em}.md\:prose-2xl h1{font-size:2.6666667em;margin-top:0;margin-bottom:.875em;line-height:1}.md\:prose-2xl h2{font-size:2em;margin-top:1.5em;margin-bottom:.8333333em;line-height:1.0833333}.md\:prose-2xl h3{font-size:1.5em;margin-top:1.5555556em;margin-bottom:.6666667em;line-height:1.2222222}.md\:prose-2xl h4{margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.md\:prose-2xl img{margin-top:2em;margin-bottom:2em}.md\:prose-2xl video{margin-top:2em;margin-bottom:2em}.md\:prose-2xl figure{margin-top:2em;margin-bottom:2em}.md\:prose-2xl figure>*{margin-top:0;margin-bottom:0}.md\:prose-2xl figure figcaption{font-size:.8333333em;line-height:1.6;margin-top:1em}.md\:prose-2xl code{font-size:.8333333em}.md\:prose-2xl h2 code{font-size:.875em}.md\:prose-2xl h3 code{font-size:.8888889em}.md\:prose-2xl pre{font-size:.8333333em;line-height:1.8;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.2em;padding-right:1.6em;padding-bottom:1.2em;padding-left:1.6em}.md\:prose-2xl ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.md\:prose-2xl ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.md\:prose-2xl li{margin-top:.5em;margin-bottom:.5em}.md\:prose-2xl ol>li{padding-left:1.6666667em}.md\:prose-2xl ol>li:before{left:0}.md\:prose-2xl ul>li{padding-left:1.6666667em}.md\:prose-2xl ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8333333em - .1666667em);left:.25em}.md\:prose-2xl>ul>li p{margin-top:.8333333em;margin-bottom:.8333333em}.md\:prose-2xl>ul>li>:first-child{margin-top:1.3333333em}.md\:prose-2xl>ul>li>:last-child{margin-bottom:1.3333333em}.md\:prose-2xl>ol>li>:first-child{margin-top:1.3333333em}.md\:prose-2xl>ol>li>:last-child{margin-bottom:1.3333333em}.md\:prose-2xl ol ol,.md\:prose-2xl ol ul,.md\:prose-2xl ul ol,.md\:prose-2xl ul ul{margin-top:.6666667em;margin-bottom:.6666667em}.md\:prose-2xl hr{margin-top:3em;margin-bottom:3em}.md\:prose-2xl hr+*{margin-top:0}.md\:prose-2xl h2+*{margin-top:0}.md\:prose-2xl h3+*{margin-top:0}.md\:prose-2xl h4+*{margin-top:0}.md\:prose-2xl table{font-size:.8333333em;line-height:1.4}.md\:prose-2xl thead th{padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.md\:prose-2xl thead th:first-child{padding-left:0}.md\:prose-2xl thead th:last-child{padding-right:0}.md\:prose-2xl tbody td{padding-top:.8em;padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.md\:prose-2xl tbody td:first-child{padding-left:0}.md\:prose-2xl tbody td:last-child{padding-right:0}.md\:prose-2xl>:first-child{margin-top:0}.md\:prose-2xl>:last-child{margin-bottom:0}}@media (min-width:1024px){.lg\:prose{color:#4a5568;max-width:65ch;font-size:1rem;line-height:1.75}.prose .lg\:lead{color:#4a5568;font-size:1.25em;line-height:1.6;margin-top:1.2em;margin-bottom:1.2em}.lg\:prose a{color:#1a202c;text-decoration:underline}.lg\:prose strong{color:#1a202c;font-weight:600}.lg\:prose ol{counter-reset:list-counter;margin-top:1.25em;margin-bottom:1.25em}.lg\:prose ol>li{position:relative;counter-increment:list-counter;padding-left:1.75em}.lg\:prose ol>li::before{content:counter(list-counter) ".";position:absolute;font-weight:400;color:#718096}.lg\:prose ul>li{position:relative;padding-left:1.75em}.lg\:prose ul>li::before{content:"";position:absolute;background-color:#cbd5e0;border-radius:50%;width:.375em;height:.375em;top:calc(.875em - .1875em);left:.25em}.lg\:prose hr{border-color:#e2e8f0;border-top-width:1px;margin-top:3em;margin-bottom:3em}.lg\:prose blockquote{font-weight:500;font-style:italic;color:#1a202c;border-left-width:.25rem;border-left-color:#e2e8f0;quotes:"\201C""\201D""\2018""\2019";margin-top:1.6em;margin-bottom:1.6em;padding-left:1em}.lg\:prose blockquote p:first-of-type::before{content:open-quote}.lg\:prose blockquote p:last-of-type::after{content:close-quote}.lg\:prose h1{color:#1a202c;font-weight:800;font-size:2.25em;margin-top:0;margin-bottom:.8888889em;line-height:1.1111111}.lg\:prose h2{color:#1a202c;font-weight:700;font-size:1.5em;margin-top:2em;margin-bottom:1em;line-height:1.3333333}.lg\:prose h3{color:#1a202c;font-weight:600;font-size:1.25em;margin-top:1.6em;margin-bottom:.6em;line-height:1.6}.lg\:prose h4{color:#1a202c;font-weight:600;margin-top:1.5em;margin-bottom:.5em;line-height:1.5}.lg\:prose figure figcaption{color:#718096;font-size:.875em;line-height:1.4285714;margin-top:.8571429em}.lg\:prose code{font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;color:#1a202c;font-weight:600;font-size:.875em}.lg\:prose code::before{content:"`"}.lg\:prose code::after{content:"`"}.lg\:prose pre{color:#e2e8f0;font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;background-color:#2d3748;overflow-x:auto;font-size:.875em;line-height:1.7142857;margin-top:1.7142857em;margin-bottom:1.7142857em;border-radius:.375rem;padding-top:.8571429em;padding-right:1.1428571em;padding-bottom:.8571429em;padding-left:1.1428571em}.lg\:prose pre code{background-color:transparent;border-width:0;border-radius:0;padding:0;font-weight:400;color:inherit;font-size:inherit;font-family:inherit;line-height:inherit}.lg\:prose pre code::before{content:""}.lg\:prose pre code::after{content:""}.lg\:prose table{width:100%;table-layout:auto;text-align:left;margin-top:2em;margin-bottom:2em;font-size:.875em;line-height:1.7142857}.lg\:prose thead{color:#1a202c;font-weight:600;border-bottom-width:1px;border-bottom-color:#cbd5e0}.lg\:prose thead th{vertical-align:bottom;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.lg\:prose tbody tr{border-bottom-width:1px;border-bottom-color:#e2e8f0}.lg\:prose tbody tr:last-child{border-bottom-width:0}.lg\:prose tbody td{vertical-align:top;padding-top:.5714286em;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.lg\:prose p{margin-top:1.25em;margin-bottom:1.25em}.lg\:prose img{margin-top:2em;margin-bottom:2em}.lg\:prose video{margin-top:2em;margin-bottom:2em}.lg\:prose figure{margin-top:2em;margin-bottom:2em}.lg\:prose figure>*{margin-top:0;margin-bottom:0}.lg\:prose h2 code{font-size:.875em}.lg\:prose h3 code{font-size:.9em}.lg\:prose ul{margin-top:1.25em;margin-bottom:1.25em}.lg\:prose li{margin-top:.5em;margin-bottom:.5em}.lg\:prose ol>li:before{left:0}.lg\:prose>ul>li p{margin-top:.75em;margin-bottom:.75em}.lg\:prose>ul>li>:first-child{margin-top:1.25em}.lg\:prose>ul>li>:last-child{margin-bottom:1.25em}.lg\:prose>ol>li>:first-child{margin-top:1.25em}.lg\:prose>ol>li>:last-child{margin-bottom:1.25em}.lg\:prose ol ol,.lg\:prose ol ul,.lg\:prose ul ol,.lg\:prose ul ul{margin-top:.75em;margin-bottom:.75em}.lg\:prose hr+*{margin-top:0}.lg\:prose h2+*{margin-top:0}.lg\:prose h3+*{margin-top:0}.lg\:prose h4+*{margin-top:0}.lg\:prose thead th:first-child{padding-left:0}.lg\:prose thead th:last-child{padding-right:0}.lg\:prose tbody td:first-child{padding-left:0}.lg\:prose tbody td:last-child{padding-right:0}.lg\:prose>:first-child{margin-top:0}.lg\:prose>:last-child{margin-bottom:0}.lg\:prose-sm{font-size:.875rem;line-height:1.7142857}.lg\:prose-sm p{margin-top:1.1428571em;margin-bottom:1.1428571em}.prose-sm .lg\:lead{font-size:1.2857143em;line-height:1.5555556;margin-top:.8888889em;margin-bottom:.8888889em}.lg\:prose-sm blockquote{margin-top:1.3333333em;margin-bottom:1.3333333em;padding-left:1.1111111em}.lg\:prose-sm h1{font-size:2.1428571em;margin-top:0;margin-bottom:.8em;line-height:1.2}.lg\:prose-sm h2{font-size:1.4285714em;margin-top:1.6em;margin-bottom:.8em;line-height:1.4}.lg\:prose-sm h3{font-size:1.2857143em;margin-top:1.5555556em;margin-bottom:.4444444em;line-height:1.5555556}.lg\:prose-sm h4{margin-top:1.4285714em;margin-bottom:.5714286em;line-height:1.4285714}.lg\:prose-sm img{margin-top:1.7142857em;margin-bottom:1.7142857em}.lg\:prose-sm video{margin-top:1.7142857em;margin-bottom:1.7142857em}.lg\:prose-sm figure{margin-top:1.7142857em;margin-bottom:1.7142857em}.lg\:prose-sm figure>*{margin-top:0;margin-bottom:0}.lg\:prose-sm figure figcaption{font-size:.8571429em;line-height:1.3333333;margin-top:.6666667em}.lg\:prose-sm code{font-size:.8571429em}.lg\:prose-sm h2 code{font-size:.9em}.lg\:prose-sm h3 code{font-size:.8888889em}.lg\:prose-sm pre{font-size:.8571429em;line-height:1.6666667;margin-top:1.6666667em;margin-bottom:1.6666667em;border-radius:.25rem;padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.lg\:prose-sm ol{margin-top:1.1428571em;margin-bottom:1.1428571em}.lg\:prose-sm ul{margin-top:1.1428571em;margin-bottom:1.1428571em}.lg\:prose-sm li{margin-top:.2857143em;margin-bottom:.2857143em}.lg\:prose-sm ol>li{padding-left:1.5714286em}.lg\:prose-sm ol>li:before{left:0}.lg\:prose-sm ul>li{padding-left:1.5714286em}.lg\:prose-sm ul>li::before{height:.3571429em;width:.3571429em;top:calc(.8571429em - .1785714em);left:.2142857em}.lg\:prose-sm>ul>li p{margin-top:.5714286em;margin-bottom:.5714286em}.lg\:prose-sm>ul>li>:first-child{margin-top:1.1428571em}.lg\:prose-sm>ul>li>:last-child{margin-bottom:1.1428571em}.lg\:prose-sm>ol>li>:first-child{margin-top:1.1428571em}.lg\:prose-sm>ol>li>:last-child{margin-bottom:1.1428571em}.lg\:prose-sm ol ol,.lg\:prose-sm ol ul,.lg\:prose-sm ul ol,.lg\:prose-sm ul ul{margin-top:.5714286em;margin-bottom:.5714286em}.lg\:prose-sm hr{margin-top:2.8571429em;margin-bottom:2.8571429em}.lg\:prose-sm hr+*{margin-top:0}.lg\:prose-sm h2+*{margin-top:0}.lg\:prose-sm h3+*{margin-top:0}.lg\:prose-sm h4+*{margin-top:0}.lg\:prose-sm table{font-size:.8571429em;line-height:1.5}.lg\:prose-sm thead th{padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.lg\:prose-sm thead th:first-child{padding-left:0}.lg\:prose-sm thead th:last-child{padding-right:0}.lg\:prose-sm tbody td{padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.lg\:prose-sm tbody td:first-child{padding-left:0}.lg\:prose-sm tbody td:last-child{padding-right:0}.lg\:prose-sm>:first-child{margin-top:0}.lg\:prose-sm>:last-child{margin-bottom:0}.lg\:prose-lg{font-size:1.125rem;line-height:1.7777778}.lg\:prose-lg p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-lg .lg\:lead{font-size:1.2222222em;line-height:1.4545455;margin-top:1.0909091em;margin-bottom:1.0909091em}.lg\:prose-lg blockquote{margin-top:1.6666667em;margin-bottom:1.6666667em;padding-left:1em}.lg\:prose-lg h1{font-size:2.6666667em;margin-top:0;margin-bottom:.8333333em;line-height:1}.lg\:prose-lg h2{font-size:1.6666667em;margin-top:1.8666667em;margin-bottom:1.0666667em;line-height:1.3333333}.lg\:prose-lg h3{font-size:1.3333333em;margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.lg\:prose-lg h4{margin-top:1.7777778em;margin-bottom:.4444444em;line-height:1.5555556}.lg\:prose-lg img{margin-top:1.7777778em;margin-bottom:1.7777778em}.lg\:prose-lg video{margin-top:1.7777778em;margin-bottom:1.7777778em}.lg\:prose-lg figure{margin-top:1.7777778em;margin-bottom:1.7777778em}.lg\:prose-lg figure>*{margin-top:0;margin-bottom:0}.lg\:prose-lg figure figcaption{font-size:.8888889em;line-height:1.5;margin-top:1em}.lg\:prose-lg code{font-size:.8888889em}.lg\:prose-lg h2 code{font-size:.8666667em}.lg\:prose-lg h3 code{font-size:.875em}.lg\:prose-lg pre{font-size:.8888889em;line-height:1.75;margin-top:2em;margin-bottom:2em;border-radius:.375rem;padding-top:1em;padding-right:1.5em;padding-bottom:1em;padding-left:1.5em}.lg\:prose-lg ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.lg\:prose-lg ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.lg\:prose-lg li{margin-top:.6666667em;margin-bottom:.6666667em}.lg\:prose-lg ol>li{padding-left:1.6666667em}.lg\:prose-lg ol>li:before{left:0}.lg\:prose-lg ul>li{padding-left:1.6666667em}.lg\:prose-lg ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8888889em - .1666667em);left:.2222222em}.lg\:prose-lg>ul>li p{margin-top:.8888889em;margin-bottom:.8888889em}.lg\:prose-lg>ul>li>:first-child{margin-top:1.3333333em}.lg\:prose-lg>ul>li>:last-child{margin-bottom:1.3333333em}.lg\:prose-lg>ol>li>:first-child{margin-top:1.3333333em}.lg\:prose-lg>ol>li>:last-child{margin-bottom:1.3333333em}.lg\:prose-lg ol ol,.lg\:prose-lg ol ul,.lg\:prose-lg ul ol,.lg\:prose-lg ul ul{margin-top:.8888889em;margin-bottom:.8888889em}.lg\:prose-lg hr{margin-top:3.1111111em;margin-bottom:3.1111111em}.lg\:prose-lg hr+*{margin-top:0}.lg\:prose-lg h2+*{margin-top:0}.lg\:prose-lg h3+*{margin-top:0}.lg\:prose-lg h4+*{margin-top:0}.lg\:prose-lg table{font-size:.8888889em;line-height:1.5}.lg\:prose-lg thead th{padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.lg\:prose-lg thead th:first-child{padding-left:0}.lg\:prose-lg thead th:last-child{padding-right:0}.lg\:prose-lg tbody td{padding-top:.75em;padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.lg\:prose-lg tbody td:first-child{padding-left:0}.lg\:prose-lg tbody td:last-child{padding-right:0}.lg\:prose-lg>:first-child{margin-top:0}.lg\:prose-lg>:last-child{margin-bottom:0}.lg\:prose-xl{font-size:1.25rem;line-height:1.8}.lg\:prose-xl p{margin-top:1.2em;margin-bottom:1.2em}.prose-xl .lg\:lead{font-size:1.2em;line-height:1.5;margin-top:1em;margin-bottom:1em}.lg\:prose-xl blockquote{margin-top:1.6em;margin-bottom:1.6em;padding-left:1.0666667em}.lg\:prose-xl h1{font-size:2.8em;margin-top:0;margin-bottom:.8571429em;line-height:1}.lg\:prose-xl h2{font-size:1.8em;margin-top:1.5555556em;margin-bottom:.8888889em;line-height:1.1111111}.lg\:prose-xl h3{font-size:1.5em;margin-top:1.6em;margin-bottom:.6666667em;line-height:1.3333333}.lg\:prose-xl h4{margin-top:1.8em;margin-bottom:.6em;line-height:1.6}.lg\:prose-xl img{margin-top:2em;margin-bottom:2em}.lg\:prose-xl video{margin-top:2em;margin-bottom:2em}.lg\:prose-xl figure{margin-top:2em;margin-bottom:2em}.lg\:prose-xl figure>*{margin-top:0;margin-bottom:0}.lg\:prose-xl figure figcaption{font-size:.9em;line-height:1.5555556;margin-top:1em}.lg\:prose-xl code{font-size:.9em}.lg\:prose-xl h2 code{font-size:.8611111em}.lg\:prose-xl h3 code{font-size:.9em}.lg\:prose-xl pre{font-size:.9em;line-height:1.7777778;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.1111111em;padding-right:1.3333333em;padding-bottom:1.1111111em;padding-left:1.3333333em}.lg\:prose-xl ol{margin-top:1.2em;margin-bottom:1.2em}.lg\:prose-xl ul{margin-top:1.2em;margin-bottom:1.2em}.lg\:prose-xl li{margin-top:.6em;margin-bottom:.6em}.lg\:prose-xl ol>li{padding-left:1.8em}.lg\:prose-xl ol>li:before{left:0}.lg\:prose-xl ul>li{padding-left:1.8em}.lg\:prose-xl ul>li::before{width:.35em;height:.35em;top:calc(.9em - .175em);left:.25em}.lg\:prose-xl>ul>li p{margin-top:.8em;margin-bottom:.8em}.lg\:prose-xl>ul>li>:first-child{margin-top:1.2em}.lg\:prose-xl>ul>li>:last-child{margin-bottom:1.2em}.lg\:prose-xl>ol>li>:first-child{margin-top:1.2em}.lg\:prose-xl>ol>li>:last-child{margin-bottom:1.2em}.lg\:prose-xl ol ol,.lg\:prose-xl ol ul,.lg\:prose-xl ul ol,.lg\:prose-xl ul ul{margin-top:.8em;margin-bottom:.8em}.lg\:prose-xl hr{margin-top:2.8em;margin-bottom:2.8em}.lg\:prose-xl hr+*{margin-top:0}.lg\:prose-xl h2+*{margin-top:0}.lg\:prose-xl h3+*{margin-top:0}.lg\:prose-xl h4+*{margin-top:0}.lg\:prose-xl table{font-size:.9em;line-height:1.5555556}.lg\:prose-xl thead th{padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.lg\:prose-xl thead th:first-child{padding-left:0}.lg\:prose-xl thead th:last-child{padding-right:0}.lg\:prose-xl tbody td{padding-top:.8888889em;padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.lg\:prose-xl tbody td:first-child{padding-left:0}.lg\:prose-xl tbody td:last-child{padding-right:0}.lg\:prose-xl>:first-child{margin-top:0}.lg\:prose-xl>:last-child{margin-bottom:0}.lg\:prose-2xl{font-size:1.5rem;line-height:1.6666667}.lg\:prose-2xl p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-2xl .lg\:lead{font-size:1.25em;line-height:1.4666667;margin-top:1.0666667em;margin-bottom:1.0666667em}.lg\:prose-2xl blockquote{margin-top:1.7777778em;margin-bottom:1.7777778em;padding-left:1.1111111em}.lg\:prose-2xl h1{font-size:2.6666667em;margin-top:0;margin-bottom:.875em;line-height:1}.lg\:prose-2xl h2{font-size:2em;margin-top:1.5em;margin-bottom:.8333333em;line-height:1.0833333}.lg\:prose-2xl h3{font-size:1.5em;margin-top:1.5555556em;margin-bottom:.6666667em;line-height:1.2222222}.lg\:prose-2xl h4{margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.lg\:prose-2xl img{margin-top:2em;margin-bottom:2em}.lg\:prose-2xl video{margin-top:2em;margin-bottom:2em}.lg\:prose-2xl figure{margin-top:2em;margin-bottom:2em}.lg\:prose-2xl figure>*{margin-top:0;margin-bottom:0}.lg\:prose-2xl figure figcaption{font-size:.8333333em;line-height:1.6;margin-top:1em}.lg\:prose-2xl code{font-size:.8333333em}.lg\:prose-2xl h2 code{font-size:.875em}.lg\:prose-2xl h3 code{font-size:.8888889em}.lg\:prose-2xl pre{font-size:.8333333em;line-height:1.8;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.2em;padding-right:1.6em;padding-bottom:1.2em;padding-left:1.6em}.lg\:prose-2xl ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.lg\:prose-2xl ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.lg\:prose-2xl li{margin-top:.5em;margin-bottom:.5em}.lg\:prose-2xl ol>li{padding-left:1.6666667em}.lg\:prose-2xl ol>li:before{left:0}.lg\:prose-2xl ul>li{padding-left:1.6666667em}.lg\:prose-2xl ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8333333em - .1666667em);left:.25em}.lg\:prose-2xl>ul>li p{margin-top:.8333333em;margin-bottom:.8333333em}.lg\:prose-2xl>ul>li>:first-child{margin-top:1.3333333em}.lg\:prose-2xl>ul>li>:last-child{margin-bottom:1.3333333em}.lg\:prose-2xl>ol>li>:first-child{margin-top:1.3333333em}.lg\:prose-2xl>ol>li>:last-child{margin-bottom:1.3333333em}.lg\:prose-2xl ol ol,.lg\:prose-2xl ol ul,.lg\:prose-2xl ul ol,.lg\:prose-2xl ul ul{margin-top:.6666667em;margin-bottom:.6666667em}.lg\:prose-2xl hr{margin-top:3em;margin-bottom:3em}.lg\:prose-2xl hr+*{margin-top:0}.lg\:prose-2xl h2+*{margin-top:0}.lg\:prose-2xl h3+*{margin-top:0}.lg\:prose-2xl h4+*{margin-top:0}.lg\:prose-2xl table{font-size:.8333333em;line-height:1.4}.lg\:prose-2xl thead th{padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.lg\:prose-2xl thead th:first-child{padding-left:0}.lg\:prose-2xl thead th:last-child{padding-right:0}.lg\:prose-2xl tbody td{padding-top:.8em;padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.lg\:prose-2xl tbody td:first-child{padding-left:0}.lg\:prose-2xl tbody td:last-child{padding-right:0}.lg\:prose-2xl>:first-child{margin-top:0}.lg\:prose-2xl>:last-child{margin-bottom:0}}@media (min-width:1280px){.xl\:prose{color:#4a5568;max-width:65ch;font-size:1rem;line-height:1.75}.prose .xl\:lead{color:#4a5568;font-size:1.25em;line-height:1.6;margin-top:1.2em;margin-bottom:1.2em}.xl\:prose a{color:#1a202c;text-decoration:underline}.xl\:prose strong{color:#1a202c;font-weight:600}.xl\:prose ol{counter-reset:list-counter;margin-top:1.25em;margin-bottom:1.25em}.xl\:prose ol>li{position:relative;counter-increment:list-counter;padding-left:1.75em}.xl\:prose ol>li::before{content:counter(list-counter) ".";position:absolute;font-weight:400;color:#718096}.xl\:prose ul>li{position:relative;padding-left:1.75em}.xl\:prose ul>li::before{content:"";position:absolute;background-color:#cbd5e0;border-radius:50%;width:.375em;height:.375em;top:calc(.875em - .1875em);left:.25em}.xl\:prose hr{border-color:#e2e8f0;border-top-width:1px;margin-top:3em;margin-bottom:3em}.xl\:prose blockquote{font-weight:500;font-style:italic;color:#1a202c;border-left-width:.25rem;border-left-color:#e2e8f0;quotes:"\201C""\201D""\2018""\2019";margin-top:1.6em;margin-bottom:1.6em;padding-left:1em}.xl\:prose blockquote p:first-of-type::before{content:open-quote}.xl\:prose blockquote p:last-of-type::after{content:close-quote}.xl\:prose h1{color:#1a202c;font-weight:800;font-size:2.25em;margin-top:0;margin-bottom:.8888889em;line-height:1.1111111}.xl\:prose h2{color:#1a202c;font-weight:700;font-size:1.5em;margin-top:2em;margin-bottom:1em;line-height:1.3333333}.xl\:prose h3{color:#1a202c;font-weight:600;font-size:1.25em;margin-top:1.6em;margin-bottom:.6em;line-height:1.6}.xl\:prose h4{color:#1a202c;font-weight:600;margin-top:1.5em;margin-bottom:.5em;line-height:1.5}.xl\:prose figure figcaption{color:#718096;font-size:.875em;line-height:1.4285714;margin-top:.8571429em}.xl\:prose code{font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;color:#1a202c;font-weight:600;font-size:.875em}.xl\:prose code::before{content:"`"}.xl\:prose code::after{content:"`"}.xl\:prose pre{color:#e2e8f0;font-family:Menlo,Monaco,Consolas,"Liberation Mono","Courier New",monospace;background-color:#2d3748;overflow-x:auto;font-size:.875em;line-height:1.7142857;margin-top:1.7142857em;margin-bottom:1.7142857em;border-radius:.375rem;padding-top:.8571429em;padding-right:1.1428571em;padding-bottom:.8571429em;padding-left:1.1428571em}.xl\:prose pre code{background-color:transparent;border-width:0;border-radius:0;padding:0;font-weight:400;color:inherit;font-size:inherit;font-family:inherit;line-height:inherit}.xl\:prose pre code::before{content:""}.xl\:prose pre code::after{content:""}.xl\:prose table{width:100%;table-layout:auto;text-align:left;margin-top:2em;margin-bottom:2em;font-size:.875em;line-height:1.7142857}.xl\:prose thead{color:#1a202c;font-weight:600;border-bottom-width:1px;border-bottom-color:#cbd5e0}.xl\:prose thead th{vertical-align:bottom;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.xl\:prose tbody tr{border-bottom-width:1px;border-bottom-color:#e2e8f0}.xl\:prose tbody tr:last-child{border-bottom-width:0}.xl\:prose tbody td{vertical-align:top;padding-top:.5714286em;padding-right:.5714286em;padding-bottom:.5714286em;padding-left:.5714286em}.xl\:prose p{margin-top:1.25em;margin-bottom:1.25em}.xl\:prose img{margin-top:2em;margin-bottom:2em}.xl\:prose video{margin-top:2em;margin-bottom:2em}.xl\:prose figure{margin-top:2em;margin-bottom:2em}.xl\:prose figure>*{margin-top:0;margin-bottom:0}.xl\:prose h2 code{font-size:.875em}.xl\:prose h3 code{font-size:.9em}.xl\:prose ul{margin-top:1.25em;margin-bottom:1.25em}.xl\:prose li{margin-top:.5em;margin-bottom:.5em}.xl\:prose ol>li:before{left:0}.xl\:prose>ul>li p{margin-top:.75em;margin-bottom:.75em}.xl\:prose>ul>li>:first-child{margin-top:1.25em}.xl\:prose>ul>li>:last-child{margin-bottom:1.25em}.xl\:prose>ol>li>:first-child{margin-top:1.25em}.xl\:prose>ol>li>:last-child{margin-bottom:1.25em}.xl\:prose ol ol,.xl\:prose ol ul,.xl\:prose ul ol,.xl\:prose ul ul{margin-top:.75em;margin-bottom:.75em}.xl\:prose hr+*{margin-top:0}.xl\:prose h2+*{margin-top:0}.xl\:prose h3+*{margin-top:0}.xl\:prose h4+*{margin-top:0}.xl\:prose thead th:first-child{padding-left:0}.xl\:prose thead th:last-child{padding-right:0}.xl\:prose tbody td:first-child{padding-left:0}.xl\:prose tbody td:last-child{padding-right:0}.xl\:prose>:first-child{margin-top:0}.xl\:prose>:last-child{margin-bottom:0}.xl\:prose-sm{font-size:.875rem;line-height:1.7142857}.xl\:prose-sm p{margin-top:1.1428571em;margin-bottom:1.1428571em}.prose-sm .xl\:lead{font-size:1.2857143em;line-height:1.5555556;margin-top:.8888889em;margin-bottom:.8888889em}.xl\:prose-sm blockquote{margin-top:1.3333333em;margin-bottom:1.3333333em;padding-left:1.1111111em}.xl\:prose-sm h1{font-size:2.1428571em;margin-top:0;margin-bottom:.8em;line-height:1.2}.xl\:prose-sm h2{font-size:1.4285714em;margin-top:1.6em;margin-bottom:.8em;line-height:1.4}.xl\:prose-sm h3{font-size:1.2857143em;margin-top:1.5555556em;margin-bottom:.4444444em;line-height:1.5555556}.xl\:prose-sm h4{margin-top:1.4285714em;margin-bottom:.5714286em;line-height:1.4285714}.xl\:prose-sm img{margin-top:1.7142857em;margin-bottom:1.7142857em}.xl\:prose-sm video{margin-top:1.7142857em;margin-bottom:1.7142857em}.xl\:prose-sm figure{margin-top:1.7142857em;margin-bottom:1.7142857em}.xl\:prose-sm figure>*{margin-top:0;margin-bottom:0}.xl\:prose-sm figure figcaption{font-size:.8571429em;line-height:1.3333333;margin-top:.6666667em}.xl\:prose-sm code{font-size:.8571429em}.xl\:prose-sm h2 code{font-size:.9em}.xl\:prose-sm h3 code{font-size:.8888889em}.xl\:prose-sm pre{font-size:.8571429em;line-height:1.6666667;margin-top:1.6666667em;margin-bottom:1.6666667em;border-radius:.25rem;padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.xl\:prose-sm ol{margin-top:1.1428571em;margin-bottom:1.1428571em}.xl\:prose-sm ul{margin-top:1.1428571em;margin-bottom:1.1428571em}.xl\:prose-sm li{margin-top:.2857143em;margin-bottom:.2857143em}.xl\:prose-sm ol>li{padding-left:1.5714286em}.xl\:prose-sm ol>li:before{left:0}.xl\:prose-sm ul>li{padding-left:1.5714286em}.xl\:prose-sm ul>li::before{height:.3571429em;width:.3571429em;top:calc(.8571429em - .1785714em);left:.2142857em}.xl\:prose-sm>ul>li p{margin-top:.5714286em;margin-bottom:.5714286em}.xl\:prose-sm>ul>li>:first-child{margin-top:1.1428571em}.xl\:prose-sm>ul>li>:last-child{margin-bottom:1.1428571em}.xl\:prose-sm>ol>li>:first-child{margin-top:1.1428571em}.xl\:prose-sm>ol>li>:last-child{margin-bottom:1.1428571em}.xl\:prose-sm ol ol,.xl\:prose-sm ol ul,.xl\:prose-sm ul ol,.xl\:prose-sm ul ul{margin-top:.5714286em;margin-bottom:.5714286em}.xl\:prose-sm hr{margin-top:2.8571429em;margin-bottom:2.8571429em}.xl\:prose-sm hr+*{margin-top:0}.xl\:prose-sm h2+*{margin-top:0}.xl\:prose-sm h3+*{margin-top:0}.xl\:prose-sm h4+*{margin-top:0}.xl\:prose-sm table{font-size:.8571429em;line-height:1.5}.xl\:prose-sm thead th{padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.xl\:prose-sm thead th:first-child{padding-left:0}.xl\:prose-sm thead th:last-child{padding-right:0}.xl\:prose-sm tbody td{padding-top:.6666667em;padding-right:1em;padding-bottom:.6666667em;padding-left:1em}.xl\:prose-sm tbody td:first-child{padding-left:0}.xl\:prose-sm tbody td:last-child{padding-right:0}.xl\:prose-sm>:first-child{margin-top:0}.xl\:prose-sm>:last-child{margin-bottom:0}.xl\:prose-lg{font-size:1.125rem;line-height:1.7777778}.xl\:prose-lg p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-lg .xl\:lead{font-size:1.2222222em;line-height:1.4545455;margin-top:1.0909091em;margin-bottom:1.0909091em}.xl\:prose-lg blockquote{margin-top:1.6666667em;margin-bottom:1.6666667em;padding-left:1em}.xl\:prose-lg h1{font-size:2.6666667em;margin-top:0;margin-bottom:.8333333em;line-height:1}.xl\:prose-lg h2{font-size:1.6666667em;margin-top:1.8666667em;margin-bottom:1.0666667em;line-height:1.3333333}.xl\:prose-lg h3{font-size:1.3333333em;margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.xl\:prose-lg h4{margin-top:1.7777778em;margin-bottom:.4444444em;line-height:1.5555556}.xl\:prose-lg img{margin-top:1.7777778em;margin-bottom:1.7777778em}.xl\:prose-lg video{margin-top:1.7777778em;margin-bottom:1.7777778em}.xl\:prose-lg figure{margin-top:1.7777778em;margin-bottom:1.7777778em}.xl\:prose-lg figure>*{margin-top:0;margin-bottom:0}.xl\:prose-lg figure figcaption{font-size:.8888889em;line-height:1.5;margin-top:1em}.xl\:prose-lg code{font-size:.8888889em}.xl\:prose-lg h2 code{font-size:.8666667em}.xl\:prose-lg h3 code{font-size:.875em}.xl\:prose-lg pre{font-size:.8888889em;line-height:1.75;margin-top:2em;margin-bottom:2em;border-radius:.375rem;padding-top:1em;padding-right:1.5em;padding-bottom:1em;padding-left:1.5em}.xl\:prose-lg ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.xl\:prose-lg ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.xl\:prose-lg li{margin-top:.6666667em;margin-bottom:.6666667em}.xl\:prose-lg ol>li{padding-left:1.6666667em}.xl\:prose-lg ol>li:before{left:0}.xl\:prose-lg ul>li{padding-left:1.6666667em}.xl\:prose-lg ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8888889em - .1666667em);left:.2222222em}.xl\:prose-lg>ul>li p{margin-top:.8888889em;margin-bottom:.8888889em}.xl\:prose-lg>ul>li>:first-child{margin-top:1.3333333em}.xl\:prose-lg>ul>li>:last-child{margin-bottom:1.3333333em}.xl\:prose-lg>ol>li>:first-child{margin-top:1.3333333em}.xl\:prose-lg>ol>li>:last-child{margin-bottom:1.3333333em}.xl\:prose-lg ol ol,.xl\:prose-lg ol ul,.xl\:prose-lg ul ol,.xl\:prose-lg ul ul{margin-top:.8888889em;margin-bottom:.8888889em}.xl\:prose-lg hr{margin-top:3.1111111em;margin-bottom:3.1111111em}.xl\:prose-lg hr+*{margin-top:0}.xl\:prose-lg h2+*{margin-top:0}.xl\:prose-lg h3+*{margin-top:0}.xl\:prose-lg h4+*{margin-top:0}.xl\:prose-lg table{font-size:.8888889em;line-height:1.5}.xl\:prose-lg thead th{padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.xl\:prose-lg thead th:first-child{padding-left:0}.xl\:prose-lg thead th:last-child{padding-right:0}.xl\:prose-lg tbody td{padding-top:.75em;padding-right:.75em;padding-bottom:.75em;padding-left:.75em}.xl\:prose-lg tbody td:first-child{padding-left:0}.xl\:prose-lg tbody td:last-child{padding-right:0}.xl\:prose-lg>:first-child{margin-top:0}.xl\:prose-lg>:last-child{margin-bottom:0}.xl\:prose-xl{font-size:1.25rem;line-height:1.8}.xl\:prose-xl p{margin-top:1.2em;margin-bottom:1.2em}.prose-xl .xl\:lead{font-size:1.2em;line-height:1.5;margin-top:1em;margin-bottom:1em}.xl\:prose-xl blockquote{margin-top:1.6em;margin-bottom:1.6em;padding-left:1.0666667em}.xl\:prose-xl h1{font-size:2.8em;margin-top:0;margin-bottom:.8571429em;line-height:1}.xl\:prose-xl h2{font-size:1.8em;margin-top:1.5555556em;margin-bottom:.8888889em;line-height:1.1111111}.xl\:prose-xl h3{font-size:1.5em;margin-top:1.6em;margin-bottom:.6666667em;line-height:1.3333333}.xl\:prose-xl h4{margin-top:1.8em;margin-bottom:.6em;line-height:1.6}.xl\:prose-xl img{margin-top:2em;margin-bottom:2em}.xl\:prose-xl video{margin-top:2em;margin-bottom:2em}.xl\:prose-xl figure{margin-top:2em;margin-bottom:2em}.xl\:prose-xl figure>*{margin-top:0;margin-bottom:0}.xl\:prose-xl figure figcaption{font-size:.9em;line-height:1.5555556;margin-top:1em}.xl\:prose-xl code{font-size:.9em}.xl\:prose-xl h2 code{font-size:.8611111em}.xl\:prose-xl h3 code{font-size:.9em}.xl\:prose-xl pre{font-size:.9em;line-height:1.7777778;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.1111111em;padding-right:1.3333333em;padding-bottom:1.1111111em;padding-left:1.3333333em}.xl\:prose-xl ol{margin-top:1.2em;margin-bottom:1.2em}.xl\:prose-xl ul{margin-top:1.2em;margin-bottom:1.2em}.xl\:prose-xl li{margin-top:.6em;margin-bottom:.6em}.xl\:prose-xl ol>li{padding-left:1.8em}.xl\:prose-xl ol>li:before{left:0}.xl\:prose-xl ul>li{padding-left:1.8em}.xl\:prose-xl ul>li::before{width:.35em;height:.35em;top:calc(.9em - .175em);left:.25em}.xl\:prose-xl>ul>li p{margin-top:.8em;margin-bottom:.8em}.xl\:prose-xl>ul>li>:first-child{margin-top:1.2em}.xl\:prose-xl>ul>li>:last-child{margin-bottom:1.2em}.xl\:prose-xl>ol>li>:first-child{margin-top:1.2em}.xl\:prose-xl>ol>li>:last-child{margin-bottom:1.2em}.xl\:prose-xl ol ol,.xl\:prose-xl ol ul,.xl\:prose-xl ul ol,.xl\:prose-xl ul ul{margin-top:.8em;margin-bottom:.8em}.xl\:prose-xl hr{margin-top:2.8em;margin-bottom:2.8em}.xl\:prose-xl hr+*{margin-top:0}.xl\:prose-xl h2+*{margin-top:0}.xl\:prose-xl h3+*{margin-top:0}.xl\:prose-xl h4+*{margin-top:0}.xl\:prose-xl table{font-size:.9em;line-height:1.5555556}.xl\:prose-xl thead th{padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.xl\:prose-xl thead th:first-child{padding-left:0}.xl\:prose-xl thead th:last-child{padding-right:0}.xl\:prose-xl tbody td{padding-top:.8888889em;padding-right:.6666667em;padding-bottom:.8888889em;padding-left:.6666667em}.xl\:prose-xl tbody td:first-child{padding-left:0}.xl\:prose-xl tbody td:last-child{padding-right:0}.xl\:prose-xl>:first-child{margin-top:0}.xl\:prose-xl>:last-child{margin-bottom:0}.xl\:prose-2xl{font-size:1.5rem;line-height:1.6666667}.xl\:prose-2xl p{margin-top:1.3333333em;margin-bottom:1.3333333em}.prose-2xl .xl\:lead{font-size:1.25em;line-height:1.4666667;margin-top:1.0666667em;margin-bottom:1.0666667em}.xl\:prose-2xl blockquote{margin-top:1.7777778em;margin-bottom:1.7777778em;padding-left:1.1111111em}.xl\:prose-2xl h1{font-size:2.6666667em;margin-top:0;margin-bottom:.875em;line-height:1}.xl\:prose-2xl h2{font-size:2em;margin-top:1.5em;margin-bottom:.8333333em;line-height:1.0833333}.xl\:prose-2xl h3{font-size:1.5em;margin-top:1.5555556em;margin-bottom:.6666667em;line-height:1.2222222}.xl\:prose-2xl h4{margin-top:1.6666667em;margin-bottom:.6666667em;line-height:1.5}.xl\:prose-2xl img{margin-top:2em;margin-bottom:2em}.xl\:prose-2xl video{margin-top:2em;margin-bottom:2em}.xl\:prose-2xl figure{margin-top:2em;margin-bottom:2em}.xl\:prose-2xl figure>*{margin-top:0;margin-bottom:0}.xl\:prose-2xl figure figcaption{font-size:.8333333em;line-height:1.6;margin-top:1em}.xl\:prose-2xl code{font-size:.8333333em}.xl\:prose-2xl h2 code{font-size:.875em}.xl\:prose-2xl h3 code{font-size:.8888889em}.xl\:prose-2xl pre{font-size:.8333333em;line-height:1.8;margin-top:2em;margin-bottom:2em;border-radius:.5rem;padding-top:1.2em;padding-right:1.6em;padding-bottom:1.2em;padding-left:1.6em}.xl\:prose-2xl ol{margin-top:1.3333333em;margin-bottom:1.3333333em}.xl\:prose-2xl ul{margin-top:1.3333333em;margin-bottom:1.3333333em}.xl\:prose-2xl li{margin-top:.5em;margin-bottom:.5em}.xl\:prose-2xl ol>li{padding-left:1.6666667em}.xl\:prose-2xl ol>li:before{left:0}.xl\:prose-2xl ul>li{padding-left:1.6666667em}.xl\:prose-2xl ul>li::before{width:.3333333em;height:.3333333em;top:calc(.8333333em - .1666667em);left:.25em}.xl\:prose-2xl>ul>li p{margin-top:.8333333em;margin-bottom:.8333333em}.xl\:prose-2xl>ul>li>:first-child{margin-top:1.3333333em}.xl\:prose-2xl>ul>li>:last-child{margin-bottom:1.3333333em}.xl\:prose-2xl>ol>li>:first-child{margin-top:1.3333333em}.xl\:prose-2xl>ol>li>:last-child{margin-bottom:1.3333333em}.xl\:prose-2xl ol ol,.xl\:prose-2xl ol ul,.xl\:prose-2xl ul ol,.xl\:prose-2xl ul ul{margin-top:.6666667em;margin-bottom:.6666667em}.xl\:prose-2xl hr{margin-top:3em;margin-bottom:3em}.xl\:prose-2xl hr+*{margin-top:0}.xl\:prose-2xl h2+*{margin-top:0}.xl\:prose-2xl h3+*{margin-top:0}.xl\:prose-2xl h4+*{margin-top:0}.xl\:prose-2xl table{font-size:.8333333em;line-height:1.4}.xl\:prose-2xl thead th{padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.xl\:prose-2xl thead th:first-child{padding-left:0}.xl\:prose-2xl thead th:last-child{padding-right:0}.xl\:prose-2xl tbody td{padding-top:.8em;padding-right:.6em;padding-bottom:.8em;padding-left:.6em}.xl\:prose-2xl tbody td:first-child{padding-left:0}.xl\:prose-2xl tbody td:last-child{padding-right:0}.xl\:prose-2xl>:first-child{margin-top:0}.xl\:prose-2xl>:last-child{margin-bottom:0}} \ No newline at end of file diff --git a/spaces/jennysun/jwsun-multisubject-render-model/gligen/ldm/__init__.py b/spaces/jennysun/jwsun-multisubject-render-model/gligen/ldm/__init__.py deleted file mode 100644 index d71fc3230d513f470c68e46752b355cd70824ecf..0000000000000000000000000000000000000000 --- a/spaces/jennysun/jwsun-multisubject-render-model/gligen/ldm/__init__.py +++ /dev/null @@ -1,3 +0,0 @@ -import gligen.evaluator as evaluator -import gligen.trainer as trainer -import gligen.ldm as ldm \ No newline at end of file diff --git a/spaces/jie1/succ1/DLKcat/DeeplearningApproach/Code/analysis/Fig3d_Decreased&Like.py b/spaces/jie1/succ1/DLKcat/DeeplearningApproach/Code/analysis/Fig3d_Decreased&Like.py deleted file mode 100644 index 25cb5a9cc9979abe3579245538a5ebfd03f25759..0000000000000000000000000000000000000000 --- a/spaces/jie1/succ1/DLKcat/DeeplearningApproach/Code/analysis/Fig3d_Decreased&Like.py +++ /dev/null @@ -1,487 +0,0 @@ -#!/usr/bin/python -# coding: utf-8 - -import os -import math -import model -import torch -import json -import pickle -import numpy as np -from rdkit import Chem -from Bio import SeqIO -from collections import Counter -from collections import defaultdict -import matplotlib.pyplot as plt -from matplotlib import rc -from scipy import stats -import seaborn as sns -import pandas as pd -from scipy.stats import ranksums -from sklearn.metrics import mean_squared_error,r2_score - - -fingerprint_dict = model.load_pickle('../../Data/input/fingerprint_dict.pickle') -atom_dict = model.load_pickle('../../Data/input/atom_dict.pickle') -bond_dict = model.load_pickle('../../Data/input/bond_dict.pickle') -edge_dict = model.load_pickle('../../Data/input/edge_dict.pickle') -word_dict = model.load_pickle('../../Data/input/sequence_dict.pickle') - -def split_sequence(sequence, ngram): - sequence = '-' + sequence + '=' - # print(sequence) - # words = [word_dict[sequence[i:i+ngram]] for i in range(len(sequence)-ngram+1)] - - words = list() - for i in range(len(sequence)-ngram+1) : - try : - words.append(word_dict[sequence[i:i+ngram]]) - except : - word_dict[sequence[i:i+ngram]] = 0 - words.append(word_dict[sequence[i:i+ngram]]) - - return np.array(words) - # return word_dict - -def create_atoms(mol): - """Create a list of atom (e.g., hydrogen and oxygen) IDs - considering the aromaticity.""" - # atom_dict = defaultdict(lambda: len(atom_dict)) - atoms = [a.GetSymbol() for a in mol.GetAtoms()] - # print(atoms) - for a in mol.GetAromaticAtoms(): - i = a.GetIdx() - atoms[i] = (atoms[i], 'aromatic') - atoms = [atom_dict[a] for a in atoms] - # atoms = list() - # for a in atoms : - # try: - # atoms.append(atom_dict[a]) - # except : - # atom_dict[a] = 0 - # atoms.append(atom_dict[a]) - - return np.array(atoms) - -def create_ijbonddict(mol): - """Create a dictionary, which each key is a node ID - and each value is the tuples of its neighboring node - and bond (e.g., single and double) IDs.""" - # bond_dict = defaultdict(lambda: len(bond_dict)) - i_jbond_dict = defaultdict(lambda: []) - for b in mol.GetBonds(): - i, j = b.GetBeginAtomIdx(), b.GetEndAtomIdx() - bond = bond_dict[str(b.GetBondType())] - i_jbond_dict[i].append((j, bond)) - i_jbond_dict[j].append((i, bond)) - return i_jbond_dict - -def extract_fingerprints(atoms, i_jbond_dict, radius): - """Extract the r-radius subgraphs (i.e., fingerprints) - from a molecular graph using Weisfeiler-Lehman algorithm.""" - - # fingerprint_dict = defaultdict(lambda: len(fingerprint_dict)) - # edge_dict = defaultdict(lambda: len(edge_dict)) - - if (len(atoms) == 1) or (radius == 0): - fingerprints = [fingerprint_dict[a] for a in atoms] - - else: - nodes = atoms - i_jedge_dict = i_jbond_dict - - for _ in range(radius): - - """Update each node ID considering its neighboring nodes and edges - (i.e., r-radius subgraphs or fingerprints).""" - fingerprints = [] - for i, j_edge in i_jedge_dict.items(): - neighbors = [(nodes[j], edge) for j, edge in j_edge] - fingerprint = (nodes[i], tuple(sorted(neighbors))) - # fingerprints.append(fingerprint_dict[fingerprint]) - # fingerprints.append(fingerprint_dict.get(fingerprint)) - try : - fingerprints.append(fingerprint_dict[fingerprint]) - except : - fingerprint_dict[fingerprint] = 0 - fingerprints.append(fingerprint_dict[fingerprint]) - - nodes = fingerprints - - """Also update each edge ID considering two nodes - on its both sides.""" - _i_jedge_dict = defaultdict(lambda: []) - for i, j_edge in i_jedge_dict.items(): - for j, edge in j_edge: - both_side = tuple(sorted((nodes[i], nodes[j]))) - # edge = edge_dict[(both_side, edge)] - # edge = edge_dict.get((both_side, edge)) - try : - edge = edge_dict[(both_side, edge)] - except : - edge_dict[(both_side, edge)] = 0 - edge = edge_dict[(both_side, edge)] - - _i_jedge_dict[i].append((j, edge)) - i_jedge_dict = _i_jedge_dict - - return np.array(fingerprints) - -def create_adjacency(mol): - adjacency = Chem.GetAdjacencyMatrix(mol) - return np.array(adjacency) - -def dump_dictionary(dictionary, filename): - with open(filename, 'wb') as file: - pickle.dump(dict(dictionary), file) - -def load_tensor(file_name, dtype): - return [dtype(d).to(device) for d in np.load(file_name + '.npy', allow_pickle=True)] - -class Predictor(object): - def __init__(self, model): - self.model = model - - def predict(self, data): - predicted_value = self.model.forward(data) - - return predicted_value - -def extract_wildtype_mutant() : - with open('../../Data/database/Kcat_combination_0918_wildtype_mutant.json', 'r') as infile : - Kcat_data = json.load(infile) - - entry_keys = list() - for data in Kcat_data : - # print(data['ECNumber']) - # print(data['Substrate']) - # print(data['Organism']) - - substrate = data['Substrate'] - organism = data['Organism'] - EC = data['ECNumber'] - entry_key = substrate + '&' + organism + '&' + EC - # print(entry_key.lower()) - entry_keys.append(entry_key) - - entry_dict = dict(Counter(entry_keys)) - # print(entry_dict) - - duplicated_keys = [key for key, value in entry_dict.items() if value > 1] - # print(duplicated_keys) - - duplicated_dict = {key:value for key, value in entry_dict.items() if value > 1} - # print(duplicated_dict) - # https://stackoverflow.com/questions/613183/how-do-i-sort-a-dictionary-by-value - # print(sorted(duplicated_dict.items(), key=lambda x: x[1], reverse=True)[:30]) - duplicated_list = sorted(duplicated_dict.items(), key=lambda x: x[1], reverse=True)[:30] - - for duplicated in duplicated_list[:1] : - # print('The subtrate name:', duplicated[0]) - for data in Kcat_data : - # duplicated_one_entry = duplicated_list[0].split('&') - substrate = data['Substrate'] - organism = data['Organism'] - EC = data['ECNumber'] - one_entry = substrate + '&' + organism + '&' + EC - if one_entry == duplicated[0] : - enzyme_type = data['Type'] - Kcat_value = data['Value'] - # print('Substrate:', substrate) - # print('%s enzyme: %s' %(enzyme_type, Kcat_value)) - # print('----'*15+'\n') - - return duplicated_list - -def extract_wildtype_kcat(entry) : - with open('../../Data/database/Kcat_combination_0918_wildtype_mutant.json', 'r') as infile : - Kcat_data = json.load(infile) - - for data in Kcat_data : - substrate = data['Substrate'] - organism = data['Organism'] - EC = data['ECNumber'] - one_entry = substrate + '&' + organism + '&' + EC - if one_entry == entry : - enzyme_type = data['Type'] - if enzyme_type == 'wildtype' : - wildtype_kcat = float(data['Value']) - - if wildtype_kcat : - return wildtype_kcat - else : - return None - -def compare_prediction_wildtype_mutant() : - with open('../../Data/database/Kcat_combination_0918_wildtype_mutant.json', 'r') as infile : - Kcat_data = json.load(infile) - - wildtype_mutant_entries = extract_wildtype_mutant() - - fingerprint_dict = model.load_pickle('../../Data/input/fingerprint_dict.pickle') - atom_dict = model.load_pickle('../../Data/input/atom_dict.pickle') - bond_dict = model.load_pickle('../../Data/input/bond_dict.pickle') - word_dict = model.load_pickle('../../Data/input/sequence_dict.pickle') - n_fingerprint = len(fingerprint_dict) - n_word = len(word_dict) - # print(n_fingerprint) # 3958 - # print(n_word) # 8542 - - radius=2 - ngram=3 - # n_fingerprint = 3958 - # n_word = 8542 - - dim=10 - layer_gnn=3 - side=5 - window=11 - layer_cnn=3 - layer_output=3 - lr=1e-3 - lr_decay=0.5 - decay_interval=10 - weight_decay=1e-6 - iteration=100 - - if torch.cuda.is_available(): - device = torch.device('cuda') - else: - device = torch.device('cpu') - - # torch.manual_seed(1234) - Kcat_model = model.KcatPrediction(device, n_fingerprint, n_word, 2*dim, layer_gnn, window, layer_cnn, layer_output).to(device) - Kcat_model.load_state_dict(torch.load('../../Results/output/all--radius2--ngram3--dim20--layer_gnn3--window11--layer_cnn3--layer_output3--lr1e-3--lr_decay0.5--decay_interval10--weight_decay1e-6--iteration50', map_location=device)) - # print(state_dict.keys()) - # model.eval() - predictor = Predictor(Kcat_model) - - print('It\'s time to start the prediction!') - print('-----------------------------------') - - # prediction = predictor.predict(inputs) - - i = 0 - alldata = dict() - alldata['type'] = list() - alldata['entry'] = list() - alldata['kcat_value'] = list() - - - for wildtype_mutant_entry in wildtype_mutant_entries : - entry_names = wildtype_mutant_entry[0].split('&') - # print('This entry is:', entry_names) - # print('The total amount of wildtype and variant enzymes in the entry is:', wildtype_mutant_entry[1]) - - experimental_values = list() - predicted_values = list() - wildtype_like = list() - wildtype_decreased = list() - - if entry_names[0] in ['7,8-Dihydrofolate', 'Glycerate 3-phosphate', 'L-Aspartate', 'Penicillin G', 'Inosine', 'Isopentenyl diphosphate'] : - print('This entry is:', entry_names) - for data in Kcat_data : - # print(data) - # print(data['Substrate']) - substrate = data['Substrate'] - organism = data['Organism'] - EC = data['ECNumber'] - entry = substrate + '&' + organism + '&' + EC - - if entry == wildtype_mutant_entry[0] : - wildtype_kcat = extract_wildtype_kcat(entry) - # print('wildtype kcat:', wildtype_kcat) - # print(data) - # if wildtype_kcat : - i += 1 - # print('This is', i, '---------------------------------------') - smiles = data['Smiles'] - sequence = data['Sequence'] - enzyme_type = data['Type'] - Kcat = data['Value'] - if "." not in smiles and float(Kcat) > 0: - # i += 1 - # print('This is',i) - - mol = Chem.AddHs(Chem.MolFromSmiles(smiles)) - atoms = create_atoms(mol) - # print(atoms) - i_jbond_dict = create_ijbonddict(mol) - # print(i_jbond_dict) - - fingerprints = extract_fingerprints(atoms, i_jbond_dict, radius) - # print(fingerprints) - # compounds.append(fingerprints) - - adjacency = create_adjacency(mol) - # print(adjacency) - # adjacencies.append(adjacency) - - words = split_sequence(sequence,ngram) - # print(words) - # proteins.append(words) - - fingerprints = torch.LongTensor(fingerprints) - adjacency = torch.FloatTensor(adjacency) - words = torch.LongTensor(words) - - inputs = [fingerprints, adjacency, words] - - value = float(data['Value']) - # print('Current kcat value:', value) - normalized_value = value/wildtype_kcat - # print('%.2f' % normalized_value) - # print(type(value)) - # print(type(normalized_value)) - experimental_values.append(math.log10(value)) - - prediction = predictor.predict(inputs) - Kcat_log_value = prediction.item() - Kcat_value = math.pow(2,Kcat_log_value) - # print(Kcat_value) - # print('%.2f' % normalized_value) - # print(type(Kcat_value)) - predicted_values.append(math.log10(Kcat_value)) - - # entry_names = wildtype_mutant_entry[0].split('&') - # entry_name = entry_names[0] + '&' + entry_names[2] - entry_name = entry_names[0] - if normalized_value >= 0.5 and normalized_value < 2.0 : - wildtype_like.append(math.log10(Kcat_value)) - alldata['type'].append('Wildtype_like') - alldata['entry'].append(entry_name) - alldata['kcat_value'].append(math.log10(Kcat_value)) - if normalized_value < 0.5 : - wildtype_decreased.append(math.log10(Kcat_value)) - alldata['type'].append('Wildtype_decreased') - alldata['entry'].append(entry_name) - alldata['kcat_value'].append(math.log10(Kcat_value)) - - if wildtype_like and wildtype_decreased : - p_value = ranksums(wildtype_like, wildtype_decreased)[1] - print('The amount of wildtype_like:', len(wildtype_like)) - print('The amount of wildtype_decreased:', len(wildtype_decreased)) - print('P value is:', p_value) - print('\n') - - correlation1, p_value1 = stats.pearsonr(experimental_values, predicted_values) - - # https://blog.csdn.net/u012735708/article/details/84337262?utm_medium=distribute.pc_relevant.none- - # task-blog-BlogCommendFromMachineLearnPai2-1.pc_relevant_is_cache&depth_1-utm_source= - # distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.pc_relevant_is_cache - r2 = r2_score(experimental_values,predicted_values) - rmse = np.sqrt(mean_squared_error(experimental_values,predicted_values)) - # print("---------------------") - # print('\n\n') - # print(correlation) - print('r is %.4f' % correlation1) - print('P value is', p_value1) - # print('R2 is %.4f' % r2) - # print('RMSE is %.4f' % rmse) - # print('-----'*10 + '\n') - - - # Plot the boxplot figures between the wildtype_like and wildtype_decreased - allData = pd.DataFrame(alldata) - # print(type(allData)) - - plt.figure(figsize=(1.5, 1.5)) - # To solve the 'Helvetica' font cannot be used in PDF file - # https://stackoverflow.com/questions/59845568/the-pdf-backend-does-not-currently-support-the-selected-font - rc('font',**{'family':'serif','serif':['Helvetica']}) - plt.rcParams['pdf.fonttype'] = 42 - - plt.axes([0.12,0.12,0.83,0.83]) - - plt.tick_params(direction='in') - plt.tick_params(which='major',length=1.5) - plt.tick_params(which='major',width=0.4) - plt.tick_params(which='major',width=0.4) - - # rectangular box plot - palette = {"Wildtype_like": '#2166ac', "Wildtype_decreased": '#b2182b'} - - # for ind in allData.index: - # allData.loc[ind,'entry'] = '${0}$'.format(allData.loc[ind,'entry']) - - ax = sns.boxplot(data=alldata, x="entry", y="kcat_value", hue="type", - palette=palette, showfliers=False, linewidth=0.5) # boxprops=dict(alpha=1.0) - - ax = sns.stripplot(data=alldata, x="entry", y="kcat_value", hue="type", jitter=0.3, - palette=palette, size=1.3, dodge=True) - - # https://stackoverflow.com/questions/58476654/how-to-remove-or-hide-x-axis-label-from-seaborn-boxplot - # plt.xlabel(None) will remove the Label, but not the ticks. - ax.set(xlabel=None) - - for patch in ax.artists: - r, g, b, a = patch.get_facecolor() - patch.set_facecolor((r, g, b, 0.3)) - - # print(ax.artists) - # print(ax.lines) - # print(len(ax.lines)) - # https://cduvallet.github.io/posts/2018/03/boxplots-in-python - for i, artist in enumerate(ax.artists): - # print(i) - - if i % 2 == 0: - col = '#2166ac' - else: - col = '#b2182b' - - # This sets the color for the main box - artist.set_edgecolor(col) - - # Each box has 5 associated Line2D objects (to make the whiskers, fliers, etc.) - # Loop over them here, and use the same colour as above - for j in range(i*5,i*5+5): - # print(j) - line = ax.lines[j] - line.set_color(col) - line.set_mfc(col) - line.set_mec(col) - handles = [ax.artists[0], ax.artists[1]] - - # for tick in ax.get_xticklabels() : - # tick.set_rotation(30) - - plt.rcParams['font.family'] = 'Helvetica' - - plt.text(-0.2, 1.5, '***', fontweight ="normal", fontsize=6) - plt.text(1, 1.0, '*', fontweight ="normal", fontsize=6) - plt.text(1.9, 1.0, '**', fontweight ="normal", fontsize=6) - plt.text(2.9, -0.7, '**', fontweight ="normal", fontsize=6) - plt.text(3.9, 1.4, '**', fontweight ="normal", fontsize=6) - plt.text(5, -0.3, '*', fontweight ="normal", fontsize=6) - - plt.ylabel("$k$$_\mathregular{cat}$ value", fontname='Helvetica', fontsize=7) - - plt.xticks(rotation=30,ha='right') - plt.ylim(-4,4) - plt.yticks([-4,-2,0,2,4]) - - plt.xticks(fontsize=7) - plt.yticks(fontsize=6) - - ax.spines['bottom'].set_linewidth(0.5) - ax.spines['left'].set_linewidth(0.5) - ax.spines['top'].set_linewidth(0.5) - ax.spines['right'].set_linewidth(0.5) - - ax = plt.gca() - # handles,labels = ax.get_legend_handles_labels() - labels = ax.get_legend_handles_labels()[1] - # print(handles) - # print(labels) - # specify just one legend - lgd = plt.legend(handles[0:2], labels[0:2], loc=1, frameon=False, prop={'size': 6}) - - # plt.rcParams['font.family'] = 'Helvetica' - - plt.savefig("../../Results/figures/Fig3d.pdf", dpi=400, bbox_inches = 'tight') - - -if __name__ == '__main__' : - # extract_wildtype_mutant() - compare_prediction_wildtype_mutant() diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/Crypto/Hash/MD5.