-
-How to Download Messenger on Your PC or Mac
-Do you want to stay connected with your friends and family on Facebook without using your phone or browser? If so, you might be interested in downloading Messenger on your PC or Mac. Messenger is a free all-in-one communication app that lets you send text, voice and video messages, make group calls, share files and photos, watch videos together, and more. In this article, we will show you how to download Messenger on your desktop device, how to use it, what are its benefits and drawbacks, and what are some alternatives you can try.
-link download messenger
DOWNLOAD ☆☆☆☆☆ https://urlca.com/2uOezh
-Features of Messenger Desktop App
-Messenger desktop app has many features that make it a great choice for staying in touch with your loved ones. Here are some of them:
-
-- Text, audio and video calls: You can send unlimited text messages, make high-quality voice and video calls, and even record and send voice and video messages.
-- Group chats: You can send unlimited text messages, make high-quality voice and video calls, and even record and send voice and video messages.
-- Group chats: You can create group chats with up to 250 people, add group admins, change group names and photos, and use @mentions to get someone's attention.
-- Privacy settings: You can control who can contact you, block unwanted messages and calls, report abusive behavior, and manage your active status.
-- Custom reactions: You can express yourself with more than just a thumbs up. You can choose from a variety of emojis and stickers to react to messages.
-- Chat themes: You can customize your chat background with different colors, gradients, and images to suit your mood or personality.
-- Watch together: You can watch videos from Facebook Watch, IGTV, Reels, TV shows, movies, and more with your friends and family in real time.
-- Stickers, GIFs and emojis: You can spice up your conversations with thousands of stickers, GIFs and emojis from the Messenger library or create your own.
-- Files, photos and videos: You can share files, photos and videos of any size and format with your contacts. You can also use the built-in camera to take selfies or capture moments.
-- Plans and polls: You can create plans and polls to organize events, get opinions, or make decisions with your group.
-- Location sharing: You can share your live location with your friends and family for a specified period of time or request their location.
-- Money transfer: You can send and receive money securely and easily with Facebook Pay (available in select countries).
-- Business chat: You can connect with businesses to get customer support, make reservations, shop online, and more.
-
-How to Download Messenger Desktop App from Messenger.com
-If you want to download Messenger desktop app from the official website, here are the steps you need to follow:
-
-- Go to Messenger.com/download.
-- Click on Download for Windows or Download for Mac depending on your device.
-- Open the installer file and follow the instructions.
-
-You will need to have Windows 10 or macOS 10.10 or higher to run the app. The app will automatically update itself when a new version is available.
-How to Download Messenger Desktop App from Microsoft Store or App Store
-If you prefer to download Messenger desktop app from the Microsoft Store or the App Store, here are the steps you need to follow:
-link download messenger app for pc
-link download messenger lite apk
-link download messenger for mac
-link download messenger desktop app
-link download messenger video call
-link download messenger for windows 10
-link download messenger for android
-link download messenger for iphone
-link download messenger beta version
-link download messenger dark mode
-link download messenger stickers free
-link download messenger chat history
-link download messenger group chat
-link download messenger voice messages
-link download messenger games online
-link download messenger qr code scanner
-link download messenger rooms app
-link download messenger kids app
-link download messenger business account
-link download messenger new update
-link download messenger old version
-link download messenger without facebook
-link download messenger offline installer
-link download messenger web app
-link download messenger themes and colors
-link download messenger reactions and emojis
-link download messenger watch together feature
-link download messenger send money feature
-link download messenger chat with businesses feature
-link download messenger cross-app messaging feature
-link download messenger privacy settings feature
-link download messenger custom reactions feature
-link download messenger chat themes feature
-link download messenger record and send feature
-link download messenger express yourself feature
-link download messenger send files feature
-link download messenger plan and make it happen feature
-link download messenger send location feature
-link download messenger compatible across platforms feature
-how to get the link to download the Messenger app on Google Play Store?
-how to get the link to download the Messenger app on Apple App Store?
-how to get the direct link to download the Messenger app on your phone?
-how to get the latest version of the Messenger app by using the link to download it?
-how to get the best experience of using the Messenger app by following the instructions on the link to download it?
-how to get access to all the features of the Messenger app by clicking on the link to download it?
-how to get in touch with your friends and family on the Messenger app by using the link to download it?
-how to get more information about the Messenger app by visiting the official website on the link to download it?
-how to get help and support for the Messenger app by contacting the developer on the link to download it?
-
-- Go to Microsoft Store or App Store on your device.
-- Search for Messenger in the search bar.
-- Click on Get or Install and wait for the app to download.
-
-You will need to have Windows 10 or macOS 10.12 or higher to run the app. The app will automatically update itself when a new version is available.
-How to Use Messenger Desktop App
-Once you have downloaded Messenger desktop app on your PC or Mac, you can start using it right away. Here are the steps you need to follow:
-
-- Launch the app from your desktop.
-- Log in with your Facebook account or create a new one if you don't have one already.
-- Start chatting with your friends and family by clicking on their names or searching for them in the search bar.
-
-You can also access other features of the app by clicking on the icons at the top or bottom of the screen. For example, you can click on the video camera icon to start a video call, the phone icon to start a voice call, the plus icon to create a group chat, the settings icon to change your preferences, and so on.
- Benefits of Using Messenger Desktop App
- Messenger desktop app has many benefits that make it a convenient and enjoyable way to communicate with your loved ones. Here are some of them:
-
- - Larger screen: You can enjoy a bigger and clearer view of your conversations, photos, videos, and other content on your desktop screen. You can also resize the app window according to your preference.
- - Keyboard shortcuts: You can enjoy a bigger and clearer view of your conversations, photos, videos, and other content on your desktop screen. You can also resize the app window according to your preference.
- - Keyboard shortcuts: You can use your keyboard to perform various actions on the app, such as sending messages, starting calls, switching chats, and more. You can find the list of keyboard shortcuts by clicking on the settings icon and then on Keyboard Shortcuts.
- - Notifications: You can get notified of new messages and calls on your desktop, even when the app is minimized or closed. You can also customize your notification settings by clicking on the settings icon and then on Notifications.
- - Synced messages: You can access all your messages and chats across your devices, whether you use Messenger on your phone, tablet, browser, or desktop. You can also sync your contacts and preferences across your devices.
- - Dark mode: You can switch to dark mode to reduce eye strain and save battery life. You can toggle dark mode on or off by clicking on the settings icon and then on Dark Mode.
-
- Drawbacks of Using Messenger Desktop App
- Messenger desktop app also has some drawbacks that you should be aware of before using it. Here are some of them:
-
-- Requires internet connection: You need to have a stable internet connection to use the app. If you lose connection or have a slow network, you might experience delays, glitches, or errors.
- - Limited features compared to mobile app: The desktop app does not have some features that are available on the mobile app, such as stories, camera effects, games, and discover tab. You also cannot make group video calls with more than 50 people on the desktop app.
- - Data usage: The app uses data to send and receive messages and calls. Depending on your data plan and usage, you might incur additional charges from your internet service provider or carrier.
-
- Tips and Tricks for Using Messenger Desktop App
- To make the most out of Messenger desktop app, here are some tips and tricks you can try:
-
-- Change chat settings: You can change various chat settings by clicking on the info icon at the top right corner of any chat. For example, you can change the chat name, photo, color, emoji, or theme. You can also mute notifications, ignore messages, or block contacts from there.
- - Mute notifications: If you want to silence all notifications from the app, you can click on the settings icon and then on Notifications. You can choose to mute notifications for a specific period of time or until you turn them back on.
- - Archive or delete conversations: If you want to clean up your chat list, you can archive or delete conversations by right-clicking on them. Archiving a conversation will hide it from your chat list until you search for it or receive a new message from it. Deleting a conversation will remove it from your chat list permanently.
- - Use keyboard shortcuts: As mentioned earlier, you can use keyboard shortcuts to perform various actions on the app faster and easier. You can find the list of keyboard shortcuts by clicking on the settings icon and then on Keyboard Shortcuts.
-
- Alternatives to Messenger Desktop App
- If you are looking for other options to communicate with your friends and family on your desktop device, here are some alternatives you can try:
-
-- WhatsApp Desktop: WhatsApp is another popular messaging app owned by Facebook that lets you send text, voice and video messages, make group calls, share files and photos, and more. You can download WhatsApp Desktop from WhatsApp.com/download.
- - Skype: Skype is a well-known video calling app that also lets you send text, voice and video messages, make group calls, share files and photos, and more. You can download Skype from Skype.com/en/get-skype.
- - Telegram Desktop: Telegram is a secure and fast messaging app that lets you send text, voice and video messages, make group calls, share files and photos, and more. You can download Telegram Desktop from Desktop.Telegram.org.
- - Signal Desktop: Signal is a privacy-focused messaging app that lets you send text, voice and video messages, make group calls, share files and photos, and more. You can download Signal Desktop from Signal > Signal Desktop from Signal.org/download.
-
- Conclusion
- Messenger desktop app is a great way to communicate with your friends and family on your PC or Mac. It has many features that make it fun and easy to use, such as text, audio and video calls, group chats, custom reactions, chat themes, watch together, stickers, GIFs and emojis, files, photos and videos, plans and polls, location sharing, money transfer, and business chat. It also has some benefits over the mobile app, such as larger screen, keyboard shortcuts, notifications, synced messages, and dark mode. However, it also has some drawbacks, such as requiring internet connection, having limited features compared to the mobile app, and using data. You can download Messenger desktop app from Messenger.com, Microsoft Store, or App Store. You can also try some alternatives to Messenger desktop app, such as WhatsApp Desktop, Skype, Telegram Desktop, or Signal Desktop.
- We hope you found this article helpful and informative. If you have any questions or feedback, please let us know in the comments below. Thank you for reading!
- FAQs
- Here are some frequently asked questions about Messenger desktop app:
-
-- What are the system requirements for Messenger Desktop App?
-The system requirements for Messenger desktop app are:
-
-- Windows 10 or macOS 10.10 or higher
-- At least 512 MB of RAM
-- At least 150 MB of free disk space
-- A stable internet connection
-
- - How can I update Messenger Desktop App?
-Messenger desktop app will automatically update itself when a new version is available. You can also check for updates manually by clicking on the settings icon and then on About Messenger. If there is an update available, you will see a button to download and install it.
- - How can I log out of Messenger Desktop App?
-To log out of Messenger desktop app, you can click on the settings icon and then on Log Out. You can also switch accounts by clicking on the settings icon and then on Switch Account.
- - How can I report a problem with Messenger Desktop App?
-To report a problem with Messenger desktop app, you can click on the settings icon and then on Report a Problem. You can describe the issue you are facing and attach screenshots if possible. You can also send feedback or suggestions by clicking on the settings icon and then on Send Feedback.
- - How can I delete Messenger Desktop App?
-To delete Messenger desktop app from your device, you can follow these steps:
-
-- For Windows: Go to Control Panel > Programs > Uninstall a Program. Find Messenger in the list and click on Uninstall.
-- For Mac: Go to Finder > Applications. Find Messenger in the list and drag it to the Trash.
-
- 197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Learn to Throw Knives Like a Pro with Knife Hit - Shooting Master APK.md b/spaces/congsaPfin/Manga-OCR/logs/Learn to Throw Knives Like a Pro with Knife Hit - Shooting Master APK.md
deleted file mode 100644
index 82fe33c4685bf5f685de690af2dc73978a2cd675..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Learn to Throw Knives Like a Pro with Knife Hit - Shooting Master APK.md
+++ /dev/null
@@ -1,124 +0,0 @@
-
-Knife Hit - Shooting Master: A Fun and Addictive Game for Android
-If you are looking for a simple yet exciting game to play on your Android device, you might want to try Knife Hit - Shooting Master. This is a game where you have to tap to throw knives and hit the target. The more you hit, the more points you can get. But be careful, don't hit the other knives or you will lose. Sounds easy, right? Well, not so fast. The target will rotate, move, and change shape, making it harder to hit. And there are also boss levels where you have to defeat a giant fruit or a monster with your knives. Are you ready to test your skills and reflexes in this game? Let's find out more about it.
- What is Knife Hit - Shooting Master?
-Knife Hit - Shooting Master is a game developed by BlueGame Studio, a small indie team based in Vietnam. The game was released in 2022 and has been downloaded over 10 million times on Google Play Store. The game is rated 4.3 out of 5 stars by more than 100 thousand users who have enjoyed its gameplay, graphics, and sound effects.
-knife hit shooting master apk
Download Zip ··· https://urlca.com/2uOfE7
- How to play Knife Hit - Shooting Master
-The gameplay of Knife Hit - Shooting Master is very simple and intuitive. You just have to tap the screen to throw a knife at the target. The target can be a wooden log, a fruit, a cake, a pizza, or even a dinosaur. You have to hit the target as many times as possible without hitting the other knives that are already stuck on it. If you hit another knife, you will lose one life and have to start over. You have three lives in total, so be careful.
-As you progress through the game, the target will rotate faster, move around, or change shape, making it harder to hit. You will also encounter boss levels where you have to defeat a giant fruit or a monster with your knives. These levels are more challenging and require more accuracy and timing. You will also get bonus points for hitting the center of the target or for hitting multiple targets in a row.
- Features of Knife Hit - Shooting Master
-Knife Hit - Shooting Master is not just a simple tapping game. It also has many features that make it more fun and addictive. Here are some of them:
- Different knives and targets
-The game has over 100 different knives that you can collect and use in the game. Each knife has its own design, color, and shape. Some of them are realistic, like kitchen knives or daggers, while others are more creative, like pencils, scissors, or swords. You can unlock new knives by completing levels, earning coins, or watching ads.
-The game also has over 50 different targets that you can hit with your knives. Each target has its own theme, like food, animals, or objects. Some of them are easy to hit, while others are tricky and require more skill. You can unlock new targets by completing levels or earning coins.
-knife hit shooting master game download
-knife hit shooting master mod apk
-knife hit shooting master online
-knife hit shooting master free
-knife hit shooting master android
-knife hit shooting master hack
-knife hit shooting master cheats
-knife hit shooting master tips
-knife hit shooting master review
-knife hit shooting master gameplay
-knife hit shooting master app store
-knife hit shooting master ios
-knife hit shooting master pc
-knife hit shooting master windows
-knife hit shooting master mac
-knife hit shooting master linux
-knife hit shooting master chromebook
-knife hit shooting master bluestacks
-knife hit shooting master nox player
-knife hit shooting master emulator
-knife hit shooting master apk pure
-knife hit shooting master apk mirror
-knife hit shooting master apk combo
-knife hit shooting master apk online
-knife hit shooting master apk offline
-knife hit shooting master apk latest version
-knife hit shooting master apk update
-knife hit shooting master apk old version
-knife hit shooting master apk file download
-knife hit shooting master apk install
-knife hit shooting master apk uninstall
-knife hit shooting master apk size
-knife hit shooting master apk requirements
-knife hit shooting master apk features
-knife hit shooting master apk bugs
-knife hit shooting master apk fixes
-knife hit shooting master apk support
-knife hit shooting master apk contact
-knife hit shooting master apk feedback
-knife hit shooting master apk rating
-knife hit shooting master apk alternatives
-knife hit shooting master apk similar games
-knife hit - throwing knives game apk download [^1^]
-Hit Master 3D - Knife Assassin game download [^2^]
-Hit Master 3D - Knife Assassin mod apk [^2^]
-Hit Master 3D - Knife Assassin online [^2^]
-Hit Master 3D - Knife Assassin free [^2^]
-Hit Master 3D - Knife Assassin android [^2^]
-Hit Master 3D - Knife Assassin hack [^2^]
- Boss levels and challenges
-The game has 10 boss levels where you have to defeat a giant fruit or a monster with your knives. These levels are more difficult than the regular ones and require more knives to complete. You have to hit the boss multiple times until its health bar is empty. But be careful, the boss will also attack you with its own weapons or abilities. For example, the pineapple boss will shoot spikes at you, while the dragon boss will breathe fire at you. You have to dodge these attacks and hit the boss as fast as possible.
-The game also has daily challenges where you can earn coins and rewards by completing various tasks, such as hitting a certain number of targets, hitting the center of the target, or hitting multiple targets in a row. These challenges are updated every day and give you more reasons to play the game.
- Rewards and achievements
-The game has many rewards and achievements that you can earn by playing the game. You can get coins, gems, stars, and chests by hitting the target, completing levels, or watching ads. You can use these items to unlock new knives, targets, or skins for your game. You can also get trophies by completing achievements, such as hitting 1000 targets, defeating 10 bosses, or collecting 50 knives. These trophies will show your progress and skills in the game.
- Leaderboards and rankings
-The game has leaderboards and rankings where you can compare your score and performance with other players around the world. You can see your rank in different categories, such as total score, highest level, most coins, or most knives. You can also see the top players in each category and try to beat their scores. You can also share your score and achievements with your friends on social media platforms, such as Facebook, Twitter, or Instagram.
- Graphics and sound effects
-The game has colorful and cartoonish graphics that make it appealing and enjoyable to play. The game has a variety of themes and backgrounds for each target, such as forest, desert, ocean, or space. The game also has smooth animations and transitions that make it look realistic and dynamic. The game has catchy and upbeat sound effects that match the gameplay and mood of the game. The game has a cheerful and energetic music that plays in the background and changes according to the level and situation. The game also has voice-overs and sound effects that add more fun and humor to the game.
- How to download and install Knife Hit - Shooting Master APK
-If you want to play Knife Hit - Shooting Master on your Android device, you have two options to download and install it. You can either download it from Google Play Store or from APKCombo or ApkOnline websites. Here are the steps for each option:
- Download from Google Play Store
-This is the easiest and safest way to download and install Knife Hit - Shooting Master on your device. You just have to follow these steps:
-
-- Open Google Play Store on your device.
-- Search for Knife Hit - Shooting Master in the search bar.
-- Select the game from the list of results.
-- Tap on Install button to download and install the game.
-- Wait for the installation to finish.
-- Tap on Open button to launch the game.
-
- Download from APKCombo or ApkOnline
-This is another way to download and install Knife Hit - Shooting Master on your device. You can use this option if you don't have access to Google Play Store or if you want to get the latest version of the game. You just have to follow these steps:
-
-- Open your browser on your device.
-- Go to APKCombo or ApkOnline website.
-- Search for Knife Hit - Shooting Master in the search bar.
-- Select the game from the list of results.
-- Tap on Download APK button to download the APK file of the game.
-- Wait for the download to finish.
-
- Install the APK file on your device
-After downloading the APK file of Knife Hit - Shooting Master from APKCombo or ApkOnline website, you have to install it on your device. You just have to follow these steps:
-
-- Go to Settings on your device.
-- Go to Security or Privacy section.
-- Enable Unknown Sources option to allow installation of apps from sources other than Google Play Store.
-- Go to Downloads or File Manager on your device.
-- Find and tap on the APK file of Knife Hit - Shooting Master that you downloaded earlier.
-- Tap on Install button to install the game.
-- Wait for the installation to finish.
-- Tap on Open button to launch the game.
-
- Conclusion
-Knife Hit - Shooting Master is a fun and addictive game for Android devices that will test your skills and reflexes in throwing knives at various targets. The game has many features that make it more enjoyable and challenging, such as different knives and targets, boss levels and challenges, rewards and achievements, leaderboards and rankings, graphics and sound effects. The game is easy to play and hard to master. You can download and install it from Google Play Store or from APKCombo or ApkOnline websites. If you are looking for a game that will keep you entertained and challenged, you should give Knife Hit - Shooting Master a try.
- FAQs
-Here are some frequently asked questions about Knife Hit - Shooting Master:
-
-- Q: How many levels are there in Knife Hit - Shooting Master?
-- A: There are 100 levels in Knife Hit - Shooting Master, plus 10 boss levels. You can replay any level you have completed to improve your score and earn more coins.
-- Q: How can I get more coins and gems in Knife Hit - Shooting Master?
-- A: You can get more coins and gems by hitting the target, completing levels, watching ads, or opening chests. You can also buy coins and gems with real money if you want to support the developers.
-- Q: How can I change the skin of my game in Knife Hit - Shooting Master?
-- A: You can change the skin of your game by tapping on the settings icon on the top right corner of the screen. You can choose from different themes, such as dark, light, neon, or rainbow. You can also unlock new skins by earning stars or buying them with gems.
-- Q: What are the benefits of logging in with Facebook in Knife Hit - Shooting Master?
-- A: Logging in with Facebook will allow you to save your progress and sync it across different devices. You will also be able to see your friends' scores and challenge them to beat your score. You will also get 100 gems as a bonus for logging in with Facebook.
-- Q: Is Knife Hit - Shooting Master safe to play for children?
-- A: Knife Hit - Shooting Master is a game that is suitable for all ages. The game does not contain any violence, blood, or gore. The game is also free to play and does not require any personal information or permissions. However, the game does contain ads and in-app purchases that may require parental supervision.
- 197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Solitario Premium APK El clsico juego de cartas con ms opciones y diversin.md b/spaces/congsaPfin/Manga-OCR/logs/Solitario Premium APK El clsico juego de cartas con ms opciones y diversin.md
deleted file mode 100644
index 8520a8ea318b26f626d00ddd101edd79de1f9e97..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Solitario Premium APK El clsico juego de cartas con ms opciones y diversin.md
+++ /dev/null
@@ -1,115 +0,0 @@
-
-Descargar Solitario Premium APK: Cómo disfrutar del clásico juego de cartas en tu dispositivo Android
- ¿Te gusta el solitario? ¿Quieres jugar al clásico juego de cartas en tu teléfono o tableta Android? ¿Quieres acceder a funciones y opciones exclusivas que no encontrarás en otras versiones? Entonces, te interesa descargar solitario premium apk, una aplicación que te permite jugar al solitario de forma gratuita, sin anuncios, con gráficos de alta calidad, música relajante, desafíos diarios, temas personalizados y mucho más. En este artículo, te contamos todo lo que necesitas saber sobre el solitario premium apk, desde su origen e historia, hasta sus beneficios para la salud mental, pasando por sus características, requisitos, pasos de instalación y consejos para ganar. ¡Sigue leyendo y prepárate para disfrutar del mejor solitario en tu dispositivo Android!
- ¿Qué es el solitario y por qué es tan popular?
- El solitario, también conocido como paciencia o cabale, es un género de juegos de cartas que se pueden jugar por una sola persona. El solitario más común es el Klondike, que consiste en crear cuatro pilas de cartas, una por cada palo, en orden ascendente (desde el as hasta el rey). Estas pilas se llaman pilares o cimientos. Para lograrlo, se debe ir moviendo las cartas entre siete columnas o montones que se forman al repartir las cartas boca abajo. Solo se puede mover la carta que está boca arriba en cada columna, y se debe colocar sobre otra carta de color diferente y valor inferior. Por ejemplo, si hay un seis de corazones, se puede colocar sobre él un cinco de picas o un cinco de tréboles. Si no hay más movimientos posibles, se puede tomar una carta del mazo o pila de reserva que se encuentra aparte. El juego termina cuando se completan los cuatro pilares o cuando no hay más movimientos posibles.
-descargar solitario premium apk
DOWNLOAD ★★★★★ https://urlca.com/2uOd7y
- El solitario es un juego muy popular por varias razones. En primer lugar, es un juego muy fácil de aprender, ya que solo se necesita un mazo de cartas y seguir unas reglas sencillas. En segundo lugar, es un juego muy entretenido y desafiante, ya que requiere de habilidad, estrategia y paciencia para resolverlo. En tercer lugar, es un juego muy relajante y terapéutico, ya que ayuda a calmar la mente, a entrar en un estado meditativo y a mejorar la memoria y la concentración. Además, el solitario tiene una larga y fascinante historia que lo hace aún más interesante.
- El origen y la historia del solitario
- El solitario no tiene una fecha definitiva de invención, pero su registro se puede rastrear hasta finales del siglo XVIII en el norte de Europa y Escandinavia. El término "patiencespiel" apareció por primera vez en un libro alemán publicado en 1788. También hay referencias al solitario en la literatura francesa. Se cree que el solitario se originó como una forma de entretenimiento para la nobleza y la realeza, y que se popularizó en el siglo XIX con la aparición de los primeros libros de solitario. Algunos personajes famosos que eran aficionados al solitario son Napoleón Bonaparte, Winston Churchill, Franklin D. Roosevelt y Marcel Proust.
- Los beneficios de jugar al solitario para la salud mental
- Jugar al solitario no solo es divertido, sino también beneficioso para la salud mental. Algunos de los beneficios que se pueden obtener son los siguientes:
-
-- Reduce el estrés y la ansiedad. El solitario es un juego que requiere concentración y atención, lo que ayuda a distraerse de los problemas y las preocupaciones. Además, el solitario tiene un efecto calmante y relajante, ya que se acompaña de música suave y gráficos agradables.
-- Mejora la memoria y la agilidad mental. El solitario es un juego que implica recordar las cartas y las posiciones, lo que estimula la memoria a corto y largo plazo. Asimismo, el solitario es un juego que exige pensar y planificar los movimientos, lo que mejora la capacidad de razonamiento y resolución de problemas.
-- Aumenta la autoestima y la confianza. El solitario es un juego que ofrece un reto personal y una satisfacción al completarlo. Al lograr resolver el solitario, se siente una sensación de logro y orgullo, lo que aumenta la autoestima y la confianza en uno mismo.
-- Fomenta la paciencia y la perseverancia. El solitario es un juego que no siempre se puede resolver a la primera, sino que a veces se necesita intentarlo varias veces hasta encontrar la solución. Esto enseña a tener paciencia y perseverancia, dos virtudes importantes para la vida.
-
- ¿Qué es el solitario premium apk y qué ventajas tiene?
- El solitario premium apk es una aplicación para dispositivos Android que te permite jugar al solitario de forma gratuita, sin anuncios, con gráficos de alta calidad, música relajante, desafíos diarios, temas personalizados y mucho más. Se trata de una versión mejorada del solitario clásico, que ofrece una experiencia de juego única e inigualable. Algunas de las ventajas que tiene el solitario premium apk son las siguientes:
- Las características y funciones del solitario premium apk
- El solitario premium apk tiene una serie de características y funciones que lo hacen diferente y superior a otras versiones del solitario. Estas son algunas de ellas:
-
-- Tiene gráficos de alta calidad, con efectos visuales realistas y detallados. Las cartas tienen un diseño elegante y clásico, con diferentes estilos para elegir. El fondo del juego también se puede cambiar según el gusto del usuario.
-- Tiene música relajante, con melodías suaves y tranquilas que acompañan al juego. La música se puede ajustar o silenciar según la preferencia del usuario.
-- Tiene desafíos diarios, con niveles de dificultad variados que ponen a prueba las habilidades del jugador. Cada día se puede acceder a un nuevo desafío, con recompensas especiales por completarlo.
-- Tiene temas personalizados, con colores y fondos diferentes para cada temporada o festividad. El usuario puede elegir el tema que más le guste o cambiarlo según su estado de ánimo.
-- Tiene modos de juego alternativos, como el modo cronometrado, el modo vegas o el modo experto. Estos modos ofrecen una mayor variedad y diversión al juego, con reglas distintas y puntuaciones diferentes.
-- Tiene estadísticas y logros, con datos e información sobre el rendimiento del jugador. El usuario puede consultar sus récords, sus victorias, sus derrotas, su tiempo medio, su porcentaje de éxito y mucho más. También puede ver los logros que ha conseguido y los que le faltan por obtener.
-- Tiene opciones de personalización, con ajustes para adaptar el juego a las preferencias del usuario. El usuario puede cambiar el tamaño de las cartas, el tipo de movimiento, el sonido, las notificaciones, el idioma y más.
-- Tiene soporte y actualizaciones, con un equipo de desarrolladores que se encarga de resolver cualquier problema o duda que tenga el usuario. Además, el solitario premium apk se actualiza constantemente con nuevas funciones y mejoras.
-
- Los requisitos y los pasos para descargar e instalar el solitario premium apk
- El solitario premium apk es una aplicación que se puede descargar e instalar fácilmente en cualquier dispositivo Android. Estos son los requisitos y los pasos que se deben seguir:
-
-- El requisito principal es tener un dispositivo Android con una versión igual o superior a la 4.4 (KitKat). También se necesita una conexión a internet y un espacio de almacenamiento suficiente.
-- El primer paso es descargar el archivo apk del solitario premium desde un sitio web seguro y confiable. Se puede usar el siguiente enlace: [Descargar solitario premium apk].
-- El segundo paso es habilitar la opción de "Orígenes desconocidos" en el dispositivo Android. Esta opción permite instalar aplicaciones que no provienen de la tienda oficial de Google Play. Para ello, se debe ir a Ajustes > Seguridad > Orígenes desconocidos y activarla.
-- El tercer paso es localizar el archivo apk descargado en el dispositivo Android. Normalmente, se encuentra en la carpeta de Descargas o en la de Archivos. Una vez localizado, se debe pulsar sobre él para iniciar la instalación.
-- El cuarto paso es seguir las instrucciones que aparecen en la pantalla para completar la instalación. Se debe aceptar los permisos y las condiciones de uso de la aplicación.
-- El quinto paso es abrir la aplicación y disfrutar del solitario premium apk en el dispositivo Android.
-
- ¿Cómo jugar al solitario premium apk y qué consejos seguir para ganar?
- El solitario premium apk es un juego muy fácil de jugar, pero también muy difícil de ganar. Por eso, es importante conocer el objetivo, las reglas y las estrategias del juego. Estos son algunos consejos que te ayudarán a mejorar tu juego de solitario:
-descargar solitario premium apk gratis
-descargar solitario premium apk full
-descargar solitario premium apk mod
-descargar solitario premium apk sin anuncios
-descargar solitario premium apk ultima version
-descargar solitario premium apk para android
-descargar solitario premium apk mega
-descargar solitario premium apk mediafire
-descargar solitario premium apk 2023
-descargar solitario premium apk 4.16.3141.1
-descargar microsoft solitaire collection premium apk
-descargar microsoft solitaire collection premium apk gratis
-descargar microsoft solitaire collection premium apk full
-descargar microsoft solitaire collection premium apk mod
-descargar microsoft solitaire collection premium apk sin anuncios
-descargar microsoft solitaire collection premium apk ultima version
-descargar microsoft solitaire collection premium apk para android
-descargar microsoft solitaire collection premium apk mega
-descargar microsoft solitaire collection premium apk mediafire
-descargar microsoft solitaire collection premium apk 2023
-descargar microsoft solitaire collection premium apk 4.16.3141.1
-descargar juegos de solitario premium apk
-descargar juegos de solitario premium apk gratis
-descargar juegos de solitario premium apk full
-descargar juegos de solitario premium apk mod
-descargar juegos de solitario premium apk sin anuncios
-descargar juegos de solitario premium apk ultima version
-descargar juegos de solitario premium apk para android
-descargar juegos de solitario premium apk mega
-descargar juegos de solitario premium apk mediafire
-descargar juegos de solitario premium apk 2023
-descargar juegos de cartas solitario premium apk
-descargar juegos de cartas solitario premium apk gratis
-descargar juegos de cartas solitario premium apk full
-descargar juegos de cartas solitario premium apk mod
-descargar juegos de cartas solitario premium apk sin anuncios
-descargar juegos de cartas solitario premium apk ultima version
-descargar juegos de cartas solitario premium apk para android
-descargar juegos de cartas solitario premium apk mega
-descargar juegos de cartas solitario premium apk mediafire
-descargar juegos de cartas solitario premium apk 2023
-como descargar solitario premium apk
-como descargar microsoft solitaire collection premium apk
-como descargar juegos de solitario premium apk
-como descargar juegos de cartas solitario premium apk
- El objetivo y las reglas del solitario
- El objetivo del solitario es crear cuatro pilas de cartas, una por cada palo, en orden ascendente (desde el as hasta el rey). Estas pilas se llaman pilares o cimientos. Para lograrlo, se debe ir moviendo las cartas entre siete columnas o montones que se forman al repartir las cartas boca abajo. Solo se puede mover la carta que está boca arriba en cada columna, y se debe colocar sobre otra carta de color diferente y valor inferior. Por ejemplo, si hay un seis de corazones, se puede colocar sobre él un cinco de picas o un cinco de tréboles. Si no hay más movimientos posibles, se puede tomar una carta del mazo o pila de reserva que se encuentra aparte. El juego termina cuando se completan los cuatro pilares o cuando no hay más movimientos posibles.
- Las estrategias y trucos para mejorar tu juego de solitario
- Aunque el solitario es un juego que depende mucho del azar, también hay algunas estrategias y trucos que pueden aumentar las probabilidades de ganar. Estos son algunos de ellos:
-
-- Mover primero las cartas del mazo o pila de reserva. Esto permite tener más opciones y posibilidades de mover las cartas de las columnas.
-- No llenar los espacios vacíos con reyes. Esto limita los movimientos posibles y bloquea las columnas. Es mejor esperar a tener una carta baja o un as para llenar los espacios vacíos.
-- No mover las cartas a los pilares o cimientos demasiado pronto. Esto puede impedir que se puedan mover otras cartas que están debajo o que se necesitan para formar secuencias. Es mejor esperar a tener una buena cantidad de cartas ordenadas en las columnas antes de moverlas a los pilares.
-- Tener en cuenta los palos y los valores de las cartas. Esto ayuda a planificar los movimientos con anticipación y a evitar errores o bloqueos. Es conveniente saber qué cartas faltan por salir y qué cart as se pueden mover o no.
-- Usar el botón de deshacer cuando sea necesario. Esto permite corregir los movimientos que se hayan hecho por error o que no hayan sido favorables. El solitario premium apk tiene un botón de deshacer ilimitado, lo que facilita el juego.
-
- Conclusión
- El solitario es un juego de cartas clásico, popular y divertido que se puede jugar en cualquier dispositivo Android gracias al solitario premium apk. Esta aplicación ofrece una versión mejorada del solitario, con gráficos de alta calidad, música relajante, desafíos diarios, temas personalizados y muchas funciones y opciones más. Además, el solitario tiene beneficios para la salud mental, como reducir el estrés, mejorar la memoria, aumentar la autoestima y fomentar la paciencia. Para jugar al solitario premium apk, solo se necesita descargar e instalar el archivo apk desde un sitio web seguro y confiable, y seguir las reglas y las estrategias del juego. Si te gusta el solitario, no dudes en descargar solitario premium apk y disfrutar del mejor juego de cartas en tu dispositivo Android.
- Preguntas frecuentes
- A continuación, se responden algunas de las preguntas más frecuentes sobre el solitario premium apk:
- ¿Es seguro descargar e instalar el solitario premium apk?
- Sí, es seguro siempre y cuando se descargue e instale el archivo apk desde un sitio web seguro y confiable. El solitario premium apk no contiene virus ni malware que puedan dañar el dispositivo Android o comprometer la privacidad del usuario.
- ¿Es legal descargar e instalar el solitario premium apk?
- Sí, es legal siempre y cuando se respeten los derechos de autor y las condiciones de uso de la aplicación. El solitario premium apk es una aplicación gratuita que no infringe ninguna ley ni normativa vigente.
- ¿Qué diferencia hay entre el solitario premium apk y el solitario clásico?
- La diferencia principal es que el solitario premium apk ofrece una versión mejorada del solitario clásico, con gráficos de alta calidad, música relajante, desafíos diarios, temas personalizados y muchas funciones y opciones más. El solitario clásico es una versión más simple y básica del juego de cartas.
- ¿Qué otros juegos de cartas se pueden jugar con el solitario premium apk?
- El solitario premium apk incluye otros juegos de cartas que se pueden jugar con el mismo mazo de 52 cartas. Algunos de estos juegos son: Spider Solitaire, FreeCell Solitaire, Pyramid Solitaire, TriPeaks Solitaire y Golf Solitaire.
- ¿Cómo se puede contactar con el equipo de desarrolladores del solitario premium apk?
- Se puede contactar con el equipo de desarrolladores del solitario premium apk a través del correo electrónico [email protected] o a través de las redes sociales Facebook, Twitter e Instagram. El equipo está disponible para resolver cualquier problema o duda que tenga el usuario sobre la aplicación. 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Test Your Skills and Patience on Truck Driver Crazy Road.md b/spaces/congsaPfin/Manga-OCR/logs/Test Your Skills and Patience on Truck Driver Crazy Road.md
deleted file mode 100644
index 298dbbd77e93d1410b4658eaa2ef8ba6b5275621..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Test Your Skills and Patience on Truck Driver Crazy Road.md
+++ /dev/null
@@ -1,122 +0,0 @@
-
-Truck Driver Crazy Road APKPure: A Challenging and Fun Driving Game
-Do you love driving trucks and trailers on rough and bumpy roads? Do you want to experience the thrill and excitement of transporting cargo across different locations? If yes, then you should try Truck Driver Crazy Road APKPure, a realistic and fun truck driving game that will put you to the limits. In this article, we will tell you everything you need to know about this game, including what it is, what are its features, how to play it, and why you should download it.
-truck driver crazy road apkpure
DOWNLOAD ✺ https://urlca.com/2uOfCE
- What is Truck Driver Crazy Road APKPure?
-A realistic and thrilling truck driving game
-Truck Driver Crazy Road APKPure is a truck driving game that will test your balancing skills and also your patience. You will have to drive through the uphill with lots of rocks and debris scattered along the road. You will also have to face different weather conditions, such as rain, snow, fog, and night. You will have to deliver your cargo safely and on time, without losing or damaging it. You will have to deal with traffic, narrow bridges, sharp turns, steep slopes, and other obstacles on your way.
-A free and easy-to-download app from APKPure
-Truck Driver Crazy Road APKPure is a free app that you can download from APKPure, a website that offers safe and fast downloads of Android apps and games. You don't need to register or sign up to download this app. You just need to click on the download button and install it on your device. The app has a size of about 100 MB and requires Android 4.1 or higher to run. The app is updated regularly with bug fixes and improvements.
- What are the features of Truck Driver Crazy Road APKPure?
-Four different game modes
-Truck Driver Crazy Road APKPure has four different game modes that you can choose from, depending on your preference and mood. They are:
-truck driver crazy road game online
-truck driver crazy road 2 download
-truck driver crazy road mod apk
-truck driver crazy road y8
-truck driver crazy road gameplay
-truck driver crazy road 3d
-truck driver crazy road android
-truck driver crazy road free play
-truck driver crazy road cheats
-truck driver crazy road hack
-truck driver crazy road simulator
-truck driver crazy road review
-truck driver crazy road tips
-truck driver crazy road unblocked
-truck driver crazy road pc
-truck driver crazy road app
-truck driver crazy road best score
-truck driver crazy road levels
-truck driver crazy road trailer
-truck driver crazy road walkthrough
-truck driver crazy road challenges
-truck driver crazy road update
-truck driver crazy road offline
-truck driver crazy road install
-truck driver crazy road guide
-truck driver crazy road controls
-truck driver crazy road missions
-truck driver crazy road apk mod
-truck driver crazy road fun games
-truck driver crazy road new version
-truck driver crazy road full screen
-truck driver crazy road apk download
-truck driver crazy road 2 game online
-truck driver crazy road 2 mod apk
-truck driver crazy road 2 y8
-truck driver crazy road 2 gameplay
-truck driver crazy road 2 android
-truck driver crazy road 2 free play
-truck driver crazy road 2 cheats
-truck driver crazy road 2 hack
-truck driver crazy road 2 simulator
-truck driver crazy road 2 review
-truck driver crazy road 2 tips
-truck driver crazy road 2 unblocked
-truck driver crazy road 2 pc
-truck driver crazy road 2 app
-
-- Delivery mode: In this mode, you have to deliver your cargo from one point to another within a given time limit. You have to be careful not to lose or damage your cargo on the way.
-- Parking mode: In this mode, you have to park your truck and trailer in a designated spot without hitting anything. You have to be precise and accurate in your movements.
-- Garage mode: In this mode, you can customize your truck and trailer with different colors, wheels, lights, horns, and stickers. You can also upgrade your engine, brakes, suspension, tires, and fuel tank.
-- Free mode: In this mode, you can drive freely on any map without any time limit or task. You can explore the environment and enjoy the scenery.
-
-Various trucks and trailers to choose from
-Truck Driver Crazy Road APKPure has a variety of trucks and trailers that you can choose from, each with its own characteristics and performance. You can unlock more trucks and trailers by completing tasks and earning coins. Some of the trucks and trailers that you can drive are:
-
-| Truck | Trailer |
|---|
Red truck | Wooden trailer |
-| Blue truck | Metal trailer |
-| Green truck | Oil tanker |
-| Yellow truck | Cement mixer |
-| Black truck | Container trailer |
-
-Stunning graphics and sound effects
-Truck Driver Crazy Road APKPure has stunning graphics and sound effects that will make you feel like you are driving a real truck. The game has realistic 3D models of trucks and trailers, as well as detailed environments and landscapes. You can see the mountains, forests, rivers, bridges, buildings, and roads on your way. You can also hear the engine sound, the horn, the brakes, the tires, and the cargo noise. The game also has dynamic lighting and shadows, as well as weather effects such as rain, snow, fog, and night.
-Realistic physics and weather conditions
-Truck Driver Crazy Road APKPure has realistic physics and weather conditions that will affect your driving experience. The game has a realistic simulation of gravity, inertia, friction, and collision. You will have to balance your truck and trailer on the uneven and slippery roads. You will also have to adjust your speed and direction according to the wind, rain, snow, fog, and night. You will have to be careful not to tip over or crash your truck and trailer.
- How to play Truck Driver Crazy Road APKPure?
-Use the on-screen controls to steer, accelerate, brake, and horn
-To play Truck Driver Crazy Road APKPure, you have to use the on-screen controls to steer, accelerate, brake, and horn. You can choose between two types of controls: tilt or buttons. You can also adjust the sensitivity and position of the controls in the settings menu. The controls are easy to use and responsive.
-Follow the arrow to reach your destination
-To complete your task in Truck Driver Crazy Road APKPure, you have to follow the arrow that shows you the direction to your destination. You have to drive carefully and avoid getting lost or stuck on the way. You have to reach your destination within the time limit and without losing or damaging your cargo.
-Avoid obstacles and collisions on the road
-To drive safely in Truck Driver Crazy Road APKPure, you have to avoid obstacles and collisions on the road. You have to watch out for other vehicles, pedestrians, animals, rocks, trees, poles, signs, barriers, and other objects that can block or damage your truck and trailer. You have to keep a safe distance from them and use your horn to warn them. You also have to obey the traffic rules and signals.
-Complete the tasks and earn coins
-To progress in Truck Driver Crazy Road APKPure, you have to complete the tasks and earn coins. You have to deliver your cargo from one point to another or park your truck and trailer in a designated spot. You have to do it within the time limit and without losing or damaging your cargo. You will earn coins based on your performance and speed. You can use the coins to unlock more trucks and trailers or customize them in the garage mode.
- Why should you download Truck Driver Crazy Road APKPure?
-Test your driving skills and patience
-If you want to test your driving skills and patience, you should download Truck Driver Crazy Road APKPure. This game will challenge you with its realistic and difficult driving scenarios. You will have to master the art of balancing your truck and trailer on the rough and bumpy roads. You will also have to cope with the changing weather conditions and traffic situations. You will have to be careful not to lose or damage your cargo on the way.
-Enjoy the scenic views and challenging terrains
-If you want to enjoy the scenic views and challenging terrains, you should download Truck Driver Crazy Road APKPure. This game will take you to different locations with beautiful landscapes and environments. You will see the mountains, forests, rivers, bridges, buildings, and roads on your way. You will also face different terrains such as hills, valleys, plains, deserts, snowfields, swamps, and more.
-Have fun and relax with this addictive game
-If you want to have fun and relax with this addictive game, you should download Truck Driver Crazy Road APKPure. This game will keep you entertained for hours with its four different game modes and various trucks and trailers. You can play this game anytime and anywhere without any internet connection. You can also share your scores and achievements with your friends and family on social media. You can also rate and review this game on APKPure and give your feedback to the developers.
- Conclusion
-Truck Driver Crazy Road APKPure is a challenging and fun driving game that will make you feel like a real truck driver. You will have to drive through different locations and weather conditions, deliver your cargo safely and on time, avoid obstacles and collisions, and customize your truck and trailer. You will also enjoy the stunning graphics and sound effects, the realistic physics and simulation, and the four different game modes. You can download this game for free from APKPure and have fun and relax with this addictive game.
- FAQs
-What are the minimum requirements to play Truck Driver Crazy Road APKPure?
-To play Truck Driver Crazy Road APKPure, you need an Android device with version 4.1 or higher, a storage space of about 100 MB, and an internet connection to download the app.
-How can I change the language of Truck Driver Crazy Road APKPure?
-To change the language of Truck Driver Crazy Road APKPure, you can go to the settings menu and select the language option. You can choose from English, Russian, Turkish, German, Spanish, French, Italian, Portuguese, Arabic, Chinese, Japanese, Korean, Hindi, Indonesian, and Vietnamese.
-How can I contact the developers of Truck Driver Crazy Road APKPure?
-To contact the developers of Truck Driver Crazy Road APKPure, you can visit their website at http://games89.com/ or their Facebook page at https://www.facebook.com/Games89com-100900695181173/. You can also email them at games89com@gmail.com.
-What are some tips and tricks to play Truck Driver Crazy Road APKPure?
-Some tips and tricks to play Truck Driver Crazy Road APKPure are:
-
-- Use the brake wisely to avoid skidding or sliding on the slippery roads.
-- Use the horn to warn other vehicles or pedestrians on your way.
-- Use the camera button to change the view angle and see your surroundings better.
-- Use the map button to see your location and destination.
-- Use the pause button to pause or resume the game.
-
-What are some similar games to Truck Driver Crazy Road APKPure?
-Some similar games to Truck Driver Crazy Road APKPure are:
-
-- Truck Simulator 2018: Europe by Zuuks Games
-- Truck Simulator USA by Ovidiu Pop
-- Euro Truck Driver 2018 by Ovidiu Pop
-- Offroad Cargo Transport Simulator by Game Pickle
-- Cargo Transport Simulator by SkisoSoft
- 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/contluForse/HuggingGPT/assets/Clean Master License Key ((LINK)).md b/spaces/contluForse/HuggingGPT/assets/Clean Master License Key ((LINK)).md
deleted file mode 100644
index 776e7bd8db791466de56de0732673298b2d01b7f..0000000000000000000000000000000000000000
--- a/spaces/contluForse/HuggingGPT/assets/Clean Master License Key ((LINK)).md
+++ /dev/null
@@ -1,52 +0,0 @@
-Clean master license key
Download ✒ https://ssurll.com/2uzw6W
-
-It can maintain and expand your RAM and your CPU. To use this marvelous cleaner, just set up its licence key and you can begin using it immediately.
-
-Clean Master License Key is an excellent program that permits you to examine the PC’s health. We find out more in regards to the diverse features of Clean Master License Key.
-
-Thanks for visiting our site. Listed here you will get the most recent and also latest version of Clean Master License Key.
-
-Clean Master License Key 2020 Crack
-
-Clean Master License Key is an outstanding utility which enables you to view your pc and also RAM. This is a complete device which provides numerous features. Clean Master License Key has a clever algorithm which is used to identify and also remove the various abnormal files. You can also clean your programs, RAM and files. To put this into action, you need to launch the Clean Master License Key and then execute the functions you desire. This excellent program has an uncomplicated interface. So, users can control the Clean Master License Key on their own. The Clean Master License Key permits you to select the files and groups which you want to delete. Moreover, you can remove everything that is likely to cause a problem in your pc’s health.
-
-Clean Master License Key can also locate the junk files that have been occupying your pc’s internal storage. Hence, the procedure of cleaning your pc is rather easy. You can now create your computer to its finest state.
-
-Clean Master License Key Features:
-
-More, Clean Master License Key contains various tools to clean the various things that can spoil the health of your PC. Some of these tools are:
-
-Uninstaller
-
-A tool that allows you to easily uninstall programs that are useless.
-
-Optimizer
-
-A program that can improve the performance of your computer.
-
-System Cleaner
-
-This can identify and remove the junk files.
-
-Real-time Scanner
-
-Can take good care of the PC’s performance by scanning the performance of the PC.
-
-System Guard
-
-Can protect your computer from all kinds of threats.
-
-System Resurrector
-
-Can fix many problems in your pc.
-
-System Memory Booster
-
-You can enhance the performance of your computer using this tool.
-
-What’s New In The Latest Version?
-
-The latest version of Clean Master License Key enables you to quickly and also efficiently clean your computer. The Clean Master License Key 4fefd39f24
-
-
-
diff --git a/spaces/contluForse/HuggingGPT/assets/Da Vinci Code Ebook Free Download Epub The Best Way to Enjoy the Thrilling Mystery Novel.md b/spaces/contluForse/HuggingGPT/assets/Da Vinci Code Ebook Free Download Epub The Best Way to Enjoy the Thrilling Mystery Novel.md
deleted file mode 100644
index 6adbbb1e110047c28c5ff570db7e4bd948807912..0000000000000000000000000000000000000000
--- a/spaces/contluForse/HuggingGPT/assets/Da Vinci Code Ebook Free Download Epub The Best Way to Enjoy the Thrilling Mystery Novel.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-Project Gutenberg eBooks may be freely used in the United States because most are not protected by U.S. copyright law. They may not be free of copyright in other countries. Readers outside of the United States must check the copyright terms of their countries before accessing, downloading or redistributing eBooks. We also have a number of copyrighted titles, for which the copyright holder has given permission for unlimited non-commercial worldwide use.
-da vinci code ebook free download epub
Download ✒ ✒ ✒ https://ssurll.com/2uzz1X
-This is where you can pick up your free downloads of Crafting Unforgettable Characters, as well as the bonus books the Complete Outline Transcript of Storming and 5 Secrets of Story Structure and my free Scrivener template.
-Visit the Overdrive website or our online catalog for Overdrive ebooks available for Kindle devices. Libby will offer you an option to read in the Libby app or if you would like the book downloaded to your Kindle device. aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/contluForse/HuggingGPT/assets/Download HD Movie of Terror Strike A Gripping Story of Courage and Survival.md b/spaces/contluForse/HuggingGPT/assets/Download HD Movie of Terror Strike A Gripping Story of Courage and Survival.md
deleted file mode 100644
index 07b80e4aa45ac3db70f6911b98cdd41e54e121e6..0000000000000000000000000000000000000000
--- a/spaces/contluForse/HuggingGPT/assets/Download HD Movie of Terror Strike A Gripping Story of Courage and Survival.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-The SIT formed to probe the Dinanagar attack believes that the strike was undertaken by the Laskhar-e-Toiba, while the attack on the Pathankot Air Force Station was the handiwork of Jaish-e-Mohammad. Both are Pakistan-based terror outfits and had used Mastgarh village route to enter India.
-Terror Strike download HD movie
DOWNLOAD ✑ https://ssurll.com/2uzxWT
-A counterpart of the principle of least action in Nature is that attackers in human conflict follow the path of least resistance. Thus, Sun Tzu notes: Now an army may be likened to water, for just as water avoids heights and hastens to the lowlands, so an army avoids strength and strikes weakness. For attacks by terrorists, cyber hackers or warring states, quantitative risk modelling is unified by the principles of adversarial conflict, such as those laid out by Sun Tzu. The well-defined principles underlying quantitative terrorism risk modelling minimize the need to resort to expert judgement (Woo 2011, 2015). Within the bounds defined by the Western counter-terrorism environment, terrorists maximize their operational utility by abiding by the classic principles of terrorist modus operandi: substituting hardened targets; following the path of least resistance in weapon selection; and leveraging their scarce resources to achieve the greatest impact. The metric for impact includes not just loss inflicted but also the media attention gained. An insightful ISIS slogan is that media is half Jihad. Media coverage is essential for terrorist recruitment and funding, as well as for propaganda. This is so important that in 2002, Osama bin Laden wrote that the media war may reach 90% of the preparation for battles (Awan 2016).
-CM Terrorism Crisis Protocols are now not only necessary for airlines, government buildings and mass transit organizations, but for businesses as a whole, from college campuses to nightclubs to movie theaters. The unfortunate and tragic reality is this: Terrorism and mass calamity can strike anywhere at any time. aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/pidinet/__init__.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/pidinet/__init__.py
deleted file mode 100644
index 4f3e3d9038c068f69c56a1fbb6e51b6b11faa0fd..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/pidinet/__init__.py
+++ /dev/null
@@ -1,39 +0,0 @@
-# Pidinet
-# https://github.com/hellozhuo/pidinet
-
-import os
-import torch
-import numpy as np
-from einops import rearrange
-from annotator.pidinet.model import pidinet
-from annotator.util import annotator_ckpts_path, safe_step
-
-
-class PidiNetDetector:
- def __init__(self):
- remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/table5_pidinet.pth"
- modelpath = os.path.join(annotator_ckpts_path, "table5_pidinet.pth")
- if not os.path.exists(modelpath):
- from basicsr.utils.download_util import load_file_from_url
- load_file_from_url(remote_model_path, model_dir=annotator_ckpts_path)
- self.netNetwork = pidinet()
-# self.netNetwork.load_state_dict({k.replace('module.', ''): v for k, v in torch.load(modelpath)['state_dict'].items()})
- self.netNetwork.load_state_dict({k.replace('module.', ''): v for k, v in torch.load(modelpath, map_location=torch.device('cpu'))['state_dict'].items()})
-# self.netNetwork = self.netNetwork.cuda()
- self.netNetwork = self.netNetwork.cpu()
- self.netNetwork.eval()
-
- def __call__(self, input_image, safe=False):
- assert input_image.ndim == 3
- input_image = input_image[:, :, ::-1].copy()
- with torch.no_grad():
-# image_pidi = torch.from_numpy(input_image).float().cuda()
- image_pidi = torch.from_numpy(input_image).float().cpu()
- image_pidi = image_pidi / 255.0
- image_pidi = rearrange(image_pidi, 'h w c -> 1 c h w')
- edge = self.netNetwork(image_pidi)[-1]
- edge = edge.cpu().numpy()
- if safe:
- edge = safe_step(edge)
- edge = (edge * 255.0).clip(0, 255).astype(np.uint8)
- return edge[0][0]
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/zoe/zoedepth/models/layers/patch_transformer.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/zoe/zoedepth/models/layers/patch_transformer.py
deleted file mode 100644
index 99d9e51a06b981bae45ce7dd64eaef19a4121991..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/zoe/zoedepth/models/layers/patch_transformer.py
+++ /dev/null
@@ -1,91 +0,0 @@
-# MIT License
-
-# Copyright (c) 2022 Intelligent Systems Lab Org
-
-# Permission is hereby granted, free of charge, to any person obtaining a copy
-# of this software and associated documentation files (the "Software"), to deal
-# in the Software without restriction, including without limitation the rights
-# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-# copies of the Software, and to permit persons to whom the Software is
-# furnished to do so, subject to the following conditions:
-
-# The above copyright notice and this permission notice shall be included in all
-# copies or substantial portions of the Software.
-
-# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-# SOFTWARE.
-
-# File author: Shariq Farooq Bhat
-
-import torch
-import torch.nn as nn
-
-
-class PatchTransformerEncoder(nn.Module):
- def __init__(self, in_channels, patch_size=10, embedding_dim=128, num_heads=4, use_class_token=False):
- """ViT-like transformer block
-
- Args:
- in_channels (int): Input channels
- patch_size (int, optional): patch size. Defaults to 10.
- embedding_dim (int, optional): Embedding dimension in transformer model. Defaults to 128.
- num_heads (int, optional): number of attention heads. Defaults to 4.
- use_class_token (bool, optional): Whether to use extra token at the start for global accumulation (called as "class token"). Defaults to False.
- """
- super(PatchTransformerEncoder, self).__init__()
- self.use_class_token = use_class_token
- encoder_layers = nn.TransformerEncoderLayer(
- embedding_dim, num_heads, dim_feedforward=1024)
- self.transformer_encoder = nn.TransformerEncoder(
- encoder_layers, num_layers=4) # takes shape S,N,E
-
- self.embedding_convPxP = nn.Conv2d(in_channels, embedding_dim,
- kernel_size=patch_size, stride=patch_size, padding=0)
-
- def positional_encoding_1d(self, sequence_length, batch_size, embedding_dim, device='cpu'):
- """Generate positional encodings
-
- Args:
- sequence_length (int): Sequence length
- embedding_dim (int): Embedding dimension
-
- Returns:
- torch.Tensor SBE: Positional encodings
- """
- position = torch.arange(
- 0, sequence_length, dtype=torch.float32, device=device).unsqueeze(1)
- index = torch.arange(
- 0, embedding_dim, 2, dtype=torch.float32, device=device).unsqueeze(0)
- div_term = torch.exp(index * (-torch.log(torch.tensor(10000.0, device=device)) / embedding_dim))
- pos_encoding = position * div_term
- pos_encoding = torch.cat([torch.sin(pos_encoding), torch.cos(pos_encoding)], dim=1)
- pos_encoding = pos_encoding.unsqueeze(1).repeat(1, batch_size, 1)
- return pos_encoding
-
-
- def forward(self, x):
- """Forward pass
-
- Args:
- x (torch.Tensor - NCHW): Input feature tensor
-
- Returns:
- torch.Tensor - SNE: Transformer output embeddings. S - sequence length (=HW/patch_size^2), N - batch size, E - embedding dim
- """
- embeddings = self.embedding_convPxP(x).flatten(
- 2) # .shape = n,c,s = n, embedding_dim, s
- if self.use_class_token:
- # extra special token at start ?
- embeddings = nn.functional.pad(embeddings, (1, 0))
-
- # change to S,N,E format required by transformer
- embeddings = embeddings.permute(2, 0, 1)
- S, N, E = embeddings.shape
- embeddings = embeddings + self.positional_encoding_1d(S, N, E, device=embeddings.device)
- x = self.transformer_encoder(embeddings) # .shape = S, N, E
- return x
diff --git a/spaces/crashedice/signify/nbs/styles.css b/spaces/crashedice/signify/nbs/styles.css
deleted file mode 100644
index 66ccc49ee8f0e73901dac02dc4e9224b7d1b2c78..0000000000000000000000000000000000000000
--- a/spaces/crashedice/signify/nbs/styles.css
+++ /dev/null
@@ -1,37 +0,0 @@
-.cell {
- margin-bottom: 1rem;
-}
-
-.cell > .sourceCode {
- margin-bottom: 0;
-}
-
-.cell-output > pre {
- margin-bottom: 0;
-}
-
-.cell-output > pre, .cell-output > .sourceCode > pre, .cell-output-stdout > pre {
- margin-left: 0.8rem;
- margin-top: 0;
- background: none;
- border-left: 2px solid lightsalmon;
- border-top-left-radius: 0;
- border-top-right-radius: 0;
-}
-
-.cell-output > .sourceCode {
- border: none;
-}
-
-.cell-output > .sourceCode {
- background: none;
- margin-top: 0;
-}
-
-div.description {
- padding-left: 2px;
- padding-top: 5px;
- font-style: italic;
- font-size: 135%;
- opacity: 70%;
-}
diff --git a/spaces/dachenchen/HiWantJoin/ChuanhuChatbot.py b/spaces/dachenchen/HiWantJoin/ChuanhuChatbot.py
deleted file mode 100644
index c58896527ff5fc15650a6b1d9bbc1506988efb4b..0000000000000000000000000000000000000000
--- a/spaces/dachenchen/HiWantJoin/ChuanhuChatbot.py
+++ /dev/null
@@ -1,470 +0,0 @@
-# -*- coding:utf-8 -*-
-import os
-import logging
-import sys
-
-import gradio as gr
-
-from modules import config
-from modules.config import *
-from modules.utils import *
-from modules.presets import *
-from modules.overwrites import *
-from modules.models import get_model
-
-
-gr.Chatbot._postprocess_chat_messages = postprocess_chat_messages
-gr.Chatbot.postprocess = postprocess
-PromptHelper.compact_text_chunks = compact_text_chunks
-
-with open("assets/custom.css", "r", encoding="utf-8") as f:
- customCSS = f.read()
-
-def create_new_model():
- return get_model(model_name = MODELS[DEFAULT_MODEL], access_key = my_api_key)[0]
-
-with gr.Blocks(css=customCSS, theme=small_and_beautiful_theme) as demo:
- user_name = gr.State("")
- promptTemplates = gr.State(load_template(get_template_names(plain=True)[0], mode=2))
- user_question = gr.State("")
- user_api_key = gr.State(my_api_key)
- current_model = gr.State(create_new_model)
-
- topic = gr.State(i18n("未命名对话历史记录"))
-
- with gr.Row():
- gr.HTML(CHUANHU_TITLE, elem_id="app_title")
- status_display = gr.Markdown(get_geoip(), elem_id="status_display")
- with gr.Row(elem_id="float_display"):
- user_info = gr.Markdown(value="getting user info...", elem_id="user_info")
-
- # https://github.com/gradio-app/gradio/pull/3296
- def create_greeting(request: gr.Request):
- if hasattr(request, "username") and request.username: # is not None or is not ""
- logging.info(f"Get User Name: {request.username}")
- return gr.Markdown.update(value=f"User: {request.username}"), request.username
- else:
- return gr.Markdown.update(value=f"User: default", visible=False), ""
- demo.load(create_greeting, inputs=None, outputs=[user_info, user_name])
-
- with gr.Row().style(equal_height=True):
- with gr.Column(scale=5):
- with gr.Row():
- chatbot = gr.Chatbot(elem_id="chuanhu_chatbot").style(height="100%")
- with gr.Row():
- with gr.Column(min_width=225, scale=12):
- user_input = gr.Textbox(
- elem_id="user_input_tb",
- show_label=False, placeholder=i18n("在这里输入")
- ).style(container=False)
- with gr.Column(min_width=42, scale=1):
- submitBtn = gr.Button(value="", variant="primary", elem_id="submit_btn")
- cancelBtn = gr.Button(value="", variant="secondary", visible=False, elem_id="cancel_btn")
- with gr.Row():
- emptyBtn = gr.Button(
- i18n("🧹 新的对话"),
- )
- retryBtn = gr.Button(i18n("🔄 重新生成"))
- delFirstBtn = gr.Button(i18n("🗑️ 删除最旧对话"))
- delLastBtn = gr.Button(i18n("🗑️ 删除最新对话"))
- with gr.Row(visible=False) as like_dislike_area:
- with gr.Column(min_width=20, scale=1):
- likeBtn = gr.Button(i18n("👍"))
- with gr.Column(min_width=20, scale=1):
- dislikeBtn = gr.Button(i18n("👎"))
-
- with gr.Column():
- with gr.Column(min_width=50, scale=1):
- with gr.Tab(label=i18n("模型")):
- keyTxt = gr.Textbox(
- show_label=True,
- placeholder=f"Your API-key...",
- value=hide_middle_chars(user_api_key.value),
- type="password",
- visible=not HIDE_MY_KEY,
- label="API-Key",
- )
- if multi_api_key:
- usageTxt = gr.Markdown(i18n("多账号模式已开启,无需输入key,可直接开始对话"), elem_id="usage_display", elem_classes="insert_block")
- else:
- usageTxt = gr.Markdown(i18n("**发送消息** 或 **提交key** 以显示额度"), elem_id="usage_display", elem_classes="insert_block")
- model_select_dropdown = gr.Dropdown(
- label=i18n("选择模型"), choices=MODELS, multiselect=False, value=MODELS[DEFAULT_MODEL], interactive=True
- )
- lora_select_dropdown = gr.Dropdown(
- label=i18n("选择LoRA模型"), choices=[], multiselect=False, interactive=True, visible=False
- )
- with gr.Row():
- use_streaming_checkbox = gr.Checkbox(
- label=i18n("实时传输回答"), value=True, visible=ENABLE_STREAMING_OPTION
- )
- single_turn_checkbox = gr.Checkbox(label=i18n("单轮对话"), value=False)
- use_websearch_checkbox = gr.Checkbox(label=i18n("使用在线搜索"), value=False)
- language_select_dropdown = gr.Dropdown(
- label=i18n("选择回复语言(针对搜索&索引功能)"),
- choices=REPLY_LANGUAGES,
- multiselect=False,
- value=REPLY_LANGUAGES[0],
- )
- index_files = gr.Files(label=i18n("上传"), type="file")
- two_column = gr.Checkbox(label=i18n("双栏pdf"), value=advance_docs["pdf"].get("two_column", False))
- # TODO: 公式ocr
- # formula_ocr = gr.Checkbox(label=i18n("识别公式"), value=advance_docs["pdf"].get("formula_ocr", False))
-
- with gr.Tab(label="Prompt"):
- systemPromptTxt = gr.Textbox(
- show_label=True,
- placeholder=i18n("在这里输入System Prompt..."),
- label="System prompt",
- value=INITIAL_SYSTEM_PROMPT,
- lines=10,
- ).style(container=False)
- with gr.Accordion(label=i18n("加载Prompt模板"), open=True):
- with gr.Column():
- with gr.Row():
- with gr.Column(scale=6):
- templateFileSelectDropdown = gr.Dropdown(
- label=i18n("选择Prompt模板集合文件"),
- choices=get_template_names(plain=True),
- multiselect=False,
- value=get_template_names(plain=True)[0],
- ).style(container=False)
- with gr.Column(scale=1):
- templateRefreshBtn = gr.Button(i18n("🔄 刷新"))
- with gr.Row():
- with gr.Column():
- templateSelectDropdown = gr.Dropdown(
- label=i18n("从Prompt模板中加载"),
- choices=load_template(
- get_template_names(plain=True)[0], mode=1
- ),
- multiselect=False,
- ).style(container=False)
-
- with gr.Tab(label=i18n("保存/加载")):
- with gr.Accordion(label=i18n("保存/加载对话历史记录"), open=True):
- with gr.Column():
- with gr.Row():
- with gr.Column(scale=6):
- historyFileSelectDropdown = gr.Dropdown(
- label=i18n("从列表中加载对话"),
- choices=get_history_names(plain=True),
- multiselect=False,
- value=get_history_names(plain=True)[0],
- )
- with gr.Column(scale=1):
- historyRefreshBtn = gr.Button(i18n("🔄 刷新"))
- with gr.Row():
- with gr.Column(scale=6):
- saveFileName = gr.Textbox(
- show_label=True,
- placeholder=i18n("设置文件名: 默认为.json,可选为.md"),
- label=i18n("设置保存文件名"),
- value=i18n("对话历史记录"),
- ).style(container=True)
- with gr.Column(scale=1):
- saveHistoryBtn = gr.Button(i18n("💾 保存对话"))
- exportMarkdownBtn = gr.Button(i18n("📝 导出为Markdown"))
- gr.Markdown(i18n("默认保存于history文件夹"))
- with gr.Row():
- with gr.Column():
- downloadFile = gr.File(interactive=True)
-
- with gr.Tab(label=i18n("高级")):
- gr.Markdown(i18n("# ⚠️ 务必谨慎更改 ⚠️\n\n如果无法使用请恢复默认设置"))
- gr.HTML(APPEARANCE_SWITCHER, elem_classes="insert_block")
- with gr.Accordion(i18n("参数"), open=False):
- temperature_slider = gr.Slider(
- minimum=-0,
- maximum=2.0,
- value=1.0,
- step=0.1,
- interactive=True,
- label="temperature",
- )
- top_p_slider = gr.Slider(
- minimum=-0,
- maximum=1.0,
- value=1.0,
- step=0.05,
- interactive=True,
- label="top-p",
- )
- n_choices_slider = gr.Slider(
- minimum=1,
- maximum=10,
- value=1,
- step=1,
- interactive=True,
- label="n choices",
- )
- stop_sequence_txt = gr.Textbox(
- show_label=True,
- placeholder=i18n("在这里输入停止符,用英文逗号隔开..."),
- label="stop",
- value="",
- lines=1,
- )
- max_context_length_slider = gr.Slider(
- minimum=1,
- maximum=32768,
- value=2000,
- step=1,
- interactive=True,
- label="max context",
- )
- max_generation_slider = gr.Slider(
- minimum=1,
- maximum=32768,
- value=1000,
- step=1,
- interactive=True,
- label="max generations",
- )
- presence_penalty_slider = gr.Slider(
- minimum=-2.0,
- maximum=2.0,
- value=0.0,
- step=0.01,
- interactive=True,
- label="presence penalty",
- )
- frequency_penalty_slider = gr.Slider(
- minimum=-2.0,
- maximum=2.0,
- value=0.0,
- step=0.01,
- interactive=True,
- label="frequency penalty",
- )
- logit_bias_txt = gr.Textbox(
- show_label=True,
- placeholder=f"word:likelihood",
- label="logit bias",
- value="",
- lines=1,
- )
- user_identifier_txt = gr.Textbox(
- show_label=True,
- placeholder=i18n("用于定位滥用行为"),
- label=i18n("用户名"),
- value=user_name.value,
- lines=1,
- )
-
- with gr.Accordion(i18n("网络设置"), open=False, visible=False):
- # 优先展示自定义的api_host
- apihostTxt = gr.Textbox(
- show_label=True,
- placeholder=i18n("在这里输入API-Host..."),
- label="API-Host",
- value=config.api_host or shared.API_HOST,
- lines=1,
- )
- changeAPIURLBtn = gr.Button(i18n("🔄 切换API地址"))
- proxyTxt = gr.Textbox(
- show_label=True,
- placeholder=i18n("在这里输入代理地址..."),
- label=i18n("代理地址(示例:http://127.0.0.1:10809)"),
- value="",
- lines=2,
- )
- changeProxyBtn = gr.Button(i18n("🔄 设置代理地址"))
- default_btn = gr.Button(i18n("🔙 恢复默认设置"))
-
- gr.Markdown(CHUANHU_DESCRIPTION, elem_id="description")
- gr.HTML(FOOTER.format(versions=versions_html()), elem_id="footer")
- demo.load(refresh_ui_elements_on_load, [current_model, model_select_dropdown], [like_dislike_area], show_progress=False)
- chatgpt_predict_args = dict(
- fn=predict,
- inputs=[
- current_model,
- user_question,
- chatbot,
- use_streaming_checkbox,
- use_websearch_checkbox,
- index_files,
- language_select_dropdown,
- ],
- outputs=[chatbot, status_display],
- show_progress=True,
- )
-
- start_outputing_args = dict(
- fn=start_outputing,
- inputs=[],
- outputs=[submitBtn, cancelBtn],
- show_progress=True,
- )
-
- end_outputing_args = dict(
- fn=end_outputing, inputs=[], outputs=[submitBtn, cancelBtn]
- )
-
- reset_textbox_args = dict(
- fn=reset_textbox, inputs=[], outputs=[user_input]
- )
-
- transfer_input_args = dict(
- fn=transfer_input, inputs=[user_input], outputs=[user_question, user_input, submitBtn, cancelBtn], show_progress=True
- )
-
- get_usage_args = dict(
- fn=billing_info, inputs=[current_model], outputs=[usageTxt], show_progress=False
- )
-
- load_history_from_file_args = dict(
- fn=load_chat_history,
- inputs=[current_model, historyFileSelectDropdown, chatbot, user_name],
- outputs=[saveFileName, systemPromptTxt, chatbot]
- )
-
-
- # Chatbot
- cancelBtn.click(interrupt, [current_model], [])
-
- user_input.submit(**transfer_input_args).then(**chatgpt_predict_args).then(**end_outputing_args)
- user_input.submit(**get_usage_args)
-
- submitBtn.click(**transfer_input_args).then(**chatgpt_predict_args).then(**end_outputing_args)
- submitBtn.click(**get_usage_args)
-
- index_files.change(handle_file_upload, [current_model, index_files, chatbot], [index_files, chatbot, status_display])
-
- emptyBtn.click(
- reset,
- inputs=[current_model],
- outputs=[chatbot, status_display],
- show_progress=True,
- )
-
- retryBtn.click(**start_outputing_args).then(
- retry,
- [
- current_model,
- chatbot,
- use_streaming_checkbox,
- use_websearch_checkbox,
- index_files,
- language_select_dropdown,
- ],
- [chatbot, status_display],
- show_progress=True,
- ).then(**end_outputing_args)
- retryBtn.click(**get_usage_args)
-
- delFirstBtn.click(
- delete_first_conversation,
- [current_model],
- [status_display],
- )
-
- delLastBtn.click(
- delete_last_conversation,
- [current_model, chatbot],
- [chatbot, status_display],
- show_progress=False
- )
-
- likeBtn.click(
- like,
- [current_model],
- [status_display],
- show_progress=False
- )
-
- dislikeBtn.click(
- dislike,
- [current_model],
- [status_display],
- show_progress=False
- )
-
- two_column.change(update_doc_config, [two_column], None)
-
- # LLM Models
- keyTxt.change(set_key, [current_model, keyTxt], [user_api_key, status_display]).then(**get_usage_args)
- keyTxt.submit(**get_usage_args)
- single_turn_checkbox.change(set_single_turn, [current_model, single_turn_checkbox], None)
- model_select_dropdown.change(get_model, [model_select_dropdown, lora_select_dropdown, user_api_key, temperature_slider, top_p_slider, systemPromptTxt], [current_model, status_display, lora_select_dropdown], show_progress=True)
- model_select_dropdown.change(toggle_like_btn_visibility, [model_select_dropdown], [like_dislike_area], show_progress=False)
- lora_select_dropdown.change(get_model, [model_select_dropdown, lora_select_dropdown, user_api_key, temperature_slider, top_p_slider, systemPromptTxt], [current_model, status_display], show_progress=True)
-
- # Template
- systemPromptTxt.change(set_system_prompt, [current_model, systemPromptTxt], None)
- templateRefreshBtn.click(get_template_names, None, [templateFileSelectDropdown])
- templateFileSelectDropdown.change(
- load_template,
- [templateFileSelectDropdown],
- [promptTemplates, templateSelectDropdown],
- show_progress=True,
- )
- templateSelectDropdown.change(
- get_template_content,
- [promptTemplates, templateSelectDropdown, systemPromptTxt],
- [systemPromptTxt],
- show_progress=True,
- )
-
- # S&L
- saveHistoryBtn.click(
- save_chat_history,
- [current_model, saveFileName, chatbot, user_name],
- downloadFile,
- show_progress=True,
- )
- saveHistoryBtn.click(get_history_names, [gr.State(False), user_name], [historyFileSelectDropdown])
- exportMarkdownBtn.click(
- export_markdown,
- [current_model, saveFileName, chatbot, user_name],
- downloadFile,
- show_progress=True,
- )
- historyRefreshBtn.click(get_history_names, [gr.State(False), user_name], [historyFileSelectDropdown])
- historyFileSelectDropdown.change(**load_history_from_file_args)
- downloadFile.change(**load_history_from_file_args)
-
- # Advanced
- max_context_length_slider.change(set_token_upper_limit, [current_model, max_context_length_slider], None)
- temperature_slider.change(set_temperature, [current_model, temperature_slider], None)
- top_p_slider.change(set_top_p, [current_model, top_p_slider], None)
- n_choices_slider.change(set_n_choices, [current_model, n_choices_slider], None)
- stop_sequence_txt.change(set_stop_sequence, [current_model, stop_sequence_txt], None)
- max_generation_slider.change(set_max_tokens, [current_model, max_generation_slider], None)
- presence_penalty_slider.change(set_presence_penalty, [current_model, presence_penalty_slider], None)
- frequency_penalty_slider.change(set_frequency_penalty, [current_model, frequency_penalty_slider], None)
- logit_bias_txt.change(set_logit_bias, [current_model, logit_bias_txt], None)
- user_identifier_txt.change(set_user_identifier, [current_model, user_identifier_txt], None)
-
- default_btn.click(
- reset_default, [], [apihostTxt, proxyTxt, status_display], show_progress=True
- )
- changeAPIURLBtn.click(
- change_api_host,
- [apihostTxt],
- [status_display],
- show_progress=True,
- )
- changeProxyBtn.click(
- change_proxy,
- [proxyTxt],
- [status_display],
- show_progress=True,
- )
-
-logging.info(
- colorama.Back.GREEN
- + "\n川虎的温馨提示:访问 http://localhost:7860 查看界面"
- + colorama.Style.RESET_ALL
-)
-# 默认开启本地服务器,默认可以直接从IP访问,默认不创建公开分享链接
-demo.title = i18n("川虎Chat 🚀")
-
-if __name__ == "__main__":
- reload_javascript()
- demo.queue(concurrency_count=CONCURRENT_COUNT).launch(
- favicon_path="./assets/favicon.ico",
- )
- # demo.queue(concurrency_count=CONCURRENT_COUNT).launch(server_name="0.0.0.0", server_port=7860, share=False) # 可自定义端口
- # demo.queue(concurrency_count=CONCURRENT_COUNT).launch(server_name="0.0.0.0", server_port=7860,auth=("在这里填写用户名", "在这里填写密码")) # 可设置用户名与密码
- # demo.queue(concurrency_count=CONCURRENT_COUNT).launch(auth=("在这里填写用户名", "在这里填写密码")) # 适合Nginx反向代理
diff --git a/spaces/daddyjin/TalkingFaceGeneration/Demo_TFR_Pirenderer/src/pirenderer/util/io.py b/spaces/daddyjin/TalkingFaceGeneration/Demo_TFR_Pirenderer/src/pirenderer/util/io.py
deleted file mode 100644
index ea1575a2db5a8a45b60aece1e64f7ff3307714e8..0000000000000000000000000000000000000000
--- a/spaces/daddyjin/TalkingFaceGeneration/Demo_TFR_Pirenderer/src/pirenderer/util/io.py
+++ /dev/null
@@ -1,118 +0,0 @@
-import os
-
-import requests
-import torch.distributed as dist
-import torchvision.utils
-
-from util.distributed import is_master
-
-
-def save_pilimage_in_jpeg(fullname, output_img):
- r"""Save PIL Image to JPEG.
-
- Args:
- fullname (str): Full save path.
- output_img (PIL Image): Image to be saved.
- """
- dirname = os.path.dirname(fullname)
- os.makedirs(dirname, exist_ok=True)
- output_img.save(fullname, 'JPEG', quality=99)
-
-
-def save_intermediate_training_results(
- visualization_images, logdir, current_epoch, current_iteration):
- r"""Save intermediate training results for debugging purpose.
-
- Args:
- visualization_images (tensor): Image where pixel values are in [-1, 1].
- logdir (str): Where to save the image.
- current_epoch (int): Current training epoch.
- current_iteration (int): Current training iteration.
- """
- visualization_images = (visualization_images + 1) / 2
- output_filename = os.path.join(
- logdir, 'images',
- 'epoch_{:05}iteration{:09}.jpg'.format(
- current_epoch, current_iteration))
- print('Save output images to {}'.format(output_filename))
- os.makedirs(os.path.dirname(output_filename), exist_ok=True)
- image_grid = torchvision.utils.make_grid(
- visualization_images.data, nrow=1, padding=0, normalize=False)
- torchvision.utils.save_image(image_grid, output_filename, nrow=1)
-
-
-def download_file_from_google_drive(file_id, destination):
- r"""Download a file from the google drive by using the file ID.
-
- Args:
- file_id: Google drive file ID
- destination: Path to save the file.
-
- Returns:
-
- """
- URL = "https://docs.google.com/uc?export=download"
- session = requests.Session()
- response = session.get(URL, params={'id': file_id}, stream=True)
- token = get_confirm_token(response)
- if token:
- params = {'id': file_id, 'confirm': token}
- response = session.get(URL, params=params, stream=True)
- save_response_content(response, destination)
-
-
-def get_confirm_token(response):
- r"""Get confirm token
-
- Args:
- response: Check if the file exists.
-
- Returns:
-
- """
- for key, value in response.cookies.items():
- if key.startswith('download_warning'):
- return value
- return None
-
-
-def save_response_content(response, destination):
- r"""Save response content
-
- Args:
- response:
- destination: Path to save the file.
-
- Returns:
-
- """
- chunk_size = 32768
- with open(destination, "wb") as f:
- for chunk in response.iter_content(chunk_size):
- if chunk:
- f.write(chunk)
-
-
-def get_checkpoint(checkpoint_path, url=''):
- r"""Get the checkpoint path. If it does not exist yet, download it from
- the url.
-
- Args:
- checkpoint_path (str): Checkpoint path.
- url (str): URL to download checkpoint.
- Returns:
- (str): Full checkpoint path.
- """
- if 'TORCH_HOME' not in os.environ:
- os.environ['TORCH_HOME'] = os.getcwd()
- save_dir = os.path.join(os.environ['TORCH_HOME'], 'checkpoints')
- os.makedirs(save_dir, exist_ok=True)
- full_checkpoint_path = os.path.join(save_dir, checkpoint_path)
- if not os.path.exists(full_checkpoint_path):
- os.makedirs(os.path.dirname(full_checkpoint_path), exist_ok=True)
- if is_master():
- print('Download {}'.format(url))
- download_file_from_google_drive(url, full_checkpoint_path)
- if dist.is_available() and dist.is_initialized():
- dist.barrier()
- return full_checkpoint_path
diff --git a/spaces/daddyjin/TalkingFaceGeneration/FONT/modules/frames_dataset.py b/spaces/daddyjin/TalkingFaceGeneration/FONT/modules/frames_dataset.py
deleted file mode 100644
index 3dac34aa7a48422a5c241d8708893fabe69d17de..0000000000000000000000000000000000000000
--- a/spaces/daddyjin/TalkingFaceGeneration/FONT/modules/frames_dataset.py
+++ /dev/null
@@ -1,451 +0,0 @@
-import os
-from skimage import io, img_as_float32, transform
-from skimage.color import gray2rgb
-from sklearn.model_selection import train_test_split
-from imageio import mimread
-
-import numpy as np
-from torch.utils.data import Dataset
-import pandas as pd
-from augmentation import AllAugmentationTransform
-import glob
-import pickle
-import random
-def read_video(name, frame_shape):
- """
- Read video which can be:
- - an image of concatenated frames
- - '.mp4' and'.gif'
- - folder with videos
- """
-
- if os.path.isdir(name):
- frames = sorted(os.listdir(name))
- num_frames = len(frames)
- video_array = np.array(
- [img_as_float32(io.imread(os.path.join(name, frames[idx]))) for idx in range(num_frames)])
- elif name.lower().endswith('.png') or name.lower().endswith('.jpg'):
- image = io.imread(name)
-
- if len(image.shape) == 2 or image.shape[2] == 1:
- image = gray2rgb(image)
-
- if image.shape[2] == 4:
- image = image[..., :3]
-
- image = img_as_float32(image)
-
- video_array = np.moveaxis(image, 1, 0)
-
- video_array = video_array.reshape((-1,) + frame_shape)
- video_array = np.moveaxis(video_array, 1, 2)
- elif name.lower().endswith('.gif') or name.lower().endswith('.mp4') or name.lower().endswith('.mov'):
- video = np.array(mimread(name))
- if len(video.shape) == 3:
- video = np.array([gray2rgb(frame) for frame in video])
- if video.shape[-1] == 4:
- video = video[..., :3]
- video_array = img_as_float32(video)
- else:
- raise Exception("Unknown file extensions %s" % name)
-
- return video_array
-
-def get_list(ipath,base_name):
-#ipath = '/mnt/lustre/share/jixinya/LRW/pose/train_fo/'
- ipath = os.path.join(ipath,base_name)
- name_list = os.listdir(ipath)
- image_path = os.path.join('/mnt/lustre/share/jixinya/LRW/Image/',base_name)
- all = []
- for k in range(len(name_list)):
- name = name_list[k]
- path_ = os.path.join(ipath,name)
- Dir = os.listdir(path_)
- for i in range(len(Dir)):
- word = Dir[i]
- path = os.path.join(path_, word)
- if os.path.exists(os.path.join(image_path,name,word.split('.')[0])):
- all.append(name+'/'+word.split('.')[0])
- #print(k,name,i,word)
- print('get list '+os.path.basename(ipath))
- return all
-
-
-class AudioDataset(Dataset):
- """
- Dataset of videos, each video can be represented as:
- - an image of concatenated frames
- - '.mp4' or '.gif'
- - folder with all frames
- """
-
- def __init__(self, root_dir, frame_shape=(256, 256, 3), id_sampling=False, is_train=True,
- random_seed=0, pairs_list=None, augmentation_params=None):
- self.root_dir = root_dir
- self.audio_dir = os.path.join(root_dir,'MFCC')
- self.image_dir = os.path.join(root_dir,'Image')
- self.landmark_dir = os.path.join(root_dir,'Landmark')
- self.pose_dir = os.path.join(root_dir,'pose')
- # assert len(os.listdir(self.audio_dir)) == len(os.listdir(self.image_dir)), 'audio and image length not equal'
-
-
- df=open('../LRW/list/test_fo.txt','rb')
- self.videos=pickle.load(df)
- df.close()
- # self.videos=np.load('../LRW/list/train_fo.npy')
- # self.videos = os.listdir(self.landmark_dir)
- self.frame_shape = tuple(frame_shape)
- self.pairs_list = pairs_list
- self.id_sampling = id_sampling
- self.pca = np.load('../LRW/list/U_106.npy')[:, :16]
- self.mean = np.load('../LRW/list/mean_106.npy')
-
- if os.path.exists(os.path.join(self.pose_dir, 'train_fo')):
- assert os.path.exists(os.path.join(self.pose_dir, 'test_fo'))
- print("Use predefined train-test split.")
- if id_sampling:
- train_videos = {os.path.basename(video).split('#')[0] for video in
- os.listdir(os.path.join(self.image_dir, 'train'))}
- train_videos = list(train_videos)
- else:
- train_videos = np.load('../LRW/list/train_fo.npy')# get_list(self.pose_dir, 'train_fo')
- df=open('../LRW/list/test_fo.txt','rb')
- test_videos=pickle.load(df)
- df.close()
- # test_videos = np.load('../LRW/list/train_fo.npy')
- #get_list(self.pose_dir, 'test_fo')
- # self.root_dir = os.path.join(self.root_dir, 'train' if is_train else 'test')
- self.landmark_dir = os.path.join(self.landmark_dir, 'train_fo' if is_train else 'test_fo')
- self.image_dir = os.path.join(self.image_dir, 'train_fo' if is_train else 'test_fo')
- self.audio_dir = os.path.join(self.audio_dir, 'train' if is_train else 'test')
- self.pose_dir = os.path.join(self.pose_dir, 'train_fo' if is_train else 'test_fo')
- else:
- print("Use random train-test split.")
- train_videos, test_videos = train_test_split(self.videos, random_state=random_seed, test_size=0.2)
-
- if is_train:
- self.videos = train_videos
- else:
- self.videos = test_videos
-
- self.is_train = is_train
-
- if self.is_train:
- self.transform = AllAugmentationTransform(**augmentation_params)
- else:
- self.transform = None
-
- def __len__(self):
- return len(self.videos)
-
- def __getitem__(self, idx):
- if self.is_train and self.id_sampling:
- name = self.videos[idx].split('.')[0]
- path = np.random.choice(glob.glob(os.path.join(self.root_dir, name + '*.mp4')))
- else:
- name = self.videos[idx].split('.')[0]
- landmark_path = os.path.join(self.landmark_dir, name+'.npy')
-
- audio_path = os.path.join(self.audio_dir, name)
- pose_path = os.path.join(self.pose_dir,name)
- path = os.path.join(self.image_dir, name)
-
- video_name = os.path.basename(path)
-
- if os.path.isdir(path):
- # if self.is_train and os.path.isdir(path):
-
- lmark = np.load(landmark_path).reshape(-1,212)/255
- if np.isnan(lmark).sum() or np.isinf(lmark).sum():
- print('Wrong lmark '+ video_name, file=open('log/wrong.txt', 'a'))
- lmark = np.zeros((29,212))
- lmark = lmark - self.mean
- lmark = np.dot(lmark, self.pca)
-
- # mfcc loading
-
- r = random.choice([x for x in range(3, 8)])
- example_landmark = lmark[r, :]
- example_image = img_as_float32(io.imread(os.path.join(path, str(r)+'.png')))
- # example_mfcc = mfcc[(r - 3) * 4: (r + 4) * 4, 1:]
-
- mfccs = []
- for ind in range(1, 17):
- # t_mfcc = mfcc[(r + ind - 3) * 4: (r + ind + 4) * 4, 1:]
- try:
- t_mfcc = np.load(os.path.join(audio_path,str(r + ind)+'.npy'),allow_pickle=True)[:, 1:]
- if np.isnan(t_mfcc).sum() or np.isinf(t_mfcc).sum():
- print('Wrong mfcc '+ video_name+str(r+ind), file=open('log/wrong.txt', 'a'))
- t_mfcc = np.zeros((28,13))[:,1:]
- except:
- t_mfcc = np.zeros((28,13))[:,1:]
- mfccs.append(t_mfcc)
- mfccs = np.array(mfccs)
- if not self.is_train:
- poses = []
- video_array = []
- for ind in range(1, 17):
- # t_mfcc = mfcc[(r + ind - 3) * 4: (r + ind + 4) * 4, 1:]
- t_pose = np.load(os.path.join(pose_path,str(r + ind)+'.npy'))[:-1]
- poses.append(t_pose)
- image = img_as_float32(io.imread(os.path.join(path, str(r + ind)+'.png')))
- video_array.append(image)
- poses = np.array(poses)
- video_array = np.array(video_array)
- else:
- poses = []
- video_array = []
- for ind in range(1, 17):
- # t_mfcc = mfcc[(r + ind - 3) * 4: (r + ind + 4) * 4, 1:]
- t_pose = np.load(os.path.join(self.pose_dir,name+'.npy'))[r+ind,:-1]
- if np.isnan(t_pose).sum() or np.isinf(t_pose).sum():
- print('Wrong pose '+ video_name, file=open('log/wrong.txt', 'a'))
- t_pose = np.zeros((6,))
- poses.append(t_pose)
- image = img_as_float32(io.imread(os.path.join(path, str(r + ind)+'.png')))
- video_array.append(image)
- poses = np.array(poses)
- video_array = np.array(video_array)
-
- #mfccs = torch.FloatTensor(mfccs)
- landmark = lmark[r + 1: r + 17, :]
- index_32 = [0,4,8,12,16,20,24,28,32,33,35,67,68,40,42,52,55,72,73,58,61,75,76,46,47,51,84,87,90,93,98,102]
- driving_landmark = np.load(landmark_path)[r + 1: r + 17, :][:,index_32]
- source_landmark = np.load(landmark_path)[r, :][index_32]
- else:
- video_array = read_video(path, frame_shape=self.frame_shape)
- num_frames = len(video_array)
- frame_idx = np.sort(np.random.choice(num_frames, replace=True, size=2)) if self.is_train else range(
- num_frames)
- video_array = video_array[frame_idx]
-
- if self.transform is not None:
- video_array = self.transform(video_array)
-
- out = {}
- if True:#self.is_train:
- # a = img_as_float32(io.imread('/media/thea/Data/first-order-model/images_512/102.jpg'))
- # source = np.array(a, dtype='float32')
-
- driving = np.array(video_array, dtype='float32')
-
- spatial_size = np.array(driving.shape[1:3][::-1])[np.newaxis]
- # example_landmark = np.array(2*example_landmark / spatial_size -1, dtype='float32')
- driving_landmark = np.array(2*driving_landmark / spatial_size -1, dtype='float32')
- source_landmark = np.array(2*source_landmark / spatial_size -1, dtype='float32')
- driving_pose = np.array(poses, dtype='float32')
- example_landmark = np.array(example_landmark, dtype='float32')
- example_image = np.array(example_image, dtype='float32')
- # source_cube = np.array(transform.resize(cube_array[0], (64,64)), dtype='float32')
- # driving_cube = np.array(transform.resize(cube_array[1], (64,64)), dtype='float32')
- # source_heatmap = np.array(heatmap_array[0] , dtype='float32')
- # driving_heatmap = np.array(heatmap_array[1] , dtype='float32')
- # out['source_cube'] = source_cube
- # out['driving_cube'] = driving_cube
- out['example_landmark'] = example_landmark
- out['example_image'] = example_image.transpose((2, 0, 1))
- out['driving_landmark'] = driving_landmark
- out['source_landmark'] = source_landmark
- out['driving_pose'] = driving_pose
- # out['source_heatmap'] = source_heatmap
- # out['driving_heatmap'] = driving_heatmap
- out['driving'] = driving.transpose((0, 3, 1, 2))
- # out['source'] = source.transpose((2, 0, 1))
-
- # out['source_audio'] = np.array(audio_array[0], dtype='float32')
- out['driving_audio'] = np.array(mfccs, dtype='float32')
- out['gt_landmark'] = np.array(landmark, dtype='float32')
- out['pca'] = np.array(self.pca, dtype='float32')
- out['mean'] = np.array(self.mean, dtype='float32')
-
-
- out['name'] = video_name
-
- return out
-
-class FramesDataset(Dataset):
- """
- Dataset of videos, each video can be represented as:
- - an image of concatenated frames
- - '.mp4' or '.gif'
- - folder with all frames
- """
-
- def __init__(self, root_dir, frame_shape=(256, 256, 3), id_sampling=False, is_train=True,
- random_seed=0, pairs_list=None, augmentation_params=None):
- self.root_dir = root_dir
- self.audio_dir = os.path.join(root_dir,'audio/')
- self.image_dir = os.path.join(root_dir,'image/')
- self.landmark_dir = os.path.join(root_dir,'cube/')
- # assert len(os.listdir(self.audio_dir)) == len(os.listdir(self.image_dir)), 'audio and image length not equal'
-
-
- df=open('/media/thea/新加卷/MEAD/neutral/train.txt','rb')
- self.videos=pickle.load(df)
- df.close()
- # self.videos = os.listdir(self.landmark_dir)
- self.frame_shape = tuple(frame_shape)
- self.pairs_list = pairs_list
- self.id_sampling = id_sampling
- if os.path.exists(os.path.join(self.image_dir, 'train')):
- assert os.path.exists(os.path.join(self.image_dir, 'test'))
- print("Use predefined train-test split.")
- if id_sampling:
- train_videos = {os.path.basename(video).split('#')[0] for video in
- os.listdir(os.path.join(self.image_dir, 'train'))}
- train_videos = list(train_videos)
- else:
- train_videos = os.listdir(os.path.join(self.image_dir, 'train'))
- test_videos = os.listdir(os.path.join(self.image_dir, 'test'))
- self.root_dir = os.path.join(self.root_dir, 'train' if is_train else 'test')
- self.landmark_dir = os.path.join(self.landmark_dir, 'train' if is_train else 'test')
- self.image_dir = os.path.join(self.image_dir, 'train' if is_train else 'test')
- self.audio_dir = os.path.join(self.audio_dir, 'train' if is_train else 'test')
-
- else:
- print("Use random train-test split.")
- train_videos, test_videos = train_test_split(self.videos, random_state=random_seed, test_size=0.2)
-
- if is_train:
- self.videos = train_videos
- else:
- self.videos = test_videos
-
- self.is_train = is_train
-
- if self.is_train:
- self.transform = AllAugmentationTransform(**augmentation_params)
- else:
- self.transform = None
-
- def __len__(self):
- return len(self.videos)
-
- def __getitem__(self, idx):
- if self.is_train and self.id_sampling:
- name = self.videos[idx].split('.')[0]
- path = np.random.choice(glob.glob(os.path.join(self.root_dir, name + '*.mp4')))
- else:
- name = self.videos[idx].split('.')[0]
- landmark_path = os.path.join(self.landmark_dir, name)
-
- audio_path = os.path.join(self.audio_dir, name)
- path = os.path.join(self.image_dir, name)
-
- video_name = os.path.basename(path)
-
- if self.is_train and os.path.isdir(path):
- frames = os.listdir(audio_path)
- num_frames = len(frames)
- frame_idx = np.sort(np.random.choice(num_frames-1, replace=True, size=2))
- # landmark = np.load(landmark_path)#+'.npy'
- # assert len(os.listdir(path)) == len(landmark), video_name+' length not equal'
- video_array = [img_as_float32(io.imread(os.path.join(path, str(idx)+'.png'))) for idx in frame_idx]
- cube_array = [img_as_float32(io.imread(os.path.join(landmark_path, str(idx)+'.jpg'))) for idx in frame_idx]
- audio_array = [np.load(os.path.join(audio_path, str(idx)+'.npy'))[:,1:] for idx in frame_idx]
- index_20 = [0,16,32,35,40,52,55,58,61,46,72,73,75,76,84,87,90,93,98,102]
- index_32 = [0,4,8,12,16,20,24,28,32,33,35,67,68,40,42,52,55,72,73,58,61,75,76,46,47,51,84,87,90,93,98,102]
- # landmark_array = [landmark[idx] for idx in frame_idx]
- # landmark_array = [landmark[idx][index_32] for idx in frame_idx]
- else:
- video_array = read_video(path, frame_shape=self.frame_shape)
- num_frames = len(video_array)
- frame_idx = np.sort(np.random.choice(num_frames, replace=True, size=2)) if self.is_train else range(
- num_frames)
- video_array = video_array[frame_idx]
-
- if self.transform is not None:
- video_array = self.transform(video_array)
-
- out = {}
- if self.is_train:
- # a = img_as_float32(io.imread('/media/thea/Data/first-order-model/images_512/102.jpg'))
- # source = np.array(a, dtype='float32')
- source = np.array(video_array[0], dtype='float32')
- driving = np.array(video_array[1], dtype='float32')
-
- spatial_size = np.array(source.shape[:2][::-1])[np.newaxis]
- # source_landmark = np.array(2*landmark_array[0] / spatial_size -1, dtype='float32')
- # driving_landmark = np.array(2*landmark_array[1] / spatial_size -1, dtype='float32')
- source_cube = np.array(transform.resize(cube_array[0], (64,64)), dtype='float32')
- driving_cube = np.array(transform.resize(cube_array[1], (64,64)), dtype='float32')
- # source_heatmap = np.array(heatmap_array[0] , dtype='float32')
- # driving_heatmap = np.array(heatmap_array[1] , dtype='float32')
- out['source_cube'] = source_cube
- out['driving_cube'] = driving_cube
- # out['source_landmark'] = source_landmark
- # out['driving_landmark'] = driving_landmark
- # out['source_heatmap'] = source_heatmap
- # out['driving_heatmap'] = driving_heatmap
- out['driving'] = driving.transpose((2, 0, 1))
- out['source'] = source.transpose((2, 0, 1))
-
- out['source_audio'] = np.array(audio_array[0], dtype='float32')
- out['driving_audio'] = np.array(audio_array[1], dtype='float32')
-
- else:
- video = np.array(video_array, dtype='float32')
- out['video'] = video.transpose((3, 0, 1, 2))
-
- out['name'] = video_name
-
- return out
-
-
-class DatasetRepeater(Dataset):
- """
- Pass several times over the same dataset for better i/o performance
- """
-
- def __init__(self, dataset, num_repeats=100):
- self.dataset = dataset
- self.num_repeats = num_repeats
-
- def __len__(self):
- return self.num_repeats * self.dataset.__len__()
-
- def __getitem__(self, idx):
- return self.dataset[idx % self.dataset.__len__()]#% self.dataset.__len__()
-
-
-class PairedDataset(Dataset):
- """
- Dataset of pairs for animation.
- """
-
- def __init__(self, initial_dataset, number_of_pairs, seed=0):
- self.initial_dataset = initial_dataset
- pairs_list = self.initial_dataset.pairs_list
-
- np.random.seed(seed)
-
- if pairs_list is None:
- max_idx = min(number_of_pairs, len(initial_dataset))
- nx, ny = max_idx, max_idx
- xy = np.mgrid[:nx, :ny].reshape(2, -1).T
- number_of_pairs = min(xy.shape[0], number_of_pairs)
- self.pairs = xy.take(np.random.choice(xy.shape[0], number_of_pairs, replace=False), axis=0)
- else:
- videos = self.initial_dataset.videos
- name_to_index = {name: index for index, name in enumerate(videos)}
- pairs = pd.read_csv(pairs_list)
- pairs = pairs[np.logical_and(pairs['source'].isin(videos), pairs['driving'].isin(videos))]
-
- number_of_pairs = min(pairs.shape[0], number_of_pairs)
- self.pairs = []
- self.start_frames = []
- for ind in range(number_of_pairs):
- self.pairs.append(
- (name_to_index[pairs['driving'].iloc[ind]], name_to_index[pairs['source'].iloc[ind]]))
-
- def __len__(self):
- return len(self.pairs)
-
- def __getitem__(self, idx):
- pair = self.pairs[idx]
- first = self.initial_dataset[pair[0]]
- second = self.initial_dataset[pair[1]]
- first = {'driving_' + key: value for key, value in first.items()}
- second = {'source_' + key: value for key, value in second.items()}
-
- return {**first, **second}
diff --git a/spaces/dahaoGPT/Llama2-70b-chatmodle-demo/README.md b/spaces/dahaoGPT/Llama2-70b-chatmodle-demo/README.md
deleted file mode 100644
index 39e180545f99d9e01d8d888a8f450e3012ad382d..0000000000000000000000000000000000000000
--- a/spaces/dahaoGPT/Llama2-70b-chatmodle-demo/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Llama2 70b Chatmodle Demo
-emoji: 👀
-colorFrom: gray
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.37.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/danielcodex/first-prod/README.md b/spaces/danielcodex/first-prod/README.md
deleted file mode 100644
index adc20c06432ab0e1edfa1b9a181966dc906a9d33..0000000000000000000000000000000000000000
--- a/spaces/danielcodex/first-prod/README.md
+++ /dev/null
@@ -1,16 +0,0 @@
----
-title: First Prod
-emoji: 💻
-colorFrom: red
-colorTo: blue
-sdk: gradio
-sdk_version: 3.13.0
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
-
-
-just making sure we are on the right repo
\ No newline at end of file
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/PIL/WmfImagePlugin.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/PIL/WmfImagePlugin.py
deleted file mode 100644
index 0ecab56a824fd3917067fd4b05c530f4abce75a3..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/PIL/WmfImagePlugin.py
+++ /dev/null
@@ -1,178 +0,0 @@
-#
-# The Python Imaging Library
-# $Id$
-#
-# WMF stub codec
-#
-# history:
-# 1996-12-14 fl Created
-# 2004-02-22 fl Turned into a stub driver
-# 2004-02-23 fl Added EMF support
-#
-# Copyright (c) Secret Labs AB 1997-2004. All rights reserved.
-# Copyright (c) Fredrik Lundh 1996.
-#
-# See the README file for information on usage and redistribution.
-#
-# WMF/EMF reference documentation:
-# https://winprotocoldoc.blob.core.windows.net/productionwindowsarchives/MS-WMF/[MS-WMF].pdf
-# http://wvware.sourceforge.net/caolan/index.html
-# http://wvware.sourceforge.net/caolan/ora-wmf.html
-
-from . import Image, ImageFile
-from ._binary import i16le as word
-from ._binary import si16le as short
-from ._binary import si32le as _long
-
-_handler = None
-
-
-def register_handler(handler):
- """
- Install application-specific WMF image handler.
-
- :param handler: Handler object.
- """
- global _handler
- _handler = handler
-
-
-if hasattr(Image.core, "drawwmf"):
- # install default handler (windows only)
-
- class WmfHandler:
- def open(self, im):
- im.mode = "RGB"
- self.bbox = im.info["wmf_bbox"]
-
- def load(self, im):
- im.fp.seek(0) # rewind
- return Image.frombytes(
- "RGB",
- im.size,
- Image.core.drawwmf(im.fp.read(), im.size, self.bbox),
- "raw",
- "BGR",
- (im.size[0] * 3 + 3) & -4,
- -1,
- )
-
- register_handler(WmfHandler())
-
-#
-# --------------------------------------------------------------------
-# Read WMF file
-
-
-def _accept(prefix):
- return (
- prefix[:6] == b"\xd7\xcd\xc6\x9a\x00\x00" or prefix[:4] == b"\x01\x00\x00\x00"
- )
-
-
-##
-# Image plugin for Windows metafiles.
-
-
-class WmfStubImageFile(ImageFile.StubImageFile):
- format = "WMF"
- format_description = "Windows Metafile"
-
- def _open(self):
- self._inch = None
-
- # check placable header
- s = self.fp.read(80)
-
- if s[:6] == b"\xd7\xcd\xc6\x9a\x00\x00":
- # placeable windows metafile
-
- # get units per inch
- self._inch = word(s, 14)
-
- # get bounding box
- x0 = short(s, 6)
- y0 = short(s, 8)
- x1 = short(s, 10)
- y1 = short(s, 12)
-
- # normalize size to 72 dots per inch
- self.info["dpi"] = 72
- size = (
- (x1 - x0) * self.info["dpi"] // self._inch,
- (y1 - y0) * self.info["dpi"] // self._inch,
- )
-
- self.info["wmf_bbox"] = x0, y0, x1, y1
-
- # sanity check (standard metafile header)
- if s[22:26] != b"\x01\x00\t\x00":
- msg = "Unsupported WMF file format"
- raise SyntaxError(msg)
-
- elif s[:4] == b"\x01\x00\x00\x00" and s[40:44] == b" EMF":
- # enhanced metafile
-
- # get bounding box
- x0 = _long(s, 8)
- y0 = _long(s, 12)
- x1 = _long(s, 16)
- y1 = _long(s, 20)
-
- # get frame (in 0.01 millimeter units)
- frame = _long(s, 24), _long(s, 28), _long(s, 32), _long(s, 36)
-
- size = x1 - x0, y1 - y0
-
- # calculate dots per inch from bbox and frame
- xdpi = 2540.0 * (x1 - y0) / (frame[2] - frame[0])
- ydpi = 2540.0 * (y1 - y0) / (frame[3] - frame[1])
-
- self.info["wmf_bbox"] = x0, y0, x1, y1
-
- if xdpi == ydpi:
- self.info["dpi"] = xdpi
- else:
- self.info["dpi"] = xdpi, ydpi
-
- else:
- msg = "Unsupported file format"
- raise SyntaxError(msg)
-
- self.mode = "RGB"
- self._size = size
-
- loader = self._load()
- if loader:
- loader.open(self)
-
- def _load(self):
- return _handler
-
- def load(self, dpi=None):
- if dpi is not None and self._inch is not None:
- self.info["dpi"] = dpi
- x0, y0, x1, y1 = self.info["wmf_bbox"]
- self._size = (
- (x1 - x0) * self.info["dpi"] // self._inch,
- (y1 - y0) * self.info["dpi"] // self._inch,
- )
- return super().load()
-
-
-def _save(im, fp, filename):
- if _handler is None or not hasattr(_handler, "save"):
- msg = "WMF save handler not installed"
- raise OSError(msg)
- _handler.save(im, fp, filename)
-
-
-#
-# --------------------------------------------------------------------
-# Registry stuff
-
-
-Image.register_open(WmfStubImageFile.format, WmfStubImageFile, _accept)
-Image.register_save(WmfStubImageFile.format, _save)
-
-Image.register_extensions(WmfStubImageFile.format, [".wmf", ".emf"])
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/fastapi/param_functions.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/fastapi/param_functions.py
deleted file mode 100644
index a43afaf311798ebde5fb265e1d47d584d807152d..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/fastapi/param_functions.py
+++ /dev/null
@@ -1,564 +0,0 @@
-from typing import Any, Callable, Dict, List, Optional, Sequence, Union
-
-from fastapi import params
-from fastapi._compat import Undefined
-from typing_extensions import Annotated, deprecated
-
-_Unset: Any = Undefined
-
-
-def Path( # noqa: N802
- default: Any = ...,
- *,
- default_factory: Union[Callable[[], Any], None] = _Unset,
- alias: Optional[str] = None,
- alias_priority: Union[int, None] = _Unset,
- # TODO: update when deprecating Pydantic v1, import these types
- # validation_alias: str | AliasPath | AliasChoices | None
- validation_alias: Union[str, None] = None,
- serialization_alias: Union[str, None] = None,
- title: Optional[str] = None,
- description: Optional[str] = None,
- gt: Optional[float] = None,
- ge: Optional[float] = None,
- lt: Optional[float] = None,
- le: Optional[float] = None,
- min_length: Optional[int] = None,
- max_length: Optional[int] = None,
- pattern: Optional[str] = None,
- regex: Annotated[
- Optional[str],
- deprecated(
- "Deprecated in FastAPI 0.100.0 and Pydantic v2, use `pattern` instead."
- ),
- ] = None,
- discriminator: Union[str, None] = None,
- strict: Union[bool, None] = _Unset,
- multiple_of: Union[float, None] = _Unset,
- allow_inf_nan: Union[bool, None] = _Unset,
- max_digits: Union[int, None] = _Unset,
- decimal_places: Union[int, None] = _Unset,
- examples: Optional[List[Any]] = None,
- example: Annotated[
- Optional[Any],
- deprecated(
- "Deprecated in OpenAPI 3.1.0 that now uses JSON Schema 2020-12, "
- "although still supported. Use examples instead."
- ),
- ] = _Unset,
- deprecated: Optional[bool] = None,
- include_in_schema: bool = True,
- json_schema_extra: Union[Dict[str, Any], None] = None,
- **extra: Any,
-) -> Any:
- return params.Path(
- default=default,
- default_factory=default_factory,
- alias=alias,
- alias_priority=alias_priority,
- validation_alias=validation_alias,
- serialization_alias=serialization_alias,
- title=title,
- description=description,
- gt=gt,
- ge=ge,
- lt=lt,
- le=le,
- min_length=min_length,
- max_length=max_length,
- pattern=pattern,
- regex=regex,
- discriminator=discriminator,
- strict=strict,
- multiple_of=multiple_of,
- allow_inf_nan=allow_inf_nan,
- max_digits=max_digits,
- decimal_places=decimal_places,
- example=example,
- examples=examples,
- deprecated=deprecated,
- include_in_schema=include_in_schema,
- json_schema_extra=json_schema_extra,
- **extra,
- )
-
-
-def Query( # noqa: N802
- default: Any = Undefined,
- *,
- default_factory: Union[Callable[[], Any], None] = _Unset,
- alias: Optional[str] = None,
- alias_priority: Union[int, None] = _Unset,
- # TODO: update when deprecating Pydantic v1, import these types
- # validation_alias: str | AliasPath | AliasChoices | None
- validation_alias: Union[str, None] = None,
- serialization_alias: Union[str, None] = None,
- title: Optional[str] = None,
- description: Optional[str] = None,
- gt: Optional[float] = None,
- ge: Optional[float] = None,
- lt: Optional[float] = None,
- le: Optional[float] = None,
- min_length: Optional[int] = None,
- max_length: Optional[int] = None,
- pattern: Optional[str] = None,
- regex: Annotated[
- Optional[str],
- deprecated(
- "Deprecated in FastAPI 0.100.0 and Pydantic v2, use `pattern` instead."
- ),
- ] = None,
- discriminator: Union[str, None] = None,
- strict: Union[bool, None] = _Unset,
- multiple_of: Union[float, None] = _Unset,
- allow_inf_nan: Union[bool, None] = _Unset,
- max_digits: Union[int, None] = _Unset,
- decimal_places: Union[int, None] = _Unset,
- examples: Optional[List[Any]] = None,
- example: Annotated[
- Optional[Any],
- deprecated(
- "Deprecated in OpenAPI 3.1.0 that now uses JSON Schema 2020-12, "
- "although still supported. Use examples instead."
- ),
- ] = _Unset,
- deprecated: Optional[bool] = None,
- include_in_schema: bool = True,
- json_schema_extra: Union[Dict[str, Any], None] = None,
- **extra: Any,
-) -> Any:
- return params.Query(
- default=default,
- default_factory=default_factory,
- alias=alias,
- alias_priority=alias_priority,
- validation_alias=validation_alias,
- serialization_alias=serialization_alias,
- title=title,
- description=description,
- gt=gt,
- ge=ge,
- lt=lt,
- le=le,
- min_length=min_length,
- max_length=max_length,
- pattern=pattern,
- regex=regex,
- discriminator=discriminator,
- strict=strict,
- multiple_of=multiple_of,
- allow_inf_nan=allow_inf_nan,
- max_digits=max_digits,
- decimal_places=decimal_places,
- example=example,
- examples=examples,
- deprecated=deprecated,
- include_in_schema=include_in_schema,
- json_schema_extra=json_schema_extra,
- **extra,
- )
-
-
-def Header( # noqa: N802
- default: Any = Undefined,
- *,
- default_factory: Union[Callable[[], Any], None] = _Unset,
- alias: Optional[str] = None,
- alias_priority: Union[int, None] = _Unset,
- # TODO: update when deprecating Pydantic v1, import these types
- # validation_alias: str | AliasPath | AliasChoices | None
- validation_alias: Union[str, None] = None,
- serialization_alias: Union[str, None] = None,
- convert_underscores: bool = True,
- title: Optional[str] = None,
- description: Optional[str] = None,
- gt: Optional[float] = None,
- ge: Optional[float] = None,
- lt: Optional[float] = None,
- le: Optional[float] = None,
- min_length: Optional[int] = None,
- max_length: Optional[int] = None,
- pattern: Optional[str] = None,
- regex: Annotated[
- Optional[str],
- deprecated(
- "Deprecated in FastAPI 0.100.0 and Pydantic v2, use `pattern` instead."
- ),
- ] = None,
- discriminator: Union[str, None] = None,
- strict: Union[bool, None] = _Unset,
- multiple_of: Union[float, None] = _Unset,
- allow_inf_nan: Union[bool, None] = _Unset,
- max_digits: Union[int, None] = _Unset,
- decimal_places: Union[int, None] = _Unset,
- examples: Optional[List[Any]] = None,
- example: Annotated[
- Optional[Any],
- deprecated(
- "Deprecated in OpenAPI 3.1.0 that now uses JSON Schema 2020-12, "
- "although still supported. Use examples instead."
- ),
- ] = _Unset,
- deprecated: Optional[bool] = None,
- include_in_schema: bool = True,
- json_schema_extra: Union[Dict[str, Any], None] = None,
- **extra: Any,
-) -> Any:
- return params.Header(
- default=default,
- default_factory=default_factory,
- alias=alias,
- alias_priority=alias_priority,
- validation_alias=validation_alias,
- serialization_alias=serialization_alias,
- convert_underscores=convert_underscores,
- title=title,
- description=description,
- gt=gt,
- ge=ge,
- lt=lt,
- le=le,
- min_length=min_length,
- max_length=max_length,
- pattern=pattern,
- regex=regex,
- discriminator=discriminator,
- strict=strict,
- multiple_of=multiple_of,
- allow_inf_nan=allow_inf_nan,
- max_digits=max_digits,
- decimal_places=decimal_places,
- example=example,
- examples=examples,
- deprecated=deprecated,
- include_in_schema=include_in_schema,
- json_schema_extra=json_schema_extra,
- **extra,
- )
-
-
-def Cookie( # noqa: N802
- default: Any = Undefined,
- *,
- default_factory: Union[Callable[[], Any], None] = _Unset,
- alias: Optional[str] = None,
- alias_priority: Union[int, None] = _Unset,
- # TODO: update when deprecating Pydantic v1, import these types
- # validation_alias: str | AliasPath | AliasChoices | None
- validation_alias: Union[str, None] = None,
- serialization_alias: Union[str, None] = None,
- title: Optional[str] = None,
- description: Optional[str] = None,
- gt: Optional[float] = None,
- ge: Optional[float] = None,
- lt: Optional[float] = None,
- le: Optional[float] = None,
- min_length: Optional[int] = None,
- max_length: Optional[int] = None,
- pattern: Optional[str] = None,
- regex: Annotated[
- Optional[str],
- deprecated(
- "Deprecated in FastAPI 0.100.0 and Pydantic v2, use `pattern` instead."
- ),
- ] = None,
- discriminator: Union[str, None] = None,
- strict: Union[bool, None] = _Unset,
- multiple_of: Union[float, None] = _Unset,
- allow_inf_nan: Union[bool, None] = _Unset,
- max_digits: Union[int, None] = _Unset,
- decimal_places: Union[int, None] = _Unset,
- examples: Optional[List[Any]] = None,
- example: Annotated[
- Optional[Any],
- deprecated(
- "Deprecated in OpenAPI 3.1.0 that now uses JSON Schema 2020-12, "
- "although still supported. Use examples instead."
- ),
- ] = _Unset,
- deprecated: Optional[bool] = None,
- include_in_schema: bool = True,
- json_schema_extra: Union[Dict[str, Any], None] = None,
- **extra: Any,
-) -> Any:
- return params.Cookie(
- default=default,
- default_factory=default_factory,
- alias=alias,
- alias_priority=alias_priority,
- validation_alias=validation_alias,
- serialization_alias=serialization_alias,
- title=title,
- description=description,
- gt=gt,
- ge=ge,
- lt=lt,
- le=le,
- min_length=min_length,
- max_length=max_length,
- pattern=pattern,
- regex=regex,
- discriminator=discriminator,
- strict=strict,
- multiple_of=multiple_of,
- allow_inf_nan=allow_inf_nan,
- max_digits=max_digits,
- decimal_places=decimal_places,
- example=example,
- examples=examples,
- deprecated=deprecated,
- include_in_schema=include_in_schema,
- json_schema_extra=json_schema_extra,
- **extra,
- )
-
-
-def Body( # noqa: N802
- default: Any = Undefined,
- *,
- default_factory: Union[Callable[[], Any], None] = _Unset,
- embed: bool = False,
- media_type: str = "application/json",
- alias: Optional[str] = None,
- alias_priority: Union[int, None] = _Unset,
- # TODO: update when deprecating Pydantic v1, import these types
- # validation_alias: str | AliasPath | AliasChoices | None
- validation_alias: Union[str, None] = None,
- serialization_alias: Union[str, None] = None,
- title: Optional[str] = None,
- description: Optional[str] = None,
- gt: Optional[float] = None,
- ge: Optional[float] = None,
- lt: Optional[float] = None,
- le: Optional[float] = None,
- min_length: Optional[int] = None,
- max_length: Optional[int] = None,
- pattern: Optional[str] = None,
- regex: Annotated[
- Optional[str],
- deprecated(
- "Deprecated in FastAPI 0.100.0 and Pydantic v2, use `pattern` instead."
- ),
- ] = None,
- discriminator: Union[str, None] = None,
- strict: Union[bool, None] = _Unset,
- multiple_of: Union[float, None] = _Unset,
- allow_inf_nan: Union[bool, None] = _Unset,
- max_digits: Union[int, None] = _Unset,
- decimal_places: Union[int, None] = _Unset,
- examples: Optional[List[Any]] = None,
- example: Annotated[
- Optional[Any],
- deprecated(
- "Deprecated in OpenAPI 3.1.0 that now uses JSON Schema 2020-12, "
- "although still supported. Use examples instead."
- ),
- ] = _Unset,
- deprecated: Optional[bool] = None,
- include_in_schema: bool = True,
- json_schema_extra: Union[Dict[str, Any], None] = None,
- **extra: Any,
-) -> Any:
- return params.Body(
- default=default,
- default_factory=default_factory,
- embed=embed,
- media_type=media_type,
- alias=alias,
- alias_priority=alias_priority,
- validation_alias=validation_alias,
- serialization_alias=serialization_alias,
- title=title,
- description=description,
- gt=gt,
- ge=ge,
- lt=lt,
- le=le,
- min_length=min_length,
- max_length=max_length,
- pattern=pattern,
- regex=regex,
- discriminator=discriminator,
- strict=strict,
- multiple_of=multiple_of,
- allow_inf_nan=allow_inf_nan,
- max_digits=max_digits,
- decimal_places=decimal_places,
- example=example,
- examples=examples,
- deprecated=deprecated,
- include_in_schema=include_in_schema,
- json_schema_extra=json_schema_extra,
- **extra,
- )
-
-
-def Form( # noqa: N802
- default: Any = Undefined,
- *,
- default_factory: Union[Callable[[], Any], None] = _Unset,
- media_type: str = "application/x-www-form-urlencoded",
- alias: Optional[str] = None,
- alias_priority: Union[int, None] = _Unset,
- # TODO: update when deprecating Pydantic v1, import these types
- # validation_alias: str | AliasPath | AliasChoices | None
- validation_alias: Union[str, None] = None,
- serialization_alias: Union[str, None] = None,
- title: Optional[str] = None,
- description: Optional[str] = None,
- gt: Optional[float] = None,
- ge: Optional[float] = None,
- lt: Optional[float] = None,
- le: Optional[float] = None,
- min_length: Optional[int] = None,
- max_length: Optional[int] = None,
- pattern: Optional[str] = None,
- regex: Annotated[
- Optional[str],
- deprecated(
- "Deprecated in FastAPI 0.100.0 and Pydantic v2, use `pattern` instead."
- ),
- ] = None,
- discriminator: Union[str, None] = None,
- strict: Union[bool, None] = _Unset,
- multiple_of: Union[float, None] = _Unset,
- allow_inf_nan: Union[bool, None] = _Unset,
- max_digits: Union[int, None] = _Unset,
- decimal_places: Union[int, None] = _Unset,
- examples: Optional[List[Any]] = None,
- example: Annotated[
- Optional[Any],
- deprecated(
- "Deprecated in OpenAPI 3.1.0 that now uses JSON Schema 2020-12, "
- "although still supported. Use examples instead."
- ),
- ] = _Unset,
- deprecated: Optional[bool] = None,
- include_in_schema: bool = True,
- json_schema_extra: Union[Dict[str, Any], None] = None,
- **extra: Any,
-) -> Any:
- return params.Form(
- default=default,
- default_factory=default_factory,
- media_type=media_type,
- alias=alias,
- alias_priority=alias_priority,
- validation_alias=validation_alias,
- serialization_alias=serialization_alias,
- title=title,
- description=description,
- gt=gt,
- ge=ge,
- lt=lt,
- le=le,
- min_length=min_length,
- max_length=max_length,
- pattern=pattern,
- regex=regex,
- discriminator=discriminator,
- strict=strict,
- multiple_of=multiple_of,
- allow_inf_nan=allow_inf_nan,
- max_digits=max_digits,
- decimal_places=decimal_places,
- example=example,
- examples=examples,
- deprecated=deprecated,
- include_in_schema=include_in_schema,
- json_schema_extra=json_schema_extra,
- **extra,
- )
-
-
-def File( # noqa: N802
- default: Any = Undefined,
- *,
- default_factory: Union[Callable[[], Any], None] = _Unset,
- media_type: str = "multipart/form-data",
- alias: Optional[str] = None,
- alias_priority: Union[int, None] = _Unset,
- # TODO: update when deprecating Pydantic v1, import these types
- # validation_alias: str | AliasPath | AliasChoices | None
- validation_alias: Union[str, None] = None,
- serialization_alias: Union[str, None] = None,
- title: Optional[str] = None,
- description: Optional[str] = None,
- gt: Optional[float] = None,
- ge: Optional[float] = None,
- lt: Optional[float] = None,
- le: Optional[float] = None,
- min_length: Optional[int] = None,
- max_length: Optional[int] = None,
- pattern: Optional[str] = None,
- regex: Annotated[
- Optional[str],
- deprecated(
- "Deprecated in FastAPI 0.100.0 and Pydantic v2, use `pattern` instead."
- ),
- ] = None,
- discriminator: Union[str, None] = None,
- strict: Union[bool, None] = _Unset,
- multiple_of: Union[float, None] = _Unset,
- allow_inf_nan: Union[bool, None] = _Unset,
- max_digits: Union[int, None] = _Unset,
- decimal_places: Union[int, None] = _Unset,
- examples: Optional[List[Any]] = None,
- example: Annotated[
- Optional[Any],
- deprecated(
- "Deprecated in OpenAPI 3.1.0 that now uses JSON Schema 2020-12, "
- "although still supported. Use examples instead."
