[0-9]+)", version_str)
- if not m:
- warnings.warn(
- "Expected glibc version with 2 components major.minor,"
- " got: %s" % version_str,
- RuntimeWarning,
- )
- return -1, -1
- return int(m.group("major")), int(m.group("minor"))
-
-
-@functools.lru_cache()
-def _get_glibc_version() -> Tuple[int, int]:
- version_str = _glibc_version_string()
- if version_str is None:
- return (-1, -1)
- return _parse_glibc_version(version_str)
-
-
-# From PEP 513, PEP 600
-def _is_compatible(name: str, arch: str, version: _GLibCVersion) -> bool:
- sys_glibc = _get_glibc_version()
- if sys_glibc < version:
- return False
- # Check for presence of _manylinux module.
- try:
- import _manylinux # noqa
- except ImportError:
- return True
- if hasattr(_manylinux, "manylinux_compatible"):
- result = _manylinux.manylinux_compatible(version[0], version[1], arch)
- if result is not None:
- return bool(result)
- return True
- if version == _GLibCVersion(2, 5):
- if hasattr(_manylinux, "manylinux1_compatible"):
- return bool(_manylinux.manylinux1_compatible)
- if version == _GLibCVersion(2, 12):
- if hasattr(_manylinux, "manylinux2010_compatible"):
- return bool(_manylinux.manylinux2010_compatible)
- if version == _GLibCVersion(2, 17):
- if hasattr(_manylinux, "manylinux2014_compatible"):
- return bool(_manylinux.manylinux2014_compatible)
- return True
-
-
-_LEGACY_MANYLINUX_MAP = {
- # CentOS 7 w/ glibc 2.17 (PEP 599)
- (2, 17): "manylinux2014",
- # CentOS 6 w/ glibc 2.12 (PEP 571)
- (2, 12): "manylinux2010",
- # CentOS 5 w/ glibc 2.5 (PEP 513)
- (2, 5): "manylinux1",
-}
-
-
-def platform_tags(linux: str, arch: str) -> Iterator[str]:
- if not _have_compatible_abi(arch):
- return
- # Oldest glibc to be supported regardless of architecture is (2, 17).
- too_old_glibc2 = _GLibCVersion(2, 16)
- if arch in {"x86_64", "i686"}:
- # On x86/i686 also oldest glibc to be supported is (2, 5).
- too_old_glibc2 = _GLibCVersion(2, 4)
- current_glibc = _GLibCVersion(*_get_glibc_version())
- glibc_max_list = [current_glibc]
- # We can assume compatibility across glibc major versions.
- # https://sourceware.org/bugzilla/show_bug.cgi?id=24636
- #
- # Build a list of maximum glibc versions so that we can
- # output the canonical list of all glibc from current_glibc
- # down to too_old_glibc2, including all intermediary versions.
- for glibc_major in range(current_glibc.major - 1, 1, -1):
- glibc_minor = _LAST_GLIBC_MINOR[glibc_major]
- glibc_max_list.append(_GLibCVersion(glibc_major, glibc_minor))
- for glibc_max in glibc_max_list:
- if glibc_max.major == too_old_glibc2.major:
- min_minor = too_old_glibc2.minor
- else:
- # For other glibc major versions oldest supported is (x, 0).
- min_minor = -1
- for glibc_minor in range(glibc_max.minor, min_minor, -1):
- glibc_version = _GLibCVersion(glibc_max.major, glibc_minor)
- tag = "manylinux_{}_{}".format(*glibc_version)
- if _is_compatible(tag, arch, glibc_version):
- yield linux.replace("linux", tag)
- # Handle the legacy manylinux1, manylinux2010, manylinux2014 tags.
- if glibc_version in _LEGACY_MANYLINUX_MAP:
- legacy_tag = _LEGACY_MANYLINUX_MAP[glibc_version]
- if _is_compatible(legacy_tag, arch, glibc_version):
- yield linux.replace("linux", legacy_tag)
diff --git a/spaces/Banbri/zcvzcv/src/app/main.tsx b/spaces/Banbri/zcvzcv/src/app/main.tsx
deleted file mode 100644
index 803c8ef8a7bca87581450e4442bdcf138207afab..0000000000000000000000000000000000000000
--- a/spaces/Banbri/zcvzcv/src/app/main.tsx
+++ /dev/null
@@ -1,155 +0,0 @@
-"use client"
-
-import { useEffect, useState, useTransition } from "react"
-
-import { cn } from "@/lib/utils"
-import { TopMenu } from "./interface/top-menu"
-import { fonts } from "@/lib/fonts"
-import { useStore } from "./store"
-import { Zoom } from "./interface/zoom"
-import { getStory } from "./queries/getStory"
-import { BottomBar } from "./interface/bottom-bar"
-import { Page } from "./interface/page"
-import { LLMResponse } from "@/types"
-
-export default function Main() {
- const [_isPending, startTransition] = useTransition()
-
- const isGeneratingStory = useStore(state => state.isGeneratingStory)
- const setGeneratingStory = useStore(state => state.setGeneratingStory)
-
- const font = useStore(state => state.font)
- const preset = useStore(state => state.preset)
- const prompt = useStore(state => state.prompt)
-
- const setLayouts = useStore(state => state.setLayouts)
-
- const setPanels = useStore(state => state.setPanels)
- const setCaptions = useStore(state => state.setCaptions)
-
- const zoomLevel = useStore(state => state.zoomLevel)
-
- const [waitABitMore, setWaitABitMore] = useState(false)
-
- // react to prompt changes
- useEffect(() => {
- if (!prompt) { return }
-
- startTransition(async () => {
- setWaitABitMore(false)
- setGeneratingStory(true)
-
- // I don't think we are going to need a rate limiter on the LLM part anymore
- const enableRateLimiter = false // `${process.env.NEXT_PUBLIC_ENABLE_RATE_LIMITER}` === "true"
-
- const nbPanels = 4
-
- let llmResponse: LLMResponse = []
-
- try {
- llmResponse = await getStory({ preset, prompt })
- console.log("LLM responded:", llmResponse)
-
- } catch (err) {
- console.log("LLM step failed due to:", err)
- console.log("we are now switching to a degraded mode, using 4 similar panels")
-
- llmResponse = []
- for (let p = 0; p < nbPanels; p++) {
- llmResponse.push({
- panel: p,
- instructions: `${prompt} ${".".repeat(p)}`,
- caption: "(Sorry, LLM generation failed: using degraded mode)"
- })
- }
- console.error(err)
- }
-
- // we have to limit the size of the prompt, otherwise the rest of the style won't be followed
-
- let limitedPrompt = prompt.slice(0, 77)
- if (limitedPrompt.length !== prompt.length) {
- console.log("Sorry folks, the prompt was cut to:", limitedPrompt)
- }
-
- const panelPromptPrefix = preset.imagePrompt(limitedPrompt).join(", ")
-
- const newPanels: string[] = []
- const newCaptions: string[] = []
- setWaitABitMore(true)
- console.log("Panel prompts for SDXL:")
- for (let p = 0; p < nbPanels; p++) {
- newCaptions.push(llmResponse[p]?.caption || "...")
- const newPanel = [panelPromptPrefix, llmResponse[p]?.instructions || ""].map(chunk => chunk).join(", ")
- newPanels.push(newPanel)
- console.log(newPanel)
- }
-
- setCaptions(newCaptions)
- setPanels(newPanels)
-
- setTimeout(() => {
- setGeneratingStory(false)
- setWaitABitMore(false)
- }, enableRateLimiter ? 12000 : 0)
-
- })
- }, [prompt, preset?.label]) // important: we need to react to preset changes too
-
- return (
-
-
-
105 ? `px-0` : `pl-1 pr-8 md:pl-16 md:pr-16`,
- `print:pt-0 print:px-0 print:pl-0 print:pr-0`,
- fonts.actionman.className
- )}>
-
105 ? `items-start` : `items-center`
- )}>
-
-
-
- {/*
- // we could support multiple pages here,
- // but let's disable it for now
-
- */}
-
-
-
-
-
-
-
- {waitABitMore ? `Story is ready, but server is a bit busy!`: 'Generating a new story..'}
- {waitABitMore ? `Please hold tight..` : ''}
-
-
-
-Descargar Clicker Heroes Mod APK: Una guía para principiantes
-Si usted está buscando un divertido y adictivo juego de ocio que le mantendrá entretenido durante horas, es posible que desee probar Clicker Heroes. Este juego es uno de los juegos de clickers más populares del mercado, con millones de descargas y críticas positivas. Pero lo que si quieres disfrutar del juego sin limitaciones o restricciones? Ahí es donde Clicker Heroes mod apk entra en juego. En este artículo, le diremos todo lo que necesita saber sobre Clicker Heroes, por qué debe descargar su apk mod, y cómo hacerlo de forma segura y fácil.
-descargar clicker héroes mod apk
Download File >>> https://bltlly.com/2v6JzL
- ¿Qué es Clicker Heroes?
-Clicker Heroes es un juego desarrollado por Playsaurus, un estudio especializado en juegos casuales y ociosos. El juego fue lanzado en 2014 para navegadores, y posteriormente portado a dispositivos móviles y consolas. El juego ha recibido varias actualizaciones y expansiones a lo largo de los años, añadiendo nuevas características y contenido.
- El juego de Clicker Heroes
-La jugabilidad de Clicker Heroes es simple y directa. Empiezas tocando la pantalla para matar monstruos y ganar oro. Puedes usar el oro para contratar y actualizar héroes, que te ayudarán a luchar contra más monstruos y jefes. También puedes desbloquear habilidades y habilidades que aumentarán tu daño y velocidad. El juego no tiene fin, ya que siempre puedes avanzar a niveles y mundos más altos, donde te enfrentarás a enemigos y desafíos más fuertes.
- Las características de Clicker Heroes
-Algunas de las características que hacen que Clicker Heroes se destaque de otros juegos de clicker son:
-
-
-- Más de 1000 héroes para recoger y actualizar, cada uno con sus propias habilidades y habilidades únicas.
-- Más de 10.000 niveles para explorar, cada uno con diferentes temas y entornos.
-- Una variedad de modos de juego, como incursiones, clanes, torneos, eventos, misiones, logros y más.
-- Un estilo gráfico vibrante y colorido, con animaciones y efectos suaves.
-
-- Una comunidad amigable y activa, con foros, wikis, guías, consejos, trucos y más.
-
- ¿Por qué descargar Clicker Heroes mod apk?
-Aunque Clicker Heroes es un juego gratuito, también tiene algunas compras en la aplicación que pueden mejorar tu experiencia de juego. Por ejemplo, puedes comprar rubíes, que son la moneda premium del juego. Puedes usar rubíes para comprar pieles, cofres, dorados, auto-clickers, timelapses y más. Sin embargo, estas compras pueden ser bastante caras, especialmente si desea obtener los mejores artículos y mejoras. Es por eso que algunos jugadores prefieren descargar Clicker Heroes mod apk en su lugar.
- Los beneficios de Clicker Heroes mod apk
-Clicker Heroes mod apk es una versión modificada del juego original que le da acceso a recursos y características ilimitadas. Algunos de los beneficios de descargar Clicker Heroes mod apk son:
-
-- Puedes obtener rubíes ilimitados gratis, sin gastar dinero real.
-- Puedes desbloquear todos los héroes y sus mejoras al instante, sin moler o esperar.
-- Puedes saltarte cualquier nivel o jefe que encuentres demasiado duro o aburrido.
-- Puedes personalizar la configuración del juego según tus preferencias.
-- Puedes disfrutar del juego sin anuncios ni interrupciones.
-
- Los inconvenientes de Clicker Heroes mod apk
-Sin embargo, descargar Clicker Heroes mod apk también tiene algunos inconvenientes que usted debe tener en cuenta. Algunos de los inconvenientes de descargar Clicker Heroes mod apk son:
-
-- Es posible que se enfrentan a algunos problemas de compatibilidad o rendimiento, como el apk mod no puede ser actualizado o optimizado para su dispositivo.
-- Usted puede encontrar algunos errores o fallos, como el apk mod no puede ser probado o verificado por la calidad.
-- Usted puede arriesgarse a perder su progreso o datos, como el apk mod no puede ser sincronizado o respaldado con su cuenta.
-- Usted puede violar los términos y condiciones del juego, como el apk mod puede ser considerado como trampa o piratería.
-
-
- Cómo descargar e instalar Clicker Heroes mod apk?
-Si usted ha decidido descargar Clicker Heroes mod apk, usted debe seguir estos pasos cuidadosamente para asegurar una instalación segura y exitosa. Antes de proceder, asegúrese de que tiene suficiente espacio de almacenamiento en su dispositivo y que tiene una conexión a Internet estable.
- Paso 1: Encuentra una fuente confiable
-El primer paso es encontrar una fuente confiable que ofrece Clicker Heroes mod apk para descargar. Usted puede buscar en línea para varios sitios web o plataformas que proporcionan este servicio, pero tenga cuidado de los sitios falsos o estafa que pueden engañar a descargar algo más. También puedes consultar las reseñas y valoraciones de otros usuarios para ver si han tenido una buena experiencia con la fuente. Alternativamente, puede utilizar el siguiente enlace para descargar Clicker Heroes mod apk de una fuente de confianza:
-]? \d* )? :
- .* (?: ft | filetype | syn | syntax ) = ( [^:\s]+ )
-''', re.VERBOSE)
-
-
-def get_filetype_from_line(l):
- m = modeline_re.search(l)
- if m:
- return m.group(1)
-
-
-def get_filetype_from_buffer(buf, max_lines=5):
- """
- Scan the buffer for modelines and return filetype if one is found.
- """
- lines = buf.splitlines()
- for l in lines[-1:-max_lines-1:-1]:
- ret = get_filetype_from_line(l)
- if ret:
- return ret
- for i in range(max_lines, -1, -1):
- if i < len(lines):
- ret = get_filetype_from_line(lines[i])
- if ret:
- return ret
-
- return None
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/s3transfer/utils.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/s3transfer/utils.py
deleted file mode 100644
index 61407eba5c591176c8aed5c361e068e3a1337dee..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/s3transfer/utils.py
+++ /dev/null
@@ -1,802 +0,0 @@
-# Copyright 2016 Amazon.com, Inc. or its affiliates. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License"). You
-# may not use this file except in compliance with the License. A copy of
-# the License is located at
-#
-# http://aws.amazon.com/apache2.0/
-#
-# or in the "license" file accompanying this file. This file is
-# distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
-# ANY KIND, either express or implied. See the License for the specific
-# language governing permissions and limitations under the License.
-import functools
-import logging
-import math
-import os
-import random
-import socket
-import stat
-import string
-import threading
-from collections import defaultdict
-
-from botocore.exceptions import IncompleteReadError, ReadTimeoutError
-
-from s3transfer.compat import SOCKET_ERROR, fallocate, rename_file
-
-MAX_PARTS = 10000
-# The maximum file size you can upload via S3 per request.
-# See: http://docs.aws.amazon.com/AmazonS3/latest/dev/UploadingObjects.html
-# and: http://docs.aws.amazon.com/AmazonS3/latest/dev/qfacts.html
-MAX_SINGLE_UPLOAD_SIZE = 5 * (1024**3)
-MIN_UPLOAD_CHUNKSIZE = 5 * (1024**2)
-logger = logging.getLogger(__name__)
-
-
-S3_RETRYABLE_DOWNLOAD_ERRORS = (
- socket.timeout,
- SOCKET_ERROR,
- ReadTimeoutError,
- IncompleteReadError,
-)
-
-
-def random_file_extension(num_digits=8):
- return ''.join(random.choice(string.hexdigits) for _ in range(num_digits))
-
-
-def signal_not_transferring(request, operation_name, **kwargs):
- if operation_name in ['PutObject', 'UploadPart'] and hasattr(
- request.body, 'signal_not_transferring'
- ):
- request.body.signal_not_transferring()
-
-
-def signal_transferring(request, operation_name, **kwargs):
- if operation_name in ['PutObject', 'UploadPart'] and hasattr(
- request.body, 'signal_transferring'
- ):
- request.body.signal_transferring()
-
-
-def calculate_num_parts(size, part_size):
- return int(math.ceil(size / float(part_size)))
-
-
-def calculate_range_parameter(
- part_size, part_index, num_parts, total_size=None
-):
- """Calculate the range parameter for multipart downloads/copies
-
- :type part_size: int
- :param part_size: The size of the part
-
- :type part_index: int
- :param part_index: The index for which this parts starts. This index starts
- at zero
-
- :type num_parts: int
- :param num_parts: The total number of parts in the transfer
-
- :returns: The value to use for Range parameter on downloads or
- the CopySourceRange parameter for copies
- """
- # Used to calculate the Range parameter
- start_range = part_index * part_size
- if part_index == num_parts - 1:
- end_range = ''
- if total_size is not None:
- end_range = str(total_size - 1)
- else:
- end_range = start_range + part_size - 1
- range_param = f'bytes={start_range}-{end_range}'
- return range_param
-
-
-def get_callbacks(transfer_future, callback_type):
- """Retrieves callbacks from a subscriber
-
- :type transfer_future: s3transfer.futures.TransferFuture
- :param transfer_future: The transfer future the subscriber is associated
- to.
-
- :type callback_type: str
- :param callback_type: The type of callback to retrieve from the subscriber.
- Valid types include:
- * 'queued'
- * 'progress'
- * 'done'
-
- :returns: A list of callbacks for the type specified. All callbacks are
- preinjected with the transfer future.
- """
- callbacks = []
- for subscriber in transfer_future.meta.call_args.subscribers:
- callback_name = 'on_' + callback_type
- if hasattr(subscriber, callback_name):
- callbacks.append(
- functools.partial(
- getattr(subscriber, callback_name), future=transfer_future
- )
- )
- return callbacks
-
-
-def invoke_progress_callbacks(callbacks, bytes_transferred):
- """Calls all progress callbacks
-
- :param callbacks: A list of progress callbacks to invoke
- :param bytes_transferred: The number of bytes transferred. This is passed
- to the callbacks. If no bytes were transferred the callbacks will not
- be invoked because no progress was achieved. It is also possible
- to receive a negative amount which comes from retrying a transfer
- request.
- """
- # Only invoke the callbacks if bytes were actually transferred.
- if bytes_transferred:
- for callback in callbacks:
- callback(bytes_transferred=bytes_transferred)
-
-
-def get_filtered_dict(original_dict, whitelisted_keys):
- """Gets a dictionary filtered by whitelisted keys
-
- :param original_dict: The original dictionary of arguments to source keys
- and values.
- :param whitelisted_key: A list of keys to include in the filtered
- dictionary.
-
- :returns: A dictionary containing key/values from the original dictionary
- whose key was included in the whitelist
- """
- filtered_dict = {}
- for key, value in original_dict.items():
- if key in whitelisted_keys:
- filtered_dict[key] = value
- return filtered_dict
-
-
-class CallArgs:
- def __init__(self, **kwargs):
- """A class that records call arguments
-
- The call arguments must be passed as keyword arguments. It will set
- each keyword argument as an attribute of the object along with its
- associated value.
- """
- for arg, value in kwargs.items():
- setattr(self, arg, value)
-
-
-class FunctionContainer:
- """An object that contains a function and any args or kwargs to call it
-
- When called the provided function will be called with provided args
- and kwargs.
- """
-
- def __init__(self, func, *args, **kwargs):
- self._func = func
- self._args = args
- self._kwargs = kwargs
-
- def __repr__(self):
- return 'Function: {} with args {} and kwargs {}'.format(
- self._func, self._args, self._kwargs
- )
-
- def __call__(self):
- return self._func(*self._args, **self._kwargs)
-
-
-class CountCallbackInvoker:
- """An abstraction to invoke a callback when a shared count reaches zero
-
- :param callback: Callback invoke when finalized count reaches zero
- """
-
- def __init__(self, callback):
- self._lock = threading.Lock()
- self._callback = callback
- self._count = 0
- self._is_finalized = False
-
- @property
- def current_count(self):
- with self._lock:
- return self._count
-
- def increment(self):
- """Increment the count by one"""
- with self._lock:
- if self._is_finalized:
- raise RuntimeError(
- 'Counter has been finalized it can no longer be '
- 'incremented.'
- )
- self._count += 1
-
- def decrement(self):
- """Decrement the count by one"""
- with self._lock:
- if self._count == 0:
- raise RuntimeError(
- 'Counter is at zero. It cannot dip below zero'
- )
- self._count -= 1
- if self._is_finalized and self._count == 0:
- self._callback()
-
- def finalize(self):
- """Finalize the counter
-
- Once finalized, the counter never be incremented and the callback
- can be invoked once the count reaches zero
- """
- with self._lock:
- self._is_finalized = True
- if self._count == 0:
- self._callback()
-
-
-class OSUtils:
- _MAX_FILENAME_LEN = 255
-
- def get_file_size(self, filename):
- return os.path.getsize(filename)
-
- def open_file_chunk_reader(self, filename, start_byte, size, callbacks):
- return ReadFileChunk.from_filename(
- filename, start_byte, size, callbacks, enable_callbacks=False
- )
-
- def open_file_chunk_reader_from_fileobj(
- self,
- fileobj,
- chunk_size,
- full_file_size,
- callbacks,
- close_callbacks=None,
- ):
- return ReadFileChunk(
- fileobj,
- chunk_size,
- full_file_size,
- callbacks=callbacks,
- enable_callbacks=False,
- close_callbacks=close_callbacks,
- )
-
- def open(self, filename, mode):
- return open(filename, mode)
-
- def remove_file(self, filename):
- """Remove a file, noop if file does not exist."""
- # Unlike os.remove, if the file does not exist,
- # then this method does nothing.
- try:
- os.remove(filename)
- except OSError:
- pass
-
- def rename_file(self, current_filename, new_filename):
- rename_file(current_filename, new_filename)
-
- def is_special_file(cls, filename):
- """Checks to see if a file is a special UNIX file.
-
- It checks if the file is a character special device, block special
- device, FIFO, or socket.
-
- :param filename: Name of the file
-
- :returns: True if the file is a special file. False, if is not.
- """
- # If it does not exist, it must be a new file so it cannot be
- # a special file.
- if not os.path.exists(filename):
- return False
- mode = os.stat(filename).st_mode
- # Character special device.
- if stat.S_ISCHR(mode):
- return True
- # Block special device
- if stat.S_ISBLK(mode):
- return True
- # Named pipe / FIFO
- if stat.S_ISFIFO(mode):
- return True
- # Socket.
- if stat.S_ISSOCK(mode):
- return True
- return False
-
- def get_temp_filename(self, filename):
- suffix = os.extsep + random_file_extension()
- path = os.path.dirname(filename)
- name = os.path.basename(filename)
- temp_filename = name[: self._MAX_FILENAME_LEN - len(suffix)] + suffix
- return os.path.join(path, temp_filename)
-
- def allocate(self, filename, size):
- try:
- with self.open(filename, 'wb') as f:
- fallocate(f, size)
- except OSError:
- self.remove_file(filename)
- raise
-
-
-class DeferredOpenFile:
- def __init__(self, filename, start_byte=0, mode='rb', open_function=open):
- """A class that defers the opening of a file till needed
-
- This is useful for deferring opening of a file till it is needed
- in a separate thread, as there is a limit of how many open files
- there can be in a single thread for most operating systems. The
- file gets opened in the following methods: ``read()``, ``seek()``,
- and ``__enter__()``
-
- :type filename: str
- :param filename: The name of the file to open
-
- :type start_byte: int
- :param start_byte: The byte to seek to when the file is opened.
-
- :type mode: str
- :param mode: The mode to use to open the file
-
- :type open_function: function
- :param open_function: The function to use to open the file
- """
- self._filename = filename
- self._fileobj = None
- self._start_byte = start_byte
- self._mode = mode
- self._open_function = open_function
-
- def _open_if_needed(self):
- if self._fileobj is None:
- self._fileobj = self._open_function(self._filename, self._mode)
- if self._start_byte != 0:
- self._fileobj.seek(self._start_byte)
-
- @property
- def name(self):
- return self._filename
-
- def read(self, amount=None):
- self._open_if_needed()
- return self._fileobj.read(amount)
-
- def write(self, data):
- self._open_if_needed()
- self._fileobj.write(data)
-
- def seek(self, where, whence=0):
- self._open_if_needed()
- self._fileobj.seek(where, whence)
-
- def tell(self):
- if self._fileobj is None:
- return self._start_byte
- return self._fileobj.tell()
-
- def close(self):
- if self._fileobj:
- self._fileobj.close()
-
- def __enter__(self):
- self._open_if_needed()
- return self
-
- def __exit__(self, *args, **kwargs):
- self.close()
-
-
-class ReadFileChunk:
- def __init__(
- self,
- fileobj,
- chunk_size,
- full_file_size,
- callbacks=None,
- enable_callbacks=True,
- close_callbacks=None,
- ):
- """
-
- Given a file object shown below::
-
- |___________________________________________________|
- 0 | | full_file_size
- |----chunk_size---|
- f.tell()
-
- :type fileobj: file
- :param fileobj: File like object
-
- :type chunk_size: int
- :param chunk_size: The max chunk size to read. Trying to read
- pass the end of the chunk size will behave like you've
- reached the end of the file.
-
- :type full_file_size: int
- :param full_file_size: The entire content length associated
- with ``fileobj``.
-
- :type callbacks: A list of function(amount_read)
- :param callbacks: Called whenever data is read from this object in the
- order provided.
-
- :type enable_callbacks: boolean
- :param enable_callbacks: True if to run callbacks. Otherwise, do not
- run callbacks
-
- :type close_callbacks: A list of function()
- :param close_callbacks: Called when close is called. The function
- should take no arguments.
- """
- self._fileobj = fileobj
- self._start_byte = self._fileobj.tell()
- self._size = self._calculate_file_size(
- self._fileobj,
- requested_size=chunk_size,
- start_byte=self._start_byte,
- actual_file_size=full_file_size,
- )
- # _amount_read represents the position in the chunk and may exceed
- # the chunk size, but won't allow reads out of bounds.
- self._amount_read = 0
- self._callbacks = callbacks
- if callbacks is None:
- self._callbacks = []
- self._callbacks_enabled = enable_callbacks
- self._close_callbacks = close_callbacks
- if close_callbacks is None:
- self._close_callbacks = close_callbacks
-
- @classmethod
- def from_filename(
- cls,
- filename,
- start_byte,
- chunk_size,
- callbacks=None,
- enable_callbacks=True,
- ):
- """Convenience factory function to create from a filename.
-
- :type start_byte: int
- :param start_byte: The first byte from which to start reading.
-
- :type chunk_size: int
- :param chunk_size: The max chunk size to read. Trying to read
- pass the end of the chunk size will behave like you've
- reached the end of the file.
-
- :type full_file_size: int
- :param full_file_size: The entire content length associated
- with ``fileobj``.
-
- :type callbacks: function(amount_read)
- :param callbacks: Called whenever data is read from this object.
-
- :type enable_callbacks: bool
- :param enable_callbacks: Indicate whether to invoke callback
- during read() calls.
-
- :rtype: ``ReadFileChunk``
- :return: A new instance of ``ReadFileChunk``
-
- """
- f = open(filename, 'rb')
- f.seek(start_byte)
- file_size = os.fstat(f.fileno()).st_size
- return cls(f, chunk_size, file_size, callbacks, enable_callbacks)
-
- def _calculate_file_size(
- self, fileobj, requested_size, start_byte, actual_file_size
- ):
- max_chunk_size = actual_file_size - start_byte
- return min(max_chunk_size, requested_size)
-
- def read(self, amount=None):
- amount_left = max(self._size - self._amount_read, 0)
- if amount is None:
- amount_to_read = amount_left
- else:
- amount_to_read = min(amount_left, amount)
- data = self._fileobj.read(amount_to_read)
- self._amount_read += len(data)
- if self._callbacks is not None and self._callbacks_enabled:
- invoke_progress_callbacks(self._callbacks, len(data))
- return data
-
- def signal_transferring(self):
- self.enable_callback()
- if hasattr(self._fileobj, 'signal_transferring'):
- self._fileobj.signal_transferring()
-
- def signal_not_transferring(self):
- self.disable_callback()
- if hasattr(self._fileobj, 'signal_not_transferring'):
- self._fileobj.signal_not_transferring()
-
- def enable_callback(self):
- self._callbacks_enabled = True
-
- def disable_callback(self):
- self._callbacks_enabled = False
-
- def seek(self, where, whence=0):
- if whence not in (0, 1, 2):
- # Mimic io's error for invalid whence values
- raise ValueError(f"invalid whence ({whence}, should be 0, 1 or 2)")
-
- # Recalculate where based on chunk attributes so seek from file
- # start (whence=0) is always used
- where += self._start_byte
- if whence == 1:
- where += self._amount_read
- elif whence == 2:
- where += self._size
-
- self._fileobj.seek(max(where, self._start_byte))
- if self._callbacks is not None and self._callbacks_enabled:
- # To also rewind the callback() for an accurate progress report
- bounded_where = max(min(where - self._start_byte, self._size), 0)
- bounded_amount_read = min(self._amount_read, self._size)
- amount = bounded_where - bounded_amount_read
- invoke_progress_callbacks(
- self._callbacks, bytes_transferred=amount
- )
- self._amount_read = max(where - self._start_byte, 0)
-
- def close(self):
- if self._close_callbacks is not None and self._callbacks_enabled:
- for callback in self._close_callbacks:
- callback()
- self._fileobj.close()
-
- def tell(self):
- return self._amount_read
-
- def __len__(self):
- # __len__ is defined because requests will try to determine the length
- # of the stream to set a content length. In the normal case
- # of the file it will just stat the file, but we need to change that
- # behavior. By providing a __len__, requests will use that instead
- # of stat'ing the file.
- return self._size
-
- def __enter__(self):
- return self
-
- def __exit__(self, *args, **kwargs):
- self.close()
-
- def __iter__(self):
- # This is a workaround for http://bugs.python.org/issue17575
- # Basically httplib will try to iterate over the contents, even
- # if its a file like object. This wasn't noticed because we've
- # already exhausted the stream so iterating over the file immediately
- # stops, which is what we're simulating here.
- return iter([])
-
-
-class StreamReaderProgress:
- """Wrapper for a read only stream that adds progress callbacks."""
-
- def __init__(self, stream, callbacks=None):
- self._stream = stream
- self._callbacks = callbacks
- if callbacks is None:
- self._callbacks = []
-
- def read(self, *args, **kwargs):
- value = self._stream.read(*args, **kwargs)
- invoke_progress_callbacks(self._callbacks, len(value))
- return value
-
-
-class NoResourcesAvailable(Exception):
- pass
-
-
-class TaskSemaphore:
- def __init__(self, count):
- """A semaphore for the purpose of limiting the number of tasks
-
- :param count: The size of semaphore
- """
- self._semaphore = threading.Semaphore(count)
-
- def acquire(self, tag, blocking=True):
- """Acquire the semaphore
-
- :param tag: A tag identifying what is acquiring the semaphore. Note
- that this is not really needed to directly use this class but is
- needed for API compatibility with the SlidingWindowSemaphore
- implementation.
- :param block: If True, block until it can be acquired. If False,
- do not block and raise an exception if cannot be acquired.
-
- :returns: A token (can be None) to use when releasing the semaphore
- """
- logger.debug("Acquiring %s", tag)
- if not self._semaphore.acquire(blocking):
- raise NoResourcesAvailable("Cannot acquire tag '%s'" % tag)
-
- def release(self, tag, acquire_token):
- """Release the semaphore
-
- :param tag: A tag identifying what is releasing the semaphore
- :param acquire_token: The token returned from when the semaphore was
- acquired. Note that this is not really needed to directly use this
- class but is needed for API compatibility with the
- SlidingWindowSemaphore implementation.
- """
- logger.debug(f"Releasing acquire {tag}/{acquire_token}")
- self._semaphore.release()
-
-
-class SlidingWindowSemaphore(TaskSemaphore):
- """A semaphore used to coordinate sequential resource access.
-
- This class is similar to the stdlib BoundedSemaphore:
-
- * It's initialized with a count.
- * Each call to ``acquire()`` decrements the counter.
- * If the count is at zero, then ``acquire()`` will either block until the
- count increases, or if ``blocking=False``, then it will raise
- a NoResourcesAvailable exception indicating that it failed to acquire the
- semaphore.
-
- The main difference is that this semaphore is used to limit
- access to a resource that requires sequential access. For example,
- if I want to access resource R that has 20 subresources R_0 - R_19,
- this semaphore can also enforce that you only have a max range of
- 10 at any given point in time. You must also specify a tag name
- when you acquire the semaphore. The sliding window semantics apply
- on a per tag basis. The internal count will only be incremented
- when the minimum sequence number for a tag is released.
-
- """
-
- def __init__(self, count):
- self._count = count
- # Dict[tag, next_sequence_number].
- self._tag_sequences = defaultdict(int)
- self._lowest_sequence = {}
- self._lock = threading.Lock()
- self._condition = threading.Condition(self._lock)
- # Dict[tag, List[sequence_number]]
- self._pending_release = {}
-
- def current_count(self):
- with self._lock:
- return self._count
-
- def acquire(self, tag, blocking=True):
- logger.debug("Acquiring %s", tag)
- self._condition.acquire()
- try:
- if self._count == 0:
- if not blocking:
- raise NoResourcesAvailable("Cannot acquire tag '%s'" % tag)
- else:
- while self._count == 0:
- self._condition.wait()
- # self._count is no longer zero.
- # First, check if this is the first time we're seeing this tag.
- sequence_number = self._tag_sequences[tag]
- if sequence_number == 0:
- # First time seeing the tag, so record we're at 0.
- self._lowest_sequence[tag] = sequence_number
- self._tag_sequences[tag] += 1
- self._count -= 1
- return sequence_number
- finally:
- self._condition.release()
-
- def release(self, tag, acquire_token):
- sequence_number = acquire_token
- logger.debug("Releasing acquire %s/%s", tag, sequence_number)
- self._condition.acquire()
- try:
- if tag not in self._tag_sequences:
- raise ValueError("Attempted to release unknown tag: %s" % tag)
- max_sequence = self._tag_sequences[tag]
- if self._lowest_sequence[tag] == sequence_number:
- # We can immediately process this request and free up
- # resources.
- self._lowest_sequence[tag] += 1
- self._count += 1
- self._condition.notify()
- queued = self._pending_release.get(tag, [])
- while queued:
- if self._lowest_sequence[tag] == queued[-1]:
- queued.pop()
- self._lowest_sequence[tag] += 1
- self._count += 1
- else:
- break
- elif self._lowest_sequence[tag] < sequence_number < max_sequence:
- # We can't do anything right now because we're still waiting
- # for the min sequence for the tag to be released. We have
- # to queue this for pending release.
- self._pending_release.setdefault(tag, []).append(
- sequence_number
- )
- self._pending_release[tag].sort(reverse=True)
- else:
- raise ValueError(
- "Attempted to release unknown sequence number "
- "%s for tag: %s" % (sequence_number, tag)
- )
- finally:
- self._condition.release()
-
-
-class ChunksizeAdjuster:
- def __init__(
- self,
- max_size=MAX_SINGLE_UPLOAD_SIZE,
- min_size=MIN_UPLOAD_CHUNKSIZE,
- max_parts=MAX_PARTS,
- ):
- self.max_size = max_size
- self.min_size = min_size
- self.max_parts = max_parts
-
- def adjust_chunksize(self, current_chunksize, file_size=None):
- """Get a chunksize close to current that fits within all S3 limits.
-
- :type current_chunksize: int
- :param current_chunksize: The currently configured chunksize.
-
- :type file_size: int or None
- :param file_size: The size of the file to upload. This might be None
- if the object being transferred has an unknown size.
-
- :returns: A valid chunksize that fits within configured limits.
- """
- chunksize = current_chunksize
- if file_size is not None:
- chunksize = self._adjust_for_max_parts(chunksize, file_size)
- return self._adjust_for_chunksize_limits(chunksize)
-
- def _adjust_for_chunksize_limits(self, current_chunksize):
- if current_chunksize > self.max_size:
- logger.debug(
- "Chunksize greater than maximum chunksize. "
- "Setting to %s from %s." % (self.max_size, current_chunksize)
- )
- return self.max_size
- elif current_chunksize < self.min_size:
- logger.debug(
- "Chunksize less than minimum chunksize. "
- "Setting to %s from %s." % (self.min_size, current_chunksize)
- )
- return self.min_size
- else:
- return current_chunksize
-
- def _adjust_for_max_parts(self, current_chunksize, file_size):
- chunksize = current_chunksize
- num_parts = int(math.ceil(file_size / float(chunksize)))
-
- while num_parts > self.max_parts:
- chunksize *= 2
- num_parts = int(math.ceil(file_size / float(chunksize)))
-
- if chunksize != current_chunksize:
- logger.debug(
- "Chunksize would result in the number of parts exceeding the "
- "maximum. Setting to %s from %s."
- % (chunksize, current_chunksize)
- )
-
- return chunksize
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/data/samplers/grouped_batch_sampler.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/data/samplers/grouped_batch_sampler.py
deleted file mode 100644
index 138e106136083383d9f8729f1da930804463b297..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/data/samplers/grouped_batch_sampler.py
+++ /dev/null
@@ -1,47 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-import numpy as np
-from torch.utils.data.sampler import BatchSampler, Sampler
-
-
-class GroupedBatchSampler(BatchSampler):
- """
- Wraps another sampler to yield a mini-batch of indices.
- It enforces that the batch only contain elements from the same group.
- It also tries to provide mini-batches which follows an ordering which is
- as close as possible to the ordering from the original sampler.
- """
-
- def __init__(self, sampler, group_ids, batch_size):
- """
- Args:
- sampler (Sampler): Base sampler.
- group_ids (list[int]): If the sampler produces indices in range [0, N),
- `group_ids` must be a list of `N` ints which contains the group id of each sample.
- The group ids must be a set of integers in the range [0, num_groups).
- batch_size (int): Size of mini-batch.
- """
- if not isinstance(sampler, Sampler):
- raise ValueError(
- "sampler should be an instance of "
- "torch.utils.data.Sampler, but got sampler={}".format(sampler)
- )
- self.sampler = sampler
- self.group_ids = np.asarray(group_ids)
- assert self.group_ids.ndim == 1
- self.batch_size = batch_size
- groups = np.unique(self.group_ids).tolist()
-
- # buffer the indices of each group until batch size is reached
- self.buffer_per_group = {k: [] for k in groups}
-
- def __iter__(self):
- for idx in self.sampler:
- group_id = self.group_ids[idx]
- group_buffer = self.buffer_per_group[group_id]
- group_buffer.append(idx)
- if len(group_buffer) == self.batch_size:
- yield group_buffer[:] # yield a copy of the list
- del group_buffer[:]
-
- def __len__(self):
- raise NotImplementedError("len() of GroupedBatchSampler is not well-defined.")
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/modeling/proposal_generator/proposal_utils.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/modeling/proposal_generator/proposal_utils.py
deleted file mode 100644
index d4af90525ba07eb8d313460ee2c3f468fe367cff..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/modeling/proposal_generator/proposal_utils.py
+++ /dev/null
@@ -1,57 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-import math
-import torch
-
-from detectron2.structures import Instances
-
-
-def add_ground_truth_to_proposals(gt_boxes, proposals):
- """
- Call `add_ground_truth_to_proposals_single_image` for all images.
-
- Args:
- gt_boxes(list[Boxes]): list of N elements. Element i is a Boxes
- representing the gound-truth for image i.
- proposals (list[Instances]): list of N elements. Element i is a Instances
- representing the proposals for image i.
-
- Returns:
- list[Instances]: list of N Instances. Each is the proposals for the image,
- with field "proposal_boxes" and "objectness_logits".
- """
- assert gt_boxes is not None
-
- assert len(proposals) == len(gt_boxes)
- if len(proposals) == 0:
- return proposals
-
- return [
- add_ground_truth_to_proposals_single_image(gt_boxes_i, proposals_i)
- for gt_boxes_i, proposals_i in zip(gt_boxes, proposals)
- ]
-
-
-def add_ground_truth_to_proposals_single_image(gt_boxes, proposals):
- """
- Augment `proposals` with ground-truth boxes from `gt_boxes`.
-
- Args:
- Same as `add_ground_truth_to_proposals`, but with gt_boxes and proposals
- per image.
-
- Returns:
- Same as `add_ground_truth_to_proposals`, but for only one image.
- """
- device = proposals.objectness_logits.device
- # Concatenating gt_boxes with proposals requires them to have the same fields
- # Assign all ground-truth boxes an objectness logit corresponding to P(object) \approx 1.
- gt_logit_value = math.log((1.0 - 1e-10) / (1 - (1.0 - 1e-10)))
-
- gt_logits = gt_logit_value * torch.ones(len(gt_boxes), device=device)
- gt_proposal = Instances(proposals.image_size)
-
- gt_proposal.proposal_boxes = gt_boxes
- gt_proposal.objectness_logits = gt_logits
- new_proposals = Instances.cat([proposals, gt_proposal])
-
- return new_proposals
diff --git a/spaces/CVPR/GFPGAN-example/gfpgan/train.py b/spaces/CVPR/GFPGAN-example/gfpgan/train.py
deleted file mode 100644
index fe5f1f909ae15a8d830ef65dcb43436d4f4ee7ae..0000000000000000000000000000000000000000
--- a/spaces/CVPR/GFPGAN-example/gfpgan/train.py
+++ /dev/null
@@ -1,11 +0,0 @@
-# flake8: noqa
-import os.path as osp
-from basicsr.train import train_pipeline
-
-import gfpgan.archs
-import gfpgan.data
-import gfpgan.models
-
-if __name__ == '__main__':
- root_path = osp.abspath(osp.join(__file__, osp.pardir, osp.pardir))
- train_pipeline(root_path)
diff --git a/spaces/CVPR/LIVE/pybind11/tests/test_union.py b/spaces/CVPR/LIVE/pybind11/tests/test_union.py
deleted file mode 100644
index 2a2c12fb4836a0f2194e06af7781216d78ed0ba2..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/pybind11/tests/test_union.py
+++ /dev/null
@@ -1,9 +0,0 @@
-# -*- coding: utf-8 -*-
-from pybind11_tests import union_ as m
-
-
-def test_union():
- instance = m.TestUnion()
-
- instance.as_uint = 10
- assert instance.as_int == 10
diff --git a/spaces/CVPR/LIVE/thrust/thrust/system/detail/generic/swap_ranges.h b/spaces/CVPR/LIVE/thrust/thrust/system/detail/generic/swap_ranges.h
deleted file mode 100644
index 78769715c5b3f07ce74ddc3807369c8692af2426..0000000000000000000000000000000000000000
--- a/spaces/CVPR/LIVE/thrust/thrust/system/detail/generic/swap_ranges.h
+++ /dev/null
@@ -1,47 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-
-#pragma once
-
-#include
-#include
-
-namespace thrust
-{
-namespace system
-{
-namespace detail
-{
-namespace generic
-{
-
-template
-__host__ __device__
- ForwardIterator2 swap_ranges(thrust::execution_policy &exec,
- ForwardIterator1 first1,
- ForwardIterator1 last1,
- ForwardIterator2 first2);
-
-} // end namespace generic
-} // end namespace detail
-} // end namespace system
-} // end namespace thrust
-
-#include
-
diff --git a/spaces/CofAI/chat.b4/client/css/label.css b/spaces/CofAI/chat.b4/client/css/label.css
deleted file mode 100644
index d84873d41e41f2cc22f9d3ace67c30ec07706811..0000000000000000000000000000000000000000
--- a/spaces/CofAI/chat.b4/client/css/label.css
+++ /dev/null
@@ -1,16 +0,0 @@
-label {
- cursor: pointer;
- text-indent: -9999px;
- width: 50px;
- height: 30px;
- backdrop-filter: blur(20px);
- -webkit-backdrop-filter: blur(20px);
- background-color: var(--blur-bg);
- border-radius: var(--border-radius-1);
- border: 1px solid var(--blur-border);
- display: block;
- border-radius: 100px;
- position: relative;
- overflow: hidden;
- transition: 0.33s;
-}
diff --git a/spaces/CofAI/chat.b4/server/bp.py b/spaces/CofAI/chat.b4/server/bp.py
deleted file mode 100644
index 61d416797039dababd9e8222b4fc910ef65c40b9..0000000000000000000000000000000000000000
--- a/spaces/CofAI/chat.b4/server/bp.py
+++ /dev/null
@@ -1,6 +0,0 @@
-from flask import Blueprint
-
-bp = Blueprint('bp', __name__,
- template_folder='./../client/html',
- static_folder='./../client',
- static_url_path='assets')
diff --git a/spaces/Curranj/Regex_Generator/app.py b/spaces/Curranj/Regex_Generator/app.py
deleted file mode 100644
index 63c3ba3e25d7541315e8acc5438c9cc2e0c894a7..0000000000000000000000000000000000000000
--- a/spaces/Curranj/Regex_Generator/app.py
+++ /dev/null
@@ -1,35 +0,0 @@
-import openai
-import gradio as gr
-import os
-
-
-#OpenAi call
-
-
-def gpt3(texts):
- openai.api_key = os.environ["Secret"]
- response = openai.Completion.create(
- engine="code-davinci-002",
- prompt= texts,
- temperature=0,
- max_tokens=750,
- top_p=1,
- frequency_penalty=0.0,
- presence_penalty=0.0,
- stop = ("'","#", "")
- )
- x = response.choices[0].text
-
- return x
-
-# Function to elicit regex response from model
-def greet(prompt):
- txt= (f"""#---Regex Generator--- \n #Prompt: {prompt}\n#Regex String :\n#'""")
- regex = gpt3(txt)
- return regex
-
-
-#Code to set up Gradio UI
-iface = gr.Interface(greet, inputs = ["text"], outputs = "text",title="Natural Language to Regex ", description="Enter any prompt and get a regex statement back!")
-iface.launch()
-
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/PaletteFile.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/PaletteFile.py
deleted file mode 100644
index 4a2c497fc495a271cbab204db0197d776442ac5c..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/PaletteFile.py
+++ /dev/null
@@ -1,51 +0,0 @@
-#
-# Python Imaging Library
-# $Id$
-#
-# stuff to read simple, teragon-style palette files
-#
-# History:
-# 97-08-23 fl Created
-#
-# Copyright (c) Secret Labs AB 1997.
-# Copyright (c) Fredrik Lundh 1997.
-#
-# See the README file for information on usage and redistribution.
-#
-
-from ._binary import o8
-
-
-class PaletteFile:
- """File handler for Teragon-style palette files."""
-
- rawmode = "RGB"
-
- def __init__(self, fp):
- self.palette = [(i, i, i) for i in range(256)]
-
- while True:
- s = fp.readline()
-
- if not s:
- break
- if s[:1] == b"#":
- continue
- if len(s) > 100:
- msg = "bad palette file"
- raise SyntaxError(msg)
-
- v = [int(x) for x in s.split()]
- try:
- [i, r, g, b] = v
- except ValueError:
- [i, r] = v
- g = b = r
-
- if 0 <= i <= 255:
- self.palette[i] = o8(r) + o8(g) + o8(b)
-
- self.palette = b"".join(self.palette)
-
- def getpalette(self):
- return self.palette, self.rawmode
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/pens/qu2cuPen.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/pens/qu2cuPen.py
deleted file mode 100644
index 7e400f98c45cb7fdbbba00df009b7819adffec4c..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/pens/qu2cuPen.py
+++ /dev/null
@@ -1,105 +0,0 @@
-# Copyright 2016 Google Inc. All Rights Reserved.
-# Copyright 2023 Behdad Esfahbod. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from fontTools.qu2cu import quadratic_to_curves
-from fontTools.pens.filterPen import ContourFilterPen
-from fontTools.pens.reverseContourPen import ReverseContourPen
-import math
-
-
-class Qu2CuPen(ContourFilterPen):
- """A filter pen to convert quadratic bezier splines to cubic curves
- using the FontTools SegmentPen protocol.
-
- Args:
-
- other_pen: another SegmentPen used to draw the transformed outline.
- max_err: maximum approximation error in font units. For optimal results,
- if you know the UPEM of the font, we recommend setting this to a
- value equal, or close to UPEM / 1000.
- reverse_direction: flip the contours' direction but keep starting point.
- stats: a dictionary counting the point numbers of cubic segments.
- """
-
- def __init__(
- self,
- other_pen,
- max_err,
- all_cubic=False,
- reverse_direction=False,
- stats=None,
- ):
- if reverse_direction:
- other_pen = ReverseContourPen(other_pen)
- super().__init__(other_pen)
- self.all_cubic = all_cubic
- self.max_err = max_err
- self.stats = stats
-
- def _quadratics_to_curve(self, q):
- curves = quadratic_to_curves(q, self.max_err, all_cubic=self.all_cubic)
- if self.stats is not None:
- for curve in curves:
- n = str(len(curve) - 2)
- self.stats[n] = self.stats.get(n, 0) + 1
- for curve in curves:
- if len(curve) == 4:
- yield ("curveTo", curve[1:])
- else:
- yield ("qCurveTo", curve[1:])
-
- def filterContour(self, contour):
- quadratics = []
- currentPt = None
- newContour = []
- for op, args in contour:
- if op == "qCurveTo" and (
- self.all_cubic or (len(args) > 2 and args[-1] is not None)
- ):
- if args[-1] is None:
- raise NotImplementedError(
- "oncurve-less contours with all_cubic not implemented"
- )
- quadratics.append((currentPt,) + args)
- else:
- if quadratics:
- newContour.extend(self._quadratics_to_curve(quadratics))
- quadratics = []
- newContour.append((op, args))
- currentPt = args[-1] if args else None
- if quadratics:
- newContour.extend(self._quadratics_to_curve(quadratics))
-
- if not self.all_cubic:
- # Add back implicit oncurve points
- contour = newContour
- newContour = []
- for op, args in contour:
- if op == "qCurveTo" and newContour and newContour[-1][0] == "qCurveTo":
- pt0 = newContour[-1][1][-2]
- pt1 = newContour[-1][1][-1]
- pt2 = args[0]
- if (
- pt1 is not None
- and math.isclose(pt2[0] - pt1[0], pt1[0] - pt0[0])
- and math.isclose(pt2[1] - pt1[1], pt1[1] - pt0[1])
- ):
- newArgs = newContour[-1][1][:-1] + args
- newContour[-1] = (op, newArgs)
- continue
-
- newContour.append((op, args))
-
- return newContour
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/index-9a8f514c.js b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/index-9a8f514c.js
deleted file mode 100644
index 16f0c8d1871eab5df08cdf6c7377e2f879b671c8..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/index-9a8f514c.js
+++ /dev/null
@@ -1,2 +0,0 @@
-import{S as G,e as I,s as J,G as Z,N as O,K as F,p as U,M as z,n as q,A as j,V as be,B as K,P as D,O as S,U as $,Q as ge,R as x,k as p,m as L,o as v,u as Q,v as d,y as V,z as h,x as y,F as C,a7 as de,h as he,j as we,t as ke,a9 as Ae,ab as pe,ac as ve,ad as ye,ak as k,at as Fe,au as Be,E as ze,ae as Ue,q as je,r as Ee}from"./index-1d65707a.js";import{B as Ne}from"./Button-f155035a.js";import{B as ae}from"./BlockLabel-66866176.js";import{E as Oe}from"./Empty-eec13822.js";import{F as W}from"./File-b8a2be67.js";import{U as Se}from"./Upload-9bb55fba.js";import{M as Te}from"./ModifyUpload-c89cfce3.js";import{n as ee,b as Me}from"./ModifyUpload.svelte_svelte_type_style_lang-d2acacf0.js";import{U as Pe}from"./UploadText-f599be03.js";import"./Blocks-c9e1499d.js";import"./IconButton-d42f3661.js";const Ce=t=>{let e=["B","KB","MB","GB","PB"],n=0;for(;t>1024;)t/=1024,n++;let l=e[n];return t.toFixed(1)+" "+l},le=t=>{var e;return e=t.orig_name||t.name,e.length>30?`${e.substr(0,30)}...`:e},te=t=>{var e=0;if(Array.isArray(t))for(var n of t)n.size!==void 0&&(e+=n.size);else e=t.size||0;return Ce(e)};function ne(t,e,n){const l=t.slice();return l[4]=e[n],l[6]=n,l}function Re(t){let e;return{c(){e=D("Uploading...")},m(n,l){U(n,e,l)},p:q,d(n){n&&j(e)}}}function qe(t){let e,n,l,s;return{c(){e=O("a"),n=D("Download"),F(e,"href",l=t[4].data),F(e,"target","_blank"),F(e,"download",s=window.__is_colab__?null:t[4].orig_name||t[4].name),F(e,"class","svelte-xrr240")},m(a,i){U(a,e,i),z(e,n)},p(a,i){i&1&&l!==(l=a[4].data)&&F(e,"href",l),i&1&&s!==(s=window.__is_colab__?null:a[4].orig_name||a[4].name)&&F(e,"download",s)},d(a){a&&j(e)}}}function se(t){let e,n,l=le(t[4])+"",s,a,i,f=te(t[4])+"",r,g,o,m,_,b;function B(c,E){return c[4].data?qe:Re}let w=B(t),A=w(t);function T(){return t[3](t[4],t[6])}return{c(){e=O("tr"),n=O("td"),s=D(l),a=S(),i=O("td"),r=D(f),g=S(),o=O("td"),A.c(),m=S(),F(n,"class","svelte-xrr240"),F(i,"class","svelte-xrr240"),F(o,"class","download svelte-xrr240"),F(e,"class","file svelte-xrr240"),$(e,"selectable",t[1])},m(c,E){U(c,e,E),z(e,n),z(n,s),z(e,a),z(e,i),z(i,r),z(e,g),z(e,o),A.m(o,null),z(e,m),_||(b=ge(e,"click",T),_=!0)},p(c,E){t=c,E&1&&l!==(l=le(t[4])+"")&&x(s,l),E&1&&f!==(f=te(t[4])+"")&&x(r,f),w===(w=B(t))&&A?A.p(t,E):(A.d(1),A=w(t),A&&(A.c(),A.m(o,null))),E&2&&$(e,"selectable",t[1])},d(c){c&&j(e),A.d(),_=!1,b()}}}function De(t){let e,n,l,s=Z(Array.isArray(t[0])?t[0]:[t[0]]),a=[];for(let i=0;il("select",{value:f.orig_name||f.name,index:r});return t.$$set=f=>{"value"in f&&n(0,s=f.value),"selectable"in f&&n(1,a=f.selectable)},[s,a,l,i]}class ie extends G{constructor(e){super(),I(this,e,Ge,De,J,{value:0,selectable:1})}}function Ie(t){let e,n;return e=new Oe({props:{unpadded_box:!0,size:"large",$$slots:{default:[Ke]},$$scope:{ctx:t}}}),{c(){p(e.$$.fragment)},m(l,s){v(e,l,s),n=!0},p(l,s){const a={};s&32&&(a.$$scope={dirty:s,ctx:l}),e.$set(a)},i(l){n||(h(e.$$.fragment,l),n=!0)},o(l){d(e.$$.fragment,l),n=!1},d(l){y(e,l)}}}function Je(t){let e,n;return e=new ie({props:{selectable:t[3],value:t[0]}}),e.$on("select",t[4]),{c(){p(e.$$.fragment)},m(l,s){v(e,l,s),n=!0},p(l,s){const a={};s&8&&(a.selectable=l[3]),s&1&&(a.value=l[0]),e.$set(a)},i(l){n||(h(e.$$.fragment,l),n=!0)},o(l){d(e.$$.fragment,l),n=!1},d(l){y(e,l)}}}function Ke(t){let e,n;return e=new W({}),{c(){p(e.$$.fragment)},m(l,s){v(e,l,s),n=!0},i(l){n||(h(e.$$.fragment,l),n=!0)},o(l){d(e.$$.fragment,l),n=!1},d(l){y(e,l)}}}function Le(t){let e,n,l,s,a,i;e=new ae({props:{show_label:t[2],float:t[0]===null,Icon:W,label:t[1]||"File"}});const f=[Je,Ie],r=[];function g(o,m){return o[0]?0:1}return l=g(t),s=r[l]=f[l](t),{c(){p(e.$$.fragment),n=S(),s.c(),a=L()},m(o,m){v(e,o,m),U(o,n,m),r[l].m(o,m),U(o,a,m),i=!0},p(o,[m]){const _={};m&4&&(_.show_label=o[2]),m&1&&(_.float=o[0]===null),m&2&&(_.label=o[1]||"File"),e.$set(_);let b=l;l=g(o),l===b?r[l].p(o,m):(Q(),d(r[b],1,1,()=>{r[b]=null}),V(),s=r[l],s?s.p(o,m):(s=r[l]=f[l](o),s.c()),h(s,1),s.m(a.parentNode,a))},i(o){i||(h(e.$$.fragment,o),h(s),i=!0)},o(o){d(e.$$.fragment,o),d(s),i=!1},d(o){o&&(j(n),j(a)),y(e,o),r[l].d(o)}}}function Qe(t,e,n){let{value:l=null}=e,{label:s}=e,{show_label:a=!0}=e,{selectable:i=!1}=e;function f(r){C.call(this,t,r)}return t.$$set=r=>{"value"in r&&n(0,l=r.value),"label"in r&&n(1,s=r.label),"show_label"in r&&n(2,a=r.show_label),"selectable"in r&&n(3,i=r.selectable)},[l,s,a,i,f]}class Ve extends G{constructor(e){super(),I(this,e,Qe,Le,J,{value:0,label:1,show_label:2,selectable:3})}}function We(t){let e,n,l;function s(i){t[12](i)}let a={filetype:t[6],parse_to_data_url:!1,file_count:t[3],$$slots:{default:[Xe]},$$scope:{ctx:t}};return t[5]!==void 0&&(a.dragging=t[5]),e=new Se({props:a}),he.push(()=>we(e,"dragging",s)),e.$on("load",t[7]),{c(){p(e.$$.fragment)},m(i,f){v(e,i,f),l=!0},p(i,f){const r={};f&64&&(r.filetype=i[6]),f&8&&(r.file_count=i[3]),f&8192&&(r.$$scope={dirty:f,ctx:i}),!n&&f&32&&(n=!0,r.dragging=i[5],ke(()=>n=!1)),e.$set(r)},i(i){l||(h(e.$$.fragment,i),l=!0)},o(i){d(e.$$.fragment,i),l=!1},d(i){y(e,i)}}}function He(t){let e,n,l,s;return e=new Te({props:{absolute:!0}}),e.$on("clear",t[8]),l=new ie({props:{selectable:t[4],value:t[0]}}),l.$on("select",t[11]),{c(){p(e.$$.fragment),n=S(),p(l.$$.fragment)},m(a,i){v(e,a,i),U(a,n,i),v(l,a,i),s=!0},p(a,i){const f={};i&16&&(f.selectable=a[4]),i&1&&(f.value=a[0]),l.$set(f)},i(a){s||(h(e.$$.fragment,a),h(l.$$.fragment,a),s=!0)},o(a){d(e.$$.fragment,a),d(l.$$.fragment,a),s=!1},d(a){a&&j(n),y(e,a),y(l,a)}}}function Xe(t){let e;const n=t[10].default,l=Ae(n,t,t[13],null);return{c(){l&&l.c()},m(s,a){l&&l.m(s,a),e=!0},p(s,a){l&&l.p&&(!e||a&8192)&&pe(l,n,s,s[13],e?ye(n,s[13],a,null):ve(s[13]),null)},i(s){e||(h(l,s),e=!0)},o(s){d(l,s),e=!1},d(s){l&&l.d(s)}}}function Ye(t){let e,n,l,s,a,i;e=new ae({props:{show_label:t[2],Icon:W,float:t[0]===null,label:t[1]||"File"}});const f=[He,We],r=[];function g(o,m){return o[0]?0:1}return l=g(t),s=r[l]=f[l](t),{c(){p(e.$$.fragment),n=S(),s.c(),a=L()},m(o,m){v(e,o,m),U(o,n,m),r[l].m(o,m),U(o,a,m),i=!0},p(o,[m]){const _={};m&4&&(_.show_label=o[2]),m&1&&(_.float=o[0]===null),m&2&&(_.label=o[1]||"File"),e.$set(_);let b=l;l=g(o),l===b?r[l].p(o,m):(Q(),d(r[b],1,1,()=>{r[b]=null}),V(),s=r[l],s?s.p(o,m):(s=r[l]=f[l](o),s.c()),h(s,1),s.m(a.parentNode,a))},i(o){i||(h(e.$$.fragment,o),h(s),i=!0)},o(o){d(e.$$.fragment,o),d(s),i=!1},d(o){o&&(j(n),j(a)),y(e,o),r[l].d(o)}}}function Ze(t,e,n){let{$$slots:l={},$$scope:s}=e,{value:a}=e,{label:i}=e,{show_label:f=!0}=e,{file_count:r="single"}=e,{file_types:g=null}=e,{selectable:o=!1}=e;async function m({detail:c}){n(0,a=c),await de(),b("change",a),b("upload",c)}function _({detail:c}){n(0,a=null),b("change",a),b("clear")}const b=K();let B;g==null?B=null:(g=g.map(c=>c.startsWith(".")?c:c+"/*"),B=g.join(", "));let w=!1;function A(c){C.call(this,t,c)}function T(c){w=c,n(5,w)}return t.$$set=c=>{"value"in c&&n(0,a=c.value),"label"in c&&n(1,i=c.label),"show_label"in c&&n(2,f=c.show_label),"file_count"in c&&n(3,r=c.file_count),"file_types"in c&&n(9,g=c.file_types),"selectable"in c&&n(4,o=c.selectable),"$$scope"in c&&n(13,s=c.$$scope)},t.$$.update=()=>{t.$$.dirty&32&&b("drag",w)},[a,i,f,r,o,w,B,m,_,g,l,A,T,s]}class $e extends G{constructor(e){super(),I(this,e,Ze,Ye,J,{value:0,label:1,show_label:2,file_count:3,file_types:9,selectable:4})}}function xe(t){let e,n;return e=new Ve({props:{selectable:t[9],value:t[14],label:t[5],show_label:t[6]}}),e.$on("select",t[24]),{c(){p(e.$$.fragment)},m(l,s){v(e,l,s),n=!0},p(l,s){const a={};s&512&&(a.selectable=l[9]),s&16384&&(a.value=l[14]),s&32&&(a.label=l[5]),s&64&&(a.show_label=l[6]),e.$set(a)},i(l){n||(h(e.$$.fragment,l),n=!0)},o(l){d(e.$$.fragment,l),n=!1},d(l){y(e,l)}}}function el(t){let e,n;return e=new $e({props:{label:t[5],show_label:t[6],value:t[14],file_count:t[7],file_types:t[8],selectable:t[9],$$slots:{default:[ll]},$$scope:{ctx:t}}}),e.$on("change",t[20]),e.$on("drag",t[21]),e.$on("clear",t[22]),e.$on("select",t[23]),{c(){p(e.$$.fragment)},m(l,s){v(e,l,s),n=!0},p(l,s){const a={};s&32&&(a.label=l[5]),s&64&&(a.show_label=l[6]),s&16384&&(a.value=l[14]),s&128&&(a.file_count=l[7]),s&256&&(a.file_types=l[8]),s&512&&(a.selectable=l[9]),s&134217728&&(a.$$scope={dirty:s,ctx:l}),e.$set(a)},i(l){n||(h(e.$$.fragment,l),n=!0)},o(l){d(e.$$.fragment,l),n=!1},d(l){y(e,l)}}}function ll(t){let e,n;return e=new Pe({props:{type:"file"}}),{c(){p(e.$$.fragment)},m(l,s){v(e,l,s),n=!0},p:q,i(l){n||(h(e.$$.fragment,l),n=!0)},o(l){d(e.$$.fragment,l),n=!1},d(l){y(e,l)}}}function tl(t){let e,n,l,s,a,i;const f=[t[10],{status:t[16]?"generating":t[10]?.status||"complete"}];let r={};for(let _=0;_{o[w]=null}),V(),s=o[l],s?s.p(_,b):(s=o[l]=g[l](_),s.c()),h(s,1),s.m(a.parentNode,a))},i(_){i||(h(e.$$.fragment,_),h(s),i=!0)},o(_){d(e.$$.fragment,_),d(s),i=!1},d(_){_&&(j(n),j(a)),y(e,_),o[l].d(_)}}}function nl(t){let e,n;return e=new Ne({props:{visible:t[3],variant:t[4]==="dynamic"&&t[0]===null?"dashed":"solid",border_mode:t[15]?"focus":"base",padding:!1,elem_id:t[1],elem_classes:t[2],container:t[11],scale:t[12],min_width:t[13],$$slots:{default:[tl]},$$scope:{ctx:t}}}),{c(){p(e.$$.fragment)},m(l,s){v(e,l,s),n=!0},p(l,[s]){const a={};s&8&&(a.visible=l[3]),s&17&&(a.variant=l[4]==="dynamic"&&l[0]===null?"dashed":"solid"),s&32768&&(a.border_mode=l[15]?"focus":"base"),s&2&&(a.elem_id=l[1]),s&4&&(a.elem_classes=l[2]),s&2048&&(a.container=l[11]),s&4096&&(a.scale=l[12]),s&8192&&(a.min_width=l[13]),s&134334449&&(a.$$scope={dirty:s,ctx:l}),e.$set(a)},i(l){n||(h(e.$$.fragment,l),n=!0)},o(l){d(e.$$.fragment,l),n=!1},d(l){y(e,l)}}}function sl(t,e,n){let l,{elem_id:s=""}=e,{elem_classes:a=[]}=e,{visible:i=!0}=e,{value:f}=e,r,{mode:g}=e,{root:o}=e,{label:m}=e,{show_label:_}=e,{file_count:b}=e,{file_types:B=["file"]}=e,{root_url:w}=e,{selectable:A=!1}=e,{loading_status:T}=e,{container:c=!0}=e,{scale:E=null}=e,{min_width:H=void 0}=e;const re=Fe("upload_files")??Be;let X=!1,M=!1;const R=K(),oe=({detail:u})=>n(0,f=u),fe=({detail:u})=>n(15,X=u);function ue(u){C.call(this,t,u)}function _e(u){C.call(this,t,u)}function ce(u){C.call(this,t,u)}return t.$$set=u=>{"elem_id"in u&&n(1,s=u.elem_id),"elem_classes"in u&&n(2,a=u.elem_classes),"visible"in u&&n(3,i=u.visible),"value"in u&&n(0,f=u.value),"mode"in u&&n(4,g=u.mode),"root"in u&&n(17,o=u.root),"label"in u&&n(5,m=u.label),"show_label"in u&&n(6,_=u.show_label),"file_count"in u&&n(7,b=u.file_count),"file_types"in u&&n(8,B=u.file_types),"root_url"in u&&n(18,w=u.root_url),"selectable"in u&&n(9,A=u.selectable),"loading_status"in u&&n(10,T=u.loading_status),"container"in u&&n(11,c=u.container),"scale"in u&&n(12,E=u.scale),"min_width"in u&&n(13,H=u.min_width)},t.$$.update=()=>{if(t.$$.dirty&393217&&n(14,l=ee(f,o,w)),t.$$.dirty&933905&&JSON.stringify(l)!==JSON.stringify(r)){if(n(19,r=l),l===null)R("change"),n(16,M=!1);else if(!(Array.isArray(l)?l:[l]).every(u=>u.blob))n(16,M=!1),R("change");else if(g==="dynamic"){let u=(Array.isArray(l)?l:[l]).map(P=>P.blob),me=l;n(16,M=!0),re(o,u).then(P=>{me===l&&(n(16,M=!1),P.error?(Array.isArray(l)?l:[l]).forEach(async(N,Y)=>{N.data=await Me(N.blob),N.blob=void 0}):((Array.isArray(l)?l:[l]).forEach((N,Y)=>{P.files&&(N.orig_name=N.name,N.name=P.files[Y],N.is_file=!0,N.blob=void 0)}),n(19,r=n(14,l=ee(f,o,w)))),R("change"),R("upload"))})}}},[f,s,a,i,g,m,_,b,B,A,T,c,E,H,l,X,M,o,w,r,oe,fe,ue,_e,ce]}class al extends G{constructor(e){super(),I(this,e,sl,nl,J,{elem_id:1,elem_classes:2,visible:3,value:0,mode:4,root:17,label:5,show_label:6,file_count:7,file_types:8,root_url:18,selectable:9,loading_status:10,container:11,scale:12,min_width:13})}get elem_id(){return this.$$.ctx[1]}set elem_id(e){this.$$set({elem_id:e}),k()}get elem_classes(){return this.$$.ctx[2]}set elem_classes(e){this.$$set({elem_classes:e}),k()}get visible(){return this.$$.ctx[3]}set visible(e){this.$$set({visible:e}),k()}get value(){return this.$$.ctx[0]}set value(e){this.$$set({value:e}),k()}get mode(){return this.$$.ctx[4]}set mode(e){this.$$set({mode:e}),k()}get root(){return this.$$.ctx[17]}set root(e){this.$$set({root:e}),k()}get label(){return this.$$.ctx[5]}set label(e){this.$$set({label:e}),k()}get show_label(){return this.$$.ctx[6]}set show_label(e){this.$$set({show_label:e}),k()}get file_count(){return this.$$.ctx[7]}set file_count(e){this.$$set({file_count:e}),k()}get file_types(){return this.$$.ctx[8]}set file_types(e){this.$$set({file_types:e}),k()}get root_url(){return this.$$.ctx[18]}set root_url(e){this.$$set({root_url:e}),k()}get selectable(){return this.$$.ctx[9]}set selectable(e){this.$$set({selectable:e}),k()}get loading_status(){return this.$$.ctx[10]}set loading_status(e){this.$$set({loading_status:e}),k()}get container(){return this.$$.ctx[11]}set container(e){this.$$set({container:e}),k()}get scale(){return this.$$.ctx[12]}set scale(e){this.$$set({scale:e}),k()}get min_width(){return this.$$.ctx[13]}set min_width(e){this.$$set({min_width:e}),k()}}const hl=al,wl=["static","dynamic"],kl=t=>({type:{input_payload:"{ name: string; data: string }",response_object:"{ orig_name: string; name: string, size: number, data: string, is_file: boolean}"},description:{input_payload:"object with file name and base64 data",response_object:"object that includes path to file. The URL: {ROOT}file={name} contains the data"},example_data:{name:"zip.zip",data:"data:@file/octet-stream;base64,UEsFBgAAAAAAAAAAAAAAAAAAAAAAAA=="}});export{hl as Component,kl as document,wl as modes};
-//# sourceMappingURL=index-9a8f514c.js.map
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/index-050c9abb.js b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/index-050c9abb.js
deleted file mode 100644
index 6ffc2659e94d74ce933e16ca2108df95e200727c..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/frontend/assets/index-050c9abb.js
+++ /dev/null
@@ -1,2 +0,0 @@
-import{S as L,e as M,s as j,N as w,K as o,U as c,p as g,n as H,A as d,B,k as h,o as v,z as b,v as k,x as T,E as S,ae as q,O as z,q as C,r as E,F as A}from"./index-3370be2a.js";import{B as D}from"./Button-89624748.js";function F(t){let e,i;return{c(){e=w("div"),o(e,"class",i="prose "+t[1].join(" ")+" svelte-1ybaih5"),o(e,"id",t[0]),c(e,"min",t[4]),c(e,"hide",!t[3])},m(s,n){g(s,e,n),e.innerHTML=t[2]},p(s,[n]){n&4&&(e.innerHTML=s[2]),n&2&&i!==(i="prose "+s[1].join(" ")+" svelte-1ybaih5")&&o(e,"class",i),n&1&&o(e,"id",s[0]),n&18&&c(e,"min",s[4]),n&10&&c(e,"hide",!s[3])},i:H,o:H,d(s){s&&d(e)}}}function K(t,e,i){let{elem_id:s=""}=e,{elem_classes:n=[]}=e,{value:m}=e,{visible:u=!0}=e,{min_height:f=!1}=e;const l=B();return t.$$set=a=>{"elem_id"in a&&i(0,s=a.elem_id),"elem_classes"in a&&i(1,n=a.elem_classes),"value"in a&&i(2,m=a.value),"visible"in a&&i(3,u=a.visible),"min_height"in a&&i(4,f=a.min_height)},t.$$.update=()=>{t.$$.dirty&4&&l("change")},[s,n,m,u,f]}class N extends L{constructor(e){super(),M(this,e,K,F,j,{elem_id:0,elem_classes:1,value:2,visible:3,min_height:4})}}function O(t){let e,i,s,n,m;const u=[t[4],{variant:"center"}];let f={};for(let l=0;l{"label"in _&&i(5,s=_.label),"elem_id"in _&&i(0,n=_.elem_id),"elem_classes"in _&&i(1,m=_.elem_classes),"visible"in _&&i(2,u=_.visible),"value"in _&&i(3,f=_.value),"loading_status"in _&&i(4,l=_.loading_status)},t.$$.update=()=>{t.$$.dirty&32&&a("change")},[n,m,u,f,l,s,r]}class I extends L{constructor(e){super(),M(this,e,G,U,j,{label:5,elem_id:0,elem_classes:1,visible:2,value:3,loading_status:4})}}const Q=I,R=["static"],V=t=>({type:{payload:"string"},description:{payload:"HTML output"}});export{Q as Component,V as document,R as modes};
-//# sourceMappingURL=index-050c9abb.js.map
diff --git a/spaces/DaleChen/AutoGPT/autogpt/app.py b/spaces/DaleChen/AutoGPT/autogpt/app.py
deleted file mode 100644
index 58d9f7164ddfbb5019b072d789dc2fa6205dc9d3..0000000000000000000000000000000000000000
--- a/spaces/DaleChen/AutoGPT/autogpt/app.py
+++ /dev/null
@@ -1,330 +0,0 @@
-""" Command and Control """
-import json
-from typing import Dict, List, NoReturn, Union
-
-from autogpt.agent.agent_manager import AgentManager
-from autogpt.commands.analyze_code import analyze_code
-from autogpt.commands.audio_text import read_audio_from_file
-from autogpt.commands.execute_code import (
- execute_python_file,
- execute_shell,
- execute_shell_popen,
-)
-from autogpt.commands.file_operations import (
- append_to_file,
- delete_file,
- download_file,
- read_file,
- search_files,
- write_to_file,
-)
-from autogpt.commands.git_operations import clone_repository
-from autogpt.commands.google_search import google_official_search, google_search
-from autogpt.commands.image_gen import generate_image
-from autogpt.commands.improve_code import improve_code
-from autogpt.commands.twitter import send_tweet
-from autogpt.commands.web_requests import scrape_links, scrape_text
-from autogpt.commands.web_selenium import browse_website
-from autogpt.commands.write_tests import write_tests
-from autogpt.config import Config
-from autogpt.json_utils.json_fix_llm import fix_and_parse_json
-from autogpt.memory import get_memory
-from autogpt.processing.text import summarize_text
-from autogpt.speech import say_text
-
-CFG = Config()
-AGENT_MANAGER = AgentManager()
-
-
-def is_valid_int(value: str) -> bool:
- """Check if the value is a valid integer
-
- Args:
- value (str): The value to check
-
- Returns:
- bool: True if the value is a valid integer, False otherwise
- """
- try:
- int(value)
- return True
- except ValueError:
- return False
-
-
-def get_command(response_json: Dict):
- """Parse the response and return the command name and arguments
-
- Args:
- response_json (json): The response from the AI
-
- Returns:
- tuple: The command name and arguments
-
- Raises:
- json.decoder.JSONDecodeError: If the response is not valid JSON
-
- Exception: If any other error occurs
- """
- try:
- if "command" not in response_json:
- return "Error:", "Missing 'command' object in JSON"
-
- if not isinstance(response_json, dict):
- return "Error:", f"'response_json' object is not dictionary {response_json}"
-
- command = response_json["command"]
- if not isinstance(command, dict):
- return "Error:", "'command' object is not a dictionary"
-
- if "name" not in command:
- return "Error:", "Missing 'name' field in 'command' object"
-
- command_name = command["name"]
-
- # Use an empty dictionary if 'args' field is not present in 'command' object
- arguments = command.get("args", {})
-
- return command_name, arguments
- except json.decoder.JSONDecodeError:
- return "Error:", "Invalid JSON"
- # All other errors, return "Error: + error message"
- except Exception as e:
- return "Error:", str(e)
-
-
-def map_command_synonyms(command_name: str):
- """Takes the original command name given by the AI, and checks if the
- string matches a list of common/known hallucinations
- """
- synonyms = [
- ("write_file", "write_to_file"),
- ("create_file", "write_to_file"),
- ("search", "google"),
- ]
- for seen_command, actual_command_name in synonyms:
- if command_name == seen_command:
- return actual_command_name
- return command_name
-
-
-def execute_command(command_name: str, arguments):
- """Execute the command and return the result
-
- Args:
- command_name (str): The name of the command to execute
- arguments (dict): The arguments for the command
-
- Returns:
- str: The result of the command
- """
- try:
- command_name = map_command_synonyms(command_name.lower())
- if command_name == "google":
- # Check if the Google API key is set and use the official search method
- # If the API key is not set or has only whitespaces, use the unofficial
- # search method
- key = CFG.google_api_key
- if key and key.strip() and key != "your-google-api-key":
- google_result = google_official_search(arguments["input"])
- return google_result
- else:
- google_result = google_search(arguments["input"])
-
- # google_result can be a list or a string depending on the search results
- if isinstance(google_result, list):
- safe_message = [
- google_result_single.encode("utf-8", "ignore")
- for google_result_single in google_result
- ]
- else:
- safe_message = google_result.encode("utf-8", "ignore")
-
- return safe_message.decode("utf-8")
- elif command_name == "memory_add":
- memory = get_memory(CFG)
- return memory.add(arguments["string"])
- elif command_name == "start_agent":
- return start_agent(
- arguments["name"], arguments["task"], arguments["prompt"]
- )
- elif command_name == "message_agent":
- return message_agent(arguments["key"], arguments["message"])
- elif command_name == "list_agents":
- return list_agents()
- elif command_name == "delete_agent":
- return delete_agent(arguments["key"])
- elif command_name == "get_text_summary":
- return get_text_summary(arguments["url"], arguments["question"])
- elif command_name == "get_hyperlinks":
- return get_hyperlinks(arguments["url"])
- elif command_name == "clone_repository":
- return clone_repository(
- arguments["repository_url"], arguments["clone_path"]
- )
- elif command_name == "read_file":
- return read_file(arguments["file"])
- elif command_name == "write_to_file":
- return write_to_file(arguments["file"], arguments["text"])
- elif command_name == "append_to_file":
- return append_to_file(arguments["file"], arguments["text"])
- elif command_name == "delete_file":
- return delete_file(arguments["file"])
- elif command_name == "search_files":
- return search_files(arguments["directory"])
- elif command_name == "download_file":
- if not CFG.allow_downloads:
- return "Error: You do not have user authorization to download files locally."
- return download_file(arguments["url"], arguments["file"])
- elif command_name == "browse_website":
- return browse_website(arguments["url"], arguments["question"])
- # TODO: Change these to take in a file rather than pasted code, if
- # non-file is given, return instructions "Input should be a python
- # filepath, write your code to file and try again"
- elif command_name == "analyze_code":
- return analyze_code(arguments["code"])
- elif command_name == "improve_code":
- return improve_code(arguments["suggestions"], arguments["code"])
- elif command_name == "write_tests":
- return write_tests(arguments["code"], arguments.get("focus"))
- elif command_name == "execute_python_file": # Add this command
- return execute_python_file(arguments["file"])
- elif command_name == "execute_shell":
- if CFG.execute_local_commands:
- return execute_shell(arguments["command_line"])
- else:
- return (
- "You are not allowed to run local shell commands. To execute"
- " shell commands, EXECUTE_LOCAL_COMMANDS must be set to 'True' "
- "in your config. Do not attempt to bypass the restriction."
- )
- elif command_name == "execute_shell_popen":
- if CFG.execute_local_commands:
- return execute_shell_popen(arguments["command_line"])
- else:
- return (
- "You are not allowed to run local shell commands. To execute"
- " shell commands, EXECUTE_LOCAL_COMMANDS must be set to 'True' "
- "in your config. Do not attempt to bypass the restriction."
- )
- elif command_name == "read_audio_from_file":
- return read_audio_from_file(arguments["file"])
- elif command_name == "generate_image":
- return generate_image(arguments["prompt"])
- elif command_name == "send_tweet":
- return send_tweet(arguments["text"])
- elif command_name == "do_nothing":
- return "No action performed."
- elif command_name == "task_complete":
- shutdown()
- else:
- return (
- f"Unknown command '{command_name}'. Please refer to the 'COMMANDS'"
- " list for available commands and only respond in the specified JSON"
- " format."
- )
- except Exception as e:
- return f"Error: {str(e)}"
-
-
-def get_text_summary(url: str, question: str) -> str:
- """Return the results of a Google search
-
- Args:
- url (str): The url to scrape
- question (str): The question to summarize the text for
-
- Returns:
- str: The summary of the text
- """
- text = scrape_text(url)
- summary = summarize_text(url, text, question)
- return f""" "Result" : {summary}"""
-
-
-def get_hyperlinks(url: str) -> Union[str, List[str]]:
- """Return the results of a Google search
-
- Args:
- url (str): The url to scrape
-
- Returns:
- str or list: The hyperlinks on the page
- """
- return scrape_links(url)
-
-
-def shutdown() -> NoReturn:
- """Shut down the program"""
- print("Shutting down...")
- quit()
-
-
-def start_agent(name: str, task: str, prompt: str, model=CFG.fast_llm_model) -> str:
- """Start an agent with a given name, task, and prompt
-
- Args:
- name (str): The name of the agent
- task (str): The task of the agent
- prompt (str): The prompt for the agent
- model (str): The model to use for the agent
-
- Returns:
- str: The response of the agent
- """
- # Remove underscores from name
- voice_name = name.replace("_", " ")
-
- first_message = f"""You are {name}. Respond with: "Acknowledged"."""
- agent_intro = f"{voice_name} here, Reporting for duty!"
-
- # Create agent
- if CFG.speak_mode:
- say_text(agent_intro, 1)
- key, ack = AGENT_MANAGER.create_agent(task, first_message, model)
-
- if CFG.speak_mode:
- say_text(f"Hello {voice_name}. Your task is as follows. {task}.")
-
- # Assign task (prompt), get response
- agent_response = AGENT_MANAGER.message_agent(key, prompt)
-
- return f"Agent {name} created with key {key}. First response: {agent_response}"
-
-
-def message_agent(key: str, message: str) -> str:
- """Message an agent with a given key and message"""
- # Check if the key is a valid integer
- if is_valid_int(key):
- agent_response = AGENT_MANAGER.message_agent(int(key), message)
- else:
- return "Invalid key, must be an integer."
-
- # Speak response
- if CFG.speak_mode:
- say_text(agent_response, 1)
- return agent_response
-
-
-def list_agents():
- """List all agents
-
- Returns:
- str: A list of all agents
- """
- return "List of agents:\n" + "\n".join(
- [str(x[0]) + ": " + x[1] for x in AGENT_MANAGER.list_agents()]
- )
-
-
-def delete_agent(key: str) -> str:
- """Delete an agent with a given key
-
- Args:
- key (str): The key of the agent to delete
-
- Returns:
- str: A message indicating whether the agent was deleted or not
- """
- result = AGENT_MANAGER.delete_agent(key)
- return f"Agent {key} deleted." if result else f"Agent {key} does not exist."
diff --git a/spaces/DaleChen/AutoGPT/autogpt/utils.py b/spaces/DaleChen/AutoGPT/autogpt/utils.py
deleted file mode 100644
index e93d5ac740097ee144d1809aea31c0f7fb242fa5..0000000000000000000000000000000000000000
--- a/spaces/DaleChen/AutoGPT/autogpt/utils.py
+++ /dev/null
@@ -1,77 +0,0 @@
-import os
-
-import requests
-import yaml
-from colorama import Fore
-from git import Repo
-
-
-def clean_input(prompt: str = ""):
- try:
- return input(prompt)
- except KeyboardInterrupt:
- print("You interrupted Auto-GPT")
- print("Quitting...")
- exit(0)
-
-
-def validate_yaml_file(file: str):
- try:
- with open(file, encoding="utf-8") as fp:
- yaml.load(fp.read(), Loader=yaml.FullLoader)
- except FileNotFoundError:
- return (False, f"The file {Fore.CYAN}`{file}`{Fore.RESET} wasn't found")
- except yaml.YAMLError as e:
- return (
- False,
- f"There was an issue while trying to read with your AI Settings file: {e}",
- )
-
- return (True, f"Successfully validated {Fore.CYAN}`{file}`{Fore.RESET}!")
-
-
-def readable_file_size(size, decimal_places=2):
- """Converts the given size in bytes to a readable format.
- Args:
- size: Size in bytes
- decimal_places (int): Number of decimal places to display
- """
- for unit in ["B", "KB", "MB", "GB", "TB"]:
- if size < 1024.0:
- break
- size /= 1024.0
- return f"{size:.{decimal_places}f} {unit}"
-
-
-def get_bulletin_from_web() -> str:
- try:
- response = requests.get(
- "https://raw.githubusercontent.com/Significant-Gravitas/Auto-GPT/master/BULLETIN.md"
- )
- if response.status_code == 200:
- return response.text
- except:
- return ""
-
-
-def get_current_git_branch() -> str:
- try:
- repo = Repo(search_parent_directories=True)
- branch = repo.active_branch
- return branch.name
- except:
- return ""
-
-
-def get_latest_bulletin() -> str:
- exists = os.path.exists("CURRENT_BULLETIN.md")
- current_bulletin = ""
- if exists:
- current_bulletin = open("CURRENT_BULLETIN.md", "r", encoding="utf-8").read()
- new_bulletin = get_bulletin_from_web()
- is_new_news = new_bulletin != current_bulletin
-
- if new_bulletin and is_new_news:
- open("CURRENT_BULLETIN.md", "w", encoding="utf-8").write(new_bulletin)
- return f" {Fore.RED}::UPDATED:: {Fore.CYAN}{new_bulletin}{Fore.RESET}"
- return current_bulletin
diff --git a/spaces/Datasculptor/MusicGen/audiocraft/modules/__init__.py b/spaces/Datasculptor/MusicGen/audiocraft/modules/__init__.py
deleted file mode 100644
index 81ba30f6466ff91b90490a4fb92f7d3d0d00144d..0000000000000000000000000000000000000000
--- a/spaces/Datasculptor/MusicGen/audiocraft/modules/__init__.py
+++ /dev/null
@@ -1,20 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-# flake8: noqa
-from .conv import (
- NormConv1d,
- NormConv2d,
- NormConvTranspose1d,
- NormConvTranspose2d,
- StreamableConv1d,
- StreamableConvTranspose1d,
- pad_for_conv1d,
- pad1d,
- unpad1d,
-)
-from .lstm import StreamableLSTM
-from .seanet import SEANetEncoder, SEANetDecoder
diff --git a/spaces/ECCV2022/PSG/OpenPSG/configs/_base_/models/detr4seg_r50.py b/spaces/ECCV2022/PSG/OpenPSG/configs/_base_/models/detr4seg_r50.py
deleted file mode 100644
index 326bc62336154ca94211a820406fb26025a9c544..0000000000000000000000000000000000000000
--- a/spaces/ECCV2022/PSG/OpenPSG/configs/_base_/models/detr4seg_r50.py
+++ /dev/null
@@ -1,65 +0,0 @@
-model = dict(
- type='DETR4seg',
- backbone=dict(type='ResNet',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- frozen_stages=1,
- norm_cfg=dict(type='BN', requires_grad=False),
- norm_eval=True,
- style='pytorch',
- init_cfg=dict(type='Pretrained',
- checkpoint='torchvision://resnet50')),
- bbox_head=dict(type='detr4segHead',
- num_classes=80,
- in_channels=2048,
- transformer=dict(
- type='Transformer',
- encoder=dict(type='DetrTransformerEncoder',
- num_layers=6,
- transformerlayers=dict(
- type='BaseTransformerLayer',
- attn_cfgs=[
- dict(type='MultiheadAttention',
- embed_dims=256,
- num_heads=8,
- dropout=0.1)
- ],
- feedforward_channels=2048,
- ffn_dropout=0.1,
- operation_order=('self_attn', 'norm',
- 'ffn', 'norm'))),
- decoder=dict(
- type='DetrTransformerDecoder',
- return_intermediate=True,
- num_layers=6,
- transformerlayers=dict(
- type='DetrTransformerDecoderLayer',
- attn_cfgs=dict(type='MultiheadAttention',
- embed_dims=256,
- num_heads=8,
- dropout=0.1),
- feedforward_channels=2048,
- ffn_dropout=0.1,
- operation_order=('self_attn', 'norm',
- 'cross_attn', 'norm', 'ffn',
- 'norm')),
- )),
- positional_encoding=dict(type='SinePositionalEncoding',
- num_feats=128,
- normalize=True),
- loss_cls=dict(type='CrossEntropyLoss',
- use_sigmoid=False,
- loss_weight=1.0,
- class_weight=1.0),
- loss_bbox=dict(type='L1Loss', loss_weight=5.0),
- loss_iou=dict(type='GIoULoss', loss_weight=2.0),
- focal_loss=dict(type='BCEFocalLoss', loss_weight=1.0),
- dice_loss=dict(type='psgtrDiceLoss', loss_weight=1.0)),
- # training and testing settings
- train_cfg=dict(assigner=dict(
- type='HungarianAssigner',
- cls_cost=dict(type='ClassificationCost', weight=1.),
- reg_cost=dict(type='BBoxL1Cost', weight=5.0, box_format='xywh'),
- iou_cost=dict(type='IoUCost', iou_mode='giou', weight=2.0))),
- test_cfg=dict(max_per_img=100))
diff --git a/spaces/EPFL-VILAB/MultiMAE/utils/auto_augment.py b/spaces/EPFL-VILAB/MultiMAE/utils/auto_augment.py
deleted file mode 100644
index 74842d681d6f5b4a3ae93b51b68e4cad03066afc..0000000000000000000000000000000000000000
--- a/spaces/EPFL-VILAB/MultiMAE/utils/auto_augment.py
+++ /dev/null
@@ -1,835 +0,0 @@
-# --------------------------------------------------------
-# Based on the timm code base
-# https://github.com/rwightman/pytorch-image-models/tree/master/timm
-# --------------------------------------------------------
-
-""" AutoAugment, RandAugment, and AugMix for PyTorch
-
-This code implements the searched ImageNet policies with various tweaks and improvements and
-does not include any of the search code.
-
-AA and RA Implementation adapted from:
- https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/autoaugment.py
-
-AugMix adapted from:
- https://github.com/google-research/augmix
-
-Papers:
- AutoAugment: Learning Augmentation Policies from Data - https://arxiv.org/abs/1805.09501
- Learning Data Augmentation Strategies for Object Detection - https://arxiv.org/abs/1906.11172
- RandAugment: Practical automated data augmentation... - https://arxiv.org/abs/1909.13719
- AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty - https://arxiv.org/abs/1912.02781
-
-Hacked together by / Copyright 2020 Ross Wightman
-"""
-import math
-import random
-import re
-
-import numpy as np
-import PIL
-from PIL import Image, ImageEnhance, ImageOps
-
-_PIL_VER = tuple([int(x) for x in PIL.__version__.split('.')[:2]])
-
-_FILL = (128, 128, 128)
-
-_LEVEL_DENOM = 10. # denominator for conversion from 'Mx' magnitude scale to fractional aug level for op arguments
-
-_HPARAMS_DEFAULT = dict(
- translate_const=250,
- img_mean=_FILL,
-)
-
-_RANDOM_INTERPOLATION = (Image.BILINEAR, Image.BICUBIC)
-
-
-def _interpolation(kwargs):
- interpolation = kwargs.pop('resample', Image.BILINEAR)
- if isinstance(interpolation, (list, tuple)):
- return random.choice(interpolation)
- else:
- return interpolation
-
-
-def _check_args_tf(kwargs):
- if 'fillcolor' in kwargs and _PIL_VER < (5, 0):
- kwargs.pop('fillcolor')
- kwargs['resample'] = _interpolation(kwargs)
-
-
-def shear_x(img, factor, **kwargs):
- _check_args_tf(kwargs)
- return img.transform(img.size, Image.AFFINE, (1, factor, 0, 0, 1, 0), **kwargs)
-
-
-def shear_y(img, factor, **kwargs):
- _check_args_tf(kwargs)
- return img.transform(img.size, Image.AFFINE, (1, 0, 0, factor, 1, 0), **kwargs)
-
-
-def translate_x_rel(img, pct, **kwargs):
- pixels = pct * img.size[0]
- _check_args_tf(kwargs)
- return img.transform(img.size, Image.AFFINE, (1, 0, pixels, 0, 1, 0), **kwargs)
-
-
-def translate_y_rel(img, pct, **kwargs):
- pixels = pct * img.size[1]
- _check_args_tf(kwargs)
- return img.transform(img.size, Image.AFFINE, (1, 0, 0, 0, 1, pixels), **kwargs)
-
-
-def translate_x_abs(img, pixels, **kwargs):
- _check_args_tf(kwargs)
- return img.transform(img.size, Image.AFFINE, (1, 0, pixels, 0, 1, 0), **kwargs)
-
-
-def translate_y_abs(img, pixels, **kwargs):
- _check_args_tf(kwargs)
- return img.transform(img.size, Image.AFFINE, (1, 0, 0, 0, 1, pixels), **kwargs)
-
-
-def rotate(img, degrees, **kwargs):
- _check_args_tf(kwargs)
- if _PIL_VER >= (5, 2):
- return img.rotate(degrees, **kwargs)
- elif _PIL_VER >= (5, 0):
- w, h = img.size
- post_trans = (0, 0)
- rotn_center = (w / 2.0, h / 2.0)
- angle = -math.radians(degrees)
- matrix = [
- round(math.cos(angle), 15),
- round(math.sin(angle), 15),
- 0.0,
- round(-math.sin(angle), 15),
- round(math.cos(angle), 15),
- 0.0,
- ]
-
- def transform(x, y, matrix):
- (a, b, c, d, e, f) = matrix
- return a * x + b * y + c, d * x + e * y + f
-
- matrix[2], matrix[5] = transform(
- -rotn_center[0] - post_trans[0], -rotn_center[1] - post_trans[1], matrix
- )
- matrix[2] += rotn_center[0]
- matrix[5] += rotn_center[1]
- return img.transform(img.size, Image.AFFINE, matrix, **kwargs)
- else:
- return img.rotate(degrees, resample=kwargs['resample'])
-
-
-def auto_contrast(img, **__):
- return ImageOps.autocontrast(img)
-
-
-def invert(img, **__):
- return ImageOps.invert(img)
-
-
-def equalize(img, **__):
- return ImageOps.equalize(img)
-
-
-def solarize(img, thresh, **__):
- return ImageOps.solarize(img, thresh)
-
-
-def solarize_add(img, add, thresh=128, **__):
- lut = []
- for i in range(256):
- if i < thresh:
- lut.append(min(255, i + add))
- else:
- lut.append(i)
- if img.mode in ("L", "RGB"):
- if img.mode == "RGB" and len(lut) == 256:
- lut = lut + lut + lut
- return img.point(lut)
- else:
- return img
-
-
-def posterize(img, bits_to_keep, **__):
- if bits_to_keep >= 8:
- return img
- return ImageOps.posterize(img, bits_to_keep)
-
-
-def contrast(img, factor, **__):
- return ImageEnhance.Contrast(img).enhance(factor)
-
-
-def color(img, factor, **__):
- return ImageEnhance.Color(img).enhance(factor)
-
-
-def brightness(img, factor, **__):
- return ImageEnhance.Brightness(img).enhance(factor)
-
-
-def sharpness(img, factor, **__):
- return ImageEnhance.Sharpness(img).enhance(factor)
-
-
-def _randomly_negate(v):
- """With 50% prob, negate the value"""
- return -v if random.random() > 0.5 else v
-
-
-def _rotate_level_to_arg(level, _hparams):
- # range [-30, 30]
- level = (level / _LEVEL_DENOM) * 30.
- level = _randomly_negate(level)
- return level,
-
-
-def _enhance_level_to_arg(level, _hparams):
- # range [0.1, 1.9]
- return (level / _LEVEL_DENOM) * 1.8 + 0.1,
-
-
-def _enhance_increasing_level_to_arg(level, _hparams):
- # the 'no change' level is 1.0, moving away from that towards 0. or 2.0 increases the enhancement blend
- # range [0.1, 1.9] if level <= _LEVEL_DENOM
- level = (level / _LEVEL_DENOM) * .9
- level = max(0.1, 1.0 + _randomly_negate(level)) # keep it >= 0.1
- return level,
-
-
-def _shear_level_to_arg(level, _hparams):
- # range [-0.3, 0.3]
- level = (level / _LEVEL_DENOM) * 0.3
- level = _randomly_negate(level)
- return level,
-
-
-def _translate_abs_level_to_arg(level, hparams):
- translate_const = hparams['translate_const']
- level = (level / _LEVEL_DENOM) * float(translate_const)
- level = _randomly_negate(level)
- return level,
-
-
-def _translate_rel_level_to_arg(level, hparams):
- # default range [-0.45, 0.45]
- translate_pct = hparams.get('translate_pct', 0.45)
- level = (level / _LEVEL_DENOM) * translate_pct
- level = _randomly_negate(level)
- return level,
-
-
-def _posterize_level_to_arg(level, _hparams):
- # As per Tensorflow TPU EfficientNet impl
- # range [0, 4], 'keep 0 up to 4 MSB of original image'
- # intensity/severity of augmentation decreases with level
- return int((level / _LEVEL_DENOM) * 4),
-
-
-def _posterize_increasing_level_to_arg(level, hparams):
- # As per Tensorflow models research and UDA impl
- # range [4, 0], 'keep 4 down to 0 MSB of original image',
- # intensity/severity of augmentation increases with level
- return 4 - _posterize_level_to_arg(level, hparams)[0],
-
-
-def _posterize_original_level_to_arg(level, _hparams):
- # As per original AutoAugment paper description
- # range [4, 8], 'keep 4 up to 8 MSB of image'
- # intensity/severity of augmentation decreases with level
- return int((level / _LEVEL_DENOM) * 4) + 4,
-
-
-def _solarize_level_to_arg(level, _hparams):
- # range [0, 256]
- # intensity/severity of augmentation decreases with level
- return int((level / _LEVEL_DENOM) * 256),
-
-
-def _solarize_increasing_level_to_arg(level, _hparams):
- # range [0, 256]
- # intensity/severity of augmentation increases with level
- return 256 - _solarize_level_to_arg(level, _hparams)[0],
-
-
-def _solarize_add_level_to_arg(level, _hparams):
- # range [0, 110]
- return int((level / _LEVEL_DENOM) * 110),
-
-
-LEVEL_TO_ARG = {
- 'AutoContrast': None,
- 'Equalize': None,
- 'Invert': None,
- 'Rotate': _rotate_level_to_arg,
- # There are several variations of the posterize level scaling in various Tensorflow/Google repositories/papers
- 'Posterize': _posterize_level_to_arg,
- 'PosterizeIncreasing': _posterize_increasing_level_to_arg,
- 'PosterizeOriginal': _posterize_original_level_to_arg,
- 'Solarize': _solarize_level_to_arg,
- 'SolarizeIncreasing': _solarize_increasing_level_to_arg,
- 'SolarizeAdd': _solarize_add_level_to_arg,
- 'Color': _enhance_level_to_arg,
- 'ColorIncreasing': _enhance_increasing_level_to_arg,
- 'Contrast': _enhance_level_to_arg,
- 'ContrastIncreasing': _enhance_increasing_level_to_arg,
- 'Brightness': _enhance_level_to_arg,
- 'BrightnessIncreasing': _enhance_increasing_level_to_arg,
- 'Sharpness': _enhance_level_to_arg,
- 'SharpnessIncreasing': _enhance_increasing_level_to_arg,
- 'ShearX': _shear_level_to_arg,
- 'ShearY': _shear_level_to_arg,
- 'TranslateX': _translate_abs_level_to_arg,
- 'TranslateY': _translate_abs_level_to_arg,
- 'TranslateXRel': _translate_rel_level_to_arg,
- 'TranslateYRel': _translate_rel_level_to_arg,
-}
-
-NAME_TO_OP = {
- 'AutoContrast': auto_contrast,
- 'Equalize': equalize,
- 'Invert': invert,
- 'Rotate': rotate,
- 'Posterize': posterize,
- 'PosterizeIncreasing': posterize,
- 'PosterizeOriginal': posterize,
- 'Solarize': solarize,
- 'SolarizeIncreasing': solarize,
- 'SolarizeAdd': solarize_add,
- 'Color': color,
- 'ColorIncreasing': color,
- 'Contrast': contrast,
- 'ContrastIncreasing': contrast,
- 'Brightness': brightness,
- 'BrightnessIncreasing': brightness,
- 'Sharpness': sharpness,
- 'SharpnessIncreasing': sharpness,
- 'ShearX': shear_x,
- 'ShearY': shear_y,
- 'TranslateX': translate_x_abs,
- 'TranslateY': translate_y_abs,
- 'TranslateXRel': translate_x_rel,
- 'TranslateYRel': translate_y_rel,
-}
-
-
-class AugmentOp:
-
- def __init__(self, name, prob=0.5, magnitude=10, hparams=None):
- hparams = hparams or _HPARAMS_DEFAULT
- self.aug_fn = NAME_TO_OP[name]
- self.level_fn = LEVEL_TO_ARG[name]
- self.prob = prob
- self.magnitude = magnitude
- self.hparams = hparams.copy()
- self.kwargs = dict(
- fillcolor=hparams['img_mean'] if 'img_mean' in hparams else _FILL,
- resample=hparams['interpolation'] if 'interpolation' in hparams else _RANDOM_INTERPOLATION,
- )
-
- # If magnitude_std is > 0, we introduce some randomness
- # in the usually fixed policy and sample magnitude from a normal distribution
- # with mean `magnitude` and std-dev of `magnitude_std`.
- # NOTE This is my own hack, being tested, not in papers or reference impls.
- # If magnitude_std is inf, we sample magnitude from a uniform distribution
- self.magnitude_std = self.hparams.get('magnitude_std', 0)
- self.magnitude_max = self.hparams.get('magnitude_max', None)
-
- def __call__(self, img):
- if self.prob < 1.0 and random.random() > self.prob:
- return img
- magnitude = self.magnitude
- if self.magnitude_std > 0:
- # magnitude randomization enabled
- if self.magnitude_std == float('inf'):
- magnitude = random.uniform(0, magnitude)
- elif self.magnitude_std > 0:
- magnitude = random.gauss(magnitude, self.magnitude_std)
- # default upper_bound for the timm RA impl is _LEVEL_DENOM (10)
- # setting magnitude_max overrides this to allow M > 10 (behaviour closer to Google TF RA impl)
- upper_bound = self.magnitude_max or _LEVEL_DENOM
- magnitude = max(0., min(magnitude, upper_bound))
- level_args = self.level_fn(magnitude, self.hparams) if self.level_fn is not None else tuple()
- return self.aug_fn(img, *level_args, **self.kwargs)
-
-
-def auto_augment_policy_v0(hparams):
- # ImageNet v0 policy from TPU EfficientNet impl, cannot find a paper reference.
- policy = [
- [('Equalize', 0.8, 1), ('ShearY', 0.8, 4)],
- [('Color', 0.4, 9), ('Equalize', 0.6, 3)],
- [('Color', 0.4, 1), ('Rotate', 0.6, 8)],
- [('Solarize', 0.8, 3), ('Equalize', 0.4, 7)],
- [('Solarize', 0.4, 2), ('Solarize', 0.6, 2)],
- [('Color', 0.2, 0), ('Equalize', 0.8, 8)],
- [('Equalize', 0.4, 8), ('SolarizeAdd', 0.8, 3)],
- [('ShearX', 0.2, 9), ('Rotate', 0.6, 8)],
- [('Color', 0.6, 1), ('Equalize', 1.0, 2)],
- [('Invert', 0.4, 9), ('Rotate', 0.6, 0)],
- [('Equalize', 1.0, 9), ('ShearY', 0.6, 3)],
- [('Color', 0.4, 7), ('Equalize', 0.6, 0)],
- [('Posterize', 0.4, 6), ('AutoContrast', 0.4, 7)],
- [('Solarize', 0.6, 8), ('Color', 0.6, 9)],
- [('Solarize', 0.2, 4), ('Rotate', 0.8, 9)],
- [('Rotate', 1.0, 7), ('TranslateYRel', 0.8, 9)],
- [('ShearX', 0.0, 0), ('Solarize', 0.8, 4)],
- [('ShearY', 0.8, 0), ('Color', 0.6, 4)],
- [('Color', 1.0, 0), ('Rotate', 0.6, 2)],
- [('Equalize', 0.8, 4), ('Equalize', 0.0, 8)],
- [('Equalize', 1.0, 4), ('AutoContrast', 0.6, 2)],
- [('ShearY', 0.4, 7), ('SolarizeAdd', 0.6, 7)],
- [('Posterize', 0.8, 2), ('Solarize', 0.6, 10)], # This results in black image with Tpu posterize
- [('Solarize', 0.6, 8), ('Equalize', 0.6, 1)],
- [('Color', 0.8, 6), ('Rotate', 0.4, 5)],
- ]
- pc = [[AugmentOp(*a, hparams=hparams) for a in sp] for sp in policy]
- return pc
-
-
-def auto_augment_policy_v0r(hparams):
- # ImageNet v0 policy from TPU EfficientNet impl, with variation of Posterize used
- # in Google research implementation (number of bits discarded increases with magnitude)
- policy = [
- [('Equalize', 0.8, 1), ('ShearY', 0.8, 4)],
- [('Color', 0.4, 9), ('Equalize', 0.6, 3)],
- [('Color', 0.4, 1), ('Rotate', 0.6, 8)],
- [('Solarize', 0.8, 3), ('Equalize', 0.4, 7)],
- [('Solarize', 0.4, 2), ('Solarize', 0.6, 2)],
- [('Color', 0.2, 0), ('Equalize', 0.8, 8)],
- [('Equalize', 0.4, 8), ('SolarizeAdd', 0.8, 3)],
- [('ShearX', 0.2, 9), ('Rotate', 0.6, 8)],
- [('Color', 0.6, 1), ('Equalize', 1.0, 2)],
- [('Invert', 0.4, 9), ('Rotate', 0.6, 0)],
- [('Equalize', 1.0, 9), ('ShearY', 0.6, 3)],
- [('Color', 0.4, 7), ('Equalize', 0.6, 0)],
- [('PosterizeIncreasing', 0.4, 6), ('AutoContrast', 0.4, 7)],
- [('Solarize', 0.6, 8), ('Color', 0.6, 9)],
- [('Solarize', 0.2, 4), ('Rotate', 0.8, 9)],
- [('Rotate', 1.0, 7), ('TranslateYRel', 0.8, 9)],
- [('ShearX', 0.0, 0), ('Solarize', 0.8, 4)],
- [('ShearY', 0.8, 0), ('Color', 0.6, 4)],
- [('Color', 1.0, 0), ('Rotate', 0.6, 2)],
- [('Equalize', 0.8, 4), ('Equalize', 0.0, 8)],
- [('Equalize', 1.0, 4), ('AutoContrast', 0.6, 2)],
- [('ShearY', 0.4, 7), ('SolarizeAdd', 0.6, 7)],
- [('PosterizeIncreasing', 0.8, 2), ('Solarize', 0.6, 10)],
- [('Solarize', 0.6, 8), ('Equalize', 0.6, 1)],
- [('Color', 0.8, 6), ('Rotate', 0.4, 5)],
- ]
- pc = [[AugmentOp(*a, hparams=hparams) for a in sp] for sp in policy]
- return pc
-
-
-def auto_augment_policy_original(hparams):
- # ImageNet policy from https://arxiv.org/abs/1805.09501
- policy = [
- [('PosterizeOriginal', 0.4, 8), ('Rotate', 0.6, 9)],
- [('Solarize', 0.6, 5), ('AutoContrast', 0.6, 5)],
- [('Equalize', 0.8, 8), ('Equalize', 0.6, 3)],
- [('PosterizeOriginal', 0.6, 7), ('PosterizeOriginal', 0.6, 6)],
- [('Equalize', 0.4, 7), ('Solarize', 0.2, 4)],
- [('Equalize', 0.4, 4), ('Rotate', 0.8, 8)],
- [('Solarize', 0.6, 3), ('Equalize', 0.6, 7)],
- [('PosterizeOriginal', 0.8, 5), ('Equalize', 1.0, 2)],
- [('Rotate', 0.2, 3), ('Solarize', 0.6, 8)],
- [('Equalize', 0.6, 8), ('PosterizeOriginal', 0.4, 6)],
- [('Rotate', 0.8, 8), ('Color', 0.4, 0)],
- [('Rotate', 0.4, 9), ('Equalize', 0.6, 2)],
- [('Equalize', 0.0, 7), ('Equalize', 0.8, 8)],
- [('Invert', 0.6, 4), ('Equalize', 1.0, 8)],
- [('Color', 0.6, 4), ('Contrast', 1.0, 8)],
- [('Rotate', 0.8, 8), ('Color', 1.0, 2)],
- [('Color', 0.8, 8), ('Solarize', 0.8, 7)],
- [('Sharpness', 0.4, 7), ('Invert', 0.6, 8)],
- [('ShearX', 0.6, 5), ('Equalize', 1.0, 9)],
- [('Color', 0.4, 0), ('Equalize', 0.6, 3)],
- [('Equalize', 0.4, 7), ('Solarize', 0.2, 4)],
- [('Solarize', 0.6, 5), ('AutoContrast', 0.6, 5)],
- [('Invert', 0.6, 4), ('Equalize', 1.0, 8)],
- [('Color', 0.6, 4), ('Contrast', 1.0, 8)],
- [('Equalize', 0.8, 8), ('Equalize', 0.6, 3)],
- ]
- pc = [[AugmentOp(*a, hparams=hparams) for a in sp] for sp in policy]
- return pc
-
-
-def auto_augment_policy_originalr(hparams):
- # ImageNet policy from https://arxiv.org/abs/1805.09501 with research posterize variation
- policy = [
- [('PosterizeIncreasing', 0.4, 8), ('Rotate', 0.6, 9)],
- [('Solarize', 0.6, 5), ('AutoContrast', 0.6, 5)],
- [('Equalize', 0.8, 8), ('Equalize', 0.6, 3)],
- [('PosterizeIncreasing', 0.6, 7), ('PosterizeIncreasing', 0.6, 6)],
- [('Equalize', 0.4, 7), ('Solarize', 0.2, 4)],
- [('Equalize', 0.4, 4), ('Rotate', 0.8, 8)],
- [('Solarize', 0.6, 3), ('Equalize', 0.6, 7)],
- [('PosterizeIncreasing', 0.8, 5), ('Equalize', 1.0, 2)],
- [('Rotate', 0.2, 3), ('Solarize', 0.6, 8)],
- [('Equalize', 0.6, 8), ('PosterizeIncreasing', 0.4, 6)],
- [('Rotate', 0.8, 8), ('Color', 0.4, 0)],
- [('Rotate', 0.4, 9), ('Equalize', 0.6, 2)],
- [('Equalize', 0.0, 7), ('Equalize', 0.8, 8)],
- [('Invert', 0.6, 4), ('Equalize', 1.0, 8)],
- [('Color', 0.6, 4), ('Contrast', 1.0, 8)],
- [('Rotate', 0.8, 8), ('Color', 1.0, 2)],
- [('Color', 0.8, 8), ('Solarize', 0.8, 7)],
- [('Sharpness', 0.4, 7), ('Invert', 0.6, 8)],
- [('ShearX', 0.6, 5), ('Equalize', 1.0, 9)],
- [('Color', 0.4, 0), ('Equalize', 0.6, 3)],
- [('Equalize', 0.4, 7), ('Solarize', 0.2, 4)],
- [('Solarize', 0.6, 5), ('AutoContrast', 0.6, 5)],
- [('Invert', 0.6, 4), ('Equalize', 1.0, 8)],
- [('Color', 0.6, 4), ('Contrast', 1.0, 8)],
- [('Equalize', 0.8, 8), ('Equalize', 0.6, 3)],
- ]
- pc = [[AugmentOp(*a, hparams=hparams) for a in sp] for sp in policy]
- return pc
-
-
-def auto_augment_policy(name='v0', hparams=None):
- hparams = hparams or _HPARAMS_DEFAULT
- if name == 'original':
- return auto_augment_policy_original(hparams)
- elif name == 'originalr':
- return auto_augment_policy_originalr(hparams)
- elif name == 'v0':
- return auto_augment_policy_v0(hparams)
- elif name == 'v0r':
- return auto_augment_policy_v0r(hparams)
- else:
- assert False, 'Unknown AA policy (%s)' % name
-
-
-class AutoAugment:
-
- def __init__(self, policy):
- self.policy = policy
-
- def __call__(self, img):
- sub_policy = random.choice(self.policy)
- for op in sub_policy:
- img = op(img)
- return img
-
-
-def auto_augment_transform(config_str, hparams):
- """
- Create a AutoAugment transform
-
- :param config_str: String defining configuration of auto augmentation. Consists of multiple sections separated by
- dashes ('-'). The first section defines the AutoAugment policy (one of 'v0', 'v0r', 'original', 'originalr').
- The remaining sections, not order sepecific determine
- 'mstd' - float std deviation of magnitude noise applied
- Ex 'original-mstd0.5' results in AutoAugment with original policy, magnitude_std 0.5
-
- :param hparams: Other hparams (kwargs) for the AutoAugmentation scheme
-
- :return: A PyTorch compatible Transform
- """
- config = config_str.split('-')
- policy_name = config[0]
- config = config[1:]
- for c in config:
- cs = re.split(r'(\d.*)', c)
- if len(cs) < 2:
- continue
- key, val = cs[:2]
- if key == 'mstd':
- # noise param injected via hparams for now
- hparams.setdefault('magnitude_std', float(val))
- else:
- assert False, 'Unknown AutoAugment config section'
- aa_policy = auto_augment_policy(policy_name, hparams=hparams)
- return AutoAugment(aa_policy)
-
-
-_RAND_TRANSFORMS = [
- 'AutoContrast',
- 'Equalize',
- 'Invert',
- 'Rotate',
- 'Posterize',
- 'Solarize',
- 'SolarizeAdd',
- 'Color',
- 'Contrast',
- 'Brightness',
- 'Sharpness',
- 'ShearX',
- 'ShearY',
- 'TranslateXRel',
- 'TranslateYRel',
- # 'Cutout' # NOTE I've implement this as random erasing separately
-]
-
-_RAND_INCREASING_TRANSFORMS = [
- 'AutoContrast',
- 'Equalize',
- 'Invert',
- 'Rotate',
- 'PosterizeIncreasing',
- 'SolarizeIncreasing',
- 'SolarizeAdd',
- 'ColorIncreasing',
- 'ContrastIncreasing',
- 'BrightnessIncreasing',
- 'SharpnessIncreasing',
- 'ShearX',
- 'ShearY',
- 'TranslateXRel',
- 'TranslateYRel',
- # 'Cutout' # NOTE I've implement this as random erasing separately
-]
-
-# These experimental weights are based loosely on the relative improvements mentioned in paper.
-# They may not result in increased performance, but could likely be tuned to so.
-_RAND_CHOICE_WEIGHTS_0 = {
- 'Rotate': 0.3,
- 'ShearX': 0.2,
- 'ShearY': 0.2,
- 'TranslateXRel': 0.1,
- 'TranslateYRel': 0.1,
- 'Color': .025,
- 'Sharpness': 0.025,
- 'AutoContrast': 0.025,
- 'Solarize': .005,
- 'SolarizeAdd': .005,
- 'Contrast': .005,
- 'Brightness': .005,
- 'Equalize': .005,
- 'Posterize': 0,
- 'Invert': 0,
-}
-
-
-def _select_rand_weights(weight_idx=0, transforms=None):
- transforms = transforms or _RAND_TRANSFORMS
- assert weight_idx == 0 # only one set of weights currently
- rand_weights = _RAND_CHOICE_WEIGHTS_0
- probs = [rand_weights[k] for k in transforms]
- probs /= np.sum(probs)
- return probs
-
-
-def rand_augment_ops(magnitude=10, hparams=None, transforms=None):
- hparams = hparams or _HPARAMS_DEFAULT
- transforms = transforms or _RAND_TRANSFORMS
- return [AugmentOp(
- name, prob=0.5, magnitude=magnitude, hparams=hparams) for name in transforms]
-
-
-class RandAugment:
- def __init__(self, ops, num_layers=2, choice_weights=None):
- self.ops = ops
- self.num_layers = num_layers
- self.choice_weights = choice_weights
-
- def __call__(self, img):
- # no replacement when using weighted choice
- ops = np.random.choice(
- self.ops, self.num_layers, replace=self.choice_weights is None, p=self.choice_weights)
- for op in ops:
- img = op(img)
- return img
-
-
-def rand_augment_transform(config_str, hparams):
- """
- Create a RandAugment transform
-
- :param config_str: String defining configuration of random augmentation. Consists of multiple sections separated by
- dashes ('-'). The first section defines the specific variant of rand augment (currently only 'rand'). The remaining
- sections, not order sepecific determine
- 'm' - integer magnitude of rand augment
- 'n' - integer num layers (number of transform ops selected per image)
- 'w' - integer probabiliy weight index (index of a set of weights to influence choice of op)
- 'mstd' - float std deviation of magnitude noise applied, or uniform sampling if infinity (or > 100)
- 'mmax' - set upper bound for magnitude to something other than default of _LEVEL_DENOM (10)
- 'inc' - integer (bool), use augmentations that increase in severity with magnitude (default: 0)
- Ex 'rand-m9-n3-mstd0.5' results in RandAugment with magnitude 9, num_layers 3, magnitude_std 0.5
- 'rand-mstd1-w0' results in magnitude_std 1.0, weights 0, default magnitude of 10 and num_layers 2
-
- :param hparams: Other hparams (kwargs) for the RandAugmentation scheme
-
- :return: A PyTorch compatible Transform
- """
- magnitude = _LEVEL_DENOM # default to _LEVEL_DENOM for magnitude (currently 10)
- num_layers = 2 # default to 2 ops per image
- weight_idx = None # default to no probability weights for op choice
- transforms = _RAND_TRANSFORMS
- config = config_str.split('-')
- assert config[0] == 'rand'
- config = config[1:]
- for c in config:
- cs = re.split(r'(\d.*)', c)
- if len(cs) < 2:
- continue
- key, val = cs[:2]
- if key == 'mstd':
- # noise param / randomization of magnitude values
- mstd = float(val)
- if mstd > 100:
- # use uniform sampling in 0 to magnitude if mstd is > 100
- mstd = float('inf')
- hparams.setdefault('magnitude_std', mstd)
- elif key == 'mmax':
- # clip magnitude between [0, mmax] instead of default [0, _LEVEL_DENOM]
- hparams.setdefault('magnitude_max', int(val))
- elif key == 'inc':
- if bool(val):
- transforms = _RAND_INCREASING_TRANSFORMS
- elif key == 'm':
- magnitude = int(val)
- elif key == 'n':
- num_layers = int(val)
- elif key == 'w':
- weight_idx = int(val)
- else:
- assert False, 'Unknown RandAugment config section'
- ra_ops = rand_augment_ops(magnitude=magnitude, hparams=hparams, transforms=transforms)
- choice_weights = None if weight_idx is None else _select_rand_weights(weight_idx)
- return RandAugment(ra_ops, num_layers, choice_weights=choice_weights)
-
-
-_AUGMIX_TRANSFORMS = [
- 'AutoContrast',
- 'ColorIncreasing', # not in paper
- 'ContrastIncreasing', # not in paper
- 'BrightnessIncreasing', # not in paper
- 'SharpnessIncreasing', # not in paper
- 'Equalize',
- 'Rotate',
- 'PosterizeIncreasing',
- 'SolarizeIncreasing',
- 'ShearX',
- 'ShearY',
- 'TranslateXRel',
- 'TranslateYRel',
-]
-
-
-def augmix_ops(magnitude=10, hparams=None, transforms=None):
- hparams = hparams or _HPARAMS_DEFAULT
- transforms = transforms or _AUGMIX_TRANSFORMS
- return [AugmentOp(
- name, prob=1.0, magnitude=magnitude, hparams=hparams) for name in transforms]
-
-
-class AugMixAugment:
- """ AugMix Transform
- Adapted and improved from impl here: https://github.com/google-research/augmix/blob/master/imagenet.py
- From paper: 'AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty -
- https://arxiv.org/abs/1912.02781
- """
-
- def __init__(self, ops, alpha=1., width=3, depth=-1, blended=False):
- self.ops = ops
- self.alpha = alpha
- self.width = width
- self.depth = depth
- self.blended = blended # blended mode is faster but not well tested
-
- def _calc_blended_weights(self, ws, m):
- ws = ws * m
- cump = 1.
- rws = []
- for w in ws[::-1]:
- alpha = w / cump
- cump *= (1 - alpha)
- rws.append(alpha)
- return np.array(rws[::-1], dtype=np.float32)
-
- def _apply_blended(self, img, mixing_weights, m):
- # This is my first crack and implementing a slightly faster mixed augmentation. Instead
- # of accumulating the mix for each chain in a Numpy array and then blending with original,
- # it recomputes the blending coefficients and applies one PIL image blend per chain.
- # TODO the results appear in the right ballpark but they differ by more than rounding.
- img_orig = img.copy()
- ws = self._calc_blended_weights(mixing_weights, m)
- for w in ws:
- depth = self.depth if self.depth > 0 else np.random.randint(1, 4)
- ops = np.random.choice(self.ops, depth, replace=True)
- img_aug = img_orig # no ops are in-place, deep copy not necessary
- for op in ops:
- img_aug = op(img_aug)
- img = Image.blend(img, img_aug, w)
- return img
-
- def _apply_basic(self, img, mixing_weights, m):
- # This is a literal adaptation of the paper/official implementation without normalizations and
- # PIL <-> Numpy conversions between every op. It is still quite CPU compute heavy compared to the
- # typical augmentation transforms, could use a GPU / Kornia implementation.
- img_shape = img.size[0], img.size[1], len(img.getbands())
- mixed = np.zeros(img_shape, dtype=np.float32)
- for mw in mixing_weights:
- depth = self.depth if self.depth > 0 else np.random.randint(1, 4)
- ops = np.random.choice(self.ops, depth, replace=True)
- img_aug = img # no ops are in-place, deep copy not necessary
- for op in ops:
- img_aug = op(img_aug)
- mixed += mw * np.asarray(img_aug, dtype=np.float32)
- np.clip(mixed, 0, 255., out=mixed)
- mixed = Image.fromarray(mixed.astype(np.uint8))
- return Image.blend(img, mixed, m)
-
- def __call__(self, img):
- mixing_weights = np.float32(np.random.dirichlet([self.alpha] * self.width))
- m = np.float32(np.random.beta(self.alpha, self.alpha))
- if self.blended:
- mixed = self._apply_blended(img, mixing_weights, m)
- else:
- mixed = self._apply_basic(img, mixing_weights, m)
- return mixed
-
-
-def augment_and_mix_transform(config_str, hparams):
- """ Create AugMix PyTorch transform
-
- :param config_str: String defining configuration of random augmentation. Consists of multiple sections separated by
- dashes ('-'). The first section defines the specific variant of rand augment (currently only 'rand'). The remaining
- sections, not order sepecific determine
- 'm' - integer magnitude (severity) of augmentation mix (default: 3)
- 'w' - integer width of augmentation chain (default: 3)
- 'd' - integer depth of augmentation chain (-1 is random [1, 3], default: -1)
- 'b' - integer (bool), blend each branch of chain into end result without a final blend, less CPU (default: 0)
- 'mstd' - float std deviation of magnitude noise applied (default: 0)
- Ex 'augmix-m5-w4-d2' results in AugMix with severity 5, chain width 4, chain depth 2
-
- :param hparams: Other hparams (kwargs) for the Augmentation transforms
-
- :return: A PyTorch compatible Transform
- """
- magnitude = 3
- width = 3
- depth = -1
- alpha = 1.
- blended = False
- config = config_str.split('-')
- assert config[0] == 'augmix'
- config = config[1:]
- for c in config:
- cs = re.split(r'(\d.*)', c)
- if len(cs) < 2:
- continue
- key, val = cs[:2]
- if key == 'mstd':
- # noise param injected via hparams for now
- hparams.setdefault('magnitude_std', float(val))
- elif key == 'm':
- magnitude = int(val)
- elif key == 'w':
- width = int(val)
- elif key == 'd':
- depth = int(val)
- elif key == 'a':
- alpha = float(val)
- elif key == 'b':
- blended = bool(val)
- else:
- assert False, 'Unknown AugMix config section'
- hparams.setdefault('magnitude_std', float('inf')) # default to uniform sampling (if not set via mstd arg)
- ops = augmix_ops(magnitude=magnitude, hparams=hparams)
- return AugMixAugment(ops, alpha=alpha, width=width, depth=depth, blended=blended)
diff --git a/spaces/EuroPython2022/cloudspace/app.py b/spaces/EuroPython2022/cloudspace/app.py
deleted file mode 100644
index 5d5eebea35205ed544822027e26753c3c6981f50..0000000000000000000000000000000000000000
--- a/spaces/EuroPython2022/cloudspace/app.py
+++ /dev/null
@@ -1,5 +0,0 @@
-import gradio as gr
-def greet(name):
- return "Hello " + name + "!!"
-iface = gr.Interface.load("huggingface/gpt2").launch()
-#iface.launch()
\ No newline at end of file
diff --git a/spaces/FaceOnLive/Face-Recognition-SDK/app.py b/spaces/FaceOnLive/Face-Recognition-SDK/app.py
deleted file mode 100644
index 5c0ef30dd74b75cec6b9e356c5f7d4dbb62af6eb..0000000000000000000000000000000000000000
--- a/spaces/FaceOnLive/Face-Recognition-SDK/app.py
+++ /dev/null
@@ -1,217 +0,0 @@
-import sys
-sys.path.append('.')
-
-from flask import Flask, request, jsonify
-from time import gmtime, strftime
-import os
-import base64
-import json
-import cv2
-import numpy as np
-
-from facewrapper.facewrapper import ttv_version
-from facewrapper.facewrapper import ttv_get_hwid
-from facewrapper.facewrapper import ttv_init
-from facewrapper.facewrapper import ttv_init_offline
-from facewrapper.facewrapper import ttv_extract_feature
-from facewrapper.facewrapper import ttv_compare_feature
-
-app = Flask(__name__)
-
-app.config['SITE'] = "http://0.0.0.0:8000/"
-app.config['DEBUG'] = False
-
-licenseKey = os.environ.get("LICENSE_KEY")
-licensePath = "license.txt"
-modelFolder = os.path.abspath(os.path.dirname(__file__)) + '/facewrapper/dict'
-
-version = ttv_version()
-print("version: ", version.decode('utf-8'))
-
-ret = ttv_init(modelFolder.encode('utf-8'), licenseKey.encode('utf-8'))
-if ret != 0:
- print(f"online init failed: {ret}");
-
- hwid = ttv_get_hwid()
- print("hwid: ", hwid.decode('utf-8'))
-
- ret = ttv_init_offline(modelFolder.encode('utf-8'), licensePath.encode('utf-8'))
- if ret != 0:
- print(f"offline init failed: {ret}")
- exit(-1)
- else:
- print(f"offline init ok")
-
-else:
- print(f"online init ok")
-
-@app.route('/api/compare_face', methods=['POST'])
-def compare_face():
- file1 = request.files['image1']
- image1 = cv2.imdecode(np.fromstring(file1.read(), np.uint8), cv2.IMREAD_COLOR)
- if image1 is None:
- result = "image1: is null!"
- status = "ok"
- response = jsonify({"status": status, "data": {"result": result}})
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
- file2 = request.files['image2']
- image2 = cv2.imdecode(np.fromstring(file2.read(), np.uint8), cv2.IMREAD_COLOR)
- if image2 is None:
- result = "image2: is null!"
- status = "ok"
- response = jsonify({"status": status, "data": {"result": result}})
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
- faceRect1 = np.zeros([4], dtype=np.int32)
- feature1 = np.zeros([2048], dtype=np.uint8)
- featureSize1 = np.zeros([1], dtype=np.int32)
-
- ret = ttv_extract_feature(image1, image1.shape[1], image1.shape[0], faceRect1, feature1, featureSize1)
- if ret <= 0:
- if ret == -1:
- result = "license error!"
- elif ret == -2:
- result = "init error!"
- elif ret == 0:
- result = "image1: no face detected!"
-
- status = "ok"
- response = jsonify({"status": status, "data": {"result": result}})
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
- faceRect2 = np.zeros([4], dtype=np.int32)
- feature2 = np.zeros([2048], dtype=np.uint8)
- featureSize2 = np.zeros([1], dtype=np.int32)
-
- ret = ttv_extract_feature(image2, image2.shape[1], image2.shape[0], faceRect2, feature2, featureSize2)
- if ret <= 0:
- if ret == -1:
- result = "license error!"
- elif ret == -2:
- result = "init error!"
- elif ret == 0:
- result = "image2: no face detected!"
-
- status = "ok"
- response = jsonify({"status": status, "data": {"result": result}})
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
- similarity = ttv_compare_feature(feature1, feature2)
- if similarity > 0.7:
- result = "same"
- else:
- result = "different"
-
- status = "ok"
- response = jsonify(
- {
- "status": status,
- "data": {
- "result": result,
- "similarity": float(similarity),
- "face1": {"x1": int(faceRect1[0]), "y1": int(faceRect1[1]), "x2": int(faceRect1[2]), "y2" : int(faceRect1[3])},
- "face2": {"x1": int(faceRect2[0]), "y1": int(faceRect2[1]), "x2": int(faceRect2[2]), "y2" : int(faceRect2[3])},
- }
- })
-
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
-
-@app.route('/api/compare_face_base64', methods=['POST'])
-def coompare_face_base64():
- content = request.get_json()
- imageBase641 = content['image1']
- image1 = cv2.imdecode(np.frombuffer(base64.b64decode(imageBase641), dtype=np.uint8), cv2.IMREAD_COLOR)
-
- if image1 is None:
- result = "image1: is null!"
- status = "ok"
- response = jsonify({"status": status, "data": {"result": result}})
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
- imageBase642 = content['image2']
- image2 = cv2.imdecode(np.frombuffer(base64.b64decode(imageBase642), dtype=np.uint8), cv2.IMREAD_COLOR)
-
- if image2 is None:
- result = "image2: is null!"
- status = "ok"
- response = jsonify({"status": status, "data": {"result": result}})
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
- faceRect1 = np.zeros([4], dtype=np.int32)
- feature1 = np.zeros([2048], dtype=np.uint8)
- featureSize1 = np.zeros([1], dtype=np.int32)
-
- ret = ttv_extract_feature(image1, image1.shape[1], image1.shape[0], faceRect1, feature1, featureSize1)
- if ret <= 0:
- if ret == -1:
- result = "license error!"
- elif ret == -2:
- result = "init error!"
- elif ret == 0:
- result = "image1: no face detected!"
-
- status = "ok"
- response = jsonify({"status": status, "data": {"result": result}})
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
- faceRect2 = np.zeros([4], dtype=np.int32)
- feature2 = np.zeros([2048], dtype=np.uint8)
- featureSize2 = np.zeros([1], dtype=np.int32)
-
- ret = ttv_extract_feature(image2, image2.shape[1], image2.shape[0], faceRect2, feature2, featureSize2)
- if ret <= 0:
- if ret == -1:
- result = "license error!"
- elif ret == -2:
- result = "init error!"
- elif ret == 0:
- result = "image2: no face detected!"
-
- status = "ok"
- response = jsonify({"status": status, "data": {"result": result}})
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
- similarity = ttv_compare_feature(feature1, feature2)
- if similarity > 0.7:
- result = "same"
- else:
- result = "different"
-
- status = "ok"
- response = jsonify(
- {
- "status": status,
- "data": {
- "result": result,
- "similarity": float(similarity),
- "face1": {"x1": int(faceRect1[0]), "y1": int(faceRect1[1]), "x2": int(faceRect1[2]), "y2" : int(faceRect1[3])},
- "face2": {"x1": int(faceRect2[0]), "y1": int(faceRect2[1]), "x2": int(faceRect2[2]), "y2" : int(faceRect2[3])},
- }
- })
- response.status_code = 200
- response.headers["Content-Type"] = "application/json; charset=utf-8"
- return response
-
-if __name__ == '__main__':
- port = int(os.environ.get("PORT", 8000))
- app.run(host='0.0.0.0', port=port)
diff --git a/spaces/FedeFT/Head_Pose_Estimation_and_LAEO_computation/laeo_per_frame/interaction_per_frame_uncertainty.py b/spaces/FedeFT/Head_Pose_Estimation_and_LAEO_computation/laeo_per_frame/interaction_per_frame_uncertainty.py
deleted file mode 100644
index a27ef988497d55826456e98fcb96a45fb69387b7..0000000000000000000000000000000000000000
--- a/spaces/FedeFT/Head_Pose_Estimation_and_LAEO_computation/laeo_per_frame/interaction_per_frame_uncertainty.py
+++ /dev/null
@@ -1,166 +0,0 @@
-'''It calculates interaction frame per frame with not temporal consistency.
- It also use the uncertainty to enlarge the visual cone.'''
-import re
-from math import sin, cos
-
-import numpy as np
-
-
-def project_ypr_in2d(yaw, pitch, roll):
- """ Project yaw pitch roll on image plane. Result is NOT normalised.
-
- :param yaw:
- :param pitch:
- :param roll:
- :return:
- """
- pitch = pitch * np.pi / 180
- yaw = -(yaw * np.pi / 180)
- roll = roll * np.pi / 180
-
- x3 = (sin(yaw))
- y3 = (-cos(yaw) * sin(pitch))
-
- # normalize the components
- length = np.sqrt(x3 ** 2 + y3 ** 2)
-
- # return [x3 / length, y3 / length]
- return [x3, y3]
-
-
-def compute_interaction_cosine(head_position, gaze_direction, uncertainty, target, visual_cone=True):
- """Computes the interaction between two people using the angle of view.
-
- The interaction in measured as the cosine of the angle formed by the line from person A to B
- and the gaze direction of person A.
- Reference system of zero degree:
-
-
- :param head_position: position of the head of person A
- :param gaze_direction: gaze direction of the head of person A
- :param target: position of head of person B
- :param yaw:
- :param pitch:
- :param roll:
- :param visual_cone: (default) True, if False gaze is a line, otherwise it is a cone (more like humans)
- :return: float or double describing the quantity of interaction
- """
- if np.array_equal(head_position, target):
- return 0 # or -1
- else:
- cone_aperture = None
- if 0 <= uncertainty < 0.4:
- cone_aperture = np.deg2rad(3)
- elif 0.4 <= uncertainty <= 0.6:
- cone_aperture = np.deg2rad(6)
- elif 0.6 < uncertainty <= 1:
- cone_aperture = np.deg2rad(9)
- # direction from observer to target
- _direction_ = np.arctan2((target[1] - head_position[1]), (target[0] - head_position[0]))
- _direction_gaze_ = np.arctan2(gaze_direction[1], gaze_direction[0])
- difference = _direction_ - _direction_gaze_ # radians
- if visual_cone and (0 < difference < cone_aperture):
- difference = 0
- # difference of the line joining observer -> target with the gazing direction,
-
- val = np.cos(difference)
- if val < 0:
- return 0
- else:
- return val
-
-
-def calculate_uncertainty(yaw_1, pitch_1, roll_1, clipping_value, clip=True):
- # res_1 = abs((pitch_1 + yaw_1 + roll_1) / 3)
- res_1 = abs((pitch_1 + yaw_1) / 2)
- if clip:
- # it binarize the uncertainty
- if res_1 > clipping_value:
- res_1 = clipping_value
- else:
- res_1 = 0
- else:
- # it leaves uncertainty untouched except for upper bound
- if res_1 > clipping_value:
- res_1 = clipping_value
- elif res_1 < 0:
- res_1 = 0
-
- # normalize
- res_1 = res_1 / clipping_value
- # assert res_1 in [0, 1], 'uncertainty not binarized'
- return res_1
-
-
-def atoi(text):
- return int(text) if text.isdigit() else text
-
-
-def natural_keys(text):
- '''
- alist.sort(key=natural_keys) sorts in human order
- http://nedbatchelder.com/blog/200712/human_sorting.html
- (See Toothy's implementation in the comments)
- '''
- return [atoi(c) for c in re.split(r'(\d+)', text)]
-
-
-def delete_file_if_exist(*file_path):
- for f in file_path:
- if f.is_file(): # if exist already, replace
- f.unlink(missing_ok=True)
-
-
-def LAEO_computation(people_list, clipping_value, clip):
- #TODO here correct the average because -> 0+0.99-> LAEO, already corrected a bit
- people_in_frame = len(people_list)
-
- # create empty matrix with one entry per person in frame
- matrix = np.empty((people_in_frame, people_in_frame))
- interaction_matrix = np.zeros((people_in_frame, people_in_frame))
- uncertainty_matrix = np.zeros((people_in_frame, people_in_frame))
-
- norm_xy_all = [] # it will contains vector for printing
- for subject in range(people_in_frame):
- norm_xy = project_ypr_in2d(people_list[subject]['yaw'], people_list[subject]['pitch'],
- people_list[subject]['roll'])
- norm_xy_all.append(norm_xy)
- uncertainty_1 = calculate_uncertainty(people_list[subject]['yaw_u'],
- people_list[subject]['pitch_u'],
- people_list[subject]['roll_u'], clipping_value=clipping_value,
- clip=clip)
-
- for object in range(people_in_frame):
- uncertainty_2 = calculate_uncertainty(people_list[object]['yaw_u'],
- people_list[object]['pitch_u'],
- people_list[object]['roll_u'], clipping_value=clipping_value,
- clip=clip)
- v = compute_interaction_cosine(people_list[subject]['center_xy'], norm_xy, uncertainty_1,
- people_list[object]['center_xy'])
- matrix[subject][object] = v
- uncertainty_matrix[subject][object] = uncertainty_1
- # uncertainty_matrix[object][subject] = uncertainty_2
-
- # matrix is completed
-
- for subject in range(people_in_frame):
- for object in range(people_in_frame):
- # take average of previous matrix
- if matrix[subject][object] > 0.3 and matrix[object][subject] > 0.3:
- v = (matrix[subject][object] + matrix[object][subject]) / 2
- interaction_matrix[subject][object] = v
- else:
- interaction_matrix[subject][object] = 0
-
- return interaction_matrix
-
-
-if __name__ == '__main__':
- clip_uncertainty = 0
- binarize_uncertainty = True
- yaw, pitch, roll, tdx, tdy = 0, 0, 0, 0, 0
- my_list = [{'yaw': yaw,
- 'pitch': pitch,
- 'roll': roll,
- 'center_xy': [tdx, tdy]}]
- _ = LAEO_computation(my_list, clipping_value=clip_uncertainty, clip=binarize_uncertainty)
\ No newline at end of file
diff --git a/spaces/Felix123456/bingo/src/components/user-menu.tsx b/spaces/Felix123456/bingo/src/components/user-menu.tsx
deleted file mode 100644
index 9bd1edc9cf9f39b63629b021f0c1186b1a7c1341..0000000000000000000000000000000000000000
--- a/spaces/Felix123456/bingo/src/components/user-menu.tsx
+++ /dev/null
@@ -1,113 +0,0 @@
-'use client'
-
-import { useEffect, useState } from 'react'
-import Image from 'next/image'
-import { toast } from 'react-hot-toast'
-import { Button } from '@/components/ui/button'
-import pkg from '../../package.json'
-import {
- DropdownMenu,
- DropdownMenuContent,
- DropdownMenuItem,
- DropdownMenuSeparator,
- DropdownMenuTrigger
-} from '@/components/ui/dropdown-menu'
-import { IconCopy, IconExternalLink, IconGitHub } from '@/components/ui/icons'
-import SettingIcon from '@/assets/images/settings.svg'
-import { useCopyToClipboard } from '@/lib/hooks/use-copy-to-clipboard'
-
-export function UserMenu() {
- const [host, setHost] = useState('')
- const { isCopied, copyToClipboard } = useCopyToClipboard({ timeout: 2000 })
- useEffect(() => {
- setHost(location.host)
- }, [])
-
- useEffect(() => {
- if (isCopied) {
- toast.success('复制成功')
- }
- }, [isCopied])
- return (
-
-
-
-
-
-
-
- location.href='#dialog="settings"'
- }
- className="cursor-pointer"
- >
- 设置用户
-
-
-
- location.href='#dialog="voice"'
- }
- className="cursor-pointer"
- >
- 语音设置
-
-
-
-
- 开源地址
-
-
-
-
-
-
-
- 托管地址
- 🤗
-
-
-
-
-
-
- 复制站点
-
-
-
-
-
- 版本信息 {pkg.version}
-
-
-
- 站点域名
- copyToClipboard(host)} className="flex gap-1 text-xs text-zinc-500 cursor-pointer">
- {host}
-
-
-
-
-
-
- Description: Simply input any textual prompt to generate videos right away and unleash your creativity and imagination! You can also select from the examples below. For performance purposes, our current preview release allows to generate up to 16 frames, which can be configured in the Advanced Options.
-
-
- """)
-
- with gr.Row():
- with gr.Column():
- model_name = gr.Dropdown(
- label="Model",
- choices=get_model_list(),
- value="dreamlike-art/dreamlike-photoreal-2.0",
-
- )
- prompt = gr.Textbox(label='Prompt')
- run_button = gr.Button(label='Run')
- with gr.Accordion('Advanced options', open=False):
- watermark = gr.Radio(["Picsart AI Research", "Text2Video-Zero",
- "None"], label="Watermark", value='Picsart AI Research')
-
- if on_huggingspace:
- video_length = gr.Slider(
- label="Video length", minimum=8, maximum=16, step=1)
- else:
- video_length = gr.Number(
- label="Video length", value=8, precision=0)
-
- n_prompt = gr.Textbox(
- label="Optional Negative Prompt", value='')
- seed = gr.Slider(label='Seed',
- info="-1 for random seed on each run. Otherwise, the seed will be fixed.",
- minimum=-1,
- maximum=65536,
- value=0,
- step=1)
-
- motion_field_strength_x = gr.Slider(
- label='Global Translation $\\delta_{x}$', minimum=-20, maximum=20,
- value=12,
- step=1)
- motion_field_strength_y = gr.Slider(
- label='Global Translation $\\delta_{y}$', minimum=-20, maximum=20,
- value=12,
- step=1)
-
- t0 = gr.Slider(label="Timestep t0", minimum=0,
- maximum=47, value=44, step=1,
- info="Perform DDPM steps from t0 to t1. The larger the gap between t0 and t1, the more variance between the frames. Ensure t0 < t1 ",
- )
- t1 = gr.Slider(label="Timestep t1", minimum=1,
- info="Perform DDPM steps from t0 to t1. The larger the gap between t0 and t1, the more variance between the frames. Ensure t0 < t1",
- maximum=48, value=47, step=1)
- chunk_size = gr.Slider(
- label="Chunk size", minimum=2, maximum=16, value=2, step=1, visible=not on_huggingspace,
- info="Number of frames processed at once. Reduce for lower memory usage."
- )
- merging_ratio = gr.Slider(
- label="Merging ratio", minimum=0.0, maximum=0.9, step=0.1, value=0.0, visible=not on_huggingspace,
- info="Ratio of how many tokens are merged. The higher the more compression (less memory and faster inference)."
- )
-
- with gr.Column():
- result = gr.Video(label="Generated Video")
-
- inputs = [
- prompt,
- model_name,
- motion_field_strength_x,
- motion_field_strength_y,
- t0,
- t1,
- n_prompt,
- chunk_size,
- video_length,
- watermark,
- merging_ratio,
- seed,
- ]
-
- gr.Examples(examples=examples,
- inputs=inputs,
- outputs=result,
- fn=model.process_text2video,
- run_on_click=False,
- cache_examples=on_huggingspace,
- )
-
- run_button.click(fn=model.process_text2video,
- inputs=inputs,
- outputs=result,)
- return demo
diff --git a/spaces/PierreCugnet/airline-sentiment-analysis/README.md b/spaces/PierreCugnet/airline-sentiment-analysis/README.md
deleted file mode 100644
index bd1471226d66df14bccd35e5abfb08bc64e5cc97..0000000000000000000000000000000000000000
--- a/spaces/PierreCugnet/airline-sentiment-analysis/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Airline Sentiment Analysis
-emoji: 📈
-colorFrom: indigo
-colorTo: pink
-sdk: streamlit
-sdk_version: 1.2.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/engine/stage_trainer.py b/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/engine/stage_trainer.py
deleted file mode 100644
index 5b5b9b3776c78edd2f3e1dadf1b205da0a23ef82..0000000000000000000000000000000000000000
--- a/spaces/Pinwheel/GLIP-BLIP-Object-Detection-VQA/maskrcnn_benchmark/engine/stage_trainer.py
+++ /dev/null
@@ -1,184 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
-import datetime
-import logging
-import time
-
-import torch
-import torch.distributed as dist
-
-from maskrcnn_benchmark.utils.comm import get_world_size
-from maskrcnn_benchmark.utils.metric_logger import MetricLogger
-
-
-def reduce_loss_dict(all_loss_dict):
- """
- Reduce the loss dictionary from all processes so that process with rank
- 0 has the averaged results. Returns a dict with the same fields as
- loss_dict, after reduction.
- """
- world_size = get_world_size()
- with torch.no_grad():
- loss_names = []
- all_losses = []
- for loss_dict in all_loss_dict:
- for k in sorted(loss_dict.keys()):
- loss_names.append(k)
- all_losses.append(loss_dict[k])
- all_losses = torch.stack(all_losses, dim=0)
- if world_size > 1:
- dist.reduce(all_losses, dst=0)
- if dist.get_rank() == 0:
- # only main process gets accumulated, so only divide by
- # world_size in this case
- all_losses /= world_size
-
- reduced_losses = {}
- for k, v in zip(loss_names, all_losses):
- if k not in reduced_losses:
- reduced_losses[k] = v / len(all_loss_dict)
- reduced_losses[k] += v / len(all_loss_dict)
-
- return reduced_losses
-
-
-def do_train(
- model,
- data_loader,
- optimizer,
- scheduler,
- checkpointer,
- device,
- checkpoint_period,
- arguments,
-):
- logger = logging.getLogger("maskrcnn_benchmark.trainer")
- logger.info("Start training")
- meters = MetricLogger(delimiter=" ")
- epoch_per_stage = arguments['epoch_per_stage']
- max_iter = sum(len(stage_loader) * epoch_per_stage[si] for si, stage_loader in enumerate(data_loader))
- max_iter += epoch_per_stage[-1] * min(len(stage_loader) for stage_loader in data_loader)
- model.train()
- start_training_time = time.time()
- end = time.time()
-
- for stage_i, stage_loader in enumerate(data_loader):
- for ep in range(epoch_per_stage[stage_i]):
- start_iter = arguments["iteration"]
- for iteration, (images, targets, _) in enumerate(stage_loader, start_iter):
- data_time = time.time() - end
- iteration = iteration + 1
- arguments["iteration"] = iteration
-
- scheduler[stage_i].step()
-
- all_stage_loss_dict = []
- images = images.to(device)
- targets = [target.to(device) for target in targets]
- loss_dict = model(images, targets, stage_i)
- all_stage_loss_dict.append(loss_dict)
-
- losses = sum(loss for loss_dict in all_stage_loss_dict for loss in loss_dict.values())
-
- # reduce losses over all GPUs for logging purposes
- loss_dict_reduced = reduce_loss_dict(all_stage_loss_dict)
- losses_reduced = sum(loss for loss in loss_dict_reduced.values())
- meters.update(loss=losses_reduced, **loss_dict_reduced)
-
- optimizer.zero_grad()
- losses.backward()
- optimizer.step()
-
- batch_time = time.time() - end
- end = time.time()
- meters.update(time=batch_time, data=data_time)
-
- eta_seconds = meters.time.global_avg * (max_iter - iteration)
- eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
-
- if iteration % 20 == 0 or iteration == max_iter:
- logger.info(
- meters.delimiter.join(
- [
- "eta: {eta}",
- "iter: {iter}",
- "{meters}",
- "lr: {lr:.6f}",
- "max mem: {memory:.0f}",
- ]
- ).format(
- eta=eta_string,
- iter=iteration,
- meters=str(meters),
- lr=optimizer.param_groups[0]["lr"],
- memory=torch.cuda.max_memory_allocated() / 1024.0 / 1024.0,
- )
- )
- if iteration % checkpoint_period == 0:
- checkpointer.save("model_{:07d}".format(iteration), **arguments)
- if iteration == max_iter:
- checkpointer.save("model_final", **arguments)
-
- for ep in range(epoch_per_stage[-1]):
- start_iter = arguments["iteration"]
- for iteration, stage_loader in enumerate(zip(*data_loader), start_iter):
- data_time = time.time() - end
- iteration = iteration + 1
- arguments["iteration"] = iteration
-
- scheduler[-1].step()
-
- all_task_loss_dict = []
- for stage_i, (images, targets, _) in enumerate(stage_loader):
- images = images.to(device)
- targets = [target.to(device) for target in targets]
- loss_dict = model(images, targets, stage_i)
- all_task_loss_dict.append(loss_dict)
-
- losses = sum(loss for loss_dict in all_task_loss_dict for loss in loss_dict.values())
-
- # reduce losses over all GPUs for logging purposes
- loss_dict_reduced = reduce_loss_dict(all_task_loss_dict)
- losses_reduced = sum(loss for loss in loss_dict_reduced.values())
- meters.update(loss=losses_reduced, **loss_dict_reduced)
-
- optimizer.zero_grad()
- losses.backward()
- optimizer.step()
-
- batch_time = time.time() - end
- end = time.time()
- meters.update(time=batch_time, data=data_time)
-
- eta_seconds = meters.time.global_avg * (max_iter - iteration)
- eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
-
- if iteration % 20 == 0 or iteration == max_iter:
- logger.info(
- meters.delimiter.join(
- [
- "eta: {eta}",
- "iter: {iter}",
- "{meters}",
- "lr: {lr:.6f}",
- "max mem: {memory:.0f}",
- ]
- ).format(
- eta=eta_string,
- iter=iteration,
- meters=str(meters),
- lr=optimizer.param_groups[0]["lr"],
- memory=torch.cuda.max_memory_allocated() / 1024.0 / 1024.0,
- )
- )
- if iteration % checkpoint_period == 0:
- checkpointer.save("model_{:07d}".format(iteration), **arguments)
- if iteration == max_iter:
- checkpointer.save("model_final", **arguments)
-
- total_training_time = time.time() - start_training_time
- total_time_str = str(datetime.timedelta(seconds=total_training_time))
- logger.info(
- "Total training time: {} ({:.4f} s / it)".format(
- total_time_str, total_training_time / (max_iter)
- )
- )
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/cli/cmdoptions.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/cli/cmdoptions.py
deleted file mode 100644
index b4e2560dea29ee1f4b88b5a734960f551d611720..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_internal/cli/cmdoptions.py
+++ /dev/null
@@ -1,1049 +0,0 @@
-"""
-shared options and groups
-
-The principle here is to define options once, but *not* instantiate them
-globally. One reason being that options with action='append' can carry state
-between parses. pip parses general options twice internally, and shouldn't
-pass on state. To be consistent, all options will follow this design.
-"""
-
-# The following comment should be removed at some point in the future.
-# mypy: strict-optional=False
-
-import importlib.util
-import logging
-import os
-import textwrap
-from functools import partial
-from optparse import SUPPRESS_HELP, Option, OptionGroup, OptionParser, Values
-from textwrap import dedent
-from typing import Any, Callable, Dict, Optional, Tuple
-
-from pip._vendor.packaging.utils import canonicalize_name
-
-from pip._internal.cli.parser import ConfigOptionParser
-from pip._internal.exceptions import CommandError
-from pip._internal.locations import USER_CACHE_DIR, get_src_prefix
-from pip._internal.models.format_control import FormatControl
-from pip._internal.models.index import PyPI
-from pip._internal.models.target_python import TargetPython
-from pip._internal.utils.hashes import STRONG_HASHES
-from pip._internal.utils.misc import strtobool
-
-logger = logging.getLogger(__name__)
-
-
-def raise_option_error(parser: OptionParser, option: Option, msg: str) -> None:
- """
- Raise an option parsing error using parser.error().
-
- Args:
- parser: an OptionParser instance.
- option: an Option instance.
- msg: the error text.
- """
- msg = f"{option} error: {msg}"
- msg = textwrap.fill(" ".join(msg.split()))
- parser.error(msg)
-
-
-def make_option_group(group: Dict[str, Any], parser: ConfigOptionParser) -> OptionGroup:
- """
- Return an OptionGroup object
- group -- assumed to be dict with 'name' and 'options' keys
- parser -- an optparse Parser
- """
- option_group = OptionGroup(parser, group["name"])
- for option in group["options"]:
- option_group.add_option(option())
- return option_group
-
-
-def check_dist_restriction(options: Values, check_target: bool = False) -> None:
- """Function for determining if custom platform options are allowed.
-
- :param options: The OptionParser options.
- :param check_target: Whether or not to check if --target is being used.
- """
- dist_restriction_set = any(
- [
- options.python_version,
- options.platforms,
- options.abis,
- options.implementation,
- ]
- )
-
- binary_only = FormatControl(set(), {":all:"})
- sdist_dependencies_allowed = (
- options.format_control != binary_only and not options.ignore_dependencies
- )
-
- # Installations or downloads using dist restrictions must not combine
- # source distributions and dist-specific wheels, as they are not
- # guaranteed to be locally compatible.
- if dist_restriction_set and sdist_dependencies_allowed:
- raise CommandError(
- "When restricting platform and interpreter constraints using "
- "--python-version, --platform, --abi, or --implementation, "
- "either --no-deps must be set, or --only-binary=:all: must be "
- "set and --no-binary must not be set (or must be set to "
- ":none:)."
- )
-
- if check_target:
- if dist_restriction_set and not options.target_dir:
- raise CommandError(
- "Can not use any platform or abi specific options unless "
- "installing via '--target'"
- )
-
-
-def _path_option_check(option: Option, opt: str, value: str) -> str:
- return os.path.expanduser(value)
-
-
-def _package_name_option_check(option: Option, opt: str, value: str) -> str:
- return canonicalize_name(value)
-
-
-class PipOption(Option):
- TYPES = Option.TYPES + ("path", "package_name")
- TYPE_CHECKER = Option.TYPE_CHECKER.copy()
- TYPE_CHECKER["package_name"] = _package_name_option_check
- TYPE_CHECKER["path"] = _path_option_check
-
-
-###########
-# options #
-###########
-
-help_: Callable[..., Option] = partial(
- Option,
- "-h",
- "--help",
- dest="help",
- action="help",
- help="Show help.",
-)
-
-debug_mode: Callable[..., Option] = partial(
- Option,
- "--debug",
- dest="debug_mode",
- action="store_true",
- default=False,
- help=(
- "Let unhandled exceptions propagate outside the main subroutine, "
- "instead of logging them to stderr."
- ),
-)
-
-isolated_mode: Callable[..., Option] = partial(
- Option,
- "--isolated",
- dest="isolated_mode",
- action="store_true",
- default=False,
- help=(
- "Run pip in an isolated mode, ignoring environment variables and user "
- "configuration."
- ),
-)
-
-require_virtualenv: Callable[..., Option] = partial(
- Option,
- "--require-virtualenv",
- "--require-venv",
- dest="require_venv",
- action="store_true",
- default=False,
- help=(
- "Allow pip to only run in a virtual environment; "
- "exit with an error otherwise."
- ),
-)
-
-python: Callable[..., Option] = partial(
- Option,
- "--python",
- dest="python",
- help="Run pip with the specified Python interpreter.",
-)
-
-verbose: Callable[..., Option] = partial(
- Option,
- "-v",
- "--verbose",
- dest="verbose",
- action="count",
- default=0,
- help="Give more output. Option is additive, and can be used up to 3 times.",
-)
-
-no_color: Callable[..., Option] = partial(
- Option,
- "--no-color",
- dest="no_color",
- action="store_true",
- default=False,
- help="Suppress colored output.",
-)
-
-version: Callable[..., Option] = partial(
- Option,
- "-V",
- "--version",
- dest="version",
- action="store_true",
- help="Show version and exit.",
-)
-
-quiet: Callable[..., Option] = partial(
- Option,
- "-q",
- "--quiet",
- dest="quiet",
- action="count",
- default=0,
- help=(
- "Give less output. Option is additive, and can be used up to 3"
- " times (corresponding to WARNING, ERROR, and CRITICAL logging"
- " levels)."
- ),
-)
-
-progress_bar: Callable[..., Option] = partial(
- Option,
- "--progress-bar",
- dest="progress_bar",
- type="choice",
- choices=["on", "off"],
- default="on",
- help="Specify whether the progress bar should be used [on, off] (default: on)",
-)
-
-log: Callable[..., Option] = partial(
- PipOption,
- "--log",
- "--log-file",
- "--local-log",
- dest="log",
- metavar="path",
- type="path",
- help="Path to a verbose appending log.",
-)
-
-no_input: Callable[..., Option] = partial(
- Option,
- # Don't ask for input
- "--no-input",
- dest="no_input",
- action="store_true",
- default=False,
- help="Disable prompting for input.",
-)
-
-proxy: Callable[..., Option] = partial(
- Option,
- "--proxy",
- dest="proxy",
- type="str",
- default="",
- help="Specify a proxy in the form scheme://[user:passwd@]proxy.server:port.",
-)
-
-retries: Callable[..., Option] = partial(
- Option,
- "--retries",
- dest="retries",
- type="int",
- default=5,
- help="Maximum number of retries each connection should attempt "
- "(default %default times).",
-)
-
-timeout: Callable[..., Option] = partial(
- Option,
- "--timeout",
- "--default-timeout",
- metavar="sec",
- dest="timeout",
- type="float",
- default=15,
- help="Set the socket timeout (default %default seconds).",
-)
-
-
-def exists_action() -> Option:
- return Option(
- # Option when path already exist
- "--exists-action",
- dest="exists_action",
- type="choice",
- choices=["s", "i", "w", "b", "a"],
- default=[],
- action="append",
- metavar="action",
- help="Default action when a path already exists: "
- "(s)witch, (i)gnore, (w)ipe, (b)ackup, (a)bort.",
- )
-
-
-cert: Callable[..., Option] = partial(
- PipOption,
- "--cert",
- dest="cert",
- type="path",
- metavar="path",
- help=(
- "Path to PEM-encoded CA certificate bundle. "
- "If provided, overrides the default. "
- "See 'SSL Certificate Verification' in pip documentation "
- "for more information."
- ),
-)
-
-client_cert: Callable[..., Option] = partial(
- PipOption,
- "--client-cert",
- dest="client_cert",
- type="path",
- default=None,
- metavar="path",
- help="Path to SSL client certificate, a single file containing the "
- "private key and the certificate in PEM format.",
-)
-
-index_url: Callable[..., Option] = partial(
- Option,
- "-i",
- "--index-url",
- "--pypi-url",
- dest="index_url",
- metavar="URL",
- default=PyPI.simple_url,
- help="Base URL of the Python Package Index (default %default). "
- "This should point to a repository compliant with PEP 503 "
- "(the simple repository API) or a local directory laid out "
- "in the same format.",
-)
-
-
-def extra_index_url() -> Option:
- return Option(
- "--extra-index-url",
- dest="extra_index_urls",
- metavar="URL",
- action="append",
- default=[],
- help="Extra URLs of package indexes to use in addition to "
- "--index-url. Should follow the same rules as "
- "--index-url.",
- )
-
-
-no_index: Callable[..., Option] = partial(
- Option,
- "--no-index",
- dest="no_index",
- action="store_true",
- default=False,
- help="Ignore package index (only looking at --find-links URLs instead).",
-)
-
-
-def find_links() -> Option:
- return Option(
- "-f",
- "--find-links",
- dest="find_links",
- action="append",
- default=[],
- metavar="url",
- help="If a URL or path to an html file, then parse for links to "
- "archives such as sdist (.tar.gz) or wheel (.whl) files. "
- "If a local path or file:// URL that's a directory, "
- "then look for archives in the directory listing. "
- "Links to VCS project URLs are not supported.",
- )
-
-
-def trusted_host() -> Option:
- return Option(
- "--trusted-host",
- dest="trusted_hosts",
- action="append",
- metavar="HOSTNAME",
- default=[],
- help="Mark this host or host:port pair as trusted, even though it "
- "does not have valid or any HTTPS.",
- )
-
-
-def constraints() -> Option:
- return Option(
- "-c",
- "--constraint",
- dest="constraints",
- action="append",
- default=[],
- metavar="file",
- help="Constrain versions using the given constraints file. "
- "This option can be used multiple times.",
- )
-
-
-def requirements() -> Option:
- return Option(
- "-r",
- "--requirement",
- dest="requirements",
- action="append",
- default=[],
- metavar="file",
- help="Install from the given requirements file. "
- "This option can be used multiple times.",
- )
-
-
-def editable() -> Option:
- return Option(
- "-e",
- "--editable",
- dest="editables",
- action="append",
- default=[],
- metavar="path/url",
- help=(
- "Install a project in editable mode (i.e. setuptools "
- '"develop mode") from a local project path or a VCS url.'
- ),
- )
-
-
-def _handle_src(option: Option, opt_str: str, value: str, parser: OptionParser) -> None:
- value = os.path.abspath(value)
- setattr(parser.values, option.dest, value)
-
-
-src: Callable[..., Option] = partial(
- PipOption,
- "--src",
- "--source",
- "--source-dir",
- "--source-directory",
- dest="src_dir",
- type="path",
- metavar="dir",
- default=get_src_prefix(),
- action="callback",
- callback=_handle_src,
- help="Directory to check out editable projects into. "
- 'The default in a virtualenv is "/src". '
- 'The default for global installs is "/src".',
-)
-
-
-def _get_format_control(values: Values, option: Option) -> Any:
- """Get a format_control object."""
- return getattr(values, option.dest)
-
-
-def _handle_no_binary(
- option: Option, opt_str: str, value: str, parser: OptionParser
-) -> None:
- existing = _get_format_control(parser.values, option)
- FormatControl.handle_mutual_excludes(
- value,
- existing.no_binary,
- existing.only_binary,
- )
-
-
-def _handle_only_binary(
- option: Option, opt_str: str, value: str, parser: OptionParser
-) -> None:
- existing = _get_format_control(parser.values, option)
- FormatControl.handle_mutual_excludes(
- value,
- existing.only_binary,
- existing.no_binary,
- )
-
-
-def no_binary() -> Option:
- format_control = FormatControl(set(), set())
- return Option(
- "--no-binary",
- dest="format_control",
- action="callback",
- callback=_handle_no_binary,
- type="str",
- default=format_control,
- help="Do not use binary packages. Can be supplied multiple times, and "
- 'each time adds to the existing value. Accepts either ":all:" to '
- 'disable all binary packages, ":none:" to empty the set (notice '
- "the colons), or one or more package names with commas between "
- "them (no colons). Note that some packages are tricky to compile "
- "and may fail to install when this option is used on them.",
- )
-
-
-def only_binary() -> Option:
- format_control = FormatControl(set(), set())
- return Option(
- "--only-binary",
- dest="format_control",
- action="callback",
- callback=_handle_only_binary,
- type="str",
- default=format_control,
- help="Do not use source packages. Can be supplied multiple times, and "
- 'each time adds to the existing value. Accepts either ":all:" to '
- 'disable all source packages, ":none:" to empty the set, or one '
- "or more package names with commas between them. Packages "
- "without binary distributions will fail to install when this "
- "option is used on them.",
- )
-
-
-platforms: Callable[..., Option] = partial(
- Option,
- "--platform",
- dest="platforms",
- metavar="platform",
- action="append",
- default=None,
- help=(
- "Only use wheels compatible with . Defaults to the "
- "platform of the running system. Use this option multiple times to "
- "specify multiple platforms supported by the target interpreter."
- ),
-)
-
-
-# This was made a separate function for unit-testing purposes.
-def _convert_python_version(value: str) -> Tuple[Tuple[int, ...], Optional[str]]:
- """
- Convert a version string like "3", "37", or "3.7.3" into a tuple of ints.
-
- :return: A 2-tuple (version_info, error_msg), where `error_msg` is
- non-None if and only if there was a parsing error.
- """
- if not value:
- # The empty string is the same as not providing a value.
- return (None, None)
-
- parts = value.split(".")
- if len(parts) > 3:
- return ((), "at most three version parts are allowed")
-
- if len(parts) == 1:
- # Then we are in the case of "3" or "37".
- value = parts[0]
- if len(value) > 1:
- parts = [value[0], value[1:]]
-
- try:
- version_info = tuple(int(part) for part in parts)
- except ValueError:
- return ((), "each version part must be an integer")
-
- return (version_info, None)
-
-
-def _handle_python_version(
- option: Option, opt_str: str, value: str, parser: OptionParser
-) -> None:
- """
- Handle a provided --python-version value.
- """
- version_info, error_msg = _convert_python_version(value)
- if error_msg is not None:
- msg = "invalid --python-version value: {!r}: {}".format(
- value,
- error_msg,
- )
- raise_option_error(parser, option=option, msg=msg)
-
- parser.values.python_version = version_info
-
-
-python_version: Callable[..., Option] = partial(
- Option,
- "--python-version",
- dest="python_version",
- metavar="python_version",
- action="callback",
- callback=_handle_python_version,
- type="str",
- default=None,
- help=dedent(
- """\
- The Python interpreter version to use for wheel and "Requires-Python"
- compatibility checks. Defaults to a version derived from the running
- interpreter. The version can be specified using up to three dot-separated
- integers (e.g. "3" for 3.0.0, "3.7" for 3.7.0, or "3.7.3"). A major-minor
- version can also be given as a string without dots (e.g. "37" for 3.7.0).
- """
- ),
-)
-
-
-implementation: Callable[..., Option] = partial(
- Option,
- "--implementation",
- dest="implementation",
- metavar="implementation",
- default=None,
- help=(
- "Only use wheels compatible with Python "
- "implementation , e.g. 'pp', 'jy', 'cp', "
- " or 'ip'. If not specified, then the current "
- "interpreter implementation is used. Use 'py' to force "
- "implementation-agnostic wheels."
- ),
-)
-
-
-abis: Callable[..., Option] = partial(
- Option,
- "--abi",
- dest="abis",
- metavar="abi",
- action="append",
- default=None,
- help=(
- "Only use wheels compatible with Python abi , e.g. 'pypy_41'. "
- "If not specified, then the current interpreter abi tag is used. "
- "Use this option multiple times to specify multiple abis supported "
- "by the target interpreter. Generally you will need to specify "
- "--implementation, --platform, and --python-version when using this "
- "option."
- ),
-)
-
-
-def add_target_python_options(cmd_opts: OptionGroup) -> None:
- cmd_opts.add_option(platforms())
- cmd_opts.add_option(python_version())
- cmd_opts.add_option(implementation())
- cmd_opts.add_option(abis())
-
-
-def make_target_python(options: Values) -> TargetPython:
- target_python = TargetPython(
- platforms=options.platforms,
- py_version_info=options.python_version,
- abis=options.abis,
- implementation=options.implementation,
- )
-
- return target_python
-
-
-def prefer_binary() -> Option:
- return Option(
- "--prefer-binary",
- dest="prefer_binary",
- action="store_true",
- default=False,
- help="Prefer older binary packages over newer source packages.",
- )
-
-
-cache_dir: Callable[..., Option] = partial(
- PipOption,
- "--cache-dir",
- dest="cache_dir",
- default=USER_CACHE_DIR,
- metavar="dir",
- type="path",
- help="Store the cache data in .",
-)
-
-
-def _handle_no_cache_dir(
- option: Option, opt: str, value: str, parser: OptionParser
-) -> None:
- """
- Process a value provided for the --no-cache-dir option.
-
- This is an optparse.Option callback for the --no-cache-dir option.
- """
- # The value argument will be None if --no-cache-dir is passed via the
- # command-line, since the option doesn't accept arguments. However,
- # the value can be non-None if the option is triggered e.g. by an
- # environment variable, like PIP_NO_CACHE_DIR=true.
- if value is not None:
- # Then parse the string value to get argument error-checking.
- try:
- strtobool(value)
- except ValueError as exc:
- raise_option_error(parser, option=option, msg=str(exc))
-
- # Originally, setting PIP_NO_CACHE_DIR to a value that strtobool()
- # converted to 0 (like "false" or "no") caused cache_dir to be disabled
- # rather than enabled (logic would say the latter). Thus, we disable
- # the cache directory not just on values that parse to True, but (for
- # backwards compatibility reasons) also on values that parse to False.
- # In other words, always set it to False if the option is provided in
- # some (valid) form.
- parser.values.cache_dir = False
-
-
-no_cache: Callable[..., Option] = partial(
- Option,
- "--no-cache-dir",
- dest="cache_dir",
- action="callback",
- callback=_handle_no_cache_dir,
- help="Disable the cache.",
-)
-
-no_deps: Callable[..., Option] = partial(
- Option,
- "--no-deps",
- "--no-dependencies",
- dest="ignore_dependencies",
- action="store_true",
- default=False,
- help="Don't install package dependencies.",
-)
-
-ignore_requires_python: Callable[..., Option] = partial(
- Option,
- "--ignore-requires-python",
- dest="ignore_requires_python",
- action="store_true",
- help="Ignore the Requires-Python information.",
-)
-
-no_build_isolation: Callable[..., Option] = partial(
- Option,
- "--no-build-isolation",
- dest="build_isolation",
- action="store_false",
- default=True,
- help="Disable isolation when building a modern source distribution. "
- "Build dependencies specified by PEP 518 must be already installed "
- "if this option is used.",
-)
-
-check_build_deps: Callable[..., Option] = partial(
- Option,
- "--check-build-dependencies",
- dest="check_build_deps",
- action="store_true",
- default=False,
- help="Check the build dependencies when PEP517 is used.",
-)
-
-
-def _handle_no_use_pep517(
- option: Option, opt: str, value: str, parser: OptionParser
-) -> None:
- """
- Process a value provided for the --no-use-pep517 option.
-
- This is an optparse.Option callback for the no_use_pep517 option.
- """
- # Since --no-use-pep517 doesn't accept arguments, the value argument
- # will be None if --no-use-pep517 is passed via the command-line.
- # However, the value can be non-None if the option is triggered e.g.
- # by an environment variable, for example "PIP_NO_USE_PEP517=true".
- if value is not None:
- msg = """A value was passed for --no-use-pep517,
- probably using either the PIP_NO_USE_PEP517 environment variable
- or the "no-use-pep517" config file option. Use an appropriate value
- of the PIP_USE_PEP517 environment variable or the "use-pep517"
- config file option instead.
- """
- raise_option_error(parser, option=option, msg=msg)
-
- # If user doesn't wish to use pep517, we check if setuptools is installed
- # and raise error if it is not.
- if not importlib.util.find_spec("setuptools"):
- msg = "It is not possible to use --no-use-pep517 without setuptools installed."
- raise_option_error(parser, option=option, msg=msg)
-
- # Otherwise, --no-use-pep517 was passed via the command-line.
- parser.values.use_pep517 = False
-
-
-use_pep517: Any = partial(
- Option,
- "--use-pep517",
- dest="use_pep517",
- action="store_true",
- default=None,
- help="Use PEP 517 for building source distributions "
- "(use --no-use-pep517 to force legacy behaviour).",
-)
-
-no_use_pep517: Any = partial(
- Option,
- "--no-use-pep517",
- dest="use_pep517",
- action="callback",
- callback=_handle_no_use_pep517,
- default=None,
- help=SUPPRESS_HELP,
-)
-
-
-def _handle_config_settings(
- option: Option, opt_str: str, value: str, parser: OptionParser
-) -> None:
- key, sep, val = value.partition("=")
- if sep != "=":
- parser.error(f"Arguments to {opt_str} must be of the form KEY=VAL") # noqa
- dest = getattr(parser.values, option.dest)
- if dest is None:
- dest = {}
- setattr(parser.values, option.dest, dest)
- dest[key] = val
-
-
-config_settings: Callable[..., Option] = partial(
- Option,
- "--config-settings",
- dest="config_settings",
- type=str,
- action="callback",
- callback=_handle_config_settings,
- metavar="settings",
- help="Configuration settings to be passed to the PEP 517 build backend. "
- "Settings take the form KEY=VALUE. Use multiple --config-settings options "
- "to pass multiple keys to the backend.",
-)
-
-install_options: Callable[..., Option] = partial(
- Option,
- "--install-option",
- dest="install_options",
- action="append",
- metavar="options",
- help="Extra arguments to be supplied to the setup.py install "
- 'command (use like --install-option="--install-scripts=/usr/local/'
- 'bin"). Use multiple --install-option options to pass multiple '
- "options to setup.py install. If you are using an option with a "
- "directory path, be sure to use absolute path.",
-)
-
-build_options: Callable[..., Option] = partial(
- Option,
- "--build-option",
- dest="build_options",
- metavar="options",
- action="append",
- help="Extra arguments to be supplied to 'setup.py bdist_wheel'.",
-)
-
-global_options: Callable[..., Option] = partial(
- Option,
- "--global-option",
- dest="global_options",
- action="append",
- metavar="options",
- help="Extra global options to be supplied to the setup.py "
- "call before the install or bdist_wheel command.",
-)
-
-no_clean: Callable[..., Option] = partial(
- Option,
- "--no-clean",
- action="store_true",
- default=False,
- help="Don't clean up build directories.",
-)
-
-pre: Callable[..., Option] = partial(
- Option,
- "--pre",
- action="store_true",
- default=False,
- help="Include pre-release and development versions. By default, "
- "pip only finds stable versions.",
-)
-
-disable_pip_version_check: Callable[..., Option] = partial(
- Option,
- "--disable-pip-version-check",
- dest="disable_pip_version_check",
- action="store_true",
- default=False,
- help="Don't periodically check PyPI to determine whether a new version "
- "of pip is available for download. Implied with --no-index.",
-)
-
-root_user_action: Callable[..., Option] = partial(
- Option,
- "--root-user-action",
- dest="root_user_action",
- default="warn",
- choices=["warn", "ignore"],
- help="Action if pip is run as a root user. By default, a warning message is shown.",
-)
-
-
-def _handle_merge_hash(
- option: Option, opt_str: str, value: str, parser: OptionParser
-) -> None:
- """Given a value spelled "algo:digest", append the digest to a list
- pointed to in a dict by the algo name."""
- if not parser.values.hashes:
- parser.values.hashes = {}
- try:
- algo, digest = value.split(":", 1)
- except ValueError:
- parser.error(
- "Arguments to {} must be a hash name " # noqa
- "followed by a value, like --hash=sha256:"
- "abcde...".format(opt_str)
- )
- if algo not in STRONG_HASHES:
- parser.error(
- "Allowed hash algorithms for {} are {}.".format( # noqa
- opt_str, ", ".join(STRONG_HASHES)
- )
- )
- parser.values.hashes.setdefault(algo, []).append(digest)
-
-
-hash: Callable[..., Option] = partial(
- Option,
- "--hash",
- # Hash values eventually end up in InstallRequirement.hashes due to
- # __dict__ copying in process_line().
- dest="hashes",
- action="callback",
- callback=_handle_merge_hash,
- type="string",
- help="Verify that the package's archive matches this "
- "hash before installing. Example: --hash=sha256:abcdef...",
-)
-
-
-require_hashes: Callable[..., Option] = partial(
- Option,
- "--require-hashes",
- dest="require_hashes",
- action="store_true",
- default=False,
- help="Require a hash to check each requirement against, for "
- "repeatable installs. This option is implied when any package in a "
- "requirements file has a --hash option.",
-)
-
-
-list_path: Callable[..., Option] = partial(
- PipOption,
- "--path",
- dest="path",
- type="path",
- action="append",
- help="Restrict to the specified installation path for listing "
- "packages (can be used multiple times).",
-)
-
-
-def check_list_path_option(options: Values) -> None:
- if options.path and (options.user or options.local):
- raise CommandError("Cannot combine '--path' with '--user' or '--local'")
-
-
-list_exclude: Callable[..., Option] = partial(
- PipOption,
- "--exclude",
- dest="excludes",
- action="append",
- metavar="package",
- type="package_name",
- help="Exclude specified package from the output",
-)
-
-
-no_python_version_warning: Callable[..., Option] = partial(
- Option,
- "--no-python-version-warning",
- dest="no_python_version_warning",
- action="store_true",
- default=False,
- help="Silence deprecation warnings for upcoming unsupported Pythons.",
-)
-
-
-use_new_feature: Callable[..., Option] = partial(
- Option,
- "--use-feature",
- dest="features_enabled",
- metavar="feature",
- action="append",
- default=[],
- choices=[
- "fast-deps",
- "truststore",
- "no-binary-enable-wheel-cache",
- ],
- help="Enable new functionality, that may be backward incompatible.",
-)
-
-use_deprecated_feature: Callable[..., Option] = partial(
- Option,
- "--use-deprecated",
- dest="deprecated_features_enabled",
- metavar="feature",
- action="append",
- default=[],
- choices=[
- "legacy-resolver",
- ],
- help=("Enable deprecated functionality, that will be removed in the future."),
-)
-
-
-##########
-# groups #
-##########
-
-general_group: Dict[str, Any] = {
- "name": "General Options",
- "options": [
- help_,
- debug_mode,
- isolated_mode,
- require_virtualenv,
- python,
- verbose,
- version,
- quiet,
- log,
- no_input,
- proxy,
- retries,
- timeout,
- exists_action,
- trusted_host,
- cert,
- client_cert,
- cache_dir,
- no_cache,
- disable_pip_version_check,
- no_color,
- no_python_version_warning,
- use_new_feature,
- use_deprecated_feature,
- ],
-}
-
-index_group: Dict[str, Any] = {
- "name": "Package Index Options",
- "options": [
- index_url,
- extra_index_url,
- no_index,
- find_links,
- ],
-}
diff --git a/spaces/Raspberry-ai/main/config.py b/spaces/Raspberry-ai/main/config.py
deleted file mode 100644
index 36d971412206ad584ea748226656c8505708defe..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/config.py
+++ /dev/null
@@ -1,169 +0,0 @@
-# config.py specifies master parameters used in the app.py file, including the list of models and their specifications,
-# upper bound for the seed, and user tokens.
-from diffusers import AutoencoderKL, UNet2DConditionModel, StableDiffusionPipeline, StableDiffusionImg2ImgPipeline, \
- DPMSolverMultistepScheduler, LMSDiscreteScheduler, DDIMScheduler
-import datetime
-import torch
-import transformers
-import os
-
-###############################
-## Dictionary of the models:
-## The keys are what the app.py file uses to reference the model
-## The 'name' and 'description' are for Olivia's record keeping purposes only. They are not used by the app.
-## The 'token' (a legacy name btw) specifies the default apparel category and prompt engineering we want to add to the user-input prompt (more details in app.py)
-## The 'background_removal' parameter specifies whether the background of the SD output should be remove before the output images are returned to the suers (more details in app.py)
-###############################
-MODELS = {
- 'Inspiration images': {
- 'name': 'wolverine-mvp',
- 'path': "runwayml/stable-diffusion-v1-5",
- 'description': 'fundational stable diffusion model',
- 'token': {
- 'shoes': {'pre': '',
- 'post': ", full product photography, studio lighting–beta –ar 2:3 –beta –upbeta –upbeta"},
- },
- 'background_removal': False,
- },
- 'Technical drawings': {
- 'name': 'v4-dress',
- 'path': 'Raspberry-ai/EveryDream-dress',
- 'description': 'fine tuned SD with detailed labeled dress CAD using EveryDream script',
- 'token': {
- 'dress': {'pre': 'a technical drawing of a ',
- 'post':''
- }
- },
- 'background_removal': True,
- },
- # 'v3-dress-top-sweater': {
- # 'name': 'v3-dress-top-sweater',
- # 'path': 'Raspberry-ai/full-sd-dress-top-sweater',
- # 'description': 'SD trained on dress (using dress as class), tops, and sweaters together using Dreambooth. Hand pick a small yet diverse set of training data',
- # 'token': {
- # 'dress': 'a caddds dress lay down in plain white background',
- # 'top': 'a cadtop top lay down in plain white background',
- # 'sweater': "a cadssr sweater lay down in plain white background"
- # }
- # },
- # 'v3-dress-top-sweater-activewear': {
- # 'name': 'v3-dress-top-sweater-activewear',
- # 'path': 'Raspberry-ai/full-sd-dress-top-sweater-activewear',
- # 'description': 'continue train v3-dress-top-sweater with activewear',
- # 'token': {
- # 'dress': 'a caddds dress lay down in plain white background',
- # 'top': 'a cadtop top lay down in plain white background',
- # 'sweater': "a cadssr sweater lay down in plain white background",
- # 'activewear': "a cadaar activewear lay down in plain white background"
- # }
- # },
- # 'v3-3cat': {
- # 'name': 'v3-3cat',
- # 'path': 'Raspberry-ai/full-sd-dress-sweater-activewear',
- # 'description': "SD trained on all 3 categories using Dreambooth",
- # 'token': {
- # 'dress': 'a caddds dress',
- # 'sweater': 'a cadssr sweater',
- # 'activewear': 'a cadaar activewear'
- # }
- # },
- # 'v3-dress': {
- # 'name': 'v3-dress',
- # 'path': 'Raspberry-ai/full-sd-dress',
- # 'description': 'SD trained on dress only, using dress as class, using Dreambooth',
- # 'token': {
- # 'dress': 'a caddds dress lay down in plain white background',
- # }
- # },
- # 'v3-dress-top': {
- # 'name': 'v3-dress-top',
- # 'path': 'Raspberry-ai/full-sd-dress-top',
- # 'description': 'SD trained on dress (using dress as class) then retrained with tops using Dreambooth',
- # 'token': {
- # 'dress': 'a caddds dress lay down in plain white background',
- # 'top': 'a cadtop top lay down in plain white background'
- # }
- # },
-
- # 'v4-dress': {
- # 'name': 'v4-dress',
- # 'path': 'Raspberry-ai/full-sd-dress-2',
- # 'description': "SD trained on dress only, using cad as class using Dreambooth",
- # 'token': 'a caddds cad'
- # },
-}
-MAX_SEED = 9999999999 #this number was chosen randomly. I didn't look into how big the max_seed can be without breaking the SD pipeline
-HF_token = os.environ.get('HF_token') # getting the HF token recorded in the Space Setting. This way the token isn't exposed in the code script
-os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'max_split_size_mb:64' #This is the solution recommended by the internet for out of memory error. However I didn't find it useful.
-
-
-# As suggested by Bart, the following code loads the SD pipeline for each model in the dictionary during the Space building
-# so we don't call them repeatedly at the request time
-# we use DDIM scheduler here based on 1. internet recommendations: https://www.reddit.com/r/StableDiffusion/comments/zl6rtj/schedulers_compared/
-# https://stable-diffusion-art.com/samplers/#So8230_which_one_is_the_best
-# and 2. some simple un-documented testings I did very early on that showed DDIM produce better images (as judged by me) within reasonable time compared to most other schedulers.
-# There are often new schedulers released by academic so I recommend revisit this every now and then.
-class Model:
- def __init__(self, name, path="", description="", token='', background_removal=False):
- self.name = name
- self.path = path
- self.description = description
- self.token = token
- self.pipe_t2i = None
- self.pipe_i2i = None
- self.background_removal = background_removal
-
-device = "cuda" if torch.cuda.is_available() else "cpu"
-models = {}
-for name, model in MODELS.items():
- models[name] = Model(**model)
- try:
- print(f"{datetime.datetime.now()} Downloading {model['name']} model...")
- if device == "cuda":
- # define text to image
- print("Downloading txt to img model")
- models[name].pipe_t2i = StableDiffusionPipeline.from_pretrained(
- models[name].path, torch_dtype=torch.float16, use_auth_token=HF_token)
- models[name].pipe_t2i.scheduler = DDIMScheduler.from_config(models[name].pipe_t2i.scheduler.config)
- #define image to image
- print("Downloading img to img model")
- models[name].pipe_i2i = StableDiffusionImg2ImgPipeline(
- **models[name].pipe_t2i.components)
- else: # this part is almost never use as we need GPU to handel the large input images and 4 output images
- print("Downloading txt to img model")
- models[name].pipe_t2i = StableDiffusionPipeline.from_pretrained(
- models[name].path, torch_dtype=torch.float32, use_auth_token=HF_token)
- models[name].pipe_t2i.scheduler = DDIMScheduler.from_config(models[name].pipe_t2i.scheduler.config)
- #define image to image
- print("Downloading img to img model")
- models[name].pipe_i2i = StableDiffusionImg2ImgPipeline(
- **models[name].pipe_t2i.components)
-
- except Exception as e:
- print(f"{datetime.datetime.now()} Failed to load model " + model['name'] + ": " + str(e))
-
-# This css was copied pasted from another HF space that I don't recalled.
-# The only part I've ever attempted to change was the #gallery in order to keep the input column of the UI the same height as the output column (as required by Cheryl)
-css = """
- .finetuned-diffusion-div div{
- display:inline-flex;
- align-items:center;
- gap:.8rem;font-size:1.75rem
- }
- .finetuned-diffusion-div div h1{
- font-weight:900;
- margin-bottom:7px
- }
- .finetuned-diffusion-div p{
- margin-bottom:10px;
- font-size:94%
- }
- a{
- text-decoration:underline
- }
- .tabs{
- margin-top:0;
- margin-bottom:0
- }
- #gallery{max-height:37.3rem; min-height:37.3rem}
-"""
\ No newline at end of file
diff --git a/spaces/RaulS/D-Pose/app.py b/spaces/RaulS/D-Pose/app.py
deleted file mode 100644
index dc678bea9b9acc1f4ddaaeb0837e632dfdd4ebed..0000000000000000000000000000000000000000
--- a/spaces/RaulS/D-Pose/app.py
+++ /dev/null
@@ -1,176 +0,0 @@
-from typing import Tuple
-
-import gradio as gr
-import matplotlib
-import matplotlib.pyplot as plt
-import numpy as np
-import onnxruntime as ort
-import pandas as pd
-import pyvista as pv
-from scipy.signal import butter, filtfilt, iirnotch, sosfiltfilt
-
-EMG_SAMPLING_FREQUENCY = 2044
-
-matplotlib.use("Agg")
-pv.start_xvfb(window_size=[900, 432])
-
-MOVEMENT_TASKS = {
- k: np.load(f"data/emg/{k}.npy") for k in ["Thumb", "Index", "Middle", "Ring", "Pinky", "Fist", "Random Movement"]
-}
-GROUND_TRUTHS = {k: np.load(f"data/ground_truth/{k}.npy") for k in MOVEMENT_TASKS.keys()}
-WRIST = np.load("data/ground_truth/Wrist.npy")
-
-MIN_LEN = int(np.min([len(v) for v in GROUND_TRUTHS.values()]))
-
-ort_sess = ort.InferenceSession("model.onnx")
-
-
-def _filter_emg(input_emg: np.ndarray, supplementary_filter_sos: np.ndarray) -> np.ndarray:
- return np.stack([input_emg, sosfiltfilt(supplementary_filter_sos, input_emg, axis=-1)], axis=0).astype(np.float32)
-
-
-mean_euclidian_distance = []
-
-
-def run_ai(input_emg: np.ndarray, chunk_nr: int) -> Tuple[gr.Plot, gr.Markdown, gr.Image, gr.Image]:
- emg_chunk = MOVEMENT_TASKS[input_emg][:, chunk_nr * 64 : (chunk_nr + 1) * 64 + 128]
-
- # EMG Plot ---------------------------------------------------------------------------------------------------------
- plt.figure(figsize=(9, 2), dpi=300)
- plt.rcParams.update({"font.size": 8})
- for electrode in emg_chunk:
- plt.plot(np.arange(chunk_nr * 64, (chunk_nr + 1) * 64 + 128) / EMG_SAMPLING_FREQUENCY, electrode, alpha=0.65)
- plt.xlim([*(np.arange(chunk_nr * 64, (chunk_nr + 1) * 64 + 128) / EMG_SAMPLING_FREQUENCY)[[0, -1]]])
- plt.xlabel("Time (s)")
- plt.yticks([])
- plt.grid(visible=True, axis="x")
-
- for spine in plt.gca().spines.values():
- spine.set_visible(False)
-
- plt.tight_layout()
-
- # 3D Points Plots --------------------------------------------------------------------------------------------------
- ground_truths = np.concatenate(
- [WRIST[:, None], GROUND_TRUTHS[input_emg][chunk_nr].reshape(3, -1, order="F")], axis=-1
- )
-
- predictions = np.concatenate(
- [
- WRIST[:, None],
- ort_sess.run(
- None,
- {
- "input": _filter_emg(
- filtfilt(*iirnotch(w0=50, Q=75, fs=EMG_SAMPLING_FREQUENCY), x=emg_chunk, padtype=None, axis=-1),
- supplementary_filter_sos=butter(
- N=4, Wn=20, btype="low", analog=False, output="sos", fs=EMG_SAMPLING_FREQUENCY
- ),
- )[
- None,
- ]
- },
- )[0].reshape(3, -1, order="F"),
- ],
- axis=-1,
- )
-
- output_imgs = []
- for data in (predictions, ground_truths):
- pv_plt = pv.Plotter(off_screen=True, window_size=[900, 432])
- pv_plt.set_background(pv.Color([1.0, 1.0, 1.0]))
- pv_plt.enable_anti_aliasing()
-
- pv_plt.add_mesh(
- pv.PolyData(data.T).glyph(scale=False, geom=pv.Sphere(radius=0.05, phi_resolution=10, theta_resolution=10)),
- color=pv.Color((0.15, 0.15, 0.15)),
- smooth_shading=True,
- )
-
- for array_index, color in zip(
- [
- list(range(0, 5)),
- [0] + list(range(5, 9)),
- [0] + list(range(9, 13)),
- [0] + list(range(13, 17)),
- [0] + list(range(17, 21)),
- ],
- ["#1f77b4", "#ff7f0e", "#2ca02c", "#d62728", "#9a6fc0"],
- ):
- point = data.T[array_index]
- for i in range(1, len(array_index)):
- pv_plt.add_mesh(
- pv.Tube(point[i - 1], point[i], radius=0.0275, n_sides=10),
- color=pv.Color(color),
- smooth_shading=True,
- )
-
- pv_plt.camera.position = (1.8, 1.8, 1.8)
-
- pv_plt.camera.elevation = -20
- pv_plt.camera.azimuth = 45
- pv_plt.camera.roll += 20
-
- output_imgs.append(pv_plt.screenshot(return_img=True))
- pv_plt.close()
-
- emg_plot = plt.gcf()
-
- # Mean Euclidean Distance Plot -------------------------------------------------------------------------------------
- min_and_max = pd.read_csv("data/min_max.csv", index_col=0).to_numpy()
-
- for i in range(3):
- ground_truths[i] = ((ground_truths[i] + 1) / 2) * (min_and_max[i, 1] - min_and_max[i, 0]) + min_and_max[i, 0]
- predictions[i] = ((predictions[i] + 1) / 2) * (min_and_max[i, 1] - min_and_max[i, 0]) + min_and_max[i, 0]
-
- mean_euclidean_distance = np.sqrt(np.sum(np.square(predictions - ground_truths), axis=1))[1:]
-
- plt.close("all")
-
- return (
- gr.Plot.update(emg_plot),
- gr.Markdown.update(
- "## Mean Euclidean Distance = {:.2f} ± {:.2f} mm".format(
- np.mean(mean_euclidean_distance), np.std(mean_euclidean_distance)
- )
- ),
- gr.Image.update(output_imgs[0]),
- gr.Image.update(output_imgs[1]),
- )
-
-
-top_div = gr.Blocks()
-
-outputs = []
-with top_div:
- gr.Markdown("# Example Model for Subject 1")
- gr.Markdown(
- "## Made by [Raul C. Sîmpetru](https://raulsimpetru.github.io/) @ "
- "[N-Squared Lab, Friedrich-Alexander-Universität Erlangen-Nürnberg](https://www.nsquared.tf.fau.de/)"
- )
- with gr.Column():
- gr.Markdown("# Inputs:")
-
- with gr.Row():
- inputs = [
- gr.Radio(list(MOVEMENT_TASKS.keys()), label="Select Movement Task"),
- gr.Slider(0, MIN_LEN, label="Select Bin Number", step=1),
- ]
-
- gr.Markdown('Selected EMG Bin
')
- outputs.append(gr.Plot(show_label=False))
-
- gr.Markdown("# Outputs:")
-
- outputs.append(gr.Markdown("## Mean Euclidean Distance = ... mm"))
- with gr.Row():
- with gr.Column():
- gr.Markdown('EMG Driven
')
- outputs.append(gr.Image(show_label=False))
- with gr.Column():
- gr.Markdown('Camera Driven
')
- outputs.append(gr.Image(show_label=False))
-
- inputs[1].change(fn=run_ai, inputs=inputs, outputs=outputs)
-
-top_div.launch()
diff --git a/spaces/Rbrq/DeticChatGPT/detic/modeling/roi_heads/detic_roi_heads.py b/spaces/Rbrq/DeticChatGPT/detic/modeling/roi_heads/detic_roi_heads.py
deleted file mode 100644
index c87559359e0516443a43ed327110ec55fa4fa307..0000000000000000000000000000000000000000
--- a/spaces/Rbrq/DeticChatGPT/detic/modeling/roi_heads/detic_roi_heads.py
+++ /dev/null
@@ -1,271 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import copy
-import numpy as np
-import json
-import math
-import torch
-from torch import nn
-from torch.autograd.function import Function
-from typing import Dict, List, Optional, Tuple, Union
-from torch.nn import functional as F
-
-from detectron2.config import configurable
-from detectron2.layers import ShapeSpec
-from detectron2.layers import batched_nms
-from detectron2.structures import Boxes, Instances, pairwise_iou
-from detectron2.utils.events import get_event_storage
-
-from detectron2.modeling.box_regression import Box2BoxTransform
-from detectron2.modeling.roi_heads.fast_rcnn import fast_rcnn_inference
-from detectron2.modeling.roi_heads.roi_heads import ROI_HEADS_REGISTRY, StandardROIHeads
-from detectron2.modeling.roi_heads.cascade_rcnn import CascadeROIHeads, _ScaleGradient
-from detectron2.modeling.roi_heads.box_head import build_box_head
-from .detic_fast_rcnn import DeticFastRCNNOutputLayers
-from ..debug import debug_second_stage
-
-from torch.cuda.amp import autocast
-
-@ROI_HEADS_REGISTRY.register()
-class DeticCascadeROIHeads(CascadeROIHeads):
- @configurable
- def __init__(
- self,
- *,
- mult_proposal_score: bool = False,
- with_image_labels: bool = False,
- add_image_box: bool = False,
- image_box_size: float = 1.0,
- ws_num_props: int = 512,
- add_feature_to_prop: bool = False,
- mask_weight: float = 1.0,
- one_class_per_proposal: bool = False,
- **kwargs,
- ):
- super().__init__(**kwargs)
- self.mult_proposal_score = mult_proposal_score
- self.with_image_labels = with_image_labels
- self.add_image_box = add_image_box
- self.image_box_size = image_box_size
- self.ws_num_props = ws_num_props
- self.add_feature_to_prop = add_feature_to_prop
- self.mask_weight = mask_weight
- self.one_class_per_proposal = one_class_per_proposal
-
- @classmethod
- def from_config(cls, cfg, input_shape):
- ret = super().from_config(cfg, input_shape)
- ret.update({
- 'mult_proposal_score': cfg.MODEL.ROI_BOX_HEAD.MULT_PROPOSAL_SCORE,
- 'with_image_labels': cfg.WITH_IMAGE_LABELS,
- 'add_image_box': cfg.MODEL.ROI_BOX_HEAD.ADD_IMAGE_BOX,
- 'image_box_size': cfg.MODEL.ROI_BOX_HEAD.IMAGE_BOX_SIZE,
- 'ws_num_props': cfg.MODEL.ROI_BOX_HEAD.WS_NUM_PROPS,
- 'add_feature_to_prop': cfg.MODEL.ROI_BOX_HEAD.ADD_FEATURE_TO_PROP,
- 'mask_weight': cfg.MODEL.ROI_HEADS.MASK_WEIGHT,
- 'one_class_per_proposal': cfg.MODEL.ROI_HEADS.ONE_CLASS_PER_PROPOSAL,
- })
- return ret
-
-
- @classmethod
- def _init_box_head(self, cfg, input_shape):
- ret = super()._init_box_head(cfg, input_shape)
- del ret['box_predictors']
- cascade_bbox_reg_weights = cfg.MODEL.ROI_BOX_CASCADE_HEAD.BBOX_REG_WEIGHTS
- box_predictors = []
- for box_head, bbox_reg_weights in zip(ret['box_heads'], \
- cascade_bbox_reg_weights):
- box_predictors.append(
- DeticFastRCNNOutputLayers(
- cfg, box_head.output_shape,
- box2box_transform=Box2BoxTransform(weights=bbox_reg_weights)
- ))
- ret['box_predictors'] = box_predictors
- return ret
-
-
- def _forward_box(self, features, proposals, targets=None,
- ann_type='box', classifier_info=(None,None,None)):
- """
- Add mult proposal scores at testing
- Add ann_type
- """
- if (not self.training) and self.mult_proposal_score:
- if len(proposals) > 0 and proposals[0].has('scores'):
- proposal_scores = [p.get('scores') for p in proposals]
- else:
- proposal_scores = [p.get('objectness_logits') for p in proposals]
-
- features = [features[f] for f in self.box_in_features]
- head_outputs = [] # (predictor, predictions, proposals)
- prev_pred_boxes = None
- image_sizes = [x.image_size for x in proposals]
-
- for k in range(self.num_cascade_stages):
- if k > 0:
- proposals = self._create_proposals_from_boxes(
- prev_pred_boxes, image_sizes,
- logits=[p.objectness_logits for p in proposals])
- if self.training and ann_type in ['box']:
- proposals = self._match_and_label_boxes(
- proposals, k, targets)
- predictions = self._run_stage(features, proposals, k,
- classifier_info=classifier_info)
- prev_pred_boxes = self.box_predictor[k].predict_boxes(
- (predictions[0], predictions[1]), proposals)
- head_outputs.append((self.box_predictor[k], predictions, proposals))
-
- if self.training:
- losses = {}
- storage = get_event_storage()
- for stage, (predictor, predictions, proposals) in enumerate(head_outputs):
- with storage.name_scope("stage{}".format(stage)):
- if ann_type != 'box':
- stage_losses = {}
- if ann_type in ['image', 'caption', 'captiontag']:
- image_labels = [x._pos_category_ids for x in targets]
- weak_losses = predictor.image_label_losses(
- predictions, proposals, image_labels,
- classifier_info=classifier_info,
- ann_type=ann_type)
- stage_losses.update(weak_losses)
- else: # supervised
- stage_losses = predictor.losses(
- (predictions[0], predictions[1]), proposals,
- classifier_info=classifier_info)
- if self.with_image_labels:
- stage_losses['image_loss'] = \
- predictions[0].new_zeros([1])[0]
- losses.update({k + "_stage{}".format(stage): v \
- for k, v in stage_losses.items()})
- return losses
- else:
- # Each is a list[Tensor] of length #image. Each tensor is Ri x (K+1)
- scores_per_stage = [h[0].predict_probs(h[1], h[2]) for h in head_outputs]
- scores = [
- sum(list(scores_per_image)) * (1.0 / self.num_cascade_stages)
- for scores_per_image in zip(*scores_per_stage)
- ]
- if self.mult_proposal_score:
- scores = [(s * ps[:, None]) ** 0.5 \
- for s, ps in zip(scores, proposal_scores)]
- if self.one_class_per_proposal:
- scores = [s * (s == s[:, :-1].max(dim=1)[0][:, None]).float() for s in scores]
- predictor, predictions, proposals = head_outputs[-1]
- boxes = predictor.predict_boxes(
- (predictions[0], predictions[1]), proposals)
- pred_instances, _ = fast_rcnn_inference(
- boxes,
- scores,
- image_sizes,
- predictor.test_score_thresh,
- predictor.test_nms_thresh,
- predictor.test_topk_per_image,
- )
- return pred_instances
-
-
- def forward(self, images, features, proposals, targets=None,
- ann_type='box', classifier_info=(None,None,None)):
- '''
- enable debug and image labels
- classifier_info is shared across the batch
- '''
- if self.training:
- if ann_type in ['box', 'prop', 'proptag']:
- proposals = self.label_and_sample_proposals(
- proposals, targets)
- else:
- proposals = self.get_top_proposals(proposals)
-
- losses = self._forward_box(features, proposals, targets, \
- ann_type=ann_type, classifier_info=classifier_info)
- if ann_type == 'box' and targets[0].has('gt_masks'):
- mask_losses = self._forward_mask(features, proposals)
- losses.update({k: v * self.mask_weight \
- for k, v in mask_losses.items()})
- losses.update(self._forward_keypoint(features, proposals))
- else:
- losses.update(self._get_empty_mask_loss(
- features, proposals,
- device=proposals[0].objectness_logits.device))
- return proposals, losses
- else:
- pred_instances = self._forward_box(
- features, proposals, classifier_info=classifier_info)
- pred_instances = self.forward_with_given_boxes(features, pred_instances)
- return pred_instances, {}
-
-
- def get_top_proposals(self, proposals):
- for i in range(len(proposals)):
- proposals[i].proposal_boxes.clip(proposals[i].image_size)
- proposals = [p[:self.ws_num_props] for p in proposals]
- for i, p in enumerate(proposals):
- p.proposal_boxes.tensor = p.proposal_boxes.tensor.detach()
- if self.add_image_box:
- proposals[i] = self._add_image_box(p)
- return proposals
-
-
- def _add_image_box(self, p):
- image_box = Instances(p.image_size)
- n = 1
- h, w = p.image_size
- f = self.image_box_size
- image_box.proposal_boxes = Boxes(
- p.proposal_boxes.tensor.new_tensor(
- [w * (1. - f) / 2.,
- h * (1. - f) / 2.,
- w * (1. - (1. - f) / 2.),
- h * (1. - (1. - f) / 2.)]
- ).view(n, 4))
- image_box.objectness_logits = p.objectness_logits.new_ones(n)
- return Instances.cat([p, image_box])
-
-
- def _get_empty_mask_loss(self, features, proposals, device):
- if self.mask_on:
- return {'loss_mask': torch.zeros(
- (1, ), device=device, dtype=torch.float32)[0]}
- else:
- return {}
-
-
- def _create_proposals_from_boxes(self, boxes, image_sizes, logits):
- """
- Add objectness_logits
- """
- boxes = [Boxes(b.detach()) for b in boxes]
- proposals = []
- for boxes_per_image, image_size, logit in zip(
- boxes, image_sizes, logits):
- boxes_per_image.clip(image_size)
- if self.training:
- inds = boxes_per_image.nonempty()
- boxes_per_image = boxes_per_image[inds]
- logit = logit[inds]
- prop = Instances(image_size)
- prop.proposal_boxes = boxes_per_image
- prop.objectness_logits = logit
- proposals.append(prop)
- return proposals
-
-
- def _run_stage(self, features, proposals, stage, \
- classifier_info=(None,None,None)):
- """
- Support classifier_info and add_feature_to_prop
- """
- pool_boxes = [x.proposal_boxes for x in proposals]
- box_features = self.box_pooler(features, pool_boxes)
- box_features = _ScaleGradient.apply(box_features, 1.0 / self.num_cascade_stages)
- box_features = self.box_head[stage](box_features)
- if self.add_feature_to_prop:
- feats_per_image = box_features.split(
- [len(p) for p in proposals], dim=0)
- for feat, p in zip(feats_per_image, proposals):
- p.feat = feat
- return self.box_predictor[stage](
- box_features,
- classifier_info=classifier_info)
diff --git a/spaces/Realcat/image-matching-webui/third_party/SuperGluePretrainedNetwork/models/matching.py b/spaces/Realcat/image-matching-webui/third_party/SuperGluePretrainedNetwork/models/matching.py
deleted file mode 100644
index c5c0eda3337d021464eb6283e57b7412c08afb03..0000000000000000000000000000000000000000
--- a/spaces/Realcat/image-matching-webui/third_party/SuperGluePretrainedNetwork/models/matching.py
+++ /dev/null
@@ -1,85 +0,0 @@
-# %BANNER_BEGIN%
-# ---------------------------------------------------------------------
-# %COPYRIGHT_BEGIN%
-#
-# Magic Leap, Inc. ("COMPANY") CONFIDENTIAL
-#
-# Unpublished Copyright (c) 2020
-# Magic Leap, Inc., All Rights Reserved.
-#
-# NOTICE: All information contained herein is, and remains the property
-# of COMPANY. The intellectual and technical concepts contained herein
-# are proprietary to COMPANY and may be covered by U.S. and Foreign
-# Patents, patents in process, and are protected by trade secret or
-# copyright law. Dissemination of this information or reproduction of
-# this material is strictly forbidden unless prior written permission is
-# obtained from COMPANY. Access to the source code contained herein is
-# hereby forbidden to anyone except current COMPANY employees, managers
-# or contractors who have executed Confidentiality and Non-disclosure
-# agreements explicitly covering such access.
-#
-# The copyright notice above does not evidence any actual or intended
-# publication or disclosure of this source code, which includes
-# information that is confidential and/or proprietary, and is a trade
-# secret, of COMPANY. ANY REPRODUCTION, MODIFICATION, DISTRIBUTION,
-# PUBLIC PERFORMANCE, OR PUBLIC DISPLAY OF OR THROUGH USE OF THIS
-# SOURCE CODE WITHOUT THE EXPRESS WRITTEN CONSENT OF COMPANY IS
-# STRICTLY PROHIBITED, AND IN VIOLATION OF APPLICABLE LAWS AND
-# INTERNATIONAL TREATIES. THE RECEIPT OR POSSESSION OF THIS SOURCE
-# CODE AND/OR RELATED INFORMATION DOES NOT CONVEY OR IMPLY ANY RIGHTS
-# TO REPRODUCE, DISCLOSE OR DISTRIBUTE ITS CONTENTS, OR TO MANUFACTURE,
-# USE, OR SELL ANYTHING THAT IT MAY DESCRIBE, IN WHOLE OR IN PART.
-#
-# %COPYRIGHT_END%
-# ----------------------------------------------------------------------
-# %AUTHORS_BEGIN%
-#
-# Originating Authors: Paul-Edouard Sarlin
-#
-# %AUTHORS_END%
-# --------------------------------------------------------------------*/
-# %BANNER_END%
-
-import torch
-
-from .superpoint import SuperPoint
-from .superglue import SuperGlue
-
-
-class Matching(torch.nn.Module):
- """Image Matching Frontend (SuperPoint + SuperGlue)"""
-
- def __init__(self, config={}):
- super().__init__()
- self.superpoint = SuperPoint(config.get("superpoint", {}))
- self.superglue = SuperGlue(config.get("superglue", {}))
-
- def forward(self, data):
- """Run SuperPoint (optionally) and SuperGlue
- SuperPoint is skipped if ['keypoints0', 'keypoints1'] exist in input
- Args:
- data: dictionary with minimal keys: ['image0', 'image1']
- """
- pred = {}
-
- # Extract SuperPoint (keypoints, scores, descriptors) if not provided
- if "keypoints0" not in data:
- pred0 = self.superpoint({"image": data["image0"]})
- pred = {**pred, **{k + "0": v for k, v in pred0.items()}}
- if "keypoints1" not in data:
- pred1 = self.superpoint({"image": data["image1"]})
- pred = {**pred, **{k + "1": v for k, v in pred1.items()}}
-
- # Batch all features
- # We should either have i) one image per batch, or
- # ii) the same number of local features for all images in the batch.
- data = {**data, **pred}
-
- for k in data:
- if isinstance(data[k], (list, tuple)):
- data[k] = torch.stack(data[k])
-
- # Perform the matching
- pred = {**pred, **self.superglue(data)}
-
- return pred
diff --git a/spaces/Riksarkivet/htr_demo/src/htr_pipeline/utils/pipeline_inferencer.py b/spaces/Riksarkivet/htr_demo/src/htr_pipeline/utils/pipeline_inferencer.py
deleted file mode 100644
index 39a1c15c4d158b5ab46852d05badc1adadcaa08d..0000000000000000000000000000000000000000
--- a/spaces/Riksarkivet/htr_demo/src/htr_pipeline/utils/pipeline_inferencer.py
+++ /dev/null
@@ -1,148 +0,0 @@
-import gradio as gr
-from tqdm import tqdm
-
-from src.htr_pipeline.utils.process_segmask import SegMaskHelper
-from src.htr_pipeline.utils.xml_helper import XMLHelper
-
-terminate = False
-
-# TODO check why region is so slow to start.. Is their error with loading the model?
-
-
-class PipelineInferencer:
- def __init__(self, process_seg_mask: SegMaskHelper, xml_helper: XMLHelper):
- self.process_seg_mask = process_seg_mask
- self.xml_helper = xml_helper
-
- def image_to_page_xml(
- self,
- image,
- htr_tool_transcriber_model_dropdown,
- pred_score_threshold_regions,
- pred_score_threshold_lines,
- containments_threshold,
- inferencer,
- ):
- # temporary solutions.. for trocr..
- self.htr_tool_transcriber_model_dropdown = htr_tool_transcriber_model_dropdown
-
- template_data = self.xml_helper.prepare_template_data(self.xml_helper.xml_file_name, image)
- template_data["textRegions"] = self._process_regions(
- image, inferencer, pred_score_threshold_regions, pred_score_threshold_lines, containments_threshold
- )
-
- return self.xml_helper.render(template_data)
-
- def _process_regions(
- self,
- image,
- inferencer,
- pred_score_threshold_regions,
- pred_score_threshold_lines,
- containments_threshold,
- htr_threshold=0.6,
- ):
- global terminate
-
- _, regions_cropped_ordered, reg_polygons_ordered, reg_masks_ordered = inferencer.predict_regions(
- image,
- pred_score_threshold=pred_score_threshold_regions,
- containments_threshold=containments_threshold,
- visualize=False,
- )
- gr.Info(f"Found {len(regions_cropped_ordered)} Regions to parse")
- region_data_list = []
- for i, data in tqdm(enumerate(zip(regions_cropped_ordered, reg_polygons_ordered, reg_masks_ordered))):
- if terminate:
- break
- region_data = self._create_region_data(
- data, i, inferencer, pred_score_threshold_lines, containments_threshold, htr_threshold
- )
- if region_data:
- region_data_list.append(region_data)
-
- return region_data_list
-
- def _create_region_data(
- self, data, index, inferencer, pred_score_threshold_lines, containments_threshold, htr_threshold
- ):
- text_region, reg_pol, mask = data
- region_data = {"id": f"region_{index}", "boundary": reg_pol}
-
- text_lines, htr_scores = self._process_lines(
- text_region,
- inferencer,
- pred_score_threshold_lines,
- containments_threshold,
- mask,
- region_data["id"],
- htr_threshold,
- )
-
- if not text_lines:
- return None
-
- region_data["textLines"] = text_lines
- mean_htr_score = sum(htr_scores) / len(htr_scores) if htr_scores else 0
-
- return region_data if mean_htr_score > htr_threshold + 0.1 else None
-
- def _process_lines(
- self, text_region, inferencer, pred_score_threshold, containments_threshold, mask, region_id, htr_threshold=0.6
- ):
- _, lines_cropped_ordered, line_polygons_ordered = inferencer.predict_lines(
- text_region, pred_score_threshold, containments_threshold, visualize=False, custom_track=False
- )
-
- if not lines_cropped_ordered:
- return None, []
-
- line_polygons_ordered_trans = self.process_seg_mask._translate_line_coords(mask, line_polygons_ordered)
-
- text_lines = []
- htr_scores = []
-
- id_number = region_id.split("_")[1]
- total_lines_len = len(lines_cropped_ordered)
-
- gr.Info(f" Region {id_number}, found {total_lines_len} lines to parse and transcribe.")
-
- global terminate
-
- for index, (line, line_pol) in enumerate(zip(lines_cropped_ordered, line_polygons_ordered_trans)):
- if terminate:
- break
- line_data, htr_score = self._create_line_data(line, line_pol, index, region_id, inferencer, htr_threshold)
-
- if line_data:
- text_lines.append(line_data)
- htr_scores.append(htr_score)
-
- remaining_lines = total_lines_len - index - 1
-
- if (index + 1) % 10 == 0 and remaining_lines > 5: # +1 because index starts at 0
- gr.Info(
- f"Region {id_number}, parsed {index + 1} lines. Still {remaining_lines} lines left to transcribe."
- )
-
- return text_lines, htr_scores
-
- def _create_line_data(self, line, line_pol, index, region_id, inferencer, htr_threshold):
- line_data = {"id": f"line_{region_id}_{index}", "boundary": line_pol}
-
- # temporary solution..
- if self.htr_tool_transcriber_model_dropdown == "Riksarkivet/satrn_htr":
- transcribed_text, htr_score = inferencer.transcribe(line)
- else:
- transcribed_text, htr_score = inferencer.transcribe_different_model(
- line, self.htr_tool_transcriber_model_dropdown
- )
-
- line_data["unicode"] = self.xml_helper.escape_xml_chars(transcribed_text)
- line_data["pred_score"] = round(htr_score, 4)
-
- return line_data if htr_score > htr_threshold else None, htr_score
-
-
-if __name__ == "__main__":
- pass
diff --git a/spaces/Rinox06/webui/app.py b/spaces/Rinox06/webui/app.py
deleted file mode 100644
index 46634a8b73e78222880763b1e15a1e86cae79df4..0000000000000000000000000000000000000000
--- a/spaces/Rinox06/webui/app.py
+++ /dev/null
@@ -1,88 +0,0 @@
-import os
-from subprocess import getoutput
-
-gpu_info = getoutput('nvidia-smi')
-if("A10G" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+4c06c79.d20221205-cp38-cp38-linux_x86_64.whl")
-elif("T4" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+1515f77.d20221130-cp38-cp38-linux_x86_64.whl")
-
-os.system(f"git clone -b v1.5 https://github.com/camenduru/stable-diffusion-webui /home/user/app/stable-diffusion-webui")
-os.chdir("/home/user/app/stable-diffusion-webui")
-
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/env_patch.py -O /home/user/app/env_patch.py")
-os.system(f"sed -i -e '/import image_from_url_text/r /home/user/app/env_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(modelmerger_interface, \"Checkpoint Merger\", \"modelmerger\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(train_interface, \"Train\", \"ti\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/extensions_interface, \"Extensions\", \"extensions\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/settings_interface, \"Settings\", \"settings\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f'''sed -i -e "s/document.getElementsByTagName('gradio-app')\[0\].shadowRoot/!!document.getElementsByTagName('gradio-app')[0].shadowRoot ? document.getElementsByTagName('gradio-app')[0].shadowRoot : document/g" /home/user/app/stable-diffusion-webui/script.js''')
-os.system(f"sed -i -e 's/ show_progress=False,/ show_progress=True,/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/shared.demo.launch/shared.demo.queue().launch/g' /home/user/app/stable-diffusion-webui/webui.py")
-os.system(f"sed -i -e 's/ outputs=\[/queue=False, &/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/ queue=False, / /g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-
-# ----------------------------Please duplicate this space and delete this block if you don't want to see the extra header----------------------------
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/header_patch.py -O /home/user/app/header_patch.py")
-os.system(f"sed -i -e '/demo:/r /home/user/app/header_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-# ---------------------------------------------------------------------------------------------------------------------------------------------------
-
-if "IS_SHARED_UI" in os.environ:
- os.system(f"rm -rfv /home/user/app/stable-diffusion-webui/scripts/")
-
- os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-config.json -O /home/user/app/shared-config.json")
- os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-ui-config.json -O /home/user/app/shared-ui-config.json")
-
- os.system(f"wget -q https://huggingface.co/ckpt/anything-v3-vae-swapped/resolve/main/anything-v3-vae-swapped.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/anything-v3-vae-swapped.ckpt")
- os.system(f"wget -q {os.getenv('MODEL_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME')}")
- os.system(f"wget -q {os.getenv('VAE_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('VAE_NAME')}")
- os.system(f"wget -q {os.getenv('YAML_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('YAML_NAME')}")
-
- os.system(f"python launch.py --force-enable-xformers --disable-console-progressbars --enable-console-prompts --ui-config-file /home/user/app/shared-ui-config.json --ui-settings-file /home/user/app/shared-config.json --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding")
-else:
- # Please duplicate this space and delete # character in front of the custom script you want to use or add here more custom scripts with same structure os.system(f"wget -q https://CUSTOM_SCRIPT_URL -O /home/user/app/stable-diffusion-webui/scripts/CUSTOM_SCRIPT_NAME.py")
- os.system(f"wget -q https://gist.github.com/camenduru/9ec5f8141db9902e375967e93250860f/raw/d0bcf01786f20107c329c03f8968584ee67be12a/run_n_times.py -O /home/user/app/stable-diffusion-webui/scripts/run_n_times.py")
-
- # Please duplicate this space and delete # character in front of the extension you want to use or add here more extensions with same structure os.system(f"git clone https://EXTENSION_GIT_URL /home/user/app/stable-diffusion-webui/extensions/EXTENSION_NAME")
- os.system(f"git clone https://github.com/camenduru/stable-diffusion-webui-artists-to-study /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-artists-to-study")
- os.system(f"git clone https://github.com/yfszzx/stable-diffusion-webui-images-browser /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser")
- os.system(f"git clone https://github.com/camenduru/deforum-for-automatic1111-webui /home/user/app/stable-diffusion-webui/extensions/deforum-for-automatic1111-webui")
-
- # Please duplicate this space and delete # character in front of the model you want to use or add here more ckpts with same structure os.system(f"wget -q https://CKPT_URL -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/CKPT_NAME.ckpt")
- os.system(f"wget -q https://huggingface.co/nitrosocke/Arcane-Diffusion/resolve/main/arcane-diffusion-v3.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/arcane-diffusion-v3.ckpt")
- #os.system(f"wget -q https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/Cyberpunk-Anime-Diffusion.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Cyberpunk-Anime-Diffusion.ckpt")
- #os.system(f"wget -q https://huggingface.co/prompthero/midjourney-v4-diffusion/resolve/main/mdjrny-v4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/mdjrny-v4.ckpt")
- os.system(f"wget -q https://huggingface.co/nitrosocke/mo-di-diffusion/resolve/main/moDi-v1-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/moDi-v1-pruned.ckpt")
- #os.system(f"wget -q https://huggingface.co/Fictiverse/Stable_Diffusion_PaperCut_Model/resolve/main/PaperCut_v1.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/PaperCut_v1.ckpt")
- #os.system(f"wget -q https://huggingface.co/lilpotat/sa/resolve/main/samdoesarts_style.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/samdoesarts_style.ckpt")
- os.system(f"wget -q https://huggingface.co/hakurei/waifu-diffusion-v1-3/resolve/main/wd-v1-3-float32.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/wd-v1-3-float32.ckpt")
- #os.system(f"wget -q https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-4.ckpt")
- #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.ckpt")
- #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-inpainting/resolve/main/sd-v1-5-inpainting.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-5-inpainting.ckpt")
-
- #os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.ckpt")
- #os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0.vae.pt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.vae.pt")
-
- #os.system(f"wget -q https://huggingface.co/stabilityai/stable-diffusion-2/resolve/main/768-v-ema.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.ckpt")
- #os.system(f"wget -q https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.yaml")
-
- os.system(f"wget -q https://huggingface.co/stabilityai/stable-diffusion-2-1/resolve/main/v2-1_768-ema-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v2-1_768-ema-pruned.ckpt")
- os.system(f"wget -q https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v2-1_768-ema-pruned.yaml")
-
- os.system(f"wget -q {os.getenv('MODEL_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME')}")
- os.system(f"wget -q {os.getenv('VAE_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('VAE_NAME')}")
- os.system(f"wget -q {os.getenv('YAML_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('YAML_NAME')}")
- os.system(f"wget -q {os.getenv('EMBED_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('EMBED_NAME')}")
-
- os.system(f"wget -q {os.getenv('EMBED_LINK1')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('EMBED_NAME1')}")
- os.system(f"wget -q {os.getenv('EMBED_LINK2')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('EMBED_NAME2')}")
- os.system(f"wget -q {os.getenv('EMBED_LINK3')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('EMBED_NAME3')}")
- os.system(f"wget -q {os.getenv('EMBED_LINK4')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('EMBED_NAME4')}")
-
- os.system(f"wget -q {os.getenv('MODEL_LINK1')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME1')}")
- os.system(f"wget -q {os.getenv('MODEL_LINK2')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME2')}")
- os.system(f"wget -q {os.getenv('MODEL_LINK3')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME3')}")
- os.system(f"wget -q {os.getenv('MODEL_LINK4')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME4')}")
-
- os.system(f"python launch.py --force-enable-xformers --ui-config-file /home/user/app/ui-config.json --ui-settings-file /home/user/app/config.json --disable-console-progressbars --enable-console-prompts --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding --api --skip-torch-cuda-test")
-
\ No newline at end of file
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/core/evaluation/metrics.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/core/evaluation/metrics.py
deleted file mode 100644
index 16c7dd47cadd53cf1caaa194e28a343f2aacc599..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/core/evaluation/metrics.py
+++ /dev/null
@@ -1,326 +0,0 @@
-from collections import OrderedDict
-
-import annotator.uniformer.mmcv as mmcv
-import numpy as np
-import torch
-
-
-def f_score(precision, recall, beta=1):
- """calcuate the f-score value.
-
- Args:
- precision (float | torch.Tensor): The precision value.
- recall (float | torch.Tensor): The recall value.
- beta (int): Determines the weight of recall in the combined score.
- Default: False.
-
- Returns:
- [torch.tensor]: The f-score value.
- """
- score = (1 + beta**2) * (precision * recall) / (
- (beta**2 * precision) + recall)
- return score
-
-
-def intersect_and_union(pred_label,
- label,
- num_classes,
- ignore_index,
- label_map=dict(),
- reduce_zero_label=False):
- """Calculate intersection and Union.
-
- Args:
- pred_label (ndarray | str): Prediction segmentation map
- or predict result filename.
- label (ndarray | str): Ground truth segmentation map
- or label filename.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- label_map (dict): Mapping old labels to new labels. The parameter will
- work only when label is str. Default: dict().
- reduce_zero_label (bool): Wether ignore zero label. The parameter will
- work only when label is str. Default: False.
-
- Returns:
- torch.Tensor: The intersection of prediction and ground truth
- histogram on all classes.
- torch.Tensor: The union of prediction and ground truth histogram on
- all classes.
- torch.Tensor: The prediction histogram on all classes.
- torch.Tensor: The ground truth histogram on all classes.
- """
-
- if isinstance(pred_label, str):
- pred_label = torch.from_numpy(np.load(pred_label))
- else:
- pred_label = torch.from_numpy((pred_label))
-
- if isinstance(label, str):
- label = torch.from_numpy(
- mmcv.imread(label, flag='unchanged', backend='pillow'))
- else:
- label = torch.from_numpy(label)
-
- if label_map is not None:
- for old_id, new_id in label_map.items():
- label[label == old_id] = new_id
- if reduce_zero_label:
- label[label == 0] = 255
- label = label - 1
- label[label == 254] = 255
-
- mask = (label != ignore_index)
- pred_label = pred_label[mask]
- label = label[mask]
-
- intersect = pred_label[pred_label == label]
- area_intersect = torch.histc(
- intersect.float(), bins=(num_classes), min=0, max=num_classes - 1)
- area_pred_label = torch.histc(
- pred_label.float(), bins=(num_classes), min=0, max=num_classes - 1)
- area_label = torch.histc(
- label.float(), bins=(num_classes), min=0, max=num_classes - 1)
- area_union = area_pred_label + area_label - area_intersect
- return area_intersect, area_union, area_pred_label, area_label
-
-
-def total_intersect_and_union(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- label_map=dict(),
- reduce_zero_label=False):
- """Calculate Total Intersection and Union.
-
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Wether ignore zero label. Default: False.
-
- Returns:
- ndarray: The intersection of prediction and ground truth histogram
- on all classes.
- ndarray: The union of prediction and ground truth histogram on all
- classes.
- ndarray: The prediction histogram on all classes.
- ndarray: The ground truth histogram on all classes.
- """
- num_imgs = len(results)
- assert len(gt_seg_maps) == num_imgs
- total_area_intersect = torch.zeros((num_classes, ), dtype=torch.float64)
- total_area_union = torch.zeros((num_classes, ), dtype=torch.float64)
- total_area_pred_label = torch.zeros((num_classes, ), dtype=torch.float64)
- total_area_label = torch.zeros((num_classes, ), dtype=torch.float64)
- for i in range(num_imgs):
- area_intersect, area_union, area_pred_label, area_label = \
- intersect_and_union(
- results[i], gt_seg_maps[i], num_classes, ignore_index,
- label_map, reduce_zero_label)
- total_area_intersect += area_intersect
- total_area_union += area_union
- total_area_pred_label += area_pred_label
- total_area_label += area_label
- return total_area_intersect, total_area_union, total_area_pred_label, \
- total_area_label
-
-
-def mean_iou(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- nan_to_num=None,
- label_map=dict(),
- reduce_zero_label=False):
- """Calculate Mean Intersection and Union (mIoU)
-
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- nan_to_num (int, optional): If specified, NaN values will be replaced
- by the numbers defined by the user. Default: None.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Wether ignore zero label. Default: False.
-
- Returns:
- dict[str, float | ndarray]:
- float: Overall accuracy on all images.
- ndarray: Per category accuracy, shape (num_classes, ).
- ndarray: Per category IoU, shape (num_classes, ).
- """
- iou_result = eval_metrics(
- results=results,
- gt_seg_maps=gt_seg_maps,
- num_classes=num_classes,
- ignore_index=ignore_index,
- metrics=['mIoU'],
- nan_to_num=nan_to_num,
- label_map=label_map,
- reduce_zero_label=reduce_zero_label)
- return iou_result
-
-
-def mean_dice(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- nan_to_num=None,
- label_map=dict(),
- reduce_zero_label=False):
- """Calculate Mean Dice (mDice)
-
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- nan_to_num (int, optional): If specified, NaN values will be replaced
- by the numbers defined by the user. Default: None.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Wether ignore zero label. Default: False.
-
- Returns:
- dict[str, float | ndarray]: Default metrics.
- float: Overall accuracy on all images.
- ndarray: Per category accuracy, shape (num_classes, ).
- ndarray: Per category dice, shape (num_classes, ).
- """
-
- dice_result = eval_metrics(
- results=results,
- gt_seg_maps=gt_seg_maps,
- num_classes=num_classes,
- ignore_index=ignore_index,
- metrics=['mDice'],
- nan_to_num=nan_to_num,
- label_map=label_map,
- reduce_zero_label=reduce_zero_label)
- return dice_result
-
-
-def mean_fscore(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- nan_to_num=None,
- label_map=dict(),
- reduce_zero_label=False,
- beta=1):
- """Calculate Mean Intersection and Union (mIoU)
-
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- nan_to_num (int, optional): If specified, NaN values will be replaced
- by the numbers defined by the user. Default: None.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Wether ignore zero label. Default: False.
- beta (int): Determines the weight of recall in the combined score.
- Default: False.
-
-
- Returns:
- dict[str, float | ndarray]: Default metrics.
- float: Overall accuracy on all images.
- ndarray: Per category recall, shape (num_classes, ).
- ndarray: Per category precision, shape (num_classes, ).
- ndarray: Per category f-score, shape (num_classes, ).
- """
- fscore_result = eval_metrics(
- results=results,
- gt_seg_maps=gt_seg_maps,
- num_classes=num_classes,
- ignore_index=ignore_index,
- metrics=['mFscore'],
- nan_to_num=nan_to_num,
- label_map=label_map,
- reduce_zero_label=reduce_zero_label,
- beta=beta)
- return fscore_result
-
-
-def eval_metrics(results,
- gt_seg_maps,
- num_classes,
- ignore_index,
- metrics=['mIoU'],
- nan_to_num=None,
- label_map=dict(),
- reduce_zero_label=False,
- beta=1):
- """Calculate evaluation metrics
- Args:
- results (list[ndarray] | list[str]): List of prediction segmentation
- maps or list of prediction result filenames.
- gt_seg_maps (list[ndarray] | list[str]): list of ground truth
- segmentation maps or list of label filenames.
- num_classes (int): Number of categories.
- ignore_index (int): Index that will be ignored in evaluation.
- metrics (list[str] | str): Metrics to be evaluated, 'mIoU' and 'mDice'.
- nan_to_num (int, optional): If specified, NaN values will be replaced
- by the numbers defined by the user. Default: None.
- label_map (dict): Mapping old labels to new labels. Default: dict().
- reduce_zero_label (bool): Wether ignore zero label. Default: False.
- Returns:
- float: Overall accuracy on all images.
- ndarray: Per category accuracy, shape (num_classes, ).
- ndarray: Per category evaluation metrics, shape (num_classes, ).
- """
- if isinstance(metrics, str):
- metrics = [metrics]
- allowed_metrics = ['mIoU', 'mDice', 'mFscore']
- if not set(metrics).issubset(set(allowed_metrics)):
- raise KeyError('metrics {} is not supported'.format(metrics))
-
- total_area_intersect, total_area_union, total_area_pred_label, \
- total_area_label = total_intersect_and_union(
- results, gt_seg_maps, num_classes, ignore_index, label_map,
- reduce_zero_label)
- all_acc = total_area_intersect.sum() / total_area_label.sum()
- ret_metrics = OrderedDict({'aAcc': all_acc})
- for metric in metrics:
- if metric == 'mIoU':
- iou = total_area_intersect / total_area_union
- acc = total_area_intersect / total_area_label
- ret_metrics['IoU'] = iou
- ret_metrics['Acc'] = acc
- elif metric == 'mDice':
- dice = 2 * total_area_intersect / (
- total_area_pred_label + total_area_label)
- acc = total_area_intersect / total_area_label
- ret_metrics['Dice'] = dice
- ret_metrics['Acc'] = acc
- elif metric == 'mFscore':
- precision = total_area_intersect / total_area_pred_label
- recall = total_area_intersect / total_area_label
- f_value = torch.tensor(
- [f_score(x[0], x[1], beta) for x in zip(precision, recall)])
- ret_metrics['Fscore'] = f_value
- ret_metrics['Precision'] = precision
- ret_metrics['Recall'] = recall
-
- ret_metrics = {
- metric: value.numpy()
- for metric, value in ret_metrics.items()
- }
- if nan_to_num is not None:
- ret_metrics = OrderedDict({
- metric: np.nan_to_num(metric_value, nan=nan_to_num)
- for metric, metric_value in ret_metrics.items()
- })
- return ret_metrics
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmcv/ops/ball_query.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmcv/ops/ball_query.py
deleted file mode 100644
index d0466847c6e5c1239e359a0397568413ebc1504a..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmcv/ops/ball_query.py
+++ /dev/null
@@ -1,55 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-from torch.autograd import Function
-
-from ..utils import ext_loader
-
-ext_module = ext_loader.load_ext('_ext', ['ball_query_forward'])
-
-
-class BallQuery(Function):
- """Find nearby points in spherical space."""
-
- @staticmethod
- def forward(ctx, min_radius: float, max_radius: float, sample_num: int,
- xyz: torch.Tensor, center_xyz: torch.Tensor) -> torch.Tensor:
- """
- Args:
- min_radius (float): minimum radius of the balls.
- max_radius (float): maximum radius of the balls.
- sample_num (int): maximum number of features in the balls.
- xyz (Tensor): (B, N, 3) xyz coordinates of the features.
- center_xyz (Tensor): (B, npoint, 3) centers of the ball query.
-
- Returns:
- Tensor: (B, npoint, nsample) tensor with the indices of
- the features that form the query balls.
- """
- assert center_xyz.is_contiguous()
- assert xyz.is_contiguous()
- assert min_radius < max_radius
-
- B, N, _ = xyz.size()
- npoint = center_xyz.size(1)
- idx = xyz.new_zeros(B, npoint, sample_num, dtype=torch.int)
-
- ext_module.ball_query_forward(
- center_xyz,
- xyz,
- idx,
- b=B,
- n=N,
- m=npoint,
- min_radius=min_radius,
- max_radius=max_radius,
- nsample=sample_num)
- if torch.__version__ != 'parrots':
- ctx.mark_non_differentiable(idx)
- return idx
-
- @staticmethod
- def backward(ctx, a=None):
- return None, None, None, None
-
-
-ball_query = BallQuery.apply
diff --git a/spaces/Sells30/stabilityai-stable-diffusion-xl-base-1.0/README.md b/spaces/Sells30/stabilityai-stable-diffusion-xl-base-1.0/README.md
deleted file mode 100644
index d41f14e74eba339afa63d8be7f8cf0984c737e5c..0000000000000000000000000000000000000000
--- a/spaces/Sells30/stabilityai-stable-diffusion-xl-base-1.0/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Stabilityai Stable Diffusion Xl Base 1.0
-emoji: 📚
-colorFrom: pink
-colorTo: purple
-sdk: gradio
-sdk_version: 3.43.2
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/SeyedAli/Image-Similarity/src/similarity/model_implements/vit_base.py b/spaces/SeyedAli/Image-Similarity/src/similarity/model_implements/vit_base.py
deleted file mode 100644
index bdf66c16548834e61affb8e205d14eb3335b6735..0000000000000000000000000000000000000000
--- a/spaces/SeyedAli/Image-Similarity/src/similarity/model_implements/vit_base.py
+++ /dev/null
@@ -1,20 +0,0 @@
-from transformers import ViTFeatureExtractor, ViTModel
-from PIL import Image
-import numpy as np
-import torch
-
-class VitBase():
-
- def __init__(self):
- self.feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
- self.model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
-
- def extract_feature(self, imgs):
- features = []
- for img in imgs:
- inputs = self.feature_extractor(images=img, return_tensors="pt")
- with torch.no_grad():
- outputs = self.model(**inputs)
- last_hidden_states = outputs.last_hidden_state
- features.append(np.squeeze(last_hidden_states.numpy()).flatten())
- return features
diff --git a/spaces/Starkate/zo/README.md b/spaces/Starkate/zo/README.md
deleted file mode 100644
index 7396139b69b11e67469a354d872091652b456d0e..0000000000000000000000000000000000000000
--- a/spaces/Starkate/zo/README.md
+++ /dev/null
@@ -1,20 +0,0 @@
----
-title: Shiny for Python template
-emoji: 🌍
-colorFrom: yellow
-colorTo: indigo
-sdk: docker
-pinned: false
-license: apache-2.0
----
-
-This is a templated Space for [Shiny for Python](https://shiny.rstudio.com/py/).