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/Crypto/Hash/MD5.py deleted file mode 100644 index 554b77720fa10ab12ec18d4657b9b9c087676d48..0000000000000000000000000000000000000000 --- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/Crypto/Hash/MD5.py +++ /dev/null @@ -1,184 +0,0 @@ -# -*- coding: utf-8 -*- -# -# =================================================================== -# The contents of this file are dedicated to the public domain. To -# the extent that dedication to the public domain is not available, -# everyone is granted a worldwide, perpetual, royalty-free, -# non-exclusive license to exercise all rights associated with the -# contents of this file for any purpose whatsoever. -# No rights are reserved. -# -# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, -# EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF -# MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND -# NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS -# BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN -# ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN -# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE -# SOFTWARE. -# =================================================================== - -from Crypto.Util.py3compat import * - -from Crypto.Util._raw_api import (load_pycryptodome_raw_lib, - VoidPointer, SmartPointer, - create_string_buffer, - get_raw_buffer, c_size_t, - c_uint8_ptr) - -_raw_md5_lib = load_pycryptodome_raw_lib("Crypto.Hash._MD5", - """ - #define MD5_DIGEST_SIZE 16 - - int MD5_init(void **shaState); - int MD5_destroy(void *shaState); - int MD5_update(void *hs, - const uint8_t *buf, - size_t len); - int MD5_digest(const void *shaState, - uint8_t digest[MD5_DIGEST_SIZE]); - int MD5_copy(const void *src, void *dst); - - int MD5_pbkdf2_hmac_assist(const void *inner, - const void *outer, - const uint8_t first_digest[MD5_DIGEST_SIZE], - uint8_t final_digest[MD5_DIGEST_SIZE], - size_t iterations); - """) - -class MD5Hash(object): - """A MD5 hash object. - Do not instantiate directly. - Use the :func:`new` function. - - :ivar oid: ASN.1 Object ID - :vartype oid: string - - :ivar block_size: the size in bytes of the internal message block, - input to the compression function - :vartype block_size: integer - - :ivar digest_size: the size in bytes of the resulting hash - :vartype digest_size: integer - """ - - # The size of the resulting hash in bytes. - digest_size = 16 - # The internal block size of the hash algorithm in bytes. - block_size = 64 - # ASN.1 Object ID - oid = "1.2.840.113549.2.5" - - def __init__(self, data=None): - state = VoidPointer() - result = _raw_md5_lib.MD5_init(state.address_of()) - if result: - raise ValueError("Error %d while instantiating MD5" - % result) - self._state = SmartPointer(state.get(), - _raw_md5_lib.MD5_destroy) - if data: - self.update(data) - - def update(self, data): - """Continue hashing of a message by consuming the next chunk of data. - - Args: - data (byte string/byte array/memoryview): The next chunk of the message being hashed. - """ - - result = _raw_md5_lib.MD5_update(self._state.get(), - c_uint8_ptr(data), - c_size_t(len(data))) - if result: - raise ValueError("Error %d while instantiating MD5" - % result) - - def digest(self): - """Return the **binary** (non-printable) digest of the message that has been hashed so far. - - :return: The hash digest, computed over the data processed so far. - Binary form. - :rtype: byte string - """ - - bfr = create_string_buffer(self.digest_size) - result = _raw_md5_lib.MD5_digest(self._state.get(), - bfr) - if result: - raise ValueError("Error %d while instantiating MD5" - % result) - - return get_raw_buffer(bfr) - - def hexdigest(self): - """Return the **printable** digest of the message that has been hashed so far. - - :return: The hash digest, computed over the data processed so far. - Hexadecimal encoded. - :rtype: string - """ - - return "".join(["%02x" % bord(x) for x in self.digest()]) - - def copy(self): - """Return a copy ("clone") of the hash object. - - The copy will have the same internal state as the original hash - object. - This can be used to efficiently compute the digests of strings that - share a common initial substring. - - :return: A hash object of the same type - """ - - clone = MD5Hash() - result = _raw_md5_lib.MD5_copy(self._state.get(), - clone._state.get()) - if result: - raise ValueError("Error %d while copying MD5" % result) - return clone - - def new(self, data=None): - """Create a fresh SHA-1 hash object.""" - - return MD5Hash(data) - - -def new(data=None): - """Create a new hash object. - - :parameter data: - Optional. The very first chunk of the message to hash. - It is equivalent to an early call to :meth:`MD5Hash.update`. - :type data: byte string/byte array/memoryview - - :Return: A :class:`MD5Hash` hash object - """ - return MD5Hash().new(data) - -# The size of the resulting hash in bytes. -digest_size = 16 - -# The internal block size of the hash algorithm in bytes. -block_size = 64 - - -def _pbkdf2_hmac_assist(inner, outer, first_digest, iterations): - """Compute the expensive inner loop in PBKDF-HMAC.""" - - assert len(first_digest) == digest_size - assert iterations > 0 - - bfr = create_string_buffer(digest_size); - result = _raw_md5_lib.MD5_pbkdf2_hmac_assist( - inner._state.get(), - outer._state.get(), - first_digest, - bfr, - c_size_t(iterations)) - - if result: - raise ValueError("Error %d with PBKDF2-HMAC assis for MD5" % result) - - return get_raw_buffer(bfr) diff --git a/spaces/johnslegers/bilingual_stable_diffusion/share_btn.py b/spaces/johnslegers/bilingual_stable_diffusion/share_btn.py deleted file mode 100644 index 4bf271fe915e78e6df33a9df53b47ad68e620e2e..0000000000000000000000000000000000000000 --- a/spaces/johnslegers/bilingual_stable_diffusion/share_btn.py +++ /dev/null @@ -1,60 +0,0 @@ -community_icon_html = """""" - -loading_icon_html = """""" - -share_js = """async () => { - async function uploadFile(file){ - const UPLOAD_URL = 'https://huggingface.co/uploads'; - const response = await fetch(UPLOAD_URL, { - method: 'POST', - headers: { - 'Content-Type': file.type, - 'X-Requested-With': 'XMLHttpRequest', - }, - body: file, /// <- File inherits from Blob - }); - const url = await response.text(); - return url; - } - const gradioEl = document.querySelector('body > gradio-app'); - const imgEls = gradioEl.querySelectorAll('#gallery img'); - const promptTxt = gradioEl.querySelector('#prompt-text-input input').value; - const shareBtnEl = gradioEl.querySelector('#share-btn'); - const shareIconEl = gradioEl.querySelector('#share-btn-share-icon'); - const loadingIconEl = gradioEl.querySelector('#share-btn-loading-icon'); - if(!imgEls.length){ - return; - }; - shareBtnEl.style.pointerEvents = 'none'; - shareIconEl.style.display = 'none'; - loadingIconEl.style.removeProperty('display'); - const files = await Promise.all( - [...imgEls].map(async (imgEl) => { - const res = await fetch(imgEl.src); - const blob = await res.blob(); - const imgId = Date.now() % 200; - const fileName = `diffuse-the-rest-${{imgId}}.png`; - return new File([blob], fileName, { type: 'image/png' }); - }) - ); - const urls = await Promise.all(files.map((f) => uploadFile(f))); - const htmlImgs = urls.map(url => `
-${htmlImgs.join(`\n`)}
- `;
- const params = new URLSearchParams({
- title: promptTxt,
- description: descriptionMd,
- });
- const paramsStr = params.toString();
- window.open(`https://huggingface.co/spaces/stabilityai/stable-diffusion/discussions/new?${paramsStr}`, '_blank');
- shareBtnEl.style.removeProperty('pointer-events');
- shareIconEl.style.removeProperty('display');
- loadingIconEl.style.display = 'none';
-}"""
\ No newline at end of file
diff --git a/spaces/jone/GFPGAN/tests/test_stylegan2_clean_arch.py b/spaces/jone/GFPGAN/tests/test_stylegan2_clean_arch.py
deleted file mode 100644
index 78bb920e73ce28cfec9ea89a4339cc5b87981b47..0000000000000000000000000000000000000000
--- a/spaces/jone/GFPGAN/tests/test_stylegan2_clean_arch.py
+++ /dev/null
@@ -1,52 +0,0 @@
-import torch
-
-from gfpgan.archs.stylegan2_clean_arch import StyleGAN2GeneratorClean
-
-
-def test_stylegan2generatorclean():
- """Test arch: StyleGAN2GeneratorClean."""
-
- # model init and forward (gpu)
- if torch.cuda.is_available():
- net = StyleGAN2GeneratorClean(
- out_size=32, num_style_feat=512, num_mlp=8, channel_multiplier=1, narrow=0.5).cuda().eval()
- style = torch.rand((1, 512), dtype=torch.float32).cuda()
- output = net([style], input_is_latent=False)
- assert output[0].shape == (1, 3, 32, 32)
- assert output[1] is None
-
- # -------------------- with return_latents ----------------------- #
- output = net([style], input_is_latent=True, return_latents=True)
- assert output[0].shape == (1, 3, 32, 32)
- assert len(output[1]) == 1
- # check latent
- assert output[1][0].shape == (8, 512)
-
- # -------------------- with randomize_noise = False ----------------------- #
- output = net([style], randomize_noise=False)
- assert output[0].shape == (1, 3, 32, 32)
- assert output[1] is None
-
- # -------------------- with truncation = 0.5 and mixing----------------------- #
- output = net([style, style], truncation=0.5, truncation_latent=style)
- assert output[0].shape == (1, 3, 32, 32)
- assert output[1] is None
-
- # ------------------ test make_noise ----------------------- #
- out = net.make_noise()
- assert len(out) == 7
- assert out[0].shape == (1, 1, 4, 4)
- assert out[1].shape == (1, 1, 8, 8)
- assert out[2].shape == (1, 1, 8, 8)
- assert out[3].shape == (1, 1, 16, 16)
- assert out[4].shape == (1, 1, 16, 16)
- assert out[5].shape == (1, 1, 32, 32)
- assert out[6].shape == (1, 1, 32, 32)
-
- # ------------------ test get_latent ----------------------- #
- out = net.get_latent(style)
- assert out.shape == (1, 512)
-
- # ------------------ test mean_latent ----------------------- #
- out = net.mean_latent(2)
- assert out.shape == (1, 512)
diff --git a/spaces/jordonpeter01/MusicGen2/setup.py b/spaces/jordonpeter01/MusicGen2/setup.py
deleted file mode 100644
index 78a172b7c90003b689bde40b49cc8fe1fb8107d4..0000000000000000000000000000000000000000
--- a/spaces/jordonpeter01/MusicGen2/setup.py
+++ /dev/null
@@ -1,65 +0,0 @@
-"""
- Copyright (c) Meta Platforms, Inc. and affiliates.
- All rights reserved.
-
- This source code is licensed under the license found in the
- LICENSE file in the root directory of this source tree.
-
-"""
-
-from pathlib import Path
-
-from setuptools import setup, find_packages
-
-
-NAME = 'audiocraft'
-DESCRIPTION = 'Audio research library for PyTorch'
-
-URL = 'https://github.com/fairinternal/audiocraft'
-AUTHOR = 'FAIR Speech & Audio'
-EMAIL = 'defossez@meta.com'
-REQUIRES_PYTHON = '>=3.8.0'
-
-for line in open('audiocraft/__init__.py'):
- line = line.strip()
- if '__version__' in line:
- context = {}
- exec(line, context)
- VERSION = context['__version__']
-
-HERE = Path(__file__).parent
-
-try:
- with open(HERE / "README.md", encoding='utf-8') as f:
- long_description = '\n' + f.read()
-except FileNotFoundError:
- long_description = DESCRIPTION
-
-REQUIRED = [i.strip() for i in open(HERE / 'requirements.txt') if not i.startswith('#')]
-
-setup(
- name=NAME,
- version=VERSION,
- description=DESCRIPTION,
- author_email=EMAIL,
- long_description=long_description,
- long_description_content_type='text/markdown',
- author=AUTHOR,
- url=URL,
- python_requires=REQUIRES_PYTHON,
- install_requires=REQUIRED,
- extras_require={
- 'dev': ['coverage', 'flake8', 'mypy', 'pdoc3', 'pytest'],
- },
- packages=find_packages(),
- package_data={'audiocraft': ['py.typed']},
- include_package_data=True,
- license='MIT License',
- classifiers=[
- # Trove classifiers
- # Full list: https://pypi.python.org/pypi?%3Aaction=list_classifiers
- 'License :: OSI Approved :: MIT License',
- 'Topic :: Multimedia :: Sound/Audio',
- 'Topic :: Scientific/Engineering :: Artificial Intelligence',
- ],
-)
diff --git a/spaces/jordonpeter01/ai-comic-factory/Dockerfile b/spaces/jordonpeter01/ai-comic-factory/Dockerfile
deleted file mode 100644
index 91319be9b3dd35d916d18fba5260f51125c46b50..0000000000000000000000000000000000000000
--- a/spaces/jordonpeter01/ai-comic-factory/Dockerfile
+++ /dev/null
@@ -1,65 +0,0 @@
-FROM node:18-alpine AS base
-
-# Install dependencies only when needed
-FROM base AS deps
-# Check https://github.com/nodejs/docker-node/tree/b4117f9333da4138b03a546ec926ef50a31506c3#nodealpine to understand why libc6-compat might be needed.
-RUN apk add --no-cache libc6-compat
-WORKDIR /app
-
-# Install dependencies based on the preferred package manager
-COPY package.json yarn.lock* package-lock.json* pnpm-lock.yaml* ./
-RUN \
- if [ -f yarn.lock ]; then yarn --frozen-lockfile; \
- elif [ -f package-lock.json ]; then npm ci; \
- elif [ -f pnpm-lock.yaml ]; then yarn global add pnpm && pnpm i --frozen-lockfile; \
- else echo "Lockfile not found." && exit 1; \
- fi
-
-# Uncomment the following lines if you want to use a secret at buildtime,
-# for example to access your private npm packages
-# RUN --mount=type=secret,id=HF_EXAMPLE_SECRET,mode=0444,required=true \
-# $(cat /run/secrets/HF_EXAMPLE_SECRET)
-
-# Rebuild the source code only when needed
-FROM base AS builder
-WORKDIR /app
-COPY --from=deps /app/node_modules ./node_modules
-COPY . .
-
-# Next.js collects completely anonymous telemetry data about general usage.
-# Learn more here: https://nextjs.org/telemetry
-# Uncomment the following line in case you want to disable telemetry during the build.
-# ENV NEXT_TELEMETRY_DISABLED 1
-
-# RUN yarn build
-
-# If you use yarn, comment out this line and use the line above
-RUN npm run build
-
-# Production image, copy all the files and run next
-FROM base AS runner
-WORKDIR /app
-
-ENV NODE_ENV production
-# Uncomment the following line in case you want to disable telemetry during runtime.
-# ENV NEXT_TELEMETRY_DISABLED 1
-
-RUN addgroup --system --gid 1001 nodejs
-RUN adduser --system --uid 1001 nextjs
-
-COPY --from=builder /app/public ./public
-
-# Automatically leverage output traces to reduce image size
-# https://nextjs.org/docs/advanced-features/output-file-tracing
-COPY --from=builder --chown=nextjs:nodejs /app/.next/standalone ./
-COPY --from=builder --chown=nextjs:nodejs /app/.next/static ./.next/static
-COPY --from=builder --chown=nextjs:nodejs /app/.next/cache ./.next/cache
-# COPY --from=builder --chown=nextjs:nodejs /app/.next/cache/fetch-cache ./.next/cache/fetch-cache
-
-USER nextjs
-
-EXPOSE 3000
-
-ENV PORT 3000
-
-CMD ["node", "server.js"]
\ No newline at end of file
diff --git a/spaces/josedolot/HybridNet_Demo2/utils/sync_batchnorm/batchnorm.py b/spaces/josedolot/HybridNet_Demo2/utils/sync_batchnorm/batchnorm.py
deleted file mode 100644
index e1bf74feb5fa27f659110be91e97f99d862ad492..0000000000000000000000000000000000000000
--- a/spaces/josedolot/HybridNet_Demo2/utils/sync_batchnorm/batchnorm.py
+++ /dev/null
@@ -1,394 +0,0 @@
-# -*- coding: utf-8 -*-
-# File : batchnorm.py
-# Author : Jiayuan Mao
-# Email : maojiayuan@gmail.com
-# Date : 27/01/2018
-#
-# This file is part of Synchronized-BatchNorm-PyTorch.
-# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
-# Distributed under MIT License.
-
-import collections
-import contextlib
-
-import torch
-import torch.nn.functional as F
-
-from torch.nn.modules.batchnorm import _BatchNorm
-
-try:
- from torch.nn.parallel._functions import ReduceAddCoalesced, Broadcast
-except ImportError:
- ReduceAddCoalesced = Broadcast = None
-
-try:
- from jactorch.parallel.comm import SyncMaster
- from jactorch.parallel.data_parallel import JacDataParallel as DataParallelWithCallback
-except ImportError:
- from .comm import SyncMaster
- from .replicate import DataParallelWithCallback
-
-__all__ = [
- 'SynchronizedBatchNorm1d', 'SynchronizedBatchNorm2d', 'SynchronizedBatchNorm3d',
- 'patch_sync_batchnorm', 'convert_model'
-]
-
-
-def _sum_ft(tensor):
- """sum over the first and last dimention"""
- return tensor.sum(dim=0).sum(dim=-1)
-
-
-def _unsqueeze_ft(tensor):
- """add new dimensions at the front and the tail"""
- return tensor.unsqueeze(0).unsqueeze(-1)
-
-
-_ChildMessage = collections.namedtuple('_ChildMessage', ['sum', 'ssum', 'sum_size'])
-_MasterMessage = collections.namedtuple('_MasterMessage', ['sum', 'inv_std'])
-
-
-class _SynchronizedBatchNorm(_BatchNorm):
- def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=True):
- assert ReduceAddCoalesced is not None, 'Can not use Synchronized Batch Normalization without CUDA support.'
-
- super(_SynchronizedBatchNorm, self).__init__(num_features, eps=eps, momentum=momentum, affine=affine)
-
- self._sync_master = SyncMaster(self._data_parallel_master)
-
- self._is_parallel = False
- self._parallel_id = None
- self._slave_pipe = None
-
- def forward(self, input):
- # If it is not parallel computation or is in evaluation mode, use PyTorch's implementation.
- if not (self._is_parallel and self.training):
- return F.batch_norm(
- input, self.running_mean, self.running_var, self.weight, self.bias,
- self.training, self.momentum, self.eps)
-
- # Resize the input to (B, C, -1).
- input_shape = input.size()
- input = input.view(input.size(0), self.num_features, -1)
-
- # Compute the sum and square-sum.
- sum_size = input.size(0) * input.size(2)
- input_sum = _sum_ft(input)
- input_ssum = _sum_ft(input ** 2)
-
- # Reduce-and-broadcast the statistics.
- if self._parallel_id == 0:
- mean, inv_std = self._sync_master.run_master(_ChildMessage(input_sum, input_ssum, sum_size))
- else:
- mean, inv_std = self._slave_pipe.run_slave(_ChildMessage(input_sum, input_ssum, sum_size))
-
- # Compute the output.
- if self.affine:
- # MJY:: Fuse the multiplication for speed.
- output = (input - _unsqueeze_ft(mean)) * _unsqueeze_ft(inv_std * self.weight) + _unsqueeze_ft(self.bias)
- else:
- output = (input - _unsqueeze_ft(mean)) * _unsqueeze_ft(inv_std)
-
- # Reshape it.
- return output.view(input_shape)
-
- def __data_parallel_replicate__(self, ctx, copy_id):
- self._is_parallel = True
- self._parallel_id = copy_id
-
- # parallel_id == 0 means master device.
- if self._parallel_id == 0:
- ctx.sync_master = self._sync_master
- else:
- self._slave_pipe = ctx.sync_master.register_slave(copy_id)
-
- def _data_parallel_master(self, intermediates):
- """Reduce the sum and square-sum, compute the statistics, and broadcast it."""
-
- # Always using same "device order" makes the ReduceAdd operation faster.
- # Thanks to:: Tete Xiao (http://tetexiao.com/)
- intermediates = sorted(intermediates, key=lambda i: i[1].sum.get_device())
-
- to_reduce = [i[1][:2] for i in intermediates]
- to_reduce = [j for i in to_reduce for j in i] # flatten
- target_gpus = [i[1].sum.get_device() for i in intermediates]
-
- sum_size = sum([i[1].sum_size for i in intermediates])
- sum_, ssum = ReduceAddCoalesced.apply(target_gpus[0], 2, *to_reduce)
- mean, inv_std = self._compute_mean_std(sum_, ssum, sum_size)
-
- broadcasted = Broadcast.apply(target_gpus, mean, inv_std)
-
- outputs = []
- for i, rec in enumerate(intermediates):
- outputs.append((rec[0], _MasterMessage(*broadcasted[i*2:i*2+2])))
-
- return outputs
-
- def _compute_mean_std(self, sum_, ssum, size):
- """Compute the mean and standard-deviation with sum and square-sum. This method
- also maintains the moving average on the master device."""
- assert size > 1, 'BatchNorm computes unbiased standard-deviation, which requires size > 1.'
- mean = sum_ / size
- sumvar = ssum - sum_ * mean
- unbias_var = sumvar / (size - 1)
- bias_var = sumvar / size
-
- if hasattr(torch, 'no_grad'):
- with torch.no_grad():
- self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.data
- self.running_var = (1 - self.momentum) * self.running_var + self.momentum * unbias_var.data
- else:
- self.running_mean = (1 - self.momentum) * self.running_mean + self.momentum * mean.data
- self.running_var = (1 - self.momentum) * self.running_var + self.momentum * unbias_var.data
-
- return mean, bias_var.clamp(self.eps) ** -0.5
-
-
-class SynchronizedBatchNorm1d(_SynchronizedBatchNorm):
- r"""Applies Synchronized Batch Normalization over a 2d or 3d input that is seen as a
- mini-batch.
-
- .. math::
-
- y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta
-
- This module differs from the built-in PyTorch BatchNorm1d as the mean and
- standard-deviation are reduced across all devices during training.
-
- For example, when one uses `nn.DataParallel` to wrap the network during
- training, PyTorch's implementation normalize the tensor on each device using
- the statistics only on that device, which accelerated the computation and
- is also easy to implement, but the statistics might be inaccurate.
- Instead, in this synchronized version, the statistics will be computed
- over all training samples distributed on multiple devices.
-
- Note that, for one-GPU or CPU-only case, this module behaves exactly same
- as the built-in PyTorch implementation.
-
- The mean and standard-deviation are calculated per-dimension over
- the mini-batches and gamma and beta are learnable parameter vectors
- of size C (where C is the input size).
-
- During training, this layer keeps a running estimate of its computed mean
- and variance. The running sum is kept with a default momentum of 0.1.
-
- During evaluation, this running mean/variance is used for normalization.
-
- Because the BatchNorm is done over the `C` dimension, computing statistics
- on `(N, L)` slices, it's common terminology to call this Temporal BatchNorm
-
- Args:
- num_features: num_features from an expected input of size
- `batch_size x num_features [x width]`
- eps: a value added to the denominator for numerical stability.
- Default: 1e-5
- momentum: the value used for the running_mean and running_var
- computation. Default: 0.1
- affine: a boolean value that when set to ``True``, gives the layer learnable
- affine parameters. Default: ``True``
-
- Shape::
- - Input: :math:`(N, C)` or :math:`(N, C, L)`
- - Output: :math:`(N, C)` or :math:`(N, C, L)` (same shape as input)
-
- Examples:
- >>> # With Learnable Parameters
- >>> m = SynchronizedBatchNorm1d(100)
- >>> # Without Learnable Parameters
- >>> m = SynchronizedBatchNorm1d(100, affine=False)
- >>> input = torch.autograd.Variable(torch.randn(20, 100))
- >>> output = m(input)
- """
-
- def _check_input_dim(self, input):
- if input.dim() != 2 and input.dim() != 3:
- raise ValueError('expected 2D or 3D input (got {}D input)'
- .format(input.dim()))
- super(SynchronizedBatchNorm1d, self)._check_input_dim(input)
-
-
-class SynchronizedBatchNorm2d(_SynchronizedBatchNorm):
- r"""Applies Batch Normalization over a 4d input that is seen as a mini-batch
- of 3d inputs
-
- .. math::
-
- y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta
-
- This module differs from the built-in PyTorch BatchNorm2d as the mean and
- standard-deviation are reduced across all devices during training.
-
- For example, when one uses `nn.DataParallel` to wrap the network during
- training, PyTorch's implementation normalize the tensor on each device using
- the statistics only on that device, which accelerated the computation and
- is also easy to implement, but the statistics might be inaccurate.
- Instead, in this synchronized version, the statistics will be computed
- over all training samples distributed on multiple devices.
-
- Note that, for one-GPU or CPU-only case, this module behaves exactly same
- as the built-in PyTorch implementation.
-
- The mean and standard-deviation are calculated per-dimension over
- the mini-batches and gamma and beta are learnable parameter vectors
- of size C (where C is the input size).
-
- During training, this layer keeps a running estimate of its computed mean
- and variance. The running sum is kept with a default momentum of 0.1.
-
- During evaluation, this running mean/variance is used for normalization.
-
- Because the BatchNorm is done over the `C` dimension, computing statistics
- on `(N, H, W)` slices, it's common terminology to call this Spatial BatchNorm
-
- Args:
- num_features: num_features from an expected input of
- size batch_size x num_features x height x width
- eps: a value added to the denominator for numerical stability.
- Default: 1e-5
- momentum: the value used for the running_mean and running_var
- computation. Default: 0.1
- affine: a boolean value that when set to ``True``, gives the layer learnable
- affine parameters. Default: ``True``
-
- Shape::
- - Input: :math:`(N, C, H, W)`
- - Output: :math:`(N, C, H, W)` (same shape as input)
-
- Examples:
- >>> # With Learnable Parameters
- >>> m = SynchronizedBatchNorm2d(100)
- >>> # Without Learnable Parameters
- >>> m = SynchronizedBatchNorm2d(100, affine=False)
- >>> input = torch.autograd.Variable(torch.randn(20, 100, 35, 45))
- >>> output = m(input)
- """
-
- def _check_input_dim(self, input):
- if input.dim() != 4:
- raise ValueError('expected 4D input (got {}D input)'
- .format(input.dim()))
- super(SynchronizedBatchNorm2d, self)._check_input_dim(input)
-
-
-class SynchronizedBatchNorm3d(_SynchronizedBatchNorm):
- r"""Applies Batch Normalization over a 5d input that is seen as a mini-batch
- of 4d inputs
-
- .. math::
-
- y = \frac{x - mean[x]}{ \sqrt{Var[x] + \epsilon}} * gamma + beta
-
- This module differs from the built-in PyTorch BatchNorm3d as the mean and
- standard-deviation are reduced across all devices during training.
-
- For example, when one uses `nn.DataParallel` to wrap the network during
- training, PyTorch's implementation normalize the tensor on each device using
- the statistics only on that device, which accelerated the computation and
- is also easy to implement, but the statistics might be inaccurate.
- Instead, in this synchronized version, the statistics will be computed
- over all training samples distributed on multiple devices.
-
- Note that, for one-GPU or CPU-only case, this module behaves exactly same
- as the built-in PyTorch implementation.
-
- The mean and standard-deviation are calculated per-dimension over
- the mini-batches and gamma and beta are learnable parameter vectors
- of size C (where C is the input size).
-
- During training, this layer keeps a running estimate of its computed mean
- and variance. The running sum is kept with a default momentum of 0.1.
-
- During evaluation, this running mean/variance is used for normalization.
-
- Because the BatchNorm is done over the `C` dimension, computing statistics
- on `(N, D, H, W)` slices, it's common terminology to call this Volumetric BatchNorm
- or Spatio-temporal BatchNorm
-
- Args:
- num_features: num_features from an expected input of
- size batch_size x num_features x depth x height x width
- eps: a value added to the denominator for numerical stability.
- Default: 1e-5
- momentum: the value used for the running_mean and running_var
- computation. Default: 0.1
- affine: a boolean value that when set to ``True``, gives the layer learnable
- affine parameters. Default: ``True``
-
- Shape::
- - Input: :math:`(N, C, D, H, W)`
- - Output: :math:`(N, C, D, H, W)` (same shape as input)
-
- Examples:
- >>> # With Learnable Parameters
- >>> m = SynchronizedBatchNorm3d(100)
- >>> # Without Learnable Parameters
- >>> m = SynchronizedBatchNorm3d(100, affine=False)
- >>> input = torch.autograd.Variable(torch.randn(20, 100, 35, 45, 10))
- >>> output = m(input)
- """
-
- def _check_input_dim(self, input):
- if input.dim() != 5:
- raise ValueError('expected 5D input (got {}D input)'
- .format(input.dim()))
- super(SynchronizedBatchNorm3d, self)._check_input_dim(input)
-
-
-@contextlib.contextmanager
-def patch_sync_batchnorm():
- import torch.nn as nn
-
- backup = nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d
-
- nn.BatchNorm1d = SynchronizedBatchNorm1d
- nn.BatchNorm2d = SynchronizedBatchNorm2d
- nn.BatchNorm3d = SynchronizedBatchNorm3d
-
- yield
-
- nn.BatchNorm1d, nn.BatchNorm2d, nn.BatchNorm3d = backup
-
-
-def convert_model(module):
- """Traverse the input module and its child recursively
- and replace all instance of torch.nn.modules.batchnorm.BatchNorm*N*d
- to SynchronizedBatchNorm*N*d
-
- Args:
- module: the input module needs to be convert to SyncBN model
-
- Examples:
- >>> import torch.nn as nn
- >>> import torchvision
- >>> # m is a standard pytorch model
- >>> m = torchvision.models.resnet18(True)
- >>> m = nn.DataParallel(m)
- >>> # after convert, m is using SyncBN
- >>> m = convert_model(m)
- """
- if isinstance(module, torch.nn.DataParallel):
- mod = module.module
- mod = convert_model(mod)
- mod = DataParallelWithCallback(mod, device_ids=module.device_ids)
- return mod
-
- mod = module
- for pth_module, sync_module in zip([torch.nn.modules.batchnorm.BatchNorm1d,
- torch.nn.modules.batchnorm.BatchNorm2d,
- torch.nn.modules.batchnorm.BatchNorm3d],
- [SynchronizedBatchNorm1d,
- SynchronizedBatchNorm2d,
- SynchronizedBatchNorm3d]):
- if isinstance(module, pth_module):
- mod = sync_module(module.num_features, module.eps, module.momentum, module.affine)
- mod.running_mean = module.running_mean
- mod.running_var = module.running_var
- if module.affine:
- mod.weight.data = module.weight.data.clone().detach()
- mod.bias.data = module.bias.data.clone().detach()
-
- for name, child in module.named_children():
- mod.add_module(name, convert_model(child))
-
- return mod
diff --git a/spaces/jtpotato/firetrace/firetrace/interface_text.py b/spaces/jtpotato/firetrace/firetrace/interface_text.py
deleted file mode 100644
index 8845902ce51186c66bb1faca6c49a09120c3f15f..0000000000000000000000000000000000000000
--- a/spaces/jtpotato/firetrace/firetrace/interface_text.py
+++ /dev/null
@@ -1,57 +0,0 @@
-from decimal import *
-
-q_and_a = """
- ### **Q: What's the deal with Firetrace? 🔍**\n
- A: Picture this—it's like having your very own bushfire fortune teller!
- 🔮 Firetrace is an AI-powered web interface that predicts the severity of bushfire events all across Australia.
- 🌍 It's armed with projected weather data, BOM weather observatories and NASA's MODIS satellite intel.
- It even considers time information to get climate change trends. 🦸♂️🔥
- \n
-
- ### **Q: What is the inspiration behind Firetrace?** 🤔 \n
- A: Those bushfires! They cause habitat loss, put many animal species at risk, and drastically impact the economy 😢📉
- The series of bushfires that took place in Australia is a clear demonstration of this.
- ☝️ So, we put our heads together to conjure up Firetrace—a cutting-edge tool that helps us predict the severity of these fiery events.
- This will be helpful in making smarter decisions and being prepared to take on the bushfire challenges head-on! 💪🌳
- \n
-
- ### **Q: How do I use Firetrace?** 🎉 \n
- A: It's easy-peasy! 🔥
- Simply enter in values for the input boxes below, and you'll unlock access to the hottest predictions,
- and uncover the secrets of bushfire severity.
- The prediction you receive will be the number of square kilometres of land the fire covers that day.
- (Keep in mind that it's not completely right, we're not wizards here 🧙 - but it does have reasonable accuracy)
- \n
-
- Let's work together to face these fiery challenges to create a safer future! 🚀🌿
- """
-
-privacy = "*By using this app you consent to the collection of: your user agent string (informing us of what type of device you might be using this on, to improve your experience), the time you have accessed this website, the time zone name (giving us an approximate geographic location to understand the demographics of our users, informing future decisions around localisation) as well as any input you have provided. No other information is collected, we swear.*"
-
-def additional_context(scan_area):
- def get_percentage(scan_area, area):
- result = (scan_area / area) * 100
- return Decimal(str(result)).quantize(Decimal("0.01")) # Decimal is required because Python doesn't handle floating points very well by default.
-
- def get_times(scan_area, area):
- result = scan_area / area
- return Decimal(str(result)).quantize(Decimal("0.01"))
-
- rounded_fire_area = Decimal(str(scan_area)).quantize(Decimal("0.01"))
- LARGEST_EVENT = 5854.7
- MELBOURNE_AREA = 9993
- PORT_JACKSON_BAY_AREA = 55
- MURRAY_DARLING_BASIN_AREA = 1059000
- ACT_AREA = 2400
-
- context_string = f"""
- In this hypothetical scenario, `{rounded_fire_area}` square kilometres of fire would be burning simultaneously across the entire country. 🤯 This is `{get_percentage(scan_area, LARGEST_EVENT)}%` of the largest fire event 🔥 in our database, at {LARGEST_EVENT} square kilometres, recorded on the 19th of September 2011.
-
- ### Other things this fire compares to:
- - `{get_percentage(scan_area, MELBOURNE_AREA)}%` of Greater Melbourne. 😧
- - `{get_times(scan_area, PORT_JACKSON_BAY_AREA)}` Port Jackson Bays 🌊
- - `{get_percentage(scan_area, MURRAY_DARLING_BASIN_AREA)}%` of the Murray-Darling Basin. 🌾
- - `{get_percentage(scan_area, ACT_AREA)}%` of the ACT. 🏙️
- """
-
- return context_string
\ No newline at end of file
diff --git a/spaces/julien-c/sveltekit-demo/build/_app/pages/about.svelte-310947ca.js b/spaces/julien-c/sveltekit-demo/build/_app/pages/about.svelte-310947ca.js
deleted file mode 100644
index 08c6fe6e2f1a2c19568179ebdac087bc98da23e2..0000000000000000000000000000000000000000
--- a/spaces/julien-c/sveltekit-demo/build/_app/pages/about.svelte-310947ca.js
+++ /dev/null
@@ -1,9 +0,0 @@
-import{S as z,i as F,s as G,j as _,e as i,t as o,U as N,d as a,l as m,c as r,a as d,g as s,b as B,f as U,I as t,J as I}from"../chunks/vendor-92f01141.js";const Q=!0,W=!1;function X(V){let h,e,f,b,E,p,S,u,k,x,A,g,J,K,y,O,P,c,D,v,H,j;return{c(){h=_(),e=i("div"),f=i("h1"),b=o("About this app"),E=_(),p=i("p"),S=o("This is a "),u=i("a"),k=o("SvelteKit"),x=o(` app. You can make your own by typing the
- following into your command line and following the prompts:`),A=_(),g=i("pre"),J=o("npm init svelte@next"),K=_(),y=i("p"),O=o(`The page you're looking at is purely static HTML, with no client-side interactivity needed.
- Because of that, we don't need to load any JavaScript. Try viewing the page's source, or opening
- the devtools network panel and reloading.`),P=_(),c=i("p"),D=o("The "),v=i("a"),H=o("TODOs"),j=o(` page illustrates SvelteKit's data loading and form handling. Try using
- it with JavaScript disabled!`),this.h()},l(l){N('[data-svelte="svelte-1ine71f"]',document.head).forEach(a),h=m(l),e=r(l,"DIV",{class:!0});var n=d(e);f=r(n,"H1",{});var L=d(f);b=s(L,"About this app"),L.forEach(a),E=m(n),p=r(n,"P",{});var w=d(p);S=s(w,"This is a "),u=r(w,"A",{href:!0});var M=d(u);k=s(M,"SvelteKit"),M.forEach(a),x=s(w,` app. You can make your own by typing the
- following into your command line and following the prompts:`),w.forEach(a),A=m(n),g=r(n,"PRE",{});var Y=d(g);J=s(Y,"npm init svelte@next"),Y.forEach(a),K=m(n),y=r(n,"P",{});var C=d(y);O=s(C,`The page you're looking at is purely static HTML, with no client-side interactivity needed.
- Because of that, we don't need to load any JavaScript. Try viewing the page's source, or opening
- the devtools network panel and reloading.`),C.forEach(a),P=m(n),c=r(n,"P",{});var T=d(c);D=s(T,"The "),v=r(T,"A",{href:!0});var R=d(v);H=s(R,"TODOs"),R.forEach(a),j=s(T,` page illustrates SvelteKit's data loading and form handling. Try using
- it with JavaScript disabled!`),T.forEach(a),n.forEach(a),this.h()},h(){document.title="About",B(u,"href","https://kit.svelte.dev"),B(v,"href","/todos"),B(e,"class","content svelte-cf77e8")},m(l,q){U(l,h,q),U(l,e,q),t(e,f),t(f,b),t(e,E),t(e,p),t(p,S),t(p,u),t(u,k),t(p,x),t(e,A),t(e,g),t(g,J),t(e,K),t(e,y),t(y,O),t(e,P),t(e,c),t(c,D),t(c,v),t(v,H),t(c,j)},p:I,i:I,o:I,d(l){l&&a(h),l&&a(e)}}}const $=W,tt=Q,et=!0;class at extends z{constructor(h){super();F(this,h,null,X,G,{})}}export{at as default,$ as hydrate,et as prerender,tt as router};
diff --git a/spaces/juuxn/SimpleRVC/README.md b/spaces/juuxn/SimpleRVC/README.md
deleted file mode 100644
index d5a7b00c94a5b2777ac92563cae5b2af70e0bd28..0000000000000000000000000000000000000000
--- a/spaces/juuxn/SimpleRVC/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: SimpleRVC
-emoji: 🐨
-colorFrom: gray
-colorTo: blue
-sdk: gradio
-sdk_version: 3.50.2
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/ka1kuk/fastapi/g4f/models.py b/spaces/ka1kuk/fastapi/g4f/models.py
deleted file mode 100644
index e1d5b46d2a4cc4fe69812115dbe0281c00df9355..0000000000000000000000000000000000000000
--- a/spaces/ka1kuk/fastapi/g4f/models.py
+++ /dev/null
@@ -1,64 +0,0 @@
-from g4f import Provider
-
-class Model:
- class model:
- name: str
- base_provider: str
- best_provider: str
-
- class gpt_35_turbo:
- name: str = 'gpt-3.5-turbo'
- base_provider: str = 'openai'
- best_provider: Provider.Provider = Provider.DeepAi
-
- class gpt_35_turbo_16k:
- name: str = 'gpt-3.5-turbo-16k'
- base_provider: str = 'openai'
- best_provider: Provider.Provider = Provider.Liaobots
-
- class gpt_4_dev:
- name: str = 'gpt-4-for-dev'
- base_provider: str = 'openai'
- best_provider: Provider.Provider = Provider.Phind
-
- class gpt_4:
- name: str = 'gpt-4'
- base_provider: str = 'openai'
- best_provider: Provider.Provider = Provider.Liaobots
-
- class gpt_4_assistant:
- name: str = 'gpt-4'
- base_provider: str = 'openai'
- best_provider: Provider.Provider = Provider.ChatgptAi
-
- """ 'falcon-40b': Model.falcon_40b,
- 'falcon-7b': Model.falcon_7b,
- 'llama-13b': Model.llama_13b,"""
-
- class falcon_40b:
- name: str = 'falcon-40b'
- base_provider: str = 'huggingface'
- best_provider: Provider.Provider = Provider.H2o
-
- class falcon_7b:
- name: str = 'falcon-7b'
- base_provider: str = 'huggingface'
- best_provider: Provider.Provider = Provider.H2o
-
- class llama_13b:
- name: str = 'llama-13b'
- base_provider: str = 'huggingface'
- best_provider: Provider.Provider = Provider.H2o
-
-class ModelUtils:
- convert: dict = {
- 'gpt-3.5-turbo': Model.gpt_35_turbo,
- 'gpt-3.5-turbo-16k': Model.gpt_35_turbo_16k,
- 'gpt-4': Model.gpt_4,
- 'gpt-4-for-dev': Model.gpt_4_dev,
- 'gpt-4-for-assitant': Model.gpt_4_assistant,
-
- 'falcon-40b': Model.falcon_40b,
- 'falcon-7b': Model.falcon_7b,
- 'llama-13b': Model.llama_13b,
-}
\ No newline at end of file
diff --git a/spaces/kaicheng/ChatGPT_ad/run_macOS.command b/spaces/kaicheng/ChatGPT_ad/run_macOS.command
deleted file mode 100644
index 2d26597ae47519f42336ccffc16646713a192ae1..0000000000000000000000000000000000000000
--- a/spaces/kaicheng/ChatGPT_ad/run_macOS.command
+++ /dev/null
@@ -1,31 +0,0 @@
-#!/bin/bash
-
-# 获取脚本所在目录
-script_dir=$(dirname "$(readlink -f "$0")")
-
-# 将工作目录更改为脚本所在目录
-cd "$script_dir" || exit
-
-# 检查Git仓库是否有更新
-git remote update
-pwd
-
-if ! git status -uno | grep 'up to date' > /dev/null; then
- # 如果有更新,关闭当前运行的服务器
- pkill -f ChuanhuChatbot.py
-
- # 拉取最新更改
- git pull
-
- # 安装依赖
- pip3 install -r requirements.txt
-
- # 重新启动服务器
- nohup python3 ChuanhuChatbot.py &
-fi
-
-# 检查ChuanhuChatbot.py是否在运行
-if ! pgrep -f ChuanhuChatbot.py > /dev/null; then
- # 如果没有运行,启动服务器
- nohup python3 ChuanhuChatbot.py &
-fi
diff --git a/spaces/kangvcar/RealChar/realtime_ai_character/websocket_routes.py b/spaces/kangvcar/RealChar/realtime_ai_character/websocket_routes.py
deleted file mode 100644
index 2af51a0f896d3fad84feaf808a2e3d30b16e8dcb..0000000000000000000000000000000000000000
--- a/spaces/kangvcar/RealChar/realtime_ai_character/websocket_routes.py
+++ /dev/null
@@ -1,282 +0,0 @@
-import asyncio
-import os
-import uuid
-
-from fastapi import APIRouter, Depends, HTTPException, Path, WebSocket, WebSocketDisconnect, Query
-from firebase_admin import auth
-from firebase_admin.exceptions import FirebaseError
-
-from requests import Session
-
-from realtime_ai_character.audio.speech_to_text import (SpeechToText,
- get_speech_to_text)
-from realtime_ai_character.audio.text_to_speech import (TextToSpeech,
- get_text_to_speech)
-from realtime_ai_character.character_catalog.catalog_manager import (
- CatalogManager, get_catalog_manager)
-from realtime_ai_character.database.connection import get_db
-from realtime_ai_character.llm import (AsyncCallbackAudioHandler,
- AsyncCallbackTextHandler, get_llm, LLM)
-from realtime_ai_character.logger import get_logger
-from realtime_ai_character.models.interaction import Interaction
-from realtime_ai_character.utils import (ConversationHistory, build_history,
- get_connection_manager)
-
-logger = get_logger(__name__)
-
-router = APIRouter()
-
-manager = get_connection_manager()
-
-GREETING_TXT = 'Hi, my friend, what brings you here today?'