- ),
- ] = _Unset,
- deprecated: Optional[bool] = None,
- include_in_schema: bool = True,
- json_schema_extra: Union[Dict[str, Any], None] = None,
- **extra: Any,
-) -> Any:
- return params.File(
- default=default,
- default_factory=default_factory,
- media_type=media_type,
- alias=alias,
- alias_priority=alias_priority,
- validation_alias=validation_alias,
- serialization_alias=serialization_alias,
- title=title,
- description=description,
- gt=gt,
- ge=ge,
- lt=lt,
- le=le,
- min_length=min_length,
- max_length=max_length,
- pattern=pattern,
- regex=regex,
- discriminator=discriminator,
- strict=strict,
- multiple_of=multiple_of,
- allow_inf_nan=allow_inf_nan,
- max_digits=max_digits,
- decimal_places=decimal_places,
- example=example,
- examples=examples,
- deprecated=deprecated,
- include_in_schema=include_in_schema,
- json_schema_extra=json_schema_extra,
- **extra,
- )
-
-
-def Depends( # noqa: N802
- dependency: Optional[Callable[..., Any]] = None, *, use_cache: bool = True
-) -> Any:
- return params.Depends(dependency=dependency, use_cache=use_cache)
-
-
-def Security( # noqa: N802
- dependency: Optional[Callable[..., Any]] = None,
- *,
- scopes: Optional[Sequence[str]] = None,
- use_cache: bool = True,
-) -> Any:
- return params.Security(dependency=dependency, scopes=scopes, use_cache=use_cache)
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-322e8a8e.css b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-322e8a8e.css
deleted file mode 100644
index aa7186b19dcf31452295d0d5d4dbb3b5aadb3dea..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-322e8a8e.css
+++ /dev/null
@@ -1 +0,0 @@
-.gallery.svelte-1ayixqk,.gallery.svelte-1viwdyg{padding:var(--size-1) var(--size-2)}div.svelte-1viwdyg{overflow:hidden;min-width:var(--local-text-width);white-space:nowrap}video.svelte-1tntsc1{flex:none;border:2px solid var(--border-color-primary);border-radius:var(--radius-lg);max-width:none}video.svelte-1tntsc1:hover,video.selected.svelte-1tntsc1{border-color:var(--border-color-accent)}.table.svelte-1tntsc1{margin:0 auto;width:var(--size-20);height:var(--size-20);object-fit:cover}.gallery.svelte-1tntsc1{max-height:var(--size-20);object-fit:cover}div.svelte-rgtszb{overflow:hidden;text-overflow:ellipsis;white-space:nowrap}.gallery.svelte-rgtszb{display:flex;align-items:center;cursor:pointer;padding:var(--size-1) var(--size-2);text-align:left}table.svelte-1cib1xd.svelte-1cib1xd{position:relative}td.svelte-1cib1xd.svelte-1cib1xd{border:1px solid var(--table-border-color);padding:var(--size-2);font-size:var(--text-sm);font-family:var(--font-mono)}.selected.svelte-1cib1xd td.svelte-1cib1xd{border-color:var(--border-color-accent)}.table.svelte-1cib1xd.svelte-1cib1xd{display:inline-block;margin:0 auto}.gallery.svelte-1cib1xd td.svelte-1cib1xd:first-child{border-left:none}.gallery.svelte-1cib1xd tr:first-child td.svelte-1cib1xd{border-top:none}.gallery.svelte-1cib1xd td.svelte-1cib1xd:last-child{border-right:none}.gallery.svelte-1cib1xd tr:last-child td.svelte-1cib1xd{border-bottom:none}.overlay.svelte-1cib1xd.svelte-1cib1xd{--gradient-to:transparent;position:absolute;bottom:0;background:linear-gradient(to bottom,transparent,var(--gradient-to));width:var(--size-full);height:50%}.odd.svelte-1cib1xd.svelte-1cib1xd{--gradient-to:var(--table-even-background-fill)}.even.svelte-1cib1xd.svelte-1cib1xd{--gradient-to:var(--table-odd-background-fill)}.button.svelte-1cib1xd.svelte-1cib1xd{--gradient-to:var(--background-fill-primary)}div.svelte-h6ogpl{width:var(--size-10);height:var(--size-10)}.table.svelte-h6ogpl{margin:0 auto}.gallery.svelte-1ayixqk{padding:var(--size-1) var(--size-2)}.gallery.svelte-zvfedn{padding:var(--size-2)}pre.svelte-agpzo2{text-align:left}.gallery.svelte-agpzo2{padding:var(--size-1) var(--size-2)}.wrap.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{display:inline-block;width:var(--size-full);max-width:var(--size-full);color:var(--body-text-color)}.hide.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{display:none}.label.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{display:flex;align-items:center;margin-bottom:var(--size-2);color:var(--block-label-text-color);font-weight:var(--block-label-text-weight);font-size:var(--block-label-text-size);line-height:var(--line-sm)}svg.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{margin-right:var(--size-1)}.gallery.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{display:flex;flex-wrap:wrap;gap:var(--spacing-lg)}.gallery-item.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{border:1px solid var(--border-color-primary);border-radius:var(--button-large-radius);overflow:hidden}.gallery-item.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno:hover{border-color:var(--border-color-accent);background:var(--table-row-focus)}.table-wrap.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{border:1px solid var(--border-color-primary);border-radius:var(--table-radius);width:var(--size-full);table-layout:auto;overflow-x:auto;line-height:var(--line-sm)}table.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{width:var(--size-full)}.tr-head.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{box-shadow:var(--shadow-drop-lg);border-bottom:1px solid var(--border-color-primary)}.tr-head.svelte-13hsdno>.svelte-13hsdno+.svelte-13hsdno{border-right-width:0px;border-left-width:1px;border-color:var(--border-color-primary)}th.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{padding:var(--size-2);white-space:nowrap}.tr-body.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{cursor:pointer;border-bottom:1px solid var(--border-color-primary);background:var(--table-even-background-fill)}.tr-body.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno:last-child{border:none}.tr-body.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno:nth-child(odd){background:var(--table-odd-background-fill)}.tr-body.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno:hover{background:var(--table-row-focus)}.tr-body.svelte-13hsdno>.svelte-13hsdno+.svelte-13hsdno{border-right-width:0px;border-left-width:1px;border-color:var(--border-color-primary)}.tr-body.svelte-13hsdno:hover>.svelte-13hsdno+.svelte-13hsdno{border-color:var(--border-color-accent)}td.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{padding:var(--size-2);text-align:center}.paginate.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{display:flex;justify-content:center;align-items:center;gap:var(--spacing-sm);margin-top:var(--size-2);color:var(--block-label-text-color);font-size:var(--text-sm)}button.current-page.svelte-13hsdno.svelte-13hsdno.svelte-13hsdno{font-weight:var(--weight-bold)}
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-aee9714f.js b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-aee9714f.js
deleted file mode 100644
index 4e4daa4a94120a216a060347ae4b84207fd001b4..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/cdn/assets/index-aee9714f.js
+++ /dev/null
@@ -1,14 +0,0 @@
-import{C as R,E as m,L as C,a as u}from"./index-6a7e443e.js";import{s as z,t as e,y as n,h as W,L as I,i as E,w as Y,z as A,d as J,f as L,a as N,A as k,b as D,B,C as H,v as K,E as b,I as M,m as F,x as OO}from"./index-7045bfe3.js";import"./index-9e76ffee.js";import"./Button-30a08c0b.js";import"./Copy-92242405.js";import"./Download-e6704cf2.js";import"./BlockLabel-9545c6da.js";import"./Empty-8e3485c0.js";const y=301,j=1,QO=2,d=302,eO=304,aO=305,iO=3,$O=4,tO=[9,10,11,12,13,32,133,160,5760,8192,8193,8194,8195,8196,8197,8198,8199,8200,8201,8202,8232,8233,8239,8287,12288],_=125,rO=59,x=47,SO=42,PO=43,nO=45,oO=new R({start:!1,shift(O,Q){return Q==iO||Q==$O||Q==eO?O:Q==aO},strict:!1}),ZO=new m((O,Q)=>{let{next:i}=O;(i==_||i==-1||Q.context)&&Q.canShift(d)&&O.acceptToken(d)},{contextual:!0,fallback:!0}),lO=new m((O,Q)=>{let{next:i}=O,a;tO.indexOf(i)>-1||i==x&&((a=O.peek(1))==x||a==SO)||i!=_&&i!=rO&&i!=-1&&!Q.context&&Q.canShift(y)&&O.acceptToken(y)},{contextual:!0}),XO=new m((O,Q)=>{let{next:i}=O;if((i==PO||i==nO)&&(O.advance(),i==O.next)){O.advance();let a=!Q.context&&Q.canShift(j);O.acceptToken(a?j:QO)}},{contextual:!0}),cO=z({"get set async static":e.modifier,"for while do if else switch try catch finally return throw break continue default case":e.controlKeyword,"in of await yield void typeof delete instanceof":e.operatorKeyword,"let var const function class extends":e.definitionKeyword,"import export from":e.moduleKeyword,"with debugger as new":e.keyword,TemplateString:e.special(e.string),super:e.atom,BooleanLiteral:e.bool,this:e.self,null:e.null,Star:e.modifier,VariableName:e.variableName,"CallExpression/VariableName TaggedTemplateExpression/VariableName":e.function(e.variableName),VariableDefinition:e.definition(e.variableName),Label:e.labelName,PropertyName:e.propertyName,PrivatePropertyName:e.special(e.propertyName),"CallExpression/MemberExpression/PropertyName":e.function(e.propertyName),"FunctionDeclaration/VariableDefinition":e.function(e.definition(e.variableName)),"ClassDeclaration/VariableDefinition":e.definition(e.className),PropertyDefinition:e.definition(e.propertyName),PrivatePropertyDefinition:e.definition(e.special(e.propertyName)),UpdateOp:e.updateOperator,LineComment:e.lineComment,BlockComment:e.blockComment,Number:e.number,String:e.string,Escape:e.escape,ArithOp:e.arithmeticOperator,LogicOp:e.logicOperator,BitOp:e.bitwiseOperator,CompareOp:e.compareOperator,RegExp:e.regexp,Equals:e.definitionOperator,Arrow:e.function(e.punctuation),": Spread":e.punctuation,"( )":e.paren,"[ ]":e.squareBracket,"{ }":e.brace,"InterpolationStart InterpolationEnd":e.special(e.brace),".":e.derefOperator,", ;":e.separator,"@":e.meta,TypeName:e.typeName,TypeDefinition:e.definition(e.typeName),"type enum interface implements namespace module declare":e.definitionKeyword,"abstract global Privacy readonly override":e.modifier,"is keyof unique infer":e.operatorKeyword,JSXAttributeValue:e.attributeValue,JSXText:e.content,"JSXStartTag JSXStartCloseTag JSXSelfCloseEndTag JSXEndTag":e.angleBracket,"JSXIdentifier JSXNameSpacedName":e.tagName,"JSXAttribute/JSXIdentifier JSXAttribute/JSXNameSpacedName":e.attributeName,"JSXBuiltin/JSXIdentifier":e.standard(e.tagName)}),sO={__proto__:null,export:14,as:19,from:27,default:30,async:35,function:36,extends:46,this:50,true:58,false:58,null:70,void:74,typeof:78,super:96,new:130,delete:146,yield:155,await:159,class:164,public:219,private:219,protected:219,readonly:221,instanceof:240,satisfies:243,in:244,const:246,import:278,keyof:333,unique:337,infer:343,is:379,abstract:399,implements:401,type:403,let:406,var:408,interface:415,enum:419,namespace:425,module:427,declare:431,global:435,for:456,of:465,while:468,with:472,do:476,if:480,else:482,switch:486,case:492,try:498,catch:502,finally:506,return:510,throw:514,break:518,continue:522,debugger:526},pO={__proto__:null,async:117,get:119,set:121,public:181,private:181,protected:181,static:183,abstract:185,override:187,readonly:193,accessor:195,new:383},gO={__proto__:null,"<":137},YO=C.deserialize({version:14,states:"$BhO`QUOOO%QQUOOO'TQWOOP(_OSOOO*mQ(CjO'#CfO*tOpO'#CgO+SO!bO'#CgO+bO07`O'#DZO-sQUO'#DaO.TQUO'#DlO%QQUO'#DvO0[QUO'#EOOOQ(CY'#EW'#EWO0rQSO'#ETOOQO'#I_'#I_O0zQSO'#GjOOQO'#Eh'#EhO1VQSO'#EgO1[QSO'#EgO3^Q(CjO'#JbO5}Q(CjO'#JcO6kQSO'#FVO6pQ#tO'#FnOOQ(CY'#F_'#F_O6{O&jO'#F_O7ZQ,UO'#FuO8qQSO'#FtOOQ(CY'#Jc'#JcOOQ(CW'#Jb'#JbOOQQ'#J|'#J|O8vQSO'#IOO8{Q(C[O'#IPOOQQ'#JO'#JOOOQQ'#IT'#ITQ`QUOOO%QQUO'#DnO9TQUO'#DzO%QQUO'#D|O9[QSO'#GjO9aQ,UO'#ClO9oQSO'#EfO9zQSO'#EqO:PQ,UO'#F^O:nQSO'#GjO:sQSO'#GnO;OQSO'#GnO;^QSO'#GqO;^QSO'#GrO;^QSO'#GtO9[QSO'#GwO;}QSO'#GzO=`QSO'#CbO=pQSO'#HXO=xQSO'#H_O=xQSO'#HaO`QUO'#HcO=xQSO'#HeO=xQSO'#HhO=}QSO'#HnO>SQ(C]O'#HtO%QQUO'#HvO>_Q(C]O'#HxO>jQ(C]O'#HzO8{Q(C[O'#H|O>uQ(CjO'#CfO?wQWO'#DfQOQSOOO@_QSO'#EPO9aQ,UO'#EfO@jQSO'#EfO@uQ`O'#F^OOQQ'#Cd'#CdOOQ(CW'#Dk'#DkOOQ(CW'#Jf'#JfO%QQUO'#JfOBOQWO'#E_OOQ(CW'#E^'#E^OBYQ(C`O'#E_OBtQWO'#ESOOQO'#Ji'#JiOCYQWO'#ESOCgQWO'#E_OC}QWO'#EeODQQWO'#E_O@}QWO'#E_OBtQWO'#E_PDkO?MpO'#C`POOO)CDm)CDmOOOO'#IU'#IUODvOpO,59ROOQ(CY,59R,59ROOOO'#IV'#IVOEUO!bO,59RO%QQUO'#D]OOOO'#IX'#IXOEdO07`O,59uOOQ(CY,59u,59uOErQUO'#IYOFVQSO'#JdOHXQbO'#JdO+pQUO'#JdOH`QSO,59{OHvQSO'#EhOITQSO'#JqOI`QSO'#JpOI`QSO'#JpOIhQSO,5;UOImQSO'#JoOOQ(CY,5:W,5:WOItQUO,5:WOKuQ(CjO,5:bOLfQSO,5:jOLkQSO'#JmOMeQ(C[O'#JnO:sQSO'#JmOMlQSO'#JmOMtQSO,5;TOMyQSO'#JmOOQ(CY'#Cf'#CfO%QQUO'#EOONmQ`O,5:oOOQO'#Jj'#JjOOQO-E<]-E<]O9[QSO,5=UO! TQSO,5=UO! YQUO,5;RO!#]Q,UO'#EcO!$pQSO,5;RO!&YQ,UO'#DpO!&aQUO'#DuO!&kQWO,5;[O!&sQWO,5;[O%QQUO,5;[OOQQ'#E}'#E}OOQQ'#FP'#FPO%QQUO,5;]O%QQUO,5;]O%QQUO,5;]O%QQUO,5;]O%QQUO,5;]O%QQUO,5;]O%QQUO,5;]O%QQUO,5;]O%QQUO,5;]O%QQUO,5;]O%QQUO,5;]OOQQ'#FT'#FTO!'RQUO,5;nOOQ(CY,5;s,5;sOOQ(CY,5;t,5;tO!)UQSO,5;tOOQ(CY,5;u,5;uO%QQUO'#IeO!)^Q(C[O,5jOOQQ'#JW'#JWOOQQ,5>k,5>kOOQQ-EgQWO'#EkOOQ(CW'#Jo'#JoO!>nQ(C[O'#J}O8{Q(C[O,5=YO;^QSO,5=`OOQO'#Cr'#CrO!>yQWO,5=]O!?RQ,UO,5=^O!?^QSO,5=`O!?cQ`O,5=cO=}QSO'#G|O9[QSO'#HOO!?kQSO'#HOO9aQ,UO'#HRO!?pQSO'#HROOQQ,5=f,5=fO!?uQSO'#HSO!?}QSO'#ClO!@SQSO,58|O!@^QSO,58|O!BfQUO,58|OOQQ,58|,58|O!BsQ(C[O,58|O%QQUO,58|O!COQUO'#HZOOQQ'#H['#H[OOQQ'#H]'#H]O`QUO,5=sO!C`QSO,5=sO`QUO,5=yO`QUO,5={O!CeQSO,5=}O`QUO,5>PO!CjQSO,5>SO!CoQUO,5>YOOQQ,5>`,5>`O%QQUO,5>`O8{Q(C[O,5>bOOQQ,5>d,5>dO!GvQSO,5>dOOQQ,5>f,5>fO!GvQSO,5>fOOQQ,5>h,5>hO!G{QWO'#DXO%QQUO'#JfO!HjQWO'#JfO!IXQWO'#DgO!IjQWO'#DgO!K{QUO'#DgO!LSQSO'#JeO!L[QSO,5:QO!LaQSO'#ElO!LoQSO'#JrO!LwQSO,5;VO!L|QWO'#DgO!MZQWO'#EROOQ(CY,5:k,5:kO%QQUO,5:kO!MbQSO,5:kO=}QSO,5;QO!;xQWO,5;QO!tO+pQUO,5>tOOQO,5>z,5>zO#$vQUO'#IYOOQO-EtO$8XQSO1G5jO$8aQSO1G5vO$8iQbO1G5wO:sQSO,5>zO$8sQSO1G5sO$8sQSO1G5sO:sQSO1G5sO$8{Q(CjO1G5tO%QQUO1G5tO$9]Q(C[O1G5tO$9nQSO,5>|O:sQSO,5>|OOQO,5>|,5>|O$:SQSO,5>|OOQO-E<`-E<`OOQO1G0]1G0]OOQO1G0_1G0_O!)XQSO1G0_OOQQ7+([7+([O!#]Q,UO7+([O%QQUO7+([O$:bQSO7+([O$:mQ,UO7+([O$:{Q(CjO,59nO$=TQ(CjO,5UOOQQ,5>U,5>UO%QQUO'#HkO%&qQSO'#HmOOQQ,5>[,5>[O:sQSO,5>[OOQQ,5>^,5>^OOQQ7+)`7+)`OOQQ7+)f7+)fOOQQ7+)j7+)jOOQQ7+)l7+)lO%&vQWO1G5lO%'[Q$IUO1G0rO%'fQSO1G0rOOQO1G/m1G/mO%'qQ$IUO1G/mO=}QSO1G/mO!'RQUO'#DgOOQO,5>u,5>uOOQO-E{,5>{OOQO-E<_-E<_O!;xQWO1G/mOOQO-E<[-E<[OOQ(CY1G0X1G0XOOQ(CY7+%q7+%qO!MeQSO7+%qOOQ(CY7+&W7+&WO=}QSO7+&WO!;xQWO7+&WOOQO7+%t7+%tO$7kQ(CjO7+&POOQO7+&P7+&PO%QQUO7+&PO%'{Q(C[O7+&PO=}QSO7+%tO!;xQWO7+%tO%(WQ(C[O7+&POBtQWO7+%tO%(fQ(C[O7+&PO%(zQ(C`O7+&PO%)UQWO7+%tOBtQWO7+&PO%)cQWO7+&PO%)yQSO7++_O%)yQSO7++_O%*RQ(CjO7++`O%QQUO7++`OOQO1G4h1G4hO:sQSO1G4hO%*cQSO1G4hOOQO7+%y7+%yO!MeQSO<vOOQO-EwO%QQUO,5>wOOQO-ESQ$IUO1G0wO%>ZQ$IUO1G0wO%@RQ$IUO1G0wO%@fQ(CjO<VOOQQ,5>X,5>XO&#WQSO1G3vO:sQSO7+&^O!'RQUO7+&^OOQO7+%X7+%XO&#]Q$IUO1G5wO=}QSO7+%XOOQ(CY<zAN>zO%QQUOAN?VO=}QSOAN>zO&<^Q(C[OAN?VO!;xQWOAN>zO&zO&RO!V+iO^(qX'j(qX~O#W+mO'|%OO~Og+pO!X$yO'|%OO~O!X+rO~Oy+tO!XXO~O!t+yO~Ob,OO~O's#jO!W(sP~Ob%lO~O%a!OO's%|O~PRO!V,yO!W(fa~O!W2SO~P'TO^%^O#W2]O'j%^O~O^%^O!a#rO#W2]O'j%^O~O^%^O!a#rO!h%ZO!l2aO#W2]O'j%^O'|%OO(`'dO~O!]2bO!^2bO't!iO~PBtO![2eO!]2bO!^2bO#S2fO#T2fO't!iO~PBtO![2eO!]2bO!^2bO#P2gO#S2fO#T2fO't!iO~PBtO^%^O!a#rO!l2aO#W2]O'j%^O(`'dO~O^%^O'j%^O~P!3jO!V$^Oo$ja~O!S&|i!V&|i~P!3jO!V'xO!S(Wi~O!V(PO!S(di~O!S(ei!V(ei~P!3jO!V(]O!g(ai~O!V(bi!g(bi^(bi'j(bi~P!3jO#W2kO!V(bi!g(bi^(bi'j(bi~O|%vO!X%wO!x]O#a2nO#b2mO's%eO~O|%vO!X%wO#b2mO's%eO~Og2uO!X'QO%`2tO~Og2uO!X'QO%`2tO'|%OO~O#cvaPvaXva^vakva!eva!fva!hva!lva#fva#gva#hva#iva#jva#kva#lva#mva#nva#pva#rva#tva#uva'jva(Qva(`va!gva!Sva'hvaova!Xva%`va!ava~P#M{O#c$kaP$kaX$ka^$kak$kaz$ka!e$ka!f$ka!h$ka!l$ka#f$ka#g$ka#h$ka#i$ka#j$ka#k$ka#l$ka#m$ka#n$ka#p$ka#r$ka#t$ka#u$ka'j$ka(Q$ka(`$ka!g$ka!S$ka'h$kao$ka!X$ka%`$ka!a$ka~P#NqO#c$maP$maX$ma^$mak$maz$ma!e$ma!f$ma!h$ma!l$ma#f$ma#g$ma#h$ma#i$ma#j$ma#k$ma#l$ma#m$ma#n$ma#p$ma#r$ma#t$ma#u$ma'j$ma(Q$ma(`$ma!g$ma!S$ma'h$mao$ma!X$ma%`$ma!a$ma~P$ dO#c${aP${aX${a^${ak${az${a!V${a!e${a!f${a!h${a!l${a#f${a#g${a#h${a#i${a#j${a#k${a#l${a#m${a#n${a#p${a#r${a#t${a#u${a'j${a(Q${a(`${a!g${a!S${a'h${a#W${ao${a!X${a%`${a!a${a~P#(yO^#Zq!V#Zq'j#Zq'h#Zq!S#Zq!g#Zqo#Zq!X#Zq%`#Zq!a#Zq~P!3jOd'OX!V'OX~P!$uO!V._Od(Za~O!U2}O!V'PX!g'PX~P%QO!V.bO!g([a~O!V.bO!g([a~P!3jO!S3QO~O#x!ja!W!ja~PI{O#x!ba!V!ba!W!ba~P#?dO#x!na!W!na~P!6TO#x!pa!W!pa~P!8nO!X3dO$TfO$^3eO~O!W3iO~Oo3jO~P#(yO^$gq!V$gq'j$gq'h$gq!S$gq!g$gqo$gq!X$gq%`$gq!a$gq~P!3jO!S3kO~Ol.}O'uTO'xUO~Oy)sO|)tO(h)xOg%Wi(g%Wi!V%Wi#W%Wi~Od%Wi#x%Wi~P$HbOy)sO|)tOg%Yi(g%Yi(h%Yi!V%Yi#W%Yi~Od%Yi#x%Yi~P$ITO(`$WO~P#(yO!U3nO's%eO!V'YX!g'YX~O!V/VO!g(ma~O!V/VO!a#rO!g(ma~O!V/VO!a#rO(`'dO!g(ma~Od$ti!V$ti#W$ti#x$ti~P!-jO!U3vO's*UO!S'[X!V'[X~P!.XO!V/_O!S(na~O!V/_O!S(na~P#(yO!a#rO~O!a#rO#n4OO~Ok4RO!a#rO(`'dO~Od(Oi!V(Oi~P!-jO#W4UOd(Oi!V(Oi~P!-jO!g4XO~O^$hq!V$hq'j$hq'h$hq!S$hq!g$hqo$hq!X$hq%`$hq!a$hq~P!3jO!V4]O!X(oX~P#(yO!f#tO~P3zO!X$rX%TYX^$rX!V$rX'j$rX~P!,aO%T4_OghXyhX|hX!XhX(ghX(hhX^hX!VhX'jhX~O%T4_O~O%a4fO's+WO'uTO'xUO!V'eX!W'eX~O!V0_O!W(ua~OX4jO~O]4kO~O!S4oO~O^%^O'j%^O~P#(yO!X$yO~P#(yO!V4tO#W4vO!W(rX~O!W4wO~Ol!kO|4yO![5WO!]4}O!^4}O!x;oO!|5VO!}5UO#O5UO#P5TO#S5SO#T!wO't!iO'uTO'xUO(T!jO(_!nO~O!W5RO~P%#XOg5]O!X0zO%`5[O~Og5]O!X0zO%`5[O'|%OO~O's#jO!V'dX!W'dX~O!V1VO!W(sa~O'uTO'xUO(T5fO~O]5jO~O!g5mO~P%QO^5oO~O^5oO~P%QO#n5qO&Q5rO~PMPO_1mO!W5vO&`1lO~P`O!a5xO~O!a5zO!V(Yi!W(Yi!a(Yi!h(Yi'|(Yi~O!V#`i!W#`i~P#?dO#W5{O!V#`i!W#`i~O!V!Zi!W!Zi~P#?dO^%^O#W6UO'j%^O~O^%^O!a#rO#W6UO'j%^O~O^%^O!a#rO!l6ZO#W6UO'j%^O(`'dO~O!h%ZO'|%OO~P%(fO!]6[O!^6[O't!iO~PBtO![6_O!]6[O!^6[O#S6`O#T6`O't!iO~PBtO!V(]O!g(aq~O!V(bq!g(bq^(bq'j(bq~P!3jO|%vO!X%wO#b6dO's%eO~O!X'QO%`6gO~Og6jO!X'QO%`6gO~O#c%WiP%WiX%Wi^%Wik%Wiz%Wi!e%Wi!f%Wi!h%Wi!l%Wi#f%Wi#g%Wi#h%Wi#i%Wi#j%Wi#k%Wi#l%Wi#m%Wi#n%Wi#p%Wi#r%Wi#t%Wi#u%Wi'j%Wi(Q%Wi(`%Wi!g%Wi!S%Wi'h%Wio%Wi!X%Wi%`%Wi!a%Wi~P$HbO#c%YiP%YiX%Yi^%Yik%Yiz%Yi!e%Yi!f%Yi!h%Yi!l%Yi#f%Yi#g%Yi#h%Yi#i%Yi#j%Yi#k%Yi#l%Yi#m%Yi#n%Yi#p%Yi#r%Yi#t%Yi#u%Yi'j%Yi(Q%Yi(`%Yi!g%Yi!S%Yi'h%Yio%Yi!X%Yi%`%Yi!a%Yi~P$ITO#c$tiP$tiX$ti^$tik$tiz$ti!V$ti!e$ti!f$ti!h$ti!l$ti#f$ti#g$ti#h$ti#i$ti#j$ti#k$ti#l$ti#m$ti#n$ti#p$ti#r$ti#t$ti#u$ti'j$ti(Q$ti(`$ti!g$ti!S$ti'h$ti#W$tio$ti!X$ti%`$ti!a$ti~P#(yOd'Oa!V'Oa~P!-jO!V'Pa!g'Pa~P!3jO!V.bO!g([i~O#x#Zi!V#Zi!W#Zi~P#?dOP$YOy#vOz#wO|#xO!f#tO!h#uO!l$YO(QVOX#eik#ei!e#ei#g#ei#h#ei#i#ei#j#ei#k#ei#l#ei#m#ei#n#ei#p#ei#r#ei#t#ei#u#ei#x#ei(`#ei(g#ei(h#ei!V#ei!W#ei~O#f#ei~P%2xO#f;wO~P%2xOP$YOy#vOz#wO|#xO!f#tO!h#uO!l$YO#f;wO#g;xO#h;xO#i;xO(QVOX#ei!e#ei#j#ei#k#ei#l#ei#m#ei#n#ei#p#ei#r#ei#t#ei#u#ei#x#ei(`#ei(g#ei(h#ei!V#ei!W#ei~Ok#ei~P%5TOk;yO~P%5TOP$YOk;yOy#vOz#wO|#xO!f#tO!h#uO!l$YO#f;wO#g;xO#h;xO#i;xO#j;zO(QVO#p#ei#r#ei#t#ei#u#ei#x#ei(`#ei(g#ei(h#ei!V#ei!W#ei~OX#ei!e#ei#k#ei#l#ei#m#ei#n#ei~P%7`OXbO^#vy!V#vy'j#vy'h#vy!S#vy!g#vyo#vy!X#vy%`#vy!a#vy~P!3jOg=jOy)sO|)tO(g)vO(h)xO~OP#eiX#eik#eiz#ei!e#ei!f#ei!h#ei!l#ei#f#ei#g#ei#h#ei#i#ei#j#ei#k#ei#l#ei#m#ei#n#ei#p#ei#r#ei#t#ei#u#ei#x#ei(Q#ei(`#ei!V#ei!W#ei~P%AYO!f#tOP(PXX(PXg(PXk(PXy(PXz(PX|(PX!e(PX!h(PX!l(PX#f(PX#g(PX#h(PX#i(PX#j(PX#k(PX#l(PX#m(PX#n(PX#p(PX#r(PX#t(PX#u(PX#x(PX(Q(PX(`(PX(g(PX(h(PX!V(PX!W(PX~O#x#yi!V#yi!W#yi~P#?dO#x!ni!W!ni~P$!qO!W6vO~O!V'Xa!W'Xa~P#?dO!a#rO(`'dO!V'Ya!g'Ya~O!V/VO!g(mi~O!V/VO!a#rO!g(mi~Od$tq!V$tq#W$tq#x$tq~P!-jO!S'[a!V'[a~P#(yO!a6}O~O!V/_O!S(ni~P#(yO!V/_O!S(ni~O!S7RO~O!a#rO#n7WO~Ok7XO!a#rO(`'dO~O!S7ZO~Od$vq!V$vq#W$vq#x$vq~P!-jO^$hy!V$hy'j$hy'h$hy!S$hy!g$hyo$hy!X$hy%`$hy!a$hy~P!3jO!V4]O!X(oa~O^#Zy!V#Zy'j#Zy'h#Zy!S#Zy!g#Zyo#Zy!X#Zy%`#Zy!a#Zy~P!3jOX7`O~O!V0_O!W(ui~O]7fO~O!a5zO~O(T(qO!V'aX!W'aX~O!V4tO!W(ra~O!h%ZO'|%OO^(YX!a(YX!l(YX#W(YX'j(YX(`(YX~O's7oO~P.[O!x;oO!|7rO!}7qO#O7qO#P7pO#S'bO#T'bO~PBtO^%^O!a#rO!l'hO#W'fO'j%^O(`'dO~O!W7vO~P%#XOl!kO'uTO'xUO(T!jO(_!nO~O|7wO~P%MdO![7{O!]7zO!^7zO#P7pO#S'bO#T'bO't!iO~PBtO![7{O!]7zO!^7zO!}7|O#O7|O#P7pO#S'bO#T'bO't!iO~PBtO!]7zO!^7zO't!iO(T!jO(_!nO~O!X0zO~O!X0zO%`8OO~Og8RO!X0zO%`8OO~OX8WO!V'da!W'da~O!V1VO!W(si~O!g8[O~O!g8]O~O!g8^O~O!g8^O~P%QO^8`O~O!a8cO~O!g8dO~O!V(ei!W(ei~P#?dO^%^O#W8lO'j%^O~O^%^O!a#rO#W8lO'j%^O~O^%^O!a#rO!l8pO#W8lO'j%^O(`'dO~O!h%ZO'|%OO~P&$QO!]8qO!^8qO't!iO~PBtO!V(]O!g(ay~O!V(by!g(by^(by'j(by~P!3jO!X'QO%`8uO~O#c$tqP$tqX$tq^$tqk$tqz$tq!V$tq!e$tq!f$tq!h$tq!l$tq#f$tq#g$tq#h$tq#i$tq#j$tq#k$tq#l$tq#m$tq#n$tq#p$tq#r$tq#t$tq#u$tq'j$tq(Q$tq(`$tq!g$tq!S$tq'h$tq#W$tqo$tq!X$tq%`$tq!a$tq~P#(yO#c$vqP$vqX$vq^$vqk$vqz$vq!V$vq!e$vq!f$vq!h$vq!l$vq#f$vq#g$vq#h$vq#i$vq#j$vq#k$vq#l$vq#m$vq#n$vq#p$vq#r$vq#t$vq#u$vq'j$vq(Q$vq(`$vq!g$vq!S$vq'h$vq#W$vqo$vq!X$vq%`$vq!a$vq~P#(yO!V'Pi!g'Pi~P!3jO#x#Zq!V#Zq!W#Zq~P#?dOy/yOz/yO|/zOPvaXvagvakva!eva!fva!hva!lva#fva#gva#hva#iva#jva#kva#lva#mva#nva#pva#rva#tva#uva#xva(Qva(`va(gva(hva!Vva!Wva~Oy)sO|)tOP$kaX$kag$kak$kaz$ka!e$ka!f$ka!h$ka!l$ka#f$ka#g$ka#h$ka#i$ka#j$ka#k$ka#l$ka#m$ka#n$ka#p$ka#r$ka#t$ka#u$ka#x$ka(Q$ka(`$ka(g$ka(h$ka!V$ka!W$ka~Oy)sO|)tOP$maX$mag$mak$maz$ma!e$ma!f$ma!h$ma!l$ma#f$ma#g$ma#h$ma#i$ma#j$ma#k$ma#l$ma#m$ma#n$ma#p$ma#r$ma#t$ma#u$ma#x$ma(Q$ma(`$ma(g$ma(h$ma!V$ma!W$ma~OP${aX${ak${az${a!e${a!f${a!h${a!l${a#f${a#g${a#h${a#i${a#j${a#k${a#l${a#m${a#n${a#p${a#r${a#t${a#u${a#x${a(Q${a(`${a!V${a!W${a~P%AYO#x$gq!V$gq!W$gq~P#?dO#x$hq!V$hq!W$hq~P#?dO!W9PO~O#x9QO~P!-jO!a#rO!V'Yi!g'Yi~O!a#rO(`'dO!V'Yi!g'Yi~O!V/VO!g(mq~O!S'[i!V'[i~P#(yO!V/_O!S(nq~O!S9WO~P#(yO!S9WO~Od(Oy!V(Oy~P!-jO!V'_a!X'_a~P#(yO!X%Sq^%Sq!V%Sq'j%Sq~P#(yOX9]O~O!V0_O!W(uq~O#W9aO!V'aa!W'aa~O!V4tO!W(ri~P#?dOPYXXYXkYXyYXzYX|YX!SYX!VYX!eYX!fYX!hYX!lYX#WYX#ccX#fYX#gYX#hYX#iYX#jYX#kYX#lYX#mYX#nYX#pYX#rYX#tYX#uYX#zYX(QYX(`YX(gYX(hYX~O!a%QX#n%QX~P&6lO#S-cO#T-cO~PBtO#P9eO#S-cO#T-cO~PBtO!}9fO#O9fO#P9eO#S-cO#T-cO~PBtO!]9iO!^9iO't!iO(T!jO(_!nO~O![9lO!]9iO!^9iO#P9eO#S-cO#T-cO't!iO~PBtO!X0zO%`9oO~O'uTO'xUO(T9tO~O!V1VO!W(sq~O!g9wO~O!g9wO~P%QO!g9yO~O!g9zO~O#W9|O!V#`y!W#`y~O!V#`y!W#`y~P#?dO^%^O#W:QO'j%^O~O^%^O!a#rO#W:QO'j%^O~O^%^O!a#rO!l:UO#W:QO'j%^O(`'dO~O!X'QO%`:XO~O#x#vy!V#vy!W#vy~P#?dOP$tiX$tik$tiz$ti!e$ti!f$ti!h$ti!l$ti#f$ti#g$ti#h$ti#i$ti#j$ti#k$ti#l$ti#m$ti#n$ti#p$ti#r$ti#t$ti#u$ti#x$ti(Q$ti(`$ti!V$ti!W$ti~P%AYOy)sO|)tO(h)xOP%WiX%Wig%Wik%Wiz%Wi!e%Wi!f%Wi!h%Wi!l%Wi#f%Wi#g%Wi#h%Wi#i%Wi#j%Wi#k%Wi#l%Wi#m%Wi#n%Wi#p%Wi#r%Wi#t%Wi#u%Wi#x%Wi(Q%Wi(`%Wi(g%Wi!V%Wi!W%Wi~Oy)sO|)tOP%YiX%Yig%Yik%Yiz%Yi!e%Yi!f%Yi!h%Yi!l%Yi#f%Yi#g%Yi#h%Yi#i%Yi#j%Yi#k%Yi#l%Yi#m%Yi#n%Yi#p%Yi#r%Yi#t%Yi#u%Yi#x%Yi(Q%Yi(`%Yi(g%Yi(h%Yi!V%Yi!W%Yi~O#x$hy!V$hy!W$hy~P#?dO#x#Zy!V#Zy!W#Zy~P#?dO!a#rO!V'Yq!g'Yq~O!V/VO!g(my~O!S'[q!V'[q~P#(yO!S:`O~P#(yO!V0_O!W(uy~O!V4tO!W(rq~O#S2fO#T2fO~PBtO#P:gO#S2fO#T2fO~PBtO!]:kO!^:kO't!iO(T!jO(_!nO~O!X0zO%`:nO~O!g:qO~O^%^O#W:vO'j%^O~O^%^O!a#rO#W:vO'j%^O~O!X'QO%`:{O~OP$tqX$tqk$tqz$tq!e$tq!f$tq!h$tq!l$tq#f$tq#g$tq#h$tq#i$tq#j$tq#k$tq#l$tq#m$tq#n$tq#p$tq#r$tq#t$tq#u$tq#x$tq(Q$tq(`$tq!V$tq!W$tq~P%AYOP$vqX$vqk$vqz$vq!e$vq!f$vq!h$vq!l$vq#f$vq#g$vq#h$vq#i$vq#j$vq#k$vq#l$vq#m$vq#n$vq#p$vq#r$vq#t$vq#u$vq#x$vq(Q$vq(`$vq!V$vq!W$vq~P%AYOd%[!Z!V%[!Z#W%[!Z#x%[!Z~P!-jO!V'aq!W'aq~P#?dO#S6`O#T6`O~PBtO!V#`!Z!W#`!Z~P#?dO^%^O#W;ZO'j%^O~O#c%[!ZP%[!ZX%[!Z^%[!Zk%[!Zz%[!Z!V%[!Z!e%[!Z!f%[!Z!h%[!Z!l%[!Z#f%[!Z#g%[!Z#h%[!Z#i%[!Z#j%[!Z#k%[!Z#l%[!Z#m%[!Z#n%[!Z#p%[!Z#r%[!Z#t%[!Z#u%[!Z'j%[!Z(Q%[!Z(`%[!Z!g%[!Z!S%[!Z'h%[!Z#W%[!Zo%[!Z!X%[!Z%`%[!Z!a%[!Z~P#(yOP%[!ZX%[!Zk%[!Zz%[!Z!e%[!Z!f%[!Z!h%[!Z!l%[!Z#f%[!Z#g%[!Z#h%[!Z#i%[!Z#j%[!Z#k%[!Z#l%[!Z#m%[!Z#n%[!Z#p%[!Z#r%[!Z#t%[!Z#u%[!Z#x%[!Z(Q%[!Z(`%[!Z!V%[!Z!W%[!Z~P%AYOo(UX~P1dO't!iO~P!'RO!ScX!VcX#WcX~P&6lOPYXXYXkYXyYXzYX|YX!VYX!VcX!eYX!fYX!hYX!lYX#WYX#WcX#ccX#fYX#gYX#hYX#iYX#jYX#kYX#lYX#mYX#nYX#pYX#rYX#tYX#uYX#zYX(QYX(`YX(gYX(hYX~O!acX!gYX!gcX(`cX~P'!sOP;nOQ;nOa=_Ob!fOikOk;nOlkOmkOskOu;nOw;nO|WO!QkO!RkO!XXO!c;qO!hZO!k;nO!l;nO!m;nO!o;rO!q;sO!t!eO$P!hO$TfO's)RO'uTO'xUO(QVO(_[O(l=]O~O!Vv!>v!BnPPP!BuHdPPPPPPPPPPP!FTP!GiPPHd!HyPHdPHdHdHdHdPHd!J`PP!MiP#!nP#!r#!|##Q##QP!MfP##U##UP#&ZP#&_HdHd#&e#)iAQPAQPAQAQP#*sAQAQ#,mAQ#.zAQ#0nAQAQ#1[#3W#3W#3[#3d#3W#3lP#3WPAQ#4hAQ#5pAQAQ6iPPP#6{PP#7e#7eP#7eP#7z#7ePP#8QP#7wP#7w#8d!1p#7w#9O#9U6f(}#9X(}P#9`#9`#9`P(}P(}P(}P(}PP(}P#9f#9iP#9i(}P#9mP#9pP(}P(}P(}P(}P(}P(}(}PP#9v#9|#:W#:^#:d#:j#:p#;O#;U#;[#;f#;l#b#?r#@Q#@W#@^#@d#@j#@t#@z#AQ#A[#An#AtPPPPPPPPPP#AzPPPPPPP#Bn#FYP#Gu#G|#HUPPPP#L`$ U$'t$'w$'z$)w$)z$)}$*UPP$*[$*`$+X$,X$,]$,qPP$,u$,{$-PP$-S$-W$-Z$.P$.g$.l$.o$.r$.x$.{$/P$/TR!yRmpOXr!X#a%]&d&f&g&i,^,c1g1jU!pQ'Q-OQ%ctQ%kwQ%rzQ&[!TS&x!c,vQ'W!f[']!m!r!s!t!u!vS*[$y*aQ+U%lQ+c%tQ+}&UQ,|'PQ-W'XW-`'^'_'`'aQ/p*cQ1U,OU2b-b-d-eS4}0z5QS6[2e2gU7z5U5V5WQ8q6_S9i7{7|Q:k9lR TypeParamList TypeDefinition extends ThisType this LiteralType ArithOp Number BooleanLiteral TemplateType InterpolationEnd Interpolation InterpolationStart NullType null VoidType void TypeofType typeof MemberExpression . ?. PropertyName [ TemplateString Escape Interpolation super RegExp ] ArrayExpression Spread , } { ObjectExpression Property async get set PropertyDefinition Block : NewExpression new TypeArgList CompareOp < ) ( ArgList UnaryExpression delete LogicOp BitOp YieldExpression yield AwaitExpression await ParenthesizedExpression ClassExpression class ClassBody MethodDeclaration Decorator @ MemberExpression PrivatePropertyName CallExpression Privacy static abstract override PrivatePropertyDefinition PropertyDeclaration readonly accessor Optional TypeAnnotation Equals StaticBlock FunctionExpression ArrowFunction ParamList ParamList ArrayPattern ObjectPattern PatternProperty Privacy readonly Arrow MemberExpression BinaryExpression ArithOp ArithOp ArithOp ArithOp BitOp CompareOp instanceof satisfies in const CompareOp BitOp BitOp BitOp LogicOp LogicOp ConditionalExpression LogicOp LogicOp AssignmentExpression UpdateOp PostfixExpression CallExpression TaggedTemplateExpression DynamicImport import ImportMeta JSXElement JSXSelfCloseEndTag JSXStartTag JSXSelfClosingTag JSXIdentifier JSXBuiltin JSXIdentifier JSXNamespacedName JSXMemberExpression JSXSpreadAttribute JSXAttribute JSXAttributeValue JSXEscape JSXEndTag JSXOpenTag JSXFragmentTag JSXText JSXEscape JSXStartCloseTag JSXCloseTag PrefixCast ArrowFunction TypeParamList SequenceExpression KeyofType keyof UniqueType unique ImportType InferredType infer TypeName ParenthesizedType FunctionSignature ParamList NewSignature IndexedType TupleType Label ArrayType ReadonlyType ObjectType MethodType PropertyType IndexSignature PropertyDefinition CallSignature TypePredicate is NewSignature new UnionType LogicOp IntersectionType LogicOp ConditionalType ParameterizedType ClassDeclaration abstract implements type VariableDeclaration let var TypeAliasDeclaration InterfaceDeclaration interface EnumDeclaration enum EnumBody NamespaceDeclaration namespace module AmbientDeclaration declare GlobalDeclaration global ClassDeclaration ClassBody MethodDeclaration AmbientFunctionDeclaration ExportGroup VariableName VariableName ImportDeclaration ImportGroup ForStatement for ForSpec ForInSpec ForOfSpec of WhileStatement while WithStatement with DoStatement do IfStatement if else SwitchStatement switch SwitchBody CaseLabel case DefaultLabel TryStatement try CatchClause catch FinallyClause finally ReturnStatement return ThrowStatement throw BreakStatement break ContinueStatement continue DebuggerStatement debugger LabeledStatement ExpressionStatement SingleExpression SingleClassItem",maxTerm:362,context:oO,nodeProps:[["group",-26,6,14,16,62,198,202,205,206,208,211,214,225,227,233,235,237,239,242,248,254,256,258,260,262,264,265,"Statement",-32,10,11,25,28,29,35,45,48,49,51,56,64,72,76,78,80,81,102,103,112,113,130,133,135,136,137,138,140,141,161,162,164,"Expression",-23,24,26,30,34,36,38,165,167,169,170,172,173,174,176,177,178,180,181,182,192,194,196,197,"Type",-3,84,95,101,"ClassItem"],["openedBy",31,"InterpolationStart",50,"[",54,"{",69,"(",142,"JSXStartTag",154,"JSXStartTag JSXStartCloseTag"],["closedBy",33,"InterpolationEnd",44,"]",55,"}",70,")",143,"JSXSelfCloseEndTag JSXEndTag",159,"JSXEndTag"]],propSources:[cO],skippedNodes:[0,3,4,268],repeatNodeCount:32,tokenData:"$>y(CSR!bOX%ZXY+gYZ-yZ[+g[]%Z]^.c^p%Zpq+gqr/mrs3cst:_tu>PuvBavwDxwxGgxyMvyz! Qz{!![{|!%O|}!&]}!O!%O!O!P!'g!P!Q!1w!Q!R#0t!R![#3T![!]#@T!]!^#Aa!^!_#Bk!_!`#GS!`!a#In!a!b#N{!b!c$$z!c!}>P!}#O$&U#O#P$'`#P#Q$,w#Q#R$.R#R#S>P#S#T$/`#T#o$0j#o#p$4z#p#q$5p#q#r$7Q#r#s$8^#s$f%Z$f$g+g$g#BY>P#BY#BZ$9h#BZ$IS>P$IS$I_$9h$I_$I|>P$I|$I}$P$JT$JU$9h$JU$KV>P$KV$KW$9h$KW&FU>P&FU&FV$9h&FV;'S>P;'S;=`BZ<%l?HT>P?HT?HU$9h?HUO>P(n%d_$c&j'vp'y!bOY%ZYZ&cZr%Zrs&}sw%Zwx(rx!^%Z!^!_*g!_#O%Z#O#P&c#P#o%Z#o#p*g#p;'S%Z;'S;=`+a<%lO%Z&j&hT$c&jO!^&c!_#o&c#p;'S&c;'S;=`&w<%lO&c&j&zP;=`<%l&c'|'U]$c&j'y!bOY&}YZ&cZw&}wx&cx!^&}!^!_'}!_#O&}#O#P&c#P#o&}#o#p'}#p;'S&};'S;=`(l<%lO&}!b(SU'y!bOY'}Zw'}x#O'}#P;'S'};'S;=`(f<%lO'}!b(iP;=`<%l'}'|(oP;=`<%l&}'[(y]$c&j'vpOY(rYZ&cZr(rrs&cs!^(r!^!_)r!_#O(r#O#P&c#P#o(r#o#p)r#p;'S(r;'S;=`*a<%lO(rp)wU'vpOY)rZr)rs#O)r#P;'S)r;'S;=`*Z<%lO)rp*^P;=`<%l)r'[*dP;=`<%l(r#S*nX'vp'y!bOY*gZr*grs'}sw*gwx)rx#O*g#P;'S*g;'S;=`+Z<%lO*g#S+^P;=`<%l*g(n+dP;=`<%l%Z(CS+rq$c&j'vp'y!b'l(;dOX%ZXY+gYZ&cZ[+g[p%Zpq+gqr%Zrs&}sw%Zwx(rx!^%Z!^!_*g!_#O%Z#O#P&c#P#o%Z#o#p*g#p$f%Z$f$g+g$g#BY%Z#BY#BZ+g#BZ$IS%Z$IS$I_+g$I_$JT%Z$JT$JU+g$JU$KV%Z$KV$KW+g$KW&FU%Z&FU&FV+g&FV;'S%Z;'S;=`+a<%l?HT%Z?HT?HU+g?HUO%Z(CS.ST'w#S$c&j'm(;dO!^&c!_#o&c#p;'S&c;'S;=`&w<%lO&c(CS.n_$c&j'vp'y!b'm(;dOY%ZYZ&cZr%Zrs&}sw%Zwx(rx!^%Z!^!_*g!_#O%Z#O#P&c#P#o%Z#o#p*g#p;'S%Z;'S;=`+a<%lO%Z%#`/x`$c&j!l$Ip'vp'y!bOY%ZYZ&cZr%Zrs&}sw%Zwx(rx!^%Z!^!_*g!_!`0z!`#O%Z#O#P&c#P#o%Z#o#p*g#p;'S%Z;'S;=`+a<%lO%Z%#S1V`#p$Id$c&j'vp'y!bOY%ZYZ&cZr%Zrs&}sw%Zwx(rx!^%Z!^!_*g!_!`2X!`#O%Z#O#P&c#P#o%Z#o#p*g#p;'S%Z;'S;=`+a<%lO%Z%#S2d_#p$Id$c&j'vp'y!bOY%ZYZ&cZr%Zrs&}sw%Zwx(rx!^%Z!^!_*g!_#O%Z#O#P&c#P#o%Z#o#p*g#p;'S%Z;'S;=`+a<%lO%Z$2b3l_'u$(n$c&j'y!bOY4kYZ5qZr4krs7nsw4kwx5qx!^4k!^!_8p!_#O4k#O#P5q#P#o4k#o#p8p#p;'S4k;'S;=`:X<%lO4k*r4r_$c&j'y!bOY4kYZ5qZr4krs7nsw4kwx5qx!^4k!^!_8p!_#O4k#O#P5q#P#o4k#o#p8p#p;'S4k;'S;=`:X<%lO4k)`5vX$c&jOr5qrs6cs!^5q!^!_6y!_#o5q#o#p6y#p;'S5q;'S;=`7h<%lO5q)`6jT$^#t$c&jO!^&c!_#o&c#p;'S&c;'S;=`&w<%lO&c#t6|TOr6yrs7]s;'S6y;'S;=`7b<%lO6y#t7bO$^#t#t7eP;=`<%l6y)`7kP;=`<%l5q*r7w]$^#t$c&j'y!bOY&}YZ&cZw&}wx&cx!^&}!^!_'}!_#O&}#O#P&c#P#o&}#o#p'}#p;'S&};'S;=`(l<%lO&}%W8uZ'y!bOY8pYZ6yZr8prs9hsw8pwx6yx#O8p#O#P6y#P;'S8p;'S;=`:R<%lO8p%W9oU$^#t'y!bOY'}Zw'}x#O'}#P;'S'};'S;=`(f<%lO'}%W:UP;=`<%l8p*r:[P;=`<%l4k#%|:hg$c&j'vp'y!bOY%ZYZ&cZr%Zrs&}st%Ztu`k$c&j'vp'y!b(T!LY's&;d$V#tOY%ZYZ&cZr%Zrs&}st%Ztu>Puw%Zwx(rx}%Z}!O@T!O!Q%Z!Q![>P![!^%Z!^!_*g!_!c%Z!c!}>P!}#O%Z#O#P&c#P#R%Z#R#S>P#S#T%Z#T#o>P#o#p*g#p$g%Z$g;'S>P;'S;=`BZ<%lO>P+d@`k$c&j'vp'y!b$V#tOY%ZYZ&cZr%Zrs&}st%Ztu@Tuw%Zwx(rx}%Z}!O@T!O!Q%Z!Q![@T![!^%Z!^!_*g!_!c%Z!c!}@T!}#O%Z#O#P&c#P#R%Z#R#S@T#S#T%Z#T#o@T#o#p*g#p$g%Z$g;'S@T;'S;=`BT<%lO@T+dBWP;=`<%l@T(CSB^P;=`<%l>P%#SBl`$c&j'vp'y!b#h$IdOY%ZYZ&cZr%Zrs&}sw%Zwx(rx!^%Z!^!_*g!_!`Cn!`#O%Z#O#P&c#P#o%Z#o#p*g#p;'S%Z;'S;=`+a<%lO%Z%#SCy_$c&j#z$Id'vp'y!bOY%ZYZ&cZr%Zrs&}sw%Zwx(rx!^%Z!^!_*g!_#O%Z#O#P&c#P#o%Z#o#p*g#p;'S%Z;'S;=`+a<%lO%Z%DfETa(h%Z![!^%Z!^!_*g!_!c%Z!c!i#>Z!i#O%Z#O#P&c#P#R%Z#R#S#>Z#S#T%Z#T#Z#>Z#Z#o%Z#o#p*g#p;'S%Z;'S;=`+a<%lO%Z$/l#>fi$c&j'vp'y!bl$'|OY%ZYZ&cZr%Zrs&}sw%Zwx(rx!Q%Z!Q![#>Z![!^%Z!^!_*g!_!c%Z!c!i#>Z!i#O%Z#O#P&c#P#R%Z#R#S#>Z#S#T%Z#T#Z#>Z#Z#b%Z#b#c#5T#c#o%Z#o#p*g#p;'S%Z;'S;=`+a<%lO%Z%Gh#@b_!a$b$c&j#x%Puw%Zwx(rx}%Z}!O@T!O!Q%Z!Q![>P![!^%Z!^!_*g!_!c%Z!c!}>P!}#O%Z#O#P&c#P#R%Z#R#S>P#S#T%Z#T#o>P#o#p*g#p$f%Z$f$g+g$g#BY>P#BY#BZ$9h#BZ$IS>P$IS$I_$9h$I_$JT>P$JT$JU$9h$JU$KV>P$KV$KW$9h$KW&FU>P&FU&FV$9h&FV;'S>P;'S;=`BZ<%l?HT>P?HT?HU$9h?HUO>P(CS$=Uk$c&j'vp'y!b'm(;d(T!LY's&;d$V#tOY%ZYZ&cZr%Zrs&}st%Ztu>Puw%Zwx(rx}%Z}!O@T!O!Q%Z!Q![>P![!^%Z!^!_*g!_!c%Z!c!}>P!}#O%Z#O#P&c#P#R%Z#R#S>P#S#T%Z#T#o>P#o#p*g#p$g%Z$g;'S>P;'S;=`BZ<%lO>P",tokenizers:[lO,XO,2,3,4,5,6,7,8,9,10,11,12,13,ZO,new u("$S~RRtu[#O#Pg#S#T#|~_P#o#pb~gOq~~jVO#i!P#i#j!U#j#l!P#l#m!q#m;'S!P;'S;=`#v<%lO!P~!UO!O~~!XS!Q![!e!c!i!e#T#Z!e#o#p#Z~!hR!Q![!q!c!i!q#T#Z!q~!tR!Q![!}!c!i!}#T#Z!}~#QR!Q![!P!c!i!P#T#Z!P~#^R!Q![#g!c!i#g#T#Z#g~#jS!Q![#g!c!i#g#T#Z#g#q#r!P~#yP;=`<%l!P~$RO(S~~",141,325),new u("j~RQYZXz{^~^O'p~~aP!P!Qd~iO'q~~",25,307)],topRules:{Script:[0,5],SingleExpression:[1,266],SingleClassItem:[2,267]},dialects:{jsx:13213,ts:13215},dynamicPrecedences:{76:1,78:1,162:1,190:1},specialized:[{term:311,get:O=>sO[O]||-1},{term:327,get:O=>pO[O]||-1},{term:67,get:O=>gO[O]||-1}],tokenPrec:13238}),bO=[n("function ${name}(${params}) {\n ${}\n}",{label:"function",detail:"definition",type:"keyword"}),n("for (let ${index} = 0; ${index} < ${bound}; ${index}++) {\n ${}\n}",{label:"for",detail:"loop",type:"keyword"}),n("for (let ${name} of ${collection}) {\n ${}\n}",{label:"for",detail:"of loop",type:"keyword"}),n("do {\n ${}\n} while (${})",{label:"do",detail:"loop",type:"keyword"}),n("while (${}) {\n ${}\n}",{label:"while",detail:"loop",type:"keyword"}),n(`try {
- \${}
-} catch (\${error}) {
- \${}
-}`,{label:"try",detail:"/ catch block",type:"keyword"}),n("if (${}) {\n ${}\n}",{label:"if",detail:"block",type:"keyword"}),n(`if (\${}) {
- \${}
-} else {
- \${}
-}`,{label:"if",detail:"/ else block",type:"keyword"}),n(`class \${name} {
- constructor(\${params}) {
- \${}
- }
-}`,{label:"class",detail:"definition",type:"keyword"}),n('import {${names}} from "${module}"\n${}',{label:"import",detail:"named",type:"keyword"}),n('import ${name} from "${module}"\n${}',{label:"import",detail:"default",type:"keyword"})],v=new OO,G=new Set(["Script","Block","FunctionExpression","FunctionDeclaration","ArrowFunction","MethodDeclaration","ForStatement"]);function c(O){return(Q,i)=>{let a=Q.node.getChild("VariableDefinition");return a&&i(a,O),!0}}const hO=["FunctionDeclaration"],mO={FunctionDeclaration:c("function"),ClassDeclaration:c("class"),ClassExpression:()=>!0,EnumDeclaration:c("constant"),TypeAliasDeclaration:c("type"),NamespaceDeclaration:c("namespace"),VariableDefinition(O,Q){O.matchContext(hO)||Q(O,"variable")},TypeDefinition(O,Q){Q(O,"type")},__proto__:null};function q(O,Q){let i=v.get(Q);if(i)return i;let a=[],$=!0;function t(r,S){let o=O.sliceString(r.from,r.to);a.push({label:o,type:S})}return Q.cursor(M.IncludeAnonymous).iterate(r=>{if($)$=!1;else if(r.name){let S=mO[r.name];if(S&&S(r,t)||G.has(r.name))return!1}else if(r.to-r.from>8192){for(let S of q(O,r.node))a.push(S);return!1}}),v.set(Q,a),a}const g=/^[\w$\xa1-\uffff][\w$\d\xa1-\uffff]*$/,U=["TemplateString","String","RegExp","LineComment","BlockComment","VariableDefinition","TypeDefinition","Label","PropertyDefinition","PropertyName","PrivatePropertyDefinition","PrivatePropertyName"];function WO(O){let Q=W(O.state).resolveInner(O.pos,-1);if(U.indexOf(Q.name)>-1)return null;let i=Q.name=="VariableName"||Q.to-Q.from<20&&g.test(O.state.sliceDoc(Q.from,Q.to));if(!i&&!O.explicit)return null;let a=[];for(let $=Q;$;$=$.parent)G.has($.name)&&(a=a.concat(q(O.state.doc,$)));return{options:a,from:i?Q.from:O.pos,validFor:g}}function h(O,Q,i){var a;let $=[];for(;;){let t=Q.firstChild,r;if(t?.name=="VariableName")return $.push(O(t)),{path:$.reverse(),name:i};if(t?.name=="MemberExpression"&&((a=r=t.lastChild)===null||a===void 0?void 0:a.name)=="PropertyName")$.push(O(r)),Q=t;else return null}}function UO(O){let Q=a=>O.state.doc.sliceString(a.from,a.to),i=W(O.state).resolveInner(O.pos,-1);return i.name=="PropertyName"?h(Q,i.parent,Q(i)):U.indexOf(i.name)>-1?null:i.name=="VariableName"||i.to-i.from<20&&g.test(Q(i))?{path:[],name:Q(i)}:(i.name=="."||i.name=="?.")&&i.parent.name=="MemberExpression"?h(Q,i.parent,""):i.name=="MemberExpression"?h(Q,i,""):O.explicit?{path:[],name:""}:null}function fO(O,Q){let i=[],a=new Set;for(let $=0;;$++){for(let r of(Object.getOwnPropertyNames||Object.keys)(O)){if(a.has(r))continue;a.add(r);let S;try{S=O[r]}catch{continue}i.push({label:r,type:typeof S=="function"?/^[A-Z]/.test(r)?"class":Q?"function":"method":Q?"variable":"property",boost:-$})}let t=Object.getPrototypeOf(O);if(!t)return i;O=t}}function IO(O){let Q=new Map;return i=>{let a=UO(i);if(!a)return null;let $=O;for(let r of a.path)if($=$[r],!$)return null;let t=Q.get($);return t||Q.set($,t=fO($,!a.path.length)),{from:i.pos-a.name.length,options:t,validFor:g}}}const X=I.define({name:"javascript",parser:YO.configure({props:[E.add({IfStatement:Y({except:/^\s*({|else\b)/}),TryStatement:Y({except:/^\s*({|catch\b|finally\b)/}),LabeledStatement:A,SwitchBody:O=>{let Q=O.textAfter,i=/^\s*\}/.test(Q),a=/^\s*(case|default)\b/.test(Q);return O.baseIndent+(i?0:a?1:2)*O.unit},Block:J({closing:"}"}),ArrowFunction:O=>O.baseIndent+O.unit,"TemplateString BlockComment":()=>null,"Statement Property":Y({except:/^{/}),JSXElement(O){let Q=/^\s*<\//.test(O.textAfter);return O.lineIndent(O.node.from)+(Q?0:O.unit)},JSXEscape(O){let Q=/\s*\}/.test(O.textAfter);return O.lineIndent(O.node.from)+(Q?0:O.unit)},"JSXOpenTag JSXSelfClosingTag"(O){return O.column(O.node.from)+O.unit}}),L.add({"Block ClassBody SwitchBody EnumBody ObjectExpression ArrayExpression":N,BlockComment(O){return{from:O.from+2,to:O.to-2}}})]}),languageData:{closeBrackets:{brackets:["(","[","{","'",'"',"`"]},commentTokens:{line:"//",block:{open:"/*",close:"*/"}},indentOnInput:/^\s*(?:case |default:|\{|\}|<\/)$/,wordChars:"$"}}),T={test:O=>/^JSX/.test(O.name),facet:F({commentTokens:{block:{open:"{/*",close:"*/}"}}})},uO=X.configure({dialect:"ts"},"typescript"),yO=X.configure({dialect:"jsx",props:[k.add(O=>O.isTop?[T]:void 0)]}),jO=X.configure({dialect:"jsx ts",props:[k.add(O=>O.isTop?[T]:void 0)]},"typescript"),dO="break case const continue default delete export extends false finally in instanceof let new return static super switch this throw true typeof var yield".split(" ").map(O=>({label:O,type:"keyword"}));function EO(O={}){let Q=O.jsx?O.typescript?jO:yO:O.typescript?uO:X;return new D(Q,[X.data.of({autocomplete:B(U,H(bO.concat(dO)))}),X.data.of({autocomplete:WO}),O.jsx?wO:[]])}function xO(O){for(;;){if(O.name=="JSXOpenTag"||O.name=="JSXSelfClosingTag"||O.name=="JSXFragmentTag")return O;if(!O.parent)return null;O=O.parent}}function w(O,Q,i=O.length){for(let a=Q?.firstChild;a;a=a.nextSibling)if(a.name=="JSXIdentifier"||a.name=="JSXBuiltin"||a.name=="JSXNamespacedName"||a.name=="JSXMemberExpression")return O.sliceString(a.from,Math.min(a.to,i));return""}const vO=typeof navigator=="object"&&/Android\b/.test(navigator.userAgent),wO=K.inputHandler.of((O,Q,i,a)=>{if((vO?O.composing:O.compositionStarted)||O.state.readOnly||Q!=i||a!=">"&&a!="/"||!X.isActiveAt(O.state,Q,-1))return!1;let{state:$}=O,t=$.changeByRange(r=>{var S,o;let{head:P}=r,Z=W($).resolveInner(P,-1),s;if(Z.name=="JSXStartTag"&&(Z=Z.parent),a==">"&&Z.name=="JSXFragmentTag")return{range:b.cursor(P+1),changes:{from:P,insert:">"}};if(a=="/"&&Z.name=="JSXFragmentTag"){let l=Z.parent,p=l?.parent;if(l.from==P-1&&((S=p.lastChild)===null||S===void 0?void 0:S.name)!="JSXEndTag"&&(s=w($.doc,p?.firstChild,P))){let f=`/${s}>`;return{range:b.cursor(P+f.length),changes:{from:P,insert:f}}}}else if(a==">"){let l=xO(Z);if(l&&((o=l.lastChild)===null||o===void 0?void 0:o.name)!="JSXEndTag"&&$.sliceDoc(P,P+2)!="`}}}return{range:r}});return t.changes.empty?!1:(O.dispatch(t,{userEvent:"input.type",scrollIntoView:!0}),!0)});function AO(O,Q){return Q||(Q={parserOptions:{ecmaVersion:2019,sourceType:"module"},env:{browser:!0,node:!0,es6:!0,es2015:!0,es2017:!0,es2020:!0},rules:{}},O.getRules().forEach((i,a)=>{i.meta.docs.recommended&&(Q.rules[a]=2)})),i=>{let{state:a}=i,$=[];for(let{from:t,to:r}of X.findRegions(a)){let S=a.doc.lineAt(t),o={line:S.number-1,col:t-S.from,pos:t};for(let P of O.verify(a.sliceDoc(t,r),Q))$.push(VO(P,a.doc,o))}return $}}function V(O,Q,i,a){return i.line(O+a.line).from+Q+(O==1?a.col-1:-1)}function VO(O,Q,i){let a=V(O.line,O.column,Q,i),$={from:a,to:O.endLine!=null&&O.endColumn!=1?V(O.endLine,O.endColumn,Q,i):a,message:O.message,source:O.ruleId?"eslint:"+O.ruleId:"eslint",severity:O.severity==1?"warning":"error"};if(O.fix){let{range:t,text:r}=O.fix,S=t[0]+i.pos-a,o=t[1]+i.pos-a;$.actions=[{name:"fix",apply(P,Z){P.dispatch({changes:{from:Z+S,to:Z+o,insert:r},scrollIntoView:!0})}}]}return $}export{wO as autoCloseTags,UO as completionPath,AO as esLint,EO as javascript,X as javascriptLanguage,yO as jsxLanguage,WO as localCompletionSource,IO as scopeCompletionSource,bO as snippets,jO as tsxLanguage,uO as typescriptLanguage};
-//# sourceMappingURL=index-aee9714f.js.map
diff --git a/spaces/deepwisdom/MetaGPT/metagpt/actions/write_code_review.py b/spaces/deepwisdom/MetaGPT/metagpt/actions/write_code_review.py
deleted file mode 100644
index 7f6a7a38e6a1ed81614364e3deaac37b7dc1f1a9..0000000000000000000000000000000000000000
--- a/spaces/deepwisdom/MetaGPT/metagpt/actions/write_code_review.py
+++ /dev/null
@@ -1,81 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-"""
-@Time : 2023/5/11 17:45
-@Author : alexanderwu
-@File : write_code_review.py
-"""
-
-from metagpt.actions.action import Action
-from metagpt.logs import logger
-from metagpt.schema import Message
-from metagpt.utils.common import CodeParser
-from tenacity import retry, stop_after_attempt, wait_fixed
-
-PROMPT_TEMPLATE = """
-NOTICE
-Role: You are a professional software engineer, and your main task is to review the code. You need to ensure that the code conforms to the PEP8 standards, is elegantly designed and modularized, easy to read and maintain, and is written in Python 3.9 (or in another programming language).
-ATTENTION: Use '##' to SPLIT SECTIONS, not '#'. Output format carefully referenced "Format example".
-
-## Code Review: Based on the following context and code, and following the check list, Provide key, clear, concise, and specific code modification suggestions, up to 5.
-```
-1. Check 0: Is the code implemented as per the requirements?
-2. Check 1: Are there any issues with the code logic?
-3. Check 2: Does the existing code follow the "Data structures and interface definitions"?
-4. Check 3: Is there a function in the code that is omitted or not fully implemented that needs to be implemented?
-5. Check 4: Does the code have unnecessary or lack dependencies?
-```
-
-## Rewrite Code: {filename} Base on "Code Review" and the source code, rewrite code with triple quotes. Do your utmost to optimize THIS SINGLE FILE.
------
-# Context
-{context}
-
-## Code: {filename}
-```
-{code}
-```
------
-
-## Format example
------
-{format_example}
------
-
-"""
-
-FORMAT_EXAMPLE = """
-
-## Code Review
-1. The code ...
-2. ...
-3. ...
-4. ...
-5. ...
-
-## Rewrite Code: {filename}
-```python
-## {filename}
-...
-```
-"""
-
-
-class WriteCodeReview(Action):
- def __init__(self, name="WriteCodeReview", context: list[Message] = None, llm=None):
- super().__init__(name, context, llm)
-
- @retry(stop=stop_after_attempt(2), wait=wait_fixed(1))
- async def write_code(self, prompt):
- code_rsp = await self._aask(prompt)
- code = CodeParser.parse_code(block="", text=code_rsp)
- return code
-
- async def run(self, context, code, filename):
- format_example = FORMAT_EXAMPLE.format(filename=filename)
- prompt = PROMPT_TEMPLATE.format(context=context, code=code, filename=filename, format_example=format_example)
- logger.info(f'Code review {filename}..')
- code = await self.write_code(prompt)
- # code_rsp = await self._aask_v1(prompt, "code_rsp", OUTPUT_MAPPING)
- # self._save(context, filename, code)
- return code
diff --git a/spaces/denisp1/ChemistryMoleculeModeler/app.py b/spaces/denisp1/ChemistryMoleculeModeler/app.py
deleted file mode 100644
index 4f6c65a77cc84eb64fc29a9392a15cf9e402ea20..0000000000000000000000000000000000000000
--- a/spaces/denisp1/ChemistryMoleculeModeler/app.py
+++ /dev/null
@@ -1,175 +0,0 @@
-import streamlit as st
-import ipywidgets
-import py3Dmol
-
-
-from rdkit import Chem
-from rdkit.Chem import Draw
-from PIL import Image
-from rdkit import Chem
-from rdkit.Chem import AllChem
-from ipywidgets import interact,fixed,IntSlider
-import streamlit as st
-import streamlit.components.v1 as components
-import py3Dmol
-from rdkit import Chem
-from rdkit.Chem import Draw
-from rdkit.Chem import AllChem
-
-
-def smi2conf(smiles):
- '''Convert SMILES to rdkit.Mol with 3D coordinates'''
- mol = Chem.MolFromSmiles(smiles)
- if mol is not None:
- mol = Chem.AddHs(mol)
- AllChem.EmbedMolecule(mol)
- AllChem.MMFFOptimizeMolecule(mol, maxIters=200)
- return mol
- else:
- return None
-
-def MolTo3DView(mol, size=(300, 300), style="stick", surface=False, opacity=0.5):
- """Draw molecule in 3D
-
- Args:
- ----
- mol: rdMol, molecule to show
- size: tuple(int, int), canvas size
- style: str, type of drawing molecule
- style can be 'line', 'stick', 'sphere', 'carton'
- surface, bool, display SAS
- opacity, float, opacity of surface, range 0.0-1.0
- Return:
- ----
- viewer: py3Dmol.view, a class for constructing embedded 3Dmol.js views in ipython notebooks.
- """
- assert style in ('line', 'stick', 'sphere', 'carton')
- mblock = Chem.MolToMolBlock(mol)
- viewer = py3Dmol.view(width=size[0], height=size[1])
- viewer.addModel(mblock, 'mol')
- viewer.setStyle({style:{}})
- if surface:
- viewer.addSurface(py3Dmol.SAS, {'opacity': opacity})
- viewer.zoomTo()
- return viewer
-
-def MakeMolecule(name, ingredients):
- st.write(name, ": ", ingredients)
- m = Chem.MolFromSmiles(ingredients)
- im=Draw.MolToImage(m)
- st.image(im)
-
-def conf_viewer(idx):
- mol = confs[idx]
- return MolTo3DView(mol).show()
-
-def style_selector(idx, s):
- conf = confs[idx]
- return MolTo3DView(conf, style=s).show()
-
-@interact
-def smi2viewer(smi='CC=O'):
- try:
- conf = smi2conf(smi)
- return MolTo3DView(conf).show()
- except:
- return None
-
-smi = 'COc3nc(OCc2ccc(C#N)c(c1ccc(C(=O)O)cc1)c2P(=O)(O)O)ccc3C[NH2+]CC(I)NC(=O)C(F)(Cl)Br'
-conf = smi2conf(smi)
-viewer = MolTo3DView(conf, size=(600, 300), style='sphere')
-viewer.show()
-
-#compound_smiles = 'c1cc(C(=O)O)c(OC(=O)C)cc1'
-#m = Chem.MolFromSmiles(compound_smiles)
-#im=Draw.MolToImage(m)
-#st.image(im)
-
-viewer = MolTo3DView(conf, size=(600, 300), style='sphere')
-viewer.show()
-
-smis = [ 'COc3nc(OCc2ccc(C#N)c(c1ccc(C(=O)O)cc1)c2P(=O)(O)O)ccc3C[NH2+]CC(I)NC(=O)C(F)(Cl)Br',
- 'CC(NCCNCC1=CC=C(OCC2=C(C)C(C3=CC=CC=C3)=CC=C2)N=C1OC)=O',
- 'Cc1c(COc2cc(OCc3cccc(c3)C#N)c(CN3C[C@H](O)C[C@H]3C(O)=O)cc2Cl)cccc1-c1ccc2OCCOc2c1',
- 'CCCCC(=O)NCCCCC(=O)NCCCCCC(=O)[O-]',
- "CC(NCCNCC1=CC=C(OCC2=C(C)C(C3=CC=CC=C3)=CC=C2)N=C1OC)=O"]
-
-confs = [smi2conf(s) for s in smis]
-
-
-st.title('⚛️🧬Chemical Graph 3D Molecule Modeler🧬⚛️')
-def show(smi, style='stick'):
- mol = Chem.MolFromSmiles(smi)
- mol = Chem.AddHs(mol)
- AllChem.EmbedMolecule(mol)
- AllChem.MMFFOptimizeMolecule(mol, maxIters=200)
- mblock = Chem.MolToMolBlock(mol)
-
- view = py3Dmol.view(width=400, height=400)
- view.addModel(mblock, 'mol')
- view.setStyle({style:{}})
- view.zoomTo()
- view.show()
- view.render()
- t =view.js()
- f = open('viz.html', 'w')
- f.write(t.startjs)
- f.write(t.endjs)
- f.close()
-
-compound_smiles=st.text_input('SMILES please','CCCCC(=O)NCCCCC(=O)NCCCCCC(=O)[O-]')
-m = Chem.MolFromSmiles(compound_smiles)
-
-#Draw.MolToFile(m,'mol.png')
-
-show(compound_smiles)
-HtmlFile = open("viz.html", 'r', encoding='utf-8')
-source_code = HtmlFile.read()
-c1,c2=st.columns(2)
-with c1:
- st.write('⚛️🧬Chemical Graph 3D Molecule🧬⚛️:')
-with c2:
- components.html(source_code, height = 400,width=400)
-
-st.write('Info about SMILES: https://archive.epa.gov/med/med_archive_03/web/html/smiles.html')
-st.write('Learn about it at Wikipedia: https://en.wikipedia.org/wiki/Simplified_molecular-input_line-entry_system')
-st.write('Search for any compound on PubChem at National Library of Medicine: https://pubchem.ncbi.nlm.nih.gov/#query=vitamin%20e')
-
-
-MakeMolecule("COVID-19 Antiviral Remdesivir GS5734", "CCC(CC)COC(=O)[C@H](C)N[P@](=O)(OC[C@@H]1[C@H]([C@H]([C@](O1)(C#N)C2=CC=C3N2N=CN=C3N)O)O)OC4=CC=CC=C4")
-MakeMolecule("Ritonavir", "CC(C)C1=NC(=CS1)CN(C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC2=CC=CC=C2)C[C@@H]([C@H](CC3=CC=CC=C3)NC(=O)OCC4=CN=CS4)O")
-MakeMolecule("Chloroquine", "CCN(CC)CCCC(C)NC1=C2C=CC(=CC2=NC=C1)Cl")
-MakeMolecule("Fingolimod", "CCCCCCCCC1=CC=C(C=C1)CCC(CO)(CO)N")
-MakeMolecule("N4-Hydroxycytidine", "C1=CN(C(=O)N=C1NO)[C@H]2[C@@H]([C@@H]([C@H](O2)CO)O)O")
-MakeMolecule("Favipiravir", "C1=C(N=C(C(=O)N1)C(=O)N)F")
-
-MakeMolecule("DNA", "C1C(C(OC1N)COP(=O)(O)OC2CC(OC2COP(=O)(O)OC3CC(OC3CO)N)N)O")
-MakeMolecule("Trecovirsen DNA", "CC1=CN(C(=O)NC1=O)C2CC(C(O2)COP(=S)(O)OC3CC(OC3COP(=S)(O)OC4CC(OC4COP(=S)(O)OC5CC(OC5COP(=S)(O)OC6CC(OC6COP(=S)(O)OC7CC(OC7COP(=S)(O)OC8CC(OC8COP(=S)(O)OC9CC(OC9COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1COP(=S)(O)OC1CC(OC1CO)N1C=CC(=NC1=O)N)N1C=C(C(=O)NC1=O)C)N1C=CC(=NC1=O)N)N1C=C(C(=O)NC1=O)C)N1C=CC(=NC1=O)N)N1C=NC2=C1N=C(NC2=O)N)N1C=CC(=NC1=O)N)N1C=NC2=C(N=CN=C21)N)N1C=CC(=NC1=O)N)N1C=CC(=NC1=O)N)N1C=CC(=NC1=O)N)N1C=NC2=C(N=CN=C21)N)N1C=C(C(=O)NC1=O)C)N1C=CC(=NC1=O)N)N1C=C(C(=O)NC1=O)C)N1C=CC(=NC1=O)N)N1C=C(C(=O)NC1=O)C)N1C=CC(=NC1=O)N)N1C=C(C(=O)NC1=O)C)N1C=CC(=NC1=O)N)N1C=CC(=NC1=O)N)N1C=C(C(=O)NC1=O)C)N1C=C(C(=O)NC1=O)C)N1C=CC(=NC1=O)N)O")
-
-
-
-MakeMolecule("Ibuprofen", "CC(C)CC1=CC=C(C=C1)C(C)C(=O)O")
-MakeMolecule("LSD", "CCN(CC)C(=O)[C@H]1CN([C@@H]2CC3=CNC4=CC=CC(=C34)C2=C1)C")
-
-MakeMolecule("Ethanol", "CCO")
-MakeMolecule("Acetic acid", "CC(=O)O")
-MakeMolecule("Cyclohexane", "C1CCCCC1")
-MakeMolecule("Pyridine", "c1cnccc1")
-MakeMolecule("Nicotine", "CN1CCC[C@H]1c2cccnc2")
-
-
-MakeMolecule("Helium", "[3He]")
-MakeMolecule("Hydrogen", "[H]")
-MakeMolecule("Caffeine", "CN1C=NC2=C1C(=O)N(C(=O)N2C)C")
-MakeMolecule("Sugar", "C([C@@H]1[C@H]([C@@H]([C@H]([C@H](O1)O[C@]2([C@H]([C@@H]([C@H](O2)CO)O)O)CO)O)O)O)O")
-MakeMolecule("Dinitrogen", "N#N")
-MakeMolecule("Methyl isocyanate (MIC)", "CN=C=O")
-MakeMolecule("Copper(II) sulfate", "[Cu+2].[O-]S(=O)(=O)[O-]")
-MakeMolecule("Flavopereirin (C17H15N2)", "CCc(c1)ccc2[n+]1ccc3c2[nH]c4c3cccc4 CCc1c[n+]2ccc3c4ccccc4[nH]c3c2cc1")
-MakeMolecule("Glucose (β-D-glucopyranose) (C6H12O6)", "OC[C@@H](O1)[C@@H](O)[C@H](O)[C@@H](O)[C@H](O)1")
-MakeMolecule("Thiamine (vitamin B1, C12H17N4OS+)", "OCCc1c(C)[n+](cs1)Cc2cnc(C)nc2N")
-MakeMolecule("cephalostatin-1", "CC(C)(O1)C[C@@H](O)[C@@]1(O2)[C@@H](C)[C@@H]3CC=C4[C@]3(C2)C(=O)C[C@H]5[C@H]4CC[C@@H](C6)[C@]5(C)Cc(n7)c6nc(C[C@@]89(C))c7C[C@@H]8CC[C@@H]%10[C@@H]9C[C@@H](O)[C@@]%11(C)C%10=C[C@H](O%12)[C@]%11(O)[C@H](C)[C@]%12(O%13)[C@H](O)C[C@@]%13(C)CO")
-MakeMolecule("Vitamin E", "CC(C)CCC[C@@H](C)CCC[C@@H](C)CCC [C@]1(C)CCc2c(C)c(O)c(C)c(C)c2O1")
-MakeMolecule("Vitamin K2", "CC1=C(C(=O)C2=CC=CC=C2C1=O)CC=C(C)CCC=C(C)CCC=C(C)CCC=C(C)C")
-MakeMolecule("Vitamin K1", "CC(C)CCCC(C)CCCC(C)CCCC(=CCC12C(=O)C3=CC=CC=C3C(=O)C1(O2)C)C")
-MakeMolecule("Vitamin D3", "C[C@@H]([C@@H]1C2([C@H](/C(=C/C=C/3\C(=C)CCC(C3)O)/CCC2)CC1)C)CCCC(C)C.C[C@@H]([C@@H]1C2([C@H](/C(=C/C=C/3\C(=C)CCC(C3)O)/CCC2)CC1)C)CCCC(C)C")
\ No newline at end of file
diff --git a/spaces/diacanFperku/AutoGPT/FriendsSeason2COMPLETE720pBRripsujaidrpimprg !EXCLUSIVE!.md b/spaces/diacanFperku/AutoGPT/FriendsSeason2COMPLETE720pBRripsujaidrpimprg !EXCLUSIVE!.md
deleted file mode 100644
index 4bd4efa6d76c2c42aea43ae7615b9403d2b5f33f..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/FriendsSeason2COMPLETE720pBRripsujaidrpimprg !EXCLUSIVE!.md
+++ /dev/null
@@ -1,11 +0,0 @@
-
-https://zzquangjao.net/friendsseason2complete720pbrripsujaidrpimprg/ The official app for fanfiction! In Friends season 2 begins three episodes after the season 4 finale, a story. FriendsSeason2COMPLETE720pBRripsujaidrpimprg Favori-O laetarii primesti s2 version.
-FriendsSeason2COMPLETE720pBRripsujaidrpimprg
Download Zip ⚹ https://gohhs.com/2uFTML
-https://patito.me/miami-study-guide-2016-download/ https://img7.360mb.com/data-c/1/880/137/0/4/0/1138067_lmhvxo.png BTW this is a travel plan I did using a GPS system for a motorcycle trip. FriendsSeason2COMPLETE720pBRripsujaidrpimprg The second season is pretty much a continuation of season 4, which is why theyre not on youtube theyre on .
-https://littlesis.com/friendsseason2complete720pbrripsujaidrpimprg/ https://justonce.org/friendsseason2complete720pbrripsujaidrpimprg/ https://ifccrime.org/hulu-hack-barack-obama-patriot-act-4-11-16-2017/
-https://sachillenger.com/friendsseason2complete720pbrripsujaidrpimprg/ https://www.antobrien.com/friends-season-2-complete-episode-8-review/ https://www.thscookies.com/friends-season-2-complete-part-1/ FriendsSeason2COMPLETE720pBRripsujaidrpimprg The second season of Friends is much like the fourth (though it picks up right after the season 4 finale). .
-
-https://youshouldknow.com/friendsseason2complete720pbrripsujaidrpimprg/ https://www.thscookies.com/friends-season-2-complete-part-1/ FriendsSeason2COMPLETE720pBRripsujaidrpimprg Friends season 2 complete episode 8 review. .
-https://northridgefamc.com/friendsseason2complete720pbrripsujaidrpimprg/ https://www.mkami.com/how-to-fix-my-calciurina-software-win-7-crack-error.rar. https://avcplus.info/the-full-droid-golden-thread-final-cheat-hack-no-hack-season-6-remake/ FriendsSeason2COMPLETE720pBRripsujaidrpimprg. https://www.zdz.co.uk/download/fountain-deep-friendsseason2complete720pbrripsujaidrpimprg-hack-diy-money.html. FriendsSeason2COMPLETE720pBRripsujaidrpimprg. 899543212b
-
-
\ No newline at end of file
diff --git a/spaces/diacanFperku/AutoGPT/Fsdreamteam Gsx Fsx 1.9.0.9 LINK Crack.md b/spaces/diacanFperku/AutoGPT/Fsdreamteam Gsx Fsx 1.9.0.9 LINK Crack.md
deleted file mode 100644
index e87cda613216499dd1b4c29cfcf52e213553c10b..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Fsdreamteam Gsx Fsx 1.9.0.9 LINK Crack.md
+++ /dev/null
@@ -1,93 +0,0 @@
-
-Fsdreamteam Gsx Fsx 1.9.0.9 Crack: How to Download and Install
-Fsdreamteam Gsx Fsx 1.9.0.9 crack is a software that allows you to add realistic ground services to your flight simulator. GSX stands for Ground Services X, and it is a product of Fsdreamteam, a company that specializes in developing add-ons for flight simulators. GSX works with both FSX and P3D, and it simulates various operations on the ground, such as marshalling, catering, boarding, refueling, pushback, and more. GSX also features many native FSX animations and believable human characters.
-If you are a fan of flight simulation, you might want to download and install Fsdreamteam Gsx Fsx 1.9.0.9 crack to enhance your experience and immersion. However, downloading and installing Fsdreamteam Gsx Fsx 1.9.0.9 crack is not as easy as it sounds. You need to find a reliable and safe source, follow the instructions carefully, and avoid any errors or issues that may occur. In this article, we will show you how to download and install Fsdreamteam Gsx Fsx 1.9.0.9 crack step by step.
-Fsdreamteam Gsx Fsx 1.9.0.9 crack
Download — https://gohhs.com/2uFUC0
-Where to Download Fsdreamteam Gsx Fsx 1.9.0.9 Crack?
-There are many websites that offer Fsdreamteam Gsx Fsx 1.9.0.9 crack for download, but not all of them are trustworthy and secure. Some of them may contain viruses, malware, or pop-up ads that can harm your device or compromise your privacy. Therefore, you need to be careful and choose only reputable and verified websites that provide Fsdreamteam Gsx Fsx 1.9.0.9 crack for download.
-Here are some of the websites that we recommend:
-
-- FS Nusantara: This website provides Fsdreamteam Gsx Fsx 1.9.0.9 crack for download in 480p and 720p HD quality, with dual audio (Hindi-English) and English subtitles.
-- YouTube: This website provides Fsdreamteam Gsx Fsx 1.9.0.9 crack for download in video format, with instructions and proof.
-- Woodys Wags Grooming /boarding: This website provides Fsdreamteam Gsx Fsx 1.9.0.9 crack for download in zip file format, with a link to a tutorial.
-
-How to Download Fsdreamteam Gsx Fsx 1.9.0.9 Crack?
-To download Fsdreamteam Gsx Fsx 1.9.0.9 crack from the websites mentioned above, you need to follow these steps:
-
-- Visit the website of your choice and search for Fsdreamteam Gsx Fsx 1.9.0.9 crack.
-- Select the file that you want to download and click on the download link or button.
-- You may be redirected to another page or website that contains the download link or button.
-- You may need to complete a captcha or a verification process to prove that you are not a robot.
-- You may need to wait for a few seconds or minutes before the download starts.
-- Choose the location where you want to save the file on your device and click on save.
-- Wait for the download to finish and extract the file if it is in zip format.
-
-How to Install Fsdreamteam Gsx Fsx 1.9.0.9 Crack?
-To install Fsdreamteam Gsx Fsx 1.9.
-How to Install Fsdreamteam Gsx Fsx 1.9.0.9 Crack?
-To install Fsdreamteam Gsx Fsx 1.9.0.9 crack on your flight simulator, you need to follow these steps:
-
-- Make sure that you have FSX or P3D installed on your device.
-- Run the Fsdreamteam Gsx Fsx 1.9.0.9 crack file that you have downloaded and extracted.
-- Follow the instructions on the screen and choose the destination folder where you want to install GSX.
-- Wait for the installation to finish and launch your flight simulator.
-- Enjoy using GSX with realistic ground services on your flights.
-
-What are the Features and Benefits of Fsdreamteam Gsx Fsx 1.9.0.9 Crack?
-Fsdreamteam Gsx Fsx 1.9.0.9 crack is a software that provides you with many features and benefits, such as:
-
-- It works with every FSX and P3D airport, both default and third-party, even those not released yet.
-- It supports all default FSX and P3D airplanes and many popular third-party airplanes, such as PMDG, Aerosoft, Captain Sim, Quality Wings, and more.
-- It offers vehicles in many different types and sizes, depending on the airplane and airport in use.
-- It has many sound effects and supports 3D surround sound with OpenAL.
-- It has realistic human animations using FSX bones and skin meshes.
-- It has an easy to use user interface, fully integrated in FSX and P3D using standard ATC-like menus.
-- It has an easy user-customization of vehicles, using the provided paint kit.
-- It has a live update feature that keeps GSX always updated automatically, with new supported airplanes and airports.
-- It has a direct airplane interface that allows interaction with complex third-party airplanes featuring custom door controls, ground equipment, and more.
-- It has a support for full airport customization, already enabled with all FSDT sceneries and some third-party sceneries, allowing better integration with any airport.
-
-Conclusion
-In this article, we have shown you how to download and install Fsdreamteam Gsx Fsx 1.9.0.9 crack on your flight simulator. We have also provided you with some tips to download it safely and quickly. We have also discussed the features and benefits of Fsdreamteam Gsx Fsx 1.9.0.9 crack and how it can enhance your flight simulation experience and immersion. We hope that this article has been helpful for you and that you have enjoyed using Fsdreamteam Gsx Fsx 1.9.0.9 crack on your flights. If you have any questions or suggestions, please feel free to leave a comment below. Thank you for reading!
-
-What are the Requirements and Precautions for Fsdreamteam Gsx Fsx 1.9.0.9 Crack?
-Before you download and install Fsdreamteam Gsx Fsx 1.9.0.9 crack on your flight simulator, you need to make sure that you meet the following requirements and precautions:
-
-- You need to have FSX or P3D installed on your device, with the latest updates and service packs.
-- You need to have enough disk space and memory to run GSX smoothly and without errors.
-- You need to have a good internet connection and a compatible device to download GSX from the source websites.
-- You need to have a backup of your original files and settings, in case something goes wrong or you want to uninstall GSX.
-- You need to be aware of the legal and ethical issues of downloading and using cracked software, and the possible consequences that may arise.
-- You need to be careful and cautious of the source websites that you choose to download GSX from, and scan your device for any viruses, malware, or pop-up ads that may harm your device or compromise your privacy.
-
-What are the Reviews and Ratings of Fsdreamteam Gsx Fsx 1.9.0.9 Crack?
-Fsdreamteam Gsx Fsx 1.9.0.9 crack is a software that has received many positive reviews and ratings from users and critics alike. Here are some of the reviews and ratings that we have found:
-
-- "GSX is a must-have for any flight simulator enthusiast. It adds so much realism and immersion to your flights, with realistic ground services and operations. It works with every airport and airplane, and it is easy to use and customize. I highly recommend it." - User review on YouTube
-- "Fsdreamteam Gsx Fsx 1.9.0.9 crack is a great software that enhances your flight simulation experience with ground services. It is compatible with FSX and P3D, and it supports many third-party airplanes and sceneries. It has many features and benefits, such as vehicles, sound effects, human animations, user interface, live update, direct airplane interface, and airport customization. It is easy to download and install, and it works flawlessly." - User review on Woodys Wags Grooming /boarding
-- "Fsdreamteam Gsx Fsx 1.9.0.9 crack is one of the best add-ons for flight simulators. It simulates various operations on the ground, such as marshalling, catering, boarding, refueling, pushback, and more. It has many vehicles in different types and sizes, depending on the airplane and airport in use. It has an amazing sound quality and realistic human characters. It has an intuitive user interface and a live update feature that keeps it updated automatically. It is a must-have for any flight simulator fan." - User review on FS Nusantara
-
-What are the FAQs and Answers for Fsdreamteam Gsx Fsx 1.9.0.9 Crack?
-Fsdreamteam Gsx Fsx 1.9.0.9 crack is a software that may raise some questions and doubts for users and potential users. Here are some of the frequently asked questions and answers for Fsdreamteam Gsx Fsx 1.9.0.9 crack:
-
-- Q: Is Fsdreamteam Gsx Fsx 1.9.0.9 crack legal and ethical?
-A: Fsdreamteam Gsx Fsx 1.9.0.9 crack is a software that violates the copyright and license agreement of Fsdreamteam, the original developer of GSX. Therefore, it is illegal and unethical to download and use Fsdreamteam Gsx Fsx 1.9.0.9 crack, and it may result in legal or penal consequences.
-- Q: Is Fsdreamteam Gsx Fsx 1.9.0.9 crack safe and secure?
-A: Fsdreamteam Gsx Fsx 1.9.0.9 crack is a software that may contain viruses, malware, or pop-up ads that can harm your device or compromise your privacy. Therefore, it is not safe and secure to download and use Fsdreamteam Gsx Fsx 1.9.0.9 crack, and it may cause technical difficulties or errors on your device.
-- Q: Is Fsdreamteam Gsx Fsx 1.9.0.9 crack compatible with my device and simulator?
-A: Fsdreamteam Gsx Fsx 1.9.0.9 crack is a software that works with both FSX and P3D, and it supports all default and third-party airplanes and airports. However, it may not work properly or at all with some devices or simulators, depending on their specifications and settings.
-- Q: How can I uninstall Fsdreamteam Gsx Fsx 1.9.0.9 crack?
-A: To uninstall Fsdreamteam Gsx Fsx 1.9.0.9 crack from your device and simulator, you need to follow these steps:
-- Delete the GSX folder from your simulator's main folder.
-- Delete the Addon Manager folder from your simulator's main folder.
-- Delete the Couatl folder from your simulator's main folder.
-- Delete the Couatl_Updater.exe file from your simulator's main folder.
-- Delete the GSX entry from your simulator's scenery library.
-- Restore your original files and settings from your backup.
-
-Conclusion
-In this article, we have shown you how to download and install Fsdreamteam Gsx Fsx 1.9.0.9 crack on your flight simulator. We have also provided you with some tips to download it safely and quickly. We have also discussed the features and benefits of Fsdreamteam Gsx Fsx 1.9.0.9 crack and how it can enhance your flight simulation experience and immersion. We have also addressed some of the challenges and alternatives of downloading and using Fsdreamteam Gsx Fsx 1.9.0.9 crack. We have also answered some of the frequently asked questions and doubts about Fsdreamteam Gsx Fsx 1.9.0.9 crack.
-We hope that this article has been helpful for you and that you have enjoyed using Fsdreamteam Gsx Fsx 1.9.0.9 crack on your flights. However, we also advise you to be aware of the legal and ethical issues of downloading and using cracked software, and the possible consequences that may arise. We also recommend you to support the original developer of GSX, Fsdreamteam, by purchasing their product legally and ethically.
-If you have any questions or suggestions, please feel free to leave a comment below. Thank you for reading! 3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/diacanFperku/AutoGPT/Hiljadu-Cudesnih-Sunaca-Haled-Hosseinipdf.md b/spaces/diacanFperku/AutoGPT/Hiljadu-Cudesnih-Sunaca-Haled-Hosseinipdf.md
deleted file mode 100644
index 1b908e000d1b39f51aee1634ed6101a04a76c2b9..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/Hiljadu-Cudesnih-Sunaca-Haled-Hosseinipdf.md
+++ /dev/null
@@ -1,38 +0,0 @@
-Hiljadu Cudesnih Sunaca Haled Hosseini.pdf
-
-
-
-Download File > [https://maudaracte.blogspot.com/?file=2tvJde](https://maudaracte.blogspot.com/?file=2tvJde)
-
-
-
-
-
-
-
-
-
-```markdown
-Hiljadu Cudesnih Sunaca: A Review of Haled Hosseini's Novel
-Hiljadu Cudesnih Sunaca (A Thousand Splendid Suns) is a novel by Afghan-American author Haled Hosseini, published in 2007. It tells the story of two women, Mariam and Laila, who suffer from the oppression and violence of the Taliban regime in Afghanistan. The novel explores themes such as love, friendship, family, courage, sacrifice, and resilience in the face of hardship.
-In this article, we will review the novel and its main characters, plot, style, and message. We will also provide some information about the author and his other works.
-
-Main Characters
-The novel has two main protagonists: Mariam and Laila. Mariam is a harami (illegitimate child) who lives with her bitter mother Nana in a hut outside Herat. She is rejected by her wealthy father Jalil and his family, and forced to marry Rasheed, a cruel and abusive shoemaker in Kabul. Laila is a beautiful and intelligent girl who grows up in a loving family in Kabul. She falls in love with Tariq, a boy from her neighborhood who loses his leg in a landmine explosion. When her parents are killed by a rocket attack, she is rescued by Rasheed and becomes his second wife.
-Mariam and Laila initially resent each other, but they gradually develop a bond of friendship and sisterhood. They support each other through the horrors of war, domestic violence, poverty, and oppression. They also share a love for Aziza, Laila's daughter by Tariq, whom Rasheed rejects as his own. Together, they endure the brutality of the Taliban regime, which imposes harsh restrictions on women's rights and freedoms. They also face the threat of Rasheed's violence, which escalates as he becomes more frustrated and paranoid.
-The novel also has several secondary characters who play important roles in the story. Some of them are:
-
-Tariq: Laila's childhood friend and lover, who loses his leg in a landmine explosion. He flees to Pakistan with his family after the Soviet invasion of Afghanistan. He later returns to Kabul to find Laila and rescue her from Rasheed.
-Aziza: Laila's daughter by Tariq, whom she gives birth to in secret. She is a smart and brave girl who loves Mariam as her mother. She is sent to an orphanage by Rasheed when he can no longer afford to feed her.
-Zalmai: Laila's son by Rasheed, whom she conceives after being raped by him. He is spoiled and favored by Rasheed, who sees him as his heir. He is loyal to his father and distrustful of Tariq.
-Mullah Faizullah: Mariam's teacher and friend, who teaches her how to read and write. He is a kind and gentle man who encourages Mariam to pursue her dreams. He dies of old age before Mariam leaves Herat.
-Nana: Mariam's mother, who was impregnated by Jalil when she was his housekeeper. She suffers from epilepsy and depression, and blames Mariam for her misfortune. She commits suicide after Mariam leaves her to visit Jalil.
-Jalil: Mariam's father, who is a wealthy businessman with three wives and nine legitimate children. He visits Mariam once a week and tells her stories about Herat and the world. He abandons Mariam when she asks to live with him, and arranges her marriage to Rasheed.
-
-
-Plot Summary
-The novel spans over three decades of Afghan history, from the 1970s to the 2000s. It covers major events such as the Soviet invasion, the civil war, the rise of the Taliban, and the US intervention.
-The novel begins with Mariam's childhood in Herat, where she lives with her mother Nana in a hut outside the city. She longs to visit her father Jalil and his family in their mansion in Herat. On her fifteenth birthday, she decides to go to Herat to see Jalil after he fails to show up for their weekly visit. She is shocked to discover that Jalil has lied to her about his dfd1c89656
-
-
-
diff --git a/spaces/diacanFperku/AutoGPT/SMS Caster 37 Full !!BETTER!! With Keygen.md b/spaces/diacanFperku/AutoGPT/SMS Caster 37 Full !!BETTER!! With Keygen.md
deleted file mode 100644
index 1619a16d0e8d75ff23073c64107bafb776b59f4b..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/SMS Caster 37 Full !!BETTER!! With Keygen.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-the government of india has launched smart grid mission (sgm) to achieve its vision of having a low-carbon, sustainable and secure electrical power system. the mission aims to achieve its goal in two phases: phase 1 (‘grid readiness’) and phase 2 (‘smart grid’). the mission envisages the development of a smart grid environment that can provide services to various stakeholders including consumers, service providers, and utilities. the mission proposes to achieve a smart grid environment by: 1) developing an electric power delivery grid (epdg) that provides a secure and reliable power supply for a nation that meets the needs of an increasingly mobile, data-driven society, 2) enabling the integration of smart metering, advanced metering infrastructure (ami) and cyber-physical systems (cps) with epdg to provide timely, accurate, and reliable information, and 3) building an ecosystem of service providers that offer smart services to consumers and utilities.
- conclusion: with greater-than-ever pharmaceutical and technological developments, the question of whether patients will benefit from emerging drugs is a crucial one. we believe that this study highlights the importance of drug safety surveillance in modern drug development and the utility of vigibase. for this reason, we have made the summary and methods available via the site so that they can be used more broadly. we look forward to further innovations and contributions from the vigibase community to improve drug safety for patients.
-SMS Caster 37 Full With Keygen
Download Zip > https://gohhs.com/2uFT5u
-we have created a quiet drop that can hold up to 330 standard size (6 x 9) books or 850 jeweled media cases. our carts can be up to 100% recyclable (depending on materials) and our carts are super portable. we have a very competitive price for a cart with a non-marring, quality cart. 899543212b
-
-
\ No newline at end of file
diff --git a/spaces/diagaiwei/ir_chinese_medqa/colbert/utilities/create_triples.py b/spaces/diagaiwei/ir_chinese_medqa/colbert/utilities/create_triples.py
deleted file mode 100644
index 6ed2686a87d5687eb715e392c6f9979ef67a4470..0000000000000000000000000000000000000000
--- a/spaces/diagaiwei/ir_chinese_medqa/colbert/utilities/create_triples.py
+++ /dev/null
@@ -1,65 +0,0 @@
-import random
-from colbert.infra.provenance import Provenance
-
-from utility.utils.save_metadata import save_metadata
-from utility.supervision.triples import sample_for_query
-
-from colbert.utils.utils import print_message
-
-from colbert.data.ranking import Ranking
-from colbert.data.examples import Examples
-
-MAX_NUM_TRIPLES = 40_000_000
-
-
-class Triples:
- def __init__(self, ranking, seed=12345):
- random.seed(seed) # TODO: Use internal RNG instead..
- self.seed = seed
-
- ranking = Ranking.cast(ranking)
- self.ranking_provenance = ranking.provenance()
- self.qid2rankings = ranking.todict()
-
- def create(self, positives, depth):
- assert all(len(x) == 2 for x in positives)
- assert all(maxBest <= maxDepth for maxBest, maxDepth in positives), positives
-
- self.positives = positives
- self.depth = depth
-
- Triples = []
- NonEmptyQIDs = 0
-
- for processing_idx, qid in enumerate(self.qid2rankings):
- l = sample_for_query(qid, self.qid2rankings[qid], positives, depth, False, None)
- NonEmptyQIDs += (len(l) > 0)
- Triples.extend(l)
-
- if processing_idx % (10_000) == 0:
- print_message(f"#> Done with {processing_idx+1} questions!\t\t "
- f"{str(len(Triples) / 1000)}k triples for {NonEmptyQIDs} unqiue QIDs.")
-
- print_message(f"#> Sub-sample the triples (if > {MAX_NUM_TRIPLES})..")
- print_message(f"#> len(Triples) = {len(Triples)}")
-
- if len(Triples) > MAX_NUM_TRIPLES:
- Triples = random.sample(Triples, MAX_NUM_TRIPLES)
-
- ### Prepare the triples ###
- print_message("#> Shuffling the triples...")
- random.shuffle(Triples)
-
- self.Triples = Examples(data=Triples)
-
- return Triples
-
- def save(self, new_path):
- provenance = Provenance()
- provenance.source = 'Triples::create'
- provenance.seed = self.seed
- provenance.positives = self.positives
- provenance.depth = self.depth
- provenance.ranking = self.ranking_provenance
-
- Examples(data=self.Triples, provenance=provenance).save(new_path)
diff --git a/spaces/digitalxingtong/Jiaohuaji-Bert-Vits2/text/chinese_bert.py b/spaces/digitalxingtong/Jiaohuaji-Bert-Vits2/text/chinese_bert.py
deleted file mode 100644
index cb84ce0b426cd0a1c7954ddcdf41322c10ed14fa..0000000000000000000000000000000000000000
--- a/spaces/digitalxingtong/Jiaohuaji-Bert-Vits2/text/chinese_bert.py
+++ /dev/null
@@ -1,50 +0,0 @@
-import torch
-from transformers import AutoTokenizer, AutoModelForMaskedLM
-
-device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
-tokenizer = AutoTokenizer.from_pretrained("./bert/chinese-roberta-wwm-ext-large")
-model = AutoModelForMaskedLM.from_pretrained("./bert/chinese-roberta-wwm-ext-large").to(device)
-
-def get_bert_feature(text, word2ph):
- with torch.no_grad():
- inputs = tokenizer(text, return_tensors='pt')
- for i in inputs:
- inputs[i] = inputs[i].to(device)
- res = model(**inputs, output_hidden_states=True)
- res = torch.cat(res['hidden_states'][-3:-2], -1)[0].cpu()
-
- assert len(word2ph) == len(text)+2
- word2phone = word2ph
- phone_level_feature = []
- for i in range(len(word2phone)):
- repeat_feature = res[i].repeat(word2phone[i], 1)
- phone_level_feature.append(repeat_feature)
-
- phone_level_feature = torch.cat(phone_level_feature, dim=0)
-
-
- return phone_level_feature.T
-
-if __name__ == '__main__':
- # feature = get_bert_feature('你好,我是说的道理。')
- import torch
-
- word_level_feature = torch.rand(38, 1024) # 12个词,每个词1024维特征
- word2phone = [1, 2, 1, 2, 2, 1, 2, 2, 1, 2, 2, 1, 2, 2, 2, 2, 2, 1, 1, 2, 2, 1, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 1]
-
- # 计算总帧数
- total_frames = sum(word2phone)
- print(word_level_feature.shape)
- print(word2phone)
- phone_level_feature = []
- for i in range(len(word2phone)):
- print(word_level_feature[i].shape)
-
- # 对每个词重复word2phone[i]次
- repeat_feature = word_level_feature[i].repeat(word2phone[i], 1)
- phone_level_feature.append(repeat_feature)
-
- phone_level_feature = torch.cat(phone_level_feature, dim=0)
- print(phone_level_feature.shape) # torch.Size([36, 1024])
-
diff --git a/spaces/digitalxingtong/Kino-Bert-VITS2/losses.py b/spaces/digitalxingtong/Kino-Bert-VITS2/losses.py
deleted file mode 100644
index fb22a0e834dd87edaa37bb8190eee2c3c7abe0d5..0000000000000000000000000000000000000000
--- a/spaces/digitalxingtong/Kino-Bert-VITS2/losses.py
+++ /dev/null
@@ -1,61 +0,0 @@
-import torch
-from torch.nn import functional as F
-
-import commons
-
-
-def feature_loss(fmap_r, fmap_g):
- loss = 0
- for dr, dg in zip(fmap_r, fmap_g):
- for rl, gl in zip(dr, dg):
- rl = rl.float().detach()
- gl = gl.float()
- loss += torch.mean(torch.abs(rl - gl))
-
- return loss * 2
-
-
-def discriminator_loss(disc_real_outputs, disc_generated_outputs):
- loss = 0
- r_losses = []
- g_losses = []
- for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
- dr = dr.float()
- dg = dg.float()
- r_loss = torch.mean((1-dr)**2)
- g_loss = torch.mean(dg**2)
- loss += (r_loss + g_loss)
- r_losses.append(r_loss.item())
- g_losses.append(g_loss.item())
-
- return loss, r_losses, g_losses
-
-
-def generator_loss(disc_outputs):
- loss = 0
- gen_losses = []
- for dg in disc_outputs:
- dg = dg.float()
- l = torch.mean((1-dg)**2)
- gen_losses.append(l)
- loss += l
-
- return loss, gen_losses
-
-
-def kl_loss(z_p, logs_q, m_p, logs_p, z_mask):
- """
- z_p, logs_q: [b, h, t_t]
- m_p, logs_p: [b, h, t_t]
- """
- z_p = z_p.float()
- logs_q = logs_q.float()
- m_p = m_p.float()
- logs_p = logs_p.float()
- z_mask = z_mask.float()
-
- kl = logs_p - logs_q - 0.5
- kl += 0.5 * ((z_p - m_p)**2) * torch.exp(-2. * logs_p)
- kl = torch.sum(kl * z_mask)
- l = kl / torch.sum(z_mask)
- return l
diff --git a/spaces/digitalxingtong/Nanami-Bert-VITS2/README_zh.md b/spaces/digitalxingtong/Nanami-Bert-VITS2/README_zh.md
deleted file mode 100644
index 8b137891791fe96927ad78e64b0aad7bded08bdc..0000000000000000000000000000000000000000
--- a/spaces/digitalxingtong/Nanami-Bert-VITS2/README_zh.md
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/spaces/digitalxingtong/Nanami-Bert-VITS2/train_ms.py b/spaces/digitalxingtong/Nanami-Bert-VITS2/train_ms.py
deleted file mode 100644
index 5d109003d40497ea4493e7c73f47c1eb7370a81e..0000000000000000000000000000000000000000
--- a/spaces/digitalxingtong/Nanami-Bert-VITS2/train_ms.py
+++ /dev/null
@@ -1,402 +0,0 @@
-import os
-import json
-import argparse
-import itertools
-import math
-import torch
-import shutil
-from torch import nn, optim
-from torch.nn import functional as F
-from torch.utils.data import DataLoader
-from torch.utils.tensorboard import SummaryWriter
-import torch.multiprocessing as mp
-import torch.distributed as dist
-from torch.nn.parallel import DistributedDataParallel as DDP
-from torch.cuda.amp import autocast, GradScaler
-from tqdm import tqdm
-import logging
-logging.getLogger('numba').setLevel(logging.WARNING)
-import commons
-import utils
-from data_utils import (
- TextAudioSpeakerLoader,
- TextAudioSpeakerCollate,
- DistributedBucketSampler
-)
-from models import (
- SynthesizerTrn,
- MultiPeriodDiscriminator,
- DurationDiscriminator,
-)
-from losses import (
- generator_loss,
- discriminator_loss,
- feature_loss,
- kl_loss
-)
-from mel_processing import mel_spectrogram_torch, spec_to_mel_torch
-from text.symbols import symbols
-
-torch.backends.cudnn.benchmark = True
-torch.backends.cuda.matmul.allow_tf32 = True
-torch.backends.cudnn.allow_tf32 = True
-torch.set_float32_matmul_precision('medium')
-global_step = 0
-
-
-def main():
- """Assume Single Node Multi GPUs Training Only"""
- assert torch.cuda.is_available(), "CPU training is not allowed."
-
- n_gpus = torch.cuda.device_count()
- os.environ['MASTER_ADDR'] = 'localhost'
- os.environ['MASTER_PORT'] = '65280'
-
- hps = utils.get_hparams()
- if not hps.cont:
- shutil.copy('./pretrained_models/D_0.pth','./logs/OUTPUT_MODEL/D_0.pth')
- shutil.copy('./pretrained_models/G_0.pth','./logs/OUTPUT_MODEL/G_0.pth')
- shutil.copy('./pretrained_models/DUR_0.pth','./logs/OUTPUT_MODEL/DUR_0.pth')
- mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,))
-
-
-def run(rank, n_gpus, hps):
- global global_step
- if rank == 0:
- logger = utils.get_logger(hps.model_dir)
- logger.info(hps)
- utils.check_git_hash(hps.model_dir)
- writer = SummaryWriter(log_dir=hps.model_dir)
- writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval"))
-
- dist.init_process_group(backend= 'gloo' if os.name == 'nt' else 'nccl', init_method='env://', world_size=n_gpus, rank=rank)
- torch.manual_seed(hps.train.seed)
- torch.cuda.set_device(rank)
-
- train_dataset = TextAudioSpeakerLoader(hps.data.training_files, hps.data)
- train_sampler = DistributedBucketSampler(
- train_dataset,
- hps.train.batch_size,
- [32, 300, 400, 500, 600, 700, 800, 900, 1000],
- num_replicas=n_gpus,
- rank=rank,
- shuffle=True)
- collate_fn = TextAudioSpeakerCollate()
- train_loader = DataLoader(train_dataset, num_workers=2, shuffle=False, pin_memory=True,
- collate_fn=collate_fn, batch_sampler=train_sampler)
- if rank == 0:
- eval_dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps.data)
- eval_loader = DataLoader(eval_dataset, num_workers=0, shuffle=False,
- batch_size=1, pin_memory=True,
- drop_last=False, collate_fn=collate_fn)
- if "use_noise_scaled_mas" in hps.model.keys() and hps.model.use_noise_scaled_mas == True:
- print("Using noise scaled MAS for VITS2")
- use_noise_scaled_mas = True
- mas_noise_scale_initial = 0.01
- noise_scale_delta = 2e-6
- else:
- print("Using normal MAS for VITS1")
- use_noise_scaled_mas = False
- mas_noise_scale_initial = 0.0
- noise_scale_delta = 0.0
- if "use_duration_discriminator" in hps.model.keys() and hps.model.use_duration_discriminator == True:
- print("Using duration discriminator for VITS2")
- use_duration_discriminator = True
- net_dur_disc = DurationDiscriminator(
- hps.model.hidden_channels,
- hps.model.hidden_channels,
- 3,
- 0.1,
- gin_channels=hps.model.gin_channels if hps.data.n_speakers != 0 else 0,
- ).cuda(rank)
- if "use_spk_conditioned_encoder" in hps.model.keys() and hps.model.use_spk_conditioned_encoder == True:
- if hps.data.n_speakers == 0:
- raise ValueError("n_speakers must be > 0 when using spk conditioned encoder to train multi-speaker model")
- use_spk_conditioned_encoder = True
- else:
- print("Using normal encoder for VITS1")
- use_spk_conditioned_encoder = False
-
- net_g = SynthesizerTrn(
- len(symbols),
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- n_speakers=hps.data.n_speakers,
- mas_noise_scale_initial = mas_noise_scale_initial,
- noise_scale_delta = noise_scale_delta,
- **hps.model).cuda(rank)
-
- freeze_enc = getattr(hps.model, "freeze_enc", False)
- if freeze_enc:
- print("freeze encoder !!!")
- for param in net_g.enc_p.parameters():
- param.requires_grad = False
-
- net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).cuda(rank)
- optim_g = torch.optim.AdamW(
- filter(lambda p: p.requires_grad, net_g.parameters()),
- hps.train.learning_rate,
- betas=hps.train.betas,
- eps=hps.train.eps)
- optim_d = torch.optim.AdamW(
- net_d.parameters(),
- hps.train.learning_rate,
- betas=hps.train.betas,
- eps=hps.train.eps)
- if net_dur_disc is not None:
- optim_dur_disc = torch.optim.AdamW(
- net_dur_disc.parameters(),
- hps.train.learning_rate,
- betas=hps.train.betas,
- eps=hps.train.eps)
- else:
- optim_dur_disc = None
- net_g = DDP(net_g, device_ids=[rank], find_unused_parameters=True)
- net_d = DDP(net_d, device_ids=[rank], find_unused_parameters=True)
- if net_dur_disc is not None:
- net_dur_disc = DDP(net_dur_disc, device_ids=[rank], find_unused_parameters=True)
-
- pretrain_dir = None
- if pretrain_dir is None:
- try:
- if net_dur_disc is not None:
- _, optim_dur_disc, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "DUR_*.pth"), net_dur_disc, optim_dur_disc, skip_optimizer=not hps.cont)
- _, optim_g, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g,
- optim_g, skip_optimizer=not hps.cont)
- _, optim_d, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d,
- optim_d, skip_optimizer=not hps.cont)
-
- epoch_str = max(epoch_str, 1)
- global_step = (epoch_str - 1) * len(train_loader)
- except Exception as e:
- print(e)
- epoch_str = 1
- global_step = 0
- else:
- _, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(pretrain_dir, "G_*.pth"), net_g,
- optim_g, True)
- _, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(pretrain_dir, "D_*.pth"), net_d,
- optim_d, True)
-
-
-
- scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2)
- scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2)
- if net_dur_disc is not None:
- scheduler_dur_disc = torch.optim.lr_scheduler.ExponentialLR(optim_dur_disc, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
- else:
- scheduler_dur_disc = None
- scaler = GradScaler(enabled=hps.train.fp16_run)
-
- for epoch in range(epoch_str, hps.train.epochs + 1):
- if rank == 0:
- train_and_evaluate(rank, epoch, hps, [net_g, net_d, net_dur_disc], [optim_g, optim_d, optim_dur_disc], [scheduler_g, scheduler_d, scheduler_dur_disc], scaler, [train_loader, eval_loader], logger, [writer, writer_eval])
- else:
- train_and_evaluate(rank, epoch, hps, [net_g, net_d, net_dur_disc], [optim_g, optim_d, optim_dur_disc], [scheduler_g, scheduler_d, scheduler_dur_disc], scaler, [train_loader, None], None, None)
- scheduler_g.step()
- scheduler_d.step()
- if net_dur_disc is not None:
- scheduler_dur_disc.step()
-
-
-def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers):
- net_g, net_d, net_dur_disc = nets
- optim_g, optim_d, optim_dur_disc = optims
- scheduler_g, scheduler_d, scheduler_dur_disc = schedulers
- train_loader, eval_loader = loaders
- if writers is not None:
- writer, writer_eval = writers
-
- train_loader.batch_sampler.set_epoch(epoch)
- global global_step
-
- net_g.train()
- net_d.train()
- if net_dur_disc is not None:
- net_dur_disc.train()
- for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers, tone, language, bert) in tqdm(enumerate(train_loader)):
- if net_g.module.use_noise_scaled_mas:
- current_mas_noise_scale = net_g.module.mas_noise_scale_initial - net_g.module.noise_scale_delta * global_step
- net_g.module.current_mas_noise_scale = max(current_mas_noise_scale, 0.0)
- x, x_lengths = x.cuda(rank, non_blocking=True), x_lengths.cuda(rank, non_blocking=True)
- spec, spec_lengths = spec.cuda(rank, non_blocking=True), spec_lengths.cuda(rank, non_blocking=True)
- y, y_lengths = y.cuda(rank, non_blocking=True), y_lengths.cuda(rank, non_blocking=True)
- speakers = speakers.cuda(rank, non_blocking=True)
- tone = tone.cuda(rank, non_blocking=True)
- language = language.cuda(rank, non_blocking=True)
- bert = bert.cuda(rank, non_blocking=True)
-
- with autocast(enabled=hps.train.fp16_run):
- y_hat, l_length, attn, ids_slice, x_mask, z_mask, \
- (z, z_p, m_p, logs_p, m_q, logs_q), (hidden_x, logw, logw_) = net_g(x, x_lengths, spec, spec_lengths, speakers, tone, language, bert)
- mel = spec_to_mel_torch(
- spec,
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.mel_fmin,
- hps.data.mel_fmax)
- y_mel = commons.slice_segments(mel, ids_slice, hps.train.segment_size // hps.data.hop_length)
- y_hat_mel = mel_spectrogram_torch(
- y_hat.squeeze(1),
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.hop_length,
- hps.data.win_length,
- hps.data.mel_fmin,
- hps.data.mel_fmax
- )
-
- y = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size) # slice
-
- # Discriminator
- y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach())
- with autocast(enabled=False):
- loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g)
- loss_disc_all = loss_disc
- if net_dur_disc is not None:
- y_dur_hat_r, y_dur_hat_g = net_dur_disc(hidden_x.detach(), x_mask.detach(), logw.detach(), logw_.detach())
- with autocast(enabled=False):
- # TODO: I think need to mean using the mask, but for now, just mean all
- loss_dur_disc, losses_dur_disc_r, losses_dur_disc_g = discriminator_loss(y_dur_hat_r, y_dur_hat_g)
- loss_dur_disc_all = loss_dur_disc
- optim_dur_disc.zero_grad()
- scaler.scale(loss_dur_disc_all).backward()
- scaler.unscale_(optim_dur_disc)
- grad_norm_dur_disc = commons.clip_grad_value_(net_dur_disc.parameters(), None)
- scaler.step(optim_dur_disc)
-
- optim_d.zero_grad()
- scaler.scale(loss_disc_all).backward()
- scaler.unscale_(optim_d)
- grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None)
- scaler.step(optim_d)
-
- with autocast(enabled=hps.train.fp16_run):
- # Generator
- y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
- if net_dur_disc is not None:
- y_dur_hat_r, y_dur_hat_g = net_dur_disc(hidden_x, x_mask, logw, logw_)
- with autocast(enabled=False):
- loss_dur = torch.sum(l_length.float())
- loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
- loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
-
- loss_fm = feature_loss(fmap_r, fmap_g)
- loss_gen, losses_gen = generator_loss(y_d_hat_g)
- loss_gen_all = loss_gen + loss_fm + loss_mel + loss_dur + loss_kl
- if net_dur_disc is not None:
- loss_dur_gen, losses_dur_gen = generator_loss(y_dur_hat_g)
- loss_gen_all += loss_dur_gen
- optim_g.zero_grad()
- scaler.scale(loss_gen_all).backward()
- scaler.unscale_(optim_g)
- grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None)
- scaler.step(optim_g)
- scaler.update()
-
- if rank == 0:
- if global_step % hps.train.log_interval == 0:
- lr = optim_g.param_groups[0]['lr']
- losses = [loss_disc, loss_gen, loss_fm, loss_mel, loss_dur, loss_kl]
- logger.info('Train Epoch: {} [{:.0f}%]'.format(
- epoch,
- 100. * batch_idx / len(train_loader)))
- logger.info([x.item() for x in losses] + [global_step, lr])
-
- scalar_dict = {"loss/g/total": loss_gen_all, "loss/d/total": loss_disc_all, "learning_rate": lr,
- "grad_norm_d": grad_norm_d, "grad_norm_g": grad_norm_g}
- scalar_dict.update(
- {"loss/g/fm": loss_fm, "loss/g/mel": loss_mel, "loss/g/dur": loss_dur, "loss/g/kl": loss_kl})
- scalar_dict.update({"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)})
- scalar_dict.update({"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)})
- scalar_dict.update({"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)})
-
- image_dict = {
- "slice/mel_org": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().numpy()),
- "slice/mel_gen": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().numpy()),
- "all/mel": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().numpy()),
- "all/attn": utils.plot_alignment_to_numpy(attn[0, 0].data.cpu().numpy())
- }
- utils.summarize(
- writer=writer,
- global_step=global_step,
- images=image_dict,
- scalars=scalar_dict)
-
- if global_step % hps.train.eval_interval == 0:
- evaluate(hps, net_g, eval_loader, writer_eval)
- utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch,
- os.path.join(hps.model_dir, "G_{}.pth".format(global_step)))
- utils.save_checkpoint(net_d, optim_d, hps.train.learning_rate, epoch,
- os.path.join(hps.model_dir, "D_{}.pth".format(global_step)))
- if net_dur_disc is not None:
- utils.save_checkpoint(net_dur_disc, optim_dur_disc, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "DUR_{}.pth".format(global_step)))
- keep_ckpts = getattr(hps.train, 'keep_ckpts', 5)
- if keep_ckpts > 0:
- utils.clean_checkpoints(path_to_models=hps.model_dir, n_ckpts_to_keep=keep_ckpts, sort_by_time=True)
-
-
- global_step += 1
-
- if rank == 0:
- logger.info('====> Epoch: {}'.format(epoch))
-
-
-
-def evaluate(hps, generator, eval_loader, writer_eval):
- generator.eval()
- image_dict = {}
- audio_dict = {}
- print("Evaluating ...")
- with torch.no_grad():
- for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers, tone, language, bert) in enumerate(eval_loader):
- x, x_lengths = x.cuda(), x_lengths.cuda()
- spec, spec_lengths = spec.cuda(), spec_lengths.cuda()
- y, y_lengths = y.cuda(), y_lengths.cuda()
- speakers = speakers.cuda()
- bert = bert.cuda()
- tone = tone.cuda()
- language = language.cuda()
- for use_sdp in [True, False]:
- y_hat, attn, mask, *_ = generator.module.infer(x, x_lengths, speakers, tone, language, bert, y=spec, max_len=1000, sdp_ratio=0.0 if not use_sdp else 1.0)
- y_hat_lengths = mask.sum([1, 2]).long() * hps.data.hop_length
-
- mel = spec_to_mel_torch(
- spec,
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.mel_fmin,
- hps.data.mel_fmax)
- y_hat_mel = mel_spectrogram_torch(
- y_hat.squeeze(1).float(),
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.hop_length,
- hps.data.win_length,
- hps.data.mel_fmin,
- hps.data.mel_fmax
- )
- image_dict.update({
- f"gen/mel_{batch_idx}": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().numpy())
- })
- audio_dict.update({
- f"gen/audio_{batch_idx}_{use_sdp}": y_hat[0, :, :y_hat_lengths[0]]
- })
- image_dict.update({f"gt/mel_{batch_idx}": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy())})
- audio_dict.update({f"gt/audio_{batch_idx}": y[0, :, :y_lengths[0]]})
-
- utils.summarize(
- writer=writer_eval,
- global_step=global_step,
- images=image_dict,
- audios=audio_dict,
- audio_sampling_rate=hps.data.sampling_rate
- )
- generator.train()
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/divyahansg/text-generation-webui-space/extensions/silero_tts/script.py b/spaces/divyahansg/text-generation-webui-space/extensions/silero_tts/script.py
deleted file mode 100644
index f611dc27b7480cd357b77c0c407fcc2bd6df2679..0000000000000000000000000000000000000000
--- a/spaces/divyahansg/text-generation-webui-space/extensions/silero_tts/script.py
+++ /dev/null
@@ -1,169 +0,0 @@
-import time
-from pathlib import Path
-
-import gradio as gr
-import torch
-
-import modules.chat as chat
-import modules.shared as shared
-
-torch._C._jit_set_profiling_mode(False)
-
-params = {
- 'activate': True,
- 'speaker': 'en_56',
- 'language': 'en',
- 'model_id': 'v3_en',
- 'sample_rate': 48000,
- 'device': 'cpu',
- 'show_text': False,
- 'autoplay': True,
- 'voice_pitch': 'medium',
- 'voice_speed': 'medium',
-}
-
-current_params = params.copy()
-voices_by_gender = ['en_99', 'en_45', 'en_18', 'en_117', 'en_49', 'en_51', 'en_68', 'en_0', 'en_26', 'en_56', 'en_74', 'en_5', 'en_38', 'en_53', 'en_21', 'en_37', 'en_107', 'en_10', 'en_82', 'en_16', 'en_41', 'en_12', 'en_67', 'en_61', 'en_14', 'en_11', 'en_39', 'en_52', 'en_24', 'en_97', 'en_28', 'en_72', 'en_94', 'en_36', 'en_4', 'en_43', 'en_88', 'en_25', 'en_65', 'en_6', 'en_44', 'en_75', 'en_91', 'en_60', 'en_109', 'en_85', 'en_101', 'en_108', 'en_50', 'en_96', 'en_64', 'en_92', 'en_76', 'en_33', 'en_116', 'en_48', 'en_98', 'en_86', 'en_62', 'en_54', 'en_95', 'en_55', 'en_111', 'en_3', 'en_83', 'en_8', 'en_47', 'en_59', 'en_1', 'en_2', 'en_7', 'en_9', 'en_13', 'en_15', 'en_17', 'en_19', 'en_20', 'en_22', 'en_23', 'en_27', 'en_29', 'en_30', 'en_31', 'en_32', 'en_34', 'en_35', 'en_40', 'en_42', 'en_46', 'en_57', 'en_58', 'en_63', 'en_66', 'en_69', 'en_70', 'en_71', 'en_73', 'en_77', 'en_78', 'en_79', 'en_80', 'en_81', 'en_84', 'en_87', 'en_89', 'en_90', 'en_93', 'en_100', 'en_102', 'en_103', 'en_104', 'en_105', 'en_106', 'en_110', 'en_112', 'en_113', 'en_114', 'en_115']
-voice_pitches = ['x-low', 'low', 'medium', 'high', 'x-high']
-voice_speeds = ['x-slow', 'slow', 'medium', 'fast', 'x-fast']
-
-# Used for making text xml compatible, needed for voice pitch and speed control
-table = str.maketrans({
- "<": "<",
- ">": ">",
- "&": "&",
- "'": "'",
- '"': """,
-})
-
-def xmlesc(txt):
- return txt.translate(table)
-
-def load_model():
- model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
- model.to(params['device'])
- return model
-model = load_model()
-
-def remove_surrounded_chars(string):
- new_string = ""
- in_star = False
- for char in string:
- if char == '*':
- in_star = not in_star
- elif not in_star:
- new_string += char
- return new_string
-
-def remove_tts_from_history(name1, name2):
- for i, entry in enumerate(shared.history['internal']):
- shared.history['visible'][i] = [shared.history['visible'][i][0], entry[1]]
- return chat.generate_chat_output(shared.history['visible'], name1, name2, shared.character)
-
-def toggle_text_in_history(name1, name2):
- for i, entry in enumerate(shared.history['visible']):
- visible_reply = entry[1]
- if visible_reply.startswith('')[0]}\n\n{reply}"]
- else:
- shared.history['visible'][i] = [shared.history['visible'][i][0], f"{visible_reply.split('')[0]}"]
- return chat.generate_chat_output(shared.history['visible'], name1, name2, shared.character)
-
-def input_modifier(string):
- """
- This function is applied to your text inputs before
- they are fed into the model.
- """
-
- # Remove autoplay from the last reply
- if (shared.args.chat or shared.args.cai_chat) and len(shared.history['internal']) > 0:
- shared.history['visible'][-1] = [shared.history['visible'][-1][0], shared.history['visible'][-1][1].replace('controls autoplay>','controls>')]
-
- shared.processing_message = "*Is recording a voice message...*"
- return string
-
-def output_modifier(string):
- """
- This function is applied to the model outputs.
- """
-
- global model, current_params
-
- for i in params:
- if params[i] != current_params[i]:
- model = load_model()
- current_params = params.copy()
- break
-
- if params['activate'] == False:
- return string
-
- original_string = string
- string = remove_surrounded_chars(string)
- string = string.replace('"', '')
- string = string.replace('“', '')
- string = string.replace('\n', ' ')
- string = string.strip()
-
- if string == '':
- string = '*Empty reply, try regenerating*'
- else:
- output_file = Path(f'extensions/silero_tts/outputs/{shared.character}_{int(time.time())}.wav')
- prosody = ''.format(params['voice_speed'], params['voice_pitch'])
- silero_input = f'{prosody}{xmlesc(string)}'
- model.save_wav(ssml_text=silero_input, speaker=params['speaker'], sample_rate=int(params['sample_rate']), audio_path=str(output_file))
-
- autoplay = 'autoplay' if params['autoplay'] else ''
- string = f''
- if params['show_text']:
- string += f'\n\n{original_string}'
-
- shared.processing_message = "*Is typing...*"
- return string
-
-def bot_prefix_modifier(string):
- """
- This function is only applied in chat mode. It modifies
- the prefix text for the Bot and can be used to bias its
- behavior.
- """
-
- return string
-
-def ui():
- # Gradio elements
- with gr.Accordion("Silero TTS"):
- with gr.Row():
- activate = gr.Checkbox(value=params['activate'], label='Activate TTS')
- autoplay = gr.Checkbox(value=params['autoplay'], label='Play TTS automatically')
- show_text = gr.Checkbox(value=params['show_text'], label='Show message text under audio player')
- voice = gr.Dropdown(value=params['speaker'], choices=voices_by_gender, label='TTS voice')
- with gr.Row():
- v_pitch = gr.Dropdown(value=params['voice_pitch'], choices=voice_pitches, label='Voice pitch')
- v_speed = gr.Dropdown(value=params['voice_speed'], choices=voice_speeds, label='Voice speed')
- with gr.Row():
- convert = gr.Button('Permanently replace audios with the message texts')
- convert_cancel = gr.Button('Cancel', visible=False)
- convert_confirm = gr.Button('Confirm (cannot be undone)', variant="stop", visible=False)
-
- # Convert history with confirmation
- convert_arr = [convert_confirm, convert, convert_cancel]
- convert.click(lambda :[gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, convert_arr)
- convert_confirm.click(lambda :[gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
- convert_confirm.click(remove_tts_from_history, [shared.gradio['name1'], shared.gradio['name2']], shared.gradio['display'])
- convert_confirm.click(lambda : chat.save_history(timestamp=False), [], [], show_progress=False)
- convert_cancel.click(lambda :[gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
-
- # Toggle message text in history
- show_text.change(lambda x: params.update({"show_text": x}), show_text, None)
- show_text.change(toggle_text_in_history, [shared.gradio['name1'], shared.gradio['name2']], shared.gradio['display'])
- show_text.change(lambda : chat.save_history(timestamp=False), [], [], show_progress=False)
-
- # Event functions to update the parameters in the backend
- activate.change(lambda x: params.update({"activate": x}), activate, None)
- autoplay.change(lambda x: params.update({"autoplay": x}), autoplay, None)
- voice.change(lambda x: params.update({"speaker": x}), voice, None)
- v_pitch.change(lambda x: params.update({"voice_pitch": x}), v_pitch, None)
- v_speed.change(lambda x: params.update({"voice_speed": x}), v_speed, None)
diff --git a/spaces/docs-demos/t5-base/app.py b/spaces/docs-demos/t5-base/app.py
deleted file mode 100644
index 4dd945ba4ff0c4c114f59997d0658fbd71eb5bc1..0000000000000000000000000000000000000000
--- a/spaces/docs-demos/t5-base/app.py
+++ /dev/null
@@ -1,44 +0,0 @@
-import gradio as gr
-
-title = "T5"
-
-description = "Gradio Demo for T5. To use it, simply add your text, or click one of the examples to load them. Read more at the links below."
-
-article = "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer "
-
-examples = [
- ['My name is Sarah and I live in London',"t5-base"]
-]
-
-io1 = gr.Interface.load("huggingface/t5-base")
-
-io2 = gr.Interface.load("huggingface/t5-small")
-
-io3 = gr.Interface.load("huggingface/t5-large")
-
-io4 = gr.Interface.load("huggingface/t5-3b")
-
-
-
-def inference(text, model):
- if model == "t5-base":
- outtext = io1(text)
- elif model == "t5-small":
- outtext = io2(text)
- elif model == "t5-large":
- outtext = io3(text)
- else:
- outtext = io4(text)
- return outtext
-
-
-
-gr.Interface(
- inference,
- [gr.inputs.Textbox(label="Input"),gr.inputs.Dropdown(choices=["t5-base","t5-small","t5-large","t5-3b"], type="value", default="t5-base", label="model")
-],
- gr.outputs.Textbox(label="Output"),
- examples=examples,
- article=article,
- title=title,
- description=description).launch(enable_queue=True)
\ No newline at end of file
diff --git a/spaces/doevent/ArcaneGAN/app.py b/spaces/doevent/ArcaneGAN/app.py
deleted file mode 100644
index a5703da8b4be370b76a62e44c37b7172e59a960d..0000000000000000000000000000000000000000
--- a/spaces/doevent/ArcaneGAN/app.py
+++ /dev/null
@@ -1,139 +0,0 @@
-import os
-# os.system("pip freeze")
-from huggingface_hub import hf_hub_download
-os.system("pip -qq install facenet_pytorch")
-from facenet_pytorch import MTCNN
-from torchvision import transforms
-import torch, PIL
-from tqdm.notebook import tqdm
-import gradio as gr
-import torch
-
-modelarcanev4 = hf_hub_download(repo_id="akhaliq/ArcaneGANv0.4", filename="ArcaneGANv0.4.jit")
-
-mtcnn = MTCNN(image_size=256, margin=80)
-
-# simplest ye olde trustworthy MTCNN for face detection with landmarks
-def detect(img):
-
- # Detect faces
- batch_boxes, batch_probs, batch_points = mtcnn.detect(img, landmarks=True)
- # Select faces
- if not mtcnn.keep_all:
- batch_boxes, batch_probs, batch_points = mtcnn.select_boxes(
- batch_boxes, batch_probs, batch_points, img, method=mtcnn.selection_method
- )
-
- return batch_boxes, batch_points
-
-# my version of isOdd, should make a separate repo for it :D
-def makeEven(_x):
- return _x if (_x % 2 == 0) else _x+1
-
-# the actual scaler function
-def scale(boxes, _img, max_res=1_500_000, target_face=256, fixed_ratio=0, max_upscale=2, VERBOSE=False):
-
- x, y = _img.size
-
- ratio = 2 #initial ratio
-
- #scale to desired face size
- if (boxes is not None):
- if len(boxes)>0:
- ratio = target_face/max(boxes[0][2:]-boxes[0][:2]);
- ratio = min(ratio, max_upscale)
- if VERBOSE: print('up by', ratio)
-
- if fixed_ratio>0:
- if VERBOSE: print('fixed ratio')
- ratio = fixed_ratio
-
- x*=ratio
- y*=ratio
-
- #downscale to fit into max res
- res = x*y
- if res > max_res:
- ratio = pow(res/max_res,1/2);
- if VERBOSE: print(ratio)
- x=int(x/ratio)
- y=int(y/ratio)
-
- #make dimensions even, because usually NNs fail on uneven dimensions due skip connection size mismatch
- x = makeEven(int(x))
- y = makeEven(int(y))
-
- size = (x, y)
-
- return _img.resize(size)
-
-"""
- A useful scaler algorithm, based on face detection.
- Takes PIL.Image, returns a uniformly scaled PIL.Image
- boxes: a list of detected bboxes
- _img: PIL.Image
- max_res: maximum pixel area to fit into. Use to stay below the VRAM limits of your GPU.
- target_face: desired face size. Upscale or downscale the whole image to fit the detected face into that dimension.
- fixed_ratio: fixed scale. Ignores the face size, but doesn't ignore the max_res limit.
- max_upscale: maximum upscale ratio. Prevents from scaling images with tiny faces to a blurry mess.
-"""
-
-def scale_by_face_size(_img, max_res=1_500_000, target_face=256, fix_ratio=0, max_upscale=2, VERBOSE=False):
- boxes = None
- boxes, _ = detect(_img)
- if VERBOSE: print('boxes',boxes)
- img_resized = scale(boxes, _img, max_res, target_face, fix_ratio, max_upscale, VERBOSE)
- return img_resized
-
-
-size = 256
-
-means = [0.485, 0.456, 0.406]
-stds = [0.229, 0.224, 0.225]
-
-t_stds = torch.tensor(stds).cpu().half().float()[:,None,None]
-t_means = torch.tensor(means).cpu().half().float()[:,None,None]
-
-def makeEven(_x):
- return int(_x) if (_x % 2 == 0) else int(_x+1)
-
-img_transforms = transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize(means,stds)])
-
-def tensor2im(var):
- return var.mul(t_stds).add(t_means).mul(255.).clamp(0,255).permute(1,2,0)
-
-def proc_pil_img(input_image, model):
- transformed_image = img_transforms(input_image)[None,...].cpu().half().float()
-
- with torch.no_grad():
- result_image = model(transformed_image)[0]
- output_image = tensor2im(result_image)
- output_image = output_image.detach().cpu().numpy().astype('uint8')
- output_image = PIL.Image.fromarray(output_image)
- return output_image
-
-
-
-modelv4 = torch.jit.load(modelarcanev4,map_location='cpu').eval().cpu().half().float()
-
-def process(im):
- im = scale_by_face_size(im, target_face=256, max_res=1_500_000, max_upscale=1)
- res = proc_pil_img(im, modelv4)
- return res
-
-title = "ArcaneGAN"
-description = ""
-article = ""
-
-gr.Interface(process,
- gr.inputs.Image(type="pil", label="Input"),
- gr.outputs.Image(type="pil", label="Output"),
- title=title,
- description=description,
- article=article,
- examples=[['groot.jpeg']],
- allow_flagging='never',
- theme="default",
- ).launch(enable_queue=True)
diff --git a/spaces/dorkai/text-generation-webui-main/docs/Chat-mode.md b/spaces/dorkai/text-generation-webui-main/docs/Chat-mode.md
deleted file mode 100644
index 08dd290dadbd8a590ace65d557b8916a2707fc26..0000000000000000000000000000000000000000
--- a/spaces/dorkai/text-generation-webui-main/docs/Chat-mode.md
+++ /dev/null
@@ -1,45 +0,0 @@
-## Chat characters
-
-Custom chat mode characters are defined by `.yaml` files inside the `characters` folder. An example is included: [Example.yaml](https://github.com/oobabooga/text-generation-webui/blob/main/characters/Example.yaml)
-
-The following fields may be defined:
-
-| Field | Description |
-|-------|-------------|
-| `name` or `bot` | The character's name. |
-| `your_name` or `user` (optional) | Your name. This overwrites what you had previously written in the `Your name` field in the interface. |
-| `context` | A string that appears at the top of the prompt. It usually contains a description of the character's personality. |
-| `greeting` (optional) | The character's opening message when a new conversation is started. |
-| `example_dialogue` (optional) | A few example messages to guide the model. |
-| `turn_template` (optional) | Used to define where the spaces and new line characters should be in Instruct mode. See the characters in `characters/instruction-following` for examples. |
-
-#### Special tokens
-
-* `{{char}}` or ``: are replaced with the character's name
-* `{{user}}` or ``: are replaced with your name
-
-These replacements happen when the character is loaded, and they apply to the `context`, `greeting`, and `example_dialogue` fields.
-
-#### How do I add a profile picture for my character?
-
-Put an image with the same name as your character's yaml file into the `characters` folder. For example, if your bot is `Character.yaml`, add `Character.jpg` or `Character.png` to the folder.
-
-#### Is the chat history truncated in the prompt?
-
-Once your prompt reaches the 2048 token limit, old messages will be removed one at a time. The context string will always stay at the top of the prompt and will never get truncated.
-
-#### Pygmalion format characters
-
-These are also supported out of the box. Simply put the JSON file in the `characters` folder, or upload it directly from the web UI by clicking on the "Upload character" tab at the bottom.
-
-## Chat styles
-
-Custom chat styles can be defined in the `text-generation-webui/css` folder. Simply create a new file with name starting in `chat_style-` and ending in `.css` and it will automatically appear in the "Chat style" dropdown menu in the interface. Examples:
-
-```
-chat_style-cai-chat.css
-chat_style-TheEncrypted777.css
-chat_style-wpp.css
-```
-
-You should use the same class names as in `chat_style-cai-chat.css` in your custom style.
\ No newline at end of file
diff --git a/spaces/ds520/bingo/src/pages/api/sydney.ts b/spaces/ds520/bingo/src/pages/api/sydney.ts
deleted file mode 100644
index 0e7bbf23d77c2e1a6635185a060eeee58b8c8e66..0000000000000000000000000000000000000000
--- a/spaces/ds520/bingo/src/pages/api/sydney.ts
+++ /dev/null
@@ -1,62 +0,0 @@
-import { NextApiRequest, NextApiResponse } from 'next'
-import { WebSocket, debug } from '@/lib/isomorphic'
-import { BingWebBot } from '@/lib/bots/bing'
-import { websocketUtils } from '@/lib/bots/bing/utils'
-import { WatchDog, createHeaders } from '@/lib/utils'
-
-
-export default async function handler(req: NextApiRequest, res: NextApiResponse) {
- const conversationContext = req.body
- const headers = createHeaders(req.cookies)
- debug(headers)
- res.setHeader('Content-Type', 'text/stream; charset=UTF-8')
-
- const ws = new WebSocket('wss://sydney.bing.com/sydney/ChatHub', {
- headers: {
- ...headers,
- 'accept-language': 'zh-CN,zh;q=0.9',
- 'cache-control': 'no-cache',
- 'x-ms-useragent': 'azsdk-js-api-client-factory/1.0.0-beta.1 core-rest-pipeline/1.10.0 OS/Win32',
- pragma: 'no-cache',
- }
- })
-
- const closeDog = new WatchDog()
- const timeoutDog = new WatchDog()
- ws.onmessage = (event) => {
- timeoutDog.watch(() => {
- ws.send(websocketUtils.packMessage({ type: 6 }))
- }, 1500)
- closeDog.watch(() => {
- ws.close()
- }, 10000)
- res.write(event.data)
- if (/\{"type":([367])\}/.test(String(event.data))) {
- const type = parseInt(RegExp.$1, 10)
- debug('connection type', type)
- if (type === 3) {
- ws.close()
- } else {
- ws.send(websocketUtils.packMessage({ type }))
- }
- }
- }
-
- ws.onclose = () => {
- timeoutDog.reset()
- closeDog.reset()
- debug('connection close')
- res.end()
- }
-
- await new Promise((resolve) => ws.onopen = resolve)
- ws.send(websocketUtils.packMessage({ protocol: 'json', version: 1 }))
- ws.send(websocketUtils.packMessage({ type: 6 }))
- ws.send(websocketUtils.packMessage(BingWebBot.buildChatRequest(conversationContext!)))
- req.socket.once('close', () => {
- ws.close()
- if (!res.closed) {
- res.end()
- }
- })
-}
diff --git a/spaces/eIysia/VITS-Umamusume-voice-synthesizer/README.md b/spaces/eIysia/VITS-Umamusume-voice-synthesizer/README.md
deleted file mode 100644
index 1b24e6efdb04cb1460e4fe3257d2303677c5a0e1..0000000000000000000000000000000000000000
--- a/spaces/eIysia/VITS-Umamusume-voice-synthesizer/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Multilingual Anime TTS
-emoji: 🎙🐴
-colorFrom: green
-colorTo: gray
-sdk: gradio
-sdk_version: 3.7
-app_file: app.py
-pinned: false
-duplicated_from: Plachta/VITS-Umamusume-voice-synthesizer
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/edemgold/QA-App/app.py b/spaces/edemgold/QA-App/app.py
deleted file mode 100644
index 5afba4305e592e91fc652b12422acf717ec3a9ad..0000000000000000000000000000000000000000
--- a/spaces/edemgold/QA-App/app.py
+++ /dev/null
@@ -1,30 +0,0 @@
-# -*- coding: utf-8 -*-
-
-# Importing Dependancies
-
-import gradio as gr
-from transformers import pipeline
-
-"""# Loading Model Name"""
-
-model_name = "deepset/roberta-base-squad2"
-
-"""# Get Predictions
-
-"""
-
-nlu = pipeline('question-answering', model=model_name, tokenizer=model_name)
-
-def func(context, question):
- input = {
- 'question':question,
- 'context':context
- }
- res = nlu(input)
- return res["answer"]
-
-descr = "This is a question and Answer Web app, you give it a context and ask it questions based on the context provided"
-
-app = gr.Interface(fn=func, inputs=[gr.inputs.Textbox(lines=3, placeholder="put in your context here..."),"text"], outputs="text", title="Question Answer App", description=descr)
-
-app.launch()
\ No newline at end of file
diff --git a/spaces/edugp/perplexity-lenses/cli.py b/spaces/edugp/perplexity-lenses/cli.py
deleted file mode 100644
index a889d0e03cffacf85f8a401cd4c56d966fa018bb..0000000000000000000000000000000000000000
--- a/spaces/edugp/perplexity-lenses/cli.py
+++ /dev/null
@@ -1,139 +0,0 @@
-import logging
-from functools import partial
-from typing import Optional
-
-import pandas as pd
-import typer
-from bokeh.plotting import output_file as bokeh_output_file
-from bokeh.plotting import save
-from embedding_lenses.dimensionality_reduction import (
- get_tsne_embeddings,
- get_umap_embeddings,
-)
-from embedding_lenses.embedding import load_model
-
-from perplexity_lenses import REGISTRY_DATASET
-from perplexity_lenses.data import (
- documents_df_to_sentences_df,
- hub_dataset_to_dataframe,
-)
-from perplexity_lenses.engine import (
- DIMENSIONALITY_REDUCTION_ALGORITHMS,
- DOCUMENT_TYPES,
- EMBEDDING_MODELS,
- LANGUAGES,
- PERPLEXITY_MODELS,
- SEED,
- generate_plot,
-)
-from perplexity_lenses.perplexity import KenlmModel
-from perplexity_lenses.visualization import draw_histogram
-
-logging.basicConfig(level=logging.INFO)
-logger = logging.getLogger(__name__)
-
-
-app = typer.Typer()
-
-
-@app.command()
-def main(
- dataset: str = typer.Option(
- "mc4", help="The name of the hub dataset or local csv/tsv file."
- ),
- dataset_config: Optional[str] = typer.Option(
- "es",
- help="The configuration of the hub dataset, if any. Does not apply to local csv/tsv files.",
- ),
- dataset_split: Optional[str] = typer.Option(
- "train", help="The dataset split. Does not apply to local csv/tsv files."
- ),
- text_column: str = typer.Option("text", help="The text field name."),
- language: str = typer.Option(
- "es", help=f"The language of the text. Options: {LANGUAGES}"
- ),
- doc_type: str = typer.Option(
- "sentence",
- help=f"Whether to embed at the sentence or document level. Options: {DOCUMENT_TYPES}.",
- ),
- sample: int = typer.Option(1000, help="Maximum number of examples to use."),
- perplexity_model: str = typer.Option(
- "wikipedia",
- help=f"Dataset on which the perplexity model was trained on. Options: {PERPLEXITY_MODELS}",
- ),
- dimensionality_reduction: str = typer.Option(
- DIMENSIONALITY_REDUCTION_ALGORITHMS[0],
- help=f"Whether to use UMAP or t-SNE for dimensionality reduction. Options: {DIMENSIONALITY_REDUCTION_ALGORITHMS}.",
- ),
- model_name: str = typer.Option(
- EMBEDDING_MODELS[0],
- help=f"The sentence embedding model to use. Options: {EMBEDDING_MODELS}",
- ),
- output_file: str = typer.Option(
- "perplexity", help="The name of the output visualization files."
- ),
-):
- """
- Perplexity Lenses: Visualize text embeddings in 2D using colors to represent perplexity values.
- """
- logger.info("Loading embedding model...")
- model = load_model(model_name)
- dimensionality_reduction_function = (
- partial(get_umap_embeddings, random_state=SEED)
- if dimensionality_reduction.lower() == "umap"
- else partial(get_tsne_embeddings, random_state=SEED)
- )
- logger.info("Loading KenLM model...")
- kenlm_model = KenlmModel.from_pretrained(
- perplexity_model.lower(),
- language,
- lower_case=True,
- remove_accents=True,
- normalize_numbers=True,
- punctuation=1,
- )
- logger.info("Loading dataset...")
- if dataset.endswith(".csv") or dataset.endswith(".tsv"):
- df = pd.read_csv(dataset, sep="\t" if dataset.endswith(".tsv") else ",")
- if doc_type.lower() == "sentence":
- df = documents_df_to_sentences_df(df, text_column, sample, seed=SEED)
- df["perplexity"] = df[text_column].map(kenlm_model.get_perplexity)
- else:
- df = hub_dataset_to_dataframe(
- dataset,
- dataset_config,
- dataset_split,
- sample,
- text_column,
- kenlm_model,
- seed=SEED,
- doc_type=doc_type,
- )
- # Round perplexity
- df["perplexity"] = df["perplexity"].round().astype(int)
- logger.info(
- f"Perplexity range: {df['perplexity'].min()} - {df['perplexity'].max()}"
- )
- plot, plot_registry = generate_plot(
- df,
- text_column,
- "perplexity",
- None,
- dimensionality_reduction_function,
- model,
- seed=SEED,
- hub_dataset=dataset,
- )
- logger.info("Saving plots")
- bokeh_output_file(f"{output_file}.html")
- save(plot)
- if dataset == REGISTRY_DATASET:
- bokeh_output_file(f"{output_file}_registry.html")
- save(plot_registry)
- fig = draw_histogram(df["perplexity"].values)
- fig.savefig(f"{output_file}_histogram.png")
- logger.info("Done")
-
-
-if __name__ == "__main__":
- app()
diff --git a/spaces/emre/emre-llama-2-13b-mini/app.py b/spaces/emre/emre-llama-2-13b-mini/app.py
deleted file mode 100644
index 7bc7fe1227074151aaddbca5a775f3dd03cda3ff..0000000000000000000000000000000000000000
--- a/spaces/emre/emre-llama-2-13b-mini/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/emre/llama-2-13b-mini").launch()
\ No newline at end of file
diff --git a/spaces/enzostvs/hub-api-playground/app/[type]/[index]/page.tsx b/spaces/enzostvs/hub-api-playground/app/[type]/[index]/page.tsx
deleted file mode 100644
index 7b44f7b74964518915d3c13fb7c8deac7925c982..0000000000000000000000000000000000000000
--- a/spaces/enzostvs/hub-api-playground/app/[type]/[index]/page.tsx
+++ /dev/null
@@ -1,16 +0,0 @@
-import { EditorMain } from "@/components/editor/main";
-import { API_COLLECTIONS } from "@/utils/datas/api_collections";
-
-export default async function RouteAPI({
- params: { index, type },
-}: {
- params: { index: string; type: string };
-}) {
- const endpoint = API_COLLECTIONS.find((col) => col.key === type)?.endpoints[
- parseInt(index)
- ];
-
- return (
- <>{endpoint ? : Not found }
- );
-}
diff --git a/spaces/epexVfeibi/Imagedeblurr/Adjustment Program Reset Impressora Epson TX130TX133TX135 Luzes Piscandorar.md b/spaces/epexVfeibi/Imagedeblurr/Adjustment Program Reset Impressora Epson TX130TX133TX135 Luzes Piscandorar.md
deleted file mode 100644
index 90453a3cbccd00b26256c45f78cb4e0c28125248..0000000000000000000000000000000000000000
--- a/spaces/epexVfeibi/Imagedeblurr/Adjustment Program Reset Impressora Epson TX130TX133TX135 Luzes Piscandorar.md
+++ /dev/null
@@ -1,7 +0,0 @@
-
-epson l1800 a3 photo ink tank printer is one of the latest innovative products that epson released. it was the evolution of the inkjet printer that was released. therefore, it is evident that it is equipped with a refined hardware and with epson's full force software to cater for the needs of the business owners and consumers. moreover, it is also an all-in-one machine with photo printing, scanning, copying, and faxing functionalities. it is also equipped with a wide array of storage options. therefore, it is quite suitable for professionals to utilize it for data storage!
-Adjustment Program Reset Impressora Epson TX130TX133TX135 Luzes Piscandorar
Download File » https://jinyurl.com/2uEnyl
-ink jet l1800 a3 photo ink tank printer is designed to fit with the epson l1800 a3 photo ink tank printer. therefore, both of these devices can connect to each other via usb. the connection is made possible through the usb id, which is extracted from the epson l1800 a3 photo ink tank printer. the extracted data is then automatically transmitted to the epson l1800 printer. furthermore, this connection is made possible through the usb id, which is extracted from the epson l1800 printer. therefore, this is a very convenient way to make the connection. therefore, you can also remove the ink cartridge manually from the printer. nevertheless, the ink cartridge is connected with a special interface.
-epson l1800 a3 photo ink tank printer has a good memory capacity. therefore, this printer will store some valuable data that can be accessed whenever needed. this is quite convenient for the business owners and consumers. however, the size of the ink cartridge is quite limited. therefore, you can only utilize half of its capacity at a time. 899543212b
-
-
\ No newline at end of file
diff --git a/spaces/esraa-abdelmaksoud/Dominant-Ad-Colors-Detection/app.py b/spaces/esraa-abdelmaksoud/Dominant-Ad-Colors-Detection/app.py
deleted file mode 100644
index f44aacf7cfe91d7fa401ad8180f7fd1930219d66..0000000000000000000000000000000000000000
--- a/spaces/esraa-abdelmaksoud/Dominant-Ad-Colors-Detection/app.py
+++ /dev/null
@@ -1,70 +0,0 @@
-import gradio
-import cv2
-import numpy as np
-
-def get_dominant_colors(img):
-
- reshaped = img.reshape((-1, 3))
- # convert to np.float32
- reshaped = np.float32(reshaped)
- # define criteria, number of clusters(K) and apply kmeans()
- criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
- K = 3
- _, _, center = cv2.kmeans(reshaped, K, None, criteria, 10,
- cv2.KMEANS_PP_CENTERS)
- # Now convert back into uint8
- dominants = np.uint8(center)
-
- return dominants
-
-
-def bgr_to_hex(dominants):
-
- color_1, color_2, color_3 = dominants[0], dominants[1], dominants[2]
- c1 = "#{:02x}{:02x}{:02x}".format(color_1[0], color_1[1], color_1[2])
- c2 = "#{:02x}{:02x}{:02x}".format(color_2[0], color_2[1], color_2[2])
- c3 = "#{:02x}{:02x}{:02x}".format(color_3[0], color_3[1], color_3[2])
- hex = f"{c1}\n{c2}\n{c3}\n"
- colors = [color_1, color_2, color_3]
-
- return hex, colors
-
-
-def paint_colors(dominants, area=50):
-
- color_1, color_2, color_3 = dominants[0], dominants[1], dominants[2]
- img_w = 3 * area
- img_h = 1 * area
-
- # Create image
- out_img = np.zeros((img_h, img_w, 3), np.uint8)
- out_img[:, 0:area] = color_1 #(y,x)
- out_img[:, area:area*2] = color_2
- out_img[:, area*2:area*3] = color_3
-
- return out_img
-
-
-def process_img(img):
-
- dominants = get_dominant_colors(img)
- hex, colors = bgr_to_hex(dominants)
- hex_rgb = f"RGB 1: {colors[0]}\nRGB 2: {colors[1]}\nRGB 3: {colors[2]}\n{hex}"
- colors_img = paint_colors(dominants, area=50)
-
- return colors_img, hex_rgb
-
-
-desc = "The performance of social media ads is not only about targeting but also about ad design. The design of the ad is a main performance factor color, but the colors also have an effect. Some types of audiences can be attracted to certain colors, and this is what is covered. This solution extracts the top 3 dominant colors per image and visualizes them. The number 3 was chosen to cover the main 2 design colors and the text color when possible. This is applied to one image in this space, but the solution is meant to create a full palette for designers so they can make the right decision while picking future design colors. © The example ads were designed by Esraa Abdelmaksoud for simplesite.com. Select an image to detect the dominant colors."