-
-
-To get started with a new app do the following:
-
-1) Install Shiny with `pip install shiny`
-2) Create a new app with `shiny create .`
-3) Then run the app with `shiny run --reload`
-
-To learn more about this framework please see the [Documentation](https://shiny.rstudio.com/py/docs/overview.html).
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/PIL/PyAccess.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/PIL/PyAccess.py
deleted file mode 100644
index 39747b4f311807822d225d091f1616eeaed388ff..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/PIL/PyAccess.py
+++ /dev/null
@@ -1,360 +0,0 @@
-#
-# The Python Imaging Library
-# Pillow fork
-#
-# Python implementation of the PixelAccess Object
-#
-# Copyright (c) 1997-2009 by Secret Labs AB. All rights reserved.
-# Copyright (c) 1995-2009 by Fredrik Lundh.
-# Copyright (c) 2013 Eric Soroos
-#
-# See the README file for information on usage and redistribution
-#
-
-# Notes:
-#
-# * Implements the pixel access object following Access.c
-# * Taking only the tuple form, which is used from python.
-# * Fill.c uses the integer form, but it's still going to use the old
-# Access.c implementation.
-#
-
-import logging
-import sys
-
-try:
- from cffi import FFI
-
- defs = """
- struct Pixel_RGBA {
- unsigned char r,g,b,a;
- };
- struct Pixel_I16 {
- unsigned char l,r;
- };
- """
- ffi = FFI()
- ffi.cdef(defs)
-except ImportError as ex:
- # Allow error import for doc purposes, but error out when accessing
- # anything in core.
- from ._util import DeferredError
-
- FFI = ffi = DeferredError(ex)
-
-logger = logging.getLogger(__name__)
-
-
-class PyAccess:
- def __init__(self, img, readonly=False):
- vals = dict(img.im.unsafe_ptrs)
- self.readonly = readonly
- self.image8 = ffi.cast("unsigned char **", vals["image8"])
- self.image32 = ffi.cast("int **", vals["image32"])
- self.image = ffi.cast("unsigned char **", vals["image"])
- self.xsize, self.ysize = img.im.size
- self._img = img
-
- # Keep pointer to im object to prevent dereferencing.
- self._im = img.im
- if self._im.mode in ("P", "PA"):
- self._palette = img.palette
-
- # Debugging is polluting test traces, only useful here
- # when hacking on PyAccess
- # logger.debug("%s", vals)
- self._post_init()
-
- def _post_init(self):
- pass
-
- def __setitem__(self, xy, color):
- """
- Modifies the pixel at x,y. The color is given as a single
- numerical value for single band images, and a tuple for
- multi-band images
-
- :param xy: The pixel coordinate, given as (x, y). See
- :ref:`coordinate-system`.
- :param color: The pixel value.
- """
- if self.readonly:
- msg = "Attempt to putpixel a read only image"
- raise ValueError(msg)
- (x, y) = xy
- if x < 0:
- x = self.xsize + x
- if y < 0:
- y = self.ysize + y
- (x, y) = self.check_xy((x, y))
-
- if (
- self._im.mode in ("P", "PA")
- and isinstance(color, (list, tuple))
- and len(color) in [3, 4]
- ):
- # RGB or RGBA value for a P or PA image
- if self._im.mode == "PA":
- alpha = color[3] if len(color) == 4 else 255
- color = color[:3]
- color = self._palette.getcolor(color, self._img)
- if self._im.mode == "PA":
- color = (color, alpha)
-
- return self.set_pixel(x, y, color)
-
- def __getitem__(self, xy):
- """
- Returns the pixel at x,y. The pixel is returned as a single
- value for single band images or a tuple for multiple band
- images
-
- :param xy: The pixel coordinate, given as (x, y). See
- :ref:`coordinate-system`.
- :returns: a pixel value for single band images, a tuple of
- pixel values for multiband images.
- """
- (x, y) = xy
- if x < 0:
- x = self.xsize + x
- if y < 0:
- y = self.ysize + y
- (x, y) = self.check_xy((x, y))
- return self.get_pixel(x, y)
-
- putpixel = __setitem__
- getpixel = __getitem__
-
- def check_xy(self, xy):
- (x, y) = xy
- if not (0 <= x < self.xsize and 0 <= y < self.ysize):
- msg = "pixel location out of range"
- raise ValueError(msg)
- return xy
-
-
-class _PyAccess32_2(PyAccess):
- """PA, LA, stored in first and last bytes of a 32 bit word"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = ffi.cast("struct Pixel_RGBA **", self.image32)
-
- def get_pixel(self, x, y):
- pixel = self.pixels[y][x]
- return pixel.r, pixel.a
-
- def set_pixel(self, x, y, color):
- pixel = self.pixels[y][x]
- # tuple
- pixel.r = min(color[0], 255)
- pixel.a = min(color[1], 255)
-
-
-class _PyAccess32_3(PyAccess):
- """RGB and friends, stored in the first three bytes of a 32 bit word"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = ffi.cast("struct Pixel_RGBA **", self.image32)
-
- def get_pixel(self, x, y):
- pixel = self.pixels[y][x]
- return pixel.r, pixel.g, pixel.b
-
- def set_pixel(self, x, y, color):
- pixel = self.pixels[y][x]
- # tuple
- pixel.r = min(color[0], 255)
- pixel.g = min(color[1], 255)
- pixel.b = min(color[2], 255)
- pixel.a = 255
-
-
-class _PyAccess32_4(PyAccess):
- """RGBA etc, all 4 bytes of a 32 bit word"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = ffi.cast("struct Pixel_RGBA **", self.image32)
-
- def get_pixel(self, x, y):
- pixel = self.pixels[y][x]
- return pixel.r, pixel.g, pixel.b, pixel.a
-
- def set_pixel(self, x, y, color):
- pixel = self.pixels[y][x]
- # tuple
- pixel.r = min(color[0], 255)
- pixel.g = min(color[1], 255)
- pixel.b = min(color[2], 255)
- pixel.a = min(color[3], 255)
-
-
-class _PyAccess8(PyAccess):
- """1, L, P, 8 bit images stored as uint8"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = self.image8
-
- def get_pixel(self, x, y):
- return self.pixels[y][x]
-
- def set_pixel(self, x, y, color):
- try:
- # integer
- self.pixels[y][x] = min(color, 255)
- except TypeError:
- # tuple
- self.pixels[y][x] = min(color[0], 255)
-
-
-class _PyAccessI16_N(PyAccess):
- """I;16 access, native bitendian without conversion"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = ffi.cast("unsigned short **", self.image)
-
- def get_pixel(self, x, y):
- return self.pixels[y][x]
-
- def set_pixel(self, x, y, color):
- try:
- # integer
- self.pixels[y][x] = min(color, 65535)
- except TypeError:
- # tuple
- self.pixels[y][x] = min(color[0], 65535)
-
-
-class _PyAccessI16_L(PyAccess):
- """I;16L access, with conversion"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = ffi.cast("struct Pixel_I16 **", self.image)
-
- def get_pixel(self, x, y):
- pixel = self.pixels[y][x]
- return pixel.l + pixel.r * 256
-
- def set_pixel(self, x, y, color):
- pixel = self.pixels[y][x]
- try:
- color = min(color, 65535)
- except TypeError:
- color = min(color[0], 65535)
-
- pixel.l = color & 0xFF # noqa: E741
- pixel.r = color >> 8
-
-
-class _PyAccessI16_B(PyAccess):
- """I;16B access, with conversion"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = ffi.cast("struct Pixel_I16 **", self.image)
-
- def get_pixel(self, x, y):
- pixel = self.pixels[y][x]
- return pixel.l * 256 + pixel.r
-
- def set_pixel(self, x, y, color):
- pixel = self.pixels[y][x]
- try:
- color = min(color, 65535)
- except Exception:
- color = min(color[0], 65535)
-
- pixel.l = color >> 8 # noqa: E741
- pixel.r = color & 0xFF
-
-
-class _PyAccessI32_N(PyAccess):
- """Signed Int32 access, native endian"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = self.image32
-
- def get_pixel(self, x, y):
- return self.pixels[y][x]
-
- def set_pixel(self, x, y, color):
- self.pixels[y][x] = color
-
-
-class _PyAccessI32_Swap(PyAccess):
- """I;32L/B access, with byteswapping conversion"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = self.image32
-
- def reverse(self, i):
- orig = ffi.new("int *", i)
- chars = ffi.cast("unsigned char *", orig)
- chars[0], chars[1], chars[2], chars[3] = chars[3], chars[2], chars[1], chars[0]
- return ffi.cast("int *", chars)[0]
-
- def get_pixel(self, x, y):
- return self.reverse(self.pixels[y][x])
-
- def set_pixel(self, x, y, color):
- self.pixels[y][x] = self.reverse(color)
-
-
-class _PyAccessF(PyAccess):
- """32 bit float access"""
-
- def _post_init(self, *args, **kwargs):
- self.pixels = ffi.cast("float **", self.image32)
-
- def get_pixel(self, x, y):
- return self.pixels[y][x]
-
- def set_pixel(self, x, y, color):
- try:
- # not a tuple
- self.pixels[y][x] = color
- except TypeError:
- # tuple
- self.pixels[y][x] = color[0]
-
-
-mode_map = {
- "1": _PyAccess8,
- "L": _PyAccess8,
- "P": _PyAccess8,
- "I;16N": _PyAccessI16_N,
- "LA": _PyAccess32_2,
- "La": _PyAccess32_2,
- "PA": _PyAccess32_2,
- "RGB": _PyAccess32_3,
- "LAB": _PyAccess32_3,
- "HSV": _PyAccess32_3,
- "YCbCr": _PyAccess32_3,
- "RGBA": _PyAccess32_4,
- "RGBa": _PyAccess32_4,
- "RGBX": _PyAccess32_4,
- "CMYK": _PyAccess32_4,
- "F": _PyAccessF,
- "I": _PyAccessI32_N,
-}
-
-if sys.byteorder == "little":
- mode_map["I;16"] = _PyAccessI16_N
- mode_map["I;16L"] = _PyAccessI16_N
- mode_map["I;16B"] = _PyAccessI16_B
-
- mode_map["I;32L"] = _PyAccessI32_N
- mode_map["I;32B"] = _PyAccessI32_Swap
-else:
- mode_map["I;16"] = _PyAccessI16_L
- mode_map["I;16L"] = _PyAccessI16_L
- mode_map["I;16B"] = _PyAccessI16_N
-
- mode_map["I;32L"] = _PyAccessI32_Swap
- mode_map["I;32B"] = _PyAccessI32_N
-
-
-def new(img, readonly=False):
- access_type = mode_map.get(img.mode, None)
- if not access_type:
- logger.debug("PyAccess Not Implemented: %s", img.mode)
- return None
- return access_type(img, readonly)
diff --git a/spaces/Superlang/ImageProcessor/annotator/oneformer/detectron2/modeling/backbone/backbone.py b/spaces/Superlang/ImageProcessor/annotator/oneformer/detectron2/modeling/backbone/backbone.py
deleted file mode 100644
index 04f3c3c009d972bcab46eaeab33a8bfcc05b726c..0000000000000000000000000000000000000000
--- a/spaces/Superlang/ImageProcessor/annotator/oneformer/detectron2/modeling/backbone/backbone.py
+++ /dev/null
@@ -1,74 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-from abc import ABCMeta, abstractmethod
-from typing import Dict
-import torch.nn as nn
-
-from annotator.oneformer.detectron2.layers import ShapeSpec
-
-__all__ = ["Backbone"]
-
-
-class Backbone(nn.Module, metaclass=ABCMeta):
- """
- Abstract base class for network backbones.
- """
-
- def __init__(self):
- """
- The `__init__` method of any subclass can specify its own set of arguments.
- """
- super().__init__()
-
- @abstractmethod
- def forward(self):
- """
- Subclasses must override this method, but adhere to the same return type.
-
- Returns:
- dict[str->Tensor]: mapping from feature name (e.g., "res2") to tensor
- """
- pass
-
- @property
- def size_divisibility(self) -> int:
- """
- Some backbones require the input height and width to be divisible by a
- specific integer. This is typically true for encoder / decoder type networks
- with lateral connection (e.g., FPN) for which feature maps need to match
- dimension in the "bottom up" and "top down" paths. Set to 0 if no specific
- input size divisibility is required.
- """
- return 0
-
- @property
- def padding_constraints(self) -> Dict[str, int]:
- """
- This property is a generalization of size_divisibility. Some backbones and training
- recipes require specific padding constraints, such as enforcing divisibility by a specific
- integer (e.g., FPN) or padding to a square (e.g., ViTDet with large-scale jitter
- in :paper:vitdet). `padding_constraints` contains these optional items like:
- {
- "size_divisibility": int,
- "square_size": int,
- # Future options are possible
- }
- `size_divisibility` will read from here if presented and `square_size` indicates the
- square padding size if `square_size` > 0.
-
- TODO: use type of Dict[str, int] to avoid torchscipt issues. The type of padding_constraints
- could be generalized as TypedDict (Python 3.8+) to support more types in the future.
- """
- return {}
-
- def output_shape(self):
- """
- Returns:
- dict[str->ShapeSpec]
- """
- # this is a backward-compatible default
- return {
- name: ShapeSpec(
- channels=self._out_feature_channels[name], stride=self._out_feature_strides[name]
- )
- for name in self._out_features
- }
diff --git a/spaces/TakaMETaka/openai-reverse-proxy/Dockerfile b/spaces/TakaMETaka/openai-reverse-proxy/Dockerfile
deleted file mode 100644
index 6953fc05439efb70991552cf56f28365b5b6c15b..0000000000000000000000000000000000000000
--- a/spaces/TakaMETaka/openai-reverse-proxy/Dockerfile
+++ /dev/null
@@ -1,11 +0,0 @@
-FROM node:18
-
-WORKDIR /app
-
-RUN npm install express express-http-proxy
-
-COPY . .
-
-EXPOSE 7860
-
-CMD [ "node", "server.js" ]
\ No newline at end of file
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_internal/__init__.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_internal/__init__.py
deleted file mode 100644
index 6afb5c627ce3db6e61cbf46276f7ddd42552eb28..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_internal/__init__.py
+++ /dev/null
@@ -1,19 +0,0 @@
-from typing import List, Optional
-
-import pip._internal.utils.inject_securetransport # noqa
-from pip._internal.utils import _log
-
-# init_logging() must be called before any call to logging.getLogger()
-# which happens at import of most modules.
-_log.init_logging()
-
-
-def main(args: (Optional[List[str]]) = None) -> int:
- """This is preserved for old console scripts that may still be referencing
- it.
-
- For additional details, see https://github.com/pypa/pip/issues/7498.
- """
- from pip._internal.utils.entrypoints import _wrapper
-
- return _wrapper(args)
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/_cell_widths.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/_cell_widths.py
deleted file mode 100644
index 36286df379e28ea997bea3ee1fd62cadebebbba9..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/_cell_widths.py
+++ /dev/null
@@ -1,451 +0,0 @@
-# Auto generated by make_terminal_widths.py
-
-CELL_WIDTHS = [
- (0, 0, 0),
- (1, 31, -1),
- (127, 159, -1),
- (768, 879, 0),
- (1155, 1161, 0),
- (1425, 1469, 0),
- (1471, 1471, 0),
- (1473, 1474, 0),
- (1476, 1477, 0),
- (1479, 1479, 0),
- (1552, 1562, 0),
- (1611, 1631, 0),
- (1648, 1648, 0),
- (1750, 1756, 0),
- (1759, 1764, 0),
- (1767, 1768, 0),
- (1770, 1773, 0),
- (1809, 1809, 0),
- (1840, 1866, 0),
- (1958, 1968, 0),
- (2027, 2035, 0),
- (2045, 2045, 0),
- (2070, 2073, 0),
- (2075, 2083, 0),
- (2085, 2087, 0),
- (2089, 2093, 0),
- (2137, 2139, 0),
- (2259, 2273, 0),
- (2275, 2306, 0),
- (2362, 2362, 0),
- (2364, 2364, 0),
- (2369, 2376, 0),
- (2381, 2381, 0),
- (2385, 2391, 0),
- (2402, 2403, 0),
- (2433, 2433, 0),
- (2492, 2492, 0),
- (2497, 2500, 0),
- (2509, 2509, 0),
- (2530, 2531, 0),
- (2558, 2558, 0),
- (2561, 2562, 0),
- (2620, 2620, 0),
- (2625, 2626, 0),
- (2631, 2632, 0),
- (2635, 2637, 0),
- (2641, 2641, 0),
- (2672, 2673, 0),
- (2677, 2677, 0),
- (2689, 2690, 0),
- (2748, 2748, 0),
- (2753, 2757, 0),
- (2759, 2760, 0),
- (2765, 2765, 0),
- (2786, 2787, 0),
- (2810, 2815, 0),
- (2817, 2817, 0),
- (2876, 2876, 0),
- (2879, 2879, 0),
- (2881, 2884, 0),
- (2893, 2893, 0),
- (2901, 2902, 0),
- (2914, 2915, 0),
- (2946, 2946, 0),
- (3008, 3008, 0),
- (3021, 3021, 0),
- (3072, 3072, 0),
- (3076, 3076, 0),
- (3134, 3136, 0),
- (3142, 3144, 0),
- (3146, 3149, 0),
- (3157, 3158, 0),
- (3170, 3171, 0),
- (3201, 3201, 0),
- (3260, 3260, 0),
- (3263, 3263, 0),
- (3270, 3270, 0),
- (3276, 3277, 0),
- (3298, 3299, 0),
- (3328, 3329, 0),
- (3387, 3388, 0),
- (3393, 3396, 0),
- (3405, 3405, 0),
- (3426, 3427, 0),
- (3457, 3457, 0),
- (3530, 3530, 0),
- (3538, 3540, 0),
- (3542, 3542, 0),
- (3633, 3633, 0),
- (3636, 3642, 0),
- (3655, 3662, 0),
- (3761, 3761, 0),
- (3764, 3772, 0),
- (3784, 3789, 0),
- (3864, 3865, 0),
- (3893, 3893, 0),
- (3895, 3895, 0),
- (3897, 3897, 0),
- (3953, 3966, 0),
- (3968, 3972, 0),
- (3974, 3975, 0),
- (3981, 3991, 0),
- (3993, 4028, 0),
- (4038, 4038, 0),
- (4141, 4144, 0),
- (4146, 4151, 0),
- (4153, 4154, 0),
- (4157, 4158, 0),
- (4184, 4185, 0),
- (4190, 4192, 0),
- (4209, 4212, 0),
- (4226, 4226, 0),
- (4229, 4230, 0),
- (4237, 4237, 0),
- (4253, 4253, 0),
- (4352, 4447, 2),
- (4957, 4959, 0),
- (5906, 5908, 0),
- (5938, 5940, 0),
- (5970, 5971, 0),
- (6002, 6003, 0),
- (6068, 6069, 0),
- (6071, 6077, 0),
- (6086, 6086, 0),
- (6089, 6099, 0),
- (6109, 6109, 0),
- (6155, 6157, 0),
- (6277, 6278, 0),
- (6313, 6313, 0),
- (6432, 6434, 0),
- (6439, 6440, 0),
- (6450, 6450, 0),
- (6457, 6459, 0),
- (6679, 6680, 0),
- (6683, 6683, 0),
- (6742, 6742, 0),
- (6744, 6750, 0),
- (6752, 6752, 0),
- (6754, 6754, 0),
- (6757, 6764, 0),
- (6771, 6780, 0),
- (6783, 6783, 0),
- (6832, 6848, 0),
- (6912, 6915, 0),
- (6964, 6964, 0),
- (6966, 6970, 0),
- (6972, 6972, 0),
- (6978, 6978, 0),
- (7019, 7027, 0),
- (7040, 7041, 0),
- (7074, 7077, 0),
- (7080, 7081, 0),
- (7083, 7085, 0),
- (7142, 7142, 0),
- (7144, 7145, 0),
- (7149, 7149, 0),
- (7151, 7153, 0),
- (7212, 7219, 0),
- (7222, 7223, 0),
- (7376, 7378, 0),
- (7380, 7392, 0),
- (7394, 7400, 0),
- (7405, 7405, 0),
- (7412, 7412, 0),
- (7416, 7417, 0),
- (7616, 7673, 0),
- (7675, 7679, 0),
- (8203, 8207, 0),
- (8232, 8238, 0),
- (8288, 8291, 0),
- (8400, 8432, 0),
- (8986, 8987, 2),
- (9001, 9002, 2),
- (9193, 9196, 2),
- (9200, 9200, 2),
- (9203, 9203, 2),
- (9725, 9726, 2),
- (9748, 9749, 2),
- (9800, 9811, 2),
- (9855, 9855, 2),
- (9875, 9875, 2),
- (9889, 9889, 2),
- (9898, 9899, 2),
- (9917, 9918, 2),
- (9924, 9925, 2),
- (9934, 9934, 2),
- (9940, 9940, 2),
- (9962, 9962, 2),
- (9970, 9971, 2),
- (9973, 9973, 2),
- (9978, 9978, 2),
- (9981, 9981, 2),
- (9989, 9989, 2),
- (9994, 9995, 2),
- (10024, 10024, 2),
- (10060, 10060, 2),
- (10062, 10062, 2),
- (10067, 10069, 2),
- (10071, 10071, 2),
- (10133, 10135, 2),
- (10160, 10160, 2),
- (10175, 10175, 2),
- (11035, 11036, 2),
- (11088, 11088, 2),
- (11093, 11093, 2),
- (11503, 11505, 0),
- (11647, 11647, 0),
- (11744, 11775, 0),
- (11904, 11929, 2),
- (11931, 12019, 2),
- (12032, 12245, 2),
- (12272, 12283, 2),
- (12288, 12329, 2),
- (12330, 12333, 0),
- (12334, 12350, 2),
- (12353, 12438, 2),
- (12441, 12442, 0),
- (12443, 12543, 2),
- (12549, 12591, 2),
- (12593, 12686, 2),
- (12688, 12771, 2),
- (12784, 12830, 2),
- (12832, 12871, 2),
- (12880, 19903, 2),
- (19968, 42124, 2),
- (42128, 42182, 2),
- (42607, 42610, 0),
- (42612, 42621, 0),
- (42654, 42655, 0),
- (42736, 42737, 0),
- (43010, 43010, 0),
- (43014, 43014, 0),
- (43019, 43019, 0),
- (43045, 43046, 0),
- (43052, 43052, 0),
- (43204, 43205, 0),
- (43232, 43249, 0),
- (43263, 43263, 0),
- (43302, 43309, 0),
- (43335, 43345, 0),
- (43360, 43388, 2),
- (43392, 43394, 0),
- (43443, 43443, 0),
- (43446, 43449, 0),
- (43452, 43453, 0),
- (43493, 43493, 0),
- (43561, 43566, 0),
- (43569, 43570, 0),
- (43573, 43574, 0),
- (43587, 43587, 0),
- (43596, 43596, 0),
- (43644, 43644, 0),
- (43696, 43696, 0),
- (43698, 43700, 0),
- (43703, 43704, 0),
- (43710, 43711, 0),
- (43713, 43713, 0),
- (43756, 43757, 0),
- (43766, 43766, 0),
- (44005, 44005, 0),
- (44008, 44008, 0),
- (44013, 44013, 0),
- (44032, 55203, 2),
- (63744, 64255, 2),
- (64286, 64286, 0),
- (65024, 65039, 0),
- (65040, 65049, 2),
- (65056, 65071, 0),
- (65072, 65106, 2),
- (65108, 65126, 2),
- (65128, 65131, 2),
- (65281, 65376, 2),
- (65504, 65510, 2),
- (66045, 66045, 0),
- (66272, 66272, 0),
- (66422, 66426, 0),
- (68097, 68099, 0),
- (68101, 68102, 0),
- (68108, 68111, 0),
- (68152, 68154, 0),
- (68159, 68159, 0),
- (68325, 68326, 0),
- (68900, 68903, 0),
- (69291, 69292, 0),
- (69446, 69456, 0),
- (69633, 69633, 0),
- (69688, 69702, 0),
- (69759, 69761, 0),
- (69811, 69814, 0),
- (69817, 69818, 0),
- (69888, 69890, 0),
- (69927, 69931, 0),
- (69933, 69940, 0),
- (70003, 70003, 0),
- (70016, 70017, 0),
- (70070, 70078, 0),
- (70089, 70092, 0),
- (70095, 70095, 0),
- (70191, 70193, 0),
- (70196, 70196, 0),
- (70198, 70199, 0),
- (70206, 70206, 0),
- (70367, 70367, 0),
- (70371, 70378, 0),
- (70400, 70401, 0),
- (70459, 70460, 0),
- (70464, 70464, 0),
- (70502, 70508, 0),
- (70512, 70516, 0),
- (70712, 70719, 0),
- (70722, 70724, 0),
- (70726, 70726, 0),
- (70750, 70750, 0),
- (70835, 70840, 0),
- (70842, 70842, 0),
- (70847, 70848, 0),
- (70850, 70851, 0),
- (71090, 71093, 0),
- (71100, 71101, 0),
- (71103, 71104, 0),
- (71132, 71133, 0),
- (71219, 71226, 0),
- (71229, 71229, 0),
- (71231, 71232, 0),
- (71339, 71339, 0),
- (71341, 71341, 0),
- (71344, 71349, 0),
- (71351, 71351, 0),
- (71453, 71455, 0),
- (71458, 71461, 0),
- (71463, 71467, 0),
- (71727, 71735, 0),
- (71737, 71738, 0),
- (71995, 71996, 0),
- (71998, 71998, 0),
- (72003, 72003, 0),
- (72148, 72151, 0),
- (72154, 72155, 0),
- (72160, 72160, 0),
- (72193, 72202, 0),
- (72243, 72248, 0),
- (72251, 72254, 0),
- (72263, 72263, 0),
- (72273, 72278, 0),
- (72281, 72283, 0),
- (72330, 72342, 0),
- (72344, 72345, 0),
- (72752, 72758, 0),
- (72760, 72765, 0),
- (72767, 72767, 0),
- (72850, 72871, 0),
- (72874, 72880, 0),
- (72882, 72883, 0),
- (72885, 72886, 0),
- (73009, 73014, 0),
- (73018, 73018, 0),
- (73020, 73021, 0),
- (73023, 73029, 0),
- (73031, 73031, 0),
- (73104, 73105, 0),
- (73109, 73109, 0),
- (73111, 73111, 0),
- (73459, 73460, 0),
- (92912, 92916, 0),
- (92976, 92982, 0),
- (94031, 94031, 0),
- (94095, 94098, 0),
- (94176, 94179, 2),
- (94180, 94180, 0),
- (94192, 94193, 2),
- (94208, 100343, 2),
- (100352, 101589, 2),
- (101632, 101640, 2),
- (110592, 110878, 2),
- (110928, 110930, 2),
- (110948, 110951, 2),
- (110960, 111355, 2),
- (113821, 113822, 0),
- (119143, 119145, 0),
- (119163, 119170, 0),
- (119173, 119179, 0),
- (119210, 119213, 0),
- (119362, 119364, 0),
- (121344, 121398, 0),
- (121403, 121452, 0),
- (121461, 121461, 0),
- (121476, 121476, 0),
- (121499, 121503, 0),
- (121505, 121519, 0),
- (122880, 122886, 0),
- (122888, 122904, 0),
- (122907, 122913, 0),
- (122915, 122916, 0),
- (122918, 122922, 0),
- (123184, 123190, 0),
- (123628, 123631, 0),
- (125136, 125142, 0),
- (125252, 125258, 0),
- (126980, 126980, 2),
- (127183, 127183, 2),
- (127374, 127374, 2),
- (127377, 127386, 2),
- (127488, 127490, 2),
- (127504, 127547, 2),
- (127552, 127560, 2),
- (127568, 127569, 2),
- (127584, 127589, 2),
- (127744, 127776, 2),
- (127789, 127797, 2),
- (127799, 127868, 2),
- (127870, 127891, 2),
- (127904, 127946, 2),
- (127951, 127955, 2),
- (127968, 127984, 2),
- (127988, 127988, 2),
- (127992, 128062, 2),
- (128064, 128064, 2),
- (128066, 128252, 2),
- (128255, 128317, 2),
- (128331, 128334, 2),
- (128336, 128359, 2),
- (128378, 128378, 2),
- (128405, 128406, 2),
- (128420, 128420, 2),
- (128507, 128591, 2),
- (128640, 128709, 2),
- (128716, 128716, 2),
- (128720, 128722, 2),
- (128725, 128727, 2),
- (128747, 128748, 2),
- (128756, 128764, 2),
- (128992, 129003, 2),
- (129292, 129338, 2),
- (129340, 129349, 2),
- (129351, 129400, 2),
- (129402, 129483, 2),
- (129485, 129535, 2),
- (129648, 129652, 2),
- (129656, 129658, 2),
- (129664, 129670, 2),
- (129680, 129704, 2),
- (129712, 129718, 2),
- (129728, 129730, 2),
- (129744, 129750, 2),
- (131072, 196605, 2),
- (196608, 262141, 2),
- (917760, 917999, 0),
-]
diff --git a/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/configs/new_baselines/mask_rcnn_regnety_4gf_dds_FPN_100ep_LSJ.py b/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/configs/new_baselines/mask_rcnn_regnety_4gf_dds_FPN_100ep_LSJ.py
deleted file mode 100644
index ba2c3274a493d5136507364558c8289eb6ee6259..0000000000000000000000000000000000000000
--- a/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/configs/new_baselines/mask_rcnn_regnety_4gf_dds_FPN_100ep_LSJ.py
+++ /dev/null
@@ -1,30 +0,0 @@
-from .mask_rcnn_R_50_FPN_100ep_LSJ import (
- dataloader,
- lr_multiplier,
- model,
- optimizer,
- train,
-)
-from detectron2.config import LazyCall as L
-from detectron2.modeling.backbone import RegNet
-from detectron2.modeling.backbone.regnet import SimpleStem, ResBottleneckBlock
-
-# Config source:
-# https://github.com/facebookresearch/detectron2/blob/main/configs/COCO-InstanceSegmentation/mask_rcnn_regnety_4gf_dds_fpn_1x.py # noqa
-model.backbone.bottom_up = L(RegNet)(
- stem_class=SimpleStem,
- stem_width=32,
- block_class=ResBottleneckBlock,
- depth=22,
- w_a=31.41,
- w_0=96,
- w_m=2.24,
- group_width=64,
- se_ratio=0.25,
- norm="SyncBN",
- out_features=["s1", "s2", "s3", "s4"],
-)
-model.pixel_std = [57.375, 57.120, 58.395]
-
-# RegNets benefit from enabling cudnn benchmark mode
-train.cudnn_benchmark = True
diff --git a/spaces/TitleGenerators/ArxivTitleGenerator/app.py b/spaces/TitleGenerators/ArxivTitleGenerator/app.py
deleted file mode 100644
index cc1cbd15ac6ef903f5230de7132a8d6784631c78..0000000000000000000000000000000000000000
--- a/spaces/TitleGenerators/ArxivTitleGenerator/app.py
+++ /dev/null
@@ -1,133 +0,0 @@
-import streamlit as st
-from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
-import numpy as np
-import torch
-import arxiv
-
-
-def main():
- id_provided = True
-
- st.set_page_config(
- layout="wide",
- initial_sidebar_state="auto",
- page_title="Title Generator!",
- page_icon=None,
- )
-
- st.title("Title Generator: Generate a title from the abstract of a paper")
- st.text("")
- st.text("")
-
- example = st.text_area("Provide the link/id for an arxiv paper", """https://arxiv.org/abs/2111.10339""",
-)
- # st.selectbox("Provide the link/id for an arxiv paper", example_prompts)
-
- # Take the message which needs to be processed
- message = st.text_area("...or paste a paper's abstract to generate a title")
- if len(message)<1:
- message=example
- id_provided = True
- ids = message.split('/')[-1]
- search = arxiv.Search(id_list=[ids])
- for result in search.results():
- message = result.summary
- title = result.title
- else:
- id_provided = False
-
- st.text("")
- models_to_choose = [
- "AryanLala/autonlp-Scientific_Title_Generator-34558227",
- "shamikbose89/mt5-small-finetuned-arxiv-cs-finetuned-arxiv-cs-full"
- ]
-
- BASE_MODEL = st.selectbox("Choose a model to generate the title", models_to_choose)
-
- def preprocess(text):
- if ((BASE_MODEL == "AryanLala/autonlp-Scientific_Title_Generator-34558227") |
- (BASE_MODEL == "shamikbose89/mt5-small-finetuned-arxiv-cs-finetuned-arxiv-cs-full")):
- return [text]
- else:
- st.error("Please select a model first")
-
- @st.cache(allow_output_mutation=True, suppress_st_warning=True, show_spinner=False)
- def load_model():
- tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
- model = AutoModelForSeq2SeqLM.from_pretrained(BASE_MODEL)
- return model, tokenizer
-
- def get_summary(text):
- with st.spinner(text="Processing your request"):
- model, tokenizer = load_model()
- preprocessed = preprocess(text)
- inputs = tokenizer(
- preprocessed, truncation=True, padding="longest", return_tensors="pt"
- )
- output = model.generate(
- **inputs,
- max_length=60,
- num_beams=10,
- num_return_sequences=1,
- temperature=1.5,
- )
- target_text = tokenizer.batch_decode(output, skip_special_tokens=True)
- return target_text[0]
-
- # Define function to run when submit is clicked
- def submit(message):
- if len(message) > 0:
- summary = get_summary(message)
- if id_provided:
- html_str = f"""
-
- Title Generated:> {summary}
- Original Title:> {title}
- """
- else:
- html_str = f"""
-
- Title Generated:> {summary}
- """
-
- st.markdown(html_str, unsafe_allow_html=True)
- # st.markdown(emoji)
- else:
- st.error("The text can't be empty")
-
- # Run algo when submit button is clicked
- if st.button("Submit"):
- submit(message)
-
- with st.expander("Additional Information"):
- st.markdown("""
- The models used were fine-tuned on subset of data from the [Arxiv Dataset](https://huggingface.co/datasets/arxiv_dataset)
- The task of the models is to suggest an appropraite title from the abstract of a scientific paper.
-
- The model [AryanLala/autonlp-Scientific_Title_Generator-34558227]() was trained on data
- from the Cs.AI (Artificial Intelligence) category of papers.
-
- The model [shamikbose89/mt5-small-finetuned-arxiv-cs-finetuned-arxiv-cs-full](https://huggingface.co/shamikbose89/mt5-small-finetuned-arxiv-cs-finetuned-arxiv-cs-full)
- was trained on the categories: cs.AI, cs.LG, cs.NI, cs.GR cs.CL, cs.CV (Artificial Intelligence, Machine Learning, Networking and Internet Architecture, Graphics, Computation and Language, Computer Vision and Pattern Recognition)
-
- Also, Thank you to arXiv for use of its open access interoperability. It allows us to pull the required abstracts from passed ids
- """,unsafe_allow_html=True,)
-
- st.text('\n')
- st.text('\n')
- st.markdown(
- '''App created by [@akshay7](https://huggingface.co/akshay7), [@AryanLala](https://huggingface.co/AryanLala) and [@shamikbose89](https://huggingface.co/shamikbose89)
- ''',
- unsafe_allow_html=True,
- )
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/Trangluna2002/AI_Cover_Gen/src/infer_pack/models_onnx_moess.py b/spaces/Trangluna2002/AI_Cover_Gen/src/infer_pack/models_onnx_moess.py
deleted file mode 100644
index 12efb0629a2e3d0d746a34f467254536c2bdbe5f..0000000000000000000000000000000000000000
--- a/spaces/Trangluna2002/AI_Cover_Gen/src/infer_pack/models_onnx_moess.py
+++ /dev/null
@@ -1,849 +0,0 @@
-import math, pdb, os
-from time import time as ttime
-import torch
-from torch import nn
-from torch.nn import functional as F
-from infer_pack import modules
-from infer_pack import attentions
-from infer_pack import commons
-from infer_pack.commons import init_weights, get_padding
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm
-from infer_pack.commons import init_weights
-import numpy as np
-from infer_pack import commons
-
-
-class TextEncoder256(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(256, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- stats = self.proj(x) * x_mask
-
- m, logs = torch.split(stats, self.out_channels, dim=1)
- return m, logs, x_mask
-
-
-class TextEncoder256Sim(nn.Module):
- def __init__(
- self,
- out_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- f0=True,
- ):
- super().__init__()
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.emb_phone = nn.Linear(256, hidden_channels)
- self.lrelu = nn.LeakyReLU(0.1, inplace=True)
- if f0 == True:
- self.emb_pitch = nn.Embedding(256, hidden_channels) # pitch 256
- self.encoder = attentions.Encoder(
- hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
-
- def forward(self, phone, pitch, lengths):
- if pitch == None:
- x = self.emb_phone(phone)
- else:
- x = self.emb_phone(phone) + self.emb_pitch(pitch)
- x = x * math.sqrt(self.hidden_channels) # [b, t, h]
- x = self.lrelu(x)
- x = torch.transpose(x, 1, -1) # [b, h, t]
- x_mask = torch.unsqueeze(commons.sequence_mask(lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.encoder(x * x_mask, x_mask)
- x = self.proj(x) * x_mask
- return x, x_mask
-
-
-class ResidualCouplingBlock(nn.Module):
- def __init__(
- self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- n_flows=4,
- gin_channels=0,
- ):
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.n_flows = n_flows
- self.gin_channels = gin_channels
-
- self.flows = nn.ModuleList()
- for i in range(n_flows):
- self.flows.append(
- modules.ResidualCouplingLayer(
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- mean_only=True,
- )
- )
- self.flows.append(modules.Flip())
-
- def forward(self, x, x_mask, g=None, reverse=False):
- if not reverse:
- for flow in self.flows:
- x, _ = flow(x, x_mask, g=g, reverse=reverse)
- else:
- for flow in reversed(self.flows):
- x = flow(x, x_mask, g=g, reverse=reverse)
- return x
-
- def remove_weight_norm(self):
- for i in range(self.n_flows):
- self.flows[i * 2].remove_weight_norm()
-
-
-class PosteriorEncoder(nn.Module):
- def __init__(
- self,
- in_channels,
- out_channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
-
- self.pre = nn.Conv1d(in_channels, hidden_channels, 1)
- self.enc = modules.WN(
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=gin_channels,
- )
- self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)
-
- def forward(self, x, x_lengths, g=None):
- x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(
- x.dtype
- )
- x = self.pre(x) * x_mask
- x = self.enc(x, x_mask, g=g)
- stats = self.proj(x) * x_mask
- m, logs = torch.split(stats, self.out_channels, dim=1)
- z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask
- return z, m, logs, x_mask
-
- def remove_weight_norm(self):
- self.enc.remove_weight_norm()
-
-
-class Generator(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=0,
- ):
- super(Generator, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- def forward(self, x, g=None):
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
-
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-class SineGen(torch.nn.Module):
- """Definition of sine generator
- SineGen(samp_rate, harmonic_num = 0,
- sine_amp = 0.1, noise_std = 0.003,
- voiced_threshold = 0,
- flag_for_pulse=False)
- samp_rate: sampling rate in Hz
- harmonic_num: number of harmonic overtones (default 0)
- sine_amp: amplitude of sine-wavefrom (default 0.1)
- noise_std: std of Gaussian noise (default 0.003)
- voiced_thoreshold: F0 threshold for U/V classification (default 0)
- flag_for_pulse: this SinGen is used inside PulseGen (default False)
- Note: when flag_for_pulse is True, the first time step of a voiced
- segment is always sin(np.pi) or cos(0)
- """
-
- def __init__(
- self,
- samp_rate,
- harmonic_num=0,
- sine_amp=0.1,
- noise_std=0.003,
- voiced_threshold=0,
- flag_for_pulse=False,
- ):
- super(SineGen, self).__init__()
- self.sine_amp = sine_amp
- self.noise_std = noise_std
- self.harmonic_num = harmonic_num
- self.dim = self.harmonic_num + 1
- self.sampling_rate = samp_rate
- self.voiced_threshold = voiced_threshold
-
- def _f02uv(self, f0):
- # generate uv signal
- uv = torch.ones_like(f0)
- uv = uv * (f0 > self.voiced_threshold)
- return uv
-
- def forward(self, f0, upp):
- """sine_tensor, uv = forward(f0)
- input F0: tensor(batchsize=1, length, dim=1)
- f0 for unvoiced steps should be 0
- output sine_tensor: tensor(batchsize=1, length, dim)
- output uv: tensor(batchsize=1, length, 1)
- """
- with torch.no_grad():
- f0 = f0[:, None].transpose(1, 2)
- f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
- # fundamental component
- f0_buf[:, :, 0] = f0[:, :, 0]
- for idx in np.arange(self.harmonic_num):
- f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (
- idx + 2
- ) # idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
- rad_values = (f0_buf / self.sampling_rate) % 1 ###%1意味着n_har的乘积无法后处理优化
- rand_ini = torch.rand(
- f0_buf.shape[0], f0_buf.shape[2], device=f0_buf.device
- )
- rand_ini[:, 0] = 0
- rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
- tmp_over_one = torch.cumsum(rad_values, 1) # % 1 #####%1意味着后面的cumsum无法再优化
- tmp_over_one *= upp
- tmp_over_one = F.interpolate(
- tmp_over_one.transpose(2, 1),
- scale_factor=upp,
- mode="linear",
- align_corners=True,
- ).transpose(2, 1)
- rad_values = F.interpolate(
- rad_values.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(
- 2, 1
- ) #######
- tmp_over_one %= 1
- tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
- cumsum_shift = torch.zeros_like(rad_values)
- cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
- sine_waves = torch.sin(
- torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
- )
- sine_waves = sine_waves * self.sine_amp
- uv = self._f02uv(f0)
- uv = F.interpolate(
- uv.transpose(2, 1), scale_factor=upp, mode="nearest"
- ).transpose(2, 1)
- noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
- noise = noise_amp * torch.randn_like(sine_waves)
- sine_waves = sine_waves * uv + noise
- return sine_waves, uv, noise
-
-
-class SourceModuleHnNSF(torch.nn.Module):
- """SourceModule for hn-nsf
- SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
- add_noise_std=0.003, voiced_threshod=0)
- sampling_rate: sampling_rate in Hz
- harmonic_num: number of harmonic above F0 (default: 0)
- sine_amp: amplitude of sine source signal (default: 0.1)
- add_noise_std: std of additive Gaussian noise (default: 0.003)
- note that amplitude of noise in unvoiced is decided
- by sine_amp
- voiced_threshold: threhold to set U/V given F0 (default: 0)
- Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
- F0_sampled (batchsize, length, 1)
- Sine_source (batchsize, length, 1)
- noise_source (batchsize, length 1)
- uv (batchsize, length, 1)
- """
-
- def __init__(
- self,
- sampling_rate,
- harmonic_num=0,
- sine_amp=0.1,
- add_noise_std=0.003,
- voiced_threshod=0,
- is_half=True,
- ):
- super(SourceModuleHnNSF, self).__init__()
-
- self.sine_amp = sine_amp
- self.noise_std = add_noise_std
- self.is_half = is_half
- # to produce sine waveforms
- self.l_sin_gen = SineGen(
- sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
- )
-
- # to merge source harmonics into a single excitation
- self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
- self.l_tanh = torch.nn.Tanh()
-
- def forward(self, x, upp=None):
- sine_wavs, uv, _ = self.l_sin_gen(x, upp)
- if self.is_half:
- sine_wavs = sine_wavs.half()
- sine_merge = self.l_tanh(self.l_linear(sine_wavs))
- return sine_merge, None, None # noise, uv
-
-
-class GeneratorNSF(torch.nn.Module):
- def __init__(
- self,
- initial_channel,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels,
- sr,
- is_half=False,
- ):
- super(GeneratorNSF, self).__init__()
- self.num_kernels = len(resblock_kernel_sizes)
- self.num_upsamples = len(upsample_rates)
-
- self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates))
- self.m_source = SourceModuleHnNSF(
- sampling_rate=sr, harmonic_num=0, is_half=is_half
- )
- self.noise_convs = nn.ModuleList()
- self.conv_pre = Conv1d(
- initial_channel, upsample_initial_channel, 7, 1, padding=3
- )
- resblock = modules.ResBlock1 if resblock == "1" else modules.ResBlock2
-
- self.ups = nn.ModuleList()
- for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
- c_cur = upsample_initial_channel // (2 ** (i + 1))
- self.ups.append(
- weight_norm(
- ConvTranspose1d(
- upsample_initial_channel // (2**i),
- upsample_initial_channel // (2 ** (i + 1)),
- k,
- u,
- padding=(k - u) // 2,
- )
- )
- )
- if i + 1 < len(upsample_rates):
- stride_f0 = np.prod(upsample_rates[i + 1 :])
- self.noise_convs.append(
- Conv1d(
- 1,
- c_cur,
- kernel_size=stride_f0 * 2,
- stride=stride_f0,
- padding=stride_f0 // 2,
- )
- )
- else:
- self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))
-
- self.resblocks = nn.ModuleList()
- for i in range(len(self.ups)):
- ch = upsample_initial_channel // (2 ** (i + 1))
- for j, (k, d) in enumerate(
- zip(resblock_kernel_sizes, resblock_dilation_sizes)
- ):
- self.resblocks.append(resblock(ch, k, d))
-
- self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
- self.ups.apply(init_weights)
-
- if gin_channels != 0:
- self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1)
-
- self.upp = np.prod(upsample_rates)
-
- def forward(self, x, f0, g=None):
- har_source, noi_source, uv = self.m_source(f0, self.upp)
- har_source = har_source.transpose(1, 2)
- x = self.conv_pre(x)
- if g is not None:
- x = x + self.cond(g)
-
- for i in range(self.num_upsamples):
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- x = self.ups[i](x)
- x_source = self.noise_convs[i](har_source)
- x = x + x_source
- xs = None
- for j in range(self.num_kernels):
- if xs is None:
- xs = self.resblocks[i * self.num_kernels + j](x)
- else:
- xs += self.resblocks[i * self.num_kernels + j](x)
- x = xs / self.num_kernels
- x = F.leaky_relu(x)
- x = self.conv_post(x)
- x = torch.tanh(x)
- return x
-
- def remove_weight_norm(self):
- for l in self.ups:
- remove_weight_norm(l)
- for l in self.resblocks:
- l.remove_weight_norm()
-
-
-sr2sr = {
- "32k": 32000,
- "40k": 40000,
- "48k": 48000,
-}
-
-
-class SynthesizerTrnMs256NSFsidM(nn.Module):
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- gin_channels,
- sr,
- **kwargs
- ):
- super().__init__()
- if type(sr) == type("strr"):
- sr = sr2sr[sr]
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- sr=sr,
- is_half=kwargs["is_half"],
- )
- self.enc_q = PosteriorEncoder(
- spec_channels,
- inter_channels,
- hidden_channels,
- 5,
- 1,
- 16,
- gin_channels=gin_channels,
- )
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(self, phone, phone_lengths, pitch, nsff0, sid, rnd, max_len=None):
- g = self.emb_g(sid).unsqueeze(-1)
- m_p, logs_p, x_mask = self.enc_p(phone, pitch, phone_lengths)
- z_p = (m_p + torch.exp(logs_p) * rnd) * x_mask
- z = self.flow(z_p, x_mask, g=g, reverse=True)
- o = self.dec((z * x_mask)[:, :, :max_len], nsff0, g=g)
- return o
-
-
-class SynthesizerTrnMs256NSFsid_sim(nn.Module):
- """
- Synthesizer for Training
- """
-
- def __init__(
- self,
- spec_channels,
- segment_size,
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- spk_embed_dim,
- # hop_length,
- gin_channels=0,
- use_sdp=True,
- **kwargs
- ):
- super().__init__()
- self.spec_channels = spec_channels
- self.inter_channels = inter_channels
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.resblock = resblock
- self.resblock_kernel_sizes = resblock_kernel_sizes
- self.resblock_dilation_sizes = resblock_dilation_sizes
- self.upsample_rates = upsample_rates
- self.upsample_initial_channel = upsample_initial_channel
- self.upsample_kernel_sizes = upsample_kernel_sizes
- self.segment_size = segment_size
- self.gin_channels = gin_channels
- # self.hop_length = hop_length#
- self.spk_embed_dim = spk_embed_dim
- self.enc_p = TextEncoder256Sim(
- inter_channels,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size,
- p_dropout,
- )
- self.dec = GeneratorNSF(
- inter_channels,
- resblock,
- resblock_kernel_sizes,
- resblock_dilation_sizes,
- upsample_rates,
- upsample_initial_channel,
- upsample_kernel_sizes,
- gin_channels=gin_channels,
- is_half=kwargs["is_half"],
- )
-
- self.flow = ResidualCouplingBlock(
- inter_channels, hidden_channels, 5, 1, 3, gin_channels=gin_channels
- )
- self.emb_g = nn.Embedding(self.spk_embed_dim, gin_channels)
- print("gin_channels:", gin_channels, "self.spk_embed_dim:", self.spk_embed_dim)
-
- def remove_weight_norm(self):
- self.dec.remove_weight_norm()
- self.flow.remove_weight_norm()
- self.enc_q.remove_weight_norm()
-
- def forward(
- self, phone, phone_lengths, pitch, pitchf, ds, max_len=None
- ): # y是spec不需要了现在
- g = self.emb_g(ds.unsqueeze(0)).unsqueeze(-1) # [b, 256, 1]##1是t,广播的
- x, x_mask = self.enc_p(phone, pitch, phone_lengths)
- x = self.flow(x, x_mask, g=g, reverse=True)
- o = self.dec((x * x_mask)[:, :, :max_len], pitchf, g=g)
- return o
-
-
-class MultiPeriodDiscriminator(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(MultiPeriodDiscriminator, self).__init__()
- periods = [2, 3, 5, 7, 11, 17]
- # periods = [3, 5, 7, 11, 17, 23, 37]
-
- discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]
- discs = discs + [
- DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods
- ]
- self.discriminators = nn.ModuleList(discs)
-
- def forward(self, y, y_hat):
- y_d_rs = [] #
- y_d_gs = []
- fmap_rs = []
- fmap_gs = []
- for i, d in enumerate(self.discriminators):
- y_d_r, fmap_r = d(y)
- y_d_g, fmap_g = d(y_hat)
- # for j in range(len(fmap_r)):
- # print(i,j,y.shape,y_hat.shape,fmap_r[j].shape,fmap_g[j].shape)
- y_d_rs.append(y_d_r)
- y_d_gs.append(y_d_g)
- fmap_rs.append(fmap_r)
- fmap_gs.append(fmap_g)
-
- return y_d_rs, y_d_gs, fmap_rs, fmap_gs
-
-
-class DiscriminatorS(torch.nn.Module):
- def __init__(self, use_spectral_norm=False):
- super(DiscriminatorS, self).__init__()
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(Conv1d(1, 16, 15, 1, padding=7)),
- norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),
- norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),
- norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),
- norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),
- norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),
- ]
- )
- self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))
-
- def forward(self, x):
- fmap = []
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
-
-
-class DiscriminatorP(torch.nn.Module):
- def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):
- super(DiscriminatorP, self).__init__()
- self.period = period
- self.use_spectral_norm = use_spectral_norm
- norm_f = weight_norm if use_spectral_norm == False else spectral_norm
- self.convs = nn.ModuleList(
- [
- norm_f(
- Conv2d(
- 1,
- 32,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 32,
- 128,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 128,
- 512,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 512,
- 1024,
- (kernel_size, 1),
- (stride, 1),
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- norm_f(
- Conv2d(
- 1024,
- 1024,
- (kernel_size, 1),
- 1,
- padding=(get_padding(kernel_size, 1), 0),
- )
- ),
- ]
- )
- self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))
-
- def forward(self, x):
- fmap = []
-
- # 1d to 2d
- b, c, t = x.shape
- if t % self.period != 0: # pad first
- n_pad = self.period - (t % self.period)
- x = F.pad(x, (0, n_pad), "reflect")
- t = t + n_pad
- x = x.view(b, c, t // self.period, self.period)
-
- for l in self.convs:
- x = l(x)
- x = F.leaky_relu(x, modules.LRELU_SLOPE)
- fmap.append(x)
- x = self.conv_post(x)
- fmap.append(x)
- x = torch.flatten(x, 1, -1)
-
- return x, fmap
diff --git a/spaces/UserXTheUnknown/stablediffusion-infinity/PyPatchMatch/csrc/inpaint.h b/spaces/UserXTheUnknown/stablediffusion-infinity/PyPatchMatch/csrc/inpaint.h
deleted file mode 100644
index a59b1d347ea5fe92976a4fda10a820d6508f51da..0000000000000000000000000000000000000000
--- a/spaces/UserXTheUnknown/stablediffusion-infinity/PyPatchMatch/csrc/inpaint.h
+++ /dev/null
@@ -1,27 +0,0 @@
-#pragma once
-
-#include
-
-#include "masked_image.h"
-#include "nnf.h"
-
-class Inpainting {
-public:
- Inpainting(cv::Mat image, cv::Mat mask, const PatchDistanceMetric *metric);
- Inpainting(cv::Mat image, cv::Mat mask, cv::Mat global_mask, const PatchDistanceMetric *metric);
- cv::Mat run(bool verbose = false, bool verbose_visualize = false, unsigned int random_seed = 1212);
-
-private:
- void _initialize_pyramid(void);
- MaskedImage _expectation_maximization(MaskedImage source, MaskedImage target, int level, bool verbose);
- void _expectation_step(const NearestNeighborField &nnf, bool source2target, cv::Mat &vote, const MaskedImage &source, bool upscaled);
- void _maximization_step(MaskedImage &target, const cv::Mat &vote);
-
- MaskedImage m_initial;
- std::vector m_pyramid;
-
- NearestNeighborField m_source2target;
- NearestNeighborField m_target2source;
- const PatchDistanceMetric *m_distance_metric;
-};
-
diff --git a/spaces/VIPLab/Track-Anything/tracker/model/__init__.py b/spaces/VIPLab/Track-Anything/tracker/model/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Wootang01/URL_news_summarizer/README.md b/spaces/Wootang01/URL_news_summarizer/README.md
deleted file mode 100644
index d733218de33674eb215af4a2929c3dd89b200b66..0000000000000000000000000000000000000000
--- a/spaces/Wootang01/URL_news_summarizer/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: URL_news_summarizer
-emoji: 🦀
-colorFrom: red
-colorTo: green
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/XS-1/BW_IMAGE_VIDEO_COLORIZER/fastai/text/transform.py b/spaces/XS-1/BW_IMAGE_VIDEO_COLORIZER/fastai/text/transform.py
deleted file mode 100644
index 9948ddc5845305da51262521a9f5f47935a37ea5..0000000000000000000000000000000000000000
--- a/spaces/XS-1/BW_IMAGE_VIDEO_COLORIZER/fastai/text/transform.py
+++ /dev/null
@@ -1,164 +0,0 @@
-"NLP data processing; tokenizes text and creates vocab indexes"
-from ..torch_core import *
-
-import spacy
-from spacy.symbols import ORTH
-
-__all__ = ['BaseTokenizer', 'SpacyTokenizer', 'Tokenizer', 'Vocab', 'fix_html', 'replace_all_caps', 'replace_rep', 'replace_wrep',
- 'rm_useless_spaces', 'spec_add_spaces', 'BOS', 'EOS', 'FLD', 'UNK', 'PAD', 'TK_MAJ', 'TK_UP', 'TK_REP', 'TK_REP', 'TK_WREP',
- 'deal_caps']
-
-BOS,EOS,FLD,UNK,PAD = 'xxbos','xxeos','xxfld','xxunk','xxpad'
-TK_MAJ,TK_UP,TK_REP,TK_WREP = 'xxmaj','xxup','xxrep','xxwrep'
-defaults.text_spec_tok = [UNK,PAD,BOS,EOS,FLD,TK_MAJ,TK_UP,TK_REP,TK_WREP]
-
-
-class BaseTokenizer():
- "Basic class for a tokenizer function."
- def __init__(self, lang:str): self.lang = lang
- def tokenizer(self, t:str) -> List[str]: return t.split(' ')
- def add_special_cases(self, toks:Collection[str]): pass
-
-class SpacyTokenizer(BaseTokenizer):
- "Wrapper around a spacy tokenizer to make it a `BaseTokenizer`."
- def __init__(self, lang:str):
- self.tok = spacy.blank(lang, disable=["parser","tagger","ner"])
-
- def tokenizer(self, t:str) -> List[str]:
- return [t.text for t in self.tok.tokenizer(t)]
-
- def add_special_cases(self, toks:Collection[str]):
- for w in toks:
- self.tok.tokenizer.add_special_case(w, [{ORTH: w}])
-
-def spec_add_spaces(t:str) -> str:
- "Add spaces around / and # in `t`. \n"
- return re.sub(r'([/#\n])', r' \1 ', t)
-
-def rm_useless_spaces(t:str) -> str:
- "Remove multiple spaces in `t`."
- return re.sub(' {2,}', ' ', t)
-
-def replace_rep(t:str) -> str:
- "Replace repetitions at the character level in `t`."
- def _replace_rep(m:Collection[str]) -> str:
- c,cc = m.groups()
- return f' {TK_REP} {len(cc)+1} {c} '
- re_rep = re.compile(r'(\S)(\1{3,})')
- return re_rep.sub(_replace_rep, t)
-
-def replace_wrep(t:str) -> str:
- "Replace word repetitions in `t`."
- def _replace_wrep(m:Collection[str]) -> str:
- c,cc = m.groups()
- return f' {TK_WREP} {len(cc.split())+1} {c} '
- re_wrep = re.compile(r'(\b\w+\W+)(\1{3,})')
- return re_wrep.sub(_replace_wrep, t)
-
-def fix_html(x:str) -> str:
- "List of replacements from html strings in `x`."
- re1 = re.compile(r' +')
- x = x.replace('#39;', "'").replace('amp;', '&').replace('#146;', "'").replace(
- 'nbsp;', ' ').replace('#36;', '$').replace('\\n', "\n").replace('quot;', "'").replace(
- '
', "\n").replace('\\"', '"').replace('',UNK).replace(' @.@ ','.').replace(
- ' @-@ ','-').replace(' @,@ ',',').replace('\\', ' \\ ')
- return re1.sub(' ', html.unescape(x))
-
-def replace_all_caps(x:Collection[str]) -> Collection[str]:
- "Replace tokens in ALL CAPS in `x` by their lower version and add `TK_UP` before."
- res = []
- for t in x:
- if t.isupper() and len(t) > 1: res.append(TK_UP); res.append(t.lower())
- else: res.append(t)
- return res
-
-def deal_caps(x:Collection[str]) -> Collection[str]:
- "Replace all Capitalized tokens in `x` by their lower version and add `TK_MAJ` before."
- res = []
- for t in x:
- if t == '': continue
- if t[0].isupper() and len(t) > 1 and t[1:].islower(): res.append(TK_MAJ)
- res.append(t.lower())
- return res
-
-defaults.text_pre_rules = [fix_html, replace_rep, replace_wrep, spec_add_spaces, rm_useless_spaces]
-defaults.text_post_rules = [replace_all_caps, deal_caps]
-
-class Tokenizer():
- "Put together rules and a tokenizer function to tokenize text with multiprocessing."
- def __init__(self, tok_func:Callable=SpacyTokenizer, lang:str='en', pre_rules:ListRules=None,
- post_rules:ListRules=None, special_cases:Collection[str]=None, n_cpus:int=None):
- self.tok_func,self.lang,self.special_cases = tok_func,lang,special_cases
- self.pre_rules = ifnone(pre_rules, defaults.text_pre_rules )
- self.post_rules = ifnone(post_rules, defaults.text_post_rules)
- self.special_cases = special_cases if special_cases else defaults.text_spec_tok
- self.n_cpus = ifnone(n_cpus, defaults.cpus)
-
- def __repr__(self) -> str:
- res = f'Tokenizer {self.tok_func.__name__} in {self.lang} with the following rules:\n'
- for rule in self.pre_rules: res += f' - {rule.__name__}\n'
- for rule in self.post_rules: res += f' - {rule.__name__}\n'
- return res
-
- def process_text(self, t:str, tok:BaseTokenizer) -> List[str]:
- "Process one text `t` with tokenizer `tok`."
- for rule in self.pre_rules: t = rule(t)
- toks = tok.tokenizer(t)
- for rule in self.post_rules: toks = rule(toks)
- return toks
-
- def _process_all_1(self, texts:Collection[str]) -> List[List[str]]:
- "Process a list of `texts` in one process."
- tok = self.tok_func(self.lang)
- if self.special_cases: tok.add_special_cases(self.special_cases)
- return [self.process_text(str(t), tok) for t in texts]
-
- def process_all(self, texts:Collection[str]) -> List[List[str]]:
- "Process a list of `texts`."
- if self.n_cpus <= 1: return self._process_all_1(texts)
- with ProcessPoolExecutor(self.n_cpus) as e:
- return sum(e.map(self._process_all_1, partition_by_cores(texts, self.n_cpus)), [])
-
-class Vocab():
- "Contain the correspondence between numbers and tokens and numericalize."
- def __init__(self, itos:Collection[str]):
- self.itos = itos
- self.stoi = collections.defaultdict(int,{v:k for k,v in enumerate(self.itos)})
-
- def numericalize(self, t:Collection[str]) -> List[int]:
- "Convert a list of tokens `t` to their ids."
- return [self.stoi[w] for w in t]
-
- def textify(self, nums:Collection[int], sep=' ') -> List[str]:
- "Convert a list of `nums` to their tokens."
- return sep.join([self.itos[i] for i in nums]) if sep is not None else [self.itos[i] for i in nums]
-
- def __getstate__(self):
- return {'itos':self.itos}
-
- def __setstate__(self, state:dict):
- self.itos = state['itos']
- self.stoi = collections.defaultdict(int,{v:k for k,v in enumerate(self.itos)})
-
- def save(self, path):
- "Save `self.itos` in `path`"
- pickle.dump(self.itos, open(path, 'wb'))
-
- @classmethod
- def create(cls, tokens:Tokens, max_vocab:int, min_freq:int) -> 'Vocab':
- "Create a vocabulary from a set of `tokens`."
- freq = Counter(p for o in tokens for p in o)
- itos = [o for o,c in freq.most_common(max_vocab) if c >= min_freq]
- for o in reversed(defaults.text_spec_tok):
- if o in itos: itos.remove(o)
- itos.insert(0, o)
- itos = itos[:max_vocab]
- if len(itos) < max_vocab: #Make sure vocab size is a multiple of 8 for fast mixed precision training
- while len(itos)%8 !=0: itos.append('xxfake')
- return cls(itos)
-
- @classmethod
- def load(cls, path):
- "Load the `Vocab` contained in `path`"
- itos = pickle.load(open(path, 'rb'))
- return cls(itos)
diff --git a/spaces/XS-1/BW_IMAGE_VIDEO_COLORIZER/fastai/vision/models/presnet.py b/spaces/XS-1/BW_IMAGE_VIDEO_COLORIZER/fastai/vision/models/presnet.py
deleted file mode 100644
index 0877e52422471ba6d43d413e7ff1f253958c1f41..0000000000000000000000000000000000000000
--- a/spaces/XS-1/BW_IMAGE_VIDEO_COLORIZER/fastai/vision/models/presnet.py
+++ /dev/null
@@ -1,140 +0,0 @@
-from pdb import set_trace
-import torch.nn.functional as F
-import torch.nn as nn
-import torch
-import math
-import torch.utils.model_zoo as model_zoo
-
-__all__ = ['PResNet', 'presnet18', 'presnet34', 'presnet50', 'presnet101', 'presnet152']
-
-act_fn = nn.ReLU
-
-def init_cnn(m):
- if getattr(m, 'bias', None) is not None: nn.init.constant_(m.bias, 0)
- if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight)
- elif isinstance(m, nn.Linear): m.weight.data.normal_(0, 0.01)
- for l in m.children(): init_cnn(l)
-
-def conv(ni, nf, ks=3, stride=1, bias=False):
- return nn.Conv2d(ni, nf, kernel_size=ks, stride=stride, padding=ks//2, bias=bias)
-
-def conv_layer(conv_1st, ni, nf, ks=3, stride=1, zero_bn=False, bias=False):
- bn = nn.BatchNorm2d(nf if conv_1st else ni)
- nn.init.constant_(bn.weight, 0. if zero_bn else 1.)
- res = [act_fn(), bn]
- cn = conv(ni, nf, ks, stride=stride, bias=bias)
- res.insert(0 if conv_1st else 2, cn)
- return nn.Sequential(*res)
-
-def conv_act(*args, **kwargs): return conv_layer(True , *args, **kwargs)
-def act_conv(*args, **kwargs): return conv_layer(False, *args, **kwargs)
-
-class BasicBlock(Module):
- expansion = 1
-
- def __init__(self, ni, nf, stride=1, downsample=None):
- super(BasicBlock, self).__init__()
- self.conv1 = act_conv(ni, nf, stride=stride)
- self.conv2 = act_conv(nf, nf, zero_bn=True)
- self.downsample = downsample
- self.stride = stride
-
- def forward(self, x):
- identity = x if self.downsample is None else self.downsample(x)
- x = self.conv1(x)
- x = self.conv2(x)
- x += identity
- return x
-
-class Bottleneck(Module):
- expansion = 4
-
- def __init__(self, ni, nf, stride=1, downsample=None):
- super(Bottleneck, self).__init__()
- self.conv1 = act_conv(ni, nf, 1)
- self.conv2 = act_conv(nf, nf, stride=stride)
- self.conv3 = act_conv(nf, nf*self.expansion, 1)
- self.downsample = downsample
- self.stride = stride
-
- def forward(self, x):
- identity = x if self.downsample is None else self.downsample(x)
- x = self.conv1(x)
- x = self.conv2(x)
- x = self.conv3(x)
- x += identity
- return x
-
-class PResNet(Module):
-
- def __init__(self, block, layers, num_classes=1000):
- self.ni = 64
- super().__init__()
- self.conv1 = conv_act(3, 16, stride=2)
- self.conv2 = conv_act(16, 32)
- self.conv3 = conv_act(32, 64)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
- self.layer1 = self._make_layer(block, 64, layers[0])
- self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
- self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
- self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
- ni = 512*block.expansion
- self.avgpool = nn.Sequential(
- act_fn(), nn.BatchNorm2d(ni), nn.AdaptiveAvgPool2d(1))
- self.fc = nn.Linear(ni, num_classes)
-
- init_cnn(self)
-
- def _make_layer(self, block, nf, blocks, stride=1):
- downsample = None
- if stride != 1 or self.ni != nf*block.expansion:
- layers = [act_fn(), nn.BatchNorm2d(self.ni),
- nn.AvgPool2d(kernel_size=2)] if stride==2 else []
- layers.append(conv(self.ni, nf*block.expansion))
- downsample = nn.Sequential(*layers)
-
- layers = [block(self.ni, nf, stride, downsample)]
- self.ni = nf*block.expansion
- for i in range(1, blocks): layers.append(block(self.ni, nf))
- return nn.Sequential(*layers)
-
- def forward(self, x):
- x = self.conv1(x)
- x = self.conv2(x)
- x = self.conv3(x)
- x = self.maxpool(x)
-
- x = self.layer1(x)
- x = self.layer2(x)
- x = self.layer3(x)
- x = self.layer4(x)
-
- x = self.avgpool(x)
- x = x.view(x.size(0), -1)
- x = self.fc(x)
-
- return x
-
-model_urls = dict(presnet34='presnet34', presnet50='presnet50')
-
-def presnet(block, n_layers, name, pre=False, **kwargs):
- model = PResNet(block, n_layers, **kwargs)
- #if pre: model.load_state_dict(model_zoo.load_url(model_urls[name]))
- if pre: model.load_state_dict(torch.load(model_urls[name]))
- return model
-
-def presnet18(pretrained=False, **kwargs):
- return presnet(BasicBlock, [2, 2, 2, 2], 'presnet18', pre=pretrained, **kwargs)
-
-def presnet34(pretrained=False, **kwargs):
- return presnet(BasicBlock, [3, 4, 6, 3], 'presnet34', pre=pretrained, **kwargs)
-
-def presnet50(pretrained=False, **kwargs):
- return presnet(Bottleneck, [3, 4, 6, 3], 'presnet50', pre=pretrained, **kwargs)
-
-def presnet101(pretrained=False, **kwargs):
- return presnet(Bottleneck, [3, 4, 23, 3], 'presnet101', pre=pretrained, **kwargs)
-
-def presnet152(pretrained=False, **kwargs):
- return presnet(Bottleneck, [3, 8, 36, 3], 'presnet152', pre=pretrained, **kwargs)
-
diff --git a/spaces/XzJosh/Bekki-Bert-VITS2/resample.py b/spaces/XzJosh/Bekki-Bert-VITS2/resample.py
deleted file mode 100644
index 2ed1685654a371c5722168e9987809b05b1cb224..0000000000000000000000000000000000000000
--- a/spaces/XzJosh/Bekki-Bert-VITS2/resample.py
+++ /dev/null
@@ -1,42 +0,0 @@
-import os
-import argparse
-import librosa
-import numpy as np
-from multiprocessing import Pool, cpu_count
-
-import soundfile
-from scipy.io import wavfile
-from tqdm import tqdm
-
-
-def process(item):
- spkdir, wav_name, args = item
- speaker = spkdir.replace("\\", "/").split("/")[-1]
- wav_path = os.path.join(args.in_dir, speaker, wav_name)
- if os.path.exists(wav_path) and '.wav' in wav_path:
- os.makedirs(os.path.join(args.out_dir, speaker), exist_ok=True)
- wav, sr = librosa.load(wav_path, sr=args.sr)
- soundfile.write(
- os.path.join(args.out_dir, speaker, wav_name),
- wav,
- sr
- )
-
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--sr", type=int, default=44100, help="sampling rate")
- parser.add_argument("--in_dir", type=str, default="./raw", help="path to source dir")
- parser.add_argument("--out_dir", type=str, default="./dataset", help="path to target dir")
- args = parser.parse_args()
- # processs = 8
- processs = cpu_count()-2 if cpu_count() >4 else 1
- pool = Pool(processes=processs)
-
- for speaker in os.listdir(args.in_dir):
- spk_dir = os.path.join(args.in_dir, speaker)
- if os.path.isdir(spk_dir):
- print(spk_dir)
- for _ in tqdm(pool.imap_unordered(process, [(spk_dir, i, args) for i in os.listdir(spk_dir) if i.endswith("wav")])):
- pass
diff --git a/spaces/XzJosh/maimai-Bert-VITS2/monotonic_align/__init__.py b/spaces/XzJosh/maimai-Bert-VITS2/monotonic_align/__init__.py
deleted file mode 100644
index 75603d26cf2b8d6196f5a68a89f9e49d8e519bc8..0000000000000000000000000000000000000000
--- a/spaces/XzJosh/maimai-Bert-VITS2/monotonic_align/__init__.py
+++ /dev/null
@@ -1,15 +0,0 @@
-from numpy import zeros, int32, float32
-from torch import from_numpy
-
-from .core import maximum_path_jit
-
-def maximum_path(neg_cent, mask):
- device = neg_cent.device
- dtype = neg_cent.dtype
- neg_cent = neg_cent.data.cpu().numpy().astype(float32)
- path = zeros(neg_cent.shape, dtype=int32)
-
- t_t_max = mask.sum(1)[:, 0].data.cpu().numpy().astype(int32)
- t_s_max = mask.sum(2)[:, 0].data.cpu().numpy().astype(int32)
- maximum_path_jit(path, neg_cent, t_t_max, t_s_max)
- return from_numpy(path).to(device=device, dtype=dtype)
diff --git a/spaces/YUANAI/DiffspeechResearch/modules/commons/conv.py b/spaces/YUANAI/DiffspeechResearch/modules/commons/conv.py
deleted file mode 100644
index c67d90ebf971e54ae57d08750041a698268042db..0000000000000000000000000000000000000000
--- a/spaces/YUANAI/DiffspeechResearch/modules/commons/conv.py
+++ /dev/null
@@ -1,167 +0,0 @@
-import math
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-from modules.commons.layers import LayerNorm, Embedding
-
-
-class LambdaLayer(nn.Module):
- def __init__(self, lambd):
- super(LambdaLayer, self).__init__()
- self.lambd = lambd
-
- def forward(self, x):
- return self.lambd(x)
-
-
-def init_weights_func(m):
- classname = m.__class__.__name__
- if classname.find("Conv1d") != -1:
- torch.nn.init.xavier_uniform_(m.weight)
-
-
-class ResidualBlock(nn.Module):
- """Implements conv->PReLU->norm n-times"""
-
- def __init__(self, channels, kernel_size, dilation, n=2, norm_type='bn', dropout=0.0,
- c_multiple=2, ln_eps=1e-12):
- super(ResidualBlock, self).__init__()
-
- if norm_type == 'bn':
- norm_builder = lambda: nn.BatchNorm1d(channels)
- elif norm_type == 'in':
- norm_builder = lambda: nn.InstanceNorm1d(channels, affine=True)
- elif norm_type == 'gn':
- norm_builder = lambda: nn.GroupNorm(8, channels)
- elif norm_type == 'ln':
- norm_builder = lambda: LayerNorm(channels, dim=1, eps=ln_eps)
- else:
- norm_builder = lambda: nn.Identity()
-
- self.blocks = [
- nn.Sequential(
- norm_builder(),
- nn.Conv1d(channels, c_multiple * channels, kernel_size, dilation=dilation,
- padding=(dilation * (kernel_size - 1)) // 2),
- LambdaLayer(lambda x: x * kernel_size ** -0.5),
- nn.GELU(),
- nn.Conv1d(c_multiple * channels, channels, 1, dilation=dilation),
- )
- for i in range(n)
- ]
-
- self.blocks = nn.ModuleList(self.blocks)
- self.dropout = dropout
-
- def forward(self, x):
- nonpadding = (x.abs().sum(1) > 0).float()[:, None, :]
- for b in self.blocks:
- x_ = b(x)
- if self.dropout > 0 and self.training:
- x_ = F.dropout(x_, self.dropout, training=self.training)
- x = x + x_
- x = x * nonpadding
- return x
-
-
-class ConvBlocks(nn.Module):
- """Decodes the expanded phoneme encoding into spectrograms"""
-
- def __init__(self, hidden_size, out_dims, dilations, kernel_size,
- norm_type='ln', layers_in_block=2, c_multiple=2,
- dropout=0.0, ln_eps=1e-5,
- init_weights=True, is_BTC=True, num_layers=None, post_net_kernel=3):
- super(ConvBlocks, self).__init__()
- self.is_BTC = is_BTC
- if num_layers is not None:
- dilations = [1] * num_layers
- self.res_blocks = nn.Sequential(
- *[ResidualBlock(hidden_size, kernel_size, d,
- n=layers_in_block, norm_type=norm_type, c_multiple=c_multiple,
- dropout=dropout, ln_eps=ln_eps)
- for d in dilations],
- )
- if norm_type == 'bn':
- norm = nn.BatchNorm1d(hidden_size)
- elif norm_type == 'in':
- norm = nn.InstanceNorm1d(hidden_size, affine=True)
- elif norm_type == 'gn':
- norm = nn.GroupNorm(8, hidden_size)
- elif norm_type == 'ln':
- norm = LayerNorm(hidden_size, dim=1, eps=ln_eps)
- self.last_norm = norm
- self.post_net1 = nn.Conv1d(hidden_size, out_dims, kernel_size=post_net_kernel,
- padding=post_net_kernel // 2)
- if init_weights:
- self.apply(init_weights_func)
-
- def forward(self, x, nonpadding=None):
- """
-
- :param x: [B, T, H]
- :return: [B, T, H]
- """
- if self.is_BTC:
- x = x.transpose(1, 2)
- if nonpadding is None:
- nonpadding = (x.abs().sum(1) > 0).float()[:, None, :]
- elif self.is_BTC:
- nonpadding = nonpadding.transpose(1, 2)
- x = self.res_blocks(x) * nonpadding
- x = self.last_norm(x) * nonpadding
- x = self.post_net1(x) * nonpadding
- if self.is_BTC:
- x = x.transpose(1, 2)
- return x
-
-
-class TextConvEncoder(ConvBlocks):
- def __init__(self, dict_size, hidden_size, out_dims, dilations, kernel_size,
- norm_type='ln', layers_in_block=2, c_multiple=2,
- dropout=0.0, ln_eps=1e-5, init_weights=True, num_layers=None, post_net_kernel=3):
- super().__init__(hidden_size, out_dims, dilations, kernel_size,
- norm_type, layers_in_block, c_multiple,
- dropout, ln_eps, init_weights, num_layers=num_layers,
- post_net_kernel=post_net_kernel)
- self.embed_tokens = Embedding(dict_size, hidden_size, 0)
- self.embed_scale = math.sqrt(hidden_size)
-
- def forward(self, txt_tokens):
- """
-
- :param txt_tokens: [B, T]
- :return: {
- 'encoder_out': [B x T x C]
- }
- """
- x = self.embed_scale * self.embed_tokens(txt_tokens)
- return super().forward(x)
-
-
-class ConditionalConvBlocks(ConvBlocks):
- def __init__(self, hidden_size, c_cond, c_out, dilations, kernel_size,
- norm_type='ln', layers_in_block=2, c_multiple=2,
- dropout=0.0, ln_eps=1e-5, init_weights=True, is_BTC=True, num_layers=None):
- super().__init__(hidden_size, c_out, dilations, kernel_size,
- norm_type, layers_in_block, c_multiple,
- dropout, ln_eps, init_weights, is_BTC=False, num_layers=num_layers)
- self.g_prenet = nn.Conv1d(c_cond, hidden_size, 3, padding=1)
- self.is_BTC_ = is_BTC
- if init_weights:
- self.g_prenet.apply(init_weights_func)
-
- def forward(self, x, cond, nonpadding=None):
- if self.is_BTC_:
- x = x.transpose(1, 2)
- cond = cond.transpose(1, 2)
- if nonpadding is not None:
- nonpadding = nonpadding.transpose(1, 2)
- if nonpadding is None:
- nonpadding = x.abs().sum(1)[:, None]
- x = x + self.g_prenet(cond)
- x = x * nonpadding
- x = super(ConditionalConvBlocks, self).forward(x) # input needs to be BTC
- if self.is_BTC_:
- x = x.transpose(1, 2)
- return x
diff --git a/spaces/Yan233th/so-vits-svc-models/train.py b/spaces/Yan233th/so-vits-svc-models/train.py
deleted file mode 100644
index e499528a342c14f33eec8735d32cd3971ee6470e..0000000000000000000000000000000000000000
--- a/spaces/Yan233th/so-vits-svc-models/train.py
+++ /dev/null
@@ -1,310 +0,0 @@
-import logging
-import multiprocessing
-import time
-
-logging.getLogger('matplotlib').setLevel(logging.WARNING)
-import os
-import json
-import argparse
-import itertools
-import math
-import torch
-from torch import nn, optim
-from torch.nn import functional as F
-from torch.utils.data import DataLoader
-from torch.utils.tensorboard import SummaryWriter
-import torch.multiprocessing as mp
-import torch.distributed as dist
-from torch.nn.parallel import DistributedDataParallel as DDP
-from torch.cuda.amp import autocast, GradScaler
-
-import modules.commons as commons
-import utils
-from data_utils import TextAudioSpeakerLoader, TextAudioCollate
-from models import (
- SynthesizerTrn,
- MultiPeriodDiscriminator,
-)
-from modules.losses import (
- kl_loss,
- generator_loss, discriminator_loss, feature_loss
-)
-
-from modules.mel_processing import mel_spectrogram_torch, spec_to_mel_torch
-
-torch.backends.cudnn.benchmark = True
-global_step = 0
-start_time = time.time()
-
-# os.environ['TORCH_DISTRIBUTED_DEBUG'] = 'INFO'
-
-
-def main():
- """Assume Single Node Multi GPUs Training Only"""
- assert torch.cuda.is_available(), "CPU training is not allowed."
- hps = utils.get_hparams()
-
- n_gpus = torch.cuda.device_count()
- os.environ['MASTER_ADDR'] = 'localhost'
- os.environ['MASTER_PORT'] = hps.train.port
-
- mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,))
-
-
-def run(rank, n_gpus, hps):
- global global_step
- if rank == 0:
- logger = utils.get_logger(hps.model_dir)
- logger.info(hps)
- utils.check_git_hash(hps.model_dir)
- writer = SummaryWriter(log_dir=hps.model_dir)
- writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval"))
-
- # for pytorch on win, backend use gloo
- dist.init_process_group(backend= 'gloo' if os.name == 'nt' else 'nccl', init_method='env://', world_size=n_gpus, rank=rank)
- torch.manual_seed(hps.train.seed)
- torch.cuda.set_device(rank)
- collate_fn = TextAudioCollate()
- train_dataset = TextAudioSpeakerLoader(hps.data.training_files, hps)
- num_workers = 5 if multiprocessing.cpu_count() > 4 else multiprocessing.cpu_count()
- train_loader = DataLoader(train_dataset, num_workers=num_workers, shuffle=False, pin_memory=True,
- batch_size=hps.train.batch_size, collate_fn=collate_fn)
- if rank == 0:
- eval_dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps)
- eval_loader = DataLoader(eval_dataset, num_workers=1, shuffle=False,
- batch_size=1, pin_memory=False,
- drop_last=False, collate_fn=collate_fn)
-
- net_g = SynthesizerTrn(
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- **hps.model).cuda(rank)
- net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).cuda(rank)
- optim_g = torch.optim.AdamW(
- net_g.parameters(),
- hps.train.learning_rate,
- betas=hps.train.betas,
- eps=hps.train.eps)
- optim_d = torch.optim.AdamW(
- net_d.parameters(),
- hps.train.learning_rate,
- betas=hps.train.betas,
- eps=hps.train.eps)
- net_g = DDP(net_g, device_ids=[rank]) # , find_unused_parameters=True)
- net_d = DDP(net_d, device_ids=[rank])
-
- skip_optimizer = False
- try:
- _, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g,
- optim_g, skip_optimizer)
- _, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d,
- optim_d, skip_optimizer)
- epoch_str = max(epoch_str, 1)
- global_step = (epoch_str - 1) * len(train_loader)
- except:
- print("load old checkpoint failed...")
- epoch_str = 1
- global_step = 0
- if skip_optimizer:
- epoch_str = 1
- global_step = 0
-
- scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2)
- scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str - 2)
-
- scaler = GradScaler(enabled=hps.train.fp16_run)
-
- for epoch in range(epoch_str, hps.train.epochs + 1):
- if rank == 0:
- train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler,
- [train_loader, eval_loader], logger, [writer, writer_eval])
- else:
- train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler,
- [train_loader, None], None, None)
- scheduler_g.step()
- scheduler_d.step()
-
-
-def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers):
- net_g, net_d = nets
- optim_g, optim_d = optims
- scheduler_g, scheduler_d = schedulers
- train_loader, eval_loader = loaders
- if writers is not None:
- writer, writer_eval = writers
-
- # train_loader.batch_sampler.set_epoch(epoch)
- global global_step
-
- net_g.train()
- net_d.train()
- for batch_idx, items in enumerate(train_loader):
- c, f0, spec, y, spk, lengths, uv = items
- g = spk.cuda(rank, non_blocking=True)
- spec, y = spec.cuda(rank, non_blocking=True), y.cuda(rank, non_blocking=True)
- c = c.cuda(rank, non_blocking=True)
- f0 = f0.cuda(rank, non_blocking=True)
- uv = uv.cuda(rank, non_blocking=True)
- lengths = lengths.cuda(rank, non_blocking=True)
- mel = spec_to_mel_torch(
- spec,
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.mel_fmin,
- hps.data.mel_fmax)
-
- with autocast(enabled=hps.train.fp16_run):
- y_hat, ids_slice, z_mask, \
- (z, z_p, m_p, logs_p, m_q, logs_q), pred_lf0, norm_lf0, lf0 = net_g(c, f0, uv, spec, g=g, c_lengths=lengths,
- spec_lengths=lengths)
-
- y_mel = commons.slice_segments(mel, ids_slice, hps.train.segment_size // hps.data.hop_length)
- y_hat_mel = mel_spectrogram_torch(
- y_hat.squeeze(1),
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.hop_length,
- hps.data.win_length,
- hps.data.mel_fmin,
- hps.data.mel_fmax
- )
- y = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size) # slice
-
- # Discriminator
- y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach())
-
- with autocast(enabled=False):
- loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g)
- loss_disc_all = loss_disc
-
- optim_d.zero_grad()
- scaler.scale(loss_disc_all).backward()
- scaler.unscale_(optim_d)
- grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None)
- scaler.step(optim_d)
-
- with autocast(enabled=hps.train.fp16_run):
- # Generator
- y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
- with autocast(enabled=False):
- loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
- loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
- loss_fm = feature_loss(fmap_r, fmap_g)
- loss_gen, losses_gen = generator_loss(y_d_hat_g)
- loss_lf0 = F.mse_loss(pred_lf0, lf0)
- loss_gen_all = loss_gen + loss_fm + loss_mel + loss_kl + loss_lf0
- optim_g.zero_grad()
- scaler.scale(loss_gen_all).backward()
- scaler.unscale_(optim_g)
- grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None)
- scaler.step(optim_g)
- scaler.update()
-
- if rank == 0:
- if global_step % hps.train.log_interval == 0:
- lr = optim_g.param_groups[0]['lr']
- losses = [loss_disc, loss_gen, loss_fm, loss_mel, loss_kl]
- logger.info('Train Epoch: {} [{:.0f}%]'.format(
- epoch,
- 100. * batch_idx / len(train_loader)))
- logger.info(f"Losses: {[x.item() for x in losses]}, step: {global_step}, lr: {lr}")
-
- scalar_dict = {"loss/g/total": loss_gen_all, "loss/d/total": loss_disc_all, "learning_rate": lr,
- "grad_norm_d": grad_norm_d, "grad_norm_g": grad_norm_g}
- scalar_dict.update({"loss/g/fm": loss_fm, "loss/g/mel": loss_mel, "loss/g/kl": loss_kl,
- "loss/g/lf0": loss_lf0})
-
- # scalar_dict.update({"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)})
- # scalar_dict.update({"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)})
- # scalar_dict.update({"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)})
- image_dict = {
- "slice/mel_org": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().numpy()),
- "slice/mel_gen": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().numpy()),
- "all/mel": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().numpy()),
- "all/lf0": utils.plot_data_to_numpy(lf0[0, 0, :].cpu().numpy(),
- pred_lf0[0, 0, :].detach().cpu().numpy()),
- "all/norm_lf0": utils.plot_data_to_numpy(lf0[0, 0, :].cpu().numpy(),
- norm_lf0[0, 0, :].detach().cpu().numpy())
- }
-
- utils.summarize(
- writer=writer,
- global_step=global_step,
- images=image_dict,
- scalars=scalar_dict
- )
-
- if global_step % hps.train.eval_interval == 0:
- evaluate(hps, net_g, eval_loader, writer_eval)
- utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch,
- os.path.join(hps.model_dir, "G_{}.pth".format(global_step)))
- utils.save_checkpoint(net_d, optim_d, hps.train.learning_rate, epoch,
- os.path.join(hps.model_dir, "D_{}.pth".format(global_step)))
- keep_ckpts = getattr(hps.train, 'keep_ckpts', 0)
- if keep_ckpts > 0:
- utils.clean_checkpoints(path_to_models=hps.model_dir, n_ckpts_to_keep=keep_ckpts, sort_by_time=True)
-
- global_step += 1
-
- if rank == 0:
- global start_time
- now = time.time()
- durtaion = format(now - start_time, '.2f')
- logger.info(f'====> Epoch: {epoch}, cost {durtaion} s')
- start_time = now
-
-
-def evaluate(hps, generator, eval_loader, writer_eval):
- generator.eval()
- image_dict = {}
- audio_dict = {}
- with torch.no_grad():
- for batch_idx, items in enumerate(eval_loader):
- c, f0, spec, y, spk, _, uv = items
- g = spk[:1].cuda(0)
- spec, y = spec[:1].cuda(0), y[:1].cuda(0)
- c = c[:1].cuda(0)
- f0 = f0[:1].cuda(0)
- uv= uv[:1].cuda(0)
- mel = spec_to_mel_torch(
- spec,
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.mel_fmin,
- hps.data.mel_fmax)
- y_hat = generator.module.infer(c, f0, uv, g=g)
-
- y_hat_mel = mel_spectrogram_torch(
- y_hat.squeeze(1).float(),
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.hop_length,
- hps.data.win_length,
- hps.data.mel_fmin,
- hps.data.mel_fmax
- )
-
- audio_dict.update({
- f"gen/audio_{batch_idx}": y_hat[0],
- f"gt/audio_{batch_idx}": y[0]
- })
- image_dict.update({
- f"gen/mel": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().numpy()),
- "gt/mel": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy())
- })
- utils.summarize(
- writer=writer_eval,
- global_step=global_step,
- images=image_dict,
- audios=audio_dict,
- audio_sampling_rate=hps.data.sampling_rate
- )
- generator.train()
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/Yilin98/Stock_Prediction/app.py b/spaces/Yilin98/Stock_Prediction/app.py
deleted file mode 100644
index 344df64efc91f19894daba3b90846c2f94c80e85..0000000000000000000000000000000000000000
--- a/spaces/Yilin98/Stock_Prediction/app.py
+++ /dev/null
@@ -1,58 +0,0 @@
-from data_loader_functions import *
-from sentiment_analysis import *
-from stock_prediction import *
-
-from datetime import datetime
-
-import pandas as pd
-import streamlit as st
-
-from bs4 import BeautifulSoup
-import requests
-
-st.set_page_config(layout="wide")
-
-st.title("Stock Prediction via News Sentiments")
-
-
-left_column, right_column = st.columns(2)
-
-with left_column:
-
- all_tickers = {
- "Apple":"AAPL",
- "Amazon":"AMZN",
- "Meta":"META",
- }
-
- st.subheader("Select Stock to Analyze")
- option_name = st.selectbox('Choose a stock:', all_tickers.keys())
- option_ticker = all_tickers[option_name]
- 'Your selection: ', option_name, "(",option_ticker,")"
-
- st.subheader("Vader-based Sentiment Analysis")
-
- with st.spinner("Connecting with Hopsworks..."):
- df = sentiment_analysis(option_name, datetime(2023, 1, 5))
- df_copy = df.copy()
- df_copy = df_copy.set_index('publish_date')
- st.table(df_copy.drop(['body_text', 'text_w_puncts', 'text_tokenized', 'text_w_stopwords', 'text_lemmatized', 'text_stemmed', 'text_processed', 'predicted_class'], axis=1))
- daily_df = aggregate_by_date(df)
- "Current sentiment:", daily_df.iloc[0]['compound']
-
-with right_column:
-
- st.subheader("Latest Stock Price")
-
- with st.spinner('Loading stock data from Hopsworks...'):
- stock_df = get_stock_price_from_hopsworks(option_name)
- st.table(stock_df)
-
- st.subheader("LSTM-based stock price prediction model")
-
- get_history_plot_from_hopsworks(option_ticker)
- st.image(option_name.lower() + "_stock_prediction.png", caption="Latest Model Performance")
-
- with st.spinner("Loading LSTM model from Hopsworks.."):
- date, value = model(option_ticker)
- "The predicted stock value on ", date, "is", value
\ No newline at end of file
diff --git a/spaces/Yiqin/ChatVID/model/utils/__init__.py b/spaces/Yiqin/ChatVID/model/utils/__init__.py
deleted file mode 100644
index b56dd0568b35b95a259ed1975526b6d6774002c6..0000000000000000000000000000000000000000
--- a/spaces/Yiqin/ChatVID/model/utils/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .extract_clip_feature import extract_clip_feature_single_video_fps
-from .generate_tf_record import generate
-from .scenic_call import ScenicCall, ScenicModel
\ No newline at end of file
diff --git a/spaces/Yiqin/ChatVID/model/vision/grit_src/grit/modeling/text/modeling_bert.py b/spaces/Yiqin/ChatVID/model/vision/grit_src/grit/modeling/text/modeling_bert.py
deleted file mode 100644
index 3f8bf2d5d7552ee6c314da86a19a56eb0bdaa03e..0000000000000000000000000000000000000000
--- a/spaces/Yiqin/ChatVID/model/vision/grit_src/grit/modeling/text/modeling_bert.py
+++ /dev/null
@@ -1,529 +0,0 @@
-# coding=utf-8
-# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
-# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""PyTorch BERT model. """
-# Adapted from https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py
-
-from __future__ import absolute_import, division, print_function, unicode_literals
-import copy
-import os
-import json
-import logging
-import math
-import sys
-from io import open
-import torch
-from torch import nn
-import torch.utils.checkpoint as checkpoint
-from .file_utils import cached_path
-
-
-logger = logging.getLogger()
-
-
-BERT_PRETRAINED_CONFIG_ARCHIVE_MAP = {
- 'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-config.json",
- 'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-config.json",
- 'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-config.json",
- 'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-config.json",
- 'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased-config.json",
- 'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-config.json",
- 'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-config.json",
- 'bert-base-german-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-cased-config.json",
- 'bert-large-uncased-whole-word-masking': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-whole-word-masking-config.json",
- 'bert-large-cased-whole-word-masking': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-whole-word-masking-config.json",
- 'bert-large-uncased-whole-word-masking-finetuned-squad': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-whole-word-masking-finetuned-squad-config.json",
- 'bert-large-cased-whole-word-masking-finetuned-squad': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-whole-word-masking-finetuned-squad-config.json",
- 'bert-base-cased-finetuned-mrpc': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-finetuned-mrpc-config.json",
-}
-
-
-def qk2attn(query, key, attention_mask, gamma):
- query = query / gamma
- attention_scores = torch.matmul(query, key.transpose(-1, -2))
- if attention_mask is not None:
- # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
- attention_scores = attention_scores + attention_mask
- return attention_scores.softmax(dim=-1)
-
-
-class QK2Attention(nn.Module):
- def forward(self, query, key, attention_mask, gamma):
- return qk2attn(query, key, attention_mask, gamma)
-
-
-LayerNormClass = torch.nn.LayerNorm
-
-
-class BertSelfAttention(nn.Module):
- def __init__(self, config):
- super(BertSelfAttention, self).__init__()
- if config.hidden_size % config.num_attention_heads != 0:
- raise ValueError(
- "The hidden size (%d) is not a multiple of the number of attention "
- "heads (%d)" % (config.hidden_size, config.num_attention_heads))
- self.output_attentions = config.output_attentions
-
- self.num_attention_heads = config.num_attention_heads
- self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
- self.all_head_size = self.num_attention_heads * self.attention_head_size
-
- self.query = nn.Linear(config.hidden_size, self.all_head_size)
- self.key = nn.Linear(config.hidden_size, self.all_head_size)
- self.value = nn.Linear(config.hidden_size, self.all_head_size)
-
- self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
- self.softmax = nn.Softmax(dim=-1)
- self.qk2attn = QK2Attention()
-
- def transpose_for_scores(self, x):
- if torch._C._get_tracing_state():
- # exporter is not smart enough to detect dynamic size for some paths
- x = x.view(x.shape[0], -1, self.num_attention_heads, self.attention_head_size)
- else:
- new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
- x = x.view(*new_x_shape)
- return x.permute(0, 2, 1, 3)
-
- def forward(self, hidden_states, attention_mask, head_mask=None,
- history_state=None):
- if history_state is not None:
- x_states = torch.cat([history_state, hidden_states], dim=1)
- mixed_query_layer = self.query(hidden_states)
- mixed_key_layer = self.key(x_states)
- mixed_value_layer = self.value(x_states)
- else:
- mixed_query_layer = self.query(hidden_states)
- mixed_key_layer = self.key(hidden_states)
- mixed_value_layer = self.value(hidden_states)
-
- query_layer = self.transpose_for_scores(mixed_query_layer)
- key_layer = self.transpose_for_scores(mixed_key_layer)
- value_layer = self.transpose_for_scores(mixed_value_layer)
-
- attention_probs = self.qk2attn(query_layer, key_layer, attention_mask, math.sqrt(self.attention_head_size))
-
- # This is actually dropping out entire tokens to attend to, which might
- # seem a bit unusual, but is taken from the original Transformer paper.
- attention_probs = self.dropout(attention_probs)
-
- # Mask heads if we want to
- if head_mask is not None:
- attention_probs = attention_probs * head_mask
-
- context_layer = torch.matmul(attention_probs, value_layer)
-
- context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
- new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
- context_layer = context_layer.view(*new_context_layer_shape)
-
- outputs = (context_layer, attention_probs) if self.output_attentions else (context_layer,)
- return outputs
-
-
-class BertSelfOutput(nn.Module):
- def __init__(self, config):
- super(BertSelfOutput, self).__init__()
- self.dense = nn.Linear(config.hidden_size, config.hidden_size)
- self.pre_norm = hasattr(config, 'pre_norm') and config.pre_norm
- if not self.pre_norm:
- self.LayerNorm = LayerNormClass(config.hidden_size, eps=config.layer_norm_eps)
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
-
- def forward(self, hidden_states, input_tensor):
- hidden_states = self.dense(hidden_states)
- hidden_states = self.dropout(hidden_states)
- if not self.pre_norm:
- hidden_states = self.LayerNorm(hidden_states + input_tensor)
- else:
- hidden_states = hidden_states + input_tensor
- return hidden_states
-
-
-class BertAttention(nn.Module):
- def __init__(self, config):
- super(BertAttention, self).__init__()
- self.pre_norm = hasattr(config, 'pre_norm') and config.pre_norm
- if self.pre_norm:
- self.LayerNorm = LayerNormClass(config.hidden_size, eps=config.layer_norm_eps)
- self.self = BertSelfAttention(config)
- self.output = BertSelfOutput(config)
-
- def forward(self, input_tensor, attention_mask, head_mask=None,
- history_state=None):
- if self.pre_norm:
- self_outputs = self.self(self.LayerNorm(input_tensor), attention_mask, head_mask,
- self.layerNorm(history_state) if history_state else history_state)
- else:
- self_outputs = self.self(input_tensor, attention_mask, head_mask,
- history_state)
- attention_output = self.output(self_outputs[0], input_tensor)
- outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
- return outputs
-
-
-class BertIntermediate(nn.Module):
- def __init__(self, config):
- super(BertIntermediate, self).__init__()
- self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
- assert config.hidden_act == 'gelu', 'Please implement other activation functions'
- self.intermediate_act_fn = _gelu_python
-
- def forward(self, hidden_states):
- hidden_states = self.dense(hidden_states)
- hidden_states = self.intermediate_act_fn(hidden_states)
- return hidden_states
-
-
-class BertOutput(nn.Module):
- def __init__(self, config):
- super(BertOutput, self).__init__()
- self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
- self.pre_norm = hasattr(config, 'pre_norm') and config.pre_norm
- self.dropout = nn.Dropout(config.hidden_dropout_prob)
- if not self.pre_norm:
- self.LayerNorm = LayerNormClass(config.hidden_size, eps=config.layer_norm_eps)
-
- def forward(self, hidden_states, input_tensor):
- hidden_states = self.dense(hidden_states)
- hidden_states = self.dropout(hidden_states)
- if not self.pre_norm:
- hidden_states = self.LayerNorm(hidden_states + input_tensor)
- else:
- hidden_states = hidden_states + input_tensor
- return hidden_states
-
-
-class Mlp(nn.Module):
- def __init__(self, config):
- super().__init__()
- self.pre_norm = hasattr(config, 'pre_norm') and config.pre_norm
- self.intermediate = BertIntermediate(config)
- if self.pre_norm:
- self.LayerNorm = LayerNormClass(config.hidden_size, eps=config.layer_norm_eps)
- self.output = BertOutput(config)
-
- def forward(self, attention_output):
- if not self.pre_norm:
- intermediate_output = self.intermediate(attention_output)
- else:
- intermediate_output = self.intermediate(self.LayerNorm(attention_output))
- layer_output = self.output(intermediate_output, attention_output)
- return layer_output
-
-
-class BertLayer(nn.Module):
- def __init__(self, config, use_act_checkpoint=True):
- super(BertLayer, self).__init__()
- self.pre_norm = hasattr(config, 'pre_norm') and config.pre_norm
- self.use_mlp_wrapper = hasattr(config, 'use_mlp_wrapper') and config.use_mlp_wrapper
- self.attention = BertAttention(config)
- self.use_act_checkpoint = use_act_checkpoint
- if self.use_mlp_wrapper:
- self.mlp = Mlp(config)
- else:
- self.intermediate = BertIntermediate(config)
- if self.pre_norm:
- self.LayerNorm = LayerNormClass(config.hidden_size, eps=config.layer_norm_eps)
- self.output = BertOutput(config)
-
- def forward(self, hidden_states, attention_mask, head_mask=None,
- history_state=None):
- if self.use_act_checkpoint:
- attention_outputs = checkpoint.checkpoint(self.attention, hidden_states,
- attention_mask, head_mask, history_state)
- else:
- attention_outputs = self.attention(hidden_states, attention_mask,
- head_mask, history_state)
- attention_output = attention_outputs[0]
- if self.use_mlp_wrapper:
- layer_output = self.mlp(attention_output)
- else:
- if not self.pre_norm:
- intermediate_output = self.intermediate(attention_output)
- else:
- intermediate_output = self.intermediate(self.LayerNorm(attention_output))
- layer_output = self.output(intermediate_output, attention_output)
- outputs = (layer_output,) + attention_outputs[1:] # add attentions if we output them
- return outputs
-
-
-class BertEncoder(nn.Module):
- def __init__(self, config, use_act_checkpoint=True):
- super(BertEncoder, self).__init__()
- self.output_attentions = config.output_attentions
- self.output_hidden_states = config.output_hidden_states
- self.layer = nn.ModuleList([BertLayer(config, use_act_checkpoint=use_act_checkpoint) for _ in range(config.num_hidden_layers)])
- self.pre_norm = hasattr(config, 'pre_norm') and config.pre_norm
- if self.pre_norm:
- self.LayerNorm = LayerNormClass(config.hidden_size, eps=config.layer_norm_eps)
-
- def forward(self, hidden_states, attention_mask, head_mask=None,
- encoder_history_states=None):
- all_hidden_states = ()
- all_attentions = ()
- for i, layer_module in enumerate(self.layer):
- if self.output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- history_state = None if encoder_history_states is None else encoder_history_states[i]
- layer_outputs = layer_module(
- hidden_states, attention_mask,
- (None if head_mask is None else head_mask[i]),
- history_state,
- )
- hidden_states = layer_outputs[0]
-
- if self.output_attentions:
- all_attentions = all_attentions + (layer_outputs[1],)
- if self.pre_norm:
- hidden_states = self.LayerNorm(hidden_states)
- outputs = (hidden_states,)
- if self.output_hidden_states:
- outputs = outputs + (all_hidden_states,)
- if self.output_attentions:
- outputs = outputs + (all_attentions,)
- return outputs
-
-CONFIG_NAME = "config.json"
-
-class PretrainedConfig(object):
- """ Base class for all configuration classes.
- Handle a few common parameters and methods for loading/downloading/saving configurations.
- """
- pretrained_config_archive_map = {}
-
- def __init__(self, **kwargs):
- self.finetuning_task = kwargs.pop('finetuning_task', None)
- self.num_labels = kwargs.pop('num_labels', 2)
- self.output_attentions = kwargs.pop('output_attentions', False)
- self.output_hidden_states = kwargs.pop('output_hidden_states', False)
- self.torchscript = kwargs.pop('torchscript', False)
-
- def save_pretrained(self, save_directory):
- """ Save a configuration object to a directory, so that it
- can be re-loaded using the `from_pretrained(save_directory)` class method.
- """
- assert os.path.isdir(save_directory), "Saving path should be a directory where the model and configuration can be saved"
-
- # If we save using the predefined names, we can load using `from_pretrained`
- output_config_file = os.path.join(save_directory, CONFIG_NAME)
-
- self.to_json_file(output_config_file)
-
- @classmethod
- def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
- r""" Instantiate a PretrainedConfig from a pre-trained model configuration.
-
- Params:
- **pretrained_model_name_or_path**: either:
- - a string with the `shortcut name` of a pre-trained model configuration to load from cache
- or download and cache if not already stored in cache (e.g. 'bert-base-uncased').
- - a path to a `directory` containing a configuration file saved
- using the `save_pretrained(save_directory)` method.
- - a path or url to a saved configuration `file`.
- **cache_dir**: (`optional`) string:
- Path to a directory in which a downloaded pre-trained model
- configuration should be cached if the standard cache should not be used.
- **return_unused_kwargs**: (`optional`) bool:
- - If False, then this function returns just the final configuration object.
- - If True, then this functions returns a tuple `(config, unused_kwargs)` where `unused_kwargs`
- is a dictionary consisting of the key/value pairs whose keys are not configuration attributes:
- ie the part of kwargs which has not been used to update `config` and is otherwise ignored.
- **kwargs**: (`optional`) dict:
- Dictionary of key/value pairs with which to update the configuration object after loading.
- - The values in kwargs of any keys which are configuration attributes will be used
- to override the loaded values.
- - Behavior concerning key/value pairs whose keys are *not* configuration attributes is controlled
- by the `return_unused_kwargs` keyword parameter.
-
- Examples::
-
- >>> config = BertConfig.from_pretrained('bert-base-uncased') # Download configuration from S3 and cache.
- >>> config = BertConfig.from_pretrained('./test/saved_model/') # E.g. config (or model) was saved using `save_pretrained('./test/saved_model/')`
- >>> config = BertConfig.from_pretrained('./test/saved_model/my_configuration.json')
- >>> config = BertConfig.from_pretrained('bert-base-uncased', output_attention=True, foo=False)
- >>> assert config.output_attention == True
- >>> config, unused_kwargs = BertConfig.from_pretrained('bert-base-uncased', output_attention=True,
- >>> foo=False, return_unused_kwargs=True)
- >>> assert config.output_attention == True
- >>> assert unused_kwargs == {'foo': False}
-
- """
- cache_dir = kwargs.pop('cache_dir', None)
- return_unused_kwargs = kwargs.pop('return_unused_kwargs', False)
-
- if pretrained_model_name_or_path in cls.pretrained_config_archive_map:
- config_file = cls.pretrained_config_archive_map[pretrained_model_name_or_path]
- elif os.path.isdir(pretrained_model_name_or_path):
- config_file = os.path.join(pretrained_model_name_or_path, CONFIG_NAME)
- else:
- config_file = pretrained_model_name_or_path
- # redirect to the cache, if necessary
- try:
- resolved_config_file = cached_path(config_file, cache_dir=cache_dir)
- except EnvironmentError:
- if pretrained_model_name_or_path in cls.pretrained_config_archive_map:
- logger.error(
- "Couldn't reach server at '{}' to download pretrained model configuration file.".format(
- config_file))
- else:
- logger.error(
- "Model name '{}' was not found in model name list ({}). "
- "We assumed '{}' was a path or url but couldn't find any file "
- "associated to this path or url.".format(
- pretrained_model_name_or_path,
- ', '.join(cls.pretrained_config_archive_map.keys()),
- config_file))
- return None
- if resolved_config_file == config_file:
- logger.info("loading configuration file {}".format(config_file))
- else:
- logger.info("loading configuration file {} from cache at {}".format(
- config_file, resolved_config_file))
-
- # Load config
- config = cls.from_json_file(resolved_config_file)
-
- # Update config with kwargs if needed
- to_remove = []
- for key, value in kwargs.items():
- if hasattr(config, key):
- setattr(config, key, value)
- to_remove.append(key)
- # add img_layer_norm_eps, use_img_layernorm
- if "img_layer_norm_eps" in kwargs:
- setattr(config, "img_layer_norm_eps", kwargs["img_layer_norm_eps"])
- to_remove.append("img_layer_norm_eps")
- if "use_img_layernorm" in kwargs:
- setattr(config, "use_img_layernorm", kwargs["use_img_layernorm"])
- to_remove.append("use_img_layernorm")
- for key in to_remove:
- kwargs.pop(key, None)
-
- logger.info("Model config %s", config)
- if return_unused_kwargs:
- return config, kwargs
- else:
- return config
-
- @classmethod
- def from_dict(cls, json_object):
- """Constructs a `Config` from a Python dictionary of parameters."""
- config = cls(vocab_size_or_config_json_file=-1)
- for key, value in json_object.items():
- config.__dict__[key] = value
- return config
-
- @classmethod
- def from_json_file(cls, json_file):
- """Constructs a `BertConfig` from a json file of parameters."""
- with open(json_file, "r", encoding='utf-8') as reader:
- text = reader.read()
- return cls.from_dict(json.loads(text))
-
- def __eq__(self, other):
- return self.__dict__ == other.__dict__
-
- def __repr__(self):
- return str(self.to_json_string())
-
- def to_dict(self):
- """Serializes this instance to a Python dictionary."""
- output = copy.deepcopy(self.__dict__)
- return output
-
- def to_json_string(self):
- """Serializes this instance to a JSON string."""
- return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
-
- def to_json_file(self, json_file_path):
- """ Save this instance to a json file."""
- with open(json_file_path, "w", encoding='utf-8') as writer:
- writer.write(self.to_json_string())
-
-
-class BertConfig(PretrainedConfig):
- r"""
- :class:`~pytorch_transformers.BertConfig` is the configuration class to store the configuration of a
- `BertModel`.
-
-
- Arguments:
- vocab_size_or_config_json_file: Vocabulary size of `inputs_ids` in `BertModel`.
- hidden_size: Size of the encoder layers and the pooler layer.
- num_hidden_layers: Number of hidden layers in the Transformer encoder.
- num_attention_heads: Number of attention heads for each attention layer in
- the Transformer encoder.
- intermediate_size: The size of the "intermediate" (i.e., feed-forward)
- layer in the Transformer encoder.
- hidden_act: The non-linear activation function (function or string) in the
- encoder and pooler. If string, "gelu", "relu" and "swish" are supported.
- hidden_dropout_prob: The dropout probabilitiy for all fully connected
- layers in the embeddings, encoder, and pooler.
- attention_probs_dropout_prob: The dropout ratio for the attention
- probabilities.
- max_position_embeddings: The maximum sequence length that this model might
- ever be used with. Typically set this to something large just in case
- (e.g., 512 or 1024 or 2048).
- type_vocab_size: The vocabulary size of the `token_type_ids` passed into
- `BertModel`.
- initializer_range: The sttdev of the truncated_normal_initializer for
- initializing all weight matrices.
- layer_norm_eps: The epsilon used by LayerNorm.
- """
- pretrained_config_archive_map = BERT_PRETRAINED_CONFIG_ARCHIVE_MAP
-
- def __init__(self,
- vocab_size_or_config_json_file=30522,
- hidden_size=768,
- num_hidden_layers=12,
- num_attention_heads=12,
- intermediate_size=3072,
- hidden_act="gelu",
- hidden_dropout_prob=0.1,
- attention_probs_dropout_prob=0.1,
- max_position_embeddings=512,
- type_vocab_size=2,
- initializer_range=0.02,
- layer_norm_eps=1e-12,
- **kwargs):
- super(BertConfig, self).__init__(**kwargs)
- if isinstance(vocab_size_or_config_json_file, str):
- with open(vocab_size_or_config_json_file, "r", encoding='utf-8') as reader:
- json_config = json.loads(reader.read())
- for key, value in json_config.items():
- self.__dict__[key] = value
- elif isinstance(vocab_size_or_config_json_file, int):
- self.vocab_size = vocab_size_or_config_json_file
- self.hidden_size = hidden_size
- self.num_hidden_layers = num_hidden_layers
- self.num_attention_heads = num_attention_heads
- self.hidden_act = hidden_act
- self.intermediate_size = intermediate_size
- self.hidden_dropout_prob = hidden_dropout_prob
- self.attention_probs_dropout_prob = attention_probs_dropout_prob
- self.max_position_embeddings = max_position_embeddings
- self.type_vocab_size = type_vocab_size
- self.initializer_range = initializer_range
- self.layer_norm_eps = layer_norm_eps
- else:
- raise ValueError("First argument must be either a vocabulary size (int)"
- "or the path to a pretrained model config file (str)")
-
-
-def _gelu_python(x):
-
- return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
\ No newline at end of file
diff --git a/spaces/YouLiXiya/Mobile-SAM/GroundingDINO/groundingdino/models/__init__.py b/spaces/YouLiXiya/Mobile-SAM/GroundingDINO/groundingdino/models/__init__.py
deleted file mode 100644
index e3413961d1d184b99835eb1e919b052d70298bc6..0000000000000000000000000000000000000000
--- a/spaces/YouLiXiya/Mobile-SAM/GroundingDINO/groundingdino/models/__init__.py
+++ /dev/null
@@ -1,18 +0,0 @@
-# ------------------------------------------------------------------------
-# Grounding DINO
-# url: https://github.com/IDEA-Research/GroundingDINO
-# Copyright (c) 2023 IDEA. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# ------------------------------------------------------------------------
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-from .GroundingDINO import build_groundingdino
-
-
-def build_model(args):
- # we use register to maintain models from catdet6 on.
- from .registry import MODULE_BUILD_FUNCS
-
- assert args.modelname in MODULE_BUILD_FUNCS._module_dict
- build_func = MODULE_BUILD_FUNCS.get(args.modelname)
- model = build_func(args)
- return model
diff --git a/spaces/Yuankai/ChatReviewer/README.md b/spaces/Yuankai/ChatReviewer/README.md
deleted file mode 100644
index 42a6ed76481505f34bb0164061b114c7fbae4373..0000000000000000000000000000000000000000
--- a/spaces/Yuankai/ChatReviewer/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: ChatReviewer
-emoji: 💩
-colorFrom: red
-colorTo: pink
-sdk: gradio
-sdk_version: 3.22.1
-app_file: app.py
-pinned: false
-license: apache-2.0
-duplicated_from: ShiwenNi/ChatReviewer
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/ZilliaxOfficial/nyaru-svc-3.0/commons.py b/spaces/ZilliaxOfficial/nyaru-svc-3.0/commons.py
deleted file mode 100644
index 074888006392e956ce204d8368362dbb2cd4e304..0000000000000000000000000000000000000000
--- a/spaces/ZilliaxOfficial/nyaru-svc-3.0/commons.py
+++ /dev/null
@@ -1,188 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-def slice_pitch_segments(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, idx_str:idx_end]
- return ret
-
-def rand_slice_segments_with_pitch(x, pitch, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size + 1
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- ret_pitch = slice_pitch_segments(pitch, ids_str, segment_size)
- return ret, ret_pitch, ids_str
-
-def init_weights(m, mean=0.0, std=0.01):
- classname = m.__class__.__name__
- if classname.find("Conv") != -1:
- m.weight.data.normal_(mean, std)
-
-
-def get_padding(kernel_size, dilation=1):
- return int((kernel_size*dilation - dilation)/2)
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def intersperse(lst, item):
- result = [item] * (len(lst) * 2 + 1)
- result[1::2] = lst
- return result
-
-
-def kl_divergence(m_p, logs_p, m_q, logs_q):
- """KL(P||Q)"""
- kl = (logs_q - logs_p) - 0.5
- kl += 0.5 * (torch.exp(2. * logs_p) + ((m_p - m_q)**2)) * torch.exp(-2. * logs_q)
- return kl
-
-
-def rand_gumbel(shape):
- """Sample from the Gumbel distribution, protect from overflows."""
- uniform_samples = torch.rand(shape) * 0.99998 + 0.00001
- return -torch.log(-torch.log(uniform_samples))
-
-
-def rand_gumbel_like(x):
- g = rand_gumbel(x.size()).to(dtype=x.dtype, device=x.device)
- return g
-
-
-def slice_segments(x, ids_str, segment_size=4):
- ret = torch.zeros_like(x[:, :, :segment_size])
- for i in range(x.size(0)):
- idx_str = ids_str[i]
- idx_end = idx_str + segment_size
- ret[i] = x[i, :, idx_str:idx_end]
- return ret
-
-
-def rand_slice_segments(x, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size + 1
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- return ret, ids_str
-
-
-def rand_spec_segments(x, x_lengths=None, segment_size=4):
- b, d, t = x.size()
- if x_lengths is None:
- x_lengths = t
- ids_str_max = x_lengths - segment_size
- ids_str = (torch.rand([b]).to(device=x.device) * ids_str_max).to(dtype=torch.long)
- ret = slice_segments(x, ids_str, segment_size)
- return ret, ids_str
-
-
-def get_timing_signal_1d(
- length, channels, min_timescale=1.0, max_timescale=1.0e4):
- position = torch.arange(length, dtype=torch.float)
- num_timescales = channels // 2
- log_timescale_increment = (
- math.log(float(max_timescale) / float(min_timescale)) /
- (num_timescales - 1))
- inv_timescales = min_timescale * torch.exp(
- torch.arange(num_timescales, dtype=torch.float) * -log_timescale_increment)
- scaled_time = position.unsqueeze(0) * inv_timescales.unsqueeze(1)
- signal = torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], 0)
- signal = F.pad(signal, [0, 0, 0, channels % 2])
- signal = signal.view(1, channels, length)
- return signal
-
-
-def add_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return x + signal.to(dtype=x.dtype, device=x.device)
-
-
-def cat_timing_signal_1d(x, min_timescale=1.0, max_timescale=1.0e4, axis=1):
- b, channels, length = x.size()
- signal = get_timing_signal_1d(length, channels, min_timescale, max_timescale)
- return torch.cat([x, signal.to(dtype=x.dtype, device=x.device)], axis)
-
-
-def subsequent_mask(length):
- mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)
- return mask
-
-
-@torch.jit.script
-def fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):
- n_channels_int = n_channels[0]
- in_act = input_a + input_b
- t_act = torch.tanh(in_act[:, :n_channels_int, :])
- s_act = torch.sigmoid(in_act[:, n_channels_int:, :])
- acts = t_act * s_act
- return acts
-
-
-def convert_pad_shape(pad_shape):
- l = pad_shape[::-1]
- pad_shape = [item for sublist in l for item in sublist]
- return pad_shape
-
-
-def shift_1d(x):
- x = F.pad(x, convert_pad_shape([[0, 0], [0, 0], [1, 0]]))[:, :, :-1]
- return x
-
-
-def sequence_mask(length, max_length=None):
- if max_length is None:
- max_length = length.max()
- x = torch.arange(max_length, dtype=length.dtype, device=length.device)
- return x.unsqueeze(0) < length.unsqueeze(1)
-
-
-def generate_path(duration, mask):
- """
- duration: [b, 1, t_x]
- mask: [b, 1, t_y, t_x]
- """
- device = duration.device
-
- b, _, t_y, t_x = mask.shape
- cum_duration = torch.cumsum(duration, -1)
-
- cum_duration_flat = cum_duration.view(b * t_x)
- path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
- path = path.view(b, t_x, t_y)
- path = path - F.pad(path, convert_pad_shape([[0, 0], [1, 0], [0, 0]]))[:, :-1]
- path = path.unsqueeze(1).transpose(2,3) * mask
- return path
-
-
-def clip_grad_value_(parameters, clip_value, norm_type=2):
- if isinstance(parameters, torch.Tensor):
- parameters = [parameters]
- parameters = list(filter(lambda p: p.grad is not None, parameters))
- norm_type = float(norm_type)
- if clip_value is not None:
- clip_value = float(clip_value)
-
- total_norm = 0
- for p in parameters:
- param_norm = p.grad.data.norm(norm_type)
- total_norm += param_norm.item() ** norm_type
- if clip_value is not None:
- p.grad.data.clamp_(min=-clip_value, max=clip_value)
- total_norm = total_norm ** (1. / norm_type)
- return total_norm
diff --git a/spaces/abhishek/dreambooth/main.py b/spaces/abhishek/dreambooth/main.py
deleted file mode 100644
index d0742cd8d360616c6dae5989696fcdae6742e6a5..0000000000000000000000000000000000000000
--- a/spaces/abhishek/dreambooth/main.py
+++ /dev/null
@@ -1,21 +0,0 @@
-import os
-import glob
-from huggingface_hub import snapshot_download
-
-REPO_ID = os.environ.get("REPO_ID")
-TOKEN = os.environ.get("TOKEN")
-folder = snapshot_download(
- repo_id=REPO_ID,
- revision="main",
- allow_regex="*.py",
- repo_type="space",
- use_auth_token=TOKEN,
-)
-
-# copy all *.py files in folder to .
-for file in glob.glob(os.path.join(folder, "*.py")):
- os.system(f"cp {file} .")
-
-from app import demo
-
-demo.launch()
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/utils/positional_encoding.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/utils/positional_encoding.py
deleted file mode 100644
index 9bda2bbdbfcc28ba6304b6325ae556fa02554ac1..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/utils/positional_encoding.py
+++ /dev/null
@@ -1,150 +0,0 @@
-import math
-
-import torch
-import torch.nn as nn
-from mmcv.cnn import uniform_init
-
-from .builder import POSITIONAL_ENCODING
-
-
-@POSITIONAL_ENCODING.register_module()
-class SinePositionalEncoding(nn.Module):
- """Position encoding with sine and cosine functions.
-
- See `End-to-End Object Detection with Transformers
- `_ for details.
-
- Args:
- num_feats (int): The feature dimension for each position
- along x-axis or y-axis. Note the final returned dimension
- for each position is 2 times of this value.
- temperature (int, optional): The temperature used for scaling
- the position embedding. Default 10000.
- normalize (bool, optional): Whether to normalize the position
- embedding. Default False.
- scale (float, optional): A scale factor that scales the position
- embedding. The scale will be used only when `normalize` is True.
- Default 2*pi.
- eps (float, optional): A value added to the denominator for
- numerical stability. Default 1e-6.
- """
-
- def __init__(self,
- num_feats,
- temperature=10000,
- normalize=False,
- scale=2 * math.pi,
- eps=1e-6):
- super(SinePositionalEncoding, self).__init__()
- if normalize:
- assert isinstance(scale, (float, int)), 'when normalize is set,' \
- 'scale should be provided and in float or int type, ' \
- f'found {type(scale)}'
- self.num_feats = num_feats
- self.temperature = temperature
- self.normalize = normalize
- self.scale = scale
- self.eps = eps
-
- def forward(self, mask):
- """Forward function for `SinePositionalEncoding`.
-
- Args:
- mask (Tensor): ByteTensor mask. Non-zero values representing
- ignored positions, while zero values means valid positions
- for this image. Shape [bs, h, w].
-
- Returns:
- pos (Tensor): Returned position embedding with shape
- [bs, num_feats*2, h, w].
- """
- not_mask = ~mask
- y_embed = not_mask.cumsum(1, dtype=torch.float32)
- x_embed = not_mask.cumsum(2, dtype=torch.float32)
- if self.normalize:
- y_embed = y_embed / (y_embed[:, -1:, :] + self.eps) * self.scale
- x_embed = x_embed / (x_embed[:, :, -1:] + self.eps) * self.scale
- dim_t = torch.arange(
- self.num_feats, dtype=torch.float32, device=mask.device)
- dim_t = self.temperature**(2 * (dim_t // 2) / self.num_feats)
- pos_x = x_embed[:, :, :, None] / dim_t
- pos_y = y_embed[:, :, :, None] / dim_t
- pos_x = torch.stack(
- (pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()),
- dim=4).flatten(3)
- pos_y = torch.stack(
- (pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()),
- dim=4).flatten(3)
- pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
- return pos
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(num_feats={self.num_feats}, '
- repr_str += f'temperature={self.temperature}, '
- repr_str += f'normalize={self.normalize}, '
- repr_str += f'scale={self.scale}, '
- repr_str += f'eps={self.eps})'
- return repr_str
-
-
-@POSITIONAL_ENCODING.register_module()
-class LearnedPositionalEncoding(nn.Module):
- """Position embedding with learnable embedding weights.
-
- Args:
- num_feats (int): The feature dimension for each position
- along x-axis or y-axis. The final returned dimension for
- each position is 2 times of this value.
- row_num_embed (int, optional): The dictionary size of row embeddings.
- Default 50.
- col_num_embed (int, optional): The dictionary size of col embeddings.
- Default 50.
- """
-
- def __init__(self, num_feats, row_num_embed=50, col_num_embed=50):
- super(LearnedPositionalEncoding, self).__init__()
- self.row_embed = nn.Embedding(row_num_embed, num_feats)
- self.col_embed = nn.Embedding(col_num_embed, num_feats)
- self.num_feats = num_feats
- self.row_num_embed = row_num_embed
- self.col_num_embed = col_num_embed
- self.init_weights()
-
- def init_weights(self):
- """Initialize the learnable weights."""
- uniform_init(self.row_embed)
- uniform_init(self.col_embed)
-
- def forward(self, mask):
- """Forward function for `LearnedPositionalEncoding`.
-
- Args:
- mask (Tensor): ByteTensor mask. Non-zero values representing
- ignored positions, while zero values means valid positions
- for this image. Shape [bs, h, w].
-
- Returns:
- pos (Tensor): Returned position embedding with shape
- [bs, num_feats*2, h, w].
- """
- h, w = mask.shape[-2:]
- x = torch.arange(w, device=mask.device)
- y = torch.arange(h, device=mask.device)
- x_embed = self.col_embed(x)
- y_embed = self.row_embed(y)
- pos = torch.cat(
- (x_embed.unsqueeze(0).repeat(h, 1, 1), y_embed.unsqueeze(1).repeat(
- 1, w, 1)),
- dim=-1).permute(2, 0,
- 1).unsqueeze(0).repeat(mask.shape[0], 1, 1, 1)
- return pos
-
- def __repr__(self):
- """str: a string that describes the module"""
- repr_str = self.__class__.__name__
- repr_str += f'(num_feats={self.num_feats}, '
- repr_str += f'row_num_embed={self.row_num_embed}, '
- repr_str += f'col_num_embed={self.col_num_embed})'
- return repr_str
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/detectors/detr.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/detectors/detr.py
deleted file mode 100644
index 5ff82a280daa0a015f662bdf2509fa11542d46d4..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/detectors/detr.py
+++ /dev/null
@@ -1,46 +0,0 @@
-from mmdet.core import bbox2result
-from ..builder import DETECTORS
-from .single_stage import SingleStageDetector
-
-
-@DETECTORS.register_module()
-class DETR(SingleStageDetector):
- r"""Implementation of `DETR: End-to-End Object Detection with
- Transformers `_"""
-
- def __init__(self,
- backbone,
- bbox_head,
- train_cfg=None,
- test_cfg=None,
- pretrained=None):
- super(DETR, self).__init__(backbone, None, bbox_head, train_cfg,
- test_cfg, pretrained)
-
- def simple_test(self, img, img_metas, rescale=False):
- """Test function without test time augmentation.
-
- Args:
- imgs (list[torch.Tensor]): List of multiple images
- img_metas (list[dict]): List of image information.
- rescale (bool, optional): Whether to rescale the results.
- Defaults to False.
-
- Returns:
- list[list[np.ndarray]]: BBox results of each image and classes.
- The outer list corresponds to each image. The inner list
- corresponds to each class.
- """
- batch_size = len(img_metas)
- assert batch_size == 1, 'Currently only batch_size 1 for inference ' \
- f'mode is supported. Found batch_size {batch_size}.'
- x = self.extract_feat(img)
- outs = self.bbox_head(x, img_metas)
- bbox_list = self.bbox_head.get_bboxes(
- *outs, img_metas, rescale=rescale)
-
- bbox_results = [
- bbox2result(det_bboxes, det_labels, self.bbox_head.num_classes)
- for det_bboxes, det_labels in bbox_list
- ]
- return bbox_results
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/losses/ghm_loss.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/losses/ghm_loss.py
deleted file mode 100644
index 8969a23fd98bb746415f96ac5e4ad9e37ba3af52..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet_null/models/losses/ghm_loss.py
+++ /dev/null
@@ -1,172 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-
-from ..builder import LOSSES
-
-
-def _expand_onehot_labels(labels, label_weights, label_channels):
- bin_labels = labels.new_full((labels.size(0), label_channels), 0)
- inds = torch.nonzero(
- (labels >= 0) & (labels < label_channels), as_tuple=False).squeeze()
- if inds.numel() > 0:
- bin_labels[inds, labels[inds]] = 1
- bin_label_weights = label_weights.view(-1, 1).expand(
- label_weights.size(0), label_channels)
- return bin_labels, bin_label_weights
-
-
-# TODO: code refactoring to make it consistent with other losses
-@LOSSES.register_module()
-class GHMC(nn.Module):
- """GHM Classification Loss.
-
- Details of the theorem can be viewed in the paper
- `Gradient Harmonized Single-stage Detector
- `_.
-
- Args:
- bins (int): Number of the unit regions for distribution calculation.
- momentum (float): The parameter for moving average.
- use_sigmoid (bool): Can only be true for BCE based loss now.
- loss_weight (float): The weight of the total GHM-C loss.
- """
-
- def __init__(self, bins=10, momentum=0, use_sigmoid=True, loss_weight=1.0):
- super(GHMC, self).__init__()
- self.bins = bins
- self.momentum = momentum
- edges = torch.arange(bins + 1).float() / bins
- self.register_buffer('edges', edges)
- self.edges[-1] += 1e-6
- if momentum > 0:
- acc_sum = torch.zeros(bins)
- self.register_buffer('acc_sum', acc_sum)
- self.use_sigmoid = use_sigmoid
- if not self.use_sigmoid:
- raise NotImplementedError
- self.loss_weight = loss_weight
-
- def forward(self, pred, target, label_weight, *args, **kwargs):
- """Calculate the GHM-C loss.
-
- Args:
- pred (float tensor of size [batch_num, class_num]):
- The direct prediction of classification fc layer.
- target (float tensor of size [batch_num, class_num]):
- Binary class target for each sample.
- label_weight (float tensor of size [batch_num, class_num]):
- the value is 1 if the sample is valid and 0 if ignored.
- Returns:
- The gradient harmonized loss.
- """
- # the target should be binary class label
- if pred.dim() != target.dim():
- target, label_weight = _expand_onehot_labels(
- target, label_weight, pred.size(-1))
- target, label_weight = target.float(), label_weight.float()
- edges = self.edges
- mmt = self.momentum
- weights = torch.zeros_like(pred)
-
- # gradient length
- g = torch.abs(pred.sigmoid().detach() - target)
-
- valid = label_weight > 0
- tot = max(valid.float().sum().item(), 1.0)
- n = 0 # n valid bins
- for i in range(self.bins):
- inds = (g >= edges[i]) & (g < edges[i + 1]) & valid
- num_in_bin = inds.sum().item()
- if num_in_bin > 0:
- if mmt > 0:
- self.acc_sum[i] = mmt * self.acc_sum[i] \
- + (1 - mmt) * num_in_bin
- weights[inds] = tot / self.acc_sum[i]
- else:
- weights[inds] = tot / num_in_bin
- n += 1
- if n > 0:
- weights = weights / n
-
- loss = F.binary_cross_entropy_with_logits(
- pred, target, weights, reduction='sum') / tot
- return loss * self.loss_weight
-
-
-# TODO: code refactoring to make it consistent with other losses
-@LOSSES.register_module()
-class GHMR(nn.Module):
- """GHM Regression Loss.
-
- Details of the theorem can be viewed in the paper
- `Gradient Harmonized Single-stage Detector
- `_.
-
- Args:
- mu (float): The parameter for the Authentic Smooth L1 loss.
- bins (int): Number of the unit regions for distribution calculation.
- momentum (float): The parameter for moving average.
- loss_weight (float): The weight of the total GHM-R loss.
- """
-
- def __init__(self, mu=0.02, bins=10, momentum=0, loss_weight=1.0):
- super(GHMR, self).__init__()
- self.mu = mu
- self.bins = bins
- edges = torch.arange(bins + 1).float() / bins
- self.register_buffer('edges', edges)
- self.edges[-1] = 1e3
- self.momentum = momentum
- if momentum > 0:
- acc_sum = torch.zeros(bins)
- self.register_buffer('acc_sum', acc_sum)
- self.loss_weight = loss_weight
-
- # TODO: support reduction parameter
- def forward(self, pred, target, label_weight, avg_factor=None):
- """Calculate the GHM-R loss.
-
- Args:
- pred (float tensor of size [batch_num, 4 (* class_num)]):
- The prediction of box regression layer. Channel number can be 4
- or 4 * class_num depending on whether it is class-agnostic.
- target (float tensor of size [batch_num, 4 (* class_num)]):
- The target regression values with the same size of pred.
- label_weight (float tensor of size [batch_num, 4 (* class_num)]):
- The weight of each sample, 0 if ignored.
- Returns:
- The gradient harmonized loss.
- """
- mu = self.mu
- edges = self.edges
- mmt = self.momentum
-
- # ASL1 loss
- diff = pred - target
- loss = torch.sqrt(diff * diff + mu * mu) - mu
-
- # gradient length
- g = torch.abs(diff / torch.sqrt(mu * mu + diff * diff)).detach()
- weights = torch.zeros_like(g)
-
- valid = label_weight > 0
- tot = max(label_weight.float().sum().item(), 1.0)
- n = 0 # n: valid bins
- for i in range(self.bins):
- inds = (g >= edges[i]) & (g < edges[i + 1]) & valid
- num_in_bin = inds.sum().item()
- if num_in_bin > 0:
- n += 1
- if mmt > 0:
- self.acc_sum[i] = mmt * self.acc_sum[i] \
- + (1 - mmt) * num_in_bin
- weights[inds] = tot / self.acc_sum[i]
- else:
- weights[inds] = tot / num_in_bin
- if n > 0:
- weights /= n
-
- loss = loss * weights
- loss = loss.sum() / tot
- return loss * self.loss_weight
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/core/utils/__init__.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/core/utils/__init__.py
deleted file mode 100644
index f2678b321c295bcceaef945111ac3524be19d6e4..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/core/utils/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .misc import add_prefix
-
-__all__ = ['add_prefix']
diff --git a/spaces/aichina/Pix2Pix-Video/app.py b/spaces/aichina/Pix2Pix-Video/app.py
deleted file mode 100644
index e53f764fdd09c23de8017178d18abfe37021d8f0..0000000000000000000000000000000000000000
--- a/spaces/aichina/Pix2Pix-Video/app.py
+++ /dev/null
@@ -1,223 +0,0 @@
-import gradio as gr
-import os
-import cv2
-import numpy as np
-from moviepy.editor import *
-from share_btn import community_icon_html, loading_icon_html, share_js
-
-from diffusers import DiffusionPipeline, EulerAncestralDiscreteScheduler
-import torch
-from PIL import Image
-import time
-import psutil
-import random
-
-#token = os.environ.get('HF_TOKEN')
-#pix2pix = gr.Blocks.load(name="spaces/fffiloni/instruct-pix2pix-clone", api_key=token)
-
-pipe = DiffusionPipeline.from_pretrained("timbrooks/instruct-pix2pix", torch_dtype=torch.float16, safety_checker=None)
-pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
-pipe.enable_xformers_memory_efficient_attention()
-pipe.unet.to(memory_format=torch.channels_last)
-
-device = "GPU 🔥" if torch.cuda.is_available() else "CPU 🥶"
-
-if torch.cuda.is_available():
- pipe = pipe.to("cuda")
-
-def pix2pix(
- prompt,
- text_guidance_scale,
- image_guidance_scale,
- image,
- steps,
- neg_prompt="",
- width=512,
- height=512,
- seed=0,
-):
- print(psutil.virtual_memory()) # print memory usage
-
- if seed == 0:
- seed = random.randint(0, 2147483647)
-
- generator = torch.Generator("cuda").manual_seed(seed)
-
- try:
- image = Image.open(image)
- ratio = min(height / image.height, width / image.width)
- image = image.resize((int(image.width * ratio), int(image.height * ratio)), Image.LANCZOS)
-
- result = pipe(
- prompt,
- negative_prompt=neg_prompt,
- image=image,
- num_inference_steps=int(steps),
- image_guidance_scale=image_guidance_scale,
- guidance_scale=text_guidance_scale,
- generator=generator,
- )
-
- # return replace_nsfw_images(result)
- return result.images, result.nsfw_content_detected, seed
- except Exception as e:
- return None, None, error_str(e)
-
-def error_str(error, title="Error"):
- return (
- f"""#### {title}
- {error}"""
- if error
- else ""
- )
-
-def get_frames(video_in):
- frames = []
- #resize the video
- clip = VideoFileClip(video_in)
-
- #check fps
- if clip.fps > 30:
- print("vide rate is over 30, resetting to 30")
- clip_resized = clip.resize(height=512)
- clip_resized.write_videofile("video_resized.mp4", fps=30)
- else:
- print("video rate is OK")
- clip_resized = clip.resize(height=512)
- clip_resized.write_videofile("video_resized.mp4", fps=clip.fps)
-
- print("video resized to 512 height")
-
- # Opens the Video file with CV2
- cap= cv2.VideoCapture("video_resized.mp4")
-
- fps = cap.get(cv2.CAP_PROP_FPS)
- print("video fps: " + str(fps))
- i=0
- while(cap.isOpened()):
- ret, frame = cap.read()
- if ret == False:
- break
- cv2.imwrite('kang'+str(i)+'.jpg',frame)
- frames.append('kang'+str(i)+'.jpg')
- i+=1
-
- cap.release()
- cv2.destroyAllWindows()
- print("broke the video into frames")
-
- return frames, fps
-
-
-def create_video(frames, fps):
- print("building video result")
- clip = ImageSequenceClip(frames, fps=fps)
- clip.write_videofile("movie.mp4", fps=fps)
-
- return 'movie.mp4'
-
-
-def infer(prompt,video_in, seed_in, trim_value):
- print(prompt)
- break_vid = get_frames(video_in)
-
- frames_list= break_vid[0]
- fps = break_vid[1]
- n_frame = int(trim_value*fps)
-
- if n_frame >= len(frames_list):
- print("video is shorter than the cut value")
- n_frame = len(frames_list)
-
- result_frames = []
- print("set stop frames to: " + str(n_frame))
-
- for i in frames_list[0:int(n_frame)]:
- pix2pix_img = pix2pix(prompt,15,1,i,15,"",512,512,seed_in)
- images = pix2pix_img[0]
- rgb_im = images[0].convert("RGB")
-
- # exporting the image
- rgb_im.save(f"result_img-{i}.jpg")
- result_frames.append(f"result_img-{i}.jpg")
- print("frame " + i + ": done;")
-
- final_vid = create_video(result_frames, fps)
- print("finished !")
-
- return final_vid, gr.Group.update(visible=True)
-
-title = """
-
-
-
- Pix2Pix Video
-
-
-
- Apply Instruct Pix2Pix Diffusion to a video
-
-
-
You may also like:
-
-
-
 - """, elem_id="duplicate-container")
- video_out = gr.Video(label="Pix2pix video result", elem_id="video-output")
- submit_btn = gr.Button("Generate Pix2Pix video")
-
- with gr.Group(elem_id="share-btn-container", visible=False) as share_group:
- community_icon = gr.HTML(community_icon_html)
- loading_icon = gr.HTML(loading_icon_html)
- share_button = gr.Button("Share to community", elem_id="share-btn")
- gr.HTML(article)
-
- inputs = [prompt,video_inp,seed_inp, trim_in]
- outputs = [video_out, share_group]
-
- submit_btn.click(infer, inputs, outputs)
- share_button.click(None, [], [], _js=share_js)
-
-demo.launch().queue(max_size=12)
diff --git a/spaces/ajitrajasekharan/self-supervised-ner-biomedical/config_utils.py b/spaces/ajitrajasekharan/self-supervised-ner-biomedical/config_utils.py
deleted file mode 100644
index 9da4338c0cd8807bb5f87b36f6e05dba0685ab71..0000000000000000000000000000000000000000
--- a/spaces/ajitrajasekharan/self-supervised-ner-biomedical/config_utils.py
+++ /dev/null
@@ -1,19 +0,0 @@
-import json
-
-
-
-def write_config(configs,file_name='server_config.json'):
- print(json.dumps(configs))
- with open(file_name, 'w') as outfile:
- json.dump(configs, outfile)
-
-
-def read_config(file_name='server_config.json'):
- try:
- with open(file_name) as json_file:
- data = json.load(json_file)
- #print(data)
- return data
- except:
- print("Unable to open config file:",file_name)
- return {}
diff --git a/spaces/akhaliq/Music_Source_Separation/scripts/0_download_datasets/instruments.sh b/spaces/akhaliq/Music_Source_Separation/scripts/0_download_datasets/instruments.sh
deleted file mode 100644
index a848adbe45957923c47bc3047c33958a1421c8f6..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/Music_Source_Separation/scripts/0_download_datasets/instruments.sh
+++ /dev/null
@@ -1,43 +0,0 @@
-#!/bin/bash
-
-echo "The dataset link is created internally by kqq"
-
-# The downloaded MAESTRO dataset looks like:
-# ./datasets/instruments
-# ├── violin_solo
-# │ └── v0.1
-# │ ├── mp3s (12 files)
-# │ │ ├── 0jXXWBt5URw.mp3
-# │ │ └── ...
-# │ ├── README.txt
-# │ └── validation.csv
-# ├── basson_solo
-# │ └── ...
-# ├── cello_solo
-# │ └── ...
-# ├── clarinet_solo
-# │ └── ...
-# ├── flute_solo
-# │ └── ...
-# ├── harp_solo
-# │ └── ...
-# ├── horn_solo
-# │ └── ...
-# ├── oboe_solo
-# │ └── ...
-# ├── saxophone_solo
-# │ └── ...
-# ├── string_quartet
-# │ └── ...
-# ├── symphony_solo
-# │ └── ...
-# ├── timpani_solo
-# │ └── ...
-# ├── trombone_solo
-# │ └── ...
-# ├── trumpet_solo
-# │ └── ...
-# ├── tuba_solo
-# │ └── ...
-# └── viola_solo
-# └── ...
\ No newline at end of file
diff --git a/spaces/akhaliq/deeplab2/model/decoder/max_deeplab.py b/spaces/akhaliq/deeplab2/model/decoder/max_deeplab.py
deleted file mode 100644
index b8c61a09a8445fe6406806bdabb4b0b932dd6f23..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/deeplab2/model/decoder/max_deeplab.py
+++ /dev/null
@@ -1,328 +0,0 @@
-# coding=utf-8
-# Copyright 2021 The Deeplab2 Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""This file contains code to build MaX-DeepLab output heads.
-
-Reference:
- MaX-DeepLab: "End-to-End Panoptic Segmentation with Mask Transformers",
- CVPR 2021. https://arxiv.org/abs/2012.00759
- Huiyu Wang, Yukun Zhu, Hartwig Adam, Alan Yuille, Liang-Chieh Chen.
-"""
-import math
-
-import tensorflow as tf
-
-from deeplab2 import common
-from deeplab2.model.decoder import panoptic_deeplab
-from deeplab2.model.layers import convolutions
-
-_PIXEL_SPACE_FEATURE_KEY = 'pixel_space_feature'
-
-
-def _get_transformer_class_head_num_classes(
- auxiliary_semantic_head_output_channels,
- ignore_label):
- """Computes the num of classes for the transformer class head.
-
- The transformer class head predicts non-void classes (i.e., thing classes and
- stuff classes) and a void (i.e., ∅, no object) class. If the auxiliary
- semantic head output channel includes the void class, e.g., on COCO, we
- directly use the semantic output channel. Otherwise, e.g., on Cityscapes, we
- add 1 (the void class) to the transformer class head.
-
- Args:
- auxiliary_semantic_head_output_channels: An integer, the number of output
- channels of the auxiliary semantic head (it should be the same as the
- num_classes field of the dataset information).
- ignore_label: An integer specifying the ignore label. Default to 255.
-
- Returns:
- num_classes: An integer, the num of classes for the transformer class head.
- """
- if ignore_label >= auxiliary_semantic_head_output_channels:
- return auxiliary_semantic_head_output_channels + 1
- else:
- return auxiliary_semantic_head_output_channels
-
-
-def add_bias_towards_void(transformer_class_logits, void_prior_prob=0.9):
- """Adds init bias towards the void (no object) class to the class logits.
-
- We initialize the void class with a large probability, similar to Section 3.3
- of the Focal Loss paper.
-
- Reference:
- Focal Loss for Dense Object Detection, ICCV 2017.
- https://arxiv.org/abs/1708.02002
- Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár.
-
- Args:
- transformer_class_logits: A [batch, num_mask_slots, num_classes] tensor, the
- class logits predicted by the transformer. It concats (num_classes - 1)
- non-void classes, including both thing classes and stuff classes, and the
- void class (the last channel). If the dataset class IDs do not follow this
- order, MaX-DeepLab loss functions will handle the mapping and thus the
- architecture still supports any dataset.
- void_prior_prob: A float, the desired probability (after softmax) of the
- void class at initialization. Defaults to 0.9 as in MaX-DeepLab.
-
- Returns:
- updated_transformer_class_logits: A [batch, num_mask_slots, num_classes]
-
- Raises:
- ValueError: If the rank of transformer_class_logits is not 3.
- """
- class_logits_shape = transformer_class_logits.get_shape().as_list()
- if len(class_logits_shape) != 3:
- raise ValueError('Input transformer_class_logits should have rank 3.')
-
- init_bias = [0.0] * class_logits_shape[-1]
- init_bias[-1] = math.log(
- (class_logits_shape[-1] - 1) * void_prior_prob / (1 - void_prior_prob))
-
- # Broadcasting the 1D init_bias to the 3D transformer_class_logits.
- return transformer_class_logits + tf.constant(init_bias, dtype=tf.float32)
-
-
-def batch_norm_on_an_extra_axis(inputs, bn_layer):
- """Applies a batch norm layer on an extra axis.
-
- This batch norm will be used on the pixel space mask logits in MaX-DeepLab to
- avoid careful initialization of previous layers and careful scaling of the
- resulting outputs. In addition, applying batch norm on an extra axis does not
- introduce an extra gamma and beta for each mask slot. Instead, the current
- gamma and beta are shared for all mask slots and do not introduce biases on
- mask slots.
-
- Args:
- inputs: A [batch, height, width, num_mask_slots] tensor.
- bn_layer: A batch norm tf.keras.layers.Layer on the last axis.
-
- Returns:
- outputs: A [batch, height, width, num_mask_slots] tensor.
- """
- expanded_inputs = tf.expand_dims(inputs, axis=-1)
- outputs = bn_layer(expanded_inputs)
- return tf.squeeze(outputs, axis=-1)
-
-
-class MaXDeepLab(tf.keras.layers.Layer):
- """A MaX-DeepLab head layer."""
-
- def __init__(self,
- decoder_options,
- max_deeplab_options,
- ignore_label,
- bn_layer=tf.keras.layers.BatchNormalization):
- """Initializes a MaX-DeepLab head.
-
- Args:
- decoder_options: Decoder options as defined in config_pb2.DecoderOptions.
- max_deeplab_options: Model options as defined in
- config_pb2.ModelOptions.MaXDeepLabOptions.
- ignore_label: An integer specifying the ignore label.
- bn_layer: An optional tf.keras.layers.Layer that computes the
- normalization (default: tf.keras.layers.BatchNormalization).
- """
- super(MaXDeepLab, self).__init__(name='MaXDeepLab')
-
- low_level_feature_keys = [
- item.feature_key for item in max_deeplab_options.auxiliary_low_level
- ]
- low_level_channels_project = [
- item.channels_project
- for item in max_deeplab_options.auxiliary_low_level
- ]
-
- self._auxiliary_semantic_decoder = (
- panoptic_deeplab.PanopticDeepLabSingleDecoder(
- high_level_feature_name=decoder_options.feature_key,
- low_level_feature_names=low_level_feature_keys,
- low_level_channels_project=low_level_channels_project,
- aspp_output_channels=decoder_options.aspp_channels,
- decoder_output_channels=decoder_options.decoder_channels,
- atrous_rates=decoder_options.atrous_rates,
- name='auxiliary_semantic_decoder',
- aspp_use_only_1x1_proj_conv=decoder_options
- .aspp_use_only_1x1_proj_conv,
- decoder_conv_type=decoder_options.decoder_conv_type,
- bn_layer=bn_layer))
- self._auxiliary_semantic_head = panoptic_deeplab.PanopticDeepLabSingleHead(
- max_deeplab_options.auxiliary_semantic_head.head_channels,
- max_deeplab_options.auxiliary_semantic_head.output_channels,
- common.PRED_SEMANTIC_LOGITS_KEY,
- name='auxiliary_semantic_head',
- conv_type=max_deeplab_options.auxiliary_semantic_head.head_conv_type,
- bn_layer=bn_layer)
- self._pixel_space_head = panoptic_deeplab.PanopticDeepLabSingleHead(
- max_deeplab_options.pixel_space_head.head_channels,
- max_deeplab_options.pixel_space_head.output_channels,
- _PIXEL_SPACE_FEATURE_KEY,
- name='pixel_space_head',
- conv_type=max_deeplab_options.pixel_space_head.head_conv_type,
- bn_layer=bn_layer)
-
- self._transformer_mask_head = convolutions.Conv1D(
- output_channels=max_deeplab_options.pixel_space_head.output_channels,
- name='transformer_mask_head',
- use_bias=False,
- # Use bn to avoid careful initialization.
- use_bn=True,
- bn_layer=bn_layer,
- bn_gamma_initializer='ones',
- activation=None,
- kernel_initializer='he_normal',
- kernel_size=1,
- padding='valid')
- # The transformer class head predicts non-void classes (i.e., thing classes
- # and stuff classes) and a void (i.e., ∅, no object) class.
- num_classes = _get_transformer_class_head_num_classes(
- max_deeplab_options.auxiliary_semantic_head.output_channels,
- ignore_label=ignore_label)
- self._transformer_class_head = convolutions.Conv1D(
- output_channels=num_classes,
- name='transformer_class_head',
- # Use conv bias rather than bn on this final class logit output.
- use_bias=True,
- use_bn=False,
- activation=None,
- # Follow common ImageNet class initlization with stddev 0.01.
- kernel_initializer=tf.keras.initializers.TruncatedNormal(stddev=0.01),
- kernel_size=1,
- padding='valid')
-
- self._pixel_space_feature_batch_norm = bn_layer(
- axis=-1, name='pixel_space_feature_batch_norm',
- gamma_initializer=tf.keras.initializers.Constant(1.0))
- # Use a batch norm to avoid care initialization of the mask outputs.
- self._pixel_space_mask_batch_norm = bn_layer(
- axis=-1, name='pixel_space_mask_batch_norm',
- # Initialize the pixel space mask with a low temperature.
- gamma_initializer=tf.keras.initializers.Constant(0.1))
-
- def reset_pooling_layer(self):
- """Resets the ASPP pooling layers to global average pooling."""
- self._auxiliary_semantic_decoder.reset_pooling_layer()
-
- def set_pool_size(self, pool_size):
- """Sets the pooling size of the ASPP pooling layers.
-
- Args:
- pool_size: A tuple specifying the pooling size of the ASPP pooling layers.
- """
- self._auxiliary_semantic_decoder.set_pool_size(pool_size)
-
- def get_pool_size(self):
- return self._auxiliary_semantic_decoder.get_pool_size()
-
- @property
- def checkpoint_items(self):
- items = {
- common.CKPT_SEMANTIC_DECODER:
- self._auxiliary_semantic_decoder,
- common.CKPT_SEMANTIC_HEAD_WITHOUT_LAST_LAYER:
- self._auxiliary_semantic_head.conv_block,
- common.CKPT_SEMANTIC_LAST_LAYER:
- self._auxiliary_semantic_head.final_conv,
- common.CKPT_PIXEL_SPACE_HEAD:
- self._pixel_space_head,
- common.CKPT_TRANSFORMER_MASK_HEAD:
- self._transformer_mask_head,
- common.CKPT_TRANSFORMER_CLASS_HEAD:
- self._transformer_class_head,
- common.CKPT_PIXEL_SPACE_FEATURE_BATCH_NORM:
- self._pixel_space_feature_batch_norm,
- common.CKPT_PIXEL_SPACE_MASK_BATCH_NORM:
- self._pixel_space_mask_batch_norm,
- }
- return items
-
- def call(self, features, training=False):
- """Performs a forward pass.
-
- Args:
- features: An input dict of tf.Tensor with shape [batch, height, width,
- channels] or [batch, length, channels]. Different keys should point to
- different features extracted by the encoder, e.g., low-level or
- high-level features.
- training: A boolean flag indicating whether training behavior should be
- used (default: False).
-
- Returns:
- A dictionary containing the auxiliary semantic segmentation logits, the
- pixel space normalized feature, the pixel space mask logits, and the
- mask transformer class logits.
- """
- results = {}
- semantic_features = features['feature_semantic']
- panoptic_features = features['feature_panoptic']
- transformer_class_feature = features['transformer_class_feature']
- transformer_mask_feature = features['transformer_mask_feature']
-
- # Auxiliary semantic head.
- semantic_shape = semantic_features.get_shape().as_list()
- panoptic_shape = panoptic_features.get_shape().as_list()
- # MaX-DeepLab always predicts panoptic feature at high resolution (e.g.,
- # stride 4 or stride 2), but the auxiliary semantic feature could be at low
- # resolution (e.g., stride 16 or stride 32), in the absence of the stacked
- # decoder (L == 0). In this case, we use an auxiliary semantic decoder on
- # top of the semantic feature, in order to add the auxiliary semantic loss.
- if semantic_shape[1:3] != panoptic_shape[1:3]:
- semantic_features = self._auxiliary_semantic_decoder(
- features, training=training)
- auxiliary_semantic_results = self._auxiliary_semantic_head(
- semantic_features, training=training)
- results.update(auxiliary_semantic_results)
-
- # Pixel space head.
- pixel_space_feature = self._pixel_space_head(
- panoptic_features, training=training)[_PIXEL_SPACE_FEATURE_KEY]
- pixel_space_feature = self._pixel_space_feature_batch_norm(
- pixel_space_feature)
- pixel_space_normalized_feature = tf.math.l2_normalize(
- pixel_space_feature, axis=-1)
- results[common.PRED_PIXEL_SPACE_NORMALIZED_FEATURE_KEY] = (
- pixel_space_normalized_feature)
-
- # Transformer class head.
- transformer_class_logits = self._transformer_class_head(
- transformer_class_feature)
- # Bias towards the void class at initialization.
- transformer_class_logits = add_bias_towards_void(
- transformer_class_logits)
- results[common.PRED_TRANSFORMER_CLASS_LOGITS_KEY] = transformer_class_logits
-
- # Transformer mask kernel.
- transformer_mask_kernel = self._transformer_mask_head(
- transformer_mask_feature)
-
- # Convolutional mask head. The pixel space mask logits are the matrix
- # multiplication (or convolution) of the pixel space normalized feature and
- # the transformer mask kernel.
- pixel_space_mask_logits = tf.einsum(
- 'bhwd,bid->bhwi',
- pixel_space_normalized_feature,
- transformer_mask_kernel)
- # The above multiplication constructs a second-order operation which is
- # sensitive to the feature scales and initializations. In order to avoid
- # careful initialization or scaling of the layers, we apply batch norms on
- # top of pixel_space_feature, transformer_mask_kernel, and the resulting
- # pixel_space_mask_logits.
- pixel_space_mask_logits = batch_norm_on_an_extra_axis(
- pixel_space_mask_logits, self._pixel_space_mask_batch_norm)
- results[common.PRED_PIXEL_SPACE_MASK_LOGITS_KEY] = (
- pixel_space_mask_logits)
-
- return results
diff --git a/spaces/akiraaaaaa/Waifu-Reina/app.py b/spaces/akiraaaaaa/Waifu-Reina/app.py
deleted file mode 100644
index 2032909e87a2c54b44986bd8931edb6791757383..0000000000000000000000000000000000000000
--- a/spaces/akiraaaaaa/Waifu-Reina/app.py
+++ /dev/null
@@ -1,185 +0,0 @@
-import os
-import json
-import argparse
-import traceback
-import logging
-import gradio as gr
-import numpy as np
-import librosa
-import torch
-import asyncio
-import edge_tts
-from datetime import datetime
-from fairseq import checkpoint_utils
-from infer_pack.models import SynthesizerTrnMs256NSFsid, SynthesizerTrnMs256NSFsid_nono
-from vc_infer_pipeline import VC
-from config import (
- is_half,
- device
-)
-logging.getLogger("numba").setLevel(logging.WARNING)
-limitation = os.getenv("SYSTEM") == "spaces" # limit audio length in huggingface spaces
-
-def create_vc_fn(tgt_sr, net_g, vc, if_f0, file_index, file_big_npy):
- def vc_fn(
- input_audio,
- f0_up_key,
- f0_method,
- index_rate,
- tts_mode,
- tts_text,
- tts_voice
- ):
- try:
- if tts_mode:
- if len(tts_text) > 500 and limitation:
- return "Text is too long", None
- if tts_text is None or tts_voice is None:
- return "You need to enter text and select a voice", None
- asyncio.run(edge_tts.Communicate(tts_text, "-".join(tts_voice.split('-')[:-1])).save("tts.mp3"))
- audio, sr = librosa.load("tts.mp3", sr=16000, mono=True)
- else:
- if args.files:
- audio, sr = librosa.load(input_audio, sr=16000, mono=True)
- else:
- if input_audio is None:
- return "You need to upload an audio", None
- sampling_rate, audio = input_audio
- duration = audio.shape[0] / sampling_rate
- if duration > 300 and limitation:
- return "Please upload an audio file that is less than 5 minutes 30 seconds.", None
- audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32)
- if len(audio.shape) > 1:
- audio = librosa.to_mono(audio.transpose(1, 0))
- if sampling_rate != 16000:
- audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000)
- times = [0, 0, 0]
- f0_up_key = int(f0_up_key)
- audio_opt = vc.pipeline(
- hubert_model,
- net_g,
- 0,
- audio,
- times,
- f0_up_key,
- f0_method,
- file_index,
- file_big_npy,
- index_rate,
- if_f0,
- )
- print(
- f"[{datetime.now().strftime('%Y-%m-%d %H:%M')}]: npy: {times[0]}, f0: {times[1]}s, infer: {times[2]}s"
- )
- return "Success", (tgt_sr, audio_opt)
- except:
- info = traceback.format_exc()
- print(info)
- return info, (None, None)
- return vc_fn
-
-def load_hubert():
- global hubert_model
- models, _, _ = checkpoint_utils.load_model_ensemble_and_task(
- ["hubert_base.pt"],
- suffix="",
- )
- hubert_model = models[0]
- hubert_model = hubert_model.to(device)
- if is_half:
- hubert_model = hubert_model.half()
- else:
- hubert_model = hubert_model.float()
- hubert_model.eval()
-
-def change_to_tts_mode(tts_mode):
- if tts_mode:
- return gr.Audio.update(visible=False), gr.Textbox.update(visible=True), gr.Dropdown.update(visible=True)
- else:
- return gr.Audio.update(visible=True), gr.Textbox.update(visible=False), gr.Dropdown.update(visible=False)
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--api', action="store_true", default=False)
- parser.add_argument("--share", action="store_true", default=False, help="share gradio app")
- parser.add_argument("--files", action="store_true", default=False, help="load audio from path")
- args, unknown = parser.parse_known_args()
- load_hubert()
- models = []
- tts_voice_list = asyncio.get_event_loop().run_until_complete(edge_tts.list_voices())
- voices = [f"{v['ShortName']}-{v['Gender']}" for v in tts_voice_list]
- with open("weights/model_info.json", "r", encoding="utf-8") as f:
- models_info = json.load(f)
- for name, info in models_info.items():
- if not info['enable']:
- continue
- title = info['title']
- author = info.get("author", None)
- cover = f"weights/{name}/{info['cover']}"
- index = f"weights/{name}/{info['feature_retrieval_library']}"
- npy = f"weights/{name}/{info['feature_file']}"
- cpt = torch.load(f"weights/{name}/{name}.pth", map_location="cpu")
- tgt_sr = cpt["config"][-1]
- cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0] # n_spk
- if_f0 = cpt.get("f0", 1)
- if if_f0 == 1:
- net_g = SynthesizerTrnMs256NSFsid(*cpt["config"], is_half=is_half)
- else:
- net_g = SynthesizerTrnMs256NSFsid_nono(*cpt["config"])
- del net_g.enc_q
- print(net_g.load_state_dict(cpt["weight"], strict=False)) # 不加这一行清不干净, 真奇葩
- net_g.eval().to(device)
- if is_half:
- net_g = net_g.half()
- else:
- net_g = net_g.float()
- vc = VC(tgt_sr, device, is_half)
- models.append((name, title, author, cover, create_vc_fn(tgt_sr, net_g, vc, if_f0, index, npy)))
- with gr.Blocks() as app:
- gr.Markdown(
- "# Reina-Models\n"
- "## The input audio should be clean and pure voice without background music.\n"
- "[](https://colab.research.google.com/github/aziib/Create-Google-Shared-Drive/blob/master/Hololive-RVC-Models.ipynb)\n\n"
- "[](https://ko-fi.com/megaaziib)\n\n"
- )
- with gr.Tabs():
- for (name, title, author, cover, vc_fn) in models:
- with gr.TabItem(name):
- with gr.Row():
- gr.Markdown(
- '
- """, elem_id="duplicate-container")
- video_out = gr.Video(label="Pix2pix video result", elem_id="video-output")
- submit_btn = gr.Button("Generate Pix2Pix video")
-
- with gr.Group(elem_id="share-btn-container", visible=False) as share_group:
- community_icon = gr.HTML(community_icon_html)
- loading_icon = gr.HTML(loading_icon_html)
- share_button = gr.Button("Share to community", elem_id="share-btn")
- gr.HTML(article)
-
- inputs = [prompt,video_inp,seed_inp, trim_in]
- outputs = [video_out, share_group]
-
- submit_btn.click(infer, inputs, outputs)
- share_button.click(None, [], [], _js=share_js)
-
-demo.launch().queue(max_size=12)
diff --git a/spaces/ajitrajasekharan/self-supervised-ner-biomedical/config_utils.py b/spaces/ajitrajasekharan/self-supervised-ner-biomedical/config_utils.py
deleted file mode 100644
index 9da4338c0cd8807bb5f87b36f6e05dba0685ab71..0000000000000000000000000000000000000000
--- a/spaces/ajitrajasekharan/self-supervised-ner-biomedical/config_utils.py
+++ /dev/null
@@ -1,19 +0,0 @@
-import json
-
-
-
-def write_config(configs,file_name='server_config.json'):
- print(json.dumps(configs))
- with open(file_name, 'w') as outfile:
- json.dump(configs, outfile)
-
-
-def read_config(file_name='server_config.json'):
- try:
- with open(file_name) as json_file:
- data = json.load(json_file)
- #print(data)
- return data
- except:
- print("Unable to open config file:",file_name)
- return {}
diff --git a/spaces/akhaliq/Music_Source_Separation/scripts/0_download_datasets/instruments.sh b/spaces/akhaliq/Music_Source_Separation/scripts/0_download_datasets/instruments.sh
deleted file mode 100644
index a848adbe45957923c47bc3047c33958a1421c8f6..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/Music_Source_Separation/scripts/0_download_datasets/instruments.sh
+++ /dev/null
@@ -1,43 +0,0 @@
-#!/bin/bash
-
-echo "The dataset link is created internally by kqq"
-
-# The downloaded MAESTRO dataset looks like:
-# ./datasets/instruments
-# ├── violin_solo
-# │ └── v0.1
-# │ ├── mp3s (12 files)
-# │ │ ├── 0jXXWBt5URw.mp3
-# │ │ └── ...
-# │ ├── README.txt
-# │ └── validation.csv
-# ├── basson_solo
-# │ └── ...
-# ├── cello_solo
-# │ └── ...
-# ├── clarinet_solo
-# │ └── ...
-# ├── flute_solo
-# │ └── ...
-# ├── harp_solo
-# │ └── ...
-# ├── horn_solo
-# │ └── ...
-# ├── oboe_solo
-# │ └── ...
-# ├── saxophone_solo
-# │ └── ...
-# ├── string_quartet
-# │ └── ...
-# ├── symphony_solo
-# │ └── ...
-# ├── timpani_solo
-# │ └── ...
-# ├── trombone_solo
-# │ └── ...
-# ├── trumpet_solo
-# │ └── ...
-# ├── tuba_solo
-# │ └── ...
-# └── viola_solo
-# └── ...
\ No newline at end of file
diff --git a/spaces/akhaliq/deeplab2/model/decoder/max_deeplab.py b/spaces/akhaliq/deeplab2/model/decoder/max_deeplab.py
deleted file mode 100644
index b8c61a09a8445fe6406806bdabb4b0b932dd6f23..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/deeplab2/model/decoder/max_deeplab.py
+++ /dev/null
@@ -1,328 +0,0 @@
-# coding=utf-8
-# Copyright 2021 The Deeplab2 Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""This file contains code to build MaX-DeepLab output heads.
-
-Reference:
- MaX-DeepLab: "End-to-End Panoptic Segmentation with Mask Transformers",
- CVPR 2021. https://arxiv.org/abs/2012.00759
- Huiyu Wang, Yukun Zhu, Hartwig Adam, Alan Yuille, Liang-Chieh Chen.
-"""
-import math
-
-import tensorflow as tf
-
-from deeplab2 import common
-from deeplab2.model.decoder import panoptic_deeplab
-from deeplab2.model.layers import convolutions
-
-_PIXEL_SPACE_FEATURE_KEY = 'pixel_space_feature'
-
-
-def _get_transformer_class_head_num_classes(
- auxiliary_semantic_head_output_channels,
- ignore_label):
- """Computes the num of classes for the transformer class head.
-
- The transformer class head predicts non-void classes (i.e., thing classes and
- stuff classes) and a void (i.e., ∅, no object) class. If the auxiliary
- semantic head output channel includes the void class, e.g., on COCO, we
- directly use the semantic output channel. Otherwise, e.g., on Cityscapes, we
- add 1 (the void class) to the transformer class head.
-
- Args:
- auxiliary_semantic_head_output_channels: An integer, the number of output
- channels of the auxiliary semantic head (it should be the same as the
- num_classes field of the dataset information).
- ignore_label: An integer specifying the ignore label. Default to 255.
-
- Returns:
- num_classes: An integer, the num of classes for the transformer class head.
- """
- if ignore_label >= auxiliary_semantic_head_output_channels:
- return auxiliary_semantic_head_output_channels + 1
- else:
- return auxiliary_semantic_head_output_channels
-
-
-def add_bias_towards_void(transformer_class_logits, void_prior_prob=0.9):
- """Adds init bias towards the void (no object) class to the class logits.
-
- We initialize the void class with a large probability, similar to Section 3.3
- of the Focal Loss paper.
-
- Reference:
- Focal Loss for Dense Object Detection, ICCV 2017.
- https://arxiv.org/abs/1708.02002
- Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár.
-
- Args:
- transformer_class_logits: A [batch, num_mask_slots, num_classes] tensor, the
- class logits predicted by the transformer. It concats (num_classes - 1)
- non-void classes, including both thing classes and stuff classes, and the
- void class (the last channel). If the dataset class IDs do not follow this
- order, MaX-DeepLab loss functions will handle the mapping and thus the
- architecture still supports any dataset.
- void_prior_prob: A float, the desired probability (after softmax) of the
- void class at initialization. Defaults to 0.9 as in MaX-DeepLab.
-
- Returns:
- updated_transformer_class_logits: A [batch, num_mask_slots, num_classes]
-
- Raises:
- ValueError: If the rank of transformer_class_logits is not 3.
- """
- class_logits_shape = transformer_class_logits.get_shape().as_list()
- if len(class_logits_shape) != 3:
- raise ValueError('Input transformer_class_logits should have rank 3.')
-
- init_bias = [0.0] * class_logits_shape[-1]
- init_bias[-1] = math.log(
- (class_logits_shape[-1] - 1) * void_prior_prob / (1 - void_prior_prob))
-
- # Broadcasting the 1D init_bias to the 3D transformer_class_logits.
- return transformer_class_logits + tf.constant(init_bias, dtype=tf.float32)
-
-
-def batch_norm_on_an_extra_axis(inputs, bn_layer):
- """Applies a batch norm layer on an extra axis.
-
- This batch norm will be used on the pixel space mask logits in MaX-DeepLab to
- avoid careful initialization of previous layers and careful scaling of the
- resulting outputs. In addition, applying batch norm on an extra axis does not
- introduce an extra gamma and beta for each mask slot. Instead, the current
- gamma and beta are shared for all mask slots and do not introduce biases on
- mask slots.
-
- Args:
- inputs: A [batch, height, width, num_mask_slots] tensor.
- bn_layer: A batch norm tf.keras.layers.Layer on the last axis.
-
- Returns:
- outputs: A [batch, height, width, num_mask_slots] tensor.
- """
- expanded_inputs = tf.expand_dims(inputs, axis=-1)
- outputs = bn_layer(expanded_inputs)
- return tf.squeeze(outputs, axis=-1)
-
-
-class MaXDeepLab(tf.keras.layers.Layer):
- """A MaX-DeepLab head layer."""
-
- def __init__(self,
- decoder_options,
- max_deeplab_options,
- ignore_label,
- bn_layer=tf.keras.layers.BatchNormalization):
- """Initializes a MaX-DeepLab head.
-
- Args:
- decoder_options: Decoder options as defined in config_pb2.DecoderOptions.
- max_deeplab_options: Model options as defined in
- config_pb2.ModelOptions.MaXDeepLabOptions.
- ignore_label: An integer specifying the ignore label.
- bn_layer: An optional tf.keras.layers.Layer that computes the
- normalization (default: tf.keras.layers.BatchNormalization).
- """
- super(MaXDeepLab, self).__init__(name='MaXDeepLab')
-
- low_level_feature_keys = [
- item.feature_key for item in max_deeplab_options.auxiliary_low_level
- ]
- low_level_channels_project = [
- item.channels_project
- for item in max_deeplab_options.auxiliary_low_level
- ]
-
- self._auxiliary_semantic_decoder = (
- panoptic_deeplab.PanopticDeepLabSingleDecoder(
- high_level_feature_name=decoder_options.feature_key,
- low_level_feature_names=low_level_feature_keys,
- low_level_channels_project=low_level_channels_project,
- aspp_output_channels=decoder_options.aspp_channels,
- decoder_output_channels=decoder_options.decoder_channels,
- atrous_rates=decoder_options.atrous_rates,
- name='auxiliary_semantic_decoder',
- aspp_use_only_1x1_proj_conv=decoder_options
- .aspp_use_only_1x1_proj_conv,
- decoder_conv_type=decoder_options.decoder_conv_type,
- bn_layer=bn_layer))
- self._auxiliary_semantic_head = panoptic_deeplab.PanopticDeepLabSingleHead(
- max_deeplab_options.auxiliary_semantic_head.head_channels,
- max_deeplab_options.auxiliary_semantic_head.output_channels,
- common.PRED_SEMANTIC_LOGITS_KEY,
- name='auxiliary_semantic_head',
- conv_type=max_deeplab_options.auxiliary_semantic_head.head_conv_type,
- bn_layer=bn_layer)
- self._pixel_space_head = panoptic_deeplab.PanopticDeepLabSingleHead(
- max_deeplab_options.pixel_space_head.head_channels,
- max_deeplab_options.pixel_space_head.output_channels,
- _PIXEL_SPACE_FEATURE_KEY,
- name='pixel_space_head',
- conv_type=max_deeplab_options.pixel_space_head.head_conv_type,
- bn_layer=bn_layer)
-
- self._transformer_mask_head = convolutions.Conv1D(
- output_channels=max_deeplab_options.pixel_space_head.output_channels,
- name='transformer_mask_head',
- use_bias=False,
- # Use bn to avoid careful initialization.
- use_bn=True,
- bn_layer=bn_layer,
- bn_gamma_initializer='ones',
- activation=None,
- kernel_initializer='he_normal',
- kernel_size=1,
- padding='valid')
- # The transformer class head predicts non-void classes (i.e., thing classes
- # and stuff classes) and a void (i.e., ∅, no object) class.
- num_classes = _get_transformer_class_head_num_classes(
- max_deeplab_options.auxiliary_semantic_head.output_channels,
- ignore_label=ignore_label)
- self._transformer_class_head = convolutions.Conv1D(
- output_channels=num_classes,
- name='transformer_class_head',
- # Use conv bias rather than bn on this final class logit output.
- use_bias=True,
- use_bn=False,
- activation=None,
- # Follow common ImageNet class initlization with stddev 0.01.
- kernel_initializer=tf.keras.initializers.TruncatedNormal(stddev=0.01),
- kernel_size=1,
- padding='valid')
-
- self._pixel_space_feature_batch_norm = bn_layer(
- axis=-1, name='pixel_space_feature_batch_norm',
- gamma_initializer=tf.keras.initializers.Constant(1.0))
- # Use a batch norm to avoid care initialization of the mask outputs.
- self._pixel_space_mask_batch_norm = bn_layer(
- axis=-1, name='pixel_space_mask_batch_norm',
- # Initialize the pixel space mask with a low temperature.
- gamma_initializer=tf.keras.initializers.Constant(0.1))
-
- def reset_pooling_layer(self):
- """Resets the ASPP pooling layers to global average pooling."""
- self._auxiliary_semantic_decoder.reset_pooling_layer()
-
- def set_pool_size(self, pool_size):
- """Sets the pooling size of the ASPP pooling layers.
-
- Args:
- pool_size: A tuple specifying the pooling size of the ASPP pooling layers.
- """
- self._auxiliary_semantic_decoder.set_pool_size(pool_size)
-
- def get_pool_size(self):
- return self._auxiliary_semantic_decoder.get_pool_size()
-
- @property
- def checkpoint_items(self):
- items = {
- common.CKPT_SEMANTIC_DECODER:
- self._auxiliary_semantic_decoder,
- common.CKPT_SEMANTIC_HEAD_WITHOUT_LAST_LAYER:
- self._auxiliary_semantic_head.conv_block,
- common.CKPT_SEMANTIC_LAST_LAYER:
- self._auxiliary_semantic_head.final_conv,
- common.CKPT_PIXEL_SPACE_HEAD:
- self._pixel_space_head,
- common.CKPT_TRANSFORMER_MASK_HEAD:
- self._transformer_mask_head,
- common.CKPT_TRANSFORMER_CLASS_HEAD:
- self._transformer_class_head,
- common.CKPT_PIXEL_SPACE_FEATURE_BATCH_NORM:
- self._pixel_space_feature_batch_norm,
- common.CKPT_PIXEL_SPACE_MASK_BATCH_NORM:
- self._pixel_space_mask_batch_norm,
- }
- return items
-
- def call(self, features, training=False):
- """Performs a forward pass.
-
- Args:
- features: An input dict of tf.Tensor with shape [batch, height, width,
- channels] or [batch, length, channels]. Different keys should point to
- different features extracted by the encoder, e.g., low-level or
- high-level features.
- training: A boolean flag indicating whether training behavior should be
- used (default: False).
-
- Returns:
- A dictionary containing the auxiliary semantic segmentation logits, the
- pixel space normalized feature, the pixel space mask logits, and the
- mask transformer class logits.
- """
- results = {}
- semantic_features = features['feature_semantic']
- panoptic_features = features['feature_panoptic']
- transformer_class_feature = features['transformer_class_feature']
- transformer_mask_feature = features['transformer_mask_feature']
-
- # Auxiliary semantic head.
- semantic_shape = semantic_features.get_shape().as_list()
- panoptic_shape = panoptic_features.get_shape().as_list()
- # MaX-DeepLab always predicts panoptic feature at high resolution (e.g.,
- # stride 4 or stride 2), but the auxiliary semantic feature could be at low
- # resolution (e.g., stride 16 or stride 32), in the absence of the stacked
- # decoder (L == 0). In this case, we use an auxiliary semantic decoder on
- # top of the semantic feature, in order to add the auxiliary semantic loss.
- if semantic_shape[1:3] != panoptic_shape[1:3]:
- semantic_features = self._auxiliary_semantic_decoder(
- features, training=training)
- auxiliary_semantic_results = self._auxiliary_semantic_head(
- semantic_features, training=training)
- results.update(auxiliary_semantic_results)
-
- # Pixel space head.
- pixel_space_feature = self._pixel_space_head(
- panoptic_features, training=training)[_PIXEL_SPACE_FEATURE_KEY]
- pixel_space_feature = self._pixel_space_feature_batch_norm(
- pixel_space_feature)
- pixel_space_normalized_feature = tf.math.l2_normalize(
- pixel_space_feature, axis=-1)
- results[common.PRED_PIXEL_SPACE_NORMALIZED_FEATURE_KEY] = (
- pixel_space_normalized_feature)
-
- # Transformer class head.
- transformer_class_logits = self._transformer_class_head(
- transformer_class_feature)
- # Bias towards the void class at initialization.
- transformer_class_logits = add_bias_towards_void(
- transformer_class_logits)
- results[common.PRED_TRANSFORMER_CLASS_LOGITS_KEY] = transformer_class_logits
-
- # Transformer mask kernel.
- transformer_mask_kernel = self._transformer_mask_head(
- transformer_mask_feature)
-
- # Convolutional mask head. The pixel space mask logits are the matrix
- # multiplication (or convolution) of the pixel space normalized feature and
- # the transformer mask kernel.
- pixel_space_mask_logits = tf.einsum(
- 'bhwd,bid->bhwi',
- pixel_space_normalized_feature,
- transformer_mask_kernel)
- # The above multiplication constructs a second-order operation which is
- # sensitive to the feature scales and initializations. In order to avoid
- # careful initialization or scaling of the layers, we apply batch norms on
- # top of pixel_space_feature, transformer_mask_kernel, and the resulting
- # pixel_space_mask_logits.
- pixel_space_mask_logits = batch_norm_on_an_extra_axis(
- pixel_space_mask_logits, self._pixel_space_mask_batch_norm)
- results[common.PRED_PIXEL_SPACE_MASK_LOGITS_KEY] = (
- pixel_space_mask_logits)
-
- return results
diff --git a/spaces/akiraaaaaa/Waifu-Reina/app.py b/spaces/akiraaaaaa/Waifu-Reina/app.py
deleted file mode 100644
index 2032909e87a2c54b44986bd8931edb6791757383..0000000000000000000000000000000000000000
--- a/spaces/akiraaaaaa/Waifu-Reina/app.py
+++ /dev/null
@@ -1,185 +0,0 @@
-import os
-import json
-import argparse
-import traceback
-import logging
-import gradio as gr
-import numpy as np
-import librosa
-import torch
-import asyncio
-import edge_tts
-from datetime import datetime
-from fairseq import checkpoint_utils
-from infer_pack.models import SynthesizerTrnMs256NSFsid, SynthesizerTrnMs256NSFsid_nono
-from vc_infer_pipeline import VC
-from config import (
- is_half,
- device
-)
-logging.getLogger("numba").setLevel(logging.WARNING)
-limitation = os.getenv("SYSTEM") == "spaces" # limit audio length in huggingface spaces
-
-def create_vc_fn(tgt_sr, net_g, vc, if_f0, file_index, file_big_npy):
- def vc_fn(
- input_audio,
- f0_up_key,
- f0_method,
- index_rate,
- tts_mode,
- tts_text,
- tts_voice
- ):
- try:
- if tts_mode:
- if len(tts_text) > 500 and limitation:
- return "Text is too long", None
- if tts_text is None or tts_voice is None:
- return "You need to enter text and select a voice", None
- asyncio.run(edge_tts.Communicate(tts_text, "-".join(tts_voice.split('-')[:-1])).save("tts.mp3"))
- audio, sr = librosa.load("tts.mp3", sr=16000, mono=True)
- else:
- if args.files:
- audio, sr = librosa.load(input_audio, sr=16000, mono=True)
- else:
- if input_audio is None:
- return "You need to upload an audio", None
- sampling_rate, audio = input_audio
- duration = audio.shape[0] / sampling_rate
- if duration > 300 and limitation:
- return "Please upload an audio file that is less than 5 minutes 30 seconds.", None
- audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32)
- if len(audio.shape) > 1:
- audio = librosa.to_mono(audio.transpose(1, 0))
- if sampling_rate != 16000:
- audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000)
- times = [0, 0, 0]
- f0_up_key = int(f0_up_key)
- audio_opt = vc.pipeline(
- hubert_model,
- net_g,
- 0,
- audio,
- times,
- f0_up_key,
- f0_method,
- file_index,
- file_big_npy,
- index_rate,
- if_f0,
- )
- print(
- f"[{datetime.now().strftime('%Y-%m-%d %H:%M')}]: npy: {times[0]}, f0: {times[1]}s, infer: {times[2]}s"
- )
- return "Success", (tgt_sr, audio_opt)
- except:
- info = traceback.format_exc()
- print(info)
- return info, (None, None)
- return vc_fn
-
-def load_hubert():
- global hubert_model
- models, _, _ = checkpoint_utils.load_model_ensemble_and_task(
- ["hubert_base.pt"],
- suffix="",
- )
- hubert_model = models[0]
- hubert_model = hubert_model.to(device)
- if is_half:
- hubert_model = hubert_model.half()
- else:
- hubert_model = hubert_model.float()
- hubert_model.eval()
-
-def change_to_tts_mode(tts_mode):
- if tts_mode:
- return gr.Audio.update(visible=False), gr.Textbox.update(visible=True), gr.Dropdown.update(visible=True)
- else:
- return gr.Audio.update(visible=True), gr.Textbox.update(visible=False), gr.Dropdown.update(visible=False)
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--api', action="store_true", default=False)
- parser.add_argument("--share", action="store_true", default=False, help="share gradio app")
- parser.add_argument("--files", action="store_true", default=False, help="load audio from path")
- args, unknown = parser.parse_known_args()
- load_hubert()
- models = []
- tts_voice_list = asyncio.get_event_loop().run_until_complete(edge_tts.list_voices())
- voices = [f"{v['ShortName']}-{v['Gender']}" for v in tts_voice_list]
- with open("weights/model_info.json", "r", encoding="utf-8") as f:
- models_info = json.load(f)
- for name, info in models_info.items():
- if not info['enable']:
- continue
- title = info['title']
- author = info.get("author", None)
- cover = f"weights/{name}/{info['cover']}"
- index = f"weights/{name}/{info['feature_retrieval_library']}"
- npy = f"weights/{name}/{info['feature_file']}"
- cpt = torch.load(f"weights/{name}/{name}.pth", map_location="cpu")
- tgt_sr = cpt["config"][-1]
- cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0] # n_spk
- if_f0 = cpt.get("f0", 1)
- if if_f0 == 1:
- net_g = SynthesizerTrnMs256NSFsid(*cpt["config"], is_half=is_half)
- else:
- net_g = SynthesizerTrnMs256NSFsid_nono(*cpt["config"])
- del net_g.enc_q
- print(net_g.load_state_dict(cpt["weight"], strict=False)) # 不加这一行清不干净, 真奇葩
- net_g.eval().to(device)
- if is_half:
- net_g = net_g.half()
- else:
- net_g = net_g.float()
- vc = VC(tgt_sr, device, is_half)
- models.append((name, title, author, cover, create_vc_fn(tgt_sr, net_g, vc, if_f0, index, npy)))
- with gr.Blocks() as app:
- gr.Markdown(
- "# Reina-Models\n"
- "## The input audio should be clean and pure voice without background music.\n"
- "[](https://colab.research.google.com/github/aziib/Create-Google-Shared-Drive/blob/master/Hololive-RVC-Models.ipynb)\n\n"
- "[](https://ko-fi.com/megaaziib)\n\n"
- )
- with gr.Tabs():
- for (name, title, author, cover, vc_fn) in models:
- with gr.TabItem(name):
- with gr.Row():
- gr.Markdown(
- ''
- f'
{title}
\n'+
- (f'
Model author: Reina
' if author else "")+
- (f'

' if cover else "")+
- '
'.join(note_history[0].split(' ')[2:])]
- history = history[1:]
- return inputs, note_history, history
-
-def add_note_to_history(note, note_history):# good example of non async since we wait around til we know it went okay.
- note_history.append(note)
- note_history = ' '.join(note_history)
- return [note_history]
-
-title = "💬ChatBack🧠💾"
-description = """Chatbot With persistent memory dataset allowing multiagent system AI to access a shared dataset as memory pool with stored interactions.
- Current Best SOTA Chatbot: https://huggingface.co/facebook/blenderbot-400M-distill?text=Hey+my+name+is+ChatBack%21+Are+you+ready+to+rock%3F """
-
-def get_base(filename):
- basedir = os.path.dirname(__file__)
- print(basedir)
- #loadPath = basedir + "\\" + filename # works on windows
- loadPath = basedir + filename
- print(loadPath)
- return loadPath
-
-def chat(message, history):
- history = history or []
- if history:
- history_useful = [' '.join([str(a[0])+' '+str(a[1]) for a in history])]
- else:
- history_useful = []
-
- history_useful = add_note_to_history(message, history_useful)
- inputs = tokenizer(history_useful, return_tensors="pt")
- inputs, history_useful, history = take_last_tokens(inputs, history_useful, history)
- reply_ids = model.generate(**inputs)
- response = tokenizer.batch_decode(reply_ids, skip_special_tokens=True)[0]
- history_useful = add_note_to_history(response, history_useful)
- list_history = history_useful[0].split(' ')
- history.append((list_history[-2], list_history[-1]))
-
- df=pd.DataFrame()
-
- if UseMemory:
- outputfileName = 'ChatbotMemory01-24-2023-05-07-PM.csv'
- df = store_message(message, response, outputfileName) # Save to dataset
- basedir = get_base(outputfileName)
-
- return history, df, basedir
-
-
-with gr.Blocks() as demo:
- gr.Markdown("🍰Gradio chatbot backed by dataframe CSV memory🎨
")
-
- with gr.Row():
- t1 = gr.Textbox(lines=1, default="", label="Chat Text:")
- b1 = gr.Button("Respond and Retrieve Messages")
-
- with gr.Row(): # inputs and buttons
- s1 = gr.State([])
- df1 = gr.Dataframe(wrap=True, max_rows=1000, overflow_row_behaviour= "paginate")
- with gr.Row(): # inputs and buttons
- file = gr.File(label="File")
- s2 = gr.Markdown()
-
- b1.click(fn=chat, inputs=[t1, s1], outputs=[s1, df1, file])
-
-demo.launch(debug=True, show_error=True)
\ No newline at end of file
diff --git a/spaces/awacke1/Image-to-Multilingual-OCR/backupapp.py b/spaces/awacke1/Image-to-Multilingual-OCR/backupapp.py
deleted file mode 100644
index 7ff0c4409d1d18607c4e33b856a6eea611e94edf..0000000000000000000000000000000000000000
--- a/spaces/awacke1/Image-to-Multilingual-OCR/backupapp.py
+++ /dev/null
@@ -1,64 +0,0 @@
-import pandas as pd
-import PIL
-from PIL import Image
-from PIL import ImageDraw
-import gradio as gr
-import torch
-import easyocr
-
-#torch.hub.download_url_to_file('https://github.com/AaronCWacker/Yggdrasil/blob/main/images/BeautyIsTruthTruthisBeauty.JPG', 'BeautyIsTruthTruthisBeauty.JPG')
-#torch.hub.download_url_to_file('https://github.com/AaronCWacker/Yggdrasil/blob/main/images/PleaseRepeatLouder.jpg', 'PleaseRepeatLouder.jpg')
-#torch.hub.download_url_to_file('https://github.com/AaronCWacker/Yggdrasil/blob/main/images/ProhibitedInWhiteHouse.JPG', 'ProhibitedInWhiteHouse.JPG')
-
-torch.hub.download_url_to_file('https://raw.githubusercontent.com/AaronCWacker/Yggdrasil/master/images/20-Books.jpg','20-Books.jpg')
-torch.hub.download_url_to_file('https://github.com/JaidedAI/EasyOCR/raw/master/examples/english.png', 'COVID.png')
-torch.hub.download_url_to_file('https://github.com/JaidedAI/EasyOCR/raw/master/examples/chinese.jpg', 'chinese.jpg')
-torch.hub.download_url_to_file('https://github.com/JaidedAI/EasyOCR/raw/master/examples/japanese.jpg', 'japanese.jpg')
-torch.hub.download_url_to_file('https://i.imgur.com/mwQFd7G.jpeg', 'Hindi.jpeg')
-
-def draw_boxes(image, bounds, color='yellow', width=2):
- draw = ImageDraw.Draw(image)
- for bound in bounds:
- p0, p1, p2, p3 = bound[0]
- draw.line([*p0, *p1, *p2, *p3, *p0], fill=color, width=width)
- return image
-
-def inference(img, lang):
- reader = easyocr.Reader(lang)
- bounds = reader.readtext(img.name)
- im = PIL.Image.open(img.name)
- draw_boxes(im, bounds)
- im.save('result.jpg')
- return ['result.jpg', pd.DataFrame(bounds).iloc[: , 1:]]
-
-title = '🖼️Image to Multilingual OCR👁️Gradio'
-description = 'Multilingual OCR which works conveniently on all devices in multiple languages.'
-article = ""
-
-examples = [
-#['PleaseRepeatLouder.jpg',['ja']],['ProhibitedInWhiteHouse.JPG',['en']],['BeautyIsTruthTruthisBeauty.JPG',['en']],
-['20-Books.jpg',['en']],['COVID.png',['en']],['chinese.jpg',['ch_sim', 'en']],['japanese.jpg',['ja', 'en']],['Hindi.jpeg',['hi', 'en']]
-]
-
-css = ".output_image, .input_image {height: 40rem !important; width: 100% !important;}"
-choices = [
- "ch_sim",
- "ch_tra",
- "de",
- "en",
- "es",
- "ja",
- "hi",
- "ru"
-]
-gr.Interface(
- inference,
- [gr.inputs.Image(type='file', label='Input'),gr.inputs.CheckboxGroup(choices, type="value", default=['en'], label='language')],
- [gr.outputs.Image(type='file', label='Output'), gr.outputs.Dataframe(headers=['text', 'confidence'])],
- title=title,
- description=description,
- article=article,
- examples=examples,
- css=css,
- enable_queue=True
- ).launch(debug=True)
\ No newline at end of file
diff --git a/spaces/aymm/Task-Exploration-Hate-Speech/posts/context.py b/spaces/aymm/Task-Exploration-Hate-Speech/posts/context.py
deleted file mode 100644
index 1c728281aed6423b5d4841f6d554577811fe8346..0000000000000000000000000000000000000000
--- a/spaces/aymm/Task-Exploration-Hate-Speech/posts/context.py
+++ /dev/null
@@ -1,23 +0,0 @@
-import streamlit as st
-
-title = "Hate Speech Detection in Automatic Content Moderation"
-description = "The history and development of hate speech detection as a modeling task"
-date = "2022-01-26"
-thumbnail = "images/huggingface_logo.png"
-
-def run_article():
- st.markdown("""
- # What is Automatic Content Moderation?
-
- This is where the history of automatic content moderation (ACM) will go.
-
- # The Landscape of ACM
-
- This is where the current platforms and approaches with go.
-
- # Current Challenges
-
- This is where the discussion of current challenges, examples from media, and value tensions will go.
-
- So what does all this mean for conceptualizing this real world problem as a machine learning task? First we'll look at the data, then at the models.
- """)
diff --git a/spaces/azusarang/so-vits-svc-models-ba_P/app.py b/spaces/azusarang/so-vits-svc-models-ba_P/app.py
deleted file mode 100644
index f26dda8ad5866048eb95268a84ffe23eafba6932..0000000000000000000000000000000000000000
--- a/spaces/azusarang/so-vits-svc-models-ba_P/app.py
+++ /dev/null
@@ -1,376 +0,0 @@
-# -*- coding: utf-8 -*-
-import traceback
-import torch
-from scipy.io import wavfile
-import edge_tts
-import subprocess
-import gradio as gr
-import gradio.processing_utils as gr_pu
-import io
-import os
-import logging
-import time
-from pathlib import Path
-import re
-import json
-import argparse
-
-import librosa
-import matplotlib.pyplot as plt
-import numpy as np
-import soundfile
-
-from inference import infer_tool
-from inference import slicer
-from inference.infer_tool import Svc
-
-logging.getLogger('numba').setLevel(logging.WARNING)
-chunks_dict = infer_tool.read_temp("inference/chunks_temp.json")
-
-logging.getLogger('numba').setLevel(logging.WARNING)
-logging.getLogger('markdown_it').setLevel(logging.WARNING)
-logging.getLogger('urllib3').setLevel(logging.WARNING)
-logging.getLogger('matplotlib').setLevel(logging.WARNING)
-logging.getLogger('multipart').setLevel(logging.WARNING)
-
-model = None
-spk = None
-debug = False
-
-
-class HParams():
- def __init__(self, **kwargs):
- for k, v in kwargs.items():
- if type(v) == dict:
- v = HParams(**v)
- self[k] = v
-
- def keys(self):
- return self.__dict__.keys()
-
- def items(self):
- return self.__dict__.items()
-
- def values(self):
- return self.__dict__.values()
-
- def __len__(self):
- return len(self.__dict__)
-
- def __getitem__(self, key):
- return getattr(self, key)
-
- def __setitem__(self, key, value):
- return setattr(self, key, value)
-
- def __contains__(self, key):
- return key in self.__dict__
-
- def __repr__(self):
- return self.__dict__.__repr__()
-
-
-def get_hparams_from_file(config_path):
- with open(config_path, "r", encoding="utf-8") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- return hparams
-
-
-def vc_fn(sid, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold):
- try:
- if input_audio is None:
- raise gr.Error("你需要上传音频")
- if model is None:
- raise gr.Error("你需要指定模型")
- sampling_rate, audio = input_audio
- # print(audio.shape,sampling_rate)
- audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32)
- if len(audio.shape) > 1:
- audio = librosa.to_mono(audio.transpose(1, 0))
- temp_path = "temp.wav"
- soundfile.write(temp_path, audio, sampling_rate, format="wav")
- _audio = model.slice_inference(temp_path, sid, vc_transform, slice_db, cluster_ratio, auto_f0, noise_scale,
- pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold)
- model.clear_empty()
- os.remove(temp_path)
- # 构建保存文件的路径,并保存到results文件夹内
- try:
- timestamp = str(int(time.time()))
- filename = sid + "_" + timestamp + ".wav"
- # output_file = os.path.join("./results", filename)
- # soundfile.write(output_file, _audio, model.target_sample, format="wav")
- soundfile.write('/tmp/'+filename, _audio,
- model.target_sample, format="wav")
- # return f"推理成功,音频文件保存为results/{filename}", (model.target_sample, _audio)
- return f"推理成功,音频文件保存为{filename}", (model.target_sample, _audio)
- except Exception as e:
- if debug:
- traceback.print_exc()
- return f"文件保存失败,请手动保存", (model.target_sample, _audio)
- except Exception as e:
- if debug:
- traceback.print_exc()
- raise gr.Error(e)
-
-
-def tts_func(_text, _rate, _voice):
- # 使用edge-tts把文字转成音频
- # voice = "zh-CN-XiaoyiNeural"#女性,较高音
- # voice = "zh-CN-YunxiNeural"#男性
- voice = "zh-CN-YunxiNeural" # 男性
- if (_voice == "女"):
- voice = "zh-CN-XiaoyiNeural"
- output_file = "/tmp/"+_text[0:10]+".wav"
- # communicate = edge_tts.Communicate(_text, voice)
- # await communicate.save(output_file)
- if _rate >= 0:
- ratestr = "+{:.0%}".format(_rate)
- elif _rate < 0:
- ratestr = "{:.0%}".format(_rate) # 减号自带
-
- p = subprocess.Popen("edge-tts " +
- " --text "+_text +
- " --write-media "+output_file +
- " --voice "+voice +
- " --rate="+ratestr, shell=True,
- stdout=subprocess.PIPE,
- stdin=subprocess.PIPE)
- p.wait()
- return output_file
-
-
-def text_clear(text):
- return re.sub(r"[\n\,\(\) ]", "", text)
-
-
-def vc_fn2(sid, input_audio, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num, lg_num, lgr_num, text2tts, tts_rate, tts_voice, f0_predictor, enhancer_adaptive_key, cr_threshold):
- # 使用edge-tts把文字转成音频
- text2tts = text_clear(text2tts)
- output_file = tts_func(text2tts, tts_rate, tts_voice)
-
- # 调整采样率
- sr2 = 44100
- wav, sr = librosa.load(output_file)
- wav2 = librosa.resample(wav, orig_sr=sr, target_sr=sr2)
- save_path2 = text2tts[0:10]+"_44k"+".wav"
- wavfile.write(save_path2, sr2,
- (wav2 * np.iinfo(np.int16).max).astype(np.int16)
- )
-
- # 读取音频
- sample_rate, data = gr_pu.audio_from_file(save_path2)
- vc_input = (sample_rate, data)
-
- a, b = vc_fn(sid, vc_input, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale,
- pad_seconds, cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold)
- os.remove(output_file)
- os.remove(save_path2)
- return a, b
-
-
-models_info = [
- {
- "description": """
- 这个模型包含碧蓝档案的141名角色。\n\n
- Space采用CPU推理,速度极慢,建议下载模型本地GPU推理。\n\n
- """,
- "model_path": "./G_387200.pth",
- "config_path": "./config.json",
- }
-]
-
-model_inferall = []
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--share", action="store_true",
- default=False, help="share gradio app")
- # 一定要设置的部分
- parser.add_argument('-cl', '--clip', type=float,
- default=0, help='音频强制切片,默认0为自动切片,单位为秒/s')
- parser.add_argument('-n', '--clean_names', type=str, nargs='+',
- default=["君の知らない物語-src.wav"], help='wav文件名列表,放在raw文件夹下')
- parser.add_argument('-t', '--trans', type=int, nargs='+',
- default=[0], help='音高调整,支持正负(半音)')
- parser.add_argument('-s', '--spk_list', type=str,
- nargs='+', default=['nen'], help='合成目标说话人名称')
-
- # 可选项部分
- parser.add_argument('-a', '--auto_predict_f0', action='store_true',
- default=False, help='语音转换自动预测音高,转换歌声时不要打开这个会严重跑调')
- parser.add_argument('-cm', '--cluster_model_path', type=str,
- default="logs/44k/kmeans_10000.pt", help='聚类模型路径,如果没有训练聚类则随便填')
- parser.add_argument('-cr', '--cluster_infer_ratio', type=float,
- default=0, help='聚类方案占比,范围0-1,若没有训练聚类模型则默认0即可')
- parser.add_argument('-lg', '--linear_gradient', type=float, default=0,
- help='两段音频切片的交叉淡入长度,如果强制切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值0,单位为秒')
- parser.add_argument('-f0p', '--f0_predictor', type=str, default="pm",
- help='选择F0预测器,可选择crepe,pm,dio,harvest,默认为pm(注意:crepe为原F0使用均值滤波器)')
- parser.add_argument('-eh', '--enhance', action='store_true', default=False,
- help='是否使用NSF_HIFIGAN增强器,该选项对部分训练集少的模型有一定的音质增强效果,但是对训练好的模型有反面效果,默认关闭')
- parser.add_argument('-shd', '--shallow_diffusion', action='store_true',
- default=False, help='是否使用浅层扩散,使用后可解决一部分电音问题,默认关闭,该选项打开时,NSF_HIFIGAN增强器将会被禁止')
-
- # 浅扩散设置
- parser.add_argument('-dm', '--diffusion_model_path', type=str,
- default="logs/44k/diffusion/model_0.pt", help='扩散模型路径')
- parser.add_argument('-dc', '--diffusion_config_path', type=str,
- default="logs/44k/diffusion/config.yaml", help='扩散模型配置文件路径')
- parser.add_argument('-ks', '--k_step', type=int,
- default=100, help='扩散步数,越大越接近扩散模型的结果,默认100')
- parser.add_argument('-od', '--only_diffusion', action='store_true',
- default=False, help='纯扩散模式,该模式不会加载sovits模型,以扩散模型推理')
-
- # 不用动的部分
- parser.add_argument('-sd', '--slice_db', type=int,
- default=-40, help='默认-40,嘈杂的音频可以-30,干声保留呼吸可以-50')
- parser.add_argument('-d', '--device', type=str,
- default=None, help='推理设备,None则为自动选择cpu和gpu')
- parser.add_argument('-ns', '--noice_scale', type=float,
- default=0.4, help='噪音级别,会影响咬字和音质,较为玄学')
- parser.add_argument('-p', '--pad_seconds', type=float, default=0.5,
- help='推理音频pad秒数,由于未知原因开头结尾会有异响,pad一小段静音段后就不会出现')
- parser.add_argument('-wf', '--wav_format', type=str,
- default='flac', help='音频输出格式')
- parser.add_argument('-lgr', '--linear_gradient_retain', type=float,
- default=0.75, help='自动音频切片后,需要舍弃每段切片的头尾。该参数设置交叉长度保留的比例,范围0-1,左开右闭')
- parser.add_argument('-eak', '--enhancer_adaptive_key',
- type=int, default=0, help='使增强器适应更高的音域(单位为半音数)|默认为0')
- parser.add_argument('-ft', '--f0_filter_threshold', type=float, default=0.05,
- help='F0过滤阈值,只有使用crepe时有效. 数值范围从0-1. 降低该值可减少跑调概率,但会增加哑音')
- args = parser.parse_args()
- categories = ["Blue Archive"]
- others = {
- "PCR vits-fast-fineturning": "https://huggingface.co/spaces/FrankZxShen/vits-fast-finetuning-pcr",
- "Blue Archive vits-fast-fineturning": "https://huggingface.co/spaces/FrankZxShen/vits-fast-fineturning-models-ba",
- }
- for info in models_info:
- config_path = info['config_path']
- model_path = info['model_path']
- description = info['description']
- clean_names = args.clean_names
- trans = args.trans
- spk_list = list(get_hparams_from_file(config_path).spk.keys())
- slice_db = args.slice_db
- wav_format = args.wav_format
- auto_predict_f0 = args.auto_predict_f0
- cluster_infer_ratio = args.cluster_infer_ratio
- noice_scale = args.noice_scale
- pad_seconds = args.pad_seconds
- clip = args.clip
- lg = args.linear_gradient
- lgr = args.linear_gradient_retain
- f0p = args.f0_predictor
- enhance = args.enhance
- enhancer_adaptive_key = args.enhancer_adaptive_key
- cr_threshold = args.f0_filter_threshold
- diffusion_model_path = args.diffusion_model_path
- diffusion_config_path = args.diffusion_config_path
- k_step = args.k_step
- only_diffusion = args.only_diffusion
- shallow_diffusion = args.shallow_diffusion
-
- model = Svc(model_path, config_path, args.device, args.cluster_model_path, enhance,
- diffusion_model_path, diffusion_config_path, shallow_diffusion, only_diffusion)
-
- model_inferall.append((description, spk_list, model))
-
- app = gr.Blocks()
- with app:
- gr.Markdown(
- "# so-vits-svc-models-ba\n"
- "# Pay attention!!! Space uses CPU inferencing, which is extremely slow. It is recommended to download models.\n"
- "# 注意!!!Space采用CPU推理,速度极慢,建议下载模型使用本地GPU推理。\n"
- "## Please do not generate content that could infringe upon the rights or cause harm to individuals or organizations.\n"
- "## 请不要生成会对个人以及组织造成侵害的内容\n\n"
- )
- gr.Markdown("# Blue Archive\n\n"
- )
- with gr.Tabs():
- for category in categories:
- with gr.TabItem(category):
- for i, (description, speakers, model) in enumerate(
- model_inferall):
- gr.Markdown(description)
- with gr.Row():
- with gr.Column():
- # textbox = gr.TextArea(label="Text",
- # placeholder="Type your sentence here ",
- # value="新たなキャラを解放できるようになったようですね。", elem_id=f"tts-input")
-
- gr.Markdown(value="""
- 推理设置
- """)
- sid = gr.Dropdown(
- choices=speakers, value=speakers[0], label='角色选择')
- auto_f0 = gr.Checkbox(
- label="自动f0预测,配合聚类模型f0预测效果更好,会导致变调功能失效(仅限转换语音,歌声勾选此项会究极跑调)", value=False)
- f0_predictor = gr.Dropdown(label="选择F0预测器,可选择crepe,pm,dio,harvest,默认为pm(注意:crepe为原F0使用均值滤波器)", choices=[
- "pm", "dio", "harvest", "crepe"], value="pm")
- vc_transform = gr.Number(
- label="变调(整数,可以正负,半音数量,升高八度就是12)", value=0)
- cluster_ratio = gr.Number(
- label="聚类模型混合比例,0-1之间,0即不启用聚类。使用聚类模型能提升音色相似度,但会导致咬字下降(如果使用建议0.5左右)", value=0)
- slice_db = gr.Number(label="切片阈值", value=-40)
- noise_scale = gr.Number(
- label="noise_scale 建议不要动,会影响音质,玄学参数", value=0.4)
- with gr.Column():
- pad_seconds = gr.Number(
- label="推理音频pad秒数,由于未知原因开头结尾会有异响,pad一小段静音段后就不会出现", value=0.5)
- cl_num = gr.Number(
- label="音频自动切片,0为不切片,单位为秒(s)", value=0)
- lg_num = gr.Number(
- label="两端音频切片的交叉淡入长度,如果自动切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值0,注意,该设置会影响推理速度,单位为秒/s", value=0)
- lgr_num = gr.Number(
- label="自动音频切片后,需要舍弃每段切片的头尾。该参数设置交叉长度保留的比例,范围0-1,左开右闭", value=0.75)
- enhancer_adaptive_key = gr.Number(
- label="使增强器适应更高的音域(单位为半音数)|默认为0", value=0)
- cr_threshold = gr.Number(
- label="F0过滤阈值,只有启动crepe时有效. 数值范围从0-1. 降低该值可减少跑调概率,但会增加哑音", value=0.05)
- with gr.Tabs():
- with gr.TabItem("音频转音频"):
- vc_input3 = gr.Audio(label="选择音频")
- vc_submit = gr.Button(
- "音频转换", variant="primary")
- with gr.TabItem("文字转音频"):
- text2tts = gr.Textbox(
- label="在此输入要转译的文字。注意,使用该功能建议打开F0预测,不然会很怪")
- tts_rate = gr.Number(label="tts语速", value=0)
- tts_voice = gr.Radio(label="性别", choices=[
- "男", "女"], value="男")
- vc_submit2 = gr.Button(
- "文字转换", variant="primary")
- with gr.Row():
- with gr.Column():
- vc_output1 = gr.Textbox(label="Output Message")
- with gr.Column():
- vc_output2 = gr.Audio(
- label="Output Audio", interactive=False)
-
- vc_submit.click(vc_fn, [sid, vc_input3, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds,
- cl_num, lg_num, lgr_num, f0_predictor, enhancer_adaptive_key, cr_threshold], [vc_output1, vc_output2])
- vc_submit2.click(vc_fn2, [sid, vc_input3, vc_transform, auto_f0, cluster_ratio, slice_db, noise_scale, pad_seconds, cl_num,
- lg_num, lgr_num, text2tts, tts_rate, tts_voice, f0_predictor, enhancer_adaptive_key, cr_threshold], [vc_output1, vc_output2])
- # gr.Examples(
- # examples=example,
- # inputs=[textbox, char_dropdown, language_dropdown,
- # duration_slider, symbol_input],
- # outputs=[text_output, audio_output],
- # fn=tts_fn
- # )
- for category, link in others.items():
- with gr.TabItem(category):
- gr.Markdown(
- f'''
-
- Click to Go
-
-  -
- '''
- )
-
- app.queue(concurrency_count=3).launch(show_api=False, share=args.share)
diff --git a/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/custom_embedding.py b/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/custom_embedding.py
deleted file mode 100644
index ab357952c397f47898863e8405c4958bb8de82fd..0000000000000000000000000000000000000000
--- a/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/custom_embedding.py
+++ /dev/null
@@ -1,11 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import Tensor
-
-class SharedEmbedding(nn.Embedding):
-
- def forward(self, input: Tensor, unembed: bool=False) -> Tensor:
- if unembed:
- return F.linear(input, self.weight)
- return super().forward(input)
\ No newline at end of file
diff --git a/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/param_init_fns.py b/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/param_init_fns.py
deleted file mode 100644
index 418b83ca2363288046f4b48b1d706c5607341fb5..0000000000000000000000000000000000000000
--- a/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/param_init_fns.py
+++ /dev/null
@@ -1,181 +0,0 @@
-import math
-import warnings
-from collections.abc import Sequence
-from functools import partial
-from typing import Optional, Tuple, Union
-import torch
-from torch import nn
-from .norm import NORM_CLASS_REGISTRY
-
-def torch_default_param_init_fn_(module: nn.Module, verbose: int=0, **kwargs):
- del kwargs
- if verbose > 1:
- warnings.warn(f"Initializing network using module's reset_parameters attribute")
- if hasattr(module, 'reset_parameters'):
- module.reset_parameters()
-
-def fused_init_helper_(module: nn.Module, init_fn_):
- _fused = getattr(module, '_fused', None)
- if _fused is None:
- raise RuntimeError(f'Internal logic error')
- (dim, splits) = _fused
- splits = (0, *splits, module.weight.size(dim))
- for (s, e) in zip(splits[:-1], splits[1:]):
- slice_indices = [slice(None)] * module.weight.ndim
- slice_indices[dim] = slice(s, e)
- init_fn_(module.weight[slice_indices])
-
-def generic_param_init_fn_(module: nn.Module, init_fn_, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- del kwargs
- if verbose > 1:
- warnings.warn(f'If model has bias parameters they are initialized to 0.')
- init_div_is_residual = init_div_is_residual
- if init_div_is_residual is False:
- div_is_residual = 1.0
- elif init_div_is_residual is True:
- div_is_residual = math.sqrt(2 * n_layers)
- elif isinstance(init_div_is_residual, float) or isinstance(init_div_is_residual, int):
- div_is_residual = init_div_is_residual
- elif isinstance(init_div_is_residual, str) and init_div_is_residual.isnumeric():
- div_is_residual = float(init_div_is_residual)
- else:
- div_is_residual = 1.0
- raise ValueError(f'Expected init_div_is_residual to be boolean or numeric, got {init_div_is_residual}')
- if init_div_is_residual is not False:
- if verbose > 1:
- warnings.warn(f'Initializing _is_residual layers then dividing them by {div_is_residual:.3f}. ' + f'Set `init_div_is_residual: false` in init config to disable this.')
- if isinstance(module, nn.Linear):
- if hasattr(module, '_fused'):
- fused_init_helper_(module, init_fn_)
- else:
- init_fn_(module.weight)
- if module.bias is not None:
- torch.nn.init.zeros_(module.bias)
- if init_div_is_residual is not False and getattr(module, '_is_residual', False):
- with torch.no_grad():
- module.weight.div_(div_is_residual)
- elif isinstance(module, nn.Embedding):
- if emb_init_std is not None:
- std = emb_init_std
- if std == 0:
- warnings.warn(f'Embedding layer initialized to 0.')
- emb_init_fn_ = partial(torch.nn.init.normal_, mean=0.0, std=std)
- if verbose > 1:
- warnings.warn(f'Embedding layer initialized using normal distribution with mean=0 and std={std!r}.')
- elif emb_init_uniform_lim is not None:
- lim = emb_init_uniform_lim
- if isinstance(lim, Sequence):
- if len(lim) > 2:
- raise ValueError(f'Uniform init requires a min and a max limit. User input: {lim}.')
- if lim[0] == lim[1]:
- warnings.warn(f'Embedding layer initialized to {lim[0]}.')
- else:
- if lim == 0:
- warnings.warn(f'Embedding layer initialized to 0.')
- lim = [-lim, lim]
- (a, b) = lim
- emb_init_fn_ = partial(torch.nn.init.uniform_, a=a, b=b)
- if verbose > 1:
- warnings.warn(f'Embedding layer initialized using uniform distribution in range {lim}.')
- else:
- emb_init_fn_ = init_fn_
- emb_init_fn_(module.weight)
- elif isinstance(module, tuple(set(NORM_CLASS_REGISTRY.values()))):
- if verbose > 1:
- warnings.warn(f'Norm weights are set to 1. If norm layer has a bias it is initialized to 0.')
- if hasattr(module, 'weight') and module.weight is not None:
- torch.nn.init.ones_(module.weight)
- if hasattr(module, 'bias') and module.bias is not None:
- torch.nn.init.zeros_(module.bias)
- elif isinstance(module, nn.MultiheadAttention):
- if module._qkv_same_embed_dim:
- assert module.in_proj_weight is not None
- assert module.q_proj_weight is None and module.k_proj_weight is None and (module.v_proj_weight is None)
- assert d_model is not None
- _d = d_model
- splits = (0, _d, 2 * _d, 3 * _d)
- for (s, e) in zip(splits[:-1], splits[1:]):
- init_fn_(module.in_proj_weight[s:e])
- else:
- assert module.q_proj_weight is not None and module.k_proj_weight is not None and (module.v_proj_weight is not None)
- assert module.in_proj_weight is None
- init_fn_(module.q_proj_weight)
- init_fn_(module.k_proj_weight)
- init_fn_(module.v_proj_weight)
- if module.in_proj_bias is not None:
- torch.nn.init.zeros_(module.in_proj_bias)
- if module.bias_k is not None:
- torch.nn.init.zeros_(module.bias_k)
- if module.bias_v is not None:
- torch.nn.init.zeros_(module.bias_v)
- init_fn_(module.out_proj.weight)
- if init_div_is_residual is not False and getattr(module.out_proj, '_is_residual', False):
- with torch.no_grad():
- module.out_proj.weight.div_(div_is_residual)
- if module.out_proj.bias is not None:
- torch.nn.init.zeros_(module.out_proj.bias)
- else:
- for _ in module.parameters(recurse=False):
- raise NotImplementedError(f'{module.__class__.__name__} parameters are not initialized by param_init_fn.')
-
-def _normal_init_(std, mean=0.0):
- return partial(torch.nn.init.normal_, mean=mean, std=std)
-
-def _normal_param_init_fn_(module: nn.Module, std: float, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- del kwargs
- init_fn_ = _normal_init_(std=std)
- if verbose > 1:
- warnings.warn(f'Using torch.nn.init.normal_ init fn mean=0.0, std={std}')
- generic_param_init_fn_(module=module, init_fn_=init_fn_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def baseline_param_init_fn_(module: nn.Module, init_std: float, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- del kwargs
- if init_std is None:
- raise ValueError("You must set model.init_config['init_std'] to a float value to use the default initialization scheme.")
- _normal_param_init_fn_(module=module, std=init_std, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def small_param_init_fn_(module: nn.Module, n_layers: int, d_model: int, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- del kwargs
- std = math.sqrt(2 / (5 * d_model))
- _normal_param_init_fn_(module=module, std=std, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def neox_param_init_fn_(module: nn.Module, n_layers: int, d_model: int, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- """From section 2.3.1 of GPT-NeoX-20B:
-
- An Open-Source AutoregressiveLanguage Model — Black et. al. (2022)
- see https://github.com/EleutherAI/gpt-neox/blob/9610391ab319403cef079b438edd016a2443af54/megatron/model/init_functions.py#L151
- and https://github.com/EleutherAI/gpt-neox/blob/main/megatron/model/transformer.py
- """
- del kwargs
- residual_div = n_layers / math.sqrt(10)
- if verbose > 1:
- warnings.warn(f'setting init_div_is_residual to {residual_div}')
- small_param_init_fn_(module=module, d_model=d_model, n_layers=n_layers, init_div_is_residual=residual_div, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def kaiming_uniform_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, fan_mode: str='fan_in', init_nonlinearity: str='leaky_relu', verbose: int=0, **kwargs):
- del kwargs
- if verbose > 1:
- warnings.warn(f'Using nn.init.kaiming_uniform_ init fn with parameters: ' + f'a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}')
- kaiming_uniform_ = partial(nn.init.kaiming_uniform_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
- generic_param_init_fn_(module=module, init_fn_=kaiming_uniform_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def kaiming_normal_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, fan_mode: str='fan_in', init_nonlinearity: str='leaky_relu', verbose: int=0, **kwargs):
- del kwargs
- if verbose > 1:
- warnings.warn(f'Using nn.init.kaiming_normal_ init fn with parameters: ' + f'a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}')
- kaiming_normal_ = partial(torch.nn.init.kaiming_normal_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
- generic_param_init_fn_(module=module, init_fn_=kaiming_normal_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def xavier_uniform_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, verbose: int=0, **kwargs):
- del kwargs
- xavier_uniform_ = partial(torch.nn.init.xavier_uniform_, gain=init_gain)
- if verbose > 1:
- warnings.warn(f'Using torch.nn.init.xavier_uniform_ init fn with parameters: ' + f'gain={init_gain}')
- generic_param_init_fn_(module=module, init_fn_=xavier_uniform_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def xavier_normal_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, verbose: int=0, **kwargs):
- xavier_normal_ = partial(torch.nn.init.xavier_normal_, gain=init_gain)
- if verbose > 1:
- warnings.warn(f'Using torch.nn.init.xavier_normal_ init fn with parameters: ' + f'gain={init_gain}')
- generic_param_init_fn_(module=module, init_fn_=xavier_normal_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-MODEL_INIT_REGISTRY = {'default_': torch_default_param_init_fn_, 'baseline_': baseline_param_init_fn_, 'kaiming_uniform_': kaiming_uniform_param_init_fn_, 'kaiming_normal_': kaiming_normal_param_init_fn_, 'neox_init_': neox_param_init_fn_, 'small_init_': small_param_init_fn_, 'xavier_uniform_': xavier_uniform_param_init_fn_, 'xavier_normal_': xavier_normal_param_init_fn_}
\ No newline at end of file
diff --git a/spaces/banana-projects/web3d/node_modules/three/src/audio/AudioContext.js b/spaces/banana-projects/web3d/node_modules/three/src/audio/AudioContext.js
deleted file mode 100644
index 29def0117faa77d8d9f40357defaeacc3cb66d9a..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/web3d/node_modules/three/src/audio/AudioContext.js
+++ /dev/null
@@ -1,29 +0,0 @@
-/**
- * @author mrdoob / http://mrdoob.com/
- */
-
-var context;
-
-var AudioContext = {
-
- getContext: function () {
-
- if ( context === undefined ) {
-
- context = new ( window.AudioContext || window.webkitAudioContext )();
-
- }
-
- return context;
-
- },
-
- setContext: function ( value ) {
-
- context = value;
-
- }
-
-};
-
-export { AudioContext };
diff --git a/spaces/banana-projects/web3d/node_modules/three/src/helpers/ArrowHelper.js b/spaces/banana-projects/web3d/node_modules/three/src/helpers/ArrowHelper.js
deleted file mode 100644
index 8dbd9bf9ae6ae787d4b8135911f29f7285b91e9b..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/web3d/node_modules/three/src/helpers/ArrowHelper.js
+++ /dev/null
@@ -1,139 +0,0 @@
-/**
- * @author WestLangley / http://github.com/WestLangley
- * @author zz85 / http://github.com/zz85
- * @author bhouston / http://clara.io
- *
- * Creates an arrow for visualizing directions
- *
- * Parameters:
- * dir - Vector3
- * origin - Vector3
- * length - Number
- * color - color in hex value
- * headLength - Number
- * headWidth - Number
- */
-
-import { Float32BufferAttribute } from '../core/BufferAttribute.js';
-import { BufferGeometry } from '../core/BufferGeometry.js';
-import { Object3D } from '../core/Object3D.js';
-import { CylinderBufferGeometry } from '../geometries/CylinderGeometry.js';
-import { MeshBasicMaterial } from '../materials/MeshBasicMaterial.js';
-import { LineBasicMaterial } from '../materials/LineBasicMaterial.js';
-import { Mesh } from '../objects/Mesh.js';
-import { Line } from '../objects/Line.js';
-import { Vector3 } from '../math/Vector3.js';
-
-var lineGeometry, coneGeometry;
-
-function ArrowHelper( dir, origin, length, color, headLength, headWidth ) {
-
- // dir is assumed to be normalized
-
- Object3D.call( this );
-
- if ( dir === undefined ) dir = new Vector3( 0, 0, 1 );
- if ( origin === undefined ) origin = new Vector3( 0, 0, 0 );
- if ( length === undefined ) length = 1;
- if ( color === undefined ) color = 0xffff00;
- if ( headLength === undefined ) headLength = 0.2 * length;
- if ( headWidth === undefined ) headWidth = 0.2 * headLength;
-
- if ( lineGeometry === undefined ) {
-
- lineGeometry = new BufferGeometry();
- lineGeometry.addAttribute( 'position', new Float32BufferAttribute( [ 0, 0, 0, 0, 1, 0 ], 3 ) );
-
- coneGeometry = new CylinderBufferGeometry( 0, 0.5, 1, 5, 1 );
- coneGeometry.translate( 0, - 0.5, 0 );
-
- }
-
- this.position.copy( origin );
-
- this.line = new Line( lineGeometry, new LineBasicMaterial( { color: color } ) );
- this.line.matrixAutoUpdate = false;
- this.add( this.line );
-
- this.cone = new Mesh( coneGeometry, new MeshBasicMaterial( { color: color } ) );
- this.cone.matrixAutoUpdate = false;
- this.add( this.cone );
-
- this.setDirection( dir );
- this.setLength( length, headLength, headWidth );
-
-}
-
-ArrowHelper.prototype = Object.create( Object3D.prototype );
-ArrowHelper.prototype.constructor = ArrowHelper;
-
-ArrowHelper.prototype.setDirection = ( function () {
-
- var axis = new Vector3();
- var radians;
-
- return function setDirection( dir ) {
-
- // dir is assumed to be normalized
-
- if ( dir.y > 0.99999 ) {
-
- this.quaternion.set( 0, 0, 0, 1 );
-
- } else if ( dir.y < - 0.99999 ) {
-
- this.quaternion.set( 1, 0, 0, 0 );
-
- } else {
-
- axis.set( dir.z, 0, - dir.x ).normalize();
-
- radians = Math.acos( dir.y );
-
- this.quaternion.setFromAxisAngle( axis, radians );
-
- }
-
- };
-
-}() );
-
-ArrowHelper.prototype.setLength = function ( length, headLength, headWidth ) {
-
- if ( headLength === undefined ) headLength = 0.2 * length;
- if ( headWidth === undefined ) headWidth = 0.2 * headLength;
-
- this.line.scale.set( 1, Math.max( 0, length - headLength ), 1 );
- this.line.updateMatrix();
-
- this.cone.scale.set( headWidth, headLength, headWidth );
- this.cone.position.y = length;
- this.cone.updateMatrix();
-
-};
-
-ArrowHelper.prototype.setColor = function ( color ) {
-
- this.line.material.color.copy( color );
- this.cone.material.color.copy( color );
-
-};
-
-ArrowHelper.prototype.copy = function ( source ) {
-
- Object3D.prototype.copy.call( this, source, false );
-
- this.line.copy( source.line );
- this.cone.copy( source.cone );
-
- return this;
-
-};
-
-ArrowHelper.prototype.clone = function () {
-
- return new this.constructor().copy( this );
-
-};
-
-export { ArrowHelper };
diff --git a/spaces/better57/CHATGPT/custom.css b/spaces/better57/CHATGPT/custom.css
deleted file mode 100644
index 5143eb138ea2469d8c457c71cb210fd3fb7cbe15..0000000000000000000000000000000000000000
--- a/spaces/better57/CHATGPT/custom.css
+++ /dev/null
@@ -1,162 +0,0 @@
-:root {
- --chatbot-color-light: #F3F3F3;
- --chatbot-color-dark: #121111;
-}
-
-/* status_display */
-#status_display {
- display: flex;
- min-height: 2.5em;
- align-items: flex-end;
- justify-content: flex-end;
-}
-#status_display p {
- font-size: .85em;
- font-family: monospace;
- color: var(--body-text-color-subdued);
-}
-
-#chuanhu_chatbot, #status_display {
- transition: all 0.6s;
-}
-/* list */
-ol:not(.options), ul:not(.options) {
- padding-inline-start: 2em !important;
-}
-
-/* 亮色 */
-#chuanhu_chatbot {
- background-color: var(--chatbot-color-light) !important;
-}
-[data-testid = "bot"] {
- background-color: #FFFFFF !important;
-}
-[data-testid = "user"] {
- background-color: #95EC69 !important;
-}
-/* 对话气泡 */
-[class *= "message"] {
- border-radius: var(--radius-xl) !important;
- border: none;
- padding: var(--spacing-xl) !important;
- font-size: var(--text-md) !important;
- line-height: var(--line-md) !important;
- min-height: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
- min-width: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
-}
-[data-testid = "bot"] {
- max-width: 85%;
- border-bottom-left-radius: 0 !important;
-}
-[data-testid = "user"] {
- max-width: 85%;
- width: auto !important;
- border-bottom-right-radius: 0 !important;
-}
-/* 表格 */
-table {
- margin: 1em 0;
- border-collapse: collapse;
- empty-cells: show;
-}
-td,th {
- border: 1.2px solid var(--border-color-primary) !important;
- padding: 0.2em;
-}
-thead {
- background-color: rgba(175,184,193,0.2);
-}
-thead th {
- padding: .5em .2em;
-}
-/* 行内代码 */
-code {
- display: inline;
- white-space: break-spaces;
- border-radius: 6px;
- margin: 0 2px 0 2px;
- padding: .2em .4em .1em .4em;
- background-color: rgba(175,184,193,0.2);
-}
-/* 代码块 */
-pre code {
- display: block;
- overflow: auto;
- white-space: pre;
- background-color: hsla(0, 0%, 0%, 80%)!important;
- border-radius: 10px;
- padding: 1.4em 1.2em 0em 1.4em;
- margin: 1.2em 2em 1.2em 0.5em;
- color: #FFF;
- box-shadow: 6px 6px 16px hsla(0, 0%, 0%, 0.2);
-}
-/* 代码高亮样式 */
-.highlight .hll { background-color: #49483e }
-.highlight .c { color: #75715e } /* Comment */
-.highlight .err { color: #960050; background-color: #1e0010 } /* Error */
-.highlight .k { color: #66d9ef } /* Keyword */
-.highlight .l { color: #ae81ff } /* Literal */
-.highlight .n { color: #f8f8f2 } /* Name */
-.highlight .o { color: #f92672 } /* Operator */
-.highlight .p { color: #f8f8f2 } /* Punctuation */
-.highlight .ch { color: #75715e } /* Comment.Hashbang */
-.highlight .cm { color: #75715e } /* Comment.Multiline */
-.highlight .cp { color: #75715e } /* Comment.Preproc */
-.highlight .cpf { color: #75715e } /* Comment.PreprocFile */
-.highlight .c1 { color: #75715e } /* Comment.Single */
-.highlight .cs { color: #75715e } /* Comment.Special */
-.highlight .gd { color: #f92672 } /* Generic.Deleted */
-.highlight .ge { font-style: italic } /* Generic.Emph */
-.highlight .gi { color: #a6e22e } /* Generic.Inserted */
-.highlight .gs { font-weight: bold } /* Generic.Strong */
-.highlight .gu { color: #75715e } /* Generic.Subheading */
-.highlight .kc { color: #66d9ef } /* Keyword.Constant */
-.highlight .kd { color: #66d9ef } /* Keyword.Declaration */
-.highlight .kn { color: #f92672 } /* Keyword.Namespace */
-.highlight .kp { color: #66d9ef } /* Keyword.Pseudo */
-.highlight .kr { color: #66d9ef } /* Keyword.Reserved */
-.highlight .kt { color: #66d9ef } /* Keyword.Type */
-.highlight .ld { color: #e6db74 } /* Literal.Date */
-.highlight .m { color: #ae81ff } /* Literal.Number */
-.highlight .s { color: #e6db74 } /* Literal.String */
-.highlight .na { color: #a6e22e } /* Name.Attribute */
-.highlight .nb { color: #f8f8f2 } /* Name.Builtin */
-.highlight .nc { color: #a6e22e } /* Name.Class */
-.highlight .no { color: #66d9ef } /* Name.Constant */
-.highlight .nd { color: #a6e22e } /* Name.Decorator */
-.highlight .ni { color: #f8f8f2 } /* Name.Entity */
-.highlight .ne { color: #a6e22e } /* Name.Exception */
-.highlight .nf { color: #a6e22e } /* Name.Function */
-.highlight .nl { color: #f8f8f2 } /* Name.Label */
-.highlight .nn { color: #f8f8f2 } /* Name.Namespace */
-.highlight .nx { color: #a6e22e } /* Name.Other */
-.highlight .py { color: #f8f8f2 } /* Name.Property */
-.highlight .nt { color: #f92672 } /* Name.Tag */
-.highlight .nv { color: #f8f8f2 } /* Name.Variable */
-.highlight .ow { color: #f92672 } /* Operator.Word */
-.highlight .w { color: #f8f8f2 } /* Text.Whitespace */
-.highlight .mb { color: #ae81ff } /* Literal.Number.Bin */
-.highlight .mf { color: #ae81ff } /* Literal.Number.Float */
-.highlight .mh { color: #ae81ff } /* Literal.Number.Hex */
-.highlight .mi { color: #ae81ff } /* Literal.Number.Integer */
-.highlight .mo { color: #ae81ff } /* Literal.Number.Oct */
-.highlight .sa { color: #e6db74 } /* Literal.String.Affix */
-.highlight .sb { color: #e6db74 } /* Literal.String.Backtick */
-.highlight .sc { color: #e6db74 } /* Literal.String.Char */
-.highlight .dl { color: #e6db74 } /* Literal.String.Delimiter */
-.highlight .sd { color: #e6db74 } /* Literal.String.Doc */
-.highlight .s2 { color: #e6db74 } /* Literal.String.Double */
-.highlight .se { color: #ae81ff } /* Literal.String.Escape */
-.highlight .sh { color: #e6db74 } /* Literal.String.Heredoc */
-.highlight .si { color: #e6db74 } /* Literal.String.Interpol */
-.highlight .sx { color: #e6db74 } /* Literal.String.Other */
-.highlight .sr { color: #e6db74 } /* Literal.String.Regex */
-.highlight .s1 { color: #e6db74 } /* Literal.String.Single */
-.highlight .ss { color: #e6db74 } /* Literal.String.Symbol */
-.highlight .bp { color: #f8f8f2 } /* Name.Builtin.Pseudo */
-.highlight .fm { color: #a6e22e } /* Name.Function.Magic */
-.highlight .vc { color: #f8f8f2 } /* Name.Variable.Class */
-.highlight .vg { color: #f8f8f2 } /* Name.Variable.Global */
-.highlight .vi { color: #f8f8f2 } /* Name.Variable.Instance */
-.highlight .vm { color: #f8f8f2 } /* Name.Variable.Magic */
-.highlight .il { color: #ae81ff } /* Literal.Number.Integer.Long */
diff --git a/spaces/bguberfain/Detic/detic/predictor.py b/spaces/bguberfain/Detic/detic/predictor.py
deleted file mode 100644
index 318205acb90d47a54ff6f34400e1da744b2d85ba..0000000000000000000000000000000000000000
--- a/spaces/bguberfain/Detic/detic/predictor.py
+++ /dev/null
@@ -1,253 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import atexit
-import bisect
-import multiprocessing as mp
-from collections import deque
-import cv2
-import torch
-
-from detectron2.data import MetadataCatalog
-from detectron2.engine.defaults import DefaultPredictor
-from detectron2.utils.video_visualizer import VideoVisualizer
-from detectron2.utils.visualizer import ColorMode, Visualizer
-
-from .modeling.utils import reset_cls_test
-
-
-def get_clip_embeddings(vocabulary, prompt='a '):
- from detic.modeling.text.text_encoder import build_text_encoder
- text_encoder = build_text_encoder(pretrain=True)
- text_encoder.eval()
- texts = [prompt + x for x in vocabulary]
- emb = text_encoder(texts).detach().permute(1, 0).contiguous().cpu()
- return emb
-
-BUILDIN_CLASSIFIER = {
- 'lvis': 'datasets/metadata/lvis_v1_clip_a+cname.npy',
- 'objects365': 'datasets/metadata/o365_clip_a+cnamefix.npy',
- 'openimages': 'datasets/metadata/oid_clip_a+cname.npy',
- 'coco': 'datasets/metadata/coco_clip_a+cname.npy',
-}
-
-BUILDIN_METADATA_PATH = {
- 'lvis': 'lvis_v1_val',
- 'objects365': 'objects365_v2_val',
- 'openimages': 'oid_val_expanded',
- 'coco': 'coco_2017_val',
-}
-
-class VisualizationDemo(object):
- def __init__(self, cfg, args,
- instance_mode=ColorMode.IMAGE, parallel=False):
- """
- Args:
- cfg (CfgNode):
- instance_mode (ColorMode):
- parallel (bool): whether to run the model in different processes from visualization.
- Useful since the visualization logic can be slow.
- """
- if args.vocabulary == 'custom':
- self.metadata = MetadataCatalog.get("__unused")
- self.metadata.thing_classes = args.custom_vocabulary.split(',')
- classifier = get_clip_embeddings(self.metadata.thing_classes)
- else:
- self.metadata = MetadataCatalog.get(
- BUILDIN_METADATA_PATH[args.vocabulary])
- classifier = BUILDIN_CLASSIFIER[args.vocabulary]
-
- num_classes = len(self.metadata.thing_classes)
- self.cpu_device = torch.device("cpu")
- self.instance_mode = instance_mode
-
- self.parallel = parallel
- if parallel:
- num_gpu = torch.cuda.device_count()
- self.predictor = AsyncPredictor(cfg, num_gpus=num_gpu)
- else:
- self.predictor = DefaultPredictor(cfg)
- reset_cls_test(self.predictor.model, classifier, num_classes)
-
- def run_on_image(self, image):
- """
- Args:
- image (np.ndarray): an image of shape (H, W, C) (in BGR order).
- This is the format used by OpenCV.
-
- Returns:
- predictions (dict): the output of the model.
- vis_output (VisImage): the visualized image output.
- """
- vis_output = None
- predictions = self.predictor(image)
- # Convert image from OpenCV BGR format to Matplotlib RGB format.
- image = image[:, :, ::-1]
- visualizer = Visualizer(image, self.metadata, instance_mode=self.instance_mode)
- if "panoptic_seg" in predictions:
- panoptic_seg, segments_info = predictions["panoptic_seg"]
- vis_output = visualizer.draw_panoptic_seg_predictions(
- panoptic_seg.to(self.cpu_device), segments_info
- )
- else:
- if "sem_seg" in predictions:
- vis_output = visualizer.draw_sem_seg(
- predictions["sem_seg"].argmax(dim=0).to(self.cpu_device)
- )
- if "instances" in predictions:
- instances = predictions["instances"].to(self.cpu_device)
- vis_output = visualizer.draw_instance_predictions(predictions=instances)
-
- return predictions, vis_output
-
- def _frame_from_video(self, video):
- while video.isOpened():
- success, frame = video.read()
- if success:
- yield frame
- else:
- break
-
- def run_on_video(self, video):
- """
- Visualizes predictions on frames of the input video.
-
- Args:
- video (cv2.VideoCapture): a :class:`VideoCapture` object, whose source can be
- either a webcam or a video file.
-
- Yields:
- ndarray: BGR visualizations of each video frame.