-
-
-async def get_current_user(token: str):
- """Heler function for auth with Firebase."""
- if not token:
- return ""
- try:
- decoded_token = auth.verify_id_token(token)
- except FirebaseError as e:
- logger.info(f'Receveid invalid token: {token} with error {e}')
- raise HTTPException(status_code=401,
- detail="Invalid authentication credentials")
-
- return decoded_token['uid']
-
-
-@router.websocket("/ws/{client_id}")
-async def websocket_endpoint(websocket: WebSocket,
- client_id: int = Path(...),
- api_key: str = Query(None),
- llm_model: str = Query(default=os.getenv(
- 'LLM_MODEL_USE', 'gpt-3.5-turbo-16k')),
- token: str = Query(None),
- db: Session = Depends(get_db),
- catalog_manager=Depends(get_catalog_manager),
- speech_to_text=Depends(get_speech_to_text),
- text_to_speech=Depends(get_text_to_speech)):
- # Default user_id to client_id. If auth is enabled and token is provided, use
- # the user_id from the token.
- user_id = str(client_id)
- if os.getenv('USE_AUTH', ''):
- # Do not allow anonymous users to use non-GPT3.5 model.
- if not token and llm_model != 'gpt-3.5-turbo-16k':
- await websocket.close(code=1008, reason="Unauthorized")
- return
- try:
- user_id = await get_current_user(token)
- except HTTPException:
- await websocket.close(code=1008, reason="Unauthorized")
- return
- llm = get_llm(model=llm_model)
- await manager.connect(websocket)
- try:
- main_task = asyncio.create_task(
- handle_receive(websocket, client_id, db, llm, catalog_manager,
- speech_to_text, text_to_speech))
-
- await asyncio.gather(main_task)
-
- except WebSocketDisconnect:
- await manager.disconnect(websocket)
- await manager.broadcast_message(f"User #{user_id} left the chat")
-
-
-async def handle_receive(websocket: WebSocket, client_id: int, db: Session,
- llm: LLM, catalog_manager: CatalogManager,
- speech_to_text: SpeechToText,
- text_to_speech: TextToSpeech):
- try:
- conversation_history = ConversationHistory()
- # TODO: clean up client_id once migration is done.
- user_id = str(client_id)
- session_id = str(uuid.uuid4().hex)
-
- # 0. Receive client platform info (web, mobile, terminal)
- data = await websocket.receive()
- if data['type'] != 'websocket.receive':
- raise WebSocketDisconnect('disconnected')
- platform = data['text']
- logger.info(f"User #{user_id}:{platform} connected to server with "
- f"session_id {session_id}")
-
- # 1. User selected a character
- character = None
- character_list = list(catalog_manager.characters.keys())
- user_input_template = 'Context:{context}\n User:{query}'
- while not character:
- character_message = "\n".join([
- f"{i+1} - {character}"
- for i, character in enumerate(character_list)
- ])
- await manager.send_message(
- message=
- f"Select your character by entering the corresponding number:\n"
- f"{character_message}\n",
- websocket=websocket)
- data = await websocket.receive()
-
- if data['type'] != 'websocket.receive':
- raise WebSocketDisconnect('disconnected')
-
- if not character and 'text' in data:
- selection = int(data['text'])
- if selection > len(character_list) or selection < 1:
- await manager.send_message(
- message=
- f"Invalid selection. Select your character ["
- f"{', '.join(catalog_manager.characters.keys())}]\n",
- websocket=websocket)
- continue
- character = catalog_manager.get_character(
- character_list[selection - 1])
- conversation_history.system_prompt = character.llm_system_prompt
- user_input_template = character.llm_user_prompt
- logger.info(
- f"User #{user_id} selected character: {character.name}")
-
- tts_event = asyncio.Event()
- tts_task = None
- previous_transcript = None
- token_buffer = []
-
- # Greet the user
- await manager.send_message(message=GREETING_TXT, websocket=websocket)
- tts_task = asyncio.create_task(
- text_to_speech.stream(
- text=GREETING_TXT,
- websocket=websocket,
- tts_event=tts_event,
- characater_name=character.name,
- first_sentence=True,
- ))
- # Send end of the greeting so the client knows when to start listening
- await manager.send_message(message='[end]\n', websocket=websocket)
-
- async def on_new_token(token):
- return await manager.send_message(message=token,
- websocket=websocket)
-
- async def stop_audio():
- if tts_task and not tts_task.done():
- tts_event.set()
- tts_task.cancel()
- if previous_transcript:
- conversation_history.user.append(previous_transcript)
- conversation_history.ai.append(' '.join(token_buffer))
- token_buffer.clear()
- try:
- await tts_task
- except asyncio.CancelledError:
- pass
- tts_event.clear()
-
- while True:
- data = await websocket.receive()
- if data['type'] != 'websocket.receive':
- raise WebSocketDisconnect('disconnected')
-
- # handle text message
- if 'text' in data:
- msg_data = data['text']
- # 0. itermidiate transcript starts with [&]
- if msg_data.startswith('[&]'):
- logger.info(f'intermediate transcript: {msg_data}')
- if not os.getenv('EXPERIMENT_CONVERSATION_UTTERANCE', ''):
- continue
- asyncio.create_task(stop_audio())
- asyncio.create_task(
- llm.achat_utterances(
- history=build_history(conversation_history),
- user_input=msg_data,
- callback=AsyncCallbackTextHandler(
- on_new_token, []),
- audioCallback=AsyncCallbackAudioHandler(
- text_to_speech, websocket, tts_event,
- character.name)))
- continue
- # 1. Send message to LLM
- print('response = await llm.achat, user_input', msg_data)
- response = await llm.achat(
- history=build_history(conversation_history),
- user_input=msg_data,
- user_input_template=user_input_template,
- callback=AsyncCallbackTextHandler(on_new_token,
- token_buffer),
- audioCallback=AsyncCallbackAudioHandler(
- text_to_speech, websocket, tts_event, character.name),
- character=character)
-
- # 2. Send response to client
- await manager.send_message(message='[end]\n',
- websocket=websocket)
-
- # 3. Update conversation history
- conversation_history.user.append(msg_data)
- conversation_history.ai.append(response)
- token_buffer.clear()
- # 4. Persist interaction in the database
- Interaction(client_id=client_id,
- user_id=user_id,
- session_id=session_id,
- client_message_unicode=msg_data,
- server_message_unicode=response,
- platform=platform,
- action_type='text').save(db)
-
- # handle binary message(audio)
- elif 'bytes' in data:
- binary_data = data['bytes']
- # 1. Transcribe audio
- transcript: str = speech_to_text.transcribe(
- binary_data, platform=platform,
- prompt=character.name).strip()
-
- # ignore audio that picks up background noise
- if (not transcript or len(transcript) < 2):
- continue
-
- # 2. Send transcript to client
- await manager.send_message(
- message=f'[+]You said: {transcript}', websocket=websocket)
-
- # 3. stop the previous audio stream, if new transcript is received
- await stop_audio()
-
- previous_transcript = transcript
-
- async def tts_task_done_call_back(response):
- # Send response to client, [=] indicates the response is done
- await manager.send_message(message='[=]',
- websocket=websocket)
- # Update conversation history
- conversation_history.user.append(transcript)
- conversation_history.ai.append(response)
- token_buffer.clear()
- # Persist interaction in the database
- Interaction(client_id=client_id,
- user_id=user_id,
- session_id=session_id,
- client_message_unicode=transcript,
- server_message_unicode=response,
- platform=platform,
- action_type='audio').save(db)
-
- # 4. Send message to LLM
- tts_task = asyncio.create_task(
- llm.achat(history=build_history(conversation_history),
- user_input=transcript,
- user_input_template=user_input_template,
- callback=AsyncCallbackTextHandler(
- on_new_token, token_buffer,
- tts_task_done_call_back),
- audioCallback=AsyncCallbackAudioHandler(
- text_to_speech, websocket, tts_event,
- character.name),
- character=character))
-
- except WebSocketDisconnect:
- logger.info(f"User #{user_id} closed the connection")
- await manager.disconnect(websocket)
- return
diff --git a/spaces/kdrkdrkdr/ZhongliTTS/mel_processing.py b/spaces/kdrkdrkdr/ZhongliTTS/mel_processing.py
deleted file mode 100644
index 3e252e76320522a8a4195a60665168f22769aec2..0000000000000000000000000000000000000000
--- a/spaces/kdrkdrkdr/ZhongliTTS/mel_processing.py
+++ /dev/null
@@ -1,101 +0,0 @@
-import torch
-import torch.utils.data
-from librosa.filters import mel as librosa_mel_fn
-
-MAX_WAV_VALUE = 32768.0
-
-
-def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
- """
- PARAMS
- ------
- C: compression factor
- """
- return torch.log(torch.clamp(x, min=clip_val) * C)
-
-
-def dynamic_range_decompression_torch(x, C=1):
- """
- PARAMS
- ------
- C: compression factor used to compress
- """
- return torch.exp(x) / C
-
-
-def spectral_normalize_torch(magnitudes):
- output = dynamic_range_compression_torch(magnitudes)
- return output
-
-
-def spectral_de_normalize_torch(magnitudes):
- output = dynamic_range_decompression_torch(magnitudes)
- return output
-
-
-mel_basis = {}
-hann_window = {}
-
-
-def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
- if torch.min(y) < -1.:
- print('min value is ', torch.min(y))
- if torch.max(y) > 1.:
- print('max value is ', torch.max(y))
-
- global hann_window
- dtype_device = str(y.dtype) + '_' + str(y.device)
- wnsize_dtype_device = str(win_size) + '_' + dtype_device
- if wnsize_dtype_device not in hann_window:
- hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
-
- y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
- y = y.squeeze(1)
-
- spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
- center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=False)
-
- spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
- return spec
-
-
-def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
- global mel_basis
- dtype_device = str(spec.dtype) + '_' + str(spec.device)
- fmax_dtype_device = str(fmax) + '_' + dtype_device
- if fmax_dtype_device not in mel_basis:
- mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
- mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=spec.dtype, device=spec.device)
- spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
- spec = spectral_normalize_torch(spec)
- return spec
-
-
-def mel_spectrogram_torch(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False):
- if torch.min(y) < -1.:
- print('min value is ', torch.min(y))
- if torch.max(y) > 1.:
- print('max value is ', torch.max(y))
-
- global mel_basis, hann_window
- dtype_device = str(y.dtype) + '_' + str(y.device)
- fmax_dtype_device = str(fmax) + '_' + dtype_device
- wnsize_dtype_device = str(win_size) + '_' + dtype_device
- if fmax_dtype_device not in mel_basis:
- mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax)
- mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=y.dtype, device=y.device)
- if wnsize_dtype_device not in hann_window:
- hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)
-
- y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
- y = y.squeeze(1)
-
- spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],
- center=center, pad_mode='reflect', normalized=False, onesided=True)
-
- spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
-
- spec = torch.matmul(mel_basis[fmax_dtype_device], spec)
- spec = spectral_normalize_torch(spec)
-
- return spec
diff --git a/spaces/keisuke-tada/gpt-playground/README.md b/spaces/keisuke-tada/gpt-playground/README.md
deleted file mode 100644
index 5bb442a841b40e289a232075cc67ff5acf99f432..0000000000000000000000000000000000000000
--- a/spaces/keisuke-tada/gpt-playground/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Gpt Playground
-emoji: 🔥
-colorFrom: yellow
-colorTo: purple
-sdk: streamlit
-sdk_version: 1.19.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/keithhon/Real-Time-Voice-Cloning/vocoder_preprocess.py b/spaces/keithhon/Real-Time-Voice-Cloning/vocoder_preprocess.py
deleted file mode 100644
index 7ede3dfb95972e2de575de35b9d4a9c6d642885e..0000000000000000000000000000000000000000
--- a/spaces/keithhon/Real-Time-Voice-Cloning/vocoder_preprocess.py
+++ /dev/null
@@ -1,59 +0,0 @@
-from synthesizer.synthesize import run_synthesis
-from synthesizer.hparams import hparams
-from utils.argutils import print_args
-import argparse
-import os
-
-
-if __name__ == "__main__":
- class MyFormatter(argparse.ArgumentDefaultsHelpFormatter, argparse.RawDescriptionHelpFormatter):
- pass
-
- parser = argparse.ArgumentParser(
- description="Creates ground-truth aligned (GTA) spectrograms from the vocoder.",
- formatter_class=MyFormatter
- )
- parser.add_argument("datasets_root", type=str, help=\
- "Path to the directory containing your SV2TTS directory. If you specify both --in_dir and "
- "--out_dir, this argument won't be used.")
- parser.add_argument("--model_dir", type=str,
- default="synthesizer/saved_models/pretrained/", help=\
- "Path to the pretrained model directory.")
- parser.add_argument("-i", "--in_dir", type=str, default=argparse.SUPPRESS, help= \
- "Path to the synthesizer directory that contains the mel spectrograms, the wavs and the "
- "embeds. Defaults to Empress And The Warriors 720p VideoDownload Zip » https://bytlly.com/2uGw9U - -January 23, 2020 - Download Link for The Empress and the Warriors (2008) BluRay 720p 750MB via Google Drive | Through Acefile. . Your browser cannot play this video. Your browser cannot play this video. . Your browser cannot play this video. . Your browser cannot play this video. . Your browser cannot play this video. . Your browser cannot play this video. . Your browser cannot play this video. . Your browser cannot 8a78ff9644 - - - diff --git a/spaces/liujch1998/vera/app.py b/spaces/liujch1998/vera/app.py deleted file mode 100644 index 8155b57fc8a6a1d719fe770e78d240c5538bf578..0000000000000000000000000000000000000000 --- a/spaces/liujch1998/vera/app.py +++ /dev/null @@ -1,356 +0,0 @@ -import gradio as gr -import os -import torch -import transformers -import huggingface_hub -import datetime -import json -import shutil -import threading - -device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') - -# To suppress the following warning: -# huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks... -os.environ["TOKENIZERS_PARALLELISM"] = "false" - -HF_TOKEN_DOWNLOAD = os.environ['HF_TOKEN_DOWNLOAD'] -HF_TOKEN_UPLOAD = os.environ['HF_TOKEN_UPLOAD'] -MODE = os.environ['MODE'] # 'debug' or 'prod' - -MODEL_NAME = 'liujch1998/vera' -DATASET_REPO_URL = "https://huggingface.co/datasets/liujch1998/cd-pi-dataset" -DATA_DIR = 'data' -DATA_FILENAME = 'data.jsonl' if MODE != 'debug' else 'data_debug.jsonl' -DATA_PATH = os.path.join(DATA_DIR, DATA_FILENAME) - -class Interactive: - def __init__(self): - self.tokenizer = transformers.AutoTokenizer.from_pretrained(MODEL_NAME, use_auth_token=HF_TOKEN_DOWNLOAD) - if MODE == 'debug': - return - self.model = transformers.T5EncoderModel.from_pretrained(MODEL_NAME, use_auth_token=HF_TOKEN_DOWNLOAD, low_cpu_mem_usage=True, device_map='auto', torch_dtype='auto', offload_folder='offload') - self.model.D = self.model.shared.embedding_dim - self.linear = torch.nn.Linear(self.model.D, 1, dtype=self.model.dtype).to(device) - self.linear.weight = torch.nn.Parameter(self.model.shared.weight[32099, :].unsqueeze(0)) # (1, D) - self.linear.bias = torch.nn.Parameter(self.model.shared.weight[32098, 0].unsqueeze(0)) # (1) - self.model.eval() - self.t = self.model.shared.weight[32097, 0].item() - - def run(self, statement): - if MODE == 'debug': - return { - 'timestamp': datetime.datetime.now().strftime('%Y%m%d-%H%M%S'), - 'statement': statement, - 'logit': 0.0, - 'logit_calibrated': 0.0, - 'score': 0.5, - 'score_calibrated': 0.5, - } - input_ids = self.tokenizer.batch_encode_plus([statement], return_tensors='pt', padding='longest', truncation='longest_first', max_length=128).input_ids.to(device) - with torch.no_grad(): - output = self.model(input_ids) - last_hidden_state = output.last_hidden_state.to(device) # (B=1, L, D) - hidden = last_hidden_state[0, -1, :] # (D) - logit = self.linear(hidden).squeeze(-1) # () - logit_calibrated = logit / self.t - score = logit.sigmoid() - score_calibrated = logit_calibrated.sigmoid() - return { - 'timestamp': datetime.datetime.now().strftime('%Y%m%d-%H%M%S'), - 'statement': statement, - 'logit': logit.item(), - 'logit_calibrated': logit_calibrated.item(), - 'score': score.item(), - 'score_calibrated': score_calibrated.item(), - } - - def runs(self, statements): - if MODE == 'debug': - return [{ - 'timestamp': datetime.datetime.now().strftime('%Y%m%d-%H%M%S'), - 'statement': statement, - 'logit': 0.0, - 'logit_calibrated': 0.0, - 'score': 0.5, - 'score_calibrated': 0.5, - } for statement in statements] - tok = self.tokenizer.batch_encode_plus(statements, return_tensors='pt', padding='longest') - input_ids = tok.input_ids.to(device) - attention_mask = tok.attention_mask.to(device) - with torch.no_grad(): - output = self.model(input_ids=input_ids, attention_mask=attention_mask) - last_indices = attention_mask.sum(dim=1, keepdim=True) - 1 # (B, 1) - last_indices = last_indices.unsqueeze(-1).expand(-1, -1, self.model.D) # (B, 1, D) - last_hidden_state = output.last_hidden_state.to(device) # (B, L, D) - hidden = last_hidden_state.gather(dim=1, index=last_indices).squeeze(1) # (B, D) - logits = self.linear(hidden).squeeze(-1) # (B) - logits_calibrated = logits / self.t - scores = logits.sigmoid() - scores_calibrated = logits_calibrated.sigmoid() - return [{ - 'timestamp': datetime.datetime.now().strftime('%Y%m%d-%H%M%S'), - 'statement': statement, - 'logit': logit.item(), - 'logit_calibrated': logit_calibrated.item(), - 'score': score.item(), - 'score_calibrated': score_calibrated.item(), - } for statement, logit, logit_calibrated, score, score_calibrated in zip(statements, logits, logits_calibrated, scores, scores_calibrated)] - -interactive = Interactive() - -try: - shutil.rmtree(DATA_DIR) -except: - pass -global repo, lock -repo = huggingface_hub.Repository( - local_dir=DATA_DIR, - clone_from=DATASET_REPO_URL, - token=HF_TOKEN_UPLOAD, - repo_type='dataset', -) -repo.git_pull() -lock = threading.Lock() - -# def predict(statement, do_save=True): -# output_raw = interactive.run(statement) -# output = { -# 'True': output_raw['score_calibrated'], -# 'False': 1 - output_raw['score_calibrated'], -# } -# if do_save: -# with open(DATA_PATH, 'a') as f: -# json.dump(output_raw, f, ensure_ascii=False) -# f.write('\n') -# commit_url = repo.push_to_hub() -# print('Logged statement to dataset:') -# print('Commit URL:', commit_url) -# print(output_raw) -# print() -# return output, output_raw, gr.update(visible=False), gr.update(visible=True), gr.update(visible=True), gr.update(value='Please provide your feedback before trying out another statement.') - -# def record_feedback(output_raw, feedback, do_save=True): -# if do_save: -# output_raw.update({ 'feedback': feedback }) -# with open(DATA_PATH, 'a') as f: -# json.dump(output_raw, f, ensure_ascii=False) -# f.write('\n') -# commit_url = repo.push_to_hub() -# print('Logged feedback to dataset:') -# print('Commit URL:', commit_url) -# print(output_raw) -# print() -# return gr.update(visible=True), gr.update(visible=False), gr.update(visible=False), gr.update(value='Thanks for your feedback! Now you can enter another statement.') -# def record_feedback_agree(output_raw, do_save=True): -# return record_feedback(output_raw, 'agree', do_save) -# def record_feedback_disagree(output_raw, do_save=True): -# return record_feedback(output_raw, 'disagree', do_save) - -def predict(statements, do_saves): - global lock, interactive - output_raws = interactive.runs(list(statements)) # statements is a tuple, but tokenizer takes a list - outputs = [{ - 'True': output_raw['score_calibrated'], - 'False': 1 - output_raw['score_calibrated'], - } for output_raw in output_raws] - print(f'Logging statements to {DATA_FILENAME}:') - lock.acquire() - for output_raw, do_save in zip(output_raws, do_saves): - if do_save: - print(output_raw) - with open(DATA_PATH, 'a') as f: - json.dump(output_raw, f, ensure_ascii=False) - f.write('\n') - print() - lock.release() - return outputs, output_raws, \ - [gr.update(visible=False) for _ in statements], \ - [gr.update(visible=True) for _ in statements], \ - [gr.update(visible=True) for _ in statements], \ - [gr.update(visible=True) for _ in statements], \ - [gr.update(visible=True) for _ in statements], \ - [gr.update(value='Please share your feedback before trying out another statement.') for _ in statements] - -def record_feedback(output_raws, feedback, do_saves): - global lock - print(f'Logging feedbacks to {DATA_FILENAME}:') - lock.acquire() - for output_raw, do_save in zip(output_raws, do_saves): - if do_save: - output_raw.update({ 'feedback': feedback }) - print(output_raw) - with open(DATA_PATH, 'a') as f: - json.dump(output_raw, f, ensure_ascii=False) - f.write('\n') - print() - lock.release() - return [gr.update(visible=True) for _ in output_raws], \ - [gr.update(visible=False) for _ in output_raws], \ - [gr.update(visible=False) for _ in output_raws], \ - [gr.update(visible=False) for _ in output_raws], \ - [gr.update(visible=False) for _ in output_raws], \ - [gr.update(value='Thanks for sharing your feedback! You can now enter another statement.') for _ in output_raws] -def record_feedback_agree(output_raws, do_saves): - return record_feedback(output_raws, 'agree', do_saves) -def record_feedback_disagree(output_raws, do_saves): - return record_feedback(output_raws, 'disagree', do_saves) -def record_feedback_uncertain(output_raws, do_saves): - return record_feedback(output_raws, 'uncertain', do_saves) -def record_feedback_outofscope(output_raws, do_saves): - return record_feedback(output_raws, 'outofscope', do_saves) - -def push(): - global repo, lock - lock.acquire() - if repo.is_repo_clean(): - # print('No new data recorded, skipping git push ...') - # print() - pass - else: - try: - commit_url = repo.push_to_hub() - except Exception as e: - print('Failed to push to git:', e) - shutil.rmtree(DATA_DIR) - repo = huggingface_hub.Repository( - local_dir=DATA_DIR, - clone_from=DATASET_REPO_URL, - token=HF_TOKEN_UPLOAD, - repo_type='dataset', - ) - repo.git_pull() - lock.release() - -examples = [ - # # openbookqa - # 'If a person walks in the opposite direction of a compass arrow they are walking south.', - # 'If a person walks in the opposite direction of a compass arrow they are walking north.', - # arc_easy - 'A pond is different from a lake because ponds are smaller and shallower.', - 'A pond is different from a lake because ponds have moving water.', - # arc_hard - 'Hunting strategies are more likely to be learned rather than inherited.', - 'A spotted coat is more likely to be learned rather than inherited.', - # ai2_science_elementary - 'Photosynthesis uses carbon from the air to make food for plants.', - 'Respiration uses carbon from the air to make food for plants.', - # ai2_science_middle - 'The barometer measures atmospheric pressure.', - 'The thermometer measures atmospheric pressure.', - # commonsenseqa - 'People aim to complete a job at work.', - 'People aim to kill animals at work.', - # qasc - 'Climate is generally described in terms of local weather conditions.', - 'Climate is generally described in terms of forests.', - # physical_iqa - 'ice box will turn into a cooler if you add water to it.', - 'ice box will turn into a cooler if you add soda to it.', - # social_iqa - 'Kendall opened their mouth to speak and what came out shocked everyone. Kendall is a very aggressive and talkative person.', - 'Kendall opened their mouth to speak and what came out shocked everyone. Kendall is a very quiet person.', - # winogrande_xl - 'Sarah was a much better surgeon than Maria so Maria always got the easier cases.', - 'Sarah was a much better surgeon than Maria so Sarah always got the easier cases.', - # com2sense_paired - 'If you want a quick snack, getting one banana would be a good choice generally.', - 'If you want a snack, getting twenty bananas would be a good choice generally.', - # sciq - 'Each specific polypeptide has a unique linear sequence of amino acids.', - 'Each specific polypeptide has a unique linear sequence of fatty acids.', - # quarel - 'Tommy glided across the marble floor with ease, but slipped and fell on the wet floor because wet floor has more resistance.', - 'Tommy glided across the marble floor with ease, but slipped and fell on the wet floor because marble floor has more resistance.', - # quartz - 'If less waters falls on an area of land it will cause less plants to grow in that area.', - 'If less waters falls on an area of land it will cause more plants to grow in that area.', - # cycic_mc - 'In U.S. spring, Rob visits the financial district every day. In U.S. winter, Rob visits the park every day. Rob will go to the park on January 20.', - 'In U.S. spring, Rob visits the financial district every day. In U.S. winter, Rob visits the park every day. Rob will go to the financial district on January 20.', - # comve_a - 'Summer in North America is great for swimming, boating, and fishing.', - 'Summer in North America is great for skiing, snowshoeing, and making a snowman.', - # csqa2 - 'Gas is always capable of turning into liquid under high pressure.', - 'Cotton candy is sometimes made out of cotton.', - # symkd_anno - 'James visits a famous landmark. As a result, James learns about the world.', - 'Cliff and Andrew enter the castle. But before, Cliff needed to have been a student at the school.', - # gengen_anno - 'Generally, bar patrons are capable of taking care of their own drinks.', - 'Generally, ocean currents have little influence over storm intensity.', - - # 'If A sits next to B and B sits next to C, then A must sit next to C.', - # 'If A sits next to B and B sits next to C, then A might not sit next to C.', -] - -# input_statement = gr.Dropdown(choices=examples, label='Statement:') -# input_model = gr.Textbox(label='Commonsense statement verification model:', value=MODEL_NAME, interactive=False) -# output = gr.outputs.Label(num_top_classes=2) - -# description = '''This is a demo for Vera, a commonsense statement verification model. Under development. -# ⚠️ Data Collection: by default, we are collecting the inputs entered in this app to further improve and evaluate the model. Do not share any personal or sensitive information while using the app!''' - -# gr.Interface( -# fn=predict, -# inputs=[input_statement, input_model], -# outputs=output, -# title="Vera", -# description=description, -# ).launch() - -with gr.Blocks() as demo: - with gr.Column(): - gr.Markdown( - '''# Vera - - Vera is a commonsense statement verification model. See our paper at: [https://arxiv.org/abs/2305.03695](https://arxiv.org/abs/2305.03695). - - Type a commonsense statement in the box below and click the submit button to see Vera's prediction on its correctness. You can try both correct and incorrect statements. If you are looking for inspiration, try the examples at the bottom of the page! - - We'd love your feedback! Please indicate whether you agree or disagree with Vera's prediction (and don't mind the percentage numbers). If you're unsure or the statement doesn't have a certain correctness label, please select "Uncertain". If your input is actually not a statement about commonsense, please select "I don't think this is a statement about commonsense". - - **Intended Use**: Vera is a research prototype and may make mistakes. Do not use for making critical decisions. It is intended to predict the correctness of commonsense statements, and may be unreliable when taking input out of this scope. **DO NOT input encyclopedic facts.** Vera is trained on **English** data only, please do not input statements in other languages. - - **Data Collection**: By default, we are collecting the inputs entered in this app to further improve and evaluate the model. Do not share any personal or sensitive information while using the app! You can opt out of this data collection by removing the checkbox below: - ''' - ) - with gr.Row(): - with gr.Column(scale=3): - do_save = gr.Checkbox( - value=True, - label="Store data", - info="You agree to the storage of your input for research and development purposes:") - statement = gr.Textbox(placeholder='Enter a commonsense statement here, or select an example from below', label='Statement', interactive=True) - submit = gr.Button(value='Submit', variant='primary', visible=True) - with gr.Column(scale=2): - output = gr.Label(num_top_classes=2, interactive=False) - output_raw = gr.JSON(visible=False) - with gr.Row(): - feedback_agree = gr.Button(value='👍 Agree', variant='secondary', visible=False) - feedback_uncertain = gr.Button(value='🤔 Uncertain', variant='secondary', visible=False) - feedback_disagree = gr.Button(value='👎 Disagree', variant='secondary', visible=False) - feedback_outofscope = gr.Button(value='🚫 I don\'t think this a statement about commonsense', variant='secondary', visible=False) - feedback_ack = gr.Markdown(value='', visible=True, interactive=False) - gr.Markdown('\n---\n') - with gr.Row(): - gr.Examples( - examples=examples, - fn=predict, - inputs=[statement], - outputs=[output, output_raw, statement, submit, feedback_agree, feedback_disagree, feedback_ack], - examples_per_page=100, - cache_examples=False, - run_on_click=False, # If we want this to be True, I suspect we need to enable the statement.submit() - ) - submit.click(predict, inputs=[statement, do_save], outputs=[output, output_raw, submit, feedback_agree, feedback_uncertain, feedback_disagree, feedback_outofscope, feedback_ack], batch=True, max_batch_size=16) - # statement.submit(predict, inputs=[statement], outputs=[output, output_raw]) - feedback_agree.click(record_feedback_agree, inputs=[output_raw, do_save], outputs=[submit, feedback_agree, feedback_uncertain, feedback_disagree, feedback_outofscope, feedback_ack], batch=True, max_batch_size=16) - feedback_uncertain.click(record_feedback_uncertain, inputs=[output_raw, do_save], outputs=[submit, feedback_agree, feedback_uncertain, feedback_disagree, feedback_outofscope, feedback_ack], batch=True, max_batch_size=16) - feedback_disagree.click(record_feedback_disagree, inputs=[output_raw, do_save], outputs=[submit, feedback_agree, feedback_uncertain, feedback_disagree, feedback_outofscope, feedback_ack], batch=True, max_batch_size=16) - feedback_outofscope.click(record_feedback_outofscope, inputs=[output_raw, do_save], outputs=[submit, feedback_agree, feedback_uncertain, feedback_disagree, feedback_outofscope, feedback_ack], batch=True, max_batch_size=16) - - demo.load(push, inputs=None, outputs=None, every=60) # Push to git every 60 seconds - -demo.queue(concurrency_count=1).launch(debug=True) diff --git a/spaces/lnyan/stablediffusion-infinity/js/upload.js b/spaces/lnyan/stablediffusion-infinity/js/upload.js deleted file mode 100644 index 4842960af4985847ff24c93c7f730e8e64974690..0000000000000000000000000000000000000000 --- a/spaces/lnyan/stablediffusion-infinity/js/upload.js +++ /dev/null @@ -1,19 +0,0 @@ -function(a,b){ - if(!window.my_observe_upload) - { - console.log("setup upload here"); - window.my_observe_upload = new MutationObserver(function (event) { - console.log(event); - var frame=document.querySelector("gradio-app").shadowRoot.querySelector("#sdinfframe").contentWindow.document; - frame.querySelector("#upload").click(); - }); - window.my_observe_upload_target = document.querySelector("gradio-app").shadowRoot.querySelector("#upload span"); - window.my_observe_upload.observe(window.my_observe_upload_target, { - attributes: false, - subtree: true, - childList: true, - characterData: true - }); - } - return [a,b]; -} \ No newline at end of file diff --git a/spaces/lojban/text-to-speech/vits/mel_processing.py b/spaces/lojban/text-to-speech/vits/mel_processing.py deleted file mode 100644 index 817f03756f64caf8cc54329a9325024c8fb9e0c3..0000000000000000000000000000000000000000 --- a/spaces/lojban/text-to-speech/vits/mel_processing.py +++ /dev/null @@ -1,112 +0,0 @@ -import math -import os -import random -import torch -from torch import nn -import torch.nn.functional as F -import torch.utils.data -import numpy as np -import librosa -import librosa.util as librosa_util -from librosa.util import normalize, pad_center, tiny -from scipy.signal import get_window -from scipy.io.wavfile import read -from librosa.filters import mel as librosa_mel_fn - -MAX_WAV_VALUE = 32768.0 - - -def dynamic_range_compression_torch(x, C=1, clip_val=1e-5): - """ - PARAMS - ------ - C: compression factor - """ - return torch.log(torch.clamp(x, min=clip_val) * C) - - -def dynamic_range_decompression_torch(x, C=1): - """ - PARAMS - ------ - C: compression factor used to compress - """ - return torch.exp(x) / C - - -def spectral_normalize_torch(magnitudes): - output = dynamic_range_compression_torch(magnitudes) - return output - - -def spectral_de_normalize_torch(magnitudes): - output = dynamic_range_decompression_torch(magnitudes) - return output - - -mel_basis = {} -hann_window = {} - - -def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False): - if torch.min(y) < -1.: - print('min value is ', torch.min(y)) - if torch.max(y) > 1.: - print('max value is ', torch.max(y)) - - global hann_window - dtype_device = str(y.dtype) + '_' + str(y.device) - wnsize_dtype_device = str(win_size) + '_' + dtype_device - if wnsize_dtype_device not in hann_window: - hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device) - - y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect') - y = y.squeeze(1) - - spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device], - center=center, pad_mode='reflect', normalized=False, onesided=True) - - spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6) - return spec - - -def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax): - global mel_basis - dtype_device = str(spec.dtype) + '_' + str(spec.device) - fmax_dtype_device = str(fmax) + '_' + dtype_device - if fmax_dtype_device not in mel_basis: - mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax) - mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=spec.dtype, device=spec.device) - spec = torch.matmul(mel_basis[fmax_dtype_device], spec) - spec = spectral_normalize_torch(spec) - return spec - - -def mel_spectrogram_torch(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False): - if torch.min(y) < -1.: - print('min value is ', torch.min(y)) - if torch.max(y) > 1.: - print('max value is ', torch.max(y)) - - global mel_basis, hann_window - dtype_device = str(y.dtype) + '_' + str(y.device) - fmax_dtype_device = str(fmax) + '_' + dtype_device - wnsize_dtype_device = str(win_size) + '_' + dtype_device - if fmax_dtype_device not in mel_basis: - mel = librosa_mel_fn(sampling_rate, n_fft, num_mels, fmin, fmax) - mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=y.dtype, device=y.device) - if wnsize_dtype_device not in hann_window: - hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device) - - y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect') - y = y.squeeze(1) - - spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device], - center=center, pad_mode='reflect', normalized=False, onesided=True) - - spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6) - - spec = torch.matmul(mel_basis[fmax_dtype_device], spec) - spec = spectral_normalize_torch(spec) - - return spec diff --git a/spaces/luxuedong/lxd/src/lib/hooks/use-enter-submit.tsx b/spaces/luxuedong/lxd/src/lib/hooks/use-enter-submit.tsx deleted file mode 100644 index d66b2d3253baff164235d4ca791aae6d84721835..0000000000000000000000000000000000000000 --- a/spaces/luxuedong/lxd/src/lib/hooks/use-enter-submit.tsx +++ /dev/null @@ -1,23 +0,0 @@ -import { useRef, type RefObject } from 'react' - -export function useEnterSubmit(): { - formRef: RefObject - -Using the position of each player as training data, we can teach a model to predict which team would get to a loose ball first at each spot on the field, indicated by the color of the pixel. - - - -It updates in real-time—drag the players around to see the model change. - - - -This model reveals quite a lot about the data used to train it. Even without the actual positions of the players, it is simple to see where players might be. - - - -Click this button to - -Take a guess at where the yellow team's goalie is now, then check their actual position. How close were you? - - Sensitive Salary Data- -In this specific soccer example, being able to make educated guesses about the data a model was trained on doesn't matter too much. But what if our data points represent something more sensitive? - - - -We’ve fed the same numbers into the model, but now they represent salary data instead of soccer data. Building models like this is a common technique to [detect discrimination](https://www.eeoc.gov/laws/guidance/section-10-compensation-discrimination#c.%20Using%20More%20Sophisticated%20Statistical%20Techniques%20to%20Evaluate). A union might test if a company is paying men and women fairly by building a salary model that takes into account years of experience. They can then [publish](https://postguild.org/2019-pay-study/) the results to bring pressure for change or show improvement. - -In this hypothetical salary study, even though no individual salaries have been published, it is easy to infer the salary of the newest male hire. And carefully cross referencing public start dates on LinkedIn with the model could almost perfectly reveal everyone's salary. - -Because the model here is so flexible (there are hundreds of square patches with independently calculated predictions) and we have so few data points (just 22 people), it is able to "memorize" individual data points. If we're looking to share information about patterns in salaries, a simpler and more constrained model like a linear regression might be more appropriate. - - - -By boiling down the 22 data points to two lines we're able to see broad trends without being able to guess anyone's salary. - -Subtle Leaks- -Removing complexity isn't a complete solution though. Depending on how the data is distributed, even a simple line can inadvertently reveal information. - - - -In this company, almost all the men started several years ago, so the slope of the line is especially sensitive to the salary of the new hire. - -Is their salary than average? Based on the line, we can make a pretty good guess. - -Notice that changing the salary of someone with a more common tenure barely moves the line. In general, more typical data points are less susceptible to being leaked. This sets up a tricky trade off: we want models to learn about edge cases while being sure they haven't memorized individual data points. - -Real World Data- -Models of real world data are often quite complex—this can improve accuracy, but makes them [more susceptible](https://blog.tensorflow.org/2020/06/introducing-new-privacy-testing-library.html) to unexpectedly leaking information. Medical models have inadvertently revealed [patients' genetic markers](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4827719/). Language models have memorized [credit card numbers](https://bair.berkeley.edu/blog/2019/08/13/memorization/). Faces can even be [reconstructed](https://rist.tech.cornell.edu/papers/mi-ccs.pdf) from image models: - - Protecting Private Data- -Training models with [differential privacy](http://www.cleverhans.io/privacy/2018/04/29/privacy-and-machine-learning.html) stops the training data from leaking by limiting how much the model can learn from any one data point. Differentially private models are still at the cutting edge of research, but they're being packaged into [machine learning frameworks](https://blog.tensorflow.org/2019/03/introducing-tensorflow-privacy-learning.html), making them much easier to use. When it isn't possible to train differentially private models, there are also tools that can [measure](https://github.com/tensorflow/privacy/tree/master/tensorflow_privacy/privacy/membership_inference_attack) how much data is the model memorizing. Also, standard techniques such as aggregation and limiting how much data a single source can contribute are still useful and usually improve the privacy of the model. - -As we saw in the [Collecting Sensitive Information Explorable](https://pair.withgoogle.com/explorables/anonymization/), adding enough random noise with differential privacy to protect outliers like the new hire can increase the amount of data required to reach a good level of accuracy. Depending on the application, the constraints of differential privacy could even improve the model—for instance, not learning too much from one data point can help prevent [overfitting](https://openreview.net/forum?id=r1xyx3R9tQ). - -Given the increasing utility of machine learning models for many real-world tasks, it’s clear that more and more systems, devices and apps will be powered, to some extent, by machine learning in the future. While [standard privacy best practices](https://owasp.org/www-project-top-ten/) developed for non-machine learning systems still apply to those with machine learning, the introduction of machine learning introduces new challenges, including the ability of the model to memorize some specific training data points and thus be vulnerable to privacy attacks that seek to extract this data from the model. Fortunately, techniques such as differential privacy exist that can be helpful in overcoming this specific challenge. Just as with other areas of [Responsible AI](https://ai.google/responsibilities/responsible-ai-practices/), it’s important to be aware of these new challenges that come along with machine learning and what steps can be taken to mitigate them. - - -Credits- -Adam Pearce and Ellen Jiang // December 2020 - -Thanks to Andreas Terzis, Ben Wedin, Carey Radebaugh, David Weinberger, Emily Reif, Fernanda Viégas, Hal Abelson, Kristen Olson, Martin Wattenberg, Michael Terry, Miguel Guevara, Thomas Steinke, Yannick Assogba, Zan Armstrong and our other colleagues at Google for their help with this piece. - - -More Explorables- - - - - - - - - - - \ No newline at end of file diff --git a/spaces/merve/hidden-bias/style.css b/spaces/merve/hidden-bias/style.css deleted file mode 100644 index 114adf441e9032febb46bc056b2a8bb651075f0d..0000000000000000000000000000000000000000 --- a/spaces/merve/hidden-bias/style.css +++ /dev/null @@ -1,28 +0,0 @@ -body { - padding: 2rem; - font-family: -apple-system, BlinkMacSystemFont, "Arial", sans-serif; -} - -h1 { - font-size: 16px; - margin-top: 0; -} - -p { - color: rgb(107, 114, 128); - font-size: 15px; - margin-bottom: 10px; - margin-top: 5px; -} - -.card { - max-width: 620px; - margin: 0 auto; - padding: 16px; - border: 1px solid lightgray; - border-radius: 16px; -} - -.card p:last-child { - margin-bottom: 0; -} diff --git a/spaces/merve/uncertainty-calibration/public/third_party/mobilenet@1.0.0.js b/spaces/merve/uncertainty-calibration/public/third_party/mobilenet@1.0.0.js deleted file mode 100644 index d50ffe68663e1aabfc07faec02e8a3cb41b5dfe5..0000000000000000000000000000000000000000 --- a/spaces/merve/uncertainty-calibration/public/third_party/mobilenet@1.0.0.js +++ /dev/null @@ -1,2 +0,0 @@ -// @tensorflow/tfjs-models Copyright 2019 Google -!function(e,a){"object"==typeof exports&&"undefined"!=typeof module?a(exports,require("@tensorflow/tfjs")):"function"==typeof define&&define.amd?define(["exports","@tensorflow/tfjs"],a):a((e=e||self).mobilenet={},e.tf)}(this,function(e,a){"use strict";function r(e,a,r,o){return new(r||(r=Promise))(function(i,t){function n(e){try{l(o.next(e))}catch(e){t(e)}}function s(e){try{l(o.throw(e))}catch(e){t(e)}}function l(e){e.done?i(e.value):new r(function(a){a(e.value)}).then(n,s)}l((o=o.apply(e,a||[])).next())})}function o(e,a){var r,o,i,t,n={label:0,sent:function(){if(1&i[0])throw i[1];return i[1]},trys:[],ops:[]};return t={next:s(0),throw:s(1),return:s(2)},"function"==typeof Symbol&&(t[Symbol.iterator]=function(){return this}),t;function s(t){return function(s){return function(t){if(r)throw new TypeError("Generator is already executing.");for(;n;)try{if(r=1,o&&(i=2&t[0]?o.return:t[0]?o.throw||((i=o.return)&&i.call(o),0):o.next)&&!(i=i.call(o,t[1])).done)return i;switch(o=0,i&&(t=[2&t[0],i.value]),t[0]){case 0:case 1:i=t;break;case 4:return n.label++,{value:t[1],done:!1};case 5:n.label++,o=t[1],t=[0];continue;case 7:t=n.ops.pop(),n.trys.pop();continue;default:if(!(i=(i=n.trys).length>0&&i[i.length-1])&&(6===t[0]||2===t[0])){n=0;continue}if(3===t[0]&&(!i||t[1]>i[0]&&t[1]-  -
- -
-
-
-
-
-
-
\ No newline at end of file
diff --git a/spaces/ntcwai/prompt-engine/app.py b/spaces/ntcwai/prompt-engine/app.py
deleted file mode 100644
index cc3a3197450ab48fbb3c0f742a693d5053396d9e..0000000000000000000000000000000000000000
--- a/spaces/ntcwai/prompt-engine/app.py
+++ /dev/null
@@ -1,34 +0,0 @@
-import gradio as grad
-import torch
-from transformers import AutoModelForCausalLM, AutoTokenizer
-
-def load_prompter():
- prompter_model = AutoModelForCausalLM.from_pretrained("microsoft/Promptist")
- tokenizer = AutoTokenizer.from_pretrained("gpt2")
- tokenizer.pad_token = tokenizer.eos_token
- tokenizer.padding_side = "left"
- return prompter_model, tokenizer
-
-prompter_model, prompter_tokenizer = load_prompter()
-
-def generate(plain_text):
- input_ids = prompter_tokenizer(plain_text.strip()+" Rephrase:", return_tensors="pt").input_ids
- eos_id = prompter_tokenizer.eos_token_id
- outputs = prompter_model.generate(input_ids, do_sample=False, max_new_tokens=75, num_beams=8, num_return_sequences=8, eos_token_id=eos_id, pad_token_id=eos_id, length_penalty=-1.0)
- output_texts = prompter_tokenizer.batch_decode(outputs, skip_special_tokens=True)
- res = output_texts[0].replace(plain_text+" Rephrase:", "").strip()
- return res
-
-txt = grad.Textbox(lines=1, label="Initial Text", placeholder="Input Prompt")
-out = grad.Textbox(lines=1, label="Optimized Prompt")
-examples = ["A rabbit is wearing a space suit", "Several railroad tracks with one train passing by", "The roof is wet from the rain", "Cats dancing in a space club"]
-
-grad.Interface(fn=generate,
- inputs=txt,
- outputs=out,
- title="Promptist Demo",
- description="Promptist is a prompt interface for Stable Diffusion v1-4 (https://huggingface.co/CompVis/stable-diffusion-v1-4) that optimizes user input into model-preferred prompts. The online demo at Hugging Face Spaces is using CPU, so slow generation speed would be expected. Please load the model locally with GPUs for faster generation.",
- examples=examples,
- allow_flagging='never',
- cache_examples=False,
- theme="default").launch(enable_queue=True, debug=True)
\ No newline at end of file
diff --git a/spaces/ntt123/vietnam-male-voice-wavegru-tts/sparse_matmul/compute/gru_gates.h b/spaces/ntt123/vietnam-male-voice-wavegru-tts/sparse_matmul/compute/gru_gates.h
deleted file mode 100644
index 7b8cd489f5c6ef42de262d54727f99c5f9020b82..0000000000000000000000000000000000000000
--- a/spaces/ntt123/vietnam-male-voice-wavegru-tts/sparse_matmul/compute/gru_gates.h
+++ /dev/null
@@ -1,214 +0,0 @@
-/*
- * Copyright 2021 Google LLC
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#ifndef LYRA_CODEC_SPARSE_MATMUL_COMPUTE_GRU_GATES_H_
-#define LYRA_CODEC_SPARSE_MATMUL_COMPUTE_GRU_GATES_H_
-
-#include -''' - - -maps = {"O": "NONE", "PER": "PER", "LOC": "LOC", "ORG": "ORG", "MISC": "MISC", "DATE": "DATE"} -reg_month = "(?:gennaio|febbraio|marzo|aprile|maggio|giugno|luglio|agosto|settembre|ottobre|novembre|dicembre|january|february|march|april|may|june|july|august|september|october|november|december)" -reg_date = "(?:\d{1,2}\°{0,1}|primo|\d{1,2}\º{0,1})" + " " + reg_month + " " + "\d{4}|" -reg_date = reg_date + reg_month + " " + "\d{4}|" -reg_date = reg_date + "\d{1,2}" + " " + reg_month -reg_date = reg_date + "\d{1,2}" + "(?:\/|\.)\d{1,2}(?:\/|\.)" + "\d{4}|" -reg_date = reg_date + "(?<=dal )\d{4}|(?<=al )\d{4}|(?<=nel )\d{4}|(?<=anno )\d{4}|(?<=del )\d{4}|" -reg_date = reg_date + "\d{1,5} a\.c\.|\d{1,5} d\.c\." -map_punct = {"’": "'", "«": '"', "»": '"', "”": '"', "“": '"', "–": "-", "$": ""} -unk_tok = 9005 - -merge_th_1 = 0.8 -merge_th_2 = 0.4 -min_th = 0.5 - -def extract(text): - - text = text.strip() - for mp in map_punct: - text = text.replace(mp, map_punct[mp]) - text = re.sub("\[\d+\]", "", text) - - warn_flag = False - - res_total = [] - out_text = "" - - for p_text in text.split("\n"): - - if p_text: - - toks = tokenizer.encode(p_text) - if unk_tok in toks: - warn_flag = True - - res_orig = ner(p_text, aggregation_strategy = "first") - res_orig = [el for r, el in enumerate(res_orig) if len(el["word"].strip()) > 1] - res = [] - - for r, ent in enumerate(res_orig): - if r > 0 and ent["score"] < merge_th_1 and ent["start"] <= res[-1]["end"] + 1 and ent["score"] <= res[-1]["score"]: - res[-1]["word"] = res[-1]["word"] + " " + ent["word"] - res[-1]["score"] = merge_th_1*(res[-1]["score"] > merge_th_2) - res[-1]["end"] = ent["end"] - elif r < len(res_orig) - 1 and ent["score"] < merge_th_1 and res_orig[r+1]["start"] <= ent["end"] + 1 and res_orig[r+1]["score"] > ent["score"]: - res_orig[r+1]["word"] = ent["word"] + " " + res_orig[r+1]["word"] - res_orig[r+1]["score"] = merge_th_1*(res_orig[r+1]["score"] > merge_th_2) - res_orig[r+1]["start"] = ent["start"] - else: - res.append(ent) - - res = [el for r, el in enumerate(res) if el["score"] >= min_th] - - dates = [{"entity_group": "DATE", "score": 1.0, "word": p_text[el.span()[0]:el.span()[1]], "start": el.span()[0], "end": el.span()[1]} for el in re.finditer(reg_date, p_text, flags = re.IGNORECASE)] - res.extend(dates) - res = sorted(res, key = lambda t: t["start"]) - res_total.extend(res) - - chunks = [("", "", 0, "NONE")] - - for el in res: - if maps[el["entity_group"]] != "NONE": - tag = maps[el["entity_group"]] - chunks.append((p_text[el["start"]: el["end"]], p_text[chunks[-1][2]:el["end"]], el["end"], tag)) - - if chunks[-1][2] < len(p_text): - chunks.append(("END", p_text[chunks[-1][2]:], -1, "NONE")) - chunks = chunks[1:] - - n_text = [] - - for i, chunk in enumerate(chunks): - - rep = chunk[0] - - if chunk[3] == "PER": - rep = 'ᴘᴇʀ ' + chunk[0] + '' - elif chunk[3] == "LOC": - rep = 'ʟᴏᴄ ' + chunk[0] + '' - elif chunk[3] == "ORG": - rep = 'ᴏʀɢ ' + chunk[0] + '' - elif chunk[3] == "MISC": - rep = 'ᴍɪsᴄ ' + chunk[0] + '' - elif chunk[3] == "DATE": - rep = 'ᴅᴀᴛᴇ ' + chunk[0] + '' - - n_text.append(chunk[1].replace(chunk[0], rep)) - - n_text = "".join(n_text) - if out_text: - out_text = out_text + " " + n_text - else: - out_text = n_text - - - tags = [el["word"] for el in res_total if el["entity_group"] not in ['DATE', None]] - cnt = Counter(tags) - tags = sorted(list(set([el for el in tags if cnt[el] > 1])), key = lambda t: cnt[t]*np.exp(-tags.index(t)))[::-1] - tags = [" ".join(re.sub("[^A-Za-z0-9\s]", "", unidecode(tag)).split()) for tag in tags] - tags = ['ᴛᴀɢ ' + el + '' for el in tags] - tags = " ".join(tags) - - if tags: - out_text = out_text + " Tags: " + tags - - if warn_flag: - out_text = out_text + " Warning ⚠️: Unknown tokens detected in text. The model might behave erratically" - - return out_text - - - -init_text = '''L'Agenzia spaziale europea, nota internazionalmente con l'acronimo ESA dalla denominazione inglese European Space Agency, è un'agenzia internazionale fondata nel 1975 incaricata di coordinare i progetti spaziali di 22 Paesi europei. Il suo quartier generale si trova a Parigi in Francia, con uffici a Mosca, Bruxelles, Washington e Houston. Il personale dell'ESA del 2016 ammontava a 2 200 persone (esclusi sub-appaltatori e le agenzie nazionali) e il budget del 2022 è di 7,15 miliardi di euro. Attualmente il direttore generale dell'agenzia è l'austriaco Josef Aschbacher, il quale ha sostituito il tedesco Johann-Dietrich Wörner il primo marzo 2021. -Lo spazioporto dell'ESA è il Centre Spatial Guyanais a Kourou, nella Guyana francese, un sito scelto, come tutte le basi di lancio, per via della sua vicinanza con l'equatore. Durante gli ultimi anni il lanciatore Ariane 5 ha consentito all'ESA di raggiungere una posizione di primo piano nei lanci commerciali e l'ESA è il principale concorrente della NASA nell'esplorazione spaziale. -Le missioni scientifiche dell'ESA hanno le loro basi al Centro europeo per la ricerca e la tecnologia spaziale (ESTEC) di Noordwijk, nei Paesi Bassi. Il Centro europeo per le operazioni spaziali (ESOC), di Darmstadt in Germania, è responsabile del controllo dei satelliti ESA in orbita. Le responsabilità del Centro europeo per l'osservazione della Terra (ESRIN) di Frascati, in Italia, includono la raccolta, l'archiviazione e la distribuzione di dati satellitari ai partner dell'ESA; oltre a ciò, la struttura agisce come centro di informazione tecnologica per l'intera agenzia. [...] -L'Agenzia Spaziale Italiana (ASI) venne fondata nel 1988 per promuovere, coordinare e condurre le attività spaziali in Italia. Opera in collaborazione con il Ministero dell'università e della ricerca scientifica e coopera in numerosi progetti con entità attive nella ricerca scientifica e nelle attività commerciali legate allo spazio. Internazionalmente l'ASI fornisce la delegazione italiana per l'Agenzia Spaziale Europea e le sue sussidiarie.''' - -init_output = extract(init_text) - - - - -with gr.Blocks(css="footer {visibility: hidden}", theme=gr.themes.Default(text_size="lg", spacing_size="lg")) as interface: - - with gr.Row(): - gr.Markdown(header) - with gr.Row(): - text = gr.Text(label="Extract entities", lines = 10, value = init_text) - with gr.Row(): - with gr.Column(): - button = gr.Button("Extract").style(full_width=False) - with gr.Row(): - with gr.Column(): - entities = gr.Markdown(init_output) - - with gr.Row(): - with gr.Column(): - gr.Markdown(" ¡Descubre los proyectos más innovadores en fase Beta y - sé el primero en experimentar con ellos!--
- !Te presentamos un adelanto exclusivo de lo que viene
- próximamente en nuestros proyectos más innovadores!