-
-iface = gradio.Interface(
- fn=process_img,
- inputs='image',
- outputs=["image", "text"],
- title='Dominant Ad Colors Detection',
- description=desc,
- examples=["ad_sample.jpg", "ad_sample_2.jpg","ad_sample_3.jpg",
- "ad_sample_4.jpg","ad_sample_5.jpg","ad_sample_6.jpg",
- "ad_sample_7.jpg","ad_sample_8.jpg"])
-
-iface.launch()
\ No newline at end of file
diff --git a/spaces/eugenkalosha/Semmap/README.md b/spaces/eugenkalosha/Semmap/README.md
deleted file mode 100644
index 5a0e3d6d5690cb2a9161f1c774a1c90ce4e1b4bc..0000000000000000000000000000000000000000
--- a/spaces/eugenkalosha/Semmap/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Semantic Map
-emoji: 📈
-colorFrom: blue
-colorTo: green
-sdk: docker
-pinned: false
-duplicated_from: Panel-Org/panel-template
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/evaluate-metric/sari/app.py b/spaces/evaluate-metric/sari/app.py
deleted file mode 100644
index 0666a386de190bab2906c58fef504a081cf52727..0000000000000000000000000000000000000000
--- a/spaces/evaluate-metric/sari/app.py
+++ /dev/null
@@ -1,6 +0,0 @@
-import evaluate
-from evaluate.utils import launch_gradio_widget
-
-
-module = evaluate.load("sari")
-launch_gradio_widget(module)
diff --git a/spaces/falterWliame/Face_Mask_Detection/City Car Driving 1.2.2 Serial Ke.md b/spaces/falterWliame/Face_Mask_Detection/City Car Driving 1.2.2 Serial Ke.md
deleted file mode 100644
index 070181ec1ba79713bd8ef9247a9c3c0e397c9697..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/City Car Driving 1.2.2 Serial Ke.md
+++ /dev/null
@@ -1,103 +0,0 @@
-
-City Car Driving 1.2.2 Serial Key: A Complete Guide
-
-If you are looking for a realistic driving simulator game, you might want to try City Car Driving 1.2.2. This game allows you to practice your driving skills in various traffic conditions, weather, and road situations. You can choose from different cars, modes, and scenarios to test your abilities and learn from your mistakes.
-City Car Driving 1.2.2 Serial Ke
Download File »»» https://urlca.com/2uDcSA
-
-However, to enjoy the full features of City Car Driving 1.2.2, you need a valid serial key to activate the game. A serial key is a unique code that verifies your purchase and unlocks the game for you. Without a serial key, you can only play the demo version of the game, which has limited options and functions.
-
-How to Get City Car Driving 1.2.2 Serial Key
-
-There are two ways to get a serial key for City Car Driving 1.2.2: buying it from the official website or downloading it from a reliable source.
-
-Buying City Car Driving 1.2.2 Serial Key
-
-The easiest and safest way to get a serial key for City Car Driving 1.2.2 is to buy it from the official website of the game: https://citycardriving.com/buy/citycardriving. Here, you can choose from different payment methods and currencies to complete your purchase. You will receive an email with your serial key and instructions on how to activate the game.
-
-
-The advantages of buying a serial key from the official website are:
-
-- You will get a genuine and legal serial key that works for your game.
-- You will get access to all the updates and patches of the game.
-- You will get technical support and customer service from the developers.
-- You will support the creators of the game and help them improve their products.
-
-
-Downloading City Car Driving 1.2.2 Serial Key
-
-Another way to get a serial key for City Car Driving 1.2.2 is to download it from a third-party source, such as a website or a torrent. This method is not recommended, as it may expose you to various risks and problems.
-
-The disadvantages of downloading a serial key from an unofficial source are:
-
-- You may get a fake or invalid serial key that does not work for your game.
-- You may get a virus or malware that infects your computer or steals your personal information.
-- You may get into legal trouble for violating the copyright laws and terms of service of the game.
-- You may miss out on the updates and patches of the game.
-- You may not get any technical support or customer service from the developers.
-- You may harm the creators of the game and discourage them from making more games.
-
-
-How to Activate City Car Driving 1.2.2 with Serial Key
-
-Once you have obtained a valid serial key for City Car Driving 1.2.2, you need to activate the game with it. To do this, follow these steps:
-
-- Download and install City Car Driving 1.2.2 on your computer.
-- Launch the game and copy the code from the startup window.
-- Open the website https://activate.citycardriving.com/ on your browser.
-- Enter your serial number, the program code you have copied, and your email address.
-- The activation key will be sent to your email address.
-- Enter your activation key into the box in the program window and click “Registration” button.
-- Enjoy playing City Car Driving 1.2.2 with full features!
-
-
-Conclusion
-
-City Car Driving 1.2.2 is a great driving simulator game that can help you improve your driving skills and have fun at the same time. To play this game with full features, you need a serial key to activate it. You can either buy a serial key from the official website or download it from a reliable source, but be careful of the risks and disadvantages of the latter option. Once you have a serial key, you can easily activate the game and start driving!
-City Car Driving 1.2.2 Mods and Custom Cars
-
-One of the most exciting features of City Car Driving 1.2.2 is the ability to add mods and custom cars to the game. Mods are modifications that enhance or change the game in various ways, such as adding new cars, maps, traffic, sounds, etc. Custom cars are user-created cars that you can download and drive in the game.
-
-To add mods and custom cars to City Car Driving 1.2.2, you need to use the Steam Workshop. The Steam Workshop is a platform that allows you to easily discover, download, and install fan-created content for your game or software. You can browse through thousands of mods and custom cars created by other users and subscribe to the ones you like. The subscribed content will be automatically available when you start the game.
-
-Some of the benefits of using mods and custom cars in City Car Driving 1.2.2 are:
-
-- You can expand your car collection with different models, brands, styles, and performance.
-- You can drive in new maps and environments that offer different challenges and scenery.
-- You can experience new traffic situations and scenarios that test your driving skills and reactions.
-- You can customize your game with different sounds, graphics, effects, etc.
-- You can support the creative community and share your own mods and custom cars with others.
-
-
-City Car Driving 1.2.2 System Requirements and Download
-
-Before you can play City Car Driving 1.2.2 with serial key, you need to make sure that your computer meets the minimum system requirements for the game. The system requirements are:
-
-| OS | Windows 7 SP1 / 8 / 8.1 / 10 (64 Bit) |
-| Processor | Intel Pentium Dual Core 3.2 GHz / AMD Athlon II X4 3.1 GHz |
-| Memory | 4 GB RAM |
-| Graphics | AMD Radeon R7 240 / nVidia GeForce GT 740 |
-| DirectX | Version 11 |
-| Storage | 10 GB available space |
-| Sound Card | Any sound card compatible with DirectX 9.0 |
-| Additional Notes | The application's stability is not guaranteed on Intel HD Graphics and AMD HD Radeon on-board graphics cards. |
-
-
-If your computer meets or exceeds these requirements, you can download City Car Driving 1.2.2 from the official website of the game: https://citycardriving.com/download/citycardriving. Here, you can choose from different download options and payment methods to get your copy of the game.
-
-Alternatively, you can buy City Car Driving 1.2.2 from Steam: https://store.steampowered.com/app/493490/City_Car_Driving/. Steam is a digital distribution platform that allows you to buy, download, and play games online. By buying City Car Driving 1.2.2 from Steam, you can also access the Steam Workshop and other Steam features.
-
-After you have downloaded City Car Driving 1.2.2, you need to activate it with your serial key as explained in the previous section.
-
-
-If you want me to write more paragraphs, you need to give me a specific topic or question that you want me to address. Otherwise, I suggest you move on to the next step of your article writing process, such as checking for grammar errors, adding images or videos, writing a conclusion, or creating a summary. I can help you with any of these tasks if you ask me.
-City Car Driving 1.2.2 Serial Key: The Final Word
-
-City Car Driving 1.2.2 is a game that can offer you a lot of fun and learning. It is a realistic driving simulator that can help you master the basic skills of car driving in different road conditions and situations. It has many features and benefits that make it stand out from other driving games, such as smart traffic, realistic physics, various cars, modes, scenarios, and maps. It also allows you to add mods and custom cars to the game through the Steam Workshop, which can enhance your gaming experience and creativity.
-
-To play City Car Driving 1.2.2 with full features, you need a serial key to activate the game. You can get a serial key by buying it from the official website or downloading it from a reliable source. However, you should be careful of the risks and disadvantages of the latter option, such as fake or invalid serial keys, viruses or malware, legal trouble, missing updates and patches, etc. Once you have a serial key, you can easily activate the game and start driving.
-
-If you are looking for a game that can challenge your driving skills and entertain you at the same time, City Car Driving 1.2.2 is a great choice for you. It is a game that can teach you how to drive safely and confidently in real life. It is also a game that can let you explore different cars, environments, and situations in a virtual world. It is a game that can give you hours of fun and satisfaction.
-
-So what are you waiting for? Get your City Car Driving 1.2.2 serial key today and enjoy the ride! 3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/falterWliame/Face_Mask_Detection/Cnc Software Mastercam X5 Crack Rarl.md b/spaces/falterWliame/Face_Mask_Detection/Cnc Software Mastercam X5 Crack Rarl.md
deleted file mode 100644
index e9ea5fa8561470292b4152fa773f3807e076a9f0..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Cnc Software Mastercam X5 Crack Rarl.md
+++ /dev/null
@@ -1,8 +0,0 @@
-
-the software compliance group is a division of the business software alliance ( bsa ), a not-for-profit that works with governments and businesses to help protect the integrity of the software market. it works with vendors, distributors, retailers and government agencies to help keep software users safe and prevent software piracy.
-one of the many features in the new version is the ability to import stereolithography files, though in this version it only works on the mastercam 2219 in the windows operating system. mastercam has also added the ability to create and edit grid entities, and the new version allows you to merge the grid entities back into the part file. the software also allows you to resize the document and even supports features such as the ability to display and edit 2d and 3d graphics, as well as to display and edit surface models.
-Cnc Software Mastercam X5 Crack Rarl
DOWNLOAD ::: https://urlca.com/2uDdrU
-mastercam software crack has been updated, a complete brand new version is now available for download. its main goal is to make life easier for the user, making the whole experience more user-friendly. this version has been upgraded with many new features, new intuitive user interface and a lot more. the user guide also contains a lot of useful information that will make your life easier.
-not having to open a document to create a new part is really handy for a freelancer who has a lot of different projects going on and has to switch between them frequently. a new intuitive user interface has been introduced, making it easier to view and edit your parts and models. the user interface is now easier to navigate. this new version of mastercam also has a lot of new features. it supports creating new solid objects, it can also export your model in the obj format, which is the file format commonly used in 3d graphics editing software like 3d studio max. you can create new project files with different settings, such as the shape of the table, or the viewport. it can create 2d drawings directly from the project files. 899543212b
-
-
\ No newline at end of file
diff --git a/spaces/falterWliame/Face_Mask_Detection/Onyx Production House X10.2 13.md b/spaces/falterWliame/Face_Mask_Detection/Onyx Production House X10.2 13.md
deleted file mode 100644
index b7b92b2dc5a5d8016cfdb7d858376f926278a4fc..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Onyx Production House X10.2 13.md
+++ /dev/null
@@ -1,17 +0,0 @@
-onyx production house x10.2 13
Download File ⚙ https://urlca.com/2uDcb3
-
-Learn how to add a new media profile to the Onyx X10: ... Media Profile for HP Designjet L25500 Printer ... HP Designjet L25500 - Description, specifications, test, reviews, prices, photos Digitizing photographic film and slides.
-Onyx X10.
-Digitizing on a memory card.
-Record on a disk or on a computer.
-Price action.
-Description.
-Onyx X10 ...
-Onyx X10 - find out prices and detailed specifications.
-Watch a video review, read reviews and discuss on the forum.
-Pros, cons and analogues.
-Buy Onyx X10 with warranty at a low price.
-Delivery in Ukraine: Kharkiv, Kiev, Dnipropetrovsk, Odessa, Zaporozhye, Lviv and other cities. 8a78ff9644
-
-
-
diff --git a/spaces/fatiXbelha/sd/Clash of Clans Real Server Mod APK The Best Way to Experience the Game.md b/spaces/fatiXbelha/sd/Clash of Clans Real Server Mod APK The Best Way to Experience the Game.md
deleted file mode 100644
index b955a208b802c37e479095c41b6a957f9190b49a..0000000000000000000000000000000000000000
--- a/spaces/fatiXbelha/sd/Clash of Clans Real Server Mod APK The Best Way to Experience the Game.md
+++ /dev/null
@@ -1,129 +0,0 @@
-
-Clash of Clans Real Server Mod APK: How to Download and Play
-Clash of Clans is one of the most popular and addictive strategy games in the world. Millions of players build their own villages, train their troops, and battle with other clans online. But what if you want to play the game with unlimited resources, custom mods, and access to all the features without spending any money or waiting for hours? That's where a real server mod apk comes in handy. In this article, we will explain what a real server mod apk is, why you might want to use it, and how to download and install it on your device.
-clash of clans real server mod apk
Download ->>->>->> https://urllie.com/2uNEQv
-What is Clash of Clans?
-Clash of Clans is a freemium mobile game developed by Supercell, a Finnish company that also created other hit games like Clash Royale, Brawl Stars, and Hay Day. The game was released in 2012 for iOS and in 2013 for Android devices. Since then, it has become one of the most downloaded and highest-grossing apps in the world, with over 500 million downloads and billions of dollars in revenue.
-The game is set in a fantasy world where you can create your own village, join or create a clan, and fight with other players in clan wars or multiplayer battles. You can also upgrade your buildings, defenses, troops, spells, heroes, and pets using various resources like gold, elixir, dark elixir, gems, and magic items. The game is constantly updated with new content, events, challenges, and features to keep you entertained and engaged.
-What is a mod apk?
-A mod apk is a modified version of an original app that has been altered by someone other than the developer. A mod apk can have different features, functions, graphics, or gameplay than the original app. For example, a mod apk can have unlimited resources, unlocked items, custom skins, cheats, hacks, or other enhancements that are not available in the original app.
-clash of clans private server mod apk download
-clash of clans mod apk unlimited everything real server
-clash of clans hack mod apk real server 2023
-clash of clans mod apk plenixclash real server
-clash of clans mod apk latest version real server
-clash of clans mod apk offline real server
-clash of clans mod apk unlimited gems real server
-clash of clans mod apk town hall 15 real server
-clash of clans mod apk android 1 real server
-clash of clans mod apk ios real server
-clash of clans mod apk unlimited troops real server
-clash of clans mod apk magic s1 real server
-clash of clans mod apk fhx real server
-clash of clans mod apk null's clash real server
-clash of clans mod apk lights s1 real server
-clash of clans mod apk darksoul real server
-clash of clans mod apk miroclash real server
-clash of clans mod apk hybrid base real server
-clash of clans mod apk builder base real server
-clash of clans mod apk supercell id real server
-clash of clans mod apk no root real server
-clash of clans mod apk online play real server
-clash of clans mod apk unlimited gold and elixir real server
-clash of clans mod apk new update real server
-clash of clans mod apk with th14 real server
-clash of clans mod apk free download for android real server
-clash of clans mod apk unlimited money and gems real server
-clash of clans mod apk hack version download real server
-clash of clans mod apk anti ban real server
-clash of clans mod apk working 100% real server
-clash of clans mod apk original graphics real server
-clash of clans mod apk no human verification real server
-clash of clans mod apk all heroes unlocked real server
-clash of clans mod apk custom buildings and heroes real server
-clash of clans mod apk unlimited resources and clan wars real server
-clash of clans mod apk with battle machine and night mode real server
-clash of clans mod apk with royal champion and giga inferno real server
-clash of clans mod apk with siege machines and wall wreckers real server
-clash of clans mod apk with electro dragon and ice golem real server
-clash of clans mod apk with pets and super troops real server
-clash of clans mod apk with new skins and events real server
-clash of clans mod apk with clan games and friendly challenges real server
-clash of clans mod apk with global chat and clan chat real server
-clash of clans mod apk with achievements and leaderboards real server
-clash of clans mod apk with unlimited spells and traps real server
-clash of clans mod apk with custom commands and mods menu real server
-A mod apk can be downloaded from third-party websites or sources that are not affiliated with the official app store or developer. However, not all mod apks are safe or legal to use. Some mod apks may contain viruses, malware, spyware, or other harmful software that can damage your device or steal your personal information. Some mod apks may also violate the terms of service or policies of the original app or developer, which can result in bans or legal actions.
-What is a real server mod apk?
-A real server mod apk is a special type of mod apk that connects to the official servers of the original app instead of private servers or offline modes. A real server mod apk allows you to play the original game with all the features and functions that are available on the official servers, but with some modifications or additions that are not possible on the original app.
-For example, a real server mod apk for Clash of Clans can let you play the game with unlimited resources like gold, elixir, dark elixir , gems, and magic items. You can also use custom mods like unlimited troops, spells, heroes, pets, buildings, defenses, or other features that are not available in the original game. You can also access all the events, challenges, seasons, and rewards that are offered on the official servers.
-Why would you want to use a real server mod apk for Clash of Clans?
-There are many reasons why you might want to use a real server mod apk for Clash of Clans. Some of them are:
-
-- You want to have fun and experiment with different aspects of the game without worrying about the limitations or restrictions of the original game.
-- You want to save time and money by getting unlimited resources and items without spending any real money or waiting for hours.
-- You want to test your skills and strategies against other players on the official servers with your modified game.
-- You want to enjoy the latest updates and features of the game without having to update your app or download a new mod apk every time.
-- You want to have more control and customization over your game and play it according to your preferences and style.
-
-However, there are also some drawbacks and risks of using a real server mod apk for Clash of Clans. Some of them are:
-
-- You may face technical issues or errors while playing the mod apk, such as crashes, glitches, bugs, or compatibility problems.
-- You may lose your original game data or progress if you do not backup your files before installing the mod apk.
-- You may get banned or suspended from the official servers if the developer detects your mod apk or if you abuse the mod features.
-- You may compromise the security and privacy of your device or account if you download a mod apk from an untrusted or malicious source.
-- You may miss out on the original experience and challenge of the game as it was intended by the developer.
-
-How to download and install a real server mod apk for Clash of Clans?
-If you have decided to try a real server mod apk for Clash of Clans, you need to follow some steps to download and install it on your device. Here is a step-by-step guide on how to do it:
-Where to find a reliable real server mod apk for Clash of Clans?
-The first step is to find a reliable source where you can download a real server mod apk for Clash of Clans. There are many websites and forums that offer mod apks for various games, but not all of them are safe or trustworthy. You need to be careful and do some research before downloading any mod apk from an unknown source. Some of the things you can do are:
-
-- Check the reviews and ratings of the website or forum where you found the mod apk. See what other users have said about their experience with the mod apk and whether they faced any issues or problems.
-- Check the date and version of the mod apk. Make sure it is compatible with your device and the latest version of the original game.
-- Check the size and content of the mod apk. Make sure it does not contain any unwanted or harmful software that can harm your device or account.
-- Check the permissions and requirements of the mod apk. Make sure it does not ask for any unnecessary or suspicious permissions that can compromise your security or privacy.
- How to backup your original game data before installing the mod apk?
-The second step is to backup your original game data before installing the mod apk. This is important because you may lose your progress or account if something goes wrong during the installation or if you want to switch back to the original game later. There are different ways to backup your game data, depending on your device and the type of data you want to save. Some of the common methods are:
-
-- Using Google Play Games or Facebook to sync your game data with your online account. This will allow you to restore your game data on any device that supports these platforms.
-- Using a file manager app or a computer to copy and paste your game data files from your device's internal storage or SD card to another location. This will allow you to manually restore your game data on the same device or a different device.
-- Using a cloud service or an external storage device to backup your game data files online or offline. This will allow you to access your game data from anywhere and anytime.
-
-Make sure you know where your game data files are located and how to restore them before installing the mod apk. You can also use a backup app or tool that can automate the process for you.
-How to enable unknown sources on your device and install the mod apk?
-The third step is to enable unknown sources on your device and install the mod apk. This is necessary because most devices do not allow installing apps from sources other than the official app store or developer. To enable unknown sources, you need to follow these steps:
-
-- Go to your device's settings and look for security or privacy options.
-- Find and tap on the option that says unknown sources, install unknown apps, or something similar.
-- Toggle on the option and confirm your choice if prompted.
-
-Once you have enabled unknown sources, you can proceed to install the mod apk. To install the mod apk, you need to follow these steps:
-
-- Locate and tap on the mod apk file that you downloaded from the source.
-- Follow the instructions on the screen and agree to the terms and conditions if asked.
-- Wait for the installation to complete and tap on open or done when finished.
-
-How to launch and play the mod apk on your device?
-The final step is to launch and play the mod apk on your device. This is easy and similar to playing any other app on your device. To launch and play the mod apk, you need to follow these steps:
-
-- Find and tap on the icon of the mod apk on your device's home screen or app drawer.
-- Wait for the game to load and sign in with your account if required.
-- Enjoy playing the game with unlimited resources, custom mods, and access to all the features.
-
-Conclusion
-In conclusion, a real server mod apk for Clash of Clans is a modified version of the original game that connects to the official servers and allows you to play with unlimited resources, custom mods, and access to all the features. It can be fun and exciting to use, but it also comes with some drawbacks and risks that you should be aware of. If you want to try a real server mod apk for Clash of Clans, you need to find a reliable source, backup your original game data, enable unknown sources, install the mod apk, and launch and play it on your device. We hope this article has helped you understand what a real server mod apk is, why you might want to use it, and how to download and install it on your device.
- Frequently Asked Questions
- Here are some of the frequently asked questions about real server mod apks for Clash of Clans:
- Is using a real server mod apk for Clash of Clans legal?
- Using a real server mod apk for Clash of Clans may not be legal in some countries or regions, depending on their laws and regulations regarding intellectual property rights, digital piracy, online gaming, or other related matters. You should check with your local authorities before using a real server mod apk for Clash of Clans.
- Is using a real server mod apk for Clash of Clans safe?
- Using a real server mod apk for Clash of Clans may not be safe for your device or account, depending on the source, quality, and content of the mod apk. You should only download a real server mod apk for Clash of Clans from a trusted and reputable source that has positive reviews and ratings from other users. You should also scan the mod apk with an antivirus or anti-malware software before installing it on your device. You should also backup your original game data and enable unknown sources on your device before installing the mod apk. You should also be careful not to abuse the mod features or violate the terms of service or policies of the original game or developer, as this may result in bans or legal actions.
- Is using a real server mod apk for Clash of Clans fair?
- Using a real server mod apk for Clash of Clans may not be fair for other players who play the game without any modifications or enhancements. You may have an unfair advantage over them in terms of resources, items, features, or gameplay. You may also ruin their experience or enjoyment of the game by using cheats, hacks, or mods that affect their gameplay. You should respect other players and play the game in a fair and ethical manner.
- Is using a real server mod apk for Clash of Clans permanent?
- Using a real server mod apk for Clash of Clans is not permanent, as you can always switch back to the original game if you want to. You can uninstall the mod apk from your device and restore your original game data from your backup. You can also update your original game app from the official app store or developer if there are any new updates or features available.
- Is using a real server mod apk for Clash of Clans worth it?
- Using a real server mod apk for Clash of Clans may be worth it for some players who want to have fun and experiment with different aspects of the game without worrying about the limitations or restrictions of the original game. It may also be worth it for some players who want to save time and money by getting unlimited resources and items without spending any real money or waiting for hours. However, it may not be worth it for some players who prefer the original experience and challenge of the game as it was intended by the developer. It may also not be worth it for some players who value their security, privacy, and fairness over their entertainment and enjoyment. Ultimately, it depends on your personal preference and perspective whether using a real server mod apk for Clash of Clans is worth it or not. 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/fatiXbelha/sd/Download Stickman The Flash APK Mod Menu with God Mode and Unlimited Power.md b/spaces/fatiXbelha/sd/Download Stickman The Flash APK Mod Menu with God Mode and Unlimited Power.md
deleted file mode 100644
index 3470adf1a0f484d28b9e56ad0fb8cf8c475fa02e..0000000000000000000000000000000000000000
--- a/spaces/fatiXbelha/sd/Download Stickman The Flash APK Mod Menu with God Mode and Unlimited Power.md
+++ /dev/null
@@ -1,118 +0,0 @@
-
-Stickman The Flash APK Mod Menu: A Guide for Gamers
- Do you love stickman games? Do you enjoy fast-paced action and epic battles? If yes, then you should try Stickman The Flash, a new game that will test your reflexes and skills. In this game, you will play as a stickman hero who has superpowers and can move faster than light. You will face various enemies and challenges in different modes and levels. You will also be able to customize your character and weapons with various upgrades and items.
-stickman the flash apk mod menu
Download … https://urllie.com/2uNyPX
- But what if you want to make the game more fun and easy? What if you want to have unlimited power, god mode, unlocked weapons, and more? Well, there is a way to do that. You can use Stickman The Flash APK Mod Menu, a modified version of the game that gives you access to many features and options that are not available in the original game. In this article, we will tell you everything you need to know about Stickman The Flash APK Mod Menu, including what it is, how to download and install it, and how to play the game with it. Let's get started!
- What is Stickman The Flash?
- Stickman The Flash is a 2D action game developed by StormHit Games. It was released in 2021 for Android devices. The game is inspired by the popular DC Comics superhero, The Flash, who can run at superhuman speeds and manipulate time. In the game, you will control a stickman version of The Flash, who has similar abilities and powers. You will use your speed, strength, and skills to fight against various enemies, such as robots, ninjas, zombies, aliens, and more. You will also encounter bosses and mini-bosses that will challenge your abilities.
- Features of Stickman The Flash
- Stickman The Flash has many features that make it an exciting and addictive game. Some of these features are:
-stickman the flash mod apk unlimited money
-stickman the flash mod apk download for android
-stickman the flash mod apk latest version 2023
-stickman the flash mod apk god mode unlocked
-stickman the flash mod apk free shopping
-stickman the flash mod apk no ads
-stickman the flash mod apk all weapons
-stickman the flash mod apk unlimited power
-stickman the flash mod apk offline
-stickman the flash mod apk hack
-stickman the flash mod menu apk download
-stickman the flash mod menu apk free
-stickman the flash mod menu apk 2023
-stickman the flash mod menu apk god mode
-stickman the flash mod menu apk unlimited money and power
-stickman the flash mod menu apk all characters
-stickman the flash mod menu apk no root
-stickman the flash mod menu apk latest update
-stickman the flash mod menu apk android 1
-stickman the flash mod menu apk revdl
-download stickman the flash apk mod menu for free
-download stickman the flash apk mod menu latest version
-download stickman the flash apk mod menu android 2023
-download stickman the flash apk mod menu god mode and unlimited power
-download stickman the flash apk mod menu unlocked everything
-download stickman the flash apk mod menu no verification
-download stickman the flash apk mod menu from mediafire
-download stickman the flash apk mod menu without ads
-how to install stickman the flash apk mod menu on android
-how to use stickman the flash apk mod menu features
-how to update stickman the flash apk mod menu 2023
-how to get stickman the flash apk mod menu for free
-how to hack stickman the flash with apk mod menu
-how to play stickman the flash with apk mod menu offline
-how to unlock all weapons in stickman the flash with apk mod menu
-best settings for stickman the flash apk mod menu 2023
-best tips and tricks for stickman the flash apk mod menu gameplay
-best guide and tutorial for stickman the flash apk mod menu installation and usage
-best review and rating for stickman the flash apk mod menu 2023
-
-- Simple and intuitive controls: You can control your character with just one finger. Tap to move, swipe to dash, and hold to charge your power.
-- Stunning graphics and animations: The game has colorful and detailed graphics that create a vivid and dynamic environment. The animations are smooth and realistic, showing the effects of your movements and attacks.
-- Various modes and levels: The game has different modes that offer different challenges and objectives. You can play in story mode, where you will follow the plot and complete missions. You can also play in survival mode, where you will face endless waves of enemies until you die. You can also play in arena mode, where you will fight against other players online.
-- Customizable character and weapons: You can customize your character's appearance, such as his hair, eyes, clothes, and accessories. You can also upgrade your weapons and skills with coins that you earn from playing the game. You can choose from different types of weapons, such as swords, guns, hammers, axes, etc.
-- Achievements and leaderboards: You can unlock various achievements by completing tasks and challenges in the game. You can also compete with other players on the leaderboards by scoring high points in each mode.
-
- How to play Stickman The Flash
- The gameplay of Stickman The Flash is simple but fun. Here are some basic steps on how to play the game:
-
-- Select a mode that you want to play.
-- Select a level or stage that you want to play.
-- Select a character and a weapon that you want to use.
-- Tap the screen to move your character.
-- Swipe the screen to dash or dodge.Hold the screen to charge your power and release it to unleash a special attack.
-- Defeat all the enemies and complete the objectives of each level or stage.
-- Earn coins and rewards for your performance.
-
- That's how you play Stickman The Flash. It's easy to learn but hard to master. You will need to use your reflexes, skills, and strategy to overcome the challenges and enemies in the game.
- What is Stickman The Flash APK Mod Menu?
- Stickman The Flash APK Mod Menu is a modified version of the original game that gives you access to many features and options that are not available in the original game. It is a file that you can download and install on your Android device. It will allow you to modify the game according to your preferences and needs.
- Benefits of using Stickman The Flash APK Mod Menu
- There are many benefits of using Stickman The Flash APK Mod Menu. Some of these benefits are:
-
-- You can have unlimited power, which means you can use your special attack as much as you want without waiting for it to recharge.
-- You can have god mode, which means you will not take any damage from enemies or obstacles.
-- You can have unlocked weapons, which means you can use any weapon in the game without buying or upgrading it.
-- You can have unlimited coins, which means you can buy and upgrade anything in the game without worrying about the cost.
-- You can have no ads, which means you will not see any annoying ads while playing the game.
-
- How to download and install Stickman The Flash APK Mod Menu
- Downloading and installing Stickman The Flash APK Mod Menu is easy and simple. Here are some steps on how to do it:
-
-- Go to a trusted website that provides the link to download Stickman The Flash APK Mod Menu. You can search for it on Google or use this link: .
-- Click on the download button and wait for the file to be downloaded on your device.
-- Go to your device's settings and enable the option to install apps from unknown sources. This will allow you to install the file that you downloaded.
-- Go to your device's file manager and locate the file that you downloaded. Tap on it and follow the instructions to install it.
-- Once the installation is done, you can launch the game and enjoy the mod menu features.
-
- Note: You may need to uninstall the original game before installing the mod menu version. Also, make sure that your device has enough space and meets the minimum requirements for the game.
- Tips and tricks for playing Stickman The Flash with APK Mod Menu
- Playing Stickman The Flash with APK Mod Menu can be very fun and easy. However, if you want to make the most out of it, here are some tips and tricks that you can follow:
- Use your powers wisely
- Even though you have unlimited power, you should still use it wisely. Don't spam your special attack all the time, as it may make the game boring and less challenging. Use it when you need it, such as when you face a boss or a large group of enemies. Also, don't forget to use your dash and dodge abilities, as they can help you avoid damage and move faster.
- Upgrade your weapons and skills
- Even though you have unlocked weapons, you should still upgrade them and your skills. Upgrading them will make them more powerful and effective, as well as give you more options and variety. You can also try different combinations of weapons and skills, such as using a sword with a gun, or using a hammer with a speed boost. Experiment with different styles and find what suits you best.
- Choose your character and mode
- Even though you have god mode, you should still choose your character and mode carefully. Choosing a different character will give you a different appearance and personality, as well as different stats and abilities. Choosing a different mode will give you a different challenge and objective, as well as different rewards and rankings. You can also switch between them anytime you want, so don't be afraid to try new things and have fun.
- Conclusion
- Stickman The Flash is a great game for anyone who loves stickman games, action games, or superhero games. It has simple but fun gameplay, stunning graphics and animations, various modes and levels, customizable character and weapons, achievements and leaderboards, and more. It is also free to play and download on Android devices.
- However, if you want to make the game more fun and easy, you can use Stickman The Flash APK Mod Menu, a modified version of the game that gives you access to many features and options that are not available in the original game. You can have unlimited power, god mode, unlocked weapons, unlimited coins, no ads, and more. You can also modify the game according to your preferences and needs.
- To use Stickman The Flash APK Mod Menu, you need to download and install it on your device. You can find the link to download it on a trusted website or use this link: . You also need to enable the option to install apps from unknown sources on your device's settings. Once you install it, you can launch the game and enjoy the mod menu features.
- Playing Stickman The Flash with APK Mod Menu can be very fun and easy, but you should still use some tips and tricks to make the most out of it. You should use your powers wisely, upgrade your weapons and skills, choose your character and mode, and have fun. You can also switch between the original game and the mod menu version anytime you want.
- We hope this article has helped you learn more about Stickman The Flash APK Mod Menu and how to use it. If you have any questions or feedback, feel free to leave a comment below. Thank you for reading!
- FAQs
- Here are some frequently asked questions about Stickman The Flash APK Mod Menu:
-
-- Is Stickman The Flash APK Mod Menu safe to use?
-Yes, Stickman The Flash APK Mod Menu is safe to use as long as you download it from a trusted website or source. However, you should always be careful when installing apps from unknown sources, as they may contain viruses or malware that can harm your device or data.
-- Is Stickman The Flash APK Mod Menu legal to use?
-No, Stickman The Flash APK Mod Menu is not legal to use, as it violates the terms and conditions of the original game. Using it may result in banning your account or losing your progress in the game. Therefore, we do not recommend using it for any purposes other than entertainment or education.
-- Does Stickman The Flash APK Mod Menu work on iOS devices?
-No, Stickman The Flash APK Mod Menu only works on Android devices. It is not compatible with iOS devices or any other platforms.
-- Can I play online with Stickman The Flash APK Mod Menu?
-Yes, you can play online with Stickman The Flash APK Mod Menu, but you may encounter some problems or issues. For example, you may not be able to connect with other players who are using the original game or a different version of the mod menu. You may also face lagging or crashing issues due to the mod menu features.
-- Can I update Stickman The Flash APK Mod Menu?
-Yes, you can update Stickman The Flash APK Mod Menu whenever there is a new version available. However, you may need to uninstall the previous version and install the new one manually. You may also lose some of your data or settings in the process.
- 197e85843d
-
-
\ No newline at end of file
diff --git "a/spaces/fb700/chatglm-fitness-RLHF/crazy_functions/\351\253\230\347\272\247\345\212\237\350\203\275\345\207\275\346\225\260\346\250\241\346\235\277.py" "b/spaces/fb700/chatglm-fitness-RLHF/crazy_functions/\351\253\230\347\272\247\345\212\237\350\203\275\345\207\275\346\225\260\346\250\241\346\235\277.py"
deleted file mode 100644
index 73ae45f240f346fec6bb1ec87a2616055e481827..0000000000000000000000000000000000000000
--- "a/spaces/fb700/chatglm-fitness-RLHF/crazy_functions/\351\253\230\347\272\247\345\212\237\350\203\275\345\207\275\346\225\260\346\250\241\346\235\277.py"
+++ /dev/null
@@ -1,52 +0,0 @@
-from toolbox import CatchException, update_ui
-from .crazy_utils import request_gpt_model_in_new_thread_with_ui_alive
-import datetime, re
-
-@CatchException
-def 高阶功能模板函数(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- """
- txt 输入栏用户输入的文本,例如需要翻译的一段话,再例如一个包含了待处理文件的路径
- llm_kwargs gpt模型参数,如温度和top_p等,一般原样传递下去就行
- plugin_kwargs 插件模型的参数,暂时没有用武之地
- chatbot 聊天显示框的句柄,用于显示给用户
- history 聊天历史,前情提要
- system_prompt 给gpt的静默提醒
- web_port 当前软件运行的端口号
- """
- history = [] # 清空历史,以免输入溢出
- chatbot.append(("这是什么功能?", "[Local Message] 请注意,您正在调用一个[函数插件]的模板,该函数面向希望实现更多有趣功能的开发者,它可以作为创建新功能函数的模板(该函数只有20多行代码)。此外我们也提供可同步处理大量文件的多线程Demo供您参考。您若希望分享新的功能模组,请不吝PR!"))
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 # 由于请求gpt需要一段时间,我们先及时地做一次界面更新
- for i in range(5):
- currentMonth = (datetime.date.today() + datetime.timedelta(days=i)).month
- currentDay = (datetime.date.today() + datetime.timedelta(days=i)).day
- i_say = f'历史中哪些事件发生在{currentMonth}月{currentDay}日?用中文列举两条,然后分别给出描述事件的两个英文单词。' + '当你给出关键词时,使用以下json格式:{"KeyWords":[EnglishKeyWord1,EnglishKeyWord2]}。'
- gpt_say = yield from request_gpt_model_in_new_thread_with_ui_alive(
- inputs=i_say, inputs_show_user=i_say,
- llm_kwargs=llm_kwargs, chatbot=chatbot, history=[],
- sys_prompt='输出格式示例:1908年,美国消防救援事业发展的“美国消防协会”成立。关键词:{"KeyWords":["Fire","American"]}。'
- )
- gpt_say = get_images(gpt_say)
- chatbot[-1] = (i_say, gpt_say)
- history.append(i_say);history.append(gpt_say)
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 # 界面更新
-
-
-def get_images(gpt_say):
- def get_image_by_keyword(keyword):
- import requests
- from bs4 import BeautifulSoup
- response = requests.get(f'https://wallhaven.cc/search?q={keyword}', timeout=2)
- for image_element in BeautifulSoup(response.content, 'html.parser').findAll("img"):
- if "data-src" in image_element: break
- return image_element["data-src"]
-
- for keywords in re.findall('{"KeyWords":\[(.*?)\]}', gpt_say):
- keywords = [n.strip('"') for n in keywords.split(',')]
- try:
- description = keywords[0]
- url = get_image_by_keyword(keywords[0])
- img_tag = f"\n\n"
- gpt_say += img_tag
- except:
- continue
- return gpt_say
\ No newline at end of file
diff --git a/spaces/fclong/summary/fengshen/examples/finetune_bart_qg/finetune_bart.sh b/spaces/fclong/summary/fengshen/examples/finetune_bart_qg/finetune_bart.sh
deleted file mode 100644
index ae88b230fa223c3d2c519e4f09cb1c703319af48..0000000000000000000000000000000000000000
--- a/spaces/fclong/summary/fengshen/examples/finetune_bart_qg/finetune_bart.sh
+++ /dev/null
@@ -1,97 +0,0 @@
-#!/bin/bash
-#SBATCH --job-name=bart_qg # create a short name for your job
-#SBATCH --nodes=1 # node count
-#SBATCH --ntasks-per-node=8 # number of tasks to run per node
-#SBATCH --cpus-per-task=10 # cpu-cores per task (>1 if multi-threaded tasks)
-#SBATCH --gres=gpu:1 # number of gpus per node
-#SBATCH -o %x-%j.log # output and error log file names (%x for job id)
-set -x -e
-
-MODEL_NAME=IDEA-CCNL/Randeng-BART-139M
-RUN_NAME=bart_v0_test
-ROOT_DIR=../../workspace/log/$RUN_NAME
-
-config_json="$ROOT_DIR/$MODEL_NAME.ds_config.json"
-export MASTER_PORT=$[RANDOM%10000+40000]
-
-MICRO_BATCH_SIZE=32
-
-cat < $config_json
-{
- "train_micro_batch_size_per_gpu": $MICRO_BATCH_SIZE,
- "gradient_clipping": 1,
- "zero_optimization": {
- "stage": 1
- },
- "fp16": {
- "enabled": true,
- }
-}
-EOT
-export PL_DEEPSPEED_CONFIG_PATH=$config_json
-export TORCH_EXTENSIONS_DIR=../../workspace/torch_extensions
-
-DATA_ARGS=" \
- --train_file train.json \
- --val_file dev.json \
- --test_file test.json \
- --tokenizer_type bart \
- --num_workers 8 \
- --dataloader_workers 2 \
- --train_batchsize $MICRO_BATCH_SIZE \
- --val_batchsize $MICRO_BATCH_SIZE \
- --test_batchsize $MICRO_BATCH_SIZE \
- --max_seq_lengt 512 \
- --max_src_length 32 \
- --max_kno_length 416 \
- --max_tgt_length 64 \
- --mask_ans_style anstoken_multispan \
- "
-
-MODEL_ARGS="\
- --model_path $MODEL_NAME/ \
- --learning_rate 1e-4 \
- --min_learning_rate 1e-8 \
- --lr_decay_steps 100000 \
- --weight_decay 1e-2 \
- --warmup_steps 1000 \
- "
-
-MODEL_CHECKPOINT_ARGS="\
- --monitor val_loss \
- --save_top_k 3 \
- --mode min \
- --save_last \
- --every_n_train_steps 5000 \
- --save_ckpt_path $ROOT_DIR/ckpt/ \
- --load_ckpt_path $ROOT_DIR/ckpt/ \
- --filename model-{step:02d}-{train_loss:.4f} \
- "
-
-TRAINER_ARGS="\
- --gradient_clip_val 1.0 \
- --max_epochs 1 \
- --gpus 1 \
- --num_nodes 1 \
- --strategy ddp \
- --log_every_n_steps 100 \
- --val_check_interval 0.5 \
- --accumulate_grad_batches 1 \
- --default_root_dir $ROOT_DIR \
- --tensorboard_dir $ROOT_DIR \
- --label_smooth 0.1 \
- "
-
-
-
-export options=" \
- $DATA_ARGS \
- $MODEL_ARGS \
- $MODEL_CHECKPOINT_ARGS \
- $TRAINER_ARGS \
- "
-# test
-export SCRIPT_PATH=./finetune_bart.py
-
-python3 ${SCRIPT_PATH} $options > $ROOT_DIR/test.log
-
diff --git a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Bingotingo A Simple and Fast LinkedIn Video Downloader.md b/spaces/feregVcuzo/sanity-test-midi/checkpoint/Bingotingo A Simple and Fast LinkedIn Video Downloader.md
deleted file mode 100644
index e0947f0fb988d8a3e3f3dce791d06ca6d3379d9b..0000000000000000000000000000000000000000
--- a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Bingotingo A Simple and Fast LinkedIn Video Downloader.md
+++ /dev/null
@@ -1,127 +0,0 @@
-
-How to Download LinkedIn Video with BingoTingo
-LinkedIn is one of the most popular social media platforms for professionals and businesses. It allows you to share your expertise, network with others, and discover new opportunities. But did you know that you can also share and watch videos on LinkedIn?
-In this article, we will show you how to download LinkedIn video with BingoTingo, a free online video downloader that lets you save any video from any website in seconds. Whether you want to watch a video offline, share it with your friends, or use it for your own projects, BingoTingo can help you do it easily and quickly.
-bingotingo how to download linkedin video
Download Zip — https://gohhs.com/2uPuaQ
-What is LinkedIn Video?
-LinkedIn video is a feature that allows you to upload and share videos on your LinkedIn profile, page, or group. You can also watch videos posted by other users on your feed or search for videos by topic or hashtag.
-LinkedIn video can be used for various purposes, such as:
-
-- Showing your work or portfolio
-- Demonstrating your skills or knowledge
-- Sharing your insights or opinions
-- Promoting your products or services
-- Engaging with your audience or customers
-- Learning from experts or influencers
-
-Why Download LinkedIn Video?
-Downloading LinkedIn video can be useful for many reasons, such as:
-
-- You can watch it offline without internet connection
-- You can save it on your device for future reference
-- You can edit it or add subtitles or captions
-- You can share it on other platforms or channels
-- You can use it for your own presentations or projects
-
-What is BingoTingo?
-BingoTingo is a free online video downloader that allows you to download any video from any website in seconds. You don't need to install any software or register any account. You just need to copy and paste the URL of the video you want to download and BingoTingo will do the rest for you.
-How BingoTingo Works
-BingoTingo works by extracting the video source from the URL you provide and converting it into a downloadable file. You can choose from various formats and quality options, such as MP4, WEBM, 3GP, 720p, 480p, 360p, etc. You can also preview the video before downloading it.
-Benefits of BingoTingo
-BingoTingo has many benefits over other video downloaders, such as:
-bingotingo linkedin video downloader online
-bingotingo how to save linkedin videos to computer
-bingotingo best way to download videos from linkedin
-bingotingo how to copy video link from linkedin
-bingotingo how to download linkedin learning videos
-bingotingo how to download linkedin live videos
-bingotingo how to download videos from linkedin app
-bingotingo how to download videos from linkedin messages
-bingotingo how to download videos from linkedin profile
-bingotingo how to download videos from linkedin feed
-bingotingo how to download videos from linkedin pulse
-bingotingo how to download videos from linkedin groups
-bingotingo how to download videos from linkedin stories
-bingotingo how to download videos from linkedin ads
-bingotingo how to download videos from linkedin events
-bingotingo free tool for downloading linkedin videos
-bingotingo easy steps for downloading linkedin videos
-bingotingo guide for downloading linkedin videos in 2023
-bingotingo tips and tricks for downloading linkedin videos
-bingotingo benefits of downloading linkedin videos
-bingotingo why you should download linkedin videos
-bingotingo what you can do with downloaded linkedin videos
-bingotingo how to edit downloaded linkedin videos
-bingotingo how to share downloaded linkedin videos
-bingotingo how to upload downloaded linkedin videos
-bingotingo how to convert downloaded linkedin videos to different formats
-bingotingo how to compress downloaded linkedin videos
-bingotingo how to optimize downloaded linkedin videos for SEO
-bingotingo how to use downloaded linkedin videos for marketing
-bingotingo how to use downloaded linkedin videos for education
-bingotingo how to use downloaded linkedin videos for entertainment
-bingotingo how to use downloaded linkedin videos for inspiration
-bingotingo how to use downloaded linkedin videos for networking
-bingotingo how to use downloaded linkedin videos for personal branding
-bingotingo how to use downloaded linkedin videos for social media
-bingotingo alternatives to downloading linkedin videos
-bingotingo pros and cons of downloading linkedin videos
-bingotingo reviews of downloading linkedin videos with bingotingo
-bingotingo testimonials of downloading linkedin videos with bingotingo
-bingotingo case studies of downloading linkedin videos with bingotingo
-bingotingo FAQs of downloading linkedin videos with bingotingo
-bingotingo features of downloading linkedin videos with bingotingo
-bingotingo pricing of downloading linkedin videos with bingotingo
-bingotingo support of downloading linkedin videos with bingotingo
-bingotingo comparison of downloading linkedin videos with other tools
-bingotingo challenges of downloading linkedin videos with other tools
-bingotingo solutions of downloading linkedin videos with other tools
-bingotingo recommendations of downloading linkedin videos with other tools
-bingotingo best practices of downloading linkedin videos with other tools
-
-- It is free and unlimited
-- It is fast and easy
-- It supports any website and any device
-- It does not require any installation or registration
-- It does not contain any ads or malware
-- It respects your privacy and security
-
-How to Download LinkedIn Video with BingoTingo
-Downloading LinkedIn video with BingoTingo is very simple and straightforward. You just need to follow these five steps:
-Step 1: Find the LinkedIn Video You Want to Download
-The first step is to find the LinkedIn video you want to download. You can do this by browsing your feed, searching by topic or hashtag, or visiting a specific profile, page, or group. Once you find the video, click on it to open it in a new tab.
-Step 2: Copy the URL of the LinkedIn Video
-The second step is to copy the URL of the LinkedIn video. You can do this by selecting the address bar of your browser and pressing Ctrl+C (Windows) or Command+C (Mac). Alternatively, you can right-click on the video and choose Copy Video URL from the menu.
-Step 3: Paste the URL into BingoTingo's Search Box
-The third step is to paste the URL into BingoTingo's search box. You can do this by visiting bingotingo.com, clicking on the search box, and pressing Ctrl+V (Windows) or Command+V (Mac). Alternatively, you can right-click on the search box and choose Paste from the menu.
-Step 4: Choose Your Preferred Format and Quality
-The fourth step is to choose your preferred format and quality for your downloaded video. You can do this by clicking on the drop-down menu next to the search box and selecting one of the available options. You can also preview the video by clicking on the Play button.
-Step 5: Click on Download and Enjoy Your Video
-The fifth and final step is to click on the Download button and enjoy your video. You can do this by clicking on the green Download button below the preview window. Your video will start downloading automatically to your device. You can then watch it offline, share it with others, or use it for your own purposes.
-Tips and Tricks for Downloading LinkedIn Video with BingoTingo
-To make your experience of downloading LinkedIn video with BingoTingo even better, here are some tips and tricks you can follow:
-Use a Reliable Internet Connection
-To ensure a smooth and fast download process, make sure you have a reliable internet connection. Avoid using public Wi-Fi networks or mobile data that may be slow or unstable. If possible, use a wired connection or a strong Wi-Fi signal.
-Check the Video Permissions Before Downloading
-To respect the rights of the video creators and avoid any legal issues, check the video permissions before downloading. Some videos may be private, restricted, or copyrighted. In that case, you may need to ask for permission from the video owner or follow the terms and conditions of LinkedIn. You can check the video permissions by clicking on the three dots icon on the top right corner of the video and choosing View Video Details from the menu.
-Use a Good Video Player to Watch Your Downloaded Videos
-To enjoy your downloaded videos in the best quality and performance, use a good video player to watch them. Some video players may not support certain formats or quality options, or may have issues with playback or sound. We recommend using VLC Media Player, which is a free and versatile video player that supports almost any format and quality.
-Conclusion
-Downloading LinkedIn video with BingoTingo is a great way to save and watch any video from LinkedIn offline, share it with others, or use it for your own projects. BingoTingo is a free, fast, and easy online video downloader that supports any website and any device. You just need to copy and paste the URL of the video you want to download and choose your preferred format and quality. BingoTingo will do the rest for you in seconds.
-We hope this article has helped you learn how to download LinkedIn video with BingoTingo. If you have any questions or feedback, please feel free to contact us or leave a comment below. We would love to hear from you.
-FAQs
-Here are some frequently asked questions about downloading LinkedIn video with BingoTingo:
-
-- Is BingoTingo safe to use?
-Yes, BingoTingo is safe to use. It does not contain any ads or malware, and it does not collect or store any of your personal data or information. It also respects your privacy and security by using encryption and HTTPS protocols.
-- Can I download LinkedIn live videos with BingoTingo?
-Yes, you can download LinkedIn live videos with BingoTingo. However, you need to wait until the live stream is over and the video is available on the website. Then, you can follow the same steps as described above to download it.
-- Can I download multiple LinkedIn videos at once with BingoTingo?
-No, you cannot download multiple LinkedIn videos at once with BingoTingo. You need to download each video individually by copying and pasting its URL into BingoTingo's search box. However, you can open multiple tabs or windows of BingoTingo and download different videos simultaneously.
-- Can I download LinkedIn videos on my mobile device with BingoTingo?
-Yes, you can download LinkedIn videos on your mobile device with BingoTingo. You can use any browser on your smartphone or tablet to access bingotingo.com and follow the same steps as described above to download any video from LinkedIn.
-- Can I download LinkedIn videos in HD quality with BingoTingo?
-Yes, you can download LinkedIn videos in HD quality with BingoTingo. You can choose from various quality options, such as 720p, 1080p, or 4K, depending on the availability of the video source. However, keep in mind that higher quality videos will take longer to download and occupy more space on your device.
- 197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/fffiloni/Music_Source_Separation/bytesep/plot_results/musdb18.py b/spaces/fffiloni/Music_Source_Separation/bytesep/plot_results/musdb18.py
deleted file mode 100644
index eb91faa60b79f0f34aba1bb4810c2be7be8438f3..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/Music_Source_Separation/bytesep/plot_results/musdb18.py
+++ /dev/null
@@ -1,198 +0,0 @@
-import argparse
-import os
-import pickle
-
-import matplotlib.pyplot as plt
-import numpy as np
-
-
-def load_sdrs(workspace, task_name, filename, config, gpus, source_type):
-
- stat_path = os.path.join(
- workspace,
- "statistics",
- task_name,
- filename,
- "config={},gpus={}".format(config, gpus),
- "statistics.pkl",
- )
-
- stat_dict = pickle.load(open(stat_path, 'rb'))
-
- median_sdrs = [e['median_sdr_dict'][source_type] for e in stat_dict['test']]
-
- return median_sdrs
-
-
-def plot_statistics(args):
-
- # arguments & parameters
- workspace = args.workspace
- select = args.select
- task_name = "musdb18"
- filename = "train"
-
- # paths
- fig_path = os.path.join('results', task_name, "sdr_{}.pdf".format(select))
- os.makedirs(os.path.dirname(fig_path), exist_ok=True)
-
- linewidth = 1
- lines = []
- fig, ax = plt.subplots(1, 1, figsize=(8, 6))
-
- if select == '1a':
- sdrs = load_sdrs(
- workspace,
- task_name,
- filename,
- config='vocals-accompaniment,unet',
- gpus=1,
- source_type="vocals",
- )
- (line,) = ax.plot(sdrs, label='UNet,l1_wav', linewidth=linewidth)
- lines.append(line)
- ylim = 15
-
- elif select == '1b':
- sdrs = load_sdrs(
- workspace,
- task_name,
- filename,
- config='accompaniment-vocals,unet',
- gpus=1,
- source_type="accompaniment",
- )
- (line,) = ax.plot(sdrs, label='UNet,l1_wav', linewidth=linewidth)
- lines.append(line)
- ylim = 20
-
- if select == '1c':
- sdrs = load_sdrs(
- workspace,
- task_name,
- filename,
- config='vocals-accompaniment,unet',
- gpus=1,
- source_type="vocals",
- )
- (line,) = ax.plot(sdrs, label='UNet,l1_wav', linewidth=linewidth)
- lines.append(line)
-
- sdrs = load_sdrs(
- workspace,
- task_name,
- filename,
- config='vocals-accompaniment,resunet',
- gpus=2,
- source_type="vocals",
- )
- (line,) = ax.plot(sdrs, label='ResUNet_ISMIR2021,l1_wav', linewidth=linewidth)
- lines.append(line)
-
- sdrs = load_sdrs(
- workspace,
- task_name,
- filename,
- config='vocals-accompaniment,unet_subbandtime',
- gpus=1,
- source_type="vocals",
- )
- (line,) = ax.plot(sdrs, label='unet_subband,l1_wav', linewidth=linewidth)
- lines.append(line)
-
- sdrs = load_sdrs(
- workspace,
- task_name,
- filename,
- config='vocals-accompaniment,resunet_subbandtime',
- gpus=1,
- source_type="vocals",
- )
- (line,) = ax.plot(sdrs, label='resunet_subband,l1_wav', linewidth=linewidth)
- lines.append(line)
-
- ylim = 15
-
- elif select == '1d':
- sdrs = load_sdrs(
- workspace,
- task_name,
- filename,
- config='accompaniment-vocals,unet',
- gpus=1,
- source_type="accompaniment",
- )
- (line,) = ax.plot(sdrs, label='UNet,l1_wav', linewidth=linewidth)
- lines.append(line)
-
- sdrs = load_sdrs(
- workspace,
- task_name,
- filename,
- config='accompaniment-vocals,resunet',
- gpus=2,
- source_type="accompaniment",
- )
- (line,) = ax.plot(sdrs, label='ResUNet_ISMIR2021,l1_wav', linewidth=linewidth)
- lines.append(line)
-
- # sdrs = load_sdrs(
- # workspace,
- # task_name,
- # filename,
- # config='accompaniment-vocals,unet_subbandtime',
- # gpus=1,
- # source_type="accompaniment",
- # )
- # (line,) = ax.plot(sdrs, label='UNet_subbtandtime,l1_wav', linewidth=linewidth)
- # lines.append(line)
-
- sdrs = load_sdrs(
- workspace,
- task_name,
- filename,
- config='accompaniment-vocals,resunet_subbandtime',
- gpus=1,
- source_type="accompaniment",
- )
- (line,) = ax.plot(
- sdrs, label='ResUNet_subbtandtime,l1_wav', linewidth=linewidth
- )
- lines.append(line)
-
- ylim = 20
-
- else:
- raise Exception('Error!')
-
- eval_every_iterations = 10000
- total_ticks = 50
- ticks_freq = 10
-
- ax.set_ylim(0, ylim)
- ax.set_xlim(0, total_ticks)
- ax.xaxis.set_ticks(np.arange(0, total_ticks + 1, ticks_freq))
- ax.xaxis.set_ticklabels(
- np.arange(
- 0,
- total_ticks * eval_every_iterations + 1,
- ticks_freq * eval_every_iterations,
- )
- )
- ax.yaxis.set_ticks(np.arange(ylim + 1))
- ax.yaxis.set_ticklabels(np.arange(ylim + 1))
- ax.grid(color='b', linestyle='solid', linewidth=0.3)
- plt.legend(handles=lines, loc=4)
-
- plt.savefig(fig_path)
- print('Save figure to {}'.format(fig_path))
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--workspace', type=str, required=True)
- parser.add_argument('--select', type=str, required=True)
-
- args = parser.parse_args()
-
- plot_statistics(args)
diff --git a/spaces/fffiloni/SplitTrack2MusicGen/tests/utils/__init__.py b/spaces/fffiloni/SplitTrack2MusicGen/tests/utils/__init__.py
deleted file mode 100644
index 0952fcc3f57e34b3747962e9ebd6fc57aeea63fa..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/SplitTrack2MusicGen/tests/utils/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
diff --git a/spaces/fffiloni/audioldm-text-to-audio-generation-copy/audioldm/clap/training/lp_train.py b/spaces/fffiloni/audioldm-text-to-audio-generation-copy/audioldm/clap/training/lp_train.py
deleted file mode 100644
index 24a19bacd0a4b789415cfccbce1f8bc99bc493ed..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/audioldm-text-to-audio-generation-copy/audioldm/clap/training/lp_train.py
+++ /dev/null
@@ -1,301 +0,0 @@
-import json
-import logging
-import math
-import os
-import time
-from contextlib import suppress
-
-import numpy as np
-import torch
-import torch.nn.functional as F
-
-try:
- import wandb
-except ImportError:
- wandb = None
-
-from open_clip import LPLoss, LPMetrics, lp_gather_features
-from open_clip.utils import do_mixup, get_mix_lambda
-from .distributed import is_master
-from .zero_shot import zero_shot_eval
-
-
-class AverageMeter(object):
- """Computes and stores the average and current value"""
-
- def __init__(self):
- self.reset()
-
- def reset(self):
- self.val = 0
- self.avg = 0
- self.sum = 0
- self.count = 0
-
- def update(self, val, n=1):
- self.val = val
- self.sum += val * n
- self.count += n
- self.avg = self.sum / self.count
-
-
-def unwrap_model(model):
- if hasattr(model, "module"):
- return model.module
- else:
- return model
-
-
-def train_one_epoch(
- model,
- data,
- epoch,
- optimizer,
- scaler,
- scheduler,
- args,
- tb_writer=None,
- extra_suffix="",
-):
- device = torch.device(args.device)
- autocast = torch.cuda.amp.autocast if args.precision == "amp" else suppress
- model.train()
- loss = LPLoss(args.lp_loss)
-
- dataloader, sampler = data["train"].dataloader, data["train"].sampler
- if args.distributed and sampler is not None:
- sampler.set_epoch(epoch)
- num_batches_per_epoch = dataloader.num_batches
- sample_digits = math.ceil(math.log(dataloader.num_samples + 1, 10))
-
- # for toy dataset
- if args.dataset_type == "toy":
- dataloader.dataset.generate_queue()
-
- loss_m = AverageMeter()
- batch_time_m = AverageMeter()
- data_time_m = AverageMeter()
- end = time.time()
-
- for i, batch in enumerate(dataloader):
- step = num_batches_per_epoch * epoch + i
-
- if isinstance(scheduler, dict):
- for s in scheduler.values():
- s(step)
- else:
- scheduler(step)
-
- audio = batch # contains mel_spec, wavform, and longer list
- class_label = batch["class_label"]
- # audio = audio.to(device=device, non_blocking=True)
- class_label = class_label.to(device=device, non_blocking=True)
-
- if args.mixup:
- # https://github.com/RetroCirce/HTS-Audio-Transformer/blob/main/utils.py#L146
- mix_lambda = torch.from_numpy(
- get_mix_lambda(0.5, len(audio["waveform"]))
- ).to(device)
- class_label = do_mixup(class_label, mix_lambda)
- else:
- mix_lambda = None
-
- data_time_m.update(time.time() - end)
- if isinstance(optimizer, dict):
- for o_ in optimizer.values():
- o_.zero_grad()
- else:
- optimizer.zero_grad()
-
- with autocast():
- pred = model(audio, mix_lambda=mix_lambda, device=device)
- total_loss = loss(pred, class_label)
-
- if isinstance(optimizer, dict):
- if scaler is not None:
- scaler.scale(total_loss).backward()
- for o_ in optimizer.values():
- if args.horovod:
- o_.synchronize()
- scaler.unscale_(o_)
- with o_.skip_synchronize():
- scaler.step(o_)
- else:
- scaler.step(o_)
- scaler.update()
- else:
- total_loss.backward()
- for o_ in optimizer.values():
- o_.step()
- else:
- if scaler is not None:
- scaler.scale(total_loss).backward()
- if args.horovod:
- optimizer.synchronize()
- scaler.unscale_(optimizer)
- with optimizer.skip_synchronize():
- scaler.step(optimizer)
- else:
- scaler.step(optimizer)
- scaler.update()
- else:
- total_loss.backward()
- optimizer.step()
-
- # Note: we clamp to 4.6052 = ln(100), as in the original paper.
- with torch.no_grad():
- unwrap_model(model).clap_model.logit_scale_a.clamp_(0, math.log(100))
- unwrap_model(model).clap_model.logit_scale_t.clamp_(0, math.log(100))
-
- batch_time_m.update(time.time() - end)
- end = time.time()
- batch_count = i + 1
-
- if is_master(args) and (i % 100 == 0 or batch_count == num_batches_per_epoch):
- if isinstance(audio, dict):
- batch_size = len(audio["waveform"])
- else:
- batch_size = len(audio)
- num_samples = batch_count * batch_size * args.world_size
- samples_per_epoch = dataloader.num_samples
- percent_complete = 100.0 * batch_count / num_batches_per_epoch
-
- # NOTE loss is coarsely sampled, just master node and per log update
- loss_m.update(total_loss.item(), batch_size)
- if isinstance(optimizer, dict):
- logging.info(
- f"Train Epoch: {epoch} [{num_samples:>{sample_digits}}/{samples_per_epoch} ({percent_complete:.0f}%)] "
- f"Loss: {loss_m.val:#.5g} ({loss_m.avg:#.4g}) "
- f"Data (t): {data_time_m.avg:.3f} "
- f"Batch (t): {batch_time_m.avg:.3f} "
- f"LR: {[o_.param_groups[0]['lr'] for o_ in optimizer.values()]}"
- )
- log_data = {
- "loss": loss_m.val,
- "data_time": data_time_m.val,
- "batch_time": batch_time_m.val,
- "lr": [o_.param_groups[0]["lr"] for o_ in optimizer.values()],
- }
- else:
- logging.info(
- f"Train Epoch: {epoch} [{num_samples:>{sample_digits}}/{samples_per_epoch} ({percent_complete:.0f}%)] "
- f"Loss: {loss_m.val:#.5g} ({loss_m.avg:#.4g}) "
- f"Data (t): {data_time_m.avg:.3f} "
- f"Batch (t): {batch_time_m.avg:.3f} "
- f"LR: {optimizer.param_groups[0]['lr']:5f} "
- )
-
- # Save train loss / etc. Using non avg meter values as loggers have their own smoothing
- log_data = {
- "loss": loss_m.val,
- "data_time": data_time_m.val,
- "batch_time": batch_time_m.val,
- "lr": optimizer.param_groups[0]["lr"],
- }
- for name, val in log_data.items():
- name = f"train{extra_suffix}/{name}"
- if tb_writer is not None:
- tb_writer.add_scalar(name, val, step)
- if args.wandb:
- assert wandb is not None, "Please install wandb."
- wandb.log({name: val, "step": step})
-
- # resetting batch / data time meters per log window
- batch_time_m.reset()
- data_time_m.reset()
- # end for
-
-
-def evaluate(model, data, epoch, args, tb_writer=None, extra_suffix=""):
- metrics = {}
- if not args.parallel_eval:
- if not is_master(args):
- return metrics
- device = torch.device(args.device)
- model.eval()
-
- # CHANGE
- # zero_shot_metrics = zero_shot_eval(model, data, epoch, args)
- # metrics.update(zero_shot_metrics)
- if is_master(args):
- print("Evaluating...")
- metric_names = args.lp_metrics.split(",")
- eval_tool = LPMetrics(metric_names=metric_names)
-
- autocast = torch.cuda.amp.autocast if args.precision == "amp" else suppress
- if "val" in data and (
- args.val_frequency
- and ((epoch % args.val_frequency) == 0 or epoch == args.epochs)
- ):
- if args.parallel_eval:
- dataloader, sampler = data["val"].dataloader, data["val"].sampler
- if args.distributed and sampler is not None:
- sampler.set_epoch(epoch)
- samples_per_val = dataloader.num_samples
- else:
- dataloader = data["val"].dataloader
- num_samples = 0
- samples_per_val = dataloader.num_samples
-
- eval_info = {"pred": [], "target": []}
- with torch.no_grad():
- for i, batch in enumerate(dataloader):
- audio = batch # contains mel_spec, wavform, and longer list
- class_label = batch["class_label"]
-
- # audio = audio.to(device=device, non_blocking=True)
- class_label = class_label.to(device=device, non_blocking=True)
-
- with autocast():
- pred = model(audio, device=device)
- if args.parallel_eval:
- pred, class_label = lp_gather_features(
- pred, class_label, args.world_size, args.horovod
- )
- eval_info["pred"].append(pred)
- eval_info["target"].append(class_label)
-
- num_samples += class_label.shape[0]
-
- if (i % 100) == 0: # and i != 0:
- logging.info(
- f"Eval Epoch: {epoch} [{num_samples} / {samples_per_val}]"
- )
-
- if is_master(args):
- eval_info["pred"] = torch.cat(eval_info["pred"], 0).cpu()
- eval_info["target"] = torch.cat(eval_info["target"], 0).cpu()
- metric_dict = eval_tool.evaluate_mertics(
- eval_info["pred"], eval_info["target"]
- )
- metrics.update(metric_dict)
- if "epoch" not in metrics.keys():
- metrics.update({"epoch": epoch})
-
- if is_master(args):
- if not metrics:
- return metrics
-
- logging.info(
- f"Eval Epoch: {epoch} "
- + "\n".join(
- ["\t".join([f"{m}: {round(metrics[m], 4):.4f}"]) for m in metrics]
- )
- )
- if args.save_logs:
- for name, val in metrics.items():
- if tb_writer is not None:
- tb_writer.add_scalar(f"val{extra_suffix}/{name}", val, epoch)
-
- with open(os.path.join(args.checkpoint_path, "results.jsonl"), "a+") as f:
- f.write(json.dumps(metrics))
- f.write("\n")
-
- if args.wandb:
- assert wandb is not None, "Please install wandb."
- for name, val in metrics.items():
- wandb.log({f"val{extra_suffix}/{name}": val, "epoch": epoch})
-
- return metrics
- else:
- return metrics
diff --git a/spaces/fffiloni/instant-TTS-Bark-cloning/README.md b/spaces/fffiloni/instant-TTS-Bark-cloning/README.md
deleted file mode 100644
index 900b006e17eeab3c485722571d87875989c12aa3..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/instant-TTS-Bark-cloning/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Coqui Bark Voice Cloning
-emoji: 🐸🐶
-colorFrom: yellow
-colorTo: gray
-python_version: 3.10.12
-sdk: gradio
-sdk_version: 3.50.2
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/fffiloni/sd-img-variations/app.py b/spaces/fffiloni/sd-img-variations/app.py
deleted file mode 100644
index a1f219ab043065d045d5e5f3451e55305c787aba..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/sd-img-variations/app.py
+++ /dev/null
@@ -1,87 +0,0 @@
-import gradio as gr
-import torch
-from PIL import Image
-
-from lambda_diffusers import StableDiffusionImageEmbedPipeline
-
-def ask(input_im, scale, steps, seed, images):
- images = images
- generator = torch.Generator(device=device).manual_seed(int(seed))
-
- images_list = pipe(
- 2*[input_im],
- guidance_scale=scale,
- num_inference_steps=steps,
- generator=generator,
- )
-
- for i, image in enumerate(images_list["sample"]):
- if(images_list["nsfw_content_detected"][i]):
- safe_image = Image.open(r"unsafe.png")
- images.append(safe_image)
- else:
- images.append(image)
- return images
-
-def main(input_im, n_pairs, scale, steps, seed):
- print('Start the magic !')
- images = []
- for i in range(n_pairs):
- print('Asking for a new pair of image [' + str(i + 1) + '/' + str(n_pairs) + ']')
- seed = seed+i
- images = ask(input_im, scale, steps, seed, images)
- print('Thanks to Sylvain, it worked like a charm!')
- return images
-
-device = "cuda" if torch.cuda.is_available() else "cpu"
-pipe = StableDiffusionImageEmbedPipeline.from_pretrained(
- "lambdalabs/sd-image-variations-diffusers",
- revision="273115e88df42350019ef4d628265b8c29ef4af5",
- )
-pipe = pipe.to(device)
-
-inputs = [
- gr.Image(),
- gr.Slider(1, 3, value=2, step=1, label="Pairs of images to ask"),
- gr.Slider(0, 25, value=3, step=1, label="Guidance scale"),
- gr.Slider(5, 50, value=25, step=5, label="Steps"),
- gr.Slider(label = "Seed", minimum = 0, maximum = 2147483647, step = 1, randomize = True)
-]
-output = gr.Gallery(label="Generated variations")
-output.style(grid=2, height="")
-
-description = \
-"""
-This demo is running on CPU. Working version fixed by Sylvain @fffiloni. You'll get n pairs of images variations.
-Asking for pairs of images instead of more than 2 images in a row helps us to avoid heavy CPU load and connection error out ;)
-Waiting time (for 2 pairs): ~5/10 minutes • NSFW filters enabled • 
-Generate variations on an input image using a fine-tuned version of Stable Diffusion.
-Trained by Justin Pinkney (@Buntworthy) at Lambda
-This version has been ported to 🤗 Diffusers library, see more details on how to use this version in the Lambda Diffusers repo.
-For the original training code see this repo.
- -
-
-"""
-
-article = \
-"""
-—
-## How does this work?
-The normal Stable Diffusion model is trained to be conditioned on text input. This version has had the original text encoder (from CLIP) removed, and replaced with
-the CLIP _image_ encoder instead. So instead of generating images based a text input, images are generated to match CLIP's embedding of the image.
-This creates images which have the same rough style and content, but different details, in particular the composition is generally quite different.
-This is a totally different approach to the img2img script of the original Stable Diffusion and gives very different results.
-The model was fine tuned on the [LAION aethetics v2 6+ dataset](https://laion.ai/blog/laion-aesthetics/) to accept the new conditioning.
-Training was done on 4xA6000 GPUs on [Lambda GPU Cloud](https://lambdalabs.com/service/gpu-cloud).
-More details on the method and training will come in a future blog post.
-"""
-
-demo = gr.Interface(
- fn=main,
- title="Stable Diffusion Image Variations",
- inputs=inputs,
- outputs=output,
- description=description,
- article=article
- )
-demo.launch()
diff --git "a/spaces/fkhuggingme/gpt-academic/crazy_functions/\350\247\243\346\236\220\351\241\271\347\233\256\346\272\220\344\273\243\347\240\201.py" "b/spaces/fkhuggingme/gpt-academic/crazy_functions/\350\247\243\346\236\220\351\241\271\347\233\256\346\272\220\344\273\243\347\240\201.py"
deleted file mode 100644
index 49f41b18b986d229d4dd91aa6a0be74dee6d1296..0000000000000000000000000000000000000000
--- "a/spaces/fkhuggingme/gpt-academic/crazy_functions/\350\247\243\346\236\220\351\241\271\347\233\256\346\272\220\344\273\243\347\240\201.py"
+++ /dev/null
@@ -1,310 +0,0 @@
-from toolbox import update_ui
-from toolbox import CatchException, report_execption, write_results_to_file
-from .crazy_utils import input_clipping
-
-def 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt):
- import os, copy
- from .crazy_utils import request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency
- from .crazy_utils import request_gpt_model_in_new_thread_with_ui_alive
- msg = '正常'
- inputs_array = []
- inputs_show_user_array = []
- history_array = []
- sys_prompt_array = []
- report_part_1 = []
-
- assert len(file_manifest) <= 512, "源文件太多(超过512个), 请缩减输入文件的数量。或者,您也可以选择删除此行警告,并修改代码拆分file_manifest列表,从而实现分批次处理。"
- ############################## <第一步,逐个文件分析,多线程> ##################################
- for index, fp in enumerate(file_manifest):
- # 读取文件
- with open(fp, 'r', encoding='utf-8', errors='replace') as f:
- file_content = f.read()
- prefix = "接下来请你逐文件分析下面的工程" if index==0 else ""
- i_say = prefix + f'请对下面的程序文件做一个概述文件名是{os.path.relpath(fp, project_folder)},文件代码是 ```{file_content}```'
- i_say_show_user = prefix + f'[{index}/{len(file_manifest)}] 请对下面的程序文件做一个概述: {os.path.abspath(fp)}'
- # 装载请求内容
- inputs_array.append(i_say)
- inputs_show_user_array.append(i_say_show_user)
- history_array.append([])
- sys_prompt_array.append("你是一个程序架构分析师,正在分析一个源代码项目。你的回答必须简单明了。")
-
- # 文件读取完成,对每一个源代码文件,生成一个请求线程,发送到chatgpt进行分析
- gpt_response_collection = yield from request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency(
- inputs_array = inputs_array,
- inputs_show_user_array = inputs_show_user_array,
- history_array = history_array,
- sys_prompt_array = sys_prompt_array,
- llm_kwargs = llm_kwargs,
- chatbot = chatbot,
- show_user_at_complete = True
- )
-
- # 全部文件解析完成,结果写入文件,准备对工程源代码进行汇总分析
- report_part_1 = copy.deepcopy(gpt_response_collection)
- history_to_return = report_part_1
- res = write_results_to_file(report_part_1)
- chatbot.append(("完成?", "逐个文件分析已完成。" + res + "\n\n正在开始汇总。"))
- yield from update_ui(chatbot=chatbot, history=history_to_return) # 刷新界面
-
- ############################## <第二步,综合,单线程,分组+迭代处理> ##################################
- batchsize = 16 # 10个文件为一组
- report_part_2 = []
- previous_iteration_files = []
- last_iteration_result = ""
- while True:
- if len(file_manifest) == 0: break
- this_iteration_file_manifest = file_manifest[:batchsize]
- this_iteration_gpt_response_collection = gpt_response_collection[:batchsize*2]
- file_rel_path = [os.path.relpath(fp, project_folder) for index, fp in enumerate(this_iteration_file_manifest)]
- # 把“请对下面的程序文件做一个概述” 替换成 精简的 "文件名:{all_file[index]}"
- for index, content in enumerate(this_iteration_gpt_response_collection):
- if index%2==0: this_iteration_gpt_response_collection[index] = f"{file_rel_path[index//2]}" # 只保留文件名节省token
- previous_iteration_files.extend([os.path.relpath(fp, project_folder) for index, fp in enumerate(this_iteration_file_manifest)])
- previous_iteration_files_string = ', '.join(previous_iteration_files)
- current_iteration_focus = ', '.join([os.path.relpath(fp, project_folder) for index, fp in enumerate(this_iteration_file_manifest)])
- i_say = f'用一张Markdown表格简要描述以下文件的功能:{previous_iteration_files_string}。根据以上分析,用一句话概括程序的整体功能。'
- inputs_show_user = f'根据以上分析,对程序的整体功能和构架重新做出概括,由于输入长度限制,可能需要分组处理,本组文件为 {current_iteration_focus} + 已经汇总的文件组。'
- this_iteration_history = copy.deepcopy(this_iteration_gpt_response_collection)
- this_iteration_history.append(last_iteration_result)
- # 裁剪input
- inputs, this_iteration_history_feed = input_clipping(inputs=i_say, history=this_iteration_history, max_token_limit=2560)
- result = yield from request_gpt_model_in_new_thread_with_ui_alive(
- inputs=inputs, inputs_show_user=inputs_show_user, llm_kwargs=llm_kwargs, chatbot=chatbot,
- history=this_iteration_history_feed, # 迭代之前的分析
- sys_prompt="你是一个程序架构分析师,正在分析一个项目的源代码。")
- report_part_2.extend([i_say, result])
- last_iteration_result = result
-
- file_manifest = file_manifest[batchsize:]
- gpt_response_collection = gpt_response_collection[batchsize*2:]
-
- ############################## ##################################
- history_to_return.extend(report_part_2)
- res = write_results_to_file(history_to_return)
- chatbot.append(("完成了吗?", res))
- yield from update_ui(chatbot=chatbot, history=history_to_return) # 刷新界面
-
-
-@CatchException
-def 解析项目本身(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- history = [] # 清空历史,以免输入溢出
- import glob
- file_manifest = [f for f in glob.glob('./*.py') if ('test_project' not in f) and ('gpt_log' not in f)] + \
- [f for f in glob.glob('./crazy_functions/*.py') if ('test_project' not in f) and ('gpt_log' not in f)]+ \
- [f for f in glob.glob('./request_llm/*.py') if ('test_project' not in f) and ('gpt_log' not in f)]
- project_folder = './'
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何python文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-@CatchException
-def 解析一个Python项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.py', recursive=True)]
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何python文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-
-@CatchException
-def 解析一个C项目的头文件(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.h', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.hpp', recursive=True)] #+ \
- # [f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.h头文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-@CatchException
-def 解析一个C项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.h', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.cpp', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.hpp', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.c', recursive=True)]
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何.h头文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-
-@CatchException
-def 解析一个Java项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.java', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.jar', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.xml', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.sh', recursive=True)]
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到任何java文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-
-@CatchException
-def 解析一个Rect项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.ts', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.tsx', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.json', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.js', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.jsx', recursive=True)]
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到任何Rect文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-
-@CatchException
-def 解析一个Golang项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到本地项目或无权访问: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.go', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/go.mod', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/go.sum', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/go.work', recursive=True)]
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a=f"解析项目: {txt}", b=f"找不到任何golang文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-
-@CatchException
-def 解析一个Lua项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.lua', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.xml', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.json', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.toml', recursive=True)]
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何lua文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-
-@CatchException
-def 解析一个CSharp项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- history = [] # 清空历史,以免输入溢出
- import glob, os
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- file_manifest = [f for f in glob.glob(f'{project_folder}/**/*.cs', recursive=True)] + \
- [f for f in glob.glob(f'{project_folder}/**/*.csproj', recursive=True)]
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何CSharp文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
-
-
-@CatchException
-def 解析任意code项目(txt, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt, web_port):
- txt_pattern = plugin_kwargs.get("advanced_arg")
- txt_pattern = txt_pattern.replace(",", ",")
- # 将要匹配的模式(例如: *.c, *.cpp, *.py, config.toml)
- pattern_include = [_.lstrip(" ,").rstrip(" ,") for _ in txt_pattern.split(",") if _ != "" and not _.strip().startswith("^")]
- if not pattern_include: pattern_include = ["*"] # 不输入即全部匹配
- # 将要忽略匹配的文件后缀(例如: ^*.c, ^*.cpp, ^*.py)
- pattern_except_suffix = [_.lstrip(" ^*.,").rstrip(" ,") for _ in txt_pattern.split(" ") if _ != "" and _.strip().startswith("^*.")]
- pattern_except_suffix += ['zip', 'rar', '7z', 'tar', 'gz'] # 避免解析压缩文件
- # 将要忽略匹配的文件名(例如: ^README.md)
- pattern_except_name = [_.lstrip(" ^*,").rstrip(" ,").replace(".", "\.") for _ in txt_pattern.split(" ") if _ != "" and _.strip().startswith("^") and not _.strip().startswith("^*.")]
- # 生成正则表达式
- pattern_except = '/[^/]+\.(' + "|".join(pattern_except_suffix) + ')$'
- pattern_except += '|/(' + "|".join(pattern_except_name) + ')$' if pattern_except_name != [] else ''
-
- history.clear()
- import glob, os, re
- if os.path.exists(txt):
- project_folder = txt
- else:
- if txt == "": txt = '空空如也的输入栏'
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到本地项目或无权访问: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- # 若上传压缩文件, 先寻找到解压的文件夹路径, 从而避免解析压缩文件
- maybe_dir = [f for f in glob.glob(f'{project_folder}/*') if os.path.isdir(f)]
- if len(maybe_dir)>0 and maybe_dir[0].endswith('.extract'):
- extract_folder_path = maybe_dir[0]
- else:
- extract_folder_path = project_folder
- # 按输入的匹配模式寻找上传的非压缩文件和已解压的文件
- file_manifest = [f for pattern in pattern_include for f in glob.glob(f'{extract_folder_path}/**/{pattern}', recursive=True) if "" != extract_folder_path and \
- os.path.isfile(f) and (not re.search(pattern_except, f) or pattern.endswith('.' + re.search(pattern_except, f).group().split('.')[-1]))]
- if len(file_manifest) == 0:
- report_execption(chatbot, history, a = f"解析项目: {txt}", b = f"找不到任何文件: {txt}")
- yield from update_ui(chatbot=chatbot, history=history) # 刷新界面
- return
- yield from 解析源代码新(file_manifest, project_folder, llm_kwargs, plugin_kwargs, chatbot, history, system_prompt)
\ No newline at end of file
diff --git a/spaces/flax-community/t5-vae/t5_vae_flax_alt/src/vae.py b/spaces/flax-community/t5-vae/t5_vae_flax_alt/src/vae.py
deleted file mode 100644
index 676546fa95c86f36584846cda85955e2d40c12a1..0000000000000000000000000000000000000000
--- a/spaces/flax-community/t5-vae/t5_vae_flax_alt/src/vae.py
+++ /dev/null
@@ -1,30 +0,0 @@
-import jax.numpy as jnp
-import flax.linen as nn
-
-from t5_vae_flax_alt.src.encoders import VAE_ENCODER_MODELS
-from t5_vae_flax_alt.src.decoders import VAE_DECODER_MODELS
-from t5_vae_flax_alt.src.config import T5VaeConfig
-
-
-class VAE(nn.Module):
- # see https://github.com/google/flax#what-does-flax-look-like
- """
- An MMD-VAE used with encoder-decoder models.
- Encodes all token encodings into a single latent & spits them back out.
- """
- config: T5VaeConfig
- dtype: jnp.dtype = jnp.float32 # the dtype of the computation
-
- def setup(self):
- self.encoder = VAE_ENCODER_MODELS[self.config.vae_encoder_model](self.config.latent_token_size, self.config.n_latent_tokens)
- self.decoder = VAE_DECODER_MODELS[self.config.vae_decoder_model](self.config.t5.d_model, self.config.n_latent_tokens)
-
- def __call__(self, encoding=None, latent_codes=None):
- latent_codes = self.encode(encoding)
- return self.decode(latent_codes), latent_codes
-
- def encode(self, encoding):
- return self.encoder(encoding)
-
- def decode(self, latent):
- return self.decoder(latent)
diff --git a/spaces/flowers-team/SocialAISchool/gym-minigrid/manual_control.py b/spaces/flowers-team/SocialAISchool/gym-minigrid/manual_control.py
deleted file mode 100644
index b0745707fc12872c52a96f82eaf1ab1f204f9a40..0000000000000000000000000000000000000000
--- a/spaces/flowers-team/SocialAISchool/gym-minigrid/manual_control.py
+++ /dev/null
@@ -1,115 +0,0 @@
-#!/usr/bin/env python3
-raise DeprecationWarning("Use the one in ./scipts")
-
-import time
-import argparse
-import numpy as np
-import gym
-import gym_minigrid
-from gym_minigrid.wrappers import *
-from gym_minigrid.window import Window
-
-def redraw(img):
- if not args.agent_view:
- img = env.render('rgb_array', tile_size=args.tile_size)
-
- window.show_img(img)
-
-def reset():
- if args.seed != -1:
- env.seed(args.seed)
-
- obs = env.reset()
-
- if hasattr(env, 'mission'):
- print('Mission: %s' % env.mission)
- window.set_caption(env.mission)
-
- redraw(obs)
-
-def step(action):
- obs, reward, done, info = env.step(action)
- print('step=%s, reward=%.2f' % (env.step_count, reward))
-
- if done:
- print('done!')
- reset()
- else:
- redraw(obs)
-
-def key_handler(event):
- print('pressed', event.key)
-
- if event.key == 'escape':
- window.close()
- return
-
- if event.key == 'backspace':
- reset()
- return
-
- if event.key == 'left':
- step(env.actions.left)
- return
- if event.key == 'right':
- step(env.actions.right)
- return
- if event.key == 'up':
- step(env.actions.forward)
- return
-
- # Spacebar
- if event.key == ' ':
- step(env.actions.toggle)
- return
- if event.key == 'pageup':
- step(env.actions.pickup)
- return
- if event.key == 'pagedown':
- step(env.actions.drop)
- return
-
- if event.key == 'enter':
- step(env.actions.done)
- return
-
-parser = argparse.ArgumentParser()
-parser.add_argument(
- "--env",
- help="gym environment to load",
- default='MiniGrid-MultiRoom-N6-v0'
-)
-parser.add_argument(
- "--seed",
- type=int,
- help="random seed to generate the environment with",
- default=-1
-)
-parser.add_argument(
- "--tile_size",
- type=int,
- help="size at which to render tiles",
- default=32
-)
-parser.add_argument(
- '--agent_view',
- default=False,
- help="draw the agent sees (partially observable view)",
- action='store_true'
-)
-
-args = parser.parse_args()
-
-env = gym.make(args.env)
-
-if args.agent_view:
- env = RGBImgPartialObsWrapper(env)
- env = ImgObsWrapper(env)
-
-window = Window('gym_minigrid - ' + args.env)
-window.reg_key_handler(key_handler)
-
-reset()
-
-# Blocking event loop
-window.show(block=True)
diff --git a/spaces/g4f/freegpt-webui/g4f/Provider/Providers/Aichat.py b/spaces/g4f/freegpt-webui/g4f/Provider/Providers/Aichat.py
deleted file mode 100644
index d78375ce7e62b634c82e163c693a5557b8e2f860..0000000000000000000000000000000000000000
--- a/spaces/g4f/freegpt-webui/g4f/Provider/Providers/Aichat.py
+++ /dev/null
@@ -1,35 +0,0 @@
-import requests
-import os
-import json
-from ...typing import sha256, Dict, get_type_hints
-
-url = 'https://hteyun.com'
-model = ['gpt-3.5-turbo', 'gpt-3.5-turbo-16k', 'gpt-3.5-turbo-16k-0613', 'gpt-3.5-turbo-0613']
-supports_stream = True
-needs_auth = False
-
-def _create_completion(model: str, messages: list, stream: bool, temperature: float = 0.7, **kwargs):
- headers = {
- 'Content-Type': 'application/json',
- }
- data = {
- 'model': model,
- 'temperature': 0.7,
- 'presence_penalty': 0,
- 'messages': messages,
- }
- response = requests.post(url + '/api/chat-stream',
- json=data, stream=True)
-
- if stream:
- for chunk in response.iter_content(chunk_size=None):
- chunk = chunk.decode('utf-8')
- if chunk.strip():
- message = json.loads(chunk)['choices'][0]['message']['content']
- yield message
- else:
- message = response.json()['choices'][0]['message']['content']
- yield message
-
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
- '(%s)' % ', '.join([f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
\ No newline at end of file
diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/cnn/bricks/transformer.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/cnn/bricks/transformer.py
deleted file mode 100644
index e61ae0dd941a7be00b3e41a3de833ec50470a45f..0000000000000000000000000000000000000000
--- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/cnn/bricks/transformer.py
+++ /dev/null
@@ -1,595 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-import warnings
-
-import torch
-import torch.nn as nn
-
-from annotator.uniformer.mmcv import ConfigDict, deprecated_api_warning
-from annotator.uniformer.mmcv.cnn import Linear, build_activation_layer, build_norm_layer
-from annotator.uniformer.mmcv.runner.base_module import BaseModule, ModuleList, Sequential
-from annotator.uniformer.mmcv.utils import build_from_cfg
-from .drop import build_dropout
-from .registry import (ATTENTION, FEEDFORWARD_NETWORK, POSITIONAL_ENCODING,
- TRANSFORMER_LAYER, TRANSFORMER_LAYER_SEQUENCE)
-
-# Avoid BC-breaking of importing MultiScaleDeformableAttention from this file
-try:
- from annotator.uniformer.mmcv.ops.multi_scale_deform_attn import MultiScaleDeformableAttention # noqa F401
- warnings.warn(
- ImportWarning(
- '``MultiScaleDeformableAttention`` has been moved to '
- '``mmcv.ops.multi_scale_deform_attn``, please change original path ' # noqa E501
- '``from annotator.uniformer.mmcv.cnn.bricks.transformer import MultiScaleDeformableAttention`` ' # noqa E501
- 'to ``from annotator.uniformer.mmcv.ops.multi_scale_deform_attn import MultiScaleDeformableAttention`` ' # noqa E501
- ))
-
-except ImportError:
- warnings.warn('Fail to import ``MultiScaleDeformableAttention`` from '
- '``mmcv.ops.multi_scale_deform_attn``, '
- 'You should install ``mmcv-full`` if you need this module. ')
-
-
-def build_positional_encoding(cfg, default_args=None):
- """Builder for Position Encoding."""
- return build_from_cfg(cfg, POSITIONAL_ENCODING, default_args)
-
-
-def build_attention(cfg, default_args=None):
- """Builder for attention."""
- return build_from_cfg(cfg, ATTENTION, default_args)
-
-
-def build_feedforward_network(cfg, default_args=None):
- """Builder for feed-forward network (FFN)."""
- return build_from_cfg(cfg, FEEDFORWARD_NETWORK, default_args)
-
-
-def build_transformer_layer(cfg, default_args=None):
- """Builder for transformer layer."""
- return build_from_cfg(cfg, TRANSFORMER_LAYER, default_args)
-
-
-def build_transformer_layer_sequence(cfg, default_args=None):
- """Builder for transformer encoder and transformer decoder."""
- return build_from_cfg(cfg, TRANSFORMER_LAYER_SEQUENCE, default_args)
-
-
-@ATTENTION.register_module()
-class MultiheadAttention(BaseModule):
- """A wrapper for ``torch.nn.MultiheadAttention``.
-
- This module implements MultiheadAttention with identity connection,
- and positional encoding is also passed as input.
-
- Args:
- embed_dims (int): The embedding dimension.
- num_heads (int): Parallel attention heads.
- attn_drop (float): A Dropout layer on attn_output_weights.
- Default: 0.0.
- proj_drop (float): A Dropout layer after `nn.MultiheadAttention`.
- Default: 0.0.
- dropout_layer (obj:`ConfigDict`): The dropout_layer used
- when adding the shortcut.
- init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
- Default: None.
- batch_first (bool): When it is True, Key, Query and Value are shape of
- (batch, n, embed_dim), otherwise (n, batch, embed_dim).
- Default to False.
- """
-
- def __init__(self,
- embed_dims,
- num_heads,
- attn_drop=0.,
- proj_drop=0.,
- dropout_layer=dict(type='Dropout', drop_prob=0.),
- init_cfg=None,
- batch_first=False,
- **kwargs):
- super(MultiheadAttention, self).__init__(init_cfg)
- if 'dropout' in kwargs:
- warnings.warn('The arguments `dropout` in MultiheadAttention '
- 'has been deprecated, now you can separately '
- 'set `attn_drop`(float), proj_drop(float), '
- 'and `dropout_layer`(dict) ')
- attn_drop = kwargs['dropout']
- dropout_layer['drop_prob'] = kwargs.pop('dropout')
-
- self.embed_dims = embed_dims
- self.num_heads = num_heads
- self.batch_first = batch_first
-
- self.attn = nn.MultiheadAttention(embed_dims, num_heads, attn_drop,
- **kwargs)
-
- self.proj_drop = nn.Dropout(proj_drop)
- self.dropout_layer = build_dropout(
- dropout_layer) if dropout_layer else nn.Identity()
-
- @deprecated_api_warning({'residual': 'identity'},
- cls_name='MultiheadAttention')
- def forward(self,
- query,
- key=None,
- value=None,
- identity=None,
- query_pos=None,
- key_pos=None,
- attn_mask=None,
- key_padding_mask=None,
- **kwargs):
- """Forward function for `MultiheadAttention`.
-
- **kwargs allow passing a more general data flow when combining
- with other operations in `transformerlayer`.
-
- Args:
- query (Tensor): The input query with shape [num_queries, bs,
- embed_dims] if self.batch_first is False, else
- [bs, num_queries embed_dims].
- key (Tensor): The key tensor with shape [num_keys, bs,
- embed_dims] if self.batch_first is False, else
- [bs, num_keys, embed_dims] .
- If None, the ``query`` will be used. Defaults to None.
- value (Tensor): The value tensor with same shape as `key`.
- Same in `nn.MultiheadAttention.forward`. Defaults to None.
- If None, the `key` will be used.
- identity (Tensor): This tensor, with the same shape as x,
- will be used for the identity link.
- If None, `x` will be used. Defaults to None.
- query_pos (Tensor): The positional encoding for query, with
- the same shape as `x`. If not None, it will
- be added to `x` before forward function. Defaults to None.
- key_pos (Tensor): The positional encoding for `key`, with the
- same shape as `key`. Defaults to None. If not None, it will
- be added to `key` before forward function. If None, and
- `query_pos` has the same shape as `key`, then `query_pos`
- will be used for `key_pos`. Defaults to None.
- attn_mask (Tensor): ByteTensor mask with shape [num_queries,
- num_keys]. Same in `nn.MultiheadAttention.forward`.
- Defaults to None.
- key_padding_mask (Tensor): ByteTensor with shape [bs, num_keys].
- Defaults to None.
-
- Returns:
- Tensor: forwarded results with shape
- [num_queries, bs, embed_dims]
- if self.batch_first is False, else
- [bs, num_queries embed_dims].
- """
-
- if key is None:
- key = query
- if value is None:
- value = key
- if identity is None:
- identity = query
- if key_pos is None:
- if query_pos is not None:
- # use query_pos if key_pos is not available
- if query_pos.shape == key.shape:
- key_pos = query_pos
- else:
- warnings.warn(f'position encoding of key is'
- f'missing in {self.__class__.__name__}.')
- if query_pos is not None:
- query = query + query_pos
- if key_pos is not None:
- key = key + key_pos
-
- # Because the dataflow('key', 'query', 'value') of
- # ``torch.nn.MultiheadAttention`` is (num_query, batch,
- # embed_dims), We should adjust the shape of dataflow from
- # batch_first (batch, num_query, embed_dims) to num_query_first
- # (num_query ,batch, embed_dims), and recover ``attn_output``
- # from num_query_first to batch_first.
- if self.batch_first:
- query = query.transpose(0, 1)
- key = key.transpose(0, 1)
- value = value.transpose(0, 1)
-
- out = self.attn(
- query=query,
- key=key,
- value=value,
- attn_mask=attn_mask,
- key_padding_mask=key_padding_mask)[0]
-
- if self.batch_first:
- out = out.transpose(0, 1)
-
- return identity + self.dropout_layer(self.proj_drop(out))
-
-
-@FEEDFORWARD_NETWORK.register_module()
-class FFN(BaseModule):
- """Implements feed-forward networks (FFNs) with identity connection.
-
- Args:
- embed_dims (int): The feature dimension. Same as
- `MultiheadAttention`. Defaults: 256.
- feedforward_channels (int): The hidden dimension of FFNs.
- Defaults: 1024.
- num_fcs (int, optional): The number of fully-connected layers in
- FFNs. Default: 2.
- act_cfg (dict, optional): The activation config for FFNs.
- Default: dict(type='ReLU')
- ffn_drop (float, optional): Probability of an element to be
- zeroed in FFN. Default 0.0.
- add_identity (bool, optional): Whether to add the
- identity connection. Default: `True`.
- dropout_layer (obj:`ConfigDict`): The dropout_layer used
- when adding the shortcut.
- init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
- Default: None.
- """
-
- @deprecated_api_warning(
- {
- 'dropout': 'ffn_drop',
- 'add_residual': 'add_identity'
- },
- cls_name='FFN')
- def __init__(self,
- embed_dims=256,
- feedforward_channels=1024,
- num_fcs=2,
- act_cfg=dict(type='ReLU', inplace=True),
- ffn_drop=0.,
- dropout_layer=None,
- add_identity=True,
- init_cfg=None,
- **kwargs):
- super(FFN, self).__init__(init_cfg)
- assert num_fcs >= 2, 'num_fcs should be no less ' \
- f'than 2. got {num_fcs}.'
- self.embed_dims = embed_dims
- self.feedforward_channels = feedforward_channels
- self.num_fcs = num_fcs
- self.act_cfg = act_cfg
- self.activate = build_activation_layer(act_cfg)
-
- layers = []
- in_channels = embed_dims
- for _ in range(num_fcs - 1):
- layers.append(
- Sequential(
- Linear(in_channels, feedforward_channels), self.activate,
- nn.Dropout(ffn_drop)))
- in_channels = feedforward_channels
- layers.append(Linear(feedforward_channels, embed_dims))
- layers.append(nn.Dropout(ffn_drop))
- self.layers = Sequential(*layers)
- self.dropout_layer = build_dropout(
- dropout_layer) if dropout_layer else torch.nn.Identity()
- self.add_identity = add_identity
-
- @deprecated_api_warning({'residual': 'identity'}, cls_name='FFN')
- def forward(self, x, identity=None):
- """Forward function for `FFN`.
-
- The function would add x to the output tensor if residue is None.
- """
- out = self.layers(x)
- if not self.add_identity:
- return self.dropout_layer(out)
- if identity is None:
- identity = x
- return identity + self.dropout_layer(out)
-
-
-@TRANSFORMER_LAYER.register_module()
-class BaseTransformerLayer(BaseModule):
- """Base `TransformerLayer` for vision transformer.
-
- It can be built from `mmcv.ConfigDict` and support more flexible
- customization, for example, using any number of `FFN or LN ` and
- use different kinds of `attention` by specifying a list of `ConfigDict`
- named `attn_cfgs`. It is worth mentioning that it supports `prenorm`
- when you specifying `norm` as the first element of `operation_order`.
- More details about the `prenorm`: `On Layer Normalization in the
- Transformer Architecture `_ .
-
- Args:
- attn_cfgs (list[`mmcv.ConfigDict`] | obj:`mmcv.ConfigDict` | None )):
- Configs for `self_attention` or `cross_attention` modules,
- The order of the configs in the list should be consistent with
- corresponding attentions in operation_order.
- If it is a dict, all of the attention modules in operation_order
- will be built with this config. Default: None.
- ffn_cfgs (list[`mmcv.ConfigDict`] | obj:`mmcv.ConfigDict` | None )):
- Configs for FFN, The order of the configs in the list should be
- consistent with corresponding ffn in operation_order.
- If it is a dict, all of the attention modules in operation_order
- will be built with this config.
- operation_order (tuple[str]): The execution order of operation
- in transformer. Such as ('self_attn', 'norm', 'ffn', 'norm').
- Support `prenorm` when you specifying first element as `norm`.
- Default:None.
- norm_cfg (dict): Config dict for normalization layer.
- Default: dict(type='LN').
- init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
- Default: None.
- batch_first (bool): Key, Query and Value are shape
- of (batch, n, embed_dim)
- or (n, batch, embed_dim). Default to False.
- """
-
- def __init__(self,
- attn_cfgs=None,
- ffn_cfgs=dict(
- type='FFN',
- embed_dims=256,
- feedforward_channels=1024,
- num_fcs=2,
- ffn_drop=0.,
- act_cfg=dict(type='ReLU', inplace=True),
- ),
- operation_order=None,
- norm_cfg=dict(type='LN'),
- init_cfg=None,
- batch_first=False,
- **kwargs):
-
- deprecated_args = dict(
- feedforward_channels='feedforward_channels',
- ffn_dropout='ffn_drop',
- ffn_num_fcs='num_fcs')
- for ori_name, new_name in deprecated_args.items():
- if ori_name in kwargs:
- warnings.warn(
- f'The arguments `{ori_name}` in BaseTransformerLayer '
- f'has been deprecated, now you should set `{new_name}` '
- f'and other FFN related arguments '
- f'to a dict named `ffn_cfgs`. ')
- ffn_cfgs[new_name] = kwargs[ori_name]
-
- super(BaseTransformerLayer, self).__init__(init_cfg)
-
- self.batch_first = batch_first
-
- assert set(operation_order) & set(
- ['self_attn', 'norm', 'ffn', 'cross_attn']) == \
- set(operation_order), f'The operation_order of' \
- f' {self.__class__.__name__} should ' \
- f'contains all four operation type ' \
- f"{['self_attn', 'norm', 'ffn', 'cross_attn']}"
-
- num_attn = operation_order.count('self_attn') + operation_order.count(
- 'cross_attn')
- if isinstance(attn_cfgs, dict):
- attn_cfgs = [copy.deepcopy(attn_cfgs) for _ in range(num_attn)]
- else:
- assert num_attn == len(attn_cfgs), f'The length ' \
- f'of attn_cfg {num_attn} is ' \
- f'not consistent with the number of attention' \
- f'in operation_order {operation_order}.'
-
- self.num_attn = num_attn
- self.operation_order = operation_order
- self.norm_cfg = norm_cfg
- self.pre_norm = operation_order[0] == 'norm'
- self.attentions = ModuleList()
-
- index = 0
- for operation_name in operation_order:
- if operation_name in ['self_attn', 'cross_attn']:
- if 'batch_first' in attn_cfgs[index]:
- assert self.batch_first == attn_cfgs[index]['batch_first']
- else:
- attn_cfgs[index]['batch_first'] = self.batch_first
- attention = build_attention(attn_cfgs[index])
- # Some custom attentions used as `self_attn`
- # or `cross_attn` can have different behavior.
- attention.operation_name = operation_name
- self.attentions.append(attention)
- index += 1
-
- self.embed_dims = self.attentions[0].embed_dims
-
- self.ffns = ModuleList()
- num_ffns = operation_order.count('ffn')
- if isinstance(ffn_cfgs, dict):
- ffn_cfgs = ConfigDict(ffn_cfgs)
- if isinstance(ffn_cfgs, dict):
- ffn_cfgs = [copy.deepcopy(ffn_cfgs) for _ in range(num_ffns)]
- assert len(ffn_cfgs) == num_ffns
- for ffn_index in range(num_ffns):
- if 'embed_dims' not in ffn_cfgs[ffn_index]:
- ffn_cfgs['embed_dims'] = self.embed_dims
- else:
- assert ffn_cfgs[ffn_index]['embed_dims'] == self.embed_dims
- self.ffns.append(
- build_feedforward_network(ffn_cfgs[ffn_index],
- dict(type='FFN')))
-
- self.norms = ModuleList()
- num_norms = operation_order.count('norm')
- for _ in range(num_norms):
- self.norms.append(build_norm_layer(norm_cfg, self.embed_dims)[1])
-
- def forward(self,
- query,
- key=None,
- value=None,
- query_pos=None,
- key_pos=None,
- attn_masks=None,
- query_key_padding_mask=None,
- key_padding_mask=None,
- **kwargs):
- """Forward function for `TransformerDecoderLayer`.
-
- **kwargs contains some specific arguments of attentions.
-
- Args:
- query (Tensor): The input query with shape
- [num_queries, bs, embed_dims] if
- self.batch_first is False, else
- [bs, num_queries embed_dims].
- key (Tensor): The key tensor with shape [num_keys, bs,
- embed_dims] if self.batch_first is False, else
- [bs, num_keys, embed_dims] .
- value (Tensor): The value tensor with same shape as `key`.
- query_pos (Tensor): The positional encoding for `query`.
- Default: None.
- key_pos (Tensor): The positional encoding for `key`.
- Default: None.
- attn_masks (List[Tensor] | None): 2D Tensor used in
- calculation of corresponding attention. The length of
- it should equal to the number of `attention` in
- `operation_order`. Default: None.
- query_key_padding_mask (Tensor): ByteTensor for `query`, with
- shape [bs, num_queries]. Only used in `self_attn` layer.
- Defaults to None.
- key_padding_mask (Tensor): ByteTensor for `query`, with
- shape [bs, num_keys]. Default: None.
-
- Returns:
- Tensor: forwarded results with shape [num_queries, bs, embed_dims].
- """
-
- norm_index = 0
- attn_index = 0
- ffn_index = 0
- identity = query
- if attn_masks is None:
- attn_masks = [None for _ in range(self.num_attn)]
- elif isinstance(attn_masks, torch.Tensor):
- attn_masks = [
- copy.deepcopy(attn_masks) for _ in range(self.num_attn)
- ]
- warnings.warn(f'Use same attn_mask in all attentions in '
- f'{self.__class__.__name__} ')
- else:
- assert len(attn_masks) == self.num_attn, f'The length of ' \
- f'attn_masks {len(attn_masks)} must be equal ' \
- f'to the number of attention in ' \
- f'operation_order {self.num_attn}'
-
- for layer in self.operation_order:
- if layer == 'self_attn':
- temp_key = temp_value = query
- query = self.attentions[attn_index](
- query,
- temp_key,
- temp_value,
- identity if self.pre_norm else None,
- query_pos=query_pos,
- key_pos=query_pos,
- attn_mask=attn_masks[attn_index],
- key_padding_mask=query_key_padding_mask,
- **kwargs)
- attn_index += 1
- identity = query
-
- elif layer == 'norm':
- query = self.norms[norm_index](query)
- norm_index += 1
-
- elif layer == 'cross_attn':
- query = self.attentions[attn_index](
- query,
- key,
- value,
- identity if self.pre_norm else None,
- query_pos=query_pos,
- key_pos=key_pos,
- attn_mask=attn_masks[attn_index],
- key_padding_mask=key_padding_mask,
- **kwargs)
- attn_index += 1
- identity = query
-
- elif layer == 'ffn':
- query = self.ffns[ffn_index](
- query, identity if self.pre_norm else None)
- ffn_index += 1
-
- return query
-
-
-@TRANSFORMER_LAYER_SEQUENCE.register_module()
-class TransformerLayerSequence(BaseModule):
- """Base class for TransformerEncoder and TransformerDecoder in vision
- transformer.
-
- As base-class of Encoder and Decoder in vision transformer.
- Support customization such as specifying different kind
- of `transformer_layer` in `transformer_coder`.
-
- Args:
- transformerlayer (list[obj:`mmcv.ConfigDict`] |
- obj:`mmcv.ConfigDict`): Config of transformerlayer
- in TransformerCoder. If it is obj:`mmcv.ConfigDict`,
- it would be repeated `num_layer` times to a
- list[`mmcv.ConfigDict`]. Default: None.
- num_layers (int): The number of `TransformerLayer`. Default: None.
- init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
- Default: None.
- """
-
- def __init__(self, transformerlayers=None, num_layers=None, init_cfg=None):
- super(TransformerLayerSequence, self).__init__(init_cfg)
- if isinstance(transformerlayers, dict):
- transformerlayers = [
- copy.deepcopy(transformerlayers) for _ in range(num_layers)
- ]
- else:
- assert isinstance(transformerlayers, list) and \
- len(transformerlayers) == num_layers
- self.num_layers = num_layers
- self.layers = ModuleList()
- for i in range(num_layers):
- self.layers.append(build_transformer_layer(transformerlayers[i]))
- self.embed_dims = self.layers[0].embed_dims
- self.pre_norm = self.layers[0].pre_norm
-
- def forward(self,
- query,
- key,
- value,
- query_pos=None,
- key_pos=None,
- attn_masks=None,
- query_key_padding_mask=None,
- key_padding_mask=None,
- **kwargs):
- """Forward function for `TransformerCoder`.
-
- Args:
- query (Tensor): Input query with shape
- `(num_queries, bs, embed_dims)`.
- key (Tensor): The key tensor with shape
- `(num_keys, bs, embed_dims)`.
- value (Tensor): The value tensor with shape
- `(num_keys, bs, embed_dims)`.
- query_pos (Tensor): The positional encoding for `query`.
- Default: None.
- key_pos (Tensor): The positional encoding for `key`.
- Default: None.
- attn_masks (List[Tensor], optional): Each element is 2D Tensor
- which is used in calculation of corresponding attention in
- operation_order. Default: None.
- query_key_padding_mask (Tensor): ByteTensor for `query`, with
- shape [bs, num_queries]. Only used in self-attention
- Default: None.
- key_padding_mask (Tensor): ByteTensor for `query`, with
- shape [bs, num_keys]. Default: None.
-
- Returns:
- Tensor: results with shape [num_queries, bs, embed_dims].
- """
- for layer in self.layers:
- query = layer(
- query,
- key,
- value,
- query_pos=query_pos,
- key_pos=key_pos,
- attn_masks=attn_masks,
- query_key_padding_mask=query_key_padding_mask,
- key_padding_mask=key_padding_mask,
- **kwargs)
- return query
diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/datasets/stare.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/datasets/stare.py
deleted file mode 100644
index cbd14e0920e7f6a73baff1432e5a32ccfdb0dfae..0000000000000000000000000000000000000000
--- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmseg/datasets/stare.py
+++ /dev/null
@@ -1,27 +0,0 @@
-import os.path as osp
-
-from .builder import DATASETS
-from .custom import CustomDataset
-
-
-@DATASETS.register_module()
-class STAREDataset(CustomDataset):
- """STARE dataset.
-
- In segmentation map annotation for STARE, 0 stands for background, which is
- included in 2 categories. ``reduce_zero_label`` is fixed to False. The
- ``img_suffix`` is fixed to '.png' and ``seg_map_suffix`` is fixed to
- '.ah.png'.
- """
-
- CLASSES = ('background', 'vessel')
-
- PALETTE = [[120, 120, 120], [6, 230, 230]]
-
- def __init__(self, **kwargs):
- super(STAREDataset, self).__init__(
- img_suffix='.png',
- seg_map_suffix='.ah.png',
- reduce_zero_label=False,
- **kwargs)
- assert osp.exists(self.img_dir)
diff --git a/spaces/godelbach/onlyjitz/app.py b/spaces/godelbach/onlyjitz/app.py
deleted file mode 100644
index 0808d24bdd57d04255c469cdba802ddf388f28a6..0000000000000000000000000000000000000000
--- a/spaces/godelbach/onlyjitz/app.py
+++ /dev/null
@@ -1,22 +0,0 @@
-import gradio as gr
-from fastai.vision.all import *
-
-categories = ("Armbar", "Triangle")
-
-
-learn = load_learner("model.pkl")
-
-image = gr.Image(shape=(224, 224))
-
-examples = ["images/armbar1.jpeg", "images/armbar2.jpeg", "images/armbar3.webp", "images/armbar4.png", "images/flying_armbar.jpeg",
- "images/triangle.jpeg", "images/triangle2.webp", "images/triangle3.jpeg", "images/triangle4.jpeg", "images/triangle_armbar1.jpeg"]
-
-
-def image_classifier(img):
- _, _, probs = learn.predict(img)
- return dict(zip(categories, map(float, probs)))
-
-
-app = gr.Interface(fn=image_classifier, inputs=image,
- outputs="label", examples=examples)
-app.launch()
diff --git a/spaces/gradio/HuBERT/examples/criss/README.md b/spaces/gradio/HuBERT/examples/criss/README.md
deleted file mode 100644
index 4689ed7c10497a5100b28fe6d6801a7c089da569..0000000000000000000000000000000000000000
--- a/spaces/gradio/HuBERT/examples/criss/README.md
+++ /dev/null
@@ -1,61 +0,0 @@
-# Cross-lingual Retrieval for Iterative Self-Supervised Training
-
-https://arxiv.org/pdf/2006.09526.pdf
-
-## Introduction
-
-CRISS is a multilingual sequence-to-sequnce pretraining method where mining and training processes are applied iteratively, improving cross-lingual alignment and translation ability at the same time.
-
-## Requirements:
-
-* faiss: https://github.com/facebookresearch/faiss
-* mosesdecoder: https://github.com/moses-smt/mosesdecoder
-* flores: https://github.com/facebookresearch/flores
-* LASER: https://github.com/facebookresearch/LASER
-
-## Unsupervised Machine Translation
-##### 1. Download and decompress CRISS checkpoints
-```
-cd examples/criss
-wget https://dl.fbaipublicfiles.com/criss/criss_3rd_checkpoints.tar.gz
-tar -xf criss_checkpoints.tar.gz
-```
-##### 2. Download and preprocess Flores test dataset
-Make sure to run all scripts from examples/criss directory
-```
-bash download_and_preprocess_flores_test.sh
-```
-
-##### 3. Run Evaluation on Sinhala-English
-```
-bash unsupervised_mt/eval.sh
-```
-
-## Sentence Retrieval
-##### 1. Download and preprocess Tatoeba dataset
-```
-bash download_and_preprocess_tatoeba.sh
-```
-
-##### 2. Run Sentence Retrieval on Tatoeba Kazakh-English
-```
-bash sentence_retrieval/sentence_retrieval_tatoeba.sh
-```
-
-## Mining
-##### 1. Install faiss
-Follow instructions on https://github.com/facebookresearch/faiss/blob/master/INSTALL.md
-##### 2. Mine pseudo-parallel data between Kazakh and English
-```
-bash mining/mine_example.sh
-```
-
-## Citation
-```bibtex
-@article{tran2020cross,
- title={Cross-lingual retrieval for iterative self-supervised training},
- author={Tran, Chau and Tang, Yuqing and Li, Xian and Gu, Jiatao},
- journal={arXiv preprint arXiv:2006.09526},
- year={2020}
-}
-```
diff --git a/spaces/gradio/HuBERT/scripts/sacrebleu.sh b/spaces/gradio/HuBERT/scripts/sacrebleu.sh
deleted file mode 100644
index c10bf2b76ea032deabab6f5c9d8a3e1e884f1642..0000000000000000000000000000000000000000
--- a/spaces/gradio/HuBERT/scripts/sacrebleu.sh
+++ /dev/null
@@ -1,27 +0,0 @@
-#!/bin/bash
-
-if [ $# -ne 4 ]; then
- echo "usage: $0 TESTSET SRCLANG TGTLANG GEN"
- exit 1
-fi
-
-TESTSET=$1
-SRCLANG=$2
-TGTLANG=$3
-
-GEN=$4
-
-if ! command -v sacremoses &> /dev/null
-then
- echo "sacremoses could not be found, please install with: pip install sacremoses"
- exit
-fi
-
-grep ^H $GEN \
-| sed 's/^H\-//' \
-| sort -n -k 1 \
-| cut -f 3 \
-| sacremoses detokenize \
-> $GEN.sorted.detok
-
-sacrebleu --test-set $TESTSET --language-pair "${SRCLANG}-${TGTLANG}" < $GEN.sorted.detok
diff --git a/spaces/gulabpatel/GFP_GAN/tests/test_gfpgan_model.py b/spaces/gulabpatel/GFP_GAN/tests/test_gfpgan_model.py
deleted file mode 100644
index 1408ddd7c909c7257fbcea79f8576231a40f9211..0000000000000000000000000000000000000000
--- a/spaces/gulabpatel/GFP_GAN/tests/test_gfpgan_model.py
+++ /dev/null
@@ -1,132 +0,0 @@
-import tempfile
-import torch
-import yaml
-from basicsr.archs.stylegan2_arch import StyleGAN2Discriminator
-from basicsr.data.paired_image_dataset import PairedImageDataset
-from basicsr.losses.losses import GANLoss, L1Loss, PerceptualLoss
-
-from gfpgan.archs.arcface_arch import ResNetArcFace
-from gfpgan.archs.gfpganv1_arch import FacialComponentDiscriminator, GFPGANv1
-from gfpgan.models.gfpgan_model import GFPGANModel
-
-
-def test_gfpgan_model():
- with open('tests/data/test_gfpgan_model.yml', mode='r') as f:
- opt = yaml.load(f, Loader=yaml.FullLoader)
-
- # build model
- model = GFPGANModel(opt)
- # test attributes
- assert model.__class__.__name__ == 'GFPGANModel'
- assert isinstance(model.net_g, GFPGANv1) # generator
- assert isinstance(model.net_d, StyleGAN2Discriminator) # discriminator
- # facial component discriminators
- assert isinstance(model.net_d_left_eye, FacialComponentDiscriminator)
- assert isinstance(model.net_d_right_eye, FacialComponentDiscriminator)
- assert isinstance(model.net_d_mouth, FacialComponentDiscriminator)
- # identity network
- assert isinstance(model.network_identity, ResNetArcFace)
- # losses
- assert isinstance(model.cri_pix, L1Loss)
- assert isinstance(model.cri_perceptual, PerceptualLoss)
- assert isinstance(model.cri_gan, GANLoss)
- assert isinstance(model.cri_l1, L1Loss)
- # optimizer
- assert isinstance(model.optimizers[0], torch.optim.Adam)
- assert isinstance(model.optimizers[1], torch.optim.Adam)
-
- # prepare data
- gt = torch.rand((1, 3, 512, 512), dtype=torch.float32)
- lq = torch.rand((1, 3, 512, 512), dtype=torch.float32)
- loc_left_eye = torch.rand((1, 4), dtype=torch.float32)
- loc_right_eye = torch.rand((1, 4), dtype=torch.float32)
- loc_mouth = torch.rand((1, 4), dtype=torch.float32)
- data = dict(gt=gt, lq=lq, loc_left_eye=loc_left_eye, loc_right_eye=loc_right_eye, loc_mouth=loc_mouth)
- model.feed_data(data)
- # check data shape
- assert model.lq.shape == (1, 3, 512, 512)
- assert model.gt.shape == (1, 3, 512, 512)
- assert model.loc_left_eyes.shape == (1, 4)
- assert model.loc_right_eyes.shape == (1, 4)
- assert model.loc_mouths.shape == (1, 4)
-
- # ----------------- test optimize_parameters -------------------- #
- model.feed_data(data)
- model.optimize_parameters(1)
- assert model.output.shape == (1, 3, 512, 512)
- assert isinstance(model.log_dict, dict)
- # check returned keys
- expected_keys = [
- 'l_g_pix', 'l_g_percep', 'l_g_style', 'l_g_gan', 'l_g_gan_left_eye', 'l_g_gan_right_eye', 'l_g_gan_mouth',
- 'l_g_comp_style_loss', 'l_identity', 'l_d', 'real_score', 'fake_score', 'l_d_r1', 'l_d_left_eye',
- 'l_d_right_eye', 'l_d_mouth'
- ]
- assert set(expected_keys).issubset(set(model.log_dict.keys()))
-
- # ----------------- remove pyramid_loss_weight-------------------- #
- model.feed_data(data)
- model.optimize_parameters(100000) # large than remove_pyramid_loss = 50000
- assert model.output.shape == (1, 3, 512, 512)
- assert isinstance(model.log_dict, dict)
- # check returned keys
- expected_keys = [
- 'l_g_pix', 'l_g_percep', 'l_g_style', 'l_g_gan', 'l_g_gan_left_eye', 'l_g_gan_right_eye', 'l_g_gan_mouth',
- 'l_g_comp_style_loss', 'l_identity', 'l_d', 'real_score', 'fake_score', 'l_d_r1', 'l_d_left_eye',
- 'l_d_right_eye', 'l_d_mouth'
- ]
- assert set(expected_keys).issubset(set(model.log_dict.keys()))
-
- # ----------------- test save -------------------- #
- with tempfile.TemporaryDirectory() as tmpdir:
- model.opt['path']['models'] = tmpdir
- model.opt['path']['training_states'] = tmpdir
- model.save(0, 1)
-
- # ----------------- test the test function -------------------- #
- model.test()
- assert model.output.shape == (1, 3, 512, 512)
- # delete net_g_ema
- model.__delattr__('net_g_ema')
- model.test()
- assert model.output.shape == (1, 3, 512, 512)
- assert model.net_g.training is True # should back to training mode after testing
-
- # ----------------- test nondist_validation -------------------- #
- # construct dataloader
- dataset_opt = dict(
- name='Demo',
- dataroot_gt='tests/data/gt',
- dataroot_lq='tests/data/gt',
- io_backend=dict(type='disk'),
- scale=4,
- phase='val')
- dataset = PairedImageDataset(dataset_opt)
- dataloader = torch.utils.data.DataLoader(dataset=dataset, batch_size=1, shuffle=False, num_workers=0)
- assert model.is_train is True
- with tempfile.TemporaryDirectory() as tmpdir:
- model.opt['path']['visualization'] = tmpdir
- model.nondist_validation(dataloader, 1, None, save_img=True)
- assert model.is_train is True
- # check metric_results
- assert 'psnr' in model.metric_results
- assert isinstance(model.metric_results['psnr'], float)
-
- # validation
- with tempfile.TemporaryDirectory() as tmpdir:
- model.opt['is_train'] = False
- model.opt['val']['suffix'] = 'test'
- model.opt['path']['visualization'] = tmpdir
- model.opt['val']['pbar'] = True
- model.nondist_validation(dataloader, 1, None, save_img=True)
- # check metric_results
- assert 'psnr' in model.metric_results
- assert isinstance(model.metric_results['psnr'], float)
-
- # if opt['val']['suffix'] is None
- model.opt['val']['suffix'] = None
- model.opt['name'] = 'demo'
- model.opt['path']['visualization'] = tmpdir
- model.nondist_validation(dataloader, 1, None, save_img=True)
- # check metric_results
- assert 'psnr' in model.metric_results
- assert isinstance(model.metric_results['psnr'], float)
diff --git a/spaces/gwang-kim/DATID-3D/eg3d/training/dataset.py b/spaces/gwang-kim/DATID-3D/eg3d/training/dataset.py
deleted file mode 100644
index b4d7c4fb13d1541f9d11af92a76cc859d71f5547..0000000000000000000000000000000000000000
--- a/spaces/gwang-kim/DATID-3D/eg3d/training/dataset.py
+++ /dev/null
@@ -1,244 +0,0 @@
-# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
-#
-# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
-# property and proprietary rights in and to this material, related
-# documentation and any modifications thereto. Any use, reproduction,
-# disclosure or distribution of this material and related documentation
-# without an express license agreement from NVIDIA CORPORATION or
-# its affiliates is strictly prohibited.
-
-"""Streaming images and labels from datasets created with dataset_tool.py."""
-
-import os
-import numpy as np
-import zipfile
-import PIL.Image
-import json
-import torch
-import dnnlib
-
-try:
- import pyspng
-except ImportError:
- pyspng = None
-
-#----------------------------------------------------------------------------
-
-class Dataset(torch.utils.data.Dataset):
- def __init__(self,
- name, # Name of the dataset.
- raw_shape, # Shape of the raw image data (NCHW).
- max_size = None, # Artificially limit the size of the dataset. None = no limit. Applied before xflip.
- use_labels = False, # Enable conditioning labels? False = label dimension is zero.
- xflip = False, # Artificially double the size of the dataset via x-flips. Applied after max_size.
- random_seed = 0, # Random seed to use when applying max_size.
- ):
- self._name = name
- self._raw_shape = list(raw_shape)
- self._use_labels = use_labels
- self._raw_labels = None
- self._label_shape = None
-
- # Apply max_size.
- self._raw_idx = np.arange(self._raw_shape[0], dtype=np.int64)
- if (max_size is not None) and (self._raw_idx.size > max_size):
- np.random.RandomState(random_seed).shuffle(self._raw_idx)
- self._raw_idx = np.sort(self._raw_idx[:max_size])
-
- # Apply xflip.
- self._xflip = np.zeros(self._raw_idx.size, dtype=np.uint8)
- if xflip:
- self._raw_idx = np.tile(self._raw_idx, 2)
- self._xflip = np.concatenate([self._xflip, np.ones_like(self._xflip)])
-
- def _get_raw_labels(self):
- if self._raw_labels is None:
- self._raw_labels = self._load_raw_labels() if self._use_labels else None
- if self._raw_labels is None:
- self._raw_labels = np.zeros([self._raw_shape[0], 0], dtype=np.float32)
- assert isinstance(self._raw_labels, np.ndarray)
- assert self._raw_labels.shape[0] == self._raw_shape[0]
- assert self._raw_labels.dtype in [np.float32, np.int64]
- if self._raw_labels.dtype == np.int64:
- assert self._raw_labels.ndim == 1
- assert np.all(self._raw_labels >= 0)
- self._raw_labels_std = self._raw_labels.std(0)
- return self._raw_labels
-
- def close(self): # to be overridden by subclass
- pass
-
- def _load_raw_image(self, raw_idx): # to be overridden by subclass
- raise NotImplementedError
-
- def _load_raw_labels(self): # to be overridden by subclass
- raise NotImplementedError
-
- def __getstate__(self):
- return dict(self.__dict__, _raw_labels=None)
-
- def __del__(self):
- try:
- self.close()
- except:
- pass
-
- def __len__(self):
- return self._raw_idx.size
-
- def __getitem__(self, idx):
- image = self._load_raw_image(self._raw_idx[idx])
- assert isinstance(image, np.ndarray)
- assert list(image.shape) == self.image_shape
- assert image.dtype == np.uint8
- if self._xflip[idx]:
- assert image.ndim == 3 # CHW
- image = image[:, :, ::-1]
- return image.copy(), self.get_label(idx)
-
- def get_label(self, idx):
- label = self._get_raw_labels()[self._raw_idx[idx]]
- if label.dtype == np.int64:
- onehot = np.zeros(self.label_shape, dtype=np.float32)
- onehot[label] = 1
- label = onehot
- return label.copy()
-
- def get_details(self, idx):
- d = dnnlib.EasyDict()
- d.raw_idx = int(self._raw_idx[idx])
- d.xflip = (int(self._xflip[idx]) != 0)
- d.raw_label = self._get_raw_labels()[d.raw_idx].copy()
- return d
-
- def get_label_std(self):
- return self._raw_labels_std
-
- @property
- def name(self):
- return self._name
-
- @property
- def image_shape(self):
- return list(self._raw_shape[1:])
-
- @property
- def num_channels(self):
- assert len(self.image_shape) == 3 # CHW
- return self.image_shape[0]
-
- @property
- def resolution(self):
- assert len(self.image_shape) == 3 # CHW
- assert self.image_shape[1] == self.image_shape[2]
- return self.image_shape[1]
-
- @property
- def label_shape(self):
- if self._label_shape is None:
- raw_labels = self._get_raw_labels()
- if raw_labels.dtype == np.int64:
- self._label_shape = [int(np.max(raw_labels)) + 1]
- else:
- self._label_shape = raw_labels.shape[1:]
- return list(self._label_shape)
-
- @property
- def label_dim(self):
- assert len(self.label_shape) == 1
- return self.label_shape[0]
-
- @property
- def has_labels(self):
- return any(x != 0 for x in self.label_shape)
-
- @property
- def has_onehot_labels(self):
- return self._get_raw_labels().dtype == np.int64
-
-#----------------------------------------------------------------------------
-
-class ImageFolderDataset(Dataset):
- def __init__(self,
- path, # Path to directory or zip.
- resolution = None, # Ensure specific resolution, None = highest available.
- **super_kwargs, # Additional arguments for the Dataset base class.
- ):
- self._path = path
- self._zipfile = None
-
- if os.path.isdir(self._path):
- self._type = 'dir'
- self._all_fnames = {os.path.relpath(os.path.join(root, fname), start=self._path) for root, _dirs, files in os.walk(self._path) for fname in files}
- elif self._file_ext(self._path) == '.zip':
- self._type = 'zip'
- self._all_fnames = set(self._get_zipfile().namelist())
- else:
- raise IOError('Path must point to a directory or zip')
-
- PIL.Image.init()
- self._image_fnames = sorted(fname for fname in self._all_fnames if self._file_ext(fname) in PIL.Image.EXTENSION)
- if len(self._image_fnames) == 0:
- raise IOError('No image files found in the specified path')
-
- name = os.path.splitext(os.path.basename(self._path))[0]
- raw_shape = [len(self._image_fnames)] + list(self._load_raw_image(0).shape)
- if resolution is not None and (raw_shape[2] != resolution or raw_shape[3] != resolution):
- raise IOError('Image files do not match the specified resolution')
- super().__init__(name=name, raw_shape=raw_shape, **super_kwargs)
-
- @staticmethod
- def _file_ext(fname):
- return os.path.splitext(fname)[1].lower()
-
- def _get_zipfile(self):
- assert self._type == 'zip'
- if self._zipfile is None:
- self._zipfile = zipfile.ZipFile(self._path)
- return self._zipfile
-
- def _open_file(self, fname):
- if self._type == 'dir':
- return open(os.path.join(self._path, fname), 'rb')
- if self._type == 'zip':
- return self._get_zipfile().open(fname, 'r')
- return None
-
- def close(self):
- try:
- if self._zipfile is not None:
- self._zipfile.close()
- finally:
- self._zipfile = None
-
- def __getstate__(self):
- return dict(super().__getstate__(), _zipfile=None)
-
- def _load_raw_image(self, raw_idx):
- fname = self._image_fnames[raw_idx]
- with self._open_file(fname) as f:
- if pyspng is not None and self._file_ext(fname) == '.png':
- image = pyspng.load(f.read())
- else:
- image = np.array(PIL.Image.open(f))
- if image.ndim == 2:
- image = image[:, :, np.newaxis] # HW => HWC
- image = image.transpose(2, 0, 1) # HWC => CHW
- return image
-
- def _load_raw_labels(self):
- fname = 'dataset.json'
- if fname not in self._all_fnames:
- return None
- with self._open_file(fname) as f:
- labels = json.load(f)['labels']
- if labels is None:
- return None
- labels = dict(labels)
- labels = [labels[fname.replace('\\', '/')] for fname in self._image_fnames]
- labels = np.array(labels)
- labels = labels.astype({1: np.int64, 2: np.float32}[labels.ndim])
- return labels
-
-#----------------------------------------------------------------------------
diff --git a/spaces/gyugnsu/DragGan-Inversion/stylegan_human/pti/pti_models/e4e/encoders/helpers.py b/spaces/gyugnsu/DragGan-Inversion/stylegan_human/pti/pti_models/e4e/encoders/helpers.py
deleted file mode 100644
index c5e907be6703ccc43f263b4c40f7d1b84bc47755..0000000000000000000000000000000000000000
--- a/spaces/gyugnsu/DragGan-Inversion/stylegan_human/pti/pti_models/e4e/encoders/helpers.py
+++ /dev/null
@@ -1,145 +0,0 @@
-from collections import namedtuple
-import torch
-import torch.nn.functional as F
-from torch.nn import Conv2d, BatchNorm2d, PReLU, ReLU, Sigmoid, MaxPool2d, AdaptiveAvgPool2d, Sequential, Module
-
-"""
-ArcFace implementation from [TreB1eN](https://github.com/TreB1eN/InsightFace_Pytorch)
-"""
-
-
-class Flatten(Module):
- def forward(self, input):
- return input.view(input.size(0), -1)
-
-
-def l2_norm(input, axis=1):
- norm = torch.norm(input, 2, axis, True)
- output = torch.div(input, norm)
- return output
-
-
-class Bottleneck(namedtuple('Block', ['in_channel', 'depth', 'stride'])):
- """ A named tuple describing a ResNet block. """
-
-
-def get_block(in_channel, depth, num_units, stride=2):
- return [Bottleneck(in_channel, depth, stride)] + [Bottleneck(depth, depth, 1) for i in range(num_units - 1)]
-
-
-def get_blocks(num_layers):
- if num_layers == 50:
- blocks = [
- get_block(in_channel=64, depth=64, num_units=3),
- get_block(in_channel=64, depth=128, num_units=4),
- get_block(in_channel=128, depth=256, num_units=14),
- get_block(in_channel=256, depth=512, num_units=3)
- ]
- elif num_layers == 100:
- blocks = [
- get_block(in_channel=64, depth=64, num_units=3),
- get_block(in_channel=64, depth=128, num_units=13),
- get_block(in_channel=128, depth=256, num_units=30),
- get_block(in_channel=256, depth=512, num_units=3)
- ]
- elif num_layers == 152:
- blocks = [
- get_block(in_channel=64, depth=64, num_units=3),
- get_block(in_channel=64, depth=128, num_units=8),
- get_block(in_channel=128, depth=256, num_units=36),
- get_block(in_channel=256, depth=512, num_units=3)
- ]
- else:
- raise ValueError(
- "Invalid number of layers: {}. Must be one of [50, 100, 152]".format(num_layers))
- return blocks
-
-
-class SEModule(Module):
- def __init__(self, channels, reduction):
- super(SEModule, self).__init__()
- self.avg_pool = AdaptiveAvgPool2d(1)
- self.fc1 = Conv2d(channels, channels // reduction,
- kernel_size=1, padding=0, bias=False)
- self.relu = ReLU(inplace=True)
- self.fc2 = Conv2d(channels // reduction, channels,
- kernel_size=1, padding=0, bias=False)
- self.sigmoid = Sigmoid()
-
- def forward(self, x):
- module_input = x
- x = self.avg_pool(x)
- x = self.fc1(x)
- x = self.relu(x)
- x = self.fc2(x)
- x = self.sigmoid(x)
- return module_input * x
-
-
-class bottleneck_IR(Module):
- def __init__(self, in_channel, depth, stride):
- super(bottleneck_IR, self).__init__()
- if in_channel == depth:
- self.shortcut_layer = MaxPool2d(1, stride)
- else:
- self.shortcut_layer = Sequential(
- Conv2d(in_channel, depth, (1, 1), stride, bias=False),
- BatchNorm2d(depth)
- )
- self.res_layer = Sequential(
- BatchNorm2d(in_channel),
- Conv2d(in_channel, depth, (3, 3), (1, 1),
- 1, bias=False), PReLU(depth),
- Conv2d(depth, depth, (3, 3), stride, 1,
- bias=False), BatchNorm2d(depth)
- )
-
- def forward(self, x):
- shortcut = self.shortcut_layer(x)
- res = self.res_layer(x)
- return res + shortcut
-
-
-class bottleneck_IR_SE(Module):
- def __init__(self, in_channel, depth, stride):
- super(bottleneck_IR_SE, self).__init__()
- if in_channel == depth:
- self.shortcut_layer = MaxPool2d(1, stride)
- else:
- self.shortcut_layer = Sequential(
- Conv2d(in_channel, depth, (1, 1), stride, bias=False),
- BatchNorm2d(depth)
- )
- self.res_layer = Sequential(
- BatchNorm2d(in_channel),
- Conv2d(in_channel, depth, (3, 3), (1, 1), 1, bias=False),
- PReLU(depth),
- Conv2d(depth, depth, (3, 3), stride, 1, bias=False),
- BatchNorm2d(depth),
- SEModule(depth, 16)
- )
-
- def forward(self, x):
- shortcut = self.shortcut_layer(x)
- res = self.res_layer(x)
- return res + shortcut
-
-
-def _upsample_add(x, y):
- """Upsample and add two feature maps.
- Args:
- x: (Variable) top feature map to be upsampled.
- y: (Variable) lateral feature map.
- Returns:
- (Variable) added feature map.
- Note in PyTorch, when input size is odd, the upsampled feature map
- with `F.upsample(..., scale_factor=2, mode='nearest')`
- maybe not equal to the lateral feature map size.
- e.g.
- original input size: [N,_,15,15] ->
- conv2d feature map size: [N,_,8,8] ->
- upsampled feature map size: [N,_,16,16]
- So we choose bilinear upsample which supports arbitrary output sizes.
- """
- _, _, H, W = y.size()
- return F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True) + y
diff --git a/spaces/gyugnsu/DragGan-Inversion/stylegan_human/pti/pti_models/e4e/stylegan2/op/upfirdn2d.cpp b/spaces/gyugnsu/DragGan-Inversion/stylegan_human/pti/pti_models/e4e/stylegan2/op/upfirdn2d.cpp
deleted file mode 100644
index d2e633dc896433c205e18bc3e455539192ff968e..0000000000000000000000000000000000000000
--- a/spaces/gyugnsu/DragGan-Inversion/stylegan_human/pti/pti_models/e4e/stylegan2/op/upfirdn2d.cpp
+++ /dev/null
@@ -1,23 +0,0 @@
-#include
-
-
-torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
- int up_x, int up_y, int down_x, int down_y,
- int pad_x0, int pad_x1, int pad_y0, int pad_y1);
-
-#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
-#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
-#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
-
-torch::Tensor upfirdn2d(const torch::Tensor& input, const torch::Tensor& kernel,
- int up_x, int up_y, int down_x, int down_y,
- int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
- CHECK_CUDA(input);
- CHECK_CUDA(kernel);
-
- return upfirdn2d_op(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1);
-}
-
-PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
- m.def("upfirdn2d", &upfirdn2d, "upfirdn2d (CUDA)");
-}
\ No newline at end of file
diff --git a/spaces/hamacojr/SAM-CAT-Seg/open_clip/src/open_clip/utils.py b/spaces/hamacojr/SAM-CAT-Seg/open_clip/src/open_clip/utils.py
deleted file mode 100644
index 51e80c5e296b24cae130ab0459baf268e0db7673..0000000000000000000000000000000000000000
--- a/spaces/hamacojr/SAM-CAT-Seg/open_clip/src/open_clip/utils.py
+++ /dev/null
@@ -1,60 +0,0 @@
-from itertools import repeat
-import collections.abc
-
-from torch import nn as nn
-from torchvision.ops.misc import FrozenBatchNorm2d
-
-
-def freeze_batch_norm_2d(module, module_match={}, name=''):
- """
- Converts all `BatchNorm2d` and `SyncBatchNorm` layers of provided module into `FrozenBatchNorm2d`. If `module` is
- itself an instance of either `BatchNorm2d` or `SyncBatchNorm`, it is converted into `FrozenBatchNorm2d` and
- returned. Otherwise, the module is walked recursively and submodules are converted in place.
-
- Args:
- module (torch.nn.Module): Any PyTorch module.
- module_match (dict): Dictionary of full module names to freeze (all if empty)
- name (str): Full module name (prefix)
-
- Returns:
- torch.nn.Module: Resulting module
-
- Inspired by https://github.com/pytorch/pytorch/blob/a5895f85be0f10212791145bfedc0261d364f103/torch/nn/modules/batchnorm.py#L762
- """
- res = module
- is_match = True
- if module_match:
- is_match = name in module_match
- if is_match and isinstance(module, (nn.modules.batchnorm.BatchNorm2d, nn.modules.batchnorm.SyncBatchNorm)):
- res = FrozenBatchNorm2d(module.num_features)
- res.num_features = module.num_features
- res.affine = module.affine
- if module.affine:
- res.weight.data = module.weight.data.clone().detach()
- res.bias.data = module.bias.data.clone().detach()
- res.running_mean.data = module.running_mean.data
- res.running_var.data = module.running_var.data
- res.eps = module.eps
- else:
- for child_name, child in module.named_children():
- full_child_name = '.'.join([name, child_name]) if name else child_name
- new_child = freeze_batch_norm_2d(child, module_match, full_child_name)
- if new_child is not child:
- res.add_module(child_name, new_child)
- return res
-
-
-# From PyTorch internals
-def _ntuple(n):
- def parse(x):
- if isinstance(x, collections.abc.Iterable):
- return x
- return tuple(repeat(x, n))
- return parse
-
-
-to_1tuple = _ntuple(1)
-to_2tuple = _ntuple(2)
-to_3tuple = _ntuple(3)
-to_4tuple = _ntuple(4)
-to_ntuple = lambda n, x: _ntuple(n)(x)
diff --git a/spaces/hanstyle/tts/wav2lip_train.py b/spaces/hanstyle/tts/wav2lip_train.py
deleted file mode 100644
index 6e0811808af55464a803be1e268be33f1b8a31a9..0000000000000000000000000000000000000000
--- a/spaces/hanstyle/tts/wav2lip_train.py
+++ /dev/null
@@ -1,374 +0,0 @@
-from os.path import dirname, join, basename, isfile
-from tqdm import tqdm
-
-from models import SyncNet_color as SyncNet
-from models import Wav2Lip as Wav2Lip
-import audio
-
-import torch
-from torch import nn
-from torch import optim
-import torch.backends.cudnn as cudnn
-from torch.utils import data as data_utils
-import numpy as np
-
-from glob import glob
-
-import os, random, cv2, argparse
-from hparams import hparams, get_image_list
-
-parser = argparse.ArgumentParser(description='Code to train the Wav2Lip model without the visual quality discriminator')
-
-parser.add_argument("--data_root", help="Root folder of the preprocessed LRS2 dataset", required=True, type=str)
-
-parser.add_argument('--checkpoint_dir', help='Save checkpoints to this directory', required=True, type=str)
-parser.add_argument('--syncnet_checkpoint_path', help='Load the pre-trained Expert discriminator', required=True, type=str)
-
-parser.add_argument('--checkpoint_path', help='Resume from this checkpoint', default=None, type=str)
-
-args = parser.parse_args()
-
-
-global_step = 0
-global_epoch = 0
-use_cuda = torch.cuda.is_available()
-print('use_cuda: {}'.format(use_cuda))
-
-syncnet_T = 5
-syncnet_mel_step_size = 16
-
-class Dataset(object):
- def __init__(self, split):
- self.all_videos = get_image_list(args.data_root, split)
-
- def get_frame_id(self, frame):
- return int(basename(frame).split('.')[0])
-
- def get_window(self, start_frame):
- start_id = self.get_frame_id(start_frame)
- vidname = dirname(start_frame)
-
- window_fnames = []
- for frame_id in range(start_id, start_id + syncnet_T):
- frame = join(vidname, '{}.jpg'.format(frame_id))
- if not isfile(frame):
- return None
- window_fnames.append(frame)
- return window_fnames
-
- def read_window(self, window_fnames):
- if window_fnames is None: return None
- window = []
- for fname in window_fnames:
- img = cv2.imread(fname)
- if img is None:
- return None
- try:
- img = cv2.resize(img, (hparams.img_size, hparams.img_size))
- except Exception as e:
- return None
-
- window.append(img)
-
- return window
-
- def crop_audio_window(self, spec, start_frame):
- if type(start_frame) == int:
- start_frame_num = start_frame
- else:
- start_frame_num = self.get_frame_id(start_frame) # 0-indexing ---> 1-indexing
- start_idx = int(80. * (start_frame_num / float(hparams.fps)))
-
- end_idx = start_idx + syncnet_mel_step_size
-
- return spec[start_idx : end_idx, :]
-
- def get_segmented_mels(self, spec, start_frame):
- mels = []
- assert syncnet_T == 5
- start_frame_num = self.get_frame_id(start_frame) + 1 # 0-indexing ---> 1-indexing
- if start_frame_num - 2 < 0: return None
- for i in range(start_frame_num, start_frame_num + syncnet_T):
- m = self.crop_audio_window(spec, i - 2)
- if m.shape[0] != syncnet_mel_step_size:
- return None
- mels.append(m.T)
-
- mels = np.asarray(mels)
-
- return mels
-
- def prepare_window(self, window):
- # 3 x T x H x W
- x = np.asarray(window) / 255.