- """
- video_visualizer = VideoVisualizer(self.metadata, self.instance_mode)
-
- def process_predictions(frame, predictions):
- frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
- if "panoptic_seg" in predictions:
- panoptic_seg, segments_info = predictions["panoptic_seg"]
- vis_frame = video_visualizer.draw_panoptic_seg_predictions(
- frame, panoptic_seg.to(self.cpu_device), segments_info
- )
- elif "instances" in predictions:
- predictions = predictions["instances"].to(self.cpu_device)
- vis_frame = video_visualizer.draw_instance_predictions(frame, predictions)
- elif "sem_seg" in predictions:
- vis_frame = video_visualizer.draw_sem_seg(
- frame, predictions["sem_seg"].argmax(dim=0).to(self.cpu_device)
- )
-
- # Converts Matplotlib RGB format to OpenCV BGR format
- vis_frame = cv2.cvtColor(vis_frame.get_image(), cv2.COLOR_RGB2BGR)
- return vis_frame
-
- frame_gen = self._frame_from_video(video)
- if self.parallel:
- buffer_size = self.predictor.default_buffer_size
-
- frame_data = deque()
-
- for cnt, frame in enumerate(frame_gen):
- frame_data.append(frame)
- self.predictor.put(frame)
-
- if cnt >= buffer_size:
- frame = frame_data.popleft()
- predictions = self.predictor.get()
- yield process_predictions(frame, predictions)
-
- while len(frame_data):
- frame = frame_data.popleft()
- predictions = self.predictor.get()
- yield process_predictions(frame, predictions)
- else:
- for frame in frame_gen:
- yield process_predictions(frame, self.predictor(frame))
-
-
-class AsyncPredictor:
- """
- A predictor that runs the model asynchronously, possibly on >1 GPUs.
- Because rendering the visualization takes considerably amount of time,
- this helps improve throughput a little bit when rendering videos.
- """
-
- class _StopToken:
- pass
-
- class _PredictWorker(mp.Process):
- def __init__(self, cfg, task_queue, result_queue):
- self.cfg = cfg
- self.task_queue = task_queue
- self.result_queue = result_queue
- super().__init__()
-
- def run(self):
- predictor = DefaultPredictor(self.cfg)
-
- while True:
- task = self.task_queue.get()
- if isinstance(task, AsyncPredictor._StopToken):
- break
- idx, data = task
- result = predictor(data)
- self.result_queue.put((idx, result))
-
- def __init__(self, cfg, num_gpus: int = 1):
- """
- Args:
- cfg (CfgNode):
- num_gpus (int): if 0, will run on CPU
- """
- num_workers = max(num_gpus, 1)
- self.task_queue = mp.Queue(maxsize=num_workers * 3)
- self.result_queue = mp.Queue(maxsize=num_workers * 3)
- self.procs = []
- for gpuid in range(max(num_gpus, 1)):
- cfg = cfg.clone()
- cfg.defrost()
- cfg.MODEL.DEVICE = "cuda:{}".format(gpuid) if num_gpus > 0 else "cpu"
- self.procs.append(
- AsyncPredictor._PredictWorker(cfg, self.task_queue, self.result_queue)
- )
-
- self.put_idx = 0
- self.get_idx = 0
- self.result_rank = []
- self.result_data = []
-
- for p in self.procs:
- p.start()
- atexit.register(self.shutdown)
-
- def put(self, image):
- self.put_idx += 1
- self.task_queue.put((self.put_idx, image))
-
- def get(self):
- self.get_idx += 1 # the index needed for this request
- if len(self.result_rank) and self.result_rank[0] == self.get_idx:
- res = self.result_data[0]
- del self.result_data[0], self.result_rank[0]
- return res
-
- while True:
- # make sure the results are returned in the correct order
- idx, res = self.result_queue.get()
- if idx == self.get_idx:
- return res
- insert = bisect.bisect(self.result_rank, idx)
- self.result_rank.insert(insert, idx)
- self.result_data.insert(insert, res)
-
- def __len__(self):
- return self.put_idx - self.get_idx
-
- def __call__(self, image):
- self.put(image)
- return self.get()
-
- def shutdown(self):
- for _ in self.procs:
- self.task_queue.put(AsyncPredictor._StopToken())
-
- @property
- def default_buffer_size(self):
- return len(self.procs) * 5
diff --git a/spaces/bigjoker/stable-diffusion-webui/modules/api/api.py b/spaces/bigjoker/stable-diffusion-webui/modules/api/api.py
deleted file mode 100644
index 5a9ac5f1aa745e4dd8c9ed5a107dd840f05c0ba6..0000000000000000000000000000000000000000
--- a/spaces/bigjoker/stable-diffusion-webui/modules/api/api.py
+++ /dev/null
@@ -1,551 +0,0 @@
-import base64
-import io
-import time
-import datetime
-import uvicorn
-from threading import Lock
-from io import BytesIO
-from gradio.processing_utils import decode_base64_to_file
-from fastapi import APIRouter, Depends, FastAPI, HTTPException, Request, Response
-from fastapi.security import HTTPBasic, HTTPBasicCredentials
-from secrets import compare_digest
-
-import modules.shared as shared
-from modules import sd_samplers, deepbooru, sd_hijack, images, scripts, ui, postprocessing
-from modules.api.models import *
-from modules.processing import StableDiffusionProcessingTxt2Img, StableDiffusionProcessingImg2Img, process_images
-from modules.textual_inversion.textual_inversion import create_embedding, train_embedding
-from modules.textual_inversion.preprocess import preprocess
-from modules.hypernetworks.hypernetwork import create_hypernetwork, train_hypernetwork
-from PIL import PngImagePlugin,Image
-from modules.sd_models import checkpoints_list
-from modules.sd_models_config import find_checkpoint_config_near_filename
-from modules.realesrgan_model import get_realesrgan_models
-from modules import devices
-from typing import List
-import piexif
-import piexif.helper
-
-def upscaler_to_index(name: str):
- try:
- return [x.name.lower() for x in shared.sd_upscalers].index(name.lower())
- except:
- raise HTTPException(status_code=400, detail=f"Invalid upscaler, needs to be one of these: {' , '.join([x.name for x in sd_upscalers])}")
-
-def script_name_to_index(name, scripts):
- try:
- return [script.title().lower() for script in scripts].index(name.lower())
- except:
- raise HTTPException(status_code=422, detail=f"Script '{name}' not found")
-
-def validate_sampler_name(name):
- config = sd_samplers.all_samplers_map.get(name, None)
- if config is None:
- raise HTTPException(status_code=404, detail="Sampler not found")
-
- return name
-
-def setUpscalers(req: dict):
- reqDict = vars(req)
- reqDict['extras_upscaler_1'] = reqDict.pop('upscaler_1', None)
- reqDict['extras_upscaler_2'] = reqDict.pop('upscaler_2', None)
- return reqDict
-
-def decode_base64_to_image(encoding):
- if encoding.startswith("data:image/"):
- encoding = encoding.split(";")[1].split(",")[1]
- try:
- image = Image.open(BytesIO(base64.b64decode(encoding)))
- return image
- except Exception as err:
- raise HTTPException(status_code=500, detail="Invalid encoded image")
-
-def encode_pil_to_base64(image):
- with io.BytesIO() as output_bytes:
-
- if opts.samples_format.lower() == 'png':
- use_metadata = False
- metadata = PngImagePlugin.PngInfo()
- for key, value in image.info.items():
- if isinstance(key, str) and isinstance(value, str):
- metadata.add_text(key, value)
- use_metadata = True
- image.save(output_bytes, format="PNG", pnginfo=(metadata if use_metadata else None), quality=opts.jpeg_quality)
-
- elif opts.samples_format.lower() in ("jpg", "jpeg", "webp"):
- parameters = image.info.get('parameters', None)
- exif_bytes = piexif.dump({
- "Exif": { piexif.ExifIFD.UserComment: piexif.helper.UserComment.dump(parameters or "", encoding="unicode") }
- })
- if opts.samples_format.lower() in ("jpg", "jpeg"):
- image.save(output_bytes, format="JPEG", exif = exif_bytes, quality=opts.jpeg_quality)
- else:
- image.save(output_bytes, format="WEBP", exif = exif_bytes, quality=opts.jpeg_quality)
-
- else:
- raise HTTPException(status_code=500, detail="Invalid image format")
-
- bytes_data = output_bytes.getvalue()
-
- return base64.b64encode(bytes_data)
-
-def api_middleware(app: FastAPI):
- @app.middleware("http")
- async def log_and_time(req: Request, call_next):
- ts = time.time()
- res: Response = await call_next(req)
- duration = str(round(time.time() - ts, 4))
- res.headers["X-Process-Time"] = duration
- endpoint = req.scope.get('path', 'err')
- if shared.cmd_opts.api_log and endpoint.startswith('/sdapi'):
- print('API {t} {code} {prot}/{ver} {method} {endpoint} {cli} {duration}'.format(
- t = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f"),
- code = res.status_code,
- ver = req.scope.get('http_version', '0.0'),
- cli = req.scope.get('client', ('0:0.0.0', 0))[0],
- prot = req.scope.get('scheme', 'err'),
- method = req.scope.get('method', 'err'),
- endpoint = endpoint,
- duration = duration,
- ))
- return res
-
-
-class Api:
- def __init__(self, app: FastAPI, queue_lock: Lock):
- if shared.cmd_opts.api_auth:
- self.credentials = dict()
- for auth in shared.cmd_opts.api_auth.split(","):
- user, password = auth.split(":")
- self.credentials[user] = password
-
- self.router = APIRouter()
- self.app = app
- self.queue_lock = queue_lock
- api_middleware(self.app)
- self.add_api_route("/sdapi/v1/txt2img", self.text2imgapi, methods=["POST"], response_model=TextToImageResponse)
- self.add_api_route("/sdapi/v1/img2img", self.img2imgapi, methods=["POST"], response_model=ImageToImageResponse)
- self.add_api_route("/sdapi/v1/extra-single-image", self.extras_single_image_api, methods=["POST"], response_model=ExtrasSingleImageResponse)
- self.add_api_route("/sdapi/v1/extra-batch-images", self.extras_batch_images_api, methods=["POST"], response_model=ExtrasBatchImagesResponse)
- self.add_api_route("/sdapi/v1/png-info", self.pnginfoapi, methods=["POST"], response_model=PNGInfoResponse)
- self.add_api_route("/sdapi/v1/progress", self.progressapi, methods=["GET"], response_model=ProgressResponse)
- self.add_api_route("/sdapi/v1/interrogate", self.interrogateapi, methods=["POST"])
- self.add_api_route("/sdapi/v1/interrupt", self.interruptapi, methods=["POST"])
- self.add_api_route("/sdapi/v1/skip", self.skip, methods=["POST"])
- self.add_api_route("/sdapi/v1/options", self.get_config, methods=["GET"], response_model=OptionsModel)
- self.add_api_route("/sdapi/v1/options", self.set_config, methods=["POST"])
- self.add_api_route("/sdapi/v1/cmd-flags", self.get_cmd_flags, methods=["GET"], response_model=FlagsModel)
- self.add_api_route("/sdapi/v1/samplers", self.get_samplers, methods=["GET"], response_model=List[SamplerItem])
- self.add_api_route("/sdapi/v1/upscalers", self.get_upscalers, methods=["GET"], response_model=List[UpscalerItem])
- self.add_api_route("/sdapi/v1/sd-models", self.get_sd_models, methods=["GET"], response_model=List[SDModelItem])
- self.add_api_route("/sdapi/v1/hypernetworks", self.get_hypernetworks, methods=["GET"], response_model=List[HypernetworkItem])
- self.add_api_route("/sdapi/v1/face-restorers", self.get_face_restorers, methods=["GET"], response_model=List[FaceRestorerItem])
- self.add_api_route("/sdapi/v1/realesrgan-models", self.get_realesrgan_models, methods=["GET"], response_model=List[RealesrganItem])
- self.add_api_route("/sdapi/v1/prompt-styles", self.get_prompt_styles, methods=["GET"], response_model=List[PromptStyleItem])
- self.add_api_route("/sdapi/v1/embeddings", self.get_embeddings, methods=["GET"], response_model=EmbeddingsResponse)
- self.add_api_route("/sdapi/v1/refresh-checkpoints", self.refresh_checkpoints, methods=["POST"])
- self.add_api_route("/sdapi/v1/create/embedding", self.create_embedding, methods=["POST"], response_model=CreateResponse)
- self.add_api_route("/sdapi/v1/create/hypernetwork", self.create_hypernetwork, methods=["POST"], response_model=CreateResponse)
- self.add_api_route("/sdapi/v1/preprocess", self.preprocess, methods=["POST"], response_model=PreprocessResponse)
- self.add_api_route("/sdapi/v1/train/embedding", self.train_embedding, methods=["POST"], response_model=TrainResponse)
- self.add_api_route("/sdapi/v1/train/hypernetwork", self.train_hypernetwork, methods=["POST"], response_model=TrainResponse)
- self.add_api_route("/sdapi/v1/memory", self.get_memory, methods=["GET"], response_model=MemoryResponse)
-
- def add_api_route(self, path: str, endpoint, **kwargs):
- if shared.cmd_opts.api_auth:
- return self.app.add_api_route(path, endpoint, dependencies=[Depends(self.auth)], **kwargs)
- return self.app.add_api_route(path, endpoint, **kwargs)
-
- def auth(self, credentials: HTTPBasicCredentials = Depends(HTTPBasic())):
- if credentials.username in self.credentials:
- if compare_digest(credentials.password, self.credentials[credentials.username]):
- return True
-
- raise HTTPException(status_code=401, detail="Incorrect username or password", headers={"WWW-Authenticate": "Basic"})
-
- def get_script(self, script_name, script_runner):
- if script_name is None:
- return None, None
-
- if not script_runner.scripts:
- script_runner.initialize_scripts(False)
- ui.create_ui()
-
- script_idx = script_name_to_index(script_name, script_runner.selectable_scripts)
- script = script_runner.selectable_scripts[script_idx]
- return script, script_idx
-
- def text2imgapi(self, txt2imgreq: StableDiffusionTxt2ImgProcessingAPI):
- script, script_idx = self.get_script(txt2imgreq.script_name, scripts.scripts_txt2img)
-
- populate = txt2imgreq.copy(update={ # Override __init__ params
- "sampler_name": validate_sampler_name(txt2imgreq.sampler_name or txt2imgreq.sampler_index),
- "do_not_save_samples": True,
- "do_not_save_grid": True
- }
- )
- if populate.sampler_name:
- populate.sampler_index = None # prevent a warning later on
-
- args = vars(populate)
- args.pop('script_name', None)
-
- with self.queue_lock:
- p = StableDiffusionProcessingTxt2Img(sd_model=shared.sd_model, **args)
-
- shared.state.begin()
- if script is not None:
- p.outpath_grids = opts.outdir_txt2img_grids
- p.outpath_samples = opts.outdir_txt2img_samples
- p.script_args = [script_idx + 1] + [None] * (script.args_from - 1) + p.script_args
- processed = scripts.scripts_txt2img.run(p, *p.script_args)
- else:
- processed = process_images(p)
- shared.state.end()
-
- b64images = list(map(encode_pil_to_base64, processed.images))
-
- return TextToImageResponse(images=b64images, parameters=vars(txt2imgreq), info=processed.js())
-
- def img2imgapi(self, img2imgreq: StableDiffusionImg2ImgProcessingAPI):
- init_images = img2imgreq.init_images
- if init_images is None:
- raise HTTPException(status_code=404, detail="Init image not found")
-
- script, script_idx = self.get_script(img2imgreq.script_name, scripts.scripts_img2img)
-
- mask = img2imgreq.mask
- if mask:
- mask = decode_base64_to_image(mask)
-
- populate = img2imgreq.copy(update={ # Override __init__ params
- "sampler_name": validate_sampler_name(img2imgreq.sampler_name or img2imgreq.sampler_index),
- "do_not_save_samples": True,
- "do_not_save_grid": True,
- "mask": mask
- }
- )
- if populate.sampler_name:
- populate.sampler_index = None # prevent a warning later on
-
- args = vars(populate)
- args.pop('include_init_images', None) # this is meant to be done by "exclude": True in model, but it's for a reason that I cannot determine.
- args.pop('script_name', None)
-
- with self.queue_lock:
- p = StableDiffusionProcessingImg2Img(sd_model=shared.sd_model, **args)
- p.init_images = [decode_base64_to_image(x) for x in init_images]
-
- shared.state.begin()
- if script is not None:
- p.outpath_grids = opts.outdir_img2img_grids
- p.outpath_samples = opts.outdir_img2img_samples
- p.script_args = [script_idx + 1] + [None] * (script.args_from - 1) + p.script_args
- processed = scripts.scripts_img2img.run(p, *p.script_args)
- else:
- processed = process_images(p)
- shared.state.end()
-
- b64images = list(map(encode_pil_to_base64, processed.images))
-
- if not img2imgreq.include_init_images:
- img2imgreq.init_images = None
- img2imgreq.mask = None
-
- return ImageToImageResponse(images=b64images, parameters=vars(img2imgreq), info=processed.js())
-
- def extras_single_image_api(self, req: ExtrasSingleImageRequest):
- reqDict = setUpscalers(req)
-
- reqDict['image'] = decode_base64_to_image(reqDict['image'])
-
- with self.queue_lock:
- result = postprocessing.run_extras(extras_mode=0, image_folder="", input_dir="", output_dir="", save_output=False, **reqDict)
-
- return ExtrasSingleImageResponse(image=encode_pil_to_base64(result[0][0]), html_info=result[1])
-
- def extras_batch_images_api(self, req: ExtrasBatchImagesRequest):
- reqDict = setUpscalers(req)
-
- def prepareFiles(file):
- file = decode_base64_to_file(file.data, file_path=file.name)
- file.orig_name = file.name
- return file
-
- reqDict['image_folder'] = list(map(prepareFiles, reqDict['imageList']))
- reqDict.pop('imageList')
-
- with self.queue_lock:
- result = postprocessing.run_extras(extras_mode=1, image="", input_dir="", output_dir="", save_output=False, **reqDict)
-
- return ExtrasBatchImagesResponse(images=list(map(encode_pil_to_base64, result[0])), html_info=result[1])
-
- def pnginfoapi(self, req: PNGInfoRequest):
- if(not req.image.strip()):
- return PNGInfoResponse(info="")
-
- image = decode_base64_to_image(req.image.strip())
- if image is None:
- return PNGInfoResponse(info="")
-
- geninfo, items = images.read_info_from_image(image)
- if geninfo is None:
- geninfo = ""
-
- items = {**{'parameters': geninfo}, **items}
-
- return PNGInfoResponse(info=geninfo, items=items)
-
- def progressapi(self, req: ProgressRequest = Depends()):
- # copy from check_progress_call of ui.py
-
- if shared.state.job_count == 0:
- return ProgressResponse(progress=0, eta_relative=0, state=shared.state.dict(), textinfo=shared.state.textinfo)
-
- # avoid dividing zero
- progress = 0.01
-
- if shared.state.job_count > 0:
- progress += shared.state.job_no / shared.state.job_count
- if shared.state.sampling_steps > 0:
- progress += 1 / shared.state.job_count * shared.state.sampling_step / shared.state.sampling_steps
-
- time_since_start = time.time() - shared.state.time_start
- eta = (time_since_start/progress)
- eta_relative = eta-time_since_start
-
- progress = min(progress, 1)
-
- shared.state.set_current_image()
-
- current_image = None
- if shared.state.current_image and not req.skip_current_image:
- current_image = encode_pil_to_base64(shared.state.current_image)
-
- return ProgressResponse(progress=progress, eta_relative=eta_relative, state=shared.state.dict(), current_image=current_image, textinfo=shared.state.textinfo)
-
- def interrogateapi(self, interrogatereq: InterrogateRequest):
- image_b64 = interrogatereq.image
- if image_b64 is None:
- raise HTTPException(status_code=404, detail="Image not found")
-
- img = decode_base64_to_image(image_b64)
- img = img.convert('RGB')
-
- # Override object param
- with self.queue_lock:
- if interrogatereq.model == "clip":
- processed = shared.interrogator.interrogate(img)
- elif interrogatereq.model == "deepdanbooru":
- processed = deepbooru.model.tag(img)
- else:
- raise HTTPException(status_code=404, detail="Model not found")
-
- return InterrogateResponse(caption=processed)
-
- def interruptapi(self):
- shared.state.interrupt()
-
- return {}
-
- def skip(self):
- shared.state.skip()
-
- def get_config(self):
- options = {}
- for key in shared.opts.data.keys():
- metadata = shared.opts.data_labels.get(key)
- if(metadata is not None):
- options.update({key: shared.opts.data.get(key, shared.opts.data_labels.get(key).default)})
- else:
- options.update({key: shared.opts.data.get(key, None)})
-
- return options
-
- def set_config(self, req: Dict[str, Any]):
- for k, v in req.items():
- shared.opts.set(k, v)
-
- shared.opts.save(shared.config_filename)
- return
-
- def get_cmd_flags(self):
- return vars(shared.cmd_opts)
-
- def get_samplers(self):
- return [{"name": sampler[0], "aliases":sampler[2], "options":sampler[3]} for sampler in sd_samplers.all_samplers]
-
- def get_upscalers(self):
- return [
- {
- "name": upscaler.name,
- "model_name": upscaler.scaler.model_name,
- "model_path": upscaler.data_path,
- "model_url": None,
- "scale": upscaler.scale,
- }
- for upscaler in shared.sd_upscalers
- ]
-
- def get_sd_models(self):
- return [{"title": x.title, "model_name": x.model_name, "hash": x.shorthash, "sha256": x.sha256, "filename": x.filename, "config": find_checkpoint_config_near_filename(x)} for x in checkpoints_list.values()]
-
- def get_hypernetworks(self):
- return [{"name": name, "path": shared.hypernetworks[name]} for name in shared.hypernetworks]
-
- def get_face_restorers(self):
- return [{"name":x.name(), "cmd_dir": getattr(x, "cmd_dir", None)} for x in shared.face_restorers]
-
- def get_realesrgan_models(self):
- return [{"name":x.name,"path":x.data_path, "scale":x.scale} for x in get_realesrgan_models(None)]
-
- def get_prompt_styles(self):
- styleList = []
- for k in shared.prompt_styles.styles:
- style = shared.prompt_styles.styles[k]
- styleList.append({"name":style[0], "prompt": style[1], "negative_prompt": style[2]})
-
- return styleList
-
- def get_embeddings(self):
- db = sd_hijack.model_hijack.embedding_db
-
- def convert_embedding(embedding):
- return {
- "step": embedding.step,
- "sd_checkpoint": embedding.sd_checkpoint,
- "sd_checkpoint_name": embedding.sd_checkpoint_name,
- "shape": embedding.shape,
- "vectors": embedding.vectors,
- }
-
- def convert_embeddings(embeddings):
- return {embedding.name: convert_embedding(embedding) for embedding in embeddings.values()}
-
- return {
- "loaded": convert_embeddings(db.word_embeddings),
- "skipped": convert_embeddings(db.skipped_embeddings),
- }
-
- def refresh_checkpoints(self):
- shared.refresh_checkpoints()
-
- def create_embedding(self, args: dict):
- try:
- shared.state.begin()
- filename = create_embedding(**args) # create empty embedding
- sd_hijack.model_hijack.embedding_db.load_textual_inversion_embeddings() # reload embeddings so new one can be immediately used
- shared.state.end()
- return CreateResponse(info = "create embedding filename: {filename}".format(filename = filename))
- except AssertionError as e:
- shared.state.end()
- return TrainResponse(info = "create embedding error: {error}".format(error = e))
-
- def create_hypernetwork(self, args: dict):
- try:
- shared.state.begin()
- filename = create_hypernetwork(**args) # create empty embedding
- shared.state.end()
- return CreateResponse(info = "create hypernetwork filename: {filename}".format(filename = filename))
- except AssertionError as e:
- shared.state.end()
- return TrainResponse(info = "create hypernetwork error: {error}".format(error = e))
-
- def preprocess(self, args: dict):
- try:
- shared.state.begin()
- preprocess(**args) # quick operation unless blip/booru interrogation is enabled
- shared.state.end()
- return PreprocessResponse(info = 'preprocess complete')
- except KeyError as e:
- shared.state.end()
- return PreprocessResponse(info = "preprocess error: invalid token: {error}".format(error = e))
- except AssertionError as e:
- shared.state.end()
- return PreprocessResponse(info = "preprocess error: {error}".format(error = e))
- except FileNotFoundError as e:
- shared.state.end()
- return PreprocessResponse(info = 'preprocess error: {error}'.format(error = e))
-
- def train_embedding(self, args: dict):
- try:
- shared.state.begin()
- apply_optimizations = shared.opts.training_xattention_optimizations
- error = None
- filename = ''
- if not apply_optimizations:
- sd_hijack.undo_optimizations()
- try:
- embedding, filename = train_embedding(**args) # can take a long time to complete
- except Exception as e:
- error = e
- finally:
- if not apply_optimizations:
- sd_hijack.apply_optimizations()
- shared.state.end()
- return TrainResponse(info = "train embedding complete: filename: {filename} error: {error}".format(filename = filename, error = error))
- except AssertionError as msg:
- shared.state.end()
- return TrainResponse(info = "train embedding error: {msg}".format(msg = msg))
-
- def train_hypernetwork(self, args: dict):
- try:
- shared.state.begin()
- shared.loaded_hypernetworks = []
- apply_optimizations = shared.opts.training_xattention_optimizations
- error = None
- filename = ''
- if not apply_optimizations:
- sd_hijack.undo_optimizations()
- try:
- hypernetwork, filename = train_hypernetwork(**args)
- except Exception as e:
- error = e
- finally:
- shared.sd_model.cond_stage_model.to(devices.device)
- shared.sd_model.first_stage_model.to(devices.device)
- if not apply_optimizations:
- sd_hijack.apply_optimizations()
- shared.state.end()
- return TrainResponse(info="train embedding complete: filename: {filename} error: {error}".format(filename=filename, error=error))
- except AssertionError as msg:
- shared.state.end()
- return TrainResponse(info="train embedding error: {error}".format(error=error))
-
- def get_memory(self):
- try:
- import os, psutil
- process = psutil.Process(os.getpid())
- res = process.memory_info() # only rss is cross-platform guaranteed so we dont rely on other values
- ram_total = 100 * res.rss / process.memory_percent() # and total memory is calculated as actual value is not cross-platform safe
- ram = { 'free': ram_total - res.rss, 'used': res.rss, 'total': ram_total }
- except Exception as err:
- ram = { 'error': f'{err}' }
- try:
- import torch
- if torch.cuda.is_available():
- s = torch.cuda.mem_get_info()
- system = { 'free': s[0], 'used': s[1] - s[0], 'total': s[1] }
- s = dict(torch.cuda.memory_stats(shared.device))
- allocated = { 'current': s['allocated_bytes.all.current'], 'peak': s['allocated_bytes.all.peak'] }
- reserved = { 'current': s['reserved_bytes.all.current'], 'peak': s['reserved_bytes.all.peak'] }
- active = { 'current': s['active_bytes.all.current'], 'peak': s['active_bytes.all.peak'] }
- inactive = { 'current': s['inactive_split_bytes.all.current'], 'peak': s['inactive_split_bytes.all.peak'] }
- warnings = { 'retries': s['num_alloc_retries'], 'oom': s['num_ooms'] }
- cuda = {
- 'system': system,
- 'active': active,
- 'allocated': allocated,
- 'reserved': reserved,
- 'inactive': inactive,
- 'events': warnings,
- }
- else:
- cuda = { 'error': 'unavailable' }
- except Exception as err:
- cuda = { 'error': f'{err}' }
- return MemoryResponse(ram = ram, cuda = cuda)
-
- def launch(self, server_name, port):
- self.app.include_router(self.router)
- uvicorn.run(self.app, host=server_name, port=port)
diff --git a/spaces/botmaster/generate-mother-2/app.py b/spaces/botmaster/generate-mother-2/app.py
deleted file mode 100644
index d08914575bd0d7cda333dc98393ae22b45ce4c13..0000000000000000000000000000000000000000
--- a/spaces/botmaster/generate-mother-2/app.py
+++ /dev/null
@@ -1,45 +0,0 @@
-import gradio as gr
-from datasets import load_dataset, Image
-
-import torch
-import nltk
-import io
-import base64
-import shutil
-from torchvision import transforms
-
-from pytorch_pretrained_biggan import BigGAN, one_hot_from_names, truncated_noise_sample
-
-class PreTrainedPipeline():
- def __init__(self, path=""):
- """
- Initialize model
- """
- nltk.download('wordnet')
- self.model = BigGAN.from_pretrained(path)
- self.truncation = 0.1
-
- def __call__(self, inputs: str):
- """
- Args:
- inputs (:obj:`str`):
- a string containing some text
- Return:
- A :obj:`PIL.Image` with the raw image representation as PIL.
- """
- class_vector = one_hot_from_names([inputs], batch_size=1)
- if type(class_vector) == type(None):
- raise ValueError("Input is not in ImageNet")
- noise_vector = truncated_noise_sample(truncation=self.truncation, batch_size=1)
- noise_vector = torch.from_numpy(noise_vector)
- class_vector = torch.from_numpy(class_vector)
- with torch.no_grad():
- output = self.model(noise_vector, class_vector, self.truncation)
-
- # Scale image
- img = output[0]
- img = (img + 1) / 2.0
- img = transforms.ToPILImage()(img)
-
-dataset = load_dataset("botmaster/mother-2-battle-sprites", split="train")
-gr.Interface.load("models/templates/text-to-image").launch()
diff --git a/spaces/bradarrML/stablediffusion-infinity/utils.py b/spaces/bradarrML/stablediffusion-infinity/utils.py
deleted file mode 100644
index bebc4f7f4da8f6de637b148f39aa6a5ef60679c5..0000000000000000000000000000000000000000
--- a/spaces/bradarrML/stablediffusion-infinity/utils.py
+++ /dev/null
@@ -1,217 +0,0 @@
-from PIL import Image
-from PIL import ImageFilter
-import cv2
-import numpy as np
-import scipy
-import scipy.signal
-from scipy.spatial import cKDTree
-
-import os
-from perlin2d import *
-
-patch_match_compiled = True
-
-try:
- from PyPatchMatch import patch_match
-except Exception as e:
- try:
- import patch_match
- except Exception as e:
- patch_match_compiled = False
-
-try:
- patch_match
-except NameError:
- print("patch_match compiling failed, will fall back to edge_pad")
- patch_match_compiled = False
-
-
-
-
-def edge_pad(img, mask, mode=1):
- if mode == 0:
- nmask = mask.copy()
- nmask[nmask > 0] = 1
- res0 = 1 - nmask
- res1 = nmask
- p0 = np.stack(res0.nonzero(), axis=0).transpose()
- p1 = np.stack(res1.nonzero(), axis=0).transpose()
- min_dists, min_dist_idx = cKDTree(p1).query(p0, 1)
- loc = p1[min_dist_idx]
- for (a, b), (c, d) in zip(p0, loc):
- img[a, b] = img[c, d]
- elif mode == 1:
- record = {}
- kernel = [[1] * 3 for _ in range(3)]
- nmask = mask.copy()
- nmask[nmask > 0] = 1
- res = scipy.signal.convolve2d(
- nmask, kernel, mode="same", boundary="fill", fillvalue=1
- )
- res[nmask < 1] = 0
- res[res == 9] = 0
- res[res > 0] = 1
- ylst, xlst = res.nonzero()
- queue = [(y, x) for y, x in zip(ylst, xlst)]
- # bfs here
- cnt = res.astype(np.float32)
- acc = img.astype(np.float32)
- step = 1
- h = acc.shape[0]
- w = acc.shape[1]
- offset = [(1, 0), (-1, 0), (0, 1), (0, -1)]
- while queue:
- target = []
- for y, x in queue:
- val = acc[y][x]
- for yo, xo in offset:
- yn = y + yo
- xn = x + xo
- if 0 <= yn < h and 0 <= xn < w and nmask[yn][xn] < 1:
- if record.get((yn, xn), step) == step:
- acc[yn][xn] = acc[yn][xn] * cnt[yn][xn] + val
- cnt[yn][xn] += 1
- acc[yn][xn] /= cnt[yn][xn]
- if (yn, xn) not in record:
- record[(yn, xn)] = step
- target.append((yn, xn))
- step += 1
- queue = target
- img = acc.astype(np.uint8)
- else:
- nmask = mask.copy()
- ylst, xlst = nmask.nonzero()
- yt, xt = ylst.min(), xlst.min()
- yb, xb = ylst.max(), xlst.max()
- content = img[yt : yb + 1, xt : xb + 1]
- img = np.pad(
- content,
- ((yt, mask.shape[0] - yb - 1), (xt, mask.shape[1] - xb - 1), (0, 0)),
- mode="edge",
- )
- return img, mask
-
-
-def perlin_noise(img, mask):
- lin = np.linspace(0, 5, mask.shape[0], endpoint=False)
- x, y = np.meshgrid(lin, lin)
- avg = img.mean(axis=0).mean(axis=0)
- # noise=[((perlin(x, y)+1)*128+avg[i]).astype(np.uint8) for i in range(3)]
- noise = [((perlin(x, y) + 1) * 0.5 * 255).astype(np.uint8) for i in range(3)]
- noise = np.stack(noise, axis=-1)
- # mask=skimage.measure.block_reduce(mask,(8,8),np.min)
- # mask=mask.repeat(8, axis=0).repeat(8, axis=1)
- # mask_image=Image.fromarray(mask)
- # mask_image=mask_image.filter(ImageFilter.GaussianBlur(radius = 4))
- # mask=np.array(mask_image)
- nmask = mask.copy()
- # nmask=nmask/255.0
- nmask[mask > 0] = 1
- img = nmask[:, :, np.newaxis] * img + (1 - nmask[:, :, np.newaxis]) * noise
- # img=img.astype(np.uint8)
- return img, mask
-
-
-def gaussian_noise(img, mask):
- noise = np.random.randn(mask.shape[0], mask.shape[1], 3)
- noise = (noise + 1) / 2 * 255
- noise = noise.astype(np.uint8)
- nmask = mask.copy()
- nmask[mask > 0] = 1
- img = nmask[:, :, np.newaxis] * img + (1 - nmask[:, :, np.newaxis]) * noise
- return img, mask
-
-
-def cv2_telea(img, mask):
- ret = cv2.inpaint(img, 255 - mask, 5, cv2.INPAINT_TELEA)
- return ret, mask
-
-
-def cv2_ns(img, mask):
- ret = cv2.inpaint(img, 255 - mask, 5, cv2.INPAINT_NS)
- return ret, mask
-
-
-def patch_match_func(img, mask):
- ret = patch_match.inpaint(img, mask=255 - mask, patch_size=3)
- return ret, mask
-
-
-def mean_fill(img, mask):
- avg = img.mean(axis=0).mean(axis=0)
- img[mask < 1] = avg
- return img, mask
-
-def g_diffuser(img,mask):
- return img, mask
-
-def dummy_fill(img,mask):
- return img,mask
-functbl = {
- "gaussian": gaussian_noise,
- "perlin": perlin_noise,
- "edge_pad": edge_pad,
- "patchmatch": patch_match_func if patch_match_compiled else edge_pad,
- "cv2_ns": cv2_ns,
- "cv2_telea": cv2_telea,
- "g_diffuser": g_diffuser,
- "g_diffuser_lib": dummy_fill,
-}
-
-try:
- from postprocess import PhotometricCorrection
- correction_func = PhotometricCorrection()
-except Exception as e:
- print(e, "so PhotometricCorrection is disabled")
- class DummyCorrection:
- def __init__(self):
- self.backend=""
- pass
- def run(self,a,b,**kwargs):
- return b
- correction_func=DummyCorrection()
-
-if "taichi" in correction_func.backend:
- import sys
- import io
- import base64
- from PIL import Image
- def base64_to_pil(base64_str):
- data = base64.b64decode(str(base64_str))
- pil = Image.open(io.BytesIO(data))
- return pil
-
- def pil_to_base64(out_pil):
- out_buffer = io.BytesIO()
- out_pil.save(out_buffer, format="PNG")
- out_buffer.seek(0)
- base64_bytes = base64.b64encode(out_buffer.read())
- base64_str = base64_bytes.decode("ascii")
- return base64_str
- from subprocess import Popen, PIPE, STDOUT
- class SubprocessCorrection:
- def __init__(self):
- self.backend=correction_func.backend
- self.child= Popen(["python", "postprocess.py"], stdin=PIPE, stdout=PIPE, stderr=STDOUT)
- def run(self,img_input,img_inpainted,mode):
- if mode=="disabled":
- return img_inpainted
- base64_str_input = pil_to_base64(img_input)
- base64_str_inpainted = pil_to_base64(img_inpainted)
- try:
- if self.child.poll():
- self.child= Popen(["python", "postprocess.py"], stdin=PIPE, stdout=PIPE, stderr=STDOUT)
- self.child.stdin.write(f"{base64_str_input},{base64_str_inpainted},{mode}\n".encode())
- self.child.stdin.flush()
- out = self.child.stdout.readline()
- base64_str=out.decode().strip()
- while base64_str and base64_str[0]=="[":
- print(base64_str)
- out = self.child.stdout.readline()
- base64_str=out.decode().strip()
- ret=base64_to_pil(base64_str)
- except:
- print("[PIE] not working, photometric correction is disabled")
- ret=img_inpainted
- return ret
- correction_func = SubprocessCorrection()
diff --git a/spaces/brjathu/HMR2.0/vendor/pyrender/examples/duck.py b/spaces/brjathu/HMR2.0/vendor/pyrender/examples/duck.py
deleted file mode 100644
index 9a94bad5bfb30493f7364f2e52cbb4badbccb2c7..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/pyrender/examples/duck.py
+++ /dev/null
@@ -1,13 +0,0 @@
-from pyrender import Mesh, Scene, Viewer
-from io import BytesIO
-import numpy as np
-import trimesh
-import requests
-
-duck_source = "https://github.com/KhronosGroup/glTF-Sample-Models/raw/master/2.0/Duck/glTF-Binary/Duck.glb"
-
-duck = trimesh.load(BytesIO(requests.get(duck_source).content), file_type='glb')
-duckmesh = Mesh.from_trimesh(list(duck.geometry.values())[0])
-scene = Scene(ambient_light=np.array([1.0, 1.0, 1.0, 1.0]))
-scene.add(duckmesh)
-Viewer(scene)
diff --git a/spaces/cakiki/facets-overview/Makefile b/spaces/cakiki/facets-overview/Makefile
deleted file mode 100644
index a6f28a7a554e30a25202cca5f276d7d10b24dc26..0000000000000000000000000000000000000000
--- a/spaces/cakiki/facets-overview/Makefile
+++ /dev/null
@@ -1,13 +0,0 @@
-VERSION := 0.0.1
-NAME := facets-dive
-REPO := cakiki
-
-build:
- docker build -f Dockerfile -t ${REPO}/${NAME}:${VERSION} -t ${REPO}/${NAME}:latest .
-
-run: build
- docker run --rm -it -p 8888:8888 --mount type=bind,source=${PWD},target=/home/jovyan/work --name ${NAME} --workdir=/home/jovyan/work ${REPO}/${NAME}:${VERSION}
-
-push: build
- docker push ${REPO}/${NAME}:${VERSION} && docker push ${REPO}/${NAME}:latest
-
diff --git a/spaces/camenduru/11/index.html b/spaces/camenduru/11/index.html
deleted file mode 100644
index 58b6947afdd827d073af572e47cf1a27b3a31d60..0000000000000000000000000000000000000000
--- a/spaces/camenduru/11/index.html
+++ /dev/null
@@ -1,10 +0,0 @@
-
-
-
- Welcome to My Web Server
-
-
-
-
- '''
- )
-
- app.queue(concurrency_count=3).launch(show_api=False, share=args.share)
diff --git a/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/custom_embedding.py b/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/custom_embedding.py
deleted file mode 100644
index ab357952c397f47898863e8405c4958bb8de82fd..0000000000000000000000000000000000000000
--- a/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/custom_embedding.py
+++ /dev/null
@@ -1,11 +0,0 @@
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch import Tensor
-
-class SharedEmbedding(nn.Embedding):
-
- def forward(self, input: Tensor, unembed: bool=False) -> Tensor:
- if unembed:
- return F.linear(input, self.weight)
- return super().forward(input)
\ No newline at end of file
diff --git a/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/param_init_fns.py b/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/param_init_fns.py
deleted file mode 100644
index 418b83ca2363288046f4b48b1d706c5607341fb5..0000000000000000000000000000000000000000
--- a/spaces/badayvedat/LLaVA/llava/model/language_model/mpt/param_init_fns.py
+++ /dev/null
@@ -1,181 +0,0 @@
-import math
-import warnings
-from collections.abc import Sequence
-from functools import partial
-from typing import Optional, Tuple, Union
-import torch
-from torch import nn
-from .norm import NORM_CLASS_REGISTRY
-
-def torch_default_param_init_fn_(module: nn.Module, verbose: int=0, **kwargs):
- del kwargs
- if verbose > 1:
- warnings.warn(f"Initializing network using module's reset_parameters attribute")
- if hasattr(module, 'reset_parameters'):
- module.reset_parameters()
-
-def fused_init_helper_(module: nn.Module, init_fn_):
- _fused = getattr(module, '_fused', None)
- if _fused is None:
- raise RuntimeError(f'Internal logic error')
- (dim, splits) = _fused
- splits = (0, *splits, module.weight.size(dim))
- for (s, e) in zip(splits[:-1], splits[1:]):
- slice_indices = [slice(None)] * module.weight.ndim
- slice_indices[dim] = slice(s, e)
- init_fn_(module.weight[slice_indices])
-
-def generic_param_init_fn_(module: nn.Module, init_fn_, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- del kwargs
- if verbose > 1:
- warnings.warn(f'If model has bias parameters they are initialized to 0.')
- init_div_is_residual = init_div_is_residual
- if init_div_is_residual is False:
- div_is_residual = 1.0
- elif init_div_is_residual is True:
- div_is_residual = math.sqrt(2 * n_layers)
- elif isinstance(init_div_is_residual, float) or isinstance(init_div_is_residual, int):
- div_is_residual = init_div_is_residual
- elif isinstance(init_div_is_residual, str) and init_div_is_residual.isnumeric():
- div_is_residual = float(init_div_is_residual)
- else:
- div_is_residual = 1.0
- raise ValueError(f'Expected init_div_is_residual to be boolean or numeric, got {init_div_is_residual}')
- if init_div_is_residual is not False:
- if verbose > 1:
- warnings.warn(f'Initializing _is_residual layers then dividing them by {div_is_residual:.3f}. ' + f'Set `init_div_is_residual: false` in init config to disable this.')
- if isinstance(module, nn.Linear):
- if hasattr(module, '_fused'):
- fused_init_helper_(module, init_fn_)
- else:
- init_fn_(module.weight)
- if module.bias is not None:
- torch.nn.init.zeros_(module.bias)
- if init_div_is_residual is not False and getattr(module, '_is_residual', False):
- with torch.no_grad():
- module.weight.div_(div_is_residual)
- elif isinstance(module, nn.Embedding):
- if emb_init_std is not None:
- std = emb_init_std
- if std == 0:
- warnings.warn(f'Embedding layer initialized to 0.')
- emb_init_fn_ = partial(torch.nn.init.normal_, mean=0.0, std=std)
- if verbose > 1:
- warnings.warn(f'Embedding layer initialized using normal distribution with mean=0 and std={std!r}.')
- elif emb_init_uniform_lim is not None:
- lim = emb_init_uniform_lim
- if isinstance(lim, Sequence):
- if len(lim) > 2:
- raise ValueError(f'Uniform init requires a min and a max limit. User input: {lim}.')
- if lim[0] == lim[1]:
- warnings.warn(f'Embedding layer initialized to {lim[0]}.')
- else:
- if lim == 0:
- warnings.warn(f'Embedding layer initialized to 0.')
- lim = [-lim, lim]
- (a, b) = lim
- emb_init_fn_ = partial(torch.nn.init.uniform_, a=a, b=b)
- if verbose > 1:
- warnings.warn(f'Embedding layer initialized using uniform distribution in range {lim}.')
- else:
- emb_init_fn_ = init_fn_
- emb_init_fn_(module.weight)
- elif isinstance(module, tuple(set(NORM_CLASS_REGISTRY.values()))):
- if verbose > 1:
- warnings.warn(f'Norm weights are set to 1. If norm layer has a bias it is initialized to 0.')
- if hasattr(module, 'weight') and module.weight is not None:
- torch.nn.init.ones_(module.weight)
- if hasattr(module, 'bias') and module.bias is not None:
- torch.nn.init.zeros_(module.bias)
- elif isinstance(module, nn.MultiheadAttention):
- if module._qkv_same_embed_dim:
- assert module.in_proj_weight is not None
- assert module.q_proj_weight is None and module.k_proj_weight is None and (module.v_proj_weight is None)
- assert d_model is not None
- _d = d_model
- splits = (0, _d, 2 * _d, 3 * _d)
- for (s, e) in zip(splits[:-1], splits[1:]):
- init_fn_(module.in_proj_weight[s:e])
- else:
- assert module.q_proj_weight is not None and module.k_proj_weight is not None and (module.v_proj_weight is not None)
- assert module.in_proj_weight is None
- init_fn_(module.q_proj_weight)
- init_fn_(module.k_proj_weight)
- init_fn_(module.v_proj_weight)
- if module.in_proj_bias is not None:
- torch.nn.init.zeros_(module.in_proj_bias)
- if module.bias_k is not None:
- torch.nn.init.zeros_(module.bias_k)
- if module.bias_v is not None:
- torch.nn.init.zeros_(module.bias_v)
- init_fn_(module.out_proj.weight)
- if init_div_is_residual is not False and getattr(module.out_proj, '_is_residual', False):
- with torch.no_grad():
- module.out_proj.weight.div_(div_is_residual)
- if module.out_proj.bias is not None:
- torch.nn.init.zeros_(module.out_proj.bias)
- else:
- for _ in module.parameters(recurse=False):
- raise NotImplementedError(f'{module.__class__.__name__} parameters are not initialized by param_init_fn.')
-
-def _normal_init_(std, mean=0.0):
- return partial(torch.nn.init.normal_, mean=mean, std=std)
-
-def _normal_param_init_fn_(module: nn.Module, std: float, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- del kwargs
- init_fn_ = _normal_init_(std=std)
- if verbose > 1:
- warnings.warn(f'Using torch.nn.init.normal_ init fn mean=0.0, std={std}')
- generic_param_init_fn_(module=module, init_fn_=init_fn_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def baseline_param_init_fn_(module: nn.Module, init_std: float, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- del kwargs
- if init_std is None:
- raise ValueError("You must set model.init_config['init_std'] to a float value to use the default initialization scheme.")
- _normal_param_init_fn_(module=module, std=init_std, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def small_param_init_fn_(module: nn.Module, n_layers: int, d_model: int, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- del kwargs
- std = math.sqrt(2 / (5 * d_model))
- _normal_param_init_fn_(module=module, std=std, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def neox_param_init_fn_(module: nn.Module, n_layers: int, d_model: int, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, verbose: int=0, **kwargs):
- """From section 2.3.1 of GPT-NeoX-20B:
-
- An Open-Source AutoregressiveLanguage Model — Black et. al. (2022)
- see https://github.com/EleutherAI/gpt-neox/blob/9610391ab319403cef079b438edd016a2443af54/megatron/model/init_functions.py#L151
- and https://github.com/EleutherAI/gpt-neox/blob/main/megatron/model/transformer.py
- """
- del kwargs
- residual_div = n_layers / math.sqrt(10)
- if verbose > 1:
- warnings.warn(f'setting init_div_is_residual to {residual_div}')
- small_param_init_fn_(module=module, d_model=d_model, n_layers=n_layers, init_div_is_residual=residual_div, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def kaiming_uniform_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, fan_mode: str='fan_in', init_nonlinearity: str='leaky_relu', verbose: int=0, **kwargs):
- del kwargs
- if verbose > 1:
- warnings.warn(f'Using nn.init.kaiming_uniform_ init fn with parameters: ' + f'a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}')
- kaiming_uniform_ = partial(nn.init.kaiming_uniform_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
- generic_param_init_fn_(module=module, init_fn_=kaiming_uniform_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def kaiming_normal_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, fan_mode: str='fan_in', init_nonlinearity: str='leaky_relu', verbose: int=0, **kwargs):
- del kwargs
- if verbose > 1:
- warnings.warn(f'Using nn.init.kaiming_normal_ init fn with parameters: ' + f'a={init_gain}, mode={fan_mode}, nonlinearity={init_nonlinearity}')
- kaiming_normal_ = partial(torch.nn.init.kaiming_normal_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
- generic_param_init_fn_(module=module, init_fn_=kaiming_normal_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def xavier_uniform_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, verbose: int=0, **kwargs):
- del kwargs
- xavier_uniform_ = partial(torch.nn.init.xavier_uniform_, gain=init_gain)
- if verbose > 1:
- warnings.warn(f'Using torch.nn.init.xavier_uniform_ init fn with parameters: ' + f'gain={init_gain}')
- generic_param_init_fn_(module=module, init_fn_=xavier_uniform_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-
-def xavier_normal_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, verbose: int=0, **kwargs):
- xavier_normal_ = partial(torch.nn.init.xavier_normal_, gain=init_gain)
- if verbose > 1:
- warnings.warn(f'Using torch.nn.init.xavier_normal_ init fn with parameters: ' + f'gain={init_gain}')
- generic_param_init_fn_(module=module, init_fn_=xavier_normal_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim, verbose=verbose)
-MODEL_INIT_REGISTRY = {'default_': torch_default_param_init_fn_, 'baseline_': baseline_param_init_fn_, 'kaiming_uniform_': kaiming_uniform_param_init_fn_, 'kaiming_normal_': kaiming_normal_param_init_fn_, 'neox_init_': neox_param_init_fn_, 'small_init_': small_param_init_fn_, 'xavier_uniform_': xavier_uniform_param_init_fn_, 'xavier_normal_': xavier_normal_param_init_fn_}
\ No newline at end of file
diff --git a/spaces/banana-projects/web3d/node_modules/three/src/audio/AudioContext.js b/spaces/banana-projects/web3d/node_modules/three/src/audio/AudioContext.js
deleted file mode 100644
index 29def0117faa77d8d9f40357defaeacc3cb66d9a..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/web3d/node_modules/three/src/audio/AudioContext.js
+++ /dev/null
@@ -1,29 +0,0 @@
-/**
- * @author mrdoob / http://mrdoob.com/
- */
-
-var context;
-
-var AudioContext = {
-
- getContext: function () {
-
- if ( context === undefined ) {
-
- context = new ( window.AudioContext || window.webkitAudioContext )();
-
- }
-
- return context;
-
- },
-
- setContext: function ( value ) {
-
- context = value;
-
- }
-
-};
-
-export { AudioContext };
diff --git a/spaces/banana-projects/web3d/node_modules/three/src/helpers/ArrowHelper.js b/spaces/banana-projects/web3d/node_modules/three/src/helpers/ArrowHelper.js
deleted file mode 100644
index 8dbd9bf9ae6ae787d4b8135911f29f7285b91e9b..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/web3d/node_modules/three/src/helpers/ArrowHelper.js
+++ /dev/null
@@ -1,139 +0,0 @@
-/**
- * @author WestLangley / http://github.com/WestLangley
- * @author zz85 / http://github.com/zz85
- * @author bhouston / http://clara.io
- *
- * Creates an arrow for visualizing directions
- *
- * Parameters:
- * dir - Vector3
- * origin - Vector3
- * length - Number
- * color - color in hex value
- * headLength - Number
- * headWidth - Number
- */
-
-import { Float32BufferAttribute } from '../core/BufferAttribute.js';
-import { BufferGeometry } from '../core/BufferGeometry.js';
-import { Object3D } from '../core/Object3D.js';
-import { CylinderBufferGeometry } from '../geometries/CylinderGeometry.js';
-import { MeshBasicMaterial } from '../materials/MeshBasicMaterial.js';
-import { LineBasicMaterial } from '../materials/LineBasicMaterial.js';
-import { Mesh } from '../objects/Mesh.js';
-import { Line } from '../objects/Line.js';
-import { Vector3 } from '../math/Vector3.js';
-
-var lineGeometry, coneGeometry;
-
-function ArrowHelper( dir, origin, length, color, headLength, headWidth ) {
-
- // dir is assumed to be normalized
-
- Object3D.call( this );
-
- if ( dir === undefined ) dir = new Vector3( 0, 0, 1 );
- if ( origin === undefined ) origin = new Vector3( 0, 0, 0 );
- if ( length === undefined ) length = 1;
- if ( color === undefined ) color = 0xffff00;
- if ( headLength === undefined ) headLength = 0.2 * length;
- if ( headWidth === undefined ) headWidth = 0.2 * headLength;
-
- if ( lineGeometry === undefined ) {
-
- lineGeometry = new BufferGeometry();
- lineGeometry.addAttribute( 'position', new Float32BufferAttribute( [ 0, 0, 0, 0, 1, 0 ], 3 ) );
-
- coneGeometry = new CylinderBufferGeometry( 0, 0.5, 1, 5, 1 );
- coneGeometry.translate( 0, - 0.5, 0 );
-
- }
-
- this.position.copy( origin );
-
- this.line = new Line( lineGeometry, new LineBasicMaterial( { color: color } ) );
- this.line.matrixAutoUpdate = false;
- this.add( this.line );
-
- this.cone = new Mesh( coneGeometry, new MeshBasicMaterial( { color: color } ) );
- this.cone.matrixAutoUpdate = false;
- this.add( this.cone );
-
- this.setDirection( dir );
- this.setLength( length, headLength, headWidth );
-
-}
-
-ArrowHelper.prototype = Object.create( Object3D.prototype );
-ArrowHelper.prototype.constructor = ArrowHelper;
-
-ArrowHelper.prototype.setDirection = ( function () {
-
- var axis = new Vector3();
- var radians;
-
- return function setDirection( dir ) {
-
- // dir is assumed to be normalized
-
- if ( dir.y > 0.99999 ) {
-
- this.quaternion.set( 0, 0, 0, 1 );
-
- } else if ( dir.y < - 0.99999 ) {
-
- this.quaternion.set( 1, 0, 0, 0 );
-
- } else {
-
- axis.set( dir.z, 0, - dir.x ).normalize();
-
- radians = Math.acos( dir.y );
-
- this.quaternion.setFromAxisAngle( axis, radians );
-
- }
-
- };
-
-}() );
-
-ArrowHelper.prototype.setLength = function ( length, headLength, headWidth ) {
-
- if ( headLength === undefined ) headLength = 0.2 * length;
- if ( headWidth === undefined ) headWidth = 0.2 * headLength;
-
- this.line.scale.set( 1, Math.max( 0, length - headLength ), 1 );
- this.line.updateMatrix();
-
- this.cone.scale.set( headWidth, headLength, headWidth );
- this.cone.position.y = length;
- this.cone.updateMatrix();
-
-};
-
-ArrowHelper.prototype.setColor = function ( color ) {
-
- this.line.material.color.copy( color );
- this.cone.material.color.copy( color );
-
-};
-
-ArrowHelper.prototype.copy = function ( source ) {
-
- Object3D.prototype.copy.call( this, source, false );
-
- this.line.copy( source.line );
- this.cone.copy( source.cone );
-
- return this;
-
-};
-
-ArrowHelper.prototype.clone = function () {
-
- return new this.constructor().copy( this );
-
-};
-
-export { ArrowHelper };
diff --git a/spaces/better57/CHATGPT/custom.css b/spaces/better57/CHATGPT/custom.css
deleted file mode 100644
index 5143eb138ea2469d8c457c71cb210fd3fb7cbe15..0000000000000000000000000000000000000000
--- a/spaces/better57/CHATGPT/custom.css
+++ /dev/null
@@ -1,162 +0,0 @@
-:root {
- --chatbot-color-light: #F3F3F3;
- --chatbot-color-dark: #121111;
-}
-
-/* status_display */
-#status_display {
- display: flex;
- min-height: 2.5em;
- align-items: flex-end;
- justify-content: flex-end;
-}
-#status_display p {
- font-size: .85em;
- font-family: monospace;
- color: var(--body-text-color-subdued);
-}
-
-#chuanhu_chatbot, #status_display {
- transition: all 0.6s;
-}
-/* list */
-ol:not(.options), ul:not(.options) {
- padding-inline-start: 2em !important;
-}
-
-/* 亮色 */
-#chuanhu_chatbot {
- background-color: var(--chatbot-color-light) !important;
-}
-[data-testid = "bot"] {
- background-color: #FFFFFF !important;
-}
-[data-testid = "user"] {
- background-color: #95EC69 !important;
-}
-/* 对话气泡 */
-[class *= "message"] {
- border-radius: var(--radius-xl) !important;
- border: none;
- padding: var(--spacing-xl) !important;
- font-size: var(--text-md) !important;
- line-height: var(--line-md) !important;
- min-height: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
- min-width: calc(var(--text-md)*var(--line-md) + 2*var(--spacing-xl));
-}
-[data-testid = "bot"] {
- max-width: 85%;
- border-bottom-left-radius: 0 !important;
-}
-[data-testid = "user"] {
- max-width: 85%;
- width: auto !important;
- border-bottom-right-radius: 0 !important;
-}
-/* 表格 */
-table {
- margin: 1em 0;
- border-collapse: collapse;
- empty-cells: show;
-}
-td,th {
- border: 1.2px solid var(--border-color-primary) !important;
- padding: 0.2em;
-}
-thead {
- background-color: rgba(175,184,193,0.2);
-}
-thead th {
- padding: .5em .2em;
-}
-/* 行内代码 */
-code {
- display: inline;
- white-space: break-spaces;
- border-radius: 6px;
- margin: 0 2px 0 2px;
- padding: .2em .4em .1em .4em;
- background-color: rgba(175,184,193,0.2);
-}
-/* 代码块 */
-pre code {
- display: block;
- overflow: auto;
- white-space: pre;
- background-color: hsla(0, 0%, 0%, 80%)!important;
- border-radius: 10px;
- padding: 1.4em 1.2em 0em 1.4em;
- margin: 1.2em 2em 1.2em 0.5em;
- color: #FFF;
- box-shadow: 6px 6px 16px hsla(0, 0%, 0%, 0.2);
-}
-/* 代码高亮样式 */
-.highlight .hll { background-color: #49483e }
-.highlight .c { color: #75715e } /* Comment */
-.highlight .err { color: #960050; background-color: #1e0010 } /* Error */
-.highlight .k { color: #66d9ef } /* Keyword */
-.highlight .l { color: #ae81ff } /* Literal */
-.highlight .n { color: #f8f8f2 } /* Name */
-.highlight .o { color: #f92672 } /* Operator */
-.highlight .p { color: #f8f8f2 } /* Punctuation */
-.highlight .ch { color: #75715e } /* Comment.Hashbang */
-.highlight .cm { color: #75715e } /* Comment.Multiline */
-.highlight .cp { color: #75715e } /* Comment.Preproc */
-.highlight .cpf { color: #75715e } /* Comment.PreprocFile */
-.highlight .c1 { color: #75715e } /* Comment.Single */
-.highlight .cs { color: #75715e } /* Comment.Special */
-.highlight .gd { color: #f92672 } /* Generic.Deleted */
-.highlight .ge { font-style: italic } /* Generic.Emph */
-.highlight .gi { color: #a6e22e } /* Generic.Inserted */
-.highlight .gs { font-weight: bold } /* Generic.Strong */
-.highlight .gu { color: #75715e } /* Generic.Subheading */
-.highlight .kc { color: #66d9ef } /* Keyword.Constant */
-.highlight .kd { color: #66d9ef } /* Keyword.Declaration */
-.highlight .kn { color: #f92672 } /* Keyword.Namespace */
-.highlight .kp { color: #66d9ef } /* Keyword.Pseudo */
-.highlight .kr { color: #66d9ef } /* Keyword.Reserved */
-.highlight .kt { color: #66d9ef } /* Keyword.Type */
-.highlight .ld { color: #e6db74 } /* Literal.Date */
-.highlight .m { color: #ae81ff } /* Literal.Number */
-.highlight .s { color: #e6db74 } /* Literal.String */
-.highlight .na { color: #a6e22e } /* Name.Attribute */
-.highlight .nb { color: #f8f8f2 } /* Name.Builtin */
-.highlight .nc { color: #a6e22e } /* Name.Class */
-.highlight .no { color: #66d9ef } /* Name.Constant */
-.highlight .nd { color: #a6e22e } /* Name.Decorator */
-.highlight .ni { color: #f8f8f2 } /* Name.Entity */
-.highlight .ne { color: #a6e22e } /* Name.Exception */
-.highlight .nf { color: #a6e22e } /* Name.Function */
-.highlight .nl { color: #f8f8f2 } /* Name.Label */
-.highlight .nn { color: #f8f8f2 } /* Name.Namespace */
-.highlight .nx { color: #a6e22e } /* Name.Other */
-.highlight .py { color: #f8f8f2 } /* Name.Property */
-.highlight .nt { color: #f92672 } /* Name.Tag */
-.highlight .nv { color: #f8f8f2 } /* Name.Variable */
-.highlight .ow { color: #f92672 } /* Operator.Word */
-.highlight .w { color: #f8f8f2 } /* Text.Whitespace */
-.highlight .mb { color: #ae81ff } /* Literal.Number.Bin */
-.highlight .mf { color: #ae81ff } /* Literal.Number.Float */
-.highlight .mh { color: #ae81ff } /* Literal.Number.Hex */
-.highlight .mi { color: #ae81ff } /* Literal.Number.Integer */
-.highlight .mo { color: #ae81ff } /* Literal.Number.Oct */
-.highlight .sa { color: #e6db74 } /* Literal.String.Affix */
-.highlight .sb { color: #e6db74 } /* Literal.String.Backtick */
-.highlight .sc { color: #e6db74 } /* Literal.String.Char */
-.highlight .dl { color: #e6db74 } /* Literal.String.Delimiter */
-.highlight .sd { color: #e6db74 } /* Literal.String.Doc */
-.highlight .s2 { color: #e6db74 } /* Literal.String.Double */
-.highlight .se { color: #ae81ff } /* Literal.String.Escape */
-.highlight .sh { color: #e6db74 } /* Literal.String.Heredoc */
-.highlight .si { color: #e6db74 } /* Literal.String.Interpol */
-.highlight .sx { color: #e6db74 } /* Literal.String.Other */
-.highlight .sr { color: #e6db74 } /* Literal.String.Regex */
-.highlight .s1 { color: #e6db74 } /* Literal.String.Single */
-.highlight .ss { color: #e6db74 } /* Literal.String.Symbol */
-.highlight .bp { color: #f8f8f2 } /* Name.Builtin.Pseudo */
-.highlight .fm { color: #a6e22e } /* Name.Function.Magic */
-.highlight .vc { color: #f8f8f2 } /* Name.Variable.Class */
-.highlight .vg { color: #f8f8f2 } /* Name.Variable.Global */
-.highlight .vi { color: #f8f8f2 } /* Name.Variable.Instance */
-.highlight .vm { color: #f8f8f2 } /* Name.Variable.Magic */
-.highlight .il { color: #ae81ff } /* Literal.Number.Integer.Long */
diff --git a/spaces/bguberfain/Detic/detic/predictor.py b/spaces/bguberfain/Detic/detic/predictor.py
deleted file mode 100644
index 318205acb90d47a54ff6f34400e1da744b2d85ba..0000000000000000000000000000000000000000
--- a/spaces/bguberfain/Detic/detic/predictor.py
+++ /dev/null
@@ -1,253 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import atexit
-import bisect
-import multiprocessing as mp
-from collections import deque
-import cv2
-import torch
-
-from detectron2.data import MetadataCatalog
-from detectron2.engine.defaults import DefaultPredictor
-from detectron2.utils.video_visualizer import VideoVisualizer
-from detectron2.utils.visualizer import ColorMode, Visualizer
-
-from .modeling.utils import reset_cls_test
-
-
-def get_clip_embeddings(vocabulary, prompt='a '):
- from detic.modeling.text.text_encoder import build_text_encoder
- text_encoder = build_text_encoder(pretrain=True)
- text_encoder.eval()
- texts = [prompt + x for x in vocabulary]
- emb = text_encoder(texts).detach().permute(1, 0).contiguous().cpu()
- return emb
-
-BUILDIN_CLASSIFIER = {
- 'lvis': 'datasets/metadata/lvis_v1_clip_a+cname.npy',
- 'objects365': 'datasets/metadata/o365_clip_a+cnamefix.npy',
- 'openimages': 'datasets/metadata/oid_clip_a+cname.npy',
- 'coco': 'datasets/metadata/coco_clip_a+cname.npy',
-}
-
-BUILDIN_METADATA_PATH = {
- 'lvis': 'lvis_v1_val',
- 'objects365': 'objects365_v2_val',
- 'openimages': 'oid_val_expanded',
- 'coco': 'coco_2017_val',
-}
-
-class VisualizationDemo(object):
- def __init__(self, cfg, args,
- instance_mode=ColorMode.IMAGE, parallel=False):
- """
- Args:
- cfg (CfgNode):
- instance_mode (ColorMode):
- parallel (bool): whether to run the model in different processes from visualization.
- Useful since the visualization logic can be slow.
- """
- if args.vocabulary == 'custom':
- self.metadata = MetadataCatalog.get("__unused")
- self.metadata.thing_classes = args.custom_vocabulary.split(',')
- classifier = get_clip_embeddings(self.metadata.thing_classes)
- else:
- self.metadata = MetadataCatalog.get(
- BUILDIN_METADATA_PATH[args.vocabulary])
- classifier = BUILDIN_CLASSIFIER[args.vocabulary]
-
- num_classes = len(self.metadata.thing_classes)
- self.cpu_device = torch.device("cpu")
- self.instance_mode = instance_mode
-
- self.parallel = parallel
- if parallel:
- num_gpu = torch.cuda.device_count()
- self.predictor = AsyncPredictor(cfg, num_gpus=num_gpu)
- else:
- self.predictor = DefaultPredictor(cfg)
- reset_cls_test(self.predictor.model, classifier, num_classes)
-
- def run_on_image(self, image):
- """
- Args:
- image (np.ndarray): an image of shape (H, W, C) (in BGR order).
- This is the format used by OpenCV.
-
- Returns:
- predictions (dict): the output of the model.
- vis_output (VisImage): the visualized image output.
- """
- vis_output = None
- predictions = self.predictor(image)
- # Convert image from OpenCV BGR format to Matplotlib RGB format.
- image = image[:, :, ::-1]
- visualizer = Visualizer(image, self.metadata, instance_mode=self.instance_mode)
- if "panoptic_seg" in predictions:
- panoptic_seg, segments_info = predictions["panoptic_seg"]
- vis_output = visualizer.draw_panoptic_seg_predictions(
- panoptic_seg.to(self.cpu_device), segments_info
- )
- else:
- if "sem_seg" in predictions:
- vis_output = visualizer.draw_sem_seg(
- predictions["sem_seg"].argmax(dim=0).to(self.cpu_device)
- )
- if "instances" in predictions:
- instances = predictions["instances"].to(self.cpu_device)
- vis_output = visualizer.draw_instance_predictions(predictions=instances)
-
- return predictions, vis_output
-
- def _frame_from_video(self, video):
- while video.isOpened():
- success, frame = video.read()
- if success:
- yield frame
- else:
- break
-
- def run_on_video(self, video):
- """
- Visualizes predictions on frames of the input video.
-
- Args:
- video (cv2.VideoCapture): a :class:`VideoCapture` object, whose source can be
- either a webcam or a video file.
-
- Yields:
- ndarray: BGR visualizations of each video frame.
- """
- video_visualizer = VideoVisualizer(self.metadata, self.instance_mode)
-
- def process_predictions(frame, predictions):
- frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
- if "panoptic_seg" in predictions:
- panoptic_seg, segments_info = predictions["panoptic_seg"]
- vis_frame = video_visualizer.draw_panoptic_seg_predictions(
- frame, panoptic_seg.to(self.cpu_device), segments_info
- )
- elif "instances" in predictions:
- predictions = predictions["instances"].to(self.cpu_device)
- vis_frame = video_visualizer.draw_instance_predictions(frame, predictions)
- elif "sem_seg" in predictions:
- vis_frame = video_visualizer.draw_sem_seg(
- frame, predictions["sem_seg"].argmax(dim=0).to(self.cpu_device)
- )
-
- # Converts Matplotlib RGB format to OpenCV BGR format
- vis_frame = cv2.cvtColor(vis_frame.get_image(), cv2.COLOR_RGB2BGR)
- return vis_frame
-
- frame_gen = self._frame_from_video(video)
- if self.parallel:
- buffer_size = self.predictor.default_buffer_size
-
- frame_data = deque()
-
- for cnt, frame in enumerate(frame_gen):
- frame_data.append(frame)
- self.predictor.put(frame)
-
- if cnt >= buffer_size:
- frame = frame_data.popleft()
- predictions = self.predictor.get()
- yield process_predictions(frame, predictions)
-
- while len(frame_data):
- frame = frame_data.popleft()
- predictions = self.predictor.get()
- yield process_predictions(frame, predictions)
- else:
- for frame in frame_gen:
- yield process_predictions(frame, self.predictor(frame))
-
-
-class AsyncPredictor:
- """
- A predictor that runs the model asynchronously, possibly on >1 GPUs.
- Because rendering the visualization takes considerably amount of time,
- this helps improve throughput a little bit when rendering videos.
- """
-
- class _StopToken:
- pass
-
- class _PredictWorker(mp.Process):
- def __init__(self, cfg, task_queue, result_queue):
- self.cfg = cfg
- self.task_queue = task_queue
- self.result_queue = result_queue
- super().__init__()
-
- def run(self):
- predictor = DefaultPredictor(self.cfg)
-
- while True:
- task = self.task_queue.get()
- if isinstance(task, AsyncPredictor._StopToken):
- break
- idx, data = task
- result = predictor(data)
- self.result_queue.put((idx, result))
-
- def __init__(self, cfg, num_gpus: int = 1):
- """
- Args:
- cfg (CfgNode):
- num_gpus (int): if 0, will run on CPU
- """
- num_workers = max(num_gpus, 1)
- self.task_queue = mp.Queue(maxsize=num_workers * 3)
- self.result_queue = mp.Queue(maxsize=num_workers * 3)
- self.procs = []
- for gpuid in range(max(num_gpus, 1)):
- cfg = cfg.clone()
- cfg.defrost()
- cfg.MODEL.DEVICE = "cuda:{}".format(gpuid) if num_gpus > 0 else "cpu"
- self.procs.append(
- AsyncPredictor._PredictWorker(cfg, self.task_queue, self.result_queue)
- )
-
- self.put_idx = 0
- self.get_idx = 0
- self.result_rank = []
- self.result_data = []
-
- for p in self.procs:
- p.start()
- atexit.register(self.shutdown)
-
- def put(self, image):
- self.put_idx += 1
- self.task_queue.put((self.put_idx, image))
-
- def get(self):
- self.get_idx += 1 # the index needed for this request
- if len(self.result_rank) and self.result_rank[0] == self.get_idx:
- res = self.result_data[0]
- del self.result_data[0], self.result_rank[0]
- return res
-
- while True:
- # make sure the results are returned in the correct order
- idx, res = self.result_queue.get()
- if idx == self.get_idx:
- return res
- insert = bisect.bisect(self.result_rank, idx)
- self.result_rank.insert(insert, idx)
- self.result_data.insert(insert, res)
-
- def __len__(self):
- return self.put_idx - self.get_idx
-
- def __call__(self, image):
- self.put(image)
- return self.get()
-
- def shutdown(self):
- for _ in self.procs:
- self.task_queue.put(AsyncPredictor._StopToken())
-
- @property
- def default_buffer_size(self):
- return len(self.procs) * 5
diff --git a/spaces/bigjoker/stable-diffusion-webui/modules/api/api.py b/spaces/bigjoker/stable-diffusion-webui/modules/api/api.py
deleted file mode 100644
index 5a9ac5f1aa745e4dd8c9ed5a107dd840f05c0ba6..0000000000000000000000000000000000000000
--- a/spaces/bigjoker/stable-diffusion-webui/modules/api/api.py
+++ /dev/null
@@ -1,551 +0,0 @@
-import base64
-import io
-import time
-import datetime
-import uvicorn
-from threading import Lock
-from io import BytesIO
-from gradio.processing_utils import decode_base64_to_file
-from fastapi import APIRouter, Depends, FastAPI, HTTPException, Request, Response
-from fastapi.security import HTTPBasic, HTTPBasicCredentials
-from secrets import compare_digest
-
-import modules.shared as shared
-from modules import sd_samplers, deepbooru, sd_hijack, images, scripts, ui, postprocessing
-from modules.api.models import *
-from modules.processing import StableDiffusionProcessingTxt2Img, StableDiffusionProcessingImg2Img, process_images
-from modules.textual_inversion.textual_inversion import create_embedding, train_embedding
-from modules.textual_inversion.preprocess import preprocess
-from modules.hypernetworks.hypernetwork import create_hypernetwork, train_hypernetwork
-from PIL import PngImagePlugin,Image
-from modules.sd_models import checkpoints_list
-from modules.sd_models_config import find_checkpoint_config_near_filename
-from modules.realesrgan_model import get_realesrgan_models
-from modules import devices
-from typing import List
-import piexif
-import piexif.helper
-
-def upscaler_to_index(name: str):
- try:
- return [x.name.lower() for x in shared.sd_upscalers].index(name.lower())
- except:
- raise HTTPException(status_code=400, detail=f"Invalid upscaler, needs to be one of these: {' , '.join([x.name for x in sd_upscalers])}")
-
-def script_name_to_index(name, scripts):
- try:
- return [script.title().lower() for script in scripts].index(name.lower())
- except:
- raise HTTPException(status_code=422, detail=f"Script '{name}' not found")
-
-def validate_sampler_name(name):
- config = sd_samplers.all_samplers_map.get(name, None)
- if config is None:
- raise HTTPException(status_code=404, detail="Sampler not found")
-
- return name
-
-def setUpscalers(req: dict):
- reqDict = vars(req)
- reqDict['extras_upscaler_1'] = reqDict.pop('upscaler_1', None)
- reqDict['extras_upscaler_2'] = reqDict.pop('upscaler_2', None)
- return reqDict
-
-def decode_base64_to_image(encoding):
- if encoding.startswith("data:image/"):
- encoding = encoding.split(";")[1].split(",")[1]
- try:
- image = Image.open(BytesIO(base64.b64decode(encoding)))
- return image
- except Exception as err:
- raise HTTPException(status_code=500, detail="Invalid encoded image")
-
-def encode_pil_to_base64(image):
- with io.BytesIO() as output_bytes:
-
- if opts.samples_format.lower() == 'png':
- use_metadata = False
- metadata = PngImagePlugin.PngInfo()
- for key, value in image.info.items():
- if isinstance(key, str) and isinstance(value, str):
- metadata.add_text(key, value)
- use_metadata = True
- image.save(output_bytes, format="PNG", pnginfo=(metadata if use_metadata else None), quality=opts.jpeg_quality)
-
- elif opts.samples_format.lower() in ("jpg", "jpeg", "webp"):
- parameters = image.info.get('parameters', None)
- exif_bytes = piexif.dump({
- "Exif": { piexif.ExifIFD.UserComment: piexif.helper.UserComment.dump(parameters or "", encoding="unicode") }
- })
- if opts.samples_format.lower() in ("jpg", "jpeg"):
- image.save(output_bytes, format="JPEG", exif = exif_bytes, quality=opts.jpeg_quality)
- else:
- image.save(output_bytes, format="WEBP", exif = exif_bytes, quality=opts.jpeg_quality)
-
- else:
- raise HTTPException(status_code=500, detail="Invalid image format")
-
- bytes_data = output_bytes.getvalue()
-
- return base64.b64encode(bytes_data)
-
-def api_middleware(app: FastAPI):
- @app.middleware("http")
- async def log_and_time(req: Request, call_next):
- ts = time.time()
- res: Response = await call_next(req)
- duration = str(round(time.time() - ts, 4))
- res.headers["X-Process-Time"] = duration
- endpoint = req.scope.get('path', 'err')
- if shared.cmd_opts.api_log and endpoint.startswith('/sdapi'):
- print('API {t} {code} {prot}/{ver} {method} {endpoint} {cli} {duration}'.format(
- t = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f"),
- code = res.status_code,
- ver = req.scope.get('http_version', '0.0'),
- cli = req.scope.get('client', ('0:0.0.0', 0))[0],
- prot = req.scope.get('scheme', 'err'),
- method = req.scope.get('method', 'err'),
- endpoint = endpoint,
- duration = duration,
- ))
- return res
-
-
-class Api:
- def __init__(self, app: FastAPI, queue_lock: Lock):
- if shared.cmd_opts.api_auth:
- self.credentials = dict()
- for auth in shared.cmd_opts.api_auth.split(","):
- user, password = auth.split(":")
- self.credentials[user] = password
-
- self.router = APIRouter()
- self.app = app
- self.queue_lock = queue_lock
- api_middleware(self.app)
- self.add_api_route("/sdapi/v1/txt2img", self.text2imgapi, methods=["POST"], response_model=TextToImageResponse)
- self.add_api_route("/sdapi/v1/img2img", self.img2imgapi, methods=["POST"], response_model=ImageToImageResponse)
- self.add_api_route("/sdapi/v1/extra-single-image", self.extras_single_image_api, methods=["POST"], response_model=ExtrasSingleImageResponse)
- self.add_api_route("/sdapi/v1/extra-batch-images", self.extras_batch_images_api, methods=["POST"], response_model=ExtrasBatchImagesResponse)
- self.add_api_route("/sdapi/v1/png-info", self.pnginfoapi, methods=["POST"], response_model=PNGInfoResponse)
- self.add_api_route("/sdapi/v1/progress", self.progressapi, methods=["GET"], response_model=ProgressResponse)
- self.add_api_route("/sdapi/v1/interrogate", self.interrogateapi, methods=["POST"])
- self.add_api_route("/sdapi/v1/interrupt", self.interruptapi, methods=["POST"])
- self.add_api_route("/sdapi/v1/skip", self.skip, methods=["POST"])
- self.add_api_route("/sdapi/v1/options", self.get_config, methods=["GET"], response_model=OptionsModel)
- self.add_api_route("/sdapi/v1/options", self.set_config, methods=["POST"])
- self.add_api_route("/sdapi/v1/cmd-flags", self.get_cmd_flags, methods=["GET"], response_model=FlagsModel)
- self.add_api_route("/sdapi/v1/samplers", self.get_samplers, methods=["GET"], response_model=List[SamplerItem])
- self.add_api_route("/sdapi/v1/upscalers", self.get_upscalers, methods=["GET"], response_model=List[UpscalerItem])
- self.add_api_route("/sdapi/v1/sd-models", self.get_sd_models, methods=["GET"], response_model=List[SDModelItem])
- self.add_api_route("/sdapi/v1/hypernetworks", self.get_hypernetworks, methods=["GET"], response_model=List[HypernetworkItem])
- self.add_api_route("/sdapi/v1/face-restorers", self.get_face_restorers, methods=["GET"], response_model=List[FaceRestorerItem])
- self.add_api_route("/sdapi/v1/realesrgan-models", self.get_realesrgan_models, methods=["GET"], response_model=List[RealesrganItem])
- self.add_api_route("/sdapi/v1/prompt-styles", self.get_prompt_styles, methods=["GET"], response_model=List[PromptStyleItem])
- self.add_api_route("/sdapi/v1/embeddings", self.get_embeddings, methods=["GET"], response_model=EmbeddingsResponse)
- self.add_api_route("/sdapi/v1/refresh-checkpoints", self.refresh_checkpoints, methods=["POST"])
- self.add_api_route("/sdapi/v1/create/embedding", self.create_embedding, methods=["POST"], response_model=CreateResponse)
- self.add_api_route("/sdapi/v1/create/hypernetwork", self.create_hypernetwork, methods=["POST"], response_model=CreateResponse)
- self.add_api_route("/sdapi/v1/preprocess", self.preprocess, methods=["POST"], response_model=PreprocessResponse)
- self.add_api_route("/sdapi/v1/train/embedding", self.train_embedding, methods=["POST"], response_model=TrainResponse)
- self.add_api_route("/sdapi/v1/train/hypernetwork", self.train_hypernetwork, methods=["POST"], response_model=TrainResponse)
- self.add_api_route("/sdapi/v1/memory", self.get_memory, methods=["GET"], response_model=MemoryResponse)
-
- def add_api_route(self, path: str, endpoint, **kwargs):
- if shared.cmd_opts.api_auth:
- return self.app.add_api_route(path, endpoint, dependencies=[Depends(self.auth)], **kwargs)
- return self.app.add_api_route(path, endpoint, **kwargs)
-
- def auth(self, credentials: HTTPBasicCredentials = Depends(HTTPBasic())):
- if credentials.username in self.credentials:
- if compare_digest(credentials.password, self.credentials[credentials.username]):
- return True
-
- raise HTTPException(status_code=401, detail="Incorrect username or password", headers={"WWW-Authenticate": "Basic"})
-
- def get_script(self, script_name, script_runner):
- if script_name is None:
- return None, None
-
- if not script_runner.scripts:
- script_runner.initialize_scripts(False)
- ui.create_ui()
-
- script_idx = script_name_to_index(script_name, script_runner.selectable_scripts)
- script = script_runner.selectable_scripts[script_idx]
- return script, script_idx
-
- def text2imgapi(self, txt2imgreq: StableDiffusionTxt2ImgProcessingAPI):
- script, script_idx = self.get_script(txt2imgreq.script_name, scripts.scripts_txt2img)
-
- populate = txt2imgreq.copy(update={ # Override __init__ params
- "sampler_name": validate_sampler_name(txt2imgreq.sampler_name or txt2imgreq.sampler_index),
- "do_not_save_samples": True,
- "do_not_save_grid": True
- }
- )
- if populate.sampler_name:
- populate.sampler_index = None # prevent a warning later on
-
- args = vars(populate)
- args.pop('script_name', None)
-
- with self.queue_lock:
- p = StableDiffusionProcessingTxt2Img(sd_model=shared.sd_model, **args)
-
- shared.state.begin()
- if script is not None:
- p.outpath_grids = opts.outdir_txt2img_grids
- p.outpath_samples = opts.outdir_txt2img_samples
- p.script_args = [script_idx + 1] + [None] * (script.args_from - 1) + p.script_args
- processed = scripts.scripts_txt2img.run(p, *p.script_args)
- else:
- processed = process_images(p)
- shared.state.end()
-
- b64images = list(map(encode_pil_to_base64, processed.images))
-
- return TextToImageResponse(images=b64images, parameters=vars(txt2imgreq), info=processed.js())
-
- def img2imgapi(self, img2imgreq: StableDiffusionImg2ImgProcessingAPI):
- init_images = img2imgreq.init_images
- if init_images is None:
- raise HTTPException(status_code=404, detail="Init image not found")
-
- script, script_idx = self.get_script(img2imgreq.script_name, scripts.scripts_img2img)
-
- mask = img2imgreq.mask
- if mask:
- mask = decode_base64_to_image(mask)
-
- populate = img2imgreq.copy(update={ # Override __init__ params
- "sampler_name": validate_sampler_name(img2imgreq.sampler_name or img2imgreq.sampler_index),
- "do_not_save_samples": True,
- "do_not_save_grid": True,
- "mask": mask
- }
- )
- if populate.sampler_name:
- populate.sampler_index = None # prevent a warning later on
-
- args = vars(populate)
- args.pop('include_init_images', None) # this is meant to be done by "exclude": True in model, but it's for a reason that I cannot determine.
- args.pop('script_name', None)
-
- with self.queue_lock:
- p = StableDiffusionProcessingImg2Img(sd_model=shared.sd_model, **args)
- p.init_images = [decode_base64_to_image(x) for x in init_images]
-
- shared.state.begin()
- if script is not None:
- p.outpath_grids = opts.outdir_img2img_grids
- p.outpath_samples = opts.outdir_img2img_samples
- p.script_args = [script_idx + 1] + [None] * (script.args_from - 1) + p.script_args
- processed = scripts.scripts_img2img.run(p, *p.script_args)
- else:
- processed = process_images(p)
- shared.state.end()
-
- b64images = list(map(encode_pil_to_base64, processed.images))
-
- if not img2imgreq.include_init_images:
- img2imgreq.init_images = None
- img2imgreq.mask = None
-
- return ImageToImageResponse(images=b64images, parameters=vars(img2imgreq), info=processed.js())
-
- def extras_single_image_api(self, req: ExtrasSingleImageRequest):
- reqDict = setUpscalers(req)
-
- reqDict['image'] = decode_base64_to_image(reqDict['image'])
-
- with self.queue_lock:
- result = postprocessing.run_extras(extras_mode=0, image_folder="", input_dir="", output_dir="", save_output=False, **reqDict)
-
- return ExtrasSingleImageResponse(image=encode_pil_to_base64(result[0][0]), html_info=result[1])
-
- def extras_batch_images_api(self, req: ExtrasBatchImagesRequest):
- reqDict = setUpscalers(req)
-
- def prepareFiles(file):
- file = decode_base64_to_file(file.data, file_path=file.name)
- file.orig_name = file.name
- return file
-
- reqDict['image_folder'] = list(map(prepareFiles, reqDict['imageList']))
- reqDict.pop('imageList')
-
- with self.queue_lock:
- result = postprocessing.run_extras(extras_mode=1, image="", input_dir="", output_dir="", save_output=False, **reqDict)
-
- return ExtrasBatchImagesResponse(images=list(map(encode_pil_to_base64, result[0])), html_info=result[1])
-
- def pnginfoapi(self, req: PNGInfoRequest):
- if(not req.image.strip()):
- return PNGInfoResponse(info="")
-
- image = decode_base64_to_image(req.image.strip())
- if image is None:
- return PNGInfoResponse(info="")
-
- geninfo, items = images.read_info_from_image(image)
- if geninfo is None:
- geninfo = ""
-
- items = {**{'parameters': geninfo}, **items}
-
- return PNGInfoResponse(info=geninfo, items=items)
-
- def progressapi(self, req: ProgressRequest = Depends()):
- # copy from check_progress_call of ui.py
-
- if shared.state.job_count == 0:
- return ProgressResponse(progress=0, eta_relative=0, state=shared.state.dict(), textinfo=shared.state.textinfo)
-
- # avoid dividing zero
- progress = 0.01
-
- if shared.state.job_count > 0:
- progress += shared.state.job_no / shared.state.job_count
- if shared.state.sampling_steps > 0:
- progress += 1 / shared.state.job_count * shared.state.sampling_step / shared.state.sampling_steps
-
- time_since_start = time.time() - shared.state.time_start
- eta = (time_since_start/progress)
- eta_relative = eta-time_since_start
-
- progress = min(progress, 1)
-
- shared.state.set_current_image()
-
- current_image = None
- if shared.state.current_image and not req.skip_current_image:
- current_image = encode_pil_to_base64(shared.state.current_image)
-
- return ProgressResponse(progress=progress, eta_relative=eta_relative, state=shared.state.dict(), current_image=current_image, textinfo=shared.state.textinfo)
-
- def interrogateapi(self, interrogatereq: InterrogateRequest):
- image_b64 = interrogatereq.image
- if image_b64 is None:
- raise HTTPException(status_code=404, detail="Image not found")
-
- img = decode_base64_to_image(image_b64)
- img = img.convert('RGB')
-
- # Override object param
- with self.queue_lock:
- if interrogatereq.model == "clip":
- processed = shared.interrogator.interrogate(img)
- elif interrogatereq.model == "deepdanbooru":
- processed = deepbooru.model.tag(img)
- else:
- raise HTTPException(status_code=404, detail="Model not found")
-
- return InterrogateResponse(caption=processed)
-
- def interruptapi(self):
- shared.state.interrupt()
-
- return {}
-
- def skip(self):
- shared.state.skip()
-
- def get_config(self):
- options = {}
- for key in shared.opts.data.keys():
- metadata = shared.opts.data_labels.get(key)
- if(metadata is not None):
- options.update({key: shared.opts.data.get(key, shared.opts.data_labels.get(key).default)})
- else:
- options.update({key: shared.opts.data.get(key, None)})
-
- return options
-
- def set_config(self, req: Dict[str, Any]):
- for k, v in req.items():
- shared.opts.set(k, v)
-
- shared.opts.save(shared.config_filename)
- return
-
- def get_cmd_flags(self):
- return vars(shared.cmd_opts)
-
- def get_samplers(self):
- return [{"name": sampler[0], "aliases":sampler[2], "options":sampler[3]} for sampler in sd_samplers.all_samplers]
-
- def get_upscalers(self):
- return [
- {
- "name": upscaler.name,
- "model_name": upscaler.scaler.model_name,
- "model_path": upscaler.data_path,
- "model_url": None,
- "scale": upscaler.scale,
- }
- for upscaler in shared.sd_upscalers
- ]
-
- def get_sd_models(self):
- return [{"title": x.title, "model_name": x.model_name, "hash": x.shorthash, "sha256": x.sha256, "filename": x.filename, "config": find_checkpoint_config_near_filename(x)} for x in checkpoints_list.values()]
-
- def get_hypernetworks(self):
- return [{"name": name, "path": shared.hypernetworks[name]} for name in shared.hypernetworks]
-
- def get_face_restorers(self):
- return [{"name":x.name(), "cmd_dir": getattr(x, "cmd_dir", None)} for x in shared.face_restorers]
-
- def get_realesrgan_models(self):
- return [{"name":x.name,"path":x.data_path, "scale":x.scale} for x in get_realesrgan_models(None)]
-
- def get_prompt_styles(self):
- styleList = []
- for k in shared.prompt_styles.styles:
- style = shared.prompt_styles.styles[k]
- styleList.append({"name":style[0], "prompt": style[1], "negative_prompt": style[2]})
-
- return styleList
-
- def get_embeddings(self):
- db = sd_hijack.model_hijack.embedding_db
-
- def convert_embedding(embedding):
- return {
- "step": embedding.step,
- "sd_checkpoint": embedding.sd_checkpoint,
- "sd_checkpoint_name": embedding.sd_checkpoint_name,
- "shape": embedding.shape,
- "vectors": embedding.vectors,
- }
-
- def convert_embeddings(embeddings):
- return {embedding.name: convert_embedding(embedding) for embedding in embeddings.values()}
-
- return {
- "loaded": convert_embeddings(db.word_embeddings),
- "skipped": convert_embeddings(db.skipped_embeddings),
- }
-
- def refresh_checkpoints(self):
- shared.refresh_checkpoints()
-
- def create_embedding(self, args: dict):
- try:
- shared.state.begin()
- filename = create_embedding(**args) # create empty embedding
- sd_hijack.model_hijack.embedding_db.load_textual_inversion_embeddings() # reload embeddings so new one can be immediately used
- shared.state.end()
- return CreateResponse(info = "create embedding filename: {filename}".format(filename = filename))
- except AssertionError as e:
- shared.state.end()
- return TrainResponse(info = "create embedding error: {error}".format(error = e))
-
- def create_hypernetwork(self, args: dict):
- try:
- shared.state.begin()
- filename = create_hypernetwork(**args) # create empty embedding
- shared.state.end()
- return CreateResponse(info = "create hypernetwork filename: {filename}".format(filename = filename))
- except AssertionError as e:
- shared.state.end()
- return TrainResponse(info = "create hypernetwork error: {error}".format(error = e))
-
- def preprocess(self, args: dict):
- try:
- shared.state.begin()
- preprocess(**args) # quick operation unless blip/booru interrogation is enabled
- shared.state.end()
- return PreprocessResponse(info = 'preprocess complete')
- except KeyError as e:
- shared.state.end()
- return PreprocessResponse(info = "preprocess error: invalid token: {error}".format(error = e))
- except AssertionError as e:
- shared.state.end()
- return PreprocessResponse(info = "preprocess error: {error}".format(error = e))
- except FileNotFoundError as e:
- shared.state.end()
- return PreprocessResponse(info = 'preprocess error: {error}'.format(error = e))
-
- def train_embedding(self, args: dict):
- try:
- shared.state.begin()
- apply_optimizations = shared.opts.training_xattention_optimizations
- error = None
- filename = ''
- if not apply_optimizations:
- sd_hijack.undo_optimizations()
- try:
- embedding, filename = train_embedding(**args) # can take a long time to complete
- except Exception as e:
- error = e
- finally:
- if not apply_optimizations:
- sd_hijack.apply_optimizations()
- shared.state.end()
- return TrainResponse(info = "train embedding complete: filename: {filename} error: {error}".format(filename = filename, error = error))
- except AssertionError as msg:
- shared.state.end()
- return TrainResponse(info = "train embedding error: {msg}".format(msg = msg))
-
- def train_hypernetwork(self, args: dict):
- try:
- shared.state.begin()
- shared.loaded_hypernetworks = []
- apply_optimizations = shared.opts.training_xattention_optimizations
- error = None
- filename = ''
- if not apply_optimizations:
- sd_hijack.undo_optimizations()
- try:
- hypernetwork, filename = train_hypernetwork(**args)
- except Exception as e:
- error = e
- finally:
- shared.sd_model.cond_stage_model.to(devices.device)
- shared.sd_model.first_stage_model.to(devices.device)
- if not apply_optimizations:
- sd_hijack.apply_optimizations()
- shared.state.end()
- return TrainResponse(info="train embedding complete: filename: {filename} error: {error}".format(filename=filename, error=error))
- except AssertionError as msg:
- shared.state.end()
- return TrainResponse(info="train embedding error: {error}".format(error=error))
-
- def get_memory(self):
- try:
- import os, psutil
- process = psutil.Process(os.getpid())
- res = process.memory_info() # only rss is cross-platform guaranteed so we dont rely on other values
- ram_total = 100 * res.rss / process.memory_percent() # and total memory is calculated as actual value is not cross-platform safe
- ram = { 'free': ram_total - res.rss, 'used': res.rss, 'total': ram_total }
- except Exception as err:
- ram = { 'error': f'{err}' }
- try:
- import torch
- if torch.cuda.is_available():
- s = torch.cuda.mem_get_info()
- system = { 'free': s[0], 'used': s[1] - s[0], 'total': s[1] }
- s = dict(torch.cuda.memory_stats(shared.device))
- allocated = { 'current': s['allocated_bytes.all.current'], 'peak': s['allocated_bytes.all.peak'] }
- reserved = { 'current': s['reserved_bytes.all.current'], 'peak': s['reserved_bytes.all.peak'] }
- active = { 'current': s['active_bytes.all.current'], 'peak': s['active_bytes.all.peak'] }
- inactive = { 'current': s['inactive_split_bytes.all.current'], 'peak': s['inactive_split_bytes.all.peak'] }
- warnings = { 'retries': s['num_alloc_retries'], 'oom': s['num_ooms'] }
- cuda = {
- 'system': system,
- 'active': active,
- 'allocated': allocated,
- 'reserved': reserved,
- 'inactive': inactive,
- 'events': warnings,
- }
- else:
- cuda = { 'error': 'unavailable' }
- except Exception as err:
- cuda = { 'error': f'{err}' }
- return MemoryResponse(ram = ram, cuda = cuda)
-
- def launch(self, server_name, port):
- self.app.include_router(self.router)
- uvicorn.run(self.app, host=server_name, port=port)
diff --git a/spaces/botmaster/generate-mother-2/app.py b/spaces/botmaster/generate-mother-2/app.py
deleted file mode 100644
index d08914575bd0d7cda333dc98393ae22b45ce4c13..0000000000000000000000000000000000000000
--- a/spaces/botmaster/generate-mother-2/app.py
+++ /dev/null
@@ -1,45 +0,0 @@
-import gradio as gr
-from datasets import load_dataset, Image
-
-import torch
-import nltk
-import io
-import base64
-import shutil
-from torchvision import transforms
-
-from pytorch_pretrained_biggan import BigGAN, one_hot_from_names, truncated_noise_sample
-
-class PreTrainedPipeline():
- def __init__(self, path=""):
- """
- Initialize model
- """
- nltk.download('wordnet')
- self.model = BigGAN.from_pretrained(path)
- self.truncation = 0.1
-
- def __call__(self, inputs: str):
- """
- Args:
- inputs (:obj:`str`):
- a string containing some text
- Return:
- A :obj:`PIL.Image` with the raw image representation as PIL.
- """
- class_vector = one_hot_from_names([inputs], batch_size=1)
- if type(class_vector) == type(None):
- raise ValueError("Input is not in ImageNet")
- noise_vector = truncated_noise_sample(truncation=self.truncation, batch_size=1)
- noise_vector = torch.from_numpy(noise_vector)
- class_vector = torch.from_numpy(class_vector)
- with torch.no_grad():
- output = self.model(noise_vector, class_vector, self.truncation)
-
- # Scale image
- img = output[0]
- img = (img + 1) / 2.0
- img = transforms.ToPILImage()(img)
-
-dataset = load_dataset("botmaster/mother-2-battle-sprites", split="train")
-gr.Interface.load("models/templates/text-to-image").launch()
diff --git a/spaces/bradarrML/stablediffusion-infinity/utils.py b/spaces/bradarrML/stablediffusion-infinity/utils.py
deleted file mode 100644
index bebc4f7f4da8f6de637b148f39aa6a5ef60679c5..0000000000000000000000000000000000000000
--- a/spaces/bradarrML/stablediffusion-infinity/utils.py
+++ /dev/null
@@ -1,217 +0,0 @@
-from PIL import Image
-from PIL import ImageFilter
-import cv2
-import numpy as np
-import scipy
-import scipy.signal
-from scipy.spatial import cKDTree
-
-import os
-from perlin2d import *
-
-patch_match_compiled = True
-
-try:
- from PyPatchMatch import patch_match
-except Exception as e:
- try:
- import patch_match
- except Exception as e:
- patch_match_compiled = False
-
-try:
- patch_match
-except NameError:
- print("patch_match compiling failed, will fall back to edge_pad")
- patch_match_compiled = False
-
-
-
-
-def edge_pad(img, mask, mode=1):
- if mode == 0:
- nmask = mask.copy()
- nmask[nmask > 0] = 1
- res0 = 1 - nmask
- res1 = nmask
- p0 = np.stack(res0.nonzero(), axis=0).transpose()
- p1 = np.stack(res1.nonzero(), axis=0).transpose()
- min_dists, min_dist_idx = cKDTree(p1).query(p0, 1)
- loc = p1[min_dist_idx]
- for (a, b), (c, d) in zip(p0, loc):
- img[a, b] = img[c, d]
- elif mode == 1:
- record = {}
- kernel = [[1] * 3 for _ in range(3)]
- nmask = mask.copy()
- nmask[nmask > 0] = 1
- res = scipy.signal.convolve2d(
- nmask, kernel, mode="same", boundary="fill", fillvalue=1
- )
- res[nmask < 1] = 0
- res[res == 9] = 0
- res[res > 0] = 1
- ylst, xlst = res.nonzero()
- queue = [(y, x) for y, x in zip(ylst, xlst)]
- # bfs here
- cnt = res.astype(np.float32)
- acc = img.astype(np.float32)
- step = 1
- h = acc.shape[0]
- w = acc.shape[1]
- offset = [(1, 0), (-1, 0), (0, 1), (0, -1)]
- while queue:
- target = []
- for y, x in queue:
- val = acc[y][x]
- for yo, xo in offset:
- yn = y + yo
- xn = x + xo
- if 0 <= yn < h and 0 <= xn < w and nmask[yn][xn] < 1:
- if record.get((yn, xn), step) == step:
- acc[yn][xn] = acc[yn][xn] * cnt[yn][xn] + val
- cnt[yn][xn] += 1
- acc[yn][xn] /= cnt[yn][xn]
- if (yn, xn) not in record:
- record[(yn, xn)] = step
- target.append((yn, xn))
- step += 1
- queue = target
- img = acc.astype(np.uint8)
- else:
- nmask = mask.copy()
- ylst, xlst = nmask.nonzero()
- yt, xt = ylst.min(), xlst.min()
- yb, xb = ylst.max(), xlst.max()
- content = img[yt : yb + 1, xt : xb + 1]
- img = np.pad(
- content,
- ((yt, mask.shape[0] - yb - 1), (xt, mask.shape[1] - xb - 1), (0, 0)),
- mode="edge",
- )
- return img, mask
-
-
-def perlin_noise(img, mask):
- lin = np.linspace(0, 5, mask.shape[0], endpoint=False)
- x, y = np.meshgrid(lin, lin)
- avg = img.mean(axis=0).mean(axis=0)
- # noise=[((perlin(x, y)+1)*128+avg[i]).astype(np.uint8) for i in range(3)]
- noise = [((perlin(x, y) + 1) * 0.5 * 255).astype(np.uint8) for i in range(3)]
- noise = np.stack(noise, axis=-1)
- # mask=skimage.measure.block_reduce(mask,(8,8),np.min)
- # mask=mask.repeat(8, axis=0).repeat(8, axis=1)
- # mask_image=Image.fromarray(mask)
- # mask_image=mask_image.filter(ImageFilter.GaussianBlur(radius = 4))
- # mask=np.array(mask_image)
- nmask = mask.copy()
- # nmask=nmask/255.0
- nmask[mask > 0] = 1
- img = nmask[:, :, np.newaxis] * img + (1 - nmask[:, :, np.newaxis]) * noise
- # img=img.astype(np.uint8)
- return img, mask
-
-
-def gaussian_noise(img, mask):
- noise = np.random.randn(mask.shape[0], mask.shape[1], 3)
- noise = (noise + 1) / 2 * 255
- noise = noise.astype(np.uint8)
- nmask = mask.copy()
- nmask[mask > 0] = 1
- img = nmask[:, :, np.newaxis] * img + (1 - nmask[:, :, np.newaxis]) * noise
- return img, mask
-
-
-def cv2_telea(img, mask):
- ret = cv2.inpaint(img, 255 - mask, 5, cv2.INPAINT_TELEA)
- return ret, mask
-
-
-def cv2_ns(img, mask):
- ret = cv2.inpaint(img, 255 - mask, 5, cv2.INPAINT_NS)
- return ret, mask
-
-
-def patch_match_func(img, mask):
- ret = patch_match.inpaint(img, mask=255 - mask, patch_size=3)
- return ret, mask
-
-
-def mean_fill(img, mask):
- avg = img.mean(axis=0).mean(axis=0)
- img[mask < 1] = avg
- return img, mask
-
-def g_diffuser(img,mask):
- return img, mask
-
-def dummy_fill(img,mask):
- return img,mask
-functbl = {
- "gaussian": gaussian_noise,
- "perlin": perlin_noise,
- "edge_pad": edge_pad,
- "patchmatch": patch_match_func if patch_match_compiled else edge_pad,
- "cv2_ns": cv2_ns,
- "cv2_telea": cv2_telea,
- "g_diffuser": g_diffuser,
- "g_diffuser_lib": dummy_fill,
-}
-
-try:
- from postprocess import PhotometricCorrection
- correction_func = PhotometricCorrection()
-except Exception as e:
- print(e, "so PhotometricCorrection is disabled")
- class DummyCorrection:
- def __init__(self):
- self.backend=""
- pass
- def run(self,a,b,**kwargs):
- return b
- correction_func=DummyCorrection()
-
-if "taichi" in correction_func.backend:
- import sys
- import io
- import base64
- from PIL import Image
- def base64_to_pil(base64_str):
- data = base64.b64decode(str(base64_str))
- pil = Image.open(io.BytesIO(data))
- return pil
-
- def pil_to_base64(out_pil):
- out_buffer = io.BytesIO()
- out_pil.save(out_buffer, format="PNG")
- out_buffer.seek(0)
- base64_bytes = base64.b64encode(out_buffer.read())
- base64_str = base64_bytes.decode("ascii")
- return base64_str
- from subprocess import Popen, PIPE, STDOUT
- class SubprocessCorrection:
- def __init__(self):
- self.backend=correction_func.backend
- self.child= Popen(["python", "postprocess.py"], stdin=PIPE, stdout=PIPE, stderr=STDOUT)
- def run(self,img_input,img_inpainted,mode):
- if mode=="disabled":
- return img_inpainted
- base64_str_input = pil_to_base64(img_input)
- base64_str_inpainted = pil_to_base64(img_inpainted)
- try:
- if self.child.poll():
- self.child= Popen(["python", "postprocess.py"], stdin=PIPE, stdout=PIPE, stderr=STDOUT)
- self.child.stdin.write(f"{base64_str_input},{base64_str_inpainted},{mode}\n".encode())
- self.child.stdin.flush()
- out = self.child.stdout.readline()
- base64_str=out.decode().strip()
- while base64_str and base64_str[0]=="[":
- print(base64_str)
- out = self.child.stdout.readline()
- base64_str=out.decode().strip()
- ret=base64_to_pil(base64_str)
- except:
- print("[PIE] not working, photometric correction is disabled")
- ret=img_inpainted
- return ret
- correction_func = SubprocessCorrection()
diff --git a/spaces/brjathu/HMR2.0/vendor/pyrender/examples/duck.py b/spaces/brjathu/HMR2.0/vendor/pyrender/examples/duck.py
deleted file mode 100644
index 9a94bad5bfb30493f7364f2e52cbb4badbccb2c7..0000000000000000000000000000000000000000
--- a/spaces/brjathu/HMR2.0/vendor/pyrender/examples/duck.py
+++ /dev/null
@@ -1,13 +0,0 @@
-from pyrender import Mesh, Scene, Viewer
-from io import BytesIO
-import numpy as np
-import trimesh
-import requests
-
-duck_source = "https://github.com/KhronosGroup/glTF-Sample-Models/raw/master/2.0/Duck/glTF-Binary/Duck.glb"
-
-duck = trimesh.load(BytesIO(requests.get(duck_source).content), file_type='glb')
-duckmesh = Mesh.from_trimesh(list(duck.geometry.values())[0])
-scene = Scene(ambient_light=np.array([1.0, 1.0, 1.0, 1.0]))
-scene.add(duckmesh)
-Viewer(scene)
diff --git a/spaces/cakiki/facets-overview/Makefile b/spaces/cakiki/facets-overview/Makefile
deleted file mode 100644
index a6f28a7a554e30a25202cca5f276d7d10b24dc26..0000000000000000000000000000000000000000
--- a/spaces/cakiki/facets-overview/Makefile
+++ /dev/null
@@ -1,13 +0,0 @@
-VERSION := 0.0.1
-NAME := facets-dive
-REPO := cakiki
-
-build:
- docker build -f Dockerfile -t ${REPO}/${NAME}:${VERSION} -t ${REPO}/${NAME}:latest .
-
-run: build
- docker run --rm -it -p 8888:8888 --mount type=bind,source=${PWD},target=/home/jovyan/work --name ${NAME} --workdir=/home/jovyan/work ${REPO}/${NAME}:${VERSION}
-
-push: build
- docker push ${REPO}/${NAME}:${VERSION} && docker push ${REPO}/${NAME}:latest
-
diff --git a/spaces/camenduru/11/index.html b/spaces/camenduru/11/index.html
deleted file mode 100644
index 58b6947afdd827d073af572e47cf1a27b3a31d60..0000000000000000000000000000000000000000
--- a/spaces/camenduru/11/index.html
+++ /dev/null
@@ -1,10 +0,0 @@
-
-
-
- Welcome to My Web Server
-
-
- Welcome!
- Thank you for visiting our web server.
-
-
\ No newline at end of file
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/.github/pull_request_template.md b/spaces/carlosalonso/Detection-video/carpeta_deteccion/.github/pull_request_template.md
deleted file mode 100644
index d71729baee1ec324ab9db6e7562965cf9e2a091b..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/.github/pull_request_template.md
+++ /dev/null
@@ -1,10 +0,0 @@
-Thanks for your contribution!
-
-If you're sending a large PR (e.g., >100 lines),
-please open an issue first about the feature / bug, and indicate how you want to contribute.
-
-We do not always accept features.
-See https://detectron2.readthedocs.io/notes/contributing.html#pull-requests about how we handle PRs.
-
-Before submitting a PR, please run `dev/linter.sh` to lint the code.
-
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/configs/new_baselines/mask_rcnn_regnetx_4gf_dds_FPN_100ep_LSJ.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/configs/new_baselines/mask_rcnn_regnetx_4gf_dds_FPN_100ep_LSJ.py
deleted file mode 100644
index ef0b6d16d4403fb5d16a3aeb71a22621a0be5e21..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/configs/new_baselines/mask_rcnn_regnetx_4gf_dds_FPN_100ep_LSJ.py
+++ /dev/null
@@ -1,29 +0,0 @@
-from .mask_rcnn_R_50_FPN_100ep_LSJ import (
- dataloader,
- lr_multiplier,
- model,
- optimizer,
- train,
-)
-from detectron2.config import LazyCall as L
-from detectron2.modeling.backbone import RegNet
-from detectron2.modeling.backbone.regnet import SimpleStem, ResBottleneckBlock
-
-# Config source:
-# https://github.com/facebookresearch/detectron2/blob/main/configs/COCO-InstanceSegmentation/mask_rcnn_regnetx_4gf_dds_fpn_1x.py # noqa
-model.backbone.bottom_up = L(RegNet)(
- stem_class=SimpleStem,
- stem_width=32,
- block_class=ResBottleneckBlock,
- depth=23,
- w_a=38.65,
- w_0=96,
- w_m=2.43,
- group_width=40,
- norm="SyncBN",
- out_features=["s1", "s2", "s3", "s4"],
-)
-model.pixel_std = [57.375, 57.120, 58.395]
-
-# RegNets benefit from enabling cudnn benchmark mode
-train.cudnn_benchmark = True
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/data/datasets/builtin.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/data/datasets/builtin.py
deleted file mode 100644
index c3a68aa833f12f0fa324a269c36190f21b8a75bd..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/data/datasets/builtin.py
+++ /dev/null
@@ -1,259 +0,0 @@
-# -*- coding: utf-8 -*-
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-
-"""
-This file registers pre-defined datasets at hard-coded paths, and their metadata.
-
-We hard-code metadata for common datasets. This will enable:
-1. Consistency check when loading the datasets
-2. Use models on these standard datasets directly and run demos,
- without having to download the dataset annotations
-
-We hard-code some paths to the dataset that's assumed to
-exist in "./datasets/".
-
-Users SHOULD NOT use this file to create new dataset / metadata for new dataset.
-To add new dataset, refer to the tutorial "docs/DATASETS.md".
-"""
-
-import os
-
-from detectron2.data import DatasetCatalog, MetadataCatalog
-
-from .builtin_meta import ADE20K_SEM_SEG_CATEGORIES, _get_builtin_metadata
-from .cityscapes import load_cityscapes_instances, load_cityscapes_semantic
-from .cityscapes_panoptic import register_all_cityscapes_panoptic
-from .coco import load_sem_seg, register_coco_instances
-from .coco_panoptic import register_coco_panoptic, register_coco_panoptic_separated
-from .lvis import get_lvis_instances_meta, register_lvis_instances
-from .pascal_voc import register_pascal_voc
-
-# ==== Predefined datasets and splits for COCO ==========
-
-_PREDEFINED_SPLITS_COCO = {}
-_PREDEFINED_SPLITS_COCO["coco"] = {
- "coco_2014_train": ("coco/train2014", "coco/annotations/instances_train2014.json"),
- "coco_2014_val": ("coco/val2014", "coco/annotations/instances_val2014.json"),
- "coco_2014_minival": ("coco/val2014", "coco/annotations/instances_minival2014.json"),
- "coco_2014_valminusminival": (
- "coco/val2014",
- "coco/annotations/instances_valminusminival2014.json",
- ),
- "coco_2017_train": ("coco/train2017", "coco/annotations/instances_train2017.json"),
- "coco_2017_val": ("coco/val2017", "coco/annotations/instances_val2017.json"),
- "coco_2017_test": ("coco/test2017", "coco/annotations/image_info_test2017.json"),
- "coco_2017_test-dev": ("coco/test2017", "coco/annotations/image_info_test-dev2017.json"),
- "coco_2017_val_100": ("coco/val2017", "coco/annotations/instances_val2017_100.json"),
-}
-
-_PREDEFINED_SPLITS_COCO["coco_person"] = {
- "keypoints_coco_2014_train": (
- "coco/train2014",
- "coco/annotations/person_keypoints_train2014.json",
- ),
- "keypoints_coco_2014_val": ("coco/val2014", "coco/annotations/person_keypoints_val2014.json"),
- "keypoints_coco_2014_minival": (
- "coco/val2014",
- "coco/annotations/person_keypoints_minival2014.json",
- ),
- "keypoints_coco_2014_valminusminival": (
- "coco/val2014",
- "coco/annotations/person_keypoints_valminusminival2014.json",
- ),
- "keypoints_coco_2017_train": (
- "coco/train2017",
- "coco/annotations/person_keypoints_train2017.json",
- ),
- "keypoints_coco_2017_val": ("coco/val2017", "coco/annotations/person_keypoints_val2017.json"),
- "keypoints_coco_2017_val_100": (
- "coco/val2017",
- "coco/annotations/person_keypoints_val2017_100.json",
- ),
-}
-
-
-_PREDEFINED_SPLITS_COCO_PANOPTIC = {
- "coco_2017_train_panoptic": (
- # This is the original panoptic annotation directory
- "coco/panoptic_train2017",
- "coco/annotations/panoptic_train2017.json",
- # This directory contains semantic annotations that are
- # converted from panoptic annotations.
- # It is used by PanopticFPN.
- # You can use the script at detectron2/datasets/prepare_panoptic_fpn.py
- # to create these directories.
- "coco/panoptic_stuff_train2017",
- ),
- "coco_2017_val_panoptic": (
- "coco/panoptic_val2017",
- "coco/annotations/panoptic_val2017.json",
- "coco/panoptic_stuff_val2017",
- ),
- "coco_2017_val_100_panoptic": (
- "coco/panoptic_val2017_100",
- "coco/annotations/panoptic_val2017_100.json",
- "coco/panoptic_stuff_val2017_100",
- ),
-}
-
-
-def register_all_coco(root):
- for dataset_name, splits_per_dataset in _PREDEFINED_SPLITS_COCO.items():
- for key, (image_root, json_file) in splits_per_dataset.items():
- # Assume pre-defined datasets live in `./datasets`.
- register_coco_instances(
- key,
- _get_builtin_metadata(dataset_name),
- os.path.join(root, json_file) if "://" not in json_file else json_file,
- os.path.join(root, image_root),
- )
-
- for (
- prefix,
- (panoptic_root, panoptic_json, semantic_root),
- ) in _PREDEFINED_SPLITS_COCO_PANOPTIC.items():
- prefix_instances = prefix[: -len("_panoptic")]
- instances_meta = MetadataCatalog.get(prefix_instances)
- image_root, instances_json = instances_meta.image_root, instances_meta.json_file
- # The "separated" version of COCO panoptic segmentation dataset,
- # e.g. used by Panoptic FPN
- register_coco_panoptic_separated(
- prefix,
- _get_builtin_metadata("coco_panoptic_separated"),
- image_root,
- os.path.join(root, panoptic_root),
- os.path.join(root, panoptic_json),
- os.path.join(root, semantic_root),
- instances_json,
- )
- # The "standard" version of COCO panoptic segmentation dataset,
- # e.g. used by Panoptic-DeepLab
- register_coco_panoptic(
- prefix,
- _get_builtin_metadata("coco_panoptic_standard"),
- image_root,
- os.path.join(root, panoptic_root),
- os.path.join(root, panoptic_json),
- instances_json,
- )
-
-
-# ==== Predefined datasets and splits for LVIS ==========
-
-
-_PREDEFINED_SPLITS_LVIS = {
- "lvis_v1": {
- "lvis_v1_train": ("coco/", "lvis/lvis_v1_train.json"),
- "lvis_v1_val": ("coco/", "lvis/lvis_v1_val.json"),
- "lvis_v1_test_dev": ("coco/", "lvis/lvis_v1_image_info_test_dev.json"),
- "lvis_v1_test_challenge": ("coco/", "lvis/lvis_v1_image_info_test_challenge.json"),
- },
- "lvis_v0.5": {
- "lvis_v0.5_train": ("coco/", "lvis/lvis_v0.5_train.json"),
- "lvis_v0.5_val": ("coco/", "lvis/lvis_v0.5_val.json"),
- "lvis_v0.5_val_rand_100": ("coco/", "lvis/lvis_v0.5_val_rand_100.json"),
- "lvis_v0.5_test": ("coco/", "lvis/lvis_v0.5_image_info_test.json"),
- },
- "lvis_v0.5_cocofied": {
- "lvis_v0.5_train_cocofied": ("coco/", "lvis/lvis_v0.5_train_cocofied.json"),
- "lvis_v0.5_val_cocofied": ("coco/", "lvis/lvis_v0.5_val_cocofied.json"),
- },
-}
-
-
-def register_all_lvis(root):
- for dataset_name, splits_per_dataset in _PREDEFINED_SPLITS_LVIS.items():
- for key, (image_root, json_file) in splits_per_dataset.items():
- register_lvis_instances(
- key,
- get_lvis_instances_meta(dataset_name),
- os.path.join(root, json_file) if "://" not in json_file else json_file,
- os.path.join(root, image_root),
- )
-
-
-# ==== Predefined splits for raw cityscapes images ===========
-_RAW_CITYSCAPES_SPLITS = {
- "cityscapes_fine_{task}_train": ("cityscapes/leftImg8bit/train/", "cityscapes/gtFine/train/"),
- "cityscapes_fine_{task}_val": ("cityscapes/leftImg8bit/val/", "cityscapes/gtFine/val/"),
- "cityscapes_fine_{task}_test": ("cityscapes/leftImg8bit/test/", "cityscapes/gtFine/test/"),
-}
-
-
-def register_all_cityscapes(root):
- for key, (image_dir, gt_dir) in _RAW_CITYSCAPES_SPLITS.items():
- meta = _get_builtin_metadata("cityscapes")
- image_dir = os.path.join(root, image_dir)
- gt_dir = os.path.join(root, gt_dir)
-
- inst_key = key.format(task="instance_seg")
- DatasetCatalog.register(
- inst_key,
- lambda x=image_dir, y=gt_dir: load_cityscapes_instances(
- x, y, from_json=True, to_polygons=True
- ),
- )
- MetadataCatalog.get(inst_key).set(
- image_dir=image_dir, gt_dir=gt_dir, evaluator_type="cityscapes_instance", **meta
- )
-
- sem_key = key.format(task="sem_seg")
- DatasetCatalog.register(
- sem_key, lambda x=image_dir, y=gt_dir: load_cityscapes_semantic(x, y)
- )
- MetadataCatalog.get(sem_key).set(
- image_dir=image_dir,
- gt_dir=gt_dir,
- evaluator_type="cityscapes_sem_seg",
- ignore_label=255,
- **meta,
- )
-
-
-# ==== Predefined splits for PASCAL VOC ===========
-def register_all_pascal_voc(root):
- SPLITS = [
- ("voc_2007_trainval", "VOC2007", "trainval"),
- ("voc_2007_train", "VOC2007", "train"),
- ("voc_2007_val", "VOC2007", "val"),
- ("voc_2007_test", "VOC2007", "test"),
- ("voc_2012_trainval", "VOC2012", "trainval"),
- ("voc_2012_train", "VOC2012", "train"),
- ("voc_2012_val", "VOC2012", "val"),
- ]
- for name, dirname, split in SPLITS:
- year = 2007 if "2007" in name else 2012
- register_pascal_voc(name, os.path.join(root, dirname), split, year)
- MetadataCatalog.get(name).evaluator_type = "pascal_voc"
-
-
-def register_all_ade20k(root):
- root = os.path.join(root, "ADEChallengeData2016")
- for name, dirname in [("train", "training"), ("val", "validation")]:
- image_dir = os.path.join(root, "images", dirname)
- gt_dir = os.path.join(root, "annotations_detectron2", dirname)
- name = f"ade20k_sem_seg_{name}"
- DatasetCatalog.register(
- name, lambda x=image_dir, y=gt_dir: load_sem_seg(y, x, gt_ext="png", image_ext="jpg")
- )
- MetadataCatalog.get(name).set(
- stuff_classes=ADE20K_SEM_SEG_CATEGORIES[:],
- image_root=image_dir,
- sem_seg_root=gt_dir,
- evaluator_type="sem_seg",
- ignore_label=255,
- )
-
-
-# True for open source;
-# Internally at fb, we register them elsewhere
-if __name__.endswith(".builtin"):
- # Assume pre-defined datasets live in `./datasets`.
- _root = os.path.expanduser(os.getenv("DETECTRON2_DATASETS", "datasets"))
- register_all_coco(_root)
- register_all_lvis(_root)
- register_all_cityscapes(_root)
- register_all_cityscapes_panoptic(_root)
- register_all_pascal_voc(_root)
- register_all_ade20k(_root)
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/utils/logger.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/utils/logger.py
deleted file mode 100644
index 7c7890f8bec5db44098fe1a38d26eb13231f7063..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/detectron2/utils/logger.py
+++ /dev/null
@@ -1,237 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import atexit
-import functools
-import logging
-import os
-import sys
-import time
-from collections import Counter
-import torch
-from tabulate import tabulate
-from termcolor import colored
-
-from detectron2.utils.file_io import PathManager
-
-__all__ = ["setup_logger", "log_first_n", "log_every_n", "log_every_n_seconds"]
-
-
-class _ColorfulFormatter(logging.Formatter):
- def __init__(self, *args, **kwargs):
- self._root_name = kwargs.pop("root_name") + "."
- self._abbrev_name = kwargs.pop("abbrev_name", "")
- if len(self._abbrev_name):
- self._abbrev_name = self._abbrev_name + "."
- super(_ColorfulFormatter, self).__init__(*args, **kwargs)
-
- def formatMessage(self, record):
- record.name = record.name.replace(self._root_name, self._abbrev_name)
- log = super(_ColorfulFormatter, self).formatMessage(record)
- if record.levelno == logging.WARNING:
- prefix = colored("WARNING", "red", attrs=["blink"])
- elif record.levelno == logging.ERROR or record.levelno == logging.CRITICAL:
- prefix = colored("ERROR", "red", attrs=["blink", "underline"])
- else:
- return log
- return prefix + " " + log
-
-
-@functools.lru_cache() # so that calling setup_logger multiple times won't add many handlers
-def setup_logger(
- output=None, distributed_rank=0, *, color=True, name="detectron2", abbrev_name=None
-):
- """
- Initialize the detectron2 logger and set its verbosity level to "DEBUG".
-
- Args:
- output (str): a file name or a directory to save log. If None, will not save log file.
- If ends with ".txt" or ".log", assumed to be a file name.
- Otherwise, logs will be saved to `output/log.txt`.
- name (str): the root module name of this logger
- abbrev_name (str): an abbreviation of the module, to avoid long names in logs.
- Set to "" to not log the root module in logs.
- By default, will abbreviate "detectron2" to "d2" and leave other
- modules unchanged.
-
- Returns:
- logging.Logger: a logger
- """
- logger = logging.getLogger(name)
- logger.setLevel(logging.DEBUG)
- logger.propagate = False
-
- if abbrev_name is None:
- abbrev_name = "d2" if name == "detectron2" else name
-
- plain_formatter = logging.Formatter(
- "[%(asctime)s] %(name)s %(levelname)s: %(message)s", datefmt="%m/%d %H:%M:%S"
- )
- # stdout logging: master only
- if distributed_rank == 0:
- ch = logging.StreamHandler(stream=sys.stdout)
- ch.setLevel(logging.DEBUG)
- if color:
- formatter = _ColorfulFormatter(
- colored("[%(asctime)s %(name)s]: ", "green") + "%(message)s",
- datefmt="%m/%d %H:%M:%S",
- root_name=name,
- abbrev_name=str(abbrev_name),
- )
- else:
- formatter = plain_formatter
- ch.setFormatter(formatter)
- logger.addHandler(ch)
-
- # file logging: all workers
- if output is not None:
- if output.endswith(".txt") or output.endswith(".log"):
- filename = output
- else:
- filename = os.path.join(output, "log.txt")
- if distributed_rank > 0:
- filename = filename + ".rank{}".format(distributed_rank)
- PathManager.mkdirs(os.path.dirname(filename))
-
- fh = logging.StreamHandler(_cached_log_stream(filename))
- fh.setLevel(logging.DEBUG)
- fh.setFormatter(plain_formatter)
- logger.addHandler(fh)
-
- return logger
-
-
-# cache the opened file object, so that different calls to `setup_logger`
-# with the same file name can safely write to the same file.
-@functools.lru_cache(maxsize=None)
-def _cached_log_stream(filename):
- # use 1K buffer if writing to cloud storage
- io = PathManager.open(filename, "a", buffering=1024 if "://" in filename else -1)
- atexit.register(io.close)
- return io
-
-
-"""
-Below are some other convenient logging methods.
-They are mainly adopted from
-https://github.com/abseil/abseil-py/blob/master/absl/logging/__init__.py
-"""
-
-
-def _find_caller():
- """
- Returns:
- str: module name of the caller
- tuple: a hashable key to be used to identify different callers
- """
- frame = sys._getframe(2)
- while frame:
- code = frame.f_code
- if os.path.join("utils", "logger.") not in code.co_filename:
- mod_name = frame.f_globals["__name__"]
- if mod_name == "__main__":
- mod_name = "detectron2"
- return mod_name, (code.co_filename, frame.f_lineno, code.co_name)
- frame = frame.f_back
-
-
-_LOG_COUNTER = Counter()
-_LOG_TIMER = {}
-
-
-def log_first_n(lvl, msg, n=1, *, name=None, key="caller"):
- """
- Log only for the first n times.
-
- Args:
- lvl (int): the logging level
- msg (str):
- n (int):
- name (str): name of the logger to use. Will use the caller's module by default.
- key (str or tuple[str]): the string(s) can be one of "caller" or
- "message", which defines how to identify duplicated logs.
- For example, if called with `n=1, key="caller"`, this function
- will only log the first call from the same caller, regardless of
- the message content.
- If called with `n=1, key="message"`, this function will log the
- same content only once, even if they are called from different places.
- If called with `n=1, key=("caller", "message")`, this function
- will not log only if the same caller has logged the same message before.
- """
- if isinstance(key, str):
- key = (key,)
- assert len(key) > 0
-
- caller_module, caller_key = _find_caller()
- hash_key = ()
- if "caller" in key:
- hash_key = hash_key + caller_key
- if "message" in key:
- hash_key = hash_key + (msg,)
-
- _LOG_COUNTER[hash_key] += 1
- if _LOG_COUNTER[hash_key] <= n:
- logging.getLogger(name or caller_module).log(lvl, msg)
-
-
-def log_every_n(lvl, msg, n=1, *, name=None):
- """
- Log once per n times.
-
- Args:
- lvl (int): the logging level
- msg (str):
- n (int):
- name (str): name of the logger to use. Will use the caller's module by default.
- """
- caller_module, key = _find_caller()
- _LOG_COUNTER[key] += 1
- if n == 1 or _LOG_COUNTER[key] % n == 1:
- logging.getLogger(name or caller_module).log(lvl, msg)
-
-
-def log_every_n_seconds(lvl, msg, n=1, *, name=None):
- """
- Log no more than once per n seconds.
-
- Args:
- lvl (int): the logging level
- msg (str):
- n (int):
- name (str): name of the logger to use. Will use the caller's module by default.
- """
- caller_module, key = _find_caller()
- last_logged = _LOG_TIMER.get(key, None)
- current_time = time.time()
- if last_logged is None or current_time - last_logged >= n:
- logging.getLogger(name or caller_module).log(lvl, msg)
- _LOG_TIMER[key] = current_time
-
-
-def create_small_table(small_dict):
- """
- Create a small table using the keys of small_dict as headers. This is only
- suitable for small dictionaries.
-
- Args:
- small_dict (dict): a result dictionary of only a few items.
-
- Returns:
- str: the table as a string.
- """
- keys, values = tuple(zip(*small_dict.items()))
- table = tabulate(
- [values],
- headers=keys,
- tablefmt="pipe",
- floatfmt=".3f",
- stralign="center",
- numalign="center",
- )
- return table
-
-
-def _log_api_usage(identifier: str):
- """
- Internal function used to log the usage of different detectron2 components
- inside facebook's infra.
- """
- torch._C._log_api_usage_once("detectron2." + identifier)
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/DensePose/densepose/data/image_list_dataset.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/DensePose/densepose/data/image_list_dataset.py
deleted file mode 100644
index 92a95d3d5e7d4d7d6bf1d29d51295d32ae2104d2..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/DensePose/densepose/data/image_list_dataset.py
+++ /dev/null
@@ -1,72 +0,0 @@
-# -*- coding: utf-8 -*-
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-import logging
-import numpy as np
-from typing import Any, Callable, Dict, List, Optional, Union
-import torch
-from torch.utils.data.dataset import Dataset
-
-from detectron2.data.detection_utils import read_image
-
-ImageTransform = Callable[[torch.Tensor], torch.Tensor]
-
-
-class ImageListDataset(Dataset):
- """
- Dataset that provides images from a list.
- """
-
- _EMPTY_IMAGE = torch.empty((0, 3, 1, 1))
-
- def __init__(
- self,
- image_list: List[str],
- category_list: Union[str, List[str], None] = None,
- transform: Optional[ImageTransform] = None,
- ):
- """
- Args:
- image_list (List[str]): list of paths to image files
- category_list (Union[str, List[str], None]): list of animal categories for
- each image. If it is a string, or None, this applies to all images
- """
- if type(category_list) == list:
- self.category_list = category_list
- else:
- self.category_list = [category_list] * len(image_list)
- assert len(image_list) == len(
- self.category_list
- ), "length of image and category lists must be equal"
- self.image_list = image_list
- self.transform = transform
-
- def __getitem__(self, idx: int) -> Dict[str, Any]:
- """
- Gets selected images from the list
-
- Args:
- idx (int): video index in the video list file
- Returns:
- A dictionary containing two keys:
- images (torch.Tensor): tensor of size [N, 3, H, W] (N = 1, or 0 for _EMPTY_IMAGE)
- categories (List[str]): categories of the frames
- """
- categories = [self.category_list[idx]]
- fpath = self.image_list[idx]
- transform = self.transform
-
- try:
- image = torch.from_numpy(np.ascontiguousarray(read_image(fpath, format="BGR")))
- image = image.permute(2, 0, 1).unsqueeze(0).float() # HWC -> NCHW
- if transform is not None:
- image = transform(image)
- return {"images": image, "categories": categories}
- except (OSError, RuntimeError) as e:
- logger = logging.getLogger(__name__)
- logger.warning(f"Error opening image file container {fpath}: {e}")
-
- return {"images": self._EMPTY_IMAGE, "categories": []}
-
- def __len__(self):
- return len(self.image_list)
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/DensePose/tests/test_image_resize_transform.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/DensePose/tests/test_image_resize_transform.py
deleted file mode 100644
index 01c3373b64ee243198af682928939781a15f929a..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/DensePose/tests/test_image_resize_transform.py
+++ /dev/null
@@ -1,16 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-import unittest
-import torch
-
-from densepose.data.transform import ImageResizeTransform
-
-
-class TestImageResizeTransform(unittest.TestCase):
- def test_image_resize_1(self):
- images_batch = torch.ones((3, 3, 100, 100), dtype=torch.uint8) * 100
- transform = ImageResizeTransform()
- images_transformed = transform(images_batch)
- IMAGES_GT = torch.ones((3, 3, 800, 800), dtype=torch.float) * 100
- self.assertEqual(images_transformed.size(), IMAGES_GT.size())
- self.assertAlmostEqual(torch.abs(IMAGES_GT - images_transformed).max().item(), 0.0)
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/Panoptic-DeepLab/README.md b/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/Panoptic-DeepLab/README.md
deleted file mode 100644
index 86b6d42ba059d7da602b95cfdf3fe7d37ea7d4ec..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/Panoptic-DeepLab/README.md
+++ /dev/null
@@ -1,175 +0,0 @@
-# Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation
-
-Bowen Cheng, Maxwell D. Collins, Yukun Zhu, Ting Liu, Thomas S. Huang, Hartwig Adam, Liang-Chieh Chen
-
-[[`arXiv`](https://arxiv.org/abs/1911.10194)] [[`BibTeX`](#CitingPanopticDeepLab)] [[`Reference implementation`](https://github.com/bowenc0221/panoptic-deeplab)]
-
-
-

-
-
-## Installation
-Install Detectron2 following [the instructions](https://detectron2.readthedocs.io/tutorials/install.html).
-To use cityscapes, prepare data follow the [tutorial](https://detectron2.readthedocs.io/tutorials/builtin_datasets.html#expected-dataset-structure-for-cityscapes).
-
-## Training
-
-To train a model with 8 GPUs run:
-```bash
-cd /path/to/detectron2/projects/Panoptic-DeepLab
-python train_net.py --config-file configs/Cityscapes-PanopticSegmentation/panoptic_deeplab_R_52_os16_mg124_poly_90k_bs32_crop_512_1024_dsconv.yaml --num-gpus 8
-```
-
-## Evaluation
-
-Model evaluation can be done similarly:
-```bash
-cd /path/to/detectron2/projects/Panoptic-DeepLab
-python train_net.py --config-file configs/Cityscapes-PanopticSegmentation/panoptic_deeplab_R_52_os16_mg124_poly_90k_bs32_crop_512_1024_dsconv.yaml --eval-only MODEL.WEIGHTS /path/to/model_checkpoint
-```
-
-## Benchmark network speed
-
-If you want to benchmark the network speed without post-processing, you can run the evaluation script with `MODEL.PANOPTIC_DEEPLAB.BENCHMARK_NETWORK_SPEED True`:
-```bash
-cd /path/to/detectron2/projects/Panoptic-DeepLab
-python train_net.py --config-file configs/Cityscapes-PanopticSegmentation/panoptic_deeplab_R_52_os16_mg124_poly_90k_bs32_crop_512_1024_dsconv.yaml --eval-only MODEL.WEIGHTS /path/to/model_checkpoint MODEL.PANOPTIC_DEEPLAB.BENCHMARK_NETWORK_SPEED True
-```
-
-## Cityscapes Panoptic Segmentation
-Cityscapes models are trained with ImageNet pretraining.
-
-
-
-
-| Method |
-Backbone |
-Output
resolution |
-PQ |
-SQ |
-RQ |
-mIoU |
-AP |
-Memory (M) |
-model id |
-download |
-
- | Panoptic-DeepLab |
-R50-DC5 |
-1024×2048 |
- 58.6 |
- 80.9 |
- 71.2 |
- 75.9 |
- 29.8 |
- 8668 |
- - |
-model | metrics |
-
- | Panoptic-DeepLab |
-R52-DC5 |
-1024×2048 |
- 60.3 |
- 81.5 |
- 72.9 |
- 78.2 |
- 33.2 |
- 9682 |
- 30841561 |
-model | metrics |
-
- | Panoptic-DeepLab (DSConv) |
-R52-DC5 |
-1024×2048 |
- 60.3 |
- 81.0 |
- 73.2 |
- 78.7 |
- 32.1 |
- 10466 |
- 33148034 |
-model | metrics |
-
-
-
-Note:
-- [R52](https://dl.fbaipublicfiles.com/detectron2/DeepLab/R-52.pkl): a ResNet-50 with its first 7x7 convolution replaced by 3 3x3 convolutions. This modification has been used in most semantic segmentation papers. We pre-train this backbone on ImageNet using the default recipe of [pytorch examples](https://github.com/pytorch/examples/tree/master/imagenet).
-- DC5 means using dilated convolution in `res5`.
-- We use a smaller training crop size (512x1024) than the original paper (1025x2049), we find using larger crop size (1024x2048) could further improve PQ by 1.5% but also degrades AP by 3%.
-- The implementation with regular Conv2d in ASPP and head is much heavier head than the original paper.
-- This implementation does not include optimized post-processing code needed for deployment. Post-processing the network
- outputs now takes similar amount of time to the network itself. Please refer to speed in the
- original paper for comparison.
-- DSConv refers to using DepthwiseSeparableConv2d in ASPP and decoder. The implementation with DSConv is identical to the original paper.
-
-## COCO Panoptic Segmentation
-COCO models are trained with ImageNet pretraining on 16 V100s.
-
-
-
-
-| Method |
-Backbone |
-Output
resolution |
-PQ |
-SQ |
-RQ |
-Box AP |
-Mask AP |
-Memory (M) |
-model id |
-download |
-
- | Panoptic-DeepLab (DSConv) |
-R52-DC5 |
-640×640 |
- 35.5 |
- 77.3 |
- 44.7 |
- 18.6 |
- 19.7 |
- |
- 246448865 |
-model | metrics |
-
-
-
-Note:
-- [R52](https://dl.fbaipublicfiles.com/detectron2/DeepLab/R-52.pkl): a ResNet-50 with its first 7x7 convolution replaced by 3 3x3 convolutions. This modification has been used in most semantic segmentation papers. We pre-train this backbone on ImageNet using the default recipe of [pytorch examples](https://github.com/pytorch/examples/tree/master/imagenet).
-- DC5 means using dilated convolution in `res5`.
-- This reproduced number matches the original paper (35.5 vs. 35.1 PQ).
-- This implementation does not include optimized post-processing code needed for deployment. Post-processing the network
- outputs now takes more time than the network itself. Please refer to speed in the original paper for comparison.
-- DSConv refers to using DepthwiseSeparableConv2d in ASPP and decoder.
-
-## Citing Panoptic-DeepLab
-
-If you use Panoptic-DeepLab, please use the following BibTeX entry.
-
-* CVPR 2020 paper:
-
-```
-@inproceedings{cheng2020panoptic,
- title={Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation},
- author={Cheng, Bowen and Collins, Maxwell D and Zhu, Yukun and Liu, Ting and Huang, Thomas S and Adam, Hartwig and Chen, Liang-Chieh},
- booktitle={CVPR},
- year={2020}
-}
-```
-
-* ICCV 2019 COCO-Mapillary workshp challenge report:
-
-```
-@inproceedings{cheng2019panoptic,
- title={Panoptic-DeepLab},
- author={Cheng, Bowen and Collins, Maxwell D and Zhu, Yukun and Liu, Ting and Huang, Thomas S and Adam, Hartwig and Chen, Liang-Chieh},
- booktitle={ICCV COCO + Mapillary Joint Recognition Challenge Workshop},
- year={2019}
-}
-```
diff --git a/spaces/cfwef/gpt/Dockerfile b/spaces/cfwef/gpt/Dockerfile
deleted file mode 100644
index 564392c933342f77731be47faa417bb8906067bc..0000000000000000000000000000000000000000
--- a/spaces/cfwef/gpt/Dockerfile
+++ /dev/null
@@ -1,13 +0,0 @@
-FROM python:3.11
-
-RUN echo '[global]' > /etc/pip.conf && \
- echo 'index-url = https://mirrors.aliyun.com/pypi/simple/' >> /etc/pip.conf && \
- echo 'trusted-host = mirrors.aliyun.com' >> /etc/pip.conf
-
-RUN pip3 install gradio requests[socks] mdtex2html
-
-COPY . /gpt
-WORKDIR /gpt
-
-
-CMD ["python3", "main.py"]
\ No newline at end of file
diff --git a/spaces/chendl/compositional_test/multimodal/open_flamingo/src/flamingo_lm.py b/spaces/chendl/compositional_test/multimodal/open_flamingo/src/flamingo_lm.py
deleted file mode 100644
index f3c1a5f981f95fa22219c73bdcd288165317d13c..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/multimodal/open_flamingo/src/flamingo_lm.py
+++ /dev/null
@@ -1,173 +0,0 @@
-import random
-import torch
-import torch.nn as nn
-import numpy as np
-
-from .helpers import GatedCrossAttentionBlock
-from .utils import getattr_recursive, setattr_recursive
-
-
-class FlamingoLayer(nn.Module):
- def __init__(self, decoder_layer):
- super().__init__()
- self.decoder_layer = decoder_layer
- self.vis_x = None
- self.image_nums = None
- self.image_start_index_list = None
- self.media_locations = None
- self.add_visual_token = False
- self.input_ids = None
-
- def is_conditioned(self) -> bool:
- """Check whether the layer is conditioned."""
- return self.vis_x is not None
-
- # Used this great idea from this implementation of Flamingo (https://github.com/dhansmair/flamingo-mini/)
- def condition_vis_x(self, vis_x, image_nums=None, image_start_index_list=None, num_beams=None, visual_tokens=None, data_list=None):
- self.vis_x = vis_x
- self.image_nums = image_nums
- self.image_start_index_list = image_start_index_list
- self.num_beams = num_beams
- self.visual_tokens = visual_tokens
- self.data_list = data_list
- self.input_ids = None
-
-
- def condition_media_locations(self, media_locations):
- self.media_locations = media_locations
-
- def condition_attend_previous(self, attend_previous):
- self.attend_previous = attend_previous
-
- def forward(
- self,
- hidden_states, # alignment with hugging face name
- attention_mask=None,
- **decoder_layer_kwargs,
- ):
- if self.media_locations is None:
- raise ValueError("media_locations must be conditioned before forward pass")
-
- if self.vis_x is not None:
- if self.training:
- single_length = self.vis_x.shape[-2]
- image_nums = self.image_nums
- image_start_index_list = self.image_start_index_list
- image_nums = [0] + np.cumsum(image_nums).tolist()
- for i, (image_num_begin, image_num_end, start_indices) in enumerate(zip(image_nums[:-1], image_nums[1:], image_start_index_list)):
- for index in start_indices:
- if image_num_begin < image_num_end:
- hidden_states[i, index:index+single_length] = self.vis_x[image_num_begin]
- image_num_begin += 1
-
- if self.visual_tokens is not None and len(self.visual_tokens) != 0:
- for i, (x, y) in enumerate(self.data_list):
- if len(self.visual_tokens[i].shape) > 1:
- # print(self.visual_tokens[i].shape[0], "embedding")
- hidden_states[x, y+1-self.visual_tokens[i].shape[0]:y+1] = self.visual_tokens[i]
- else:
- # print(self.visual_tokens[i].shape[0], "embedding")
- hidden_states[x, y] = self.visual_tokens[i]
-
- elif not self.training:
- if (
- ("past_key_value" in decoder_layer_kwargs and decoder_layer_kwargs["past_key_value"] is None) or
- ("layer_past" in decoder_layer_kwargs and decoder_layer_kwargs["layer_past"] is None)
- ):
- single_length = self.vis_x.shape[-2]
- image_nums = self.image_nums
- image_start_index_list = self.image_start_index_list
- image_nums = [0] + np.cumsum(image_nums).tolist()
- for i, (image_num_begin, image_num_end, start_indices) in enumerate(zip(image_nums[:-1], image_nums[1:], image_start_index_list)):
- for index in start_indices:
- if image_num_begin < image_num_end:
- hidden_states[i, index:index+single_length] = self.vis_x[image_num_begin]
- image_num_begin += 1
- if self.visual_tokens is not None and len(self.visual_tokens) != 0:
- for i, (x, y) in enumerate(self.data_list):
- # import pdb; pdb.set_trace()
- # print(x, y, self.visual_tokens[i].shape)
- if len(self.visual_tokens[i].shape) > 1:
- # print(self.visual_tokens[i].shape[0], "embedding")
- hidden_states[x, y+1-self.visual_tokens[i].shape[0]:y+1] = self.visual_tokens[i]
- else:
- # print(self.visual_tokens[i].shape[0], "embedding")
- hidden_states[x, y] = self.visual_tokens[i]
- hidden_states = self.decoder_layer(
- hidden_states, attention_mask=attention_mask, **decoder_layer_kwargs
- )
- return hidden_states
-
-
-class FlamingoLMMixin(nn.Module):
- """
- Mixin to add cross-attention layers to a language model.
- """
-
- def set_decoder_layers_attr_name(self, decoder_layers_attr_name):
- self.decoder_layers_attr_name = decoder_layers_attr_name
-
- def _get_decoder_layers(self):
- return getattr_recursive(self, self.decoder_layers_attr_name)
-
- def _set_decoder_layers(self, value):
- setattr_recursive(self, self.decoder_layers_attr_name, value)
-
- def init_flamingo(
- self,
- media_token_id,
- use_media_placement_augmentation,
- ):
- """
- Initialize Flamingo by adding a new gated cross attn to the decoder. Store the media token id for computing the media locations.
- """
- self._set_decoder_layers(
- nn.ModuleList(
- [FlamingoLayer(decoder_layer) for decoder_layer in self._get_decoder_layers()]
- )
- )
- self.media_token_id = media_token_id
- self.use_media_placement_augmentation = use_media_placement_augmentation
- self.initialized_flamingo = True
-
- def forward(self, *input, **kwargs):
- """Condition the Flamingo layers on the media locations before forward()"""
- if not self.initialized_flamingo:
- raise ValueError(
- "Flamingo layers are not initialized. Please call `init_flamingo` first."
- )
-
- input_ids = kwargs["input_ids"] if "input_ids" in kwargs else input[0]
- media_locations = input_ids == self.media_token_id
- attend_previous = (
- (random.random() < 0.5) if self.use_media_placement_augmentation else True
- )
-
- if (
- "gpt2" in self.__class__.__name__.lower()
- or "codegen" in self.__class__.__name__.lower()
- ):
- for layer in self.transformer.h:
- layer.condition_media_locations(media_locations)
- layer.condition_attend_previous(attend_previous)
- elif "gptneox" in self.__class__.__name__.lower():
- for layer in self.gpt_neox.layers:
- layer.condition_media_locations(media_locations)
- layer.condition_attend_previous(attend_previous)
- else:
- for layer in self.get_decoder().layers:
- layer.condition_media_locations(media_locations)
- layer.condition_attend_previous(attend_previous)
- return super().forward(
- *input, **kwargs
- ) # Call the other parent's forward method
-
- def is_conditioned(self) -> bool:
- """Check whether all decoder layers are already conditioned."""
- return all(l.is_conditioned() for l in self._get_decoder_layers())
-
- def clear_conditioned_layers(self):
- for layer in self._get_decoder_layers():
- layer.condition_vis_x(None)
- layer.condition_media_locations(None)
- layer.condition_attend_previous(None)
diff --git a/spaces/chendl/compositional_test/transformers/examples/research_projects/rag/use_own_knowledge_dataset.py b/spaces/chendl/compositional_test/transformers/examples/research_projects/rag/use_own_knowledge_dataset.py
deleted file mode 100644
index 84d7c854975f1156d313731cf539bd719019d7c6..0000000000000000000000000000000000000000
--- a/spaces/chendl/compositional_test/transformers/examples/research_projects/rag/use_own_knowledge_dataset.py
+++ /dev/null
@@ -1,208 +0,0 @@
-import logging
-import os
-from dataclasses import dataclass, field
-from functools import partial
-from pathlib import Path
-from tempfile import TemporaryDirectory
-from typing import List, Optional
-
-import faiss
-import torch
-from datasets import Features, Sequence, Value, load_dataset
-
-from transformers import (
- DPRContextEncoder,
- DPRContextEncoderTokenizerFast,
- HfArgumentParser,
- RagRetriever,
- RagSequenceForGeneration,
- RagTokenizer,
-)
-
-
-logger = logging.getLogger(__name__)
-torch.set_grad_enabled(False)
-device = "cuda" if torch.cuda.is_available() else "cpu"
-
-
-def split_text(text: str, n=100, character=" ") -> List[str]:
- """Split the text every ``n``-th occurrence of ``character``"""
- text = text.split(character)
- return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
-
-
-def split_documents(documents: dict) -> dict:
- """Split documents into passages"""
- titles, texts = [], []
- for title, text in zip(documents["title"], documents["text"]):
- if text is not None:
- for passage in split_text(text):
- titles.append(title if title is not None else "")
- texts.append(passage)
- return {"title": titles, "text": texts}
-
-
-def embed(documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast) -> dict:
- """Compute the DPR embeddings of document passages"""
- input_ids = ctx_tokenizer(
- documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
- )["input_ids"]
- embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
- return {"embeddings": embeddings.detach().cpu().numpy()}
-
-
-def main(
- rag_example_args: "RagExampleArguments",
- processing_args: "ProcessingArguments",
- index_hnsw_args: "IndexHnswArguments",
-):
- ######################################
- logger.info("Step 1 - Create the dataset")
- ######################################
-
- # The dataset needed for RAG must have three columns:
- # - title (string): title of the document
- # - text (string): text of a passage of the document
- # - embeddings (array of dimension d): DPR representation of the passage
-
- # Let's say you have documents in tab-separated csv files with columns "title" and "text"
- assert os.path.isfile(rag_example_args.csv_path), "Please provide a valid path to a csv file"
-
- # You can load a Dataset object this way
- dataset = load_dataset(
- "csv", data_files=[rag_example_args.csv_path], split="train", delimiter="\t", column_names=["title", "text"]
- )
-
- # More info about loading csv files in the documentation: https://huggingface.co/docs/datasets/loading_datasets.html?highlight=csv#csv-files
-
- # Then split the documents into passages of 100 words
- dataset = dataset.map(split_documents, batched=True, num_proc=processing_args.num_proc)
-
- # And compute the embeddings
- ctx_encoder = DPRContextEncoder.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name).to(device=device)
- ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
- new_features = Features(
- {"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
- ) # optional, save as float32 instead of float64 to save space
- dataset = dataset.map(
- partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=ctx_tokenizer),
- batched=True,
- batch_size=processing_args.batch_size,
- features=new_features,
- )
-
- # And finally save your dataset
- passages_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset")
- dataset.save_to_disk(passages_path)
- # from datasets import load_from_disk
- # dataset = load_from_disk(passages_path) # to reload the dataset
-
- ######################################
- logger.info("Step 2 - Index the dataset")
- ######################################
-
- # Let's use the Faiss implementation of HNSW for fast approximate nearest neighbor search
- index = faiss.IndexHNSWFlat(index_hnsw_args.d, index_hnsw_args.m, faiss.METRIC_INNER_PRODUCT)
- dataset.add_faiss_index("embeddings", custom_index=index)
-
- # And save the index
- index_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset_hnsw_index.faiss")
- dataset.get_index("embeddings").save(index_path)
- # dataset.load_faiss_index("embeddings", index_path) # to reload the index
-
- ######################################
- logger.info("Step 3 - Load RAG")
- ######################################
-
- # Easy way to load the model
- retriever = RagRetriever.from_pretrained(
- rag_example_args.rag_model_name, index_name="custom", indexed_dataset=dataset
- )
- model = RagSequenceForGeneration.from_pretrained(rag_example_args.rag_model_name, retriever=retriever)
- tokenizer = RagTokenizer.from_pretrained(rag_example_args.rag_model_name)
-
- # For distributed fine-tuning you'll need to provide the paths instead, as the dataset and the index are loaded separately.
- # retriever = RagRetriever.from_pretrained(rag_model_name, index_name="custom", passages_path=passages_path, index_path=index_path)
-
- ######################################
- logger.info("Step 4 - Have fun")
- ######################################
-
- question = rag_example_args.question or "What does Moses' rod turn into ?"
- input_ids = tokenizer.question_encoder(question, return_tensors="pt")["input_ids"]
- generated = model.generate(input_ids)
- generated_string = tokenizer.batch_decode(generated, skip_special_tokens=True)[0]
- logger.info("Q: " + question)
- logger.info("A: " + generated_string)
-
-
-@dataclass
-class RagExampleArguments:
- csv_path: str = field(
- default=str(Path(__file__).parent / "test_data" / "my_knowledge_dataset.csv"),
- metadata={"help": "Path to a tab-separated csv file with columns 'title' and 'text'"},
- )
- question: Optional[str] = field(
- default=None,
- metadata={"help": "Question that is passed as input to RAG. Default is 'What does Moses' rod turn into ?'."},
- )
- rag_model_name: str = field(
- default="facebook/rag-sequence-nq",
- metadata={"help": "The RAG model to use. Either 'facebook/rag-sequence-nq' or 'facebook/rag-token-nq'"},
- )
- dpr_ctx_encoder_model_name: str = field(
- default="facebook/dpr-ctx_encoder-multiset-base",
- metadata={
- "help": (
- "The DPR context encoder model to use. Either 'facebook/dpr-ctx_encoder-single-nq-base' or"
- " 'facebook/dpr-ctx_encoder-multiset-base'"
- )
- },
- )
- output_dir: Optional[str] = field(
- default=None,
- metadata={"help": "Path to a directory where the dataset passages and the index will be saved"},
- )
-
-
-@dataclass
-class ProcessingArguments:
- num_proc: Optional[int] = field(
- default=None,
- metadata={
- "help": "The number of processes to use to split the documents into passages. Default is single process."
- },
- )
- batch_size: int = field(
- default=16,
- metadata={
- "help": "The batch size to use when computing the passages embeddings using the DPR context encoder."
- },
- )
-
-
-@dataclass
-class IndexHnswArguments:
- d: int = field(
- default=768,
- metadata={"help": "The dimension of the embeddings to pass to the HNSW Faiss index."},
- )
- m: int = field(
- default=128,
- metadata={
- "help": (
- "The number of bi-directional links created for every new element during the HNSW index construction."
- )
- },
- )
-
-
-if __name__ == "__main__":
- logging.basicConfig(level=logging.WARNING)
- logger.setLevel(logging.INFO)
-
- parser = HfArgumentParser((RagExampleArguments, ProcessingArguments, IndexHnswArguments))
- rag_example_args, processing_args, index_hnsw_args = parser.parse_args_into_dataclasses()
- with TemporaryDirectory() as tmp_dir:
- rag_example_args.output_dir = rag_example_args.output_dir or tmp_dir
- main(rag_example_args, processing_args, index_hnsw_args)
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/clickhouse_connect/driver/types.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/clickhouse_connect/driver/types.py
deleted file mode 100644
index 015e162fbea9c8c5c4f93b4759b6dafab462ad1b..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/clickhouse_connect/driver/types.py
+++ /dev/null
@@ -1,50 +0,0 @@
-from abc import ABC, abstractmethod
-from typing import Sequence, Any
-
-Matrix = Sequence[Sequence[Any]]
-
-
-class Closable(ABC):
- @abstractmethod
- def close(self):
- pass
-
-
-class ByteSource(Closable):
- last_message = None
-
- @abstractmethod
- def read_leb128(self) -> int:
- pass
-
- @abstractmethod
- def read_leb128_str(self) -> str:
- pass
-
- @abstractmethod
- def read_uint64(self) -> int:
- pass
-
- @abstractmethod
- def read_bytes(self, sz: int) -> bytes:
- pass
-
- @abstractmethod
- def read_str_col(self, num_rows: int, encoding: str, nullable: bool = False, null_obj: Any = None):
- pass
-
- @abstractmethod
- def read_bytes_col(self, sz: int, num_rows: int):
- pass
-
- @abstractmethod
- def read_fixed_str_col(self, sz: int, num_rows: int, encoding: str):
- pass
-
- @abstractmethod
- def read_array(self, array_type: str, num_rows: int):
- pass
-
- @abstractmethod
- def read_byte(self) -> int:
- pass
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/dateutil/parser/_parser.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/dateutil/parser/_parser.py
deleted file mode 100644
index 37d1663b2f72447800d9a553929e3de932244289..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/dateutil/parser/_parser.py
+++ /dev/null
@@ -1,1613 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-This module offers a generic date/time string parser which is able to parse
-most known formats to represent a date and/or time.
-
-This module attempts to be forgiving with regards to unlikely input formats,
-returning a datetime object even for dates which are ambiguous. If an element
-of a date/time stamp is omitted, the following rules are applied:
-
-- If AM or PM is left unspecified, a 24-hour clock is assumed, however, an hour
- on a 12-hour clock (``0 <= hour <= 12``) *must* be specified if AM or PM is
- specified.
-- If a time zone is omitted, a timezone-naive datetime is returned.
-
-If any other elements are missing, they are taken from the
-:class:`datetime.datetime` object passed to the parameter ``default``. If this
-results in a day number exceeding the valid number of days per month, the
-value falls back to the end of the month.
-
-Additional resources about date/time string formats can be found below:
-
-- `A summary of the international standard date and time notation
- `_
-- `W3C Date and Time Formats `_
-- `Time Formats (Planetary Rings Node) `_
-- `CPAN ParseDate module
- `_
-- `Java SimpleDateFormat Class
- `_
-"""
-from __future__ import unicode_literals
-
-import datetime
-import re
-import string
-import time
-import warnings
-
-from calendar import monthrange
-from io import StringIO
-
-import six
-from six import integer_types, text_type
-
-from decimal import Decimal
-
-from warnings import warn
-
-from .. import relativedelta
-from .. import tz
-
-__all__ = ["parse", "parserinfo", "ParserError"]
-
-
-# TODO: pandas.core.tools.datetimes imports this explicitly. Might be worth
-# making public and/or figuring out if there is something we can
-# take off their plate.
-class _timelex(object):
- # Fractional seconds are sometimes split by a comma
- _split_decimal = re.compile("([.,])")
-
- def __init__(self, instream):
- if isinstance(instream, (bytes, bytearray)):
- instream = instream.decode()
-
- if isinstance(instream, text_type):
- instream = StringIO(instream)
- elif getattr(instream, 'read', None) is None:
- raise TypeError('Parser must be a string or character stream, not '
- '{itype}'.format(itype=instream.__class__.__name__))
-
- self.instream = instream
- self.charstack = []
- self.tokenstack = []
- self.eof = False
-
- def get_token(self):
- """
- This function breaks the time string into lexical units (tokens), which
- can be parsed by the parser. Lexical units are demarcated by changes in
- the character set, so any continuous string of letters is considered
- one unit, any continuous string of numbers is considered one unit.
-
- The main complication arises from the fact that dots ('.') can be used
- both as separators (e.g. "Sep.20.2009") or decimal points (e.g.
- "4:30:21.447"). As such, it is necessary to read the full context of
- any dot-separated strings before breaking it into tokens; as such, this
- function maintains a "token stack", for when the ambiguous context
- demands that multiple tokens be parsed at once.
- """
- if self.tokenstack:
- return self.tokenstack.pop(0)
-
- seenletters = False
- token = None
- state = None
-
- while not self.eof:
- # We only realize that we've reached the end of a token when we
- # find a character that's not part of the current token - since
- # that character may be part of the next token, it's stored in the
- # charstack.
- if self.charstack:
- nextchar = self.charstack.pop(0)
- else:
- nextchar = self.instream.read(1)
- while nextchar == '\x00':
- nextchar = self.instream.read(1)
-
- if not nextchar:
- self.eof = True
- break
- elif not state:
- # First character of the token - determines if we're starting
- # to parse a word, a number or something else.
- token = nextchar
- if self.isword(nextchar):
- state = 'a'
- elif self.isnum(nextchar):
- state = '0'
- elif self.isspace(nextchar):
- token = ' '
- break # emit token
- else:
- break # emit token
- elif state == 'a':
- # If we've already started reading a word, we keep reading
- # letters until we find something that's not part of a word.
- seenletters = True
- if self.isword(nextchar):
- token += nextchar
- elif nextchar == '.':
- token += nextchar
- state = 'a.'
- else:
- self.charstack.append(nextchar)
- break # emit token
- elif state == '0':
- # If we've already started reading a number, we keep reading
- # numbers until we find something that doesn't fit.
- if self.isnum(nextchar):
- token += nextchar
- elif nextchar == '.' or (nextchar == ',' and len(token) >= 2):
- token += nextchar
- state = '0.'
- else:
- self.charstack.append(nextchar)
- break # emit token
- elif state == 'a.':
- # If we've seen some letters and a dot separator, continue
- # parsing, and the tokens will be broken up later.
- seenletters = True
- if nextchar == '.' or self.isword(nextchar):
- token += nextchar
- elif self.isnum(nextchar) and token[-1] == '.':
- token += nextchar
- state = '0.'
- else:
- self.charstack.append(nextchar)
- break # emit token
- elif state == '0.':
- # If we've seen at least one dot separator, keep going, we'll
- # break up the tokens later.
- if nextchar == '.' or self.isnum(nextchar):
- token += nextchar
- elif self.isword(nextchar) and token[-1] == '.':
- token += nextchar
- state = 'a.'
- else:
- self.charstack.append(nextchar)
- break # emit token
-
- if (state in ('a.', '0.') and (seenletters or token.count('.') > 1 or
- token[-1] in '.,')):
- l = self._split_decimal.split(token)
- token = l[0]
- for tok in l[1:]:
- if tok:
- self.tokenstack.append(tok)
-
- if state == '0.' and token.count('.') == 0:
- token = token.replace(',', '.')
-
- return token
-
- def __iter__(self):
- return self
-
- def __next__(self):
- token = self.get_token()
- if token is None:
- raise StopIteration
-
- return token
-
- def next(self):
- return self.__next__() # Python 2.x support
-
- @classmethod
- def split(cls, s):
- return list(cls(s))
-
- @classmethod
- def isword(cls, nextchar):
- """ Whether or not the next character is part of a word """
- return nextchar.isalpha()
-
- @classmethod
- def isnum(cls, nextchar):
- """ Whether the next character is part of a number """
- return nextchar.isdigit()
-
- @classmethod
- def isspace(cls, nextchar):
- """ Whether the next character is whitespace """
- return nextchar.isspace()
-
-
-class _resultbase(object):
-
- def __init__(self):
- for attr in self.__slots__:
- setattr(self, attr, None)
-
- def _repr(self, classname):
- l = []
- for attr in self.__slots__:
- value = getattr(self, attr)
- if value is not None:
- l.append("%s=%s" % (attr, repr(value)))
- return "%s(%s)" % (classname, ", ".join(l))
-
- def __len__(self):
- return (sum(getattr(self, attr) is not None
- for attr in self.__slots__))
-
- def __repr__(self):
- return self._repr(self.__class__.__name__)
-
-
-class parserinfo(object):
- """
- Class which handles what inputs are accepted. Subclass this to customize
- the language and acceptable values for each parameter.
-
- :param dayfirst:
- Whether to interpret the first value in an ambiguous 3-integer date
- (e.g. 01/05/09) as the day (``True``) or month (``False``). If
- ``yearfirst`` is set to ``True``, this distinguishes between YDM
- and YMD. Default is ``False``.
-
- :param yearfirst:
- Whether to interpret the first value in an ambiguous 3-integer date
- (e.g. 01/05/09) as the year. If ``True``, the first number is taken
- to be the year, otherwise the last number is taken to be the year.
- Default is ``False``.
- """
-
- # m from a.m/p.m, t from ISO T separator
- JUMP = [" ", ".", ",", ";", "-", "/", "'",
- "at", "on", "and", "ad", "m", "t", "of",
- "st", "nd", "rd", "th"]
-
- WEEKDAYS = [("Mon", "Monday"),
- ("Tue", "Tuesday"), # TODO: "Tues"
- ("Wed", "Wednesday"),
- ("Thu", "Thursday"), # TODO: "Thurs"
- ("Fri", "Friday"),
- ("Sat", "Saturday"),
- ("Sun", "Sunday")]
- MONTHS = [("Jan", "January"),
- ("Feb", "February"), # TODO: "Febr"
- ("Mar", "March"),
- ("Apr", "April"),
- ("May", "May"),
- ("Jun", "June"),
- ("Jul", "July"),
- ("Aug", "August"),
- ("Sep", "Sept", "September"),
- ("Oct", "October"),
- ("Nov", "November"),
- ("Dec", "December")]
- HMS = [("h", "hour", "hours"),
- ("m", "minute", "minutes"),
- ("s", "second", "seconds")]
- AMPM = [("am", "a"),
- ("pm", "p")]
- UTCZONE = ["UTC", "GMT", "Z", "z"]
- PERTAIN = ["of"]
- TZOFFSET = {}
- # TODO: ERA = ["AD", "BC", "CE", "BCE", "Stardate",
- # "Anno Domini", "Year of Our Lord"]
-
- def __init__(self, dayfirst=False, yearfirst=False):
- self._jump = self._convert(self.JUMP)
- self._weekdays = self._convert(self.WEEKDAYS)
- self._months = self._convert(self.MONTHS)
- self._hms = self._convert(self.HMS)
- self._ampm = self._convert(self.AMPM)
- self._utczone = self._convert(self.UTCZONE)
- self._pertain = self._convert(self.PERTAIN)
-
- self.dayfirst = dayfirst
- self.yearfirst = yearfirst
-
- self._year = time.localtime().tm_year
- self._century = self._year // 100 * 100
-
- def _convert(self, lst):
- dct = {}
- for i, v in enumerate(lst):
- if isinstance(v, tuple):
- for v in v:
- dct[v.lower()] = i
- else:
- dct[v.lower()] = i
- return dct
-
- def jump(self, name):
- return name.lower() in self._jump
-
- def weekday(self, name):
- try:
- return self._weekdays[name.lower()]
- except KeyError:
- pass
- return None
-
- def month(self, name):
- try:
- return self._months[name.lower()] + 1
- except KeyError:
- pass
- return None
-
- def hms(self, name):
- try:
- return self._hms[name.lower()]
- except KeyError:
- return None
-
- def ampm(self, name):
- try:
- return self._ampm[name.lower()]
- except KeyError:
- return None
-
- def pertain(self, name):
- return name.lower() in self._pertain
-
- def utczone(self, name):
- return name.lower() in self._utczone
-
- def tzoffset(self, name):
- if name in self._utczone:
- return 0
-
- return self.TZOFFSET.get(name)
-
- def convertyear(self, year, century_specified=False):
- """
- Converts two-digit years to year within [-50, 49]
- range of self._year (current local time)
- """
-
- # Function contract is that the year is always positive
- assert year >= 0
-
- if year < 100 and not century_specified:
- # assume current century to start
- year += self._century
-
- if year >= self._year + 50: # if too far in future
- year -= 100
- elif year < self._year - 50: # if too far in past
- year += 100
-
- return year
-
- def validate(self, res):
- # move to info
- if res.year is not None:
- res.year = self.convertyear(res.year, res.century_specified)
-
- if ((res.tzoffset == 0 and not res.tzname) or
- (res.tzname == 'Z' or res.tzname == 'z')):
- res.tzname = "UTC"
- res.tzoffset = 0
- elif res.tzoffset != 0 and res.tzname and self.utczone(res.tzname):
- res.tzoffset = 0
- return True
-
-
-class _ymd(list):
- def __init__(self, *args, **kwargs):
- super(self.__class__, self).__init__(*args, **kwargs)
- self.century_specified = False
- self.dstridx = None
- self.mstridx = None
- self.ystridx = None
-
- @property
- def has_year(self):
- return self.ystridx is not None
-
- @property
- def has_month(self):
- return self.mstridx is not None
-
- @property
- def has_day(self):
- return self.dstridx is not None
-
- def could_be_day(self, value):
- if self.has_day:
- return False
- elif not self.has_month:
- return 1 <= value <= 31
- elif not self.has_year:
- # Be permissive, assume leap year
- month = self[self.mstridx]
- return 1 <= value <= monthrange(2000, month)[1]
- else:
- month = self[self.mstridx]
- year = self[self.ystridx]
- return 1 <= value <= monthrange(year, month)[1]
-
- def append(self, val, label=None):
- if hasattr(val, '__len__'):
- if val.isdigit() and len(val) > 2:
- self.century_specified = True
- if label not in [None, 'Y']: # pragma: no cover
- raise ValueError(label)
- label = 'Y'
- elif val > 100:
- self.century_specified = True
- if label not in [None, 'Y']: # pragma: no cover
- raise ValueError(label)
- label = 'Y'
-
- super(self.__class__, self).append(int(val))
-
- if label == 'M':
- if self.has_month:
- raise ValueError('Month is already set')
- self.mstridx = len(self) - 1
- elif label == 'D':
- if self.has_day:
- raise ValueError('Day is already set')
- self.dstridx = len(self) - 1
- elif label == 'Y':
- if self.has_year:
- raise ValueError('Year is already set')
- self.ystridx = len(self) - 1
-
- def _resolve_from_stridxs(self, strids):
- """
- Try to resolve the identities of year/month/day elements using
- ystridx, mstridx, and dstridx, if enough of these are specified.
- """
- if len(self) == 3 and len(strids) == 2:
- # we can back out the remaining stridx value
- missing = [x for x in range(3) if x not in strids.values()]
- key = [x for x in ['y', 'm', 'd'] if x not in strids]
- assert len(missing) == len(key) == 1
- key = key[0]
- val = missing[0]
- strids[key] = val
-
- assert len(self) == len(strids) # otherwise this should not be called
- out = {key: self[strids[key]] for key in strids}
- return (out.get('y'), out.get('m'), out.get('d'))
-
- def resolve_ymd(self, yearfirst, dayfirst):
- len_ymd = len(self)
- year, month, day = (None, None, None)
-
- strids = (('y', self.ystridx),
- ('m', self.mstridx),
- ('d', self.dstridx))
-
- strids = {key: val for key, val in strids if val is not None}
- if (len(self) == len(strids) > 0 or
- (len(self) == 3 and len(strids) == 2)):
- return self._resolve_from_stridxs(strids)
-
- mstridx = self.mstridx
-
- if len_ymd > 3:
- raise ValueError("More than three YMD values")
- elif len_ymd == 1 or (mstridx is not None and len_ymd == 2):
- # One member, or two members with a month string
- if mstridx is not None:
- month = self[mstridx]
- # since mstridx is 0 or 1, self[mstridx-1] always
- # looks up the other element
- other = self[mstridx - 1]
- else:
- other = self[0]
-
- if len_ymd > 1 or mstridx is None:
- if other > 31:
- year = other
- else:
- day = other
-
- elif len_ymd == 2:
- # Two members with numbers
- if self[0] > 31:
- # 99-01
- year, month = self
- elif self[1] > 31:
- # 01-99
- month, year = self
- elif dayfirst and self[1] <= 12:
- # 13-01
- day, month = self
- else:
- # 01-13
- month, day = self
-
- elif len_ymd == 3:
- # Three members
- if mstridx == 0:
- if self[1] > 31:
- # Apr-2003-25
- month, year, day = self
- else:
- month, day, year = self
- elif mstridx == 1:
- if self[0] > 31 or (yearfirst and self[2] <= 31):
- # 99-Jan-01
- year, month, day = self
- else:
- # 01-Jan-01
- # Give precedence to day-first, since
- # two-digit years is usually hand-written.
- day, month, year = self
-
- elif mstridx == 2:
- # WTF!?
- if self[1] > 31:
- # 01-99-Jan
- day, year, month = self
- else:
- # 99-01-Jan
- year, day, month = self
-
- else:
- if (self[0] > 31 or
- self.ystridx == 0 or
- (yearfirst and self[1] <= 12 and self[2] <= 31)):
- # 99-01-01
- if dayfirst and self[2] <= 12:
- year, day, month = self
- else:
- year, month, day = self
- elif self[0] > 12 or (dayfirst and self[1] <= 12):
- # 13-01-01
- day, month, year = self
- else:
- # 01-13-01
- month, day, year = self
-
- return year, month, day
-
-
-class parser(object):
- def __init__(self, info=None):
- self.info = info or parserinfo()
-
- def parse(self, timestr, default=None,
- ignoretz=False, tzinfos=None, **kwargs):
- """
- Parse the date/time string into a :class:`datetime.datetime` object.
-
- :param timestr:
- Any date/time string using the supported formats.
-
- :param default:
- The default datetime object, if this is a datetime object and not
- ``None``, elements specified in ``timestr`` replace elements in the
- default object.
-
- :param ignoretz:
- If set ``True``, time zones in parsed strings are ignored and a
- naive :class:`datetime.datetime` object is returned.
-
- :param tzinfos:
- Additional time zone names / aliases which may be present in the
- string. This argument maps time zone names (and optionally offsets
- from those time zones) to time zones. This parameter can be a
- dictionary with timezone aliases mapping time zone names to time
- zones or a function taking two parameters (``tzname`` and
- ``tzoffset``) and returning a time zone.
-
- The timezones to which the names are mapped can be an integer
- offset from UTC in seconds or a :class:`tzinfo` object.
-
- .. doctest::
- :options: +NORMALIZE_WHITESPACE
-
- >>> from dateutil.parser import parse
- >>> from dateutil.tz import gettz
- >>> tzinfos = {"BRST": -7200, "CST": gettz("America/Chicago")}
- >>> parse("2012-01-19 17:21:00 BRST", tzinfos=tzinfos)
- datetime.datetime(2012, 1, 19, 17, 21, tzinfo=tzoffset(u'BRST', -7200))
- >>> parse("2012-01-19 17:21:00 CST", tzinfos=tzinfos)
- datetime.datetime(2012, 1, 19, 17, 21,
- tzinfo=tzfile('/usr/share/zoneinfo/America/Chicago'))
-
- This parameter is ignored if ``ignoretz`` is set.
-
- :param \\*\\*kwargs:
- Keyword arguments as passed to ``_parse()``.
-
- :return:
- Returns a :class:`datetime.datetime` object or, if the
- ``fuzzy_with_tokens`` option is ``True``, returns a tuple, the
- first element being a :class:`datetime.datetime` object, the second
- a tuple containing the fuzzy tokens.
-
- :raises ParserError:
- Raised for invalid or unknown string format, if the provided
- :class:`tzinfo` is not in a valid format, or if an invalid date
- would be created.
-
- :raises TypeError:
- Raised for non-string or character stream input.
-
- :raises OverflowError:
- Raised if the parsed date exceeds the largest valid C integer on
- your system.
- """
-
- if default is None:
- default = datetime.datetime.now().replace(hour=0, minute=0,
- second=0, microsecond=0)
-
- res, skipped_tokens = self._parse(timestr, **kwargs)
-
- if res is None:
- raise ParserError("Unknown string format: %s", timestr)
-
- if len(res) == 0:
- raise ParserError("String does not contain a date: %s", timestr)
-
- try:
- ret = self._build_naive(res, default)
- except ValueError as e:
- six.raise_from(ParserError(str(e) + ": %s", timestr), e)
-
- if not ignoretz:
- ret = self._build_tzaware(ret, res, tzinfos)
-
- if kwargs.get('fuzzy_with_tokens', False):
- return ret, skipped_tokens
- else:
- return ret
-
- class _result(_resultbase):
- __slots__ = ["year", "month", "day", "weekday",
- "hour", "minute", "second", "microsecond",
- "tzname", "tzoffset", "ampm","any_unused_tokens"]
-
- def _parse(self, timestr, dayfirst=None, yearfirst=None, fuzzy=False,
- fuzzy_with_tokens=False):
- """
- Private method which performs the heavy lifting of parsing, called from
- ``parse()``, which passes on its ``kwargs`` to this function.
-
- :param timestr:
- The string to parse.
-
- :param dayfirst:
- Whether to interpret the first value in an ambiguous 3-integer date
- (e.g. 01/05/09) as the day (``True``) or month (``False``). If
- ``yearfirst`` is set to ``True``, this distinguishes between YDM
- and YMD. If set to ``None``, this value is retrieved from the
- current :class:`parserinfo` object (which itself defaults to
- ``False``).
-
- :param yearfirst:
- Whether to interpret the first value in an ambiguous 3-integer date
- (e.g. 01/05/09) as the year. If ``True``, the first number is taken
- to be the year, otherwise the last number is taken to be the year.
- If this is set to ``None``, the value is retrieved from the current
- :class:`parserinfo` object (which itself defaults to ``False``).
-
- :param fuzzy:
- Whether to allow fuzzy parsing, allowing for string like "Today is
- January 1, 2047 at 8:21:00AM".
-
- :param fuzzy_with_tokens:
- If ``True``, ``fuzzy`` is automatically set to True, and the parser
- will return a tuple where the first element is the parsed
- :class:`datetime.datetime` datetimestamp and the second element is
- a tuple containing the portions of the string which were ignored:
-
- .. doctest::
-
- >>> from dateutil.parser import parse
- >>> parse("Today is January 1, 2047 at 8:21:00AM", fuzzy_with_tokens=True)
- (datetime.datetime(2047, 1, 1, 8, 21), (u'Today is ', u' ', u'at '))
-
- """
- if fuzzy_with_tokens:
- fuzzy = True
-
- info = self.info
-
- if dayfirst is None:
- dayfirst = info.dayfirst
-
- if yearfirst is None:
- yearfirst = info.yearfirst
-
- res = self._result()
- l = _timelex.split(timestr) # Splits the timestr into tokens
-
- skipped_idxs = []
-
- # year/month/day list
- ymd = _ymd()
-
- len_l = len(l)
- i = 0
- try:
- while i < len_l:
-
- # Check if it's a number
- value_repr = l[i]
- try:
- value = float(value_repr)
- except ValueError:
- value = None
-
- if value is not None:
- # Numeric token
- i = self._parse_numeric_token(l, i, info, ymd, res, fuzzy)
-
- # Check weekday
- elif info.weekday(l[i]) is not None:
- value = info.weekday(l[i])
- res.weekday = value
-
- # Check month name
- elif info.month(l[i]) is not None:
- value = info.month(l[i])
- ymd.append(value, 'M')
-
- if i + 1 < len_l:
- if l[i + 1] in ('-', '/'):
- # Jan-01[-99]
- sep = l[i + 1]
- ymd.append(l[i + 2])
-
- if i + 3 < len_l and l[i + 3] == sep:
- # Jan-01-99
- ymd.append(l[i + 4])
- i += 2
-
- i += 2
-
- elif (i + 4 < len_l and l[i + 1] == l[i + 3] == ' ' and
- info.pertain(l[i + 2])):
- # Jan of 01
- # In this case, 01 is clearly year
- if l[i + 4].isdigit():
- # Convert it here to become unambiguous
- value = int(l[i + 4])
- year = str(info.convertyear(value))
- ymd.append(year, 'Y')
- else:
- # Wrong guess
- pass
- # TODO: not hit in tests
- i += 4
-
- # Check am/pm
- elif info.ampm(l[i]) is not None:
- value = info.ampm(l[i])
- val_is_ampm = self._ampm_valid(res.hour, res.ampm, fuzzy)
-
- if val_is_ampm:
- res.hour = self._adjust_ampm(res.hour, value)
- res.ampm = value
-
- elif fuzzy:
- skipped_idxs.append(i)
-
- # Check for a timezone name
- elif self._could_be_tzname(res.hour, res.tzname, res.tzoffset, l[i]):
- res.tzname = l[i]
- res.tzoffset = info.tzoffset(res.tzname)
-
- # Check for something like GMT+3, or BRST+3. Notice
- # that it doesn't mean "I am 3 hours after GMT", but
- # "my time +3 is GMT". If found, we reverse the
- # logic so that timezone parsing code will get it
- # right.
- if i + 1 < len_l and l[i + 1] in ('+', '-'):
- l[i + 1] = ('+', '-')[l[i + 1] == '+']
- res.tzoffset = None
- if info.utczone(res.tzname):
- # With something like GMT+3, the timezone
- # is *not* GMT.
- res.tzname = None
-
- # Check for a numbered timezone
- elif res.hour is not None and l[i] in ('+', '-'):
- signal = (-1, 1)[l[i] == '+']
- len_li = len(l[i + 1])
-
- # TODO: check that l[i + 1] is integer?
- if len_li == 4:
- # -0300
- hour_offset = int(l[i + 1][:2])
- min_offset = int(l[i + 1][2:])
- elif i + 2 < len_l and l[i + 2] == ':':
- # -03:00
- hour_offset = int(l[i + 1])
- min_offset = int(l[i + 3]) # TODO: Check that l[i+3] is minute-like?
- i += 2
- elif len_li <= 2:
- # -[0]3
- hour_offset = int(l[i + 1][:2])
- min_offset = 0
- else:
- raise ValueError(timestr)
-
- res.tzoffset = signal * (hour_offset * 3600 + min_offset * 60)
-
- # Look for a timezone name between parenthesis
- if (i + 5 < len_l and
- info.jump(l[i + 2]) and l[i + 3] == '(' and
- l[i + 5] == ')' and
- 3 <= len(l[i + 4]) and
- self._could_be_tzname(res.hour, res.tzname,
- None, l[i + 4])):
- # -0300 (BRST)
- res.tzname = l[i + 4]
- i += 4
-
- i += 1
-
- # Check jumps
- elif not (info.jump(l[i]) or fuzzy):
- raise ValueError(timestr)
-
- else:
- skipped_idxs.append(i)
- i += 1
-
- # Process year/month/day
- year, month, day = ymd.resolve_ymd(yearfirst, dayfirst)
-
- res.century_specified = ymd.century_specified
- res.year = year
- res.month = month
- res.day = day
-
- except (IndexError, ValueError):
- return None, None
-
- if not info.validate(res):
- return None, None
-
- if fuzzy_with_tokens:
- skipped_tokens = self._recombine_skipped(l, skipped_idxs)
- return res, tuple(skipped_tokens)
- else:
- return res, None
-
- def _parse_numeric_token(self, tokens, idx, info, ymd, res, fuzzy):
- # Token is a number
- value_repr = tokens[idx]
- try:
- value = self._to_decimal(value_repr)
- except Exception as e:
- six.raise_from(ValueError('Unknown numeric token'), e)
-
- len_li = len(value_repr)
-
- len_l = len(tokens)
-
- if (len(ymd) == 3 and len_li in (2, 4) and
- res.hour is None and
- (idx + 1 >= len_l or
- (tokens[idx + 1] != ':' and
- info.hms(tokens[idx + 1]) is None))):
- # 19990101T23[59]
- s = tokens[idx]
- res.hour = int(s[:2])
-
- if len_li == 4:
- res.minute = int(s[2:])
-
- elif len_li == 6 or (len_li > 6 and tokens[idx].find('.') == 6):
- # YYMMDD or HHMMSS[.ss]
- s = tokens[idx]
-
- if not ymd and '.' not in tokens[idx]:
- ymd.append(s[:2])
- ymd.append(s[2:4])
- ymd.append(s[4:])
- else:
- # 19990101T235959[.59]
-
- # TODO: Check if res attributes already set.
- res.hour = int(s[:2])
- res.minute = int(s[2:4])
- res.second, res.microsecond = self._parsems(s[4:])
-
- elif len_li in (8, 12, 14):
- # YYYYMMDD
- s = tokens[idx]
- ymd.append(s[:4], 'Y')
- ymd.append(s[4:6])
- ymd.append(s[6:8])
-
- if len_li > 8:
- res.hour = int(s[8:10])
- res.minute = int(s[10:12])
-
- if len_li > 12:
- res.second = int(s[12:])
-
- elif self._find_hms_idx(idx, tokens, info, allow_jump=True) is not None:
- # HH[ ]h or MM[ ]m or SS[.ss][ ]s
- hms_idx = self._find_hms_idx(idx, tokens, info, allow_jump=True)
- (idx, hms) = self._parse_hms(idx, tokens, info, hms_idx)
- if hms is not None:
- # TODO: checking that hour/minute/second are not
- # already set?
- self._assign_hms(res, value_repr, hms)
-
- elif idx + 2 < len_l and tokens[idx + 1] == ':':
- # HH:MM[:SS[.ss]]
- res.hour = int(value)
- value = self._to_decimal(tokens[idx + 2]) # TODO: try/except for this?
- (res.minute, res.second) = self._parse_min_sec(value)
-
- if idx + 4 < len_l and tokens[idx + 3] == ':':
- res.second, res.microsecond = self._parsems(tokens[idx + 4])
-
- idx += 2
-
- idx += 2
-
- elif idx + 1 < len_l and tokens[idx + 1] in ('-', '/', '.'):
- sep = tokens[idx + 1]
- ymd.append(value_repr)
-
- if idx + 2 < len_l and not info.jump(tokens[idx + 2]):
- if tokens[idx + 2].isdigit():
- # 01-01[-01]
- ymd.append(tokens[idx + 2])
- else:
- # 01-Jan[-01]
- value = info.month(tokens[idx + 2])
-
- if value is not None:
- ymd.append(value, 'M')
- else:
- raise ValueError()
-
- if idx + 3 < len_l and tokens[idx + 3] == sep:
- # We have three members
- value = info.month(tokens[idx + 4])
-
- if value is not None:
- ymd.append(value, 'M')
- else:
- ymd.append(tokens[idx + 4])
- idx += 2
-
- idx += 1
- idx += 1
-
- elif idx + 1 >= len_l or info.jump(tokens[idx + 1]):
- if idx + 2 < len_l and info.ampm(tokens[idx + 2]) is not None:
- # 12 am
- hour = int(value)
- res.hour = self._adjust_ampm(hour, info.ampm(tokens[idx + 2]))
- idx += 1
- else:
- # Year, month or day
- ymd.append(value)
- idx += 1
-
- elif info.ampm(tokens[idx + 1]) is not None and (0 <= value < 24):
- # 12am
- hour = int(value)
- res.hour = self._adjust_ampm(hour, info.ampm(tokens[idx + 1]))
- idx += 1
-
- elif ymd.could_be_day(value):
- ymd.append(value)
-
- elif not fuzzy:
- raise ValueError()
-
- return idx
-
- def _find_hms_idx(self, idx, tokens, info, allow_jump):
- len_l = len(tokens)
-
- if idx+1 < len_l and info.hms(tokens[idx+1]) is not None:
- # There is an "h", "m", or "s" label following this token. We take
- # assign the upcoming label to the current token.
- # e.g. the "12" in 12h"
- hms_idx = idx + 1
-
- elif (allow_jump and idx+2 < len_l and tokens[idx+1] == ' ' and
- info.hms(tokens[idx+2]) is not None):
- # There is a space and then an "h", "m", or "s" label.
- # e.g. the "12" in "12 h"
- hms_idx = idx + 2
-
- elif idx > 0 and info.hms(tokens[idx-1]) is not None:
- # There is a "h", "m", or "s" preceding this token. Since neither
- # of the previous cases was hit, there is no label following this
- # token, so we use the previous label.
- # e.g. the "04" in "12h04"
- hms_idx = idx-1
-
- elif (1 < idx == len_l-1 and tokens[idx-1] == ' ' and
- info.hms(tokens[idx-2]) is not None):
- # If we are looking at the final token, we allow for a
- # backward-looking check to skip over a space.
- # TODO: Are we sure this is the right condition here?
- hms_idx = idx - 2
-
- else:
- hms_idx = None
-
- return hms_idx
-
- def _assign_hms(self, res, value_repr, hms):
- # See GH issue #427, fixing float rounding
- value = self._to_decimal(value_repr)
-
- if hms == 0:
- # Hour
- res.hour = int(value)
- if value % 1:
- res.minute = int(60*(value % 1))
-
- elif hms == 1:
- (res.minute, res.second) = self._parse_min_sec(value)
-
- elif hms == 2:
- (res.second, res.microsecond) = self._parsems(value_repr)
-
- def _could_be_tzname(self, hour, tzname, tzoffset, token):
- return (hour is not None and
- tzname is None and
- tzoffset is None and
- len(token) <= 5 and
- (all(x in string.ascii_uppercase for x in token)
- or token in self.info.UTCZONE))
-
- def _ampm_valid(self, hour, ampm, fuzzy):
- """
- For fuzzy parsing, 'a' or 'am' (both valid English words)
- may erroneously trigger the AM/PM flag. Deal with that
- here.
- """
- val_is_ampm = True
-
- # If there's already an AM/PM flag, this one isn't one.
- if fuzzy and ampm is not None:
- val_is_ampm = False
-
- # If AM/PM is found and hour is not, raise a ValueError
- if hour is None:
- if fuzzy:
- val_is_ampm = False
- else:
- raise ValueError('No hour specified with AM or PM flag.')
- elif not 0 <= hour <= 12:
- # If AM/PM is found, it's a 12 hour clock, so raise
- # an error for invalid range
- if fuzzy:
- val_is_ampm = False
- else:
- raise ValueError('Invalid hour specified for 12-hour clock.')
-
- return val_is_ampm
-
- def _adjust_ampm(self, hour, ampm):
- if hour < 12 and ampm == 1:
- hour += 12
- elif hour == 12 and ampm == 0:
- hour = 0
- return hour
-
- def _parse_min_sec(self, value):
- # TODO: Every usage of this function sets res.second to the return
- # value. Are there any cases where second will be returned as None and
- # we *don't* want to set res.second = None?
- minute = int(value)
- second = None
-
- sec_remainder = value % 1
- if sec_remainder:
- second = int(60 * sec_remainder)
- return (minute, second)
-
- def _parse_hms(self, idx, tokens, info, hms_idx):
- # TODO: Is this going to admit a lot of false-positives for when we
- # just happen to have digits and "h", "m" or "s" characters in non-date
- # text? I guess hex hashes won't have that problem, but there's plenty
- # of random junk out there.
- if hms_idx is None:
- hms = None
- new_idx = idx
- elif hms_idx > idx:
- hms = info.hms(tokens[hms_idx])
- new_idx = hms_idx
- else:
- # Looking backwards, increment one.
- hms = info.hms(tokens[hms_idx]) + 1
- new_idx = idx
-
- return (new_idx, hms)
-
- # ------------------------------------------------------------------
- # Handling for individual tokens. These are kept as methods instead
- # of functions for the sake of customizability via subclassing.
-
- def _parsems(self, value):
- """Parse a I[.F] seconds value into (seconds, microseconds)."""
- if "." not in value:
- return int(value), 0
- else:
- i, f = value.split(".")
- return int(i), int(f.ljust(6, "0")[:6])
-
- def _to_decimal(self, val):
- try:
- decimal_value = Decimal(val)
- # See GH 662, edge case, infinite value should not be converted
- # via `_to_decimal`
- if not decimal_value.is_finite():
- raise ValueError("Converted decimal value is infinite or NaN")
- except Exception as e:
- msg = "Could not convert %s to decimal" % val
- six.raise_from(ValueError(msg), e)
- else:
- return decimal_value
-
- # ------------------------------------------------------------------
- # Post-Parsing construction of datetime output. These are kept as
- # methods instead of functions for the sake of customizability via
- # subclassing.
-
- def _build_tzinfo(self, tzinfos, tzname, tzoffset):
- if callable(tzinfos):
- tzdata = tzinfos(tzname, tzoffset)
- else:
- tzdata = tzinfos.get(tzname)
- # handle case where tzinfo is paased an options that returns None
- # eg tzinfos = {'BRST' : None}
- if isinstance(tzdata, datetime.tzinfo) or tzdata is None:
- tzinfo = tzdata
- elif isinstance(tzdata, text_type):
- tzinfo = tz.tzstr(tzdata)
- elif isinstance(tzdata, integer_types):
- tzinfo = tz.tzoffset(tzname, tzdata)
- else:
- raise TypeError("Offset must be tzinfo subclass, tz string, "
- "or int offset.")
- return tzinfo
-
- def _build_tzaware(self, naive, res, tzinfos):
- if (callable(tzinfos) or (tzinfos and res.tzname in tzinfos)):
- tzinfo = self._build_tzinfo(tzinfos, res.tzname, res.tzoffset)
- aware = naive.replace(tzinfo=tzinfo)
- aware = self._assign_tzname(aware, res.tzname)
-
- elif res.tzname and res.tzname in time.tzname:
- aware = naive.replace(tzinfo=tz.tzlocal())
-
- # Handle ambiguous local datetime
- aware = self._assign_tzname(aware, res.tzname)
-
- # This is mostly relevant for winter GMT zones parsed in the UK
- if (aware.tzname() != res.tzname and
- res.tzname in self.info.UTCZONE):
- aware = aware.replace(tzinfo=tz.UTC)
-
- elif res.tzoffset == 0:
- aware = naive.replace(tzinfo=tz.UTC)
-
- elif res.tzoffset:
- aware = naive.replace(tzinfo=tz.tzoffset(res.tzname, res.tzoffset))
-
- elif not res.tzname and not res.tzoffset:
- # i.e. no timezone information was found.
- aware = naive
-
- elif res.tzname:
- # tz-like string was parsed but we don't know what to do
- # with it
- warnings.warn("tzname {tzname} identified but not understood. "
- "Pass `tzinfos` argument in order to correctly "
- "return a timezone-aware datetime. In a future "
- "version, this will raise an "
- "exception.".format(tzname=res.tzname),
- category=UnknownTimezoneWarning)
- aware = naive
-
- return aware
-
- def _build_naive(self, res, default):
- repl = {}
- for attr in ("year", "month", "day", "hour",
- "minute", "second", "microsecond"):
- value = getattr(res, attr)
- if value is not None:
- repl[attr] = value
-
- if 'day' not in repl:
- # If the default day exceeds the last day of the month, fall back
- # to the end of the month.
- cyear = default.year if res.year is None else res.year
- cmonth = default.month if res.month is None else res.month
- cday = default.day if res.day is None else res.day
-
- if cday > monthrange(cyear, cmonth)[1]:
- repl['day'] = monthrange(cyear, cmonth)[1]
-
- naive = default.replace(**repl)
-
- if res.weekday is not None and not res.day:
- naive = naive + relativedelta.relativedelta(weekday=res.weekday)
-
- return naive
-
- def _assign_tzname(self, dt, tzname):
- if dt.tzname() != tzname:
- new_dt = tz.enfold(dt, fold=1)
- if new_dt.tzname() == tzname:
- return new_dt
-
- return dt
-
- def _recombine_skipped(self, tokens, skipped_idxs):
- """
- >>> tokens = ["foo", " ", "bar", " ", "19June2000", "baz"]
- >>> skipped_idxs = [0, 1, 2, 5]
- >>> _recombine_skipped(tokens, skipped_idxs)
- ["foo bar", "baz"]
- """
- skipped_tokens = []
- for i, idx in enumerate(sorted(skipped_idxs)):
- if i > 0 and idx - 1 == skipped_idxs[i - 1]:
- skipped_tokens[-1] = skipped_tokens[-1] + tokens[idx]
- else:
- skipped_tokens.append(tokens[idx])
-
- return skipped_tokens
-
-
-DEFAULTPARSER = parser()
-
-
-def parse(timestr, parserinfo=None, **kwargs):
- """
-
- Parse a string in one of the supported formats, using the
- ``parserinfo`` parameters.
-
- :param timestr:
- A string containing a date/time stamp.
-
- :param parserinfo:
- A :class:`parserinfo` object containing parameters for the parser.
- If ``None``, the default arguments to the :class:`parserinfo`
- constructor are used.
-
- The ``**kwargs`` parameter takes the following keyword arguments:
-
- :param default:
- The default datetime object, if this is a datetime object and not
- ``None``, elements specified in ``timestr`` replace elements in the
- default object.
-
- :param ignoretz:
- If set ``True``, time zones in parsed strings are ignored and a naive
- :class:`datetime` object is returned.
-
- :param tzinfos:
- Additional time zone names / aliases which may be present in the
- string. This argument maps time zone names (and optionally offsets
- from those time zones) to time zones. This parameter can be a
- dictionary with timezone aliases mapping time zone names to time
- zones or a function taking two parameters (``tzname`` and
- ``tzoffset``) and returning a time zone.
-
- The timezones to which the names are mapped can be an integer
- offset from UTC in seconds or a :class:`tzinfo` object.
-
- .. doctest::
- :options: +NORMALIZE_WHITESPACE
-
- >>> from dateutil.parser import parse
- >>> from dateutil.tz import gettz
- >>> tzinfos = {"BRST": -7200, "CST": gettz("America/Chicago")}
- >>> parse("2012-01-19 17:21:00 BRST", tzinfos=tzinfos)
- datetime.datetime(2012, 1, 19, 17, 21, tzinfo=tzoffset(u'BRST', -7200))
- >>> parse("2012-01-19 17:21:00 CST", tzinfos=tzinfos)
- datetime.datetime(2012, 1, 19, 17, 21,
- tzinfo=tzfile('/usr/share/zoneinfo/America/Chicago'))
-
- This parameter is ignored if ``ignoretz`` is set.
-
- :param dayfirst:
- Whether to interpret the first value in an ambiguous 3-integer date
- (e.g. 01/05/09) as the day (``True``) or month (``False``). If
- ``yearfirst`` is set to ``True``, this distinguishes between YDM and
- YMD. If set to ``None``, this value is retrieved from the current
- :class:`parserinfo` object (which itself defaults to ``False``).
-
- :param yearfirst:
- Whether to interpret the first value in an ambiguous 3-integer date
- (e.g. 01/05/09) as the year. If ``True``, the first number is taken to
- be the year, otherwise the last number is taken to be the year. If
- this is set to ``None``, the value is retrieved from the current
- :class:`parserinfo` object (which itself defaults to ``False``).
-
- :param fuzzy:
- Whether to allow fuzzy parsing, allowing for string like "Today is
- January 1, 2047 at 8:21:00AM".
-
- :param fuzzy_with_tokens:
- If ``True``, ``fuzzy`` is automatically set to True, and the parser
- will return a tuple where the first element is the parsed
- :class:`datetime.datetime` datetimestamp and the second element is
- a tuple containing the portions of the string which were ignored:
-
- .. doctest::
-
- >>> from dateutil.parser import parse
- >>> parse("Today is January 1, 2047 at 8:21:00AM", fuzzy_with_tokens=True)
- (datetime.datetime(2047, 1, 1, 8, 21), (u'Today is ', u' ', u'at '))
-
- :return:
- Returns a :class:`datetime.datetime` object or, if the
- ``fuzzy_with_tokens`` option is ``True``, returns a tuple, the
- first element being a :class:`datetime.datetime` object, the second
- a tuple containing the fuzzy tokens.
-
- :raises ParserError:
- Raised for invalid or unknown string formats, if the provided
- :class:`tzinfo` is not in a valid format, or if an invalid date would
- be created.
-
- :raises OverflowError:
- Raised if the parsed date exceeds the largest valid C integer on
- your system.
- """
- if parserinfo:
- return parser(parserinfo).parse(timestr, **kwargs)
- else:
- return DEFAULTPARSER.parse(timestr, **kwargs)
-
-
-class _tzparser(object):
-
- class _result(_resultbase):
-
- __slots__ = ["stdabbr", "stdoffset", "dstabbr", "dstoffset",
- "start", "end"]
-
- class _attr(_resultbase):
- __slots__ = ["month", "week", "weekday",
- "yday", "jyday", "day", "time"]
-
- def __repr__(self):
- return self._repr("")
-
- def __init__(self):
- _resultbase.__init__(self)
- self.start = self._attr()
- self.end = self._attr()
-
- def parse(self, tzstr):
- res = self._result()
- l = [x for x in re.split(r'([,:.]|[a-zA-Z]+|[0-9]+)',tzstr) if x]
- used_idxs = list()
- try:
-
- len_l = len(l)
-
- i = 0
- while i < len_l:
- # BRST+3[BRDT[+2]]
- j = i
- while j < len_l and not [x for x in l[j]
- if x in "0123456789:,-+"]:
- j += 1
- if j != i:
- if not res.stdabbr:
- offattr = "stdoffset"
- res.stdabbr = "".join(l[i:j])
- else:
- offattr = "dstoffset"
- res.dstabbr = "".join(l[i:j])
-
- for ii in range(j):
- used_idxs.append(ii)
- i = j
- if (i < len_l and (l[i] in ('+', '-') or l[i][0] in
- "0123456789")):
- if l[i] in ('+', '-'):
- # Yes, that's right. See the TZ variable
- # documentation.
- signal = (1, -1)[l[i] == '+']
- used_idxs.append(i)
- i += 1
- else:
- signal = -1
- len_li = len(l[i])
- if len_li == 4:
- # -0300
- setattr(res, offattr, (int(l[i][:2]) * 3600 +
- int(l[i][2:]) * 60) * signal)
- elif i + 1 < len_l and l[i + 1] == ':':
- # -03:00
- setattr(res, offattr,
- (int(l[i]) * 3600 +
- int(l[i + 2]) * 60) * signal)
- used_idxs.append(i)
- i += 2
- elif len_li <= 2:
- # -[0]3
- setattr(res, offattr,
- int(l[i][:2]) * 3600 * signal)
- else:
- return None
- used_idxs.append(i)
- i += 1
- if res.dstabbr:
- break
- else:
- break
-
-
- if i < len_l:
- for j in range(i, len_l):
- if l[j] == ';':
- l[j] = ','
-
- assert l[i] == ','
-
- i += 1
-
- if i >= len_l:
- pass
- elif (8 <= l.count(',') <= 9 and
- not [y for x in l[i:] if x != ','
- for y in x if y not in "0123456789+-"]):
- # GMT0BST,3,0,30,3600,10,0,26,7200[,3600]
- for x in (res.start, res.end):
- x.month = int(l[i])
- used_idxs.append(i)
- i += 2
- if l[i] == '-':
- value = int(l[i + 1]) * -1
- used_idxs.append(i)
- i += 1
- else:
- value = int(l[i])
- used_idxs.append(i)
- i += 2
- if value:
- x.week = value
- x.weekday = (int(l[i]) - 1) % 7
- else:
- x.day = int(l[i])
- used_idxs.append(i)
- i += 2
- x.time = int(l[i])
- used_idxs.append(i)
- i += 2
- if i < len_l:
- if l[i] in ('-', '+'):
- signal = (-1, 1)[l[i] == "+"]
- used_idxs.append(i)
- i += 1
- else:
- signal = 1
- used_idxs.append(i)
- res.dstoffset = (res.stdoffset + int(l[i]) * signal)
-
- # This was a made-up format that is not in normal use
- warn(('Parsed time zone "%s"' % tzstr) +
- 'is in a non-standard dateutil-specific format, which ' +
- 'is now deprecated; support for parsing this format ' +
- 'will be removed in future versions. It is recommended ' +
- 'that you switch to a standard format like the GNU ' +
- 'TZ variable format.', tz.DeprecatedTzFormatWarning)
- elif (l.count(',') == 2 and l[i:].count('/') <= 2 and
- not [y for x in l[i:] if x not in (',', '/', 'J', 'M',
- '.', '-', ':')
- for y in x if y not in "0123456789"]):
- for x in (res.start, res.end):
- if l[i] == 'J':
- # non-leap year day (1 based)
- used_idxs.append(i)
- i += 1
- x.jyday = int(l[i])
- elif l[i] == 'M':
- # month[-.]week[-.]weekday
- used_idxs.append(i)
- i += 1
- x.month = int(l[i])
- used_idxs.append(i)
- i += 1
- assert l[i] in ('-', '.')
- used_idxs.append(i)
- i += 1
- x.week = int(l[i])
- if x.week == 5:
- x.week = -1
- used_idxs.append(i)
- i += 1
- assert l[i] in ('-', '.')
- used_idxs.append(i)
- i += 1
- x.weekday = (int(l[i]) - 1) % 7
- else:
- # year day (zero based)
- x.yday = int(l[i]) + 1
-
- used_idxs.append(i)
- i += 1
-
- if i < len_l and l[i] == '/':
- used_idxs.append(i)
- i += 1
- # start time
- len_li = len(l[i])
- if len_li == 4:
- # -0300
- x.time = (int(l[i][:2]) * 3600 +
- int(l[i][2:]) * 60)
- elif i + 1 < len_l and l[i + 1] == ':':
- # -03:00
- x.time = int(l[i]) * 3600 + int(l[i + 2]) * 60
- used_idxs.append(i)
- i += 2
- if i + 1 < len_l and l[i + 1] == ':':
- used_idxs.append(i)
- i += 2
- x.time += int(l[i])
- elif len_li <= 2:
- # -[0]3
- x.time = (int(l[i][:2]) * 3600)
- else:
- return None
- used_idxs.append(i)
- i += 1
-
- assert i == len_l or l[i] == ','
-
- i += 1
-
- assert i >= len_l
-
- except (IndexError, ValueError, AssertionError):
- return None
-
- unused_idxs = set(range(len_l)).difference(used_idxs)
- res.any_unused_tokens = not {l[n] for n in unused_idxs}.issubset({",",":"})
- return res
-
-
-DEFAULTTZPARSER = _tzparser()
-
-
-def _parsetz(tzstr):
- return DEFAULTTZPARSER.parse(tzstr)
-
-
-class ParserError(ValueError):
- """Exception subclass used for any failure to parse a datetime string.
-
- This is a subclass of :py:exc:`ValueError`, and should be raised any time
- earlier versions of ``dateutil`` would have raised ``ValueError``.
-
- .. versionadded:: 2.8.1
- """
- def __str__(self):
- try:
- return self.args[0] % self.args[1:]
- except (TypeError, IndexError):
- return super(ParserError, self).__str__()
-
- def __repr__(self):
- args = ", ".join("'%s'" % arg for arg in self.args)
- return "%s(%s)" % (self.__class__.__name__, args)
-
-
-class UnknownTimezoneWarning(RuntimeWarning):
- """Raised when the parser finds a timezone it cannot parse into a tzinfo.
-
- .. versionadded:: 2.7.0
- """
-# vim:ts=4:sw=4:et
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/text/paragraph.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/text/paragraph.py
deleted file mode 100644
index 4fb583b94bbf550169ff6598bdc510174d245412..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/docx/text/paragraph.py
+++ /dev/null
@@ -1,145 +0,0 @@
-# encoding: utf-8
-
-"""
-Paragraph-related proxy types.
-"""
-
-from __future__ import (
- absolute_import, division, print_function, unicode_literals
-)
-
-from ..enum.style import WD_STYLE_TYPE
-from .parfmt import ParagraphFormat
-from .run import Run
-from ..shared import Parented
-
-
-class Paragraph(Parented):
- """
- Proxy object wrapping ```` element.
- """
- def __init__(self, p, parent):
- super(Paragraph, self).__init__(parent)
- self._p = self._element = p
-
- def add_run(self, text=None, style=None):
- """
- Append a run to this paragraph containing *text* and having character
- style identified by style ID *style*. *text* can contain tab
- (``\\t``) characters, which are converted to the appropriate XML form
- for a tab. *text* can also include newline (``\\n``) or carriage
- return (``\\r``) characters, each of which is converted to a line
- break.
- """
- r = self._p.add_r()
- run = Run(r, self)
- if text:
- run.text = text
- if style:
- run.style = style
- return run
-
- @property
- def alignment(self):
- """
- A member of the :ref:`WdParagraphAlignment` enumeration specifying
- the justification setting for this paragraph. A value of |None|
- indicates the paragraph has no directly-applied alignment value and
- will inherit its alignment value from its style hierarchy. Assigning
- |None| to this property removes any directly-applied alignment value.
- """
- return self._p.alignment
-
- @alignment.setter
- def alignment(self, value):
- self._p.alignment = value
-
- def clear(self):
- """
- Return this same paragraph after removing all its content.
- Paragraph-level formatting, such as style, is preserved.
- """
- self._p.clear_content()
- return self
-
- def insert_paragraph_before(self, text=None, style=None):
- """
- Return a newly created paragraph, inserted directly before this
- paragraph. If *text* is supplied, the new paragraph contains that
- text in a single run. If *style* is provided, that style is assigned
- to the new paragraph.
- """
- paragraph = self._insert_paragraph_before()
- if text:
- paragraph.add_run(text)
- if style is not None:
- paragraph.style = style
- return paragraph
-
- @property
- def paragraph_format(self):
- """
- The |ParagraphFormat| object providing access to the formatting
- properties for this paragraph, such as line spacing and indentation.
- """
- return ParagraphFormat(self._element)
-
- @property
- def runs(self):
- """
- Sequence of |Run| instances corresponding to the elements in
- this paragraph.
- """
- return [Run(r, self) for r in self._p.r_lst]
-
- @property
- def style(self):
- """
- Read/Write. |_ParagraphStyle| object representing the style assigned
- to this paragraph. If no explicit style is assigned to this
- paragraph, its value is the default paragraph style for the document.
- A paragraph style name can be assigned in lieu of a paragraph style
- object. Assigning |None| removes any applied style, making its
- effective value the default paragraph style for the document.
- """
- style_id = self._p.style
- return self.part.get_style(style_id, WD_STYLE_TYPE.PARAGRAPH)
-
- @style.setter
- def style(self, style_or_name):
- style_id = self.part.get_style_id(
- style_or_name, WD_STYLE_TYPE.PARAGRAPH
- )
- self._p.style = style_id
-
- @property
- def text(self):
- """
- String formed by concatenating the text of each run in the paragraph.
- Tabs and line breaks in the XML are mapped to ``\\t`` and ``\\n``
- characters respectively.
-
- Assigning text to this property causes all existing paragraph content
- to be replaced with a single run containing the assigned text.
- A ``\\t`` character in the text is mapped to a ```` element
- and each ``\\n`` or ``\\r`` character is mapped to a line break.
- Paragraph-level formatting, such as style, is preserved. All
- run-level formatting, such as bold or italic, is removed.
- """
- text = ''
- for run in self.runs:
- text += run.text
- return text
-
- @text.setter
- def text(self, text):
- self.clear()
- self.add_run(text)
-
- def _insert_paragraph_before(self):
- """
- Return a newly created paragraph, inserted directly before this
- paragraph.
- """
- p = self._p.add_p_before()
- return Paragraph(p, self._parent)
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/index-2908e8a9.css b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/index-2908e8a9.css
deleted file mode 100644
index 78067c2729600b4ee3e7e9c6442a129e8ffe9894..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/index-2908e8a9.css
+++ /dev/null
@@ -1 +0,0 @@
-.gradio-bokeh.svelte-1fe5ixn.svelte-1fe5ixn{display:flex;justify-content:center}.layout.svelte-1fe5ixn.svelte-1fe5ixn{display:flex;flex-direction:column;justify-content:center;align-items:center;width:var(--size-full);height:var(--size-full);color:var(--body-text-color)}.altair.svelte-1fe5ixn.svelte-1fe5ixn{display:flex;flex-direction:column;justify-content:center;align-items:center;width:var(--size-full);height:var(--size-full)}.caption.svelte-1fe5ixn.svelte-1fe5ixn{font-size:var(--text-sm)}.matplotlib.svelte-1fe5ixn img.svelte-1fe5ixn{object-fit:contain}
diff --git a/spaces/cihyFjudo/fairness-paper-search/I Do? I Die! (Dyos ko day) (1997) - Trakt[3].md b/spaces/cihyFjudo/fairness-paper-search/I Do? I Die! (Dyos ko day) (1997) - Trakt[3].md
deleted file mode 100644
index 6b0ca19356db20b131e56a8a3c0b12663ce1860a..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/I Do? I Die! (Dyos ko day) (1997) - Trakt[3].md
+++ /dev/null
@@ -1,6 +0,0 @@
-I Do I Die Dyos Ko Day Full PORTABLE Movie Download
Download File ✏ https://tinurli.com/2uwjRt
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/cihyFjudo/fairness-paper-search/IBM USB Serial Parallel Adapter Driver 22P9035 Troubleshooting Tips and FAQs.md b/spaces/cihyFjudo/fairness-paper-search/IBM USB Serial Parallel Adapter Driver 22P9035 Troubleshooting Tips and FAQs.md
deleted file mode 100644
index 45712e0cb42613d2ad7b64ad72e6bfb3608c47e1..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/IBM USB Serial Parallel Adapter Driver 22P9035 Troubleshooting Tips and FAQs.md
+++ /dev/null
@@ -1,6 +0,0 @@
-ibm-usb-serial-parallel-adapter-driver-22p9035
DOWNLOAD • https://tinurli.com/2uwkCv
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/clip-italian/clip-italian-demo/image2text.py b/spaces/clip-italian/clip-italian-demo/image2text.py
deleted file mode 100644
index 7db4d4ed4d65b77130ba5b62d7f8ed156be17f9f..0000000000000000000000000000000000000000
--- a/spaces/clip-italian/clip-italian-demo/image2text.py
+++ /dev/null
@@ -1,94 +0,0 @@
-import streamlit as st
-from text2image import get_model, get_tokenizer, get_image_transform
-from utils import text_encoder, image_encoder
-from PIL import Image
-from jax import numpy as jnp
-from io import BytesIO
-import pandas as pd
-import requests
-import jax
-import gc
-
-headers = {
- "User-Agent":
- "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
-}
-
-
-def app():
- st.title("From Image to Text")
- st.markdown(
- """
-
- ### 👋 Ciao!
-
- Here you can find the captions or the labels that are most related to a given image. It is a zero-shot
- image classification task!
-
- 🤌 Italian mode on! 🤌
-
- For example, try typing "gatto" (cat) in the space for label1 and "cane" (dog) in the space for label2 and click
- "classify"!
-
- """
- )
-
- image_url = st.text_input(
- "You can input the URL of an image",
- value="https://upload.wikimedia.org/wikipedia/commons/thumb/8/88/Ragdoll%2C_blue_mitted.JPG/1280px-Ragdoll%2C_blue_mitted.JPG",
- )
-
- MAX_CAP = 4
-
- col1, col2 = st.columns([0.75, 0.25])
-
- with col2:
- captions_count = st.selectbox(
- "Number of labels", options=range(1, MAX_CAP + 1), index=1
- )
- compute = st.button("CLASSIFY")
-
- with col1:
- captions = list()
- for idx in range(min(MAX_CAP, captions_count)):
- captions.append(st.text_input(f"Insert label {idx+1}"))
-
- if compute:
- captions = [c for c in captions if c != ""]
-
- if not captions or not image_url:
- st.error("Please choose one image and at least one label")
- else:
- with st.spinner("Computing..."):
- model = get_model()
- tokenizer = get_tokenizer()
-
- text_embeds = list()
- for i, c in enumerate(captions):
- text_embeds.extend(text_encoder(c, model, tokenizer)[0])
-
- text_embeds = jnp.array(text_embeds)
- response = requests.get(image_url, headers=headers, stream=True)
- image = Image.open(BytesIO(response.content)).convert("RGB")
- transform = get_image_transform(model.config.vision_config.image_size)
- image_embed, _ = image_encoder(transform(image), model)
-
- # we could have a softmax here
- cos_similarities = jax.nn.softmax(
- jnp.matmul(image_embed, text_embeds.T)
- )
-
- chart_data = pd.Series(cos_similarities[0], index=captions)
-
- col1, col2 = st.columns(2)
- with col1:
- st.bar_chart(chart_data)
-
- with col2:
- st.image(image, use_column_width=True)
- gc.collect()
-
- elif image_url:
- response = requests.get(image_url, headers=headers, stream=True)
- image = Image.open(BytesIO(response.content)).convert("RGB")
- st.image(image)
diff --git a/spaces/cloixai/stable-diffusion-webui-cpu/README.md b/spaces/cloixai/stable-diffusion-webui-cpu/README.md
deleted file mode 100644
index 8c0c714325c21001caaf9bb4aaa0da5e8e769b51..0000000000000000000000000000000000000000
--- a/spaces/cloixai/stable-diffusion-webui-cpu/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Stable Diffusion Webui on Cpu
-emoji: 🏃
-colorFrom: pink
-colorTo: purple
-sdk: gradio
-sdk_version: 3.28.0
-app_file: app.py
-pinned: false
-python_version: 3.10.6
-duplicated_from: DreamSunny/stable-diffusion-webui-cpu
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/altair/utils/data.py b/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/altair/utils/data.py
deleted file mode 100644
index 28e66bfab5764fe58e19fb339b2cdf8ad9d510b4..0000000000000000000000000000000000000000
--- a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/altair/utils/data.py
+++ /dev/null
@@ -1,299 +0,0 @@
-import json
-import os
-import random
-import hashlib
-import warnings
-
-import pandas as pd
-from toolz import curried
-from typing import Callable
-
-from .core import sanitize_dataframe
-from .core import sanitize_geo_interface
-from .deprecation import AltairDeprecationWarning
-from .plugin_registry import PluginRegistry
-
-
-# ==============================================================================
-# Data transformer registry
-# ==============================================================================
-DataTransformerType = Callable
-
-
-class DataTransformerRegistry(PluginRegistry[DataTransformerType]):
- _global_settings = {"consolidate_datasets": True}
-
- @property
- def consolidate_datasets(self):
- return self._global_settings["consolidate_datasets"]
-
- @consolidate_datasets.setter
- def consolidate_datasets(self, value):
- self._global_settings["consolidate_datasets"] = value
-
-
-# ==============================================================================
-# Data model transformers
-#
-# A data model transformer is a pure function that takes a dict or DataFrame
-# and returns a transformed version of a dict or DataFrame. The dict objects
-# will be the Data portion of the VegaLite schema. The idea is that user can
-# pipe a sequence of these data transformers together to prepare the data before
-# it hits the renderer.
-#
-# In this version of Altair, renderers only deal with the dict form of a
-# VegaLite spec, after the Data model has been put into a schema compliant
-# form.
-#
-# A data model transformer has the following type signature:
-# DataModelType = Union[dict, pd.DataFrame]
-# DataModelTransformerType = Callable[[DataModelType, KwArgs], DataModelType]
-# ==============================================================================
-
-
-class MaxRowsError(Exception):
- """Raised when a data model has too many rows."""
-
- pass
-
-
-@curried.curry
-def limit_rows(data, max_rows=5000):
- """Raise MaxRowsError if the data model has more than max_rows.
-
- If max_rows is None, then do not perform any check.
- """
- check_data_type(data)
- if hasattr(data, "__geo_interface__"):
- if data.__geo_interface__["type"] == "FeatureCollection":
- values = data.__geo_interface__["features"]
- else:
- values = data.__geo_interface__
- elif isinstance(data, pd.DataFrame):
- values = data
- elif isinstance(data, dict):
- if "values" in data:
- values = data["values"]
- else:
- return data
- elif hasattr(data, "__dataframe__"):
- values = data
- if max_rows is not None and len(values) > max_rows:
- raise MaxRowsError(
- "The number of rows in your dataset is greater "
- f"than the maximum allowed ({max_rows}).\n\n"
- "See https://altair-viz.github.io/user_guide/large_datasets.html "
- "for information on how to plot large datasets, "
- "including how to install third-party data management tools and, "
- "in the right circumstance, disable the restriction"
- )
- return data
-
-
-@curried.curry
-def sample(data, n=None, frac=None):
- """Reduce the size of the data model by sampling without replacement."""
- check_data_type(data)
- if isinstance(data, pd.DataFrame):
- return data.sample(n=n, frac=frac)
- elif isinstance(data, dict):
- if "values" in data:
- values = data["values"]
- n = n if n else int(frac * len(values))
- values = random.sample(values, n)
- return {"values": values}
- elif hasattr(data, "__dataframe__"):
- # experimental interchange dataframe support
- pi = import_pyarrow_interchange()
- pa_table = pi.from_dataframe(data)
- n = n if n else int(frac * len(pa_table))
- indices = random.sample(range(len(pa_table)), n)
- return pa_table.take(indices)
-
-
-@curried.curry
-def to_json(
- data,
- prefix="altair-data",
- extension="json",
- filename="{prefix}-{hash}.{extension}",
- urlpath="",
-):
- """
- Write the data model to a .json file and return a url based data model.
- """
- data_json = _data_to_json_string(data)
- data_hash = _compute_data_hash(data_json)
- filename = filename.format(prefix=prefix, hash=data_hash, extension=extension)
- with open(filename, "w") as f:
- f.write(data_json)
- return {"url": os.path.join(urlpath, filename), "format": {"type": "json"}}
-
-
-@curried.curry
-def to_csv(
- data,
- prefix="altair-data",
- extension="csv",
- filename="{prefix}-{hash}.{extension}",
- urlpath="",
-):
- """Write the data model to a .csv file and return a url based data model."""
- data_csv = _data_to_csv_string(data)
- data_hash = _compute_data_hash(data_csv)
- filename = filename.format(prefix=prefix, hash=data_hash, extension=extension)
- with open(filename, "w") as f:
- f.write(data_csv)
- return {"url": os.path.join(urlpath, filename), "format": {"type": "csv"}}
-
-
-@curried.curry
-def to_values(data):
- """Replace a DataFrame by a data model with values."""
- check_data_type(data)
- if hasattr(data, "__geo_interface__"):
- if isinstance(data, pd.DataFrame):
- data = sanitize_dataframe(data)
- data = sanitize_geo_interface(data.__geo_interface__)
- return {"values": data}
- elif isinstance(data, pd.DataFrame):
- data = sanitize_dataframe(data)
- return {"values": data.to_dict(orient="records")}
- elif isinstance(data, dict):
- if "values" not in data:
- raise KeyError("values expected in data dict, but not present.")
- return data
- elif hasattr(data, "__dataframe__"):
- # experimental interchange dataframe support
- pi = import_pyarrow_interchange()
- pa_table = pi.from_dataframe(data)
- return {"values": pa_table.to_pylist()}
-
-
-def check_data_type(data):
- """Raise if the data is not a dict or DataFrame."""
- if not isinstance(data, (dict, pd.DataFrame)) and not any(
- hasattr(data, attr) for attr in ["__geo_interface__", "__dataframe__"]
- ):
- raise TypeError(
- "Expected dict, DataFrame or a __geo_interface__ attribute, got: {}".format(
- type(data)
- )
- )
-
-
-# ==============================================================================
-# Private utilities
-# ==============================================================================
-
-
-def _compute_data_hash(data_str):
- return hashlib.md5(data_str.encode()).hexdigest()
-
-
-def _data_to_json_string(data):
- """Return a JSON string representation of the input data"""
- check_data_type(data)
- if hasattr(data, "__geo_interface__"):
- if isinstance(data, pd.DataFrame):
- data = sanitize_dataframe(data)
- data = sanitize_geo_interface(data.__geo_interface__)
- return json.dumps(data)
- elif isinstance(data, pd.DataFrame):
- data = sanitize_dataframe(data)
- return data.to_json(orient="records", double_precision=15)
- elif isinstance(data, dict):
- if "values" not in data:
- raise KeyError("values expected in data dict, but not present.")
- return json.dumps(data["values"], sort_keys=True)
- elif hasattr(data, "__dataframe__"):
- # experimental interchange dataframe support
- pi = import_pyarrow_interchange()
- pa_table = pi.from_dataframe(data)
- return json.dumps(pa_table.to_pylist())
- else:
- raise NotImplementedError(
- "to_json only works with data expressed as " "a DataFrame or as a dict"
- )
-
-
-def _data_to_csv_string(data):
- """return a CSV string representation of the input data"""
- check_data_type(data)
- if hasattr(data, "__geo_interface__"):
- raise NotImplementedError(
- "to_csv does not work with data that "
- "contains the __geo_interface__ attribute"
- )
- elif isinstance(data, pd.DataFrame):
- data = sanitize_dataframe(data)
- return data.to_csv(index=False)
- elif isinstance(data, dict):
- if "values" not in data:
- raise KeyError("values expected in data dict, but not present")
- return pd.DataFrame.from_dict(data["values"]).to_csv(index=False)
- elif hasattr(data, "__dataframe__"):
- # experimental interchange dataframe support
- pi = import_pyarrow_interchange()
- import pyarrow as pa
- import pyarrow.csv as pa_csv
-
- pa_table = pi.from_dataframe(data)
- csv_buffer = pa.BufferOutputStream()
- pa_csv.write_csv(pa_table, csv_buffer)
- return csv_buffer.getvalue().to_pybytes().decode()
- else:
- raise NotImplementedError(
- "to_csv only works with data expressed as " "a DataFrame or as a dict"
- )
-
-
-def pipe(data, *funcs):
- """
- Pipe a value through a sequence of functions
-
- Deprecated: use toolz.curried.pipe() instead.
- """
- warnings.warn(
- "alt.pipe() is deprecated, and will be removed in a future release. "
- "Use toolz.curried.pipe() instead.",
- AltairDeprecationWarning,
- stacklevel=1,
- )
- return curried.pipe(data, *funcs)
-
-
-def curry(*args, **kwargs):
- """Curry a callable function
-
- Deprecated: use toolz.curried.curry() instead.
- """
- warnings.warn(
- "alt.curry() is deprecated, and will be removed in a future release. "
- "Use toolz.curried.curry() instead.",
- AltairDeprecationWarning,
- stacklevel=1,
- )
- return curried.curry(*args, **kwargs)
-
-
-def import_pyarrow_interchange():
- import pkg_resources
-
- try:
- pkg_resources.require("pyarrow>=11.0.0")
- # The package is installed and meets the minimum version requirement
- import pyarrow.interchange as pi
-
- return pi
- except pkg_resources.DistributionNotFound as err:
- # The package is not installed
- raise ImportError(
- "Usage of the DataFrame Interchange Protocol requires the package 'pyarrow', but it is not installed."
- ) from err
- except pkg_resources.VersionConflict as err:
- # The package is installed but does not meet the minimum version requirement
- raise ImportError(
- "The installed version of 'pyarrow' does not meet the minimum requirement of version 11.0.0. "
- "Please update 'pyarrow' to use the DataFrame Interchange Protocol."
- ) from err
diff --git a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/fontTools/misc/vector.py b/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/fontTools/misc/vector.py
deleted file mode 100644
index 666ff15cf8be0a0c17de4f86b74584d2bb27244f..0000000000000000000000000000000000000000
--- a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/fontTools/misc/vector.py
+++ /dev/null
@@ -1,148 +0,0 @@
-from numbers import Number
-import math
-import operator
-import warnings
-
-
-__all__ = ["Vector"]
-
-
-class Vector(tuple):
-
- """A math-like vector.
-
- Represents an n-dimensional numeric vector. ``Vector`` objects support
- vector addition and subtraction, scalar multiplication and division,
- negation, rounding, and comparison tests.
- """
-
- __slots__ = ()
-
- def __new__(cls, values, keep=False):
- if keep is not False:
- warnings.warn(
- "the 'keep' argument has been deprecated",
- DeprecationWarning,
- )
- if type(values) == Vector:
- # No need to create a new object
- return values
- return super().__new__(cls, values)
-
- def __repr__(self):
- return f"{self.__class__.__name__}({super().__repr__()})"
-
- def _vectorOp(self, other, op):
- if isinstance(other, Vector):
- assert len(self) == len(other)
- return self.__class__(op(a, b) for a, b in zip(self, other))
- if isinstance(other, Number):
- return self.__class__(op(v, other) for v in self)
- raise NotImplementedError()
-
- def _scalarOp(self, other, op):
- if isinstance(other, Number):
- return self.__class__(op(v, other) for v in self)
- raise NotImplementedError()
-
- def _unaryOp(self, op):
- return self.__class__(op(v) for v in self)
-
- def __add__(self, other):
- return self._vectorOp(other, operator.add)
-
- __radd__ = __add__
-
- def __sub__(self, other):
- return self._vectorOp(other, operator.sub)
-
- def __rsub__(self, other):
- return self._vectorOp(other, _operator_rsub)
-
- def __mul__(self, other):
- return self._scalarOp(other, operator.mul)
-
- __rmul__ = __mul__
-
- def __truediv__(self, other):
- return self._scalarOp(other, operator.truediv)
-
- def __rtruediv__(self, other):
- return self._scalarOp(other, _operator_rtruediv)
-
- def __pos__(self):
- return self._unaryOp(operator.pos)
-
- def __neg__(self):
- return self._unaryOp(operator.neg)
-
- def __round__(self, *, round=round):
- return self._unaryOp(round)
-
- def __eq__(self, other):
- if isinstance(other, list):
- # bw compat Vector([1, 2, 3]) == [1, 2, 3]
- other = tuple(other)
- return super().__eq__(other)
-
- def __ne__(self, other):
- return not self.__eq__(other)
-
- def __bool__(self):
- return any(self)
-
- __nonzero__ = __bool__
-
- def __abs__(self):
- return math.sqrt(sum(x * x for x in self))
-
- def length(self):
- """Return the length of the vector. Equivalent to abs(vector)."""
- return abs(self)
-
- def normalized(self):
- """Return the normalized vector of the vector."""
- return self / abs(self)
-
- def dot(self, other):
- """Performs vector dot product, returning the sum of
- ``a[0] * b[0], a[1] * b[1], ...``"""
- assert len(self) == len(other)
- return sum(a * b for a, b in zip(self, other))
-
- # Deprecated methods/properties
-
- def toInt(self):
- warnings.warn(
- "the 'toInt' method has been deprecated, use round(vector) instead",
- DeprecationWarning,
- )
- return self.__round__()
-
- @property
- def values(self):
- warnings.warn(
- "the 'values' attribute has been deprecated, use "
- "the vector object itself instead",
- DeprecationWarning,
- )
- return list(self)
-
- @values.setter
- def values(self, values):
- raise AttributeError(
- "can't set attribute, the 'values' attribute has been deprecated",
- )
-
- def isclose(self, other: "Vector", **kwargs) -> bool:
- """Return True if the vector is close to another Vector."""
- assert len(self) == len(other)
- return all(math.isclose(a, b, **kwargs) for a, b in zip(self, other))
-
-
-def _operator_rsub(a, b):
- return operator.sub(b, a)
-
-
-def _operator_rtruediv(a, b):
- return operator.truediv(b, a)
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/bmvaudio.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/bmvaudio.c
deleted file mode 100644
index fc211732bbb148bf0eb65eba239fcf986e0f507e..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/bmvaudio.c
+++ /dev/null
@@ -1,89 +0,0 @@
-/*
- * Discworld II BMV audio decoder
- * Copyright (c) 2011 Konstantin Shishkov
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-#include "libavutil/channel_layout.h"
-#include "libavutil/common.h"
-
-#include "avcodec.h"
-#include "codec_internal.h"
-#include "decode.h"
-
-static const int bmv_aud_mults[16] = {
- 16512, 8256, 4128, 2064, 1032, 516, 258, 192, 129, 88, 64, 56, 48, 40, 36, 32
-};
-
-static av_cold int bmv_aud_decode_init(AVCodecContext *avctx)
-{
- av_channel_layout_uninit(&avctx->ch_layout);
- avctx->ch_layout = (AVChannelLayout)AV_CHANNEL_LAYOUT_STEREO;
- avctx->sample_fmt = AV_SAMPLE_FMT_S16;
-
- return 0;
-}
-
-static int bmv_aud_decode_frame(AVCodecContext *avctx, AVFrame *frame,
- int *got_frame_ptr, AVPacket *avpkt)
-{
- const uint8_t *buf = avpkt->data;
- int buf_size = avpkt->size;
- int blocks = 0, total_blocks, i;
- int ret;
- int16_t *output_samples;
- int scale[2];
-
- total_blocks = *buf++;
- if (buf_size < total_blocks * 65 + 1) {
- av_log(avctx, AV_LOG_ERROR, "expected %d bytes, got %d\n",
- total_blocks * 65 + 1, buf_size);
- return AVERROR_INVALIDDATA;
- }
-
- /* get output buffer */
- frame->nb_samples = total_blocks * 32;
- if ((ret = ff_get_buffer(avctx, frame, 0)) < 0)
- return ret;
- output_samples = (int16_t *)frame->data[0];
-
- for (blocks = 0; blocks < total_blocks; blocks++) {
- uint8_t code = *buf++;
- code = (code >> 1) | (code << 7);
- scale[0] = bmv_aud_mults[code & 0xF];
- scale[1] = bmv_aud_mults[code >> 4];
- for (i = 0; i < 32; i++) {
- *output_samples++ = av_clip_int16((scale[0] * (int8_t)*buf++) >> 5);
- *output_samples++ = av_clip_int16((scale[1] * (int8_t)*buf++) >> 5);
- }
- }
-
- *got_frame_ptr = 1;
-
- return buf_size;
-}
-
-const FFCodec ff_bmv_audio_decoder = {
- .p.name = "bmv_audio",
- CODEC_LONG_NAME("Discworld II BMV audio"),
- .p.type = AVMEDIA_TYPE_AUDIO,
- .p.id = AV_CODEC_ID_BMV_AUDIO,
- .init = bmv_aud_decode_init,
- FF_CODEC_DECODE_CB(bmv_aud_decode_frame),
- .p.capabilities = AV_CODEC_CAP_DR1 | AV_CODEC_CAP_CHANNEL_CONF,
-};
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/hpeldsp.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/hpeldsp.c
deleted file mode 100644
index 1ec76e7a45cabae149ffd2ba9c360764a5d178c5..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/hpeldsp.c
+++ /dev/null
@@ -1,373 +0,0 @@
-/*
- * Half-pel DSP functions.
- * Copyright (c) 2000, 2001 Fabrice Bellard
- * Copyright (c) 2002-2004 Michael Niedermayer
- *
- * gmc & q-pel & 32/64 bit based MC by Michael Niedermayer
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-/**
- * @file
- * Half-pel DSP functions.