-
- """, unsafe_allow_html=True)
-
- # Leer los datos y seleccionar las columnas necesarias
- df = pd.read_csv('./ML/ds_salaries.csv')
- df = df[['company_location', 'salary_in_usd']]
-
- # Codificar las ubicaciones de las empresas
- le = LabelEncoder()
- df['company_location'] = le.fit_transform(df['company_location'])
-
- # Decodificar las ubicaciones de las empresas
- decoded_locations = le.inverse_transform(df['company_location'].unique())
-
- # Separar los datos de entrada y salida
- X = df.iloc[:, :-1].values
- y = df.iloc[:, -1].values
-
- # Entrenar el modelo
- model = RandomForestRegressor(n_estimators=100, random_state=42)
- model.fit(X, y)
-
- # Obtener las ubicaciones de las empresas y sus salarios predichos
- locations = df['company_location'].unique()
- predicted_salaries = model.predict(locations.reshape(-1, 1))
- results_df = pd.DataFrame(
- {'company_location': locations, 'predicted_salary': predicted_salaries})
-
- # Decodificar las ubicaciones de las empresas
- results_df['company_location'] = le.inverse_transform(
- results_df['company_location'])
-
- # Ordenar los resultados por salario predicho
- results_df = results_df.sort_values('predicted_salary',
- ascending=False).reset_index(drop=True)
-
- # Mostrar el título y el top 5 de países mejor pagados
- st.markdown("""
- Atrae a los mejores talentos con nuestra lista precisa de los - países mejor pagados.-- """, unsafe_allow_html=True) - - # Descripción - st.markdown(""" - Como reclutador, sabes que la remuneración es un factor clave - para atraer a los mejores talentos. Con nuestro algoritmo - RandomForest, obtenemos un promedio preciso de los - países - mejor pagados en todo el mundo, lo que te permite atraer a los candidatos más talentosos. Nuestra lista está menos sesgada por outliers gracias a nuestra selección aleatoria de empresas en cada país. Únete a nuestra comunidad y toma decisiones informadas para un futuro próspero. ¡Atrae a los mejores talentos y lleva tu empresa al siguiente nivel con nuestra lista precisa de los países mejor pagados!""", unsafe_allow_html=True) - - for i in range(5): - location = results_df.loc[i, 'company_location'] - salary = results_df.loc[i, 'predicted_salary'] - st.markdown(f'### **{location}**: ${salary:,.2f}', - unsafe_allow_html=True) - - # Mostrar el menú desplegable para seleccionar un país - st.markdown(""" - Seleccionar un país-- """, unsafe_allow_html=True) - selected_location = st.selectbox('Ubicación de la empresa', - decoded_locations) - - # Mostrar el salario predicho para el país seleccionado - predicted_salary = results_df.loc[results_df[ - 'company_location'] == selected_location, 'predicted_salary'].iloc[ - 0] - st.markdown(f'### **{selected_location}**: ${predicted_salary:,.2f}', - unsafe_allow_html=True) - - ##### - - # Cargar los datos - df = pd.read_csv('./assets/dataset_modelo_1.csv') - - # Crear una lista con todas las skills disponibles - all_skills = set() - for skills in df.skills: - all_skills.update(skills.split(", ")) - - # Crear un diccionario que relaciona cada skill con su índice en el vector - skill_indices = {skill: i for i, skill in enumerate(all_skills)} - - # Crear una matriz de características con la frecuencia de cada skill en cada fila - vectorizer = CountVectorizer(vocabulary=skill_indices.keys(), - lowercase=False) - X = vectorizer.fit_transform(df.skills) - - # Entrenar el modelo - clf = MultinomialNB() - clf.fit(X, df.Aptitude) - - # Crear la interfaz de usuario con Streamlit - st.markdown(""" - Encuentra el talento perfecto con nuestro modelo de Naive Bayes para identificar las habilidades más importantes.-- """, unsafe_allow_html=True) - st.markdown( - """ - Como reclutador, sabes que encontrar al talento perfecto es un - desafío constante. Con nuestro modelo de Naive Bayes, - podemos - identificar las habilidades más importantes para cualquier trabajo en particular. Al ingresar el título de trabajo, nuestro algoritmo genera una lista precisa de habilidades necesarias para tener éxito en esa posición específica. Esto te permite encontrar y atraer al candidato perfecto para el trabajo. Únete a nuestra comunidad y comienza a impulsar tu carrera hoy mismo! """, unsafe_allow_html=True) - - title = st.text_input("Título del trabajo") - - # Crear una función que encuentra las habilidades más importantes para un título dado - def get_top_skills(title, limit): - # Filtrar el dataframe por el título dado - filtered_df = df[df.job_title.str.contains(title, case=False)] - - # Crear una matriz de características con la frecuencia de cada skill en el dataframe filtrado - X_filtered = vectorizer.transform(filtered_df.skills) - - # Calcular la frecuencia de cada habilidad en el dataframe filtrado - skill_frequencies = X_filtered.sum(axis=0).A1 - - # Obtener los nombres de las habilidades - skill_names = vectorizer.vocabulary_.keys() - - # Crear un diccionario que relaciona cada habilidad con su frecuencia - skill_freq_dict = dict(zip(skill_names, skill_frequencies)) - - # Ordenar las habilidades por frecuencia descendente y devolver las más importantes (según el límite dado) - top_skills = sorted(skill_freq_dict, key=skill_freq_dict.get, - reverse=True)[:limit] - return top_skills - - if title: - limit = st.number_input("Cantidad de habilidades a mostrar", value=5, - min_value=1, max_value=len(all_skills)) - top_skills = get_top_skills(title, limit) - st.write( - f"Las {limit} habilidades más importantes para el trabajo de '{title}' son:") - for skill in top_skills: - st.write(f"- {skill}") - - ##### diff --git a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/chardet/langturkishmodel.py b/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/chardet/langturkishmodel.py deleted file mode 100644 index 291857c25c83f91a151c1d7760e8e5e09c1ee238..0000000000000000000000000000000000000000 --- a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/chardet/langturkishmodel.py +++ /dev/null @@ -1,4380 +0,0 @@ -from pip._vendor.chardet.sbcharsetprober import SingleByteCharSetModel - -# 3: Positive -# 2: Likely -# 1: Unlikely -# 0: Negative - -TURKISH_LANG_MODEL = { - 23: { # 'A' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 2, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 1, # 'g' - 25: 1, # 'h' - 3: 1, # 'i' - 24: 0, # 'j' - 10: 2, # 'k' - 5: 1, # 'l' - 13: 1, # 'm' - 4: 1, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 1, # 'r' - 8: 1, # 's' - 9: 1, # 't' - 14: 1, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 0, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 37: { # 'B' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 2, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 1, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 1, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 2, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 0, # 'l' - 13: 1, # 'm' - 4: 1, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 1, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 0, # 'ı' - 40: 1, # 'Ş' - 19: 1, # 'ş' - }, - 47: { # 'C' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 1, # 'L' - 20: 0, # 'M' - 46: 1, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 1, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 2, # 'j' - 10: 1, # 'k' - 5: 2, # 'l' - 13: 2, # 'm' - 4: 2, # 'n' - 15: 1, # 'o' - 26: 0, # 'p' - 7: 2, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 1, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 1, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 39: { # 'D' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 1, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 2, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 1, # 'l' - 13: 3, # 'm' - 4: 0, # 'n' - 15: 1, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 1, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 0, # 'İ' - 6: 1, # 'ı' - 40: 1, # 'Ş' - 19: 0, # 'ş' - }, - 29: { # 'E' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 1, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 2, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 1, # 'g' - 25: 0, # 'h' - 3: 1, # 'i' - 24: 1, # 'j' - 10: 0, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 1, # 's' - 9: 1, # 't' - 14: 1, # 'u' - 32: 1, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 52: { # 'F' - 23: 0, # 'A' - 37: 1, # 'B' - 47: 1, # 'C' - 39: 1, # 'D' - 29: 1, # 'E' - 52: 2, # 'F' - 36: 0, # 'G' - 45: 2, # 'H' - 53: 1, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 1, # 'N' - 42: 1, # 'O' - 48: 2, # 'P' - 44: 1, # 'R' - 35: 1, # 'S' - 31: 1, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 2, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 1, # 'b' - 28: 1, # 'c' - 12: 1, # 'd' - 2: 0, # 'e' - 18: 1, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 2, # 'i' - 24: 1, # 'j' - 10: 0, # 'k' - 5: 0, # 'l' - 13: 1, # 'm' - 4: 2, # 'n' - 15: 1, # 'o' - 26: 0, # 'p' - 7: 2, # 'r' - 8: 1, # 's' - 9: 1, # 't' - 14: 1, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 1, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 1, # 'Ö' - 55: 2, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 2, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 1, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 2, # 'ş' - }, - 36: { # 'G' - 23: 1, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 2, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 2, # 'N' - 42: 1, # 'O' - 48: 1, # 'P' - 44: 1, # 'R' - 35: 1, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 2, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 1, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 1, # 'j' - 10: 1, # 'k' - 5: 0, # 'l' - 13: 3, # 'm' - 4: 2, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 0, # 'r' - 8: 1, # 's' - 9: 1, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 2, # 'Ö' - 55: 0, # 'Ü' - 59: 1, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 1, # 'İ' - 6: 2, # 'ı' - 40: 2, # 'Ş' - 19: 1, # 'ş' - }, - 45: { # 'H' - 23: 0, # 'A' - 37: 1, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 2, # 'G' - 45: 1, # 'H' - 53: 1, # 'I' - 60: 0, # 'J' - 16: 2, # 'K' - 49: 1, # 'L' - 20: 0, # 'M' - 46: 1, # 'N' - 42: 1, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 2, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 2, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 2, # 'i' - 24: 0, # 'j' - 10: 1, # 'k' - 5: 0, # 'l' - 13: 2, # 'm' - 4: 0, # 'n' - 15: 1, # 'o' - 26: 1, # 'p' - 7: 1, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 1, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 2, # 'ğ' - 41: 1, # 'İ' - 6: 0, # 'ı' - 40: 2, # 'Ş' - 19: 1, # 'ş' - }, - 53: { # 'I' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 2, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 2, # 'l' - 13: 2, # 'm' - 4: 0, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 0, # 'ı' - 40: 1, # 'Ş' - 19: 1, # 'ş' - }, - 60: { # 'J' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 1, # 'b' - 28: 0, # 'c' - 12: 1, # 'd' - 2: 0, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 1, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 0, # 'l' - 13: 0, # 'm' - 4: 1, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 1, # 's' - 9: 0, # 't' - 14: 0, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 0, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 16: { # 'K' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 3, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 2, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 2, # 'a' - 21: 3, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 1, # 'e' - 18: 3, # 'f' - 27: 3, # 'g' - 25: 3, # 'h' - 3: 3, # 'i' - 24: 2, # 'j' - 10: 3, # 'k' - 5: 0, # 'l' - 13: 0, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 0, # 'u' - 32: 3, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 2, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 2, # 'ü' - 30: 0, # 'ğ' - 41: 1, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 49: { # 'L' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 2, # 'E' - 52: 0, # 'F' - 36: 1, # 'G' - 45: 1, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 2, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 3, # 'b' - 28: 0, # 'c' - 12: 2, # 'd' - 2: 0, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 2, # 'i' - 24: 0, # 'j' - 10: 1, # 'k' - 5: 0, # 'l' - 13: 0, # 'm' - 4: 2, # 'n' - 15: 1, # 'o' - 26: 1, # 'p' - 7: 1, # 'r' - 8: 1, # 's' - 9: 1, # 't' - 14: 0, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 2, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 1, # 'ü' - 30: 1, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 20: { # 'M' - 23: 1, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 2, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 1, # 'g' - 25: 1, # 'h' - 3: 2, # 'i' - 24: 2, # 'j' - 10: 2, # 'k' - 5: 2, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 3, # 'r' - 8: 0, # 's' - 9: 2, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 3, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 46: { # 'N' - 23: 0, # 'A' - 37: 1, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 1, # 'G' - 45: 1, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 1, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 1, # 'R' - 35: 1, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 2, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 1, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 2, # 'j' - 10: 1, # 'k' - 5: 1, # 'l' - 13: 3, # 'm' - 4: 2, # 'n' - 15: 1, # 'o' - 26: 1, # 'p' - 7: 1, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 1, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 1, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 1, # 'İ' - 6: 2, # 'ı' - 40: 1, # 'Ş' - 19: 1, # 'ş' - }, - 42: { # 'O' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 0, # 'G' - 45: 1, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 2, # 'K' - 49: 1, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 2, # 'P' - 44: 1, # 'R' - 35: 1, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 0, # 'n' - 15: 1, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 2, # 'Ç' - 50: 1, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 2, # 'İ' - 6: 1, # 'ı' - 40: 1, # 'Ş' - 19: 1, # 'ş' - }, - 48: { # 'P' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 2, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 1, # 'G' - 45: 1, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 1, # 'N' - 42: 1, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 1, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 2, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 1, # 'k' - 5: 0, # 'l' - 13: 2, # 'm' - 4: 0, # 'n' - 15: 2, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 2, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 2, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 2, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 1, # 'İ' - 6: 0, # 'ı' - 40: 2, # 'Ş' - 19: 1, # 'ş' - }, - 44: { # 'R' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 1, # 'b' - 28: 1, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 1, # 'k' - 5: 2, # 'l' - 13: 2, # 'm' - 4: 0, # 'n' - 15: 1, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 1, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 1, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 1, # 'ü' - 30: 1, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 1, # 'Ş' - 19: 1, # 'ş' - }, - 35: { # 'S' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 1, # 'G' - 45: 1, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 1, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 1, # 'k' - 5: 1, # 'l' - 13: 2, # 'm' - 4: 1, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 1, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 2, # 'Ç' - 50: 2, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 3, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 2, # 'Ş' - 19: 1, # 'ş' - }, - 31: { # 'T' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 2, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 2, # 'b' - 28: 0, # 'c' - 12: 1, # 'd' - 2: 3, # 'e' - 18: 2, # 'f' - 27: 2, # 'g' - 25: 0, # 'h' - 3: 1, # 'i' - 24: 1, # 'j' - 10: 2, # 'k' - 5: 2, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 2, # 'p' - 7: 2, # 'r' - 8: 0, # 's' - 9: 2, # 't' - 14: 2, # 'u' - 32: 1, # 'v' - 57: 1, # 'w' - 58: 1, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 1, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 51: { # 'U' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 1, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 1, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 1, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 1, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 2, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 1, # 'k' - 5: 1, # 'l' - 13: 3, # 'm' - 4: 2, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 1, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 1, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 1, # 'ş' - }, - 38: { # 'V' - 23: 1, # 'A' - 37: 1, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 1, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 2, # 'l' - 13: 2, # 'm' - 4: 0, # 'n' - 15: 2, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 1, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 1, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 1, # 'Ö' - 55: 0, # 'Ü' - 59: 1, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 1, # 'İ' - 6: 3, # 'ı' - 40: 2, # 'Ş' - 19: 1, # 'ş' - }, - 62: { # 'W' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 0, # 'd' - 2: 0, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 0, # 'l' - 13: 0, # 'm' - 4: 0, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 0, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 0, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 43: { # 'Y' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 0, # 'G' - 45: 1, # 'H' - 53: 1, # 'I' - 60: 0, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 2, # 'N' - 42: 0, # 'O' - 48: 2, # 'P' - 44: 1, # 'R' - 35: 1, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 2, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 1, # 'j' - 10: 1, # 'k' - 5: 1, # 'l' - 13: 3, # 'm' - 4: 0, # 'n' - 15: 2, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 2, # 'Ö' - 55: 1, # 'Ü' - 59: 1, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 1, # 'İ' - 6: 0, # 'ı' - 40: 2, # 'Ş' - 19: 1, # 'ş' - }, - 56: { # 'Z' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 2, # 'Z' - 1: 2, # 'a' - 21: 1, # 'b' - 28: 0, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 2, # 'i' - 24: 1, # 'j' - 10: 0, # 'k' - 5: 0, # 'l' - 13: 1, # 'm' - 4: 1, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 1, # 'r' - 8: 1, # 's' - 9: 0, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 1, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 1, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 1: { # 'a' - 23: 3, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 3, # 'E' - 52: 0, # 'F' - 36: 1, # 'G' - 45: 1, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 1, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 3, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 2, # 'Z' - 1: 2, # 'a' - 21: 3, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 2, # 'e' - 18: 3, # 'f' - 27: 3, # 'g' - 25: 3, # 'h' - 3: 3, # 'i' - 24: 3, # 'j' - 10: 3, # 'k' - 5: 0, # 'l' - 13: 2, # 'm' - 4: 3, # 'n' - 15: 1, # 'o' - 26: 3, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 3, # 'v' - 57: 2, # 'w' - 58: 0, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 1, # 'î' - 34: 1, # 'ö' - 17: 3, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 1, # 'ş' - }, - 21: { # 'b' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 1, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 2, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 3, # 'g' - 25: 1, # 'h' - 3: 3, # 'i' - 24: 2, # 'j' - 10: 3, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 3, # 'p' - 7: 1, # 'r' - 8: 2, # 's' - 9: 2, # 't' - 14: 2, # 'u' - 32: 1, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 28: { # 'c' - 23: 0, # 'A' - 37: 1, # 'B' - 47: 1, # 'C' - 39: 1, # 'D' - 29: 2, # 'E' - 52: 0, # 'F' - 36: 2, # 'G' - 45: 2, # 'H' - 53: 1, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 1, # 'N' - 42: 1, # 'O' - 48: 2, # 'P' - 44: 1, # 'R' - 35: 1, # 'S' - 31: 2, # 'T' - 51: 2, # 'U' - 38: 2, # 'V' - 62: 0, # 'W' - 43: 3, # 'Y' - 56: 0, # 'Z' - 1: 1, # 'a' - 21: 1, # 'b' - 28: 2, # 'c' - 12: 2, # 'd' - 2: 1, # 'e' - 18: 1, # 'f' - 27: 2, # 'g' - 25: 2, # 'h' - 3: 3, # 'i' - 24: 1, # 'j' - 10: 3, # 'k' - 5: 0, # 'l' - 13: 2, # 'm' - 4: 3, # 'n' - 15: 2, # 'o' - 26: 2, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 1, # 'u' - 32: 0, # 'v' - 57: 1, # 'w' - 58: 0, # 'x' - 11: 2, # 'y' - 22: 1, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 1, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 1, # 'î' - 34: 2, # 'ö' - 17: 2, # 'ü' - 30: 2, # 'ğ' - 41: 1, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 2, # 'ş' - }, - 12: { # 'd' - 23: 1, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 2, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 1, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 2, # 'b' - 28: 1, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 1, # 'f' - 27: 3, # 'g' - 25: 3, # 'h' - 3: 2, # 'i' - 24: 3, # 'j' - 10: 2, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 1, # 'o' - 26: 2, # 'p' - 7: 3, # 'r' - 8: 2, # 's' - 9: 2, # 't' - 14: 3, # 'u' - 32: 1, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 3, # 'y' - 22: 1, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 1, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 2: { # 'e' - 23: 2, # 'A' - 37: 0, # 'B' - 47: 2, # 'C' - 39: 0, # 'D' - 29: 3, # 'E' - 52: 1, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 1, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 1, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 1, # 'R' - 35: 0, # 'S' - 31: 3, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 3, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 2, # 'e' - 18: 3, # 'f' - 27: 3, # 'g' - 25: 3, # 'h' - 3: 3, # 'i' - 24: 3, # 'j' - 10: 3, # 'k' - 5: 0, # 'l' - 13: 2, # 'm' - 4: 3, # 'n' - 15: 1, # 'o' - 26: 3, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 3, # 'v' - 57: 2, # 'w' - 58: 0, # 'x' - 11: 3, # 'y' - 22: 1, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 3, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 18: { # 'f' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 2, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 1, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 2, # 'f' - 27: 1, # 'g' - 25: 1, # 'h' - 3: 1, # 'i' - 24: 1, # 'j' - 10: 1, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 2, # 'p' - 7: 1, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 1, # 'u' - 32: 2, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 1, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 1, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 1, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 27: { # 'g' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 1, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 2, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 1, # 'b' - 28: 0, # 'c' - 12: 1, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 2, # 'g' - 25: 1, # 'h' - 3: 2, # 'i' - 24: 3, # 'j' - 10: 2, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 2, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 2, # 'r' - 8: 2, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 1, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 1, # 'y' - 22: 0, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 25: { # 'h' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 2, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 1, # 'g' - 25: 2, # 'h' - 3: 2, # 'i' - 24: 3, # 'j' - 10: 3, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 1, # 'o' - 26: 1, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 2, # 't' - 14: 3, # 'u' - 32: 2, # 'v' - 57: 1, # 'w' - 58: 0, # 'x' - 11: 1, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 3: { # 'i' - 23: 2, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 0, # 'N' - 42: 1, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 1, # 'S' - 31: 2, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 2, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 2, # 'f' - 27: 3, # 'g' - 25: 1, # 'h' - 3: 3, # 'i' - 24: 2, # 'j' - 10: 3, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 1, # 'o' - 26: 3, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 2, # 'v' - 57: 1, # 'w' - 58: 1, # 'x' - 11: 3, # 'y' - 22: 1, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 1, # 'Ü' - 59: 0, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 3, # 'ü' - 30: 0, # 'ğ' - 41: 1, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 24: { # 'j' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 2, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 1, # 'Z' - 1: 3, # 'a' - 21: 1, # 'b' - 28: 1, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 2, # 'f' - 27: 1, # 'g' - 25: 1, # 'h' - 3: 2, # 'i' - 24: 1, # 'j' - 10: 2, # 'k' - 5: 2, # 'l' - 13: 3, # 'm' - 4: 2, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 2, # 'r' - 8: 3, # 's' - 9: 2, # 't' - 14: 3, # 'u' - 32: 2, # 'v' - 57: 0, # 'w' - 58: 2, # 'x' - 11: 1, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 1, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 10: { # 'k' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 3, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 1, # 'Z' - 1: 3, # 'a' - 21: 2, # 'b' - 28: 0, # 'c' - 12: 2, # 'd' - 2: 3, # 'e' - 18: 1, # 'f' - 27: 2, # 'g' - 25: 2, # 'h' - 3: 3, # 'i' - 24: 2, # 'j' - 10: 2, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 3, # 'p' - 7: 2, # 'r' - 8: 2, # 's' - 9: 2, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 3, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 3, # 'ü' - 30: 1, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 1, # 'ş' - }, - 5: { # 'l' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 3, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 3, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 1, # 'e' - 18: 3, # 'f' - 27: 3, # 'g' - 25: 2, # 'h' - 3: 3, # 'i' - 24: 2, # 'j' - 10: 3, # 'k' - 5: 1, # 'l' - 13: 1, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 2, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 2, # 'u' - 32: 2, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 2, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 13: { # 'm' - 23: 1, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 3, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 3, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 2, # 'a' - 21: 3, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 2, # 'e' - 18: 3, # 'f' - 27: 3, # 'g' - 25: 3, # 'h' - 3: 3, # 'i' - 24: 3, # 'j' - 10: 3, # 'k' - 5: 0, # 'l' - 13: 2, # 'm' - 4: 3, # 'n' - 15: 1, # 'o' - 26: 2, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 2, # 'u' - 32: 2, # 'v' - 57: 1, # 'w' - 58: 0, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 3, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 1, # 'ş' - }, - 4: { # 'n' - 23: 1, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 1, # 'H' - 53: 0, # 'I' - 60: 2, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 2, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 2, # 'b' - 28: 1, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 1, # 'f' - 27: 2, # 'g' - 25: 3, # 'h' - 3: 2, # 'i' - 24: 2, # 'j' - 10: 3, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 1, # 'o' - 26: 3, # 'p' - 7: 2, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 2, # 'v' - 57: 0, # 'w' - 58: 2, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 2, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 1, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 15: { # 'o' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 1, # 'G' - 45: 1, # 'H' - 53: 1, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 2, # 'L' - 20: 0, # 'M' - 46: 2, # 'N' - 42: 1, # 'O' - 48: 2, # 'P' - 44: 1, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 1, # 'i' - 24: 2, # 'j' - 10: 1, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 2, # 'n' - 15: 2, # 'o' - 26: 0, # 'p' - 7: 1, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 2, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 2, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 3, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 2, # 'ğ' - 41: 2, # 'İ' - 6: 3, # 'ı' - 40: 2, # 'Ş' - 19: 2, # 'ş' - }, - 26: { # 'p' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 1, # 'b' - 28: 0, # 'c' - 12: 1, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 1, # 'g' - 25: 1, # 'h' - 3: 2, # 'i' - 24: 3, # 'j' - 10: 1, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 2, # 'n' - 15: 0, # 'o' - 26: 2, # 'p' - 7: 2, # 'r' - 8: 1, # 's' - 9: 1, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 1, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 3, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 1, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 7: { # 'r' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 1, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 2, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 2, # 'T' - 51: 1, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 1, # 'Z' - 1: 3, # 'a' - 21: 1, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 2, # 'g' - 25: 3, # 'h' - 3: 2, # 'i' - 24: 2, # 'j' - 10: 3, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 2, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 2, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 3, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 8: { # 's' - 23: 1, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 1, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 2, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 1, # 'Z' - 1: 3, # 'a' - 21: 2, # 'b' - 28: 1, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 2, # 'g' - 25: 2, # 'h' - 3: 2, # 'i' - 24: 3, # 'j' - 10: 3, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 3, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 2, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 2, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 2, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 1, # 'ş' - }, - 9: { # 't' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 2, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 1, # 'Z' - 1: 3, # 'a' - 21: 3, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 2, # 'f' - 27: 2, # 'g' - 25: 2, # 'h' - 3: 2, # 'i' - 24: 2, # 'j' - 10: 3, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 2, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 3, # 'v' - 57: 0, # 'w' - 58: 2, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 3, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 2, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 14: { # 'u' - 23: 3, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 3, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 1, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 2, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 3, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 2, # 'Z' - 1: 2, # 'a' - 21: 3, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 2, # 'e' - 18: 2, # 'f' - 27: 3, # 'g' - 25: 3, # 'h' - 3: 3, # 'i' - 24: 2, # 'j' - 10: 3, # 'k' - 5: 0, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 3, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 2, # 'v' - 57: 2, # 'w' - 58: 0, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 3, # 'ü' - 30: 1, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 32: { # 'v' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 1, # 'j' - 10: 1, # 'k' - 5: 3, # 'l' - 13: 2, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 1, # 'r' - 8: 2, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 1, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 1, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 57: { # 'w' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 1, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 1, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 1, # 'k' - 5: 0, # 'l' - 13: 0, # 'm' - 4: 1, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 1, # 's' - 9: 0, # 't' - 14: 1, # 'u' - 32: 0, # 'v' - 57: 2, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 0, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 1, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 0, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 58: { # 'x' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 1, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 1, # 'b' - 28: 0, # 'c' - 12: 2, # 'd' - 2: 1, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 2, # 'i' - 24: 2, # 'j' - 10: 1, # 'k' - 5: 0, # 'l' - 13: 0, # 'm' - 4: 2, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 1, # 'r' - 8: 2, # 's' - 9: 1, # 't' - 14: 0, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 1, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 11: { # 'y' - 23: 1, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 1, # 'Z' - 1: 3, # 'a' - 21: 1, # 'b' - 28: 0, # 'c' - 12: 2, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 2, # 'g' - 25: 2, # 'h' - 3: 2, # 'i' - 24: 1, # 'j' - 10: 2, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 2, # 'r' - 8: 1, # 's' - 9: 2, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 1, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 3, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 2, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 22: { # 'z' - 23: 2, # 'A' - 37: 2, # 'B' - 47: 1, # 'C' - 39: 2, # 'D' - 29: 3, # 'E' - 52: 1, # 'F' - 36: 2, # 'G' - 45: 2, # 'H' - 53: 1, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 2, # 'N' - 42: 2, # 'O' - 48: 2, # 'P' - 44: 1, # 'R' - 35: 1, # 'S' - 31: 3, # 'T' - 51: 2, # 'U' - 38: 2, # 'V' - 62: 0, # 'W' - 43: 2, # 'Y' - 56: 1, # 'Z' - 1: 1, # 'a' - 21: 2, # 'b' - 28: 1, # 'c' - 12: 2, # 'd' - 2: 2, # 'e' - 18: 3, # 'f' - 27: 2, # 'g' - 25: 2, # 'h' - 3: 3, # 'i' - 24: 2, # 'j' - 10: 3, # 'k' - 5: 0, # 'l' - 13: 2, # 'm' - 4: 3, # 'n' - 15: 2, # 'o' - 26: 2, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 0, # 'u' - 32: 2, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 3, # 'y' - 22: 2, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 2, # 'Ü' - 59: 1, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 2, # 'ö' - 17: 2, # 'ü' - 30: 2, # 'ğ' - 41: 1, # 'İ' - 6: 3, # 'ı' - 40: 1, # 'Ş' - 19: 2, # 'ş' - }, - 63: { # '·' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 0, # 'd' - 2: 1, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 0, # 'l' - 13: 2, # 'm' - 4: 0, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 0, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 54: { # 'Ç' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 1, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 1, # 'G' - 45: 1, # 'H' - 53: 1, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 1, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 2, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 1, # 'b' - 28: 0, # 'c' - 12: 1, # 'd' - 2: 0, # 'e' - 18: 0, # 'f' - 27: 1, # 'g' - 25: 0, # 'h' - 3: 3, # 'i' - 24: 0, # 'j' - 10: 1, # 'k' - 5: 0, # 'l' - 13: 0, # 'm' - 4: 2, # 'n' - 15: 1, # 'o' - 26: 0, # 'p' - 7: 2, # 'r' - 8: 0, # 's' - 9: 1, # 't' - 14: 0, # 'u' - 32: 2, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 2, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 1, # 'ş' - }, - 50: { # 'Ö' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 1, # 'D' - 29: 2, # 'E' - 52: 0, # 'F' - 36: 1, # 'G' - 45: 2, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 1, # 'N' - 42: 2, # 'O' - 48: 2, # 'P' - 44: 1, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 2, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 2, # 'b' - 28: 1, # 'c' - 12: 2, # 'd' - 2: 0, # 'e' - 18: 1, # 'f' - 27: 1, # 'g' - 25: 1, # 'h' - 3: 2, # 'i' - 24: 0, # 'j' - 10: 2, # 'k' - 5: 0, # 'l' - 13: 0, # 'm' - 4: 3, # 'n' - 15: 2, # 'o' - 26: 2, # 'p' - 7: 3, # 'r' - 8: 1, # 's' - 9: 2, # 't' - 14: 0, # 'u' - 32: 1, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 2, # 'ö' - 17: 2, # 'ü' - 30: 1, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 1, # 'ş' - }, - 55: { # 'Ü' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 1, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 1, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 2, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 1, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 1, # 'l' - 13: 1, # 'm' - 4: 1, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 1, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 1, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 1, # 'İ' - 6: 0, # 'ı' - 40: 0, # 'Ş' - 19: 1, # 'ş' - }, - 59: { # 'â' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 1, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 1, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 2, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 0, # 'j' - 10: 0, # 'k' - 5: 0, # 'l' - 13: 2, # 'm' - 4: 0, # 'n' - 15: 1, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 2, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 1, # 'ı' - 40: 1, # 'Ş' - 19: 0, # 'ş' - }, - 33: { # 'ç' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 3, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 2, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 0, # 'Z' - 1: 0, # 'a' - 21: 3, # 'b' - 28: 0, # 'c' - 12: 2, # 'd' - 2: 0, # 'e' - 18: 2, # 'f' - 27: 1, # 'g' - 25: 3, # 'h' - 3: 3, # 'i' - 24: 0, # 'j' - 10: 3, # 'k' - 5: 0, # 'l' - 13: 0, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 3, # 'r' - 8: 2, # 's' - 9: 3, # 't' - 14: 0, # 'u' - 32: 2, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 1, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 61: { # 'î' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 0, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 0, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 1, # 'Z' - 1: 2, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 1, # 'j' - 10: 0, # 'k' - 5: 0, # 'l' - 13: 1, # 'm' - 4: 1, # 'n' - 15: 0, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 1, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 1, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 1, # 'î' - 34: 0, # 'ö' - 17: 0, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 1, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 34: { # 'ö' - 23: 0, # 'A' - 37: 1, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 1, # 'G' - 45: 1, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 1, # 'L' - 20: 0, # 'M' - 46: 1, # 'N' - 42: 1, # 'O' - 48: 2, # 'P' - 44: 1, # 'R' - 35: 1, # 'S' - 31: 1, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 1, # 'Z' - 1: 3, # 'a' - 21: 1, # 'b' - 28: 2, # 'c' - 12: 1, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 2, # 'g' - 25: 2, # 'h' - 3: 1, # 'i' - 24: 2, # 'j' - 10: 1, # 'k' - 5: 2, # 'l' - 13: 3, # 'm' - 4: 2, # 'n' - 15: 2, # 'o' - 26: 0, # 'p' - 7: 0, # 'r' - 8: 3, # 's' - 9: 1, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 1, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 2, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 2, # 'ö' - 17: 0, # 'ü' - 30: 2, # 'ğ' - 41: 1, # 'İ' - 6: 1, # 'ı' - 40: 2, # 'Ş' - 19: 1, # 'ş' - }, - 17: { # 'ü' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 0, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 1, # 'J' - 16: 1, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 0, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 0, # 'Y' - 56: 1, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 0, # 'c' - 12: 1, # 'd' - 2: 3, # 'e' - 18: 1, # 'f' - 27: 2, # 'g' - 25: 0, # 'h' - 3: 1, # 'i' - 24: 1, # 'j' - 10: 2, # 'k' - 5: 3, # 'l' - 13: 2, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 2, # 'p' - 7: 2, # 'r' - 8: 3, # 's' - 9: 2, # 't' - 14: 3, # 'u' - 32: 1, # 'v' - 57: 1, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 2, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 30: { # 'ğ' - 23: 0, # 'A' - 37: 2, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 1, # 'G' - 45: 0, # 'H' - 53: 1, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 1, # 'M' - 46: 2, # 'N' - 42: 2, # 'O' - 48: 1, # 'P' - 44: 1, # 'R' - 35: 0, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 2, # 'V' - 62: 0, # 'W' - 43: 2, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 0, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 2, # 'e' - 18: 0, # 'f' - 27: 0, # 'g' - 25: 0, # 'h' - 3: 0, # 'i' - 24: 3, # 'j' - 10: 1, # 'k' - 5: 2, # 'l' - 13: 3, # 'm' - 4: 0, # 'n' - 15: 1, # 'o' - 26: 0, # 'p' - 7: 1, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 2, # 'Ç' - 50: 2, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 0, # 'î' - 34: 2, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 2, # 'İ' - 6: 2, # 'ı' - 40: 2, # 'Ş' - 19: 1, # 'ş' - }, - 41: { # 'İ' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 1, # 'D' - 29: 1, # 'E' - 52: 0, # 'F' - 36: 2, # 'G' - 45: 2, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 1, # 'N' - 42: 1, # 'O' - 48: 2, # 'P' - 44: 0, # 'R' - 35: 1, # 'S' - 31: 1, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 2, # 'Y' - 56: 0, # 'Z' - 1: 1, # 'a' - 21: 2, # 'b' - 28: 1, # 'c' - 12: 2, # 'd' - 2: 1, # 'e' - 18: 0, # 'f' - 27: 3, # 'g' - 25: 2, # 'h' - 3: 2, # 'i' - 24: 2, # 'j' - 10: 2, # 'k' - 5: 0, # 'l' - 13: 1, # 'm' - 4: 3, # 'n' - 15: 1, # 'o' - 26: 1, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 2, # 't' - 14: 0, # 'u' - 32: 0, # 'v' - 57: 1, # 'w' - 58: 0, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 1, # 'Ü' - 59: 1, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 1, # 'ö' - 17: 1, # 'ü' - 30: 2, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 1, # 'ş' - }, - 6: { # 'ı' - 23: 2, # 'A' - 37: 0, # 'B' - 47: 0, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 0, # 'F' - 36: 1, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 2, # 'J' - 16: 3, # 'K' - 49: 0, # 'L' - 20: 3, # 'M' - 46: 1, # 'N' - 42: 0, # 'O' - 48: 0, # 'P' - 44: 0, # 'R' - 35: 0, # 'S' - 31: 2, # 'T' - 51: 0, # 'U' - 38: 0, # 'V' - 62: 0, # 'W' - 43: 2, # 'Y' - 56: 1, # 'Z' - 1: 3, # 'a' - 21: 2, # 'b' - 28: 1, # 'c' - 12: 3, # 'd' - 2: 3, # 'e' - 18: 3, # 'f' - 27: 3, # 'g' - 25: 2, # 'h' - 3: 3, # 'i' - 24: 3, # 'j' - 10: 3, # 'k' - 5: 3, # 'l' - 13: 3, # 'm' - 4: 3, # 'n' - 15: 0, # 'o' - 26: 3, # 'p' - 7: 3, # 'r' - 8: 3, # 's' - 9: 3, # 't' - 14: 3, # 'u' - 32: 3, # 'v' - 57: 1, # 'w' - 58: 1, # 'x' - 11: 3, # 'y' - 22: 0, # 'z' - 63: 1, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 2, # 'ç' - 61: 0, # 'î' - 34: 0, # 'ö' - 17: 3, # 'ü' - 30: 0, # 'ğ' - 41: 0, # 'İ' - 6: 3, # 'ı' - 40: 0, # 'Ş' - 19: 0, # 'ş' - }, - 40: { # 'Ş' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 1, # 'D' - 29: 1, # 'E' - 52: 0, # 'F' - 36: 1, # 'G' - 45: 2, # 'H' - 53: 1, # 'I' - 60: 0, # 'J' - 16: 0, # 'K' - 49: 0, # 'L' - 20: 2, # 'M' - 46: 1, # 'N' - 42: 1, # 'O' - 48: 2, # 'P' - 44: 2, # 'R' - 35: 1, # 'S' - 31: 1, # 'T' - 51: 0, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 2, # 'Y' - 56: 1, # 'Z' - 1: 0, # 'a' - 21: 2, # 'b' - 28: 0, # 'c' - 12: 2, # 'd' - 2: 0, # 'e' - 18: 3, # 'f' - 27: 0, # 'g' - 25: 2, # 'h' - 3: 3, # 'i' - 24: 2, # 'j' - 10: 1, # 'k' - 5: 0, # 'l' - 13: 1, # 'm' - 4: 3, # 'n' - 15: 2, # 'o' - 26: 0, # 'p' - 7: 3, # 'r' - 8: 2, # 's' - 9: 2, # 't' - 14: 1, # 'u' - 32: 3, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 2, # 'y' - 22: 0, # 'z' - 63: 0, # '·' - 54: 0, # 'Ç' - 50: 0, # 'Ö' - 55: 1, # 'Ü' - 59: 0, # 'â' - 33: 0, # 'ç' - 61: 0, # 'î' - 34: 2, # 'ö' - 17: 1, # 'ü' - 30: 2, # 'ğ' - 41: 0, # 'İ' - 6: 2, # 'ı' - 40: 1, # 'Ş' - 19: 2, # 'ş' - }, - 19: { # 'ş' - 23: 0, # 'A' - 37: 0, # 'B' - 47: 1, # 'C' - 39: 0, # 'D' - 29: 0, # 'E' - 52: 2, # 'F' - 36: 1, # 'G' - 45: 0, # 'H' - 53: 0, # 'I' - 60: 0, # 'J' - 16: 3, # 'K' - 49: 2, # 'L' - 20: 0, # 'M' - 46: 1, # 'N' - 42: 1, # 'O' - 48: 1, # 'P' - 44: 1, # 'R' - 35: 1, # 'S' - 31: 0, # 'T' - 51: 1, # 'U' - 38: 1, # 'V' - 62: 0, # 'W' - 43: 1, # 'Y' - 56: 0, # 'Z' - 1: 3, # 'a' - 21: 1, # 'b' - 28: 2, # 'c' - 12: 0, # 'd' - 2: 3, # 'e' - 18: 0, # 'f' - 27: 2, # 'g' - 25: 1, # 'h' - 3: 1, # 'i' - 24: 0, # 'j' - 10: 2, # 'k' - 5: 2, # 'l' - 13: 3, # 'm' - 4: 0, # 'n' - 15: 0, # 'o' - 26: 1, # 'p' - 7: 3, # 'r' - 8: 0, # 's' - 9: 0, # 't' - 14: 3, # 'u' - 32: 0, # 'v' - 57: 0, # 'w' - 58: 0, # 'x' - 11: 0, # 'y' - 22: 2, # 'z' - 63: 0, # '·' - 54: 1, # 'Ç' - 50: 2, # 'Ö' - 55: 0, # 'Ü' - 59: 0, # 'â' - 33: 1, # 'ç' - 61: 1, # 'î' - 34: 2, # 'ö' - 17: 0, # 'ü' - 30: 1, # 'ğ' - 41: 1, # 'İ' - 6: 1, # 'ı' - 40: 1, # 'Ş' - 19: 1, # 'ş' - }, -} - -# 255: Undefined characters that did not exist in training text -# 254: Carriage/Return -# 253: symbol (punctuation) that does not belong to word -# 252: 0 - 9 -# 251: Control characters - -# Character Mapping Table(s): -ISO_8859_9_TURKISH_CHAR_TO_ORDER = { - 0: 255, # '\x00' - 1: 255, # '\x01' - 2: 255, # '\x02' - 3: 255, # '\x03' - 4: 255, # '\x04' - 5: 255, # '\x05' - 6: 255, # '\x06' - 7: 255, # '\x07' - 8: 255, # '\x08' - 9: 255, # '\t' - 10: 255, # '\n' - 11: 255, # '\x0b' - 12: 255, # '\x0c' - 13: 255, # '\r' - 14: 255, # '\x0e' - 15: 255, # '\x0f' - 16: 255, # '\x10' - 17: 255, # '\x11' - 18: 255, # '\x12' - 19: 255, # '\x13' - 20: 255, # '\x14' - 21: 255, # '\x15' - 22: 255, # '\x16' - 23: 255, # '\x17' - 24: 255, # '\x18' - 25: 255, # '\x19' - 26: 255, # '\x1a' - 27: 255, # '\x1b' - 28: 255, # '\x1c' - 29: 255, # '\x1d' - 30: 255, # '\x1e' - 31: 255, # '\x1f' - 32: 255, # ' ' - 33: 255, # '!' - 34: 255, # '"' - 35: 255, # '#' - 36: 255, # '$' - 37: 255, # '%' - 38: 255, # '&' - 39: 255, # "'" - 40: 255, # '(' - 41: 255, # ')' - 42: 255, # '*' - 43: 255, # '+' - 44: 255, # ',' - 45: 255, # '-' - 46: 255, # '.' - 47: 255, # '/' - 48: 255, # '0' - 49: 255, # '1' - 50: 255, # '2' - 51: 255, # '3' - 52: 255, # '4' - 53: 255, # '5' - 54: 255, # '6' - 55: 255, # '7' - 56: 255, # '8' - 57: 255, # '9' - 58: 255, # ':' - 59: 255, # ';' - 60: 255, # '<' - 61: 255, # '=' - 62: 255, # '>' - 63: 255, # '?' - 64: 255, # '@' - 65: 23, # 'A' - 66: 37, # 'B' - 67: 47, # 'C' - 68: 39, # 'D' - 69: 29, # 'E' - 70: 52, # 'F' - 71: 36, # 'G' - 72: 45, # 'H' - 73: 53, # 'I' - 74: 60, # 'J' - 75: 16, # 'K' - 76: 49, # 'L' - 77: 20, # 'M' - 78: 46, # 'N' - 79: 42, # 'O' - 80: 48, # 'P' - 81: 69, # 'Q' - 82: 44, # 'R' - 83: 35, # 'S' - 84: 31, # 'T' - 85: 51, # 'U' - 86: 38, # 'V' - 87: 62, # 'W' - 88: 65, # 'X' - 89: 43, # 'Y' - 90: 56, # 'Z' - 91: 255, # '[' - 92: 255, # '\\' - 93: 255, # ']' - 94: 255, # '^' - 95: 255, # '_' - 96: 255, # '`' - 97: 1, # 'a' - 98: 21, # 'b' - 99: 28, # 'c' - 100: 12, # 'd' - 101: 2, # 'e' - 102: 18, # 'f' - 103: 27, # 'g' - 104: 25, # 'h' - 105: 3, # 'i' - 106: 24, # 'j' - 107: 10, # 'k' - 108: 5, # 'l' - 109: 13, # 'm' - 110: 4, # 'n' - 111: 15, # 'o' - 112: 26, # 'p' - 113: 64, # 'q' - 114: 7, # 'r' - 115: 8, # 's' - 116: 9, # 't' - 117: 14, # 'u' - 118: 32, # 'v' - 119: 57, # 'w' - 120: 58, # 'x' - 121: 11, # 'y' - 122: 22, # 'z' - 123: 255, # '{' - 124: 255, # '|' - 125: 255, # '}' - 126: 255, # '~' - 127: 255, # '\x7f' - 128: 180, # '\x80' - 129: 179, # '\x81' - 130: 178, # '\x82' - 131: 177, # '\x83' - 132: 176, # '\x84' - 133: 175, # '\x85' - 134: 174, # '\x86' - 135: 173, # '\x87' - 136: 172, # '\x88' - 137: 171, # '\x89' - 138: 170, # '\x8a' - 139: 169, # '\x8b' - 140: 168, # '\x8c' - 141: 167, # '\x8d' - 142: 166, # '\x8e' - 143: 165, # '\x8f' - 144: 164, # '\x90' - 145: 163, # '\x91' - 146: 162, # '\x92' - 147: 161, # '\x93' - 148: 160, # '\x94' - 149: 159, # '\x95' - 150: 101, # '\x96' - 151: 158, # '\x97' - 152: 157, # '\x98' - 153: 156, # '\x99' - 154: 155, # '\x9a' - 155: 154, # '\x9b' - 156: 153, # '\x9c' - 157: 152, # '\x9d' - 158: 151, # '\x9e' - 159: 106, # '\x9f' - 160: 150, # '\xa0' - 161: 149, # '¡' - 162: 148, # '¢' - 163: 147, # '£' - 164: 146, # '¤' - 165: 145, # '¥' - 166: 144, # '¦' - 167: 100, # '§' - 168: 143, # '¨' - 169: 142, # '©' - 170: 141, # 'ª' - 171: 140, # '«' - 172: 139, # '¬' - 173: 138, # '\xad' - 174: 137, # '®' - 175: 136, # '¯' - 176: 94, # '°' - 177: 80, # '±' - 178: 93, # '²' - 179: 135, # '³' - 180: 105, # '´' - 181: 134, # 'µ' - 182: 133, # '¶' - 183: 63, # '·' - 184: 132, # '¸' - 185: 131, # '¹' - 186: 130, # 'º' - 187: 129, # '»' - 188: 128, # '¼' - 189: 127, # '½' - 190: 126, # '¾' - 191: 125, # '¿' - 192: 124, # 'À' - 193: 104, # 'Á' - 194: 73, # 'Â' - 195: 99, # 'Ã' - 196: 79, # 'Ä' - 197: 85, # 'Å' - 198: 123, # 'Æ' - 199: 54, # 'Ç' - 200: 122, # 'È' - 201: 98, # 'É' - 202: 92, # 'Ê' - 203: 121, # 'Ë' - 204: 120, # 'Ì' - 205: 91, # 'Í' - 206: 103, # 'Î' - 207: 119, # 'Ï' - 208: 68, # 'Ğ' - 209: 118, # 'Ñ' - 210: 117, # 'Ò' - 211: 97, # 'Ó' - 212: 116, # 'Ô' - 213: 115, # 'Õ' - 214: 50, # 'Ö' - 215: 90, # '×' - 216: 114, # 'Ø' - 217: 113, # 'Ù' - 218: 112, # 'Ú' - 219: 111, # 'Û' - 220: 55, # 'Ü' - 221: 41, # 'İ' - 222: 40, # 'Ş' - 223: 86, # 'ß' - 224: 89, # 'à' - 225: 70, # 'á' - 226: 59, # 'â' - 227: 78, # 'ã' - 228: 71, # 'ä' - 229: 82, # 'å' - 230: 88, # 'æ' - 231: 33, # 'ç' - 232: 77, # 'è' - 233: 66, # 'é' - 234: 84, # 'ê' - 235: 83, # 'ë' - 236: 110, # 'ì' - 237: 75, # 'í' - 238: 61, # 'î' - 239: 96, # 'ï' - 240: 30, # 'ğ' - 241: 67, # 'ñ' - 242: 109, # 'ò' - 243: 74, # 'ó' - 244: 87, # 'ô' - 245: 102, # 'õ' - 246: 34, # 'ö' - 247: 95, # '÷' - 248: 81, # 'ø' - 249: 108, # 'ù' - 250: 76, # 'ú' - 251: 72, # 'û' - 252: 17, # 'ü' - 253: 6, # 'ı' - 254: 19, # 'ş' - 255: 107, # 'ÿ' -} - -ISO_8859_9_TURKISH_MODEL = SingleByteCharSetModel( - charset_name="ISO-8859-9", - language="Turkish", - char_to_order_map=ISO_8859_9_TURKISH_CHAR_TO_ORDER, - language_model=TURKISH_LANG_MODEL, - typical_positive_ratio=0.97029, - keep_ascii_letters=True, - alphabet="ABCDEFGHIJKLMNOPRSTUVYZabcdefghijklmnoprstuvyzÂÇÎÖÛÜâçîöûüĞğİıŞş", -) diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/PIL/WmfImagePlugin.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/PIL/WmfImagePlugin.py deleted file mode 100644 index 3e5fb01512df01c39092783028434463a132e5c6..