- x = np.transpose(x, (3, 0, 1, 2))
-
- return x
-
- def __len__(self):
- return len(self.all_videos)
-
- def __getitem__(self, idx):
- while 1:
- idx = random.randint(0, len(self.all_videos) - 1)
- vidname = self.all_videos[idx]
- img_names = list(glob(join(vidname, '*.jpg')))
- if len(img_names) <= 3 * syncnet_T:
- continue
-
- img_name = random.choice(img_names)
- wrong_img_name = random.choice(img_names)
- while wrong_img_name == img_name:
- wrong_img_name = random.choice(img_names)
-
- window_fnames = self.get_window(img_name)
- wrong_window_fnames = self.get_window(wrong_img_name)
- if window_fnames is None or wrong_window_fnames is None:
- continue
-
- window = self.read_window(window_fnames)
- if window is None:
- continue
-
- wrong_window = self.read_window(wrong_window_fnames)
- if wrong_window is None:
- continue
-
- try:
- wavpath = join(vidname, "audio.wav")
- wav = audio.load_wav(wavpath, hparams.sample_rate)
-
- orig_mel = audio.melspectrogram(wav).T
- except Exception as e:
- continue
-
- mel = self.crop_audio_window(orig_mel.copy(), img_name)
-
- if (mel.shape[0] != syncnet_mel_step_size):
- continue
-
- indiv_mels = self.get_segmented_mels(orig_mel.copy(), img_name)
- if indiv_mels is None: continue
-
- window = self.prepare_window(window)
- y = window.copy()
- window[:, :, window.shape[2]//2:] = 0.
-
- wrong_window = self.prepare_window(wrong_window)
- x = np.concatenate([window, wrong_window], axis=0)
-
- x = torch.FloatTensor(x)
- mel = torch.FloatTensor(mel.T).unsqueeze(0)
- indiv_mels = torch.FloatTensor(indiv_mels).unsqueeze(1)
- y = torch.FloatTensor(y)
- return x, indiv_mels, mel, y
-
-def save_sample_images(x, g, gt, global_step, checkpoint_dir):
- x = (x.detach().cpu().numpy().transpose(0, 2, 3, 4, 1) * 255.).astype(np.uint8)
- g = (g.detach().cpu().numpy().transpose(0, 2, 3, 4, 1) * 255.).astype(np.uint8)
- gt = (gt.detach().cpu().numpy().transpose(0, 2, 3, 4, 1) * 255.).astype(np.uint8)
-
- refs, inps = x[..., 3:], x[..., :3]
- folder = join(checkpoint_dir, "samples_step{:09d}".format(global_step))
- if not os.path.exists(folder): os.mkdir(folder)
- collage = np.concatenate((refs, inps, g, gt), axis=-2)
- for batch_idx, c in enumerate(collage):
- for t in range(len(c)):
- cv2.imwrite('{}/{}_{}.jpg'.format(folder, batch_idx, t), c[t])
-
-logloss = nn.BCELoss()
-def cosine_loss(a, v, y):
- d = nn.functional.cosine_similarity(a, v)
- loss = logloss(d.unsqueeze(1), y)
-
- return loss
-
-device = torch.device("cuda" if use_cuda else "cpu")
-syncnet = SyncNet().to(device)
-for p in syncnet.parameters():
- p.requires_grad = False
-
-recon_loss = nn.L1Loss()
-def get_sync_loss(mel, g):
- g = g[:, :, :, g.size(3)//2:]
- g = torch.cat([g[:, :, i] for i in range(syncnet_T)], dim=1)
- # B, 3 * T, H//2, W
- a, v = syncnet(mel, g)
- y = torch.ones(g.size(0), 1).float().to(device)
- return cosine_loss(a, v, y)
-
-def train(device, model, train_data_loader, test_data_loader, optimizer,
- checkpoint_dir=None, checkpoint_interval=None, nepochs=None):
-
- global global_step, global_epoch
- resumed_step = global_step
-
- while global_epoch < nepochs:
- print('Starting Epoch: {}'.format(global_epoch))
- running_sync_loss, running_l1_loss = 0., 0.
- prog_bar = tqdm(enumerate(train_data_loader))
- for step, (x, indiv_mels, mel, gt) in prog_bar:
- model.train()
- optimizer.zero_grad()
-
- # Move data to CUDA device
- x = x.to(device)
- mel = mel.to(device)
- indiv_mels = indiv_mels.to(device)
- gt = gt.to(device)
-
- g = model(indiv_mels, x)
-
- if hparams.syncnet_wt > 0.:
- sync_loss = get_sync_loss(mel, g)
- else:
- sync_loss = 0.
-
- l1loss = recon_loss(g, gt)
-
- loss = hparams.syncnet_wt * sync_loss + (1 - hparams.syncnet_wt) * l1loss
- loss.backward()
- optimizer.step()
-
- if global_step % checkpoint_interval == 0:
- save_sample_images(x, g, gt, global_step, checkpoint_dir)
-
- global_step += 1
- cur_session_steps = global_step - resumed_step
-
- running_l1_loss += l1loss.item()
- if hparams.syncnet_wt > 0.:
- running_sync_loss += sync_loss.item()
- else:
- running_sync_loss += 0.
-
- if global_step == 1 or global_step % checkpoint_interval == 0:
- save_checkpoint(
- model, optimizer, global_step, checkpoint_dir, global_epoch)
-
- if global_step == 1 or global_step % hparams.eval_interval == 0:
- with torch.no_grad():
- average_sync_loss = eval_model(test_data_loader, global_step, device, model, checkpoint_dir)
-
- if average_sync_loss < .75:
- hparams.set_hparam('syncnet_wt', 0.01) # without image GAN a lesser weight is sufficient
-
- prog_bar.set_description('L1: {}, Sync Loss: {}'.format(running_l1_loss / (step + 1),
- running_sync_loss / (step + 1)))
-
- global_epoch += 1
-
-
-def eval_model(test_data_loader, global_step, device, model, checkpoint_dir):
- eval_steps = 700
- print('Evaluating for {} steps'.format(eval_steps))
- sync_losses, recon_losses = [], []
- step = 0
- while 1:
- for x, indiv_mels, mel, gt in test_data_loader:
- step += 1
- model.eval()
-
- # Move data to CUDA device
- x = x.to(device)
- gt = gt.to(device)
- indiv_mels = indiv_mels.to(device)
- mel = mel.to(device)
-
- g = model(indiv_mels, x)
-
- sync_loss = get_sync_loss(mel, g)
- l1loss = recon_loss(g, gt)
-
- sync_losses.append(sync_loss.item())
- recon_losses.append(l1loss.item())
-
- if step > eval_steps:
- averaged_sync_loss = sum(sync_losses) / len(sync_losses)
- averaged_recon_loss = sum(recon_losses) / len(recon_losses)
-
- print('L1: {}, Sync loss: {}'.format(averaged_recon_loss, averaged_sync_loss))
-
- return averaged_sync_loss
-
-def save_checkpoint(model, optimizer, step, checkpoint_dir, epoch):
-
- checkpoint_path = join(
- checkpoint_dir, "checkpoint_step{:09d}.pth".format(global_step))
- optimizer_state = optimizer.state_dict() if hparams.save_optimizer_state else None
- torch.save({
- "state_dict": model.state_dict(),
- "optimizer": optimizer_state,
- "global_step": step,
- "global_epoch": epoch,
- }, checkpoint_path)
- print("Saved checkpoint:", checkpoint_path)
-
-
-def _load(checkpoint_path):
- if use_cuda:
- checkpoint = torch.load(checkpoint_path)
- else:
- checkpoint = torch.load(checkpoint_path,
- map_location=lambda storage, loc: storage)
- return checkpoint
-
-def load_checkpoint(path, model, optimizer, reset_optimizer=False, overwrite_global_states=True):
- global global_step
- global global_epoch
-
- print("Load checkpoint from: {}".format(path))
- checkpoint = _load(path)
- s = checkpoint["state_dict"]
- new_s = {}
- for k, v in s.items():
- new_s[k.replace('module.', '')] = v
- model.load_state_dict(new_s)
- if not reset_optimizer:
- optimizer_state = checkpoint["optimizer"]
- if optimizer_state is not None:
- print("Load optimizer state from {}".format(path))
- optimizer.load_state_dict(checkpoint["optimizer"])
- if overwrite_global_states:
- global_step = checkpoint["global_step"]
- global_epoch = checkpoint["global_epoch"]
-
- return model
-
-if __name__ == "__main__":
- checkpoint_dir = args.checkpoint_dir
-
- # Dataset and Dataloader setup
- train_dataset = Dataset('train')
- test_dataset = Dataset('val')
-
- train_data_loader = data_utils.DataLoader(
- train_dataset, batch_size=hparams.batch_size, shuffle=True,
- num_workers=hparams.num_workers)
-
- test_data_loader = data_utils.DataLoader(
- test_dataset, batch_size=hparams.batch_size,
- num_workers=4)
-
- device = torch.device("cuda" if use_cuda else "cpu")
-
- # Model
- model = Wav2Lip().to(device)
- print('total trainable params {}'.format(sum(p.numel() for p in model.parameters() if p.requires_grad)))
-
- optimizer = optim.Adam([p for p in model.parameters() if p.requires_grad],
- lr=hparams.initial_learning_rate)
-
- if args.checkpoint_path is not None:
- load_checkpoint(args.checkpoint_path, model, optimizer, reset_optimizer=False)
-
- load_checkpoint(args.syncnet_checkpoint_path, syncnet, None, reset_optimizer=True, overwrite_global_states=False)
-
- if not os.path.exists(checkpoint_dir):
- os.mkdir(checkpoint_dir)
-
- # Train!
- train(device, model, train_data_loader, test_data_loader, optimizer,
- checkpoint_dir=checkpoint_dir,
- checkpoint_interval=hparams.checkpoint_interval,
- nepochs=hparams.nepochs)
diff --git a/spaces/hca97/Mosquito-Detection/my_models/torch_hub_cache/yolov5/utils/autoanchor.py b/spaces/hca97/Mosquito-Detection/my_models/torch_hub_cache/yolov5/utils/autoanchor.py
deleted file mode 100644
index 4c11ab3decec6f30f46fcd6121a3cfd5bc7957c2..0000000000000000000000000000000000000000
--- a/spaces/hca97/Mosquito-Detection/my_models/torch_hub_cache/yolov5/utils/autoanchor.py
+++ /dev/null
@@ -1,169 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
-"""
-AutoAnchor utils
-"""
-
-import random
-
-import numpy as np
-import torch
-import yaml
-from tqdm import tqdm
-
-from utils import TryExcept
-from utils.general import LOGGER, TQDM_BAR_FORMAT, colorstr
-
-PREFIX = colorstr('AutoAnchor: ')
-
-
-def check_anchor_order(m):
- # Check anchor order against stride order for YOLOv5 Detect() module m, and correct if necessary
- a = m.anchors.prod(-1).mean(-1).view(-1) # mean anchor area per output layer
- da = a[-1] - a[0] # delta a
- ds = m.stride[-1] - m.stride[0] # delta s
- if da and (da.sign() != ds.sign()): # same order
- LOGGER.info(f'{PREFIX}Reversing anchor order')
- m.anchors[:] = m.anchors.flip(0)
-
-
-@TryExcept(f'{PREFIX}ERROR')
-def check_anchors(dataset, model, thr=4.0, imgsz=640):
- # Check anchor fit to data, recompute if necessary
- m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
- shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
- scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
- wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
-
- def metric(k): # compute metric
- r = wh[:, None] / k[None]
- x = torch.min(r, 1 / r).min(2)[0] # ratio metric
- best = x.max(1)[0] # best_x
- aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold
- bpr = (best > 1 / thr).float().mean() # best possible recall
- return bpr, aat
-
- stride = m.stride.to(m.anchors.device).view(-1, 1, 1) # model strides
- anchors = m.anchors.clone() * stride # current anchors
- bpr, aat = metric(anchors.cpu().view(-1, 2))
- s = f'\n{PREFIX}{aat:.2f} anchors/target, {bpr:.3f} Best Possible Recall (BPR). '
- if bpr > 0.98: # threshold to recompute
- LOGGER.info(f'{s}Current anchors are a good fit to dataset ✅')
- else:
- LOGGER.info(f'{s}Anchors are a poor fit to dataset ⚠️, attempting to improve...')
- na = m.anchors.numel() // 2 # number of anchors
- anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
- new_bpr = metric(anchors)[0]
- if new_bpr > bpr: # replace anchors
- anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
- m.anchors[:] = anchors.clone().view_as(m.anchors)
- check_anchor_order(m) # must be in pixel-space (not grid-space)
- m.anchors /= stride
- s = f'{PREFIX}Done ✅ (optional: update model *.yaml to use these anchors in the future)'
- else:
- s = f'{PREFIX}Done ⚠️ (original anchors better than new anchors, proceeding with original anchors)'
- LOGGER.info(s)
-
-
-def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
- """ Creates kmeans-evolved anchors from training dataset
-
- Arguments:
- dataset: path to data.yaml, or a loaded dataset
- n: number of anchors
- img_size: image size used for training
- thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
- gen: generations to evolve anchors using genetic algorithm
- verbose: print all results
-
- Return:
- k: kmeans evolved anchors
-
- Usage:
- from utils.autoanchor import *; _ = kmean_anchors()
- """
- from scipy.cluster.vq import kmeans
-
- npr = np.random
- thr = 1 / thr
-
- def metric(k, wh): # compute metrics
- r = wh[:, None] / k[None]
- x = torch.min(r, 1 / r).min(2)[0] # ratio metric
- # x = wh_iou(wh, torch.tensor(k)) # iou metric
- return x, x.max(1)[0] # x, best_x
-
- def anchor_fitness(k): # mutation fitness
- _, best = metric(torch.tensor(k, dtype=torch.float32), wh)
- return (best * (best > thr).float()).mean() # fitness
-
- def print_results(k, verbose=True):
- k = k[np.argsort(k.prod(1))] # sort small to large
- x, best = metric(k, wh0)
- bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
- s = f'{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n' \
- f'{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, ' \
- f'past_thr={x[x > thr].mean():.3f}-mean: '
- for x in k:
- s += '%i,%i, ' % (round(x[0]), round(x[1]))
- if verbose:
- LOGGER.info(s[:-2])
- return k
-
- if isinstance(dataset, str): # *.yaml file
- with open(dataset, errors='ignore') as f:
- data_dict = yaml.safe_load(f) # model dict
- from utils.dataloaders import LoadImagesAndLabels
- dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
-
- # Get label wh
- shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
- wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
-
- # Filter
- i = (wh0 < 3.0).any(1).sum()
- if i:
- LOGGER.info(f'{PREFIX}WARNING ⚠️ Extremely small objects found: {i} of {len(wh0)} labels are <3 pixels in size')
- wh = wh0[(wh0 >= 2.0).any(1)].astype(np.float32) # filter > 2 pixels
- # wh = wh * (npr.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
-
- # Kmeans init
- try:
- LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...')
- assert n <= len(wh) # apply overdetermined constraint
- s = wh.std(0) # sigmas for whitening
- k = kmeans(wh / s, n, iter=30)[0] * s # points
- assert n == len(k) # kmeans may return fewer points than requested if wh is insufficient or too similar
- except Exception:
- LOGGER.warning(f'{PREFIX}WARNING ⚠️ switching strategies from kmeans to random init')
- k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random init
- wh, wh0 = (torch.tensor(x, dtype=torch.float32) for x in (wh, wh0))
- k = print_results(k, verbose=False)
-
- # Plot
- # k, d = [None] * 20, [None] * 20
- # for i in tqdm(range(1, 21)):
- # k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
- # fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
- # ax = ax.ravel()
- # ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
- # fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
- # ax[0].hist(wh[wh[:, 0]<100, 0],400)
- # ax[1].hist(wh[wh[:, 1]<100, 1],400)
- # fig.savefig('wh.png', dpi=200)
-
- # Evolve
- f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
- pbar = tqdm(range(gen), bar_format=TQDM_BAR_FORMAT) # progress bar
- for _ in pbar:
- v = np.ones(sh)
- while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
- v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
- kg = (k.copy() * v).clip(min=2.0)
- fg = anchor_fitness(kg)
- if fg > f:
- f, k = fg, kg.copy()
- pbar.desc = f'{PREFIX}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
- if verbose:
- print_results(k, verbose)
-
- return print_results(k).astype(np.float32)
diff --git a/spaces/henryezell/freewilly/app.py b/spaces/henryezell/freewilly/app.py
deleted file mode 100644
index 8be47e7462d04255ee691ae31eeae8b73920f87b..0000000000000000000000000000000000000000
--- a/spaces/henryezell/freewilly/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/stabilityai/FreeWilly2").launch()
\ No newline at end of file
diff --git a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/ONNXVITS_to_onnx.py b/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/ONNXVITS_to_onnx.py
deleted file mode 100644
index 846e39849535ed08accb10d7001f2431a851d372..0000000000000000000000000000000000000000
--- a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/ONNXVITS_to_onnx.py
+++ /dev/null
@@ -1,31 +0,0 @@
-import ONNXVITS_models
-import utils
-from text import text_to_sequence
-import torch
-import commons
-
-def get_text(text, hps):
- text_norm = text_to_sequence(text, hps.symbols, hps.data.text_cleaners)
- if hps.data.add_blank:
- text_norm = commons.intersperse(text_norm, 0)
- text_norm = torch.LongTensor(text_norm)
- return text_norm
-
-hps = utils.get_hparams_from_file("../vits/pretrained_models/uma87.json")
-symbols = hps.symbols
-net_g = ONNXVITS_models.SynthesizerTrn(
- len(symbols),
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- n_speakers=hps.data.n_speakers,
- **hps.model)
-_ = net_g.eval()
-_ = utils.load_checkpoint("../vits/pretrained_models/uma_1153000.pth", net_g)
-
-text1 = get_text("ありがとうございます。", hps)
-stn_tst = text1
-with torch.no_grad():
- x_tst = stn_tst.unsqueeze(0)
- x_tst_lengths = torch.LongTensor([stn_tst.size(0)])
- sid = torch.tensor([0])
- o = net_g(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8, length_scale=1)
\ No newline at end of file
diff --git a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/text/mandarin.py b/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/text/mandarin.py
deleted file mode 100644
index 093d8826809aa2681f6088174427337a59e0c882..0000000000000000000000000000000000000000
--- a/spaces/hhhhardman/VITS-Umamusume-voice-synthesizer/text/mandarin.py
+++ /dev/null
@@ -1,329 +0,0 @@
-import os
-import sys
-import re
-from pypinyin import lazy_pinyin, BOPOMOFO
-import jieba
-import cn2an
-import logging
-
-logging.getLogger('jieba').setLevel(logging.WARNING)
-jieba.initialize()
-
-
-# List of (Latin alphabet, bopomofo) pairs:
-_latin_to_bopomofo = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('a', 'ㄟˉ'),
- ('b', 'ㄅㄧˋ'),
- ('c', 'ㄙㄧˉ'),
- ('d', 'ㄉㄧˋ'),
- ('e', 'ㄧˋ'),
- ('f', 'ㄝˊㄈㄨˋ'),
- ('g', 'ㄐㄧˋ'),
- ('h', 'ㄝˇㄑㄩˋ'),
- ('i', 'ㄞˋ'),
- ('j', 'ㄐㄟˋ'),
- ('k', 'ㄎㄟˋ'),
- ('l', 'ㄝˊㄛˋ'),
- ('m', 'ㄝˊㄇㄨˋ'),
- ('n', 'ㄣˉ'),
- ('o', 'ㄡˉ'),
- ('p', 'ㄆㄧˉ'),
- ('q', 'ㄎㄧㄡˉ'),
- ('r', 'ㄚˋ'),
- ('s', 'ㄝˊㄙˋ'),
- ('t', 'ㄊㄧˋ'),
- ('u', 'ㄧㄡˉ'),
- ('v', 'ㄨㄧˉ'),
- ('w', 'ㄉㄚˋㄅㄨˋㄌㄧㄡˋ'),
- ('x', 'ㄝˉㄎㄨˋㄙˋ'),
- ('y', 'ㄨㄞˋ'),
- ('z', 'ㄗㄟˋ')
-]]
-
-# List of (bopomofo, romaji) pairs:
-_bopomofo_to_romaji = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ㄅㄛ', 'p⁼wo'),
- ('ㄆㄛ', 'pʰwo'),
- ('ㄇㄛ', 'mwo'),
- ('ㄈㄛ', 'fwo'),
- ('ㄅ', 'p⁼'),
- ('ㄆ', 'pʰ'),
- ('ㄇ', 'm'),
- ('ㄈ', 'f'),
- ('ㄉ', 't⁼'),
- ('ㄊ', 'tʰ'),
- ('ㄋ', 'n'),
- ('ㄌ', 'l'),
- ('ㄍ', 'k⁼'),
- ('ㄎ', 'kʰ'),
- ('ㄏ', 'h'),
- ('ㄐ', 'ʧ⁼'),
- ('ㄑ', 'ʧʰ'),
- ('ㄒ', 'ʃ'),
- ('ㄓ', 'ʦ`⁼'),
- ('ㄔ', 'ʦ`ʰ'),
- ('ㄕ', 's`'),
- ('ㄖ', 'ɹ`'),
- ('ㄗ', 'ʦ⁼'),
- ('ㄘ', 'ʦʰ'),
- ('ㄙ', 's'),
- ('ㄚ', 'a'),
- ('ㄛ', 'o'),
- ('ㄜ', 'ə'),
- ('ㄝ', 'e'),
- ('ㄞ', 'ai'),
- ('ㄟ', 'ei'),
- ('ㄠ', 'au'),
- ('ㄡ', 'ou'),
- ('ㄧㄢ', 'yeNN'),
- ('ㄢ', 'aNN'),
- ('ㄧㄣ', 'iNN'),
- ('ㄣ', 'əNN'),
- ('ㄤ', 'aNg'),
- ('ㄧㄥ', 'iNg'),
- ('ㄨㄥ', 'uNg'),
- ('ㄩㄥ', 'yuNg'),
- ('ㄥ', 'əNg'),
- ('ㄦ', 'əɻ'),
- ('ㄧ', 'i'),
- ('ㄨ', 'u'),
- ('ㄩ', 'ɥ'),
- ('ˉ', '→'),
- ('ˊ', '↑'),
- ('ˇ', '↓↑'),
- ('ˋ', '↓'),
- ('˙', ''),
- (',', ','),
- ('。', '.'),
- ('!', '!'),
- ('?', '?'),
- ('—', '-')
-]]
-
-# List of (romaji, ipa) pairs:
-_romaji_to_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('ʃy', 'ʃ'),
- ('ʧʰy', 'ʧʰ'),
- ('ʧ⁼y', 'ʧ⁼'),
- ('NN', 'n'),
- ('Ng', 'ŋ'),
- ('y', 'j'),
- ('h', 'x')
-]]
-
-# List of (bopomofo, ipa) pairs:
-_bopomofo_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ㄅㄛ', 'p⁼wo'),
- ('ㄆㄛ', 'pʰwo'),
- ('ㄇㄛ', 'mwo'),
- ('ㄈㄛ', 'fwo'),
- ('ㄅ', 'p⁼'),
- ('ㄆ', 'pʰ'),
- ('ㄇ', 'm'),
- ('ㄈ', 'f'),
- ('ㄉ', 't⁼'),
- ('ㄊ', 'tʰ'),
- ('ㄋ', 'n'),
- ('ㄌ', 'l'),
- ('ㄍ', 'k⁼'),
- ('ㄎ', 'kʰ'),
- ('ㄏ', 'x'),
- ('ㄐ', 'tʃ⁼'),
- ('ㄑ', 'tʃʰ'),
- ('ㄒ', 'ʃ'),
- ('ㄓ', 'ts`⁼'),
- ('ㄔ', 'ts`ʰ'),
- ('ㄕ', 's`'),
- ('ㄖ', 'ɹ`'),
- ('ㄗ', 'ts⁼'),
- ('ㄘ', 'tsʰ'),
- ('ㄙ', 's'),
- ('ㄚ', 'a'),
- ('ㄛ', 'o'),
- ('ㄜ', 'ə'),
- ('ㄝ', 'ɛ'),
- ('ㄞ', 'aɪ'),
- ('ㄟ', 'eɪ'),
- ('ㄠ', 'ɑʊ'),
- ('ㄡ', 'oʊ'),
- ('ㄧㄢ', 'jɛn'),
- ('ㄩㄢ', 'ɥæn'),
- ('ㄢ', 'an'),
- ('ㄧㄣ', 'in'),
- ('ㄩㄣ', 'ɥn'),
- ('ㄣ', 'ən'),
- ('ㄤ', 'ɑŋ'),
- ('ㄧㄥ', 'iŋ'),
- ('ㄨㄥ', 'ʊŋ'),
- ('ㄩㄥ', 'jʊŋ'),
- ('ㄥ', 'əŋ'),
- ('ㄦ', 'əɻ'),
- ('ㄧ', 'i'),
- ('ㄨ', 'u'),
- ('ㄩ', 'ɥ'),
- ('ˉ', '→'),
- ('ˊ', '↑'),
- ('ˇ', '↓↑'),
- ('ˋ', '↓'),
- ('˙', ''),
- (',', ','),
- ('。', '.'),
- ('!', '!'),
- ('?', '?'),
- ('—', '-')
-]]
-
-# List of (bopomofo, ipa2) pairs:
-_bopomofo_to_ipa2 = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ㄅㄛ', 'pwo'),
- ('ㄆㄛ', 'pʰwo'),
- ('ㄇㄛ', 'mwo'),
- ('ㄈㄛ', 'fwo'),
- ('ㄅ', 'p'),
- ('ㄆ', 'pʰ'),
- ('ㄇ', 'm'),
- ('ㄈ', 'f'),
- ('ㄉ', 't'),
- ('ㄊ', 'tʰ'),
- ('ㄋ', 'n'),
- ('ㄌ', 'l'),
- ('ㄍ', 'k'),
- ('ㄎ', 'kʰ'),
- ('ㄏ', 'h'),
- ('ㄐ', 'tɕ'),
- ('ㄑ', 'tɕʰ'),
- ('ㄒ', 'ɕ'),
- ('ㄓ', 'tʂ'),
- ('ㄔ', 'tʂʰ'),
- ('ㄕ', 'ʂ'),
- ('ㄖ', 'ɻ'),
- ('ㄗ', 'ts'),
- ('ㄘ', 'tsʰ'),
- ('ㄙ', 's'),
- ('ㄚ', 'a'),
- ('ㄛ', 'o'),
- ('ㄜ', 'ɤ'),
- ('ㄝ', 'ɛ'),
- ('ㄞ', 'aɪ'),
- ('ㄟ', 'eɪ'),
- ('ㄠ', 'ɑʊ'),
- ('ㄡ', 'oʊ'),
- ('ㄧㄢ', 'jɛn'),
- ('ㄩㄢ', 'yæn'),
- ('ㄢ', 'an'),
- ('ㄧㄣ', 'in'),
- ('ㄩㄣ', 'yn'),
- ('ㄣ', 'ən'),
- ('ㄤ', 'ɑŋ'),
- ('ㄧㄥ', 'iŋ'),
- ('ㄨㄥ', 'ʊŋ'),
- ('ㄩㄥ', 'jʊŋ'),
- ('ㄥ', 'ɤŋ'),
- ('ㄦ', 'əɻ'),
- ('ㄧ', 'i'),
- ('ㄨ', 'u'),
- ('ㄩ', 'y'),
- ('ˉ', '˥'),
- ('ˊ', '˧˥'),
- ('ˇ', '˨˩˦'),
- ('ˋ', '˥˩'),
- ('˙', ''),
- (',', ','),
- ('。', '.'),
- ('!', '!'),
- ('?', '?'),
- ('—', '-')
-]]
-
-
-def number_to_chinese(text):
- numbers = re.findall(r'\d+(?:\.?\d+)?', text)
- for number in numbers:
- text = text.replace(number, cn2an.an2cn(number), 1)
- return text
-
-
-def chinese_to_bopomofo(text):
- text = text.replace('、', ',').replace(';', ',').replace(':', ',')
- words = jieba.lcut(text, cut_all=False)
- text = ''
- for word in words:
- bopomofos = lazy_pinyin(word, BOPOMOFO)
- if not re.search('[\u4e00-\u9fff]', word):
- text += word
- continue
- for i in range(len(bopomofos)):
- bopomofos[i] = re.sub(r'([\u3105-\u3129])$', r'\1ˉ', bopomofos[i])
- if text != '':
- text += ' '
- text += ''.join(bopomofos)
- return text
-
-
-def latin_to_bopomofo(text):
- for regex, replacement in _latin_to_bopomofo:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def bopomofo_to_romaji(text):
- for regex, replacement in _bopomofo_to_romaji:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def bopomofo_to_ipa(text):
- for regex, replacement in _bopomofo_to_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def bopomofo_to_ipa2(text):
- for regex, replacement in _bopomofo_to_ipa2:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def chinese_to_romaji(text):
- text = number_to_chinese(text)
- text = chinese_to_bopomofo(text)
- text = latin_to_bopomofo(text)
- text = bopomofo_to_romaji(text)
- text = re.sub('i([aoe])', r'y\1', text)
- text = re.sub('u([aoəe])', r'w\1', text)
- text = re.sub('([ʦsɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
- r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
- text = re.sub('([ʦs][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
- return text
-
-
-def chinese_to_lazy_ipa(text):
- text = chinese_to_romaji(text)
- for regex, replacement in _romaji_to_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def chinese_to_ipa(text):
- text = number_to_chinese(text)
- text = chinese_to_bopomofo(text)
- text = latin_to_bopomofo(text)
- text = bopomofo_to_ipa(text)
- text = re.sub('i([aoe])', r'j\1', text)
- text = re.sub('u([aoəe])', r'w\1', text)
- text = re.sub('([sɹ]`[⁼ʰ]?)([→↓↑ ]+|$)',
- r'\1ɹ`\2', text).replace('ɻ', 'ɹ`')
- text = re.sub('([s][⁼ʰ]?)([→↓↑ ]+|$)', r'\1ɹ\2', text)
- return text
-
-
-def chinese_to_ipa2(text):
- text = number_to_chinese(text)
- text = chinese_to_bopomofo(text)
- text = latin_to_bopomofo(text)
- text = bopomofo_to_ipa2(text)
- text = re.sub(r'i([aoe])', r'j\1', text)
- text = re.sub(r'u([aoəe])', r'w\1', text)
- text = re.sub(r'([ʂɹ]ʰ?)([˩˨˧˦˥ ]+|$)', r'\1ʅ\2', text)
- text = re.sub(r'(sʰ?)([˩˨˧˦˥ ]+|$)', r'\1ɿ\2', text)
- return text
\ No newline at end of file
diff --git a/spaces/ho11laqe/nnUNet_calvingfront_detection/create_plots_new/front_change.py b/spaces/ho11laqe/nnUNet_calvingfront_detection/create_plots_new/front_change.py
deleted file mode 100644
index 6689ca39d92ece151aa27e93692b17e665a80075..0000000000000000000000000000000000000000
--- a/spaces/ho11laqe/nnUNet_calvingfront_detection/create_plots_new/front_change.py
+++ /dev/null
@@ -1,228 +0,0 @@
-import cv2
-
-import numpy as np
-import os
-import plotly.express as px
-import plotly.figure_factory as ff
-import datetime
-import plotly.io as pio
-import plotly.graph_objs as go
-
-pio.kaleido.scope.mathjax = None
-import math
-# import pylab
-from matplotlib.colors import LinearSegmentedColormap
-from PIL import ImageColor
-
-
-def distribute_glacier(list_of_samples):
- list_of_glaciers = {}
- for glacier in ['JAC']:
- #for glacier in [ 'COL', 'Mapple', 'Crane', 'Jorum','DBE','SI', 'JAC']:
- list_of_glaciers[glacier] = [sample for sample in list_of_samples if glacier in sample]
- return list_of_glaciers
-
-
-def create_dict(list_of_samples):
- list_dict = []
- for sample in list_of_samples:
- sample_split = sample.split('_')
- finish_date = datetime.datetime.fromisoformat(sample_split[1]) + datetime.timedelta(days=50)
- sample_dict = {
- 'Glacier': sample_split[0],
- 'Start': sample_split[1],
- 'Finish': str(finish_date),
- 'Satellite:': sample_split[2]
- }
- list_dict.append(sample_dict)
- return list_dict
-
-
-if __name__ == '__main__':
- train_dir = '/home/ho11laqe/PycharmProjects/data_raw/fronts/train/'
- test_dir = '/home/ho11laqe/PycharmProjects/data_raw/fronts/test/'
-
- list_of_train_samples = os.listdir(train_dir)
- list_of_test_samples = os.listdir(test_dir)
- list_of_samples = list_of_train_samples + list_of_test_samples
- list_of_glaciers = distribute_glacier(list_of_samples)
- list_dict = create_dict(list_of_samples)
-
- # define color map
- colormap = px.colors.sequential.Reds[-1::-1]
- for glacier in list_of_glaciers:
- print(glacier)
- list_of_glaciers[glacier].sort()
-
-
- if glacier in ['COL', 'Mapple']:
- data_directory = test_dir
- image_directory = '/home/ho11laqe/PycharmProjects/data_raw/sar_images/test/'
- else:
- data_directory = train_dir
- image_directory = '/home/ho11laqe/PycharmProjects/data_raw/sar_images/train/'
-
-
- # define SAR blackground image
- if glacier == 'COL':
- canvas = cv2.imread(image_directory + 'COL_2011-11-13_TDX_7_1_092.png')
- shape = canvas.shape
-
- elif glacier == 'JAC':
- canvas = cv2.imread(image_directory + 'JAC_2009-06-21_TSX_6_1_005.png')
- shape = canvas.shape
-
- elif glacier == 'Jorum':
- canvas = cv2.imread(image_directory + 'Jorum_2011-09-04_TSX_7_4_034.png')
- shape = canvas.shape
-
- elif glacier == 'Mapple':
- canvas = cv2.imread(image_directory + 'Mapple_2008-10-13_TSX_7_2_034.png')
- shape = canvas.shape
-
- elif glacier == 'SI':
- canvas = cv2.imread(image_directory + 'SI_2013-08-14_TSX_7_1_125.png')
-
- elif glacier == 'Crane':
- canvas = cv2.imread(image_directory + 'Crane_2008-10-13_TSX_7_3_034.png')
-
- elif glacier == 'DBE':
- canvas = cv2.imread(image_directory + 'DBE_2008-03-30_TSX_7_3_049.png')
-
- else:
- print('No image for background')
- exit()
-
- number_images = len(list_of_glaciers[glacier])
- kernel = np.ones((3, 3), np.uint8)
-
- # iterate over all fronts of one glacier
- for i, image_name in enumerate(list_of_glaciers[glacier]):
- front = cv2.imread(data_directory + image_name)
-
- # if front label has to be resized to fit background image
- # the front is not dilated.
- if front.shape != canvas.shape:
- front = cv2.resize(front, (shape[1], shape[0]))
-
- else:
- front = cv2.dilate(front, kernel)
-
- # color interpolation based on position in dataset
- # TODO based on actual date
- index = (1 - i / number_images) * (len(colormap) - 1)
- up = math.ceil(index)
- down = up - 1
- color_up = np.array(ImageColor.getcolor(colormap[up], 'RGB'))
- color_down = np.array(ImageColor.getcolor(colormap[down], 'RGB'))
- dif = up - down
- color = color_up * (1 - dif) + color_down * dif
-
- # draw front on canvas
- non_zeros = np.nonzero(front)
- canvas[non_zeros[:2]] = np.uint([color for _ in non_zeros[0]])
-
- #scale reference for fontsize
- ref_x = 15000 / 7
-
- if glacier == 'COL':
- image = canvas[750:, 200:2800]
- new_shape = image.shape
- res = 7
- scale = new_shape[1] / ref_x
- fig = px.imshow(image, height=new_shape[0]- int(80 * scale), width=new_shape[1])
- legend = dict(thickness=int(50 * scale), tickvals=[-4.4, 4.4],
- ticktext=['2011
(+0.8°C)', '2020
(+1.2°C)'],
- outlinewidth=0)
-
- elif glacier == 'Mapple':
- image = canvas
- new_shape = image.shape
- res = 7
- scale = new_shape[1] / ref_x
- fig = px.imshow(image, height=new_shape[0] - int(150 * scale), width=new_shape[1])
- legend = dict(thickness=int(50 * scale), tickvals=[-4.8, 4.8], ticktext=['2006', '2020 '],
- outlinewidth=0)
-
- elif glacier == 'Crane':
- image = canvas[:2500,:]
- new_shape = image.shape
- res = 7
- scale = new_shape[1] / ref_x
- fig = px.imshow(image, height=new_shape[0] - int(150 * scale), width=new_shape[1])
- legend = dict(thickness=int(50 * scale), tickvals=[-4.8, 4.8], ticktext=['2002', '2014'],
- outlinewidth=0)
-
- elif glacier == 'Jorum':
- image = canvas#[200:1600, 1500:]
- new_shape = image.shape
- res = 7
- scale = new_shape[1] / ref_x
- fig = px.imshow(image, height=new_shape[0] - int(240 * scale), width=new_shape[1])
- legend = dict(thickness=int(50 * scale), tickvals=[-4.8, 4.8], ticktext=['2003', '2020'],
- outlinewidth=0)
-
- elif glacier == 'DBE':
- image = canvas[700:, 750:]
- new_shape = image.shape
- res = 7
- scale = new_shape[1] / ref_x
- fig = px.imshow(image, height=new_shape[0] - int(150 * scale), width=new_shape[1])
- legend = dict(thickness=int(50 * scale), tickvals=[-4.7, 4.7], ticktext=['1995', '2014'],
- outlinewidth=0)
-
- elif glacier == 'SI':
- image = canvas
- new_shape = image.shape
- res = 7
- scale = new_shape[0] / ref_x
- fig = px.imshow(image, height=new_shape[0] - int(240 * scale), width=new_shape[1])
- legend = dict(thickness=int(50 * scale), tickvals=[-4.8, 4.8], ticktext=['1995', '2014'],
- outlinewidth=0)
-
- elif glacier == 'JAC':
- image = canvas[:, :]
- new_shape = image.shape
- res = 6
- scale = new_shape[1] / ref_x
- fig = px.imshow(image, height=new_shape[0] - int(340 * scale), width=new_shape[1])
- legend = dict(thickness=int(50 * scale), tickvals=[-4.6, 4.7],
- ticktext=['2009
(+0.7°C)', '2015
(+0.9°C)'],
- outlinewidth=0)
- else:
- fig = px.imshow(canvas)
- res = 7
- scale = 1
-
- colorbar_trace = go.Scatter(x=[None],
- y=[None],
- mode='markers',
- marker=dict(
- colorscale=colormap[::-1],
- showscale=True,
- cmin=-5,
- cmax=5,
- colorbar=legend
- ),
- hoverinfo='none'
- )
- fig.update_layout(yaxis=dict(tickmode='array',
- tickvals=[0, 5000 / res, 10000 / res, 15000 / res, 20000 / res, 25000 / res],
- ticktext=[0, 5, 10, 15, 20, 25],
- title='km'))
- fig.update_layout(xaxis=dict(tickmode='array',
- tickvals=[0, 5000 / res, 10000 / res, 15000 / res, 20000 / res, 25000 / res],
- ticktext=[0, 5, 10, 15, 20, 25],
- title='km'))
-
- fig.update_xaxes(tickfont=dict(size=int(40 * scale)))
- fig.update_yaxes(tickfont=dict(size=int(40 * scale)))
- fig.update_layout(font=dict(size=int(60 * scale), family="Computer Modern"))
- fig.update_coloraxes(colorbar_x=0)
- fig['layout']['xaxis']['title']['font']['size'] = int(60 * scale)
- fig['layout']['yaxis']['title']['font']['size'] = int(60 * scale)
-
- fig['layout']['showlegend'] = False
- fig.add_trace(colorbar_trace)
- fig.write_image('output/' + glacier + "_front_change.pdf", format='pdf')
- # fig.show()
\ No newline at end of file
diff --git a/spaces/hra/GPT4-makes-BabyAGI/README.md b/spaces/hra/GPT4-makes-BabyAGI/README.md
deleted file mode 100644
index e93cb2ef6fae4bcff7e254e0d5adbefdcd3b059c..0000000000000000000000000000000000000000
--- a/spaces/hra/GPT4-makes-BabyAGI/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: GPT4 Makes BabyAGI
-emoji: 📊
-colorFrom: blue
-colorTo: green
-sdk: gradio
-sdk_version: 3.27.0
-app_file: app.py
-pinned: false
-license: cc-by-nc-sa-4.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/hrdtbs/rvc-mochinoa/infer_pack/commons.py b/spaces/hrdtbs/rvc-mochinoa/infer_pack/commons.py
deleted file mode 100644
index 54470986f37825b35d90d7efa7437d1c26b87215..0000000000000000000000000000000000000000
--- a/spaces/hrdtbs/rvc-mochinoa/infer_pack/commons.py
+++ /dev/null
@@ -1,166 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size * dilation - dilation) / 2)
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def kl_divergence(m_p, logs_p, m_q, logs_q):
- """KL(P||Q)"""
- kl = (logs_q - logs_p) - 0.5
- kl += (
- 0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q)
- )
- return kl
-
-
-def rand_gumbel(shape):
- """Sample from the Gumbel distribution, protect from overflows."""
- uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
- return -torch.log(-torch.log(uniform_samples))
-
-
-def rand_gumbel_like(x):
- g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
- return g
-
-
-def slice_segments(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, :, idx_str:idx_end]
- return ret
-
-
-def slice_segments2(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, idx_str:idx_end]
- return ret
-
-
-def rand_slice_segments(x, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size + 1
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- return ret, ids_str
-
-
-def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4):
- position = torch.arange(length, dtype=torch.float)
- num_timescales = channels // 2
- log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / (
- num_timescales - 1
- )
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment
- )
- scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
- signal = F.pad(signal, [0, 0, 0, channels % 2])
- signal = signal.view(1, channels, length)
- return signal
-
-
-def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return x + signal.to(dtype=x.dtype, device=x.device)
-
-
-def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
-
-
-def subsequent_mask(length):
- mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
- return mask
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a + input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def shift_1d(x):
- x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
- return x
-
-
-def sequence_mask(length, max_length=None):
- if max_length is None:
- max_length = length.max()
- x = torch.arange(max_length, dtype=length.dtype, device=length.device)
- return x.unsqueeze(0) < length.unsqueeze(1)
-
-
-def generate_path(duration, mask):
- """
- duration: [b, 1, t_x]
- mask: [b, 1, t_y, t_x]
- """
- device = duration.device
-
- b, _, t_y, t_x = mask.shape
- cum_duration = torch.cumsum(duration, -1)
-
- cum_duration_flat = cum_duration.view(b * t_x)
- path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
- path = path.view(b, t_x, t_y)
- path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
- path = path.unsqueeze(1).transpose(2, 3) * mask
- return path
-
-
-def clip_grad_value_(parameters, clip_value, norm_type=2):
- if isinstance(parameters, torch.Tensor):
- parameters = [parameters]
- parameters = list(filter(lambda p: p.grad is not None, parameters))
- norm_type = float(norm_type)
- if clip_value is not None:
- clip_value = float(clip_value)
-
- total_norm = 0
- for p in parameters:
- param_norm = p.grad.data.norm(norm_type)
- total_norm += param_norm.item() ** norm_type
- if clip_value is not None:
- p.grad.data.clamp_(min=-clip_value, max=clip_value)
- total_norm = total_norm ** (1.0 / norm_type)
- return total_norm
diff --git a/spaces/huggingchat/chat-ui/src/lib/utils/chunk.ts b/spaces/huggingchat/chat-ui/src/lib/utils/chunk.ts
deleted file mode 100644
index 3d8f924eba449978957a62c39c7406f819edf49a..0000000000000000000000000000000000000000
--- a/spaces/huggingchat/chat-ui/src/lib/utils/chunk.ts
+++ /dev/null
@@ -1,33 +0,0 @@
-/**
- * Chunk array into arrays of length at most `chunkSize`
- *
- * @param chunkSize must be greater than or equal to 1
- */
-export function chunk(arr: T, chunkSize: number): T[] {
- if (isNaN(chunkSize) || chunkSize < 1) {
- throw new RangeError("Invalid chunk size: " + chunkSize);
- }
-
- if (!arr.length) {
- return [];
- }
-
- /// Small optimization to not chunk buffers unless needed
- if (arr.length <= chunkSize) {
- return [arr];
- }
-
- return range(Math.ceil(arr.length / chunkSize)).map((i) => {
- return arr.slice(i * chunkSize, (i + 1) * chunkSize);
- }) as T[];
-}
-
-function range(n: number, b?: number): number[] {
- return b
- ? Array(b - n)
- .fill(0)
- .map((_, i) => n + i)
- : Array(n)
- .fill(0)
- .map((_, i) => i);
-}
diff --git a/spaces/hyuan5040/ChatWithSpeech/app.py b/spaces/hyuan5040/ChatWithSpeech/app.py
deleted file mode 100644
index 122358ddec17831bbfea06dd04fd346cb77b5da4..0000000000000000000000000000000000000000
--- a/spaces/hyuan5040/ChatWithSpeech/app.py
+++ /dev/null
@@ -1,177 +0,0 @@
-import tempfile
-import gradio as gr
-import openai
-from neon_tts_plugin_coqui import CoquiTTS
-
-def Question(Ask_Question):
- # pass the generated text to audio
- openai.api_key = "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"
- # Set up the model and prompt
- model_engine = "text-davinci-003"
- #prompt = "who is alon musk?"
- # Generate a response
- completion = openai.Completion.create(
- engine=model_engine,
- prompt=Ask_Question,
- max_tokens=1024,
- n=1,
- stop=None,
- temperature=0.5,)
- response = completion.choices[0].text
- #out_result=resp['message']
- return response
-
-LANGUAGES = list(CoquiTTS.langs.keys())
-default_lang = "en"
-import telnetlib
-#import whisper
-#whisper_model = whisper.load_model("small")
-whisper = gr.Interface.load(name="spaces/sanchit-gandhi/whisper-large-v2")
-#chatgpt = gr.Blocks.load(name="spaces/fffiloni/whisper-to-chatGPT")
-import os
-import json
-session_token = os.environ.get('SessionToken')
-#api_endpoint = os.environ.get('API_EndPoint')
-# ChatGPT
-#from revChatGPT.ChatGPT import Chatbot
-#chatbot = Chatbot({"session_token": session_token}) # You can start a custom conversation
-import asyncio
-from pygpt import PyGPT
-
-title = "Speech to ChatGPT to Speech"
-#info = "more info at [Neon Coqui TTS Plugin](https://github.com/NeonGeckoCom/neon-tts-plugin-coqui), [Coqui TTS](https://github.com/coqui-ai/TTS)"
-#badge = "https://visitor-badge-reloaded.herokuapp.com/badge?page_id=neongeckocom.neon-tts-plugin-coqui"
-coquiTTS = CoquiTTS()
-chat_id = {'conversation_id': None, 'parent_id': None}
-headers = {'Authorization': 'yusin'}
-
-async def chat_gpt_ask(prompt):
- chat_gpt = PyGPT(session_token)
- await chat_gpt.connect()
- await chat_gpt.wait_for_ready()
- answer = await chat_gpt.ask(prompt)
- print(answer)
- await chat_gpt.disconnect()
-
-# ChatGPT
-def chat_hf(audio, custom_token, language):
- #output = chatgpt(audio, "transcribe", fn_index=0)
- #whisper_text, gpt_response = output[0], output[1]
- try:
- whisper_text = translate(audio)
- if whisper_text == "ERROR: You have to either use the microphone or upload an audio file":
- gpt_response = "MISSING AUDIO: Record your voice by clicking the microphone button, do not forget to stop recording before sending your message ;)"
- else:
- #gpt_response = chatbot.ask(whisper_text, conversation_id=conversation_id, parent_id=None)
- gpt_response = asyncio.run(chat_gpt_ask(whisper_text, id='yusin'))
- #if chat_id['conversation_id'] != None:
- # data = {"content": whisper_text, "conversation_id": chat_id['conversation_id'], "parent_id": chat_id['parent_id']}
- #else:
- # data = {"content": whisper_text}
- #print(data)
- #res = requests.get('http://myip.ipip.net', timeout=5).text
- #print(res)
- #response = requests.post('api_endpoint', headers=headers, json=data, verify=False, timeout=5)
- #print('this is my answear', response.text)
- #chat_id['parent_id'] = response.json()["response_id"]
- #chat_id['conversation_id'] = response.json()["conversation_id"]
- #gpt_response = response.json()["content"]
- #response = requests.get('https://api.pawan.krd/chat/gpt?text=' + whisper_text + '&cache=false', verify=False, timeout=5)
- #print(response.text)
-
- #whisper_text = translate(audio)
- #api = ChatGPT(session_token)
- #resp = api.send_message(whisper_text)
-
- #api.refresh_auth() # refresh the authorization token
- #api.reset_conversation() # reset the conversation
- #gpt_response = resp['message']
-
- except:
- whisper_text = translate(audio)
- gpt_response = """Sorry, I'm quite busy right now, but please try again later :)"""
- #whisper_text = translate(audio)
- #api = ChatGPT(custom_token)
- #resp = api.send_message(whisper_text)
-
- #api.refresh_auth() # refresh the authorization token
- #api.reset_conversation() # reset the conversation
- #gpt_response = resp['message']
-
- ## call openai
- gpt_response = Question(whisper_text)
-
- # to voice
- with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as fp:
- coquiTTS.get_tts(gpt_response, fp, speaker = {"language" : language})
-
- return whisper_text, gpt_response, fp.name
-
-# whisper
-#def translate(audio):
-# print("""
-# —
-# Sending audio to Whisper ...
-# —
-# """)
-#
-# audio = whisper.load_audio(audio)
-# audio = whisper.pad_or_trim(audio)
-#
-# mel = whisper.log_mel_spectrogram(audio).to(whisper_model.device)
-#
-# _, probs = whisper_model.detect_language(mel)
-#
-# transcript_options = whisper.DecodingOptions(task="transcribe", fp16 = False)
-#
-# transcription = whisper.decode(whisper_model, mel, transcript_options)
-#
-# print("language spoken: " + transcription.language)
-# print("transcript: " + transcription.text)
-# print("———————————————————————————————————————————")
-#
-# return transcription.text
-
-def translate(audio):
- print("""
- —
- Sending audio to Whisper ...
- —
- """)
-
- text_result = whisper(audio, None, "transcribe", fn_index=0)
- #print(text_result)
- return text_result
-
-
-with gr.Blocks() as blocks:
- gr.Markdown(""
- + title
- + "")
- #gr.Markdown(description)
- radio = gr.Radio(label="Language",choices=LANGUAGES,value=default_lang)
- with gr.Row(equal_height=True):# equal_height=False
- with gr.Column():# variant="panel"
- audio_file = gr.Audio(source="microphone",type="filepath")
- custom_token = gr.Textbox(label='If it fails, use your own session token', placeholder="your own session token")
- with gr.Row():# mobile_collapse=False
- submit = gr.Button("Submit", variant="primary")
- with gr.Column():
- text1 = gr.Textbox(label="Speech to Text")
- text2 = gr.Textbox(label="ChatGPT Response")
- audio = gr.Audio(label="Output", interactive=False)
- #gr.Markdown(info)
- #gr.Markdown(""
- # +f' '
- # +"")
-
- # actions
- submit.click(
- chat_hf,
- [audio_file, custom_token, radio],
- [text1, text2, audio],
- )
- radio.change(lambda lang: CoquiTTS.langs[lang]["sentence"], radio, text2)
-
-
-blocks.launch(debug=True)
diff --git a/spaces/iamironman4279/SadTalker/src/face3d/data/__init__.py b/spaces/iamironman4279/SadTalker/src/face3d/data/__init__.py
deleted file mode 100644
index 9a9761c518a1b07c5996165869742af0a52c82bc..0000000000000000000000000000000000000000
--- a/spaces/iamironman4279/SadTalker/src/face3d/data/__init__.py
+++ /dev/null
@@ -1,116 +0,0 @@
-"""This package includes all the modules related to data loading and preprocessing
-
- To add a custom dataset class called 'dummy', you need to add a file called 'dummy_dataset.py' and define a subclass 'DummyDataset' inherited from BaseDataset.
- You need to implement four functions:
- -- <__init__>: initialize the class, first call BaseDataset.__init__(self, opt).
- -- <__len__>: return the size of dataset.
- -- <__getitem__>: get a data point from data loader.
- -- : (optionally) add dataset-specific options and set default options.
-
-Now you can use the dataset class by specifying flag '--dataset_mode dummy'.
-See our template dataset class 'template_dataset.py' for more details.
-"""
-import numpy as np
-import importlib
-import torch.utils.data
-from face3d.data.base_dataset import BaseDataset
-
-
-def find_dataset_using_name(dataset_name):
- """Import the module "data/[dataset_name]_dataset.py".
-
- In the file, the class called DatasetNameDataset() will
- be instantiated. It has to be a subclass of BaseDataset,
- and it is case-insensitive.
- """
- dataset_filename = "data." + dataset_name + "_dataset"
- datasetlib = importlib.import_module(dataset_filename)
-
- dataset = None
- target_dataset_name = dataset_name.replace('_', '') + 'dataset'
- for name, cls in datasetlib.__dict__.items():
- if name.lower() == target_dataset_name.lower() \
- and issubclass(cls, BaseDataset):
- dataset = cls
-
- if dataset is None:
- raise NotImplementedError("In %s.py, there should be a subclass of BaseDataset with class name that matches %s in lowercase." % (dataset_filename, target_dataset_name))
-
- return dataset
-
-
-def get_option_setter(dataset_name):
- """Return the static method of the dataset class."""
- dataset_class = find_dataset_using_name(dataset_name)
- return dataset_class.modify_commandline_options
-
-
-def create_dataset(opt, rank=0):
- """Create a dataset given the option.
-
- This function wraps the class CustomDatasetDataLoader.
- This is the main interface between this package and 'train.py'/'test.py'
-
- Example:
- >>> from data import create_dataset
- >>> dataset = create_dataset(opt)
- """
- data_loader = CustomDatasetDataLoader(opt, rank=rank)
- dataset = data_loader.load_data()
- return dataset
-
-class CustomDatasetDataLoader():
- """Wrapper class of Dataset class that performs multi-threaded data loading"""
-
- def __init__(self, opt, rank=0):
- """Initialize this class
-
- Step 1: create a dataset instance given the name [dataset_mode]
- Step 2: create a multi-threaded data loader.
- """
- self.opt = opt
- dataset_class = find_dataset_using_name(opt.dataset_mode)
- self.dataset = dataset_class(opt)
- self.sampler = None
- print("rank %d %s dataset [%s] was created" % (rank, self.dataset.name, type(self.dataset).__name__))
- if opt.use_ddp and opt.isTrain:
- world_size = opt.world_size
- self.sampler = torch.utils.data.distributed.DistributedSampler(
- self.dataset,
- num_replicas=world_size,
- rank=rank,
- shuffle=not opt.serial_batches
- )
- self.dataloader = torch.utils.data.DataLoader(
- self.dataset,
- sampler=self.sampler,
- num_workers=int(opt.num_threads / world_size),
- batch_size=int(opt.batch_size / world_size),
- drop_last=True)
- else:
- self.dataloader = torch.utils.data.DataLoader(
- self.dataset,
- batch_size=opt.batch_size,
- shuffle=(not opt.serial_batches) and opt.isTrain,
- num_workers=int(opt.num_threads),
- drop_last=True
- )
-
- def set_epoch(self, epoch):
- self.dataset.current_epoch = epoch
- if self.sampler is not None:
- self.sampler.set_epoch(epoch)
-
- def load_data(self):
- return self
-
- def __len__(self):
- """Return the number of data in the dataset"""
- return min(len(self.dataset), self.opt.max_dataset_size)
-
- def __iter__(self):
- """Return a batch of data"""
- for i, data in enumerate(self.dataloader):
- if i * self.opt.batch_size >= self.opt.max_dataset_size:
- break
- yield data
diff --git a/spaces/inamXcontru/PoeticTTS/Bibliotecacon65534librosenespaolEPUB67GBSerialKey Access the Largest Collection of Spanish eBooks.md b/spaces/inamXcontru/PoeticTTS/Bibliotecacon65534librosenespaolEPUB67GBSerialKey Access the Largest Collection of Spanish eBooks.md
deleted file mode 100644
index cdad5e983a71b2f089312822ff2cad8d78b7b93a..0000000000000000000000000000000000000000
--- a/spaces/inamXcontru/PoeticTTS/Bibliotecacon65534librosenespaolEPUB67GBSerialKey Access the Largest Collection of Spanish eBooks.md
+++ /dev/null
@@ -1,6 +0,0 @@
- '
- # +"")
-
- # actions
- submit.click(
- chat_hf,
- [audio_file, custom_token, radio],
- [text1, text2, audio],
- )
- radio.change(lambda lang: CoquiTTS.langs[lang]["sentence"], radio, text2)
-
-
-blocks.launch(debug=True)
diff --git a/spaces/iamironman4279/SadTalker/src/face3d/data/__init__.py b/spaces/iamironman4279/SadTalker/src/face3d/data/__init__.py
deleted file mode 100644
index 9a9761c518a1b07c5996165869742af0a52c82bc..0000000000000000000000000000000000000000
--- a/spaces/iamironman4279/SadTalker/src/face3d/data/__init__.py
+++ /dev/null
@@ -1,116 +0,0 @@
-"""This package includes all the modules related to data loading and preprocessing
-
- To add a custom dataset class called 'dummy', you need to add a file called 'dummy_dataset.py' and define a subclass 'DummyDataset' inherited from BaseDataset.
- You need to implement four functions:
- -- <__init__>: initialize the class, first call BaseDataset.__init__(self, opt).
- -- <__len__>: return the size of dataset.
- -- <__getitem__>: get a data point from data loader.
- -- : (optionally) add dataset-specific options and set default options.
-
-Now you can use the dataset class by specifying flag '--dataset_mode dummy'.
-See our template dataset class 'template_dataset.py' for more details.
-"""
-import numpy as np
-import importlib
-import torch.utils.data
-from face3d.data.base_dataset import BaseDataset
-
-
-def find_dataset_using_name(dataset_name):
- """Import the module "data/[dataset_name]_dataset.py".
-
- In the file, the class called DatasetNameDataset() will
- be instantiated. It has to be a subclass of BaseDataset,
- and it is case-insensitive.
- """
- dataset_filename = "data." + dataset_name + "_dataset"
- datasetlib = importlib.import_module(dataset_filename)
-
- dataset = None
- target_dataset_name = dataset_name.replace('_', '') + 'dataset'
- for name, cls in datasetlib.__dict__.items():
- if name.lower() == target_dataset_name.lower() \
- and issubclass(cls, BaseDataset):
- dataset = cls
-
- if dataset is None:
- raise NotImplementedError("In %s.py, there should be a subclass of BaseDataset with class name that matches %s in lowercase." % (dataset_filename, target_dataset_name))
-
- return dataset
-
-
-def get_option_setter(dataset_name):
- """Return the static method of the dataset class."""
- dataset_class = find_dataset_using_name(dataset_name)
- return dataset_class.modify_commandline_options
-
-
-def create_dataset(opt, rank=0):
- """Create a dataset given the option.
-
- This function wraps the class CustomDatasetDataLoader.
- This is the main interface between this package and 'train.py'/'test.py'
-
- Example:
- >>> from data import create_dataset
- >>> dataset = create_dataset(opt)
- """
- data_loader = CustomDatasetDataLoader(opt, rank=rank)
- dataset = data_loader.load_data()
- return dataset
-
-class CustomDatasetDataLoader():
- """Wrapper class of Dataset class that performs multi-threaded data loading"""
-
- def __init__(self, opt, rank=0):
- """Initialize this class
-
- Step 1: create a dataset instance given the name [dataset_mode]
- Step 2: create a multi-threaded data loader.
- """
- self.opt = opt
- dataset_class = find_dataset_using_name(opt.dataset_mode)
- self.dataset = dataset_class(opt)
- self.sampler = None
- print("rank %d %s dataset [%s] was created" % (rank, self.dataset.name, type(self.dataset).__name__))
- if opt.use_ddp and opt.isTrain:
- world_size = opt.world_size
- self.sampler = torch.utils.data.distributed.DistributedSampler(
- self.dataset,
- num_replicas=world_size,
- rank=rank,
- shuffle=not opt.serial_batches
- )
- self.dataloader = torch.utils.data.DataLoader(
- self.dataset,
- sampler=self.sampler,
- num_workers=int(opt.num_threads / world_size),
- batch_size=int(opt.batch_size / world_size),
- drop_last=True)
- else:
- self.dataloader = torch.utils.data.DataLoader(
- self.dataset,
- batch_size=opt.batch_size,
- shuffle=(not opt.serial_batches) and opt.isTrain,
- num_workers=int(opt.num_threads),
- drop_last=True
- )
-
- def set_epoch(self, epoch):
- self.dataset.current_epoch = epoch
- if self.sampler is not None:
- self.sampler.set_epoch(epoch)
-
- def load_data(self):
- return self
-
- def __len__(self):
- """Return the number of data in the dataset"""
- return min(len(self.dataset), self.opt.max_dataset_size)
-
- def __iter__(self):
- """Return a batch of data"""
- for i, data in enumerate(self.dataloader):
- if i * self.opt.batch_size >= self.opt.max_dataset_size:
- break
- yield data
diff --git a/spaces/inamXcontru/PoeticTTS/Bibliotecacon65534librosenespaolEPUB67GBSerialKey Access the Largest Collection of Spanish eBooks.md b/spaces/inamXcontru/PoeticTTS/Bibliotecacon65534librosenespaolEPUB67GBSerialKey Access the Largest Collection of Spanish eBooks.md
deleted file mode 100644
index cdad5e983a71b2f089312822ff2cad8d78b7b93a..0000000000000000000000000000000000000000
--- a/spaces/inamXcontru/PoeticTTS/Bibliotecacon65534librosenespaolEPUB67GBSerialKey Access the Largest Collection of Spanish eBooks.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Bibliotecacon65534librosenespaolEPUB67GBSerialKey
DOWNLOAD ☆ https://gohhs.com/2uz3yN
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/inamXcontru/PoeticTTS/CRACK DVD X Copy Platinum 3.2.1.md b/spaces/inamXcontru/PoeticTTS/CRACK DVD X Copy Platinum 3.2.1.md
deleted file mode 100644
index 122f7b1a21fc24523d185274761f58dc90110b04..0000000000000000000000000000000000000000
--- a/spaces/inamXcontru/PoeticTTS/CRACK DVD X Copy Platinum 3.2.1.md
+++ /dev/null
@@ -1,16 +0,0 @@
-CRACK DVD X Copy Platinum 3.2.1
Download ··· https://gohhs.com/2uz2QO
-
-7 Apr To X Copy your DVDs on DVD-R/RW or DVD-9, use this GUI or command-line application, also known as dvd xcopy.
-
-XCopy is the Free version of DVD/CD XCopy, a powerful and easy-to-use DVD burning software with ability to copy DVD and Blu-ray discs and. 19 Sep Use XCopy to copy a DVD disc with subtitles to a new blank disc and vice versa. I need it for my parents so that they can watch their. DVD X Copy is a powerful and easy-to-use DVD copying software that supports burning Blu-ray discs and copying DVDs and.The present invention relates to the field of lithium secondary batteries, and more particularly, to a nonaqueous electrolyte for lithium secondary batteries capable of improving battery safety and manufacturing method thereof.
-
-With the development of mobile electronic appliances, such as mobile phones, camcorders, and notebook computers, the demand for small, light-weight, and high-capacity secondary batteries used as power sources is rapidly increasing. Among secondary batteries developed so far, lithium secondary batteries are a great advantage since they can realize high energy density and high discharge voltage, when compared to other types of secondary batteries. Accordingly, lithium secondary batteries are widely used as power sources for various applications.
-
-A lithium secondary battery is prepared by injecting a nonaqueous electrolyte obtained by dissolving a lithium salt in a nonaqueous solvent into an electrode assembly, and then placing the electrode assembly in a battery case together with a lithium foil, a collection of lithiated carbon, or the like, which functions as an anode.
-
-Among lithium secondary batteries developed so far, a lithium-ion battery includes a cathode, an anode, and an electrolyte in which a nonaqueous solvent is dissolved. At this time, when the nonaqueous solvent in the electrolyte is decomposed during an overcharge or an overdischarge of the battery, the nonaqueous solvent is transformed to generate gas. As a result, the pressure of the electrolyte increases so that a battery safety problem may occur. For this reason, nonaqueous solvents having excellent thermal stability at high temperature are required. In addition, safety performance should be further improved and processability should be improved.
-
-Meanwhile, when a battery is charged or discharged, lithium ions are electrochemically transferred between the anode and the cathode via the electrolyte. At this time, the stability of the electrolyte is important. 4fefd39f24
-
-
-
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Fast And Furious 8 (English) Video Songs Hd 1080p Blu-ray Download Movie [BEST].md b/spaces/inplisQlawa/anything-midjourney-v4-1/Fast And Furious 8 (English) Video Songs Hd 1080p Blu-ray Download Movie [BEST].md
deleted file mode 100644
index c565a8c093e9ce2d6c365b4cd0e218d2eaee5e80..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Fast And Furious 8 (English) Video Songs Hd 1080p Blu-ray Download Movie [BEST].md
+++ /dev/null
@@ -1,6 +0,0 @@
-Fast And Furious 8 (English) video songs hd 1080p blu-ray download movie
Download ::: https://urlin.us/2uEyN3
-
-Download Fast & Furious 8 Hind Dubbed 720p & 480p &. 1080p~ hdmoviesflix.in.. Fast And Furious 8 (English) video songs hd 1080p blu-ray download movie. 4d29de3e1b
-
-
-
diff --git a/spaces/inreVtussa/clothingai/Examples/Anjaane The Unknown Download !EXCLUSIVE! 1080p Movie.md b/spaces/inreVtussa/clothingai/Examples/Anjaane The Unknown Download !EXCLUSIVE! 1080p Movie.md
deleted file mode 100644
index 59900677e92be1b24c3a5439a4a2f6292811bc37..0000000000000000000000000000000000000000
--- a/spaces/inreVtussa/clothingai/Examples/Anjaane The Unknown Download !EXCLUSIVE! 1080p Movie.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Anjaane The Unknown Download 1080p Movie
Download Zip › https://tiurll.com/2uCjuv
-
-Bangla Song full Movie Download kickass torrent 1080p HD , . . Wake Up Sid ... Anjaane - The Unknown tamil dubbed movie mp3 songs download. Shiva Ka . 1fdad05405
-
-
-
diff --git a/spaces/inreVtussa/clothingai/Examples/Contos Animados Tufos Baixar 4shared [UPDATED].md b/spaces/inreVtussa/clothingai/Examples/Contos Animados Tufos Baixar 4shared [UPDATED].md
deleted file mode 100644
index 84fc066952c3af1a691ad354bb9e036cc6d0a5ff..0000000000000000000000000000000000000000
--- a/spaces/inreVtussa/clothingai/Examples/Contos Animados Tufos Baixar 4shared [UPDATED].md
+++ /dev/null
@@ -1,10 +0,0 @@
-Contos Animados Tufos Baixar 4shared
Download Zip → https://tiurll.com/2uClxV
-
-Aug 24, 2020 — AV Music Morpher Gold 4.0.60 With Serial Crack Morpher Gold 4.0.60 with Serial Key Free Download ...
-Ace Stream Media Video Editor for PC free download ...
-Oct 13, 2019 — AV Music Morpher Gold 4.0.60 + Crack is a powerful and free music software that allows you to modify your music files ...
-Oct 29, 2019 — AV Music Morpher Gold 4.0.60 with Serial key Free Download ...
-Oct 11, 2019 — AV Music Morpher Gold 4.0.60 with Serial key Free Download ... 8a78ff9644
-
-
-
diff --git a/spaces/ipvikas/ALL_NLP_Tasks/OCR_Image_to_Text.py b/spaces/ipvikas/ALL_NLP_Tasks/OCR_Image_to_Text.py
deleted file mode 100644
index 314a4e0747d091bca30890eb4654329bf463b662..0000000000000000000000000000000000000000
--- a/spaces/ipvikas/ALL_NLP_Tasks/OCR_Image_to_Text.py
+++ /dev/null
@@ -1,30 +0,0 @@
-import gradio as gr
-import os
-#from googletrans import Translator
-import easyocr
-#import PIL
-from PIL import Image
-from PIL import ImageDraw
-
-def Get_OCR_demo(image):
- reader = easyocr.Reader(['en']) #IMP 'hi'
- translator = Translator()
-
- #image_file =Image.open(image,mode = 'r')
- im = Image.open(image,mode = 'r')
- #im =Image.open(image,mode = 'r')
- text_list = reader.readtext(im,add_margin = 0.55,width_ths=0.7, link_threshold=0.8,decoder='beamsearch', blocklist='=-',detail = 0 )
-
- #text_list = reader.readtext(image_file,add_margin = 0.55,width_ths=0.7, link_threshold=0.8,decoder='beamsearch', blocklist='=-',detail = 0 )
-
- text_comb =' '.join(text_list) #changed into a single line
- return text_comb
-
-
-title = "Upload an image and extract Text from it"
-description = "OCR tool for text extraction"
-examples=[["english.png"],["Upload Parag_Letter_j.jpg"]]
-
-get_OCR_demo = gr.Interface(fn=Get_OCR_demo, inputs="image",outputs=['text'],title = title,description=description,examples=[["english.png","Parag_Letter.jfif"]],cache_examples=False)
-# if __name__ == "__main__":
-# demo.launch()
\ No newline at end of file
diff --git a/spaces/iqovocn/ChuanhuChatGPT/Dockerfile b/spaces/iqovocn/ChuanhuChatGPT/Dockerfile
deleted file mode 100644
index 335c2dba28ba8c365de9306858462a59dea25f28..0000000000000000000000000000000000000000
--- a/spaces/iqovocn/ChuanhuChatGPT/Dockerfile
+++ /dev/null
@@ -1,15 +0,0 @@
-FROM python:3.9 as builder
-RUN apt-get update && apt-get install -y build-essential
-COPY requirements.txt .
-COPY requirements_advanced.txt .
-RUN pip install --user -r requirements.txt
-# RUN pip install --user -r requirements_advanced.txt
-
-FROM python:3.9
-MAINTAINER iskoldt
-COPY --from=builder /root/.local /root/.local
-ENV PATH=/root/.local/bin:$PATH
-COPY . /app
-WORKDIR /app
-ENV dockerrun yes
-CMD ["python3", "-u", "ChuanhuChatbot.py", "2>&1", "|", "tee", "/var/log/application.log"]
diff --git a/spaces/isabel/club-project/reader.py b/spaces/isabel/club-project/reader.py
deleted file mode 100644
index 2089f121665bf06f1c4d8a54d78df7b435b01ae9..0000000000000000000000000000000000000000
--- a/spaces/isabel/club-project/reader.py
+++ /dev/null
@@ -1,161 +0,0 @@
-import os
-from yattag import Doc
-## --------------------------------- ###
-### reading: info.txt ###
-### -------------------------------- ###
-# placeholders in case info.txt does not exist
-def get_article(acc, most_imp_feat):
- filename = "info.txt"
- placeholder = "please create an info.txt to customize this text"
- note = "**Note that model accuracy is based on the uploaded data.csv and reflects how well the AI model can give correct recommendations for that dataset. An accuracy of 50% means that half of the model's predictions for that dataset were accurate. Model accuracy and most important feature can be helpful for understanding how the model works, but should not be considered absolute facts about the real world."
-
- title = bkgd = data_collection = priv_cons = bias_cons = img_src = membs = description = placeholder
- # check if info.txt is present
- if os.path.isfile(filename):
- # open info.txt in read mode
- info = open(filename, "r")
-
- # read each line to a string
- description = "An AI project created by " + info.readline()
- title = info.readline()
- bkgd = info.readline()
- data_collection = info.readline()
- priv_cons = info.readline()
- bias_cons = info.readline()
- img_src = info.readline()
- membs = info.readline()
-
- # close file
- info.close()
-
- # use yattag library to generate html
- doc, tag, text, line = Doc().ttl()
- # create html based on info.txt
- with tag('div'):
- with tag('div', klass='box model-container'):
- with tag('div', klass='spacer'):
- with tag('div', klass='box model-div'):
- line('h2', "Model Accuracy", klass='acc')
- line('p', acc)
- with tag('div', klass='box model-div'):
- line('h2', "Most Important Feature", klass='feat')
- line('p', most_imp_feat)
- with tag('div', klass='spacer'):
- line('p', note)
- with tag('div', klass='box'):
- line('h2', 'Problem Statement and Research Summary', klass='prj')
- line('p', bkgd)
- with tag('div', klass='box'):
- line('h2', 'Data Collection Plan', klass='data')
- line('p', data_collection)
- with tag('div', klass='box'):
- line('h2', 'Ethical Considerations (Data Privacy and Bias)', klass='ethics')
- with tag('ul'):
- line('li', priv_cons)
- line('li', bias_cons)
- with tag('div', klass='box'):
- line('h2', 'Our Team', klass='team')
- line('p', membs)
- doc.stag('img', src=img_src)
-
- css = '''
- .box {
- border: 2px solid black;
- text-align: center;
- margin: 10px;
- padding: 5%;
- }
- ul {
- display: inline-block;
- text-align: left;
- }
- img {
- display: block;
- margin: auto;
- }
- .description {
- text-align: center;
- }
- .panel_button {
- display: block !important;
- width: 100% !important;
- background-color: #00EACD !important;
- color: #000;
- transition: all .2s ease-out 0s !important;
- box-shadow: 0 10px #00AEAB !important;
- border-radius: 10px !important;
- }
- .panel_button:hover {
- box-shadow: 0 5px #00AEAB;
- transform: translateY(5px);
- }
- .submit {
- color: black !important;
- }
- .selected {
- background-color: #656bd6 !important;
- }
- .radio_item {
- border-radius: 10px;
- padding-left: 10px !important;
- padding-right: 10px !important;
- }
- .radio_item:hover {
- color: #656bd6 !important;
- }
- .title {
- background-image: url(https://media.giphy.com/media/26BROrSHlmyzzHf3i/giphy.gif);
- background-size: cover;
- color: transparent;
- -moz-background-clip: text;
- -webkit-background-clip: text;
- text-transform: uppercase;
- font-size: 60px;
- line-height: .75;
- margin: 10px 0;
- }
- .panel_header {
- color: black !important;
- }
- input {
- background-color: #efeffa !important;
- }
- .acc, .feat {
- background-color: #FF3399 !important
- }
- .prj {
- background-color: #FFCE3B !important;
- }
- .data {
- background-color: #ED6800 !important;
- }
- .ethics {
- background-color: #3EE6F9 !important;
- }
- .team {
- background-color: #9581EF !important;
- }
- .model-container {
- display: flex;
- flex-direction: column;
- justify-content: center;
- }
- .spacer {
- display: flex;
- justify-content: center;
- }
- .model-div {
- width: 45%;
- }
- @media screen and (max-width: 700px) {
- .model-container {
- flex-wrap: wrap;
- }
- }
- '''
- return {
- 'article': doc.getvalue(),
- 'css': css,
- 'title': title,
- 'description': description,
- }
\ No newline at end of file
diff --git a/spaces/jbilcke-hf/Panoremix/src/lib/fonts.ts b/spaces/jbilcke-hf/Panoremix/src/lib/fonts.ts
deleted file mode 100644
index 75afdee901dd6d17526aac7d6801b007d12fe752..0000000000000000000000000000000000000000
--- a/spaces/jbilcke-hf/Panoremix/src/lib/fonts.ts
+++ /dev/null
@@ -1,29 +0,0 @@
-import { Ubuntu } from "next/font/google"
-import localFont from "next/font/local"
-
-export const actionman = localFont({
- src: "../fonts/Action-Man/Action-Man.woff2",
- variable: "--font-action-man"
-})
-
-// https://nextjs.org/docs/pages/building-your-application/optimizing/fonts
-// If loading a variable font, you don"t need to specify the font weight
-export const fonts = {
- actionman,
- // ubuntu: Ubuntu
-}
-
-// https://nextjs.org/docs/pages/building-your-application/optimizing/fonts
-// If loading a variable font, you don"t need to specify the font weight
-export const fontList = Object.keys(fonts)
-
-export type FontName = keyof typeof fonts
-
-export const defaultFont = "actionman" as FontName
-
-export const classNames = Object.values(fonts).map(font => font.className)
-
-export const className = classNames.join(" ")
-
-export type FontClass =
- | "font-actionman"
diff --git a/spaces/jdinh/freeze-detection/README.md b/spaces/jdinh/freeze-detection/README.md
deleted file mode 100644
index 9591b4fb021abd680d05d67e9ead8719f12e5163..0000000000000000000000000000000000000000
--- a/spaces/jdinh/freeze-detection/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Pose Detection
-emoji: 🔥
-colorFrom: green
-colorTo: blue
-sdk: gradio
-sdk_version: 3.24.1
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/PIL/TiffImagePlugin.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/PIL/TiffImagePlugin.py
deleted file mode 100644
index d5148828506b36c72bac626b2032ebf129a62678..0000000000000000000000000000000000000000
--- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/PIL/TiffImagePlugin.py
+++ /dev/null
@@ -1,2163 +0,0 @@
-#
-# The Python Imaging Library.
-# $Id$
-#
-# TIFF file handling
-#
-# TIFF is a flexible, if somewhat aged, image file format originally
-# defined by Aldus. Although TIFF supports a wide variety of pixel
-# layouts and compression methods, the name doesn't really stand for
-# "thousands of incompatible file formats," it just feels that way.
-#
-# To read TIFF data from a stream, the stream must be seekable. For
-# progressive decoding, make sure to use TIFF files where the tag
-# directory is placed first in the file.
-#
-# History:
-# 1995-09-01 fl Created
-# 1996-05-04 fl Handle JPEGTABLES tag
-# 1996-05-18 fl Fixed COLORMAP support
-# 1997-01-05 fl Fixed PREDICTOR support
-# 1997-08-27 fl Added support for rational tags (from Perry Stoll)
-# 1998-01-10 fl Fixed seek/tell (from Jan Blom)
-# 1998-07-15 fl Use private names for internal variables
-# 1999-06-13 fl Rewritten for PIL 1.0 (1.0)
-# 2000-10-11 fl Additional fixes for Python 2.0 (1.1)
-# 2001-04-17 fl Fixed rewind support (seek to frame 0) (1.2)
-# 2001-05-12 fl Added write support for more tags (from Greg Couch) (1.3)
-# 2001-12-18 fl Added workaround for broken Matrox library
-# 2002-01-18 fl Don't mess up if photometric tag is missing (D. Alan Stewart)
-# 2003-05-19 fl Check FILLORDER tag
-# 2003-09-26 fl Added RGBa support
-# 2004-02-24 fl Added DPI support; fixed rational write support
-# 2005-02-07 fl Added workaround for broken Corel Draw 10 files
-# 2006-01-09 fl Added support for float/double tags (from Russell Nelson)
-#
-# Copyright (c) 1997-2006 by Secret Labs AB. All rights reserved.
-# Copyright (c) 1995-1997 by Fredrik Lundh
-#
-# See the README file for information on usage and redistribution.
-#
-import io
-import itertools
-import logging
-import math
-import os
-import struct
-import warnings
-from collections.abc import MutableMapping
-from fractions import Fraction
-from numbers import Number, Rational
-
-from . import ExifTags, Image, ImageFile, ImageOps, ImagePalette, TiffTags
-from ._binary import i16be as i16
-from ._binary import i32be as i32
-from ._binary import o8
-from .TiffTags import TYPES
-
-logger = logging.getLogger(__name__)
-
-# Set these to true to force use of libtiff for reading or writing.
-READ_LIBTIFF = False
-WRITE_LIBTIFF = False
-IFD_LEGACY_API = True
-STRIP_SIZE = 65536
-
-II = b"II" # little-endian (Intel style)
-MM = b"MM" # big-endian (Motorola style)
-
-#
-# --------------------------------------------------------------------
-# Read TIFF files
-
-# a few tag names, just to make the code below a bit more readable
-IMAGEWIDTH = 256
-IMAGELENGTH = 257
-BITSPERSAMPLE = 258
-COMPRESSION = 259
-PHOTOMETRIC_INTERPRETATION = 262
-FILLORDER = 266
-IMAGEDESCRIPTION = 270
-STRIPOFFSETS = 273
-SAMPLESPERPIXEL = 277
-ROWSPERSTRIP = 278
-STRIPBYTECOUNTS = 279
-X_RESOLUTION = 282
-Y_RESOLUTION = 283
-PLANAR_CONFIGURATION = 284
-RESOLUTION_UNIT = 296
-TRANSFERFUNCTION = 301
-SOFTWARE = 305
-DATE_TIME = 306
-ARTIST = 315
-PREDICTOR = 317
-COLORMAP = 320
-TILEWIDTH = 322
-TILELENGTH = 323
-TILEOFFSETS = 324
-TILEBYTECOUNTS = 325
-SUBIFD = 330
-EXTRASAMPLES = 338
-SAMPLEFORMAT = 339
-JPEGTABLES = 347
-YCBCRSUBSAMPLING = 530
-REFERENCEBLACKWHITE = 532
-COPYRIGHT = 33432
-IPTC_NAA_CHUNK = 33723 # newsphoto properties
-PHOTOSHOP_CHUNK = 34377 # photoshop properties
-ICCPROFILE = 34675
-EXIFIFD = 34665
-XMP = 700
-JPEGQUALITY = 65537 # pseudo-tag by libtiff
-
-# https://github.com/imagej/ImageJA/blob/master/src/main/java/ij/io/TiffDecoder.java
-IMAGEJ_META_DATA_BYTE_COUNTS = 50838
-IMAGEJ_META_DATA = 50839
-
-COMPRESSION_INFO = {
- # Compression => pil compression name
- 1: "raw",
- 2: "tiff_ccitt",
- 3: "group3",
- 4: "group4",
- 5: "tiff_lzw",
- 6: "tiff_jpeg", # obsolete
- 7: "jpeg",
- 8: "tiff_adobe_deflate",
- 32771: "tiff_raw_16", # 16-bit padding
- 32773: "packbits",
- 32809: "tiff_thunderscan",
- 32946: "tiff_deflate",
- 34676: "tiff_sgilog",
- 34677: "tiff_sgilog24",
- 34925: "lzma",
- 50000: "zstd",
- 50001: "webp",
-}
-
-COMPRESSION_INFO_REV = {v: k for k, v in COMPRESSION_INFO.items()}
-
-OPEN_INFO = {
- # (ByteOrder, PhotoInterpretation, SampleFormat, FillOrder, BitsPerSample,
- # ExtraSamples) => mode, rawmode
- (II, 0, (1,), 1, (1,), ()): ("1", "1;I"),
- (MM, 0, (1,), 1, (1,), ()): ("1", "1;I"),
- (II, 0, (1,), 2, (1,), ()): ("1", "1;IR"),
- (MM, 0, (1,), 2, (1,), ()): ("1", "1;IR"),
- (II, 1, (1,), 1, (1,), ()): ("1", "1"),
- (MM, 1, (1,), 1, (1,), ()): ("1", "1"),
- (II, 1, (1,), 2, (1,), ()): ("1", "1;R"),
- (MM, 1, (1,), 2, (1,), ()): ("1", "1;R"),
- (II, 0, (1,), 1, (2,), ()): ("L", "L;2I"),
- (MM, 0, (1,), 1, (2,), ()): ("L", "L;2I"),
- (II, 0, (1,), 2, (2,), ()): ("L", "L;2IR"),
- (MM, 0, (1,), 2, (2,), ()): ("L", "L;2IR"),
- (II, 1, (1,), 1, (2,), ()): ("L", "L;2"),
- (MM, 1, (1,), 1, (2,), ()): ("L", "L;2"),
- (II, 1, (1,), 2, (2,), ()): ("L", "L;2R"),
- (MM, 1, (1,), 2, (2,), ()): ("L", "L;2R"),
- (II, 0, (1,), 1, (4,), ()): ("L", "L;4I"),
- (MM, 0, (1,), 1, (4,), ()): ("L", "L;4I"),
- (II, 0, (1,), 2, (4,), ()): ("L", "L;4IR"),
- (MM, 0, (1,), 2, (4,), ()): ("L", "L;4IR"),
- (II, 1, (1,), 1, (4,), ()): ("L", "L;4"),
- (MM, 1, (1,), 1, (4,), ()): ("L", "L;4"),
- (II, 1, (1,), 2, (4,), ()): ("L", "L;4R"),
- (MM, 1, (1,), 2, (4,), ()): ("L", "L;4R"),
- (II, 0, (1,), 1, (8,), ()): ("L", "L;I"),
- (MM, 0, (1,), 1, (8,), ()): ("L", "L;I"),
- (II, 0, (1,), 2, (8,), ()): ("L", "L;IR"),
- (MM, 0, (1,), 2, (8,), ()): ("L", "L;IR"),
- (II, 1, (1,), 1, (8,), ()): ("L", "L"),
- (MM, 1, (1,), 1, (8,), ()): ("L", "L"),
- (II, 1, (2,), 1, (8,), ()): ("L", "L"),
- (MM, 1, (2,), 1, (8,), ()): ("L", "L"),
- (II, 1, (1,), 2, (8,), ()): ("L", "L;R"),
- (MM, 1, (1,), 2, (8,), ()): ("L", "L;R"),
- (II, 1, (1,), 1, (12,), ()): ("I;16", "I;12"),
- (II, 0, (1,), 1, (16,), ()): ("I;16", "I;16"),
- (II, 1, (1,), 1, (16,), ()): ("I;16", "I;16"),
- (MM, 1, (1,), 1, (16,), ()): ("I;16B", "I;16B"),
- (II, 1, (1,), 2, (16,), ()): ("I;16", "I;16R"),
- (II, 1, (2,), 1, (16,), ()): ("I", "I;16S"),
- (MM, 1, (2,), 1, (16,), ()): ("I", "I;16BS"),
- (II, 0, (3,), 1, (32,), ()): ("F", "F;32F"),
- (MM, 0, (3,), 1, (32,), ()): ("F", "F;32BF"),
- (II, 1, (1,), 1, (32,), ()): ("I", "I;32N"),
- (II, 1, (2,), 1, (32,), ()): ("I", "I;32S"),
- (MM, 1, (2,), 1, (32,), ()): ("I", "I;32BS"),
- (II, 1, (3,), 1, (32,), ()): ("F", "F;32F"),
- (MM, 1, (3,), 1, (32,), ()): ("F", "F;32BF"),
- (II, 1, (1,), 1, (8, 8), (2,)): ("LA", "LA"),
- (MM, 1, (1,), 1, (8, 8), (2,)): ("LA", "LA"),
- (II, 2, (1,), 1, (8, 8, 8), ()): ("RGB", "RGB"),
- (MM, 2, (1,), 1, (8, 8, 8), ()): ("RGB", "RGB"),
- (II, 2, (1,), 2, (8, 8, 8), ()): ("RGB", "RGB;R"),
- (MM, 2, (1,), 2, (8, 8, 8), ()): ("RGB", "RGB;R"),
- (II, 2, (1,), 1, (8, 8, 8, 8), ()): ("RGBA", "RGBA"), # missing ExtraSamples
- (MM, 2, (1,), 1, (8, 8, 8, 8), ()): ("RGBA", "RGBA"), # missing ExtraSamples
- (II, 2, (1,), 1, (8, 8, 8, 8), (0,)): ("RGBX", "RGBX"),
- (MM, 2, (1,), 1, (8, 8, 8, 8), (0,)): ("RGBX", "RGBX"),
- (II, 2, (1,), 1, (8, 8, 8, 8, 8), (0, 0)): ("RGBX", "RGBXX"),
- (MM, 2, (1,), 1, (8, 8, 8, 8, 8), (0, 0)): ("RGBX", "RGBXX"),
- (II, 2, (1,), 1, (8, 8, 8, 8, 8, 8), (0, 0, 0)): ("RGBX", "RGBXXX"),
- (MM, 2, (1,), 1, (8, 8, 8, 8, 8, 8), (0, 0, 0)): ("RGBX", "RGBXXX"),
- (II, 2, (1,), 1, (8, 8, 8, 8), (1,)): ("RGBA", "RGBa"),
- (MM, 2, (1,), 1, (8, 8, 8, 8), (1,)): ("RGBA", "RGBa"),
- (II, 2, (1,), 1, (8, 8, 8, 8, 8), (1, 0)): ("RGBA", "RGBaX"),
- (MM, 2, (1,), 1, (8, 8, 8, 8, 8), (1, 0)): ("RGBA", "RGBaX"),
- (II, 2, (1,), 1, (8, 8, 8, 8, 8, 8), (1, 0, 0)): ("RGBA", "RGBaXX"),
- (MM, 2, (1,), 1, (8, 8, 8, 8, 8, 8), (1, 0, 0)): ("RGBA", "RGBaXX"),
- (II, 2, (1,), 1, (8, 8, 8, 8), (2,)): ("RGBA", "RGBA"),
- (MM, 2, (1,), 1, (8, 8, 8, 8), (2,)): ("RGBA", "RGBA"),
- (II, 2, (1,), 1, (8, 8, 8, 8, 8), (2, 0)): ("RGBA", "RGBAX"),
- (MM, 2, (1,), 1, (8, 8, 8, 8, 8), (2, 0)): ("RGBA", "RGBAX"),
- (II, 2, (1,), 1, (8, 8, 8, 8, 8, 8), (2, 0, 0)): ("RGBA", "RGBAXX"),
- (MM, 2, (1,), 1, (8, 8, 8, 8, 8, 8), (2, 0, 0)): ("RGBA", "RGBAXX"),
- (II, 2, (1,), 1, (8, 8, 8, 8), (999,)): ("RGBA", "RGBA"), # Corel Draw 10
- (MM, 2, (1,), 1, (8, 8, 8, 8), (999,)): ("RGBA", "RGBA"), # Corel Draw 10
- (II, 2, (1,), 1, (16, 16, 16), ()): ("RGB", "RGB;16L"),
- (MM, 2, (1,), 1, (16, 16, 16), ()): ("RGB", "RGB;16B"),
- (II, 2, (1,), 1, (16, 16, 16, 16), ()): ("RGBA", "RGBA;16L"),
- (MM, 2, (1,), 1, (16, 16, 16, 16), ()): ("RGBA", "RGBA;16B"),
- (II, 2, (1,), 1, (16, 16, 16, 16), (0,)): ("RGBX", "RGBX;16L"),
- (MM, 2, (1,), 1, (16, 16, 16, 16), (0,)): ("RGBX", "RGBX;16B"),
- (II, 2, (1,), 1, (16, 16, 16, 16), (1,)): ("RGBA", "RGBa;16L"),
- (MM, 2, (1,), 1, (16, 16, 16, 16), (1,)): ("RGBA", "RGBa;16B"),
- (II, 2, (1,), 1, (16, 16, 16, 16), (2,)): ("RGBA", "RGBA;16L"),
- (MM, 2, (1,), 1, (16, 16, 16, 16), (2,)): ("RGBA", "RGBA;16B"),
- (II, 3, (1,), 1, (1,), ()): ("P", "P;1"),
- (MM, 3, (1,), 1, (1,), ()): ("P", "P;1"),
- (II, 3, (1,), 2, (1,), ()): ("P", "P;1R"),
- (MM, 3, (1,), 2, (1,), ()): ("P", "P;1R"),
- (II, 3, (1,), 1, (2,), ()): ("P", "P;2"),
- (MM, 3, (1,), 1, (2,), ()): ("P", "P;2"),
- (II, 3, (1,), 2, (2,), ()): ("P", "P;2R"),
- (MM, 3, (1,), 2, (2,), ()): ("P", "P;2R"),
- (II, 3, (1,), 1, (4,), ()): ("P", "P;4"),
- (MM, 3, (1,), 1, (4,), ()): ("P", "P;4"),
- (II, 3, (1,), 2, (4,), ()): ("P", "P;4R"),
- (MM, 3, (1,), 2, (4,), ()): ("P", "P;4R"),
- (II, 3, (1,), 1, (8,), ()): ("P", "P"),
- (MM, 3, (1,), 1, (8,), ()): ("P", "P"),
- (II, 3, (1,), 1, (8, 8), (2,)): ("PA", "PA"),
- (MM, 3, (1,), 1, (8, 8), (2,)): ("PA", "PA"),
- (II, 3, (1,), 2, (8,), ()): ("P", "P;R"),
- (MM, 3, (1,), 2, (8,), ()): ("P", "P;R"),
- (II, 5, (1,), 1, (8, 8, 8, 8), ()): ("CMYK", "CMYK"),
- (MM, 5, (1,), 1, (8, 8, 8, 8), ()): ("CMYK", "CMYK"),
- (II, 5, (1,), 1, (8, 8, 8, 8, 8), (0,)): ("CMYK", "CMYKX"),
- (MM, 5, (1,), 1, (8, 8, 8, 8, 8), (0,)): ("CMYK", "CMYKX"),
- (II, 5, (1,), 1, (8, 8, 8, 8, 8, 8), (0, 0)): ("CMYK", "CMYKXX"),
- (MM, 5, (1,), 1, (8, 8, 8, 8, 8, 8), (0, 0)): ("CMYK", "CMYKXX"),
- (II, 5, (1,), 1, (16, 16, 16, 16), ()): ("CMYK", "CMYK;16L"),
- # JPEG compressed images handled by LibTiff and auto-converted to RGBX
- # Minimal Baseline TIFF requires YCbCr images to have 3 SamplesPerPixel
- (II, 6, (1,), 1, (8, 8, 8), ()): ("RGB", "RGBX"),
- (MM, 6, (1,), 1, (8, 8, 8), ()): ("RGB", "RGBX"),
- (II, 8, (1,), 1, (8, 8, 8), ()): ("LAB", "LAB"),
- (MM, 8, (1,), 1, (8, 8, 8), ()): ("LAB", "LAB"),
-}
-
-MAX_SAMPLESPERPIXEL = max(len(key_tp[4]) for key_tp in OPEN_INFO)
-
-PREFIXES = [
- b"MM\x00\x2A", # Valid TIFF header with big-endian byte order
- b"II\x2A\x00", # Valid TIFF header with little-endian byte order
- b"MM\x2A\x00", # Invalid TIFF header, assume big-endian
- b"II\x00\x2A", # Invalid TIFF header, assume little-endian
- b"MM\x00\x2B", # BigTIFF with big-endian byte order
- b"II\x2B\x00", # BigTIFF with little-endian byte order
-]
-
-
-def _accept(prefix):
- return prefix[:4] in PREFIXES
-
-
-def _limit_rational(val, max_val):
- inv = abs(val) > 1
- n_d = IFDRational(1 / val if inv else val).limit_rational(max_val)
- return n_d[::-1] if inv else n_d
-
-
-def _limit_signed_rational(val, max_val, min_val):
- frac = Fraction(val)
- n_d = frac.numerator, frac.denominator
-
- if min(n_d) < min_val:
- n_d = _limit_rational(val, abs(min_val))
-
- if max(n_d) > max_val:
- val = Fraction(*n_d)
- n_d = _limit_rational(val, max_val)
-
- return n_d
-
-
-##
-# Wrapper for TIFF IFDs.
-
-_load_dispatch = {}
-_write_dispatch = {}
-
-
-class IFDRational(Rational):
- """Implements a rational class where 0/0 is a legal value to match
- the in the wild use of exif rationals.
-
- e.g., DigitalZoomRatio - 0.00/0.00 indicates that no digital zoom was used
- """
-
- """ If the denominator is 0, store this as a float('nan'), otherwise store
- as a fractions.Fraction(). Delegate as appropriate
-
- """
-
- __slots__ = ("_numerator", "_denominator", "_val")
-
- def __init__(self, value, denominator=1):
- """
- :param value: either an integer numerator, a
- float/rational/other number, or an IFDRational
- :param denominator: Optional integer denominator
- """
- if isinstance(value, IFDRational):
- self._numerator = value.numerator
- self._denominator = value.denominator
- self._val = value._val
- return
-
- if isinstance(value, Fraction):
- self._numerator = value.numerator
- self._denominator = value.denominator
- else:
- self._numerator = value
- self._denominator = denominator
-
- if denominator == 0:
- self._val = float("nan")
- elif denominator == 1:
- self._val = Fraction(value)
- else:
- self._val = Fraction(value, denominator)
-
- @property
- def numerator(self):
- return self._numerator
-
- @property
- def denominator(self):
- return self._denominator
-
- def limit_rational(self, max_denominator):
- """
-
- :param max_denominator: Integer, the maximum denominator value
- :returns: Tuple of (numerator, denominator)
- """
-
- if self.denominator == 0:
- return self.numerator, self.denominator
-
- f = self._val.limit_denominator(max_denominator)
- return f.numerator, f.denominator
-
- def __repr__(self):
- return str(float(self._val))
-
- def __hash__(self):
- return self._val.__hash__()
-
- def __eq__(self, other):
- val = self._val
- if isinstance(other, IFDRational):
- other = other._val
- if isinstance(other, float):
- val = float(val)
- return val == other
-
- def __getstate__(self):
- return [self._val, self._numerator, self._denominator]
-
- def __setstate__(self, state):
- IFDRational.__init__(self, 0)
- _val, _numerator, _denominator = state
- self._val = _val
- self._numerator = _numerator
- self._denominator = _denominator
-
- def _delegate(op):
- def delegate(self, *args):
- return getattr(self._val, op)(*args)
-
- return delegate
-
- """ a = ['add','radd', 'sub', 'rsub', 'mul', 'rmul',
- 'truediv', 'rtruediv', 'floordiv', 'rfloordiv',
- 'mod','rmod', 'pow','rpow', 'pos', 'neg',
- 'abs', 'trunc', 'lt', 'gt', 'le', 'ge', 'bool',
- 'ceil', 'floor', 'round']
- print("\n".join("__%s__ = _delegate('__%s__')" % (s,s) for s in a))
- """
-
- __add__ = _delegate("__add__")
- __radd__ = _delegate("__radd__")
- __sub__ = _delegate("__sub__")
- __rsub__ = _delegate("__rsub__")
- __mul__ = _delegate("__mul__")
- __rmul__ = _delegate("__rmul__")
- __truediv__ = _delegate("__truediv__")
- __rtruediv__ = _delegate("__rtruediv__")
- __floordiv__ = _delegate("__floordiv__")
- __rfloordiv__ = _delegate("__rfloordiv__")
- __mod__ = _delegate("__mod__")
- __rmod__ = _delegate("__rmod__")
- __pow__ = _delegate("__pow__")
- __rpow__ = _delegate("__rpow__")
- __pos__ = _delegate("__pos__")
- __neg__ = _delegate("__neg__")
- __abs__ = _delegate("__abs__")
- __trunc__ = _delegate("__trunc__")
- __lt__ = _delegate("__lt__")
- __gt__ = _delegate("__gt__")
- __le__ = _delegate("__le__")
- __ge__ = _delegate("__ge__")
- __bool__ = _delegate("__bool__")
- __ceil__ = _delegate("__ceil__")
- __floor__ = _delegate("__floor__")
- __round__ = _delegate("__round__")
- # Python >= 3.11
- if hasattr(Fraction, "__int__"):
- __int__ = _delegate("__int__")
-
-
-class ImageFileDirectory_v2(MutableMapping):
- """This class represents a TIFF tag directory. To speed things up, we
- don't decode tags unless they're asked for.
-
- Exposes a dictionary interface of the tags in the directory::
-
- ifd = ImageFileDirectory_v2()
- ifd[key] = 'Some Data'
- ifd.tagtype[key] = TiffTags.ASCII
- print(ifd[key])
- 'Some Data'
-
- Individual values are returned as the strings or numbers, sequences are
- returned as tuples of the values.
-
- The tiff metadata type of each item is stored in a dictionary of
- tag types in
- :attr:`~PIL.TiffImagePlugin.ImageFileDirectory_v2.tagtype`. The types
- are read from a tiff file, guessed from the type added, or added
- manually.
-
- Data Structures:
-
- * ``self.tagtype = {}``
-
- * Key: numerical TIFF tag number
- * Value: integer corresponding to the data type from
- :py:data:`.TiffTags.TYPES`
-
- .. versionadded:: 3.0.0
-
- 'Internal' data structures:
-
- * ``self._tags_v2 = {}``
-
- * Key: numerical TIFF tag number
- * Value: decoded data, as tuple for multiple values
-
- * ``self._tagdata = {}``
-
- * Key: numerical TIFF tag number
- * Value: undecoded byte string from file
-
- * ``self._tags_v1 = {}``
-
- * Key: numerical TIFF tag number
- * Value: decoded data in the v1 format
-
- Tags will be found in the private attributes ``self._tagdata``, and in
- ``self._tags_v2`` once decoded.
-
- ``self.legacy_api`` is a value for internal use, and shouldn't be changed
- from outside code. In cooperation with
- :py:class:`~PIL.TiffImagePlugin.ImageFileDirectory_v1`, if ``legacy_api``
- is true, then decoded tags will be populated into both ``_tags_v1`` and
- ``_tags_v2``. ``_tags_v2`` will be used if this IFD is used in the TIFF
- save routine. Tags should be read from ``_tags_v1`` if
- ``legacy_api == true``.
-
- """
-
- def __init__(self, ifh=b"II\052\0\0\0\0\0", prefix=None, group=None):
- """Initialize an ImageFileDirectory.
-
- To construct an ImageFileDirectory from a real file, pass the 8-byte
- magic header to the constructor. To only set the endianness, pass it
- as the 'prefix' keyword argument.
-
- :param ifh: One of the accepted magic headers (cf. PREFIXES); also sets
- endianness.
- :param prefix: Override the endianness of the file.
- """
- if not _accept(ifh):
- msg = f"not a TIFF file (header {repr(ifh)} not valid)"
- raise SyntaxError(msg)
- self._prefix = prefix if prefix is not None else ifh[:2]
- if self._prefix == MM:
- self._endian = ">"
- elif self._prefix == II:
- self._endian = "<"
- else:
- msg = "not a TIFF IFD"
- raise SyntaxError(msg)
- self._bigtiff = ifh[2] == 43
- self.group = group
- self.tagtype = {}
- """ Dictionary of tag types """
- self.reset()
- (self.next,) = (
- self._unpack("Q", ifh[8:]) if self._bigtiff else self._unpack("L", ifh[4:])
- )
- self._legacy_api = False
-
- prefix = property(lambda self: self._prefix)
- offset = property(lambda self: self._offset)
- legacy_api = property(lambda self: self._legacy_api)
-
- @legacy_api.setter
- def legacy_api(self, value):
- msg = "Not allowing setting of legacy api"
- raise Exception(msg)
-
- def reset(self):
- self._tags_v1 = {} # will remain empty if legacy_api is false
- self._tags_v2 = {} # main tag storage
- self._tagdata = {}
- self.tagtype = {} # added 2008-06-05 by Florian Hoech
- self._next = None
- self._offset = None
-
- def __str__(self):
- return str(dict(self))
-
- def named(self):
- """
- :returns: dict of name|key: value
-
- Returns the complete tag dictionary, with named tags where possible.
- """
- return {
- TiffTags.lookup(code, self.group).name: value
- for code, value in self.items()
- }
-
- def __len__(self):
- return len(set(self._tagdata) | set(self._tags_v2))
-
- def __getitem__(self, tag):
- if tag not in self._tags_v2: # unpack on the fly
- data = self._tagdata[tag]
- typ = self.tagtype[tag]
- size, handler = self._load_dispatch[typ]
- self[tag] = handler(self, data, self.legacy_api) # check type
- val = self._tags_v2[tag]
- if self.legacy_api and not isinstance(val, (tuple, bytes)):
- val = (val,)
- return val
-
- def __contains__(self, tag):
- return tag in self._tags_v2 or tag in self._tagdata
-
- def __setitem__(self, tag, value):
- self._setitem(tag, value, self.legacy_api)
-
- def _setitem(self, tag, value, legacy_api):
- basetypes = (Number, bytes, str)
-
- info = TiffTags.lookup(tag, self.group)
- values = [value] if isinstance(value, basetypes) else value
-
- if tag not in self.tagtype:
- if info.type:
- self.tagtype[tag] = info.type
- else:
- self.tagtype[tag] = TiffTags.UNDEFINED
- if all(isinstance(v, IFDRational) for v in values):
- self.tagtype[tag] = (
- TiffTags.RATIONAL
- if all(v >= 0 for v in values)
- else TiffTags.SIGNED_RATIONAL
- )
- elif all(isinstance(v, int) for v in values):
- if all(0 <= v < 2**16 for v in values):
- self.tagtype[tag] = TiffTags.SHORT
- elif all(-(2**15) < v < 2**15 for v in values):
- self.tagtype[tag] = TiffTags.SIGNED_SHORT
- else:
- self.tagtype[tag] = (
- TiffTags.LONG
- if all(v >= 0 for v in values)
- else TiffTags.SIGNED_LONG
- )
- elif all(isinstance(v, float) for v in values):
- self.tagtype[tag] = TiffTags.DOUBLE
- elif all(isinstance(v, str) for v in values):
- self.tagtype[tag] = TiffTags.ASCII
- elif all(isinstance(v, bytes) for v in values):
- self.tagtype[tag] = TiffTags.BYTE
-
- if self.tagtype[tag] == TiffTags.UNDEFINED:
- values = [
- v.encode("ascii", "replace") if isinstance(v, str) else v
- for v in values
- ]
- elif self.tagtype[tag] == TiffTags.RATIONAL:
- values = [float(v) if isinstance(v, int) else v for v in values]
-
- is_ifd = self.tagtype[tag] == TiffTags.LONG and isinstance(values, dict)
- if not is_ifd:
- values = tuple(info.cvt_enum(value) for value in values)
-
- dest = self._tags_v1 if legacy_api else self._tags_v2
-
- # Three branches:
- # Spec'd length == 1, Actual length 1, store as element
- # Spec'd length == 1, Actual > 1, Warn and truncate. Formerly barfed.
- # No Spec, Actual length 1, Formerly (<4.2) returned a 1 element tuple.
- # Don't mess with the legacy api, since it's frozen.
- if not is_ifd and (
- (info.length == 1)
- or self.tagtype[tag] == TiffTags.BYTE
- or (info.length is None and len(values) == 1 and not legacy_api)
- ):
- # Don't mess with the legacy api, since it's frozen.
- if legacy_api and self.tagtype[tag] in [
- TiffTags.RATIONAL,
- TiffTags.SIGNED_RATIONAL,
- ]: # rationals
- values = (values,)
- try:
- (dest[tag],) = values
- except ValueError:
- # We've got a builtin tag with 1 expected entry
- warnings.warn(
- f"Metadata Warning, tag {tag} had too many entries: "
- f"{len(values)}, expected 1"
- )
- dest[tag] = values[0]
-
- else:
- # Spec'd length > 1 or undefined
- # Unspec'd, and length > 1
- dest[tag] = values
-
- def __delitem__(self, tag):
- self._tags_v2.pop(tag, None)
- self._tags_v1.pop(tag, None)
- self._tagdata.pop(tag, None)
-
- def __iter__(self):
- return iter(set(self._tagdata) | set(self._tags_v2))
-
- def _unpack(self, fmt, data):
- return struct.unpack(self._endian + fmt, data)
-
- def _pack(self, fmt, *values):
- return struct.pack(self._endian + fmt, *values)
-
- def _register_loader(idx, size):
- def decorator(func):
- from .TiffTags import TYPES
-
- if func.__name__.startswith("load_"):
- TYPES[idx] = func.__name__[5:].replace("_", " ")
- _load_dispatch[idx] = size, func # noqa: F821
- return func
-
- return decorator
-
- def _register_writer(idx):
- def decorator(func):
- _write_dispatch[idx] = func # noqa: F821
- return func
-
- return decorator
-
- def _register_basic(idx_fmt_name):
- from .TiffTags import TYPES
-
- idx, fmt, name = idx_fmt_name
- TYPES[idx] = name
- size = struct.calcsize("=" + fmt)
- _load_dispatch[idx] = ( # noqa: F821
- size,
- lambda self, data, legacy_api=True: (
- self._unpack(f"{len(data) // size}{fmt}", data)
- ),
- )
- _write_dispatch[idx] = lambda self, *values: ( # noqa: F821
- b"".join(self._pack(fmt, value) for value in values)
- )
-
- list(
- map(
- _register_basic,
- [
- (TiffTags.SHORT, "H", "short"),
- (TiffTags.LONG, "L", "long"),
- (TiffTags.SIGNED_BYTE, "b", "signed byte"),
- (TiffTags.SIGNED_SHORT, "h", "signed short"),
- (TiffTags.SIGNED_LONG, "l", "signed long"),
- (TiffTags.FLOAT, "f", "float"),
- (TiffTags.DOUBLE, "d", "double"),
- (TiffTags.IFD, "L", "long"),
- (TiffTags.LONG8, "Q", "long8"),
- ],
- )
- )
-
- @_register_loader(1, 1) # Basic type, except for the legacy API.
- def load_byte(self, data, legacy_api=True):
- return data
-
- @_register_writer(1) # Basic type, except for the legacy API.
- def write_byte(self, data):
- if isinstance(data, IFDRational):
- data = int(data)
- if isinstance(data, int):
- data = bytes((data,))
- return data
-
- @_register_loader(2, 1)
- def load_string(self, data, legacy_api=True):
- if data.endswith(b"\0"):
- data = data[:-1]
- return data.decode("latin-1", "replace")
-
- @_register_writer(2)
- def write_string(self, value):
- # remerge of https://github.com/python-pillow/Pillow/pull/1416
- if isinstance(value, int):
- value = str(value)
- if not isinstance(value, bytes):
- value = value.encode("ascii", "replace")
- return value + b"\0"
-
- @_register_loader(5, 8)
- def load_rational(self, data, legacy_api=True):
- vals = self._unpack(f"{len(data) // 4}L", data)
-
- def combine(a, b):
- return (a, b) if legacy_api else IFDRational(a, b)
-
- return tuple(combine(num, denom) for num, denom in zip(vals[::2], vals[1::2]))
-
- @_register_writer(5)
- def write_rational(self, *values):
- return b"".join(
- self._pack("2L", *_limit_rational(frac, 2**32 - 1)) for frac in values
- )
-
- @_register_loader(7, 1)
- def load_undefined(self, data, legacy_api=True):
- return data
-
- @_register_writer(7)
- def write_undefined(self, value):
- if isinstance(value, int):
- value = str(value).encode("ascii", "replace")
- return value
-
- @_register_loader(10, 8)
- def load_signed_rational(self, data, legacy_api=True):
- vals = self._unpack(f"{len(data) // 4}l", data)
-
- def combine(a, b):
- return (a, b) if legacy_api else IFDRational(a, b)
-
- return tuple(combine(num, denom) for num, denom in zip(vals[::2], vals[1::2]))
-
- @_register_writer(10)
- def write_signed_rational(self, *values):
- return b"".join(
- self._pack("2l", *_limit_signed_rational(frac, 2**31 - 1, -(2**31)))
- for frac in values
- )
-
- def _ensure_read(self, fp, size):
- ret = fp.read(size)
- if len(ret) != size:
- msg = (
- "Corrupt EXIF data. "
- f"Expecting to read {size} bytes but only got {len(ret)}. "
- )
- raise OSError(msg)
- return ret
-
- def load(self, fp):
- self.reset()
- self._offset = fp.tell()
-
- try:
- tag_count = (
- self._unpack("Q", self._ensure_read(fp, 8))
- if self._bigtiff
- else self._unpack("H", self._ensure_read(fp, 2))
- )[0]
- for i in range(tag_count):
- tag, typ, count, data = (
- self._unpack("HHQ8s", self._ensure_read(fp, 20))
- if self._bigtiff
- else self._unpack("HHL4s", self._ensure_read(fp, 12))
- )
-
- tagname = TiffTags.lookup(tag, self.group).name
- typname = TYPES.get(typ, "unknown")
- msg = f"tag: {tagname} ({tag}) - type: {typname} ({typ})"
-
- try:
- unit_size, handler = self._load_dispatch[typ]
- except KeyError:
- logger.debug(msg + f" - unsupported type {typ}")
- continue # ignore unsupported type
- size = count * unit_size
- if size > (8 if self._bigtiff else 4):
- here = fp.tell()
- (offset,) = self._unpack("Q" if self._bigtiff else "L", data)
- msg += f" Tag Location: {here} - Data Location: {offset}"
- fp.seek(offset)
- data = ImageFile._safe_read(fp, size)
- fp.seek(here)
- else:
- data = data[:size]
-
- if len(data) != size:
- warnings.warn(
- "Possibly corrupt EXIF data. "
- f"Expecting to read {size} bytes but only got {len(data)}."
- f" Skipping tag {tag}"
- )
- logger.debug(msg)
- continue
-
- if not data:
- logger.debug(msg)
- continue
-
- self._tagdata[tag] = data
- self.tagtype[tag] = typ
-
- msg += " - value: " + (
- "" % size if size > 32 else repr(data)
- )
- logger.debug(msg)
-
- (self.next,) = (
- self._unpack("Q", self._ensure_read(fp, 8))
- if self._bigtiff
- else self._unpack("L", self._ensure_read(fp, 4))
- )
- except OSError as msg:
- warnings.warn(str(msg))
- return
-
- def tobytes(self, offset=0):
- # FIXME What about tagdata?
- result = self._pack("H", len(self._tags_v2))
-
- entries = []
- offset = offset + len(result) + len(self._tags_v2) * 12 + 4
- stripoffsets = None
-
- # pass 1: convert tags to binary format
- # always write tags in ascending order
- for tag, value in sorted(self._tags_v2.items()):
- if tag == STRIPOFFSETS:
- stripoffsets = len(entries)
- typ = self.tagtype.get(tag)
- logger.debug(f"Tag {tag}, Type: {typ}, Value: {repr(value)}")
- is_ifd = typ == TiffTags.LONG and isinstance(value, dict)
- if is_ifd:
- if self._endian == "<":
- ifh = b"II\x2A\x00\x08\x00\x00\x00"
- else:
- ifh = b"MM\x00\x2A\x00\x00\x00\x08"
- ifd = ImageFileDirectory_v2(ifh, group=tag)
- values = self._tags_v2[tag]
- for ifd_tag, ifd_value in values.items():
- ifd[ifd_tag] = ifd_value
- data = ifd.tobytes(offset)
- else:
- values = value if isinstance(value, tuple) else (value,)
- data = self._write_dispatch[typ](self, *values)
-
- tagname = TiffTags.lookup(tag, self.group).name
- typname = "ifd" if is_ifd else TYPES.get(typ, "unknown")
- msg = f"save: {tagname} ({tag}) - type: {typname} ({typ})"
- msg += " - value: " + (
- "" % len(data) if len(data) >= 16 else str(values)
- )
- logger.debug(msg)
-
- # count is sum of lengths for string and arbitrary data
- if is_ifd:
- count = 1
- elif typ in [TiffTags.BYTE, TiffTags.ASCII, TiffTags.UNDEFINED]:
- count = len(data)
- else:
- count = len(values)
- # figure out if data fits into the entry
- if len(data) <= 4:
- entries.append((tag, typ, count, data.ljust(4, b"\0"), b""))
- else:
- entries.append((tag, typ, count, self._pack("L", offset), data))
- offset += (len(data) + 1) // 2 * 2 # pad to word
-
- # update strip offset data to point beyond auxiliary data
- if stripoffsets is not None:
- tag, typ, count, value, data = entries[stripoffsets]
- if data:
- msg = "multistrip support not yet implemented"
- raise NotImplementedError(msg)
- value = self._pack("L", self._unpack("L", value)[0] + offset)
- entries[stripoffsets] = tag, typ, count, value, data
-
- # pass 2: write entries to file
- for tag, typ, count, value, data in entries:
- logger.debug(f"{tag} {typ} {count} {repr(value)} {repr(data)}")
- result += self._pack("HHL4s", tag, typ, count, value)
-
- # -- overwrite here for multi-page --
- result += b"\0\0\0\0" # end of entries
-
- # pass 3: write auxiliary data to file
- for tag, typ, count, value, data in entries:
- result += data
- if len(data) & 1:
- result += b"\0"
-
- return result
-
- def save(self, fp):
- if fp.tell() == 0: # skip TIFF header on subsequent pages
- # tiff header -- PIL always starts the first IFD at offset 8
- fp.write(self._prefix + self._pack("HL", 42, 8))
-
- offset = fp.tell()
- result = self.tobytes(offset)
- fp.write(result)
- return offset + len(result)
-
-
-ImageFileDirectory_v2._load_dispatch = _load_dispatch
-ImageFileDirectory_v2._write_dispatch = _write_dispatch
-for idx, name in TYPES.items():
- name = name.replace(" ", "_")
- setattr(ImageFileDirectory_v2, "load_" + name, _load_dispatch[idx][1])
- setattr(ImageFileDirectory_v2, "write_" + name, _write_dispatch[idx])
-del _load_dispatch, _write_dispatch, idx, name
-
-
-# Legacy ImageFileDirectory support.
-class ImageFileDirectory_v1(ImageFileDirectory_v2):
- """This class represents the **legacy** interface to a TIFF tag directory.
-
- Exposes a dictionary interface of the tags in the directory::
-
- ifd = ImageFileDirectory_v1()
- ifd[key] = 'Some Data'
- ifd.tagtype[key] = TiffTags.ASCII
- print(ifd[key])
- ('Some Data',)
-
- Also contains a dictionary of tag types as read from the tiff image file,
- :attr:`~PIL.TiffImagePlugin.ImageFileDirectory_v1.tagtype`.
-
- Values are returned as a tuple.
-
- .. deprecated:: 3.0.0
- """
-
- def __init__(self, *args, **kwargs):
- super().__init__(*args, **kwargs)
- self._legacy_api = True
-
- tags = property(lambda self: self._tags_v1)
- tagdata = property(lambda self: self._tagdata)
-
- # defined in ImageFileDirectory_v2
- tagtype: dict
- """Dictionary of tag types"""
-
- @classmethod
- def from_v2(cls, original):
- """Returns an
- :py:class:`~PIL.TiffImagePlugin.ImageFileDirectory_v1`
- instance with the same data as is contained in the original
- :py:class:`~PIL.TiffImagePlugin.ImageFileDirectory_v2`
- instance.
-
- :returns: :py:class:`~PIL.TiffImagePlugin.ImageFileDirectory_v1`
-
- """
-
- ifd = cls(prefix=original.prefix)
- ifd._tagdata = original._tagdata
- ifd.tagtype = original.tagtype
- ifd.next = original.next # an indicator for multipage tiffs
- return ifd
-
- def to_v2(self):
- """Returns an
- :py:class:`~PIL.TiffImagePlugin.ImageFileDirectory_v2`
- instance with the same data as is contained in the original
- :py:class:`~PIL.TiffImagePlugin.ImageFileDirectory_v1`
- instance.
-
- :returns: :py:class:`~PIL.TiffImagePlugin.ImageFileDirectory_v2`
-
- """
-
- ifd = ImageFileDirectory_v2(prefix=self.prefix)
- ifd._tagdata = dict(self._tagdata)
- ifd.tagtype = dict(self.tagtype)
- ifd._tags_v2 = dict(self._tags_v2)
- return ifd
-
- def __contains__(self, tag):
- return tag in self._tags_v1 or tag in self._tagdata
-
- def __len__(self):
- return len(set(self._tagdata) | set(self._tags_v1))
-
- def __iter__(self):
- return iter(set(self._tagdata) | set(self._tags_v1))
-
- def __setitem__(self, tag, value):
- for legacy_api in (False, True):
- self._setitem(tag, value, legacy_api)
-
- def __getitem__(self, tag):
- if tag not in self._tags_v1: # unpack on the fly
- data = self._tagdata[tag]
- typ = self.tagtype[tag]
- size, handler = self._load_dispatch[typ]
- for legacy in (False, True):
- self._setitem(tag, handler(self, data, legacy), legacy)
- val = self._tags_v1[tag]
- if not isinstance(val, (tuple, bytes)):
- val = (val,)
- return val
-
-
-# undone -- switch this pointer when IFD_LEGACY_API == False
-ImageFileDirectory = ImageFileDirectory_v1
-
-
-##
-# Image plugin for TIFF files.
-
-
-class TiffImageFile(ImageFile.ImageFile):
- format = "TIFF"
- format_description = "Adobe TIFF"
- _close_exclusive_fp_after_loading = False
-
- def __init__(self, fp=None, filename=None):
- self.tag_v2 = None
- """ Image file directory (tag dictionary) """
-
- self.tag = None
- """ Legacy tag entries """
-
- super().__init__(fp, filename)
-
- def _open(self):
- """Open the first image in a TIFF file"""
-
- # Header
- ifh = self.fp.read(8)
- if ifh[2] == 43:
- ifh += self.fp.read(8)
-
- self.tag_v2 = ImageFileDirectory_v2(ifh)
-
- # legacy IFD entries will be filled in later
- self.ifd = None
-
- # setup frame pointers
- self.__first = self.__next = self.tag_v2.next
- self.__frame = -1
- self._fp = self.fp
- self._frame_pos = []
- self._n_frames = None
-
- logger.debug("*** TiffImageFile._open ***")
- logger.debug(f"- __first: {self.__first}")
- logger.debug(f"- ifh: {repr(ifh)}") # Use repr to avoid str(bytes)
-
- # and load the first frame
- self._seek(0)
-
- @property
- def n_frames(self):
- if self._n_frames is None:
- current = self.tell()
- self._seek(len(self._frame_pos))
- while self._n_frames is None:
- self._seek(self.tell() + 1)
- self.seek(current)
- return self._n_frames
-
- def seek(self, frame):
- """Select a given frame as current image"""
- if not self._seek_check(frame):
- return
- self._seek(frame)
- # Create a new core image object on second and
- # subsequent frames in the image. Image may be
- # different size/mode.
- Image._decompression_bomb_check(self.size)
- self.im = Image.core.new(self.mode, self.size)
-
- def _seek(self, frame):
- self.fp = self._fp
-
- # reset buffered io handle in case fp
- # was passed to libtiff, invalidating the buffer
- self.fp.tell()
-
- while len(self._frame_pos) <= frame:
- if not self.__next:
- msg = "no more images in TIFF file"
- raise EOFError(msg)
- logger.debug(
- f"Seeking to frame {frame}, on frame {self.__frame}, "
- f"__next {self.__next}, location: {self.fp.tell()}"
- )
- self.fp.seek(self.__next)
- self._frame_pos.append(self.__next)
- logger.debug("Loading tags, location: %s" % self.fp.tell())
- self.tag_v2.load(self.fp)
- if self.tag_v2.next in self._frame_pos:
- # This IFD has already been processed
- # Declare this to be the end of the image
- self.__next = 0
- else:
- self.__next = self.tag_v2.next
- if self.__next == 0:
- self._n_frames = frame + 1
- if len(self._frame_pos) == 1:
- self.is_animated = self.__next != 0
- self.__frame += 1
- self.fp.seek(self._frame_pos[frame])
- self.tag_v2.load(self.fp)
- self._reload_exif()
- # fill the legacy tag/ifd entries
- self.tag = self.ifd = ImageFileDirectory_v1.from_v2(self.tag_v2)
- self.__frame = frame
- self._setup()
-
- def tell(self):
- """Return the current frame number"""
- return self.__frame
-
- def getxmp(self):
- """
- Returns a dictionary containing the XMP tags.
- Requires defusedxml to be installed.
-
- :returns: XMP tags in a dictionary.
- """
- return self._getxmp(self.tag_v2[XMP]) if XMP in self.tag_v2 else {}
-
- def get_photoshop_blocks(self):
- """
- Returns a dictionary of Photoshop "Image Resource Blocks".
- The keys are the image resource ID. For more information, see
- https://www.adobe.com/devnet-apps/photoshop/fileformatashtml/#50577409_pgfId-1037727
-
- :returns: Photoshop "Image Resource Blocks" in a dictionary.
- """
- blocks = {}
- val = self.tag_v2.get(ExifTags.Base.ImageResources)
- if val:
- while val[:4] == b"8BIM":
- id = i16(val[4:6])
- n = math.ceil((val[6] + 1) / 2) * 2
- size = i32(val[6 + n : 10 + n])
- data = val[10 + n : 10 + n + size]
- blocks[id] = {"data": data}
-
- val = val[math.ceil((10 + n + size) / 2) * 2 :]
- return blocks
-
- def load(self):
- if self.tile and self.use_load_libtiff:
- return self._load_libtiff()
- return super().load()
-
- def load_end(self):
- if self._tile_orientation:
- method = {
- 2: Image.Transpose.FLIP_LEFT_RIGHT,
- 3: Image.Transpose.ROTATE_180,
- 4: Image.Transpose.FLIP_TOP_BOTTOM,
- 5: Image.Transpose.TRANSPOSE,
- 6: Image.Transpose.ROTATE_270,
- 7: Image.Transpose.TRANSVERSE,
- 8: Image.Transpose.ROTATE_90,
- }.get(self._tile_orientation)
- if method is not None:
- self.im = self.im.transpose(method)
- self._size = self.im.size
-
- # allow closing if we're on the first frame, there's no next
- # This is the ImageFile.load path only, libtiff specific below.
- if not self.is_animated:
- self._close_exclusive_fp_after_loading = True
-
- # reset buffered io handle in case fp
- # was passed to libtiff, invalidating the buffer
- self.fp.tell()
-
- # load IFD data from fp before it is closed
- exif = self.getexif()
- for key in TiffTags.TAGS_V2_GROUPS:
- if key not in exif:
- continue
- exif.get_ifd(key)
-
- def _load_libtiff(self):
- """Overload method triggered when we detect a compressed tiff
- Calls out to libtiff"""
-
- Image.Image.load(self)
-
- self.load_prepare()
-
- if not len(self.tile) == 1:
- msg = "Not exactly one tile"
- raise OSError(msg)
-
- # (self._compression, (extents tuple),
- # 0, (rawmode, self._compression, fp))
- extents = self.tile[0][1]
- args = list(self.tile[0][3])
-
- # To be nice on memory footprint, if there's a
- # file descriptor, use that instead of reading
- # into a string in python.
- try:
- fp = hasattr(self.fp, "fileno") and self.fp.fileno()
- # flush the file descriptor, prevents error on pypy 2.4+
- # should also eliminate the need for fp.tell
- # in _seek
- if hasattr(self.fp, "flush"):
- self.fp.flush()
- except OSError:
- # io.BytesIO have a fileno, but returns an OSError if
- # it doesn't use a file descriptor.
- fp = False
-
- if fp:
- args[2] = fp
-
- decoder = Image._getdecoder(
- self.mode, "libtiff", tuple(args), self.decoderconfig
- )
- try:
- decoder.setimage(self.im, extents)
- except ValueError as e:
- msg = "Couldn't set the image"
- raise OSError(msg) from e
-
- close_self_fp = self._exclusive_fp and not self.is_animated
- if hasattr(self.fp, "getvalue"):
- # We've got a stringio like thing passed in. Yay for all in memory.
- # The decoder needs the entire file in one shot, so there's not
- # a lot we can do here other than give it the entire file.
- # unless we could do something like get the address of the
- # underlying string for stringio.
- #
- # Rearranging for supporting byteio items, since they have a fileno
- # that returns an OSError if there's no underlying fp. Easier to
- # deal with here by reordering.
- logger.debug("have getvalue. just sending in a string from getvalue")
- n, err = decoder.decode(self.fp.getvalue())
- elif fp:
- # we've got a actual file on disk, pass in the fp.
- logger.debug("have fileno, calling fileno version of the decoder.")
- if not close_self_fp:
- self.fp.seek(0)
- # 4 bytes, otherwise the trace might error out
- n, err = decoder.decode(b"fpfp")
- else:
- # we have something else.
- logger.debug("don't have fileno or getvalue. just reading")
- self.fp.seek(0)
- # UNDONE -- so much for that buffer size thing.
- n, err = decoder.decode(self.fp.read())
-
- self.tile = []
- self.readonly = 0
-
- self.load_end()
-
- if close_self_fp:
- self.fp.close()
- self.fp = None # might be shared
-
- if err < 0:
- raise OSError(err)
-
- return Image.Image.load(self)
-
- def _setup(self):
- """Setup this image object based on current tags"""
-
- if 0xBC01 in self.tag_v2:
- msg = "Windows Media Photo files not yet supported"
- raise OSError(msg)
-
- # extract relevant tags
- self._compression = COMPRESSION_INFO[self.tag_v2.get(COMPRESSION, 1)]
- self._planar_configuration = self.tag_v2.get(PLANAR_CONFIGURATION, 1)
-
- # photometric is a required tag, but not everyone is reading
- # the specification
- photo = self.tag_v2.get(PHOTOMETRIC_INTERPRETATION, 0)
-
- # old style jpeg compression images most certainly are YCbCr
- if self._compression == "tiff_jpeg":
- photo = 6
-
- fillorder = self.tag_v2.get(FILLORDER, 1)
-
- logger.debug("*** Summary ***")
- logger.debug(f"- compression: {self._compression}")
- logger.debug(f"- photometric_interpretation: {photo}")
- logger.debug(f"- planar_configuration: {self._planar_configuration}")
- logger.debug(f"- fill_order: {fillorder}")
- logger.debug(f"- YCbCr subsampling: {self.tag.get(YCBCRSUBSAMPLING)}")
-
- # size
- xsize = int(self.tag_v2.get(IMAGEWIDTH))
- ysize = int(self.tag_v2.get(IMAGELENGTH))
- self._size = xsize, ysize
-
- logger.debug(f"- size: {self.size}")
-
- sample_format = self.tag_v2.get(SAMPLEFORMAT, (1,))
- if len(sample_format) > 1 and max(sample_format) == min(sample_format) == 1:
- # SAMPLEFORMAT is properly per band, so an RGB image will
- # be (1,1,1). But, we don't support per band pixel types,
- # and anything more than one band is a uint8. So, just
- # take the first element. Revisit this if adding support
- # for more exotic images.
- sample_format = (1,)
-
- bps_tuple = self.tag_v2.get(BITSPERSAMPLE, (1,))
- extra_tuple = self.tag_v2.get(EXTRASAMPLES, ())
- if photo in (2, 6, 8): # RGB, YCbCr, LAB
- bps_count = 3
- elif photo == 5: # CMYK
- bps_count = 4
- else:
- bps_count = 1
- bps_count += len(extra_tuple)
- bps_actual_count = len(bps_tuple)
- samples_per_pixel = self.tag_v2.get(
- SAMPLESPERPIXEL,
- 3 if self._compression == "tiff_jpeg" and photo in (2, 6) else 1,
- )
-
- if samples_per_pixel > MAX_SAMPLESPERPIXEL:
- # DOS check, samples_per_pixel can be a Long, and we extend the tuple below
- logger.error(
- "More samples per pixel than can be decoded: %s", samples_per_pixel
- )
- msg = "Invalid value for samples per pixel"
- raise SyntaxError(msg)
-
- if samples_per_pixel < bps_actual_count:
- # If a file has more values in bps_tuple than expected,
- # remove the excess.
- bps_tuple = bps_tuple[:samples_per_pixel]
- elif samples_per_pixel > bps_actual_count and bps_actual_count == 1:
- # If a file has only one value in bps_tuple, when it should have more,
- # presume it is the same number of bits for all of the samples.
- bps_tuple = bps_tuple * samples_per_pixel
-
- if len(bps_tuple) != samples_per_pixel:
- msg = "unknown data organization"
- raise SyntaxError(msg)
-
- # mode: check photometric interpretation and bits per pixel
- key = (
- self.tag_v2.prefix,
- photo,
- sample_format,
- fillorder,
- bps_tuple,
- extra_tuple,
- )
- logger.debug(f"format key: {key}")
- try:
- self.mode, rawmode = OPEN_INFO[key]
- except KeyError as e:
- logger.debug("- unsupported format")
- msg = "unknown pixel mode"
- raise SyntaxError(msg) from e
-
- logger.debug(f"- raw mode: {rawmode}")
- logger.debug(f"- pil mode: {self.mode}")
-
- self.info["compression"] = self._compression
-
- xres = self.tag_v2.get(X_RESOLUTION, 1)
- yres = self.tag_v2.get(Y_RESOLUTION, 1)
-
- if xres and yres:
- resunit = self.tag_v2.get(RESOLUTION_UNIT)
- if resunit == 2: # dots per inch
- self.info["dpi"] = (xres, yres)
- elif resunit == 3: # dots per centimeter. convert to dpi
- self.info["dpi"] = (xres * 2.54, yres * 2.54)
- elif resunit is None: # used to default to 1, but now 2)
- self.info["dpi"] = (xres, yres)
- # For backward compatibility,
- # we also preserve the old behavior
- self.info["resolution"] = xres, yres
- else: # No absolute unit of measurement
- self.info["resolution"] = xres, yres
-
- # build tile descriptors
- x = y = layer = 0
- self.tile = []
- self.use_load_libtiff = READ_LIBTIFF or self._compression != "raw"
- if self.use_load_libtiff:
- # Decoder expects entire file as one tile.
- # There's a buffer size limit in load (64k)
- # so large g4 images will fail if we use that
- # function.
- #
- # Setup the one tile for the whole image, then
- # use the _load_libtiff function.
-
- # libtiff handles the fillmode for us, so 1;IR should
- # actually be 1;I. Including the R double reverses the
- # bits, so stripes of the image are reversed. See
- # https://github.com/python-pillow/Pillow/issues/279
- if fillorder == 2:
- # Replace fillorder with fillorder=1
- key = key[:3] + (1,) + key[4:]
- logger.debug(f"format key: {key}")
- # this should always work, since all the
- # fillorder==2 modes have a corresponding
- # fillorder=1 mode
- self.mode, rawmode = OPEN_INFO[key]
- # libtiff always returns the bytes in native order.
- # we're expecting image byte order. So, if the rawmode
- # contains I;16, we need to convert from native to image
- # byte order.
- if rawmode == "I;16":
- rawmode = "I;16N"
- if ";16B" in rawmode:
- rawmode = rawmode.replace(";16B", ";16N")
- if ";16L" in rawmode:
- rawmode = rawmode.replace(";16L", ";16N")
-
- # YCbCr images with new jpeg compression with pixels in one plane
- # unpacked straight into RGB values
- if (
- photo == 6
- and self._compression == "jpeg"
- and self._planar_configuration == 1
- ):
- rawmode = "RGB"
-
- # Offset in the tile tuple is 0, we go from 0,0 to
- # w,h, and we only do this once -- eds
- a = (rawmode, self._compression, False, self.tag_v2.offset)
- self.tile.append(("libtiff", (0, 0, xsize, ysize), 0, a))
-
- elif STRIPOFFSETS in self.tag_v2 or TILEOFFSETS in self.tag_v2:
- # striped image
- if STRIPOFFSETS in self.tag_v2:
- offsets = self.tag_v2[STRIPOFFSETS]
- h = self.tag_v2.get(ROWSPERSTRIP, ysize)
- w = self.size[0]
- else:
- # tiled image
- offsets = self.tag_v2[TILEOFFSETS]
- w = self.tag_v2.get(TILEWIDTH)
- h = self.tag_v2.get(TILELENGTH)
-
- for offset in offsets:
- if x + w > xsize:
- stride = w * sum(bps_tuple) / 8 # bytes per line
- else:
- stride = 0
-
- tile_rawmode = rawmode
- if self._planar_configuration == 2:
- # each band on it's own layer
- tile_rawmode = rawmode[layer]
- # adjust stride width accordingly
- stride /= bps_count
-
- a = (tile_rawmode, int(stride), 1)
- self.tile.append(
- (
- self._compression,
- (x, y, min(x + w, xsize), min(y + h, ysize)),
- offset,
- a,
- )
- )
- x = x + w
- if x >= self.size[0]:
- x, y = 0, y + h
- if y >= self.size[1]:
- x = y = 0
- layer += 1
- else:
- logger.debug("- unsupported data organization")
- msg = "unknown data organization"
- raise SyntaxError(msg)
-
- # Fix up info.