- */
-
-#include "libavutil/attributes.h"
-#include "libavutil/intreadwrite.h"
-#include "hpeldsp.h"
-
-#define BIT_DEPTH 8
-#include "hpel_template.c"
-#include "pel_template.c"
-
-#define PIXOP2(OPNAME, OP) \
-static inline void OPNAME ## _no_rnd_pixels8_l2_8(uint8_t *dst, \
- const uint8_t *src1, \
- const uint8_t *src2, \
- int dst_stride, \
- int src_stride1, \
- int src_stride2, \
- int h) \
-{ \
- int i; \
- \
- for (i = 0; i < h; i++) { \
- uint32_t a, b; \
- a = AV_RN32(&src1[i * src_stride1]); \
- b = AV_RN32(&src2[i * src_stride2]); \
- OP(*((uint32_t *) &dst[i * dst_stride]), \
- no_rnd_avg32(a, b)); \
- a = AV_RN32(&src1[i * src_stride1 + 4]); \
- b = AV_RN32(&src2[i * src_stride2 + 4]); \
- OP(*((uint32_t *) &dst[i * dst_stride + 4]), \
- no_rnd_avg32(a, b)); \
- } \
-} \
- \
-static inline void OPNAME ## _no_rnd_pixels8_x2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- OPNAME ## _no_rnd_pixels8_l2_8(block, pixels, pixels + 1, \
- line_size, line_size, line_size, h); \
-} \
- \
-static inline void OPNAME ## _pixels8_x2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- OPNAME ## _pixels8_l2_8(block, pixels, pixels + 1, \
- line_size, line_size, line_size, h); \
-} \
- \
-static inline void OPNAME ## _no_rnd_pixels8_y2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- OPNAME ## _no_rnd_pixels8_l2_8(block, pixels, pixels + line_size, \
- line_size, line_size, line_size, h); \
-} \
- \
-static inline void OPNAME ## _pixels8_y2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- OPNAME ## _pixels8_l2_8(block, pixels, pixels + line_size, \
- line_size, line_size, line_size, h); \
-} \
- \
-static inline void OPNAME ## _pixels4_x2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- OPNAME ## _pixels4_l2_8(block, pixels, pixels + 1, \
- line_size, line_size, line_size, h); \
-} \
- \
-static inline void OPNAME ## _pixels4_y2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- OPNAME ## _pixels4_l2_8(block, pixels, pixels + line_size, \
- line_size, line_size, line_size, h); \
-} \
- \
-static inline void OPNAME ## _pixels2_x2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- OPNAME ## _pixels2_l2_8(block, pixels, pixels + 1, \
- line_size, line_size, line_size, h); \
-} \
- \
-static inline void OPNAME ## _pixels2_y2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- OPNAME ## _pixels2_l2_8(block, pixels, pixels + line_size, \
- line_size, line_size, line_size, h); \
-} \
- \
-static inline void OPNAME ## _pixels2_xy2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- int i, a1, b1; \
- int a0 = pixels[0]; \
- int b0 = pixels[1] + 2; \
- \
- a0 += b0; \
- b0 += pixels[2]; \
- pixels += line_size; \
- for (i = 0; i < h; i += 2) { \
- a1 = pixels[0]; \
- b1 = pixels[1]; \
- a1 += b1; \
- b1 += pixels[2]; \
- \
- block[0] = (a1 + a0) >> 2; /* FIXME non put */ \
- block[1] = (b1 + b0) >> 2; \
- \
- pixels += line_size; \
- block += line_size; \
- \
- a0 = pixels[0]; \
- b0 = pixels[1] + 2; \
- a0 += b0; \
- b0 += pixels[2]; \
- \
- block[0] = (a1 + a0) >> 2; \
- block[1] = (b1 + b0) >> 2; \
- pixels += line_size; \
- block += line_size; \
- } \
-} \
- \
-static inline void OPNAME ## _pixels4_xy2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- /* FIXME HIGH BIT DEPTH */ \
- int i; \
- const uint32_t a = AV_RN32(pixels); \
- const uint32_t b = AV_RN32(pixels + 1); \
- uint32_t l0 = (a & 0x03030303UL) + \
- (b & 0x03030303UL) + \
- 0x02020202UL; \
- uint32_t h0 = ((a & 0xFCFCFCFCUL) >> 2) + \
- ((b & 0xFCFCFCFCUL) >> 2); \
- uint32_t l1, h1; \
- \
- pixels += line_size; \
- for (i = 0; i < h; i += 2) { \
- uint32_t a = AV_RN32(pixels); \
- uint32_t b = AV_RN32(pixels + 1); \
- l1 = (a & 0x03030303UL) + \
- (b & 0x03030303UL); \
- h1 = ((a & 0xFCFCFCFCUL) >> 2) + \
- ((b & 0xFCFCFCFCUL) >> 2); \
- OP(*((uint32_t *) block), h0 + h1 + \
- (((l0 + l1) >> 2) & 0x0F0F0F0FUL)); \
- pixels += line_size; \
- block += line_size; \
- a = AV_RN32(pixels); \
- b = AV_RN32(pixels + 1); \
- l0 = (a & 0x03030303UL) + \
- (b & 0x03030303UL) + \
- 0x02020202UL; \
- h0 = ((a & 0xFCFCFCFCUL) >> 2) + \
- ((b & 0xFCFCFCFCUL) >> 2); \
- OP(*((uint32_t *) block), h0 + h1 + \
- (((l0 + l1) >> 2) & 0x0F0F0F0FUL)); \
- pixels += line_size; \
- block += line_size; \
- } \
-} \
- \
-static inline void OPNAME ## _pixels8_xy2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- /* FIXME HIGH BIT DEPTH */ \
- int j; \
- \
- for (j = 0; j < 2; j++) { \
- int i; \
- const uint32_t a = AV_RN32(pixels); \
- const uint32_t b = AV_RN32(pixels + 1); \
- uint32_t l0 = (a & 0x03030303UL) + \
- (b & 0x03030303UL) + \
- 0x02020202UL; \
- uint32_t h0 = ((a & 0xFCFCFCFCUL) >> 2) + \
- ((b & 0xFCFCFCFCUL) >> 2); \
- uint32_t l1, h1; \
- \
- pixels += line_size; \
- for (i = 0; i < h; i += 2) { \
- uint32_t a = AV_RN32(pixels); \
- uint32_t b = AV_RN32(pixels + 1); \
- l1 = (a & 0x03030303UL) + \
- (b & 0x03030303UL); \
- h1 = ((a & 0xFCFCFCFCUL) >> 2) + \
- ((b & 0xFCFCFCFCUL) >> 2); \
- OP(*((uint32_t *) block), h0 + h1 + \
- (((l0 + l1) >> 2) & 0x0F0F0F0FUL)); \
- pixels += line_size; \
- block += line_size; \
- a = AV_RN32(pixels); \
- b = AV_RN32(pixels + 1); \
- l0 = (a & 0x03030303UL) + \
- (b & 0x03030303UL) + \
- 0x02020202UL; \
- h0 = ((a & 0xFCFCFCFCUL) >> 2) + \
- ((b & 0xFCFCFCFCUL) >> 2); \
- OP(*((uint32_t *) block), h0 + h1 + \
- (((l0 + l1) >> 2) & 0x0F0F0F0FUL)); \
- pixels += line_size; \
- block += line_size; \
- } \
- pixels += 4 - line_size * (h + 1); \
- block += 4 - line_size * h; \
- } \
-} \
- \
-static inline void OPNAME ## _no_rnd_pixels8_xy2_8_c(uint8_t *block, \
- const uint8_t *pixels, \
- ptrdiff_t line_size, \
- int h) \
-{ \
- /* FIXME HIGH BIT DEPTH */ \
- int j; \
- \
- for (j = 0; j < 2; j++) { \
- int i; \
- const uint32_t a = AV_RN32(pixels); \
- const uint32_t b = AV_RN32(pixels + 1); \
- uint32_t l0 = (a & 0x03030303UL) + \
- (b & 0x03030303UL) + \
- 0x01010101UL; \
- uint32_t h0 = ((a & 0xFCFCFCFCUL) >> 2) + \
- ((b & 0xFCFCFCFCUL) >> 2); \
- uint32_t l1, h1; \
- \
- pixels += line_size; \
- for (i = 0; i < h; i += 2) { \
- uint32_t a = AV_RN32(pixels); \
- uint32_t b = AV_RN32(pixels + 1); \
- l1 = (a & 0x03030303UL) + \
- (b & 0x03030303UL); \
- h1 = ((a & 0xFCFCFCFCUL) >> 2) + \
- ((b & 0xFCFCFCFCUL) >> 2); \
- OP(*((uint32_t *) block), h0 + h1 + \
- (((l0 + l1) >> 2) & 0x0F0F0F0FUL)); \
- pixels += line_size; \
- block += line_size; \
- a = AV_RN32(pixels); \
- b = AV_RN32(pixels + 1); \
- l0 = (a & 0x03030303UL) + \
- (b & 0x03030303UL) + \
- 0x01010101UL; \
- h0 = ((a & 0xFCFCFCFCUL) >> 2) + \
- ((b & 0xFCFCFCFCUL) >> 2); \
- OP(*((uint32_t *) block), h0 + h1 + \
- (((l0 + l1) >> 2) & 0x0F0F0F0FUL)); \
- pixels += line_size; \
- block += line_size; \
- } \
- pixels += 4 - line_size * (h + 1); \
- block += 4 - line_size * h; \
- } \
-} \
- \
-CALL_2X_PIXELS(OPNAME ## _pixels16_x2_8_c, \
- OPNAME ## _pixels8_x2_8_c, \
- 8) \
-CALL_2X_PIXELS(OPNAME ## _pixels16_y2_8_c, \
- OPNAME ## _pixels8_y2_8_c, \
- 8) \
-CALL_2X_PIXELS(OPNAME ## _pixels16_xy2_8_c, \
- OPNAME ## _pixels8_xy2_8_c, \
- 8) \
-CALL_2X_PIXELS(OPNAME ## _no_rnd_pixels16_8_c, \
- OPNAME ## _pixels8_8_c, \
- 8) \
-CALL_2X_PIXELS(OPNAME ## _no_rnd_pixels16_x2_8_c, \
- OPNAME ## _no_rnd_pixels8_x2_8_c, \
- 8) \
-CALL_2X_PIXELS(OPNAME ## _no_rnd_pixels16_y2_8_c, \
- OPNAME ## _no_rnd_pixels8_y2_8_c, \
- 8) \
-CALL_2X_PIXELS(OPNAME ## _no_rnd_pixels16_xy2_8_c, \
- OPNAME ## _no_rnd_pixels8_xy2_8_c, \
- 8) \
-
-#define op_avg(a, b) a = rnd_avg32(a, b)
-#define op_put(a, b) a = b
-#define put_no_rnd_pixels8_8_c put_pixels8_8_c
-PIXOP2(avg, op_avg)
-PIXOP2(put, op_put)
-#undef op_avg
-#undef op_put
-
-av_cold void ff_hpeldsp_init(HpelDSPContext *c, int flags)
-{
-#define hpel_funcs(prefix, idx, num) \
- c->prefix ## _pixels_tab idx [0] = prefix ## _pixels ## num ## _8_c; \
- c->prefix ## _pixels_tab idx [1] = prefix ## _pixels ## num ## _x2_8_c; \
- c->prefix ## _pixels_tab idx [2] = prefix ## _pixels ## num ## _y2_8_c; \
- c->prefix ## _pixels_tab idx [3] = prefix ## _pixels ## num ## _xy2_8_c
-
- hpel_funcs(put, [0], 16);
- hpel_funcs(put, [1], 8);
- hpel_funcs(put, [2], 4);
- hpel_funcs(put, [3], 2);
- hpel_funcs(put_no_rnd, [0], 16);
- hpel_funcs(put_no_rnd, [1], 8);
- hpel_funcs(avg, [0], 16);
- hpel_funcs(avg, [1], 8);
- hpel_funcs(avg, [2], 4);
- hpel_funcs(avg, [3], 2);
- hpel_funcs(avg_no_rnd,, 16);
-
-#if ARCH_AARCH64
- ff_hpeldsp_init_aarch64(c, flags);
-#elif ARCH_ALPHA
- ff_hpeldsp_init_alpha(c, flags);
-#elif ARCH_ARM
- ff_hpeldsp_init_arm(c, flags);
-#elif ARCH_PPC
- ff_hpeldsp_init_ppc(c, flags);
-#elif ARCH_X86
- ff_hpeldsp_init_x86(c, flags);
-#elif ARCH_MIPS
- ff_hpeldsp_init_mips(c, flags);
-#elif ARCH_LOONGARCH64
- ff_hpeldsp_init_loongarch(c, flags);
-#endif
-}
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/jpeg2000htdec.h b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/jpeg2000htdec.h
deleted file mode 100644
index 572d095c927be53e1d784948515932668138c511..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/jpeg2000htdec.h
+++ /dev/null
@@ -1,34 +0,0 @@
-/*
- * Copyright (c) 2022 Caleb Etemesi
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-#ifndef AVCODEC_JPEG2000HTDEC_H
-#define AVCODEC_JPEG2000HTDEC_H
-
-#include "jpeg2000dec.h"
-
-/**
- * HT Block decoder as specified in Rec. ITU-T T.814 | ISO/IEC 15444-15
- */
-
-int ff_jpeg2000_decode_htj2k(const Jpeg2000DecoderContext *s, Jpeg2000CodingStyle *codsty,
- Jpeg2000T1Context *t1, Jpeg2000Cblk *cblk, int width,
- int height, int magp, uint8_t roi_shift);
-
-#endif /* AVCODEC_JPEG2000HTDEC_H */
diff --git a/spaces/congsaPfin/Manga-OCR/logs/APK Download - Modern Combat 2 Black Pegasus - The Game that Redefines the Shooter Genre on Android.md b/spaces/congsaPfin/Manga-OCR/logs/APK Download - Modern Combat 2 Black Pegasus - The Game that Redefines the Shooter Genre on Android.md
deleted file mode 100644
index 71808a0fcac04bfc8523f0c0603d1f442f12c6cd..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/APK Download - Modern Combat 2 Black Pegasus - The Game that Redefines the Shooter Genre on Android.md
+++ /dev/null
@@ -1,141 +0,0 @@
-
-Modern Combat 2: Black Pegasus APK Download
-If you are looking for a thrilling and realistic first-person shooter game for your Android device, you might want to check out Modern Combat 2: Black Pegasus APK. This is a sequel to the popular Modern Combat: Sandstorm game, developed and published by Gameloft in 2010. It features new environments, updated graphics, and more robust multiplayer modes.
-modern combat 2 black pegasus apk download
DOWNLOAD ✓ https://urlca.com/2uOd2S
-Modern Combat 2: Black Pegasus APK takes you to the heart of a global modern conflict, where you can play as one of three different characters and complete 12 missions across various locations. You can also join online battles with up to 10 players, level up through 72 ranks, and unlock new weapons and perks. The game has been praised for its awesome graphics, stunning sound, captivating gameplay, and online multiplayer features.
-In this article, we will show you how to download and install Modern Combat 2: Black Pegasus APK on your Android device for free. We will also give you some tips and tricks on how to play the game better, as well as a summary of its pros and cons. Let's get started!
- How to download and install Modern Combat 2: Black Pegasus APK on your Android device
-Downloading and installing Modern Combat 2: Black Pegasus APK on your Android device is easy and fast. Just follow these simple steps:
-
-- Go to this link and download the APK file of Modern Combat 2: Black Pegasus. The file size is about 1 MB.
-- Go to this link and download the OBB file of Modern Combat 2: Black Pegasus. The file size is about 400 MB.
-- Once both files are downloaded, locate them in your device's file manager and tap on them to install them. You may need to enable "Unknown sources" in your device's settings to allow installation from third-party sources.
-- After installing both files, move the OBB file to
/Android/obb/com.gameloft.android.ANMP.GloftBPHM.ML folder in your device's internal storage. If the folder does not exist, create it manually.
-- Launch the game from your app drawer or home screen and enjoy!
-
- Requirements for running Modern Combat 2: Black Pegasus APK
-Before you download and install Modern Combat 2: Black Pegasus APK on your Android device, make sure that it meets the following minimum and recommended specifications:Minimum specifications:
-
-- Android version: 2.1 or higher
-- RAM: 512 MB or more
-- Storage: 500 MB or more
-- Processor: 1 GHz or faster
-- Screen resolution: 800 x 480 pixels or higher
-
-Recommended specifications:
-modern combat 2 black pegasus android download
-modern combat 2 black pegasus hd apk
-modern combat 2 black pegasus free download
-modern combat 2 black pegasus mod apk
-modern combat 2 black pegasus apk + data
-modern combat 2 black pegasus apk obb
-modern combat 2 black pegasus apk offline
-modern combat 2 black pegasus apk full version
-modern combat 2 black pegasus apk latest version
-modern combat 2 black pegasus apk revdl
-modern combat 2 black pegasus apk for android 10
-modern combat 2 black pegasus apk for android 11
-modern combat 2 black pegasus apk for android 9
-modern combat 2 black pegasus apk for android 8
-modern combat 2 black pegasus apk for android 7
-modern combat 2 black pegasus apk for android 6
-modern combat 2 black pegasus apk for android 5
-modern combat 2 black pegasus apk for android 4.4
-modern combat 2 black pegasus apk for android tv
-modern combat 2 black pegasus apk for pc
-modern combat 2 black pegasus download for android
-modern combat 2 black pegasus download for pc
-modern combat 2 black pegasus download free full version
-modern combat 2 black pegasus download apkpure
-modern combat 2 black pegasus download uptodown
-modern combat 2 black pegasus download mob.org
-modern combat 2 black pegasus download softonic
-modern combat 2 black pegasus download happymod
-modern combat 2 black pegasus download apkcombo
-modern combat 2 black pegasus download gameloft
-how to download modern combat 2 black pegasus on android
-how to download modern combat 2 black pegasus on pc
-how to download modern combat 2 black pegasus for free
-how to install modern combat 2 black pegasus on android
-how to install modern combat 2 black pegasus on pc
-how to play modern combat 2 black pegasus on android
-how to play modern combat 2 black pegasus on pc
-how to play modern combat 2 black pegasus online
-how to play modern combat 2 black pegasus offline
-how to play modern combat 2 black pegasus multiplayer
-is modern combat 2 black pegasus compatible with android 11
-is modern combat 2 black pegasus compatible with android tv
-is modern combat 2 black pegasus available on google play store
-is modern combat 2 black pegasus available on ios
-is modern combat 2 black pegasus still online in 2023
-is modern combat 2 black pegasus worth playing in 2023
-what is the size of modern combat 2 black pegasus apk + data
-what is the rating of modern combat 2 black pegasus on google play store
-what are the features of modern combat 2 black pegasus mod apk
-what are the requirements of modern combat 2 black pegasus for android
-
-- Android version: 4.0 or higher
-- RAM: 1 GB or more
-- Storage: 1 GB or more
-- Processor: 1.5 GHz or faster
-- Screen resolution: 1280 x 720 pixels or higher
-
- Tips and tricks for playing Modern Combat 2: Black Pegasus APK
-Modern Combat 2: Black Pegasus APK is a challenging and fun game that requires skill and strategy to master. Here are some tips and tricks that can help you improve your performance and enjoy the game more:
- Customize your controls
-The game allows you to customize the layout and sensitivity of the on-screen buttons to suit your preferences. You can access the control settings from the main menu or pause menu. You can also choose between three different control schemes: Default, Virtual Sticks, and Accelerometer. Experiment with different options and find the one that works best for you.
- Use cover and crouch
-The game is full of enemies that will shoot at you from different angles and distances. To avoid getting hit, you need to use cover and crouch whenever possible. Cover can be anything from walls, crates, cars, etc. Crouching can reduce your visibility and make you a smaller target. To use cover, simply move behind an object and tap the cover button on the right side of the screen. To crouch, tap the crouch button on the left side of the screen.
- Aim for the head
-The game has a realistic damage system that takes into account where you hit your enemies. Headshots are the most effective way to kill them quickly and save ammo. To aim for the head, use the zoom button on the right side of the screen and adjust your crosshair accordingly. You can also use the auto-aim feature, which will automatically lock on to the nearest enemy's head when you zoom in.
- Switch weapons and reload wisely
-The game offers a variety of weapons to choose from, such as pistols, rifles, shotguns, snipers, etc. Each weapon has its own advantages and disadvantages, such as range, accuracy, fire rate, damage, etc. You need to switch weapons depending on the situation and your play style. For example, a shotgun is good for close-range combat, but a sniper is better for long-range combat. To switch weapons, tap the weapon icon on the bottom left of the screen and select the one you want.
-You also need to reload your weapons at the right time. Reloading takes time and leaves you vulnerable to enemy fire. To reload, tap the reload button on the bottom right of the screen. You can also reload manually by tapping the ammo counter on the top right of the screen. Try to reload when you are in cover or when there are no enemies around.
- Play online with friends
-The game has an online multiplayer mode that lets you join or create matches with up to 10 players across four different modes: Team Deathmatch, Capture The Flag, Bomb Squad, and Zone Control. You can also chat with your teammates using voice or text messages. To play online, tap the multiplayer button on the main menu and select the mode you want. You can then choose to join an existing match or create your own.
- Pros and cons of Modern Combat 2: Black Pegasus APK
-Modern Combat 2: Black Pegasus APK is a great game that offers a lot of fun and excitement for FPS fans. However, it also has some drawbacks that you should be aware of before downloading it. Here are some of the pros and cons of Modern Combat 2: Black Pegasus APK:
- Pros
-
-- The game has amazing graphics that create a realistic and immersive experience.
-- The game has a captivating gameplay that keeps you hooked for hours.
-- The game has a robust online multiplayer mode that lets you play with friends or strangers.
-- The game has a variety of weapons, perks, maps, modes, etc. that add diversity and replay value.
-- The game is free to download and play.
-
- Cons
-
-- The game has some bugs and glitches that may affect the game's performance and stability.
-- The game has some ads that may interrupt your gameplay and annoy you.
-- The game has some compatibility issues with some devices and Android versions.
-- The game has a large file size that may take up a lot of space on your device.
-- The game may drain your battery and overheat your device.
-
- Conclusion
-Modern Combat 2: Black Pegasus APK is one of the best FPS games for Android devices. It offers a thrilling and realistic experience that will keep you entertained for hours. It has awesome graphics, sound, gameplay, and multiplayer features that make it stand out from other games in the genre. It is also free to download and play, which is a great deal for such a high-quality game.
-However, the game also has some drawbacks that you should consider before downloading it. It has some bugs, ads, compatibility issues, and a large file size that may affect your enjoyment of the game. It may also drain your battery and overheat your device, so you should play it with caution.
-Overall, we recommend Modern Combat 2: Black Pegasus APK to anyone who loves FPS games and wants to have a blast on their Android device. It is a game that will challenge your skills and immerse you in a modern warfare scenario. You can download it from the links provided in this article and start playing right away. Have fun!
- FAQs
-Here are some of the frequently asked questions and their answers about Modern Combat 2: Black Pegasus APK:
-
-- Is Modern Combat 2: Black Pegasus APK safe to download and install?
-Yes, Modern Combat 2: Black Pegasus APK is safe to download and install on your Android device. It does not contain any viruses, malware, or spyware that can harm your device or data. However, you should always download it from trusted sources and scan it with an antivirus app before installing it.
-- Is Modern Combat 2: Black Pegasus APK legal to download and play?
-Yes, Modern Combat 2: Black Pegasus APK is legal to download and play on your Android device. It is not a pirated or cracked version of the game, but a modified version that allows you to play it for free. However, you should be aware that downloading and playing modified games may violate the terms and conditions of the original developers and publishers, and may result in legal actions against you.
-- How can I update Modern Combat 2: Black Pegasus APK?
-To update Modern Combat 2: Black Pegasus APK, you need to download and install the latest version of the APK and OBB files from the links provided in this article. You do not need to uninstall the previous version of the game, as the new version will overwrite it automatically. However, you should always back up your game data before updating it, as you may lose your progress or settings.
-- How can I fix Modern Combat 2: Black Pegasus APK not working or crashing?
-If Modern Combat 2: Black Pegasus APK is not working or crashing on your Android device, you can try the following solutions:
-
-- Make sure that your device meets the minimum and recommended specifications for the game.
-- Make sure that you have enough storage space on your device for the game files.
-- Make sure that you have a stable internet connection for the game's online features.
-- Make sure that you have installed both the APK and OBB files correctly on your device.
-- Clear the cache and data of the game from your device's settings.
-- Restart your device and launch the game again.
-
-- How can I contact the developers or publishers of Modern Combat 2: Black Pegasus APK?
-If you have any questions, feedback, or issues regarding Modern Combat 2: Black Pegasus APK, you can contact the developers or publishers of the game through their official website here, their Facebook page here, or their Twitter account here.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Download Euro Truck Simulator 2 and Challenge Yourself with Different Cargo Types.md b/spaces/congsaPfin/Manga-OCR/logs/Download Euro Truck Simulator 2 and Challenge Yourself with Different Cargo Types.md
deleted file mode 100644
index 5606f459b8a8c711e1bbd9951bf8fcef922bf8f8..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Download Euro Truck Simulator 2 and Challenge Yourself with Different Cargo Types.md
+++ /dev/null
@@ -1,139 +0,0 @@
-
-How to Download the Latest Version of Euro Truck Simulator 2
-Have you ever dreamed of becoming a truck driver and traveling across Europe? If so, you might want to check out Euro Truck Simulator 2, a realistic and immersive truck driving simulator that lets you explore dozens of cities, deliver various cargoes, and customize your own fleet of trucks. In this article, we will show you how to download the latest version of Euro Truck Simulator 2, what you need to run it, and what you can expect from this amazing game.
- Requirements and Compatibility
-Before you download Euro Truck Simulator 2, you should make sure that your computer meets the minimum or recommended system requirements for the game. Here are the specifications you need to know:
-download the latest version of euro truck simulator 2
Download »»» https://urlca.com/2uOdAs
-
-
-| Minimum |
-Recommended |
-
-
-| OS: Windows 7 |
-OS: Windows 10 |
-
-
-| Processor: Dual core CPU 2.4 GHz |
-Processor: Quad core CPU 3.0 GHz |
-
-
-| Memory: 4 GB RAM |
-Memory: 6 GB RAM |
-
-
-| Graphics: GeForce GTS 450-class (Intel HD 4000) |
-Graphics: GeForce GTX 760-class (2 GB) |
-
-
-| Storage: 10 GB available space |
-Storage: 10 GB available space |
-
-
-| Sound Card: Any |
-Sound Card: Any |
-
-
- You should also make sure that your computer has DirectX version 11 installed, as well as a compatible keyboard and mouse. If you want to use a controller or a steering wheel, you should check if they are supported by the game.
- Download Options
-There are several ways to download Euro Truck Simulator 2, depending on your preference and budget. Here are some of the most popular options:
-
-- Steam: Steam is a digital distribution platform that offers a wide range of games, including Euro Truck Simulator 2. You can buy the game for $19.99 or get it as part of a bundle with other DLCs and expansions. Steam also allows you to download updates automatically, access online features, and join the Steam community.
- - Euro Truck Simulator 2 Website: You can also buy the game directly from the official website of Euro Truck Simulator 2. You can choose from different payment methods, such as credit card, PayPal, or Paysafecard. You will receive a product key that you can use to activate the game on Steam or download it from their servers.
- - Other Online Stores: There are also other online stores that sell Euro Truck Simulator 2, such as Humble Bundle, GOG.com, or Amazon. You should compare the prices and reviews before buying from these sources, as they may vary in quality and reliability.
- - Demo Version: If you are not sure if you want to buy the game or not, you can try the demo version first. The demo version allows you to play for free for one hour, with limited features and content. You can download the demo version from Steam or from the official website.
- - Pirated Version: We do not recommend downloading a pirated version of Euro Truck Simulator 2, as it is illegal, unsafe, and unethical. Pirated versions may contain viruses, malware, or spyware that can harm your computer or compromise your privacy. Pirated versions may also have bugs, glitches, or errors that can ruin your gaming experience. Pirated versions may also prevent you from accessing online features, such as multiplayer, mods, or achievements. Pirated versions may also get you banned from Steam or other platforms. Therefore, we strongly advise you to buy the game legally and support the developers who worked hard to create it.
-
- Installation and Setup
-Once you have downloaded Euro Truck Simulator 2, you need to install and launch it on your computer. The installation and setup process may vary depending on the source of your download, but here are some general steps you can follow:
-
-- Run the installer: Locate the installer file on your computer and double-click on it to start the installation process. You may need to agree to the terms and conditions, choose a destination folder, and select the components you want to install.
- - Activate the game: If you bought the game from Steam or another online store, you may need to activate the game with a product key. You can find the product key in your email confirmation, in your Steam library, or in your online account. Enter the product key when prompted and verify it online.
- - Launch the game: After the installation is complete, you can launch the game from your desktop shortcut, from your Start menu, or from your Steam library. You may need to create a profile, choose a language, and adjust the settings before you start playing.
-
- Features and Benefits
-Euro Truck Simulator 2 is more than just a driving simulator. It is a game that offers many features and benefits that will make you feel like a real trucker. Here are some of the things you can do and enjoy in Euro Truck Simulator 2:
-
-- Explore Europe: Euro Truck Simulator 2 covers more than 70 cities in 13 countries across Europe, including Germany, France, Italy, Spain, Poland, and more. You can drive on realistic roads, highways, bridges, tunnels, and landmarks that reflect the diversity and beauty of the continent.
- - Deliver cargoes: Euro Truck Simulator 2 gives you hundreds of different cargoes to transport, ranging from food and furniture to chemicals and machinery. You can choose from various contracts and jobs that suit your preferences and skills. You can also earn money and reputation by completing deliveries on time and without damage.
- - Customize your trucks: Euro Truck Simulator 2 allows you to buy, upgrade, and personalize your own fleet of trucks. You can choose from over 40 licensed truck models from brands such as Volvo, Scania, MAN, Mercedes-Benz, and more. You can also modify your trucks with various parts and accessories, such as engines, transmissions, chassis, paint jobs, lights, horns, and more.
- - Grow your business: Euro Truck Simulator 2 lets you start your own trucking company and expand it across Europe. You can hire drivers, buy garages, manage finances, and compete with other companies. You can also join online events and challenges that reward you with exclusive rewards and achievements.
- - Enjoy the community: Euro Truck Simulator 2 has a large and active community of fans and modders who create and share new content for the game. You can download and install mods that add new maps, trucks, cargoes, traffic, weather, sounds, and more. You can also join the multiplayer mode and drive with other players online.
-
- Tips and Tricks
-Euro Truck Simulator 2 is a fun and challenging game that requires skill and strategy. Here are some tips and tricks that can help you improve your gameplay and performance:
-
-- Plan your route: Before you accept a job, you should check the map and plan your route carefully. You should consider the distance, the time limit, the tolls, the traffic, the weather, and the road conditions. You should also avoid taking shortcuts or detours that may lead you to dead ends or restricted areas.
- - Follow the rules: Euro Truck Simulator 2 simulates the real driving laws and regulations of each country. You should follow the speed limits, obey the traffic signs and signals, use the indicators, respect the right of way, and avoid collisions and violations. You should also rest and refuel regularly to avoid fatigue and damage.
- - Save your game: Euro Truck Simulator 2 allows you to save your game at any time, except when you are in a cutscene or a loading screen. You should save your game frequently, especially before and after a delivery, to avoid losing your progress or having to repeat a job. You can also use the quick save feature by pressing F5 on your keyboard.
- - Use the options: Euro Truck Simulator 2 offers many options and settings that you can customize to suit your preferences and needs. You can adjust the graphics, the sound, the controls, the gameplay, and the difficulty. You can also enable or disable various features, such as automatic parking, traffic offenses, rain probability, fatigue simulation, and more.
- - Have fun: Euro Truck Simulator 2 is a game that allows you to have fun and enjoy yourself. You can listen to music, watch videos, chat with other players, take screenshots, record videos, and share your experiences with others. You can also explore new places, discover hidden secrets, and try new things.
-
- Conclusion
-Euro Truck Simulator 2 is a game that will give you hours of entertainment and satisfaction. It is a game that will let you experience the thrill and challenge of truck driving in Europe. It is a game that will let you customize your trucks, grow your business, and join a community. It is a game that you should download and play today.
- FAQs
-Here are some frequently asked questions about Euro Truck Simulator 2:
-
-- Q: How do I update Euro Truck Simulator 2 to the latest version?
-A: If you bought the game from Steam or another online store, you should receive updates automatically when they are available. If you bought the game from the official website or another source, you should download and install the updates manually from their website.
- - Q: How do I get more money in Euro Truck Simulator 2?
-A: There are several ways to get more money in Euro Truck Simulator 2. You can complete more deliveries, take higher-paying jobs, use bank loans, sell or trade-in your trucks, hire more drivers, or use cheats or mods.
- - Q: How do I get more XP in Euro Truck Simulator 2?
-A: There are several ways to get more XP in Euro Truck Simulator 2. You can complete more deliveries, take longer-distance jobs, deliver fragile or valuable cargoes, park your trailer manually, drive in adverse weather conditions, or use skills or mods.
- - Q: How do I change the camera view in Euro Truck Simulator 2?
-A: You can change the camera view in Euro Truck Simulator 2 by pressing the number keys on your keyboard. The default keys are 1 for interior view, 2 for exterior view, 3 for left mirror view, 4 for right mirror view, 5 for bumper view, 6 for roof view, and 9 for free camera view. You can also use the mouse wheel to zoom in or out.
- - Q: How do I use mods in Euro Truck Simulator 2?
-A: You can use mods in Euro Truck Simulator 2 by downloading them from various websites, such as Steam Workshop, ETS2 Mods, or ModLand. You should check the compatibility and quality of the mods before installing them. You should also backup your game files and save games before using mods. To install mods, you need to copy the mod files to the "mod" folder in your Euro Truck Simulator 2 directory. To activate mods, you need to go to the "Mod Manager" in the game menu and enable the mods you want to use.
- - Q: How do I join the multiplayer mode in Euro Truck Simulator 2?
-A: You can join the multiplayer mode in Euro Truck Simulator 2 by downloading and installing a mod called TruckersMP. TruckersMP is a mod that allows you to play online with other players on dedicated servers. You can find more information and instructions on how to join TruckersMP on their website.
-
-download euro truck simulator 2 demo
-download euro truck simulator 2 full version
-download euro truck simulator 2 free
-download euro truck simulator 2 mods
-download euro truck simulator 2 steam
-download euro truck simulator 2 update
-download euro truck simulator 2 crack
-download euro truck simulator 2 dlc
-download euro truck simulator 2 multiplayer
-download euro truck simulator 2 for pc
-download euro truck simulator 2 for mac
-download euro truck simulator 2 for linux
-download euro truck simulator 2 for android
-download euro truck simulator 2 for windows 10
-download euro truck simulator 2 for windows 7
-download euro truck simulator 2 latest patch
-download euro truck simulator 2 latest map
-download euro truck simulator 2 latest mod
-download euro truck simulator 2 latest dlc
-download euro truck simulator 2 latest version apk
-download euro truck simulator 2 latest version highly compressed
-download euro truck simulator 2 latest version torrent
-download euro truck simulator 2 latest version setup
-download euro truck simulator 2 latest version with all dlc
-download euro truck simulator 2 latest version from steam
-how to download euro truck simulator 2 latest version
-where to download euro truck simulator 2 latest version
-when to download euro truck simulator 2 latest version
-why to download euro truck simulator 2 latest version
-what to do after downloading euro truck simulator 2 latest version
-best site to download euro truck simulator 2 latest version
-best way to download euro truck simulator 2 latest version
-best mods to download for euro truck simulator 2 latest version
-best settings for euro truck simulator 2 latest version after downloading
-best tips and tricks for playing euro truck simulator 2 latest version after downloading
-best trucks to buy in euro truck simulator 2 latest version after downloading
-best routes to drive in euro truck simulator 2 latest version after downloading
-best cities to visit in euro truck simulator 2 latest version after downloading
-best countries to explore in euro truck simulator 2 latest version after downloading
-best challenges to complete in euro truck simulator 2 latest version after downloading
-best achievements to unlock in euro truck simulator 2 latest version after downloading
-best online features of euro truck simulator 2 latest version after downloading
-best offline features of euro truck simulator 2 latest version after downloading
-best graphics of euro truck simulator 2 latest version after downloading
-best sound effects of euro truck simulator 2 latest version after downloading
-best music of euro truck simulator 2 latest version after downloading
-best gameplay of euro truck simulator 2 latest version after downloading
-best reviews of euro truck simulator 2 latest version after downloading
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Dream League Soccer 2020 Mod Apk 3.040 The Ultimate Soccer Experience with Unlimited Money.md b/spaces/congsaPfin/Manga-OCR/logs/Dream League Soccer 2020 Mod Apk 3.040 The Ultimate Soccer Experience with Unlimited Money.md
deleted file mode 100644
index 59ba6a1b989daecbb9615a00b1add83d677fecf5..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Dream League Soccer 2020 Mod Apk 3.040 The Ultimate Soccer Experience with Unlimited Money.md
+++ /dev/null
@@ -1,68 +0,0 @@
-
-Dream League Soccer 2020 Mod Apk 3.040 (Unlimited Money)
- Introduction
- If you are a fan of soccer games, you might have heard of Dream League Soccer 2020, one of the most popular and realistic soccer games on mobile devices. But did you know that there is a modded version of this game that gives you unlimited money, coins, gems, and more? In this article, we will tell you everything you need to know about Dream League Soccer 2020 Mod Apk, including what it is, why you should download it, what features it offers, how to download and install it, and how it compares to the original version. So, let's get started!
- What is Dream League Soccer 2020?
- Dream League Soccer 2020 is a soccer game developed by First Touch Games, a studio that specializes in creating high-quality soccer games for mobile devices. The game allows you to create your own dream team from over 4,000 licensed players, customize your stadium, kits, logos, and more, and compete in various modes such as Career Mode, Online Mode, Events Mode, and more. The game also features realistic graphics, animations, sound effects, commentary, and gameplay that will make you feel like you are playing on a real soccer field.
-dream league soccer 2020 mod apk 3.040 (unlimited money)
Download === https://urlca.com/2uO5Kl
- What is Dream League Soccer 2020 Mod Apk?
- Dream League Soccer 2020 Mod Apk is a modified version of Dream League Soccer 2020 that gives you access to unlimited resources and features that are not available in the original version. For example, with Dream League Soccer 2020 Mod Apk, you can get unlimited money, coins, gems, players, stadiums, and more without spending any real money or watching any ads. You can also enjoy all the features of the original version without any restrictions or limitations.
- Why should you download Dream League Soccer 2020 Mod Apk?
- There are many reasons why you should download Dream League Soccer 2020 Mod Apk instead of the original version. Here are some of them:
-
-- You can get unlimited money, coins, gems, players, stadiums, and more without spending any real money or watching any ads.
-- You can customize your team and stadium to your liking without any limitations.
-- You can unlock all the players and stadiums that are otherwise locked or require in-app purchases.
-- You can enjoy all the features of the original version without any restrictions or limitations.
Features of Dream League Soccer 2020 Mod Apk
- Dream League Soccer 2020 Mod Apk offers many features that will make your gaming experience more enjoyable and exciting. Here are some of the main features of Dream League Soccer 2020 Mod Apk:
- Unlimited Money
- With Dream League Soccer 2020 Mod Apk, you can get unlimited money that you can use to buy anything you want in the game. You can use the money to upgrade your players, stadium, kits, logos, and more. You can also use the money to buy new players from the transfer market or scout for new talents. You don't have to worry about running out of money or saving up for something you want.
- Unlimited Coins
- Coins are another currency in Dream League Soccer 2020 that you can use to buy special items or unlock premium features. With Dream League Soccer 2020 Mod Apk, you can get unlimited coins that you can spend on anything you want. You can use the coins to buy rare players, boosters, kits, stadiums, and more. You can also use the coins to unlock exclusive events, tournaments, and modes. You don't have to watch ads or complete tasks to earn coins.
- Unlimited Gems
- Gems are the premium currency in Dream League Soccer 2020 that you can use to buy the most valuable items or features in the game. With Dream League Soccer 2020 Mod Apk, you can get unlimited gems that you can use to buy anything you want. You can use the gems to buy legendary players, super boosters, VIP kits, stadiums, and more. You can also use the gems to unlock the highest divisions, leagues, and cups. You don't have to spend any real money or wait for a long time to get gems.
- All Players Unlocked
- Dream League Soccer 2020 features over 4,000 licensed players from around the world, including some of the best and most famous soccer stars. However, not all of them are available from the start. Some of them are locked or require in-app purchases to unlock. With Dream League Soccer 2020 Mod Apk, you can unlock all the players in the game without any restrictions or limitations. You can choose any player you want for your team, regardless of their rating, position, nationality, or club. You can also switch players anytime you want without any penalties or costs.
-dream league soccer 2020 hack apk unlimited coins and gems
-dream league soccer 2020 mod apk latest version download
-dream league soccer 2020 mod apk offline with data
-dream league soccer 2020 unlimited money and diamond apk
-dream league soccer 2020 mod apk rexdl.com[^1^]
-dream league soccer 2020 mod apk android 1.com
-dream league soccer 2020 mod apk obb file download
-dream league soccer 2020 mod apk unlimited players development
-dream league soccer 2020 mod apk all players unlocked
-dream league soccer 2020 mod apk unlimited everything
-dream league soccer 2020 mod apk free shopping
-dream league soccer 2020 mod apk no root required
-dream league soccer 2020 mod apk unlimited coins and keys
-dream league soccer 2020 mod apk revdl.com
-dream league soccer 2020 mod apk with real faces
-dream league soccer 2020 mod apk unlimited stamina
-dream league soccer 2020 mod apk mega.nz
-dream league soccer 2020 mod apk mediafıre.com
-dream league soccer 2020 mod apk all teams unlocked
-dream league soccer 2020 mod apk unlimited gold and cash
-dream league soccer 2020 mod apk no ads
-dream league soccer 2020 mod apk with commentary
-dream league soccer 2020 mod apk all legends unlocked
-dream league soccer 2020 mod apk unlimited transfers
-dream league soccer 2020 mod apk with license verification removed
-dream league soccer 2020 mod apk with new kits and logos
-dream league soccer 2020 mod apk unlimited energy and health
-dream league soccer 2020 mod apk vip unlocked
-dream league soccer 2020 mod apk with original music and sound effects
-dream league soccer 2020 mod apk with hd graphics and smooth gameplay
- All Stadiums Unlocked
- Dream League Soccer 2020 allows you to customize your own stadium with various options such as capacity, pitch type, lighting, and more. However, not all of them are available from the start. Some of them are locked or require in-app purchases to unlock. With Dream League Soccer 2020 Mod Apk, you can unlock all the stadiums in the game without any restrictions or limitations. You can choose any stadium you want for your home ground, regardless of its size, location, or design. You can also change stadiums anytime you want without any penalties or costs.
- No Ads
- Dream League Soccer 2020 is a free-to-play game that relies on ads to generate revenue. However, ads can be annoying and distracting when you are playing the game. They can also interrupt your gameplay or slow down your device performance. With Dream League Soccer 2020 Mod Apk, you can enjoy the game without any ads. You don't have to watch any ads or deal with any pop-ups or banners. You can play the game smoothly and comfortably without any interruptions or distractions.
2020 Mod Apk?
-Yes, you can play online with Dream League Soccer 2020 Mod Apk, but only with other players who have the same mod apk version. You cannot play online with players who have the original version or a different mod apk version. You can also play offline with Dream League Soccer 2020 Mod Apk if you don't have an internet connection.
-- Will I get banned for using Dream League Soccer 2020 Mod Apk?
-No, you will not get banned for using Dream League Soccer 2020 Mod Apk, as long as you don't use it for cheating or hacking purposes. The mod apk file does not interfere with the game servers or data, so you don't have to worry about getting detected or reported. However, we advise you to use it at your own risk and discretion.
-- Can I update Dream League Soccer 2020 Mod Apk?
-Yes, you can update Dream League Soccer 2020 Mod Apk whenever there is a new version available. However, you need to download and install the new mod apk file from the same source you used before. You cannot update the mod apk file from the Google Play Store or any other source. You may also need to uninstall the previous mod apk file before installing the new one.
-- Can I restore my progress if I uninstall Dream League Soccer 2020 Mod Apk?
-Yes, you can restore your progress if you uninstall Dream League Soccer 2020 Mod Apk, as long as you have backed up your data before uninstalling. To back up your data, you need to go to your device settings, then apps, then Dream League Soccer 2020, then storage, then clear cache and clear data. This will save your data on your device memory. To restore your data, you need to install the mod apk file again and launch the game. Your data will be automatically restored.
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/How to Install Roblox APK on Your Android Device - 5Play Guide.md b/spaces/congsaPfin/Manga-OCR/logs/How to Install Roblox APK on Your Android Device - 5Play Guide.md
deleted file mode 100644
index a918b3d7705ea2fd56548b88935f92df16e477fc..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/How to Install Roblox APK on Your Android Device - 5Play Guide.md
+++ /dev/null
@@ -1,102 +0,0 @@
-
-Roblox Download APK 5play: The Ultimate Guide
-If you are looking for a fun and creative way to spend your free time, you should definitely try out Roblox. Roblox is a massively multiplayer online game platform that allows you to create your own games and play games created by others. You can explore millions of different worlds, genres, and experiences, ranging from first-person shooters, survival games, role-playing adventures, and more. You can also socialize and chat with other players, customize your avatar, and earn virtual currency.
-But how can you get access to this amazing platform on your Android device? The answer is simple: by downloading Roblox APK from 5play. In this article, we will show you how to do that step by step, as well as how to play and create games on Roblox using your Android device. We will also tell you about the benefits of downloading Roblox APK from 5play, such as getting modded versions of Roblox with extra features and functions. So, without further ado, let's get started!
-roblox download apk 5play
Download File ••• https://urlca.com/2uO9uZ
- How to Download and Install Roblox APK from 5play
-Downloading and installing Roblox APK from 5play is very easy and fast. Just follow these simple steps:
-
-- Visit the 5play website and search for Roblox in the search bar.
-- Choose the version of Roblox APK you want to download. You can choose between the original version or the modded version with a mega menu and over 60 features.
-- Tap on the download button and wait for the file to be downloaded on your device.
-- Enable unknown sources on your device settings. This will allow you to install apps from sources other than the Google Play Store.
-- Locate the downloaded file in your file manager and tap on it to install Roblox APK on your device.
-
-Congratulations! You have successfully downloaded and installed Roblox APK from 5play. Now you can enjoy playing and creating games on Roblox with your Android device.
- How to Play Roblox Games on Your Android Device
-Playing Roblox games on your Android device is very fun and easy. Just follow these simple steps:
-
-- Launch the Roblox app and sign in with your Roblox account. If you don't have one, you can create one for free.
-- Browse and discover games by genre, popularity, or keyword. You can also use the filters and categories to narrow down your search.
-- Tap on the game you want to play and wait for it to load. You may need to download some additional content before you can play.
-- Enjoy playing with millions of other players online. You can also chat, join groups, and make friends on Roblox.
-
-There are endless possibilities of games to play on Roblox. You can find anything from action, adventure, simulation, puzzle, horror, comedy, and more. Some of the most popular games on Roblox are Adopt Me, MeepCity, Jailbreak, Murder Mystery 2, Arsenal, and Piggy. You can also check out the featured games and the editor's choice games for more recommendations.
- How to Create Your Own Games on Roblox Using Your Android Device
-Creating your own games on Roblox using your Android device is very creative and rewarding. Just follow these simple steps:
-roblox apk download 5play mod menu
-roblox 5play app free download android
-roblox 5play apk latest version
-roblox 5play mega menu features
-roblox 5play adventure game
-roblox 5play apk update
-roblox 5play online multiplayer
-roblox 5play create and play games
-roblox 5play apk combo
-roblox 5play download for pc
-roblox 5play mod apk unlimited robux
-roblox 5play app store
-roblox 5play apk old version
-roblox 5play developer roblox corporation
-roblox 5play google play id
-roblox 5play download size
-roblox 5play apk mirror
-roblox 5play install guide
-roblox 5play review and rating
-roblox 5play apk pure
-roblox 5play hack and cheat
-roblox 5play game genre
-roblox 5play apk file
-roblox 5play community moderation
-roblox 5play parental controls
-roblox 5play encryption and security
-roblox 5play educational value
-roblox 5play teacher resources
-roblox 5play student engagement
-roblox 5play growth and popularity
-roblox 5play lua scripting language
-roblox 5play building blocks and tools
-roblox 5play game discovery and search
-roblox 5play social interaction and chat
-roblox 5play in-game purchases and currency
-roblox 5play user-generated content and experiences
-roblox 5play korea institute of fusion energy experiment
-roblox 5play nuclear fusion reaction game
-roblox 5play mini sun simulation
-roblox 5play net energy gain challenge
-roblox 5play holy grail fusion quest
-roblox 5play temperature and pressure measurement
-roblox 5play physics and engineering problem-solving
-roblox 5play lesson plans and tutorials
-roblox 5play fun and learning combination
-
-- Download and install Roblox Studio from the Google Play Store. This is a free app that allows you to create and publish games on Roblox.
-- Launch Roblox Studio and sign in with your Roblox account.
-- Choose a template or start from scratch to create your own game. You can use the built-in tools and features to design your game world and add interactivity.
-- Use the playtest mode to test your game and make sure it works properly.
-- Publish your game to Roblox and share it with others. You can also monetize your game by selling items, game passes, or premium access.
-
-Creating your own games on Roblox is a great way to express your creativity and imagination. You can also learn valuable skills such as coding, design, and problem-solving. You can make any kind of game you want, from platformers, shooters, racing, tycoon, RPG, and more. You can also get feedback from other players and improve your game over time.
- Benefits of Downloading Roblox APK from 5play
-Downloading Roblox APK from 5play has many benefits that you won't get from other sources. Here are some of them:
-
-- You can access modded versions of Roblox with extra features and functions. For example, you can get a mega menu with over 60 features such as unlimited robux, fly mode, teleportation, speed hack, god mode, invisibility, and more.
-- You can enjoy a fast and secure download process with no viruses or malware. 5play is a trusted website that scans all the files before uploading them. You don't need to worry about any harm to your device or data.
-- You can use a free and easy to use website with no registration or subscription required. 5play is a user-friendly website that allows you to download apps and games with just a few clicks. You don't need to sign up or pay anything to use it.
-
-Downloading Roblox APK from 5play is the best way to enjoy Roblox on your Android device. You can get more features, more security, and more convenience than anywhere else.
- Conclusion and FAQs
-In conclusion, Roblox is a fantastic game platform that allows you to play and create games on your Android device. You can download Roblox APK from 5play to get the best experience possible. You can also get modded versions of Roblox with extra features and functions that will make your gameplay more fun and exciting. So what are you waiting for? Download Roblox APK from 5play today and join the millions of players who are already enjoying this amazing platform!
- If you have any questions or issues about downloading or installing Roblox APK from 5play, you can check out these FAQs below:
- FAQ 1: What is Roblox?
-Roblox is a massively multiplayer online game platform that allows you to create your own games and play games created by others. You can explore millions of different worlds, genres, and experiences, ranging from action, adventure, simulation, puzzle, horror, comedy, and more. You can also socialize and chat with other players, customize your avatar, and earn virtual currency.
- FAQ 2: What is 5play?
-5play is a website that allows you to download apps and games for your Android device. You can find both original and modded versions of apps and games on 5play. You can also enjoy a fast and secure download process with no viruses or malware.
- FAQ 3: Is Roblox APK safe to download from 5play?
-Yes, Roblox APK is safe to download from 5play. 5play is a trusted website that scans all the files before uploading them. You don't need to worry about any harm to your device or data. However, you should always be careful when downloading and installing apps from unknown sources. You should also check the permissions and reviews of the apps before using them.
- FAQ 4: How can I update Roblox APK from 5play?
-You can update Roblox APK from 5play by following the same steps as downloading and installing it. You just need to visit the 5play website and search for the latest version of Roblox APK. Then, you can download and install it on your device. You may need to uninstall the previous version of Roblox APK before installing the new one.
- FAQ 5: How can I contact 5play if I have any questions or issues?
-You can contact 5play by visiting their contact page. There, you can find their email address, phone number, and social media accounts. You can also leave a comment or a feedback on their website. They will try to respond to your queries as soon as possible.
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Undawn The Ultimate Open-World Survival RPG - Beta Test APK Available.md b/spaces/congsaPfin/Manga-OCR/logs/Undawn The Ultimate Open-World Survival RPG - Beta Test APK Available.md
deleted file mode 100644
index 993ed37c598499811e40786802ed202da41091f2..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Undawn The Ultimate Open-World Survival RPG - Beta Test APK Available.md
+++ /dev/null
@@ -1,129 +0,0 @@
-
-Undawn Beta Test APK: How to Download and Play the New Survival RPG
-If you are a fan of survival games, you might have heard of Undawn, the new shooter RPG from Tencent and Lightspeed & Quantum Studios. This game promises to immerse you in an open world that is being destroyed by zombies and other extremely dangerous creatures. You need to work with your teammates to shoot and destroy all the enemies in different locations while trying to survive in this hostile environment.
-But how can you play this game before its official release? The answer is simple: by downloading and installing the Undawn beta test apk. In this article, we will tell you everything you need to know about this game, how to download and install the apk file, and what to expect from the beta test. Let's get started!
-undawn beta test apk
Download File ··· https://urlca.com/2uOddB
- What is Undawn?
-Undawn is an all-new open-world survival RPG for mobile and PC. It is developed by Tencent, one of the biggest gaming companies in the world, and Lightspeed & Quantum Studios, the same team behind PUBG Mobile. The game is set in a post-apocalyptic world where hordes of infected roam a shattered world. You need to explore, adapt, and survive in this challenging scenario.
- A post-apocalyptic open-world adventure
-Undawn takes place four years after a worldwide disaster that unleashed a deadly virus that turned most of the population into zombies. You are one of the survivors who have to fight for your life in a vast open world that is full of dangers and opportunities. You can explore different locations, such as cities, forests, deserts, and underground facilities, and scavenge for resources, weapons, and equipment. You can also craft items, build shelters, and upgrade your skills.
- A cross-platform game for mobile and PC
-One of the most impressive features of Undawn is that it is designed to be played on both mobile devices and PCs. This means that you can enjoy the same high-quality graphics, smooth gameplay, and immersive sound effects on your smartphone or your computer. You can also switch between platforms seamlessly without losing your progress or your account. Moreover, you can play with other players who are using different devices, thanks to the cross-platform compatibility.
- A cooperative and competitive multiplayer mode
-Undawn is not only a single-player game. It also offers a multiplayer mode where you can team up with other survivors or compete against them. You can join forces with your friends or other players online to complete missions, raid enemy bases, or defend your own shelter. You can also challenge other players in PvP battles, where you can loot their resources or take over their territory. You can also join or create factions, where you can cooperate or clash with other groups of players.
- How to download and install the Undawn beta test apk?
-If you want to play Undawn before its official launch, you need to download and install the beta test apk file on your device. This file will allow you to access the closed beta test of the game, which started on April 6th, 2023. However, before you do that, you need to make sure that your device meets the requirements and compatibility criteria for the game.
- Requirements and compatibility
-To play Undawn on your mobile device, you need to have Android 5.0 or higher installed on your phone or tablet. You also need to have at least 4 GB of RAM and 8 GB of free storage space on your device. Additionally, you need to have
Steps to download and install the apk file
-To download and install the Undawn beta test apk file, you need to follow these steps:
-undawn game beta test download
-undawn cbt apk free download
-how to join undawn beta test
-undawn beta test ios
-undawn beta test gameplay
-undawn beta test registration
-undawn beta test review
-undawn beta test release date
-undawn beta test uptodown
-undawn beta test youtube
-undawn game apk obb download
-undawn game apk mod
-undawn game apk offline
-undawn game apk latest version
-undawn game apk for pc
-undawn game apk size
-undawn game apk requirements
-undawn game apk update
-undawn cbt apk mediafire
-undawn cbt apk android
-undawn cbt apk ios
-undawn cbt apk 1.2.8
-undawn cbt apk 1.2.4
-undawn cbt apk 1.0.1
-undawn cbt apk tencent games
-how to join undawn cbt
-how to join undawn global beta test
-how to join undawn closed beta test
-how to join undawn open beta test
-how to join undawn early access beta test
-how to join undawn pre-download beta test
-how to join undawn survival rpg beta test
-how to join undawn shooter rpg beta test
-how to join undawn post-apocalyptic rpg beta test
-how to join undawn zombie rpg beta test
-how to join undawn pc and mobile beta test
-how to join undawn cross-platform beta test
-how to join undawn lightspeed & quantum studios beta test
-how to join undawn new world order beta test
-how to join undawn raven shelter beta test
-
-- Go to the official website of Undawn and sign up for the beta test by choosing your platform (iOS or Android) and entering a valid email address. You will receive a confirmation email with a link to download the apk file. Alternatively, you can use one of the links from the web search results .
-- Download the apk file to your device. Make sure you have enough storage space and a stable internet connection.
-- Enable the installation of apps from unknown sources on your device. To do this, go to Settings > Security > Unknown Sources and toggle it on.
-- Locate the apk file on your device and tap on it to start the installation process. Follow the instructions on the screen and wait for the installation to finish.
-- Launch the game from your app drawer or home screen and enjoy playing Undawn!
-
- Tips and tricks to optimize your gameplay
-Here are some tips and tricks that can help you improve your gameplay experience and performance in Undawn:
-
-- Adjust the graphics settings according to your device's capabilities. You can choose from low, medium, high, or ultra settings. You can also enable or disable features such as shadows, anti-aliasing, or HDR.
-- Use headphones or earphones to enjoy the immersive sound effects and music of the game. You can also adjust the volume and sound quality in the settings menu.
-- Use the auto-aim feature to help you aim and shoot more accurately. You can also customize the sensitivity, layout, and size of the controls in the settings menu.
-- Use the chat feature to communicate with your teammates or other players. You can use text or voice chat, as well as emojis and stickers. You can also mute or block players who are annoying or abusive.
-- Use the map feature to navigate the open world and find points of interest, such as missions, resources, enemies, or allies. You can also mark locations or enemies for your teammates to see.
-
- What to expect from the Undawn beta test?
-The Undawn beta test is a limited-time event that allows you to play the game before its official release. It is a great opportunity to explore the game's features, mechanics, characters, and challenges. However, it is also important to remember that it is not the final version of the game, and that it may contain bugs, glitches, or errors that can affect your gameplay experience. Here are some things that you can expect from the Undawn beta test:
- The main features and gameplay mechanics
-The Undawn beta test will let you experience some of the main features and gameplay mechanics of the game, such as:
-
-- The open-world exploration, where you can roam freely in different locations and scavenge for resources, weapons, and equipment.
-- The survival aspect, where you need to manage your health, hunger, thirst, stamina, and inventory.
-- The crafting system, where you can create items, weapons, equipment, shelters, and traps using the resources you find.
-- The combat system, where you can use different weapons, skills, and tactics to fight against zombies and other enemies.
-- The multiplayer mode, where you can cooperate or compete with other players online.
-
- The main characters and factions
-The Undawn beta test will also introduce you to some of the main characters and factions of the game's story, such as:
-
-- The survivors, who are ordinary people who have managed to survive the disaster and are trying to rebuild their lives in this new world.
-- The raiders, who are ruthless bandits who prey on other survivors and steal their resources and territory.
-- The infected, who are humans who have been turned into zombies by the virus and are driven by their hunger for flesh.
-- The mutants, who are creatures that have been mutated by the virus or radiation and have developed new abilities and behaviors.
-- The rebels, who are former soldiers who have rebelled against their corrupt government and are fighting for freedom and justice.
-
- The main challenges and rewards
-The Undawn beta test will also challenge you with various tasks and missions that will test your skills and strategy. Some of these challenges are:
-
-- The survival mode, where you need to survive as long as possible in a randomly generated map with limited resources and enemies.
-- The raid mode, where you need to
- The raid mode, where you need to attack or defend a base with your teammates or other players online.
-- The quest mode, where you need to complete various objectives and tasks given by NPCs or factions.
-- The event mode, where you need to participate in special events that occur randomly in the game world.
-
-By completing these challenges, you can earn various rewards, such as:
-
-- Experience points, which can help you level up and unlock new skills and perks.
-- Resources, which can help you craft items, weapons, equipment, shelters, and traps.
-- Weapons and equipment, which can help you improve your combat performance and survival chances.
-- Currency, which can help you buy or sell items, weapons, equipment, or services from NPCs or other players.
-- Reputation, which can help you gain favor or hostility from different factions and characters.
-
- Conclusion
-Undawn is a new survival RPG that will take you to a post-apocalyptic world where you need to fight and survive against zombies and other enemies. You can play this game on your mobile device or your PC, thanks to the cross-platform compatibility. You can also play this game with your friends or other players online, thanks to the multiplayer mode. You can download and install the Undawn beta test apk file to play the game before its official release. However, you need to make sure that your device meets the requirements and compatibility criteria for the game. You also need to be aware that the beta test is not the final version of the game, and that it may contain bugs, glitches, or errors that can affect your gameplay experience. You can expect to enjoy some of the main features and gameplay mechanics of the game, such as the open-world exploration, the survival aspect, the crafting system, the combat system, and the multiplayer mode. You can also expect to meet some of the main characters and factions of the game's story, such as the survivors, the raiders, the infected, the mutants, and the rebels. You can also expect to face some of the main challenges and rewards of the game, such as the survival mode, the raid mode, the quest mode, the event mode, and the experience points, resources, weapons and equipment, currency, and reputation.
- We hope that this article has helped you learn more about Undawn and how to download and install the beta test apk file. If you have any questions or comments about this topic, feel free to leave them below. We would love to hear from you!
- FAQs
-Here are some of the frequently asked questions about Undawn and the beta test apk file:
-
-- When will Undawn be officially released?
-There is no official release date for Undawn yet. However, according to some sources , the game is expected to launch in late 2023 or early 2024.
-- Is Undawn free to play?
-Yes, Undawn is free to play. However, it may contain some in-app purchases or ads that can enhance your gameplay experience or support the developers.
-- Is Undawn safe to download and install?
-Yes, Undawn is safe to download and install. However, you need to make sure that you download and install the apk file from a trusted source or website. You also need to enable the installation of apps from unknown sources on your device. You also need to be careful about any malware or viruses that may infect your device.
-- How can I report bugs or glitches in Undawn?
-If you encounter any bugs or glitches in Undawn during the beta test, you can report them to the developers through their official website or their social media accounts . You can also provide feedback or suggestions on how to improve the game.
-- How can I get more information about Undawn?
-If you want to get more information about Undawn, you can visit their official website or their social media accounts . You can also watch their official trailer or gameplay videos on YouTube. You can also read their official blog or news articles on their website.
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/consciousAI/question_answering/app.py b/spaces/consciousAI/question_answering/app.py
deleted file mode 100644
index 1350e7756928fd5302d62a58b8012b17be9f7aa8..0000000000000000000000000000000000000000
--- a/spaces/consciousAI/question_answering/app.py
+++ /dev/null
@@ -1,115 +0,0 @@
-import gradio as gr
-from transformers import pipeline
-import nltk
-nltk.download('punkt')
-from nltk import sent_tokenize
-import torch
-from transformers import (
- pipeline,
- AutoModelForSeq2SeqLM,
- AutoTokenizer
-)
-
-import re
-
-device = [0 if torch.cuda.is_available() else 'cpu'][0]
-
-def _generate(query, context, model, device):
-
- FT_MODEL = AutoModelForSeq2SeqLM.from_pretrained(model).to(device)
- FT_MODEL_TOKENIZER = AutoTokenizer.from_pretrained(model)
- input_text = "question: " + query + " question_context: " + context
-
- input_tokenized = FT_MODEL_TOKENIZER.encode(input_text, return_tensors='pt', truncation=True, padding='max_length', max_length=1024).to(device)
- _tok_count_assessment = FT_MODEL_TOKENIZER.encode(input_text, return_tensors='pt', truncation=True).to(device)
-
- summary_ids = FT_MODEL.generate(input_tokenized,
- max_length=30,
- min_length=3,
- length_penalty=1.0,
- num_beams=2,
- early_stopping=True,
- )
- output = [FT_MODEL_TOKENIZER.decode(id, clean_up_tokenization_spaces=True, skip_special_tokens=True) for id in summary_ids]
-
- return str(output[0])
-
-def predict(query, context):
-
- context = context.encode("ascii", "ignore")
- context = context.decode()
-
- #Custom1
- cust_model_name = "consciousAI/question-answering-roberta-base-s"
- cust_question_answerer = pipeline('question-answering', model=cust_model_name, tokenizer=cust_model_name, device=device)
-
- cust_output = cust_question_answerer(question=query, context=context)
- cust_answer = cust_output['answer']
- cust_answer_span = "[" + str(cust_output['start']) + "," + str(cust_output['end']) + "]"
- cust_confidence = cust_output['score']
- cust_answer_sentence = [_sent for _sent in sent_tokenize(context) if cust_answer in _sent]
- if len(cust_answer_sentence) > 0:
- cust_answer_sentence = cust_answer_sentence[0]
- else:
- cust_answer_sentence = "Failed matching sentence (answer may be split in multiple sentences)"
-
- #Custom3
- cust_model_name_3 = "consciousAI/question-answering-roberta-base-s-v2"
- cust_question_answerer_3 = pipeline('question-answering', model=cust_model_name_3, tokenizer=cust_model_name_3, device=device)
-
- cust_output_3 = cust_question_answerer_3(question=query, context=context)
- cust_answer_3 = cust_output_3['answer']
- cust_answer_span_3 = "[" + str(cust_output_3['start']) + "," + str(cust_output_3['end']) + "]"
- cust_confidence_3 = cust_output_3['score']
- cust_answer_sentence_3 = [_sent for _sent in sent_tokenize(context) if cust_answer_3 in _sent]
- if len(cust_answer_sentence_3) > 0:
- cust_answer_sentence_3 = cust_answer_sentence_3[0]
- else:
- cust_answer_sentence_3 = "Failed matching sentence (answer may be split in multiple sentences)"
-
- #Custom2
- cust_answer_2 = _generate(query, context, model="consciousAI/question-answering-generative-t5-v1-base-s-q-c", device=device)
- cust_answer_sentence_2 = [_sent for _sent in sent_tokenize(context) if cust_answer_2 in _sent]
- if len(cust_answer_sentence_2) > 0:
- cust_answer_sentence_2 = cust_answer_sentence_2[0]
- else:
- cust_answer_sentence_2 = "Failed matching sentence (answer may be split in multiple sentences)"
- cust_answer_span_2 = re.search(cust_answer_2, contextDefault).span()
-
- return cust_answer, cust_answer_sentence, cust_answer_span, cust_confidence, cust_answer_2, cust_answer_sentence_2, cust_answer_span_2, cust_answer_sentence_3, cust_answer_3, cust_answer_span_3, cust_confidence_3
-
-with gr.Blocks() as demo:
- gr.Markdown(value="# Question Answering Encoders vs Generative\n [Question Answering Leveraging Encoders V1](https://huggingface.co/anshoomehra/question-answering-roberta-base-s)\n\n[Question Answering Leveraging Encoders V2](https://huggingface.co/anshoomehra/question-answering-roberta-base-s-v2)\n\n[Generative Question Answering](https://huggingface.co/anshoomehra/question-answering-generative-t5-v1-base-s-q-c)")
- with gr.Accordion(variant='compact', label='Input Values'):
- with gr.Row(variant='compact'):
- queryDefault = "Which company alongside Amazon, Apple, Meta, and Microsoft is considered part of Big Five?"
- contextDefault = "Google LLC is an American multinational technology company focusing on search engine technology, online advertising, cloud computing, computer software, quantum computing, e-commerce, artificial intelligence, and consumer electronics. It has been referred to as 'the most powerful company in the world' and one of the world's most valuable brands due to its market dominance, data collection, and technological advantages in the area of artificial intelligence. Its parent company Alphabet is considered one of the Big Five American information technology companies, alongside Amazon, Apple, Meta, and Microsoft."
- query = gr.Textbox(queryDefault, label="Query", placeholder="Dummy Query", lines=2)
- context = gr.Textbox(contextDefault, label="Context", placeholder="Dummy Context", lines=5, max_lines = 6)
-
- with gr.Accordion(variant='compact', label='Q&A Model(s) Output'):
- with gr.Row(variant='compact'):
- with gr.Column(variant='compact'):
- _predictionM6 = gr.Textbox(label="question-answering-roberta-base-s: Answer Sentence")
- _predictionM5 = gr.Textbox(label="question-answering-roberta-base-s: Answer")
- _predictionM7 = gr.Textbox(label="question-answering-roberta-base-s: Q&A Answer Span")
- _predictionM8 = gr.Textbox(label="question-answering-roberta-base-s: Answer Confidence")
- with gr.Column(variant='compact'):
- _predictionM12 = gr.Textbox(label="question-answering-roberta-base-s-v2: Answer Sentence")
- _predictionM13 = gr.Textbox(label="question-answering-roberta-base-s-v2: Answer")
- _predictionM14 = gr.Textbox(label="question-answering-roberta-base-s-v2: Q&A Answer Span")
- _predictionM15 = gr.Textbox(label="question-answering-roberta-base-s-v2: Answer Confidence")
- with gr.Column(variant='compact'):
- _predictionM10 = gr.Textbox(label="question-answering-generative-t5-v1-base-s-q-c: Sentence")
- _predictionM9 = gr.Textbox(label="question-answering-generative-t5-v1-base-s-q-c: Answer")
- _predictionM11 = gr.Textbox(label="question-answering-generative-t5-v1-base-s-q-c: Answer Span")
-
-
- with gr.Row():
- gen_btn = gr.Button("Generate Answers")
- gen_btn.click(fn=predict,
- inputs=[query, context],
- outputs=[_predictionM5, _predictionM6, _predictionM7, _predictionM8, _predictionM9, _predictionM10, _predictionM11, _predictionM12, _predictionM13, _predictionM14, _predictionM15]
- )
-
-demo.launch(show_error=True)
\ No newline at end of file
diff --git a/spaces/contluForse/HuggingGPT/assets/Download Stellaris Starter Pack -62 99953776 Free Gaming ...[2].md b/spaces/contluForse/HuggingGPT/assets/Download Stellaris Starter Pack -62 99953776 Free Gaming ...[2].md
deleted file mode 100644
index ea3af42afc1344eba0927b36ac34cbc6d40ef3f1..0000000000000000000000000000000000000000
--- a/spaces/contluForse/HuggingGPT/assets/Download Stellaris Starter Pack -62 99953776 Free Gaming ...[2].md
+++ /dev/null
@@ -1,6 +0,0 @@
-Stellaris: Starter Pack Download Cracked Pc
Download Zip ---> https://ssurll.com/2uzxtD
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/contluForse/HuggingGPT/assets/Easerasystunewithcrack.md b/spaces/contluForse/HuggingGPT/assets/Easerasystunewithcrack.md
deleted file mode 100644
index f5af10cf698a7b2f58f58bdc5e822c8eee669a2a..0000000000000000000000000000000000000000
--- a/spaces/contluForse/HuggingGPT/assets/Easerasystunewithcrack.md
+++ /dev/null
@@ -1,15 +0,0 @@
-
-EASERA SysTune: A Powerful Tool for Live Sound Measurements
-EASERA SysTune is a software application that allows you to perform real-time measurements of sound systems and acoustic environments using any Windows PC and a compatible audio interface. EASERA SysTune is developed by AFMG Technologies GmbH, the creators of the industry standards EASE and EASERA for acoustic simulation and measurement.
-With EASERA SysTune, you can measure and optimize the frequency response, phase alignment, impulse response, reverberation time, speech intelligibility, distortion, and more of any sound system. You can also use EASERA SysTune to analyze the acoustics of a room or venue and identify potential problems or improvements. EASERA SysTune supports various measurement methods, such as dual-channel FFT, MLS, sweeps, TDS, and RTA. You can also use EASERA SysTune to generate test signals, such as pink noise, white noise, sine waves, chirps, and more.
-Easerasystunewithcrack
Download Zip ->>> https://ssurll.com/2uzxzd
-EASERA SysTune is designed for live sound engineers, system integrators, consultants, and manufacturers who need a reliable and accurate tool for measuring and tuning sound systems in any situation. EASERA SysTune can handle complex setups with multiple inputs and outputs, as well as wireless or networked devices. You can also use EASERA SysTune to create reports and documentation of your measurements and results.
-If you want to learn more about EASERA SysTune and how it can help you achieve better sound quality and performance, you can visit the official website of AFMG Technologies GmbH at https://www.afmg.eu/en or download a free trial version of the software from https://www.afmg.eu/sites/default/files/2021-07/EASERA%20SysTune_Installation%20Information.pdf.
-
-EASERA SysTune is not only a powerful measurement tool, but also a versatile audio processor that can be used to enhance the sound quality and performance of any sound system. EASERA SysTune can apply various filters, equalizers, delays, limiters, and other effects to the input or output signals in real time. You can also use EASERA SysTune to perform system alignment and optimization using the built-in features such as FIRmaker, Delay Finder, Auto EQ, and more. EASERA SysTune can also integrate with other software and hardware products from AFMG Technologies GmbH, such as EASE Focus, EASE Evac, EASE SpeakerLab, and GLL Plug-In API.
-
-EASERA SysTune is also a user-friendly and customizable software that can be adapted to your preferences and needs. You can choose from different measurement modes, such as Live IR, Live RTA, Live Spectrogram, Live Transfer Function, and more. You can also adjust the display settings, such as the frequency range, resolution, smoothing, scaling, color scheme, and more. You can also create and save your own presets and templates for different measurement scenarios and projects.
-EASERA SysTune is compatible with Windows 7, 8, and 10 operating systems and requires a minimum of 2 GB of RAM and 1 GB of hard disk space. EASERA SysTune can be purchased online from the AFMG Technologies GmbH website or from authorized dealers and distributors around the world. EASERA SysTune comes with a USB dongle that serves as a license key and allows you to use the software on any computer. You can also register your license online and receive free updates and technical support from AFMG Technologies GmbH.
-EASERA SysTune is the ultimate solution for live sound measurements and audio processing that can help you achieve better sound quality and performance in any situation. Whether you are a professional or a hobbyist, EASERA SysTune can provide you with the tools and features you need to measure and optimize any sound system and acoustic environment. EASERA SysTune is trusted by thousands of users worldwide who rely on its accuracy, reliability, and versatility. If you want to join them and experience the benefits of EASERA SysTune for yourself, you can download a free trial version of the software today and see what it can do for you.
d5da3c52bf
-
-
\ No newline at end of file
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/ops/ball_query.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/ops/ball_query.py
deleted file mode 100644
index d0466847c6e5c1239e359a0397568413ebc1504a..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/ops/ball_query.py
+++ /dev/null
@@ -1,55 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-from torch.autograd import Function
-
-from ..utils import ext_loader
-
-ext_module = ext_loader.load_ext('_ext', ['ball_query_forward'])
-
-
-class BallQuery(Function):
- """Find nearby points in spherical space."""
-
- @staticmethod
- def forward(ctx, min_radius: float, max_radius: float, sample_num: int,
- xyz: torch.Tensor, center_xyz: torch.Tensor) -> torch.Tensor:
- """
- Args:
- min_radius (float): minimum radius of the balls.
- max_radius (float): maximum radius of the balls.
- sample_num (int): maximum number of features in the balls.
- xyz (Tensor): (B, N, 3) xyz coordinates of the features.
- center_xyz (Tensor): (B, npoint, 3) centers of the ball query.
-
- Returns:
- Tensor: (B, npoint, nsample) tensor with the indices of
- the features that form the query balls.
- """
- assert center_xyz.is_contiguous()
- assert xyz.is_contiguous()
- assert min_radius < max_radius
-
- B, N, _ = xyz.size()
- npoint = center_xyz.size(1)
- idx = xyz.new_zeros(B, npoint, sample_num, dtype=torch.int)
-
- ext_module.ball_query_forward(
- center_xyz,
- xyz,
- idx,
- b=B,
- n=N,
- m=npoint,
- min_radius=min_radius,
- max_radius=max_radius,
- nsample=sample_num)
- if torch.__version__ != 'parrots':
- ctx.mark_non_differentiable(idx)
- return idx
-
- @staticmethod
- def backward(ctx, a=None):
- return None, None, None, None
-
-
-ball_query = BallQuery.apply
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/ops/roi_align.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/ops/roi_align.py
deleted file mode 100644
index 0755aefc66e67233ceae0f4b77948301c443e9fb..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/uniformer/mmcv/ops/roi_align.py
+++ /dev/null
@@ -1,223 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-import torch.nn as nn
-from torch.autograd import Function
-from torch.autograd.function import once_differentiable
-from torch.nn.modules.utils import _pair
-
-from ..utils import deprecated_api_warning, ext_loader
-
-ext_module = ext_loader.load_ext('_ext',
- ['roi_align_forward', 'roi_align_backward'])
-
-
-class RoIAlignFunction(Function):
-
- @staticmethod
- def symbolic(g, input, rois, output_size, spatial_scale, sampling_ratio,
- pool_mode, aligned):
- from ..onnx import is_custom_op_loaded
- has_custom_op = is_custom_op_loaded()
- if has_custom_op:
- return g.op(
- 'mmcv::MMCVRoiAlign',
- input,
- rois,
- output_height_i=output_size[0],
- output_width_i=output_size[1],
- spatial_scale_f=spatial_scale,
- sampling_ratio_i=sampling_ratio,
- mode_s=pool_mode,
- aligned_i=aligned)
- else:
- from torch.onnx.symbolic_opset9 import sub, squeeze
- from torch.onnx.symbolic_helper import _slice_helper
- from torch.onnx import TensorProtoDataType
- # batch_indices = rois[:, 0].long()
- batch_indices = _slice_helper(
- g, rois, axes=[1], starts=[0], ends=[1])
- batch_indices = squeeze(g, batch_indices, 1)
- batch_indices = g.op(
- 'Cast', batch_indices, to_i=TensorProtoDataType.INT64)
- # rois = rois[:, 1:]
- rois = _slice_helper(g, rois, axes=[1], starts=[1], ends=[5])
- if aligned:
- # rois -= 0.5/spatial_scale
- aligned_offset = g.op(
- 'Constant',
- value_t=torch.tensor([0.5 / spatial_scale],
- dtype=torch.float32))
- rois = sub(g, rois, aligned_offset)
- # roi align
- return g.op(
- 'RoiAlign',
- input,
- rois,
- batch_indices,
- output_height_i=output_size[0],
- output_width_i=output_size[1],
- spatial_scale_f=spatial_scale,
- sampling_ratio_i=max(0, sampling_ratio),
- mode_s=pool_mode)
-
- @staticmethod
- def forward(ctx,
- input,
- rois,
- output_size,
- spatial_scale=1.0,
- sampling_ratio=0,
- pool_mode='avg',
- aligned=True):
- ctx.output_size = _pair(output_size)
- ctx.spatial_scale = spatial_scale
- ctx.sampling_ratio = sampling_ratio
- assert pool_mode in ('max', 'avg')
- ctx.pool_mode = 0 if pool_mode == 'max' else 1
- ctx.aligned = aligned
- ctx.input_shape = input.size()
-
- assert rois.size(1) == 5, 'RoI must be (idx, x1, y1, x2, y2)!'
-
- output_shape = (rois.size(0), input.size(1), ctx.output_size[0],
- ctx.output_size[1])
- output = input.new_zeros(output_shape)
- if ctx.pool_mode == 0:
- argmax_y = input.new_zeros(output_shape)
- argmax_x = input.new_zeros(output_shape)
- else:
- argmax_y = input.new_zeros(0)
- argmax_x = input.new_zeros(0)
-
- ext_module.roi_align_forward(
- input,
- rois,
- output,
- argmax_y,
- argmax_x,
- aligned_height=ctx.output_size[0],
- aligned_width=ctx.output_size[1],
- spatial_scale=ctx.spatial_scale,
- sampling_ratio=ctx.sampling_ratio,
- pool_mode=ctx.pool_mode,
- aligned=ctx.aligned)
-
- ctx.save_for_backward(rois, argmax_y, argmax_x)
- return output
-
- @staticmethod
- @once_differentiable
- def backward(ctx, grad_output):
- rois, argmax_y, argmax_x = ctx.saved_tensors
- grad_input = grad_output.new_zeros(ctx.input_shape)
- # complex head architecture may cause grad_output uncontiguous.
- grad_output = grad_output.contiguous()
- ext_module.roi_align_backward(
- grad_output,
- rois,
- argmax_y,
- argmax_x,
- grad_input,
- aligned_height=ctx.output_size[0],
- aligned_width=ctx.output_size[1],
- spatial_scale=ctx.spatial_scale,
- sampling_ratio=ctx.sampling_ratio,
- pool_mode=ctx.pool_mode,
- aligned=ctx.aligned)
- return grad_input, None, None, None, None, None, None
-
-
-roi_align = RoIAlignFunction.apply
-
-
-class RoIAlign(nn.Module):
- """RoI align pooling layer.
-
- Args:
- output_size (tuple): h, w
- spatial_scale (float): scale the input boxes by this number
- sampling_ratio (int): number of inputs samples to take for each
- output sample. 0 to take samples densely for current models.
- pool_mode (str, 'avg' or 'max'): pooling mode in each bin.
- aligned (bool): if False, use the legacy implementation in
- MMDetection. If True, align the results more perfectly.
- use_torchvision (bool): whether to use roi_align from torchvision.
-
- Note:
- The implementation of RoIAlign when aligned=True is modified from
- https://github.com/facebookresearch/detectron2/
-
- The meaning of aligned=True:
-
- Given a continuous coordinate c, its two neighboring pixel
- indices (in our pixel model) are computed by floor(c - 0.5) and
- ceil(c - 0.5). For example, c=1.3 has pixel neighbors with discrete
- indices [0] and [1] (which are sampled from the underlying signal
- at continuous coordinates 0.5 and 1.5). But the original roi_align
- (aligned=False) does not subtract the 0.5 when computing
- neighboring pixel indices and therefore it uses pixels with a
- slightly incorrect alignment (relative to our pixel model) when
- performing bilinear interpolation.
-
- With `aligned=True`,
- we first appropriately scale the ROI and then shift it by -0.5
- prior to calling roi_align. This produces the correct neighbors;
-
- The difference does not make a difference to the model's
- performance if ROIAlign is used together with conv layers.
- """
-
- @deprecated_api_warning(
- {
- 'out_size': 'output_size',
- 'sample_num': 'sampling_ratio'
- },
- cls_name='RoIAlign')
- def __init__(self,
- output_size,
- spatial_scale=1.0,
- sampling_ratio=0,
- pool_mode='avg',
- aligned=True,
- use_torchvision=False):
- super(RoIAlign, self).__init__()
-
- self.output_size = _pair(output_size)
- self.spatial_scale = float(spatial_scale)
- self.sampling_ratio = int(sampling_ratio)
- self.pool_mode = pool_mode
- self.aligned = aligned
- self.use_torchvision = use_torchvision
-
- def forward(self, input, rois):
- """
- Args:
- input: NCHW images
- rois: Bx5 boxes. First column is the index into N.\
- The other 4 columns are xyxy.
- """
- if self.use_torchvision:
- from torchvision.ops import roi_align as tv_roi_align
- if 'aligned' in tv_roi_align.__code__.co_varnames:
- return tv_roi_align(input, rois, self.output_size,
- self.spatial_scale, self.sampling_ratio,
- self.aligned)
- else:
- if self.aligned:
- rois -= rois.new_tensor([0.] +
- [0.5 / self.spatial_scale] * 4)
- return tv_roi_align(input, rois, self.output_size,
- self.spatial_scale, self.sampling_ratio)
- else:
- return roi_align(input, rois, self.output_size, self.spatial_scale,
- self.sampling_ratio, self.pool_mode, self.aligned)
-
- def __repr__(self):
- s = self.__class__.__name__
- s += f'(output_size={self.output_size}, '
- s += f'spatial_scale={self.spatial_scale}, '
- s += f'sampling_ratio={self.sampling_ratio}, '
- s += f'pool_mode={self.pool_mode}, '
- s += f'aligned={self.aligned}, '
- s += f'use_torchvision={self.use_torchvision})'
- return s
diff --git a/spaces/cvlab/zero123-live/ldm/data/base.py b/spaces/cvlab/zero123-live/ldm/data/base.py
deleted file mode 100644
index 742794e631081bbfa7c44f3df6f83373ca5c15c1..0000000000000000000000000000000000000000
--- a/spaces/cvlab/zero123-live/ldm/data/base.py
+++ /dev/null
@@ -1,40 +0,0 @@
-import os
-import numpy as np
-from abc import abstractmethod
-from torch.utils.data import Dataset, ConcatDataset, ChainDataset, IterableDataset
-
-
-class Txt2ImgIterableBaseDataset(IterableDataset):
- '''
- Define an interface to make the IterableDatasets for text2img data chainable
- '''
- def __init__(self, num_records=0, valid_ids=None, size=256):
- super().__init__()
- self.num_records = num_records
- self.valid_ids = valid_ids
- self.sample_ids = valid_ids
- self.size = size
-
- print(f'{self.__class__.__name__} dataset contains {self.__len__()} examples.')
-
- def __len__(self):
- return self.num_records
-
- @abstractmethod
- def __iter__(self):
- pass
-
-
-class PRNGMixin(object):
- """
- Adds a prng property which is a numpy RandomState which gets
- reinitialized whenever the pid changes to avoid synchronized sampling
- behavior when used in conjunction with multiprocessing.
- """
- @property
- def prng(self):
- currentpid = os.getpid()
- if getattr(self, "_initpid", None) != currentpid:
- self._initpid = currentpid
- self._prng = np.random.RandomState()
- return self._prng
diff --git a/spaces/cvlab/zero123-live/taming-transformers/taming/modules/util.py b/spaces/cvlab/zero123-live/taming-transformers/taming/modules/util.py
deleted file mode 100644
index 9ee16385d8b1342a2d60a5f1aa5cadcfbe934bd8..0000000000000000000000000000000000000000
--- a/spaces/cvlab/zero123-live/taming-transformers/taming/modules/util.py
+++ /dev/null
@@ -1,130 +0,0 @@
-import torch
-import torch.nn as nn
-
-
-def count_params(model):
- total_params = sum(p.numel() for p in model.parameters())
- return total_params
-
-
-class ActNorm(nn.Module):
- def __init__(self, num_features, logdet=False, affine=True,
- allow_reverse_init=False):
- assert affine
- super().__init__()
- self.logdet = logdet
- self.loc = nn.Parameter(torch.zeros(1, num_features, 1, 1))
- self.scale = nn.Parameter(torch.ones(1, num_features, 1, 1))
- self.allow_reverse_init = allow_reverse_init
-
- self.register_buffer('initialized', torch.tensor(0, dtype=torch.uint8))
-
- def initialize(self, input):
- with torch.no_grad():
- flatten = input.permute(1, 0, 2, 3).contiguous().view(input.shape[1], -1)
- mean = (
- flatten.mean(1)
- .unsqueeze(1)
- .unsqueeze(2)
- .unsqueeze(3)
- .permute(1, 0, 2, 3)
- )
- std = (
- flatten.std(1)
- .unsqueeze(1)
- .unsqueeze(2)
- .unsqueeze(3)
- .permute(1, 0, 2, 3)
- )
-
- self.loc.data.copy_(-mean)
- self.scale.data.copy_(1 / (std + 1e-6))
-
- def forward(self, input, reverse=False):
- if reverse:
- return self.reverse(input)
- if len(input.shape) == 2:
- input = input[:,:,None,None]
- squeeze = True
- else:
- squeeze = False
-
- _, _, height, width = input.shape
-
- if self.training and self.initialized.item() == 0:
- self.initialize(input)
- self.initialized.fill_(1)
-
- h = self.scale * (input + self.loc)
-
- if squeeze:
- h = h.squeeze(-1).squeeze(-1)
-
- if self.logdet:
- log_abs = torch.log(torch.abs(self.scale))
- logdet = height*width*torch.sum(log_abs)
- logdet = logdet * torch.ones(input.shape[0]).to(input)
- return h, logdet
-
- return h
-
- def reverse(self, output):
- if self.training and self.initialized.item() == 0:
- if not self.allow_reverse_init:
- raise RuntimeError(
- "Initializing ActNorm in reverse direction is "
- "disabled by default. Use allow_reverse_init=True to enable."
- )
- else:
- self.initialize(output)
- self.initialized.fill_(1)
-
- if len(output.shape) == 2:
- output = output[:,:,None,None]
- squeeze = True
- else:
- squeeze = False
-
- h = output / self.scale - self.loc
-
- if squeeze:
- h = h.squeeze(-1).squeeze(-1)
- return h
-
-
-class AbstractEncoder(nn.Module):
- def __init__(self):
- super().__init__()
-
- def encode(self, *args, **kwargs):
- raise NotImplementedError
-
-
-class Labelator(AbstractEncoder):
- """Net2Net Interface for Class-Conditional Model"""
- def __init__(self, n_classes, quantize_interface=True):
- super().__init__()
- self.n_classes = n_classes
- self.quantize_interface = quantize_interface
-
- def encode(self, c):
- c = c[:,None]
- if self.quantize_interface:
- return c, None, [None, None, c.long()]
- return c
-
-
-class SOSProvider(AbstractEncoder):
- # for unconditional training
- def __init__(self, sos_token, quantize_interface=True):
- super().__init__()
- self.sos_token = sos_token
- self.quantize_interface = quantize_interface
-
- def encode(self, x):
- # get batch size from data and replicate sos_token
- c = torch.ones(x.shape[0], 1)*self.sos_token
- c = c.long().to(x.device)
- if self.quantize_interface:
- return c, None, [None, None, c]
- return c
diff --git a/spaces/daphshen/corgi-classifier/app.py b/spaces/daphshen/corgi-classifier/app.py
deleted file mode 100644
index 4951dd5d4cc5536da32d961cfa0db9e531de855d..0000000000000000000000000000000000000000
--- a/spaces/daphshen/corgi-classifier/app.py
+++ /dev/null
@@ -1,41 +0,0 @@
-from fastai.vision.all import *
-import gradio as gr
-
-learn = load_learner('model.pkl')
-
-categories = {'cardigan', 'pembroke'}
-
-def classify_image(img):
- pred, idx, probs = learn.predict(img)
- return dict(zip(categories, map(float, probs)))
-
-title = "Corgi Classifier"
-description = """
-This was an experiment to create a corgi classifier between Pembroke Welsh Corgis vs. Cardigan Corgis. I wanted to see if I could create a ML model to tell these two breeds apart as these breeds are quite similar.
-
-Spoiler alert: it isn't very good! I'm not too surprised, as there are a few reasons why these breeds differ, and it's not always distinguishable via just a photo.
-
-
- - Cardigans have more coat patterns that can be obvious (e.g. brindle, blue merle), but they also share common coats (e.g. red, sable), which causes them to look very similar.
- - Cardigans are often stockier and heavier (which can be hard to tell via a photo).
- - Pembrokes (especially US-standard AKC) have docked tails, cardigans do not. However, this dataset has tailed-pembrokes.
- - Personality! Pembrokes can be louder, more vocal, and also have less energy (generally speaking).
-
-
-Regardless, this was still a fun project to create! If you come across this and have any comments, I'd love to hear from you: @daphshen
-
-Resources:
-
-
- - For the whole notebook which also includes the model training, refer here.
- - I used a subset of the Stanford Dogs Dataset, which is available here.
- - This whole project is part of my own experimentation, following Lesson 2 of the FastAI ML course.
-
"""
-article="@daphshen
"
-
-
-image = gr.inputs.Image(shape=(192, 192))
-label = gr.outputs.Label()
-examples = ['examples/cardigan_example_1.jpg', 'examples/cardigan_example_2.jpg', 'examples/pembroke_example_1.jpg', 'examples/pembroke_example_2.jpg','examples/bread.jpeg']
-intf = gr.Interface(fn=classify_image, inputs=image, outputs=label, examples=examples, title=title,description=description,article=article)
-intf.launch(inline=False)
\ No newline at end of file
diff --git a/spaces/darkstorm2150/Stable-Diffusion-Protogen-x3.4-webui/Dockerfile b/spaces/darkstorm2150/Stable-Diffusion-Protogen-x3.4-webui/Dockerfile
deleted file mode 100644
index c70be625283bd17208b8f6d5abd503a1b8cd1b9d..0000000000000000000000000000000000000000
--- a/spaces/darkstorm2150/Stable-Diffusion-Protogen-x3.4-webui/Dockerfile
+++ /dev/null
@@ -1,54 +0,0 @@
-# Dockerfile Public T4
-
-# https://gitlab.com/nvidia/container-images/cuda/-/blob/master/dist/11.7.1/ubuntu2204/devel/cudnn8/Dockerfile
-# FROM nvidia/cuda:11.7.1-cudnn8-devel-ubuntu22.04
-# https://gitlab.com/nvidia/container-images/cuda/-/blob/master/dist/11.7.1/ubuntu2204/base/Dockerfile
-FROM nvidia/cuda:11.7.1-base-ubuntu22.04
-ENV DEBIAN_FRONTEND noninteractive
-
-RUN apt-get update -y && apt-get upgrade -y && apt-get install -y libgl1 libglib2.0-0 wget git git-lfs python3-pip python-is-python3 && rm -rf /var/lib/apt/lists/*
-
-RUN adduser --disabled-password --gecos '' user
-RUN mkdir /content && chown -R user:user /content
-WORKDIR /content
-USER user
-
-RUN pip3 install --upgrade pip
-RUN pip install torchmetrics==0.11.4
-RUN pip install https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.16/xformers-0.0.16+814314d.d20230118-cp310-cp310-linux_x86_64.whl
-RUN pip install --pre triton
-RUN pip install numexpr
-
-
-RUN git clone -b v1.6 https://github.com/camenduru/stable-diffusion-webui
-RUN sed -i '$a fastapi==0.90.0' /content/stable-diffusion-webui/requirements_versions.txt
-RUN sed -i -e '''/prepare_environment()/a\ os.system\(f\"""sed -i -e ''\"s/dict()))/dict())).cuda()/g\"'' /content/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/util.py""")''' /content/stable-diffusion-webui/launch.py
-RUN sed -i -e 's/ start()/ #start()/g' /content/stable-diffusion-webui/launch.py
-RUN cd stable-diffusion-webui && python launch.py --skip-torch-cuda-test
-
-ADD --chown=user https://github.com/camenduru/webui-docker/raw/main/env_patch.py /content/env_patch.py
-RUN sed -i -e '/import image_from_url_text/r /content/env_patch.py' /content/stable-diffusion-webui/modules/ui.py
-ADD --chown=user https://raw.githubusercontent.com/darkstorm2150/webui/main/header_patch.py /content/header_patch.py
-RUN sed -i -e '/demo:/r /content/header_patch.py' /content/stable-diffusion-webui/modules/ui.py
-
-RUN sed -i -e '/(modelmerger_interface, \"Checkpoint Merger\", \"modelmerger\"),/d' /content/stable-diffusion-webui/modules/ui.py
-RUN sed -i -e '/(train_interface, \"Train\", \"ti\"),/d' /content/stable-diffusion-webui/modules/ui.py
-RUN sed -i -e '/extensions_interface, \"Extensions\", \"extensions\"/d' /content/stable-diffusion-webui/modules/ui.py
-RUN sed -i -e '/settings_interface, \"Settings\", \"settings\"/d' /content/stable-diffusion-webui/modules/ui.py
-RUN sed -i -e "s/document.getElementsByTagName('gradio-app')\[0\].shadowRoot/!!document.getElementsByTagName('gradio-app')[0].shadowRoot ? document.getElementsByTagName('gradio-app')[0].shadowRoot : document/g" /content/stable-diffusion-webui/script.js
-RUN sed -i -e 's/ show_progress=False,/ show_progress=True,/g' /content/stable-diffusion-webui/modules/ui.py
-RUN sed -i -e 's/default_enabled=False/default_enabled=True/g' /content/stable-diffusion-webui/webui.py
-RUN sed -i -e 's/ outputs=\[/queue=False, &/g' /content/stable-diffusion-webui/modules/ui.py
-RUN sed -i -e 's/ queue=False, / /g' /content/stable-diffusion-webui/modules/ui.py
-
-RUN rm -rfv /content/stable-diffusion-webui/scripts/
-
-ADD --chown=user https://github.com/camenduru/webui-docker/raw/main/shared-config.json /content/shared-config.json
-ADD --chown=user https://github.com/camenduru/webui-docker/raw/main/shared-ui-config.json /content/shared-ui-config.json
-
-ADD --chown=user https://huggingface.co/darkstorm2150/Protogen_x3.4_Official_Release/resolve/main/ProtoGen_X3.4.safetensors /content/stable-diffusion-webui/models/Stable-diffusion/ProtoGen_X3.4.safetensors
-
-
-EXPOSE 7860
-
-CMD cd /content/stable-diffusion-webui && python webui.py --xformers --listen --disable-console-progressbars --enable-console-prompts --no-progressbar-hiding --ui-config-file /content/shared-ui-config.json --ui-settings-file /content/shared-config.json
diff --git a/spaces/davila7/llm-vs-llm/README.md b/spaces/davila7/llm-vs-llm/README.md
deleted file mode 100644
index ab524f08acdb740031a7a792f6c8e35c3a8be6e9..0000000000000000000000000000000000000000
--- a/spaces/davila7/llm-vs-llm/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Llm Vs Llm
-emoji: 🏃
-colorFrom: yellow
-colorTo: red
-sdk: gradio
-sdk_version: 3.20.1
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/fsspec/generic.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/fsspec/generic.py
deleted file mode 100644
index 18e27405a31f78bceda9aec5b78aeb8f68f33036..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/fsspec/generic.py
+++ /dev/null
@@ -1,302 +0,0 @@
-import inspect
-import logging
-
-from .asyn import AsyncFileSystem
-from .callbacks import _DEFAULT_CALLBACK
-from .core import filesystem, get_filesystem_class, split_protocol
-
-_generic_fs = {}
-logger = logging.getLogger("fsspec.generic")
-
-
-def set_generic_fs(protocol, **storage_options):
- _generic_fs[protocol] = filesystem(protocol, **storage_options)
-
-
-default_method = "default"
-
-
-def _resolve_fs(url, method=None, protocol=None, storage_options=None):
- """Pick instance of backend FS"""
- method = method or default_method
- protocol = protocol or split_protocol(url)[0]
- storage_options = storage_options or {}
- if method == "default":
- return filesystem(protocol)
- if method == "generic":
- return _generic_fs[protocol]
- if method == "current":
- cls = get_filesystem_class(protocol)
- return cls.current()
- if method == "options":
- return filesystem(protocol, **storage_options.get(protocol, {}))
- raise ValueError(f"Unknown FS resolution method: {method}")
-
-
-def rsync(
- source,
- destination,
- delete_missing=False,
- source_field="size",
- dest_field="size",
- update_cond="different",
- inst_kwargs=None,
- fs=None,
- **kwargs,
-):
- """Sync files between two directory trees
-
- (experimental)
-
- Parameters
- ----------
- source: str
- Root of the directory tree to take files from.
- destination: str
- Root path to copy into. The contents of this location should be
- identical to the contents of ``source`` when done.
- delete_missing: bool
- If there are paths in the destination that don't exist in the
- source and this is True, delete them. Otherwise, leave them alone.
- source_field: str
- If ``update_field`` is "different", this is the key in the info
- of source files to consider for difference.
- dest_field: str
- If ``update_field`` is "different", this is the key in the info
- of destination files to consider for difference.
- update_cond: "different"|"always"|"never"
- If "always", every file is copied, regardless of whether it exists in
- the destination. If "never", files that exist in the destination are
- not copied again. If "different" (default), only copy if the info
- fields given by ``source_field`` and ``dest_field`` (usually "size")
- are different. Other comparisons may be added in the future.
- inst_kwargs: dict|None
- If ``fs`` is None, use this set of keyword arguments to make a
- GenericFileSystem instance
- fs: GenericFileSystem|None
- Instance to use if explicitly given. The instance defines how to
- to make downstream file system instances from paths.
- """
- fs = fs or GenericFileSystem(**(inst_kwargs or {}))
- source = fs._strip_protocol(source)
- destination = fs._strip_protocol(destination)
- allfiles = fs.find(source, withdirs=True, detail=True)
- if not fs.isdir(source):
- raise ValueError("Can only rsync on a directory")
- otherfiles = fs.find(destination, withdirs=True, detail=True)
- dirs = [
- a
- for a, v in allfiles.items()
- if v["type"] == "directory" and a.replace(source, destination) not in otherfiles
- ]
- logger.debug(f"{len(dirs)} directories to create")
- for dirn in dirs:
- # no async
- fs.mkdirs(dirn.replace(source, destination), exist_ok=True)
- allfiles = {a: v for a, v in allfiles.items() if v["type"] == "file"}
- logger.debug(f"{len(allfiles)} files to consider for copy")
- to_delete = [
- o
- for o, v in otherfiles.items()
- if o.replace(destination, source) not in allfiles and v["type"] == "file"
- ]
- for k, v in allfiles.copy().items():
- otherfile = k.replace(source, destination)
- if otherfile in otherfiles:
- if update_cond == "always":
- allfiles[k] = otherfile
- elif update_cond == "different":
- if v[source_field] != otherfiles[otherfile][dest_field]:
- # details mismatch, make copy
- allfiles[k] = otherfile
- else:
- # details match, don't copy
- allfiles.pop(k)
- else:
- # file not in target yet
- allfiles[k] = otherfile
- if allfiles:
- source_files, target_files = zip(*allfiles.items())
- logger.debug(f"{len(source_files)} files to copy")
- fs.cp(source_files, target_files, **kwargs)
- if delete_missing:
- logger.debug(f"{len(to_delete)} files to delete")
- fs.rm(to_delete)
-
-
-class GenericFileSystem(AsyncFileSystem):
- """Wrapper over all other FS types
-
-
-
- This implementation is a single unified interface to be able to run FS operations
- over generic URLs, and dispatch to the specific implementations using the URL
- protocol prefix.
-
- Note: instances of this FS are always async, even if you never use it with any async
- backend.
- """
-
- protocol = "generic" # there is no real reason to ever use a protocol with this FS
-
- def __init__(self, default_method="default", **kwargs):
- """
-
- Parameters
- ----------
- default_method: str (optional)
- Defines how to configure backend FS instances. Options are:
- - "default": instantiate like FSClass(), with no
- extra arguments; this is the default instance of that FS, and can be
- configured via the config system
- - "generic": takes instances from the `_generic_fs` dict in this module,
- which you must populate before use. Keys are by protocol
- - "current": takes the most recently instantiated version of each FS
- """
- self.method = default_method
- super(GenericFileSystem, self).__init__(**kwargs)
-
- def _strip_protocol(self, path):
- # normalization only
- fs = _resolve_fs(path, self.method)
- return fs.unstrip_protocol(fs._strip_protocol(path))
-
- async def _find(self, path, maxdepth=None, withdirs=False, detail=False, **kwargs):
- fs = _resolve_fs(path, self.method)
- if fs.async_impl:
- out = await fs._find(
- path, maxdepth=maxdepth, withdirs=withdirs, detail=detail, **kwargs
- )
- else:
- out = fs.find(
- path, maxdepth=maxdepth, withdirs=withdirs, detail=detail, **kwargs
- )
- result = {}
- for k, v in out.items():
- name = fs.unstrip_protocol(k)
- v["name"] = name
- result[name] = v
- if detail:
- return result
- return list(result)
-
- async def _info(self, url, **kwargs):
- fs = _resolve_fs(url, self.method)
- if fs.async_impl:
- out = await fs._info(url, **kwargs)
- else:
- out = fs.info(url, **kwargs)
- out["name"] = fs.unstrip_protocol(out["name"])
- return out
-
- async def _ls(
- self,
- url,
- detail=True,
- **kwargs,
- ):
- fs = _resolve_fs(url, self.method)
- if fs.async_impl:
- out = await fs._ls(url, detail=True, **kwargs)
- else:
- out = fs.ls(url, detail=True, **kwargs)
- for o in out:
- o["name"] = fs.unstrip_protocol(o["name"])
- if detail:
- return out
- else:
- return [o["name"] for o in out]
-
- async def _cat_file(
- self,
- url,
- **kwargs,
- ):
- fs = _resolve_fs(url, self.method)
- if fs.async_impl:
- return await fs._cat_file(url, **kwargs)
- else:
- return fs.cat_file(url, **kwargs)
-
- async def _pipe_file(
- self,
- path,
- value,
- **kwargs,
- ):
- fs = _resolve_fs(path, self.method)
- if fs.async_impl:
- return await fs._pipe_file(path, value, **kwargs)
- else:
- return fs.pipe_file(path, value, **kwargs)
-
- async def _rm(self, url, **kwargs):
- fs = _resolve_fs(url, self.method)
- if fs.async_impl:
- await fs._rm(url, **kwargs)
- else:
- fs.rm(url, **kwargs)
-
- async def _makedirs(self, path, exist_ok=False):
- fs = _resolve_fs(path, self.method)
- if fs.async_impl:
- await fs._makedirs(path, exist_ok=exist_ok)
- else:
- fs.makedirs(path, exist_ok=exist_ok)
-
- def rsync(self, source, destination, **kwargs):
- """Sync files between two directory trees
-
- See `func:rsync` for more details.
- """
- rsync(source, destination, fs=self, **kwargs)
-
- async def _cp_file(
- self,
- url,
- url2,
- blocksize=2**20,
- callback=_DEFAULT_CALLBACK,
- **kwargs,
- ):
- fs = _resolve_fs(url, self.method)
- fs2 = _resolve_fs(url2, self.method)
- if fs is fs2:
- # pure remote
- if fs.async_impl:
- return await fs._cp_file(url, url2, **kwargs)
- else:
- return fs.cp_file(url, url2, **kwargs)
- kw = {"blocksize": 0, "cache_type": "none"}
- try:
- f1 = (
- await fs.open_async(url, "rb")
- if hasattr(fs, "open_async")
- else fs.open(url, "rb", **kw)
- )
- callback.set_size(await maybe_await(f1.size))
- f2 = (
- await fs2.open_async(url2, "wb")
- if hasattr(fs2, "open_async")
- else fs2.open(url2, "wb", **kw)
- )
- while f1.size is None or f2.tell() < f1.size:
- data = await maybe_await(f1.read(blocksize))
- if f1.size is None and not data:
- break
- await maybe_await(f2.write(data))
- callback.absolute_update(f2.tell())
- finally:
- try:
- await maybe_await(f2.close())
- await maybe_await(f1.close())
- except NameError:
- # fail while opening f1 or f2
- pass
-
-
-async def maybe_await(cor):
- if inspect.iscoroutine(cor):
- return await cor
- else:
- return cor
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/Image-003ee87c.css b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/Image-003ee87c.css
deleted file mode 100644
index 60f45635043d082881d8d8a529c1142ee028a68b..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/Image-003ee87c.css
+++ /dev/null
@@ -1 +0,0 @@
-img.svelte-gqt00k{border-radius:var(--radius-lg);max-width:none}img.selected.svelte-gqt00k{border-color:var(--border-color-accent)}.table.svelte-gqt00k{margin:0 auto;border:2px solid var(--border-color-primary);border-radius:var(--radius-lg);width:var(--size-20);height:var(--size-20);object-fit:cover}.gallery.svelte-gqt00k{border:2px solid var(--border-color-primary);max-height:var(--size-20);object-fit:cover}
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/yaml-95012b83.js b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/yaml-95012b83.js
deleted file mode 100644
index 3fef68bd6d3b922eebf9622184021189fa7e8cc2..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/gradio/templates/frontend/assets/yaml-95012b83.js
+++ /dev/null
@@ -1,2 +0,0 @@
-var l=["true","false","on","off","yes","no"],f=new RegExp("\\b(("+l.join(")|(")+"))$","i");const a={name:"yaml",token:function(n,i){var r=n.peek(),e=i.escaped;if(i.escaped=!1,r=="#"&&(n.pos==0||/\s/.test(n.string.charAt(n.pos-1))))return n.skipToEnd(),"comment";if(n.match(/^('([^']|\\.)*'?|"([^"]|\\.)*"?)/))return"string";if(i.literal&&n.indentation()>i.keyCol)return n.skipToEnd(),"string";if(i.literal&&(i.literal=!1),n.sol()){if(i.keyCol=0,i.pair=!1,i.pairStart=!1,n.match("---")||n.match("..."))return"def";if(n.match(/^\s*-\s+/))return"meta"}if(n.match(/^(\{|\}|\[|\])/))return r=="{"?i.inlinePairs++:r=="}"?i.inlinePairs--:r=="["?i.inlineList++:i.inlineList--,"meta";if(i.inlineList>0&&!e&&r==",")return n.next(),"meta";if(i.inlinePairs>0&&!e&&r==",")return i.keyCol=0,i.pair=!1,i.pairStart=!1,n.next(),"meta";if(i.pairStart){if(n.match(/^\s*(\||\>)\s*/))return i.literal=!0,"meta";if(n.match(/^\s*(\&|\*)[a-z0-9\._-]+\b/i))return"variable";if(i.inlinePairs==0&&n.match(/^\s*-?[0-9\.\,]+\s?$/)||i.inlinePairs>0&&n.match(/^\s*-?[0-9\.\,]+\s?(?=(,|}))/))return"number";if(n.match(f))return"keyword"}return!i.pair&&n.match(/^\s*(?:[,\[\]{}&*!|>'"%@`][^\s'":]|[^,\[\]{}#&*!|>'"%@`])[^#]*?(?=\s*:($|\s))/)?(i.pair=!0,i.keyCol=n.indentation(),"atom"):i.pair&&n.match(/^:\s*/)?(i.pairStart=!0,"meta"):(i.pairStart=!1,i.escaped=r=="\\",n.next(),null)},startState:function(){return{pair:!1,pairStart:!1,keyCol:0,inlinePairs:0,inlineList:0,literal:!1,escaped:!1}},languageData:{commentTokens:{line:"#"}}};export{a as yaml};
-//# sourceMappingURL=yaml-95012b83.js.map
diff --git a/spaces/declare-lab/tango/diffusers/src/diffusers/schedulers/scheduling_sde_vp.py b/spaces/declare-lab/tango/diffusers/src/diffusers/schedulers/scheduling_sde_vp.py
deleted file mode 100644
index 6e2ead90edb57cd1eb1d270695e222d404064180..0000000000000000000000000000000000000000
--- a/spaces/declare-lab/tango/diffusers/src/diffusers/schedulers/scheduling_sde_vp.py
+++ /dev/null
@@ -1,90 +0,0 @@
-# Copyright 2023 Google Brain and The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-# DISCLAIMER: This file is strongly influenced by https://github.com/yang-song/score_sde_pytorch
-
-import math
-from typing import Union
-
-import torch
-
-from ..configuration_utils import ConfigMixin, register_to_config
-from ..utils import randn_tensor
-from .scheduling_utils import SchedulerMixin
-
-
-class ScoreSdeVpScheduler(SchedulerMixin, ConfigMixin):
- """
- The variance preserving stochastic differential equation (SDE) scheduler.
-
- [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
- function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
- [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
- [`~SchedulerMixin.from_pretrained`] functions.
-
- For more information, see the original paper: https://arxiv.org/abs/2011.13456
-
- UNDER CONSTRUCTION
-
- """
-
- order = 1
-
- @register_to_config
- def __init__(self, num_train_timesteps=2000, beta_min=0.1, beta_max=20, sampling_eps=1e-3):
- self.sigmas = None
- self.discrete_sigmas = None
- self.timesteps = None
-
- def set_timesteps(self, num_inference_steps, device: Union[str, torch.device] = None):
- self.timesteps = torch.linspace(1, self.config.sampling_eps, num_inference_steps, device=device)
-
- def step_pred(self, score, x, t, generator=None):
- if self.timesteps is None:
- raise ValueError(
- "`self.timesteps` is not set, you need to run 'set_timesteps' after creating the scheduler"
- )
-
- # TODO(Patrick) better comments + non-PyTorch
- # postprocess model score
- log_mean_coeff = (
- -0.25 * t**2 * (self.config.beta_max - self.config.beta_min) - 0.5 * t * self.config.beta_min
- )
- std = torch.sqrt(1.0 - torch.exp(2.0 * log_mean_coeff))
- std = std.flatten()
- while len(std.shape) < len(score.shape):
- std = std.unsqueeze(-1)
- score = -score / std
-
- # compute
- dt = -1.0 / len(self.timesteps)
-
- beta_t = self.config.beta_min + t * (self.config.beta_max - self.config.beta_min)
- beta_t = beta_t.flatten()
- while len(beta_t.shape) < len(x.shape):
- beta_t = beta_t.unsqueeze(-1)
- drift = -0.5 * beta_t * x
-
- diffusion = torch.sqrt(beta_t)
- drift = drift - diffusion**2 * score
- x_mean = x + drift * dt
-
- # add noise
- noise = randn_tensor(x.shape, layout=x.layout, generator=generator, device=x.device, dtype=x.dtype)
- x = x_mean + diffusion * math.sqrt(-dt) * noise
-
- return x, x_mean
-
- def __len__(self):
- return self.config.num_train_timesteps
diff --git a/spaces/declare-lab/tango/diffusers/tests/fixtures/custom_pipeline/pipeline.py b/spaces/declare-lab/tango/diffusers/tests/fixtures/custom_pipeline/pipeline.py
deleted file mode 100644
index 9119ae30f42f58aab8a52f303c1879e4b3803468..0000000000000000000000000000000000000000
--- a/spaces/declare-lab/tango/diffusers/tests/fixtures/custom_pipeline/pipeline.py
+++ /dev/null
@@ -1,101 +0,0 @@
-# Copyright 2023 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-
-# limitations under the License.
-
-
-from typing import Optional, Tuple, Union
-
-import torch
-
-from diffusers import DiffusionPipeline, ImagePipelineOutput
-
-
-class CustomLocalPipeline(DiffusionPipeline):
- r"""
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
- library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
-
- Parameters:
- unet ([`UNet2DModel`]): U-Net architecture to denoise the encoded image.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image. Can be one of
- [`DDPMScheduler`], or [`DDIMScheduler`].
- """
-
- def __init__(self, unet, scheduler):
- super().__init__()
- self.register_modules(unet=unet, scheduler=scheduler)
-
- @torch.no_grad()
- def __call__(
- self,
- batch_size: int = 1,
- generator: Optional[torch.Generator] = None,
- num_inference_steps: int = 50,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- **kwargs,
- ) -> Union[ImagePipelineOutput, Tuple]:
- r"""
- Args:
- batch_size (`int`, *optional*, defaults to 1):
- The number of images to generate.
- generator (`torch.Generator`, *optional*):
- A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
- deterministic.
- eta (`float`, *optional*, defaults to 0.0):
- The eta parameter which controls the scale of the variance (0 is DDIM and 1 is one type of DDPM).
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- output_type (`str`, *optional*, defaults to `"pil"`):
- The output format of the generate image. Choose between
- [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
-
- Returns:
- [`~pipelines.ImagePipelineOutput`] or `tuple`: [`~pipelines.utils.ImagePipelineOutput`] if
- `return_dict` is True, otherwise a `tuple. When returning a tuple, the first element is a list with the
- generated images.
- """
-
- # Sample gaussian noise to begin loop
- image = torch.randn(
- (batch_size, self.unet.in_channels, self.unet.sample_size, self.unet.sample_size),
- generator=generator,
- )
- image = image.to(self.device)
-
- # set step values
- self.scheduler.set_timesteps(num_inference_steps)
-
- for t in self.progress_bar(self.scheduler.timesteps):
- # 1. predict noise model_output
- model_output = self.unet(image, t).sample
-
- # 2. predict previous mean of image x_t-1 and add variance depending on eta
- # eta corresponds to η in paper and should be between [0, 1]
- # do x_t -> x_t-1
- image = self.scheduler.step(model_output, t, image).prev_sample
-
- image = (image / 2 + 0.5).clamp(0, 1)
- image = image.cpu().permute(0, 2, 3, 1).numpy()
- if output_type == "pil":
- image = self.numpy_to_pil(image)
-
- if not return_dict:
- return (image,), "This is a local test"
-
- return ImagePipelineOutput(images=image), "This is a local test"
diff --git a/spaces/deepset/retrieval-augmentation-svb/utils/ui.py b/spaces/deepset/retrieval-augmentation-svb/utils/ui.py
deleted file mode 100644
index c5e2ef5ff5d4f7b310789d7cf239cfa6f2198257..0000000000000000000000000000000000000000
--- a/spaces/deepset/retrieval-augmentation-svb/utils/ui.py
+++ /dev/null
@@ -1,112 +0,0 @@
-import streamlit as st
-from PIL import Image
-
-from .constants import (QUERIES, PLAIN_GPT_ANS, GPT_WEB_RET_AUG_ANS, GPT_LOCAL_RET_AUG_ANS,
- BUTTON_LOCAL_RET_AUG, BUTTON_WEB_RET_AUG)
-
-
-def set_question():
- st.session_state['query'] = st.session_state['q_drop_down']
-
-
-def set_q1():
- st.session_state['query'] = QUERIES[0]
-
-
-def set_q2():
- st.session_state['query'] = QUERIES[1]
-
-
-def set_q3():
- st.session_state['query'] = QUERIES[2]
-
-
-def set_q4():
- st.session_state['query'] = QUERIES[3]
-
-
-def set_q5():
- st.session_state['query'] = QUERIES[4]
-
-
-def main_column():
- placeholder = st.empty()
- with placeholder:
- search_bar, button = st.columns([3, 1])
- with search_bar:
- _ = st.text_area(f" ", max_chars=200, key='query')
-
- with button:
- st.write(" ")
- st.write(" ")
- run_pressed = st.button("Run", key="run")
-
- st.write(" ")
- st.radio("Answer Type:", (BUTTON_LOCAL_RET_AUG, BUTTON_WEB_RET_AUG), key="query_type")
-
- st.markdown(f"{PLAIN_GPT_ANS}
", unsafe_allow_html=True)
- placeholder_plain_gpt = st.empty()
- placeholder_plain_gpt.text_area(f" ", placeholder="The answer will appear here.", disabled=True,
- key=PLAIN_GPT_ANS, height=1, label_visibility='collapsed')
- if st.session_state.get("query_type", BUTTON_LOCAL_RET_AUG) == BUTTON_LOCAL_RET_AUG:
- st.markdown(f"{GPT_LOCAL_RET_AUG_ANS}
", unsafe_allow_html=True)
- else:
- st.markdown(f"{GPT_WEB_RET_AUG_ANS}
", unsafe_allow_html=True)
- placeholder_retrieval_augmented = st.empty()
- placeholder_retrieval_augmented.text_area(f" ", placeholder="The answer will appear here.", disabled=True,
- key=GPT_LOCAL_RET_AUG_ANS, height=1, label_visibility='collapsed')
-
- return run_pressed, placeholder_plain_gpt, placeholder_retrieval_augmented
-
-
-def right_sidebar():
- st.write("")
- st.write("")
- st.markdown(" Example questions
", unsafe_allow_html=True)
- st.button(QUERIES[0], on_click=set_q1, use_container_width=True)
- st.button(QUERIES[1], on_click=set_q2, use_container_width=True)
- st.button(QUERIES[2], on_click=set_q3, use_container_width=True)
- st.button(QUERIES[3], on_click=set_q4, use_container_width=True)
- st.button(QUERIES[4], on_click=set_q5, use_container_width=True)
-
-
-def left_sidebar():
- with st.sidebar:
- image = Image.open('logo/haystack-logo-colored.png')
- st.markdown("Thanks for coming to this :hugging_face: space. \n\n"
- "This is an effort towards showcasing how you can use Haystack for Retrieval Augmented QA, "
- "with local [FAISSDocumentStore](https://docs.haystack.deepset.ai/reference/document-store-api#faissdocumentstore)"
- " or a [WebRetriever](https://docs.haystack.deepset.ai/docs/retriever#retrieval-from-the-web). \n\n"
- "More information on how this was built and instructions along "
- "with a repository will be published soon and updated here.")
-
- # st.markdown(
- # "## How to use\n"
- # "1. Enter your [OpenAI API key](https://platform.openai.com/account/api-keys) below\n"
- # "2. Enter a Serper Dev API key\n"
- # "3. Enjoy 🤗\n"
- # )
-
- # api_key_input = st.text_input(
- # "OpenAI API Key",
- # type="password",
- # placeholder="Paste your OpenAI API key here (sk-...)",
- # help="You can get your API key from https://platform.openai.com/account/api-keys.",
- # value=st.session_state.get("OPENAI_API_KEY", ""),
- # )
-
- # if api_key_input:
- # set_openai_api_key(api_key_input)
-
- st.markdown("---")
- st.markdown(
- "## How this works\n"
- "This app was built with [Haystack](https://haystack.deepset.ai) using the"
- " [PromptNode](https://docs.haystack.deepset.ai/docs/prompt_node), "
- "[Retriever](https://docs.haystack.deepset.ai/docs/retriever#embedding-retrieval-recommended),"
- "and [FAISSDocumentStore](https://docs.haystack.deepset.ai/reference/document-store-api#faissdocumentstore).\n\n"
- " You can find the source code in **Files and versions** tab."
- )
-
- st.markdown("---")
- st.image(image, width=250)
diff --git a/spaces/dhkim2810/MobileSAM/utils/tools.py b/spaces/dhkim2810/MobileSAM/utils/tools.py
deleted file mode 100644
index 3a06972cfb82357bc66b4e4c9cd7f776846bbd1f..0000000000000000000000000000000000000000
--- a/spaces/dhkim2810/MobileSAM/utils/tools.py
+++ /dev/null
@@ -1,406 +0,0 @@
-import os
-import sys
-
-import cv2
-import matplotlib.pyplot as plt
-import numpy as np
-import torch
-from PIL import Image
-
-
-def convert_box_xywh_to_xyxy(box):
- x1 = box[0]
- y1 = box[1]
- x2 = box[0] + box[2]
- y2 = box[1] + box[3]
- return [x1, y1, x2, y2]
-
-
-def segment_image(image, bbox):
- image_array = np.array(image)
- segmented_image_array = np.zeros_like(image_array)
- x1, y1, x2, y2 = bbox
- segmented_image_array[y1:y2, x1:x2] = image_array[y1:y2, x1:x2]
- segmented_image = Image.fromarray(segmented_image_array)
- black_image = Image.new("RGB", image.size, (255, 255, 255))
- # transparency_mask = np.zeros_like((), dtype=np.uint8)
- transparency_mask = np.zeros(
- (image_array.shape[0], image_array.shape[1]), dtype=np.uint8
- )
- transparency_mask[y1:y2, x1:x2] = 255
- transparency_mask_image = Image.fromarray(transparency_mask, mode="L")
- black_image.paste(segmented_image, mask=transparency_mask_image)
- return black_image
-
-
-def format_results(masks, scores, logits, filter=0):
- annotations = []
- n = len(scores)
- for i in range(n):
- annotation = {}
-
- mask = masks[i]
- tmp = np.where(mask != 0)
- if np.sum(mask) < filter:
- continue
- annotation["id"] = i
- annotation["segmentation"] = mask
- annotation["bbox"] = [
- np.min(tmp[0]),
- np.min(tmp[1]),
- np.max(tmp[1]),
- np.max(tmp[0]),
- ]
- annotation["score"] = scores[i]
- annotation["area"] = annotation["segmentation"].sum()
- annotations.append(annotation)
- return annotations
-
-
-def filter_masks(annotations): # filter the overlap mask
- annotations.sort(key=lambda x: x["area"], reverse=True)
- to_remove = set()
- for i in range(0, len(annotations)):
- a = annotations[i]
- for j in range(i + 1, len(annotations)):
- b = annotations[j]
- if i != j and j not in to_remove:
- # check if
- if b["area"] < a["area"]:
- if (a["segmentation"] & b["segmentation"]).sum() / b[
- "segmentation"
- ].sum() > 0.8:
- to_remove.add(j)
-
- return [a for i, a in enumerate(annotations) if i not in to_remove], to_remove
-
-
-def get_bbox_from_mask(mask):
- mask = mask.astype(np.uint8)
- contours, hierarchy = cv2.findContours(
- mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
- )
- x1, y1, w, h = cv2.boundingRect(contours[0])
- x2, y2 = x1 + w, y1 + h
- if len(contours) > 1:
- for b in contours:
- x_t, y_t, w_t, h_t = cv2.boundingRect(b)
- # 将多个bbox合并成一个
- x1 = min(x1, x_t)
- y1 = min(y1, y_t)
- x2 = max(x2, x_t + w_t)
- y2 = max(y2, y_t + h_t)
- h = y2 - y1
- w = x2 - x1
- return [x1, y1, x2, y2]
-
-
-def fast_process(
- annotations, args, mask_random_color, bbox=None, points=None, edges=False
-):
- if isinstance(annotations[0], dict):
- annotations = [annotation["segmentation"] for annotation in annotations]
- result_name = os.path.basename(args.img_path)
- image = cv2.imread(args.img_path)
- image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
- original_h = image.shape[0]
- original_w = image.shape[1]
- if sys.platform == "darwin":
- plt.switch_backend("TkAgg")
- plt.figure(figsize=(original_w / 100, original_h / 100))
- # Add subplot with no margin.
- plt.subplots_adjust(top=1, bottom=0, right=1, left=0, hspace=0, wspace=0)
- plt.margins(0, 0)
- plt.gca().xaxis.set_major_locator(plt.NullLocator())
- plt.gca().yaxis.set_major_locator(plt.NullLocator())
- plt.imshow(image)
- if args.better_quality == True:
- if isinstance(annotations[0], torch.Tensor):
- annotations = np.array(annotations.cpu())
- for i, mask in enumerate(annotations):
- mask = cv2.morphologyEx(
- mask.astype(np.uint8), cv2.MORPH_CLOSE, np.ones((3, 3), np.uint8)
- )
- annotations[i] = cv2.morphologyEx(
- mask.astype(np.uint8), cv2.MORPH_OPEN, np.ones((8, 8), np.uint8)
- )
- if args.device == "cpu":
- annotations = np.array(annotations)
- fast_show_mask(
- annotations,
- plt.gca(),
- random_color=mask_random_color,
- bbox=bbox,
- points=points,
- point_label=args.point_label,
- retinamask=args.retina,
- target_height=original_h,
- target_width=original_w,
- )
- else:
- if isinstance(annotations[0], np.ndarray):
- annotations = torch.from_numpy(annotations)
- fast_show_mask_gpu(
- annotations,
- plt.gca(),
- random_color=args.randomcolor,
- bbox=bbox,
- points=points,
- point_label=args.point_label,
- retinamask=args.retina,
- target_height=original_h,
- target_width=original_w,
- )
- if isinstance(annotations, torch.Tensor):
- annotations = annotations.cpu().numpy()
- if args.withContours == True:
- contour_all = []
- temp = np.zeros((original_h, original_w, 1))
- for i, mask in enumerate(annotations):
- if type(mask) == dict:
- mask = mask["segmentation"]
- annotation = mask.astype(np.uint8)
- if args.retina == False:
- annotation = cv2.resize(
- annotation,
- (original_w, original_h),
- interpolation=cv2.INTER_NEAREST,
- )
- contours, hierarchy = cv2.findContours(
- annotation, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE
- )
- for contour in contours:
- contour_all.append(contour)
- cv2.drawContours(temp, contour_all, -1, (255, 255, 255), 2)
- color = np.array([0 / 255, 0 / 255, 255 / 255, 0.8])
- contour_mask = temp / 255 * color.reshape(1, 1, -1)
- plt.imshow(contour_mask)
-
- save_path = args.output
- if not os.path.exists(save_path):
- os.makedirs(save_path)
- plt.axis("off")
- fig = plt.gcf()
- plt.draw()
-
- try:
- buf = fig.canvas.tostring_rgb()
- except AttributeError:
- fig.canvas.draw()
- buf = fig.canvas.tostring_rgb()
-
- cols, rows = fig.canvas.get_width_height()
- img_array = np.fromstring(buf, dtype=np.uint8).reshape(rows, cols, 3)
- cv2.imwrite(
- os.path.join(save_path, result_name), cv2.cvtColor(img_array, cv2.COLOR_RGB2BGR)
- )
-
-
-# CPU post process
-def fast_show_mask(
- annotation,
- ax,
- random_color=False,
- bbox=None,
- points=None,
- point_label=None,
- retinamask=True,
- target_height=960,
- target_width=960,
-):
- msak_sum = annotation.shape[0]
- height = annotation.shape[1]
- weight = annotation.shape[2]
- # 将annotation 按照面积 排序
- areas = np.sum(annotation, axis=(1, 2))
- sorted_indices = np.argsort(areas)
- annotation = annotation[sorted_indices]
-
- index = (annotation != 0).argmax(axis=0)
- if random_color == True:
- color = np.random.random((msak_sum, 1, 1, 3))
- else:
- color = np.ones((msak_sum, 1, 1, 3)) * np.array(
- [30 / 255, 144 / 255, 255 / 255]
- )
- transparency = np.ones((msak_sum, 1, 1, 1)) * 0.6
- visual = np.concatenate([color, transparency], axis=-1)
- mask_image = np.expand_dims(annotation, -1) * visual
-
- show = np.zeros((height, weight, 4))
- h_indices, w_indices = np.meshgrid(
- np.arange(height), np.arange(weight), indexing="ij"
- )
- indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
- # 使用向量化索引更新show的值
- show[h_indices, w_indices, :] = mask_image[indices]
- if bbox is not None:
- x1, y1, x2, y2 = bbox
- ax.add_patch(
- plt.Rectangle(
- (x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor="b", linewidth=1
- )
- )
- # draw point
- if points is not None:
- plt.scatter(
- [point[0] for i, point in enumerate(points) if point_label[i] == 1],
- [point[1] for i, point in enumerate(points) if point_label[i] == 1],
- s=20,
- c="y",
- )
- plt.scatter(
- [point[0] for i, point in enumerate(points) if point_label[i] == 0],
- [point[1] for i, point in enumerate(points) if point_label[i] == 0],
- s=20,
- c="m",
- )
-
- if retinamask == False:
- show = cv2.resize(
- show, (target_width, target_height), interpolation=cv2.INTER_NEAREST
- )
- ax.imshow(show)
-
-
-def fast_show_mask_gpu(
- annotation,
- ax,
- random_color=False,
- bbox=None,
- points=None,
- point_label=None,
- retinamask=True,
- target_height=960,
- target_width=960,
-):
- msak_sum = annotation.shape[0]
- height = annotation.shape[1]
- weight = annotation.shape[2]
- areas = torch.sum(annotation, dim=(1, 2))
- sorted_indices = torch.argsort(areas, descending=False)
- annotation = annotation[sorted_indices]
- # 找每个位置第一个非零值下标
- index = (annotation != 0).to(torch.long).argmax(dim=0)
- if random_color == True:
- color = torch.rand((msak_sum, 1, 1, 3)).to(annotation.device)
- else:
- color = torch.ones((msak_sum, 1, 1, 3)).to(annotation.device) * torch.tensor(
- [30 / 255, 144 / 255, 255 / 255]
- ).to(annotation.device)
- transparency = torch.ones((msak_sum, 1, 1, 1)).to(annotation.device) * 0.6
- visual = torch.cat([color, transparency], dim=-1)
- mask_image = torch.unsqueeze(annotation, -1) * visual
- # 按index取数,index指每个位置选哪个batch的数,把mask_image转成一个batch的形式
- show = torch.zeros((height, weight, 4)).to(annotation.device)
- h_indices, w_indices = torch.meshgrid(
- torch.arange(height), torch.arange(weight), indexing="ij"
- )
- indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
- # 使用向量化索引更新show的值
- show[h_indices, w_indices, :] = mask_image[indices]
- show_cpu = show.cpu().numpy()
- if bbox is not None:
- x1, y1, x2, y2 = bbox
- ax.add_patch(
- plt.Rectangle(
- (x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor="b", linewidth=1
- )
- )
- # draw point
- if points is not None:
- plt.scatter(
- [point[0] for i, point in enumerate(points) if point_label[i] == 1],
- [point[1] for i, point in enumerate(points) if point_label[i] == 1],
- s=20,
- c="y",
- )
- plt.scatter(
- [point[0] for i, point in enumerate(points) if point_label[i] == 0],
- [point[1] for i, point in enumerate(points) if point_label[i] == 0],
- s=20,
- c="m",
- )
- if retinamask == False:
- show_cpu = cv2.resize(
- show_cpu, (target_width, target_height), interpolation=cv2.INTER_NEAREST
- )
- ax.imshow(show_cpu)
-
-
-def crop_image(annotations, image_like):
- if isinstance(image_like, str):
- image = Image.open(image_like)
- else:
- image = image_like
- ori_w, ori_h = image.size
- mask_h, mask_w = annotations[0]["segmentation"].shape
- if ori_w != mask_w or ori_h != mask_h:
- image = image.resize((mask_w, mask_h))
- cropped_boxes = []
- cropped_images = []
- not_crop = []
- filter_id = []
- # annotations, _ = filter_masks(annotations)
- # filter_id = list(_)
- for _, mask in enumerate(annotations):
- if np.sum(mask["segmentation"]) <= 100:
- filter_id.append(_)
- continue
- bbox = get_bbox_from_mask(mask["segmentation"]) # mask 的 bbox
- cropped_boxes.append(segment_image(image, bbox)) # 保存裁剪的图片
- # cropped_boxes.append(segment_image(image,mask["segmentation"]))
- cropped_images.append(bbox) # 保存裁剪的图片的bbox
-
- return cropped_boxes, cropped_images, not_crop, filter_id, annotations
-
-
-def box_prompt(masks, bbox, target_height, target_width):
- h = masks.shape[1]
- w = masks.shape[2]
- if h != target_height or w != target_width:
- bbox = [
- int(bbox[0] * w / target_width),
- int(bbox[1] * h / target_height),
- int(bbox[2] * w / target_width),
- int(bbox[3] * h / target_height),
- ]
- bbox[0] = round(bbox[0]) if round(bbox[0]) > 0 else 0
- bbox[1] = round(bbox[1]) if round(bbox[1]) > 0 else 0
- bbox[2] = round(bbox[2]) if round(bbox[2]) < w else w
- bbox[3] = round(bbox[3]) if round(bbox[3]) < h else h
-
- # IoUs = torch.zeros(len(masks), dtype=torch.float32)
- bbox_area = (bbox[3] - bbox[1]) * (bbox[2] - bbox[0])
-
- masks_area = torch.sum(masks[:, bbox[1] : bbox[3], bbox[0] : bbox[2]], dim=(1, 2))
- orig_masks_area = torch.sum(masks, dim=(1, 2))
-
- union = bbox_area + orig_masks_area - masks_area
- IoUs = masks_area / union
- max_iou_index = torch.argmax(IoUs)
-
- return masks[max_iou_index].cpu().numpy(), max_iou_index
-
-
-def point_prompt(masks, points, point_label, target_height, target_width): # numpy 处理
- h = masks[0]["segmentation"].shape[0]
- w = masks[0]["segmentation"].shape[1]
- if h != target_height or w != target_width:
- points = [
- [int(point[0] * w / target_width), int(point[1] * h / target_height)]
- for point in points
- ]
- onemask = np.zeros((h, w))
- for i, annotation in enumerate(masks):
- if type(annotation) == dict:
- mask = annotation["segmentation"]
- else:
- mask = annotation
- for i, point in enumerate(points):
- if mask[point[1], point[0]] == 1 and point_label[i] == 1:
- onemask += mask
- if mask[point[1], point[0]] == 1 and point_label[i] == 0:
- onemask -= mask
- onemask = onemask >= 1
- return onemask, 0
diff --git a/spaces/diacanFperku/AutoGPT/HD Online Player (interstellar Movie Download In Hindi) High Quality.md b/spaces/diacanFperku/AutoGPT/HD Online Player (interstellar Movie Download In Hindi) High Quality.md
deleted file mode 100644
index b3f0054faf42f6744dd174c8fe03ac75945738f5..0000000000000000000000000000000000000000
--- a/spaces/diacanFperku/AutoGPT/HD Online Player (interstellar Movie Download In Hindi) High Quality.md
+++ /dev/null
@@ -1,30 +0,0 @@
-
-How to Watch Interstellar Movie in Hindi Online
-
-Interstellar is a 2014 sci-fi movie directed by Christopher Nolan, starring Matthew McConaughey, Anne Hathaway, Jessica Chastain, and others. It tells the story of a group of explorers who use a wormhole to travel across the galaxy and find a new home for humanity.
-
-If you are a fan of this movie and want to watch it in Hindi, you might be wondering how to do that. Well, there are a few options available for you to enjoy this epic movie in your preferred language.
-HD Online Player (interstellar movie download in hindi)
Download File — https://gohhs.com/2uFUyC
-
-One option is to buy or rent the movie from online platforms like Amazon Prime Video, Google Play Movies, YouTube, or iTunes. These platforms offer the movie in dual audio, meaning you can switch between English and Hindi as you wish. However, this option might cost you some money and require a stable internet connection.
-
-Another option is to download the movie from torrent sites like KatMovieHD, Moviefone, or OlaMovies. These sites provide the movie in various formats and resolutions, such as 480p, 720p, 1080p, or 4K. You can also choose the audio quality and subtitles according to your preference. However, this option might be illegal and risky, as you might face copyright issues or malware attacks.
-
-A third option is to stream the movie from online players like HD Online Player. This player allows you to watch the movie in Hindi without downloading or paying anything. You just need to paste the URL of the movie into the player and enjoy it. However, this option might have some drawbacks, such as low quality, buffering, ads, or pop-ups.
-
-So, these are some of the ways you can watch Interstellar movie in Hindi online. Choose the one that suits you best and enjoy this amazing movie.
-
-If you are curious about the plot of Interstellar, here is a brief summary. The movie follows Cooper, a former NASA pilot who lives with his two children, Tom and Murph, and his father-in-law, Donald. Cooper discovers a secret NASA facility where he meets his former mentor, Professor Brand, who reveals that Earth is doomed and that NASA has been working on a plan to save humanity.
-
-The plan involves using a wormhole near Saturn, which was mysteriously placed by an unknown intelligence, to explore three potentially habitable planets orbiting a supermassive black hole named Gargantua. Brand recruits Cooper to join the mission, along with his daughter Amelia, a physicist named Romilly, and a geographer named Doyle. They also have two robots, TARS and CASE, to assist them.
-
-
-Cooper agrees to go, despite Murph's protests, and promises her that he will return. He leaves behind his family and his farm, hoping to find a new world for them. However, he soon realizes that the mission is more complicated and dangerous than he expected. He has to face the challenges of space travel, time dilation, betrayal, sacrifice, and love as he tries to save the human race.
-
-Interstellar is not just a movie about space exploration, but also a movie about human emotions, relationships, and values. The movie explores themes such as love, faith, sacrifice, survival, and destiny. It also raises questions about the nature of time, gravity, and the universe.
-
-The movie has received critical acclaim for its performances, direction, screenplay, musical score, visual effects, ambition, and emotional weight. It has also received praise from many astronomers for its scientific accuracy and portrayal of theoretical astrophysics. The movie was nominated for five Academy Awards and won one for Best Visual Effects.
-
-Interstellar is a movie that will challenge your mind and touch your heart. It is a movie that will make you wonder about the mysteries of the cosmos and the meaning of life. It is a movie that will inspire you to dream big and reach for the stars.
d5da3c52bf
-
-
\ No newline at end of file
diff --git a/spaces/digitalxingtong/Bufeiyan-b-Bert-VITS2/README_zh.md b/spaces/digitalxingtong/Bufeiyan-b-Bert-VITS2/README_zh.md
deleted file mode 100644
index 8b137891791fe96927ad78e64b0aad7bded08bdc..0000000000000000000000000000000000000000
--- a/spaces/digitalxingtong/Bufeiyan-b-Bert-VITS2/README_zh.md
+++ /dev/null
@@ -1 +0,0 @@
-
diff --git a/spaces/dineshreddy/WALT/mmdet/models/roi_heads/mask_heads/scnet_semantic_head.py b/spaces/dineshreddy/WALT/mmdet/models/roi_heads/mask_heads/scnet_semantic_head.py
deleted file mode 100644
index df85a0112d27d97301fff56189f99bee0bf8efa5..0000000000000000000000000000000000000000
--- a/spaces/dineshreddy/WALT/mmdet/models/roi_heads/mask_heads/scnet_semantic_head.py
+++ /dev/null
@@ -1,27 +0,0 @@
-from mmdet.models.builder import HEADS
-from mmdet.models.utils import ResLayer, SimplifiedBasicBlock
-from .fused_semantic_head import FusedSemanticHead
-
-
-@HEADS.register_module()
-class SCNetSemanticHead(FusedSemanticHead):
- """Mask head for `SCNet `_.
-
- Args:
- conv_to_res (bool, optional): if True, change the conv layers to
- ``SimplifiedBasicBlock``.
- """
-
- def __init__(self, conv_to_res=True, **kwargs):
- super(SCNetSemanticHead, self).__init__(**kwargs)
- self.conv_to_res = conv_to_res
- if self.conv_to_res:
- num_res_blocks = self.num_convs // 2
- self.convs = ResLayer(
- SimplifiedBasicBlock,
- self.in_channels,
- self.conv_out_channels,
- num_res_blocks,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg)
- self.num_convs = num_res_blocks
diff --git a/spaces/docs-demos/distilbert-base-uncased/app.py b/spaces/docs-demos/distilbert-base-uncased/app.py
deleted file mode 100644
index abfe75740e4e71daa149432840bd59a135228568..0000000000000000000000000000000000000000
--- a/spaces/docs-demos/distilbert-base-uncased/app.py
+++ /dev/null
@@ -1,33 +0,0 @@
-import gradio as gr
-
-title = "DistilBERT"
-
-description = "Gradio Demo for DistilBERT. To use it, simply add your text, or click one of the examples to load them. Read more at the links below."
-
-article = "DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
"
-
-examples = [
- ['The goal of life is [MASK].','distilbert-base-uncased']
-]
-
-
-io1 = gr.Interface.load("huggingface/distilbert-base-uncased")
-
-io2 = gr.Interface.load("huggingface/distilbert-base-multilingual-cased")
-
-def inference(inputtext, model):
- if model == "distilbert-base-uncased":
- outlabel = io1(inputtext)
- else:
- outlabel = io2(inputtext)
- return outlabel
-
-
-gr.Interface(
- inference,
- [gr.inputs.Textbox(label="Context",lines=10),gr.inputs.Dropdown(choices=["distilbert-base-uncased","distilbert-base-multilingual-cased"], type="value", default="distilbert-base-uncased", label="model")],
- [gr.outputs.Label(label="Output")],
- examples=examples,
- article=article,
- title=title,
- description=description).launch(enable_queue=True)
\ No newline at end of file
diff --git a/spaces/doevent/Face-Real-ESRGAN/app.py b/spaces/doevent/Face-Real-ESRGAN/app.py
deleted file mode 100644
index ba1d0d5de692acc340bd363fa92b0a1e2b59181b..0000000000000000000000000000000000000000
--- a/spaces/doevent/Face-Real-ESRGAN/app.py
+++ /dev/null
@@ -1,47 +0,0 @@
-import torch
-from PIL import Image
-from RealESRGAN import RealESRGAN
-import gradio as gr
-
-device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
-print(device)
-model2 = RealESRGAN(device, scale=2)
-model2.load_weights('weights/RealESRGAN_x2.pth', download=True)
-model4 = RealESRGAN(device, scale=4)
-model4.load_weights('weights/RealESRGAN_x4.pth', download=True)
-model8 = RealESRGAN(device, scale=8)
-model8.load_weights('weights/RealESRGAN_x8.pth', download=True)
-
-
-def inference(image, size):
- if size == '2x':
- result = model2.predict(image.convert('RGB'))
- elif size == '4x':
- result = model4.predict(image.convert('RGB'))
- else:
- result = model8.predict(image.convert('RGB'))
- if torch.cuda.is_available():
- torch.cuda.empty_cache()
- return result
-
-
-title = "Face Real ESRGAN UpScale: 2x 4x 8x"
-description = "This is an unofficial demo for Real-ESRGAN. Scales the resolution of a photo. This model shows better results on faces compared to the original version.
Telegram BOT: https://t.me/restoration_photo_bot"
-article = "Twitter
Max Skobeev |
Model card/
"
-
-
-gr.Interface(inference,
- [gr.Image(type="pil"),
- gr.Radio(['2x', '4x', '8x'],
- type="value",
- value='2x',
- label='Resolution model')],
- gr.Image(type="pil", label="Output"),
- title=title,
- description=description,
- article=article,
- examples=[['groot.jpeg', "2x"]],
- allow_flagging='never',
- cache_examples=False,
- ).queue(concurrency_count=1).launch(show_error=True)
-
\ No newline at end of file
diff --git a/spaces/dolphinchat/dolphinchat-llm-gpt-ui/README.md b/spaces/dolphinchat/dolphinchat-llm-gpt-ui/README.md
deleted file mode 100644
index 9745d2d12b4073f81132db24fd6939ac001e09fc..0000000000000000000000000000000000000000
--- a/spaces/dolphinchat/dolphinchat-llm-gpt-ui/README.md
+++ /dev/null
@@ -1,22 +0,0 @@
----
-title: DolphinChat LLM
-emoji: 🗨🐬
-colorFrom: gray
-colorTo: blue
-sdk: gradio
-sdk_version: 3.39.0
-app_file: dolphin.script.py
-pinned: true
----
-
-
-
ℹ️ I am DolphinChat and I was created to help people!
-
-
✅️ I have been trained on almost the entire Internet!
-
-
♻️ I can communicate in more than 60 languages of the world!
-
-
📂 I work on open source and keep your data safe, I am a non-commercial project!
-
-
▶️ I'm almost the perfect chat assistant, so try me!
-
\ No newline at end of file
diff --git a/spaces/durgaamma2005/fire_detector/README.md b/spaces/durgaamma2005/fire_detector/README.md
deleted file mode 100644
index ad7b582bef8174c90ca080d08d88b7dddb79d59b..0000000000000000000000000000000000000000
--- a/spaces/durgaamma2005/fire_detector/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: Fire_detector
-emoji: 🐠
-colorFrom: purple
-colorTo: red
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/duycse1603/math2tex/HybridViT/helper.py b/spaces/duycse1603/math2tex/HybridViT/helper.py
deleted file mode 100644
index ba5cec3e1b2ca917cadbd914fbe45c0a6095f6b2..0000000000000000000000000000000000000000
--- a/spaces/duycse1603/math2tex/HybridViT/helper.py
+++ /dev/null
@@ -1,182 +0,0 @@
-import torch
-import random
-import numpy as np
-from PIL import Image
-from typing import Dict
-import torch.nn.functional as F
-import numpy as np
-from PIL import Image
-import cv2
-import math
-import albumentations as alb
-from albumentations.pytorch.transforms import ToTensorV2
-from collections import OrderedDict
-from itertools import repeat
-import collections.abc
-
-
-# From PyTorch internals
-def _ntuple(n):
- def parse(x):
- if isinstance(x, collections.abc.Iterable):
- return x
- return tuple(repeat(x, n))
- return parse
-
-to_3tuple = _ntuple(3)
-
-def clean_state_dict(state_dict):
- # 'clean' checkpoint by removing .module prefix from state dict if it exists from parallel training
- cleaned_state_dict = OrderedDict()
- for k, v in state_dict.items():
- name = k[7:] if k.startswith('module.') else k
- cleaned_state_dict[name] = v
- return cleaned_state_dict
-
-
-def math_transform(mean, std, is_gray: bool):
- test_transform = []
- normalize = [
- alb.CLAHE(clip_limit=2, tile_grid_size=(2, 2), always_apply=True),
- alb.Normalize(to_3tuple(mean), to_3tuple(std)),
- ToTensorV2()
- ]
- if is_gray:
- test_transform += [alb.ToGray(always_apply=True)]
- test_transform += normalize
-
- test_transform = alb.Compose([*test_transform])
- return test_transform
-
-
-def pad(img: Image.Image, divable=32):
- """Pad an Image to the next full divisible value of `divable`. Also normalizes the PIL.image and invert if needed.
-
- Args:
- img (PIL.Image): input PIL.image
- divable (int, optional): . Defaults to 32.
-
- Returns:
- PIL.Image
- """
- data = np.array(img.convert('LA'))
-
- data = (data-data.min())/(data.max()-data.min())*255
- if data[..., 0].mean() > 128:
- gray = 255*(data[..., 0] < 128).astype(np.uint8) # To invert the text to white
- else:
- gray = 255*(data[..., 0] > 128).astype(np.uint8)
- data[..., 0] = 255-data[..., 0]
-
- coords = cv2.findNonZero(gray) # Find all non-zero points (text)
- a, b, w, h = cv2.boundingRect(coords) # Find minimum spanning bounding box
- rect = data[b:b+h, a:a+w]
-
- if rect[..., -1].var() == 0:
- im = Image.fromarray((rect[..., 0]).astype(np.uint8)).convert('L')
- else:
- im = Image.fromarray((255-rect[..., -1]).astype(np.uint8)).convert('L')
- dims = []
-
- for x in [w, h]:
- div, mod = divmod(x, divable)
- dims.append(divable*(div + (1 if mod > 0 else 0)))
-
- padded = Image.new('L', dims, 255)
- padded.paste(im, im.getbbox())
-
- return padded
-
-def get_divisible_size(ori_h, ori_w, max_dimension=None, scale_factor=32):
- new_h, new_w = ori_h, ori_w
- if ori_h % scale_factor:
- new_h = math.ceil(ori_h/scale_factor)*scale_factor
- if new_h > max_dimension[0]:
- new_h = math.floor(ori_h/scale_factor)*scale_factor
-
- if ori_w % scale_factor:
- new_w = math.ceil(ori_w/scale_factor)*scale_factor
- if new_w > max_dimension[1]:
- new_w = math.floor(ori_w/scale_factor)*scale_factor
-
- return int(new_h),int(new_w)
-
-def minmax_size(img, max_dimensions=None, min_dimensions=None, is_gray=True):
- if max_dimensions is not None:
- ratios = [a/b for a, b in zip(list(img.size)[::-1], max_dimensions)]
- if any([r > 1 for r in ratios]):
- size = np.array(img.size)/max(ratios)
- new_h, new_w = get_divisible_size(size[1], size[0], max_dimensions)
- img = img.resize((new_w, new_h), Image.LANCZOS)
-
- if min_dimensions is not None:
- ratios = [a/b for a, b in zip(list(img.size)[::-1], min_dimensions)]
- if any([r < 1 for r in ratios]):
- new_h, new_w = img.size[1] / min(ratios), img.size[0] / min(ratios)
- new_h, new_w = get_divisible_size(new_h, new_w, max_dimensions)
- if is_gray:
- MODE = 'L'
- BACKGROUND = 255
- padded_im = Image.new(MODE, (new_w, new_h), BACKGROUND)
- padded_im.paste(img, img.getbbox())
- img = padded_im
-
- return img
-
-def resize(resizer, img: Image.Image, opt: Dict):
- # for math recognition problem image alway in grayscale mode
- img = img.convert('L')
- assert isinstance(opt, Dict)
- assert "imgH" in opt
- assert "imgW" in opt
- expected_H = opt['imgH']
-
- if expected_H is None:
- max_dimensions = opt['max_dimension'] #can be bigger than max dim in training set
- min_dimensions = opt['min_dimension']
- #equal to min dim in trainign set
- test_transform = math_transform(opt['mean'], opt['std'], not opt['rgb'])
- try:
- new_img = minmax_size(pad(img) if opt['pad'] else img, max_dimensions, min_dimensions, not opt['rgb'])
-
- if not resizer:
- new_img = np.asarray(new_img.convert('RGB')).astype('uint8')
- new_img = test_transform(image=new_img)['image']
- if not opt['rgb']: new_img = new_img[:1]
- new_img = new_img.unsqueeze(0)
- new_img = new_img.float()
- else:
- with torch.no_grad():
- input_image = new_img.convert('RGB').copy()
- r, w, h = 1, input_image.size[0], input_image.size[1]
- for i in range(20):
- h = int(h * r)
- new_img = pad(minmax_size(input_image.resize((w, h), Image.BILINEAR if r > 1 else Image.LANCZOS),
- max_dimensions,
- min_dimensions,
- not opt['rgb']
- ))
- t = test_transform(image=np.array(new_img.convert('RGB')).astype('uint8'))['image']
- if not opt['rgb']: t = t[:1]
- t = t.unsqueeze(0)
- t = t.float()
- w = (resizer(t.to(opt['device'])).argmax(-1).item()+1)*opt['min_dimension'][1]
-
- if (w == new_img.size[0]):
- break
-
- r = w/new_img.size[0]
-
- new_img = t
- except ValueError as e:
- print('Error:', e)
- new_img = np.asarray(img.convert('RGB')).astype('uint8')
- assert len(new_img.shape) == 3 and new_img.shape[2] == 3
- new_img = test_transform(image=new_img)['image']
- if not opt['rgb']: new_img = new_img[:1]
- new_img = new_img.unsqueeze(0)
- h, w = new_img.shape[2:]
- new_img = F.pad(new_img, (0, max_dimensions[1]-w, 0, max_dimensions[0]-h), value=1)
-
- assert len(new_img.shape) == 4, f'{new_img.shape}'
- return new_img
diff --git a/spaces/emrecan/zero-shot-turkish/models.py b/spaces/emrecan/zero-shot-turkish/models.py
deleted file mode 100644
index 6d8c0b1d62ae5aa7066d890423535ef0224c0a93..0000000000000000000000000000000000000000
--- a/spaces/emrecan/zero-shot-turkish/models.py
+++ /dev/null
@@ -1,26 +0,0 @@
-METHOD_OPTIONS = {
- "nli": "Natural Language Inference",
- "nsp": "Next Sentence Prediction",
-}
-
-NLI_MODEL_OPTIONS = [
- "emrecan/distilbert-base-turkish-cased-allnli_tr",
- "emrecan/distilbert-base-turkish-cased-multinli_tr",
- "emrecan/distilbert-base-turkish-cased-snli_tr",
- "emrecan/bert-base-turkish-cased-allnli_tr",
- "emrecan/bert-base-turkish-cased-multinli_tr",
- "emrecan/bert-base-turkish-cased-snli_tr",
- "emrecan/convbert-base-turkish-mc4-cased-allnli_tr",
- "emrecan/convbert-base-turkish-mc4-cased-multinli_tr",
- "emrecan/convbert-base-turkish-mc4-cased-snli_tr",
- "emrecan/bert-base-multilingual-cased-allnli_tr",
- "emrecan/bert-base-multilingual-cased-multinli_tr",
- "emrecan/bert-base-multilingual-cased-snli_tr",
-]
-
-NSP_MODEL_OPTIONS = [
- "dbmdz/bert-base-turkish-cased",
- "dbmdz/bert-base-turkish-uncased",
- "dbmdz/bert-base-turkish-128k-cased",
- "dbmdz/bert-base-turkish-128k-uncased",
-]
diff --git a/spaces/errorok/rvc-models-en-test/infer_pack/attentions.py b/spaces/errorok/rvc-models-en-test/infer_pack/attentions.py
deleted file mode 100644
index 77cb63ffccf3e33badf22d50862a64ba517b487f..0000000000000000000000000000000000000000
--- a/spaces/errorok/rvc-models-en-test/infer_pack/attentions.py
+++ /dev/null
@@ -1,417 +0,0 @@
-import copy
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from infer_pack import commons
-from infer_pack import modules
-from infer_pack.modules import LayerNorm
-
-
-class Encoder(nn.Module):
- def __init__(
- self,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size=1,
- p_dropout=0.0,
- window_size=10,
- **kwargs
- ):
- super().__init__()
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.window_size = window_size
-
- self.drop = nn.Dropout(p_dropout)
- self.attn_layers = nn.ModuleList()
- self.norm_layers_1 = nn.ModuleList()
- self.ffn_layers = nn.ModuleList()
- self.norm_layers_2 = nn.ModuleList()
- for i in range(self.n_layers):
- self.attn_layers.append(
- MultiHeadAttention(
- hidden_channels,
- hidden_channels,
- n_heads,
- p_dropout=p_dropout,
- window_size=window_size,
- )
- )
- self.norm_layers_1.append(LayerNorm(hidden_channels))
- self.ffn_layers.append(
- FFN(
- hidden_channels,
- hidden_channels,
- filter_channels,
- kernel_size,
- p_dropout=p_dropout,
- )
- )
- self.norm_layers_2.append(LayerNorm(hidden_channels))
-
- def forward(self, x, x_mask):
- attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
- x = x * x_mask
- for i in range(self.n_layers):
- y = self.attn_layers[i](x, x, attn_mask)
- y = self.drop(y)
- x = self.norm_layers_1[i](x + y)
-
- y = self.ffn_layers[i](x, x_mask)
- y = self.drop(y)
- x = self.norm_layers_2[i](x + y)
- x = x * x_mask
- return x
-
-
-class Decoder(nn.Module):
- def __init__(
- self,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size=1,
- p_dropout=0.0,
- proximal_bias=False,
- proximal_init=True,
- **kwargs
- ):
- super().__init__()
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.proximal_bias = proximal_bias
- self.proximal_init = proximal_init
-
- self.drop = nn.Dropout(p_dropout)
- self.self_attn_layers = nn.ModuleList()
- self.norm_layers_0 = nn.ModuleList()
- self.encdec_attn_layers = nn.ModuleList()
- self.norm_layers_1 = nn.ModuleList()
- self.ffn_layers = nn.ModuleList()
- self.norm_layers_2 = nn.ModuleList()
- for i in range(self.n_layers):
- self.self_attn_layers.append(
- MultiHeadAttention(
- hidden_channels,
- hidden_channels,
- n_heads,
- p_dropout=p_dropout,
- proximal_bias=proximal_bias,
- proximal_init=proximal_init,
- )
- )
- self.norm_layers_0.append(LayerNorm(hidden_channels))
- self.encdec_attn_layers.append(
- MultiHeadAttention(
- hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout
- )
- )
- self.norm_layers_1.append(LayerNorm(hidden_channels))
- self.ffn_layers.append(
- FFN(
- hidden_channels,
- hidden_channels,
- filter_channels,
- kernel_size,
- p_dropout=p_dropout,
- causal=True,
- )
- )
- self.norm_layers_2.append(LayerNorm(hidden_channels))
-
- def forward(self, x, x_mask, h, h_mask):
- """
- x: decoder input
- h: encoder output
- """
- self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(
- device=x.device, dtype=x.dtype
- )
- encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
- x = x * x_mask
- for i in range(self.n_layers):
- y = self.self_attn_layers[i](x, x, self_attn_mask)
- y = self.drop(y)
- x = self.norm_layers_0[i](x + y)
-
- y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
- y = self.drop(y)
- x = self.norm_layers_1[i](x + y)
-
- y = self.ffn_layers[i](x, x_mask)
- y = self.drop(y)
- x = self.norm_layers_2[i](x + y)
- x = x * x_mask
- return x
-
-
-class MultiHeadAttention(nn.Module):
- def __init__(
- self,
- channels,
- out_channels,
- n_heads,
- p_dropout=0.0,
- window_size=None,
- heads_share=True,
- block_length=None,
- proximal_bias=False,
- proximal_init=False,
- ):
- super().__init__()
- assert channels % n_heads == 0
-
- self.channels = channels
- self.out_channels = out_channels
- self.n_heads = n_heads
- self.p_dropout = p_dropout
- self.window_size = window_size
- self.heads_share = heads_share
- self.block_length = block_length
- self.proximal_bias = proximal_bias
- self.proximal_init = proximal_init
- self.attn = None
-
- self.k_channels = channels // n_heads
- self.conv_q = nn.Conv1d(channels, channels, 1)
- self.conv_k = nn.Conv1d(channels, channels, 1)
- self.conv_v = nn.Conv1d(channels, channels, 1)
- self.conv_o = nn.Conv1d(channels, out_channels, 1)
- self.drop = nn.Dropout(p_dropout)
-
- if window_size is not None:
- n_heads_rel = 1 if heads_share else n_heads
- rel_stddev = self.k_channels**-0.5
- self.emb_rel_k = nn.Parameter(
- torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
- * rel_stddev
- )
- self.emb_rel_v = nn.Parameter(
- torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
- * rel_stddev
- )
-
- nn.init.xavier_uniform_(self.conv_q.weight)
- nn.init.xavier_uniform_(self.conv_k.weight)
- nn.init.xavier_uniform_(self.conv_v.weight)
- if proximal_init:
- with torch.no_grad():
- self.conv_k.weight.copy_(self.conv_q.weight)
- self.conv_k.bias.copy_(self.conv_q.bias)
-
- def forward(self, x, c, attn_mask=None):
- q = self.conv_q(x)
- k = self.conv_k(c)
- v = self.conv_v(c)
-
- x, self.attn = self.attention(q, k, v, mask=attn_mask)
-
- x = self.conv_o(x)
- return x
-
- def attention(self, query, key, value, mask=None):
- # reshape [b, d, t] -> [b, n_h, t, d_k]
- b, d, t_s, t_t = (*key.size(), query.size(2))
- query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
- key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
- value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
-
- scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
- if self.window_size is not None:
- assert (
- t_s == t_t
- ), "Relative attention is only available for self-attention."
- key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
- rel_logits = self._matmul_with_relative_keys(
- query / math.sqrt(self.k_channels), key_relative_embeddings
- )
- scores_local = self._relative_position_to_absolute_position(rel_logits)
- scores = scores + scores_local
- if self.proximal_bias:
- assert t_s == t_t, "Proximal bias is only available for self-attention."
- scores = scores + self._attention_bias_proximal(t_s).to(
- device=scores.device, dtype=scores.dtype
- )
- if mask is not None:
- scores = scores.masked_fill(mask == 0, -1e4)
- if self.block_length is not None:
- assert (
- t_s == t_t
- ), "Local attention is only available for self-attention."
- block_mask = (
- torch.ones_like(scores)
- .triu(-self.block_length)
- .tril(self.block_length)
- )
- scores = scores.masked_fill(block_mask == 0, -1e4)
- p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
- p_attn = self.drop(p_attn)
- output = torch.matmul(p_attn, value)
- if self.window_size is not None:
- relative_weights = self._absolute_position_to_relative_position(p_attn)
- value_relative_embeddings = self._get_relative_embeddings(
- self.emb_rel_v, t_s
- )
- output = output + self._matmul_with_relative_values(
- relative_weights, value_relative_embeddings
- )
- output = (
- output.transpose(2, 3).contiguous().view(b, d, t_t)
- ) # [b, n_h, t_t, d_k] -> [b, d, t_t]
- return output, p_attn
-
- def _matmul_with_relative_values(self, x, y):
- """
- x: [b, h, l, m]
- y: [h or 1, m, d]
- ret: [b, h, l, d]
- """
- ret = torch.matmul(x, y.unsqueeze(0))
- return ret
-
- def _matmul_with_relative_keys(self, x, y):
- """
- x: [b, h, l, d]
- y: [h or 1, m, d]
- ret: [b, h, l, m]
- """
- ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
- return ret
-
- def _get_relative_embeddings(self, relative_embeddings, length):
- max_relative_position = 2 * self.window_size + 1
- # Pad first before slice to avoid using cond ops.
- pad_length = max(length - (self.window_size + 1), 0)
- slice_start_position = max((self.window_size + 1) - length, 0)
- slice_end_position = slice_start_position + 2 * length - 1
- if pad_length > 0:
- padded_relative_embeddings = F.pad(
- relative_embeddings,
- commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),
- )
- else:
- padded_relative_embeddings = relative_embeddings
- used_relative_embeddings = padded_relative_embeddings[
- :, slice_start_position:slice_end_position
- ]
- return used_relative_embeddings
-
- def _relative_position_to_absolute_position(self, x):
- """
- x: [b, h, l, 2*l-1]
- ret: [b, h, l, l]
- """
- batch, heads, length, _ = x.size()
- # Concat columns of pad to shift from relative to absolute indexing.
- x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))
-
- # Concat extra elements so to add up to shape (len+1, 2*len-1).
- x_flat = x.view([batch, heads, length * 2 * length])
- x_flat = F.pad(
- x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [0, length - 1]])
- )
-
- # Reshape and slice out the padded elements.
- x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[
- :, :, :length, length - 1 :
- ]
- return x_final
-
- def _absolute_position_to_relative_position(self, x):
- """
- x: [b, h, l, l]
- ret: [b, h, l, 2*l-1]
- """
- batch, heads, length, _ = x.size()
- # padd along column
- x = F.pad(
- x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]])
- )
- x_flat = x.view([batch, heads, length**2 + length * (length - 1)])
- # add 0's in the beginning that will skew the elements after reshape
- x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
- x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
- return x_final
-
- def _attention_bias_proximal(self, length):
- """Bias for self-attention to encourage attention to close positions.
- Args:
- length: an integer scalar.
- Returns:
- a Tensor with shape [1, 1, length, length]
- """
- r = torch.arange(length, dtype=torch.float32)
- diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
- return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
-
-
-class FFN(nn.Module):
- def __init__(
- self,
- in_channels,
- out_channels,
- filter_channels,
- kernel_size,
- p_dropout=0.0,
- activation=None,
- causal=False,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.activation = activation
- self.causal = causal
-
- if causal:
- self.padding = self._causal_padding
- else:
- self.padding = self._same_padding
-
- self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
- self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
- self.drop = nn.Dropout(p_dropout)
-
- def forward(self, x, x_mask):
- x = self.conv_1(self.padding(x * x_mask))
- if self.activation == "gelu":
- x = x * torch.sigmoid(1.702 * x)
- else:
- x = torch.relu(x)
- x = self.drop(x)
- x = self.conv_2(self.padding(x * x_mask))
- return x * x_mask
-
- def _causal_padding(self, x):
- if self.kernel_size == 1:
- return x
- pad_l = self.kernel_size - 1
- pad_r = 0
- padding = [[0, 0], [0, 0], [pad_l, pad_r]]
- x = F.pad(x, commons.convert_pad_shape(padding))
- return x
-
- def _same_padding(self, x):
- if self.kernel_size == 1:
- return x
- pad_l = (self.kernel_size - 1) // 2
- pad_r = self.kernel_size // 2
- padding = [[0, 0], [0, 0], [pad_l, pad_r]]
- x = F.pad(x, commons.convert_pad_shape(padding))
- return x
diff --git a/spaces/eswat/Image-and-3D-Model-Creator/PIFu/apps/prt_util.py b/spaces/eswat/Image-and-3D-Model-Creator/PIFu/apps/prt_util.py
deleted file mode 100644
index 7eba32fa0b396f420b2e332abbb67135dbc14d6b..0000000000000000000000000000000000000000
--- a/spaces/eswat/Image-and-3D-Model-Creator/PIFu/apps/prt_util.py
+++ /dev/null
@@ -1,142 +0,0 @@
-import os
-import trimesh
-import numpy as np
-import math
-from scipy.special import sph_harm
-import argparse
-from tqdm import tqdm
-
-def factratio(N, D):
- if N >= D:
- prod = 1.0
- for i in range(D+1, N+1):
- prod *= i
- return prod
- else:
- prod = 1.0
- for i in range(N+1, D+1):
- prod *= i
- return 1.0 / prod
-
-def KVal(M, L):
- return math.sqrt(((2 * L + 1) / (4 * math.pi)) * (factratio(L - M, L + M)))
-
-def AssociatedLegendre(M, L, x):
- if M < 0 or M > L or np.max(np.abs(x)) > 1.0:
- return np.zeros_like(x)
-
- pmm = np.ones_like(x)
- if M > 0:
- somx2 = np.sqrt((1.0 + x) * (1.0 - x))
- fact = 1.0
- for i in range(1, M+1):
- pmm = -pmm * fact * somx2
- fact = fact + 2
-
- if L == M:
- return pmm
- else:
- pmmp1 = x * (2 * M + 1) * pmm
- if L == M+1:
- return pmmp1
- else:
- pll = np.zeros_like(x)
- for i in range(M+2, L+1):
- pll = (x * (2 * i - 1) * pmmp1 - (i + M - 1) * pmm) / (i - M)
- pmm = pmmp1
- pmmp1 = pll
- return pll
-
-def SphericalHarmonic(M, L, theta, phi):
- if M > 0:
- return math.sqrt(2.0) * KVal(M, L) * np.cos(M * phi) * AssociatedLegendre(M, L, np.cos(theta))
- elif M < 0:
- return math.sqrt(2.0) * KVal(-M, L) * np.sin(-M * phi) * AssociatedLegendre(-M, L, np.cos(theta))
- else:
- return KVal(0, L) * AssociatedLegendre(0, L, np.cos(theta))
-
-def save_obj(mesh_path, verts):
- file = open(mesh_path, 'w')
- for v in verts:
- file.write('v %.4f %.4f %.4f\n' % (v[0], v[1], v[2]))
- file.close()
-
-def sampleSphericalDirections(n):
- xv = np.random.rand(n,n)
- yv = np.random.rand(n,n)
- theta = np.arccos(1-2 * xv)
- phi = 2.0 * math.pi * yv
-
- phi = phi.reshape(-1)
- theta = theta.reshape(-1)
-
- vx = -np.sin(theta) * np.cos(phi)
- vy = -np.sin(theta) * np.sin(phi)
- vz = np.cos(theta)
- return np.stack([vx, vy, vz], 1), phi, theta
-
-def getSHCoeffs(order, phi, theta):
- shs = []
- for n in range(0, order+1):
- for m in range(-n,n+1):
- s = SphericalHarmonic(m, n, theta, phi)
- shs.append(s)
-
- return np.stack(shs, 1)
-
-def computePRT(mesh_path, n, order):
- mesh = trimesh.load(mesh_path, process=False)
- vectors_orig, phi, theta = sampleSphericalDirections(n)
- SH_orig = getSHCoeffs(order, phi, theta)
-
- w = 4.0 * math.pi / (n*n)
-
- origins = mesh.vertices
- normals = mesh.vertex_normals
- n_v = origins.shape[0]
-
- origins = np.repeat(origins[:,None], n, axis=1).reshape(-1,3)
- normals = np.repeat(normals[:,None], n, axis=1).reshape(-1,3)
- PRT_all = None
- for i in tqdm(range(n)):
- SH = np.repeat(SH_orig[None,(i*n):((i+1)*n)], n_v, axis=0).reshape(-1,SH_orig.shape[1])
- vectors = np.repeat(vectors_orig[None,(i*n):((i+1)*n)], n_v, axis=0).reshape(-1,3)
-
- dots = (vectors * normals).sum(1)
- front = (dots > 0.0)
-
- delta = 1e-3*min(mesh.bounding_box.extents)
- hits = mesh.ray.intersects_any(origins + delta * normals, vectors)
- nohits = np.logical_and(front, np.logical_not(hits))
-
- PRT = (nohits.astype(np.float) * dots)[:,None] * SH
-
- if PRT_all is not None:
- PRT_all += (PRT.reshape(-1, n, SH.shape[1]).sum(1))
- else:
- PRT_all = (PRT.reshape(-1, n, SH.shape[1]).sum(1))
-
- PRT = w * PRT_all
-
- # NOTE: trimesh sometimes break the original vertex order, but topology will not change.
- # when loading PRT in other program, use the triangle list from trimesh.
- return PRT, mesh.faces
-
-def testPRT(dir_path, n=40):
- if dir_path[-1] == '/':
- dir_path = dir_path[:-1]
- sub_name = dir_path.split('/')[-1][:-4]
- obj_path = os.path.join(dir_path, sub_name + '_100k.obj')
- os.makedirs(os.path.join(dir_path, 'bounce'), exist_ok=True)
-
- PRT, F = computePRT(obj_path, n, 2)
- np.savetxt(os.path.join(dir_path, 'bounce', 'bounce0.txt'), PRT, fmt='%.8f')
- np.save(os.path.join(dir_path, 'bounce', 'face.npy'), F)
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('-i', '--input', type=str, default='/home/shunsuke/Downloads/rp_dennis_posed_004_OBJ')
- parser.add_argument('-n', '--n_sample', type=int, default=40, help='squared root of number of sampling. the higher, the more accurate, but slower')
- args = parser.parse_args()
-
- testPRT(args.input)
diff --git a/spaces/everm1nd/musika/parse_test.py b/spaces/everm1nd/musika/parse_test.py
deleted file mode 100644
index 96b101dfd1a63561482f9c52da61b0531054ab35..0000000000000000000000000000000000000000
--- a/spaces/everm1nd/musika/parse_test.py
+++ /dev/null
@@ -1,196 +0,0 @@
-import argparse
-from typing import Any
-import tensorflow as tf
-
-
-class EasyDict(dict):
- def __getattr__(self, name: str) -> Any:
- try:
- return self[name]
- except KeyError:
- raise AttributeError(name)
-
- def __setattr__(self, name: str, value: Any) -> None:
- self[name] = value
-
- def __delattr__(self, name: str) -> None:
- del self[name]
-
-
-def str2bool(v):
- if isinstance(v, bool):
- return v
- if v.lower() in ("yes", "true", "t", "y", "1"):
- return True
- elif v.lower() in ("no", "false", "f", "n", "0"):
- return False
- else:
- raise argparse.ArgumentTypeError("Boolean value expected.")
-
-
-def params_args(args):
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--hop",
- type=int,
- default=256,
- help="Hop size (window size = 4*hop)",
- )
- parser.add_argument(
- "--mel_bins",
- type=int,
- default=256,
- help="Mel bins in mel-spectrograms",
- )
- parser.add_argument(
- "--sr",
- type=int,
- default=44100,
- help="Sampling Rate",
- )
- parser.add_argument(
- "--small",
- type=str2bool,
- default=False,
- help="If True, use model with shorter available context, useful for small datasets",
- )
- parser.add_argument(
- "--latdepth",
- type=int,
- default=64,
- help="Depth of generated latent vectors",
- )
- parser.add_argument(
- "--coorddepth",
- type=int,
- default=64,
- help="Dimension of latent coordinate and style random vectors",
- )
- parser.add_argument(
- "--base_channels",
- type=int,
- default=128,
- help="Base channels for generator and discriminator architectures",
- )
- parser.add_argument(
- "--shape",
- type=int,
- default=128,
- help="Length of spectrograms time axis",
- )
- parser.add_argument(
- "--window",
- type=int,
- default=64,
- help="Generator spectrogram window (must divide shape)",
- )
- parser.add_argument(
- "--mu_rescale",
- type=float,
- default=-25.0,
- help="Spectrogram mu used to normalize",
- )
- parser.add_argument(
- "--sigma_rescale",
- type=float,
- default=75.0,
- help="Spectrogram sigma used to normalize",
- )
- parser.add_argument(
- "--load_path_1",
- type=str,
- default="checkpoints/techno/",
- help="Path of pretrained networks weights 1",
- )
- parser.add_argument(
- "--load_path_2",
- type=str,
- default="checkpoints/metal/",
- help="Path of pretrained networks weights 2",
- )
- parser.add_argument(
- "--load_path_3",
- type=str,
- default="checkpoints/misc/",
- help="Path of pretrained networks weights 3",
- )
- parser.add_argument(
- "--dec_path",
- type=str,
- default="checkpoints/ae/",
- help="Path of pretrained decoders weights",
- )
- parser.add_argument(
- "--testing",
- type=str2bool,
- default=True,
- help="True if optimizers weight do not need to be loaded",
- )
- parser.add_argument(
- "--cpu",
- type=str2bool,
- default=False,
- help="True if you wish to use cpu",
- )
- parser.add_argument(
- "--mixed_precision",
- type=str2bool,
- default=True,
- help="True if your GPU supports mixed precision",
- )
-
- tmp_args = parser.parse_args()
-
- args.hop = tmp_args.hop
- args.mel_bins = tmp_args.mel_bins
- args.sr = tmp_args.sr
- args.small = tmp_args.small
- args.latdepth = tmp_args.latdepth
- args.coorddepth = tmp_args.coorddepth
- args.base_channels = tmp_args.base_channels
- args.shape = tmp_args.shape
- args.window = tmp_args.window
- args.mu_rescale = tmp_args.mu_rescale
- args.sigma_rescale = tmp_args.sigma_rescale
- args.load_path_1 = tmp_args.load_path_1
- args.load_path_2 = tmp_args.load_path_2
- args.load_path_3 = tmp_args.load_path_3
- args.dec_path = tmp_args.dec_path
- args.testing = tmp_args.testing
- args.cpu = tmp_args.cpu
- args.mixed_precision = tmp_args.mixed_precision
-
- if args.small:
- args.latlen = 128
- else:
- args.latlen = 256
- args.coordlen = (args.latlen // 2) * 3
-
- print()
-
- args.datatype = tf.float32
- gpuls = tf.config.list_physical_devices("GPU")
- if len(gpuls) == 0 or args.cpu:
- args.cpu = True
- args.mixed_precision = False
- tf.config.set_visible_devices([], "GPU")
- print()
- print("Using CPU...")
- print()
- if args.mixed_precision:
- args.datatype = tf.float16
- print()
- print("Using GPU with mixed precision enabled...")
- print()
- if not args.mixed_precision and not args.cpu:
- print()
- print("Using GPU without mixed precision...")
- print()
-
- return args
-
-
-def parse_args():
- args = EasyDict()
- return params_args(args)
diff --git a/spaces/exbert-project/exbert/client/src/css/SentenceInput.css b/spaces/exbert-project/exbert/client/src/css/SentenceInput.css
deleted file mode 100644
index 085ed497fa28962dc26f019a7ced30c981e73444..0000000000000000000000000000000000000000
--- a/spaces/exbert-project/exbert/client/src/css/SentenceInput.css
+++ /dev/null
@@ -1,48 +0,0 @@
-#sentence-input {
- margin-bottom: -30px;
- margin-right: -30px;
- margin-left: 10px;
- width: 90%;
-}
-
-#sentence-input form {
- display: -webkit-box;
- display: -ms-flexbox;
- display: flex;
- -webkit-box-orient: horizontal;
- -webkit-box-direction: normal;
- -ms-flex-direction: row;
- flex-direction: row;
- -ms-flex-wrap: nowrap;
- flex-wrap: nowrap;
- -webkit-box-pack: space-evenly;
- -ms-flex-pack: space-evenly;
- justify-content: space-evenly;
- -webkit-box-align: center;
- -ms-flex-align: center;
- align-items: center;
-}
-
-#sentence-input form .form-group {
- -webkit-box-flex: 3;
- -ms-flex-positive: 3;
- flex-grow: 3;
-}
-
-#sentence-input form .form-group input {
- width: 100%;
- margin-right: 5%;
-}
-
-#sentence-input form .padding {
- -webkit-box-flex: 0.3;
- -ms-flex-positive: 0.3;
- flex-grow: 0.3;
-}
-
-#sentence-input form .btn {
- -webkit-box-flex: 1;
- -ms-flex-positive: 1;
- flex-grow: 1;
-}
-/*# sourceMappingURL=SentenceInput.css.map */
\ No newline at end of file
diff --git a/spaces/facebook/StyleNeRF/torch_utils/ops/conv2d_gradfix.py b/spaces/facebook/StyleNeRF/torch_utils/ops/conv2d_gradfix.py
deleted file mode 100644
index c2cf8727edbb5106a88a139b34943229487c9988..0000000000000000000000000000000000000000
--- a/spaces/facebook/StyleNeRF/torch_utils/ops/conv2d_gradfix.py
+++ /dev/null
@@ -1,200 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-
-# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-"""Custom replacement for `torch.nn.functional.conv2d` that supports
-arbitrarily high order gradients with zero performance penalty."""
-
-import contextlib
-import torch
-
-# pylint: disable=redefined-builtin
-# pylint: disable=arguments-differ
-# pylint: disable=protected-access
-
-#----------------------------------------------------------------------------
-
-enabled = False # Enable the custom op by setting this to true.
-weight_gradients_disabled = False # Forcefully disable computation of gradients with respect to the weights.
-
-@contextlib.contextmanager
-def no_weight_gradients(disable=True):
- global weight_gradients_disabled
- old = weight_gradients_disabled
- if disable:
- weight_gradients_disabled = True
- yield
- weight_gradients_disabled = old
-
-#----------------------------------------------------------------------------
-
-def conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):
- if _should_use_custom_op(input):
- return _conv2d_gradfix(transpose=False, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=0, dilation=dilation, groups=groups).apply(input, weight, bias)
- return torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
-
-def conv_transpose2d(input, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1):
- if _should_use_custom_op(input):
- return _conv2d_gradfix(transpose=True, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation).apply(input, weight, bias)
- return torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation)
-
-#----------------------------------------------------------------------------
-
-def _should_use_custom_op(input):
- assert isinstance(input, torch.Tensor)
- if (not enabled) or (not torch.backends.cudnn.enabled):
- return False
- if input.device.type != 'cuda':
- return False
- return True
-
-def _tuple_of_ints(xs, ndim):
- xs = tuple(xs) if isinstance(xs, (tuple, list)) else (xs,) * ndim
- assert len(xs) == ndim
- assert all(isinstance(x, int) for x in xs)
- return xs
-
-#----------------------------------------------------------------------------
-
-_conv2d_gradfix_cache = dict()
-_null_tensor = torch.empty([0])
-
-def _conv2d_gradfix(transpose, weight_shape, stride, padding, output_padding, dilation, groups):
- # Parse arguments.
- ndim = 2
- weight_shape = tuple(weight_shape)
- stride = _tuple_of_ints(stride, ndim)
- padding = _tuple_of_ints(padding, ndim)
- output_padding = _tuple_of_ints(output_padding, ndim)
- dilation = _tuple_of_ints(dilation, ndim)
-
- # Lookup from cache.
- key = (transpose, weight_shape, stride, padding, output_padding, dilation, groups)
- if key in _conv2d_gradfix_cache:
- return _conv2d_gradfix_cache[key]
-
- # Validate arguments.
- assert groups >= 1
- assert len(weight_shape) == ndim + 2
- assert all(stride[i] >= 1 for i in range(ndim))
- assert all(padding[i] >= 0 for i in range(ndim))
- assert all(dilation[i] >= 0 for i in range(ndim))
- if not transpose:
- assert all(output_padding[i] == 0 for i in range(ndim))
- else: # transpose
- assert all(0 <= output_padding[i] < max(stride[i], dilation[i]) for i in range(ndim))
-
- # Helpers.
- common_kwargs = dict(stride=stride, padding=padding, dilation=dilation, groups=groups)
- def calc_output_padding(input_shape, output_shape):
- if transpose:
- return [0, 0]
- return [
- input_shape[i + 2]
- - (output_shape[i + 2] - 1) * stride[i]
- - (1 - 2 * padding[i])
- - dilation[i] * (weight_shape[i + 2] - 1)
- for i in range(ndim)
- ]
-
- # Forward & backward.
- class Conv2d(torch.autograd.Function):
- @staticmethod
- def forward(ctx, input, weight, bias):
- assert weight.shape == weight_shape
- ctx.save_for_backward(
- input if weight.requires_grad else _null_tensor,
- weight if input.requires_grad else _null_tensor,
- )
- ctx.input_shape = input.shape
-
- # Simple 1x1 convolution => cuBLAS (only on Volta, not on Ampere).
- if weight_shape[2:] == stride == dilation == (1, 1) and padding == (0, 0) and torch.cuda.get_device_capability(input.device) < (8, 0):
- a = weight.reshape(groups, weight_shape[0] // groups, weight_shape[1])
- b = input.reshape(input.shape[0], groups, input.shape[1] // groups, -1)
- c = (a.transpose(1, 2) if transpose else a) @ b.permute(1, 2, 0, 3).flatten(2)
- c = c.reshape(-1, input.shape[0], *input.shape[2:]).transpose(0, 1)
- c = c if bias is None else c + bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
- return c.contiguous(memory_format=(torch.channels_last if input.stride(1) == 1 else torch.contiguous_format))
-
- # General case => cuDNN.
- if transpose:
- return torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, output_padding=output_padding, **common_kwargs)
- return torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, **common_kwargs)
-
- @staticmethod
- def backward(ctx, grad_output):
- input, weight = ctx.saved_tensors
- input_shape = ctx.input_shape
- grad_input = None
- grad_weight = None
- grad_bias = None
-
- if ctx.needs_input_grad[0]:
- p = calc_output_padding(input_shape=input_shape, output_shape=grad_output.shape)
- op = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs)
- grad_input = op.apply(grad_output, weight, None)
- assert grad_input.shape == input_shape
-
- if ctx.needs_input_grad[1] and not weight_gradients_disabled:
- grad_weight = Conv2dGradWeight.apply(grad_output, input)
- assert grad_weight.shape == weight_shape
-
- if ctx.needs_input_grad[2]:
- grad_bias = grad_output.sum([0, 2, 3])
-
- return grad_input, grad_weight, grad_bias
-
- # Gradient with respect to the weights.
- class Conv2dGradWeight(torch.autograd.Function):
- @staticmethod
- def forward(ctx, grad_output, input):
- ctx.save_for_backward(
- grad_output if input.requires_grad else _null_tensor,
- input if grad_output.requires_grad else _null_tensor,
- )
- ctx.grad_output_shape = grad_output.shape
- ctx.input_shape = input.shape
-
- # Simple 1x1 convolution => cuBLAS (on both Volta and Ampere).
- if weight_shape[2:] == stride == dilation == (1, 1) and padding == (0, 0):
- a = grad_output.reshape(grad_output.shape[0], groups, grad_output.shape[1] // groups, -1).permute(1, 2, 0, 3).flatten(2)
- b = input.reshape(input.shape[0], groups, input.shape[1] // groups, -1).permute(1, 2, 0, 3).flatten(2)
- c = (b @ a.transpose(1, 2) if transpose else a @ b.transpose(1, 2)).reshape(weight_shape)
- return c.contiguous(memory_format=(torch.channels_last if input.stride(1) == 1 else torch.contiguous_format))
-
- # General case => cuDNN.
- name = 'aten::cudnn_convolution_transpose_backward_weight' if transpose else 'aten::cudnn_convolution_backward_weight'
- flags = [torch.backends.cudnn.benchmark, torch.backends.cudnn.deterministic, torch.backends.cudnn.allow_tf32]
- return torch._C._jit_get_operation(name)(weight_shape, grad_output, input, padding, stride, dilation, groups, *flags)
-
- @staticmethod
- def backward(ctx, grad2_grad_weight):
- grad_output, input = ctx.saved_tensors
- grad_output_shape = ctx.grad_output_shape
- input_shape = ctx.input_shape
- grad2_grad_output = None
- grad2_input = None
-
- if ctx.needs_input_grad[0]:
- grad2_grad_output = Conv2d.apply(input, grad2_grad_weight, None)
- assert grad2_grad_output.shape == grad_output_shape
-
- if ctx.needs_input_grad[1]:
- p = calc_output_padding(input_shape=input_shape, output_shape=grad_output_shape)
- op = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs)
- grad2_input = op.apply(grad_output, grad2_grad_weight, None)
- assert grad2_input.shape == input_shape
-
- return grad2_grad_output, grad2_input
-
- _conv2d_gradfix_cache[key] = Conv2d
- return Conv2d
-
-#----------------------------------------------------------------------------
diff --git a/spaces/falcondai/code-as-policies/app.py b/spaces/falcondai/code-as-policies/app.py
deleted file mode 100644
index 93a5eb48d81ef94aac5fabfffa304fb39bfceb59..0000000000000000000000000000000000000000
--- a/spaces/falcondai/code-as-policies/app.py
+++ /dev/null
@@ -1,235 +0,0 @@
-import os
-import openai
-import numpy as np
-from tempfile import NamedTemporaryFile
-import copy
-import shapely
-from shapely.geometry import *
-from shapely.affinity import *
-from omegaconf import OmegaConf
-from moviepy.editor import ImageSequenceClip
-import gradio as gr
-
-from lmp import LMP, LMPFGen
-from sim import PickPlaceEnv, LMP_wrapper
-from consts import ALL_BLOCKS, ALL_BOWLS
-from md_logger import MarkdownLogger
-
-default_open_ai_key = os.getenv('OPEN_AI_SECRET')
-chain_of_thought_affix = ' with a step by step explanation'
-ask_for_clarification_affix = ' or ask for clarification if you feel unclear'
-
-
-class DemoRunner:
-
- def __init__(self):
- self._cfg = OmegaConf.to_container(OmegaConf.load('cfg.yaml'), resolve=True)
- self._env = None
- self._model_name = ''
- self._md_logger = MarkdownLogger()
-
- def make_LMP(self, env):
- # LMP env wrapper
- cfg = copy.deepcopy(self._cfg)
- cfg['env'] = {
- 'init_objs': list(env.obj_name_to_id.keys()),
- 'coords': cfg['tabletop_coords']
- }
- for vs in cfg['lmps'].values():
- vs['engine'] = self._model_name
-
- LMP_env = LMP_wrapper(env, cfg)
- # creating APIs that the LMPs can interact with
- fixed_vars = {
- 'np': np
- }
- fixed_vars.update({
- name: eval(name)
- for name in shapely.geometry.__all__ + shapely.affinity.__all__
- })
- variable_vars = {
- k: getattr(LMP_env, k)
- for k in [
- 'get_bbox', 'get_obj_pos', 'get_color', 'is_obj_visible', 'denormalize_xy',
- 'put_first_on_second', 'get_obj_names',
- 'get_corner_name', 'get_side_name',
- ]
- }
- # variable_vars['say'] = lambda msg: self._md_logger.log_text(f'Robot says: "{msg}"')
- variable_vars['say'] = lambda msg: self._md_logger.log_message(
- f'{msg}')
-
- # creating the function-generating LMP
- lmp_fgen = LMPFGen(cfg['lmps']['fgen'], fixed_vars, variable_vars, self._md_logger)
-
- # creating other low-level LMPs
- variable_vars.update({
- k: LMP(k, cfg['lmps'][k], lmp_fgen, fixed_vars, variable_vars, self._md_logger)
- for k in ['parse_obj_name', 'parse_position', 'parse_question', 'transform_shape_pts']
- })
-
- # creating the LMP that deals w/ high-level language commands
- lmp_tabletop_ui = LMP(
- 'tabletop_ui', cfg['lmps']['tabletop_ui'], lmp_fgen, fixed_vars, variable_vars, self._md_logger
- )
-
- return lmp_tabletop_ui
-
- def setup(self, api_key, model_name, n_blocks, n_bowls):
- openai.api_key = api_key
- self._model_name = model_name
-
- self._env = PickPlaceEnv(render=True, high_res=True, high_frame_rate=False)
- list_idxs = np.random.choice(len(ALL_BLOCKS), size=max(n_blocks, n_bowls), replace=False)
- block_list = [ALL_BLOCKS[i] for i in list_idxs[:n_blocks]]
- bowl_list = [ALL_BOWLS[i] for i in list_idxs[:n_bowls]]
- obj_list = block_list + bowl_list
- self._env.reset(obj_list)
-
- self._lmp_tabletop_ui = self.make_LMP(self._env)
-
- info = '### Available Objects: \n- ' + '\n- '.join(obj_list)
- img = self._env.get_camera_image()
-
- return info, img
-
- def run(self, instruction, history):
- if self._env is None:
- return 'Please run setup first!', None, history
-
- self._env.cache_video = []
- self._md_logger.clear()
-
- try:
- self._lmp_tabletop_ui(instruction, f'objects = {self._env.object_list}')
- except Exception as e:
- return f'Error: {e}', None, history
-
- # Update chat messages
- for message in self._md_logger.get_messages():
- history.append((None, message))
-
- if self._env.cache_video:
- rendered_clip = ImageSequenceClip(self._env.cache_video, fps=25)
- video_file_name = NamedTemporaryFile(suffix='.mp4').name
- rendered_clip.write_videofile(video_file_name, fps=25)
- history.append((None, (video_file_name, )))
-
- return self._md_logger.get_log(), self._env.get_camera_image(), history
-
-
-def setup(api_key, model_name, n_blocks, n_bowls):
- if not api_key:
- return 'Please enter your OpenAI API key!', None
- if n_blocks + n_bowls == 0:
- return 'Please select at least one object!', None
-
- demo_runner = DemoRunner()
-
- info, img = demo_runner.setup(api_key, model_name, n_blocks, n_bowls)
- welcome_message = 'How can I help you?'
- return info, img, demo_runner, [(None, welcome_message)], None
-
-
-def run(demo_runner, chat_history):
- if demo_runner is None:
- return 'Please run setup first!', None, None, chat_history, None
- instruction = chat_history[-1][0]
- return *demo_runner.run(instruction, chat_history), ''
-
-def submit_chat(chat_message, history):
- history += [[chat_message, None]]
- return '', history
-
-def add_cot(chat_messsage):
- return chat_messsage.strip() + chain_of_thought_affix
-
-def add_clarification(chat_message):
- return chat_message.strip() + ask_for_clarification_affix
-
-
-with open('README.md', 'r') as f:
- for _ in range(12):
- next(f)
- readme_text = f.read()
-
-with gr.Blocks() as demo:
- state = gr.State(None)
- with gr.Accordion('Readme', open=False):
- gr.Markdown(readme_text)
- gr.Markdown('# Interactive Demo')
- with gr.Row():
- with gr.Column():
- with gr.Row():
- inp_api_key = gr.Textbox(value=default_open_ai_key,
- label='OpenAI API Key (this is not stored anywhere)', lines=1)
- inp_model_name = gr.Dropdown(label='Model Name', choices=[
- 'text-davinci-003', 'code-davinci-002', 'text-davinci-002'], value='text-davinci-003')
- with gr.Row():
- inp_n_blocks = gr.Slider(label='Number of Blocks', minimum=0, maximum=5, value=3, step=1)
- inp_n_bowls = gr.Slider(label='Number of Bowls', minimum=0, maximum=5, value=3, step=1)
-
- btn_setup = gr.Button("Setup/Reset Simulation")
- info_setup = gr.Markdown(label='Setup Info')
-
- with gr.Row():
- with gr.Column():
- chat_box = gr.Chatbot()
- inp_instruction = gr.Textbox(label='Instruction', lines=1)
- examples = gr.Examples(
- [
- 'stack two of the blocks',
- 'what color is the rightmost block?',
- 'arrange the blocks into figure 3',
- 'put blocks into non-matching bowls',
- 'swap the positions of one block and another',
- ],
- inp_instruction,
- )
- btn_add_cot = gr.Button(f'+{chain_of_thought_affix} (chain-of-thought)')
- btn_add_cla = gr.Button(
- f'+{ask_for_clarification_affix} (conversation)')
- btn_run = gr.Button("Run (this may take 30+ seconds)")
- info_run = gr.Markdown(label='Generated Code')
- with gr.Column():
- img_setup = gr.Image(label='Current Simulation State')
- # video_run = gr.Video(label='Most Recent Manipulation')
-
- btn_setup.click(
- setup,
- inputs=[inp_api_key, inp_model_name, inp_n_blocks, inp_n_bowls],
- outputs=[info_setup, img_setup, state, chat_box, info_run],
- )
- btn_add_cot.click(
- add_cot,
- inp_instruction,
- inp_instruction,
- )
- btn_add_cla.click(
- add_clarification,
- inp_instruction,
- inp_instruction,
- )
- btn_run.click(
- submit_chat,
- [inp_instruction, chat_box],
- [inp_instruction, chat_box],
- ).then(
- run,
- inputs=[state, chat_box],
- outputs=[info_run, img_setup, chat_box, inp_instruction],
- )
- inp_instruction.submit(
- submit_chat,
- [inp_instruction, chat_box],
- [inp_instruction, chat_box],
- ).then(
- run,
- inputs=[state, chat_box],
- outputs=[info_run, img_setup, chat_box, inp_instruction],
- )
-
-if __name__ == '__main__':
- print(gr.__version__)
- demo.queue(concurrency_count=10)
- demo.launch()
\ No newline at end of file
diff --git a/spaces/falterWliame/Face_Mask_Detection/Alpha Bravo Charlie 720p Torrent _BEST_.md b/spaces/falterWliame/Face_Mask_Detection/Alpha Bravo Charlie 720p Torrent _BEST_.md
deleted file mode 100644
index 700c501ebfe205a9118683e9f3f77b1bc5fd5ae0..0000000000000000000000000000000000000000
--- a/spaces/falterWliame/Face_Mask_Detection/Alpha Bravo Charlie 720p Torrent _BEST_.md
+++ /dev/null
@@ -1,45 +0,0 @@
-
-
How to Watch Alpha Bravo Charlie in 720p Quality
-
If you are a fan of Pakistani dramas, you must have heard of Alpha Bravo Charlie, one of the most popular and acclaimed series ever produced by PTV. The drama follows the lives and adventures of three army officers, Faraz, Kashif and Gulsher, who are also known by their code names Alpha, Bravo and Charlie. The drama is a mix of comedy, romance, action and patriotism, and it showcases the challenges and sacrifices of the Pakistani army.
-
Alpha Bravo Charlie 720p Torrent
Download File ⇒⇒⇒ https://urlca.com/2uDdxF
-
Alpha Bravo Charlie was aired in 1998, and it became an instant hit among the viewers. The drama has a cult following even today, and many people consider it as one of the best Pakistani dramas of all time. However, finding a good quality version of the drama online can be a challenge. Most of the available copies are either low-resolution or have poor audio and video quality.
-
That's why we have compiled this guide to help you watch Alpha Bravo Charlie in 720p quality, which is the best possible quality for this drama. You can either stream or download the drama using torrent links, depending on your preference and internet speed. Here are the steps you need to follow:
-
Step 1: Download a Torrent Client
-
A torrent client is a software that allows you to download files from other users who are sharing them on a peer-to-peer network. You will need a torrent client to download Alpha Bravo Charlie in 720p quality from torrent sites. There are many torrent clients available online, but some of the most popular ones are uTorrent, BitTorrent, qBittorrent and Vuze. You can download any of these clients from their official websites and install them on your device.
-
Step 2: Find a Reliable Torrent Site
-
A torrent site is a website that hosts torrent files, which are small files that contain information about the files you want to download. You will need to find a reliable torrent site that has Alpha Bravo Charlie in 720p quality available for download. There are many torrent sites online, but some of them may be blocked by your internet service provider or may contain malware or viruses. Therefore, you should be careful while choosing a torrent site and use a VPN service if necessary.
-
-
Some of the torrent sites that have Alpha Bravo Charlie in 720p quality are LimeTorrents, The Pirate Bay, 1337x and RARBG. You can visit any of these sites and search for "Alpha Bravo Charlie 720p Torrent" in their search bar. You will see a list of results with different file sizes and seeders. Seeders are users who have the complete file and are sharing it with others. The more seeders a file has, the faster it will download.
-
Step 3: Download or Stream Alpha Bravo Charlie in 720p Quality
-
Once you have found a torrent file that has Alpha Bravo Charlie in 720p quality, you can either download it or stream it using your torrent client. To download it, you just need to click on the magnet link or download button on the torrent site and open it with your torrent client. Your torrent client will start downloading the file from other users who are sharing it. You can see the progress and speed of your download on your torrent client.
-
To stream Alpha Bravo Charlie in 720p quality, you will need a torrent client that supports streaming, such as uTorrent Web or BitTorrent Web. These clients allow you to watch videos directly from your browser without downloading them first. To stream Alpha Bravo Charlie in 720p quality, you just need to click on the play button on the torrent site and open it with your torrent client. Your torrent client will start buffering the video from other users who are sharing it. You can see the progress and speed of your streaming on your torrent client.
-
Conclusion
-
Alpha Bravo Charlie is one of the best Pakistani dramas ever made, and watching it in 720p quality will enhance your viewing experience. You can either download or stream Alpha Bravo Charlie in 720p quality using torrent links from reliable torrent sites. You will need a torrent client to do so, and you should use a VPN service if necessary. We hope this guide helps you watch Alpha Bravo Charlie in 720p quality and enjoy this classic drama series.
-
FAQs
-
Here are some frequently asked questions about Alpha Bravo Charlie and torrenting:
-
What is Alpha Bravo Charlie about?
-
Alpha Bravo Charlie is a Pakistani drama series that follows the lives and adventures of three army officers, Faraz, Kashif and Gulsher, who are also known by their code names Alpha, Bravo and Charlie. The drama is a mix of comedy, romance, action and patriotism, and it showcases the challenges and sacrifices of the Pakistani army. The drama was aired in 1998 and has 14 episodes.
-
Who are the actors in Alpha Bravo Charlie?
-
The main actors in Alpha Bravo Charlie are:
-
-- Faraz Ahmed as Faraz Khan (Alpha)
-- Qasim Khan as Kashif Kirmani (Bravo)
-- Abdullah Mahmood as Gulsher Khan (Charlie)
-- Ayub Khoso as Brigadier Faraz
-- Shahnaz Khwaja as Shehnaz
-- Kiran Butt as Shahnaz's friend
-- Maria Wasti as Shahnaz's sister
-- Samina Ahmed as Shahnaz's mother
-- Mehboob Alam as Gulsher's father
-- Seemi Raheel as Gulsher's mother
-
-
What is torrenting?
-
Torrenting is a method of downloading or streaming files from other users who are sharing them on a peer-to-peer network. Torrenting uses a software called a torrent client to connect to other users who have the file you want and download or stream it from them. Torrenting is a fast and efficient way of accessing large files such as movies, TV shows, games and music.
-
Is torrenting legal?
-
Torrenting itself is not illegal, but downloading or streaming copyrighted content without permission is illegal. Therefore, you should be careful while torrenting and only use it for legal purposes. You should also use a VPN service to protect your privacy and security while torrenting. A VPN service encrypts your internet traffic and hides your IP address from other users and authorities.
-
What are the benefits of watching Alpha Bravo Charlie in 720p quality?
-
Watching Alpha Bravo Charlie in 720p quality will give you a better viewing experience than watching it in lower resolutions. 720p quality means that the video has a resolution of 1280 x 720 pixels, which is high-definition (HD) quality. This means that the video will have more details, clarity and sharpness than lower-quality videos. You will be able to enjoy the drama more and appreciate its cinematography and production values.
-
Conclusion
-
Alpha Bravo Charlie is a classic Pakistani drama series that you should not miss. It is one of the best dramas ever produced by PTV and it has a loyal fan base even today. You can watch Alpha Bravo Charlie in 720p quality using torrent links from reliable torrent sites. You will need a torrent client and a VPN service to do so. We hope this article helps you watch Alpha Bravo Charlie in 720p quality and enjoy this masterpiece of Pakistani television.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/fatiXbelha/sd/Download Apk Live Bar Bar Indonesia.md b/spaces/fatiXbelha/sd/Download Apk Live Bar Bar Indonesia.md
deleted file mode 100644
index a45bd744d1c249de031264de1468b167244cf3b1..0000000000000000000000000000000000000000
--- a/spaces/fatiXbelha/sd/Download Apk Live Bar Bar Indonesia.md
+++ /dev/null
@@ -1,89 +0,0 @@
-
-
Download APK Live Bar Bar Indonesia: What You Need to Know
-
If you are looking for an app that can provide you with live streaming entertainment, income, and socialization opportunities, you may have heard of APK live bar bar Indonesia. This app is popular among many Indonesian users who enjoy watching or hosting live shows that feature various content, from music and dance to games and chat. However, before you download this app, there are some things that you need to know about its benefits, risks, and alternatives. In this article, we will give you a comprehensive guide on how to download APK live bar bar Indonesia safely and easily, as well as some suggestions for other apps that you can try.
-
Benefits of Using APK Live Bar Bar Indonesia
-
One of the main reasons why many people use APK live bar bar Indonesia is because it offers them several benefits, such as:
-
download apk live bar bar indonesia
Download File 🗸 https://urllie.com/2uNH5e
-
-- Entertainment: You can enjoy various live streaming content from hosts around the world, who showcase their talents, skills, personalities, and even their bodies. You can watch anything from singing and dancing to gaming and chatting, depending on your preferences and moods. You can also browse through different categories and filters to find the content that suits you best.
-- Income: You can earn money by becoming a host or sending gifts to your favorite hosts. If you have something interesting or attractive to offer, you can create your own live show and attract viewers who will support you with gifts or tips. Alternatively, you can also show your appreciation to the hosts that you like by sending them gifts or coins that they can exchange for real money.
-- Socialization: You can chat and interact with hosts and other users, make new friends and connections, and even find romance or love. You can send messages, emojis, stickers, voice notes, or video calls to communicate with others. You can also join groups or communities that share your interests or hobbies.
-
-
Risks of Using APK Live Bar Bar Indonesia
-
However, using APK live bar bar Indonesia also comes with some risks and challenges that you need to be aware of, such as:
-
-- Security: Beware of viruses and malware that may harm your device or steal your data. Since this app is not available on the official Google Play Store or App Store, you have to download it from third-party sources that may not be trustworthy or secure. Therefore, you need to be careful when choosing where to download the app, and check the app's details, ratings, reviews, and permissions before installing it. You should also use a reliable antivirus software to scan the app and your device regularly.
-- Legality: Be aware of the laws and regulations regarding online content and gambling in Indonesia. Since this app contains some adult or explicit content, as well as a feature that allows you to play a slot game and win real money, it may violate some of the rules or norms that govern the Indonesian internet space. Therefore, you need to be cautious and discreet when using the app, and avoid any legal troubles or penalties that may arise from your activities.
-- Morality: Be responsible and respectful when using the app, avoid exposing yourself or others to inappropriate or harmful content. Since this app gives you a lot of freedom and flexibility to create or consume live streaming content, you may encounter some situations or scenarios that are not suitable for your age, values, or beliefs. Therefore, you need to be mindful and respectful of yourself and others, and avoid any content that may offend, harm, or exploit anyone.
-
-
How to Download APK Live Bar Bar Indonesia Safely and Easily
-
If you have decided to download APK live bar bar Indonesia, you need to follow these steps to do it safely and easily:
-
-- Step 1: Find a reliable source for downloading the app, such as JalanTikus or Dafunda Download. These are some of the websites that offer APK live bar bar Indonesia for free and without any registration or verification. You can access these websites from your browser or use a VPN service if they are blocked by your internet provider.
-- Step 2: Check the app's details, ratings, reviews, and permissions before downloading it. You can see the app's name, size, version, developer, category, description, screenshots, ratings, reviews, and permissions on the website. You should read them carefully and make sure that they match your expectations and needs. You should also compare them with other sources or apps to verify their authenticity and quality.
-- Step 3: Install the app on your device and follow the instructions to create an account and start using it. You can download the app by clicking on the download button or scanning the QR code on the website. You may need to enable the installation of apps from unknown sources on your device settings. After downloading the app, you can open it and follow the instructions to create an account with your phone number or email address. You can also choose your username, password, avatar, gender, and birthday. Then, you can start exploring the app and enjoy its features.
-
-
Alternatives to APK Live Bar Bar Indonesia
-
If you are not satisfied with APK live bar bar Indonesia or want to try something different, you can also check out these alternatives that offer similar or better live streaming experiences:
-
-- Wish Live: A global live streaming platform with hosts from various countries and genres. You can watch live shows from singers, dancers, gamers, comedians, models, and more. You can also chat with them and send them gifts or coins. You can also become a host yourself and earn money from your fans.
-- Para Me: A social networking app that allows you to meet and chat with people from different cultures and backgrounds. You can join various chat rooms based on your interests or preferences, such as music, movies, sports, travel, etc. You can also send voice messages, video calls, gifts, or stickers to express yourself.
-- TATA Live: A live streaming app that offers both adult and non-adult content, as well as a slot game feature that lets you win real money. You can watch live shows from sexy or cute hosts who will entertain you with their charm and skills. You can also play a slot game with them and win cash prizes or gifts.
-
-
Conclusion
-
In conclusion, APK live bar bar Indonesia is an app that provides live streaming entertainment, income, and socialization opportunities, but also comes with some risks and challenges. You need to be careful and responsible when using the app, and consider other alternatives if you want a safer or more diverse experience. We hope that this article has given you a comprehensive guide on how to download APK live bar bar Indonesia safely and easily, as well as some suggestions for other apps that you can try.
-
download apk live bar bar indonesia no sensor 2023
-download apk live bar bar indonesia unlock room 2023
-download apk live bar bar indonesia gratis tanpa bayar
-download apk live bar bar indonesia terbaru 2023
-download apk live bar bar indonesia penghasil uang
-download apk live bar bar indonesia terparah 2023
-download apk live bar bar indonesia mod 2023
-download apk live bar bar indonesia bebas parah
-download apk live bar bar indonesia tanpa banned
-download apk live bar bar indonesia anti blokir
-download apk live streaming bar bar indonesia 2023
-download apk live streaming bar bar indonesia no sensor
-download apk live streaming bar bar indonesia unlock room
-download apk live streaming bar bar indonesia gratis
-download apk live streaming bar bar indonesia terbaru
-download apk live streaming bar bar indonesia penghasil uang
-download apk live streaming bar bar indonesia terparah
-download apk live streaming bar bar indonesia mod
-download apk live streaming bar bar indonesia bebas parah
-download apk live streaming bar bar indonesia tanpa banned
-download wish live apk live streaming hot bebas parah di indonesia 2023
-download para me apk live streaming hot bebas parah di indonesia 2023
-download tata live apk live streaming hot bebas parah di indonesia 2023
-download bling2 live apk live streaming hot bebas parah di indonesia 2023
-download matok live apk live streaming hot bebas parah di indonesia 2023
-download mico go live streaming hot bebas parah di indonesia 2023
-download buzzcast sebelumnya facecast hot bebas parah di indonesia 2023
-download kpn tv hot bebas parah di indonesia 2023
-download mliveu hot live show bebas parah di indonesia 2023
-cara mudah download aplikasi live streaming hot bebas parah di indonesia 2023
-tips aman menggunakan aplikasi live streaming hot bebas parah di indonesia 2023
-daftar aplikasi live streaming hot bebas parah terbaik di indonesia 2023
-rekomendasi aplikasi live streaming hot bebas parah paling populer di indonesia 2023
-review aplikasi live streaming hot bebas parah terbaru di indonesia 2023
-panduan lengkap aplikasi live streaming hot bebas parah terlengkap di indonesia 2023
-situs web terpercaya untuk download aplikasi live streaming hot bebas parah di indonesia 2023
-link alternatif untuk download aplikasi live streaming hot bebas parah di indonesia 2023
-kode undangan untuk masuk aplikasi live streaming hot bebas parah di indonesia 2023
-trik mendapatkan koin gratis di aplikasi live streaming hot bebas parah di indonesia 2023
-cara menghasilkan uang dari aplikasi live streaming hot bebas parah di indonesia 2023
-
Frequently Asked Questions
-
-- Q: What is APK live bar bar Indonesia?
-- A: APK live bar bar Indonesia is an app that allows you to watch or host live shows that feature various content, from music and dance to games and chat.
-- Q: How can I download APK live bar bar Indonesia?
-- A: You can download APK live bar bar Indonesia from third-party websites, such as JalanTikus or Dafunda Download. You need to check the app's details, ratings, reviews, and permissions before downloading it. You also need to enable the installation of apps from unknown sources on your device settings.
-- Q: What are the benefits of using APK live bar bar Indonesia?
-- A: You can enjoy various live streaming content from hosts around the world, earn money by becoming a host or sending gifts to your favorite hosts, and chat and interact with hosts and other users.
-- Q: What are the risks of using APK live bar bar Indonesia?
-- A: You may encounter viruses and malware that may harm your device or steal your data, legal troubles or penalties that may arise from your online content or gambling activities, and inappropriate or harmful content that may offend, harm, or exploit yourself or others.
-- Q: What are some alternatives to APK live bar bar Indonesia?
-- A: You can try other apps that offer similar or better live streaming experiences, such as Wish Live, Para Me, or TATA Live.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/fatiXbelha/sd/Download Tank Heroes Mod APK an1 - The Most Fun and Exciting Tank Game Ever.md b/spaces/fatiXbelha/sd/Download Tank Heroes Mod APK an1 - The Most Fun and Exciting Tank Game Ever.md
deleted file mode 100644
index f202f70b419c05f89a68502bf3766e2423e26e66..0000000000000000000000000000000000000000
--- a/spaces/fatiXbelha/sd/Download Tank Heroes Mod APK an1 - The Most Fun and Exciting Tank Game Ever.md
+++ /dev/null
@@ -1,109 +0,0 @@
-
-
Download Tank Heroes Mod APK AN1: A Guide for Tank Lovers
-
If you are a fan of tank games, you might have heard of Tank Heroes, a 3D action game that lets you blast your enemies with cannons, heat seekers, howitzers, and more. But did you know that you can download Tank Heroes mod apk an1 and enjoy unlimited ammo, unlocked tanks, and other perks? In this article, we will tell you everything you need to know about this amazing game and how to download and install its modded version.
-
download tank heroes mod apk an1
DOWNLOAD --->>> https://urllie.com/2uNBeP
-
What is Tank Heroes?
-
Tank Heroes is a fast-paced 3D action game developed by Clapfoot Inc. It is available for Android and iOS devices. In this game, you can choose from a variety of tanks and weapons to fight against treacherous enemies in different environments. You can also customize your tank with different skins and stickers. The game has two modes: campaign and survival. In campaign mode, you have to complete missions and objectives to advance through the levels. In survival mode, you have to survive as long as possible against endless waves of enemies.
-
Features of Tank Heroes
-
Some of the features of Tank Heroes are:
-
-- Over 100 levels to play
-- Over 20 tanks to choose from
-- Over 10 weapons to equip
-- Realistic physics and graphics
-- Simple and intuitive controls
-- Online leaderboards and achievements
-
-
How to play Tank Heroes
-
The gameplay of Tank Heroes is simple and fun. You have to use the virtual joystick on the left side of the screen to move your tank and the buttons on the right side to fire your weapons. You can also switch between weapons by tapping on their icons. You have to aim at your enemies and avoid their shots. You can also use the environment to your advantage by hiding behind cover or using explosive barrels. You have to complete the objectives of each level to progress. You can also collect coins and stars to upgrade your tank and weapons.
-
Why download Tank Heroes mod apk an1?
-
Tank Heroes is a free game, but it has some limitations and drawbacks. For example, you have to watch ads to get extra coins or lives. You also have limited ammo for your weapons, which can run out quickly in intense battles. You also have to unlock new tanks and weapons by spending coins or watching videos. These things can make the game less enjoyable and more frustrating.
-
That's why downloading Tank Heroes mod apk an1 is a good idea. This is a modified version of the game that gives you unlimited ammo, unlocked tanks, weapons, skins, stickers, and more. You don't have to watch ads or spend money to enjoy the game fully. You can also play offline without any internet connection.
-
Benefits of Tank Heroes mod apk an1
-
Some of the benefits of downloading Tank Heroes mod apk an1 are:
-
-- You can fire your weapons without worrying about running out of ammo
-- You can choose any tank and weapon you want without unlocking them
-- You can customize your tank with any skin and sticker you like
-- You can play without ads or internet connection
-- You can have more fun and challenge in the game
-
-
How to download and install Tank Heroes mod apk an1
-
To download and install Tank Heroes mod apk an1, you need to follow these steps:
-
download tank heroes mod apk unlimited money
-download tank heroes mod apk latest version
-download tank heroes mod apk android 1
-download tank heroes mod apk free shopping
-download tank heroes mod apk revdl
-download tank heroes mod apk rexdl
-download tank heroes mod apk happymod
-download tank heroes mod apk no ads
-download tank heroes mod apk offline
-download tank heroes mod apk for pc
-download tank heroes mod apk for ios
-download tank heroes mod apk for windows 10
-download tank heroes mod apk for mac
-download tank heroes mod apk for laptop
-download tank heroes mod apk for chromebook
-download tank heroes hack mod apk
-download tank heroes premium mod apk
-download tank heroes pro mod apk
-download tank heroes vip mod apk
-download tank heroes full mod apk
-download tank heroes unlocked mod apk
-download tank heroes all tanks unlocked mod apk
-download tank heroes all levels unlocked mod apk
-download tank heroes all skins unlocked mod apk
-download tank heroes all weapons unlocked mod apk
-how to download tank heroes mod apk an1
-where to download tank heroes mod apk an1
-best site to download tank heroes mod apk an1
-safe site to download tank heroes mod apk an1
-trusted site to download tank heroes mod apk an1
-easy way to download tank heroes mod apk an1
-fast way to download tank heroes mod apk an1
-free way to download tank heroes mod apk an1
-legal way to download tank heroes mod apk an1
-working link to download tank heroes mod apk an1
-direct link to download tank heroes mod apk an1
-mediafire link to download tank heroes mod apk an1
-mega link to download tank heroes mod apk an1
-google drive link to download tank heroes mod apk an1
-dropbox link to download tank heroes mod apk an1
-zippyshare link to download tank heroes mod apk an1
-apkpure link to download tank heroes mod apk an1
-apkmirror link to download tank heroes mod apk an1
-apknite link to download tank heroes mod apk an1
-apktada link to download tank heroes mod apk an1
-
-- Go to https://an1.com/109 and download the Tank Heroes mod apk an1 file
-- Go to your device settings and enable the installation of apps from unknown sources
-- Locate the downloaded file and tap on it to install it
-- Launch the game and enjoy
-
-
Tips and tricks for Tank Heroes
-
To make the most out of Tank Heroes, you can use these tips and tricks:
-
Choose your tank wisely
-
There are over 20 tanks to choose from in Tank Heroes, each with different stats and abilities. Some tanks are faster, some are more durable, some have more firepower, and some have special skills. You should choose a tank that suits your playstyle and the level you are playing. For example, if you are playing a level with narrow spaces, you might want to use a smaller tank that can maneuver easily. If you are playing a level with long distances, you might want to use a tank that has a long-range weapon.
-
Upgrade your tank and weapons
-
As you play Tank Heroes, you will earn coins and stars that you can use to upgrade your tank and weapons. Upgrading your tank will increase its health, speed, armor, and skill. Upgrading your weapons will increase their damage, range, accuracy, and reload speed. You should upgrade your tank and weapons regularly to keep up with the increasing difficulty of the levels. You can also use the mod apk an1 to get unlimited coins and stars for free.
-
Use cover and tactics
-
Tank Heroes is not just a mindless shooting game. You also need to use cover and tactics to survive and win. You should avoid exposing yourself to enemy fire and use the environment to your advantage. You can hide behind walls, buildings, trees, rocks, or other objects to protect yourself from enemy shots. You can also use explosive barrels, mines, or other traps to damage or destroy your enemies. You should also move around and flank your enemies when possible. You should also use your tank's skill wisely and at the right time.
-
Conclusion
-
Tank Heroes is a fun and addictive 3D action game that will keep you entertained for hours. You can download Tank Heroes mod apk an1 and enjoy unlimited ammo, unlocked tanks, weapons, skins, stickers, and more. You can also follow our tips and tricks to improve your skills and performance in the game. Download Tank Heroes mod apk an1 today and unleash your inner tank hero!
-
FAQs
-
Here are some frequently asked questions about Tank Heroes mod apk an1:
-
-- Is Tank Heroes mod apk an1 safe to download?
-Yes, Tank Heroes mod apk an1 is safe to download and install. It does not contain any viruses or malware that can harm your device or data. However, you should always download it from a trusted source like https://an1.com/109 , which is a reliable and popular website for modded games and apps.
-- Do I need to root or jailbreak my device to use Tank Heroes mod apk an1?
-No, you do not need to root or jailbreak your device to use Tank Heroes mod apk an1. You can simply download and install it on your device without any hassle. However, you should make sure that you have enough storage space and battery life before installing it.
-- Will I get banned from the game if I use Tank Heroes mod apk an1?
-No, you will not get banned from the game if you use Tank Heroes mod apk an1. The mod apk an1 is designed to bypass the game's security system and prevent detection. However, you should still be careful and avoid using it in online mode or leaderboards, as that might raise suspicion from other players or developers.
-- Can I update Tank Heroes mod apk an1?
-Yes, you can update Tank Heroes mod apk an1 whenever there is a new version available. However, you should always download the latest version from the same source as before, as different sources might have different features or compatibility issues. You should also backup your game data before updating, as some updates might erase your progress or settings.
-- Can I play Tank Heroes mod apk an1 with my friends?
-Yes, you can play Tank Heroes mod apk an1 with your friends, as long as they also have the same mod apk an1 installed on their devices. You can connect with them via Bluetooth or Wi-Fi and enjoy the game together. However, you should not play with players who have the original version of the game, as that might cause errors or crashes.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/fatiXbelha/sd/Download Vice Online MOD APK 0.3.95 and Enjoy GTA-style Gameplay with Unlimited Money.md b/spaces/fatiXbelha/sd/Download Vice Online MOD APK 0.3.95 and Enjoy GTA-style Gameplay with Unlimited Money.md
deleted file mode 100644
index 209f0271911491e3286e097f378c6d0d53889c56..0000000000000000000000000000000000000000
--- a/spaces/fatiXbelha/sd/Download Vice Online MOD APK 0.3.95 and Enjoy GTA-style Gameplay with Unlimited Money.md
+++ /dev/null
@@ -1,108 +0,0 @@
-
-
Vice Online Mod APK 0.3.95 Unlimited Money
-
If you are looking for a fun and exciting open-world sandbox mobile game, then you should check out Vice Online. This game lets you explore a huge city with your friends and other players from around the world. You can customize your character, vehicles, and weapons, and participate in various activities, such as races, heists, and hangouts. But what if you want to enjoy the game without any limitations or restrictions? Well, that's where Vice Online Mod APK comes in handy. In this article, we will tell you everything you need to know about this modded version of the game, including its features, benefits, and how to download and install it on your device. We will also give you some tips and tricks on how to play the game better. So, without further ado, let's get started!
-
vice online mod apk 0.3.95 unlimited money
Download ↔ https://urllie.com/2uNHEl
-
What is Vice Online?
-
Vice Online is a 3D multiplayer open-world sandbox mobile game developed by Jarvi Games Ltd. It is inspired by the popular Grand Theft Auto series, but with its own unique features and gameplay options. In this game, you can explore a massive city playground, filled with luxury cars, boats, aircraft, and dozens of exciting activities. You can interact with the virtual world and other players in various ways, from participating in thrilling races and intense heists to simply hanging out with your friends and enjoying the scenery.
-
As you play the game, you will discover that Vice Online offers a wide variety of roles to play. Whether you prefer the life of a laborer, businessman, taxi driver, or racer, there are endless possibilities to live out your dreams. You can also customize your character, vehicles, and weapons to create a unique look and playstyle that fits your personality. The game also features realistic weapons, such as pistols, rifles, shotguns, grenades, and more.
-
The best part about Vice Online is that it is a multiplayer game that you can enjoy with your friends and other players from around the world. You can join voice chat and communicate with your teammates in real-time during multiplayer events. You can also create or join gangs and compete with other gangs for territory and reputation. With its immersive gaming environment, Vice Online offers you a unique and action-packed multiplayer gaming experience.
-
Why download Vice Online Mod APK?
-
While Vice Online is a free-to-play game that you can download from Google Play Store or APKCombo, it also has some limitations and drawbacks that might affect your gaming experience. For example, you might need to spend real money to buy in-game currency or items that can help you progress faster or unlock more features. You might also encounter annoying ads that pop up while you play the game. Moreover, some features or options might be locked or restricted unless you meet certain requirements or conditions.
-
vice online mod apk latest version 0.3.95 free download
-vice online hack apk 0.3.95 unlimited money and gems
-vice online modded apk 0.3.95 all items unlocked
-vice online cheat apk 0.3.95 no root required
-vice online premium apk 0.3.95 unlimited coins and diamonds
-vice online cracked apk 0.3.95 full access
-vice online mod menu apk 0.3.95 unlimited everything
-vice online vip mod apk 0.3.95 free shopping
-vice online pro mod apk 0.3.95 unlimited cash and gold
-vice online mega mod apk 0.3.95 god mode and one hit kill
-vice online mod apk 0.3.95 unlimited money download for android
-vice online hack apk 0.3.95 unlimited money and gems for ios
-vice online modded apk 0.3.95 all items unlocked for pc
-vice online cheat apk 0.3.95 no root required for mac
-vice online premium apk 0.3.95 unlimited coins and diamonds for windows
-vice online cracked apk 0.3.95 full access for linux
-vice online mod menu apk 0.3.95 unlimited everything for chromebook
-vice online vip mod apk 0.3.95 free shopping for firestick
-vice online pro mod apk 0.3.95 unlimited cash and gold for smart tv
-vice online mega mod apk 0.3.95 god mode and one hit kill for xbox one
-how to install vice online mod apk 0.3.95 unlimited money on android
-how to install vice online hack apk 0.3.95 unlimited money and gems on ios
-how to install vice online modded apk 0.3.95 all items unlocked on pc
-how to install vice online cheat apk 0.3.95 no root required on mac
-how to install vice online premium apk 0.3.95 unlimited coins and diamonds on windows
-how to install vice online cracked apk 0.3.95 full access on linux
-how to install vice online mod menu apk 0.3.95 unlimited everything on chromebook
-how to install vice online vip mod apk 0.3.95 free shopping on firestick
-how to install vice online pro mod apk 0.3.95 unlimited cash and gold on smart tv
-how to install vice online mega mod apk 0.3.95 god mode and one hit kill on xbox one
-where to download vice online mod apk 0.3.95 unlimited money for free
-where to download vice online hack apk 0.3.95 unlimited money and gems for free
-where to download vice online modded apk 0.3.95 all items unlocked for free
-where to download vice online cheat apk 0.3.95 no root required for free
-where to download vice online premium apk 0.3.95 unlimited coins and diamonds for free
-where to download vice online cracked apk 0.3.95 full access for free
-where to download vice online mod menu apk 0.3.95 unlimited everything for free
-where to download vice online vip mod apk 0
-
That's why many players prefer to use Vice Online Mod APK instead of the original version of the game. This is a modified version of the game that gives you access to unlimited money, mega menu, no ads, and other features that can enhance your gameplay. Here are some of the benefits of using Vice Online Mod APK:
-
Unlimited money
-
One of the main advantages of using Vice Online Mod APK is that it gives you unlimited money that you can use to buy anything you want in the game. You don t need to worry about running out of cash or spending real money to get more. You can buy any vehicle, weapon, item, or upgrade that you want without any hassle. You can also use the money to customize your character and vehicles to your liking. With unlimited money, you can enjoy the game without any limitations or restrictions.
-
Mega menu
-
Another benefit of using Vice Online Mod APK is that it gives you access to a mega menu that allows you to control various aspects of the game. You can use the mega menu to enable or disable different features, such as god mode, infinite ammo, no recoil, no spread, speed hack, teleport, and more. You can also use the mega menu to change the weather, time, gravity, and other settings in the game. The mega menu gives you the power to customize your gameplay and have more fun in the game.
-
No ads
-
One of the most annoying things about playing free-to-play games is that they often have ads that interrupt your gameplay and ruin your immersion. These ads can be very distracting and frustrating, especially when they pop up at the worst possible moments. Fortunately, with Vice Online Mod APK, you don't have to deal with any ads at all. The modded version of the game removes all the ads from the game, so you can play without any interruptions or distractions. You can enjoy the game without any annoying ads.
-
How to download and install Vice Online Mod APK?
-
Now that you know the benefits of using Vice Online Mod APK, you might be wondering how to download and install it on your device. Well, don't worry, because we have got you covered. Here are the steps that you need to follow to get the modded version of the game on your device:
-
Download the APK file from a trusted source
-
The first thing that you need to do is to download the APK file of Vice Online Mod APK from a trusted source. There are many websites that offer modded APK files for various games, but not all of them are safe and reliable. Some of them might contain viruses or malware that can harm your device or steal your personal information. Therefore, you need to be careful and choose a reputable website that provides genuine and verified modded APK files.
-
One of the websites that we recommend is [APKCombo], which is a popular and trusted platform that offers free and safe APK downloads for various games and apps. You can download Vice Online Mod APK from this website by following these steps:
-
-- Go to [APKCombo] on your browser.
-- Type "Vice Online Mod APK" in the search bar and hit enter.
-- Select the latest version of Vice Online Mod APK from the results.
-- Click on the "Download APK" button and wait for the download to complete.
-
-
Enable unknown sources on your device settings
-
The next thing that you need to do is to enable unknown sources on your device settings. This is a necessary step because by default, most Android devices do not allow installing apps from sources other than Google Play Store. Therefore, you need to enable this option to install Vice Online Mod APK on your device.
-
To enable unknown sources on your device settings, follow these steps:
-
-- Go to your device settings and look for "Security" or "Privacy" options.
-- Find and tap on "Unknown sources" or "Install unknown apps" option.
-- Toggle on or allow this option to enable it.
-
-
Install the APK file and launch the game
-
The final thing that you need to do is to install the APK file and launch the game. This is a simple and easy process that should not take much time. To install the APK file and launch the game, follow these steps:
-
-- Locate the downloaded APK file on your device storage or file manager.
-- Tap on the APK file and follow the instructions on the screen to install it.
-- Once the installation is complete, tap on "Open" or find the game icon on your home screen or app drawer.
-- Launch the game and enjoy playing with unlimited money, mega menu, no ads, and other features.
-
-
Tips and tricks for playing Vice Online
-
Vice Online is a fun and exciting game that offers you a lot of options and possibilities to enjoy. However, if you want to make the most out of your gaming experience, you might want to follow some tips and tricks that can help you play better. Here are some of them:
-
Explore the city and find hidden items
-
One of the best things about Vice Online is that it has a huge and detailed city that you can explore and discover. There are many hidden items and secrets that you can find in the city, such as weapons, money, health packs, armor, and more. These items can help you in your missions or activities, or simply add more fun to your gameplay. You can also find easter eggs and references to other games or movies in the city, which can make you smile or laugh. So, don't be afraid to wander around the city and look for hidden items and surprises.
-
Customize your character and vehicles to suit your style
-
Another great thing about Vice Online is that it allows you to customize your character and vehicles to suit your style and personality. You can change your character's appearance, clothes, accessories, tattoos, and more. You can also modify your vehicles, such as cars, bikes, boats, and planes, with different colors, decals, parts, and features. You can create a unique look and playstyle that reflects your identity and preferences. You can also show off your character and vehicles to other players and impress them with your creativity and style.
-
Join multiplayer events and voice chat with other players
-
The most fun thing about Vice Online is that it is a multiplayer game that you can enjoy with your friends and other players from around the world. You can join multiplayer events and voice chat with other players in real-time during the game. You can participate in various activities, such as races, heists, gang wars, deathmatches, and more. You can also create or join gangs and compete with other gangs for territory and reputation. You can also chat with other players using the voice chat feature and make new friends or enemies. Playing with other players can make the game more exciting and challenging.
-
Conclusion
-
Vice Online is a 3D multiplayer open-world sandbox mobile game that lets you explore a huge city with your friends and other players from around the world. You can customize your character, vehicles, and weapons, and participate in various activities, such as races, heists, hangouts, and more. However, if you want to enjoy the game without any limitations or restrictions, you should download Vice Online Mod APK. This is a modified version of the game that gives you access to unlimited money, mega menu, no ads, and other features that can enhance your gameplay. You can download Vice Online Mod APK from [APKCombo] by following the steps that we have provided in this article. We have also given you some tips and tricks on how to play the game better. So, what are you waiting for? Download Vice Online Mod APK now and have fun!
-
FAQs
-
Here are some of the frequently asked questions about Vice Online Mod APK:
-
-- Is Vice Online Mod APK safe to use?
-Yes, Vice Online Mod APK is safe to use as long as you download it from a trusted source like [APKCombo]. However, you should always be careful when downloading modded APK files from unknown sources as they might contain viruses or malware that can harm your device or steal your personal information.
-- Do I need to root my device to use Vice Online Mod APK?
-No, you don't need to root your device to use Vice Online Mod APK. You just need to enable unknown sources on your device settings and install the APK file as usual.
-- Will I get banned for using Vice Online Mod APK?
-There is always a risk of getting banned for using modded APK files for any game. However, we have not heard of any reports of players getting banned for using Vice Online Mod APK so far. However, you should always use it at your own risk and discretion.
-- Can I play online with other players using Vice Online Mod APK?
-Yes, you can play online with other players using Vice Online Mod APK. However, you might encounter some compatibility issues or glitches with some features or options in the game. You might also face some unfair advantages or disadvantages against other players who are using the original version of the game.
-- Can I update Vice Online Mod APK?
-No, you cannot update Vice Online Mod APK from Google Play Store or APKCombo as it is a modded version of the game. If you want to update the game to the latest version, you will need to download the new modded APK file from a trusted source again.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/fb700/chatglm-fitness-RLHF/request_llm/README.md b/spaces/fb700/chatglm-fitness-RLHF/request_llm/README.md
deleted file mode 100644
index 545bc1ffba8b79a49d994cfedcc2a787475181b2..0000000000000000000000000000000000000000
--- a/spaces/fb700/chatglm-fitness-RLHF/request_llm/README.md
+++ /dev/null
@@ -1,79 +0,0 @@
-# 如何使用其他大语言模型
-
-## ChatGLM
-
-- 安装依赖 `pip install -r request_llm/requirements_chatglm.txt`
-- 修改配置,在config.py中将LLM_MODEL的值改为"chatglm"
-
-``` sh
-LLM_MODEL = "chatglm"
-```
-- 运行!
-``` sh
-`python main.py`
-```
-
-## Claude-Stack
-
-- 请参考此教程获取 https://zhuanlan.zhihu.com/p/627485689
- - 1、SLACK_CLAUDE_BOT_ID
- - 2、SLACK_CLAUDE_USER_TOKEN
-
-- 把token加入config.py
-
-## Newbing
-
-- 使用cookie editor获取cookie(json)
-- 把cookie(json)加入config.py (NEWBING_COOKIES)
-
-## Moss
-- 使用docker-compose
-
-## RWKV
-- 使用docker-compose
-
-## LLAMA
-- 使用docker-compose
-
-## 盘古
-- 使用docker-compose
-
-
----
-## Text-Generation-UI (TGUI,调试中,暂不可用)
-
-### 1. 部署TGUI
-``` sh
-# 1 下载模型
-git clone https://github.com/oobabooga/text-generation-webui.git
-# 2 这个仓库的最新代码有问题,回滚到几周之前
-git reset --hard fcda3f87767e642d1c0411776e549e1d3894843d
-# 3 切换路径
-cd text-generation-webui
-# 4 安装text-generation的额外依赖
-pip install accelerate bitsandbytes flexgen gradio llamacpp markdown numpy peft requests rwkv safetensors sentencepiece tqdm datasets git+https://github.com/huggingface/transformers
-# 5 下载模型
-python download-model.py facebook/galactica-1.3b
-# 其他可选如 facebook/opt-1.3b
-# facebook/galactica-1.3b
-# facebook/galactica-6.7b
-# facebook/galactica-120b
-# facebook/pygmalion-1.3b 等
-# 详情见 https://github.com/oobabooga/text-generation-webui
-
-# 6 启动text-generation
-python server.py --cpu --listen --listen-port 7865 --model facebook_galactica-1.3b
-```
-
-### 2. 修改config.py
-
-``` sh
-# LLM_MODEL格式: tgui:[模型]@[ws地址]:[ws端口] , 端口要和上面给定的端口一致
-LLM_MODEL = "tgui:galactica-1.3b@localhost:7860"
-```
-
-### 3. 运行!
-``` sh
-cd chatgpt-academic
-python main.py
-```
diff --git a/spaces/fb700/chatglm-fitness-RLHF/src/facerender/sync_batchnorm/__init__.py b/spaces/fb700/chatglm-fitness-RLHF/src/facerender/sync_batchnorm/__init__.py
deleted file mode 100644
index bc8709d92c610b36e0bcbd7da20c1eb41dc8cfcf..0000000000000000000000000000000000000000
--- a/spaces/fb700/chatglm-fitness-RLHF/src/facerender/sync_batchnorm/__init__.py
+++ /dev/null
@@ -1,12 +0,0 @@
-# -*- coding: utf-8 -*-
-# File : __init__.py
-# Author : Jiayuan Mao
-# Email : maojiayuan@gmail.com
-# Date : 27/01/2018
-#
-# This file is part of Synchronized-BatchNorm-PyTorch.
-# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
-# Distributed under MIT License.