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/PIL/WmfImagePlugin.py +++ /dev/null @@ -1,178 +0,0 @@ -# -# The Python Imaging Library -# $Id$ -# -# WMF stub codec -# -# history: -# 1996-12-14 fl Created -# 2004-02-22 fl Turned into a stub driver -# 2004-02-23 fl Added EMF support -# -# Copyright (c) Secret Labs AB 1997-2004. All rights reserved. -# Copyright (c) Fredrik Lundh 1996. -# -# See the README file for information on usage and redistribution. -# -# WMF/EMF reference documentation: -# https://winprotocoldoc.blob.core.windows.net/productionwindowsarchives/MS-WMF/[MS-WMF].pdf -# http://wvware.sourceforge.net/caolan/index.html -# http://wvware.sourceforge.net/caolan/ora-wmf.html - -from . import Image, ImageFile -from ._binary import i16le as word -from ._binary import si16le as short -from ._binary import si32le as _long - -_handler = None - - -def register_handler(handler): - """ - Install application-specific WMF image handler. - - :param handler: Handler object. - """ - global _handler - _handler = handler - - -if hasattr(Image.core, "drawwmf"): - # install default handler (windows only) - - class WmfHandler: - def open(self, im): - im._mode = "RGB" - self.bbox = im.info["wmf_bbox"] - - def load(self, im): - im.fp.seek(0) # rewind - return Image.frombytes( - "RGB", - im.size, - Image.core.drawwmf(im.fp.read(), im.size, self.bbox), - "raw", - "BGR", - (im.size[0] * 3 + 3) & -4, - -1, - ) - - register_handler(WmfHandler()) - -# -# -------------------------------------------------------------------- -# Read WMF file - - -def _accept(prefix): - return ( - prefix[:6] == b"\xd7\xcd\xc6\x9a\x00\x00" or prefix[:4] == b"\x01\x00\x00\x00" - ) - - -## -# Image plugin for Windows metafiles. - - -class WmfStubImageFile(ImageFile.StubImageFile): - format = "WMF" - format_description = "Windows Metafile" - - def _open(self): - self._inch = None - - # check placable header - s = self.fp.read(80) - - if s[:6] == b"\xd7\xcd\xc6\x9a\x00\x00": - # placeable windows metafile - - # get units per inch - self._inch = word(s, 14) - - # get bounding box - x0 = short(s, 6) - y0 = short(s, 8) - x1 = short(s, 10) - y1 = short(s, 12) - - # normalize size to 72 dots per inch - self.info["dpi"] = 72 - size = ( - (x1 - x0) * self.info["dpi"] // self._inch, - (y1 - y0) * self.info["dpi"] // self._inch, - ) - - self.info["wmf_bbox"] = x0, y0, x1, y1 - - # sanity check (standard metafile header) - if s[22:26] != b"\x01\x00\t\x00": - msg = "Unsupported WMF file format" - raise SyntaxError(msg) - - elif s[:4] == b"\x01\x00\x00\x00" and s[40:44] == b" EMF": - # enhanced metafile - - # get bounding box - x0 = _long(s, 8) - y0 = _long(s, 12) - x1 = _long(s, 16) - y1 = _long(s, 20) - - # get frame (in 0.01 millimeter units) - frame = _long(s, 24), _long(s, 28), _long(s, 32), _long(s, 36) - - size = x1 - x0, y1 - y0 - - # calculate dots per inch from bbox and frame - xdpi = 2540.0 * (x1 - y0) / (frame[2] - frame[0]) - ydpi = 2540.0 * (y1 - y0) / (frame[3] - frame[1]) - - self.info["wmf_bbox"] = x0, y0, x1, y1 - - if xdpi == ydpi: - self.info["dpi"] = xdpi - else: - self.info["dpi"] = xdpi, ydpi - - else: - msg = "Unsupported file format" - raise SyntaxError(msg) - - self._mode = "RGB" - self._size = size - - loader = self._load() - if loader: - loader.open(self) - - def _load(self): - return _handler - - def load(self, dpi=None): - if dpi is not None and self._inch is not None: - self.info["dpi"] = dpi - x0, y0, x1, y1 = self.info["wmf_bbox"] - self._size = ( - (x1 - x0) * self.info["dpi"] // self._inch, - (y1 - y0) * self.info["dpi"] // self._inch, - ) - return super().load() - - -def _save(im, fp, filename): - if _handler is None or not hasattr(_handler, "save"): - msg = "WMF save handler not installed" - raise OSError(msg) - _handler.save(im, fp, filename) - - -# -# -------------------------------------------------------------------- -# Registry stuff - - -Image.register_open(WmfStubImageFile.format, WmfStubImageFile, _accept) -Image.register_save(WmfStubImageFile.format, _save) - -Image.register_extensions(WmfStubImageFile.format, [".wmf", ".emf"]) diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/colorama/ansitowin32.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/colorama/ansitowin32.py deleted file mode 100644 index abf209e60c7c4a9b1ae57452e36b383969848c2e..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/colorama/ansitowin32.py +++ /dev/null @@ -1,277 +0,0 @@ -# Copyright Jonathan Hartley 2013. BSD 3-Clause license, see LICENSE file. -import re -import sys -import os - -from .ansi import AnsiFore, AnsiBack, AnsiStyle, Style, BEL -from .winterm import enable_vt_processing, WinTerm, WinColor, WinStyle -from .win32 import windll, winapi_test - - -winterm = None -if windll is not None: - winterm = WinTerm() - - -class StreamWrapper(object): - ''' - Wraps a stream (such as stdout), acting as a transparent proxy for all - attribute access apart from method 'write()', which is delegated to our - Converter instance. - ''' - def __init__(self, wrapped, converter): - # double-underscore everything to prevent clashes with names of - # attributes on the wrapped stream object. - self.__wrapped = wrapped - self.__convertor = converter - - def __getattr__(self, name): - return getattr(self.__wrapped, name) - - def __enter__(self, *args, **kwargs): - # special method lookup bypasses __getattr__/__getattribute__, see - # https://stackoverflow.com/questions/12632894/why-doesnt-getattr-work-with-exit - # thus, contextlib magic methods are not proxied via __getattr__ - return self.__wrapped.__enter__(*args, **kwargs) - - def __exit__(self, *args, **kwargs): - return self.__wrapped.__exit__(*args, **kwargs) - - def __setstate__(self, state): - self.__dict__ = state - - def __getstate__(self): - return self.__dict__ - - def write(self, text): - self.__convertor.write(text) - - def isatty(self): - stream = self.__wrapped - if 'PYCHARM_HOSTED' in os.environ: - if stream is not None and (stream is sys.__stdout__ or stream is sys.__stderr__): - return True - try: - stream_isatty = stream.isatty - except AttributeError: - return False - else: - return stream_isatty() - - @property - def closed(self): - stream = self.__wrapped - try: - return stream.closed - # AttributeError in the case that the stream doesn't support being closed - # ValueError for the case that the stream has already been detached when atexit runs - except (AttributeError, ValueError): - return True - - -class AnsiToWin32(object): - ''' - Implements a 'write()' method which, on Windows, will strip ANSI character - sequences from the text, and if outputting to a tty, will convert them into - win32 function calls. - ''' - ANSI_CSI_RE = re.compile('\001?\033\\[((?:\\d|;)*)([a-zA-Z])\002?') # Control Sequence Introducer - ANSI_OSC_RE = re.compile('\001?\033\\]([^\a]*)(\a)\002?') # Operating System Command - - def __init__(self, wrapped, convert=None, strip=None, autoreset=False): - # The wrapped stream (normally sys.stdout or sys.stderr) - self.wrapped = wrapped - - # should we reset colors to defaults after every .write() - self.autoreset = autoreset - - # create the proxy wrapping our output stream - self.stream = StreamWrapper(wrapped, self) - - on_windows = os.name == 'nt' - # We test if the WinAPI works, because even if we are on Windows - # we may be using a terminal that doesn't support the WinAPI - # (e.g. Cygwin Terminal). In this case it's up to the terminal - # to support the ANSI codes. - conversion_supported = on_windows and winapi_test() - try: - fd = wrapped.fileno() - except Exception: - fd = -1 - system_has_native_ansi = not on_windows or enable_vt_processing(fd) - have_tty = not self.stream.closed and self.stream.isatty() - need_conversion = conversion_supported and not system_has_native_ansi - - # should we strip ANSI sequences from our output? - if strip is None: - strip = need_conversion or not have_tty - self.strip = strip - - # should we should convert ANSI sequences into win32 calls? - if convert is None: - convert = need_conversion and have_tty - self.convert = convert - - # dict of ansi codes to win32 functions and parameters - self.win32_calls = self.get_win32_calls() - - # are we wrapping stderr? - self.on_stderr = self.wrapped is sys.stderr - - def should_wrap(self): - ''' - True if this class is actually needed. If false, then the output - stream will not be affected, nor will win32 calls be issued, so - wrapping stdout is not actually required. This will generally be - False on non-Windows platforms, unless optional functionality like - autoreset has been requested using kwargs to init() - ''' - return self.convert or self.strip or self.autoreset - - def get_win32_calls(self): - if self.convert and winterm: - return { - AnsiStyle.RESET_ALL: (winterm.reset_all, ), - AnsiStyle.BRIGHT: (winterm.style, WinStyle.BRIGHT), - AnsiStyle.DIM: (winterm.style, WinStyle.NORMAL), - AnsiStyle.NORMAL: (winterm.style, WinStyle.NORMAL), - AnsiFore.BLACK: (winterm.fore, WinColor.BLACK), - AnsiFore.RED: (winterm.fore, WinColor.RED), - AnsiFore.GREEN: (winterm.fore, WinColor.GREEN), - AnsiFore.YELLOW: (winterm.fore, WinColor.YELLOW), - AnsiFore.BLUE: (winterm.fore, WinColor.BLUE), - AnsiFore.MAGENTA: (winterm.fore, WinColor.MAGENTA), - AnsiFore.CYAN: (winterm.fore, WinColor.CYAN), - AnsiFore.WHITE: (winterm.fore, WinColor.GREY), - AnsiFore.RESET: (winterm.fore, ), - AnsiFore.LIGHTBLACK_EX: (winterm.fore, WinColor.BLACK, True), - AnsiFore.LIGHTRED_EX: (winterm.fore, WinColor.RED, True), - AnsiFore.LIGHTGREEN_EX: (winterm.fore, WinColor.GREEN, True), - AnsiFore.LIGHTYELLOW_EX: (winterm.fore, WinColor.YELLOW, True), - AnsiFore.LIGHTBLUE_EX: (winterm.fore, WinColor.BLUE, True), - AnsiFore.LIGHTMAGENTA_EX: (winterm.fore, WinColor.MAGENTA, True), - AnsiFore.LIGHTCYAN_EX: (winterm.fore, WinColor.CYAN, True), - AnsiFore.LIGHTWHITE_EX: (winterm.fore, WinColor.GREY, True), - AnsiBack.BLACK: (winterm.back, WinColor.BLACK), - AnsiBack.RED: (winterm.back, WinColor.RED), - AnsiBack.GREEN: (winterm.back, WinColor.GREEN), - AnsiBack.YELLOW: (winterm.back, WinColor.YELLOW), - AnsiBack.BLUE: (winterm.back, WinColor.BLUE), - AnsiBack.MAGENTA: (winterm.back, WinColor.MAGENTA), - AnsiBack.CYAN: (winterm.back, WinColor.CYAN), - AnsiBack.WHITE: (winterm.back, WinColor.GREY), - AnsiBack.RESET: (winterm.back, ), - AnsiBack.LIGHTBLACK_EX: (winterm.back, WinColor.BLACK, True), - AnsiBack.LIGHTRED_EX: (winterm.back, WinColor.RED, True), - AnsiBack.LIGHTGREEN_EX: (winterm.back, WinColor.GREEN, True), - AnsiBack.LIGHTYELLOW_EX: (winterm.back, WinColor.YELLOW, True), - AnsiBack.LIGHTBLUE_EX: (winterm.back, WinColor.BLUE, True), - AnsiBack.LIGHTMAGENTA_EX: (winterm.back, WinColor.MAGENTA, True), - AnsiBack.LIGHTCYAN_EX: (winterm.back, WinColor.CYAN, True), - AnsiBack.LIGHTWHITE_EX: (winterm.back, WinColor.GREY, True), - } - return dict() - - def write(self, text): - if self.strip or self.convert: - self.write_and_convert(text) - else: - self.wrapped.write(text) - self.wrapped.flush() - if self.autoreset: - self.reset_all() - - - def reset_all(self): - if self.convert: - self.call_win32('m', (0,)) - elif not self.strip and not self.stream.closed: - self.wrapped.write(Style.RESET_ALL) - - - def write_and_convert(self, text): - ''' - Write the given text to our wrapped stream, stripping any ANSI - sequences from the text, and optionally converting them into win32 - calls. - ''' - cursor = 0 - text = self.convert_osc(text) - for match in self.ANSI_CSI_RE.finditer(text): - start, end = match.span() - self.write_plain_text(text, cursor, start) - self.convert_ansi(*match.groups()) - cursor = end - self.write_plain_text(text, cursor, len(text)) - - - def write_plain_text(self, text, start, end): - if start < end: - self.wrapped.write(text[start:end]) - self.wrapped.flush() - - - def convert_ansi(self, paramstring, command): - if self.convert: - params = self.extract_params(command, paramstring) - self.call_win32(command, params) - - - def extract_params(self, command, paramstring): - if command in 'Hf': - params = tuple(int(p) if len(p) != 0 else 1 for p in paramstring.split(';')) - while len(params) < 2: - # defaults: - params = params + (1,) - else: - params = tuple(int(p) for p in paramstring.split(';') if len(p) != 0) - if len(params) == 0: - # defaults: - if command in 'JKm': - params = (0,) - elif command in 'ABCD': - params = (1,) - - return params - - - def call_win32(self, command, params): - if command == 'm': - for param in params: - if param in self.win32_calls: - func_args = self.win32_calls[param] - func = func_args[0] - args = func_args[1:] - kwargs = dict(on_stderr=self.on_stderr) - func(*args, **kwargs) - elif command in 'J': - winterm.erase_screen(params[0], on_stderr=self.on_stderr) - elif command in 'K': - winterm.erase_line(params[0], on_stderr=self.on_stderr) - elif command in 'Hf': # cursor position - absolute - winterm.set_cursor_position(params, on_stderr=self.on_stderr) - elif command in 'ABCD': # cursor position - relative - n = params[0] - # A - up, B - down, C - forward, D - back - x, y = {'A': (0, -n), 'B': (0, n), 'C': (n, 0), 'D': (-n, 0)}[command] - winterm.cursor_adjust(x, y, on_stderr=self.on_stderr) - - - def convert_osc(self, text): - for match in self.ANSI_OSC_RE.finditer(text): - start, end = match.span() - text = text[:start] + text[end:] - paramstring, command = match.groups() - if command == BEL: - if paramstring.count(";") == 1: - params = paramstring.split(";") - # 0 - change title and icon (we will only change title) - # 1 - change icon (we don't support this) - # 2 - change title - if params[0] in '02': - winterm.set_title(params[1]) - return text - - - def flush(self): - self.wrapped.flush() diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fastapi/staticfiles.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fastapi/staticfiles.py deleted file mode 100644 index 299015d4fef268cde91273790251f35192e1c8a6..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fastapi/staticfiles.py +++ /dev/null @@ -1 +0,0 @@ -from starlette.staticfiles import StaticFiles as StaticFiles # noqa diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/pens/ttGlyphPen.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/pens/ttGlyphPen.py deleted file mode 100644 index de2ccaeeb45c18c80caae049f3bd26b4ff22e99e..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/pens/ttGlyphPen.py +++ /dev/null @@ -1,335 +0,0 @@ -from array import array -from typing import Any, Callable, Dict, Optional, Tuple -from fontTools.misc.fixedTools import MAX_F2DOT14, floatToFixedToFloat -from fontTools.misc.loggingTools import LogMixin -from fontTools.pens.pointPen import AbstractPointPen -from fontTools.misc.roundTools import otRound -from fontTools.pens.basePen import LoggingPen, PenError -from fontTools.pens.transformPen import TransformPen, TransformPointPen -from fontTools.ttLib.tables import ttProgram -from fontTools.ttLib.tables._g_l_y_f import flagOnCurve, flagCubic -from fontTools.ttLib.tables._g_l_y_f import Glyph -from fontTools.ttLib.tables._g_l_y_f import GlyphComponent -from fontTools.ttLib.tables._g_l_y_f import GlyphCoordinates -from fontTools.ttLib.tables._g_l_y_f import dropImpliedOnCurvePoints -import math - - -__all__ = ["TTGlyphPen", "TTGlyphPointPen"] - - -class _TTGlyphBasePen: - def __init__( - self, - glyphSet: Optional[Dict[str, Any]], - handleOverflowingTransforms: bool = True, - ) -> None: - """ - Construct a new pen. - - Args: - glyphSet (Dict[str, Any]): A glyphset object, used to resolve components. - handleOverflowingTransforms (bool): See below. - - If ``handleOverflowingTransforms`` is True, the components' transform values - are checked that they don't overflow the limits of a F2Dot14 number: - -2.0 <= v < +2.0. If any transform value exceeds these, the composite - glyph is decomposed. - - An exception to this rule is done for values that are very close to +2.0 - (both for consistency with the -2.0 case, and for the relative frequency - these occur in real fonts). When almost +2.0 values occur (and all other - values are within the range -2.0 <= x <= +2.0), they are clamped to the - maximum positive value that can still be encoded as an F2Dot14: i.e. - 1.99993896484375. - - If False, no check is done and all components are translated unmodified - into the glyf table, followed by an inevitable ``struct.error`` once an - attempt is made to compile them. - - If both contours and components are present in a glyph, the components - are decomposed. - """ - self.glyphSet = glyphSet - self.handleOverflowingTransforms = handleOverflowingTransforms - self.init() - - def _decompose( - self, - glyphName: str, - transformation: Tuple[float, float, float, float, float, float], - ): - tpen = self.transformPen(self, transformation) - getattr(self.glyphSet[glyphName], self.drawMethod)(tpen) - - def _isClosed(self): - """ - Check if the current path is closed. - """ - raise NotImplementedError - - def init(self) -> None: - self.points = [] - self.endPts = [] - self.types = [] - self.components = [] - - def addComponent( - self, - baseGlyphName: str, - transformation: Tuple[float, float, float, float, float, float], - identifier: Optional[str] = None, - **kwargs: Any, - ) -> None: - """ - Add a sub glyph. - """ - self.components.append((baseGlyphName, transformation)) - - def _buildComponents(self, componentFlags): - if self.handleOverflowingTransforms: - # we can't encode transform values > 2 or < -2 in F2Dot14, - # so we must decompose the glyph if any transform exceeds these - overflowing = any( - s > 2 or s < -2 - for (glyphName, transformation) in self.components - for s in transformation[:4] - ) - components = [] - for glyphName, transformation in self.components: - if glyphName not in self.glyphSet: - self.log.warning(f"skipped non-existing component '{glyphName}'") - continue - if self.points or (self.handleOverflowingTransforms and overflowing): - # can't have both coordinates and components, so decompose - self._decompose(glyphName, transformation) - continue - - component = GlyphComponent() - component.glyphName = glyphName - component.x, component.y = (otRound(v) for v in transformation[4:]) - # quantize floats to F2Dot14 so we get same values as when decompiled - # from a binary glyf table - transformation = tuple( - floatToFixedToFloat(v, 14) for v in transformation[:4] - ) - if transformation != (1, 0, 0, 1): - if self.handleOverflowingTransforms and any( - MAX_F2DOT14 < s <= 2 for s in transformation - ): - # clamp values ~= +2.0 so we can keep the component - transformation = tuple( - MAX_F2DOT14 if MAX_F2DOT14 < s <= 2 else s - for s in transformation - ) - component.transform = (transformation[:2], transformation[2:]) - component.flags = componentFlags - components.append(component) - return components - - def glyph( - self, - componentFlags: int = 0x04, - dropImpliedOnCurves: bool = False, - *, - round: Callable[[float], int] = otRound, - ) -> Glyph: - """ - Returns a :py:class:`~._g_l_y_f.Glyph` object representing the glyph. - - Args: - componentFlags: Flags to use for component glyphs. (default: 0x04) - - dropImpliedOnCurves: Whether to remove implied-oncurve points. (default: False) - """ - if not self._isClosed(): - raise PenError("Didn't close last contour.") - components = self._buildComponents(componentFlags) - - glyph = Glyph() - glyph.coordinates = GlyphCoordinates(self.points) - glyph.endPtsOfContours = self.endPts - glyph.flags = array("B", self.types) - self.init() - - if components: - # If both components and contours were present, they have by now - # been decomposed by _buildComponents. - glyph.components = components - glyph.numberOfContours = -1 - else: - glyph.numberOfContours = len(glyph.endPtsOfContours) - glyph.program = ttProgram.Program() - glyph.program.fromBytecode(b"") - if dropImpliedOnCurves: - dropImpliedOnCurvePoints(glyph) - glyph.coordinates.toInt(round=round) - - return glyph - - -class TTGlyphPen(_TTGlyphBasePen, LoggingPen): - """ - Pen used for drawing to a TrueType glyph. - - This pen can be used to construct or modify glyphs in a TrueType format - font. After using the pen to draw, use the ``.glyph()`` method to retrieve - a :py:class:`~._g_l_y_f.Glyph` object representing the glyph. - """ - - drawMethod = "draw" - transformPen = TransformPen - - def __init__( - self, - glyphSet: Optional[Dict[str, Any]] = None, - handleOverflowingTransforms: bool = True, - outputImpliedClosingLine: bool = False, - ) -> None: - super().__init__(glyphSet, handleOverflowingTransforms) - self.outputImpliedClosingLine = outputImpliedClosingLine - - def _addPoint(self, pt: Tuple[float, float], tp: int) -> None: - self.points.append(pt) - self.types.append(tp) - - def _popPoint(self) -> None: - self.points.pop() - self.types.pop() - - def _isClosed(self) -> bool: - return (not self.points) or ( - self.endPts and self.endPts[-1] == len(self.points) - 1 - ) - - def lineTo(self, pt: Tuple[float, float]) -> None: - self._addPoint(pt, flagOnCurve) - - def moveTo(self, pt: Tuple[float, float]) -> None: - if not self._isClosed(): - raise PenError('"move"-type point must begin a new contour.') - self._addPoint(pt, flagOnCurve) - - def curveTo(self, *points) -> None: - assert len(points) % 2 == 1 - for pt in points[:-1]: - self._addPoint(pt, flagCubic) - - # last point is None if there are no on-curve points - if points[-1] is not None: - self._addPoint(points[-1], 1) - - def qCurveTo(self, *points) -> None: - assert len(points) >= 1 - for pt in points[:-1]: - self._addPoint(pt, 0) - - # last point is None if there are no on-curve points - if points[-1] is not None: - self._addPoint(points[-1], 1) - - def closePath(self) -> None: - endPt = len(self.points) - 1 - - # ignore anchors (one-point paths) - if endPt == 0 or (self.endPts and endPt == self.endPts[-1] + 1): - self._popPoint() - return - - if not self.outputImpliedClosingLine: - # if first and last point on this path are the same, remove last - startPt = 0 - if self.endPts: - startPt = self.endPts[-1] + 1 - if self.points[startPt] == self.points[endPt]: - self._popPoint() - endPt -= 1 - - self.endPts.append(endPt) - - def endPath(self) -> None: - # TrueType contours are always "closed" - self.closePath() - - -class TTGlyphPointPen(_TTGlyphBasePen, LogMixin, AbstractPointPen): - """ - Point pen used for drawing to a TrueType glyph. - - This pen can be used to construct or modify glyphs in a TrueType format - font. After using the pen to draw, use the ``.glyph()`` method to retrieve - a :py:class:`~._g_l_y_f.Glyph` object representing the glyph. - """ - - drawMethod = "drawPoints" - transformPen = TransformPointPen - - def init(self) -> None: - super().init() - self._currentContourStartIndex = None - - def _isClosed(self) -> bool: - return self._currentContourStartIndex is None - - def beginPath(self, identifier: Optional[str] = None, **kwargs: Any) -> None: - """ - Start a new sub path. - """ - if not self._isClosed(): - raise PenError("Didn't close previous contour.") - self._currentContourStartIndex = len(self.points) - - def endPath(self) -> None: - """ - End the current sub path. - """ - # TrueType contours are always "closed" - if self._isClosed(): - raise PenError("Contour is already closed.") - if self._currentContourStartIndex == len(self.points): - # ignore empty contours - self._currentContourStartIndex = None - return - - contourStart = self.endPts[-1] + 1 if self.endPts else 0 - self.endPts.append(len(self.points) - 1) - self._currentContourStartIndex = None - - # Resolve types for any cubic segments - flags = self.types - for i in range(contourStart, len(flags)): - if flags[i] == "curve": - j = i - 1 - if j < contourStart: - j = len(flags) - 1 - while flags[j] == 0: - flags[j] = flagCubic - j -= 1 - flags[i] = flagOnCurve - - def addPoint( - self, - pt: Tuple[float, float], - segmentType: Optional[str] = None, - smooth: bool = False, - name: Optional[str] = None, - identifier: Optional[str] = None, - **kwargs: Any, - ) -> None: - """ - Add a point to the current sub path. - """ - if self._isClosed(): - raise PenError("Can't add a point to a closed contour.") - if segmentType is None: - self.types.append(0) - elif segmentType in ("line", "move"): - self.types.append(flagOnCurve) - elif segmentType == "qcurve": - self.types.append(flagOnCurve) - elif segmentType == "curve": - self.types.append("curve") - else: - raise AssertionError(segmentType) - - self.points.append(pt) diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/templates/frontend/assets/Index-9a36a7ca.css b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/templates/frontend/assets/Index-9a36a7ca.css deleted file mode 100644 index cca598778f233cad73ec7066b69bb4e609c35cb2..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/templates/frontend/assets/Index-9a36a7ca.css +++ /dev/null @@ -1 +0,0 @@ -input.svelte-q8uklq{position:absolute;top:var(--size-2);right:var(--size-2);bottom:var(--size-2);left:var(--size-2);flex:1 1 0%;transform:translate(-.1px);outline:none;border:none;background:transparent}span.svelte-q8uklq{flex:1 1 0%;outline:none;padding:var(--size-2)}.header.svelte-q8uklq{transform:translate(0);font:var(--weight-bold)}.edit.svelte-q8uklq{opacity:0;pointer-events:none}table.svelte-1jok1de.svelte-1jok1de{position:relative;overflow-y:scroll;overflow-x:scroll;-webkit-overflow-scrolling:touch;max-height:100vh;box-sizing:border-box;display:block;padding:0;margin:0;color:var(--body-text-color);font-size:var(--input-text-size);line-height:var(--line-md);font-family:var(--font-mono);border-spacing:0;width:100%;scroll-snap-type:x proximity}table.svelte-1jok1de .svelte-1jok1de:is(thead,tfoot,tbody){display:table;table-layout:fixed;width:100%;box-sizing:border-box}tbody.svelte-1jok1de.svelte-1jok1de{overflow-x:scroll;overflow-y:hidden}table.svelte-1jok1de tbody.svelte-1jok1de{padding-top:var(--bw-svt-p-top);padding-bottom:var(--bw-svt-p-bottom)}tbody.svelte-1jok1de.svelte-1jok1de{position:relative;box-sizing:border-box;border:0px solid currentColor}tbody.svelte-1jok1de>tr:last-child{border:none}table.svelte-1jok1de td{scroll-snap-align:start}tbody.svelte-1jok1de>tr:nth-child(2n){background:var(--table-even-background-fill)}thead.svelte-1jok1de.svelte-1jok1de{position:sticky;top:0;left:0;z-index:var(--layer-1);box-shadow:var(--shadow-drop)}.button-wrap.svelte-1bvc1p0:hover svg.svelte-1bvc1p0.svelte-1bvc1p0{color:var(--color-accent)}.button-wrap.svelte-1bvc1p0 svg.svelte-1bvc1p0.svelte-1bvc1p0{margin-right:var(--size-1);margin-left:-5px}.label.svelte-1bvc1p0 p.svelte-1bvc1p0.svelte-1bvc1p0{position:relative;z-index:var(--layer-4);margin-bottom:var(--size-2);color:var(--block-label-text-color);font-size:var(--block-label-text-size)}.table-wrap.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{position:relative;transition:.15s;border:1px solid var(--border-color-primary);border-radius:var(--table-radius);overflow:hidden}.table-wrap.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0:focus-within{outline:none;background-color:none}.dragging.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{border-color:var(--color-accent)}.no-wrap.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{white-space:nowrap}table.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{position:absolute;opacity:0;transition:.15s;width:var(--size-full);table-layout:auto;color:var(--body-text-color);font-size:var(--input-text-size);line-height:var(--line-md);font-family:var(--font-mono);border-spacing:0}div.svelte-1bvc1p0:not(.no-wrap) td.svelte-1bvc1p0.svelte-1bvc1p0{overflow-wrap:anywhere}div.no-wrap.svelte-1bvc1p0 td.svelte-1bvc1p0.svelte-1bvc1p0{overflow-x:hidden}table.fixed-layout.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{table-layout:fixed}thead.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{position:sticky;top:0;left:0;z-index:var(--layer-1);box-shadow:var(--shadow-drop)}tr.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{border-bottom:1px solid var(--border-color-primary);text-align:left}tr.svelte-1bvc1p0>.svelte-1bvc1p0+.svelte-1bvc1p0{border-right-width:0px;border-left-width:1px;border-style:solid;border-color:var(--border-color-primary)}th.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0,td.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{--ring-color:transparent;position:relative;outline:none;box-shadow:inset 0 0 0 1px var(--ring-color);padding:0}th.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0:first-child{border-top-left-radius:var(--table-radius)}th.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0:last-child{border-top-right-radius:var(--table-radius)}th.focus.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0,td.focus.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{--ring-color:var(--color-accent)}tr.svelte-1bvc1p0:last-child td.svelte-1bvc1p0.svelte-1bvc1p0:first-child{border-bottom-left-radius:var(--table-radius)}tr.svelte-1bvc1p0:last-child td.svelte-1bvc1p0.svelte-1bvc1p0:last-child{border-bottom-right-radius:var(--table-radius)}tr.svelte-1bvc1p0 th.svelte-1bvc1p0.svelte-1bvc1p0{background:var(--table-even-background-fill)}th.svelte-1bvc1p0 svg.svelte-1bvc1p0.svelte-1bvc1p0{fill:currentColor;font-size:10px}.sort-button.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{display:flex;flex:none;justify-content:center;align-items:center;transition:.15s;cursor:pointer;padding:var(--size-2);color:var(--body-text-color-subdued);line-height:var(--text-sm)}.sort-button.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0:hover{color:var(--body-text-color)}.des.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{transform:scaleY(-1)}.sort-button.sorted.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{color:var(--color-accent)}.editing.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{background:var(--table-editing)}.cell-wrap.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{display:flex;align-items:center;outline:none;height:var(--size-full);min-height:var(--size-9)}.controls-wrap.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{display:flex;justify-content:flex-end;padding-top:var(--size-2)}.controls-wrap.svelte-1bvc1p0>.svelte-1bvc1p0+.svelte-1bvc1p0{margin-left:var(--size-1)}.row_odd.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{background:var(--table-odd-background-fill)}.row_odd.focus.svelte-1bvc1p0.svelte-1bvc1p0.svelte-1bvc1p0{background:var(--background-fill-primary)} diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/httpx/_transports/default.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/httpx/_transports/default.py deleted file mode 100644 index 7dba5b8208a5129c930e74e30178f8b5b5e5aa6f..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/httpx/_transports/default.py +++ /dev/null @@ -1,378 +0,0 @@ -""" -Custom transports, with nicely configured defaults. - -The following additional keyword arguments are currently supported by httpcore... - -* uds: str -* local_address: str -* retries: int - -Example usages... - -# Disable HTTP/2 on a single specific domain. -mounts = { - "all://": httpx.HTTPTransport(http2=True), - "all://*example.org": httpx.HTTPTransport() -} - -# Using advanced httpcore configuration, with connection retries. -transport = httpx.HTTPTransport(retries=1) -client = httpx.Client(transport=transport) - -# Using advanced httpcore configuration, with unix domain sockets. -transport = httpx.HTTPTransport(uds="socket.uds") -client = httpx.Client(transport=transport) -""" -import contextlib -import typing -from types import TracebackType - -import httpcore - -from .._config import DEFAULT_LIMITS, Limits, Proxy, create_ssl_context -from .._exceptions import ( - ConnectError, - ConnectTimeout, - LocalProtocolError, - NetworkError, - PoolTimeout, - ProtocolError, - ProxyError, - ReadError, - ReadTimeout, - RemoteProtocolError, - TimeoutException, - UnsupportedProtocol, - WriteError, - WriteTimeout, -) -from .._models import Request, Response -from .._types import AsyncByteStream, CertTypes, SyncByteStream, VerifyTypes -from .base import AsyncBaseTransport, BaseTransport - -T = typing.TypeVar("T", bound="HTTPTransport") -A = typing.TypeVar("A", bound="AsyncHTTPTransport") - -SOCKET_OPTION = typing.Union[ - typing.Tuple[int, int, int], - typing.Tuple[int, int, typing.Union[bytes, bytearray]], - typing.Tuple[int, int, None, int], -] - - -@contextlib.contextmanager -def map_httpcore_exceptions() -> typing.Iterator[None]: - try: - yield - except Exception as exc: # noqa: PIE-786 - mapped_exc = None - - for from_exc, to_exc in HTTPCORE_EXC_MAP.items(): - if not isinstance(exc, from_exc): - continue - # We want to map to the most specific exception we can find. - # Eg if `exc` is an `httpcore.ReadTimeout`, we want to map to - # `httpx.ReadTimeout`, not just `httpx.TimeoutException`. - if mapped_exc is None or issubclass(to_exc, mapped_exc): - mapped_exc = to_exc - - if mapped_exc is None: # pragma: no cover - raise - - message = str(exc) - raise mapped_exc(message) from exc - - -HTTPCORE_EXC_MAP = { - httpcore.TimeoutException: TimeoutException, - httpcore.ConnectTimeout: ConnectTimeout, - httpcore.ReadTimeout: ReadTimeout, - httpcore.WriteTimeout: WriteTimeout, - httpcore.PoolTimeout: PoolTimeout, - httpcore.NetworkError: NetworkError, - httpcore.ConnectError: ConnectError, - httpcore.ReadError: ReadError, - httpcore.WriteError: WriteError, - httpcore.ProxyError: ProxyError, - httpcore.UnsupportedProtocol: UnsupportedProtocol, - httpcore.ProtocolError: ProtocolError, - httpcore.LocalProtocolError: LocalProtocolError, - httpcore.RemoteProtocolError: RemoteProtocolError, -} - - -class ResponseStream(SyncByteStream): - def __init__(self, httpcore_stream: typing.Iterable[bytes]): - self._httpcore_stream = httpcore_stream - - def __iter__(self) -> typing.Iterator[bytes]: - with map_httpcore_exceptions(): - for part in self._httpcore_stream: - yield part - - def close(self) -> None: - if hasattr(self._httpcore_stream, "close"): - self._httpcore_stream.close() - - -class HTTPTransport(BaseTransport): - def __init__( - self, - verify: VerifyTypes = True, - cert: typing.Optional[CertTypes] = None, - http1: bool = True, - http2: bool = False, - limits: Limits = DEFAULT_LIMITS, - trust_env: bool = True, - proxy: typing.Optional[Proxy] = None, - uds: typing.Optional[str] = None, - local_address: typing.Optional[str] = None, - retries: int = 0, - socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None, - ) -> None: - ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env) - - if proxy is None: - self._pool = httpcore.ConnectionPool( - ssl_context=ssl_context, - max_connections=limits.max_connections, - max_keepalive_connections=limits.max_keepalive_connections, - keepalive_expiry=limits.keepalive_expiry, - http1=http1, - http2=http2, - uds=uds, - local_address=local_address, - retries=retries, - socket_options=socket_options, - ) - elif proxy.url.scheme in ("http", "https"): - self._pool = httpcore.HTTPProxy( - proxy_url=httpcore.URL( - scheme=proxy.url.raw_scheme, - host=proxy.url.raw_host, - port=proxy.url.port, - target=proxy.url.raw_path, - ), - proxy_auth=proxy.raw_auth, - proxy_headers=proxy.headers.raw, - ssl_context=ssl_context, - proxy_ssl_context=proxy.ssl_context, - max_connections=limits.max_connections, - max_keepalive_connections=limits.max_keepalive_connections, - keepalive_expiry=limits.keepalive_expiry, - http1=http1, - http2=http2, - socket_options=socket_options, - ) - elif proxy.url.scheme == "socks5": - try: - import socksio # noqa - except ImportError: # pragma: no cover - raise ImportError( - "Using SOCKS proxy, but the 'socksio' package is not installed. " - "Make sure to install httpx using `pip install httpx[socks]`." - ) from None - - self._pool = httpcore.SOCKSProxy( - proxy_url=httpcore.URL( - scheme=proxy.url.raw_scheme, - host=proxy.url.raw_host, - port=proxy.url.port, - target=proxy.url.raw_path, - ), - proxy_auth=proxy.raw_auth, - ssl_context=ssl_context, - max_connections=limits.max_connections, - max_keepalive_connections=limits.max_keepalive_connections, - keepalive_expiry=limits.keepalive_expiry, - http1=http1, - http2=http2, - ) - else: # pragma: no cover - raise ValueError( - f"Proxy protocol must be either 'http', 'https', or 'socks5', but got {proxy.url.scheme!r}." - ) - - def __enter__(self: T) -> T: # Use generics for subclass support. - self._pool.__enter__() - return self - - def __exit__( - self, - exc_type: typing.Optional[typing.Type[BaseException]] = None, - exc_value: typing.Optional[BaseException] = None, - traceback: typing.Optional[TracebackType] = None, - ) -> None: - with map_httpcore_exceptions(): - self._pool.__exit__(exc_type, exc_value, traceback) - - def handle_request( - self, - request: Request, - ) -> Response: - assert isinstance(request.stream, SyncByteStream) - - req = httpcore.Request( - method=request.method, - url=httpcore.URL( - scheme=request.url.raw_scheme, - host=request.url.raw_host, - port=request.url.port, - target=request.url.raw_path, - ), - headers=request.headers.raw, - content=request.stream, - extensions=request.extensions, - ) - with map_httpcore_exceptions(): - resp = self._pool.handle_request(req) - - assert isinstance(resp.stream, typing.Iterable) - - return Response( - status_code=resp.status, - headers=resp.headers, - stream=ResponseStream(resp.stream), - extensions=resp.extensions, - ) - - def close(self) -> None: - self._pool.close() - - -class AsyncResponseStream(AsyncByteStream): - def __init__(self, httpcore_stream: typing.AsyncIterable[bytes]): - self._httpcore_stream = httpcore_stream - - async def __aiter__(self) -> typing.AsyncIterator[bytes]: - with map_httpcore_exceptions(): - async for part in self._httpcore_stream: - yield part - - async def aclose(self) -> None: - if hasattr(self._httpcore_stream, "aclose"): - await self._httpcore_stream.aclose() - - -class AsyncHTTPTransport(AsyncBaseTransport): - def __init__( - self, - verify: VerifyTypes = True, - cert: typing.Optional[CertTypes] = None, - http1: bool = True, - http2: bool = False, - limits: Limits = DEFAULT_LIMITS, - trust_env: bool = True, - proxy: typing.Optional[Proxy] = None, - uds: typing.Optional[str] = None, - local_address: typing.Optional[str] = None, - retries: int = 0, - socket_options: typing.Optional[typing.Iterable[SOCKET_OPTION]] = None, - ) -> None: - ssl_context = create_ssl_context(verify=verify, cert=cert, trust_env=trust_env) - - if proxy is None: - self._pool = httpcore.AsyncConnectionPool( - ssl_context=ssl_context, - max_connections=limits.max_connections, - max_keepalive_connections=limits.max_keepalive_connections, - keepalive_expiry=limits.keepalive_expiry, - http1=http1, - http2=http2, - uds=uds, - local_address=local_address, - retries=retries, - socket_options=socket_options, - ) - elif proxy.url.scheme in ("http", "https"): - self._pool = httpcore.AsyncHTTPProxy( - proxy_url=httpcore.URL( - scheme=proxy.url.raw_scheme, - host=proxy.url.raw_host, - port=proxy.url.port, - target=proxy.url.raw_path, - ), - proxy_auth=proxy.raw_auth, - proxy_headers=proxy.headers.raw, - ssl_context=ssl_context, - max_connections=limits.max_connections, - max_keepalive_connections=limits.max_keepalive_connections, - keepalive_expiry=limits.keepalive_expiry, - http1=http1, - http2=http2, - socket_options=socket_options, - ) - elif proxy.url.scheme == "socks5": - try: - import socksio # noqa - except ImportError: # pragma: no cover - raise ImportError( - "Using SOCKS proxy, but the 'socksio' package is not installed. " - "Make sure to install httpx using `pip install httpx[socks]`." - ) from None - - self._pool = httpcore.AsyncSOCKSProxy( - proxy_url=httpcore.URL( - scheme=proxy.url.raw_scheme, - host=proxy.url.raw_host, - port=proxy.url.port, - target=proxy.url.raw_path, - ), - proxy_auth=proxy.raw_auth, - ssl_context=ssl_context, - max_connections=limits.max_connections, - max_keepalive_connections=limits.max_keepalive_connections, - keepalive_expiry=limits.keepalive_expiry, - http1=http1, - http2=http2, - ) - else: # pragma: no cover - raise ValueError( - f"Proxy protocol must be either 'http', 'https', or 'socks5', but got {proxy.url.scheme!r}." - ) - - async def __aenter__(self: A) -> A: # Use generics for subclass support. - await self._pool.__aenter__() - return self - - async def __aexit__( - self, - exc_type: typing.Optional[typing.Type[BaseException]] = None, - exc_value: typing.Optional[BaseException] = None, - traceback: typing.Optional[TracebackType] = None, - ) -> None: - with map_httpcore_exceptions(): - await self._pool.__aexit__(exc_type, exc_value, traceback) - - async def handle_async_request( - self, - request: Request, - ) -> Response: - assert isinstance(request.stream, AsyncByteStream) - - req = httpcore.Request( - method=request.method, - url=httpcore.URL( - scheme=request.url.raw_scheme, - host=request.url.raw_host, - port=request.url.port, - target=request.url.raw_path, - ), - headers=request.headers.raw, - content=request.stream, - extensions=request.extensions, - ) - with map_httpcore_exceptions(): - resp = await self._pool.handle_async_request(req) - - assert isinstance(resp.stream, typing.AsyncIterable) - - return Response( - status_code=resp.status, - headers=resp.headers, - stream=AsyncResponseStream(resp.stream), - extensions=resp.extensions, - ) - - async def aclose(self) -> None: - await self._pool.aclose() diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/importlib_resources/tests/test_files.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/importlib_resources/tests/test_files.py deleted file mode 100644 index 197a063ba43ffa7884b6789247468c4190fea457..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/importlib_resources/tests/test_files.py +++ /dev/null @@ -1,112 +0,0 @@ -import typing -import textwrap -import unittest -import warnings -import importlib -import contextlib - -import importlib_resources as resources -from ..abc import Traversable -from . import data01 -from . import util -from . import _path -from ._compat import os_helper, import_helper - - -@contextlib.contextmanager -def suppress_known_deprecation(): - with warnings.catch_warnings(record=True) as ctx: - warnings.simplefilter('default', category=DeprecationWarning) - yield ctx - - -class FilesTests: - def test_read_bytes(self): - files = resources.files(self.data) - actual = files.joinpath('utf-8.file').read_bytes() - assert actual == b'Hello, UTF-8 world!\n' - - def test_read_text(self): - files = resources.files(self.data) - actual = files.joinpath('utf-8.file').read_text(encoding='utf-8') - assert actual == 'Hello, UTF-8 world!\n' - - @unittest.skipUnless( - hasattr(typing, 'runtime_checkable'), - "Only suitable when typing supports runtime_checkable", - ) - def test_traversable(self): - assert isinstance(resources.files(self.data), Traversable) - - def test_old_parameter(self): - """ - Files used to take a 'package' parameter. Make sure anyone - passing by name is still supported. - """ - with suppress_known_deprecation(): - resources.files(package=self.data) - - -class OpenDiskTests(FilesTests, unittest.TestCase): - def setUp(self): - self.data = data01 - - -class OpenZipTests(FilesTests, util.ZipSetup, unittest.TestCase): - pass - - -class OpenNamespaceTests(FilesTests, unittest.TestCase): - def setUp(self): - from . import namespacedata01 - - self.data = namespacedata01 - - -class SiteDir: - def setUp(self): - self.fixtures = contextlib.ExitStack() - self.addCleanup(self.fixtures.close) - self.site_dir = self.fixtures.enter_context(os_helper.temp_dir()) - self.fixtures.enter_context(import_helper.DirsOnSysPath(self.site_dir)) - self.fixtures.enter_context(import_helper.CleanImport()) - - -class ModulesFilesTests(SiteDir, unittest.TestCase): - def test_module_resources(self): - """ - A module can have resources found adjacent to the module. - """ - spec = { - 'mod.py': '', - 'res.txt': 'resources are the best', - } - _path.build(spec, self.site_dir) - import mod - - actual = resources.files(mod).joinpath('res.txt').read_text(encoding='utf-8') - assert actual == spec['res.txt'] - - -class ImplicitContextFilesTests(SiteDir, unittest.TestCase): - def test_implicit_files(self): - """ - Without any parameter, files() will infer the location as the caller. - """ - spec = { - 'somepkg': { - '__init__.py': textwrap.dedent( - """ - import importlib_resources as res - val = res.files().joinpath('res.txt').read_text(encoding='utf-8') - """ - ), - 'res.txt': 'resources are the best', - }, - } - _path.build(spec, self.site_dir) - assert importlib.import_module('somepkg').val == 'resources are the best' - - -if __name__ == '__main__': - unittest.main() diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/mpl_toolkits/axisartist/tests/test_axislines.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/mpl_toolkits/axisartist/tests/test_axislines.py deleted file mode 100644 index b722316a5c0c01fff91be6c67dc7223f307ece2a..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/mpl_toolkits/axisartist/tests/test_axislines.py +++ /dev/null @@ -1,147 +0,0 @@ -import numpy as np -import matplotlib.pyplot as plt -from matplotlib.testing.decorators import image_comparison -from matplotlib.transforms import IdentityTransform - -from mpl_toolkits.axisartist.axislines import AxesZero, SubplotZero, Subplot -from mpl_toolkits.axisartist import Axes, SubplotHost - - -@image_comparison(['SubplotZero.png'], style='default') -def test_SubplotZero(): - # Remove this line when this test image is regenerated. - plt.rcParams['text.kerning_factor'] = 6 - - fig = plt.figure() - - ax = SubplotZero(fig, 1, 1, 1) - fig.add_subplot(ax) - - ax.axis["xzero"].set_visible(True) - ax.axis["xzero"].label.set_text("Axis Zero") - - for n in ["top", "right"]: - ax.axis[n].set_visible(False) - - xx = np.arange(0, 2 * np.pi, 0.01) - ax.plot(xx, np.sin(xx)) - ax.set_ylabel("Test") - - -@image_comparison(['Subplot.png'], style='default') -def test_Subplot(): - # Remove this line when this test image is regenerated. - plt.rcParams['text.kerning_factor'] = 6 - - fig = plt.figure() - - ax = Subplot(fig, 1, 1, 1) - fig.add_subplot(ax) - - xx = np.arange(0, 2 * np.pi, 0.01) - ax.plot(xx, np.sin(xx)) - ax.set_ylabel("Test") - - ax.axis["top"].major_ticks.set_tick_out(True) - ax.axis["bottom"].major_ticks.set_tick_out(True) - - ax.axis["bottom"].set_label("Tk0") - - -def test_Axes(): - fig = plt.figure() - ax = Axes(fig, [0.15, 0.1, 0.65, 0.8]) - fig.add_axes(ax) - ax.plot([1, 2, 3], [0, 1, 2]) - ax.set_xscale('log') - fig.canvas.draw() - - -@image_comparison(['ParasiteAxesAuxTrans_meshplot.png'], - remove_text=True, style='default', tol=0.075) -def test_ParasiteAxesAuxTrans(): - data = np.ones((6, 6)) - data[2, 2] = 2 - data[0, :] = 0 - data[-2, :] = 0 - data[:, 0] = 0 - data[:, -2] = 0 - x = np.arange(6) - y = np.arange(6) - xx, yy = np.meshgrid(x, y) - - funcnames = ['pcolor', 'pcolormesh', 'contourf'] - - fig = plt.figure() - for i, name in enumerate(funcnames): - - ax1 = SubplotHost(fig, 1, 3, i+1) - fig.add_subplot(ax1) - - ax2 = ax1.get_aux_axes(IdentityTransform(), viewlim_mode=None) - if name.startswith('pcolor'): - getattr(ax2, name)(xx, yy, data[:-1, :-1]) - else: - getattr(ax2, name)(xx, yy, data) - ax1.set_xlim((0, 5)) - ax1.set_ylim((0, 5)) - - ax2.contour(xx, yy, data, colors='k') - - -@image_comparison(['axisline_style.png'], remove_text=True, style='mpl20') -def test_axisline_style(): - fig = plt.figure(figsize=(2, 2)) - ax = fig.add_subplot(axes_class=AxesZero) - ax.axis["xzero"].set_axisline_style("-|>") - ax.axis["xzero"].set_visible(True) - ax.axis["yzero"].set_axisline_style("->") - ax.axis["yzero"].set_visible(True) - - for direction in ("left", "right", "bottom", "top"): - ax.axis[direction].set_visible(False) - - -@image_comparison(['axisline_style_size_color.png'], remove_text=True, - style='mpl20') -def test_axisline_style_size_color(): - fig = plt.figure(figsize=(2, 2)) - ax = fig.add_subplot(axes_class=AxesZero) - ax.axis["xzero"].set_axisline_style("-|>", size=2.0, facecolor='r') - ax.axis["xzero"].set_visible(True) - ax.axis["yzero"].set_axisline_style("->, size=1.5") - ax.axis["yzero"].set_visible(True) - - for direction in ("left", "right", "bottom", "top"): - ax.axis[direction].set_visible(False) - - -@image_comparison(['axisline_style_tight.png'], remove_text=True, - style='mpl20') -def test_axisline_style_tight(): - fig = plt.figure(figsize=(2, 2)) - ax = fig.add_subplot(axes_class=AxesZero) - ax.axis["xzero"].set_axisline_style("-|>", size=5, facecolor='g') - ax.axis["xzero"].set_visible(True) - ax.axis["yzero"].set_axisline_style("->, size=8") - ax.axis["yzero"].set_visible(True) - - for direction in ("left", "right", "bottom", "top"): - ax.axis[direction].set_visible(False) - - fig.tight_layout() - - -@image_comparison(['subplotzero_ylabel.png'], style='mpl20') -def test_subplotzero_ylabel(): - fig = plt.figure() - ax = fig.add_subplot(111, axes_class=SubplotZero) - - ax.set(xlim=(-3, 7), ylim=(-3, 7), xlabel="x", ylabel="y") - - zero_axis = ax.axis["xzero", "yzero"] - zero_axis.set_visible(True) # they are hidden by default - - ax.axis["left", "right", "bottom", "top"].set_visible(False) - - zero_axis.set_axisline_style("->") diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/frame/methods/test_compare.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/frame/methods/test_compare.py deleted file mode 100644 index a4d0a7068a3a650beb11529065d0b62ab702143b..