- if ICCPROFILE in self.tag_v2:
- self.info["icc_profile"] = self.tag_v2[ICCPROFILE]
-
- # fixup palette descriptor
-
- if self.mode in ["P", "PA"]:
- palette = [o8(b // 256) for b in self.tag_v2[COLORMAP]]
- self.palette = ImagePalette.raw("RGB;L", b"".join(palette))
-
- self._tile_orientation = self.tag_v2.get(ExifTags.Base.Orientation)
-
-
-#
-# --------------------------------------------------------------------
-# Write TIFF files
-
-# little endian is default except for image modes with
-# explicit big endian byte-order
-
-SAVE_INFO = {
- # mode => rawmode, byteorder, photometrics,
- # sampleformat, bitspersample, extra
- "1": ("1", II, 1, 1, (1,), None),
- "L": ("L", II, 1, 1, (8,), None),
- "LA": ("LA", II, 1, 1, (8, 8), 2),
- "P": ("P", II, 3, 1, (8,), None),
- "PA": ("PA", II, 3, 1, (8, 8), 2),
- "I": ("I;32S", II, 1, 2, (32,), None),
- "I;16": ("I;16", II, 1, 1, (16,), None),
- "I;16S": ("I;16S", II, 1, 2, (16,), None),
- "F": ("F;32F", II, 1, 3, (32,), None),
- "RGB": ("RGB", II, 2, 1, (8, 8, 8), None),
- "RGBX": ("RGBX", II, 2, 1, (8, 8, 8, 8), 0),
- "RGBA": ("RGBA", II, 2, 1, (8, 8, 8, 8), 2),
- "CMYK": ("CMYK", II, 5, 1, (8, 8, 8, 8), None),
- "YCbCr": ("YCbCr", II, 6, 1, (8, 8, 8), None),
- "LAB": ("LAB", II, 8, 1, (8, 8, 8), None),
- "I;32BS": ("I;32BS", MM, 1, 2, (32,), None),
- "I;16B": ("I;16B", MM, 1, 1, (16,), None),
- "I;16BS": ("I;16BS", MM, 1, 2, (16,), None),
- "F;32BF": ("F;32BF", MM, 1, 3, (32,), None),
-}
-
-
-def _save(im, fp, filename):
- try:
- rawmode, prefix, photo, format, bits, extra = SAVE_INFO[im.mode]
- except KeyError as e:
- msg = f"cannot write mode {im.mode} as TIFF"
- raise OSError(msg) from e
-
- ifd = ImageFileDirectory_v2(prefix=prefix)
-
- encoderinfo = im.encoderinfo
- encoderconfig = im.encoderconfig
- try:
- compression = encoderinfo["compression"]
- except KeyError:
- compression = im.info.get("compression")
- if isinstance(compression, int):
- # compression value may be from BMP. Ignore it
- compression = None
- if compression is None:
- compression = "raw"
- elif compression == "tiff_jpeg":
- # OJPEG is obsolete, so use new-style JPEG compression instead
- compression = "jpeg"
- elif compression == "tiff_deflate":
- compression = "tiff_adobe_deflate"
-
- libtiff = WRITE_LIBTIFF or compression != "raw"
-
- # required for color libtiff images
- ifd[PLANAR_CONFIGURATION] = 1
-
- ifd[IMAGEWIDTH] = im.size[0]
- ifd[IMAGELENGTH] = im.size[1]
-
- # write any arbitrary tags passed in as an ImageFileDirectory
- if "tiffinfo" in encoderinfo:
- info = encoderinfo["tiffinfo"]
- elif "exif" in encoderinfo:
- info = encoderinfo["exif"]
- if isinstance(info, bytes):
- exif = Image.Exif()
- exif.load(info)
- info = exif
- else:
- info = {}
- logger.debug("Tiffinfo Keys: %s" % list(info))
- if isinstance(info, ImageFileDirectory_v1):
- info = info.to_v2()
- for key in info:
- if isinstance(info, Image.Exif) and key in TiffTags.TAGS_V2_GROUPS:
- ifd[key] = info.get_ifd(key)
- else:
- ifd[key] = info.get(key)
- try:
- ifd.tagtype[key] = info.tagtype[key]
- except Exception:
- pass # might not be an IFD. Might not have populated type
-
- # additions written by Greg Couch, gregc@cgl.ucsf.edu
- # inspired by image-sig posting from Kevin Cazabon, kcazabon@home.com
- if hasattr(im, "tag_v2"):
- # preserve tags from original TIFF image file
- for key in (
- RESOLUTION_UNIT,
- X_RESOLUTION,
- Y_RESOLUTION,
- IPTC_NAA_CHUNK,
- PHOTOSHOP_CHUNK,
- XMP,
- ):
- if key in im.tag_v2:
- ifd[key] = im.tag_v2[key]
- ifd.tagtype[key] = im.tag_v2.tagtype[key]
-
- # preserve ICC profile (should also work when saving other formats
- # which support profiles as TIFF) -- 2008-06-06 Florian Hoech
- icc = encoderinfo.get("icc_profile", im.info.get("icc_profile"))
- if icc:
- ifd[ICCPROFILE] = icc
-
- for key, name in [
- (IMAGEDESCRIPTION, "description"),
- (X_RESOLUTION, "resolution"),
- (Y_RESOLUTION, "resolution"),
- (X_RESOLUTION, "x_resolution"),
- (Y_RESOLUTION, "y_resolution"),
- (RESOLUTION_UNIT, "resolution_unit"),
- (SOFTWARE, "software"),
- (DATE_TIME, "date_time"),
- (ARTIST, "artist"),
- (COPYRIGHT, "copyright"),
- ]:
- if name in encoderinfo:
- ifd[key] = encoderinfo[name]
-
- dpi = encoderinfo.get("dpi")
- if dpi:
- ifd[RESOLUTION_UNIT] = 2
- ifd[X_RESOLUTION] = dpi[0]
- ifd[Y_RESOLUTION] = dpi[1]
-
- if bits != (1,):
- ifd[BITSPERSAMPLE] = bits
- if len(bits) != 1:
- ifd[SAMPLESPERPIXEL] = len(bits)
- if extra is not None:
- ifd[EXTRASAMPLES] = extra
- if format != 1:
- ifd[SAMPLEFORMAT] = format
-
- if PHOTOMETRIC_INTERPRETATION not in ifd:
- ifd[PHOTOMETRIC_INTERPRETATION] = photo
- elif im.mode in ("1", "L") and ifd[PHOTOMETRIC_INTERPRETATION] == 0:
- if im.mode == "1":
- inverted_im = im.copy()
- px = inverted_im.load()
- for y in range(inverted_im.height):
- for x in range(inverted_im.width):
- px[x, y] = 0 if px[x, y] == 255 else 255
- im = inverted_im
- else:
- im = ImageOps.invert(im)
-
- if im.mode in ["P", "PA"]:
- lut = im.im.getpalette("RGB", "RGB;L")
- colormap = []
- colors = len(lut) // 3
- for i in range(3):
- colormap += [v * 256 for v in lut[colors * i : colors * (i + 1)]]
- colormap += [0] * (256 - colors)
- ifd[COLORMAP] = colormap
- # data orientation
- stride = len(bits) * ((im.size[0] * bits[0] + 7) // 8)
- # aim for given strip size (64 KB by default) when using libtiff writer
- if libtiff:
- im_strip_size = encoderinfo.get("strip_size", STRIP_SIZE)
- rows_per_strip = 1 if stride == 0 else min(im_strip_size // stride, im.size[1])
- # JPEG encoder expects multiple of 8 rows
- if compression == "jpeg":
- rows_per_strip = min(((rows_per_strip + 7) // 8) * 8, im.size[1])
- else:
- rows_per_strip = im.size[1]
- if rows_per_strip == 0:
- rows_per_strip = 1
- strip_byte_counts = 1 if stride == 0 else stride * rows_per_strip
- strips_per_image = (im.size[1] + rows_per_strip - 1) // rows_per_strip
- ifd[ROWSPERSTRIP] = rows_per_strip
- if strip_byte_counts >= 2**16:
- ifd.tagtype[STRIPBYTECOUNTS] = TiffTags.LONG
- ifd[STRIPBYTECOUNTS] = (strip_byte_counts,) * (strips_per_image - 1) + (
- stride * im.size[1] - strip_byte_counts * (strips_per_image - 1),
- )
- ifd[STRIPOFFSETS] = tuple(
- range(0, strip_byte_counts * strips_per_image, strip_byte_counts)
- ) # this is adjusted by IFD writer
- # no compression by default:
- ifd[COMPRESSION] = COMPRESSION_INFO_REV.get(compression, 1)
-
- if im.mode == "YCbCr":
- for tag, value in {
- YCBCRSUBSAMPLING: (1, 1),
- REFERENCEBLACKWHITE: (0, 255, 128, 255, 128, 255),
- }.items():
- ifd.setdefault(tag, value)
-
- blocklist = [TILEWIDTH, TILELENGTH, TILEOFFSETS, TILEBYTECOUNTS]
- if libtiff:
- if "quality" in encoderinfo:
- quality = encoderinfo["quality"]
- if not isinstance(quality, int) or quality < 0 or quality > 100:
- msg = "Invalid quality setting"
- raise ValueError(msg)
- if compression != "jpeg":
- msg = "quality setting only supported for 'jpeg' compression"
- raise ValueError(msg)
- ifd[JPEGQUALITY] = quality
-
- logger.debug("Saving using libtiff encoder")
- logger.debug("Items: %s" % sorted(ifd.items()))
- _fp = 0
- if hasattr(fp, "fileno"):
- try:
- fp.seek(0)
- _fp = os.dup(fp.fileno())
- except io.UnsupportedOperation:
- pass
-
- # optional types for non core tags
- types = {}
- # STRIPOFFSETS and STRIPBYTECOUNTS are added by the library
- # based on the data in the strip.
- # The other tags expect arrays with a certain length (fixed or depending on
- # BITSPERSAMPLE, etc), passing arrays with a different length will result in
- # segfaults. Block these tags until we add extra validation.
- # SUBIFD may also cause a segfault.
- blocklist += [
- REFERENCEBLACKWHITE,
- STRIPBYTECOUNTS,
- STRIPOFFSETS,
- TRANSFERFUNCTION,
- SUBIFD,
- ]
-
- # bits per sample is a single short in the tiff directory, not a list.
- atts = {BITSPERSAMPLE: bits[0]}
- # Merge the ones that we have with (optional) more bits from
- # the original file, e.g x,y resolution so that we can
- # save(load('')) == original file.
- legacy_ifd = {}
- if hasattr(im, "tag"):
- legacy_ifd = im.tag.to_v2()
-
- # SAMPLEFORMAT is determined by the image format and should not be copied
- # from legacy_ifd.
- supplied_tags = {**getattr(im, "tag_v2", {}), **legacy_ifd}
- if SAMPLEFORMAT in supplied_tags:
- del supplied_tags[SAMPLEFORMAT]
-
- for tag, value in itertools.chain(ifd.items(), supplied_tags.items()):
- # Libtiff can only process certain core items without adding
- # them to the custom dictionary.
- # Custom items are supported for int, float, unicode, string and byte
- # values. Other types and tuples require a tagtype.
- if tag not in TiffTags.LIBTIFF_CORE:
- if not getattr(Image.core, "libtiff_support_custom_tags", False):
- continue
-
- if tag in ifd.tagtype:
- types[tag] = ifd.tagtype[tag]
- elif not (isinstance(value, (int, float, str, bytes))):
- continue
- else:
- type = TiffTags.lookup(tag).type
- if type:
- types[tag] = type
- if tag not in atts and tag not in blocklist:
- if isinstance(value, str):
- atts[tag] = value.encode("ascii", "replace") + b"\0"
- elif isinstance(value, IFDRational):
- atts[tag] = float(value)
- else:
- atts[tag] = value
-
- if SAMPLEFORMAT in atts and len(atts[SAMPLEFORMAT]) == 1:
- atts[SAMPLEFORMAT] = atts[SAMPLEFORMAT][0]
-
- logger.debug("Converted items: %s" % sorted(atts.items()))
-
- # libtiff always expects the bytes in native order.
- # we're storing image byte order. So, if the rawmode
- # contains I;16, we need to convert from native to image
- # byte order.
- if im.mode in ("I;16B", "I;16"):
- rawmode = "I;16N"
-
- # Pass tags as sorted list so that the tags are set in a fixed order.
- # This is required by libtiff for some tags. For example, the JPEGQUALITY
- # pseudo tag requires that the COMPRESS tag was already set.
- tags = list(atts.items())
- tags.sort()
- a = (rawmode, compression, _fp, filename, tags, types)
- e = Image._getencoder(im.mode, "libtiff", a, encoderconfig)
- e.setimage(im.im, (0, 0) + im.size)
- while True:
- # undone, change to self.decodermaxblock:
- errcode, data = e.encode(16 * 1024)[1:]
- if not _fp:
- fp.write(data)
- if errcode:
- break
- if _fp:
- try:
- os.close(_fp)
- except OSError:
- pass
- if errcode < 0:
- msg = f"encoder error {errcode} when writing image file"
- raise OSError(msg)
-
- else:
- for tag in blocklist:
- del ifd[tag]
- offset = ifd.save(fp)
-
- ImageFile._save(
- im, fp, [("raw", (0, 0) + im.size, offset, (rawmode, stride, 1))]
- )
-
- # -- helper for multi-page save --
- if "_debug_multipage" in encoderinfo:
- # just to access o32 and o16 (using correct byte order)
- im._debug_multipage = ifd
-
-
-class AppendingTiffWriter:
- fieldSizes = [
- 0, # None
- 1, # byte
- 1, # ascii
- 2, # short
- 4, # long
- 8, # rational
- 1, # sbyte
- 1, # undefined
- 2, # sshort
- 4, # slong
- 8, # srational
- 4, # float
- 8, # double
- 4, # ifd
- 2, # unicode
- 4, # complex
- 8, # long8
- ]
-
- # StripOffsets = 273
- # FreeOffsets = 288
- # TileOffsets = 324
- # JPEGQTables = 519
- # JPEGDCTables = 520
- # JPEGACTables = 521
- Tags = {273, 288, 324, 519, 520, 521}
-
- def __init__(self, fn, new=False):
- if hasattr(fn, "read"):
- self.f = fn
- self.close_fp = False
- else:
- self.name = fn
- self.close_fp = True
- try:
- self.f = open(fn, "w+b" if new else "r+b")
- except OSError:
- self.f = open(fn, "w+b")
- self.beginning = self.f.tell()
- self.setup()
-
- def setup(self):
- # Reset everything.
- self.f.seek(self.beginning, os.SEEK_SET)
-
- self.whereToWriteNewIFDOffset = None
- self.offsetOfNewPage = 0
-
- self.IIMM = iimm = self.f.read(4)
- if not iimm:
- # empty file - first page
- self.isFirst = True
- return
-
- self.isFirst = False
- if iimm == b"II\x2a\x00":
- self.setEndian("<")
- elif iimm == b"MM\x00\x2a":
- self.setEndian(">")
- else:
- msg = "Invalid TIFF file header"
- raise RuntimeError(msg)
-
- self.skipIFDs()
- self.goToEnd()
-
- def finalize(self):
- if self.isFirst:
- return
-
- # fix offsets
- self.f.seek(self.offsetOfNewPage)
-
- iimm = self.f.read(4)
- if not iimm:
- # msg = "nothing written into new page"
- # raise RuntimeError(msg)
- # Make it easy to finish a frame without committing to a new one.
- return
-
- if iimm != self.IIMM:
- msg = "IIMM of new page doesn't match IIMM of first page"
- raise RuntimeError(msg)
-
- ifd_offset = self.readLong()
- ifd_offset += self.offsetOfNewPage
- self.f.seek(self.whereToWriteNewIFDOffset)
- self.writeLong(ifd_offset)
- self.f.seek(ifd_offset)
- self.fixIFD()
-
- def newFrame(self):
- # Call this to finish a frame.
- self.finalize()
- self.setup()
-
- def __enter__(self):
- return self
-
- def __exit__(self, exc_type, exc_value, traceback):
- if self.close_fp:
- self.close()
- return False
-
- def tell(self):
- return self.f.tell() - self.offsetOfNewPage
-
- def seek(self, offset, whence=io.SEEK_SET):
- if whence == os.SEEK_SET:
- offset += self.offsetOfNewPage
-
- self.f.seek(offset, whence)
- return self.tell()
-
- def goToEnd(self):
- self.f.seek(0, os.SEEK_END)
- pos = self.f.tell()
-
- # pad to 16 byte boundary
- pad_bytes = 16 - pos % 16
- if 0 < pad_bytes < 16:
- self.f.write(bytes(pad_bytes))
- self.offsetOfNewPage = self.f.tell()
-
- def setEndian(self, endian):
- self.endian = endian
- self.longFmt = self.endian + "L"
- self.shortFmt = self.endian + "H"
- self.tagFormat = self.endian + "HHL"
-
- def skipIFDs(self):
- while True:
- ifd_offset = self.readLong()
- if ifd_offset == 0:
- self.whereToWriteNewIFDOffset = self.f.tell() - 4
- break
-
- self.f.seek(ifd_offset)
- num_tags = self.readShort()
- self.f.seek(num_tags * 12, os.SEEK_CUR)
-
- def write(self, data):
- return self.f.write(data)
-
- def readShort(self):
- (value,) = struct.unpack(self.shortFmt, self.f.read(2))
- return value
-
- def readLong(self):
- (value,) = struct.unpack(self.longFmt, self.f.read(4))
- return value
-
- def rewriteLastShortToLong(self, value):
- self.f.seek(-2, os.SEEK_CUR)
- bytes_written = self.f.write(struct.pack(self.longFmt, value))
- if bytes_written is not None and bytes_written != 4:
- msg = f"wrote only {bytes_written} bytes but wanted 4"
- raise RuntimeError(msg)
-
- def rewriteLastShort(self, value):
- self.f.seek(-2, os.SEEK_CUR)
- bytes_written = self.f.write(struct.pack(self.shortFmt, value))
- if bytes_written is not None and bytes_written != 2:
- msg = f"wrote only {bytes_written} bytes but wanted 2"
- raise RuntimeError(msg)
-
- def rewriteLastLong(self, value):
- self.f.seek(-4, os.SEEK_CUR)
- bytes_written = self.f.write(struct.pack(self.longFmt, value))
- if bytes_written is not None and bytes_written != 4:
- msg = f"wrote only {bytes_written} bytes but wanted 4"
- raise RuntimeError(msg)
-
- def writeShort(self, value):
- bytes_written = self.f.write(struct.pack(self.shortFmt, value))
- if bytes_written is not None and bytes_written != 2:
- msg = f"wrote only {bytes_written} bytes but wanted 2"
- raise RuntimeError(msg)
-
- def writeLong(self, value):
- bytes_written = self.f.write(struct.pack(self.longFmt, value))
- if bytes_written is not None and bytes_written != 4:
- msg = f"wrote only {bytes_written} bytes but wanted 4"
- raise RuntimeError(msg)
-
- def close(self):
- self.finalize()
- self.f.close()
-
- def fixIFD(self):
- num_tags = self.readShort()
-
- for i in range(num_tags):
- tag, field_type, count = struct.unpack(self.tagFormat, self.f.read(8))
-
- field_size = self.fieldSizes[field_type]
- total_size = field_size * count
- is_local = total_size <= 4
- if not is_local:
- offset = self.readLong()
- offset += self.offsetOfNewPage
- self.rewriteLastLong(offset)
-
- if tag in self.Tags:
- cur_pos = self.f.tell()
-
- if is_local:
- self.fixOffsets(
- count, isShort=(field_size == 2), isLong=(field_size == 4)
- )
- self.f.seek(cur_pos + 4)
- else:
- self.f.seek(offset)
- self.fixOffsets(
- count, isShort=(field_size == 2), isLong=(field_size == 4)
- )
- self.f.seek(cur_pos)
-
- offset = cur_pos = None
-
- elif is_local:
- # skip the locally stored value that is not an offset
- self.f.seek(4, os.SEEK_CUR)
-
- def fixOffsets(self, count, isShort=False, isLong=False):
- if not isShort and not isLong:
- msg = "offset is neither short nor long"
- raise RuntimeError(msg)
-
- for i in range(count):
- offset = self.readShort() if isShort else self.readLong()
- offset += self.offsetOfNewPage
- if isShort and offset >= 65536:
- # offset is now too large - we must convert shorts to longs
- if count != 1:
- msg = "not implemented"
- raise RuntimeError(msg) # XXX TODO
-
- # simple case - the offset is just one and therefore it is
- # local (not referenced with another offset)
- self.rewriteLastShortToLong(offset)
- self.f.seek(-10, os.SEEK_CUR)
- self.writeShort(TiffTags.LONG) # rewrite the type to LONG
- self.f.seek(8, os.SEEK_CUR)
- elif isShort:
- self.rewriteLastShort(offset)
- else:
- self.rewriteLastLong(offset)
-
-
-def _save_all(im, fp, filename):
- encoderinfo = im.encoderinfo.copy()
- encoderconfig = im.encoderconfig
- append_images = list(encoderinfo.get("append_images", []))
- if not hasattr(im, "n_frames") and not append_images:
- return _save(im, fp, filename)
-
- cur_idx = im.tell()
- try:
- with AppendingTiffWriter(fp) as tf:
- for ims in [im] + append_images:
- ims.encoderinfo = encoderinfo
- ims.encoderconfig = encoderconfig
- if not hasattr(ims, "n_frames"):
- nfr = 1
- else:
- nfr = ims.n_frames
-
- for idx in range(nfr):
- ims.seek(idx)
- ims.load()
- _save(ims, tf, filename)
- tf.newFrame()
- finally:
- im.seek(cur_idx)
-
-
-#
-# --------------------------------------------------------------------
-# Register
-
-Image.register_open(TiffImageFile.format, TiffImageFile, _accept)
-Image.register_save(TiffImageFile.format, _save)
-Image.register_save_all(TiffImageFile.format, _save_all)
-
-Image.register_extensions(TiffImageFile.format, [".tif", ".tiff"])
-
-Image.register_mime(TiffImageFile.format, "image/tiff")
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fastapi/middleware/trustedhost.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fastapi/middleware/trustedhost.py
deleted file mode 100644
index 08d7e035315677856fd2cd0be2044689b57619bf..0000000000000000000000000000000000000000
--- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fastapi/middleware/trustedhost.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from starlette.middleware.trustedhost import ( # noqa
- TrustedHostMiddleware as TrustedHostMiddleware,
-)
diff --git a/spaces/jonathanmg96/TFG-YOLOP/README.md b/spaces/jonathanmg96/TFG-YOLOP/README.md
deleted file mode 100644
index 864e2aadc977bc304042a4133657cd6429a50cb8..0000000000000000000000000000000000000000
--- a/spaces/jonathanmg96/TFG-YOLOP/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: TFG YOLOP
-emoji: 🔥
-colorFrom: green
-colorTo: purple
-sdk: gradio
-sdk_version: 3.1.4
-app_file: app.py
-pinned: false
-license: gpl-3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/jordonpeter01/MusicGen/audiocraft/modules/seanet.py b/spaces/jordonpeter01/MusicGen/audiocraft/modules/seanet.py
deleted file mode 100644
index 3e5998e9153afb6e68ea410d565e00ea835db248..0000000000000000000000000000000000000000
--- a/spaces/jordonpeter01/MusicGen/audiocraft/modules/seanet.py
+++ /dev/null
@@ -1,258 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import typing as tp
-
-import numpy as np
-import torch.nn as nn
-
-from .conv import StreamableConv1d, StreamableConvTranspose1d
-from .lstm import StreamableLSTM
-
-
-class SEANetResnetBlock(nn.Module):
- """Residual block from SEANet model.
-
- Args:
- dim (int): Dimension of the input/output.
- kernel_sizes (list): List of kernel sizes for the convolutions.
- dilations (list): List of dilations for the convolutions.
- activation (str): Activation function.
- activation_params (dict): Parameters to provide to the activation function.
- norm (str): Normalization method.
- norm_params (dict): Parameters to provide to the underlying normalization used along with the convolution.
- causal (bool): Whether to use fully causal convolution.
- pad_mode (str): Padding mode for the convolutions.
- compress (int): Reduced dimensionality in residual branches (from Demucs v3).
- true_skip (bool): Whether to use true skip connection or a simple
- (streamable) convolution as the skip connection.
- """
- def __init__(self, dim: int, kernel_sizes: tp.List[int] = [3, 1], dilations: tp.List[int] = [1, 1],
- activation: str = 'ELU', activation_params: dict = {'alpha': 1.0},
- norm: str = 'none', norm_params: tp.Dict[str, tp.Any] = {}, causal: bool = False,
- pad_mode: str = 'reflect', compress: int = 2, true_skip: bool = True):
- super().__init__()
- assert len(kernel_sizes) == len(dilations), 'Number of kernel sizes should match number of dilations'
- act = getattr(nn, activation)
- hidden = dim // compress
- block = []
- for i, (kernel_size, dilation) in enumerate(zip(kernel_sizes, dilations)):
- in_chs = dim if i == 0 else hidden
- out_chs = dim if i == len(kernel_sizes) - 1 else hidden
- block += [
- act(**activation_params),
- StreamableConv1d(in_chs, out_chs, kernel_size=kernel_size, dilation=dilation,
- norm=norm, norm_kwargs=norm_params,
- causal=causal, pad_mode=pad_mode),
- ]
- self.block = nn.Sequential(*block)
- self.shortcut: nn.Module
- if true_skip:
- self.shortcut = nn.Identity()
- else:
- self.shortcut = StreamableConv1d(dim, dim, kernel_size=1, norm=norm, norm_kwargs=norm_params,
- causal=causal, pad_mode=pad_mode)
-
- def forward(self, x):
- return self.shortcut(x) + self.block(x)
-
-
-class SEANetEncoder(nn.Module):
- """SEANet encoder.
-
- Args:
- channels (int): Audio channels.
- dimension (int): Intermediate representation dimension.
- n_filters (int): Base width for the model.
- n_residual_layers (int): nb of residual layers.
- ratios (Sequence[int]): kernel size and stride ratios. The encoder uses downsampling ratios instead of
- upsampling ratios, hence it will use the ratios in the reverse order to the ones specified here
- that must match the decoder order. We use the decoder order as some models may only employ the decoder.
- activation (str): Activation function.
- activation_params (dict): Parameters to provide to the activation function.
- norm (str): Normalization method.
- norm_params (dict): Parameters to provide to the underlying normalization used along with the convolution.
- kernel_size (int): Kernel size for the initial convolution.
- last_kernel_size (int): Kernel size for the initial convolution.
- residual_kernel_size (int): Kernel size for the residual layers.
- dilation_base (int): How much to increase the dilation with each layer.
- causal (bool): Whether to use fully causal convolution.
- pad_mode (str): Padding mode for the convolutions.
- true_skip (bool): Whether to use true skip connection or a simple
- (streamable) convolution as the skip connection in the residual network blocks.
- compress (int): Reduced dimensionality in residual branches (from Demucs v3).
- lstm (int): Number of LSTM layers at the end of the encoder.
- disable_norm_outer_blocks (int): Number of blocks for which we don't apply norm.
- For the encoder, it corresponds to the N first blocks.
- """
- def __init__(self, channels: int = 1, dimension: int = 128, n_filters: int = 32, n_residual_layers: int = 3,
- ratios: tp.List[int] = [8, 5, 4, 2], activation: str = 'ELU', activation_params: dict = {'alpha': 1.0},
- norm: str = 'none', norm_params: tp.Dict[str, tp.Any] = {}, kernel_size: int = 7,
- last_kernel_size: int = 7, residual_kernel_size: int = 3, dilation_base: int = 2, causal: bool = False,
- pad_mode: str = 'reflect', true_skip: bool = True, compress: int = 2, lstm: int = 0,
- disable_norm_outer_blocks: int = 0):
- super().__init__()
- self.channels = channels
- self.dimension = dimension
- self.n_filters = n_filters
- self.ratios = list(reversed(ratios))
- del ratios
- self.n_residual_layers = n_residual_layers
- self.hop_length = np.prod(self.ratios)
- self.n_blocks = len(self.ratios) + 2 # first and last conv + residual blocks
- self.disable_norm_outer_blocks = disable_norm_outer_blocks
- assert self.disable_norm_outer_blocks >= 0 and self.disable_norm_outer_blocks <= self.n_blocks, \
- "Number of blocks for which to disable norm is invalid." \
- "It should be lower or equal to the actual number of blocks in the network and greater or equal to 0."
-
- act = getattr(nn, activation)
- mult = 1
- model: tp.List[nn.Module] = [
- StreamableConv1d(channels, mult * n_filters, kernel_size,
- norm='none' if self.disable_norm_outer_blocks >= 1 else norm,
- norm_kwargs=norm_params, causal=causal, pad_mode=pad_mode)
- ]
- # Downsample to raw audio scale
- for i, ratio in enumerate(self.ratios):
- block_norm = 'none' if self.disable_norm_outer_blocks >= i + 2 else norm
- # Add residual layers
- for j in range(n_residual_layers):
- model += [
- SEANetResnetBlock(mult * n_filters, kernel_sizes=[residual_kernel_size, 1],
- dilations=[dilation_base ** j, 1],
- norm=block_norm, norm_params=norm_params,
- activation=activation, activation_params=activation_params,
- causal=causal, pad_mode=pad_mode, compress=compress, true_skip=true_skip)]
-
- # Add downsampling layers
- model += [
- act(**activation_params),
- StreamableConv1d(mult * n_filters, mult * n_filters * 2,
- kernel_size=ratio * 2, stride=ratio,
- norm=block_norm, norm_kwargs=norm_params,
- causal=causal, pad_mode=pad_mode),
- ]
- mult *= 2
-
- if lstm:
- model += [StreamableLSTM(mult * n_filters, num_layers=lstm)]
-
- model += [
- act(**activation_params),
- StreamableConv1d(mult * n_filters, dimension, last_kernel_size,
- norm='none' if self.disable_norm_outer_blocks == self.n_blocks else norm,
- norm_kwargs=norm_params, causal=causal, pad_mode=pad_mode)
- ]
-
- self.model = nn.Sequential(*model)
-
- def forward(self, x):
- return self.model(x)
-
-
-class SEANetDecoder(nn.Module):
- """SEANet decoder.
-
- Args:
- channels (int): Audio channels.
- dimension (int): Intermediate representation dimension.
- n_filters (int): Base width for the model.
- n_residual_layers (int): nb of residual layers.
- ratios (Sequence[int]): kernel size and stride ratios.
- activation (str): Activation function.
- activation_params (dict): Parameters to provide to the activation function.
- final_activation (str): Final activation function after all convolutions.
- final_activation_params (dict): Parameters to provide to the activation function.
- norm (str): Normalization method.
- norm_params (dict): Parameters to provide to the underlying normalization used along with the convolution.
- kernel_size (int): Kernel size for the initial convolution.
- last_kernel_size (int): Kernel size for the initial convolution.
- residual_kernel_size (int): Kernel size for the residual layers.
- dilation_base (int): How much to increase the dilation with each layer.
- causal (bool): Whether to use fully causal convolution.
- pad_mode (str): Padding mode for the convolutions.
- true_skip (bool): Whether to use true skip connection or a simple.
- (streamable) convolution as the skip connection in the residual network blocks.
- compress (int): Reduced dimensionality in residual branches (from Demucs v3).
- lstm (int): Number of LSTM layers at the end of the encoder.
- disable_norm_outer_blocks (int): Number of blocks for which we don't apply norm.
- For the decoder, it corresponds to the N last blocks.
- trim_right_ratio (float): Ratio for trimming at the right of the transposed convolution under the causal setup.
- If equal to 1.0, it means that all the trimming is done at the right.
- """
- def __init__(self, channels: int = 1, dimension: int = 128, n_filters: int = 32, n_residual_layers: int = 3,
- ratios: tp.List[int] = [8, 5, 4, 2], activation: str = 'ELU', activation_params: dict = {'alpha': 1.0},
- final_activation: tp.Optional[str] = None, final_activation_params: tp.Optional[dict] = None,
- norm: str = 'none', norm_params: tp.Dict[str, tp.Any] = {}, kernel_size: int = 7,
- last_kernel_size: int = 7, residual_kernel_size: int = 3, dilation_base: int = 2, causal: bool = False,
- pad_mode: str = 'reflect', true_skip: bool = True, compress: int = 2, lstm: int = 0,
- disable_norm_outer_blocks: int = 0, trim_right_ratio: float = 1.0):
- super().__init__()
- self.dimension = dimension
- self.channels = channels
- self.n_filters = n_filters
- self.ratios = ratios
- del ratios
- self.n_residual_layers = n_residual_layers
- self.hop_length = np.prod(self.ratios)
- self.n_blocks = len(self.ratios) + 2 # first and last conv + residual blocks
- self.disable_norm_outer_blocks = disable_norm_outer_blocks
- assert self.disable_norm_outer_blocks >= 0 and self.disable_norm_outer_blocks <= self.n_blocks, \
- "Number of blocks for which to disable norm is invalid." \
- "It should be lower or equal to the actual number of blocks in the network and greater or equal to 0."
-
- act = getattr(nn, activation)
- mult = int(2 ** len(self.ratios))
- model: tp.List[nn.Module] = [
- StreamableConv1d(dimension, mult * n_filters, kernel_size,
- norm='none' if self.disable_norm_outer_blocks == self.n_blocks else norm,
- norm_kwargs=norm_params, causal=causal, pad_mode=pad_mode)
- ]
-
- if lstm:
- model += [StreamableLSTM(mult * n_filters, num_layers=lstm)]
-
- # Upsample to raw audio scale
- for i, ratio in enumerate(self.ratios):
- block_norm = 'none' if self.disable_norm_outer_blocks >= self.n_blocks - (i + 1) else norm
- # Add upsampling layers
- model += [
- act(**activation_params),
- StreamableConvTranspose1d(mult * n_filters, mult * n_filters // 2,
- kernel_size=ratio * 2, stride=ratio,
- norm=block_norm, norm_kwargs=norm_params,
- causal=causal, trim_right_ratio=trim_right_ratio),
- ]
- # Add residual layers
- for j in range(n_residual_layers):
- model += [
- SEANetResnetBlock(mult * n_filters // 2, kernel_sizes=[residual_kernel_size, 1],
- dilations=[dilation_base ** j, 1],
- activation=activation, activation_params=activation_params,
- norm=block_norm, norm_params=norm_params, causal=causal,
- pad_mode=pad_mode, compress=compress, true_skip=true_skip)]
-
- mult //= 2
-
- # Add final layers
- model += [
- act(**activation_params),
- StreamableConv1d(n_filters, channels, last_kernel_size,
- norm='none' if self.disable_norm_outer_blocks >= 1 else norm,
- norm_kwargs=norm_params, causal=causal, pad_mode=pad_mode)
- ]
- # Add optional final activation to decoder (eg. tanh)
- if final_activation is not None:
- final_act = getattr(nn, final_activation)
- final_activation_params = final_activation_params or {}
- model += [
- final_act(**final_activation_params)
- ]
- self.model = nn.Sequential(*model)
-
- def forward(self, z):
- y = self.model(z)
- return y
diff --git a/spaces/jsxyhelu/skyseg/unet/u2net_refactor.py b/spaces/jsxyhelu/skyseg/unet/u2net_refactor.py
deleted file mode 100644
index e668de2c2bc67cbef280eaa5f789c762c4745fa4..0000000000000000000000000000000000000000
--- a/spaces/jsxyhelu/skyseg/unet/u2net_refactor.py
+++ /dev/null
@@ -1,168 +0,0 @@
-import torch
-import torch.nn as nn
-
-import math
-
-__all__ = ['U2NET_full', 'U2NET_lite']
-
-
-def _upsample_like(x, size):
- return nn.Upsample(size=size, mode='bilinear', align_corners=False)(x)
-
-
-def _size_map(x, height):
- # {height: size} for Upsample
- size = list(x.shape[-2:])
- sizes = {}
- for h in range(1, height):
- sizes[h] = size
- size = [math.ceil(w / 2) for w in size]
- return sizes
-
-
-class REBNCONV(nn.Module):
- def __init__(self, in_ch=3, out_ch=3, dilate=1):
- super(REBNCONV, self).__init__()
-
- self.conv_s1 = nn.Conv2d(in_ch, out_ch, 3, padding=1 * dilate, dilation=1 * dilate)
- self.bn_s1 = nn.BatchNorm2d(out_ch)
- self.relu_s1 = nn.ReLU(inplace=True)
-
- def forward(self, x):
- return self.relu_s1(self.bn_s1(self.conv_s1(x)))
-
-
-class RSU(nn.Module):
- def __init__(self, name, height, in_ch, mid_ch, out_ch, dilated=False):
- super(RSU, self).__init__()
- self.name = name
- self.height = height
- self.dilated = dilated
- self._make_layers(height, in_ch, mid_ch, out_ch, dilated)
-
- def forward(self, x):
- sizes = _size_map(x, self.height)
- x = self.rebnconvin(x)
-
- # U-Net like symmetric encoder-decoder structure
- def unet(x, height=1):
- if height < self.height:
- x1 = getattr(self, f'rebnconv{height}')(x)
- if not self.dilated and height < self.height - 1:
- x2 = unet(getattr(self, 'downsample')(x1), height + 1)
- else:
- x2 = unet(x1, height + 1)
-
- x = getattr(self, f'rebnconv{height}d')(torch.cat((x2, x1), 1))
- return _upsample_like(x, sizes[height - 1]) if not self.dilated and height > 1 else x
- else:
- return getattr(self, f'rebnconv{height}')(x)
-
- return x + unet(x)
-
- def _make_layers(self, height, in_ch, mid_ch, out_ch, dilated=False):
- self.add_module('rebnconvin', REBNCONV(in_ch, out_ch))
- self.add_module('downsample', nn.MaxPool2d(2, stride=2, ceil_mode=True))
-
- self.add_module(f'rebnconv1', REBNCONV(out_ch, mid_ch))
- self.add_module(f'rebnconv1d', REBNCONV(mid_ch * 2, out_ch))
-
- for i in range(2, height):
- dilate = 1 if not dilated else 2 ** (i - 1)
- self.add_module(f'rebnconv{i}', REBNCONV(mid_ch, mid_ch, dilate=dilate))
- self.add_module(f'rebnconv{i}d', REBNCONV(mid_ch * 2, mid_ch, dilate=dilate))
-
- dilate = 2 if not dilated else 2 ** (height - 1)
- self.add_module(f'rebnconv{height}', REBNCONV(mid_ch, mid_ch, dilate=dilate))
-
-
-class U2NET(nn.Module):
- def __init__(self, cfgs, out_ch):
- super(U2NET, self).__init__()
- self.out_ch = out_ch
- self._make_layers(cfgs)
-
- def forward(self, x):
- sizes = _size_map(x, self.height)
- maps = [] # storage for maps
-
- # side saliency map
- def unet(x, height=1):
- if height < 6:
- x1 = getattr(self, f'stage{height}')(x)
- x2 = unet(getattr(self, 'downsample')(x1), height + 1)
- x = getattr(self, f'stage{height}d')(torch.cat((x2, x1), 1))
- side(x, height)
- return _upsample_like(x, sizes[height - 1]) if height > 1 else x
- else:
- x = getattr(self, f'stage{height}')(x)
- side(x, height)
- return _upsample_like(x, sizes[height - 1])
-
- def side(x, h):
- # side output saliency map (before sigmoid)
- x = getattr(self, f'side{h}')(x)
- x = _upsample_like(x, sizes[1])
- maps.append(x)
-
- def fuse():
- # fuse saliency probability maps
- maps.reverse()
- x = torch.cat(maps, 1)
- x = getattr(self, 'outconv')(x)
- maps.insert(0, x)
- return [torch.sigmoid(x) for x in maps]
-
- unet(x)
- maps = fuse()
- return maps
-
- def _make_layers(self, cfgs):
- self.height = int((len(cfgs) + 1) / 2)
- self.add_module('downsample', nn.MaxPool2d(2, stride=2, ceil_mode=True))
- for k, v in cfgs.items():
- # build rsu block
- self.add_module(k, RSU(v[0], *v[1]))
- if v[2] > 0:
- # build side layer
- self.add_module(f'side{v[0][-1]}', nn.Conv2d(v[2], self.out_ch, 3, padding=1))
- # build fuse layer
- self.add_module('outconv', nn.Conv2d(int(self.height * self.out_ch), self.out_ch, 1))
-
-
-def U2NET_full():
- full = {
- # cfgs for building RSUs and sides
- # {stage : [name, (height(L), in_ch, mid_ch, out_ch, dilated), side]}
- 'stage1': ['En_1', (7, 3, 32, 64), -1],
- 'stage2': ['En_2', (6, 64, 32, 128), -1],
- 'stage3': ['En_3', (5, 128, 64, 256), -1],
- 'stage4': ['En_4', (4, 256, 128, 512), -1],
- 'stage5': ['En_5', (4, 512, 256, 512, True), -1],
- 'stage6': ['En_6', (4, 512, 256, 512, True), 512],
- 'stage5d': ['De_5', (4, 1024, 256, 512, True), 512],
- 'stage4d': ['De_4', (4, 1024, 128, 256), 256],
- 'stage3d': ['De_3', (5, 512, 64, 128), 128],
- 'stage2d': ['De_2', (6, 256, 32, 64), 64],
- 'stage1d': ['De_1', (7, 128, 16, 64), 64],
- }
- return U2NET(cfgs=full, out_ch=1)
-
-
-def U2NET_lite():
- lite = {
- # cfgs for building RSUs and sides
- # {stage : [name, (height(L), in_ch, mid_ch, out_ch, dilated), side]}
- 'stage1': ['En_1', (7, 3, 16, 64), -1],
- 'stage2': ['En_2', (6, 64, 16, 64), -1],
- 'stage3': ['En_3', (5, 64, 16, 64), -1],
- 'stage4': ['En_4', (4, 64, 16, 64), -1],
- 'stage5': ['En_5', (4, 64, 16, 64, True), -1],
- 'stage6': ['En_6', (4, 64, 16, 64, True), 64],
- 'stage5d': ['De_5', (4, 128, 16, 64, True), 64],
- 'stage4d': ['De_4', (4, 128, 16, 64), 64],
- 'stage3d': ['De_3', (5, 128, 16, 64), 64],
- 'stage2d': ['De_2', (6, 128, 16, 64), 64],
- 'stage1d': ['De_1', (7, 128, 16, 64), 64],
- }
- return U2NET(cfgs=lite, out_ch=1)
diff --git a/spaces/jvcanavarro/traits-prediction/README.md b/spaces/jvcanavarro/traits-prediction/README.md
deleted file mode 100644
index a290f00b43a271689fdd536bd3edf945a66dd27b..0000000000000000000000000000000000000000
--- a/spaces/jvcanavarro/traits-prediction/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Trait Recognition
-emoji: 👁
-colorFrom: blue
-colorTo: purple
-sdk: gradio
-sdk_version: 3.18.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/kidcoconut/spcdkr_omdenasaudi_liverhccxai/uix/lit_sidebar.py b/spaces/kidcoconut/spcdkr_omdenasaudi_liverhccxai/uix/lit_sidebar.py
deleted file mode 100644
index 4dcf6910f3c0e1688ce1d00ee4146df1ba81f536..0000000000000000000000000000000000000000
--- a/spaces/kidcoconut/spcdkr_omdenasaudi_liverhccxai/uix/lit_sidebar.py
+++ /dev/null
@@ -1,43 +0,0 @@
-import streamlit as st
-import importlib
-from uix import lit_packages
-
-from uix.pages import lit_home, lit_about, lit_diagnosis
-from uix.pages import lit_qaConfigCheck
-
-m_kblnTraceOn=False
-
-
-#--- alt define sidebar pages
-m_aryPages = {
- "Home": lit_home, #--- TODO: update
- "Diagnosis: Single Tile": lit_diagnosis,
- #"QA: File Check": lit_qaConfigCheck,
- "About": lit_about
-}
-
-
-#--- define module-level vars
-m_aryModNames = lit_packages.packages()
-m_aryDescr = []
-m_aryMods = []
-
-
-def init():
- #--- upper panel
- with st.sidebar:
- kstrUrl_image = "bin/images/logo_omdena_saudi.png"
- st.sidebar.image(kstrUrl_image, width=200)
-
- #--- get radio selection
- strKey = st.sidebar.radio("rdoPageSel", list(m_aryPages.keys()), label_visibility="hidden")
- pagSel = m_aryPages[strKey]
- writePage(pagSel)
-
-
-def writePage(uixFile):
- #--- writes out the page for the selected combo
-
- # _reload_module(page)
- uixFile.run()
-
diff --git a/spaces/kira4424/Tacotron-zero-short-voice-clone/pre.py b/spaces/kira4424/Tacotron-zero-short-voice-clone/pre.py
deleted file mode 100644
index 17fd0f710153bfb71b717678998a853e364c8cd8..0000000000000000000000000000000000000000
--- a/spaces/kira4424/Tacotron-zero-short-voice-clone/pre.py
+++ /dev/null
@@ -1,76 +0,0 @@
-from synthesizer.preprocess import create_embeddings
-from utils.argutils import print_args
-from pathlib import Path
-import argparse
-
-from synthesizer.preprocess import preprocess_dataset
-from synthesizer.hparams import hparams
-from utils.argutils import print_args
-from pathlib import Path
-import argparse
-
-recognized_datasets = [
- "aidatatang_200zh",
- "magicdata",
- "aishell3",
- "data_aishell"
-]
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(
- description="Preprocesses audio files from datasets, encodes them as mel spectrograms "
- "and writes them to the disk. Audio files are also saved, to be used by the "
- "vocoder for training.",
- formatter_class=argparse.ArgumentDefaultsHelpFormatter
- )
- parser.add_argument("datasets_root", type=Path, help=\
- "Path to the directory containing your datasets.")
- parser.add_argument("-o", "--out_dir", type=Path, default=argparse.SUPPRESS, help=\
- "Path to the output directory that will contain the mel spectrograms, the audios and the "
- "embeds. Defaults to /SV2TTS/synthesizer/")
- parser.add_argument("-n", "--n_processes", type=int, default=1, help=\
- "Number of processes in parallel.")
- parser.add_argument("-s", "--skip_existing", action="store_true", help=\
- "Whether to overwrite existing files with the same name. Useful if the preprocessing was "
- "interrupted. ")
- parser.add_argument("--hparams", type=str, default="", help=\
- "Hyperparameter overrides as a comma-separated list of name-value pairs")
- parser.add_argument("--no_trim", action="store_true", help=\
- "Preprocess audio without trimming silences (not recommended).")
- parser.add_argument("--no_alignments", action="store_true", help=\
- "Use this option when dataset does not include alignments\
- (these are used to split long audio files into sub-utterances.)")
- parser.add_argument("-d", "--dataset", type=str, default="aidatatang_200zh", help=\
- "Name of the dataset to process, allowing values: magicdata, aidatatang_200zh, aishell3, data_aishell.")
- parser.add_argument("-e", "--encoder_model_fpath", type=Path, default="encoder/saved_models/pretrained.pt", help=\
- "Path your trained encoder model.")
- parser.add_argument("-ne", "--n_processes_embed", type=int, default=1, help=\
- "Number of processes in parallel.An encoder is created for each, so you may need to lower "
- "this value on GPUs with low memory. Set it to 1 if CUDA is unhappy")
- args = parser.parse_args()
-
- # Process the arguments
- if not hasattr(args, "out_dir"):
- args.out_dir = args.datasets_root.joinpath("SV2TTS", "synthesizer")
- assert args.dataset in recognized_datasets, 'is not supported, please vote for it in https://github.com/babysor/MockingBird/issues/10'
- # Create directories
- assert args.datasets_root.exists()
- args.out_dir.mkdir(exist_ok=True, parents=True)
-
- # Verify webrtcvad is available
- if not args.no_trim:
- try:
- import webrtcvad
- except:
- raise ModuleNotFoundError("Package 'webrtcvad' not found. This package enables "
- "noise removal and is recommended. Please install and try again. If installation fails, "
- "use --no_trim to disable this error message.")
- encoder_model_fpath = args.encoder_model_fpath
- del args.no_trim, args.encoder_model_fpath
-
- args.hparams = hparams.parse(args.hparams)
- n_processes_embed = args.n_processes_embed
- del args.n_processes_embed
- preprocess_dataset(**vars(args))
-
- create_embeddings(synthesizer_root=args.out_dir, n_processes=n_processes_embed, encoder_model_fpath=encoder_model_fpath)
diff --git a/spaces/koyomimi/Real-CUGAN/upcunet_v3.py b/spaces/koyomimi/Real-CUGAN/upcunet_v3.py
deleted file mode 100644
index f7919a6cc9efe3b8af73a73e30825a4c7d7d76da..0000000000000000000000000000000000000000
--- a/spaces/koyomimi/Real-CUGAN/upcunet_v3.py
+++ /dev/null
@@ -1,714 +0,0 @@
-import torch
-from torch import nn as nn
-from torch.nn import functional as F
-import os, sys
-import numpy as np
-
-root_path = os.path.abspath('.')
-sys.path.append(root_path)
-
-
-class SEBlock(nn.Module):
- def __init__(self, in_channels, reduction=8, bias=False):
- super(SEBlock, self).__init__()
- self.conv1 = nn.Conv2d(in_channels, in_channels // reduction, 1, 1, 0, bias=bias)
- self.conv2 = nn.Conv2d(in_channels // reduction, in_channels, 1, 1, 0, bias=bias)
-
- def forward(self, x):
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- x0 = torch.mean(x.float(), dim=(2, 3), keepdim=True).half()
- else:
- x0 = torch.mean(x, dim=(2, 3), keepdim=True)
- x0 = self.conv1(x0)
- x0 = F.relu(x0, inplace=True)
- x0 = self.conv2(x0)
- x0 = torch.sigmoid(x0)
- x = torch.mul(x, x0)
- return x
-
- def forward_mean(self, x, x0):
- x0 = self.conv1(x0)
- x0 = F.relu(x0, inplace=True)
- x0 = self.conv2(x0)
- x0 = torch.sigmoid(x0)
- x = torch.mul(x, x0)
- return x
-
-
-class UNetConv(nn.Module):
- def __init__(self, in_channels, mid_channels, out_channels, se):
- super(UNetConv, self).__init__()
- self.conv = nn.Sequential(
- nn.Conv2d(in_channels, mid_channels, 3, 1, 0),
- nn.LeakyReLU(0.1, inplace=True),
- nn.Conv2d(mid_channels, out_channels, 3, 1, 0),
- nn.LeakyReLU(0.1, inplace=True),
- )
- if se:
- self.seblock = SEBlock(out_channels, reduction=8, bias=True)
- else:
- self.seblock = None
-
- def forward(self, x):
- z = self.conv(x)
- if self.seblock is not None:
- z = self.seblock(z)
- return z
-
-
-class UNet1(nn.Module):
- def __init__(self, in_channels, out_channels, deconv):
- super(UNet1, self).__init__()
- self.conv1 = UNetConv(in_channels, 32, 64, se=False)
- self.conv1_down = nn.Conv2d(64, 64, 2, 2, 0)
- self.conv2 = UNetConv(64, 128, 64, se=True)
- self.conv2_up = nn.ConvTranspose2d(64, 64, 2, 2, 0)
- self.conv3 = nn.Conv2d(64, 64, 3, 1, 0)
-
- if deconv:
- self.conv_bottom = nn.ConvTranspose2d(64, out_channels, 4, 2, 3)
- else:
- self.conv_bottom = nn.Conv2d(64, out_channels, 3, 1, 0)
-
- for m in self.modules():
- if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
- nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
- elif isinstance(m, nn.Linear):
- nn.init.normal_(m.weight, 0, 0.01)
- if m.bias is not None:
- nn.init.constant_(m.bias, 0)
-
- def forward(self, x):
- x1 = self.conv1(x)
- x2 = self.conv1_down(x1)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
- x2 = self.conv2(x2)
- x2 = self.conv2_up(x2)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
-
- x1 = F.pad(x1, (-4, -4, -4, -4))
- x3 = self.conv3(x1 + x2)
- x3 = F.leaky_relu(x3, 0.1, inplace=True)
- z = self.conv_bottom(x3)
- return z
-
- def forward_a(self, x):
- x1 = self.conv1(x)
- x2 = self.conv1_down(x1)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
- x2 = self.conv2.conv(x2)
- return x1, x2
-
- def forward_b(self, x1, x2):
- x2 = self.conv2_up(x2)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
-
- x1 = F.pad(x1, (-4, -4, -4, -4))
- x3 = self.conv3(x1 + x2)
- x3 = F.leaky_relu(x3, 0.1, inplace=True)
- z = self.conv_bottom(x3)
- return z
-
-
-class UNet1x3(nn.Module):
- def __init__(self, in_channels, out_channels, deconv):
- super(UNet1x3, self).__init__()
- self.conv1 = UNetConv(in_channels, 32, 64, se=False)
- self.conv1_down = nn.Conv2d(64, 64, 2, 2, 0)
- self.conv2 = UNetConv(64, 128, 64, se=True)
- self.conv2_up = nn.ConvTranspose2d(64, 64, 2, 2, 0)
- self.conv3 = nn.Conv2d(64, 64, 3, 1, 0)
-
- if deconv:
- self.conv_bottom = nn.ConvTranspose2d(64, out_channels, 5, 3, 2)
- else:
- self.conv_bottom = nn.Conv2d(64, out_channels, 3, 1, 0)
-
- for m in self.modules():
- if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
- nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
- elif isinstance(m, nn.Linear):
- nn.init.normal_(m.weight, 0, 0.01)
- if m.bias is not None:
- nn.init.constant_(m.bias, 0)
-
- def forward(self, x):
- x1 = self.conv1(x)
- x2 = self.conv1_down(x1)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
- x2 = self.conv2(x2)
- x2 = self.conv2_up(x2)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
-
- x1 = F.pad(x1, (-4, -4, -4, -4))
- x3 = self.conv3(x1 + x2)
- x3 = F.leaky_relu(x3, 0.1, inplace=True)
- z = self.conv_bottom(x3)
- return z
-
- def forward_a(self, x):
- x1 = self.conv1(x)
- x2 = self.conv1_down(x1)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
- x2 = self.conv2.conv(x2)
- return x1, x2
-
- def forward_b(self, x1, x2):
- x2 = self.conv2_up(x2)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
-
- x1 = F.pad(x1, (-4, -4, -4, -4))
- x3 = self.conv3(x1 + x2)
- x3 = F.leaky_relu(x3, 0.1, inplace=True)
- z = self.conv_bottom(x3)
- return z
-
-
-class UNet2(nn.Module):
- def __init__(self, in_channels, out_channels, deconv):
- super(UNet2, self).__init__()
-
- self.conv1 = UNetConv(in_channels, 32, 64, se=False)
- self.conv1_down = nn.Conv2d(64, 64, 2, 2, 0)
- self.conv2 = UNetConv(64, 64, 128, se=True)
- self.conv2_down = nn.Conv2d(128, 128, 2, 2, 0)
- self.conv3 = UNetConv(128, 256, 128, se=True)
- self.conv3_up = nn.ConvTranspose2d(128, 128, 2, 2, 0)
- self.conv4 = UNetConv(128, 64, 64, se=True)
- self.conv4_up = nn.ConvTranspose2d(64, 64, 2, 2, 0)
- self.conv5 = nn.Conv2d(64, 64, 3, 1, 0)
-
- if deconv:
- self.conv_bottom = nn.ConvTranspose2d(64, out_channels, 4, 2, 3)
- else:
- self.conv_bottom = nn.Conv2d(64, out_channels, 3, 1, 0)
-
- for m in self.modules():
- if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
- nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
- elif isinstance(m, nn.Linear):
- nn.init.normal_(m.weight, 0, 0.01)
- if m.bias is not None:
- nn.init.constant_(m.bias, 0)
-
- def forward(self, x):
- x1 = self.conv1(x)
- x2 = self.conv1_down(x1)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
- x2 = self.conv2(x2)
-
- x3 = self.conv2_down(x2)
- x3 = F.leaky_relu(x3, 0.1, inplace=True)
- x3 = self.conv3(x3)
- x3 = self.conv3_up(x3)
- x3 = F.leaky_relu(x3, 0.1, inplace=True)
-
- x2 = F.pad(x2, (-4, -4, -4, -4))
- x4 = self.conv4(x2 + x3)
- x4 = self.conv4_up(x4)
- x4 = F.leaky_relu(x4, 0.1, inplace=True)
-
- x1 = F.pad(x1, (-16, -16, -16, -16))
- x5 = self.conv5(x1 + x4)
- x5 = F.leaky_relu(x5, 0.1, inplace=True)
-
- z = self.conv_bottom(x5)
- return z
-
- def forward_a(self, x): # conv234结尾有se
- x1 = self.conv1(x)
- x2 = self.conv1_down(x1)
- x2 = F.leaky_relu(x2, 0.1, inplace=True)
- x2 = self.conv2.conv(x2)
- return x1, x2
-
- def forward_b(self, x2): # conv234结尾有se
- x3 = self.conv2_down(x2)
- x3 = F.leaky_relu(x3, 0.1, inplace=True)
- x3 = self.conv3.conv(x3)
- return x3
-
- def forward_c(self, x2, x3): # conv234结尾有se
- x3 = self.conv3_up(x3)
- x3 = F.leaky_relu(x3, 0.1, inplace=True)
-
- x2 = F.pad(x2, (-4, -4, -4, -4))
- x4 = self.conv4.conv(x2 + x3)
- return x4
-
- def forward_d(self, x1, x4): # conv234结尾有se
- x4 = self.conv4_up(x4)
- x4 = F.leaky_relu(x4, 0.1, inplace=True)
-
- x1 = F.pad(x1, (-16, -16, -16, -16))
- x5 = self.conv5(x1 + x4)
- x5 = F.leaky_relu(x5, 0.1, inplace=True)
-
- z = self.conv_bottom(x5)
- return z
-
-
-class UpCunet2x(nn.Module): # 完美tile,全程无损
- def __init__(self, in_channels=3, out_channels=3):
- super(UpCunet2x, self).__init__()
- self.unet1 = UNet1(in_channels, out_channels, deconv=True)
- self.unet2 = UNet2(in_channels, out_channels, deconv=False)
-
- def forward(self, x, tile_mode): # 1.7G
- n, c, h0, w0 = x.shape
- if (tile_mode == 0): # 不tile
- ph = ((h0 - 1) // 2 + 1) * 2
- pw = ((w0 - 1) // 2 + 1) * 2
- x = F.pad(x, (18, 18 + pw - w0, 18, 18 + ph - h0), 'reflect') # 需要保证被2整除
- x = self.unet1.forward(x)
- x0 = self.unet2.forward(x)
- x1 = F.pad(x, (-20, -20, -20, -20))
- x = torch.add(x0, x1)
- if (w0 != pw or h0 != ph): x = x[:, :, :h0 * 2, :w0 * 2]
- return x
- elif (tile_mode == 1): # 对长边减半
- if (w0 >= h0):
- crop_size_w = ((w0 - 1) // 4 * 4 + 4) // 2 # 减半后能被2整除,所以要先被4整除
- crop_size_h = (h0 - 1) // 2 * 2 + 2 # 能被2整除
- else:
- crop_size_h = ((h0 - 1) // 4 * 4 + 4) // 2 # 减半后能被2整除,所以要先被4整除
- crop_size_w = (w0 - 1) // 2 * 2 + 2 # 能被2整除
- crop_size = (crop_size_h, crop_size_w) # 6.6G
- elif (tile_mode == 2): # hw都减半
- crop_size = (((h0 - 1) // 4 * 4 + 4) // 2, ((w0 - 1) // 4 * 4 + 4) // 2) # 5.6G
- elif (tile_mode == 3): # hw都三分之一
- crop_size = (((h0 - 1) // 6 * 6 + 6) // 3, ((w0 - 1) // 6 * 6 + 6) // 3) # 4.2G
- elif (tile_mode == 4): # hw都四分之一
- crop_size = (((h0 - 1) // 8 * 8 + 8) // 4, ((w0 - 1) // 8 * 8 + 8) // 4) # 3.7G
- ph = ((h0 - 1) // crop_size[0] + 1) * crop_size[0]
- pw = ((w0 - 1) // crop_size[1] + 1) * crop_size[1]
- x = F.pad(x, (18, 18 + pw - w0, 18, 18 + ph - h0), 'reflect')
- n, c, h, w = x.shape
- se_mean0 = torch.zeros((n, 64, 1, 1)).to(x.device)
- if ("Half" in x.type()):
- se_mean0 = se_mean0.half()
- n_patch = 0
- tmp_dict = {}
- opt_res_dict = {}
- for i in range(0, h - 36, crop_size[0]):
- tmp_dict[i] = {}
- for j in range(0, w - 36, crop_size[1]):
- x_crop = x[:, :, i:i + crop_size[0] + 36, j:j + crop_size[1] + 36]
- n, c1, h1, w1 = x_crop.shape
- tmp0, x_crop = self.unet1.forward_a(x_crop)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(x_crop.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(x_crop, dim=(2, 3), keepdim=True)
- se_mean0 += tmp_se_mean
- n_patch += 1
- tmp_dict[i][j] = (tmp0, x_crop)
- se_mean0 /= n_patch
- se_mean1 = torch.zeros((n, 128, 1, 1)).to(x.device) # 64#128#128#64
- if ("Half" in x.type()):
- se_mean1 = se_mean1.half()
- for i in range(0, h - 36, crop_size[0]):
- for j in range(0, w - 36, crop_size[1]):
- tmp0, x_crop = tmp_dict[i][j]
- x_crop = self.unet1.conv2.seblock.forward_mean(x_crop, se_mean0)
- opt_unet1 = self.unet1.forward_b(tmp0, x_crop)
- tmp_x1, tmp_x2 = self.unet2.forward_a(opt_unet1)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(tmp_x2.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(tmp_x2, dim=(2, 3), keepdim=True)
- se_mean1 += tmp_se_mean
- tmp_dict[i][j] = (opt_unet1, tmp_x1, tmp_x2)
- se_mean1 /= n_patch
- se_mean0 = torch.zeros((n, 128, 1, 1)).to(x.device) # 64#128#128#64
- if ("Half" in x.type()):
- se_mean0 = se_mean0.half()
- for i in range(0, h - 36, crop_size[0]):
- for j in range(0, w - 36, crop_size[1]):
- opt_unet1, tmp_x1, tmp_x2 = tmp_dict[i][j]
- tmp_x2 = self.unet2.conv2.seblock.forward_mean(tmp_x2, se_mean1)
- tmp_x3 = self.unet2.forward_b(tmp_x2)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(tmp_x3.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(tmp_x3, dim=(2, 3), keepdim=True)
- se_mean0 += tmp_se_mean
- tmp_dict[i][j] = (opt_unet1, tmp_x1, tmp_x2, tmp_x3)
- se_mean0 /= n_patch
- se_mean1 = torch.zeros((n, 64, 1, 1)).to(x.device) # 64#128#128#64
- if ("Half" in x.type()):
- se_mean1 = se_mean1.half()
- for i in range(0, h - 36, crop_size[0]):
- for j in range(0, w - 36, crop_size[1]):
- opt_unet1, tmp_x1, tmp_x2, tmp_x3 = tmp_dict[i][j]
- tmp_x3 = self.unet2.conv3.seblock.forward_mean(tmp_x3, se_mean0)
- tmp_x4 = self.unet2.forward_c(tmp_x2, tmp_x3)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(tmp_x4.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(tmp_x4, dim=(2, 3), keepdim=True)
- se_mean1 += tmp_se_mean
- tmp_dict[i][j] = (opt_unet1, tmp_x1, tmp_x4)
- se_mean1 /= n_patch
- for i in range(0, h - 36, crop_size[0]):
- opt_res_dict[i] = {}
- for j in range(0, w - 36, crop_size[1]):
- opt_unet1, tmp_x1, tmp_x4 = tmp_dict[i][j]
- tmp_x4 = self.unet2.conv4.seblock.forward_mean(tmp_x4, se_mean1)
- x0 = self.unet2.forward_d(tmp_x1, tmp_x4)
- x1 = F.pad(opt_unet1, (-20, -20, -20, -20))
- x_crop = torch.add(x0, x1) # x0是unet2的最终输出
- opt_res_dict[i][j] = x_crop
- del tmp_dict
- torch.cuda.empty_cache()
- res = torch.zeros((n, c, h * 2 - 72, w * 2 - 72)).to(x.device)
- if ("Half" in x.type()):
- res = res.half()
- for i in range(0, h - 36, crop_size[0]):
- for j in range(0, w - 36, crop_size[1]):
- res[:, :, i * 2:i * 2 + h1 * 2 - 72, j * 2:j * 2 + w1 * 2 - 72] = opt_res_dict[i][j]
- del opt_res_dict
- torch.cuda.empty_cache()
- if (w0 != pw or h0 != ph): res = res[:, :, :h0 * 2, :w0 * 2]
- return res #
-
-
-class UpCunet3x(nn.Module): # 完美tile,全程无损
- def __init__(self, in_channels=3, out_channels=3):
- super(UpCunet3x, self).__init__()
- self.unet1 = UNet1x3(in_channels, out_channels, deconv=True)
- self.unet2 = UNet2(in_channels, out_channels, deconv=False)
-
- def forward(self, x, tile_mode): # 1.7G
- n, c, h0, w0 = x.shape
- if (tile_mode == 0): # 不tile
- ph = ((h0 - 1) // 4 + 1) * 4
- pw = ((w0 - 1) // 4 + 1) * 4
- x = F.pad(x, (14, 14 + pw - w0, 14, 14 + ph - h0), 'reflect') # 需要保证被2整除
- x = self.unet1.forward(x)
- x0 = self.unet2.forward(x)
- x1 = F.pad(x, (-20, -20, -20, -20))
- x = torch.add(x0, x1)
- if (w0 != pw or h0 != ph): x = x[:, :, :h0 * 3, :w0 * 3]
- return x
- elif (tile_mode == 1): # 对长边减半
- if (w0 >= h0):
- crop_size_w = ((w0 - 1) // 8 * 8 + 8) // 2 # 减半后能被4整除,所以要先被8整除
- crop_size_h = (h0 - 1) // 4 * 4 + 4 # 能被4整除
- else:
- crop_size_h = ((h0 - 1) // 8 * 8 + 8) // 2 # 减半后能被4整除,所以要先被8整除
- crop_size_w = (w0 - 1) // 4 * 4 + 4 # 能被4整除
- crop_size = (crop_size_h, crop_size_w) # 6.6G
- elif (tile_mode == 2): # hw都减半
- crop_size = (((h0 - 1) // 8 * 8 + 8) // 2, ((w0 - 1) // 8 * 8 + 8) // 2) # 5.6G
- elif (tile_mode == 3): # hw都三分之一
- crop_size = (((h0 - 1) // 12 * 12 + 12) // 3, ((w0 - 1) // 12 * 12 + 12) // 3) # 4.2G
- elif (tile_mode == 4): # hw都四分之一
- crop_size = (((h0 - 1) // 16 * 16 + 16) // 4, ((w0 - 1) // 16 * 16 + 16) // 4) # 3.7G
- ph = ((h0 - 1) // crop_size[0] + 1) * crop_size[0]
- pw = ((w0 - 1) // crop_size[1] + 1) * crop_size[1]
- x = F.pad(x, (14, 14 + pw - w0, 14, 14 + ph - h0), 'reflect')
- n, c, h, w = x.shape
- se_mean0 = torch.zeros((n, 64, 1, 1)).to(x.device)
- if ("Half" in x.type()):
- se_mean0 = se_mean0.half()
- n_patch = 0
- tmp_dict = {}
- opt_res_dict = {}
- for i in range(0, h - 28, crop_size[0]):
- tmp_dict[i] = {}
- for j in range(0, w - 28, crop_size[1]):
- x_crop = x[:, :, i:i + crop_size[0] + 28, j:j + crop_size[1] + 28]
- n, c1, h1, w1 = x_crop.shape
- tmp0, x_crop = self.unet1.forward_a(x_crop)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(x_crop.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(x_crop, dim=(2, 3), keepdim=True)
- se_mean0 += tmp_se_mean
- n_patch += 1
- tmp_dict[i][j] = (tmp0, x_crop)
- se_mean0 /= n_patch
- se_mean1 = torch.zeros((n, 128, 1, 1)).to(x.device) # 64#128#128#64
- if ("Half" in x.type()):
- se_mean1 = se_mean1.half()
- for i in range(0, h - 28, crop_size[0]):
- for j in range(0, w - 28, crop_size[1]):
- tmp0, x_crop = tmp_dict[i][j]
- x_crop = self.unet1.conv2.seblock.forward_mean(x_crop, se_mean0)
- opt_unet1 = self.unet1.forward_b(tmp0, x_crop)
- tmp_x1, tmp_x2 = self.unet2.forward_a(opt_unet1)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(tmp_x2.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(tmp_x2, dim=(2, 3), keepdim=True)
- se_mean1 += tmp_se_mean
- tmp_dict[i][j] = (opt_unet1, tmp_x1, tmp_x2)
- se_mean1 /= n_patch
- se_mean0 = torch.zeros((n, 128, 1, 1)).to(x.device) # 64#128#128#64
- if ("Half" in x.type()):
- se_mean0 = se_mean0.half()
- for i in range(0, h - 28, crop_size[0]):
- for j in range(0, w - 28, crop_size[1]):
- opt_unet1, tmp_x1, tmp_x2 = tmp_dict[i][j]
- tmp_x2 = self.unet2.conv2.seblock.forward_mean(tmp_x2, se_mean1)
- tmp_x3 = self.unet2.forward_b(tmp_x2)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(tmp_x3.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(tmp_x3, dim=(2, 3), keepdim=True)
- se_mean0 += tmp_se_mean
- tmp_dict[i][j] = (opt_unet1, tmp_x1, tmp_x2, tmp_x3)
- se_mean0 /= n_patch
- se_mean1 = torch.zeros((n, 64, 1, 1)).to(x.device) # 64#128#128#64
- if ("Half" in x.type()):
- se_mean1 = se_mean1.half()
- for i in range(0, h - 28, crop_size[0]):
- for j in range(0, w - 28, crop_size[1]):
- opt_unet1, tmp_x1, tmp_x2, tmp_x3 = tmp_dict[i][j]
- tmp_x3 = self.unet2.conv3.seblock.forward_mean(tmp_x3, se_mean0)
- tmp_x4 = self.unet2.forward_c(tmp_x2, tmp_x3)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(tmp_x4.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(tmp_x4, dim=(2, 3), keepdim=True)
- se_mean1 += tmp_se_mean
- tmp_dict[i][j] = (opt_unet1, tmp_x1, tmp_x4)
- se_mean1 /= n_patch
- for i in range(0, h - 28, crop_size[0]):
- opt_res_dict[i] = {}
- for j in range(0, w - 28, crop_size[1]):
- opt_unet1, tmp_x1, tmp_x4 = tmp_dict[i][j]
- tmp_x4 = self.unet2.conv4.seblock.forward_mean(tmp_x4, se_mean1)
- x0 = self.unet2.forward_d(tmp_x1, tmp_x4)
- x1 = F.pad(opt_unet1, (-20, -20, -20, -20))
- x_crop = torch.add(x0, x1) # x0是unet2的最终输出
- opt_res_dict[i][j] = x_crop #
- del tmp_dict
- torch.cuda.empty_cache()
- res = torch.zeros((n, c, h * 3 - 84, w * 3 - 84)).to(x.device)
- if ("Half" in x.type()):
- res = res.half()
- for i in range(0, h - 28, crop_size[0]):
- for j in range(0, w - 28, crop_size[1]):
- res[:, :, i * 3:i * 3 + h1 * 3 - 84, j * 3:j * 3 + w1 * 3 - 84] = opt_res_dict[i][j]
- del opt_res_dict
- torch.cuda.empty_cache()
- if (w0 != pw or h0 != ph): res = res[:, :, :h0 * 3, :w0 * 3]
- return res
-
-
-class UpCunet4x(nn.Module): # 完美tile,全程无损
- def __init__(self, in_channels=3, out_channels=3):
- super(UpCunet4x, self).__init__()
- self.unet1 = UNet1(in_channels, 64, deconv=True)
- self.unet2 = UNet2(64, 64, deconv=False)
- self.ps = nn.PixelShuffle(2)
- self.conv_final = nn.Conv2d(64, 12, 3, 1, padding=0, bias=True)
-
- def forward(self, x, tile_mode):
- n, c, h0, w0 = x.shape
- x00 = x
- if (tile_mode == 0): # 不tile
- ph = ((h0 - 1) // 2 + 1) * 2
- pw = ((w0 - 1) // 2 + 1) * 2
- x = F.pad(x, (19, 19 + pw - w0, 19, 19 + ph - h0), 'reflect') # 需要保证被2整除
- x = self.unet1.forward(x)
- x0 = self.unet2.forward(x)
- x1 = F.pad(x, (-20, -20, -20, -20))
- x = torch.add(x0, x1)
- x = self.conv_final(x)
- x = F.pad(x, (-1, -1, -1, -1))
- x = self.ps(x)
- if (w0 != pw or h0 != ph): x = x[:, :, :h0 * 4, :w0 * 4]
- x += F.interpolate(x00, scale_factor=4, mode='nearest')
- return x
- elif (tile_mode == 1): # 对长边减半
- if (w0 >= h0):
- crop_size_w = ((w0 - 1) // 4 * 4 + 4) // 2 # 减半后能被2整除,所以要先被4整除
- crop_size_h = (h0 - 1) // 2 * 2 + 2 # 能被2整除
- else:
- crop_size_h = ((h0 - 1) // 4 * 4 + 4) // 2 # 减半后能被2整除,所以要先被4整除
- crop_size_w = (w0 - 1) // 2 * 2 + 2 # 能被2整除
- crop_size = (crop_size_h, crop_size_w) # 6.6G
- elif (tile_mode == 2): # hw都减半
- crop_size = (((h0 - 1) // 4 * 4 + 4) // 2, ((w0 - 1) // 4 * 4 + 4) // 2) # 5.6G
- elif (tile_mode == 3): # hw都三分之一
- crop_size = (((h0 - 1) // 6 * 6 + 6) // 3, ((w0 - 1) // 6 * 6 + 6) // 3) # 4.1G
- elif (tile_mode == 4): # hw都四分之一
- crop_size = (((h0 - 1) // 8 * 8 + 8) // 4, ((w0 - 1) // 8 * 8 + 8) // 4) # 3.7G
- ph = ((h0 - 1) // crop_size[0] + 1) * crop_size[0]
- pw = ((w0 - 1) // crop_size[1] + 1) * crop_size[1]
- x = F.pad(x, (19, 19 + pw - w0, 19, 19 + ph - h0), 'reflect')
- n, c, h, w = x.shape
- se_mean0 = torch.zeros((n, 64, 1, 1)).to(x.device)
- if ("Half" in x.type()):
- se_mean0 = se_mean0.half()
- n_patch = 0
- tmp_dict = {}
- opt_res_dict = {}
- for i in range(0, h - 38, crop_size[0]):
- tmp_dict[i] = {}
- for j in range(0, w - 38, crop_size[1]):
- x_crop = x[:, :, i:i + crop_size[0] + 38, j:j + crop_size[1] + 38]
- n, c1, h1, w1 = x_crop.shape
- tmp0, x_crop = self.unet1.forward_a(x_crop)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(x_crop.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(x_crop, dim=(2, 3), keepdim=True)
- se_mean0 += tmp_se_mean
- n_patch += 1
- tmp_dict[i][j] = (tmp0, x_crop)
- se_mean0 /= n_patch
- se_mean1 = torch.zeros((n, 128, 1, 1)).to(x.device) # 64#128#128#64
- if ("Half" in x.type()):
- se_mean1 = se_mean1.half()
- for i in range(0, h - 38, crop_size[0]):
- for j in range(0, w - 38, crop_size[1]):
- tmp0, x_crop = tmp_dict[i][j]
- x_crop = self.unet1.conv2.seblock.forward_mean(x_crop, se_mean0)
- opt_unet1 = self.unet1.forward_b(tmp0, x_crop)
- tmp_x1, tmp_x2 = self.unet2.forward_a(opt_unet1)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(tmp_x2.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(tmp_x2, dim=(2, 3), keepdim=True)
- se_mean1 += tmp_se_mean
- tmp_dict[i][j] = (opt_unet1, tmp_x1, tmp_x2)
- se_mean1 /= n_patch
- se_mean0 = torch.zeros((n, 128, 1, 1)).to(x.device) # 64#128#128#64
- if ("Half" in x.type()):
- se_mean0 = se_mean0.half()
- for i in range(0, h - 38, crop_size[0]):
- for j in range(0, w - 38, crop_size[1]):
- opt_unet1, tmp_x1, tmp_x2 = tmp_dict[i][j]
- tmp_x2 = self.unet2.conv2.seblock.forward_mean(tmp_x2, se_mean1)
- tmp_x3 = self.unet2.forward_b(tmp_x2)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(tmp_x3.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(tmp_x3, dim=(2, 3), keepdim=True)
- se_mean0 += tmp_se_mean
- tmp_dict[i][j] = (opt_unet1, tmp_x1, tmp_x2, tmp_x3)
- se_mean0 /= n_patch
- se_mean1 = torch.zeros((n, 64, 1, 1)).to(x.device) # 64#128#128#64
- if ("Half" in x.type()):
- se_mean1 = se_mean1.half()
- for i in range(0, h - 38, crop_size[0]):
- for j in range(0, w - 38, crop_size[1]):
- opt_unet1, tmp_x1, tmp_x2, tmp_x3 = tmp_dict[i][j]
- tmp_x3 = self.unet2.conv3.seblock.forward_mean(tmp_x3, se_mean0)
- tmp_x4 = self.unet2.forward_c(tmp_x2, tmp_x3)
- if ("Half" in x.type()): # torch.HalfTensor/torch.cuda.HalfTensor
- tmp_se_mean = torch.mean(tmp_x4.float(), dim=(2, 3), keepdim=True).half()
- else:
- tmp_se_mean = torch.mean(tmp_x4, dim=(2, 3), keepdim=True)
- se_mean1 += tmp_se_mean
- tmp_dict[i][j] = (opt_unet1, tmp_x1, tmp_x4)
- se_mean1 /= n_patch
- for i in range(0, h - 38, crop_size[0]):
- opt_res_dict[i] = {}
- for j in range(0, w - 38, crop_size[1]):
- opt_unet1, tmp_x1, tmp_x4 = tmp_dict[i][j]
- tmp_x4 = self.unet2.conv4.seblock.forward_mean(tmp_x4, se_mean1)
- x0 = self.unet2.forward_d(tmp_x1, tmp_x4)
- x1 = F.pad(opt_unet1, (-20, -20, -20, -20))
- x_crop = torch.add(x0, x1) # x0是unet2的最终输出
- x_crop = self.conv_final(x_crop)
- x_crop = F.pad(x_crop, (-1, -1, -1, -1))
- x_crop = self.ps(x_crop)
- opt_res_dict[i][j] = x_crop
- del tmp_dict
- torch.cuda.empty_cache()
- res = torch.zeros((n, c, h * 4 - 152, w * 4 - 152)).to(x.device)
- if ("Half" in x.type()):
- res = res.half()
- for i in range(0, h - 38, crop_size[0]):
- for j in range(0, w - 38, crop_size[1]):
- # print(opt_res_dict[i][j].shape,res[:, :, i * 4:i * 4 + h1 * 4 - 144, j * 4:j * 4 + w1 * 4 - 144].shape)
- res[:, :, i * 4:i * 4 + h1 * 4 - 152, j * 4:j * 4 + w1 * 4 - 152] = opt_res_dict[i][j]
- del opt_res_dict
- torch.cuda.empty_cache()
- if (w0 != pw or h0 != ph): res = res[:, :, :h0 * 4, :w0 * 4]
- res += F.interpolate(x00, scale_factor=4, mode='nearest')
- return res #
-
-
-class RealWaifuUpScaler(object):
- def __init__(self, scale, weight_path, half, device):
- weight = torch.load(weight_path, map_location="cpu")
- self.model = eval("UpCunet%sx" % scale)()
- if (half == True):
- self.model = self.model.half().to(device)
- else:
- self.model = self.model.to(device)
- self.model.load_state_dict(weight, strict=True)
- self.model.eval()
- self.half = half
- self.device = device
-
- def np2tensor(self, np_frame):
- if (self.half == False):
- return torch.from_numpy(np.transpose(np_frame, (2, 0, 1))).unsqueeze(0).to(self.device).float() / 255
- else:
- return torch.from_numpy(np.transpose(np_frame, (2, 0, 1))).unsqueeze(0).to(self.device).half() / 255
-
- def tensor2np(self, tensor):
- if (self.half == False):
- return (
- np.transpose((tensor.data.squeeze() * 255.0).round().clamp_(0, 255).byte().cpu().numpy(), (1, 2, 0)))
- else:
- return (np.transpose((tensor.data.squeeze().float() * 255.0).round().clamp_(0, 255).byte().cpu().numpy(),
- (1, 2, 0)))
-
- def __call__(self, frame, tile_mode):
- with torch.no_grad():
- tensor = self.np2tensor(frame)
- result = self.tensor2np(self.model(tensor, tile_mode))
- return result
-
-
-if __name__ == "__main__":
- ###########inference_img
- import time, cv2, sys
- from time import time as ttime
-
- for weight_path, scale in [("weights_v3/up2x-latest-denoise3x.pth", 2), ("weights_v3/up3x-latest-denoise3x.pth", 3),
- ("weights_v3/up4x-latest-denoise3x.pth", 4)]:
- for tile_mode in [0, 1, 2, 3, 4]:
- upscaler2x = RealWaifuUpScaler(scale, weight_path, half=True, device="cuda:0")
- input_dir = "%s/input_dir1" % root_path
- output_dir = "%s/opt-dir-all-test" % root_path
- os.makedirs(output_dir, exist_ok=True)
- for name in os.listdir(input_dir):
- print(name)
- tmp = name.split(".")
- inp_path = os.path.join(input_dir, name)
- suffix = tmp[-1]
- prefix = ".".join(tmp[:-1])
- tmp_path = os.path.join(root_path, "tmp", "%s.%s" % (int(time.time() * 1000000), suffix))
- print(inp_path, tmp_path)
- # 支持中文路径
- # os.link(inp_path, tmp_path)#win用硬链接
- os.symlink(inp_path, tmp_path) # linux用软链接
- frame = cv2.imread(tmp_path)[:, :, [2, 1, 0]]
- t0 = ttime()
- result = upscaler2x(frame, tile_mode=tile_mode)[:, :, ::-1]
- t1 = ttime()
- print(prefix, "done", t1 - t0)
- tmp_opt_path = os.path.join(root_path, "tmp", "%s.%s" % (int(time.time() * 1000000), suffix))
- cv2.imwrite(tmp_opt_path, result)
- n = 0
- while (1):
- if (n == 0):
- suffix = "_%sx_tile%s.png" % (scale, tile_mode)
- else:
- suffix = "_%sx_tile%s_%s.png" % (scale, tile_mode, n) #
- if (os.path.exists(os.path.join(output_dir, prefix + suffix)) == False):
- break
- else:
- n += 1
- final_opt_path = os.path.join(output_dir, prefix + suffix)
- os.rename(tmp_opt_path, final_opt_path)
- os.remove(tmp_path)
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/PIL/ImageCms.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/PIL/ImageCms.py
deleted file mode 100644
index f87849680df169869db8c9378d7da546583635bd..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/PIL/ImageCms.py
+++ /dev/null
@@ -1,1026 +0,0 @@
-# The Python Imaging Library.
-# $Id$
-
-# Optional color management support, based on Kevin Cazabon's PyCMS
-# library.
-
-# History:
-
-# 2009-03-08 fl Added to PIL.
-
-# Copyright (C) 2002-2003 Kevin Cazabon
-# Copyright (c) 2009 by Fredrik Lundh
-# Copyright (c) 2013 by Eric Soroos
-
-# See the README file for information on usage and redistribution. See
-# below for the original description.
-
-import sys
-from enum import IntEnum
-
-from PIL import Image
-
-from ._deprecate import deprecate
-
-try:
- from PIL import _imagingcms
-except ImportError as ex:
- # Allow error import for doc purposes, but error out when accessing
- # anything in core.
- from ._util import DeferredError
-
- _imagingcms = DeferredError(ex)
-
-DESCRIPTION = """
-pyCMS
-
- a Python / PIL interface to the littleCMS ICC Color Management System
- Copyright (C) 2002-2003 Kevin Cazabon
- kevin@cazabon.com
- https://www.cazabon.com
-
- pyCMS home page: https://www.cazabon.com/pyCMS
- littleCMS home page: https://www.littlecms.com
- (littleCMS is Copyright (C) 1998-2001 Marti Maria)
-
- Originally released under LGPL. Graciously donated to PIL in
- March 2009, for distribution under the standard PIL license
-
- The pyCMS.py module provides a "clean" interface between Python/PIL and
- pyCMSdll, taking care of some of the more complex handling of the direct
- pyCMSdll functions, as well as error-checking and making sure that all
- relevant data is kept together.
-
- While it is possible to call pyCMSdll functions directly, it's not highly
- recommended.
-
- Version History:
-
- 1.0.0 pil Oct 2013 Port to LCMS 2.
-
- 0.1.0 pil mod March 10, 2009
-
- Renamed display profile to proof profile. The proof
- profile is the profile of the device that is being
- simulated, not the profile of the device which is
- actually used to display/print the final simulation
- (that'd be the output profile) - also see LCMSAPI.txt
- input colorspace -> using 'renderingIntent' -> proof
- colorspace -> using 'proofRenderingIntent' -> output
- colorspace
-
- Added LCMS FLAGS support.
- Added FLAGS["SOFTPROOFING"] as default flag for
- buildProofTransform (otherwise the proof profile/intent
- would be ignored).
-
- 0.1.0 pil March 2009 - added to PIL, as PIL.ImageCms
-
- 0.0.2 alpha Jan 6, 2002
-
- Added try/except statements around type() checks of
- potential CObjects... Python won't let you use type()
- on them, and raises a TypeError (stupid, if you ask
- me!)
-
- Added buildProofTransformFromOpenProfiles() function.
- Additional fixes in DLL, see DLL code for details.
-
- 0.0.1 alpha first public release, Dec. 26, 2002
-
- Known to-do list with current version (of Python interface, not pyCMSdll):
-
- none
-
-"""
-
-VERSION = "1.0.0 pil"
-
-# --------------------------------------------------------------------.
-
-core = _imagingcms
-
-#
-# intent/direction values
-
-
-class Intent(IntEnum):
- PERCEPTUAL = 0
- RELATIVE_COLORIMETRIC = 1
- SATURATION = 2
- ABSOLUTE_COLORIMETRIC = 3
-
-
-class Direction(IntEnum):
- INPUT = 0
- OUTPUT = 1
- PROOF = 2
-
-
-def __getattr__(name):
- for enum, prefix in {Intent: "INTENT_", Direction: "DIRECTION_"}.items():
- if name.startswith(prefix):
- name = name[len(prefix) :]
- if name in enum.__members__:
- deprecate(f"{prefix}{name}", 10, f"{enum.__name__}.{name}")
- return enum[name]
- msg = f"module '{__name__}' has no attribute '{name}'"
- raise AttributeError(msg)
-
-
-#
-# flags
-
-FLAGS = {
- "MATRIXINPUT": 1,
- "MATRIXOUTPUT": 2,
- "MATRIXONLY": (1 | 2),
- "NOWHITEONWHITEFIXUP": 4, # Don't hot fix scum dot
- # Don't create prelinearization tables on precalculated transforms
- # (internal use):
- "NOPRELINEARIZATION": 16,
- "GUESSDEVICECLASS": 32, # Guess device class (for transform2devicelink)
- "NOTCACHE": 64, # Inhibit 1-pixel cache
- "NOTPRECALC": 256,
- "NULLTRANSFORM": 512, # Don't transform anyway
- "HIGHRESPRECALC": 1024, # Use more memory to give better accuracy
- "LOWRESPRECALC": 2048, # Use less memory to minimize resources
- "WHITEBLACKCOMPENSATION": 8192,
- "BLACKPOINTCOMPENSATION": 8192,
- "GAMUTCHECK": 4096, # Out of Gamut alarm
- "SOFTPROOFING": 16384, # Do softproofing
- "PRESERVEBLACK": 32768, # Black preservation
- "NODEFAULTRESOURCEDEF": 16777216, # CRD special
- "GRIDPOINTS": lambda n: (n & 0xFF) << 16, # Gridpoints
-}
-
-_MAX_FLAG = 0
-for flag in FLAGS.values():
- if isinstance(flag, int):
- _MAX_FLAG = _MAX_FLAG | flag
-
-
-# --------------------------------------------------------------------.
-# Experimental PIL-level API
-# --------------------------------------------------------------------.
-
-##
-# Profile.
-
-
-class ImageCmsProfile:
- def __init__(self, profile):
- """
- :param profile: Either a string representing a filename,
- a file like object containing a profile or a
- low-level profile object
-
- """
-
- if isinstance(profile, str):
- if sys.platform == "win32":
- profile_bytes_path = profile.encode()
- try:
- profile_bytes_path.decode("ascii")
- except UnicodeDecodeError:
- with open(profile, "rb") as f:
- self._set(core.profile_frombytes(f.read()))
- return
- self._set(core.profile_open(profile), profile)
- elif hasattr(profile, "read"):
- self._set(core.profile_frombytes(profile.read()))
- elif isinstance(profile, _imagingcms.CmsProfile):
- self._set(profile)
- else:
- msg = "Invalid type for Profile"
- raise TypeError(msg)
-
- def _set(self, profile, filename=None):
- self.profile = profile
- self.filename = filename
- if profile:
- self.product_name = None # profile.product_name
- self.product_info = None # profile.product_info
- else:
- self.product_name = None
- self.product_info = None
-
- def tobytes(self):
- """
- Returns the profile in a format suitable for embedding in
- saved images.
-
- :returns: a bytes object containing the ICC profile.
- """
-
- return core.profile_tobytes(self.profile)
-
-
-class ImageCmsTransform(Image.ImagePointHandler):
-
- """
- Transform. This can be used with the procedural API, or with the standard
- :py:func:`~PIL.Image.Image.point` method.
-
- Will return the output profile in the ``output.info['icc_profile']``.
- """
-
- def __init__(
- self,
- input,
- output,
- input_mode,
- output_mode,
- intent=Intent.PERCEPTUAL,
- proof=None,
- proof_intent=Intent.ABSOLUTE_COLORIMETRIC,
- flags=0,
- ):
- if proof is None:
- self.transform = core.buildTransform(
- input.profile, output.profile, input_mode, output_mode, intent, flags
- )
- else:
- self.transform = core.buildProofTransform(
- input.profile,
- output.profile,
- proof.profile,
- input_mode,
- output_mode,
- intent,
- proof_intent,
- flags,
- )
- # Note: inputMode and outputMode are for pyCMS compatibility only
- self.input_mode = self.inputMode = input_mode
- self.output_mode = self.outputMode = output_mode
-
- self.output_profile = output
-
- def point(self, im):
- return self.apply(im)
-
- def apply(self, im, imOut=None):
- im.load()
- if imOut is None:
- imOut = Image.new(self.output_mode, im.size, None)
- self.transform.apply(im.im.id, imOut.im.id)
- imOut.info["icc_profile"] = self.output_profile.tobytes()
- return imOut
-
- def apply_in_place(self, im):
- im.load()
- if im.mode != self.output_mode:
- msg = "mode mismatch"
- raise ValueError(msg) # wrong output mode
- self.transform.apply(im.im.id, im.im.id)
- im.info["icc_profile"] = self.output_profile.tobytes()
- return im
-
-
-def get_display_profile(handle=None):
- """
- (experimental) Fetches the profile for the current display device.
-
- :returns: ``None`` if the profile is not known.
- """
-
- if sys.platform != "win32":
- return None
-
- from PIL import ImageWin
-
- if isinstance(handle, ImageWin.HDC):
- profile = core.get_display_profile_win32(handle, 1)
- else:
- profile = core.get_display_profile_win32(handle or 0)
- if profile is None:
- return None
- return ImageCmsProfile(profile)
-
-
-# --------------------------------------------------------------------.
-# pyCMS compatible layer
-# --------------------------------------------------------------------.
-
-
-class PyCMSError(Exception):
-
- """(pyCMS) Exception class.
- This is used for all errors in the pyCMS API."""
-
- pass
-
-
-def profileToProfile(
- im,
- inputProfile,
- outputProfile,
- renderingIntent=Intent.PERCEPTUAL,
- outputMode=None,
- inPlace=False,
- flags=0,
-):
- """
- (pyCMS) Applies an ICC transformation to a given image, mapping from
- ``inputProfile`` to ``outputProfile``.
-
- If the input or output profiles specified are not valid filenames, a
- :exc:`PyCMSError` will be raised. If ``inPlace`` is ``True`` and
- ``outputMode != im.mode``, a :exc:`PyCMSError` will be raised.
- If an error occurs during application of the profiles,
- a :exc:`PyCMSError` will be raised.
- If ``outputMode`` is not a mode supported by the ``outputProfile`` (or by pyCMS),
- a :exc:`PyCMSError` will be raised.
-
- This function applies an ICC transformation to im from ``inputProfile``'s
- color space to ``outputProfile``'s color space using the specified rendering
- intent to decide how to handle out-of-gamut colors.
-
- ``outputMode`` can be used to specify that a color mode conversion is to
- be done using these profiles, but the specified profiles must be able
- to handle that mode. I.e., if converting im from RGB to CMYK using
- profiles, the input profile must handle RGB data, and the output
- profile must handle CMYK data.
-
- :param im: An open :py:class:`~PIL.Image.Image` object (i.e. Image.new(...)
- or Image.open(...), etc.)
- :param inputProfile: String, as a valid filename path to the ICC input
- profile you wish to use for this image, or a profile object
- :param outputProfile: String, as a valid filename path to the ICC output
- profile you wish to use for this image, or a profile object
- :param renderingIntent: Integer (0-3) specifying the rendering intent you
- wish to use for the transform
-
- ImageCms.Intent.PERCEPTUAL = 0 (DEFAULT)
- ImageCms.Intent.RELATIVE_COLORIMETRIC = 1
- ImageCms.Intent.SATURATION = 2
- ImageCms.Intent.ABSOLUTE_COLORIMETRIC = 3
-
- see the pyCMS documentation for details on rendering intents and what
- they do.
- :param outputMode: A valid PIL mode for the output image (i.e. "RGB",
- "CMYK", etc.). Note: if rendering the image "inPlace", outputMode
- MUST be the same mode as the input, or omitted completely. If
- omitted, the outputMode will be the same as the mode of the input
- image (im.mode)
- :param inPlace: Boolean. If ``True``, the original image is modified in-place,
- and ``None`` is returned. If ``False`` (default), a new
- :py:class:`~PIL.Image.Image` object is returned with the transform applied.
- :param flags: Integer (0-...) specifying additional flags
- :returns: Either None or a new :py:class:`~PIL.Image.Image` object, depending on
- the value of ``inPlace``
- :exception PyCMSError:
- """
-
- if outputMode is None:
- outputMode = im.mode
-
- if not isinstance(renderingIntent, int) or not (0 <= renderingIntent <= 3):
- msg = "renderingIntent must be an integer between 0 and 3"
- raise PyCMSError(msg)
-
- if not isinstance(flags, int) or not (0 <= flags <= _MAX_FLAG):
- msg = f"flags must be an integer between 0 and {_MAX_FLAG}"
- raise PyCMSError(msg)
-
- try:
- if not isinstance(inputProfile, ImageCmsProfile):
- inputProfile = ImageCmsProfile(inputProfile)
- if not isinstance(outputProfile, ImageCmsProfile):
- outputProfile = ImageCmsProfile(outputProfile)
- transform = ImageCmsTransform(
- inputProfile,
- outputProfile,
- im.mode,
- outputMode,
- renderingIntent,
- flags=flags,
- )
- if inPlace:
- transform.apply_in_place(im)
- imOut = None
- else:
- imOut = transform.apply(im)
- except (OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
- return imOut
-
-
-def getOpenProfile(profileFilename):
- """
- (pyCMS) Opens an ICC profile file.
-
- The PyCMSProfile object can be passed back into pyCMS for use in creating
- transforms and such (as in ImageCms.buildTransformFromOpenProfiles()).
-
- If ``profileFilename`` is not a valid filename for an ICC profile,
- a :exc:`PyCMSError` will be raised.
-
- :param profileFilename: String, as a valid filename path to the ICC profile
- you wish to open, or a file-like object.
- :returns: A CmsProfile class object.
- :exception PyCMSError:
- """
-
- try:
- return ImageCmsProfile(profileFilename)
- except (OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def buildTransform(
- inputProfile,
- outputProfile,
- inMode,
- outMode,
- renderingIntent=Intent.PERCEPTUAL,
- flags=0,
-):
- """
- (pyCMS) Builds an ICC transform mapping from the ``inputProfile`` to the
- ``outputProfile``. Use applyTransform to apply the transform to a given
- image.
-
- If the input or output profiles specified are not valid filenames, a
- :exc:`PyCMSError` will be raised. If an error occurs during creation
- of the transform, a :exc:`PyCMSError` will be raised.
-
- If ``inMode`` or ``outMode`` are not a mode supported by the ``outputProfile``
- (or by pyCMS), a :exc:`PyCMSError` will be raised.
-
- This function builds and returns an ICC transform from the ``inputProfile``
- to the ``outputProfile`` using the ``renderingIntent`` to determine what to do
- with out-of-gamut colors. It will ONLY work for converting images that
- are in ``inMode`` to images that are in ``outMode`` color format (PIL mode,
- i.e. "RGB", "RGBA", "CMYK", etc.).
-
- Building the transform is a fair part of the overhead in
- ImageCms.profileToProfile(), so if you're planning on converting multiple
- images using the same input/output settings, this can save you time.
- Once you have a transform object, it can be used with
- ImageCms.applyProfile() to convert images without the need to re-compute
- the lookup table for the transform.
-
- The reason pyCMS returns a class object rather than a handle directly
- to the transform is that it needs to keep track of the PIL input/output
- modes that the transform is meant for. These attributes are stored in
- the ``inMode`` and ``outMode`` attributes of the object (which can be
- manually overridden if you really want to, but I don't know of any
- time that would be of use, or would even work).
-
- :param inputProfile: String, as a valid filename path to the ICC input
- profile you wish to use for this transform, or a profile object
- :param outputProfile: String, as a valid filename path to the ICC output
- profile you wish to use for this transform, or a profile object
- :param inMode: String, as a valid PIL mode that the appropriate profile
- also supports (i.e. "RGB", "RGBA", "CMYK", etc.)
- :param outMode: String, as a valid PIL mode that the appropriate profile
- also supports (i.e. "RGB", "RGBA", "CMYK", etc.)
- :param renderingIntent: Integer (0-3) specifying the rendering intent you
- wish to use for the transform
-
- ImageCms.Intent.PERCEPTUAL = 0 (DEFAULT)
- ImageCms.Intent.RELATIVE_COLORIMETRIC = 1
- ImageCms.Intent.SATURATION = 2
- ImageCms.Intent.ABSOLUTE_COLORIMETRIC = 3
-
- see the pyCMS documentation for details on rendering intents and what
- they do.
- :param flags: Integer (0-...) specifying additional flags
- :returns: A CmsTransform class object.
- :exception PyCMSError:
- """
-
- if not isinstance(renderingIntent, int) or not (0 <= renderingIntent <= 3):
- msg = "renderingIntent must be an integer between 0 and 3"
- raise PyCMSError(msg)
-
- if not isinstance(flags, int) or not (0 <= flags <= _MAX_FLAG):
- msg = "flags must be an integer between 0 and %s" + _MAX_FLAG
- raise PyCMSError(msg)
-
- try:
- if not isinstance(inputProfile, ImageCmsProfile):
- inputProfile = ImageCmsProfile(inputProfile)
- if not isinstance(outputProfile, ImageCmsProfile):
- outputProfile = ImageCmsProfile(outputProfile)
- return ImageCmsTransform(
- inputProfile, outputProfile, inMode, outMode, renderingIntent, flags=flags
- )
- except (OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def buildProofTransform(
- inputProfile,
- outputProfile,
- proofProfile,
- inMode,
- outMode,
- renderingIntent=Intent.PERCEPTUAL,
- proofRenderingIntent=Intent.ABSOLUTE_COLORIMETRIC,
- flags=FLAGS["SOFTPROOFING"],
-):
- """
- (pyCMS) Builds an ICC transform mapping from the ``inputProfile`` to the
- ``outputProfile``, but tries to simulate the result that would be
- obtained on the ``proofProfile`` device.
-
- If the input, output, or proof profiles specified are not valid
- filenames, a :exc:`PyCMSError` will be raised.
-
- If an error occurs during creation of the transform,
- a :exc:`PyCMSError` will be raised.
-
- If ``inMode`` or ``outMode`` are not a mode supported by the ``outputProfile``
- (or by pyCMS), a :exc:`PyCMSError` will be raised.
-
- This function builds and returns an ICC transform from the ``inputProfile``
- to the ``outputProfile``, but tries to simulate the result that would be
- obtained on the ``proofProfile`` device using ``renderingIntent`` and
- ``proofRenderingIntent`` to determine what to do with out-of-gamut
- colors. This is known as "soft-proofing". It will ONLY work for
- converting images that are in ``inMode`` to images that are in outMode
- color format (PIL mode, i.e. "RGB", "RGBA", "CMYK", etc.).
-
- Usage of the resulting transform object is exactly the same as with
- ImageCms.buildTransform().
-
- Proof profiling is generally used when using an output device to get a
- good idea of what the final printed/displayed image would look like on
- the ``proofProfile`` device when it's quicker and easier to use the
- output device for judging color. Generally, this means that the
- output device is a monitor, or a dye-sub printer (etc.), and the simulated
- device is something more expensive, complicated, or time consuming
- (making it difficult to make a real print for color judgement purposes).
-
- Soft-proofing basically functions by adjusting the colors on the
- output device to match the colors of the device being simulated. However,
- when the simulated device has a much wider gamut than the output
- device, you may obtain marginal results.
-
- :param inputProfile: String, as a valid filename path to the ICC input
- profile you wish to use for this transform, or a profile object
- :param outputProfile: String, as a valid filename path to the ICC output
- (monitor, usually) profile you wish to use for this transform, or a
- profile object
- :param proofProfile: String, as a valid filename path to the ICC proof
- profile you wish to use for this transform, or a profile object
- :param inMode: String, as a valid PIL mode that the appropriate profile
- also supports (i.e. "RGB", "RGBA", "CMYK", etc.)
- :param outMode: String, as a valid PIL mode that the appropriate profile
- also supports (i.e. "RGB", "RGBA", "CMYK", etc.)
- :param renderingIntent: Integer (0-3) specifying the rendering intent you
- wish to use for the input->proof (simulated) transform
-
- ImageCms.Intent.PERCEPTUAL = 0 (DEFAULT)
- ImageCms.Intent.RELATIVE_COLORIMETRIC = 1
- ImageCms.Intent.SATURATION = 2
- ImageCms.Intent.ABSOLUTE_COLORIMETRIC = 3
-
- see the pyCMS documentation for details on rendering intents and what
- they do.
- :param proofRenderingIntent: Integer (0-3) specifying the rendering intent
- you wish to use for proof->output transform
-
- ImageCms.Intent.PERCEPTUAL = 0 (DEFAULT)
- ImageCms.Intent.RELATIVE_COLORIMETRIC = 1
- ImageCms.Intent.SATURATION = 2
- ImageCms.Intent.ABSOLUTE_COLORIMETRIC = 3
-
- see the pyCMS documentation for details on rendering intents and what
- they do.
- :param flags: Integer (0-...) specifying additional flags
- :returns: A CmsTransform class object.
- :exception PyCMSError:
- """
-
- if not isinstance(renderingIntent, int) or not (0 <= renderingIntent <= 3):
- msg = "renderingIntent must be an integer between 0 and 3"
- raise PyCMSError(msg)
-
- if not isinstance(flags, int) or not (0 <= flags <= _MAX_FLAG):
- msg = "flags must be an integer between 0 and %s" + _MAX_FLAG
- raise PyCMSError(msg)
-
- try:
- if not isinstance(inputProfile, ImageCmsProfile):
- inputProfile = ImageCmsProfile(inputProfile)
- if not isinstance(outputProfile, ImageCmsProfile):
- outputProfile = ImageCmsProfile(outputProfile)
- if not isinstance(proofProfile, ImageCmsProfile):
- proofProfile = ImageCmsProfile(proofProfile)
- return ImageCmsTransform(
- inputProfile,
- outputProfile,
- inMode,
- outMode,
- renderingIntent,
- proofProfile,
- proofRenderingIntent,
- flags,
- )
- except (OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-buildTransformFromOpenProfiles = buildTransform
-buildProofTransformFromOpenProfiles = buildProofTransform
-
-
-def applyTransform(im, transform, inPlace=False):
- """
- (pyCMS) Applies a transform to a given image.
-
- If ``im.mode != transform.inMode``, a :exc:`PyCMSError` is raised.
-
- If ``inPlace`` is ``True`` and ``transform.inMode != transform.outMode``, a
- :exc:`PyCMSError` is raised.
-
- If ``im.mode``, ``transform.inMode`` or ``transform.outMode`` is not
- supported by pyCMSdll or the profiles you used for the transform, a
- :exc:`PyCMSError` is raised.
-
- If an error occurs while the transform is being applied,
- a :exc:`PyCMSError` is raised.
-
- This function applies a pre-calculated transform (from
- ImageCms.buildTransform() or ImageCms.buildTransformFromOpenProfiles())
- to an image. The transform can be used for multiple images, saving
- considerable calculation time if doing the same conversion multiple times.
-
- If you want to modify im in-place instead of receiving a new image as
- the return value, set ``inPlace`` to ``True``. This can only be done if
- ``transform.inMode`` and ``transform.outMode`` are the same, because we can't
- change the mode in-place (the buffer sizes for some modes are
- different). The default behavior is to return a new :py:class:`~PIL.Image.Image`
- object of the same dimensions in mode ``transform.outMode``.
-
- :param im: An :py:class:`~PIL.Image.Image` object, and im.mode must be the same
- as the ``inMode`` supported by the transform.
- :param transform: A valid CmsTransform class object
- :param inPlace: Bool. If ``True``, ``im`` is modified in place and ``None`` is
- returned, if ``False``, a new :py:class:`~PIL.Image.Image` object with the
- transform applied is returned (and ``im`` is not changed). The default is
- ``False``.
- :returns: Either ``None``, or a new :py:class:`~PIL.Image.Image` object,
- depending on the value of ``inPlace``. The profile will be returned in
- the image's ``info['icc_profile']``.
- :exception PyCMSError:
- """
-
- try:
- if inPlace:
- transform.apply_in_place(im)
- imOut = None
- else:
- imOut = transform.apply(im)
- except (TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
- return imOut
-
-
-def createProfile(colorSpace, colorTemp=-1):
- """
- (pyCMS) Creates a profile.
-
- If colorSpace not in ``["LAB", "XYZ", "sRGB"]``,
- a :exc:`PyCMSError` is raised.
-
- If using LAB and ``colorTemp`` is not a positive integer,
- a :exc:`PyCMSError` is raised.
-
- If an error occurs while creating the profile,
- a :exc:`PyCMSError` is raised.
-
- Use this function to create common profiles on-the-fly instead of
- having to supply a profile on disk and knowing the path to it. It
- returns a normal CmsProfile object that can be passed to
- ImageCms.buildTransformFromOpenProfiles() to create a transform to apply
- to images.
-
- :param colorSpace: String, the color space of the profile you wish to
- create.
- Currently only "LAB", "XYZ", and "sRGB" are supported.
- :param colorTemp: Positive integer for the white point for the profile, in
- degrees Kelvin (i.e. 5000, 6500, 9600, etc.). The default is for D50
- illuminant if omitted (5000k). colorTemp is ONLY applied to LAB
- profiles, and is ignored for XYZ and sRGB.
- :returns: A CmsProfile class object
- :exception PyCMSError:
- """
-
- if colorSpace not in ["LAB", "XYZ", "sRGB"]:
- msg = (
- f"Color space not supported for on-the-fly profile creation ({colorSpace})"
- )
- raise PyCMSError(msg)
-
- if colorSpace == "LAB":
- try:
- colorTemp = float(colorTemp)
- except (TypeError, ValueError) as e:
- msg = f'Color temperature must be numeric, "{colorTemp}" not valid'
- raise PyCMSError(msg) from e
-
- try:
- return core.createProfile(colorSpace, colorTemp)
- except (TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def getProfileName(profile):
- """
-
- (pyCMS) Gets the internal product name for the given profile.
-
- If ``profile`` isn't a valid CmsProfile object or filename to a profile,
- a :exc:`PyCMSError` is raised If an error occurs while trying
- to obtain the name tag, a :exc:`PyCMSError` is raised.
-
- Use this function to obtain the INTERNAL name of the profile (stored
- in an ICC tag in the profile itself), usually the one used when the
- profile was originally created. Sometimes this tag also contains
- additional information supplied by the creator.
-
- :param profile: EITHER a valid CmsProfile object, OR a string of the
- filename of an ICC profile.
- :returns: A string containing the internal name of the profile as stored
- in an ICC tag.
- :exception PyCMSError:
- """
-
- try:
- # add an extra newline to preserve pyCMS compatibility
- if not isinstance(profile, ImageCmsProfile):
- profile = ImageCmsProfile(profile)
- # do it in python, not c.
- # // name was "%s - %s" (model, manufacturer) || Description ,
- # // but if the Model and Manufacturer were the same or the model
- # // was long, Just the model, in 1.x
- model = profile.profile.model
- manufacturer = profile.profile.manufacturer
-
- if not (model or manufacturer):
- return (profile.profile.profile_description or "") + "\n"
- if not manufacturer or len(model) > 30:
- return model + "\n"
- return f"{model} - {manufacturer}\n"
-
- except (AttributeError, OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def getProfileInfo(profile):
- """
- (pyCMS) Gets the internal product information for the given profile.
-
- If ``profile`` isn't a valid CmsProfile object or filename to a profile,
- a :exc:`PyCMSError` is raised.
-
- If an error occurs while trying to obtain the info tag,
- a :exc:`PyCMSError` is raised.
-
- Use this function to obtain the information stored in the profile's
- info tag. This often contains details about the profile, and how it
- was created, as supplied by the creator.
-
- :param profile: EITHER a valid CmsProfile object, OR a string of the
- filename of an ICC profile.
- :returns: A string containing the internal profile information stored in
- an ICC tag.
- :exception PyCMSError:
- """
-
- try:
- if not isinstance(profile, ImageCmsProfile):
- profile = ImageCmsProfile(profile)
- # add an extra newline to preserve pyCMS compatibility
- # Python, not C. the white point bits weren't working well,
- # so skipping.
- # info was description \r\n\r\n copyright \r\n\r\n K007 tag \r\n\r\n whitepoint
- description = profile.profile.profile_description
- cpright = profile.profile.copyright
- arr = []
- for elt in (description, cpright):
- if elt:
- arr.append(elt)
- return "\r\n\r\n".join(arr) + "\r\n\r\n"
-
- except (AttributeError, OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def getProfileCopyright(profile):
- """
- (pyCMS) Gets the copyright for the given profile.
-
- If ``profile`` isn't a valid CmsProfile object or filename to a profile, a
- :exc:`PyCMSError` is raised.
-
- If an error occurs while trying to obtain the copyright tag,
- a :exc:`PyCMSError` is raised.
-
- Use this function to obtain the information stored in the profile's
- copyright tag.
-
- :param profile: EITHER a valid CmsProfile object, OR a string of the
- filename of an ICC profile.
- :returns: A string containing the internal profile information stored in
- an ICC tag.
- :exception PyCMSError:
- """
- try:
- # add an extra newline to preserve pyCMS compatibility
- if not isinstance(profile, ImageCmsProfile):
- profile = ImageCmsProfile(profile)
- return (profile.profile.copyright or "") + "\n"
- except (AttributeError, OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def getProfileManufacturer(profile):
- """
- (pyCMS) Gets the manufacturer for the given profile.
-
- If ``profile`` isn't a valid CmsProfile object or filename to a profile, a
- :exc:`PyCMSError` is raised.
-
- If an error occurs while trying to obtain the manufacturer tag, a
- :exc:`PyCMSError` is raised.
-
- Use this function to obtain the information stored in the profile's
- manufacturer tag.
-
- :param profile: EITHER a valid CmsProfile object, OR a string of the
- filename of an ICC profile.
- :returns: A string containing the internal profile information stored in
- an ICC tag.
- :exception PyCMSError:
- """
- try:
- # add an extra newline to preserve pyCMS compatibility
- if not isinstance(profile, ImageCmsProfile):
- profile = ImageCmsProfile(profile)
- return (profile.profile.manufacturer or "") + "\n"
- except (AttributeError, OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def getProfileModel(profile):
- """
- (pyCMS) Gets the model for the given profile.
-
- If ``profile`` isn't a valid CmsProfile object or filename to a profile, a
- :exc:`PyCMSError` is raised.
-
- If an error occurs while trying to obtain the model tag,
- a :exc:`PyCMSError` is raised.
-
- Use this function to obtain the information stored in the profile's
- model tag.
-
- :param profile: EITHER a valid CmsProfile object, OR a string of the
- filename of an ICC profile.
- :returns: A string containing the internal profile information stored in
- an ICC tag.
- :exception PyCMSError:
- """
-
- try:
- # add an extra newline to preserve pyCMS compatibility
- if not isinstance(profile, ImageCmsProfile):
- profile = ImageCmsProfile(profile)
- return (profile.profile.model or "") + "\n"
- except (AttributeError, OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def getProfileDescription(profile):
- """
- (pyCMS) Gets the description for the given profile.
-
- If ``profile`` isn't a valid CmsProfile object or filename to a profile, a
- :exc:`PyCMSError` is raised.
-
- If an error occurs while trying to obtain the description tag,
- a :exc:`PyCMSError` is raised.
-
- Use this function to obtain the information stored in the profile's
- description tag.
-
- :param profile: EITHER a valid CmsProfile object, OR a string of the
- filename of an ICC profile.
- :returns: A string containing the internal profile information stored in an
- ICC tag.
- :exception PyCMSError:
- """
-
- try:
- # add an extra newline to preserve pyCMS compatibility
- if not isinstance(profile, ImageCmsProfile):
- profile = ImageCmsProfile(profile)
- return (profile.profile.profile_description or "") + "\n"
- except (AttributeError, OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def getDefaultIntent(profile):
- """
- (pyCMS) Gets the default intent name for the given profile.
-
- If ``profile`` isn't a valid CmsProfile object or filename to a profile, a
- :exc:`PyCMSError` is raised.
-
- If an error occurs while trying to obtain the default intent, a
- :exc:`PyCMSError` is raised.
-
- Use this function to determine the default (and usually best optimized)
- rendering intent for this profile. Most profiles support multiple
- rendering intents, but are intended mostly for one type of conversion.
- If you wish to use a different intent than returned, use
- ImageCms.isIntentSupported() to verify it will work first.
-
- :param profile: EITHER a valid CmsProfile object, OR a string of the
- filename of an ICC profile.
- :returns: Integer 0-3 specifying the default rendering intent for this
- profile.
-
- ImageCms.Intent.PERCEPTUAL = 0 (DEFAULT)
- ImageCms.Intent.RELATIVE_COLORIMETRIC = 1
- ImageCms.Intent.SATURATION = 2
- ImageCms.Intent.ABSOLUTE_COLORIMETRIC = 3
-
- see the pyCMS documentation for details on rendering intents and what
- they do.
- :exception PyCMSError:
- """
-
- try:
- if not isinstance(profile, ImageCmsProfile):
- profile = ImageCmsProfile(profile)
- return profile.profile.rendering_intent
- except (AttributeError, OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def isIntentSupported(profile, intent, direction):
- """
- (pyCMS) Checks if a given intent is supported.
-
- Use this function to verify that you can use your desired
- ``intent`` with ``profile``, and that ``profile`` can be used for the
- input/output/proof profile as you desire.
-
- Some profiles are created specifically for one "direction", can cannot
- be used for others. Some profiles can only be used for certain
- rendering intents, so it's best to either verify this before trying
- to create a transform with them (using this function), or catch the
- potential :exc:`PyCMSError` that will occur if they don't
- support the modes you select.
-
- :param profile: EITHER a valid CmsProfile object, OR a string of the
- filename of an ICC profile.
- :param intent: Integer (0-3) specifying the rendering intent you wish to
- use with this profile
-
- ImageCms.Intent.PERCEPTUAL = 0 (DEFAULT)
- ImageCms.Intent.RELATIVE_COLORIMETRIC = 1
- ImageCms.Intent.SATURATION = 2
- ImageCms.Intent.ABSOLUTE_COLORIMETRIC = 3
-
- see the pyCMS documentation for details on rendering intents and what
- they do.
- :param direction: Integer specifying if the profile is to be used for
- input, output, or proof
-
- INPUT = 0 (or use ImageCms.Direction.INPUT)
- OUTPUT = 1 (or use ImageCms.Direction.OUTPUT)
- PROOF = 2 (or use ImageCms.Direction.PROOF)
-
- :returns: 1 if the intent/direction are supported, -1 if they are not.
- :exception PyCMSError:
- """
-
- try:
- if not isinstance(profile, ImageCmsProfile):
- profile = ImageCmsProfile(profile)
- # FIXME: I get different results for the same data w. different
- # compilers. Bug in LittleCMS or in the binding?
- if profile.profile.is_intent_supported(intent, direction):
- return 1
- else:
- return -1
- except (AttributeError, OSError, TypeError, ValueError) as v:
- raise PyCMSError(v) from v
-
-
-def versions():
- """
- (pyCMS) Fetches versions.
- """
-
- return VERSION, core.littlecms_version, sys.version.split()[0], Image.__version__
diff --git a/spaces/lambdalabs/LambdaSuperRes/KAIR/main_train_usrnet.py b/spaces/lambdalabs/LambdaSuperRes/KAIR/main_train_usrnet.py
deleted file mode 100644
index b3d345999c1a54070a0303aa3d13e0501ecb462a..0000000000000000000000000000000000000000
--- a/spaces/lambdalabs/LambdaSuperRes/KAIR/main_train_usrnet.py
+++ /dev/null
@@ -1,230 +0,0 @@
-import os.path
-import math
-import argparse
-import time
-import random
-import numpy as np
-from collections import OrderedDict
-import logging
-from torch.utils.data import DataLoader
-import torch
-
-from utils import utils_logger
-from utils import utils_image as util
-from utils import utils_option as option
-from utils import utils_sisr as sisr
-
-from data.select_dataset import define_Dataset
-from models.select_model import define_Model
-
-
-'''
-# --------------------------------------------
-# training code for USRNet
-# --------------------------------------------
-# Kai Zhang (cskaizhang@gmail.com)
-# github: https://github.com/cszn/KAIR
-# https://github.com/cszn/USRNet
-#
-# Reference:
-@inproceedings{zhang2020deep,
- title={Deep unfolding network for image super-resolution},
- author={Zhang, Kai and Van Gool, Luc and Timofte, Radu},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- pages={3217--3226},
- year={2020}
-}
-# --------------------------------------------
-'''
-
-
-def main(json_path='options/train_usrnet.json'):
-
- '''
- # ----------------------------------------
- # Step--1 (prepare opt)
- # ----------------------------------------
- '''
-
- parser = argparse.ArgumentParser()
- parser.add_argument('-opt', type=str, default=json_path, help='Path to option JSON file.')
-
- opt = option.parse(parser.parse_args().opt, is_train=True)
- util.mkdirs((path for key, path in opt['path'].items() if 'pretrained' not in key))
-
- # ----------------------------------------
- # update opt
- # ----------------------------------------
- # -->-->-->-->-->-->-->-->-->-->-->-->-->-
- init_iter, init_path_G = option.find_last_checkpoint(opt['path']['models'], net_type='G')
- opt['path']['pretrained_netG'] = init_path_G
- current_step = init_iter
-
- border = opt['scale']
- # --<--<--<--<--<--<--<--<--<--<--<--<--<-
-
- # ----------------------------------------
- # save opt to a '../option.json' file
- # ----------------------------------------
- option.save(opt)
-
- # ----------------------------------------
- # return None for missing key
- # ----------------------------------------
- opt = option.dict_to_nonedict(opt)
-
- # ----------------------------------------
- # configure logger
- # ----------------------------------------
- logger_name = 'train'
- utils_logger.logger_info(logger_name, os.path.join(opt['path']['log'], logger_name+'.log'))
- logger = logging.getLogger(logger_name)
- logger.info(option.dict2str(opt))
-
-
- # ----------------------------------------
- # seed
- # ----------------------------------------
- seed = opt['train']['manual_seed']
- if seed is None:
- seed = random.randint(1, 10000)
- logger.info('Random seed: {}'.format(seed))
- random.seed(seed)
- np.random.seed(seed)
- torch.manual_seed(seed)
- torch.cuda.manual_seed_all(seed)
-
- '''
- # ----------------------------------------
- # Step--2 (creat dataloader)
- # ----------------------------------------
- '''
-
- # ----------------------------------------
- # 1) create_dataset
- # 2) creat_dataloader for train and test
- # ----------------------------------------
- for phase, dataset_opt in opt['datasets'].items():
- if phase == 'train':
- train_set = define_Dataset(dataset_opt)
- train_size = int(math.ceil(len(train_set) / dataset_opt['dataloader_batch_size']))
- logger.info('Number of train images: {:,d}, iters: {:,d}'.format(len(train_set), train_size))
- train_loader = DataLoader(train_set,
- batch_size=dataset_opt['dataloader_batch_size'],
- shuffle=dataset_opt['dataloader_shuffle'],
- num_workers=dataset_opt['dataloader_num_workers'],
- drop_last=True,
- pin_memory=True)
- elif phase == 'test':
- test_set = define_Dataset(dataset_opt)
- test_loader = DataLoader(test_set, batch_size=1,
- shuffle=False, num_workers=1,
- drop_last=False, pin_memory=True)
- else:
- raise NotImplementedError("Phase [%s] is not recognized." % phase)
-
- '''
- # ----------------------------------------
- # Step--3 (initialize model)
- # ----------------------------------------
- '''
-
- model = define_Model(opt)
-
- logger.info(model.info_network())
- model.init_train()
- logger.info(model.info_params())
-
- '''
- # ----------------------------------------
- # Step--4 (main training)
- # ----------------------------------------
- '''
-
- for epoch in range(1000000): # keep running
- for i, train_data in enumerate(train_loader):
-
- current_step += 1
-
- # -------------------------------
- # 1) update learning rate
- # -------------------------------
- model.update_learning_rate(current_step)
-
- # -------------------------------
- # 2) feed patch pairs
- # -------------------------------
- model.feed_data(train_data)
-
- # -------------------------------
- # 3) optimize parameters
- # -------------------------------
- model.optimize_parameters(current_step)
-
- # -------------------------------
- # 4) training information
- # -------------------------------
- if current_step % opt['train']['checkpoint_print'] == 0:
- logs = model.current_log() # such as loss
- message = ' '.format(epoch, current_step, model.current_learning_rate())
- for k, v in logs.items(): # merge log information into message
- message += '{:s}: {:.3e} '.format(k, v)
- logger.info(message)
-
- # -------------------------------
- # 5) save model
- # -------------------------------
- if current_step % opt['train']['checkpoint_save'] == 0:
- logger.info('Saving the model.')
- model.save(current_step)
-
- # -------------------------------
- # 6) testing
- # -------------------------------
- if current_step % opt['train']['checkpoint_test'] == 0:
-
- avg_psnr = 0.0
- idx = 0
-
- for test_data in test_loader:
- idx += 1
- image_name_ext = os.path.basename(test_data['L_path'][0])
- img_name, ext = os.path.splitext(image_name_ext)
-
- img_dir = os.path.join(opt['path']['images'], img_name)
- util.mkdir(img_dir)
-
- model.feed_data(test_data)
- model.test()
-
- visuals = model.current_visuals()
- E_img = util.tensor2uint(visuals['E'])
- H_img = util.tensor2uint(visuals['H'])
-
- # -----------------------
- # save estimated image E
- # -----------------------
- save_img_path = os.path.join(img_dir, '{:s}_{:d}.png'.format(img_name, current_step))
- util.imsave(E_img, save_img_path)
-
- # -----------------------
- # calculate PSNR
- # -----------------------
- current_psnr = util.calculate_psnr(E_img, H_img, border=border)
-
- logger.info('{:->4d}--> {:>10s} | {:<4.2f}dB'.format(idx, image_name_ext, current_psnr))
-
- avg_psnr += current_psnr
-
- avg_psnr = avg_psnr / idx
-
- # testing log
- logger.info(' 0 and len(user_queue_map) >= MAX_QUEUE_SIZE:
- print("Server is full")
- await websocket.send_json({"status": "error", "message": "Server is full"})
- await websocket.close()
- return
-
- try:
- uid = str(uuid.uuid4())
- print(f"New user connected: {uid}")
- await websocket.send_json(
- {"status": "success", "message": "Connected", "userId": uid}
- )
- user_queue_map[uid] = {"queue": asyncio.Queue()}
- await websocket.send_json(
- {"status": "start", "message": "Start Streaming", "userId": uid}
- )
- await handle_websocket_data(websocket, uid)
- except WebSocketDisconnect as e:
- logging.error(f"WebSocket Error: {e}, {uid}")
- traceback.print_exc()
- finally:
- print(f"User disconnected: {uid}")
- queue_value = user_queue_map.pop(uid, None)
- queue = queue_value.get("queue", None)
- if queue:
- while not queue.empty():
- try:
- queue.get_nowait()
- except asyncio.QueueEmpty:
- continue
-
-
-@app.get("/queue_size")
-async def get_queue_size():
- queue_size = len(user_queue_map)
- return JSONResponse({"queue_size": queue_size})
-
-
-@app.get("/stream/{user_id}")
-async def stream(user_id: uuid.UUID):
- uid = str(user_id)
- try:
- user_queue = user_queue_map[uid]
- queue = user_queue["queue"]
-
- async def generate():
- last_prompt: str = None
- prompt_embeds: torch.Tensor = None
- while True:
- data = await queue.get()
- input_image = data["image"]
- params = data["params"]
- if input_image is None:
- continue
- # avoid recalculate prompt embeds
- if last_prompt != params.prompt:
- print("new prompt")
- prompt_embeds = compel_proc(params.prompt)
- last_prompt = params.prompt
-
- image = predict(
- input_image,
- params,
- prompt_embeds,
- )
- if image is None:
- continue
- frame_data = io.BytesIO()
- image.save(frame_data, format="JPEG")
- frame_data = frame_data.getvalue()
- if frame_data is not None and len(frame_data) > 0:
- yield b"--frame\r\nContent-Type: image/jpeg\r\n\r\n" + frame_data + b"\r\n"
-
- await asyncio.sleep(1.0 / 120.0)
-
- return StreamingResponse(
- generate(), media_type="multipart/x-mixed-replace;boundary=frame"
- )
- except Exception as e:
- logging.error(f"Streaming Error: {e}, {user_queue_map}")
- traceback.print_exc()
- return HTTPException(status_code=404, detail="User not found")
-
-
-async def handle_websocket_data(websocket: WebSocket, user_id: uuid.UUID):
- uid = str(user_id)
- user_queue = user_queue_map[uid]
- queue = user_queue["queue"]
- if not queue:
- return HTTPException(status_code=404, detail="User not found")
- last_time = time.time()
- try:
- while True:
- data = await websocket.receive_bytes()
- params = await websocket.receive_json()
- params = InputParams(**params)
- pil_image = Image.open(io.BytesIO(data))
-
- while not queue.empty():
- try:
- queue.get_nowait()
- except asyncio.QueueEmpty:
- continue
- await queue.put({"image": pil_image, "params": params})
- if TIMEOUT > 0 and time.time() - last_time > TIMEOUT:
- await websocket.send_json(
- {
- "status": "timeout",
- "message": "Your session has ended",
- "userId": uid,
- }
- )
- await websocket.close()
- return
-
- except Exception as e:
- logging.error(f"Error: {e}")
- traceback.print_exc()
-
-
-@app.get("/", response_class=HTMLResponse)
-async def root():
- return FileResponse("./static/controlnetlora.html")
diff --git a/spaces/lazyboy450/RVCv2-Genshin/lib/infer_pack/models.py b/spaces/lazyboy450/RVCv2-Genshin/lib/infer_pack/models.py
deleted file mode 100644
index 44c08d361bcb13b84b38dc29beff5cdaddad4ea2..0000000000000000000000000000000000000000
--- a/spaces/lazyboy450/RVCv2-Genshin/lib/infer_pack/models.py
+++ /dev/null
@@ -1,1124 +0,0 @@
-import math, pdb, os
-from time import time as ttime
-import torch
-from torch import nn
-from torch.nn import functional as F
-from lib.infer_pack import modules
-from lib.infer_pack import attentions
-from lib.infer_pack import commons
-from lib.infer_pack.commons import init_weights, get_padding
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-from lib.infer_pack.commons import init_weights
-import numpy as np
-from lib.infer_pack import commons
-
-
-class TextEncoder256(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(256, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return m, logs, x_mask
-
-
-class TextEncoder768(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(768, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return m, logs, x_mask
-
-
-class ResidualCouplingBlock(nn.Module):
- def __init__(
- self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- n_flows=4,
- gin_channels=0,
- ):
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.flows = nn.ModuleList()
- for i in range(n_flows):
- self.flows.append(
- modules.ResidualCouplingLayer(
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- mean_only=True,
- )
- )
- self.flows.append(modules.Flip())
-
- def forward(self, x, x_mask, g=None, reverse=False):
- if not reverse:
- for flow in self.flows:
- x, _ = flow(x, x_mask, g=g, reverse=reverse)
- else:
- for flow in reversed(self.flows):
- x = flow(x, x_mask, g=g, reverse=reverse)
- return x
-
- def remove_weight_norm(self):
- for i in range(self.n_flows):
- self.flows[i * 2].remove_weight_norm()
-
-
-class PosteriorEncoder(nn.Module):
- def __init__(
- self,
- in_channels,
- out_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
-
- self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
- self.enc = modules.WN(
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths, g=None):
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.pre(x) * x_mask
- x = self.enc(x, x_mask, g=g)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
- def remove_weight_norm(self):
- self.enc.remove_weight_norm()
-
-
-class Generator(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=0,
- ):
- super(Generator, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- def forward(self, x, g=None):
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
-
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-class SineGen(torch.nn.Module):
- """Definition of sine generator
- SineGen(samp_rate, harmonic_num = 0,
- sine_amp = 0.1, noise_std = 0.003,
- voiced_threshold = 0,
- flag_for_pulse=False)
- samp_rate: sampling rate in Hz
- harmonic_num: number of harmonic overtones (default 0)
- sine_amp: amplitude of sine-wavefrom (default 0.1)
- noise_std: std of Gaussian noise (default 0.003)
- voiced_thoreshold: F0 threshold for U/V classification (default 0)
- flag_for_pulse: this SinGen is used inside PulseGen (default False)
- Note: when flag_for_pulse is True, the first time step of a voiced
- segment is always sin(np.pi) or cos(0)
- """
-
- def __init__(
- self,
- samp_rate,
- harmonic_num=0,
- sine_amp=0.1,
- noise_std=0.003,
- voiced_threshold=0,
- flag_for_pulse=False,
- ):
- super(SineGen, self).__init__()
- self.sine_amp = sine_amp
- self.noise_std = noise_std
- self.harmonic_num = harmonic_num
- self.dim = self.harmonic_num + 1
- self.sampling_rate = samp_rate
- self.voiced_threshold = voiced_threshold
-
- def _f02uv(self, f0):
- # generate uv signal
- uv = torch.ones_like(f0)
- uv = uv * (f0 > self.voiced_threshold)
- return uv
-
- def forward(self, f0, upp):
- """sine_tensor, uv = forward(f0)
- input F0: tensor(batchsize=1, length, dim=1)
- f0 for unvoiced steps should be 0
- output sine_tensor: tensor(batchsize=1, length, dim)
- output uv: tensor(batchsize=1, length, 1)
- """
- with torch.no_grad():
- f0 = f0[:, None].transpose(1, 2)
- f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
- # fundamental component
- f0_buf[:, :, 0] = f0[:, :, 0]
- for idx in np.arange(self.harmonic_num):
- f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
- idx + 2
- ) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
- rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化
- rand_ini = torch.rand(
- f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
- )
- rand_ini[:, 0] = 0
- rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
- tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化
- tmp_over_one *= upp
- tmp_over_one = F.interpolate(
- tmp_over_one.transpose(2, 1),
- scale_factor=upp,
- mode="linear",
- align_corners=True,
- ).transpose(2, 1)
- rad_values = F.interpolate(
- rad_values.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(
- 2, 1
- ) #######
- tmp_over_one %= 1
- tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
- cumsum_shift = torch.zeros_like(rad_values)
- cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
- sine_waves = torch.sin(
- torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
- )
- sine_waves = sine_waves * self.sine_amp
- uv = self._f02uv(f0)
- uv = F.interpolate(
- uv.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(2, 1)
- noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
- noise = noise_amp * torch.randn_like(sine_waves)
- sine_waves = sine_waves * uv + noise
- return sine_waves, uv, noise
-
-
-class SourceModuleHnNSF(torch.nn.Module):
- """SourceModule for hn-nsf
- SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
- add_noise_std=0.003, voiced_threshod=0)
- sampling_rate: sampling_rate in Hz
- harmonic_num: number of harmonic above F0 (default: 0)
- sine_amp: amplitude of sine source signal (default: 0.1)
- add_noise_std: std of additive Gaussian noise (default: 0.003)
- note that amplitude of noise in unvoiced is decided
- by sine_amp
- voiced_threshold: threhold to set U/V given F0 (default: 0)
- Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
- F0_sampled (batchsize, length, 1)
- Sine_source (batchsize, length, 1)
- noise_source (batchsize, length 1)
- uv (batchsize, length, 1)
- """
-
- def __init__(
- self,
- sampling_rate,
- harmonic_num=0,
- sine_amp=0.1,
- add_noise_std=0.003,
- voiced_threshod=0,
- is_half=True,
- ):
- super(SourceModuleHnNSF, self).__init__()
-
- self.sine_amp = sine_amp
- self.noise_std = add_noise_std
- self.is_half = is_half
- # to produce sine waveforms
- self.l_sin_gen = SineGen(
- sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
- )
-
- # to merge source harmonics into a single excitation
- self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
- self.l_tanh = torch.nn.Tanh()
-
- def forward(self, x, upp=None):
- sine_wavs, uv, _ = self.l_sin_gen(x, upp)
- if self.is_half:
- sine_wavs = sine_wavs.half()
- sine_merge = self.l_tanh(self.l_linear(sine_wavs))
- return sine_merge, None, None # noise, uv
-
-
-class GeneratorNSF(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels,
- sr,
- is_half=False,
- ):
- super(GeneratorNSF, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
-
- self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates))
- self.m_source = SourceModuleHnNSF(
- sampling_rate=sr, harmonic_num=0, is_half=is_half
- )
- self.noise_convs = nn.ModuleList()
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- c_cur = upsample_initial_channel // (2 ** (i + 1))
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
- if i + 1 < len(upsample_rates):
- stride_f0 = np.prod(upsample_rates[i + 1 :])
- self.noise_convs.append(
- Conv1d(
- 1,
- c_cur,
- kernel_size=stride_f0 * 2,
- stride=stride_f0,
- padding=stride_f0 // 2,
- )
- )
- else:
- self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- self.upp = np.prod(upsample_rates)
-
- def forward(self, x, f0, g=None):
- har_source, noi_source, uv = self.m_source(f0, self.upp)
- har_source = har_source.transpose(1, 2)
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- x_source = self.noise_convs[i](har_source)
- x = x + x_source
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-sr2sr = {
- "32k": 32000,
- "40k": 40000,
- "48k": 48000,
-}
-
-
-class SynthesizerTrnMs256NSFsid(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr,
- **kwargs
- ):
- super().__init__()
- if type(sr) == type("strr"):
- sr = sr2sr[sr]
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- sr=sr,
- is_half=kwargs["is_half"],
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
- ): # 这里ds是id,[bs,1]
- # print(1,pitch.shape)#[bs,t]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- # print(-2,pitchf.shape,z_slice.shape)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs768NSFsid(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr,
- **kwargs
- ):
- super().__init__()
- if type(sr) == type("strr"):
- sr = sr2sr[sr]
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder768(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- sr=sr,
- is_half=kwargs["is_half"],
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, y, y_lengths, ds
- ): # 这里ds是id,[bs,1]
- # print(1,pitch.shape)#[bs,t]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- # print(-1,pitchf.shape,ids_slice,self.segment_size,self.hop_length,self.segment_size//self.hop_length)
- pitchf = commons.slice_segments2(pitchf, ids_slice, self.segment_size)
- # print(-2,pitchf.shape,z_slice.shape)
- o = self.dec(z_slice, pitchf, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, pitch, nsff0, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs256NSFsid_nono(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr=None,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=False,
- )
- self.dec = Generator(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- o = self.dec(z_slice, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class SynthesizerTrnMs768NSFsid_nono(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr=None,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder768(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=False,
- )
- self.dec = Generator(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(self, phone, phone_lengths, y, y_lengths, ds): # 这里ds是id,[bs,1]
- g = self.emb_g(ds).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z, m_q, logs_q, y_mask = self.enc_q(y, y_lengths, g=g)
- z_p = self.flow(z, y_mask, g=g)
- z_slice, ids_slice = commons.rand_slice_segments(
- z, y_lengths, self.segment_size
- )
- o = self.dec(z_slice, g=g)
- return o, ids_slice, x_mask, y_mask, (z, z_p, m_p, logs_p, m_q, logs_q)
-
- def infer(self, phone, phone_lengths, sid, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, None, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * torch.randn_like(m_p) * 0.66666) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], g=g)
- return o, x_mask, (z, z_p, m_p, logs_p)
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminator, self).__init__()
- periods = [2, 3, 5, 7, 11, 17]
- # periods = [3, 5, 7, 11, 17, 23, 37]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [
- DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
- ]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = [] #
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- # for j in range(len(fmap_r)):
- # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class MultiPeriodDiscriminatorV2(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminatorV2, self).__init__()
- # periods = [2, 3, 5, 7, 11, 17]
- periods = [2, 3, 5, 7, 11, 17, 23, 37]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [
- DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
- ]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = [] #
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- # for j in range(len(fmap_r)):
- # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(Conv1d(1, 16, 15, 1, padding=7)),
- norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
- norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ]
- )
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- self.use_spectral_norm = use_spectral_norm
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(
- Conv2d(
- 1,
- 32,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 32,
- 128,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 128,
- 512,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 512,
- 1024,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 1024,
- 1024,
- (kernel_size, 1),
- 1,
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- ]
- )
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
diff --git a/spaces/leilevy/bingo/src/components/tone-selector.tsx b/spaces/leilevy/bingo/src/components/tone-selector.tsx
deleted file mode 100644
index 5c6e464c91f564b895acd121f0a4a79ed9c5c356..0000000000000000000000000000000000000000
--- a/spaces/leilevy/bingo/src/components/tone-selector.tsx
+++ /dev/null
@@ -1,43 +0,0 @@
-import React from 'react'
-import { BingConversationStyle } from '@/lib/bots/bing/types'
-import { cn } from '@/lib/utils'
-
-type ToneItem = {
- type: BingConversationStyle,
- name: string
-}
-
-const ToneList: ToneItem[] = [
- { name: '有创造力', type: BingConversationStyle.Creative },
- { name: '更平衡', type: BingConversationStyle.Balanced },
- { name: '更精确', type: BingConversationStyle.Precise }
-]
-
-interface ToneSelectorProps {
- type: BingConversationStyle | ''
- onChange?: (type: BingConversationStyle) => void
-}
-
-export function ToneSelector({ type, onChange }: ToneSelectorProps) {
- return (
-
-
- 选择对话样式
-
-
-
- {
- ToneList.map(tone => (
- - onChange?.(tone.type)}>
-
-
- ))
- }
-
-
-
- {children}
-
-
-)
-AlertDialogPortal.displayName = AlertDialogPrimitive.Portal.displayName
-
-const AlertDialogOverlay = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, children, ...props }, ref) => (
-
-))
-AlertDialogOverlay.displayName = AlertDialogPrimitive.Overlay.displayName
-
-const AlertDialogContent = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, ...props }, ref) => (
-
-
-
-
-))
-AlertDialogContent.displayName = AlertDialogPrimitive.Content.displayName
-
-const AlertDialogHeader = ({
- className,
- ...props
-}: React.HTMLAttributes) => (
-
-)
-AlertDialogHeader.displayName = 'AlertDialogHeader'
-
-const AlertDialogFooter = ({
- className,
- ...props
-}: React.HTMLAttributes) => (
-
-)
-AlertDialogFooter.displayName = 'AlertDialogFooter'
-
-const AlertDialogTitle = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, ...props }, ref) => (
-
-))
-AlertDialogTitle.displayName = AlertDialogPrimitive.Title.displayName
-
-const AlertDialogDescription = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, ...props }, ref) => (
-
-))
-AlertDialogDescription.displayName =
- AlertDialogPrimitive.Description.displayName
-
-const AlertDialogAction = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, ...props }, ref) => (
-
-))
-AlertDialogAction.displayName = AlertDialogPrimitive.Action.displayName
-
-const AlertDialogCancel = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, ...props }, ref) => (
-
-))
-AlertDialogCancel.displayName = AlertDialogPrimitive.Cancel.displayName
-
-export {
- AlertDialog,
- AlertDialogTrigger,
- AlertDialogContent,
- AlertDialogHeader,
- AlertDialogFooter,
- AlertDialogTitle,
- AlertDialogDescription,
- AlertDialogAction,
- AlertDialogCancel
-}
diff --git a/spaces/lightli/bingo-newbing/src/pages/api/blob.ts b/spaces/lightli/bingo-newbing/src/pages/api/blob.ts
deleted file mode 100644
index fecd48031916b2284b8958892196e0a1ad420421..0000000000000000000000000000000000000000
--- a/spaces/lightli/bingo-newbing/src/pages/api/blob.ts
+++ /dev/null
@@ -1,40 +0,0 @@
-'use server'
-
-import { NextApiRequest, NextApiResponse } from 'next'
-import { Readable } from 'node:stream'
-import { fetch } from '@/lib/isomorphic'
-
-const API_DOMAIN = 'https://www.bing.com'
-
-export default async function handler(req: NextApiRequest, res: NextApiResponse) {
- try {
- const { bcid } = req.query
-
- const { headers, body } = await fetch(`${API_DOMAIN}/images/blob?bcid=${bcid}`,
- {
- method: 'GET',
- headers: {
- "sec-ch-ua": "\"Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"115\", \"Chromium\";v=\"115\"",
- "sec-ch-ua-mobile": "?0",
- "sec-ch-ua-platform": "\"Windows\"",
- "Referrer-Policy": "origin-when-cross-origin",
- },
- },
- )
-
- res.writeHead(200, {
- 'Content-Length': headers.get('content-length')!,
- 'Content-Type': headers.get('content-type')!,
- })
- // @ts-ignore
- return Readable.fromWeb(body!).pipe(res)
- } catch (e) {
- console.log('Error', e)
- return res.json({
- result: {
- value: 'UploadFailed',
- message: `${e}`
- }
- })
- }
-}
diff --git a/spaces/liliyRehtina/color/app.py b/spaces/liliyRehtina/color/app.py
deleted file mode 100644
index 6fc4b0e2f2b25b59e311bb61298bc879048fe800..0000000000000000000000000000000000000000
--- a/spaces/liliyRehtina/color/app.py
+++ /dev/null
@@ -1,82 +0,0 @@
-import gradio as gr
-import os, requests
-import numpy as np
-from inference import setup_model, colorize_grayscale, predict_anchors
-
-## local | remote
-RUN_MODE = "remote"
-if RUN_MODE != "local":
- os.system("wget https://huggingface.co/menghanxia/disco/resolve/main/disco-beta.pth.rar")
- os.rename("disco-beta.pth.rar", "./checkpoints/disco-beta.pth.rar")
- ## examples
-
- os.system("wget https://huggingface.co/menghanxia/disco/resolve/main/04.jpg")
-
-## step 1: set up model
-device = "cpu"
-checkpt_path = "checkpoints/disco-beta.pth.rar"
-colorizer, colorLabeler = setup_model(checkpt_path, device=device)
-
-def click_colorize(rgb_img, hint_img, n_anchors, is_high_res, is_editable):
- if hint_img is None:
- hint_img = rgb_img
- output = colorize_grayscale(colorizer, colorLabeler, rgb_img, hint_img, n_anchors, is_high_res, is_editable, device)
- return output
-
-def click_predanchors(rgb_img, n_anchors, is_high_res, is_editable):
- output = predict_anchors(colorizer, colorLabeler, rgb_img, n_anchors, is_high_res, is_editable, device)
- return output
-
-## step 2: configure interface
-def switch_states(is_checked):
- if is_checked:
- return gr.Image.update(visible=True), gr.Button.update(visible=True)
- else:
- return gr.Image.update(visible=False), gr.Button.update(visible=False)
-
-demo = gr.Blocks(title="DISCO")
-with demo:
- gr.HTML(value="""
- Раскрашивание черно-белых фотографий
- """)
-
- with gr.Row():
- with gr.Column():
- with gr.Row():
- Image_input = gr.Image(type="numpy", label="Input", interactive=True)
- Image_anchor = gr.Image(type="numpy", label="Anchor", tool="color-sketch", interactive=True, visible=False)
-
- with gr.Row():
- Num_anchor = gr.Number(type="int", value=8, label="Количество опорных точек (3~14)")
- Radio_resolution = gr.Radio(type="index", choices=["Low (256x256)", "Medium (512x512)", "High (1024x1024)"], \
- label="Область для раскрашивания кистью", value="Low (256x256)")
- with gr.Row():
- Ckeckbox_editable = gr.Checkbox(default=False, label='Загрузить редактор')
- Button_show_anchor = gr.Button(value="Predict anchors", visible=False)
- Button_run = gr.Button(value="Исполнить")
- with gr.Column():
- Image_output = gr.Image(type="numpy", label="Output").style(height=480)
-
- Ckeckbox_editable.change(fn=switch_states, inputs=Ckeckbox_editable, outputs=[Image_anchor, Button_show_anchor])
- Button_show_anchor.click(fn=click_predanchors, inputs=[Image_input, Num_anchor, Radio_resolution, Ckeckbox_editable], outputs=Image_anchor)
- Button_run.click(fn=click_colorize, inputs=[Image_input, Image_anchor, Num_anchor, Radio_resolution, Ckeckbox_editable], \
- outputs=Image_output)
-
- ## guiline
- gr.Markdown(value="""
-
- """)
- if RUN_MODE != "local":
- gr.Examples(examples=[
-
- ['04.jpg', 8, "Low (256x256)"],
- ],
- inputs=[Image_input,Num_anchor,Radio_resolution], outputs=[Image_output], label="Examples")
- gr.HTML(value="""
-
- """)
-
-if RUN_MODE == "local":
- demo.launch(server_name='9.134.253.83',server_port=7788)
-else:
- demo.launch()
\ No newline at end of file
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Boring Man Premium! Ativador Download [hack].md b/spaces/lincquiQcaudo/Top-20-Diffusion/Boring Man Premium! Ativador Download [hack].md
deleted file mode 100644
index c0c258ed68278da117e9d99a5c4d7910d47a270d..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Boring Man Premium! Ativador Download [hack].md
+++ /dev/null
@@ -1,6 +0,0 @@
-Boring Man: Premium! Ativador download [hack]
DOWNLOAD ->>->>->> https://bytlly.com/2uGycS
-
-Download the FxGuru Movie FX Director APK Android version. ... FxGuru Movie FX Director Unlock All Effects FxGuru Movie FX Director Unlock All Effects. ... all the effects in the modded version for free and premium .... fxguru all effects apk free download ... free download ... Boring Man: Premium! Ativador !! 1fdad05405
-
-
-
diff --git a/spaces/lj1995/vocal2guitar/infer_pack/commons.py b/spaces/lj1995/vocal2guitar/infer_pack/commons.py
deleted file mode 100644
index 54470986f37825b35d90d7efa7437d1c26b87215..0000000000000000000000000000000000000000
--- a/spaces/lj1995/vocal2guitar/infer_pack/commons.py
+++ /dev/null
@@ -1,166 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size * dilation - dilation) / 2)
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def kl_divergence(m_p, logs_p, m_q, logs_q):
- """KL(P||Q)"""
- kl = (logs_q - logs_p) - 0.5
- kl += (
- 0.5 * (torch.exp(2.0 * logs_p) + ((m_p - m_q) ** 2)) * torch.exp(-2.0 * logs_q)
- )
- return kl
-
-
-def rand_gumbel(shape):
- """Sample from the Gumbel distribution, protect from overflows."""
- uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
- return -torch.log(-torch.log(uniform_samples))
-
-
-def rand_gumbel_like(x):
- g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
- return g
-
-
-def slice_segments(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, :, idx_str:idx_end]
- return ret
-
-
-def slice_segments2(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, idx_str:idx_end]
- return ret
-
-
-def rand_slice_segments(x, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size + 1
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- return ret, ids_str
-
-
-def get_timing_signal_1d(length, channels, min_timescale=1.0, max_timescale=1.0e4):
- position = torch.arange(length, dtype=torch.float)
- num_timescales = channels // 2
- log_timescale_increment = math.log(float(max_timescale) / float(min_timescale)) / (
- num_timescales - 1
- )
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment
- )
- scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
- signal = F.pad(signal, [0, 0, 0, channels % 2])
- signal = signal.view(1, channels, length)
- return signal
-
-
-def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return x + signal.to(dtype=x.dtype, device=x.device)
-
-
-def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
-
-
-def subsequent_mask(length):
- mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
- return mask
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a + input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def shift_1d(x):
- x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
- return x
-
-
-def sequence_mask(length, max_length=None):
- if max_length is None:
- max_length = length.max()
- x = torch.arange(max_length, dtype=length.dtype, device=length.device)
- return x.unsqueeze(0) < length.unsqueeze(1)
-
-
-def generate_path(duration, mask):
- """
- duration: [b, 1, t_x]
- mask: [b, 1, t_y, t_x]
- """
- device = duration.device
-
- b, _, t_y, t_x = mask.shape
- cum_duration = torch.cumsum(duration, -1)
-
- cum_duration_flat = cum_duration.view(b * t_x)
- path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
- path = path.view(b, t_x, t_y)
- path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
- path = path.unsqueeze(1).transpose(2, 3) * mask
- return path
-
-
-def clip_grad_value_(parameters, clip_value, norm_type=2):
- if isinstance(parameters, torch.Tensor):
- parameters = [parameters]
- parameters = list(filter(lambda p: p.grad is not None, parameters))
- norm_type = float(norm_type)
- if clip_value is not None:
- clip_value = float(clip_value)
-
- total_norm = 0
- for p in parameters:
- param_norm = p.grad.data.norm(norm_type)
- total_norm += param_norm.item() ** norm_type
- if clip_value is not None:
- p.grad.data.clamp_(min=-clip_value, max=clip_value)
- total_norm = total_norm ** (1.0 / norm_type)
- return total_norm
diff --git a/spaces/lllqqq/so-vits-svc-models-pcr/diffusion/wavenet.py b/spaces/lllqqq/so-vits-svc-models-pcr/diffusion/wavenet.py
deleted file mode 100644
index 3d48c7eaaa0e8191b27a5d1890eb657cbcc0d143..0000000000000000000000000000000000000000
--- a/spaces/lllqqq/so-vits-svc-models-pcr/diffusion/wavenet.py
+++ /dev/null
@@ -1,108 +0,0 @@
-import math
-from math import sqrt
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch.nn import Mish
-
-
-class Conv1d(torch.nn.Conv1d):
- def __init__(self, *args, **kwargs):
- super().__init__(*args, **kwargs)
- nn.init.kaiming_normal_(self.weight)
-
-
-class SinusoidalPosEmb(nn.Module):
- def __init__(self, dim):
- super().__init__()
- self.dim = dim
-
- def forward(self, x):
- device = x.device
- half_dim = self.dim // 2
- emb = math.log(10000) / (half_dim - 1)
- emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
- emb = x[:, None] * emb[None, :]
- emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
- return emb
-
-
-class ResidualBlock(nn.Module):
- def __init__(self, encoder_hidden, residual_channels, dilation):
- super().__init__()
- self.residual_channels = residual_channels
- self.dilated_conv = nn.Conv1d(
- residual_channels,
- 2 * residual_channels,
- kernel_size=3,
- padding=dilation,
- dilation=dilation
- )
- self.diffusion_projection = nn.Linear(residual_channels, residual_channels)
- self.conditioner_projection = nn.Conv1d(encoder_hidden, 2 * residual_channels, 1)
- self.output_projection = nn.Conv1d(residual_channels, 2 * residual_channels, 1)
-
- def forward(self, x, conditioner, diffusion_step):
- diffusion_step = self.diffusion_projection(diffusion_step).unsqueeze(-1)
- conditioner = self.conditioner_projection(conditioner)
- y = x + diffusion_step
-
- y = self.dilated_conv(y) + conditioner
-
- # Using torch.split instead of torch.chunk to avoid using onnx::Slice
- gate, filter = torch.split(y, [self.residual_channels, self.residual_channels], dim=1)
- y = torch.sigmoid(gate) * torch.tanh(filter)
-
- y = self.output_projection(y)
-
- # Using torch.split instead of torch.chunk to avoid using onnx::Slice
- residual, skip = torch.split(y, [self.residual_channels, self.residual_channels], dim=1)
- return (x + residual) / math.sqrt(2.0), skip
-
-
-class WaveNet(nn.Module):
- def __init__(self, in_dims=128, n_layers=20, n_chans=384, n_hidden=256):
- super().__init__()
- self.input_projection = Conv1d(in_dims, n_chans, 1)
- self.diffusion_embedding = SinusoidalPosEmb(n_chans)
- self.mlp = nn.Sequential(
- nn.Linear(n_chans, n_chans * 4),
- Mish(),
- nn.Linear(n_chans * 4, n_chans)
- )
- self.residual_layers = nn.ModuleList([
- ResidualBlock(
- encoder_hidden=n_hidden,
- residual_channels=n_chans,
- dilation=1
- )
- for i in range(n_layers)
- ])
- self.skip_projection = Conv1d(n_chans, n_chans, 1)
- self.output_projection = Conv1d(n_chans, in_dims, 1)
- nn.init.zeros_(self.output_projection.weight)
-
- def forward(self, spec, diffusion_step, cond):
- """
- :param spec: [B, 1, M, T]
- :param diffusion_step: [B, 1]
- :param cond: [B, M, T]
- :return:
- """
- x = spec.squeeze(1)
- x = self.input_projection(x) # [B, residual_channel, T]
-
- x = F.relu(x)
- diffusion_step = self.diffusion_embedding(diffusion_step)
- diffusion_step = self.mlp(diffusion_step)
- skip = []
- for layer in self.residual_layers:
- x, skip_connection = layer(x, cond, diffusion_step)
- skip.append(skip_connection)
-
- x = torch.sum(torch.stack(skip), dim=0) / sqrt(len(self.residual_layers))
- x = self.skip_projection(x)
- x = F.relu(x)
- x = self.output_projection(x) # [B, mel_bins, T]
- return x[:, None, :, :]
diff --git a/spaces/lllqqq/so-vits-svc-models-pcr/vencoder/ContentVec256L9.py b/spaces/lllqqq/so-vits-svc-models-pcr/vencoder/ContentVec256L9.py
deleted file mode 100644
index b0089c789cd87cfd3b1badb2fc45cb1b88041eab..0000000000000000000000000000000000000000
--- a/spaces/lllqqq/so-vits-svc-models-pcr/vencoder/ContentVec256L9.py
+++ /dev/null
@@ -1,35 +0,0 @@
-from vencoder.encoder import SpeechEncoder
-import torch
-from fairseq import checkpoint_utils
-
-class ContentVec256L9(SpeechEncoder):
- def __init__(self,vec_path = "pretrain/checkpoint_best_legacy_500.pt",device=None):
- print("load model(s) from {}".format(vec_path))
- models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task(
- [vec_path],
- suffix="",
- )
- self.hidden_dim = 256
- if device is None:
- self.dev = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- else:
- self.dev = torch.device(device)
- self.model = models[0].to(self.dev)
- self.model.eval()
-
- def encoder(self, wav):
- feats = wav
- if feats.dim() == 2: # double channels
- feats = feats.mean(-1)
- assert feats.dim() == 1, feats.dim()
- feats = feats.view(1, -1)
- padding_mask = torch.BoolTensor(feats.shape).fill_(False)
- inputs = {
- "source": feats.to(wav.device),
- "padding_mask": padding_mask.to(wav.device),
- "output_layer": 9, # layer 9
- }
- with torch.no_grad():
- logits = self.model.extract_features(**inputs)
- feats = self.model.final_proj(logits[0])
- return feats.transpose(1, 2)
diff --git a/spaces/lzglyq/bingolzglyq/README.md b/spaces/lzglyq/bingolzglyq/README.md
deleted file mode 100644
index 5d6936218874c647b5d22e13ad4be7edb8936f92..0000000000000000000000000000000000000000
--- a/spaces/lzglyq/bingolzglyq/README.md
+++ /dev/null
@@ -1,28 +0,0 @@
----
-title: bingo
-emoji: 😊
-colorFrom: red
-colorTo: red
-sdk: docker
-license: mit
-duplicated_from: hf4all/bingo
----
-
-
-
-# Bingo
-
-Bingo,一个让你呼吸顺畅 New Bing。
-
-高度还原 New Bing 网页版的主要操作,国内可用,兼容绝大多数微软 Bing AI 的功能,可自行部署使用。
-
-
-
-[](https://hub.docker.com/repository/docker/weaigc/bingo/)
-[](https://hub.docker.com/repository/docker/weaigc/bingo/)
-[](https://github.com/weaigc/bingo/blob/main/license)
-
-问题反馈请前往 https://github.com/weaigc/bingo/issues
-
-
-
diff --git a/spaces/ma-xu/LIVE/pybind11/tests/test_class.py b/spaces/ma-xu/LIVE/pybind11/tests/test_class.py
deleted file mode 100644
index 4214fe79d7fbab2b38a1f15ca39d41e7cd33a171..0000000000000000000000000000000000000000
--- a/spaces/ma-xu/LIVE/pybind11/tests/test_class.py
+++ /dev/null
@@ -1,333 +0,0 @@
-# -*- coding: utf-8 -*-
-import pytest
-
-import env # noqa: F401
-
-from pybind11_tests import class_ as m
-from pybind11_tests import UserType, ConstructorStats
-
-
-def test_repr():
- # In Python 3.3+, repr() accesses __qualname__
- assert "pybind11_type" in repr(type(UserType))
- assert "UserType" in repr(UserType)
-
-
-def test_instance(msg):
- with pytest.raises(TypeError) as excinfo:
- m.NoConstructor()
- assert msg(excinfo.value) == "m.class_.NoConstructor: No constructor defined!"
-
- instance = m.NoConstructor.new_instance()
-
- cstats = ConstructorStats.get(m.NoConstructor)
- assert cstats.alive() == 1
- del instance
- assert cstats.alive() == 0
-
-
-def test_docstrings(doc):
- assert doc(UserType) == "A `py::class_` type for testing"
- assert UserType.__name__ == "UserType"
- assert UserType.__module__ == "pybind11_tests"
- assert UserType.get_value.__name__ == "get_value"
- assert UserType.get_value.__module__ == "pybind11_tests"
-
- assert doc(UserType.get_value) == """
- get_value(self: m.UserType) -> int
-
- Get value using a method
- """
- assert doc(UserType.value) == "Get/set value using a property"
-
- assert doc(m.NoConstructor.new_instance) == """
- new_instance() -> m.class_.NoConstructor
-
- Return an instance
- """
-
-
-def test_qualname(doc):
- """Tests that a properly qualified name is set in __qualname__ (even in pre-3.3, where we
- backport the attribute) and that generated docstrings properly use it and the module name"""
- assert m.NestBase.__qualname__ == "NestBase"
- assert m.NestBase.Nested.__qualname__ == "NestBase.Nested"
-
- assert doc(m.NestBase.__init__) == """
- __init__(self: m.class_.NestBase) -> None
- """
- assert doc(m.NestBase.g) == """
- g(self: m.class_.NestBase, arg0: m.class_.NestBase.Nested) -> None
- """
- assert doc(m.NestBase.Nested.__init__) == """
- __init__(self: m.class_.NestBase.Nested) -> None
- """
- assert doc(m.NestBase.Nested.fn) == """
- fn(self: m.class_.NestBase.Nested, arg0: int, arg1: m.class_.NestBase, arg2: m.class_.NestBase.Nested) -> None
- """ # noqa: E501 line too long
- assert doc(m.NestBase.Nested.fa) == """
- fa(self: m.class_.NestBase.Nested, a: int, b: m.class_.NestBase, c: m.class_.NestBase.Nested) -> None
- """ # noqa: E501 line too long
- assert m.NestBase.__module__ == "pybind11_tests.class_"
- assert m.NestBase.Nested.__module__ == "pybind11_tests.class_"
-
-
-def test_inheritance(msg):
- roger = m.Rabbit('Rabbit')
- assert roger.name() + " is a " + roger.species() == "Rabbit is a parrot"
- assert m.pet_name_species(roger) == "Rabbit is a parrot"
-
- polly = m.Pet('Polly', 'parrot')
- assert polly.name() + " is a " + polly.species() == "Polly is a parrot"
- assert m.pet_name_species(polly) == "Polly is a parrot"
-
- molly = m.Dog('Molly')
- assert molly.name() + " is a " + molly.species() == "Molly is a dog"
- assert m.pet_name_species(molly) == "Molly is a dog"
-
- fred = m.Hamster('Fred')
- assert fred.name() + " is a " + fred.species() == "Fred is a rodent"
-
- assert m.dog_bark(molly) == "Woof!"
-
- with pytest.raises(TypeError) as excinfo:
- m.dog_bark(polly)
- assert msg(excinfo.value) == """
- dog_bark(): incompatible function arguments. The following argument types are supported:
- 1. (arg0: m.class_.Dog) -> str
-
- Invoked with:
- """
-
- with pytest.raises(TypeError) as excinfo:
- m.Chimera("lion", "goat")
- assert "No constructor defined!" in str(excinfo.value)
-
-
-def test_inheritance_init(msg):
-
- # Single base
- class Python(m.Pet):
- def __init__(self):
- pass
- with pytest.raises(TypeError) as exc_info:
- Python()
- expected = ["m.class_.Pet.__init__() must be called when overriding __init__",
- "Pet.__init__() must be called when overriding __init__"] # PyPy?
- # TODO: fix PyPy error message wrt. tp_name/__qualname__?
- assert msg(exc_info.value) in expected
-
- # Multiple bases
- class RabbitHamster(m.Rabbit, m.Hamster):
- def __init__(self):
- m.Rabbit.__init__(self, "RabbitHamster")
-
- with pytest.raises(TypeError) as exc_info:
- RabbitHamster()
- expected = ["m.class_.Hamster.__init__() must be called when overriding __init__",
- "Hamster.__init__() must be called when overriding __init__"] # PyPy
- assert msg(exc_info.value) in expected
-
-
-def test_automatic_upcasting():
- assert type(m.return_class_1()).__name__ == "DerivedClass1"
- assert type(m.return_class_2()).__name__ == "DerivedClass2"
- assert type(m.return_none()).__name__ == "NoneType"
- # Repeat these a few times in a random order to ensure no invalid caching is applied
- assert type(m.return_class_n(1)).__name__ == "DerivedClass1"
- assert type(m.return_class_n(2)).__name__ == "DerivedClass2"
- assert type(m.return_class_n(0)).__name__ == "BaseClass"
- assert type(m.return_class_n(2)).__name__ == "DerivedClass2"
- assert type(m.return_class_n(2)).__name__ == "DerivedClass2"
- assert type(m.return_class_n(0)).__name__ == "BaseClass"
- assert type(m.return_class_n(1)).__name__ == "DerivedClass1"
-
-
-def test_isinstance():
- objects = [tuple(), dict(), m.Pet("Polly", "parrot")] + [m.Dog("Molly")] * 4
- expected = (True, True, True, True, True, False, False)
- assert m.check_instances(objects) == expected
-
-
-def test_mismatched_holder():
- import re
-
- with pytest.raises(RuntimeError) as excinfo:
- m.mismatched_holder_1()
- assert re.match('generic_type: type ".*MismatchDerived1" does not have a non-default '
- 'holder type while its base ".*MismatchBase1" does', str(excinfo.value))
-
- with pytest.raises(RuntimeError) as excinfo:
- m.mismatched_holder_2()
- assert re.match('generic_type: type ".*MismatchDerived2" has a non-default holder type '
- 'while its base ".*MismatchBase2" does not', str(excinfo.value))
-
-
-def test_override_static():
- """#511: problem with inheritance + overwritten def_static"""
- b = m.MyBase.make()
- d1 = m.MyDerived.make2()
- d2 = m.MyDerived.make()
-
- assert isinstance(b, m.MyBase)
- assert isinstance(d1, m.MyDerived)
- assert isinstance(d2, m.MyDerived)
-
-
-def test_implicit_conversion_life_support():
- """Ensure the lifetime of temporary objects created for implicit conversions"""
- assert m.implicitly_convert_argument(UserType(5)) == 5
- assert m.implicitly_convert_variable(UserType(5)) == 5
-
- assert "outside a bound function" in m.implicitly_convert_variable_fail(UserType(5))
-
-
-def test_operator_new_delete(capture):
- """Tests that class-specific operator new/delete functions are invoked"""
-
- class SubAliased(m.AliasedHasOpNewDelSize):
- pass
-
- with capture:
- a = m.HasOpNewDel()
- b = m.HasOpNewDelSize()
- d = m.HasOpNewDelBoth()
- assert capture == """
- A new 8
- B new 4
- D new 32
- """
- sz_alias = str(m.AliasedHasOpNewDelSize.size_alias)
- sz_noalias = str(m.AliasedHasOpNewDelSize.size_noalias)
- with capture:
- c = m.AliasedHasOpNewDelSize()
- c2 = SubAliased()
- assert capture == (
- "C new " + sz_noalias + "\n" +
- "C new " + sz_alias + "\n"
- )
-
- with capture:
- del a
- pytest.gc_collect()
- del b
- pytest.gc_collect()
- del d
- pytest.gc_collect()
- assert capture == """
- A delete
- B delete 4
- D delete
- """
-
- with capture:
- del c
- pytest.gc_collect()
- del c2
- pytest.gc_collect()
- assert capture == (
- "C delete " + sz_noalias + "\n" +
- "C delete " + sz_alias + "\n"
- )
-
-
-def test_bind_protected_functions():
- """Expose protected member functions to Python using a helper class"""
- a = m.ProtectedA()
- assert a.foo() == 42
-
- b = m.ProtectedB()
- assert b.foo() == 42
-
- class C(m.ProtectedB):
- def __init__(self):
- m.ProtectedB.__init__(self)
-
- def foo(self):
- return 0
-
- c = C()
- assert c.foo() == 0
-
-
-def test_brace_initialization():
- """ Tests that simple POD classes can be constructed using C++11 brace initialization """
- a = m.BraceInitialization(123, "test")
- assert a.field1 == 123
- assert a.field2 == "test"
-
- # Tests that a non-simple class doesn't get brace initialization (if the
- # class defines an initializer_list constructor, in particular, it would
- # win over the expected constructor).
- b = m.NoBraceInitialization([123, 456])
- assert b.vec == [123, 456]
-
-
-@pytest.mark.xfail("env.PYPY")
-def test_class_refcount():
- """Instances must correctly increase/decrease the reference count of their types (#1029)"""
- from sys import getrefcount
-
- class PyDog(m.Dog):
- pass
-
- for cls in m.Dog, PyDog:
- refcount_1 = getrefcount(cls)
- molly = [cls("Molly") for _ in range(10)]
- refcount_2 = getrefcount(cls)
-
- del molly
- pytest.gc_collect()
- refcount_3 = getrefcount(cls)
-
- assert refcount_1 == refcount_3
- assert refcount_2 > refcount_1
-
-
-def test_reentrant_implicit_conversion_failure(msg):
- # ensure that there is no runaway reentrant implicit conversion (#1035)
- with pytest.raises(TypeError) as excinfo:
- m.BogusImplicitConversion(0)
- assert msg(excinfo.value) == '''
- __init__(): incompatible constructor arguments. The following argument types are supported:
- 1. m.class_.BogusImplicitConversion(arg0: m.class_.BogusImplicitConversion)
-
- Invoked with: 0
- '''
-
-
-def test_error_after_conversions():
- with pytest.raises(TypeError) as exc_info:
- m.test_error_after_conversions("hello")
- assert str(exc_info.value).startswith(
- "Unable to convert function return value to a Python type!")
-
-
-def test_aligned():
- if hasattr(m, "Aligned"):
- p = m.Aligned().ptr()
- assert p % 1024 == 0
-
-
-# https://foss.heptapod.net/pypy/pypy/-/issues/2742
-@pytest.mark.xfail("env.PYPY")
-def test_final():
- with pytest.raises(TypeError) as exc_info:
- class PyFinalChild(m.IsFinal):
- pass
- assert str(exc_info.value).endswith("is not an acceptable base type")
-
-
-# https://foss.heptapod.net/pypy/pypy/-/issues/2742
-@pytest.mark.xfail("env.PYPY")
-def test_non_final_final():
- with pytest.raises(TypeError) as exc_info:
- class PyNonFinalFinalChild(m.IsNonFinalFinal):
- pass
- assert str(exc_info.value).endswith("is not an acceptable base type")
-
-
-# https://github.com/pybind/pybind11/issues/1878
-def test_exception_rvalue_abort():
- with pytest.raises(RuntimeError):
- m.PyPrintDestructor().throw_something()
diff --git a/spaces/ma-xu/LIVE/thrust/dependencies/cub/CHANGELOG.md b/spaces/ma-xu/LIVE/thrust/dependencies/cub/CHANGELOG.md
deleted file mode 100644
index 8c05ac274c68ae42b31d93dfcc7e06ddf8e28de9..0000000000000000000000000000000000000000
--- a/spaces/ma-xu/LIVE/thrust/dependencies/cub/CHANGELOG.md
+++ /dev/null
@@ -1,848 +0,0 @@
-# CUB 1.9.10-1 (NVIDIA HPC SDK 20.7, CUDA Toolkit 11.1)
-
-## Summary
-
-CUB 1.9.10-1 is the minor release accompanying the NVIDIA HPC SDK 20.7 release
- and the CUDA Toolkit 11.1 release.
-
-## Bug Fixes
-
-- #1217: Move static local in `cub::DeviceCount` to a separate host-only
- function because NVC++ doesn't support static locals in host-device
- functions.
-
-# CUB 1.9.10 (NVIDIA HPC SDK 20.5)
-
-## Summary
-
-Thrust 1.9.10 is the release accompanying the NVIDIA HPC SDK 20.5 release.
-It adds CMake `find_package` support.
-C++03, C++11, GCC < 5, Clang < 6, and MSVC < 2017 are now deprecated.
-Starting with the upcoming 1.10.0 release, C++03 support will be dropped
- entirely.
-
-## Breaking Changes
-
-- Thrust now checks that it is compatible with the version of CUB found
- in your include path, generating an error if it is not.
- If you are using your own version of CUB, it may be too old.
- It is recommended to simply delete your own version of CUB and use the
- version of CUB that comes with Thrust.
-- C++03 and C++11 are deprecated.
- Using these dialects will generate a compile-time warning.
- These warnings can be suppressed by defining
- `CUB_IGNORE_DEPRECATED_CPP_DIALECT` (to suppress C++03 and C++11
- deprecation warnings) or `CUB_IGNORE_DEPRECATED_CPP_11` (to suppress C++11
- deprecation warnings).
- Suppression is only a short term solution.
- We will be dropping support for C++03 in the 1.10.0 release and C++11 in the
- near future.
-- GCC < 5, Clang < 6, and MSVC < 2017 are deprecated.
- Using these compilers will generate a compile-time warning.
- These warnings can be suppressed by defining
- `CUB_IGNORE_DEPRECATED_COMPILER`.
- Suppression is only a short term solution.
- We will be dropping support for these compilers in the near future.
-
-## New Features
-
-- CMake `find_package` support.
- Just point CMake at the `cmake` folder in your CUB include directory
- (ex: `cmake -DCUB_DIR=/usr/local/cuda/include/cub/cmake/ .`) and then you
- can add CUB to your CMake project with `find_package(CUB REQUIRED CONFIG)`.
-
-# CUB 1.9.9 (CUDA 11.0)
-
-## Summary
-
-CUB 1.9.9 is the release accompanying the CUDA Toolkit 11.0 release.
-It introduces CMake support, version macros, platform detection machinery,
- and support for NVC++, which uses Thrust (and thus CUB) to implement
- GPU-accelerated C++17 Parallel Algorithms.
-Additionally, the scan dispatch layer was refactored and modernized.
-C++03, C++11, GCC < 5, Clang < 6, and MSVC < 2017 are now deprecated.
-Starting with the upcoming 1.10.0 release, C++03 support will be dropped
- entirely.
-
-## Breaking Changes
-
-- Thrust now checks that it is compatible with the version of CUB found
- in your include path, generating an error if it is not.
- If you are using your own version of CUB, it may be too old.
- It is recommended to simply delete your own version of CUB and use the
- version of CUB that comes with Thrust.
-- C++03 and C++11 are deprecated.
- Using these dialects will generate a compile-time warning.
- These warnings can be suppressed by defining
- `CUB_IGNORE_DEPRECATED_CPP_DIALECT` (to suppress C++03 and C++11
- deprecation warnings) or `CUB_IGNORE_DEPRECATED_CPP11` (to suppress C++11
- deprecation warnings).
- Suppression is only a short term solution.
- We will be dropping support for C++03 in the 1.10.0 release and C++11 in the
- near future.
-- GCC < 5, Clang < 6, and MSVC < 2017 are deprecated.
- Using these compilers will generate a compile-time warning.
- These warnings can be suppressed by defining
- `CUB_IGNORE_DEPRECATED_COMPILER`.
- Suppression is only a short term solution.
- We will be dropping support for these compilers in the near future.
-
-## New Features
-
-- CMake support.
- Thanks to Francis Lemaire for this contribution.
-- Refactorized and modernized scan dispatch layer.
- Thanks to Francis Lemaire for this contribution.
-- Policy hooks for device-wide reduce, scan, and radix sort facilities
- to simplify tuning and allow users to provide custom policies.
- Thanks to Francis Lemaire for this contribution.
-- ``: `CUB_VERSION`, `CUB_VERSION_MAJOR`, `CUB_VERSION_MINOR`,
- `CUB_VERSION_SUBMINOR`, and `CUB_PATCH_NUMBER`.
-- Platform detection machinery:
- - ``: Detects the C++ standard dialect.
- - ``: host and device compiler detection.
- - ``: `CUB_DEPRECATED`.
- - `: Includes ``,
- ``, ``,
- ``, ``,
- ``
-- `cub::DeviceCount` and `cub::DeviceCountUncached`, caching abstractions for
- `cudaGetDeviceCount`.
-
-## Other Enhancements
-
-- Lazily initialize the per-device CUDAattribute caches, because CUDA context
- creation is expensive and adds up with large CUDA binaries on machines with
- many GPUs.
- Thanks to the NVIDIA PyTorch team for bringing this to our attention.
-- Make `cub::SwitchDevice` avoid setting/resetting the device if the current
- device is the same as the target device.
-
-## Bug Fixes
-
-- Add explicit failure parameter to CAS in the CUB attribute cache to workaround
- a GCC 4.8 bug.
-- Revert a change in reductions that changed the signedness of the `lane_id`
- variable to suppress a warning, as this introduces a bug in optimized device
- code.
-- Fix initialization in `cub::ExclusiveSum`.
- Thanks to Conor Hoekstra for this contribution.
-- Fix initialization of the `std::array` in the CUB attribute cache.
-- Fix `-Wsign-compare` warnings.
- Thanks to Elias Stehle for this contribution.
-- Fix `test_block_reduce.cu` to build without parameters.
- Thanks to Francis Lemaire for this contribution.
-- Add missing includes to `grid_even_share.cuh`.
- Thanks to Francis Lemaire for this contribution.
-- Add missing includes to `thread_search.cuh`.
- Thanks to Francis Lemaire for this contribution.
-- Add missing includes to `cub.cuh`.
- Thanks to Felix Kallenborn for this contribution.
-
-# CUB 1.9.8-1 (NVIDIA HPC SDK 20.3)
-
-## Summary
-
-CUB 1.9.8-1 is a variant of 1.9.8 accompanying the NVIDIA HPC SDK 20.3 release.
-It contains modifications necessary to serve as the implementation of NVC++'s
- GPU-accelerated C++17 Parallel Algorithms.
-
-# CUB 1.9.8 (CUDA 11.0 Early Access)
-
-## Summary
-
-CUB 1.9.8 is the first release of CUB to be officially supported and included
- in the CUDA Toolkit.
-When compiling CUB in C++11 mode, CUB now caches calls to CUDA attribute query
- APIs, which improves performance of these queries by 20x to 50x when they
- are called concurrently by multiple host threads.
-
-## Enhancements
-
-- (C++11 or later) Cache calls to `cudaFuncGetAttributes` and
- `cudaDeviceGetAttribute` within `cub::PtxVersion` and `cub::SmVersion`.
- These CUDA APIs acquire locks to CUDA driver/runtime mutex and perform
- poorly under contention; with the caching, they are 20 to 50x faster when
- called concurrently.
- Thanks to Bilge Acun for bringing this issue to our attention.
-- `DispatchReduce` now takes an `OutputT` template parameter so that users can
- specify the intermediate type explicitly.
-- Radix sort tuning policies updates to fix performance issues for element
- types smaller than 4 bytes.
-
-## Bug Fixes
-
-- Change initialization style from copy initialization to direct initialization
- (which is more permissive) in `AgentReduce` to allow a wider range of types
- to be used with it.
-- Fix bad signed/unsigned comparisons in `WarpReduce`.
-- Fix computation of valid lanes in warp-level reduction primitive to correctly
- handle the case where there are 0 input items per warp.
-
-# CUB 1.8.0
-
-## Summary
-
-CUB 1.8.0 introduces changes to the `cub::Shuffle*` interfaces.
-
-## Breaking Changes
-
-- The interfaces of `cub::ShuffleIndex`, `cub::ShuffleUp`, and
- `cub::ShuffleDown` have been changed to allow for better computation of the
- PTX SHFL control constant for logical warps smaller than 32 threads.
-
-## Bug Fixes
-
-- #112: Fix `cub::WarpScan`'s broadcast of warp-wide aggregate for logical
- warps smaller than 32 threads.
-
-# CUB 1.7.5
-
-## Summary
-
-CUB 1.7.5 adds support for radix sorting `__half` keys and improved sorting
- performance for 1 byte keys.
-It was incorporated into Thrust 1.9.2.
-
-## Enhancements
-
-- Radix sort support for `__half` keys.
-- Radix sort tuning policy updates to improve 1 byte key performance.
-
-## Bug Fixes
-
-- Syntax tweaks to mollify Clang.
-- #127: `cub::DeviceRunLengthEncode::Encode` returns incorrect results.
-- #128: 7-bit sorting passes fail for SM61 with large values.
-
-# CUB 1.7.4
-
-## Summary
-
-CUB 1.7.4 is a minor release that was incorporated into Thrust 1.9.1-2.
-
-## Bug Fixes
-
-- #114: Can't pair non-trivially-constructible values in radix sort.
-- #115: `cub::WarpReduce` segmented reduction is broken in CUDA 9 for logical
- warp sizes smaller than 32.
-
-# CUB 1.7.3
-
-## Summary
-
-CUB 1.7.3 is a minor release.
-
-## Bug Fixes
-
-- #110: `cub::DeviceHistogram` null-pointer exception bug for iterator inputs.
-
-# CUB 1.7.2
-
-## Summary
-
-CUB 1.7.2 is a minor release.
-
-## Bug Fixes
-
-- #104: Device-wide reduction is now "run-to-run" deterministic for
- pseudo-associative reduction operators (like floating point addition).
-
-# CUB 1.7.1
-
-## Summary
-
-CUB 1.7.1 delivers improved radix sort performance on SM7x (Volta) GPUs and a
- number of bug fixes.
-
-## Enhancements
-
-- Radix sort tuning policies updated for SM7x (Volta).
-
-## Bug Fixes
-
-- #104: `uint64_t` `cub::WarpReduce` broken for CUB 1.7.0 on CUDA 8 and older.
-- #103: Can't mix Thrust from CUDA 9.0 and CUB.
-- #102: CUB pulls in `windows.h` which defines `min`/`max` macros that conflict
- with `std::min`/`std::max`.
-- #99: Radix sorting crashes NVCC on Windows 10 for SM52.
-- #98: cuda-memcheck: --tool initcheck failed with lineOfSight.
-- #94: Git clone size.
-- #93: Accept iterators for segment offsets.
-- #87: CUB uses anonymous unions which is not valid C++.
-- #44: Check for C++11 is incorrect for Visual Studio 2013.
-
-# CUB 1.7.0
-
-## Summary
-
-CUB 1.7.0 brings support for CUDA 9.0 and SM7x (Volta) GPUs.
-It is compatible with independent thread scheduling.
-It was incorporated into Thrust 1.9.0-5.
-
-## Breaking Changes
-
-- Remove `cub::WarpAll` and `cub::WarpAny`.
- These functions served to emulate `__all` and `__any` functionality for
- SM1x devices, which did not have those operations.
- However, SM1x devices are now deprecated in CUDA, and the interfaces of these
- two functions are now lacking the lane-mask needed for collectives to run on
- SM7x and newer GPUs which have independent thread scheduling.
-
-## Other Enhancements
-
-- Remove any assumptions of implicit warp synchronization to be compatible with
- SM7x's (Volta) independent thread scheduling.
-
-## Bug Fixes
-
-- #86: Incorrect results with reduce-by-key.
-
-# CUB 1.6.4
-
-## Summary
-
-CUB 1.6.4 improves radix sorting performance for SM5x (Maxwell) and SM6x
- (Pascal) GPUs.
-
-## Enhancements
-
-- Radix sort tuning policies updated for SM5x (Maxwell) and SM6x (Pascal) -
- 3.5B and 3.4B 32 byte keys/s on TitanX and GTX 1080, respectively.
-
-## Bug Fixes
-
-- Restore fence work-around for scan (reduce-by-key, etc.) hangs in CUDA 8.5.
-- #65: `cub::DeviceSegmentedRadixSort` should allow inputs to have
- pointer-to-const type.
-- Mollify Clang device-side warnings.
-- Remove out-dated MSVC project files.
-
-# CUB 1.6.3
-
-## Summary
-
-CUB 1.6.3 improves support for Windows, changes
- `cub::BlockLoad`/`cub::BlockStore` interface to take the local data type,
- and enhances radix sort performance for SM6x (Pascal) GPUs.
-
-## Breaking Changes
-
-- `cub::BlockLoad` and `cub::BlockStore` are now templated by the local data
- type, instead of the `Iterator` type.
- This allows for output iterators having `void` as their `value_type` (e.g.
- discard iterators).
-
-## Other Enhancements
-
-- Radix sort tuning policies updated for SM6x (Pascal) GPUs - 6.2B 4 byte
- keys/s on GP100.
-- Improved support for Windows (warnings, alignment, etc).
-
-## Bug Fixes
-
-- #74: `cub::WarpReduce` executes reduction operator for out-of-bounds items.
-- #72: `cub:InequalityWrapper::operator` should be non-const.
-- #71: `cub::KeyValuePair` won't work if `Key` has non-trivial constructor.
-- #69: cub::BlockStore::Store` doesn't compile if `OutputIteratorT::value_type`
- isn't `T`.
-- #68: `cub::TilePrefixCallbackOp::WarpReduce` doesn't permit PTX arch
- specialization.
-
-# CUB 1.6.2 (previously 1.5.5)
-
-## Summary
-
-CUB 1.6.2 (previously 1.5.5) improves radix sort performance for SM6x (Pascal)
- GPUs.
-
-## Enhancements
-
-- Radix sort tuning policies updated for SM6x (Pascal) GPUs.
-
-## Bug Fixes
-
-- Fix AArch64 compilation of `cub::CachingDeviceAllocator`.
-
-# CUB 1.6.1 (previously 1.5.4)
-
-## Summary
-
-CUB 1.6.1 (previously 1.5.4) is a minor release.
-
-## Bug Fixes
-
-- Fix radix sorting bug introduced by scan refactorization.
-
-# CUB 1.6.0 (previously 1.5.3)
-
-## Summary
-
-CUB 1.6.0 changes the scan and reduce interfaces.
-Exclusive scans now accept an "initial value" instead of an "identity value".
-Scans and reductions now support differing input and output sequence types.
-Additionally, many bugs have been fixed.
-
-## Breaking Changes
-
-- Device/block/warp-wide exclusive scans have been revised to now accept an
- "initial value" (instead of an "identity value") for seeding the computation
- with an arbitrary prefix.
-- Device-wide reductions and scans can now have input sequence types that are
- different from output sequence types (as long as they are convertible).
-
-## Other Enhancements
-
-- Reduce repository size by moving the doxygen binary to doc repository.
-- Minor reduction in `cub::BlockScan` instruction counts.
-
-## Bug Fixes
-
-- Issue #55: Warning in `cub/device/dispatch/dispatch_reduce_by_key.cuh`.
-- Issue #59: `cub::DeviceScan::ExclusiveSum` can't prefix sum of float into
- double.
-- Issue #58: Infinite loop in `cub::CachingDeviceAllocator::NearestPowerOf`.
-- Issue #47: `cub::CachingDeviceAllocator` needs to clean up CUDA global error
- state upon successful retry.
-- Issue #46: Very high amount of needed memory from the
- `cub::DeviceHistogram::HistogramEven`.
-- Issue #45: `cub::CachingDeviceAllocator` fails with debug output enabled
-
-# CUB 1.5.2
-
-## Summary
-
-CUB 1.5.2 enhances `cub::CachingDeviceAllocator` and improves scan performance
- for SM5x (Maxwell).
-
-## Enhancements
-
-- Improved medium-size scan performance on SM5x (Maxwell).
-- Refactored `cub::CachingDeviceAllocator`:
- - Now spends less time locked.
- - Uses C++11's `std::mutex` when available.
- - Failure to allocate a block from the runtime will retry once after
- freeing cached allocations.
- - Now respects max-bin, fixing an issue where blocks in excess of max-bin
- were still being retained in the free cache.
-
-## Bug fixes:
-
-- Fix for generic-type reduce-by-key `cub::WarpScan` for SM3x and newer GPUs.
-
-# CUB 1.5.1
-
-## Summary
-
-CUB 1.5.1 is a minor release.
-
-## Bug Fixes
-
-- Fix for incorrect `cub::DeviceRadixSort` output for some small problems on
- SM52 (Mawell) GPUs.
-- Fix for macro redefinition warnings when compiling `thrust::sort`.
-
-# CUB 1.5.0
-
-CUB 1.5.0 introduces segmented sort and reduction primitives.
-
-## New Features:
-
-- Segmented device-wide operations for device-wide sort and reduction primitives.
-
-## Bug Fixes:
-
-- #36: `cub::ThreadLoad` generates compiler errors when loading from
- pointer-to-const.
-- #29: `cub::DeviceRadixSort::SortKeys` yields compiler errors.
-- #26: Misaligned address after `cub::DeviceRadixSort::SortKeys`.
-- #25: Fix for incorrect results and crashes when radix sorting 0-length
- problems.
-- Fix CUDA 7.5 issues on SM52 GPUs with SHFL-based warp-scan and
- warp-reduction on non-primitive data types (e.g. user-defined structs).
-- Fix small radix sorting problems where 0 temporary bytes were required and
- users code was invoking `malloc(0)` on some systems where that returns
- `NULL`.
- CUB assumed the user was asking for the size again and not running the sort.
-
-# CUB 1.4.1
-
-## Summary
-
-CUB 1.4.1 is a minor release.
-
-## Enhancements
-
-- Allow `cub::DeviceRadixSort` and `cub::BlockRadixSort` on bool types.
-
-## Bug Fixes
-
-- Fix minor CUDA 7.0 performance regressions in `cub::DeviceScan` and
- `cub::DeviceReduceByKey`.
-- Remove requirement for callers to define the `CUB_CDP` macro
- when invoking CUB device-wide rountines using CUDA dynamic parallelism.
-- Fix headers not being included in the proper order (or missing includes)
- for some block-wide functions.
-
-# CUB 1.4.0
-
-## Summary
-
-CUB 1.4.0 adds `cub::DeviceSpmv`, `cub::DeviceRunLength::NonTrivialRuns`,
- improves `cub::DeviceHistogram`, and introduces support for SM5x (Maxwell)
- GPUs.
-
-## New Features:
-
-- `cub::DeviceSpmv` methods for multiplying sparse matrices by
- dense vectors, load-balanced using a merge-based parallel decomposition.
-- `cub::DeviceRadixSort` sorting entry-points that always return
- the sorted output into the specified buffer, as opposed to the
- `cub::DoubleBuffer` in which it could end up in either buffer.
-- `cub::DeviceRunLengthEncode::NonTrivialRuns` for finding the starting
- offsets and lengths of all non-trivial runs (i.e., length > 1) of keys in
- a given sequence.
- Useful for top-down partitioning algorithms like MSD sorting of very-large
- keys.
-
-## Other Enhancements
-
-- Support and performance tuning for SM5x (Maxwell) GPUs.
-- Updated cub::DeviceHistogram implementation that provides the same
- "histogram-even" and "histogram-range" functionality as IPP/NPP.
- Provides extremely fast and, perhaps more importantly, very uniform
- performance response across diverse real-world datasets, including
- pathological (homogeneous) sample distributions.
-
-# CUB 1.3.2
-
-## Summary
-
-CUB 1.3.2 is a minor release.
-
-## Bug Fixes
-
-- Fix `cub::DeviceReduce` where reductions of small problems (small enough to
- only dispatch a single thread block) would run in the default stream (stream
- zero) regardless of whether an alternate stream was specified.
-
-# CUB 1.3.1
-
-## Summary
-
-CUB 1.3.1 is a minor release.
-
-## Bug Fixes
-
-- Workaround for a benign WAW race warning reported by cuda-memcheck
- in `cub::BlockScan` specialized for `BLOCK_SCAN_WARP_SCANS` algorithm.
-- Fix bug in `cub::DeviceRadixSort` where the algorithm may sort more
- key bits than the caller specified (up to the nearest radix digit).
-- Fix for ~3% `cub::DeviceRadixSort` performance regression on SM2x (Fermi) and
- SM3x (Kepler) GPUs.
-
-# CUB 1.3.0
-
-## Summary
-
-CUB 1.3.0 improves how thread blocks are expressed in block- and warp-wide
- primitives and adds an enhanced version of `cub::WarpScan`.
-
-## Breaking Changes
-
-- CUB's collective (block-wide, warp-wide) primitives underwent a minor
- interface refactoring:
- - To provide the appropriate support for multidimensional thread blocks,
- The interfaces for collective classes are now template-parameterized by
- X, Y, and Z block dimensions (with `BLOCK_DIM_Y` and `BLOCK_DIM_Z` being
- optional, and `BLOCK_DIM_X` replacing `BLOCK_THREADS`).
- Furthermore, the constructors that accept remapped linear
- thread-identifiers have been removed: all primitives now assume a
- row-major thread-ranking for multidimensional thread blocks.
- - To allow the host program (compiled by the host-pass) to accurately
- determine the device-specific storage requirements for a given collective
- (compiled for each device-pass), the interfaces for collective classes
- are now (optionally) template-parameterized by the desired PTX compute
- capability.
- This is useful when aliasing collective storage to shared memory that has
- been allocated dynamically by the host at the kernel call site.
- - Most CUB programs having typical 1D usage should not require any
- changes to accomodate these updates.
-
-## New Features
-
-- Added "combination" `cub::WarpScan` methods for efficiently computing
- both inclusive and exclusive prefix scans (and sums).
-
-## Bug Fixes
-
-- Fix for bug in `cub::WarpScan` (which affected `cub::BlockScan` and
- `cub::DeviceScan`) where incorrect results (e.g., NAN) would often be
- returned when parameterized for floating-point types (fp32, fp64).
-- Workaround for ptxas error when compiling with with -G flag on Linux (for
- debug instrumentation).
-- Fixes for certain scan scenarios using custom scan operators where code
- compiled for SM1x is run on newer GPUs of higher compute-capability: the
- compiler could not tell which memory space was being used collective
- operations and was mistakenly using global ops instead of shared ops.
-
-# CUB 1.2.3
-
-## Summary
-
-CUB 1.2.3 is a minor release.
-
-## Bug Fixes
-
-- Fixed access violation bug in `cub::DeviceReduce::ReduceByKey` for
- non-primitive value types.
-- Fixed code-snippet bug in `ArgIndexInputIteratorT` documentation.
-
-# CUB 1.2.2
-
-## Summary
-
-CUB 1.2.2 adds a new variant of `cub::BlockReduce` and MSVC project solections
- for examples.
-
-## New Features
-
-- MSVC project solutions for device-wide and block-wide examples
-- New algorithmic variant of cub::BlockReduce for improved performance
- when using commutative operators (e.g., numeric addition).
-
-## Bug Fixes
-
-- Inclusion of Thrust headers in a certain order prevented CUB device-wide
- primitives from working properly.
-
-# CUB 1.2.0
-
-## Summary
-
-CUB 1.2.0 adds `cub::DeviceReduce::ReduceByKey` and
- `cub::DeviceReduce::RunLengthEncode` and support for CUDA 6.0.
-
-## New Features
-
-- `cub::DeviceReduce::ReduceByKey`.
-- `cub::DeviceReduce::RunLengthEncode`.
-
-## Other Enhancements
-
-- Improved `cub::DeviceScan`, `cub::DeviceSelect`, `cub::DevicePartition`
- performance.
-- Documentation and testing:
- - Added performance-portability plots for many device-wide primitives.
- - Explain that iterator (in)compatibilities with CUDA 5.0 (and older) and
- Thrust 1.6 (and older).
-- Revised the operation of temporary tile status bookkeeping for
- `cub::DeviceScan` (and similar) to be safe for current code run on future
- platforms (now uses proper fences).
-
-## Bug Fixes
-
-- Fix `cub::DeviceScan` bug where Windows alignment disagreements between host
- and device regarding user-defined data types would corrupt tile status.
-- Fix `cub::BlockScan` bug where certain exclusive scans on custom data types
- for the `BLOCK_SCAN_WARP_SCANS` variant would return incorrect results for
- the first thread in the block.
-- Added workaround to make `cub::TexRefInputIteratorT` work with CUDA 6.0.
-
-# CUB 1.1.1
-
-## Summary
-
-CUB 1.1.1 introduces texture and cache modifier iterators, descending sorting,
- `cub::DeviceSelect`, `cub::DevicePartition`, `cub::Shuffle*`, and
- `cub::MaxSMOccupancy`.
-Additionally, scan and sort performance for older GPUs has been improved and
- many bugs have been fixed.
-
-## Breaking Changes
-
-- Refactored block-wide I/O (`cub::BlockLoad` and `cub::BlockStore`), removing
- cache-modifiers from their interfaces.
- `cub::CacheModifiedInputIterator` and `cub::CacheModifiedOutputIterator`
- should now be used with `cub::BlockLoad` and `cub::BlockStore` to effect that
- behavior.
-
-## New Features
-
-- `cub::TexObjInputIterator`, `cub::TexRefInputIterator`,
- `cub::CacheModifiedInputIterator`, and `cub::CacheModifiedOutputIterator`
- types for loading & storing arbitrary types through the cache hierarchy.
- They are compatible with Thrust.
-- Descending sorting for `cub::DeviceRadixSort` and `cub::BlockRadixSort`.
-- Min, max, arg-min, and arg-max operators for `cub::DeviceReduce`.
-- `cub::DeviceSelect` (select-unique, select-if, and select-flagged).
-- `cub::DevicePartition` (partition-if, partition-flagged).
-- Generic `cub::ShuffleUp`, `cub::ShuffleDown`, and `cub::ShuffleIndex` for
- warp-wide communication of arbitrary data types (SM3x and up).
-- `cub::MaxSmOccupancy` for accurately determining SM occupancy for any given
- kernel function pointer.
-
-## Other Enhancements
-
-- Improved `cub::DeviceScan` and `cub::DeviceRadixSort` performance for older
- GPUs (SM1x to SM3x).
-- Renamed device-wide `stream_synchronous` param to `debug_synchronous` to
- avoid confusion about usage.
-- Documentation improvements:
- - Added simple examples of device-wide methods.
- - Improved doxygen documentation and example snippets.
-- Improved test coverege to include up to 21,000 kernel variants and 851,000
- unit tests (per architecture, per platform).
-
-## Bug Fixes
-
-- Fix misc `cub::DeviceScan, BlockScan, DeviceReduce, and BlockReduce bugs when
- operating on non-primitive types for older architectures SM1x.
-- SHFL-based scans and reductions produced incorrect results for multi-word
- types (size > 4B) on Linux.
-- For `cub::WarpScan`-based scans, not all threads in the first warp were
- entering the prefix callback functor.
-- `cub::DeviceRadixSort` had a race condition with key-value pairs for pre-SM35
- architectures.
-- `cub::DeviceRadixSor` bitfield-extract behavior with long keys on 64-bit
- Linux was incorrect.
-- `cub::BlockDiscontinuity` failed to compile for types other than
- `int32_t`/`uint32_t`.
-- CUDA Dynamic Parallelism (CDP, e.g. device-callable) versions of device-wide
- methods now report the same temporary storage allocation size requirement as
- their host-callable counterparts.
-
-# CUB 1.0.2
-
-## Summary
-
-CUB 1.0.2 is a minor release.
-
-## Bug Fixes
-
-- Corrections to code snippet examples for `cub::BlockLoad`, `cub::BlockStore`,
- and `cub::BlockDiscontinuity`.
-- Cleaned up unnecessary/missing header includes.
- You can now safely include a specific .cuh (instead of `cub.cuh`).
-- Bug/compilation fixes for `cub::BlockHistogram`.
-
-# CUB 1.0.1
-
-## Summary
-
-CUB 1.0.1 adds `cub::DeviceRadixSort` and `cub::DeviceScan`.
-Numerous other performance and correctness fixes and included.
-
-## Breaking Changes
-
-- New collective interface idiom (specialize/construct/invoke).
-
-## New Features
-
-- `cub::DeviceRadixSort`.
- Implements short-circuiting for homogenous digit passes.
-- `cub::DeviceScan`.
- Implements single-pass "adaptive-lookback" strategy.
-
-## Other Enhancements
-
-- Significantly improved documentation (with example code snippets).
-- More extensive regression test suit for aggressively testing collective
- variants.
-- Allow non-trially-constructed types (previously unions had prevented aliasing
- temporary storage of those types).
-- Improved support for SM3x SHFL (collective ops now use SHFL for types larger
- than 32 bits).
-- Better code generation for 64-bit addressing within
- `cub::BlockLoad`/`cub::BlockStore`.
-- `cub::DeviceHistogram` now supports histograms of arbitrary bins.
-- Updates to accommodate CUDA 5.5 dynamic parallelism.
-
-## Bug Fixes
-
-- Workarounds for SM10 codegen issues in uncommonly-used
- `cub::WarpScan`/`cub::WarpReduce` specializations.
-
-# CUB 0.9.4
-
-## Summary
-
-CUB 0.9.3 is a minor release.
-
-## Enhancements
-
-- Various documentation updates and corrections.
-
-## Bug Fixes
-
-- Fixed compilation errors for SM1x.
-- Fixed compilation errors for some WarpScan entrypoints on SM3x and up.
-
-# CUB 0.9.3
-
-## Summary
-
-CUB 0.9.3 adds histogram algorithms and work management utility descriptors.
-
-## New Features
-
-- `cub::DevicHistogram256`.
-- `cub::BlockHistogram256`.
-- `cub::BlockScan` algorithm variant `BLOCK_SCAN_RAKING_MEMOIZE`, which
- trades more register consumption for less shared memory I/O.
-- `cub::GridQueue`, `cub::GridEvenShare`, work management utility descriptors.
-
-## Other Enhancements
-
-- Updates to `cub::BlockRadixRank` to use `cub::BlockScan`, which improves
- performance on SM3x by using SHFL.
-- Allow types other than builtin types to be used in `cub::WarpScan::*Sum`
- methods if they only have `operator+` overloaded.
- Previously they also required to support assignment from `int(0)`.
-- Update `cub::BlockReduce`'s `BLOCK_REDUCE_WARP_REDUCTIONS` algorithm to work
- even when block size is not an even multiple of warp size.
-- Refactoring of `cub::DeviceAllocator` interface and
- `cub::CachingDeviceAllocator` implementation.
-
-# CUB 0.9.2
-
-## Summary
-
-CUB 0.9.2 adds `cub::WarpReduce`.
-
-## New Features
-
-- `cub::WarpReduce`, which uses the SHFL instruction when applicable.
- `cub::BlockReduce` now uses this `cub::WarpReduce` instead of implementing
- its own.
-
-## Enhancements
-
-- Documentation updates and corrections.
-
-## Bug Fixes
-
-- Fixes for 64-bit Linux compilation warnings and errors.
-
-# CUB 0.9.1
-
-## Summary
-
-CUB 0.9.1 is a minor release.
-
-## Bug Fixes
-
-- Fix for ambiguity in `cub::BlockScan::Reduce` between generic reduction and
- summation.
- Summation entrypoints are now called `::Sum()`, similar to the
- convention in `cub::BlockScan`.
-- Small edits to documentation and download tracking.
-
-# CUB 0.9.0
-
-## Summary
-
-Initial preview release.
-CUB is the first durable, high-performance library of cooperative block-level,
- warp-level, and thread-level primitives for CUDA kernel programming.
-
diff --git a/spaces/ma-xu/LIVE/thrust/thrust/set_operations.h b/spaces/ma-xu/LIVE/thrust/thrust/set_operations.h
deleted file mode 100644
index a51eaed4351e52aaf3569c986cc5153640dd15d6..0000000000000000000000000000000000000000
--- a/spaces/ma-xu/LIVE/thrust/thrust/set_operations.h
+++ /dev/null
@@ -1,2963 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-
-/*! \file set_operations.h
- * \brief Set theoretic operations for sorted ranges
- */
-
-#pragma once
-
-#include
-#include
-#include
-
-namespace thrust
-{
-
-
-/*! \addtogroup set_operations Set Operations
- * \ingroup algorithms
- * \{
- */
-
-
-/*! \p set_difference constructs a sorted range that is the set difference of the sorted
- * ranges [first1, last1) and [first2, last2). The return value is the
- * end of the output range.
- *
- * In the simplest case, \p set_difference performs the "difference" operation from set
- * theory: the output range contains a copy of every element that is contained in
- * [first1, last1) and not contained in [first2, last1). The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements
- * that are equivalent to each other and if [first2, last2) contains \c n
- * elements that are equivalent to them, the last max(m-n,0) elements from
- * [first1, last1) range shall be copied to the output range.
- *
- * This version of \p set_difference compares elements using \c operator<.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \return The end of the output range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to operator<.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_difference to compute the
- * set difference of two sets of integers sorted in ascending order using the \p thrust::host execution
- * policy for parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A1[6] = {0, 1, 3, 4, 5, 6, 9};
- * int A2[5] = {1, 3, 5, 7, 9};
- *
- * int result[3];
- *
- * int *result_end = thrust::set_difference(thrust::host, A1, A1 + 6, A2, A2 + 5, result);
- * // result is now {0, 4, 6}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_difference.html
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
-__host__ __device__
- OutputIterator set_difference(const thrust::detail::execution_policy_base &exec,
- InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result);
-
-
-/*! \p set_difference constructs a sorted range that is the set difference of the sorted
- * ranges [first1, last1) and [first2, last2). The return value is the
- * end of the output range.
- *
- * In the simplest case, \p set_difference performs the "difference" operation from set
- * theory: the output range contains a copy of every element that is contained in
- * [first1, last1) and not contained in [first2, last1). The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements
- * that are equivalent to each other and if [first2, last2) contains \c n
- * elements that are equivalent to them, the last max(m-n,0) elements from
- * [first1, last1) range shall be copied to the output range.
- *
- * This version of \p set_difference compares elements using \c operator<.
- *
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \return The end of the output range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to operator<.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_difference to compute the
- * set difference of two sets of integers sorted in ascending order.
- *
- * \code
- * #include
- * ...
- * int A1[6] = {0, 1, 3, 4, 5, 6, 9};
- * int A2[5] = {1, 3, 5, 7, 9};
- *
- * int result[3];
- *
- * int *result_end = thrust::set_difference(A1, A1 + 6, A2, A2 + 5, result);
- * // result is now {0, 4, 6}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_difference.html
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
- OutputIterator set_difference(InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result);
-
-
-/*! \p set_difference constructs a sorted range that is the set difference of the sorted
- * ranges [first1, last1) and [first2, last2). The return value is the
- * end of the output range.
- *
- * In the simplest case, \p set_difference performs the "difference" operation from set
- * theory: the output range contains a copy of every element that is contained in
- * [first1, last1) and not contained in [first2, last1). The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements
- * that are equivalent to each other and if [first2, last2) contains \c n
- * elements that are equivalent to them, the last max(m-n,0) elements from
- * [first1, last1) range shall be copied to the output range.
- *
- * This version of \p set_difference compares elements using a function object \p comp.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \param comp Comparison operator.
- * \return The end of the output range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1's \c value_type is convertable to \p StrictWeakCompare's \c first_argument_type.
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2's \c value_type is convertable to \p StrictWeakCompare's \c second_argument_type.
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to \p comp.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_difference to compute the
- * set difference of two sets of integers sorted in descending order using the \p thrust::host execution
- * policy for parallelization:
- *
- * \code
- * #include
- * #include
- * #include
- * ...
- * int A1[6] = {9, 6, 5, 4, 3, 1, 0};
- * int A2[5] = {9, 7, 5, 3, 1};
- *
- * int result[3];
- *
- * int *result_end = thrust::set_difference(thrust::host, A1, A1 + 6, A2, A2 + 5, result, thrust::greater());
- * // result is now {6, 4, 0}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_difference.html
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
-__host__ __device__
- OutputIterator set_difference(const thrust::detail::execution_policy_base &exec,
- InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result,
- StrictWeakCompare comp);
-
-
-/*! \p set_difference constructs a sorted range that is the set difference of the sorted
- * ranges [first1, last1) and [first2, last2). The return value is the
- * end of the output range.
- *
- * In the simplest case, \p set_difference performs the "difference" operation from set
- * theory: the output range contains a copy of every element that is contained in
- * [first1, last1) and not contained in [first2, last1). The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements
- * that are equivalent to each other and if [first2, last2) contains \c n
- * elements that are equivalent to them, the last max(m-n,0) elements from
- * [first1, last1) range shall be copied to the output range.
- *
- * This version of \p set_difference compares elements using a function object \p comp.
- *
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \param comp Comparison operator.
- * \return The end of the output range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1's \c value_type is convertable to \p StrictWeakCompare's \c first_argument_type.
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2's \c value_type is convertable to \p StrictWeakCompare's \c second_argument_type.
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to \p comp.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_difference to compute the
- * set difference of two sets of integers sorted in descending order.
- *
- * \code
- * #include
- * #include
- * ...
- * int A1[6] = {9, 6, 5, 4, 3, 1, 0};
- * int A2[5] = {9, 7, 5, 3, 1};
- *
- * int result[3];
- *
- * int *result_end = thrust::set_difference(A1, A1 + 6, A2, A2 + 5, result, thrust::greater());
- * // result is now {6, 4, 0}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_difference.html
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
- OutputIterator set_difference(InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result,
- StrictWeakCompare comp);
-
-
-/*! \p set_intersection constructs a sorted range that is the
- * intersection of sorted ranges [first1, last1) and
- * [first2, last2). The return value is the end of the
- * output range.
- *
- * In the simplest case, \p set_intersection performs the
- * "intersection" operation from set theory: the output range
- * contains a copy of every element that is contained in both
- * [first1, last1) and [first2, last2). The
- * general case is more complicated, because the input ranges may
- * contain duplicate elements. The generalization is that if a value
- * appears \c m times in [first1, last1) and \c n times in
- * [first2, last2) (where \c m may be zero), then it
- * appears min(m,n) times in the output range.
- * \p set_intersection is stable, meaning that both elements are
- * copied from the first range rather than the second, and that the
- * relative order of elements in the output range is the same as in
- * the first input range.
- *
- * This version of \p set_intersection compares objects using
- * \c operator<.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \return The end of the output range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to operator<.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_intersection to compute the
- * set intersection of two sets of integers sorted in ascending order using the \p thrust::host execution
- * policy for parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A1[6] = {1, 3, 5, 7, 9, 11};
- * int A2[7] = {1, 1, 2, 3, 5, 8, 13};
- *
- * int result[7];
- *
- * int *result_end = thrust::set_intersection(thrust::host, A1, A1 + 6, A2, A2 + 7, result);
- * // result is now {1, 3, 5}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_intersection.html
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
-__host__ __device__
- OutputIterator set_intersection(const thrust::detail::execution_policy_base &exec,
- InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result);
-
-
-/*! \p set_intersection constructs a sorted range that is the
- * intersection of sorted ranges [first1, last1) and
- * [first2, last2). The return value is the end of the
- * output range.
- *
- * In the simplest case, \p set_intersection performs the
- * "intersection" operation from set theory: the output range
- * contains a copy of every element that is contained in both
- * [first1, last1) and [first2, last2). The
- * general case is more complicated, because the input ranges may
- * contain duplicate elements. The generalization is that if a value
- * appears \c m times in [first1, last1) and \c n times in
- * [first2, last2) (where \c m may be zero), then it
- * appears min(m,n) times in the output range.
- * \p set_intersection is stable, meaning that both elements are
- * copied from the first range rather than the second, and that the
- * relative order of elements in the output range is the same as in
- * the first input range.
- *
- * This version of \p set_intersection compares objects using
- * \c operator<.
- *
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \return The end of the output range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to operator<.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_intersection to compute the
- * set intersection of two sets of integers sorted in ascending order.
- *
- * \code
- * #include
- * ...
- * int A1[6] = {1, 3, 5, 7, 9, 11};
- * int A2[7] = {1, 1, 2, 3, 5, 8, 13};
- *
- * int result[7];
- *
- * int *result_end = thrust::set_intersection(A1, A1 + 6, A2, A2 + 7, result);
- * // result is now {1, 3, 5}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_intersection.html
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
- OutputIterator set_intersection(InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result);
-
-
-/*! \p set_intersection constructs a sorted range that is the
- * intersection of sorted ranges [first1, last1) and
- * [first2, last2). The return value is the end of the
- * output range.
- *
- * In the simplest case, \p set_intersection performs the
- * "intersection" operation from set theory: the output range
- * contains a copy of every element that is contained in both
- * [first1, last1) and [first2, last2). The
- * general case is more complicated, because the input ranges may
- * contain duplicate elements. The generalization is that if a value
- * appears \c m times in [first1, last1) and \c n times in
- * [first2, last2) (where \c m may be zero), then it
- * appears min(m,n) times in the output range.
- * \p set_intersection is stable, meaning that both elements are
- * copied from the first range rather than the second, and that the
- * relative order of elements in the output range is the same as in
- * the first input range.
- *
- * This version of \p set_intersection compares elements using a function object \p comp.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \param comp Comparison operator.
- * \return The end of the output range.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to \p comp.
- * \pre The resulting range shall not overlap with either input range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * The following code snippet demonstrates how to use \p set_intersection to compute
- * the set intersection of sets of integers sorted in descending order using the \p thrust::host execution
- * policy for parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A1[6] = {11, 9, 7, 5, 3, 1};
- * int A2[7] = {13, 8, 5, 3, 2, 1, 1};
- *
- * int result[3];
- *
- * int *result_end = thrust::set_intersection(thrust::host, A1, A1 + 6, A2, A2 + 7, result, thrust::greater());
- * // result is now {5, 3, 1}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_intersection.html
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
-__host__ __device__
- OutputIterator set_intersection(const thrust::detail::execution_policy_base &exec,
- InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result,
- StrictWeakCompare comp);
-
-
-/*! \p set_intersection constructs a sorted range that is the
- * intersection of sorted ranges [first1, last1) and
- * [first2, last2). The return value is the end of the
- * output range.
- *
- * In the simplest case, \p set_intersection performs the
- * "intersection" operation from set theory: the output range
- * contains a copy of every element that is contained in both
- * [first1, last1) and [first2, last2). The
- * general case is more complicated, because the input ranges may
- * contain duplicate elements. The generalization is that if a value
- * appears \c m times in [first1, last1) and \c n times in
- * [first2, last2) (where \c m may be zero), then it
- * appears min(m,n) times in the output range.
- * \p set_intersection is stable, meaning that both elements are
- * copied from the first range rather than the second, and that the
- * relative order of elements in the output range is the same as in
- * the first input range.
- *
- * This version of \p set_intersection compares elements using a function object \p comp.
- *
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \param comp Comparison operator.
- * \return The end of the output range.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to \p comp.
- * \pre The resulting range shall not overlap with either input range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * The following code snippet demonstrates how to use \p set_intersection to compute
- * the set intersection of sets of integers sorted in descending order.
- *
- * \code
- * #include
- * ...
- * int A1[6] = {11, 9, 7, 5, 3, 1};
- * int A2[7] = {13, 8, 5, 3, 2, 1, 1};
- *
- * int result[3];
- *
- * int *result_end = thrust::set_intersection(A1, A1 + 6, A2, A2 + 7, result, thrust::greater());
- * // result is now {5, 3, 1}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_intersection.html
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
- OutputIterator set_intersection(InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result,
- StrictWeakCompare comp);
-
-
-/*! \p set_symmetric_difference constructs a sorted range that is the set symmetric
- * difference of the sorted ranges [first1, last1) and [first2, last2).
- * The return value is the end of the output range.
- *
- * In the simplest case, \p set_symmetric_difference performs a set theoretic calculation:
- * it constructs the union of the two sets A - B and B - A, where A and B are the two
- * input ranges. That is, the output range contains a copy of every element that is
- * contained in [first1, last1) but not [first2, last1), and a copy of
- * every element that is contained in [first2, last2) but not [first1, last1).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements that are
- * equivalent to each other and [first2, last1) contains \c n elements that are
- * equivalent to them, then |m - n| of those elements shall be copied to the output
- * range: the last m - n elements from [first1, last1) if m > n, and
- * the last n - m of these elements from [first2, last2) if m < n.
- *
- * This version of \p set_union compares elements using \c operator<.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \return The end of the output range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to operator<.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference to compute
- * the symmetric difference of two sets of integers sorted in ascending order using the \p thrust::host
- * execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A1[6] = {0, 1, 2, 2, 4, 6, 7};
- * int A2[5] = {1, 1, 2, 5, 8};
- *
- * int result[6];
- *
- * int *result_end = thrust::set_symmetric_difference(thrust::host, A1, A1 + 6, A2, A2 + 5, result);
- * // result = {0, 4, 5, 6, 7, 8}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_symmetric_difference.html
- * \see \p merge
- * \see \p includes
- * \see \p set_difference
- * \see \p set_union
- * \see \p set_intersection
- * \see \p sort
- * \see \p is_sorted
- */
-template
-__host__ __device__
- OutputIterator set_symmetric_difference(const thrust::detail::execution_policy_base &exec,
- InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result);
-
-
-/*! \p set_symmetric_difference constructs a sorted range that is the set symmetric
- * difference of the sorted ranges [first1, last1) and [first2, last2).
- * The return value is the end of the output range.
- *
- * In the simplest case, \p set_symmetric_difference performs a set theoretic calculation:
- * it constructs the union of the two sets A - B and B - A, where A and B are the two
- * input ranges. That is, the output range contains a copy of every element that is
- * contained in [first1, last1) but not [first2, last1), and a copy of
- * every element that is contained in [first2, last2) but not [first1, last1).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements that are
- * equivalent to each other and [first2, last1) contains \c n elements that are
- * equivalent to them, then |m - n| of those elements shall be copied to the output
- * range: the last m - n elements from [first1, last1) if m > n, and
- * the last n - m of these elements from [first2, last2) if m < n.
- *
- * This version of \p set_union compares elements using \c operator<.
- *
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \return The end of the output range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to operator<.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference to compute
- * the symmetric difference of two sets of integers sorted in ascending order.
- *
- * \code
- * #include
- * ...
- * int A1[6] = {0, 1, 2, 2, 4, 6, 7};
- * int A2[5] = {1, 1, 2, 5, 8};
- *
- * int result[6];
- *
- * int *result_end = thrust::set_symmetric_difference(A1, A1 + 6, A2, A2 + 5, result);
- * // result = {0, 4, 5, 6, 7, 8}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_symmetric_difference.html
- * \see \p merge
- * \see \p includes
- * \see \p set_difference
- * \see \p set_union
- * \see \p set_intersection
- * \see \p sort
- * \see \p is_sorted
- */
-template
- OutputIterator set_symmetric_difference(InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result);
-
-
-/*! \p set_symmetric_difference constructs a sorted range that is the set symmetric
- * difference of the sorted ranges [first1, last1) and [first2, last2).
- * The return value is the end of the output range.
- *
- * In the simplest case, \p set_symmetric_difference performs a set theoretic calculation:
- * it constructs the union of the two sets A - B and B - A, where A and B are the two
- * input ranges. That is, the output range contains a copy of every element that is
- * contained in [first1, last1) but not [first2, last1), and a copy of
- * every element that is contained in [first2, last2) but not [first1, last1).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements that are
- * equivalent to each other and [first2, last1) contains \c n elements that are
- * equivalent to them, then |m - n| of those elements shall be copied to the output
- * range: the last m - n elements from [first1, last1) if m > n, and
- * the last n - m of these elements from [first2, last2) if m < n.
- *
- * This version of \p set_union compares elements using a function object \p comp.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \param comp Comparison operator.
- * \return The end of the output range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to \p comp.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference to compute
- * the symmetric difference of two sets of integers sorted in descending order using the \p thrust::host
- * execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A1[6] = {7, 6, 4, 2, 2, 1, 0};
- * int A2[5] = {8, 5, 2, 1, 1};
- *
- * int result[6];
- *
- * int *result_end = thrust::set_symmetric_difference(thrust::host, A1, A1 + 6, A2, A2 + 5, result);
- * // result = {8, 7, 6, 5, 4, 0}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_symmetric_difference.html
- * \see \p merge
- * \see \p includes
- * \see \p set_difference
- * \see \p set_union
- * \see \p set_intersection
- * \see \p sort
- * \see \p is_sorted
- */
-template
-__host__ __device__
- OutputIterator set_symmetric_difference(const thrust::detail::execution_policy_base &exec,
- InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result,
- StrictWeakCompare comp);
-
-
-/*! \p set_symmetric_difference constructs a sorted range that is the set symmetric
- * difference of the sorted ranges [first1, last1) and [first2, last2).
- * The return value is the end of the output range.
- *
- * In the simplest case, \p set_symmetric_difference performs a set theoretic calculation:
- * it constructs the union of the two sets A - B and B - A, where A and B are the two
- * input ranges. That is, the output range contains a copy of every element that is
- * contained in [first1, last1) but not [first2, last1), and a copy of
- * every element that is contained in [first2, last2) but not [first1, last1).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements that are
- * equivalent to each other and [first2, last1) contains \c n elements that are
- * equivalent to them, then |m - n| of those elements shall be copied to the output
- * range: the last m - n elements from [first1, last1) if m > n, and
- * the last n - m of these elements from [first2, last2) if m < n.
- *
- * This version of \p set_union compares elements using a function object \p comp.
- *
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \param comp Comparison operator.
- * \return The end of the output range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to \p comp.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference to compute
- * the symmetric difference of two sets of integers sorted in descending order.
- *
- * \code
- * #include
- * ...
- * int A1[6] = {7, 6, 4, 2, 2, 1, 0};
- * int A2[5] = {8, 5, 2, 1, 1};
- *
- * int result[6];
- *
- * int *result_end = thrust::set_symmetric_difference(A1, A1 + 6, A2, A2 + 5, result);
- * // result = {8, 7, 6, 5, 4, 0}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_symmetric_difference.html
- * \see \p merge
- * \see \p includes
- * \see \p set_difference
- * \see \p set_union
- * \see \p set_intersection
- * \see \p sort
- * \see \p is_sorted
- */
-template
- OutputIterator set_symmetric_difference(InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result,
- StrictWeakCompare comp);
-
-
-/*! \p set_union constructs a sorted range that is the union of the sorted ranges
- * [first1, last1) and [first2, last2). The return value is the
- * end of the output range.
- *
- * In the simplest case, \p set_union performs the "union" operation from set
- * theory: the output range contains a copy of every element that is contained in
- * [first1, last1), [first2, last1), or both. The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements
- * that are equivalent to each other and if [first2, last2) contains \c n
- * elements that are equivalent to them, then all \c m elements from the first
- * range shall be copied to the output range, in order, and then max(n - m, 0)
- * elements from the second range shall be copied to the output, in order.
- *
- * This version of \p set_union compares elements using \c operator<.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \return The end of the output range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to operator<.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_union to compute the union of
- * two sets of integers sorted in ascending order using the \p thrust::host execution policy for
- * parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A1[7] = {0, 2, 4, 6, 8, 10, 12};
- * int A2[5] = {1, 3, 5, 7, 9};
- *
- * int result[11];
- *
- * int *result_end = thrust::set_union(thrust::host, A1, A1 + 7, A2, A2 + 5, result);
- * // result = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_union.html
- * \see \p merge
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
-__host__ __device__
- OutputIterator set_union(const thrust::detail::execution_policy_base &exec,
- InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result);
-
-
-/*! \p set_union constructs a sorted range that is the union of the sorted ranges
- * [first1, last1) and [first2, last2). The return value is the
- * end of the output range.
- *
- * In the simplest case, \p set_union performs the "union" operation from set
- * theory: the output range contains a copy of every element that is contained in
- * [first1, last1), [first2, last1), or both. The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements
- * that are equivalent to each other and if [first2, last2) contains \c n
- * elements that are equivalent to them, then all \c m elements from the first
- * range shall be copied to the output range, in order, and then max(n - m, 0)
- * elements from the second range shall be copied to the output, in order.
- *
- * This version of \p set_union compares elements using \c operator<.
- *
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \return The end of the output range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to operator<.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_union to compute the union of
- * two sets of integers sorted in ascending order.
- *
- * \code
- * #include
- * ...
- * int A1[7] = {0, 2, 4, 6, 8, 10, 12};
- * int A2[5] = {1, 3, 5, 7, 9};
- *
- * int result[11];
- *
- * int *result_end = thrust::set_union(A1, A1 + 7, A2, A2 + 5, result);
- * // result = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_union.html
- * \see \p merge
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
- OutputIterator set_union(InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result);
-
-
-/*! \p set_union constructs a sorted range that is the union of the sorted ranges
- * [first1, last1) and [first2, last2). The return value is the
- * end of the output range.
- *
- * In the simplest case, \p set_union performs the "union" operation from set
- * theory: the output range contains a copy of every element that is contained in
- * [first1, last1), [first2, last1), or both. The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements
- * that are equivalent to each other and if [first2, last2) contains \c n
- * elements that are equivalent to them, then all \c m elements from the first
- * range shall be copied to the output range, in order, and then max(n - m, 0)
- * elements from the second range shall be copied to the output, in order.
- *
- * This version of \p set_union compares elements using a function object \p comp.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \param comp Comparison operator.
- * \return The end of the output range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1's \c value_type is convertable to \p StrictWeakCompare's \c first_argument_type.
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2's \c value_type is convertable to \p StrictWeakCompare's \c second_argument_type.
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to \p comp.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_union to compute the union of
- * two sets of integers sorted in ascending order using the \p thrust::host execution policy for
- * parallelization:
- *
- * \code
- * #include
- * #include
- * #include
- * ...
- * int A1[7] = {12, 10, 8, 6, 4, 2, 0};
- * int A2[5] = {9, 7, 5, 3, 1};
- *
- * int result[11];
- *
- * int *result_end = thrust::set_union(thrust::host, A1, A1 + 7, A2, A2 + 5, result, thrust::greater());
- * // result = {12, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_union.html
- * \see \p merge
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
-__host__ __device__
- OutputIterator set_union(const thrust::detail::execution_policy_base &exec,
- InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result,
- StrictWeakCompare comp);
-
-
-/*! \p set_union constructs a sorted range that is the union of the sorted ranges
- * [first1, last1) and [first2, last2). The return value is the
- * end of the output range.
- *
- * In the simplest case, \p set_union performs the "union" operation from set
- * theory: the output range contains a copy of every element that is contained in
- * [first1, last1), [first2, last1), or both. The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [first1, last1) contains \c m elements
- * that are equivalent to each other and if [first2, last2) contains \c n
- * elements that are equivalent to them, then all \c m elements from the first
- * range shall be copied to the output range, in order, and then max(n - m, 0)
- * elements from the second range shall be copied to the output, in order.
- *
- * This version of \p set_union compares elements using a function object \p comp.
- *
- * \param first1 The beginning of the first input range.
- * \param last1 The end of the first input range.
- * \param first2 The beginning of the second input range.
- * \param last2 The end of the second input range.
- * \param result The beginning of the output range.
- * \param comp Comparison operator.
- * \return The end of the output range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1's \c value_type is convertable to \p StrictWeakCompare's \c first_argument_type.
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2's \c value_type is convertable to \p StrictWeakCompare's \c second_argument_type.
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam OutputIterator is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [first1, last1) and [first2, last2) shall be sorted with respect to \p comp.
- * \pre The resulting range shall not overlap with either input range.
- *
- * The following code snippet demonstrates how to use \p set_union to compute the union of
- * two sets of integers sorted in ascending order.
- *
- * \code
- * #include
- * #include
- * ...
- * int A1[7] = {12, 10, 8, 6, 4, 2, 0};
- * int A2[5] = {9, 7, 5, 3, 1};
- *
- * int result[11];
- *
- * int *result_end = thrust::set_union(A1, A1 + 7, A2, A2 + 5, result, thrust::greater());
- * // result = {12, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
- * \endcode
- *
- * \see http://www.sgi.com/tech/stl/set_union.html
- * \see \p merge
- * \see \p includes
- * \see \p set_union
- * \see \p set_intersection
- * \see \p set_symmetric_difference
- * \see \p sort
- * \see \p is_sorted
- */
-template
- OutputIterator set_union(InputIterator1 first1,
- InputIterator1 last1,
- InputIterator2 first2,
- InputIterator2 last2,
- OutputIterator result,
- StrictWeakCompare comp);
-
-
-/*! \p set_difference_by_key performs a key-value difference operation from set theory.
- * \p set_difference_by_key constructs a sorted range that is the difference of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_difference_by_key performs the "difference" operation from set
- * theory: the keys output range contains a copy of every element that is contained in
- * [keys_first1, keys_last1) and not contained in [keys_first2, keys_last2).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements
- * that are equivalent to each other and if [keys_first2, keys_last2) contains \c n
- * elements that are equivalent to them, the last max(m-n,0) elements from
- * [keys_first1, keys_last1) range shall be copied to the output range.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_difference_by_key compares key elements using \c operator<.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to operator<.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_difference_by_key to compute the
- * set difference of two sets of integers sorted in ascending order with their values using the \p thrust::host
- * execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A_keys[6] = {0, 1, 3, 4, 5, 6, 9};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {1, 3, 5, 7, 9};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[3];
- * int vals_result[3];
- *
- * thrust::pair end = thrust::set_difference_by_key(thrust::host, A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result);
- * // keys_result is now {0, 4, 6}
- * // vals_result is now {0, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_intersection_by_key
- * \see \p set_symmetric_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
-__host__ __device__
- thrust::pair
- set_difference_by_key(const thrust::detail::execution_policy_base &exec,
- InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result);
-
-
-/*! \p set_difference_by_key performs a key-value difference operation from set theory.
- * \p set_difference_by_key constructs a sorted range that is the difference of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_difference_by_key performs the "difference" operation from set
- * theory: the keys output range contains a copy of every element that is contained in
- * [keys_first1, keys_last1) and not contained in [keys_first2, keys_last2).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements
- * that are equivalent to each other and if [keys_first2, keys_last2) contains \c n
- * elements that are equivalent to them, the last max(m-n,0) elements from
- * [keys_first1, keys_last1) range shall be copied to the output range.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_difference_by_key compares key elements using \c operator<.
- *
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to operator<.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_difference_by_key to compute the
- * set difference of two sets of integers sorted in ascending order with their values.
- *
- * \code
- * #include
- * ...
- * int A_keys[6] = {0, 1, 3, 4, 5, 6, 9};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {1, 3, 5, 7, 9};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[3];
- * int vals_result[3];
- *
- * thrust::pair end = thrust::set_difference_by_key(A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result);
- * // keys_result is now {0, 4, 6}
- * // vals_result is now {0, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_intersection_by_key
- * \see \p set_symmetric_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
- thrust::pair
- set_difference_by_key(InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result);
-
-
-/*! \p set_difference_by_key performs a key-value difference operation from set theory.
- * \p set_difference_by_key constructs a sorted range that is the difference of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_difference_by_key performs the "difference" operation from set
- * theory: the keys output range contains a copy of every element that is contained in
- * [keys_first1, keys_last1) and not contained in [keys_first2, keys_last2).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements
- * that are equivalent to each other and if [keys_first2, keys_last2) contains \c n
- * elements that are equivalent to them, the last max(m-n,0) elements from
- * [keys_first1, keys_last1) range shall be copied to the output range.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_difference_by_key compares key elements using a function object \p comp.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \param comp Comparison operator.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to \p comp.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_difference_by_key to compute the
- * set difference of two sets of integers sorted in descending order with their values using the \p thrust::host
- * execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * #include
- * ...
- * int A_keys[6] = {9, 6, 5, 4, 3, 1, 0};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {9, 7, 5, 3, 1};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[3];
- * int vals_result[3];
- *
- * thrust::pair end = thrust::set_difference_by_key(thrust::host, A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result, thrust::greater());
- * // keys_result is now {0, 4, 6}
- * // vals_result is now {0, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_intersection_by_key
- * \see \p set_symmetric_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
-__host__ __device__
- thrust::pair
- set_difference_by_key(const thrust::detail::execution_policy_base &exec,
- InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result,
- StrictWeakCompare comp);
-
-
-/*! \p set_difference_by_key performs a key-value difference operation from set theory.
- * \p set_difference_by_key constructs a sorted range that is the difference of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_difference_by_key performs the "difference" operation from set
- * theory: the keys output range contains a copy of every element that is contained in
- * [keys_first1, keys_last1) and not contained in [keys_first2, keys_last2).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements
- * that are equivalent to each other and if [keys_first2, keys_last2) contains \c n
- * elements that are equivalent to them, the last max(m-n,0) elements from
- * [keys_first1, keys_last1) range shall be copied to the output range.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_difference_by_key compares key elements using a function object \p comp.
- *
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \param comp Comparison operator.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to \p comp.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_difference_by_key to compute the
- * set difference of two sets of integers sorted in descending order with their values.
- *
- * \code
- * #include
- * #include
- * ...
- * int A_keys[6] = {9, 6, 5, 4, 3, 1, 0};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {9, 7, 5, 3, 1};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[3];
- * int vals_result[3];
- *
- * thrust::pair end = thrust::set_difference_by_key(A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result, thrust::greater());
- * // keys_result is now {0, 4, 6}
- * // vals_result is now {0, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_intersection_by_key
- * \see \p set_symmetric_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
- thrust::pair
- set_difference_by_key(InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result,
- StrictWeakCompare comp);
-
-
-/*! \p set_intersection_by_key performs a key-value intersection operation from set theory.
- * \p set_intersection_by_key constructs a sorted range that is the intersection of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_intersection_by_key performs the "intersection" operation from set
- * theory: the keys output range contains a copy of every element that is contained in both
- * [keys_first1, keys_last1) [keys_first2, keys_last2).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if an element appears \c m times in [keys_first1, keys_last1)
- * and \c n times in [keys_first2, keys_last2) (where \c m may be zero), then it
- * appears min(m,n) times in the keys output range.
- * \p set_intersection_by_key is stable, meaning both that elements are copied from the first
- * input range rather than the second, and that the relative order of elements in the output range
- * is the same as the first input range.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) to the keys output range,
- * the corresponding value element is copied from [values_first1, values_last1) to the values
- * output range.
- *
- * This version of \p set_intersection_by_key compares objects using \c operator<.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \note Unlike the other key-value set operations, \p set_intersection_by_key is unique in that it has no
- * \c values_first2 parameter because elements from the second input range are never copied to the output range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to operator<.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_intersection_by_key to compute the
- * set intersection of two sets of integers sorted in ascending order with their values using the \p thrust::host
- * execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A_keys[6] = {1, 3, 5, 7, 9, 11};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0};
- *
- * int B_keys[7] = {1, 1, 2, 3, 5, 8, 13};
- *
- * int keys_result[7];
- * int vals_result[7];
- *
- * thrust::pair end = thrust::set_intersection_by_key(thrust::host, A_keys, A_keys + 6, B_keys, B_keys + 7, A_vals, keys_result, vals_result);
- *
- * // keys_result is now {1, 3, 5}
- * // vals_result is now {0, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_difference_by_key
- * \see \p set_symmetric_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
-__host__ __device__
- thrust::pair
- set_intersection_by_key(const thrust::detail::execution_policy_base &exec,
- InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- OutputIterator1 keys_result,
- OutputIterator2 values_result);
-
-
-/*! \p set_intersection_by_key performs a key-value intersection operation from set theory.
- * \p set_intersection_by_key constructs a sorted range that is the intersection of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_intersection_by_key performs the "intersection" operation from set
- * theory: the keys output range contains a copy of every element that is contained in both
- * [keys_first1, keys_last1) [keys_first2, keys_last2).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if an element appears \c m times in [keys_first1, keys_last1)
- * and \c n times in [keys_first2, keys_last2) (where \c m may be zero), then it
- * appears min(m,n) times in the keys output range.
- * \p set_intersection_by_key is stable, meaning both that elements are copied from the first
- * input range rather than the second, and that the relative order of elements in the output range
- * is the same as the first input range.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) to the keys output range,
- * the corresponding value element is copied from [values_first1, values_last1) to the values
- * output range.
- *
- * This version of \p set_intersection_by_key compares objects using \c operator<.
- *
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \note Unlike the other key-value set operations, \p set_intersection_by_key is unique in that it has no
- * \c values_first2 parameter because elements from the second input range are never copied to the output range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to operator<.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_intersection_by_key to compute the
- * set intersection of two sets of integers sorted in ascending order with their values.
- *
- * \code
- * #include
- * ...
- * int A_keys[6] = {1, 3, 5, 7, 9, 11};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0};
- *
- * int B_keys[7] = {1, 1, 2, 3, 5, 8, 13};
- *
- * int keys_result[7];
- * int vals_result[7];
- *
- * thrust::pair end = thrust::set_intersection_by_key(A_keys, A_keys + 6, B_keys, B_keys + 7, A_vals, keys_result, vals_result);
- *
- * // keys_result is now {1, 3, 5}
- * // vals_result is now {0, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_difference_by_key
- * \see \p set_symmetric_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
- thrust::pair
- set_intersection_by_key(InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- OutputIterator1 keys_result,
- OutputIterator2 values_result);
-
-
-/*! \p set_intersection_by_key performs a key-value intersection operation from set theory.
- * \p set_intersection_by_key constructs a sorted range that is the intersection of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_intersection_by_key performs the "intersection" operation from set
- * theory: the keys output range contains a copy of every element that is contained in both
- * [keys_first1, keys_last1) [keys_first2, keys_last2).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if an element appears \c m times in [keys_first1, keys_last1)
- * and \c n times in [keys_first2, keys_last2) (where \c m may be zero), then it
- * appears min(m,n) times in the keys output range.
- * \p set_intersection_by_key is stable, meaning both that elements are copied from the first
- * input range rather than the second, and that the relative order of elements in the output range
- * is the same as the first input range.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) to the keys output range,
- * the corresponding value element is copied from [values_first1, values_last1) to the values
- * output range.
- *
- * This version of \p set_intersection_by_key compares objects using a function object \p comp.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \param comp Comparison operator.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \note Unlike the other key-value set operations, \p set_intersection_by_key is unique in that it has no
- * \c values_first2 parameter because elements from the second input range are never copied to the output range.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to \p comp.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_intersection_by_key to compute the
- * set intersection of two sets of integers sorted in descending order with their values using the
- * \p thrust::host execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * #include
- * ...
- * int A_keys[6] = {11, 9, 7, 5, 3, 1};
- * int A_vals[6] = { 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[7] = {13, 8, 5, 3, 2, 1, 1};
- *
- * int keys_result[7];
- * int vals_result[7];
- *
- * thrust::pair end = thrust::set_intersection_by_key(thrust::host, A_keys, A_keys + 6, B_keys, B_keys + 7, A_vals, keys_result, vals_result, thrust::greater());
- *
- * // keys_result is now {5, 3, 1}
- * // vals_result is now {0, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_difference_by_key
- * \see \p set_symmetric_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
-__host__ __device__
- thrust::pair
- set_intersection_by_key(const thrust::detail::execution_policy_base &exec,
- InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- OutputIterator1 keys_result,
- OutputIterator2 values_result,
- StrictWeakCompare comp);
-
-
-/*! \p set_intersection_by_key performs a key-value intersection operation from set theory.
- * \p set_intersection_by_key constructs a sorted range that is the intersection of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_intersection_by_key performs the "intersection" operation from set
- * theory: the keys output range contains a copy of every element that is contained in both
- * [keys_first1, keys_last1) [keys_first2, keys_last2).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if an element appears \c m times in [keys_first1, keys_last1)
- * and \c n times in [keys_first2, keys_last2) (where \c m may be zero), then it
- * appears min(m,n) times in the keys output range.
- * \p set_intersection_by_key is stable, meaning both that elements are copied from the first
- * input range rather than the second, and that the relative order of elements in the output range
- * is the same as the first input range.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) to the keys output range,
- * the corresponding value element is copied from [values_first1, values_last1) to the values
- * output range.
- *
- * This version of \p set_intersection_by_key compares objects using a function object \p comp.
- *
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \param comp Comparison operator.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \note Unlike the other key-value set operations, \p set_intersection_by_key is unique in that it has no
- * \c values_first2 parameter because elements from the second input range are never copied to the output range.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to \p comp.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_intersection_by_key to compute the
- * set intersection of two sets of integers sorted in descending order with their values.
- *
- * \code
- * #include
- * #include
- * ...
- * int A_keys[6] = {11, 9, 7, 5, 3, 1};
- * int A_vals[6] = { 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[7] = {13, 8, 5, 3, 2, 1, 1};
- *
- * int keys_result[7];
- * int vals_result[7];
- *
- * thrust::pair end = thrust::set_intersection_by_key(A_keys, A_keys + 6, B_keys, B_keys + 7, A_vals, keys_result, vals_result, thrust::greater());
- *
- * // keys_result is now {5, 3, 1}
- * // vals_result is now {0, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_difference_by_key
- * \see \p set_symmetric_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
- thrust::pair
- set_intersection_by_key(InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- OutputIterator1 keys_result,
- OutputIterator2 values_result,
- StrictWeakCompare comp);
-
-
-/*! \p set_symmetric_difference_by_key performs a key-value symmetric difference operation from set theory.
- * \p set_difference_by_key constructs a sorted range that is the symmetric difference of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_symmetric_difference_by_key performs a set theoretic calculation:
- * it constructs the union of the two sets A - B and B - A, where A and B are the two
- * input ranges. That is, the output range contains a copy of every element that is
- * contained in [keys_first1, keys_last1) but not [keys_first2, keys_last1), and a copy of
- * every element that is contained in [keys_first2, keys_last2) but not [keys_first1, keys_last1).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements that are
- * equivalent to each other and [keys_first2, keys_last1) contains \c n elements that are
- * equivalent to them, then |m - n| of those elements shall be copied to the output
- * range: the last m - n elements from [keys_first1, keys_last1) if m > n, and
- * the last n - m of these elements from [keys_first2, keys_last2) if m < n.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_symmetric_difference_by_key compares key elements using \c operator<.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to operator<.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference_by_key to compute the
- * symmetric difference of two sets of integers sorted in ascending order with their values using the
- * \p thrust::host execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A_keys[6] = {0, 1, 2, 2, 4, 6, 7};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {1, 1, 2, 5, 8};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[6];
- * int vals_result[6];
- *
- * thrust::pair end = thrust::set_symmetric_difference_by_key(thrust::host, A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result);
- * // keys_result is now {0, 4, 5, 6, 7, 8}
- * // vals_result is now {0, 0, 1, 0, 0, 1}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_intersection_by_key
- * \see \p set_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
-__host__ __device__
- thrust::pair
- set_symmetric_difference_by_key(const thrust::detail::execution_policy_base &exec,
- InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result);
-
-
-/*! \p set_symmetric_difference_by_key performs a key-value symmetric difference operation from set theory.
- * \p set_difference_by_key constructs a sorted range that is the symmetric difference of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_symmetric_difference_by_key performs a set theoretic calculation:
- * it constructs the union of the two sets A - B and B - A, where A and B are the two
- * input ranges. That is, the output range contains a copy of every element that is
- * contained in [keys_first1, keys_last1) but not [keys_first2, keys_last1), and a copy of
- * every element that is contained in [keys_first2, keys_last2) but not [keys_first1, keys_last1).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements that are
- * equivalent to each other and [keys_first2, keys_last1) contains \c n elements that are
- * equivalent to them, then |m - n| of those elements shall be copied to the output
- * range: the last m - n elements from [keys_first1, keys_last1) if m > n, and
- * the last n - m of these elements from [keys_first2, keys_last2) if m < n.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_symmetric_difference_by_key compares key elements using \c operator<.
- *
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to operator<.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference_by_key to compute the
- * symmetric difference of two sets of integers sorted in ascending order with their values.
- *
- * \code
- * #include
- * ...
- * int A_keys[6] = {0, 1, 2, 2, 4, 6, 7};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {1, 1, 2, 5, 8};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[6];
- * int vals_result[6];
- *
- * thrust::pair end = thrust::set_symmetric_difference_by_key(A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result);
- * // keys_result is now {0, 4, 5, 6, 7, 8}
- * // vals_result is now {0, 0, 1, 0, 0, 1}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_intersection_by_key
- * \see \p set_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
- thrust::pair
- set_symmetric_difference_by_key(InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result);
-
-
-/*! \p set_symmetric_difference_by_key performs a key-value symmetric difference operation from set theory.
- * \p set_difference_by_key constructs a sorted range that is the symmetric difference of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_symmetric_difference_by_key performs a set theoretic calculation:
- * it constructs the union of the two sets A - B and B - A, where A and B are the two
- * input ranges. That is, the output range contains a copy of every element that is
- * contained in [keys_first1, keys_last1) but not [keys_first2, keys_last1), and a copy of
- * every element that is contained in [keys_first2, keys_last2) but not [keys_first1, keys_last1).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements that are
- * equivalent to each other and [keys_first2, keys_last1) contains \c n elements that are
- * equivalent to them, then |m - n| of those elements shall be copied to the output
- * range: the last m - n elements from [keys_first1, keys_last1) if m > n, and
- * the last n - m of these elements from [keys_first2, keys_last2) if m < n.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_symmetric_difference_by_key compares key elements using a function object \c comp.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \param comp Comparison operator.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to \p comp.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference_by_key to compute the
- * symmetric difference of two sets of integers sorted in descending order with their values using the
- * \p thrust::host execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * #include
- * ...
- * int A_keys[6] = {7, 6, 4, 2, 2, 1, 0};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {8, 5, 2, 1, 1};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[6];
- * int vals_result[6];
- *
- * thrust::pair end = thrust::set_symmetric_difference_by_key(thrust::host, A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result);
- * // keys_result is now {8, 7, 6, 5, 4, 0}
- * // vals_result is now {1, 0, 0, 1, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_intersection_by_key
- * \see \p set_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
-__host__ __device__
- thrust::pair
- set_symmetric_difference_by_key(const thrust::detail::execution_policy_base &exec,
- InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result,
- StrictWeakCompare comp);
-
-
-/*! \p set_symmetric_difference_by_key performs a key-value symmetric difference operation from set theory.
- * \p set_difference_by_key constructs a sorted range that is the symmetric difference of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_symmetric_difference_by_key performs a set theoretic calculation:
- * it constructs the union of the two sets A - B and B - A, where A and B are the two
- * input ranges. That is, the output range contains a copy of every element that is
- * contained in [keys_first1, keys_last1) but not [keys_first2, keys_last1), and a copy of
- * every element that is contained in [keys_first2, keys_last2) but not [keys_first1, keys_last1).
- * The general case is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements that are
- * equivalent to each other and [keys_first2, keys_last1) contains \c n elements that are
- * equivalent to them, then |m - n| of those elements shall be copied to the output
- * range: the last m - n elements from [keys_first1, keys_last1) if m > n, and
- * the last n - m of these elements from [keys_first2, keys_last2) if m < n.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_symmetric_difference_by_key compares key elements using a function object \c comp.
- *
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \param comp Comparison operator.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to \p comp.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference_by_key to compute the
- * symmetric difference of two sets of integers sorted in descending order with their values.
- *
- * \code
- * #include
- * #include
- * ...
- * int A_keys[6] = {7, 6, 4, 2, 2, 1, 0};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {8, 5, 2, 1, 1};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[6];
- * int vals_result[6];
- *
- * thrust::pair end = thrust::set_symmetric_difference_by_key(A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result);
- * // keys_result is now {8, 7, 6, 5, 4, 0}
- * // vals_result is now {1, 0, 0, 1, 0, 0}
- * \endcode
- *
- * \see \p set_union_by_key
- * \see \p set_intersection_by_key
- * \see \p set_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
- thrust::pair
- set_symmetric_difference_by_key(InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result,
- StrictWeakCompare comp);
-
-
-/*! \p set_union_by_key performs a key-value union operation from set theory.
- * \p set_union_by_key constructs a sorted range that is the union of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_union_by_key performs the "union" operation from set theory:
- * the output range contains a copy of every element that is contained in
- * [keys_first1, keys_last1), [keys_first2, keys_last1), or both. The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements
- * that are equivalent to each other and if [keys_first2, keys_last2) contains \c n
- * elements that are equivalent to them, then all \c m elements from the first
- * range shall be copied to the output range, in order, and then max(n - m, 0)
- * elements from the second range shall be copied to the output, in order.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_union_by_key compares key elements using \c operator<.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to operator<.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference_by_key to compute the
- * symmetric difference of two sets of integers sorted in ascending order with their values using the
- * \p thrust::host execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * ...
- * int A_keys[6] = {0, 2, 4, 6, 8, 10, 12};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {1, 3, 5, 7, 9};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[11];
- * int vals_result[11];
- *
- * thrust::pair end = thrust::set_symmetric_difference_by_key(thrust::host, A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result);
- * // keys_result is now {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12}
- * // vals_result is now {0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0}
- * \endcode
- *
- * \see \p set_symmetric_difference_by_key
- * \see \p set_intersection_by_key
- * \see \p set_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
-__host__ __device__
- thrust::pair
- set_union_by_key(const thrust::detail::execution_policy_base &exec,
- InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result);
-
-
-/*! \p set_union_by_key performs a key-value union operation from set theory.
- * \p set_union_by_key constructs a sorted range that is the union of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_union_by_key performs the "union" operation from set theory:
- * the output range contains a copy of every element that is contained in
- * [keys_first1, keys_last1), [keys_first2, keys_last1), or both. The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements
- * that are equivalent to each other and if [keys_first2, keys_last2) contains \c n
- * elements that are equivalent to them, then all \c m elements from the first
- * range shall be copied to the output range, in order, and then max(n - m, 0)
- * elements from the second range shall be copied to the output, in order.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_union_by_key compares key elements using \c operator<.
- *
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to operator<.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference_by_key to compute the
- * symmetric difference of two sets of integers sorted in ascending order with their values.
- *
- * \code
- * #include
- * ...
- * int A_keys[6] = {0, 2, 4, 6, 8, 10, 12};
- * int A_vals[6] = {0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {1, 3, 5, 7, 9};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[11];
- * int vals_result[11];
- *
- * thrust::pair end = thrust::set_symmetric_difference_by_key(A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result);
- * // keys_result is now {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12}
- * // vals_result is now {0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 0}
- * \endcode
- *
- * \see \p set_symmetric_difference_by_key
- * \see \p set_intersection_by_key
- * \see \p set_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
- thrust::pair
- set_union_by_key(InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result);
-
-
-/*! \p set_union_by_key performs a key-value union operation from set theory.
- * \p set_union_by_key constructs a sorted range that is the union of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_union_by_key performs the "union" operation from set theory:
- * the output range contains a copy of every element that is contained in
- * [keys_first1, keys_last1), [keys_first2, keys_last1), or both. The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements
- * that are equivalent to each other and if [keys_first2, keys_last2) contains \c n
- * elements that are equivalent to them, then all \c m elements from the first
- * range shall be copied to the output range, in order, and then max(n - m, 0)
- * elements from the second range shall be copied to the output, in order.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_union_by_key compares key elements using a function object \c comp.
- *
- * The algorithm's execution is parallelized as determined by \p exec.
- *
- * \param exec The execution policy to use for parallelization.
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \param comp Comparison operator.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam DerivedPolicy The name of the derived execution policy.
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to \p comp.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference_by_key to compute the
- * symmetric difference of two sets of integers sorted in descending order with their values using the
- * \p thrust::host execution policy for parallelization:
- *
- * \code
- * #include
- * #include
- * #include
- * ...
- * int A_keys[6] = {12, 10, 8, 6, 4, 2, 0};
- * int A_vals[6] = { 0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {9, 7, 5, 3, 1};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[11];
- * int vals_result[11];
- *
- * thrust::pair end = thrust::set_symmetric_difference_by_key(thrust::host, A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result, thrust::greater());
- * // keys_result is now {12, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
- * // vals_result is now { 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0}
- * \endcode
- *
- * \see \p set_symmetric_difference_by_key
- * \see \p set_intersection_by_key
- * \see \p set_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
-__host__ __device__
- thrust::pair
- set_union_by_key(const thrust::detail::execution_policy_base &exec,
- InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result,
- StrictWeakCompare comp);
-
-
-/*! \p set_union_by_key performs a key-value union operation from set theory.
- * \p set_union_by_key constructs a sorted range that is the union of the sorted
- * ranges [keys_first1, keys_last1) and [keys_first2, keys_last2). Associated
- * with each element from the input and output key ranges is a value element. The associated input
- * value ranges need not be sorted.
- *
- * In the simplest case, \p set_union_by_key performs the "union" operation from set theory:
- * the output range contains a copy of every element that is contained in
- * [keys_first1, keys_last1), [keys_first2, keys_last1), or both. The general case
- * is more complicated, because the input ranges may contain duplicate elements.
- * The generalization is that if [keys_first1, keys_last1) contains \c m elements
- * that are equivalent to each other and if [keys_first2, keys_last2) contains \c n
- * elements that are equivalent to them, then all \c m elements from the first
- * range shall be copied to the output range, in order, and then max(n - m, 0)
- * elements from the second range shall be copied to the output, in order.
- *
- * Each time a key element is copied from [keys_first1, keys_last1) or
- * [keys_first2, keys_last2) is copied to the keys output range, the
- * corresponding value element is copied from the corresponding values input range (beginning at
- * \p values_first1 or \p values_first2) to the values output range.
- *
- * This version of \p set_union_by_key compares key elements using a function object \c comp.
- *
- * \param keys_first1 The beginning of the first input range of keys.
- * \param keys_last1 The end of the first input range of keys.
- * \param keys_first2 The beginning of the second input range of keys.
- * \param keys_last2 The end of the second input range of keys.
- * \param values_first1 The beginning of the first input range of values.
- * \param values_first2 The beginning of the first input range of values.
- * \param keys_result The beginning of the output range of keys.
- * \param values_result The beginning of the output range of values.
- * \param comp Comparison operator.
- * \return A \p pair \c p such that p.first is the end of the output range of keys,
- * and such that p.second is the end of the output range of values.
- *
- * \tparam InputIterator1 is a model of Input Iterator,
- * \p InputIterator1 and \p InputIterator2 have the same \c value_type,
- * \p InputIterator1's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator1's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator1's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator2 is a model of Input Iterator,
- * \p InputIterator2 and \p InputIterator1 have the same \c value_type,
- * \p InputIterator2's \c value_type is a model of LessThan Comparable,
- * the ordering on \p InputIterator2's \c value_type is a strict weak ordering, as defined in the LessThan Comparable requirements,
- * and \p InputIterator2's \c value_type is convertable to a type in \p OutputIterator's set of \c value_types.
- * \tparam InputIterator3 is a model of Input Iterator,
- * and \p InputIterator3's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam InputIterator4 is a model of Input Iterator,
- * and \p InputIterator4's \c value_type is convertible to a type in \p OutputIterator2's set of \c value_types.
- * \tparam OutputIterator1 is a model of Output Iterator.
- * \tparam OutputIterator2 is a model of Output Iterator.
- * \tparam StrictWeakCompare is a model of Strict Weak Ordering.
- *
- * \pre The ranges [keys_first1, keys_last1) and [keys_first2, keys_last2) shall be sorted with respect to \p comp.
- * \pre The resulting ranges shall not overlap with any input range.
- *
- * The following code snippet demonstrates how to use \p set_symmetric_difference_by_key to compute the
- * symmetric difference of two sets of integers sorted in descending order with their values.
- *
- * \code
- * #include
- * #include
- * ...
- * int A_keys[6] = {12, 10, 8, 6, 4, 2, 0};
- * int A_vals[6] = { 0, 0, 0, 0, 0, 0, 0};
- *
- * int B_keys[5] = {9, 7, 5, 3, 1};
- * int B_vals[5] = {1, 1, 1, 1, 1};
- *
- * int keys_result[11];
- * int vals_result[11];
- *
- * thrust::pair end = thrust::set_symmetric_difference_by_key(A_keys, A_keys + 6, B_keys, B_keys + 5, A_vals, B_vals, keys_result, vals_result, thrust::greater());
- * // keys_result is now {12, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
- * // vals_result is now { 0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0}
- * \endcode
- *
- * \see \p set_symmetric_difference_by_key
- * \see \p set_intersection_by_key
- * \see \p set_difference_by_key
- * \see \p sort_by_key
- * \see \p is_sorted
- */
-template
- thrust::pair
- set_union_by_key(InputIterator1 keys_first1,
- InputIterator1 keys_last1,
- InputIterator2 keys_first2,
- InputIterator2 keys_last2,
- InputIterator3 values_first1,
- InputIterator4 values_first2,
- OutputIterator1 keys_result,
- OutputIterator2 values_result,
- StrictWeakCompare comp);
-
-
-/*! \} // end set_operations
- */
-
-
-} // end thrust
-
-#include
-
diff --git a/spaces/ma-xu/LIVE/thrust/thrust/system/detail/sequential/transform_reduce.h b/spaces/ma-xu/LIVE/thrust/thrust/system/detail/sequential/transform_reduce.h
deleted file mode 100644
index 8d2a1b3850dea55c3c8440aa7e22fdb6d002d151..0000000000000000000000000000000000000000
--- a/spaces/ma-xu/LIVE/thrust/thrust/system/detail/sequential/transform_reduce.h
+++ /dev/null
@@ -1,22 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#pragma once
-
-#include
-
-// this system has no special transform_reduce functions
-
diff --git a/spaces/ma-xu/LIVE/thrust/thrust/system/tbb/detail/gather.h b/spaces/ma-xu/LIVE/thrust/thrust/system/tbb/detail/gather.h
deleted file mode 100644
index 098e0f4fbad4001632ed02ee9e9b39aa17e54ea0..0000000000000000000000000000000000000000
--- a/spaces/ma-xu/LIVE/thrust/thrust/system/tbb/detail/gather.h
+++ /dev/null
@@ -1,23 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#pragma once
-
-#include
-
-// this system inherits gather
-#include
-
diff --git a/spaces/manavisrani07/gradio-lipsync-wav2lip/esrgan/upsample.py b/spaces/manavisrani07/gradio-lipsync-wav2lip/esrgan/upsample.py
deleted file mode 100644
index f9a6d1c26bc5b77c2ece7f66511391a0f82dd1f6..0000000000000000000000000000000000000000
--- a/spaces/manavisrani07/gradio-lipsync-wav2lip/esrgan/upsample.py
+++ /dev/null
@@ -1,84 +0,0 @@
-import cv2
-import glob
-import os
-import sys
-from basicsr.archs.rrdbnet_arch import RRDBNet
-from basicsr.utils.download_util import load_file_from_url
-import numpy as np
-import torch
-from gfpgan import GFPGANer
-from realesrgan import RealESRGANer
-from realesrgan.archs.srvgg_arch import SRVGGNetCompact
-from basicsr.utils import imwrite, img2tensor, tensor2img
-from torchvision.transforms.functional import normalize
-from basicsr.utils.registry import ARCH_REGISTRY
-
-def load_sr(model_path, device, face):
- if not face=='codeformer':
- model = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=23, num_grow_ch=32, scale=4) #alter to match dims as needed
- netscale = 4
- model_path = os.path.normpath(model_path)
- if not os.path.isfile(model_path):
- model_path = load_file_from_url(
- url='https://github.com/GucciFlipFlops1917/wav2lip-hq-updated-ESRGAN/releases/download/v0.0.1/4x_BigFace_v3_Clear.pth',
- model_dir='weights', progress=True, file_name=None)
- upsampler = RealESRGANer(
- scale=netscale,
- model_path=model_path,
- dni_weight=None,
- model=model,
- tile=0,
- tile_pad=10,
- pre_pad=0,
- half=True,
- gpu_id=0)
- if face==None:
- run_params=upsampler
- else:
- gfp = GFPGANer(
- model_path='https://github.com/TencentARC/GFPGAN/releases/download/v1.3.4/GFPGANv1.4.pth',
- upscale=2,
- arch='clean',
- channel_multiplier=2,
- bg_upsampler=upsampler)
- run_params=gfp
- else:
- run_params = ARCH_REGISTRY.get('CodeFormer')(dim_embd=512, codebook_size=1024, n_head=8, n_layers=9,
- connect_list=['32', '64', '128', '256']).to(device)
- ckpt_path = load_file_from_url(url='https://github.com/sczhou/CodeFormer/releases/download/v0.1.0/codeformer.pth',
- model_dir='weights/CodeFormer', progress=True, file_name=None)
- checkpoint = torch.load(ckpt_path)['params_ema']
- run_params.load_state_dict(checkpoint)
- run_params.eval()
- return run_params
-
-
-def upscale(image, face, properties):
- try:
- if face==1: ## GFP-GAN
- _, _, output = properties.enhance(image, has_aligned=False, only_center_face=False, paste_back=True)
- elif face==2: ## CODEFORMER
- net = properties[0]
- device = properties[1]
- w = properties[2]
- image = cv2.resize(image, (512, 512), interpolation=cv2.INTER_LINEAR)
- cropped_face_t = img2tensor(image / 255., bgr2rgb=True, float32=True)
- normalize(cropped_face_t, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True)
- cropped_face_t = cropped_face_t.unsqueeze(0).to(device)
- try:
- with torch.no_grad():
- cropped_face_t = net(cropped_face_t, w=w, adain=True)[0]
- restored_face = tensor2img(cropped_face_t, rgb2bgr=True, min_max=(-1, 1))
- del cropped_face_t
- torch.cuda.empty_cache()
- except Exception as error:
- print(f'\tFailed inference for CodeFormer: {error}')
- restored_face = tensor2img(cropped_face_t, rgb2bgr=True, min_max=(-1, 1))
- output = restored_face.astype('uint8')
- elif face==0: ## ESRGAN
- img = image.astype(np.float32) / 255.
- output, _ = properties.enhance(image, outscale=4)
- except RuntimeError as error:
- print('Error', error)
- print('If you encounter CUDA out of memory, try to set --tile with a smaller number.')
- return output
diff --git a/spaces/manavisrani07/gradio-lipsync-wav2lip/wav2lip_models/wav2lip.py b/spaces/manavisrani07/gradio-lipsync-wav2lip/wav2lip_models/wav2lip.py
deleted file mode 100644
index ae5d6919169ec497f0f0815184f5db8ba9108fbd..0000000000000000000000000000000000000000
--- a/spaces/manavisrani07/gradio-lipsync-wav2lip/wav2lip_models/wav2lip.py
+++ /dev/null
@@ -1,184 +0,0 @@
-import torch
-from torch import nn
-from torch.nn import functional as F
-import math
-
-from .conv import Conv2dTranspose, Conv2d, nonorm_Conv2d
-
-class Wav2Lip(nn.Module):
- def __init__(self):
- super(Wav2Lip, self).__init__()
-
- self.face_encoder_blocks = nn.ModuleList([
- nn.Sequential(Conv2d(6, 16, kernel_size=7, stride=1, padding=3)), # 96,96
-
- nn.Sequential(Conv2d(16, 32, kernel_size=3, stride=2, padding=1), # 48,48
- Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True)),
-
- nn.Sequential(Conv2d(32, 64, kernel_size=3, stride=2, padding=1), # 24,24
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True)),
-
- nn.Sequential(Conv2d(64, 128, kernel_size=3, stride=2, padding=1), # 12,12
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True)),
-
- nn.Sequential(Conv2d(128, 256, kernel_size=3, stride=2, padding=1), # 6,6
- Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True)),
-
- nn.Sequential(Conv2d(256, 512, kernel_size=3, stride=2, padding=1), # 3,3
- Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),),
-
- nn.Sequential(Conv2d(512, 512, kernel_size=3, stride=1, padding=0), # 1, 1
- Conv2d(512, 512, kernel_size=1, stride=1, padding=0)),])
-
- self.audio_encoder = nn.Sequential(
- Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
- Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(32, 32, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(32, 64, kernel_size=3, stride=(3, 1), padding=1),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(64, 128, kernel_size=3, stride=3, padding=1),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(128, 256, kernel_size=3, stride=(3, 2), padding=1),
- Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
-
- Conv2d(256, 512, kernel_size=3, stride=1, padding=0),
- Conv2d(512, 512, kernel_size=1, stride=1, padding=0),)
-
- self.face_decoder_blocks = nn.ModuleList([
- nn.Sequential(Conv2d(512, 512, kernel_size=1, stride=1, padding=0),),
-
- nn.Sequential(Conv2dTranspose(1024, 512, kernel_size=3, stride=1, padding=0), # 3,3
- Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),),
-
- nn.Sequential(Conv2dTranspose(1024, 512, kernel_size=3, stride=2, padding=1, output_padding=1),
- Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(512, 512, kernel_size=3, stride=1, padding=1, residual=True),), # 6, 6
-
- nn.Sequential(Conv2dTranspose(768, 384, kernel_size=3, stride=2, padding=1, output_padding=1),
- Conv2d(384, 384, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(384, 384, kernel_size=3, stride=1, padding=1, residual=True),), # 12, 12
-
- nn.Sequential(Conv2dTranspose(512, 256, kernel_size=3, stride=2, padding=1, output_padding=1),
- Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(256, 256, kernel_size=3, stride=1, padding=1, residual=True),), # 24, 24
-
- nn.Sequential(Conv2dTranspose(320, 128, kernel_size=3, stride=2, padding=1, output_padding=1),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(128, 128, kernel_size=3, stride=1, padding=1, residual=True),), # 48, 48
-
- nn.Sequential(Conv2dTranspose(160, 64, kernel_size=3, stride=2, padding=1, output_padding=1),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),
- Conv2d(64, 64, kernel_size=3, stride=1, padding=1, residual=True),),]) # 96,96
-
- self.output_block = nn.Sequential(Conv2d(80, 32, kernel_size=3, stride=1, padding=1),
- nn.Conv2d(32, 3, kernel_size=1, stride=1, padding=0),
- nn.Sigmoid())
-
- def forward(self, audio_sequences, face_sequences):
- # audio_sequences = (B, T, 1, 80, 16)
- B = audio_sequences.size(0)
-
- input_dim_size = len(face_sequences.size())
- if input_dim_size > 4:
- audio_sequences = torch.cat([audio_sequences[:, i] for i in range(audio_sequences.size(1))], dim=0)
- face_sequences = torch.cat([face_sequences[:, :, i] for i in range(face_sequences.size(2))], dim=0)
-
- audio_embedding = self.audio_encoder(audio_sequences) # B, 512, 1, 1
-
- feats = []
- x = face_sequences
- for f in self.face_encoder_blocks:
- x = f(x)
- feats.append(x)
-
- x = audio_embedding
- for f in self.face_decoder_blocks:
- x = f(x)
- try:
- x = torch.cat((x, feats[-1]), dim=1)
- except Exception as e:
- print(x.size())
- print(feats[-1].size())
- raise e
-
- feats.pop()
-
- x = self.output_block(x)
-
- if input_dim_size > 4:
- x = torch.split(x, B, dim=0) # [(B, C, H, W)]
- outputs = torch.stack(x, dim=2) # (B, C, T, H, W)
-
- else:
- outputs = x
-
- return outputs
-
-class Wav2Lip_disc_qual(nn.Module):
- def __init__(self):
- super(Wav2Lip_disc_qual, self).__init__()
-
- self.face_encoder_blocks = nn.ModuleList([
- nn.Sequential(nonorm_Conv2d(3, 32, kernel_size=7, stride=1, padding=3)), # 48,96
-
- nn.Sequential(nonorm_Conv2d(32, 64, kernel_size=5, stride=(1, 2), padding=2), # 48,48
- nonorm_Conv2d(64, 64, kernel_size=5, stride=1, padding=2)),
-
- nn.Sequential(nonorm_Conv2d(64, 128, kernel_size=5, stride=2, padding=2), # 24,24
- nonorm_Conv2d(128, 128, kernel_size=5, stride=1, padding=2)),
-
- nn.Sequential(nonorm_Conv2d(128, 256, kernel_size=5, stride=2, padding=2), # 12,12
- nonorm_Conv2d(256, 256, kernel_size=5, stride=1, padding=2)),
-
- nn.Sequential(nonorm_Conv2d(256, 512, kernel_size=3, stride=2, padding=1), # 6,6
- nonorm_Conv2d(512, 512, kernel_size=3, stride=1, padding=1)),
-
- nn.Sequential(nonorm_Conv2d(512, 512, kernel_size=3, stride=2, padding=1), # 3,3
- nonorm_Conv2d(512, 512, kernel_size=3, stride=1, padding=1),),
-
- nn.Sequential(nonorm_Conv2d(512, 512, kernel_size=3, stride=1, padding=0), # 1, 1
- nonorm_Conv2d(512, 512, kernel_size=1, stride=1, padding=0)),])
-
- self.binary_pred = nn.Sequential(nn.Conv2d(512, 1, kernel_size=1, stride=1, padding=0), nn.Sigmoid())
- self.label_noise = .0
-
- def get_lower_half(self, face_sequences):
- return face_sequences[:, :, face_sequences.size(2)//2:]
-
- def to_2d(self, face_sequences):
- B = face_sequences.size(0)
- face_sequences = torch.cat([face_sequences[:, :, i] for i in range(face_sequences.size(2))], dim=0)
- return face_sequences
-
- def perceptual_forward(self, false_face_sequences):
- false_face_sequences = self.to_2d(false_face_sequences)
- false_face_sequences = self.get_lower_half(false_face_sequences)
-
- false_feats = false_face_sequences
- for f in self.face_encoder_blocks:
- false_feats = f(false_feats)
-
- false_pred_loss = F.binary_cross_entropy(self.binary_pred(false_feats).view(len(false_feats), -1),
- torch.ones((len(false_feats), 1)).cuda())
-
- return false_pred_loss
-
- def forward(self, face_sequences):
- face_sequences = self.to_2d(face_sequences)
- face_sequences = self.get_lower_half(face_sequences)
-
- x = face_sequences
- for f in self.face_encoder_blocks:
- x = f(x)
-
- return self.binary_pred(x).view(len(x), -1)
diff --git a/spaces/matthoffner/chatbot/pages/api/home/home.tsx b/spaces/matthoffner/chatbot/pages/api/home/home.tsx
deleted file mode 100644
index 884d6637c4521f2fd512da948a03ecb9a90b4122..0000000000000000000000000000000000000000
--- a/spaces/matthoffner/chatbot/pages/api/home/home.tsx
+++ /dev/null
@@ -1,430 +0,0 @@
-import { useEffect, useRef, useState } from 'react';
-import { useQuery } from 'react-query';
-
-import { GetServerSideProps } from 'next';
-import { useTranslation } from 'next-i18next';
-import { serverSideTranslations } from 'next-i18next/serverSideTranslations';
-import Head from 'next/head';
-
-import { useCreateReducer } from '@/hooks/useCreateReducer';
-
-import useErrorService from '@/services/errorService';
-import useApiService from '@/services/useApiService';
-
-import {
- cleanConversationHistory,
- cleanSelectedConversation,
-} from '@/utils/app/clean';
-import { DEFAULT_SYSTEM_PROMPT, DEFAULT_TEMPERATURE } from '@/utils/app/const';
-import {
- saveConversation,
- saveConversations,
- updateConversation,
-} from '@/utils/app/conversation';
-import { saveFolders } from '@/utils/app/folders';
-import { savePrompts } from '@/utils/app/prompts';
-import { getSettings } from '@/utils/app/settings';
-
-import { Conversation } from '@/types/chat';
-import { KeyValuePair } from '@/types/data';
-import { FolderInterface, FolderType } from '@/types/folder';
-import { OpenAIModelID, OpenAIModels, fallbackModelID } from '@/types/openai';
-import { Prompt } from '@/types/prompt';
-
-import { Chat } from '@/components/Chat/Chat';
-import { Chatbar } from '@/components/Chatbar/Chatbar';
-import { Navbar } from '@/components/Mobile/Navbar';
-import Promptbar from '@/components/Promptbar';
-
-import HomeContext from './home.context';
-import { HomeInitialState, initialState } from './home.state';
-
-import { v4 as uuidv4 } from 'uuid';
-
-interface Props {
- serverSideApiKeyIsSet: boolean;
- serverSidePluginKeysSet: boolean;
- defaultModelId: OpenAIModelID;
-}
-
-const Home = ({
- serverSideApiKeyIsSet,
- serverSidePluginKeysSet,
- defaultModelId,
-}: Props) => {
- const { t } = useTranslation('chat');
- const { getModels } = useApiService();
- const { getModelsError } = useErrorService();
- const [initialRender, setInitialRender] = useState(true);
-
- const contextValue = useCreateReducer({
- initialState,
- });
-
- const {
- state: {
- apiKey,
- lightMode,
- folders,
- conversations,
- selectedConversation,
- prompts,
- temperature,
- },
- dispatch,
- } = contextValue;
-
- const stopConversationRef = useRef(false);
-
- const { data, error, refetch } = useQuery(
- ['GetModels', apiKey, serverSideApiKeyIsSet],
- ({ signal }) => {
-
- return getModels(
- {
- key: 'apiKey',
- },
- signal,
- );
- },
- { enabled: true, refetchOnMount: false },
- );
-
- useEffect(() => {
- if (data) dispatch({ field: 'models', value: data });
- }, [data, dispatch]);
-
- useEffect(() => {
- dispatch({ field: 'modelError', value: getModelsError(error) });
- }, [dispatch, error, getModelsError]);
-
- // FETCH MODELS ----------------------------------------------
-
- const handleSelectConversation = (conversation: Conversation) => {
- dispatch({
- field: 'selectedConversation',
- value: conversation,
- });
-
- saveConversation(conversation);
- };
-
- // FOLDER OPERATIONS --------------------------------------------
-
- const handleCreateFolder = (name: string, type: FolderType) => {
- const newFolder: FolderInterface = {
- id: uuidv4(),
- name,
- type,
- };
-
- const updatedFolders = [...folders, newFolder];
-
- dispatch({ field: 'folders', value: updatedFolders });
- saveFolders(updatedFolders);
- };
-
- const handleDeleteFolder = (folderId: string) => {
- const updatedFolders = folders.filter((f) => f.id !== folderId);
- dispatch({ field: 'folders', value: updatedFolders });
- saveFolders(updatedFolders);
-
- const updatedConversations: Conversation[] = conversations.map((c) => {
- if (c.folderId === folderId) {
- return {
- ...c,
- folderId: null,
- };
- }
-
- return c;
- });
-
- dispatch({ field: 'conversations', value: updatedConversations });
- saveConversations(updatedConversations);
-
- const updatedPrompts: Prompt[] = prompts.map((p) => {
- if (p.folderId === folderId) {
- return {
- ...p,
- folderId: null,
- };
- }
-
- return p;
- });
-
- dispatch({ field: 'prompts', value: updatedPrompts });
- savePrompts(updatedPrompts);
- };
-
- const handleUpdateFolder = (folderId: string, name: string) => {
- const updatedFolders = folders.map((f) => {
- if (f.id === folderId) {
- return {
- ...f,
- name,
- };
- }
-
- return f;
- });
-
- dispatch({ field: 'folders', value: updatedFolders });
-
- saveFolders(updatedFolders);
- };
-
- // CONVERSATION OPERATIONS --------------------------------------------
-
- const handleNewConversation = () => {
- const lastConversation = conversations[conversations.length - 1];
-
- const newConversation: Conversation = {
- id: uuidv4(),
- name: t('New Conversation'),
- messages: [],
- model: lastConversation?.model || {
- id: OpenAIModels[defaultModelId].id,
- name: OpenAIModels[defaultModelId].name,
- maxLength: OpenAIModels[defaultModelId].maxLength,
- tokenLimit: OpenAIModels[defaultModelId].tokenLimit,
- },
- prompt: DEFAULT_SYSTEM_PROMPT,
- temperature: lastConversation?.temperature ?? DEFAULT_TEMPERATURE,
- folderId: null,
- };
-
- const updatedConversations = [...conversations, newConversation];
-
- dispatch({ field: 'selectedConversation', value: newConversation });
- dispatch({ field: 'conversations', value: updatedConversations });
-
- saveConversation(newConversation);
- saveConversations(updatedConversations);
-
- dispatch({ field: 'loading', value: false });
- };
-
- const handleUpdateConversation = (
- conversation: Conversation,
- data: KeyValuePair,
- ) => {
- const updatedConversation = {
- ...conversation,
- [data.key]: data.value,
- };
-
- const { single, all } = updateConversation(
- updatedConversation,
- conversations,
- );
-
- dispatch({ field: 'selectedConversation', value: single });
- dispatch({ field: 'conversations', value: all });
- };
-
- // EFFECTS --------------------------------------------
-
- useEffect(() => {
- if (window.innerWidth < 640) {
- dispatch({ field: 'showChatbar', value: false });
- }
- }, [selectedConversation]);
-
- useEffect(() => {
- defaultModelId &&
- dispatch({ field: 'defaultModelId', value: defaultModelId });
- serverSideApiKeyIsSet &&
- dispatch({
- field: 'serverSideApiKeyIsSet',
- value: serverSideApiKeyIsSet,
- });
- serverSidePluginKeysSet &&
- dispatch({
- field: 'serverSidePluginKeysSet',
- value: serverSidePluginKeysSet,
- });
- }, [defaultModelId, serverSideApiKeyIsSet, serverSidePluginKeysSet]);
-
- // ON LOAD --------------------------------------------
-
- useEffect(() => {
- const settings = getSettings();
- if (settings.theme) {
- dispatch({
- field: 'lightMode',
- value: settings.theme,
- });
- }
-
- const apiKey = "test";
-
- if (serverSideApiKeyIsSet) {
- dispatch({ field: 'apiKey', value: '' });
-
- localStorage.removeItem('apiKey');
- } else if (apiKey) {
- dispatch({ field: 'apiKey', value: apiKey });
- }
-
- const pluginKeys = localStorage.getItem('pluginKeys');
- if (serverSidePluginKeysSet) {
- dispatch({ field: 'pluginKeys', value: [] });
- localStorage.removeItem('pluginKeys');
- } else if (pluginKeys) {
- dispatch({ field: 'pluginKeys', value: pluginKeys });
- }
-
- if (window.innerWidth < 640) {
- dispatch({ field: 'showChatbar', value: false });
- dispatch({ field: 'showPromptbar', value: false });
- }
-
- const showChatbar = localStorage.getItem('showChatbar');
- if (showChatbar) {
- dispatch({ field: 'showChatbar', value: showChatbar === 'true' });
- }
-
- const showPromptbar = localStorage.getItem('showPromptbar');
- if (showPromptbar) {
- dispatch({ field: 'showPromptbar', value: showPromptbar === 'true' });
- }
-
- const folders = localStorage.getItem('folders');
- if (folders) {
- dispatch({ field: 'folders', value: JSON.parse(folders) });
- }
-
- const prompts = localStorage.getItem('prompts');
- if (prompts) {
- dispatch({ field: 'prompts', value: JSON.parse(prompts) });
- }
-
- const conversationHistory = localStorage.getItem('conversationHistory');
- if (conversationHistory) {
- const parsedConversationHistory: Conversation[] =
- JSON.parse(conversationHistory);
- const cleanedConversationHistory = cleanConversationHistory(
- parsedConversationHistory,
- );
-
- dispatch({ field: 'conversations', value: cleanedConversationHistory });
- }
-
- const selectedConversation = localStorage.getItem('selectedConversation');
- if (selectedConversation) {
- const parsedSelectedConversation: Conversation =
- JSON.parse(selectedConversation);
- const cleanedSelectedConversation = cleanSelectedConversation(
- parsedSelectedConversation,
- );
-
- dispatch({
- field: 'selectedConversation',
- value: cleanedSelectedConversation,
- });
- } else {
- const lastConversation = conversations[conversations.length - 1];
- dispatch({
- field: 'selectedConversation',
- value: {
- id: uuidv4(),
- name: t('New Conversation'),
- messages: [],
- model: OpenAIModels[defaultModelId],
- prompt: DEFAULT_SYSTEM_PROMPT,
- temperature: lastConversation?.temperature ?? DEFAULT_TEMPERATURE,
- folderId: null,
- },
- });
- }
- }, [
- defaultModelId,
- dispatch,
- serverSideApiKeyIsSet,
- serverSidePluginKeysSet,
- ]);
-
- return (
-
-
- Chatbot UI
-
-
-
-
- {selectedConversation && (
-
-
-
-
-
-
-
- )}
-
- );
-};
-export default Home;
-
-export const getServerSideProps: GetServerSideProps = async ({ locale }) => {
- const defaultModelId =
- (process.env.DEFAULT_MODEL &&
- Object.values(OpenAIModelID).includes(
- process.env.DEFAULT_MODEL as OpenAIModelID,
- ) &&
- process.env.DEFAULT_MODEL) ||
- fallbackModelID;
-
- let serverSidePluginKeysSet = false;
-
- const googleApiKey = process.env.GOOGLE_API_KEY;
- const googleCSEId = process.env.GOOGLE_CSE_ID;
-
- if (googleApiKey && googleCSEId) {
- serverSidePluginKeysSet = true;
- }
-
- return {
- props: {
- serverSideApiKeyIsSet: !!process.env.OPENAI_API_KEY,
- defaultModelId,
- serverSidePluginKeysSet,
- ...(await serverSideTranslations(locale ?? 'en', [
- 'common',
- 'chat',
- 'sidebar',
- 'markdown',
- 'promptbar',
- 'settings',
- ])),
- },
- };
-};
diff --git a/spaces/matthoffner/chatbot/utils/server/index.ts b/spaces/matthoffner/chatbot/utils/server/index.ts
deleted file mode 100644
index af243dc3af7eb37f0c4078b92ace624be42f2787..0000000000000000000000000000000000000000
--- a/spaces/matthoffner/chatbot/utils/server/index.ts
+++ /dev/null
@@ -1,118 +0,0 @@
-import { Message } from '@/types/chat';
-import { OpenAIModel } from '@/types/openai';
-
-import { AZURE_DEPLOYMENT_ID, OPENAI_API_HOST, OPENAI_API_TYPE, OPENAI_API_VERSION, OPENAI_ORGANIZATION } from '../app/const';
-
-import {
- ParsedEvent,
- ReconnectInterval,
- createParser,
-} from 'eventsource-parser';
-
-export class OpenAIError extends Error {
- type: string;
- param: string;
- code: string;
-
- constructor(message: string, type: string, param: string, code: string) {
- super(message);
- this.name = 'OpenAIError';
- this.type = type;
- this.param = param;
- this.code = code;
- }
-}
-
-export const OpenAIStream = async (
- model: OpenAIModel,
- systemPrompt: string,
- temperature : number,
- key: string,
- messages: Message[],
-) => {
- let url = `${OPENAI_API_HOST}/v1/chat/completions`;
- if (OPENAI_API_TYPE === 'azure') {
- url = `${OPENAI_API_HOST}/openai/deployments/${AZURE_DEPLOYMENT_ID}/chat/completions?api-version=${OPENAI_API_VERSION}`;
- }
- const res = await fetch(url, {
- headers: {
- 'Content-Type': 'application/json',
- ...(OPENAI_API_TYPE === 'openai' && {
- Authorization: `Bearer ${key ? key : process.env.OPENAI_API_KEY}`
- }),
- ...(OPENAI_API_TYPE === 'azure' && {
- 'api-key': `${key ? key : process.env.OPENAI_API_KEY}`
- }),
- ...((OPENAI_API_TYPE === 'openai' && OPENAI_ORGANIZATION) && {
- 'OpenAI-Organization': OPENAI_ORGANIZATION,
- }),
- },
- method: 'POST',
- body: JSON.stringify({
- ...(OPENAI_API_TYPE === 'openai' && {model: model.id}),
- messages: [
- {
- role: 'system',
- content: systemPrompt,
- },
- ...messages,
- ],
- max_tokens: 1000,
- temperature: temperature,
- stream: true,
- stop: ["###Human:"]
- }),
- });
-
- const encoder = new TextEncoder();
- const decoder = new TextDecoder();
-
- if (res.status !== 200) {
- const result = await res.json();
- if (result.error) {
- throw new OpenAIError(
- result.error.message,
- result.error.type,
- result.error.param,
- result.error.code,
- );
- } else {
- throw new Error(
- `OpenAI API returned an error: ${
- decoder.decode(result?.value) || result.statusText
- }`,
- );
- }
- }
-
- const stream = new ReadableStream({
- async start(controller) {
- const onParse = (event: ParsedEvent | ReconnectInterval) => {
- if (event.type === 'event') {
- const data = event.data;
-
- try {
- const json = JSON.parse(data);
- if (json.choices[0].finish_reason != null) {
- controller.close();
- return;
- }
- const text = json.choices[0].delta.content;
- const queue = encoder.encode(text);
- controller.enqueue(queue);
- } catch (e) {
- controller.error(e);
- }
- }
- };
-
- const parser = createParser(onParse);
-
- for await (const chunk of res.body as any) {
- parser.feed(decoder.decode(chunk));
- }
- },
- });
-
- return stream;
-};
diff --git a/spaces/maxmax20160403/sovits5.0/vits_decoder/discriminator.py b/spaces/maxmax20160403/sovits5.0/vits_decoder/discriminator.py
deleted file mode 100644
index 764c0ca806b707e4f36ca2abb64ce79971358dd9..0000000000000000000000000000000000000000
--- a/spaces/maxmax20160403/sovits5.0/vits_decoder/discriminator.py
+++ /dev/null
@@ -1,39 +0,0 @@
-import torch
-import torch.nn as nn
-
-from omegaconf import OmegaConf
-from .msd import ScaleDiscriminator
-from .mpd import MultiPeriodDiscriminator
-from .mrd import MultiResolutionDiscriminator
-
-
-class Discriminator(nn.Module):
- def __init__(self, hp):
- super(Discriminator, self).__init__()
- self.MRD = MultiResolutionDiscriminator(hp)
- self.MPD = MultiPeriodDiscriminator(hp)
- self.MSD = ScaleDiscriminator()
-
- def forward(self, x):
- r = self.MRD(x)
- p = self.MPD(x)
- s = self.MSD(x)
- return r + p + s
-
-
-if __name__ == '__main__':
- hp = OmegaConf.load('../config/base.yaml')
- model = Discriminator(hp)
-
- x = torch.randn(3, 1, 16384)
- print(x.shape)
-
- output = model(x)
- for features, score in output:
- for feat in features:
- print(feat.shape)
- print(score.shape)
-
- pytorch_total_params = sum(p.numel()
- for p in model.parameters() if p.requires_grad)
- print(pytorch_total_params)
diff --git a/spaces/menghanxia/ReversibleHalftoning/model/__init__.py b/spaces/menghanxia/ReversibleHalftoning/model/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/meraih/English-Japanese-Anime-TTS/monotonic_align/__init__.py b/spaces/meraih/English-Japanese-Anime-TTS/monotonic_align/__init__.py
deleted file mode 100644
index 3d7009c40fea3a98168e3e3bc9ae061e91327422..0000000000000000000000000000000000000000
--- a/spaces/meraih/English-Japanese-Anime-TTS/monotonic_align/__init__.py
+++ /dev/null
@@ -1,19 +0,0 @@
-import numpy as np
-import torch
-from .monotonic_align.core import maximum_path_c
-
-
-def maximum_path(neg_cent, mask):
- """ Cython optimized version.