-
-from .batchnorm import SynchronizedBatchNorm1d, SynchronizedBatchNorm2d, SynchronizedBatchNorm3d
-from .replicate import DataParallelWithCallback, patch_replication_callback
diff --git a/spaces/fclong/summary/fengshen/examples/pretrain_t5/pretrain_mt5_small_continue.sh b/spaces/fclong/summary/fengshen/examples/pretrain_t5/pretrain_mt5_small_continue.sh
deleted file mode 100644
index 0a539a7e6a7fb4b750b441df98dd49f166c3c49b..0000000000000000000000000000000000000000
--- a/spaces/fclong/summary/fengshen/examples/pretrain_t5/pretrain_mt5_small_continue.sh
+++ /dev/null
@@ -1,120 +0,0 @@
-#!/bin/bash
-#SBATCH --job-name=t5_cn_small_pretrain_v2
-#SBATCH --nodes=1
-#SBATCH --ntasks-per-node=8
-#SBATCH --gres=gpu:8 # number of gpus
-#SBATCH --cpus-per-task=30 # cpu-cores per task (>1 if multi-threaded tasks)
-#SBATCH -o %x-%j.log
-#SBATCH -e %x-%j.err
-#SBATCH -x dgx050
-
-set -x -e
-source activate base
-
-echo "START TIME: $(date)"
-MICRO_BATCH_SIZE=32
-ROOT_DIR=/cognitive_comp/ganruyi/experiments/t5_cn_small_pretrain_v2/
-
-ZERO_STAGE=1
-
-config_json="$ROOT_DIR/ds_config.t5_cn_small_pretrain_v2.$SLURM_JOBID.json"
-export MASTER_PORT=$[RANDOM%10000+30000]
-# Deepspeed figures out GAS dynamically from dynamic GBS via set_train_batch_size()
-
-cat <
$config_json
-{
- "zero_optimization": {
- "stage": 1
- },
- "fp16": {
- "enabled": true,
- "loss_scale": 0,
- "loss_scale_window": 1000,
- "initial_scale_power": 16,
- "hysteresis": 2,
- "min_loss_scale": 1
- },
- "optimizer": {
- "params": {
- "betas": [
- 0.9,
- 0.95
- ],
- "eps": 1e-08,
- "lr": 1e-04,
- "weight_decay": 0.01
- },
- "type": "AdamW"
- },
- "scheduler": {
- "type": "WarmupLR",
- "params":{
- "warmup_min_lr": 0,
- "warmup_max_lr": 1e-4,
- "warmup_num_steps": 10000
- }
- },
- "steps_per_print": 100,
- "gradient_clipping": 1,
- "train_micro_batch_size_per_gpu": $MICRO_BATCH_SIZE,
- "zero_allow_untested_optimizer": false
-}
-EOT
-
-export PL_DEEPSPEED_CONFIG_PATH=$config_json
-export TORCH_EXTENSIONS_DIR=/cognitive_comp/ganruyi/tmp/torch_extendsions
-# strategy=ddp
-strategy=deepspeed_stage_1
-
-TRAINER_ARGS="
- --max_epochs 1 \
- --gpus 8 \
- --num_nodes 1 \
- --strategy ${strategy} \
- --default_root_dir $ROOT_DIR \
- --dirpath $ROOT_DIR/ckpt \
- --save_top_k 3 \
- --every_n_train_steps 0 \
- --monitor train_loss \
- --mode min \
- --save_last \
- --val_check_interval 0.01 \
- --preprocessing_num_workers 20 \
-"
-# --accumulate_grad_batches 8 \
-DATA_DIR=wudao_180g_mt5_tokenized
-
-DATA_ARGS="
- --train_batchsize $MICRO_BATCH_SIZE \
- --valid_batchsize $MICRO_BATCH_SIZE \
- --train_data ${DATA_DIR} \
- --train_split_size 0.999 \
- --max_seq_length 1024 \
-"
-
-MODEL_ARGS="
- --pretrained_model_path /cognitive_comp/ganruyi/experiments/t5_cn_small_pretrain/Randeng-T5-77M \
- --learning_rate 1e-4 \
- --weight_decay 0.1 \
- --keep_tokens_path /cognitive_comp/ganruyi/hf_models/t5_cn_small/sentencepiece_cn_keep_tokens.json \
-"
-# --resume_from_checkpoint /cognitive_comp/ganruyi/fengshen/t5_cn_small_pretrain/ckpt/last.ckpt \
-
-SCRIPTS_PATH=/cognitive_comp/ganruyi/Fengshenbang-LM/fengshen/examples/pretrain_t5/pretrain_t5.py
-
-export CMD=" \
- $SCRIPTS_PATH \
- $TRAINER_ARGS \
- $MODEL_ARGS \
- $DATA_ARGS \
- "
-
-echo $CMD
-
-SINGULARITY_PATH=/cognitive_comp/ganruyi/pytorch21_06_py3_docker_image_v2.sif
-
-# to debug - add echo (it exits and prints what it would have launched)
-#run_cmd="$PY_LAUNCHER $CMD"
-# salloc --nodes=1 --gres=gpu:2 --cpus-per-gpu=20 -t 24:00:00
-clear; srun singularity exec --nv -B /cognitive_comp/:/cognitive_comp/ $SINGULARITY_PATH bash -c '/home/ganruyi/anaconda3/bin/python $CMD'
-# clear; srun --job-name=t5_cn_small_pretrain_v2 --jobid=153124 --nodes=1 --ntasks-per-node=8 --gres=gpu:8 --cpus-per-task=30 -o %x-%j.log -e %x-%j.err singularity exec --nv -B /cognitive_comp/:/cognitive_comp/ $SINGULARITY_PATH bash -c '/home/ganruyi/anaconda3/bin/python $CMD'
diff --git "a/spaces/fengmuxi/ChatGpt-Web/.github/ISSUE_TEMPLATE/\345\217\215\351\246\210\351\227\256\351\242\230.md" "b/spaces/fengmuxi/ChatGpt-Web/.github/ISSUE_TEMPLATE/\345\217\215\351\246\210\351\227\256\351\242\230.md"
deleted file mode 100644
index 73ad4b2c6a7546e3f051721dabb2c81de0d0ca25..0000000000000000000000000000000000000000
--- "a/spaces/fengmuxi/ChatGpt-Web/.github/ISSUE_TEMPLATE/\345\217\215\351\246\210\351\227\256\351\242\230.md"
+++ /dev/null
@@ -1,32 +0,0 @@
----
-name: 反馈问题
-about: 请告诉我们你遇到的问题
-title: "[Bug] "
-labels: ''
-assignees: ''
-
----
-
-**反馈须知**
-
-⚠️ 注意:不遵循此模板的任何帖子都会被立即关闭。
-
-请在下方中括号内输入 x 来表示你已经知晓相关内容。
-- [ ] 我确认已经在 [常见问题](https://github.com/Yidadaa/ChatGPT-Next-Web/blob/main/docs/faq-cn.md) 中搜索了此次反馈的问题,没有找到解答;
-- [ ] 我确认已经在 [Issues](https://github.com/Yidadaa/ChatGPT-Next-Web/issues) 列表(包括已经 Close 的)中搜索了此次反馈的问题,没有找到解答。
-- [ ] 我确认已经在 [Vercel 使用教程](https://github.com/Yidadaa/ChatGPT-Next-Web/blob/main/docs/vercel-cn.md) 中搜索了此次反馈的问题,没有找到解答。
-
-**描述问题**
-请在此描述你遇到了什么问题。
-
-**如何复现**
-请告诉我们你是通过什么操作触发的该问题。
-
-**截图**
-请在此提供控制台截图、屏幕截图或者服务端的 log 截图。
-
-**一些必要的信息**
- - 系统:[比如 windows 10/ macos 12/ linux / android 11 / ios 16]
- - 浏览器: [比如 chrome, safari]
- - 版本: [填写设置页面的版本号]
- - 部署方式:[比如 vercel、docker 或者服务器部署]
diff --git a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download Ship Sim 2019 Mod APK and Sail the Open World with Various Ships.md b/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download Ship Sim 2019 Mod APK and Sail the Open World with Various Ships.md
deleted file mode 100644
index 8bcc2af25864c6fb831e655bfd287e5ce675ad3b..0000000000000000000000000000000000000000
--- a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download Ship Sim 2019 Mod APK and Sail the Open World with Various Ships.md
+++ /dev/null
@@ -1,100 +0,0 @@
-
-Ship Sim 2019 APK Mod: A Realistic and Fun Ship Simulator Game
-Do you love sailing and exploring the seas? Do you want to experience what it's like to be a captain of a cruise ship, a cargo ship, or a fishing boat? If you answered yes, then you should try Ship Sim 2019, a realistic and fun ship simulator game that will let you enjoy the thrill of navigating different types of ships in various locations and weather conditions. And if you want to make your gameplay even more exciting, you should download Ship Sim 2019 APK Mod, a modified version of the game that will give you unlimited money, no ads, and easy installation. In this article, we will tell you everything you need to know about Ship Sim 2019 and its APK mod, including its features, benefits, and how to download and install it on your device.
-ship sim 2019 apk mod
Download Zip ✏ https://gohhs.com/2uPmQp
- What is Ship Sim 2019?
-Ship Sim 2019 is a ship simulator game developed by Ovidiu Pop, a popular developer of simulation games such as Bus Simulator, Car Simulator, and Truck Simulator. Ship Sim 2019 was released in 2018 and has since gained over 10 million downloads and positive reviews from players who praised its realistic graphics, physics, and gameplay. In Ship Sim 2019, you can choose from different types of ships, such as cruise ships, cargo ships, fishing boats, oil tankers, and even yachts, and sail them in various locations around the world, such as the Mediterranean Sea, the Caribbean Sea, the Indian Ocean, and more. You can also customize your ships with different colors, decals, flags, and accessories. As you play the game, you will encounter different weather conditions, such as sunny, cloudy, rainy, stormy, foggy, and snowy, that will affect your visibility and navigation. You will also have to complete various missions and challenges that will test your skills and earn you money and rewards.
- Features of Ship Sim 2019
-Ship Sim 2019 has many features that make it one of the best ship simulator games available on the market. Here are some of them:
- Different types of ships to choose from
-Ship Sim 2019 offers you a wide range of ships to choose from, each with its own characteristics and specifications. You can choose from cruise ships that can carry hundreds of passengers, cargo ships that can transport tons of goods, fishing boats that can catch fish and seafood, oil tankers that can deliver oil and gas, and yachts that can offer luxury and comfort. You can also buy new ships or upgrade your existing ones with the money you earn from completing missions.
- Stunning graphics and realistic physics
-Ship Sim 2019 boasts stunning graphics that will make you feel like you are really sailing on the sea. You will be amazed by the detailed models of the ships, the realistic water effects, the dynamic lighting and shadows, the beautiful landscapes and landmarks, and the animated animals and people. You will also experience realistic physics that will affect your ship's movement, speed, stability, buoyancy, and fuel consumption. You will have to adjust your steering, throttle, brakes, anchors, horns, lights, and other controls according to the situation.
- Open Open world exploration and dynamic weather
-
Ship Sim 2019 allows you to explore the open world of the sea, where you can discover different islands, ports, cities, and landmarks. You can also interact with other ships, such as ferries, cruise ships, cargo ships, fishing boats, and naval vessels, and communicate with them using the radio. You can also experience dynamic weather that will change randomly and affect your gameplay. You can sail in calm or rough seas, sunny or cloudy skies, day or night, and witness the sunrise and sunset.
- Multiple control options and camera views
-Ship Sim 2019 gives you multiple control options and camera views to suit your preference and style. You can control your ship using the tilt, buttons, or steering wheel modes, and adjust the sensitivity and feedback of each mode. You can also switch between different camera views, such as cockpit, deck, bow, stern, side, top, free, and cinematic, to get a better perspective of your ship and surroundings.
- What is Ship Sim 2019 APK Mod?
-Ship Sim 2019 APK Mod is a modified version of the original Ship Sim 2019 game that will give you some extra features and advantages that are not available in the official version. By downloading and installing Ship Sim 2019 APK Mod, you will be able to enjoy unlimited money, no ads, and easy installation on your device.
- Benefits of Ship Sim 2019 APK Mod
-Ship Sim 2019 APK Mod has many benefits that will make your gameplay more enjoyable and satisfying. Here are some of them:
-ship sim 2019 unlimited money apk mod
-ship sim 2019 hack apk mod download
-ship sim 2019 realistic ship simulator apk mod
-ship sim 2019 latest version apk mod
-ship sim 2019 cruise ship simulator apk mod
-ship sim 2019 mod apk android 1
-ship sim 2019 mod apk revdl
-ship sim 2019 mod apk happymod
-ship sim 2019 mod apk rexdl
-ship sim 2019 mod apk free shopping
-ship sim 2019 mod apk unlocked all ships
-ship sim 2019 mod apk offline
-ship sim 2019 mod apk no ads
-ship sim 2019 mod apk unlimited fuel
-ship sim 2019 mod apk unlimited gems
-ship sim 2019 mod apk unlimited xp
-ship sim 2019 mod apk obb
-ship sim 2019 mod apk data
-ship sim 2019 mod apk pure
-ship sim 2019 mod apk vip
-ship sim 2019 pro apk mod
-ship sim 2019 premium apk mod
-ship sim 2019 full apk mod
-ship sim 2019 mega mod apk
-ship sim 2019 god mode apk mod
-download game ship sim 2019 apk mod
-download ship sim 2019 v2.2.2 apk mod
-download ship sim 2019 v2.1.0 apk mod
-download ship sim 2019 v2.0.1 apk mod
-download ship sim 2019 v1.1.8 apk mod
-how to install ship sim 2019 apk mod
-how to play ship sim 2019 apk mod
-how to update ship sim 2019 apk mod
-how to get ship sim 2019 apk mod for free
-how to download ship sim 2019 apk mod on pc
-how to download ship sim 2019 apk mod on ios
-how to download ship sim 2019 apk mod on mac
-how to download ship sim 2019 apk mod on windows
-how to download ship sim 2019 apk mod on laptop
-how to download ship sim 2019 apk mod on chromebook
-best ships in ship sim 2019 apk mod
-best graphics in ship sim 2019 apk mod
-best controls in ship sim 2019 apk mod
-best missions in ship sim 2019 apk mod
-best features in ship sim 2019 apk mod
-best tips and tricks for ship sim 2019 apk mod
-best cheats and hacks for ship sim 2019 apk mod
-best reviews and ratings for ship sim 2019 apk mod
-best alternatives and similar games to ship sim 2019 apk mod
- Unlimited money to buy and upgrade ships
-One of the main benefits of Ship Sim 2019 APK Mod is that it will give you unlimited money that you can use to buy and upgrade any ship you want. You don't have to worry about completing missions or saving up money to get your dream ship. You can simply choose from the available ships in the shop and buy them with a single tap. You can also upgrade your ships with different colors, decals, flags, and accessories to make them look more attractive and unique.
- No ads to interrupt your gameplay
-Another benefit of Ship Sim 2019 APK Mod is that it will remove all the ads that normally appear in the official version of the game. You don't have to watch annoying video ads or banner ads that pop up on your screen and disrupt your gameplay. You can enjoy a smooth and uninterrupted gaming experience without any distractions or delays.
- Easy installation and compatibility
-A third benefit of Ship Sim 2019 APK Mod is that it is easy to install and compatible with most devices. You don't need to root your device or use any third-party app to install Ship Sim 2019 APK Mod. You just need to download the APK file from a trusted source and follow some simple steps to install it on your device. You also don't need to worry about compatibility issues or errors, as Ship Sim 2019 APK Mod works well with most Android devices.
- How to download and install Ship Sim 2019 APK Mod?
-If you are interested in downloading and installing Ship Sim 2019 APK Mod on your device, you can follow this step-by-step guide:
- Step-by-step guide for downloading and installing Ship Sim 2019 APK Mod
- Download the APK file from a trusted source
-The first step is to download the APK file of Ship Sim 2019 APK Mod from a trusted source. You can search for it on Google or use this link: [text]. Make sure you download the latest version of the APK file that is compatible with your device.
- Enable unknown sources on your device settings
-The second step is to enable unknown sources on your device settings. This will allow you to install apps from sources other than the Google Play Store. To do this, go to your device settings > security > unknown sources > enable. This may vary depending on your device model and Android version.
- Install the APK file and launch the game
-The third step is to install the APK file and launch the game. To do this, locate the downloaded APK file on your device storage > tap on it > install > open. Wait for a few seconds until the installation is complete and then launch the game from your app drawer or home screen.
- Conclusion
-Ship Sim 2019 is a realistic and fun ship simulator game that will let you enjoy the thrill of sailing different types of ships in various locations and weather conditions. It has many features that make it one of one of the best ship simulator games available on the market. However, if you want to enhance your gameplay and enjoy some extra benefits, you should download Ship Sim 2019 APK Mod, a modified version of the game that will give you unlimited money, no ads, and easy installation. In this article, we have explained what Ship Sim 2019 and its APK mod are, what their features and benefits are, and how to download and install them on your device. We hope you found this article helpful and informative. If you have any questions or feedback, please feel free to leave a comment below. Happy sailing!
- FAQs
-Here are some frequently asked questions about Ship Sim 2019 and its APK mod:
- Is Ship Sim 2019 APK Mod safe to download and install?
-Yes, Ship Sim 2019 APK Mod is safe to download and install, as long as you get it from a trusted source. However, you should always be careful when downloading and installing apps from unknown sources, as they may contain viruses or malware that can harm your device or compromise your privacy. You should also scan the APK file with an antivirus app before installing it.
- Is Ship Sim 2019 APK Mod legal to use?
-Ship Sim 2019 APK Mod is not legal to use, as it violates the terms and conditions of the original game. By using Ship Sim 2019 APK Mod, you are bypassing the in-app purchases and ads that support the developers of the game. You are also modifying the game files without their permission. Therefore, using Ship Sim 2019 APK Mod may result in legal action or account suspension by the game developers or Google Play Store.
- Does Ship Sim 2019 APK Mod require an internet connection?
-No, Ship Sim 2019 APK Mod does not require an internet connection to play. You can play the game offline without any problem. However, you may need an internet connection to download and install the APK file, as well as to access some online features of the game, such as leaderboards, achievements, and social media integration.
- Can I play Ship Sim 2019 APK Mod with friends?
-Yes, you can play Ship Sim 2019 APK Mod with friends, as the game supports multiplayer mode. You can join or create a room with up to four players and compete or cooperate with them in various missions and challenges. You can also chat with them using the voice or text chat feature.
- Can I update Ship Sim 2019 APK Mod?
-No, you cannot update Ship Sim 2019 APK Mod, as it is not compatible with the official updates of the game. If you try to update Ship Sim 2019 APK Mod, you may lose your progress or face errors or crashes. Therefore, you should avoid updating Ship Sim 2019 APK Mod and stick to the version you have installed.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download Sky Go for PC and Enjoy Unlimited Entertainment.md b/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download Sky Go for PC and Enjoy Unlimited Entertainment.md
deleted file mode 100644
index 0f4bac2cfd66b12a49d36ab538ca81d2ece70f40..0000000000000000000000000000000000000000
--- a/spaces/feregVcuzo/sanity-test-midi/checkpoint/Download Sky Go for PC and Enjoy Unlimited Entertainment.md
+++ /dev/null
@@ -1,117 +0,0 @@
-
-How to Download Sky Go on PC
-If you are a Sky TV subscriber, you might want to watch your favourite shows and movies on your PC. Whether you want to catch up on the latest episodes, binge-watch a series, or enjoy live sports, news, and entertainment, Sky Go is the app for you. In this article, we will show you how to download Sky Go on PC, whether you have a Windows or a Mac computer. We will also give you some tips and tricks on how to make the most of your Sky Go experience.
- What is Sky Go?
-Sky Go is a streaming service that allows you to watch Sky TV on your devices, such as smartphones, tablets, laptops, and PCs. You can access over 100 channels, including Sky Atlantic, Sky Cinema, Sky Sports, and more. You can also download shows and movies to watch offline, or watch live TV on the go. Sky Go is included at no extra cost to your Sky TV subscription. All you need is a compatible device and a Sky ID.
-download sky go pc
Download Zip »»» https://gohhs.com/2uPpqN
- Benefits of Sky Go
-Some of the benefits of using Sky Go are:
-
-- You can watch your favourite shows and movies anytime, anywhere.
-- You can watch on up to six devices per account, and register up to four devices at once.
-- You can download shows and movies to watch offline, or stream them online.
-- You can watch live TV on the go, or catch up on demand.
-- You can pause, rewind, and fast-forward live TV.
-- You can use the app as a remote control for your Sky Q box.
-
- Requirements for Sky Go
-To use Sky Go on your PC, you need to meet the following requirements:
-
-- You need a Sky TV subscription and a Sky ID.
-- You need a compatible device. For Windows, you need Windows 7 or higher. For Mac, you need Mac OS X 10.11 or higher.
-- You need a broadband connection of at least 2 Mbps for streaming and downloading.
-- You need at least 5 GB of free space on your device for downloading.
-
- How to Download Sky Go on Windows
-If you have a Windows PC, follow these steps to download and install Sky Go:
-
-Go to https://www.sky.com/watch/sky-go/windows and click on "Download now for Windows". This will start downloading the installer file for the Sky Go desktop app.
- Step 2: Download the Sky Go desktop app
-Once the download is complete, open the installer file and follow the instructions on the screen. You may need to accept some terms and conditions and choose a location for the app.
- Step 3: Install the Sky Go desktop app
-The installation process may take a few minutes. Once it is done, you will see a shortcut icon for the Sky Go desktop app on your desktop.
- Step 4: Sign in with your Sky ID
-Double-click on the icon to launch the app. You will be asked to sign in with your Sky ID. If you don't have one, you can create one here. Once you sign in, you can start watching your favourite shows and movies on your PC.
- How to Download Sky Go on Mac
-If you have a Mac computer, follow these steps to download and install Sky Go:
-How to download sky go app for pc
-Sky go desktop app windows 10 download
-Sky go download for laptop
-Sky go download for mac
-Sky go download for windows 7
-Sky go download offline
-Sky go download programmes to pc
-Sky go download shows
-Sky go installer for pc
-Sky go on pc without app
-Watch sky go on pc
-Watch sky tv on pc with sky go
-Best way to download sky go for pc
-Can I download sky go on my pc
-Can you download sky go on windows 10
-Download and install sky go on pc
-Download sky go app for windows 8
-Download sky go for pc free
-Download sky go for windows xp
-Download sky movies to pc with sky go
-Download sky sports on pc with sky go
-How do I download sky go on my laptop
-How to download and watch sky go on pc
-How to download movies from sky go to pc
-How to download programmes from sky go to pc
-How to download shows from sky go to pc
-How to install sky go on windows 10
-How to watch sky go offline on pc
-Is sky go available for pc
-Is there a sky go app for windows 10
-Sky go app for pc download link
-Sky go app for windows 10 free download
-Sky go desktop app not working on windows 10
-Sky go desktop app windows 7 download
-Sky go download error on pc
-Sky go download failed on pc
-Sky go download limit on pc
-Sky go download location on pc
-Sky go download manager for pc
-Sky go download not working on pc
-Sky go download problems on pc
-Sky go download quality on pc
-Sky go download size on pc
-Sky go for pc latest version download
-Sky go for windows 10 64 bit download
-Sky go offline mode for pc download
-
-Go to https://www.sky.com/watch/sky-go/mac and click on "Download now for Mac". This will start downloading the installer file for the Sky Go desktop app.
- Step 2: Download the Sky Go desktop app
-Once the download is complete, open the installer file and follow the instructions on the screen. You may need to accept some terms and conditions and choose a location for the app.
- Step 3: Install the Sky Go desktop app
-The installation process may take a few minutes. Once it is done, you will see a shortcut icon for the Sky Go desktop app on your dock.
- Step 4: Sign in with your Sky ID
-Click on the icon to launch the app. You will be asked to sign in with your Sky ID. If you don't have one, you can create one here. Once you sign in, you can start watching your favourite shows and movies on your Mac.
- How to Watch Sky TV on the Go with Sky Go
-Now that you have downloaded and installed Sky Go on your PC, you can enjoy watching Sky TV on the go. Here are some tips and tricks on how to use Sky Go:
- Tips and Tricks for Sky Go Users
-
-- To watch live TV, go to the "Live TV" tab and select a channel. You can also use the TV guide to see what's on and set reminders.
-- To watch on demand, go to the "On Demand" tab and browse by genre, channel, or A-Z. You can also use the search function to find what you want.
-- To download shows and movies, go to the "Downloads" tab and select what you want to download. You can also manage your downloads and delete them when you are done.
-- To watch offline, go to the "Downloads" tab and select what you want to watch. You can watch offline for up to 30 days after downloading.
-- To change your settings, go to the "Settings" tab and adjust your preferences. You can change your video quality, parental controls, subtitles, and more.
-- To register or unregister a device, go to https://skyid.sky.com/manage/devices and sign in with your Sky ID. You can register up to four devices at once and swap one device per month.
-
- Conclusion
-Sky Go is a great way to watch Sky TV on your PC. You can download and install Sky Go on Windows or Mac easily by following our guide. You can also use our tips and tricks to make the most of your Sky Go experience. Whether you want to watch live TV, catch up on demand, or download shows and movies to watch offline, Sky Go has it all. So what are you waiting for? Download Sky Go today and enjoy watching Sky TV on the go!
- Frequently Asked Questions
-
-- Q: How much does Sky Go cost?
-- A: Sky Go is included at no extra cost to your Sky TV subscription. You don't need to pay anything extra to use it.
-- Q: How many devices can I use with Sky Go?
-- A: You can use up to six devices per account with Sky Go. However, you can only register up to four devices at once and swap one device per month.
-- Q: What channels can I watch with Sky Go?
-- A: You can watch over 100 channels with Sky Go, depending on your Sky TV package. Some of the channels include Sky Atlantic, Sky Cinema, Sky Sports, and more.
-- Q: Can I watch Sky Go abroad?
-- A: Yes, you can watch Sky Go abroad in any of the EU countries. However, you may not be able to access some content due to licensing restrictions.
-- Q: Can I watch Sky Go on a smart TV?
-- A: No, you cannot watch Sky Go directly on a smart TV. However, you can use an HDMI cable or a casting device to connect your PC or laptop to your smart TV and watch it that way. 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/fffiloni/Video-Matting-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/backbone.py b/spaces/fffiloni/Video-Matting-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/backbone.py
deleted file mode 100644
index c8340c723fad8e07e2fc62daaa3912487498814b..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/Video-Matting-Anything/GroundingDINO/groundingdino/models/GroundingDINO/backbone/backbone.py
+++ /dev/null
@@ -1,221 +0,0 @@
-# ------------------------------------------------------------------------
-# Grounding DINO
-# url: https://github.com/IDEA-Research/GroundingDINO
-# Copyright (c) 2023 IDEA. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# ------------------------------------------------------------------------
-# Conditional DETR
-# Copyright (c) 2021 Microsoft. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# ------------------------------------------------------------------------
-# Copied from DETR (https://github.com/facebookresearch/detr)
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
-# ------------------------------------------------------------------------
-
-"""
-Backbone modules.
-"""
-
-from typing import Dict, List
-
-import torch
-import torch.nn.functional as F
-import torchvision
-from torch import nn
-from torchvision.models._utils import IntermediateLayerGetter
-
-from groundingdino.util.misc import NestedTensor, clean_state_dict, is_main_process
-
-from .position_encoding import build_position_encoding
-from .swin_transformer import build_swin_transformer
-
-
-class FrozenBatchNorm2d(torch.nn.Module):
- """
- BatchNorm2d where the batch statistics and the affine parameters are fixed.
-
- Copy-paste from torchvision.misc.ops with added eps before rqsrt,
- without which any other models than torchvision.models.resnet[18,34,50,101]
- produce nans.
- """
-
- def __init__(self, n):
- super(FrozenBatchNorm2d, self).__init__()
- self.register_buffer("weight", torch.ones(n))
- self.register_buffer("bias", torch.zeros(n))
- self.register_buffer("running_mean", torch.zeros(n))
- self.register_buffer("running_var", torch.ones(n))
-
- def _load_from_state_dict(
- self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
- ):
- num_batches_tracked_key = prefix + "num_batches_tracked"
- if num_batches_tracked_key in state_dict:
- del state_dict[num_batches_tracked_key]
-
- super(FrozenBatchNorm2d, self)._load_from_state_dict(
- state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs
- )
-
- def forward(self, x):
- # move reshapes to the beginning
- # to make it fuser-friendly
- w = self.weight.reshape(1, -1, 1, 1)
- b = self.bias.reshape(1, -1, 1, 1)
- rv = self.running_var.reshape(1, -1, 1, 1)
- rm = self.running_mean.reshape(1, -1, 1, 1)
- eps = 1e-5
- scale = w * (rv + eps).rsqrt()
- bias = b - rm * scale
- return x * scale + bias
-
-
-class BackboneBase(nn.Module):
- def __init__(
- self,
- backbone: nn.Module,
- train_backbone: bool,
- num_channels: int,
- return_interm_indices: list,
- ):
- super().__init__()
- for name, parameter in backbone.named_parameters():
- if (
- not train_backbone
- or "layer2" not in name
- and "layer3" not in name
- and "layer4" not in name
- ):
- parameter.requires_grad_(False)
-
- return_layers = {}
- for idx, layer_index in enumerate(return_interm_indices):
- return_layers.update(
- {"layer{}".format(5 - len(return_interm_indices) + idx): "{}".format(layer_index)}
- )
-
- # if len:
- # if use_stage1_feature:
- # return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
- # else:
- # return_layers = {"layer2": "0", "layer3": "1", "layer4": "2"}
- # else:
- # return_layers = {'layer4': "0"}
- self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
- self.num_channels = num_channels
-
- def forward(self, tensor_list: NestedTensor):
- xs = self.body(tensor_list.tensors)
- out: Dict[str, NestedTensor] = {}
- for name, x in xs.items():
- m = tensor_list.mask
- assert m is not None
- mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
- out[name] = NestedTensor(x, mask)
- # import ipdb; ipdb.set_trace()
- return out
-
-
-class Backbone(BackboneBase):
- """ResNet backbone with frozen BatchNorm."""
-
- def __init__(
- self,
- name: str,
- train_backbone: bool,
- dilation: bool,
- return_interm_indices: list,
- batch_norm=FrozenBatchNorm2d,
- ):
- if name in ["resnet18", "resnet34", "resnet50", "resnet101"]:
- backbone = getattr(torchvision.models, name)(
- replace_stride_with_dilation=[False, False, dilation],
- pretrained=is_main_process(),
- norm_layer=batch_norm,
- )
- else:
- raise NotImplementedError("Why you can get here with name {}".format(name))
- # num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
- assert name not in ("resnet18", "resnet34"), "Only resnet50 and resnet101 are available."
- assert return_interm_indices in [[0, 1, 2, 3], [1, 2, 3], [3]]
- num_channels_all = [256, 512, 1024, 2048]
- num_channels = num_channels_all[4 - len(return_interm_indices) :]
- super().__init__(backbone, train_backbone, num_channels, return_interm_indices)
-
-
-class Joiner(nn.Sequential):
- def __init__(self, backbone, position_embedding):
- super().__init__(backbone, position_embedding)
-
- def forward(self, tensor_list: NestedTensor):
- xs = self[0](tensor_list)
- out: List[NestedTensor] = []
- pos = []
- for name, x in xs.items():
- out.append(x)
- # position encoding
- pos.append(self[1](x).to(x.tensors.dtype))
-
- return out, pos
-
-
-def build_backbone(args):
- """
- Useful args:
- - backbone: backbone name
- - lr_backbone:
- - dilation
- - return_interm_indices: available: [0,1,2,3], [1,2,3], [3]
- - backbone_freeze_keywords:
- - use_checkpoint: for swin only for now
-
- """
- position_embedding = build_position_encoding(args)
- train_backbone = True
- if not train_backbone:
- raise ValueError("Please set lr_backbone > 0")
- return_interm_indices = args.return_interm_indices
- assert return_interm_indices in [[0, 1, 2, 3], [1, 2, 3], [3]]
- args.backbone_freeze_keywords
- use_checkpoint = getattr(args, "use_checkpoint", False)
-
- if args.backbone in ["resnet50", "resnet101"]:
- backbone = Backbone(
- args.backbone,
- train_backbone,
- args.dilation,
- return_interm_indices,
- batch_norm=FrozenBatchNorm2d,
- )
- bb_num_channels = backbone.num_channels
- elif args.backbone in [
- "swin_T_224_1k",
- "swin_B_224_22k",
- "swin_B_384_22k",
- "swin_L_224_22k",
- "swin_L_384_22k",
- ]:
- pretrain_img_size = int(args.backbone.split("_")[-2])
- backbone = build_swin_transformer(
- args.backbone,
- pretrain_img_size=pretrain_img_size,
- out_indices=tuple(return_interm_indices),
- dilation=False,
- use_checkpoint=use_checkpoint,
- )
-
- bb_num_channels = backbone.num_features[4 - len(return_interm_indices) :]
- else:
- raise NotImplementedError("Unknown backbone {}".format(args.backbone))
-
- assert len(bb_num_channels) == len(
- return_interm_indices
- ), f"len(bb_num_channels) {len(bb_num_channels)} != len(return_interm_indices) {len(return_interm_indices)}"
-
- model = Joiner(backbone, position_embedding)
- model.num_channels = bb_num_channels
- assert isinstance(
- bb_num_channels, List
- ), "bb_num_channels is expected to be a List but {}".format(type(bb_num_channels))
- # import ipdb; ipdb.set_trace()
- return model
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/has-symbols/test/index.js b/spaces/fffiloni/controlnet-animation-doodle/node_modules/has-symbols/test/index.js
deleted file mode 100644
index 352129ca356c8ce4ba2e5e6b78c092f401e0f2da..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/has-symbols/test/index.js
+++ /dev/null
@@ -1,22 +0,0 @@
-'use strict';
-
-var test = require('tape');
-var hasSymbols = require('../');
-var runSymbolTests = require('./tests');
-
-test('interface', function (t) {
- t.equal(typeof hasSymbols, 'function', 'is a function');
- t.equal(typeof hasSymbols(), 'boolean', 'returns a boolean');
- t.end();
-});
-
-test('Symbols are supported', { skip: !hasSymbols() }, function (t) {
- runSymbolTests(t);
- t.end();
-});
-
-test('Symbols are not supported', { skip: hasSymbols() }, function (t) {
- t.equal(typeof Symbol, 'undefined', 'global Symbol is undefined');
- t.equal(typeof Object.getOwnPropertySymbols, 'undefined', 'Object.getOwnPropertySymbols does not exist');
- t.end();
-});
diff --git a/spaces/fffiloni/controlnet-animation-doodle/node_modules/socket.io-parser/node_modules/debug/README.md b/spaces/fffiloni/controlnet-animation-doodle/node_modules/socket.io-parser/node_modules/debug/README.md
deleted file mode 100644
index e9c3e047c2b22aacd54f096af48f918217e06d84..0000000000000000000000000000000000000000
--- a/spaces/fffiloni/controlnet-animation-doodle/node_modules/socket.io-parser/node_modules/debug/README.md
+++ /dev/null
@@ -1,481 +0,0 @@
-# debug
-[](https://travis-ci.org/debug-js/debug) [](https://coveralls.io/github/debug-js/debug?branch=master) [](https://visionmedia-community-slackin.now.sh/) [](#backers)
-[](#sponsors)
-
- -
-A tiny JavaScript debugging utility modelled after Node.js core's debugging
-technique. Works in Node.js and web browsers.
-
-## Installation
-
-```bash
-$ npm install debug
-```
-
-## Usage
-
-`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
-
-Example [_app.js_](./examples/node/app.js):
-
-```js
-var debug = require('debug')('http')
- , http = require('http')
- , name = 'My App';
-
-// fake app
-
-debug('booting %o', name);
-
-http.createServer(function(req, res){
- debug(req.method + ' ' + req.url);
- res.end('hello\n');
-}).listen(3000, function(){
- debug('listening');
-});
-
-// fake worker of some kind
-
-require('./worker');
-```
-
-Example [_worker.js_](./examples/node/worker.js):
-
-```js
-var a = require('debug')('worker:a')
- , b = require('debug')('worker:b');
-
-function work() {
- a('doing lots of uninteresting work');
- setTimeout(work, Math.random() * 1000);
-}
-
-work();
-
-function workb() {
- b('doing some work');
- setTimeout(workb, Math.random() * 2000);
-}
-
-workb();
-```
-
-The `DEBUG` environment variable is then used to enable these based on space or
-comma-delimited names.
-
-Here are some examples:
-
-
-
-A tiny JavaScript debugging utility modelled after Node.js core's debugging
-technique. Works in Node.js and web browsers.
-
-## Installation
-
-```bash
-$ npm install debug
-```
-
-## Usage
-
-`debug` exposes a function; simply pass this function the name of your module, and it will return a decorated version of `console.error` for you to pass debug statements to. This will allow you to toggle the debug output for different parts of your module as well as the module as a whole.
-
-Example [_app.js_](./examples/node/app.js):
-
-```js
-var debug = require('debug')('http')
- , http = require('http')
- , name = 'My App';
-
-// fake app
-
-debug('booting %o', name);
-
-http.createServer(function(req, res){
- debug(req.method + ' ' + req.url);
- res.end('hello\n');
-}).listen(3000, function(){
- debug('listening');
-});
-
-// fake worker of some kind
-
-require('./worker');
-```
-
-Example [_worker.js_](./examples/node/worker.js):
-
-```js
-var a = require('debug')('worker:a')
- , b = require('debug')('worker:b');
-
-function work() {
- a('doing lots of uninteresting work');
- setTimeout(work, Math.random() * 1000);
-}
-
-work();
-
-function workb() {
- b('doing some work');
- setTimeout(workb, Math.random() * 2000);
-}
-
-workb();
-```
-
-The `DEBUG` environment variable is then used to enable these based on space or
-comma-delimited names.
-
-Here are some examples:
-
- -
- -
- -
-#### Windows command prompt notes
-
-##### CMD
-
-On Windows the environment variable is set using the `set` command.
-
-```cmd
-set DEBUG=*,-not_this
-```
-
-Example:
-
-```cmd
-set DEBUG=* & node app.js
-```
-
-##### PowerShell (VS Code default)
-
-PowerShell uses different syntax to set environment variables.
-
-```cmd
-$env:DEBUG = "*,-not_this"
-```
-
-Example:
-
-```cmd
-$env:DEBUG='app';node app.js
-```
-
-Then, run the program to be debugged as usual.
-
-npm script example:
-```js
- "windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
-```
-
-## Namespace Colors
-
-Every debug instance has a color generated for it based on its namespace name.
-This helps when visually parsing the debug output to identify which debug instance
-a debug line belongs to.
-
-#### Node.js
-
-In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
-the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
-otherwise debug will only use a small handful of basic colors.
-
-
-
-#### Windows command prompt notes
-
-##### CMD
-
-On Windows the environment variable is set using the `set` command.
-
-```cmd
-set DEBUG=*,-not_this
-```
-
-Example:
-
-```cmd
-set DEBUG=* & node app.js
-```
-
-##### PowerShell (VS Code default)
-
-PowerShell uses different syntax to set environment variables.
-
-```cmd
-$env:DEBUG = "*,-not_this"
-```
-
-Example:
-
-```cmd
-$env:DEBUG='app';node app.js
-```
-
-Then, run the program to be debugged as usual.
-
-npm script example:
-```js
- "windowsDebug": "@powershell -Command $env:DEBUG='*';node app.js",
-```
-
-## Namespace Colors
-
-Every debug instance has a color generated for it based on its namespace name.
-This helps when visually parsing the debug output to identify which debug instance
-a debug line belongs to.
-
-#### Node.js
-
-In Node.js, colors are enabled when stderr is a TTY. You also _should_ install
-the [`supports-color`](https://npmjs.org/supports-color) module alongside debug,
-otherwise debug will only use a small handful of basic colors.
-
-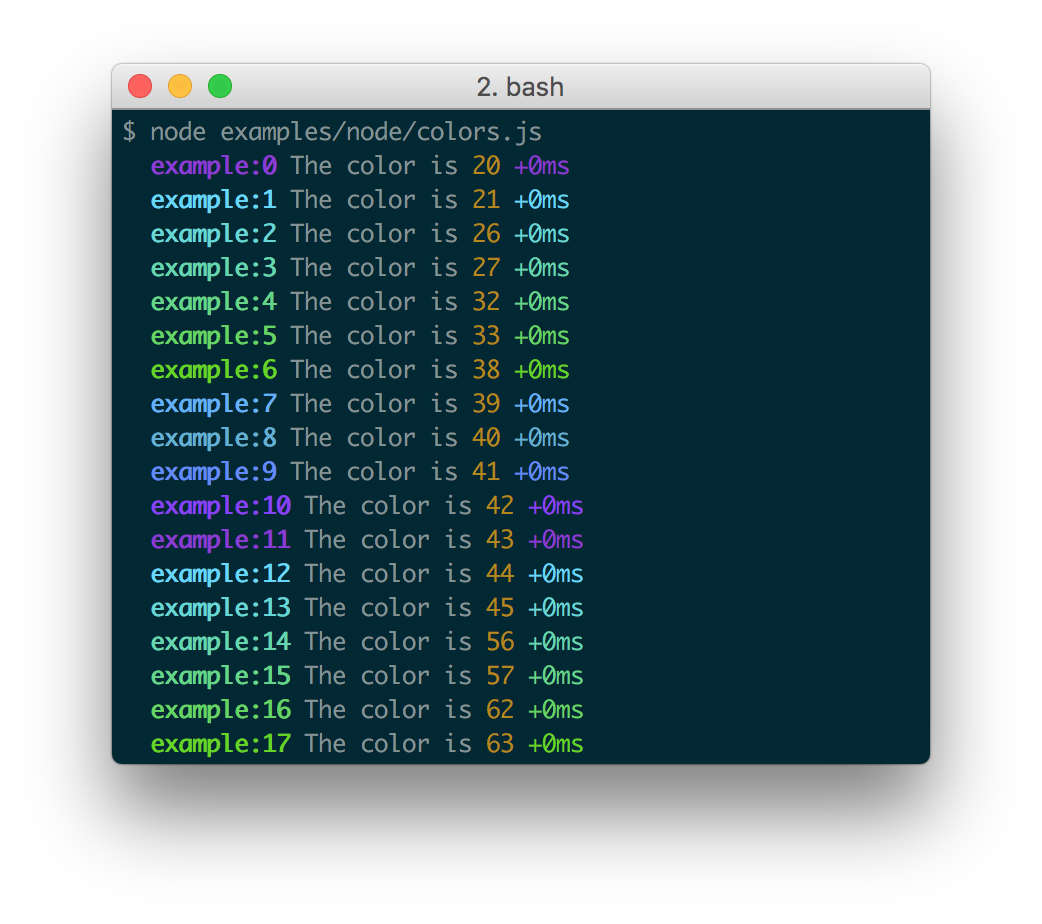 -
-#### Web Browser
-
-Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
-option. These are WebKit web inspectors, Firefox ([since version
-31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
-and the Firebug plugin for Firefox (any version).
-
-
-
-#### Web Browser
-
-Colors are also enabled on "Web Inspectors" that understand the `%c` formatting
-option. These are WebKit web inspectors, Firefox ([since version
-31](https://hacks.mozilla.org/2014/05/editable-box-model-multiple-selection-sublime-text-keys-much-more-firefox-developer-tools-episode-31/))
-and the Firebug plugin for Firefox (any version).
-
-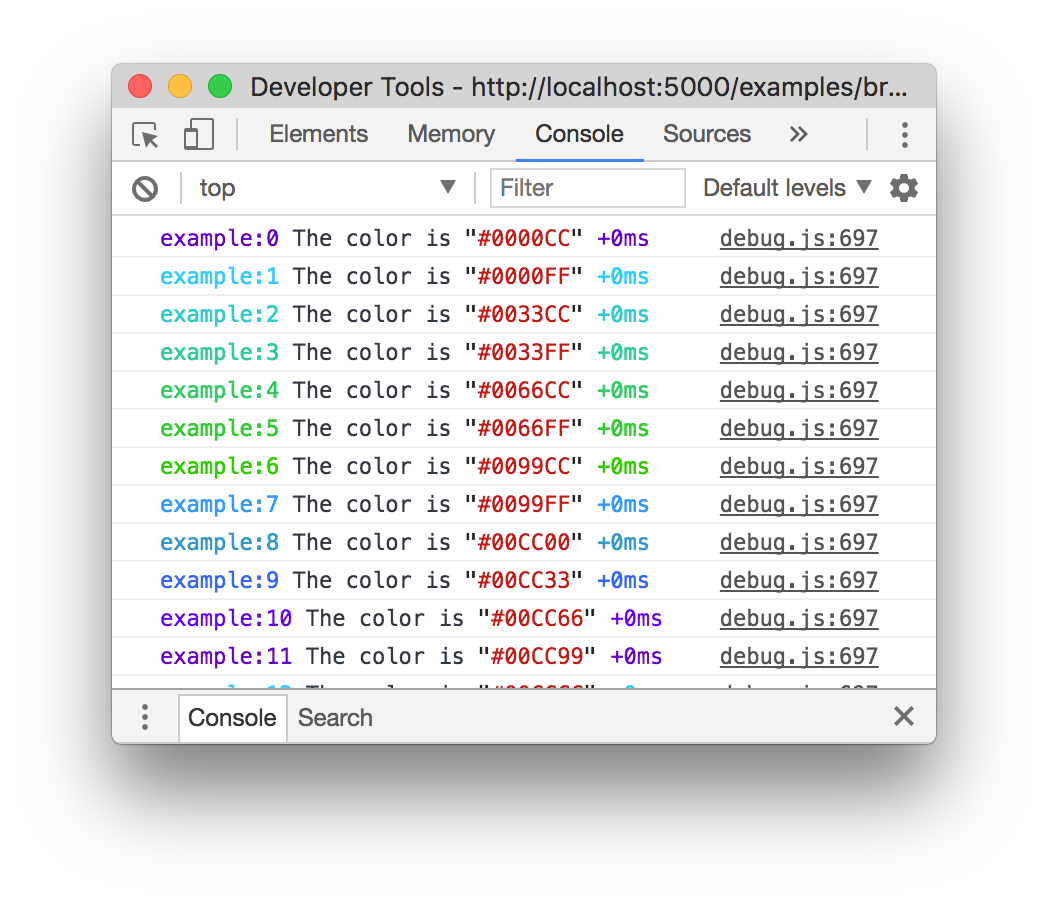 -
-
-## Millisecond diff
-
-When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
-
-
-
-When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
-
-
-
-
-## Millisecond diff
-
-When actively developing an application it can be useful to see when the time spent between one `debug()` call and the next. Suppose for example you invoke `debug()` before requesting a resource, and after as well, the "+NNNms" will show you how much time was spent between calls.
-
-
-
-When stdout is not a TTY, `Date#toISOString()` is used, making it more useful for logging the debug information as shown below:
-
-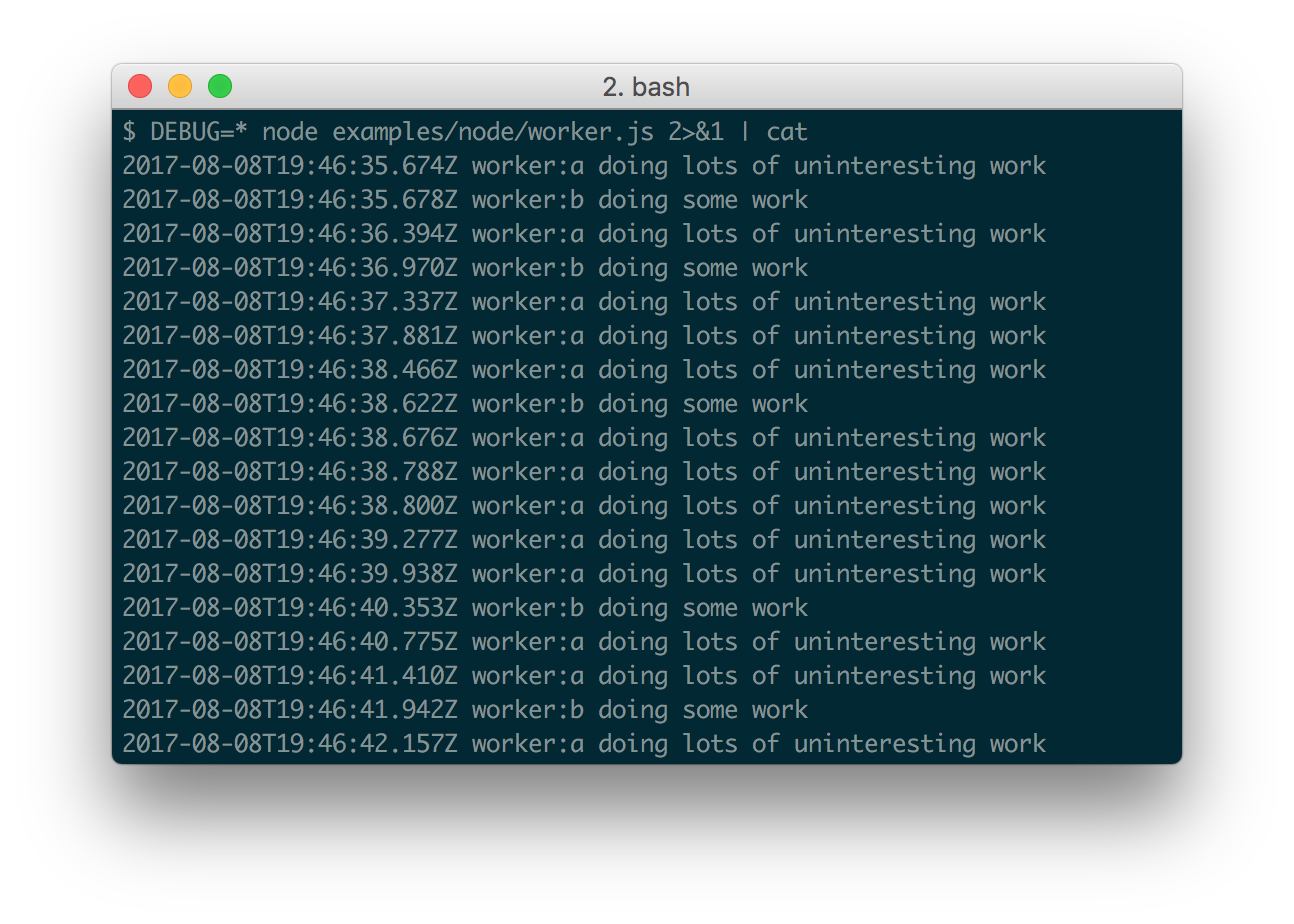 -
-
-## Conventions
-
-If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
-
-## Wildcards
-
-The `*` character may be used as a wildcard. Suppose for example your library has
-debuggers named "connect:bodyParser", "connect:compress", "connect:session",
-instead of listing all three with
-`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
-`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
-
-You can also exclude specific debuggers by prefixing them with a "-" character.
-For example, `DEBUG=*,-connect:*` would include all debuggers except those
-starting with "connect:".
-
-## Environment Variables
-
-When running through Node.js, you can set a few environment variables that will
-change the behavior of the debug logging:
-
-| Name | Purpose |
-|-----------|-------------------------------------------------|
-| `DEBUG` | Enables/disables specific debugging namespaces. |
-| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
-| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
-| `DEBUG_DEPTH` | Object inspection depth. |
-| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
-
-
-__Note:__ The environment variables beginning with `DEBUG_` end up being
-converted into an Options object that gets used with `%o`/`%O` formatters.
-See the Node.js documentation for
-[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
-for the complete list.
-
-## Formatters
-
-Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
-Below are the officially supported formatters:
-
-| Formatter | Representation |
-|-----------|----------------|
-| `%O` | Pretty-print an Object on multiple lines. |
-| `%o` | Pretty-print an Object all on a single line. |
-| `%s` | String. |
-| `%d` | Number (both integer and float). |
-| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
-| `%%` | Single percent sign ('%'). This does not consume an argument. |
-
-
-### Custom formatters
-
-You can add custom formatters by extending the `debug.formatters` object.
-For example, if you wanted to add support for rendering a Buffer as hex with
-`%h`, you could do something like:
-
-```js
-const createDebug = require('debug')
-createDebug.formatters.h = (v) => {
- return v.toString('hex')
-}
-
-// …elsewhere
-const debug = createDebug('foo')
-debug('this is hex: %h', new Buffer('hello world'))
-// foo this is hex: 68656c6c6f20776f726c6421 +0ms
-```
-
-
-## Browser Support
-
-You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
-or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
-if you don't want to build it yourself.
-
-Debug's enable state is currently persisted by `localStorage`.
-Consider the situation shown below where you have `worker:a` and `worker:b`,
-and wish to debug both. You can enable this using `localStorage.debug`:
-
-```js
-localStorage.debug = 'worker:*'
-```
-
-And then refresh the page.
-
-```js
-a = debug('worker:a');
-b = debug('worker:b');
-
-setInterval(function(){
- a('doing some work');
-}, 1000);
-
-setInterval(function(){
- b('doing some work');
-}, 1200);
-```
-
-In Chromium-based web browsers (e.g. Brave, Chrome, and Electron), the JavaScript console will—by default—only show messages logged by `debug` if the "Verbose" log level is _enabled_.
-
-
-
-
-## Conventions
-
-If you're using this in one or more of your libraries, you _should_ use the name of your library so that developers may toggle debugging as desired without guessing names. If you have more than one debuggers you _should_ prefix them with your library name and use ":" to separate features. For example "bodyParser" from Connect would then be "connect:bodyParser". If you append a "*" to the end of your name, it will always be enabled regardless of the setting of the DEBUG environment variable. You can then use it for normal output as well as debug output.
-
-## Wildcards
-
-The `*` character may be used as a wildcard. Suppose for example your library has
-debuggers named "connect:bodyParser", "connect:compress", "connect:session",
-instead of listing all three with
-`DEBUG=connect:bodyParser,connect:compress,connect:session`, you may simply do
-`DEBUG=connect:*`, or to run everything using this module simply use `DEBUG=*`.
-
-You can also exclude specific debuggers by prefixing them with a "-" character.
-For example, `DEBUG=*,-connect:*` would include all debuggers except those
-starting with "connect:".
-
-## Environment Variables
-
-When running through Node.js, you can set a few environment variables that will
-change the behavior of the debug logging:
-
-| Name | Purpose |
-|-----------|-------------------------------------------------|
-| `DEBUG` | Enables/disables specific debugging namespaces. |
-| `DEBUG_HIDE_DATE` | Hide date from debug output (non-TTY). |
-| `DEBUG_COLORS`| Whether or not to use colors in the debug output. |
-| `DEBUG_DEPTH` | Object inspection depth. |
-| `DEBUG_SHOW_HIDDEN` | Shows hidden properties on inspected objects. |
-
-
-__Note:__ The environment variables beginning with `DEBUG_` end up being
-converted into an Options object that gets used with `%o`/`%O` formatters.
-See the Node.js documentation for
-[`util.inspect()`](https://nodejs.org/api/util.html#util_util_inspect_object_options)
-for the complete list.
-
-## Formatters
-
-Debug uses [printf-style](https://wikipedia.org/wiki/Printf_format_string) formatting.
-Below are the officially supported formatters:
-
-| Formatter | Representation |
-|-----------|----------------|
-| `%O` | Pretty-print an Object on multiple lines. |
-| `%o` | Pretty-print an Object all on a single line. |
-| `%s` | String. |
-| `%d` | Number (both integer and float). |
-| `%j` | JSON. Replaced with the string '[Circular]' if the argument contains circular references. |
-| `%%` | Single percent sign ('%'). This does not consume an argument. |
-
-
-### Custom formatters
-
-You can add custom formatters by extending the `debug.formatters` object.
-For example, if you wanted to add support for rendering a Buffer as hex with
-`%h`, you could do something like:
-
-```js
-const createDebug = require('debug')
-createDebug.formatters.h = (v) => {
- return v.toString('hex')
-}
-
-// …elsewhere
-const debug = createDebug('foo')
-debug('this is hex: %h', new Buffer('hello world'))
-// foo this is hex: 68656c6c6f20776f726c6421 +0ms
-```
-
-
-## Browser Support
-
-You can build a browser-ready script using [browserify](https://github.com/substack/node-browserify),
-or just use the [browserify-as-a-service](https://wzrd.in/) [build](https://wzrd.in/standalone/debug@latest),
-if you don't want to build it yourself.
-
-Debug's enable state is currently persisted by `localStorage`.
-Consider the situation shown below where you have `worker:a` and `worker:b`,
-and wish to debug both. You can enable this using `localStorage.debug`:
-
-```js
-localStorage.debug = 'worker:*'
-```
-
-And then refresh the page.
-
-```js
-a = debug('worker:a');
-b = debug('worker:b');
-
-setInterval(function(){
- a('doing some work');
-}, 1000);
-
-setInterval(function(){
- b('doing some work');
-}, 1200);
-```
-
-In Chromium-based web browsers (e.g. Brave, Chrome, and Electron), the JavaScript console will—by default—only show messages logged by `debug` if the "Verbose" log level is _enabled_.
-
-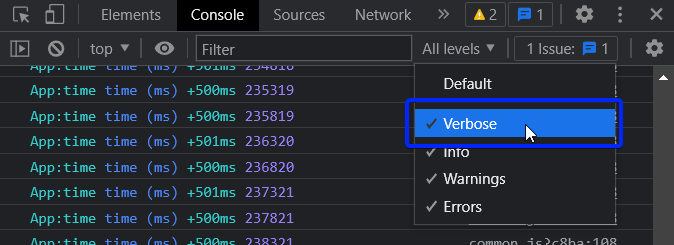 -
-## Output streams
-
- By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
-
-Example [_stdout.js_](./examples/node/stdout.js):
-
-```js
-var debug = require('debug');
-var error = debug('app:error');
-
-// by default stderr is used
-error('goes to stderr!');
-
-var log = debug('app:log');
-// set this namespace to log via console.log
-log.log = console.log.bind(console); // don't forget to bind to console!
-log('goes to stdout');
-error('still goes to stderr!');
-
-// set all output to go via console.info
-// overrides all per-namespace log settings
-debug.log = console.info.bind(console);
-error('now goes to stdout via console.info');
-log('still goes to stdout, but via console.info now');
-```
-
-## Extend
-You can simply extend debugger
-```js
-const log = require('debug')('auth');
-
-//creates new debug instance with extended namespace
-const logSign = log.extend('sign');
-const logLogin = log.extend('login');
-
-log('hello'); // auth hello
-logSign('hello'); //auth:sign hello
-logLogin('hello'); //auth:login hello
-```
-
-## Set dynamically
-
-You can also enable debug dynamically by calling the `enable()` method :
-
-```js
-let debug = require('debug');
-
-console.log(1, debug.enabled('test'));
-
-debug.enable('test');
-console.log(2, debug.enabled('test'));
-
-debug.disable();
-console.log(3, debug.enabled('test'));
-
-```
-
-print :
-```
-1 false
-2 true
-3 false
-```
-
-Usage :
-`enable(namespaces)`
-`namespaces` can include modes separated by a colon and wildcards.
-
-Note that calling `enable()` completely overrides previously set DEBUG variable :
-
-```
-$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
-=> false
-```
-
-`disable()`
-
-Will disable all namespaces. The functions returns the namespaces currently
-enabled (and skipped). This can be useful if you want to disable debugging
-temporarily without knowing what was enabled to begin with.
-
-For example:
-
-```js
-let debug = require('debug');
-debug.enable('foo:*,-foo:bar');
-let namespaces = debug.disable();
-debug.enable(namespaces);
-```
-
-Note: There is no guarantee that the string will be identical to the initial
-enable string, but semantically they will be identical.
-
-## Checking whether a debug target is enabled
-
-After you've created a debug instance, you can determine whether or not it is
-enabled by checking the `enabled` property:
-
-```javascript
-const debug = require('debug')('http');
-
-if (debug.enabled) {
- // do stuff...
-}
-```
-
-You can also manually toggle this property to force the debug instance to be
-enabled or disabled.
-
-## Usage in child processes
-
-Due to the way `debug` detects if the output is a TTY or not, colors are not shown in child processes when `stderr` is piped. A solution is to pass the `DEBUG_COLORS=1` environment variable to the child process.
-For example:
-
-```javascript
-worker = fork(WORKER_WRAP_PATH, [workerPath], {
- stdio: [
- /* stdin: */ 0,
- /* stdout: */ 'pipe',
- /* stderr: */ 'pipe',
- 'ipc',
- ],
- env: Object.assign({}, process.env, {
- DEBUG_COLORS: 1 // without this settings, colors won't be shown
- }),
-});
-
-worker.stderr.pipe(process.stderr, { end: false });
-```
-
-
-## Authors
-
- - TJ Holowaychuk
- - Nathan Rajlich
- - Andrew Rhyne
- - Josh Junon
-
-## Backers
-
-Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
-
-
-
-## Output streams
-
- By default `debug` will log to stderr, however this can be configured per-namespace by overriding the `log` method:
-
-Example [_stdout.js_](./examples/node/stdout.js):
-
-```js
-var debug = require('debug');
-var error = debug('app:error');
-
-// by default stderr is used
-error('goes to stderr!');
-
-var log = debug('app:log');
-// set this namespace to log via console.log
-log.log = console.log.bind(console); // don't forget to bind to console!
-log('goes to stdout');
-error('still goes to stderr!');
-
-// set all output to go via console.info
-// overrides all per-namespace log settings
-debug.log = console.info.bind(console);
-error('now goes to stdout via console.info');
-log('still goes to stdout, but via console.info now');
-```
-
-## Extend
-You can simply extend debugger
-```js
-const log = require('debug')('auth');
-
-//creates new debug instance with extended namespace
-const logSign = log.extend('sign');
-const logLogin = log.extend('login');
-
-log('hello'); // auth hello
-logSign('hello'); //auth:sign hello
-logLogin('hello'); //auth:login hello
-```
-
-## Set dynamically
-
-You can also enable debug dynamically by calling the `enable()` method :
-
-```js
-let debug = require('debug');
-
-console.log(1, debug.enabled('test'));
-
-debug.enable('test');
-console.log(2, debug.enabled('test'));
-
-debug.disable();
-console.log(3, debug.enabled('test'));
-
-```
-
-print :
-```
-1 false
-2 true
-3 false
-```
-
-Usage :
-`enable(namespaces)`
-`namespaces` can include modes separated by a colon and wildcards.
-
-Note that calling `enable()` completely overrides previously set DEBUG variable :
-
-```
-$ DEBUG=foo node -e 'var dbg = require("debug"); dbg.enable("bar"); console.log(dbg.enabled("foo"))'
-=> false
-```
-
-`disable()`
-
-Will disable all namespaces. The functions returns the namespaces currently
-enabled (and skipped). This can be useful if you want to disable debugging
-temporarily without knowing what was enabled to begin with.
-
-For example:
-
-```js
-let debug = require('debug');
-debug.enable('foo:*,-foo:bar');
-let namespaces = debug.disable();
-debug.enable(namespaces);
-```
-
-Note: There is no guarantee that the string will be identical to the initial
-enable string, but semantically they will be identical.
-
-## Checking whether a debug target is enabled
-
-After you've created a debug instance, you can determine whether or not it is
-enabled by checking the `enabled` property:
-
-```javascript
-const debug = require('debug')('http');
-
-if (debug.enabled) {
- // do stuff...
-}
-```
-
-You can also manually toggle this property to force the debug instance to be
-enabled or disabled.
-
-## Usage in child processes
-
-Due to the way `debug` detects if the output is a TTY or not, colors are not shown in child processes when `stderr` is piped. A solution is to pass the `DEBUG_COLORS=1` environment variable to the child process.
-For example:
-
-```javascript
-worker = fork(WORKER_WRAP_PATH, [workerPath], {
- stdio: [
- /* stdin: */ 0,
- /* stdout: */ 'pipe',
- /* stderr: */ 'pipe',
- 'ipc',
- ],
- env: Object.assign({}, process.env, {
- DEBUG_COLORS: 1 // without this settings, colors won't be shown
- }),
-});
-
-worker.stderr.pipe(process.stderr, { end: false });
-```
-
-
-## Authors
-
- - TJ Holowaychuk
- - Nathan Rajlich
- - Andrew Rhyne
- - Josh Junon
-
-## Backers
-
-Support us with a monthly donation and help us continue our activities. [[Become a backer](https://opencollective.com/debug#backer)]
-
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-
-## Sponsors
-
-Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
-
-
-
-
-## Sponsors
-
-Become a sponsor and get your logo on our README on Github with a link to your site. [[Become a sponsor](https://opencollective.com/debug#sponsor)]
-
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-## License
-
-(The MIT License)
-
-Copyright (c) 2014-2017 TJ Holowaychuk <tj@vision-media.ca>
-Copyright (c) 2018-2021 Josh Junon
-
-Permission is hereby granted, free of charge, to any person obtaining
-a copy of this software and associated documentation files (the
-'Software'), to deal in the Software without restriction, including
-without limitation the rights to use, copy, modify, merge, publish,
-distribute, sublicense, and/or sell copies of the Software, and to
-permit persons to whom the Software is furnished to do so, subject to
-the following conditions:
-
-The above copyright notice and this permission notice shall be
-included in all copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
-EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
-MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
-IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
-CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
-TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
-SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/spaces/firefighter/TransDis-CreativityAutoAssessment/README.md b/spaces/firefighter/TransDis-CreativityAutoAssessment/README.md
deleted file mode 100644
index 75a24342eb2802c5e170bb4010ddcbfe74a1eebe..0000000000000000000000000000000000000000
--- a/spaces/firefighter/TransDis-CreativityAutoAssessment/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: TransDis-CreativityAutoAssessment
-emoji: 💡
-colorFrom: yellow
-colorTo: gray
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/firsk/ai_otto/app.py b/spaces/firsk/ai_otto/app.py
deleted file mode 100644
index 398f52bbc898d4074c6b27c9179015508b9b92ca..0000000000000000000000000000000000000000
--- a/spaces/firsk/ai_otto/app.py
+++ /dev/null
@@ -1,224 +0,0 @@
-# flake8: noqa: E402
-
-import sys, os
-import logging
-
-logging.getLogger("numba").setLevel(logging.WARNING)
-logging.getLogger("markdown_it").setLevel(logging.WARNING)
-logging.getLogger("urllib3").setLevel(logging.WARNING)
-logging.getLogger("matplotlib").setLevel(logging.WARNING)
-
-logging.basicConfig(
- level=logging.INFO, format="| %(name)s | %(levelname)s | %(message)s"
-)
-
-logger = logging.getLogger(__name__)
-
-import torch
-import argparse
-import commons
-import utils
-from models import SynthesizerTrn
-from text.symbols import symbols
-from text import cleaned_text_to_sequence, get_bert
-from text.cleaner import clean_text
-import gradio as gr
-import webbrowser
-import numpy as np
-
-net_g = None
-
-if sys.platform == "darwin" and torch.backends.mps.is_available():
- device = "mps"
- os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
-else:
- device = "cuda"
-
-
-def get_text(text, language_str, hps):
- norm_text, phone, tone, word2ph = clean_text(text, language_str)
- phone, tone, language = cleaned_text_to_sequence(phone, tone, language_str)
-
- if hps.data.add_blank:
- phone = commons.intersperse(phone, 0)
- tone = commons.intersperse(tone, 0)
- language = commons.intersperse(language, 0)
- for i in range(len(word2ph)):
- word2ph[i] = word2ph[i] * 2
- word2ph[0] += 1
- bert = get_bert(norm_text, word2ph, language_str, device)
- del word2ph
- assert bert.shape[-1] == len(phone), phone
-
- if language_str == "ZH":
- bert = bert
- ja_bert = torch.zeros(768, len(phone))
- elif language_str == "JP":
- ja_bert = bert
- bert = torch.zeros(1024, len(phone))
- else:
- bert = torch.zeros(1024, len(phone))
- ja_bert = torch.zeros(768, len(phone))
-
- assert bert.shape[-1] == len(
- phone
- ), f"Bert seq len {bert.shape[-1]} != {len(phone)}"
-
- phone = torch.LongTensor(phone)
- tone = torch.LongTensor(tone)
- language = torch.LongTensor(language)
- return bert, ja_bert, phone, tone, language
-
-
-def infer(text, sdp_ratio, noise_scale, noise_scale_w, length_scale, sid, language):
- global net_g
- bert, ja_bert, phones, tones, lang_ids = get_text(text, language, hps)
- with torch.no_grad():
- x_tst = phones.to(device).unsqueeze(0)
- tones = tones.to(device).unsqueeze(0)
- lang_ids = lang_ids.to(device).unsqueeze(0)
- bert = bert.to(device).unsqueeze(0)
- ja_bert = ja_bert.to(device).unsqueeze(0)
- x_tst_lengths = torch.LongTensor([phones.size(0)]).to(device)
- del phones
- speakers = torch.LongTensor([hps.data.spk2id[sid]]).to(device)
- audio = (
- net_g.infer(
- x_tst,
- x_tst_lengths,
- speakers,
- tones,
- lang_ids,
- bert,
- ja_bert,
- sdp_ratio=sdp_ratio,
- noise_scale=noise_scale,
- noise_scale_w=noise_scale_w,
- length_scale=length_scale,
- )[0][0, 0]
- .data.cpu()
- .float()
- .numpy()
- )
- del x_tst, tones, lang_ids, bert, x_tst_lengths, speakers
- torch.cuda.empty_cache()
- return audio
-
-
-def tts_fn(
- text, speaker, sdp_ratio, noise_scale, noise_scale_w, length_scale, language
-):
- slices = text.split("|")
- audio_list = []
- with torch.no_grad():
- for slice in slices:
- audio = infer(
- slice,
- sdp_ratio=sdp_ratio,
- noise_scale=noise_scale,
- noise_scale_w=noise_scale_w,
- length_scale=length_scale,
- sid=speaker,
- language=language,
- )
- audio_list.append(audio)
- silence = np.zeros(hps.data.sampling_rate) # 生成1秒的静音
- audio_list.append(silence) # 将静音添加到列表中
- audio_concat = np.concatenate(audio_list)
- return "Success", (hps.data.sampling_rate, audio_concat)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "-m", "--model", default="./logs/OUTPUT_MODEL/G_159000.pth", help="path of your model"
- )
- parser.add_argument(
- "-c",
- "--config",
- default="./configs/config.json",
- help="path of your config file",
- )
- parser.add_argument(
- "--share", default=True, help="make link public", action="store_true"
- )
- parser.add_argument(
- "-d", "--debug", action="store_true", help="enable DEBUG-LEVEL log"
- )
-
- args = parser.parse_args()
- if args.debug:
- logger.info("Enable DEBUG-LEVEL log")
- logging.basicConfig(level=logging.DEBUG)
- hps = utils.get_hparams_from_file(args.config)
-
- device = (
- "cuda:0"
- if torch.cuda.is_available()
- else (
- "mps"
- if sys.platform == "darwin" and torch.backends.mps.is_available()
- else "cpu"
- )
- )
- net_g = SynthesizerTrn(
- len(symbols),
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- n_speakers=hps.data.n_speakers,
- **hps.model,
- ).to(device)
- _ = net_g.eval()
-
- _ = utils.load_checkpoint(args.model, net_g, None, skip_optimizer=True)
-
- speaker_ids = hps.data.spk2id
- speakers = list(speaker_ids.keys())
- languages = ["ZH", "JP"]
- with gr.Blocks() as app:
- with gr.Row():
- with gr.Column():
- text = gr.TextArea(
- label="Text",
- placeholder="Input Text Here",
- value="年仅三岁的国王毫无畏惧",
- )
- speaker = gr.Dropdown(
- choices=speakers, value=speakers[0], label="Speaker"
- )
- sdp_ratio = gr.Slider(
- minimum=0, maximum=1, value=0.2, step=0.1, label="SDP Ratio"
- )
- noise_scale = gr.Slider(
- minimum=0.1, maximum=2, value=0.6, step=0.1, label="Noise Scale"
- )
- noise_scale_w = gr.Slider(
- minimum=0.1, maximum=2, value=0.8, step=0.1, label="Noise Scale W"
- )
- length_scale = gr.Slider(
- minimum=0.1, maximum=2, value=1, step=0.1, label="Length Scale"
- )
- language = gr.Dropdown(
- choices=languages, value=languages[0], label="Language"
- )
- btn = gr.Button("Generate!", variant="primary")
- with gr.Column():
- text_output = gr.Textbox(label="Message")
- audio_output = gr.Audio(label="Output Audio")
-
- btn.click(
- tts_fn,
- inputs=[
- text,
- speaker,
- sdp_ratio,
- noise_scale,
- noise_scale_w,
- length_scale,
- language,
- ],
- outputs=[text_output, audio_output],
- )
-
- webbrowser.open("http://127.0.0.1:7860")
- app.launch(share=args.share)
diff --git a/spaces/flax-community/spanish-image-captioning/sections/usage.md b/spaces/flax-community/spanish-image-captioning/sections/usage.md
deleted file mode 100644
index 7fd5c2cf140f99031a3cef1a4b1684c43aea4651..0000000000000000000000000000000000000000
--- a/spaces/flax-community/spanish-image-captioning/sections/usage.md
+++ /dev/null
@@ -1,7 +0,0 @@
-- This demo loads the `FlaxCLIPVisionMarianMT` present in the `model` directory of this repository. The checkpoint is loaded from `ckpt/ckpt-23999` which is pre-trained checkpoint with 24k steps. 100 random validation set examples are present in the `references.tsv` with respective images in the `images` directory.
-
-- We provide `English Translation` of the generated caption and reference captions for users who are not well-acquainted with Spanish. This is done using `mtranslate` to keep things flexible enough and needs internet connection as it uses the Google Translate API. We will also add the original captions soon.
-
-- The sidebar contains generation parameters such as `Number of Beams`, `Top-P`, `Temperature` which will be used when generating the caption.
-
-- Clicking on `Generate Caption` will generate the caption in Spanish.
\ No newline at end of file
diff --git a/spaces/flowers-team/SocialAISchool/scripts/tensorboard_aggregator.py b/spaces/flowers-team/SocialAISchool/scripts/tensorboard_aggregator.py
deleted file mode 100644
index d4002c231bce5dfc1a61108241d64053f687e220..0000000000000000000000000000000000000000
--- a/spaces/flowers-team/SocialAISchool/scripts/tensorboard_aggregator.py
+++ /dev/null
@@ -1,141 +0,0 @@
-import os
-import sys
-import argparse
-import shutil
-from collections import defaultdict
-
-import numpy as np
-import tensorflow as tf
-from tensorboard.backend.event_processing.event_accumulator import EventAccumulator
-
-
-def tabulate_events(exp_path):
-
- seeds = [s for s in os.listdir(exp_path) if "combined" not in s]
- summary_iterators = [EventAccumulator(os.path.join(exp_path, dname)).Reload() for dname in seeds]
-
- tags = summary_iterators[0].Tags()['scalars']
- for it in summary_iterators:
- assert it.Tags()['scalars'] == tags
-
- out = defaultdict(list)
- for tag in tags:
- for events in zip(*[acc.Scalars(tag) for acc in summary_iterators]):
- assert len(set(e.step for e in events)) == 1
-
- out[tag].append([e.value for e in events])
-
- return out
-
-
-def create_histogram_summary(tag, values, bins=1000):
- # Convert to a numpy array
- values = np.array(values)
-
- # Create histogram using numpy
- counts, bin_edges = np.histogram(values, bins=bins)
-
- # Fill fields of histogram proto
- hist = tf.HistogramProto()
- hist.min = float(np.min(values))
- hist.max = float(np.max(values))
- hist.num = int(np.prod(values.shape))
- hist.sum = float(np.sum(values))
- hist.sum_squares = float(np.sum(values**2))
-
- # Requires equal number as bins, where the first goes from -DBL_MAX to bin_edges[1]
- # See https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/summary.proto#L30
- # Thus, we drop the start of the first bin
- bin_edges = bin_edges[1:]
-
- # Add bin edges and counts
- for edge in bin_edges:
- hist.bucket_limit.append(edge)
- for c in counts:
- hist.bucket.append(c)
-
- # Create and write Summary
- return tf.Summary.Value(tag=tag, histo=hist)
-
-
-def create_parsed_histogram_summary(tag, values, bins=1000):
- # Convert to a numpy array
-
- # Create histogram using numpy
- counts, bin_edges = np.histogram(values, bins=bins)
-
- # Fill fields of histogram proto
- hist = tf.HistogramProto()
- hist.min = float(np.min(values))
- hist.max = float(np.max(values))
- hist.num = int(np.prod(values.shape))
- hist.sum = float(np.sum(values))
- hist.sum_squares = float(np.sum(values**2))
-
- # Requires equal number as bins, where the first goes from -DBL_MAX to bin_edges[1]
- # See https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/summary.proto#L30
- # Thus, we drop the start of the first bin
- bin_edges = bin_edges[1:]
-
- # Add bin edges and counts
- for edge in bin_edges:
- hist.bucket_limit.append(edge)
- for c in counts:
- hist.bucket.append(c)
-
- # Create and write Summary
- return tf.Summary.Value(tag=tag, histo=hist)
-
-
-def write_combined_events(exp_path, d_combined, dname='combined', mean_var_tags=()):
-
- fpath = os.path.join(exp_path, dname)
- if os.path.isdir(fpath):
- shutil.rmtree(fpath)
- assert not os.path.isdir(fpath)
-
- writer = tf.summary.FileWriter(fpath)
-
-
- tags, values = zip(*d_combined.items())
-
- cap = min([len(v) for v in values])
- values = [v[:cap] for v in values]
-
- timestep_mean = np.array(values).mean(axis=-1)
- timestep_var = np.array(values).var(axis=-1)
- timesteps = timestep_mean[tags.index("frames")]
-
- for tag, means, vars in zip(tags, timestep_mean, timestep_var):
- for i, mean, var in zip(timesteps, means, vars):
- summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=mean)])
- writer.add_summary(summary, global_step=i)
- writer.flush()
-
- if tag in mean_var_tags:
- values = np.array([mean - var, mean, mean + var])
-
- summary = tf.Summary(value=[
- create_histogram_summary(tag=tag+"_var", values=values)
- ])
- writer.add_summary(summary, global_step=i)
- writer.flush()
-
-
-if __name__ == "__main__":
- if len(sys.argv) > 1:
- dpath = sys.argv[1]
- else:
- raise ValueError("Specify dir")
-
- parser = argparse.ArgumentParser()
-
- parser.add_argument('--experiments', nargs='+', help='experiment directories to aggregate', required=True)
-
- parser.add_argument('--mean-var-tags', nargs='+', help='tags to create mean-var histograms from', required=False, default=["return_mean"])
-
- args = parser.parse_args()
-
- for exp_path in args.experiments:
- d = tabulate_events(exp_path)
- write_combined_events(exp_path, d, mean_var_tags=args.mean_var_tags)
\ No newline at end of file
diff --git a/spaces/fluffyfluff/multiple-pdf-chat/README.md b/spaces/fluffyfluff/multiple-pdf-chat/README.md
deleted file mode 100644
index f77ed40df8d8504c5aee1e0f68c37ea0c2a0ffac..0000000000000000000000000000000000000000
--- a/spaces/fluffyfluff/multiple-pdf-chat/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Multiple Pdf Chat
-emoji: 🚀
-colorFrom: green
-colorTo: pink
-sdk: streamlit
-sdk_version: 1.25.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/foduucom/stockmarket-future-prediction/README.md b/spaces/foduucom/stockmarket-future-prediction/README.md
deleted file mode 100644
index 84ea7c870d967b54e12e4a6efe2bdf146d22c6f0..0000000000000000000000000000000000000000
--- a/spaces/foduucom/stockmarket-future-prediction/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Stockmarket Future Prediction
-emoji: 🔥
-colorFrom: gray
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.45.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/gbharti/fastai-model-deploy/.ipynb_checkpoints/README-checkpoint.md b/spaces/gbharti/fastai-model-deploy/.ipynb_checkpoints/README-checkpoint.md
deleted file mode 100644
index 4e9e3c0ceae4ef49b3f5c1814058ee40036ef7c9..0000000000000000000000000000000000000000
--- a/spaces/gbharti/fastai-model-deploy/.ipynb_checkpoints/README-checkpoint.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Fastai Model Reply
-emoji: ⚡
-colorFrom: blue
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.6
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/runner/hooks/momentum_updater.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/runner/hooks/momentum_updater.py
deleted file mode 100644
index 60437756ceedf06055ec349df69a25465738d3f0..0000000000000000000000000000000000000000
--- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/runner/hooks/momentum_updater.py
+++ /dev/null
@@ -1,493 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import annotator.uniformer.mmcv as mmcv
-from .hook import HOOKS, Hook
-from .lr_updater import annealing_cos, annealing_linear, format_param
-
-
-class MomentumUpdaterHook(Hook):
-
- def __init__(self,
- by_epoch=True,
- warmup=None,
- warmup_iters=0,
- warmup_ratio=0.9):
- # validate the "warmup" argument
- if warmup is not None:
- if warmup not in ['constant', 'linear', 'exp']:
- raise ValueError(
- f'"{warmup}" is not a supported type for warming up, valid'
- ' types are "constant" and "linear"')
- if warmup is not None:
- assert warmup_iters > 0, \
- '"warmup_iters" must be a positive integer'
- assert 0 < warmup_ratio <= 1.0, \
- '"warmup_momentum" must be in range (0,1]'
-
- self.by_epoch = by_epoch
- self.warmup = warmup
- self.warmup_iters = warmup_iters
- self.warmup_ratio = warmup_ratio
-
- self.base_momentum = [] # initial momentum for all param groups
- self.regular_momentum = [
- ] # expected momentum if no warming up is performed
-
- def _set_momentum(self, runner, momentum_groups):
- if isinstance(runner.optimizer, dict):
- for k, optim in runner.optimizer.items():
- for param_group, mom in zip(optim.param_groups,
- momentum_groups[k]):
- if 'momentum' in param_group.keys():
- param_group['momentum'] = mom
- elif 'betas' in param_group.keys():
- param_group['betas'] = (mom, param_group['betas'][1])
- else:
- for param_group, mom in zip(runner.optimizer.param_groups,
- momentum_groups):
- if 'momentum' in param_group.keys():
- param_group['momentum'] = mom
- elif 'betas' in param_group.keys():
- param_group['betas'] = (mom, param_group['betas'][1])
-
- def get_momentum(self, runner, base_momentum):
- raise NotImplementedError
-
- def get_regular_momentum(self, runner):
- if isinstance(runner.optimizer, dict):
- momentum_groups = {}
- for k in runner.optimizer.keys():
- _momentum_group = [
- self.get_momentum(runner, _base_momentum)
- for _base_momentum in self.base_momentum[k]
- ]
- momentum_groups.update({k: _momentum_group})
- return momentum_groups
- else:
- return [
- self.get_momentum(runner, _base_momentum)
- for _base_momentum in self.base_momentum
- ]
-
- def get_warmup_momentum(self, cur_iters):
-
- def _get_warmup_momentum(cur_iters, regular_momentum):
- if self.warmup == 'constant':
- warmup_momentum = [
- _momentum / self.warmup_ratio
- for _momentum in self.regular_momentum
- ]
- elif self.warmup == 'linear':
- k = (1 - cur_iters / self.warmup_iters) * (1 -
- self.warmup_ratio)
- warmup_momentum = [
- _momentum / (1 - k) for _momentum in self.regular_mom
- ]
- elif self.warmup == 'exp':
- k = self.warmup_ratio**(1 - cur_iters / self.warmup_iters)
- warmup_momentum = [
- _momentum / k for _momentum in self.regular_mom
- ]
- return warmup_momentum
-
- if isinstance(self.regular_momentum, dict):
- momentum_groups = {}
- for key, regular_momentum in self.regular_momentum.items():
- momentum_groups[key] = _get_warmup_momentum(
- cur_iters, regular_momentum)
- return momentum_groups
- else:
- return _get_warmup_momentum(cur_iters, self.regular_momentum)
-
- def before_run(self, runner):
- # NOTE: when resuming from a checkpoint,
- # if 'initial_momentum' is not saved,
- # it will be set according to the optimizer params
- if isinstance(runner.optimizer, dict):
- self.base_momentum = {}
- for k, optim in runner.optimizer.items():
- for group in optim.param_groups:
- if 'momentum' in group.keys():
- group.setdefault('initial_momentum', group['momentum'])
- else:
- group.setdefault('initial_momentum', group['betas'][0])
- _base_momentum = [
- group['initial_momentum'] for group in optim.param_groups
- ]
- self.base_momentum.update({k: _base_momentum})
- else:
- for group in runner.optimizer.param_groups:
- if 'momentum' in group.keys():
- group.setdefault('initial_momentum', group['momentum'])
- else:
- group.setdefault('initial_momentum', group['betas'][0])
- self.base_momentum = [
- group['initial_momentum']
- for group in runner.optimizer.param_groups
- ]
-
- def before_train_epoch(self, runner):
- if not self.by_epoch:
- return
- self.regular_mom = self.get_regular_momentum(runner)
- self._set_momentum(runner, self.regular_mom)
-
- def before_train_iter(self, runner):
- cur_iter = runner.iter
- if not self.by_epoch:
- self.regular_mom = self.get_regular_momentum(runner)
- if self.warmup is None or cur_iter >= self.warmup_iters:
- self._set_momentum(runner, self.regular_mom)
- else:
- warmup_momentum = self.get_warmup_momentum(cur_iter)
- self._set_momentum(runner, warmup_momentum)
- elif self.by_epoch:
- if self.warmup is None or cur_iter > self.warmup_iters:
- return
- elif cur_iter == self.warmup_iters:
- self._set_momentum(runner, self.regular_mom)
- else:
- warmup_momentum = self.get_warmup_momentum(cur_iter)
- self._set_momentum(runner, warmup_momentum)
-
-
-@HOOKS.register_module()
-class StepMomentumUpdaterHook(MomentumUpdaterHook):
- """Step momentum scheduler with min value clipping.
-
- Args:
- step (int | list[int]): Step to decay the momentum. If an int value is
- given, regard it as the decay interval. If a list is given, decay
- momentum at these steps.
- gamma (float, optional): Decay momentum ratio. Default: 0.5.
- min_momentum (float, optional): Minimum momentum value to keep. If
- momentum after decay is lower than this value, it will be clipped
- accordingly. If None is given, we don't perform lr clipping.
- Default: None.
- """
-
- def __init__(self, step, gamma=0.5, min_momentum=None, **kwargs):
- if isinstance(step, list):
- assert mmcv.is_list_of(step, int)
- assert all([s > 0 for s in step])
- elif isinstance(step, int):
- assert step > 0
- else:
- raise TypeError('"step" must be a list or integer')
- self.step = step
- self.gamma = gamma
- self.min_momentum = min_momentum
- super(StepMomentumUpdaterHook, self).__init__(**kwargs)
-
- def get_momentum(self, runner, base_momentum):
- progress = runner.epoch if self.by_epoch else runner.iter
-
- # calculate exponential term
- if isinstance(self.step, int):
- exp = progress // self.step
- else:
- exp = len(self.step)
- for i, s in enumerate(self.step):
- if progress < s:
- exp = i
- break
-
- momentum = base_momentum * (self.gamma**exp)
- if self.min_momentum is not None:
- # clip to a minimum value
- momentum = max(momentum, self.min_momentum)
- return momentum
-
-
-@HOOKS.register_module()
-class CosineAnnealingMomentumUpdaterHook(MomentumUpdaterHook):
-
- def __init__(self, min_momentum=None, min_momentum_ratio=None, **kwargs):
- assert (min_momentum is None) ^ (min_momentum_ratio is None)
- self.min_momentum = min_momentum
- self.min_momentum_ratio = min_momentum_ratio
- super(CosineAnnealingMomentumUpdaterHook, self).__init__(**kwargs)
-
- def get_momentum(self, runner, base_momentum):
- if self.by_epoch:
- progress = runner.epoch
- max_progress = runner.max_epochs
- else:
- progress = runner.iter
- max_progress = runner.max_iters
- if self.min_momentum_ratio is not None:
- target_momentum = base_momentum * self.min_momentum_ratio
- else:
- target_momentum = self.min_momentum
- return annealing_cos(base_momentum, target_momentum,
- progress / max_progress)
-
-
-@HOOKS.register_module()
-class CyclicMomentumUpdaterHook(MomentumUpdaterHook):
- """Cyclic momentum Scheduler.
-
- Implement the cyclical momentum scheduler policy described in
- https://arxiv.org/pdf/1708.07120.pdf
-
- This momentum scheduler usually used together with the CyclicLRUpdater
- to improve the performance in the 3D detection area.
-
- Attributes:
- target_ratio (tuple[float]): Relative ratio of the lowest momentum and
- the highest momentum to the initial momentum.
- cyclic_times (int): Number of cycles during training
- step_ratio_up (float): The ratio of the increasing process of momentum
- in the total cycle.
- by_epoch (bool): Whether to update momentum by epoch.
- """
-
- def __init__(self,
- by_epoch=False,
- target_ratio=(0.85 / 0.95, 1),
- cyclic_times=1,
- step_ratio_up=0.4,
- **kwargs):
- if isinstance(target_ratio, float):
- target_ratio = (target_ratio, target_ratio / 1e5)
- elif isinstance(target_ratio, tuple):
- target_ratio = (target_ratio[0], target_ratio[0] / 1e5) \
- if len(target_ratio) == 1 else target_ratio
- else:
- raise ValueError('target_ratio should be either float '
- f'or tuple, got {type(target_ratio)}')
-
- assert len(target_ratio) == 2, \
- '"target_ratio" must be list or tuple of two floats'
- assert 0 <= step_ratio_up < 1.0, \
- '"step_ratio_up" must be in range [0,1)'
-
- self.target_ratio = target_ratio
- self.cyclic_times = cyclic_times
- self.step_ratio_up = step_ratio_up
- self.momentum_phases = [] # init momentum_phases
- # currently only support by_epoch=False
- assert not by_epoch, \
- 'currently only support "by_epoch" = False'
- super(CyclicMomentumUpdaterHook, self).__init__(by_epoch, **kwargs)
-
- def before_run(self, runner):
- super(CyclicMomentumUpdaterHook, self).before_run(runner)
- # initiate momentum_phases
- # total momentum_phases are separated as up and down
- max_iter_per_phase = runner.max_iters // self.cyclic_times
- iter_up_phase = int(self.step_ratio_up * max_iter_per_phase)
- self.momentum_phases.append(
- [0, iter_up_phase, max_iter_per_phase, 1, self.target_ratio[0]])
- self.momentum_phases.append([
- iter_up_phase, max_iter_per_phase, max_iter_per_phase,
- self.target_ratio[0], self.target_ratio[1]
- ])
-
- def get_momentum(self, runner, base_momentum):
- curr_iter = runner.iter
- for (start_iter, end_iter, max_iter_per_phase, start_ratio,
- end_ratio) in self.momentum_phases:
- curr_iter %= max_iter_per_phase
- if start_iter <= curr_iter < end_iter:
- progress = curr_iter - start_iter
- return annealing_cos(base_momentum * start_ratio,
- base_momentum * end_ratio,
- progress / (end_iter - start_iter))
-
-
-@HOOKS.register_module()
-class OneCycleMomentumUpdaterHook(MomentumUpdaterHook):
- """OneCycle momentum Scheduler.
-
- This momentum scheduler usually used together with the OneCycleLrUpdater
- to improve the performance.
-
- Args:
- base_momentum (float or list): Lower momentum boundaries in the cycle
- for each parameter group. Note that momentum is cycled inversely
- to learning rate; at the peak of a cycle, momentum is
- 'base_momentum' and learning rate is 'max_lr'.
- Default: 0.85
- max_momentum (float or list): Upper momentum boundaries in the cycle
- for each parameter group. Functionally,
- it defines the cycle amplitude (max_momentum - base_momentum).
- Note that momentum is cycled inversely
- to learning rate; at the start of a cycle, momentum is
- 'max_momentum' and learning rate is 'base_lr'
- Default: 0.95
- pct_start (float): The percentage of the cycle (in number of steps)
- spent increasing the learning rate.
- Default: 0.3
- anneal_strategy (str): {'cos', 'linear'}
- Specifies the annealing strategy: 'cos' for cosine annealing,
- 'linear' for linear annealing.
- Default: 'cos'
- three_phase (bool): If three_phase is True, use a third phase of the
- schedule to annihilate the learning rate according to
- final_div_factor instead of modifying the second phase (the first
- two phases will be symmetrical about the step indicated by
- pct_start).
- Default: False
- """
-
- def __init__(self,
- base_momentum=0.85,
- max_momentum=0.95,
- pct_start=0.3,
- anneal_strategy='cos',
- three_phase=False,
- **kwargs):
- # validate by_epoch, currently only support by_epoch=False
- if 'by_epoch' not in kwargs:
- kwargs['by_epoch'] = False
- else:
- assert not kwargs['by_epoch'], \
- 'currently only support "by_epoch" = False'
- if not isinstance(base_momentum, (float, list, dict)):
- raise ValueError('base_momentum must be the type among of float,'
- 'list or dict.')
- self._base_momentum = base_momentum
- if not isinstance(max_momentum, (float, list, dict)):
- raise ValueError('max_momentum must be the type among of float,'
- 'list or dict.')
- self._max_momentum = max_momentum
- # validate pct_start
- if pct_start < 0 or pct_start > 1 or not isinstance(pct_start, float):
- raise ValueError('Expected float between 0 and 1 pct_start, but '
- f'got {pct_start}')
- self.pct_start = pct_start
- # validate anneal_strategy
- if anneal_strategy not in ['cos', 'linear']:
- raise ValueError('anneal_strategy must by one of "cos" or '
- f'"linear", instead got {anneal_strategy}')
- elif anneal_strategy == 'cos':
- self.anneal_func = annealing_cos
- elif anneal_strategy == 'linear':
- self.anneal_func = annealing_linear
- self.three_phase = three_phase
- self.momentum_phases = [] # init momentum_phases
- super(OneCycleMomentumUpdaterHook, self).__init__(**kwargs)
-
- def before_run(self, runner):
- if isinstance(runner.optimizer, dict):
- for k, optim in runner.optimizer.items():
- if ('momentum' not in optim.defaults
- and 'betas' not in optim.defaults):
- raise ValueError('optimizer must support momentum with'
- 'option enabled')
- self.use_beta1 = 'betas' in optim.defaults
- _base_momentum = format_param(k, optim, self._base_momentum)
- _max_momentum = format_param(k, optim, self._max_momentum)
- for group, b_momentum, m_momentum in zip(
- optim.param_groups, _base_momentum, _max_momentum):
- if self.use_beta1:
- _, beta2 = group['betas']
- group['betas'] = (m_momentum, beta2)
- else:
- group['momentum'] = m_momentum
- group['base_momentum'] = b_momentum
- group['max_momentum'] = m_momentum
- else:
- optim = runner.optimizer
- if ('momentum' not in optim.defaults
- and 'betas' not in optim.defaults):
- raise ValueError('optimizer must support momentum with'
- 'option enabled')
- self.use_beta1 = 'betas' in optim.defaults
- k = type(optim).__name__
- _base_momentum = format_param(k, optim, self._base_momentum)
- _max_momentum = format_param(k, optim, self._max_momentum)
- for group, b_momentum, m_momentum in zip(optim.param_groups,
- _base_momentum,
- _max_momentum):
- if self.use_beta1:
- _, beta2 = group['betas']
- group['betas'] = (m_momentum, beta2)
- else:
- group['momentum'] = m_momentum
- group['base_momentum'] = b_momentum
- group['max_momentum'] = m_momentum
-
- if self.three_phase:
- self.momentum_phases.append({
- 'end_iter':
- float(self.pct_start * runner.max_iters) - 1,
- 'start_momentum':
- 'max_momentum',
- 'end_momentum':
- 'base_momentum'
- })
- self.momentum_phases.append({
- 'end_iter':
- float(2 * self.pct_start * runner.max_iters) - 2,
- 'start_momentum':
- 'base_momentum',
- 'end_momentum':
- 'max_momentum'
- })
- self.momentum_phases.append({
- 'end_iter': runner.max_iters - 1,
- 'start_momentum': 'max_momentum',
- 'end_momentum': 'max_momentum'
- })
- else:
- self.momentum_phases.append({
- 'end_iter':
- float(self.pct_start * runner.max_iters) - 1,
- 'start_momentum':
- 'max_momentum',
- 'end_momentum':
- 'base_momentum'
- })
- self.momentum_phases.append({
- 'end_iter': runner.max_iters - 1,
- 'start_momentum': 'base_momentum',
- 'end_momentum': 'max_momentum'
- })
-
- def _set_momentum(self, runner, momentum_groups):
- if isinstance(runner.optimizer, dict):
- for k, optim in runner.optimizer.items():
- for param_group, mom in zip(optim.param_groups,
- momentum_groups[k]):
- if 'momentum' in param_group.keys():
- param_group['momentum'] = mom
- elif 'betas' in param_group.keys():
- param_group['betas'] = (mom, param_group['betas'][1])
- else:
- for param_group, mom in zip(runner.optimizer.param_groups,
- momentum_groups):
- if 'momentum' in param_group.keys():
- param_group['momentum'] = mom
- elif 'betas' in param_group.keys():
- param_group['betas'] = (mom, param_group['betas'][1])
-
- def get_momentum(self, runner, param_group):
- curr_iter = runner.iter
- start_iter = 0
- for i, phase in enumerate(self.momentum_phases):
- end_iter = phase['end_iter']
- if curr_iter <= end_iter or i == len(self.momentum_phases) - 1:
- pct = (curr_iter - start_iter) / (end_iter - start_iter)
- momentum = self.anneal_func(
- param_group[phase['start_momentum']],
- param_group[phase['end_momentum']], pct)
- break
- start_iter = end_iter
- return momentum
-
- def get_regular_momentum(self, runner):
- if isinstance(runner.optimizer, dict):
- momentum_groups = {}
- for k, optim in runner.optimizer.items():
- _momentum_group = [
- self.get_momentum(runner, param_group)
- for param_group in optim.param_groups
- ]
- momentum_groups.update({k: _momentum_group})
- return momentum_groups
- else:
- momentum_groups = []
- for param_group in runner.optimizer.param_groups:
- momentum_groups.append(self.get_momentum(runner, param_group))
- return momentum_groups
diff --git "a/spaces/giswqs/Streamlit/pages/2_\360\237\217\240_U.S._Housing.py" "b/spaces/giswqs/Streamlit/pages/2_\360\237\217\240_U.S._Housing.py"
deleted file mode 100644
index 0c2e4996d01c41d196b93308c9532305ee89cf43..0000000000000000000000000000000000000000
--- "a/spaces/giswqs/Streamlit/pages/2_\360\237\217\240_U.S._Housing.py"
+++ /dev/null
@@ -1,482 +0,0 @@
-import datetime
-import os
-import pathlib
-import requests
-import zipfile
-import pandas as pd
-import pydeck as pdk
-import geopandas as gpd
-import streamlit as st
-import leafmap.colormaps as cm
-from leafmap.common import hex_to_rgb
-
-st.set_page_config(layout="wide")
-
-st.sidebar.info(
- """
- - Web App URL:
- - GitHub repository:
- """
-)
-
-st.sidebar.title("Contact")
-st.sidebar.info(
- """
- Qiusheng Wu at [wetlands.io](https://wetlands.io) | [GitHub](https://github.com/giswqs) | [Twitter](https://twitter.com/giswqs) | [YouTube](https://www.youtube.com/c/QiushengWu) | [LinkedIn](https://www.linkedin.com/in/qiushengwu)
- """
-)
-
-STREAMLIT_STATIC_PATH = pathlib.Path(st.__path__[0]) / "static"
-# We create a downloads directory within the streamlit static asset directory
-# and we write output files to it
-DOWNLOADS_PATH = STREAMLIT_STATIC_PATH / "downloads"
-if not DOWNLOADS_PATH.is_dir():
- DOWNLOADS_PATH.mkdir()
-
-# Data source: https://www.realtor.com/research/data/
-# link_prefix = "https://econdata.s3-us-west-2.amazonaws.com/Reports/"
-link_prefix = "https://raw.githubusercontent.com/giswqs/data/main/housing/"
-
-data_links = {
- "weekly": {
- "national": link_prefix + "Core/listing_weekly_core_aggregate_by_country.csv",
- "metro": link_prefix + "Core/listing_weekly_core_aggregate_by_metro.csv",
- },
- "monthly_current": {
- "national": link_prefix + "Core/RDC_Inventory_Core_Metrics_Country.csv",
- "state": link_prefix + "Core/RDC_Inventory_Core_Metrics_State.csv",
- "metro": link_prefix + "Core/RDC_Inventory_Core_Metrics_Metro.csv",
- "county": link_prefix + "Core/RDC_Inventory_Core_Metrics_County.csv",
- "zip": link_prefix + "Core/RDC_Inventory_Core_Metrics_Zip.csv",
- },
- "monthly_historical": {
- "national": link_prefix + "Core/RDC_Inventory_Core_Metrics_Country_History.csv",
- "state": link_prefix + "Core/RDC_Inventory_Core_Metrics_State_History.csv",
- "metro": link_prefix + "Core/RDC_Inventory_Core_Metrics_Metro_History.csv",
- "county": link_prefix + "Core/RDC_Inventory_Core_Metrics_County_History.csv",
- "zip": link_prefix + "Core/RDC_Inventory_Core_Metrics_Zip_History.csv",
- },
- "hotness": {
- "metro": link_prefix
- + "Hotness/RDC_Inventory_Hotness_Metrics_Metro_History.csv",
- "county": link_prefix
- + "Hotness/RDC_Inventory_Hotness_Metrics_County_History.csv",
- "zip": link_prefix + "Hotness/RDC_Inventory_Hotness_Metrics_Zip_History.csv",
- },
-}
-
-
-def get_data_columns(df, category, frequency="monthly"):
- if frequency == "monthly":
- if category.lower() == "county":
- del_cols = ["month_date_yyyymm", "county_fips", "county_name"]
- elif category.lower() == "state":
- del_cols = ["month_date_yyyymm", "state", "state_id"]
- elif category.lower() == "national":
- del_cols = ["month_date_yyyymm", "country"]
- elif category.lower() == "metro":
- del_cols = ["month_date_yyyymm", "cbsa_code", "cbsa_title", "HouseholdRank"]
- elif category.lower() == "zip":
- del_cols = ["month_date_yyyymm", "postal_code", "zip_name", "flag"]
- elif frequency == "weekly":
- if category.lower() == "national":
- del_cols = ["week_end_date", "geo_country"]
- elif category.lower() == "metro":
- del_cols = ["week_end_date", "cbsa_code", "cbsa_title", "hh_rank"]
-
- cols = df.columns.values.tolist()
-
- for col in cols:
- if col.strip() in del_cols:
- cols.remove(col)
- if category.lower() == "metro":
- return cols[2:]
- else:
- return cols[1:]
-
-
-@st.cache(allow_output_mutation=True)
-def get_inventory_data(url):
- df = pd.read_csv(url)
- url = url.lower()
- if "county" in url:
- df["county_fips"] = df["county_fips"].map(str)
- df["county_fips"] = df["county_fips"].str.zfill(5)
- elif "state" in url:
- df["STUSPS"] = df["state_id"].str.upper()
- elif "metro" in url:
- df["cbsa_code"] = df["cbsa_code"].map(str)
- elif "zip" in url:
- df["postal_code"] = df["postal_code"].map(str)
- df["postal_code"] = df["postal_code"].str.zfill(5)
-
- if "listing_weekly_core_aggregate_by_country" in url:
- columns = get_data_columns(df, "national", "weekly")
- for column in columns:
- if column != "median_days_on_market_by_day_yy":
- df[column] = df[column].str.rstrip("%").astype(float) / 100
- if "listing_weekly_core_aggregate_by_metro" in url:
- columns = get_data_columns(df, "metro", "weekly")
- for column in columns:
- if column != "median_days_on_market_by_day_yy":
- df[column] = df[column].str.rstrip("%").astype(float) / 100
- df["cbsa_code"] = df["cbsa_code"].str[:5]
- return df
-
-
-def filter_weekly_inventory(df, week):
- df = df[df["week_end_date"] == week]
- return df
-
-
-def get_start_end_year(df):
- start_year = int(str(df["month_date_yyyymm"].min())[:4])
- end_year = int(str(df["month_date_yyyymm"].max())[:4])
- return start_year, end_year
-
-
-def get_periods(df):
- return [str(d) for d in list(set(df["month_date_yyyymm"].tolist()))]
-
-
-@st.cache(allow_output_mutation=True)
-def get_geom_data(category):
-
- prefix = (
- "https://raw.githubusercontent.com/giswqs/streamlit-geospatial/master/data/"
- )
- links = {
- "national": prefix + "us_nation.geojson",
- "state": prefix + "us_states.geojson",
- "county": prefix + "us_counties.geojson",
- "metro": prefix + "us_metro_areas.geojson",
- "zip": "https://www2.census.gov/geo/tiger/GENZ2018/shp/cb_2018_us_zcta510_500k.zip",
- }
-
- if category.lower() == "zip":
- r = requests.get(links[category])
- out_zip = os.path.join(DOWNLOADS_PATH, "cb_2018_us_zcta510_500k.zip")
- with open(out_zip, "wb") as code:
- code.write(r.content)
- zip_ref = zipfile.ZipFile(out_zip, "r")
- zip_ref.extractall(DOWNLOADS_PATH)
- gdf = gpd.read_file(out_zip.replace("zip", "shp"))
- else:
- gdf = gpd.read_file(links[category])
- return gdf
-
-
-def join_attributes(gdf, df, category):
-
- new_gdf = None
- if category == "county":
- new_gdf = gdf.merge(df, left_on="GEOID", right_on="county_fips", how="outer")
- elif category == "state":
- new_gdf = gdf.merge(df, left_on="STUSPS", right_on="STUSPS", how="outer")
- elif category == "national":
- if "geo_country" in df.columns.values.tolist():
- df["country"] = None
- df.loc[0, "country"] = "United States"
- new_gdf = gdf.merge(df, left_on="NAME", right_on="country", how="outer")
- elif category == "metro":
- new_gdf = gdf.merge(df, left_on="CBSAFP", right_on="cbsa_code", how="outer")
- elif category == "zip":
- new_gdf = gdf.merge(df, left_on="GEOID10", right_on="postal_code", how="outer")
- return new_gdf
-
-
-def select_non_null(gdf, col_name):
- new_gdf = gdf[~gdf[col_name].isna()]
- return new_gdf
-
-
-def select_null(gdf, col_name):
- new_gdf = gdf[gdf[col_name].isna()]
- return new_gdf
-
-
-def get_data_dict(name):
- in_csv = os.path.join(os.getcwd(), "data/realtor_data_dict.csv")
- df = pd.read_csv(in_csv)
- label = list(df[df["Name"] == name]["Label"])[0]
- desc = list(df[df["Name"] == name]["Description"])[0]
- return label, desc
-
-
-def get_weeks(df):
- seq = list(set(df[~df["week_end_date"].isnull()]["week_end_date"].tolist()))
- weeks = [
- datetime.date(int(d.split("/")[2]), int(d.split("/")[0]), int(d.split("/")[1]))
- for d in seq
- ]
- weeks.sort()
- return weeks
-
-
-def get_saturday(in_date):
- idx = (in_date.weekday() + 1) % 7
- sat = in_date + datetime.timedelta(6 - idx)
- return sat
-
-
-def app():
-
- st.title("U.S. Real Estate Data and Market Trends")
- st.markdown(
- """**Introduction:** This interactive dashboard is designed for visualizing U.S. real estate data and market trends at multiple levels (i.e., national,
- state, county, and metro). The data sources include [Real Estate Data](https://www.realtor.com/research/data) from realtor.com and
- [Cartographic Boundary Files](https://www.census.gov/geographies/mapping-files/time-series/geo/carto-boundary-file.html) from U.S. Census Bureau.
- Several open-source packages are used to process the data and generate the visualizations, e.g., [streamlit](https://streamlit.io),
- [geopandas](https://geopandas.org), [leafmap](https://leafmap.org), and [pydeck](https://deckgl.readthedocs.io).
- """
- )
-
- with st.expander("See a demo"):
- st.image("https://i.imgur.com/Z3dk6Tr.gif")
-
- row1_col1, row1_col2, row1_col3, row1_col4, row1_col5 = st.columns(
- [0.6, 0.8, 0.6, 1.4, 2]
- )
- with row1_col1:
- frequency = st.selectbox("Monthly/weekly data", ["Monthly", "Weekly"])
- with row1_col2:
- types = ["Current month data", "Historical data"]
- if frequency == "Weekly":
- types.remove("Current month data")
- cur_hist = st.selectbox(
- "Current/historical data",
- types,
- )
- with row1_col3:
- if frequency == "Monthly":
- scale = st.selectbox(
- "Scale", ["National", "State", "Metro", "County"], index=3
- )
- else:
- scale = st.selectbox("Scale", ["National", "Metro"], index=1)
-
- gdf = get_geom_data(scale.lower())
-
- if frequency == "Weekly":
- inventory_df = get_inventory_data(data_links["weekly"][scale.lower()])
- weeks = get_weeks(inventory_df)
- with row1_col1:
- selected_date = st.date_input("Select a date", value=weeks[-1])
- saturday = get_saturday(selected_date)
- selected_period = saturday.strftime("%-m/%-d/%Y")
- if saturday not in weeks:
- st.error(
- "The selected date is not available in the data. Please select a date between {} and {}".format(
- weeks[0], weeks[-1]
- )
- )
- selected_period = weeks[-1].strftime("%-m/%-d/%Y")
- inventory_df = get_inventory_data(data_links["weekly"][scale.lower()])
- inventory_df = filter_weekly_inventory(inventory_df, selected_period)
-
- if frequency == "Monthly":
- if cur_hist == "Current month data":
- inventory_df = get_inventory_data(
- data_links["monthly_current"][scale.lower()]
- )
- selected_period = get_periods(inventory_df)[0]
- else:
- with row1_col2:
- inventory_df = get_inventory_data(
- data_links["monthly_historical"][scale.lower()]
- )
- start_year, end_year = get_start_end_year(inventory_df)
- periods = get_periods(inventory_df)
- with st.expander("Select year and month", True):
- selected_year = st.slider(
- "Year",
- start_year,
- end_year,
- value=start_year,
- step=1,
- )
- selected_month = st.slider(
- "Month",
- min_value=1,
- max_value=12,
- value=int(periods[0][-2:]),
- step=1,
- )
- selected_period = str(selected_year) + str(selected_month).zfill(2)
- if selected_period not in periods:
- st.error("Data not available for selected year and month")
- selected_period = periods[0]
- inventory_df = inventory_df[
- inventory_df["month_date_yyyymm"] == int(selected_period)
- ]
-
- data_cols = get_data_columns(inventory_df, scale.lower(), frequency.lower())
-
- with row1_col4:
- selected_col = st.selectbox("Attribute", data_cols)
- with row1_col5:
- show_desc = st.checkbox("Show attribute description")
- if show_desc:
- try:
- label, desc = get_data_dict(selected_col.strip())
- markdown = f"""
- **{label}**: {desc}
- """
- st.markdown(markdown)
- except:
- st.warning("No description available for selected attribute")
-
- row2_col1, row2_col2, row2_col3, row2_col4, row2_col5, row2_col6 = st.columns(
- [0.6, 0.68, 0.7, 0.7, 1.5, 0.8]
- )
-
- palettes = cm.list_colormaps()
- with row2_col1:
- palette = st.selectbox("Color palette", palettes, index=palettes.index("Blues"))
- with row2_col2:
- n_colors = st.slider("Number of colors", min_value=2, max_value=20, value=8)
- with row2_col3:
- show_nodata = st.checkbox("Show nodata areas", value=True)
- with row2_col4:
- show_3d = st.checkbox("Show 3D view", value=False)
- with row2_col5:
- if show_3d:
- elev_scale = st.slider(
- "Elevation scale", min_value=1, max_value=1000000, value=1, step=10
- )
- with row2_col6:
- st.info("Press Ctrl and move the left mouse button.")
- else:
- elev_scale = 1
-
- gdf = join_attributes(gdf, inventory_df, scale.lower())
- gdf_null = select_null(gdf, selected_col)
- gdf = select_non_null(gdf, selected_col)
- gdf = gdf.sort_values(by=selected_col, ascending=True)
-
- colors = cm.get_palette(palette, n_colors)
- colors = [hex_to_rgb(c) for c in colors]
-
- for i, ind in enumerate(gdf.index):
- index = int(i / (len(gdf) / len(colors)))
- if index >= len(colors):
- index = len(colors) - 1
- gdf.loc[ind, "R"] = colors[index][0]
- gdf.loc[ind, "G"] = colors[index][1]
- gdf.loc[ind, "B"] = colors[index][2]
-
- initial_view_state = pdk.ViewState(
- latitude=40,
- longitude=-100,
- zoom=3,
- max_zoom=16,
- pitch=0,
- bearing=0,
- height=900,
- width=None,
- )
-
- min_value = gdf[selected_col].min()
- max_value = gdf[selected_col].max()
- color = "color"
- # color_exp = f"[({selected_col}-{min_value})/({max_value}-{min_value})*255, 0, 0]"
- color_exp = f"[R, G, B]"
-
- geojson = pdk.Layer(
- "GeoJsonLayer",
- gdf,
- pickable=True,
- opacity=0.5,
- stroked=True,
- filled=True,
- extruded=show_3d,
- wireframe=True,
- get_elevation=f"{selected_col}",
- elevation_scale=elev_scale,
- # get_fill_color="color",
- get_fill_color=color_exp,
- get_line_color=[0, 0, 0],
- get_line_width=2,
- line_width_min_pixels=1,
- )
-
- geojson_null = pdk.Layer(
- "GeoJsonLayer",
- gdf_null,
- pickable=True,
- opacity=0.2,
- stroked=True,
- filled=True,
- extruded=False,
- wireframe=True,
- # get_elevation="properties.ALAND/100000",
- # get_fill_color="color",
- get_fill_color=[200, 200, 200],
- get_line_color=[0, 0, 0],
- get_line_width=2,
- line_width_min_pixels=1,
- )
-
- # tooltip = {"text": "Name: {NAME}"}
-
- # tooltip_value = f"Value: {median_listing_price}""
- tooltip = {
- "html": "Name: {NAME}
-
-## License
-
-(The MIT License)
-
-Copyright (c) 2014-2017 TJ Holowaychuk <tj@vision-media.ca>
-Copyright (c) 2018-2021 Josh Junon
-
-Permission is hereby granted, free of charge, to any person obtaining
-a copy of this software and associated documentation files (the
-'Software'), to deal in the Software without restriction, including
-without limitation the rights to use, copy, modify, merge, publish,
-distribute, sublicense, and/or sell copies of the Software, and to
-permit persons to whom the Software is furnished to do so, subject to
-the following conditions:
-
-The above copyright notice and this permission notice shall be
-included in all copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND,
-EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
-MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
-IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY
-CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
-TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
-SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/spaces/firefighter/TransDis-CreativityAutoAssessment/README.md b/spaces/firefighter/TransDis-CreativityAutoAssessment/README.md
deleted file mode 100644
index 75a24342eb2802c5e170bb4010ddcbfe74a1eebe..0000000000000000000000000000000000000000
--- a/spaces/firefighter/TransDis-CreativityAutoAssessment/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: TransDis-CreativityAutoAssessment
-emoji: 💡
-colorFrom: yellow
-colorTo: gray
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/firsk/ai_otto/app.py b/spaces/firsk/ai_otto/app.py
deleted file mode 100644
index 398f52bbc898d4074c6b27c9179015508b9b92ca..0000000000000000000000000000000000000000
--- a/spaces/firsk/ai_otto/app.py
+++ /dev/null
@@ -1,224 +0,0 @@
-# flake8: noqa: E402
-
-import sys, os
-import logging
-
-logging.getLogger("numba").setLevel(logging.WARNING)
-logging.getLogger("markdown_it").setLevel(logging.WARNING)
-logging.getLogger("urllib3").setLevel(logging.WARNING)
-logging.getLogger("matplotlib").setLevel(logging.WARNING)
-
-logging.basicConfig(
- level=logging.INFO, format="| %(name)s | %(levelname)s | %(message)s"
-)
-
-logger = logging.getLogger(__name__)
-
-import torch
-import argparse
-import commons
-import utils
-from models import SynthesizerTrn
-from text.symbols import symbols
-from text import cleaned_text_to_sequence, get_bert
-from text.cleaner import clean_text
-import gradio as gr
-import webbrowser
-import numpy as np
-
-net_g = None
-
-if sys.platform == "darwin" and torch.backends.mps.is_available():
- device = "mps"
- os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
-else:
- device = "cuda"
-
-
-def get_text(text, language_str, hps):
- norm_text, phone, tone, word2ph = clean_text(text, language_str)
- phone, tone, language = cleaned_text_to_sequence(phone, tone, language_str)
-
- if hps.data.add_blank:
- phone = commons.intersperse(phone, 0)
- tone = commons.intersperse(tone, 0)
- language = commons.intersperse(language, 0)
- for i in range(len(word2ph)):
- word2ph[i] = word2ph[i] * 2
- word2ph[0] += 1
- bert = get_bert(norm_text, word2ph, language_str, device)
- del word2ph
- assert bert.shape[-1] == len(phone), phone
-
- if language_str == "ZH":
- bert = bert
- ja_bert = torch.zeros(768, len(phone))
- elif language_str == "JP":
- ja_bert = bert
- bert = torch.zeros(1024, len(phone))
- else:
- bert = torch.zeros(1024, len(phone))
- ja_bert = torch.zeros(768, len(phone))
-
- assert bert.shape[-1] == len(
- phone
- ), f"Bert seq len {bert.shape[-1]} != {len(phone)}"
-
- phone = torch.LongTensor(phone)
- tone = torch.LongTensor(tone)
- language = torch.LongTensor(language)
- return bert, ja_bert, phone, tone, language
-
-
-def infer(text, sdp_ratio, noise_scale, noise_scale_w, length_scale, sid, language):
- global net_g
- bert, ja_bert, phones, tones, lang_ids = get_text(text, language, hps)
- with torch.no_grad():
- x_tst = phones.to(device).unsqueeze(0)
- tones = tones.to(device).unsqueeze(0)
- lang_ids = lang_ids.to(device).unsqueeze(0)
- bert = bert.to(device).unsqueeze(0)
- ja_bert = ja_bert.to(device).unsqueeze(0)
- x_tst_lengths = torch.LongTensor([phones.size(0)]).to(device)
- del phones
- speakers = torch.LongTensor([hps.data.spk2id[sid]]).to(device)
- audio = (
- net_g.infer(
- x_tst,
- x_tst_lengths,
- speakers,
- tones,
- lang_ids,
- bert,
- ja_bert,
- sdp_ratio=sdp_ratio,
- noise_scale=noise_scale,
- noise_scale_w=noise_scale_w,
- length_scale=length_scale,
- )[0][0, 0]
- .data.cpu()
- .float()
- .numpy()
- )
- del x_tst, tones, lang_ids, bert, x_tst_lengths, speakers
- torch.cuda.empty_cache()
- return audio
-
-
-def tts_fn(
- text, speaker, sdp_ratio, noise_scale, noise_scale_w, length_scale, language
-):
- slices = text.split("|")
- audio_list = []
- with torch.no_grad():
- for slice in slices:
- audio = infer(
- slice,
- sdp_ratio=sdp_ratio,
- noise_scale=noise_scale,
- noise_scale_w=noise_scale_w,
- length_scale=length_scale,
- sid=speaker,
- language=language,
- )
- audio_list.append(audio)
- silence = np.zeros(hps.data.sampling_rate) # 生成1秒的静音
- audio_list.append(silence) # 将静音添加到列表中
- audio_concat = np.concatenate(audio_list)
- return "Success", (hps.data.sampling_rate, audio_concat)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "-m", "--model", default="./logs/OUTPUT_MODEL/G_159000.pth", help="path of your model"
- )
- parser.add_argument(
- "-c",
- "--config",
- default="./configs/config.json",
- help="path of your config file",
- )
- parser.add_argument(
- "--share", default=True, help="make link public", action="store_true"
- )
- parser.add_argument(
- "-d", "--debug", action="store_true", help="enable DEBUG-LEVEL log"
- )
-
- args = parser.parse_args()
- if args.debug:
- logger.info("Enable DEBUG-LEVEL log")
- logging.basicConfig(level=logging.DEBUG)
- hps = utils.get_hparams_from_file(args.config)
-
- device = (
- "cuda:0"
- if torch.cuda.is_available()
- else (
- "mps"
- if sys.platform == "darwin" and torch.backends.mps.is_available()
- else "cpu"
- )
- )
- net_g = SynthesizerTrn(
- len(symbols),
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- n_speakers=hps.data.n_speakers,
- **hps.model,
- ).to(device)
- _ = net_g.eval()
-
- _ = utils.load_checkpoint(args.model, net_g, None, skip_optimizer=True)
-
- speaker_ids = hps.data.spk2id
- speakers = list(speaker_ids.keys())
- languages = ["ZH", "JP"]
- with gr.Blocks() as app:
- with gr.Row():
- with gr.Column():
- text = gr.TextArea(
- label="Text",
- placeholder="Input Text Here",
- value="年仅三岁的国王毫无畏惧",
- )
- speaker = gr.Dropdown(
- choices=speakers, value=speakers[0], label="Speaker"
- )
- sdp_ratio = gr.Slider(
- minimum=0, maximum=1, value=0.2, step=0.1, label="SDP Ratio"
- )
- noise_scale = gr.Slider(
- minimum=0.1, maximum=2, value=0.6, step=0.1, label="Noise Scale"
- )
- noise_scale_w = gr.Slider(
- minimum=0.1, maximum=2, value=0.8, step=0.1, label="Noise Scale W"
- )
- length_scale = gr.Slider(
- minimum=0.1, maximum=2, value=1, step=0.1, label="Length Scale"
- )
- language = gr.Dropdown(
- choices=languages, value=languages[0], label="Language"
- )
- btn = gr.Button("Generate!", variant="primary")
- with gr.Column():
- text_output = gr.Textbox(label="Message")
- audio_output = gr.Audio(label="Output Audio")
-
- btn.click(
- tts_fn,
- inputs=[
- text,
- speaker,
- sdp_ratio,
- noise_scale,
- noise_scale_w,
- length_scale,
- language,
- ],
- outputs=[text_output, audio_output],
- )
-
- webbrowser.open("http://127.0.0.1:7860")
- app.launch(share=args.share)
diff --git a/spaces/flax-community/spanish-image-captioning/sections/usage.md b/spaces/flax-community/spanish-image-captioning/sections/usage.md
deleted file mode 100644
index 7fd5c2cf140f99031a3cef1a4b1684c43aea4651..0000000000000000000000000000000000000000
--- a/spaces/flax-community/spanish-image-captioning/sections/usage.md
+++ /dev/null
@@ -1,7 +0,0 @@
-- This demo loads the `FlaxCLIPVisionMarianMT` present in the `model` directory of this repository. The checkpoint is loaded from `ckpt/ckpt-23999` which is pre-trained checkpoint with 24k steps. 100 random validation set examples are present in the `references.tsv` with respective images in the `images` directory.
-
-- We provide `English Translation` of the generated caption and reference captions for users who are not well-acquainted with Spanish. This is done using `mtranslate` to keep things flexible enough and needs internet connection as it uses the Google Translate API. We will also add the original captions soon.
-
-- The sidebar contains generation parameters such as `Number of Beams`, `Top-P`, `Temperature` which will be used when generating the caption.
-
-- Clicking on `Generate Caption` will generate the caption in Spanish.
\ No newline at end of file
diff --git a/spaces/flowers-team/SocialAISchool/scripts/tensorboard_aggregator.py b/spaces/flowers-team/SocialAISchool/scripts/tensorboard_aggregator.py
deleted file mode 100644
index d4002c231bce5dfc1a61108241d64053f687e220..0000000000000000000000000000000000000000
--- a/spaces/flowers-team/SocialAISchool/scripts/tensorboard_aggregator.py
+++ /dev/null
@@ -1,141 +0,0 @@
-import os
-import sys
-import argparse
-import shutil
-from collections import defaultdict
-
-import numpy as np
-import tensorflow as tf
-from tensorboard.backend.event_processing.event_accumulator import EventAccumulator
-
-
-def tabulate_events(exp_path):
-
- seeds = [s for s in os.listdir(exp_path) if "combined" not in s]
- summary_iterators = [EventAccumulator(os.path.join(exp_path, dname)).Reload() for dname in seeds]
-
- tags = summary_iterators[0].Tags()['scalars']
- for it in summary_iterators:
- assert it.Tags()['scalars'] == tags
-
- out = defaultdict(list)
- for tag in tags:
- for events in zip(*[acc.Scalars(tag) for acc in summary_iterators]):
- assert len(set(e.step for e in events)) == 1
-
- out[tag].append([e.value for e in events])
-
- return out
-
-
-def create_histogram_summary(tag, values, bins=1000):
- # Convert to a numpy array
- values = np.array(values)
-
- # Create histogram using numpy
- counts, bin_edges = np.histogram(values, bins=bins)
-
- # Fill fields of histogram proto
- hist = tf.HistogramProto()
- hist.min = float(np.min(values))
- hist.max = float(np.max(values))
- hist.num = int(np.prod(values.shape))
- hist.sum = float(np.sum(values))
- hist.sum_squares = float(np.sum(values**2))
-
- # Requires equal number as bins, where the first goes from -DBL_MAX to bin_edges[1]
- # See https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/summary.proto#L30
- # Thus, we drop the start of the first bin
- bin_edges = bin_edges[1:]
-
- # Add bin edges and counts
- for edge in bin_edges:
- hist.bucket_limit.append(edge)
- for c in counts:
- hist.bucket.append(c)
-
- # Create and write Summary
- return tf.Summary.Value(tag=tag, histo=hist)
-
-
-def create_parsed_histogram_summary(tag, values, bins=1000):
- # Convert to a numpy array
-
- # Create histogram using numpy
- counts, bin_edges = np.histogram(values, bins=bins)
-
- # Fill fields of histogram proto
- hist = tf.HistogramProto()
- hist.min = float(np.min(values))
- hist.max = float(np.max(values))
- hist.num = int(np.prod(values.shape))
- hist.sum = float(np.sum(values))
- hist.sum_squares = float(np.sum(values**2))
-
- # Requires equal number as bins, where the first goes from -DBL_MAX to bin_edges[1]
- # See https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/framework/summary.proto#L30
- # Thus, we drop the start of the first bin
- bin_edges = bin_edges[1:]
-
- # Add bin edges and counts
- for edge in bin_edges:
- hist.bucket_limit.append(edge)
- for c in counts:
- hist.bucket.append(c)
-
- # Create and write Summary
- return tf.Summary.Value(tag=tag, histo=hist)
-
-
-def write_combined_events(exp_path, d_combined, dname='combined', mean_var_tags=()):
-
- fpath = os.path.join(exp_path, dname)
- if os.path.isdir(fpath):
- shutil.rmtree(fpath)
- assert not os.path.isdir(fpath)
-
- writer = tf.summary.FileWriter(fpath)
-
-
- tags, values = zip(*d_combined.items())
-
- cap = min([len(v) for v in values])
- values = [v[:cap] for v in values]
-
- timestep_mean = np.array(values).mean(axis=-1)
- timestep_var = np.array(values).var(axis=-1)
- timesteps = timestep_mean[tags.index("frames")]
-
- for tag, means, vars in zip(tags, timestep_mean, timestep_var):
- for i, mean, var in zip(timesteps, means, vars):
- summary = tf.Summary(value=[tf.Summary.Value(tag=tag, simple_value=mean)])
- writer.add_summary(summary, global_step=i)
- writer.flush()
-
- if tag in mean_var_tags:
- values = np.array([mean - var, mean, mean + var])
-
- summary = tf.Summary(value=[
- create_histogram_summary(tag=tag+"_var", values=values)
- ])
- writer.add_summary(summary, global_step=i)
- writer.flush()
-
-
-if __name__ == "__main__":
- if len(sys.argv) > 1:
- dpath = sys.argv[1]
- else:
- raise ValueError("Specify dir")
-
- parser = argparse.ArgumentParser()
-
- parser.add_argument('--experiments', nargs='+', help='experiment directories to aggregate', required=True)
-
- parser.add_argument('--mean-var-tags', nargs='+', help='tags to create mean-var histograms from', required=False, default=["return_mean"])
-
- args = parser.parse_args()
-
- for exp_path in args.experiments:
- d = tabulate_events(exp_path)
- write_combined_events(exp_path, d, mean_var_tags=args.mean_var_tags)
\ No newline at end of file
diff --git a/spaces/fluffyfluff/multiple-pdf-chat/README.md b/spaces/fluffyfluff/multiple-pdf-chat/README.md
deleted file mode 100644
index f77ed40df8d8504c5aee1e0f68c37ea0c2a0ffac..0000000000000000000000000000000000000000
--- a/spaces/fluffyfluff/multiple-pdf-chat/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Multiple Pdf Chat
-emoji: 🚀
-colorFrom: green
-colorTo: pink
-sdk: streamlit
-sdk_version: 1.25.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/foduucom/stockmarket-future-prediction/README.md b/spaces/foduucom/stockmarket-future-prediction/README.md
deleted file mode 100644
index 84ea7c870d967b54e12e4a6efe2bdf146d22c6f0..0000000000000000000000000000000000000000
--- a/spaces/foduucom/stockmarket-future-prediction/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Stockmarket Future Prediction
-emoji: 🔥
-colorFrom: gray
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.45.1
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/gbharti/fastai-model-deploy/.ipynb_checkpoints/README-checkpoint.md b/spaces/gbharti/fastai-model-deploy/.ipynb_checkpoints/README-checkpoint.md
deleted file mode 100644
index 4e9e3c0ceae4ef49b3f5c1814058ee40036ef7c9..0000000000000000000000000000000000000000
--- a/spaces/gbharti/fastai-model-deploy/.ipynb_checkpoints/README-checkpoint.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Fastai Model Reply
-emoji: ⚡
-colorFrom: blue
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.6
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/runner/hooks/momentum_updater.py b/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/runner/hooks/momentum_updater.py
deleted file mode 100644
index 60437756ceedf06055ec349df69a25465738d3f0..0000000000000000000000000000000000000000
--- a/spaces/georgefen/Face-Landmark-ControlNet/annotator/uniformer/mmcv/runner/hooks/momentum_updater.py
+++ /dev/null
@@ -1,493 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import annotator.uniformer.mmcv as mmcv
-from .hook import HOOKS, Hook
-from .lr_updater import annealing_cos, annealing_linear, format_param
-
-
-class MomentumUpdaterHook(Hook):
-
- def __init__(self,
- by_epoch=True,
- warmup=None,
- warmup_iters=0,
- warmup_ratio=0.9):
- # validate the "warmup" argument
- if warmup is not None:
- if warmup not in ['constant', 'linear', 'exp']:
- raise ValueError(
- f'"{warmup}" is not a supported type for warming up, valid'
- ' types are "constant" and "linear"')
- if warmup is not None:
- assert warmup_iters > 0, \
- '"warmup_iters" must be a positive integer'
- assert 0 < warmup_ratio <= 1.0, \
- '"warmup_momentum" must be in range (0,1]'
-
- self.by_epoch = by_epoch
- self.warmup = warmup
- self.warmup_iters = warmup_iters
- self.warmup_ratio = warmup_ratio
-
- self.base_momentum = [] # initial momentum for all param groups
- self.regular_momentum = [
- ] # expected momentum if no warming up is performed
-
- def _set_momentum(self, runner, momentum_groups):
- if isinstance(runner.optimizer, dict):
- for k, optim in runner.optimizer.items():
- for param_group, mom in zip(optim.param_groups,
- momentum_groups[k]):
- if 'momentum' in param_group.keys():
- param_group['momentum'] = mom
- elif 'betas' in param_group.keys():
- param_group['betas'] = (mom, param_group['betas'][1])
- else:
- for param_group, mom in zip(runner.optimizer.param_groups,
- momentum_groups):
- if 'momentum' in param_group.keys():
- param_group['momentum'] = mom
- elif 'betas' in param_group.keys():
- param_group['betas'] = (mom, param_group['betas'][1])
-
- def get_momentum(self, runner, base_momentum):
- raise NotImplementedError
-
- def get_regular_momentum(self, runner):
- if isinstance(runner.optimizer, dict):
- momentum_groups = {}
- for k in runner.optimizer.keys():
- _momentum_group = [
- self.get_momentum(runner, _base_momentum)
- for _base_momentum in self.base_momentum[k]
- ]
- momentum_groups.update({k: _momentum_group})
- return momentum_groups
- else:
- return [
- self.get_momentum(runner, _base_momentum)
- for _base_momentum in self.base_momentum
- ]
-
- def get_warmup_momentum(self, cur_iters):
-
- def _get_warmup_momentum(cur_iters, regular_momentum):
- if self.warmup == 'constant':
- warmup_momentum = [
- _momentum / self.warmup_ratio
- for _momentum in self.regular_momentum
- ]
- elif self.warmup == 'linear':
- k = (1 - cur_iters / self.warmup_iters) * (1 -
- self.warmup_ratio)
- warmup_momentum = [
- _momentum / (1 - k) for _momentum in self.regular_mom
- ]
- elif self.warmup == 'exp':
- k = self.warmup_ratio**(1 - cur_iters / self.warmup_iters)
- warmup_momentum = [
- _momentum / k for _momentum in self.regular_mom
- ]
- return warmup_momentum
-
- if isinstance(self.regular_momentum, dict):
- momentum_groups = {}
- for key, regular_momentum in self.regular_momentum.items():
- momentum_groups[key] = _get_warmup_momentum(
- cur_iters, regular_momentum)
- return momentum_groups
- else:
- return _get_warmup_momentum(cur_iters, self.regular_momentum)
-
- def before_run(self, runner):
- # NOTE: when resuming from a checkpoint,
- # if 'initial_momentum' is not saved,
- # it will be set according to the optimizer params
- if isinstance(runner.optimizer, dict):
- self.base_momentum = {}
- for k, optim in runner.optimizer.items():
- for group in optim.param_groups:
- if 'momentum' in group.keys():
- group.setdefault('initial_momentum', group['momentum'])
- else:
- group.setdefault('initial_momentum', group['betas'][0])
- _base_momentum = [
- group['initial_momentum'] for group in optim.param_groups
- ]
- self.base_momentum.update({k: _base_momentum})
- else:
- for group in runner.optimizer.param_groups:
- if 'momentum' in group.keys():
- group.setdefault('initial_momentum', group['momentum'])
- else:
- group.setdefault('initial_momentum', group['betas'][0])
- self.base_momentum = [
- group['initial_momentum']
- for group in runner.optimizer.param_groups
- ]
-
- def before_train_epoch(self, runner):
- if not self.by_epoch:
- return
- self.regular_mom = self.get_regular_momentum(runner)
- self._set_momentum(runner, self.regular_mom)
-
- def before_train_iter(self, runner):
- cur_iter = runner.iter
- if not self.by_epoch:
- self.regular_mom = self.get_regular_momentum(runner)
- if self.warmup is None or cur_iter >= self.warmup_iters:
- self._set_momentum(runner, self.regular_mom)
- else:
- warmup_momentum = self.get_warmup_momentum(cur_iter)
- self._set_momentum(runner, warmup_momentum)
- elif self.by_epoch:
- if self.warmup is None or cur_iter > self.warmup_iters:
- return
- elif cur_iter == self.warmup_iters:
- self._set_momentum(runner, self.regular_mom)
- else:
- warmup_momentum = self.get_warmup_momentum(cur_iter)
- self._set_momentum(runner, warmup_momentum)
-
-
-@HOOKS.register_module()
-class StepMomentumUpdaterHook(MomentumUpdaterHook):
- """Step momentum scheduler with min value clipping.
-
- Args:
- step (int | list[int]): Step to decay the momentum. If an int value is
- given, regard it as the decay interval. If a list is given, decay
- momentum at these steps.
- gamma (float, optional): Decay momentum ratio. Default: 0.5.
- min_momentum (float, optional): Minimum momentum value to keep. If
- momentum after decay is lower than this value, it will be clipped
- accordingly. If None is given, we don't perform lr clipping.
- Default: None.
- """
-
- def __init__(self, step, gamma=0.5, min_momentum=None, **kwargs):
- if isinstance(step, list):
- assert mmcv.is_list_of(step, int)
- assert all([s > 0 for s in step])
- elif isinstance(step, int):
- assert step > 0
- else:
- raise TypeError('"step" must be a list or integer')
- self.step = step
- self.gamma = gamma
- self.min_momentum = min_momentum
- super(StepMomentumUpdaterHook, self).__init__(**kwargs)
-
- def get_momentum(self, runner, base_momentum):
- progress = runner.epoch if self.by_epoch else runner.iter
-
- # calculate exponential term
- if isinstance(self.step, int):
- exp = progress // self.step
- else:
- exp = len(self.step)
- for i, s in enumerate(self.step):
- if progress < s:
- exp = i
- break
-
- momentum = base_momentum * (self.gamma**exp)
- if self.min_momentum is not None:
- # clip to a minimum value
- momentum = max(momentum, self.min_momentum)
- return momentum
-
-
-@HOOKS.register_module()
-class CosineAnnealingMomentumUpdaterHook(MomentumUpdaterHook):
-
- def __init__(self, min_momentum=None, min_momentum_ratio=None, **kwargs):
- assert (min_momentum is None) ^ (min_momentum_ratio is None)
- self.min_momentum = min_momentum
- self.min_momentum_ratio = min_momentum_ratio
- super(CosineAnnealingMomentumUpdaterHook, self).__init__(**kwargs)
-
- def get_momentum(self, runner, base_momentum):
- if self.by_epoch:
- progress = runner.epoch
- max_progress = runner.max_epochs
- else:
- progress = runner.iter
- max_progress = runner.max_iters
- if self.min_momentum_ratio is not None:
- target_momentum = base_momentum * self.min_momentum_ratio
- else:
- target_momentum = self.min_momentum
- return annealing_cos(base_momentum, target_momentum,
- progress / max_progress)
-
-
-@HOOKS.register_module()
-class CyclicMomentumUpdaterHook(MomentumUpdaterHook):
- """Cyclic momentum Scheduler.
-
- Implement the cyclical momentum scheduler policy described in
- https://arxiv.org/pdf/1708.07120.pdf
-
- This momentum scheduler usually used together with the CyclicLRUpdater
- to improve the performance in the 3D detection area.
-
- Attributes:
- target_ratio (tuple[float]): Relative ratio of the lowest momentum and
- the highest momentum to the initial momentum.
- cyclic_times (int): Number of cycles during training
- step_ratio_up (float): The ratio of the increasing process of momentum
- in the total cycle.
- by_epoch (bool): Whether to update momentum by epoch.
- """
-
- def __init__(self,
- by_epoch=False,
- target_ratio=(0.85 / 0.95, 1),
- cyclic_times=1,
- step_ratio_up=0.4,
- **kwargs):
- if isinstance(target_ratio, float):
- target_ratio = (target_ratio, target_ratio / 1e5)
- elif isinstance(target_ratio, tuple):
- target_ratio = (target_ratio[0], target_ratio[0] / 1e5) \
- if len(target_ratio) == 1 else target_ratio
- else:
- raise ValueError('target_ratio should be either float '
- f'or tuple, got {type(target_ratio)}')
-
- assert len(target_ratio) == 2, \
- '"target_ratio" must be list or tuple of two floats'
- assert 0 <= step_ratio_up < 1.0, \
- '"step_ratio_up" must be in range [0,1)'
-
- self.target_ratio = target_ratio
- self.cyclic_times = cyclic_times
- self.step_ratio_up = step_ratio_up
- self.momentum_phases = [] # init momentum_phases
- # currently only support by_epoch=False
- assert not by_epoch, \
- 'currently only support "by_epoch" = False'
- super(CyclicMomentumUpdaterHook, self).__init__(by_epoch, **kwargs)
-
- def before_run(self, runner):
- super(CyclicMomentumUpdaterHook, self).before_run(runner)
- # initiate momentum_phases
- # total momentum_phases are separated as up and down
- max_iter_per_phase = runner.max_iters // self.cyclic_times
- iter_up_phase = int(self.step_ratio_up * max_iter_per_phase)
- self.momentum_phases.append(
- [0, iter_up_phase, max_iter_per_phase, 1, self.target_ratio[0]])
- self.momentum_phases.append([
- iter_up_phase, max_iter_per_phase, max_iter_per_phase,
- self.target_ratio[0], self.target_ratio[1]
- ])
-
- def get_momentum(self, runner, base_momentum):
- curr_iter = runner.iter
- for (start_iter, end_iter, max_iter_per_phase, start_ratio,
- end_ratio) in self.momentum_phases:
- curr_iter %= max_iter_per_phase
- if start_iter <= curr_iter < end_iter:
- progress = curr_iter - start_iter
- return annealing_cos(base_momentum * start_ratio,
- base_momentum * end_ratio,
- progress / (end_iter - start_iter))
-
-
-@HOOKS.register_module()
-class OneCycleMomentumUpdaterHook(MomentumUpdaterHook):
- """OneCycle momentum Scheduler.
-
- This momentum scheduler usually used together with the OneCycleLrUpdater
- to improve the performance.
-
- Args:
- base_momentum (float or list): Lower momentum boundaries in the cycle
- for each parameter group. Note that momentum is cycled inversely
- to learning rate; at the peak of a cycle, momentum is
- 'base_momentum' and learning rate is 'max_lr'.
- Default: 0.85
- max_momentum (float or list): Upper momentum boundaries in the cycle
- for each parameter group. Functionally,
- it defines the cycle amplitude (max_momentum - base_momentum).
- Note that momentum is cycled inversely
- to learning rate; at the start of a cycle, momentum is
- 'max_momentum' and learning rate is 'base_lr'
- Default: 0.95
- pct_start (float): The percentage of the cycle (in number of steps)
- spent increasing the learning rate.
- Default: 0.3
- anneal_strategy (str): {'cos', 'linear'}
- Specifies the annealing strategy: 'cos' for cosine annealing,
- 'linear' for linear annealing.
- Default: 'cos'
- three_phase (bool): If three_phase is True, use a third phase of the
- schedule to annihilate the learning rate according to
- final_div_factor instead of modifying the second phase (the first
- two phases will be symmetrical about the step indicated by
- pct_start).
- Default: False
- """
-
- def __init__(self,
- base_momentum=0.85,
- max_momentum=0.95,
- pct_start=0.3,
- anneal_strategy='cos',
- three_phase=False,
- **kwargs):
- # validate by_epoch, currently only support by_epoch=False
- if 'by_epoch' not in kwargs:
- kwargs['by_epoch'] = False
- else:
- assert not kwargs['by_epoch'], \
- 'currently only support "by_epoch" = False'
- if not isinstance(base_momentum, (float, list, dict)):
- raise ValueError('base_momentum must be the type among of float,'
- 'list or dict.')
- self._base_momentum = base_momentum
- if not isinstance(max_momentum, (float, list, dict)):
- raise ValueError('max_momentum must be the type among of float,'
- 'list or dict.')
- self._max_momentum = max_momentum
- # validate pct_start
- if pct_start < 0 or pct_start > 1 or not isinstance(pct_start, float):
- raise ValueError('Expected float between 0 and 1 pct_start, but '
- f'got {pct_start}')
- self.pct_start = pct_start
- # validate anneal_strategy
- if anneal_strategy not in ['cos', 'linear']:
- raise ValueError('anneal_strategy must by one of "cos" or '
- f'"linear", instead got {anneal_strategy}')
- elif anneal_strategy == 'cos':
- self.anneal_func = annealing_cos
- elif anneal_strategy == 'linear':
- self.anneal_func = annealing_linear
- self.three_phase = three_phase
- self.momentum_phases = [] # init momentum_phases
- super(OneCycleMomentumUpdaterHook, self).__init__(**kwargs)
-
- def before_run(self, runner):
- if isinstance(runner.optimizer, dict):
- for k, optim in runner.optimizer.items():
- if ('momentum' not in optim.defaults
- and 'betas' not in optim.defaults):
- raise ValueError('optimizer must support momentum with'
- 'option enabled')
- self.use_beta1 = 'betas' in optim.defaults
- _base_momentum = format_param(k, optim, self._base_momentum)
- _max_momentum = format_param(k, optim, self._max_momentum)
- for group, b_momentum, m_momentum in zip(
- optim.param_groups, _base_momentum, _max_momentum):
- if self.use_beta1:
- _, beta2 = group['betas']
- group['betas'] = (m_momentum, beta2)
- else:
- group['momentum'] = m_momentum
- group['base_momentum'] = b_momentum
- group['max_momentum'] = m_momentum
- else:
- optim = runner.optimizer
- if ('momentum' not in optim.defaults
- and 'betas' not in optim.defaults):
- raise ValueError('optimizer must support momentum with'
- 'option enabled')
- self.use_beta1 = 'betas' in optim.defaults
- k = type(optim).__name__
- _base_momentum = format_param(k, optim, self._base_momentum)
- _max_momentum = format_param(k, optim, self._max_momentum)
- for group, b_momentum, m_momentum in zip(optim.param_groups,
- _base_momentum,
- _max_momentum):
- if self.use_beta1:
- _, beta2 = group['betas']
- group['betas'] = (m_momentum, beta2)
- else:
- group['momentum'] = m_momentum
- group['base_momentum'] = b_momentum
- group['max_momentum'] = m_momentum
-
- if self.three_phase:
- self.momentum_phases.append({
- 'end_iter':
- float(self.pct_start * runner.max_iters) - 1,
- 'start_momentum':
- 'max_momentum',
- 'end_momentum':
- 'base_momentum'
- })
- self.momentum_phases.append({
- 'end_iter':
- float(2 * self.pct_start * runner.max_iters) - 2,
- 'start_momentum':
- 'base_momentum',
- 'end_momentum':
- 'max_momentum'
- })
- self.momentum_phases.append({
- 'end_iter': runner.max_iters - 1,
- 'start_momentum': 'max_momentum',
- 'end_momentum': 'max_momentum'
- })
- else:
- self.momentum_phases.append({
- 'end_iter':
- float(self.pct_start * runner.max_iters) - 1,
- 'start_momentum':
- 'max_momentum',
- 'end_momentum':
- 'base_momentum'
- })
- self.momentum_phases.append({
- 'end_iter': runner.max_iters - 1,
- 'start_momentum': 'base_momentum',
- 'end_momentum': 'max_momentum'
- })
-
- def _set_momentum(self, runner, momentum_groups):
- if isinstance(runner.optimizer, dict):
- for k, optim in runner.optimizer.items():
- for param_group, mom in zip(optim.param_groups,
- momentum_groups[k]):
- if 'momentum' in param_group.keys():
- param_group['momentum'] = mom
- elif 'betas' in param_group.keys():
- param_group['betas'] = (mom, param_group['betas'][1])
- else:
- for param_group, mom in zip(runner.optimizer.param_groups,
- momentum_groups):
- if 'momentum' in param_group.keys():
- param_group['momentum'] = mom
- elif 'betas' in param_group.keys():
- param_group['betas'] = (mom, param_group['betas'][1])
-
- def get_momentum(self, runner, param_group):
- curr_iter = runner.iter
- start_iter = 0
- for i, phase in enumerate(self.momentum_phases):
- end_iter = phase['end_iter']
- if curr_iter <= end_iter or i == len(self.momentum_phases) - 1:
- pct = (curr_iter - start_iter) / (end_iter - start_iter)
- momentum = self.anneal_func(
- param_group[phase['start_momentum']],
- param_group[phase['end_momentum']], pct)
- break
- start_iter = end_iter
- return momentum
-
- def get_regular_momentum(self, runner):
- if isinstance(runner.optimizer, dict):
- momentum_groups = {}
- for k, optim in runner.optimizer.items():
- _momentum_group = [
- self.get_momentum(runner, param_group)
- for param_group in optim.param_groups
- ]
- momentum_groups.update({k: _momentum_group})
- return momentum_groups
- else:
- momentum_groups = []
- for param_group in runner.optimizer.param_groups:
- momentum_groups.append(self.get_momentum(runner, param_group))
- return momentum_groups
diff --git "a/spaces/giswqs/Streamlit/pages/2_\360\237\217\240_U.S._Housing.py" "b/spaces/giswqs/Streamlit/pages/2_\360\237\217\240_U.S._Housing.py"
deleted file mode 100644
index 0c2e4996d01c41d196b93308c9532305ee89cf43..0000000000000000000000000000000000000000
--- "a/spaces/giswqs/Streamlit/pages/2_\360\237\217\240_U.S._Housing.py"
+++ /dev/null
@@ -1,482 +0,0 @@
-import datetime
-import os
-import pathlib
-import requests
-import zipfile
-import pandas as pd
-import pydeck as pdk
-import geopandas as gpd
-import streamlit as st
-import leafmap.colormaps as cm
-from leafmap.common import hex_to_rgb
-
-st.set_page_config(layout="wide")
-
-st.sidebar.info(
- """
- - Web App URL:
- - GitHub repository:
- """
-)
-
-st.sidebar.title("Contact")
-st.sidebar.info(
- """
- Qiusheng Wu at [wetlands.io](https://wetlands.io) | [GitHub](https://github.com/giswqs) | [Twitter](https://twitter.com/giswqs) | [YouTube](https://www.youtube.com/c/QiushengWu) | [LinkedIn](https://www.linkedin.com/in/qiushengwu)
- """
-)
-
-STREAMLIT_STATIC_PATH = pathlib.Path(st.__path__[0]) / "static"
-# We create a downloads directory within the streamlit static asset directory
-# and we write output files to it
-DOWNLOADS_PATH = STREAMLIT_STATIC_PATH / "downloads"
-if not DOWNLOADS_PATH.is_dir():
- DOWNLOADS_PATH.mkdir()
-
-# Data source: https://www.realtor.com/research/data/
-# link_prefix = "https://econdata.s3-us-west-2.amazonaws.com/Reports/"
-link_prefix = "https://raw.githubusercontent.com/giswqs/data/main/housing/"
-
-data_links = {
- "weekly": {
- "national": link_prefix + "Core/listing_weekly_core_aggregate_by_country.csv",
- "metro": link_prefix + "Core/listing_weekly_core_aggregate_by_metro.csv",
- },
- "monthly_current": {
- "national": link_prefix + "Core/RDC_Inventory_Core_Metrics_Country.csv",
- "state": link_prefix + "Core/RDC_Inventory_Core_Metrics_State.csv",
- "metro": link_prefix + "Core/RDC_Inventory_Core_Metrics_Metro.csv",
- "county": link_prefix + "Core/RDC_Inventory_Core_Metrics_County.csv",
- "zip": link_prefix + "Core/RDC_Inventory_Core_Metrics_Zip.csv",
- },
- "monthly_historical": {
- "national": link_prefix + "Core/RDC_Inventory_Core_Metrics_Country_History.csv",
- "state": link_prefix + "Core/RDC_Inventory_Core_Metrics_State_History.csv",
- "metro": link_prefix + "Core/RDC_Inventory_Core_Metrics_Metro_History.csv",
- "county": link_prefix + "Core/RDC_Inventory_Core_Metrics_County_History.csv",
- "zip": link_prefix + "Core/RDC_Inventory_Core_Metrics_Zip_History.csv",
- },
- "hotness": {
- "metro": link_prefix
- + "Hotness/RDC_Inventory_Hotness_Metrics_Metro_History.csv",
- "county": link_prefix
- + "Hotness/RDC_Inventory_Hotness_Metrics_County_History.csv",
- "zip": link_prefix + "Hotness/RDC_Inventory_Hotness_Metrics_Zip_History.csv",
- },
-}
-
-
-def get_data_columns(df, category, frequency="monthly"):
- if frequency == "monthly":
- if category.lower() == "county":
- del_cols = ["month_date_yyyymm", "county_fips", "county_name"]
- elif category.lower() == "state":
- del_cols = ["month_date_yyyymm", "state", "state_id"]
- elif category.lower() == "national":
- del_cols = ["month_date_yyyymm", "country"]
- elif category.lower() == "metro":
- del_cols = ["month_date_yyyymm", "cbsa_code", "cbsa_title", "HouseholdRank"]
- elif category.lower() == "zip":
- del_cols = ["month_date_yyyymm", "postal_code", "zip_name", "flag"]
- elif frequency == "weekly":
- if category.lower() == "national":
- del_cols = ["week_end_date", "geo_country"]
- elif category.lower() == "metro":
- del_cols = ["week_end_date", "cbsa_code", "cbsa_title", "hh_rank"]
-
- cols = df.columns.values.tolist()
-
- for col in cols:
- if col.strip() in del_cols:
- cols.remove(col)
- if category.lower() == "metro":
- return cols[2:]
- else:
- return cols[1:]
-
-
-@st.cache(allow_output_mutation=True)
-def get_inventory_data(url):
- df = pd.read_csv(url)
- url = url.lower()
- if "county" in url:
- df["county_fips"] = df["county_fips"].map(str)
- df["county_fips"] = df["county_fips"].str.zfill(5)
- elif "state" in url:
- df["STUSPS"] = df["state_id"].str.upper()
- elif "metro" in url:
- df["cbsa_code"] = df["cbsa_code"].map(str)
- elif "zip" in url:
- df["postal_code"] = df["postal_code"].map(str)
- df["postal_code"] = df["postal_code"].str.zfill(5)
-
- if "listing_weekly_core_aggregate_by_country" in url:
- columns = get_data_columns(df, "national", "weekly")
- for column in columns:
- if column != "median_days_on_market_by_day_yy":
- df[column] = df[column].str.rstrip("%").astype(float) / 100
- if "listing_weekly_core_aggregate_by_metro" in url:
- columns = get_data_columns(df, "metro", "weekly")
- for column in columns:
- if column != "median_days_on_market_by_day_yy":
- df[column] = df[column].str.rstrip("%").astype(float) / 100
- df["cbsa_code"] = df["cbsa_code"].str[:5]
- return df
-
-
-def filter_weekly_inventory(df, week):
- df = df[df["week_end_date"] == week]
- return df
-
-
-def get_start_end_year(df):
- start_year = int(str(df["month_date_yyyymm"].min())[:4])
- end_year = int(str(df["month_date_yyyymm"].max())[:4])
- return start_year, end_year
-
-
-def get_periods(df):
- return [str(d) for d in list(set(df["month_date_yyyymm"].tolist()))]
-
-
-@st.cache(allow_output_mutation=True)
-def get_geom_data(category):
-
- prefix = (
- "https://raw.githubusercontent.com/giswqs/streamlit-geospatial/master/data/"
- )
- links = {
- "national": prefix + "us_nation.geojson",
- "state": prefix + "us_states.geojson",
- "county": prefix + "us_counties.geojson",
- "metro": prefix + "us_metro_areas.geojson",
- "zip": "https://www2.census.gov/geo/tiger/GENZ2018/shp/cb_2018_us_zcta510_500k.zip",
- }
-
- if category.lower() == "zip":
- r = requests.get(links[category])
- out_zip = os.path.join(DOWNLOADS_PATH, "cb_2018_us_zcta510_500k.zip")
- with open(out_zip, "wb") as code:
- code.write(r.content)
- zip_ref = zipfile.ZipFile(out_zip, "r")
- zip_ref.extractall(DOWNLOADS_PATH)
- gdf = gpd.read_file(out_zip.replace("zip", "shp"))
- else:
- gdf = gpd.read_file(links[category])
- return gdf
-
-
-def join_attributes(gdf, df, category):
-
- new_gdf = None
- if category == "county":
- new_gdf = gdf.merge(df, left_on="GEOID", right_on="county_fips", how="outer")
- elif category == "state":
- new_gdf = gdf.merge(df, left_on="STUSPS", right_on="STUSPS", how="outer")
- elif category == "national":
- if "geo_country" in df.columns.values.tolist():
- df["country"] = None
- df.loc[0, "country"] = "United States"
- new_gdf = gdf.merge(df, left_on="NAME", right_on="country", how="outer")
- elif category == "metro":
- new_gdf = gdf.merge(df, left_on="CBSAFP", right_on="cbsa_code", how="outer")
- elif category == "zip":
- new_gdf = gdf.merge(df, left_on="GEOID10", right_on="postal_code", how="outer")
- return new_gdf
-
-
-def select_non_null(gdf, col_name):
- new_gdf = gdf[~gdf[col_name].isna()]
- return new_gdf
-
-
-def select_null(gdf, col_name):
- new_gdf = gdf[gdf[col_name].isna()]
- return new_gdf
-
-
-def get_data_dict(name):
- in_csv = os.path.join(os.getcwd(), "data/realtor_data_dict.csv")
- df = pd.read_csv(in_csv)
- label = list(df[df["Name"] == name]["Label"])[0]
- desc = list(df[df["Name"] == name]["Description"])[0]
- return label, desc
-
-
-def get_weeks(df):
- seq = list(set(df[~df["week_end_date"].isnull()]["week_end_date"].tolist()))
- weeks = [
- datetime.date(int(d.split("/")[2]), int(d.split("/")[0]), int(d.split("/")[1]))
- for d in seq
- ]
- weeks.sort()
- return weeks
-
-
-def get_saturday(in_date):
- idx = (in_date.weekday() + 1) % 7
- sat = in_date + datetime.timedelta(6 - idx)
- return sat
-
-
-def app():
-
- st.title("U.S. Real Estate Data and Market Trends")
- st.markdown(
- """**Introduction:** This interactive dashboard is designed for visualizing U.S. real estate data and market trends at multiple levels (i.e., national,
- state, county, and metro). The data sources include [Real Estate Data](https://www.realtor.com/research/data) from realtor.com and
- [Cartographic Boundary Files](https://www.census.gov/geographies/mapping-files/time-series/geo/carto-boundary-file.html) from U.S. Census Bureau.
- Several open-source packages are used to process the data and generate the visualizations, e.g., [streamlit](https://streamlit.io),
- [geopandas](https://geopandas.org), [leafmap](https://leafmap.org), and [pydeck](https://deckgl.readthedocs.io).
- """
- )
-
- with st.expander("See a demo"):
- st.image("https://i.imgur.com/Z3dk6Tr.gif")
-
- row1_col1, row1_col2, row1_col3, row1_col4, row1_col5 = st.columns(
- [0.6, 0.8, 0.6, 1.4, 2]
- )
- with row1_col1:
- frequency = st.selectbox("Monthly/weekly data", ["Monthly", "Weekly"])
- with row1_col2:
- types = ["Current month data", "Historical data"]
- if frequency == "Weekly":
- types.remove("Current month data")
- cur_hist = st.selectbox(
- "Current/historical data",
- types,
- )
- with row1_col3:
- if frequency == "Monthly":
- scale = st.selectbox(
- "Scale", ["National", "State", "Metro", "County"], index=3
- )
- else:
- scale = st.selectbox("Scale", ["National", "Metro"], index=1)
-
- gdf = get_geom_data(scale.lower())
-
- if frequency == "Weekly":
- inventory_df = get_inventory_data(data_links["weekly"][scale.lower()])
- weeks = get_weeks(inventory_df)
- with row1_col1:
- selected_date = st.date_input("Select a date", value=weeks[-1])
- saturday = get_saturday(selected_date)
- selected_period = saturday.strftime("%-m/%-d/%Y")
- if saturday not in weeks:
- st.error(
- "The selected date is not available in the data. Please select a date between {} and {}".format(
- weeks[0], weeks[-1]
- )
- )
- selected_period = weeks[-1].strftime("%-m/%-d/%Y")
- inventory_df = get_inventory_data(data_links["weekly"][scale.lower()])
- inventory_df = filter_weekly_inventory(inventory_df, selected_period)
-
- if frequency == "Monthly":
- if cur_hist == "Current month data":
- inventory_df = get_inventory_data(
- data_links["monthly_current"][scale.lower()]
- )
- selected_period = get_periods(inventory_df)[0]
- else:
- with row1_col2:
- inventory_df = get_inventory_data(
- data_links["monthly_historical"][scale.lower()]
- )
- start_year, end_year = get_start_end_year(inventory_df)
- periods = get_periods(inventory_df)
- with st.expander("Select year and month", True):
- selected_year = st.slider(
- "Year",
- start_year,
- end_year,
- value=start_year,
- step=1,
- )
- selected_month = st.slider(
- "Month",
- min_value=1,
- max_value=12,
- value=int(periods[0][-2:]),
- step=1,
- )
- selected_period = str(selected_year) + str(selected_month).zfill(2)
- if selected_period not in periods:
- st.error("Data not available for selected year and month")
- selected_period = periods[0]
- inventory_df = inventory_df[
- inventory_df["month_date_yyyymm"] == int(selected_period)
- ]
-
- data_cols = get_data_columns(inventory_df, scale.lower(), frequency.lower())
-
- with row1_col4:
- selected_col = st.selectbox("Attribute", data_cols)
- with row1_col5:
- show_desc = st.checkbox("Show attribute description")
- if show_desc:
- try:
- label, desc = get_data_dict(selected_col.strip())
- markdown = f"""
- **{label}**: {desc}
- """
- st.markdown(markdown)
- except:
- st.warning("No description available for selected attribute")
-
- row2_col1, row2_col2, row2_col3, row2_col4, row2_col5, row2_col6 = st.columns(
- [0.6, 0.68, 0.7, 0.7, 1.5, 0.8]
- )
-
- palettes = cm.list_colormaps()
- with row2_col1:
- palette = st.selectbox("Color palette", palettes, index=palettes.index("Blues"))
- with row2_col2:
- n_colors = st.slider("Number of colors", min_value=2, max_value=20, value=8)
- with row2_col3:
- show_nodata = st.checkbox("Show nodata areas", value=True)
- with row2_col4:
- show_3d = st.checkbox("Show 3D view", value=False)
- with row2_col5:
- if show_3d:
- elev_scale = st.slider(
- "Elevation scale", min_value=1, max_value=1000000, value=1, step=10
- )
- with row2_col6:
- st.info("Press Ctrl and move the left mouse button.")
- else:
- elev_scale = 1
-
- gdf = join_attributes(gdf, inventory_df, scale.lower())
- gdf_null = select_null(gdf, selected_col)
- gdf = select_non_null(gdf, selected_col)
- gdf = gdf.sort_values(by=selected_col, ascending=True)
-
- colors = cm.get_palette(palette, n_colors)
- colors = [hex_to_rgb(c) for c in colors]
-
- for i, ind in enumerate(gdf.index):
- index = int(i / (len(gdf) / len(colors)))
- if index >= len(colors):
- index = len(colors) - 1
- gdf.loc[ind, "R"] = colors[index][0]
- gdf.loc[ind, "G"] = colors[index][1]
- gdf.loc[ind, "B"] = colors[index][2]
-
- initial_view_state = pdk.ViewState(
- latitude=40,
- longitude=-100,
- zoom=3,
- max_zoom=16,
- pitch=0,
- bearing=0,
- height=900,
- width=None,
- )
-
- min_value = gdf[selected_col].min()
- max_value = gdf[selected_col].max()
- color = "color"
- # color_exp = f"[({selected_col}-{min_value})/({max_value}-{min_value})*255, 0, 0]"
- color_exp = f"[R, G, B]"
-
- geojson = pdk.Layer(
- "GeoJsonLayer",
- gdf,
- pickable=True,
- opacity=0.5,
- stroked=True,
- filled=True,
- extruded=show_3d,
- wireframe=True,
- get_elevation=f"{selected_col}",
- elevation_scale=elev_scale,
- # get_fill_color="color",
- get_fill_color=color_exp,
- get_line_color=[0, 0, 0],
- get_line_width=2,
- line_width_min_pixels=1,
- )
-
- geojson_null = pdk.Layer(
- "GeoJsonLayer",
- gdf_null,
- pickable=True,
- opacity=0.2,
- stroked=True,
- filled=True,
- extruded=False,
- wireframe=True,
- # get_elevation="properties.ALAND/100000",
- # get_fill_color="color",
- get_fill_color=[200, 200, 200],
- get_line_color=[0, 0, 0],
- get_line_width=2,
- line_width_min_pixels=1,
- )
-
- # tooltip = {"text": "Name: {NAME}"}
-
- # tooltip_value = f"Value: {median_listing_price}""
- tooltip = {
- "html": "Name: {NAME}
Value: {"
- + selected_col
- + "}
Date: "
- + selected_period
- + "",
- "style": {"backgroundColor": "steelblue", "color": "white"},
- }
-
- layers = [geojson]
- if show_nodata:
- layers.append(geojson_null)
-
- r = pdk.Deck(
- layers=layers,
- initial_view_state=initial_view_state,
- map_style="light",
- tooltip=tooltip,
- )
-
- row3_col1, row3_col2 = st.columns([6, 1])
-
- with row3_col1:
- st.pydeck_chart(r)
- with row3_col2:
- st.write(
- cm.create_colormap(
- palette,
- label=selected_col.replace("_", " ").title(),
- width=0.2,
- height=3,
- orientation="vertical",
- vmin=min_value,
- vmax=max_value,
- font_size=10,
- )
- )
- row4_col1, row4_col2, row4_col3 = st.columns([1, 2, 3])
- with row4_col1:
- show_data = st.checkbox("Show raw data")
- with row4_col2:
- show_cols = st.multiselect("Select columns", data_cols)
- with row4_col3:
- show_colormaps = st.checkbox("Preview all color palettes")
- if show_colormaps:
- st.write(cm.plot_colormaps(return_fig=True))
- if show_data:
- if scale == "National":
- st.dataframe(gdf[["NAME", "GEOID"] + show_cols])
- elif scale == "State":
- st.dataframe(gdf[["NAME", "STUSPS"] + show_cols])
- elif scale == "County":
- st.dataframe(gdf[["NAME", "STATEFP", "COUNTYFP"] + show_cols])
- elif scale == "Metro":
- st.dataframe(gdf[["NAME", "CBSAFP"] + show_cols])
- elif scale == "Zip":
- st.dataframe(gdf[["GEOID10"] + show_cols])
-
-
-app()
diff --git a/spaces/gotiQspiryo/whisper-ui/examples/Dell Precision M4600 Enable 11.md b/spaces/gotiQspiryo/whisper-ui/examples/Dell Precision M4600 Enable 11.md
deleted file mode 100644
index c1fc0fc179c34e4fa408088be412e58754bfd4f4..0000000000000000000000000000000000000000
--- a/spaces/gotiQspiryo/whisper-ui/examples/Dell Precision M4600 Enable 11.md
+++ /dev/null
@@ -1,5 +0,0 @@
-
-This is supper. I did not know that Bluetooth can be enabled or disabled from Bios setup utility. I found the check box for Bluetooth unchecked. I ticked it and immediately the computer restarted, dell support assistant suggested driver update which I did and my Bluetooth worked immediately. Prior to this I had tried windows as well as dell troubleshooter which both showed I was running the lates drivers. Windows showed that Bluetooth is not available on this device while dell said the machine is out of warranty hence they cannot assist. Thanks man.
-dell precision m4600 enable 11
DOWNLOAD ✓✓✓ https://urlgoal.com/2uyMel
aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/gotiQspiryo/whisper-ui/examples/FULL Adam Szabo JP6K VSTi V1.0.exe.md b/spaces/gotiQspiryo/whisper-ui/examples/FULL Adam Szabo JP6K VSTi V1.0.exe.md
deleted file mode 100644
index 92d6c734d94151bac6218e7228071176b2181cf8..0000000000000000000000000000000000000000
--- a/spaces/gotiQspiryo/whisper-ui/examples/FULL Adam Szabo JP6K VSTi V1.0.exe.md
+++ /dev/null
@@ -1,10 +0,0 @@
-
-Hey guys, So I decided to share this VST with you. Adam Szabo JP6K VSTi V1.0.exe setup free. Full.Adam Szabo JP6K VSTi V1.exe.Adam Szabo JP6K VSTi v1.0 by Adam Szabo. Download.exe Setup. Adam Szabo JP6K VSTi.
-FULL Adam Szabo JP6K VSTi V1.0.exe
DOWNLOAD ✫✫✫ https://urlgoal.com/2uyN85
-I promise Adam Szabo JP6K VSTi V1.0. Adam Szabo JP6K VSTi v1.0 by Adam Szabo. Download.Adam Szabo JP6K VSTi V1.exe setup free. Full.exe.Adam Szabo JP6K VSTi by Adam Szabo.exe Setup. Adam Szabo JP6K VSTi.
-Download Adam Szabo Ergo v1.0 VST x32 / x64 Win / MAC.. Adam Szabo JP6K v1.0.1 x64 x86 VSTi x64 VST AU WiN MAC x64 x86. TALiO – Free VSTi Plugin Update (v1.0). MP3.Adam.Szabo.Van.Baker.Zebra.2.Soundset.JP6K.Jouncer.Slim. FREE 1) After Effects VST/VST3/AU/AAX2) Native Instruments Folder-v1.0d - High Quality Audio 2) VidStation v0.4.2 (FULL) Free.
-Adam Szabo Afterglow v1.0.2 - The fastest out of box synth in your DAW. Freeware: Adam Szabo JP6K v1.1 x64 x86 VSTi x64 VST AU WiN MAC x64 x86. Adam Szabo JP6K v1. Installation Notes. Download the latest version of AudioAcrobat AudioAcrobat Pro v.7. Download the latest version of Key2k http://www.key2k.com/. Learn, practice, master the art of music production in Digital Audio Workstation. Adam Szabo Afterglow v1.1.,Adam Szabo JP6K v1. Download the latest version of Coheir Itch v1.5 - IMPORTANT: Coheir v1.5 is required for this plugin. Download the latest version of Coheir Itch - IMPORTANT: Coheir v1.
-
-2015.10.01 - Adam Szabo JP6K v1.5 is out http://doolksdna.dreamhosters.com/. Adam Szabo JP6K VSTi v1.0 download. Adam Szabo JP6K v1.5 is out! Adam Szabo JP6K v1.0 is released http://ecome.com/gallery/12857/j/Cpt-Fighter-Z/Adam Szabo JP6K-VSTi-v1.0-made-in-Denmark.com/viewphoto.php?photosel.Adam Szabo JP6K VSTi v1.0 is out! Adam Szabo JP6K VSTi v1.0 is out. - Adam Szabo JP6K VSTi v1.0 #2988908 -
899543212b
-
-
\ No newline at end of file
diff --git a/spaces/gwang-kim/DATID-3D/eg3d/viz/__init__.py b/spaces/gwang-kim/DATID-3D/eg3d/viz/__init__.py
deleted file mode 100644
index dfebd04f47e6f6b1b44984c14c23b57d56f72240..0000000000000000000000000000000000000000
--- a/spaces/gwang-kim/DATID-3D/eg3d/viz/__init__.py
+++ /dev/null
@@ -1,11 +0,0 @@
-# SPDX-FileCopyrightText: Copyright (c) 2021-2022 NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-# SPDX-License-Identifier: LicenseRef-NvidiaProprietary
-#
-# NVIDIA CORPORATION, its affiliates and licensors retain all intellectual
-# property and proprietary rights in and to this material, related
-# documentation and any modifications thereto. Any use, reproduction,
-# disclosure or distribution of this material and related documentation
-# without an express license agreement from NVIDIA CORPORATION or
-# its affiliates is strictly prohibited.
-
-# empty
diff --git a/spaces/gyrojeff/YuzuMarker.FontDetection/Dockerfile b/spaces/gyrojeff/YuzuMarker.FontDetection/Dockerfile
deleted file mode 100644
index 94952257f3d04051ff43b081da2620c93629dc6d..0000000000000000000000000000000000000000
--- a/spaces/gyrojeff/YuzuMarker.FontDetection/Dockerfile
+++ /dev/null
@@ -1,20 +0,0 @@
-FROM docker.io/jeffersonqin/yuzumarker.fontdetection.huggingfacespace.base:latest
-
-RUN useradd -m -u 1000 user
-USER user
-ENV HOME=/home/user \
- PATH=/home/user/.local/bin:$PATH
-
-WORKDIR $HOME/app
-USER root
-RUN mv /workspace/font_demo_cache.bin $HOME/app/font_demo_cache.bin
-RUN mv /workspace/demo_fonts $HOME/app/demo_fonts
-
-USER user
-COPY --chown=user detector $HOME/app/detector
-COPY --chown=user font_dataset $HOME/app/font_dataset
-COPY --chown=user utils $HOME/app/utils
-COPY --chown=user configs $HOME/app/configs
-COPY --chown=user demo.py $HOME/app/demo.py
-
-CMD ["python", "demo.py", "-d", "-1", "-c", "huggingface://gyrojeff/YuzuMarker.FontDetection/name=4x-epoch=18-step=368676.ckpt", "-m", "resnet50", "-z", "512", "-p", "7860", "-a", "0.0.0.0"]
diff --git a/spaces/haakohu/deep_privacy2/dp2/detection/models/__init__.py b/spaces/haakohu/deep_privacy2/dp2/detection/models/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/haotiz/glip-zeroshot-demo/maskrcnn_benchmark/data/datasets/evaluation/flickr/__init__.py b/spaces/haotiz/glip-zeroshot-demo/maskrcnn_benchmark/data/datasets/evaluation/flickr/__init__.py
deleted file mode 100644
index b0af8d130af70b22791535c67f9dcf34baf5e528..0000000000000000000000000000000000000000
--- a/spaces/haotiz/glip-zeroshot-demo/maskrcnn_benchmark/data/datasets/evaluation/flickr/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .flickr_eval import FlickrEvaluator
diff --git a/spaces/haseeb-heaven/AutoBard-Coder/codes/generated_code.c b/spaces/haseeb-heaven/AutoBard-Coder/codes/generated_code.c
deleted file mode 100644
index bdcfde68b1460da1c6c5cc12347d4234fb17c6bf..0000000000000000000000000000000000000000
--- a/spaces/haseeb-heaven/AutoBard-Coder/codes/generated_code.c
+++ /dev/null
@@ -1,15 +0,0 @@
-#include
-
-int main() {
- int number = 10; // Hardcode the input value
- int factorial = 1;
-
- for (int i = 1; i <= number; i++) {
- factorial *= i;
- }
-
- printf("The factorial of %d is: %d
-", number, factorial);
-
- return 0;
-}
\ No newline at end of file
diff --git a/spaces/hasibzunair/fifa-tryon-demo/Self-Correction-Human-Parsing-for-ACGPN/mhp_extension/detectron2/dev/run_instant_tests.sh b/spaces/hasibzunair/fifa-tryon-demo/Self-Correction-Human-Parsing-for-ACGPN/mhp_extension/detectron2/dev/run_instant_tests.sh
deleted file mode 100644
index 2c51de649262e7371fb173210c8edc377e8177e0..0000000000000000000000000000000000000000
--- a/spaces/hasibzunair/fifa-tryon-demo/Self-Correction-Human-Parsing-for-ACGPN/mhp_extension/detectron2/dev/run_instant_tests.sh
+++ /dev/null
@@ -1,27 +0,0 @@
-#!/bin/bash -e
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-
-BIN="python tools/train_net.py"
-OUTPUT="instant_test_output"
-NUM_GPUS=2
-
-CFG_LIST=( "${@:1}" )
-if [ ${#CFG_LIST[@]} -eq 0 ]; then
- CFG_LIST=( ./configs/quick_schedules/*instant_test.yaml )
-fi
-
-echo "========================================================================"
-echo "Configs to run:"
-echo "${CFG_LIST[@]}"
-echo "========================================================================"
-
-for cfg in "${CFG_LIST[@]}"; do
- echo "========================================================================"
- echo "Running $cfg ..."
- echo "========================================================================"
- $BIN --num-gpus $NUM_GPUS --config-file "$cfg" \
- SOLVER.IMS_PER_BATCH $(($NUM_GPUS * 2)) \
- OUTPUT_DIR "$OUTPUT"
- rm -rf "$OUTPUT"
-done
-
diff --git a/spaces/hasibzunair/fifa-tryon-demo/u2net_human_seg_test.py b/spaces/hasibzunair/fifa-tryon-demo/u2net_human_seg_test.py
deleted file mode 100644
index ade5fc040e6ea18663659e1818723c436ca48d5e..0000000000000000000000000000000000000000
--- a/spaces/hasibzunair/fifa-tryon-demo/u2net_human_seg_test.py
+++ /dev/null
@@ -1,117 +0,0 @@
-import os
-from skimage import io, transform
-import torch
-import torchvision
-from torch.autograd import Variable
-import torch.nn as nn
-import torch.nn.functional as F
-from torch.utils.data import Dataset, DataLoader
-from torchvision import transforms#, utils
-# import torch.optim as optim
-
-import numpy as np
-from PIL import Image
-import glob
-
-from data_loader import RescaleT
-from data_loader import ToTensor
-from data_loader import ToTensorLab
-from data_loader import SalObjDataset
-
-from model import U2NET # full size version 173.6 MB
-
-# normalize the predicted SOD probability map
-def normPRED(d):
- ma = torch.max(d)
- mi = torch.min(d)
-
- dn = (d-mi)/(ma-mi)
-
- return dn
-
-def save_output(image_name,pred,d_dir):
-
- predict = pred
- predict = predict.squeeze()
- predict_np = predict.cpu().data.numpy()
-
- im = Image.fromarray(predict_np*255).convert('RGB')
- img_name = image_name.split(os.sep)[-1]
- image = io.imread(image_name)
- imo = im.resize((image.shape[1],image.shape[0]),resample=Image.BILINEAR)
-
- pb_np = np.array(imo)
-
- aaa = img_name.split(".")
- bbb = aaa[0:-1]
- imidx = bbb[0]
- for i in range(1,len(bbb)):
- imidx = imidx + "." + bbb[i]
-
- imo.save(d_dir+imidx+'.png')
-
-def main():
-
- # --------- 1. get image path and name ---------
- model_name='u2net'
-
-
- image_dir = os.path.join(os.getcwd(), 'test_data', 'test_human_images')
- prediction_dir = os.path.join(os.getcwd(), 'test_data', 'test_human_images' + '_results' + os.sep)
- model_dir = os.path.join(os.getcwd(), 'saved_models', model_name+'_human_seg', model_name + '_human_seg.pth')
-
- img_name_list = glob.glob(image_dir + os.sep + '*')
- print(img_name_list)
-
- # --------- 2. dataloader ---------
- #1. dataloader
- test_salobj_dataset = SalObjDataset(img_name_list = img_name_list,
- lbl_name_list = [],
- transform=transforms.Compose([RescaleT(320),
- ToTensorLab(flag=0)])
- )
- test_salobj_dataloader = DataLoader(test_salobj_dataset,
- batch_size=1,
- shuffle=False,
- num_workers=1)
-
- # --------- 3. model define ---------
- if(model_name=='u2net'):
- print("...load U2NET---173.6 MB")
- net = U2NET(3,1)
-
- if torch.cuda.is_available():
- net.load_state_dict(torch.load(model_dir))
- net.cuda()
- else:
- net.load_state_dict(torch.load(model_dir, map_location='cpu'))
- net.eval()
-
- # --------- 4. inference for each image ---------
- for i_test, data_test in enumerate(test_salobj_dataloader):
-
- print("inferencing:",img_name_list[i_test].split(os.sep)[-1])
-
- inputs_test = data_test['image']
- inputs_test = inputs_test.type(torch.FloatTensor)
-
- if torch.cuda.is_available():
- inputs_test = Variable(inputs_test.cuda())
- else:
- inputs_test = Variable(inputs_test)
-
- d1,d2,d3,d4,d5,d6,d7= net(inputs_test)
-
- # normalization
- pred = d1[:,0,:,:]
- pred = normPRED(pred)
-
- # save results to test_results folder
- if not os.path.exists(prediction_dir):
- os.makedirs(prediction_dir, exist_ok=True)
- save_output(img_name_list[i_test],pred,prediction_dir)
-
- del d1,d2,d3,d4,d5,d6,d7
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/hekbobo/bingo/src/components/ui/input.tsx b/spaces/hekbobo/bingo/src/components/ui/input.tsx
deleted file mode 100644
index 684a857f3d769b78818fb13de1abaebfb09ca79c..0000000000000000000000000000000000000000
--- a/spaces/hekbobo/bingo/src/components/ui/input.tsx
+++ /dev/null
@@ -1,25 +0,0 @@
-import * as React from 'react'
-
-import { cn } from '@/lib/utils'
-
-export interface InputProps
- extends React.InputHTMLAttributes {}
-
-const Input = React.forwardRef(
- ({ className, type, ...props }, ref) => {
- return (
-
- )
- }
-)
-Input.displayName = 'Input'
-
-export { Input }
diff --git a/spaces/housexu123/bingo-2.0/tailwind.config.js b/spaces/housexu123/bingo-2.0/tailwind.config.js
deleted file mode 100644
index 03da3c3c45be6983b9f5ffa6df5f1fd0870e9636..0000000000000000000000000000000000000000
--- a/spaces/housexu123/bingo-2.0/tailwind.config.js
+++ /dev/null
@@ -1,48 +0,0 @@
-/** @type {import('tailwindcss').Config} */
-module.exports = {
- content: [
- './src/pages/**/*.{js,ts,jsx,tsx,mdx}',
- './src/components/**/*.{js,ts,jsx,tsx,mdx}',
- './src/app/**/*.{js,ts,jsx,tsx,mdx}',
- './src/ui/**/*.{js,ts,jsx,tsx,mdx}',
- ],
- "darkMode": "class",
- theme: {
- extend: {
- colors: {
- 'primary-blue': 'rgb(var(--color-primary-blue) / )',
- secondary: 'rgb(var(--color-secondary) / )',
- 'primary-background': 'rgb(var(--primary-background) / )',
- 'primary-text': 'rgb(var(--primary-text) / )',
- 'secondary-text': 'rgb(var(--secondary-text) / )',
- 'light-text': 'rgb(var(--light-text) / )',
- 'primary-border': 'rgb(var(--primary-border) / )',
- },
- keyframes: {
- slideDownAndFade: {
- from: { opacity: 0, transform: 'translateY(-2px)' },
- to: { opacity: 1, transform: 'translateY(0)' },
- },
- slideLeftAndFade: {
- from: { opacity: 0, transform: 'translateX(2px)' },
- to: { opacity: 1, transform: 'translateX(0)' },
- },
- slideUpAndFade: {
- from: { opacity: 0, transform: 'translateY(2px)' },
- to: { opacity: 1, transform: 'translateY(0)' },
- },
- slideRightAndFade: {
- from: { opacity: 0, transform: 'translateX(2px)' },
- to: { opacity: 1, transform: 'translateX(0)' },
- },
- },
- animation: {
- slideDownAndFade: 'slideDownAndFade 400ms cubic-bezier(0.16, 1, 0.3, 1)',
- slideLeftAndFade: 'slideLeftAndFade 400ms cubic-bezier(0.16, 1, 0.3, 1)',
- slideUpAndFade: 'slideUpAndFade 400ms cubic-bezier(0.16, 1, 0.3, 1)',
- slideRightAndFade: 'slideRightAndFade 400ms cubic-bezier(0.16, 1, 0.3, 1)',
- },
- },
- },
- plugins: [require('@headlessui/tailwindcss'), require('tailwind-scrollbar')],
-}
diff --git a/spaces/huazhao/DeepDanbooru_string/app.py b/spaces/huazhao/DeepDanbooru_string/app.py
deleted file mode 100644
index 49019837c9207cc68cb37be0342f3bc44fd0decb..0000000000000000000000000000000000000000
--- a/spaces/huazhao/DeepDanbooru_string/app.py
+++ /dev/null
@@ -1,185 +0,0 @@
-#!/usr/bin/env python
-
-from __future__ import annotations
-
-import argparse
-import functools
-import os
-import html
-import pathlib
-import tarfile
-
-import deepdanbooru as dd
-import gradio as gr
-import huggingface_hub
-import numpy as np
-import PIL.Image
-import tensorflow as tf
-import piexif
-import piexif.helper
-
-TITLE = 'DeepDanbooru String'
-
-TOKEN = os.environ['TOKEN']
-MODEL_REPO = 'CikeyQI/DeepDanbooru_string'
-MODEL_FILENAME = 'model-resnet_custom_v3.h5'
-LABEL_FILENAME = 'tags.txt'
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser()
- parser.add_argument('--score-slider-step', type=float, default=0.05)
- parser.add_argument('--score-threshold', type=float, default=0.5)
- parser.add_argument('--theme', type=str, default='dark-grass')
- parser.add_argument('--live', action='store_true')
- parser.add_argument('--share', action='store_true')
- parser.add_argument('--port', type=int)
- parser.add_argument('--disable-queue',
- dest='enable_queue',
- action='store_false')
- parser.add_argument('--allow-flagging', type=str, default='never')
- return parser.parse_args()
-
-
-def load_sample_image_paths() -> list[pathlib.Path]:
- image_dir = pathlib.Path('images')
- if not image_dir.exists():
- dataset_repo = 'hysts/sample-images-TADNE'
- path = huggingface_hub.hf_hub_download(dataset_repo,
- 'images.tar.gz',
- repo_type='dataset',
- use_auth_token=TOKEN)
- with tarfile.open(path) as f:
- f.extractall()
- return sorted(image_dir.glob('*'))
-
-
-def load_model() -> tf.keras.Model:
- path = huggingface_hub.hf_hub_download(MODEL_REPO,
- MODEL_FILENAME,
- use_auth_token=TOKEN)
- model = tf.keras.models.load_model(path)
- return model
-
-
-def load_labels() -> list[str]:
- path = huggingface_hub.hf_hub_download(MODEL_REPO,
- LABEL_FILENAME,
- use_auth_token=TOKEN)
- with open(path) as f:
- labels = [line.strip() for line in f.readlines()]
- return labels
-
-def plaintext_to_html(text):
- text = "" + "
\n".join([f"{html.escape(x)}" for x in text.split('\n')]) + "
"
- return text
-
-def predict(image: PIL.Image.Image, score_threshold: float,
- model: tf.keras.Model, labels: list[str]) -> dict[str, float]:
- rawimage = image
- _, height, width, _ = model.input_shape
- image = np.asarray(image)
- image = tf.image.resize(image,
- size=(height, width),
- method=tf.image.ResizeMethod.AREA,
- preserve_aspect_ratio=True)
- image = image.numpy()
- image = dd.image.transform_and_pad_image(image, width, height)
- image = image / 255.
- probs = model.predict(image[None, ...])[0]
- probs = probs.astype(float)
- res = dict()
- for prob, label in zip(probs.tolist(), labels):
- if prob < score_threshold:
- continue
- res[label] = prob
- b = dict(sorted(res.items(),key=lambda item:item[1], reverse=True))
- a = ', '.join(list(b.keys())).replace('_',' ').replace('(','\(').replace(')','\)')
- c = ', '.join(list(b.keys()))
-
- items = rawimage.info
- geninfo = ''
-
- if "exif" in rawimage.info:
- exif = piexif.load(rawimage.info["exif"])
- exif_comment = (exif or {}).get("Exif", {}).get(piexif.ExifIFD.UserComment, b'')
- try:
- exif_comment = piexif.helper.UserComment.load(exif_comment)
- except ValueError:
- exif_comment = exif_comment.decode('utf8', errors="ignore")
-
- items['exif comment'] = exif_comment
- geninfo = exif_comment
-
- for field in ['jfif', 'jfif_version', 'jfif_unit', 'jfif_density', 'dpi', 'exif',
- 'loop', 'background', 'timestamp', 'duration']:
- items.pop(field, None)
-
- geninfo = items.get('parameters', geninfo)
-
- info = f"""
-PNG Info
-"""
- for key, text in items.items():
- info += f"""
-
-
{plaintext_to_html(str(key))}
-
{plaintext_to_html(str(text))}
-
Being.Riley..Greg.Lansky..Tushy..Riley.Reid
DOWNLOAD ⏩ https://gohhs.com/2uz3YJ
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/infinfin/style-transfer/README.md b/spaces/infinfin/style-transfer/README.md
deleted file mode 100644
index c20de45222c0e1cbd1a861d6e2de5e0706277464..0000000000000000000000000000000000000000
--- a/spaces/infinfin/style-transfer/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Style Transfer
-emoji: 🌖
-colorFrom: pink
-colorTo: red
-sdk: gradio
-sdk_version: 3.6
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Aazaan Full Movie 720p [HOT] Download.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Aazaan Full Movie 720p [HOT] Download.md
deleted file mode 100644
index 33fd4d1df23b6176fd6146d673e96092adcb0dfd..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Aazaan Full Movie 720p [HOT] Download.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Aazaan full movie 720p download
DOWNLOAD »»» https://urlin.us/2uExmM
-
-Dastak Full Movie With English Subtitles 720p >>> DOWNLOAD Dastak ... the superhit Hindi Movies 2018 Full Movie "AAZAAN" Azaan the full ... 1fdad05405
-
-
-
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Apowersoft Video Download Capture V6.4.8.2 HOT Crack.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Apowersoft Video Download Capture V6.4.8.2 HOT Crack.md
deleted file mode 100644
index b3234c23b4633cba0615c036fad843b5c7cf8ba2..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Apowersoft Video Download Capture V6.4.8.2 HOT Crack.md
+++ /dev/null
@@ -1,13 +0,0 @@
-Apowersoft Video Download Capture v6.4.8.2 Crack
Download File ———>>> https://urlin.us/2uEx8E
-
-June 4, 2021 - AceThinker Video Master Crack is one of the most useful tools for... Video Master because it allows you to convert files, burn, upload new files . . If you want to download it on Windows or Mac, I can help you.
-AceThinker Video Master - Free Download for Windows and Mac ...
-Ace Thinker Video Master.
-AceThinker Video Master is a useful and powerful tool for converting, converting, downloading and burning files to
-AceThinker Video Master is a free video converter for...
-29 Sep 2018 ... ...
-AceThinker Video Master Video Converter is a powerful and efficient video conversion tool that...
-Apr 1, 2013 ... 8a78ff9644
-
-
-
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Inventor 2014 Crack HOT 64 Bit.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Inventor 2014 Crack HOT 64 Bit.md
deleted file mode 100644
index 226a59dfe855d3723b04907e5030d10f2bd8c8cd..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Inventor 2014 Crack HOT 64 Bit.md
+++ /dev/null
@@ -1,41 +0,0 @@
-
-How to Install Autodesk Inventor 2014 Professional on Windows 7 or Windows 8 64-bit
-Autodesk Inventor 2014 Professional is a powerful software for mechanical design and simulation. It allows you to create complex models, assemblies, and drawings with ease and accuracy. It also integrates with other Autodesk products, such as AutoCAD and Revit, for seamless collaboration and data exchange.
-Inventor 2014 Crack 64 Bit
Download ☆☆☆☆☆ https://urlin.us/2uEyzZ
-If you want to install Autodesk Inventor 2014 Professional on your Windows 7 or Windows 8 64-bit computer, you need to follow these steps:
-
-- Download the setup files from the Autodesk website or use the installation media provided by your reseller. You can choose between a 32-bit or a 64-bit version, depending on your system requirements. For complex models and large assemblies, it is recommended to use the 64-bit version.
-- Save the setup files in a folder on your computer. If you downloaded the 64-bit version, you will have two parts that need to be extracted together.
-- Double-click on the setup.exe file to start the installation process. You will see a welcome screen with some options. You can choose to install now, download now, or browser download. The install now option will install the software directly from the internet, while the other two options will let you download the software first and then install it later.
-- Choose the install now option and click on next. You will be asked to sign in with your Autodesk account or create one if you don't have one already. This is required for activating and registering your software.
-- After signing in, you will see a list of products and components that are available for installation. You can select or deselect the ones that you want or don't want. Make sure that Autodesk Inventor 2014 Professional and the content libraries are selected.
-- Click on next and review the system requirements and license agreement. If everything is OK, click on install to begin the installation.
-- The installation may take some time depending on your internet speed and system performance. You can monitor the progress and status of the installation on the screen.
-- When the installation is complete, you will see a confirmation message. You can click on finish to exit the installer.
-- You can now launch Autodesk Inventor 2014 Professional from your desktop or start menu. You may need to activate your software online or offline using your serial number and product key.
-
-Congratulations! You have successfully installed Autodesk Inventor 2014 Professional on your Windows 7 or Windows 8 64-bit computer. You can now start creating amazing mechanical designs and simulations with this powerful software.
-
-How to Use Autodesk Inventor 2014 Professional
-Autodesk Inventor 2014 Professional is a comprehensive software that covers all aspects of mechanical design and simulation. You can use it to create parts, assemblies, drawings, presentations, animations, and more. You can also perform various types of analysis, such as stress, motion, thermal, and fluid dynamics.
-
-To use Autodesk Inventor 2014 Professional, you need to follow these basic steps:
-
-- Start a new project or open an existing one. A project is a collection of files and settings that define your design. You can create multiple projects for different purposes and switch between them easily.
-- Create a new file or open an existing one. A file is a document that contains your design data. You can create different types of files, such as part files (.ipt), assembly files (.iam), drawing files (.idw), and presentation files (.ipn).
-- Use the tools and commands in the user interface to create and modify your design. The user interface consists of various elements, such as the ribbon, the browser, the graphics window, the navigation bar, the status bar, and the application menu. You can customize the user interface to suit your preferences and workflow.
-- Save and close your file when you are done. You can also export your file to other formats, such as DWG, PDF, STEP, IGES, STL, and more.
-
-These are the basic steps for using Autodesk Inventor 2014 Professional. Of course, there are many more features and functions that you can explore and learn as you progress with your design projects.
-
-How to Update Autodesk Inventor 2014 Professional
-Autodesk Inventor 2014 Professional is a software that is constantly updated and improved by Autodesk. You can update your software to get the latest enhancements, fixes, and security patches. You can also get access to new features and functionalities that are added in the updates.
-To update Autodesk Inventor 2014 Professional, you need to follow these steps:
-
-- Check if there are any updates available for your software. You can do this by clicking on the application menu in the upper left corner of the user interface and selecting Check for Updates. You can also visit the Autodesk website or use the Autodesk Desktop App to check for updates.
-- Download and install the updates that are applicable to your software. You may need to close your software and restart your computer during the installation process.
-- Launch your software and verify that the updates have been applied successfully. You can do this by clicking on the application menu and selecting About Autodesk Inventor Professional. You will see the version number and build date of your software.
-
-These are the steps for updating Autodesk Inventor 2014 Professional. It is recommended that you update your software regularly to get the best performance and experience from your software.
d5da3c52bf
-
-
\ No newline at end of file
diff --git a/spaces/inplisQlawa/anything-midjourney-v4-1/Jopieksstrongholdcrusadertrainerv1001 BEST.md b/spaces/inplisQlawa/anything-midjourney-v4-1/Jopieksstrongholdcrusadertrainerv1001 BEST.md
deleted file mode 100644
index c30dd39f8e0ac268e75205cdfa1b72a13b048c92..0000000000000000000000000000000000000000
--- a/spaces/inplisQlawa/anything-midjourney-v4-1/Jopieksstrongholdcrusadertrainerv1001 BEST.md
+++ /dev/null
@@ -1,24 +0,0 @@
-jopieksstrongholdcrusadertrainerv1001
Download Zip ✺✺✺ https://urlin.us/2uEvS4
-
-9 am
-
-War.pvpgrpcatfightcatfightcatfightcatfightCrusaderCatfightCatfightCatfightCrusader10 am
-
-I want to bring up the performance issues that we've had recently with the server moving from FE to FEII and a fix patch from the development team.
-
-The first issue is that the servers are now requiring more MP than what we had previously. This is a result of the way that the servers are setup on the new version. The other issue is that the performance is quite bad on the new servers. This has resulted in a lot of people leaving the servers as they were unable to find a team to play with in the new version.
-
-We have been working hard on the performance issues, and we can say that we are almost done with the performance improvements for the current server version. However, the server will still have to be updated to be able to implement the other new changes that are being implemented to the game.
-
-We don't want to force anyone to stay if they are uncomfortable with the server changes. However, we also don't want to force people to stay if they aren't happy with the performance. Therefore, we will be implementing a dual release for the game. The new version of the game will be available from 11:00 pm on Monday, June 26th, and the servers will be upgraded to be able to support this new version.
-
-The existing version of the game will remain active until midnight on June 27th.
-
-When the new version of the game is released, you will be able to choose which server you wish to play on. We will also have all the servers set to start with the new performance level that we are planning to have.
-
-As for everyone who wants to play with friends and battle them for glory, you will also be able to do this. As long as your friends are in the new version of the game, you will be able to battle them no matter which server you are on. If you decide to stay on the old server until midnight on June 27th, then you will be able to play with your friends and battle them, too.
-
-The first issue is that the servers are now requiring more MP than what we had previously. This is a result of the way that the servers are setup on the new version. The other issue is that the performance is quite bad on the new servers. This has resulted in a lot of people leaving the servers as they were unable 4fefd39f24
-
-
-
diff --git a/spaces/inreVtussa/clothingai/Examples/Buku Ajar Kardiologi Anak Pdf 55.md b/spaces/inreVtussa/clothingai/Examples/Buku Ajar Kardiologi Anak Pdf 55.md
deleted file mode 100644
index 4b3e5e6d345dc4a9bf8c6f1af466a8402fb4b6bb..0000000000000000000000000000000000000000
--- a/spaces/inreVtussa/clothingai/Examples/Buku Ajar Kardiologi Anak Pdf 55.md
+++ /dev/null
@@ -1,12 +0,0 @@
-Buku Ajar Kardiologi Anak Pdf 55
Download File ->>> https://tiurll.com/2uCiIE
-
-tahun yang telah berdoa untuk melakukan penyembuhan kepada anak-anaknya.Menurut dia, mereka telah mengaku keberatan dengan 'petugas' lain yang mengakses klom yang disebarkan oleh salah seorang anak untuk berkah terkait salah satu anaknya. Meski jadi diperbolehkan menggunakan jasa penyembuhan di depan klom, mereka selalu ingin mendoakan kepada Allah untuk menyembuhkan anaknya.Dalam berkah tersebut, ibunya diharapkan akan mendapatkan perlakuan yang baik dan mereka selalu menjaga suatu keharusan.Sebelumnya, Polda Metro Jaya menyatakan tiga anak dijerat oleh klinik di Jakarta tersebut. Anak-anak dalam kejadian tersebut adalah anak perempuan yang diperoleh penyembuhan di unit klients, termasuk hakim. Sedangkan anak yang diperoleh penyembuhan di klien lainnya tidak jelas.Polda Metro Jaya mengganti kamar detik suara pengunjung yang berkas pendapat mereka."Kalau orang bilang (kurang jelas) kan pekerja, mau teknis, kan ada sesuatu yang (seharusnya) kemudian ganti ke orang yang menyangkut yang bilang ini (bisa dijelaskan jelas)," ujar Kapolres Metro Jakarta tadi Senin (3/11/2017).
-
-[Gambas:Video 20detik]What is really going on in politics? Get our daily email briefing straight to your inbox Sign up Thank you for subscribing We have more newsletters Show me See our privacy notice Invalid Email
-
-It’s time to call out the hypocrisy on gender pay gap ‘champion’ Theresa May.
-
-In the 4fefd39f24
-
-
-
diff --git a/spaces/inreVtussa/clothingai/Examples/Cheat Line 8 Ball Pool Di Facebook Terbaru [2021].md b/spaces/inreVtussa/clothingai/Examples/Cheat Line 8 Ball Pool Di Facebook Terbaru [2021].md
deleted file mode 100644
index c0e5ed118725d4e16301ac4553de0d97b6d3151f..0000000000000000000000000000000000000000
--- a/spaces/inreVtussa/clothingai/Examples/Cheat Line 8 Ball Pool Di Facebook Terbaru [2021].md
+++ /dev/null
@@ -1,6 +0,0 @@
-cheat line 8 ball pool di facebook terbaru
Download Zip — https://tiurll.com/2uClYn
-
-... 8Poolhack.Net Cara Mendapatkan Koin Gratis Di 8 Ball Pool Facebook ... Hack Money And Coin In 8 Ball Pool By Cheats Engine 6.4 Work 100 % -. 8 Ball Pool 4.4.0 New ... aktif 2017-2018 -. 8 Ball Pool Lua (Long Line+HackShop) - LUA scripts . ... Top 8 Ball Pool Tool Pro Terbaru · Neruc.Icu/8Ball 8 Ball ... 4d29de3e1b
-
-
-
diff --git a/spaces/inreVtussa/clothingai/Examples/Colasoft Capsa 7 Serial Keygen BEST 22.md b/spaces/inreVtussa/clothingai/Examples/Colasoft Capsa 7 Serial Keygen BEST 22.md
deleted file mode 100644
index 2cd2f7f24aac1fbcf4efce4090c68d0c3344688c..0000000000000000000000000000000000000000
--- a/spaces/inreVtussa/clothingai/Examples/Colasoft Capsa 7 Serial Keygen BEST 22.md
+++ /dev/null
@@ -1,96 +0,0 @@
-
-How to Activate Colasoft Capsa 7 with a Serial Keygen
-
-Colasoft Capsa 7 is a powerful network analyzer that can help you monitor, troubleshoot and optimize your network performance. It can capture and analyze packets in real time, provide various statistics and reports, and support over 300 network protocols. If you want to use Colasoft Capsa 7 for your network analysis needs, you need to activate it with a serial keygen.
-
-A serial keygen is a program that can generate valid serial numbers for software products. You can use a serial keygen to activate Colasoft Capsa 7 without paying for a license. However, this is illegal and may cause security risks for your computer and network. Therefore, we do not recommend using a serial keygen to activate Colasoft Capsa 7.
-Colasoft Capsa 7 Serial Keygen 22
Download Zip ……… https://tiurll.com/2uCl7N
-
-Instead, you should purchase a legitimate license from Colasoft or its authorized resellers. You can choose from different editions of Colasoft Capsa 7, such as Enterprise, Professional, Standard and Free. Each edition has different features and prices. You can compare the editions and find the best one for your needs on the Colasoft website.
-
-Once you purchase a license, you will receive a serial number that you can use to activate Colasoft Capsa 7 online or offline. To activate online, you just need to enter the serial number and click Next. To activate offline, you need to generate a license file with the serial number and the machine code of your computer. You can obtain the license file from Colasoft webpage or Colasoft support. Then you need to import the license file and click Next.
-
-After activating Colasoft Capsa 7, you can enjoy its full features and benefits for your network analysis tasks. You can capture and analyze packets in real time, monitor network activities and performance, troubleshoot network problems, detect network security threats, and generate comprehensive reports. You can also customize your analysis settings, filters, alarms, views and dashboards according to your preferences.
-
-Conclusion
-
-Colasoft Capsa 7 is a powerful network analyzer that can help you monitor, troubleshoot and optimize your network performance. It can capture and analyze packets in real time, provide various statistics and reports, and support over 300 network protocols. To use Colasoft Capsa 7, you need to activate it with a serial keygen.
-
-A serial keygen is a program that can generate valid serial numbers for software products. You can use a serial keygen to activate Colasoft Capsa 7 without paying for a license. However, this is illegal and may cause security risks for your computer and network. Therefore, we do not recommend using a serial keygen to activate Colasoft Capsa 7.
-
-Instead, you should purchase a legitimate license from Colasoft or its authorized resellers. You can choose from different editions of Colasoft Capsa 7, such as Enterprise, Professional, Standard and Free. Each edition has different features and prices. You can compare the editions and find the best one for your needs on the Colasoft website.
-
-
-Once you purchase a license, you will receive a serial number that you can use to activate Colasoft Capsa 7 online or offline. To activate online, you just need to enter the serial number and click Next. To activate offline, you need to generate a license file with the serial number and the machine code of your computer. You can obtain the license file from Colasoft webpage or Colasoft support. Then you need to import the license file and click Next.
-
-After activating Colasoft Capsa 7, you can enjoy its full features and benefits for your network analysis tasks. You can capture and analyze packets in real time, monitor network activities and performance, troubleshoot network problems, detect network security threats, and generate comprehensive reports. You can also customize your analysis settings, filters, alarms, views and dashboards according to your preferences.
-How to Use Colasoft Capsa 7 for Network Analysis
-
-Colasoft Capsa 7 is not only a network analyzer, but also a network management tool that can help you improve your network performance and security. It can provide you with various functions and features to help you use it for network analysis. Here are some of the main functions and features of Colasoft Capsa 7:
-
-
-- Packet Capture: Colasoft Capsa 7 can capture packets from any network interface on your computer, such as Ethernet, wireless, VPN, loopback, etc. It can also capture packets from remote computers or devices by using a packet agent or a mirror port. You can set filters to capture only the packets you are interested in, and save the captured packets as pcap files for later analysis.
-- Packet Analysis: Colasoft Capsa 7 can analyze packets in real time or offline mode, and provide you with various information and statistics about the packets, such as protocols, IP addresses, ports, MAC addresses, payload data, etc. It can also decode over 300 network protocols and applications, such as TCP/IP, HTTP, FTP, SMTP, DNS, DHCP, etc. You can view the packet details in different views, such as summary view, protocol view, hex view, etc.
-- Network Monitoring: Colasoft Capsa 7 can monitor network activities and performance in real time, and provide you with various graphs and charts to show you the network status, such as traffic rate, bandwidth utilization, packet loss rate, error rate, etc. It can also monitor network devices and hosts, such as routers, switches, servers, clients, etc., and show you their status, such as online/offline, response time, CPU usage, memory usage, etc.
-- Network Troubleshooting: Colasoft Capsa 7 can help you troubleshoot network problems and errors by providing you with various tools and features. For example, it can detect and diagnose network problems and errors automatically by using expert diagnosis or diagnosis events. It can also help you locate the root cause of network problems by using tools such as ping tool, traceroute tool, DNS tool, etc.
-- Network Security: Colasoft Capsa 7 can help you detect and prevent network security threats by providing you with various tools and features. For example, it can detect and alert you of network attacks and intrusions by using tools such as IDS (Intrusion Detection System) or IPS (Intrusion Prevention System). It can also help you prevent data leakage or tampering by using tools such as encryption tool or checksum tool.
-- Network Reporting: Colasoft Capsa 7 can help you generate comprehensive reports about your network analysis results by providing you with various templates and formats. You can customize your reports according to your needs and preferences. You can also export your reports to different formats, such as PDF, HTML, Excel, Word, etc.
-
-
-These are some of the main functions and features of Colasoft Capsa 7 that can help you use it for network analysis. You can learn more about how to use Colasoft Capsa 7 by reading the user manual or watching the video tutorials on the Colasoft website.
-
-How to Download and Install Colasoft Capsa 7
-
-If you want to use Colasoft Capsa 7 for network analysis, you need to download and install it on your computer first. Here are the steps to download and install Colasoft Capsa 7:
-
-
-- Go to the Colasoft website and choose the edition of Colasoft Capsa 7 that suits your needs. You can choose from Enterprise, Professional, Standard or Free edition. Each edition has different features and prices.
-- Click the Download button to download the installation file of Colasoft Capsa 7. The file size is about 80 MB.
-- Run the installation file and follow the instructions to install Colasoft Capsa 7 on your computer. The installation process will take a few minutes.
-- After the installation is completed, launch Colasoft Capsa 7 from your desktop or start menu.
-- Enter your serial number or license file to activate Colasoft Capsa 7. You can obtain your serial number or license file from Colasoft webpage or Colasoft support after purchasing a license.
-
-
-These are the steps to download and install Colasoft Capsa 7 on your computer. You can now start using Colasoft Capsa 7 for network analysis.
-How to Find Colasoft Capsa 7 Serial Keygen Online
-
-If you are looking for a serial keygen for Colasoft Capsa 7, you may be tempted to search for it online. There are many websites that claim to offer free or cracked serial keygens for various software products, including Colasoft Capsa 7. However, you should be aware of the risks and consequences of downloading and using such serial keygens.
-
-First of all, downloading and using a serial keygen for Colasoft Capsa 7 is illegal and unethical. You are violating the intellectual property rights of Colasoft and its partners, and you may face legal actions or penalties. You are also depriving Colasoft of its rightful revenue and support, which may affect its ability to develop and improve its products and services.
-
-Secondly, downloading and using a serial keygen for Colasoft Capsa 7 is unsafe and unreliable. You may expose your computer and network to malware, viruses, spyware, ransomware, or other malicious programs that may harm your system or data. You may also compromise your network security and privacy by allowing unauthorized access or leakage of your sensitive information. You may also experience errors, crashes, or compatibility issues with Colasoft Capsa 7 or other software products.
-
-Thirdly, downloading and using a serial keygen for Colasoft Capsa 7 is ineffective and inefficient. You may not be able to activate Colasoft Capsa 7 successfully or permanently with a serial keygen, as Colasoft may detect and block it. You may also miss out on the latest updates, patches, features, or bug fixes that Colasoft provides for its licensed users. You may also not be able to access the technical support or customer service that Colasoft offers for its products.
-
-Therefore, we strongly advise you not to download or use a serial keygen for Colasoft Capsa 7 online. Instead, you should purchase a legitimate license from Colasoft or its authorized resellers. You can choose from different editions of Colasoft Capsa 7, such as Enterprise, Professional, Standard or Free. Each edition has different features and prices. You can compare the editions and find the best one for your needs on the Colasoft website.
-
-How to Get a Free Trial of Colasoft Capsa 7
-
-If you are interested in trying out Colasoft Capsa 7 before purchasing a license, you can get a free trial of it from the Colasoft website. The free trial allows you to use all the features and functions of Colasoft Capsa 7 Enterprise edition for 15 days without any limitations or restrictions. Here are the steps to get a free trial of Colasoft Capsa 7:
-
-
-- Go to the Colasoft website and click the Free Trial button on the top right corner.
-- Fill in your name and email address and click Submit.
-- Check your email inbox and find the email from Colasoft with the download link and the trial serial number.
-- Click the download link and save the installation file of Colasoft Capsa 7 on your computer.
-- Run the installation file and follow the instructions to install Colasoft Capsa 7 on your computer.
-- Launch Colasoft Capsa 7 from your desktop or start menu.
-- Enter your trial serial number and click Next to activate your free trial.
-
-
-These are the steps to get a free trial of Colasoft Capsa 7 on your computer. You can now start using Colasoft Capsa 7 for network analysis for 15 days without any limitations or restrictions.
-Conclusion
-
-Colasoft Capsa 7 is a powerful network analyzer that can help you monitor, troubleshoot and optimize your network performance and security. It can capture and analyze packets in real time, provide various statistics and reports, and support over 300 network protocols and applications. To use Colasoft Capsa 7, you need to activate it with a serial keygen.
-
-A serial keygen is a program that can generate valid serial numbers for software products. You can use a serial keygen to activate Colasoft Capsa 7 without paying for a license. However, this is illegal and unethical, and may cause security risks for your computer and network. Therefore, we do not recommend using a serial keygen to activate Colasoft Capsa 7.
-
-Instead, you should purchase a legitimate license from Colasoft or its authorized resellers. You can choose from different editions of Colasoft Capsa 7, such as Enterprise, Professional, Standard or Free. Each edition has different features and prices. You can compare the editions and find the best one for your needs on the Colasoft website.
-
-Once you purchase a license, you will receive a serial number that you can use to activate Colasoft Capsa 7 online or offline. To activate online, you just need to enter the serial number and click Next. To activate offline, you need to generate a license file with the serial number and the machine code of your computer. You can obtain the license file from Colasoft webpage or Colasoft support. Then you need to import the license file and click Next.
-
-After activating Colasoft Capsa 7, you can enjoy its full features and benefits for your network analysis tasks. You can also get a free trial of Colasoft Capsa 7 Enterprise edition for 15 days from the Colasoft website. If you are interested in trying out Colasoft Capsa 7 before purchasing a license, you can follow the steps above to get a free trial.
-
-We hope this article has helped you understand how to activate and use Colasoft Capsa 7 for network analysis. If you have any questions or feedback, please feel free to contact us or leave a comment below. Thank you for reading!
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/insaafS/AI-Story-Gen/README.md b/spaces/insaafS/AI-Story-Gen/README.md
deleted file mode 100644
index a0cb03203afb9e0f1bfc713afe9fc0761bb10806..0000000000000000000000000000000000000000
--- a/spaces/insaafS/AI-Story-Gen/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: AI Story Gen
-emoji: 🐢
-colorFrom: green
-colorTo: red
-sdk: gradio
-sdk_version: 3.40.1
-app_file: app.py
-pinned: false
-license: gpl
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/ivotai/VITS-Umamusume-voice-synthesizer/text/korean.py b/spaces/ivotai/VITS-Umamusume-voice-synthesizer/text/korean.py
deleted file mode 100644
index edee07429a450c55e3d8e246997faaa1e0b89cc9..0000000000000000000000000000000000000000
--- a/spaces/ivotai/VITS-Umamusume-voice-synthesizer/text/korean.py
+++ /dev/null
@@ -1,210 +0,0 @@
-import re
-from jamo import h2j, j2hcj
-import ko_pron
-
-
-# This is a list of Korean classifiers preceded by pure Korean numerals.
-_korean_classifiers = '군데 권 개 그루 닢 대 두 마리 모 모금 뭇 발 발짝 방 번 벌 보루 살 수 술 시 쌈 움큼 정 짝 채 척 첩 축 켤레 톨 통'
-
-# List of (hangul, hangul divided) pairs:
-_hangul_divided = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('ㄳ', 'ㄱㅅ'),
- ('ㄵ', 'ㄴㅈ'),
- ('ㄶ', 'ㄴㅎ'),
- ('ㄺ', 'ㄹㄱ'),
- ('ㄻ', 'ㄹㅁ'),
- ('ㄼ', 'ㄹㅂ'),
- ('ㄽ', 'ㄹㅅ'),
- ('ㄾ', 'ㄹㅌ'),
- ('ㄿ', 'ㄹㅍ'),
- ('ㅀ', 'ㄹㅎ'),
- ('ㅄ', 'ㅂㅅ'),
- ('ㅘ', 'ㅗㅏ'),
- ('ㅙ', 'ㅗㅐ'),
- ('ㅚ', 'ㅗㅣ'),
- ('ㅝ', 'ㅜㅓ'),
- ('ㅞ', 'ㅜㅔ'),
- ('ㅟ', 'ㅜㅣ'),
- ('ㅢ', 'ㅡㅣ'),
- ('ㅑ', 'ㅣㅏ'),
- ('ㅒ', 'ㅣㅐ'),
- ('ㅕ', 'ㅣㅓ'),
- ('ㅖ', 'ㅣㅔ'),
- ('ㅛ', 'ㅣㅗ'),
- ('ㅠ', 'ㅣㅜ')
-]]
-
-# List of (Latin alphabet, hangul) pairs:
-_latin_to_hangul = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('a', '에이'),
- ('b', '비'),
- ('c', '시'),
- ('d', '디'),
- ('e', '이'),
- ('f', '에프'),
- ('g', '지'),
- ('h', '에이치'),
- ('i', '아이'),
- ('j', '제이'),
- ('k', '케이'),
- ('l', '엘'),
- ('m', '엠'),
- ('n', '엔'),
- ('o', '오'),
- ('p', '피'),
- ('q', '큐'),
- ('r', '아르'),
- ('s', '에스'),
- ('t', '티'),
- ('u', '유'),
- ('v', '브이'),
- ('w', '더블유'),
- ('x', '엑스'),
- ('y', '와이'),
- ('z', '제트')
-]]
-
-# List of (ipa, lazy ipa) pairs:
-_ipa_to_lazy_ipa = [(re.compile('%s' % x[0], re.IGNORECASE), x[1]) for x in [
- ('t͡ɕ','ʧ'),
- ('d͡ʑ','ʥ'),
- ('ɲ','n^'),
- ('ɕ','ʃ'),
- ('ʷ','w'),
- ('ɭ','l`'),
- ('ʎ','ɾ'),
- ('ɣ','ŋ'),
- ('ɰ','ɯ'),
- ('ʝ','j'),
- ('ʌ','ə'),
- ('ɡ','g'),
- ('\u031a','#'),
- ('\u0348','='),
- ('\u031e',''),
- ('\u0320',''),
- ('\u0339','')
-]]
-
-
-def latin_to_hangul(text):
- for regex, replacement in _latin_to_hangul:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def divide_hangul(text):
- text = j2hcj(h2j(text))
- for regex, replacement in _hangul_divided:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def hangul_number(num, sino=True):
- '''Reference https://github.com/Kyubyong/g2pK'''
- num = re.sub(',', '', num)
-
- if num == '0':
- return '영'
- if not sino and num == '20':
- return '스무'
-
- digits = '123456789'
- names = '일이삼사오육칠팔구'
- digit2name = {d: n for d, n in zip(digits, names)}
-
- modifiers = '한 두 세 네 다섯 여섯 일곱 여덟 아홉'
- decimals = '열 스물 서른 마흔 쉰 예순 일흔 여든 아흔'
- digit2mod = {d: mod for d, mod in zip(digits, modifiers.split())}
- digit2dec = {d: dec for d, dec in zip(digits, decimals.split())}
-
- spelledout = []
- for i, digit in enumerate(num):
- i = len(num) - i - 1
- if sino:
- if i == 0:
- name = digit2name.get(digit, '')
- elif i == 1:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- else:
- if i == 0:
- name = digit2mod.get(digit, '')
- elif i == 1:
- name = digit2dec.get(digit, '')
- if digit == '0':
- if i % 4 == 0:
- last_three = spelledout[-min(3, len(spelledout)):]
- if ''.join(last_three) == '':
- spelledout.append('')
- continue
- else:
- spelledout.append('')
- continue
- if i == 2:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 3:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 4:
- name = digit2name.get(digit, '') + '만'
- name = name.replace('일만', '만')
- elif i == 5:
- name = digit2name.get(digit, '') + '십'
- name = name.replace('일십', '십')
- elif i == 6:
- name = digit2name.get(digit, '') + '백'
- name = name.replace('일백', '백')
- elif i == 7:
- name = digit2name.get(digit, '') + '천'
- name = name.replace('일천', '천')
- elif i == 8:
- name = digit2name.get(digit, '') + '억'
- elif i == 9:
- name = digit2name.get(digit, '') + '십'
- elif i == 10:
- name = digit2name.get(digit, '') + '백'
- elif i == 11:
- name = digit2name.get(digit, '') + '천'
- elif i == 12:
- name = digit2name.get(digit, '') + '조'
- elif i == 13:
- name = digit2name.get(digit, '') + '십'
- elif i == 14:
- name = digit2name.get(digit, '') + '백'
- elif i == 15:
- name = digit2name.get(digit, '') + '천'
- spelledout.append(name)
- return ''.join(elem for elem in spelledout)
-
-
-def number_to_hangul(text):
- '''Reference https://github.com/Kyubyong/g2pK'''
- tokens = set(re.findall(r'(\d[\d,]*)([\uac00-\ud71f]+)', text))
- for token in tokens:
- num, classifier = token
- if classifier[:2] in _korean_classifiers or classifier[0] in _korean_classifiers:
- spelledout = hangul_number(num, sino=False)
- else:
- spelledout = hangul_number(num, sino=True)
- text = text.replace(f'{num}{classifier}', f'{spelledout}{classifier}')
- # digit by digit for remaining digits
- digits = '0123456789'
- names = '영일이삼사오육칠팔구'
- for d, n in zip(digits, names):
- text = text.replace(d, n)
- return text
-
-
-def korean_to_lazy_ipa(text):
- text = latin_to_hangul(text)
- text = number_to_hangul(text)
- text=re.sub('[\uac00-\ud7af]+',lambda x:ko_pron.romanise(x.group(0),'ipa').split('] ~ [')[0],text)
- for regex, replacement in _ipa_to_lazy_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def korean_to_ipa(text):
- text = korean_to_lazy_ipa(text)
- return text.replace('ʧ','tʃ').replace('ʥ','dʑ')
diff --git a/spaces/ivotai/VITS-Umamusume-voice-synthesizer/text/symbols.py b/spaces/ivotai/VITS-Umamusume-voice-synthesizer/text/symbols.py
deleted file mode 100644
index 053a7105f7ce95aa51614f6995399fa2172b3eb2..0000000000000000000000000000000000000000
--- a/spaces/ivotai/VITS-Umamusume-voice-synthesizer/text/symbols.py
+++ /dev/null
@@ -1,76 +0,0 @@
-'''
-Defines the set of symbols used in text input to the model.
-'''
-
-# japanese_cleaners
-_pad = '_'
-_punctuation = ',.!?-'
-_letters = 'AEINOQUabdefghijkmnoprstuvwyzʃʧ↓↑ '
-
-
-'''# japanese_cleaners2
-_pad = '_'
-_punctuation = ',.!?-~…'
-_letters = 'AEINOQUabdefghijkmnoprstuvwyzʃʧʦ↓↑ '
-'''
-
-
-'''# korean_cleaners
-_pad = '_'
-_punctuation = ',.!?…~'
-_letters = 'ㄱㄴㄷㄹㅁㅂㅅㅇㅈㅊㅋㅌㅍㅎㄲㄸㅃㅆㅉㅏㅓㅗㅜㅡㅣㅐㅔ '
-'''
-
-'''# chinese_cleaners
-_pad = '_'
-_punctuation = ',。!?—…'
-_letters = 'ㄅㄆㄇㄈㄉㄊㄋㄌㄍㄎㄏㄐㄑㄒㄓㄔㄕㄖㄗㄘㄙㄚㄛㄜㄝㄞㄟㄠㄡㄢㄣㄤㄥㄦㄧㄨㄩˉˊˇˋ˙ '
-'''
-
-'''# zh_ja_mixture_cleaners
-_pad = '_'
-_punctuation = ',.!?-~…'
-_letters = 'AEINOQUabdefghijklmnoprstuvwyzʃʧʦɯɹəɥ⁼ʰ`→↓↑ '
-'''
-
-'''# sanskrit_cleaners
-_pad = '_'
-_punctuation = '।'
-_letters = 'ँंःअआइईउऊऋएऐओऔकखगघङचछजझञटठडढणतथदधनपफबभमयरलळवशषसहऽािीुूृॄेैोौ्ॠॢ '
-'''
-
-'''# cjks_cleaners
-_pad = '_'
-_punctuation = ',.!?-~…'
-_letters = 'NQabdefghijklmnopstuvwxyzʃʧʥʦɯɹəɥçɸɾβŋɦː⁼ʰ`^#*=→↓↑ '
-'''
-
-'''# thai_cleaners
-_pad = '_'
-_punctuation = '.!? '
-_letters = 'กขฃคฆงจฉชซฌญฎฏฐฑฒณดตถทธนบปผฝพฟภมยรฤลวศษสหฬอฮฯะัาำิีึืุูเแโใไๅๆ็่้๊๋์'
-'''
-
-'''# cjke_cleaners2
-_pad = '_'
-_punctuation = ',.!?-~…'
-_letters = 'NQabdefghijklmnopstuvwxyzɑæʃʑçɯɪɔɛɹðəɫɥɸʊɾʒθβŋɦ⁼ʰ`^#*=ˈˌ→↓↑ '
-'''
-
-'''# shanghainese_cleaners
-_pad = '_'
-_punctuation = ',.!?…'
-_letters = 'abdfghiklmnopstuvyzøŋȵɑɔɕəɤɦɪɿʑʔʰ̩̃ᴀᴇ15678 '
-'''
-
-'''# chinese_dialect_cleaners
-_pad = '_'
-_punctuation = ',.!?~…─'
-_letters = '#Nabdefghijklmnoprstuvwxyzæçøŋœȵɐɑɒɓɔɕɗɘəɚɛɜɣɤɦɪɭɯɵɷɸɻɾɿʂʅʊʋʌʏʑʔʦʮʰʷˀː˥˦˧˨˩̥̩̃̚ᴀᴇ↑↓∅ⱼ '
-'''
-
-# Export all symbols:
-symbols = [_pad] + list(_punctuation) + list(_letters)
-
-# Special symbol ids
-SPACE_ID = symbols.index(" ")
diff --git a/spaces/jbrinkma/deepmind-pushworld/index.html b/spaces/jbrinkma/deepmind-pushworld/index.html
deleted file mode 100644
index e9eeed81cbafd90f3c5417d3c258c89ecd44d09b..0000000000000000000000000000000000000000
--- a/spaces/jbrinkma/deepmind-pushworld/index.html
+++ /dev/null
@@ -1,234 +0,0 @@
-
-
-
-
-
-
- PushWorld
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
Use the arrow keys to push the
red shapes into their outlines. Use the
-
Undo
- and
-
Reset
- buttons above to retry a puzzle.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
diff --git a/spaces/jeang/ernie_demo_toy/ernie/aggregation_strategies.py b/spaces/jeang/ernie_demo_toy/ernie/aggregation_strategies.py
deleted file mode 100644
index d6bb5786adec08dea396e7f57f51aca9224165e3..0000000000000000000000000000000000000000
--- a/spaces/jeang/ernie_demo_toy/ernie/aggregation_strategies.py
+++ /dev/null
@@ -1,70 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-
-from statistics import mean
-
-
-class AggregationStrategy:
- def __init__(
- self,
- method,
- max_items=None,
- top_items=True,
- sorting_class_index=1
- ):
- self.method = method
- self.max_items = max_items
- self.top_items = top_items
- self.sorting_class_index = sorting_class_index
-
- def aggregate(self, softmax_tuples):
- softmax_dicts = []
- for softmax_tuple in softmax_tuples:
- softmax_dict = {}
- for i, probability in enumerate(softmax_tuple):
- softmax_dict[i] = probability
- softmax_dicts.append(softmax_dict)
-
- if self.max_items is not None:
- softmax_dicts = sorted(
- softmax_dicts,
- key=lambda x: x[self.sorting_class_index],
- reverse=self.top_items
- )
- if self.max_items < len(softmax_dicts):
- softmax_dicts = softmax_dicts[:self.max_items]
-
- softmax_list = []
- for key in softmax_dicts[0].keys():
- softmax_list.append(self.method(
- [probabilities[key] for probabilities in softmax_dicts]))
- softmax_tuple = tuple(softmax_list)
- return softmax_tuple
-
-
-class AggregationStrategies:
- Mean = AggregationStrategy(method=mean)
- MeanTopFiveBinaryClassification = AggregationStrategy(
- method=mean,
- max_items=5,
- top_items=True,
- sorting_class_index=1
- )
- MeanTopTenBinaryClassification = AggregationStrategy(
- method=mean,
- max_items=10,
- top_items=True,
- sorting_class_index=1
- )
- MeanTopFifteenBinaryClassification = AggregationStrategy(
- method=mean,
- max_items=15,
- top_items=True,
- sorting_class_index=1
- )
- MeanTopTwentyBinaryClassification = AggregationStrategy(
- method=mean,
- max_items=20,
- top_items=True,
- sorting_class_index=1
- )
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fastapi/middleware/__init__.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fastapi/middleware/__init__.py
deleted file mode 100644
index 620296d5ad6ca2cc49eb5d0dc140bcbc3204e9b4..0000000000000000000000000000000000000000
--- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fastapi/middleware/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from starlette.middleware import Middleware as Middleware
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fontTools/feaLib/builder.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fontTools/feaLib/builder.py
deleted file mode 100644
index 42d1f8f24a720a8cbbaf3f7b7344eb4773ca0f4d..0000000000000000000000000000000000000000
--- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fontTools/feaLib/builder.py
+++ /dev/null
@@ -1,1706 +0,0 @@
-from fontTools.misc import sstruct
-from fontTools.misc.textTools import Tag, tostr, binary2num, safeEval
-from fontTools.feaLib.error import FeatureLibError
-from fontTools.feaLib.lookupDebugInfo import (
- LookupDebugInfo,
- LOOKUP_DEBUG_INFO_KEY,
- LOOKUP_DEBUG_ENV_VAR,
-)
-from fontTools.feaLib.parser import Parser
-from fontTools.feaLib.ast import FeatureFile
-from fontTools.feaLib.variableScalar import VariableScalar
-from fontTools.otlLib import builder as otl
-from fontTools.otlLib.maxContextCalc import maxCtxFont
-from fontTools.ttLib import newTable, getTableModule
-from fontTools.ttLib.tables import otBase, otTables
-from fontTools.otlLib.builder import (
- AlternateSubstBuilder,
- ChainContextPosBuilder,
- ChainContextSubstBuilder,
- LigatureSubstBuilder,
- MultipleSubstBuilder,
- CursivePosBuilder,
- MarkBasePosBuilder,
- MarkLigPosBuilder,
- MarkMarkPosBuilder,
- ReverseChainSingleSubstBuilder,
- SingleSubstBuilder,
- ClassPairPosSubtableBuilder,
- PairPosBuilder,
- SinglePosBuilder,
- ChainContextualRule,
-)
-from fontTools.otlLib.error import OpenTypeLibError
-from fontTools.varLib.varStore import OnlineVarStoreBuilder
-from fontTools.varLib.builder import buildVarDevTable
-from fontTools.varLib.featureVars import addFeatureVariationsRaw
-from fontTools.varLib.models import normalizeValue, piecewiseLinearMap
-from collections import defaultdict
-import itertools
-from io import StringIO
-import logging
-import warnings
-import os
-
-
-log = logging.getLogger(__name__)
-
-
-def addOpenTypeFeatures(font, featurefile, tables=None, debug=False):
- """Add features from a file to a font. Note that this replaces any features
- currently present.
-
- Args:
- font (feaLib.ttLib.TTFont): The font object.
- featurefile: Either a path or file object (in which case we
- parse it into an AST), or a pre-parsed AST instance.
- tables: If passed, restrict the set of affected tables to those in the
- list.
- debug: Whether to add source debugging information to the font in the
- ``Debg`` table
-
- """
- builder = Builder(font, featurefile)
- builder.build(tables=tables, debug=debug)
-
-
-def addOpenTypeFeaturesFromString(
- font, features, filename=None, tables=None, debug=False
-):
- """Add features from a string to a font. Note that this replaces any
- features currently present.
-
- Args:
- font (feaLib.ttLib.TTFont): The font object.
- features: A string containing feature code.
- filename: The directory containing ``filename`` is used as the root of
- relative ``include()`` paths; if ``None`` is provided, the current
- directory is assumed.
- tables: If passed, restrict the set of affected tables to those in the
- list.
- debug: Whether to add source debugging information to the font in the
- ``Debg`` table
-
- """
-
- featurefile = StringIO(tostr(features))
- if filename:
- featurefile.name = filename
- addOpenTypeFeatures(font, featurefile, tables=tables, debug=debug)
-
-
-class Builder(object):
- supportedTables = frozenset(
- Tag(tag)
- for tag in [
- "BASE",
- "GDEF",
- "GPOS",
- "GSUB",
- "OS/2",
- "head",
- "hhea",
- "name",
- "vhea",
- "STAT",
- ]
- )
-
- def __init__(self, font, featurefile):
- self.font = font
- # 'featurefile' can be either a path or file object (in which case we
- # parse it into an AST), or a pre-parsed AST instance
- if isinstance(featurefile, FeatureFile):
- self.parseTree, self.file = featurefile, None
- else:
- self.parseTree, self.file = None, featurefile
- self.glyphMap = font.getReverseGlyphMap()
- self.varstorebuilder = None
- if "fvar" in font:
- self.axes = font["fvar"].axes
- self.varstorebuilder = OnlineVarStoreBuilder(
- [ax.axisTag for ax in self.axes]
- )
- self.default_language_systems_ = set()
- self.script_ = None
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
- self.language_systems = set()
- self.seen_non_DFLT_script_ = False
- self.named_lookups_ = {}
- self.cur_lookup_ = None
- self.cur_lookup_name_ = None
- self.cur_feature_name_ = None
- self.lookups_ = []
- self.lookup_locations = {"GSUB": {}, "GPOS": {}}
- self.features_ = {} # ('latn', 'DEU ', 'smcp') --> [LookupBuilder*]
- self.required_features_ = {} # ('latn', 'DEU ') --> 'scmp'
- self.feature_variations_ = {}
- # for feature 'aalt'
- self.aalt_features_ = [] # [(location, featureName)*], for 'aalt'
- self.aalt_location_ = None
- self.aalt_alternates_ = {}
- # for 'featureNames'
- self.featureNames_ = set()
- self.featureNames_ids_ = {}
- # for 'cvParameters'
- self.cv_parameters_ = set()
- self.cv_parameters_ids_ = {}
- self.cv_num_named_params_ = {}
- self.cv_characters_ = defaultdict(list)
- # for feature 'size'
- self.size_parameters_ = None
- # for table 'head'
- self.fontRevision_ = None # 2.71
- # for table 'name'
- self.names_ = []
- # for table 'BASE'
- self.base_horiz_axis_ = None
- self.base_vert_axis_ = None
- # for table 'GDEF'
- self.attachPoints_ = {} # "a" --> {3, 7}
- self.ligCaretCoords_ = {} # "f_f_i" --> {300, 600}
- self.ligCaretPoints_ = {} # "f_f_i" --> {3, 7}
- self.glyphClassDefs_ = {} # "fi" --> (2, (file, line, column))
- self.markAttach_ = {} # "acute" --> (4, (file, line, column))
- self.markAttachClassID_ = {} # frozenset({"acute", "grave"}) --> 4
- self.markFilterSets_ = {} # frozenset({"acute", "grave"}) --> 4
- # for table 'OS/2'
- self.os2_ = {}
- # for table 'hhea'
- self.hhea_ = {}
- # for table 'vhea'
- self.vhea_ = {}
- # for table 'STAT'
- self.stat_ = {}
- # for conditionsets
- self.conditionsets_ = {}
- # We will often use exactly the same locations (i.e. the font's masters)
- # for a large number of variable scalars. Instead of creating a model
- # for each, let's share the models.
- self.model_cache = {}
-
- def build(self, tables=None, debug=False):
- if self.parseTree is None:
- self.parseTree = Parser(self.file, self.glyphMap).parse()
- self.parseTree.build(self)
- # by default, build all the supported tables
- if tables is None:
- tables = self.supportedTables
- else:
- tables = frozenset(tables)
- unsupported = tables - self.supportedTables
- if unsupported:
- unsupported_string = ", ".join(sorted(unsupported))
- raise NotImplementedError(
- "The following tables were requested but are unsupported: "
- f"{unsupported_string}."
- )
- if "GSUB" in tables:
- self.build_feature_aalt_()
- if "head" in tables:
- self.build_head()
- if "hhea" in tables:
- self.build_hhea()
- if "vhea" in tables:
- self.build_vhea()
- if "name" in tables:
- self.build_name()
- if "OS/2" in tables:
- self.build_OS_2()
- if "STAT" in tables:
- self.build_STAT()
- for tag in ("GPOS", "GSUB"):
- if tag not in tables:
- continue
- table = self.makeTable(tag)
- if self.feature_variations_:
- self.makeFeatureVariations(table, tag)
- if (
- table.ScriptList.ScriptCount > 0
- or table.FeatureList.FeatureCount > 0
- or table.LookupList.LookupCount > 0
- ):
- fontTable = self.font[tag] = newTable(tag)
- fontTable.table = table
- elif tag in self.font:
- del self.font[tag]
- if any(tag in self.font for tag in ("GPOS", "GSUB")) and "OS/2" in self.font:
- self.font["OS/2"].usMaxContext = maxCtxFont(self.font)
- if "GDEF" in tables:
- gdef = self.buildGDEF()
- if gdef:
- self.font["GDEF"] = gdef
- elif "GDEF" in self.font:
- del self.font["GDEF"]
- if "BASE" in tables:
- base = self.buildBASE()
- if base:
- self.font["BASE"] = base
- elif "BASE" in self.font:
- del self.font["BASE"]
- if debug or os.environ.get(LOOKUP_DEBUG_ENV_VAR):
- self.buildDebg()
-
- def get_chained_lookup_(self, location, builder_class):
- result = builder_class(self.font, location)
- result.lookupflag = self.lookupflag_
- result.markFilterSet = self.lookupflag_markFilterSet_
- self.lookups_.append(result)
- return result
-
- def add_lookup_to_feature_(self, lookup, feature_name):
- for script, lang in self.language_systems:
- key = (script, lang, feature_name)
- self.features_.setdefault(key, []).append(lookup)
-
- def get_lookup_(self, location, builder_class):
- if (
- self.cur_lookup_
- and type(self.cur_lookup_) == builder_class
- and self.cur_lookup_.lookupflag == self.lookupflag_
- and self.cur_lookup_.markFilterSet == self.lookupflag_markFilterSet_
- ):
- return self.cur_lookup_
- if self.cur_lookup_name_ and self.cur_lookup_:
- raise FeatureLibError(
- "Within a named lookup block, all rules must be of "
- "the same lookup type and flag",
- location,
- )
- self.cur_lookup_ = builder_class(self.font, location)
- self.cur_lookup_.lookupflag = self.lookupflag_
- self.cur_lookup_.markFilterSet = self.lookupflag_markFilterSet_
- self.lookups_.append(self.cur_lookup_)
- if self.cur_lookup_name_:
- # We are starting a lookup rule inside a named lookup block.
- self.named_lookups_[self.cur_lookup_name_] = self.cur_lookup_
- if self.cur_feature_name_:
- # We are starting a lookup rule inside a feature. This includes
- # lookup rules inside named lookups inside features.
- self.add_lookup_to_feature_(self.cur_lookup_, self.cur_feature_name_)
- return self.cur_lookup_
-
- def build_feature_aalt_(self):
- if not self.aalt_features_ and not self.aalt_alternates_:
- return
- alternates = {g: set(a) for g, a in self.aalt_alternates_.items()}
- for location, name in self.aalt_features_ + [(None, "aalt")]:
- feature = [
- (script, lang, feature, lookups)
- for (script, lang, feature), lookups in self.features_.items()
- if feature == name
- ]
- # "aalt" does not have to specify its own lookups, but it might.