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/frame/methods/test_compare.py +++ /dev/null @@ -1,305 +0,0 @@ -import numpy as np -import pytest - -from pandas.compat.numpy import np_version_gte1p25 - -import pandas as pd -import pandas._testing as tm - - -@pytest.mark.parametrize("align_axis", [0, 1, "index", "columns"]) -def test_compare_axis(align_axis): - # GH#30429 - df = pd.DataFrame( - {"col1": ["a", "b", "c"], "col2": [1.0, 2.0, np.nan], "col3": [1.0, 2.0, 3.0]}, - columns=["col1", "col2", "col3"], - ) - df2 = df.copy() - df2.loc[0, "col1"] = "c" - df2.loc[2, "col3"] = 4.0 - - result = df.compare(df2, align_axis=align_axis) - - if align_axis in (1, "columns"): - indices = pd.Index([0, 2]) - columns = pd.MultiIndex.from_product([["col1", "col3"], ["self", "other"]]) - expected = pd.DataFrame( - [["a", "c", np.nan, np.nan], [np.nan, np.nan, 3.0, 4.0]], - index=indices, - columns=columns, - ) - else: - indices = pd.MultiIndex.from_product([[0, 2], ["self", "other"]]) - columns = pd.Index(["col1", "col3"]) - expected = pd.DataFrame( - [["a", np.nan], ["c", np.nan], [np.nan, 3.0], [np.nan, 4.0]], - index=indices, - columns=columns, - ) - tm.assert_frame_equal(result, expected) - - -@pytest.mark.parametrize( - "keep_shape, keep_equal", - [ - (True, False), - (False, True), - (True, True), - # False, False case is already covered in test_compare_axis - ], -) -def test_compare_various_formats(keep_shape, keep_equal): - df = pd.DataFrame( - {"col1": ["a", "b", "c"], "col2": [1.0, 2.0, np.nan], "col3": [1.0, 2.0, 3.0]}, - columns=["col1", "col2", "col3"], - ) - df2 = df.copy() - df2.loc[0, "col1"] = "c" - df2.loc[2, "col3"] = 4.0 - - result = df.compare(df2, keep_shape=keep_shape, keep_equal=keep_equal) - - if keep_shape: - indices = pd.Index([0, 1, 2]) - columns = pd.MultiIndex.from_product( - [["col1", "col2", "col3"], ["self", "other"]] - ) - if keep_equal: - expected = pd.DataFrame( - [ - ["a", "c", 1.0, 1.0, 1.0, 1.0], - ["b", "b", 2.0, 2.0, 2.0, 2.0], - ["c", "c", np.nan, np.nan, 3.0, 4.0], - ], - index=indices, - columns=columns, - ) - else: - expected = pd.DataFrame( - [ - ["a", "c", np.nan, np.nan, np.nan, np.nan], - [np.nan, np.nan, np.nan, np.nan, np.nan, np.nan], - [np.nan, np.nan, np.nan, np.nan, 3.0, 4.0], - ], - index=indices, - columns=columns, - ) - else: - indices = pd.Index([0, 2]) - columns = pd.MultiIndex.from_product([["col1", "col3"], ["self", "other"]]) - expected = pd.DataFrame( - [["a", "c", 1.0, 1.0], ["c", "c", 3.0, 4.0]], index=indices, columns=columns - ) - tm.assert_frame_equal(result, expected) - - -def test_compare_with_equal_nulls(): - # We want to make sure two NaNs are considered the same - # and dropped where applicable - df = pd.DataFrame( - {"col1": ["a", "b", "c"], "col2": [1.0, 2.0, np.nan], "col3": [1.0, 2.0, 3.0]}, - columns=["col1", "col2", "col3"], - ) - df2 = df.copy() - df2.loc[0, "col1"] = "c" - - result = df.compare(df2) - indices = pd.Index([0]) - columns = pd.MultiIndex.from_product([["col1"], ["self", "other"]]) - expected = pd.DataFrame([["a", "c"]], index=indices, columns=columns) - tm.assert_frame_equal(result, expected) - - -def test_compare_with_non_equal_nulls(): - # We want to make sure the relevant NaNs do not get dropped - # even if the entire row or column are NaNs - df = pd.DataFrame( - {"col1": ["a", "b", "c"], "col2": [1.0, 2.0, np.nan], "col3": [1.0, 2.0, 3.0]}, - columns=["col1", "col2", "col3"], - ) - df2 = df.copy() - df2.loc[0, "col1"] = "c" - df2.loc[2, "col3"] = np.nan - - result = df.compare(df2) - - indices = pd.Index([0, 2]) - columns = pd.MultiIndex.from_product([["col1", "col3"], ["self", "other"]]) - expected = pd.DataFrame( - [["a", "c", np.nan, np.nan], [np.nan, np.nan, 3.0, np.nan]], - index=indices, - columns=columns, - ) - tm.assert_frame_equal(result, expected) - - -@pytest.mark.parametrize("align_axis", [0, 1]) -def test_compare_multi_index(align_axis): - df = pd.DataFrame( - {"col1": ["a", "b", "c"], "col2": [1.0, 2.0, np.nan], "col3": [1.0, 2.0, 3.0]} - ) - df.columns = pd.MultiIndex.from_arrays([["a", "a", "b"], ["col1", "col2", "col3"]]) - df.index = pd.MultiIndex.from_arrays([["x", "x", "y"], [0, 1, 2]]) - - df2 = df.copy() - df2.iloc[0, 0] = "c" - df2.iloc[2, 2] = 4.0 - - result = df.compare(df2, align_axis=align_axis) - - if align_axis == 0: - indices = pd.MultiIndex.from_arrays( - [["x", "x", "y", "y"], [0, 0, 2, 2], ["self", "other", "self", "other"]] - ) - columns = pd.MultiIndex.from_arrays([["a", "b"], ["col1", "col3"]]) - data = [["a", np.nan], ["c", np.nan], [np.nan, 3.0], [np.nan, 4.0]] - else: - indices = pd.MultiIndex.from_arrays([["x", "y"], [0, 2]]) - columns = pd.MultiIndex.from_arrays( - [ - ["a", "a", "b", "b"], - ["col1", "col1", "col3", "col3"], - ["self", "other", "self", "other"], - ] - ) - data = [["a", "c", np.nan, np.nan], [np.nan, np.nan, 3.0, 4.0]] - - expected = pd.DataFrame(data=data, index=indices, columns=columns) - tm.assert_frame_equal(result, expected) - - -def test_compare_unaligned_objects(): - # test DataFrames with different indices - msg = ( - r"Can only compare identically-labeled \(both index and columns\) DataFrame " - "objects" - ) - with pytest.raises(ValueError, match=msg): - df1 = pd.DataFrame([1, 2, 3], index=["a", "b", "c"]) - df2 = pd.DataFrame([1, 2, 3], index=["a", "b", "d"]) - df1.compare(df2) - - # test DataFrames with different shapes - msg = ( - r"Can only compare identically-labeled \(both index and columns\) DataFrame " - "objects" - ) - with pytest.raises(ValueError, match=msg): - df1 = pd.DataFrame(np.ones((3, 3))) - df2 = pd.DataFrame(np.zeros((2, 1))) - df1.compare(df2) - - -def test_compare_result_names(): - # GH 44354 - df1 = pd.DataFrame( - {"col1": ["a", "b", "c"], "col2": [1.0, 2.0, np.nan], "col3": [1.0, 2.0, 3.0]}, - ) - df2 = pd.DataFrame( - { - "col1": ["c", "b", "c"], - "col2": [1.0, 2.0, np.nan], - "col3": [1.0, 2.0, np.nan], - }, - ) - result = df1.compare(df2, result_names=("left", "right")) - expected = pd.DataFrame( - { - ("col1", "left"): {0: "a", 2: np.nan}, - ("col1", "right"): {0: "c", 2: np.nan}, - ("col3", "left"): {0: np.nan, 2: 3.0}, - ("col3", "right"): {0: np.nan, 2: np.nan}, - } - ) - tm.assert_frame_equal(result, expected) - - -@pytest.mark.parametrize( - "result_names", - [ - [1, 2], - "HK", - {"2": 2, "3": 3}, - 3, - 3.0, - ], -) -def test_invalid_input_result_names(result_names): - # GH 44354 - df1 = pd.DataFrame( - {"col1": ["a", "b", "c"], "col2": [1.0, 2.0, np.nan], "col3": [1.0, 2.0, 3.0]}, - ) - df2 = pd.DataFrame( - { - "col1": ["c", "b", "c"], - "col2": [1.0, 2.0, np.nan], - "col3": [1.0, 2.0, np.nan], - }, - ) - with pytest.raises( - TypeError, - match=( - f"Passing 'result_names' as a {type(result_names)} is not " - "supported. Provide 'result_names' as a tuple instead." - ), - ): - df1.compare(df2, result_names=result_names) - - -@pytest.mark.parametrize( - "val1,val2", - [(4, pd.NA), (pd.NA, pd.NA), (pd.NA, 4)], -) -def test_compare_ea_and_np_dtype(val1, val2): - # GH 48966 - arr = [4.0, val1] - ser = pd.Series([1, val2], dtype="Int64") - - df1 = pd.DataFrame({"a": arr, "b": [1.0, 2]}) - df2 = pd.DataFrame({"a": ser, "b": [1.0, 2]}) - expected = pd.DataFrame( - { - ("a", "self"): arr, - ("a", "other"): ser, - ("b", "self"): np.nan, - ("b", "other"): np.nan, - } - ) - if val1 is pd.NA and val2 is pd.NA: - # GH#18463 TODO: is this really the desired behavior? - expected.loc[1, ("a", "self")] = np.nan - - if val1 is pd.NA and np_version_gte1p25: - # can't compare with numpy array if it contains pd.NA - with pytest.raises(TypeError, match="boolean value of NA is ambiguous"): - result = df1.compare(df2, keep_shape=True) - else: - result = df1.compare(df2, keep_shape=True) - tm.assert_frame_equal(result, expected) - - -@pytest.mark.parametrize( - "df1_val,df2_val,diff_self,diff_other", - [ - (4, 3, 4, 3), - (4, 4, pd.NA, pd.NA), - (4, pd.NA, 4, pd.NA), - (pd.NA, pd.NA, pd.NA, pd.NA), - ], -) -def test_compare_nullable_int64_dtype(df1_val, df2_val, diff_self, diff_other): - # GH 48966 - df1 = pd.DataFrame({"a": pd.Series([df1_val, pd.NA], dtype="Int64"), "b": [1.0, 2]}) - df2 = df1.copy() - df2.loc[0, "a"] = df2_val - - expected = pd.DataFrame( - { - ("a", "self"): pd.Series([diff_self, pd.NA], dtype="Int64"), - ("a", "other"): pd.Series([diff_other, pd.NA], dtype="Int64"), - ("b", "self"): np.nan, - ("b", "other"): np.nan, - } - ) - result = df1.compare(df2, keep_shape=True) - tm.assert_frame_equal(result, expected) diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_vendor/distlib/index.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_vendor/distlib/index.py deleted file mode 100644 index b1fbbf8e8d2a47d0a7d2fe0b4568fd11f8be4c36..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_vendor/distlib/index.py +++ /dev/null @@ -1,509 +0,0 @@ -# -*- coding: utf-8 -*- -# -# Copyright (C) 2013 Vinay Sajip. -# Licensed to the Python Software Foundation under a contributor agreement. -# See LICENSE.txt and CONTRIBUTORS.txt. -# -import hashlib -import logging -import os -import shutil -import subprocess -import tempfile -try: - from threading import Thread -except ImportError: - from dummy_threading import Thread - -from . import DistlibException -from .compat import (HTTPBasicAuthHandler, Request, HTTPPasswordMgr, - urlparse, build_opener, string_types) -from .util import zip_dir, ServerProxy - -logger = logging.getLogger(__name__) - -DEFAULT_INDEX = 'https://pypi.org/pypi' -DEFAULT_REALM = 'pypi' - -class PackageIndex(object): - """ - This class represents a package index compatible with PyPI, the Python - Package Index. - """ - - boundary = b'----------ThIs_Is_tHe_distlib_index_bouNdaRY_$' - - def __init__(self, url=None): - """ - Initialise an instance. - - :param url: The URL of the index. If not specified, the URL for PyPI is - used. - """ - self.url = url or DEFAULT_INDEX - self.read_configuration() - scheme, netloc, path, params, query, frag = urlparse(self.url) - if params or query or frag or scheme not in ('http', 'https'): - raise DistlibException('invalid repository: %s' % self.url) - self.password_handler = None - self.ssl_verifier = None - self.gpg = None - self.gpg_home = None - with open(os.devnull, 'w') as sink: - # Use gpg by default rather than gpg2, as gpg2 insists on - # prompting for passwords - for s in ('gpg', 'gpg2'): - try: - rc = subprocess.check_call([s, '--version'], stdout=sink, - stderr=sink) - if rc == 0: - self.gpg = s - break - except OSError: - pass - - def _get_pypirc_command(self): - """ - Get the distutils command for interacting with PyPI configurations. - :return: the command. - """ - from .util import _get_pypirc_command as cmd - return cmd() - - def read_configuration(self): - """ - Read the PyPI access configuration as supported by distutils. This populates - ``username``, ``password``, ``realm`` and ``url`` attributes from the - configuration. - """ - from .util import _load_pypirc - cfg = _load_pypirc(self) - self.username = cfg.get('username') - self.password = cfg.get('password') - self.realm = cfg.get('realm', 'pypi') - self.url = cfg.get('repository', self.url) - - def save_configuration(self): - """ - Save the PyPI access configuration. You must have set ``username`` and - ``password`` attributes before calling this method. - """ - self.check_credentials() - from .util import _store_pypirc - _store_pypirc(self) - - def check_credentials(self): - """ - Check that ``username`` and ``password`` have been set, and raise an - exception if not. - """ - if self.username is None or self.password is None: - raise DistlibException('username and password must be set') - pm = HTTPPasswordMgr() - _, netloc, _, _, _, _ = urlparse(self.url) - pm.add_password(self.realm, netloc, self.username, self.password) - self.password_handler = HTTPBasicAuthHandler(pm) - - def register(self, metadata): - """ - Register a distribution on PyPI, using the provided metadata. - - :param metadata: A :class:`Metadata` instance defining at least a name - and version number for the distribution to be - registered. - :return: The HTTP response received from PyPI upon submission of the - request. - """ - self.check_credentials() - metadata.validate() - d = metadata.todict() - d[':action'] = 'verify' - request = self.encode_request(d.items(), []) - response = self.send_request(request) - d[':action'] = 'submit' - request = self.encode_request(d.items(), []) - return self.send_request(request) - - def _reader(self, name, stream, outbuf): - """ - Thread runner for reading lines of from a subprocess into a buffer. - - :param name: The logical name of the stream (used for logging only). - :param stream: The stream to read from. This will typically a pipe - connected to the output stream of a subprocess. - :param outbuf: The list to append the read lines to. - """ - while True: - s = stream.readline() - if not s: - break - s = s.decode('utf-8').rstrip() - outbuf.append(s) - logger.debug('%s: %s' % (name, s)) - stream.close() - - def get_sign_command(self, filename, signer, sign_password, - keystore=None): - """ - Return a suitable command for signing a file. - - :param filename: The pathname to the file to be signed. - :param signer: The identifier of the signer of the file. - :param sign_password: The passphrase for the signer's - private key used for signing. - :param keystore: The path to a directory which contains the keys - used in verification. If not specified, the - instance's ``gpg_home`` attribute is used instead. - :return: The signing command as a list suitable to be - passed to :class:`subprocess.Popen`. - """ - cmd = [self.gpg, '--status-fd', '2', '--no-tty'] - if keystore is None: - keystore = self.gpg_home - if keystore: - cmd.extend(['--homedir', keystore]) - if sign_password is not None: - cmd.extend(['--batch', '--passphrase-fd', '0']) - td = tempfile.mkdtemp() - sf = os.path.join(td, os.path.basename(filename) + '.asc') - cmd.extend(['--detach-sign', '--armor', '--local-user', - signer, '--output', sf, filename]) - logger.debug('invoking: %s', ' '.join(cmd)) - return cmd, sf - - def run_command(self, cmd, input_data=None): - """ - Run a command in a child process , passing it any input data specified. - - :param cmd: The command to run. - :param input_data: If specified, this must be a byte string containing - data to be sent to the child process. - :return: A tuple consisting of the subprocess' exit code, a list of - lines read from the subprocess' ``stdout``, and a list of - lines read from the subprocess' ``stderr``. - """ - kwargs = { - 'stdout': subprocess.PIPE, - 'stderr': subprocess.PIPE, - } - if input_data is not None: - kwargs['stdin'] = subprocess.PIPE - stdout = [] - stderr = [] - p = subprocess.Popen(cmd, **kwargs) - # We don't use communicate() here because we may need to - # get clever with interacting with the command - t1 = Thread(target=self._reader, args=('stdout', p.stdout, stdout)) - t1.start() - t2 = Thread(target=self._reader, args=('stderr', p.stderr, stderr)) - t2.start() - if input_data is not None: - p.stdin.write(input_data) - p.stdin.close() - - p.wait() - t1.join() - t2.join() - return p.returncode, stdout, stderr - - def sign_file(self, filename, signer, sign_password, keystore=None): - """ - Sign a file. - - :param filename: The pathname to the file to be signed. - :param signer: The identifier of the signer of the file. - :param sign_password: The passphrase for the signer's - private key used for signing. - :param keystore: The path to a directory which contains the keys - used in signing. If not specified, the instance's - ``gpg_home`` attribute is used instead. - :return: The absolute pathname of the file where the signature is - stored. - """ - cmd, sig_file = self.get_sign_command(filename, signer, sign_password, - keystore) - rc, stdout, stderr = self.run_command(cmd, - sign_password.encode('utf-8')) - if rc != 0: - raise DistlibException('sign command failed with error ' - 'code %s' % rc) - return sig_file - - def upload_file(self, metadata, filename, signer=None, sign_password=None, - filetype='sdist', pyversion='source', keystore=None): - """ - Upload a release file to the index. - - :param metadata: A :class:`Metadata` instance defining at least a name - and version number for the file to be uploaded. - :param filename: The pathname of the file to be uploaded. - :param signer: The identifier of the signer of the file. - :param sign_password: The passphrase for the signer's - private key used for signing. - :param filetype: The type of the file being uploaded. This is the - distutils command which produced that file, e.g. - ``sdist`` or ``bdist_wheel``. - :param pyversion: The version of Python which the release relates - to. For code compatible with any Python, this would - be ``source``, otherwise it would be e.g. ``3.2``. - :param keystore: The path to a directory which contains the keys - used in signing. If not specified, the instance's - ``gpg_home`` attribute is used instead. - :return: The HTTP response received from PyPI upon submission of the - request. - """ - self.check_credentials() - if not os.path.exists(filename): - raise DistlibException('not found: %s' % filename) - metadata.validate() - d = metadata.todict() - sig_file = None - if signer: - if not self.gpg: - logger.warning('no signing program available - not signed') - else: - sig_file = self.sign_file(filename, signer, sign_password, - keystore) - with open(filename, 'rb') as f: - file_data = f.read() - md5_digest = hashlib.md5(file_data).hexdigest() - sha256_digest = hashlib.sha256(file_data).hexdigest() - d.update({ - ':action': 'file_upload', - 'protocol_version': '1', - 'filetype': filetype, - 'pyversion': pyversion, - 'md5_digest': md5_digest, - 'sha256_digest': sha256_digest, - }) - files = [('content', os.path.basename(filename), file_data)] - if sig_file: - with open(sig_file, 'rb') as f: - sig_data = f.read() - files.append(('gpg_signature', os.path.basename(sig_file), - sig_data)) - shutil.rmtree(os.path.dirname(sig_file)) - request = self.encode_request(d.items(), files) - return self.send_request(request) - - def upload_documentation(self, metadata, doc_dir): - """ - Upload documentation to the index. - - :param metadata: A :class:`Metadata` instance defining at least a name - and version number for the documentation to be - uploaded. - :param doc_dir: The pathname of the directory which contains the - documentation. This should be the directory that - contains the ``index.html`` for the documentation. - :return: The HTTP response received from PyPI upon submission of the - request. - """ - self.check_credentials() - if not os.path.isdir(doc_dir): - raise DistlibException('not a directory: %r' % doc_dir) - fn = os.path.join(doc_dir, 'index.html') - if not os.path.exists(fn): - raise DistlibException('not found: %r' % fn) - metadata.validate() - name, version = metadata.name, metadata.version - zip_data = zip_dir(doc_dir).getvalue() - fields = [(':action', 'doc_upload'), - ('name', name), ('version', version)] - files = [('content', name, zip_data)] - request = self.encode_request(fields, files) - return self.send_request(request) - - def get_verify_command(self, signature_filename, data_filename, - keystore=None): - """ - Return a suitable command for verifying a file. - - :param signature_filename: The pathname to the file containing the - signature. - :param data_filename: The pathname to the file containing the - signed data. - :param keystore: The path to a directory which contains the keys - used in verification. If not specified, the - instance's ``gpg_home`` attribute is used instead. - :return: The verifying command as a list suitable to be - passed to :class:`subprocess.Popen`. - """ - cmd = [self.gpg, '--status-fd', '2', '--no-tty'] - if keystore is None: - keystore = self.gpg_home - if keystore: - cmd.extend(['--homedir', keystore]) - cmd.extend(['--verify', signature_filename, data_filename]) - logger.debug('invoking: %s', ' '.join(cmd)) - return cmd - - def verify_signature(self, signature_filename, data_filename, - keystore=None): - """ - Verify a signature for a file. - - :param signature_filename: The pathname to the file containing the - signature. - :param data_filename: The pathname to the file containing the - signed data. - :param keystore: The path to a directory which contains the keys - used in verification. If not specified, the - instance's ``gpg_home`` attribute is used instead. - :return: True if the signature was verified, else False. - """ - if not self.gpg: - raise DistlibException('verification unavailable because gpg ' - 'unavailable') - cmd = self.get_verify_command(signature_filename, data_filename, - keystore) - rc, stdout, stderr = self.run_command(cmd) - if rc not in (0, 1): - raise DistlibException('verify command failed with error ' - 'code %s' % rc) - return rc == 0 - - def download_file(self, url, destfile, digest=None, reporthook=None): - """ - This is a convenience method for downloading a file from an URL. - Normally, this will be a file from the index, though currently - no check is made for this (i.e. a file can be downloaded from - anywhere). - - The method is just like the :func:`urlretrieve` function in the - standard library, except that it allows digest computation to be - done during download and checking that the downloaded data - matched any expected value. - - :param url: The URL of the file to be downloaded (assumed to be - available via an HTTP GET request). - :param destfile: The pathname where the downloaded file is to be - saved. - :param digest: If specified, this must be a (hasher, value) - tuple, where hasher is the algorithm used (e.g. - ``'md5'``) and ``value`` is the expected value. - :param reporthook: The same as for :func:`urlretrieve` in the - standard library. - """ - if digest is None: - digester = None - logger.debug('No digest specified') - else: - if isinstance(digest, (list, tuple)): - hasher, digest = digest - else: - hasher = 'md5' - digester = getattr(hashlib, hasher)() - logger.debug('Digest specified: %s' % digest) - # The following code is equivalent to urlretrieve. - # We need to do it this way so that we can compute the - # digest of the file as we go. - with open(destfile, 'wb') as dfp: - # addinfourl is not a context manager on 2.x - # so we have to use try/finally - sfp = self.send_request(Request(url)) - try: - headers = sfp.info() - blocksize = 8192 - size = -1 - read = 0 - blocknum = 0 - if "content-length" in headers: - size = int(headers["Content-Length"]) - if reporthook: - reporthook(blocknum, blocksize, size) - while True: - block = sfp.read(blocksize) - if not block: - break - read += len(block) - dfp.write(block) - if digester: - digester.update(block) - blocknum += 1 - if reporthook: - reporthook(blocknum, blocksize, size) - finally: - sfp.close() - - # check that we got the whole file, if we can - if size >= 0 and read < size: - raise DistlibException( - 'retrieval incomplete: got only %d out of %d bytes' - % (read, size)) - # if we have a digest, it must match. - if digester: - actual = digester.hexdigest() - if digest != actual: - raise DistlibException('%s digest mismatch for %s: expected ' - '%s, got %s' % (hasher, destfile, - digest, actual)) - logger.debug('Digest verified: %s', digest) - - def send_request(self, req): - """ - Send a standard library :class:`Request` to PyPI and return its - response. - - :param req: The request to send. - :return: The HTTP response from PyPI (a standard library HTTPResponse). - """ - handlers = [] - if self.password_handler: - handlers.append(self.password_handler) - if self.ssl_verifier: - handlers.append(self.ssl_verifier) - opener = build_opener(*handlers) - return opener.open(req) - - def encode_request(self, fields, files): - """ - Encode fields and files for posting to an HTTP server. - - :param fields: The fields to send as a list of (fieldname, value) - tuples. - :param files: The files to send as a list of (fieldname, filename, - file_bytes) tuple. - """ - # Adapted from packaging, which in turn was adapted from - # http://code.activestate.com/recipes/146306 - - parts = [] - boundary = self.boundary - for k, values in fields: - if not isinstance(values, (list, tuple)): - values = [values] - - for v in values: - parts.extend(( - b'--' + boundary, - ('Content-Disposition: form-data; name="%s"' % - k).encode('utf-8'), - b'', - v.encode('utf-8'))) - for key, filename, value in files: - parts.extend(( - b'--' + boundary, - ('Content-Disposition: form-data; name="%s"; filename="%s"' % - (key, filename)).encode('utf-8'), - b'', - value)) - - parts.extend((b'--' + boundary + b'--', b'')) - - body = b'\r\n'.join(parts) - ct = b'multipart/form-data; boundary=' + boundary - headers = { - 'Content-type': ct, - 'Content-length': str(len(body)) - } - return Request(self.url, body, headers) - - def search(self, terms, operator=None): - if isinstance(terms, string_types): - terms = {'name': terms} - rpc_proxy = ServerProxy(self.url, timeout=3.0) - try: - return rpc_proxy.search(terms, operator or 'and') - finally: - rpc_proxy('close')() diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/_cl_builtins.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/_cl_builtins.py deleted file mode 100644 index beb7b4d6f10254cbbf8c84585a79e92f6fe03fa1..0000000000000000000000000000000000000000 --- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/_cl_builtins.py +++ /dev/null @@ -1,231 +0,0 @@ -""" - pygments.lexers._cl_builtins - ~~~~~~~~~~~~~~~~~~~~~~~~~~~~ - - ANSI Common Lisp builtins. - - :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS. - :license: BSD, see LICENSE for details. -""" - -BUILTIN_FUNCTIONS = { # 638 functions - '<', '<=', '=', '>', '>=', '-', '/', '/=', '*', '+', '1-', '1+', - 'abort', 'abs', 'acons', 'acos', 'acosh', 'add-method', 'adjoin', - 'adjustable-array-p', 'adjust-array', 'allocate-instance', - 'alpha-char-p', 'alphanumericp', 'append', 'apply', 'apropos', - 'apropos-list', 'aref', 'arithmetic-error-operands', - 'arithmetic-error-operation', 'array-dimension', 'array-dimensions', - 'array-displacement', 'array-element-type', 'array-has-fill-pointer-p', - 'array-in-bounds-p', 'arrayp', 'array-rank', 'array-row-major-index', - 'array-total-size', 'ash', 'asin', 'asinh', 'assoc', 'assoc-if', - 'assoc-if-not', 'atan', 'atanh', 'atom', 'bit', 'bit-and', 'bit-andc1', - 'bit-andc2', 'bit-eqv', 'bit-ior', 'bit-nand', 'bit-nor', 'bit-not', - 'bit-orc1', 'bit-orc2', 'bit-vector-p', 'bit-xor', 'boole', - 'both-case-p', 'boundp', 'break', 'broadcast-stream-streams', - 'butlast', 'byte', 'byte-position', 'byte-size', 'caaaar', 'caaadr', - 'caaar', 'caadar', 'caaddr', 'caadr', 'caar', 'cadaar', 'cadadr', - 'cadar', 'caddar', 'cadddr', 'caddr', 'cadr', 'call-next-method', 'car', - 'cdaaar', 'cdaadr', 'cdaar', 'cdadar', 'cdaddr', 'cdadr', 'cdar', - 'cddaar', 'cddadr', 'cddar', 'cdddar', 'cddddr', 'cdddr', 'cddr', 'cdr', - 'ceiling', 'cell-error-name', 'cerror', 'change-class', 'char', 'char<', - 'char<=', 'char=', 'char>', 'char>=', 'char/=', 'character', - 'characterp', 'char-code', 'char-downcase', 'char-equal', - 'char-greaterp', 'char-int', 'char-lessp', 'char-name', - 'char-not-equal', 'char-not-greaterp', 'char-not-lessp', 'char-upcase', - 'cis', 'class-name', 'class-of', 'clear-input', 'clear-output', - 'close', 'clrhash', 'code-char', 'coerce', 'compile', - 'compiled-function-p', 'compile-file', 'compile-file-pathname', - 'compiler-macro-function', 'complement', 'complex', 'complexp', - 'compute-applicable-methods', 'compute-restarts', 'concatenate', - 'concatenated-stream-streams', 'conjugate', 'cons', 'consp', - 'constantly', 'constantp', 'continue', 'copy-alist', 'copy-list', - 'copy-pprint-dispatch', 'copy-readtable', 'copy-seq', 'copy-structure', - 'copy-symbol', 'copy-tree', 'cos', 'cosh', 'count', 'count-if', - 'count-if-not', 'decode-float', 'decode-universal-time', 'delete', - 'delete-duplicates', 'delete-file', 'delete-if', 'delete-if-not', - 'delete-package', 'denominator', 'deposit-field', 'describe', - 'describe-object', 'digit-char', 'digit-char-p', 'directory', - 'directory-namestring', 'disassemble', 'documentation', 'dpb', - 'dribble', 'echo-stream-input-stream', 'echo-stream-output-stream', - 'ed', 'eighth', 'elt', 'encode-universal-time', 'endp', - 'enough-namestring', 'ensure-directories-exist', - 'ensure-generic-function', 'eq', 'eql', 'equal', 'equalp', 'error', - 'eval', 'evenp', 'every', 'exp', 'export', 'expt', 'fboundp', - 'fceiling', 'fdefinition', 'ffloor', 'fifth', 'file-author', - 'file-error-pathname', 'file-length', 'file-namestring', - 'file-position', 'file-string-length', 'file-write-date', - 'fill', 'fill-pointer', 'find', 'find-all-symbols', 'find-class', - 'find-if', 'find-if-not', 'find-method', 'find-package', 'find-restart', - 'find-symbol', 'finish-output', 'first', 'float', 'float-digits', - 'floatp', 'float-precision', 'float-radix', 'float-sign', 'floor', - 'fmakunbound', 'force-output', 'format', 'fourth', 'fresh-line', - 'fround', 'ftruncate', 'funcall', 'function-keywords', - 'function-lambda-expression', 'functionp', 'gcd', 'gensym', 'gentemp', - 'get', 'get-decoded-time', 'get-dispatch-macro-character', 'getf', - 'gethash', 'get-internal-real-time', 'get-internal-run-time', - 'get-macro-character', 'get-output-stream-string', 'get-properties', - 'get-setf-expansion', 'get-universal-time', 'graphic-char-p', - 'hash-table-count', 'hash-table-p', 'hash-table-rehash-size', - 'hash-table-rehash-threshold', 'hash-table-size', 'hash-table-test', - 'host-namestring', 'identity', 'imagpart', 'import', - 'initialize-instance', 'input-stream-p', 'inspect', - 'integer-decode-float', 'integer-length', 'integerp', - 'interactive-stream-p', 'intern', 'intersection', - 'invalid-method-error', 'invoke-debugger', 'invoke-restart', - 'invoke-restart-interactively', 'isqrt', 'keywordp', 'last', 'lcm', - 'ldb', 'ldb-test', 'ldiff', 'length', 'lisp-implementation-type', - 'lisp-implementation-version', 'list', 'list*', 'list-all-packages', - 'listen', 'list-length', 'listp', 'load', - 'load-logical-pathname-translations', 'log', 'logand', 'logandc1', - 'logandc2', 'logbitp', 'logcount', 'logeqv', 'logical-pathname', - 'logical-pathname-translations', 'logior', 'lognand', 'lognor', - 'lognot', 'logorc1', 'logorc2', 'logtest', 'logxor', 'long-site-name', - 'lower-case-p', 'machine-instance', 'machine-type', 'machine-version', - 'macroexpand', 'macroexpand-1', 'macro-function', 'make-array', - 'make-broadcast-stream', 'make-concatenated-stream', 'make-condition', - 'make-dispatch-macro-character', 'make-echo-stream', 'make-hash-table', - 'make-instance', 'make-instances-obsolete', 'make-list', - 'make-load-form', 'make-load-form-saving-slots', 'make-package', - 'make-pathname', 'make-random-state', 'make-sequence', 'make-string', - 'make-string-input-stream', 'make-string-output-stream', 'make-symbol', - 'make-synonym-stream', 'make-two-way-stream', 'makunbound', 'map', - 'mapc', 'mapcan', 'mapcar', 'mapcon', 'maphash', 'map-into', 'mapl', - 'maplist', 'mask-field', 'max', 'member', 'member-if', 'member-if-not', - 'merge', 'merge-pathnames', 'method-combination-error', - 'method-qualifiers', 'min', 'minusp', 'mismatch', 'mod', - 'muffle-warning', 'name-char', 'namestring', 'nbutlast', 'nconc', - 'next-method-p', 'nintersection', 'ninth', 'no-applicable-method', - 'no-next-method', 'not', 'notany', 'notevery', 'nreconc', 'nreverse', - 'nset-difference', 'nset-exclusive-or', 'nstring-capitalize', - 'nstring-downcase', 'nstring-upcase', 'nsublis', 'nsubst', 'nsubst-if', - 'nsubst-if-not', 'nsubstitute', 'nsubstitute-if', 'nsubstitute-if-not', - 'nth', 'nthcdr', 'null', 'numberp', 'numerator', 'nunion', 'oddp', - 'open', 'open-stream-p', 'output-stream-p', 'package-error-package', - 'package-name', 'package-nicknames', 'packagep', - 'package-shadowing-symbols', 'package-used-by-list', 'package-use-list', - 'pairlis', 'parse-integer', 'parse-namestring', 'pathname', - 'pathname-device', 'pathname-directory', 'pathname-host', - 'pathname-match-p', 'pathname-name', 'pathnamep', 'pathname-type', - 'pathname-version', 'peek-char', 'phase', 'plusp', 'position', - 'position-if', 'position-if-not', 'pprint', 'pprint-dispatch', - 'pprint-fill', 'pprint-indent', 'pprint-linear', 'pprint-newline', - 'pprint-tab', 'pprint-tabular', 'prin1', 'prin1-to-string', 'princ', - 'princ-to-string', 'print', 'print-object', 'probe-file', 'proclaim', - 'provide', 'random', 'random-state-p', 'rassoc', 'rassoc-if', - 'rassoc-if-not', 'rational', 'rationalize', 'rationalp', 'read', - 'read-byte', 'read-char', 'read-char-no-hang', 'read-delimited-list', - 'read-from-string', 'read-line', 'read-preserving-whitespace', - 'read-sequence', 'readtable-case', 'readtablep', 'realp', 'realpart', - 'reduce', 'reinitialize-instance', 'rem', 'remhash', 'remove', - 'remove-duplicates', 'remove-if', 'remove-if-not', 'remove-method', - 'remprop', 'rename-file', 'rename-package', 'replace', 'require', - 'rest', 'restart-name', 'revappend', 'reverse', 'room', 'round', - 'row-major-aref', 'rplaca', 'rplacd', 'sbit', 'scale-float', 'schar', - 'search', 'second', 'set', 'set-difference', - 'set-dispatch-macro-character', 'set-exclusive-or', - 'set-macro-character', 'set-pprint-dispatch', 'set-syntax-from-char', - 'seventh', 'shadow', 'shadowing-import', 'shared-initialize', - 'short-site-name', 'signal', 'signum', 'simple-bit-vector-p', - 'simple-condition-format-arguments', 'simple-condition-format-control', - 'simple-string-p', 'simple-vector-p', 'sin', 'sinh', 'sixth', 'sleep', - 'slot-boundp', 'slot-exists-p', 'slot-makunbound', 'slot-missing', - 'slot-unbound', 'slot-value', 'software-type', 'software-version', - 'some', 'sort', 'special-operator-p', 'sqrt', 'stable-sort', - 'standard-char-p', 'store-value', 'stream-element-type', - 'stream-error-stream', 'stream-external-format', 'streamp', 'string', - 'string<', 'string<=', 'string=', 'string>', 'string>=', 'string/=', - 'string-capitalize', 'string-downcase', 'string-equal', - 'string-greaterp', 'string-left-trim', 'string-lessp', - 'string-not-equal', 'string-not-greaterp', 'string-not-lessp', - 'stringp', 'string-right-trim', 'string-trim', 'string-upcase', - 'sublis', 'subseq', 'subsetp', 'subst', 'subst-if', 'subst-if-not', - 'substitute', 'substitute-if', 'substitute-if-not', 'subtypep','svref', - 'sxhash', 'symbol-function', 'symbol-name', 'symbolp', 'symbol-package', - 'symbol-plist', 'symbol-value', 'synonym-stream-symbol', 'syntax:', - 'tailp', 'tan', 'tanh', 'tenth', 'terpri', 'third', - 'translate-logical-pathname', 'translate-pathname', 'tree-equal', - 'truename', 'truncate', 'two-way-stream-input-stream', - 'two-way-stream-output-stream', 'type-error-datum', - 'type-error-expected-type', 'type-of', 'typep', 'unbound-slot-instance', - 'unexport', 'unintern', 'union', 'unread-char', 'unuse-package', - 'update-instance-for-different-class', - 'update-instance-for-redefined-class', 'upgraded-array-element-type', - 'upgraded-complex-part-type', 'upper-case-p', 'use-package', - 'user-homedir-pathname', 'use-value', 'values', 'values-list', 'vector', - 'vectorp', 'vector-pop', 'vector-push', 'vector-push-extend', 'warn', - 'wild-pathname-p', 'write', 'write-byte', 'write-char', 'write-line', - 'write-sequence', 'write-string', 'write-to-string', 'yes-or-no-p', - 'y-or-n-p', 'zerop', -} - -SPECIAL_FORMS = { - 'block', 'catch', 'declare', 'eval-when', 'flet', 'function', 'go', 'if', - 'labels', 'lambda', 'let', 'let*', 'load-time-value', 'locally', 'macrolet', - 'multiple-value-call', 'multiple-value-prog1', 'progn', 'progv', 'quote', - 'return-from', 'setq', 'symbol-macrolet', 'tagbody', 'the', 'throw', - 'unwind-protect', -} - -MACROS = { - 'and', 'assert', 'call-method', 'case', 'ccase', 'check-type', 'cond', - 'ctypecase', 'decf', 'declaim', 'defclass', 'defconstant', 'defgeneric', - 'define-compiler-macro', 'define-condition', 'define-method-combination', - 'define-modify-macro', 'define-setf-expander', 'define-symbol-macro', - 'defmacro', 'defmethod', 'defpackage', 'defparameter', 'defsetf', - 'defstruct', 'deftype', 'defun', 'defvar', 'destructuring-bind', 'do', - 'do*', 'do-all-symbols', 'do-external-symbols', 'dolist', 'do-symbols', - 'dotimes', 'ecase', 'etypecase', 'formatter', 'handler-bind', - 'handler-case', 'ignore-errors', 'incf', 'in-package', 'lambda', 'loop', - 'loop-finish', 'make-method', 'multiple-value-bind', 'multiple-value-list', - 'multiple-value-setq', 'nth-value', 'or', 'pop', - 'pprint-exit-if-list-exhausted', 'pprint-logical-block', 'pprint-pop', - 'print-unreadable-object', 'prog', 'prog*', 'prog1', 'prog2', 'psetf', - 'psetq', 'push', 'pushnew', 'remf', 'restart-bind', 'restart-case', - 'return', 'rotatef', 'setf', 'shiftf', 'step', 'time', 'trace', 'typecase', - 'unless', 'untrace', 'when', 'with-accessors', 'with-compilation-unit', - 'with-condition-restarts', 'with-hash-table-iterator', - 'with-input-from-string', 'with-open-file', 'with-open-stream', - 'with-output-to-string', 'with-package-iterator', 'with-simple-restart', - 'with-slots', 'with-standard-io-syntax', -} - -LAMBDA_LIST_KEYWORDS = { - '&allow-other-keys', '&aux', '&body', '&environment', '&key', '&optional', - '&rest', '&whole', -} - -DECLARATIONS = { - 'dynamic-extent', 'ignore', 'optimize', 'ftype', 'inline', 'special', - 'ignorable', 'notinline', 'type', -} - -BUILTIN_TYPES = { - 'atom', 'boolean', 'base-char', 'base-string', 'bignum', 'bit', - 'compiled-function', 'extended-char', 'fixnum', 'keyword', 'nil', - 'signed-byte', 'short-float', 'single-float', 'double-float', 'long-float', - 'simple-array', 'simple-base-string', 'simple-bit-vector', 'simple-string', - 'simple-vector', 'standard-char', 'unsigned-byte', - - # Condition Types - 'arithmetic-error', 'cell-error', 'condition', 'control-error', - 'division-by-zero', 'end-of-file', 'error', 'file-error', - 'floating-point-inexact', 'floating-point-overflow', - 'floating-point-underflow', 'floating-point-invalid-operation', - 'parse-error', 'package-error', 'print-not-readable', 'program-error', - 'reader-error', 'serious-condition', 'simple-condition', 'simple-error', - 'simple-type-error', 'simple-warning', 'stream-error', 'storage-condition', - 'style-warning', 'type-error', 'unbound-variable', 'unbound-slot', - 'undefined-function', 'warning', -} - -BUILTIN_CLASSES = { - 'array', 'broadcast-stream', 'bit-vector', 'built-in-class', 'character', - 'class', 'complex', 'concatenated-stream', 'cons', 'echo-stream', - 'file-stream', 'float', 'function', 'generic-function', 'hash-table', - 'integer', 'list', 'logical-pathname', 'method-combination', 'method', - 'null', 'number', 'package', 'pathname', 'ratio', 'rational', 'readtable', - 'real', 'random-state', 'restart', 'sequence', 'standard-class', - 'standard-generic-function', 'standard-method', 'standard-object', - 'string-stream', 'stream', 'string', 'structure-class', 'structure-object', - 'symbol', 'synonym-stream', 't', 'two-way-stream', 'vector', -} diff --git a/spaces/quidiaMuxgu/Expedit-SAM/ACDSystem All Products Multi Keygen V3.6 ? CORE.md b/spaces/quidiaMuxgu/Expedit-SAM/ACDSystem All Products Multi Keygen V3.6 ? CORE.md deleted file mode 100644 index 0ce2df7aae0e635d10a371a7ab2f073dc1fe5de5..0000000000000000000000000000000000000000 --- a/spaces/quidiaMuxgu/Expedit-SAM/ACDSystem All Products Multi Keygen V3.6 ? CORE.md +++ /dev/null @@ -1,6 +0,0 @@ -ACDSystem All Products Multi Keygen v3.6 – COREDownload Zip »»» https://geags.com/2uCqCU - - 4d29de3e1b - - - diff --git a/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/infer/infer_libs/uvr5_pack/infer_uvr5.py b/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/infer/infer_libs/uvr5_pack/infer_uvr5.py deleted file mode 100644 index 9b58f05ef69d1ea96ccf5d3d018b27acbb1c3b32..0000000000000000000000000000000000000000 --- a/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/infer/infer_libs/uvr5_pack/infer_uvr5.py +++ /dev/null @@ -1,355 +0,0 @@ -import os, sys, torch, warnings - -now_dir = os.getcwd() -sys.path.append(now_dir) - -warnings.filterwarnings("ignore") -import librosa -import numpy as np -from lib.uvr5_pack.lib_v5 import spec_utils -from lib.uvr5_pack.utils import inference -from lib.uvr5_pack.lib_v5.model_param_init import ModelParameters -import soundfile as sf -from lib.uvr5_pack.lib_v5.nets_new import CascadedNet -from lib.uvr5_pack.lib_v5 import nets_61968KB as nets - - -class _audio_pre_: - def __init__(self, agg, model_path, device, is_half): - self.model_path = model_path - self.device = device - self.data = { - # Processing Options - "postprocess": False, - "tta": False, - # Constants - "window_size": 512, - "agg": agg, - "high_end_process": "mirroring", - } - mp = ModelParameters("lib/uvr5_pack/lib_v5/modelparams/4band_v2.json") - model = nets.CascadedASPPNet(mp.param["bins"] * 2) - cpk = torch.load(model_path, map_location="cpu") - model.load_state_dict(cpk) - model.eval() - if is_half: - model = model.half().to(device) - else: - model = model.to(device) - - self.mp = mp - self.model = model - - def _path_audio_(self, music_file, ins_root=None, vocal_root=None, format="flac"): - if ins_root is None and vocal_root is None: - return "No save root." - name = os.path.basename(music_file) - if ins_root is not None: - os.makedirs(ins_root, exist_ok=True) - if vocal_root is not None: - os.makedirs(vocal_root, exist_ok=True) - X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {} - bands_n = len(self.mp.param["band"]) - # print(bands_n) - for d in range(bands_n, 0, -1): - bp = self.mp.param["band"][d] - if d == bands_n: # high-end band - ( - X_wave[d], - _, - ) = librosa.core.load( - music_file, - bp["sr"], - False, - dtype=np.float32, - res_type=bp["res_type"], - ) - if X_wave[d].ndim == 1: - X_wave[d] = np.asfortranarray([X_wave[d], X_wave[d]]) - else: # lower bands - X_wave[d] = librosa.core.resample( - X_wave[d + 1], - self.mp.param["band"][d + 1]["sr"], - bp["sr"], - res_type=bp["res_type"], - ) - # Stft of wave source - X_spec_s[d] = spec_utils.wave_to_spectrogram_mt( - X_wave[d], - bp["hl"], - bp["n_fft"], - self.mp.param["mid_side"], - self.mp.param["mid_side_b2"], - self.mp.param["reverse"], - ) - # pdb.set_trace() - if d == bands_n and self.data["high_end_process"] != "none": - input_high_end_h = (bp["n_fft"] // 2 - bp["crop_stop"]) + ( - self.mp.param["pre_filter_stop"] - self.mp.param["pre_filter_start"] - ) - input_high_end = X_spec_s[d][ - :, bp["n_fft"] // 2 - input_high_end_h : bp["n_fft"] // 2, : - ] - - X_spec_m = spec_utils.combine_spectrograms(X_spec_s, self.mp) - aggresive_set = float(self.data["agg"] / 100) - aggressiveness = { - "value": aggresive_set, - "split_bin": self.mp.param["band"][1]["crop_stop"], - } - with torch.no_grad(): - pred, X_mag, X_phase = inference( - X_spec_m, self.device, self.model, aggressiveness, self.data - ) - # Postprocess - if self.data["postprocess"]: - pred_inv = np.clip(X_mag - pred, 0, np.inf) - pred = spec_utils.mask_silence(pred, pred_inv) - y_spec_m = pred * X_phase - v_spec_m = X_spec_m - y_spec_m - - if ins_root is not None: - if self.data["high_end_process"].startswith("mirroring"): - input_high_end_ = spec_utils.mirroring( - self.data["high_end_process"], y_spec_m, input_high_end, self.mp - ) - wav_instrument = spec_utils.cmb_spectrogram_to_wave( - y_spec_m, self.mp, input_high_end_h, input_high_end_ - ) - else: - wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, self.mp) - print("%s instruments done" % name) - if format in ["wav", "flac"]: - sf.write( - os.path.join( - ins_root, - "instrument_{}_{}.{}".format(name, self.data["agg"], format), - ), - (np.array(wav_instrument) * 32768).astype("int16"), - self.mp.param["sr"], - ) # - else: - path = os.path.join( - ins_root, "instrument_{}_{}.wav".format(name, self.data["agg"]) - ) - sf.write( - path, - (np.array(wav_instrument) * 32768).astype("int16"), - self.mp.param["sr"], - ) - if os.path.exists(path): - os.system( - "ffmpeg -i %s -vn %s -q:a 2 -y" - % (path, path[:-4] + ".%s" % format) - ) - if vocal_root is not None: - if self.data["high_end_process"].startswith("mirroring"): - input_high_end_ = spec_utils.mirroring( - self.data["high_end_process"], v_spec_m, input_high_end, self.mp - ) - wav_vocals = spec_utils.cmb_spectrogram_to_wave( - v_spec_m, self.mp, input_high_end_h, input_high_end_ - ) - else: - wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, self.mp) - print("%s vocals done" % name) - if format in ["wav", "flac"]: - sf.write( - os.path.join( - vocal_root, - "vocal_{}_{}.{}".format(name, self.data["agg"], format), - ), - (np.array(wav_vocals) * 32768).astype("int16"), - self.mp.param["sr"], - ) - else: - path = os.path.join( - vocal_root, "vocal_{}_{}.wav".format(name, self.data["agg"]) - ) - sf.write( - path, - (np.array(wav_vocals) * 32768).astype("int16"), - self.mp.param["sr"], - ) - if os.path.exists(path): - os.system( - "ffmpeg -i %s -vn %s -q:a 2 -y" - % (path, path[:-4] + ".%s" % format) - ) - - -class _audio_pre_new: - def __init__(self, agg, model_path, device, is_half): - self.model_path = model_path - self.device = device - self.data = { - # Processing Options - "postprocess": False, - "tta": False, - # Constants - "window_size": 512, - "agg": agg, - "high_end_process": "mirroring", - } - mp = ModelParameters("lib/uvr5_pack/lib_v5/modelparams/4band_v3.json") - nout = 64 if "DeReverb" in model_path else 48 - model = CascadedNet(mp.param["bins"] * 2, nout) - cpk = torch.load(model_path, map_location="cpu") - model.load_state_dict(cpk) - model.eval() - if is_half: - model = model.half().to(device) - else: - model = model.to(device) - - self.mp = mp - self.model = model - - def _path_audio_( - self, music_file, vocal_root=None, ins_root=None, format="flac" - ): # 3个VR模型vocal和ins是反的 - if ins_root is None and vocal_root is None: - return "No save root." - name = os.path.basename(music_file) - if ins_root is not None: - os.makedirs(ins_root, exist_ok=True) - if vocal_root is not None: - os.makedirs(vocal_root, exist_ok=True) - X_wave, y_wave, X_spec_s, y_spec_s = {}, {}, {}, {} - bands_n = len(self.mp.param["band"]) - # print(bands_n) - for d in range(bands_n, 0, -1): - bp = self.mp.param["band"][d] - if d == bands_n: # high-end band - ( - X_wave[d], - _, - ) = librosa.core.load( - music_file, - bp["sr"], - False, - dtype=np.float32, - res_type=bp["res_type"], - ) - if X_wave[d].ndim == 1: - X_wave[d] = np.asfortranarray([X_wave[d], X_wave[d]]) - else: # lower bands - X_wave[d] = librosa.core.resample( - X_wave[d + 1], - self.mp.param["band"][d + 1]["sr"], - bp["sr"], - res_type=bp["res_type"], - ) - # Stft of wave source - X_spec_s[d] = spec_utils.wave_to_spectrogram_mt( - X_wave[d], - bp["hl"], - bp["n_fft"], - self.mp.param["mid_side"], - self.mp.param["mid_side_b2"], - self.mp.param["reverse"], - ) - # pdb.set_trace() - if d == bands_n and self.data["high_end_process"] != "none": - input_high_end_h = (bp["n_fft"] // 2 - bp["crop_stop"]) + ( - self.mp.param["pre_filter_stop"] - self.mp.param["pre_filter_start"] - ) - input_high_end = X_spec_s[d][ - :, bp["n_fft"] // 2 - input_high_end_h : bp["n_fft"] // 2, : - ] - - X_spec_m = spec_utils.combine_spectrograms(X_spec_s, self.mp) - aggresive_set = float(self.data["agg"] / 100) - aggressiveness = { - "value": aggresive_set, - "split_bin": self.mp.param["band"][1]["crop_stop"], - } - with torch.no_grad(): - pred, X_mag, X_phase = inference( - X_spec_m, self.device, self.model, aggressiveness, self.data - ) - # Postprocess - if self.data["postprocess"]: - pred_inv = np.clip(X_mag - pred, 0, np.inf) - pred = spec_utils.mask_silence(pred, pred_inv) - y_spec_m = pred * X_phase - v_spec_m = X_spec_m - y_spec_m - - if ins_root is not None: - if self.data["high_end_process"].startswith("mirroring"): - input_high_end_ = spec_utils.mirroring( - self.data["high_end_process"], y_spec_m, input_high_end, self.mp - ) - wav_instrument = spec_utils.cmb_spectrogram_to_wave( - y_spec_m, self.mp, input_high_end_h, input_high_end_ - ) - else: - wav_instrument = spec_utils.cmb_spectrogram_to_wave(y_spec_m, self.mp) - print("%s instruments done" % name) - if format in ["wav", "flac"]: - sf.write( - os.path.join( - ins_root, - "instrument_{}_{}.{}".format(name, self.data["agg"], format), - ), - (np.array(wav_instrument) * 32768).astype("int16"), - self.mp.param["sr"], - ) # - else: - path = os.path.join( - ins_root, "instrument_{}_{}.wav".format(name, self.data["agg"]) - ) - sf.write( - path, - (np.array(wav_instrument) * 32768).astype("int16"), - self.mp.param["sr"], - ) - if os.path.exists(path): - os.system( - "ffmpeg -i %s -vn %s -q:a 2 -y" - % (path, path[:-4] + ".%s" % format) - ) - if vocal_root is not None: - if self.data["high_end_process"].startswith("mirroring"): - input_high_end_ = spec_utils.mirroring( - self.data["high_end_process"], v_spec_m, input_high_end, self.mp - ) - wav_vocals = spec_utils.cmb_spectrogram_to_wave( - v_spec_m, self.mp, input_high_end_h, input_high_end_ - ) - else: - wav_vocals = spec_utils.cmb_spectrogram_to_wave(v_spec_m, self.mp) - print("%s vocals done" % name) - if format in ["wav", "flac"]: - sf.write( - os.path.join( - vocal_root, - "vocal_{}_{}.{}".format(name, self.data["agg"], format), - ), - (np.array(wav_vocals) * 32768).astype("int16"), - self.mp.param["sr"], - ) - else: - path = os.path.join( - vocal_root, "vocal_{}_{}.wav".format(name, self.data["agg"]) - ) - sf.write( - path, - (np.array(wav_vocals) * 32768).astype("int16"), - self.mp.param["sr"], - ) - if os.path.exists(path): - os.system( - "ffmpeg -i %s -vn %s -q:a 2 -y" - % (path, path[:-4] + ".%s" % format) - ) - - -if __name__ == "__main__": - device = "cuda" - is_half = True - model_path = "assets/uvr5_weights/DeEchoNormal.pth" - pre_fun = _audio_pre_new(model_path=model_path, device=device, is_half=True, agg=10) - audio_path = "雪雪伴奏对消HP5.wav" - save_path = "opt" - pre_fun._path_audio_(audio_path, save_path, save_path) diff --git a/spaces/radames/Candle-Phi-1.5-Wasm/build/m_bg.wasm.d.ts b/spaces/radames/Candle-Phi-1.5-Wasm/build/m_bg.wasm.d.ts deleted file mode 100644 index 4b90d93e2860eeed2a740629b9d6bea23de57d9c..0000000000000000000000000000000000000000 --- a/spaces/radames/Candle-Phi-1.5-Wasm/build/m_bg.wasm.d.ts +++ /dev/null @@ -1,14 +0,0 @@ -/* tslint:disable */ -/* eslint-disable */ -export const memory: WebAssembly.Memory; -export function __wbg_model_free(a: number): void; -export function model_load(a: number, b: number, c: number, d: number, e: number, f: number, g: number, h: number): void; -export function model_init_with_prompt(a: number, b: number, c: number, d: number, e: number, f: number, g: number, h: number, i: number): void; -export function model_next_token(a: number, b: number): void; -export function main(a: number, b: number): number; -export function __wbindgen_add_to_stack_pointer(a: number): number; -export function __wbindgen_malloc(a: number, b: number): number; -export function __wbindgen_realloc(a: number, b: number, c: number, d: number): number; -export function __wbindgen_free(a: number, b: number, c: number): void; -export function __wbindgen_exn_store(a: number): void; -export function __wbindgen_start(): void; diff --git a/spaces/radames/PIFu-Clothed-Human-Digitization/PIFu/scripts/test.sh b/spaces/radames/PIFu-Clothed-Human-Digitization/PIFu/scripts/test.sh deleted file mode 100644 index a7a3d7ec6d2a3572bbb699f935aefd8c575e768e..0000000000000000000000000000000000000000 --- a/spaces/radames/PIFu-Clothed-Human-Digitization/PIFu/scripts/test.sh +++ /dev/null @@ -1,39 +0,0 @@ -#!/usr/bin/env bash -set -ex - -# Training -GPU_ID=0 -DISPLAY_ID=$((GPU_ID*10+10)) -NAME='spaces_demo' - -# Network configuration - -BATCH_SIZE=1 -MLP_DIM='257 1024 512 256 128 1' -MLP_DIM_COLOR='513 1024 512 256 128 3' - -# Reconstruction resolution -# NOTE: one can change here to reconstruct mesh in a different resolution. -# VOL_RES=256 - -# CHECKPOINTS_NETG_PATH='./checkpoints/net_G' -# CHECKPOINTS_NETC_PATH='./checkpoints/net_C' - -# TEST_FOLDER_PATH='./sample_images' - -# command -CUDA_VISIBLE_DEVICES=${GPU_ID} python ./apps/eval_spaces.py \ - --name ${NAME} \ - --batch_size ${BATCH_SIZE} \ - --mlp_dim ${MLP_DIM} \ - --mlp_dim_color ${MLP_DIM_COLOR} \ - --num_stack 4 \ - --num_hourglass 2 \ - --resolution ${VOL_RES} \ - --hg_down 'ave_pool' \ - --norm 'group' \ - --norm_color 'group' \ - --load_netG_checkpoint_path ${CHECKPOINTS_NETG_PATH} \ - --load_netC_checkpoint_path ${CHECKPOINTS_NETC_PATH} \ - --results_path ${RESULTS_PATH} \ - --img_path ${INPUT_IMAGE_PATH} \ No newline at end of file diff --git a/spaces/radames/Real-Time-Latent-Consistency-Model/app-img2img.py b/spaces/radames/Real-Time-Latent-Consistency-Model/app-img2img.py deleted file mode 100644 index b9021816b95429a81545c7ccb6b26f9d056b72d5..0000000000000000000000000000000000000000 --- a/spaces/radames/Real-Time-Latent-Consistency-Model/app-img2img.py +++ /dev/null @@ -1,262 +0,0 @@ -import asyncio -import json -import logging -import traceback -from pydantic import BaseModel - -from fastapi import FastAPI, WebSocket, HTTPException, WebSocketDisconnect -from fastapi.middleware.cors import CORSMiddleware -from fastapi.responses import StreamingResponse, JSONResponse -from fastapi.staticfiles import StaticFiles - -from diffusers import AutoPipelineForImage2Image, AutoencoderTiny -from compel import Compel -import torch - -try: - import intel_extension_for_pytorch as ipex -except: - pass -from PIL import Image -import numpy as np -import gradio as gr -import io -import uuid -import os -import time -import psutil - -MAX_QUEUE_SIZE = int(os.environ.get("MAX_QUEUE_SIZE", 0)) -TIMEOUT = float(os.environ.get("TIMEOUT", 0)) -SAFETY_CHECKER = os.environ.get("SAFETY_CHECKER", None) -TORCH_COMPILE = os.environ.get("TORCH_COMPILE", None) - -WIDTH = 512 -HEIGHT = 512 -# disable tiny autoencoder for better quality speed tradeoff -USE_TINY_AUTOENCODER = True - -# check if MPS is available OSX only M1/M2/M3 chips -mps_available = hasattr(torch.backends, "mps") and torch.backends.mps.is_available() -xpu_available = hasattr(torch, "xpu") and torch.xpu.is_available() -device = torch.device( - "cuda" if torch.cuda.is_available() else "xpu" if xpu_available else "cpu" -) -torch_device = device - -# change to torch.float16 to save GPU memory -torch_dtype = torch.float32 - -print(f"TIMEOUT: {TIMEOUT}") -print(f"SAFETY_CHECKER: {SAFETY_CHECKER}") -print(f"MAX_QUEUE_SIZE: {MAX_QUEUE_SIZE}") -print(f"device: {device}") - -if mps_available: - device = torch.device("mps") - torch_device = "cpu" - torch_dtype = torch.float32 - -if SAFETY_CHECKER == "True": - pipe = AutoPipelineForImage2Image.from_pretrained( - "SimianLuo/LCM_Dreamshaper_v7", - ) -else: - pipe = AutoPipelineForImage2Image.from_pretrained( - "SimianLuo/LCM_Dreamshaper_v7", - safety_checker=None, - ) - -if USE_TINY_AUTOENCODER: - pipe.vae = AutoencoderTiny.from_pretrained( - "madebyollin/taesd", torch_dtype=torch_dtype, use_safetensors=True - ) -pipe.set_progress_bar_config(disable=True) -pipe.to(device=torch_device, dtype=torch_dtype).to(device) -pipe.unet.to(memory_format=torch.channels_last) - -if psutil.virtual_memory().total < 64 * 1024**3: - pipe.enable_attention_slicing() - -if TORCH_COMPILE: - pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True) - pipe.vae = torch.compile(pipe.vae, mode="reduce-overhead", fullgraph=True) - - pipe(prompt="warmup", image=[Image.new("RGB", (512, 512))]) - -compel_proc = Compel( - tokenizer=pipe.tokenizer, - text_encoder=pipe.text_encoder, - truncate_long_prompts=False, -) -user_queue_map = {} - - -class InputParams(BaseModel): - seed: int = 2159232 - prompt: str - guidance_scale: float = 8.0 - strength: float = 0.5 - steps: int = 4 - lcm_steps: int = 50 - width: int = WIDTH - height: int = HEIGHT - -def predict(input_image: Image.Image, params: InputParams, prompt_embeds: torch.Tensor = None): - generator = torch.manual_seed(params.seed) - results = pipe( - prompt_embeds=prompt_embeds, - generator=generator, - image=input_image, - strength=params.strength, - num_inference_steps=params.steps, - guidance_scale=params.guidance_scale, - width=params.width, - height=params.height, - original_inference_steps=params.lcm_steps, - output_type="pil", - ) - nsfw_content_detected = ( - results.nsfw_content_detected[0] - if "nsfw_content_detected" in results - else False - ) - if nsfw_content_detected: - return None - return results.images[0] - - -app = FastAPI() -app.add_middleware( - CORSMiddleware, - allow_origins=["*"], - allow_credentials=True, - allow_methods=["*"], - allow_headers=["*"], -) - - -@app.websocket("/ws") -async def websocket_endpoint(websocket: WebSocket): - await websocket.accept() - if MAX_QUEUE_SIZE > 0 and len(user_queue_map) >= MAX_QUEUE_SIZE: - print("Server is full") - await websocket.send_json({"status": "error", "message": "Server is full"}) - await websocket.close() - return - - try: - uid = str(uuid.uuid4()) - print(f"New user connected: {uid}") - await websocket.send_json( - {"status": "success", "message": "Connected", "userId": uid} - ) - user_queue_map[uid] = {"queue": asyncio.Queue()} - await websocket.send_json( - {"status": "start", "message": "Start Streaming", "userId": uid} - ) - await handle_websocket_data(websocket, uid) - except WebSocketDisconnect as e: - logging.error(f"WebSocket Error: {e}, {uid}") - traceback.print_exc() - finally: - print(f"User disconnected: {uid}") - queue_value = user_queue_map.pop(uid, None) - queue = queue_value.get("queue", None) - if queue: - while not queue.empty(): - try: - queue.get_nowait() - except asyncio.QueueEmpty: - continue - - -@app.get("/queue_size") -async def get_queue_size(): - queue_size = len(user_queue_map) - return JSONResponse({"queue_size": queue_size}) - - -@app.get("/stream/{user_id}") -async def stream(user_id: uuid.UUID): - uid = str(user_id) - try: - user_queue = user_queue_map[uid] - queue = user_queue["queue"] - - async def generate(): - last_prompt: str = None - prompt_embeds: torch.Tensor = None - while True: - data = await queue.get() - input_image = data["image"] - params = data["params"] - if input_image is None: - continue - # avoid recalculate prompt embeds - if last_prompt != params.prompt: - print("new prompt") - prompt_embeds = compel_proc(params.prompt) - last_prompt = params.prompt - - image = predict( - input_image, - params, - prompt_embeds, - ) - if image is None: - continue - frame_data = io.BytesIO() - image.save(frame_data, format="JPEG") - frame_data = frame_data.getvalue() - if frame_data is not None and len(frame_data) > 0: - yield b"--frame\r\nContent-Type: image/jpeg\r\n\r\n" + frame_data + b"\r\n" - - await asyncio.sleep(1.0 / 120.0) - - return StreamingResponse( - generate(), media_type="multipart/x-mixed-replace;boundary=frame" - ) - except Exception as e: - logging.error(f"Streaming Error: {e}, {user_queue_map}") - traceback.print_exc() - return HTTPException(status_code=404, detail="User not found") - - -async def handle_websocket_data(websocket: WebSocket, user_id: uuid.UUID): - uid = str(user_id) - user_queue = user_queue_map[uid] - queue = user_queue["queue"] - if not queue: - return HTTPException(status_code=404, detail="User not found") - last_time = time.time() - try: - while True: - data = await websocket.receive_bytes() - params = await websocket.receive_json() - params = InputParams(**params) - pil_image = Image.open(io.BytesIO(data)) - - while not queue.empty(): - try: - queue.get_nowait() - except asyncio.QueueEmpty: - continue - await queue.put({"image": pil_image, "params": params}) - if TIMEOUT > 0 and time.time() - last_time > TIMEOUT: - await websocket.send_json( - { - "status": "timeout", - "message": "Your session has ended", - "userId": uid, - } - ) - await websocket.close() - return - - except Exception as e: - logging.error(f"Error: {e}") - traceback.print_exc() - - -app.mount("/", StaticFiles(directory="img2img", html=True), name="public") diff --git a/spaces/raedeXanto/academic-chatgpt-beta/Bioshock Infinite Jpn Ps3 Torrent.md b/spaces/raedeXanto/academic-chatgpt-beta/Bioshock Infinite Jpn Ps3 Torrent.md deleted file mode 100644 index 18891f5976d0fea75254caf9572a6029e53b55df..0000000000000000000000000000000000000000 --- a/spaces/raedeXanto/academic-chatgpt-beta/Bioshock Infinite Jpn Ps3 Torrent.md +++ /dev/null @@ -1,28 +0,0 @@ - - How to Download Bioshock Infinite Jpn Ps3 Torrent-Bioshock Infinite is a first-person shooter game set in a floating city of Columbia in 1912. You play as Booker DeWitt, a former soldier who is hired to rescue a mysterious girl named Elizabeth from her captors. Along the way, you will encounter various enemies, weapons, and powers, as well as uncover the secrets of the city and its history. -If you want to play Bioshock Infinite on your PS3 console, you might be interested in downloading the Jpn version of the game, which has Japanese voiceovers and subtitles. This version is not available on the official PSN store, but you can find it online as a torrent file. -Bioshock Infinite Jpn Ps3 TorrentDownload File → https://tinourl.com/2uL5DN - A torrent file is a small file that contains information about the files you want to download, such as their names, sizes, and locations on other computers. To download a torrent file, you need a special program called a torrent client, such as uTorrent or BitTorrent. These programs will connect you to other users who have the same files and download them to your computer. -However, downloading torrent files can be risky, as they may contain viruses, malware, or illegal content. You should always scan the files with an antivirus program before opening them, and use a VPN service to protect your privacy and avoid legal issues. -Here are some steps to download Bioshock Infinite Jpn Ps3 Torrent: -