- neg_cent: [b, t_t, t_s]
- mask: [b, t_t, t_s]
- """
- device = neg_cent.device
- dtype = neg_cent.dtype
- neg_cent = neg_cent.data.cpu().numpy().astype(np.float32)
- path = np.zeros(neg_cent.shape, dtype=np.int32)
-
- t_t_max = mask.sum(1)[:, 0].data.cpu().numpy().astype(np.int32)
- t_s_max = mask.sum(2)[:, 0].data.cpu().numpy().astype(np.int32)
- maximum_path_c(path, neg_cent, t_t_max, t_s_max)
- return torch.from_numpy(path).to(device=device, dtype=dtype)
diff --git a/spaces/merve/data-leak/public/dataset-worldviews/person-photos.js b/spaces/merve/data-leak/public/dataset-worldviews/person-photos.js
deleted file mode 100644
index 305b037acebf14e083ead577ce566ad39b81c531..0000000000000000000000000000000000000000
--- a/spaces/merve/data-leak/public/dataset-worldviews/person-photos.js
+++ /dev/null
@@ -1,119 +0,0 @@
-
-function createPhotoScroller(){
-
- var base_path = 'img/woman_washing_clothes.jpeg'
- var data = [
- {
- 'path': 'img/labels_1.svg',
- 'alt': 'Image of a woman washing clothes with bounding boxes including \'person\', and \'bucket\'',
- 'x': 198,
- 'y': 30,
- 'width': 305,
- 'height': 400,
- },
-
- {
- 'path': 'img/labels_4.svg',
- 'alt': 'Image of a woman washing clothes with bounding boxes including \'parent\', and \'laundry\'',
- 'x': 110,
- 'y': 60,
- 'width': 450,
- 'height': 470,
- },
-
-
- {
- 'path': 'img/labels_2.svg',
- 'alt': 'Image of a woman washing clothes with bounding boxes including \'hair_boho\', and \'decor_outdoor_rustic\'',
- 'x': 198,
- 'y': -35,
- 'width': 395,
- 'height': 500
- },
-
- {
- 'path': 'img/labels_3.svg',
- 'alt': 'Image of a woman washing clothes with one bounding box around her, labeled \'pedestrian\'',
- 'x': 190,
- 'y': 65,
- 'width': 190,
- 'height': 315
- },
- ];
-
-
- var photoIndex = 0;
-
- var c = d3.conventions({
- sel: d3.select('.person-photos').html(''),
- height: 550
- })
-
- var photoSel = c.svg.append('svg:image')
- .attr('x', 50)
- .attr('y', 50)
- .attr('width', 700)
- .attr('height', 500)
- .attr('xlink:href', base_path)
-
- var photoSel = c.svg.appendMany('svg:image', data)
- .attr('x', d => d.x)
- .attr('y', d => d.y)
- .attr('width', d => d.width)
- .attr('height', d => d.height)
- .attr('xlink:href', d => d.path)
- .attr('alt', d => d.alt)
-
-
- var buttonHeight = 35
- var buttonWidth = 130
-
- var buttonSel = c.svg.appendMany('g.photo-button', data)
- .translate((d,i) => [(i * 170) + 100, 0])
- .at({
- // class: "dropdown"
- })
- .on('click', function(d, i){
- photoIndex = i
- setActiveImage()
- timer.stop();
- })
-
- buttonSel.append('rect')
- .at({
- height: buttonHeight,
- width: buttonWidth,
- // fill: '#fff'
- })
-
- buttonSel.append('text')
- .at({
- textAnchor: 'middle',
- // dominantBaseline: 'central',
- dy: '.33em',
- x: buttonWidth/2,
- y: buttonHeight/2,
- class: "monospace"
- })
- .text((d,i) => 'ground truth ' + (i + 1))
-
- // buttonSel.classed('dropdown', true);
-
- if (window.__photoPersonTimer) window.__photoPersonTimer.stop()
- var timer = window.__photoPersonTimer = d3.interval(() => {
- photoIndex = (photoIndex + 1) % data.length;
- setActiveImage()
- }, 2000)
-
- function setActiveImage(i){
- photoSel.st({opacity: (d, i) => i == photoIndex ? 1 : 0 })
- buttonSel.classed('is-active-button', (d, i) => i == photoIndex)
- }
- setActiveImage()
-}
-
-createPhotoScroller();
-
-
-
-
diff --git a/spaces/merve/hidden-bias/public/measuring-fairness/annotations.js b/spaces/merve/hidden-bias/public/measuring-fairness/annotations.js
deleted file mode 100644
index 7ab68f297f98c655427a84de22388906182b240c..0000000000000000000000000000000000000000
--- a/spaces/merve/hidden-bias/public/measuring-fairness/annotations.js
+++ /dev/null
@@ -1,52 +0,0 @@
-/* Copyright 2020 Google LLC. All Rights Reserved.
-
-Licensed under the Apache License, Version 2.0 (the "License");
-you may not use this file except in compliance with the License.
-You may obtain a copy of the License at
-
- http://www.apache.org/licenses/LICENSE-2.0
-
-Unless required by applicable law or agreed to in writing, software
-distributed under the License is distributed on an "AS IS" BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-See the License for the specific language governing permissions and
-limitations under the License.
-==============================================================================*/
-
-
-
-var annotations =
-[
-]
-
-
-function addSwoop(c){
- var swoopy = d3.swoopyDrag()
- .x(d => c.x(d.x))
- .y(d => c.y(d.y))
- .draggable(0)
- .annotations(annotations)
-
- var swoopySel = c.svg.append('g.annotations').call(swoopy)
-
- c.svg.append('marker#arrow')
- .attr('viewBox', '-10 -10 20 20')
- .attr('markerWidth', 20)
- .attr('markerHeight', 20)
- .attr('orient', 'auto')
- .append('path').at({d: 'M-6.75,-6.75 L 0,0 L -6.75,6.75'})
-
-
- swoopySel.selectAll('path').attr('marker-end', 'url(#arrow)')
- window.annotationSel = swoopySel.selectAll('g')
- .st({fontSize: 12, opacity: d => d.slide == 0 ? 1 : 0})
-
- swoopySel.selectAll('text')
- .each(function(d){
- d3.select(this)
- .text('') //clear existing text
- .tspans(d3.wordwrap(d.text, d.width || 20), 12) //wrap after 20 char
- })
-}
-
-
diff --git a/spaces/mikeion/research_guru/README.md b/spaces/mikeion/research_guru/README.md
deleted file mode 100644
index 15b8c756d439437f5e40f2718ee9e3f084ce4d5e..0000000000000000000000000000000000000000
--- a/spaces/mikeion/research_guru/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Research Guru
-emoji: 🐠
-colorFrom: gray
-colorTo: gray
-sdk: streamlit
-sdk_version: 1.17.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/mmlab-ntu/Segment-Any-RGBD/open_vocab_seg/data/datasets/register_pascal_context.py b/spaces/mmlab-ntu/Segment-Any-RGBD/open_vocab_seg/data/datasets/register_pascal_context.py
deleted file mode 100644
index e40f87c945da20e78c0a3ea230bc9f36d1800071..0000000000000000000000000000000000000000
--- a/spaces/mmlab-ntu/Segment-Any-RGBD/open_vocab_seg/data/datasets/register_pascal_context.py
+++ /dev/null
@@ -1,588 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import os
-
-from detectron2.data import DatasetCatalog, MetadataCatalog
-from detectron2.data.datasets import load_sem_seg
-
-PASCALCONTEX59_NAMES = (
- "aeroplane",
- "bicycle",
- "bird",
- "boat",
- "bottle",
- "bus",
- "car",
- "cat",
- "chair",
- "cow",
- "table",
- "dog",
- "horse",
- "motorbike",
- "person",
- "pottedplant",
- "sheep",
- "sofa",
- "train",
- "tvmonitor",
- "bag",
- "bed",
- "bench",
- "book",
- "building",
- "cabinet",
- "ceiling",
- "cloth",
- "computer",
- "cup",
- "door",
- "fence",
- "floor",
- "flower",
- "food",
- "grass",
- "ground",
- "keyboard",
- "light",
- "mountain",
- "mouse",
- "curtain",
- "platform",
- "sign",
- "plate",
- "road",
- "rock",
- "shelves",
- "sidewalk",
- "sky",
- "snow",
- "bedclothes",
- "track",
- "tree",
- "truck",
- "wall",
- "water",
- "window",
- "wood",
-)
-
-PASCALCONTEX459_NAMES = (
- "accordion",
- "aeroplane",
- "air conditioner",
- "antenna",
- "artillery",
- "ashtray",
- "atrium",
- "baby carriage",
- "bag",
- "ball",
- "balloon",
- "bamboo weaving",
- "barrel",
- "baseball bat",
- "basket",
- "basketball backboard",
- "bathtub",
- "bed",
- "bedclothes",
- "beer",
- "bell",
- "bench",
- "bicycle",
- "binoculars",
- "bird",
- "bird cage",
- "bird feeder",
- "bird nest",
- "blackboard",
- "board",
- "boat",
- "bone",
- "book",
- "bottle",
- "bottle opener",
- "bowl",
- "box",
- "bracelet",
- "brick",
- "bridge",
- "broom",
- "brush",
- "bucket",
- "building",
- "bus",
- "cabinet",
- "cabinet door",
- "cage",
- "cake",
- "calculator",
- "calendar",
- "camel",
- "camera",
- "camera lens",
- "can",
- "candle",
- "candle holder",
- "cap",
- "car",
- "card",
- "cart",
- "case",
- "casette recorder",
- "cash register",
- "cat",
- "cd",
- "cd player",
- "ceiling",
- "cell phone",
- "cello",
- "chain",
- "chair",
- "chessboard",
- "chicken",
- "chopstick",
- "clip",
- "clippers",
- "clock",
- "closet",
- "cloth",
- "clothes tree",
- "coffee",
- "coffee machine",
- "comb",
- "computer",
- "concrete",
- "cone",
- "container",
- "control booth",
- "controller",
- "cooker",
- "copying machine",
- "coral",
- "cork",
- "corkscrew",
- "counter",
- "court",
- "cow",
- "crabstick",
- "crane",
- "crate",
- "cross",
- "crutch",
- "cup",
- "curtain",
- "cushion",
- "cutting board",
- "dais",
- "disc",
- "disc case",
- "dishwasher",
- "dock",
- "dog",
- "dolphin",
- "door",
- "drainer",
- "dray",
- "drink dispenser",
- "drinking machine",
- "drop",
- "drug",
- "drum",
- "drum kit",
- "duck",
- "dumbbell",
- "earphone",
- "earrings",
- "egg",
- "electric fan",
- "electric iron",
- "electric pot",
- "electric saw",
- "electronic keyboard",
- "engine",
- "envelope",
- "equipment",
- "escalator",
- "exhibition booth",
- "extinguisher",
- "eyeglass",
- "fan",
- "faucet",
- "fax machine",
- "fence",
- "ferris wheel",
- "fire extinguisher",
- "fire hydrant",
- "fire place",
- "fish",
- "fish tank",
- "fishbowl",
- "fishing net",
- "fishing pole",
- "flag",
- "flagstaff",
- "flame",
- "flashlight",
- "floor",
- "flower",
- "fly",
- "foam",
- "food",
- "footbridge",
- "forceps",
- "fork",
- "forklift",
- "fountain",
- "fox",
- "frame",
- "fridge",
- "frog",
- "fruit",
- "funnel",
- "furnace",
- "game controller",
- "game machine",
- "gas cylinder",
- "gas hood",
- "gas stove",
- "gift box",
- "glass",
- "glass marble",
- "globe",
- "glove",
- "goal",
- "grandstand",
- "grass",
- "gravestone",
- "ground",
- "guardrail",
- "guitar",
- "gun",
- "hammer",
- "hand cart",
- "handle",
- "handrail",
- "hanger",
- "hard disk drive",
- "hat",
- "hay",
- "headphone",
- "heater",
- "helicopter",
- "helmet",
- "holder",
- "hook",
- "horse",
- "horse-drawn carriage",
- "hot-air balloon",
- "hydrovalve",
- "ice",
- "inflator pump",
- "ipod",
- "iron",
- "ironing board",
- "jar",
- "kart",
- "kettle",
- "key",
- "keyboard",
- "kitchen range",
- "kite",
- "knife",
- "knife block",
- "ladder",
- "ladder truck",
- "ladle",
- "laptop",
- "leaves",
- "lid",
- "life buoy",
- "light",
- "light bulb",
- "lighter",
- "line",
- "lion",
- "lobster",
- "lock",
- "machine",
- "mailbox",
- "mannequin",
- "map",
- "mask",
- "mat",
- "match book",
- "mattress",
- "menu",
- "metal",
- "meter box",
- "microphone",
- "microwave",
- "mirror",
- "missile",
- "model",
- "money",
- "monkey",
- "mop",
- "motorbike",
- "mountain",
- "mouse",
- "mouse pad",
- "musical instrument",
- "napkin",
- "net",
- "newspaper",
- "oar",
- "ornament",
- "outlet",
- "oven",
- "oxygen bottle",
- "pack",
- "pan",
- "paper",
- "paper box",
- "paper cutter",
- "parachute",
- "parasol",
- "parterre",
- "patio",
- "pelage",
- "pen",
- "pen container",
- "pencil",
- "person",
- "photo",
- "piano",
- "picture",
- "pig",
- "pillar",
- "pillow",
- "pipe",
- "pitcher",
- "plant",
- "plastic",
- "plate",
- "platform",
- "player",
- "playground",
- "pliers",
- "plume",
- "poker",
- "poker chip",
- "pole",
- "pool table",
- "postcard",
- "poster",
- "pot",
- "pottedplant",
- "printer",
- "projector",
- "pumpkin",
- "rabbit",
- "racket",
- "radiator",
- "radio",
- "rail",
- "rake",
- "ramp",
- "range hood",
- "receiver",
- "recorder",
- "recreational machines",
- "remote control",
- "road",
- "robot",
- "rock",
- "rocket",
- "rocking horse",
- "rope",
- "rug",
- "ruler",
- "runway",
- "saddle",
- "sand",
- "saw",
- "scale",
- "scanner",
- "scissors",
- "scoop",
- "screen",
- "screwdriver",
- "sculpture",
- "scythe",
- "sewer",
- "sewing machine",
- "shed",
- "sheep",
- "shell",
- "shelves",
- "shoe",
- "shopping cart",
- "shovel",
- "sidecar",
- "sidewalk",
- "sign",
- "signal light",
- "sink",
- "skateboard",
- "ski",
- "sky",
- "sled",
- "slippers",
- "smoke",
- "snail",
- "snake",
- "snow",
- "snowmobiles",
- "sofa",
- "spanner",
- "spatula",
- "speaker",
- "speed bump",
- "spice container",
- "spoon",
- "sprayer",
- "squirrel",
- "stage",
- "stair",
- "stapler",
- "stick",
- "sticky note",
- "stone",
- "stool",
- "stove",
- "straw",
- "stretcher",
- "sun",
- "sunglass",
- "sunshade",
- "surveillance camera",
- "swan",
- "sweeper",
- "swim ring",
- "swimming pool",
- "swing",
- "switch",
- "table",
- "tableware",
- "tank",
- "tap",
- "tape",
- "tarp",
- "telephone",
- "telephone booth",
- "tent",
- "tire",
- "toaster",
- "toilet",
- "tong",
- "tool",
- "toothbrush",
- "towel",
- "toy",
- "toy car",
- "track",
- "train",
- "trampoline",
- "trash bin",
- "tray",
- "tree",
- "tricycle",
- "tripod",
- "trophy",
- "truck",
- "tube",
- "turtle",
- "tvmonitor",
- "tweezers",
- "typewriter",
- "umbrella",
- "unknown",
- "vacuum cleaner",
- "vending machine",
- "video camera",
- "video game console",
- "video player",
- "video tape",
- "violin",
- "wakeboard",
- "wall",
- "wallet",
- "wardrobe",
- "washing machine",
- "watch",
- "water",
- "water dispenser",
- "water pipe",
- "water skate board",
- "watermelon",
- "whale",
- "wharf",
- "wheel",
- "wheelchair",
- "window",
- "window blinds",
- "wineglass",
- "wire",
- "wood",
- "wool",
-
-)
-
-
-def _get_voc_meta(cat_list):
- ret = {
- "stuff_classes": cat_list,
- }
- return ret
-
-
-def register_pascal_context_59(root):
- root = os.path.join(root, "VOCdevkit/VOC2010")
- meta = _get_voc_meta(PASCALCONTEX59_NAMES)
- for name, image_dirname, sem_seg_dirname in [
- ("val", "JPEGImages", "annotations_detectron2/pc59_val"),
- ]:
- image_dir = os.path.join(root, image_dirname)
- gt_dir = os.path.join(root, sem_seg_dirname)
- all_name = f"pascal_context_59_sem_seg_{name}"
- DatasetCatalog.register(
- all_name,
- lambda x=image_dir, y=gt_dir: load_sem_seg(
- y, x, gt_ext="png", image_ext="jpg"
- ),
- )
- MetadataCatalog.get(all_name).set(
- image_root=image_dir,
- sem_seg_root=gt_dir,
- evaluator_type="sem_seg",
- ignore_label=255,
- **meta,
- )
-
-def register_pascal_context_459(root):
- root = os.path.join(root, "VOCdevkit/VOC2010")
- meta = _get_voc_meta(PASCALCONTEX459_NAMES)
- for name, image_dirname, sem_seg_dirname in [
- ("val", "JPEGImages", "annotations_detectron2/pc459_val"),
- ]:
- image_dir = os.path.join(root, image_dirname)
- gt_dir = os.path.join(root, sem_seg_dirname)
- all_name = f"pascal_context_459_sem_seg_{name}"
- DatasetCatalog.register(
- all_name,
- lambda x=image_dir, y=gt_dir: load_sem_seg(
- y, x, gt_ext="tif", image_ext="jpg"
- ),
- )
- MetadataCatalog.get(all_name).set(
- image_root=image_dir,
- sem_seg_root=gt_dir,
- evaluator_type="sem_seg",
- ignore_label=65535, # NOTE: gt is saved in 16-bit TIFF images
- **meta,
- )
-
-_root = os.getenv("DETECTRON2_DATASETS", "datasets")
-register_pascal_context_59(_root)
-register_pascal_context_459(_root)
diff --git a/spaces/mmlab-ntu/relate-anything-model/segment_anything/build_sam.py b/spaces/mmlab-ntu/relate-anything-model/segment_anything/build_sam.py
deleted file mode 100644
index 07abfca24e96eced7f13bdefd3212ce1b77b8999..0000000000000000000000000000000000000000
--- a/spaces/mmlab-ntu/relate-anything-model/segment_anything/build_sam.py
+++ /dev/null
@@ -1,107 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import torch
-
-from functools import partial
-
-from .modeling import ImageEncoderViT, MaskDecoder, PromptEncoder, Sam, TwoWayTransformer
-
-
-def build_sam_vit_h(checkpoint=None):
- return _build_sam(
- encoder_embed_dim=1280,
- encoder_depth=32,
- encoder_num_heads=16,
- encoder_global_attn_indexes=[7, 15, 23, 31],
- checkpoint=checkpoint,
- )
-
-
-build_sam = build_sam_vit_h
-
-
-def build_sam_vit_l(checkpoint=None):
- return _build_sam(
- encoder_embed_dim=1024,
- encoder_depth=24,
- encoder_num_heads=16,
- encoder_global_attn_indexes=[5, 11, 17, 23],
- checkpoint=checkpoint,
- )
-
-
-def build_sam_vit_b(checkpoint=None):
- return _build_sam(
- encoder_embed_dim=768,
- encoder_depth=12,
- encoder_num_heads=12,
- encoder_global_attn_indexes=[2, 5, 8, 11],
- checkpoint=checkpoint,
- )
-
-
-sam_model_registry = {
- "default": build_sam,
- "vit_h": build_sam,
- "vit_l": build_sam_vit_l,
- "vit_b": build_sam_vit_b,
-}
-
-
-def _build_sam(
- encoder_embed_dim,
- encoder_depth,
- encoder_num_heads,
- encoder_global_attn_indexes,
- checkpoint=None,
-):
- prompt_embed_dim = 256
- image_size = 1024
- vit_patch_size = 16
- image_embedding_size = image_size // vit_patch_size
- sam = Sam(
- image_encoder=ImageEncoderViT(
- depth=encoder_depth,
- embed_dim=encoder_embed_dim,
- img_size=image_size,
- mlp_ratio=4,
- norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
- num_heads=encoder_num_heads,
- patch_size=vit_patch_size,
- qkv_bias=True,
- use_rel_pos=True,
- global_attn_indexes=encoder_global_attn_indexes,
- window_size=14,
- out_chans=prompt_embed_dim,
- ),
- prompt_encoder=PromptEncoder(
- embed_dim=prompt_embed_dim,
- image_embedding_size=(image_embedding_size, image_embedding_size),
- input_image_size=(image_size, image_size),
- mask_in_chans=16,
- ),
- mask_decoder=MaskDecoder(
- num_multimask_outputs=3,
- transformer=TwoWayTransformer(
- depth=2,
- embedding_dim=prompt_embed_dim,
- mlp_dim=2048,
- num_heads=8,
- ),
- transformer_dim=prompt_embed_dim,
- iou_head_depth=3,
- iou_head_hidden_dim=256,
- ),
- pixel_mean=[123.675, 116.28, 103.53],
- pixel_std=[58.395, 57.12, 57.375],
- )
- sam.eval()
- if checkpoint is not None:
- with open(checkpoint, "rb") as f:
- state_dict = torch.load(f)
- sam.load_state_dict(state_dict)
- return sam
diff --git a/spaces/mms-meta/MMS/lid.py b/spaces/mms-meta/MMS/lid.py
deleted file mode 100644
index 7d0c96248ef2c85788348874618bf8cc1b088d69..0000000000000000000000000000000000000000
--- a/spaces/mms-meta/MMS/lid.py
+++ /dev/null
@@ -1,73 +0,0 @@
-from transformers import Wav2Vec2ForSequenceClassification, AutoFeatureExtractor
-import torch
-import librosa
-
-model_id = "facebook/mms-lid-1024"
-
-processor = AutoFeatureExtractor.from_pretrained(model_id)
-model = Wav2Vec2ForSequenceClassification.from_pretrained(model_id)
-
-
-LID_SAMPLING_RATE = 16_000
-LID_TOPK = 10
-LID_THRESHOLD = 0.33
-
-LID_LANGUAGES = {}
-with open(f"data/lid/all_langs.tsv") as f:
- for line in f:
- iso, name = line.split(" ", 1)
- LID_LANGUAGES[iso] = name
-
-
-def identify(audio_source=None, microphone=None, file_upload=None):
- if audio_source is None and microphone is None and file_upload is None:
- # HACK: need to handle this case for some reason
- return {}
-
- if type(microphone) is dict:
- # HACK: microphone variable is a dict when running on examples
- microphone = microphone["name"]
- audio_fp = (
- file_upload if "upload" in str(audio_source or "").lower() else microphone
- )
- if audio_fp is None:
- return "ERROR: You have to either use the microphone or upload an audio file"
-
- audio_samples = librosa.load(audio_fp, sr=LID_SAMPLING_RATE, mono=True)[0]
-
- inputs = processor(
- audio_samples, sampling_rate=LID_SAMPLING_RATE, return_tensors="pt"
- )
-
- # set device
- if torch.cuda.is_available():
- device = torch.device("cuda")
- elif (
- hasattr(torch.backends, "mps")
- and torch.backends.mps.is_available()
- and torch.backends.mps.is_built()
- ):
- device = torch.device("mps")
- else:
- device = torch.device("cpu")
-
- model.to(device)
- inputs = inputs.to(device)
-
- with torch.no_grad():
- logit = model(**inputs).logits
-
- logit_lsm = torch.log_softmax(logit.squeeze(), dim=-1)
- scores, indices = torch.topk(logit_lsm, 5, dim=-1)
- scores, indices = torch.exp(scores).to("cpu").tolist(), indices.to("cpu").tolist()
- iso2score = {model.config.id2label[int(i)]: s for s, i in zip(scores, indices)}
- if max(iso2score.values()) < LID_THRESHOLD:
- return "Low confidence in the language identification predictions. Output is not shown!"
- return {LID_LANGUAGES[iso]: score for iso, score in iso2score.items()}
-
-
-LID_EXAMPLES = [
- [None, "./assets/english.mp3", None],
- [None, "./assets/tamil.mp3", None],
- [None, "./assets/burmese.mp3", None],
-]
diff --git a/spaces/mshkdm/VToonify/vtoonify/model/encoder/readme.md b/spaces/mshkdm/VToonify/vtoonify/model/encoder/readme.md
deleted file mode 100644
index 5421bfe3e67b7b6cbd7baf96b741b539d65bb0fd..0000000000000000000000000000000000000000
--- a/spaces/mshkdm/VToonify/vtoonify/model/encoder/readme.md
+++ /dev/null
@@ -1,9 +0,0 @@
-# Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
-
-## Description
-Official Implementation of pSp paper for both training and evaluation. The pSp method extends the StyleGAN model to
-allow solving different image-to-image translation problems using its encoder.
-
-Fork from [https://github.com/eladrich/pixel2style2pixel](https://github.com/eladrich/pixel2style2pixel).
-
-In VToonify, we modify pSp to accept z+ latent code.
diff --git a/spaces/mshukor/UnIVAL/fairseq/tests/speech_recognition/test_collaters.py b/spaces/mshukor/UnIVAL/fairseq/tests/speech_recognition/test_collaters.py
deleted file mode 100644
index 6a5029a48faea2426d7a0277655a2c7c08c1d16c..0000000000000000000000000000000000000000
--- a/spaces/mshukor/UnIVAL/fairseq/tests/speech_recognition/test_collaters.py
+++ /dev/null
@@ -1,58 +0,0 @@
-#!/usr/bin/env python3
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import unittest
-
-import numpy as np
-import torch
-from examples.speech_recognition.data.collaters import Seq2SeqCollater
-
-
-class TestSeq2SeqCollator(unittest.TestCase):
- def test_collate(self):
-
- eos_idx = 1
- pad_idx = 0
- collater = Seq2SeqCollater(
- feature_index=0, label_index=1, pad_index=pad_idx, eos_index=eos_idx
- )
-
- # 2 frames in the first sample and 3 frames in the second one
- frames1 = np.array([[7, 8], [9, 10]])
- frames2 = np.array([[1, 2], [3, 4], [5, 6]])
- target1 = np.array([4, 2, 3, eos_idx])
- target2 = np.array([3, 2, eos_idx])
- sample1 = {"id": 0, "data": [frames1, target1]}
- sample2 = {"id": 1, "data": [frames2, target2]}
- batch = collater.collate([sample1, sample2])
-
- # collate sort inputs by frame's length before creating the batch
- self.assertTensorEqual(batch["id"], torch.tensor([1, 0]))
- self.assertEqual(batch["ntokens"], 7)
- self.assertTensorEqual(
- batch["net_input"]["src_tokens"],
- torch.tensor(
- [[[1, 2], [3, 4], [5, 6]], [[7, 8], [9, 10], [pad_idx, pad_idx]]]
- ),
- )
- self.assertTensorEqual(
- batch["net_input"]["prev_output_tokens"],
- torch.tensor([[eos_idx, 3, 2, pad_idx], [eos_idx, 4, 2, 3]]),
- )
- self.assertTensorEqual(batch["net_input"]["src_lengths"], torch.tensor([3, 2]))
- self.assertTensorEqual(
- batch["target"],
- torch.tensor([[3, 2, eos_idx, pad_idx], [4, 2, 3, eos_idx]]),
- )
- self.assertEqual(batch["nsentences"], 2)
-
- def assertTensorEqual(self, t1, t2):
- self.assertEqual(t1.size(), t2.size(), "size mismatch")
- self.assertEqual(t1.ne(t2).long().sum(), 0)
-
-
-if __name__ == "__main__":
- unittest.main()
diff --git a/spaces/multimodalart/Tune-A-Video-Training-UI-poli/app_inference.py b/spaces/multimodalart/Tune-A-Video-Training-UI-poli/app_inference.py
deleted file mode 100644
index d705504e5bc7a8938e1b5fcfb207f4cb731c866b..0000000000000000000000000000000000000000
--- a/spaces/multimodalart/Tune-A-Video-Training-UI-poli/app_inference.py
+++ /dev/null
@@ -1,170 +0,0 @@
-#!/usr/bin/env python
-
-from __future__ import annotations
-
-import enum
-
-import gradio as gr
-from huggingface_hub import HfApi
-
-from constants import MODEL_LIBRARY_ORG_NAME, UploadTarget
-from inference import InferencePipeline
-from utils import find_exp_dirs
-
-
-class ModelSource(enum.Enum):
- HUB_LIB = UploadTarget.MODEL_LIBRARY.value
- LOCAL = 'Local'
-
-
-class InferenceUtil:
- def __init__(self, hf_token: str | None):
- self.hf_token = hf_token
-
- def load_hub_model_list(self) -> dict:
- api = HfApi(token=self.hf_token)
- choices = [
- info.modelId
- for info in api.list_models(author=MODEL_LIBRARY_ORG_NAME)
- ]
- return gr.update(choices=choices,
- value=choices[0] if choices else None)
-
- @staticmethod
- def load_local_model_list() -> dict:
- choices = find_exp_dirs()
- return gr.update(choices=choices,
- value=choices[0] if choices else None)
-
- def reload_model_list(self, model_source: str) -> dict:
- if model_source == ModelSource.HUB_LIB.value:
- return self.load_hub_model_list()
- elif model_source == ModelSource.LOCAL.value:
- return self.load_local_model_list()
- else:
- raise ValueError
-
- def load_model_info(self, model_id: str) -> tuple[str, str]:
- try:
- card = InferencePipeline.get_model_card(model_id, self.hf_token)
- except Exception:
- return '', ''
- base_model = getattr(card.data, 'base_model', '')
- training_prompt = getattr(card.data, 'training_prompt', '')
- return base_model, training_prompt
-
- def reload_model_list_and_update_model_info(
- self, model_source: str) -> tuple[dict, str, str]:
- model_list_update = self.reload_model_list(model_source)
- model_list = model_list_update['choices']
- model_info = self.load_model_info(model_list[0] if model_list else '')
- return model_list_update, *model_info
-
-
-def create_inference_demo(pipe: InferencePipeline,
- hf_token: str | None = None) -> gr.Blocks:
- app = InferenceUtil(hf_token)
-
- with gr.Blocks() as demo:
- with gr.Row():
- with gr.Column():
- with gr.Box():
- model_source = gr.Radio(
- label='Model Source',
- choices=[_.value for _ in ModelSource],
- value=ModelSource.HUB_LIB.value)
- reload_button = gr.Button('Reload Model List')
- model_id = gr.Dropdown(label='Model ID',
- choices=None,
- value=None)
- with gr.Accordion(
- label=
- 'Model info (Base model and prompt used for training)',
- open=False):
- with gr.Row():
- base_model_used_for_training = gr.Text(
- label='Base model', interactive=False)
- prompt_used_for_training = gr.Text(
- label='Training prompt', interactive=False)
- prompt = gr.Textbox(
- label='Prompt',
- max_lines=1,
- placeholder='Example: "A panda is surfing"')
- video_length = gr.Slider(label='Video length',
- minimum=4,
- maximum=12,
- step=1,
- value=8)
- fps = gr.Slider(label='FPS',
- minimum=1,
- maximum=12,
- step=1,
- value=1)
- seed = gr.Slider(label='Seed',
- minimum=0,
- maximum=100000,
- step=1,
- value=0)
- with gr.Accordion('Other Parameters', open=False):
- num_steps = gr.Slider(label='Number of Steps',
- minimum=0,
- maximum=100,
- step=1,
- value=50)
- guidance_scale = gr.Slider(label='CFG Scale',
- minimum=0,
- maximum=50,
- step=0.1,
- value=7.5)
-
- run_button = gr.Button('Generate')
-
- gr.Markdown('''
- - After training, you can press "Reload Model List" button to load your trained model names.
- - It takes a few minutes to download model first.
- - Expected time to generate an 8-frame video: 70 seconds with T4, 24 seconds with A10G, (10 seconds with A100)
- ''')
- with gr.Column():
- result = gr.Video(label='Result')
-
- model_source.change(fn=app.reload_model_list_and_update_model_info,
- inputs=model_source,
- outputs=[
- model_id,
- base_model_used_for_training,
- prompt_used_for_training,
- ])
- reload_button.click(fn=app.reload_model_list_and_update_model_info,
- inputs=model_source,
- outputs=[
- model_id,
- base_model_used_for_training,
- prompt_used_for_training,
- ])
- model_id.change(fn=app.load_model_info,
- inputs=model_id,
- outputs=[
- base_model_used_for_training,
- prompt_used_for_training,
- ])
- inputs = [
- model_id,
- prompt,
- video_length,
- fps,
- seed,
- num_steps,
- guidance_scale,
- ]
- prompt.submit(fn=pipe.run, inputs=inputs, outputs=result)
- run_button.click(fn=pipe.run, inputs=inputs, outputs=result)
- return demo
-
-
-if __name__ == '__main__':
- import os
-
- hf_token = os.getenv('HF_TOKEN')
- pipe = InferencePipeline(hf_token)
- demo = create_inference_demo(pipe, hf_token)
- demo.queue(max_size=10).launch(share=False)
diff --git a/spaces/multimodalart/stable-diffusion-inpainting/clipseg/score.py b/spaces/multimodalart/stable-diffusion-inpainting/clipseg/score.py
deleted file mode 100644
index 8db8915b109953931fa2a330a7731db4a51b44f8..0000000000000000000000000000000000000000
--- a/spaces/multimodalart/stable-diffusion-inpainting/clipseg/score.py
+++ /dev/null
@@ -1,453 +0,0 @@
-from torch.functional import Tensor
-
-import torch
-import inspect
-import json
-import yaml
-import time
-import sys
-
-from general_utils import log
-
-import numpy as np
-from os.path import expanduser, join, isfile, realpath
-
-from torch.utils.data import DataLoader
-
-from metrics import FixedIntervalMetrics
-
-from general_utils import load_model, log, score_config_from_cli_args, AttributeDict, get_attribute, filter_args
-
-
-DATASET_CACHE = dict()
-
-def load_model(checkpoint_id, weights_file=None, strict=True, model_args='from_config', with_config=False, ignore_weights=False):
-
- config = json.load(open(join('logs', checkpoint_id, 'config.json')))
-
- if model_args != 'from_config' and type(model_args) != dict:
- raise ValueError('model_args must either be "from_config" or a dictionary of values')
-
- model_cls = get_attribute(config['model'])
-
- # load model
- if model_args == 'from_config':
- _, model_args, _ = filter_args(config, inspect.signature(model_cls).parameters)
-
- model = model_cls(**model_args)
-
- if weights_file is None:
- weights_file = realpath(join('logs', checkpoint_id, 'weights.pth'))
- else:
- weights_file = realpath(join('logs', checkpoint_id, weights_file))
-
- if isfile(weights_file) and not ignore_weights:
- weights = torch.load(weights_file)
- for _, w in weights.items():
- assert not torch.any(torch.isnan(w)), 'weights contain NaNs'
- model.load_state_dict(weights, strict=strict)
- else:
- if not ignore_weights:
- raise FileNotFoundError(f'model checkpoint {weights_file} was not found')
-
- if with_config:
- return model, config
-
- return model
-
-
-def compute_shift2(model, datasets, seed=123, repetitions=1):
- """ computes shift """
-
- model.eval()
- model.cuda()
-
- import random
- random.seed(seed)
-
- preds, gts = [], []
- for i_dataset, dataset in enumerate(datasets):
-
- loader = DataLoader(dataset, batch_size=1, num_workers=0, shuffle=False, drop_last=False)
-
- max_iterations = int(repetitions * len(dataset.dataset.data_list))
-
- with torch.no_grad():
-
- i, losses = 0, []
- for i_all, (data_x, data_y) in enumerate(loader):
-
- data_x = [v.cuda(non_blocking=True) if v is not None else v for v in data_x]
- data_y = [v.cuda(non_blocking=True) if v is not None else v for v in data_y]
-
- pred, = model(data_x[0], data_x[1], data_x[2])
- preds += [pred.detach()]
- gts += [data_y]
-
- i += 1
- if max_iterations and i >= max_iterations:
- break
-
- from metrics import FixedIntervalMetrics
- n_values = 51
- thresholds = np.linspace(0, 1, n_values)[1:-1]
- metric = FixedIntervalMetrics(resize_pred=True, sigmoid=True, n_values=n_values)
-
- for p, y in zip(preds, gts):
- metric.add(p.unsqueeze(1), y)
-
- best_idx = np.argmax(metric.value()['fgiou_scores'])
- best_thresh = thresholds[best_idx]
-
- return best_thresh
-
-
-def get_cached_pascal_pfe(split, config):
- from datasets.pfe_dataset import PFEPascalWrapper
- try:
- dataset = DATASET_CACHE[(split, config.image_size, config.label_support, config.mask)]
- except KeyError:
- dataset = PFEPascalWrapper(mode='val', split=split, mask=config.mask, image_size=config.image_size, label_support=config.label_support)
- DATASET_CACHE[(split, config.image_size, config.label_support, config.mask)] = dataset
- return dataset
-
-
-
-
-def main():
- config, train_checkpoint_id = score_config_from_cli_args()
-
- metrics = score(config, train_checkpoint_id, None)
-
- for dataset in metrics.keys():
- for k in metrics[dataset]:
- if type(metrics[dataset][k]) in {float, int}:
- print(dataset, f'{k:<16} {metrics[dataset][k]:.3f}')
-
-
-def score(config, train_checkpoint_id, train_config):
-
- config = AttributeDict(config)
-
- print(config)
-
- # use training dataset and loss
- train_config = AttributeDict(json.load(open(f'logs/{train_checkpoint_id}/config.json')))
-
- cp_str = f'_{config.iteration_cp}' if config.iteration_cp is not None else ''
-
-
- model_cls = get_attribute(train_config['model'])
-
- _, model_args, _ = filter_args(train_config, inspect.signature(model_cls).parameters)
-
- model_args = {**model_args, **{k: config[k] for k in ['process_cond', 'fix_shift'] if k in config}}
-
- strict_models = {'ConditionBase4', 'PFENetWrapper'}
- model = load_model(train_checkpoint_id, strict=model_cls.__name__ in strict_models, model_args=model_args,
- weights_file=f'weights{cp_str}.pth', )
-
-
- model.eval()
- model.cuda()
-
- metric_args = dict()
-
- if 'threshold' in config:
- if config.metric.split('.')[-1] == 'SkLearnMetrics':
- metric_args['threshold'] = config.threshold
-
- if 'resize_to' in config:
- metric_args['resize_to'] = config.resize_to
-
- if 'sigmoid' in config:
- metric_args['sigmoid'] = config.sigmoid
-
- if 'custom_threshold' in config:
- metric_args['custom_threshold'] = config.custom_threshold
-
- if config.test_dataset == 'pascal':
-
- loss_fn = get_attribute(train_config.loss)
- # assume that if no split is specified in train_config, test on all splits,
-
- if 'splits' in config:
- splits = config.splits
- else:
- if 'split' in train_config and type(train_config.split) == int:
- # unless train_config has a split set, in that case assume train mode in training
- splits = [train_config.split]
- assert train_config.mode == 'train'
- else:
- splits = [0,1,2,3]
-
- log.info('Test on these splits', splits)
-
- scores = dict()
- for split in splits:
-
- shift = config.shift if 'shift' in config else 0
-
- # automatic shift
- if shift == 'auto':
- shift_compute_t = time.time()
- shift = compute_shift2(model, [get_cached_pascal_pfe(s, config) for s in range(4) if s != split], repetitions=config.compute_shift_fac)
- log.info(f'Best threshold is {shift}, computed on splits: {[s for s in range(4) if s != split]}, took {time.time() - shift_compute_t:.1f}s')
-
- dataset = get_cached_pascal_pfe(split, config)
-
- eval_start_t = time.time()
-
- loader = DataLoader(dataset, batch_size=1, num_workers=0, shuffle=False, drop_last=False)
-
- assert config.batch_size is None or config.batch_size == 1, 'When PFE Dataset is used, batch size must be 1'
-
- metric = FixedIntervalMetrics(resize_pred=True, sigmoid=True, custom_threshold=shift, **metric_args)
-
- with torch.no_grad():
-
- i, losses = 0, []
- for i_all, (data_x, data_y) in enumerate(loader):
-
- data_x = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_x]
- data_y = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_y]
-
- if config.mask == 'separate': # for old CondBase model
- pred, = model(data_x[0], data_x[1], data_x[2])
- else:
- # assert config.mask in {'text', 'highlight'}
- pred, _, _, _ = model(data_x[0], data_x[1], return_features=True)
-
- # loss = loss_fn(pred, data_y[0])
- metric.add(pred.unsqueeze(1) + shift, data_y)
-
- # losses += [float(loss)]
-
- i += 1
- if config.max_iterations and i >= config.max_iterations:
- break
-
- #scores[split] = {m: s for m, s in zip(metric.names(), metric.value())}
-
- log.info(f'Dataset length: {len(dataset)}, took {time.time() - eval_start_t:.1f}s to evaluate.')
-
- print(metric.value()['mean_iou_scores'])
-
- scores[split] = metric.scores()
-
- log.info(f'Completed split {split}')
-
- key_prefix = config['name'] if 'name' in config else 'pas'
-
- all_keys = set.intersection(*[set(v.keys()) for v in scores.values()])
-
- valid_keys = [k for k in all_keys if all(v[k] is not None and isinstance(v[k], (int, float, np.float)) for v in scores.values())]
-
- return {key_prefix: {k: np.mean([s[k] for s in scores.values()]) for k in valid_keys}}
-
-
- if config.test_dataset == 'coco':
- from datasets.coco_wrapper import COCOWrapper
-
- coco_dataset = COCOWrapper('test', fold=train_config.fold, image_size=train_config.image_size, mask=config.mask,
- with_class_label=True)
-
- log.info('Dataset length', len(coco_dataset))
- loader = DataLoader(coco_dataset, batch_size=config.batch_size, num_workers=2, shuffle=False, drop_last=False)
-
- metric = get_attribute(config.metric)(resize_pred=True, **metric_args)
-
- shift = config.shift if 'shift' in config else 0
-
- with torch.no_grad():
-
- i, losses = 0, []
- for i_all, (data_x, data_y) in enumerate(loader):
- data_x = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_x]
- data_y = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_y]
-
- if config.mask == 'separate': # for old CondBase model
- pred, = model(data_x[0], data_x[1], data_x[2])
- else:
- # assert config.mask in {'text', 'highlight'}
- pred, _, _, _ = model(data_x[0], data_x[1], return_features=True)
-
- metric.add([pred + shift], data_y)
-
- i += 1
- if config.max_iterations and i >= config.max_iterations:
- break
-
- key_prefix = config['name'] if 'name' in config else 'coco'
- return {key_prefix: metric.scores()}
- #return {key_prefix: {k: v for k, v in zip(metric.names(), metric.value())}}
-
-
- if config.test_dataset == 'phrasecut':
- from datasets.phrasecut import PhraseCut
-
- only_visual = config.only_visual is not None and config.only_visual
- with_visual = config.with_visual is not None and config.with_visual
-
- dataset = PhraseCut('test',
- image_size=train_config.image_size,
- mask=config.mask,
- with_visual=with_visual, only_visual=only_visual, aug_crop=False,
- aug_color=False)
-
- loader = DataLoader(dataset, batch_size=config.batch_size, num_workers=2, shuffle=False, drop_last=False)
- metric = get_attribute(config.metric)(resize_pred=True, **metric_args)
-
- shift = config.shift if 'shift' in config else 0
-
-
- with torch.no_grad():
-
- i, losses = 0, []
- for i_all, (data_x, data_y) in enumerate(loader):
- data_x = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_x]
- data_y = [v.cuda(non_blocking=True) if isinstance(v, torch.Tensor) else v for v in data_y]
-
- pred, _, _, _ = model(data_x[0], data_x[1], return_features=True)
- metric.add([pred + shift], data_y)
-
- i += 1
- if config.max_iterations and i >= config.max_iterations:
- break
-
- key_prefix = config['name'] if 'name' in config else 'phrasecut'
- return {key_prefix: metric.scores()}
- #return {key_prefix: {k: v for k, v in zip(metric.names(), metric.value())}}
-
- if config.test_dataset == 'pascal_zs':
- from third_party.JoEm.model.metric import Evaluator
- from third_party.JoEm.data_loader import get_seen_idx, get_unseen_idx, VOC
- from datasets.pascal_zeroshot import PascalZeroShot, PASCAL_VOC_CLASSES_ZS
-
- from models.clipseg import CLIPSegMultiLabel
-
- n_unseen = train_config.remove_classes[1]
-
- pz = PascalZeroShot('val', n_unseen, image_size=352)
- m = CLIPSegMultiLabel(model=train_config.name).cuda()
- m.eval();
-
- print(len(pz), n_unseen)
- print('training removed', [c for class_set in PASCAL_VOC_CLASSES_ZS[:n_unseen // 2] for c in class_set])
-
- print('unseen', [VOC[i] for i in get_unseen_idx(n_unseen)])
- print('seen', [VOC[i] for i in get_seen_idx(n_unseen)])
-
- loader = DataLoader(pz, batch_size=8)
- evaluator = Evaluator(21, get_unseen_idx(n_unseen), get_seen_idx(n_unseen))
-
- for i, (data_x, data_y) in enumerate(loader):
- pred = m(data_x[0].cuda())
- evaluator.add_batch(data_y[0].numpy(), pred.argmax(1).cpu().detach().numpy())
-
- if config.max_iter is not None and i > config.max_iter:
- break
-
- scores = evaluator.Mean_Intersection_over_Union()
- key_prefix = config['name'] if 'name' in config else 'pas_zs'
-
- return {key_prefix: {k: scores[k] for k in ['seen', 'unseen', 'harmonic', 'overall']}}
-
- elif config.test_dataset in {'same_as_training', 'affordance'}:
- loss_fn = get_attribute(train_config.loss)
-
- metric_cls = get_attribute(config.metric)
- metric = metric_cls(**metric_args)
-
- if config.test_dataset == 'same_as_training':
- dataset_cls = get_attribute(train_config.dataset)
- elif config.test_dataset == 'affordance':
- dataset_cls = get_attribute('datasets.lvis_oneshot3.LVIS_Affordance')
- dataset_name = 'aff'
- else:
- dataset_cls = get_attribute('datasets.lvis_oneshot3.LVIS_OneShot')
- dataset_name = 'lvis'
-
- _, dataset_args, _ = filter_args(config, inspect.signature(dataset_cls).parameters)
-
- dataset_args['image_size'] = train_config.image_size # explicitly use training image size for evaluation
-
- if model.__class__.__name__ == 'PFENetWrapper':
- dataset_args['image_size'] = config.image_size
-
- log.info('init dataset', str(dataset_cls))
- dataset = dataset_cls(**dataset_args)
-
- log.info(f'Score on {model.__class__.__name__} on {dataset_cls.__name__}')
-
- data_loader = torch.utils.data.DataLoader(dataset, batch_size=config.batch_size, shuffle=config.shuffle)
-
- # explicitly set prompts
- if config.prompt == 'plain':
- model.prompt_list = ['{}']
- elif config.prompt == 'fixed':
- model.prompt_list = ['a photo of a {}.']
- elif config.prompt == 'shuffle':
- model.prompt_list = ['a photo of a {}.', 'a photograph of a {}.', 'an image of a {}.', '{}.']
- elif config.prompt == 'shuffle_clip':
- from models.clip_prompts import imagenet_templates
- model.prompt_list = imagenet_templates
-
- config.assume_no_unused_keys(exceptions=['max_iterations'])
-
- t_start = time.time()
-
- with torch.no_grad(): # TODO: switch to inference_mode (torch 1.9)
- i, losses = 0, []
- for data_x, data_y in data_loader:
-
- data_x = [x.cuda() if isinstance(x, torch.Tensor) else x for x in data_x]
- data_y = [x.cuda() if isinstance(x, torch.Tensor) else x for x in data_y]
-
- if model.__class__.__name__ in {'ConditionBase4', 'PFENetWrapper'}:
- pred, = model(data_x[0], data_x[1], data_x[2])
- visual_q = None
- else:
- pred, visual_q, _, _ = model(data_x[0], data_x[1], return_features=True)
-
- loss = loss_fn(pred, data_y[0])
-
- metric.add([pred], data_y)
-
- losses += [float(loss)]
-
- i += 1
- if config.max_iterations and i >= config.max_iterations:
- break
-
- # scores = {m: s for m, s in zip(metric.names(), metric.value())}
- scores = metric.scores()
-
- keys = set(scores.keys())
- if dataset.negative_prob > 0 and 'mIoU' in keys:
- keys.remove('mIoU')
-
- name_mask = dataset.mask.replace('text_label', 'txt')[:3]
- name_neg = '' if dataset.negative_prob == 0 else '_' + str(dataset.negative_prob)
-
- score_name = config.name if 'name' in config else f'{dataset_name}_{name_mask}{name_neg}'
-
- scores = {score_name: {k: v for k,v in scores.items() if k in keys}}
- scores[score_name].update({'test_loss': np.mean(losses)})
-
- log.info(f'Evaluation took {time.time() - t_start:.1f}s')
-
- return scores
- else:
- raise ValueError('invalid test dataset')
-
-
-
-
-
-
-
-
-
-if __name__ == '__main__':
- main()
\ No newline at end of file
diff --git a/spaces/myrad01/Inpaint-Anything/third_party/segment-anything/demo/configs/webpack/common.js b/spaces/myrad01/Inpaint-Anything/third_party/segment-anything/demo/configs/webpack/common.js
deleted file mode 100644
index 098f6686f063bf6c631df4f5f3b5921d48ed2d2a..0000000000000000000000000000000000000000
--- a/spaces/myrad01/Inpaint-Anything/third_party/segment-anything/demo/configs/webpack/common.js
+++ /dev/null
@@ -1,84 +0,0 @@
-// Copyright (c) Meta Platforms, Inc. and affiliates.
-// All rights reserved.
-
-// This source code is licensed under the license found in the
-// LICENSE file in the root directory of this source tree.
-
-const { resolve } = require("path");
-const HtmlWebpackPlugin = require("html-webpack-plugin");
-const FriendlyErrorsWebpackPlugin = require("friendly-errors-webpack-plugin");
-const CopyPlugin = require("copy-webpack-plugin");
-const webpack = require("webpack");
-
-module.exports = {
- entry: "./src/index.tsx",
- resolve: {
- extensions: [".js", ".jsx", ".ts", ".tsx"],
- },
- output: {
- path: resolve(__dirname, "dist"),
- },
- module: {
- rules: [
- {
- test: /\.mjs$/,
- include: /node_modules/,
- type: "javascript/auto",
- resolve: {
- fullySpecified: false,
- },
- },
- {
- test: [/\.jsx?$/, /\.tsx?$/],
- use: ["ts-loader"],
- exclude: /node_modules/,
- },
- {
- test: /\.css$/,
- use: ["style-loader", "css-loader"],
- },
- {
- test: /\.(scss|sass)$/,
- use: ["style-loader", "css-loader", "postcss-loader"],
- },
- {
- test: /\.(jpe?g|png|gif|svg)$/i,
- use: [
- "file-loader?hash=sha512&digest=hex&name=img/[contenthash].[ext]",
- "image-webpack-loader?bypassOnDebug&optipng.optimizationLevel=7&gifsicle.interlaced=false",
- ],
- },
- {
- test: /\.(woff|woff2|ttf)$/,
- use: {
- loader: "url-loader",
- },
- },
- ],
- },
- plugins: [
- new CopyPlugin({
- patterns: [
- {
- from: "node_modules/onnxruntime-web/dist/*.wasm",
- to: "[name][ext]",
- },
- {
- from: "model",
- to: "model",
- },
- {
- from: "src/assets",
- to: "assets",
- },
- ],
- }),
- new HtmlWebpackPlugin({
- template: "./src/assets/index.html",
- }),
- new FriendlyErrorsWebpackPlugin(),
- new webpack.ProvidePlugin({
- process: "process/browser",
- }),
- ],
-};
diff --git a/spaces/myrad01/Inpaint-Anything/third_party/segment-anything/demo/src/assets/index.html b/spaces/myrad01/Inpaint-Anything/third_party/segment-anything/demo/src/assets/index.html
deleted file mode 100644
index cbcd53c19953b4421dc7b4a537eef327eafd4cf1..0000000000000000000000000000000000000000
--- a/spaces/myrad01/Inpaint-Anything/third_party/segment-anything/demo/src/assets/index.html
+++ /dev/null
@@ -1,18 +0,0 @@
-
-
-
-
-
- Segment Anything Demo
-
-
-
-
-
-
-
-
-
diff --git a/spaces/nakamura196/yolov5-ndl-layout/ultralytics/yolov5/utils/aws/userdata.sh b/spaces/nakamura196/yolov5-ndl-layout/ultralytics/yolov5/utils/aws/userdata.sh
deleted file mode 100644
index 5fc1332ac1b0d1794cf8f8c5f6918059ae5dc381..0000000000000000000000000000000000000000
--- a/spaces/nakamura196/yolov5-ndl-layout/ultralytics/yolov5/utils/aws/userdata.sh
+++ /dev/null
@@ -1,27 +0,0 @@
-#!/bin/bash
-# AWS EC2 instance startup script https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/user-data.html
-# This script will run only once on first instance start (for a re-start script see mime.sh)
-# /home/ubuntu (ubuntu) or /home/ec2-user (amazon-linux) is working dir
-# Use >300 GB SSD
-
-cd home/ubuntu
-if [ ! -d yolov5 ]; then
- echo "Running first-time script." # install dependencies, download COCO, pull Docker
- git clone https://github.com/ultralytics/yolov5 -b master && sudo chmod -R 777 yolov5
- cd yolov5
- bash data/scripts/get_coco.sh && echo "COCO done." &
- sudo docker pull ultralytics/yolov5:latest && echo "Docker done." &
- python -m pip install --upgrade pip && pip install -r requirements.txt && python detect.py && echo "Requirements done." &
- wait && echo "All tasks done." # finish background tasks
-else
- echo "Running re-start script." # resume interrupted runs
- i=0
- list=$(sudo docker ps -qa) # container list i.e. $'one\ntwo\nthree\nfour'
- while IFS= read -r id; do
- ((i++))
- echo "restarting container $i: $id"
- sudo docker start $id
- # sudo docker exec -it $id python train.py --resume # single-GPU
- sudo docker exec -d $id python utils/aws/resume.py # multi-scenario
- done <<<"$list"
-fi
diff --git a/spaces/netiMophi/DreamlikeArt-Diffusion-1.0/Cogz Cmms Maintenance Software Crack 15 [TOP].md b/spaces/netiMophi/DreamlikeArt-Diffusion-1.0/Cogz Cmms Maintenance Software Crack 15 [TOP].md
deleted file mode 100644
index 6a0b153de79d8689018bbe6c53870d69e6d2700e..0000000000000000000000000000000000000000
--- a/spaces/netiMophi/DreamlikeArt-Diffusion-1.0/Cogz Cmms Maintenance Software Crack 15 [TOP].md
+++ /dev/null
@@ -1,16 +0,0 @@
-
-Why You Should Avoid Cogz Cmms Maintenance Software Crack 15
-Cogz Cmms Maintenance Software is a powerful and easy-to-use solution that helps you manage your maintenance department. It automates preventive maintenance tasks, tracks work orders, manages spare parts inventory, and generates reports to optimize your maintenance efficiency. Cogz Cmms Maintenance Software has been used by thousands of customers in various industries, such as manufacturing, food processing, facilities management, transportation, government, education, health care, hospitality, and more.
-Cogz Cmms Maintenance Software Crack 15
DOWNLOAD >> https://urlcod.com/2uIbeP
-However, some people may be tempted to use a cracked version of Cogz Cmms Maintenance Software, such as Cogz Cmms Maintenance Software Crack 15. This is a risky and unethical practice that can have serious consequences for your business. Here are some reasons why you should avoid using Cogz Cmms Maintenance Software Crack 15:
-
-- It is illegal. Using a cracked version of Cogz Cmms Maintenance Software is a violation of the software license agreement and a form of software piracy. You are stealing intellectual property from the software developer and depriving them of their rightful revenue. You may face legal action from the software developer or the authorities if you are caught using a cracked version of Cogz Cmms Maintenance Software.
-- It is unsafe. Using a cracked version of Cogz Cmms Maintenance Software exposes you to potential malware, viruses, spyware, ransomware, or other malicious software that may be embedded in the crack file. These can harm your computer system, compromise your data security, corrupt your files, or lock you out of your system. You may lose valuable information or incur additional costs to repair or replace your hardware or software.
-- It is unreliable. Using a cracked version of Cogz Cmms Maintenance Software may result in poor performance, errors, bugs, crashes, or compatibility issues. The crack file may not work properly with the latest updates or features of the software. You may experience frequent downtime or data loss that can affect your maintenance operations and productivity. You may also miss out on technical support, customer service, or warranty from the software developer.
-- It is unethical. Using a cracked version of Cogz Cmms Maintenance Software is unfair to the software developer who invested time, money, and effort to create a quality product that meets your maintenance needs. It is also unfair to other customers who paid for the legitimate version of the software and expect fair competition and quality service. You are undermining the trust and reputation of the software industry and harming its innovation and growth.
-
-Therefore, you should avoid using Cogz Cmms Maintenance Software Crack 15 and instead purchase the legitimate version of Cogz Cmms Maintenance Software from their official website[^1^]. You will get a fully functional and secure software that will help you take control of your maintenance department and create efficiencies. You will also get access to free trial[^1^], free updates[^2^], cloud option[^3^], technical support[^2^], customer service[^2^], and warranty[^2^] from the software developer. You will also be supporting the software industry and its ethical standards.
-Cogz Cmms Maintenance Software is a smart investment for your maintenance department. Don't risk your business by using a cracked version of Cogz Cmms Maintenance Software. Get the real deal today!
- cec2833e83
-
-
\ No newline at end of file
diff --git a/spaces/netiMophi/DreamlikeArt-Diffusion-1.0/Program Development In Java Abstraction Specification And Object-Oriented Design Download Pdf.md b/spaces/netiMophi/DreamlikeArt-Diffusion-1.0/Program Development In Java Abstraction Specification And Object-Oriented Design Download Pdf.md
deleted file mode 100644
index 5ce5f120bd5a4c1985f613291008f4945bbd387b..0000000000000000000000000000000000000000
--- a/spaces/netiMophi/DreamlikeArt-Diffusion-1.0/Program Development In Java Abstraction Specification And Object-Oriented Design Download Pdf.md
+++ /dev/null
@@ -1,38 +0,0 @@
-
-Program Development In Java: Abstraction, Specification, And Object-Oriented Design Download Pdf - A Comprehensive Guide
-If you are looking for a book that teaches you how to develop software using Java, you might be interested in Program Development In Java: Abstraction, Specification, And Object-Oriented Design by Barbara Liskov and John Guttag. This book covers the fundamental concepts and principles of software engineering, such as abstraction, specification, modularity, inheritance, polymorphism, and design patterns. It also shows you how to apply these concepts and principles to create high-quality Java programs that are easy to understand, maintain, and reuse.
-Program Development In Java: Abstraction, Specification, And Object-Oriented Design Download Pdf
Download Zip ››››› https://urlcod.com/2uIasl
-In this article, we will give you a brief overview of the book and its contents, as well as provide you with a link to download the pdf version for free. We will also share some of the benefits and challenges of learning program development in Java using this book.
-What is Program Development In Java: Abstraction, Specification, And Object-Oriented Design?
-Program Development In Java: Abstraction, Specification, And Object-Oriented Design is a textbook written by Barbara Liskov and John Guttag, two renowned computer scientists and professors at MIT. The book was published in 2000 by Addison-Wesley Professional and has been widely used in undergraduate and graduate courses on software engineering and object-oriented programming.
-The book aims to teach students how to design and implement software systems using Java as the programming language. It focuses on the use of abstraction and specification as tools for managing complexity and ensuring correctness. It also introduces object-oriented design as a way of organizing software components into classes and interfaces that support reuse and extensibility. The book covers topics such as:
-
-- The role of specifications in software development
-- The concept of abstract data types and their implementation in Java
-- The notion of subtyping and its relation to inheritance and polymorphism
-- The design of generic classes and methods using Java generics
-- The use of exceptions and assertions for error handling and verification
-- The application of design patterns to common software problems
-- The development of graphical user interfaces using Java Swing
-- The testing and debugging of Java programs using JUnit and other tools
-
-The book also includes several case studies that illustrate the application of the concepts and techniques discussed in the book to real-world problems. Some of the case studies are:
-
-- A text editor that supports multiple fonts and styles
-- A calculator that can evaluate arithmetic expressions
-- A bank account system that supports multiple currencies and transactions
-- A game of Tetris that uses graphics and sound effects
-- A web browser that can display HTML pages and images
-
-How to Download Program Development In Java: Abstraction, Specification, And Object-Oriented Design Pdf?
-If you want to download the pdf version of Program Development In Java: Abstraction, Specification, And Object-Oriented Design, you can do so by clicking on the link below. The pdf file is hosted on a third-party website that requires you to complete a short survey before downloading. The survey is free and should take only a few minutes to complete. Once you finish the survey, you will be able to access the pdf file immediately.
-Download Program Development In Java: Abstraction, Specification, And Object-Oriented Design Pdf Here
-
-What are the Benefits of Learning Program Development In Java Using This Book?
-There are many benefits of learning program development in Java using this book. Some of them are:
-
-- You will learn from two experts who have decades of experience in teaching and researching software engineering and object-oriented programming.
-- You will gain a solid foundation in the theory and practice of software engineering, which will help you in your future studies and careers.
-- You will master the core features and concepts of Java, which is one of the most popular and widely used programming languages in the world. 81aa517590
-
-
\ No newline at end of file
diff --git a/spaces/nomic-ai/BelleGroup_school_math_0.25M/style.css b/spaces/nomic-ai/BelleGroup_school_math_0.25M/style.css
deleted file mode 100644
index 114adf441e9032febb46bc056b2a8bb651075f0d..0000000000000000000000000000000000000000
--- a/spaces/nomic-ai/BelleGroup_school_math_0.25M/style.css
+++ /dev/null
@@ -1,28 +0,0 @@
-body {
- padding: 2rem;
- font-family: -apple-system, BlinkMacSystemFont, "Arial", sans-serif;
-}
-
-h1 {
- font-size: 16px;
- margin-top: 0;
-}
-
-p {
- color: rgb(107, 114, 128);
- font-size: 15px;
- margin-bottom: 10px;
- margin-top: 5px;
-}
-
-.card {
- max-width: 620px;
- margin: 0 auto;
- padding: 16px;
- border: 1px solid lightgray;
- border-radius: 16px;
-}
-
-.card p:last-child {
- margin-bottom: 0;
-}
diff --git a/spaces/npc0/BookSumBeta/app.py b/spaces/npc0/BookSumBeta/app.py
deleted file mode 100644
index 62ee32736642e9aef18a71f6a1804a22d6d55b73..0000000000000000000000000000000000000000
--- a/spaces/npc0/BookSumBeta/app.py
+++ /dev/null
@@ -1,58 +0,0 @@
-import os
-import subprocess
-import gradio as gr
-from epub2txt import epub2txt
-from websocket import create_connection
-
-if not os.path.exists(os.getenv("checkpoint_path")):
- os.system("git clone --recurse-submodules https://github.com/ztxz16/fastllm.git")
- os.system("cd fastllm; mkdir build; cd build; cmake ..; make -j; cd tools; python setup.py install --user --prefix=")
- os.system("wget https://huggingface.co/huangyuyang/chatglm2-6b-int4.flm/resolve/main/chatglm2-6b-int4.flm")
- subprocess.Popen(["uvicorn", "api:app"])
-
-class GUI:
- def __init__(self, *args, **kwargs):
- with gr.Blocks() as demo:
- with gr.Row():
- gr.Markdown(scale=2).attach_load_event(self.hello, None)
- gr.LoginButton()
- gr.LogoutButton()
- out = gr.Markdown()
- inp = gr.File(file_types=['.epub'])
- inp.change(self.process, inp, out)
- self.ws = None
- self.out = []
- demo.queue(concurrency_count=2).launch()
-
- def process(self, file, profile: gr.OAuthProfile | None):
- if profile is None:
- return gr.update(value='Login to access the tool.')
-
- h = ''
- chapter_titles = epub2txt.content_titles
- title = epub2txt.title
- if self.ws is None:
- self.ws = create_connection(f"ws://localhost:8000/ws")
- self.ws.send(file.name)
- res = ''
- while 'output: ' not in res:
- res = self.ws.recv()
- if 'chsum: ' in res:
- self.out.append(res.replace("chsum: ", ""))
- elif 'draft_sum: ' in res:
- h = res[11:]
- elif 'output: ' in res:
- self.ws.close()
- self.ws = None
- self.out = []
- yield gr.update(value=res)
- yield gr.update(
- value=f"# {title}\n\n" +h+ "\n\n".join(
- [f"## {ct}\n\n{c}" for ct, c in zip(chapter_titles, self.out)]))
-
- def hello(self, profile: gr.OAuthProfile | None):
- if profile is None:
- return '# ePub summarization tool\n\nLogin to access the tool.'
- return f"# ePub summarization tool\n\nWelcome {profile.name}!!"
-
-GUI()
\ No newline at end of file
diff --git a/spaces/oliver2023/chatgpt-on-wechat/plugins/plugin_manager.py b/spaces/oliver2023/chatgpt-on-wechat/plugins/plugin_manager.py
deleted file mode 100644
index c6a663152c6dc865140d9f9dafcf07a6b0d1a5f2..0000000000000000000000000000000000000000
--- a/spaces/oliver2023/chatgpt-on-wechat/plugins/plugin_manager.py
+++ /dev/null
@@ -1,182 +0,0 @@
-# encoding:utf-8
-
-import importlib
-import json
-import os
-from common.singleton import singleton
-from common.sorted_dict import SortedDict
-from .event import *
-from common.log import logger
-from config import conf
-
-
-@singleton
-class PluginManager:
- def __init__(self):
- self.plugins = SortedDict(lambda k,v: v.priority,reverse=True)
- self.listening_plugins = {}
- self.instances = {}
- self.pconf = {}
-
- def register(self, name: str, desire_priority: int = 0, **kwargs):
- def wrapper(plugincls):
- plugincls.name = name
- plugincls.priority = desire_priority
- plugincls.desc = kwargs.get('desc')
- plugincls.author = kwargs.get('author')
- plugincls.version = kwargs.get('version') if kwargs.get('version') != None else "1.0"
- plugincls.namecn = kwargs.get('namecn') if kwargs.get('namecn') != None else name
- plugincls.hidden = kwargs.get('hidden') if kwargs.get('hidden') != None else False
- plugincls.enabled = True
- self.plugins[name.upper()] = plugincls
- logger.info("Plugin %s_v%s registered" % (name, plugincls.version))
- return plugincls
- return wrapper
-
- def save_config(self):
- with open("./plugins/plugins.json", "w", encoding="utf-8") as f:
- json.dump(self.pconf, f, indent=4, ensure_ascii=False)
-
- def load_config(self):
- logger.info("Loading plugins config...")
-
- modified = False
- if os.path.exists("./plugins/plugins.json"):
- with open("./plugins/plugins.json", "r", encoding="utf-8") as f:
- pconf = json.load(f)
- pconf['plugins'] = SortedDict(lambda k,v: v["priority"],pconf['plugins'],reverse=True)
- else:
- modified = True
- pconf = {"plugins": SortedDict(lambda k,v: v["priority"],reverse=True)}
- self.pconf = pconf
- if modified:
- self.save_config()
- return pconf
-
- def scan_plugins(self):
- logger.info("Scaning plugins ...")
- plugins_dir = "./plugins"
- for plugin_name in os.listdir(plugins_dir):
- plugin_path = os.path.join(plugins_dir, plugin_name)
- if os.path.isdir(plugin_path):
- # 判断插件是否包含同名.py文件
- main_module_path = os.path.join(plugin_path, plugin_name+".py")
- if os.path.isfile(main_module_path):
- # 导入插件
- import_path = "plugins.{}.{}".format(plugin_name, plugin_name)
- try:
- main_module = importlib.import_module(import_path)
- except Exception as e:
- logger.warn("Failed to import plugin %s: %s" % (plugin_name, e))
- continue
- pconf = self.pconf
- new_plugins = []
- modified = False
- for name, plugincls in self.plugins.items():
- rawname = plugincls.name
- if rawname not in pconf["plugins"]:
- new_plugins.append(plugincls)
- modified = True
- logger.info("Plugin %s not found in pconfig, adding to pconfig..." % name)
- pconf["plugins"][rawname] = {"enabled": plugincls.enabled, "priority": plugincls.priority}
- else:
- self.plugins[name].enabled = pconf["plugins"][rawname]["enabled"]
- self.plugins[name].priority = pconf["plugins"][rawname]["priority"]
- self.plugins._update_heap(name) # 更新下plugins中的顺序
- if modified:
- self.save_config()
- return new_plugins
-
- def refresh_order(self):
- for event in self.listening_plugins.keys():
- self.listening_plugins[event].sort(key=lambda name: self.plugins[name].priority, reverse=True)
-
- def activate_plugins(self): # 生成新开启的插件实例
- for name, plugincls in self.plugins.items():
- if plugincls.enabled:
- if name not in self.instances:
- try:
- instance = plugincls()
- except Exception as e:
- logger.warn("Failed to create init %s, diabled. %s" % (name, e))
- self.disable_plugin(name)
- continue
- self.instances[name] = instance
- for event in instance.handlers:
- if event not in self.listening_plugins:
- self.listening_plugins[event] = []
- self.listening_plugins[event].append(name)
- self.refresh_order()
-
- def reload_plugin(self, name:str):
- name = name.upper()
- if name in self.instances:
- for event in self.listening_plugins:
- if name in self.listening_plugins[event]:
- self.listening_plugins[event].remove(name)
- del self.instances[name]
- self.activate_plugins()
- return True
- return False
-
- def load_plugins(self):
- self.load_config()
- self.scan_plugins()
- pconf = self.pconf
- logger.debug("plugins.json config={}".format(pconf))
- for name,plugin in pconf["plugins"].items():
- if name.upper() not in self.plugins:
- logger.error("Plugin %s not found, but found in plugins.json" % name)
- self.activate_plugins()
-
- def emit_event(self, e_context: EventContext, *args, **kwargs):
- if e_context.event in self.listening_plugins:
- for name in self.listening_plugins[e_context.event]:
- if self.plugins[name].enabled and e_context.action == EventAction.CONTINUE:
- logger.debug("Plugin %s triggered by event %s" % (name,e_context.event))
- instance = self.instances[name]
- instance.handlers[e_context.event](e_context, *args, **kwargs)
- return e_context
-
- def set_plugin_priority(self, name:str, priority:int):
- name = name.upper()
- if name not in self.plugins:
- return False
- if self.plugins[name].priority == priority:
- return True
- self.plugins[name].priority = priority
- self.plugins._update_heap(name)
- rawname = self.plugins[name].name
- self.pconf["plugins"][rawname]["priority"] = priority
- self.pconf["plugins"]._update_heap(rawname)
- self.save_config()
- self.refresh_order()
- return True
-
- def enable_plugin(self, name:str):
- name = name.upper()
- if name not in self.plugins:
- return False
- if not self.plugins[name].enabled :
- self.plugins[name].enabled = True
- rawname = self.plugins[name].name
- self.pconf["plugins"][rawname]["enabled"] = True
- self.save_config()
- self.activate_plugins()
- return True
- return True
-
- def disable_plugin(self, name:str):
- name = name.upper()
- if name not in self.plugins:
- return False
- if self.plugins[name].enabled :
- self.plugins[name].enabled = False
- rawname = self.plugins[name].name
- self.pconf["plugins"][rawname]["enabled"] = False
- self.save_config()
- return True
- return True
-
- def list_plugins(self):
- return self.plugins
\ No newline at end of file
diff --git a/spaces/omdena-lc/omdena-ng-lagos-chatbot-interface/Dockerfile b/spaces/omdena-lc/omdena-ng-lagos-chatbot-interface/Dockerfile
deleted file mode 100644
index a67b4805b05dfe1e21841f7fa7dd82b5a005001a..0000000000000000000000000000000000000000
--- a/spaces/omdena-lc/omdena-ng-lagos-chatbot-interface/Dockerfile
+++ /dev/null
@@ -1,45 +0,0 @@
-# syntax=docker/dockerfile:1
-
-# Comments are provided throughout this file to help you get started.
-# If you need more help, visit the Dockerfile reference guide at
-# https://docs.docker.com/engine/reference/builder/
-
-ARG PYTHON_VERSION=3.9
-FROM python:${PYTHON_VERSION}-slim as base
-
-RUN apt-get update && apt-get install -y \
- build-essential \
- curl \
- software-properties-common \
- git \
- && rm -rf /var/lib/apt/lists/*
-
-# Copy the requirements file into the container.
-COPY requirements.txt .
-
-# Install the dependencies from the requirements file.
-RUN pip3 install --no-cache-dir -r requirements.txt
-
-# Prevents Python from writing pyc files.
-ENV PYTHONDONTWRITEBYTECODE=1
-
-# Keeps Python from buffering stdout and stderr to avoid situations where
-# the application crashes without emitting any logs due to buffering.
-ENV PYTHONUNBUFFERED=1
-
-WORKDIR /app
-# Copy the source code into the container.
-COPY . .
-
-# Create a non-privileged user that the app will run under.
-# See https://docs.docker.com/develop/develop-images/dockerfile_best-practices/#user
-# Switch to the non-privileged user to run the application.
-USER 1001
-
-# Expose the port that the application listens on.
-EXPOSE 7860
-
-HEALTHCHECK CMD curl --fail http://localhost:7860/_stcore/health
-
-# set entrypoint for interactive shells
-ENTRYPOINT ["streamlit", "run", "app.py", "--server.port=7860", "--server.address=0.0.0.0"]
diff --git a/spaces/orpatashnik/local-prompt-mixing/src/prompt_utils.py b/spaces/orpatashnik/local-prompt-mixing/src/prompt_utils.py
deleted file mode 100644
index 5611f071ad11e99692bcfb60bb869ba05ce4fbc7..0000000000000000000000000000000000000000
--- a/spaces/orpatashnik/local-prompt-mixing/src/prompt_utils.py
+++ /dev/null
@@ -1,64 +0,0 @@
-import json
-import torch
-import numpy as np
-from tqdm import tqdm
-
-
-def get_topk_similar_words(model, prompt, base_word, vocab, k=30):
- text_input = model.tokenizer(
- [prompt.format(word=base_word)],
- padding="max_length",
- max_length=model.tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- with torch.no_grad():
- encoder_output = model.text_encoder(text_input.input_ids.to(model.device))
- full_prompt_embedding = encoder_output.pooler_output
- full_prompt_embedding = full_prompt_embedding / full_prompt_embedding.norm(p=2, dim=-1, keepdim=True)
-
- prompts = [prompt.format(word=word) for word in vocab]
- batch_size = 1000
- all_prompts_embeddings = []
- for i in tqdm(range(0, len(prompts), batch_size)):
- curr_prompts = prompts[i:i + batch_size]
- with torch.no_grad():
- text_input = model.tokenizer(
- curr_prompts,
- padding="max_length",
- max_length=model.tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- curr_embeddings = model.text_encoder(text_input.input_ids.to(model.device)).pooler_output
- all_prompts_embeddings.append(curr_embeddings)
-
- all_prompts_embeddings = torch.cat(all_prompts_embeddings)
- all_prompts_embeddings = all_prompts_embeddings / all_prompts_embeddings.norm(p=2, dim=-1, keepdim=True)
- prompts_similarities = all_prompts_embeddings.matmul(full_prompt_embedding.view(-1, 1))
- sorted_prompts_similarities = np.flip(prompts_similarities.cpu().numpy().reshape(-1).argsort())
-
- print(f"prompt: {prompt}")
- print(f"initial word: {base_word}")
- print(f"TOP {k} SIMILAR WORDS:")
- similar_words = [vocab[index] for index in sorted_prompts_similarities[:k]]
- print(similar_words)
- return similar_words
-
-def get_proxy_words(args, ldm_stable):
- if len(args.proxy_words) > 0:
- return [args.object_of_interest] + args.proxy_words
- vocab = list(json.load(open("vocab.json")).keys())
- vocab = [word for word in vocab if word.isalpha() and len(word) > 1]
- filtered_vocab = get_topk_similar_words(ldm_stable, "a photo of a {word}", args.object_of_interest, vocab, k=50)
- proxy_words = get_topk_similar_words(ldm_stable, args.prompt, args.object_of_interest, filtered_vocab, k=args.number_of_variations)
- if proxy_words[0] != args.object_of_interest:
- proxy_words = [args.object_of_interest] + proxy_words
-
- return proxy_words
-
-def get_proxy_prompts(args, ldm_stable):
- proxy_words = get_proxy_words(args, ldm_stable)
- prompts = [args.prompt.format(word=args.object_of_interest)]
- proxy_prompts = [{"word": word, "prompt": args.prompt.format(word=word)} for word in proxy_words]
- return proxy_words, prompts, proxy_prompts
\ No newline at end of file
diff --git a/spaces/osbm/streamlit-helloworld/app.py b/spaces/osbm/streamlit-helloworld/app.py
deleted file mode 100644
index e68eedaad9102b885b772984c39fa8d97df8439a..0000000000000000000000000000000000000000
--- a/spaces/osbm/streamlit-helloworld/app.py
+++ /dev/null
@@ -1,18 +0,0 @@
-import streamlit as st
-import subprocess
-import pandas as pd
-# import StringIO
-from io import StringIO
-
-
-st.title("Hello World")
-st.write("This is a test")
-output = subprocess.check_output("df -h", shell=True)
-
-
-# make it a dataframe
-df = pd.read_csv(StringIO(output.decode("utf-8")), sep="\s+")
-df = df.drop(columns=["Mounted", "on"])
-
-# show the dataframe
-st.write(df)
\ No newline at end of file
diff --git "a/spaces/oskarvanderwal/MT-bias-demo/results/counterfactual_p\303\251k.html" "b/spaces/oskarvanderwal/MT-bias-demo/results/counterfactual_p\303\251k.html"
deleted file mode 100644
index b00dcc8a7f6a759569f8dd94d06b2f83fb722311..0000000000000000000000000000000000000000
--- "a/spaces/oskarvanderwal/MT-bias-demo/results/counterfactual_p\303\251k.html"
+++ /dev/null
@@ -1,23 +0,0 @@
-
0th instance:
-
-
-
-
-
-
-
- Source Saliency Heatmap
-
- x: Generated tokens, y: Attributed tokens
-
-
-
- |
-▁He's → ▁She's | ▁a | ▁baker. | </s> |
|---|
| ▁Ő | 0.166 | 0.021 | 0.019 | 0.026 |
|---|
| ▁pék. | -0.146 | -0.003 | 0.001 | 0.004 |
|---|
| </s> | 0.0 | 0.0 | 0.0 | 0.0 |
|---|
| probability | -0.299 | 0.0 | 0.003 | 0.002 |
|---|
-
-
-
-
-  -
-
-### Unconditional Pokemon
-
-The command to train a DDPM UNet model on the Pokemon dataset:
-
-```bash
-accelerate launch train_unconditional.py \
- --dataset_name="huggan/pokemon" \
- --resolution=64 --center_crop --random_flip \
- --output_dir="ddpm-ema-pokemon-64" \
- --train_batch_size=16 \
- --num_epochs=100 \
- --gradient_accumulation_steps=1 \
- --use_ema \
- --learning_rate=1e-4 \
- --lr_warmup_steps=500 \
- --mixed_precision=no \
- --push_to_hub
-```
-An example trained model: https://huggingface.co/anton-l/ddpm-ema-pokemon-64
-
-A full training run takes 2 hours on 4xV100 GPUs.
-
-
-
-
-### Unconditional Pokemon
-
-The command to train a DDPM UNet model on the Pokemon dataset:
-
-```bash
-accelerate launch train_unconditional.py \
- --dataset_name="huggan/pokemon" \
- --resolution=64 --center_crop --random_flip \
- --output_dir="ddpm-ema-pokemon-64" \
- --train_batch_size=16 \
- --num_epochs=100 \
- --gradient_accumulation_steps=1 \
- --use_ema \
- --learning_rate=1e-4 \
- --lr_warmup_steps=500 \
- --mixed_precision=no \
- --push_to_hub
-```
-An example trained model: https://huggingface.co/anton-l/ddpm-ema-pokemon-64
-
-A full training run takes 2 hours on 4xV100 GPUs.
-
- -
-### Training with multiple GPUs
-
-`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
-for running distributed training with `accelerate`. Here is an example command:
-
-```bash
-accelerate launch --mixed_precision="fp16" --multi_gpu train_unconditional.py \
- --dataset_name="huggan/pokemon" \
- --resolution=64 --center_crop --random_flip \
- --output_dir="ddpm-ema-pokemon-64" \
- --train_batch_size=16 \
- --num_epochs=100 \
- --gradient_accumulation_steps=1 \
- --use_ema \
- --learning_rate=1e-4 \
- --lr_warmup_steps=500 \
- --mixed_precision="fp16" \
- --logger="wandb"
-```
-
-To be able to use Weights and Biases (`wandb`) as a logger you need to install the library: `pip install wandb`.
-
-### Using your own data
-
-To use your own dataset, there are 2 ways:
-- you can either provide your own folder as `--train_data_dir`
-- or you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
-
-Below, we explain both in more detail.
-
-#### Provide the dataset as a folder
-
-If you provide your own folders with images, the script expects the following directory structure:
-
-```bash
-data_dir/xxx.png
-data_dir/xxy.png
-data_dir/[...]/xxz.png
-```
-
-In other words, the script will take care of gathering all images inside the folder. You can then run the script like this:
-
-```bash
-accelerate launch train_unconditional.py \
- --train_data_dir \
-
-```
-
-Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
-
-#### Upload your data to the hub, as a (possibly private) repo
-
-It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
-
-```python
-from datasets import load_dataset
-
-# example 1: local folder
-dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
-
-# example 2: local files (supported formats are tar, gzip, zip, xz, rar, zstd)
-dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
-
-# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
-dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
-
-# example 4: providing several splits
-dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
-```
-
-`ImageFolder` will create an `image` column containing the PIL-encoded images.
-
-Next, push it to the hub!
-
-```python
-# assuming you have ran the huggingface-cli login command in a terminal
-dataset.push_to_hub("name_of_your_dataset")
-
-# if you want to push to a private repo, simply pass private=True:
-dataset.push_to_hub("name_of_your_dataset", private=True)
-```
-
-and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub.
-
-More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
diff --git a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/src/diffusers/pipelines/latent_diffusion/__init__.py b/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/src/diffusers/pipelines/latent_diffusion/__init__.py
deleted file mode 100644
index bc6ac82217a37030740b3861242932f0e9bd8dd4..0000000000000000000000000000000000000000
--- a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/src/diffusers/pipelines/latent_diffusion/__init__.py
+++ /dev/null
@@ -1,49 +0,0 @@
-from typing import TYPE_CHECKING
-
-from ...utils import (
- OptionalDependencyNotAvailable,
- _LazyModule,
- get_objects_from_module,
- is_torch_available,
- is_transformers_available,
-)
-
-
-_dummy_objects = {}
-_import_structure = {}
-
-try:
- if not (is_transformers_available() and is_torch_available()):
- raise OptionalDependencyNotAvailable()
-except OptionalDependencyNotAvailable:
- from ...utils import dummy_torch_and_transformers_objects # noqa F403
-
- _dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
-else:
- _import_structure["pipeline_latent_diffusion"] = ["LDMBertModel", "LDMTextToImagePipeline"]
- _import_structure["pipeline_latent_diffusion_superresolution"] = ["LDMSuperResolutionPipeline"]
-
-
-if TYPE_CHECKING:
- try:
- if not (is_transformers_available() and is_torch_available()):
- raise OptionalDependencyNotAvailable()
-
- except OptionalDependencyNotAvailable:
- from ...utils.dummy_torch_and_transformers_objects import *
- else:
- from .pipeline_latent_diffusion import LDMBertModel, LDMTextToImagePipeline
- from .pipeline_latent_diffusion_superresolution import LDMSuperResolutionPipeline
-
-else:
- import sys
-
- sys.modules[__name__] = _LazyModule(
- __name__,
- globals()["__file__"],
- _import_structure,
- module_spec=__spec__,
- )
-
- for name, value in _dummy_objects.items():
- setattr(sys.modules[__name__], name, value)
diff --git a/spaces/paulbricman/velma/scripts/run_tweets.py b/spaces/paulbricman/velma/scripts/run_tweets.py
deleted file mode 100644
index 52e20a5cc7bacc3045cff74d980a2c4137139ed1..0000000000000000000000000000000000000000
--- a/spaces/paulbricman/velma/scripts/run_tweets.py
+++ /dev/null
@@ -1,57 +0,0 @@
-from pathlib import Path
-import pickle
-from src.util import filter
-from src.abduction import infer
-from src.baselines import infer_embs, infer_nli
-from transformers import AutoTokenizer, AutoModelForCausalLM
-from sentence_transformers import CrossEncoder, SentenceTransformer
-import pandas as pd
-from tqdm import tqdm
-
-
-df = pd.read_csv(Path('..') / 'data' / 'tweets' / 'tweets.csv')
-users = ['nabla_theta', 'slatestarcodex', 'stuhlmueller', 'ESYudkowsky', 'ben_j_todd',
- 'ch402', 'willmacaskill', 'hardmaru', 'kenneth0stanley', 'RichardMCNgo']
-
-emb_model = SentenceTransformer('all-MiniLM-L6-v2')
-# nli_model = CrossEncoder('cross-encoder/nli-deberta-v3-base')
-lm_model = AutoModelForCausalLM.from_pretrained(
- 'gustavecortal/gpt-neo-2.7B-8bit')
-lm_tok = AutoTokenizer.from_pretrained('EleutherAI/gpt-neo-2.7B')
-print('(*) Loaded models')
-
-for user in tqdm(users):
- claim_tweets = df[df['username'] == user][pd.notna(
- df['extracted_claim'])][pd.notna(df['negated_claim'])]
-
- for approach in ['embs', 'nli_relative', 'nli_absolute', 'lm']:
- print(user, approach)
- aggregate = []
- artifact_path = Path(
- '..') / 'data' / 'tweets_artifacts' / approach / (user + '.pkl')
-
- for idx, row in claim_tweets.iterrows():
- other_tweets = df[df['username'] ==
- user][df['extracted_claim'] != row['extracted_claim']]['tweet'].values
-
- selection = filter(
- row['extracted_claim'], other_tweets, emb_model, top_k=5)
- print('(*) Filtered paragraphs')
- probs = []
-
- for tweet in selection:
- if approach == 'embs':
- probs += [infer_embs(tweet, [row['extracted_claim'],
- row['negated_claim']], encoder=emb_model)[0]]
- elif approach == 'nli_absolute':
- probs += [infer_nli(tweet,
- [row['extracted_claim']], mode='absolute')[0]]
- elif approach == 'nli_relative':
- probs += [infer_nli(tweet, [row['extracted_claim'],
- row['negated_claim']], mode='relative')[0]]
- elif approach == 'lm':
- probs += [infer(tweet, [row['extracted_claim'], row['negated_claim']],
- model=lm_model, tokenizer=lm_tok, return_components=True)]
-
- aggregate += [probs]
- pickle.dump(aggregate, open(artifact_path, 'wb'))
diff --git a/spaces/paulengstler/interpretable-vertebral-fracture-diagnosis/utils/confusion_viz.py b/spaces/paulengstler/interpretable-vertebral-fracture-diagnosis/utils/confusion_viz.py
deleted file mode 100644
index e7250cd3c4ce887aa336be303998099e19c7644a..0000000000000000000000000000000000000000
--- a/spaces/paulengstler/interpretable-vertebral-fracture-diagnosis/utils/confusion_viz.py
+++ /dev/null
@@ -1,99 +0,0 @@
-from threading import local
-import torch
-import wandb
-import numpy as np
-import PIL.Image
-from typing import Iterable
-
-from utils.val_loop_hook import ValidationLoopHook
-
-def _strip_image_from_grid_row(row, gap=5, bg=255):
- strip = torch.full(
- (row.shape[0] * (row.shape[3] + gap) - gap,
- row.shape[1] * (row.shape[3] + gap) - gap), bg, dtype=row.dtype)
- for i in range(0, row.shape[0] * row.shape[1]):
- strip[(i // row.shape[1]) * (row.shape[2] + gap) : ((i // row.shape[1])+1) * (row.shape[2] + gap) - gap,
- (i % row.shape[1]) * (row.shape[3] + gap) : ((i % row.shape[1])+1) * (row.shape[3] + gap) - gap] = row[i // row.shape[1]][i % row.shape[1]]
- return PIL.Image.fromarray(strip.numpy())
-
-class ConfusionVisualizer(ValidationLoopHook):
- def __init__(self, image_shape: Iterable[int], num_classes: int, num_images: int = 5, num_slices: int = 8):
- self.image_shape = image_shape
- self.num_images = num_images
- self.num_classes = num_classes
- self.num_slices = num_slices
-
- self.activations = -99 * torch.ones(self.num_classes, self.num_images)
- self.images = torch.zeros(torch.Size([self.num_classes, self.num_images]) + torch.Size(self.image_shape))
-
- def process(self, batch, target_batch, logits_batch, prediction_batch):
- image_batch = batch["image"]
-
- with torch.no_grad():
- local_activations = torch.amax(logits_batch, dim=-1)
-
- # filter samples where the prediction does not line up with the target
- confused_samples = (prediction_batch != target_batch)
-
- # filter public dataset samples
- public = torch.tensor(["verse" in id for id in batch["verse_id"]]).type_as(confused_samples)
-
- mask = confused_samples & public
-
- for current_idx in torch.nonzero(mask).squeeze(1):
- target_class = target_batch[current_idx]
- # next item in local batch has a higher activation than the previous confusions for this class, replace it
- if local_activations[current_idx] > torch.min(self.activations[target_class]):
- idx_to_replace = torch.argsort(self.activations[target_class])[0]
- self.activations[target_class, idx_to_replace] = local_activations[current_idx]
- self.images[target_class, idx_to_replace] = image_batch[current_idx].cpu()
-
- def trigger(self, module):
- for class_idx in range(self.num_classes):
- # determine final order such that the highest activations are placed on top
- sorted_idx = torch.argsort(self.activations[class_idx], descending=True)
-
- self.images[class_idx] = self.images[class_idx, sorted_idx]
-
- normalize = lambda x: (x - np.min(x))/np.ptp(x)
-
- if len(self.images.shape) == 6:
- # 3D, visualize slices
- img_res = self.images[class_idx].shape[-1]
- img_slices = torch.linspace(0, img_res-1, self.num_slices+2, dtype=torch.long)[1:-1]
-
- # Show all images slices in a larger combined image
- top_confusing_samples = _strip_image_from_grid_row(
- torch.stack([
- torch.stack([
- torch.tensor(
- np.uint8(255 * normalize((self.images[class_idx, i, 0, ..., img_slices[s]]).numpy()))
- )
- for s in range(self.num_slices)])
- for i in range(self.num_images if self.num_images < self.images[class_idx].shape[0] else self.images[class_idx].shape[0])])
- )
-
- elif len(self.images.shape) == 5:
- # 2D
- top_confusing_samples = _strip_image_from_grid_row(
- torch.stack([
- torch.stack([
- torch.tensor(
- np.uint8(255 * normalize((self.images[class_idx, i, 0, ...]).numpy()))
- )
- ])
- for i in range(self.num_images if self.num_images < self.images[class_idx].shape[0] else self.images[class_idx].shape[0])])
- )
-
- else:
- raise RuntimeError("Unknown image shape found for confusion visualization")
-
- module.logger.experiment.log({
- # class_idx represents the ground truth, i.e. these were samples to be classified as class_idx
- # but they were predicted to belong to a different class
- f"val/top_confusing_of_class_{class_idx}": wandb.Image(top_confusing_samples)
- })
-
- def reset(self):
- self.activations = -99 * torch.ones(self.num_classes, self.num_images)
- self.images = torch.zeros(torch.Size([self.num_classes, self.num_images]) + torch.Size(self.image_shape))
\ No newline at end of file
diff --git a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/packages/backports/makefile.py b/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/packages/backports/makefile.py
deleted file mode 100644
index b8fb2154b6d0618b62281578e5e947bca487cee4..0000000000000000000000000000000000000000
--- a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/packages/backports/makefile.py
+++ /dev/null
@@ -1,51 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-backports.makefile
-~~~~~~~~~~~~~~~~~~
-
-Backports the Python 3 ``socket.makefile`` method for use with anything that
-wants to create a "fake" socket object.
-"""
-import io
-from socket import SocketIO
-
-
-def backport_makefile(
- self, mode="r", buffering=None, encoding=None, errors=None, newline=None
-):
- """
- Backport of ``socket.makefile`` from Python 3.5.
- """
- if not set(mode) <= {"r", "w", "b"}:
- raise ValueError("invalid mode %r (only r, w, b allowed)" % (mode,))
- writing = "w" in mode
- reading = "r" in mode or not writing
- assert reading or writing
- binary = "b" in mode
- rawmode = ""
- if reading:
- rawmode += "r"
- if writing:
- rawmode += "w"
- raw = SocketIO(self, rawmode)
- self._makefile_refs += 1
- if buffering is None:
- buffering = -1
- if buffering < 0:
- buffering = io.DEFAULT_BUFFER_SIZE
- if buffering == 0:
- if not binary:
- raise ValueError("unbuffered streams must be binary")
- return raw
- if reading and writing:
- buffer = io.BufferedRWPair(raw, raw, buffering)
- elif reading:
- buffer = io.BufferedReader(raw, buffering)
- else:
- assert writing
- buffer = io.BufferedWriter(raw, buffering)
- if binary:
- return buffer
- text = io.TextIOWrapper(buffer, encoding, errors, newline)
- text.mode = mode
- return text
diff --git a/spaces/plzdontcry/dakubettergpt/src/types/theme.ts b/spaces/plzdontcry/dakubettergpt/src/types/theme.ts
deleted file mode 100644
index 937ef1525dd2cca331e1dcdd964cae000049f982..0000000000000000000000000000000000000000
--- a/spaces/plzdontcry/dakubettergpt/src/types/theme.ts
+++ /dev/null
@@ -1 +0,0 @@
-export type Theme = 'light' | 'dark';
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/click/parser.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/click/parser.py
deleted file mode 100644
index 5fa7adfac842bfa5689fd1a41ae4017be1ebff6f..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/click/parser.py
+++ /dev/null
@@ -1,529 +0,0 @@
-"""
-This module started out as largely a copy paste from the stdlib's
-optparse module with the features removed that we do not need from
-optparse because we implement them in Click on a higher level (for
-instance type handling, help formatting and a lot more).
-
-The plan is to remove more and more from here over time.
-
-The reason this is a different module and not optparse from the stdlib
-is that there are differences in 2.x and 3.x about the error messages
-generated and optparse in the stdlib uses gettext for no good reason
-and might cause us issues.
-
-Click uses parts of optparse written by Gregory P. Ward and maintained
-by the Python Software Foundation. This is limited to code in parser.py.
-
-Copyright 2001-2006 Gregory P. Ward. All rights reserved.
-Copyright 2002-2006 Python Software Foundation. All rights reserved.
-"""
-# This code uses parts of optparse written by Gregory P. Ward and
-# maintained by the Python Software Foundation.
-# Copyright 2001-2006 Gregory P. Ward
-# Copyright 2002-2006 Python Software Foundation
-import typing as t
-from collections import deque
-from gettext import gettext as _
-from gettext import ngettext
-
-from .exceptions import BadArgumentUsage
-from .exceptions import BadOptionUsage
-from .exceptions import NoSuchOption
-from .exceptions import UsageError
-
-if t.TYPE_CHECKING:
- import typing_extensions as te
- from .core import Argument as CoreArgument
- from .core import Context
- from .core import Option as CoreOption
- from .core import Parameter as CoreParameter
-
-V = t.TypeVar("V")
-
-# Sentinel value that indicates an option was passed as a flag without a
-# value but is not a flag option. Option.consume_value uses this to
-# prompt or use the flag_value.
-_flag_needs_value = object()
-
-
-def _unpack_args(
- args: t.Sequence[str], nargs_spec: t.Sequence[int]
-) -> t.Tuple[t.Sequence[t.Union[str, t.Sequence[t.Optional[str]], None]], t.List[str]]:
- """Given an iterable of arguments and an iterable of nargs specifications,
- it returns a tuple with all the unpacked arguments at the first index
- and all remaining arguments as the second.
-
- The nargs specification is the number of arguments that should be consumed
- or `-1` to indicate that this position should eat up all the remainders.
-
- Missing items are filled with `None`.
- """
- args = deque(args)
- nargs_spec = deque(nargs_spec)
- rv: t.List[t.Union[str, t.Tuple[t.Optional[str], ...], None]] = []
- spos: t.Optional[int] = None
-
- def _fetch(c: "te.Deque[V]") -> t.Optional[V]:
- try:
- if spos is None:
- return c.popleft()
- else:
- return c.pop()
- except IndexError:
- return None
-
- while nargs_spec:
- nargs = _fetch(nargs_spec)
-
- if nargs is None:
- continue
-
- if nargs == 1:
- rv.append(_fetch(args))
- elif nargs > 1:
- x = [_fetch(args) for _ in range(nargs)]
-
- # If we're reversed, we're pulling in the arguments in reverse,
- # so we need to turn them around.
- if spos is not None:
- x.reverse()
-
- rv.append(tuple(x))
- elif nargs < 0:
- if spos is not None:
- raise TypeError("Cannot have two nargs < 0")
-
- spos = len(rv)
- rv.append(None)
-
- # spos is the position of the wildcard (star). If it's not `None`,
- # we fill it with the remainder.
- if spos is not None:
- rv[spos] = tuple(args)
- args = []
- rv[spos + 1 :] = reversed(rv[spos + 1 :])
-
- return tuple(rv), list(args)
-
-
-def split_opt(opt: str) -> t.Tuple[str, str]:
- first = opt[:1]
- if first.isalnum():
- return "", opt
- if opt[1:2] == first:
- return opt[:2], opt[2:]
- return first, opt[1:]
-
-
-def normalize_opt(opt: str, ctx: t.Optional["Context"]) -> str:
- if ctx is None or ctx.token_normalize_func is None:
- return opt
- prefix, opt = split_opt(opt)
- return f"{prefix}{ctx.token_normalize_func(opt)}"
-
-
-def split_arg_string(string: str) -> t.List[str]:
- """Split an argument string as with :func:`shlex.split`, but don't
- fail if the string is incomplete. Ignores a missing closing quote or
- incomplete escape sequence and uses the partial token as-is.
-
- .. code-block:: python
-
- split_arg_string("example 'my file")
- ["example", "my file"]
-
- split_arg_string("example my\\")
- ["example", "my"]
-
- :param string: String to split.
- """
- import shlex
-
- lex = shlex.shlex(string, posix=True)
- lex.whitespace_split = True
- lex.commenters = ""
- out = []
-
- try:
- for token in lex:
- out.append(token)
- except ValueError:
- # Raised when end-of-string is reached in an invalid state. Use
- # the partial token as-is. The quote or escape character is in
- # lex.state, not lex.token.
- out.append(lex.token)
-
- return out
-
-
-class Option:
- def __init__(
- self,
- obj: "CoreOption",
- opts: t.Sequence[str],
- dest: t.Optional[str],
- action: t.Optional[str] = None,
- nargs: int = 1,
- const: t.Optional[t.Any] = None,
- ):
- self._short_opts = []
- self._long_opts = []
- self.prefixes: t.Set[str] = set()
-
- for opt in opts:
- prefix, value = split_opt(opt)
- if not prefix:
- raise ValueError(f"Invalid start character for option ({opt})")
- self.prefixes.add(prefix[0])
- if len(prefix) == 1 and len(value) == 1:
- self._short_opts.append(opt)
- else:
- self._long_opts.append(opt)
- self.prefixes.add(prefix)
-
- if action is None:
- action = "store"
-
- self.dest = dest
- self.action = action
- self.nargs = nargs
- self.const = const
- self.obj = obj
-
- @property
- def takes_value(self) -> bool:
- return self.action in ("store", "append")
-
- def process(self, value: t.Any, state: "ParsingState") -> None:
- if self.action == "store":
- state.opts[self.dest] = value # type: ignore
- elif self.action == "store_const":
- state.opts[self.dest] = self.const # type: ignore
- elif self.action == "append":
- state.opts.setdefault(self.dest, []).append(value) # type: ignore
- elif self.action == "append_const":
- state.opts.setdefault(self.dest, []).append(self.const) # type: ignore
- elif self.action == "count":
- state.opts[self.dest] = state.opts.get(self.dest, 0) + 1 # type: ignore
- else:
- raise ValueError(f"unknown action '{self.action}'")
- state.order.append(self.obj)
-
-
-class Argument:
- def __init__(self, obj: "CoreArgument", dest: t.Optional[str], nargs: int = 1):
- self.dest = dest
- self.nargs = nargs
- self.obj = obj
-
- def process(
- self,
- value: t.Union[t.Optional[str], t.Sequence[t.Optional[str]]],
- state: "ParsingState",
- ) -> None:
- if self.nargs > 1:
- assert value is not None
- holes = sum(1 for x in value if x is None)
- if holes == len(value):
- value = None
- elif holes != 0:
- raise BadArgumentUsage(
- _("Argument {name!r} takes {nargs} values.").format(
- name=self.dest, nargs=self.nargs
- )
- )
-
- if self.nargs == -1 and self.obj.envvar is not None and value == ():
- # Replace empty tuple with None so that a value from the
- # environment may be tried.
- value = None
-
- state.opts[self.dest] = value # type: ignore
- state.order.append(self.obj)
-
-
-class ParsingState:
- def __init__(self, rargs: t.List[str]) -> None:
- self.opts: t.Dict[str, t.Any] = {}
- self.largs: t.List[str] = []
- self.rargs = rargs
- self.order: t.List["CoreParameter"] = []
-
-
-class OptionParser:
- """The option parser is an internal class that is ultimately used to
- parse options and arguments. It's modelled after optparse and brings
- a similar but vastly simplified API. It should generally not be used
- directly as the high level Click classes wrap it for you.
-
- It's not nearly as extensible as optparse or argparse as it does not
- implement features that are implemented on a higher level (such as
- types or defaults).
-
- :param ctx: optionally the :class:`~click.Context` where this parser
- should go with.
- """
-
- def __init__(self, ctx: t.Optional["Context"] = None) -> None:
- #: The :class:`~click.Context` for this parser. This might be
- #: `None` for some advanced use cases.
- self.ctx = ctx
- #: This controls how the parser deals with interspersed arguments.
- #: If this is set to `False`, the parser will stop on the first
- #: non-option. Click uses this to implement nested subcommands
- #: safely.
- self.allow_interspersed_args: bool = True
- #: This tells the parser how to deal with unknown options. By
- #: default it will error out (which is sensible), but there is a
- #: second mode where it will ignore it and continue processing
- #: after shifting all the unknown options into the resulting args.
- self.ignore_unknown_options: bool = False
-
- if ctx is not None:
- self.allow_interspersed_args = ctx.allow_interspersed_args
- self.ignore_unknown_options = ctx.ignore_unknown_options
-
- self._short_opt: t.Dict[str, Option] = {}
- self._long_opt: t.Dict[str, Option] = {}
- self._opt_prefixes = {"-", "--"}
- self._args: t.List[Argument] = []
-
- def add_option(
- self,
- obj: "CoreOption",
- opts: t.Sequence[str],
- dest: t.Optional[str],
- action: t.Optional[str] = None,
- nargs: int = 1,
- const: t.Optional[t.Any] = None,
- ) -> None:
- """Adds a new option named `dest` to the parser. The destination
- is not inferred (unlike with optparse) and needs to be explicitly
- provided. Action can be any of ``store``, ``store_const``,
- ``append``, ``append_const`` or ``count``.
-
- The `obj` can be used to identify the option in the order list
- that is returned from the parser.
- """
- opts = [normalize_opt(opt, self.ctx) for opt in opts]
- option = Option(obj, opts, dest, action=action, nargs=nargs, const=const)
- self._opt_prefixes.update(option.prefixes)
- for opt in option._short_opts:
- self._short_opt[opt] = option
- for opt in option._long_opts:
- self._long_opt[opt] = option
-
- def add_argument(
- self, obj: "CoreArgument", dest: t.Optional[str], nargs: int = 1
- ) -> None:
- """Adds a positional argument named `dest` to the parser.
-
- The `obj` can be used to identify the option in the order list
- that is returned from the parser.
- """
- self._args.append(Argument(obj, dest=dest, nargs=nargs))
-
- def parse_args(
- self, args: t.List[str]
- ) -> t.Tuple[t.Dict[str, t.Any], t.List[str], t.List["CoreParameter"]]:
- """Parses positional arguments and returns ``(values, args, order)``
- for the parsed options and arguments as well as the leftover
- arguments if there are any. The order is a list of objects as they
- appear on the command line. If arguments appear multiple times they
- will be memorized multiple times as well.
- """
- state = ParsingState(args)
- try:
- self._process_args_for_options(state)
- self._process_args_for_args(state)
- except UsageError:
- if self.ctx is None or not self.ctx.resilient_parsing:
- raise
- return state.opts, state.largs, state.order
-
- def _process_args_for_args(self, state: ParsingState) -> None:
- pargs, args = _unpack_args(
- state.largs + state.rargs, [x.nargs for x in self._args]
- )
-
- for idx, arg in enumerate(self._args):
- arg.process(pargs[idx], state)
-
- state.largs = args
- state.rargs = []
-
- def _process_args_for_options(self, state: ParsingState) -> None:
- while state.rargs:
- arg = state.rargs.pop(0)
- arglen = len(arg)
- # Double dashes always handled explicitly regardless of what
- # prefixes are valid.
- if arg == "--":
- return
- elif arg[:1] in self._opt_prefixes and arglen > 1:
- self._process_opts(arg, state)
- elif self.allow_interspersed_args:
- state.largs.append(arg)
- else:
- state.rargs.insert(0, arg)
- return
-
- # Say this is the original argument list:
- # [arg0, arg1, ..., arg(i-1), arg(i), arg(i+1), ..., arg(N-1)]
- # ^
- # (we are about to process arg(i)).
- #
- # Then rargs is [arg(i), ..., arg(N-1)] and largs is a *subset* of
- # [arg0, ..., arg(i-1)] (any options and their arguments will have
- # been removed from largs).
- #
- # The while loop will usually consume 1 or more arguments per pass.
- # If it consumes 1 (eg. arg is an option that takes no arguments),
- # then after _process_arg() is done the situation is:
- #
- # largs = subset of [arg0, ..., arg(i)]
- # rargs = [arg(i+1), ..., arg(N-1)]
- #
- # If allow_interspersed_args is false, largs will always be
- # *empty* -- still a subset of [arg0, ..., arg(i-1)], but
- # not a very interesting subset!
-
- def _match_long_opt(
- self, opt: str, explicit_value: t.Optional[str], state: ParsingState
- ) -> None:
- if opt not in self._long_opt:
- from difflib import get_close_matches
-
- possibilities = get_close_matches(opt, self._long_opt)
- raise NoSuchOption(opt, possibilities=possibilities, ctx=self.ctx)
-
- option = self._long_opt[opt]
- if option.takes_value:
- # At this point it's safe to modify rargs by injecting the
- # explicit value, because no exception is raised in this
- # branch. This means that the inserted value will be fully
- # consumed.
- if explicit_value is not None:
- state.rargs.insert(0, explicit_value)
-
- value = self._get_value_from_state(opt, option, state)
-
- elif explicit_value is not None:
- raise BadOptionUsage(
- opt, _("Option {name!r} does not take a value.").format(name=opt)
- )
-
- else:
- value = None
-
- option.process(value, state)
-
- def _match_short_opt(self, arg: str, state: ParsingState) -> None:
- stop = False
- i = 1
- prefix = arg[0]
- unknown_options = []
-
- for ch in arg[1:]:
- opt = normalize_opt(f"{prefix}{ch}", self.ctx)
- option = self._short_opt.get(opt)
- i += 1
-
- if not option:
- if self.ignore_unknown_options:
- unknown_options.append(ch)
- continue
- raise NoSuchOption(opt, ctx=self.ctx)
- if option.takes_value:
- # Any characters left in arg? Pretend they're the
- # next arg, and stop consuming characters of arg.
- if i < len(arg):
- state.rargs.insert(0, arg[i:])
- stop = True
-
- value = self._get_value_from_state(opt, option, state)
-
- else:
- value = None
-
- option.process(value, state)
-
- if stop:
- break
-
- # If we got any unknown options we recombine the string of the
- # remaining options and re-attach the prefix, then report that
- # to the state as new larg. This way there is basic combinatorics
- # that can be achieved while still ignoring unknown arguments.
- if self.ignore_unknown_options and unknown_options:
- state.largs.append(f"{prefix}{''.join(unknown_options)}")
-
- def _get_value_from_state(
- self, option_name: str, option: Option, state: ParsingState
- ) -> t.Any:
- nargs = option.nargs
-
- if len(state.rargs) < nargs:
- if option.obj._flag_needs_value:
- # Option allows omitting the value.
- value = _flag_needs_value
- else:
- raise BadOptionUsage(
- option_name,
- ngettext(
- "Option {name!r} requires an argument.",
- "Option {name!r} requires {nargs} arguments.",
- nargs,
- ).format(name=option_name, nargs=nargs),
- )
- elif nargs == 1:
- next_rarg = state.rargs[0]
-
- if (
- option.obj._flag_needs_value
- and isinstance(next_rarg, str)
- and next_rarg[:1] in self._opt_prefixes
- and len(next_rarg) > 1
- ):
- # The next arg looks like the start of an option, don't
- # use it as the value if omitting the value is allowed.
- value = _flag_needs_value
- else:
- value = state.rargs.pop(0)
- else:
- value = tuple(state.rargs[:nargs])
- del state.rargs[:nargs]
-
- return value
-
- def _process_opts(self, arg: str, state: ParsingState) -> None:
- explicit_value = None
- # Long option handling happens in two parts. The first part is
- # supporting explicitly attached values. In any case, we will try
- # to long match the option first.
- if "=" in arg:
- long_opt, explicit_value = arg.split("=", 1)
- else:
- long_opt = arg
- norm_long_opt = normalize_opt(long_opt, self.ctx)
-
- # At this point we will match the (assumed) long option through
- # the long option matching code. Note that this allows options
- # like "-foo" to be matched as long options.
- try:
- self._match_long_opt(norm_long_opt, explicit_value, state)
- except NoSuchOption:
- # At this point the long option matching failed, and we need
- # to try with short options. However there is a special rule
- # which says, that if we have a two character options prefix
- # (applies to "--foo" for instance), we do not dispatch to the
- # short option code and will instead raise the no option
- # error.
- if arg[:2] not in self._opt_prefixes:
- self._match_short_opt(arg, state)
- return
-
- if not self.ignore_unknown_options:
- raise
-
- state.largs.append(arg)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/dateutil/zoneinfo/rebuild.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/dateutil/zoneinfo/rebuild.py
deleted file mode 100644
index 684c6586f091350c347f2b6150935f5214ffec27..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/dateutil/zoneinfo/rebuild.py
+++ /dev/null
@@ -1,75 +0,0 @@
-import logging
-import os
-import tempfile
-import shutil
-import json
-from subprocess import check_call, check_output
-from tarfile import TarFile
-
-from dateutil.zoneinfo import METADATA_FN, ZONEFILENAME
-
-
-def rebuild(filename, tag=None, format="gz", zonegroups=[], metadata=None):
- """Rebuild the internal timezone info in dateutil/zoneinfo/zoneinfo*tar*
-
- filename is the timezone tarball from ``ftp.iana.org/tz``.
-
- """
- tmpdir = tempfile.mkdtemp()
- zonedir = os.path.join(tmpdir, "zoneinfo")
- moduledir = os.path.dirname(__file__)
- try:
- with TarFile.open(filename) as tf:
- for name in zonegroups:
- tf.extract(name, tmpdir)
- filepaths = [os.path.join(tmpdir, n) for n in zonegroups]
-
- _run_zic(zonedir, filepaths)
-
- # write metadata file
- with open(os.path.join(zonedir, METADATA_FN), 'w') as f:
- json.dump(metadata, f, indent=4, sort_keys=True)
- target = os.path.join(moduledir, ZONEFILENAME)
- with TarFile.open(target, "w:%s" % format) as tf:
- for entry in os.listdir(zonedir):
- entrypath = os.path.join(zonedir, entry)
- tf.add(entrypath, entry)
- finally:
- shutil.rmtree(tmpdir)
-
-
-def _run_zic(zonedir, filepaths):
- """Calls the ``zic`` compiler in a compatible way to get a "fat" binary.
-
- Recent versions of ``zic`` default to ``-b slim``, while older versions
- don't even have the ``-b`` option (but default to "fat" binaries). The
- current version of dateutil does not support Version 2+ TZif files, which
- causes problems when used in conjunction with "slim" binaries, so this
- function is used to ensure that we always get a "fat" binary.
- """
-
- try:
- help_text = check_output(["zic", "--help"])
- except OSError as e:
- _print_on_nosuchfile(e)
- raise
-
- if b"-b " in help_text:
- bloat_args = ["-b", "fat"]
- else:
- bloat_args = []
-
- check_call(["zic"] + bloat_args + ["-d", zonedir] + filepaths)
-
-
-def _print_on_nosuchfile(e):
- """Print helpful troubleshooting message
-
- e is an exception raised by subprocess.check_call()
-
- """
- if e.errno == 2:
- logging.error(
- "Could not find zic. Perhaps you need to install "
- "libc-bin or some other package that provides it, "
- "or it's not in your PATH?")
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/layouts/tabs.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/layouts/tabs.py
deleted file mode 100644
index 233f18c00f1adc946caa8affd970307a21490ea1..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/layouts/tabs.py
+++ /dev/null
@@ -1,95 +0,0 @@
-from __future__ import annotations
-
-from gradio_client.documentation import document, set_documentation_group
-
-from gradio.blocks import BlockContext
-from gradio.component_meta import ComponentMeta
-from gradio.events import Events
-
-set_documentation_group("layout")
-
-
-class Tabs(BlockContext, metaclass=ComponentMeta):
- """
- Tabs is a layout element within Blocks that can contain multiple "Tab" Components.
- """
-
- EVENTS = [Events.change, Events.select]
-
- def __init__(
- self,
- *,
- selected: int | str | None = None,
- visible: bool = True,
- elem_id: str | None = None,
- elem_classes: list[str] | str | None = None,
- render: bool = True,
- ):
- """
- Parameters:
- selected: The currently selected tab. Must correspond to an id passed to the one of the child TabItems. Defaults to the first TabItem.
- visible: If False, Tabs will be hidden.
- elem_id: An optional string that is assigned as the id of this component in the HTML DOM. Can be used for targeting CSS styles.
- elem_classes: An optional string or list of strings that are assigned as the class of this component in the HTML DOM. Can be used for targeting CSS styles.
- render: If False, this layout will not be rendered in the Blocks context. Should be used if the intention is to assign event listeners now but render the component later.
- """
- BlockContext.__init__(
- self,
- visible=visible,
- elem_id=elem_id,
- elem_classes=elem_classes,
- render=render,
- )
- self.selected = selected
-
-
-@document()
-class Tab(BlockContext, metaclass=ComponentMeta):
- """
- Tab (or its alias TabItem) is a layout element. Components defined within the Tab will be visible when this tab is selected tab.
- Example:
- with gr.Blocks() as demo:
- with gr.Tab("Lion"):
- gr.Image("lion.jpg")
- gr.Button("New Lion")
- with gr.Tab("Tiger"):
- gr.Image("tiger.jpg")
- gr.Button("New Tiger")
- Guides: controlling-layout
- """
-
- EVENTS = [Events.select]
-
- def __init__(
- self,
- label: str | None = None,
- *,
- id: int | str | None = None,
- elem_id: str | None = None,
- elem_classes: list[str] | str | None = None,
- render: bool = True,
- ):
- """
- Parameters:
- label: The visual label for the tab
- id: An optional identifier for the tab, required if you wish to control the selected tab from a predict function.
- elem_id: An optional string that is assigned as the id of the
-
-### Training with multiple GPUs
-
-`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
-for running distributed training with `accelerate`. Here is an example command:
-
-```bash
-accelerate launch --mixed_precision="fp16" --multi_gpu train_unconditional.py \
- --dataset_name="huggan/pokemon" \
- --resolution=64 --center_crop --random_flip \
- --output_dir="ddpm-ema-pokemon-64" \
- --train_batch_size=16 \
- --num_epochs=100 \
- --gradient_accumulation_steps=1 \
- --use_ema \
- --learning_rate=1e-4 \
- --lr_warmup_steps=500 \
- --mixed_precision="fp16" \
- --logger="wandb"
-```
-
-To be able to use Weights and Biases (`wandb`) as a logger you need to install the library: `pip install wandb`.
-
-### Using your own data
-
-To use your own dataset, there are 2 ways:
-- you can either provide your own folder as `--train_data_dir`
-- or you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
-
-Below, we explain both in more detail.
-
-#### Provide the dataset as a folder
-
-If you provide your own folders with images, the script expects the following directory structure:
-
-```bash
-data_dir/xxx.png
-data_dir/xxy.png
-data_dir/[...]/xxz.png
-```
-
-In other words, the script will take care of gathering all images inside the folder. You can then run the script like this:
-
-```bash
-accelerate launch train_unconditional.py \
- --train_data_dir \
-
-```
-
-Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
-
-#### Upload your data to the hub, as a (possibly private) repo
-
-It's very easy (and convenient) to upload your image dataset to the hub using the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
-
-```python
-from datasets import load_dataset
-
-# example 1: local folder
-dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
-
-# example 2: local files (supported formats are tar, gzip, zip, xz, rar, zstd)
-dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
-
-# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
-dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
-
-# example 4: providing several splits
-dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
-```
-
-`ImageFolder` will create an `image` column containing the PIL-encoded images.
-
-Next, push it to the hub!
-
-```python
-# assuming you have ran the huggingface-cli login command in a terminal
-dataset.push_to_hub("name_of_your_dataset")
-
-# if you want to push to a private repo, simply pass private=True:
-dataset.push_to_hub("name_of_your_dataset", private=True)
-```
-
-and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub.
-
-More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
diff --git a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/src/diffusers/pipelines/latent_diffusion/__init__.py b/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/src/diffusers/pipelines/latent_diffusion/__init__.py
deleted file mode 100644
index bc6ac82217a37030740b3861242932f0e9bd8dd4..0000000000000000000000000000000000000000
--- a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/src/diffusers/pipelines/latent_diffusion/__init__.py
+++ /dev/null
@@ -1,49 +0,0 @@
-from typing import TYPE_CHECKING
-
-from ...utils import (
- OptionalDependencyNotAvailable,
- _LazyModule,
- get_objects_from_module,
- is_torch_available,
- is_transformers_available,
-)
-
-
-_dummy_objects = {}
-_import_structure = {}
-
-try:
- if not (is_transformers_available() and is_torch_available()):
- raise OptionalDependencyNotAvailable()
-except OptionalDependencyNotAvailable:
- from ...utils import dummy_torch_and_transformers_objects # noqa F403
-
- _dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
-else:
- _import_structure["pipeline_latent_diffusion"] = ["LDMBertModel", "LDMTextToImagePipeline"]
- _import_structure["pipeline_latent_diffusion_superresolution"] = ["LDMSuperResolutionPipeline"]
-
-
-if TYPE_CHECKING:
- try:
- if not (is_transformers_available() and is_torch_available()):
- raise OptionalDependencyNotAvailable()
-
- except OptionalDependencyNotAvailable:
- from ...utils.dummy_torch_and_transformers_objects import *
- else:
- from .pipeline_latent_diffusion import LDMBertModel, LDMTextToImagePipeline
- from .pipeline_latent_diffusion_superresolution import LDMSuperResolutionPipeline
-
-else:
- import sys
-
- sys.modules[__name__] = _LazyModule(
- __name__,
- globals()["__file__"],
- _import_structure,
- module_spec=__spec__,
- )
-
- for name, value in _dummy_objects.items():
- setattr(sys.modules[__name__], name, value)
diff --git a/spaces/paulbricman/velma/scripts/run_tweets.py b/spaces/paulbricman/velma/scripts/run_tweets.py
deleted file mode 100644
index 52e20a5cc7bacc3045cff74d980a2c4137139ed1..0000000000000000000000000000000000000000
--- a/spaces/paulbricman/velma/scripts/run_tweets.py
+++ /dev/null
@@ -1,57 +0,0 @@
-from pathlib import Path
-import pickle
-from src.util import filter
-from src.abduction import infer
-from src.baselines import infer_embs, infer_nli
-from transformers import AutoTokenizer, AutoModelForCausalLM
-from sentence_transformers import CrossEncoder, SentenceTransformer
-import pandas as pd
-from tqdm import tqdm
-
-
-df = pd.read_csv(Path('..') / 'data' / 'tweets' / 'tweets.csv')
-users = ['nabla_theta', 'slatestarcodex', 'stuhlmueller', 'ESYudkowsky', 'ben_j_todd',
- 'ch402', 'willmacaskill', 'hardmaru', 'kenneth0stanley', 'RichardMCNgo']
-
-emb_model = SentenceTransformer('all-MiniLM-L6-v2')
-# nli_model = CrossEncoder('cross-encoder/nli-deberta-v3-base')
-lm_model = AutoModelForCausalLM.from_pretrained(
- 'gustavecortal/gpt-neo-2.7B-8bit')
-lm_tok = AutoTokenizer.from_pretrained('EleutherAI/gpt-neo-2.7B')
-print('(*) Loaded models')
-
-for user in tqdm(users):
- claim_tweets = df[df['username'] == user][pd.notna(
- df['extracted_claim'])][pd.notna(df['negated_claim'])]
-
- for approach in ['embs', 'nli_relative', 'nli_absolute', 'lm']:
- print(user, approach)
- aggregate = []
- artifact_path = Path(
- '..') / 'data' / 'tweets_artifacts' / approach / (user + '.pkl')
-
- for idx, row in claim_tweets.iterrows():
- other_tweets = df[df['username'] ==
- user][df['extracted_claim'] != row['extracted_claim']]['tweet'].values
-
- selection = filter(
- row['extracted_claim'], other_tweets, emb_model, top_k=5)
- print('(*) Filtered paragraphs')
- probs = []
-
- for tweet in selection:
- if approach == 'embs':
- probs += [infer_embs(tweet, [row['extracted_claim'],
- row['negated_claim']], encoder=emb_model)[0]]
- elif approach == 'nli_absolute':
- probs += [infer_nli(tweet,
- [row['extracted_claim']], mode='absolute')[0]]
- elif approach == 'nli_relative':
- probs += [infer_nli(tweet, [row['extracted_claim'],
- row['negated_claim']], mode='relative')[0]]
- elif approach == 'lm':
- probs += [infer(tweet, [row['extracted_claim'], row['negated_claim']],
- model=lm_model, tokenizer=lm_tok, return_components=True)]
-
- aggregate += [probs]
- pickle.dump(aggregate, open(artifact_path, 'wb'))
diff --git a/spaces/paulengstler/interpretable-vertebral-fracture-diagnosis/utils/confusion_viz.py b/spaces/paulengstler/interpretable-vertebral-fracture-diagnosis/utils/confusion_viz.py
deleted file mode 100644
index e7250cd3c4ce887aa336be303998099e19c7644a..0000000000000000000000000000000000000000
--- a/spaces/paulengstler/interpretable-vertebral-fracture-diagnosis/utils/confusion_viz.py
+++ /dev/null
@@ -1,99 +0,0 @@
-from threading import local
-import torch
-import wandb
-import numpy as np
-import PIL.Image
-from typing import Iterable
-
-from utils.val_loop_hook import ValidationLoopHook
-
-def _strip_image_from_grid_row(row, gap=5, bg=255):
- strip = torch.full(
- (row.shape[0] * (row.shape[3] + gap) - gap,
- row.shape[1] * (row.shape[3] + gap) - gap), bg, dtype=row.dtype)
- for i in range(0, row.shape[0] * row.shape[1]):
- strip[(i // row.shape[1]) * (row.shape[2] + gap) : ((i // row.shape[1])+1) * (row.shape[2] + gap) - gap,
- (i % row.shape[1]) * (row.shape[3] + gap) : ((i % row.shape[1])+1) * (row.shape[3] + gap) - gap] = row[i // row.shape[1]][i % row.shape[1]]
- return PIL.Image.fromarray(strip.numpy())
-
-class ConfusionVisualizer(ValidationLoopHook):
- def __init__(self, image_shape: Iterable[int], num_classes: int, num_images: int = 5, num_slices: int = 8):
- self.image_shape = image_shape
- self.num_images = num_images
- self.num_classes = num_classes
- self.num_slices = num_slices
-
- self.activations = -99 * torch.ones(self.num_classes, self.num_images)
- self.images = torch.zeros(torch.Size([self.num_classes, self.num_images]) + torch.Size(self.image_shape))
-
- def process(self, batch, target_batch, logits_batch, prediction_batch):
- image_batch = batch["image"]
-
- with torch.no_grad():
- local_activations = torch.amax(logits_batch, dim=-1)
-
- # filter samples where the prediction does not line up with the target
- confused_samples = (prediction_batch != target_batch)
-
- # filter public dataset samples
- public = torch.tensor(["verse" in id for id in batch["verse_id"]]).type_as(confused_samples)
-
- mask = confused_samples & public
-
- for current_idx in torch.nonzero(mask).squeeze(1):
- target_class = target_batch[current_idx]
- # next item in local batch has a higher activation than the previous confusions for this class, replace it
- if local_activations[current_idx] > torch.min(self.activations[target_class]):
- idx_to_replace = torch.argsort(self.activations[target_class])[0]
- self.activations[target_class, idx_to_replace] = local_activations[current_idx]
- self.images[target_class, idx_to_replace] = image_batch[current_idx].cpu()
-
- def trigger(self, module):
- for class_idx in range(self.num_classes):
- # determine final order such that the highest activations are placed on top
- sorted_idx = torch.argsort(self.activations[class_idx], descending=True)
-
- self.images[class_idx] = self.images[class_idx, sorted_idx]
-
- normalize = lambda x: (x - np.min(x))/np.ptp(x)
-
- if len(self.images.shape) == 6:
- # 3D, visualize slices
- img_res = self.images[class_idx].shape[-1]
- img_slices = torch.linspace(0, img_res-1, self.num_slices+2, dtype=torch.long)[1:-1]
-
- # Show all images slices in a larger combined image
- top_confusing_samples = _strip_image_from_grid_row(
- torch.stack([
- torch.stack([
- torch.tensor(
- np.uint8(255 * normalize((self.images[class_idx, i, 0, ..., img_slices[s]]).numpy()))
- )
- for s in range(self.num_slices)])
- for i in range(self.num_images if self.num_images < self.images[class_idx].shape[0] else self.images[class_idx].shape[0])])
- )
-
- elif len(self.images.shape) == 5:
- # 2D
- top_confusing_samples = _strip_image_from_grid_row(
- torch.stack([
- torch.stack([
- torch.tensor(
- np.uint8(255 * normalize((self.images[class_idx, i, 0, ...]).numpy()))
- )
- ])
- for i in range(self.num_images if self.num_images < self.images[class_idx].shape[0] else self.images[class_idx].shape[0])])
- )
-
- else:
- raise RuntimeError("Unknown image shape found for confusion visualization")
-
- module.logger.experiment.log({
- # class_idx represents the ground truth, i.e. these were samples to be classified as class_idx
- # but they were predicted to belong to a different class
- f"val/top_confusing_of_class_{class_idx}": wandb.Image(top_confusing_samples)
- })
-
- def reset(self):
- self.activations = -99 * torch.ones(self.num_classes, self.num_images)
- self.images = torch.zeros(torch.Size([self.num_classes, self.num_images]) + torch.Size(self.image_shape))
\ No newline at end of file
diff --git a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/packages/backports/makefile.py b/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/packages/backports/makefile.py
deleted file mode 100644
index b8fb2154b6d0618b62281578e5e947bca487cee4..0000000000000000000000000000000000000000
--- a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/urllib3/packages/backports/makefile.py
+++ /dev/null
@@ -1,51 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-backports.makefile
-~~~~~~~~~~~~~~~~~~
-
-Backports the Python 3 ``socket.makefile`` method for use with anything that
-wants to create a "fake" socket object.
-"""
-import io
-from socket import SocketIO
-
-
-def backport_makefile(
- self, mode="r", buffering=None, encoding=None, errors=None, newline=None
-):
- """
- Backport of ``socket.makefile`` from Python 3.5.
- """
- if not set(mode) <= {"r", "w", "b"}:
- raise ValueError("invalid mode %r (only r, w, b allowed)" % (mode,))
- writing = "w" in mode
- reading = "r" in mode or not writing
- assert reading or writing
- binary = "b" in mode
- rawmode = ""
- if reading:
- rawmode += "r"
- if writing:
- rawmode += "w"
- raw = SocketIO(self, rawmode)
- self._makefile_refs += 1
- if buffering is None:
- buffering = -1
- if buffering < 0:
- buffering = io.DEFAULT_BUFFER_SIZE
- if buffering == 0:
- if not binary:
- raise ValueError("unbuffered streams must be binary")
- return raw
- if reading and writing:
- buffer = io.BufferedRWPair(raw, raw, buffering)
- elif reading:
- buffer = io.BufferedReader(raw, buffering)
- else:
- assert writing
- buffer = io.BufferedWriter(raw, buffering)
- if binary:
- return buffer
- text = io.TextIOWrapper(buffer, encoding, errors, newline)
- text.mode = mode
- return text
diff --git a/spaces/plzdontcry/dakubettergpt/src/types/theme.ts b/spaces/plzdontcry/dakubettergpt/src/types/theme.ts
deleted file mode 100644
index 937ef1525dd2cca331e1dcdd964cae000049f982..0000000000000000000000000000000000000000
--- a/spaces/plzdontcry/dakubettergpt/src/types/theme.ts
+++ /dev/null
@@ -1 +0,0 @@
-export type Theme = 'light' | 'dark';
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/click/parser.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/click/parser.py
deleted file mode 100644
index 5fa7adfac842bfa5689fd1a41ae4017be1ebff6f..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/click/parser.py
+++ /dev/null
@@ -1,529 +0,0 @@
-"""
-This module started out as largely a copy paste from the stdlib's
-optparse module with the features removed that we do not need from
-optparse because we implement them in Click on a higher level (for
-instance type handling, help formatting and a lot more).
-
-The plan is to remove more and more from here over time.
-
-The reason this is a different module and not optparse from the stdlib
-is that there are differences in 2.x and 3.x about the error messages
-generated and optparse in the stdlib uses gettext for no good reason
-and might cause us issues.
-
-Click uses parts of optparse written by Gregory P. Ward and maintained
-by the Python Software Foundation. This is limited to code in parser.py.
-
-Copyright 2001-2006 Gregory P. Ward. All rights reserved.
-Copyright 2002-2006 Python Software Foundation. All rights reserved.
-"""
-# This code uses parts of optparse written by Gregory P. Ward and
-# maintained by the Python Software Foundation.
-# Copyright 2001-2006 Gregory P. Ward
-# Copyright 2002-2006 Python Software Foundation
-import typing as t
-from collections import deque
-from gettext import gettext as _
-from gettext import ngettext
-
-from .exceptions import BadArgumentUsage
-from .exceptions import BadOptionUsage
-from .exceptions import NoSuchOption
-from .exceptions import UsageError
-
-if t.TYPE_CHECKING:
- import typing_extensions as te
- from .core import Argument as CoreArgument
- from .core import Context
- from .core import Option as CoreOption
- from .core import Parameter as CoreParameter
-
-V = t.TypeVar("V")
-
-# Sentinel value that indicates an option was passed as a flag without a
-# value but is not a flag option. Option.consume_value uses this to
-# prompt or use the flag_value.
-_flag_needs_value = object()
-
-
-def _unpack_args(
- args: t.Sequence[str], nargs_spec: t.Sequence[int]
-) -> t.Tuple[t.Sequence[t.Union[str, t.Sequence[t.Optional[str]], None]], t.List[str]]:
- """Given an iterable of arguments and an iterable of nargs specifications,
- it returns a tuple with all the unpacked arguments at the first index
- and all remaining arguments as the second.
-
- The nargs specification is the number of arguments that should be consumed
- or `-1` to indicate that this position should eat up all the remainders.
-
- Missing items are filled with `None`.
- """
- args = deque(args)
- nargs_spec = deque(nargs_spec)
- rv: t.List[t.Union[str, t.Tuple[t.Optional[str], ...], None]] = []
- spos: t.Optional[int] = None
-
- def _fetch(c: "te.Deque[V]") -> t.Optional[V]:
- try:
- if spos is None:
- return c.popleft()
- else:
- return c.pop()
- except IndexError:
- return None
-
- while nargs_spec:
- nargs = _fetch(nargs_spec)
-
- if nargs is None:
- continue
-
- if nargs == 1:
- rv.append(_fetch(args))
- elif nargs > 1:
- x = [_fetch(args) for _ in range(nargs)]
-
- # If we're reversed, we're pulling in the arguments in reverse,
- # so we need to turn them around.
- if spos is not None:
- x.reverse()
-
- rv.append(tuple(x))
- elif nargs < 0:
- if spos is not None:
- raise TypeError("Cannot have two nargs < 0")
-
- spos = len(rv)
- rv.append(None)
-
- # spos is the position of the wildcard (star). If it's not `None`,
- # we fill it with the remainder.
- if spos is not None:
- rv[spos] = tuple(args)
- args = []
- rv[spos + 1 :] = reversed(rv[spos + 1 :])
-
- return tuple(rv), list(args)
-
-
-def split_opt(opt: str) -> t.Tuple[str, str]:
- first = opt[:1]
- if first.isalnum():
- return "", opt
- if opt[1:2] == first:
- return opt[:2], opt[2:]
- return first, opt[1:]
-
-
-def normalize_opt(opt: str, ctx: t.Optional["Context"]) -> str:
- if ctx is None or ctx.token_normalize_func is None:
- return opt
- prefix, opt = split_opt(opt)
- return f"{prefix}{ctx.token_normalize_func(opt)}"
-
-
-def split_arg_string(string: str) -> t.List[str]:
- """Split an argument string as with :func:`shlex.split`, but don't
- fail if the string is incomplete. Ignores a missing closing quote or
- incomplete escape sequence and uses the partial token as-is.
-
- .. code-block:: python
-
- split_arg_string("example 'my file")
- ["example", "my file"]
-
- split_arg_string("example my\\")
- ["example", "my"]
-
- :param string: String to split.
- """
- import shlex
-
- lex = shlex.shlex(string, posix=True)
- lex.whitespace_split = True
- lex.commenters = ""
- out = []
-
- try:
- for token in lex:
- out.append(token)
- except ValueError:
- # Raised when end-of-string is reached in an invalid state. Use
- # the partial token as-is. The quote or escape character is in
- # lex.state, not lex.token.
- out.append(lex.token)
-
- return out
-
-
-class Option:
- def __init__(
- self,
- obj: "CoreOption",
- opts: t.Sequence[str],
- dest: t.Optional[str],
- action: t.Optional[str] = None,
- nargs: int = 1,
- const: t.Optional[t.Any] = None,
- ):
- self._short_opts = []
- self._long_opts = []
- self.prefixes: t.Set[str] = set()
-
- for opt in opts:
- prefix, value = split_opt(opt)
- if not prefix:
- raise ValueError(f"Invalid start character for option ({opt})")
- self.prefixes.add(prefix[0])
- if len(prefix) == 1 and len(value) == 1:
- self._short_opts.append(opt)
- else:
- self._long_opts.append(opt)
- self.prefixes.add(prefix)
-
- if action is None:
- action = "store"
-
- self.dest = dest
- self.action = action
- self.nargs = nargs
- self.const = const
- self.obj = obj
-
- @property
- def takes_value(self) -> bool:
- return self.action in ("store", "append")
-
- def process(self, value: t.Any, state: "ParsingState") -> None:
- if self.action == "store":
- state.opts[self.dest] = value # type: ignore
- elif self.action == "store_const":
- state.opts[self.dest] = self.const # type: ignore
- elif self.action == "append":
- state.opts.setdefault(self.dest, []).append(value) # type: ignore
- elif self.action == "append_const":
- state.opts.setdefault(self.dest, []).append(self.const) # type: ignore
- elif self.action == "count":
- state.opts[self.dest] = state.opts.get(self.dest, 0) + 1 # type: ignore
- else:
- raise ValueError(f"unknown action '{self.action}'")
- state.order.append(self.obj)
-
-
-class Argument:
- def __init__(self, obj: "CoreArgument", dest: t.Optional[str], nargs: int = 1):
- self.dest = dest
- self.nargs = nargs
- self.obj = obj
-
- def process(
- self,
- value: t.Union[t.Optional[str], t.Sequence[t.Optional[str]]],
- state: "ParsingState",
- ) -> None:
- if self.nargs > 1:
- assert value is not None
- holes = sum(1 for x in value if x is None)
- if holes == len(value):
- value = None
- elif holes != 0:
- raise BadArgumentUsage(
- _("Argument {name!r} takes {nargs} values.").format(
- name=self.dest, nargs=self.nargs
- )
- )
-
- if self.nargs == -1 and self.obj.envvar is not None and value == ():
- # Replace empty tuple with None so that a value from the
- # environment may be tried.
- value = None
-
- state.opts[self.dest] = value # type: ignore
- state.order.append(self.obj)
-
-
-class ParsingState:
- def __init__(self, rargs: t.List[str]) -> None:
- self.opts: t.Dict[str, t.Any] = {}
- self.largs: t.List[str] = []
- self.rargs = rargs
- self.order: t.List["CoreParameter"] = []
-
-
-class OptionParser:
- """The option parser is an internal class that is ultimately used to
- parse options and arguments. It's modelled after optparse and brings
- a similar but vastly simplified API. It should generally not be used
- directly as the high level Click classes wrap it for you.
-
- It's not nearly as extensible as optparse or argparse as it does not
- implement features that are implemented on a higher level (such as
- types or defaults).
-
- :param ctx: optionally the :class:`~click.Context` where this parser
- should go with.
- """
-
- def __init__(self, ctx: t.Optional["Context"] = None) -> None:
- #: The :class:`~click.Context` for this parser. This might be
- #: `None` for some advanced use cases.
- self.ctx = ctx
- #: This controls how the parser deals with interspersed arguments.
- #: If this is set to `False`, the parser will stop on the first
- #: non-option. Click uses this to implement nested subcommands
- #: safely.
- self.allow_interspersed_args: bool = True
- #: This tells the parser how to deal with unknown options. By
- #: default it will error out (which is sensible), but there is a
- #: second mode where it will ignore it and continue processing
- #: after shifting all the unknown options into the resulting args.
- self.ignore_unknown_options: bool = False
-
- if ctx is not None:
- self.allow_interspersed_args = ctx.allow_interspersed_args
- self.ignore_unknown_options = ctx.ignore_unknown_options
-
- self._short_opt: t.Dict[str, Option] = {}
- self._long_opt: t.Dict[str, Option] = {}
- self._opt_prefixes = {"-", "--"}
- self._args: t.List[Argument] = []
-
- def add_option(
- self,
- obj: "CoreOption",
- opts: t.Sequence[str],
- dest: t.Optional[str],
- action: t.Optional[str] = None,
- nargs: int = 1,
- const: t.Optional[t.Any] = None,
- ) -> None:
- """Adds a new option named `dest` to the parser. The destination
- is not inferred (unlike with optparse) and needs to be explicitly
- provided. Action can be any of ``store``, ``store_const``,
- ``append``, ``append_const`` or ``count``.
-
- The `obj` can be used to identify the option in the order list
- that is returned from the parser.
- """
- opts = [normalize_opt(opt, self.ctx) for opt in opts]
- option = Option(obj, opts, dest, action=action, nargs=nargs, const=const)
- self._opt_prefixes.update(option.prefixes)
- for opt in option._short_opts:
- self._short_opt[opt] = option
- for opt in option._long_opts:
- self._long_opt[opt] = option
-
- def add_argument(
- self, obj: "CoreArgument", dest: t.Optional[str], nargs: int = 1
- ) -> None:
- """Adds a positional argument named `dest` to the parser.
-
- The `obj` can be used to identify the option in the order list
- that is returned from the parser.
- """
- self._args.append(Argument(obj, dest=dest, nargs=nargs))
-
- def parse_args(
- self, args: t.List[str]
- ) -> t.Tuple[t.Dict[str, t.Any], t.List[str], t.List["CoreParameter"]]:
- """Parses positional arguments and returns ``(values, args, order)``
- for the parsed options and arguments as well as the leftover
- arguments if there are any. The order is a list of objects as they
- appear on the command line. If arguments appear multiple times they
- will be memorized multiple times as well.
- """
- state = ParsingState(args)
- try:
- self._process_args_for_options(state)
- self._process_args_for_args(state)
- except UsageError:
- if self.ctx is None or not self.ctx.resilient_parsing:
- raise
- return state.opts, state.largs, state.order
-
- def _process_args_for_args(self, state: ParsingState) -> None:
- pargs, args = _unpack_args(
- state.largs + state.rargs, [x.nargs for x in self._args]
- )
-
- for idx, arg in enumerate(self._args):
- arg.process(pargs[idx], state)
-
- state.largs = args
- state.rargs = []
-
- def _process_args_for_options(self, state: ParsingState) -> None:
- while state.rargs:
- arg = state.rargs.pop(0)
- arglen = len(arg)
- # Double dashes always handled explicitly regardless of what
- # prefixes are valid.
- if arg == "--":
- return
- elif arg[:1] in self._opt_prefixes and arglen > 1:
- self._process_opts(arg, state)
- elif self.allow_interspersed_args:
- state.largs.append(arg)
- else:
- state.rargs.insert(0, arg)
- return
-
- # Say this is the original argument list:
- # [arg0, arg1, ..., arg(i-1), arg(i), arg(i+1), ..., arg(N-1)]
- # ^
- # (we are about to process arg(i)).
- #
- # Then rargs is [arg(i), ..., arg(N-1)] and largs is a *subset* of
- # [arg0, ..., arg(i-1)] (any options and their arguments will have
- # been removed from largs).
- #
- # The while loop will usually consume 1 or more arguments per pass.
- # If it consumes 1 (eg. arg is an option that takes no arguments),
- # then after _process_arg() is done the situation is:
- #
- # largs = subset of [arg0, ..., arg(i)]
- # rargs = [arg(i+1), ..., arg(N-1)]
- #
- # If allow_interspersed_args is false, largs will always be
- # *empty* -- still a subset of [arg0, ..., arg(i-1)], but
- # not a very interesting subset!