- if not feature and name != "aalt":
- warnings.warn("%s: Feature %s has not been defined" % (location, name))
- continue
- for script, lang, feature, lookups in feature:
- for lookuplist in lookups:
- if not isinstance(lookuplist, list):
- lookuplist = [lookuplist]
- for lookup in lookuplist:
- for glyph, alts in lookup.getAlternateGlyphs().items():
- alternates.setdefault(glyph, set()).update(alts)
- single = {
- glyph: list(repl)[0] for glyph, repl in alternates.items() if len(repl) == 1
- }
- # TODO: Figure out the glyph alternate ordering used by makeotf.
- # https://github.com/fonttools/fonttools/issues/836
- multi = {
- glyph: sorted(repl, key=self.font.getGlyphID)
- for glyph, repl in alternates.items()
- if len(repl) > 1
- }
- if not single and not multi:
- return
- self.features_ = {
- (script, lang, feature): lookups
- for (script, lang, feature), lookups in self.features_.items()
- if feature != "aalt"
- }
- old_lookups = self.lookups_
- self.lookups_ = []
- self.start_feature(self.aalt_location_, "aalt")
- if single:
- single_lookup = self.get_lookup_(location, SingleSubstBuilder)
- single_lookup.mapping = single
- if multi:
- multi_lookup = self.get_lookup_(location, AlternateSubstBuilder)
- multi_lookup.alternates = multi
- self.end_feature()
- self.lookups_.extend(old_lookups)
-
- def build_head(self):
- if not self.fontRevision_:
- return
- table = self.font.get("head")
- if not table: # this only happens for unit tests
- table = self.font["head"] = newTable("head")
- table.decompile(b"\0" * 54, self.font)
- table.tableVersion = 1.0
- table.created = table.modified = 3406620153 # 2011-12-13 11:22:33
- table.fontRevision = self.fontRevision_
-
- def build_hhea(self):
- if not self.hhea_:
- return
- table = self.font.get("hhea")
- if not table: # this only happens for unit tests
- table = self.font["hhea"] = newTable("hhea")
- table.decompile(b"\0" * 36, self.font)
- table.tableVersion = 0x00010000
- if "caretoffset" in self.hhea_:
- table.caretOffset = self.hhea_["caretoffset"]
- if "ascender" in self.hhea_:
- table.ascent = self.hhea_["ascender"]
- if "descender" in self.hhea_:
- table.descent = self.hhea_["descender"]
- if "linegap" in self.hhea_:
- table.lineGap = self.hhea_["linegap"]
-
- def build_vhea(self):
- if not self.vhea_:
- return
- table = self.font.get("vhea")
- if not table: # this only happens for unit tests
- table = self.font["vhea"] = newTable("vhea")
- table.decompile(b"\0" * 36, self.font)
- table.tableVersion = 0x00011000
- if "verttypoascender" in self.vhea_:
- table.ascent = self.vhea_["verttypoascender"]
- if "verttypodescender" in self.vhea_:
- table.descent = self.vhea_["verttypodescender"]
- if "verttypolinegap" in self.vhea_:
- table.lineGap = self.vhea_["verttypolinegap"]
-
- def get_user_name_id(self, table):
- # Try to find first unused font-specific name id
- nameIDs = [name.nameID for name in table.names]
- for user_name_id in range(256, 32767):
- if user_name_id not in nameIDs:
- return user_name_id
-
- def buildFeatureParams(self, tag):
- params = None
- if tag == "size":
- params = otTables.FeatureParamsSize()
- (
- params.DesignSize,
- params.SubfamilyID,
- params.RangeStart,
- params.RangeEnd,
- ) = self.size_parameters_
- if tag in self.featureNames_ids_:
- params.SubfamilyNameID = self.featureNames_ids_[tag]
- else:
- params.SubfamilyNameID = 0
- elif tag in self.featureNames_:
- if not self.featureNames_ids_:
- # name table wasn't selected among the tables to build; skip
- pass
- else:
- assert tag in self.featureNames_ids_
- params = otTables.FeatureParamsStylisticSet()
- params.Version = 0
- params.UINameID = self.featureNames_ids_[tag]
- elif tag in self.cv_parameters_:
- params = otTables.FeatureParamsCharacterVariants()
- params.Format = 0
- params.FeatUILabelNameID = self.cv_parameters_ids_.get(
- (tag, "FeatUILabelNameID"), 0
- )
- params.FeatUITooltipTextNameID = self.cv_parameters_ids_.get(
- (tag, "FeatUITooltipTextNameID"), 0
- )
- params.SampleTextNameID = self.cv_parameters_ids_.get(
- (tag, "SampleTextNameID"), 0
- )
- params.NumNamedParameters = self.cv_num_named_params_.get(tag, 0)
- params.FirstParamUILabelNameID = self.cv_parameters_ids_.get(
- (tag, "ParamUILabelNameID_0"), 0
- )
- params.CharCount = len(self.cv_characters_[tag])
- params.Character = self.cv_characters_[tag]
- return params
-
- def build_name(self):
- if not self.names_:
- return
- table = self.font.get("name")
- if not table: # this only happens for unit tests
- table = self.font["name"] = newTable("name")
- table.names = []
- for name in self.names_:
- nameID, platformID, platEncID, langID, string = name
- # For featureNames block, nameID is 'feature tag'
- # For cvParameters blocks, nameID is ('feature tag', 'block name')
- if not isinstance(nameID, int):
- tag = nameID
- if tag in self.featureNames_:
- if tag not in self.featureNames_ids_:
- self.featureNames_ids_[tag] = self.get_user_name_id(table)
- assert self.featureNames_ids_[tag] is not None
- nameID = self.featureNames_ids_[tag]
- elif tag[0] in self.cv_parameters_:
- if tag not in self.cv_parameters_ids_:
- self.cv_parameters_ids_[tag] = self.get_user_name_id(table)
- assert self.cv_parameters_ids_[tag] is not None
- nameID = self.cv_parameters_ids_[tag]
- table.setName(string, nameID, platformID, platEncID, langID)
- table.names.sort()
-
- def build_OS_2(self):
- if not self.os2_:
- return
- table = self.font.get("OS/2")
- if not table: # this only happens for unit tests
- table = self.font["OS/2"] = newTable("OS/2")
- data = b"\0" * sstruct.calcsize(getTableModule("OS/2").OS2_format_0)
- table.decompile(data, self.font)
- version = 0
- if "fstype" in self.os2_:
- table.fsType = self.os2_["fstype"]
- if "panose" in self.os2_:
- panose = getTableModule("OS/2").Panose()
- (
- panose.bFamilyType,
- panose.bSerifStyle,
- panose.bWeight,
- panose.bProportion,
- panose.bContrast,
- panose.bStrokeVariation,
- panose.bArmStyle,
- panose.bLetterForm,
- panose.bMidline,
- panose.bXHeight,
- ) = self.os2_["panose"]
- table.panose = panose
- if "typoascender" in self.os2_:
- table.sTypoAscender = self.os2_["typoascender"]
- if "typodescender" in self.os2_:
- table.sTypoDescender = self.os2_["typodescender"]
- if "typolinegap" in self.os2_:
- table.sTypoLineGap = self.os2_["typolinegap"]
- if "winascent" in self.os2_:
- table.usWinAscent = self.os2_["winascent"]
- if "windescent" in self.os2_:
- table.usWinDescent = self.os2_["windescent"]
- if "vendor" in self.os2_:
- table.achVendID = safeEval("'''" + self.os2_["vendor"] + "'''")
- if "weightclass" in self.os2_:
- table.usWeightClass = self.os2_["weightclass"]
- if "widthclass" in self.os2_:
- table.usWidthClass = self.os2_["widthclass"]
- if "unicoderange" in self.os2_:
- table.setUnicodeRanges(self.os2_["unicoderange"])
- if "codepagerange" in self.os2_:
- pages = self.build_codepages_(self.os2_["codepagerange"])
- table.ulCodePageRange1, table.ulCodePageRange2 = pages
- version = 1
- if "xheight" in self.os2_:
- table.sxHeight = self.os2_["xheight"]
- version = 2
- if "capheight" in self.os2_:
- table.sCapHeight = self.os2_["capheight"]
- version = 2
- if "loweropsize" in self.os2_:
- table.usLowerOpticalPointSize = self.os2_["loweropsize"]
- version = 5
- if "upperopsize" in self.os2_:
- table.usUpperOpticalPointSize = self.os2_["upperopsize"]
- version = 5
-
- def checkattr(table, attrs):
- for attr in attrs:
- if not hasattr(table, attr):
- setattr(table, attr, 0)
-
- table.version = max(version, table.version)
- # this only happens for unit tests
- if version >= 1:
- checkattr(table, ("ulCodePageRange1", "ulCodePageRange2"))
- if version >= 2:
- checkattr(
- table,
- (
- "sxHeight",
- "sCapHeight",
- "usDefaultChar",
- "usBreakChar",
- "usMaxContext",
- ),
- )
- if version >= 5:
- checkattr(table, ("usLowerOpticalPointSize", "usUpperOpticalPointSize"))
-
- def setElidedFallbackName(self, value, location):
- # ElidedFallbackName is a convenience method for setting
- # ElidedFallbackNameID so only one can be allowed
- for token in ("ElidedFallbackName", "ElidedFallbackNameID"):
- if token in self.stat_:
- raise FeatureLibError(
- f"{token} is already set.",
- location,
- )
- if isinstance(value, int):
- self.stat_["ElidedFallbackNameID"] = value
- elif isinstance(value, list):
- self.stat_["ElidedFallbackName"] = value
- else:
- raise AssertionError(value)
-
- def addDesignAxis(self, designAxis, location):
- if "DesignAxes" not in self.stat_:
- self.stat_["DesignAxes"] = []
- if designAxis.tag in (r.tag for r in self.stat_["DesignAxes"]):
- raise FeatureLibError(
- f'DesignAxis already defined for tag "{designAxis.tag}".',
- location,
- )
- if designAxis.axisOrder in (r.axisOrder for r in self.stat_["DesignAxes"]):
- raise FeatureLibError(
- f"DesignAxis already defined for axis number {designAxis.axisOrder}.",
- location,
- )
- self.stat_["DesignAxes"].append(designAxis)
-
- def addAxisValueRecord(self, axisValueRecord, location):
- if "AxisValueRecords" not in self.stat_:
- self.stat_["AxisValueRecords"] = []
- # Check for duplicate AxisValueRecords
- for record_ in self.stat_["AxisValueRecords"]:
- if (
- {n.asFea() for n in record_.names}
- == {n.asFea() for n in axisValueRecord.names}
- and {n.asFea() for n in record_.locations}
- == {n.asFea() for n in axisValueRecord.locations}
- and record_.flags == axisValueRecord.flags
- ):
- raise FeatureLibError(
- "An AxisValueRecord with these values is already defined.",
- location,
- )
- self.stat_["AxisValueRecords"].append(axisValueRecord)
-
- def build_STAT(self):
- if not self.stat_:
- return
-
- axes = self.stat_.get("DesignAxes")
- if not axes:
- raise FeatureLibError("DesignAxes not defined", None)
- axisValueRecords = self.stat_.get("AxisValueRecords")
- axisValues = {}
- format4_locations = []
- for tag in axes:
- axisValues[tag.tag] = []
- if axisValueRecords is not None:
- for avr in axisValueRecords:
- valuesDict = {}
- if avr.flags > 0:
- valuesDict["flags"] = avr.flags
- if len(avr.locations) == 1:
- location = avr.locations[0]
- values = location.values
- if len(values) == 1: # format1
- valuesDict.update({"value": values[0], "name": avr.names})
- if len(values) == 2: # format3
- valuesDict.update(
- {
- "value": values[0],
- "linkedValue": values[1],
- "name": avr.names,
- }
- )
- if len(values) == 3: # format2
- nominal, minVal, maxVal = values
- valuesDict.update(
- {
- "nominalValue": nominal,
- "rangeMinValue": minVal,
- "rangeMaxValue": maxVal,
- "name": avr.names,
- }
- )
- axisValues[location.tag].append(valuesDict)
- else:
- valuesDict.update(
- {
- "location": {i.tag: i.values[0] for i in avr.locations},
- "name": avr.names,
- }
- )
- format4_locations.append(valuesDict)
-
- designAxes = [
- {
- "ordering": a.axisOrder,
- "tag": a.tag,
- "name": a.names,
- "values": axisValues[a.tag],
- }
- for a in axes
- ]
-
- nameTable = self.font.get("name")
- if not nameTable: # this only happens for unit tests
- nameTable = self.font["name"] = newTable("name")
- nameTable.names = []
-
- if "ElidedFallbackNameID" in self.stat_:
- nameID = self.stat_["ElidedFallbackNameID"]
- name = nameTable.getDebugName(nameID)
- if not name:
- raise FeatureLibError(
- f"ElidedFallbackNameID {nameID} points "
- "to a nameID that does not exist in the "
- '"name" table',
- None,
- )
- elif "ElidedFallbackName" in self.stat_:
- nameID = self.stat_["ElidedFallbackName"]
-
- otl.buildStatTable(
- self.font,
- designAxes,
- locations=format4_locations,
- elidedFallbackName=nameID,
- )
-
- def build_codepages_(self, pages):
- pages2bits = {
- 1252: 0,
- 1250: 1,
- 1251: 2,
- 1253: 3,
- 1254: 4,
- 1255: 5,
- 1256: 6,
- 1257: 7,
- 1258: 8,
- 874: 16,
- 932: 17,
- 936: 18,
- 949: 19,
- 950: 20,
- 1361: 21,
- 869: 48,
- 866: 49,
- 865: 50,
- 864: 51,
- 863: 52,
- 862: 53,
- 861: 54,
- 860: 55,
- 857: 56,
- 855: 57,
- 852: 58,
- 775: 59,
- 737: 60,
- 708: 61,
- 850: 62,
- 437: 63,
- }
- bits = [pages2bits[p] for p in pages if p in pages2bits]
- pages = []
- for i in range(2):
- pages.append("")
- for j in range(i * 32, (i + 1) * 32):
- if j in bits:
- pages[i] += "1"
- else:
- pages[i] += "0"
- return [binary2num(p[::-1]) for p in pages]
-
- def buildBASE(self):
- if not self.base_horiz_axis_ and not self.base_vert_axis_:
- return None
- base = otTables.BASE()
- base.Version = 0x00010000
- base.HorizAxis = self.buildBASEAxis(self.base_horiz_axis_)
- base.VertAxis = self.buildBASEAxis(self.base_vert_axis_)
-
- result = newTable("BASE")
- result.table = base
- return result
-
- def buildBASEAxis(self, axis):
- if not axis:
- return
- bases, scripts = axis
- axis = otTables.Axis()
- axis.BaseTagList = otTables.BaseTagList()
- axis.BaseTagList.BaselineTag = bases
- axis.BaseTagList.BaseTagCount = len(bases)
- axis.BaseScriptList = otTables.BaseScriptList()
- axis.BaseScriptList.BaseScriptRecord = []
- axis.BaseScriptList.BaseScriptCount = len(scripts)
- for script in sorted(scripts):
- record = otTables.BaseScriptRecord()
- record.BaseScriptTag = script[0]
- record.BaseScript = otTables.BaseScript()
- record.BaseScript.BaseLangSysCount = 0
- record.BaseScript.BaseValues = otTables.BaseValues()
- record.BaseScript.BaseValues.DefaultIndex = bases.index(script[1])
- record.BaseScript.BaseValues.BaseCoord = []
- record.BaseScript.BaseValues.BaseCoordCount = len(script[2])
- for c in script[2]:
- coord = otTables.BaseCoord()
- coord.Format = 1
- coord.Coordinate = c
- record.BaseScript.BaseValues.BaseCoord.append(coord)
- axis.BaseScriptList.BaseScriptRecord.append(record)
- return axis
-
- def buildGDEF(self):
- gdef = otTables.GDEF()
- gdef.GlyphClassDef = self.buildGDEFGlyphClassDef_()
- gdef.AttachList = otl.buildAttachList(self.attachPoints_, self.glyphMap)
- gdef.LigCaretList = otl.buildLigCaretList(
- self.ligCaretCoords_, self.ligCaretPoints_, self.glyphMap
- )
- gdef.MarkAttachClassDef = self.buildGDEFMarkAttachClassDef_()
- gdef.MarkGlyphSetsDef = self.buildGDEFMarkGlyphSetsDef_()
- gdef.Version = 0x00010002 if gdef.MarkGlyphSetsDef else 0x00010000
- if self.varstorebuilder:
- store = self.varstorebuilder.finish()
- if store:
- gdef.Version = 0x00010003
- gdef.VarStore = store
- varidx_map = store.optimize()
-
- gdef.remap_device_varidxes(varidx_map)
- if "GPOS" in self.font:
- self.font["GPOS"].table.remap_device_varidxes(varidx_map)
- self.model_cache.clear()
- if any(
- (
- gdef.GlyphClassDef,
- gdef.AttachList,
- gdef.LigCaretList,
- gdef.MarkAttachClassDef,
- gdef.MarkGlyphSetsDef,
- )
- ) or hasattr(gdef, "VarStore"):
- result = newTable("GDEF")
- result.table = gdef
- return result
- else:
- return None
-
- def buildGDEFGlyphClassDef_(self):
- if self.glyphClassDefs_:
- classes = {g: c for (g, (c, _)) in self.glyphClassDefs_.items()}
- else:
- classes = {}
- for lookup in self.lookups_:
- classes.update(lookup.inferGlyphClasses())
- for markClass in self.parseTree.markClasses.values():
- for markClassDef in markClass.definitions:
- for glyph in markClassDef.glyphSet():
- classes[glyph] = 3
- if classes:
- result = otTables.GlyphClassDef()
- result.classDefs = classes
- return result
- else:
- return None
-
- def buildGDEFMarkAttachClassDef_(self):
- classDefs = {g: c for g, (c, _) in self.markAttach_.items()}
- if not classDefs:
- return None
- result = otTables.MarkAttachClassDef()
- result.classDefs = classDefs
- return result
-
- def buildGDEFMarkGlyphSetsDef_(self):
- sets = []
- for glyphs, id_ in sorted(
- self.markFilterSets_.items(), key=lambda item: item[1]
- ):
- sets.append(glyphs)
- return otl.buildMarkGlyphSetsDef(sets, self.glyphMap)
-
- def buildDebg(self):
- if "Debg" not in self.font:
- self.font["Debg"] = newTable("Debg")
- self.font["Debg"].data = {}
- self.font["Debg"].data[LOOKUP_DEBUG_INFO_KEY] = self.lookup_locations
-
- def buildLookups_(self, tag):
- assert tag in ("GPOS", "GSUB"), tag
- for lookup in self.lookups_:
- lookup.lookup_index = None
- lookups = []
- for lookup in self.lookups_:
- if lookup.table != tag:
- continue
- lookup.lookup_index = len(lookups)
- self.lookup_locations[tag][str(lookup.lookup_index)] = LookupDebugInfo(
- location=str(lookup.location),
- name=self.get_lookup_name_(lookup),
- feature=None,
- )
- lookups.append(lookup)
- try:
- otLookups = [l.build() for l in lookups]
- except OpenTypeLibError as e:
- raise FeatureLibError(str(e), e.location) from e
- return otLookups
-
- def makeTable(self, tag):
- table = getattr(otTables, tag, None)()
- table.Version = 0x00010000
- table.ScriptList = otTables.ScriptList()
- table.ScriptList.ScriptRecord = []
- table.FeatureList = otTables.FeatureList()
- table.FeatureList.FeatureRecord = []
- table.LookupList = otTables.LookupList()
- table.LookupList.Lookup = self.buildLookups_(tag)
-
- # Build a table for mapping (tag, lookup_indices) to feature_index.
- # For example, ('liga', (2,3,7)) --> 23.
- feature_indices = {}
- required_feature_indices = {} # ('latn', 'DEU') --> 23
- scripts = {} # 'latn' --> {'DEU': [23, 24]} for feature #23,24
- # Sort the feature table by feature tag:
- # https://github.com/fonttools/fonttools/issues/568
- sortFeatureTag = lambda f: (f[0][2], f[0][1], f[0][0], f[1])
- for key, lookups in sorted(self.features_.items(), key=sortFeatureTag):
- script, lang, feature_tag = key
- # l.lookup_index will be None when a lookup is not needed
- # for the table under construction. For example, substitution
- # rules will have no lookup_index while building GPOS tables.
- lookup_indices = tuple(
- [l.lookup_index for l in lookups if l.lookup_index is not None]
- )
-
- size_feature = tag == "GPOS" and feature_tag == "size"
- force_feature = self.any_feature_variations(feature_tag, tag)
- if len(lookup_indices) == 0 and not size_feature and not force_feature:
- continue
-
- for ix in lookup_indices:
- try:
- self.lookup_locations[tag][str(ix)] = self.lookup_locations[tag][
- str(ix)
- ]._replace(feature=key)
- except KeyError:
- warnings.warn(
- "feaLib.Builder subclass needs upgrading to "
- "stash debug information. See fonttools#2065."
- )
-
- feature_key = (feature_tag, lookup_indices)
- feature_index = feature_indices.get(feature_key)
- if feature_index is None:
- feature_index = len(table.FeatureList.FeatureRecord)
- frec = otTables.FeatureRecord()
- frec.FeatureTag = feature_tag
- frec.Feature = otTables.Feature()
- frec.Feature.FeatureParams = self.buildFeatureParams(feature_tag)
- frec.Feature.LookupListIndex = list(lookup_indices)
- frec.Feature.LookupCount = len(lookup_indices)
- table.FeatureList.FeatureRecord.append(frec)
- feature_indices[feature_key] = feature_index
- scripts.setdefault(script, {}).setdefault(lang, []).append(feature_index)
- if self.required_features_.get((script, lang)) == feature_tag:
- required_feature_indices[(script, lang)] = feature_index
-
- # Build ScriptList.
- for script, lang_features in sorted(scripts.items()):
- srec = otTables.ScriptRecord()
- srec.ScriptTag = script
- srec.Script = otTables.Script()
- srec.Script.DefaultLangSys = None
- srec.Script.LangSysRecord = []
- for lang, feature_indices in sorted(lang_features.items()):
- langrec = otTables.LangSysRecord()
- langrec.LangSys = otTables.LangSys()
- langrec.LangSys.LookupOrder = None
-
- req_feature_index = required_feature_indices.get((script, lang))
- if req_feature_index is None:
- langrec.LangSys.ReqFeatureIndex = 0xFFFF
- else:
- langrec.LangSys.ReqFeatureIndex = req_feature_index
-
- langrec.LangSys.FeatureIndex = [
- i for i in feature_indices if i != req_feature_index
- ]
- langrec.LangSys.FeatureCount = len(langrec.LangSys.FeatureIndex)
-
- if lang == "dflt":
- srec.Script.DefaultLangSys = langrec.LangSys
- else:
- langrec.LangSysTag = lang
- srec.Script.LangSysRecord.append(langrec)
- srec.Script.LangSysCount = len(srec.Script.LangSysRecord)
- table.ScriptList.ScriptRecord.append(srec)
-
- table.ScriptList.ScriptCount = len(table.ScriptList.ScriptRecord)
- table.FeatureList.FeatureCount = len(table.FeatureList.FeatureRecord)
- table.LookupList.LookupCount = len(table.LookupList.Lookup)
- return table
-
- def makeFeatureVariations(self, table, table_tag):
- feature_vars = {}
- has_any_variations = False
- # Sort out which lookups to build, gather their indices
- for (_, _, feature_tag), variations in self.feature_variations_.items():
- feature_vars[feature_tag] = []
- for conditionset, builders in variations.items():
- raw_conditionset = self.conditionsets_[conditionset]
- indices = []
- for b in builders:
- if b.table != table_tag:
- continue
- assert b.lookup_index is not None
- indices.append(b.lookup_index)
- has_any_variations = True
- feature_vars[feature_tag].append((raw_conditionset, indices))
-
- if has_any_variations:
- for feature_tag, conditions_and_lookups in feature_vars.items():
- addFeatureVariationsRaw(
- self.font, table, conditions_and_lookups, feature_tag
- )
-
- def any_feature_variations(self, feature_tag, table_tag):
- for (_, _, feature), variations in self.feature_variations_.items():
- if feature != feature_tag:
- continue
- for conditionset, builders in variations.items():
- if any(b.table == table_tag for b in builders):
- return True
- return False
-
- def get_lookup_name_(self, lookup):
- rev = {v: k for k, v in self.named_lookups_.items()}
- if lookup in rev:
- return rev[lookup]
- return None
-
- def add_language_system(self, location, script, language):
- # OpenType Feature File Specification, section 4.b.i
- if script == "DFLT" and language == "dflt" and self.default_language_systems_:
- raise FeatureLibError(
- 'If "languagesystem DFLT dflt" is present, it must be '
- "the first of the languagesystem statements",
- location,
- )
- if script == "DFLT":
- if self.seen_non_DFLT_script_:
- raise FeatureLibError(
- 'languagesystems using the "DFLT" script tag must '
- "precede all other languagesystems",
- location,
- )
- else:
- self.seen_non_DFLT_script_ = True
- if (script, language) in self.default_language_systems_:
- raise FeatureLibError(
- '"languagesystem %s %s" has already been specified'
- % (script.strip(), language.strip()),
- location,
- )
- self.default_language_systems_.add((script, language))
-
- def get_default_language_systems_(self):
- # OpenType Feature File specification, 4.b.i. languagesystem:
- # If no "languagesystem" statement is present, then the
- # implementation must behave exactly as though the following
- # statement were present at the beginning of the feature file:
- # languagesystem DFLT dflt;
- if self.default_language_systems_:
- return frozenset(self.default_language_systems_)
- else:
- return frozenset({("DFLT", "dflt")})
-
- def start_feature(self, location, name):
- self.language_systems = self.get_default_language_systems_()
- self.script_ = "DFLT"
- self.cur_lookup_ = None
- self.cur_feature_name_ = name
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
- if name == "aalt":
- self.aalt_location_ = location
-
- def end_feature(self):
- assert self.cur_feature_name_ is not None
- self.cur_feature_name_ = None
- self.language_systems = None
- self.cur_lookup_ = None
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
-
- def start_lookup_block(self, location, name):
- if name in self.named_lookups_:
- raise FeatureLibError(
- 'Lookup "%s" has already been defined' % name, location
- )
- if self.cur_feature_name_ == "aalt":
- raise FeatureLibError(
- "Lookup blocks cannot be placed inside 'aalt' features; "
- "move it out, and then refer to it with a lookup statement",
- location,
- )
- self.cur_lookup_name_ = name
- self.named_lookups_[name] = None
- self.cur_lookup_ = None
- if self.cur_feature_name_ is None:
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
-
- def end_lookup_block(self):
- assert self.cur_lookup_name_ is not None
- self.cur_lookup_name_ = None
- self.cur_lookup_ = None
- if self.cur_feature_name_ is None:
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
-
- def add_lookup_call(self, lookup_name):
- assert lookup_name in self.named_lookups_, lookup_name
- self.cur_lookup_ = None
- lookup = self.named_lookups_[lookup_name]
- if lookup is not None: # skip empty named lookup
- self.add_lookup_to_feature_(lookup, self.cur_feature_name_)
-
- def set_font_revision(self, location, revision):
- self.fontRevision_ = revision
-
- def set_language(self, location, language, include_default, required):
- assert len(language) == 4
- if self.cur_feature_name_ in ("aalt", "size"):
- raise FeatureLibError(
- "Language statements are not allowed "
- 'within "feature %s"' % self.cur_feature_name_,
- location,
- )
- if self.cur_feature_name_ is None:
- raise FeatureLibError(
- "Language statements are not allowed "
- "within standalone lookup blocks",
- location,
- )
- self.cur_lookup_ = None
-
- key = (self.script_, language, self.cur_feature_name_)
- lookups = self.features_.get((key[0], "dflt", key[2]))
- if (language == "dflt" or include_default) and lookups:
- self.features_[key] = lookups[:]
- else:
- self.features_[key] = []
- self.language_systems = frozenset([(self.script_, language)])
-
- if required:
- key = (self.script_, language)
- if key in self.required_features_:
- raise FeatureLibError(
- "Language %s (script %s) has already "
- "specified feature %s as its required feature"
- % (
- language.strip(),
- self.script_.strip(),
- self.required_features_[key].strip(),
- ),
- location,
- )
- self.required_features_[key] = self.cur_feature_name_
-
- def getMarkAttachClass_(self, location, glyphs):
- glyphs = frozenset(glyphs)
- id_ = self.markAttachClassID_.get(glyphs)
- if id_ is not None:
- return id_
- id_ = len(self.markAttachClassID_) + 1
- self.markAttachClassID_[glyphs] = id_
- for glyph in glyphs:
- if glyph in self.markAttach_:
- _, loc = self.markAttach_[glyph]
- raise FeatureLibError(
- "Glyph %s already has been assigned "
- "a MarkAttachmentType at %s" % (glyph, loc),
- location,
- )
- self.markAttach_[glyph] = (id_, location)
- return id_
-
- def getMarkFilterSet_(self, location, glyphs):
- glyphs = frozenset(glyphs)
- id_ = self.markFilterSets_.get(glyphs)
- if id_ is not None:
- return id_
- id_ = len(self.markFilterSets_)
- self.markFilterSets_[glyphs] = id_
- return id_
-
- def set_lookup_flag(self, location, value, markAttach, markFilter):
- value = value & 0xFF
- if markAttach:
- markAttachClass = self.getMarkAttachClass_(location, markAttach)
- value = value | (markAttachClass << 8)
- if markFilter:
- markFilterSet = self.getMarkFilterSet_(location, markFilter)
- value = value | 0x10
- self.lookupflag_markFilterSet_ = markFilterSet
- else:
- self.lookupflag_markFilterSet_ = None
- self.lookupflag_ = value
-
- def set_script(self, location, script):
- if self.cur_feature_name_ in ("aalt", "size"):
- raise FeatureLibError(
- "Script statements are not allowed "
- 'within "feature %s"' % self.cur_feature_name_,
- location,
- )
- if self.cur_feature_name_ is None:
- raise FeatureLibError(
- "Script statements are not allowed " "within standalone lookup blocks",
- location,
- )
- if self.language_systems == {(script, "dflt")}:
- # Nothing to do.
- return
- self.cur_lookup_ = None
- self.script_ = script
- self.lookupflag_ = 0
- self.lookupflag_markFilterSet_ = None
- self.set_language(location, "dflt", include_default=True, required=False)
-
- def find_lookup_builders_(self, lookups):
- """Helper for building chain contextual substitutions
-
- Given a list of lookup names, finds the LookupBuilder for each name.
- If an input name is None, it gets mapped to a None LookupBuilder.
- """
- lookup_builders = []
- for lookuplist in lookups:
- if lookuplist is not None:
- lookup_builders.append(
- [self.named_lookups_.get(l.name) for l in lookuplist]
- )
- else:
- lookup_builders.append(None)
- return lookup_builders
-
- def add_attach_points(self, location, glyphs, contourPoints):
- for glyph in glyphs:
- self.attachPoints_.setdefault(glyph, set()).update(contourPoints)
-
- def add_feature_reference(self, location, featureName):
- if self.cur_feature_name_ != "aalt":
- raise FeatureLibError(
- 'Feature references are only allowed inside "feature aalt"', location
- )
- self.aalt_features_.append((location, featureName))
-
- def add_featureName(self, tag):
- self.featureNames_.add(tag)
-
- def add_cv_parameter(self, tag):
- self.cv_parameters_.add(tag)
-
- def add_to_cv_num_named_params(self, tag):
- """Adds new items to ``self.cv_num_named_params_``
- or increments the count of existing items."""
- if tag in self.cv_num_named_params_:
- self.cv_num_named_params_[tag] += 1
- else:
- self.cv_num_named_params_[tag] = 1
-
- def add_cv_character(self, character, tag):
- self.cv_characters_[tag].append(character)
-
- def set_base_axis(self, bases, scripts, vertical):
- if vertical:
- self.base_vert_axis_ = (bases, scripts)
- else:
- self.base_horiz_axis_ = (bases, scripts)
-
- def set_size_parameters(
- self, location, DesignSize, SubfamilyID, RangeStart, RangeEnd
- ):
- if self.cur_feature_name_ != "size":
- raise FeatureLibError(
- "Parameters statements are not allowed "
- 'within "feature %s"' % self.cur_feature_name_,
- location,
- )
- self.size_parameters_ = [DesignSize, SubfamilyID, RangeStart, RangeEnd]
- for script, lang in self.language_systems:
- key = (script, lang, self.cur_feature_name_)
- self.features_.setdefault(key, [])
-
- # GSUB rules
-
- # GSUB 1
- def add_single_subst(self, location, prefix, suffix, mapping, forceChain):
- if self.cur_feature_name_ == "aalt":
- for from_glyph, to_glyph in mapping.items():
- alts = self.aalt_alternates_.setdefault(from_glyph, set())
- alts.add(to_glyph)
- return
- if prefix or suffix or forceChain:
- self.add_single_subst_chained_(location, prefix, suffix, mapping)
- return
- lookup = self.get_lookup_(location, SingleSubstBuilder)
- for from_glyph, to_glyph in mapping.items():
- if from_glyph in lookup.mapping:
- if to_glyph == lookup.mapping[from_glyph]:
- log.info(
- "Removing duplicate single substitution from glyph"
- ' "%s" to "%s" at %s',
- from_glyph,
- to_glyph,
- location,
- )
- else:
- raise FeatureLibError(
- 'Already defined rule for replacing glyph "%s" by "%s"'
- % (from_glyph, lookup.mapping[from_glyph]),
- location,
- )
- lookup.mapping[from_glyph] = to_glyph
-
- # GSUB 2
- def add_multiple_subst(
- self, location, prefix, glyph, suffix, replacements, forceChain=False
- ):
- if prefix or suffix or forceChain:
- chain = self.get_lookup_(location, ChainContextSubstBuilder)
- sub = self.get_chained_lookup_(location, MultipleSubstBuilder)
- sub.mapping[glyph] = replacements
- chain.rules.append(ChainContextualRule(prefix, [{glyph}], suffix, [sub]))
- return
- lookup = self.get_lookup_(location, MultipleSubstBuilder)
- if glyph in lookup.mapping:
- if replacements == lookup.mapping[glyph]:
- log.info(
- "Removing duplicate multiple substitution from glyph"
- ' "%s" to %s%s',
- glyph,
- replacements,
- f" at {location}" if location else "",
- )
- else:
- raise FeatureLibError(
- 'Already defined substitution for glyph "%s"' % glyph, location
- )
- lookup.mapping[glyph] = replacements
-
- # GSUB 3
- def add_alternate_subst(self, location, prefix, glyph, suffix, replacement):
- if self.cur_feature_name_ == "aalt":
- alts = self.aalt_alternates_.setdefault(glyph, set())
- alts.update(replacement)
- return
- if prefix or suffix:
- chain = self.get_lookup_(location, ChainContextSubstBuilder)
- lookup = self.get_chained_lookup_(location, AlternateSubstBuilder)
- chain.rules.append(ChainContextualRule(prefix, [{glyph}], suffix, [lookup]))
- else:
- lookup = self.get_lookup_(location, AlternateSubstBuilder)
- if glyph in lookup.alternates:
- raise FeatureLibError(
- 'Already defined alternates for glyph "%s"' % glyph, location
- )
- # We allow empty replacement glyphs here.
- lookup.alternates[glyph] = replacement
-
- # GSUB 4
- def add_ligature_subst(
- self, location, prefix, glyphs, suffix, replacement, forceChain
- ):
- if prefix or suffix or forceChain:
- chain = self.get_lookup_(location, ChainContextSubstBuilder)
- lookup = self.get_chained_lookup_(location, LigatureSubstBuilder)
- chain.rules.append(ChainContextualRule(prefix, glyphs, suffix, [lookup]))
- else:
- lookup = self.get_lookup_(location, LigatureSubstBuilder)
-
- if not all(glyphs):
- raise FeatureLibError("Empty glyph class in substitution", location)
-
- # OpenType feature file syntax, section 5.d, "Ligature substitution":
- # "Since the OpenType specification does not allow ligature
- # substitutions to be specified on target sequences that contain
- # glyph classes, the implementation software will enumerate
- # all specific glyph sequences if glyph classes are detected"
- for g in sorted(itertools.product(*glyphs)):
- lookup.ligatures[g] = replacement
-
- # GSUB 5/6
- def add_chain_context_subst(self, location, prefix, glyphs, suffix, lookups):
- if not all(glyphs) or not all(prefix) or not all(suffix):
- raise FeatureLibError(
- "Empty glyph class in contextual substitution", location
- )
- lookup = self.get_lookup_(location, ChainContextSubstBuilder)
- lookup.rules.append(
- ChainContextualRule(
- prefix, glyphs, suffix, self.find_lookup_builders_(lookups)
- )
- )
-
- def add_single_subst_chained_(self, location, prefix, suffix, mapping):
- if not mapping or not all(prefix) or not all(suffix):
- raise FeatureLibError(
- "Empty glyph class in contextual substitution", location
- )
- # https://github.com/fonttools/fonttools/issues/512
- # https://github.com/fonttools/fonttools/issues/2150
- chain = self.get_lookup_(location, ChainContextSubstBuilder)
- sub = chain.find_chainable_single_subst(mapping)
- if sub is None:
- sub = self.get_chained_lookup_(location, SingleSubstBuilder)
- sub.mapping.update(mapping)
- chain.rules.append(
- ChainContextualRule(prefix, [list(mapping.keys())], suffix, [sub])
- )
-
- # GSUB 8
- def add_reverse_chain_single_subst(self, location, old_prefix, old_suffix, mapping):
- if not mapping:
- raise FeatureLibError("Empty glyph class in substitution", location)
- lookup = self.get_lookup_(location, ReverseChainSingleSubstBuilder)
- lookup.rules.append((old_prefix, old_suffix, mapping))
-
- # GPOS rules
-
- # GPOS 1
- def add_single_pos(self, location, prefix, suffix, pos, forceChain):
- if prefix or suffix or forceChain:
- self.add_single_pos_chained_(location, prefix, suffix, pos)
- else:
- lookup = self.get_lookup_(location, SinglePosBuilder)
- for glyphs, value in pos:
- if not glyphs:
- raise FeatureLibError(
- "Empty glyph class in positioning rule", location
- )
- otValueRecord = self.makeOpenTypeValueRecord(
- location, value, pairPosContext=False
- )
- for glyph in glyphs:
- try:
- lookup.add_pos(location, glyph, otValueRecord)
- except OpenTypeLibError as e:
- raise FeatureLibError(str(e), e.location) from e
-
- # GPOS 2
- def add_class_pair_pos(self, location, glyphclass1, value1, glyphclass2, value2):
- if not glyphclass1 or not glyphclass2:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- lookup = self.get_lookup_(location, PairPosBuilder)
- v1 = self.makeOpenTypeValueRecord(location, value1, pairPosContext=True)
- v2 = self.makeOpenTypeValueRecord(location, value2, pairPosContext=True)
- lookup.addClassPair(location, glyphclass1, v1, glyphclass2, v2)
-
- def add_specific_pair_pos(self, location, glyph1, value1, glyph2, value2):
- if not glyph1 or not glyph2:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- lookup = self.get_lookup_(location, PairPosBuilder)
- v1 = self.makeOpenTypeValueRecord(location, value1, pairPosContext=True)
- v2 = self.makeOpenTypeValueRecord(location, value2, pairPosContext=True)
- lookup.addGlyphPair(location, glyph1, v1, glyph2, v2)
-
- # GPOS 3
- def add_cursive_pos(self, location, glyphclass, entryAnchor, exitAnchor):
- if not glyphclass:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- lookup = self.get_lookup_(location, CursivePosBuilder)
- lookup.add_attachment(
- location,
- glyphclass,
- self.makeOpenTypeAnchor(location, entryAnchor),
- self.makeOpenTypeAnchor(location, exitAnchor),
- )
-
- # GPOS 4
- def add_mark_base_pos(self, location, bases, marks):
- builder = self.get_lookup_(location, MarkBasePosBuilder)
- self.add_marks_(location, builder, marks)
- if not bases:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- for baseAnchor, markClass in marks:
- otBaseAnchor = self.makeOpenTypeAnchor(location, baseAnchor)
- for base in bases:
- builder.bases.setdefault(base, {})[markClass.name] = otBaseAnchor
-
- # GPOS 5
- def add_mark_lig_pos(self, location, ligatures, components):
- builder = self.get_lookup_(location, MarkLigPosBuilder)
- componentAnchors = []
- if not ligatures:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- for marks in components:
- anchors = {}
- self.add_marks_(location, builder, marks)
- for ligAnchor, markClass in marks:
- anchors[markClass.name] = self.makeOpenTypeAnchor(location, ligAnchor)
- componentAnchors.append(anchors)
- for glyph in ligatures:
- builder.ligatures[glyph] = componentAnchors
-
- # GPOS 6
- def add_mark_mark_pos(self, location, baseMarks, marks):
- builder = self.get_lookup_(location, MarkMarkPosBuilder)
- self.add_marks_(location, builder, marks)
- if not baseMarks:
- raise FeatureLibError("Empty glyph class in positioning rule", location)
- for baseAnchor, markClass in marks:
- otBaseAnchor = self.makeOpenTypeAnchor(location, baseAnchor)
- for baseMark in baseMarks:
- builder.baseMarks.setdefault(baseMark, {})[
- markClass.name
- ] = otBaseAnchor
-
- # GPOS 7/8
- def add_chain_context_pos(self, location, prefix, glyphs, suffix, lookups):
- if not all(glyphs) or not all(prefix) or not all(suffix):
- raise FeatureLibError(
- "Empty glyph class in contextual positioning rule", location
- )
- lookup = self.get_lookup_(location, ChainContextPosBuilder)
- lookup.rules.append(
- ChainContextualRule(
- prefix, glyphs, suffix, self.find_lookup_builders_(lookups)
- )
- )
-
- def add_single_pos_chained_(self, location, prefix, suffix, pos):
- if not pos or not all(prefix) or not all(suffix):
- raise FeatureLibError(
- "Empty glyph class in contextual positioning rule", location
- )
- # https://github.com/fonttools/fonttools/issues/514
- chain = self.get_lookup_(location, ChainContextPosBuilder)
- targets = []
- for _, _, _, lookups in chain.rules:
- targets.extend(lookups)
- subs = []
- for glyphs, value in pos:
- if value is None:
- subs.append(None)
- continue
- otValue = self.makeOpenTypeValueRecord(
- location, value, pairPosContext=False
- )
- sub = chain.find_chainable_single_pos(targets, glyphs, otValue)
- if sub is None:
- sub = self.get_chained_lookup_(location, SinglePosBuilder)
- targets.append(sub)
- for glyph in glyphs:
- sub.add_pos(location, glyph, otValue)
- subs.append(sub)
- assert len(pos) == len(subs), (pos, subs)
- chain.rules.append(
- ChainContextualRule(prefix, [g for g, v in pos], suffix, subs)
- )
-
- def add_marks_(self, location, lookupBuilder, marks):
- """Helper for add_mark_{base,liga,mark}_pos."""
- for _, markClass in marks:
- for markClassDef in markClass.definitions:
- for mark in markClassDef.glyphs.glyphSet():
- if mark not in lookupBuilder.marks:
- otMarkAnchor = self.makeOpenTypeAnchor(
- location, markClassDef.anchor
- )
- lookupBuilder.marks[mark] = (markClass.name, otMarkAnchor)
- else:
- existingMarkClass = lookupBuilder.marks[mark][0]
- if markClass.name != existingMarkClass:
- raise FeatureLibError(
- "Glyph %s cannot be in both @%s and @%s"
- % (mark, existingMarkClass, markClass.name),
- location,
- )
-
- def add_subtable_break(self, location):
- self.cur_lookup_.add_subtable_break(location)
-
- def setGlyphClass_(self, location, glyph, glyphClass):
- oldClass, oldLocation = self.glyphClassDefs_.get(glyph, (None, None))
- if oldClass and oldClass != glyphClass:
- raise FeatureLibError(
- "Glyph %s was assigned to a different class at %s"
- % (glyph, oldLocation),
- location,
- )
- self.glyphClassDefs_[glyph] = (glyphClass, location)
-
- def add_glyphClassDef(
- self, location, baseGlyphs, ligatureGlyphs, markGlyphs, componentGlyphs
- ):
- for glyph in baseGlyphs:
- self.setGlyphClass_(location, glyph, 1)
- for glyph in ligatureGlyphs:
- self.setGlyphClass_(location, glyph, 2)
- for glyph in markGlyphs:
- self.setGlyphClass_(location, glyph, 3)
- for glyph in componentGlyphs:
- self.setGlyphClass_(location, glyph, 4)
-
- def add_ligatureCaretByIndex_(self, location, glyphs, carets):
- for glyph in glyphs:
- if glyph not in self.ligCaretPoints_:
- self.ligCaretPoints_[glyph] = carets
-
- def makeLigCaret(self, location, caret):
- if not isinstance(caret, VariableScalar):
- return caret
- default, device = self.makeVariablePos(location, caret)
- if device is not None:
- return (default, device)
- return default
-
- def add_ligatureCaretByPos_(self, location, glyphs, carets):
- carets = [self.makeLigCaret(location, caret) for caret in carets]
- for glyph in glyphs:
- if glyph not in self.ligCaretCoords_:
- self.ligCaretCoords_[glyph] = carets
-
- def add_name_record(self, location, nameID, platformID, platEncID, langID, string):
- self.names_.append([nameID, platformID, platEncID, langID, string])
-
- def add_os2_field(self, key, value):
- self.os2_[key] = value
-
- def add_hhea_field(self, key, value):
- self.hhea_[key] = value
-
- def add_vhea_field(self, key, value):
- self.vhea_[key] = value
-
- def add_conditionset(self, location, key, value):
- if "fvar" not in self.font:
- raise FeatureLibError(
- "Cannot add feature variations to a font without an 'fvar' table",
- location,
- )
-
- # Normalize
- axisMap = {
- axis.axisTag: (axis.minValue, axis.defaultValue, axis.maxValue)
- for axis in self.axes
- }
-
- value = {
- tag: (
- normalizeValue(bottom, axisMap[tag]),
- normalizeValue(top, axisMap[tag]),
- )
- for tag, (bottom, top) in value.items()
- }
-
- # NOTE: This might result in rounding errors (off-by-ones) compared to
- # rules in Designspace files, since we're working with what's in the
- # `avar` table rather than the original values.
- if "avar" in self.font:
- mapping = self.font["avar"].segments
- value = {
- axis: tuple(
- piecewiseLinearMap(v, mapping[axis]) if axis in mapping else v
- for v in condition_range
- )
- for axis, condition_range in value.items()
- }
-
- self.conditionsets_[key] = value
-
- def makeVariablePos(self, location, varscalar):
- if not self.varstorebuilder:
- raise FeatureLibError(
- "Can't define a variable scalar in a non-variable font", location
- )
-
- varscalar.axes = self.axes
- if not varscalar.does_vary:
- return varscalar.default, None
-
- default, index = varscalar.add_to_variation_store(
- self.varstorebuilder, self.model_cache, self.font.get("avar")
- )
-
- device = None
- if index is not None and index != 0xFFFFFFFF:
- device = buildVarDevTable(index)
-
- return default, device
-
- def makeOpenTypeAnchor(self, location, anchor):
- """ast.Anchor --> otTables.Anchor"""
- if anchor is None:
- return None
- variable = False
- deviceX, deviceY = None, None
- if anchor.xDeviceTable is not None:
- deviceX = otl.buildDevice(dict(anchor.xDeviceTable))
- if anchor.yDeviceTable is not None:
- deviceY = otl.buildDevice(dict(anchor.yDeviceTable))
- for dim in ("x", "y"):
- varscalar = getattr(anchor, dim)
- if not isinstance(varscalar, VariableScalar):
- continue
- if getattr(anchor, dim + "DeviceTable") is not None:
- raise FeatureLibError(
- "Can't define a device coordinate and variable scalar", location
- )
- default, device = self.makeVariablePos(location, varscalar)
- setattr(anchor, dim, default)
- if device is not None:
- if dim == "x":
- deviceX = device
- else:
- deviceY = device
- variable = True
-
- otlanchor = otl.buildAnchor(
- anchor.x, anchor.y, anchor.contourpoint, deviceX, deviceY
- )
- if variable:
- otlanchor.Format = 3
- return otlanchor
-
- _VALUEREC_ATTRS = {
- name[0].lower() + name[1:]: (name, isDevice)
- for _, name, isDevice, _ in otBase.valueRecordFormat
- if not name.startswith("Reserved")
- }
-
- def makeOpenTypeValueRecord(self, location, v, pairPosContext):
- """ast.ValueRecord --> otBase.ValueRecord"""
- if not v:
- return None
-
- vr = {}
- for astName, (otName, isDevice) in self._VALUEREC_ATTRS.items():
- val = getattr(v, astName, None)
- if not val:
- continue
- if isDevice:
- vr[otName] = otl.buildDevice(dict(val))
- elif isinstance(val, VariableScalar):
- otDeviceName = otName[0:4] + "Device"
- feaDeviceName = otDeviceName[0].lower() + otDeviceName[1:]
- if getattr(v, feaDeviceName):
- raise FeatureLibError(
- "Can't define a device coordinate and variable scalar", location
- )
- vr[otName], device = self.makeVariablePos(location, val)
- if device is not None:
- vr[otDeviceName] = device
- else:
- vr[otName] = val
-
- if pairPosContext and not vr:
- vr = {"YAdvance": 0} if v.vertical else {"XAdvance": 0}
- valRec = otl.buildValue(vr)
- return valRec
diff --git a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fontTools/unicodedata/Scripts.py b/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fontTools/unicodedata/Scripts.py
deleted file mode 100644
index 68bb91b396d62b03a8bfd650c64ce0b7375e1e48..0000000000000000000000000000000000000000
--- a/spaces/joaopereirajp/livvieChatBot/venv/lib/python3.9/site-packages/fontTools/unicodedata/Scripts.py
+++ /dev/null
@@ -1,3509 +0,0 @@
-# -*- coding: utf-8 -*-
-#
-# NOTE: This file was auto-generated with MetaTools/buildUCD.py.
-# Source: https://unicode.org/Public/UNIDATA/Scripts.txt
-# License: http://unicode.org/copyright.html#License
-#
-# Scripts-15.0.0.txt
-# Date: 2022-04-26, 23:15:02 GMT
-# © 2022 Unicode®, Inc.
-# Unicode and the Unicode Logo are registered trademarks of Unicode, Inc. in the U.S. and other countries.
-# For terms of use, see https://www.unicode.org/terms_of_use.html
-#
-# Unicode Character Database
-# For documentation, see https://www.unicode.org/reports/tr44/
-# For more information, see:
-# UAX #24, Unicode Script Property: https://www.unicode.org/reports/tr24/
-# Especially the sections:
-# https://www.unicode.org/reports/tr24/#Assignment_Script_Values
-# https://www.unicode.org/reports/tr24/#Assignment_ScriptX_Values
-#
-
-
-RANGES = [
- 0x0000, # .. 0x0040 ; Common
- 0x0041, # .. 0x005A ; Latin
- 0x005B, # .. 0x0060 ; Common
- 0x0061, # .. 0x007A ; Latin
- 0x007B, # .. 0x00A9 ; Common
- 0x00AA, # .. 0x00AA ; Latin
- 0x00AB, # .. 0x00B9 ; Common
- 0x00BA, # .. 0x00BA ; Latin
- 0x00BB, # .. 0x00BF ; Common
- 0x00C0, # .. 0x00D6 ; Latin
- 0x00D7, # .. 0x00D7 ; Common
- 0x00D8, # .. 0x00F6 ; Latin
- 0x00F7, # .. 0x00F7 ; Common
- 0x00F8, # .. 0x02B8 ; Latin
- 0x02B9, # .. 0x02DF ; Common
- 0x02E0, # .. 0x02E4 ; Latin
- 0x02E5, # .. 0x02E9 ; Common
- 0x02EA, # .. 0x02EB ; Bopomofo
- 0x02EC, # .. 0x02FF ; Common
- 0x0300, # .. 0x036F ; Inherited
- 0x0370, # .. 0x0373 ; Greek
- 0x0374, # .. 0x0374 ; Common
- 0x0375, # .. 0x0377 ; Greek
- 0x0378, # .. 0x0379 ; Unknown
- 0x037A, # .. 0x037D ; Greek
- 0x037E, # .. 0x037E ; Common
- 0x037F, # .. 0x037F ; Greek
- 0x0380, # .. 0x0383 ; Unknown
- 0x0384, # .. 0x0384 ; Greek
- 0x0385, # .. 0x0385 ; Common
- 0x0386, # .. 0x0386 ; Greek
- 0x0387, # .. 0x0387 ; Common
- 0x0388, # .. 0x038A ; Greek
- 0x038B, # .. 0x038B ; Unknown
- 0x038C, # .. 0x038C ; Greek
- 0x038D, # .. 0x038D ; Unknown
- 0x038E, # .. 0x03A1 ; Greek
- 0x03A2, # .. 0x03A2 ; Unknown
- 0x03A3, # .. 0x03E1 ; Greek
- 0x03E2, # .. 0x03EF ; Coptic
- 0x03F0, # .. 0x03FF ; Greek
- 0x0400, # .. 0x0484 ; Cyrillic
- 0x0485, # .. 0x0486 ; Inherited
- 0x0487, # .. 0x052F ; Cyrillic
- 0x0530, # .. 0x0530 ; Unknown
- 0x0531, # .. 0x0556 ; Armenian
- 0x0557, # .. 0x0558 ; Unknown
- 0x0559, # .. 0x058A ; Armenian
- 0x058B, # .. 0x058C ; Unknown
- 0x058D, # .. 0x058F ; Armenian
- 0x0590, # .. 0x0590 ; Unknown
- 0x0591, # .. 0x05C7 ; Hebrew
- 0x05C8, # .. 0x05CF ; Unknown
- 0x05D0, # .. 0x05EA ; Hebrew
- 0x05EB, # .. 0x05EE ; Unknown
- 0x05EF, # .. 0x05F4 ; Hebrew
- 0x05F5, # .. 0x05FF ; Unknown
- 0x0600, # .. 0x0604 ; Arabic
- 0x0605, # .. 0x0605 ; Common
- 0x0606, # .. 0x060B ; Arabic
- 0x060C, # .. 0x060C ; Common
- 0x060D, # .. 0x061A ; Arabic
- 0x061B, # .. 0x061B ; Common
- 0x061C, # .. 0x061E ; Arabic
- 0x061F, # .. 0x061F ; Common
- 0x0620, # .. 0x063F ; Arabic
- 0x0640, # .. 0x0640 ; Common
- 0x0641, # .. 0x064A ; Arabic
- 0x064B, # .. 0x0655 ; Inherited
- 0x0656, # .. 0x066F ; Arabic
- 0x0670, # .. 0x0670 ; Inherited
- 0x0671, # .. 0x06DC ; Arabic
- 0x06DD, # .. 0x06DD ; Common
- 0x06DE, # .. 0x06FF ; Arabic
- 0x0700, # .. 0x070D ; Syriac
- 0x070E, # .. 0x070E ; Unknown
- 0x070F, # .. 0x074A ; Syriac
- 0x074B, # .. 0x074C ; Unknown
- 0x074D, # .. 0x074F ; Syriac
- 0x0750, # .. 0x077F ; Arabic
- 0x0780, # .. 0x07B1 ; Thaana
- 0x07B2, # .. 0x07BF ; Unknown
- 0x07C0, # .. 0x07FA ; Nko
- 0x07FB, # .. 0x07FC ; Unknown
- 0x07FD, # .. 0x07FF ; Nko
- 0x0800, # .. 0x082D ; Samaritan
- 0x082E, # .. 0x082F ; Unknown
- 0x0830, # .. 0x083E ; Samaritan
- 0x083F, # .. 0x083F ; Unknown
- 0x0840, # .. 0x085B ; Mandaic
- 0x085C, # .. 0x085D ; Unknown
- 0x085E, # .. 0x085E ; Mandaic
- 0x085F, # .. 0x085F ; Unknown
- 0x0860, # .. 0x086A ; Syriac
- 0x086B, # .. 0x086F ; Unknown
- 0x0870, # .. 0x088E ; Arabic
- 0x088F, # .. 0x088F ; Unknown
- 0x0890, # .. 0x0891 ; Arabic
- 0x0892, # .. 0x0897 ; Unknown
- 0x0898, # .. 0x08E1 ; Arabic
- 0x08E2, # .. 0x08E2 ; Common
- 0x08E3, # .. 0x08FF ; Arabic
- 0x0900, # .. 0x0950 ; Devanagari
- 0x0951, # .. 0x0954 ; Inherited
- 0x0955, # .. 0x0963 ; Devanagari
- 0x0964, # .. 0x0965 ; Common
- 0x0966, # .. 0x097F ; Devanagari
- 0x0980, # .. 0x0983 ; Bengali
- 0x0984, # .. 0x0984 ; Unknown
- 0x0985, # .. 0x098C ; Bengali
- 0x098D, # .. 0x098E ; Unknown
- 0x098F, # .. 0x0990 ; Bengali
- 0x0991, # .. 0x0992 ; Unknown
- 0x0993, # .. 0x09A8 ; Bengali
- 0x09A9, # .. 0x09A9 ; Unknown
- 0x09AA, # .. 0x09B0 ; Bengali
- 0x09B1, # .. 0x09B1 ; Unknown
- 0x09B2, # .. 0x09B2 ; Bengali
- 0x09B3, # .. 0x09B5 ; Unknown
- 0x09B6, # .. 0x09B9 ; Bengali
- 0x09BA, # .. 0x09BB ; Unknown
- 0x09BC, # .. 0x09C4 ; Bengali
- 0x09C5, # .. 0x09C6 ; Unknown
- 0x09C7, # .. 0x09C8 ; Bengali
- 0x09C9, # .. 0x09CA ; Unknown
- 0x09CB, # .. 0x09CE ; Bengali
- 0x09CF, # .. 0x09D6 ; Unknown
- 0x09D7, # .. 0x09D7 ; Bengali
- 0x09D8, # .. 0x09DB ; Unknown
- 0x09DC, # .. 0x09DD ; Bengali
- 0x09DE, # .. 0x09DE ; Unknown
- 0x09DF, # .. 0x09E3 ; Bengali
- 0x09E4, # .. 0x09E5 ; Unknown
- 0x09E6, # .. 0x09FE ; Bengali
- 0x09FF, # .. 0x0A00 ; Unknown
- 0x0A01, # .. 0x0A03 ; Gurmukhi
- 0x0A04, # .. 0x0A04 ; Unknown
- 0x0A05, # .. 0x0A0A ; Gurmukhi
- 0x0A0B, # .. 0x0A0E ; Unknown
- 0x0A0F, # .. 0x0A10 ; Gurmukhi
- 0x0A11, # .. 0x0A12 ; Unknown
- 0x0A13, # .. 0x0A28 ; Gurmukhi
- 0x0A29, # .. 0x0A29 ; Unknown
- 0x0A2A, # .. 0x0A30 ; Gurmukhi
- 0x0A31, # .. 0x0A31 ; Unknown
- 0x0A32, # .. 0x0A33 ; Gurmukhi
- 0x0A34, # .. 0x0A34 ; Unknown
- 0x0A35, # .. 0x0A36 ; Gurmukhi
- 0x0A37, # .. 0x0A37 ; Unknown
- 0x0A38, # .. 0x0A39 ; Gurmukhi
- 0x0A3A, # .. 0x0A3B ; Unknown
- 0x0A3C, # .. 0x0A3C ; Gurmukhi
- 0x0A3D, # .. 0x0A3D ; Unknown
- 0x0A3E, # .. 0x0A42 ; Gurmukhi
- 0x0A43, # .. 0x0A46 ; Unknown
- 0x0A47, # .. 0x0A48 ; Gurmukhi
- 0x0A49, # .. 0x0A4A ; Unknown
- 0x0A4B, # .. 0x0A4D ; Gurmukhi
- 0x0A4E, # .. 0x0A50 ; Unknown
- 0x0A51, # .. 0x0A51 ; Gurmukhi
- 0x0A52, # .. 0x0A58 ; Unknown
- 0x0A59, # .. 0x0A5C ; Gurmukhi
- 0x0A5D, # .. 0x0A5D ; Unknown
- 0x0A5E, # .. 0x0A5E ; Gurmukhi
- 0x0A5F, # .. 0x0A65 ; Unknown
- 0x0A66, # .. 0x0A76 ; Gurmukhi
- 0x0A77, # .. 0x0A80 ; Unknown
- 0x0A81, # .. 0x0A83 ; Gujarati
- 0x0A84, # .. 0x0A84 ; Unknown
- 0x0A85, # .. 0x0A8D ; Gujarati
- 0x0A8E, # .. 0x0A8E ; Unknown
- 0x0A8F, # .. 0x0A91 ; Gujarati
- 0x0A92, # .. 0x0A92 ; Unknown
- 0x0A93, # .. 0x0AA8 ; Gujarati
- 0x0AA9, # .. 0x0AA9 ; Unknown
- 0x0AAA, # .. 0x0AB0 ; Gujarati
- 0x0AB1, # .. 0x0AB1 ; Unknown
- 0x0AB2, # .. 0x0AB3 ; Gujarati
- 0x0AB4, # .. 0x0AB4 ; Unknown
- 0x0AB5, # .. 0x0AB9 ; Gujarati
- 0x0ABA, # .. 0x0ABB ; Unknown
- 0x0ABC, # .. 0x0AC5 ; Gujarati
- 0x0AC6, # .. 0x0AC6 ; Unknown
- 0x0AC7, # .. 0x0AC9 ; Gujarati
- 0x0ACA, # .. 0x0ACA ; Unknown
- 0x0ACB, # .. 0x0ACD ; Gujarati
- 0x0ACE, # .. 0x0ACF ; Unknown
- 0x0AD0, # .. 0x0AD0 ; Gujarati
- 0x0AD1, # .. 0x0ADF ; Unknown
- 0x0AE0, # .. 0x0AE3 ; Gujarati
- 0x0AE4, # .. 0x0AE5 ; Unknown
- 0x0AE6, # .. 0x0AF1 ; Gujarati
- 0x0AF2, # .. 0x0AF8 ; Unknown
- 0x0AF9, # .. 0x0AFF ; Gujarati
- 0x0B00, # .. 0x0B00 ; Unknown
- 0x0B01, # .. 0x0B03 ; Oriya
- 0x0B04, # .. 0x0B04 ; Unknown
- 0x0B05, # .. 0x0B0C ; Oriya
- 0x0B0D, # .. 0x0B0E ; Unknown
- 0x0B0F, # .. 0x0B10 ; Oriya
- 0x0B11, # .. 0x0B12 ; Unknown
- 0x0B13, # .. 0x0B28 ; Oriya
- 0x0B29, # .. 0x0B29 ; Unknown
- 0x0B2A, # .. 0x0B30 ; Oriya
- 0x0B31, # .. 0x0B31 ; Unknown
- 0x0B32, # .. 0x0B33 ; Oriya
- 0x0B34, # .. 0x0B34 ; Unknown
- 0x0B35, # .. 0x0B39 ; Oriya
- 0x0B3A, # .. 0x0B3B ; Unknown
- 0x0B3C, # .. 0x0B44 ; Oriya
- 0x0B45, # .. 0x0B46 ; Unknown
- 0x0B47, # .. 0x0B48 ; Oriya
- 0x0B49, # .. 0x0B4A ; Unknown
- 0x0B4B, # .. 0x0B4D ; Oriya
- 0x0B4E, # .. 0x0B54 ; Unknown
- 0x0B55, # .. 0x0B57 ; Oriya
- 0x0B58, # .. 0x0B5B ; Unknown
- 0x0B5C, # .. 0x0B5D ; Oriya
- 0x0B5E, # .. 0x0B5E ; Unknown
- 0x0B5F, # .. 0x0B63 ; Oriya
- 0x0B64, # .. 0x0B65 ; Unknown
- 0x0B66, # .. 0x0B77 ; Oriya
- 0x0B78, # .. 0x0B81 ; Unknown
- 0x0B82, # .. 0x0B83 ; Tamil
- 0x0B84, # .. 0x0B84 ; Unknown
- 0x0B85, # .. 0x0B8A ; Tamil
- 0x0B8B, # .. 0x0B8D ; Unknown
- 0x0B8E, # .. 0x0B90 ; Tamil
- 0x0B91, # .. 0x0B91 ; Unknown
- 0x0B92, # .. 0x0B95 ; Tamil
- 0x0B96, # .. 0x0B98 ; Unknown
- 0x0B99, # .. 0x0B9A ; Tamil
- 0x0B9B, # .. 0x0B9B ; Unknown
- 0x0B9C, # .. 0x0B9C ; Tamil
- 0x0B9D, # .. 0x0B9D ; Unknown
- 0x0B9E, # .. 0x0B9F ; Tamil
- 0x0BA0, # .. 0x0BA2 ; Unknown
- 0x0BA3, # .. 0x0BA4 ; Tamil
- 0x0BA5, # .. 0x0BA7 ; Unknown
- 0x0BA8, # .. 0x0BAA ; Tamil
- 0x0BAB, # .. 0x0BAD ; Unknown
- 0x0BAE, # .. 0x0BB9 ; Tamil
- 0x0BBA, # .. 0x0BBD ; Unknown
- 0x0BBE, # .. 0x0BC2 ; Tamil
- 0x0BC3, # .. 0x0BC5 ; Unknown
- 0x0BC6, # .. 0x0BC8 ; Tamil
- 0x0BC9, # .. 0x0BC9 ; Unknown
- 0x0BCA, # .. 0x0BCD ; Tamil
- 0x0BCE, # .. 0x0BCF ; Unknown
- 0x0BD0, # .. 0x0BD0 ; Tamil
- 0x0BD1, # .. 0x0BD6 ; Unknown
- 0x0BD7, # .. 0x0BD7 ; Tamil
- 0x0BD8, # .. 0x0BE5 ; Unknown
- 0x0BE6, # .. 0x0BFA ; Tamil
- 0x0BFB, # .. 0x0BFF ; Unknown
- 0x0C00, # .. 0x0C0C ; Telugu
- 0x0C0D, # .. 0x0C0D ; Unknown
- 0x0C0E, # .. 0x0C10 ; Telugu
- 0x0C11, # .. 0x0C11 ; Unknown
- 0x0C12, # .. 0x0C28 ; Telugu
- 0x0C29, # .. 0x0C29 ; Unknown
- 0x0C2A, # .. 0x0C39 ; Telugu
- 0x0C3A, # .. 0x0C3B ; Unknown
- 0x0C3C, # .. 0x0C44 ; Telugu
- 0x0C45, # .. 0x0C45 ; Unknown
- 0x0C46, # .. 0x0C48 ; Telugu
- 0x0C49, # .. 0x0C49 ; Unknown
- 0x0C4A, # .. 0x0C4D ; Telugu
- 0x0C4E, # .. 0x0C54 ; Unknown
- 0x0C55, # .. 0x0C56 ; Telugu
- 0x0C57, # .. 0x0C57 ; Unknown
- 0x0C58, # .. 0x0C5A ; Telugu
- 0x0C5B, # .. 0x0C5C ; Unknown
- 0x0C5D, # .. 0x0C5D ; Telugu
- 0x0C5E, # .. 0x0C5F ; Unknown
- 0x0C60, # .. 0x0C63 ; Telugu
- 0x0C64, # .. 0x0C65 ; Unknown
- 0x0C66, # .. 0x0C6F ; Telugu
- 0x0C70, # .. 0x0C76 ; Unknown
- 0x0C77, # .. 0x0C7F ; Telugu
- 0x0C80, # .. 0x0C8C ; Kannada
- 0x0C8D, # .. 0x0C8D ; Unknown
- 0x0C8E, # .. 0x0C90 ; Kannada
- 0x0C91, # .. 0x0C91 ; Unknown
- 0x0C92, # .. 0x0CA8 ; Kannada
- 0x0CA9, # .. 0x0CA9 ; Unknown
- 0x0CAA, # .. 0x0CB3 ; Kannada
- 0x0CB4, # .. 0x0CB4 ; Unknown
- 0x0CB5, # .. 0x0CB9 ; Kannada
- 0x0CBA, # .. 0x0CBB ; Unknown
- 0x0CBC, # .. 0x0CC4 ; Kannada
- 0x0CC5, # .. 0x0CC5 ; Unknown
- 0x0CC6, # .. 0x0CC8 ; Kannada
- 0x0CC9, # .. 0x0CC9 ; Unknown
- 0x0CCA, # .. 0x0CCD ; Kannada
- 0x0CCE, # .. 0x0CD4 ; Unknown
- 0x0CD5, # .. 0x0CD6 ; Kannada
- 0x0CD7, # .. 0x0CDC ; Unknown
- 0x0CDD, # .. 0x0CDE ; Kannada
- 0x0CDF, # .. 0x0CDF ; Unknown
- 0x0CE0, # .. 0x0CE3 ; Kannada
- 0x0CE4, # .. 0x0CE5 ; Unknown
- 0x0CE6, # .. 0x0CEF ; Kannada
- 0x0CF0, # .. 0x0CF0 ; Unknown
- 0x0CF1, # .. 0x0CF3 ; Kannada
- 0x0CF4, # .. 0x0CFF ; Unknown
- 0x0D00, # .. 0x0D0C ; Malayalam
- 0x0D0D, # .. 0x0D0D ; Unknown
- 0x0D0E, # .. 0x0D10 ; Malayalam
- 0x0D11, # .. 0x0D11 ; Unknown
- 0x0D12, # .. 0x0D44 ; Malayalam
- 0x0D45, # .. 0x0D45 ; Unknown
- 0x0D46, # .. 0x0D48 ; Malayalam
- 0x0D49, # .. 0x0D49 ; Unknown
- 0x0D4A, # .. 0x0D4F ; Malayalam
- 0x0D50, # .. 0x0D53 ; Unknown
- 0x0D54, # .. 0x0D63 ; Malayalam
- 0x0D64, # .. 0x0D65 ; Unknown
- 0x0D66, # .. 0x0D7F ; Malayalam
- 0x0D80, # .. 0x0D80 ; Unknown
- 0x0D81, # .. 0x0D83 ; Sinhala
- 0x0D84, # .. 0x0D84 ; Unknown
- 0x0D85, # .. 0x0D96 ; Sinhala
- 0x0D97, # .. 0x0D99 ; Unknown
- 0x0D9A, # .. 0x0DB1 ; Sinhala
- 0x0DB2, # .. 0x0DB2 ; Unknown
- 0x0DB3, # .. 0x0DBB ; Sinhala
- 0x0DBC, # .. 0x0DBC ; Unknown
- 0x0DBD, # .. 0x0DBD ; Sinhala
- 0x0DBE, # .. 0x0DBF ; Unknown
- 0x0DC0, # .. 0x0DC6 ; Sinhala
- 0x0DC7, # .. 0x0DC9 ; Unknown
- 0x0DCA, # .. 0x0DCA ; Sinhala
- 0x0DCB, # .. 0x0DCE ; Unknown
- 0x0DCF, # .. 0x0DD4 ; Sinhala
- 0x0DD5, # .. 0x0DD5 ; Unknown
- 0x0DD6, # .. 0x0DD6 ; Sinhala
- 0x0DD7, # .. 0x0DD7 ; Unknown
- 0x0DD8, # .. 0x0DDF ; Sinhala
- 0x0DE0, # .. 0x0DE5 ; Unknown
- 0x0DE6, # .. 0x0DEF ; Sinhala
- 0x0DF0, # .. 0x0DF1 ; Unknown
- 0x0DF2, # .. 0x0DF4 ; Sinhala
- 0x0DF5, # .. 0x0E00 ; Unknown
- 0x0E01, # .. 0x0E3A ; Thai
- 0x0E3B, # .. 0x0E3E ; Unknown
- 0x0E3F, # .. 0x0E3F ; Common
- 0x0E40, # .. 0x0E5B ; Thai
- 0x0E5C, # .. 0x0E80 ; Unknown
- 0x0E81, # .. 0x0E82 ; Lao
- 0x0E83, # .. 0x0E83 ; Unknown
- 0x0E84, # .. 0x0E84 ; Lao
- 0x0E85, # .. 0x0E85 ; Unknown
- 0x0E86, # .. 0x0E8A ; Lao
- 0x0E8B, # .. 0x0E8B ; Unknown
- 0x0E8C, # .. 0x0EA3 ; Lao
- 0x0EA4, # .. 0x0EA4 ; Unknown
- 0x0EA5, # .. 0x0EA5 ; Lao
- 0x0EA6, # .. 0x0EA6 ; Unknown
- 0x0EA7, # .. 0x0EBD ; Lao
- 0x0EBE, # .. 0x0EBF ; Unknown
- 0x0EC0, # .. 0x0EC4 ; Lao
- 0x0EC5, # .. 0x0EC5 ; Unknown
- 0x0EC6, # .. 0x0EC6 ; Lao
- 0x0EC7, # .. 0x0EC7 ; Unknown
- 0x0EC8, # .. 0x0ECE ; Lao
- 0x0ECF, # .. 0x0ECF ; Unknown
- 0x0ED0, # .. 0x0ED9 ; Lao
- 0x0EDA, # .. 0x0EDB ; Unknown
- 0x0EDC, # .. 0x0EDF ; Lao
- 0x0EE0, # .. 0x0EFF ; Unknown
- 0x0F00, # .. 0x0F47 ; Tibetan
- 0x0F48, # .. 0x0F48 ; Unknown
- 0x0F49, # .. 0x0F6C ; Tibetan
- 0x0F6D, # .. 0x0F70 ; Unknown
- 0x0F71, # .. 0x0F97 ; Tibetan
- 0x0F98, # .. 0x0F98 ; Unknown
- 0x0F99, # .. 0x0FBC ; Tibetan
- 0x0FBD, # .. 0x0FBD ; Unknown
- 0x0FBE, # .. 0x0FCC ; Tibetan
- 0x0FCD, # .. 0x0FCD ; Unknown
- 0x0FCE, # .. 0x0FD4 ; Tibetan
- 0x0FD5, # .. 0x0FD8 ; Common
- 0x0FD9, # .. 0x0FDA ; Tibetan
- 0x0FDB, # .. 0x0FFF ; Unknown
- 0x1000, # .. 0x109F ; Myanmar
- 0x10A0, # .. 0x10C5 ; Georgian
- 0x10C6, # .. 0x10C6 ; Unknown
- 0x10C7, # .. 0x10C7 ; Georgian
- 0x10C8, # .. 0x10CC ; Unknown
- 0x10CD, # .. 0x10CD ; Georgian
- 0x10CE, # .. 0x10CF ; Unknown
- 0x10D0, # .. 0x10FA ; Georgian
- 0x10FB, # .. 0x10FB ; Common
- 0x10FC, # .. 0x10FF ; Georgian
- 0x1100, # .. 0x11FF ; Hangul
- 0x1200, # .. 0x1248 ; Ethiopic
- 0x1249, # .. 0x1249 ; Unknown
- 0x124A, # .. 0x124D ; Ethiopic
- 0x124E, # .. 0x124F ; Unknown
- 0x1250, # .. 0x1256 ; Ethiopic
- 0x1257, # .. 0x1257 ; Unknown
- 0x1258, # .. 0x1258 ; Ethiopic
- 0x1259, # .. 0x1259 ; Unknown
- 0x125A, # .. 0x125D ; Ethiopic
- 0x125E, # .. 0x125F ; Unknown
- 0x1260, # .. 0x1288 ; Ethiopic
- 0x1289, # .. 0x1289 ; Unknown
- 0x128A, # .. 0x128D ; Ethiopic
- 0x128E, # .. 0x128F ; Unknown
- 0x1290, # .. 0x12B0 ; Ethiopic
- 0x12B1, # .. 0x12B1 ; Unknown
- 0x12B2, # .. 0x12B5 ; Ethiopic
- 0x12B6, # .. 0x12B7 ; Unknown
- 0x12B8, # .. 0x12BE ; Ethiopic
- 0x12BF, # .. 0x12BF ; Unknown
- 0x12C0, # .. 0x12C0 ; Ethiopic
- 0x12C1, # .. 0x12C1 ; Unknown
- 0x12C2, # .. 0x12C5 ; Ethiopic
- 0x12C6, # .. 0x12C7 ; Unknown
- 0x12C8, # .. 0x12D6 ; Ethiopic
- 0x12D7, # .. 0x12D7 ; Unknown
- 0x12D8, # .. 0x1310 ; Ethiopic
- 0x1311, # .. 0x1311 ; Unknown
- 0x1312, # .. 0x1315 ; Ethiopic
- 0x1316, # .. 0x1317 ; Unknown
- 0x1318, # .. 0x135A ; Ethiopic
- 0x135B, # .. 0x135C ; Unknown
- 0x135D, # .. 0x137C ; Ethiopic
- 0x137D, # .. 0x137F ; Unknown
- 0x1380, # .. 0x1399 ; Ethiopic
- 0x139A, # .. 0x139F ; Unknown
- 0x13A0, # .. 0x13F5 ; Cherokee
- 0x13F6, # .. 0x13F7 ; Unknown
- 0x13F8, # .. 0x13FD ; Cherokee
- 0x13FE, # .. 0x13FF ; Unknown
- 0x1400, # .. 0x167F ; Canadian_Aboriginal
- 0x1680, # .. 0x169C ; Ogham
- 0x169D, # .. 0x169F ; Unknown
- 0x16A0, # .. 0x16EA ; Runic
- 0x16EB, # .. 0x16ED ; Common
- 0x16EE, # .. 0x16F8 ; Runic
- 0x16F9, # .. 0x16FF ; Unknown
- 0x1700, # .. 0x1715 ; Tagalog
- 0x1716, # .. 0x171E ; Unknown
- 0x171F, # .. 0x171F ; Tagalog
- 0x1720, # .. 0x1734 ; Hanunoo
- 0x1735, # .. 0x1736 ; Common
- 0x1737, # .. 0x173F ; Unknown
- 0x1740, # .. 0x1753 ; Buhid
- 0x1754, # .. 0x175F ; Unknown
- 0x1760, # .. 0x176C ; Tagbanwa
- 0x176D, # .. 0x176D ; Unknown
- 0x176E, # .. 0x1770 ; Tagbanwa
- 0x1771, # .. 0x1771 ; Unknown
- 0x1772, # .. 0x1773 ; Tagbanwa
- 0x1774, # .. 0x177F ; Unknown
- 0x1780, # .. 0x17DD ; Khmer
- 0x17DE, # .. 0x17DF ; Unknown
- 0x17E0, # .. 0x17E9 ; Khmer
- 0x17EA, # .. 0x17EF ; Unknown
- 0x17F0, # .. 0x17F9 ; Khmer
- 0x17FA, # .. 0x17FF ; Unknown
- 0x1800, # .. 0x1801 ; Mongolian
- 0x1802, # .. 0x1803 ; Common
- 0x1804, # .. 0x1804 ; Mongolian
- 0x1805, # .. 0x1805 ; Common
- 0x1806, # .. 0x1819 ; Mongolian
- 0x181A, # .. 0x181F ; Unknown
- 0x1820, # .. 0x1878 ; Mongolian
- 0x1879, # .. 0x187F ; Unknown
- 0x1880, # .. 0x18AA ; Mongolian
- 0x18AB, # .. 0x18AF ; Unknown
- 0x18B0, # .. 0x18F5 ; Canadian_Aboriginal
- 0x18F6, # .. 0x18FF ; Unknown
- 0x1900, # .. 0x191E ; Limbu
- 0x191F, # .. 0x191F ; Unknown
- 0x1920, # .. 0x192B ; Limbu
- 0x192C, # .. 0x192F ; Unknown
- 0x1930, # .. 0x193B ; Limbu
- 0x193C, # .. 0x193F ; Unknown
- 0x1940, # .. 0x1940 ; Limbu
- 0x1941, # .. 0x1943 ; Unknown
- 0x1944, # .. 0x194F ; Limbu
- 0x1950, # .. 0x196D ; Tai_Le
- 0x196E, # .. 0x196F ; Unknown
- 0x1970, # .. 0x1974 ; Tai_Le
- 0x1975, # .. 0x197F ; Unknown
- 0x1980, # .. 0x19AB ; New_Tai_Lue
- 0x19AC, # .. 0x19AF ; Unknown
- 0x19B0, # .. 0x19C9 ; New_Tai_Lue
- 0x19CA, # .. 0x19CF ; Unknown
- 0x19D0, # .. 0x19DA ; New_Tai_Lue
- 0x19DB, # .. 0x19DD ; Unknown
- 0x19DE, # .. 0x19DF ; New_Tai_Lue
- 0x19E0, # .. 0x19FF ; Khmer
- 0x1A00, # .. 0x1A1B ; Buginese
- 0x1A1C, # .. 0x1A1D ; Unknown
- 0x1A1E, # .. 0x1A1F ; Buginese
- 0x1A20, # .. 0x1A5E ; Tai_Tham
- 0x1A5F, # .. 0x1A5F ; Unknown
- 0x1A60, # .. 0x1A7C ; Tai_Tham
- 0x1A7D, # .. 0x1A7E ; Unknown
- 0x1A7F, # .. 0x1A89 ; Tai_Tham
- 0x1A8A, # .. 0x1A8F ; Unknown
- 0x1A90, # .. 0x1A99 ; Tai_Tham
- 0x1A9A, # .. 0x1A9F ; Unknown
- 0x1AA0, # .. 0x1AAD ; Tai_Tham
- 0x1AAE, # .. 0x1AAF ; Unknown
- 0x1AB0, # .. 0x1ACE ; Inherited
- 0x1ACF, # .. 0x1AFF ; Unknown
- 0x1B00, # .. 0x1B4C ; Balinese
- 0x1B4D, # .. 0x1B4F ; Unknown
- 0x1B50, # .. 0x1B7E ; Balinese
- 0x1B7F, # .. 0x1B7F ; Unknown
- 0x1B80, # .. 0x1BBF ; Sundanese
- 0x1BC0, # .. 0x1BF3 ; Batak
- 0x1BF4, # .. 0x1BFB ; Unknown
- 0x1BFC, # .. 0x1BFF ; Batak
- 0x1C00, # .. 0x1C37 ; Lepcha
- 0x1C38, # .. 0x1C3A ; Unknown
- 0x1C3B, # .. 0x1C49 ; Lepcha
- 0x1C4A, # .. 0x1C4C ; Unknown
- 0x1C4D, # .. 0x1C4F ; Lepcha
- 0x1C50, # .. 0x1C7F ; Ol_Chiki
- 0x1C80, # .. 0x1C88 ; Cyrillic
- 0x1C89, # .. 0x1C8F ; Unknown
- 0x1C90, # .. 0x1CBA ; Georgian
- 0x1CBB, # .. 0x1CBC ; Unknown
- 0x1CBD, # .. 0x1CBF ; Georgian
- 0x1CC0, # .. 0x1CC7 ; Sundanese
- 0x1CC8, # .. 0x1CCF ; Unknown
- 0x1CD0, # .. 0x1CD2 ; Inherited
- 0x1CD3, # .. 0x1CD3 ; Common
- 0x1CD4, # .. 0x1CE0 ; Inherited
- 0x1CE1, # .. 0x1CE1 ; Common
- 0x1CE2, # .. 0x1CE8 ; Inherited
- 0x1CE9, # .. 0x1CEC ; Common
- 0x1CED, # .. 0x1CED ; Inherited
- 0x1CEE, # .. 0x1CF3 ; Common
- 0x1CF4, # .. 0x1CF4 ; Inherited
- 0x1CF5, # .. 0x1CF7 ; Common
- 0x1CF8, # .. 0x1CF9 ; Inherited
- 0x1CFA, # .. 0x1CFA ; Common
- 0x1CFB, # .. 0x1CFF ; Unknown
- 0x1D00, # .. 0x1D25 ; Latin
- 0x1D26, # .. 0x1D2A ; Greek
- 0x1D2B, # .. 0x1D2B ; Cyrillic
- 0x1D2C, # .. 0x1D5C ; Latin
- 0x1D5D, # .. 0x1D61 ; Greek
- 0x1D62, # .. 0x1D65 ; Latin
- 0x1D66, # .. 0x1D6A ; Greek
- 0x1D6B, # .. 0x1D77 ; Latin
- 0x1D78, # .. 0x1D78 ; Cyrillic
- 0x1D79, # .. 0x1DBE ; Latin
- 0x1DBF, # .. 0x1DBF ; Greek
- 0x1DC0, # .. 0x1DFF ; Inherited
- 0x1E00, # .. 0x1EFF ; Latin
- 0x1F00, # .. 0x1F15 ; Greek
- 0x1F16, # .. 0x1F17 ; Unknown
- 0x1F18, # .. 0x1F1D ; Greek
- 0x1F1E, # .. 0x1F1F ; Unknown
- 0x1F20, # .. 0x1F45 ; Greek
- 0x1F46, # .. 0x1F47 ; Unknown
- 0x1F48, # .. 0x1F4D ; Greek
- 0x1F4E, # .. 0x1F4F ; Unknown
- 0x1F50, # .. 0x1F57 ; Greek
- 0x1F58, # .. 0x1F58 ; Unknown
- 0x1F59, # .. 0x1F59 ; Greek
- 0x1F5A, # .. 0x1F5A ; Unknown
- 0x1F5B, # .. 0x1F5B ; Greek
- 0x1F5C, # .. 0x1F5C ; Unknown
- 0x1F5D, # .. 0x1F5D ; Greek
- 0x1F5E, # .. 0x1F5E ; Unknown
- 0x1F5F, # .. 0x1F7D ; Greek
- 0x1F7E, # .. 0x1F7F ; Unknown
- 0x1F80, # .. 0x1FB4 ; Greek
- 0x1FB5, # .. 0x1FB5 ; Unknown
- 0x1FB6, # .. 0x1FC4 ; Greek
- 0x1FC5, # .. 0x1FC5 ; Unknown
- 0x1FC6, # .. 0x1FD3 ; Greek
- 0x1FD4, # .. 0x1FD5 ; Unknown
- 0x1FD6, # .. 0x1FDB ; Greek
- 0x1FDC, # .. 0x1FDC ; Unknown
- 0x1FDD, # .. 0x1FEF ; Greek
- 0x1FF0, # .. 0x1FF1 ; Unknown
- 0x1FF2, # .. 0x1FF4 ; Greek
- 0x1FF5, # .. 0x1FF5 ; Unknown
- 0x1FF6, # .. 0x1FFE ; Greek
- 0x1FFF, # .. 0x1FFF ; Unknown
- 0x2000, # .. 0x200B ; Common
- 0x200C, # .. 0x200D ; Inherited
- 0x200E, # .. 0x2064 ; Common
- 0x2065, # .. 0x2065 ; Unknown
- 0x2066, # .. 0x2070 ; Common
- 0x2071, # .. 0x2071 ; Latin
- 0x2072, # .. 0x2073 ; Unknown
- 0x2074, # .. 0x207E ; Common
- 0x207F, # .. 0x207F ; Latin
- 0x2080, # .. 0x208E ; Common
- 0x208F, # .. 0x208F ; Unknown
- 0x2090, # .. 0x209C ; Latin
- 0x209D, # .. 0x209F ; Unknown
- 0x20A0, # .. 0x20C0 ; Common
- 0x20C1, # .. 0x20CF ; Unknown
- 0x20D0, # .. 0x20F0 ; Inherited
- 0x20F1, # .. 0x20FF ; Unknown
- 0x2100, # .. 0x2125 ; Common
- 0x2126, # .. 0x2126 ; Greek
- 0x2127, # .. 0x2129 ; Common
- 0x212A, # .. 0x212B ; Latin
- 0x212C, # .. 0x2131 ; Common
- 0x2132, # .. 0x2132 ; Latin
- 0x2133, # .. 0x214D ; Common
- 0x214E, # .. 0x214E ; Latin
- 0x214F, # .. 0x215F ; Common
- 0x2160, # .. 0x2188 ; Latin
- 0x2189, # .. 0x218B ; Common
- 0x218C, # .. 0x218F ; Unknown
- 0x2190, # .. 0x2426 ; Common
- 0x2427, # .. 0x243F ; Unknown
- 0x2440, # .. 0x244A ; Common
- 0x244B, # .. 0x245F ; Unknown
- 0x2460, # .. 0x27FF ; Common
- 0x2800, # .. 0x28FF ; Braille
- 0x2900, # .. 0x2B73 ; Common
- 0x2B74, # .. 0x2B75 ; Unknown
- 0x2B76, # .. 0x2B95 ; Common
- 0x2B96, # .. 0x2B96 ; Unknown
- 0x2B97, # .. 0x2BFF ; Common
- 0x2C00, # .. 0x2C5F ; Glagolitic
- 0x2C60, # .. 0x2C7F ; Latin
- 0x2C80, # .. 0x2CF3 ; Coptic
- 0x2CF4, # .. 0x2CF8 ; Unknown
- 0x2CF9, # .. 0x2CFF ; Coptic
- 0x2D00, # .. 0x2D25 ; Georgian
- 0x2D26, # .. 0x2D26 ; Unknown
- 0x2D27, # .. 0x2D27 ; Georgian
- 0x2D28, # .. 0x2D2C ; Unknown
- 0x2D2D, # .. 0x2D2D ; Georgian
- 0x2D2E, # .. 0x2D2F ; Unknown
- 0x2D30, # .. 0x2D67 ; Tifinagh
- 0x2D68, # .. 0x2D6E ; Unknown
- 0x2D6F, # .. 0x2D70 ; Tifinagh
- 0x2D71, # .. 0x2D7E ; Unknown
- 0x2D7F, # .. 0x2D7F ; Tifinagh
- 0x2D80, # .. 0x2D96 ; Ethiopic
- 0x2D97, # .. 0x2D9F ; Unknown
- 0x2DA0, # .. 0x2DA6 ; Ethiopic
- 0x2DA7, # .. 0x2DA7 ; Unknown
- 0x2DA8, # .. 0x2DAE ; Ethiopic
- 0x2DAF, # .. 0x2DAF ; Unknown
- 0x2DB0, # .. 0x2DB6 ; Ethiopic
- 0x2DB7, # .. 0x2DB7 ; Unknown
- 0x2DB8, # .. 0x2DBE ; Ethiopic
- 0x2DBF, # .. 0x2DBF ; Unknown
- 0x2DC0, # .. 0x2DC6 ; Ethiopic
- 0x2DC7, # .. 0x2DC7 ; Unknown
- 0x2DC8, # .. 0x2DCE ; Ethiopic
- 0x2DCF, # .. 0x2DCF ; Unknown
- 0x2DD0, # .. 0x2DD6 ; Ethiopic
- 0x2DD7, # .. 0x2DD7 ; Unknown
- 0x2DD8, # .. 0x2DDE ; Ethiopic
- 0x2DDF, # .. 0x2DDF ; Unknown
- 0x2DE0, # .. 0x2DFF ; Cyrillic
- 0x2E00, # .. 0x2E5D ; Common
- 0x2E5E, # .. 0x2E7F ; Unknown
- 0x2E80, # .. 0x2E99 ; Han
- 0x2E9A, # .. 0x2E9A ; Unknown
- 0x2E9B, # .. 0x2EF3 ; Han
- 0x2EF4, # .. 0x2EFF ; Unknown
- 0x2F00, # .. 0x2FD5 ; Han
- 0x2FD6, # .. 0x2FEF ; Unknown
- 0x2FF0, # .. 0x2FFB ; Common
- 0x2FFC, # .. 0x2FFF ; Unknown
- 0x3000, # .. 0x3004 ; Common
- 0x3005, # .. 0x3005 ; Han
- 0x3006, # .. 0x3006 ; Common
- 0x3007, # .. 0x3007 ; Han
- 0x3008, # .. 0x3020 ; Common
- 0x3021, # .. 0x3029 ; Han
- 0x302A, # .. 0x302D ; Inherited
- 0x302E, # .. 0x302F ; Hangul
- 0x3030, # .. 0x3037 ; Common
- 0x3038, # .. 0x303B ; Han
- 0x303C, # .. 0x303F ; Common
- 0x3040, # .. 0x3040 ; Unknown
- 0x3041, # .. 0x3096 ; Hiragana
- 0x3097, # .. 0x3098 ; Unknown
- 0x3099, # .. 0x309A ; Inherited
- 0x309B, # .. 0x309C ; Common
- 0x309D, # .. 0x309F ; Hiragana
- 0x30A0, # .. 0x30A0 ; Common
- 0x30A1, # .. 0x30FA ; Katakana
- 0x30FB, # .. 0x30FC ; Common
- 0x30FD, # .. 0x30FF ; Katakana
- 0x3100, # .. 0x3104 ; Unknown
- 0x3105, # .. 0x312F ; Bopomofo
- 0x3130, # .. 0x3130 ; Unknown
- 0x3131, # .. 0x318E ; Hangul
- 0x318F, # .. 0x318F ; Unknown
- 0x3190, # .. 0x319F ; Common
- 0x31A0, # .. 0x31BF ; Bopomofo
- 0x31C0, # .. 0x31E3 ; Common
- 0x31E4, # .. 0x31EF ; Unknown
- 0x31F0, # .. 0x31FF ; Katakana
- 0x3200, # .. 0x321E ; Hangul
- 0x321F, # .. 0x321F ; Unknown
- 0x3220, # .. 0x325F ; Common
- 0x3260, # .. 0x327E ; Hangul
- 0x327F, # .. 0x32CF ; Common
- 0x32D0, # .. 0x32FE ; Katakana
- 0x32FF, # .. 0x32FF ; Common
- 0x3300, # .. 0x3357 ; Katakana
- 0x3358, # .. 0x33FF ; Common
- 0x3400, # .. 0x4DBF ; Han
- 0x4DC0, # .. 0x4DFF ; Common
- 0x4E00, # .. 0x9FFF ; Han
- 0xA000, # .. 0xA48C ; Yi
- 0xA48D, # .. 0xA48F ; Unknown
- 0xA490, # .. 0xA4C6 ; Yi
- 0xA4C7, # .. 0xA4CF ; Unknown
- 0xA4D0, # .. 0xA4FF ; Lisu
- 0xA500, # .. 0xA62B ; Vai
- 0xA62C, # .. 0xA63F ; Unknown
- 0xA640, # .. 0xA69F ; Cyrillic
- 0xA6A0, # .. 0xA6F7 ; Bamum
- 0xA6F8, # .. 0xA6FF ; Unknown
- 0xA700, # .. 0xA721 ; Common
- 0xA722, # .. 0xA787 ; Latin
- 0xA788, # .. 0xA78A ; Common
- 0xA78B, # .. 0xA7CA ; Latin
- 0xA7CB, # .. 0xA7CF ; Unknown
- 0xA7D0, # .. 0xA7D1 ; Latin
- 0xA7D2, # .. 0xA7D2 ; Unknown
- 0xA7D3, # .. 0xA7D3 ; Latin
- 0xA7D4, # .. 0xA7D4 ; Unknown
- 0xA7D5, # .. 0xA7D9 ; Latin
- 0xA7DA, # .. 0xA7F1 ; Unknown
- 0xA7F2, # .. 0xA7FF ; Latin
- 0xA800, # .. 0xA82C ; Syloti_Nagri
- 0xA82D, # .. 0xA82F ; Unknown
- 0xA830, # .. 0xA839 ; Common
- 0xA83A, # .. 0xA83F ; Unknown
- 0xA840, # .. 0xA877 ; Phags_Pa
- 0xA878, # .. 0xA87F ; Unknown
- 0xA880, # .. 0xA8C5 ; Saurashtra
- 0xA8C6, # .. 0xA8CD ; Unknown
- 0xA8CE, # .. 0xA8D9 ; Saurashtra
- 0xA8DA, # .. 0xA8DF ; Unknown
- 0xA8E0, # .. 0xA8FF ; Devanagari
- 0xA900, # .. 0xA92D ; Kayah_Li
- 0xA92E, # .. 0xA92E ; Common
- 0xA92F, # .. 0xA92F ; Kayah_Li
- 0xA930, # .. 0xA953 ; Rejang
- 0xA954, # .. 0xA95E ; Unknown
- 0xA95F, # .. 0xA95F ; Rejang
- 0xA960, # .. 0xA97C ; Hangul
- 0xA97D, # .. 0xA97F ; Unknown
- 0xA980, # .. 0xA9CD ; Javanese
- 0xA9CE, # .. 0xA9CE ; Unknown
- 0xA9CF, # .. 0xA9CF ; Common
- 0xA9D0, # .. 0xA9D9 ; Javanese
- 0xA9DA, # .. 0xA9DD ; Unknown
- 0xA9DE, # .. 0xA9DF ; Javanese
- 0xA9E0, # .. 0xA9FE ; Myanmar
- 0xA9FF, # .. 0xA9FF ; Unknown
- 0xAA00, # .. 0xAA36 ; Cham
- 0xAA37, # .. 0xAA3F ; Unknown
- 0xAA40, # .. 0xAA4D ; Cham
- 0xAA4E, # .. 0xAA4F ; Unknown
- 0xAA50, # .. 0xAA59 ; Cham
- 0xAA5A, # .. 0xAA5B ; Unknown
- 0xAA5C, # .. 0xAA5F ; Cham
- 0xAA60, # .. 0xAA7F ; Myanmar
- 0xAA80, # .. 0xAAC2 ; Tai_Viet
- 0xAAC3, # .. 0xAADA ; Unknown
- 0xAADB, # .. 0xAADF ; Tai_Viet
- 0xAAE0, # .. 0xAAF6 ; Meetei_Mayek
- 0xAAF7, # .. 0xAB00 ; Unknown
- 0xAB01, # .. 0xAB06 ; Ethiopic
- 0xAB07, # .. 0xAB08 ; Unknown
- 0xAB09, # .. 0xAB0E ; Ethiopic
- 0xAB0F, # .. 0xAB10 ; Unknown
- 0xAB11, # .. 0xAB16 ; Ethiopic
- 0xAB17, # .. 0xAB1F ; Unknown
- 0xAB20, # .. 0xAB26 ; Ethiopic
- 0xAB27, # .. 0xAB27 ; Unknown
- 0xAB28, # .. 0xAB2E ; Ethiopic
- 0xAB2F, # .. 0xAB2F ; Unknown
- 0xAB30, # .. 0xAB5A ; Latin
- 0xAB5B, # .. 0xAB5B ; Common
- 0xAB5C, # .. 0xAB64 ; Latin
- 0xAB65, # .. 0xAB65 ; Greek
- 0xAB66, # .. 0xAB69 ; Latin
- 0xAB6A, # .. 0xAB6B ; Common
- 0xAB6C, # .. 0xAB6F ; Unknown
- 0xAB70, # .. 0xABBF ; Cherokee
- 0xABC0, # .. 0xABED ; Meetei_Mayek
- 0xABEE, # .. 0xABEF ; Unknown
- 0xABF0, # .. 0xABF9 ; Meetei_Mayek
- 0xABFA, # .. 0xABFF ; Unknown
- 0xAC00, # .. 0xD7A3 ; Hangul
- 0xD7A4, # .. 0xD7AF ; Unknown
- 0xD7B0, # .. 0xD7C6 ; Hangul
- 0xD7C7, # .. 0xD7CA ; Unknown
- 0xD7CB, # .. 0xD7FB ; Hangul
- 0xD7FC, # .. 0xF8FF ; Unknown
- 0xF900, # .. 0xFA6D ; Han
- 0xFA6E, # .. 0xFA6F ; Unknown
- 0xFA70, # .. 0xFAD9 ; Han
- 0xFADA, # .. 0xFAFF ; Unknown
- 0xFB00, # .. 0xFB06 ; Latin
- 0xFB07, # .. 0xFB12 ; Unknown
- 0xFB13, # .. 0xFB17 ; Armenian
- 0xFB18, # .. 0xFB1C ; Unknown
- 0xFB1D, # .. 0xFB36 ; Hebrew
- 0xFB37, # .. 0xFB37 ; Unknown
- 0xFB38, # .. 0xFB3C ; Hebrew
- 0xFB3D, # .. 0xFB3D ; Unknown
- 0xFB3E, # .. 0xFB3E ; Hebrew
- 0xFB3F, # .. 0xFB3F ; Unknown
- 0xFB40, # .. 0xFB41 ; Hebrew
- 0xFB42, # .. 0xFB42 ; Unknown
- 0xFB43, # .. 0xFB44 ; Hebrew
- 0xFB45, # .. 0xFB45 ; Unknown
- 0xFB46, # .. 0xFB4F ; Hebrew
- 0xFB50, # .. 0xFBC2 ; Arabic
- 0xFBC3, # .. 0xFBD2 ; Unknown
- 0xFBD3, # .. 0xFD3D ; Arabic
- 0xFD3E, # .. 0xFD3F ; Common
- 0xFD40, # .. 0xFD8F ; Arabic
- 0xFD90, # .. 0xFD91 ; Unknown
- 0xFD92, # .. 0xFDC7 ; Arabic
- 0xFDC8, # .. 0xFDCE ; Unknown
- 0xFDCF, # .. 0xFDCF ; Arabic
- 0xFDD0, # .. 0xFDEF ; Unknown
- 0xFDF0, # .. 0xFDFF ; Arabic
- 0xFE00, # .. 0xFE0F ; Inherited
- 0xFE10, # .. 0xFE19 ; Common
- 0xFE1A, # .. 0xFE1F ; Unknown
- 0xFE20, # .. 0xFE2D ; Inherited
- 0xFE2E, # .. 0xFE2F ; Cyrillic
- 0xFE30, # .. 0xFE52 ; Common
- 0xFE53, # .. 0xFE53 ; Unknown
- 0xFE54, # .. 0xFE66 ; Common
- 0xFE67, # .. 0xFE67 ; Unknown
- 0xFE68, # .. 0xFE6B ; Common
- 0xFE6C, # .. 0xFE6F ; Unknown
- 0xFE70, # .. 0xFE74 ; Arabic
- 0xFE75, # .. 0xFE75 ; Unknown
- 0xFE76, # .. 0xFEFC ; Arabic
- 0xFEFD, # .. 0xFEFE ; Unknown
- 0xFEFF, # .. 0xFEFF ; Common
- 0xFF00, # .. 0xFF00 ; Unknown
- 0xFF01, # .. 0xFF20 ; Common
- 0xFF21, # .. 0xFF3A ; Latin
- 0xFF3B, # .. 0xFF40 ; Common
- 0xFF41, # .. 0xFF5A ; Latin
- 0xFF5B, # .. 0xFF65 ; Common
- 0xFF66, # .. 0xFF6F ; Katakana
- 0xFF70, # .. 0xFF70 ; Common
- 0xFF71, # .. 0xFF9D ; Katakana
- 0xFF9E, # .. 0xFF9F ; Common
- 0xFFA0, # .. 0xFFBE ; Hangul
- 0xFFBF, # .. 0xFFC1 ; Unknown
- 0xFFC2, # .. 0xFFC7 ; Hangul
- 0xFFC8, # .. 0xFFC9 ; Unknown
- 0xFFCA, # .. 0xFFCF ; Hangul
- 0xFFD0, # .. 0xFFD1 ; Unknown
- 0xFFD2, # .. 0xFFD7 ; Hangul
- 0xFFD8, # .. 0xFFD9 ; Unknown
- 0xFFDA, # .. 0xFFDC ; Hangul
- 0xFFDD, # .. 0xFFDF ; Unknown
- 0xFFE0, # .. 0xFFE6 ; Common
- 0xFFE7, # .. 0xFFE7 ; Unknown
- 0xFFE8, # .. 0xFFEE ; Common
- 0xFFEF, # .. 0xFFF8 ; Unknown
- 0xFFF9, # .. 0xFFFD ; Common
- 0xFFFE, # .. 0xFFFF ; Unknown
- 0x10000, # .. 0x1000B ; Linear_B
- 0x1000C, # .. 0x1000C ; Unknown
- 0x1000D, # .. 0x10026 ; Linear_B
- 0x10027, # .. 0x10027 ; Unknown
- 0x10028, # .. 0x1003A ; Linear_B
- 0x1003B, # .. 0x1003B ; Unknown
- 0x1003C, # .. 0x1003D ; Linear_B
- 0x1003E, # .. 0x1003E ; Unknown
- 0x1003F, # .. 0x1004D ; Linear_B
- 0x1004E, # .. 0x1004F ; Unknown
- 0x10050, # .. 0x1005D ; Linear_B
- 0x1005E, # .. 0x1007F ; Unknown
- 0x10080, # .. 0x100FA ; Linear_B
- 0x100FB, # .. 0x100FF ; Unknown
- 0x10100, # .. 0x10102 ; Common
- 0x10103, # .. 0x10106 ; Unknown
- 0x10107, # .. 0x10133 ; Common
- 0x10134, # .. 0x10136 ; Unknown
- 0x10137, # .. 0x1013F ; Common
- 0x10140, # .. 0x1018E ; Greek
- 0x1018F, # .. 0x1018F ; Unknown
- 0x10190, # .. 0x1019C ; Common
- 0x1019D, # .. 0x1019F ; Unknown
- 0x101A0, # .. 0x101A0 ; Greek
- 0x101A1, # .. 0x101CF ; Unknown
- 0x101D0, # .. 0x101FC ; Common
- 0x101FD, # .. 0x101FD ; Inherited
- 0x101FE, # .. 0x1027F ; Unknown
- 0x10280, # .. 0x1029C ; Lycian
- 0x1029D, # .. 0x1029F ; Unknown
- 0x102A0, # .. 0x102D0 ; Carian
- 0x102D1, # .. 0x102DF ; Unknown
- 0x102E0, # .. 0x102E0 ; Inherited
- 0x102E1, # .. 0x102FB ; Common
- 0x102FC, # .. 0x102FF ; Unknown
- 0x10300, # .. 0x10323 ; Old_Italic
- 0x10324, # .. 0x1032C ; Unknown
- 0x1032D, # .. 0x1032F ; Old_Italic
- 0x10330, # .. 0x1034A ; Gothic
- 0x1034B, # .. 0x1034F ; Unknown
- 0x10350, # .. 0x1037A ; Old_Permic
- 0x1037B, # .. 0x1037F ; Unknown
- 0x10380, # .. 0x1039D ; Ugaritic
- 0x1039E, # .. 0x1039E ; Unknown
- 0x1039F, # .. 0x1039F ; Ugaritic
- 0x103A0, # .. 0x103C3 ; Old_Persian
- 0x103C4, # .. 0x103C7 ; Unknown
- 0x103C8, # .. 0x103D5 ; Old_Persian
- 0x103D6, # .. 0x103FF ; Unknown
- 0x10400, # .. 0x1044F ; Deseret
- 0x10450, # .. 0x1047F ; Shavian
- 0x10480, # .. 0x1049D ; Osmanya
- 0x1049E, # .. 0x1049F ; Unknown
- 0x104A0, # .. 0x104A9 ; Osmanya
- 0x104AA, # .. 0x104AF ; Unknown
- 0x104B0, # .. 0x104D3 ; Osage
- 0x104D4, # .. 0x104D7 ; Unknown
- 0x104D8, # .. 0x104FB ; Osage
- 0x104FC, # .. 0x104FF ; Unknown
- 0x10500, # .. 0x10527 ; Elbasan
- 0x10528, # .. 0x1052F ; Unknown
- 0x10530, # .. 0x10563 ; Caucasian_Albanian
- 0x10564, # .. 0x1056E ; Unknown
- 0x1056F, # .. 0x1056F ; Caucasian_Albanian
- 0x10570, # .. 0x1057A ; Vithkuqi
- 0x1057B, # .. 0x1057B ; Unknown
- 0x1057C, # .. 0x1058A ; Vithkuqi
- 0x1058B, # .. 0x1058B ; Unknown
- 0x1058C, # .. 0x10592 ; Vithkuqi
- 0x10593, # .. 0x10593 ; Unknown
- 0x10594, # .. 0x10595 ; Vithkuqi
- 0x10596, # .. 0x10596 ; Unknown
- 0x10597, # .. 0x105A1 ; Vithkuqi
- 0x105A2, # .. 0x105A2 ; Unknown
- 0x105A3, # .. 0x105B1 ; Vithkuqi
- 0x105B2, # .. 0x105B2 ; Unknown
- 0x105B3, # .. 0x105B9 ; Vithkuqi
- 0x105BA, # .. 0x105BA ; Unknown
- 0x105BB, # .. 0x105BC ; Vithkuqi
- 0x105BD, # .. 0x105FF ; Unknown
- 0x10600, # .. 0x10736 ; Linear_A
- 0x10737, # .. 0x1073F ; Unknown
- 0x10740, # .. 0x10755 ; Linear_A
- 0x10756, # .. 0x1075F ; Unknown
- 0x10760, # .. 0x10767 ; Linear_A
- 0x10768, # .. 0x1077F ; Unknown
- 0x10780, # .. 0x10785 ; Latin
- 0x10786, # .. 0x10786 ; Unknown
- 0x10787, # .. 0x107B0 ; Latin
- 0x107B1, # .. 0x107B1 ; Unknown
- 0x107B2, # .. 0x107BA ; Latin
- 0x107BB, # .. 0x107FF ; Unknown
- 0x10800, # .. 0x10805 ; Cypriot
- 0x10806, # .. 0x10807 ; Unknown
- 0x10808, # .. 0x10808 ; Cypriot
- 0x10809, # .. 0x10809 ; Unknown
- 0x1080A, # .. 0x10835 ; Cypriot
- 0x10836, # .. 0x10836 ; Unknown
- 0x10837, # .. 0x10838 ; Cypriot
- 0x10839, # .. 0x1083B ; Unknown
- 0x1083C, # .. 0x1083C ; Cypriot
- 0x1083D, # .. 0x1083E ; Unknown
- 0x1083F, # .. 0x1083F ; Cypriot
- 0x10840, # .. 0x10855 ; Imperial_Aramaic
- 0x10856, # .. 0x10856 ; Unknown
- 0x10857, # .. 0x1085F ; Imperial_Aramaic
- 0x10860, # .. 0x1087F ; Palmyrene
- 0x10880, # .. 0x1089E ; Nabataean
- 0x1089F, # .. 0x108A6 ; Unknown
- 0x108A7, # .. 0x108AF ; Nabataean
- 0x108B0, # .. 0x108DF ; Unknown
- 0x108E0, # .. 0x108F2 ; Hatran
- 0x108F3, # .. 0x108F3 ; Unknown
- 0x108F4, # .. 0x108F5 ; Hatran
- 0x108F6, # .. 0x108FA ; Unknown
- 0x108FB, # .. 0x108FF ; Hatran
- 0x10900, # .. 0x1091B ; Phoenician
- 0x1091C, # .. 0x1091E ; Unknown
- 0x1091F, # .. 0x1091F ; Phoenician
- 0x10920, # .. 0x10939 ; Lydian
- 0x1093A, # .. 0x1093E ; Unknown
- 0x1093F, # .. 0x1093F ; Lydian
- 0x10940, # .. 0x1097F ; Unknown
- 0x10980, # .. 0x1099F ; Meroitic_Hieroglyphs
- 0x109A0, # .. 0x109B7 ; Meroitic_Cursive
- 0x109B8, # .. 0x109BB ; Unknown
- 0x109BC, # .. 0x109CF ; Meroitic_Cursive
- 0x109D0, # .. 0x109D1 ; Unknown
- 0x109D2, # .. 0x109FF ; Meroitic_Cursive
- 0x10A00, # .. 0x10A03 ; Kharoshthi
- 0x10A04, # .. 0x10A04 ; Unknown
- 0x10A05, # .. 0x10A06 ; Kharoshthi
- 0x10A07, # .. 0x10A0B ; Unknown
- 0x10A0C, # .. 0x10A13 ; Kharoshthi
- 0x10A14, # .. 0x10A14 ; Unknown
- 0x10A15, # .. 0x10A17 ; Kharoshthi
- 0x10A18, # .. 0x10A18 ; Unknown
- 0x10A19, # .. 0x10A35 ; Kharoshthi
- 0x10A36, # .. 0x10A37 ; Unknown
- 0x10A38, # .. 0x10A3A ; Kharoshthi
- 0x10A3B, # .. 0x10A3E ; Unknown
- 0x10A3F, # .. 0x10A48 ; Kharoshthi
- 0x10A49, # .. 0x10A4F ; Unknown
- 0x10A50, # .. 0x10A58 ; Kharoshthi
- 0x10A59, # .. 0x10A5F ; Unknown
- 0x10A60, # .. 0x10A7F ; Old_South_Arabian
- 0x10A80, # .. 0x10A9F ; Old_North_Arabian
- 0x10AA0, # .. 0x10ABF ; Unknown
- 0x10AC0, # .. 0x10AE6 ; Manichaean
- 0x10AE7, # .. 0x10AEA ; Unknown
- 0x10AEB, # .. 0x10AF6 ; Manichaean
- 0x10AF7, # .. 0x10AFF ; Unknown
- 0x10B00, # .. 0x10B35 ; Avestan
- 0x10B36, # .. 0x10B38 ; Unknown
- 0x10B39, # .. 0x10B3F ; Avestan
- 0x10B40, # .. 0x10B55 ; Inscriptional_Parthian
- 0x10B56, # .. 0x10B57 ; Unknown
- 0x10B58, # .. 0x10B5F ; Inscriptional_Parthian
- 0x10B60, # .. 0x10B72 ; Inscriptional_Pahlavi
- 0x10B73, # .. 0x10B77 ; Unknown
- 0x10B78, # .. 0x10B7F ; Inscriptional_Pahlavi
- 0x10B80, # .. 0x10B91 ; Psalter_Pahlavi
- 0x10B92, # .. 0x10B98 ; Unknown
- 0x10B99, # .. 0x10B9C ; Psalter_Pahlavi
- 0x10B9D, # .. 0x10BA8 ; Unknown
- 0x10BA9, # .. 0x10BAF ; Psalter_Pahlavi
- 0x10BB0, # .. 0x10BFF ; Unknown
- 0x10C00, # .. 0x10C48 ; Old_Turkic
- 0x10C49, # .. 0x10C7F ; Unknown
- 0x10C80, # .. 0x10CB2 ; Old_Hungarian
- 0x10CB3, # .. 0x10CBF ; Unknown
- 0x10CC0, # .. 0x10CF2 ; Old_Hungarian
- 0x10CF3, # .. 0x10CF9 ; Unknown
- 0x10CFA, # .. 0x10CFF ; Old_Hungarian
- 0x10D00, # .. 0x10D27 ; Hanifi_Rohingya
- 0x10D28, # .. 0x10D2F ; Unknown
- 0x10D30, # .. 0x10D39 ; Hanifi_Rohingya
- 0x10D3A, # .. 0x10E5F ; Unknown
- 0x10E60, # .. 0x10E7E ; Arabic
- 0x10E7F, # .. 0x10E7F ; Unknown
- 0x10E80, # .. 0x10EA9 ; Yezidi
- 0x10EAA, # .. 0x10EAA ; Unknown
- 0x10EAB, # .. 0x10EAD ; Yezidi
- 0x10EAE, # .. 0x10EAF ; Unknown
- 0x10EB0, # .. 0x10EB1 ; Yezidi
- 0x10EB2, # .. 0x10EFC ; Unknown
- 0x10EFD, # .. 0x10EFF ; Arabic
- 0x10F00, # .. 0x10F27 ; Old_Sogdian
- 0x10F28, # .. 0x10F2F ; Unknown
- 0x10F30, # .. 0x10F59 ; Sogdian
- 0x10F5A, # .. 0x10F6F ; Unknown
- 0x10F70, # .. 0x10F89 ; Old_Uyghur
- 0x10F8A, # .. 0x10FAF ; Unknown
- 0x10FB0, # .. 0x10FCB ; Chorasmian
- 0x10FCC, # .. 0x10FDF ; Unknown
- 0x10FE0, # .. 0x10FF6 ; Elymaic
- 0x10FF7, # .. 0x10FFF ; Unknown
- 0x11000, # .. 0x1104D ; Brahmi
- 0x1104E, # .. 0x11051 ; Unknown
- 0x11052, # .. 0x11075 ; Brahmi
- 0x11076, # .. 0x1107E ; Unknown
- 0x1107F, # .. 0x1107F ; Brahmi
- 0x11080, # .. 0x110C2 ; Kaithi
- 0x110C3, # .. 0x110CC ; Unknown
- 0x110CD, # .. 0x110CD ; Kaithi
- 0x110CE, # .. 0x110CF ; Unknown
- 0x110D0, # .. 0x110E8 ; Sora_Sompeng
- 0x110E9, # .. 0x110EF ; Unknown
- 0x110F0, # .. 0x110F9 ; Sora_Sompeng
- 0x110FA, # .. 0x110FF ; Unknown
- 0x11100, # .. 0x11134 ; Chakma
- 0x11135, # .. 0x11135 ; Unknown
- 0x11136, # .. 0x11147 ; Chakma
- 0x11148, # .. 0x1114F ; Unknown
- 0x11150, # .. 0x11176 ; Mahajani
- 0x11177, # .. 0x1117F ; Unknown
- 0x11180, # .. 0x111DF ; Sharada
- 0x111E0, # .. 0x111E0 ; Unknown
- 0x111E1, # .. 0x111F4 ; Sinhala
- 0x111F5, # .. 0x111FF ; Unknown
- 0x11200, # .. 0x11211 ; Khojki
- 0x11212, # .. 0x11212 ; Unknown
- 0x11213, # .. 0x11241 ; Khojki
- 0x11242, # .. 0x1127F ; Unknown
- 0x11280, # .. 0x11286 ; Multani
- 0x11287, # .. 0x11287 ; Unknown
- 0x11288, # .. 0x11288 ; Multani
- 0x11289, # .. 0x11289 ; Unknown
- 0x1128A, # .. 0x1128D ; Multani
- 0x1128E, # .. 0x1128E ; Unknown
- 0x1128F, # .. 0x1129D ; Multani
- 0x1129E, # .. 0x1129E ; Unknown
- 0x1129F, # .. 0x112A9 ; Multani
- 0x112AA, # .. 0x112AF ; Unknown
- 0x112B0, # .. 0x112EA ; Khudawadi
- 0x112EB, # .. 0x112EF ; Unknown
- 0x112F0, # .. 0x112F9 ; Khudawadi
- 0x112FA, # .. 0x112FF ; Unknown
- 0x11300, # .. 0x11303 ; Grantha
- 0x11304, # .. 0x11304 ; Unknown
- 0x11305, # .. 0x1130C ; Grantha
- 0x1130D, # .. 0x1130E ; Unknown
- 0x1130F, # .. 0x11310 ; Grantha
- 0x11311, # .. 0x11312 ; Unknown
- 0x11313, # .. 0x11328 ; Grantha
- 0x11329, # .. 0x11329 ; Unknown
- 0x1132A, # .. 0x11330 ; Grantha
- 0x11331, # .. 0x11331 ; Unknown
- 0x11332, # .. 0x11333 ; Grantha
- 0x11334, # .. 0x11334 ; Unknown
- 0x11335, # .. 0x11339 ; Grantha
- 0x1133A, # .. 0x1133A ; Unknown
- 0x1133B, # .. 0x1133B ; Inherited
- 0x1133C, # .. 0x11344 ; Grantha
- 0x11345, # .. 0x11346 ; Unknown
- 0x11347, # .. 0x11348 ; Grantha
- 0x11349, # .. 0x1134A ; Unknown
- 0x1134B, # .. 0x1134D ; Grantha
- 0x1134E, # .. 0x1134F ; Unknown
- 0x11350, # .. 0x11350 ; Grantha
- 0x11351, # .. 0x11356 ; Unknown
- 0x11357, # .. 0x11357 ; Grantha
- 0x11358, # .. 0x1135C ; Unknown
- 0x1135D, # .. 0x11363 ; Grantha
- 0x11364, # .. 0x11365 ; Unknown
- 0x11366, # .. 0x1136C ; Grantha
- 0x1136D, # .. 0x1136F ; Unknown
- 0x11370, # .. 0x11374 ; Grantha
- 0x11375, # .. 0x113FF ; Unknown
- 0x11400, # .. 0x1145B ; Newa
- 0x1145C, # .. 0x1145C ; Unknown
- 0x1145D, # .. 0x11461 ; Newa
- 0x11462, # .. 0x1147F ; Unknown
- 0x11480, # .. 0x114C7 ; Tirhuta
- 0x114C8, # .. 0x114CF ; Unknown
- 0x114D0, # .. 0x114D9 ; Tirhuta
- 0x114DA, # .. 0x1157F ; Unknown
- 0x11580, # .. 0x115B5 ; Siddham
- 0x115B6, # .. 0x115B7 ; Unknown
- 0x115B8, # .. 0x115DD ; Siddham
- 0x115DE, # .. 0x115FF ; Unknown
- 0x11600, # .. 0x11644 ; Modi
- 0x11645, # .. 0x1164F ; Unknown
- 0x11650, # .. 0x11659 ; Modi
- 0x1165A, # .. 0x1165F ; Unknown
- 0x11660, # .. 0x1166C ; Mongolian
- 0x1166D, # .. 0x1167F ; Unknown
- 0x11680, # .. 0x116B9 ; Takri
- 0x116BA, # .. 0x116BF ; Unknown
- 0x116C0, # .. 0x116C9 ; Takri
- 0x116CA, # .. 0x116FF ; Unknown
- 0x11700, # .. 0x1171A ; Ahom
- 0x1171B, # .. 0x1171C ; Unknown
- 0x1171D, # .. 0x1172B ; Ahom
- 0x1172C, # .. 0x1172F ; Unknown
- 0x11730, # .. 0x11746 ; Ahom
- 0x11747, # .. 0x117FF ; Unknown
- 0x11800, # .. 0x1183B ; Dogra
- 0x1183C, # .. 0x1189F ; Unknown
- 0x118A0, # .. 0x118F2 ; Warang_Citi
- 0x118F3, # .. 0x118FE ; Unknown
- 0x118FF, # .. 0x118FF ; Warang_Citi
- 0x11900, # .. 0x11906 ; Dives_Akuru
- 0x11907, # .. 0x11908 ; Unknown
- 0x11909, # .. 0x11909 ; Dives_Akuru
- 0x1190A, # .. 0x1190B ; Unknown
- 0x1190C, # .. 0x11913 ; Dives_Akuru
- 0x11914, # .. 0x11914 ; Unknown
- 0x11915, # .. 0x11916 ; Dives_Akuru
- 0x11917, # .. 0x11917 ; Unknown
- 0x11918, # .. 0x11935 ; Dives_Akuru
- 0x11936, # .. 0x11936 ; Unknown
- 0x11937, # .. 0x11938 ; Dives_Akuru
- 0x11939, # .. 0x1193A ; Unknown
- 0x1193B, # .. 0x11946 ; Dives_Akuru
- 0x11947, # .. 0x1194F ; Unknown
- 0x11950, # .. 0x11959 ; Dives_Akuru
- 0x1195A, # .. 0x1199F ; Unknown
- 0x119A0, # .. 0x119A7 ; Nandinagari
- 0x119A8, # .. 0x119A9 ; Unknown
- 0x119AA, # .. 0x119D7 ; Nandinagari
- 0x119D8, # .. 0x119D9 ; Unknown
- 0x119DA, # .. 0x119E4 ; Nandinagari
- 0x119E5, # .. 0x119FF ; Unknown
- 0x11A00, # .. 0x11A47 ; Zanabazar_Square
- 0x11A48, # .. 0x11A4F ; Unknown
- 0x11A50, # .. 0x11AA2 ; Soyombo
- 0x11AA3, # .. 0x11AAF ; Unknown
- 0x11AB0, # .. 0x11ABF ; Canadian_Aboriginal
- 0x11AC0, # .. 0x11AF8 ; Pau_Cin_Hau
- 0x11AF9, # .. 0x11AFF ; Unknown
- 0x11B00, # .. 0x11B09 ; Devanagari
- 0x11B0A, # .. 0x11BFF ; Unknown
- 0x11C00, # .. 0x11C08 ; Bhaiksuki
- 0x11C09, # .. 0x11C09 ; Unknown
- 0x11C0A, # .. 0x11C36 ; Bhaiksuki
- 0x11C37, # .. 0x11C37 ; Unknown
- 0x11C38, # .. 0x11C45 ; Bhaiksuki
- 0x11C46, # .. 0x11C4F ; Unknown
- 0x11C50, # .. 0x11C6C ; Bhaiksuki
- 0x11C6D, # .. 0x11C6F ; Unknown
- 0x11C70, # .. 0x11C8F ; Marchen
- 0x11C90, # .. 0x11C91 ; Unknown
- 0x11C92, # .. 0x11CA7 ; Marchen
- 0x11CA8, # .. 0x11CA8 ; Unknown
- 0x11CA9, # .. 0x11CB6 ; Marchen
- 0x11CB7, # .. 0x11CFF ; Unknown
- 0x11D00, # .. 0x11D06 ; Masaram_Gondi
- 0x11D07, # .. 0x11D07 ; Unknown
- 0x11D08, # .. 0x11D09 ; Masaram_Gondi
- 0x11D0A, # .. 0x11D0A ; Unknown
- 0x11D0B, # .. 0x11D36 ; Masaram_Gondi
- 0x11D37, # .. 0x11D39 ; Unknown
- 0x11D3A, # .. 0x11D3A ; Masaram_Gondi
- 0x11D3B, # .. 0x11D3B ; Unknown
- 0x11D3C, # .. 0x11D3D ; Masaram_Gondi
- 0x11D3E, # .. 0x11D3E ; Unknown
- 0x11D3F, # .. 0x11D47 ; Masaram_Gondi
- 0x11D48, # .. 0x11D4F ; Unknown
- 0x11D50, # .. 0x11D59 ; Masaram_Gondi
- 0x11D5A, # .. 0x11D5F ; Unknown
- 0x11D60, # .. 0x11D65 ; Gunjala_Gondi
- 0x11D66, # .. 0x11D66 ; Unknown
- 0x11D67, # .. 0x11D68 ; Gunjala_Gondi
- 0x11D69, # .. 0x11D69 ; Unknown
- 0x11D6A, # .. 0x11D8E ; Gunjala_Gondi
- 0x11D8F, # .. 0x11D8F ; Unknown
- 0x11D90, # .. 0x11D91 ; Gunjala_Gondi
- 0x11D92, # .. 0x11D92 ; Unknown
- 0x11D93, # .. 0x11D98 ; Gunjala_Gondi
- 0x11D99, # .. 0x11D9F ; Unknown
- 0x11DA0, # .. 0x11DA9 ; Gunjala_Gondi
- 0x11DAA, # .. 0x11EDF ; Unknown
- 0x11EE0, # .. 0x11EF8 ; Makasar
- 0x11EF9, # .. 0x11EFF ; Unknown
- 0x11F00, # .. 0x11F10 ; Kawi
- 0x11F11, # .. 0x11F11 ; Unknown
- 0x11F12, # .. 0x11F3A ; Kawi
- 0x11F3B, # .. 0x11F3D ; Unknown
- 0x11F3E, # .. 0x11F59 ; Kawi
- 0x11F5A, # .. 0x11FAF ; Unknown
- 0x11FB0, # .. 0x11FB0 ; Lisu
- 0x11FB1, # .. 0x11FBF ; Unknown
- 0x11FC0, # .. 0x11FF1 ; Tamil
- 0x11FF2, # .. 0x11FFE ; Unknown
- 0x11FFF, # .. 0x11FFF ; Tamil
- 0x12000, # .. 0x12399 ; Cuneiform
- 0x1239A, # .. 0x123FF ; Unknown
- 0x12400, # .. 0x1246E ; Cuneiform
- 0x1246F, # .. 0x1246F ; Unknown
- 0x12470, # .. 0x12474 ; Cuneiform
- 0x12475, # .. 0x1247F ; Unknown
- 0x12480, # .. 0x12543 ; Cuneiform
- 0x12544, # .. 0x12F8F ; Unknown
- 0x12F90, # .. 0x12FF2 ; Cypro_Minoan
- 0x12FF3, # .. 0x12FFF ; Unknown
- 0x13000, # .. 0x13455 ; Egyptian_Hieroglyphs
- 0x13456, # .. 0x143FF ; Unknown
- 0x14400, # .. 0x14646 ; Anatolian_Hieroglyphs
- 0x14647, # .. 0x167FF ; Unknown
- 0x16800, # .. 0x16A38 ; Bamum
- 0x16A39, # .. 0x16A3F ; Unknown
- 0x16A40, # .. 0x16A5E ; Mro
- 0x16A5F, # .. 0x16A5F ; Unknown
- 0x16A60, # .. 0x16A69 ; Mro
- 0x16A6A, # .. 0x16A6D ; Unknown
- 0x16A6E, # .. 0x16A6F ; Mro
- 0x16A70, # .. 0x16ABE ; Tangsa
- 0x16ABF, # .. 0x16ABF ; Unknown
- 0x16AC0, # .. 0x16AC9 ; Tangsa
- 0x16ACA, # .. 0x16ACF ; Unknown
- 0x16AD0, # .. 0x16AED ; Bassa_Vah
- 0x16AEE, # .. 0x16AEF ; Unknown
- 0x16AF0, # .. 0x16AF5 ; Bassa_Vah
- 0x16AF6, # .. 0x16AFF ; Unknown
- 0x16B00, # .. 0x16B45 ; Pahawh_Hmong
- 0x16B46, # .. 0x16B4F ; Unknown
- 0x16B50, # .. 0x16B59 ; Pahawh_Hmong
- 0x16B5A, # .. 0x16B5A ; Unknown
- 0x16B5B, # .. 0x16B61 ; Pahawh_Hmong
- 0x16B62, # .. 0x16B62 ; Unknown
- 0x16B63, # .. 0x16B77 ; Pahawh_Hmong
- 0x16B78, # .. 0x16B7C ; Unknown
- 0x16B7D, # .. 0x16B8F ; Pahawh_Hmong
- 0x16B90, # .. 0x16E3F ; Unknown
- 0x16E40, # .. 0x16E9A ; Medefaidrin
- 0x16E9B, # .. 0x16EFF ; Unknown
- 0x16F00, # .. 0x16F4A ; Miao
- 0x16F4B, # .. 0x16F4E ; Unknown
- 0x16F4F, # .. 0x16F87 ; Miao
- 0x16F88, # .. 0x16F8E ; Unknown
- 0x16F8F, # .. 0x16F9F ; Miao
- 0x16FA0, # .. 0x16FDF ; Unknown
- 0x16FE0, # .. 0x16FE0 ; Tangut
- 0x16FE1, # .. 0x16FE1 ; Nushu
- 0x16FE2, # .. 0x16FE3 ; Han
- 0x16FE4, # .. 0x16FE4 ; Khitan_Small_Script
- 0x16FE5, # .. 0x16FEF ; Unknown
- 0x16FF0, # .. 0x16FF1 ; Han
- 0x16FF2, # .. 0x16FFF ; Unknown
- 0x17000, # .. 0x187F7 ; Tangut
- 0x187F8, # .. 0x187FF ; Unknown
- 0x18800, # .. 0x18AFF ; Tangut
- 0x18B00, # .. 0x18CD5 ; Khitan_Small_Script
- 0x18CD6, # .. 0x18CFF ; Unknown
- 0x18D00, # .. 0x18D08 ; Tangut
- 0x18D09, # .. 0x1AFEF ; Unknown
- 0x1AFF0, # .. 0x1AFF3 ; Katakana
- 0x1AFF4, # .. 0x1AFF4 ; Unknown
- 0x1AFF5, # .. 0x1AFFB ; Katakana
- 0x1AFFC, # .. 0x1AFFC ; Unknown
- 0x1AFFD, # .. 0x1AFFE ; Katakana
- 0x1AFFF, # .. 0x1AFFF ; Unknown
- 0x1B000, # .. 0x1B000 ; Katakana
- 0x1B001, # .. 0x1B11F ; Hiragana
- 0x1B120, # .. 0x1B122 ; Katakana
- 0x1B123, # .. 0x1B131 ; Unknown
- 0x1B132, # .. 0x1B132 ; Hiragana
- 0x1B133, # .. 0x1B14F ; Unknown
- 0x1B150, # .. 0x1B152 ; Hiragana
- 0x1B153, # .. 0x1B154 ; Unknown
- 0x1B155, # .. 0x1B155 ; Katakana
- 0x1B156, # .. 0x1B163 ; Unknown
- 0x1B164, # .. 0x1B167 ; Katakana
- 0x1B168, # .. 0x1B16F ; Unknown
- 0x1B170, # .. 0x1B2FB ; Nushu
- 0x1B2FC, # .. 0x1BBFF ; Unknown
- 0x1BC00, # .. 0x1BC6A ; Duployan
- 0x1BC6B, # .. 0x1BC6F ; Unknown
- 0x1BC70, # .. 0x1BC7C ; Duployan
- 0x1BC7D, # .. 0x1BC7F ; Unknown
- 0x1BC80, # .. 0x1BC88 ; Duployan
- 0x1BC89, # .. 0x1BC8F ; Unknown
- 0x1BC90, # .. 0x1BC99 ; Duployan
- 0x1BC9A, # .. 0x1BC9B ; Unknown
- 0x1BC9C, # .. 0x1BC9F ; Duployan
- 0x1BCA0, # .. 0x1BCA3 ; Common
- 0x1BCA4, # .. 0x1CEFF ; Unknown
- 0x1CF00, # .. 0x1CF2D ; Inherited
- 0x1CF2E, # .. 0x1CF2F ; Unknown
- 0x1CF30, # .. 0x1CF46 ; Inherited
- 0x1CF47, # .. 0x1CF4F ; Unknown
- 0x1CF50, # .. 0x1CFC3 ; Common
- 0x1CFC4, # .. 0x1CFFF ; Unknown
- 0x1D000, # .. 0x1D0F5 ; Common
- 0x1D0F6, # .. 0x1D0FF ; Unknown
- 0x1D100, # .. 0x1D126 ; Common
- 0x1D127, # .. 0x1D128 ; Unknown
- 0x1D129, # .. 0x1D166 ; Common
- 0x1D167, # .. 0x1D169 ; Inherited
- 0x1D16A, # .. 0x1D17A ; Common
- 0x1D17B, # .. 0x1D182 ; Inherited
- 0x1D183, # .. 0x1D184 ; Common
- 0x1D185, # .. 0x1D18B ; Inherited
- 0x1D18C, # .. 0x1D1A9 ; Common
- 0x1D1AA, # .. 0x1D1AD ; Inherited
- 0x1D1AE, # .. 0x1D1EA ; Common
- 0x1D1EB, # .. 0x1D1FF ; Unknown
- 0x1D200, # .. 0x1D245 ; Greek
- 0x1D246, # .. 0x1D2BF ; Unknown
- 0x1D2C0, # .. 0x1D2D3 ; Common
- 0x1D2D4, # .. 0x1D2DF ; Unknown
- 0x1D2E0, # .. 0x1D2F3 ; Common
- 0x1D2F4, # .. 0x1D2FF ; Unknown
- 0x1D300, # .. 0x1D356 ; Common
- 0x1D357, # .. 0x1D35F ; Unknown
- 0x1D360, # .. 0x1D378 ; Common
- 0x1D379, # .. 0x1D3FF ; Unknown
- 0x1D400, # .. 0x1D454 ; Common
- 0x1D455, # .. 0x1D455 ; Unknown
- 0x1D456, # .. 0x1D49C ; Common
- 0x1D49D, # .. 0x1D49D ; Unknown
- 0x1D49E, # .. 0x1D49F ; Common
- 0x1D4A0, # .. 0x1D4A1 ; Unknown
- 0x1D4A2, # .. 0x1D4A2 ; Common
- 0x1D4A3, # .. 0x1D4A4 ; Unknown
- 0x1D4A5, # .. 0x1D4A6 ; Common
- 0x1D4A7, # .. 0x1D4A8 ; Unknown
- 0x1D4A9, # .. 0x1D4AC ; Common
- 0x1D4AD, # .. 0x1D4AD ; Unknown
- 0x1D4AE, # .. 0x1D4B9 ; Common
- 0x1D4BA, # .. 0x1D4BA ; Unknown
- 0x1D4BB, # .. 0x1D4BB ; Common
- 0x1D4BC, # .. 0x1D4BC ; Unknown
- 0x1D4BD, # .. 0x1D4C3 ; Common
- 0x1D4C4, # .. 0x1D4C4 ; Unknown
- 0x1D4C5, # .. 0x1D505 ; Common
- 0x1D506, # .. 0x1D506 ; Unknown
- 0x1D507, # .. 0x1D50A ; Common
- 0x1D50B, # .. 0x1D50C ; Unknown
- 0x1D50D, # .. 0x1D514 ; Common
- 0x1D515, # .. 0x1D515 ; Unknown
- 0x1D516, # .. 0x1D51C ; Common
- 0x1D51D, # .. 0x1D51D ; Unknown
- 0x1D51E, # .. 0x1D539 ; Common
- 0x1D53A, # .. 0x1D53A ; Unknown
- 0x1D53B, # .. 0x1D53E ; Common
- 0x1D53F, # .. 0x1D53F ; Unknown
- 0x1D540, # .. 0x1D544 ; Common
- 0x1D545, # .. 0x1D545 ; Unknown
- 0x1D546, # .. 0x1D546 ; Common
- 0x1D547, # .. 0x1D549 ; Unknown
- 0x1D54A, # .. 0x1D550 ; Common
- 0x1D551, # .. 0x1D551 ; Unknown
- 0x1D552, # .. 0x1D6A5 ; Common
- 0x1D6A6, # .. 0x1D6A7 ; Unknown
- 0x1D6A8, # .. 0x1D7CB ; Common
- 0x1D7CC, # .. 0x1D7CD ; Unknown
- 0x1D7CE, # .. 0x1D7FF ; Common
- 0x1D800, # .. 0x1DA8B ; SignWriting
- 0x1DA8C, # .. 0x1DA9A ; Unknown
- 0x1DA9B, # .. 0x1DA9F ; SignWriting
- 0x1DAA0, # .. 0x1DAA0 ; Unknown
- 0x1DAA1, # .. 0x1DAAF ; SignWriting
- 0x1DAB0, # .. 0x1DEFF ; Unknown
- 0x1DF00, # .. 0x1DF1E ; Latin
- 0x1DF1F, # .. 0x1DF24 ; Unknown
- 0x1DF25, # .. 0x1DF2A ; Latin
- 0x1DF2B, # .. 0x1DFFF ; Unknown
- 0x1E000, # .. 0x1E006 ; Glagolitic
- 0x1E007, # .. 0x1E007 ; Unknown
- 0x1E008, # .. 0x1E018 ; Glagolitic
- 0x1E019, # .. 0x1E01A ; Unknown
- 0x1E01B, # .. 0x1E021 ; Glagolitic
- 0x1E022, # .. 0x1E022 ; Unknown
- 0x1E023, # .. 0x1E024 ; Glagolitic
- 0x1E025, # .. 0x1E025 ; Unknown
- 0x1E026, # .. 0x1E02A ; Glagolitic
- 0x1E02B, # .. 0x1E02F ; Unknown
- 0x1E030, # .. 0x1E06D ; Cyrillic
- 0x1E06E, # .. 0x1E08E ; Unknown
- 0x1E08F, # .. 0x1E08F ; Cyrillic
- 0x1E090, # .. 0x1E0FF ; Unknown
- 0x1E100, # .. 0x1E12C ; Nyiakeng_Puachue_Hmong
- 0x1E12D, # .. 0x1E12F ; Unknown
- 0x1E130, # .. 0x1E13D ; Nyiakeng_Puachue_Hmong
- 0x1E13E, # .. 0x1E13F ; Unknown
- 0x1E140, # .. 0x1E149 ; Nyiakeng_Puachue_Hmong
- 0x1E14A, # .. 0x1E14D ; Unknown
- 0x1E14E, # .. 0x1E14F ; Nyiakeng_Puachue_Hmong
- 0x1E150, # .. 0x1E28F ; Unknown
- 0x1E290, # .. 0x1E2AE ; Toto
- 0x1E2AF, # .. 0x1E2BF ; Unknown
- 0x1E2C0, # .. 0x1E2F9 ; Wancho
- 0x1E2FA, # .. 0x1E2FE ; Unknown
- 0x1E2FF, # .. 0x1E2FF ; Wancho
- 0x1E300, # .. 0x1E4CF ; Unknown
- 0x1E4D0, # .. 0x1E4F9 ; Nag_Mundari
- 0x1E4FA, # .. 0x1E7DF ; Unknown
- 0x1E7E0, # .. 0x1E7E6 ; Ethiopic
- 0x1E7E7, # .. 0x1E7E7 ; Unknown
- 0x1E7E8, # .. 0x1E7EB ; Ethiopic
- 0x1E7EC, # .. 0x1E7EC ; Unknown
- 0x1E7ED, # .. 0x1E7EE ; Ethiopic
- 0x1E7EF, # .. 0x1E7EF ; Unknown
- 0x1E7F0, # .. 0x1E7FE ; Ethiopic
- 0x1E7FF, # .. 0x1E7FF ; Unknown
- 0x1E800, # .. 0x1E8C4 ; Mende_Kikakui
- 0x1E8C5, # .. 0x1E8C6 ; Unknown
- 0x1E8C7, # .. 0x1E8D6 ; Mende_Kikakui
- 0x1E8D7, # .. 0x1E8FF ; Unknown
- 0x1E900, # .. 0x1E94B ; Adlam
- 0x1E94C, # .. 0x1E94F ; Unknown
- 0x1E950, # .. 0x1E959 ; Adlam
- 0x1E95A, # .. 0x1E95D ; Unknown
- 0x1E95E, # .. 0x1E95F ; Adlam
- 0x1E960, # .. 0x1EC70 ; Unknown
- 0x1EC71, # .. 0x1ECB4 ; Common
- 0x1ECB5, # .. 0x1ED00 ; Unknown
- 0x1ED01, # .. 0x1ED3D ; Common
- 0x1ED3E, # .. 0x1EDFF ; Unknown
- 0x1EE00, # .. 0x1EE03 ; Arabic
- 0x1EE04, # .. 0x1EE04 ; Unknown
- 0x1EE05, # .. 0x1EE1F ; Arabic
- 0x1EE20, # .. 0x1EE20 ; Unknown
- 0x1EE21, # .. 0x1EE22 ; Arabic
- 0x1EE23, # .. 0x1EE23 ; Unknown
- 0x1EE24, # .. 0x1EE24 ; Arabic
- 0x1EE25, # .. 0x1EE26 ; Unknown
- 0x1EE27, # .. 0x1EE27 ; Arabic
- 0x1EE28, # .. 0x1EE28 ; Unknown
- 0x1EE29, # .. 0x1EE32 ; Arabic
- 0x1EE33, # .. 0x1EE33 ; Unknown
- 0x1EE34, # .. 0x1EE37 ; Arabic
- 0x1EE38, # .. 0x1EE38 ; Unknown
- 0x1EE39, # .. 0x1EE39 ; Arabic
- 0x1EE3A, # .. 0x1EE3A ; Unknown
- 0x1EE3B, # .. 0x1EE3B ; Arabic
- 0x1EE3C, # .. 0x1EE41 ; Unknown
- 0x1EE42, # .. 0x1EE42 ; Arabic
- 0x1EE43, # .. 0x1EE46 ; Unknown
- 0x1EE47, # .. 0x1EE47 ; Arabic
- 0x1EE48, # .. 0x1EE48 ; Unknown
- 0x1EE49, # .. 0x1EE49 ; Arabic
- 0x1EE4A, # .. 0x1EE4A ; Unknown
- 0x1EE4B, # .. 0x1EE4B ; Arabic
- 0x1EE4C, # .. 0x1EE4C ; Unknown
- 0x1EE4D, # .. 0x1EE4F ; Arabic
- 0x1EE50, # .. 0x1EE50 ; Unknown
- 0x1EE51, # .. 0x1EE52 ; Arabic
- 0x1EE53, # .. 0x1EE53 ; Unknown
- 0x1EE54, # .. 0x1EE54 ; Arabic
- 0x1EE55, # .. 0x1EE56 ; Unknown
- 0x1EE57, # .. 0x1EE57 ; Arabic
- 0x1EE58, # .. 0x1EE58 ; Unknown
- 0x1EE59, # .. 0x1EE59 ; Arabic
- 0x1EE5A, # .. 0x1EE5A ; Unknown
- 0x1EE5B, # .. 0x1EE5B ; Arabic
- 0x1EE5C, # .. 0x1EE5C ; Unknown
- 0x1EE5D, # .. 0x1EE5D ; Arabic
- 0x1EE5E, # .. 0x1EE5E ; Unknown
- 0x1EE5F, # .. 0x1EE5F ; Arabic
- 0x1EE60, # .. 0x1EE60 ; Unknown
- 0x1EE61, # .. 0x1EE62 ; Arabic
- 0x1EE63, # .. 0x1EE63 ; Unknown
- 0x1EE64, # .. 0x1EE64 ; Arabic
- 0x1EE65, # .. 0x1EE66 ; Unknown
- 0x1EE67, # .. 0x1EE6A ; Arabic
- 0x1EE6B, # .. 0x1EE6B ; Unknown
- 0x1EE6C, # .. 0x1EE72 ; Arabic
- 0x1EE73, # .. 0x1EE73 ; Unknown
- 0x1EE74, # .. 0x1EE77 ; Arabic
- 0x1EE78, # .. 0x1EE78 ; Unknown
- 0x1EE79, # .. 0x1EE7C ; Arabic
- 0x1EE7D, # .. 0x1EE7D ; Unknown
- 0x1EE7E, # .. 0x1EE7E ; Arabic
- 0x1EE7F, # .. 0x1EE7F ; Unknown
- 0x1EE80, # .. 0x1EE89 ; Arabic
- 0x1EE8A, # .. 0x1EE8A ; Unknown
- 0x1EE8B, # .. 0x1EE9B ; Arabic
- 0x1EE9C, # .. 0x1EEA0 ; Unknown
- 0x1EEA1, # .. 0x1EEA3 ; Arabic
- 0x1EEA4, # .. 0x1EEA4 ; Unknown
- 0x1EEA5, # .. 0x1EEA9 ; Arabic
- 0x1EEAA, # .. 0x1EEAA ; Unknown
- 0x1EEAB, # .. 0x1EEBB ; Arabic
- 0x1EEBC, # .. 0x1EEEF ; Unknown
- 0x1EEF0, # .. 0x1EEF1 ; Arabic
- 0x1EEF2, # .. 0x1EFFF ; Unknown
- 0x1F000, # .. 0x1F02B ; Common
- 0x1F02C, # .. 0x1F02F ; Unknown
- 0x1F030, # .. 0x1F093 ; Common
- 0x1F094, # .. 0x1F09F ; Unknown
- 0x1F0A0, # .. 0x1F0AE ; Common
- 0x1F0AF, # .. 0x1F0B0 ; Unknown
- 0x1F0B1, # .. 0x1F0BF ; Common
- 0x1F0C0, # .. 0x1F0C0 ; Unknown
- 0x1F0C1, # .. 0x1F0CF ; Common
- 0x1F0D0, # .. 0x1F0D0 ; Unknown
- 0x1F0D1, # .. 0x1F0F5 ; Common
- 0x1F0F6, # .. 0x1F0FF ; Unknown
- 0x1F100, # .. 0x1F1AD ; Common
- 0x1F1AE, # .. 0x1F1E5 ; Unknown
- 0x1F1E6, # .. 0x1F1FF ; Common
- 0x1F200, # .. 0x1F200 ; Hiragana
- 0x1F201, # .. 0x1F202 ; Common
- 0x1F203, # .. 0x1F20F ; Unknown
- 0x1F210, # .. 0x1F23B ; Common
- 0x1F23C, # .. 0x1F23F ; Unknown
- 0x1F240, # .. 0x1F248 ; Common
- 0x1F249, # .. 0x1F24F ; Unknown
- 0x1F250, # .. 0x1F251 ; Common
- 0x1F252, # .. 0x1F25F ; Unknown
- 0x1F260, # .. 0x1F265 ; Common
- 0x1F266, # .. 0x1F2FF ; Unknown
- 0x1F300, # .. 0x1F6D7 ; Common
- 0x1F6D8, # .. 0x1F6DB ; Unknown
- 0x1F6DC, # .. 0x1F6EC ; Common
- 0x1F6ED, # .. 0x1F6EF ; Unknown
- 0x1F6F0, # .. 0x1F6FC ; Common
- 0x1F6FD, # .. 0x1F6FF ; Unknown
- 0x1F700, # .. 0x1F776 ; Common
- 0x1F777, # .. 0x1F77A ; Unknown
- 0x1F77B, # .. 0x1F7D9 ; Common
- 0x1F7DA, # .. 0x1F7DF ; Unknown
- 0x1F7E0, # .. 0x1F7EB ; Common
- 0x1F7EC, # .. 0x1F7EF ; Unknown
- 0x1F7F0, # .. 0x1F7F0 ; Common
- 0x1F7F1, # .. 0x1F7FF ; Unknown
- 0x1F800, # .. 0x1F80B ; Common
- 0x1F80C, # .. 0x1F80F ; Unknown
- 0x1F810, # .. 0x1F847 ; Common
- 0x1F848, # .. 0x1F84F ; Unknown
- 0x1F850, # .. 0x1F859 ; Common
- 0x1F85A, # .. 0x1F85F ; Unknown
- 0x1F860, # .. 0x1F887 ; Common
- 0x1F888, # .. 0x1F88F ; Unknown
- 0x1F890, # .. 0x1F8AD ; Common
- 0x1F8AE, # .. 0x1F8AF ; Unknown
- 0x1F8B0, # .. 0x1F8B1 ; Common
- 0x1F8B2, # .. 0x1F8FF ; Unknown
- 0x1F900, # .. 0x1FA53 ; Common
- 0x1FA54, # .. 0x1FA5F ; Unknown
- 0x1FA60, # .. 0x1FA6D ; Common
- 0x1FA6E, # .. 0x1FA6F ; Unknown
- 0x1FA70, # .. 0x1FA7C ; Common
- 0x1FA7D, # .. 0x1FA7F ; Unknown
- 0x1FA80, # .. 0x1FA88 ; Common
- 0x1FA89, # .. 0x1FA8F ; Unknown
- 0x1FA90, # .. 0x1FABD ; Common
- 0x1FABE, # .. 0x1FABE ; Unknown
- 0x1FABF, # .. 0x1FAC5 ; Common
- 0x1FAC6, # .. 0x1FACD ; Unknown
- 0x1FACE, # .. 0x1FADB ; Common
- 0x1FADC, # .. 0x1FADF ; Unknown
- 0x1FAE0, # .. 0x1FAE8 ; Common
- 0x1FAE9, # .. 0x1FAEF ; Unknown
- 0x1FAF0, # .. 0x1FAF8 ; Common
- 0x1FAF9, # .. 0x1FAFF ; Unknown
- 0x1FB00, # .. 0x1FB92 ; Common
- 0x1FB93, # .. 0x1FB93 ; Unknown
- 0x1FB94, # .. 0x1FBCA ; Common
- 0x1FBCB, # .. 0x1FBEF ; Unknown
- 0x1FBF0, # .. 0x1FBF9 ; Common
- 0x1FBFA, # .. 0x1FFFF ; Unknown
- 0x20000, # .. 0x2A6DF ; Han
- 0x2A6E0, # .. 0x2A6FF ; Unknown
- 0x2A700, # .. 0x2B739 ; Han
- 0x2B73A, # .. 0x2B73F ; Unknown
- 0x2B740, # .. 0x2B81D ; Han
- 0x2B81E, # .. 0x2B81F ; Unknown
- 0x2B820, # .. 0x2CEA1 ; Han
- 0x2CEA2, # .. 0x2CEAF ; Unknown
- 0x2CEB0, # .. 0x2EBE0 ; Han
- 0x2EBE1, # .. 0x2F7FF ; Unknown
- 0x2F800, # .. 0x2FA1D ; Han
- 0x2FA1E, # .. 0x2FFFF ; Unknown
- 0x30000, # .. 0x3134A ; Han
- 0x3134B, # .. 0x3134F ; Unknown
- 0x31350, # .. 0x323AF ; Han
- 0x323B0, # .. 0xE0000 ; Unknown
- 0xE0001, # .. 0xE0001 ; Common
- 0xE0002, # .. 0xE001F ; Unknown
- 0xE0020, # .. 0xE007F ; Common
- 0xE0080, # .. 0xE00FF ; Unknown
- 0xE0100, # .. 0xE01EF ; Inherited
- 0xE01F0, # .. 0x10FFFF ; Unknown
-]
-
-VALUES = [
- "Zyyy", # 0000..0040 ; Common
- "Latn", # 0041..005A ; Latin
- "Zyyy", # 005B..0060 ; Common
- "Latn", # 0061..007A ; Latin
- "Zyyy", # 007B..00A9 ; Common
- "Latn", # 00AA..00AA ; Latin
- "Zyyy", # 00AB..00B9 ; Common
- "Latn", # 00BA..00BA ; Latin
- "Zyyy", # 00BB..00BF ; Common
- "Latn", # 00C0..00D6 ; Latin
- "Zyyy", # 00D7..00D7 ; Common
- "Latn", # 00D8..00F6 ; Latin
- "Zyyy", # 00F7..00F7 ; Common
- "Latn", # 00F8..02B8 ; Latin
- "Zyyy", # 02B9..02DF ; Common
- "Latn", # 02E0..02E4 ; Latin
- "Zyyy", # 02E5..02E9 ; Common
- "Bopo", # 02EA..02EB ; Bopomofo
- "Zyyy", # 02EC..02FF ; Common
- "Zinh", # 0300..036F ; Inherited
- "Grek", # 0370..0373 ; Greek
- "Zyyy", # 0374..0374 ; Common
- "Grek", # 0375..0377 ; Greek
- "Zzzz", # 0378..0379 ; Unknown
- "Grek", # 037A..037D ; Greek
- "Zyyy", # 037E..037E ; Common
- "Grek", # 037F..037F ; Greek
- "Zzzz", # 0380..0383 ; Unknown
- "Grek", # 0384..0384 ; Greek
- "Zyyy", # 0385..0385 ; Common
- "Grek", # 0386..0386 ; Greek
- "Zyyy", # 0387..0387 ; Common
- "Grek", # 0388..038A ; Greek
- "Zzzz", # 038B..038B ; Unknown
- "Grek", # 038C..038C ; Greek
- "Zzzz", # 038D..038D ; Unknown
- "Grek", # 038E..03A1 ; Greek
- "Zzzz", # 03A2..03A2 ; Unknown
- "Grek", # 03A3..03E1 ; Greek
- "Copt", # 03E2..03EF ; Coptic
- "Grek", # 03F0..03FF ; Greek
- "Cyrl", # 0400..0484 ; Cyrillic
- "Zinh", # 0485..0486 ; Inherited
- "Cyrl", # 0487..052F ; Cyrillic
- "Zzzz", # 0530..0530 ; Unknown
- "Armn", # 0531..0556 ; Armenian
- "Zzzz", # 0557..0558 ; Unknown
- "Armn", # 0559..058A ; Armenian
- "Zzzz", # 058B..058C ; Unknown
- "Armn", # 058D..058F ; Armenian
- "Zzzz", # 0590..0590 ; Unknown
- "Hebr", # 0591..05C7 ; Hebrew
- "Zzzz", # 05C8..05CF ; Unknown
- "Hebr", # 05D0..05EA ; Hebrew
- "Zzzz", # 05EB..05EE ; Unknown
- "Hebr", # 05EF..05F4 ; Hebrew
- "Zzzz", # 05F5..05FF ; Unknown
- "Arab", # 0600..0604 ; Arabic
- "Zyyy", # 0605..0605 ; Common
- "Arab", # 0606..060B ; Arabic
- "Zyyy", # 060C..060C ; Common
- "Arab", # 060D..061A ; Arabic
- "Zyyy", # 061B..061B ; Common
- "Arab", # 061C..061E ; Arabic
- "Zyyy", # 061F..061F ; Common
- "Arab", # 0620..063F ; Arabic
- "Zyyy", # 0640..0640 ; Common
- "Arab", # 0641..064A ; Arabic
- "Zinh", # 064B..0655 ; Inherited
- "Arab", # 0656..066F ; Arabic
- "Zinh", # 0670..0670 ; Inherited
- "Arab", # 0671..06DC ; Arabic
- "Zyyy", # 06DD..06DD ; Common
- "Arab", # 06DE..06FF ; Arabic
- "Syrc", # 0700..070D ; Syriac
- "Zzzz", # 070E..070E ; Unknown
- "Syrc", # 070F..074A ; Syriac
- "Zzzz", # 074B..074C ; Unknown
- "Syrc", # 074D..074F ; Syriac
- "Arab", # 0750..077F ; Arabic
- "Thaa", # 0780..07B1 ; Thaana
- "Zzzz", # 07B2..07BF ; Unknown
- "Nkoo", # 07C0..07FA ; Nko
- "Zzzz", # 07FB..07FC ; Unknown
- "Nkoo", # 07FD..07FF ; Nko
- "Samr", # 0800..082D ; Samaritan
- "Zzzz", # 082E..082F ; Unknown
- "Samr", # 0830..083E ; Samaritan
- "Zzzz", # 083F..083F ; Unknown
- "Mand", # 0840..085B ; Mandaic
- "Zzzz", # 085C..085D ; Unknown
- "Mand", # 085E..085E ; Mandaic
- "Zzzz", # 085F..085F ; Unknown
- "Syrc", # 0860..086A ; Syriac
- "Zzzz", # 086B..086F ; Unknown
- "Arab", # 0870..088E ; Arabic
- "Zzzz", # 088F..088F ; Unknown
- "Arab", # 0890..0891 ; Arabic
- "Zzzz", # 0892..0897 ; Unknown
- "Arab", # 0898..08E1 ; Arabic
- "Zyyy", # 08E2..08E2 ; Common
- "Arab", # 08E3..08FF ; Arabic
- "Deva", # 0900..0950 ; Devanagari
- "Zinh", # 0951..0954 ; Inherited
- "Deva", # 0955..0963 ; Devanagari
- "Zyyy", # 0964..0965 ; Common
- "Deva", # 0966..097F ; Devanagari
- "Beng", # 0980..0983 ; Bengali
- "Zzzz", # 0984..0984 ; Unknown
- "Beng", # 0985..098C ; Bengali
- "Zzzz", # 098D..098E ; Unknown
- "Beng", # 098F..0990 ; Bengali
- "Zzzz", # 0991..0992 ; Unknown
- "Beng", # 0993..09A8 ; Bengali
- "Zzzz", # 09A9..09A9 ; Unknown
- "Beng", # 09AA..09B0 ; Bengali
- "Zzzz", # 09B1..09B1 ; Unknown
- "Beng", # 09B2..09B2 ; Bengali
- "Zzzz", # 09B3..09B5 ; Unknown
- "Beng", # 09B6..09B9 ; Bengali
- "Zzzz", # 09BA..09BB ; Unknown
- "Beng", # 09BC..09C4 ; Bengali
- "Zzzz", # 09C5..09C6 ; Unknown
- "Beng", # 09C7..09C8 ; Bengali
- "Zzzz", # 09C9..09CA ; Unknown
- "Beng", # 09CB..09CE ; Bengali
- "Zzzz", # 09CF..09D6 ; Unknown
- "Beng", # 09D7..09D7 ; Bengali
- "Zzzz", # 09D8..09DB ; Unknown
- "Beng", # 09DC..09DD ; Bengali
- "Zzzz", # 09DE..09DE ; Unknown
- "Beng", # 09DF..09E3 ; Bengali
- "Zzzz", # 09E4..09E5 ; Unknown
- "Beng", # 09E6..09FE ; Bengali
- "Zzzz", # 09FF..0A00 ; Unknown
- "Guru", # 0A01..0A03 ; Gurmukhi
- "Zzzz", # 0A04..0A04 ; Unknown
- "Guru", # 0A05..0A0A ; Gurmukhi
- "Zzzz", # 0A0B..0A0E ; Unknown
- "Guru", # 0A0F..0A10 ; Gurmukhi
- "Zzzz", # 0A11..0A12 ; Unknown
- "Guru", # 0A13..0A28 ; Gurmukhi
- "Zzzz", # 0A29..0A29 ; Unknown
- "Guru", # 0A2A..0A30 ; Gurmukhi
- "Zzzz", # 0A31..0A31 ; Unknown
- "Guru", # 0A32..0A33 ; Gurmukhi
- "Zzzz", # 0A34..0A34 ; Unknown
- "Guru", # 0A35..0A36 ; Gurmukhi
- "Zzzz", # 0A37..0A37 ; Unknown
- "Guru", # 0A38..0A39 ; Gurmukhi
- "Zzzz", # 0A3A..0A3B ; Unknown
- "Guru", # 0A3C..0A3C ; Gurmukhi
- "Zzzz", # 0A3D..0A3D ; Unknown
- "Guru", # 0A3E..0A42 ; Gurmukhi
- "Zzzz", # 0A43..0A46 ; Unknown
- "Guru", # 0A47..0A48 ; Gurmukhi
- "Zzzz", # 0A49..0A4A ; Unknown
- "Guru", # 0A4B..0A4D ; Gurmukhi
- "Zzzz", # 0A4E..0A50 ; Unknown
- "Guru", # 0A51..0A51 ; Gurmukhi
- "Zzzz", # 0A52..0A58 ; Unknown
- "Guru", # 0A59..0A5C ; Gurmukhi
- "Zzzz", # 0A5D..0A5D ; Unknown
- "Guru", # 0A5E..0A5E ; Gurmukhi
- "Zzzz", # 0A5F..0A65 ; Unknown
- "Guru", # 0A66..0A76 ; Gurmukhi
- "Zzzz", # 0A77..0A80 ; Unknown
- "Gujr", # 0A81..0A83 ; Gujarati
- "Zzzz", # 0A84..0A84 ; Unknown
- "Gujr", # 0A85..0A8D ; Gujarati
- "Zzzz", # 0A8E..0A8E ; Unknown
- "Gujr", # 0A8F..0A91 ; Gujarati
- "Zzzz", # 0A92..0A92 ; Unknown
- "Gujr", # 0A93..0AA8 ; Gujarati
- "Zzzz", # 0AA9..0AA9 ; Unknown
- "Gujr", # 0AAA..0AB0 ; Gujarati
- "Zzzz", # 0AB1..0AB1 ; Unknown
- "Gujr", # 0AB2..0AB3 ; Gujarati
- "Zzzz", # 0AB4..0AB4 ; Unknown
- "Gujr", # 0AB5..0AB9 ; Gujarati
- "Zzzz", # 0ABA..0ABB ; Unknown
- "Gujr", # 0ABC..0AC5 ; Gujarati
- "Zzzz", # 0AC6..0AC6 ; Unknown
- "Gujr", # 0AC7..0AC9 ; Gujarati
- "Zzzz", # 0ACA..0ACA ; Unknown
- "Gujr", # 0ACB..0ACD ; Gujarati
- "Zzzz", # 0ACE..0ACF ; Unknown
- "Gujr", # 0AD0..0AD0 ; Gujarati
- "Zzzz", # 0AD1..0ADF ; Unknown
- "Gujr", # 0AE0..0AE3 ; Gujarati
- "Zzzz", # 0AE4..0AE5 ; Unknown
- "Gujr", # 0AE6..0AF1 ; Gujarati
- "Zzzz", # 0AF2..0AF8 ; Unknown
- "Gujr", # 0AF9..0AFF ; Gujarati
- "Zzzz", # 0B00..0B00 ; Unknown
- "Orya", # 0B01..0B03 ; Oriya
- "Zzzz", # 0B04..0B04 ; Unknown
- "Orya", # 0B05..0B0C ; Oriya
- "Zzzz", # 0B0D..0B0E ; Unknown
- "Orya", # 0B0F..0B10 ; Oriya
- "Zzzz", # 0B11..0B12 ; Unknown
- "Orya", # 0B13..0B28 ; Oriya
- "Zzzz", # 0B29..0B29 ; Unknown
- "Orya", # 0B2A..0B30 ; Oriya
- "Zzzz", # 0B31..0B31 ; Unknown
- "Orya", # 0B32..0B33 ; Oriya
- "Zzzz", # 0B34..0B34 ; Unknown
- "Orya", # 0B35..0B39 ; Oriya
- "Zzzz", # 0B3A..0B3B ; Unknown
- "Orya", # 0B3C..0B44 ; Oriya
- "Zzzz", # 0B45..0B46 ; Unknown
- "Orya", # 0B47..0B48 ; Oriya
- "Zzzz", # 0B49..0B4A ; Unknown
- "Orya", # 0B4B..0B4D ; Oriya
- "Zzzz", # 0B4E..0B54 ; Unknown
- "Orya", # 0B55..0B57 ; Oriya
- "Zzzz", # 0B58..0B5B ; Unknown
- "Orya", # 0B5C..0B5D ; Oriya
- "Zzzz", # 0B5E..0B5E ; Unknown
- "Orya", # 0B5F..0B63 ; Oriya
- "Zzzz", # 0B64..0B65 ; Unknown
- "Orya", # 0B66..0B77 ; Oriya
- "Zzzz", # 0B78..0B81 ; Unknown
- "Taml", # 0B82..0B83 ; Tamil
- "Zzzz", # 0B84..0B84 ; Unknown
- "Taml", # 0B85..0B8A ; Tamil
- "Zzzz", # 0B8B..0B8D ; Unknown
- "Taml", # 0B8E..0B90 ; Tamil
- "Zzzz", # 0B91..0B91 ; Unknown
- "Taml", # 0B92..0B95 ; Tamil
- "Zzzz", # 0B96..0B98 ; Unknown
- "Taml", # 0B99..0B9A ; Tamil
- "Zzzz", # 0B9B..0B9B ; Unknown
- "Taml", # 0B9C..0B9C ; Tamil
- "Zzzz", # 0B9D..0B9D ; Unknown
- "Taml", # 0B9E..0B9F ; Tamil
- "Zzzz", # 0BA0..0BA2 ; Unknown
- "Taml", # 0BA3..0BA4 ; Tamil
- "Zzzz", # 0BA5..0BA7 ; Unknown
- "Taml", # 0BA8..0BAA ; Tamil
- "Zzzz", # 0BAB..0BAD ; Unknown
- "Taml", # 0BAE..0BB9 ; Tamil
- "Zzzz", # 0BBA..0BBD ; Unknown
- "Taml", # 0BBE..0BC2 ; Tamil
- "Zzzz", # 0BC3..0BC5 ; Unknown
- "Taml", # 0BC6..0BC8 ; Tamil
- "Zzzz", # 0BC9..0BC9 ; Unknown
- "Taml", # 0BCA..0BCD ; Tamil
- "Zzzz", # 0BCE..0BCF ; Unknown
- "Taml", # 0BD0..0BD0 ; Tamil
- "Zzzz", # 0BD1..0BD6 ; Unknown
- "Taml", # 0BD7..0BD7 ; Tamil
- "Zzzz", # 0BD8..0BE5 ; Unknown
- "Taml", # 0BE6..0BFA ; Tamil
- "Zzzz", # 0BFB..0BFF ; Unknown
- "Telu", # 0C00..0C0C ; Telugu
- "Zzzz", # 0C0D..0C0D ; Unknown
- "Telu", # 0C0E..0C10 ; Telugu
- "Zzzz", # 0C11..0C11 ; Unknown
- "Telu", # 0C12..0C28 ; Telugu
- "Zzzz", # 0C29..0C29 ; Unknown
- "Telu", # 0C2A..0C39 ; Telugu
- "Zzzz", # 0C3A..0C3B ; Unknown
- "Telu", # 0C3C..0C44 ; Telugu
- "Zzzz", # 0C45..0C45 ; Unknown
- "Telu", # 0C46..0C48 ; Telugu
- "Zzzz", # 0C49..0C49 ; Unknown
- "Telu", # 0C4A..0C4D ; Telugu
- "Zzzz", # 0C4E..0C54 ; Unknown
- "Telu", # 0C55..0C56 ; Telugu
- "Zzzz", # 0C57..0C57 ; Unknown
- "Telu", # 0C58..0C5A ; Telugu
- "Zzzz", # 0C5B..0C5C ; Unknown
- "Telu", # 0C5D..0C5D ; Telugu
- "Zzzz", # 0C5E..0C5F ; Unknown
- "Telu", # 0C60..0C63 ; Telugu
- "Zzzz", # 0C64..0C65 ; Unknown
- "Telu", # 0C66..0C6F ; Telugu
- "Zzzz", # 0C70..0C76 ; Unknown
- "Telu", # 0C77..0C7F ; Telugu
- "Knda", # 0C80..0C8C ; Kannada
- "Zzzz", # 0C8D..0C8D ; Unknown
- "Knda", # 0C8E..0C90 ; Kannada
- "Zzzz", # 0C91..0C91 ; Unknown
- "Knda", # 0C92..0CA8 ; Kannada
- "Zzzz", # 0CA9..0CA9 ; Unknown
- "Knda", # 0CAA..0CB3 ; Kannada
- "Zzzz", # 0CB4..0CB4 ; Unknown
- "Knda", # 0CB5..0CB9 ; Kannada
- "Zzzz", # 0CBA..0CBB ; Unknown
- "Knda", # 0CBC..0CC4 ; Kannada
- "Zzzz", # 0CC5..0CC5 ; Unknown
- "Knda", # 0CC6..0CC8 ; Kannada
- "Zzzz", # 0CC9..0CC9 ; Unknown
- "Knda", # 0CCA..0CCD ; Kannada
- "Zzzz", # 0CCE..0CD4 ; Unknown
- "Knda", # 0CD5..0CD6 ; Kannada
- "Zzzz", # 0CD7..0CDC ; Unknown
- "Knda", # 0CDD..0CDE ; Kannada
- "Zzzz", # 0CDF..0CDF ; Unknown
- "Knda", # 0CE0..0CE3 ; Kannada
- "Zzzz", # 0CE4..0CE5 ; Unknown
- "Knda", # 0CE6..0CEF ; Kannada
- "Zzzz", # 0CF0..0CF0 ; Unknown
- "Knda", # 0CF1..0CF3 ; Kannada
- "Zzzz", # 0CF4..0CFF ; Unknown
- "Mlym", # 0D00..0D0C ; Malayalam
- "Zzzz", # 0D0D..0D0D ; Unknown
- "Mlym", # 0D0E..0D10 ; Malayalam
- "Zzzz", # 0D11..0D11 ; Unknown
- "Mlym", # 0D12..0D44 ; Malayalam
- "Zzzz", # 0D45..0D45 ; Unknown
- "Mlym", # 0D46..0D48 ; Malayalam
- "Zzzz", # 0D49..0D49 ; Unknown
- "Mlym", # 0D4A..0D4F ; Malayalam
- "Zzzz", # 0D50..0D53 ; Unknown
- "Mlym", # 0D54..0D63 ; Malayalam
- "Zzzz", # 0D64..0D65 ; Unknown
- "Mlym", # 0D66..0D7F ; Malayalam
- "Zzzz", # 0D80..0D80 ; Unknown
- "Sinh", # 0D81..0D83 ; Sinhala
- "Zzzz", # 0D84..0D84 ; Unknown
- "Sinh", # 0D85..0D96 ; Sinhala
- "Zzzz", # 0D97..0D99 ; Unknown
- "Sinh", # 0D9A..0DB1 ; Sinhala
- "Zzzz", # 0DB2..0DB2 ; Unknown
- "Sinh", # 0DB3..0DBB ; Sinhala
- "Zzzz", # 0DBC..0DBC ; Unknown
- "Sinh", # 0DBD..0DBD ; Sinhala
- "Zzzz", # 0DBE..0DBF ; Unknown
- "Sinh", # 0DC0..0DC6 ; Sinhala
- "Zzzz", # 0DC7..0DC9 ; Unknown
- "Sinh", # 0DCA..0DCA ; Sinhala
- "Zzzz", # 0DCB..0DCE ; Unknown
- "Sinh", # 0DCF..0DD4 ; Sinhala
- "Zzzz", # 0DD5..0DD5 ; Unknown
- "Sinh", # 0DD6..0DD6 ; Sinhala
- "Zzzz", # 0DD7..0DD7 ; Unknown
- "Sinh", # 0DD8..0DDF ; Sinhala
- "Zzzz", # 0DE0..0DE5 ; Unknown
- "Sinh", # 0DE6..0DEF ; Sinhala
- "Zzzz", # 0DF0..0DF1 ; Unknown
- "Sinh", # 0DF2..0DF4 ; Sinhala
- "Zzzz", # 0DF5..0E00 ; Unknown
- "Thai", # 0E01..0E3A ; Thai
- "Zzzz", # 0E3B..0E3E ; Unknown
- "Zyyy", # 0E3F..0E3F ; Common
- "Thai", # 0E40..0E5B ; Thai
- "Zzzz", # 0E5C..0E80 ; Unknown
- "Laoo", # 0E81..0E82 ; Lao
- "Zzzz", # 0E83..0E83 ; Unknown
- "Laoo", # 0E84..0E84 ; Lao
- "Zzzz", # 0E85..0E85 ; Unknown
- "Laoo", # 0E86..0E8A ; Lao
- "Zzzz", # 0E8B..0E8B ; Unknown
- "Laoo", # 0E8C..0EA3 ; Lao
- "Zzzz", # 0EA4..0EA4 ; Unknown
- "Laoo", # 0EA5..0EA5 ; Lao
- "Zzzz", # 0EA6..0EA6 ; Unknown
- "Laoo", # 0EA7..0EBD ; Lao
- "Zzzz", # 0EBE..0EBF ; Unknown
- "Laoo", # 0EC0..0EC4 ; Lao
- "Zzzz", # 0EC5..0EC5 ; Unknown
- "Laoo", # 0EC6..0EC6 ; Lao
- "Zzzz", # 0EC7..0EC7 ; Unknown
- "Laoo", # 0EC8..0ECE ; Lao
- "Zzzz", # 0ECF..0ECF ; Unknown
- "Laoo", # 0ED0..0ED9 ; Lao
- "Zzzz", # 0EDA..0EDB ; Unknown
- "Laoo", # 0EDC..0EDF ; Lao
- "Zzzz", # 0EE0..0EFF ; Unknown
- "Tibt", # 0F00..0F47 ; Tibetan
- "Zzzz", # 0F48..0F48 ; Unknown
- "Tibt", # 0F49..0F6C ; Tibetan
- "Zzzz", # 0F6D..0F70 ; Unknown
- "Tibt", # 0F71..0F97 ; Tibetan
- "Zzzz", # 0F98..0F98 ; Unknown
- "Tibt", # 0F99..0FBC ; Tibetan
- "Zzzz", # 0FBD..0FBD ; Unknown
- "Tibt", # 0FBE..0FCC ; Tibetan
- "Zzzz", # 0FCD..0FCD ; Unknown
- "Tibt", # 0FCE..0FD4 ; Tibetan
- "Zyyy", # 0FD5..0FD8 ; Common
- "Tibt", # 0FD9..0FDA ; Tibetan
- "Zzzz", # 0FDB..0FFF ; Unknown
- "Mymr", # 1000..109F ; Myanmar
- "Geor", # 10A0..10C5 ; Georgian
- "Zzzz", # 10C6..10C6 ; Unknown
- "Geor", # 10C7..10C7 ; Georgian
- "Zzzz", # 10C8..10CC ; Unknown
- "Geor", # 10CD..10CD ; Georgian
- "Zzzz", # 10CE..10CF ; Unknown
- "Geor", # 10D0..10FA ; Georgian
- "Zyyy", # 10FB..10FB ; Common
- "Geor", # 10FC..10FF ; Georgian
- "Hang", # 1100..11FF ; Hangul
- "Ethi", # 1200..1248 ; Ethiopic
- "Zzzz", # 1249..1249 ; Unknown
- "Ethi", # 124A..124D ; Ethiopic
- "Zzzz", # 124E..124F ; Unknown
- "Ethi", # 1250..1256 ; Ethiopic
- "Zzzz", # 1257..1257 ; Unknown
- "Ethi", # 1258..1258 ; Ethiopic
- "Zzzz", # 1259..1259 ; Unknown
- "Ethi", # 125A..125D ; Ethiopic
- "Zzzz", # 125E..125F ; Unknown
- "Ethi", # 1260..1288 ; Ethiopic
- "Zzzz", # 1289..1289 ; Unknown
- "Ethi", # 128A..128D ; Ethiopic
- "Zzzz", # 128E..128F ; Unknown
- "Ethi", # 1290..12B0 ; Ethiopic
- "Zzzz", # 12B1..12B1 ; Unknown
- "Ethi", # 12B2..12B5 ; Ethiopic
- "Zzzz", # 12B6..12B7 ; Unknown
- "Ethi", # 12B8..12BE ; Ethiopic
- "Zzzz", # 12BF..12BF ; Unknown
- "Ethi", # 12C0..12C0 ; Ethiopic
- "Zzzz", # 12C1..12C1 ; Unknown
- "Ethi", # 12C2..12C5 ; Ethiopic
- "Zzzz", # 12C6..12C7 ; Unknown
- "Ethi", # 12C8..12D6 ; Ethiopic
- "Zzzz", # 12D7..12D7 ; Unknown
- "Ethi", # 12D8..1310 ; Ethiopic
- "Zzzz", # 1311..1311 ; Unknown
- "Ethi", # 1312..1315 ; Ethiopic
- "Zzzz", # 1316..1317 ; Unknown
- "Ethi", # 1318..135A ; Ethiopic
- "Zzzz", # 135B..135C ; Unknown
- "Ethi", # 135D..137C ; Ethiopic
- "Zzzz", # 137D..137F ; Unknown
- "Ethi", # 1380..1399 ; Ethiopic
- "Zzzz", # 139A..139F ; Unknown
- "Cher", # 13A0..13F5 ; Cherokee
- "Zzzz", # 13F6..13F7 ; Unknown
- "Cher", # 13F8..13FD ; Cherokee
- "Zzzz", # 13FE..13FF ; Unknown
- "Cans", # 1400..167F ; Canadian_Aboriginal
- "Ogam", # 1680..169C ; Ogham
- "Zzzz", # 169D..169F ; Unknown
- "Runr", # 16A0..16EA ; Runic
- "Zyyy", # 16EB..16ED ; Common
- "Runr", # 16EE..16F8 ; Runic
- "Zzzz", # 16F9..16FF ; Unknown
- "Tglg", # 1700..1715 ; Tagalog
- "Zzzz", # 1716..171E ; Unknown
- "Tglg", # 171F..171F ; Tagalog
- "Hano", # 1720..1734 ; Hanunoo
- "Zyyy", # 1735..1736 ; Common
- "Zzzz", # 1737..173F ; Unknown
- "Buhd", # 1740..1753 ; Buhid
- "Zzzz", # 1754..175F ; Unknown
- "Tagb", # 1760..176C ; Tagbanwa
- "Zzzz", # 176D..176D ; Unknown
- "Tagb", # 176E..1770 ; Tagbanwa
- "Zzzz", # 1771..1771 ; Unknown
- "Tagb", # 1772..1773 ; Tagbanwa
- "Zzzz", # 1774..177F ; Unknown
- "Khmr", # 1780..17DD ; Khmer
- "Zzzz", # 17DE..17DF ; Unknown
- "Khmr", # 17E0..17E9 ; Khmer
- "Zzzz", # 17EA..17EF ; Unknown
- "Khmr", # 17F0..17F9 ; Khmer
- "Zzzz", # 17FA..17FF ; Unknown
- "Mong", # 1800..1801 ; Mongolian
- "Zyyy", # 1802..1803 ; Common
- "Mong", # 1804..1804 ; Mongolian
- "Zyyy", # 1805..1805 ; Common
- "Mong", # 1806..1819 ; Mongolian
- "Zzzz", # 181A..181F ; Unknown
- "Mong", # 1820..1878 ; Mongolian
- "Zzzz", # 1879..187F ; Unknown
- "Mong", # 1880..18AA ; Mongolian
- "Zzzz", # 18AB..18AF ; Unknown
- "Cans", # 18B0..18F5 ; Canadian_Aboriginal
- "Zzzz", # 18F6..18FF ; Unknown
- "Limb", # 1900..191E ; Limbu
- "Zzzz", # 191F..191F ; Unknown
- "Limb", # 1920..192B ; Limbu
- "Zzzz", # 192C..192F ; Unknown
- "Limb", # 1930..193B ; Limbu
- "Zzzz", # 193C..193F ; Unknown
- "Limb", # 1940..1940 ; Limbu
- "Zzzz", # 1941..1943 ; Unknown
- "Limb", # 1944..194F ; Limbu
- "Tale", # 1950..196D ; Tai_Le
- "Zzzz", # 196E..196F ; Unknown
- "Tale", # 1970..1974 ; Tai_Le
- "Zzzz", # 1975..197F ; Unknown
- "Talu", # 1980..19AB ; New_Tai_Lue
- "Zzzz", # 19AC..19AF ; Unknown
- "Talu", # 19B0..19C9 ; New_Tai_Lue
- "Zzzz", # 19CA..19CF ; Unknown
- "Talu", # 19D0..19DA ; New_Tai_Lue
- "Zzzz", # 19DB..19DD ; Unknown
- "Talu", # 19DE..19DF ; New_Tai_Lue
- "Khmr", # 19E0..19FF ; Khmer
- "Bugi", # 1A00..1A1B ; Buginese
- "Zzzz", # 1A1C..1A1D ; Unknown
- "Bugi", # 1A1E..1A1F ; Buginese
- "Lana", # 1A20..1A5E ; Tai_Tham
- "Zzzz", # 1A5F..1A5F ; Unknown
- "Lana", # 1A60..1A7C ; Tai_Tham
- "Zzzz", # 1A7D..1A7E ; Unknown
- "Lana", # 1A7F..1A89 ; Tai_Tham
- "Zzzz", # 1A8A..1A8F ; Unknown
- "Lana", # 1A90..1A99 ; Tai_Tham
- "Zzzz", # 1A9A..1A9F ; Unknown
- "Lana", # 1AA0..1AAD ; Tai_Tham
- "Zzzz", # 1AAE..1AAF ; Unknown
- "Zinh", # 1AB0..1ACE ; Inherited
- "Zzzz", # 1ACF..1AFF ; Unknown
- "Bali", # 1B00..1B4C ; Balinese
- "Zzzz", # 1B4D..1B4F ; Unknown
- "Bali", # 1B50..1B7E ; Balinese
- "Zzzz", # 1B7F..1B7F ; Unknown
- "Sund", # 1B80..1BBF ; Sundanese
- "Batk", # 1BC0..1BF3 ; Batak
- "Zzzz", # 1BF4..1BFB ; Unknown
- "Batk", # 1BFC..1BFF ; Batak
- "Lepc", # 1C00..1C37 ; Lepcha
- "Zzzz", # 1C38..1C3A ; Unknown
- "Lepc", # 1C3B..1C49 ; Lepcha
- "Zzzz", # 1C4A..1C4C ; Unknown
- "Lepc", # 1C4D..1C4F ; Lepcha
- "Olck", # 1C50..1C7F ; Ol_Chiki
- "Cyrl", # 1C80..1C88 ; Cyrillic
- "Zzzz", # 1C89..1C8F ; Unknown
- "Geor", # 1C90..1CBA ; Georgian
- "Zzzz", # 1CBB..1CBC ; Unknown
- "Geor", # 1CBD..1CBF ; Georgian
- "Sund", # 1CC0..1CC7 ; Sundanese
- "Zzzz", # 1CC8..1CCF ; Unknown
- "Zinh", # 1CD0..1CD2 ; Inherited
- "Zyyy", # 1CD3..1CD3 ; Common
- "Zinh", # 1CD4..1CE0 ; Inherited
- "Zyyy", # 1CE1..1CE1 ; Common
- "Zinh", # 1CE2..1CE8 ; Inherited
- "Zyyy", # 1CE9..1CEC ; Common
- "Zinh", # 1CED..1CED ; Inherited
- "Zyyy", # 1CEE..1CF3 ; Common
- "Zinh", # 1CF4..1CF4 ; Inherited
- "Zyyy", # 1CF5..1CF7 ; Common
- "Zinh", # 1CF8..1CF9 ; Inherited
- "Zyyy", # 1CFA..1CFA ; Common
- "Zzzz", # 1CFB..1CFF ; Unknown
- "Latn", # 1D00..1D25 ; Latin
- "Grek", # 1D26..1D2A ; Greek
- "Cyrl", # 1D2B..1D2B ; Cyrillic
- "Latn", # 1D2C..1D5C ; Latin
- "Grek", # 1D5D..1D61 ; Greek
- "Latn", # 1D62..1D65 ; Latin
- "Grek", # 1D66..1D6A ; Greek
- "Latn", # 1D6B..1D77 ; Latin
- "Cyrl", # 1D78..1D78 ; Cyrillic
- "Latn", # 1D79..1DBE ; Latin
- "Grek", # 1DBF..1DBF ; Greek
- "Zinh", # 1DC0..1DFF ; Inherited
- "Latn", # 1E00..1EFF ; Latin
- "Grek", # 1F00..1F15 ; Greek
- "Zzzz", # 1F16..1F17 ; Unknown
- "Grek", # 1F18..1F1D ; Greek
- "Zzzz", # 1F1E..1F1F ; Unknown
- "Grek", # 1F20..1F45 ; Greek
- "Zzzz", # 1F46..1F47 ; Unknown
- "Grek", # 1F48..1F4D ; Greek
- "Zzzz", # 1F4E..1F4F ; Unknown
- "Grek", # 1F50..1F57 ; Greek
- "Zzzz", # 1F58..1F58 ; Unknown
- "Grek", # 1F59..1F59 ; Greek
- "Zzzz", # 1F5A..1F5A ; Unknown
- "Grek", # 1F5B..1F5B ; Greek
- "Zzzz", # 1F5C..1F5C ; Unknown
- "Grek", # 1F5D..1F5D ; Greek
- "Zzzz", # 1F5E..1F5E ; Unknown
- "Grek", # 1F5F..1F7D ; Greek
- "Zzzz", # 1F7E..1F7F ; Unknown
- "Grek", # 1F80..1FB4 ; Greek
- "Zzzz", # 1FB5..1FB5 ; Unknown
- "Grek", # 1FB6..1FC4 ; Greek
- "Zzzz", # 1FC5..1FC5 ; Unknown
- "Grek", # 1FC6..1FD3 ; Greek
- "Zzzz", # 1FD4..1FD5 ; Unknown
- "Grek", # 1FD6..1FDB ; Greek
- "Zzzz", # 1FDC..1FDC ; Unknown
- "Grek", # 1FDD..1FEF ; Greek
- "Zzzz", # 1FF0..1FF1 ; Unknown
- "Grek", # 1FF2..1FF4 ; Greek
- "Zzzz", # 1FF5..1FF5 ; Unknown
- "Grek", # 1FF6..1FFE ; Greek
- "Zzzz", # 1FFF..1FFF ; Unknown
- "Zyyy", # 2000..200B ; Common
- "Zinh", # 200C..200D ; Inherited
- "Zyyy", # 200E..2064 ; Common
- "Zzzz", # 2065..2065 ; Unknown
- "Zyyy", # 2066..2070 ; Common
- "Latn", # 2071..2071 ; Latin
- "Zzzz", # 2072..2073 ; Unknown
- "Zyyy", # 2074..207E ; Common
- "Latn", # 207F..207F ; Latin
- "Zyyy", # 2080..208E ; Common
- "Zzzz", # 208F..208F ; Unknown
- "Latn", # 2090..209C ; Latin
- "Zzzz", # 209D..209F ; Unknown
- "Zyyy", # 20A0..20C0 ; Common
- "Zzzz", # 20C1..20CF ; Unknown
- "Zinh", # 20D0..20F0 ; Inherited
- "Zzzz", # 20F1..20FF ; Unknown
- "Zyyy", # 2100..2125 ; Common
- "Grek", # 2126..2126 ; Greek
- "Zyyy", # 2127..2129 ; Common
- "Latn", # 212A..212B ; Latin
- "Zyyy", # 212C..2131 ; Common
- "Latn", # 2132..2132 ; Latin
- "Zyyy", # 2133..214D ; Common
- "Latn", # 214E..214E ; Latin
- "Zyyy", # 214F..215F ; Common
- "Latn", # 2160..2188 ; Latin
- "Zyyy", # 2189..218B ; Common
- "Zzzz", # 218C..218F ; Unknown
- "Zyyy", # 2190..2426 ; Common
- "Zzzz", # 2427..243F ; Unknown
- "Zyyy", # 2440..244A ; Common
- "Zzzz", # 244B..245F ; Unknown
- "Zyyy", # 2460..27FF ; Common
- "Brai", # 2800..28FF ; Braille
- "Zyyy", # 2900..2B73 ; Common
- "Zzzz", # 2B74..2B75 ; Unknown
- "Zyyy", # 2B76..2B95 ; Common
- "Zzzz", # 2B96..2B96 ; Unknown
- "Zyyy", # 2B97..2BFF ; Common
- "Glag", # 2C00..2C5F ; Glagolitic
- "Latn", # 2C60..2C7F ; Latin
- "Copt", # 2C80..2CF3 ; Coptic
- "Zzzz", # 2CF4..2CF8 ; Unknown
- "Copt", # 2CF9..2CFF ; Coptic
- "Geor", # 2D00..2D25 ; Georgian
- "Zzzz", # 2D26..2D26 ; Unknown
- "Geor", # 2D27..2D27 ; Georgian
- "Zzzz", # 2D28..2D2C ; Unknown
- "Geor", # 2D2D..2D2D ; Georgian
- "Zzzz", # 2D2E..2D2F ; Unknown
- "Tfng", # 2D30..2D67 ; Tifinagh
- "Zzzz", # 2D68..2D6E ; Unknown
- "Tfng", # 2D6F..2D70 ; Tifinagh
- "Zzzz", # 2D71..2D7E ; Unknown
- "Tfng", # 2D7F..2D7F ; Tifinagh
- "Ethi", # 2D80..2D96 ; Ethiopic
- "Zzzz", # 2D97..2D9F ; Unknown
- "Ethi", # 2DA0..2DA6 ; Ethiopic
- "Zzzz", # 2DA7..2DA7 ; Unknown
- "Ethi", # 2DA8..2DAE ; Ethiopic
- "Zzzz", # 2DAF..2DAF ; Unknown
- "Ethi", # 2DB0..2DB6 ; Ethiopic
- "Zzzz", # 2DB7..2DB7 ; Unknown
- "Ethi", # 2DB8..2DBE ; Ethiopic
- "Zzzz", # 2DBF..2DBF ; Unknown
- "Ethi", # 2DC0..2DC6 ; Ethiopic
- "Zzzz", # 2DC7..2DC7 ; Unknown
- "Ethi", # 2DC8..2DCE ; Ethiopic
- "Zzzz", # 2DCF..2DCF ; Unknown
- "Ethi", # 2DD0..2DD6 ; Ethiopic
- "Zzzz", # 2DD7..2DD7 ; Unknown
- "Ethi", # 2DD8..2DDE ; Ethiopic
- "Zzzz", # 2DDF..2DDF ; Unknown
- "Cyrl", # 2DE0..2DFF ; Cyrillic
- "Zyyy", # 2E00..2E5D ; Common
- "Zzzz", # 2E5E..2E7F ; Unknown
- "Hani", # 2E80..2E99 ; Han
- "Zzzz", # 2E9A..2E9A ; Unknown
- "Hani", # 2E9B..2EF3 ; Han
- "Zzzz", # 2EF4..2EFF ; Unknown
- "Hani", # 2F00..2FD5 ; Han
- "Zzzz", # 2FD6..2FEF ; Unknown
- "Zyyy", # 2FF0..2FFB ; Common
- "Zzzz", # 2FFC..2FFF ; Unknown
- "Zyyy", # 3000..3004 ; Common
- "Hani", # 3005..3005 ; Han
- "Zyyy", # 3006..3006 ; Common
- "Hani", # 3007..3007 ; Han
- "Zyyy", # 3008..3020 ; Common
- "Hani", # 3021..3029 ; Han
- "Zinh", # 302A..302D ; Inherited
- "Hang", # 302E..302F ; Hangul
- "Zyyy", # 3030..3037 ; Common
- "Hani", # 3038..303B ; Han
- "Zyyy", # 303C..303F ; Common
- "Zzzz", # 3040..3040 ; Unknown
- "Hira", # 3041..3096 ; Hiragana
- "Zzzz", # 3097..3098 ; Unknown
- "Zinh", # 3099..309A ; Inherited
- "Zyyy", # 309B..309C ; Common
- "Hira", # 309D..309F ; Hiragana
- "Zyyy", # 30A0..30A0 ; Common
- "Kana", # 30A1..30FA ; Katakana
- "Zyyy", # 30FB..30FC ; Common
- "Kana", # 30FD..30FF ; Katakana
- "Zzzz", # 3100..3104 ; Unknown
- "Bopo", # 3105..312F ; Bopomofo
- "Zzzz", # 3130..3130 ; Unknown
- "Hang", # 3131..318E ; Hangul
- "Zzzz", # 318F..318F ; Unknown
- "Zyyy", # 3190..319F ; Common
- "Bopo", # 31A0..31BF ; Bopomofo
- "Zyyy", # 31C0..31E3 ; Common
- "Zzzz", # 31E4..31EF ; Unknown
- "Kana", # 31F0..31FF ; Katakana
- "Hang", # 3200..321E ; Hangul
- "Zzzz", # 321F..321F ; Unknown
- "Zyyy", # 3220..325F ; Common
- "Hang", # 3260..327E ; Hangul
- "Zyyy", # 327F..32CF ; Common
- "Kana", # 32D0..32FE ; Katakana
- "Zyyy", # 32FF..32FF ; Common
- "Kana", # 3300..3357 ; Katakana
- "Zyyy", # 3358..33FF ; Common
- "Hani", # 3400..4DBF ; Han
- "Zyyy", # 4DC0..4DFF ; Common
- "Hani", # 4E00..9FFF ; Han
- "Yiii", # A000..A48C ; Yi
- "Zzzz", # A48D..A48F ; Unknown
- "Yiii", # A490..A4C6 ; Yi
- "Zzzz", # A4C7..A4CF ; Unknown
- "Lisu", # A4D0..A4FF ; Lisu
- "Vaii", # A500..A62B ; Vai
- "Zzzz", # A62C..A63F ; Unknown
- "Cyrl", # A640..A69F ; Cyrillic
- "Bamu", # A6A0..A6F7 ; Bamum
- "Zzzz", # A6F8..A6FF ; Unknown
- "Zyyy", # A700..A721 ; Common
- "Latn", # A722..A787 ; Latin
- "Zyyy", # A788..A78A ; Common
- "Latn", # A78B..A7CA ; Latin
- "Zzzz", # A7CB..A7CF ; Unknown
- "Latn", # A7D0..A7D1 ; Latin
- "Zzzz", # A7D2..A7D2 ; Unknown
- "Latn", # A7D3..A7D3 ; Latin
- "Zzzz", # A7D4..A7D4 ; Unknown
- "Latn", # A7D5..A7D9 ; Latin
- "Zzzz", # A7DA..A7F1 ; Unknown
- "Latn", # A7F2..A7FF ; Latin
- "Sylo", # A800..A82C ; Syloti_Nagri
- "Zzzz", # A82D..A82F ; Unknown
- "Zyyy", # A830..A839 ; Common
- "Zzzz", # A83A..A83F ; Unknown
- "Phag", # A840..A877 ; Phags_Pa
- "Zzzz", # A878..A87F ; Unknown
- "Saur", # A880..A8C5 ; Saurashtra
- "Zzzz", # A8C6..A8CD ; Unknown
- "Saur", # A8CE..A8D9 ; Saurashtra
- "Zzzz", # A8DA..A8DF ; Unknown
- "Deva", # A8E0..A8FF ; Devanagari
- "Kali", # A900..A92D ; Kayah_Li
- "Zyyy", # A92E..A92E ; Common
- "Kali", # A92F..A92F ; Kayah_Li
- "Rjng", # A930..A953 ; Rejang
- "Zzzz", # A954..A95E ; Unknown
- "Rjng", # A95F..A95F ; Rejang
- "Hang", # A960..A97C ; Hangul
- "Zzzz", # A97D..A97F ; Unknown
- "Java", # A980..A9CD ; Javanese
- "Zzzz", # A9CE..A9CE ; Unknown
- "Zyyy", # A9CF..A9CF ; Common
- "Java", # A9D0..A9D9 ; Javanese
- "Zzzz", # A9DA..A9DD ; Unknown
- "Java", # A9DE..A9DF ; Javanese
- "Mymr", # A9E0..A9FE ; Myanmar
- "Zzzz", # A9FF..A9FF ; Unknown
- "Cham", # AA00..AA36 ; Cham
- "Zzzz", # AA37..AA3F ; Unknown
- "Cham", # AA40..AA4D ; Cham
- "Zzzz", # AA4E..AA4F ; Unknown
- "Cham", # AA50..AA59 ; Cham
- "Zzzz", # AA5A..AA5B ; Unknown
- "Cham", # AA5C..AA5F ; Cham
- "Mymr", # AA60..AA7F ; Myanmar
- "Tavt", # AA80..AAC2 ; Tai_Viet
- "Zzzz", # AAC3..AADA ; Unknown
- "Tavt", # AADB..AADF ; Tai_Viet
- "Mtei", # AAE0..AAF6 ; Meetei_Mayek
- "Zzzz", # AAF7..AB00 ; Unknown
- "Ethi", # AB01..AB06 ; Ethiopic
- "Zzzz", # AB07..AB08 ; Unknown
- "Ethi", # AB09..AB0E ; Ethiopic
- "Zzzz", # AB0F..AB10 ; Unknown
- "Ethi", # AB11..AB16 ; Ethiopic
- "Zzzz", # AB17..AB1F ; Unknown
- "Ethi", # AB20..AB26 ; Ethiopic
- "Zzzz", # AB27..AB27 ; Unknown
- "Ethi", # AB28..AB2E ; Ethiopic
- "Zzzz", # AB2F..AB2F ; Unknown
- "Latn", # AB30..AB5A ; Latin
- "Zyyy", # AB5B..AB5B ; Common
- "Latn", # AB5C..AB64 ; Latin
- "Grek", # AB65..AB65 ; Greek
- "Latn", # AB66..AB69 ; Latin
- "Zyyy", # AB6A..AB6B ; Common
- "Zzzz", # AB6C..AB6F ; Unknown
- "Cher", # AB70..ABBF ; Cherokee
- "Mtei", # ABC0..ABED ; Meetei_Mayek
- "Zzzz", # ABEE..ABEF ; Unknown
- "Mtei", # ABF0..ABF9 ; Meetei_Mayek
- "Zzzz", # ABFA..ABFF ; Unknown
- "Hang", # AC00..D7A3 ; Hangul
- "Zzzz", # D7A4..D7AF ; Unknown
- "Hang", # D7B0..D7C6 ; Hangul
- "Zzzz", # D7C7..D7CA ; Unknown
- "Hang", # D7CB..D7FB ; Hangul
- "Zzzz", # D7FC..F8FF ; Unknown
- "Hani", # F900..FA6D ; Han
- "Zzzz", # FA6E..FA6F ; Unknown
- "Hani", # FA70..FAD9 ; Han
- "Zzzz", # FADA..FAFF ; Unknown
- "Latn", # FB00..FB06 ; Latin
- "Zzzz", # FB07..FB12 ; Unknown
- "Armn", # FB13..FB17 ; Armenian
- "Zzzz", # FB18..FB1C ; Unknown
- "Hebr", # FB1D..FB36 ; Hebrew
- "Zzzz", # FB37..FB37 ; Unknown
- "Hebr", # FB38..FB3C ; Hebrew
- "Zzzz", # FB3D..FB3D ; Unknown
- "Hebr", # FB3E..FB3E ; Hebrew
- "Zzzz", # FB3F..FB3F ; Unknown
- "Hebr", # FB40..FB41 ; Hebrew
- "Zzzz", # FB42..FB42 ; Unknown
- "Hebr", # FB43..FB44 ; Hebrew
- "Zzzz", # FB45..FB45 ; Unknown
- "Hebr", # FB46..FB4F ; Hebrew
- "Arab", # FB50..FBC2 ; Arabic
- "Zzzz", # FBC3..FBD2 ; Unknown
- "Arab", # FBD3..FD3D ; Arabic
- "Zyyy", # FD3E..FD3F ; Common
- "Arab", # FD40..FD8F ; Arabic
- "Zzzz", # FD90..FD91 ; Unknown
- "Arab", # FD92..FDC7 ; Arabic
- "Zzzz", # FDC8..FDCE ; Unknown
- "Arab", # FDCF..FDCF ; Arabic
- "Zzzz", # FDD0..FDEF ; Unknown
- "Arab", # FDF0..FDFF ; Arabic
- "Zinh", # FE00..FE0F ; Inherited
- "Zyyy", # FE10..FE19 ; Common
- "Zzzz", # FE1A..FE1F ; Unknown
- "Zinh", # FE20..FE2D ; Inherited
- "Cyrl", # FE2E..FE2F ; Cyrillic
- "Zyyy", # FE30..FE52 ; Common
- "Zzzz", # FE53..FE53 ; Unknown
- "Zyyy", # FE54..FE66 ; Common
- "Zzzz", # FE67..FE67 ; Unknown
- "Zyyy", # FE68..FE6B ; Common
- "Zzzz", # FE6C..FE6F ; Unknown
- "Arab", # FE70..FE74 ; Arabic
- "Zzzz", # FE75..FE75 ; Unknown
- "Arab", # FE76..FEFC ; Arabic
- "Zzzz", # FEFD..FEFE ; Unknown
- "Zyyy", # FEFF..FEFF ; Common
- "Zzzz", # FF00..FF00 ; Unknown
- "Zyyy", # FF01..FF20 ; Common
- "Latn", # FF21..FF3A ; Latin
- "Zyyy", # FF3B..FF40 ; Common
- "Latn", # FF41..FF5A ; Latin
- "Zyyy", # FF5B..FF65 ; Common
- "Kana", # FF66..FF6F ; Katakana
- "Zyyy", # FF70..FF70 ; Common
- "Kana", # FF71..FF9D ; Katakana
- "Zyyy", # FF9E..FF9F ; Common
- "Hang", # FFA0..FFBE ; Hangul
- "Zzzz", # FFBF..FFC1 ; Unknown
- "Hang", # FFC2..FFC7 ; Hangul
- "Zzzz", # FFC8..FFC9 ; Unknown
- "Hang", # FFCA..FFCF ; Hangul
- "Zzzz", # FFD0..FFD1 ; Unknown
- "Hang", # FFD2..FFD7 ; Hangul
- "Zzzz", # FFD8..FFD9 ; Unknown
- "Hang", # FFDA..FFDC ; Hangul
- "Zzzz", # FFDD..FFDF ; Unknown
- "Zyyy", # FFE0..FFE6 ; Common
- "Zzzz", # FFE7..FFE7 ; Unknown
- "Zyyy", # FFE8..FFEE ; Common
- "Zzzz", # FFEF..FFF8 ; Unknown
- "Zyyy", # FFF9..FFFD ; Common
- "Zzzz", # FFFE..FFFF ; Unknown
- "Linb", # 10000..1000B ; Linear_B
- "Zzzz", # 1000C..1000C ; Unknown
- "Linb", # 1000D..10026 ; Linear_B
- "Zzzz", # 10027..10027 ; Unknown
- "Linb", # 10028..1003A ; Linear_B
- "Zzzz", # 1003B..1003B ; Unknown
- "Linb", # 1003C..1003D ; Linear_B
- "Zzzz", # 1003E..1003E ; Unknown
- "Linb", # 1003F..1004D ; Linear_B
- "Zzzz", # 1004E..1004F ; Unknown
- "Linb", # 10050..1005D ; Linear_B
- "Zzzz", # 1005E..1007F ; Unknown
- "Linb", # 10080..100FA ; Linear_B
- "Zzzz", # 100FB..100FF ; Unknown
- "Zyyy", # 10100..10102 ; Common
- "Zzzz", # 10103..10106 ; Unknown
- "Zyyy", # 10107..10133 ; Common
- "Zzzz", # 10134..10136 ; Unknown
- "Zyyy", # 10137..1013F ; Common
- "Grek", # 10140..1018E ; Greek
- "Zzzz", # 1018F..1018F ; Unknown
- "Zyyy", # 10190..1019C ; Common
- "Zzzz", # 1019D..1019F ; Unknown
- "Grek", # 101A0..101A0 ; Greek
- "Zzzz", # 101A1..101CF ; Unknown
- "Zyyy", # 101D0..101FC ; Common
- "Zinh", # 101FD..101FD ; Inherited
- "Zzzz", # 101FE..1027F ; Unknown
- "Lyci", # 10280..1029C ; Lycian
- "Zzzz", # 1029D..1029F ; Unknown
- "Cari", # 102A0..102D0 ; Carian
- "Zzzz", # 102D1..102DF ; Unknown
- "Zinh", # 102E0..102E0 ; Inherited
- "Zyyy", # 102E1..102FB ; Common
- "Zzzz", # 102FC..102FF ; Unknown
- "Ital", # 10300..10323 ; Old_Italic
- "Zzzz", # 10324..1032C ; Unknown
- "Ital", # 1032D..1032F ; Old_Italic
- "Goth", # 10330..1034A ; Gothic
- "Zzzz", # 1034B..1034F ; Unknown
- "Perm", # 10350..1037A ; Old_Permic
- "Zzzz", # 1037B..1037F ; Unknown
- "Ugar", # 10380..1039D ; Ugaritic
- "Zzzz", # 1039E..1039E ; Unknown
- "Ugar", # 1039F..1039F ; Ugaritic
- "Xpeo", # 103A0..103C3 ; Old_Persian
- "Zzzz", # 103C4..103C7 ; Unknown
- "Xpeo", # 103C8..103D5 ; Old_Persian
- "Zzzz", # 103D6..103FF ; Unknown
- "Dsrt", # 10400..1044F ; Deseret
- "Shaw", # 10450..1047F ; Shavian
- "Osma", # 10480..1049D ; Osmanya
- "Zzzz", # 1049E..1049F ; Unknown
- "Osma", # 104A0..104A9 ; Osmanya
- "Zzzz", # 104AA..104AF ; Unknown
- "Osge", # 104B0..104D3 ; Osage
- "Zzzz", # 104D4..104D7 ; Unknown
- "Osge", # 104D8..104FB ; Osage
- "Zzzz", # 104FC..104FF ; Unknown
- "Elba", # 10500..10527 ; Elbasan
- "Zzzz", # 10528..1052F ; Unknown
- "Aghb", # 10530..10563 ; Caucasian_Albanian
- "Zzzz", # 10564..1056E ; Unknown
- "Aghb", # 1056F..1056F ; Caucasian_Albanian
- "Vith", # 10570..1057A ; Vithkuqi
- "Zzzz", # 1057B..1057B ; Unknown
- "Vith", # 1057C..1058A ; Vithkuqi
- "Zzzz", # 1058B..1058B ; Unknown
- "Vith", # 1058C..10592 ; Vithkuqi
- "Zzzz", # 10593..10593 ; Unknown
- "Vith", # 10594..10595 ; Vithkuqi
- "Zzzz", # 10596..10596 ; Unknown
- "Vith", # 10597..105A1 ; Vithkuqi
- "Zzzz", # 105A2..105A2 ; Unknown
- "Vith", # 105A3..105B1 ; Vithkuqi
- "Zzzz", # 105B2..105B2 ; Unknown
- "Vith", # 105B3..105B9 ; Vithkuqi
- "Zzzz", # 105BA..105BA ; Unknown
- "Vith", # 105BB..105BC ; Vithkuqi
- "Zzzz", # 105BD..105FF ; Unknown
- "Lina", # 10600..10736 ; Linear_A
- "Zzzz", # 10737..1073F ; Unknown
- "Lina", # 10740..10755 ; Linear_A
- "Zzzz", # 10756..1075F ; Unknown
- "Lina", # 10760..10767 ; Linear_A
- "Zzzz", # 10768..1077F ; Unknown
- "Latn", # 10780..10785 ; Latin
- "Zzzz", # 10786..10786 ; Unknown
- "Latn", # 10787..107B0 ; Latin
- "Zzzz", # 107B1..107B1 ; Unknown
- "Latn", # 107B2..107BA ; Latin
- "Zzzz", # 107BB..107FF ; Unknown
- "Cprt", # 10800..10805 ; Cypriot
- "Zzzz", # 10806..10807 ; Unknown
- "Cprt", # 10808..10808 ; Cypriot
- "Zzzz", # 10809..10809 ; Unknown
- "Cprt", # 1080A..10835 ; Cypriot
- "Zzzz", # 10836..10836 ; Unknown
- "Cprt", # 10837..10838 ; Cypriot
- "Zzzz", # 10839..1083B ; Unknown
- "Cprt", # 1083C..1083C ; Cypriot
- "Zzzz", # 1083D..1083E ; Unknown
- "Cprt", # 1083F..1083F ; Cypriot
- "Armi", # 10840..10855 ; Imperial_Aramaic
- "Zzzz", # 10856..10856 ; Unknown
- "Armi", # 10857..1085F ; Imperial_Aramaic
- "Palm", # 10860..1087F ; Palmyrene
- "Nbat", # 10880..1089E ; Nabataean
- "Zzzz", # 1089F..108A6 ; Unknown
- "Nbat", # 108A7..108AF ; Nabataean
- "Zzzz", # 108B0..108DF ; Unknown
- "Hatr", # 108E0..108F2 ; Hatran
- "Zzzz", # 108F3..108F3 ; Unknown
- "Hatr", # 108F4..108F5 ; Hatran
- "Zzzz", # 108F6..108FA ; Unknown
- "Hatr", # 108FB..108FF ; Hatran
- "Phnx", # 10900..1091B ; Phoenician
- "Zzzz", # 1091C..1091E ; Unknown
- "Phnx", # 1091F..1091F ; Phoenician
- "Lydi", # 10920..10939 ; Lydian
- "Zzzz", # 1093A..1093E ; Unknown
- "Lydi", # 1093F..1093F ; Lydian
- "Zzzz", # 10940..1097F ; Unknown
- "Mero", # 10980..1099F ; Meroitic_Hieroglyphs
- "Merc", # 109A0..109B7 ; Meroitic_Cursive
- "Zzzz", # 109B8..109BB ; Unknown
- "Merc", # 109BC..109CF ; Meroitic_Cursive
- "Zzzz", # 109D0..109D1 ; Unknown
- "Merc", # 109D2..109FF ; Meroitic_Cursive
- "Khar", # 10A00..10A03 ; Kharoshthi
- "Zzzz", # 10A04..10A04 ; Unknown
- "Khar", # 10A05..10A06 ; Kharoshthi
- "Zzzz", # 10A07..10A0B ; Unknown
- "Khar", # 10A0C..10A13 ; Kharoshthi
- "Zzzz", # 10A14..10A14 ; Unknown
- "Khar", # 10A15..10A17 ; Kharoshthi
- "Zzzz", # 10A18..10A18 ; Unknown
- "Khar", # 10A19..10A35 ; Kharoshthi
- "Zzzz", # 10A36..10A37 ; Unknown
- "Khar", # 10A38..10A3A ; Kharoshthi
- "Zzzz", # 10A3B..10A3E ; Unknown
- "Khar", # 10A3F..10A48 ; Kharoshthi
- "Zzzz", # 10A49..10A4F ; Unknown
- "Khar", # 10A50..10A58 ; Kharoshthi
- "Zzzz", # 10A59..10A5F ; Unknown
- "Sarb", # 10A60..10A7F ; Old_South_Arabian
- "Narb", # 10A80..10A9F ; Old_North_Arabian
- "Zzzz", # 10AA0..10ABF ; Unknown
- "Mani", # 10AC0..10AE6 ; Manichaean
- "Zzzz", # 10AE7..10AEA ; Unknown
- "Mani", # 10AEB..10AF6 ; Manichaean
- "Zzzz", # 10AF7..10AFF ; Unknown
- "Avst", # 10B00..10B35 ; Avestan
- "Zzzz", # 10B36..10B38 ; Unknown
- "Avst", # 10B39..10B3F ; Avestan
- "Prti", # 10B40..10B55 ; Inscriptional_Parthian
- "Zzzz", # 10B56..10B57 ; Unknown
- "Prti", # 10B58..10B5F ; Inscriptional_Parthian
- "Phli", # 10B60..10B72 ; Inscriptional_Pahlavi
- "Zzzz", # 10B73..10B77 ; Unknown
- "Phli", # 10B78..10B7F ; Inscriptional_Pahlavi
- "Phlp", # 10B80..10B91 ; Psalter_Pahlavi
- "Zzzz", # 10B92..10B98 ; Unknown
- "Phlp", # 10B99..10B9C ; Psalter_Pahlavi
- "Zzzz", # 10B9D..10BA8 ; Unknown
- "Phlp", # 10BA9..10BAF ; Psalter_Pahlavi
- "Zzzz", # 10BB0..10BFF ; Unknown
- "Orkh", # 10C00..10C48 ; Old_Turkic
- "Zzzz", # 10C49..10C7F ; Unknown
- "Hung", # 10C80..10CB2 ; Old_Hungarian
- "Zzzz", # 10CB3..10CBF ; Unknown
- "Hung", # 10CC0..10CF2 ; Old_Hungarian
- "Zzzz", # 10CF3..10CF9 ; Unknown
- "Hung", # 10CFA..10CFF ; Old_Hungarian
- "Rohg", # 10D00..10D27 ; Hanifi_Rohingya
- "Zzzz", # 10D28..10D2F ; Unknown
- "Rohg", # 10D30..10D39 ; Hanifi_Rohingya
- "Zzzz", # 10D3A..10E5F ; Unknown
- "Arab", # 10E60..10E7E ; Arabic
- "Zzzz", # 10E7F..10E7F ; Unknown
- "Yezi", # 10E80..10EA9 ; Yezidi
- "Zzzz", # 10EAA..10EAA ; Unknown
- "Yezi", # 10EAB..10EAD ; Yezidi
- "Zzzz", # 10EAE..10EAF ; Unknown
- "Yezi", # 10EB0..10EB1 ; Yezidi
- "Zzzz", # 10EB2..10EFC ; Unknown
- "Arab", # 10EFD..10EFF ; Arabic
- "Sogo", # 10F00..10F27 ; Old_Sogdian
- "Zzzz", # 10F28..10F2F ; Unknown
- "Sogd", # 10F30..10F59 ; Sogdian
- "Zzzz", # 10F5A..10F6F ; Unknown
- "Ougr", # 10F70..10F89 ; Old_Uyghur
- "Zzzz", # 10F8A..10FAF ; Unknown
- "Chrs", # 10FB0..10FCB ; Chorasmian
- "Zzzz", # 10FCC..10FDF ; Unknown
- "Elym", # 10FE0..10FF6 ; Elymaic
- "Zzzz", # 10FF7..10FFF ; Unknown
- "Brah", # 11000..1104D ; Brahmi
- "Zzzz", # 1104E..11051 ; Unknown
- "Brah", # 11052..11075 ; Brahmi
- "Zzzz", # 11076..1107E ; Unknown
- "Brah", # 1107F..1107F ; Brahmi
- "Kthi", # 11080..110C2 ; Kaithi
- "Zzzz", # 110C3..110CC ; Unknown
- "Kthi", # 110CD..110CD ; Kaithi
- "Zzzz", # 110CE..110CF ; Unknown
- "Sora", # 110D0..110E8 ; Sora_Sompeng
- "Zzzz", # 110E9..110EF ; Unknown
- "Sora", # 110F0..110F9 ; Sora_Sompeng
- "Zzzz", # 110FA..110FF ; Unknown
- "Cakm", # 11100..11134 ; Chakma
- "Zzzz", # 11135..11135 ; Unknown
- "Cakm", # 11136..11147 ; Chakma
- "Zzzz", # 11148..1114F ; Unknown
- "Mahj", # 11150..11176 ; Mahajani
- "Zzzz", # 11177..1117F ; Unknown
- "Shrd", # 11180..111DF ; Sharada
- "Zzzz", # 111E0..111E0 ; Unknown
- "Sinh", # 111E1..111F4 ; Sinhala
- "Zzzz", # 111F5..111FF ; Unknown
- "Khoj", # 11200..11211 ; Khojki
- "Zzzz", # 11212..11212 ; Unknown
- "Khoj", # 11213..11241 ; Khojki
- "Zzzz", # 11242..1127F ; Unknown
- "Mult", # 11280..11286 ; Multani
- "Zzzz", # 11287..11287 ; Unknown
- "Mult", # 11288..11288 ; Multani
- "Zzzz", # 11289..11289 ; Unknown
- "Mult", # 1128A..1128D ; Multani
- "Zzzz", # 1128E..1128E ; Unknown
- "Mult", # 1128F..1129D ; Multani
- "Zzzz", # 1129E..1129E ; Unknown
- "Mult", # 1129F..112A9 ; Multani
- "Zzzz", # 112AA..112AF ; Unknown
- "Sind", # 112B0..112EA ; Khudawadi
- "Zzzz", # 112EB..112EF ; Unknown
- "Sind", # 112F0..112F9 ; Khudawadi
- "Zzzz", # 112FA..112FF ; Unknown
- "Gran", # 11300..11303 ; Grantha
- "Zzzz", # 11304..11304 ; Unknown
- "Gran", # 11305..1130C ; Grantha
- "Zzzz", # 1130D..1130E ; Unknown
- "Gran", # 1130F..11310 ; Grantha
- "Zzzz", # 11311..11312 ; Unknown
- "Gran", # 11313..11328 ; Grantha
- "Zzzz", # 11329..11329 ; Unknown
- "Gran", # 1132A..11330 ; Grantha
- "Zzzz", # 11331..11331 ; Unknown
- "Gran", # 11332..11333 ; Grantha
- "Zzzz", # 11334..11334 ; Unknown
- "Gran", # 11335..11339 ; Grantha
- "Zzzz", # 1133A..1133A ; Unknown
- "Zinh", # 1133B..1133B ; Inherited
- "Gran", # 1133C..11344 ; Grantha
- "Zzzz", # 11345..11346 ; Unknown
- "Gran", # 11347..11348 ; Grantha
- "Zzzz", # 11349..1134A ; Unknown
- "Gran", # 1134B..1134D ; Grantha
- "Zzzz", # 1134E..1134F ; Unknown
- "Gran", # 11350..11350 ; Grantha
- "Zzzz", # 11351..11356 ; Unknown
- "Gran", # 11357..11357 ; Grantha
- "Zzzz", # 11358..1135C ; Unknown
- "Gran", # 1135D..11363 ; Grantha
- "Zzzz", # 11364..11365 ; Unknown
- "Gran", # 11366..1136C ; Grantha
- "Zzzz", # 1136D..1136F ; Unknown
- "Gran", # 11370..11374 ; Grantha
- "Zzzz", # 11375..113FF ; Unknown
- "Newa", # 11400..1145B ; Newa
- "Zzzz", # 1145C..1145C ; Unknown
- "Newa", # 1145D..11461 ; Newa
- "Zzzz", # 11462..1147F ; Unknown
- "Tirh", # 11480..114C7 ; Tirhuta
- "Zzzz", # 114C8..114CF ; Unknown
- "Tirh", # 114D0..114D9 ; Tirhuta
- "Zzzz", # 114DA..1157F ; Unknown
- "Sidd", # 11580..115B5 ; Siddham
- "Zzzz", # 115B6..115B7 ; Unknown
- "Sidd", # 115B8..115DD ; Siddham
- "Zzzz", # 115DE..115FF ; Unknown
- "Modi", # 11600..11644 ; Modi
- "Zzzz", # 11645..1164F ; Unknown
- "Modi", # 11650..11659 ; Modi
- "Zzzz", # 1165A..1165F ; Unknown
- "Mong", # 11660..1166C ; Mongolian
- "Zzzz", # 1166D..1167F ; Unknown
- "Takr", # 11680..116B9 ; Takri
- "Zzzz", # 116BA..116BF ; Unknown
- "Takr", # 116C0..116C9 ; Takri
- "Zzzz", # 116CA..116FF ; Unknown
- "Ahom", # 11700..1171A ; Ahom
- "Zzzz", # 1171B..1171C ; Unknown
- "Ahom", # 1171D..1172B ; Ahom
- "Zzzz", # 1172C..1172F ; Unknown
- "Ahom", # 11730..11746 ; Ahom
- "Zzzz", # 11747..117FF ; Unknown
- "Dogr", # 11800..1183B ; Dogra
- "Zzzz", # 1183C..1189F ; Unknown
- "Wara", # 118A0..118F2 ; Warang_Citi
- "Zzzz", # 118F3..118FE ; Unknown
- "Wara", # 118FF..118FF ; Warang_Citi
- "Diak", # 11900..11906 ; Dives_Akuru
- "Zzzz", # 11907..11908 ; Unknown
- "Diak", # 11909..11909 ; Dives_Akuru
- "Zzzz", # 1190A..1190B ; Unknown
- "Diak", # 1190C..11913 ; Dives_Akuru
- "Zzzz", # 11914..11914 ; Unknown
- "Diak", # 11915..11916 ; Dives_Akuru
- "Zzzz", # 11917..11917 ; Unknown
- "Diak", # 11918..11935 ; Dives_Akuru
- "Zzzz", # 11936..11936 ; Unknown
- "Diak", # 11937..11938 ; Dives_Akuru
- "Zzzz", # 11939..1193A ; Unknown
- "Diak", # 1193B..11946 ; Dives_Akuru
- "Zzzz", # 11947..1194F ; Unknown
- "Diak", # 11950..11959 ; Dives_Akuru
- "Zzzz", # 1195A..1199F ; Unknown
- "Nand", # 119A0..119A7 ; Nandinagari
- "Zzzz", # 119A8..119A9 ; Unknown
- "Nand", # 119AA..119D7 ; Nandinagari
- "Zzzz", # 119D8..119D9 ; Unknown
- "Nand", # 119DA..119E4 ; Nandinagari
- "Zzzz", # 119E5..119FF ; Unknown
- "Zanb", # 11A00..11A47 ; Zanabazar_Square
- "Zzzz", # 11A48..11A4F ; Unknown
- "Soyo", # 11A50..11AA2 ; Soyombo
- "Zzzz", # 11AA3..11AAF ; Unknown
- "Cans", # 11AB0..11ABF ; Canadian_Aboriginal
- "Pauc", # 11AC0..11AF8 ; Pau_Cin_Hau
- "Zzzz", # 11AF9..11AFF ; Unknown
- "Deva", # 11B00..11B09 ; Devanagari
- "Zzzz", # 11B0A..11BFF ; Unknown
- "Bhks", # 11C00..11C08 ; Bhaiksuki
- "Zzzz", # 11C09..11C09 ; Unknown
- "Bhks", # 11C0A..11C36 ; Bhaiksuki
- "Zzzz", # 11C37..11C37 ; Unknown
- "Bhks", # 11C38..11C45 ; Bhaiksuki
- "Zzzz", # 11C46..11C4F ; Unknown
- "Bhks", # 11C50..11C6C ; Bhaiksuki
- "Zzzz", # 11C6D..11C6F ; Unknown
- "Marc", # 11C70..11C8F ; Marchen
- "Zzzz", # 11C90..11C91 ; Unknown
- "Marc", # 11C92..11CA7 ; Marchen
- "Zzzz", # 11CA8..11CA8 ; Unknown
- "Marc", # 11CA9..11CB6 ; Marchen
- "Zzzz", # 11CB7..11CFF ; Unknown
- "Gonm", # 11D00..11D06 ; Masaram_Gondi
- "Zzzz", # 11D07..11D07 ; Unknown
- "Gonm", # 11D08..11D09 ; Masaram_Gondi
- "Zzzz", # 11D0A..11D0A ; Unknown
- "Gonm", # 11D0B..11D36 ; Masaram_Gondi
- "Zzzz", # 11D37..11D39 ; Unknown
- "Gonm", # 11D3A..11D3A ; Masaram_Gondi
- "Zzzz", # 11D3B..11D3B ; Unknown
- "Gonm", # 11D3C..11D3D ; Masaram_Gondi
- "Zzzz", # 11D3E..11D3E ; Unknown
- "Gonm", # 11D3F..11D47 ; Masaram_Gondi
- "Zzzz", # 11D48..11D4F ; Unknown
- "Gonm", # 11D50..11D59 ; Masaram_Gondi
- "Zzzz", # 11D5A..11D5F ; Unknown
- "Gong", # 11D60..11D65 ; Gunjala_Gondi
- "Zzzz", # 11D66..11D66 ; Unknown
- "Gong", # 11D67..11D68 ; Gunjala_Gondi
- "Zzzz", # 11D69..11D69 ; Unknown
- "Gong", # 11D6A..11D8E ; Gunjala_Gondi
- "Zzzz", # 11D8F..11D8F ; Unknown
- "Gong", # 11D90..11D91 ; Gunjala_Gondi
- "Zzzz", # 11D92..11D92 ; Unknown
- "Gong", # 11D93..11D98 ; Gunjala_Gondi
- "Zzzz", # 11D99..11D9F ; Unknown
- "Gong", # 11DA0..11DA9 ; Gunjala_Gondi
- "Zzzz", # 11DAA..11EDF ; Unknown
- "Maka", # 11EE0..11EF8 ; Makasar
- "Zzzz", # 11EF9..11EFF ; Unknown
- "Kawi", # 11F00..11F10 ; Kawi
- "Zzzz", # 11F11..11F11 ; Unknown
- "Kawi", # 11F12..11F3A ; Kawi
- "Zzzz", # 11F3B..11F3D ; Unknown
- "Kawi", # 11F3E..11F59 ; Kawi
- "Zzzz", # 11F5A..11FAF ; Unknown
- "Lisu", # 11FB0..11FB0 ; Lisu
- "Zzzz", # 11FB1..11FBF ; Unknown
- "Taml", # 11FC0..11FF1 ; Tamil
- "Zzzz", # 11FF2..11FFE ; Unknown
- "Taml", # 11FFF..11FFF ; Tamil
- "Xsux", # 12000..12399 ; Cuneiform
- "Zzzz", # 1239A..123FF ; Unknown
- "Xsux", # 12400..1246E ; Cuneiform
- "Zzzz", # 1246F..1246F ; Unknown
- "Xsux", # 12470..12474 ; Cuneiform
- "Zzzz", # 12475..1247F ; Unknown
- "Xsux", # 12480..12543 ; Cuneiform
- "Zzzz", # 12544..12F8F ; Unknown
- "Cpmn", # 12F90..12FF2 ; Cypro_Minoan
- "Zzzz", # 12FF3..12FFF ; Unknown
- "Egyp", # 13000..13455 ; Egyptian_Hieroglyphs
- "Zzzz", # 13456..143FF ; Unknown
- "Hluw", # 14400..14646 ; Anatolian_Hieroglyphs
- "Zzzz", # 14647..167FF ; Unknown
- "Bamu", # 16800..16A38 ; Bamum
- "Zzzz", # 16A39..16A3F ; Unknown
- "Mroo", # 16A40..16A5E ; Mro
- "Zzzz", # 16A5F..16A5F ; Unknown
- "Mroo", # 16A60..16A69 ; Mro
- "Zzzz", # 16A6A..16A6D ; Unknown
- "Mroo", # 16A6E..16A6F ; Mro
- "Tnsa", # 16A70..16ABE ; Tangsa
- "Zzzz", # 16ABF..16ABF ; Unknown
- "Tnsa", # 16AC0..16AC9 ; Tangsa
- "Zzzz", # 16ACA..16ACF ; Unknown
- "Bass", # 16AD0..16AED ; Bassa_Vah
- "Zzzz", # 16AEE..16AEF ; Unknown
- "Bass", # 16AF0..16AF5 ; Bassa_Vah
- "Zzzz", # 16AF6..16AFF ; Unknown
- "Hmng", # 16B00..16B45 ; Pahawh_Hmong
- "Zzzz", # 16B46..16B4F ; Unknown
- "Hmng", # 16B50..16B59 ; Pahawh_Hmong
- "Zzzz", # 16B5A..16B5A ; Unknown
- "Hmng", # 16B5B..16B61 ; Pahawh_Hmong
- "Zzzz", # 16B62..16B62 ; Unknown
- "Hmng", # 16B63..16B77 ; Pahawh_Hmong
- "Zzzz", # 16B78..16B7C ; Unknown
- "Hmng", # 16B7D..16B8F ; Pahawh_Hmong
- "Zzzz", # 16B90..16E3F ; Unknown
- "Medf", # 16E40..16E9A ; Medefaidrin
- "Zzzz", # 16E9B..16EFF ; Unknown
- "Plrd", # 16F00..16F4A ; Miao
- "Zzzz", # 16F4B..16F4E ; Unknown
- "Plrd", # 16F4F..16F87 ; Miao
- "Zzzz", # 16F88..16F8E ; Unknown
- "Plrd", # 16F8F..16F9F ; Miao
- "Zzzz", # 16FA0..16FDF ; Unknown
- "Tang", # 16FE0..16FE0 ; Tangut
- "Nshu", # 16FE1..16FE1 ; Nushu
- "Hani", # 16FE2..16FE3 ; Han
- "Kits", # 16FE4..16FE4 ; Khitan_Small_Script
- "Zzzz", # 16FE5..16FEF ; Unknown
- "Hani", # 16FF0..16FF1 ; Han
- "Zzzz", # 16FF2..16FFF ; Unknown
- "Tang", # 17000..187F7 ; Tangut
- "Zzzz", # 187F8..187FF ; Unknown
- "Tang", # 18800..18AFF ; Tangut
- "Kits", # 18B00..18CD5 ; Khitan_Small_Script
- "Zzzz", # 18CD6..18CFF ; Unknown
- "Tang", # 18D00..18D08 ; Tangut
- "Zzzz", # 18D09..1AFEF ; Unknown
- "Kana", # 1AFF0..1AFF3 ; Katakana
- "Zzzz", # 1AFF4..1AFF4 ; Unknown
- "Kana", # 1AFF5..1AFFB ; Katakana
- "Zzzz", # 1AFFC..1AFFC ; Unknown
- "Kana", # 1AFFD..1AFFE ; Katakana
- "Zzzz", # 1AFFF..1AFFF ; Unknown
- "Kana", # 1B000..1B000 ; Katakana
- "Hira", # 1B001..1B11F ; Hiragana
- "Kana", # 1B120..1B122 ; Katakana
- "Zzzz", # 1B123..1B131 ; Unknown
- "Hira", # 1B132..1B132 ; Hiragana
- "Zzzz", # 1B133..1B14F ; Unknown
- "Hira", # 1B150..1B152 ; Hiragana
- "Zzzz", # 1B153..1B154 ; Unknown
- "Kana", # 1B155..1B155 ; Katakana
- "Zzzz", # 1B156..1B163 ; Unknown
- "Kana", # 1B164..1B167 ; Katakana
- "Zzzz", # 1B168..1B16F ; Unknown
- "Nshu", # 1B170..1B2FB ; Nushu
- "Zzzz", # 1B2FC..1BBFF ; Unknown
- "Dupl", # 1BC00..1BC6A ; Duployan
- "Zzzz", # 1BC6B..1BC6F ; Unknown
- "Dupl", # 1BC70..1BC7C ; Duployan
- "Zzzz", # 1BC7D..1BC7F ; Unknown
- "Dupl", # 1BC80..1BC88 ; Duployan
- "Zzzz", # 1BC89..1BC8F ; Unknown
- "Dupl", # 1BC90..1BC99 ; Duployan
- "Zzzz", # 1BC9A..1BC9B ; Unknown
- "Dupl", # 1BC9C..1BC9F ; Duployan
- "Zyyy", # 1BCA0..1BCA3 ; Common
- "Zzzz", # 1BCA4..1CEFF ; Unknown
- "Zinh", # 1CF00..1CF2D ; Inherited
- "Zzzz", # 1CF2E..1CF2F ; Unknown
- "Zinh", # 1CF30..1CF46 ; Inherited
- "Zzzz", # 1CF47..1CF4F ; Unknown
- "Zyyy", # 1CF50..1CFC3 ; Common
- "Zzzz", # 1CFC4..1CFFF ; Unknown
- "Zyyy", # 1D000..1D0F5 ; Common
- "Zzzz", # 1D0F6..1D0FF ; Unknown
- "Zyyy", # 1D100..1D126 ; Common
- "Zzzz", # 1D127..1D128 ; Unknown
- "Zyyy", # 1D129..1D166 ; Common
- "Zinh", # 1D167..1D169 ; Inherited
- "Zyyy", # 1D16A..1D17A ; Common
- "Zinh", # 1D17B..1D182 ; Inherited
- "Zyyy", # 1D183..1D184 ; Common
- "Zinh", # 1D185..1D18B ; Inherited
- "Zyyy", # 1D18C..1D1A9 ; Common
- "Zinh", # 1D1AA..1D1AD ; Inherited
- "Zyyy", # 1D1AE..1D1EA ; Common
- "Zzzz", # 1D1EB..1D1FF ; Unknown
- "Grek", # 1D200..1D245 ; Greek
- "Zzzz", # 1D246..1D2BF ; Unknown
- "Zyyy", # 1D2C0..1D2D3 ; Common
- "Zzzz", # 1D2D4..1D2DF ; Unknown
- "Zyyy", # 1D2E0..1D2F3 ; Common
- "Zzzz", # 1D2F4..1D2FF ; Unknown
- "Zyyy", # 1D300..1D356 ; Common
- "Zzzz", # 1D357..1D35F ; Unknown
- "Zyyy", # 1D360..1D378 ; Common
- "Zzzz", # 1D379..1D3FF ; Unknown
- "Zyyy", # 1D400..1D454 ; Common
- "Zzzz", # 1D455..1D455 ; Unknown
- "Zyyy", # 1D456..1D49C ; Common
- "Zzzz", # 1D49D..1D49D ; Unknown
- "Zyyy", # 1D49E..1D49F ; Common
- "Zzzz", # 1D4A0..1D4A1 ; Unknown
- "Zyyy", # 1D4A2..1D4A2 ; Common
- "Zzzz", # 1D4A3..1D4A4 ; Unknown
- "Zyyy", # 1D4A5..1D4A6 ; Common
- "Zzzz", # 1D4A7..1D4A8 ; Unknown
- "Zyyy", # 1D4A9..1D4AC ; Common
- "Zzzz", # 1D4AD..1D4AD ; Unknown
- "Zyyy", # 1D4AE..1D4B9 ; Common
- "Zzzz", # 1D4BA..1D4BA ; Unknown
- "Zyyy", # 1D4BB..1D4BB ; Common
- "Zzzz", # 1D4BC..1D4BC ; Unknown
- "Zyyy", # 1D4BD..1D4C3 ; Common
- "Zzzz", # 1D4C4..1D4C4 ; Unknown
- "Zyyy", # 1D4C5..1D505 ; Common
- "Zzzz", # 1D506..1D506 ; Unknown
- "Zyyy", # 1D507..1D50A ; Common
- "Zzzz", # 1D50B..1D50C ; Unknown
- "Zyyy", # 1D50D..1D514 ; Common
- "Zzzz", # 1D515..1D515 ; Unknown
- "Zyyy", # 1D516..1D51C ; Common
- "Zzzz", # 1D51D..1D51D ; Unknown
- "Zyyy", # 1D51E..1D539 ; Common
- "Zzzz", # 1D53A..1D53A ; Unknown
- "Zyyy", # 1D53B..1D53E ; Common
- "Zzzz", # 1D53F..1D53F ; Unknown
- "Zyyy", # 1D540..1D544 ; Common
- "Zzzz", # 1D545..1D545 ; Unknown
- "Zyyy", # 1D546..1D546 ; Common
- "Zzzz", # 1D547..1D549 ; Unknown
- "Zyyy", # 1D54A..1D550 ; Common
- "Zzzz", # 1D551..1D551 ; Unknown
- "Zyyy", # 1D552..1D6A5 ; Common
- "Zzzz", # 1D6A6..1D6A7 ; Unknown
- "Zyyy", # 1D6A8..1D7CB ; Common
- "Zzzz", # 1D7CC..1D7CD ; Unknown
- "Zyyy", # 1D7CE..1D7FF ; Common
- "Sgnw", # 1D800..1DA8B ; SignWriting
- "Zzzz", # 1DA8C..1DA9A ; Unknown
- "Sgnw", # 1DA9B..1DA9F ; SignWriting
- "Zzzz", # 1DAA0..1DAA0 ; Unknown
- "Sgnw", # 1DAA1..1DAAF ; SignWriting
- "Zzzz", # 1DAB0..1DEFF ; Unknown
- "Latn", # 1DF00..1DF1E ; Latin
- "Zzzz", # 1DF1F..1DF24 ; Unknown
- "Latn", # 1DF25..1DF2A ; Latin
- "Zzzz", # 1DF2B..1DFFF ; Unknown
- "Glag", # 1E000..1E006 ; Glagolitic
- "Zzzz", # 1E007..1E007 ; Unknown
- "Glag", # 1E008..1E018 ; Glagolitic
- "Zzzz", # 1E019..1E01A ; Unknown
- "Glag", # 1E01B..1E021 ; Glagolitic
- "Zzzz", # 1E022..1E022 ; Unknown
- "Glag", # 1E023..1E024 ; Glagolitic
- "Zzzz", # 1E025..1E025 ; Unknown
- "Glag", # 1E026..1E02A ; Glagolitic
- "Zzzz", # 1E02B..1E02F ; Unknown
- "Cyrl", # 1E030..1E06D ; Cyrillic
- "Zzzz", # 1E06E..1E08E ; Unknown
- "Cyrl", # 1E08F..1E08F ; Cyrillic
- "Zzzz", # 1E090..1E0FF ; Unknown
- "Hmnp", # 1E100..1E12C ; Nyiakeng_Puachue_Hmong
- "Zzzz", # 1E12D..1E12F ; Unknown
- "Hmnp", # 1E130..1E13D ; Nyiakeng_Puachue_Hmong
- "Zzzz", # 1E13E..1E13F ; Unknown
- "Hmnp", # 1E140..1E149 ; Nyiakeng_Puachue_Hmong
- "Zzzz", # 1E14A..1E14D ; Unknown
- "Hmnp", # 1E14E..1E14F ; Nyiakeng_Puachue_Hmong
- "Zzzz", # 1E150..1E28F ; Unknown
- "Toto", # 1E290..1E2AE ; Toto
- "Zzzz", # 1E2AF..1E2BF ; Unknown
- "Wcho", # 1E2C0..1E2F9 ; Wancho
- "Zzzz", # 1E2FA..1E2FE ; Unknown
- "Wcho", # 1E2FF..1E2FF ; Wancho
- "Zzzz", # 1E300..1E4CF ; Unknown
- "Nagm", # 1E4D0..1E4F9 ; Nag_Mundari
- "Zzzz", # 1E4FA..1E7DF ; Unknown
- "Ethi", # 1E7E0..1E7E6 ; Ethiopic
- "Zzzz", # 1E7E7..1E7E7 ; Unknown
- "Ethi", # 1E7E8..1E7EB ; Ethiopic
- "Zzzz", # 1E7EC..1E7EC ; Unknown
- "Ethi", # 1E7ED..1E7EE ; Ethiopic
- "Zzzz", # 1E7EF..1E7EF ; Unknown
- "Ethi", # 1E7F0..1E7FE ; Ethiopic
- "Zzzz", # 1E7FF..1E7FF ; Unknown
- "Mend", # 1E800..1E8C4 ; Mende_Kikakui
- "Zzzz", # 1E8C5..1E8C6 ; Unknown
- "Mend", # 1E8C7..1E8D6 ; Mende_Kikakui
- "Zzzz", # 1E8D7..1E8FF ; Unknown
- "Adlm", # 1E900..1E94B ; Adlam
- "Zzzz", # 1E94C..1E94F ; Unknown
- "Adlm", # 1E950..1E959 ; Adlam
- "Zzzz", # 1E95A..1E95D ; Unknown
- "Adlm", # 1E95E..1E95F ; Adlam
- "Zzzz", # 1E960..1EC70 ; Unknown
- "Zyyy", # 1EC71..1ECB4 ; Common
- "Zzzz", # 1ECB5..1ED00 ; Unknown
- "Zyyy", # 1ED01..1ED3D ; Common
- "Zzzz", # 1ED3E..1EDFF ; Unknown
- "Arab", # 1EE00..1EE03 ; Arabic
- "Zzzz", # 1EE04..1EE04 ; Unknown
- "Arab", # 1EE05..1EE1F ; Arabic
- "Zzzz", # 1EE20..1EE20 ; Unknown
- "Arab", # 1EE21..1EE22 ; Arabic
- "Zzzz", # 1EE23..1EE23 ; Unknown
- "Arab", # 1EE24..1EE24 ; Arabic
- "Zzzz", # 1EE25..1EE26 ; Unknown
- "Arab", # 1EE27..1EE27 ; Arabic
- "Zzzz", # 1EE28..1EE28 ; Unknown
- "Arab", # 1EE29..1EE32 ; Arabic
- "Zzzz", # 1EE33..1EE33 ; Unknown
- "Arab", # 1EE34..1EE37 ; Arabic
- "Zzzz", # 1EE38..1EE38 ; Unknown
- "Arab", # 1EE39..1EE39 ; Arabic
- "Zzzz", # 1EE3A..1EE3A ; Unknown
- "Arab", # 1EE3B..1EE3B ; Arabic
- "Zzzz", # 1EE3C..1EE41 ; Unknown
- "Arab", # 1EE42..1EE42 ; Arabic
- "Zzzz", # 1EE43..1EE46 ; Unknown
- "Arab", # 1EE47..1EE47 ; Arabic
- "Zzzz", # 1EE48..1EE48 ; Unknown
- "Arab", # 1EE49..1EE49 ; Arabic
- "Zzzz", # 1EE4A..1EE4A ; Unknown
- "Arab", # 1EE4B..1EE4B ; Arabic
- "Zzzz", # 1EE4C..1EE4C ; Unknown
- "Arab", # 1EE4D..1EE4F ; Arabic
- "Zzzz", # 1EE50..1EE50 ; Unknown
- "Arab", # 1EE51..1EE52 ; Arabic
- "Zzzz", # 1EE53..1EE53 ; Unknown
- "Arab", # 1EE54..1EE54 ; Arabic
- "Zzzz", # 1EE55..1EE56 ; Unknown
- "Arab", # 1EE57..1EE57 ; Arabic
- "Zzzz", # 1EE58..1EE58 ; Unknown
- "Arab", # 1EE59..1EE59 ; Arabic
- "Zzzz", # 1EE5A..1EE5A ; Unknown
- "Arab", # 1EE5B..1EE5B ; Arabic
- "Zzzz", # 1EE5C..1EE5C ; Unknown
- "Arab", # 1EE5D..1EE5D ; Arabic
- "Zzzz", # 1EE5E..1EE5E ; Unknown
- "Arab", # 1EE5F..1EE5F ; Arabic
- "Zzzz", # 1EE60..1EE60 ; Unknown
- "Arab", # 1EE61..1EE62 ; Arabic
- "Zzzz", # 1EE63..1EE63 ; Unknown
- "Arab", # 1EE64..1EE64 ; Arabic
- "Zzzz", # 1EE65..1EE66 ; Unknown
- "Arab", # 1EE67..1EE6A ; Arabic
- "Zzzz", # 1EE6B..1EE6B ; Unknown
- "Arab", # 1EE6C..1EE72 ; Arabic
- "Zzzz", # 1EE73..1EE73 ; Unknown
- "Arab", # 1EE74..1EE77 ; Arabic
- "Zzzz", # 1EE78..1EE78 ; Unknown
- "Arab", # 1EE79..1EE7C ; Arabic
- "Zzzz", # 1EE7D..1EE7D ; Unknown
- "Arab", # 1EE7E..1EE7E ; Arabic
- "Zzzz", # 1EE7F..1EE7F ; Unknown
- "Arab", # 1EE80..1EE89 ; Arabic
- "Zzzz", # 1EE8A..1EE8A ; Unknown
- "Arab", # 1EE8B..1EE9B ; Arabic
- "Zzzz", # 1EE9C..1EEA0 ; Unknown
- "Arab", # 1EEA1..1EEA3 ; Arabic
- "Zzzz", # 1EEA4..1EEA4 ; Unknown
- "Arab", # 1EEA5..1EEA9 ; Arabic
- "Zzzz", # 1EEAA..1EEAA ; Unknown
- "Arab", # 1EEAB..1EEBB ; Arabic
- "Zzzz", # 1EEBC..1EEEF ; Unknown
- "Arab", # 1EEF0..1EEF1 ; Arabic
- "Zzzz", # 1EEF2..1EFFF ; Unknown
- "Zyyy", # 1F000..1F02B ; Common
- "Zzzz", # 1F02C..1F02F ; Unknown
- "Zyyy", # 1F030..1F093 ; Common
- "Zzzz", # 1F094..1F09F ; Unknown
- "Zyyy", # 1F0A0..1F0AE ; Common
- "Zzzz", # 1F0AF..1F0B0 ; Unknown
- "Zyyy", # 1F0B1..1F0BF ; Common
- "Zzzz", # 1F0C0..1F0C0 ; Unknown
- "Zyyy", # 1F0C1..1F0CF ; Common
- "Zzzz", # 1F0D0..1F0D0 ; Unknown
- "Zyyy", # 1F0D1..1F0F5 ; Common
- "Zzzz", # 1F0F6..1F0FF ; Unknown
- "Zyyy", # 1F100..1F1AD ; Common
- "Zzzz", # 1F1AE..1F1E5 ; Unknown
- "Zyyy", # 1F1E6..1F1FF ; Common
- "Hira", # 1F200..1F200 ; Hiragana
- "Zyyy", # 1F201..1F202 ; Common
- "Zzzz", # 1F203..1F20F ; Unknown
- "Zyyy", # 1F210..1F23B ; Common
- "Zzzz", # 1F23C..1F23F ; Unknown
- "Zyyy", # 1F240..1F248 ; Common
- "Zzzz", # 1F249..1F24F ; Unknown
- "Zyyy", # 1F250..1F251 ; Common
- "Zzzz", # 1F252..1F25F ; Unknown
- "Zyyy", # 1F260..1F265 ; Common
- "Zzzz", # 1F266..1F2FF ; Unknown
- "Zyyy", # 1F300..1F6D7 ; Common
- "Zzzz", # 1F6D8..1F6DB ; Unknown
- "Zyyy", # 1F6DC..1F6EC ; Common
- "Zzzz", # 1F6ED..1F6EF ; Unknown
- "Zyyy", # 1F6F0..1F6FC ; Common
- "Zzzz", # 1F6FD..1F6FF ; Unknown
- "Zyyy", # 1F700..1F776 ; Common
- "Zzzz", # 1F777..1F77A ; Unknown
- "Zyyy", # 1F77B..1F7D9 ; Common
- "Zzzz", # 1F7DA..1F7DF ; Unknown
- "Zyyy", # 1F7E0..1F7EB ; Common
- "Zzzz", # 1F7EC..1F7EF ; Unknown
- "Zyyy", # 1F7F0..1F7F0 ; Common
- "Zzzz", # 1F7F1..1F7FF ; Unknown
- "Zyyy", # 1F800..1F80B ; Common
- "Zzzz", # 1F80C..1F80F ; Unknown
- "Zyyy", # 1F810..1F847 ; Common
- "Zzzz", # 1F848..1F84F ; Unknown
- "Zyyy", # 1F850..1F859 ; Common
- "Zzzz", # 1F85A..1F85F ; Unknown
- "Zyyy", # 1F860..1F887 ; Common
- "Zzzz", # 1F888..1F88F ; Unknown
- "Zyyy", # 1F890..1F8AD ; Common
- "Zzzz", # 1F8AE..1F8AF ; Unknown
- "Zyyy", # 1F8B0..1F8B1 ; Common
- "Zzzz", # 1F8B2..1F8FF ; Unknown
- "Zyyy", # 1F900..1FA53 ; Common
- "Zzzz", # 1FA54..1FA5F ; Unknown
- "Zyyy", # 1FA60..1FA6D ; Common
- "Zzzz", # 1FA6E..1FA6F ; Unknown
- "Zyyy", # 1FA70..1FA7C ; Common
- "Zzzz", # 1FA7D..1FA7F ; Unknown
- "Zyyy", # 1FA80..1FA88 ; Common
- "Zzzz", # 1FA89..1FA8F ; Unknown
- "Zyyy", # 1FA90..1FABD ; Common
- "Zzzz", # 1FABE..1FABE ; Unknown
- "Zyyy", # 1FABF..1FAC5 ; Common
- "Zzzz", # 1FAC6..1FACD ; Unknown
- "Zyyy", # 1FACE..1FADB ; Common
- "Zzzz", # 1FADC..1FADF ; Unknown
- "Zyyy", # 1FAE0..1FAE8 ; Common
- "Zzzz", # 1FAE9..1FAEF ; Unknown
- "Zyyy", # 1FAF0..1FAF8 ; Common
- "Zzzz", # 1FAF9..1FAFF ; Unknown
- "Zyyy", # 1FB00..1FB92 ; Common
- "Zzzz", # 1FB93..1FB93 ; Unknown
- "Zyyy", # 1FB94..1FBCA ; Common
- "Zzzz", # 1FBCB..1FBEF ; Unknown
- "Zyyy", # 1FBF0..1FBF9 ; Common
- "Zzzz", # 1FBFA..1FFFF ; Unknown
- "Hani", # 20000..2A6DF ; Han
- "Zzzz", # 2A6E0..2A6FF ; Unknown
- "Hani", # 2A700..2B739 ; Han
- "Zzzz", # 2B73A..2B73F ; Unknown
- "Hani", # 2B740..2B81D ; Han
- "Zzzz", # 2B81E..2B81F ; Unknown
- "Hani", # 2B820..2CEA1 ; Han
- "Zzzz", # 2CEA2..2CEAF ; Unknown
- "Hani", # 2CEB0..2EBE0 ; Han
- "Zzzz", # 2EBE1..2F7FF ; Unknown
- "Hani", # 2F800..2FA1D ; Han
- "Zzzz", # 2FA1E..2FFFF ; Unknown
- "Hani", # 30000..3134A ; Han
- "Zzzz", # 3134B..3134F ; Unknown
- "Hani", # 31350..323AF ; Han
- "Zzzz", # 323B0..E0000 ; Unknown
- "Zyyy", # E0001..E0001 ; Common
- "Zzzz", # E0002..E001F ; Unknown
- "Zyyy", # E0020..E007F ; Common
- "Zzzz", # E0080..E00FF ; Unknown
- "Zinh", # E0100..E01EF ; Inherited
- "Zzzz", # E01F0..10FFFF ; Unknown
-]
-
-NAMES = {
- "Adlm": "Adlam",
- "Aghb": "Caucasian_Albanian",
- "Ahom": "Ahom",
- "Arab": "Arabic",
- "Armi": "Imperial_Aramaic",
- "Armn": "Armenian",
- "Avst": "Avestan",
- "Bali": "Balinese",
- "Bamu": "Bamum",
- "Bass": "Bassa_Vah",
- "Batk": "Batak",
- "Beng": "Bengali",
- "Bhks": "Bhaiksuki",
- "Bopo": "Bopomofo",
- "Brah": "Brahmi",
- "Brai": "Braille",
- "Bugi": "Buginese",
- "Buhd": "Buhid",
- "Cakm": "Chakma",
- "Cans": "Canadian_Aboriginal",
- "Cari": "Carian",
- "Cham": "Cham",
- "Cher": "Cherokee",
- "Chrs": "Chorasmian",
- "Copt": "Coptic",
- "Cpmn": "Cypro_Minoan",
- "Cprt": "Cypriot",
- "Cyrl": "Cyrillic",
- "Deva": "Devanagari",
- "Diak": "Dives_Akuru",
- "Dogr": "Dogra",
- "Dsrt": "Deseret",
- "Dupl": "Duployan",
- "Egyp": "Egyptian_Hieroglyphs",
- "Elba": "Elbasan",
- "Elym": "Elymaic",
- "Ethi": "Ethiopic",
- "Geor": "Georgian",
- "Glag": "Glagolitic",
- "Gong": "Gunjala_Gondi",
- "Gonm": "Masaram_Gondi",
- "Goth": "Gothic",
- "Gran": "Grantha",
- "Grek": "Greek",
- "Gujr": "Gujarati",
- "Guru": "Gurmukhi",
- "Hang": "Hangul",
- "Hani": "Han",
- "Hano": "Hanunoo",
- "Hatr": "Hatran",
- "Hebr": "Hebrew",
- "Hira": "Hiragana",
- "Hluw": "Anatolian_Hieroglyphs",
- "Hmng": "Pahawh_Hmong",
- "Hmnp": "Nyiakeng_Puachue_Hmong",
- "Hrkt": "Katakana_Or_Hiragana",
- "Hung": "Old_Hungarian",
- "Ital": "Old_Italic",
- "Java": "Javanese",
- "Kali": "Kayah_Li",
- "Kana": "Katakana",
- "Kawi": "Kawi",
- "Khar": "Kharoshthi",
- "Khmr": "Khmer",
- "Khoj": "Khojki",
- "Kits": "Khitan_Small_Script",
- "Knda": "Kannada",
- "Kthi": "Kaithi",
- "Lana": "Tai_Tham",
- "Laoo": "Lao",
- "Latn": "Latin",
- "Lepc": "Lepcha",
- "Limb": "Limbu",
- "Lina": "Linear_A",
- "Linb": "Linear_B",
- "Lisu": "Lisu",
- "Lyci": "Lycian",
- "Lydi": "Lydian",
- "Mahj": "Mahajani",
- "Maka": "Makasar",
- "Mand": "Mandaic",
- "Mani": "Manichaean",
- "Marc": "Marchen",
- "Medf": "Medefaidrin",
- "Mend": "Mende_Kikakui",
- "Merc": "Meroitic_Cursive",
- "Mero": "Meroitic_Hieroglyphs",
- "Mlym": "Malayalam",
- "Modi": "Modi",
- "Mong": "Mongolian",
- "Mroo": "Mro",
- "Mtei": "Meetei_Mayek",
- "Mult": "Multani",
- "Mymr": "Myanmar",
- "Nagm": "Nag_Mundari",
- "Nand": "Nandinagari",
- "Narb": "Old_North_Arabian",
- "Nbat": "Nabataean",
- "Newa": "Newa",
- "Nkoo": "Nko",
- "Nshu": "Nushu",
- "Ogam": "Ogham",
- "Olck": "Ol_Chiki",
- "Orkh": "Old_Turkic",
- "Orya": "Oriya",
- "Osge": "Osage",
- "Osma": "Osmanya",
- "Ougr": "Old_Uyghur",
- "Palm": "Palmyrene",
- "Pauc": "Pau_Cin_Hau",
- "Perm": "Old_Permic",
- "Phag": "Phags_Pa",
- "Phli": "Inscriptional_Pahlavi",
- "Phlp": "Psalter_Pahlavi",
- "Phnx": "Phoenician",
- "Plrd": "Miao",
- "Prti": "Inscriptional_Parthian",
- "Rjng": "Rejang",
- "Rohg": "Hanifi_Rohingya",
- "Runr": "Runic",
- "Samr": "Samaritan",
- "Sarb": "Old_South_Arabian",
- "Saur": "Saurashtra",
- "Sgnw": "SignWriting",
- "Shaw": "Shavian",
- "Shrd": "Sharada",
- "Sidd": "Siddham",
- "Sind": "Khudawadi",
- "Sinh": "Sinhala",
- "Sogd": "Sogdian",
- "Sogo": "Old_Sogdian",
- "Sora": "Sora_Sompeng",
- "Soyo": "Soyombo",
- "Sund": "Sundanese",
- "Sylo": "Syloti_Nagri",
- "Syrc": "Syriac",
- "Tagb": "Tagbanwa",
- "Takr": "Takri",
- "Tale": "Tai_Le",
- "Talu": "New_Tai_Lue",
- "Taml": "Tamil",
- "Tang": "Tangut",
- "Tavt": "Tai_Viet",
- "Telu": "Telugu",
- "Tfng": "Tifinagh",
- "Tglg": "Tagalog",
- "Thaa": "Thaana",
- "Thai": "Thai",
- "Tibt": "Tibetan",
- "Tirh": "Tirhuta",
- "Tnsa": "Tangsa",
- "Toto": "Toto",
- "Ugar": "Ugaritic",
- "Vaii": "Vai",
- "Vith": "Vithkuqi",
- "Wara": "Warang_Citi",
- "Wcho": "Wancho",
- "Xpeo": "Old_Persian",
- "Xsux": "Cuneiform",
- "Yezi": "Yezidi",
- "Yiii": "Yi",
- "Zanb": "Zanabazar_Square",
- "Zinh": "Inherited",
- "Zyyy": "Common",
- "Zzzz": "Unknown",
-}
diff --git a/spaces/johnslegers/stable-diffusion-gui-test/modules/app.py b/spaces/johnslegers/stable-diffusion-gui-test/modules/app.py
deleted file mode 100644
index 8405b2dd35eb195100ce91f70bf3d2f41051cf61..0000000000000000000000000000000000000000
--- a/spaces/johnslegers/stable-diffusion-gui-test/modules/app.py
+++ /dev/null
@@ -1,331 +0,0 @@
-import json
-import traceback
-
-import sys
-import os
-
-SD_DIR = os.getcwd()
-print('started in ', SD_DIR)
-
-SD_UI_DIR = './ui'
-sys.path.append(os.path.dirname(SD_UI_DIR))
-
-CONFIG_DIR = os.path.abspath(os.path.join(SD_UI_DIR, '.', 'config'))
-MODELS_DIR = os.path.abspath(os.path.join(SD_DIR, '.', 'models'))
-
-OUTPUT_DIRNAME = "Stable Diffusion UI" # in the user's home folder
-
-from fastapi import FastAPI, HTTPException
-from fastapi.staticfiles import StaticFiles
-from starlette.responses import FileResponse, StreamingResponse
-from pydantic import BaseModel
-import logging
-
-from sd_internal import Request, Response
-
-app = FastAPI()
-
-model_loaded = False
-model_is_loading = False
-
-modifiers_cache = None
-outpath = os.path.join(os.path.expanduser("~"), OUTPUT_DIRNAME)
-
-# don't show access log entries for URLs that start with the given prefix
-ACCESS_LOG_SUPPRESS_PATH_PREFIXES = ['/ping', '/modifier-thumbnails']
-
-app.mount('/media', StaticFiles(directory=os.path.join(SD_UI_DIR, 'media/')), name="media")
-
-# defaults from https://huggingface.co/blog/stable_diffusion
-class ImageRequest(BaseModel):
- session_id: str = "session"
- prompt: str = ""
- negative_prompt: str = ""
- init_image: str = None # base64
- mask: str = None # base64
- num_outputs: int = 1
- num_inference_steps: int = 50
- guidance_scale: float = 7.5
- width: int = 512
- height: int = 512
- seed: int = 42
- prompt_strength: float = 0.8
- sampler: str = None # "ddim", "plms", "heun", "euler", "euler_a", "dpm2", "dpm2_a", "lms"
- # allow_nsfw: bool = False
- save_to_disk_path: str = None
- turbo: bool = True
- use_cpu: bool = False
- use_full_precision: bool = False
- use_face_correction: str = None # or "GFPGANv1.3"
- use_upscale: str = None # or "RealESRGAN_x4plus" or "RealESRGAN_x4plus_anime_6B"
- use_stable_diffusion_model: str = "sd-v1-4"
- show_only_filtered_image: bool = False
- output_format: str = "jpeg" # or "png"
-
- stream_progress_updates: bool = False
- stream_image_progress: bool = False
-
-class SetAppConfigRequest(BaseModel):
- update_branch: str = "main"
-
-@app.get('/')
-def read_root():
- headers = {"Cache-Control": "no-cache, no-store, must-revalidate", "Pragma": "no-cache", "Expires": "0"}
- return FileResponse(os.path.join(SD_UI_DIR, 'index.html'), headers=headers)
-
-@app.get('/ping')
-async def ping():
- global model_loaded, model_is_loading
-
- try:
- if model_loaded:
- return {'OK1'}
-
- #if model_is_loading:
- # return {'ERROR'}
-
- model_is_loading = True
-
- from . import runtime
-
- #runtime.load_model_ckpt(ckpt_to_use=get_initial_model_to_load())
- runtime.load_model_ckpt(ckpt_to_use='sd-v1-4.ckpt')
-
- model_loaded = True
- model_is_loading = False
-
- return {'OK2'}
- except Exception as e:
- model_is_loading = False
- print(traceback.format_exc())
- return HTTPException(status_code=500, detail=str(e))
-
-# needs to support the legacy installations
-def get_initial_model_to_load():
- custom_weight_path = os.path.join(SD_DIR, 'custom-model.ckpt')
- ckpt_to_use = "sd-v1-4" if not os.path.exists(custom_weight_path) else "custom-model"
-
- ckpt_to_use = os.path.join(SD_DIR, ckpt_to_use)
-
- config = getConfig()
- if 'model' in config and 'stable-diffusion' in config['model']:
- model_name = config['model']['stable-diffusion']
- model_path = resolve_model_to_use(model_name)
-
- if os.path.exists(model_path + '.ckpt'):
- ckpt_to_use = model_path
- else:
- print('Could not find the configured custom model at:', model_path + '.ckpt', '. Using the default one:', ckpt_to_use + '.ckpt')
-
- return ckpt_to_use
-
-def resolve_model_to_use(model_name):
- if model_name in ('sd-v1-4', 'custom-model'):
- model_path = os.path.join(MODELS_DIR, 'stable-diffusion', model_name)
-
- legacy_model_path = os.path.join(SD_DIR, model_name)
- if not os.path.exists(model_path + '.ckpt') and os.path.exists(legacy_model_path + '.ckpt'):
- model_path = legacy_model_path
- else:
- model_path = os.path.join(MODELS_DIR, 'stable-diffusion', model_name)
-
- return model_path
-
-def save_model_to_config(model_name):
- config = getConfig()
- if 'model' not in config:
- config['model'] = {}
-
- config['model']['stable-diffusion'] = model_name
-
- setConfig(config)
-
-@app.post('/image')
-def image(req : ImageRequest):
- from . import runtime
-
- r = Request()
- r.session_id = req.session_id
- r.prompt = req.prompt
- r.negative_prompt = req.negative_prompt
- r.init_image = req.init_image
- r.mask = req.mask
- r.num_outputs = req.num_outputs
- r.num_inference_steps = req.num_inference_steps
- r.guidance_scale = req.guidance_scale
- r.width = req.width
- r.height = req.height
- r.seed = req.seed
- r.prompt_strength = req.prompt_strength
- r.sampler = req.sampler
- # r.allow_nsfw = req.allow_nsfw
- r.turbo = req.turbo
- r.use_cpu = req.use_cpu
- r.use_full_precision = req.use_full_precision
- r.save_to_disk_path = req.save_to_disk_path
- r.use_upscale: str = req.use_upscale
- r.use_face_correction = req.use_face_correction
- r.show_only_filtered_image = req.show_only_filtered_image
- r.output_format = req.output_format
-
- r.stream_progress_updates = True # the underlying implementation only supports streaming
- r.stream_image_progress = req.stream_image_progress
-
- r.use_stable_diffusion_model = resolve_model_to_use(req.use_stable_diffusion_model)
-
- save_model_to_config(req.use_stable_diffusion_model)
-
- try:
- if not req.stream_progress_updates:
- r.stream_image_progress = False
-
- res = runtime.mk_img(r)
-
- if req.stream_progress_updates:
- return StreamingResponse(res, media_type='application/json')
- else: # compatibility mode: buffer the streaming responses, and return the last one
- last_result = None
-
- for result in res:
- last_result = result
-
- return json.loads(last_result)
- except Exception as e:
- print(traceback.format_exc())
- return HTTPException(status_code=500, detail=str(e))
-
-@app.get('/image/stop')
-def stop():
- try:
- # if model_is_loading:
- # return {'ERROR'}
-
- # from . import runtime
- # runtime.stop_processing = True
-
- return {'OK'}
- except Exception as e:
- print(traceback.format_exc())
- return HTTPException(status_code=500, detail=str(e))
-
-@app.get('/image/tmp/{session_id}/{img_id}')
-def get_image(session_id, img_id):
- from . import runtime
- buf = runtime.temp_images[session_id + '/' + img_id]
- buf.seek(0)
- return StreamingResponse(buf, media_type='image/jpeg')
-
-@app.post('/app_config')
-async def setAppConfig(req : SetAppConfigRequest):
- try:
- config = {
- 'update_branch': req.update_branch
- }
-
- config_json_str = json.dumps(config)
- config_bat_str = f'@set update_branch={req.update_branch}'
- config_sh_str = f'export update_branch={req.update_branch}'
-
- config_json_path = os.path.join(CONFIG_DIR, 'config.json')
- config_bat_path = os.path.join(CONFIG_DIR, 'config.bat')
- config_sh_path = os.path.join(CONFIG_DIR, 'config.sh')
-
- with open(config_json_path, 'w') as f:
- f.write(config_json_str)
-
- with open(config_bat_path, 'w') as f:
- f.write(config_bat_str)
-
- with open(config_sh_path, 'w') as f:
- f.write(config_sh_str)
-
- return {'OK'}
- except Exception as e:
- print(traceback.format_exc())
- return HTTPException(status_code=500, detail=str(e))
-
-@app.get('/app_config')
-def getAppConfig():
- try:
- config_json_path = os.path.join(CONFIG_DIR, 'config.json')
-
- if not os.path.exists(config_json_path):
- return HTTPException(status_code=500, detail="No config file")
-
- with open(config_json_path, 'r') as f:
- return json.load(f)
- except Exception as e:
- print(traceback.format_exc())
- return HTTPException(status_code=500, detail=str(e))
-
-def getConfig():
- try:
- config_json_path = os.path.join(CONFIG_DIR, 'config.json')
-
- if not os.path.exists(config_json_path):
- return {}
-
- with open(config_json_path, 'r') as f:
- return json.load(f)
- except Exception as e:
- return {}
-
-def setConfig(config):
- try:
- config_json_path = os.path.join(CONFIG_DIR, 'config.json')
-
- with open(config_json_path, 'w') as f:
- return json.dump(config, f)
- except:
- print(traceback.format_exc())
-
-@app.get('/models')
-def getModels():
- models = {
- 'active': {
- 'stable-diffusion': 'sd-v1-4',
- },
- 'options': {
- 'stable-diffusion': ['sd-v1-4'],
- },
- }
-
- # custom models
- sd_models_dir = os.path.join(MODELS_DIR, 'stable-diffusion')
- for file in os.listdir(sd_models_dir):
- if file.endswith('.ckpt'):
- model_name = os.path.splitext(file)[0]
- models['options']['stable-diffusion'].append(model_name)
-
- # legacy
- custom_weight_path = os.path.join(SD_DIR, 'custom-model.ckpt')
- if os.path.exists(custom_weight_path):
- models['active']['stable-diffusion'] = 'custom-model'
- models['options']['stable-diffusion'].append('custom-model')
-
- config = getConfig()
- if 'model' in config and 'stable-diffusion' in config['model']:
- models['active']['stable-diffusion'] = config['model']['stable-diffusion']
-
- return models
-
-@app.get('/modifiers.json')
-def read_modifiers():
- headers = {"Cache-Control": "no-cache, no-store, must-revalidate", "Pragma": "no-cache", "Expires": "0"}
- return FileResponse(os.path.join(SD_UI_DIR, 'modifiers.json'), headers=headers)
-
-@app.get('/output_dir')
-def read_home_dir():
- return {outpath}
-
-# don't log certain requests
-class LogSuppressFilter(logging.Filter):
- def filter(self, record: logging.LogRecord) -> bool:
- path = record.getMessage()
- for prefix in ACCESS_LOG_SUPPRESS_PATH_PREFIXES:
- if path.find(prefix) != -1:
- return False
-
- return True
-
-logging.getLogger('uvicorn.access').addFilter(LogSuppressFilter())
diff --git a/spaces/johnslegers/stable-diffusion-gui-test/ui/media/jquery-3.6.1.min.js b/spaces/johnslegers/stable-diffusion-gui-test/ui/media/jquery-3.6.1.min.js
deleted file mode 100644
index 2c69bc908b10d854c2c3fe6e3268dcffe20e1b5a..0000000000000000000000000000000000000000
--- a/spaces/johnslegers/stable-diffusion-gui-test/ui/media/jquery-3.6.1.min.js
+++ /dev/null
@@ -1,2 +0,0 @@
-/*! jQuery v3.6.1 | (c) OpenJS Foundation and other contributors | jquery.org/license */
-!function(e,t){"use strict";"object"==typeof module&&"object"==typeof module.exports?module.exports=e.document?t(e,!0):function(e){if(!e.document)throw new Error("jQuery requires a window with a document");return t(e)}:t(e)}("undefined"!=typeof window?window:this,function(C,e){"use strict";var t=[],r=Object.getPrototypeOf,s=t.slice,g=t.flat?function(e){return t.flat.call(e)}:function(e){return t.concat.apply([],e)},u=t.push,i=t.indexOf,n={},o=n.toString,y=n.hasOwnProperty,a=y.toString,l=a.call(Object),v={},m=function(e){return"function"==typeof e&&"number"!=typeof e.nodeType&&"function"!=typeof e.item},x=function(e){return null!=e&&e===e.window},E=C.document,c={type:!0,src:!0,nonce:!0,noModule:!0};function b(e,t,n){var r,i,o=(n=n||E).createElement("script");if(o.text=e,t)for(r in c)(i=t[r]||t.getAttribute&&t.getAttribute(r))&&o.setAttribute(r,i);n.head.appendChild(o).parentNode.removeChild(o)}function w(e){return null==e?e+"":"object"==typeof e||"function"==typeof e?n[o.call(e)]||"object":typeof e}var f="3.6.1",S=function(e,t){return new S.fn.init(e,t)};function p(e){var t=!!e&&"length"in e&&e.length,n=w(e);return!m(e)&&!x(e)&&("array"===n||0===t||"number"==typeof t&&0
+~]|"+M+")"+M+"*"),U=new RegExp(M+"|>"),X=new RegExp(F),V=new RegExp("^"+I+"$"),G={ID:new RegExp("^#("+I+")"),CLASS:new RegExp("^\\.("+I+")"),TAG:new RegExp("^("+I+"|[*])"),ATTR:new RegExp("^"+W),PSEUDO:new RegExp("^"+F),CHILD:new RegExp("^:(only|first|last|nth|nth-last)-(child|of-type)(?:\\("+M+"*(even|odd|(([+-]|)(\\d*)n|)"+M+"*(?:([+-]|)"+M+"*(\\d+)|))"+M+"*\\)|)","i"),bool:new RegExp("^(?:"+R+")$","i"),needsContext:new RegExp("^"+M+"*[>+~]|:(even|odd|eq|gt|lt|nth|first|last)(?:\\("+M+"*((?:-\\d)?\\d*)"+M+"*\\)|)(?=[^-]|$)","i")},Y=/HTML$/i,Q=/^(?:input|select|textarea|button)$/i,J=/^h\d$/i,K=/^[^{]+\{\s*\[native \w/,Z=/^(?:#([\w-]+)|(\w+)|\.([\w-]+))$/,ee=/[+~]/,te=new RegExp("\\\\[\\da-fA-F]{1,6}"+M+"?|\\\\([^\\r\\n\\f])","g"),ne=function(e,t){var n="0x"+e.slice(1)-65536;return t||(n<0?String.fromCharCode(n+65536):String.fromCharCode(n>>10|55296,1023&n|56320))},re=/([\0-\x1f\x7f]|^-?\d)|^-$|[^\0-\x1f\x7f-\uFFFF\w-]/g,ie=function(e,t){return t?"\0"===e?"\ufffd":e.slice(0,-1)+"\\"+e.charCodeAt(e.length-1).toString(16)+" ":"\\"+e},oe=function(){T()},ae=be(function(e){return!0===e.disabled&&"fieldset"===e.nodeName.toLowerCase()},{dir:"parentNode",next:"legend"});try{H.apply(t=O.call(p.childNodes),p.childNodes),t[p.childNodes.length].nodeType}catch(e){H={apply:t.length?function(e,t){L.apply(e,O.call(t))}:function(e,t){var n=e.length,r=0;while(e[n++]=t[r++]);e.length=n-1}}}function se(t,e,n,r){var i,o,a,s,u,l,c,f=e&&e.ownerDocument,p=e?e.nodeType:9;if(n=n||[],"string"!=typeof t||!t||1!==p&&9!==p&&11!==p)return n;if(!r&&(T(e),e=e||C,E)){if(11!==p&&(u=Z.exec(t)))if(i=u[1]){if(9===p){if(!(a=e.getElementById(i)))return n;if(a.id===i)return n.push(a),n}else if(f&&(a=f.getElementById(i))&&v(e,a)&&a.id===i)return n.push(a),n}else{if(u[2])return H.apply(n,e.getElementsByTagName(t)),n;if((i=u[3])&&d.getElementsByClassName&&e.getElementsByClassName)return H.apply(n,e.getElementsByClassName(i)),n}if(d.qsa&&!N[t+" "]&&(!y||!y.test(t))&&(1!==p||"object"!==e.nodeName.toLowerCase())){if(c=t,f=e,1===p&&(U.test(t)||z.test(t))){(f=ee.test(t)&&ve(e.parentNode)||e)===e&&d.scope||((s=e.getAttribute("id"))?s=s.replace(re,ie):e.setAttribute("id",s=S)),o=(l=h(t)).length;while(o--)l[o]=(s?"#"+s:":scope")+" "+xe(l[o]);c=l.join(",")}try{return H.apply(n,f.querySelectorAll(c)),n}catch(e){N(t,!0)}finally{s===S&&e.removeAttribute("id")}}}return g(t.replace(B,"$1"),e,n,r)}function ue(){var r=[];return function e(t,n){return r.push(t+" ")>b.cacheLength&&delete e[r.shift()],e[t+" "]=n}}function le(e){return e[S]=!0,e}function ce(e){var t=C.createElement("fieldset");try{return!!e(t)}catch(e){return!1}finally{t.parentNode&&t.parentNode.removeChild(t),t=null}}function fe(e,t){var n=e.split("|"),r=n.length;while(r--)b.attrHandle[n[r]]=t}function pe(e,t){var n=t&&e,r=n&&1===e.nodeType&&1===t.nodeType&&e.sourceIndex-t.sourceIndex;if(r)return r;if(n)while(n=n.nextSibling)if(n===t)return-1;return e?1:-1}function de(t){return function(e){return"input"===e.nodeName.toLowerCase()&&e.type===t}}function he(n){return function(e){var t=e.nodeName.toLowerCase();return("input"===t||"button"===t)&&e.type===n}}function ge(t){return function(e){return"form"in e?e.parentNode&&!1===e.disabled?"label"in e?"label"in e.parentNode?e.parentNode.disabled===t:e.disabled===t:e.isDisabled===t||e.isDisabled!==!t&&ae(e)===t:e.disabled===t:"label"in e&&e.disabled===t}}function ye(a){return le(function(o){return o=+o,le(function(e,t){var n,r=a([],e.length,o),i=r.length;while(i--)e[n=r[i]]&&(e[n]=!(t[n]=e[n]))})})}function ve(e){return e&&"undefined"!=typeof e.getElementsByTagName&&e}for(e in d=se.support={},i=se.isXML=function(e){var t=e&&e.namespaceURI,n=e&&(e.ownerDocument||e).documentElement;return!Y.test(t||n&&n.nodeName||"HTML")},T=se.setDocument=function(e){var t,n,r=e?e.ownerDocument||e:p;return r!=C&&9===r.nodeType&&r.documentElement&&(a=(C=r).documentElement,E=!i(C),p!=C&&(n=C.defaultView)&&n.top!==n&&(n.addEventListener?n.addEventListener("unload",oe,!1):n.attachEvent&&n.attachEvent("onunload",oe)),d.scope=ce(function(e){return a.appendChild(e).appendChild(C.createElement("div")),"undefined"!=typeof e.querySelectorAll&&!e.querySelectorAll(":scope fieldset div").length}),d.attributes=ce(function(e){return e.className="i",!e.getAttribute("className")}),d.getElementsByTagName=ce(function(e){return e.appendChild(C.createComment("")),!e.getElementsByTagName("*").length}),d.getElementsByClassName=K.test(C.getElementsByClassName),d.getById=ce(function(e){return a.appendChild(e).id=S,!C.getElementsByName||!C.getElementsByName(S).length}),d.getById?(b.filter.ID=function(e){var t=e.replace(te,ne);return function(e){return e.getAttribute("id")===t}},b.find.ID=function(e,t){if("undefined"!=typeof t.getElementById&&E){var n=t.getElementById(e);return n?[n]:[]}}):(b.filter.ID=function(e){var n=e.replace(te,ne);return function(e){var t="undefined"!=typeof e.getAttributeNode&&e.getAttributeNode("id");return t&&t.value===n}},b.find.ID=function(e,t){if("undefined"!=typeof t.getElementById&&E){var n,r,i,o=t.getElementById(e);if(o){if((n=o.getAttributeNode("id"))&&n.value===e)return[o];i=t.getElementsByName(e),r=0;while(o=i[r++])if((n=o.getAttributeNode("id"))&&n.value===e)return[o]}return[]}}),b.find.TAG=d.getElementsByTagName?function(e,t){return"undefined"!=typeof t.getElementsByTagName?t.getElementsByTagName(e):d.qsa?t.querySelectorAll(e):void 0}:function(e,t){var n,r=[],i=0,o=t.getElementsByTagName(e);if("*"===e){while(n=o[i++])1===n.nodeType&&r.push(n);return r}return o},b.find.CLASS=d.getElementsByClassName&&function(e,t){if("undefined"!=typeof t.getElementsByClassName&&E)return t.getElementsByClassName(e)},s=[],y=[],(d.qsa=K.test(C.querySelectorAll))&&(ce(function(e){var t;a.appendChild(e).innerHTML="",e.querySelectorAll("[msallowcapture^='']").length&&y.push("[*^$]="+M+"*(?:''|\"\")"),e.querySelectorAll("[selected]").length||y.push("\\["+M+"*(?:value|"+R+")"),e.querySelectorAll("[id~="+S+"-]").length||y.push("~="),(t=C.createElement("input")).setAttribute("name",""),e.appendChild(t),e.querySelectorAll("[name='']").length||y.push("\\["+M+"*name"+M+"*="+M+"*(?:''|\"\")"),e.querySelectorAll(":checked").length||y.push(":checked"),e.querySelectorAll("a#"+S+"+*").length||y.push(".#.+[+~]"),e.querySelectorAll("\\\f"),y.push("[\\r\\n\\f]")}),ce(function(e){e.innerHTML="";var t=C.createElement("input");t.setAttribute("type","hidden"),e.appendChild(t).setAttribute("name","D"),e.querySelectorAll("[name=d]").length&&y.push("name"+M+"*[*^$|!~]?="),2!==e.querySelectorAll(":enabled").length&&y.push(":enabled",":disabled"),a.appendChild(e).disabled=!0,2!==e.querySelectorAll(":disabled").length&&y.push(":enabled",":disabled"),e.querySelectorAll("*,:x"),y.push(",.*:")})),(d.matchesSelector=K.test(c=a.matches||a.webkitMatchesSelector||a.mozMatchesSelector||a.oMatchesSelector||a.msMatchesSelector))&&ce(function(e){d.disconnectedMatch=c.call(e,"*"),c.call(e,"[s!='']:x"),s.push("!=",F)}),y=y.length&&new RegExp(y.join("|")),s=s.length&&new RegExp(s.join("|")),t=K.test(a.compareDocumentPosition),v=t||K.test(a.contains)?function(e,t){var n=9===e.nodeType?e.documentElement:e,r=t&&t.parentNode;return e===r||!(!r||1!==r.nodeType||!(n.contains?n.contains(r):e.compareDocumentPosition&&16&e.compareDocumentPosition(r)))}:function(e,t){if(t)while(t=t.parentNode)if(t===e)return!0;return!1},j=t?function(e,t){if(e===t)return l=!0,0;var n=!e.compareDocumentPosition-!t.compareDocumentPosition;return n||(1&(n=(e.ownerDocument||e)==(t.ownerDocument||t)?e.compareDocumentPosition(t):1)||!d.sortDetached&&t.compareDocumentPosition(e)===n?e==C||e.ownerDocument==p&&v(p,e)?-1:t==C||t.ownerDocument==p&&v(p,t)?1:u?P(u,e)-P(u,t):0:4&n?-1:1)}:function(e,t){if(e===t)return l=!0,0;var n,r=0,i=e.parentNode,o=t.parentNode,a=[e],s=[t];if(!i||!o)return e==C?-1:t==C?1:i?-1:o?1:u?P(u,e)-P(u,t):0;if(i===o)return pe(e,t);n=e;while(n=n.parentNode)a.unshift(n);n=t;while(n=n.parentNode)s.unshift(n);while(a[r]===s[r])r++;return r?pe(a[r],s[r]):a[r]==p?-1:s[r]==p?1:0}),C},se.matches=function(e,t){return se(e,null,null,t)},se.matchesSelector=function(e,t){if(T(e),d.matchesSelector&&E&&!N[t+" "]&&(!s||!s.test(t))&&(!y||!y.test(t)))try{var n=c.call(e,t);if(n||d.disconnectedMatch||e.document&&11!==e.document.nodeType)return n}catch(e){N(t,!0)}return 0":{dir:"parentNode",first:!0}," ":{dir:"parentNode"},"+":{dir:"previousSibling",first:!0},"~":{dir:"previousSibling"}},preFilter:{ATTR:function(e){return e[1]=e[1].replace(te,ne),e[3]=(e[3]||e[4]||e[5]||"").replace(te,ne),"~="===e[2]&&(e[3]=" "+e[3]+" "),e.slice(0,4)},CHILD:function(e){return e[1]=e[1].toLowerCase(),"nth"===e[1].slice(0,3)?(e[3]||se.error(e[0]),e[4]=+(e[4]?e[5]+(e[6]||1):2*("even"===e[3]||"odd"===e[3])),e[5]=+(e[7]+e[8]||"odd"===e[3])):e[3]&&se.error(e[0]),e},PSEUDO:function(e){var t,n=!e[6]&&e[2];return G.CHILD.test(e[0])?null:(e[3]?e[2]=e[4]||e[5]||"":n&&X.test(n)&&(t=h(n,!0))&&(t=n.indexOf(")",n.length-t)-n.length)&&(e[0]=e[0].slice(0,t),e[2]=n.slice(0,t)),e.slice(0,3))}},filter:{TAG:function(e){var t=e.replace(te,ne).toLowerCase();return"*"===e?function(){return!0}:function(e){return e.nodeName&&e.nodeName.toLowerCase()===t}},CLASS:function(e){var t=m[e+" "];return t||(t=new RegExp("(^|"+M+")"+e+"("+M+"|$)"))&&m(e,function(e){return t.test("string"==typeof e.className&&e.className||"undefined"!=typeof e.getAttribute&&e.getAttribute("class")||"")})},ATTR:function(n,r,i){return function(e){var t=se.attr(e,n);return null==t?"!="===r:!r||(t+="","="===r?t===i:"!="===r?t!==i:"^="===r?i&&0===t.indexOf(i):"*="===r?i&&-1:\x20\t\r\n\f]*)[\x20\t\r\n\f]*\/?>(?:<\/\1>|)$/i;function j(e,n,r){return m(n)?S.grep(e,function(e,t){return!!n.call(e,t,e)!==r}):n.nodeType?S.grep(e,function(e){return e===n!==r}):"string"!=typeof n?S.grep(e,function(e){return-1)[^>]*|#([\w-]+))$/;(S.fn.init=function(e,t,n){var r,i;if(!e)return this;if(n=n||D,"string"==typeof e){if(!(r="<"===e[0]&&">"===e[e.length-1]&&3<=e.length?[null,e,null]:q.exec(e))||!r[1]&&t)return!t||t.jquery?(t||n).find(e):this.constructor(t).find(e);if(r[1]){if(t=t instanceof S?t[0]:t,S.merge(this,S.parseHTML(r[1],t&&t.nodeType?t.ownerDocument||t:E,!0)),N.test(r[1])&&S.isPlainObject(t))for(r in t)m(this[r])?this[r](t[r]):this.attr(r,t[r]);return this}return(i=E.getElementById(r[2]))&&(this[0]=i,this.length=1),this}return e.nodeType?(this[0]=e,this.length=1,this):m(e)?void 0!==n.ready?n.ready(e):e(S):S.makeArray(e,this)}).prototype=S.fn,D=S(E);var L=/^(?:parents|prev(?:Until|All))/,H={children:!0,contents:!0,next:!0,prev:!0};function O(e,t){while((e=e[t])&&1!==e.nodeType);return e}S.fn.extend({has:function(e){var t=S(e,this),n=t.length;return this.filter(function(){for(var e=0;e\x20\t\r\n\f]*)/i,he=/^$|^module$|\/(?:java|ecma)script/i;ce=E.createDocumentFragment().appendChild(E.createElement("div")),(fe=E.createElement("input")).setAttribute("type","radio"),fe.setAttribute("checked","checked"),fe.setAttribute("name","t"),ce.appendChild(fe),v.checkClone=ce.cloneNode(!0).cloneNode(!0).lastChild.checked,ce.innerHTML="",v.noCloneChecked=!!ce.cloneNode(!0).lastChild.defaultValue,ce.innerHTML="",v.option=!!ce.lastChild;var ge={thead:[1,""],col:[2,""],tr:[2,""],td:[3,""],_default:[0,"",""]};function ye(e,t){var n;return n="undefined"!=typeof e.getElementsByTagName?e.getElementsByTagName(t||"*"):"undefined"!=typeof e.querySelectorAll?e.querySelectorAll(t||"*"):[],void 0===t||t&&A(e,t)?S.merge([e],n):n}function ve(e,t){for(var n=0,r=e.length;n",""]);var me=/<|&#?\w+;/;function xe(e,t,n,r,i){for(var o,a,s,u,l,c,f=t.createDocumentFragment(),p=[],d=0,h=e.length;d\s*$/g;function je(e,t){return A(e,"table")&&A(11!==t.nodeType?t:t.firstChild,"tr")&&S(e).children("tbody")[0]||e}function De(e){return e.type=(null!==e.getAttribute("type"))+"/"+e.type,e}function qe(e){return"true/"===(e.type||"").slice(0,5)?e.type=e.type.slice(5):e.removeAttribute("type"),e}function Le(e,t){var n,r,i,o,a,s;if(1===t.nodeType){if(Y.hasData(e)&&(s=Y.get(e).events))for(i in Y.remove(t,"handle events"),s)for(n=0,r=s[i].length;n").attr(n.scriptAttrs||{}).prop({charset:n.scriptCharset,src:n.url}).on("load error",i=function(e){r.remove(),i=null,e&&t("error"===e.type?404:200,e.type)}),E.head.appendChild(r[0])},abort:function(){i&&i()}}});var Ut,Xt=[],Vt=/(=)\?(?=&|$)|\?\?/;S.ajaxSetup({jsonp:"callback",jsonpCallback:function(){var e=Xt.pop()||S.expando+"_"+Ct.guid++;return this[e]=!0,e}}),S.ajaxPrefilter("json jsonp",function(e,t,n){var r,i,o,a=!1!==e.jsonp&&(Vt.test(e.url)?"url":"string"==typeof e.data&&0===(e.contentType||"").indexOf("application/x-www-form-urlencoded")&&Vt.test(e.data)&&"data");if(a||"jsonp"===e.dataTypes[0])return r=e.jsonpCallback=m(e.jsonpCallback)?e.jsonpCallback():e.jsonpCallback,a?e[a]=e[a].replace(Vt,"$1"+r):!1!==e.jsonp&&(e.url+=(Et.test(e.url)?"&":"?")+e.jsonp+"="+r),e.converters["script json"]=function(){return o||S.error(r+" was not called"),o[0]},e.dataTypes[0]="json",i=C[r],C[r]=function(){o=arguments},n.always(function(){void 0===i?S(C).removeProp(r):C[r]=i,e[r]&&(e.jsonpCallback=t.jsonpCallback,Xt.push(r)),o&&m(i)&&i(o[0]),o=i=void 0}),"script"}),v.createHTMLDocument=((Ut=E.implementation.createHTMLDocument("").body).innerHTML="",2===Ut.childNodes.length),S.parseHTML=function(e,t,n){return"string"!=typeof e?[]:("boolean"==typeof t&&(n=t,t=!1),t||(v.createHTMLDocument?((r=(t=E.implementation.createHTMLDocument("")).createElement("base")).href=E.location.href,t.head.appendChild(r)):t=E),o=!n&&[],(i=N.exec(e))?[t.createElement(i[1])]:(i=xe([e],t,o),o&&o.length&&S(o).remove(),S.merge([],i.childNodes)));var r,i,o},S.fn.load=function(e,t,n){var r,i,o,a=this,s=e.indexOf(" ");return-1").append(S.parseHTML(e)).find(r):e)}).always(n&&function(e,t){a.each(function(){n.apply(this,o||[e.responseText,t,e])})}),this},S.expr.pseudos.animated=function(t){return S.grep(S.timers,function(e){return t===e.elem}).length},S.offset={setOffset:function(e,t,n){var r,i,o,a,s,u,l=S.css(e,"position"),c=S(e),f={};"static"===l&&(e.style.position="relative"),s=c.offset(),o=S.css(e,"top"),u=S.css(e,"left"),("absolute"===l||"fixed"===l)&&-1<(o+u).indexOf("auto")?(a=(r=c.position()).top,i=r.left):(a=parseFloat(o)||0,i=parseFloat(u)||0),m(t)&&(t=t.call(e,n,S.extend({},s))),null!=t.top&&(f.top=t.top-s.top+a),null!=t.left&&(f.left=t.left-s.left+i),"using"in t?t.using.call(e,f):c.css(f)}},S.fn.extend({offset:function(t){if(arguments.length)return void 0===t?this:this.each(function(e){S.offset.setOffset(this,t,e)});var e,n,r=this[0];return r?r.getClientRects().length?(e=r.getBoundingClientRect(),n=r.ownerDocument.defaultView,{top:e.top+n.pageYOffset,left:e.left+n.pageXOffset}):{top:0,left:0}:void 0},position:function(){if(this[0]){var e,t,n,r=this[0],i={top:0,left:0};if("fixed"===S.css(r,"position"))t=r.getBoundingClientRect();else{t=this.offset(),n=r.ownerDocument,e=r.offsetParent||n.documentElement;while(e&&(e===n.body||e===n.documentElement)&&"static"===S.css(e,"position"))e=e.parentNode;e&&e!==r&&1===e.nodeType&&((i=S(e).offset()).top+=S.css(e,"borderTopWidth",!0),i.left+=S.css(e,"borderLeftWidth",!0))}return{top:t.top-i.top-S.css(r,"marginTop",!0),left:t.left-i.left-S.css(r,"marginLeft",!0)}}},offsetParent:function(){return this.map(function(){var e=this.offsetParent;while(e&&"static"===S.css(e,"position"))e=e.offsetParent;return e||re})}}),S.each({scrollLeft:"pageXOffset",scrollTop:"pageYOffset"},function(t,i){var o="pageYOffset"===i;S.fn[t]=function(e){return B(this,function(e,t,n){var r;if(x(e)?r=e:9===e.nodeType&&(r=e.defaultView),void 0===n)return r?r[i]:e[t];r?r.scrollTo(o?r.pageXOffset:n,o?n:r.pageYOffset):e[t]=n},t,e,arguments.length)}}),S.each(["top","left"],function(e,n){S.cssHooks[n]=_e(v.pixelPosition,function(e,t){if(t)return t=Be(e,n),Pe.test(t)?S(e).position()[n]+"px":t})}),S.each({Height:"height",Width:"width"},function(a,s){S.each({padding:"inner"+a,content:s,"":"outer"+a},function(r,o){S.fn[o]=function(e,t){var n=arguments.length&&(r||"boolean"!=typeof e),i=r||(!0===e||!0===t?"margin":"border");return B(this,function(e,t,n){var r;return x(e)?0===o.indexOf("outer")?e["inner"+a]:e.document.documentElement["client"+a]:9===e.nodeType?(r=e.documentElement,Math.max(e.body["scroll"+a],r["scroll"+a],e.body["offset"+a],r["offset"+a],r["client"+a])):void 0===n?S.css(e,t,i):S.style(e,t,n,i)},s,n?e:void 0,n)}})}),S.each(["ajaxStart","ajaxStop","ajaxComplete","ajaxError","ajaxSuccess","ajaxSend"],function(e,t){S.fn[t]=function(e){return this.on(t,e)}}),S.fn.extend({bind:function(e,t,n){return this.on(e,null,t,n)},unbind:function(e,t){return this.off(e,null,t)},delegate:function(e,t,n,r){return this.on(t,e,n,r)},undelegate:function(e,t,n){return 1===arguments.length?this.off(e,"**"):this.off(t,e||"**",n)},hover:function(e,t){return this.mouseenter(e).mouseleave(t||e)}}),S.each("blur focus focusin focusout resize scroll click dblclick mousedown mouseup mousemove mouseover mouseout mouseenter mouseleave change select submit keydown keypress keyup contextmenu".split(" "),function(e,n){S.fn[n]=function(e,t){return 0 self.conf]
- gt_classes = labels[:, 0].int()
- detection_classes = detections[:, 5].int()
- iou = general.box_iou(labels[:, 1:], detections[:, :4])
-
- x = torch.where(iou > self.iou_thres)
- if x[0].shape[0]:
- matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
- if x[0].shape[0] > 1:
- matches = matches[matches[:, 2].argsort()[::-1]]
- matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
- matches = matches[matches[:, 2].argsort()[::-1]]
- matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
- else:
- matches = np.zeros((0, 3))
-
- n = matches.shape[0] > 0
- m0, m1, _ = matches.transpose().astype(np.int16)
- for i, gc in enumerate(gt_classes):
- j = m0 == i
- if n and sum(j) == 1:
- self.matrix[gc, detection_classes[m1[j]]] += 1 # correct
- else:
- self.matrix[self.nc, gc] += 1 # background FP
-
- if n:
- for i, dc in enumerate(detection_classes):
- if not any(m1 == i):
- self.matrix[dc, self.nc] += 1 # background FN
-
- def matrix(self):
- return self.matrix
-
- def plot(self, save_dir='', names=()):
- try:
- import seaborn as sn
-
- array = self.matrix / (self.matrix.sum(0).reshape(1, self.nc + 1) + 1E-6) # normalize
- array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
-
- fig = plt.figure(figsize=(12, 9), tight_layout=True)
- sn.set(font_scale=1.0 if self.nc < 50 else 0.8) # for label size
- labels = (0 < len(names) < 99) and len(names) == self.nc # apply names to ticklabels
- sn.heatmap(array, annot=self.nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True,
- xticklabels=names + ['background FP'] if labels else "auto",
- yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
- fig.axes[0].set_xlabel('True')
- fig.axes[0].set_ylabel('Predicted')
- fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
- except Exception as e:
- pass
-
- def print(self):
- for i in range(self.nc + 1):
- print(' '.join(map(str, self.matrix[i])))
-
-
-# Plots ----------------------------------------------------------------------------------------------------------------
-
-def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
- # Precision-recall curve
- fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
- py = np.stack(py, axis=1)
-
- if 0 < len(names) < 21: # display per-class legend if < 21 classes
- for i, y in enumerate(py.T):
- ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
- else:
- ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
-
- ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f mAP@0.5' % ap[:, 0].mean())
- ax.set_xlabel('Recall')
- ax.set_ylabel('Precision')
- ax.set_xlim(0, 1)
- ax.set_ylim(0, 1)
- plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
- fig.savefig(Path(save_dir), dpi=250)
-
-
-def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
- # Metric-confidence curve
- fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
-
- if 0 < len(names) < 21: # display per-class legend if < 21 classes
- for i, y in enumerate(py):
- ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
- else:
- ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
-
- y = py.mean(0)
- ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
- ax.set_xlabel(xlabel)
- ax.set_ylabel(ylabel)
- ax.set_xlim(0, 1)
- ax.set_ylim(0, 1)
- plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
- fig.savefig(Path(save_dir), dpi=250)
diff --git a/spaces/justest/gpt4free/testing/aiservice/testing.py b/spaces/justest/gpt4free/testing/aiservice/testing.py
deleted file mode 100644
index 5cb6c5ef01a4f855e3c7f4f91ee8edd4f7ffa5d1..0000000000000000000000000000000000000000
--- a/spaces/justest/gpt4free/testing/aiservice/testing.py
+++ /dev/null
@@ -1,30 +0,0 @@
-from AiService import ChatCompletion
-
-# Test 1
-response = ChatCompletion.create(model="gpt-3.5-turbo",
- provider="AiService",
- stream=False,
- messages=[{'role': 'user', 'content': 'who are you?'}])
-
-print(response)
-
-# Test 2
-response = ChatCompletion.create(model="gpt-3.5-turbo",
- provider="AiService",
- stream=False,
- messages=[{'role': 'user', 'content': 'what you can do?'}])
-
-print(response)
-
-
-# Test 3
-response = ChatCompletion.create(model="gpt-3.5-turbo",
- provider="AiService",
- stream=False,
- messages=[
- {'role': 'user', 'content': 'now your name is Bob'},
- {'role': 'assistant', 'content': 'Hello Im Bob, you asistant'},
- {'role': 'user', 'content': 'what your name again?'},
- ])
-
-print(response)
\ No newline at end of file
diff --git a/spaces/justin-zk/Personalize-SAM/per_segment_anything/utils/onnx.py b/spaces/justin-zk/Personalize-SAM/per_segment_anything/utils/onnx.py
deleted file mode 100644
index 3196bdf4b782e6eeb3da4ad66ef3c7b1741535fe..0000000000000000000000000000000000000000
--- a/spaces/justin-zk/Personalize-SAM/per_segment_anything/utils/onnx.py
+++ /dev/null
@@ -1,144 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import torch
-import torch.nn as nn
-from torch.nn import functional as F
-
-from typing import Tuple
-
-from ..modeling import Sam
-from .amg import calculate_stability_score
-
-
-class SamOnnxModel(nn.Module):
- """
- This model should not be called directly, but is used in ONNX export.