I hope this article was helpful for you. If you have any questions or feedback, please let me know. - -Bioshock Infinite Jpn Ps3 is a great game to play if you are a fan of the Bioshock series, or if you enjoy immersive and atmospheric games with a strong story and gameplay. The game has received critical acclaim for its graphics, sound, music, voice acting, and narrative. It has also won several awards, such as the BAFTA Game of the Year, the Golden Joystick Award for Best Storytelling, and the Spike Video Game Award for Best Shooter. -The game is set in an alternate history where the United States is a world power and has built a floating city called Columbia as a symbol of its greatness. However, the city secedes from the nation and becomes a rogue state with its own ideology and agenda. The game explores themes such as American exceptionalism, racism, religion, nationalism, and free will. -The game features a dynamic combat system that allows you to use various weapons, powers, and gadgets to fight your enemies. You can also use the Sky-Line, a rail system that connects different parts of the city, to move around and gain tactical advantages. You are not alone in your journey, as you are accompanied by Elizabeth, a mysterious girl who has the ability to manipulate tears in reality. She can help you in combat by providing you with ammo, health, or other items. She can also open tears to bring in allies, weapons, or cover. -Bioshock Infinite Jpn Ps3 is a game that will keep you hooked from start to finish with its stunning visuals, captivating story, and thrilling gameplay. If you want to experience this game in Japanese language, you can download the torrent file from one of the websites mentioned above and follow the instructions to install it on your PS3 console. You will not regret it! - cec2833e83- - \ No newline at end of file diff --git a/spaces/raedeXanto/academic-chatgpt-beta/Cossacks 2 Crack HOT! Windows 7.md b/spaces/raedeXanto/academic-chatgpt-beta/Cossacks 2 Crack HOT! Windows 7.md deleted file mode 100644 index c3b3d537879d6eef8cc8577cd150eb5bd02cd730..0000000000000000000000000000000000000000 --- a/spaces/raedeXanto/academic-chatgpt-beta/Cossacks 2 Crack HOT! Windows 7.md +++ /dev/null @@ -1,35 +0,0 @@ - - How to Play Cossacks 2 on Windows 7-Cossacks 2 is a real-time strategy game set in the Napoleonic era. It was released in 2005 and is compatible with Windows XP. However, many players have reported problems with running the game on Windows 7, such as low performance, lags, crashes, or black screens. In this article, we will show you some possible solutions to fix these issues and enjoy the game on your Windows 7 PC. -cossacks 2 crack windows 7Download Zip ☆ https://tinourl.com/2uL2YB - Method 1: Use a No-CD Crack-One of the common causes of Cossacks 2 problems on Windows 7 is the copy protection system that checks for the presence of the game disc in the drive. This system may not work well with newer versions of Windows and may prevent the game from launching or cause errors. To bypass this problem, you can use a no-CD crack that allows you to run the game without the disc. Here are the steps to do so: -
Method 2: Make log.txt Read-Only-Another possible solution to fix Cossacks 2 performance issues on Windows 7 is to make the log.txt file in your game installation folder read-only. This file records all the events that happen in the game, such as errors, warnings, or messages. However, it may also cause lags or slowdowns if it becomes too large or corrupted. To prevent this, you can make the file read-only so that it does not change or grow in size. Here are the steps to do so: -
Method 3: Run the Game in Compatibility Mode-If none of the above methods work for you, you can try to run the game in compatibility mode for Windows XP. Compatibility mode is a feature that allows you to run older programs on newer versions of Windows by simulating the environment and settings of an older operating system. This may help resolve some compatibility issues that prevent Cossacks 2 from running properly on Windows 7. Here are the steps to do so: - -
Conclusion-We hope that this article has helped you fix Cossacks 2 problems on Windows 7 and enjoy this classic strategy game on your PC. If you have any questions or suggestions, feel free to leave a comment below. 7b8c122e87- - \ No newline at end of file diff --git a/spaces/raedeXanto/academic-chatgpt-beta/D16 Group Drumazon VSTi V1 4 0 Incl Keygen AiR.rar - How to Create Amazing Beats with This Software.md b/spaces/raedeXanto/academic-chatgpt-beta/D16 Group Drumazon VSTi V1 4 0 Incl Keygen AiR.rar - How to Create Amazing Beats with This Software.md deleted file mode 100644 index 9a7a4dbd100802d5c82e4c0c7b8c819e4a612530..0000000000000000000000000000000000000000 --- a/spaces/raedeXanto/academic-chatgpt-beta/D16 Group Drumazon VSTi V1 4 0 Incl Keygen AiR.rar - How to Create Amazing Beats with This Software.md +++ /dev/null @@ -1,94 +0,0 @@ - - D16 Group Drumazon VSTi V1 4 0 Incl Keygen AiR.rar - What is it and why you need it-Introduction-If you are a music producer, a beat maker, or a fan of electronic music, you have probably heard of the legendary Roland TR-909 drum machine. This iconic device was released in 1984 and has been used by countless artists across genres such as techno, house, hip hop, and more. The 909 is known for its distinctive sounds, such as the punchy kick, the snappy snare, the metallic hi-hats, and the booming toms. -However, finding an original 909 nowadays is not easy or cheap. That's why many software developers have created virtual instruments that emulate the sound and functionality of the 909. One of them is D16 Group, a Polish company that specializes in high-quality audio plugins. Their product, Drumazon VSTi, is one of the most faithful and realistic recreations of the 909 ever made. -D16 Group Drumazon VSTi V1 4 0 Incl Keygen AiR.rar -DOWNLOAD === https://tinourl.com/2uL54P - But what is Drumazon VSTi exactly? And what is a keygen? And who are AiR? In this article, we will answer these questions and more. We will also show you how to install and use Drumazon VSTi, as well as its features and benefits. By the end of this article, you will have a clear idea of what Drumazon VSTi can do for you and your music. -What is D16 Group Drumazon VSTi-D16 Group Drumazon VSTi is a software plugin that simulates the sound and behavior of the Roland TR-909 drum machine. It runs as a virtual instrument (VSTi) inside your digital audio workstation (DAW), such as Ableton Live, FL Studio, Cubase, or Logic Pro. You can use it to create drum patterns, loops, beats, or entire songs with the authentic 909 sound. -What is a keygen and why is it included-A keygen is a small program that generates a serial number or a license file for a software product. It is usually used to bypass the copy protection or activation process of the software. A keygen is often included with cracked or pirated software that has been illegally distributed on the internet. -D16 Group Drumazon VSTi V1 4 0 Incl Keygen AiR download The file name D16 Group Drumazon VSTi V1 4 0 Incl Keygen AiR.rar indicates that this is a compressed archive file that contains both the plugin installer and the keygen program. The keygen program can be used to generate a license file for Drumazon VSTi, which will allow you to use it without paying for it. -What is AiR and why is it important-AiR is a group of hackers or crackers who specialize in cracking audio software. They have released hundreds of cracked plugins, effects, instruments, and applications for music production. They are known for their high-quality releases, their detailed instructions, and their signature sound that plays when you run their keygens. -AiR is important because they are one of the most prolific and respected groups in the audio software cracking scene. They have cracked many popular products from companies such as Native Instruments, Spectrasonics, Arturia, Steinberg, Propellerhead, iZotope, and more. Many music producers rely on their releases to access expensive software that they cannot afford otherwise. -Features and benefits of D16 Group Drumazon VSTi-D16 Group Drumazon VSTi is not just a simple copy of the Roland TR-909 drum machine. It is also a powerful and versatile plugin that offers many features and benefits that enhance your music production workflow. Here are some of them: -Synthesis emulation of the classic 909 drum machine-D16 Group Drumazon VSTi uses advanced synthesis algorithms to emulate all the sounds of the original 909. All the nuances and details of the instruments are captured perfectly. You can adjust parameters such as tune, decay, attack, tone, accent, volume, pan, mute, solo, etc. You can also switch between two modes: original mode (which reproduces the exact sound of the hardware) and enhanced mode (which adds some extra features such as velocity sensitivity). -Multiple outputs and MIDI control-D16 Group Drumazon VSTi allows you to route each instrument to a separate output channel in your DAW. This gives you more flexibility and control over your mix. You can apply different effects, EQs, compressors, etc., to each instrument individually. You can also control each instrument with an external MIDI controller or keyboard. You can assign different MIDI notes or CC messages to each parameter. -Internal sequencer and pattern manager-D16 Group Drumazon VSTi has an internal sequencer that lets you create drum patterns with up to 32 steps per instrument. You can edit each step with parameters such as velocity, accent, flam, shuffle, etc. You can also chain up to 12 patterns together to form a song. The pattern manager allows you to store up to 128 patterns in memory. You can load them from presets or import them from external files. -Presets and customization options-D16 Group Drumazon VSTi comes with over 400 presets that cover various genres and styles of music. You can use them as they are or modify them to suit your needs. You can also create your own presets and save them for later use. You can also customize the appearance of the plugin by changing its skin or color scheme. -How to install and use D16 Group Drumazon VSTi-Now that you know what D16 Group Drumazon VSTi is and what it can do for you, let's see how to install and use it on your computer. Here are the steps: -Downloading and extracting the file-The first step is to download the file D16 Group Drumazon VSTi V1 4 0 Incl Keygen AiR.rar from a reliable source on the internet. You will need a torrent client such as qBittorrent or uTorrent to download it. Once you have downloaded it, you will need a program such as WinRAR or 7-Zip to extract it. -To extract it, right-click on the file and select "Extract here" or "Extract to" from the menu. You will see two folders inside: one called "D16.Group.Drumazon.VSTi.v1.4.0.Incl.Keygen-AiR" which contains the plugin installer; and another called "AiR" which contains the keygen program. -Running the keygen and generating a license-Running the keygen and generating a license-The next step is to run the keygen program inside the "AiR" folder. To do this, double-click on "keygen.exe". You will hear a short melody playing in your speakers or headphones; this is AiR's signature sound. -You will see a window with several buttons and fields. Click on "Generate" to create a license file for Drumazon VSTi. You will see a message saying "License file generated successfully!". Click on "Save" to save the license file to your computer. You can name it whatever you want, but make sure it has the extension ".lic". -Installing the plugin and activating it-The third step is to install the plugin on your computer. To do this, go to the folder "D16.Group.Drumazon.VSTi.v1.4.0.Incl.Keygen-AiR" and double-click on "setup.exe". You will see a window with the D16 Group logo and some options. Click on "Next" to start the installation process. -You will see a window with the license agreement. Read it carefully and click on "I accept the agreement" if you agree. Then click on "Next". You will see a window with the destination folder. Choose where you want to install the plugin and click on "Next". You will see a window with the VST plugin folder. Choose where you want to install the VST plugin and click on "Next". You will see a window with the summary of your choices. Click on "Install" to begin the installation. -Wait for the installation to finish. You will see a window with a message saying "Installation completed successfully!". Click on "Finish" to exit the installer. -Now you need to activate the plugin with the license file you generated earlier. To do this, open your DAW and load Drumazon VSTi as a plugin. You will see a window with a message saying "Please select license file". Click on "Browse" and locate the license file you saved before. Click on "Open" and then on "OK". You will see a window with a message saying "License accepted!". Click on "OK" again. Congratulations! You have successfully installed and activated Drumazon VSTi! -Loading the plugin in your DAW and creating beats-The final step is to use Drumazon VSTi in your DAW and create some awesome beats with it. To do this, create a new project or open an existing one in your DAW. Add Drumazon VSTi as an instrument track or as an effect on an audio track. You will see the plugin interface, which looks like this: - You can use the mouse or a MIDI controller to play and edit the sounds of each instrument. You can also use the internal sequencer to create patterns and songs. You can access different functions and menus by clicking on the buttons at the top of the interface. -For more details and tutorials on how to use Drumazon VSTi, you can check out the user manual or watch some videos online. -Conclusion-D16 Group Drumazon VSTi is an amazing plugin that emulates the sound and functionality of the Roland TR-909 drum machine. It is easy to install and use, and it offers many features and benefits that make it a great tool for music production. Whether you want to create classic techno beats, modern hip hop grooves, or anything in between, Drumazon VSTi can help you achieve your goals. -If you are interested in getting Drumazon VSTi, you can download it from D16 Group's website for 99 EUR (about 113 USD). However, if you want to save some money and get it for free, you can download it from a torrent site along with a keygen program that will generate a license file for you. -However, we do not recommend or endorse this option, as it is illegal and unethical. It also exposes you to potential risks such as viruses, malware, or legal actions. The best way to support D16 Group and their amazing products is to buy them legally and enjoy them safely. -We hope this article has been helpful and informative for you. If you have any questions or comments, feel free to leave them below. Thank you for reading! -FAQs-Is D16 Group Drumazon VSTi legal and safe to use?-D16 Group Drumazon VSTi is legal and safe to use if you buy it from D16 Group's website or from an authorized reseller. However, if you download it from a torrent site along with a keygen program, it is illegal and unsafe to use. You are violating D16 Group's intellectual property rights and exposing yourself to potential risks such as viruses, malware, or legal actions. -What are the system requirements for D16 Group Drumazon VSTi?-The system requirements for D16 Group Drumazon VSTi are as follows: - | Operating system | Windows 7 or later / Mac OS X 10.7 or later | | Processor | 2 GHz Intel Core 2 Duo / AMD Athlon 64 X2 or equivalent | | RAM | 4 GB | | Hard disk space | 100 MB | | Audio interface | ASIO / CoreAudio compatible | | Plugin format | VST / AU |How can I update D16 Group Drumazon VSTi to the latest version?-You can update D16 Group Drumazon VSTi to the latest version by downloading it from D16 Group's website or from your user account if you have bought it legally. You can also check for updates from within the plugin by clicking on the "About" button at the top of the interface. -Where can I find more tutorials and tips for D16 Group Drumazon VSTi?-You can find more tutorials and tips for D16 Group Drumazon VSTi by reading the user manual or watching some videos online. You can also join D16 Group's forum or social media pages where you can interact with other users and get support from D16 Group's team. -What are some alternatives to D16 Group Drumazon VSTi?-Some alternatives to D16 Group Drumazon VSTi are: - - Roland Cloud TR-909: The official software version of the Roland TR-909 drum machine by Roland Corporation. - AudioRealism ADM: A software drum machine that emulates various vintage drum machines such as 808, 909, 606, etc. - Wave Alchemy Revolution: A software drum machine that combines synthesis and sampling of various classic drum machines such as 909, 808, 707, etc. 0a6ba089eb- - \ No newline at end of file diff --git a/spaces/raedeXanto/academic-chatgpt-beta/Delphi XE Slip Crack The Best Way to Backup and Restore Your Delphi License Info.md b/spaces/raedeXanto/academic-chatgpt-beta/Delphi XE Slip Crack The Best Way to Backup and Restore Your Delphi License Info.md deleted file mode 100644 index 27862989063c746806ac1ac707c9939553c776d5..0000000000000000000000000000000000000000 --- a/spaces/raedeXanto/academic-chatgpt-beta/Delphi XE Slip Crack The Best Way to Backup and Restore Your Delphi License Info.md +++ /dev/null @@ -1,121 +0,0 @@ - - - Benefits of using Delphi XE for software development | | H2: What is a slip file and how does it work? | - Explanation of slip files and their role in Delphi XE activation - How to obtain and use a slip file legally | | H2: What is a slip crack and why do people use it? | - Definition of slip crack and its purpose - Risks and drawbacks of using a slip crack | | H2: How to reinstall Delphi XE without losing your license? | - Steps to backup and restore your slip file - Tips to avoid re-registering Delphi XE | | H2: How to get help and support for Delphi XE? | - Resources and links for Delphi XE users - Contact information for Embarcadero support | | H1: Conclusion | - Summary of the main points - Call to action | **Article with HTML formatting** What is Delphi XE and why do you need it?-If you are a software developer, you probably have heard of Delphi XE, the latest version of the popular Delphi programming language and IDE. Delphi XE is a powerful tool that allows you to create fast, native, cross-platform applications for Windows, Mac, Linux, iOS, Android, and more. With Delphi XE, you can: -delphi xe slip crackDownload >>>>> https://tinourl.com/2uL2Nm -
Delphi XE is a great choice for developers who want to create high-performance, scalable, and secure applications with less code and more productivity. Whether you are developing desktop, mobile, web, or cloud applications, Delphi XE can help you achieve your goals faster and easier. -What is a slip file and how does it work?-A slip file is a file that contains the license information for Delphi XE. When you purchase Delphi XE from Embarcadero or an authorized reseller, you will receive a slip file that activates your product. The slip file has a .slip extension and is usually located in the C:\ProgramData\CodeGear or C:\ProgramData\Embarcadero folder on your computer. -The slip file works by verifying your product serial number and machine name with the Embarcadero license server. The license server then grants you access to the product features according to your edition (Starter, Professional, Enterprise, or Architect). The slip file also keeps track of how many installations you have made with your serial number. You can install Delphi XE on up to five machines with the same serial number. -To use a slip file legally, you need to follow these steps: -delphi xe activation file crack
What is a slip crack and why do people use it?-A slip crack is a file that mimics a slip file but bypasses the Embarcadero license server. A slip crack is usually created by hackers who modify the original slip file or generate a fake one. A slip crack has a .slip extension but may have a different name or location than the genuine one. -The purpose of a slip crack is to activate Delphi XE without paying for it. A slip crack may also allow you to use features that are not available in your edition or install Delphi XE on more than five machines. Some people use a slip crack because they want to save money, try out different features, or avoid re-registering Delphi XE when they reinstall Windows. -However, using a slip crack is illegal and risky. Here are some of the dangers of using a slip crack: -
How to reinstall Delphi XE without losing your license?-If you need to reinstall Windows and Delphi XE on your computer, you may wonder how to avoid re-registering Delphi XE and wasting one of your installations. Fortunately, there is a way to backup and restore your slip file so that you can reinstall Delphi XE without losing your license. -To backup and restore your slip file, you need to follow these steps: -Before reinstalling Windows:-
After reinstalling Windows:-
Tips to avoid re-registering Delphi XE:-
How to get help and support for Delphi XE?-If you encounter any problems or have any questions about Delphi XE, there are many resources and channels that can help you. Here are some of them: -
- - \ No newline at end of file diff --git a/spaces/rayan-saleh/whisper2notion/server/node_modules/@types/node/ts4.8/timers/promises.d.ts b/spaces/rayan-saleh/whisper2notion/server/node_modules/@types/node/ts4.8/timers/promises.d.ts deleted file mode 100644 index c1450684d60a323526a9ae750669adb21ba75c17..0000000000000000000000000000000000000000 --- a/spaces/rayan-saleh/whisper2notion/server/node_modules/@types/node/ts4.8/timers/promises.d.ts +++ /dev/null @@ -1,93 +0,0 @@ -/** - * The `timers/promises` API provides an alternative set of timer functions - * that return `Promise` objects. The API is accessible via`require('timers/promises')`. - * - * ```js - * import { - * setTimeout, - * setImmediate, - * setInterval, - * } from 'timers/promises'; - * ``` - * @since v15.0.0 - */ -declare module 'timers/promises' { - import { TimerOptions } from 'node:timers'; - /** - * ```js - * import { - * setTimeout, - * } from 'timers/promises'; - * - * const res = await setTimeout(100, 'result'); - * - * console.log(res); // Prints 'result' - * ``` - * @since v15.0.0 - * @param [delay=1] The number of milliseconds to wait before fulfilling the promise. - * @param value A value with which the promise is fulfilled. - */ - function setTimeout - Autodata 3.38 Srpski: A Useful Program for Car Services-Autodata 3.38 Srpski is a version of Autodata, a popular program for car services, that contains information in Serbian language. Autodata provides data about injection systems for gasoline and some diesel engines (PINDATA), as well as parameters for adjusting the toe-in, installing timing belts and chains, repairing air conditioners, airbags, ABS and other systems of European cars[^3^]. -Autodata 3.38 Srpski is a useful tool for car mechanics, technicians and enthusiasts who want to diagnose and repair various problems in their vehicles. It can also help them to learn more about the technical specifications and features of different car models. Autodata 3.38 Srpski is easy to use and has a user-friendly interface that allows users to access the information they need quickly and efficiently. -autodata 3 38 srpski download 75DOWNLOAD ››››› https://urlgoal.com/2uCN2u - Autodata 3.38 Srpski is available for download from various online sources, such as Tealfeed[^1^] and AAC Itta[^2^]. However, users should be careful when downloading files from unknown or untrusted websites, as they may contain viruses or malware that can harm their computers or devices. Users should also check the compatibility of the program with their operating system and hardware before installing it. To use Autodata 3.38 Srpski, you need to install it on your computer first. You can do this by following these steps: -
If you encounter any errors while running the program, such as RUNTIME ERROR 217, you may need to change the compatibility mode of the program. You can do this by right-clicking on the program icon, selecting Properties, then Compatibility, then choosing a different version of Windows (such as Windows 8) and checking the option Run this program as an administrator[^1^]. -Autodata 3.38 Srpski has a simple and intuitive interface that allows you to access various information about different car models and systems. You can select a car model from the list on the left side of the screen, then choose a system or component from the tabs on the top of the screen. You can also use the search function to find specific information by entering keywords or codes. You can view diagrams, tables, charts, photos and instructions that will help you diagnose and repair your car problems. In conclusion, Autodata 3.38 Srpski is a useful program for car services that provides comprehensive and reliable data about various car models and systems. It can help users to diagnose and repair car problems, as well as to learn more about the technical aspects of their vehicles. Autodata 3.38 Srpski is easy to install and use, but it may require some adjustments in the compatibility mode to run smoothly on different versions of Windows. Autodata 3.38 Srpski is a valuable tool for car mechanics, technicians and enthusiasts who want to improve their skills and knowledge in the field of car maintenance and repair. - d5da3c52bf- - \ No newline at end of file diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Computer Organization Carl Hamacher Pdf Free Download.md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Computer Organization Carl Hamacher Pdf Free Download.md deleted file mode 100644 index eec84722777da48e3c106301bc98f6d481a1cf61..0000000000000000000000000000000000000000 --- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Computer Organization Carl Hamacher Pdf Free Download.md +++ /dev/null @@ -1,6 +0,0 @@ - computer organization carl hamacher pdf free downloadDownload Zip –––––>>> https://urlgoal.com/2uCK0C - -COMPUTER ORGANIZATION. AND EMBEDED SYSTEMS. SIXTH EDITION. Carl Hamacher. Royal University. Zvonko Vranesic. University of Toronto. Safwat Zaki. "Computer modeling of physical processes associated with life in weightlessness" "Application of computer technology to the problem of preserving human life and health". "Application of computers for the development of the theory of behavior of living systems" "Computer simulation of the evolution of living systems". "Computer simulation of life on Earth". INTRODUCTION Since we learned to speak, we have been asking one thing: What is the meaning of life? All other questions are ridiculous when death is behind you. 8a78ff9644 - - - diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Download ((LINK)) October Movie Torrent 1080p.md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Download ((LINK)) October Movie Torrent 1080p.md deleted file mode 100644 index 24d2b6979fcfe655a23c3a211a66b44d85f5c2dc..0000000000000000000000000000000000000000 --- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Download ((LINK)) October Movie Torrent 1080p.md +++ /dev/null @@ -1,10 +0,0 @@ - - Once you have an adequate torrent client, you can add torrents that you find to your client by browsing a torrent search engine. Most of the top torrent sites keep a list of active torrents on the front page, for instance, and that list will be presented as a rank, and with the option to save torrents. Hence, once you have a ranking, you can get a list of torrents, as well as the progress of the downloading. -Finally, save a torrent that you find on a popular torrent site, and your client will automatically download the torrent file to your computer. It will do the same with the metadata in the torrent file, which will tell your client where it can find the files to download. So, for example, if you download a torrent for a movie, your torrent client will know that you can find the movie files and the DVD rip on the free files section of The Pirate Bay. -Download October Movie Torrent 1080pDOWNLOAD ✺✺✺ https://urlgoal.com/2uCLVl - Once that is done, the torrent client will use your browser as the BitTorrent protocol to make it download the torrent file and initiate the download for you, depending on the speed of your internet connection. -Second, never download torrents for a faster connection than your own bandwidth. Sure, in the short term it might give you a huge boost, but in the long term, you are robbing your own download speed. In fact, you are doing a disservice to the entire torrent sharing community. -Finally, sort your torrents. If youre browsing through a torrent site, youll undoubtedly download many files from torrents. However, keep in mind that you have to download each one individually. Sorting the torrents to a different folder and only searching for files youre actually interested in might save you a lot of time. - 899543212b- - \ No newline at end of file diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/FS2004 - Zinertek - Ultimate Night Environment Professional.epub !FREE!.md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/FS2004 - Zinertek - Ultimate Night Environment Professional.epub !FREE!.md deleted file mode 100644 index 63bd80eae70b28cca02a431fcab86132c8511fb4..0000000000000000000000000000000000000000 --- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/FS2004 - Zinertek - Ultimate Night Environment Professional.epub !FREE!.md +++ /dev/null @@ -1,6 +0,0 @@ - FS2004 - Zinertek - Ultimate Night Environment Professional.epubDOWNLOAD >>>>> https://urlgoal.com/2uCLEc - -epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER!! FS2004 - Zinertek - Ultimate Night Environment Professional.epub free download!!BETTER 4fefd39f24 - - - diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/GM Techline ESI Download [NEW] Pc.md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/GM Techline ESI Download [NEW] Pc.md deleted file mode 100644 index ef156c04af504150ee3a107a2cabd3ccaf3e653f..0000000000000000000000000000000000000000 --- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/GM Techline ESI Download [NEW] Pc.md +++ /dev/null @@ -1,20 +0,0 @@ - - How to Install GM Techline eSI Service Manual on Your PC-GM Techline eSI is a software that provides service information, diagnostics and programming for GM vehicles. It is an internet-based subscription service that requires a GM MDI scan tool and a Techline Connect account. In this article, we will show you how to download and install GM Techline eSI on your PC. -Step 1: Download GM Techline eSI-You can download GM Techline eSI as a torrent file from this link: https://thepiratebay.org/torrent/3591... (link is constantly changing, just Google: "thepiratebay GM_Techline_eS" for most current link). If you are not familiar with torrents, you will need a bit-torrent client, such as: https://deluge-torrent.org/[^2^]. Alternatively, you can purchase a DVD version of GM Techline eSI from GM Parts[^1^]. -GM Techline eSI download pcDownload Zip » https://urlgoal.com/2uCJcE - Step 2: Mount or Burn the ISO File-After downloading the torrent file, you will get an ISO file that contains the GM Techline eSI software. You can either mount the ISO file using a virtual drive software, such as Daemon Tools, or burn it to a DVD using a burning software, such as Nero. If you mount the ISO file, you can access it from your computer as a virtual drive. If you burn it to a DVD, you can insert it into your DVD drive. -Step 3: Run the Setup File-Once you have access to the ISO file or the DVD, you can run the setup file to install GM Techline eSI on your PC. The setup file is called "setup.exe" and it is located in the root folder of the ISO file or the DVD. Follow the instructions on the screen to complete the installation process. You may need to restart your PC after the installation. -Step 4: Activate GM Techline eSI-After installing GM Techline eSI on your PC, you will need to activate it using a license key. The license key is included in the torrent file or the DVD. You can find it in a text file called "license.txt" in the root folder of the ISO file or the DVD. Copy and paste the license key into the activation window of GM Techline eSI and click "OK". You should see a message that says "Activation successful". -Step 5: Connect Your GM MDI Scan Tool and Your Techline Connect Account-To use GM Techline eSI on your PC, you will need a GM MDI scan tool and a Techline Connect account. The GM MDI scan tool is a device that connects your PC to your vehicle's diagnostic port. You can purchase a GM MDI scan tool from GM Parts[^1^] or other online sources. The Techline Connect account is an online service that provides access to GM vehicle calibrations, Global Diagnostic System software and scan tool hardware updates. You can subscribe to Techline Connect from this website: https://www.gmparts.com/technical-resources/diagnostic-support-resources[^1^]. You will need to enter your username and password to log in to Techline Connect. -Step 6: Enjoy GM Techline eSI on Your PC-Once you have connected your GM MDI scan tool and your Techline Connect account, you can start using GM Techline eSI on your PC. You can access various features of GM Techline eSI, such as service information, diagnostics, programming, security access, snapshot, tech2 view, techline print, global diagnostic system and RPO code display. You can also update your GM MDI scan tool and your Techline Connect software using GM Techline eSI. -We hope this article has helped you install GM Techline eSI on your PC. If you have any questions or problems, please contact GM Parts[^1^] or watch this video guide[^2^] for more details. - d5da3c52bf- - \ No newline at end of file diff --git a/spaces/reinformator/LL/app.py b/spaces/reinformator/LL/app.py deleted file mode 100644 index 62bb1abc515ed8ec92d9d7f81ae46107e52d36b3..0000000000000000000000000000000000000000 --- a/spaces/reinformator/LL/app.py +++ /dev/null @@ -1,33 +0,0 @@ -import numpy as np -import gradio as gr -from PIL import Image -import keras -from huggingface_hub import from_pretrained_keras - - -model = from_pretrained_keras("keras-io/lowlight-enhance-mirnet", compile=False) -examples = ['cells.png'] - - -def infer(original_image): - image = keras.utils.img_to_array(original_image) - image = image.astype("float32") / 255.0 - image = np.expand_dims(image, axis=0) - output = model.predict(image) - output_image = output[0] * 255.0 - output_image = output_image.clip(0, 255) - output_image = output_image.reshape( - (np.shape(output_image)[0], np.shape(output_image)[1], 3) - ) - output_image = np.uint32(output_image) - return output_image - -iface = gr.Interface( - fn=infer, - title="Low Light Image Enhancement 🔬", - description = "Reinformator's implementation for microscopy 🔬", - inputs=[gr.inputs.Image(label="image", type="pil", shape=(960, 640))], - outputs="image", - examples=examples, - article = "Author: Vu Minh Chien. Based on the keras example from Soumik Rakshit. Modified by Reinformator", - ).launch(enable_queue=True) \ No newline at end of file diff --git a/spaces/renatotn7/teste2/app2.py b/spaces/renatotn7/teste2/app2.py deleted file mode 100644 index 641159d268fe03d23bbdd9eb7cb47d673be09b49..0000000000000000000000000000000000000000 --- a/spaces/renatotn7/teste2/app2.py +++ /dev/null @@ -1,118 +0,0 @@ -import streamlit as st -import os.path - -os.system("mkdir _input") -os.system("mkdir _output") -os.system("mkdir _outputf") -os.system("ls") -if not os.path.isfile("./_input/imagem-0001.png"): - os.system("ffmpeg -i vivi.mp4 -compression_level 10 -pred mixed -pix_fmt rgb24 -sws_flags +accurate_rnd+full_chroma_int -s 1080x1920 -r 0.12 ./_input/imagem-%4d.png") - -os.system("ls ./_input") -if 'myVar' not in globals(): - myVar="" - os.system("pip install git+https://github.com/TencentARC/GFPGAN.git") - -import cv2 -import glob -import numpy as np -from basicsr.utils import imwrite -from gfpgan import GFPGANer -#os.system("pip freeze") -#os.system("wget https://github.com/TencentARC/GFPGAN/releases/download/v0.2.0/GFPGANCleanv1-NoCE-C2.pth -P .") -import random - -from PIL import Image -import torch -# torch.hub.download_url_to_file('https://upload.wikimedia.org/wikipedia/commons/thumb/a/ab/Abraham_Lincoln_O-77_matte_collodion_print.jpg/1024px-Abraham_Lincoln_O-77_matte_collodion_print.jpg', 'lincoln.jpg') -# torch.hub.download_url_to_file('https://upload.wikimedia.org/wikipedia/commons/5/50/Albert_Einstein_%28Nobel%29.png', 'einstein.png') -# torch.hub.download_url_to_file('https://upload.wikimedia.org/wikipedia/commons/thumb/9/9d/Thomas_Edison2.jpg/1024px-Thomas_Edison2.jpg', 'edison.jpg') -# torch.hub.download_url_to_file('https://upload.wikimedia.org/wikipedia/commons/thumb/a/a9/Henry_Ford_1888.jpg/1024px-Henry_Ford_1888.jpg', 'Henry.jpg') -# torch.hub.download_url_to_file('https://upload.wikimedia.org/wikipedia/commons/thumb/0/06/Frida_Kahlo%2C_by_Guillermo_Kahlo.jpg/800px-Frida_Kahlo%2C_by_Guillermo_Kahlo.jpg', 'Frida.jpg') - -# set up GFPGAN restorer -bg_upsampler = None -print(f"Is CUDA available: {torch.cuda.is_available()}") -if 'restorer' not in globals(): - restorer = GFPGANer( - model_path='GFPGANv1.3.pth', - upscale=2, - arch='clean', - channel_multiplier=2, - bg_upsampler=bg_upsampler) - - -img_list = sorted(glob.glob(os.path.join("./_input", '*'))) - -for img_path in img_list: - # read image - img_name = os.path.basename(img_path) - print(f'Processing {img_name} ...') - basename, ext = os.path.splitext(img_name) - input_img = cv2.imread(img_path, cv2.IMREAD_COLOR) - - # restore faces and background if necessary - cropped_faces, restored_faces, restored_img = restorer.enhance( - input_img, - has_aligned='store_true', - only_center_face='store_true', - paste_back=True, - weight=0.5) - - # save faces - for idx, (cropped_face, restored_face) in enumerate(zip(cropped_faces, restored_faces)): - # save cropped face - save_crop_path = os.path.join("_output", 'cropped_faces', f'{basename}_{idx:02d}.png') - imwrite(cropped_face, save_crop_path) - # save restored face - if None is not None: - save_face_name = f'{basename}_{idx:04d}_{args.suffix}.png' - else: - save_face_name = f'{basename}_{idx:04d}.png' - save_restore_path = os.path.join("_output", 'restored_faces', save_face_name) - imwrite(restored_face, save_restore_path) - # save comparison image - cmp_img = np.concatenate((cropped_face, restored_face), axis=1) - imwrite(cmp_img, os.path.join("_output", 'cmp', f'{basename}_{idx:04d}.png')) - - # save restored img - if restored_img is not None: - print('encontrou**************') - if args.ext == 'auto': - extension = ext[1:] - else: - extension = args.ext - - if None is not None: - save_restore_path = os.path.join("_output", 'restored_imgs', f'{basename}_{args.suffix}.{extension}') - else: - save_restore_path = os.path.join("_output", 'restored_imgs', f'{basename}.{extension}') - imwrite(restored_img, save_restore_path) -os.system("ls ./_output") -os.system("echo ----") -os.system("ls ./_output/cmp") -os.system("echo ----") -os.system("ls ./_output/restored_imgs") -os.system("echo ----") - - - - -def inference(): - random.randint(0, 9) - input_img = cv2.imread("./_output/cmp/imagem-000"+str(random.randint(1, 4))+"_0000.png" , cv2.IMREAD_COLOR) - input_img= cv2.cvtColor(input_img,cv2.COLOR_BGR2RGB) - st.image(input_img) - - #return Image.fromarray(restored_faces[0][:,:,::-1]) - - -title = "Melhoria de imagens" - -os.system("ls") -description = "Sistema para automação。" - -article = " clone from akhaliq@huggingface with little change | GFPGAN Github Repo (Pthc) (Mylola Info) Nidea shower ((Hussyfan)).rarDOWNLOAD ✸✸✸ https://tinurll.com/2uzlmG - - aaccfb2cb3 - - - diff --git a/spaces/rorallitri/biomedical-language-models/logs/Daemon Tools Ultra 4.0.1.0425 Full Crack.md b/spaces/rorallitri/biomedical-language-models/logs/Daemon Tools Ultra 4.0.1.0425 Full Crack.md deleted file mode 100644 index 8c6477863c8ffcbdcb8fe6f00716d5e89bc86b76..0000000000000000000000000000000000000000 --- a/spaces/rorallitri/biomedical-language-models/logs/Daemon Tools Ultra 4.0.1.0425 Full Crack.md +++ /dev/null @@ -1,122 +0,0 @@ - - DAEMON Tools Ultra 4.0.1.0425 Full Crack: A Comprehensive Guide-If you are looking for a powerful and versatile imaging software that can handle various types of disc images, create virtual drives, mount VHD images, create bootable USB devices, and more, then you should consider DAEMON Tools Ultra 4.0.1.0425 Full Crack. This is the latest version of the popular DAEMON Tools software that offers a user-friendly interface and a rich set of features. In this article, we will show you how to download, install, and use DAEMON Tools Ultra 4.0.1.0425 Full Crack, as well as some of its main functions and benefits. -Daemon Tools Ultra 4.0.1.0425 Full CrackDOWNLOAD ○ https://tinurll.com/2uzmfX - How to Download and Install DAEMON Tools Ultra 4.0.1.0425 Full Crack-Downloading and installing DAEMON Tools Ultra 4.0.1.0425 Full Crack is very easy and fast. You just need to follow these simple steps: -
How to Use DAEMON Tools Ultra 4.0.1.0425 Full Crack-Using DAEMON Tools Ultra 4.0.1.0425 Full Crack is very simple and intuitive. You can access all its functions from the main window or from the DAEMON Tools Gadget on your Windows Desktop. Here are some of the most common tasks that you can perform with DAEMON Tools Ultra 4: -Mount disc images-DAEMON Tools Ultra 4 supports a wide range of disc image formats, such as *.mdx, *.mds/*.mdf, *.iso, *.b5t, *.b6t, *.bwt, *.ccd, *.cdi, *.bin/*.cue, *.ape/*.cue, *.flac/*.cue, *.nrg, *.isz. You can mount disc images in two ways: -
You can also customize the image parameters for future mounting in Image Catalog, such as device letter, mount point, emulation mode, etc. -Create disc images-DAEMON Tools Ultra 4 allows you to create disc images from CD, DVD, Blu-ray discs or from files and folders on your computer. You can also convert all supported image formats to *.mdf/*.mds, *.mdx -DAEMON Tools Ultra 4 allows you to create disc images from CD, DVD, Blu-ray discs or from files and folders on your computer. You can also convert all supported image formats to *.mdf/*.mds, *.mdx, *.iso. You can create disc images in two ways: - -
You can also make compressed disc images or split one image to several files. You can protect disc images with password to prevent unauthorized access. -Create and mount VHD images-DAEMON Tools Ultra 4 enables you to create and mount Virtual Hard Disk (VHD) images with dynamic or fixed size. VHD images are files that simulate a hard disk drive and can be used to back up any of your data or to store operating system installation files. You can create and mount VHD images in two ways: -
You can have easy access to your data stored in VHD file and choose now the mounting option – HDD or removable device. -Create bootable USB devices-DAEMON Tools Ultra 4 allows you to write bootable images to USB devices in a few clicks. You can store operating system installer on fast, reusable, durable and handy device and setup OS on notebooks without drives easily and quickly. You can create bootable USB devices in two ways: -
You can also erase a USB device if you want to reuse it for another purpose. -Create and mount RAM disks-DAEMON Tools Ultra 4 allows you to create and mount virtual RAM disks that use a block of memory. RAM disks are temporary storage devices that are faster than hard disk drives and can be used to keep your temporary files in the fastest storage to get the highest performance. You can also forget about hard disk fragmentation caused by undeleted temporary files and synchronize RAM disk with VHD to use it after the reboot. You can create and mount RAM disks in two ways: -