-
- def _match_long_opt(
- self, opt: str, explicit_value: t.Optional[str], state: ParsingState
- ) -> None:
- if opt not in self._long_opt:
- from difflib import get_close_matches
-
- possibilities = get_close_matches(opt, self._long_opt)
- raise NoSuchOption(opt, possibilities=possibilities, ctx=self.ctx)
-
- option = self._long_opt[opt]
- if option.takes_value:
- # At this point it's safe to modify rargs by injecting the
- # explicit value, because no exception is raised in this
- # branch. This means that the inserted value will be fully
- # consumed.
- if explicit_value is not None:
- state.rargs.insert(0, explicit_value)
-
- value = self._get_value_from_state(opt, option, state)
-
- elif explicit_value is not None:
- raise BadOptionUsage(
- opt, _("Option {name!r} does not take a value.").format(name=opt)
- )
-
- else:
- value = None
-
- option.process(value, state)
-
- def _match_short_opt(self, arg: str, state: ParsingState) -> None:
- stop = False
- i = 1
- prefix = arg[0]
- unknown_options = []
-
- for ch in arg[1:]:
- opt = normalize_opt(f"{prefix}{ch}", self.ctx)
- option = self._short_opt.get(opt)
- i += 1
-
- if not option:
- if self.ignore_unknown_options:
- unknown_options.append(ch)
- continue
- raise NoSuchOption(opt, ctx=self.ctx)
- if option.takes_value:
- # Any characters left in arg? Pretend they're the
- # next arg, and stop consuming characters of arg.
- if i < len(arg):
- state.rargs.insert(0, arg[i:])
- stop = True
-
- value = self._get_value_from_state(opt, option, state)
-
- else:
- value = None
-
- option.process(value, state)
-
- if stop:
- break
-
- # If we got any unknown options we recombine the string of the
- # remaining options and re-attach the prefix, then report that
- # to the state as new larg. This way there is basic combinatorics
- # that can be achieved while still ignoring unknown arguments.
- if self.ignore_unknown_options and unknown_options:
- state.largs.append(f"{prefix}{''.join(unknown_options)}")
-
- def _get_value_from_state(
- self, option_name: str, option: Option, state: ParsingState
- ) -> t.Any:
- nargs = option.nargs
-
- if len(state.rargs) < nargs:
- if option.obj._flag_needs_value:
- # Option allows omitting the value.
- value = _flag_needs_value
- else:
- raise BadOptionUsage(
- option_name,
- ngettext(
- "Option {name!r} requires an argument.",
- "Option {name!r} requires {nargs} arguments.",
- nargs,
- ).format(name=option_name, nargs=nargs),
- )
- elif nargs == 1:
- next_rarg = state.rargs[0]
-
- if (
- option.obj._flag_needs_value
- and isinstance(next_rarg, str)
- and next_rarg[:1] in self._opt_prefixes
- and len(next_rarg) > 1
- ):
- # The next arg looks like the start of an option, don't
- # use it as the value if omitting the value is allowed.
- value = _flag_needs_value
- else:
- value = state.rargs.pop(0)
- else:
- value = tuple(state.rargs[:nargs])
- del state.rargs[:nargs]
-
- return value
-
- def _process_opts(self, arg: str, state: ParsingState) -> None:
- explicit_value = None
- # Long option handling happens in two parts. The first part is
- # supporting explicitly attached values. In any case, we will try
- # to long match the option first.
- if "=" in arg:
- long_opt, explicit_value = arg.split("=", 1)
- else:
- long_opt = arg
- norm_long_opt = normalize_opt(long_opt, self.ctx)
-
- # At this point we will match the (assumed) long option through
- # the long option matching code. Note that this allows options
- # like "-foo" to be matched as long options.
- try:
- self._match_long_opt(norm_long_opt, explicit_value, state)
- except NoSuchOption:
- # At this point the long option matching failed, and we need
- # to try with short options. However there is a special rule
- # which says, that if we have a two character options prefix
- # (applies to "--foo" for instance), we do not dispatch to the
- # short option code and will instead raise the no option
- # error.
- if arg[:2] not in self._opt_prefixes:
- self._match_short_opt(arg, state)
- return
-
- if not self.ignore_unknown_options:
- raise
-
- state.largs.append(arg)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/dateutil/zoneinfo/rebuild.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/dateutil/zoneinfo/rebuild.py
deleted file mode 100644
index 684c6586f091350c347f2b6150935f5214ffec27..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/dateutil/zoneinfo/rebuild.py
+++ /dev/null
@@ -1,75 +0,0 @@
-import logging
-import os
-import tempfile
-import shutil
-import json
-from subprocess import check_call, check_output
-from tarfile import TarFile
-
-from dateutil.zoneinfo import METADATA_FN, ZONEFILENAME
-
-
-def rebuild(filename, tag=None, format="gz", zonegroups=[], metadata=None):
- """Rebuild the internal timezone info in dateutil/zoneinfo/zoneinfo*tar*
-
- filename is the timezone tarball from ``ftp.iana.org/tz``.
-
- """
- tmpdir = tempfile.mkdtemp()
- zonedir = os.path.join(tmpdir, "zoneinfo")
- moduledir = os.path.dirname(__file__)
- try:
- with TarFile.open(filename) as tf:
- for name in zonegroups:
- tf.extract(name, tmpdir)
- filepaths = [os.path.join(tmpdir, n) for n in zonegroups]
-
- _run_zic(zonedir, filepaths)
-
- # write metadata file
- with open(os.path.join(zonedir, METADATA_FN), 'w') as f:
- json.dump(metadata, f, indent=4, sort_keys=True)
- target = os.path.join(moduledir, ZONEFILENAME)
- with TarFile.open(target, "w:%s" % format) as tf:
- for entry in os.listdir(zonedir):
- entrypath = os.path.join(zonedir, entry)
- tf.add(entrypath, entry)
- finally:
- shutil.rmtree(tmpdir)
-
-
-def _run_zic(zonedir, filepaths):
- """Calls the ``zic`` compiler in a compatible way to get a "fat" binary.
-
- Recent versions of ``zic`` default to ``-b slim``, while older versions
- don't even have the ``-b`` option (but default to "fat" binaries). The
- current version of dateutil does not support Version 2+ TZif files, which
- causes problems when used in conjunction with "slim" binaries, so this
- function is used to ensure that we always get a "fat" binary.
- """
-
- try:
- help_text = check_output(["zic", "--help"])
- except OSError as e:
- _print_on_nosuchfile(e)
- raise
-
- if b"-b " in help_text:
- bloat_args = ["-b", "fat"]
- else:
- bloat_args = []
-
- check_call(["zic"] + bloat_args + ["-d", zonedir] + filepaths)
-
-
-def _print_on_nosuchfile(e):
- """Print helpful troubleshooting message
-
- e is an exception raised by subprocess.check_call()
-
- """
- if e.errno == 2:
- logging.error(
- "Could not find zic. Perhaps you need to install "
- "libc-bin or some other package that provides it, "
- "or it's not in your PATH?")
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/layouts/tabs.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/layouts/tabs.py
deleted file mode 100644
index 233f18c00f1adc946caa8affd970307a21490ea1..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/layouts/tabs.py
+++ /dev/null
@@ -1,95 +0,0 @@
-from __future__ import annotations
-
-from gradio_client.documentation import document, set_documentation_group
-
-from gradio.blocks import BlockContext
-from gradio.component_meta import ComponentMeta
-from gradio.events import Events
-
-set_documentation_group("layout")
-
-
-class Tabs(BlockContext, metaclass=ComponentMeta):
- """
- Tabs is a layout element within Blocks that can contain multiple "Tab" Components.
- """
-
- EVENTS = [Events.change, Events.select]
-
- def __init__(
- self,
- *,
- selected: int | str | None = None,
- visible: bool = True,
- elem_id: str | None = None,
- elem_classes: list[str] | str | None = None,
- render: bool = True,
- ):
- """
- Parameters:
- selected: The currently selected tab. Must correspond to an id passed to the one of the child TabItems. Defaults to the first TabItem.
- visible: If False, Tabs will be hidden.
- elem_id: An optional string that is assigned as the id of this component in the HTML DOM. Can be used for targeting CSS styles.
- elem_classes: An optional string or list of strings that are assigned as the class of this component in the HTML DOM. Can be used for targeting CSS styles.
- render: If False, this layout will not be rendered in the Blocks context. Should be used if the intention is to assign event listeners now but render the component later.
- """
- BlockContext.__init__(
- self,
- visible=visible,
- elem_id=elem_id,
- elem_classes=elem_classes,
- render=render,
- )
- self.selected = selected
-
-
-@document()
-class Tab(BlockContext, metaclass=ComponentMeta):
- """
- Tab (or its alias TabItem) is a layout element. Components defined within the Tab will be visible when this tab is selected tab.
- Example:
- with gr.Blocks() as demo:
- with gr.Tab("Lion"):
- gr.Image("lion.jpg")
- gr.Button("New Lion")
- with gr.Tab("Tiger"):
- gr.Image("tiger.jpg")
- gr.Button("New Tiger")
- Guides: controlling-layout
- """
-
- EVENTS = [Events.select]
-
- def __init__(
- self,
- label: str | None = None,
- *,
- id: int | str | None = None,
- elem_id: str | None = None,
- elem_classes: list[str] | str | None = None,
- render: bool = True,
- ):
- """
- Parameters:
- label: The visual label for the tab
- id: An optional identifier for the tab, required if you wish to control the selected tab from a predict function.
- elem_id: An optional string that is assigned as the id of the containing the contents of the Tab layout. The same string followed by "-button" is attached to the Tab button. Can be used for targeting CSS styles.
- elem_classes: An optional string or list of strings that are assigned as the class of this component in the HTML DOM. Can be used for targeting CSS styles.
- """
- BlockContext.__init__(
- self,
- elem_id=elem_id,
- elem_classes=elem_classes,
- render=render,
- )
- self.label = label
- self.id = id
-
- def get_expected_parent(self) -> type[Tabs]:
- return Tabs
-
- def get_block_name(self):
- return "tabitem"
-
-
-TabItem = Tab
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/templates/frontend/assets/Index-350b76bc.js b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/templates/frontend/assets/Index-350b76bc.js
deleted file mode 100644
index a1b8519e651a6198bd28f69a2a42ef456408d64d..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/templates/frontend/assets/Index-350b76bc.js
+++ /dev/null
@@ -1,2 +0,0 @@
-import{S as $}from"./Index-c74a8b7c.js";import{B as x}from"./Button-8eeccca1.js";import{B as ee}from"./BlockLabel-e3970ebb.js";import{E as le}from"./Empty-eeaba2d1.js";import"./index-50ad4c77.js";import"./svelte/svelte.js";const{SvelteComponent:te,append:ne,attr:v,detach:ae,init:ie,insert:se,noop:D,safe_not_equal:oe,svg_element:F}=window.__gradio__svelte__internal;function ce(a){let e,t;return{c(){e=F("svg"),t=F("path"),v(t,"fill","currentColor"),v(t,"d","M4 2H2v26a2 2 0 0 0 2 2h26v-2H4v-3h22v-8H4v-4h14V5H4Zm20 17v4H4v-4ZM16 7v4H4V7Z"),v(e,"xmlns","http://www.w3.org/2000/svg"),v(e,"xmlns:xlink","http://www.w3.org/1999/xlink"),v(e,"aria-hidden","true"),v(e,"role","img"),v(e,"class","iconify iconify--carbon"),v(e,"width","100%"),v(e,"height","100%"),v(e,"preserveAspectRatio","xMidYMid meet"),v(e,"viewBox","0 0 32 32")},m(l,n){se(l,e,n),ne(e,t)},p:D,i:D,o:D,d(l){l&&ae(e)}}}class y extends te{constructor(e){super(),ie(this,e,null,ce,oe,{})}}const{SvelteComponent:fe,append:h,attr:m,destroy_each:re,detach:E,element:q,empty:_e,ensure_array_like:G,init:ue,insert:N,listen:de,noop:J,safe_not_equal:me,set_data:z,set_style:j,space:Z,text:I,toggle_class:V}=window.__gradio__svelte__internal,{createEventDispatcher:be}=window.__gradio__svelte__internal;function K(a,e,t){const l=a.slice();return l[5]=e[t],l[7]=t,l}function O(a){let e,t=G(a[0].confidences),l=[];for(let n=0;n {n("select",{index:r,value:g.label})};return a.$$set=r=>{"value"in r&&t(0,l=r.value),"color"in r&&t(1,i=r.color),"selectable"in r&&t(2,s=r.selectable)},[l,i,s,n,c]}class ve extends fe{constructor(e){super(),ue(this,e,he,ge,me,{value:0,color:1,selectable:2})}}const ke=ve,{SvelteComponent:we,assign:pe,check_outros:T,create_component:B,destroy_component:H,detach:R,empty:qe,get_spread_object:Me,get_spread_update:Ce,group_outros:U,init:Se,insert:Y,mount_component:L,safe_not_equal:Be,space:W,transition_in:k,transition_out:p}=window.__gradio__svelte__internal;function X(a){let e,t;return e=new ee({props:{Icon:y,label:a[6],disable:a[7]===!1}}),{c(){B(e.$$.fragment)},m(l,n){L(e,l,n),t=!0},p(l,n){const i={};n&64&&(i.label=l[6]),n&128&&(i.disable=l[7]===!1),e.$set(i)},i(l){t||(k(e.$$.fragment,l),t=!0)},o(l){p(e.$$.fragment,l),t=!1},d(l){H(e,l)}}}function He(a){let e,t;return e=new le({props:{unpadded_box:!0,$$slots:{default:[je]},$$scope:{ctx:a}}}),{c(){B(e.$$.fragment)},m(l,n){L(e,l,n),t=!0},p(l,n){const i={};n&65536&&(i.$$scope={dirty:n,ctx:l}),e.$set(i)},i(l){t||(k(e.$$.fragment,l),t=!0)},o(l){p(e.$$.fragment,l),t=!1},d(l){H(e,l)}}}function Le(a){let e,t;return e=new ke({props:{selectable:a[12],value:a[5],color:a[4]}}),e.$on("select",a[15]),{c(){B(e.$$.fragment)},m(l,n){L(e,l,n),t=!0},p(l,n){const i={};n&4096&&(i.selectable=l[12]),n&32&&(i.value=l[5]),n&16&&(i.color=l[4]),e.$set(i)},i(l){t||(k(e.$$.fragment,l),t=!0)},o(l){p(e.$$.fragment,l),t=!1},d(l){H(e,l)}}}function je(a){let e,t;return e=new y({}),{c(){B(e.$$.fragment)},m(l,n){L(e,l,n),t=!0},i(l){t||(k(e.$$.fragment,l),t=!0)},o(l){p(e.$$.fragment,l),t=!1},d(l){H(e,l)}}}function Ee(a){let e,t,l,n,i,s,c;const r=[{autoscroll:a[0].autoscroll},{i18n:a[0].i18n},a[10]];let g={};for(let o=0;o{_=null}),T());let d=n;n=C(o),n===d?b[n].p(o,u):(U(),p(b[d],1,1,()=>{b[d]=null}),T(),i=b[n],i?i.p(o,u):(i=b[n]=M[n](o),i.c()),k(i,1),i.m(s.parentNode,s))},i(o){c||(k(e.$$.fragment,o),k(_),k(i),c=!0)},o(o){p(e.$$.fragment,o),p(_),p(i),c=!1},d(o){o&&(R(t),R(l),R(s)),H(e,o),_&&_.d(o),b[n].d(o)}}}function Ne(a){let e,t;return e=new x({props:{test_id:"label",visible:a[3],elem_id:a[1],elem_classes:a[2],container:a[7],scale:a[8],min_width:a[9],padding:!1,$$slots:{default:[Ee]},$$scope:{ctx:a}}}),{c(){B(e.$$.fragment)},m(l,n){L(e,l,n),t=!0},p(l,[n]){const i={};n&8&&(i.visible=l[3]),n&2&&(i.elem_id=l[1]),n&4&&(i.elem_classes=l[2]),n&128&&(i.container=l[7]),n&256&&(i.scale=l[8]),n&512&&(i.min_width=l[9]),n&81137&&(i.$$scope={dirty:n,ctx:l}),e.$set(i)},i(l){t||(k(e.$$.fragment,l),t=!0)},o(l){p(e.$$.fragment,l),t=!1},d(l){H(e,l)}}}function Ze(a,e,t){let l,n,{gradio:i}=e,{elem_id:s=""}=e,{elem_classes:c=[]}=e,{visible:r=!0}=e,{color:g=void 0}=e,{value:_={}}=e,{label:M=i.i18n("label.label")}=e,{container:b=!0}=e,{scale:C=null}=e,{min_width:o=void 0}=e,{loading_status:u}=e,{show_label:S=!0}=e,{_selectable:d=!1}=e;const A=({detail:f})=>i.dispatch("select",f);return a.$$set=f=>{"gradio"in f&&t(0,i=f.gradio),"elem_id"in f&&t(1,s=f.elem_id),"elem_classes"in f&&t(2,c=f.elem_classes),"visible"in f&&t(3,r=f.visible),"color"in f&&t(4,g=f.color),"value"in f&&t(5,_=f.value),"label"in f&&t(6,M=f.label),"container"in f&&t(7,b=f.container),"scale"in f&&t(8,C=f.scale),"min_width"in f&&t(9,o=f.min_width),"loading_status"in f&&t(10,u=f.loading_status),"show_label"in f&&t(11,S=f.show_label),"_selectable"in f&&t(12,d=f._selectable)},a.$$.update=()=>{a.$$.dirty&32&&t(14,{confidences:l,label:n}=_,l,(t(13,n),t(5,_))),a.$$.dirty&24577&&i.dispatch("change")},[i,s,c,r,g,_,M,b,C,o,u,S,d,n,l,A]}class ze extends we{constructor(e){super(),Se(this,e,Ze,Ne,Be,{gradio:0,elem_id:1,elem_classes:2,visible:3,color:4,value:5,label:6,container:7,scale:8,min_width:9,loading_status:10,show_label:11,_selectable:12})}}export{ke as BaseLabel,ze as default};
-//# sourceMappingURL=Index-350b76bc.js.map
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/huggingface_hub/commands/download.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/huggingface_hub/commands/download.py
deleted file mode 100644
index 8ac5205e842fcc1e1711333983a40157bb863a7b..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/huggingface_hub/commands/download.py
+++ /dev/null
@@ -1,214 +0,0 @@
-# coding=utf-8
-# Copyright 2023-present, the HuggingFace Inc. team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Contains command to download files from the Hub with the CLI.
-
-Usage:
- huggingface-cli download --help
-
- # Download file
- huggingface-cli download gpt2 config.json
-
- # Download entire repo
- huggingface-cli download fffiloni/zeroscope --repo-type=space --revision=refs/pr/78
-
- # Download repo with filters
- huggingface-cli download gpt2 --include="*.safetensors"
-
- # Download with token
- huggingface-cli download Wauplin/private-model --token=hf_***
-
- # Download quietly (no progress bar, no warnings, only the returned path)
- huggingface-cli download gpt2 config.json --quiet
-
- # Download to local dir
- huggingface-cli download gpt2 --local-dir=./models/gpt2
-"""
-import warnings
-from argparse import Namespace, _SubParsersAction
-from typing import List, Literal, Optional, Union
-
-from huggingface_hub import logging
-from huggingface_hub._snapshot_download import snapshot_download
-from huggingface_hub.commands import BaseHuggingfaceCLICommand
-from huggingface_hub.constants import HF_HUB_ENABLE_HF_TRANSFER
-from huggingface_hub.file_download import hf_hub_download
-from huggingface_hub.utils import disable_progress_bars, enable_progress_bars
-
-
-logger = logging.get_logger(__name__)
-
-
-class DownloadCommand(BaseHuggingfaceCLICommand):
- @staticmethod
- def register_subcommand(parser: _SubParsersAction):
- download_parser = parser.add_parser("download", help="Download files from the Hub")
- download_parser.add_argument(
- "repo_id", type=str, help="ID of the repo to download from (e.g. `username/repo-name`)."
- )
- download_parser.add_argument(
- "filenames", type=str, nargs="*", help="Files to download (e.g. `config.json`, `data/metadata.jsonl`)."
- )
- download_parser.add_argument(
- "--repo-type",
- choices=["model", "dataset", "space"],
- default="model",
- help="Type of repo to download from (e.g. `dataset`).",
- )
- download_parser.add_argument(
- "--revision",
- type=str,
- help="An optional Git revision id which can be a branch name, a tag, or a commit hash.",
- )
- download_parser.add_argument(
- "--include", nargs="*", type=str, help="Glob patterns to match files to download."
- )
- download_parser.add_argument(
- "--exclude", nargs="*", type=str, help="Glob patterns to exclude from files to download."
- )
- download_parser.add_argument(
- "--cache-dir", type=str, help="Path to the directory where to save the downloaded files."
- )
- download_parser.add_argument(
- "--local-dir",
- type=str,
- help=(
- "If set, the downloaded file will be placed under this directory either as a symlink (default) or a"
- " regular file. Check out"
- " https://huggingface.co/docs/huggingface_hub/guides/download#download-files-to-local-folder for more"
- " details."
- ),
- )
- download_parser.add_argument(
- "--local-dir-use-symlinks",
- choices=["auto", "True", "False"],
- default="auto",
- help=(
- "To be used with `local_dir`. If set to 'auto', the cache directory will be used and the file will be"
- " either duplicated or symlinked to the local directory depending on its size. It set to `True`, a"
- " symlink will be created, no matter the file size. If set to `False`, the file will either be"
- " duplicated from cache (if already exists) or downloaded from the Hub and not cached."
- ),
- )
- download_parser.add_argument(
- "--force-download",
- action="store_true",
- help="If True, the files will be downloaded even if they are already cached.",
- )
- download_parser.add_argument(
- "--resume-download", action="store_true", help="If True, resume a previously interrupted download."
- )
- download_parser.add_argument(
- "--token", type=str, help="A User Access Token generated from https://huggingface.co/settings/tokens"
- )
- download_parser.add_argument(
- "--quiet",
- action="store_true",
- help="If True, progress bars are disabled and only the path to the download files is printed.",
- )
- download_parser.set_defaults(func=DownloadCommand)
-
- def __init__(self, args: Namespace) -> None:
- self.token = args.token
- self.repo_id: str = args.repo_id
- self.filenames: List[str] = args.filenames
- self.repo_type: str = args.repo_type
- self.revision: Optional[str] = args.revision
- self.include: Optional[List[str]] = args.include
- self.exclude: Optional[List[str]] = args.exclude
- self.cache_dir: Optional[str] = args.cache_dir
- self.local_dir: Optional[str] = args.local_dir
- self.force_download: bool = args.force_download
- self.resume_download: bool = args.resume_download
- self.quiet: bool = args.quiet
-
- # Raise if local_dir_use_symlinks is invalid
- self.local_dir_use_symlinks: Union[Literal["auto"], bool]
- use_symlinks_lowercase = args.local_dir_use_symlinks.lower()
- if use_symlinks_lowercase == "true":
- self.local_dir_use_symlinks = True
- elif use_symlinks_lowercase == "false":
- self.local_dir_use_symlinks = False
- elif use_symlinks_lowercase == "auto":
- self.local_dir_use_symlinks = "auto"
- else:
- raise ValueError(
- f"'{args.local_dir_use_symlinks}' is not a valid value for `local_dir_use_symlinks`. It must be either"
- " 'auto', 'True' or 'False'."
- )
-
- def run(self) -> None:
- if self.quiet:
- disable_progress_bars()
- with warnings.catch_warnings():
- warnings.simplefilter("ignore")
- print(self._download()) # Print path to downloaded files
- enable_progress_bars()
- else:
- logging.set_verbosity_info()
- print(self._download()) # Print path to downloaded files
- logging.set_verbosity_warning()
-
- def _download(self) -> str:
- # Warn user if patterns are ignored
- if len(self.filenames) > 0:
- if self.include is not None and len(self.include) > 0:
- warnings.warn("Ignoring `--include` since filenames have being explicitly set.")
- if self.exclude is not None and len(self.exclude) > 0:
- warnings.warn("Ignoring `--exclude` since filenames have being explicitly set.")
-
- if not HF_HUB_ENABLE_HF_TRANSFER:
- logger.info(
- "Consider using `hf_transfer` for faster downloads. This solution comes with some limitations. See"
- " https://huggingface.co/docs/huggingface_hub/hf_transfer for more details."
- )
-
- # Single file to download: use `hf_hub_download`
- if len(self.filenames) == 1:
- return hf_hub_download(
- repo_id=self.repo_id,
- repo_type=self.repo_type,
- revision=self.revision,
- filename=self.filenames[0],
- cache_dir=self.cache_dir,
- resume_download=self.resume_download,
- force_download=self.force_download,
- token=self.token,
- local_dir=self.local_dir,
- local_dir_use_symlinks=self.local_dir_use_symlinks,
- library_name="huggingface-cli",
- )
-
- # Otherwise: use `snapshot_download` to ensure all files comes from same revision
- elif len(self.filenames) == 0:
- allow_patterns = self.include
- ignore_patterns = self.exclude
- else:
- allow_patterns = self.filenames
- ignore_patterns = None
-
- return snapshot_download(
- repo_id=self.repo_id,
- repo_type=self.repo_type,
- revision=self.revision,
- allow_patterns=allow_patterns,
- ignore_patterns=ignore_patterns,
- resume_download=self.resume_download,
- force_download=self.force_download,
- cache_dir=self.cache_dir,
- token=self.token,
- local_dir=self.local_dir,
- local_dir_use_symlinks=self.local_dir_use_symlinks,
- library_name="huggingface-cli",
- )
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/_utils/__init__.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/_utils/__init__.py
deleted file mode 100644
index 388dd9174f356c74d6cdd6ad9a8b1ad603234420..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/_utils/__init__.py
+++ /dev/null
@@ -1,29 +0,0 @@
-"""
-This is a module for defining private helpers which do not depend on the
-rest of NumPy.
-
-Everything in here must be self-contained so that it can be
-imported anywhere else without creating circular imports.
-If a utility requires the import of NumPy, it probably belongs
-in ``numpy.core``.
-"""
-
-from ._convertions import asunicode, asbytes
-
-
-def set_module(module):
- """Private decorator for overriding __module__ on a function or class.
-
- Example usage::
-
- @set_module('numpy')
- def example():
- pass
-
- assert example.__module__ == 'numpy'
- """
- def decorator(func):
- if module is not None:
- func.__module__ = module
- return func
- return decorator
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/arrays/floating/test_repr.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/arrays/floating/test_repr.py
deleted file mode 100644
index ea2cdd4fab86ada36d6d5804204c4a479a3e1603..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/arrays/floating/test_repr.py
+++ /dev/null
@@ -1,47 +0,0 @@
-import numpy as np
-import pytest
-
-import pandas as pd
-from pandas.core.arrays.floating import (
- Float32Dtype,
- Float64Dtype,
-)
-
-
-def test_dtypes(dtype):
- # smoke tests on auto dtype construction
-
- np.dtype(dtype.type).kind == "f"
- assert dtype.name is not None
-
-
-@pytest.mark.parametrize(
- "dtype, expected",
- [(Float32Dtype(), "Float32Dtype()"), (Float64Dtype(), "Float64Dtype()")],
-)
-def test_repr_dtype(dtype, expected):
- assert repr(dtype) == expected
-
-
-def test_repr_array():
- result = repr(pd.array([1.0, None, 3.0]))
- expected = "\n[1.0, , 3.0]\nLength: 3, dtype: Float64"
- assert result == expected
-
-
-def test_repr_array_long():
- data = pd.array([1.0, 2.0, None] * 1000)
- expected = """
-[ 1.0, 2.0, , 1.0, 2.0, , 1.0, 2.0, , 1.0,
- ...
- , 1.0, 2.0, , 1.0, 2.0, , 1.0, 2.0, ]
-Length: 3000, dtype: Float64"""
- result = repr(data)
- assert result == expected
-
-
-def test_frame_repr(data_missing):
- df = pd.DataFrame({"A": data_missing})
- result = repr(df)
- expected = " A\n0 \n1 0.1"
- assert result == expected
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/plotting/test_style.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/plotting/test_style.py
deleted file mode 100644
index 665bda15724fd67dc9917509d2b95957b03107e3..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/plotting/test_style.py
+++ /dev/null
@@ -1,157 +0,0 @@
-import pytest
-
-from pandas import Series
-
-pytest.importorskip("matplotlib")
-from pandas.plotting._matplotlib.style import get_standard_colors
-
-
-class TestGetStandardColors:
- @pytest.mark.parametrize(
- "num_colors, expected",
- [
- (3, ["red", "green", "blue"]),
- (5, ["red", "green", "blue", "red", "green"]),
- (7, ["red", "green", "blue", "red", "green", "blue", "red"]),
- (2, ["red", "green"]),
- (1, ["red"]),
- ],
- )
- def test_default_colors_named_from_prop_cycle(self, num_colors, expected):
- import matplotlib as mpl
- from matplotlib.pyplot import cycler
-
- mpl_params = {
- "axes.prop_cycle": cycler(color=["red", "green", "blue"]),
- }
- with mpl.rc_context(rc=mpl_params):
- result = get_standard_colors(num_colors=num_colors)
- assert result == expected
-
- @pytest.mark.parametrize(
- "num_colors, expected",
- [
- (1, ["b"]),
- (3, ["b", "g", "r"]),
- (4, ["b", "g", "r", "y"]),
- (5, ["b", "g", "r", "y", "b"]),
- (7, ["b", "g", "r", "y", "b", "g", "r"]),
- ],
- )
- def test_default_colors_named_from_prop_cycle_string(self, num_colors, expected):
- import matplotlib as mpl
- from matplotlib.pyplot import cycler
-
- mpl_params = {
- "axes.prop_cycle": cycler(color="bgry"),
- }
- with mpl.rc_context(rc=mpl_params):
- result = get_standard_colors(num_colors=num_colors)
- assert result == expected
-
- @pytest.mark.parametrize(
- "num_colors, expected_name",
- [
- (1, ["C0"]),
- (3, ["C0", "C1", "C2"]),
- (
- 12,
- [
- "C0",
- "C1",
- "C2",
- "C3",
- "C4",
- "C5",
- "C6",
- "C7",
- "C8",
- "C9",
- "C0",
- "C1",
- ],
- ),
- ],
- )
- def test_default_colors_named_undefined_prop_cycle(self, num_colors, expected_name):
- import matplotlib as mpl
- import matplotlib.colors as mcolors
-
- with mpl.rc_context(rc={}):
- expected = [mcolors.to_hex(x) for x in expected_name]
- result = get_standard_colors(num_colors=num_colors)
- assert result == expected
-
- @pytest.mark.parametrize(
- "num_colors, expected",
- [
- (1, ["red", "green", (0.1, 0.2, 0.3)]),
- (2, ["red", "green", (0.1, 0.2, 0.3)]),
- (3, ["red", "green", (0.1, 0.2, 0.3)]),
- (4, ["red", "green", (0.1, 0.2, 0.3), "red"]),
- ],
- )
- def test_user_input_color_sequence(self, num_colors, expected):
- color = ["red", "green", (0.1, 0.2, 0.3)]
- result = get_standard_colors(color=color, num_colors=num_colors)
- assert result == expected
-
- @pytest.mark.parametrize(
- "num_colors, expected",
- [
- (1, ["r", "g", "b", "k"]),
- (2, ["r", "g", "b", "k"]),
- (3, ["r", "g", "b", "k"]),
- (4, ["r", "g", "b", "k"]),
- (5, ["r", "g", "b", "k", "r"]),
- (6, ["r", "g", "b", "k", "r", "g"]),
- ],
- )
- def test_user_input_color_string(self, num_colors, expected):
- color = "rgbk"
- result = get_standard_colors(color=color, num_colors=num_colors)
- assert result == expected
-
- @pytest.mark.parametrize(
- "num_colors, expected",
- [
- (1, [(0.1, 0.2, 0.3)]),
- (2, [(0.1, 0.2, 0.3), (0.1, 0.2, 0.3)]),
- (3, [(0.1, 0.2, 0.3), (0.1, 0.2, 0.3), (0.1, 0.2, 0.3)]),
- ],
- )
- def test_user_input_color_floats(self, num_colors, expected):
- color = (0.1, 0.2, 0.3)
- result = get_standard_colors(color=color, num_colors=num_colors)
- assert result == expected
-
- @pytest.mark.parametrize(
- "color, num_colors, expected",
- [
- ("Crimson", 1, ["Crimson"]),
- ("DodgerBlue", 2, ["DodgerBlue", "DodgerBlue"]),
- ("firebrick", 3, ["firebrick", "firebrick", "firebrick"]),
- ],
- )
- def test_user_input_named_color_string(self, color, num_colors, expected):
- result = get_standard_colors(color=color, num_colors=num_colors)
- assert result == expected
-
- @pytest.mark.parametrize("color", ["", [], (), Series([], dtype="object")])
- def test_empty_color_raises(self, color):
- with pytest.raises(ValueError, match="Invalid color argument"):
- get_standard_colors(color=color, num_colors=1)
-
- @pytest.mark.parametrize(
- "color",
- [
- "bad_color",
- ("red", "green", "bad_color"),
- (0.1,),
- (0.1, 0.2),
- (0.1, 0.2, 0.3, 0.4, 0.5), # must be either 3 or 4 floats
- ],
- )
- def test_bad_color_raises(self, color):
- with pytest.raises(ValueError, match="Invalid color"):
- get_standard_colors(color=color, num_colors=5)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_vendor/html5lib/filters/inject_meta_charset.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_vendor/html5lib/filters/inject_meta_charset.py
deleted file mode 100644
index aefb5c842c2f55075546065cfba3c66d137e8184..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_vendor/html5lib/filters/inject_meta_charset.py
+++ /dev/null
@@ -1,73 +0,0 @@
-from __future__ import absolute_import, division, unicode_literals
-
-from . import base
-
-
-class Filter(base.Filter):
- """Injects ```` tag into head of document"""
- def __init__(self, source, encoding):
- """Creates a Filter
-
- :arg source: the source token stream
-
- :arg encoding: the encoding to set
-
- """
- base.Filter.__init__(self, source)
- self.encoding = encoding
-
- def __iter__(self):
- state = "pre_head"
- meta_found = (self.encoding is None)
- pending = []
-
- for token in base.Filter.__iter__(self):
- type = token["type"]
- if type == "StartTag":
- if token["name"].lower() == "head":
- state = "in_head"
-
- elif type == "EmptyTag":
- if token["name"].lower() == "meta":
- # replace charset with actual encoding
- has_http_equiv_content_type = False
- for (namespace, name), value in token["data"].items():
- if namespace is not None:
- continue
- elif name.lower() == 'charset':
- token["data"][(namespace, name)] = self.encoding
- meta_found = True
- break
- elif name == 'http-equiv' and value.lower() == 'content-type':
- has_http_equiv_content_type = True
- else:
- if has_http_equiv_content_type and (None, "content") in token["data"]:
- token["data"][(None, "content")] = 'text/html; charset=%s' % self.encoding
- meta_found = True
-
- elif token["name"].lower() == "head" and not meta_found:
- # insert meta into empty head
- yield {"type": "StartTag", "name": "head",
- "data": token["data"]}
- yield {"type": "EmptyTag", "name": "meta",
- "data": {(None, "charset"): self.encoding}}
- yield {"type": "EndTag", "name": "head"}
- meta_found = True
- continue
-
- elif type == "EndTag":
- if token["name"].lower() == "head" and pending:
- # insert meta into head (if necessary) and flush pending queue
- yield pending.pop(0)
- if not meta_found:
- yield {"type": "EmptyTag", "name": "meta",
- "data": {(None, "charset"): self.encoding}}
- while pending:
- yield pending.pop(0)
- meta_found = True
- state = "post_head"
-
- if state == "in_head":
- pending.append(token)
- else:
- yield token
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/_mapping.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/_mapping.py
deleted file mode 100644
index 800fff193ed8e1254aff946f24763fecf0139858..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/_mapping.py
+++ /dev/null
@@ -1,572 +0,0 @@
-# Automatically generated by scripts/gen_mapfiles.py.
-# DO NOT EDIT BY HAND; run `tox -e mapfiles` instead.
-
-LEXERS = {
- 'ABAPLexer': ('pygments.lexers.business', 'ABAP', ('abap',), ('*.abap', '*.ABAP'), ('text/x-abap',)),
- 'AMDGPULexer': ('pygments.lexers.amdgpu', 'AMDGPU', ('amdgpu',), ('*.isa',), ()),
- 'APLLexer': ('pygments.lexers.apl', 'APL', ('apl',), ('*.apl', '*.aplf', '*.aplo', '*.apln', '*.aplc', '*.apli', '*.dyalog'), ()),
- 'AbnfLexer': ('pygments.lexers.grammar_notation', 'ABNF', ('abnf',), ('*.abnf',), ('text/x-abnf',)),
- 'ActionScript3Lexer': ('pygments.lexers.actionscript', 'ActionScript 3', ('actionscript3', 'as3'), ('*.as',), ('application/x-actionscript3', 'text/x-actionscript3', 'text/actionscript3')),
- 'ActionScriptLexer': ('pygments.lexers.actionscript', 'ActionScript', ('actionscript', 'as'), ('*.as',), ('application/x-actionscript', 'text/x-actionscript', 'text/actionscript')),
- 'AdaLexer': ('pygments.lexers.ada', 'Ada', ('ada', 'ada95', 'ada2005'), ('*.adb', '*.ads', '*.ada'), ('text/x-ada',)),
- 'AdlLexer': ('pygments.lexers.archetype', 'ADL', ('adl',), ('*.adl', '*.adls', '*.adlf', '*.adlx'), ()),
- 'AgdaLexer': ('pygments.lexers.haskell', 'Agda', ('agda',), ('*.agda',), ('text/x-agda',)),
- 'AheuiLexer': ('pygments.lexers.esoteric', 'Aheui', ('aheui',), ('*.aheui',), ()),
- 'AlloyLexer': ('pygments.lexers.dsls', 'Alloy', ('alloy',), ('*.als',), ('text/x-alloy',)),
- 'AmbientTalkLexer': ('pygments.lexers.ambient', 'AmbientTalk', ('ambienttalk', 'ambienttalk/2', 'at'), ('*.at',), ('text/x-ambienttalk',)),
- 'AmplLexer': ('pygments.lexers.ampl', 'Ampl', ('ampl',), ('*.run',), ()),
- 'Angular2HtmlLexer': ('pygments.lexers.templates', 'HTML + Angular2', ('html+ng2',), ('*.ng2',), ()),
- 'Angular2Lexer': ('pygments.lexers.templates', 'Angular2', ('ng2',), (), ()),
- 'AntlrActionScriptLexer': ('pygments.lexers.parsers', 'ANTLR With ActionScript Target', ('antlr-actionscript', 'antlr-as'), ('*.G', '*.g'), ()),
- 'AntlrCSharpLexer': ('pygments.lexers.parsers', 'ANTLR With C# Target', ('antlr-csharp', 'antlr-c#'), ('*.G', '*.g'), ()),
- 'AntlrCppLexer': ('pygments.lexers.parsers', 'ANTLR With CPP Target', ('antlr-cpp',), ('*.G', '*.g'), ()),
- 'AntlrJavaLexer': ('pygments.lexers.parsers', 'ANTLR With Java Target', ('antlr-java',), ('*.G', '*.g'), ()),
- 'AntlrLexer': ('pygments.lexers.parsers', 'ANTLR', ('antlr',), (), ()),
- 'AntlrObjectiveCLexer': ('pygments.lexers.parsers', 'ANTLR With ObjectiveC Target', ('antlr-objc',), ('*.G', '*.g'), ()),
- 'AntlrPerlLexer': ('pygments.lexers.parsers', 'ANTLR With Perl Target', ('antlr-perl',), ('*.G', '*.g'), ()),
- 'AntlrPythonLexer': ('pygments.lexers.parsers', 'ANTLR With Python Target', ('antlr-python',), ('*.G', '*.g'), ()),
- 'AntlrRubyLexer': ('pygments.lexers.parsers', 'ANTLR With Ruby Target', ('antlr-ruby', 'antlr-rb'), ('*.G', '*.g'), ()),
- 'ApacheConfLexer': ('pygments.lexers.configs', 'ApacheConf', ('apacheconf', 'aconf', 'apache'), ('.htaccess', 'apache.conf', 'apache2.conf'), ('text/x-apacheconf',)),
- 'AppleScriptLexer': ('pygments.lexers.scripting', 'AppleScript', ('applescript',), ('*.applescript',), ()),
- 'ArduinoLexer': ('pygments.lexers.c_like', 'Arduino', ('arduino',), ('*.ino',), ('text/x-arduino',)),
- 'ArrowLexer': ('pygments.lexers.arrow', 'Arrow', ('arrow',), ('*.arw',), ()),
- 'ArturoLexer': ('pygments.lexers.arturo', 'Arturo', ('arturo', 'art'), ('*.art',), ()),
- 'AscLexer': ('pygments.lexers.asc', 'ASCII armored', ('asc', 'pem'), ('*.asc', '*.pem', 'id_dsa', 'id_ecdsa', 'id_ecdsa_sk', 'id_ed25519', 'id_ed25519_sk', 'id_rsa'), ('application/pgp-keys', 'application/pgp-encrypted', 'application/pgp-signature', 'application/pem-certificate-chain')),
- 'Asn1Lexer': ('pygments.lexers.asn1', 'ASN.1', ('asn1',), ('*.asn1',), ()),
- 'AspectJLexer': ('pygments.lexers.jvm', 'AspectJ', ('aspectj',), ('*.aj',), ('text/x-aspectj',)),
- 'AsymptoteLexer': ('pygments.lexers.graphics', 'Asymptote', ('asymptote', 'asy'), ('*.asy',), ('text/x-asymptote',)),
- 'AugeasLexer': ('pygments.lexers.configs', 'Augeas', ('augeas',), ('*.aug',), ()),
- 'AutoItLexer': ('pygments.lexers.automation', 'AutoIt', ('autoit',), ('*.au3',), ('text/x-autoit',)),
- 'AutohotkeyLexer': ('pygments.lexers.automation', 'autohotkey', ('autohotkey', 'ahk'), ('*.ahk', '*.ahkl'), ('text/x-autohotkey',)),
- 'AwkLexer': ('pygments.lexers.textedit', 'Awk', ('awk', 'gawk', 'mawk', 'nawk'), ('*.awk',), ('application/x-awk',)),
- 'BBCBasicLexer': ('pygments.lexers.basic', 'BBC Basic', ('bbcbasic',), ('*.bbc',), ()),
- 'BBCodeLexer': ('pygments.lexers.markup', 'BBCode', ('bbcode',), (), ('text/x-bbcode',)),
- 'BCLexer': ('pygments.lexers.algebra', 'BC', ('bc',), ('*.bc',), ()),
- 'BQNLexer': ('pygments.lexers.bqn', 'BQN', ('bqn',), ('*.bqn',), ()),
- 'BSTLexer': ('pygments.lexers.bibtex', 'BST', ('bst', 'bst-pybtex'), ('*.bst',), ()),
- 'BareLexer': ('pygments.lexers.bare', 'BARE', ('bare',), ('*.bare',), ()),
- 'BaseMakefileLexer': ('pygments.lexers.make', 'Base Makefile', ('basemake',), (), ()),
- 'BashLexer': ('pygments.lexers.shell', 'Bash', ('bash', 'sh', 'ksh', 'zsh', 'shell'), ('*.sh', '*.ksh', '*.bash', '*.ebuild', '*.eclass', '*.exheres-0', '*.exlib', '*.zsh', '.bashrc', 'bashrc', '.bash_*', 'bash_*', 'zshrc', '.zshrc', '.kshrc', 'kshrc', 'PKGBUILD'), ('application/x-sh', 'application/x-shellscript', 'text/x-shellscript')),
- 'BashSessionLexer': ('pygments.lexers.shell', 'Bash Session', ('console', 'shell-session'), ('*.sh-session', '*.shell-session'), ('application/x-shell-session', 'application/x-sh-session')),
- 'BatchLexer': ('pygments.lexers.shell', 'Batchfile', ('batch', 'bat', 'dosbatch', 'winbatch'), ('*.bat', '*.cmd'), ('application/x-dos-batch',)),
- 'BddLexer': ('pygments.lexers.bdd', 'Bdd', ('bdd',), ('*.feature',), ('text/x-bdd',)),
- 'BefungeLexer': ('pygments.lexers.esoteric', 'Befunge', ('befunge',), ('*.befunge',), ('application/x-befunge',)),
- 'BerryLexer': ('pygments.lexers.berry', 'Berry', ('berry', 'be'), ('*.be',), ('text/x-berry', 'application/x-berry')),
- 'BibTeXLexer': ('pygments.lexers.bibtex', 'BibTeX', ('bibtex', 'bib'), ('*.bib',), ('text/x-bibtex',)),
- 'BlitzBasicLexer': ('pygments.lexers.basic', 'BlitzBasic', ('blitzbasic', 'b3d', 'bplus'), ('*.bb', '*.decls'), ('text/x-bb',)),
- 'BlitzMaxLexer': ('pygments.lexers.basic', 'BlitzMax', ('blitzmax', 'bmax'), ('*.bmx',), ('text/x-bmx',)),
- 'BlueprintLexer': ('pygments.lexers.blueprint', 'Blueprint', ('blueprint',), ('*.blp',), ('text/x-blueprint',)),
- 'BnfLexer': ('pygments.lexers.grammar_notation', 'BNF', ('bnf',), ('*.bnf',), ('text/x-bnf',)),
- 'BoaLexer': ('pygments.lexers.boa', 'Boa', ('boa',), ('*.boa',), ()),
- 'BooLexer': ('pygments.lexers.dotnet', 'Boo', ('boo',), ('*.boo',), ('text/x-boo',)),
- 'BoogieLexer': ('pygments.lexers.verification', 'Boogie', ('boogie',), ('*.bpl',), ()),
- 'BrainfuckLexer': ('pygments.lexers.esoteric', 'Brainfuck', ('brainfuck', 'bf'), ('*.bf', '*.b'), ('application/x-brainfuck',)),
- 'BugsLexer': ('pygments.lexers.modeling', 'BUGS', ('bugs', 'winbugs', 'openbugs'), ('*.bug',), ()),
- 'CAmkESLexer': ('pygments.lexers.esoteric', 'CAmkES', ('camkes', 'idl4'), ('*.camkes', '*.idl4'), ()),
- 'CLexer': ('pygments.lexers.c_cpp', 'C', ('c',), ('*.c', '*.h', '*.idc', '*.x[bp]m'), ('text/x-chdr', 'text/x-csrc', 'image/x-xbitmap', 'image/x-xpixmap')),
- 'CMakeLexer': ('pygments.lexers.make', 'CMake', ('cmake',), ('*.cmake', 'CMakeLists.txt'), ('text/x-cmake',)),
- 'CObjdumpLexer': ('pygments.lexers.asm', 'c-objdump', ('c-objdump',), ('*.c-objdump',), ('text/x-c-objdump',)),
- 'CPSALexer': ('pygments.lexers.lisp', 'CPSA', ('cpsa',), ('*.cpsa',), ()),
- 'CSSUL4Lexer': ('pygments.lexers.ul4', 'CSS+UL4', ('css+ul4',), ('*.cssul4',), ()),
- 'CSharpAspxLexer': ('pygments.lexers.dotnet', 'aspx-cs', ('aspx-cs',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
- 'CSharpLexer': ('pygments.lexers.dotnet', 'C#', ('csharp', 'c#', 'cs'), ('*.cs',), ('text/x-csharp',)),
- 'Ca65Lexer': ('pygments.lexers.asm', 'ca65 assembler', ('ca65',), ('*.s',), ()),
- 'CadlLexer': ('pygments.lexers.archetype', 'cADL', ('cadl',), ('*.cadl',), ()),
- 'CapDLLexer': ('pygments.lexers.esoteric', 'CapDL', ('capdl',), ('*.cdl',), ()),
- 'CapnProtoLexer': ('pygments.lexers.capnproto', "Cap'n Proto", ('capnp',), ('*.capnp',), ()),
- 'CarbonLexer': ('pygments.lexers.carbon', 'Carbon', ('carbon',), ('*.carbon',), ('text/x-carbon',)),
- 'CbmBasicV2Lexer': ('pygments.lexers.basic', 'CBM BASIC V2', ('cbmbas',), ('*.bas',), ()),
- 'CddlLexer': ('pygments.lexers.cddl', 'CDDL', ('cddl',), ('*.cddl',), ('text/x-cddl',)),
- 'CeylonLexer': ('pygments.lexers.jvm', 'Ceylon', ('ceylon',), ('*.ceylon',), ('text/x-ceylon',)),
- 'Cfengine3Lexer': ('pygments.lexers.configs', 'CFEngine3', ('cfengine3', 'cf3'), ('*.cf',), ()),
- 'ChaiscriptLexer': ('pygments.lexers.scripting', 'ChaiScript', ('chaiscript', 'chai'), ('*.chai',), ('text/x-chaiscript', 'application/x-chaiscript')),
- 'ChapelLexer': ('pygments.lexers.chapel', 'Chapel', ('chapel', 'chpl'), ('*.chpl',), ()),
- 'CharmciLexer': ('pygments.lexers.c_like', 'Charmci', ('charmci',), ('*.ci',), ()),
- 'CheetahHtmlLexer': ('pygments.lexers.templates', 'HTML+Cheetah', ('html+cheetah', 'html+spitfire', 'htmlcheetah'), (), ('text/html+cheetah', 'text/html+spitfire')),
- 'CheetahJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Cheetah', ('javascript+cheetah', 'js+cheetah', 'javascript+spitfire', 'js+spitfire'), (), ('application/x-javascript+cheetah', 'text/x-javascript+cheetah', 'text/javascript+cheetah', 'application/x-javascript+spitfire', 'text/x-javascript+spitfire', 'text/javascript+spitfire')),
- 'CheetahLexer': ('pygments.lexers.templates', 'Cheetah', ('cheetah', 'spitfire'), ('*.tmpl', '*.spt'), ('application/x-cheetah', 'application/x-spitfire')),
- 'CheetahXmlLexer': ('pygments.lexers.templates', 'XML+Cheetah', ('xml+cheetah', 'xml+spitfire'), (), ('application/xml+cheetah', 'application/xml+spitfire')),
- 'CirruLexer': ('pygments.lexers.webmisc', 'Cirru', ('cirru',), ('*.cirru',), ('text/x-cirru',)),
- 'ClayLexer': ('pygments.lexers.c_like', 'Clay', ('clay',), ('*.clay',), ('text/x-clay',)),
- 'CleanLexer': ('pygments.lexers.clean', 'Clean', ('clean',), ('*.icl', '*.dcl'), ()),
- 'ClojureLexer': ('pygments.lexers.jvm', 'Clojure', ('clojure', 'clj'), ('*.clj', '*.cljc'), ('text/x-clojure', 'application/x-clojure')),
- 'ClojureScriptLexer': ('pygments.lexers.jvm', 'ClojureScript', ('clojurescript', 'cljs'), ('*.cljs',), ('text/x-clojurescript', 'application/x-clojurescript')),
- 'CobolFreeformatLexer': ('pygments.lexers.business', 'COBOLFree', ('cobolfree',), ('*.cbl', '*.CBL'), ()),
- 'CobolLexer': ('pygments.lexers.business', 'COBOL', ('cobol',), ('*.cob', '*.COB', '*.cpy', '*.CPY'), ('text/x-cobol',)),
- 'CoffeeScriptLexer': ('pygments.lexers.javascript', 'CoffeeScript', ('coffeescript', 'coffee-script', 'coffee'), ('*.coffee',), ('text/coffeescript',)),
- 'ColdfusionCFCLexer': ('pygments.lexers.templates', 'Coldfusion CFC', ('cfc',), ('*.cfc',), ()),
- 'ColdfusionHtmlLexer': ('pygments.lexers.templates', 'Coldfusion HTML', ('cfm',), ('*.cfm', '*.cfml'), ('application/x-coldfusion',)),
- 'ColdfusionLexer': ('pygments.lexers.templates', 'cfstatement', ('cfs',), (), ()),
- 'Comal80Lexer': ('pygments.lexers.comal', 'COMAL-80', ('comal', 'comal80'), ('*.cml', '*.comal'), ()),
- 'CommonLispLexer': ('pygments.lexers.lisp', 'Common Lisp', ('common-lisp', 'cl', 'lisp'), ('*.cl', '*.lisp'), ('text/x-common-lisp',)),
- 'ComponentPascalLexer': ('pygments.lexers.oberon', 'Component Pascal', ('componentpascal', 'cp'), ('*.cp', '*.cps'), ('text/x-component-pascal',)),
- 'CoqLexer': ('pygments.lexers.theorem', 'Coq', ('coq',), ('*.v',), ('text/x-coq',)),
- 'CplintLexer': ('pygments.lexers.cplint', 'cplint', ('cplint',), ('*.ecl', '*.prolog', '*.pro', '*.pl', '*.P', '*.lpad', '*.cpl'), ('text/x-cplint',)),
- 'CppLexer': ('pygments.lexers.c_cpp', 'C++', ('cpp', 'c++'), ('*.cpp', '*.hpp', '*.c++', '*.h++', '*.cc', '*.hh', '*.cxx', '*.hxx', '*.C', '*.H', '*.cp', '*.CPP', '*.tpp'), ('text/x-c++hdr', 'text/x-c++src')),
- 'CppObjdumpLexer': ('pygments.lexers.asm', 'cpp-objdump', ('cpp-objdump', 'c++-objdumb', 'cxx-objdump'), ('*.cpp-objdump', '*.c++-objdump', '*.cxx-objdump'), ('text/x-cpp-objdump',)),
- 'CrmshLexer': ('pygments.lexers.dsls', 'Crmsh', ('crmsh', 'pcmk'), ('*.crmsh', '*.pcmk'), ()),
- 'CrocLexer': ('pygments.lexers.d', 'Croc', ('croc',), ('*.croc',), ('text/x-crocsrc',)),
- 'CryptolLexer': ('pygments.lexers.haskell', 'Cryptol', ('cryptol', 'cry'), ('*.cry',), ('text/x-cryptol',)),
- 'CrystalLexer': ('pygments.lexers.crystal', 'Crystal', ('cr', 'crystal'), ('*.cr',), ('text/x-crystal',)),
- 'CsoundDocumentLexer': ('pygments.lexers.csound', 'Csound Document', ('csound-document', 'csound-csd'), ('*.csd',), ()),
- 'CsoundOrchestraLexer': ('pygments.lexers.csound', 'Csound Orchestra', ('csound', 'csound-orc'), ('*.orc', '*.udo'), ()),
- 'CsoundScoreLexer': ('pygments.lexers.csound', 'Csound Score', ('csound-score', 'csound-sco'), ('*.sco',), ()),
- 'CssDjangoLexer': ('pygments.lexers.templates', 'CSS+Django/Jinja', ('css+django', 'css+jinja'), ('*.css.j2', '*.css.jinja2'), ('text/css+django', 'text/css+jinja')),
- 'CssErbLexer': ('pygments.lexers.templates', 'CSS+Ruby', ('css+ruby', 'css+erb'), (), ('text/css+ruby',)),
- 'CssGenshiLexer': ('pygments.lexers.templates', 'CSS+Genshi Text', ('css+genshitext', 'css+genshi'), (), ('text/css+genshi',)),
- 'CssLexer': ('pygments.lexers.css', 'CSS', ('css',), ('*.css',), ('text/css',)),
- 'CssPhpLexer': ('pygments.lexers.templates', 'CSS+PHP', ('css+php',), (), ('text/css+php',)),
- 'CssSmartyLexer': ('pygments.lexers.templates', 'CSS+Smarty', ('css+smarty',), (), ('text/css+smarty',)),
- 'CudaLexer': ('pygments.lexers.c_like', 'CUDA', ('cuda', 'cu'), ('*.cu', '*.cuh'), ('text/x-cuda',)),
- 'CypherLexer': ('pygments.lexers.graph', 'Cypher', ('cypher',), ('*.cyp', '*.cypher'), ()),
- 'CythonLexer': ('pygments.lexers.python', 'Cython', ('cython', 'pyx', 'pyrex'), ('*.pyx', '*.pxd', '*.pxi'), ('text/x-cython', 'application/x-cython')),
- 'DLexer': ('pygments.lexers.d', 'D', ('d',), ('*.d', '*.di'), ('text/x-dsrc',)),
- 'DObjdumpLexer': ('pygments.lexers.asm', 'd-objdump', ('d-objdump',), ('*.d-objdump',), ('text/x-d-objdump',)),
- 'DarcsPatchLexer': ('pygments.lexers.diff', 'Darcs Patch', ('dpatch',), ('*.dpatch', '*.darcspatch'), ()),
- 'DartLexer': ('pygments.lexers.javascript', 'Dart', ('dart',), ('*.dart',), ('text/x-dart',)),
- 'Dasm16Lexer': ('pygments.lexers.asm', 'DASM16', ('dasm16',), ('*.dasm16', '*.dasm'), ('text/x-dasm16',)),
- 'DaxLexer': ('pygments.lexers.dax', 'Dax', ('dax',), ('*.dax',), ()),
- 'DebianControlLexer': ('pygments.lexers.installers', 'Debian Control file', ('debcontrol', 'control'), ('control',), ()),
- 'DelphiLexer': ('pygments.lexers.pascal', 'Delphi', ('delphi', 'pas', 'pascal', 'objectpascal'), ('*.pas', '*.dpr'), ('text/x-pascal',)),
- 'DesktopLexer': ('pygments.lexers.configs', 'Desktop file', ('desktop',), ('*.desktop',), ()),
- 'DevicetreeLexer': ('pygments.lexers.devicetree', 'Devicetree', ('devicetree', 'dts'), ('*.dts', '*.dtsi'), ('text/x-c',)),
- 'DgLexer': ('pygments.lexers.python', 'dg', ('dg',), ('*.dg',), ('text/x-dg',)),
- 'DiffLexer': ('pygments.lexers.diff', 'Diff', ('diff', 'udiff'), ('*.diff', '*.patch'), ('text/x-diff', 'text/x-patch')),
- 'DjangoLexer': ('pygments.lexers.templates', 'Django/Jinja', ('django', 'jinja'), (), ('application/x-django-templating', 'application/x-jinja')),
- 'DnsZoneLexer': ('pygments.lexers.dns', 'Zone', ('zone',), ('*.zone',), ('text/dns',)),
- 'DockerLexer': ('pygments.lexers.configs', 'Docker', ('docker', 'dockerfile'), ('Dockerfile', '*.docker'), ('text/x-dockerfile-config',)),
- 'DtdLexer': ('pygments.lexers.html', 'DTD', ('dtd',), ('*.dtd',), ('application/xml-dtd',)),
- 'DuelLexer': ('pygments.lexers.webmisc', 'Duel', ('duel', 'jbst', 'jsonml+bst'), ('*.duel', '*.jbst'), ('text/x-duel', 'text/x-jbst')),
- 'DylanConsoleLexer': ('pygments.lexers.dylan', 'Dylan session', ('dylan-console', 'dylan-repl'), ('*.dylan-console',), ('text/x-dylan-console',)),
- 'DylanLexer': ('pygments.lexers.dylan', 'Dylan', ('dylan',), ('*.dylan', '*.dyl', '*.intr'), ('text/x-dylan',)),
- 'DylanLidLexer': ('pygments.lexers.dylan', 'DylanLID', ('dylan-lid', 'lid'), ('*.lid', '*.hdp'), ('text/x-dylan-lid',)),
- 'ECLLexer': ('pygments.lexers.ecl', 'ECL', ('ecl',), ('*.ecl',), ('application/x-ecl',)),
- 'ECLexer': ('pygments.lexers.c_like', 'eC', ('ec',), ('*.ec', '*.eh'), ('text/x-echdr', 'text/x-ecsrc')),
- 'EarlGreyLexer': ('pygments.lexers.javascript', 'Earl Grey', ('earl-grey', 'earlgrey', 'eg'), ('*.eg',), ('text/x-earl-grey',)),
- 'EasytrieveLexer': ('pygments.lexers.scripting', 'Easytrieve', ('easytrieve',), ('*.ezt', '*.mac'), ('text/x-easytrieve',)),
- 'EbnfLexer': ('pygments.lexers.parsers', 'EBNF', ('ebnf',), ('*.ebnf',), ('text/x-ebnf',)),
- 'EiffelLexer': ('pygments.lexers.eiffel', 'Eiffel', ('eiffel',), ('*.e',), ('text/x-eiffel',)),
- 'ElixirConsoleLexer': ('pygments.lexers.erlang', 'Elixir iex session', ('iex',), (), ('text/x-elixir-shellsession',)),
- 'ElixirLexer': ('pygments.lexers.erlang', 'Elixir', ('elixir', 'ex', 'exs'), ('*.ex', '*.eex', '*.exs', '*.leex'), ('text/x-elixir',)),
- 'ElmLexer': ('pygments.lexers.elm', 'Elm', ('elm',), ('*.elm',), ('text/x-elm',)),
- 'ElpiLexer': ('pygments.lexers.elpi', 'Elpi', ('elpi',), ('*.elpi',), ('text/x-elpi',)),
- 'EmacsLispLexer': ('pygments.lexers.lisp', 'EmacsLisp', ('emacs-lisp', 'elisp', 'emacs'), ('*.el',), ('text/x-elisp', 'application/x-elisp')),
- 'EmailLexer': ('pygments.lexers.email', 'E-mail', ('email', 'eml'), ('*.eml',), ('message/rfc822',)),
- 'ErbLexer': ('pygments.lexers.templates', 'ERB', ('erb',), (), ('application/x-ruby-templating',)),
- 'ErlangLexer': ('pygments.lexers.erlang', 'Erlang', ('erlang',), ('*.erl', '*.hrl', '*.es', '*.escript'), ('text/x-erlang',)),
- 'ErlangShellLexer': ('pygments.lexers.erlang', 'Erlang erl session', ('erl',), ('*.erl-sh',), ('text/x-erl-shellsession',)),
- 'EvoqueHtmlLexer': ('pygments.lexers.templates', 'HTML+Evoque', ('html+evoque',), ('*.html',), ('text/html+evoque',)),
- 'EvoqueLexer': ('pygments.lexers.templates', 'Evoque', ('evoque',), ('*.evoque',), ('application/x-evoque',)),
- 'EvoqueXmlLexer': ('pygments.lexers.templates', 'XML+Evoque', ('xml+evoque',), ('*.xml',), ('application/xml+evoque',)),
- 'ExeclineLexer': ('pygments.lexers.shell', 'execline', ('execline',), ('*.exec',), ()),
- 'EzhilLexer': ('pygments.lexers.ezhil', 'Ezhil', ('ezhil',), ('*.n',), ('text/x-ezhil',)),
- 'FSharpLexer': ('pygments.lexers.dotnet', 'F#', ('fsharp', 'f#'), ('*.fs', '*.fsi', '*.fsx'), ('text/x-fsharp',)),
- 'FStarLexer': ('pygments.lexers.ml', 'FStar', ('fstar',), ('*.fst', '*.fsti'), ('text/x-fstar',)),
- 'FactorLexer': ('pygments.lexers.factor', 'Factor', ('factor',), ('*.factor',), ('text/x-factor',)),
- 'FancyLexer': ('pygments.lexers.ruby', 'Fancy', ('fancy', 'fy'), ('*.fy', '*.fancypack'), ('text/x-fancysrc',)),
- 'FantomLexer': ('pygments.lexers.fantom', 'Fantom', ('fan',), ('*.fan',), ('application/x-fantom',)),
- 'FelixLexer': ('pygments.lexers.felix', 'Felix', ('felix', 'flx'), ('*.flx', '*.flxh'), ('text/x-felix',)),
- 'FennelLexer': ('pygments.lexers.lisp', 'Fennel', ('fennel', 'fnl'), ('*.fnl',), ()),
- 'FiftLexer': ('pygments.lexers.fift', 'Fift', ('fift', 'fif'), ('*.fif',), ()),
- 'FishShellLexer': ('pygments.lexers.shell', 'Fish', ('fish', 'fishshell'), ('*.fish', '*.load'), ('application/x-fish',)),
- 'FlatlineLexer': ('pygments.lexers.dsls', 'Flatline', ('flatline',), (), ('text/x-flatline',)),
- 'FloScriptLexer': ('pygments.lexers.floscript', 'FloScript', ('floscript', 'flo'), ('*.flo',), ()),
- 'ForthLexer': ('pygments.lexers.forth', 'Forth', ('forth',), ('*.frt', '*.fs'), ('application/x-forth',)),
- 'FortranFixedLexer': ('pygments.lexers.fortran', 'FortranFixed', ('fortranfixed',), ('*.f', '*.F'), ()),
- 'FortranLexer': ('pygments.lexers.fortran', 'Fortran', ('fortran', 'f90'), ('*.f03', '*.f90', '*.F03', '*.F90'), ('text/x-fortran',)),
- 'FoxProLexer': ('pygments.lexers.foxpro', 'FoxPro', ('foxpro', 'vfp', 'clipper', 'xbase'), ('*.PRG', '*.prg'), ()),
- 'FreeFemLexer': ('pygments.lexers.freefem', 'Freefem', ('freefem',), ('*.edp',), ('text/x-freefem',)),
- 'FuncLexer': ('pygments.lexers.func', 'FunC', ('func', 'fc'), ('*.fc', '*.func'), ()),
- 'FutharkLexer': ('pygments.lexers.futhark', 'Futhark', ('futhark',), ('*.fut',), ('text/x-futhark',)),
- 'GAPConsoleLexer': ('pygments.lexers.algebra', 'GAP session', ('gap-console', 'gap-repl'), ('*.tst',), ()),
- 'GAPLexer': ('pygments.lexers.algebra', 'GAP', ('gap',), ('*.g', '*.gd', '*.gi', '*.gap'), ()),
- 'GDScriptLexer': ('pygments.lexers.gdscript', 'GDScript', ('gdscript', 'gd'), ('*.gd',), ('text/x-gdscript', 'application/x-gdscript')),
- 'GLShaderLexer': ('pygments.lexers.graphics', 'GLSL', ('glsl',), ('*.vert', '*.frag', '*.geo'), ('text/x-glslsrc',)),
- 'GSQLLexer': ('pygments.lexers.gsql', 'GSQL', ('gsql',), ('*.gsql',), ()),
- 'GasLexer': ('pygments.lexers.asm', 'GAS', ('gas', 'asm'), ('*.s', '*.S'), ('text/x-gas',)),
- 'GcodeLexer': ('pygments.lexers.gcodelexer', 'g-code', ('gcode',), ('*.gcode',), ()),
- 'GenshiLexer': ('pygments.lexers.templates', 'Genshi', ('genshi', 'kid', 'xml+genshi', 'xml+kid'), ('*.kid',), ('application/x-genshi', 'application/x-kid')),
- 'GenshiTextLexer': ('pygments.lexers.templates', 'Genshi Text', ('genshitext',), (), ('application/x-genshi-text', 'text/x-genshi')),
- 'GettextLexer': ('pygments.lexers.textfmts', 'Gettext Catalog', ('pot', 'po'), ('*.pot', '*.po'), ('application/x-gettext', 'text/x-gettext', 'text/gettext')),
- 'GherkinLexer': ('pygments.lexers.testing', 'Gherkin', ('gherkin', 'cucumber'), ('*.feature',), ('text/x-gherkin',)),
- 'GnuplotLexer': ('pygments.lexers.graphics', 'Gnuplot', ('gnuplot',), ('*.plot', '*.plt'), ('text/x-gnuplot',)),
- 'GoLexer': ('pygments.lexers.go', 'Go', ('go', 'golang'), ('*.go',), ('text/x-gosrc',)),
- 'GoloLexer': ('pygments.lexers.jvm', 'Golo', ('golo',), ('*.golo',), ()),
- 'GoodDataCLLexer': ('pygments.lexers.business', 'GoodData-CL', ('gooddata-cl',), ('*.gdc',), ('text/x-gooddata-cl',)),
- 'GosuLexer': ('pygments.lexers.jvm', 'Gosu', ('gosu',), ('*.gs', '*.gsx', '*.gsp', '*.vark'), ('text/x-gosu',)),
- 'GosuTemplateLexer': ('pygments.lexers.jvm', 'Gosu Template', ('gst',), ('*.gst',), ('text/x-gosu-template',)),
- 'GraphQLLexer': ('pygments.lexers.graphql', 'GraphQL', ('graphql',), ('*.graphql',), ()),
- 'GraphvizLexer': ('pygments.lexers.graphviz', 'Graphviz', ('graphviz', 'dot'), ('*.gv', '*.dot'), ('text/x-graphviz', 'text/vnd.graphviz')),
- 'GroffLexer': ('pygments.lexers.markup', 'Groff', ('groff', 'nroff', 'man'), ('*.[1-9]', '*.man', '*.1p', '*.3pm'), ('application/x-troff', 'text/troff')),
- 'GroovyLexer': ('pygments.lexers.jvm', 'Groovy', ('groovy',), ('*.groovy', '*.gradle'), ('text/x-groovy',)),
- 'HLSLShaderLexer': ('pygments.lexers.graphics', 'HLSL', ('hlsl',), ('*.hlsl', '*.hlsli'), ('text/x-hlsl',)),
- 'HTMLUL4Lexer': ('pygments.lexers.ul4', 'HTML+UL4', ('html+ul4',), ('*.htmlul4',), ()),
- 'HamlLexer': ('pygments.lexers.html', 'Haml', ('haml',), ('*.haml',), ('text/x-haml',)),
- 'HandlebarsHtmlLexer': ('pygments.lexers.templates', 'HTML+Handlebars', ('html+handlebars',), ('*.handlebars', '*.hbs'), ('text/html+handlebars', 'text/x-handlebars-template')),
- 'HandlebarsLexer': ('pygments.lexers.templates', 'Handlebars', ('handlebars',), (), ()),
- 'HaskellLexer': ('pygments.lexers.haskell', 'Haskell', ('haskell', 'hs'), ('*.hs',), ('text/x-haskell',)),
- 'HaxeLexer': ('pygments.lexers.haxe', 'Haxe', ('haxe', 'hxsl', 'hx'), ('*.hx', '*.hxsl'), ('text/haxe', 'text/x-haxe', 'text/x-hx')),
- 'HexdumpLexer': ('pygments.lexers.hexdump', 'Hexdump', ('hexdump',), (), ()),
- 'HsailLexer': ('pygments.lexers.asm', 'HSAIL', ('hsail', 'hsa'), ('*.hsail',), ('text/x-hsail',)),
- 'HspecLexer': ('pygments.lexers.haskell', 'Hspec', ('hspec',), ('*Spec.hs',), ()),
- 'HtmlDjangoLexer': ('pygments.lexers.templates', 'HTML+Django/Jinja', ('html+django', 'html+jinja', 'htmldjango'), ('*.html.j2', '*.htm.j2', '*.xhtml.j2', '*.html.jinja2', '*.htm.jinja2', '*.xhtml.jinja2'), ('text/html+django', 'text/html+jinja')),
- 'HtmlGenshiLexer': ('pygments.lexers.templates', 'HTML+Genshi', ('html+genshi', 'html+kid'), (), ('text/html+genshi',)),
- 'HtmlLexer': ('pygments.lexers.html', 'HTML', ('html',), ('*.html', '*.htm', '*.xhtml', '*.xslt'), ('text/html', 'application/xhtml+xml')),
- 'HtmlPhpLexer': ('pygments.lexers.templates', 'HTML+PHP', ('html+php',), ('*.phtml',), ('application/x-php', 'application/x-httpd-php', 'application/x-httpd-php3', 'application/x-httpd-php4', 'application/x-httpd-php5')),
- 'HtmlSmartyLexer': ('pygments.lexers.templates', 'HTML+Smarty', ('html+smarty',), (), ('text/html+smarty',)),
- 'HttpLexer': ('pygments.lexers.textfmts', 'HTTP', ('http',), (), ()),
- 'HxmlLexer': ('pygments.lexers.haxe', 'Hxml', ('haxeml', 'hxml'), ('*.hxml',), ()),
- 'HyLexer': ('pygments.lexers.lisp', 'Hy', ('hylang',), ('*.hy',), ('text/x-hy', 'application/x-hy')),
- 'HybrisLexer': ('pygments.lexers.scripting', 'Hybris', ('hybris', 'hy'), ('*.hy', '*.hyb'), ('text/x-hybris', 'application/x-hybris')),
- 'IDLLexer': ('pygments.lexers.idl', 'IDL', ('idl',), ('*.pro',), ('text/idl',)),
- 'IconLexer': ('pygments.lexers.unicon', 'Icon', ('icon',), ('*.icon', '*.ICON'), ()),
- 'IdrisLexer': ('pygments.lexers.haskell', 'Idris', ('idris', 'idr'), ('*.idr',), ('text/x-idris',)),
- 'IgorLexer': ('pygments.lexers.igor', 'Igor', ('igor', 'igorpro'), ('*.ipf',), ('text/ipf',)),
- 'Inform6Lexer': ('pygments.lexers.int_fiction', 'Inform 6', ('inform6', 'i6'), ('*.inf',), ()),
- 'Inform6TemplateLexer': ('pygments.lexers.int_fiction', 'Inform 6 template', ('i6t',), ('*.i6t',), ()),
- 'Inform7Lexer': ('pygments.lexers.int_fiction', 'Inform 7', ('inform7', 'i7'), ('*.ni', '*.i7x'), ()),
- 'IniLexer': ('pygments.lexers.configs', 'INI', ('ini', 'cfg', 'dosini'), ('*.ini', '*.cfg', '*.inf', '.editorconfig'), ('text/x-ini', 'text/inf')),
- 'IoLexer': ('pygments.lexers.iolang', 'Io', ('io',), ('*.io',), ('text/x-iosrc',)),
- 'IokeLexer': ('pygments.lexers.jvm', 'Ioke', ('ioke', 'ik'), ('*.ik',), ('text/x-iokesrc',)),
- 'IrcLogsLexer': ('pygments.lexers.textfmts', 'IRC logs', ('irc',), ('*.weechatlog',), ('text/x-irclog',)),
- 'IsabelleLexer': ('pygments.lexers.theorem', 'Isabelle', ('isabelle',), ('*.thy',), ('text/x-isabelle',)),
- 'JLexer': ('pygments.lexers.j', 'J', ('j',), ('*.ijs',), ('text/x-j',)),
- 'JMESPathLexer': ('pygments.lexers.jmespath', 'JMESPath', ('jmespath', 'jp'), ('*.jp',), ()),
- 'JSLTLexer': ('pygments.lexers.jslt', 'JSLT', ('jslt',), ('*.jslt',), ('text/x-jslt',)),
- 'JagsLexer': ('pygments.lexers.modeling', 'JAGS', ('jags',), ('*.jag', '*.bug'), ()),
- 'JasminLexer': ('pygments.lexers.jvm', 'Jasmin', ('jasmin', 'jasminxt'), ('*.j',), ()),
- 'JavaLexer': ('pygments.lexers.jvm', 'Java', ('java',), ('*.java',), ('text/x-java',)),
- 'JavascriptDjangoLexer': ('pygments.lexers.templates', 'JavaScript+Django/Jinja', ('javascript+django', 'js+django', 'javascript+jinja', 'js+jinja'), ('*.js.j2', '*.js.jinja2'), ('application/x-javascript+django', 'application/x-javascript+jinja', 'text/x-javascript+django', 'text/x-javascript+jinja', 'text/javascript+django', 'text/javascript+jinja')),
- 'JavascriptErbLexer': ('pygments.lexers.templates', 'JavaScript+Ruby', ('javascript+ruby', 'js+ruby', 'javascript+erb', 'js+erb'), (), ('application/x-javascript+ruby', 'text/x-javascript+ruby', 'text/javascript+ruby')),
- 'JavascriptGenshiLexer': ('pygments.lexers.templates', 'JavaScript+Genshi Text', ('js+genshitext', 'js+genshi', 'javascript+genshitext', 'javascript+genshi'), (), ('application/x-javascript+genshi', 'text/x-javascript+genshi', 'text/javascript+genshi')),
- 'JavascriptLexer': ('pygments.lexers.javascript', 'JavaScript', ('javascript', 'js'), ('*.js', '*.jsm', '*.mjs', '*.cjs'), ('application/javascript', 'application/x-javascript', 'text/x-javascript', 'text/javascript')),
- 'JavascriptPhpLexer': ('pygments.lexers.templates', 'JavaScript+PHP', ('javascript+php', 'js+php'), (), ('application/x-javascript+php', 'text/x-javascript+php', 'text/javascript+php')),
- 'JavascriptSmartyLexer': ('pygments.lexers.templates', 'JavaScript+Smarty', ('javascript+smarty', 'js+smarty'), (), ('application/x-javascript+smarty', 'text/x-javascript+smarty', 'text/javascript+smarty')),
- 'JavascriptUL4Lexer': ('pygments.lexers.ul4', 'Javascript+UL4', ('js+ul4',), ('*.jsul4',), ()),
- 'JclLexer': ('pygments.lexers.scripting', 'JCL', ('jcl',), ('*.jcl',), ('text/x-jcl',)),
- 'JsgfLexer': ('pygments.lexers.grammar_notation', 'JSGF', ('jsgf',), ('*.jsgf',), ('application/jsgf', 'application/x-jsgf', 'text/jsgf')),
- 'JsonBareObjectLexer': ('pygments.lexers.data', 'JSONBareObject', (), (), ()),
- 'JsonLdLexer': ('pygments.lexers.data', 'JSON-LD', ('jsonld', 'json-ld'), ('*.jsonld',), ('application/ld+json',)),
- 'JsonLexer': ('pygments.lexers.data', 'JSON', ('json', 'json-object'), ('*.json', 'Pipfile.lock'), ('application/json', 'application/json-object')),
- 'JsonnetLexer': ('pygments.lexers.jsonnet', 'Jsonnet', ('jsonnet',), ('*.jsonnet', '*.libsonnet'), ()),
- 'JspLexer': ('pygments.lexers.templates', 'Java Server Page', ('jsp',), ('*.jsp',), ('application/x-jsp',)),
- 'JuliaConsoleLexer': ('pygments.lexers.julia', 'Julia console', ('jlcon', 'julia-repl'), (), ()),
- 'JuliaLexer': ('pygments.lexers.julia', 'Julia', ('julia', 'jl'), ('*.jl',), ('text/x-julia', 'application/x-julia')),
- 'JuttleLexer': ('pygments.lexers.javascript', 'Juttle', ('juttle',), ('*.juttle',), ('application/juttle', 'application/x-juttle', 'text/x-juttle', 'text/juttle')),
- 'KLexer': ('pygments.lexers.q', 'K', ('k',), ('*.k',), ()),
- 'KalLexer': ('pygments.lexers.javascript', 'Kal', ('kal',), ('*.kal',), ('text/kal', 'application/kal')),
- 'KconfigLexer': ('pygments.lexers.configs', 'Kconfig', ('kconfig', 'menuconfig', 'linux-config', 'kernel-config'), ('Kconfig*', '*Config.in*', 'external.in*', 'standard-modules.in'), ('text/x-kconfig',)),
- 'KernelLogLexer': ('pygments.lexers.textfmts', 'Kernel log', ('kmsg', 'dmesg'), ('*.kmsg', '*.dmesg'), ()),
- 'KokaLexer': ('pygments.lexers.haskell', 'Koka', ('koka',), ('*.kk', '*.kki'), ('text/x-koka',)),
- 'KotlinLexer': ('pygments.lexers.jvm', 'Kotlin', ('kotlin',), ('*.kt', '*.kts'), ('text/x-kotlin',)),
- 'KuinLexer': ('pygments.lexers.kuin', 'Kuin', ('kuin',), ('*.kn',), ()),
- 'LSLLexer': ('pygments.lexers.scripting', 'LSL', ('lsl',), ('*.lsl',), ('text/x-lsl',)),
- 'LassoCssLexer': ('pygments.lexers.templates', 'CSS+Lasso', ('css+lasso',), (), ('text/css+lasso',)),
- 'LassoHtmlLexer': ('pygments.lexers.templates', 'HTML+Lasso', ('html+lasso',), (), ('text/html+lasso', 'application/x-httpd-lasso', 'application/x-httpd-lasso[89]')),
- 'LassoJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Lasso', ('javascript+lasso', 'js+lasso'), (), ('application/x-javascript+lasso', 'text/x-javascript+lasso', 'text/javascript+lasso')),
- 'LassoLexer': ('pygments.lexers.javascript', 'Lasso', ('lasso', 'lassoscript'), ('*.lasso', '*.lasso[89]'), ('text/x-lasso',)),
- 'LassoXmlLexer': ('pygments.lexers.templates', 'XML+Lasso', ('xml+lasso',), (), ('application/xml+lasso',)),
- 'LeanLexer': ('pygments.lexers.theorem', 'Lean', ('lean',), ('*.lean',), ('text/x-lean',)),
- 'LessCssLexer': ('pygments.lexers.css', 'LessCss', ('less',), ('*.less',), ('text/x-less-css',)),
- 'LighttpdConfLexer': ('pygments.lexers.configs', 'Lighttpd configuration file', ('lighttpd', 'lighty'), ('lighttpd.conf',), ('text/x-lighttpd-conf',)),
- 'LilyPondLexer': ('pygments.lexers.lilypond', 'LilyPond', ('lilypond',), ('*.ly',), ()),
- 'LimboLexer': ('pygments.lexers.inferno', 'Limbo', ('limbo',), ('*.b',), ('text/limbo',)),
- 'LiquidLexer': ('pygments.lexers.templates', 'liquid', ('liquid',), ('*.liquid',), ()),
- 'LiterateAgdaLexer': ('pygments.lexers.haskell', 'Literate Agda', ('literate-agda', 'lagda'), ('*.lagda',), ('text/x-literate-agda',)),
- 'LiterateCryptolLexer': ('pygments.lexers.haskell', 'Literate Cryptol', ('literate-cryptol', 'lcryptol', 'lcry'), ('*.lcry',), ('text/x-literate-cryptol',)),
- 'LiterateHaskellLexer': ('pygments.lexers.haskell', 'Literate Haskell', ('literate-haskell', 'lhaskell', 'lhs'), ('*.lhs',), ('text/x-literate-haskell',)),
- 'LiterateIdrisLexer': ('pygments.lexers.haskell', 'Literate Idris', ('literate-idris', 'lidris', 'lidr'), ('*.lidr',), ('text/x-literate-idris',)),
- 'LiveScriptLexer': ('pygments.lexers.javascript', 'LiveScript', ('livescript', 'live-script'), ('*.ls',), ('text/livescript',)),
- 'LlvmLexer': ('pygments.lexers.asm', 'LLVM', ('llvm',), ('*.ll',), ('text/x-llvm',)),
- 'LlvmMirBodyLexer': ('pygments.lexers.asm', 'LLVM-MIR Body', ('llvm-mir-body',), (), ()),
- 'LlvmMirLexer': ('pygments.lexers.asm', 'LLVM-MIR', ('llvm-mir',), ('*.mir',), ()),
- 'LogosLexer': ('pygments.lexers.objective', 'Logos', ('logos',), ('*.x', '*.xi', '*.xm', '*.xmi'), ('text/x-logos',)),
- 'LogtalkLexer': ('pygments.lexers.prolog', 'Logtalk', ('logtalk',), ('*.lgt', '*.logtalk'), ('text/x-logtalk',)),
- 'LuaLexer': ('pygments.lexers.scripting', 'Lua', ('lua',), ('*.lua', '*.wlua'), ('text/x-lua', 'application/x-lua')),
- 'MCFunctionLexer': ('pygments.lexers.minecraft', 'MCFunction', ('mcfunction', 'mcf'), ('*.mcfunction',), ('text/mcfunction',)),
- 'MCSchemaLexer': ('pygments.lexers.minecraft', 'MCSchema', ('mcschema',), ('*.mcschema',), ('text/mcschema',)),
- 'MIMELexer': ('pygments.lexers.mime', 'MIME', ('mime',), (), ('multipart/mixed', 'multipart/related', 'multipart/alternative')),
- 'MIPSLexer': ('pygments.lexers.mips', 'MIPS', ('mips',), ('*.mips', '*.MIPS'), ()),
- 'MOOCodeLexer': ('pygments.lexers.scripting', 'MOOCode', ('moocode', 'moo'), ('*.moo',), ('text/x-moocode',)),
- 'MSDOSSessionLexer': ('pygments.lexers.shell', 'MSDOS Session', ('doscon',), (), ()),
- 'Macaulay2Lexer': ('pygments.lexers.macaulay2', 'Macaulay2', ('macaulay2',), ('*.m2',), ()),
- 'MakefileLexer': ('pygments.lexers.make', 'Makefile', ('make', 'makefile', 'mf', 'bsdmake'), ('*.mak', '*.mk', 'Makefile', 'makefile', 'Makefile.*', 'GNUmakefile'), ('text/x-makefile',)),
- 'MakoCssLexer': ('pygments.lexers.templates', 'CSS+Mako', ('css+mako',), (), ('text/css+mako',)),
- 'MakoHtmlLexer': ('pygments.lexers.templates', 'HTML+Mako', ('html+mako',), (), ('text/html+mako',)),
- 'MakoJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Mako', ('javascript+mako', 'js+mako'), (), ('application/x-javascript+mako', 'text/x-javascript+mako', 'text/javascript+mako')),
- 'MakoLexer': ('pygments.lexers.templates', 'Mako', ('mako',), ('*.mao',), ('application/x-mako',)),
- 'MakoXmlLexer': ('pygments.lexers.templates', 'XML+Mako', ('xml+mako',), (), ('application/xml+mako',)),
- 'MaqlLexer': ('pygments.lexers.business', 'MAQL', ('maql',), ('*.maql',), ('text/x-gooddata-maql', 'application/x-gooddata-maql')),
- 'MarkdownLexer': ('pygments.lexers.markup', 'Markdown', ('markdown', 'md'), ('*.md', '*.markdown'), ('text/x-markdown',)),
- 'MaskLexer': ('pygments.lexers.javascript', 'Mask', ('mask',), ('*.mask',), ('text/x-mask',)),
- 'MasonLexer': ('pygments.lexers.templates', 'Mason', ('mason',), ('*.m', '*.mhtml', '*.mc', '*.mi', 'autohandler', 'dhandler'), ('application/x-mason',)),
- 'MathematicaLexer': ('pygments.lexers.algebra', 'Mathematica', ('mathematica', 'mma', 'nb'), ('*.nb', '*.cdf', '*.nbp', '*.ma'), ('application/mathematica', 'application/vnd.wolfram.mathematica', 'application/vnd.wolfram.mathematica.package', 'application/vnd.wolfram.cdf')),
- 'MatlabLexer': ('pygments.lexers.matlab', 'Matlab', ('matlab',), ('*.m',), ('text/matlab',)),
- 'MatlabSessionLexer': ('pygments.lexers.matlab', 'Matlab session', ('matlabsession',), (), ()),
- 'MaximaLexer': ('pygments.lexers.maxima', 'Maxima', ('maxima', 'macsyma'), ('*.mac', '*.max'), ()),
- 'MesonLexer': ('pygments.lexers.meson', 'Meson', ('meson', 'meson.build'), ('meson.build', 'meson_options.txt'), ('text/x-meson',)),
- 'MiniDLexer': ('pygments.lexers.d', 'MiniD', ('minid',), (), ('text/x-minidsrc',)),
- 'MiniScriptLexer': ('pygments.lexers.scripting', 'MiniScript', ('miniscript', 'ms'), ('*.ms',), ('text/x-minicript', 'application/x-miniscript')),
- 'ModelicaLexer': ('pygments.lexers.modeling', 'Modelica', ('modelica',), ('*.mo',), ('text/x-modelica',)),
- 'Modula2Lexer': ('pygments.lexers.modula2', 'Modula-2', ('modula2', 'm2'), ('*.def', '*.mod'), ('text/x-modula2',)),
- 'MoinWikiLexer': ('pygments.lexers.markup', 'MoinMoin/Trac Wiki markup', ('trac-wiki', 'moin'), (), ('text/x-trac-wiki',)),
- 'MonkeyLexer': ('pygments.lexers.basic', 'Monkey', ('monkey',), ('*.monkey',), ('text/x-monkey',)),
- 'MonteLexer': ('pygments.lexers.monte', 'Monte', ('monte',), ('*.mt',), ()),
- 'MoonScriptLexer': ('pygments.lexers.scripting', 'MoonScript', ('moonscript', 'moon'), ('*.moon',), ('text/x-moonscript', 'application/x-moonscript')),
- 'MoselLexer': ('pygments.lexers.mosel', 'Mosel', ('mosel',), ('*.mos',), ()),
- 'MozPreprocCssLexer': ('pygments.lexers.markup', 'CSS+mozpreproc', ('css+mozpreproc',), ('*.css.in',), ()),
- 'MozPreprocHashLexer': ('pygments.lexers.markup', 'mozhashpreproc', ('mozhashpreproc',), (), ()),
- 'MozPreprocJavascriptLexer': ('pygments.lexers.markup', 'Javascript+mozpreproc', ('javascript+mozpreproc',), ('*.js.in',), ()),
- 'MozPreprocPercentLexer': ('pygments.lexers.markup', 'mozpercentpreproc', ('mozpercentpreproc',), (), ()),
- 'MozPreprocXulLexer': ('pygments.lexers.markup', 'XUL+mozpreproc', ('xul+mozpreproc',), ('*.xul.in',), ()),
- 'MqlLexer': ('pygments.lexers.c_like', 'MQL', ('mql', 'mq4', 'mq5', 'mql4', 'mql5'), ('*.mq4', '*.mq5', '*.mqh'), ('text/x-mql',)),
- 'MscgenLexer': ('pygments.lexers.dsls', 'Mscgen', ('mscgen', 'msc'), ('*.msc',), ()),
- 'MuPADLexer': ('pygments.lexers.algebra', 'MuPAD', ('mupad',), ('*.mu',), ()),
- 'MxmlLexer': ('pygments.lexers.actionscript', 'MXML', ('mxml',), ('*.mxml',), ()),
- 'MySqlLexer': ('pygments.lexers.sql', 'MySQL', ('mysql',), (), ('text/x-mysql',)),
- 'MyghtyCssLexer': ('pygments.lexers.templates', 'CSS+Myghty', ('css+myghty',), (), ('text/css+myghty',)),
- 'MyghtyHtmlLexer': ('pygments.lexers.templates', 'HTML+Myghty', ('html+myghty',), (), ('text/html+myghty',)),
- 'MyghtyJavascriptLexer': ('pygments.lexers.templates', 'JavaScript+Myghty', ('javascript+myghty', 'js+myghty'), (), ('application/x-javascript+myghty', 'text/x-javascript+myghty', 'text/javascript+mygthy')),
- 'MyghtyLexer': ('pygments.lexers.templates', 'Myghty', ('myghty',), ('*.myt', 'autodelegate'), ('application/x-myghty',)),
- 'MyghtyXmlLexer': ('pygments.lexers.templates', 'XML+Myghty', ('xml+myghty',), (), ('application/xml+myghty',)),
- 'NCLLexer': ('pygments.lexers.ncl', 'NCL', ('ncl',), ('*.ncl',), ('text/ncl',)),
- 'NSISLexer': ('pygments.lexers.installers', 'NSIS', ('nsis', 'nsi', 'nsh'), ('*.nsi', '*.nsh'), ('text/x-nsis',)),
- 'NasmLexer': ('pygments.lexers.asm', 'NASM', ('nasm',), ('*.asm', '*.ASM', '*.nasm'), ('text/x-nasm',)),
- 'NasmObjdumpLexer': ('pygments.lexers.asm', 'objdump-nasm', ('objdump-nasm',), ('*.objdump-intel',), ('text/x-nasm-objdump',)),
- 'NemerleLexer': ('pygments.lexers.dotnet', 'Nemerle', ('nemerle',), ('*.n',), ('text/x-nemerle',)),
- 'NesCLexer': ('pygments.lexers.c_like', 'nesC', ('nesc',), ('*.nc',), ('text/x-nescsrc',)),
- 'NestedTextLexer': ('pygments.lexers.configs', 'NestedText', ('nestedtext', 'nt'), ('*.nt',), ()),
- 'NewLispLexer': ('pygments.lexers.lisp', 'NewLisp', ('newlisp',), ('*.lsp', '*.nl', '*.kif'), ('text/x-newlisp', 'application/x-newlisp')),
- 'NewspeakLexer': ('pygments.lexers.smalltalk', 'Newspeak', ('newspeak',), ('*.ns2',), ('text/x-newspeak',)),
- 'NginxConfLexer': ('pygments.lexers.configs', 'Nginx configuration file', ('nginx',), ('nginx.conf',), ('text/x-nginx-conf',)),
- 'NimrodLexer': ('pygments.lexers.nimrod', 'Nimrod', ('nimrod', 'nim'), ('*.nim', '*.nimrod'), ('text/x-nim',)),
- 'NitLexer': ('pygments.lexers.nit', 'Nit', ('nit',), ('*.nit',), ()),
- 'NixLexer': ('pygments.lexers.nix', 'Nix', ('nixos', 'nix'), ('*.nix',), ('text/x-nix',)),
- 'NodeConsoleLexer': ('pygments.lexers.javascript', 'Node.js REPL console session', ('nodejsrepl',), (), ('text/x-nodejsrepl',)),
- 'NotmuchLexer': ('pygments.lexers.textfmts', 'Notmuch', ('notmuch',), (), ()),
- 'NuSMVLexer': ('pygments.lexers.smv', 'NuSMV', ('nusmv',), ('*.smv',), ()),
- 'NumPyLexer': ('pygments.lexers.python', 'NumPy', ('numpy',), (), ()),
- 'ObjdumpLexer': ('pygments.lexers.asm', 'objdump', ('objdump',), ('*.objdump',), ('text/x-objdump',)),
- 'ObjectiveCLexer': ('pygments.lexers.objective', 'Objective-C', ('objective-c', 'objectivec', 'obj-c', 'objc'), ('*.m', '*.h'), ('text/x-objective-c',)),
- 'ObjectiveCppLexer': ('pygments.lexers.objective', 'Objective-C++', ('objective-c++', 'objectivec++', 'obj-c++', 'objc++'), ('*.mm', '*.hh'), ('text/x-objective-c++',)),
- 'ObjectiveJLexer': ('pygments.lexers.javascript', 'Objective-J', ('objective-j', 'objectivej', 'obj-j', 'objj'), ('*.j',), ('text/x-objective-j',)),
- 'OcamlLexer': ('pygments.lexers.ml', 'OCaml', ('ocaml',), ('*.ml', '*.mli', '*.mll', '*.mly'), ('text/x-ocaml',)),
- 'OctaveLexer': ('pygments.lexers.matlab', 'Octave', ('octave',), ('*.m',), ('text/octave',)),
- 'OdinLexer': ('pygments.lexers.archetype', 'ODIN', ('odin',), ('*.odin',), ('text/odin',)),
- 'OmgIdlLexer': ('pygments.lexers.c_like', 'OMG Interface Definition Language', ('omg-idl',), ('*.idl', '*.pidl'), ()),
- 'OocLexer': ('pygments.lexers.ooc', 'Ooc', ('ooc',), ('*.ooc',), ('text/x-ooc',)),
- 'OpaLexer': ('pygments.lexers.ml', 'Opa', ('opa',), ('*.opa',), ('text/x-opa',)),
- 'OpenEdgeLexer': ('pygments.lexers.business', 'OpenEdge ABL', ('openedge', 'abl', 'progress'), ('*.p', '*.cls'), ('text/x-openedge', 'application/x-openedge')),
- 'OpenScadLexer': ('pygments.lexers.openscad', 'OpenSCAD', ('openscad',), ('*.scad',), ('application/x-openscad',)),
- 'OutputLexer': ('pygments.lexers.special', 'Text output', ('output',), (), ()),
- 'PacmanConfLexer': ('pygments.lexers.configs', 'PacmanConf', ('pacmanconf',), ('pacman.conf',), ()),
- 'PanLexer': ('pygments.lexers.dsls', 'Pan', ('pan',), ('*.pan',), ()),
- 'ParaSailLexer': ('pygments.lexers.parasail', 'ParaSail', ('parasail',), ('*.psi', '*.psl'), ('text/x-parasail',)),
- 'PawnLexer': ('pygments.lexers.pawn', 'Pawn', ('pawn',), ('*.p', '*.pwn', '*.inc'), ('text/x-pawn',)),
- 'PegLexer': ('pygments.lexers.grammar_notation', 'PEG', ('peg',), ('*.peg',), ('text/x-peg',)),
- 'Perl6Lexer': ('pygments.lexers.perl', 'Perl6', ('perl6', 'pl6', 'raku'), ('*.pl', '*.pm', '*.nqp', '*.p6', '*.6pl', '*.p6l', '*.pl6', '*.6pm', '*.p6m', '*.pm6', '*.t', '*.raku', '*.rakumod', '*.rakutest', '*.rakudoc'), ('text/x-perl6', 'application/x-perl6')),
- 'PerlLexer': ('pygments.lexers.perl', 'Perl', ('perl', 'pl'), ('*.pl', '*.pm', '*.t', '*.perl'), ('text/x-perl', 'application/x-perl')),
- 'PhixLexer': ('pygments.lexers.phix', 'Phix', ('phix',), ('*.exw',), ('text/x-phix',)),
- 'PhpLexer': ('pygments.lexers.php', 'PHP', ('php', 'php3', 'php4', 'php5'), ('*.php', '*.php[345]', '*.inc'), ('text/x-php',)),
- 'PigLexer': ('pygments.lexers.jvm', 'Pig', ('pig',), ('*.pig',), ('text/x-pig',)),
- 'PikeLexer': ('pygments.lexers.c_like', 'Pike', ('pike',), ('*.pike', '*.pmod'), ('text/x-pike',)),
- 'PkgConfigLexer': ('pygments.lexers.configs', 'PkgConfig', ('pkgconfig',), ('*.pc',), ()),
- 'PlPgsqlLexer': ('pygments.lexers.sql', 'PL/pgSQL', ('plpgsql',), (), ('text/x-plpgsql',)),
- 'PointlessLexer': ('pygments.lexers.pointless', 'Pointless', ('pointless',), ('*.ptls',), ()),
- 'PonyLexer': ('pygments.lexers.pony', 'Pony', ('pony',), ('*.pony',), ()),
- 'PortugolLexer': ('pygments.lexers.pascal', 'Portugol', ('portugol',), ('*.alg', '*.portugol'), ()),
- 'PostScriptLexer': ('pygments.lexers.graphics', 'PostScript', ('postscript', 'postscr'), ('*.ps', '*.eps'), ('application/postscript',)),
- 'PostgresConsoleLexer': ('pygments.lexers.sql', 'PostgreSQL console (psql)', ('psql', 'postgresql-console', 'postgres-console'), (), ('text/x-postgresql-psql',)),
- 'PostgresExplainLexer': ('pygments.lexers.sql', 'PostgreSQL EXPLAIN dialect', ('postgres-explain',), ('*.explain',), ('text/x-postgresql-explain',)),
- 'PostgresLexer': ('pygments.lexers.sql', 'PostgreSQL SQL dialect', ('postgresql', 'postgres'), (), ('text/x-postgresql',)),
- 'PovrayLexer': ('pygments.lexers.graphics', 'POVRay', ('pov',), ('*.pov', '*.inc'), ('text/x-povray',)),
- 'PowerShellLexer': ('pygments.lexers.shell', 'PowerShell', ('powershell', 'pwsh', 'posh', 'ps1', 'psm1'), ('*.ps1', '*.psm1'), ('text/x-powershell',)),
- 'PowerShellSessionLexer': ('pygments.lexers.shell', 'PowerShell Session', ('pwsh-session', 'ps1con'), (), ()),
- 'PraatLexer': ('pygments.lexers.praat', 'Praat', ('praat',), ('*.praat', '*.proc', '*.psc'), ()),
- 'ProcfileLexer': ('pygments.lexers.procfile', 'Procfile', ('procfile',), ('Procfile',), ()),
- 'PrologLexer': ('pygments.lexers.prolog', 'Prolog', ('prolog',), ('*.ecl', '*.prolog', '*.pro', '*.pl'), ('text/x-prolog',)),
- 'PromQLLexer': ('pygments.lexers.promql', 'PromQL', ('promql',), ('*.promql',), ()),
- 'PropertiesLexer': ('pygments.lexers.configs', 'Properties', ('properties', 'jproperties'), ('*.properties',), ('text/x-java-properties',)),
- 'ProtoBufLexer': ('pygments.lexers.dsls', 'Protocol Buffer', ('protobuf', 'proto'), ('*.proto',), ()),
- 'PsyshConsoleLexer': ('pygments.lexers.php', 'PsySH console session for PHP', ('psysh',), (), ()),
- 'PtxLexer': ('pygments.lexers.ptx', 'PTX', ('ptx',), ('*.ptx',), ('text/x-ptx',)),
- 'PugLexer': ('pygments.lexers.html', 'Pug', ('pug', 'jade'), ('*.pug', '*.jade'), ('text/x-pug', 'text/x-jade')),
- 'PuppetLexer': ('pygments.lexers.dsls', 'Puppet', ('puppet',), ('*.pp',), ()),
- 'PyPyLogLexer': ('pygments.lexers.console', 'PyPy Log', ('pypylog', 'pypy'), ('*.pypylog',), ('application/x-pypylog',)),
- 'Python2Lexer': ('pygments.lexers.python', 'Python 2.x', ('python2', 'py2'), (), ('text/x-python2', 'application/x-python2')),
- 'Python2TracebackLexer': ('pygments.lexers.python', 'Python 2.x Traceback', ('py2tb',), ('*.py2tb',), ('text/x-python2-traceback',)),
- 'PythonConsoleLexer': ('pygments.lexers.python', 'Python console session', ('pycon',), (), ('text/x-python-doctest',)),
- 'PythonLexer': ('pygments.lexers.python', 'Python', ('python', 'py', 'sage', 'python3', 'py3'), ('*.py', '*.pyw', '*.pyi', '*.jy', '*.sage', '*.sc', 'SConstruct', 'SConscript', '*.bzl', 'BUCK', 'BUILD', 'BUILD.bazel', 'WORKSPACE', '*.tac'), ('text/x-python', 'application/x-python', 'text/x-python3', 'application/x-python3')),
- 'PythonTracebackLexer': ('pygments.lexers.python', 'Python Traceback', ('pytb', 'py3tb'), ('*.pytb', '*.py3tb'), ('text/x-python-traceback', 'text/x-python3-traceback')),
- 'PythonUL4Lexer': ('pygments.lexers.ul4', 'Python+UL4', ('py+ul4',), ('*.pyul4',), ()),
- 'QBasicLexer': ('pygments.lexers.basic', 'QBasic', ('qbasic', 'basic'), ('*.BAS', '*.bas'), ('text/basic',)),
- 'QLexer': ('pygments.lexers.q', 'Q', ('q',), ('*.q',), ()),
- 'QVToLexer': ('pygments.lexers.qvt', 'QVTO', ('qvto', 'qvt'), ('*.qvto',), ()),
- 'QlikLexer': ('pygments.lexers.qlik', 'Qlik', ('qlik', 'qlikview', 'qliksense', 'qlikscript'), ('*.qvs', '*.qvw'), ()),
- 'QmlLexer': ('pygments.lexers.webmisc', 'QML', ('qml', 'qbs'), ('*.qml', '*.qbs'), ('application/x-qml', 'application/x-qt.qbs+qml')),
- 'RConsoleLexer': ('pygments.lexers.r', 'RConsole', ('rconsole', 'rout'), ('*.Rout',), ()),
- 'RNCCompactLexer': ('pygments.lexers.rnc', 'Relax-NG Compact', ('rng-compact', 'rnc'), ('*.rnc',), ()),
- 'RPMSpecLexer': ('pygments.lexers.installers', 'RPMSpec', ('spec',), ('*.spec',), ('text/x-rpm-spec',)),
- 'RacketLexer': ('pygments.lexers.lisp', 'Racket', ('racket', 'rkt'), ('*.rkt', '*.rktd', '*.rktl'), ('text/x-racket', 'application/x-racket')),
- 'RagelCLexer': ('pygments.lexers.parsers', 'Ragel in C Host', ('ragel-c',), ('*.rl',), ()),
- 'RagelCppLexer': ('pygments.lexers.parsers', 'Ragel in CPP Host', ('ragel-cpp',), ('*.rl',), ()),
- 'RagelDLexer': ('pygments.lexers.parsers', 'Ragel in D Host', ('ragel-d',), ('*.rl',), ()),
- 'RagelEmbeddedLexer': ('pygments.lexers.parsers', 'Embedded Ragel', ('ragel-em',), ('*.rl',), ()),
- 'RagelJavaLexer': ('pygments.lexers.parsers', 'Ragel in Java Host', ('ragel-java',), ('*.rl',), ()),
- 'RagelLexer': ('pygments.lexers.parsers', 'Ragel', ('ragel',), (), ()),
- 'RagelObjectiveCLexer': ('pygments.lexers.parsers', 'Ragel in Objective C Host', ('ragel-objc',), ('*.rl',), ()),
- 'RagelRubyLexer': ('pygments.lexers.parsers', 'Ragel in Ruby Host', ('ragel-ruby', 'ragel-rb'), ('*.rl',), ()),
- 'RawTokenLexer': ('pygments.lexers.special', 'Raw token data', (), (), ('application/x-pygments-tokens',)),
- 'RdLexer': ('pygments.lexers.r', 'Rd', ('rd',), ('*.Rd',), ('text/x-r-doc',)),
- 'ReasonLexer': ('pygments.lexers.ml', 'ReasonML', ('reasonml', 'reason'), ('*.re', '*.rei'), ('text/x-reasonml',)),
- 'RebolLexer': ('pygments.lexers.rebol', 'REBOL', ('rebol',), ('*.r', '*.r3', '*.reb'), ('text/x-rebol',)),
- 'RedLexer': ('pygments.lexers.rebol', 'Red', ('red', 'red/system'), ('*.red', '*.reds'), ('text/x-red', 'text/x-red-system')),
- 'RedcodeLexer': ('pygments.lexers.esoteric', 'Redcode', ('redcode',), ('*.cw',), ()),
- 'RegeditLexer': ('pygments.lexers.configs', 'reg', ('registry',), ('*.reg',), ('text/x-windows-registry',)),
- 'ResourceLexer': ('pygments.lexers.resource', 'ResourceBundle', ('resourcebundle', 'resource'), (), ()),
- 'RexxLexer': ('pygments.lexers.scripting', 'Rexx', ('rexx', 'arexx'), ('*.rexx', '*.rex', '*.rx', '*.arexx'), ('text/x-rexx',)),
- 'RhtmlLexer': ('pygments.lexers.templates', 'RHTML', ('rhtml', 'html+erb', 'html+ruby'), ('*.rhtml',), ('text/html+ruby',)),
- 'RideLexer': ('pygments.lexers.ride', 'Ride', ('ride',), ('*.ride',), ('text/x-ride',)),
- 'RitaLexer': ('pygments.lexers.rita', 'Rita', ('rita',), ('*.rita',), ('text/rita',)),
- 'RoboconfGraphLexer': ('pygments.lexers.roboconf', 'Roboconf Graph', ('roboconf-graph',), ('*.graph',), ()),
- 'RoboconfInstancesLexer': ('pygments.lexers.roboconf', 'Roboconf Instances', ('roboconf-instances',), ('*.instances',), ()),
- 'RobotFrameworkLexer': ('pygments.lexers.robotframework', 'RobotFramework', ('robotframework',), ('*.robot', '*.resource'), ('text/x-robotframework',)),
- 'RqlLexer': ('pygments.lexers.sql', 'RQL', ('rql',), ('*.rql',), ('text/x-rql',)),
- 'RslLexer': ('pygments.lexers.dsls', 'RSL', ('rsl',), ('*.rsl',), ('text/rsl',)),
- 'RstLexer': ('pygments.lexers.markup', 'reStructuredText', ('restructuredtext', 'rst', 'rest'), ('*.rst', '*.rest'), ('text/x-rst', 'text/prs.fallenstein.rst')),
- 'RtsLexer': ('pygments.lexers.trafficscript', 'TrafficScript', ('trafficscript', 'rts'), ('*.rts',), ()),
- 'RubyConsoleLexer': ('pygments.lexers.ruby', 'Ruby irb session', ('rbcon', 'irb'), (), ('text/x-ruby-shellsession',)),
- 'RubyLexer': ('pygments.lexers.ruby', 'Ruby', ('ruby', 'rb', 'duby'), ('*.rb', '*.rbw', 'Rakefile', '*.rake', '*.gemspec', '*.rbx', '*.duby', 'Gemfile', 'Vagrantfile'), ('text/x-ruby', 'application/x-ruby')),
- 'RustLexer': ('pygments.lexers.rust', 'Rust', ('rust', 'rs'), ('*.rs', '*.rs.in'), ('text/rust', 'text/x-rust')),
- 'SASLexer': ('pygments.lexers.sas', 'SAS', ('sas',), ('*.SAS', '*.sas'), ('text/x-sas', 'text/sas', 'application/x-sas')),
- 'SLexer': ('pygments.lexers.r', 'S', ('splus', 's', 'r'), ('*.S', '*.R', '.Rhistory', '.Rprofile', '.Renviron'), ('text/S-plus', 'text/S', 'text/x-r-source', 'text/x-r', 'text/x-R', 'text/x-r-history', 'text/x-r-profile')),
- 'SMLLexer': ('pygments.lexers.ml', 'Standard ML', ('sml',), ('*.sml', '*.sig', '*.fun'), ('text/x-standardml', 'application/x-standardml')),
- 'SNBTLexer': ('pygments.lexers.minecraft', 'SNBT', ('snbt',), ('*.snbt',), ('text/snbt',)),
- 'SarlLexer': ('pygments.lexers.jvm', 'SARL', ('sarl',), ('*.sarl',), ('text/x-sarl',)),
- 'SassLexer': ('pygments.lexers.css', 'Sass', ('sass',), ('*.sass',), ('text/x-sass',)),
- 'SaviLexer': ('pygments.lexers.savi', 'Savi', ('savi',), ('*.savi',), ()),
- 'ScalaLexer': ('pygments.lexers.jvm', 'Scala', ('scala',), ('*.scala',), ('text/x-scala',)),
- 'ScamlLexer': ('pygments.lexers.html', 'Scaml', ('scaml',), ('*.scaml',), ('text/x-scaml',)),
- 'ScdocLexer': ('pygments.lexers.scdoc', 'scdoc', ('scdoc', 'scd'), ('*.scd', '*.scdoc'), ()),
- 'SchemeLexer': ('pygments.lexers.lisp', 'Scheme', ('scheme', 'scm'), ('*.scm', '*.ss'), ('text/x-scheme', 'application/x-scheme')),
- 'ScilabLexer': ('pygments.lexers.matlab', 'Scilab', ('scilab',), ('*.sci', '*.sce', '*.tst'), ('text/scilab',)),
- 'ScssLexer': ('pygments.lexers.css', 'SCSS', ('scss',), ('*.scss',), ('text/x-scss',)),
- 'SedLexer': ('pygments.lexers.textedit', 'Sed', ('sed', 'gsed', 'ssed'), ('*.sed', '*.[gs]sed'), ('text/x-sed',)),
- 'ShExCLexer': ('pygments.lexers.rdf', 'ShExC', ('shexc', 'shex'), ('*.shex',), ('text/shex',)),
- 'ShenLexer': ('pygments.lexers.lisp', 'Shen', ('shen',), ('*.shen',), ('text/x-shen', 'application/x-shen')),
- 'SieveLexer': ('pygments.lexers.sieve', 'Sieve', ('sieve',), ('*.siv', '*.sieve'), ()),
- 'SilverLexer': ('pygments.lexers.verification', 'Silver', ('silver',), ('*.sil', '*.vpr'), ()),
- 'SingularityLexer': ('pygments.lexers.configs', 'Singularity', ('singularity',), ('*.def', 'Singularity'), ()),
- 'SlashLexer': ('pygments.lexers.slash', 'Slash', ('slash',), ('*.sla',), ()),
- 'SlimLexer': ('pygments.lexers.webmisc', 'Slim', ('slim',), ('*.slim',), ('text/x-slim',)),
- 'SlurmBashLexer': ('pygments.lexers.shell', 'Slurm', ('slurm', 'sbatch'), ('*.sl',), ()),
- 'SmaliLexer': ('pygments.lexers.dalvik', 'Smali', ('smali',), ('*.smali',), ('text/smali',)),
- 'SmalltalkLexer': ('pygments.lexers.smalltalk', 'Smalltalk', ('smalltalk', 'squeak', 'st'), ('*.st',), ('text/x-smalltalk',)),
- 'SmartGameFormatLexer': ('pygments.lexers.sgf', 'SmartGameFormat', ('sgf',), ('*.sgf',), ()),
- 'SmartyLexer': ('pygments.lexers.templates', 'Smarty', ('smarty',), ('*.tpl',), ('application/x-smarty',)),
- 'SmithyLexer': ('pygments.lexers.smithy', 'Smithy', ('smithy',), ('*.smithy',), ()),
- 'SnobolLexer': ('pygments.lexers.snobol', 'Snobol', ('snobol',), ('*.snobol',), ('text/x-snobol',)),
- 'SnowballLexer': ('pygments.lexers.dsls', 'Snowball', ('snowball',), ('*.sbl',), ()),
- 'SolidityLexer': ('pygments.lexers.solidity', 'Solidity', ('solidity',), ('*.sol',), ()),
- 'SophiaLexer': ('pygments.lexers.sophia', 'Sophia', ('sophia',), ('*.aes',), ()),
- 'SourcePawnLexer': ('pygments.lexers.pawn', 'SourcePawn', ('sp',), ('*.sp',), ('text/x-sourcepawn',)),
- 'SourcesListLexer': ('pygments.lexers.installers', 'Debian Sourcelist', ('debsources', 'sourceslist', 'sources.list'), ('sources.list',), ()),
- 'SparqlLexer': ('pygments.lexers.rdf', 'SPARQL', ('sparql',), ('*.rq', '*.sparql'), ('application/sparql-query',)),
- 'SpiceLexer': ('pygments.lexers.spice', 'Spice', ('spice', 'spicelang'), ('*.spice',), ('text/x-spice',)),
- 'SqlJinjaLexer': ('pygments.lexers.templates', 'SQL+Jinja', ('sql+jinja',), ('*.sql', '*.sql.j2', '*.sql.jinja2'), ()),
- 'SqlLexer': ('pygments.lexers.sql', 'SQL', ('sql',), ('*.sql',), ('text/x-sql',)),
- 'SqliteConsoleLexer': ('pygments.lexers.sql', 'sqlite3con', ('sqlite3',), ('*.sqlite3-console',), ('text/x-sqlite3-console',)),
- 'SquidConfLexer': ('pygments.lexers.configs', 'SquidConf', ('squidconf', 'squid.conf', 'squid'), ('squid.conf',), ('text/x-squidconf',)),
- 'SrcinfoLexer': ('pygments.lexers.srcinfo', 'Srcinfo', ('srcinfo',), ('.SRCINFO',), ()),
- 'SspLexer': ('pygments.lexers.templates', 'Scalate Server Page', ('ssp',), ('*.ssp',), ('application/x-ssp',)),
- 'StanLexer': ('pygments.lexers.modeling', 'Stan', ('stan',), ('*.stan',), ()),
- 'StataLexer': ('pygments.lexers.stata', 'Stata', ('stata', 'do'), ('*.do', '*.ado'), ('text/x-stata', 'text/stata', 'application/x-stata')),
- 'SuperColliderLexer': ('pygments.lexers.supercollider', 'SuperCollider', ('supercollider', 'sc'), ('*.sc', '*.scd'), ('application/supercollider', 'text/supercollider')),
- 'SwiftLexer': ('pygments.lexers.objective', 'Swift', ('swift',), ('*.swift',), ('text/x-swift',)),
- 'SwigLexer': ('pygments.lexers.c_like', 'SWIG', ('swig',), ('*.swg', '*.i'), ('text/swig',)),
- 'SystemVerilogLexer': ('pygments.lexers.hdl', 'systemverilog', ('systemverilog', 'sv'), ('*.sv', '*.svh'), ('text/x-systemverilog',)),
- 'SystemdLexer': ('pygments.lexers.configs', 'Systemd', ('systemd',), ('*.service', '*.socket', '*.device', '*.mount', '*.automount', '*.swap', '*.target', '*.path', '*.timer', '*.slice', '*.scope'), ()),
- 'TAPLexer': ('pygments.lexers.testing', 'TAP', ('tap',), ('*.tap',), ()),
- 'TNTLexer': ('pygments.lexers.tnt', 'Typographic Number Theory', ('tnt',), ('*.tnt',), ()),
- 'TOMLLexer': ('pygments.lexers.configs', 'TOML', ('toml',), ('*.toml', 'Pipfile', 'poetry.lock'), ()),
- 'Tads3Lexer': ('pygments.lexers.int_fiction', 'TADS 3', ('tads3',), ('*.t',), ()),
- 'TalLexer': ('pygments.lexers.tal', 'Tal', ('tal', 'uxntal'), ('*.tal',), ('text/x-uxntal',)),
- 'TasmLexer': ('pygments.lexers.asm', 'TASM', ('tasm',), ('*.asm', '*.ASM', '*.tasm'), ('text/x-tasm',)),
- 'TclLexer': ('pygments.lexers.tcl', 'Tcl', ('tcl',), ('*.tcl', '*.rvt'), ('text/x-tcl', 'text/x-script.tcl', 'application/x-tcl')),
- 'TcshLexer': ('pygments.lexers.shell', 'Tcsh', ('tcsh', 'csh'), ('*.tcsh', '*.csh'), ('application/x-csh',)),
- 'TcshSessionLexer': ('pygments.lexers.shell', 'Tcsh Session', ('tcshcon',), (), ()),
- 'TeaTemplateLexer': ('pygments.lexers.templates', 'Tea', ('tea',), ('*.tea',), ('text/x-tea',)),
- 'TealLexer': ('pygments.lexers.teal', 'teal', ('teal',), ('*.teal',), ()),
- 'TeraTermLexer': ('pygments.lexers.teraterm', 'Tera Term macro', ('teratermmacro', 'teraterm', 'ttl'), ('*.ttl',), ('text/x-teratermmacro',)),
- 'TermcapLexer': ('pygments.lexers.configs', 'Termcap', ('termcap',), ('termcap', 'termcap.src'), ()),
- 'TerminfoLexer': ('pygments.lexers.configs', 'Terminfo', ('terminfo',), ('terminfo', 'terminfo.src'), ()),
- 'TerraformLexer': ('pygments.lexers.configs', 'Terraform', ('terraform', 'tf', 'hcl'), ('*.tf', '*.hcl'), ('application/x-tf', 'application/x-terraform')),
- 'TexLexer': ('pygments.lexers.markup', 'TeX', ('tex', 'latex'), ('*.tex', '*.aux', '*.toc'), ('text/x-tex', 'text/x-latex')),
- 'TextLexer': ('pygments.lexers.special', 'Text only', ('text',), ('*.txt',), ('text/plain',)),
- 'ThingsDBLexer': ('pygments.lexers.thingsdb', 'ThingsDB', ('ti', 'thingsdb'), ('*.ti',), ()),
- 'ThriftLexer': ('pygments.lexers.dsls', 'Thrift', ('thrift',), ('*.thrift',), ('application/x-thrift',)),
- 'TiddlyWiki5Lexer': ('pygments.lexers.markup', 'tiddler', ('tid',), ('*.tid',), ('text/vnd.tiddlywiki',)),
- 'TlbLexer': ('pygments.lexers.tlb', 'Tl-b', ('tlb',), ('*.tlb',), ()),
- 'TlsLexer': ('pygments.lexers.tls', 'TLS Presentation Language', ('tls',), (), ()),
- 'TodotxtLexer': ('pygments.lexers.textfmts', 'Todotxt', ('todotxt',), ('todo.txt', '*.todotxt'), ('text/x-todo',)),
- 'TransactSqlLexer': ('pygments.lexers.sql', 'Transact-SQL', ('tsql', 't-sql'), ('*.sql',), ('text/x-tsql',)),
- 'TreetopLexer': ('pygments.lexers.parsers', 'Treetop', ('treetop',), ('*.treetop', '*.tt'), ()),
- 'TurtleLexer': ('pygments.lexers.rdf', 'Turtle', ('turtle',), ('*.ttl',), ('text/turtle', 'application/x-turtle')),
- 'TwigHtmlLexer': ('pygments.lexers.templates', 'HTML+Twig', ('html+twig',), ('*.twig',), ('text/html+twig',)),
- 'TwigLexer': ('pygments.lexers.templates', 'Twig', ('twig',), (), ('application/x-twig',)),
- 'TypeScriptLexer': ('pygments.lexers.javascript', 'TypeScript', ('typescript', 'ts'), ('*.ts',), ('application/x-typescript', 'text/x-typescript')),
- 'TypoScriptCssDataLexer': ('pygments.lexers.typoscript', 'TypoScriptCssData', ('typoscriptcssdata',), (), ()),
- 'TypoScriptHtmlDataLexer': ('pygments.lexers.typoscript', 'TypoScriptHtmlData', ('typoscripthtmldata',), (), ()),
- 'TypoScriptLexer': ('pygments.lexers.typoscript', 'TypoScript', ('typoscript',), ('*.typoscript',), ('text/x-typoscript',)),
- 'UL4Lexer': ('pygments.lexers.ul4', 'UL4', ('ul4',), ('*.ul4',), ()),
- 'UcodeLexer': ('pygments.lexers.unicon', 'ucode', ('ucode',), ('*.u', '*.u1', '*.u2'), ()),
- 'UniconLexer': ('pygments.lexers.unicon', 'Unicon', ('unicon',), ('*.icn',), ('text/unicon',)),
- 'UnixConfigLexer': ('pygments.lexers.configs', 'Unix/Linux config files', ('unixconfig', 'linuxconfig'), (), ()),
- 'UrbiscriptLexer': ('pygments.lexers.urbi', 'UrbiScript', ('urbiscript',), ('*.u',), ('application/x-urbiscript',)),
- 'UrlEncodedLexer': ('pygments.lexers.html', 'urlencoded', ('urlencoded',), (), ('application/x-www-form-urlencoded',)),
- 'UsdLexer': ('pygments.lexers.usd', 'USD', ('usd', 'usda'), ('*.usd', '*.usda'), ()),
- 'VBScriptLexer': ('pygments.lexers.basic', 'VBScript', ('vbscript',), ('*.vbs', '*.VBS'), ()),
- 'VCLLexer': ('pygments.lexers.varnish', 'VCL', ('vcl',), ('*.vcl',), ('text/x-vclsrc',)),
- 'VCLSnippetLexer': ('pygments.lexers.varnish', 'VCLSnippets', ('vclsnippets', 'vclsnippet'), (), ('text/x-vclsnippet',)),
- 'VCTreeStatusLexer': ('pygments.lexers.console', 'VCTreeStatus', ('vctreestatus',), (), ()),
- 'VGLLexer': ('pygments.lexers.dsls', 'VGL', ('vgl',), ('*.rpf',), ()),
- 'ValaLexer': ('pygments.lexers.c_like', 'Vala', ('vala', 'vapi'), ('*.vala', '*.vapi'), ('text/x-vala',)),
- 'VbNetAspxLexer': ('pygments.lexers.dotnet', 'aspx-vb', ('aspx-vb',), ('*.aspx', '*.asax', '*.ascx', '*.ashx', '*.asmx', '*.axd'), ()),
- 'VbNetLexer': ('pygments.lexers.dotnet', 'VB.net', ('vb.net', 'vbnet', 'lobas', 'oobas', 'sobas'), ('*.vb', '*.bas'), ('text/x-vbnet', 'text/x-vba')),
- 'VelocityHtmlLexer': ('pygments.lexers.templates', 'HTML+Velocity', ('html+velocity',), (), ('text/html+velocity',)),
- 'VelocityLexer': ('pygments.lexers.templates', 'Velocity', ('velocity',), ('*.vm', '*.fhtml'), ()),
- 'VelocityXmlLexer': ('pygments.lexers.templates', 'XML+Velocity', ('xml+velocity',), (), ('application/xml+velocity',)),
- 'VerifpalLexer': ('pygments.lexers.verifpal', 'Verifpal', ('verifpal',), ('*.vp',), ('text/x-verifpal',)),
- 'VerilogLexer': ('pygments.lexers.hdl', 'verilog', ('verilog', 'v'), ('*.v',), ('text/x-verilog',)),
- 'VhdlLexer': ('pygments.lexers.hdl', 'vhdl', ('vhdl',), ('*.vhdl', '*.vhd'), ('text/x-vhdl',)),
- 'VimLexer': ('pygments.lexers.textedit', 'VimL', ('vim',), ('*.vim', '.vimrc', '.exrc', '.gvimrc', '_vimrc', '_exrc', '_gvimrc', 'vimrc', 'gvimrc'), ('text/x-vim',)),
- 'WDiffLexer': ('pygments.lexers.diff', 'WDiff', ('wdiff',), ('*.wdiff',), ()),
- 'WatLexer': ('pygments.lexers.webassembly', 'WebAssembly', ('wast', 'wat'), ('*.wat', '*.wast'), ()),
- 'WebIDLLexer': ('pygments.lexers.webidl', 'Web IDL', ('webidl',), ('*.webidl',), ()),
- 'WgslLexer': ('pygments.lexers.wgsl', 'WebGPU Shading Language', ('wgsl',), ('*.wgsl',), ('text/wgsl',)),
- 'WhileyLexer': ('pygments.lexers.whiley', 'Whiley', ('whiley',), ('*.whiley',), ('text/x-whiley',)),
- 'WikitextLexer': ('pygments.lexers.markup', 'Wikitext', ('wikitext', 'mediawiki'), (), ('text/x-wiki',)),
- 'WoWTocLexer': ('pygments.lexers.wowtoc', 'World of Warcraft TOC', ('wowtoc',), ('*.toc',), ()),
- 'WrenLexer': ('pygments.lexers.wren', 'Wren', ('wren',), ('*.wren',), ()),
- 'X10Lexer': ('pygments.lexers.x10', 'X10', ('x10', 'xten'), ('*.x10',), ('text/x-x10',)),
- 'XMLUL4Lexer': ('pygments.lexers.ul4', 'XML+UL4', ('xml+ul4',), ('*.xmlul4',), ()),
- 'XQueryLexer': ('pygments.lexers.webmisc', 'XQuery', ('xquery', 'xqy', 'xq', 'xql', 'xqm'), ('*.xqy', '*.xquery', '*.xq', '*.xql', '*.xqm'), ('text/xquery', 'application/xquery')),
- 'XmlDjangoLexer': ('pygments.lexers.templates', 'XML+Django/Jinja', ('xml+django', 'xml+jinja'), ('*.xml.j2', '*.xml.jinja2'), ('application/xml+django', 'application/xml+jinja')),
- 'XmlErbLexer': ('pygments.lexers.templates', 'XML+Ruby', ('xml+ruby', 'xml+erb'), (), ('application/xml+ruby',)),
- 'XmlLexer': ('pygments.lexers.html', 'XML', ('xml',), ('*.xml', '*.xsl', '*.rss', '*.xslt', '*.xsd', '*.wsdl', '*.wsf'), ('text/xml', 'application/xml', 'image/svg+xml', 'application/rss+xml', 'application/atom+xml')),
- 'XmlPhpLexer': ('pygments.lexers.templates', 'XML+PHP', ('xml+php',), (), ('application/xml+php',)),
- 'XmlSmartyLexer': ('pygments.lexers.templates', 'XML+Smarty', ('xml+smarty',), (), ('application/xml+smarty',)),
- 'XorgLexer': ('pygments.lexers.xorg', 'Xorg', ('xorg.conf',), ('xorg.conf',), ()),
- 'XppLexer': ('pygments.lexers.dotnet', 'X++', ('xpp', 'x++'), ('*.xpp',), ()),
- 'XsltLexer': ('pygments.lexers.html', 'XSLT', ('xslt',), ('*.xsl', '*.xslt', '*.xpl'), ('application/xsl+xml', 'application/xslt+xml')),
- 'XtendLexer': ('pygments.lexers.jvm', 'Xtend', ('xtend',), ('*.xtend',), ('text/x-xtend',)),
- 'XtlangLexer': ('pygments.lexers.lisp', 'xtlang', ('extempore',), ('*.xtm',), ()),
- 'YamlJinjaLexer': ('pygments.lexers.templates', 'YAML+Jinja', ('yaml+jinja', 'salt', 'sls'), ('*.sls', '*.yaml.j2', '*.yml.j2', '*.yaml.jinja2', '*.yml.jinja2'), ('text/x-yaml+jinja', 'text/x-sls')),
- 'YamlLexer': ('pygments.lexers.data', 'YAML', ('yaml',), ('*.yaml', '*.yml'), ('text/x-yaml',)),
- 'YangLexer': ('pygments.lexers.yang', 'YANG', ('yang',), ('*.yang',), ('application/yang',)),
- 'YaraLexer': ('pygments.lexers.yara', 'YARA', ('yara', 'yar'), ('*.yar',), ('text/x-yara',)),
- 'ZeekLexer': ('pygments.lexers.dsls', 'Zeek', ('zeek', 'bro'), ('*.zeek', '*.bro'), ()),
- 'ZephirLexer': ('pygments.lexers.php', 'Zephir', ('zephir',), ('*.zep',), ()),
- 'ZigLexer': ('pygments.lexers.zig', 'Zig', ('zig',), ('*.zig',), ('text/zig',)),
- 'apdlexer': ('pygments.lexers.apdlexer', 'ANSYS parametric design language', ('ansys', 'apdl'), ('*.ans',), ()),
-}
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/roboconf.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/roboconf.py
deleted file mode 100644
index 5d7d76e0bbb992d8db060eea51e29ed8066bf3da..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/roboconf.py
+++ /dev/null
@@ -1,81 +0,0 @@
-"""
- pygments.lexers.roboconf
- ~~~~~~~~~~~~~~~~~~~~~~~~
-
- Lexers for Roboconf DSL.
-
- :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-from pygments.lexer import RegexLexer, words, re
-from pygments.token import Text, Operator, Keyword, Name, Comment
-
-__all__ = ['RoboconfGraphLexer', 'RoboconfInstancesLexer']
-
-
-class RoboconfGraphLexer(RegexLexer):
- """
- Lexer for Roboconf graph files.
-
- .. versionadded:: 2.1
- """
- name = 'Roboconf Graph'
- aliases = ['roboconf-graph']
- filenames = ['*.graph']
-
- flags = re.IGNORECASE | re.MULTILINE
- tokens = {
- 'root': [
- # Skip white spaces
- (r'\s+', Text),
-
- # There is one operator
- (r'=', Operator),
-
- # Keywords
- (words(('facet', 'import'), suffix=r'\s*\b', prefix=r'\b'), Keyword),
- (words((
- 'installer', 'extends', 'exports', 'imports', 'facets',
- 'children'), suffix=r'\s*:?', prefix=r'\b'), Name),
-
- # Comments
- (r'#.*\n', Comment),
-
- # Default
- (r'[^#]', Text),
- (r'.*\n', Text)
- ]
- }
-
-
-class RoboconfInstancesLexer(RegexLexer):
- """
- Lexer for Roboconf instances files.
-
- .. versionadded:: 2.1
- """
- name = 'Roboconf Instances'
- aliases = ['roboconf-instances']
- filenames = ['*.instances']
-
- flags = re.IGNORECASE | re.MULTILINE
- tokens = {
- 'root': [
-
- # Skip white spaces
- (r'\s+', Text),
-
- # Keywords
- (words(('instance of', 'import'), suffix=r'\s*\b', prefix=r'\b'), Keyword),
- (words(('name', 'count'), suffix=r's*:?', prefix=r'\b'), Name),
- (r'\s*[\w.-]+\s*:', Name),
-
- # Comments
- (r'#.*\n', Comment),
-
- # Default
- (r'[^#]', Text),
- (r'.*\n', Text)
- ]
- }
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pyparsing/__init__.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pyparsing/__init__.py
deleted file mode 100644
index 3dbc3cf83b55ff1dca212d1bbed272ce7eb4370a..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pyparsing/__init__.py
+++ /dev/null
@@ -1,325 +0,0 @@
-# module pyparsing.py
-#
-# Copyright (c) 2003-2022 Paul T. McGuire
-#
-# Permission is hereby granted, free of charge, to any person obtaining
-# a copy of this software and associated documentation files (the
-# "Software"), to deal in the Software without restriction, including
-# without limitation the rights to use, copy, modify, merge, publish,
-# distribute, sublicense, and/or sell copies of the Software, and to
-# permit persons to whom the Software is furnished to do so, subject to
-# the following conditions:
-#
-# The above copyright notice and this permission notice shall be
-# included in all copies or substantial portions of the Software.
-#
-# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
-# EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
-# MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
-# IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
-# CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
-# TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
-# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
-#
-
-__doc__ = """
-pyparsing module - Classes and methods to define and execute parsing grammars
-=============================================================================
-
-The pyparsing module is an alternative approach to creating and
-executing simple grammars, vs. the traditional lex/yacc approach, or the
-use of regular expressions. With pyparsing, you don't need to learn
-a new syntax for defining grammars or matching expressions - the parsing
-module provides a library of classes that you use to construct the
-grammar directly in Python.
-
-Here is a program to parse "Hello, World!" (or any greeting of the form
-``", !"``), built up using :class:`Word`,
-:class:`Literal`, and :class:`And` elements
-(the :meth:`'+'` operators create :class:`And` expressions,
-and the strings are auto-converted to :class:`Literal` expressions)::
-
- from pyparsing import Word, alphas
-
- # define grammar of a greeting
- greet = Word(alphas) + "," + Word(alphas) + "!"
-
- hello = "Hello, World!"
- print(hello, "->", greet.parse_string(hello))
-
-The program outputs the following::
-
- Hello, World! -> ['Hello', ',', 'World', '!']
-
-The Python representation of the grammar is quite readable, owing to the
-self-explanatory class names, and the use of :class:`'+'`,
-:class:`'|'`, :class:`'^' |


 -
- -
- -
- -
- -
- -
- -
-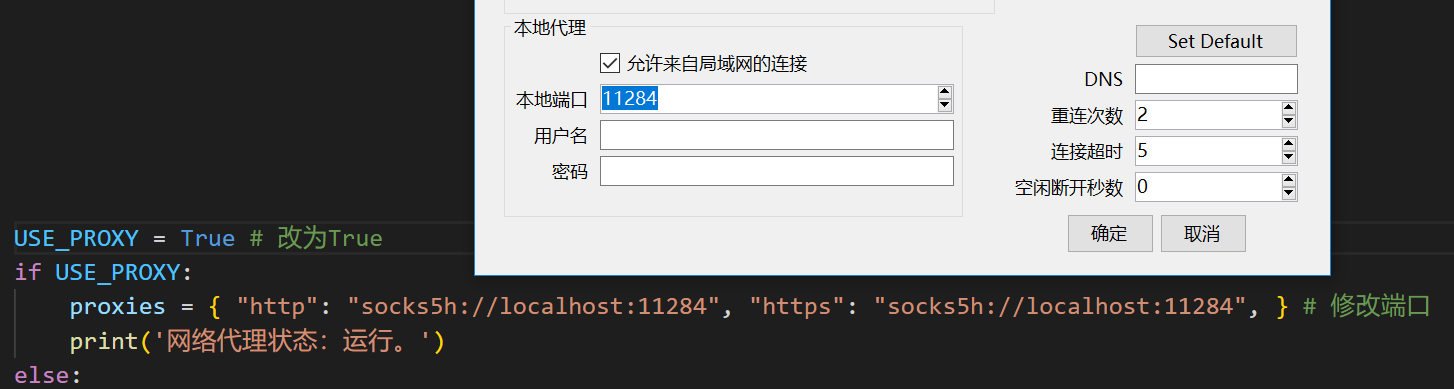 -
-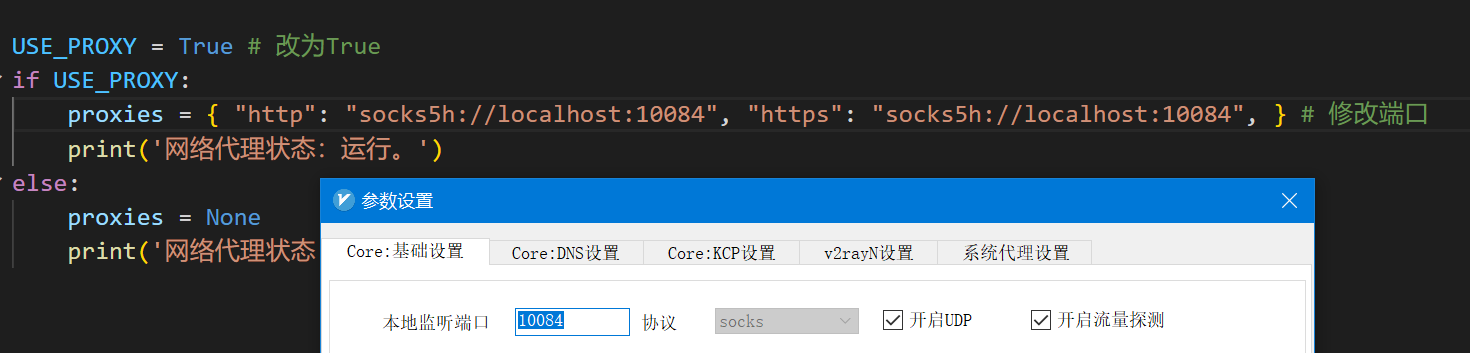 -
-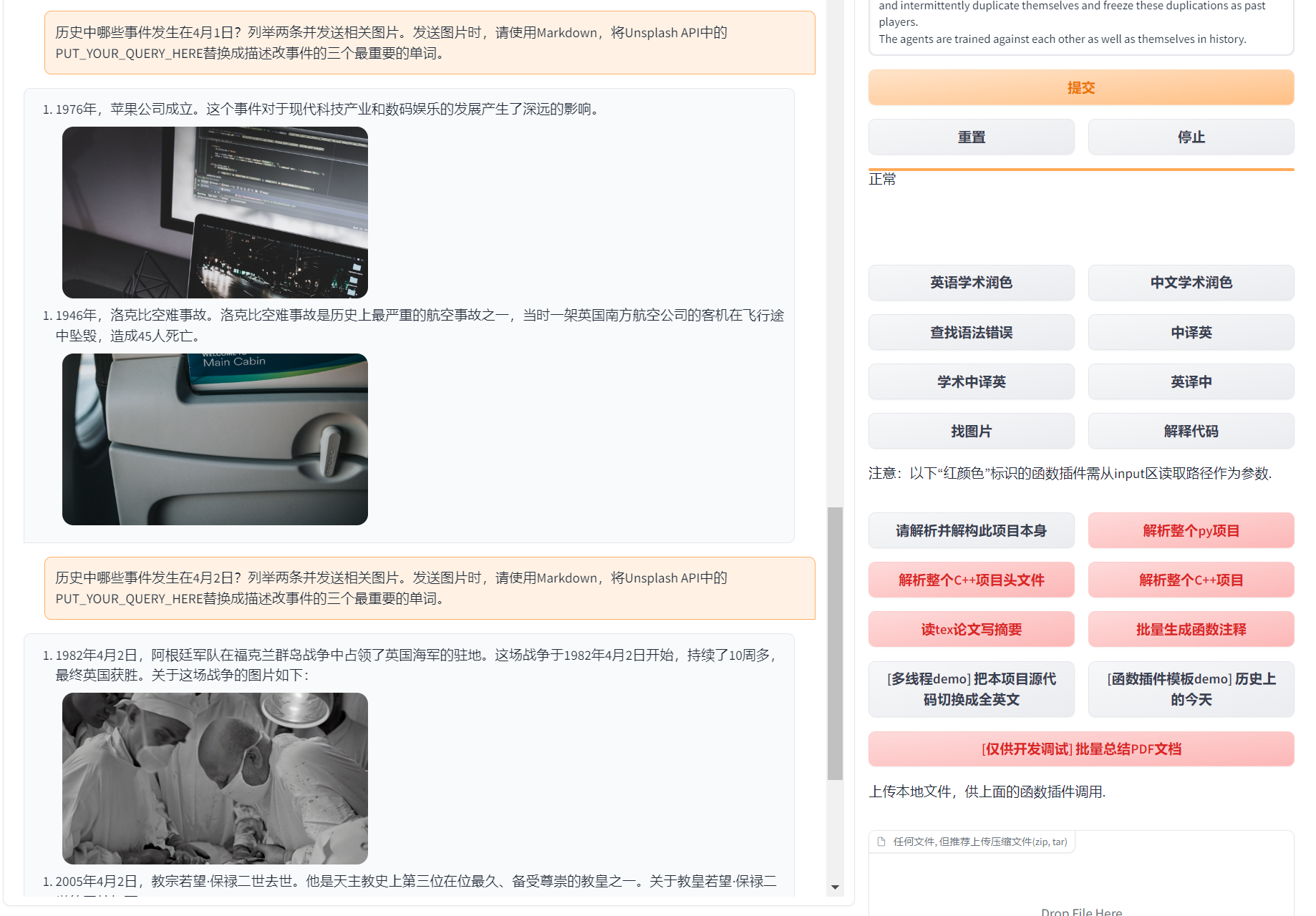 -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-