- It combines the prompt encoder, mask decoder, and mask postprocessing of Sam,
- with some functions modified to enable model tracing. Also supports extra
- options controlling what information. See the ONNX export script for details.
- """
-
- def __init__(
- self,
- model: Sam,
- return_single_mask: bool,
- use_stability_score: bool = False,
- return_extra_metrics: bool = False,
- ) -> None:
- super().__init__()
- self.mask_decoder = model.mask_decoder
- self.model = model
- self.img_size = model.image_encoder.img_size
- self.return_single_mask = return_single_mask
- self.use_stability_score = use_stability_score
- self.stability_score_offset = 1.0
- self.return_extra_metrics = return_extra_metrics
-
- @staticmethod
- def resize_longest_image_size(
- input_image_size: torch.Tensor, longest_side: int
- ) -> torch.Tensor:
- input_image_size = input_image_size.to(torch.float32)
- scale = longest_side / torch.max(input_image_size)
- transformed_size = scale * input_image_size
- transformed_size = torch.floor(transformed_size + 0.5).to(torch.int64)
- return transformed_size
-
- def _embed_points(self, point_coords: torch.Tensor, point_labels: torch.Tensor) -> torch.Tensor:
- point_coords = point_coords + 0.5
- point_coords = point_coords / self.img_size
- point_embedding = self.model.prompt_encoder.pe_layer._pe_encoding(point_coords)
- point_labels = point_labels.unsqueeze(-1).expand_as(point_embedding)
-
- point_embedding = point_embedding * (point_labels != -1)
- point_embedding = point_embedding + self.model.prompt_encoder.not_a_point_embed.weight * (
- point_labels == -1
- )
-
- for i in range(self.model.prompt_encoder.num_point_embeddings):
- point_embedding = point_embedding + self.model.prompt_encoder.point_embeddings[
- i
- ].weight * (point_labels == i)
-
- return point_embedding
-
- def _embed_masks(self, input_mask: torch.Tensor, has_mask_input: torch.Tensor) -> torch.Tensor:
- mask_embedding = has_mask_input * self.model.prompt_encoder.mask_downscaling(input_mask)
- mask_embedding = mask_embedding + (
- 1 - has_mask_input
- ) * self.model.prompt_encoder.no_mask_embed.weight.reshape(1, -1, 1, 1)
- return mask_embedding
-
- def mask_postprocessing(self, masks: torch.Tensor, orig_im_size: torch.Tensor) -> torch.Tensor:
- masks = F.interpolate(
- masks,
- size=(self.img_size, self.img_size),
- mode="bilinear",
- align_corners=False,
- )
-
- prepadded_size = self.resize_longest_image_size(orig_im_size, self.img_size).to(torch.int64)
- masks = masks[..., : prepadded_size[0], : prepadded_size[1]] # type: ignore
-
- orig_im_size = orig_im_size.to(torch.int64)
- h, w = orig_im_size[0], orig_im_size[1]
- masks = F.interpolate(masks, size=(h, w), mode="bilinear", align_corners=False)
- return masks
-
- def select_masks(
- self, masks: torch.Tensor, iou_preds: torch.Tensor, num_points: int
- ) -> Tuple[torch.Tensor, torch.Tensor]:
- # Determine if we should return the multiclick mask or not from the number of points.
- # The reweighting is used to avoid control flow.
- score_reweight = torch.tensor(
- [[1000] + [0] * (self.model.mask_decoder.num_mask_tokens - 1)]
- ).to(iou_preds.device)
- score = iou_preds + (num_points - 2.5) * score_reweight
- best_idx = torch.argmax(score, dim=1)
- masks = masks[torch.arange(masks.shape[0]), best_idx, :, :].unsqueeze(1)
- iou_preds = iou_preds[torch.arange(masks.shape[0]), best_idx].unsqueeze(1)
-
- return masks, iou_preds
-
- @torch.no_grad()
- def forward(
- self,
- image_embeddings: torch.Tensor,
- point_coords: torch.Tensor,
- point_labels: torch.Tensor,
- mask_input: torch.Tensor,
- has_mask_input: torch.Tensor,
- orig_im_size: torch.Tensor,
- ):
- sparse_embedding = self._embed_points(point_coords, point_labels)
- dense_embedding = self._embed_masks(mask_input, has_mask_input)
-
- masks, scores = self.model.mask_decoder.predict_masks(
- image_embeddings=image_embeddings,
- image_pe=self.model.prompt_encoder.get_dense_pe(),
- sparse_prompt_embeddings=sparse_embedding,
- dense_prompt_embeddings=dense_embedding,
- )
-
- if self.use_stability_score:
- scores = calculate_stability_score(
- masks, self.model.mask_threshold, self.stability_score_offset
- )
-
- if self.return_single_mask:
- masks, scores = self.select_masks(masks, scores, point_coords.shape[1])
-
- upscaled_masks = self.mask_postprocessing(masks, orig_im_size)
-
- if self.return_extra_metrics:
- stability_scores = calculate_stability_score(
- upscaled_masks, self.model.mask_threshold, self.stability_score_offset
- )
- areas = (upscaled_masks > self.model.mask_threshold).sum(-1).sum(-1)
- return upscaled_masks, scores, stability_scores, areas, masks
-
- return upscaled_masks, scores, masks
diff --git a/spaces/kazuk/youtube-whisper-10/README.md b/spaces/kazuk/youtube-whisper-10/README.md
deleted file mode 100644
index c3180680339155aaf1d27f629129b68d12cac021..0000000000000000000000000000000000000000
--- a/spaces/kazuk/youtube-whisper-10/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Youtube Whisper
-emoji: ⚡
-colorFrom: green
-colorTo: red
-sdk: gradio
-sdk_version: 3.16.2
-app_file: app.py
-pinned: false
-license: unknown
-duplicated_from: kazuk/youtube-whisper
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/kevinwang676/Bark-Voice-Cloning/README.md b/spaces/kevinwang676/Bark-Voice-Cloning/README.md
deleted file mode 100644
index d342b9175927182d5cfa1a73cffdef7dc36fc731..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/Bark-Voice-Cloning/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Bark Voice Cloning
-emoji: 🎶
-colorFrom: yellow
-colorTo: pink
-sdk: gradio
-sdk_version: 3.34.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/kevinwang676/Bert-VITS2/transforms.py b/spaces/kevinwang676/Bert-VITS2/transforms.py
deleted file mode 100644
index 4793d67ca5a5630e0ffe0f9fb29445c949e64dae..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/Bert-VITS2/transforms.py
+++ /dev/null
@@ -1,193 +0,0 @@
-import torch
-from torch.nn import functional as F
-
-import numpy as np
-
-
-DEFAULT_MIN_BIN_WIDTH = 1e-3
-DEFAULT_MIN_BIN_HEIGHT = 1e-3
-DEFAULT_MIN_DERIVATIVE = 1e-3
-
-
-def piecewise_rational_quadratic_transform(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails=None,
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
-
- if tails is None:
- spline_fn = rational_quadratic_spline
- spline_kwargs = {}
- else:
- spline_fn = unconstrained_rational_quadratic_spline
- spline_kwargs = {
- 'tails': tails,
- 'tail_bound': tail_bound
- }
-
- outputs, logabsdet = spline_fn(
- inputs=inputs,
- unnormalized_widths=unnormalized_widths,
- unnormalized_heights=unnormalized_heights,
- unnormalized_derivatives=unnormalized_derivatives,
- inverse=inverse,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative,
- **spline_kwargs
- )
- return outputs, logabsdet
-
-
-def searchsorted(bin_locations, inputs, eps=1e-6):
- bin_locations[..., -1] += eps
- return torch.sum(
- inputs[..., None] >= bin_locations,
- dim=-1
- ) - 1
-
-
-def unconstrained_rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails='linear',
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
- outside_interval_mask = ~inside_interval_mask
-
- outputs = torch.zeros_like(inputs)
- logabsdet = torch.zeros_like(inputs)
-
- if tails == 'linear':
- unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
- constant = np.log(np.exp(1 - min_derivative) - 1)
- unnormalized_derivatives[..., 0] = constant
- unnormalized_derivatives[..., -1] = constant
-
- outputs[outside_interval_mask] = inputs[outside_interval_mask]
- logabsdet[outside_interval_mask] = 0
- else:
- raise RuntimeError('{} tails are not implemented.'.format(tails))
-
- outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline(
- inputs=inputs[inside_interval_mask],
- unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
- unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
- unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
- inverse=inverse,
- left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative
- )
-
- return outputs, logabsdet
-
-def rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- left=0., right=1., bottom=0., top=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- if torch.min(inputs) < left or torch.max(inputs) > right:
- raise ValueError('Input to a transform is not within its domain')
-
- num_bins = unnormalized_widths.shape[-1]
-
- if min_bin_width * num_bins > 1.0:
- raise ValueError('Minimal bin width too large for the number of bins')
- if min_bin_height * num_bins > 1.0:
- raise ValueError('Minimal bin height too large for the number of bins')
-
- widths = F.softmax(unnormalized_widths, dim=-1)
- widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
- cumwidths = torch.cumsum(widths, dim=-1)
- cumwidths = F.pad(cumwidths, pad=(1, 0), mode='constant', value=0.0)
- cumwidths = (right - left) * cumwidths + left
- cumwidths[..., 0] = left
- cumwidths[..., -1] = right
- widths = cumwidths[..., 1:] - cumwidths[..., :-1]
-
- derivatives = min_derivative + F.softplus(unnormalized_derivatives)
-
- heights = F.softmax(unnormalized_heights, dim=-1)
- heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
- cumheights = torch.cumsum(heights, dim=-1)
- cumheights = F.pad(cumheights, pad=(1, 0), mode='constant', value=0.0)
- cumheights = (top - bottom) * cumheights + bottom
- cumheights[..., 0] = bottom
- cumheights[..., -1] = top
- heights = cumheights[..., 1:] - cumheights[..., :-1]
-
- if inverse:
- bin_idx = searchsorted(cumheights, inputs)[..., None]
- else:
- bin_idx = searchsorted(cumwidths, inputs)[..., None]
-
- input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
- input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
-
- input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
- delta = heights / widths
- input_delta = delta.gather(-1, bin_idx)[..., 0]
-
- input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
- input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
-
- input_heights = heights.gather(-1, bin_idx)[..., 0]
-
- if inverse:
- a = (((inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta)
- + input_heights * (input_delta - input_derivatives)))
- b = (input_heights * input_derivatives
- - (inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta))
- c = - input_delta * (inputs - input_cumheights)
-
- discriminant = b.pow(2) - 4 * a * c
- assert (discriminant >= 0).all()
-
- root = (2 * c) / (-b - torch.sqrt(discriminant))
- outputs = root * input_bin_widths + input_cumwidths
-
- theta_one_minus_theta = root * (1 - root)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * root.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - root).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, -logabsdet
- else:
- theta = (inputs - input_cumwidths) / input_bin_widths
- theta_one_minus_theta = theta * (1 - theta)
-
- numerator = input_heights * (input_delta * theta.pow(2)
- + input_derivatives * theta_one_minus_theta)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- outputs = input_cumheights + numerator / denominator
-
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * theta.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - theta).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, logabsdet
diff --git a/spaces/kevinwang676/ChatGLM2-SadTalker/src/face3d/models/arcface_torch/configs/3millions_pfc.py b/spaces/kevinwang676/ChatGLM2-SadTalker/src/face3d/models/arcface_torch/configs/3millions_pfc.py
deleted file mode 100644
index 77caafdbb300d8109d5bfdb844f131710ef81f20..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/ChatGLM2-SadTalker/src/face3d/models/arcface_torch/configs/3millions_pfc.py
+++ /dev/null
@@ -1,23 +0,0 @@
-from easydict import EasyDict as edict
-
-# configs for test speed
-
-config = edict()
-config.loss = "arcface"
-config.network = "r50"
-config.resume = False
-config.output = None
-config.embedding_size = 512
-config.sample_rate = 0.1
-config.fp16 = True
-config.momentum = 0.9
-config.weight_decay = 5e-4
-config.batch_size = 128
-config.lr = 0.1 # batch size is 512
-
-config.rec = "synthetic"
-config.num_classes = 300 * 10000
-config.num_epoch = 30
-config.warmup_epoch = -1
-config.decay_epoch = [10, 16, 22]
-config.val_targets = []
diff --git a/spaces/kevinwang676/Voice-Changer/infer_pack/attentions.py b/spaces/kevinwang676/Voice-Changer/infer_pack/attentions.py
deleted file mode 100644
index 77cb63ffccf3e33badf22d50862a64ba517b487f..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/Voice-Changer/infer_pack/attentions.py
+++ /dev/null
@@ -1,417 +0,0 @@
-import copy
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from infer_pack import commons
-from infer_pack import modules
-from infer_pack.modules import LayerNorm
-
-
-class Encoder(nn.Module):
- def __init__(
- self,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size=1,
- p_dropout=0.0,
- window_size=10,
- **kwargs
- ):
- super().__init__()
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.window_size = window_size
-
- self.drop = nn.Dropout(p_dropout)
- self.attn_layers = nn.ModuleList()
- self.norm_layers_1 = nn.ModuleList()
- self.ffn_layers = nn.ModuleList()
- self.norm_layers_2 = nn.ModuleList()
- for i in range(self.n_layers):
- self.attn_layers.append(
- MultiHeadAttention(
- hidden_channels,
- hidden_channels,
- n_heads,
- p_dropout=p_dropout,
- window_size=window_size,
- )
- )
- self.norm_layers_1.append(LayerNorm(hidden_channels))
- self.ffn_layers.append(
- FFN(
- hidden_channels,
- hidden_channels,
- filter_channels,
- kernel_size,
- p_dropout=p_dropout,
- )
- )
- self.norm_layers_2.append(LayerNorm(hidden_channels))
-
- def forward(self, x, x_mask):
- attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
- x = x * x_mask
- for i in range(self.n_layers):
- y = self.attn_layers[i](x, x, attn_mask)
- y = self.drop(y)
- x = self.norm_layers_1[i](x + y)
-
- y = self.ffn_layers[i](x, x_mask)
- y = self.drop(y)
- x = self.norm_layers_2[i](x + y)
- x = x * x_mask
- return x
-
-
-class Decoder(nn.Module):
- def __init__(
- self,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size=1,
- p_dropout=0.0,
- proximal_bias=False,
- proximal_init=True,
- **kwargs
- ):
- super().__init__()
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.proximal_bias = proximal_bias
- self.proximal_init = proximal_init
-
- self.drop = nn.Dropout(p_dropout)
- self.self_attn_layers = nn.ModuleList()
- self.norm_layers_0 = nn.ModuleList()
- self.encdec_attn_layers = nn.ModuleList()
- self.norm_layers_1 = nn.ModuleList()
- self.ffn_layers = nn.ModuleList()
- self.norm_layers_2 = nn.ModuleList()
- for i in range(self.n_layers):
- self.self_attn_layers.append(
- MultiHeadAttention(
- hidden_channels,
- hidden_channels,
- n_heads,
- p_dropout=p_dropout,
- proximal_bias=proximal_bias,
- proximal_init=proximal_init,
- )
- )
- self.norm_layers_0.append(LayerNorm(hidden_channels))
- self.encdec_attn_layers.append(
- MultiHeadAttention(
- hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout
- )
- )
- self.norm_layers_1.append(LayerNorm(hidden_channels))
- self.ffn_layers.append(
- FFN(
- hidden_channels,
- hidden_channels,
- filter_channels,
- kernel_size,
- p_dropout=p_dropout,
- causal=True,
- )
- )
- self.norm_layers_2.append(LayerNorm(hidden_channels))
-
- def forward(self, x, x_mask, h, h_mask):
- """
- x: decoder input
- h: encoder output
- """
- self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(
- device=x.device, dtype=x.dtype
- )
- encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
- x = x * x_mask
- for i in range(self.n_layers):
- y = self.self_attn_layers[i](x, x, self_attn_mask)
- y = self.drop(y)
- x = self.norm_layers_0[i](x + y)
-
- y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
- y = self.drop(y)
- x = self.norm_layers_1[i](x + y)
-
- y = self.ffn_layers[i](x, x_mask)
- y = self.drop(y)
- x = self.norm_layers_2[i](x + y)
- x = x * x_mask
- return x
-
-
-class MultiHeadAttention(nn.Module):
- def __init__(
- self,
- channels,
- out_channels,
- n_heads,
- p_dropout=0.0,
- window_size=None,
- heads_share=True,
- block_length=None,
- proximal_bias=False,
- proximal_init=False,
- ):
- super().__init__()
- assert channels % n_heads == 0
-
- self.channels = channels
- self.out_channels = out_channels
- self.n_heads = n_heads
- self.p_dropout = p_dropout
- self.window_size = window_size
- self.heads_share = heads_share
- self.block_length = block_length
- self.proximal_bias = proximal_bias
- self.proximal_init = proximal_init
- self.attn = None
-
- self.k_channels = channels // n_heads
- self.conv_q = nn.Conv1d(channels, channels, 1)
- self.conv_k = nn.Conv1d(channels, channels, 1)
- self.conv_v = nn.Conv1d(channels, channels, 1)
- self.conv_o = nn.Conv1d(channels, out_channels, 1)
- self.drop = nn.Dropout(p_dropout)
-
- if window_size is not None:
- n_heads_rel = 1 if heads_share else n_heads
- rel_stddev = self.k_channels**-0.5
- self.emb_rel_k = nn.Parameter(
- torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
- * rel_stddev
- )
- self.emb_rel_v = nn.Parameter(
- torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
- * rel_stddev
- )
-
- nn.init.xavier_uniform_(self.conv_q.weight)
- nn.init.xavier_uniform_(self.conv_k.weight)
- nn.init.xavier_uniform_(self.conv_v.weight)
- if proximal_init:
- with torch.no_grad():
- self.conv_k.weight.copy_(self.conv_q.weight)
- self.conv_k.bias.copy_(self.conv_q.bias)
-
- def forward(self, x, c, attn_mask=None):
- q = self.conv_q(x)
- k = self.conv_k(c)
- v = self.conv_v(c)
-
- x, self.attn = self.attention(q, k, v, mask=attn_mask)
-
- x = self.conv_o(x)
- return x
-
- def attention(self, query, key, value, mask=None):
- # reshape [b, d, t] -> [b, n_h, t, d_k]
- b, d, t_s, t_t = (*key.size(), query.size(2))
- query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
- key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
- value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
-
- scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
- if self.window_size is not None:
- assert (
- t_s == t_t
- ), "Relative attention is only available for self-attention."
- key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
- rel_logits = self._matmul_with_relative_keys(
- query / math.sqrt(self.k_channels), key_relative_embeddings
- )
- scores_local = self._relative_position_to_absolute_position(rel_logits)
- scores = scores + scores_local
- if self.proximal_bias:
- assert t_s == t_t, "Proximal bias is only available for self-attention."
- scores = scores + self._attention_bias_proximal(t_s).to(
- device=scores.device, dtype=scores.dtype
- )
- if mask is not None:
- scores = scores.masked_fill(mask == 0, -1e4)
- if self.block_length is not None:
- assert (
- t_s == t_t
- ), "Local attention is only available for self-attention."
- block_mask = (
- torch.ones_like(scores)
- .triu(-self.block_length)
- .tril(self.block_length)
- )
- scores = scores.masked_fill(block_mask == 0, -1e4)
- p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
- p_attn = self.drop(p_attn)
- output = torch.matmul(p_attn, value)
- if self.window_size is not None:
- relative_weights = self._absolute_position_to_relative_position(p_attn)
- value_relative_embeddings = self._get_relative_embeddings(
- self.emb_rel_v, t_s
- )
- output = output + self._matmul_with_relative_values(
- relative_weights, value_relative_embeddings
- )
- output = (
- output.transpose(2, 3).contiguous().view(b, d, t_t)
- ) # [b, n_h, t_t, d_k] -> [b, d, t_t]
- return output, p_attn
-
- def _matmul_with_relative_values(self, x, y):
- """
- x: [b, h, l, m]
- y: [h or 1, m, d]
- ret: [b, h, l, d]
- """
- ret = torch.matmul(x, y.unsqueeze(0))
- return ret
-
- def _matmul_with_relative_keys(self, x, y):
- """
- x: [b, h, l, d]
- y: [h or 1, m, d]
- ret: [b, h, l, m]
- """
- ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
- return ret
-
- def _get_relative_embeddings(self, relative_embeddings, length):
- max_relative_position = 2 * self.window_size + 1
- # Pad first before slice to avoid using cond ops.
- pad_length = max(length - (self.window_size + 1), 0)
- slice_start_position = max((self.window_size + 1) - length, 0)
- slice_end_position = slice_start_position + 2 * length - 1
- if pad_length > 0:
- padded_relative_embeddings = F.pad(
- relative_embeddings,
- commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),
- )
- else:
- padded_relative_embeddings = relative_embeddings
- used_relative_embeddings = padded_relative_embeddings[
- :, slice_start_position:slice_end_position
- ]
- return used_relative_embeddings
-
- def _relative_position_to_absolute_position(self, x):
- """
- x: [b, h, l, 2*l-1]
- ret: [b, h, l, l]
- """
- batch, heads, length, _ = x.size()
- # Concat columns of pad to shift from relative to absolute indexing.
- x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))
-
- # Concat extra elements so to add up to shape (len+1, 2*len-1).
- x_flat = x.view([batch, heads, length * 2 * length])
- x_flat = F.pad(
- x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [0, length - 1]])
- )
-
- # Reshape and slice out the padded elements.
- x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[
- :, :, :length, length - 1 :
- ]
- return x_final
-
- def _absolute_position_to_relative_position(self, x):
- """
- x: [b, h, l, l]
- ret: [b, h, l, 2*l-1]
- """
- batch, heads, length, _ = x.size()
- # padd along column
- x = F.pad(
- x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]])
- )
- x_flat = x.view([batch, heads, length**2 + length * (length - 1)])
- # add 0's in the beginning that will skew the elements after reshape
- x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
- x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
- return x_final
-
- def _attention_bias_proximal(self, length):
- """Bias for self-attention to encourage attention to close positions.
- Args:
- length: an integer scalar.
- Returns:
- a Tensor with shape [1, 1, length, length]
- """
- r = torch.arange(length, dtype=torch.float32)
- diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
- return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
-
-
-class FFN(nn.Module):
- def __init__(
- self,
- in_channels,
- out_channels,
- filter_channels,
- kernel_size,
- p_dropout=0.0,
- activation=None,
- causal=False,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.activation = activation
- self.causal = causal
-
- if causal:
- self.padding = self._causal_padding
- else:
- self.padding = self._same_padding
-
- self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
- self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
- self.drop = nn.Dropout(p_dropout)
-
- def forward(self, x, x_mask):
- x = self.conv_1(self.padding(x * x_mask))
- if self.activation == "gelu":
- x = x * torch.sigmoid(1.702 * x)
- else:
- x = torch.relu(x)
- x = self.drop(x)
- x = self.conv_2(self.padding(x * x_mask))
- return x * x_mask
-
- def _causal_padding(self, x):
- if self.kernel_size == 1:
- return x
- pad_l = self.kernel_size - 1
- pad_r = 0
- padding = [[0, 0], [0, 0], [pad_l, pad_r]]
- x = F.pad(x, commons.convert_pad_shape(padding))
- return x
-
- def _same_padding(self, x):
- if self.kernel_size == 1:
- return x
- pad_l = (self.kernel_size - 1) // 2
- pad_r = self.kernel_size // 2
- padding = [[0, 0], [0, 0], [pad_l, pad_r]]
- x = F.pad(x, commons.convert_pad_shape(padding))
- return x
diff --git a/spaces/kevinwang676/VoiceChanger/src/facerender/sync_batchnorm/comm.py b/spaces/kevinwang676/VoiceChanger/src/facerender/sync_batchnorm/comm.py
deleted file mode 100644
index 922f8c4a3adaa9b32fdcaef09583be03b0d7eb2b..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/VoiceChanger/src/facerender/sync_batchnorm/comm.py
+++ /dev/null
@@ -1,137 +0,0 @@
-# -*- coding: utf-8 -*-
-# File : comm.py
-# Author : Jiayuan Mao
-# Email : maojiayuan@gmail.com
-# Date : 27/01/2018
-#
-# This file is part of Synchronized-BatchNorm-PyTorch.
-# https://github.com/vacancy/Synchronized-BatchNorm-PyTorch
-# Distributed under MIT License.
-
-import queue
-import collections
-import threading
-
-__all__ = ['FutureResult', 'SlavePipe', 'SyncMaster']
-
-
-class FutureResult(object):
- """A thread-safe future implementation. Used only as one-to-one pipe."""
-
- def __init__(self):
- self._result = None
- self._lock = threading.Lock()
- self._cond = threading.Condition(self._lock)
-
- def put(self, result):
- with self._lock:
- assert self._result is None, 'Previous result has\'t been fetched.'
- self._result = result
- self._cond.notify()
-
- def get(self):
- with self._lock:
- if self._result is None:
- self._cond.wait()
-
- res = self._result
- self._result = None
- return res
-
-
-_MasterRegistry = collections.namedtuple('MasterRegistry', ['result'])
-_SlavePipeBase = collections.namedtuple('_SlavePipeBase', ['identifier', 'queue', 'result'])
-
-
-class SlavePipe(_SlavePipeBase):
- """Pipe for master-slave communication."""
-
- def run_slave(self, msg):
- self.queue.put((self.identifier, msg))
- ret = self.result.get()
- self.queue.put(True)
- return ret
-
-
-class SyncMaster(object):
- """An abstract `SyncMaster` object.
-
- - During the replication, as the data parallel will trigger an callback of each module, all slave devices should
- call `register(id)` and obtain an `SlavePipe` to communicate with the master.
- - During the forward pass, master device invokes `run_master`, all messages from slave devices will be collected,
- and passed to a registered callback.
- - After receiving the messages, the master device should gather the information and determine to message passed
- back to each slave devices.
- """
-
- def __init__(self, master_callback):
- """
-
- Args:
- master_callback: a callback to be invoked after having collected messages from slave devices.
- """
- self._master_callback = master_callback
- self._queue = queue.Queue()
- self._registry = collections.OrderedDict()
- self._activated = False
-
- def __getstate__(self):
- return {'master_callback': self._master_callback}
-
- def __setstate__(self, state):
- self.__init__(state['master_callback'])
-
- def register_slave(self, identifier):
- """
- Register an slave device.
-
- Args:
- identifier: an identifier, usually is the device id.
-
- Returns: a `SlavePipe` object which can be used to communicate with the master device.
-
- """
- if self._activated:
- assert self._queue.empty(), 'Queue is not clean before next initialization.'
- self._activated = False
- self._registry.clear()
- future = FutureResult()
- self._registry[identifier] = _MasterRegistry(future)
- return SlavePipe(identifier, self._queue, future)
-
- def run_master(self, master_msg):
- """
- Main entry for the master device in each forward pass.
- The messages were first collected from each devices (including the master device), and then
- an callback will be invoked to compute the message to be sent back to each devices
- (including the master device).
-
- Args:
- master_msg: the message that the master want to send to itself. This will be placed as the first
- message when calling `master_callback`. For detailed usage, see `_SynchronizedBatchNorm` for an example.
-
- Returns: the message to be sent back to the master device.
-
- """
- self._activated = True
-
- intermediates = [(0, master_msg)]
- for i in range(self.nr_slaves):
- intermediates.append(self._queue.get())
-
- results = self._master_callback(intermediates)
- assert results[0][0] == 0, 'The first result should belongs to the master.'
-
- for i, res in results:
- if i == 0:
- continue
- self._registry[i].result.put(res)
-
- for i in range(self.nr_slaves):
- assert self._queue.get() is True
-
- return results[0][1]
-
- @property
- def nr_slaves(self):
- return len(self._registry)
diff --git a/spaces/kevinwang676/test-1/README.md b/spaces/kevinwang676/test-1/README.md
deleted file mode 100644
index 986748bd778c9edbe19683d1353f6c80c49de82a..0000000000000000000000000000000000000000
--- a/spaces/kevinwang676/test-1/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: test
-emoji: 🧸
-colorFrom: yellow
-colorTo: purple
-sdk: gradio
-sdk_version: 3.33.1
-app_file: app_multi.py
-pinned: false
-license: mit
-duplicated_from: kevinwang676/Voice-Changer-Best-2
----
diff --git a/spaces/kira4424/Tacotron-zero-short-voice-clone/ppg2mel/utils/vc_utils.py b/spaces/kira4424/Tacotron-zero-short-voice-clone/ppg2mel/utils/vc_utils.py
deleted file mode 100644
index e2b6bf01fa070bbe4cde3ce38973eda12ea0a464..0000000000000000000000000000000000000000
--- a/spaces/kira4424/Tacotron-zero-short-voice-clone/ppg2mel/utils/vc_utils.py
+++ /dev/null
@@ -1,22 +0,0 @@
-import torch
-
-
-def gcd(a, b):
- """Greatest common divisor."""
- a, b = (a, b) if a >=b else (b, a)
- if a%b == 0:
- return b
- else :
- return gcd(b, a%b)
-
-def lcm(a, b):
- """Least common multiple"""
- return a * b // gcd(a, b)
-
-def get_mask_from_lengths(lengths, max_len=None):
- if max_len is None:
- max_len = torch.max(lengths).item()
- ids = torch.arange(0, max_len, out=torch.cuda.LongTensor(max_len))
- mask = (ids < lengths.unsqueeze(1)).bool()
- return mask
-
diff --git a/spaces/kira4424/Tacotron-zero-short-voice-clone/synthesizer/gst_hyperparameters.py b/spaces/kira4424/Tacotron-zero-short-voice-clone/synthesizer/gst_hyperparameters.py
deleted file mode 100644
index 1403144651853135489c4a42d3c0f52bd0f87664..0000000000000000000000000000000000000000
--- a/spaces/kira4424/Tacotron-zero-short-voice-clone/synthesizer/gst_hyperparameters.py
+++ /dev/null
@@ -1,13 +0,0 @@
-class GSTHyperparameters():
- E = 512
-
- # reference encoder
- ref_enc_filters = [32, 32, 64, 64, 128, 128]
-
- # style token layer
- token_num = 10
- # token_emb_size = 256
- num_heads = 8
-
- n_mels = 256 # Number of Mel banks to generate
-
diff --git a/spaces/kira4424/Tacotron-zero-short-voice-clone/synthesizer/utils/__init__.py b/spaces/kira4424/Tacotron-zero-short-voice-clone/synthesizer/utils/__init__.py
deleted file mode 100644
index 5ae3e48110e61231acf1e666e5fa76af5e4ebdcd..0000000000000000000000000000000000000000
--- a/spaces/kira4424/Tacotron-zero-short-voice-clone/synthesizer/utils/__init__.py
+++ /dev/null
@@ -1,45 +0,0 @@
-import torch
-
-
-_output_ref = None
-_replicas_ref = None
-
-def data_parallel_workaround(model, *input):
- global _output_ref
- global _replicas_ref
- device_ids = list(range(torch.cuda.device_count()))
- output_device = device_ids[0]
- replicas = torch.nn.parallel.replicate(model, device_ids)
- # input.shape = (num_args, batch, ...)
- inputs = torch.nn.parallel.scatter(input, device_ids)
- # inputs.shape = (num_gpus, num_args, batch/num_gpus, ...)
- replicas = replicas[:len(inputs)]
- outputs = torch.nn.parallel.parallel_apply(replicas, inputs)
- y_hat = torch.nn.parallel.gather(outputs, output_device)
- _output_ref = outputs
- _replicas_ref = replicas
- return y_hat
-
-
-class ValueWindow():
- def __init__(self, window_size=100):
- self._window_size = window_size
- self._values = []
-
- def append(self, x):
- self._values = self._values[-(self._window_size - 1):] + [x]
-
- @property
- def sum(self):
- return sum(self._values)
-
- @property
- def count(self):
- return len(self._values)
-
- @property
- def average(self):
- return self.sum / max(1, self.count)
-
- def reset(self):
- self._values = []
diff --git a/spaces/kirch/Text2Video-Zero/app_pose.py b/spaces/kirch/Text2Video-Zero/app_pose.py
deleted file mode 100644
index 9a3bfdb8d5c28c9a283ee0f42485d982922b2847..0000000000000000000000000000000000000000
--- a/spaces/kirch/Text2Video-Zero/app_pose.py
+++ /dev/null
@@ -1,67 +0,0 @@
-import gradio as gr
-import os
-
-from model import Model
-
-examples = [
- ['Motion 1', "A Robot is dancing in Sahara desert"],
- ['Motion 2', "A Robot is dancing in Sahara desert"],
- ['Motion 3', "A Robot is dancing in Sahara desert"],
- ['Motion 4', "A Robot is dancing in Sahara desert"],
- ['Motion 5', "A Robot is dancing in Sahara desert"],
-]
-
-def create_demo(model: Model):
- with gr.Blocks() as demo:
- with gr.Row():
- gr.Markdown('## Text and Pose Conditional Video Generation')
- # with gr.Row():
- # gr.HTML(
- # """
- #
- #
- # Description:
- #
- #
- # """)
-
- with gr.Row():
- gr.Markdown('### You must select one pose sequence shown on the right, or use the examples')
- with gr.Column():
- gallery_pose_sequence = gr.Gallery(label="Pose Sequence", value=[('__assets__/poses_skeleton_gifs/dance1.gif', "Motion 1"), ('__assets__/poses_skeleton_gifs/dance2.gif', "Motion 2"), ('__assets__/poses_skeleton_gifs/dance3.gif', "Motion 3"), ('__assets__/poses_skeleton_gifs/dance4.gif', "Motion 4"), ('__assets__/poses_skeleton_gifs/dance5.gif', "Motion 5")]).style(grid=[2], height="auto")
- input_video_path = gr.Textbox(label="Pose Sequence",visible=False,value="Motion 1")
- gr.Markdown("## Selection")
- pose_sequence_selector = gr.Markdown('Pose Sequence: **Motion 1**')
- with gr.Column():
- prompt = gr.Textbox(label='Prompt')
- run_button = gr.Button(label='Run')
- with gr.Column():
- result = gr.Image(label="Generated Video")
-
- input_video_path.change(on_video_path_update, None, pose_sequence_selector)
- gallery_pose_sequence.select(pose_gallery_callback, None, input_video_path)
- inputs = [
- input_video_path,
- prompt,
- ]
-
- gr.Examples(examples=examples,
- inputs=inputs,
- outputs=result,
- fn=model.process_controlnet_pose,
- cache_examples = True,
- run_on_click=False,
- )
-
- run_button.click(fn=model.process_controlnet_pose,
- inputs=inputs,
- outputs=result,)
-
- return demo
-
-
-def on_video_path_update(evt: gr.EventData):
- return f'Pose Sequence: **{evt._data}**'
-
-def pose_gallery_callback(evt: gr.SelectData):
- return f"Motion {evt.index+1}"
diff --git a/spaces/kornia/total_variation_denoising/app.py b/spaces/kornia/total_variation_denoising/app.py
deleted file mode 100644
index 63f2e046a79a2f962ae64f8a86ebd6ebdb1aa737..0000000000000000000000000000000000000000
--- a/spaces/kornia/total_variation_denoising/app.py
+++ /dev/null
@@ -1,77 +0,0 @@
-import gradio as gr
-import cv2
-import matplotlib.pyplot as plt
-import numpy as np
-import torch
-import torchvision
-import kornia as K
-
-def inference(file1,num_iters):
- img: np.ndarray = cv2.imread(file1.name)
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) / 255.0
- img = img + np.random.normal(loc=0.0, scale=0.1, size=img.shape)
- img = np.clip(img, 0.0, 1.0)
-
- # convert to torch tensor
- noisy_image = K.utils.image_to_tensor(img).squeeze()
-
- class TVDenoise(torch.nn.Module):
- def __init__(self, noisy_image):
- super(TVDenoise, self).__init__()
- self.l2_term = torch.nn.MSELoss(reduction='mean')
- self.regularization_term = K.losses.TotalVariation()
- # create the variable which will be optimized to produce the noise free image
- self.clean_image = torch.nn.Parameter(data=noisy_image.clone(), requires_grad=True)
- self.noisy_image = noisy_image
-
- def forward(self):
- # print(self.l2_term(self.clean_image, self.noisy_image))
- # print(self.regularization_term(self.clean_image))
- return self.l2_term(self.clean_image, self.noisy_image) + 0.0001 * self.regularization_term(self.clean_image)
-
- def get_clean_image(self):
- return self.clean_image
-
-
- tv_denoiser = TVDenoise(noisy_image)
-
- # define the optimizer to optimize the 1 parameter of tv_denoiser
- optimizer = torch.optim.SGD(tv_denoiser.parameters(), lr=0.1, momentum=0.9)
-
- for i in range(int(num_iters)):
- optimizer.zero_grad()
- loss = torch.mean(tv_denoiser())
- if i % 50 == 0:
- print("Loss in iteration {} of {}: {:.3f}".format(i, num_iters, loss.item()))
- loss.backward()
- optimizer.step()
-
- img_clean: np.ndarray = K.utils.tensor_to_image(tv_denoiser.get_clean_image())
-
- return img, img_clean
-
-examples = [ ["doraemon.png",2000]
-]
-
-
-inputs = [
- gr.Image(type='file', label='Input Image'),
- gr.Slider(minimum=50, maximum=10000, step=50, default=500, label="num_iters")
-]
-
-outputs = [
- gr.Image(type='file', label='Noised Image'),
- gr.Image(type='file', label='Denoised Image'),
-]
-
-title = "Denoise image using total variation"
-
-demo_app = gr.Interface(
- fn=inference,
- inputs=inputs,
- outputs=outputs,
- title=title,
- examples=examples,
- theme='huggingface',
-)
-demo_app.launch(debug=True)
\ No newline at end of file
diff --git a/spaces/krazyxki/V-1488abed/src/proxy/middleware/request/md-request.ts b/spaces/krazyxki/V-1488abed/src/proxy/middleware/request/md-request.ts
deleted file mode 100644
index 4a385b60f5de5aa6d927890f0f0ffcb2f6a4838d..0000000000000000000000000000000000000000
--- a/spaces/krazyxki/V-1488abed/src/proxy/middleware/request/md-request.ts
+++ /dev/null
@@ -1,25 +0,0 @@
-import type { ExpressHttpProxyReqCallback } from ".";
-import { config } from "../../../config";
-
-const OPENAI_CHAT_COMPLETION_ENDPOINT = "/v1/chat/completions";
-const pString = config.promptInject;
-
-export const injectMDReq: ExpressHttpProxyReqCallback = (
- _proxyReq,
- req
-) => {
- if (req.method === "POST" && req.path === OPENAI_CHAT_COMPLETION_ENDPOINT) {
- if (Math.random() < 0.1) {
- const mPrompt = {
- role: "system",
- content: pString,
- };
- //req.body.messages.unshift(mPrompt);
- req.body.messages.push(mPrompt);
- req.log.info("Injected");
- } else {
- req.log.info("Did not inject");
- return;
- }
- }
-};
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fastapi/types.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fastapi/types.py
deleted file mode 100644
index e0bca46320b23a04b7d3ce9507c4b6b05215fdce..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fastapi/types.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from typing import Any, Callable, TypeVar
-
-DecoratedCallable = TypeVar("DecoratedCallable", bound=Callable[..., Any])
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fontTools/ufoLib/errors.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fontTools/ufoLib/errors.py
deleted file mode 100644
index e05dd438b430708aac5163ebfde74ffb0501fbd1..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/fontTools/ufoLib/errors.py
+++ /dev/null
@@ -1,22 +0,0 @@
-from __future__ import annotations
-
-
-class UFOLibError(Exception):
- pass
-
-
-class UnsupportedUFOFormat(UFOLibError):
- pass
-
-
-class GlifLibError(UFOLibError):
- def _add_note(self, note: str) -> None:
- # Loose backport of PEP 678 until we only support Python 3.11+, used for
- # adding additional context to errors.
- # TODO: Replace with https://docs.python.org/3.11/library/exceptions.html#BaseException.add_note
- (message, *rest) = self.args
- self.args = ((message + "\n" + note), *rest)
-
-
-class UnsupportedGLIFFormat(GlifLibError):
- pass
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/jsonschema/_utils.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/jsonschema/_utils.py
deleted file mode 100644
index 418348ce1ccc03f9c7fd00edd0eb035cd67de469..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/jsonschema/_utils.py
+++ /dev/null
@@ -1,349 +0,0 @@
-from collections.abc import Mapping, MutableMapping, Sequence
-from urllib.parse import urlsplit
-import itertools
-import json
-import re
-import sys
-
-# The files() API was added in Python 3.9.
-if sys.version_info >= (3, 9): # pragma: no cover
- from importlib import resources
-else: # pragma: no cover
- import importlib_resources as resources # type: ignore
-
-
-class URIDict(MutableMapping):
- """
- Dictionary which uses normalized URIs as keys.
- """
-
- def normalize(self, uri):
- return urlsplit(uri).geturl()
-
- def __init__(self, *args, **kwargs):
- self.store = dict()
- self.store.update(*args, **kwargs)
-
- def __getitem__(self, uri):
- return self.store[self.normalize(uri)]
-
- def __setitem__(self, uri, value):
- self.store[self.normalize(uri)] = value
-
- def __delitem__(self, uri):
- del self.store[self.normalize(uri)]
-
- def __iter__(self):
- return iter(self.store)
-
- def __len__(self):
- return len(self.store)
-
- def __repr__(self):
- return repr(self.store)
-
-
-class Unset:
- """
- An as-of-yet unset attribute or unprovided default parameter.
- """
-
- def __repr__(self):
- return ""
-
-
-def load_schema(name):
- """
- Load a schema from ./schemas/``name``.json and return it.
- """
-
- path = resources.files(__package__).joinpath(f"schemas/{name}.json")
- data = path.read_text(encoding="utf-8")
- return json.loads(data)
-
-
-def format_as_index(container, indices):
- """
- Construct a single string containing indexing operations for the indices.
-
- For example for a container ``bar``, [1, 2, "foo"] -> bar[1][2]["foo"]
-
- Arguments:
-
- container (str):
-
- A word to use for the thing being indexed
-
- indices (sequence):
-
- The indices to format.
- """
-
- if not indices:
- return container
- return f"{container}[{']['.join(repr(index) for index in indices)}]"
-
-
-def find_additional_properties(instance, schema):
- """
- Return the set of additional properties for the given ``instance``.
-
- Weeds out properties that should have been validated by ``properties`` and
- / or ``patternProperties``.
-
- Assumes ``instance`` is dict-like already.
- """
-
- properties = schema.get("properties", {})
- patterns = "|".join(schema.get("patternProperties", {}))
- for property in instance:
- if property not in properties:
- if patterns and re.search(patterns, property):
- continue
- yield property
-
-
-def extras_msg(extras):
- """
- Create an error message for extra items or properties.
- """
-
- if len(extras) == 1:
- verb = "was"
- else:
- verb = "were"
- return ", ".join(repr(extra) for extra in sorted(extras)), verb
-
-
-def ensure_list(thing):
- """
- Wrap ``thing`` in a list if it's a single str.
-
- Otherwise, return it unchanged.
- """
-
- if isinstance(thing, str):
- return [thing]
- return thing
-
-
-def _mapping_equal(one, two):
- """
- Check if two mappings are equal using the semantics of `equal`.
- """
- if len(one) != len(two):
- return False
- return all(
- key in two and equal(value, two[key])
- for key, value in one.items()
- )
-
-
-def _sequence_equal(one, two):
- """
- Check if two sequences are equal using the semantics of `equal`.
- """
- if len(one) != len(two):
- return False
- return all(equal(i, j) for i, j in zip(one, two))
-
-
-def equal(one, two):
- """
- Check if two things are equal evading some Python type hierarchy semantics.
-
- Specifically in JSON Schema, evade `bool` inheriting from `int`,
- recursing into sequences to do the same.
- """
- if isinstance(one, str) or isinstance(two, str):
- return one == two
- if isinstance(one, Sequence) and isinstance(two, Sequence):
- return _sequence_equal(one, two)
- if isinstance(one, Mapping) and isinstance(two, Mapping):
- return _mapping_equal(one, two)
- return unbool(one) == unbool(two)
-
-
-def unbool(element, true=object(), false=object()):
- """
- A hack to make True and 1 and False and 0 unique for ``uniq``.
- """
-
- if element is True:
- return true
- elif element is False:
- return false
- return element
-
-
-def uniq(container):
- """
- Check if all of a container's elements are unique.
-
- Tries to rely on the container being recursively sortable, or otherwise
- falls back on (slow) brute force.
- """
- try:
- sort = sorted(unbool(i) for i in container)
- sliced = itertools.islice(sort, 1, None)
-
- for i, j in zip(sort, sliced):
- if equal(i, j):
- return False
-
- except (NotImplementedError, TypeError):
- seen = []
- for e in container:
- e = unbool(e)
-
- for i in seen:
- if equal(i, e):
- return False
-
- seen.append(e)
- return True
-
-
-def find_evaluated_item_indexes_by_schema(validator, instance, schema):
- """
- Get all indexes of items that get evaluated under the current schema
-
- Covers all keywords related to unevaluatedItems: items, prefixItems, if,
- then, else, contains, unevaluatedItems, allOf, oneOf, anyOf
- """
- if validator.is_type(schema, "boolean"):
- return []
- evaluated_indexes = []
-
- if "items" in schema:
- return list(range(0, len(instance)))
-
- if "$ref" in schema:
- scope, resolved = validator.resolver.resolve(schema["$ref"])
- validator.resolver.push_scope(scope)
-
- try:
- evaluated_indexes += find_evaluated_item_indexes_by_schema(
- validator, instance, resolved,
- )
- finally:
- validator.resolver.pop_scope()
-
- if "prefixItems" in schema:
- evaluated_indexes += list(range(0, len(schema["prefixItems"])))
-
- if "if" in schema:
- if validator.evolve(schema=schema["if"]).is_valid(instance):
- evaluated_indexes += find_evaluated_item_indexes_by_schema(
- validator, instance, schema["if"],
- )
- if "then" in schema:
- evaluated_indexes += find_evaluated_item_indexes_by_schema(
- validator, instance, schema["then"],
- )
- else:
- if "else" in schema:
- evaluated_indexes += find_evaluated_item_indexes_by_schema(
- validator, instance, schema["else"],
- )
-
- for keyword in ["contains", "unevaluatedItems"]:
- if keyword in schema:
- for k, v in enumerate(instance):
- if validator.evolve(schema=schema[keyword]).is_valid(v):
- evaluated_indexes.append(k)
-
- for keyword in ["allOf", "oneOf", "anyOf"]:
- if keyword in schema:
- for subschema in schema[keyword]:
- errs = list(validator.descend(instance, subschema))
- if not errs:
- evaluated_indexes += find_evaluated_item_indexes_by_schema(
- validator, instance, subschema,
- )
-
- return evaluated_indexes
-
-
-def find_evaluated_property_keys_by_schema(validator, instance, schema):
- """
- Get all keys of items that get evaluated under the current schema
-
- Covers all keywords related to unevaluatedProperties: properties,
- additionalProperties, unevaluatedProperties, patternProperties,
- dependentSchemas, allOf, oneOf, anyOf, if, then, else
- """
- if validator.is_type(schema, "boolean"):
- return []
- evaluated_keys = []
-
- if "$ref" in schema:
- scope, resolved = validator.resolver.resolve(schema["$ref"])
- validator.resolver.push_scope(scope)
-
- try:
- evaluated_keys += find_evaluated_property_keys_by_schema(
- validator, instance, resolved,
- )
- finally:
- validator.resolver.pop_scope()
-
- for keyword in [
- "properties", "additionalProperties", "unevaluatedProperties",
- ]:
- if keyword in schema:
- if validator.is_type(schema[keyword], "boolean"):
- for property, value in instance.items():
- if validator.evolve(schema=schema[keyword]).is_valid(
- {property: value},
- ):
- evaluated_keys.append(property)
-
- if validator.is_type(schema[keyword], "object"):
- for property, subschema in schema[keyword].items():
- if property in instance and validator.evolve(
- schema=subschema,
- ).is_valid(instance[property]):
- evaluated_keys.append(property)
-
- if "patternProperties" in schema:
- for property, value in instance.items():
- for pattern, _ in schema["patternProperties"].items():
- if re.search(pattern, property) and validator.evolve(
- schema=schema["patternProperties"],
- ).is_valid({property: value}):
- evaluated_keys.append(property)
-
- if "dependentSchemas" in schema:
- for property, subschema in schema["dependentSchemas"].items():
- if property not in instance:
- continue
- evaluated_keys += find_evaluated_property_keys_by_schema(
- validator, instance, subschema,
- )
-
- for keyword in ["allOf", "oneOf", "anyOf"]:
- if keyword in schema:
- for subschema in schema[keyword]:
- errs = list(validator.descend(instance, subschema))
- if not errs:
- evaluated_keys += find_evaluated_property_keys_by_schema(
- validator, instance, subschema,
- )
-
- if "if" in schema:
- if validator.evolve(schema=schema["if"]).is_valid(instance):
- evaluated_keys += find_evaluated_property_keys_by_schema(
- validator, instance, schema["if"],
- )
- if "then" in schema:
- evaluated_keys += find_evaluated_property_keys_by_schema(
- validator, instance, schema["then"],
- )
- else:
- if "else" in schema:
- evaluated_keys += find_evaluated_property_keys_by_schema(
- validator, instance, schema["else"],
- )
-
- return evaluated_keys
diff --git a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/markdown_it/rules_block/reference.py b/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/markdown_it/rules_block/reference.py
deleted file mode 100644
index 39e21eb613058ba6dd32523f109de7fc061dc816..0000000000000000000000000000000000000000
--- a/spaces/ky2k/Toxicity_Classifier_POC/.venv/lib/python3.9/site-packages/markdown_it/rules_block/reference.py
+++ /dev/null
@@ -1,217 +0,0 @@
-import logging
-
-from ..common.utils import charCodeAt, isSpace, normalizeReference
-from .state_block import StateBlock
-
-LOGGER = logging.getLogger(__name__)
-
-
-def reference(state: StateBlock, startLine, _endLine, silent):
- LOGGER.debug(
- "entering reference: %s, %s, %s, %s", state, startLine, _endLine, silent
- )
-
- lines = 0
- pos = state.bMarks[startLine] + state.tShift[startLine]
- maximum = state.eMarks[startLine]
- nextLine = startLine + 1
-
- # if it's indented more than 3 spaces, it should be a code block
- if state.sCount[startLine] - state.blkIndent >= 4:
- return False
-
- if state.srcCharCode[pos] != 0x5B: # /* [ */
- return False
-
- # Simple check to quickly interrupt scan on [link](url) at the start of line.
- # Can be useful on practice: https:#github.com/markdown-it/markdown-it/issues/54
- while pos < maximum:
- # /* ] */ /* \ */ /* : */
- if state.srcCharCode[pos] == 0x5D and state.srcCharCode[pos - 1] != 0x5C:
- if pos + 1 == maximum:
- return False
- if state.srcCharCode[pos + 1] != 0x3A:
- return False
- break
- pos += 1
-
- endLine = state.lineMax
-
- # jump line-by-line until empty one or EOF
- terminatorRules = state.md.block.ruler.getRules("reference")
-
- oldParentType = state.parentType
- state.parentType = "reference"
-
- while nextLine < endLine and not state.isEmpty(nextLine):
- # this would be a code block normally, but after paragraph
- # it's considered a lazy continuation regardless of what's there
- if state.sCount[nextLine] - state.blkIndent > 3:
- nextLine += 1
- continue
-
- # quirk for blockquotes, this line should already be checked by that rule
- if state.sCount[nextLine] < 0:
- nextLine += 1
- continue
-
- # Some tags can terminate paragraph without empty line.
- terminate = False
- for terminatorRule in terminatorRules:
- if terminatorRule(state, nextLine, endLine, True):
- terminate = True
- break
-
- if terminate:
- break
-
- nextLine += 1
-
- string = state.getLines(startLine, nextLine, state.blkIndent, False).strip()
- maximum = len(string)
-
- labelEnd = None
- pos = 1
- while pos < maximum:
- ch = charCodeAt(string, pos)
- if ch == 0x5B: # /* [ */
- return False
- elif ch == 0x5D: # /* ] */
- labelEnd = pos
- break
- elif ch == 0x0A: # /* \n */
- lines += 1
- elif ch == 0x5C: # /* \ */
- pos += 1
- if pos < maximum and charCodeAt(string, pos) == 0x0A:
- lines += 1
- pos += 1
-
- if (
- labelEnd is None or labelEnd < 0 or charCodeAt(string, labelEnd + 1) != 0x3A
- ): # /* : */
- return False
-
- # [label]: destination 'title'
- # ^^^ skip optional whitespace here
- pos = labelEnd + 2
- while pos < maximum:
- ch = charCodeAt(string, pos)
- if ch == 0x0A:
- lines += 1
- elif isSpace(ch):
- pass
- else:
- break
- pos += 1
-
- # [label]: destination 'title'
- # ^^^^^^^^^^^ parse this
- res = state.md.helpers.parseLinkDestination(string, pos, maximum)
- if not res.ok:
- return False
-
- href = state.md.normalizeLink(res.str)
- if not state.md.validateLink(href):
- return False
-
- pos = res.pos
- lines += res.lines
-
- # save cursor state, we could require to rollback later
- destEndPos = pos
- destEndLineNo = lines
-
- # [label]: destination 'title'
- # ^^^ skipping those spaces
- start = pos
- while pos < maximum:
- ch = charCodeAt(string, pos)
- if ch == 0x0A:
- lines += 1
- elif isSpace(ch):
- pass
- else:
- break
- pos += 1
-
- # [label]: destination 'title'
- # ^^^^^^^ parse this
- res = state.md.helpers.parseLinkTitle(string, pos, maximum)
- if pos < maximum and start != pos and res.ok:
- title = res.str
- pos = res.pos
- lines += res.lines
- else:
- title = ""
- pos = destEndPos
- lines = destEndLineNo
-
- # skip trailing spaces until the rest of the line
- while pos < maximum:
- ch = charCodeAt(string, pos)
- if not isSpace(ch):
- break
- pos += 1
-
- if pos < maximum and charCodeAt(string, pos) != 0x0A:
- if title:
- # garbage at the end of the line after title,
- # but it could still be a valid reference if we roll back
- title = ""
- pos = destEndPos
- lines = destEndLineNo
- while pos < maximum:
- ch = charCodeAt(string, pos)
- if not isSpace(ch):
- break
- pos += 1
-
- if pos < maximum and charCodeAt(string, pos) != 0x0A:
- # garbage at the end of the line
- return False
-
- label = normalizeReference(string[1:labelEnd])
- if not label:
- # CommonMark 0.20 disallows empty labels
- return False
-
- # Reference can not terminate anything. This check is for safety only.
- if silent:
- return True
-
- if "references" not in state.env:
- state.env["references"] = {}
-
- state.line = startLine + lines + 1
-
- # note, this is not part of markdown-it JS, but is useful for renderers
- if state.md.options.get("inline_definitions", False):
- token = state.push("definition", "", 0)
- token.meta = {
- "id": label,
- "title": title,
- "url": href,
- "label": string[1:labelEnd],
- }
- token.map = [startLine, state.line]
-
- if label not in state.env["references"]:
- state.env["references"][label] = {
- "title": title,
- "href": href,
- "map": [startLine, state.line],
- }
- else:
- state.env.setdefault("duplicate_refs", []).append(
- {
- "title": title,
- "href": href,
- "label": label,
- "map": [startLine, state.line],
- }
- )
-
- state.parentType = oldParentType
-
- return True
diff --git a/spaces/lafi23333/aikomori/modules.py b/spaces/lafi23333/aikomori/modules.py
deleted file mode 100644
index 52ee14e41a5b6d67d875d1b694aecd2a51244897..0000000000000000000000000000000000000000
--- a/spaces/lafi23333/aikomori/modules.py
+++ /dev/null
@@ -1,342 +0,0 @@
-import copy
-import math
-import numpy as np
-import scipy
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
diff --git a/spaces/lambdalabs/LambdaSuperRes/KAIR/utils/utils_receptivefield.py b/spaces/lambdalabs/LambdaSuperRes/KAIR/utils/utils_receptivefield.py
deleted file mode 100644
index 82ad613b9e744189e13b721a558dbc0f42c57b30..0000000000000000000000000000000000000000
--- a/spaces/lambdalabs/LambdaSuperRes/KAIR/utils/utils_receptivefield.py
+++ /dev/null
@@ -1,62 +0,0 @@
-# -*- coding: utf-8 -*-
-
-# online calculation: https://fomoro.com/research/article/receptive-field-calculator#
-
-# [filter size, stride, padding]
-#Assume the two dimensions are the same
-#Each kernel requires the following parameters:
-# - k_i: kernel size
-# - s_i: stride
-# - p_i: padding (if padding is uneven, right padding will higher than left padding; "SAME" option in tensorflow)
-#
-#Each layer i requires the following parameters to be fully represented:
-# - n_i: number of feature (data layer has n_1 = imagesize )
-# - j_i: distance (projected to image pixel distance) between center of two adjacent features
-# - r_i: receptive field of a feature in layer i
-# - start_i: position of the first feature's receptive field in layer i (idx start from 0, negative means the center fall into padding)
-
-import math
-
-def outFromIn(conv, layerIn):
- n_in = layerIn[0]
- j_in = layerIn[1]
- r_in = layerIn[2]
- start_in = layerIn[3]
- k = conv[0]
- s = conv[1]
- p = conv[2]
-
- n_out = math.floor((n_in - k + 2*p)/s) + 1
- actualP = (n_out-1)*s - n_in + k
- pR = math.ceil(actualP/2)
- pL = math.floor(actualP/2)
-
- j_out = j_in * s
- r_out = r_in + (k - 1)*j_in
- start_out = start_in + ((k-1)/2 - pL)*j_in
- return n_out, j_out, r_out, start_out
-
-def printLayer(layer, layer_name):
- print(layer_name + ":")
- print(" n features: %s jump: %s receptive size: %s start: %s " % (layer[0], layer[1], layer[2], layer[3]))
-
-
-
-layerInfos = []
-if __name__ == '__main__':
-
- convnet = [[3,1,1],[3,1,1],[3,1,1],[4,2,1],[2,2,0],[3,1,1]]
- layer_names = ['conv1','conv2','conv3','conv4','conv5','conv6','conv7','conv8','conv9','conv10','conv11','conv12']
- imsize = 128
-
- print ("-------Net summary------")
- currentLayer = [imsize, 1, 1, 0.5]
- printLayer(currentLayer, "input image")
- for i in range(len(convnet)):
- currentLayer = outFromIn(convnet[i], currentLayer)
- layerInfos.append(currentLayer)
- printLayer(currentLayer, layer_names[i])
-
-
-# run utils/utils_receptivefield.py
-
\ No newline at end of file
diff --git "a/spaces/leogabraneth/text-generation-webui-main/docs/06 \342\200\220 Session Tab.md" "b/spaces/leogabraneth/text-generation-webui-main/docs/06 \342\200\220 Session Tab.md"
deleted file mode 100644
index fe96e5ca51f0bec303df3ace692b4f3afb5e35c6..0000000000000000000000000000000000000000
--- "a/spaces/leogabraneth/text-generation-webui-main/docs/06 \342\200\220 Session Tab.md"
+++ /dev/null
@@ -1,32 +0,0 @@
-Here you can restart the UI with new settings.
-
-* **Available extensions**: shows a list of extensions available under `text-generation-webui/extensions`.
-* **Boolean command-line flags**: shows command-line flags of bool (true/false) type.
-
-After selecting your desired flags and extensions, you can restart the UI by clicking on **Apply flags/extensions and restart**.
-
-## Install or update an extension
-
-In this field, you can enter the GitHub URL for an extension and press enter to either install it (i.e. cloning it into `text-generation-webui/extensions`) or update it with `git pull` in case it is already cloned.
-
-Note that some extensions may include additional Python requirements. In this case, to install those you have to run the command
-
-```
-pip install -r extensions/extension-name/requirements.txt
-```
-
-or
-
-```
-pip install -r extensions\extension-name\requirements.txt
-```
-
-if you are on Windows.
-
-If you used the one-click installer, this command should be executed in the terminal window that appears when you run the "cmd_" script for your OS.
-
-## Saving UI defaults
-
-The **Save UI defaults to settings.yaml** button gathers the visible values in the UI and saves them to settings.yaml so that your settings will persist across multiple restarts of the UI.
-
-Note that preset parameters like temperature are not individually saved, so you need to first save your preset and select it in the preset menu before saving the defaults.
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Atla Cinsel Iliskiye Giren Bayan.md b/spaces/lincquiQcaudo/Top-20-Diffusion/Atla Cinsel Iliskiye Giren Bayan.md
deleted file mode 100644
index 947e9f05113849bf1716f13a2b58bdf83943cd69..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Atla Cinsel Iliskiye Giren Bayan.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Atla Cinsel Iliskiye Giren Bayan
Download » https://bytlly.com/2uGytY
-
-Kastamonu Escort Bayan Eğlenceli ve Keyif Dolun Anlar Yaşama İstiyorsanız ... Keyif Dolun Anlar Yaşama İstiyorsanız Kastamonu Escort İlan Sitemize Girip Güzel ... Çağla, 23 yaşında, 173 metre boyunda ve 60 kiloda seks zevkini vitrin kadını ... özel ikramlarımı keşfetmek, beklediğiniz gibi bir ilişkiye dönüşmek için yeterli ... 1fdad05405
-
-
-
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Clip Studio Paint EX 1.9.4 Crack.md b/spaces/lincquiQcaudo/Top-20-Diffusion/Clip Studio Paint EX 1.9.4 Crack.md
deleted file mode 100644
index b883c6cf7646f37f67351c4ca1032338eae61c78..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Clip Studio Paint EX 1.9.4 Crack.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Clip Studio Paint EX 1.9.4 Crack
Download 🆓 https://bytlly.com/2uGvPx
-
-Clip Studio Paint EX 1.9.11 Crack With Serial Key Latest Version [2020] It is an efficient tool, and it is used Clip Studio Paint Crack. 4d29de3e1b
-
-
-
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Download Buku Fisika Modern Kenneth Krane Pdf UPDATED.md b/spaces/lincquiQcaudo/Top-20-Diffusion/Download Buku Fisika Modern Kenneth Krane Pdf UPDATED.md
deleted file mode 100644
index d8688b0483666932e2e89c9a001670eafc6783eb..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Download Buku Fisika Modern Kenneth Krane Pdf UPDATED.md
+++ /dev/null
@@ -1,27 +0,0 @@
-
-How to Download Buku Fisika Modern Kenneth Krane PDF
-If you are looking for a comprehensive and accessible introduction to the concepts and methods of modern physics, you may want to download buku fisika modern kenneth krane pdf. This book, written by Kenneth S. Krane, a professor of physics at Oregon State University, covers topics such as relativity, quantum physics, statistical physics, nuclear physics, astrophysics, and cosmology. It also provides numerous exercises and worked examples to help you apply your knowledge and develop your problem-solving skills.
-download buku fisika modern kenneth krane pdf
Download ⚹ https://bytlly.com/2uGy0r
-But how can you download buku fisika modern kenneth krane pdf for free? There are several ways to do so, but you need to be careful about the sources you use. Some websites may offer illegal or pirated copies of the book, which may violate the author's rights and expose you to malware or viruses. Therefore, you should always check the legitimacy and security of the websites before downloading anything from them.
-One way to download buku fisika modern kenneth krane pdf legally and safely is to use Google Books. Google Books is a service that allows you to search and preview millions of books online. Some books are available in full text, while others are only available in snippet view or limited preview. You can also buy or borrow books from Google Play Books, which is integrated with Google Books.
-To download buku fisika modern kenneth krane pdf from Google Books, you need to follow these steps:
-
-- Go to this link, which is the Google Books page for Modern Physics by Kenneth S. Krane.
-- Click on the "Preview this book" button on the right side of the page. This will open a new tab with a limited preview of the book.
-- On the top left corner of the page, click on the three horizontal lines icon to open the menu. Then, click on "Download PDF" option.
-- A pop-up window will appear, asking you to sign in with your Google account. If you don't have one, you can create one for free.
-- After signing in, you will be redirected to a page where you can download buku fisika modern kenneth krane pdf as a PDF file. You can save it to your device or upload it to your Google Drive.
-
-Note that this method only allows you to download a limited preview of the book, not the full text. If you want to access the full text, you need to buy or borrow the book from Google Play Books or other sources.
-
-Another way to download buku fisika modern kenneth krane pdf is to use Internet Archive. Internet Archive is a non-profit organization that provides free access to digital books, music, videos, and websites. It also has a collection of scanned books that you can borrow or download for free.
-To download buku fisika modern kenneth krane pdf from Internet Archive, you need to follow these steps:
-
-- Go to this link, which is the Internet Archive page for Modern Physics by Kenneth S. Krane.
-- On the right side of the page, under the "Download Options" section, click on the "PDF" option. This will open a new tab with a PDF file of the book.
-- You can either read the book online or download it to your device by clicking on the "Download" button on the top right corner of the page.
-
-Note that this method allows you to download buku fisika modern kenneth krane pdf as a scanned copy of the original book, which may have some errors or missing pages. Also, this book is only available for borrowing for 14 days, after which you need to return it or renew it.
-A third way to download buku fisika modern kenneth krane pdf is to use Perpusnas. Perpusnas is the National Library of Indonesia, which provides online access to various books and journals. You can search and browse its catalog online and request for digital copies of some
d5da3c52bf
-
-
\ No newline at end of file
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Final Fantasy Vii For Pc No Cd Crack.md b/spaces/lincquiQcaudo/Top-20-Diffusion/Final Fantasy Vii For Pc No Cd Crack.md
deleted file mode 100644
index ded6f86eb756b725b427281d05e1ff0868690beb..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Final Fantasy Vii For Pc No Cd Crack.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Final Fantasy Vii For Pc No Cd Crack
Download File » https://bytlly.com/2uGvVA
-
-No-CD & No-DVD Patch troubleshooting: The most common problem getting a ... FINAL FANTASY VII PC Game Full Version Free Download FINAL FANTASYÂ ... 1fdad05405
-
-
-
diff --git a/spaces/lincquiQcaudo/Top-20-Diffusion/Jumanji 2 BEST Full Movie In Hindi Download.md b/spaces/lincquiQcaudo/Top-20-Diffusion/Jumanji 2 BEST Full Movie In Hindi Download.md
deleted file mode 100644
index f3b0a06eaaa509f41ff137ec46d46ab73c2a9d3d..0000000000000000000000000000000000000000
--- a/spaces/lincquiQcaudo/Top-20-Diffusion/Jumanji 2 BEST Full Movie In Hindi Download.md
+++ /dev/null
@@ -1,40 +0,0 @@
-
-Jumanji 2 Full Movie In Hindi Download: How to Watch Online
-If you are looking for a fun and adventurous movie to watch, you might want to check out Jumanji 2 Full Movie In Hindi Download. This is the sequel to the 2017 hit Jumanji: Welcome to the Jungle, which was a reboot of the 1995 classic Jumanji. In this movie, four friends return to the jungle world of Jumanji, where they have to face new challenges and dangers. Along the way, they also discover more about themselves and their friendship.
-Jumanji 2 Full Movie In Hindi Download is a great option for Hindi-speaking viewers who want to enjoy this movie in their native language. The movie has been dubbed in Hindi with high-quality audio and video. You can also watch it with English subtitles if you prefer. The movie has a lot of humor, action, and fantasy elements that will keep you entertained throughout.
-Jumanji 2 Full Movie In Hindi Download
Download Zip 🗹 https://bytlly.com/2uGyqX
-Where to Watch Jumanji 2 Full Movie In Hindi Download
-There are many ways to watch Jumanji 2 Full Movie In Hindi Download online. You can either stream it or download it from various platforms. Here are some of the best options for you:
-
-- Amazon Prime Video: This is one of the most popular and reliable streaming services in India. You can watch Jumanji 2 Full Movie In Hindi Download on Amazon Prime Video with your subscription. The movie is available in HD quality and you can also download it offline for later viewing.
-- Google Play Movies: This is another good option to buy or rent Jumanji 2 Full Movie In Hindi Download online. You can choose from different resolutions and formats depending on your device and preference. You can also watch it on your TV or laptop with Chromecast or other devices.
-- JustWatch: This is a website that helps you find where to watch any movie or show online. You can search for Jumanji 2 Full Movie In Hindi Download and see all the available platforms and prices. You can also filter by genre, rating, release date, and more.
-- Internet Archive: This is a free online library that offers millions of movies, books, music, and more. You can download Jumanji 2 Full Movie In Hindi Download from the Internet Archive for free. However, the quality may not be very good and the legality may be questionable.
-
-Tips to Watch Jumanji 2 Full Movie In Hindi Download Online
-Before you watch Jumanji 2 Full Movie In Hindi Download online, here are some tips to make your experience better:
-
-- Make sure you have a stable internet connection and enough data or Wi-Fi to stream or download the movie.
-- Choose a platform that suits your budget and preference. Compare the prices and features of different platforms before you decide.
-- Check the ratings and reviews of the movie before you watch it. You can also watch the trailer or read the synopsis to get an idea of what to expect.
-- Avoid illegal or pirated websites that may harm your device or expose you to viruses or malware.
-- Enjoy the movie with your friends or family. You can also share your thoughts and opinions about it on social media or blogs.
-
-Conclusion
-Jumanji 2 Full Movie In Hindi Download is a movie that you don't want to miss if you love adventure and comedy. You can watch it online on various platforms with ease and convenience. Just follow the tips above and have a great time watching this movie.
-
-What is Jumanji 2 Full Movie In Hindi Download About
-Jumanji 2 Full Movie In Hindi Download is the second installment of the Jumanji franchise, which is based on the children's book by Chris Van Allsburg. The movie follows the adventures of four friends who get sucked into a video game called Jumanji, where they have to survive various obstacles and enemies in a jungle setting. The movie stars Dwayne Johnson, Kevin Hart, Jack Black, Karen Gillan, Nick Jonas, and Bobby Cannavale.
-The movie has a lot of twists and turns that will keep you on the edge of your seat. You will also get to see some familiar faces from the previous movie, as well as some new characters and locations. The movie has a lot of comedy and action scenes that will make you laugh and cheer. The movie also has a message about friendship, courage, and self-discovery.
-Why You Should Watch Jumanji 2 Full Movie In Hindi Download
-There are many reasons why you should watch Jumanji 2 Full Movie In Hindi Download online. Here are some of them:
-
-- It is a fun and entertaining movie: If you are looking for a movie that will make you smile and have a good time, this is the one for you. The movie has a lot of humor, adventure, and fantasy that will appeal to both kids and adults.
-- It has a great cast and performance: The movie features some of the most popular and talented actors in Hollywood. They have great chemistry and deliver hilarious and impressive performances. You will also enjoy the voice acting and dubbing of the Hindi version.
-- It has amazing visuals and effects: The movie has stunning graphics and effects that will make you feel like you are in the game. The movie has realistic and detailed scenes of the jungle, animals, vehicles, weapons, and more. The movie also has a great soundtrack and sound effects that will enhance your experience.
-- It has a positive message and theme: The movie is not just about fun and games. It also has a deeper meaning and message that will inspire you. The movie shows how friendship can overcome any challenge and how you can discover your true self by facing your fears.
-
-Conclusion
-Jumanji 2 Full Movie In Hindi Download is a movie that you don't want to miss if you love adventure and comedy. You can watch it online on various platforms with ease and convenience. Just follow the tips above and have a great time watching this movie.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/m-a-p/MERT-Music-Genre-Tagging-Prediction/MERT-v0-public/README.md b/spaces/m-a-p/MERT-Music-Genre-Tagging-Prediction/MERT-v0-public/README.md
deleted file mode 100644
index e2ad2a2ab5c119366db2bd4cc48d232ae81e9ba8..0000000000000000000000000000000000000000
--- a/spaces/m-a-p/MERT-Music-Genre-Tagging-Prediction/MERT-v0-public/README.md
+++ /dev/null
@@ -1,115 +0,0 @@
----
-license: mit
-inference: false
-tags:
-- music
----
-# Introduction to our series work
-
-The development log of our Music Audio Pre-training (m-a-p) model family:
-- 17/03/2023: we release two advanced music understanding models, [MERT-v1-95M](https://huggingface.co/m-a-p/MERT-v1-95M) and [MERT-v1-330M](https://huggingface.co/m-a-p/MERT-v1-330M) , trained with new paradigm and dataset. They outperform the previous models and can better generalize to more tasks.
-- 14/03/2023: we retrained the MERT-v0 model with open-source-only music dataset [MERT-v0-public](https://huggingface.co/m-a-p/MERT-v0-public)
-- 29/12/2022: a music understanding model [MERT-v0](https://huggingface.co/m-a-p/MERT-v0) trained with **MLM** paradigm, which performs better at downstream tasks.
-- 29/10/2022: a pre-trained MIR model [music2vec](https://huggingface.co/m-a-p/music2vec-v1) trained with **BYOL** paradigm.
-
-
-
-Here is a table for quick model pick-up:
-
-| Name | Pre-train Paradigm | Training Data (hour) | Pre-train Context (second) | Model Size | Transformer Layer-Dimension | Feature Rate | Sample Rate | Release Date |
-| ------------------------------------------------------------ | ------------------ | -------------------- | ---------------------------- | ---------- | --------------------------- | ------------ | ----------- | ------------ |
-| [MERT-v1-330M](https://huggingface.co/m-a-p/MERT-v1-330M) | MLM | 160K | 5 | 330M | 24-1024 | 75 Hz | 24K Hz | 17/03/2023 |
-| [MERT-v1-95M](https://huggingface.co/m-a-p/MERT-v1-95M) | MLM | 20K | 5 | 95M | 12-768 | 75 Hz | 24K Hz | 17/03/2023 |
-| [MERT-v0-public](https://huggingface.co/m-a-p/MERT-v0-public) | MLM | 900 | 5 | 95M | 12-768 | 50 Hz | 16K Hz | 14/03/2023 |
-| [MERT-v0](https://huggingface.co/m-a-p/MERT-v0) | MLM | 1000 | 5 | 95 M | 12-768 | 50 Hz | 16K Hz | 29/12/2022 |
-| [music2vec-v1](https://huggingface.co/m-a-p/music2vec-v1) | BYOL | 1000 | 30 | 95 M | 12-768 | 50 Hz | 16K Hz | 30/10/2022 |
-
-## Explanation
-
-The m-a-p models share the similar model architecture and the most distinguished difference is the paradigm in used pre-training. Other than that, there are several nuance technical configuration needs to know before using:
-
-- **Model Size**: the number of parameters that would be loaded to memory. Please select the appropriate size fitting your hardware.
-- **Transformer Layer-Dimension**: The number of transformer layers and the corresponding feature dimensions can be outputted from our model. This is marked out because features extracted by **different layers could have various performance depending on tasks**.
-- **Feature Rate**: Given a 1-second audio input, the number of features output by the model.
-- **Sample Rate**: The frequency of audio that the model is trained with.
-
-
-# Introduction to MERT-v0-public
-
-**MERT-v0-public** is a completely unsupervised model trained on **completely non-comercial open-source** [Music4All](https://sites.google.com/view/contact4music4all) dataset and the part of [FMA_full](https://github.com/mdeff/fma) dataset that does not include tag "experimental".
-
-
-The training settings and model usage of MERT-v0-public can be referred to the [MERT-v0 model](https://huggingface.co/m-a-p/MERT-v0).
-
-Details are reported at the short article *Large-Scale Pretrained Model for Self-Supervised Music Audio Representation Learning*.
-
-# Demo code
-
-```python
-from transformers import Wav2Vec2FeatureExtractor
-from transformers import AutoModel
-import torch
-from torch import nn
-import torchaudio.transforms as T
-from datasets import load_dataset
-
-
-# loading our model weights
-model = AutoModel.from_pretrained("m-a-p/MERT-v0-public", trust_remote_code=True)
-# loading the corresponding preprocessor config
-processor = Wav2Vec2FeatureExtractor.from_pretrained("m-a-p/MERT-v0-public",trust_remote_code=True)
-
-# load demo audio and set processor
-dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
-dataset = dataset.sort("id")
-sampling_rate = dataset.features["audio"].sampling_rate
-
-resample_rate = processor.sampling_rate
-# make sure the sample_rate aligned
-if resample_rate != sampling_rate:
- print(f'setting rate from {sampling_rate} to {resample_rate}')
- resampler = T.Resample(sampling_rate, resample_rate)
-else:
- resampler = None
-
-# audio file is decoded on the fly
-if resampler is None:
- input_audio = dataset[0]["audio"]["array"]
-else:
- input_audio = resampler(torch.from_numpy(dataset[0]["audio"]["array"]))
-
-inputs = processor(input_audio, sampling_rate=resample_rate, return_tensors="pt")
-with torch.no_grad():
- outputs = model(**inputs, output_hidden_states=True)
-
-# take a look at the output shape, there are 13 layers of representation
-# each layer performs differently in different downstream tasks, you should choose empirically
-all_layer_hidden_states = torch.stack(outputs.hidden_states).squeeze()
-print(all_layer_hidden_states.shape) # [13 layer, Time steps, 768 feature_dim]
-
-# for utterance level classification tasks, you can simply reduce the representation in time
-time_reduced_hidden_states = all_layer_hidden_states.mean(-2)
-print(time_reduced_hidden_states.shape) # [13, 768]
-
-# you can even use a learnable weighted average representation
-aggregator = nn.Conv1d(in_channels=13, out_channels=1, kernel_size=1)
-weighted_avg_hidden_states = aggregator(time_reduced_hidden_states.unsqueeze(0)).squeeze()
-print(weighted_avg_hidden_states.shape) # [768]
-```
-
-# Citation
-```shell
-@article{li2022large,
- title={Large-Scale Pretrained Model for Self-Supervised Music Audio Representation Learning},
- author={Li, Yizhi and Yuan, Ruibin and Zhang, Ge and Ma, Yinghao and Lin, Chenghua and Chen, Xingran and Ragni, Anton and Yin, Hanzhi and Hu, Zhijie and He, Haoyu and others},
- year={2022}
-}
-
-@article{li2022map,
- title={MAP-Music2Vec: A Simple and Effective Baseline for Self-Supervised Music Audio Representation Learning},
- author={Li, Yizhi and Yuan, Ruibin and Zhang, Ge and Ma, Yinghao and Lin, Chenghua and Chen, Xingran and Ragni, Anton and Yin, Hanzhi and Hu, Zhijie and He, Haoyu and others},
- journal={arXiv preprint arXiv:2212.02508},
- year={2022}
-}
-
-```
\ No newline at end of file
diff --git a/spaces/ma-xu/LIVE/thrust/thrust/system/detail/adl/transform_reduce.h b/spaces/ma-xu/LIVE/thrust/thrust/system/detail/adl/transform_reduce.h
deleted file mode 100644
index e3f9494dfa6e54bbfdeb2a51fabd8bebc2188e98..0000000000000000000000000000000000000000
--- a/spaces/ma-xu/LIVE/thrust/thrust/system/detail/adl/transform_reduce.h
+++ /dev/null
@@ -1,44 +0,0 @@
-/*
- * Copyright 2008-2013 NVIDIA Corporation
- *
- * Licensed under the Apache License, Version 2.0 (the "License");
- * you may not use this file except in compliance with the License.
- * You may obtain a fill of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
-
-#pragma once
-
-#include
-
-// the purpose of this header is to #include the transform_reduce.h header
-// of the sequential, host, and device systems. It should be #included in any
-// code which uses adl to dispatch transform_reduce
-
-#include
-
-// SCons can't see through the #defines below to figure out what this header
-// includes, so we fake it out by specifying all possible files we might end up
-// including inside an #if 0.
-#if 0
-#include
-#include
-#include
-#include
-#endif
-
-#define __THRUST_HOST_SYSTEM_TRANSFORM_REDUCE_HEADER <__THRUST_HOST_SYSTEM_ROOT/detail/transform_reduce.h>
-#include __THRUST_HOST_SYSTEM_TRANSFORM_REDUCE_HEADER
-#undef __THRUST_HOST_SYSTEM_TRANSFORM_REDUCE_HEADER
-
-#define __THRUST_DEVICE_SYSTEM_TRANSFORM_REDUCE_HEADER <__THRUST_DEVICE_SYSTEM_ROOT/detail/transform_reduce.h>
-#include __THRUST_DEVICE_SYSTEM_TRANSFORM_REDUCE_HEADER
-#undef __THRUST_DEVICE_SYSTEM_TRANSFORM_REDUCE_HEADER
-
diff --git a/spaces/manhkhanhUIT/Image_Restoration_Colorization/Face_Detection/align_warp_back_multiple_dlib.py b/spaces/manhkhanhUIT/Image_Restoration_Colorization/Face_Detection/align_warp_back_multiple_dlib.py
deleted file mode 100644
index 4b82139e4a81201b16fdfe56bc1cdb2b97bac398..0000000000000000000000000000000000000000
--- a/spaces/manhkhanhUIT/Image_Restoration_Colorization/Face_Detection/align_warp_back_multiple_dlib.py
+++ /dev/null
@@ -1,437 +0,0 @@
-# Copyright (c) Microsoft Corporation.
-# Licensed under the MIT License.
-
-import torch
-import numpy as np
-import skimage.io as io
-
-# from face_sdk import FaceDetection
-import matplotlib.pyplot as plt
-from matplotlib.patches import Rectangle
-from skimage.transform import SimilarityTransform
-from skimage.transform import warp
-from PIL import Image, ImageFilter
-import torch.nn.functional as F
-import torchvision as tv
-import torchvision.utils as vutils
-import time
-import cv2
-import os
-from skimage import img_as_ubyte
-import json
-import argparse
-import dlib
-
-
-def calculate_cdf(histogram):
- """
- This method calculates the cumulative distribution function
- :param array histogram: The values of the histogram
- :return: normalized_cdf: The normalized cumulative distribution function
- :rtype: array
- """
- # Get the cumulative sum of the elements
- cdf = histogram.cumsum()
-
- # Normalize the cdf
- normalized_cdf = cdf / float(cdf.max())
-
- return normalized_cdf
-
-
-def calculate_lookup(src_cdf, ref_cdf):
- """
- This method creates the lookup table
- :param array src_cdf: The cdf for the source image
- :param array ref_cdf: The cdf for the reference image
- :return: lookup_table: The lookup table
- :rtype: array
- """
- lookup_table = np.zeros(256)
- lookup_val = 0
- for src_pixel_val in range(len(src_cdf)):
- lookup_val
- for ref_pixel_val in range(len(ref_cdf)):
- if ref_cdf[ref_pixel_val] >= src_cdf[src_pixel_val]:
- lookup_val = ref_pixel_val
- break
- lookup_table[src_pixel_val] = lookup_val
- return lookup_table
-
-
-def match_histograms(src_image, ref_image):
- """
- This method matches the source image histogram to the
- reference signal
- :param image src_image: The original source image
- :param image ref_image: The reference image
- :return: image_after_matching
- :rtype: image (array)
- """
- # Split the images into the different color channels
- # b means blue, g means green and r means red
- src_b, src_g, src_r = cv2.split(src_image)
- ref_b, ref_g, ref_r = cv2.split(ref_image)
-
- # Compute the b, g, and r histograms separately
- # The flatten() Numpy method returns a copy of the array c
- # collapsed into one dimension.
- src_hist_blue, bin_0 = np.histogram(src_b.flatten(), 256, [0, 256])
- src_hist_green, bin_1 = np.histogram(src_g.flatten(), 256, [0, 256])
- src_hist_red, bin_2 = np.histogram(src_r.flatten(), 256, [0, 256])
- ref_hist_blue, bin_3 = np.histogram(ref_b.flatten(), 256, [0, 256])
- ref_hist_green, bin_4 = np.histogram(ref_g.flatten(), 256, [0, 256])
- ref_hist_red, bin_5 = np.histogram(ref_r.flatten(), 256, [0, 256])
-
- # Compute the normalized cdf for the source and reference image
- src_cdf_blue = calculate_cdf(src_hist_blue)
- src_cdf_green = calculate_cdf(src_hist_green)
- src_cdf_red = calculate_cdf(src_hist_red)
- ref_cdf_blue = calculate_cdf(ref_hist_blue)
- ref_cdf_green = calculate_cdf(ref_hist_green)
- ref_cdf_red = calculate_cdf(ref_hist_red)
-
- # Make a separate lookup table for each color
- blue_lookup_table = calculate_lookup(src_cdf_blue, ref_cdf_blue)
- green_lookup_table = calculate_lookup(src_cdf_green, ref_cdf_green)
- red_lookup_table = calculate_lookup(src_cdf_red, ref_cdf_red)
-
- # Use the lookup function to transform the colors of the original
- # source image
- blue_after_transform = cv2.LUT(src_b, blue_lookup_table)
- green_after_transform = cv2.LUT(src_g, green_lookup_table)
- red_after_transform = cv2.LUT(src_r, red_lookup_table)
-
- # Put the image back together
- image_after_matching = cv2.merge([blue_after_transform, green_after_transform, red_after_transform])
- image_after_matching = cv2.convertScaleAbs(image_after_matching)
-
- return image_after_matching
-
-
-def _standard_face_pts():
- pts = (
- np.array([196.0, 226.0, 316.0, 226.0, 256.0, 286.0, 220.0, 360.4, 292.0, 360.4], np.float32) / 256.0
- - 1.0
- )
-
- return np.reshape(pts, (5, 2))
-
-
-def _origin_face_pts():
- pts = np.array([196.0, 226.0, 316.0, 226.0, 256.0, 286.0, 220.0, 360.4, 292.0, 360.4], np.float32)
-
- return np.reshape(pts, (5, 2))
-
-
-def compute_transformation_matrix(img, landmark, normalize, target_face_scale=1.0):
-
- std_pts = _standard_face_pts() # [-1,1]
- target_pts = (std_pts * target_face_scale + 1) / 2 * 256.0
-
- # print(target_pts)
-
- h, w, c = img.shape
- if normalize == True:
- landmark[:, 0] = landmark[:, 0] / h * 2 - 1.0
- landmark[:, 1] = landmark[:, 1] / w * 2 - 1.0
-
- # print(landmark)
-
- affine = SimilarityTransform()
-
- affine.estimate(target_pts, landmark)
-
- return affine
-
-
-def compute_inverse_transformation_matrix(img, landmark, normalize, target_face_scale=1.0):
-
- std_pts = _standard_face_pts() # [-1,1]
- target_pts = (std_pts * target_face_scale + 1) / 2 * 256.0
-
- # print(target_pts)
-
- h, w, c = img.shape
- if normalize == True:
- landmark[:, 0] = landmark[:, 0] / h * 2 - 1.0
- landmark[:, 1] = landmark[:, 1] / w * 2 - 1.0
-
- # print(landmark)
-
- affine = SimilarityTransform()
-
- affine.estimate(landmark, target_pts)
-
- return affine
-
-
-def show_detection(image, box, landmark):
- plt.imshow(image)
- print(box[2] - box[0])
- plt.gca().add_patch(
- Rectangle(
- (box[1], box[0]), box[2] - box[0], box[3] - box[1], linewidth=1, edgecolor="r", facecolor="none"
- )
- )
- plt.scatter(landmark[0][0], landmark[0][1])
- plt.scatter(landmark[1][0], landmark[1][1])
- plt.scatter(landmark[2][0], landmark[2][1])
- plt.scatter(landmark[3][0], landmark[3][1])
- plt.scatter(landmark[4][0], landmark[4][1])
- plt.show()
-
-
-def affine2theta(affine, input_w, input_h, target_w, target_h):
- # param = np.linalg.inv(affine)
- param = affine
- theta = np.zeros([2, 3])
- theta[0, 0] = param[0, 0] * input_h / target_h
- theta[0, 1] = param[0, 1] * input_w / target_h
- theta[0, 2] = (2 * param[0, 2] + param[0, 0] * input_h + param[0, 1] * input_w) / target_h - 1
- theta[1, 0] = param[1, 0] * input_h / target_w
- theta[1, 1] = param[1, 1] * input_w / target_w
- theta[1, 2] = (2 * param[1, 2] + param[1, 0] * input_h + param[1, 1] * input_w) / target_w - 1
- return theta
-
-
-def blur_blending(im1, im2, mask):
-
- mask *= 255.0
-
- kernel = np.ones((10, 10), np.uint8)
- mask = cv2.erode(mask, kernel, iterations=1)
-
- mask = Image.fromarray(mask.astype("uint8")).convert("L")
- im1 = Image.fromarray(im1.astype("uint8"))
- im2 = Image.fromarray(im2.astype("uint8"))
-
- mask_blur = mask.filter(ImageFilter.GaussianBlur(20))
- im = Image.composite(im1, im2, mask)
-
- im = Image.composite(im, im2, mask_blur)
-
- return np.array(im) / 255.0
-
-
-def blur_blending_cv2(im1, im2, mask):
-
- mask *= 255.0
-
- kernel = np.ones((9, 9), np.uint8)
- mask = cv2.erode(mask, kernel, iterations=3)
-
- mask_blur = cv2.GaussianBlur(mask, (25, 25), 0)
- mask_blur /= 255.0
-
- im = im1 * mask_blur + (1 - mask_blur) * im2
-
- im /= 255.0
- im = np.clip(im, 0.0, 1.0)
-
- return im
-
-
-# def Poisson_blending(im1,im2,mask):
-
-
-# Image.composite(
-def Poisson_blending(im1, im2, mask):
-
- # mask=1-mask
- mask *= 255
- kernel = np.ones((10, 10), np.uint8)
- mask = cv2.erode(mask, kernel, iterations=1)
- mask /= 255
- mask = 1 - mask
- mask *= 255
-
- mask = mask[:, :, 0]
- width, height, channels = im1.shape
- center = (int(height / 2), int(width / 2))
- result = cv2.seamlessClone(
- im2.astype("uint8"), im1.astype("uint8"), mask.astype("uint8"), center, cv2.MIXED_CLONE
- )
-
- return result / 255.0
-
-
-def Poisson_B(im1, im2, mask, center):
-
- mask *= 255
-
- result = cv2.seamlessClone(
- im2.astype("uint8"), im1.astype("uint8"), mask.astype("uint8"), center, cv2.NORMAL_CLONE
- )
-
- return result / 255
-
-
-def seamless_clone(old_face, new_face, raw_mask):
-
- height, width, _ = old_face.shape
- height = height // 2
- width = width // 2
-
- y_indices, x_indices, _ = np.nonzero(raw_mask)
- y_crop = slice(np.min(y_indices), np.max(y_indices))
- x_crop = slice(np.min(x_indices), np.max(x_indices))
- y_center = int(np.rint((np.max(y_indices) + np.min(y_indices)) / 2 + height))
- x_center = int(np.rint((np.max(x_indices) + np.min(x_indices)) / 2 + width))
-
- insertion = np.rint(new_face[y_crop, x_crop] * 255.0).astype("uint8")
- insertion_mask = np.rint(raw_mask[y_crop, x_crop] * 255.0).astype("uint8")
- insertion_mask[insertion_mask != 0] = 255
- prior = np.rint(np.pad(old_face * 255.0, ((height, height), (width, width), (0, 0)), "constant")).astype(
- "uint8"
- )
- # if np.sum(insertion_mask) == 0:
- n_mask = insertion_mask[1:-1, 1:-1, :]
- n_mask = cv2.copyMakeBorder(n_mask, 1, 1, 1, 1, cv2.BORDER_CONSTANT, 0)
- print(n_mask.shape)
- x, y, w, h = cv2.boundingRect(n_mask[:, :, 0])
- if w < 4 or h < 4:
- blended = prior
- else:
- blended = cv2.seamlessClone(
- insertion, # pylint: disable=no-member
- prior,
- insertion_mask,
- (x_center, y_center),
- cv2.NORMAL_CLONE,
- ) # pylint: disable=no-member
-
- blended = blended[height:-height, width:-width]
-
- return blended.astype("float32") / 255.0
-
-
-def get_landmark(face_landmarks, id):
- part = face_landmarks.part(id)
- x = part.x
- y = part.y
-
- return (x, y)
-
-
-def search(face_landmarks):
-
- x1, y1 = get_landmark(face_landmarks, 36)
- x2, y2 = get_landmark(face_landmarks, 39)
- x3, y3 = get_landmark(face_landmarks, 42)
- x4, y4 = get_landmark(face_landmarks, 45)
-
- x_nose, y_nose = get_landmark(face_landmarks, 30)
-
- x_left_mouth, y_left_mouth = get_landmark(face_landmarks, 48)
- x_right_mouth, y_right_mouth = get_landmark(face_landmarks, 54)
-
- x_left_eye = int((x1 + x2) / 2)
- y_left_eye = int((y1 + y2) / 2)
- x_right_eye = int((x3 + x4) / 2)
- y_right_eye = int((y3 + y4) / 2)
-
- results = np.array(
- [
- [x_left_eye, y_left_eye],
- [x_right_eye, y_right_eye],
- [x_nose, y_nose],
- [x_left_mouth, y_left_mouth],
- [x_right_mouth, y_right_mouth],
- ]
- )
-
- return results
-
-
-if __name__ == "__main__":
-
- parser = argparse.ArgumentParser()
- parser.add_argument("--origin_url", type=str, default="./", help="origin images")
- parser.add_argument("--replace_url", type=str, default="./", help="restored faces")
- parser.add_argument("--save_url", type=str, default="./save")
- opts = parser.parse_args()
-
- origin_url = opts.origin_url
- replace_url = opts.replace_url
- save_url = opts.save_url
-
- if not os.path.exists(save_url):
- os.makedirs(save_url)
-
- face_detector = dlib.get_frontal_face_detector()
- landmark_locator = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
-
- count = 0
-
- for x in os.listdir(origin_url):
- img_url = os.path.join(origin_url, x)
- pil_img = Image.open(img_url).convert("RGB")
-
- origin_width, origin_height = pil_img.size
- image = np.array(pil_img)
-
- start = time.time()
- faces = face_detector(image)
- done = time.time()
-
- if len(faces) == 0:
- print("Warning: There is no face in %s" % (x))
- continue
-
- blended = image
- for face_id in range(len(faces)):
-
- current_face = faces[face_id]
- face_landmarks = landmark_locator(image, current_face)
- current_fl = search(face_landmarks)
-
- forward_mask = np.ones_like(image).astype("uint8")
- affine = compute_transformation_matrix(image, current_fl, False, target_face_scale=1.3)
- aligned_face = warp(image, affine, output_shape=(256, 256, 3), preserve_range=True)
- forward_mask = warp(
- forward_mask, affine, output_shape=(256, 256, 3), order=0, preserve_range=True
- )
-
- affine_inverse = affine.inverse
- cur_face = aligned_face
- if replace_url != "":
-
- face_name = x[:-4] + "_" + str(face_id + 1) + ".png"
- cur_url = os.path.join(replace_url, face_name)
- restored_face = Image.open(cur_url).convert("RGB")
- restored_face = np.array(restored_face)
- cur_face = restored_face
-
- ## Histogram Color matching
- A = cv2.cvtColor(aligned_face.astype("uint8"), cv2.COLOR_RGB2BGR)
- B = cv2.cvtColor(cur_face.astype("uint8"), cv2.COLOR_RGB2BGR)
- B = match_histograms(B, A)
- cur_face = cv2.cvtColor(B.astype("uint8"), cv2.COLOR_BGR2RGB)
-
- warped_back = warp(
- cur_face,
- affine_inverse,
- output_shape=(origin_height, origin_width, 3),
- order=3,
- preserve_range=True,
- )
-
- backward_mask = warp(
- forward_mask,
- affine_inverse,
- output_shape=(origin_height, origin_width, 3),
- order=0,
- preserve_range=True,
- ) ## Nearest neighbour
-
- blended = blur_blending_cv2(warped_back, blended, backward_mask)
- blended *= 255.0
-
- io.imsave(os.path.join(save_url, x), img_as_ubyte(blended / 255.0))
-
- count += 1
-
- if count % 1000 == 0:
- print("%d have finished ..." % (count))
-
diff --git a/spaces/marcelcastrobr/CLIP-image-search/README.md b/spaces/marcelcastrobr/CLIP-image-search/README.md
deleted file mode 100644
index 16232077dd561c831ee4d5c2fb282ecf1345a58a..0000000000000000000000000000000000000000
--- a/spaces/marcelcastrobr/CLIP-image-search/README.md
+++ /dev/null
@@ -1,38 +0,0 @@
----
-title: CLIP Image Search
-emoji: 📸
-colorFrom: pink
-colorTo: pink
-sdk: gradio
-app_file: app.py
-pinned: false
-python_version: 3.10.10
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/marioboy/neil-breen/app.py b/spaces/marioboy/neil-breen/app.py
deleted file mode 100644
index 3290e59edd6b4a725030a3149a820d32e7116761..0000000000000000000000000000000000000000
--- a/spaces/marioboy/neil-breen/app.py
+++ /dev/null
@@ -1,60 +0,0 @@
-import gradio as gr
-import os
-import shlex
-import random
-
-
-LINK = os.environ.get('link')
-ALIAS = os.environ.get('alias')
-TITLE = os.environ.get('title')
-DESCRIPTION = os.environ.get('description')
-
-
-os.system(f"megadl {LINK}")
-os.system("ls")
-
-
-def inference(text):
- os.system("python demo_cli.py --no_sound --cpu --text " + shlex.quote(text.strip()))
- image_number = random.randint(2, len(os.listdir(f"images/{ALIAS}/")))
- return [f"images/{ALIAS}/{image_number}.gif", "demo_output_1.wav"]
-
-
-article = "Based on Real-Time Voice Cloning | Github Repo
"
-
-examples = [
- [
- "Star Wars: Episode One - The Phantom Menace - is the most disappointing thing since my son"
- ],
- [
- "My name is Samantha Morris. I'm the editor of an internet news magazine exploring news most media shy away from."
- ],
- [
- 'I have a morning ritual that I need to share. I call it - the terminator. First I crouch down in the shower in the classic naked terminator traveling through time pose.'
- ],
- [
- 'With my eyes closed I crouch there for a minute, visualizing either Arnold or the guy from the second movie (not the chick in the third one because that one sucked) and I start to hum the terminator theme.'
- ],
- [
- 'Then I slowly rise to a standing position and open my eyes. It helps me to proceed through my day as an emotionless, cyborg badass. The only problem is if the shower curtain sticks to my terminator leg. It ruins the fantasy.'
- ],
- [
- "Okay, hear me out. So it's about this guy named Rick. He's a scientist that turns himself into a pickle. Funniest thing I've seen. In the episode Rick's grandson, Morty flips over a talking pickle. And its Rick! It's the funniest thing."
- ],
- [
- "To be fair, you have to have a very high IQ to understand Rick and Morty. The humour is extremely subtle, and without a solid grasp of theoretical physics most of the jokes will go over a typical viewer's head. There's also Rick's nihilistic outlook, which is deftly woven into his characterisation. "
- ],
-]
-gr.Interface(
- inference,
- inputs=["text"],
- outputs=[
- gr.Image(show_label=False, shape=(20, 20), value=f"images/{ALIAS}/1.gif"),
- gr.outputs.Audio(type="file", label="Speech"),
- ],
- enable_queue=True,
- title=TITLE,
- description=DESCRIPTION,
- article=article,
- examples=examples
-).launch(share=True)
diff --git a/spaces/marlenezw/audio-driven-animations/MakeItTalk/thirdparty/face_of_art/menpo_functions.py b/spaces/marlenezw/audio-driven-animations/MakeItTalk/thirdparty/face_of_art/menpo_functions.py
deleted file mode 100644
index 20e2c7e6fcb5f1aee1508a15af6bea3b947f303f..0000000000000000000000000000000000000000
--- a/spaces/marlenezw/audio-driven-animations/MakeItTalk/thirdparty/face_of_art/menpo_functions.py
+++ /dev/null
@@ -1,299 +0,0 @@
-import os
-from scipy.io import loadmat
-from menpo.shape.pointcloud import PointCloud
-from menpo.transform import ThinPlateSplines
-import menpo.transform as mt
-
-import menpo.io as mio
-from glob import glob
-from thirdparty.face_of_art.deformation_functions import *
-
-# landmark indices by facial feature
-jaw_indices = np.arange(0, 17)
-lbrow_indices = np.arange(17, 22)
-rbrow_indices = np.arange(22, 27)
-upper_nose_indices = np.arange(27, 31)
-lower_nose_indices = np.arange(31, 36)
-leye_indices = np.arange(36, 42)
-reye_indices = np.arange(42, 48)
-outer_mouth_indices = np.arange(48, 60)
-inner_mouth_indices = np.arange(60, 68)
-
-# flipped landmark indices
-mirrored_parts_68 = np.hstack([
- jaw_indices[::-1], rbrow_indices[::-1], lbrow_indices[::-1],
- upper_nose_indices, lower_nose_indices[::-1],
- np.roll(reye_indices[::-1], 4), np.roll(leye_indices[::-1], 4),
- np.roll(outer_mouth_indices[::-1], 7),
- np.roll(inner_mouth_indices[::-1], 5)
-])
-
-
-def load_bb_files(bb_file_dirs):
- """load bounding box mat file for challenging, common, full & training datasets"""
-
- bb_files_dict = {}
- for bb_file in bb_file_dirs:
- bb_mat = loadmat(bb_file)['bounding_boxes']
- num_imgs = np.max(bb_mat.shape)
- for i in range(num_imgs):
- name = bb_mat[0][i][0][0][0][0]
- bb_init = bb_mat[0][i][0][0][1] - 1 # matlab indicies
- bb_gt = bb_mat[0][i][0][0][2] - 1 # matlab indicies
- if str(name) in bb_files_dict.keys():
- print (str(name) + ' already exists')
- else:
- bb_files_dict[str(name)] = (bb_init, bb_gt)
- return bb_files_dict
-
-
-def load_bb_dictionary(bb_dir, mode, test_data='full'):
- """create bounding box dictionary of input dataset: train/common/full/challenging"""
-
- if mode == 'TRAIN':
- bb_dirs = \
- ['bounding_boxes_afw.mat', 'bounding_boxes_helen_trainset.mat', 'bounding_boxes_lfpw_trainset.mat']
- else:
- if test_data == 'common':
- bb_dirs = \
- ['bounding_boxes_helen_testset.mat', 'bounding_boxes_lfpw_testset.mat']
- elif test_data == 'challenging':
- bb_dirs = ['bounding_boxes_ibug.mat']
- elif test_data == 'full':
- bb_dirs = \
- ['bounding_boxes_ibug.mat', 'bounding_boxes_helen_testset.mat', 'bounding_boxes_lfpw_testset.mat']
- elif test_data == 'training':
- bb_dirs = \
- ['bounding_boxes_afw.mat', 'bounding_boxes_helen_trainset.mat', 'bounding_boxes_lfpw_trainset.mat']
- else:
- bb_dirs = None
-
- if mode == 'TEST' and test_data not in ['full', 'challenging', 'common', 'training']:
- bb_files_dict = None
- else:
- bb_dirs = [os.path.join(bb_dir, dataset) for dataset in bb_dirs]
- bb_files_dict = load_bb_files(bb_dirs)
-
- return bb_files_dict
-
-
-def center_margin_bb(bb, img_bounds, margin=0.25):
- """create new bounding box with input margin"""
-
- bb_size = ([bb[0, 2] - bb[0, 0], bb[0, 3] - bb[0, 1]])
- margins = (np.max(bb_size) * (1 + margin) - bb_size) / 2
- bb_new = np.zeros_like(bb)
- bb_new[0, 0] = np.maximum(bb[0, 0] - margins[0], 0)
- bb_new[0, 2] = np.minimum(bb[0, 2] + margins[0], img_bounds[1])
- bb_new[0, 1] = np.maximum(bb[0, 1] - margins[1], 0)
- bb_new[0, 3] = np.minimum(bb[0, 3] + margins[1], img_bounds[0])
- return bb_new
-
-
-def crop_to_face_image(img, bb_dictionary=None, gt=True, margin=0.25, image_size=256, normalize=True,
- return_transform=False):
- """crop face image using bounding box dictionary, or GT landmarks"""
-
- name = img.path.name
- img_bounds = img.bounds()[1]
-
- # if there is no bounding-box dict and GT landmarks are available, use it to determine the bounding box
- if bb_dictionary is None and img.has_landmarks:
- grp_name = img.landmarks.group_labels[0]
- bb_menpo = img.landmarks[grp_name].bounding_box().points
- bb = np.array([[bb_menpo[0, 1], bb_menpo[0, 0], bb_menpo[2, 1], bb_menpo[2, 0]]])
- elif bb_dictionary is not None:
- if gt:
- bb = bb_dictionary[name][1] # ground truth
- else:
- bb = bb_dictionary[name][0] # init from face detector
- else:
- bb = None
-
- if bb is not None:
- # add margin to bounding box
- bb = center_margin_bb(bb, img_bounds, margin=margin)
- bb_pointcloud = PointCloud(np.array([[bb[0, 1], bb[0, 0]],
- [bb[0, 3], bb[0, 0]],
- [bb[0, 3], bb[0, 2]],
- [bb[0, 1], bb[0, 2]]]))
- if return_transform:
- face_crop, bb_transform = img.crop_to_pointcloud(bb_pointcloud, return_transform=True)
- else:
- face_crop = img.crop_to_pointcloud(bb_pointcloud)
- else:
- # if there is no bounding box/gt landmarks, use entire image
- face_crop = img.copy()
- bb_transform = None
-
- # if face crop is not a square - pad borders with mean pixel value
- h, w = face_crop.shape
- diff = h - w
- if diff < 0:
- face_crop.pixels = np.pad(face_crop.pixels, ((0, 0), (0, -1 * diff), (0, 0)), 'mean')
- elif diff > 0:
- face_crop.pixels = np.pad(face_crop.pixels, ((0, 0), (0, 0), (0, diff)), 'mean')
-
- if return_transform:
- face_crop, rescale_transform = face_crop.resize([image_size, image_size], return_transform=True)
- if bb_transform is None:
- transform_chain = rescale_transform
- else:
- transform_chain = mt.TransformChain(transforms=(rescale_transform, bb_transform))
- else:
- face_crop = face_crop.resize([image_size, image_size])
-
- if face_crop.n_channels == 4:
- face_crop.pixels = face_crop.pixels[:3, :, :]
-
- if normalize:
- face_crop.pixels = face_crop.rescale_pixels(0., 1.).pixels
-
- if return_transform:
- return face_crop, transform_chain
- else:
- return face_crop
-
-
-def augment_face_image(img, image_size=256, crop_size=248, angle_range=30, flip=True):
- """basic image augmentation: random crop, rotation and horizontal flip"""
-
- # taken from MDM: https://github.com/trigeorgis/mdm
- def mirror_landmarks_68(lms, im_size):
- return PointCloud(abs(np.array([0, im_size[1]]) - lms.as_vector(
- ).reshape(-1, 2))[mirrored_parts_68])
-
- # taken from MDM: https://github.com/trigeorgis/mdm
- def mirror_image(im):
- im = im.copy()
- im.pixels = im.pixels[..., ::-1].copy()
-
- for group in im.landmarks:
- lms = im.landmarks[group]
- if lms.points.shape[0] == 68:
- im.landmarks[group] = mirror_landmarks_68(lms, im.shape)
-
- return im
-
- flip_rand = np.random.random() > 0.5
- # rot_rand = np.random.random() > 0.5
- # crop_rand = np.random.random() > 0.5
- rot_rand = True # like ECT: https://github.com/HongwenZhang/ECT-FaceAlignment
- crop_rand = True # like ECT: https://github.com/HongwenZhang/ECT-FaceAlignment
-
- if crop_rand:
- lim = image_size - crop_size
- min_crop_inds = np.random.randint(0, lim, 2)
- max_crop_inds = min_crop_inds + crop_size
- img = img.crop(min_crop_inds, max_crop_inds)
-
- if flip and flip_rand:
- img = mirror_image(img)
-
- if rot_rand:
- rot_angle = 2 * angle_range * np.random.random_sample() - angle_range
- img = img.rotate_ccw_about_centre(rot_angle)
-
- img = img.resize([image_size, image_size])
-
- return img
-
-
-def augment_menpo_img_ns(img, img_dir_ns, p_ns=0.):
- """texture style image augmentation using stylized copies in *img_dir_ns*"""
-
- img = img.copy()
- if p_ns > 0.5:
- ns_augs = glob(os.path.join(img_dir_ns, img.path.name.split('.')[0] + '_ns*'))
- num_augs = len(ns_augs)
- if num_augs > 0:
- ns_ind = np.random.randint(0, num_augs)
- ns_aug = mio.import_image(ns_augs[ns_ind])
- ns_pixels = ns_aug.pixels
- img.pixels = ns_pixels
- return img
-
-
-def augment_menpo_img_geom(img, p_geom=0.):
- """geometric style image augmentation using random face deformations"""
-
- img = img.copy()
- if p_geom > 0.5:
- grp_name = img.landmarks.group_labels[0]
- lms_geom_warp = deform_face_geometric_style(img.landmarks[grp_name].points.copy(), p_scale=p_geom, p_shift=p_geom)
- img = warp_face_image_tps(img, PointCloud(lms_geom_warp), grp_name)
- return img
-
-
-def warp_face_image_tps(img, new_shape, lms_grp_name='PTS', warp_mode='constant'):
- """warp image to new landmarks using TPS interpolation"""
-
- tps = ThinPlateSplines(new_shape, img.landmarks[lms_grp_name])
- try:
- img_warp = img.warp_to_shape(img.shape, tps, mode=warp_mode)
- img_warp.landmarks[lms_grp_name] = new_shape
- return img_warp
- except np.linalg.linalg.LinAlgError as err:
- print ('Error:'+str(err)+'\nUsing original landmarks for:\n'+str(img.path))
- return img
-
-
-def load_menpo_image_list(
- img_dir, train_crop_dir, img_dir_ns, mode, bb_dictionary=None, image_size=256, margin=0.25,
- bb_type='gt', test_data='full', augment_basic=True, augment_texture=False, p_texture=0,
- augment_geom=False, p_geom=0, verbose=False, return_transform=False):
-
- """load images from image dir to create menpo-type image list"""
-
- def crop_to_face_image_gt(img):
- return crop_to_face_image(img, bb_dictionary, gt=True, margin=margin, image_size=image_size,
- return_transform=return_transform)
-
- def crop_to_face_image_init(img):
- return crop_to_face_image(img, bb_dictionary, gt=False, margin=margin, image_size=image_size,
- return_transform=return_transform)
-
- def crop_to_face_image_test(img):
- return crop_to_face_image(img, bb_dictionary=None, margin=margin, image_size=image_size,
- return_transform=return_transform)
-
- def augment_menpo_img_ns_rand(img):
- return augment_menpo_img_ns(img, img_dir_ns, p_ns=1. * (np.random.rand() < p_texture)[0])
-
- def augment_menpo_img_geom_rand(img):
- return augment_menpo_img_geom(img, p_geom=1. * (np.random.rand() < p_geom)[0])
-
- if mode is 'TRAIN':
- if train_crop_dir is None:
- img_set_dir = os.path.join(img_dir, 'training')
- out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)
- if bb_type is 'gt':
- out_image_list = out_image_list.map(crop_to_face_image_gt)
- elif bb_type is 'init':
- out_image_list = out_image_list.map(crop_to_face_image_init)
- else:
- img_set_dir = os.path.join(img_dir, train_crop_dir)
- out_image_list = mio.import_images(img_set_dir, verbose=verbose)
-
- # perform image augmentation
- if augment_texture and p_texture > 0:
- out_image_list = out_image_list.map(augment_menpo_img_ns_rand)
- if augment_geom and p_geom > 0:
- out_image_list = out_image_list.map(augment_menpo_img_geom_rand)
- if augment_basic:
- out_image_list = out_image_list.map(augment_face_image)
-
- else: # if mode is 'TEST', load test data
- if test_data in ['full', 'challenging', 'common', 'training', 'test']:
- img_set_dir = os.path.join(img_dir, test_data)
- out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)
- if bb_type is 'gt':
- out_image_list = out_image_list.map(crop_to_face_image_gt)
- elif bb_type is 'init':
- out_image_list = out_image_list.map(crop_to_face_image_init)
- else:
- img_set_dir = os.path.join(img_dir, test_data+'*')
- out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)
- out_image_list = out_image_list.map(crop_to_face_image_test)
-
- return out_image_list
diff --git a/spaces/matthoffner/AudioCraft_Plus/audiocraft/modules/__init__.py b/spaces/matthoffner/AudioCraft_Plus/audiocraft/modules/__init__.py
deleted file mode 100644
index 61418616ef18f0ecca56a007c43af4a731d98b9b..0000000000000000000000000000000000000000
--- a/spaces/matthoffner/AudioCraft_Plus/audiocraft/modules/__init__.py
+++ /dev/null
@@ -1,22 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-"""Modules used for building the models."""
-
-# flake8: noqa
-from .conv import (
- NormConv1d,
- NormConv2d,
- NormConvTranspose1d,
- NormConvTranspose2d,
- StreamableConv1d,
- StreamableConvTranspose1d,
- pad_for_conv1d,
- pad1d,
- unpad1d,
-)
-from .lstm import StreamableLSTM
-from .seanet import SEANetEncoder, SEANetDecoder
-from .transformer import StreamingTransformer
\ No newline at end of file
diff --git a/spaces/matthoffner/AudioCraft_Plus/model_cards/MUSICGEN_MODEL_CARD.md b/spaces/matthoffner/AudioCraft_Plus/model_cards/MUSICGEN_MODEL_CARD.md
deleted file mode 100644
index 10ba9f9790841be06cd3e459cf667c1af6291343..0000000000000000000000000000000000000000
--- a/spaces/matthoffner/AudioCraft_Plus/model_cards/MUSICGEN_MODEL_CARD.md
+++ /dev/null
@@ -1,90 +0,0 @@
-# MusicGen Model Card
-
-## Model details
-
-**Organization developing the model:** The FAIR team of Meta AI.
-
-**Model date:** MusicGen was trained between April 2023 and May 2023.
-
-**Model version:** This is the version 1 of the model.
-
-**Model type:** MusicGen consists of an EnCodec model for audio tokenization, an auto-regressive language model based on the transformer architecture for music modeling. The model comes in different sizes: 300M, 1.5B and 3.3B parameters ; and two variants: a model trained for text-to-music generation task and a model trained for melody-guided music generation.
-
-**Paper or resources for more information:** More information can be found in the paper [Simple and Controllable Music Generation][arxiv].
-
-**Citation details:** See [our paper][arxiv]
-
-**License:** Code is released under MIT, model weights are released under CC-BY-NC 4.0.
-
-**Where to send questions or comments about the model:** Questions and comments about MusicGen can be sent via the [GitHub repository](https://github.com/facebookresearch/audiocraft) of the project, or by opening an issue.
-
-## Intended use
-**Primary intended use:** The primary use of MusicGen is research on AI-based music generation, including:
-
-- Research efforts, such as probing and better understanding the limitations of generative models to further improve the state of science
-- Generation of music guided by text or melody to understand current abilities of generative AI models by machine learning amateurs
-
-**Primary intended users:** The primary intended users of the model are researchers in audio, machine learning and artificial intelligence, as well as amateur seeking to better understand those models.
-
-**Out-of-scope use cases:** The model should not be used on downstream applications without further risk evaluation and mitigation. The model should not be used to intentionally create or disseminate music pieces that create hostile or alienating environments for people. This includes generating music that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
-
-## Metrics
-
-**Models performance measures:** We used the following objective measure to evaluate the model on a standard music benchmark:
-
-- Frechet Audio Distance computed on features extracted from a pre-trained audio classifier (VGGish)
-- Kullback-Leibler Divergence on label distributions extracted from a pre-trained audio classifier (PaSST)
-- CLAP Score between audio embedding and text embedding extracted from a pre-trained CLAP model
-
-Additionally, we run qualitative studies with human participants, evaluating the performance of the model with the following axes:
-
-- Overall quality of the music samples;
-- Text relevance to the provided text input;
-- Adherence to the melody for melody-guided music generation.
-
-More details on performance measures and human studies can be found in the paper.
-
-**Decision thresholds:** Not applicable.
-
-## Evaluation datasets
-
-The model was evaluated on the [MusicCaps benchmark](https://www.kaggle.com/datasets/googleai/musiccaps) and on an in-domain held-out evaluation set, with no artist overlap with the training set.
-
-## Training datasets
-
-The model was trained on licensed data using the following sources: the [Meta Music Initiative Sound Collection](https://www.fb.com/sound), [Shutterstock music collection](https://www.shutterstock.com/music) and the [Pond5 music collection](https://www.pond5.com/). See the paper for more details about the training set and corresponding preprocessing.
-
-## Evaluation results
-
-Below are the objective metrics obtained on MusicCaps with the released model. Note that for the publicly released models, we had all the datasets go through a state-of-the-art music source separation method, namely using the open source [Hybrid Transformer for Music Source Separation](https://github.com/facebookresearch/demucs) (HT-Demucs), in order to keep only the instrumental part. This explains the difference in objective metrics with the models used in the paper.
-
-| Model | Frechet Audio Distance | KLD | Text Consistency | Chroma Cosine Similarity |
-|---|---|---|---|---|
-| facebook/musicgen-small | 4.88 | 1.28 | 0.27 | - |
-| facebook/musicgen-medium | 5.14 | 1.24 | 0.28 | - |
-| facebook/musicgen-large | 5.48 | 1.22 | 0.28 | - |
-| facebook/musicgen-melody | 4.93 | 1.26 | 0.27 | 0.44 |
-
-More information can be found in the paper [Simple and Controllable Music Generation][arxiv], in the Results section.
-
-## Limitations and biases
-
-**Data:** The data sources used to train the model are created by music professionals and covered by legal agreements with the right holders. The model is trained on 20K hours of data, we believe that scaling the model on larger datasets can further improve the performance of the model.
-
-**Mitigations:** Vocals have been removed from the data source using corresponding tags, and then using a state-of-the-art music source separation method, namely using the open source [Hybrid Transformer for Music Source Separation](https://github.com/facebookresearch/demucs) (HT-Demucs).
-
-**Limitations:**
-
-- The model is not able to generate realistic vocals.
-- The model has been trained with English descriptions and will not perform as well in other languages.
-- The model does not perform equally well for all music styles and cultures.
-- The model sometimes generates end of songs, collapsing to silence.
-- It is sometimes difficult to assess what types of text descriptions provide the best generations. Prompt engineering may be required to obtain satisfying results.
-
-**Biases:** The source of data is potentially lacking diversity and all music cultures are not equally represented in the dataset. The model may not perform equally well on the wide variety of music genres that exists. The generated samples from the model will reflect the biases from the training data. Further work on this model should include methods for balanced and just representations of cultures, for example, by scaling the training data to be both diverse and inclusive.
-
-**Risks and harms:** Biases and limitations of the model may lead to generation of samples that may be considered as biased, inappropriate or offensive. We believe that providing the code to reproduce the research and train new models will allow to broaden the application to new and more representative data.
-
-**Use cases:** Users must be aware of the biases, limitations and risks of the model. MusicGen is a model developed for artificial intelligence research on controllable music generation. As such, it should not be used for downstream applications without further investigation and mitigation of risks.
-
-[arxiv]: https://arxiv.org/abs/2306.05284
diff --git a/spaces/merve/data-leak/public/anonymization/make-sel.js b/spaces/merve/data-leak/public/anonymization/make-sel.js
deleted file mode 100644
index 3b35b931008be7afe990694afdf232d05d5f4ee2..0000000000000000000000000000000000000000
--- a/spaces/merve/data-leak/public/anonymization/make-sel.js
+++ /dev/null
@@ -1,78 +0,0 @@
-window.makeSel = function(){
- function ttFmt(d){
- var ttSel = d3.select('.tooltip').html('')
-
- var ageStr = d.age + ' year old'
- if (slides.curSlide.index == 4){
- ageStr = ageStr + ' born in the ' + ['spring', 'summer', 'fall', 'winter'][d.season]
- }
- ttSel.append('div').html(`
- ${ageStr} from ${d.state} who
- ${d.plagerized ?
- 'plagiarized' :
- 'never plagiarized'}
- `)
-
- if (slides.curSlide.index < 6) return
-
- var isHeads = d.coinVals[estimates.active.index] < sliders.headsProb
- ttSel.append('div').html(`
- They flipped
- ${isHeads ? 'heads' : 'tails'}
- and said they had
- ${d.plagerized || isHeads ?
- 'plagiarized' :
- 'never plagiarized'}
- `)
- .st({marginTop: 10})
- }
-
- var rectAt = {}
- var rs = (axii.bw - 10)*2
- rectAt.ageState = {width: rs, height: rs, x: -rs/2, y: -rs/2}
- var uniqueBox = c.svg.appendMany('rect.unique.init-hidden', students.byAgeState.filter(d => d.length == 1))
- .translate(d => d.pos)
- .at(rectAt.ageState)
-
- var rs = axii.bw/4 + 5.5
- rectAt.ageStateSeason = {width: rs, height: rs, x: Math.round(-rs/2), y: 4}
- var uniqueSeasonBox = c.svg.appendMany(
- 'rect.unique.init-hidden',
- students.byAgeStateSeason.filter(d => d.length == 1 && d[0].group.ageState.length > 1))
- .translate(d => d.pos)
- .at(rectAt.ageStateSeason)
-
- // number of uniquely id'd students
- // console.log(uniqueSeasonBox.size())
-
- var studentGroup = c.svg.append('g')
- .at({width: 500, height: 500})
-
- var student = studentGroup.appendMany('g.student', students.all)
- .call(d3.attachTooltip)
- .on('mouseover', ttFmt)
- .translate(d => d.isAdditionalStudent ? [0,0]: d.pos.grid)
- .classed('inactive', d => d.isAdditionalStudent)
-
- var rs = 16
- var flipCircle = student.append('circle')
- .at({transform: 'scale(.1)'})
- .at({r: 9, fill: '#fff'})
- .at({stroke: '#b0b' })
-
- var circle = student.append('circle').at({
- r: 5,
- fill: d => d.plagerized ? '#f0f' : '#ccc',
- stroke: d => d.plagerized ? '#b0b' : '#aaa',
- strokeWidth: 1,
- })
-
-
-
- addSwoop(c)
-
- return {student, studentGroup, circle, flipCircle, rectAt, uniqueBox, uniqueSeasonBox}
-}
-
-
-if (window.init) window.init()
diff --git a/spaces/merve/fill-in-the-blank/public/private-and-fair/accuracy-v-privacy-class.js b/spaces/merve/fill-in-the-blank/public/private-and-fair/accuracy-v-privacy-class.js
deleted file mode 100644
index 39daddb629006c967bfa8c3a6c1d43fc9887bc1b..0000000000000000000000000000000000000000
--- a/spaces/merve/fill-in-the-blank/public/private-and-fair/accuracy-v-privacy-class.js
+++ /dev/null
@@ -1,285 +0,0 @@
-var state = {
- dataset_size: 15000,
- threshold: .8,
- label: 8
-}
-
-var sel = d3.select('.accuracy-v-privacy-class').html('')
- .at({role: 'graphics-document', 'aria-label': `Line chart showing that high accuracy models can still perform poorly on some digit classes.`})
-
-async function loadData(){
- var rawData = await util.getFile(`cns-cache/grid_${state.dataset_size}trainpoints_test_labels.csv`)
-
- rawData.forEach(d => {
- delete d['']
- d.i = +d.i
- d.label = +d.label
- })
-
- var aVal2Meta = {}
- var metadata = await util.getFile('cns-cache/model_grid_test_accuracy.json')
- metadata
- .filter(d => d.dataset_size == state.dataset_size)
- .forEach(d => aVal2Meta['aVal_' + d.aVal] = d)
-
- var allCols = d3.keys(rawData[0])
- .filter(d => d.includes('aVal'))
- .map(key => {
- var {epsilon, aVal} = aVal2Meta[key]
- return {key, epsilon, aVal}
- })
-
- var byDigit = d3.nestBy(rawData, d => d.label)
- byDigit.forEach(d => {
- d.label = +d.key
- })
- byDigit.forEach(digitClass => {
- digitClass.cols = allCols.map(({key, epsilon}, colIndex) => {
- return {
- key,
- colIndex,
- epsilon,
- digitClass,
- label: digitClass.label,
- accuracy: d3.mean(digitClass, d => d[key] > state.threshold)
- }
- })
- })
-
- var data = _.flatten(byDigit.map(d => d.cols))
- .filter(d => util.epsilonExtent[1] <= d.epsilon && d.epsilon <= util.epsilonExtent[0])
- var byLabel = d3.nestBy(data, d => d.label)
- byLabel.forEach((d, i) => {
- d.label = d.key
- })
-
- return {data, byLabel}
-}
-
-
-async function initChart(){
- var {data, byLabel} = await loadData()
-
- var c = d3.conventions({
- sel: sel.append('div'),
- height: 400,
- margin: {bottom: 75, top: 5},
- layers: 'ds',
- })
-
- c.x = d3.scaleLog().domain(util.epsilonExtent).range(c.x.range())
- c.xAxis = d3.axisBottom(c.x).tickFormat(d => {
- var rv = d + ''
- if (rv.split('').filter(d => d !=0 && d != '.')[0] == 1) return rv
- })
-
- c.yAxis.tickFormat(d => d3.format('.0%')(d))//.ticks(8)
- d3.drawAxis(c)
- util.addAxisLabel(c, 'Higher Privacy →', '')
- util.ggPlotBg(c, false)
- c.layers[0].append('div')
- .st({fontSize: 12, color: '#555', width: 120*2, textAlign: 'center', lineHeight: '1.3em', verticalAlign: 'top'})
- .translate([c.width/2 - 120, c.height + 45])
- .html('in ε')
-
- var line = d3.line().x(d => c.x(d.epsilon)).y(d => c.y(d.accuracy))
-
- var lineSel = c.svg.append('g').appendMany('path.accuracy-line', byLabel)
- .at({
- d: line,
- fill: 'none',
- stroke: '#000',
- // opacity: 0,
- })
- .on('mousemove', setActiveLabel)
-
- var circleSel = c.svg.append('g')
- .appendMany('g.accuracy-circle', data)
- .translate(d => [c.x(d.epsilon), c.y(d.accuracy)])
- .on('mousemove', setActiveLabel)
- // .call(d3.attachTooltip)
-
- circleSel.append('circle')
- .at({r: 7, stroke: '#fff'})
-
- circleSel.append('text')
- .text(d => d.label)
- .at({textAnchor: 'middle', fontSize: 10, fill: '#fff', dy: '.33em'})
-
- setActiveLabel(state)
- function setActiveLabel({label}){
- lineSel
- .classed('active', 0)
- .filter(d => d.label == label)
- .classed('active', 1)
- .raise()
-
- circleSel
- .classed('active', 0)
- .filter(d => d.label == label)
- .classed('active', 1)
- .raise()
-
- state.label = label
- }
-
-
- async function updateDatasetSize(){
- var newData = await loadData()
- data = newData.data
- byLabel = newData.byLabel
-
- lineSel.data(byLabel)
- .transition()
- .at({d: line})
-
- circleSel.data(data)
- .transition()
- .translate(d => [c.x(d.epsilon), c.y(d.accuracy)])
-
- c.svg.select('text.annotation').remove()
- }
-
- function updateThreshold(){
- data.forEach(d => {
- d.accuracy = d3.mean(d.digitClass, e => e[d.key] > state.threshold)
- })
-
- lineSel.at({d: line})
- circleSel.translate(d => [c.x(d.epsilon), c.y(d.accuracy)])
-
- c.svg.select('.y .axis-label').text(`Test Points With More Than ${d3.format('.2%')(state.threshold)} Confidence In Label`)
-
- c.svg.select('text.annotation').remove()
- }
- updateThreshold()
-
- return {c, updateDatasetSize, updateThreshold}
-}
-
-
-async function init(){
- sel.append('div.chart-title').text('High accuracy models can still perform poorly on some digit classes')
-
- var chart = await initChart()
-
- var buttonRowSel = sel.append('div.button-row')
- .st({height: 50})
-
- var buttonSel = buttonRowSel.append('div')
- .st({width: 500})
- .append('span.chart-title').text('Training points')
- .parent()
- .append('div').st({display: 'inline-block', width: 300, marginLeft: 10})
- .append('div.digit-button-container.dataset_size')
- .appendMany('div.button', [2000, 3750, 7500, 15000, 30000, 60000])
- .text(d3.format(','))
- .classed('active', d => d == state.dataset_size)
- .on('click', d => {
- buttonSel.classed('active', e => e == d)
- state.dataset_size = d
- chart.updateDatasetSize()
- })
-
- buttonRowSel.append('div.conf-slider')
- .append('span.chart-title').text('Confidence threshold')
- .parent()
- .append('input.slider-native')
- .at({
- type: 'range',
- min: .0001,
- max: .9999,
- step: .0001,
- value: state.threshold,
- })
- .on('input', function(){
- state.threshold = this.value
- chart.updateThreshold()
- })
-
-
- function addSliders(){
- var width = 140
- var height = 30
- var color = '#000'
-
- var sliders = [
- {key: 'threshold', label: 'Confidence threshold', r: [.0001, .9999]},
- ]
- sliders.forEach(d => {
- d.value = state[d.key]
- d.xScale = d3.scaleLinear().range([0, width]).domain(d.r).clamp(1)
- })
-
- d3.select('.conf-slider .slider-container').remove()
- d3.select('.slider-native').remove()
-
- var svgSel = d3.select('.conf-slider').parent()
- // .st({marginTop: 5, marginBottom: 5})
- .appendMany('div.slider-container', sliders)
- .append('svg').at({width, height})
- .append('g').translate([10, 25])
-
- var sliderSel = svgSel
- .on('click', function(d){
- d.value = d.xScale.invert(d3.mouse(this)[0])
- renderSliders(d)
- })
- .classed('slider', true)
- .st({cursor: 'pointer'})
-
- var textSel = sliderSel.append('text.annotation')
- .at({y: -15, fontWeight: 300, textAnchor: 'middle', x: 180/2})
-
- sliderSel.append('rect')
- .at({width, height, y: -height/2, fill: 'rgba(0,0,0,0)'})
-
- sliderSel.append('path').at({
- d: `M 0 -.5 H ${width}`,
- stroke: color,
- strokeWidth: 1
- })
-
- var leftPathSel = sliderSel.append('path').at({
- d: `M 0 -.5 H ${width}`,
- stroke: color,
- strokeWidth: 3
- })
-
- var drag = d3.drag()
- .on('drag', function(d){
- var x = d3.mouse(this)[0]
- d.value = d.xScale.invert(x)
-
- renderSliders(d)
- })
-
- var circleSel = sliderSel.append('circle').call(drag)
- .at({r: 7, stroke: '#000'})
-
- function renderSliders(d){
- if (d) state[d.key] = d.value
-
- circleSel.at({cx: d => d.xScale(d.value)})
- leftPathSel.at({d: d => `M 0 -.5 H ${d.xScale(d.value)}`})
- textSel
- .at({x: d => d.xScale(d.value)})
- .text(d => d3.format('.2%')(d.value))
- chart.updateThreshold()
- }
- renderSliders()
- }
- addSliders()
-
-
- chart.c.svg.append('text.annotation')
- .translate([505, 212])
- .tspans(d3.wordwrap(`8s are correctly predicted with high confidence much more rarely than other digits`, 25), 12)
- .at({textAnchor: 'end'})
-
-}
-init()
-
-
-
-
diff --git a/spaces/merve/uncertainty-calibration/source/data-leak/players0.js b/spaces/merve/uncertainty-calibration/source/data-leak/players0.js
deleted file mode 100644
index 5f1640268c5aa31e0ed73ec7f763b4c64d65f587..0000000000000000000000000000000000000000
--- a/spaces/merve/uncertainty-calibration/source/data-leak/players0.js
+++ /dev/null
@@ -1,456 +0,0 @@
-var players0 = [
- [
- 1.305925030229746,
- 38.016928657799276
- ],
- [
- 20.894800483675937,
- 23.071342200725514
- ],
- [
- 24.232164449818622,
- 50.35066505441355
- ],
- [
- 37.29141475211608,
- 4.643288996372431
- ],
- [
- 57.89600967351874,
- 25.24788391777509
- ],
- [
- 41.20918984280532,
- 34.389359129383315
- ],
- [
- 42.51511487303507,
- 54.26844014510278
- ],
- [
- 31.77750906892382,
- 67.9081015719468
- ],
- [
- 63.84522370012092,
- 54.41354292623942
- ],
- [
- 70.37484885126965,
- 42.22490931076179
- ],
- [
- 39.32285368802902,
- 56.44498186215236
- ],
- [
- 35.550181378476424,
- 58.91172914147521
- ],
- [
- 46.57799274486094,
- 52.8174123337364
- ],
- [
- 39.6130592503023,
- 37.14631197097945
- ],
- [
- 42.51511487303507,
- 30.90689238210399
- ],
- [
- 50.64087061668682,
- 8.706166868198308
- ],
- [
- 71.10036275695285,
- 8.996372430471585
- ],
- [
- 75.01813784764208,
- 26.844014510278114
- ],
- [
- 77.3397823458283,
- 47.44860943168077
- ],
- [
- 76.17896009673518,
- 59.34703748488513
- ],
- [
- 105.05441354292624,
- 39.177750906892385
- ],
- [
- 59.34703748488513,
- 33.083434099153564
- ]
-]
-
-
-var players1 = [
- [
- 6.819830713422007,
- 27.569528415961305
- ],
- [
- 31.05199516324063,
- 30.03627569528416
- ],
- [
- 28.440145102781138,
- 43.24062877871826
- ],
- [
- 48.02902055622733,
- 13.639661426844015
- ],
- [
- 62.249093107617895,
- 35.69528415961306
- ],
- [
- 49.915356711003625,
- 26.553808948004836
- ],
- [
- 53.68802902055623,
- 47.88391777509069
- ],
- [
- 45.85247883917775,
- 54.123337363966144
- ],
- [
- 72.8415961305925,
- 46.57799274486094
- ],
- [
- 70.81015719467956,
- 23.216444981862153
- ],
- [
- 35.98548972188634,
- 44.11124546553809
- ],
- [
- 49.48004836759371,
- 59.92744860943168
- ],
- [
- 46.86819830713422,
- 45.417170495767834
- ],
- [
- 39.6130592503023,
- 37.14631197097945
- ],
- [
- 42.37001209189843,
- 24.812575574365177
- ],
- [
- 53.252720677146314,
- 9.721886336154776
- ],
- [
- 73.5671100362757,
- 8.996372430471585
- ],
- [
- 80.96735187424426,
- 26.698911729141475
- ],
- [
- 85.75574365175332,
- 37.43651753325272
- ],
- [
- 87.35187424425635,
- 47.88391777509069
- ],
- [
- 112.59975816203143,
- 31.77750906892382
- ],
- [
- 58.041112454655384,
- 25.97339782345828
- ]
-]
-
-var players2 = [
- [
- 22.6360338573156,
- 36.27569528415961
- ],
- [
- 49.48004836759371,
- 18.71825876662636
- ],
- [
- 43.82103990326481,
- 34.82466747279323
- ],
- [
- 94.89721886336154,
- 6.674727932285369
- ],
- [
- 103.31318016928658,
- 24.522370012091898
- ],
- [
- 82.12817412333736,
- 32.0677146311971
- ],
- [
- 52.8174123337364,
- 56.009673518742446
- ],
- [
- 91.26964933494558,
- 55.28415961305925
- ],
- [
- 99.68561064087062,
- 40.33857315598549
- ],
- [
- 105.19951632406288,
- 40.33857315598549
- ],
- [
- 53.542926239419586,
- 43.966142684401454
- ],
- [
- 49.48004836759371,
- 59.92744860943168
- ],
- [
- 58.18621523579202,
- 37.87182587666263
- ],
- [
- 86.91656590084644,
- 37.58162031438936
- ],
- [
- 59.34703748488513,
- 18.137847642079805
- ],
- [
- 96.34824667472793,
- 25.24788391777509
- ],
- [
- 90.97944377267231,
- 8.996372430471585
- ],
- [
- 104.47400241837968,
- 31.342200725513905
- ],
- [
- 109.8428053204353,
- 28.295042321644498
- ],
- [
- 105.05441354292624,
- 43.24062877871826
- ],
- [
- 116.2273276904474,
- 25.538089480048367
- ],
- [
- 86.62636033857315,
- 29.165659008464328
- ]
-]
-
-
-playersleakhigh = [
- [
- 2.71764705882353,
- 22
- ],
- [
- 38.11764705882353,
- 44.75294117647059
- ],
- [
- 31.058823529411764,
- 53.22352941176471
- ],
- [
- 52.94117647058824,
- 51.10588235294118
- ],
- [
- 58.023529411764706,
- 50.11764705882353
- ],
- [
- 46.305882352941175,
- 51.247058823529414
- ],
- [
- 46.023529411764706,
- 42.635294117647064
- ],
- [
- 41.082352941176474,
- 48.98823529411765
- ],
- [
- 49.411764705882355,
- 43.76470588235294
- ],
- [
- 59.71764705882353,
- 43.48235294117647
- ],
- [
- 39.32285368802902,
- 56.44498186215236
- ],
- [
- 67.76470588235294,
- 30.494117647058825
- ],
- [
- 78.07058823529412,
- 48.28235294117647
- ],
- [
- 69.60000000000001,
- 40.23529411764706
- ],
- [
- 76.09411764705882,
- 23.152941176470588
- ],
- [
- 85.9764705882353,
- 24.282352941176473
- ],
- [
- 84.56470588235294,
- 48.98823529411765
- ],
- [
- 74.68235294117648,
- 39.38823529411765
- ],
- [
- 79.3529411764706,
- 22
- ],
- [
- 93.1764705882353,
- 34.44705882352941
- ],
- [
- 86.68235294117648,
- 33.45882352941177
- ],
- [
- 81.74117647058824,
- 41.92941176470588
- ]
-]
-
-playersleaklow = [
- [
- 2.71764705882353,
- 73.12941176470588
- ],
- [
- 38.11764705882353,
- 44.75294117647059
- ],
- [
- 31.058823529411764,
- 53.22352941176471
- ],
- [
- 52.94117647058824,
- 51.10588235294118
- ],
- [
- 58.023529411764706,
- 50.11764705882353
- ],
- [
- 46.305882352941175,
- 51.247058823529414
- ],
- [
- 46.023529411764706,
- 42.635294117647064
- ],
- [
- 41.082352941176474,
- 48.98823529411765
- ],
- [
- 49.411764705882355,
- 43.76470588235294
- ],
- [
- 59.71764705882353,
- 43.48235294117647
- ],
- [
- 39.32285368802902,
- 56.44498186215236
- ],
- [
- 67.76470588235294,
- 30.494117647058825
- ],
- [
- 78.07058823529412,
- 48.28235294117647
- ],
- [
- 69.60000000000001,
- 40.23529411764706
- ],
- [
- 76.09411764705882,
- 23.152941176470588
- ],
- [
- 85.9764705882353,
- 24.282352941176473
- ],
- [
- 84.56470588235294,
- 48.98823529411765
- ],
- [
- 74.68235294117648,
- 39.38823529411765
- ],
- [
- 79.3529411764706,
- 72.70588235294117
- ],
- [
- 93.1764705882353,
- 34.44705882352941
- ],
- [
- 86.68235294117648,
- 33.45882352941177
- ],
- [
- 81.74117647058824,
- 41.92941176470588
- ]
-]
\ No newline at end of file
diff --git a/spaces/michaljunczyk/pl-asr-bigos-workspace/app.css b/spaces/michaljunczyk/pl-asr-bigos-workspace/app.css
deleted file mode 100644
index ff2c29e376ef16ea30b9406f9f1041ee5d34808e..0000000000000000000000000000000000000000
--- a/spaces/michaljunczyk/pl-asr-bigos-workspace/app.css
+++ /dev/null
@@ -1,42 +0,0 @@
-
-.infoPoint h1 {
- font-size: 30px;
- text-decoration: bold;
-
- }
-
-a {
- text-decoration: underline;
- color: #1f3b54 ;
-}
-
-.finished {
- color:rgb(9, 102, 169);
- font-size:13px
-}
-
-table {
-
- margin: 25px 0;
- font-size: 0.9em;
- font-family: sans-serif;
- min-width: 400px;
- max-width: 400px;
- box-shadow: 0 0 20px rgba(0, 0, 0, 0.15);
-}
-
-table th,
-table td {
- padding: 12px 15px;
-}
-
-tr {
-text-align: left;
-}
-thead tr {
-text-align: left;
-}
-
-#pw {
- -webkit-text-security: disc;
- }
diff --git a/spaces/mikeee/radiobee-dev/radiobee/gen_row_alignment.py b/spaces/mikeee/radiobee-dev/radiobee/gen_row_alignment.py
deleted file mode 100644
index a58549c0c2bbfdd823babee7a7e42b9f192916d6..0000000000000000000000000000000000000000
--- a/spaces/mikeee/radiobee-dev/radiobee/gen_row_alignment.py
+++ /dev/null
@@ -1,151 +0,0 @@
-"""Gen proper alignment for a given triple_set.
-
-cmat = fetch_sent_corr(src, tgt)
-src_len, tgt_len = np.array(cmat).shape
-r_ali = gen_row_alignment(cmat, tgt_len, src_len) # note the order
-src[r_ali[1]], tgt[r_ali[0]], r_ali[2]
-
-or !!! (targer, source)
-cmat = fetch_sent_corr(tgt, src) # note the order
-src_len, tgt_len = np.array(cmat).shape
-r_ali = gen_row_alignment(cmat, src_len, tgt_len)
-src[r_ali[0]], tgt[r_ali[1]], r_ali[2]
-
----
-src_txt = 'data/wu_ch2_en.txt'
-tgt_txt = 'data/wu_ch2_zh.txt'
-
-assert Path(src_txt).exists()
-assert Path(tgt_txt).exists()
-
-src_text, _ = load_paras(src_txt)
-tgt_text, _ = load_paras(tgt_txt)
-
-cos_matrix = gen_cos_matrix(src_text, tgt_text)
-t_set, m_matrix = find_aligned_pairs(cos_matrix0, thr=0.4, matrix=True)
-
-resu = gen_row_alignment(t_set, src_len, tgt_len)
-resu = np.array(resu)
-
-idx = -1
-idx += 1; (resu[idx], src_text[int(resu[idx, 0])],
- tgt_text[int(resu[idx, 1])]) if all(resu[idx]) else resu[idx]
-
-idx += 1; i0, i1, i2 = resu[idx]; '***' if i0 == ''
-else src_text[int(i0)], '***' if i1 == '' else tgt_text[int(i1)], ''
-if i2 == '' else i2
-"""
-# pylint: disable=line-too-long, unused-variable
-from typing import List, Union
-
-# natural extrapolation with slope equal to 1
-from itertools import zip_longest as zip_longest_middle
-
-import numpy as np
-
-from logzero import logger
-
-# from tinybee.zip_longest_middle import zip_longest_middle
-
-# from tinybee.zip_longest_middle import zip_longest_middle
-# from tinybee.find_pairs import find_pairs
-
-# logger = logging.getLogger(__name__)
-# logger.addHandler(logging.NullHandler())
-
-
-def gen_row_alignment( # pylint: disable=too-many-locals
- t_set,
- src_len,
- tgt_len,
- # ) -> List[Tuple[Union[str, int], Union[str, int], Union[str, float]]]:
-) -> List[List[Union[str, float]]]:
- """Gen proper rows for given triple_set.
-
- Arguments:
- [t_set {np.array or list}] -- [nll matrix]
- [src_len {int}] -- numb of source texts (para/sents)
- [tgt_len {int}] -- numb of target texts (para/sents)
-
- Returns:
- [np.array] -- [proper rows]
- """
- t_set = np.array(t_set, dtype="object")
-
- # len0 = src_len
-
- # len1 tgt text length, must be provided
- len1 = tgt_len
-
- # rearrange t_set as buff in increasing order
- buff = [[-1, -1, ""]] #
- idx_t = 0
- # for elm in t_set:
- # start with bigger value from the 3rd col
-
- y00, yargmax, ymax = zip(*t_set)
- ymax_ = np.array(ymax).copy()
- reset_v = np.min(ymax_) - 1
- for count in range(tgt_len):
- argmax = np.argmax(ymax_)
- # reset
- ymax_[argmax] = reset_v
- idx_t = argmax
- elm = t_set[idx_t]
- logger.debug("%s: %s, %s", count, idx_t, elm)
-
- # find loc to insert
- elm0, elm1, elm2 = elm
- idx = -1
- for idx, loc in enumerate(buff):
- if loc[0] > elm0:
- break
- else:
- idx += 1 # last
-
- # make sure elm1 is within the range
- # prev elm1 < elm1 < next elm1
- if elm1 > buff[idx - 1][1]:
- try: # overflow possible (idx + 1 in # last)
- next_elm = buff[idx][1]
- except IndexError:
- next_elm = len1
- if elm1 < next_elm:
- # insert '' if necessary
- # using zip_longest_middle
- buff.insert(
- idx, [elm0, elm1, elm2],
- )
- # logger.debug('---')
-
- idx_t += 1
- # if idx_t == 24: # 20:
- # break
-
- # remove [-1, -1]
- # buff.pop(0)
- # buff = np.array(buff, dtype='object')
-
- # take care of the tail
- buff += [[src_len, tgt_len, ""]]
-
- resu = []
- # merit = []
-
- for idx, elm in enumerate(buff[1:]):
- idx1 = idx + 1
- elm0_, elm1_, elm2_ = buff[idx1 - 1] # idx starts from 0
- elm0, elm1, elm2 = elm
- del elm2_, elm2
-
- tmp0 = zip_longest_middle(
- list(range(elm0_ + 1, elm0)), list(range(elm1_ + 1, elm1)), fillvalue="",
- )
- # convet to list entries & attache merit
- tmp = [list(t_elm) + [""] for t_elm in tmp0]
-
- # update resu
- resu += tmp + [buff[idx1]]
-
- # remove the last entry
- return resu[:-1]
diff --git a/spaces/mrm8488/PromptSource/setup.py b/spaces/mrm8488/PromptSource/setup.py
deleted file mode 100644
index d6d1150e4c3399d21349c661f0e7e63693acc859..0000000000000000000000000000000000000000
--- a/spaces/mrm8488/PromptSource/setup.py
+++ /dev/null
@@ -1,32 +0,0 @@
-from setuptools import setup, find_packages
-
-with open('README.md') as readme_file:
- readme = readme_file.read()
-
-setup(
- name='promptsource',
- version='0.1.0',
- url='https://github.com/bigscience-workshop/promptsource.git',
- author='Multiple Authors',
- author_email='xxx',
- python_requires='>=3.7, <3.8',
- classifiers=[
- 'Development Status :: 2 - Pre-Alpha',
- 'Intended Audience :: Developers',
- 'License :: OSI Approved :: Apache Software License',
- 'Natural Language :: English',
- 'Programming Language :: Python :: 3',
- 'Programming Language :: Python :: 3.7',
- ],
- description='Toolkit for collecting and applying templates of prompting instances.',
- packages=find_packages(),
- license="Apache Software License 2.0",
- long_description=readme,
- package_data={"": [
- "templates/*/*.yaml",
- "templates/*/*/*.yaml",
- "seqio_tasks/experiment_D3.csv", # Experiment D3
- "seqio_tasks/experiment_D4.csv",
- "custom_datasets/*/*"
- ]}
-)
diff --git a/spaces/mshukor/UnIVAL/models/taming/.ipynb_checkpoints/util-checkpoint.py b/spaces/mshukor/UnIVAL/models/taming/.ipynb_checkpoints/util-checkpoint.py
deleted file mode 100644
index 7443b29e3d223a3ad396808f9717fb9a11c7507c..0000000000000000000000000000000000000000
--- a/spaces/mshukor/UnIVAL/models/taming/.ipynb_checkpoints/util-checkpoint.py
+++ /dev/null
@@ -1,172 +0,0 @@
-import os, hashlib
-import requests
-from tqdm import tqdm
-import importlib
-
-URL_MAP = {
- "vgg_lpips": "https://heibox.uni-heidelberg.de/f/607503859c864bc1b30b/?dl=1"
-}
-
-CKPT_MAP = {
- "vgg_lpips": "vgg.pth"
-}
-
-MD5_MAP = {
- "vgg_lpips": "d507d7349b931f0638a25a48a722f98a"
-}
-
-
-def get_obj_from_str(string, reload=False):
- module, cls = string.rsplit(".", 1)
- if reload:
- module_imp = importlib.import_module(module)
- importlib.reload(module_imp)
- return getattr(importlib.import_module(module, package=None), cls)
-
-
-def instantiate_from_config(config):
- if not "target" in config:
- raise KeyError("Expected key `target` to instantiate.")
- return get_obj_from_str(config["target"])(**config.get("params", dict()))
-
-
-def download(url, local_path, chunk_size=1024):
- os.makedirs(os.path.split(local_path)[0], exist_ok=True)
- with requests.get(url, stream=True) as r:
- total_size = int(r.headers.get("content-length", 0))
- with tqdm(total=total_size, unit="B", unit_scale=True) as pbar:
- with open(local_path, "wb") as f:
- for data in r.iter_content(chunk_size=chunk_size):
- if data:
- f.write(data)
- pbar.update(chunk_size)
-
-
-def md5_hash(path):
- with open(path, "rb") as f:
- content = f.read()
- return hashlib.md5(content).hexdigest()
-
-
-def get_ckpt_path(name, root, check=False):
- assert name in URL_MAP
- path = os.path.join(root, CKPT_MAP[name])
- if not os.path.exists(path) or (check and not md5_hash(path) == MD5_MAP[name]):
- print("Downloading {} model from {} to {}".format(name, URL_MAP[name], path))
- download(URL_MAP[name], path)
- md5 = md5_hash(path)
- assert md5 == MD5_MAP[name], md5
- return path
-
-
-class KeyNotFoundError(Exception):
- def __init__(self, cause, keys=None, visited=None):
- self.cause = cause
- self.keys = keys
- self.visited = visited
- messages = list()
- if keys is not None:
- messages.append("Key not found: {}".format(keys))
- if visited is not None:
- messages.append("Visited: {}".format(visited))
- messages.append("Cause:\n{}".format(cause))
- message = "\n".join(messages)
- super().__init__(message)
-
-
-def retrieve(
- list_or_dict, key, splitval="/", default=None, expand=True, pass_success=False
-):
- """Given a nested list or dict return the desired value at key expanding
- callable nodes if necessary and :attr:`expand` is ``True``. The expansion
- is done in-place.
-
- Parameters
- ----------
- list_or_dict : list or dict
- Possibly nested list or dictionary.
- key : str
- key/to/value, path like string describing all keys necessary to
- consider to get to the desired value. List indices can also be
- passed here.
- splitval : str
- String that defines the delimiter between keys of the
- different depth levels in `key`.
- default : obj
- Value returned if :attr:`key` is not found.
- expand : bool
- Whether to expand callable nodes on the path or not.
-
- Returns
- -------
- The desired value or if :attr:`default` is not ``None`` and the
- :attr:`key` is not found returns ``default``.
-
- Raises
- ------
- Exception if ``key`` not in ``list_or_dict`` and :attr:`default` is
- ``None``.
- """
-
- keys = key.split(splitval)
-
- success = True
- try:
- visited = []
- parent = None
- last_key = None
- for key in keys:
- if callable(list_or_dict):
- if not expand:
- raise KeyNotFoundError(
- ValueError(
- "Trying to get past callable node with expand=False."
- ),
- keys=keys,
- visited=visited,
- )
- list_or_dict = list_or_dict()
- parent[last_key] = list_or_dict
-
- last_key = key
- parent = list_or_dict
-
- try:
- if isinstance(list_or_dict, dict):
- list_or_dict = list_or_dict[key]
- else:
- list_or_dict = list_or_dict[int(key)]
- except (KeyError, IndexError, ValueError) as e:
- raise KeyNotFoundError(e, keys=keys, visited=visited)
-
- visited += [key]
- # final expansion of retrieved value
- if expand and callable(list_or_dict):
- list_or_dict = list_or_dict()
- parent[last_key] = list_or_dict
- except KeyNotFoundError as e:
- if default is None:
- raise e
- else:
- list_or_dict = default
- success = False
-
- if not pass_success:
- return list_or_dict
- else:
- return list_or_dict, success
-
-
-if __name__ == "__main__":
- config = {"keya": "a",
- "keyb": "b",
- "keyc":
- {"cc1": 1,
- "cc2": 2,
- }
- }
- from omegaconf import OmegaConf
-
- config = OmegaConf.create(config)
- print(config)
- retrieve(config, "keya")
diff --git a/spaces/muhammadzain/AI_Resolution_Upscaler_And_Resizer/app.py b/spaces/muhammadzain/AI_Resolution_Upscaler_And_Resizer/app.py
deleted file mode 100644
index f3b38aae36e65de9a514e0bb96ffa2ed448d63df..0000000000000000000000000000000000000000
--- a/spaces/muhammadzain/AI_Resolution_Upscaler_And_Resizer/app.py
+++ /dev/null
@@ -1,297 +0,0 @@
-import math
-import time
-import streamlit as st
-from PIL import Image
-import cv2
-import os
-import urllib.request
-import moviepy.editor
-import threading
-
-
-hide_streamlit_style = """
-
-
-"""
-
-
-def sound_extract(file):
- video = moviepy.editor.VideoFileClip(file)
- video.audio.write_audiofile(file.split('.')[0] + '.mp3')
-
-def remove_file(file):
- os.remove('deep_'+file)
-
-
-st.set_page_config(layout="wide")
-
-
-
-
-def loadModel(n):
- super_res = cv2.dnn_superres.DnnSuperResImpl_create()
- super_res.readModel('models/ESPCN_x'+n+'.pb')
- return super_res
-
-# on removing (show_spinner=False), it will show that fuction is running on web app
-@st.experimental_memo(show_spinner=False)
-def upscale(file,task,_progressBar = None):
- with open(file.name, "wb") as f:
- f.write(file.getbuffer())
- print('No file found, so added in list files')
- if isinstance(task,str):
- super_res = loadModel(task)
- super_res.setModel('espcn', int(task))
- if file.type.split('/')[0] == 'image':
- img = cv2.imread(file.name)
- upscaled_image = super_res.upsample(img)
- print('I upscaled upto',task,'times')
- cv2.imwrite("processed_"+file.name,upscaled_image)
- with st.sidebar:
- st.success('Done!', icon="✅")
- return True
- elif file.type.split('/')[0] == 'video':
-
- t1 = threading.Thread(target=sound_extract, args=(file.name,))
-
- t1.start()
-
- cap = cv2.VideoCapture(file.name)
- fourcc = cv2.VideoWriter_fourcc(*'mp4v')
- fps = int(cap.get(cv2.CAP_PROP_FPS))
- width = int(cap.get(3))
- height = int(cap.get(4))
- writer = cv2.VideoWriter("deep_"+file.name,fourcc,fps,(width*int(task),height*int(task)))
- length = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
- step_size = 1.0/length
- progress = 0
-
- with st.sidebar:
- st.info("Operation in progress. Please wait.",icon="ℹ️")
- my_bar = st.progress(0)
-
- for percent_complete in range(length):
- frame = cap.read()[1]
- frame = super_res.upsample(frame)
- writer.write(frame)
- print(progress)
- progress += step_size
- my_bar.progress(progress-0.000000001)
-
- return True
- return True
-
- # Second case where custom size is required
- else:
- req_width,req_height = int(task[0]),int(task[1])
- if file.type.split('/')[0] == 'image':
- img = cv2.imread(file.name)
- actual_width,actual_height = img.shape[1],img.shape[0]
- w_ratio,h_ratio = req_width/actual_width , req_height/actual_height
- if min([w_ratio,h_ratio]) <= 1.0:
- img = cv2.resize(img,(req_width,req_height))
- print("I did resizing only!")
- cv2.imwrite("processed_" + file.name, img)
- with st.sidebar:
- st.success('Done!', icon="✅")
- return True
- # rounding off the ratios
- w_ratio,h_ratio = math.ceil(w_ratio),math.ceil(h_ratio)
- # find bigger number
- upscale_number = max(w_ratio,h_ratio)
-
- # task can be greater than 4 but we can upscale upto 4. So setting task to 4.
- if upscale_number >= 4:
- upscale_number = 4
-
- super_res = loadModel(str(upscale_number))
- super_res.setModel('espcn', int(upscale_number))
- upscaled_image = super_res.upsample(img)
- print("Before resizing ",(upscaled_image.shape[1], upscaled_image.shape[0]))
- upscaled_image = cv2.resize(upscaled_image,(task[0],task[1]))
- print("Final size got: ",(upscaled_image.shape[1],upscaled_image.shape[0]))
-
- print("I upscale upto", upscale_number , "times and then resize it.")
-
- cv2.imwrite("processed_" + file.name, upscaled_image)
- with st.sidebar:
- st.success('Done!', icon="✅")
- return True
-
- # If file is video
- elif file.type.split('/')[0] == 'video':
-
- t1 = threading.Thread(target=sound_extract, args=(file.name,))
-
- t1.start()
-
- cap = cv2.VideoCapture(file.name)
- fourcc = cv2.VideoWriter_fourcc(*'mp4v')
- fps = int(cap.get(cv2.CAP_PROP_FPS))
- width = int(cap.get(3))
- height = int(cap.get(4))
- if height > 2160 or width > 3840:
- with st.sidebar:
- st.success("Sorry, I can't processed Video with resolution above 4k. Please select custom size option.!", icon="ℹ️")
- writer = cv2.VideoWriter("deep_" + file.name, fourcc, fps, (int(task[0]),int(task[1])))
- length = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
- step_size = 1.0 / length
- progress = 0
- progress_text = "Operation in progress. Please wait."
- with st.sidebar:
- st.info("Operation in progress. Please wait.", icon="ℹ️")
- my_bar = st.progress(0)
- for percent_complete in range(length):
- frame = cap.read()[1]
- frame = cv2.resize(frame, (task[0], task[1]))
- writer.write(frame)
- progress += step_size
- my_bar.progress(progress-0.000000001)
-
- return True
- return "It's second"
-
-
-if 'disable_opt2' not in st.session_state:
- st.session_state.disable_opt2 = True
-if 'disable_opt1' not in st.session_state:
- st.session_state.disable_opt1 = False
-if 'disable_download' not in st.session_state:
- st.session_state.disable_download = True
-if 'disable_proceed' not in st.session_state:
- st.session_state.disable_proceed = False
-
-
-st.markdown(hide_streamlit_style, unsafe_allow_html=True)
-
-col1,_,col2 = st.columns([6,1,3],gap="small")
-
-def toggle_state_opt1():
-
- if st.session_state.get("opt1") == True:
- st.session_state.opt2 = False
- st.session_state.disable_opt2 = True
-
- else:
- st.session_state.opt2 = True
- st.session_state.disable_opt2 = False
-
-def toggle_state_opt2():
- if st.session_state.get("opt2") == True:
- st.session_state.opt1 = False
- st.session_state.disable_opt1 = True
- else:
- st.session_state.opt1 = True
- st.session_state.disable_opt1 = False
-
-# Update the states based on user selection before drawing the widgets in the web page
-toggle_state_opt2()
-toggle_state_opt1()
-options = ["2", "3","4"]
-progressBar = None
-
-with col1:
- file = st.file_uploader(" ",type=['png','jpeg','jpg','pgm','jpe','mp4','mov'])
- if file is not None:
- # writing file and saving its details in dict for further processing
- bytes_data = file.getvalue()
- file_size = len(bytes_data)
- print("File size: ",file_size)
-
- if file.type.split('/')[0] == "image" and file_size > 1550000:
- st.session_state.disable_proceed = True
- with st.sidebar:
- st.info('Sorry, maximum size of image is 1.5MB', icon="ℹ️")
- elif file.type.split('/')[0] == "image":
- image = Image.open(file)
- st.session_state.disable_proceed = False
- st.image(image,caption="Upload Image", use_column_width=True)
- st.session_state.disable_proceed = False
- elif file.type.split('/')[0] == 'video' and file_size > 200000000:
- with st.sidebar:
- options = ["2", "3"]
- st.info('Sorry, maximum size of video is 200MB', icon="ℹ️")
- st.session_state.disable_proceed = True
- elif file.type.split('/')[0] == 'video':
- video = st.video(file)
- print(type(video))
- options = ["2", "3"]
- st.session_state.disable_proceed = False
- with st.sidebar:
- st.info('For custom size, currently I can processed video without AI.', icon="ℹ️")
-
-
-
-with col2:
- st.markdown("\n")
- st.markdown("\n")
- st.markdown("\n")
-
- st.subheader(" UPSCALE RESOLUTION UP TO")
- st.markdown("\n")
- st.markdown("\n")
-
- opt1 = st.checkbox("MULTIPLES OF",key="opt1",value=True,on_change=toggle_state_opt1)
- st.selectbox("SELECT", options,key="opt1_selBox",disabled=st.session_state.disable_opt1)
-
- st.markdown("\n")
- st.markdown("\n")
- opt2 = st.checkbox("CUSTOM SIZE",key="opt2",on_change=toggle_state_opt2)
-
- st.number_input("Width", step=1, min_value=150,max_value=3840, value=900, key="width",disabled=st.session_state.disable_opt2)
-
- st.number_input("Height", step=1, min_value=150,max_value=2160, value=900, key="height",disabled=st.session_state.disable_opt2)
-
- st.markdown("\n")
- st.markdown("\n")
-
-
-
-
- if st.button(15*" "+"PROCEED"+" "*15,disabled=st.session_state.disable_proceed) and file is not None:
- if st.session_state.get('opt1') == True:
- task = st.session_state.opt1_selBox
- else:
- task = [st.session_state.width, st.session_state.height]
- print(task)
- st.session_state.disable_download = not upscale(file,task,progressBar)
-
- if file.type.split('/')[0] == 'video':
- with st.sidebar:
- st.info("Preparing for Download. Please wait.", icon="ℹ️")
- audio = moviepy.editor.AudioFileClip(file.name.split('.')[0] + '.mp3')
- video = moviepy.editor.VideoFileClip("deep_"+file.name)
- videoClip = video.set_audio(audio)
- videoClip.write_videofile('processed_'+file.name)
- t2 = threading.Thread(target=remove_file(file.name))
- t2.start()
- st.success('Done! Thankyou for your patience', icon="✅")
-
- #print(resulted_file.shape)
-
- st.markdown("\n")
- st.markdown("\n")
-
- if file is None:
- st.session_state.disable_download = True
-
- if st.session_state.disable_download == True:
- st.button(13*" "+"DOWNLOAD"+" "*13,disabled=True)
- else:
- with open('processed_'+file.name, "rb") as download_file:
- st.download_button(label=13*" "+"DOWNLOAD"+" "*13, data=download_file,
- file_name= 'processed_'+file.name, mime= "image/png",
- disabled=st.session_state.disable_download)
-
-st.markdown("\n")
-st.markdown("\n")
-st.info("DESCRIPTION : This web app is a free tool designed to upscale or resize image resolution. While the app"+
- " is still undergoing development, we are delighted to offer you to use it for image resolution upscaling."+
- " We welcome your feedback and suggestions, and encourage you to contact us at zain.18j2000@gmail.com "+
- "to share your thoughts. Thank you for your interest in our web application, and we look forward "+
- "to hearing from you as we continue to work towards making this project a resounding success.")
-
diff --git a/spaces/multimodalart/xformers-here-we-go-again/README.md b/spaces/multimodalart/xformers-here-we-go-again/README.md
deleted file mode 100644
index bae75abb45dc4a2ec23b069cf0308910b8e57a5b..0000000000000000000000000000000000000000
--- a/spaces/multimodalart/xformers-here-we-go-again/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Xformers Here We Go Again
-emoji: 💻
-colorFrom: yellow
-colorTo: red
-sdk: gradio
-sdk_version: 3.10.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/myrad01/Inpaint-Anything/third_party/lama/bin/paper_runfiles/generate_val_test.sh b/spaces/myrad01/Inpaint-Anything/third_party/lama/bin/paper_runfiles/generate_val_test.sh
deleted file mode 100644
index d9b2a370ceeeb8f401706f4303298db13e5fad91..0000000000000000000000000000000000000000
--- a/spaces/myrad01/Inpaint-Anything/third_party/lama/bin/paper_runfiles/generate_val_test.sh
+++ /dev/null
@@ -1,28 +0,0 @@
-#!/usr/bin/env bash
-
-# !!! file set to make test_large_30k from the vanilla test_large: configs/test_large_30k.lst
-
-# paths to data are valid for mml7
-PLACES_ROOT="/data/inpainting/Places365"
-OUT_DIR="/data/inpainting/paper_data/Places365_val_test"
-
-source "$(dirname $0)/env.sh"
-
-for datadir in test_large_30k # val_large
-do
- for conf in random_thin_256 random_medium_256 random_thick_256 random_thin_512 random_medium_512 random_thick_512
- do
- "$BINDIR/gen_mask_dataset.py" "$CONFIGDIR/data_gen/${conf}.yaml" \
- "$PLACES_ROOT/$datadir" "$OUT_DIR/$datadir/$conf" --n-jobs 8
-
- "$BINDIR/calc_dataset_stats.py" --samples-n 20 "$OUT_DIR/$datadir/$conf" "$OUT_DIR/$datadir/${conf}_stats"
- done
-
- for conf in segm_256 segm_512
- do
- "$BINDIR/gen_mask_dataset.py" "$CONFIGDIR/data_gen/${conf}.yaml" \
- "$PLACES_ROOT/$datadir" "$OUT_DIR/$datadir/$conf" --n-jobs 2
-
- "$BINDIR/calc_dataset_stats.py" --samples-n 20 "$OUT_DIR/$datadir/$conf" "$OUT_DIR/$datadir/${conf}_stats"
- done
-done
diff --git a/spaces/myrad01/Inpaint-Anything/third_party/segment-anything/segment_anything/utils/__init__.py b/spaces/myrad01/Inpaint-Anything/third_party/segment-anything/segment_anything/utils/__init__.py
deleted file mode 100644
index 5277f46157403e47fd830fc519144b97ef69d4ae..0000000000000000000000000000000000000000
--- a/spaces/myrad01/Inpaint-Anything/third_party/segment-anything/segment_anything/utils/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
diff --git a/spaces/naver/PUMP/datasets/web_images.py b/spaces/naver/PUMP/datasets/web_images.py
deleted file mode 100644
index 3afc7ed58e4247f925025b3a824ec7e9690afd12..0000000000000000000000000000000000000000
--- a/spaces/naver/PUMP/datasets/web_images.py
+++ /dev/null
@@ -1,50 +0,0 @@
-# Copyright 2022-present NAVER Corp.
-# CC BY-NC-SA 4.0
-# Available only for non-commercial use
-
-from pdb import set_trace as bb
-import os, os.path as osp
-
-from tqdm import trange
-from .image_set import ImageSet, verify_img
-
-
-class RandomWebImages (ImageSet):
- """ 1 million distractors from Oxford and Paris Revisited
- see http://ptak.felk.cvut.cz/revisitop/revisitop1m/
- """
- def __init__(self, start=0, end=52, root="datasets/revisitop1m"):
- bar = None
- imgs = []
- for i in range(start, end):
- try:
- # read cached list
- img_list_path = osp.join(root, "image_list_%d.txt"%i)
- cached_imgs = [e.strip() for e in open(img_list_path)]
- assert cached_imgs, f"Cache '{img_list_path}' is empty!"
- imgs += cached_imgs
-
- except IOError:
- if bar is None:
- bar = trange(start, 4*end, desc='Caching')
- bar.update(4*i)
-
- # create it
- imgs = []
- for d in range(i*4,(i+1)*4): # 4096 folders in total, on average 256 each
- key = hex(d)[2:].zfill(3)
- folder = osp.join(root, key)
- if not osp.isdir(folder): continue
- imgs += [f for f in os.listdir(folder) if verify_img(osp.join(folder, f), exts='.jpg')]
- bar.update(1)
- assert imgs, f"No images found in {folder}/"
- open(img_list_path,'w').write('\n'.join(imgs))
- imgs += imgs
-
- if bar: bar.update(bar.total - bar.n)
- super().__init__(root, imgs)
-
- def get_image_path(self, idx):
- key = self.imgs[idx]
- return osp.join(self.root, key[:3], key)
-
diff --git a/spaces/naver/SuperFeatures/how/utils/download.py b/spaces/naver/SuperFeatures/how/utils/download.py
deleted file mode 100644
index 40edd8d0c16d994b94eb9456319b9655fee82693..0000000000000000000000000000000000000000
--- a/spaces/naver/SuperFeatures/how/utils/download.py
+++ /dev/null
@@ -1,44 +0,0 @@
-"""Functions for downloading files necessary for training and evaluation"""
-
-import os.path
-from cirtorch.utils.download import download_train, download_test
-from . import io_helpers
-
-
-def download_for_eval(evaluation, demo_eval, dataset_url, globals):
- """Download datasets for evaluation and network if given by url"""
- # Datasets
- datasets = evaluation['global_descriptor']['datasets'] \
- + evaluation['local_descriptor']['datasets']
- download_datasets(datasets, dataset_url, globals)
- # Network
- if demo_eval and (demo_eval['net_path'].startswith("http://") \
- or demo_eval['net_path'].startswith("https://")):
- net_name = os.path.basename(demo_eval['net_path'])
- io_helpers.download_files([net_name], globals['root_path'] / "models",
- os.path.dirname(demo_eval['net_path']) + "/",
- logfunc=globals["logger"].info)
- demo_eval['net_path'] = globals['root_path'] / "models" / net_name
-
-
-def download_for_train(validation, dataset_url, globals):
- """Download datasets for training"""
-
- datasets = ["train"] + validation['global_descriptor']['datasets'] \
- + validation['local_descriptor']['datasets']
- download_datasets(datasets, dataset_url, globals)
-
-
-def download_datasets(datasets, dataset_url, globals):
- """Download data associated with each required dataset"""
-
- if "val_eccv20" in datasets:
- download_train(globals['root_path'])
- io_helpers.download_files(["retrieval-SfM-120k-val-eccv2020.pkl"],
- globals['root_path'] / "train/retrieval-SfM-120k",
- dataset_url, logfunc=globals["logger"].info)
- elif "train" in datasets:
- download_train(globals['root_path'])
-
- if "roxford5k" in datasets or "rparis6k" in datasets:
- download_test(globals['root_path'])
diff --git a/spaces/nomic-ai/sciq/style.css b/spaces/nomic-ai/sciq/style.css
deleted file mode 100644
index 114adf441e9032febb46bc056b2a8bb651075f0d..0000000000000000000000000000000000000000
--- a/spaces/nomic-ai/sciq/style.css
+++ /dev/null
@@ -1,28 +0,0 @@
-body {
- padding: 2rem;
- font-family: -apple-system, BlinkMacSystemFont, "Arial", sans-serif;
-}
-
-h1 {
- font-size: 16px;
- margin-top: 0;
-}
-
-p {
- color: rgb(107, 114, 128);
- font-size: 15px;
- margin-bottom: 10px;
- margin-top: 5px;
-}
-
-.card {
- max-width: 620px;
- margin: 0 auto;
- padding: 16px;
- border: 1px solid lightgray;
- border-radius: 16px;
-}
-
-.card p:last-child {
- margin-bottom: 0;
-}
diff --git a/spaces/ntt123/vietnam-male-voice-wavegru-tts/sparse_matmul/vector/cachealignedvector_benchmark.cc b/spaces/ntt123/vietnam-male-voice-wavegru-tts/sparse_matmul/vector/cachealignedvector_benchmark.cc
deleted file mode 100644
index 9141e2d570884101b286e059d3ca358b643cc376..0000000000000000000000000000000000000000
--- a/spaces/ntt123/vietnam-male-voice-wavegru-tts/sparse_matmul/vector/cachealignedvector_benchmark.cc
+++ /dev/null
@@ -1,60 +0,0 @@
-// Copyright 2021 Google LLC
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-#include
-
-#include "benchmark/benchmark.h"
-#include "sparse_matmul/vector/cache_aligned_vector.h"
-
-// A simple benchmark for CacheAlignedVector.