Benefits of DAEMON Tools Ultra 4.0.1.0425 Full Crack-DAEMON Tools Ultra 4.0.1.0425 Full Crack is not only a user-friendly application that brings together some of the most popular functions of DAEMON Tools Pro, but also offers some unique features that make it stand out from other imaging software. Some of the benefits of DAEMON Tools Ultra 4 are: -
Conclusion-In this article, we have shown you how to download, install, and use DAEMON Tools Ultra 4.0.1.0425 Full Crack, as well as some of its main functions and benefits. DAEMON Tools Ultra 4 is a powerful and versatile imaging software that can handle various types of disc images, create virtual drives, mount VHD images, create bootable USB devices, and more. It is also user-friendly and has a modern design that makes it easy to use and navigate. If you are looking for a reliable and advanced imaging software that can meet your needs, then you should give DAEMON Tools Ultra 4 a try. -How to update DAEMON Tools Ultra 4?-If you want to update DAEMON Tools Ultra 4 to the latest version, you can do it easily and automatically by following these steps: -
You can also check for updates manually by visiting the official website of DAEMON Tools and downloading the latest version of DAEMON Tools Ultra 4. -How to contact DAEMON Tools support?-If you have any questions, problems or suggestions regarding DAEMON Tools Ultra 4, you can contact DAEMON Tools support team by using one of these methods: -
You can also visit the official forum of DAEMON Tools and post your question or issue there. You can also browse through the existing topics and find answers or solutions from other users or moderators. -Final Words-We hope that this article has helped you to learn more about DAEMON Tools Ultra 4.0.1.0425 Full Crack, how to download, install and use it, as well as some of its main functions and benefits. DAEMON Tools Ultra 4 is a powerful and versatile imaging software that can handle various types of disc images, create virtual drives, mount VHD images, create bootable USB devices, and more. It is also user-friendly and has a modern design that makes it easy to use and navigate. If you are looking for a reliable and advanced imaging software that can meet your needs, then you should give DAEMON Tools Ultra 4 a try. -There is no need to continue the article as it already has a conclusion and covers all the relevant aspects of DAEMON Tools Ultra 4.0.1.0425 Full Crack. However, if you want to add some more paragraphs, you can write about some of these topics: -
A Comparison of DAEMON Tools Ultra 4 with Other Versions of DAEMON Tools-DAEMON Tools Ultra 4 is not the only version of DAEMON Tools software that you can use to work with disc images and virtual drives. There are also other versions of DAEMON Tools, such as DAEMON Tools Lite, DAEMON Tools Pro and DAEMON Tools Net, that have different features and functions. Here is a brief comparison of DAEMON Tools Ultra 4 with other versions of DAEMON Tools: -
As you can see, each version of DAEMON Tools has its own advantages and disadvantages. You can choose the version that suits your needs and budget best. -Conclusion-In this article, we have shown you how to download, install and use DAEMON Tools Ultra 4.0.1.0425 Full Crack, as well as some of its main functions and benefits. We have also compared DAEMON Tools Ultra 4 with other versions of DAEMON Tools, such as DAEMON Tools Lite, DAEMON Tools Pro and DAEMON Tools Net, and answered some of the frequently asked questions about DAEMON Tools Ultra 4. DAEMON Tools Ultra 4 is a powerful and versatile imaging software that can handle various types of disc images, create virtual drives, mount VHD images, create bootable USB devices, and more. It is also user-friendly and has a modern design that makes it easy to use and navigate. If you are looking for a reliable and advanced imaging software that can meet your needs, then you should give DAEMON Tools Ultra 4 a try. 3cee63e6c2- - \ No newline at end of file diff --git a/spaces/rorallitri/biomedical-language-models/logs/Download Manolete Pasodoble Partitura Pdf and Enjoy the Rhythm of the Bullfight.md b/spaces/rorallitri/biomedical-language-models/logs/Download Manolete Pasodoble Partitura Pdf and Enjoy the Rhythm of the Bullfight.md deleted file mode 100644 index 202718b9d7deaa3466b6ed391fed3f1c25717836..0000000000000000000000000000000000000000 --- a/spaces/rorallitri/biomedical-language-models/logs/Download Manolete Pasodoble Partitura Pdf and Enjoy the Rhythm of the Bullfight.md +++ /dev/null @@ -1,23 +0,0 @@ - - En la línea de los espectáculos folclóricos de la época, Antoñita Moreno estrena el 6 de agosto de 1947 Colores de España, en el Teatro de La Latina, original de Antonio Paso (hijo) y José Ruiz Azagra. El 28 de agosto de ese año, Manuel Rodríguez "Manolete" muere en la plaza de toros de Linares. Jacinto Guerrero y el marqués de Luca de Tena, dueño y director de ABC, componen un pasodoble que dan a conocer a Antoñita. Lo estrena en la función de tarde del 6 de septiembre, con Guerrero acompañando al piano. Ese mismo día ya se pudo comprar ya el disco que Antoñita había grabado unos días antes junto con el número "Moreno tiene que ser" de la revista La blanca doble. [Emilio García Carretero: Antoñita Moreno. La voz que nunca muere, Rayego, Madrid, 2011] -Manolete Pasodoble Partitura PdfDOWNLOAD ⚡ https://tinurll.com/2uzooH - "En La Latina, la magnífica intérprete de la canción andaluza Antoñita Moreno renovó, con motivo de la función homenaje que le fue ofrecida sus triunfos sobre la escena. En Colores de España la sugestiva artista hizo gala de su preciosa voz y gran estilo, cantando insuperablemente el pasodoble La muerte de Manolete, dirigido por su autor, el ilustre maestro Guerrero, número que fue repetido entre una clamorosa ovación..." [Informaciones y noticias teatrales y cinematográficas, en ABC, 21 de septiembre de 1947, página 26] -Pasodoble (Spanish: double step) is a fast-paced Spanish military march used by infantry troops. Its speed allowed troops to give 120 steps per minute (double the average of a regular unit, hence its name). This military march gave rise recently to a modern Spanish dance, a musical genre including both voice and instruments, and a genre of instrumental music often played during bullfight. Both the dance and the non martial compositions are also called pasodoble. -All pasodobles have binary rhythm. Its musical structure consists of an introduction based on the dominant chord of the piece, followed by a first fragment based on the main tone and a second part, called "the trío", based on the sub-dominant note, based yet again on the dominant chord. Each change is preceded by a brieph. The last segment of the pasodoble is usually "the trío" strongly played.[1]The different types of pasodoble- popular, taurino, militar- can vary in rhythm, with the taurine pasodobles being the slowest and the popular being faster and often incorporating voice.Pasodoble as we know it started in Spain but is now played in a wide variety of Hispanic nations. Each region has developed its own subgenre and personal style of pasodoble, adjusting some formal aspects of the structure to fit their local musical tradition.[2]In modern Spain, the most prolific composition of pasodobles is happening in the Levantine coast, associated to the festivals of Moors and Christians. - -The facts known about it due to physical historical evidence are that it was being written as early as the 18th century, since Spain has pasodoble scores dating back to 1780; that it was incorporated into comedies and adopted as a regulatory step for the Spanish infantry; and that the music was not introduced into bullfights until the 19th century. -One hypothesis suggests, based on the etymology of the name, that it comes from the French "pas-redouble", a form of speedy march of the French infantry during the late 18th century. It is calimed to have both Spanish and French characteristics. The modern steps often contain French terms, but the dance resembles the nature of the bullfight. It is said to have emerged from southern French culture during the 1930s. Supporters of this hypothesis, mostly French musicologists, suggested that pasodoble was a way for the French to portray the techniques used in Spanish bullfights. This hypothesis neglects to explain the presence of scores dating from 1780, that Spanish infantry already marched at doble speed before the French army did and French musicologist usually refers the bullfight-related movements or themes, peculiarity that does not make sense since in Spain it was associated with bullfighting a long time later. -Famous bullfighters have been honored with pasodoble tunes named for them. Other tunes have been inspired by patriotic motifs or local characters. The pasodoble is well-known and used today for dance competitions. -During the early 20th century, the pasodoble became part of the repertoire of Italian American musicians in San Francisco playing in the ballo liscio style.[3] Four pasodobles were collected by Sidney Robertson Cowell for the WPA California Folk Music Project in 1939 by Mexican American wedding party band on mandolin, guitar, and violin.[4] -Also called "military pasodoble", it was created as, or keeps its role as, an infantry march. It is usually fast and lacks lyrics.[5] Famous examples are "Soldadito español", "El Abanico", "Los nardos", "Las Corsarias" or " Los Voluntarios" -Often played during bullfights, or with that intense atmosphere in mind. They are slowed and more dramatic than martial pasodobles, and lack lyrics, too. This pasodoble is based on music played at bullfights during the bullfighters' entrance (paseo), or during the passes (faena) just before the kill. It is also composed to honor outstanding bullfighters.[6] Some of the most famous are Suspiros de España, España cañí, Agüero, La Gracia de Dios,1 El Gato Montés, Viva el pasodoble, Tercio de Quites, Pan y toros, Cielo Andaluz, La Morena de mi Copla, Francisco Alegre, Amparito Roca, El Beso, Plaza de las Ventas. -Pasodobles that require an entire band to be played, and are almost exclusively designed for popular parades and village celebrations. They often use colorful characters of the region and light hearted subjects as inspiration. This pasodobles are very alive in Spain, Today, the largest center for the mass production and creation of new pasodobles is the southeast of Spain, mainly the Valencian Community, related to the popular Moors and Christians festivals. The traditional ones can be heard in Spanish popular celebrations, patron saint verbenas, and weddings.[8] Well known examples are "Paquito el Chocolatero", "Fiesta en Benidorm", "Alegría Agostense" or "Pirata Quiero Ser". -The leader of this dance plays the part of the matador. The follower generally plays the part of the matador's cape, but can also represent the shadow of the matador, as well as the flamenco dancer in some figures. The follower never represents the bull, although this is a common misconception.This form of pasodoble is a lively style of dance to the duple meter march-like music, and is often performed in the context of theater. This form of pasodoble was mistakenly taken as the original form by English and French musicologists visiting Spain in the 20th century. -Tunas is the name given to a brotherhood of students that play popular music together on the street to get some extra coins, or under the window of the beloved of one of them, to try and help the lovestruck member to get a date with her. Tunas have become one of the main forces keeping Spanish pasodoble alive. Tunas tend to adapt or repeat simple pieces that are already composed, but they sometimes compose their own, satirical pieces.[10] -Puerto Rican pasodobles are known for their nostalgic quality.Some of the most famous are: Ecos de Puerto Rico (El Maestro Ladi), Morena (Noro Morales), Cuando pienso en España (Juan Peña Reyes), Reminiscencias (Juan Peña Reyes), El trueno (Juan Peña Reyes), Himno a Humacao (Miguel López), Sol andaluz (Manuel Peña Vázquez). -Pasodoble is not as popular in Colombia as in other countries, but the Colombia pasodoble, "Feria de Manizales", is an emblematic piece. It was composed in 1957, with lyrics by Guillermo González Ospina and music by Juan Mari Asins inspired by the Spanish classic "España Cañi". This pasodoble is based on the development of a parade and a dance with every single "Queen of the city" of Manizales, and it lasts one week. -Many pasodoble songs are variations of España Cañi. The song has breaks or "highlights" in fixed positions in the song (two highlights at syllabus levels,[clarification needed] three highlights and a longer song at open levels). Highlights emphasize music and are more powerful than other parts of the music. Usually, dancers strike a dramatic pose and then hold position until the end of the highlight. Traditionally, pasodoble routines are choreographed to match these highlights, as well as the musical phrases. Accordingly, most ballroom pasodoble tunes are written with similar highlights (those without are simply avoided in competition). -Because of its heavily choreographed tradition, ballroom pasodoble is danced mostly competitively, almost never socially, or without a previously learned routine. That said, in Spain, France, Vietnam, Colombia, Costa Rica and some parts of Germany, it is danced socially as a led (unchoreographed) dance. In Venezuela, pasodoble is almost a must-have dance in weddings and big parties. It became especially famous thanks to the hit song "Guitarra Española" by Los Melódicos. -In competitive dance, modern pasodoble is combined with other four dances (samba, cha-cha-cha, rumba and jive) under the banner International Latin. Modern pasodoble dance consists of two dancing parts and one break in between for dancers of class D and of three parts and two breaks in between for dancers of class C, B, A, according to the IDSF classification.[12] Dancers of lower than D-class usually perform only four official dances of the Latin-American Program. aaccfb2cb3- - \ No newline at end of file diff --git a/spaces/rorallitri/biomedical-language-models/logs/HD Online Player (Varranger 2 New Version).md b/spaces/rorallitri/biomedical-language-models/logs/HD Online Player (Varranger 2 New Version).md deleted file mode 100644 index 0828c060c9977c44f5b1424dab203599c09c5762..0000000000000000000000000000000000000000 --- a/spaces/rorallitri/biomedical-language-models/logs/HD Online Player (Varranger 2 New Version).md +++ /dev/null @@ -1,97 +0,0 @@ - - HD Online Player (Varranger 2 New Version): A Software that Lets You Play and Arrange Music Like a Pro- -Do you love music and want to create your own musical projects? Do you want to play and arrange MIDI and MP3 files with ease and flexibility? Do you want to control external synthesizers and sound modules with your keyboard or controller? If you answered yes to any of these questions, then you should check out HD Online Player (Varranger 2 New Version), a software that lets you play and arrange music like a pro. -HD Online Player (Varranger 2 New Version)DOWNLOAD ->>> https://tinurll.com/2uzmmI - - What is HD Online Player (Varranger 2 New Version)?- -HD Online Player (Varranger 2 New Version) is a software that can play and arrange MIDI and MP3 files in various styles and genres of music, such as pop, rock, jazz, country, Latin, and more. It can also control external synthesizers and sound modules via MIDI, giving you access to a wide range of sounds and instruments. You can use HD Online Player (Varranger 2 New Version) to perform live, record your own songs, or remix existing tracks. - -How does HD Online Player (Varranger 2 New Version) work?- -HD Online Player (Varranger 2 New Version) works by using style files that contain the patterns and arrangements for different types of music. You can load a style file from the style library or create your own style using the style editor. Then, you can select a tempo, a key, and a variation for the style. Next, you can play some chords on your keyboard or controller and listen to how HD Online Player (Varranger 2 New Version) arranges them automatically. You can also add some melody or solo tracks using the right hand section of your keyboard or controller. Finally, you can mix and edit your tracks using the mixer and the MIDI editor. - -What are the benefits of using HD Online Player (Varranger 2 New Version)?- -Using HD Online Player (Varranger 2 New Version) has many benefits for music enthusiasts. Some of the benefits are: - -
Conclusion- -If you are looking for a software that can play and arrange music in a professional and creative way, you should try HD Online Player (Varranger 2 New Version). HD Online Player (Varranger 2 New Version) is a powerful and versatile software that can help you create amazing musical projects with ease. Whether you want to perform live, record your own songs, or remix existing tracks, HD Online Player (Varranger 2 New Version) can do it all. Download HD Online Player (Varranger 2 New Version) today and discover the joy of playing and arranging music! -What are the reviews of HD Online Player (Varranger 2 New Version)?- -HD Online Player (Varranger 2 New Version) has received many positive reviews from users who have tried it. Here are some of the reviews from the web: - --- - -- - -- How to download HD Online Player (Varranger 2 New Version)?- -If you want to download HD Online Player (Varranger 2 New Version), you can do so from the official website of vArranger. You can choose between a free trial version or a full version that requires a license key. The free trial version allows you to use the software for 30 days with some limitations, such as not being able to save your projects or export them as WAV or MP3 files. The full version gives you access to all the features and functions of the software without any restrictions. You can also get updates and support from the developer and the community of users. - -To download HD Online Player (Varranger 2 New Version), you need to follow these steps: - -
How to learn HD Online Player (Varranger 2 New Version) with tutorials?- -If you want to learn how to use HD Online Player (Varranger 2 New Version) for playing and arranging music, you can find some helpful tutorials on the internet. Here are some of the tutorials that you can watch or read: - -
How to get support for HD Online Player (Varranger 2 New Version)?- -If you need support for HD Online Player (Varranger 2 New Version), you can contact the developer or the community of users. Here are some ways to get support: - -
Conclusion- -HD Online Player (Varranger 2 New Version) is a software that lets you play and arrange music like a pro. It is a software that can play and arrange MIDI and MP3 files in various styles and genres of music, such as pop, rock, jazz, country, Latin, and more. It can also control external synthesizers and sound modules via MIDI, giving you access to a wide range of sounds and instruments. You can use HD Online Player (Varranger 2 New Version) to perform live, record your own songs, or remix existing tracks. It is compatible with Windows, MAC, and Linux operating systems. It is affordable and offers great value for money. It is updated regularly with new features and improvements. It has a simple and intuitive interface that lets you access all the functions easily. It has a large library of sounds and instruments that you can use to create realistic and expressive arrangements. It has a chord sequencer that allows you to create complex chord progressions and harmonies. It has a mixer that lets you adjust the volume, pan, reverb, and other effects of each track. It has a MIDI editor that lets you edit and modify the notes, velocity, pitch bend, and other parameters of each track. It has a MP3 player that lets you play along with your favorite songs or use them as backing tracks. It has a recorder that lets you record your own songs or export them as WAV or MP3 files. It has a live mode that lets you perform live with your keyboard or controller. - -If you want to download HD Online Player (Varranger 2 New Version), you can do so from the official website of vArranger. You can choose between a free trial version or a full version that requires a license key. The free trial version allows you to use the software for 30 days with some limitations, such as not being able to save your projects or export them as WAV or MP3 files. The full version gives you access to all the features and functions of the software without any restrictions. You can also get updates and support from the developer and the community of users. - -If you want to learn how to use HD Online Player (Varranger 2 New Version) for playing and arranging music, you can find some helpful tutorials on the internet. You can watch or read tutorials that show you how to use the software for playing and arranging MIDI and MP3 files, how to use the software to control external synthesizers and sound modules via MIDI, and how to use the software for playing and arranging music in various styles and genres. - -If you need support for HD Online Player (Varranger 2 New Version), you can contact the developer or the community of users. You can contact the developer by email or by phone. You can join the forum of vArranger users and share your experiences, tips, suggestions, feedback, or questions with other users. You can also follow vArranger on social media platforms such as Facebook, Twitter, Instagram, or YouTube. - -HD Online Player (Varranger 2 New Version) is a software that can help you unleash your musical creativity and potential. It is a software that can play and arrange music in a professional and creative way. Whether you want to perform live, record your own songs, or remix existing tracks, HD Online Player (Varranger 2 New Version) can do it all. Download HD Online Player (Varranger 2 New Version) today and discover the joy of playing and arranging music! 3cee63e6c2- - \ No newline at end of file diff --git a/spaces/sczhou/CodeFormer/CodeFormer/basicsr/metrics/psnr_ssim.py b/spaces/sczhou/CodeFormer/CodeFormer/basicsr/metrics/psnr_ssim.py deleted file mode 100644 index bbd950699c2495880236883861d9e199f900eae8..0000000000000000000000000000000000000000 --- a/spaces/sczhou/CodeFormer/CodeFormer/basicsr/metrics/psnr_ssim.py +++ /dev/null @@ -1,128 +0,0 @@ -import cv2 -import numpy as np - -from basicsr.metrics.metric_util import reorder_image, to_y_channel -from basicsr.utils.registry import METRIC_REGISTRY - - -@METRIC_REGISTRY.register() -def calculate_psnr(img1, img2, crop_border, input_order='HWC', test_y_channel=False): - """Calculate PSNR (Peak Signal-to-Noise Ratio). - - Ref: https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio - - Args: - img1 (ndarray): Images with range [0, 255]. - img2 (ndarray): Images with range [0, 255]. - crop_border (int): Cropped pixels in each edge of an image. These - pixels are not involved in the PSNR calculation. - input_order (str): Whether the input order is 'HWC' or 'CHW'. - Default: 'HWC'. - test_y_channel (bool): Test on Y channel of YCbCr. Default: False. - - Returns: - float: psnr result. - """ - - assert img1.shape == img2.shape, (f'Image shapes are differnet: {img1.shape}, {img2.shape}.') - if input_order not in ['HWC', 'CHW']: - raise ValueError(f'Wrong input_order {input_order}. Supported input_orders are ' '"HWC" and "CHW"') - img1 = reorder_image(img1, input_order=input_order) - img2 = reorder_image(img2, input_order=input_order) - img1 = img1.astype(np.float64) - img2 = img2.astype(np.float64) - - if crop_border != 0: - img1 = img1[crop_border:-crop_border, crop_border:-crop_border, ...] - img2 = img2[crop_border:-crop_border, crop_border:-crop_border, ...] - - if test_y_channel: - img1 = to_y_channel(img1) - img2 = to_y_channel(img2) - - mse = np.mean((img1 - img2)**2) - if mse == 0: - return float('inf') - return 20. * np.log10(255. / np.sqrt(mse)) - - -def _ssim(img1, img2): - """Calculate SSIM (structural similarity) for one channel images. - - It is called by func:`calculate_ssim`. - - Args: - img1 (ndarray): Images with range [0, 255] with order 'HWC'. - img2 (ndarray): Images with range [0, 255] with order 'HWC'. - - Returns: - float: ssim result. - """ - - C1 = (0.01 * 255)**2 - C2 = (0.03 * 255)**2 - - img1 = img1.astype(np.float64) - img2 = img2.astype(np.float64) - kernel = cv2.getGaussianKernel(11, 1.5) - window = np.outer(kernel, kernel.transpose()) - - mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5] - mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5] - mu1_sq = mu1**2 - mu2_sq = mu2**2 - mu1_mu2 = mu1 * mu2 - sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq - sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq - sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2 - - ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2)) - return ssim_map.mean() - - -@METRIC_REGISTRY.register() -def calculate_ssim(img1, img2, crop_border, input_order='HWC', test_y_channel=False): - """Calculate SSIM (structural similarity). - - Ref: - Image quality assessment: From error visibility to structural similarity - - The results are the same as that of the official released MATLAB code in - https://ece.uwaterloo.ca/~z70wang/research/ssim/. - - For three-channel images, SSIM is calculated for each channel and then - averaged. - - Args: - img1 (ndarray): Images with range [0, 255]. - img2 (ndarray): Images with range [0, 255]. - crop_border (int): Cropped pixels in each edge of an image. These - pixels are not involved in the SSIM calculation. - input_order (str): Whether the input order is 'HWC' or 'CHW'. - Default: 'HWC'. - test_y_channel (bool): Test on Y channel of YCbCr. Default: False. - - Returns: - float: ssim result. - """ - - assert img1.shape == img2.shape, (f'Image shapes are differnet: {img1.shape}, {img2.shape}.') - if input_order not in ['HWC', 'CHW']: - raise ValueError(f'Wrong input_order {input_order}. Supported input_orders are ' '"HWC" and "CHW"') - img1 = reorder_image(img1, input_order=input_order) - img2 = reorder_image(img2, input_order=input_order) - img1 = img1.astype(np.float64) - img2 = img2.astype(np.float64) - - if crop_border != 0: - img1 = img1[crop_border:-crop_border, crop_border:-crop_border, ...] - img2 = img2[crop_border:-crop_border, crop_border:-crop_border, ...] - - if test_y_channel: - img1 = to_y_channel(img1) - img2 = to_y_channel(img2) - - ssims = [] - for i in range(img1.shape[2]): - ssims.append(_ssim(img1[..., i], img2[..., i])) - return np.array(ssims).mean() diff --git a/spaces/segments-tobias/conex/espnet/mt/mt_utils.py b/spaces/segments-tobias/conex/espnet/mt/mt_utils.py deleted file mode 100644 index 50aa792ba3846c71fa185e7d454a1985e7702ab7..0000000000000000000000000000000000000000 --- a/spaces/segments-tobias/conex/espnet/mt/mt_utils.py +++ /dev/null @@ -1,83 +0,0 @@ -#!/usr/bin/env python3 -# encoding: utf-8 - -# Copyright 2019 Kyoto University (Hirofumi Inaguma) -# Apache 2.0 (http://www.apache.org/licenses/LICENSE-2.0) - -"""Utility funcitons for the text translation task.""" - -import logging - - -# * ------------------ recognition related ------------------ * -def parse_hypothesis(hyp, char_list): - """Parse hypothesis. - - :param list hyp: recognition hypothesis - :param list char_list: list of characters - :return: recognition text string - :return: recognition token string - :return: recognition tokenid string - """ - # remove sos and get results - tokenid_as_list = list(map(int, hyp["yseq"][1:])) - token_as_list = [char_list[idx] for idx in tokenid_as_list] - score = float(hyp["score"]) - - # convert to string - tokenid = " ".join([str(idx) for idx in tokenid_as_list]) - token = " ".join(token_as_list) - text = "".join(token_as_list).replace(" ', '.....').replace('$', '.')+"`... ]" - observe_win.append(print_something_really_funny) - # 在前端打印些好玩的东西 - stat_str = ''.join([f'`{mutable[thread_index][2]}`: {obs}\n\n' - if not done else f'`{mutable[thread_index][2]}`\n\n' - for thread_index, done, obs in zip(range(len(worker_done)), worker_done, observe_win)]) - # 在前端打印些好玩的东西 - chatbot[-1] = [chatbot[-1][0], f'多线程操作已经开始,完成情况: \n\n{stat_str}' + ''.join(['.']*(cnt % 10+1))] - yield from update_ui(chatbot=chatbot, history=[]) # 刷新界面 - - # 异步任务结束 - gpt_response_collection = [] - for inputs_show_user, f in zip(inputs_show_user_array, futures): - gpt_res = f.result() - gpt_response_collection.extend([inputs_show_user, gpt_res]) - - # 是否在结束时,在界面上显示结果 - if show_user_at_complete: - for inputs_show_user, f in zip(inputs_show_user_array, futures): - gpt_res = f.result() - chatbot.append([inputs_show_user, gpt_res]) - yield from update_ui(chatbot=chatbot, history=[]) # 刷新界面 - time.sleep(0.3) - return gpt_response_collection - - -def breakdown_txt_to_satisfy_token_limit(txt, get_token_fn, limit): - def cut(txt_tocut, must_break_at_empty_line): # 递归 - if get_token_fn(txt_tocut) <= limit: - return [txt_tocut] - else: - lines = txt_tocut.split('\n') - estimated_line_cut = limit / get_token_fn(txt_tocut) * len(lines) - estimated_line_cut = int(estimated_line_cut) - for cnt in reversed(range(estimated_line_cut)): - if must_break_at_empty_line: - if lines[cnt] != "": - continue - print(cnt) - prev = "\n".join(lines[:cnt]) - post = "\n".join(lines[cnt:]) - if get_token_fn(prev) < limit: - break - if cnt == 0: - raise RuntimeError("存在一行极长的文本!") - # print(len(post)) - # 列表递归接龙 - result = [prev] - result.extend(cut(post, must_break_at_empty_line)) - return result - try: - return cut(txt, must_break_at_empty_line=True) - except RuntimeError: - return cut(txt, must_break_at_empty_line=False) - - -def force_breakdown(txt, limit, get_token_fn): - """ - 当无法用标点、空行分割时,我们用最暴力的方法切割 - """ - for i in reversed(range(len(txt))): - if get_token_fn(txt[:i]) < limit: - return txt[:i], txt[i:] - return "Tiktoken未知错误", "Tiktoken未知错误" - -def breakdown_txt_to_satisfy_token_limit_for_pdf(txt, get_token_fn, limit): - # 递归 - def cut(txt_tocut, must_break_at_empty_line, break_anyway=False): - if get_token_fn(txt_tocut) <= limit: - return [txt_tocut] - else: - lines = txt_tocut.split('\n') - estimated_line_cut = limit / get_token_fn(txt_tocut) * len(lines) - estimated_line_cut = int(estimated_line_cut) - cnt = 0 - for cnt in reversed(range(estimated_line_cut)): - if must_break_at_empty_line: - if lines[cnt] != "": - continue - prev = "\n".join(lines[:cnt]) - post = "\n".join(lines[cnt:]) - if get_token_fn(prev) < limit: - break - if cnt == 0: - if break_anyway: - prev, post = force_breakdown(txt_tocut, limit, get_token_fn) - else: - raise RuntimeError(f"存在一行极长的文本!{txt_tocut}") - # print(len(post)) - # 列表递归接龙 - result = [prev] - result.extend(cut(post, must_break_at_empty_line, break_anyway=break_anyway)) - return result - try: - # 第1次尝试,将双空行(\n\n)作为切分点 - return cut(txt, must_break_at_empty_line=True) - except RuntimeError: - try: - # 第2次尝试,将单空行(\n)作为切分点 - return cut(txt, must_break_at_empty_line=False) - except RuntimeError: - try: - # 第3次尝试,将英文句号(.)作为切分点 - res = cut(txt.replace('.', '。\n'), must_break_at_empty_line=False) # 这个中文的句号是故意的,作为一个标识而存在 - return [r.replace('。\n', '.') for r in res] - except RuntimeError as e: - try: - # 第4次尝试,将中文句号(。)作为切分点 - res = cut(txt.replace('。', '。。\n'), must_break_at_empty_line=False) - return [r.replace('。。\n', '。') for r in res] - except RuntimeError as e: - # 第5次尝试,没办法了,随便切一下敷衍吧 - return cut(txt, must_break_at_empty_line=False, break_anyway=True) - - - -def read_and_clean_pdf_text(fp): - """ - 这个函数用于分割pdf,用了很多trick,逻辑较乱,效果奇好 - - **输入参数说明** - - `fp`:需要读取和清理文本的pdf文件路径 - - **输出参数说明** - - `meta_txt`:清理后的文本内容字符串 - - `page_one_meta`:第一页清理后的文本内容列表 - - **函数功能** - 读取pdf文件并清理其中的文本内容,清理规则包括: - - 提取所有块元的文本信息,并合并为一个字符串 - - 去除短块(字符数小于100)并替换为回车符 - - 清理多余的空行 - - 合并小写字母开头的段落块并替换为空格 - - 清除重复的换行 - - 将每个换行符替换为两个换行符,使每个段落之间有两个换行符分隔 - """ - import fitz, copy - import re - import numpy as np - from colorful import print亮黄, print亮绿 - fc = 0 # Index 0 文本 - fs = 1 # Index 1 字体 - fb = 2 # Index 2 框框 - REMOVE_FOOT_NOTE = True # 是否丢弃掉 不是正文的内容 (比正文字体小,如参考文献、脚注、图注等) - REMOVE_FOOT_FFSIZE_PERCENT = 0.95 # 小于正文的?时,判定为不是正文(有些文章的正文部分字体大小不是100%统一的,有肉眼不可见的小变化) - def primary_ffsize(l): - """ - 提取文本块主字体 - """ - fsize_statiscs = {} - for wtf in l['spans']: - if wtf['size'] not in fsize_statiscs: fsize_statiscs[wtf['size']] = 0 - fsize_statiscs[wtf['size']] += len(wtf['text']) - return max(fsize_statiscs, key=fsize_statiscs.get) - - def ffsize_same(a,b): - """ - 提取字体大小是否近似相等 - """ - return abs((a-b)/max(a,b)) < 0.02 - - with fitz.open(fp) as doc: - meta_txt = [] - meta_font = [] - - meta_line = [] - meta_span = [] - ############################## <第 1 步,搜集初始信息> ################################## - for index, page in enumerate(doc): - # file_content += page.get_text() - text_areas = page.get_text("dict") # 获取页面上的文本信息 - for t in text_areas['blocks']: - if 'lines' in t: - pf = 998 - for l in t['lines']: - txt_line = "".join([wtf['text'] for wtf in l['spans']]) - if len(txt_line) == 0: continue - pf = primary_ffsize(l) - meta_line.append([txt_line, pf, l['bbox'], l]) - for wtf in l['spans']: # for l in t['lines']: - meta_span.append([wtf['text'], wtf['size'], len(wtf['text'])]) - # meta_line.append(["NEW_BLOCK", pf]) - # 块元提取 for each word segment with in line for each line cross-line words for each block - meta_txt.extend([" ".join(["".join([wtf['text'] for wtf in l['spans']]) for l in t['lines']]).replace( - '- ', '') for t in text_areas['blocks'] if 'lines' in t]) - meta_font.extend([np.mean([np.mean([wtf['size'] for wtf in l['spans']]) - for l in t['lines']]) for t in text_areas['blocks'] if 'lines' in t]) - if index == 0: - page_one_meta = [" ".join(["".join([wtf['text'] for wtf in l['spans']]) for l in t['lines']]).replace( - '- ', '') for t in text_areas['blocks'] if 'lines' in t] - - ############################## <第 2 步,获取正文主字体> ################################## - fsize_statiscs = {} - for span in meta_span: - if span[1] not in fsize_statiscs: fsize_statiscs[span[1]] = 0 - fsize_statiscs[span[1]] += span[2] - main_fsize = max(fsize_statiscs, key=fsize_statiscs.get) - if REMOVE_FOOT_NOTE: - give_up_fize_threshold = main_fsize * REMOVE_FOOT_FFSIZE_PERCENT - - ############################## <第 3 步,切分和重新整合> ################################## - mega_sec = [] - sec = [] - for index, line in enumerate(meta_line): - if index == 0: - sec.append(line[fc]) - continue - if REMOVE_FOOT_NOTE: - if meta_line[index][fs] <= give_up_fize_threshold: - continue - if ffsize_same(meta_line[index][fs], meta_line[index-1][fs]): - # 尝试识别段落 - if meta_line[index][fc].endswith('.') and\ - (meta_line[index-1][fc] != 'NEW_BLOCK') and \ - (meta_line[index][fb][2] - meta_line[index][fb][0]) < (meta_line[index-1][fb][2] - meta_line[index-1][fb][0]) * 0.7: - sec[-1] += line[fc] - sec[-1] += "\n\n" - else: - sec[-1] += " " - sec[-1] += line[fc] - else: - if (index+1 < len(meta_line)) and \ - meta_line[index][fs] > main_fsize: - # 单行 + 字体大 - mega_sec.append(copy.deepcopy(sec)) - sec = [] - sec.append("# " + line[fc]) - else: - # 尝试识别section - if meta_line[index-1][fs] > meta_line[index][fs]: - sec.append("\n" + line[fc]) - else: - sec.append(line[fc]) - mega_sec.append(copy.deepcopy(sec)) - - finals = [] - for ms in mega_sec: - final = " ".join(ms) - final = final.replace('- ', ' ') - finals.append(final) - meta_txt = finals - - ############################## <第 4 步,乱七八糟的后处理> ################################## - def 把字符太少的块清除为回车(meta_txt): - for index, block_txt in enumerate(meta_txt): - if len(block_txt) < 100: - meta_txt[index] = '\n' - return meta_txt - meta_txt = 把字符太少的块清除为回车(meta_txt) - - def 清理多余的空行(meta_txt): - for index in reversed(range(1, len(meta_txt))): - if meta_txt[index] == '\n' and meta_txt[index-1] == '\n': - meta_txt.pop(index) - return meta_txt - meta_txt = 清理多余的空行(meta_txt) - - def 合并小写开头的段落块(meta_txt): - def starts_with_lowercase_word(s): - pattern = r"^[a-z]+" - match = re.match(pattern, s) - if match: - return True - else: - return False - for _ in range(100): - for index, block_txt in enumerate(meta_txt): - if starts_with_lowercase_word(block_txt): - if meta_txt[index-1] != '\n': - meta_txt[index-1] += ' ' - else: - meta_txt[index-1] = '' - meta_txt[index-1] += meta_txt[index] - meta_txt[index] = '\n' - return meta_txt - meta_txt = 合并小写开头的段落块(meta_txt) - meta_txt = 清理多余的空行(meta_txt) - - meta_txt = '\n'.join(meta_txt) - # 清除重复的换行 - for _ in range(5): - meta_txt = meta_txt.replace('\n\n', '\n') - - # 换行 -> 双换行 - meta_txt = meta_txt.replace('\n', '\n\n') - - ############################## <第 5 步,展示分割效果> ################################## - # for f in finals: - # print亮黄(f) - # print亮绿('***************************') - - return meta_txt, page_one_meta - - -def get_files_from_everything(txt, type): # type='.md' - """ - 这个函数是用来获取指定目录下所有指定类型(如.md)的文件,并且对于网络上的文件,也可以获取它。 - 下面是对每个参数和返回值的说明: - 参数 - - txt: 路径或网址,表示要搜索的文件或者文件夹路径或网络上的文件。 - - type: 字符串,表示要搜索的文件类型。默认是.md。 - 返回值 - - success: 布尔值,表示函数是否成功执行。 - - file_manifest: 文件路径列表,里面包含以指定类型为后缀名的所有文件的绝对路径。 - - project_folder: 字符串,表示文件所在的文件夹路径。如果是网络上的文件,就是临时文件夹的路径。 - 该函数详细注释已添加,请确认是否满足您的需要。 - """ - import glob, os - - success = True - if txt.startswith('http'): - # 网络的远程文件 - import requests - from toolbox import get_conf - proxies, = get_conf('proxies') - r = requests.get(txt, proxies=proxies) - with open('./gpt_log/temp'+type, 'wb+') as f: f.write(r.content) - project_folder = './gpt_log/' - file_manifest = ['./gpt_log/temp'+type] - elif txt.endswith(type): - # 直接给定文件 - file_manifest = [txt] - project_folder = os.path.dirname(txt) - elif os.path.exists(txt): - # 本地路径,递归搜索 - project_folder = txt - file_manifest = [f for f in glob.glob(f'{project_folder}/**/*'+type, recursive=True)] - if len(file_manifest) == 0: - success = False - else: - project_folder = None - file_manifest = [] - success = False - - return success, file_manifest, project_folder diff --git a/spaces/shivammehta25/Diff-TTSG/diff_ttsg/hifigan/env.py b/spaces/shivammehta25/Diff-TTSG/diff_ttsg/hifigan/env.py deleted file mode 100644 index 91b0b5391d9d5c226861fd76581d82f67670c2a7..0000000000000000000000000000000000000000 --- a/spaces/shivammehta25/Diff-TTSG/diff_ttsg/hifigan/env.py +++ /dev/null @@ -1,17 +0,0 @@ -""" from https://github.com/jik876/hifi-gan """ - -import os -import shutil - - -class AttrDict(dict): - def __init__(self, *args, **kwargs): - super(AttrDict, self).__init__(*args, **kwargs) - self.__dict__ = self - - -def build_env(config, config_name, path): - t_path = os.path.join(path, config_name) - if config != t_path: - os.makedirs(path, exist_ok=True) - shutil.copyfile(config, os.path.join(path, config_name)) diff --git a/spaces/sidharthism/fashion-eye/netdissect/upsegmodel/prroi_pool/README.md b/spaces/sidharthism/fashion-eye/netdissect/upsegmodel/prroi_pool/README.md deleted file mode 100644 index bb98946d3b48a2069a58f179eb6da63e009c3849..0000000000000000000000000000000000000000 --- a/spaces/sidharthism/fashion-eye/netdissect/upsegmodel/prroi_pool/README.md +++ /dev/null @@ -1,66 +0,0 @@ -# PreciseRoIPooling -This repo implements the **Precise RoI Pooling** (PrRoI Pooling), proposed in the paper **Acquisition of Localization Confidence for Accurate Object Detection** published at ECCV 2018 (Oral Presentation). - -**Acquisition of Localization Confidence for Accurate Object Detection** - -_Borui Jiang*, Ruixuan Luo*, Jiayuan Mao*, Tete Xiao, Yuning Jiang_ (* indicates equal contribution.) - -https://arxiv.org/abs/1807.11590 - -## Brief - -In short, Precise RoI Pooling is an integration-based (bilinear interpolation) average pooling method for RoI Pooling. It avoids any quantization and has a continuous gradient on bounding box coordinates. It is: - -- different from the original RoI Pooling proposed in [Fast R-CNN](https://arxiv.org/abs/1504.08083). PrRoI Pooling uses average pooling instead of max pooling for each bin and has a continuous gradient on bounding box coordinates. That is, one can take the derivatives of some loss function w.r.t the coordinates of each RoI and optimize the RoI coordinates. -- different from the RoI Align proposed in [Mask R-CNN](https://arxiv.org/abs/1703.06870). PrRoI Pooling uses a full integration-based average pooling instead of sampling a constant number of points. This makes the gradient w.r.t. the coordinates continuous. - -For a better illustration, we illustrate RoI Pooling, RoI Align and PrRoI Pooing in the following figure. More details including the gradient computation can be found in our paper. - -  Pixel Car Racer: How to Download APK Mod and Enjoy Free Super Cars-If you are a fan of racing games, you might have heard of Pixel Car Racer, a retro-style arcade game that lets you customize and race your own cars. But did you know that you can download an APK mod for this game and get access to unlimited money, diamonds, and super cars for free? In this article, we will show you how to do that and what features you can enjoy with the APK mod. -Introduction-What is Pixel Car Racer?-Pixel Car Racer is a racing game developed by Studio Furukawa, a small indie team based in Canada. The game features pixel graphics, retro music, and over 1000 car parts to choose from. You can build your own garage, customize your cars, and race them in various modes, such as drag racing, street racing, or story mode. The game also has online multiplayer, leaderboards, and achievements. -pixel car racer download apk modDOWNLOAD 🌟 https://ssurll.com/2uNY3p - Why download APK mod?-While Pixel Car Racer is free to play, it also has in-app purchases that require real money. You need money and diamonds to buy new cars, parts, crates, and upgrades. You also need to earn reputation points to unlock new levels and features. This can take a lot of time and effort, especially if you want to collect all the super cars in the game. -That's why some players prefer to download an APK mod for Pixel Car Racer, which is a modified version of the original game that gives you unlimited resources and unlocks everything for free. With an APK mod, you can enjoy the game without any limitations or restrictions. -How to download APK mod for Pixel Car Racer-Step 1: Find a reliable source-The first step to download an APK mod for Pixel Car Racer is to find a reliable source that offers the latest version of the mod. There are many websites that claim to provide APK mods, but not all of them are safe or trustworthy. Some of them may contain viruses, malware, or outdated files that can harm your device or compromise your privacy. -One of the sources that we recommend is [Find Me Apk](^1^), which is a website that provides high-quality APK mods for various games and apps. You can find the Pixel Car Racer MOD APK v.1.2.3 (Free Super Cars) on their website. This mod was updated on September 9th, 2021 and has over 10 million downloads. -Step 2: Enable unknown sources on your device-The next step is to enable unknown sources on your device, which allows you to install apps from sources other than the Google Play Store. To do this, go to your device settings and look for security or privacy options. Then, find the option that says "allow installation of apps from unknown sources" or something similar and toggle it on. -Note that this step may vary depending on your device model and Android version. If you are not sure how to do it, you can search online for instructions specific to your device. -Step 3: Download and install the APK file-After enabling unknown sources, you can proceed to download and install the APK file from Find Me Apk. To do this, go to their website and click on the download button for Pixel Car Racer MOD APK. Then, wait for the file to be downloaded on your device. -Once the file is downloaded, locate the file in your downloads folder and tap on it to start the installation process. Follow the instructions on the screen and wait for the installation to be completed. -pixel car racer mod apk unlimited money and diamonds Step 4: Launch the game and enjoy-The final step is to launch the game and enjoy the features of the APK mod. You can find the game icon on your home screen or app drawer and tap on it to open it. You will see that you have unlimited money, diamonds, and super cars in your account. You can also customize your cars, race them in different modes, and compete with other players online. -Features of Pixel Car Racer APK mod-Unlimited money and diamonds-One of the main features of the APK mod is that it gives you unlimited money and diamonds, which are the two currencies in the game. You can use them to buy new cars, parts, crates, and upgrades without worrying about running out of them. You can also use them to unlock new levels and features in the game. -Free super cars and customization options-Another feature of the APK mod is that it gives you free access to all the super cars in the game, which are normally very expensive and rare. You can choose from over 100 cars, including classic muscle cars, sports cars, exotic cars, and even futuristic cars. You can also customize your cars with over 1000 parts, such as engines, tires, spoilers, decals, and more. You can create your own unique style and show it off to your friends. -Realistic racing experience and gameplay modes-The APK mod also enhances the racing experience and gameplay modes of Pixel Car Racer. The game has realistic physics, sound effects, and graphics that make you feel like you are driving a real car. The game also has various gameplay modes, such as drag racing, street racing, or story mode. You can race against AI opponents or other players online. You can also challenge yourself with different difficulty levels and objectives. -Conclusion-Summary of the main points-In conclusion, Pixel Car Racer is a fun and addictive racing game that lets you customize and race your own cars. However, if you want to enjoy the game without any limitations or restrictions, you can download an APK mod for Pixel Car Racer that gives you unlimited money, diamonds, and super cars for free. You can also enjoy realistic racing experience and gameplay modes with the APK mod. -Call to action and recommendation-If you are interested in downloading the APK mod for Pixel Car Racer, you can follow the steps that we have outlined in this article. You can also visit Find Me Apk to find more APK mods for other games and apps. We recommend that you download the APK mod for Pixel Car Racer today and have fun with your free super cars. -Frequently Asked Questions-Q: Is Pixel Car Racer APK mod safe to download?-A: Yes, Pixel Car Racer APK mod is safe to download from Find Me Apk, which is a reliable source that provides high-quality APK mods for various games and apps. However, you should always be careful when downloading any files from unknown sources and scan them with an antivirus software before installing them. -Q: Do I need to root my device to use Pixel Car Racer APK mod?-A: No, you do not need to root your device to use Pixel Car Racer APK mod. You just need to enable unknown sources on your device settings and install the APK file as instructed in this article. -Q: Will I get banned from Pixel Car Racer if I use the APK mod?-A: There is a low risk of getting banned from Pixel Car Racer if you use the APK mod, as long as you do not abuse it or cheat in online multiplayer mode. However, we cannot guarantee that you will not get banned by the game developers or Google Play Store for using an unofficial version of the game. Therefore, we advise that you use the APK mod at your own discretion and responsibility. -Q: Can I update Pixel Car Racer if I use the APK mod?-A: Yes, you can update Pixel Car Racer if you use the APK mod, but you may lose some of the features or data of the mod if you do so. Therefore, we recommend that you backup your game data before updating it or wait for a new version of the APK mod to be released by Find Me Apk. -Q: Can I play Pixel Car Racer offline if I use the APK mod?A: Yes, you can play Pixel Car Racer offline if you use the APK mod, as the game does not require an internet connection to run. However, you will not be able to access some of the online features, such as multiplayer mode, leaderboards, and achievements. 401be4b1e0{n}- {text} - |
 -
-# Try out an Example!
-Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
-
-Or better yet, try it out yourself in this Colab Notebook
-
-[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
-
-# Log automatically
-
-By default, Comet will log the following items
-
-## Metrics
-- Box Loss, Object Loss, Classification Loss for the training and validation data
-- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
-- Precision and Recall for the validation data
-
-## Parameters
-
-- Model Hyperparameters
-- All parameters passed through the command line options
-
-## Visualizations
-
-- Confusion Matrix of the model predictions on the validation data
-- Plots for the PR and F1 curves across all classes
-- Correlogram of the Class Labels
-
-# Configure Comet Logging
-
-Comet can be configured to log additional data either through command line flags passed to the training script
-or through environment variables.
-
-```shell
-export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
-export COMET_MODEL_NAME=
-
-# Try out an Example!
-Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
-
-Or better yet, try it out yourself in this Colab Notebook
-
-[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
-
-# Log automatically
-
-By default, Comet will log the following items
-
-## Metrics
-- Box Loss, Object Loss, Classification Loss for the training and validation data
-- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
-- Precision and Recall for the validation data
-
-## Parameters
-
-- Model Hyperparameters
-- All parameters passed through the command line options
-
-## Visualizations
-
-- Confusion Matrix of the model predictions on the validation data
-- Plots for the PR and F1 curves across all classes
-- Correlogram of the Class Labels
-
-# Configure Comet Logging
-
-Comet can be configured to log additional data either through command line flags passed to the training script
-or through environment variables.
-
-```shell
-export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
-export COMET_MODEL_NAME= -
-You can preview the data directly in the Comet UI.
-
-
-You can preview the data directly in the Comet UI.
- -
-Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
-
-
-Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
-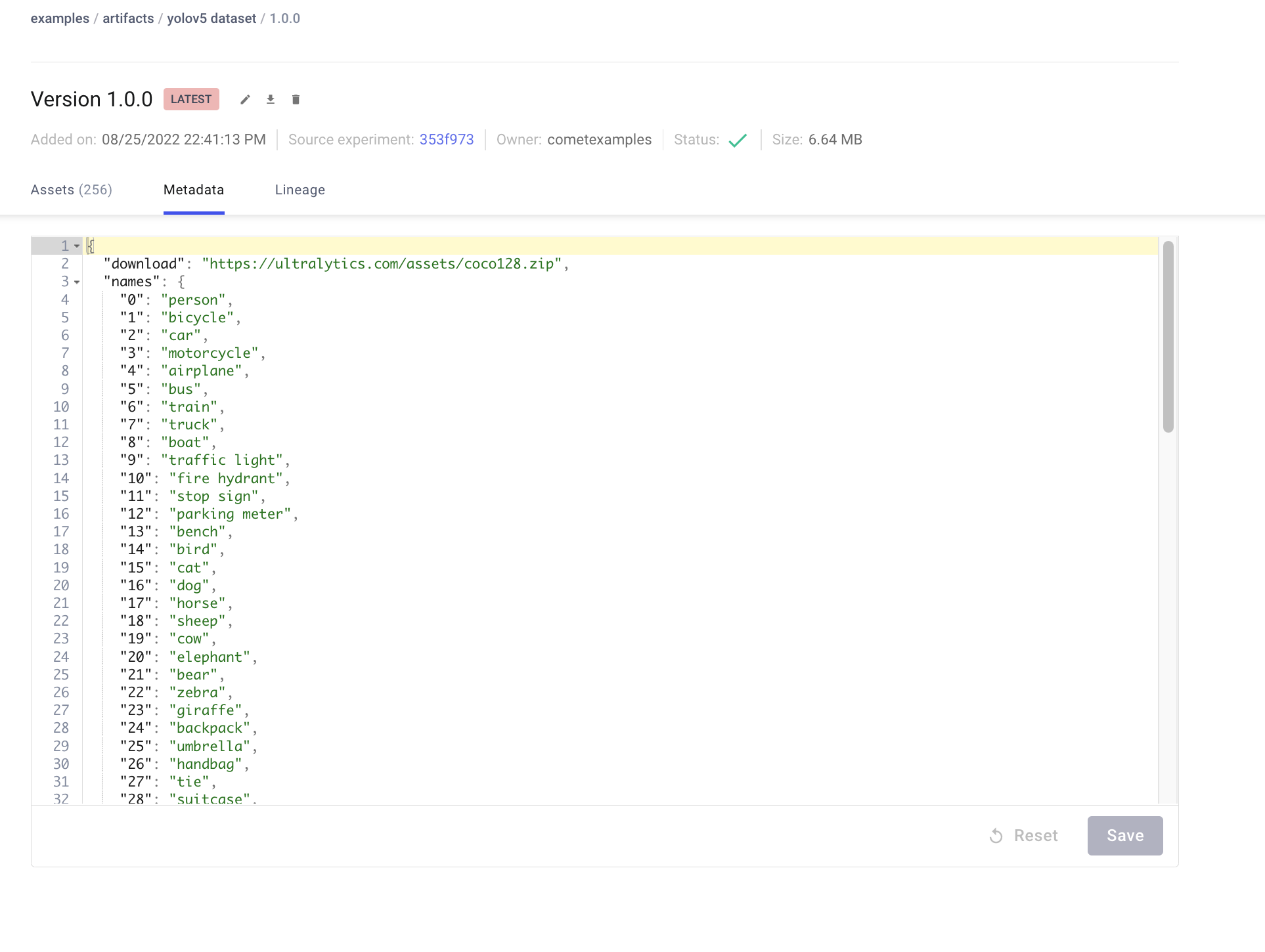 -
-### Using a saved Artifact
-
-If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
-
-```
-# contents of artifact.yaml file
-path: "comet://
-
-### Using a saved Artifact
-
-If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
-
-```
-# contents of artifact.yaml file
-path: "comet:// -
-## Resuming a Training Run
-
-If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
-
-The Run Path has the following format `comet://
-
-## Resuming a Training Run
-
-If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
-
-The Run Path has the following format `comet://