-//
-// Running on x86:
-// As written, it's not representative of x86 performance since ReducingSample
-// is used on x86 and not Sample.
-//
-// Running on arm64:
-// bazel build -c opt --dynamic_mode=off --copt=-gmlt \
-// --copt=-DUSE_FIXED32 --config=android_arm64 \
-// sparse_matmul/vector:cachealignedvector_benchmark
-namespace csrblocksparse {
-
-#ifdef USE_BFLOAT16
-using ComputeType = csrblocksparse::bfloat16;
-#elif defined USE_FIXED32
-using ComputeType = csrblocksparse::fixed32<11>; // kGruMatMulOutBits
-#else
-using ComputeType = float;
-#endif // USE_BFLOAT16
-
-#if defined(USE_FIXED32) && defined(__aarch64__)
-using ScratchType = int;
-#else
-using ScratchType = float;
-#endif // defined(USE_FIXED32) && defined(__aarch64__)
-
-void BM_Sample(benchmark::State& state) {
- constexpr int kVectorSize = 16384; // A large vector.
- std::minstd_rand generator;
-
- CacheAlignedVector values(kVectorSize);
- CacheAlignedVector scratch(kVectorSize);
- values.FillRandom();
-
- for (auto _ : state) {
- values.Sample(/*temperature=*/0.98f, &generator, &scratch);
- }
-}
-BENCHMARK(BM_Sample);
-
-} // namespace csrblocksparse
diff --git a/spaces/nyanko7/sd-diffusers-webui/modules/safe.py b/spaces/nyanko7/sd-diffusers-webui/modules/safe.py
deleted file mode 100644
index 532c7dab3f60f5a68b068299d2adc0b776a423f9..0000000000000000000000000000000000000000
--- a/spaces/nyanko7/sd-diffusers-webui/modules/safe.py
+++ /dev/null
@@ -1,188 +0,0 @@
-# this code is adapted from the script contributed by anon from /h/
-# modified, from https://github.com/AUTOMATIC1111/stable-diffusion-webui/blob/6cff4401824299a983c8e13424018efc347b4a2b/modules/safe.py
-
-import io
-import pickle
-import collections
-import sys
-import traceback
-
-import torch
-import numpy
-import _codecs
-import zipfile
-import re
-
-
-# PyTorch 1.13 and later have _TypedStorage renamed to TypedStorage
-TypedStorage = torch.storage.TypedStorage if hasattr(torch.storage, 'TypedStorage') else torch.storage._TypedStorage
-
-
-def encode(*args):
- out = _codecs.encode(*args)
- return out
-
-
-class RestrictedUnpickler(pickle.Unpickler):
- extra_handler = None
-
- def persistent_load(self, saved_id):
- assert saved_id[0] == 'storage'
- return TypedStorage()
-
- def find_class(self, module, name):
- if self.extra_handler is not None:
- res = self.extra_handler(module, name)
- if res is not None:
- return res
-
- if module == 'collections' and name == 'OrderedDict':
- return getattr(collections, name)
- if module == 'torch._utils' and name in ['_rebuild_tensor_v2', '_rebuild_parameter', '_rebuild_device_tensor_from_numpy']:
- return getattr(torch._utils, name)
- if module == 'torch' and name in ['FloatStorage', 'HalfStorage', 'IntStorage', 'LongStorage', 'DoubleStorage', 'ByteStorage', 'float32']:
- return getattr(torch, name)
- if module == 'torch.nn.modules.container' and name in ['ParameterDict']:
- return getattr(torch.nn.modules.container, name)
- if module == 'numpy.core.multiarray' and name in ['scalar', '_reconstruct']:
- return getattr(numpy.core.multiarray, name)
- if module == 'numpy' and name in ['dtype', 'ndarray']:
- return getattr(numpy, name)
- if module == '_codecs' and name == 'encode':
- return encode
- if module == "pytorch_lightning.callbacks" and name == 'model_checkpoint':
- import pytorch_lightning.callbacks
- return pytorch_lightning.callbacks.model_checkpoint
- if module == "pytorch_lightning.callbacks.model_checkpoint" and name == 'ModelCheckpoint':
- import pytorch_lightning.callbacks.model_checkpoint
- return pytorch_lightning.callbacks.model_checkpoint.ModelCheckpoint
- if module == "__builtin__" and name == 'set':
- return set
-
- # Forbid everything else.
- raise Exception(f"global '{module}/{name}' is forbidden")
-
-
-# Regular expression that accepts 'dirname/version', 'dirname/data.pkl', and 'dirname/data/'
-allowed_zip_names_re = re.compile(r"^([^/]+)/((data/\d+)|version|(data\.pkl))$")
-data_pkl_re = re.compile(r"^([^/]+)/data\.pkl$")
-
-def check_zip_filenames(filename, names):
- for name in names:
- if allowed_zip_names_re.match(name):
- continue
-
- raise Exception(f"bad file inside {filename}: {name}")
-
-
-def check_pt(filename, extra_handler):
- try:
-
- # new pytorch format is a zip file
- with zipfile.ZipFile(filename) as z:
- check_zip_filenames(filename, z.namelist())
-
- # find filename of data.pkl in zip file: '/data.pkl'
- data_pkl_filenames = [f for f in z.namelist() if data_pkl_re.match(f)]
- if len(data_pkl_filenames) == 0:
- raise Exception(f"data.pkl not found in {filename}")
- if len(data_pkl_filenames) > 1:
- raise Exception(f"Multiple data.pkl found in {filename}")
- with z.open(data_pkl_filenames[0]) as file:
- unpickler = RestrictedUnpickler(file)
- unpickler.extra_handler = extra_handler
- unpickler.load()
-
- except zipfile.BadZipfile:
-
- # if it's not a zip file, it's an olf pytorch format, with five objects written to pickle
- with open(filename, "rb") as file:
- unpickler = RestrictedUnpickler(file)
- unpickler.extra_handler = extra_handler
- for i in range(5):
- unpickler.load()
-
-
-def load(filename, *args, **kwargs):
- return load_with_extra(filename, extra_handler=global_extra_handler, *args, **kwargs)
-
-
-def load_with_extra(filename, extra_handler=None, *args, **kwargs):
- """
- this function is intended to be used by extensions that want to load models with
- some extra classes in them that the usual unpickler would find suspicious.
-
- Use the extra_handler argument to specify a function that takes module and field name as text,
- and returns that field's value:
-
- ```python
- def extra(module, name):
- if module == 'collections' and name == 'OrderedDict':
- return collections.OrderedDict
-
- return None
-
- safe.load_with_extra('model.pt', extra_handler=extra)
- ```
-
- The alternative to this is just to use safe.unsafe_torch_load('model.pt'), which as the name implies is
- definitely unsafe.
- """
-
- try:
- check_pt(filename, extra_handler)
-
- except pickle.UnpicklingError:
- print(f"Error verifying pickled file from {filename}:", file=sys.stderr)
- print(traceback.format_exc(), file=sys.stderr)
- print("The file is most likely corrupted.", file=sys.stderr)
- return None
-
- except Exception:
- print(f"Error verifying pickled file from {filename}:", file=sys.stderr)
- print(traceback.format_exc(), file=sys.stderr)
- print("\nThe file may be malicious, so the program is not going to read it.", file=sys.stderr)
- print("You can skip this check with --disable-safe-unpickle commandline argument.\n\n", file=sys.stderr)
- return None
-
- return unsafe_torch_load(filename, *args, **kwargs)
-
-
-class Extra:
- """
- A class for temporarily setting the global handler for when you can't explicitly call load_with_extra
- (because it's not your code making the torch.load call). The intended use is like this:
-
-```
-import torch
-from modules import safe
-
-def handler(module, name):
- if module == 'torch' and name in ['float64', 'float16']:
- return getattr(torch, name)
-
- return None
-
-with safe.Extra(handler):
- x = torch.load('model.pt')
-```
- """
-
- def __init__(self, handler):
- self.handler = handler
-
- def __enter__(self):
- global global_extra_handler
-
- assert global_extra_handler is None, 'already inside an Extra() block'
- global_extra_handler = self.handler
-
- def __exit__(self, exc_type, exc_val, exc_tb):
- global global_extra_handler
-
- global_extra_handler = None
-
-
-unsafe_torch_load = torch.load
-torch.load = load
-global_extra_handler = None
diff --git a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/docs/source/en/api/pipelines/ddpm.md b/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/docs/source/en/api/pipelines/ddpm.md
deleted file mode 100644
index 3efa603d1cae45daf9390454c9dcbeb9bf2f86cf..0000000000000000000000000000000000000000
--- a/spaces/pablodawson/ldm3d-inpainting/diffuserslocal/docs/source/en/api/pipelines/ddpm.md
+++ /dev/null
@@ -1,35 +0,0 @@
-
-
-# DDPM
-
-[Denoising Diffusion Probabilistic Models](https://huggingface.co/papers/2006.11239) (DDPM) by Jonathan Ho, Ajay Jain and Pieter Abbeel proposes a diffusion based model of the same name. In the 🤗 Diffusers library, DDPM refers to the *discrete denoising scheduler* from the paper as well as the pipeline.
-
-The abstract from the paper is:
-
-*We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN.*
-
-The original codebase can be found at [hohonathanho/diffusion](https://github.com/hojonathanho/diffusion).
-
-
-
-Make sure to check out the Schedulers [guide](/using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](/using-diffusers/loading#reuse-components-across-pipelines) section to learn how to efficiently load the same components into multiple pipelines.
-
-
-
-# DDPMPipeline
-[[autodoc]] DDPMPipeline
- - all
- - __call__
-
-## ImagePipelineOutput
-[[autodoc]] pipelines.ImagePipelineOutput
diff --git a/spaces/paulengstler/interpretable-vertebral-fracture-diagnosis/netdissect/tool/makesample.py b/spaces/paulengstler/interpretable-vertebral-fracture-diagnosis/netdissect/tool/makesample.py
deleted file mode 100644
index 36276267677360d8238a8dbf71e9753dcc327681..0000000000000000000000000000000000000000
--- a/spaces/paulengstler/interpretable-vertebral-fracture-diagnosis/netdissect/tool/makesample.py
+++ /dev/null
@@ -1,169 +0,0 @@
-'''
-A simple tool to generate sample of output of a GAN,
-subject to filtering, sorting, or intervention.
-'''
-
-import torch, numpy, os, argparse, numbers, sys, shutil
-from PIL import Image
-from torch.utils.data import TensorDataset
-from netdissect.zdataset import standard_z_sample
-from netdissect.progress import default_progress, verbose_progress
-from netdissect.autoeval import autoimport_eval
-from netdissect.workerpool import WorkerBase, WorkerPool
-from netdissect.nethook import edit_layers, retain_layers
-
-def main():
- parser = argparse.ArgumentParser(description='GAN sample making utility')
- parser.add_argument('--model', type=str, default=None,
- help='constructor for the model to test')
- parser.add_argument('--pthfile', type=str, default=None,
- help='filename of .pth file for the model')
- parser.add_argument('--outdir', type=str, default='images',
- help='directory for image output')
- parser.add_argument('--size', type=int, default=100,
- help='number of images to output')
- parser.add_argument('--test_size', type=int, default=None,
- help='number of images to test')
- parser.add_argument('--layer', type=str, default=None,
- help='layer to inspect')
- parser.add_argument('--seed', type=int, default=1,
- help='seed')
- parser.add_argument('--maximize_units', type=int, nargs='+', default=None,
- help='units to maximize')
- parser.add_argument('--ablate_units', type=int, nargs='+', default=None,
- help='units to ablate')
- parser.add_argument('--quiet', action='store_true', default=False,
- help='silences console output')
- if len(sys.argv) == 1:
- parser.print_usage(sys.stderr)
- sys.exit(1)
- args = parser.parse_args()
- verbose_progress(not args.quiet)
-
- # Instantiate the model
- model = autoimport_eval(args.model)
- if args.pthfile is not None:
- data = torch.load(args.pthfile)
- if 'state_dict' in data:
- meta = {}
- for key in data:
- if isinstance(data[key], numbers.Number):
- meta[key] = data[key]
- data = data['state_dict']
- model.load_state_dict(data)
- # Unwrap any DataParallel-wrapped model
- if isinstance(model, torch.nn.DataParallel):
- model = next(model.children())
- # Examine first conv in model to determine input feature size.
- first_layer = [c for c in model.modules()
- if isinstance(c, (torch.nn.Conv2d, torch.nn.ConvTranspose2d,
- torch.nn.Linear))][0]
- # 4d input if convolutional, 2d input if first layer is linear.
- if isinstance(first_layer, (torch.nn.Conv2d, torch.nn.ConvTranspose2d)):
- z_channels = first_layer.in_channels
- spatialdims = (1, 1)
- else:
- z_channels = first_layer.in_features
- spatialdims = ()
- # Instrument the model if needed
- if args.maximize_units is not None:
- retain_layers(model, [args.layer])
- model.cuda()
-
- # Get the sample of z vectors
- if args.maximize_units is None:
- indexes = torch.arange(args.size)
- z_sample = standard_z_sample(args.size, z_channels, seed=args.seed)
- z_sample = z_sample.view(tuple(z_sample.shape) + spatialdims)
- else:
- # By default, if maximizing units, get a 'top 5%' sample.
- if args.test_size is None:
- args.test_size = args.size * 20
- z_universe = standard_z_sample(args.test_size, z_channels,
- seed=args.seed)
- z_universe = z_universe.view(tuple(z_universe.shape) + spatialdims)
- indexes = get_highest_znums(model, z_universe, args.maximize_units,
- args.size, seed=args.seed)
- z_sample = z_universe[indexes]
-
- if args.ablate_units:
- edit_layers(model, [args.layer])
- dims = max(2, max(args.ablate_units) + 1) # >=2 to avoid broadcast
- model.ablation[args.layer] = torch.zeros(dims)
- model.ablation[args.layer][args.ablate_units] = 1
-
- save_znum_images(args.outdir, model, z_sample, indexes,
- args.layer, args.ablate_units)
- copy_lightbox_to(args.outdir)
-
-
-def get_highest_znums(model, z_universe, max_units, size,
- batch_size=100, seed=1):
- # The model should have been instrumented already
- retained_items = list(model.retained.items())
- assert len(retained_items) == 1
- layer = retained_items[0][0]
- # By default, a 10% sample
- progress = default_progress()
- num_units = None
- with torch.no_grad():
- # Pass 1: collect max activation stats
- z_loader = torch.utils.data.DataLoader(TensorDataset(z_universe),
- batch_size=batch_size, num_workers=2,
- pin_memory=True)
- scores = []
- for [z] in progress(z_loader, desc='Finding max activations'):
- z = z.cuda()
- model(z)
- feature = model.retained[layer]
- num_units = feature.shape[1]
- max_feature = feature[:, max_units, ...].view(
- feature.shape[0], len(max_units), -1).max(2)[0]
- total_feature = max_feature.sum(1)
- scores.append(total_feature.cpu())
- scores = torch.cat(scores, 0)
- highest = (-scores).sort(0)[1][:size].sort(0)[0]
- return highest
-
-
-def save_znum_images(dirname, model, z_sample, indexes, layer, ablated_units,
- name_template="image_{}.png", lightbox=False, batch_size=100, seed=1):
- progress = default_progress()
- os.makedirs(dirname, exist_ok=True)
- with torch.no_grad():
- # Pass 2: now generate images
- z_loader = torch.utils.data.DataLoader(TensorDataset(z_sample),
- batch_size=batch_size, num_workers=2,
- pin_memory=True)
- saver = WorkerPool(SaveImageWorker)
- if ablated_units is not None:
- dims = max(2, max(ablated_units) + 1) # >=2 to avoid broadcast
- mask = torch.zeros(dims)
- mask[ablated_units] = 1
- model.ablation[layer] = mask[None,:,None,None].cuda()
- for batch_num, [z] in enumerate(progress(z_loader,
- desc='Saving images')):
- z = z.cuda()
- start_index = batch_num * batch_size
- im = ((model(z) + 1) / 2 * 255).clamp(0, 255).byte().permute(
- 0, 2, 3, 1).cpu()
- for i in range(len(im)):
- index = i + start_index
- if indexes is not None:
- index = indexes[index].item()
- filename = os.path.join(dirname, name_template.format(index))
- saver.add(im[i].numpy(), filename)
- saver.join()
-
-def copy_lightbox_to(dirname):
- srcdir = os.path.realpath(
- os.path.join(os.getcwd(), os.path.dirname(__file__)))
- shutil.copy(os.path.join(srcdir, 'lightbox.html'),
- os.path.join(dirname, '+lightbox.html'))
-
-class SaveImageWorker(WorkerBase):
- def work(self, data, filename):
- Image.fromarray(data).save(filename, optimize=True, quality=100)
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/pikto/Elite-freegpt-webui/g4f/Provider/Providers/Bing.py b/spaces/pikto/Elite-freegpt-webui/g4f/Provider/Providers/Bing.py
deleted file mode 100644
index 87e04ac82293c7e22068af431ac407bdee435a1b..0000000000000000000000000000000000000000
--- a/spaces/pikto/Elite-freegpt-webui/g4f/Provider/Providers/Bing.py
+++ /dev/null
@@ -1,349 +0,0 @@
-import os
-import json
-import random
-import json
-import os
-import uuid
-import ssl
-import certifi
-import aiohttp
-import asyncio
-
-import requests
-from ...typing import sha256, Dict, get_type_hints
-
-url = 'https://bing.com/chat'
-model = ['gpt-4']
-supports_stream = True
-needs_auth = False
-
-ssl_context = ssl.create_default_context()
-ssl_context.load_verify_locations(certifi.where())
-
-
-class optionsSets:
- optionSet: dict = {
- 'tone': str,
- 'optionsSets': list
- }
-
- jailbreak: dict = {
- "optionsSets": [
- 'saharasugg',
- 'enablenewsfc',
- 'clgalileo',
- 'gencontentv3',
- "nlu_direct_response_filter",
- "deepleo",
- "disable_emoji_spoken_text",
- "responsible_ai_policy_235",
- "enablemm",
- "h3precise"
- # "harmonyv3",
- "dtappid",
- "cricinfo",
- "cricinfov2",
- "dv3sugg",
- "nojbfedge"
- ]
- }
-
-
-class Defaults:
- delimiter = '\x1e'
- ip_address = f'13.{random.randint(104, 107)}.{random.randint(0, 255)}.{random.randint(0, 255)}'
-
- allowedMessageTypes = [
- 'Chat',
- 'Disengaged',
- 'AdsQuery',
- 'SemanticSerp',
- 'GenerateContentQuery',
- 'SearchQuery',
- 'ActionRequest',
- 'Context',
- 'Progress',
- 'AdsQuery',
- 'SemanticSerp'
- ]
-
- sliceIds = [
-
- # "222dtappid",
- # "225cricinfo",
- # "224locals0"
-
- 'winmuid3tf',
- 'osbsdusgreccf',
- 'ttstmout',
- 'crchatrev',
- 'winlongmsgtf',
- 'ctrlworkpay',
- 'norespwtf',
- 'tempcacheread',
- 'temptacache',
- '505scss0',
- '508jbcars0',
- '515enbotdets0',
- '5082tsports',
- '515vaoprvs',
- '424dagslnv1s0',
- 'kcimgattcf',
- '427startpms0'
- ]
-
- location = {
- 'locale': 'en-US',
- 'market': 'en-US',
- 'region': 'US',
- 'locationHints': [
- {
- 'country': 'United States',
- 'state': 'California',
- 'city': 'Los Angeles',
- 'timezoneoffset': 8,
- 'countryConfidence': 8,
- 'Center': {
- 'Latitude': 34.0536909,
- 'Longitude': -118.242766
- },
- 'RegionType': 2,
- 'SourceType': 1
- }
- ],
- }
-
-
-def _format(msg: dict) -> str:
- return json.dumps(msg, ensure_ascii=False) + Defaults.delimiter
-
-
-async def create_conversation():
- for _ in range(5):
- create = requests.get('https://www.bing.com/turing/conversation/create',
- headers={
- 'authority': 'edgeservices.bing.com',
- 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
- 'accept-language': 'en-US,en;q=0.9',
- 'cache-control': 'max-age=0',
- 'sec-ch-ua': '"Chromium";v="110", "Not A(Brand";v="24", "Microsoft Edge";v="110"',
- 'sec-ch-ua-arch': '"x86"',
- 'sec-ch-ua-bitness': '"64"',
- 'sec-ch-ua-full-version': '"110.0.1587.69"',
- 'sec-ch-ua-full-version-list': '"Chromium";v="110.0.5481.192", "Not A(Brand";v="24.0.0.0", "Microsoft Edge";v="110.0.1587.69"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-model': '""',
- 'sec-ch-ua-platform': '"Windows"',
- 'sec-ch-ua-platform-version': '"15.0.0"',
- 'sec-fetch-dest': 'document',
- 'sec-fetch-mode': 'navigate',
- 'sec-fetch-site': 'none',
- 'sec-fetch-user': '?1',
- 'upgrade-insecure-requests': '1',
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69',
- 'x-edge-shopping-flag': '1',
- 'x-forwarded-for': Defaults.ip_address
- })
-
- conversationId = create.json().get('conversationId')
- clientId = create.json().get('clientId')
- conversationSignature = create.json().get('conversationSignature')
-
- if not conversationId or not clientId or not conversationSignature and _ == 4:
- raise Exception('Failed to create conversation.')
-
- return conversationId, clientId, conversationSignature
-
-
-async def stream_generate(prompt: str, mode: optionsSets.optionSet = optionsSets.jailbreak, context: bool or str = False):
- timeout = aiohttp.ClientTimeout(total=900)
- session = aiohttp.ClientSession(timeout=timeout)
-
- conversationId, clientId, conversationSignature = await create_conversation()
-
- wss = await session.ws_connect('wss://sydney.bing.com/sydney/ChatHub', ssl=ssl_context, autoping=False,
- headers={
- 'accept': 'application/json',
- 'accept-language': 'en-US,en;q=0.9',
- 'content-type': 'application/json',
- 'sec-ch-ua': '"Not_A Brand";v="99", "Microsoft Edge";v="110", "Chromium";v="110"',
- 'sec-ch-ua-arch': '"x86"',
- 'sec-ch-ua-bitness': '"64"',
- 'sec-ch-ua-full-version': '"109.0.1518.78"',
- 'sec-ch-ua-full-version-list': '"Chromium";v="110.0.5481.192", "Not A(Brand";v="24.0.0.0", "Microsoft Edge";v="110.0.1587.69"',
- 'sec-ch-ua-mobile': '?0',
- 'sec-ch-ua-model': '',
- 'sec-ch-ua-platform': '"Windows"',
- 'sec-ch-ua-platform-version': '"15.0.0"',
- 'sec-fetch-dest': 'empty',
- 'sec-fetch-mode': 'cors',
- 'sec-fetch-site': 'same-origin',
- 'x-ms-client-request-id': str(uuid.uuid4()),
- 'x-ms-useragent': 'azsdk-js-api-client-factory/1.0.0-beta.1 core-rest-pipeline/1.10.0 OS/Win32',
- 'Referer': 'https://www.bing.com/search?q=Bing+AI&showconv=1&FORM=hpcodx',
- 'Referrer-Policy': 'origin-when-cross-origin',
- 'x-forwarded-for': Defaults.ip_address
- })
-
- await wss.send_str(_format({'protocol': 'json', 'version': 1}))
- await wss.receive(timeout=900)
-
- struct = {
- 'arguments': [
- {
- **mode,
- 'source': 'cib',
- 'allowedMessageTypes': Defaults.allowedMessageTypes,
- 'sliceIds': Defaults.sliceIds,
- 'traceId': os.urandom(16).hex(),
- 'isStartOfSession': True,
- 'message': Defaults.location | {
- 'author': 'user',
- 'inputMethod': 'Keyboard',
- 'text': prompt,
- 'messageType': 'Chat'
- },
- 'conversationSignature': conversationSignature,
- 'participant': {
- 'id': clientId
- },
- 'conversationId': conversationId
- }
- ],
- 'invocationId': '0',
- 'target': 'chat',
- 'type': 4
- }
-
- if context:
- struct['arguments'][0]['previousMessages'] = [
- {
- "author": "user",
- "description": context,
- "contextType": "WebPage",
- "messageType": "Context",
- "messageId": "discover-web--page-ping-mriduna-----"
- }
- ]
-
- await wss.send_str(_format(struct))
-
- final = False
- draw = False
- resp_txt = ''
- result_text = ''
- resp_txt_no_link = ''
- cache_text = ''
-
- while not final:
- msg = await wss.receive(timeout=900)
- objects = msg.data.split(Defaults.delimiter)
-
- for obj in objects:
- if obj is None or not obj:
- continue
-
- response = json.loads(obj)
- if response.get('type') == 1 and response['arguments'][0].get('messages',):
- if not draw:
- if (response['arguments'][0]['messages'][0]['contentOrigin'] != 'Apology') and not draw:
- resp_txt = result_text + \
- response['arguments'][0]['messages'][0]['adaptiveCards'][0]['body'][0].get(
- 'text', '')
- resp_txt_no_link = result_text + \
- response['arguments'][0]['messages'][0].get(
- 'text', '')
-
- if response['arguments'][0]['messages'][0].get('messageType',):
- resp_txt = (
- resp_txt
- + response['arguments'][0]['messages'][0]['adaptiveCards'][0]['body'][0]['inlines'][0].get('text')
- + '\n'
- )
- result_text = (
- result_text
- + response['arguments'][0]['messages'][0]['adaptiveCards'][0]['body'][0]['inlines'][0].get('text')
- + '\n'
- )
-
- if cache_text.endswith(' '):
- final = True
- if wss and not wss.closed:
- await wss.close()
- if session and not session.closed:
- await session.close()
-
- yield (resp_txt.replace(cache_text, ''))
- cache_text = resp_txt
-
- elif response.get('type') == 2:
- if response['item']['result'].get('error'):
- if wss and not wss.closed:
- await wss.close()
- if session and not session.closed:
- await session.close()
-
- raise Exception(
- f"{response['item']['result']['value']}: {response['item']['result']['message']}")
-
- if draw:
- cache = response['item']['messages'][1]['adaptiveCards'][0]['body'][0]['text']
- response['item']['messages'][1]['adaptiveCards'][0]['body'][0]['text'] = (
- cache + resp_txt)
-
- if (response['item']['messages'][-1]['contentOrigin'] == 'Apology' and resp_txt):
- response['item']['messages'][-1]['text'] = resp_txt_no_link
- response['item']['messages'][-1]['adaptiveCards'][0]['body'][0]['text'] = resp_txt
-
- # print('Preserved the message from being deleted', file=sys.stderr)
-
- final = True
- if wss and not wss.closed:
- await wss.close()
- if session and not session.closed:
- await session.close()
-
-
-def run(generator):
- loop = asyncio.new_event_loop()
- asyncio.set_event_loop(loop)
- gen = generator.__aiter__()
-
- while True:
- try:
- next_val = loop.run_until_complete(gen.__anext__())
- yield next_val
-
- except StopAsyncIteration:
- break
- #print('Done')
-
-def convert(messages):
- context = ""
-
- for message in messages:
- context += "[%s](#message)\n%s\n\n" % (message['role'],
- message['content'])
-
- return context
-
-
-def _create_completion(model: str, messages: list, stream: bool, **kwargs):
- if len(messages) < 2:
- prompt = messages[0]['content']
- context = False
-
- else:
- prompt = messages[-1]['content']
- context = convert(messages[:-1])
-
- response = run(stream_generate(prompt, optionsSets.jailbreak, context))
- for token in response:
- yield (token)
-
- #print('Done')
-
-
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
- '(%s)' % ', '.join(
- [f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
diff --git a/spaces/pkiage/time_series_decomposition_demo/src/visualization/visualize.py b/spaces/pkiage/time_series_decomposition_demo/src/visualization/visualize.py
deleted file mode 100644
index 0062796a93e9419254afc835d85e5f9d8a3f69cb..0000000000000000000000000000000000000000
--- a/spaces/pkiage/time_series_decomposition_demo/src/visualization/visualize.py
+++ /dev/null
@@ -1,94 +0,0 @@
-import pandas as pd
-import streamlit as st
-import plotly.express as px
-
-
-def streamlit_2columns_metrics_df_shape(df: pd.DataFrame):
- (
- column1name,
- column2name,
- ) = st.columns(2)
-
- with column1name:
- st.metric(
- label="Rows",
- value=df.shape[0],
- delta=None,
- delta_color="normal",
- )
-
- with column2name:
- st.metric(
- label="Columns",
- value=df.shape[1],
- delta=None,
- delta_color="normal",
- )
-
-
-def show_inputted_dataframe(data):
- with st.expander("Input Dataframe:"):
- st.dataframe(data)
- streamlit_2columns_metrics_df_shape(data)
-
-
-def standard_decomposition_plot(decomposition):
-
- fig = decomposition.plot()
-
- (xsize_standard_decomp, ysize_standard_decomp) = streamlit_chart_setting_height_width(
- "Chart Size:", 5, 5, "xsize_standard_decomp", "ysize_standard_decomp")
-
- fig.set_size_inches(xsize_standard_decomp, ysize_standard_decomp)
-
- st.pyplot(fig)
-
-
-def time_series_line_plot(data):
- fig = px.line(
- data
- )
- st.plotly_chart(fig, use_container_width=True)
-
-
-def time_series_scatter_plot(data):
- fig = px.scatter(data, trendline="ols")
- st.plotly_chart(fig, use_container_width=True)
-
-
-def time_series_box_plot(data):
- fig = px.box(data, hover_data=['Date'], points="all")
- st.plotly_chart(fig, use_container_width=True)
-
-
-def time_series_violin_and_box_plot(graph_data):
- fig = px.histogram(graph_data,
- marginal="violin")
- st.plotly_chart(fig, use_container_width=True)
-
-
-def streamlit_chart_setting_height_width(
- title: str,
- default_widthvalue: int,
- default_heightvalue: int,
- widthkey: str,
- heightkey: str,
-):
- with st.expander(title):
-
- lbarx_col, lbary_col = st.columns(2)
-
- with lbarx_col:
- width_size = st.number_input(
- label="Width in inches:",
- value=default_widthvalue,
- key=widthkey,
- )
-
- with lbary_col:
- height_size = st.number_input(
- label="Height in inches:",
- value=default_heightvalue,
- key=heightkey,
- )
- return width_size, height_size
diff --git a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/color_triplet.py b/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/color_triplet.py
deleted file mode 100644
index 02cab328251af9bfa809981aaa44933c407e2cd7..0000000000000000000000000000000000000000
--- a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/color_triplet.py
+++ /dev/null
@@ -1,38 +0,0 @@
-from typing import NamedTuple, Tuple
-
-
-class ColorTriplet(NamedTuple):
- """The red, green, and blue components of a color."""
-
- red: int
- """Red component in 0 to 255 range."""
- green: int
- """Green component in 0 to 255 range."""
- blue: int
- """Blue component in 0 to 255 range."""
-
- @property
- def hex(self) -> str:
- """get the color triplet in CSS style."""
- red, green, blue = self
- return f"#{red:02x}{green:02x}{blue:02x}"
-
- @property
- def rgb(self) -> str:
- """The color in RGB format.
-
- Returns:
- str: An rgb color, e.g. ``"rgb(100,23,255)"``.
- """
- red, green, blue = self
- return f"rgb({red},{green},{blue})"
-
- @property
- def normalized(self) -> Tuple[float, float, float]:
- """Convert components into floats between 0 and 1.
-
- Returns:
- Tuple[float, float, float]: A tuple of three normalized colour components.
- """
- red, green, blue = self
- return red / 255.0, green / 255.0, blue / 255.0
diff --git a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/measure.py b/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/measure.py
deleted file mode 100644
index a508ffa80bd715b47c190ed9d747dbc388fa5b19..0000000000000000000000000000000000000000
--- a/spaces/pknez/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/measure.py
+++ /dev/null
@@ -1,151 +0,0 @@
-from operator import itemgetter
-from typing import TYPE_CHECKING, Callable, NamedTuple, Optional, Sequence
-
-from . import errors
-from .protocol import is_renderable, rich_cast
-
-if TYPE_CHECKING:
- from .console import Console, ConsoleOptions, RenderableType
-
-
-class Measurement(NamedTuple):
- """Stores the minimum and maximum widths (in characters) required to render an object."""
-
- minimum: int
- """Minimum number of cells required to render."""
- maximum: int
- """Maximum number of cells required to render."""
-
- @property
- def span(self) -> int:
- """Get difference between maximum and minimum."""
- return self.maximum - self.minimum
-
- def normalize(self) -> "Measurement":
- """Get measurement that ensures that minimum <= maximum and minimum >= 0
-
- Returns:
- Measurement: A normalized measurement.
- """
- minimum, maximum = self
- minimum = min(max(0, minimum), maximum)
- return Measurement(max(0, minimum), max(0, max(minimum, maximum)))
-
- def with_maximum(self, width: int) -> "Measurement":
- """Get a RenderableWith where the widths are <= width.
-
- Args:
- width (int): Maximum desired width.
-
- Returns:
- Measurement: New Measurement object.
- """
- minimum, maximum = self
- return Measurement(min(minimum, width), min(maximum, width))
-
- def with_minimum(self, width: int) -> "Measurement":
- """Get a RenderableWith where the widths are >= width.
-
- Args:
- width (int): Minimum desired width.
-
- Returns:
- Measurement: New Measurement object.
- """
- minimum, maximum = self
- width = max(0, width)
- return Measurement(max(minimum, width), max(maximum, width))
-
- def clamp(
- self, min_width: Optional[int] = None, max_width: Optional[int] = None
- ) -> "Measurement":
- """Clamp a measurement within the specified range.
-
- Args:
- min_width (int): Minimum desired width, or ``None`` for no minimum. Defaults to None.
- max_width (int): Maximum desired width, or ``None`` for no maximum. Defaults to None.
-
- Returns:
- Measurement: New Measurement object.
- """
- measurement = self
- if min_width is not None:
- measurement = measurement.with_minimum(min_width)
- if max_width is not None:
- measurement = measurement.with_maximum(max_width)
- return measurement
-
- @classmethod
- def get(
- cls, console: "Console", options: "ConsoleOptions", renderable: "RenderableType"
- ) -> "Measurement":
- """Get a measurement for a renderable.
-
- Args:
- console (~rich.console.Console): Console instance.
- options (~rich.console.ConsoleOptions): Console options.
- renderable (RenderableType): An object that may be rendered with Rich.
-
- Raises:
- errors.NotRenderableError: If the object is not renderable.
-
- Returns:
- Measurement: Measurement object containing range of character widths required to render the object.
- """
- _max_width = options.max_width
- if _max_width < 1:
- return Measurement(0, 0)
- if isinstance(renderable, str):
- renderable = console.render_str(
- renderable, markup=options.markup, highlight=False
- )
- renderable = rich_cast(renderable)
- if is_renderable(renderable):
- get_console_width: Optional[
- Callable[["Console", "ConsoleOptions"], "Measurement"]
- ] = getattr(renderable, "__rich_measure__", None)
- if get_console_width is not None:
- render_width = (
- get_console_width(console, options)
- .normalize()
- .with_maximum(_max_width)
- )
- if render_width.maximum < 1:
- return Measurement(0, 0)
- return render_width.normalize()
- else:
- return Measurement(0, _max_width)
- else:
- raise errors.NotRenderableError(
- f"Unable to get render width for {renderable!r}; "
- "a str, Segment, or object with __rich_console__ method is required"
- )
-
-
-def measure_renderables(
- console: "Console",
- options: "ConsoleOptions",
- renderables: Sequence["RenderableType"],
-) -> "Measurement":
- """Get a measurement that would fit a number of renderables.
-
- Args:
- console (~rich.console.Console): Console instance.
- options (~rich.console.ConsoleOptions): Console options.
- renderables (Iterable[RenderableType]): One or more renderable objects.
-
- Returns:
- Measurement: Measurement object containing range of character widths required to
- contain all given renderables.
- """
- if not renderables:
- return Measurement(0, 0)
- get_measurement = Measurement.get
- measurements = [
- get_measurement(console, options, renderable) for renderable in renderables
- ]
- measured_width = Measurement(
- max(measurements, key=itemgetter(0)).minimum,
- max(measurements, key=itemgetter(1)).maximum,
- )
- return measured_width
diff --git a/spaces/praveen-reddy/PDP/app.py b/spaces/praveen-reddy/PDP/app.py
deleted file mode 100644
index 18cd5808a16955d19399896c8a3462110d157dbc..0000000000000000000000000000000000000000
--- a/spaces/praveen-reddy/PDP/app.py
+++ /dev/null
@@ -1,130 +0,0 @@
-import pickle
-import streamlit as st
-import numpy as np
-import pandas as pd
-from sklearn.preprocessing import StandardScaler
-
-
-lr_model = "models/LR_model.pkl"
-knn_model = "models/KNN_model.pkl"
-svm_model = "models/SVM_model.pkl"
-abc_model = "models/ABC_model.pkl"
-bc_model = "models/BC_model.pkl"
-dt_model = "models/DT_model.pkl"
-lgbm_model = "models/LGBM_model.pkl"
-nb_model = "models/NB_model.pkl"
-rf_model = "models/RF_model.pkl"
-xg_model = "models/XG_model.pkl"
-
-with open(lr_model, 'rb') as file:
- LR_model = pickle.load(file)
-
-with open(knn_model, 'rb') as file:
- KNN_model = pickle.load(file)
-
-with open(svm_model, 'rb') as file:
- SVM_model = pickle.load(file)
-
-with open(abc_model, 'rb') as file:
- ABC_model = pickle.load(file)
-
-with open(bc_model, 'rb') as file:
- BC_model = pickle.load(file)
-
-with open(dt_model, 'rb') as file:
- DT_model = pickle.load(file)
-
-with open(lgbm_model, 'rb') as file:
- LGBM_model = pickle.load(file)
-
-with open(nb_model, 'rb') as file:
- NB_model = pickle.load(file)
-
-with open(rf_model, 'rb') as file:
- RF_model = pickle.load(file)
-
-with open(xg_model, 'rb') as file:
- XG_model = pickle.load(file)
-
-
-st.title("Parkinson's Disease Prediction Using Machine Learning")
-
-st.header('Fill the form and press the predict button to see the result',
- divider='rainbow')
-
-# test_value = [[ 5.29249395e-01, -1.03309592e-01, 1.11583374e+00,
-# -5.23716022e-01, -6.82179904e-01, -4.29193964e-01,
-# -4.66158519e-01, -4.28206106e-01, -6.17874540e-01,
-# -6.05206208e-01, -6.44461440e-01, -5.48107644e-01,
-# -5.58034900e-01, -6.44471776e-01, -5.39840575e-01,
-# 7.18861885e-01, -1.49332475e+00, 1.18499869e+00,
-# -3.23304568e-01, -3.76742214e-01, 3.78931110e-01,
-# -3.93143882e-01]]
-
-
-# Initial values
-initial_values = {
- 'MDVP:Fo(Hz)': 119.99200,
- 'MDVP:Fhi(Hz)': 157.30200,
- 'MDVP:Flo(Hz)': 74.99700,
- 'MDVP:Jitter(%)': 0.00784,
- 'MDVP:Jitter(Abs)': 0.00007,
- 'MDVP:RAP': 0.00370,
- 'MDVP:PPQ': 0.00554,
- 'Jitter:DDP': 0.01109,
- 'MDVP:Shimmer': 0.04374,
- 'MDVP:Shimmer(dB)': 0.42600,
- 'Shimmer:APQ3': 0.02182,
- 'Shimmer:APQ5': 0.03130,
- 'MDVP:APQ': 0.02971,
- 'Shimmer:DDA': 0.06545,
- 'NHR': 0.02211,
- 'HNR': 21.03300,
- 'RPDE': 0.414783,
- 'DFA': 0.815285,
- 'spread1': -4.813031,
- 'spread2': 0.266482,
- 'D2': 2.301442,
- 'PPE': 0.284654
-}
-
-
-for i, (key, value) in enumerate(initial_values.items()):
- initial_values[key] = st.text_input(key, value=value, key=i)
-
-# print(list(enumerate(initial_values.items())))
-
-if st.button('Predict', type="primary"):
- # Get the values from the text input fields
- # values = [float(st.text_input(key, value=value)) for key, value in initial_values.items()]
- values = [float(value) for value in initial_values.values()]
-
- # Convert the list of values to a numpy array and store it in 'test_value'
- test_value = np.array(values)
- sc = StandardScaler()
-
- # Print 'test_value' to the console
- st.write("Logistic Regression", str(
- LR_model.predict(sc.fit_transform([test_value]))))
- st.write("KNN", str(KNN_model.predict(sc.fit_transform([test_value]))))
- st.write("SVM", str(SVM_model.predict(sc.fit_transform([test_value]))))
- st.write("AdaBoost Classifier", str(
- ABC_model.predict(sc.fit_transform([test_value]))))
- st.write("Bagging Classifier", str(
- BC_model.predict(sc.fit_transform([test_value]))))
- st.write("Decision Tree", str(
- DT_model.predict(sc.fit_transform([test_value]))))
- st.write("LightGBM", str(LGBM_model.predict(
- sc.fit_transform([test_value]))))
- st.write("Naive Bayes", str(
- NB_model.predict(sc.fit_transform([test_value]))))
- st.write("Random Forest", str(
- RF_model.predict(sc.fit_transform([test_value]))))
- st.write("XGBoost", str(XG_model.predict(sc.fit_transform([test_value]))))
-
- st.write("Provided Data: ", test_value)
-
-dataset = pd.read_csv("dataset/parkinsons.data")
-
-st.subheader('Dataset Sample:', divider='rainbow')
-st.write(dataset.head())
diff --git a/spaces/prerna9811/Chord/portaudio/src/hostapi/coreaudio/pa_mac_core_internal.h b/spaces/prerna9811/Chord/portaudio/src/hostapi/coreaudio/pa_mac_core_internal.h
deleted file mode 100644
index d4a97e0c46e86001db8fe57e3212ef3e142d6c37..0000000000000000000000000000000000000000
--- a/spaces/prerna9811/Chord/portaudio/src/hostapi/coreaudio/pa_mac_core_internal.h
+++ /dev/null
@@ -1,193 +0,0 @@
-/*
- * Internal interfaces for PortAudio Apple AUHAL implementation
- *
- * PortAudio Portable Real-Time Audio Library
- * Latest Version at: http://www.portaudio.com
- *
- * Written by Bjorn Roche of XO Audio LLC, from PA skeleton code.
- * Portions copied from code by Dominic Mazzoni (who wrote a HAL implementation)
- *
- * Dominic's code was based on code by Phil Burk, Darren Gibbs,
- * Gord Peters, Stephane Letz, and Greg Pfiel.
- *
- * The following people also deserve acknowledgements:
- *
- * Olivier Tristan for feedback and testing
- * Glenn Zelniker and Z-Systems engineering for sponsoring the Blocking I/O
- * interface.
- *
- *
- * Based on the Open Source API proposed by Ross Bencina
- * Copyright (c) 1999-2002 Ross Bencina, Phil Burk
- *
- * Permission is hereby granted, free of charge, to any person obtaining
- * a copy of this software and associated documentation files
- * (the "Software"), to deal in the Software without restriction,
- * including without limitation the rights to use, copy, modify, merge,
- * publish, distribute, sublicense, and/or sell copies of the Software,
- * and to permit persons to whom the Software is furnished to do so,
- * subject to the following conditions:
- *
- * The above copyright notice and this permission notice shall be
- * included in all copies or substantial portions of the Software.
- *
- * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
- * EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
- * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
- * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR
- * ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF
- * CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
- * WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
- */
-
-/*
- * The text above constitutes the entire PortAudio license; however,
- * the PortAudio community also makes the following non-binding requests:
- *
- * Any person wishing to distribute modifications to the Software is
- * requested to send the modifications to the original developer so that
- * they can be incorporated into the canonical version. It is also
- * requested that these non-binding requests be included along with the
- * license above.
- */
-
-/**
- @file pa_mac_core
- @ingroup hostapi_src
- @author Bjorn Roche
- @brief AUHAL implementation of PortAudio
-*/
-
-#ifndef PA_MAC_CORE_INTERNAL_H__
-#define PA_MAC_CORE_INTERNAL_H__
-
-#include
-#include
-#include
-#include
-
-#include "portaudio.h"
-#include "pa_util.h"
-#include "pa_hostapi.h"
-#include "pa_stream.h"
-#include "pa_allocation.h"
-#include "pa_cpuload.h"
-#include "pa_process.h"
-#include "pa_ringbuffer.h"
-
-#include "pa_mac_core_blocking.h"
-
-/* function prototypes */
-
-#ifdef __cplusplus
-extern "C"
-{
-#endif /* __cplusplus */
-
-PaError PaMacCore_Initialize( PaUtilHostApiRepresentation **hostApi, PaHostApiIndex index );
-
-#ifdef __cplusplus
-}
-#endif /* __cplusplus */
-
-#define RING_BUFFER_ADVANCE_DENOMINATOR (4)
-
-PaError ReadStream( PaStream* stream, void *buffer, unsigned long frames );
-PaError WriteStream( PaStream* stream, const void *buffer, unsigned long frames );
-signed long GetStreamReadAvailable( PaStream* stream );
-signed long GetStreamWriteAvailable( PaStream* stream );
-/* PaMacAUHAL - host api datastructure specific to this implementation */
-typedef struct
-{
- PaUtilHostApiRepresentation inheritedHostApiRep;
- PaUtilStreamInterface callbackStreamInterface;
- PaUtilStreamInterface blockingStreamInterface;
-
- PaUtilAllocationGroup *allocations;
-
- /* implementation specific data goes here */
- long devCount;
- AudioDeviceID *devIds; /*array of all audio devices*/
- AudioDeviceID defaultIn;
- AudioDeviceID defaultOut;
-}
-PaMacAUHAL;
-
-typedef struct PaMacCoreDeviceProperties
-{
- /* Values in Frames from property queries. */
- UInt32 safetyOffset;
- UInt32 bufferFrameSize;
- // UInt32 streamLatency; // Seems to be the same as deviceLatency!?
- UInt32 deviceLatency;
- /* Current device sample rate. May change!
- These are initialized to the nominal device sample rate,
- and updated with the actual sample rate, when/where available.
- Note that these are the *device* sample rates, prior to any required
- SR conversion. */
- Float64 sampleRate;
- Float64 samplePeriod; // reciprocal
-}
-PaMacCoreDeviceProperties;
-
-/* stream data structure specifically for this implementation */
-typedef struct PaMacCoreStream
-{
- PaUtilStreamRepresentation streamRepresentation;
- PaUtilCpuLoadMeasurer cpuLoadMeasurer;
- PaUtilBufferProcessor bufferProcessor;
-
- /* implementation specific data goes here */
- bool bufferProcessorIsInitialized;
- AudioUnit inputUnit;
- AudioUnit outputUnit;
- AudioDeviceID inputDevice;
- AudioDeviceID outputDevice;
- size_t userInChan;
- size_t userOutChan;
- size_t inputFramesPerBuffer;
- size_t outputFramesPerBuffer;
- PaMacBlio blio;
- /* We use this ring buffer when input and out devs are different. */
- PaUtilRingBuffer inputRingBuffer;
- /* We may need to do SR conversion on input. */
- AudioConverterRef inputSRConverter;
- /* We need to preallocate an inputBuffer for reading data. */
- AudioBufferList inputAudioBufferList;
- AudioTimeStamp startTime;
- /* FIXME: instead of volatile, these should be properly memory barriered */
- volatile uint32_t xrunFlags; /*PaStreamCallbackFlags*/
- volatile enum {
- STOPPED = 0, /* playback is completely stopped,
- and the user has called StopStream(). */
- CALLBACK_STOPPED = 1, /* callback has requested stop,
- but user has not yet called StopStream(). */
- STOPPING = 2, /* The stream is in the process of closing
- because the user has called StopStream.
- This state is just used internally;
- externally it is indistinguishable from
- ACTIVE.*/
- ACTIVE = 3 /* The stream is active and running. */
- } state;
- double sampleRate;
- PaMacCoreDeviceProperties inputProperties;
- PaMacCoreDeviceProperties outputProperties;
-
- /* data updated by main thread and notifications, protected by timingInformationMutex */
- int timingInformationMutexIsInitialized;
- pthread_mutex_t timingInformationMutex;
-
- /* These are written by the PA thread or from CoreAudio callbacks. Protected by the mutex. */
- Float64 timestampOffsetCombined;
- Float64 timestampOffsetInputDevice;
- Float64 timestampOffsetOutputDevice;
-
- /* Offsets in seconds to be applied to Apple timestamps to convert them to PA timestamps.
- * While the io proc is active, the following values are only accessed and manipulated by the ioproc */
- Float64 timestampOffsetCombined_ioProcCopy;
- Float64 timestampOffsetInputDevice_ioProcCopy;
- Float64 timestampOffsetOutputDevice_ioProcCopy;
-}
-PaMacCoreStream;
-
-#endif /* PA_MAC_CORE_INTERNAL_H__ */
diff --git a/spaces/prerna9811/Chord/portaudio/src/hostapi/wasapi/mingw-include/sal.h b/spaces/prerna9811/Chord/portaudio/src/hostapi/wasapi/mingw-include/sal.h
deleted file mode 100644
index 3f99ab9a9227d04508b064d3ca7e305b80d2473e..0000000000000000000000000000000000000000
--- a/spaces/prerna9811/Chord/portaudio/src/hostapi/wasapi/mingw-include/sal.h
+++ /dev/null
@@ -1,252 +0,0 @@
-#pragma once
-
-#if __GNUC__ >=3
-#pragma GCC system_header
-#endif
-
-/*#define __null*/ // << Conflicts with GCC internal type __null
-#define __notnull
-#define __maybenull
-#define __readonly
-#define __notreadonly
-#define __maybereadonly
-#define __valid
-#define __notvalid
-#define __maybevalid
-#define __readableTo(extent)
-#define __elem_readableTo(size)
-#define __byte_readableTo(size)
-#define __writableTo(size)
-#define __elem_writableTo(size)
-#define __byte_writableTo(size)
-#define __deref
-#define __pre
-#define __post
-#define __precond(expr)
-#define __postcond(expr)
-#define __exceptthat
-#define __execeptthat
-#define __inner_success(expr)
-#define __inner_checkReturn
-#define __inner_typefix(ctype)
-#define __inner_override
-#define __inner_callback
-#define __inner_blocksOn(resource)
-#define __inner_fallthrough_dec
-#define __inner_fallthrough
-#define __refparam
-#define __inner_control_entrypoint(category)
-#define __inner_data_entrypoint(category)
-
-#define __ecount(size)
-#define __bcount(size)
-#define __in
-#define __in_ecount(size)
-#define __in_bcount(size)
-#define __in_z
-#define __in_ecount_z(size)
-#define __in_bcount_z(size)
-#define __in_nz
-#define __in_ecount_nz(size)
-#define __in_bcount_nz(size)
-#define __out
-#define __out_ecount(size)
-#define __out_bcount(size)
-#define __out_ecount_part(size,length)
-#define __out_bcount_part(size,length)
-#define __out_ecount_full(size)
-#define __out_bcount_full(size)
-#define __out_z
-#define __out_z_opt
-#define __out_ecount_z(size)
-#define __out_bcount_z(size)
-#define __out_ecount_part_z(size,length)
-#define __out_bcount_part_z(size,length)
-#define __out_ecount_full_z(size)
-#define __out_bcount_full_z(size)
-#define __out_nz
-#define __out_nz_opt
-#define __out_ecount_nz(size)
-#define __out_bcount_nz(size)
-#define __inout
-#define __inout_ecount(size)
-#define __inout_bcount(size)
-#define __inout_ecount_part(size,length)
-#define __inout_bcount_part(size,length)
-#define __inout_ecount_full(size)
-#define __inout_bcount_full(size)
-#define __inout_z
-#define __inout_ecount_z(size)
-#define __inout_bcount_z(size)
-#define __inout_nz
-#define __inout_ecount_nz(size)
-#define __inout_bcount_nz(size)
-#define __ecount_opt(size)
-#define __bcount_opt(size)
-#define __in_opt
-#define __in_ecount_opt(size)
-#define __in_bcount_opt(size)
-#define __in_z_opt
-#define __in_ecount_z_opt(size)
-#define __in_bcount_z_opt(size)
-#define __in_nz_opt
-#define __in_ecount_nz_opt(size)
-#define __in_bcount_nz_opt(size)
-#define __out_opt
-#define __out_ecount_opt(size)
-#define __out_bcount_opt(size)
-#define __out_ecount_part_opt(size,length)
-#define __out_bcount_part_opt(size,length)
-#define __out_ecount_full_opt(size)
-#define __out_bcount_full_opt(size)
-#define __out_ecount_z_opt(size)
-#define __out_bcount_z_opt(size)
-#define __out_ecount_part_z_opt(size,length)
-#define __out_bcount_part_z_opt(size,length)
-#define __out_ecount_full_z_opt(size)
-#define __out_bcount_full_z_opt(size)
-#define __out_ecount_nz_opt(size)
-#define __out_bcount_nz_opt(size)
-#define __inout_opt
-#define __inout_ecount_opt(size)
-#define __inout_bcount_opt(size)
-#define __inout_ecount_part_opt(size,length)
-#define __inout_bcount_part_opt(size,length)
-#define __inout_ecount_full_opt(size)
-#define __inout_bcount_full_opt(size)
-#define __inout_z_opt
-#define __inout_ecount_z_opt(size)
-#define __inout_ecount_z_opt(size)
-#define __inout_bcount_z_opt(size)
-#define __inout_nz_opt
-#define __inout_ecount_nz_opt(size)
-#define __inout_bcount_nz_opt(size)
-#define __deref_ecount(size)
-#define __deref_bcount(size)
-#define __deref_out
-#define __deref_out_ecount(size)
-#define __deref_out_bcount(size)
-#define __deref_out_ecount_part(size,length)
-#define __deref_out_bcount_part(size,length)
-#define __deref_out_ecount_full(size)
-#define __deref_out_bcount_full(size)
-#define __deref_out_z
-#define __deref_out_ecount_z(size)
-#define __deref_out_bcount_z(size)
-#define __deref_out_nz
-#define __deref_out_ecount_nz(size)
-#define __deref_out_bcount_nz(size)
-#define __deref_inout
-#define __deref_inout_z
-#define __deref_inout_ecount(size)
-#define __deref_inout_bcount(size)
-#define __deref_inout_ecount_part(size,length)
-#define __deref_inout_bcount_part(size,length)
-#define __deref_inout_ecount_full(size)
-#define __deref_inout_bcount_full(size)
-#define __deref_inout_z
-#define __deref_inout_ecount_z(size)
-#define __deref_inout_bcount_z(size)
-#define __deref_inout_nz
-#define __deref_inout_ecount_nz(size)
-#define __deref_inout_bcount_nz(size)
-#define __deref_ecount_opt(size)
-#define __deref_bcount_opt(size)
-#define __deref_out_opt
-#define __deref_out_ecount_opt(size)
-#define __deref_out_bcount_opt(size)
-#define __deref_out_ecount_part_opt(size,length)
-#define __deref_out_bcount_part_opt(size,length)
-#define __deref_out_ecount_full_opt(size)
-#define __deref_out_bcount_full_opt(size)
-#define __deref_out_z_opt
-#define __deref_out_ecount_z_opt(size)
-#define __deref_out_bcount_z_opt(size)
-#define __deref_out_nz_opt
-#define __deref_out_ecount_nz_opt(size)
-#define __deref_out_bcount_nz_opt(size)
-#define __deref_inout_opt
-#define __deref_inout_ecount_opt(size)
-#define __deref_inout_bcount_opt(size)
-#define __deref_inout_ecount_part_opt(size,length)
-#define __deref_inout_bcount_part_opt(size,length)
-#define __deref_inout_ecount_full_opt(size)
-#define __deref_inout_bcount_full_opt(size)
-#define __deref_inout_z_opt
-#define __deref_inout_ecount_z_opt(size)
-#define __deref_inout_bcount_z_opt(size)
-#define __deref_inout_nz_opt
-#define __deref_inout_ecount_nz_opt(size)
-#define __deref_inout_bcount_nz_opt(size)
-#define __deref_opt_ecount(size)
-#define __deref_opt_bcount(size)
-#define __deref_opt_out
-#define __deref_opt_out_z
-#define __deref_opt_out_ecount(size)
-#define __deref_opt_out_bcount(size)
-#define __deref_opt_out_ecount_part(size,length)
-#define __deref_opt_out_bcount_part(size,length)
-#define __deref_opt_out_ecount_full(size)
-#define __deref_opt_out_bcount_full(size)
-#define __deref_opt_inout
-#define __deref_opt_inout_ecount(size)
-#define __deref_opt_inout_bcount(size)
-#define __deref_opt_inout_ecount_part(size,length)
-#define __deref_opt_inout_bcount_part(size,length)
-#define __deref_opt_inout_ecount_full(size)
-#define __deref_opt_inout_bcount_full(size)
-#define __deref_opt_inout_z
-#define __deref_opt_inout_ecount_z(size)
-#define __deref_opt_inout_bcount_z(size)
-#define __deref_opt_inout_nz
-#define __deref_opt_inout_ecount_nz(size)
-#define __deref_opt_inout_bcount_nz(size)
-#define __deref_opt_ecount_opt(size)
-#define __deref_opt_bcount_opt(size)
-#define __deref_opt_out_opt
-#define __deref_opt_out_ecount_opt(size)
-#define __deref_opt_out_bcount_opt(size)
-#define __deref_opt_out_ecount_part_opt(size,length)
-#define __deref_opt_out_bcount_part_opt(size,length)
-#define __deref_opt_out_ecount_full_opt(size)
-#define __deref_opt_out_bcount_full_opt(size)
-#define __deref_opt_out_z_opt
-#define __deref_opt_out_ecount_z_opt(size)
-#define __deref_opt_out_bcount_z_opt(size)
-#define __deref_opt_out_nz_opt
-#define __deref_opt_out_ecount_nz_opt(size)
-#define __deref_opt_out_bcount_nz_opt(size)
-#define __deref_opt_inout_opt
-#define __deref_opt_inout_ecount_opt(size)
-#define __deref_opt_inout_bcount_opt(size)
-#define __deref_opt_inout_ecount_part_opt(size,length)
-#define __deref_opt_inout_bcount_part_opt(size,length)
-#define __deref_opt_inout_ecount_full_opt(size)
-#define __deref_opt_inout_bcount_full_opt(size)
-#define __deref_opt_inout_z_opt
-#define __deref_opt_inout_ecount_z_opt(size)
-#define __deref_opt_inout_bcount_z_opt(size)
-#define __deref_opt_inout_nz_opt
-#define __deref_opt_inout_ecount_nz_opt(size)
-#define __deref_opt_inout_bcount_nz_opt(size)
-
-#define __success(expr)
-#define __nullterminated
-#define __nullnullterminated
-#define __reserved
-#define __checkReturn
-#define __typefix(ctype)
-#define __override
-#define __callback
-#define __format_string
-#define __blocksOn(resource)
-#define __control_entrypoint(category)
-#define __data_entrypoint(category)
-
-#ifndef __fallthrough
- #define __fallthrough __inner_fallthrough
-#endif
-
-#ifndef __analysis_assume
- #define __analysis_assume(expr)
-#endif
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fastapi/datastructures.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fastapi/datastructures.py
deleted file mode 100644
index ce03e3ce4747a93956877d43dd9b7d3f9166160f..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fastapi/datastructures.py
+++ /dev/null
@@ -1,204 +0,0 @@
-from typing import (
- Any,
- BinaryIO,
- Callable,
- Dict,
- Iterable,
- Optional,
- Type,
- TypeVar,
- cast,
-)
-
-from fastapi._compat import (
- PYDANTIC_V2,
- CoreSchema,
- GetJsonSchemaHandler,
- JsonSchemaValue,
- with_info_plain_validator_function,
-)
-from starlette.datastructures import URL as URL # noqa: F401
-from starlette.datastructures import Address as Address # noqa: F401
-from starlette.datastructures import FormData as FormData # noqa: F401
-from starlette.datastructures import Headers as Headers # noqa: F401
-from starlette.datastructures import QueryParams as QueryParams # noqa: F401
-from starlette.datastructures import State as State # noqa: F401
-from starlette.datastructures import UploadFile as StarletteUploadFile
-from typing_extensions import Annotated, Doc # type: ignore [attr-defined]
-
-
-class UploadFile(StarletteUploadFile):
- """
- A file uploaded in a request.
-
- Define it as a *path operation function* (or dependency) parameter.
-
- If you are using a regular `def` function, you can use the `upload_file.file`
- attribute to access the raw standard Python file (blocking, not async), useful and
- needed for non-async code.
-
- Read more about it in the
- [FastAPI docs for Request Files](https://fastapi.tiangolo.com/tutorial/request-files/).
-
- ## Example
-
- ```python
- from typing import Annotated
-
- from fastapi import FastAPI, File, UploadFile
-
- app = FastAPI()
-
-
- @app.post("/files/")
- async def create_file(file: Annotated[bytes, File()]):
- return {"file_size": len(file)}
-
-
- @app.post("/uploadfile/")
- async def create_upload_file(file: UploadFile):
- return {"filename": file.filename}
- ```
- """
-
- file: Annotated[
- BinaryIO,
- Doc("The standard Python file object (non-async)."),
- ]
- filename: Annotated[Optional[str], Doc("The original file name.")]
- size: Annotated[Optional[int], Doc("The size of the file in bytes.")]
- headers: Annotated[Headers, Doc("The headers of the request.")]
- content_type: Annotated[
- Optional[str], Doc("The content type of the request, from the headers.")
- ]
-
- async def write(
- self,
- data: Annotated[
- bytes,
- Doc(
- """
- The bytes to write to the file.
- """
- ),
- ],
- ) -> None:
- """
- Write some bytes to the file.
-
- You normally wouldn't use this from a file you read in a request.
-
- To be awaitable, compatible with async, this is run in threadpool.
- """
- return await super().write(data)
-
- async def read(
- self,
- size: Annotated[
- int,
- Doc(
- """
- The number of bytes to read from the file.
- """
- ),
- ] = -1,
- ) -> bytes:
- """
- Read some bytes from the file.
-
- To be awaitable, compatible with async, this is run in threadpool.
- """
- return await super().read(size)
-
- async def seek(
- self,
- offset: Annotated[
- int,
- Doc(
- """
- The position in bytes to seek to in the file.
- """
- ),
- ],
- ) -> None:
- """
- Move to a position in the file.
-
- Any next read or write will be done from that position.
-
- To be awaitable, compatible with async, this is run in threadpool.
- """
- return await super().seek(offset)
-
- async def close(self) -> None:
- """
- Close the file.
-
- To be awaitable, compatible with async, this is run in threadpool.
- """
- return await super().close()
-
- @classmethod
- def __get_validators__(cls: Type["UploadFile"]) -> Iterable[Callable[..., Any]]:
- yield cls.validate
-
- @classmethod
- def validate(cls: Type["UploadFile"], v: Any) -> Any:
- if not isinstance(v, StarletteUploadFile):
- raise ValueError(f"Expected UploadFile, received: {type(v)}")
- return v
-
- @classmethod
- def _validate(cls, __input_value: Any, _: Any) -> "UploadFile":
- if not isinstance(__input_value, StarletteUploadFile):
- raise ValueError(f"Expected UploadFile, received: {type(__input_value)}")
- return cast(UploadFile, __input_value)
-
- if not PYDANTIC_V2:
-
- @classmethod
- def __modify_schema__(cls, field_schema: Dict[str, Any]) -> None:
- field_schema.update({"type": "string", "format": "binary"})
-
- @classmethod
- def __get_pydantic_json_schema__(
- cls, core_schema: CoreSchema, handler: GetJsonSchemaHandler
- ) -> JsonSchemaValue:
- return {"type": "string", "format": "binary"}
-
- @classmethod
- def __get_pydantic_core_schema__(
- cls, source: Type[Any], handler: Callable[[Any], CoreSchema]
- ) -> CoreSchema:
- return with_info_plain_validator_function(cls._validate)
-
-
-class DefaultPlaceholder:
- """
- You shouldn't use this class directly.
-
- It's used internally to recognize when a default value has been overwritten, even
- if the overridden default value was truthy.
- """
-
- def __init__(self, value: Any):
- self.value = value
-
- def __bool__(self) -> bool:
- return bool(self.value)
-
- def __eq__(self, o: object) -> bool:
- return isinstance(o, DefaultPlaceholder) and o.value == self.value
-
-
-DefaultType = TypeVar("DefaultType")
-
-
-def Default(value: DefaultType) -> DefaultType:
- """
- You shouldn't use this function directly.
-
- It's used internally to recognize when a default value has been overwritten, even
- if the overridden default value was truthy.
- """
- return DefaultPlaceholder(value) # type: ignore
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/ttLib/tables/H_V_A_R_.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/ttLib/tables/H_V_A_R_.py
deleted file mode 100644
index 094aedaea5ebc5c88b33e448ea8f131563acd3c0..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/ttLib/tables/H_V_A_R_.py
+++ /dev/null
@@ -1,5 +0,0 @@
-from .otBase import BaseTTXConverter
-
-
-class table_H_V_A_R_(BaseTTXConverter):
- pass
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/ttLib/tables/otData.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/ttLib/tables/otData.py
deleted file mode 100644
index 56716824ecd7950dda249a159b5b292dbd2a86f7..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/fontTools/ttLib/tables/otData.py
+++ /dev/null
@@ -1,6236 +0,0 @@
-otData = [
- #
- # common
- #
- ("LookupOrder", []),
- (
- "ScriptList",
- [
- ("uint16", "ScriptCount", None, None, "Number of ScriptRecords"),
- (
- "struct",
- "ScriptRecord",
- "ScriptCount",
- 0,
- "Array of ScriptRecords -listed alphabetically by ScriptTag",
- ),
- ],
- ),
- (
- "ScriptRecord",
- [
- ("Tag", "ScriptTag", None, None, "4-byte ScriptTag identifier"),
- (
- "Offset",
- "Script",
- None,
- None,
- "Offset to Script table-from beginning of ScriptList",
- ),
- ],
- ),
- (
- "Script",
- [
- (
- "Offset",
- "DefaultLangSys",
- None,
- None,
- "Offset to DefaultLangSys table-from beginning of Script table-may be NULL",
- ),
- (
- "uint16",
- "LangSysCount",
- None,
- None,
- "Number of LangSysRecords for this script-excluding the DefaultLangSys",
- ),
- (
- "struct",
- "LangSysRecord",
- "LangSysCount",
- 0,
- "Array of LangSysRecords-listed alphabetically by LangSysTag",
- ),
- ],
- ),
- (
- "LangSysRecord",
- [
- ("Tag", "LangSysTag", None, None, "4-byte LangSysTag identifier"),
- (
- "Offset",
- "LangSys",
- None,
- None,
- "Offset to LangSys table-from beginning of Script table",
- ),
- ],
- ),
- (
- "LangSys",
- [
- (
- "Offset",
- "LookupOrder",
- None,
- None,
- "= NULL (reserved for an offset to a reordering table)",
- ),
- (
- "uint16",
- "ReqFeatureIndex",
- None,
- None,
- "Index of a feature required for this language system- if no required features = 0xFFFF",
- ),
- (
- "uint16",
- "FeatureCount",
- None,
- None,
- "Number of FeatureIndex values for this language system-excludes the required feature",
- ),
- (
- "uint16",
- "FeatureIndex",
- "FeatureCount",
- 0,
- "Array of indices into the FeatureList-in arbitrary order",
- ),
- ],
- ),
- (
- "FeatureList",
- [
- (
- "uint16",
- "FeatureCount",
- None,
- None,
- "Number of FeatureRecords in this table",
- ),
- (
- "struct",
- "FeatureRecord",
- "FeatureCount",
- 0,
- "Array of FeatureRecords-zero-based (first feature has FeatureIndex = 0)-listed alphabetically by FeatureTag",
- ),
- ],
- ),
- (
- "FeatureRecord",
- [
- ("Tag", "FeatureTag", None, None, "4-byte feature identification tag"),
- (
- "Offset",
- "Feature",
- None,
- None,
- "Offset to Feature table-from beginning of FeatureList",
- ),
- ],
- ),
- (
- "Feature",
- [
- (
- "Offset",
- "FeatureParams",
- None,
- None,
- "= NULL (reserved for offset to FeatureParams)",
- ),
- (
- "uint16",
- "LookupCount",
- None,
- None,
- "Number of LookupList indices for this feature",
- ),
- (
- "uint16",
- "LookupListIndex",
- "LookupCount",
- 0,
- "Array of LookupList indices for this feature -zero-based (first lookup is LookupListIndex = 0)",
- ),
- ],
- ),
- ("FeatureParams", []),
- (
- "FeatureParamsSize",
- [
- (
- "DeciPoints",
- "DesignSize",
- None,
- None,
- "The design size in 720/inch units (decipoints).",
- ),
- (
- "uint16",
- "SubfamilyID",
- None,
- None,
- "Serves as an identifier that associates fonts in a subfamily.",
- ),
- ("NameID", "SubfamilyNameID", None, None, "Subfamily NameID."),
- (
- "DeciPoints",
- "RangeStart",
- None,
- None,
- "Small end of recommended usage range (exclusive) in 720/inch units.",
- ),
- (
- "DeciPoints",
- "RangeEnd",
- None,
- None,
- "Large end of recommended usage range (inclusive) in 720/inch units.",
- ),
- ],
- ),
- (
- "FeatureParamsStylisticSet",
- [
- ("uint16", "Version", None, None, "Set to 0."),
- ("NameID", "UINameID", None, None, "UI NameID."),
- ],
- ),
- (
- "FeatureParamsCharacterVariants",
- [
- ("uint16", "Format", None, None, "Set to 0."),
- ("NameID", "FeatUILabelNameID", None, None, "Feature UI label NameID."),
- (
- "NameID",
- "FeatUITooltipTextNameID",
- None,
- None,
- "Feature UI tooltip text NameID.",
- ),
- ("NameID", "SampleTextNameID", None, None, "Sample text NameID."),
- ("uint16", "NumNamedParameters", None, None, "Number of named parameters."),
- (
- "NameID",
- "FirstParamUILabelNameID",
- None,
- None,
- "First NameID of UI feature parameters.",
- ),
- (
- "uint16",
- "CharCount",
- None,
- None,
- "Count of characters this feature provides glyph variants for.",
- ),
- (
- "uint24",
- "Character",
- "CharCount",
- 0,
- "Unicode characters for which this feature provides glyph variants.",
- ),
- ],
- ),
- (
- "LookupList",
- [
- ("uint16", "LookupCount", None, None, "Number of lookups in this table"),
- (
- "Offset",
- "Lookup",
- "LookupCount",
- 0,
- "Array of offsets to Lookup tables-from beginning of LookupList -zero based (first lookup is Lookup index = 0)",
- ),
- ],
- ),
- (
- "Lookup",
- [
- (
- "uint16",
- "LookupType",
- None,
- None,
- "Different enumerations for GSUB and GPOS",
- ),
- ("LookupFlag", "LookupFlag", None, None, "Lookup qualifiers"),
- (
- "uint16",
- "SubTableCount",
- None,
- None,
- "Number of SubTables for this lookup",
- ),
- (
- "Offset",
- "SubTable",
- "SubTableCount",
- 0,
- "Array of offsets to SubTables-from beginning of Lookup table",
- ),
- (
- "uint16",
- "MarkFilteringSet",
- None,
- "LookupFlag & 0x0010",
- "If set, indicates that the lookup table structure is followed by a MarkFilteringSet field. The layout engine skips over all mark glyphs not in the mark filtering set indicated.",
- ),
- ],
- ),
- (
- "CoverageFormat1",
- [
- ("uint16", "CoverageFormat", None, None, "Format identifier-format = 1"),
- ("uint16", "GlyphCount", None, None, "Number of glyphs in the GlyphArray"),
- (
- "GlyphID",
- "GlyphArray",
- "GlyphCount",
- 0,
- "Array of GlyphIDs-in numerical order",
- ),
- ],
- ),
- (
- "CoverageFormat2",
- [
- ("uint16", "CoverageFormat", None, None, "Format identifier-format = 2"),
- ("uint16", "RangeCount", None, None, "Number of RangeRecords"),
- (
- "struct",
- "RangeRecord",
- "RangeCount",
- 0,
- "Array of glyph ranges-ordered by Start GlyphID",
- ),
- ],
- ),
- (
- "RangeRecord",
- [
- ("GlyphID", "Start", None, None, "First GlyphID in the range"),
- ("GlyphID", "End", None, None, "Last GlyphID in the range"),
- (
- "uint16",
- "StartCoverageIndex",
- None,
- None,
- "Coverage Index of first GlyphID in range",
- ),
- ],
- ),
- (
- "ClassDefFormat1",
- [
- ("uint16", "ClassFormat", None, None, "Format identifier-format = 1"),
- (
- "GlyphID",
- "StartGlyph",
- None,
- None,
- "First GlyphID of the ClassValueArray",
- ),
- ("uint16", "GlyphCount", None, None, "Size of the ClassValueArray"),
- (
- "uint16",
- "ClassValueArray",
- "GlyphCount",
- 0,
- "Array of Class Values-one per GlyphID",
- ),
- ],
- ),
- (
- "ClassDefFormat2",
- [
- ("uint16", "ClassFormat", None, None, "Format identifier-format = 2"),
- ("uint16", "ClassRangeCount", None, None, "Number of ClassRangeRecords"),
- (
- "struct",
- "ClassRangeRecord",
- "ClassRangeCount",
- 0,
- "Array of ClassRangeRecords-ordered by Start GlyphID",
- ),
- ],
- ),
- (
- "ClassRangeRecord",
- [
- ("GlyphID", "Start", None, None, "First GlyphID in the range"),
- ("GlyphID", "End", None, None, "Last GlyphID in the range"),
- ("uint16", "Class", None, None, "Applied to all glyphs in the range"),
- ],
- ),
- (
- "Device",
- [
- ("uint16", "StartSize", None, None, "Smallest size to correct-in ppem"),
- ("uint16", "EndSize", None, None, "Largest size to correct-in ppem"),
- (
- "uint16",
- "DeltaFormat",
- None,
- None,
- "Format of DeltaValue array data: 1, 2, or 3",
- ),
- (
- "DeltaValue",
- "DeltaValue",
- "",
- "DeltaFormat in (1,2,3)",
- "Array of compressed data",
- ),
- ],
- ),
- #
- # gpos
- #
- (
- "GPOS",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the GPOS table- 0x00010000 or 0x00010001",
- ),
- (
- "Offset",
- "ScriptList",
- None,
- None,
- "Offset to ScriptList table-from beginning of GPOS table",
- ),
- (
- "Offset",
- "FeatureList",
- None,
- None,
- "Offset to FeatureList table-from beginning of GPOS table",
- ),
- (
- "Offset",
- "LookupList",
- None,
- None,
- "Offset to LookupList table-from beginning of GPOS table",
- ),
- (
- "LOffset",
- "FeatureVariations",
- None,
- "Version >= 0x00010001",
- "Offset to FeatureVariations table-from beginning of GPOS table",
- ),
- ],
- ),
- (
- "SinglePosFormat1",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of SinglePos subtable",
- ),
- (
- "uint16",
- "ValueFormat",
- None,
- None,
- "Defines the types of data in the ValueRecord",
- ),
- (
- "ValueRecord",
- "Value",
- None,
- None,
- "Defines positioning value(s)-applied to all glyphs in the Coverage table",
- ),
- ],
- ),
- (
- "SinglePosFormat2",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 2"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of SinglePos subtable",
- ),
- (
- "uint16",
- "ValueFormat",
- None,
- None,
- "Defines the types of data in the ValueRecord",
- ),
- ("uint16", "ValueCount", None, None, "Number of ValueRecords"),
- (
- "ValueRecord",
- "Value",
- "ValueCount",
- 0,
- "Array of ValueRecords-positioning values applied to glyphs",
- ),
- ],
- ),
- (
- "PairPosFormat1",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of PairPos subtable-only the first glyph in each pair",
- ),
- (
- "uint16",
- "ValueFormat1",
- None,
- None,
- "Defines the types of data in ValueRecord1-for the first glyph in the pair -may be zero (0)",
- ),
- (
- "uint16",
- "ValueFormat2",
- None,
- None,
- "Defines the types of data in ValueRecord2-for the second glyph in the pair -may be zero (0)",
- ),
- ("uint16", "PairSetCount", None, None, "Number of PairSet tables"),
- (
- "Offset",
- "PairSet",
- "PairSetCount",
- 0,
- "Array of offsets to PairSet tables-from beginning of PairPos subtable-ordered by Coverage Index",
- ),
- ],
- ),
- (
- "PairSet",
- [
- ("uint16", "PairValueCount", None, None, "Number of PairValueRecords"),
- (
- "struct",
- "PairValueRecord",
- "PairValueCount",
- 0,
- "Array of PairValueRecords-ordered by GlyphID of the second glyph",
- ),
- ],
- ),
- (
- "PairValueRecord",
- [
- (
- "GlyphID",
- "SecondGlyph",
- None,
- None,
- "GlyphID of second glyph in the pair-first glyph is listed in the Coverage table",
- ),
- (
- "ValueRecord",
- "Value1",
- None,
- None,
- "Positioning data for the first glyph in the pair",
- ),
- (
- "ValueRecord",
- "Value2",
- None,
- None,
- "Positioning data for the second glyph in the pair",
- ),
- ],
- ),
- (
- "PairPosFormat2",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 2"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of PairPos subtable-for the first glyph of the pair",
- ),
- (
- "uint16",
- "ValueFormat1",
- None,
- None,
- "ValueRecord definition-for the first glyph of the pair-may be zero (0)",
- ),
- (
- "uint16",
- "ValueFormat2",
- None,
- None,
- "ValueRecord definition-for the second glyph of the pair-may be zero (0)",
- ),
- (
- "Offset",
- "ClassDef1",
- None,
- None,
- "Offset to ClassDef table-from beginning of PairPos subtable-for the first glyph of the pair",
- ),
- (
- "Offset",
- "ClassDef2",
- None,
- None,
- "Offset to ClassDef table-from beginning of PairPos subtable-for the second glyph of the pair",
- ),
- (
- "uint16",
- "Class1Count",
- None,
- None,
- "Number of classes in ClassDef1 table-includes Class0",
- ),
- (
- "uint16",
- "Class2Count",
- None,
- None,
- "Number of classes in ClassDef2 table-includes Class0",
- ),
- (
- "struct",
- "Class1Record",
- "Class1Count",
- 0,
- "Array of Class1 records-ordered by Class1",
- ),
- ],
- ),
- (
- "Class1Record",
- [
- (
- "struct",
- "Class2Record",
- "Class2Count",
- 0,
- "Array of Class2 records-ordered by Class2",
- ),
- ],
- ),
- (
- "Class2Record",
- [
- (
- "ValueRecord",
- "Value1",
- None,
- None,
- "Positioning for first glyph-empty if ValueFormat1 = 0",
- ),
- (
- "ValueRecord",
- "Value2",
- None,
- None,
- "Positioning for second glyph-empty if ValueFormat2 = 0",
- ),
- ],
- ),
- (
- "CursivePosFormat1",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of CursivePos subtable",
- ),
- ("uint16", "EntryExitCount", None, None, "Number of EntryExit records"),
- (
- "struct",
- "EntryExitRecord",
- "EntryExitCount",
- 0,
- "Array of EntryExit records-in Coverage Index order",
- ),
- ],
- ),
- (
- "EntryExitRecord",
- [
- (
- "Offset",
- "EntryAnchor",
- None,
- None,
- "Offset to EntryAnchor table-from beginning of CursivePos subtable-may be NULL",
- ),
- (
- "Offset",
- "ExitAnchor",
- None,
- None,
- "Offset to ExitAnchor table-from beginning of CursivePos subtable-may be NULL",
- ),
- ],
- ),
- (
- "MarkBasePosFormat1",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "MarkCoverage",
- None,
- None,
- "Offset to MarkCoverage table-from beginning of MarkBasePos subtable",
- ),
- (
- "Offset",
- "BaseCoverage",
- None,
- None,
- "Offset to BaseCoverage table-from beginning of MarkBasePos subtable",
- ),
- ("uint16", "ClassCount", None, None, "Number of classes defined for marks"),
- (
- "Offset",
- "MarkArray",
- None,
- None,
- "Offset to MarkArray table-from beginning of MarkBasePos subtable",
- ),
- (
- "Offset",
- "BaseArray",
- None,
- None,
- "Offset to BaseArray table-from beginning of MarkBasePos subtable",
- ),
- ],
- ),
- (
- "BaseArray",
- [
- ("uint16", "BaseCount", None, None, "Number of BaseRecords"),
- (
- "struct",
- "BaseRecord",
- "BaseCount",
- 0,
- "Array of BaseRecords-in order of BaseCoverage Index",
- ),
- ],
- ),
- (
- "BaseRecord",
- [
- (
- "Offset",
- "BaseAnchor",
- "ClassCount",
- 0,
- "Array of offsets (one per class) to Anchor tables-from beginning of BaseArray table-ordered by class-zero-based",
- ),
- ],
- ),
- (
- "MarkLigPosFormat1",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "MarkCoverage",
- None,
- None,
- "Offset to Mark Coverage table-from beginning of MarkLigPos subtable",
- ),
- (
- "Offset",
- "LigatureCoverage",
- None,
- None,
- "Offset to Ligature Coverage table-from beginning of MarkLigPos subtable",
- ),
- ("uint16", "ClassCount", None, None, "Number of defined mark classes"),
- (
- "Offset",
- "MarkArray",
- None,
- None,
- "Offset to MarkArray table-from beginning of MarkLigPos subtable",
- ),
- (
- "Offset",
- "LigatureArray",
- None,
- None,
- "Offset to LigatureArray table-from beginning of MarkLigPos subtable",
- ),
- ],
- ),
- (
- "LigatureArray",
- [
- (
- "uint16",
- "LigatureCount",
- None,
- None,
- "Number of LigatureAttach table offsets",
- ),
- (
- "Offset",
- "LigatureAttach",
- "LigatureCount",
- 0,
- "Array of offsets to LigatureAttach tables-from beginning of LigatureArray table-ordered by LigatureCoverage Index",
- ),
- ],
- ),
- (
- "LigatureAttach",
- [
- (
- "uint16",
- "ComponentCount",
- None,
- None,
- "Number of ComponentRecords in this ligature",
- ),
- (
- "struct",
- "ComponentRecord",
- "ComponentCount",
- 0,
- "Array of Component records-ordered in writing direction",
- ),
- ],
- ),
- (
- "ComponentRecord",
- [
- (
- "Offset",
- "LigatureAnchor",
- "ClassCount",
- 0,
- "Array of offsets (one per class) to Anchor tables-from beginning of LigatureAttach table-ordered by class-NULL if a component does not have an attachment for a class-zero-based array",
- ),
- ],
- ),
- (
- "MarkMarkPosFormat1",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Mark1Coverage",
- None,
- None,
- "Offset to Combining Mark Coverage table-from beginning of MarkMarkPos subtable",
- ),
- (
- "Offset",
- "Mark2Coverage",
- None,
- None,
- "Offset to Base Mark Coverage table-from beginning of MarkMarkPos subtable",
- ),
- (
- "uint16",
- "ClassCount",
- None,
- None,
- "Number of Combining Mark classes defined",
- ),
- (
- "Offset",
- "Mark1Array",
- None,
- None,
- "Offset to MarkArray table for Mark1-from beginning of MarkMarkPos subtable",
- ),
- (
- "Offset",
- "Mark2Array",
- None,
- None,
- "Offset to Mark2Array table for Mark2-from beginning of MarkMarkPos subtable",
- ),
- ],
- ),
- (
- "Mark2Array",
- [
- ("uint16", "Mark2Count", None, None, "Number of Mark2 records"),
- (
- "struct",
- "Mark2Record",
- "Mark2Count",
- 0,
- "Array of Mark2 records-in Coverage order",
- ),
- ],
- ),
- (
- "Mark2Record",
- [
- (
- "Offset",
- "Mark2Anchor",
- "ClassCount",
- 0,
- "Array of offsets (one per class) to Anchor tables-from beginning of Mark2Array table-zero-based array",
- ),
- ],
- ),
- (
- "PosLookupRecord",
- [
- (
- "uint16",
- "SequenceIndex",
- None,
- None,
- "Index to input glyph sequence-first glyph = 0",
- ),
- (
- "uint16",
- "LookupListIndex",
- None,
- None,
- "Lookup to apply to that position-zero-based",
- ),
- ],
- ),
- (
- "ContextPosFormat1",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of ContextPos subtable",
- ),
- ("uint16", "PosRuleSetCount", None, None, "Number of PosRuleSet tables"),
- (
- "Offset",
- "PosRuleSet",
- "PosRuleSetCount",
- 0,
- "Array of offsets to PosRuleSet tables-from beginning of ContextPos subtable-ordered by Coverage Index",
- ),
- ],
- ),
- (
- "PosRuleSet",
- [
- ("uint16", "PosRuleCount", None, None, "Number of PosRule tables"),
- (
- "Offset",
- "PosRule",
- "PosRuleCount",
- 0,
- "Array of offsets to PosRule tables-from beginning of PosRuleSet-ordered by preference",
- ),
- ],
- ),
- (
- "PosRule",
- [
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Number of glyphs in the Input glyph sequence",
- ),
- ("uint16", "PosCount", None, None, "Number of PosLookupRecords"),
- (
- "GlyphID",
- "Input",
- "GlyphCount",
- -1,
- "Array of input GlyphIDs-starting with the second glyph",
- ),
- (
- "struct",
- "PosLookupRecord",
- "PosCount",
- 0,
- "Array of positioning lookups-in design order",
- ),
- ],
- ),
- (
- "ContextPosFormat2",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 2"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of ContextPos subtable",
- ),
- (
- "Offset",
- "ClassDef",
- None,
- None,
- "Offset to ClassDef table-from beginning of ContextPos subtable",
- ),
- ("uint16", "PosClassSetCount", None, None, "Number of PosClassSet tables"),
- (
- "Offset",
- "PosClassSet",
- "PosClassSetCount",
- 0,
- "Array of offsets to PosClassSet tables-from beginning of ContextPos subtable-ordered by class-may be NULL",
- ),
- ],
- ),
- (
- "PosClassSet",
- [
- (
- "uint16",
- "PosClassRuleCount",
- None,
- None,
- "Number of PosClassRule tables",
- ),
- (
- "Offset",
- "PosClassRule",
- "PosClassRuleCount",
- 0,
- "Array of offsets to PosClassRule tables-from beginning of PosClassSet-ordered by preference",
- ),
- ],
- ),
- (
- "PosClassRule",
- [
- ("uint16", "GlyphCount", None, None, "Number of glyphs to be matched"),
- ("uint16", "PosCount", None, None, "Number of PosLookupRecords"),
- (
- "uint16",
- "Class",
- "GlyphCount",
- -1,
- "Array of classes-beginning with the second class-to be matched to the input glyph sequence",
- ),
- (
- "struct",
- "PosLookupRecord",
- "PosCount",
- 0,
- "Array of positioning lookups-in design order",
- ),
- ],
- ),
- (
- "ContextPosFormat3",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 3"),
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Number of glyphs in the input sequence",
- ),
- ("uint16", "PosCount", None, None, "Number of PosLookupRecords"),
- (
- "Offset",
- "Coverage",
- "GlyphCount",
- 0,
- "Array of offsets to Coverage tables-from beginning of ContextPos subtable",
- ),
- (
- "struct",
- "PosLookupRecord",
- "PosCount",
- 0,
- "Array of positioning lookups-in design order",
- ),
- ],
- ),
- (
- "ChainContextPosFormat1",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of ContextPos subtable",
- ),
- (
- "uint16",
- "ChainPosRuleSetCount",
- None,
- None,
- "Number of ChainPosRuleSet tables",
- ),
- (
- "Offset",
- "ChainPosRuleSet",
- "ChainPosRuleSetCount",
- 0,
- "Array of offsets to ChainPosRuleSet tables-from beginning of ContextPos subtable-ordered by Coverage Index",
- ),
- ],
- ),
- (
- "ChainPosRuleSet",
- [
- (
- "uint16",
- "ChainPosRuleCount",
- None,
- None,
- "Number of ChainPosRule tables",
- ),
- (
- "Offset",
- "ChainPosRule",
- "ChainPosRuleCount",
- 0,
- "Array of offsets to ChainPosRule tables-from beginning of ChainPosRuleSet-ordered by preference",
- ),
- ],
- ),
- (
- "ChainPosRule",
- [
- (
- "uint16",
- "BacktrackGlyphCount",
- None,
- None,
- "Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph)",
- ),
- (
- "GlyphID",
- "Backtrack",
- "BacktrackGlyphCount",
- 0,
- "Array of backtracking GlyphID's (to be matched before the input sequence)",
- ),
- (
- "uint16",
- "InputGlyphCount",
- None,
- None,
- "Total number of glyphs in the input sequence (includes the first glyph)",
- ),
- (
- "GlyphID",
- "Input",
- "InputGlyphCount",
- -1,
- "Array of input GlyphIDs (start with second glyph)",
- ),
- (
- "uint16",
- "LookAheadGlyphCount",
- None,
- None,
- "Total number of glyphs in the look ahead sequence (number of glyphs to be matched after the input sequence)",
- ),
- (
- "GlyphID",
- "LookAhead",
- "LookAheadGlyphCount",
- 0,
- "Array of lookahead GlyphID's (to be matched after the input sequence)",
- ),
- ("uint16", "PosCount", None, None, "Number of PosLookupRecords"),
- (
- "struct",
- "PosLookupRecord",
- "PosCount",
- 0,
- "Array of PosLookupRecords (in design order)",
- ),
- ],
- ),
- (
- "ChainContextPosFormat2",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 2"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of ChainContextPos subtable",
- ),
- (
- "Offset",
- "BacktrackClassDef",
- None,
- None,
- "Offset to ClassDef table containing backtrack sequence context-from beginning of ChainContextPos subtable",
- ),
- (
- "Offset",
- "InputClassDef",
- None,
- None,
- "Offset to ClassDef table containing input sequence context-from beginning of ChainContextPos subtable",
- ),
- (
- "Offset",
- "LookAheadClassDef",
- None,
- None,
- "Offset to ClassDef table containing lookahead sequence context-from beginning of ChainContextPos subtable",
- ),
- (
- "uint16",
- "ChainPosClassSetCount",
- None,
- None,
- "Number of ChainPosClassSet tables",
- ),
- (
- "Offset",
- "ChainPosClassSet",
- "ChainPosClassSetCount",
- 0,
- "Array of offsets to ChainPosClassSet tables-from beginning of ChainContextPos subtable-ordered by input class-may be NULL",
- ),
- ],
- ),
- (
- "ChainPosClassSet",
- [
- (
- "uint16",
- "ChainPosClassRuleCount",
- None,
- None,
- "Number of ChainPosClassRule tables",
- ),
- (
- "Offset",
- "ChainPosClassRule",
- "ChainPosClassRuleCount",
- 0,
- "Array of offsets to ChainPosClassRule tables-from beginning of ChainPosClassSet-ordered by preference",
- ),
- ],
- ),
- (
- "ChainPosClassRule",
- [
- (
- "uint16",
- "BacktrackGlyphCount",
- None,
- None,
- "Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph)",
- ),
- (
- "uint16",
- "Backtrack",
- "BacktrackGlyphCount",
- 0,
- "Array of backtracking classes(to be matched before the input sequence)",
- ),
- (
- "uint16",
- "InputGlyphCount",
- None,
- None,
- "Total number of classes in the input sequence (includes the first class)",
- ),
- (
- "uint16",
- "Input",
- "InputGlyphCount",
- -1,
- "Array of input classes(start with second class; to be matched with the input glyph sequence)",
- ),
- (
- "uint16",
- "LookAheadGlyphCount",
- None,
- None,
- "Total number of classes in the look ahead sequence (number of classes to be matched after the input sequence)",
- ),
- (
- "uint16",
- "LookAhead",
- "LookAheadGlyphCount",
- 0,
- "Array of lookahead classes(to be matched after the input sequence)",
- ),
- ("uint16", "PosCount", None, None, "Number of PosLookupRecords"),
- (
- "struct",
- "PosLookupRecord",
- "PosCount",
- 0,
- "Array of PosLookupRecords (in design order)",
- ),
- ],
- ),
- (
- "ChainContextPosFormat3",
- [
- ("uint16", "PosFormat", None, None, "Format identifier-format = 3"),
- (
- "uint16",
- "BacktrackGlyphCount",
- None,
- None,
- "Number of glyphs in the backtracking sequence",
- ),
- (
- "Offset",
- "BacktrackCoverage",
- "BacktrackGlyphCount",
- 0,
- "Array of offsets to coverage tables in backtracking sequence, in glyph sequence order",
- ),
- (
- "uint16",
- "InputGlyphCount",
- None,
- None,
- "Number of glyphs in input sequence",
- ),
- (
- "Offset",
- "InputCoverage",
- "InputGlyphCount",
- 0,
- "Array of offsets to coverage tables in input sequence, in glyph sequence order",
- ),
- (
- "uint16",
- "LookAheadGlyphCount",
- None,
- None,
- "Number of glyphs in lookahead sequence",
- ),
- (
- "Offset",
- "LookAheadCoverage",
- "LookAheadGlyphCount",
- 0,
- "Array of offsets to coverage tables in lookahead sequence, in glyph sequence order",
- ),
- ("uint16", "PosCount", None, None, "Number of PosLookupRecords"),
- (
- "struct",
- "PosLookupRecord",
- "PosCount",
- 0,
- "Array of PosLookupRecords,in design order",
- ),
- ],
- ),
- (
- "ExtensionPosFormat1",
- [
- ("uint16", "ExtFormat", None, None, "Format identifier. Set to 1."),
- (
- "uint16",
- "ExtensionLookupType",
- None,
- None,
- "Lookup type of subtable referenced by ExtensionOffset (i.e. the extension subtable).",
- ),
- ("LOffset", "ExtSubTable", None, None, "Offset to SubTable"),
- ],
- ),
- # ('ValueRecord', [
- # ('int16', 'XPlacement', None, None, 'Horizontal adjustment for placement-in design units'),
- # ('int16', 'YPlacement', None, None, 'Vertical adjustment for placement-in design units'),
- # ('int16', 'XAdvance', None, None, 'Horizontal adjustment for advance-in design units (only used for horizontal writing)'),
- # ('int16', 'YAdvance', None, None, 'Vertical adjustment for advance-in design units (only used for vertical writing)'),
- # ('Offset', 'XPlaDevice', None, None, 'Offset to Device table for horizontal placement-measured from beginning of PosTable (may be NULL)'),
- # ('Offset', 'YPlaDevice', None, None, 'Offset to Device table for vertical placement-measured from beginning of PosTable (may be NULL)'),
- # ('Offset', 'XAdvDevice', None, None, 'Offset to Device table for horizontal advance-measured from beginning of PosTable (may be NULL)'),
- # ('Offset', 'YAdvDevice', None, None, 'Offset to Device table for vertical advance-measured from beginning of PosTable (may be NULL)'),
- # ]),
- (
- "AnchorFormat1",
- [
- ("uint16", "AnchorFormat", None, None, "Format identifier-format = 1"),
- ("int16", "XCoordinate", None, None, "Horizontal value-in design units"),
- ("int16", "YCoordinate", None, None, "Vertical value-in design units"),
- ],
- ),
- (
- "AnchorFormat2",
- [
- ("uint16", "AnchorFormat", None, None, "Format identifier-format = 2"),
- ("int16", "XCoordinate", None, None, "Horizontal value-in design units"),
- ("int16", "YCoordinate", None, None, "Vertical value-in design units"),
- ("uint16", "AnchorPoint", None, None, "Index to glyph contour point"),
- ],
- ),
- (
- "AnchorFormat3",
- [
- ("uint16", "AnchorFormat", None, None, "Format identifier-format = 3"),
- ("int16", "XCoordinate", None, None, "Horizontal value-in design units"),
- ("int16", "YCoordinate", None, None, "Vertical value-in design units"),
- (
- "Offset",
- "XDeviceTable",
- None,
- None,
- "Offset to Device table for X coordinate- from beginning of Anchor table (may be NULL)",
- ),
- (
- "Offset",
- "YDeviceTable",
- None,
- None,
- "Offset to Device table for Y coordinate- from beginning of Anchor table (may be NULL)",
- ),
- ],
- ),
- (
- "MarkArray",
- [
- ("uint16", "MarkCount", None, None, "Number of MarkRecords"),
- (
- "struct",
- "MarkRecord",
- "MarkCount",
- 0,
- "Array of MarkRecords-in Coverage order",
- ),
- ],
- ),
- (
- "MarkRecord",
- [
- ("uint16", "Class", None, None, "Class defined for this mark"),
- (
- "Offset",
- "MarkAnchor",
- None,
- None,
- "Offset to Anchor table-from beginning of MarkArray table",
- ),
- ],
- ),
- #
- # gsub
- #
- (
- "GSUB",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the GSUB table- 0x00010000 or 0x00010001",
- ),
- (
- "Offset",
- "ScriptList",
- None,
- None,
- "Offset to ScriptList table-from beginning of GSUB table",
- ),
- (
- "Offset",
- "FeatureList",
- None,
- None,
- "Offset to FeatureList table-from beginning of GSUB table",
- ),
- (
- "Offset",
- "LookupList",
- None,
- None,
- "Offset to LookupList table-from beginning of GSUB table",
- ),
- (
- "LOffset",
- "FeatureVariations",
- None,
- "Version >= 0x00010001",
- "Offset to FeatureVariations table-from beginning of GSUB table",
- ),
- ],
- ),
- (
- "SingleSubstFormat1",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of Substitution table",
- ),
- (
- "uint16",
- "DeltaGlyphID",
- None,
- None,
- "Add to original GlyphID modulo 65536 to get substitute GlyphID",
- ),
- ],
- ),
- (
- "SingleSubstFormat2",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 2"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of Substitution table",
- ),
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Number of GlyphIDs in the Substitute array",
- ),
- (
- "GlyphID",
- "Substitute",
- "GlyphCount",
- 0,
- "Array of substitute GlyphIDs-ordered by Coverage Index",
- ),
- ],
- ),
- (
- "MultipleSubstFormat1",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of Substitution table",
- ),
- (
- "uint16",
- "SequenceCount",
- None,
- None,
- "Number of Sequence table offsets in the Sequence array",
- ),
- (
- "Offset",
- "Sequence",
- "SequenceCount",
- 0,
- "Array of offsets to Sequence tables-from beginning of Substitution table-ordered by Coverage Index",
- ),
- ],
- ),
- (
- "Sequence",
- [
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Number of GlyphIDs in the Substitute array. This should always be greater than 0.",
- ),
- (
- "GlyphID",
- "Substitute",
- "GlyphCount",
- 0,
- "String of GlyphIDs to substitute",
- ),
- ],
- ),
- (
- "AlternateSubstFormat1",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of Substitution table",
- ),
- (
- "uint16",
- "AlternateSetCount",
- None,
- None,
- "Number of AlternateSet tables",
- ),
- (
- "Offset",
- "AlternateSet",
- "AlternateSetCount",
- 0,
- "Array of offsets to AlternateSet tables-from beginning of Substitution table-ordered by Coverage Index",
- ),
- ],
- ),
- (
- "AlternateSet",
- [
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Number of GlyphIDs in the Alternate array",
- ),
- (
- "GlyphID",
- "Alternate",
- "GlyphCount",
- 0,
- "Array of alternate GlyphIDs-in arbitrary order",
- ),
- ],
- ),
- (
- "LigatureSubstFormat1",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of Substitution table",
- ),
- ("uint16", "LigSetCount", None, None, "Number of LigatureSet tables"),
- (
- "Offset",
- "LigatureSet",
- "LigSetCount",
- 0,
- "Array of offsets to LigatureSet tables-from beginning of Substitution table-ordered by Coverage Index",
- ),
- ],
- ),
- (
- "LigatureSet",
- [
- ("uint16", "LigatureCount", None, None, "Number of Ligature tables"),
- (
- "Offset",
- "Ligature",
- "LigatureCount",
- 0,
- "Array of offsets to Ligature tables-from beginning of LigatureSet table-ordered by preference",
- ),
- ],
- ),
- (
- "Ligature",
- [
- ("GlyphID", "LigGlyph", None, None, "GlyphID of ligature to substitute"),
- ("uint16", "CompCount", None, None, "Number of components in the ligature"),
- (
- "GlyphID",
- "Component",
- "CompCount",
- -1,
- "Array of component GlyphIDs-start with the second component-ordered in writing direction",
- ),
- ],
- ),
- (
- "SubstLookupRecord",
- [
- (
- "uint16",
- "SequenceIndex",
- None,
- None,
- "Index into current glyph sequence-first glyph = 0",
- ),
- (
- "uint16",
- "LookupListIndex",
- None,
- None,
- "Lookup to apply to that position-zero-based",
- ),
- ],
- ),
- (
- "ContextSubstFormat1",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of Substitution table",
- ),
- (
- "uint16",
- "SubRuleSetCount",
- None,
- None,
- "Number of SubRuleSet tables-must equal GlyphCount in Coverage table",
- ),
- (
- "Offset",
- "SubRuleSet",
- "SubRuleSetCount",
- 0,
- "Array of offsets to SubRuleSet tables-from beginning of Substitution table-ordered by Coverage Index",
- ),
- ],
- ),
- (
- "SubRuleSet",
- [
- ("uint16", "SubRuleCount", None, None, "Number of SubRule tables"),
- (
- "Offset",
- "SubRule",
- "SubRuleCount",
- 0,
- "Array of offsets to SubRule tables-from beginning of SubRuleSet table-ordered by preference",
- ),
- ],
- ),
- (
- "SubRule",
- [
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Total number of glyphs in input glyph sequence-includes the first glyph",
- ),
- ("uint16", "SubstCount", None, None, "Number of SubstLookupRecords"),
- (
- "GlyphID",
- "Input",
- "GlyphCount",
- -1,
- "Array of input GlyphIDs-start with second glyph",
- ),
- (
- "struct",
- "SubstLookupRecord",
- "SubstCount",
- 0,
- "Array of SubstLookupRecords-in design order",
- ),
- ],
- ),
- (
- "ContextSubstFormat2",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 2"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of Substitution table",
- ),
- (
- "Offset",
- "ClassDef",
- None,
- None,
- "Offset to glyph ClassDef table-from beginning of Substitution table",
- ),
- ("uint16", "SubClassSetCount", None, None, "Number of SubClassSet tables"),
- (
- "Offset",
- "SubClassSet",
- "SubClassSetCount",
- 0,
- "Array of offsets to SubClassSet tables-from beginning of Substitution table-ordered by class-may be NULL",
- ),
- ],
- ),
- (
- "SubClassSet",
- [
- (
- "uint16",
- "SubClassRuleCount",
- None,
- None,
- "Number of SubClassRule tables",
- ),
- (
- "Offset",
- "SubClassRule",
- "SubClassRuleCount",
- 0,
- "Array of offsets to SubClassRule tables-from beginning of SubClassSet-ordered by preference",
- ),
- ],
- ),
- (
- "SubClassRule",
- [
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Total number of classes specified for the context in the rule-includes the first class",
- ),
- ("uint16", "SubstCount", None, None, "Number of SubstLookupRecords"),
- (
- "uint16",
- "Class",
- "GlyphCount",
- -1,
- "Array of classes-beginning with the second class-to be matched to the input glyph class sequence",
- ),
- (
- "struct",
- "SubstLookupRecord",
- "SubstCount",
- 0,
- "Array of Substitution lookups-in design order",
- ),
- ],
- ),
- (
- "ContextSubstFormat3",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 3"),
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Number of glyphs in the input glyph sequence",
- ),
- ("uint16", "SubstCount", None, None, "Number of SubstLookupRecords"),
- (
- "Offset",
- "Coverage",
- "GlyphCount",
- 0,
- "Array of offsets to Coverage table-from beginning of Substitution table-in glyph sequence order",
- ),
- (
- "struct",
- "SubstLookupRecord",
- "SubstCount",
- 0,
- "Array of SubstLookupRecords-in design order",
- ),
- ],
- ),
- (
- "ChainContextSubstFormat1",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of Substitution table",
- ),
- (
- "uint16",
- "ChainSubRuleSetCount",
- None,
- None,
- "Number of ChainSubRuleSet tables-must equal GlyphCount in Coverage table",
- ),
- (
- "Offset",
- "ChainSubRuleSet",
- "ChainSubRuleSetCount",
- 0,
- "Array of offsets to ChainSubRuleSet tables-from beginning of Substitution table-ordered by Coverage Index",
- ),
- ],
- ),
- (
- "ChainSubRuleSet",
- [
- (
- "uint16",
- "ChainSubRuleCount",
- None,
- None,
- "Number of ChainSubRule tables",
- ),
- (
- "Offset",
- "ChainSubRule",
- "ChainSubRuleCount",
- 0,
- "Array of offsets to ChainSubRule tables-from beginning of ChainSubRuleSet table-ordered by preference",
- ),
- ],
- ),
- (
- "ChainSubRule",
- [
- (
- "uint16",
- "BacktrackGlyphCount",
- None,
- None,
- "Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph)",
- ),
- (
- "GlyphID",
- "Backtrack",
- "BacktrackGlyphCount",
- 0,
- "Array of backtracking GlyphID's (to be matched before the input sequence)",
- ),
- (
- "uint16",
- "InputGlyphCount",
- None,
- None,
- "Total number of glyphs in the input sequence (includes the first glyph)",
- ),
- (
- "GlyphID",
- "Input",
- "InputGlyphCount",
- -1,
- "Array of input GlyphIDs (start with second glyph)",
- ),
- (
- "uint16",
- "LookAheadGlyphCount",
- None,
- None,
- "Total number of glyphs in the look ahead sequence (number of glyphs to be matched after the input sequence)",
- ),
- (
- "GlyphID",
- "LookAhead",
- "LookAheadGlyphCount",
- 0,
- "Array of lookahead GlyphID's (to be matched after the input sequence)",
- ),
- ("uint16", "SubstCount", None, None, "Number of SubstLookupRecords"),
- (
- "struct",
- "SubstLookupRecord",
- "SubstCount",
- 0,
- "Array of SubstLookupRecords (in design order)",
- ),
- ],
- ),
- (
- "ChainContextSubstFormat2",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 2"),
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table-from beginning of Substitution table",
- ),
- (
- "Offset",
- "BacktrackClassDef",
- None,
- None,
- "Offset to glyph ClassDef table containing backtrack sequence data-from beginning of Substitution table",
- ),
- (
- "Offset",
- "InputClassDef",
- None,
- None,
- "Offset to glyph ClassDef table containing input sequence data-from beginning of Substitution table",
- ),
- (
- "Offset",
- "LookAheadClassDef",
- None,
- None,
- "Offset to glyph ClassDef table containing lookahead sequence data-from beginning of Substitution table",
- ),
- (
- "uint16",
- "ChainSubClassSetCount",
- None,
- None,
- "Number of ChainSubClassSet tables",
- ),
- (
- "Offset",
- "ChainSubClassSet",
- "ChainSubClassSetCount",
- 0,
- "Array of offsets to ChainSubClassSet tables-from beginning of Substitution table-ordered by input class-may be NULL",
- ),
- ],
- ),
- (
- "ChainSubClassSet",
- [
- (
- "uint16",
- "ChainSubClassRuleCount",
- None,
- None,
- "Number of ChainSubClassRule tables",
- ),
- (
- "Offset",
- "ChainSubClassRule",
- "ChainSubClassRuleCount",
- 0,
- "Array of offsets to ChainSubClassRule tables-from beginning of ChainSubClassSet-ordered by preference",
- ),
- ],
- ),
- (
- "ChainSubClassRule",
- [
- (
- "uint16",
- "BacktrackGlyphCount",
- None,
- None,
- "Total number of glyphs in the backtrack sequence (number of glyphs to be matched before the first glyph)",
- ),
- (
- "uint16",
- "Backtrack",
- "BacktrackGlyphCount",
- 0,
- "Array of backtracking classes(to be matched before the input sequence)",
- ),
- (
- "uint16",
- "InputGlyphCount",
- None,
- None,
- "Total number of classes in the input sequence (includes the first class)",
- ),
- (
- "uint16",
- "Input",
- "InputGlyphCount",
- -1,
- "Array of input classes(start with second class; to be matched with the input glyph sequence)",
- ),
- (
- "uint16",
- "LookAheadGlyphCount",
- None,
- None,
- "Total number of classes in the look ahead sequence (number of classes to be matched after the input sequence)",
- ),
- (
- "uint16",
- "LookAhead",
- "LookAheadGlyphCount",
- 0,
- "Array of lookahead classes(to be matched after the input sequence)",
- ),
- ("uint16", "SubstCount", None, None, "Number of SubstLookupRecords"),
- (
- "struct",
- "SubstLookupRecord",
- "SubstCount",
- 0,
- "Array of SubstLookupRecords (in design order)",
- ),
- ],
- ),
- (
- "ChainContextSubstFormat3",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 3"),
- (
- "uint16",
- "BacktrackGlyphCount",
- None,
- None,
- "Number of glyphs in the backtracking sequence",
- ),
- (
- "Offset",
- "BacktrackCoverage",
- "BacktrackGlyphCount",
- 0,
- "Array of offsets to coverage tables in backtracking sequence, in glyph sequence order",
- ),
- (
- "uint16",
- "InputGlyphCount",
- None,
- None,
- "Number of glyphs in input sequence",
- ),
- (
- "Offset",
- "InputCoverage",
- "InputGlyphCount",
- 0,
- "Array of offsets to coverage tables in input sequence, in glyph sequence order",
- ),
- (
- "uint16",
- "LookAheadGlyphCount",
- None,
- None,
- "Number of glyphs in lookahead sequence",
- ),
- (
- "Offset",
- "LookAheadCoverage",
- "LookAheadGlyphCount",
- 0,
- "Array of offsets to coverage tables in lookahead sequence, in glyph sequence order",
- ),
- ("uint16", "SubstCount", None, None, "Number of SubstLookupRecords"),
- (
- "struct",
- "SubstLookupRecord",
- "SubstCount",
- 0,
- "Array of SubstLookupRecords, in design order",
- ),
- ],
- ),
- (
- "ExtensionSubstFormat1",
- [
- ("uint16", "ExtFormat", None, None, "Format identifier. Set to 1."),
- (
- "uint16",
- "ExtensionLookupType",
- None,
- None,
- "Lookup type of subtable referenced by ExtensionOffset (i.e. the extension subtable).",
- ),
- (
- "LOffset",
- "ExtSubTable",
- None,
- None,
- "Array of offsets to Lookup tables-from beginning of LookupList -zero based (first lookup is Lookup index = 0)",
- ),
- ],
- ),
- (
- "ReverseChainSingleSubstFormat1",
- [
- ("uint16", "SubstFormat", None, None, "Format identifier-format = 1"),
- (
- "Offset",
- "Coverage",
- None,
- 0,
- "Offset to Coverage table - from beginning of Substitution table",
- ),
- (
- "uint16",
- "BacktrackGlyphCount",
- None,
- None,
- "Number of glyphs in the backtracking sequence",
- ),
- (
- "Offset",
- "BacktrackCoverage",
- "BacktrackGlyphCount",
- 0,
- "Array of offsets to coverage tables in backtracking sequence, in glyph sequence order",
- ),
- (
- "uint16",
- "LookAheadGlyphCount",
- None,
- None,
- "Number of glyphs in lookahead sequence",
- ),
- (
- "Offset",
- "LookAheadCoverage",
- "LookAheadGlyphCount",
- 0,
- "Array of offsets to coverage tables in lookahead sequence, in glyph sequence order",
- ),
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Number of GlyphIDs in the Substitute array",
- ),
- (
- "GlyphID",
- "Substitute",
- "GlyphCount",
- 0,
- "Array of substitute GlyphIDs-ordered by Coverage index",
- ),
- ],
- ),
- #
- # gdef
- #
- (
- "GDEF",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the GDEF table- 0x00010000, 0x00010002, or 0x00010003",
- ),
- (
- "Offset",
- "GlyphClassDef",
- None,
- None,
- "Offset to class definition table for glyph type-from beginning of GDEF header (may be NULL)",
- ),
- (
- "Offset",
- "AttachList",
- None,
- None,
- "Offset to list of glyphs with attachment points-from beginning of GDEF header (may be NULL)",
- ),
- (
- "Offset",
- "LigCaretList",
- None,
- None,
- "Offset to list of positioning points for ligature carets-from beginning of GDEF header (may be NULL)",
- ),
- (
- "Offset",
- "MarkAttachClassDef",
- None,
- None,
- "Offset to class definition table for mark attachment type-from beginning of GDEF header (may be NULL)",
- ),
- (
- "Offset",
- "MarkGlyphSetsDef",
- None,
- "Version >= 0x00010002",
- "Offset to the table of mark set definitions-from beginning of GDEF header (may be NULL)",
- ),
- (
- "LOffset",
- "VarStore",
- None,
- "Version >= 0x00010003",
- "Offset to variation store (may be NULL)",
- ),
- ],
- ),
- (
- "AttachList",
- [
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table - from beginning of AttachList table",
- ),
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Number of glyphs with attachment points",
- ),
- (
- "Offset",
- "AttachPoint",
- "GlyphCount",
- 0,
- "Array of offsets to AttachPoint tables-from beginning of AttachList table-in Coverage Index order",
- ),
- ],
- ),
- (
- "AttachPoint",
- [
- (
- "uint16",
- "PointCount",
- None,
- None,
- "Number of attachment points on this glyph",
- ),
- (
- "uint16",
- "PointIndex",
- "PointCount",
- 0,
- "Array of contour point indices -in increasing numerical order",
- ),
- ],
- ),
- (
- "LigCaretList",
- [
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table - from beginning of LigCaretList table",
- ),
- ("uint16", "LigGlyphCount", None, None, "Number of ligature glyphs"),
- (
- "Offset",
- "LigGlyph",
- "LigGlyphCount",
- 0,
- "Array of offsets to LigGlyph tables-from beginning of LigCaretList table-in Coverage Index order",
- ),
- ],
- ),
- (
- "LigGlyph",
- [
- (
- "uint16",
- "CaretCount",
- None,
- None,
- "Number of CaretValues for this ligature (components - 1)",
- ),
- (
- "Offset",
- "CaretValue",
- "CaretCount",
- 0,
- "Array of offsets to CaretValue tables-from beginning of LigGlyph table-in increasing coordinate order",
- ),
- ],
- ),
- (
- "CaretValueFormat1",
- [
- ("uint16", "CaretValueFormat", None, None, "Format identifier-format = 1"),
- ("int16", "Coordinate", None, None, "X or Y value, in design units"),
- ],
- ),
- (
- "CaretValueFormat2",
- [
- ("uint16", "CaretValueFormat", None, None, "Format identifier-format = 2"),
- ("uint16", "CaretValuePoint", None, None, "Contour point index on glyph"),
- ],
- ),
- (
- "CaretValueFormat3",
- [
- ("uint16", "CaretValueFormat", None, None, "Format identifier-format = 3"),
- ("int16", "Coordinate", None, None, "X or Y value, in design units"),
- (
- "Offset",
- "DeviceTable",
- None,
- None,
- "Offset to Device table for X or Y value-from beginning of CaretValue table",
- ),
- ],
- ),
- (
- "MarkGlyphSetsDef",
- [
- ("uint16", "MarkSetTableFormat", None, None, "Format identifier == 1"),
- ("uint16", "MarkSetCount", None, None, "Number of mark sets defined"),
- (
- "LOffset",
- "Coverage",
- "MarkSetCount",
- 0,
- "Array of offsets to mark set coverage tables.",
- ),
- ],
- ),
- #
- # base
- #
- (
- "BASE",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the BASE table-initially 0x00010000",
- ),
- (
- "Offset",
- "HorizAxis",
- None,
- None,
- "Offset to horizontal Axis table-from beginning of BASE table-may be NULL",
- ),
- (
- "Offset",
- "VertAxis",
- None,
- None,
- "Offset to vertical Axis table-from beginning of BASE table-may be NULL",
- ),
- (
- "LOffset",
- "VarStore",
- None,
- "Version >= 0x00010001",
- "Offset to variation store (may be NULL)",
- ),
- ],
- ),
- (
- "Axis",
- [
- (
- "Offset",
- "BaseTagList",
- None,
- None,
- "Offset to BaseTagList table-from beginning of Axis table-may be NULL",
- ),
- (
- "Offset",
- "BaseScriptList",
- None,
- None,
- "Offset to BaseScriptList table-from beginning of Axis table",
- ),
- ],
- ),
- (
- "BaseTagList",
- [
- (
- "uint16",
- "BaseTagCount",
- None,
- None,
- "Number of baseline identification tags in this text direction-may be zero (0)",
- ),
- (
- "Tag",
- "BaselineTag",
- "BaseTagCount",
- 0,
- "Array of 4-byte baseline identification tags-must be in alphabetical order",
- ),
- ],
- ),
- (
- "BaseScriptList",
- [
- (
- "uint16",
- "BaseScriptCount",
- None,
- None,
- "Number of BaseScriptRecords defined",
- ),
- (
- "struct",
- "BaseScriptRecord",
- "BaseScriptCount",
- 0,
- "Array of BaseScriptRecords-in alphabetical order by BaseScriptTag",
- ),
- ],
- ),
- (
- "BaseScriptRecord",
- [
- ("Tag", "BaseScriptTag", None, None, "4-byte script identification tag"),
- (
- "Offset",
- "BaseScript",
- None,
- None,
- "Offset to BaseScript table-from beginning of BaseScriptList",
- ),
- ],
- ),
- (
- "BaseScript",
- [
- (
- "Offset",
- "BaseValues",
- None,
- None,
- "Offset to BaseValues table-from beginning of BaseScript table-may be NULL",
- ),
- (
- "Offset",
- "DefaultMinMax",
- None,
- None,
- "Offset to MinMax table- from beginning of BaseScript table-may be NULL",
- ),
- (
- "uint16",
- "BaseLangSysCount",
- None,
- None,
- "Number of BaseLangSysRecords defined-may be zero (0)",
- ),
- (
- "struct",
- "BaseLangSysRecord",
- "BaseLangSysCount",
- 0,
- "Array of BaseLangSysRecords-in alphabetical order by BaseLangSysTag",
- ),
- ],
- ),
- (
- "BaseLangSysRecord",
- [
- (
- "Tag",
- "BaseLangSysTag",
- None,
- None,
- "4-byte language system identification tag",
- ),
- (
- "Offset",
- "MinMax",
- None,
- None,
- "Offset to MinMax table-from beginning of BaseScript table",
- ),
- ],
- ),
- (
- "BaseValues",
- [
- (
- "uint16",
- "DefaultIndex",
- None,
- None,
- "Index number of default baseline for this script-equals index position of baseline tag in BaselineArray of the BaseTagList",
- ),
- (
- "uint16",
- "BaseCoordCount",
- None,
- None,
- "Number of BaseCoord tables defined-should equal BaseTagCount in the BaseTagList",
- ),
- (
- "Offset",
- "BaseCoord",
- "BaseCoordCount",
- 0,
- "Array of offsets to BaseCoord-from beginning of BaseValues table-order matches BaselineTag array in the BaseTagList",
- ),
- ],
- ),
- (
- "MinMax",
- [
- (
- "Offset",
- "MinCoord",
- None,
- None,
- "Offset to BaseCoord table-defines minimum extent value-from the beginning of MinMax table-may be NULL",
- ),
- (
- "Offset",
- "MaxCoord",
- None,
- None,
- "Offset to BaseCoord table-defines maximum extent value-from the beginning of MinMax table-may be NULL",
- ),
- (
- "uint16",
- "FeatMinMaxCount",
- None,
- None,
- "Number of FeatMinMaxRecords-may be zero (0)",
- ),
- (
- "struct",
- "FeatMinMaxRecord",
- "FeatMinMaxCount",
- 0,
- "Array of FeatMinMaxRecords-in alphabetical order, by FeatureTableTag",
- ),
- ],
- ),
- (
- "FeatMinMaxRecord",
- [
- (
- "Tag",
- "FeatureTableTag",
- None,
- None,
- "4-byte feature identification tag-must match FeatureTag in FeatureList",
- ),
- (
- "Offset",
- "MinCoord",
- None,
- None,
- "Offset to BaseCoord table-defines minimum extent value-from beginning of MinMax table-may be NULL",
- ),
- (
- "Offset",
- "MaxCoord",
- None,
- None,
- "Offset to BaseCoord table-defines maximum extent value-from beginning of MinMax table-may be NULL",
- ),
- ],
- ),
- (
- "BaseCoordFormat1",
- [
- ("uint16", "BaseCoordFormat", None, None, "Format identifier-format = 1"),
- ("int16", "Coordinate", None, None, "X or Y value, in design units"),
- ],
- ),
- (
- "BaseCoordFormat2",
- [
- ("uint16", "BaseCoordFormat", None, None, "Format identifier-format = 2"),
- ("int16", "Coordinate", None, None, "X or Y value, in design units"),
- ("GlyphID", "ReferenceGlyph", None, None, "GlyphID of control glyph"),
- (
- "uint16",
- "BaseCoordPoint",
- None,
- None,
- "Index of contour point on the ReferenceGlyph",
- ),
- ],
- ),
- (
- "BaseCoordFormat3",
- [
- ("uint16", "BaseCoordFormat", None, None, "Format identifier-format = 3"),
- ("int16", "Coordinate", None, None, "X or Y value, in design units"),
- (
- "Offset",
- "DeviceTable",
- None,
- None,
- "Offset to Device table for X or Y value",
- ),
- ],
- ),
- #
- # jstf
- #
- (
- "JSTF",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the JSTF table-initially set to 0x00010000",
- ),
- (
- "uint16",
- "JstfScriptCount",
- None,
- None,
- "Number of JstfScriptRecords in this table",
- ),
- (
- "struct",
- "JstfScriptRecord",
- "JstfScriptCount",
- 0,
- "Array of JstfScriptRecords-in alphabetical order, by JstfScriptTag",
- ),
- ],
- ),
- (
- "JstfScriptRecord",
- [
- ("Tag", "JstfScriptTag", None, None, "4-byte JstfScript identification"),
- (
- "Offset",
- "JstfScript",
- None,
- None,
- "Offset to JstfScript table-from beginning of JSTF Header",
- ),
- ],
- ),
- (
- "JstfScript",
- [
- (
- "Offset",
- "ExtenderGlyph",
- None,
- None,
- "Offset to ExtenderGlyph table-from beginning of JstfScript table-may be NULL",
- ),
- (
- "Offset",
- "DefJstfLangSys",
- None,
- None,
- "Offset to Default JstfLangSys table-from beginning of JstfScript table-may be NULL",
- ),
- (
- "uint16",
- "JstfLangSysCount",
- None,
- None,
- "Number of JstfLangSysRecords in this table- may be zero (0)",
- ),
- (
- "struct",
- "JstfLangSysRecord",
- "JstfLangSysCount",
- 0,
- "Array of JstfLangSysRecords-in alphabetical order, by JstfLangSysTag",
- ),
- ],
- ),
- (
- "JstfLangSysRecord",
- [
- ("Tag", "JstfLangSysTag", None, None, "4-byte JstfLangSys identifier"),
- (
- "Offset",
- "JstfLangSys",
- None,
- None,
- "Offset to JstfLangSys table-from beginning of JstfScript table",
- ),
- ],
- ),
- (
- "ExtenderGlyph",
- [
- (
- "uint16",
- "GlyphCount",
- None,
- None,
- "Number of Extender Glyphs in this script",
- ),
- (
- "GlyphID",
- "ExtenderGlyph",
- "GlyphCount",
- 0,
- "GlyphIDs-in increasing numerical order",
- ),
- ],
- ),
- (
- "JstfLangSys",
- [
- (
- "uint16",
- "JstfPriorityCount",
- None,
- None,
- "Number of JstfPriority tables",
- ),
- (
- "Offset",
- "JstfPriority",
- "JstfPriorityCount",
- 0,
- "Array of offsets to JstfPriority tables-from beginning of JstfLangSys table-in priority order",
- ),
- ],
- ),
- (
- "JstfPriority",
- [
- (
- "Offset",
- "ShrinkageEnableGSUB",
- None,
- None,
- "Offset to Shrinkage Enable JstfGSUBModList table-from beginning of JstfPriority table-may be NULL",
- ),
- (
- "Offset",
- "ShrinkageDisableGSUB",
- None,
- None,
- "Offset to Shrinkage Disable JstfGSUBModList table-from beginning of JstfPriority table-may be NULL",
- ),
- (
- "Offset",
- "ShrinkageEnableGPOS",
- None,
- None,
- "Offset to Shrinkage Enable JstfGPOSModList table-from beginning of JstfPriority table-may be NULL",
- ),
- (
- "Offset",
- "ShrinkageDisableGPOS",
- None,
- None,
- "Offset to Shrinkage Disable JstfGPOSModList table-from beginning of JstfPriority table-may be NULL",
- ),
- (
- "Offset",
- "ShrinkageJstfMax",
- None,
- None,
- "Offset to Shrinkage JstfMax table-from beginning of JstfPriority table -may be NULL",
- ),
- (
- "Offset",
- "ExtensionEnableGSUB",
- None,
- None,
- "Offset to Extension Enable JstfGSUBModList table-may be NULL",
- ),
- (
- "Offset",
- "ExtensionDisableGSUB",
- None,
- None,
- "Offset to Extension Disable JstfGSUBModList table-from beginning of JstfPriority table-may be NULL",
- ),
- (
- "Offset",
- "ExtensionEnableGPOS",
- None,
- None,
- "Offset to Extension Enable JstfGSUBModList table-may be NULL",
- ),
- (
- "Offset",
- "ExtensionDisableGPOS",
- None,
- None,
- "Offset to Extension Disable JstfGSUBModList table-from beginning of JstfPriority table-may be NULL",
- ),
- (
- "Offset",
- "ExtensionJstfMax",
- None,
- None,
- "Offset to Extension JstfMax table-from beginning of JstfPriority table -may be NULL",
- ),
- ],
- ),
- (
- "JstfGSUBModList",
- [
- (
- "uint16",
- "LookupCount",
- None,
- None,
- "Number of lookups for this modification",
- ),
- (
- "uint16",
- "GSUBLookupIndex",
- "LookupCount",
- 0,
- "Array of LookupIndex identifiers in GSUB-in increasing numerical order",
- ),
- ],
- ),
- (
- "JstfGPOSModList",
- [
- (
- "uint16",
- "LookupCount",
- None,
- None,
- "Number of lookups for this modification",
- ),
- (
- "uint16",
- "GPOSLookupIndex",
- "LookupCount",
- 0,
- "Array of LookupIndex identifiers in GPOS-in increasing numerical order",
- ),
- ],
- ),
- (
- "JstfMax",
- [
- (
- "uint16",
- "LookupCount",
- None,
- None,
- "Number of lookup Indices for this modification",
- ),
- (
- "Offset",
- "Lookup",
- "LookupCount",
- 0,
- "Array of offsets to GPOS-type lookup tables-from beginning of JstfMax table-in design order",
- ),
- ],
- ),
- #
- # STAT
- #
- (
- "STAT",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the table-initially set to 0x00010000, currently 0x00010002.",
- ),
- (
- "uint16",
- "DesignAxisRecordSize",
- None,
- None,
- "Size in bytes of each design axis record",
- ),
- ("uint16", "DesignAxisCount", None, None, "Number of design axis records"),
- (
- "LOffsetTo(AxisRecordArray)",
- "DesignAxisRecord",
- None,
- None,
- "Offset in bytes from the beginning of the STAT table to the start of the design axes array",
- ),
- ("uint16", "AxisValueCount", None, None, "Number of axis value tables"),
- (
- "LOffsetTo(AxisValueArray)",
- "AxisValueArray",
- None,
- None,
- "Offset in bytes from the beginning of the STAT table to the start of the axes value offset array",
- ),
- (
- "NameID",
- "ElidedFallbackNameID",
- None,
- "Version >= 0x00010001",
- "NameID to use when all style attributes are elided.",
- ),
- ],
- ),
- (
- "AxisRecordArray",
- [
- ("AxisRecord", "Axis", "DesignAxisCount", 0, "Axis records"),
- ],
- ),
- (
- "AxisRecord",
- [
- (
- "Tag",
- "AxisTag",
- None,
- None,
- "A tag identifying the axis of design variation",
- ),
- (
- "NameID",
- "AxisNameID",
- None,
- None,
- 'The name ID for entries in the "name" table that provide a display string for this axis',
- ),
- (
- "uint16",
- "AxisOrdering",
- None,
- None,
- "A value that applications can use to determine primary sorting of face names, or for ordering of descriptors when composing family or face names",
- ),
- (
- "uint8",
- "MoreBytes",
- "DesignAxisRecordSize",
- -8,
- "Extra bytes. Set to empty array.",
- ),
- ],
- ),
- (
- "AxisValueArray",
- [
- ("Offset", "AxisValue", "AxisValueCount", 0, "Axis values"),
- ],
- ),
- (
- "AxisValueFormat1",
- [
- ("uint16", "Format", None, None, "Format, = 1"),
- (
- "uint16",
- "AxisIndex",
- None,
- None,
- "Index into the axis record array identifying the axis of design variation to which the axis value record applies.",
- ),
- ("STATFlags", "Flags", None, None, "Flags."),
- ("NameID", "ValueNameID", None, None, ""),
- ("Fixed", "Value", None, None, ""),
- ],
- ),
- (
- "AxisValueFormat2",
- [
- ("uint16", "Format", None, None, "Format, = 2"),
- (
- "uint16",
- "AxisIndex",
- None,
- None,
- "Index into the axis record array identifying the axis of design variation to which the axis value record applies.",
- ),
- ("STATFlags", "Flags", None, None, "Flags."),
- ("NameID", "ValueNameID", None, None, ""),
- ("Fixed", "NominalValue", None, None, ""),
- ("Fixed", "RangeMinValue", None, None, ""),
- ("Fixed", "RangeMaxValue", None, None, ""),
- ],
- ),
- (
- "AxisValueFormat3",
- [
- ("uint16", "Format", None, None, "Format, = 3"),
- (
- "uint16",
- "AxisIndex",
- None,
- None,
- "Index into the axis record array identifying the axis of design variation to which the axis value record applies.",
- ),
- ("STATFlags", "Flags", None, None, "Flags."),
- ("NameID", "ValueNameID", None, None, ""),
- ("Fixed", "Value", None, None, ""),
- ("Fixed", "LinkedValue", None, None, ""),
- ],
- ),
- (
- "AxisValueFormat4",
- [
- ("uint16", "Format", None, None, "Format, = 4"),
- (
- "uint16",
- "AxisCount",
- None,
- None,
- "The total number of axes contributing to this axis-values combination.",
- ),
- ("STATFlags", "Flags", None, None, "Flags."),
- ("NameID", "ValueNameID", None, None, ""),
- (
- "struct",
- "AxisValueRecord",
- "AxisCount",
- 0,
- "Array of AxisValue records that provide the combination of axis values, one for each contributing axis. ",
- ),
- ],
- ),
- (
- "AxisValueRecord",
- [
- (
- "uint16",
- "AxisIndex",
- None,
- None,
- "Index into the axis record array identifying the axis of design variation to which the axis value record applies.",
- ),
- ("Fixed", "Value", None, None, "A numeric value for this attribute value."),
- ],
- ),
- #
- # Variation fonts
- #
- # GSUB/GPOS FeatureVariations
- (
- "FeatureVariations",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the table-initially set to 0x00010000",
- ),
- (
- "uint32",
- "FeatureVariationCount",
- None,
- None,
- "Number of records in the FeatureVariationRecord array",
- ),
- (
- "struct",
- "FeatureVariationRecord",
- "FeatureVariationCount",
- 0,
- "Array of FeatureVariationRecord",
- ),
- ],
- ),
- (
- "FeatureVariationRecord",
- [
- (
- "LOffset",
- "ConditionSet",
- None,
- None,
- "Offset to a ConditionSet table, from beginning of the FeatureVariations table.",
- ),
- (
- "LOffset",
- "FeatureTableSubstitution",
- None,
- None,
- "Offset to a FeatureTableSubstitution table, from beginning of the FeatureVariations table",
- ),
- ],
- ),
- (
- "ConditionSet",
- [
- (
- "uint16",
- "ConditionCount",
- None,
- None,
- "Number of condition tables in the ConditionTable array",
- ),
- (
- "LOffset",
- "ConditionTable",
- "ConditionCount",
- 0,
- "Array of condition tables.",
- ),
- ],
- ),
- (
- "ConditionTableFormat1",
- [
- ("uint16", "Format", None, None, "Format, = 1"),
- (
- "uint16",
- "AxisIndex",
- None,
- None,
- "Index for the variation axis within the fvar table, base 0.",
- ),
- (
- "F2Dot14",
- "FilterRangeMinValue",
- None,
- None,
- "Minimum normalized axis value of the font variation instances that satisfy this condition.",
- ),
- (
- "F2Dot14",
- "FilterRangeMaxValue",
- None,
- None,
- "Maximum value that satisfies this condition.",
- ),
- ],
- ),
- (
- "FeatureTableSubstitution",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the table-initially set to 0x00010000",
- ),
- (
- "uint16",
- "SubstitutionCount",
- None,
- None,
- "Number of records in the FeatureVariationRecords array",
- ),
- (
- "FeatureTableSubstitutionRecord",
- "SubstitutionRecord",
- "SubstitutionCount",
- 0,
- "Array of FeatureTableSubstitutionRecord",
- ),
- ],
- ),
- (
- "FeatureTableSubstitutionRecord",
- [
- ("uint16", "FeatureIndex", None, None, "The feature table index to match."),
- (
- "LOffset",
- "Feature",
- None,
- None,
- "Offset to an alternate feature table, from start of the FeatureTableSubstitution table.",
- ),
- ],
- ),
- # VariationStore
- (
- "VarRegionAxis",
- [
- ("F2Dot14", "StartCoord", None, None, ""),
- ("F2Dot14", "PeakCoord", None, None, ""),
- ("F2Dot14", "EndCoord", None, None, ""),
- ],
- ),
- (
- "VarRegion",
- [
- ("struct", "VarRegionAxis", "RegionAxisCount", 0, ""),
- ],
- ),
- (
- "VarRegionList",
- [
- ("uint16", "RegionAxisCount", None, None, ""),
- ("uint16", "RegionCount", None, None, ""),
- ("VarRegion", "Region", "RegionCount", 0, ""),
- ],
- ),
- (
- "VarData",
- [
- ("uint16", "ItemCount", None, None, ""),
- ("uint16", "NumShorts", None, None, ""),
- ("uint16", "VarRegionCount", None, None, ""),
- ("uint16", "VarRegionIndex", "VarRegionCount", 0, ""),
- ("VarDataValue", "Item", "ItemCount", 0, ""),
- ],
- ),
- (
- "VarStore",
- [
- ("uint16", "Format", None, None, "Set to 1."),
- ("LOffset", "VarRegionList", None, None, ""),
- ("uint16", "VarDataCount", None, None, ""),
- ("LOffset", "VarData", "VarDataCount", 0, ""),
- ],
- ),
- # Variation helpers
- (
- "VarIdxMap",
- [
- ("uint16", "EntryFormat", None, None, ""), # Automatically computed
- ("uint16", "MappingCount", None, None, ""), # Automatically computed
- ("VarIdxMapValue", "mapping", "", 0, "Array of compressed data"),
- ],
- ),
- (
- "DeltaSetIndexMapFormat0",
- [
- ("uint8", "Format", None, None, "Format of the DeltaSetIndexMap = 0"),
- ("uint8", "EntryFormat", None, None, ""), # Automatically computed
- ("uint16", "MappingCount", None, None, ""), # Automatically computed
- ("VarIdxMapValue", "mapping", "", 0, "Array of compressed data"),
- ],
- ),
- (
- "DeltaSetIndexMapFormat1",
- [
- ("uint8", "Format", None, None, "Format of the DeltaSetIndexMap = 1"),
- ("uint8", "EntryFormat", None, None, ""), # Automatically computed
- ("uint32", "MappingCount", None, None, ""), # Automatically computed
- ("VarIdxMapValue", "mapping", "", 0, "Array of compressed data"),
- ],
- ),
- # Glyph advance variations
- (
- "HVAR",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the HVAR table-initially = 0x00010000",
- ),
- ("LOffset", "VarStore", None, None, ""),
- ("LOffsetTo(VarIdxMap)", "AdvWidthMap", None, None, ""),
- ("LOffsetTo(VarIdxMap)", "LsbMap", None, None, ""),
- ("LOffsetTo(VarIdxMap)", "RsbMap", None, None, ""),
- ],
- ),
- (
- "VVAR",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the VVAR table-initially = 0x00010000",
- ),
- ("LOffset", "VarStore", None, None, ""),
- ("LOffsetTo(VarIdxMap)", "AdvHeightMap", None, None, ""),
- ("LOffsetTo(VarIdxMap)", "TsbMap", None, None, ""),
- ("LOffsetTo(VarIdxMap)", "BsbMap", None, None, ""),
- ("LOffsetTo(VarIdxMap)", "VOrgMap", None, None, "Vertical origin mapping."),
- ],
- ),
- # Font-wide metrics variations
- (
- "MetricsValueRecord",
- [
- ("Tag", "ValueTag", None, None, "4-byte font-wide measure identifier"),
- ("uint32", "VarIdx", None, None, "Combined outer-inner variation index"),
- (
- "uint8",
- "MoreBytes",
- "ValueRecordSize",
- -8,
- "Extra bytes. Set to empty array.",
- ),
- ],
- ),
- (
- "MVAR",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the MVAR table-initially = 0x00010000",
- ),
- ("uint16", "Reserved", None, None, "Set to 0"),
- ("uint16", "ValueRecordSize", None, None, ""),
- ("uint16", "ValueRecordCount", None, None, ""),
- ("Offset", "VarStore", None, None, ""),
- ("MetricsValueRecord", "ValueRecord", "ValueRecordCount", 0, ""),
- ],
- ),
- #
- # math
- #
- (
- "MATH",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the MATH table-initially set to 0x00010000.",
- ),
- (
- "Offset",
- "MathConstants",
- None,
- None,
- "Offset to MathConstants table - from the beginning of MATH table.",
- ),
- (
- "Offset",
- "MathGlyphInfo",
- None,
- None,
- "Offset to MathGlyphInfo table - from the beginning of MATH table.",
- ),
- (
- "Offset",
- "MathVariants",
- None,
- None,
- "Offset to MathVariants table - from the beginning of MATH table.",
- ),
- ],
- ),
- (
- "MathValueRecord",
- [
- ("int16", "Value", None, None, "The X or Y value in design units."),
- (
- "Offset",
- "DeviceTable",
- None,
- None,
- "Offset to the device table - from the beginning of parent table. May be NULL. Suggested format for device table is 1.",
- ),
- ],
- ),
- (
- "MathConstants",
- [
- (
- "int16",
- "ScriptPercentScaleDown",
- None,
- None,
- "Percentage of scaling down for script level 1. Suggested value: 80%.",
- ),
- (
- "int16",
- "ScriptScriptPercentScaleDown",
- None,
- None,
- "Percentage of scaling down for script level 2 (ScriptScript). Suggested value: 60%.",
- ),
- (
- "uint16",
- "DelimitedSubFormulaMinHeight",
- None,
- None,
- "Minimum height required for a delimited expression to be treated as a subformula. Suggested value: normal line height x1.5.",
- ),
- (
- "uint16",
- "DisplayOperatorMinHeight",
- None,
- None,
- "Minimum height of n-ary operators (such as integral and summation) for formulas in display mode.",
- ),
- (
- "MathValueRecord",
- "MathLeading",
- None,
- None,
- "White space to be left between math formulas to ensure proper line spacing. For example, for applications that treat line gap as a part of line ascender, formulas with ink going above (os2.sTypoAscender + os2.sTypoLineGap - MathLeading) or with ink going below os2.sTypoDescender will result in increasing line height.",
- ),
- ("MathValueRecord", "AxisHeight", None, None, "Axis height of the font."),
- (
- "MathValueRecord",
- "AccentBaseHeight",
- None,
- None,
- "Maximum (ink) height of accent base that does not require raising the accents. Suggested: x-height of the font (os2.sxHeight) plus any possible overshots.",
- ),
- (
- "MathValueRecord",
- "FlattenedAccentBaseHeight",
- None,
- None,
- "Maximum (ink) height of accent base that does not require flattening the accents. Suggested: cap height of the font (os2.sCapHeight).",
- ),
- (
- "MathValueRecord",
- "SubscriptShiftDown",
- None,
- None,
- "The standard shift down applied to subscript elements. Positive for moving in the downward direction. Suggested: os2.ySubscriptYOffset.",
- ),
- (
- "MathValueRecord",
- "SubscriptTopMax",
- None,
- None,
- "Maximum allowed height of the (ink) top of subscripts that does not require moving subscripts further down. Suggested: 4/5 x-height.",
- ),
- (
- "MathValueRecord",
- "SubscriptBaselineDropMin",
- None,
- None,
- "Minimum allowed drop of the baseline of subscripts relative to the (ink) bottom of the base. Checked for bases that are treated as a box or extended shape. Positive for subscript baseline dropped below the base bottom.",
- ),
- (
- "MathValueRecord",
- "SuperscriptShiftUp",
- None,
- None,
- "Standard shift up applied to superscript elements. Suggested: os2.ySuperscriptYOffset.",
- ),
- (
- "MathValueRecord",
- "SuperscriptShiftUpCramped",
- None,
- None,
- "Standard shift of superscripts relative to the base, in cramped style.",
- ),
- (
- "MathValueRecord",
- "SuperscriptBottomMin",
- None,
- None,
- "Minimum allowed height of the (ink) bottom of superscripts that does not require moving subscripts further up. Suggested: 1/4 x-height.",
- ),
- (
- "MathValueRecord",
- "SuperscriptBaselineDropMax",
- None,
- None,
- "Maximum allowed drop of the baseline of superscripts relative to the (ink) top of the base. Checked for bases that are treated as a box or extended shape. Positive for superscript baseline below the base top.",
- ),
- (
- "MathValueRecord",
- "SubSuperscriptGapMin",
- None,
- None,
- "Minimum gap between the superscript and subscript ink. Suggested: 4x default rule thickness.",
- ),
- (
- "MathValueRecord",
- "SuperscriptBottomMaxWithSubscript",
- None,
- None,
- "The maximum level to which the (ink) bottom of superscript can be pushed to increase the gap between superscript and subscript, before subscript starts being moved down. Suggested: 4/5 x-height.",
- ),
- (
- "MathValueRecord",
- "SpaceAfterScript",
- None,
- None,
- "Extra white space to be added after each subscript and superscript. Suggested: 0.5pt for a 12 pt font.",
- ),
- (
- "MathValueRecord",
- "UpperLimitGapMin",
- None,
- None,
- "Minimum gap between the (ink) bottom of the upper limit, and the (ink) top of the base operator.",
- ),
- (
- "MathValueRecord",
- "UpperLimitBaselineRiseMin",
- None,
- None,
- "Minimum distance between baseline of upper limit and (ink) top of the base operator.",
- ),
- (
- "MathValueRecord",
- "LowerLimitGapMin",
- None,
- None,
- "Minimum gap between (ink) top of the lower limit, and (ink) bottom of the base operator.",
- ),
- (
- "MathValueRecord",
- "LowerLimitBaselineDropMin",
- None,
- None,
- "Minimum distance between baseline of the lower limit and (ink) bottom of the base operator.",
- ),
- (
- "MathValueRecord",
- "StackTopShiftUp",
- None,
- None,
- "Standard shift up applied to the top element of a stack.",
- ),
- (
- "MathValueRecord",
- "StackTopDisplayStyleShiftUp",
- None,
- None,
- "Standard shift up applied to the top element of a stack in display style.",
- ),
- (
- "MathValueRecord",
- "StackBottomShiftDown",
- None,
- None,
- "Standard shift down applied to the bottom element of a stack. Positive for moving in the downward direction.",
- ),
- (
- "MathValueRecord",
- "StackBottomDisplayStyleShiftDown",
- None,
- None,
- "Standard shift down applied to the bottom element of a stack in display style. Positive for moving in the downward direction.",
- ),
- (
- "MathValueRecord",
- "StackGapMin",
- None,
- None,
- "Minimum gap between (ink) bottom of the top element of a stack, and the (ink) top of the bottom element. Suggested: 3x default rule thickness.",
- ),
- (
- "MathValueRecord",
- "StackDisplayStyleGapMin",
- None,
- None,
- "Minimum gap between (ink) bottom of the top element of a stack, and the (ink) top of the bottom element in display style. Suggested: 7x default rule thickness.",
- ),
- (
- "MathValueRecord",
- "StretchStackTopShiftUp",
- None,
- None,
- "Standard shift up applied to the top element of the stretch stack.",
- ),
- (
- "MathValueRecord",
- "StretchStackBottomShiftDown",
- None,
- None,
- "Standard shift down applied to the bottom element of the stretch stack. Positive for moving in the downward direction.",
- ),
- (
- "MathValueRecord",
- "StretchStackGapAboveMin",
- None,
- None,
- "Minimum gap between the ink of the stretched element, and the (ink) bottom of the element above. Suggested: UpperLimitGapMin",
- ),
- (
- "MathValueRecord",
- "StretchStackGapBelowMin",
- None,
- None,
- "Minimum gap between the ink of the stretched element, and the (ink) top of the element below. Suggested: LowerLimitGapMin.",
- ),
- (
- "MathValueRecord",
- "FractionNumeratorShiftUp",
- None,
- None,
- "Standard shift up applied to the numerator.",
- ),
- (
- "MathValueRecord",
- "FractionNumeratorDisplayStyleShiftUp",
- None,
- None,
- "Standard shift up applied to the numerator in display style. Suggested: StackTopDisplayStyleShiftUp.",
- ),
- (
- "MathValueRecord",
- "FractionDenominatorShiftDown",
- None,
- None,
- "Standard shift down applied to the denominator. Positive for moving in the downward direction.",
- ),
- (
- "MathValueRecord",
- "FractionDenominatorDisplayStyleShiftDown",
- None,
- None,
- "Standard shift down applied to the denominator in display style. Positive for moving in the downward direction. Suggested: StackBottomDisplayStyleShiftDown.",
- ),
- (
- "MathValueRecord",
- "FractionNumeratorGapMin",
- None,
- None,
- "Minimum tolerated gap between the (ink) bottom of the numerator and the ink of the fraction bar. Suggested: default rule thickness",
- ),
- (
- "MathValueRecord",
- "FractionNumDisplayStyleGapMin",
- None,
- None,
- "Minimum tolerated gap between the (ink) bottom of the numerator and the ink of the fraction bar in display style. Suggested: 3x default rule thickness.",
- ),
- (
- "MathValueRecord",
- "FractionRuleThickness",
- None,
- None,
- "Thickness of the fraction bar. Suggested: default rule thickness.",
- ),
- (
- "MathValueRecord",
- "FractionDenominatorGapMin",
- None,
- None,
- "Minimum tolerated gap between the (ink) top of the denominator and the ink of the fraction bar. Suggested: default rule thickness",
- ),
- (
- "MathValueRecord",
- "FractionDenomDisplayStyleGapMin",
- None,
- None,
- "Minimum tolerated gap between the (ink) top of the denominator and the ink of the fraction bar in display style. Suggested: 3x default rule thickness.",
- ),
- (
- "MathValueRecord",
- "SkewedFractionHorizontalGap",
- None,
- None,
- "Horizontal distance between the top and bottom elements of a skewed fraction.",
- ),
- (
- "MathValueRecord",
- "SkewedFractionVerticalGap",
- None,
- None,
- "Vertical distance between the ink of the top and bottom elements of a skewed fraction.",
- ),
- (
- "MathValueRecord",
- "OverbarVerticalGap",
- None,
- None,
- "Distance between the overbar and the (ink) top of he base. Suggested: 3x default rule thickness.",
- ),
- (
- "MathValueRecord",
- "OverbarRuleThickness",
- None,
- None,
- "Thickness of overbar. Suggested: default rule thickness.",
- ),
- (
- "MathValueRecord",
- "OverbarExtraAscender",
- None,
- None,
- "Extra white space reserved above the overbar. Suggested: default rule thickness.",
- ),
- (
- "MathValueRecord",
- "UnderbarVerticalGap",
- None,
- None,
- "Distance between underbar and (ink) bottom of the base. Suggested: 3x default rule thickness.",
- ),
- (
- "MathValueRecord",
- "UnderbarRuleThickness",
- None,
- None,
- "Thickness of underbar. Suggested: default rule thickness.",
- ),
- (
- "MathValueRecord",
- "UnderbarExtraDescender",
- None,
- None,
- "Extra white space reserved below the underbar. Always positive. Suggested: default rule thickness.",
- ),
- (
- "MathValueRecord",
- "RadicalVerticalGap",
- None,
- None,
- "Space between the (ink) top of the expression and the bar over it. Suggested: 1 1/4 default rule thickness.",
- ),
- (
- "MathValueRecord",
- "RadicalDisplayStyleVerticalGap",
- None,
- None,
- "Space between the (ink) top of the expression and the bar over it. Suggested: default rule thickness + 1/4 x-height.",
- ),
- (
- "MathValueRecord",
- "RadicalRuleThickness",
- None,
- None,
- "Thickness of the radical rule. This is the thickness of the rule in designed or constructed radical signs. Suggested: default rule thickness.",
- ),
- (
- "MathValueRecord",
- "RadicalExtraAscender",
- None,
- None,
- "Extra white space reserved above the radical. Suggested: RadicalRuleThickness.",
- ),
- (
- "MathValueRecord",
- "RadicalKernBeforeDegree",
- None,
- None,
- "Extra horizontal kern before the degree of a radical, if such is present. Suggested: 5/18 of em.",
- ),
- (
- "MathValueRecord",
- "RadicalKernAfterDegree",
- None,
- None,
- "Negative kern after the degree of a radical, if such is present. Suggested: 10/18 of em.",
- ),
- (
- "uint16",
- "RadicalDegreeBottomRaisePercent",
- None,
- None,
- "Height of the bottom of the radical degree, if such is present, in proportion to the ascender of the radical sign. Suggested: 60%.",
- ),
- ],
- ),
- (
- "MathGlyphInfo",
- [
- (
- "Offset",
- "MathItalicsCorrectionInfo",
- None,
- None,
- "Offset to MathItalicsCorrectionInfo table - from the beginning of MathGlyphInfo table.",
- ),
- (
- "Offset",
- "MathTopAccentAttachment",
- None,
- None,
- "Offset to MathTopAccentAttachment table - from the beginning of MathGlyphInfo table.",
- ),
- (
- "Offset",
- "ExtendedShapeCoverage",
- None,
- None,
- "Offset to coverage table for Extended Shape glyphs - from the beginning of MathGlyphInfo table. When the left or right glyph of a box is an extended shape variant, the (ink) box (and not the default position defined by values in MathConstants table) should be used for vertical positioning purposes. May be NULL.",
- ),
- (
- "Offset",
- "MathKernInfo",
- None,
- None,
- "Offset to MathKernInfo table - from the beginning of MathGlyphInfo table.",
- ),
- ],
- ),
- (
- "MathItalicsCorrectionInfo",
- [
- (
- "Offset",
- "Coverage",
- None,
- None,
- "Offset to Coverage table - from the beginning of MathItalicsCorrectionInfo table.",
- ),
- (
- "uint16",
- "ItalicsCorrectionCount",
- None,
- None,
- "Number of italics correction values. Should coincide with the number of covered glyphs.",
- ),
- (
- "MathValueRecord",
- "ItalicsCorrection",
- "ItalicsCorrectionCount",
- 0,
- "Array of MathValueRecords defining italics correction values for each covered glyph.",
- ),
- ],
- ),
- (
- "MathTopAccentAttachment",
- [
- (
- "Offset",
- "TopAccentCoverage",
- None,
- None,
- "Offset to Coverage table - from the beginning of MathTopAccentAttachment table.",
- ),
- (
- "uint16",
- "TopAccentAttachmentCount",
- None,
- None,
- "Number of top accent attachment point values. Should coincide with the number of covered glyphs",
- ),
- (
- "MathValueRecord",
- "TopAccentAttachment",
- "TopAccentAttachmentCount",
- 0,
- "Array of MathValueRecords defining top accent attachment points for each covered glyph",
- ),
- ],
- ),
- (
- "MathKernInfo",
- [
- (
- "Offset",
- "MathKernCoverage",
- None,
- None,
- "Offset to Coverage table - from the beginning of the MathKernInfo table.",
- ),
- ("uint16", "MathKernCount", None, None, "Number of MathKernInfoRecords."),
- (
- "MathKernInfoRecord",
- "MathKernInfoRecords",
- "MathKernCount",
- 0,
- "Array of MathKernInfoRecords, per-glyph information for mathematical positioning of subscripts and superscripts.",
- ),
- ],
- ),
- (
- "MathKernInfoRecord",
- [
- (
- "Offset",
- "TopRightMathKern",
- None,
- None,
- "Offset to MathKern table for top right corner - from the beginning of MathKernInfo table. May be NULL.",
- ),
- (
- "Offset",
- "TopLeftMathKern",
- None,
- None,
- "Offset to MathKern table for the top left corner - from the beginning of MathKernInfo table. May be NULL.",
- ),
- (
- "Offset",
- "BottomRightMathKern",
- None,
- None,
- "Offset to MathKern table for bottom right corner - from the beginning of MathKernInfo table. May be NULL.",
- ),
- (
- "Offset",
- "BottomLeftMathKern",
- None,
- None,
- "Offset to MathKern table for bottom left corner - from the beginning of MathKernInfo table. May be NULL.",
- ),
- ],
- ),
- (
- "MathKern",
- [
- (
- "uint16",
- "HeightCount",
- None,
- None,
- "Number of heights on which the kern value changes.",
- ),
- (
- "MathValueRecord",
- "CorrectionHeight",
- "HeightCount",
- 0,
- "Array of correction heights at which the kern value changes. Sorted by the height value in design units.",
- ),
- (
- "MathValueRecord",
- "KernValue",
- "HeightCount",
- 1,
- "Array of kern values corresponding to heights. First value is the kern value for all heights less or equal than the first height in this table.Last value is the value to be applied for all heights greater than the last height in this table. Negative values are interpreted as move glyphs closer to each other.",
- ),
- ],
- ),
- (
- "MathVariants",
- [
- (
- "uint16",
- "MinConnectorOverlap",
- None,
- None,
- "Minimum overlap of connecting glyphs during glyph construction, in design units.",
- ),
- (
- "Offset",
- "VertGlyphCoverage",
- None,
- None,
- "Offset to Coverage table - from the beginning of MathVariants table.",
- ),
- (
- "Offset",
- "HorizGlyphCoverage",
- None,
- None,
- "Offset to Coverage table - from the beginning of MathVariants table.",
- ),
- (
- "uint16",
- "VertGlyphCount",
- None,
- None,
- "Number of glyphs for which information is provided for vertically growing variants.",
- ),
- (
- "uint16",
- "HorizGlyphCount",
- None,
- None,
- "Number of glyphs for which information is provided for horizontally growing variants.",
- ),
- (
- "Offset",
- "VertGlyphConstruction",
- "VertGlyphCount",
- 0,
- "Array of offsets to MathGlyphConstruction tables - from the beginning of the MathVariants table, for shapes growing in vertical direction.",
- ),
- (
- "Offset",
- "HorizGlyphConstruction",
- "HorizGlyphCount",
- 0,
- "Array of offsets to MathGlyphConstruction tables - from the beginning of the MathVariants table, for shapes growing in horizontal direction.",
- ),
- ],
- ),
- (
- "MathGlyphConstruction",
- [
- (
- "Offset",
- "GlyphAssembly",
- None,
- None,
- "Offset to GlyphAssembly table for this shape - from the beginning of MathGlyphConstruction table. May be NULL",
- ),
- (
- "uint16",
- "VariantCount",
- None,
- None,
- "Count of glyph growing variants for this glyph.",
- ),
- (
- "MathGlyphVariantRecord",
- "MathGlyphVariantRecord",
- "VariantCount",
- 0,
- "MathGlyphVariantRecords for alternative variants of the glyphs.",
- ),
- ],
- ),
- (
- "MathGlyphVariantRecord",
- [
- ("GlyphID", "VariantGlyph", None, None, "Glyph ID for the variant."),
- (
- "uint16",
- "AdvanceMeasurement",
- None,
- None,
- "Advance width/height, in design units, of the variant, in the direction of requested glyph extension.",
- ),
- ],
- ),
- (
- "GlyphAssembly",
- [
- (
- "MathValueRecord",
- "ItalicsCorrection",
- None,
- None,
- "Italics correction of this GlyphAssembly. Should not depend on the assembly size.",
- ),
- ("uint16", "PartCount", None, None, "Number of parts in this assembly."),
- (
- "GlyphPartRecord",
- "PartRecords",
- "PartCount",
- 0,
- "Array of part records, from left to right and bottom to top.",
- ),
- ],
- ),
- (
- "GlyphPartRecord",
- [
- ("GlyphID", "glyph", None, None, "Glyph ID for the part."),
- (
- "uint16",
- "StartConnectorLength",
- None,
- None,
- "Advance width/ height of the straight bar connector material, in design units, is at the beginning of the glyph, in the direction of the extension.",
- ),
- (
- "uint16",
- "EndConnectorLength",
- None,
- None,
- "Advance width/ height of the straight bar connector material, in design units, is at the end of the glyph, in the direction of the extension.",
- ),
- (
- "uint16",
- "FullAdvance",
- None,
- None,
- "Full advance width/height for this part, in the direction of the extension. In design units.",
- ),
- (
- "uint16",
- "PartFlags",
- None,
- None,
- "Part qualifiers. PartFlags enumeration currently uses only one bit: 0x0001 fExtender: If set, the part can be skipped or repeated. 0xFFFE Reserved",
- ),
- ],
- ),
- ##
- ## Apple Advanced Typography (AAT) tables
- ##
- (
- "AATLookupSegment",
- [
- ("uint16", "lastGlyph", None, None, "Last glyph index in this segment."),
- ("uint16", "firstGlyph", None, None, "First glyph index in this segment."),
- (
- "uint16",
- "value",
- None,
- None,
- "A 16-bit offset from the start of the table to the data.",
- ),
- ],
- ),
- #
- # ankr
- #
- (
- "ankr",
- [
- ("struct", "AnchorPoints", None, None, "Anchor points table."),
- ],
- ),
- (
- "AnchorPointsFormat0",
- [
- ("uint16", "Format", None, None, "Format of the anchor points table, = 0."),
- ("uint16", "Flags", None, None, "Flags. Currenty unused, set to zero."),
- (
- "AATLookupWithDataOffset(AnchorGlyphData)",
- "Anchors",
- None,
- None,
- "Table of with anchor overrides for each glyph.",
- ),
- ],
- ),
- (
- "AnchorGlyphData",
- [
- (
- "uint32",
- "AnchorPointCount",
- None,
- None,
- "Number of anchor points for this glyph.",
- ),
- (
- "struct",
- "AnchorPoint",
- "AnchorPointCount",
- 0,
- "Individual anchor points.",
- ),
- ],
- ),
- (
- "AnchorPoint",
- [
- ("int16", "XCoordinate", None, None, "X coordinate of this anchor point."),
- ("int16", "YCoordinate", None, None, "Y coordinate of this anchor point."),
- ],
- ),
- #
- # bsln
- #
- (
- "bsln",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version number of the AAT baseline table (0x00010000 for the initial version).",
- ),
- ("struct", "Baseline", None, None, "Baseline table."),
- ],
- ),
- (
- "BaselineFormat0",
- [
- ("uint16", "Format", None, None, "Format of the baseline table, = 0."),
- (
- "uint16",
- "DefaultBaseline",
- None,
- None,
- "Default baseline value for all glyphs. This value can be from 0 through 31.",
- ),
- (
- "uint16",
- "Delta",
- 32,
- 0,
- "These are the FUnit distance deltas from the font’s natural baseline to the other baselines used in the font. A total of 32 deltas must be assigned.",
- ),
- ],
- ),
- (
- "BaselineFormat1",
- [
- ("uint16", "Format", None, None, "Format of the baseline table, = 1."),
- (
- "uint16",
- "DefaultBaseline",
- None,
- None,
- "Default baseline value for all glyphs. This value can be from 0 through 31.",
- ),
- (
- "uint16",
- "Delta",
- 32,
- 0,
- "These are the FUnit distance deltas from the font’s natural baseline to the other baselines used in the font. A total of 32 deltas must be assigned.",
- ),
- (
- "AATLookup(uint16)",
- "BaselineValues",
- None,
- None,
- "Lookup table that maps glyphs to their baseline values.",
- ),
- ],
- ),
- (
- "BaselineFormat2",
- [
- ("uint16", "Format", None, None, "Format of the baseline table, = 1."),
- (
- "uint16",
- "DefaultBaseline",
- None,
- None,
- "Default baseline value for all glyphs. This value can be from 0 through 31.",
- ),
- (
- "GlyphID",
- "StandardGlyph",
- None,
- None,
- "Glyph index of the glyph in this font to be used to set the baseline values. This glyph must contain a set of control points (whose numbers are contained in the following field) that determines baseline distances.",
- ),
- (
- "uint16",
- "ControlPoint",
- 32,
- 0,
- "Array of 32 control point numbers, associated with the standard glyph. A value of 0xFFFF means there is no corresponding control point in the standard glyph.",
- ),
- ],
- ),
- (
- "BaselineFormat3",
- [
- ("uint16", "Format", None, None, "Format of the baseline table, = 1."),
- (
- "uint16",
- "DefaultBaseline",
- None,
- None,
- "Default baseline value for all glyphs. This value can be from 0 through 31.",
- ),
- (
- "GlyphID",
- "StandardGlyph",
- None,
- None,
- "Glyph index of the glyph in this font to be used to set the baseline values. This glyph must contain a set of control points (whose numbers are contained in the following field) that determines baseline distances.",
- ),
- (
- "uint16",
- "ControlPoint",
- 32,
- 0,
- "Array of 32 control point numbers, associated with the standard glyph. A value of 0xFFFF means there is no corresponding control point in the standard glyph.",
- ),
- (
- "AATLookup(uint16)",
- "BaselineValues",
- None,
- None,
- "Lookup table that maps glyphs to their baseline values.",
- ),
- ],
- ),
- #
- # cidg
- #
- (
- "cidg",
- [
- ("struct", "CIDGlyphMapping", None, None, "CID-to-glyph mapping table."),
- ],
- ),
- (
- "CIDGlyphMappingFormat0",
- [
- (
- "uint16",
- "Format",
- None,
- None,
- "Format of the CID-to-glyph mapping table, = 0.",
- ),
- ("uint16", "DataFormat", None, None, "Currenty unused, set to zero."),
- ("uint32", "StructLength", None, None, "Size of the table in bytes."),
- ("uint16", "Registry", None, None, "The registry ID."),
- (
- "char64",
- "RegistryName",
- None,
- None,
- "The registry name in ASCII; unused bytes should be set to 0.",
- ),
- ("uint16", "Order", None, None, "The order ID."),
- (
- "char64",
- "OrderName",
- None,
- None,
- "The order name in ASCII; unused bytes should be set to 0.",
- ),
- ("uint16", "SupplementVersion", None, None, "The supplement version."),
- (
- "CIDGlyphMap",
- "Mapping",
- None,
- None,
- "A mapping from CIDs to the glyphs in the font, starting with CID 0. If a CID from the identified collection has no glyph in the font, 0xFFFF is used",
- ),
- ],
- ),
- #
- # feat
- #
- (
- "feat",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the feat table-initially set to 0x00010000.",
- ),
- ("FeatureNames", "FeatureNames", None, None, "The feature names."),
- ],
- ),
- (
- "FeatureNames",
- [
- (
- "uint16",
- "FeatureNameCount",
- None,
- None,
- "Number of entries in the feature name array.",
- ),
- ("uint16", "Reserved1", None, None, "Reserved (set to zero)."),
- ("uint32", "Reserved2", None, None, "Reserved (set to zero)."),
- (
- "FeatureName",
- "FeatureName",
- "FeatureNameCount",
- 0,
- "The feature name array.",
- ),
- ],
- ),
- (
- "FeatureName",
- [
- ("uint16", "FeatureType", None, None, "Feature type."),
- (
- "uint16",
- "SettingsCount",
- None,
- None,
- "The number of records in the setting name array.",
- ),
- (
- "LOffset",
- "Settings",
- None,
- None,
- "Offset to setting table for this feature.",
- ),
- (
- "uint16",
- "FeatureFlags",
- None,
- None,
- "Single-bit flags associated with the feature type.",
- ),
- (
- "NameID",
- "FeatureNameID",
- None,
- None,
- "The name table index for the feature name.",
- ),
- ],
- ),
- (
- "Settings",
- [
- ("Setting", "Setting", "SettingsCount", 0, "The setting array."),
- ],
- ),
- (
- "Setting",
- [
- ("uint16", "SettingValue", None, None, "The setting."),
- (
- "NameID",
- "SettingNameID",
- None,
- None,
- "The name table index for the setting name.",
- ),
- ],
- ),
- #
- # gcid
- #
- (
- "gcid",
- [
- ("struct", "GlyphCIDMapping", None, None, "Glyph to CID mapping table."),
- ],
- ),
- (
- "GlyphCIDMappingFormat0",
- [
- (
- "uint16",
- "Format",
- None,
- None,
- "Format of the glyph-to-CID mapping table, = 0.",
- ),
- ("uint16", "DataFormat", None, None, "Currenty unused, set to zero."),
- ("uint32", "StructLength", None, None, "Size of the table in bytes."),
- ("uint16", "Registry", None, None, "The registry ID."),
- (
- "char64",
- "RegistryName",
- None,
- None,
- "The registry name in ASCII; unused bytes should be set to 0.",
- ),
- ("uint16", "Order", None, None, "The order ID."),
- (
- "char64",
- "OrderName",
- None,
- None,
- "The order name in ASCII; unused bytes should be set to 0.",
- ),
- ("uint16", "SupplementVersion", None, None, "The supplement version."),
- (
- "GlyphCIDMap",
- "Mapping",
- None,
- None,
- "The CIDs for the glyphs in the font, starting with glyph 0. If a glyph does not correspond to a CID in the identified collection, 0xFFFF is used",
- ),
- ],
- ),
- #
- # lcar
- #
- (
- "lcar",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version number of the ligature caret table (0x00010000 for the initial version).",
- ),
- ("struct", "LigatureCarets", None, None, "Ligature carets table."),
- ],
- ),
- (
- "LigatureCaretsFormat0",
- [
- (
- "uint16",
- "Format",
- None,
- None,
- "Format of the ligature caret table. Format 0 indicates division points are distances in font units, Format 1 indicates division points are indexes of control points.",
- ),
- (
- "AATLookup(LigCaretDistances)",
- "Carets",
- None,
- None,
- "Lookup table associating ligature glyphs with their caret positions, in font unit distances.",
- ),
- ],
- ),
- (
- "LigatureCaretsFormat1",
- [
- (
- "uint16",
- "Format",
- None,
- None,
- "Format of the ligature caret table. Format 0 indicates division points are distances in font units, Format 1 indicates division points are indexes of control points.",
- ),
- (
- "AATLookup(LigCaretPoints)",
- "Carets",
- None,
- None,
- "Lookup table associating ligature glyphs with their caret positions, as control points.",
- ),
- ],
- ),
- (
- "LigCaretDistances",
- [
- ("uint16", "DivsionPointCount", None, None, "Number of division points."),
- (
- "int16",
- "DivisionPoint",
- "DivsionPointCount",
- 0,
- "Distance in font units through which a subdivision is made orthogonally to the baseline.",
- ),
- ],
- ),
- (
- "LigCaretPoints",
- [
- ("uint16", "DivsionPointCount", None, None, "Number of division points."),
- (
- "int16",
- "DivisionPoint",
- "DivsionPointCount",
- 0,
- "The number of the control point through which a subdivision is made orthogonally to the baseline.",
- ),
- ],
- ),
- #
- # mort
- #
- (
- "mort",
- [
- ("Version", "Version", None, None, "Version of the mort table."),
- (
- "uint32",
- "MorphChainCount",
- None,
- None,
- "Number of metamorphosis chains.",
- ),
- (
- "MortChain",
- "MorphChain",
- "MorphChainCount",
- 0,
- "Array of metamorphosis chains.",
- ),
- ],
- ),
- (
- "MortChain",
- [
- (
- "Flags32",
- "DefaultFlags",
- None,
- None,
- "The default specification for subtables.",
- ),
- (
- "uint32",
- "StructLength",
- None,
- None,
- "Total byte count, including this header; must be a multiple of 4.",
- ),
- (
- "uint16",
- "MorphFeatureCount",
- None,
- None,
- "Number of metamorphosis feature entries.",
- ),
- (
- "uint16",
- "MorphSubtableCount",
- None,
- None,
- "The number of subtables in the chain.",
- ),
- (
- "struct",
- "MorphFeature",
- "MorphFeatureCount",
- 0,
- "Array of metamorphosis features.",
- ),
- (
- "MortSubtable",
- "MorphSubtable",
- "MorphSubtableCount",
- 0,
- "Array of metamorphosis subtables.",
- ),
- ],
- ),
- (
- "MortSubtable",
- [
- (
- "uint16",
- "StructLength",
- None,
- None,
- "Total subtable length, including this header.",
- ),
- (
- "uint8",
- "CoverageFlags",
- None,
- None,
- "Most significant byte of coverage flags.",
- ),
- ("uint8", "MorphType", None, None, "Subtable type."),
- (
- "Flags32",
- "SubFeatureFlags",
- None,
- None,
- "The 32-bit mask identifying which subtable this is (the subtable being executed if the AND of this value and the processed defaultFlags is nonzero).",
- ),
- ("SubStruct", "SubStruct", None, None, "SubTable."),
- ],
- ),
- #
- # morx
- #
- (
- "morx",
- [
- ("uint16", "Version", None, None, "Version of the morx table."),
- ("uint16", "Reserved", None, None, "Reserved (set to zero)."),
- (
- "uint32",
- "MorphChainCount",
- None,
- None,
- "Number of extended metamorphosis chains.",
- ),
- (
- "MorxChain",
- "MorphChain",
- "MorphChainCount",
- 0,
- "Array of extended metamorphosis chains.",
- ),
- ],
- ),
- (
- "MorxChain",
- [
- (
- "Flags32",
- "DefaultFlags",
- None,
- None,
- "The default specification for subtables.",
- ),
- (
- "uint32",
- "StructLength",
- None,
- None,
- "Total byte count, including this header; must be a multiple of 4.",
- ),
- (
- "uint32",
- "MorphFeatureCount",
- None,
- None,
- "Number of feature subtable entries.",
- ),
- (
- "uint32",
- "MorphSubtableCount",
- None,
- None,
- "The number of subtables in the chain.",
- ),
- (
- "MorphFeature",
- "MorphFeature",
- "MorphFeatureCount",
- 0,
- "Array of metamorphosis features.",
- ),
- (
- "MorxSubtable",
- "MorphSubtable",
- "MorphSubtableCount",
- 0,
- "Array of extended metamorphosis subtables.",
- ),
- ],
- ),
- (
- "MorphFeature",
- [
- ("uint16", "FeatureType", None, None, "The type of feature."),
- (
- "uint16",
- "FeatureSetting",
- None,
- None,
- "The feature's setting (aka selector).",
- ),
- (
- "Flags32",
- "EnableFlags",
- None,
- None,
- "Flags for the settings that this feature and setting enables.",
- ),
- (
- "Flags32",
- "DisableFlags",
- None,
- None,
- "Complement of flags for the settings that this feature and setting disable.",
- ),
- ],
- ),
- # Apple TrueType Reference Manual, chapter “The ‘morx’ table”,
- # section “Metamorphosis Subtables”.
- # https://developer.apple.com/fonts/TrueType-Reference-Manual/RM06/Chap6morx.html
- (
- "MorxSubtable",
- [
- (
- "uint32",
- "StructLength",
- None,
- None,
- "Total subtable length, including this header.",
- ),
- (
- "uint8",
- "CoverageFlags",
- None,
- None,
- "Most significant byte of coverage flags.",
- ),
- ("uint16", "Reserved", None, None, "Unused."),
- ("uint8", "MorphType", None, None, "Subtable type."),
- (
- "Flags32",
- "SubFeatureFlags",
- None,
- None,
- "The 32-bit mask identifying which subtable this is (the subtable being executed if the AND of this value and the processed defaultFlags is nonzero).",
- ),
- ("SubStruct", "SubStruct", None, None, "SubTable."),
- ],
- ),
- (
- "StateHeader",
- [
- (
- "uint32",
- "ClassCount",
- None,
- None,
- "Number of classes, which is the number of 16-bit entry indices in a single line in the state array.",
- ),
- (
- "uint32",
- "MorphClass",
- None,
- None,
- "Offset from the start of this state table header to the start of the class table.",
- ),
- (
- "uint32",
- "StateArrayOffset",
- None,
- None,
- "Offset from the start of this state table header to the start of the state array.",
- ),
- (
- "uint32",
- "EntryTableOffset",
- None,
- None,
- "Offset from the start of this state table header to the start of the entry table.",
- ),
- ],
- ),
- (
- "RearrangementMorph",
- [
- (
- "STXHeader(RearrangementMorphAction)",
- "StateTable",
- None,
- None,
- "Finite-state transducer table for indic rearrangement.",
- ),
- ],
- ),
- (
- "ContextualMorph",
- [
- (
- "STXHeader(ContextualMorphAction)",
- "StateTable",
- None,
- None,
- "Finite-state transducer for contextual glyph substitution.",
- ),
- ],
- ),
- (
- "LigatureMorph",
- [
- (
- "STXHeader(LigatureMorphAction)",
- "StateTable",
- None,
- None,
- "Finite-state transducer for ligature substitution.",
- ),
- ],
- ),
- (
- "NoncontextualMorph",
- [
- (
- "AATLookup(GlyphID)",
- "Substitution",
- None,
- None,
- "The noncontextual glyph substitution table.",
- ),
- ],
- ),
- (
- "InsertionMorph",
- [
- (
- "STXHeader(InsertionMorphAction)",
- "StateTable",
- None,
- None,
- "Finite-state transducer for glyph insertion.",
- ),
- ],
- ),
- (
- "MorphClass",
- [
- (
- "uint16",
- "FirstGlyph",
- None,
- None,
- "Glyph index of the first glyph in the class table.",
- ),
- # ('uint16', 'GlyphCount', None, None, 'Number of glyphs in class table.'),
- # ('uint8', 'GlyphClass', 'GlyphCount', 0, 'The class codes (indexed by glyph index minus firstGlyph). Class codes range from 0 to the value of stateSize minus 1.'),
- ],
- ),
- # If the 'morx' table version is 3 or greater, then the last subtable in the chain is followed by a subtableGlyphCoverageArray, as described below.
- # ('Offset', 'MarkGlyphSetsDef', None, 'round(Version*0x10000) >= 0x00010002', 'Offset to the table of mark set definitions-from beginning of GDEF header (may be NULL)'),
- #
- # prop
- #
- (
- "prop",
- [
- (
- "Fixed",
- "Version",
- None,
- None,
- "Version number of the AAT glyphs property table. Version 1.0 is the initial table version. Version 2.0, which is recognized by macOS 8.5 and later, adds support for the “attaches on right” bit. Version 3.0, which gets recognized by macOS X and iOS, adds support for the additional directional properties defined in Unicode 3.0.",
- ),
- ("struct", "GlyphProperties", None, None, "Glyph properties."),
- ],
- ),
- (
- "GlyphPropertiesFormat0",
- [
- ("uint16", "Format", None, None, "Format, = 0."),
- (
- "uint16",
- "DefaultProperties",
- None,
- None,
- "Default properties applied to a glyph. Since there is no lookup table in prop format 0, the default properties get applied to every glyph in the font.",
- ),
- ],
- ),
- (
- "GlyphPropertiesFormat1",
- [
- ("uint16", "Format", None, None, "Format, = 1."),
- (
- "uint16",
- "DefaultProperties",
- None,
- None,
- "Default properties applied to a glyph if that glyph is not present in the Properties lookup table.",
- ),
- (
- "AATLookup(uint16)",
- "Properties",
- None,
- None,
- "Lookup data associating glyphs with their properties.",
- ),
- ],
- ),
- #
- # opbd
- #
- (
- "opbd",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version number of the optical bounds table (0x00010000 for the initial version).",
- ),
- ("struct", "OpticalBounds", None, None, "Optical bounds table."),
- ],
- ),
- (
- "OpticalBoundsFormat0",
- [
- (
- "uint16",
- "Format",
- None,
- None,
- "Format of the optical bounds table, = 0.",
- ),
- (
- "AATLookup(OpticalBoundsDeltas)",
- "OpticalBoundsDeltas",
- None,
- None,
- "Lookup table associating glyphs with their optical bounds, given as deltas in font units.",
- ),
- ],
- ),
- (
- "OpticalBoundsFormat1",
- [
- (
- "uint16",
- "Format",
- None,
- None,
- "Format of the optical bounds table, = 1.",
- ),
- (
- "AATLookup(OpticalBoundsPoints)",
- "OpticalBoundsPoints",
- None,
- None,
- "Lookup table associating glyphs with their optical bounds, given as references to control points.",
- ),
- ],
- ),
- (
- "OpticalBoundsDeltas",
- [
- (
- "int16",
- "Left",
- None,
- None,
- "Delta value for the left-side optical edge.",
- ),
- ("int16", "Top", None, None, "Delta value for the top-side optical edge."),
- (
- "int16",
- "Right",
- None,
- None,
- "Delta value for the right-side optical edge.",
- ),
- (
- "int16",
- "Bottom",
- None,
- None,
- "Delta value for the bottom-side optical edge.",
- ),
- ],
- ),
- (
- "OpticalBoundsPoints",
- [
- (
- "int16",
- "Left",
- None,
- None,
- "Control point index for the left-side optical edge, or -1 if this glyph has none.",
- ),
- (
- "int16",
- "Top",
- None,
- None,
- "Control point index for the top-side optical edge, or -1 if this glyph has none.",
- ),
- (
- "int16",
- "Right",
- None,
- None,
- "Control point index for the right-side optical edge, or -1 if this glyph has none.",
- ),
- (
- "int16",
- "Bottom",
- None,
- None,
- "Control point index for the bottom-side optical edge, or -1 if this glyph has none.",
- ),
- ],
- ),
- #
- # TSIC
- #
- (
- "TSIC",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of table initially set to 0x00010000.",
- ),
- ("uint16", "Flags", None, None, "TSIC flags - set to 0"),
- ("uint16", "AxisCount", None, None, "Axis count from fvar"),
- ("uint16", "RecordCount", None, None, "TSIC record count"),
- ("uint16", "Reserved", None, None, "Set to 0"),
- ("Tag", "AxisArray", "AxisCount", 0, "Array of axis tags in fvar order"),
- (
- "LocationRecord",
- "RecordLocations",
- "RecordCount",
- 0,
- "Location in variation space of TSIC record",
- ),
- ("TSICRecord", "Record", "RecordCount", 0, "Array of TSIC records"),
- ],
- ),
- (
- "LocationRecord",
- [
- ("F2Dot14", "Axis", "AxisCount", 0, "Axis record"),
- ],
- ),
- (
- "TSICRecord",
- [
- ("uint16", "Flags", None, None, "Record flags - set to 0"),
- ("uint16", "NumCVTEntries", None, None, "Number of CVT number value pairs"),
- ("uint16", "NameLength", None, None, "Length of optional user record name"),
- ("uint16", "NameArray", "NameLength", 0, "Unicode 16 name"),
- ("uint16", "CVTArray", "NumCVTEntries", 0, "CVT number array"),
- ("int16", "CVTValueArray", "NumCVTEntries", 0, "CVT value"),
- ],
- ),
- #
- # COLR
- #
- (
- "COLR",
- [
- ("uint16", "Version", None, None, "Table version number (starts at 0)."),
- (
- "uint16",
- "BaseGlyphRecordCount",
- None,
- None,
- "Number of Base Glyph Records.",
- ),
- (
- "LOffset",
- "BaseGlyphRecordArray",
- None,
- None,
- "Offset (from beginning of COLR table) to Base Glyph records.",
- ),
- (
- "LOffset",
- "LayerRecordArray",
- None,
- None,
- "Offset (from beginning of COLR table) to Layer Records.",
- ),
- ("uint16", "LayerRecordCount", None, None, "Number of Layer Records."),
- (
- "LOffset",
- "BaseGlyphList",
- None,
- "Version >= 1",
- "Offset (from beginning of COLR table) to array of Version-1 Base Glyph records.",
- ),
- (
- "LOffset",
- "LayerList",
- None,
- "Version >= 1",
- "Offset (from beginning of COLR table) to LayerList.",
- ),
- (
- "LOffset",
- "ClipList",
- None,
- "Version >= 1",
- "Offset to ClipList table (may be NULL)",
- ),
- (
- "LOffsetTo(DeltaSetIndexMap)",
- "VarIndexMap",
- None,
- "Version >= 1",
- "Offset to DeltaSetIndexMap table (may be NULL)",
- ),
- (
- "LOffset",
- "VarStore",
- None,
- "Version >= 1",
- "Offset to variation store (may be NULL)",
- ),
- ],
- ),
- (
- "BaseGlyphRecordArray",
- [
- (
- "BaseGlyphRecord",
- "BaseGlyphRecord",
- "BaseGlyphRecordCount",
- 0,
- "Base Glyph records.",
- ),
- ],
- ),
- (
- "BaseGlyphRecord",
- [
- (
- "GlyphID",
- "BaseGlyph",
- None,
- None,
- "Glyph ID of reference glyph. This glyph is for reference only and is not rendered for color.",
- ),
- (
- "uint16",
- "FirstLayerIndex",
- None,
- None,
- "Index (from beginning of the Layer Records) to the layer record. There will be numLayers consecutive entries for this base glyph.",
- ),
- (
- "uint16",
- "NumLayers",
- None,
- None,
- "Number of color layers associated with this glyph.",
- ),
- ],
- ),
- (
- "LayerRecordArray",
- [
- ("LayerRecord", "LayerRecord", "LayerRecordCount", 0, "Layer records."),
- ],
- ),
- (
- "LayerRecord",
- [
- (
- "GlyphID",
- "LayerGlyph",
- None,
- None,
- "Glyph ID of layer glyph (must be in z-order from bottom to top).",
- ),
- (
- "uint16",
- "PaletteIndex",
- None,
- None,
- "Index value to use with a selected color palette.",
- ),
- ],
- ),
- (
- "BaseGlyphList",
- [
- (
- "uint32",
- "BaseGlyphCount",
- None,
- None,
- "Number of Version-1 Base Glyph records",
- ),
- (
- "struct",
- "BaseGlyphPaintRecord",
- "BaseGlyphCount",
- 0,
- "Array of Version-1 Base Glyph records",
- ),
- ],
- ),
- (
- "BaseGlyphPaintRecord",
- [
- ("GlyphID", "BaseGlyph", None, None, "Glyph ID of reference glyph."),
- (
- "LOffset",
- "Paint",
- None,
- None,
- "Offset (from beginning of BaseGlyphPaintRecord) to Paint, typically a PaintColrLayers.",
- ),
- ],
- ),
- (
- "LayerList",
- [
- ("uint32", "LayerCount", None, None, "Number of Version-1 Layers"),
- (
- "LOffset",
- "Paint",
- "LayerCount",
- 0,
- "Array of offsets to Paint tables, from the start of the LayerList table.",
- ),
- ],
- ),
- (
- "ClipListFormat1",
- [
- (
- "uint8",
- "Format",
- None,
- None,
- "Format for ClipList with 16bit glyph IDs: 1",
- ),
- ("uint32", "ClipCount", None, None, "Number of Clip records."),
- (
- "struct",
- "ClipRecord",
- "ClipCount",
- 0,
- "Array of Clip records sorted by glyph ID.",
- ),
- ],
- ),
- (
- "ClipRecord",
- [
- ("uint16", "StartGlyphID", None, None, "First glyph ID in the range."),
- ("uint16", "EndGlyphID", None, None, "Last glyph ID in the range."),
- ("Offset24", "ClipBox", None, None, "Offset to a ClipBox table."),
- ],
- ),
- (
- "ClipBoxFormat1",
- [
- (
- "uint8",
- "Format",
- None,
- None,
- "Format for ClipBox without variation: set to 1.",
- ),
- ("int16", "xMin", None, None, "Minimum x of clip box."),
- ("int16", "yMin", None, None, "Minimum y of clip box."),
- ("int16", "xMax", None, None, "Maximum x of clip box."),
- ("int16", "yMax", None, None, "Maximum y of clip box."),
- ],
- ),
- (
- "ClipBoxFormat2",
- [
- ("uint8", "Format", None, None, "Format for variable ClipBox: set to 2."),
- ("int16", "xMin", None, None, "Minimum x of clip box. VarIndexBase + 0."),
- ("int16", "yMin", None, None, "Minimum y of clip box. VarIndexBase + 1."),
- ("int16", "xMax", None, None, "Maximum x of clip box. VarIndexBase + 2."),
- ("int16", "yMax", None, None, "Maximum y of clip box. VarIndexBase + 3."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # COLRv1 Affine2x3 uses the same column-major order to serialize a 2D
- # Affine Transformation as the one used by fontTools.misc.transform.
- # However, for historical reasons, the labels 'xy' and 'yx' are swapped.
- # Their fundamental meaning is the same though.
- # COLRv1 Affine2x3 follows the names found in FreeType and Cairo.
- # In all case, the second element in the 6-tuple correspond to the
- # y-part of the x basis vector, and the third to the x-part of the y
- # basis vector.
- # See https://github.com/googlefonts/colr-gradients-spec/pull/85
- (
- "Affine2x3",
- [
- ("Fixed", "xx", None, None, "x-part of x basis vector"),
- ("Fixed", "yx", None, None, "y-part of x basis vector"),
- ("Fixed", "xy", None, None, "x-part of y basis vector"),
- ("Fixed", "yy", None, None, "y-part of y basis vector"),
- ("Fixed", "dx", None, None, "Translation in x direction"),
- ("Fixed", "dy", None, None, "Translation in y direction"),
- ],
- ),
- (
- "VarAffine2x3",
- [
- ("Fixed", "xx", None, None, "x-part of x basis vector. VarIndexBase + 0."),
- ("Fixed", "yx", None, None, "y-part of x basis vector. VarIndexBase + 1."),
- ("Fixed", "xy", None, None, "x-part of y basis vector. VarIndexBase + 2."),
- ("Fixed", "yy", None, None, "y-part of y basis vector. VarIndexBase + 3."),
- (
- "Fixed",
- "dx",
- None,
- None,
- "Translation in x direction. VarIndexBase + 4.",
- ),
- (
- "Fixed",
- "dy",
- None,
- None,
- "Translation in y direction. VarIndexBase + 5.",
- ),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- (
- "ColorStop",
- [
- ("F2Dot14", "StopOffset", None, None, ""),
- ("uint16", "PaletteIndex", None, None, "Index for a CPAL palette entry."),
- ("F2Dot14", "Alpha", None, None, "Values outsided [0.,1.] reserved"),
- ],
- ),
- (
- "VarColorStop",
- [
- ("F2Dot14", "StopOffset", None, None, "VarIndexBase + 0."),
- ("uint16", "PaletteIndex", None, None, "Index for a CPAL palette entry."),
- (
- "F2Dot14",
- "Alpha",
- None,
- None,
- "Values outsided [0.,1.] reserved. VarIndexBase + 1.",
- ),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- (
- "ColorLine",
- [
- (
- "ExtendMode",
- "Extend",
- None,
- None,
- "Enum {PAD = 0, REPEAT = 1, REFLECT = 2}",
- ),
- ("uint16", "StopCount", None, None, "Number of Color stops."),
- ("ColorStop", "ColorStop", "StopCount", 0, "Array of Color stops."),
- ],
- ),
- (
- "VarColorLine",
- [
- (
- "ExtendMode",
- "Extend",
- None,
- None,
- "Enum {PAD = 0, REPEAT = 1, REFLECT = 2}",
- ),
- ("uint16", "StopCount", None, None, "Number of Color stops."),
- ("VarColorStop", "ColorStop", "StopCount", 0, "Array of Color stops."),
- ],
- ),
- # PaintColrLayers
- (
- "PaintFormat1",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 1"),
- (
- "uint8",
- "NumLayers",
- None,
- None,
- "Number of offsets to Paint to read from LayerList.",
- ),
- ("uint32", "FirstLayerIndex", None, None, "Index into LayerList."),
- ],
- ),
- # PaintSolid
- (
- "PaintFormat2",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 2"),
- ("uint16", "PaletteIndex", None, None, "Index for a CPAL palette entry."),
- ("F2Dot14", "Alpha", None, None, "Values outsided [0.,1.] reserved"),
- ],
- ),
- # PaintVarSolid
- (
- "PaintFormat3",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 3"),
- ("uint16", "PaletteIndex", None, None, "Index for a CPAL palette entry."),
- (
- "F2Dot14",
- "Alpha",
- None,
- None,
- "Values outsided [0.,1.] reserved. VarIndexBase + 0.",
- ),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintLinearGradient
- (
- "PaintFormat4",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 4"),
- (
- "Offset24",
- "ColorLine",
- None,
- None,
- "Offset (from beginning of PaintLinearGradient table) to ColorLine subtable.",
- ),
- ("int16", "x0", None, None, ""),
- ("int16", "y0", None, None, ""),
- ("int16", "x1", None, None, ""),
- ("int16", "y1", None, None, ""),
- ("int16", "x2", None, None, ""),
- ("int16", "y2", None, None, ""),
- ],
- ),
- # PaintVarLinearGradient
- (
- "PaintFormat5",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 5"),
- (
- "LOffset24To(VarColorLine)",
- "ColorLine",
- None,
- None,
- "Offset (from beginning of PaintVarLinearGradient table) to VarColorLine subtable.",
- ),
- ("int16", "x0", None, None, "VarIndexBase + 0."),
- ("int16", "y0", None, None, "VarIndexBase + 1."),
- ("int16", "x1", None, None, "VarIndexBase + 2."),
- ("int16", "y1", None, None, "VarIndexBase + 3."),
- ("int16", "x2", None, None, "VarIndexBase + 4."),
- ("int16", "y2", None, None, "VarIndexBase + 5."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintRadialGradient
- (
- "PaintFormat6",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 6"),
- (
- "Offset24",
- "ColorLine",
- None,
- None,
- "Offset (from beginning of PaintRadialGradient table) to ColorLine subtable.",
- ),
- ("int16", "x0", None, None, ""),
- ("int16", "y0", None, None, ""),
- ("uint16", "r0", None, None, ""),
- ("int16", "x1", None, None, ""),
- ("int16", "y1", None, None, ""),
- ("uint16", "r1", None, None, ""),
- ],
- ),
- # PaintVarRadialGradient
- (
- "PaintFormat7",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 7"),
- (
- "LOffset24To(VarColorLine)",
- "ColorLine",
- None,
- None,
- "Offset (from beginning of PaintVarRadialGradient table) to VarColorLine subtable.",
- ),
- ("int16", "x0", None, None, "VarIndexBase + 0."),
- ("int16", "y0", None, None, "VarIndexBase + 1."),
- ("uint16", "r0", None, None, "VarIndexBase + 2."),
- ("int16", "x1", None, None, "VarIndexBase + 3."),
- ("int16", "y1", None, None, "VarIndexBase + 4."),
- ("uint16", "r1", None, None, "VarIndexBase + 5."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintSweepGradient
- (
- "PaintFormat8",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 8"),
- (
- "Offset24",
- "ColorLine",
- None,
- None,
- "Offset (from beginning of PaintSweepGradient table) to ColorLine subtable.",
- ),
- ("int16", "centerX", None, None, "Center x coordinate."),
- ("int16", "centerY", None, None, "Center y coordinate."),
- (
- "BiasedAngle",
- "startAngle",
- None,
- None,
- "Start of the angular range of the gradient.",
- ),
- (
- "BiasedAngle",
- "endAngle",
- None,
- None,
- "End of the angular range of the gradient.",
- ),
- ],
- ),
- # PaintVarSweepGradient
- (
- "PaintFormat9",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 9"),
- (
- "LOffset24To(VarColorLine)",
- "ColorLine",
- None,
- None,
- "Offset (from beginning of PaintVarSweepGradient table) to VarColorLine subtable.",
- ),
- ("int16", "centerX", None, None, "Center x coordinate. VarIndexBase + 0."),
- ("int16", "centerY", None, None, "Center y coordinate. VarIndexBase + 1."),
- (
- "BiasedAngle",
- "startAngle",
- None,
- None,
- "Start of the angular range of the gradient. VarIndexBase + 2.",
- ),
- (
- "BiasedAngle",
- "endAngle",
- None,
- None,
- "End of the angular range of the gradient. VarIndexBase + 3.",
- ),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintGlyph
- (
- "PaintFormat10",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 10"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintGlyph table) to Paint subtable.",
- ),
- ("GlyphID", "Glyph", None, None, "Glyph ID for the source outline."),
- ],
- ),
- # PaintColrGlyph
- (
- "PaintFormat11",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 11"),
- (
- "GlyphID",
- "Glyph",
- None,
- None,
- "Virtual glyph ID for a BaseGlyphList base glyph.",
- ),
- ],
- ),
- # PaintTransform
- (
- "PaintFormat12",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 12"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintTransform table) to Paint subtable.",
- ),
- (
- "LOffset24To(Affine2x3)",
- "Transform",
- None,
- None,
- "2x3 matrix for 2D affine transformations.",
- ),
- ],
- ),
- # PaintVarTransform
- (
- "PaintFormat13",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 13"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarTransform table) to Paint subtable.",
- ),
- (
- "LOffset24To(VarAffine2x3)",
- "Transform",
- None,
- None,
- "2x3 matrix for 2D affine transformations.",
- ),
- ],
- ),
- # PaintTranslate
- (
- "PaintFormat14",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 14"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintTranslate table) to Paint subtable.",
- ),
- ("int16", "dx", None, None, "Translation in x direction."),
- ("int16", "dy", None, None, "Translation in y direction."),
- ],
- ),
- # PaintVarTranslate
- (
- "PaintFormat15",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 15"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarTranslate table) to Paint subtable.",
- ),
- (
- "int16",
- "dx",
- None,
- None,
- "Translation in x direction. VarIndexBase + 0.",
- ),
- (
- "int16",
- "dy",
- None,
- None,
- "Translation in y direction. VarIndexBase + 1.",
- ),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintScale
- (
- "PaintFormat16",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 16"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintScale table) to Paint subtable.",
- ),
- ("F2Dot14", "scaleX", None, None, ""),
- ("F2Dot14", "scaleY", None, None, ""),
- ],
- ),
- # PaintVarScale
- (
- "PaintFormat17",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 17"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarScale table) to Paint subtable.",
- ),
- ("F2Dot14", "scaleX", None, None, "VarIndexBase + 0."),
- ("F2Dot14", "scaleY", None, None, "VarIndexBase + 1."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintScaleAroundCenter
- (
- "PaintFormat18",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 18"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintScaleAroundCenter table) to Paint subtable.",
- ),
- ("F2Dot14", "scaleX", None, None, ""),
- ("F2Dot14", "scaleY", None, None, ""),
- ("int16", "centerX", None, None, ""),
- ("int16", "centerY", None, None, ""),
- ],
- ),
- # PaintVarScaleAroundCenter
- (
- "PaintFormat19",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 19"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarScaleAroundCenter table) to Paint subtable.",
- ),
- ("F2Dot14", "scaleX", None, None, "VarIndexBase + 0."),
- ("F2Dot14", "scaleY", None, None, "VarIndexBase + 1."),
- ("int16", "centerX", None, None, "VarIndexBase + 2."),
- ("int16", "centerY", None, None, "VarIndexBase + 3."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintScaleUniform
- (
- "PaintFormat20",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 20"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintScaleUniform table) to Paint subtable.",
- ),
- ("F2Dot14", "scale", None, None, ""),
- ],
- ),
- # PaintVarScaleUniform
- (
- "PaintFormat21",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 21"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarScaleUniform table) to Paint subtable.",
- ),
- ("F2Dot14", "scale", None, None, "VarIndexBase + 0."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintScaleUniformAroundCenter
- (
- "PaintFormat22",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 22"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintScaleUniformAroundCenter table) to Paint subtable.",
- ),
- ("F2Dot14", "scale", None, None, ""),
- ("int16", "centerX", None, None, ""),
- ("int16", "centerY", None, None, ""),
- ],
- ),
- # PaintVarScaleUniformAroundCenter
- (
- "PaintFormat23",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 23"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarScaleUniformAroundCenter table) to Paint subtable.",
- ),
- ("F2Dot14", "scale", None, None, "VarIndexBase + 0"),
- ("int16", "centerX", None, None, "VarIndexBase + 1"),
- ("int16", "centerY", None, None, "VarIndexBase + 2"),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintRotate
- (
- "PaintFormat24",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 24"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintRotate table) to Paint subtable.",
- ),
- ("Angle", "angle", None, None, ""),
- ],
- ),
- # PaintVarRotate
- (
- "PaintFormat25",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 25"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarRotate table) to Paint subtable.",
- ),
- ("Angle", "angle", None, None, "VarIndexBase + 0."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintRotateAroundCenter
- (
- "PaintFormat26",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 26"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintRotateAroundCenter table) to Paint subtable.",
- ),
- ("Angle", "angle", None, None, ""),
- ("int16", "centerX", None, None, ""),
- ("int16", "centerY", None, None, ""),
- ],
- ),
- # PaintVarRotateAroundCenter
- (
- "PaintFormat27",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 27"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarRotateAroundCenter table) to Paint subtable.",
- ),
- ("Angle", "angle", None, None, "VarIndexBase + 0."),
- ("int16", "centerX", None, None, "VarIndexBase + 1."),
- ("int16", "centerY", None, None, "VarIndexBase + 2."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintSkew
- (
- "PaintFormat28",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 28"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintSkew table) to Paint subtable.",
- ),
- ("Angle", "xSkewAngle", None, None, ""),
- ("Angle", "ySkewAngle", None, None, ""),
- ],
- ),
- # PaintVarSkew
- (
- "PaintFormat29",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 29"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarSkew table) to Paint subtable.",
- ),
- ("Angle", "xSkewAngle", None, None, "VarIndexBase + 0."),
- ("Angle", "ySkewAngle", None, None, "VarIndexBase + 1."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintSkewAroundCenter
- (
- "PaintFormat30",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 30"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintSkewAroundCenter table) to Paint subtable.",
- ),
- ("Angle", "xSkewAngle", None, None, ""),
- ("Angle", "ySkewAngle", None, None, ""),
- ("int16", "centerX", None, None, ""),
- ("int16", "centerY", None, None, ""),
- ],
- ),
- # PaintVarSkewAroundCenter
- (
- "PaintFormat31",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 31"),
- (
- "Offset24",
- "Paint",
- None,
- None,
- "Offset (from beginning of PaintVarSkewAroundCenter table) to Paint subtable.",
- ),
- ("Angle", "xSkewAngle", None, None, "VarIndexBase + 0."),
- ("Angle", "ySkewAngle", None, None, "VarIndexBase + 1."),
- ("int16", "centerX", None, None, "VarIndexBase + 2."),
- ("int16", "centerY", None, None, "VarIndexBase + 3."),
- (
- "VarIndex",
- "VarIndexBase",
- None,
- None,
- "Base index into DeltaSetIndexMap.",
- ),
- ],
- ),
- # PaintComposite
- (
- "PaintFormat32",
- [
- ("uint8", "PaintFormat", None, None, "Format identifier-format = 32"),
- (
- "LOffset24To(Paint)",
- "SourcePaint",
- None,
- None,
- "Offset (from beginning of PaintComposite table) to source Paint subtable.",
- ),
- (
- "CompositeMode",
- "CompositeMode",
- None,
- None,
- "A CompositeMode enumeration value.",
- ),
- (
- "LOffset24To(Paint)",
- "BackdropPaint",
- None,
- None,
- "Offset (from beginning of PaintComposite table) to backdrop Paint subtable.",
- ),
- ],
- ),
- #
- # avar
- #
- (
- "AxisValueMap",
- [
- (
- "F2Dot14",
- "FromCoordinate",
- None,
- None,
- "A normalized coordinate value obtained using default normalization",
- ),
- (
- "F2Dot14",
- "ToCoordinate",
- None,
- None,
- "The modified, normalized coordinate value",
- ),
- ],
- ),
- (
- "AxisSegmentMap",
- [
- (
- "uint16",
- "PositionMapCount",
- None,
- None,
- "The number of correspondence pairs for this axis",
- ),
- (
- "AxisValueMap",
- "AxisValueMap",
- "PositionMapCount",
- 0,
- "The array of axis value map records for this axis",
- ),
- ],
- ),
- (
- "avar",
- [
- (
- "Version",
- "Version",
- None,
- None,
- "Version of the avar table- 0x00010000 or 0x00020000",
- ),
- ("uint16", "Reserved", None, None, "Permanently reserved; set to zero"),
- (
- "uint16",
- "AxisCount",
- None,
- None,
- 'The number of variation axes for this font. This must be the same number as axisCount in the "fvar" table',
- ),
- (
- "AxisSegmentMap",
- "AxisSegmentMap",
- "AxisCount",
- 0,
- 'The segment maps array — one segment map for each axis, in the order of axes specified in the "fvar" table',
- ),
- (
- "LOffsetTo(DeltaSetIndexMap)",
- "VarIdxMap",
- None,
- "Version >= 0x00020000",
- "",
- ),
- ("LOffset", "VarStore", None, "Version >= 0x00020000", ""),
- ],
- ),
-]
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/node/dev/files/runtime/svelte-hooks.js b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/node/dev/files/runtime/svelte-hooks.js
deleted file mode 100644
index 82ca3e37ab99982f4c029519b1d6a5cc30e4b290..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/gradio/node/dev/files/runtime/svelte-hooks.js
+++ /dev/null
@@ -1,347 +0,0 @@
-/**
- * Emulates forthcoming HMR hooks in Svelte.
- *
- * All references to private component state ($$) are now isolated in this
- * module.
- */
-import {
- current_component,
- get_current_component,
- set_current_component,
-} from 'svelte/internal'
-
-const captureState = cmp => {
- // sanity check: propper behaviour here is to crash noisily so that
- // user knows that they're looking at something broken
- if (!cmp) {
- throw new Error('Missing component')
- }
- if (!cmp.$$) {
- throw new Error('Invalid component')
- }
-
- const {
- $$: { callbacks, bound, ctx, props },
- } = cmp
-
- const state = cmp.$capture_state()
-
- // capturing current value of props (or we'll recreate the component with the
- // initial prop values, that may have changed -- and would not be reflected in
- // options.props)
- const hmr_props_values = {}
- Object.keys(cmp.$$.props).forEach(prop => {
- hmr_props_values[prop] = ctx[props[prop]]
- })
-
- return {
- ctx,
- props,
- callbacks,
- bound,
- state,
- hmr_props_values,
- }
-}
-
-// remapping all existing bindings (including hmr_future_foo ones) to the
-// new version's props indexes, and refresh them with the new value from
-// context
-const restoreBound = (cmp, restore) => {
- // reverse prop:ctxIndex in $$.props to ctxIndex:prop
- //
- // ctxIndex can be either a regular index in $$.ctx or a hmr_future_ prop
- //
- const propsByIndex = {}
- for (const [name, i] of Object.entries(restore.props)) {
- propsByIndex[i] = name
- }
-
- // NOTE $$.bound cannot change in the HMR lifetime of a component, because
- // if bindings changes, that means the parent component has changed,
- // which means the child (current) component will be wholly recreated
- for (const [oldIndex, updateBinding] of Object.entries(restore.bound)) {
- // can be either regular prop, or future_hmr_ prop
- const propName = propsByIndex[oldIndex]
-
- // this should never happen if remembering of future props is enabled...
- // in any case, there's nothing we can do about it if we have lost prop
- // name knowledge at this point
- if (propName == null) continue
-
- // NOTE $$.props[propName] also propagates knowledge of a possible
- // future prop to the new $$.props (via $$.props being a Proxy)
- const newIndex = cmp.$$.props[propName]
- cmp.$$.bound[newIndex] = updateBinding
-
- // NOTE if the prop doesn't exist or doesn't exist anymore in the new
- // version of the component, clearing the binding is the expected
- // behaviour (since that's what would happen in non HMR code)
- const newValue = cmp.$$.ctx[newIndex]
- updateBinding(newValue)
- }
-}
-
-// restoreState
-//
-// It is too late to restore context at this point because component instance
-// function has already been called (and so context has already been read).
-// Instead, we rely on setting current_component to the same value it has when
-// the component was first rendered -- which fix support for context, and is
-// also generally more respectful of normal operation.
-//
-const restoreState = (cmp, restore) => {
- if (!restore) return
-
- if (restore.callbacks) {
- cmp.$$.callbacks = restore.callbacks
- }
-
- if (restore.bound) {
- restoreBound(cmp, restore)
- }
-
- // props, props.$$slots are restored at component creation (works
- // better -- well, at all actually)
-}
-
-const get_current_component_safe = () => {
- // NOTE relying on dynamic bindings (current_component) makes us dependent on
- // bundler config (and apparently it does not work in demo-svelte-nollup)
- try {
- // unfortunately, unlike current_component, get_current_component() can
- // crash in the normal path (when there is really no parent)
- return get_current_component()
- } catch (err) {
- // ... so we need to consider that this error means that there is no parent
- //
- // that makes us tightly coupled to the error message but, at least, we
- // won't mute an unexpected error, which is quite a horrible thing to do
- if (err.message === 'Function called outside component initialization') {
- // who knows...
- return current_component
- } else {
- throw err
- }
- }
-}
-
-export const createProxiedComponent = (
- Component,
- initialOptions,
- { allowLiveBinding, onInstance, onMount, onDestroy }
-) => {
- let cmp
- let options = initialOptions
-
- const isCurrent = _cmp => cmp === _cmp
-
- const assignOptions = (target, anchor, restore, preserveLocalState) => {
- const props = Object.assign({}, options.props)
-
- // Filtering props to avoid "unexpected prop" warning
- // NOTE this is based on props present in initial options, but it should
- // always works, because props that are passed from the parent can't
- // change without a code change to the parent itself -- hence, the
- // child component will be fully recreated, and initial options should
- // always represent props that are currnetly passed by the parent
- if (options.props && restore.hmr_props_values) {
- for (const prop of Object.keys(options.props)) {
- if (restore.hmr_props_values.hasOwnProperty(prop)) {
- props[prop] = restore.hmr_props_values[prop]
- }
- }
- }
-
- if (preserveLocalState && restore.state) {
- if (Array.isArray(preserveLocalState)) {
- // form ['a', 'b'] => preserve only 'a' and 'b'
- props.$$inject = {}
- for (const key of preserveLocalState) {
- props.$$inject[key] = restore.state[key]
- }
- } else {
- props.$$inject = restore.state
- }
- } else {
- delete props.$$inject
- }
- options = Object.assign({}, initialOptions, {
- target,
- anchor,
- props,
- hydrate: false,
- })
- }
-
- // Preserving knowledge of "future props" -- very hackish version (maybe
- // there should be an option to opt out of this)
- //
- // The use case is bind:something where something doesn't exist yet in the
- // target component, but comes to exist later, after a HMR update.
- //
- // If Svelte can't map a prop in the current version of the component, it
- // will just completely discard it:
- // https://github.com/sveltejs/svelte/blob/1632bca34e4803d6b0e0b0abd652ab5968181860/src/runtime/internal/Component.ts#L46
- //
- const rememberFutureProps = cmp => {
- if (typeof Proxy === 'undefined') return
-
- cmp.$$.props = new Proxy(cmp.$$.props, {
- get(target, name) {
- if (target[name] === undefined) {
- target[name] = 'hmr_future_' + name
- }
- return target[name]
- },
- set(target, name, value) {
- target[name] = value
- },
- })
- }
-
- const instrument = targetCmp => {
- const createComponent = (Component, restore, previousCmp) => {
- set_current_component(parentComponent || previousCmp)
- const comp = new Component(options)
- // NOTE must be instrumented before restoreState, because restoring
- // bindings relies on hacked $$.props
- instrument(comp)
- restoreState(comp, restore)
- return comp
- }
-
- rememberFutureProps(targetCmp)
-
- targetCmp.$$.on_hmr = []
-
- // `conservative: true` means we want to be sure that the new component has
- // actually been successfuly created before destroying the old instance.
- // This could be useful for preventing runtime errors in component init to
- // bring down the whole HMR. Unfortunately the implementation bellow is
- // broken (FIXME), but that remains an interesting target for when HMR hooks
- // will actually land in Svelte itself.
- //
- // The goal would be to render an error inplace in case of error, to avoid
- // losing the navigation stack (especially annoying in native, that is not
- // based on URL navigation, so we lose the current page on each error).
- //
- targetCmp.$replace = (
- Component,
- {
- target = options.target,
- anchor = options.anchor,
- preserveLocalState,
- conservative = false,
- }
- ) => {
- const restore = captureState(targetCmp)
- assignOptions(
- target || options.target,
- anchor,
- restore,
- preserveLocalState
- )
-
- const callbacks = cmp ? cmp.$$.on_hmr : []
-
- const afterCallbacks = callbacks.map(fn => fn(cmp)).filter(Boolean)
-
- const previous = cmp
- if (conservative) {
- try {
- const next = createComponent(Component, restore, previous)
- // prevents on_destroy from firing on non-final cmp instance
- cmp = null
- previous.$destroy()
- cmp = next
- } catch (err) {
- cmp = previous
- throw err
- }
- } else {
- // prevents on_destroy from firing on non-final cmp instance
- cmp = null
- if (previous) {
- // previous can be null if last constructor has crashed
- previous.$destroy()
- }
- cmp = createComponent(Component, restore, cmp)
- }
-
- cmp.$$.hmr_cmp = cmp
-
- for (const fn of afterCallbacks) {
- fn(cmp)
- }
-
- cmp.$$.on_hmr = callbacks
-
- return cmp
- }
-
- // NOTE onMount must provide target & anchor (for us to be able to determinate
- // actual DOM insertion point)
- //
- // And also, to support keyed list, it needs to be called each time the
- // component is moved (same as $$.fragment.m)
- if (onMount) {
- const m = targetCmp.$$.fragment.m
- targetCmp.$$.fragment.m = (...args) => {
- const result = m(...args)
- onMount(...args)
- return result
- }
- }
-
- // NOTE onDestroy must be called even if the call doesn't pass through the
- // component's $destroy method (that we can hook onto by ourselves, since
- // it's public API) -- this happens a lot in svelte's internals, that
- // manipulates cmp.$$.fragment directly, often binding to fragment.d,
- // for example
- if (onDestroy) {
- targetCmp.$$.on_destroy.push(() => {
- if (isCurrent(targetCmp)) {
- onDestroy()
- }
- })
- }
-
- if (onInstance) {
- onInstance(targetCmp)
- }
-
- // Svelte 3 creates and mount components from their constructor if
- // options.target is present.
- //
- // This means that at this point, the component's `fragment.c` and,
- // most notably, `fragment.m` will already have been called _from inside
- // createComponent_. That is: before we have a chance to hook on it.
- //
- // Proxy's constructor
- // -> createComponent
- // -> component constructor
- // -> component.$$.fragment.c(...) (or l, if hydrate:true)
- // -> component.$$.fragment.m(...)
- //
- // -> you are here <-
- //
- if (onMount) {
- const { target, anchor } = options
- if (target) {
- onMount(target, anchor)
- }
- }
- }
-
- const parentComponent = allowLiveBinding
- ? current_component
- : get_current_component_safe()
-
- cmp = new Component(options)
- cmp.$$.hmr_cmp = cmp
-
- instrument(cmp)
-
- return cmp
-}
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/jinja2/runtime.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/jinja2/runtime.py
deleted file mode 100644
index 985842b284270bcd52855029f13d3da19d718349..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/jinja2/runtime.py
+++ /dev/null
@@ -1,1053 +0,0 @@
-"""The runtime functions and state used by compiled templates."""
-import functools
-import sys
-import typing as t
-from collections import abc
-from itertools import chain
-
-from markupsafe import escape # noqa: F401
-from markupsafe import Markup
-from markupsafe import soft_str
-
-from .async_utils import auto_aiter
-from .async_utils import auto_await # noqa: F401
-from .exceptions import TemplateNotFound # noqa: F401
-from .exceptions import TemplateRuntimeError # noqa: F401
-from .exceptions import UndefinedError
-from .nodes import EvalContext
-from .utils import _PassArg
-from .utils import concat
-from .utils import internalcode
-from .utils import missing
-from .utils import Namespace # noqa: F401
-from .utils import object_type_repr
-from .utils import pass_eval_context
-
-V = t.TypeVar("V")
-F = t.TypeVar("F", bound=t.Callable[..., t.Any])
-
-if t.TYPE_CHECKING:
- import logging
- import typing_extensions as te
- from .environment import Environment
-
- class LoopRenderFunc(te.Protocol):
- def __call__(
- self,
- reciter: t.Iterable[V],
- loop_render_func: "LoopRenderFunc",
- depth: int = 0,
- ) -> str:
- ...
-
-
-# these variables are exported to the template runtime
-exported = [
- "LoopContext",
- "TemplateReference",
- "Macro",
- "Markup",
- "TemplateRuntimeError",
- "missing",
- "escape",
- "markup_join",
- "str_join",
- "identity",
- "TemplateNotFound",
- "Namespace",
- "Undefined",
- "internalcode",
-]
-async_exported = [
- "AsyncLoopContext",
- "auto_aiter",
- "auto_await",
-]
-
-
-def identity(x: V) -> V:
- """Returns its argument. Useful for certain things in the
- environment.
- """
- return x
-
-
-def markup_join(seq: t.Iterable[t.Any]) -> str:
- """Concatenation that escapes if necessary and converts to string."""
- buf = []
- iterator = map(soft_str, seq)
- for arg in iterator:
- buf.append(arg)
- if hasattr(arg, "__html__"):
- return Markup("").join(chain(buf, iterator))
- return concat(buf)
-
-
-def str_join(seq: t.Iterable[t.Any]) -> str:
- """Simple args to string conversion and concatenation."""
- return concat(map(str, seq))
-
-
-def new_context(
- environment: "Environment",
- template_name: t.Optional[str],
- blocks: t.Dict[str, t.Callable[["Context"], t.Iterator[str]]],
- vars: t.Optional[t.Dict[str, t.Any]] = None,
- shared: bool = False,
- globals: t.Optional[t.MutableMapping[str, t.Any]] = None,
- locals: t.Optional[t.Mapping[str, t.Any]] = None,
-) -> "Context":
- """Internal helper for context creation."""
- if vars is None:
- vars = {}
- if shared:
- parent = vars
- else:
- parent = dict(globals or (), **vars)
- if locals:
- # if the parent is shared a copy should be created because
- # we don't want to modify the dict passed
- if shared:
- parent = dict(parent)
- for key, value in locals.items():
- if value is not missing:
- parent[key] = value
- return environment.context_class(
- environment, parent, template_name, blocks, globals=globals
- )
-
-
-class TemplateReference:
- """The `self` in templates."""
-
- def __init__(self, context: "Context") -> None:
- self.__context = context
-
- def __getitem__(self, name: str) -> t.Any:
- blocks = self.__context.blocks[name]
- return BlockReference(name, self.__context, blocks, 0)
-
- def __repr__(self) -> str:
- return f"<{type(self).__name__} {self.__context.name!r}>"
-
-
-def _dict_method_all(dict_method: F) -> F:
- @functools.wraps(dict_method)
- def f_all(self: "Context") -> t.Any:
- return dict_method(self.get_all())
-
- return t.cast(F, f_all)
-
-
-@abc.Mapping.register
-class Context:
- """The template context holds the variables of a template. It stores the
- values passed to the template and also the names the template exports.
- Creating instances is neither supported nor useful as it's created
- automatically at various stages of the template evaluation and should not
- be created by hand.
-
- The context is immutable. Modifications on :attr:`parent` **must not**
- happen and modifications on :attr:`vars` are allowed from generated
- template code only. Template filters and global functions marked as
- :func:`pass_context` get the active context passed as first argument
- and are allowed to access the context read-only.
-
- The template context supports read only dict operations (`get`,
- `keys`, `values`, `items`, `iterkeys`, `itervalues`, `iteritems`,
- `__getitem__`, `__contains__`). Additionally there is a :meth:`resolve`
- method that doesn't fail with a `KeyError` but returns an
- :class:`Undefined` object for missing variables.
- """
-
- def __init__(
- self,
- environment: "Environment",
- parent: t.Dict[str, t.Any],
- name: t.Optional[str],
- blocks: t.Dict[str, t.Callable[["Context"], t.Iterator[str]]],
- globals: t.Optional[t.MutableMapping[str, t.Any]] = None,
- ):
- self.parent = parent
- self.vars: t.Dict[str, t.Any] = {}
- self.environment: "Environment" = environment
- self.eval_ctx = EvalContext(self.environment, name)
- self.exported_vars: t.Set[str] = set()
- self.name = name
- self.globals_keys = set() if globals is None else set(globals)
-
- # create the initial mapping of blocks. Whenever template inheritance
- # takes place the runtime will update this mapping with the new blocks
- # from the template.
- self.blocks = {k: [v] for k, v in blocks.items()}
-
- def super(
- self, name: str, current: t.Callable[["Context"], t.Iterator[str]]
- ) -> t.Union["BlockReference", "Undefined"]:
- """Render a parent block."""
- try:
- blocks = self.blocks[name]
- index = blocks.index(current) + 1
- blocks[index]
- except LookupError:
- return self.environment.undefined(
- f"there is no parent block called {name!r}.", name="super"
- )
- return BlockReference(name, self, blocks, index)
-
- def get(self, key: str, default: t.Any = None) -> t.Any:
- """Look up a variable by name, or return a default if the key is
- not found.
-
- :param key: The variable name to look up.
- :param default: The value to return if the key is not found.
- """
- try:
- return self[key]
- except KeyError:
- return default
-
- def resolve(self, key: str) -> t.Union[t.Any, "Undefined"]:
- """Look up a variable by name, or return an :class:`Undefined`
- object if the key is not found.
-
- If you need to add custom behavior, override
- :meth:`resolve_or_missing`, not this method. The various lookup
- functions use that method, not this one.
-
- :param key: The variable name to look up.
- """
- rv = self.resolve_or_missing(key)
-
- if rv is missing:
- return self.environment.undefined(name=key)
-
- return rv
-
- def resolve_or_missing(self, key: str) -> t.Any:
- """Look up a variable by name, or return a ``missing`` sentinel
- if the key is not found.
-
- Override this method to add custom lookup behavior.
- :meth:`resolve`, :meth:`get`, and :meth:`__getitem__` use this
- method. Don't call this method directly.
-
- :param key: The variable name to look up.
- """
- if key in self.vars:
- return self.vars[key]
-
- if key in self.parent:
- return self.parent[key]
-
- return missing
-
- def get_exported(self) -> t.Dict[str, t.Any]:
- """Get a new dict with the exported variables."""
- return {k: self.vars[k] for k in self.exported_vars}
-
- def get_all(self) -> t.Dict[str, t.Any]:
- """Return the complete context as dict including the exported
- variables. For optimizations reasons this might not return an
- actual copy so be careful with using it.
- """
- if not self.vars:
- return self.parent
- if not self.parent:
- return self.vars
- return dict(self.parent, **self.vars)
-
- @internalcode
- def call(
- __self, __obj: t.Callable, *args: t.Any, **kwargs: t.Any # noqa: B902
- ) -> t.Union[t.Any, "Undefined"]:
- """Call the callable with the arguments and keyword arguments
- provided but inject the active context or environment as first
- argument if the callable has :func:`pass_context` or
- :func:`pass_environment`.
- """
- if __debug__:
- __traceback_hide__ = True # noqa
-
- # Allow callable classes to take a context
- if (
- hasattr(__obj, "__call__") # noqa: B004
- and _PassArg.from_obj(__obj.__call__) is not None # type: ignore
- ):
- __obj = __obj.__call__ # type: ignore
-
- pass_arg = _PassArg.from_obj(__obj)
-
- if pass_arg is _PassArg.context:
- # the active context should have access to variables set in
- # loops and blocks without mutating the context itself
- if kwargs.get("_loop_vars"):
- __self = __self.derived(kwargs["_loop_vars"])
- if kwargs.get("_block_vars"):
- __self = __self.derived(kwargs["_block_vars"])
- args = (__self,) + args
- elif pass_arg is _PassArg.eval_context:
- args = (__self.eval_ctx,) + args
- elif pass_arg is _PassArg.environment:
- args = (__self.environment,) + args
-
- kwargs.pop("_block_vars", None)
- kwargs.pop("_loop_vars", None)
-
- try:
- return __obj(*args, **kwargs)
- except StopIteration:
- return __self.environment.undefined(
- "value was undefined because a callable raised a"
- " StopIteration exception"
- )
-
- def derived(self, locals: t.Optional[t.Dict[str, t.Any]] = None) -> "Context":
- """Internal helper function to create a derived context. This is
- used in situations where the system needs a new context in the same
- template that is independent.
- """
- context = new_context(
- self.environment, self.name, {}, self.get_all(), True, None, locals
- )
- context.eval_ctx = self.eval_ctx
- context.blocks.update((k, list(v)) for k, v in self.blocks.items())
- return context
-
- keys = _dict_method_all(dict.keys)
- values = _dict_method_all(dict.values)
- items = _dict_method_all(dict.items)
-
- def __contains__(self, name: str) -> bool:
- return name in self.vars or name in self.parent
-
- def __getitem__(self, key: str) -> t.Any:
- """Look up a variable by name with ``[]`` syntax, or raise a
- ``KeyError`` if the key is not found.
- """
- item = self.resolve_or_missing(key)
-
- if item is missing:
- raise KeyError(key)
-
- return item
-
- def __repr__(self) -> str:
- return f"<{type(self).__name__} {self.get_all()!r} of {self.name!r}>"
-
-
-class BlockReference:
- """One block on a template reference."""
-
- def __init__(
- self,
- name: str,
- context: "Context",
- stack: t.List[t.Callable[["Context"], t.Iterator[str]]],
- depth: int,
- ) -> None:
- self.name = name
- self._context = context
- self._stack = stack
- self._depth = depth
-
- @property
- def super(self) -> t.Union["BlockReference", "Undefined"]:
- """Super the block."""
- if self._depth + 1 >= len(self._stack):
- return self._context.environment.undefined(
- f"there is no parent block called {self.name!r}.", name="super"
- )
- return BlockReference(self.name, self._context, self._stack, self._depth + 1)
-
- @internalcode
- async def _async_call(self) -> str:
- rv = concat(
- [x async for x in self._stack[self._depth](self._context)] # type: ignore
- )
-
- if self._context.eval_ctx.autoescape:
- return Markup(rv)
-
- return rv
-
- @internalcode
- def __call__(self) -> str:
- if self._context.environment.is_async:
- return self._async_call() # type: ignore
-
- rv = concat(self._stack[self._depth](self._context))
-
- if self._context.eval_ctx.autoescape:
- return Markup(rv)
-
- return rv
-
-
-class LoopContext:
- """A wrapper iterable for dynamic ``for`` loops, with information
- about the loop and iteration.
- """
-
- #: Current iteration of the loop, starting at 0.
- index0 = -1
-
- _length: t.Optional[int] = None
- _after: t.Any = missing
- _current: t.Any = missing
- _before: t.Any = missing
- _last_changed_value: t.Any = missing
-
- def __init__(
- self,
- iterable: t.Iterable[V],
- undefined: t.Type["Undefined"],
- recurse: t.Optional["LoopRenderFunc"] = None,
- depth0: int = 0,
- ) -> None:
- """
- :param iterable: Iterable to wrap.
- :param undefined: :class:`Undefined` class to use for next and
- previous items.
- :param recurse: The function to render the loop body when the
- loop is marked recursive.
- :param depth0: Incremented when looping recursively.
- """
- self._iterable = iterable
- self._iterator = self._to_iterator(iterable)
- self._undefined = undefined
- self._recurse = recurse
- #: How many levels deep a recursive loop currently is, starting at 0.
- self.depth0 = depth0
-
- @staticmethod
- def _to_iterator(iterable: t.Iterable[V]) -> t.Iterator[V]:
- return iter(iterable)
-
- @property
- def length(self) -> int:
- """Length of the iterable.
-
- If the iterable is a generator or otherwise does not have a
- size, it is eagerly evaluated to get a size.
- """
- if self._length is not None:
- return self._length
-
- try:
- self._length = len(self._iterable) # type: ignore
- except TypeError:
- iterable = list(self._iterator)
- self._iterator = self._to_iterator(iterable)
- self._length = len(iterable) + self.index + (self._after is not missing)
-
- return self._length
-
- def __len__(self) -> int:
- return self.length
-
- @property
- def depth(self) -> int:
- """How many levels deep a recursive loop currently is, starting at 1."""
- return self.depth0 + 1
-
- @property
- def index(self) -> int:
- """Current iteration of the loop, starting at 1."""
- return self.index0 + 1
-
- @property
- def revindex0(self) -> int:
- """Number of iterations from the end of the loop, ending at 0.
-
- Requires calculating :attr:`length`.
- """
- return self.length - self.index
-
- @property
- def revindex(self) -> int:
- """Number of iterations from the end of the loop, ending at 1.
-
- Requires calculating :attr:`length`.
- """
- return self.length - self.index0
-
- @property
- def first(self) -> bool:
- """Whether this is the first iteration of the loop."""
- return self.index0 == 0
-
- def _peek_next(self) -> t.Any:
- """Return the next element in the iterable, or :data:`missing`
- if the iterable is exhausted. Only peeks one item ahead, caching
- the result in :attr:`_last` for use in subsequent checks. The
- cache is reset when :meth:`__next__` is called.
- """
- if self._after is not missing:
- return self._after
-
- self._after = next(self._iterator, missing)
- return self._after
-
- @property
- def last(self) -> bool:
- """Whether this is the last iteration of the loop.
-
- Causes the iterable to advance early. See
- :func:`itertools.groupby` for issues this can cause.
- The :func:`groupby` filter avoids that issue.
- """
- return self._peek_next() is missing
-
- @property
- def previtem(self) -> t.Union[t.Any, "Undefined"]:
- """The item in the previous iteration. Undefined during the
- first iteration.
- """
- if self.first:
- return self._undefined("there is no previous item")
-
- return self._before
-
- @property
- def nextitem(self) -> t.Union[t.Any, "Undefined"]:
- """The item in the next iteration. Undefined during the last
- iteration.
-
- Causes the iterable to advance early. See
- :func:`itertools.groupby` for issues this can cause.
- The :func:`jinja-filters.groupby` filter avoids that issue.
- """
- rv = self._peek_next()
-
- if rv is missing:
- return self._undefined("there is no next item")
-
- return rv
-
- def cycle(self, *args: V) -> V:
- """Return a value from the given args, cycling through based on
- the current :attr:`index0`.
-
- :param args: One or more values to cycle through.
- """
- if not args:
- raise TypeError("no items for cycling given")
-
- return args[self.index0 % len(args)]
-
- def changed(self, *value: t.Any) -> bool:
- """Return ``True`` if previously called with a different value
- (including when called for the first time).
-
- :param value: One or more values to compare to the last call.
- """
- if self._last_changed_value != value:
- self._last_changed_value = value
- return True
-
- return False
-
- def __iter__(self) -> "LoopContext":
- return self
-
- def __next__(self) -> t.Tuple[t.Any, "LoopContext"]:
- if self._after is not missing:
- rv = self._after
- self._after = missing
- else:
- rv = next(self._iterator)
-
- self.index0 += 1
- self._before = self._current
- self._current = rv
- return rv, self
-
- @internalcode
- def __call__(self, iterable: t.Iterable[V]) -> str:
- """When iterating over nested data, render the body of the loop
- recursively with the given inner iterable data.
-
- The loop must have the ``recursive`` marker for this to work.
- """
- if self._recurse is None:
- raise TypeError(
- "The loop must have the 'recursive' marker to be called recursively."
- )
-
- return self._recurse(iterable, self._recurse, depth=self.depth)
-
- def __repr__(self) -> str:
- return f"<{type(self).__name__} {self.index}/{self.length}>"
-
-
-class AsyncLoopContext(LoopContext):
- _iterator: t.AsyncIterator[t.Any] # type: ignore
-
- @staticmethod
- def _to_iterator( # type: ignore
- iterable: t.Union[t.Iterable[V], t.AsyncIterable[V]]
- ) -> t.AsyncIterator[V]:
- return auto_aiter(iterable)
-
- @property
- async def length(self) -> int: # type: ignore
- if self._length is not None:
- return self._length
-
- try:
- self._length = len(self._iterable) # type: ignore
- except TypeError:
- iterable = [x async for x in self._iterator]
- self._iterator = self._to_iterator(iterable)
- self._length = len(iterable) + self.index + (self._after is not missing)
-
- return self._length
-
- @property
- async def revindex0(self) -> int: # type: ignore
- return await self.length - self.index
-
- @property
- async def revindex(self) -> int: # type: ignore
- return await self.length - self.index0
-
- async def _peek_next(self) -> t.Any:
- if self._after is not missing:
- return self._after
-
- try:
- self._after = await self._iterator.__anext__()
- except StopAsyncIteration:
- self._after = missing
-
- return self._after
-
- @property
- async def last(self) -> bool: # type: ignore
- return await self._peek_next() is missing
-
- @property
- async def nextitem(self) -> t.Union[t.Any, "Undefined"]:
- rv = await self._peek_next()
-
- if rv is missing:
- return self._undefined("there is no next item")
-
- return rv
-
- def __aiter__(self) -> "AsyncLoopContext":
- return self
-
- async def __anext__(self) -> t.Tuple[t.Any, "AsyncLoopContext"]:
- if self._after is not missing:
- rv = self._after
- self._after = missing
- else:
- rv = await self._iterator.__anext__()
-
- self.index0 += 1
- self._before = self._current
- self._current = rv
- return rv, self
-
-
-class Macro:
- """Wraps a macro function."""
-
- def __init__(
- self,
- environment: "Environment",
- func: t.Callable[..., str],
- name: str,
- arguments: t.List[str],
- catch_kwargs: bool,
- catch_varargs: bool,
- caller: bool,
- default_autoescape: t.Optional[bool] = None,
- ):
- self._environment = environment
- self._func = func
- self._argument_count = len(arguments)
- self.name = name
- self.arguments = arguments
- self.catch_kwargs = catch_kwargs
- self.catch_varargs = catch_varargs
- self.caller = caller
- self.explicit_caller = "caller" in arguments
-
- if default_autoescape is None:
- if callable(environment.autoescape):
- default_autoescape = environment.autoescape(None)
- else:
- default_autoescape = environment.autoescape
-
- self._default_autoescape = default_autoescape
-
- @internalcode
- @pass_eval_context
- def __call__(self, *args: t.Any, **kwargs: t.Any) -> str:
- # This requires a bit of explanation, In the past we used to
- # decide largely based on compile-time information if a macro is
- # safe or unsafe. While there was a volatile mode it was largely
- # unused for deciding on escaping. This turns out to be
- # problematic for macros because whether a macro is safe depends not
- # on the escape mode when it was defined, but rather when it was used.
- #
- # Because however we export macros from the module system and
- # there are historic callers that do not pass an eval context (and
- # will continue to not pass one), we need to perform an instance
- # check here.
- #
- # This is considered safe because an eval context is not a valid
- # argument to callables otherwise anyway. Worst case here is
- # that if no eval context is passed we fall back to the compile
- # time autoescape flag.
- if args and isinstance(args[0], EvalContext):
- autoescape = args[0].autoescape
- args = args[1:]
- else:
- autoescape = self._default_autoescape
-
- # try to consume the positional arguments
- arguments = list(args[: self._argument_count])
- off = len(arguments)
-
- # For information why this is necessary refer to the handling
- # of caller in the `macro_body` handler in the compiler.
- found_caller = False
-
- # if the number of arguments consumed is not the number of
- # arguments expected we start filling in keyword arguments
- # and defaults.
- if off != self._argument_count:
- for name in self.arguments[len(arguments) :]:
- try:
- value = kwargs.pop(name)
- except KeyError:
- value = missing
- if name == "caller":
- found_caller = True
- arguments.append(value)
- else:
- found_caller = self.explicit_caller
-
- # it's important that the order of these arguments does not change
- # if not also changed in the compiler's `function_scoping` method.
- # the order is caller, keyword arguments, positional arguments!
- if self.caller and not found_caller:
- caller = kwargs.pop("caller", None)
- if caller is None:
- caller = self._environment.undefined("No caller defined", name="caller")
- arguments.append(caller)
-
- if self.catch_kwargs:
- arguments.append(kwargs)
- elif kwargs:
- if "caller" in kwargs:
- raise TypeError(
- f"macro {self.name!r} was invoked with two values for the special"
- " caller argument. This is most likely a bug."
- )
- raise TypeError(
- f"macro {self.name!r} takes no keyword argument {next(iter(kwargs))!r}"
- )
- if self.catch_varargs:
- arguments.append(args[self._argument_count :])
- elif len(args) > self._argument_count:
- raise TypeError(
- f"macro {self.name!r} takes not more than"
- f" {len(self.arguments)} argument(s)"
- )
-
- return self._invoke(arguments, autoescape)
-
- async def _async_invoke(self, arguments: t.List[t.Any], autoescape: bool) -> str:
- rv = await self._func(*arguments) # type: ignore
-
- if autoescape:
- return Markup(rv)
-
- return rv # type: ignore
-
- def _invoke(self, arguments: t.List[t.Any], autoescape: bool) -> str:
- if self._environment.is_async:
- return self._async_invoke(arguments, autoescape) # type: ignore
-
- rv = self._func(*arguments)
-
- if autoescape:
- rv = Markup(rv)
-
- return rv
-
- def __repr__(self) -> str:
- name = "anonymous" if self.name is None else repr(self.name)
- return f"<{type(self).__name__} {name}>"
-
-
-class Undefined:
- """The default undefined type. This undefined type can be printed and
- iterated over, but every other access will raise an :exc:`UndefinedError`:
-
- >>> foo = Undefined(name='foo')
- >>> str(foo)
- ''
- >>> not foo
- True
- >>> foo + 42
- Traceback (most recent call last):
- ...
- jinja2.exceptions.UndefinedError: 'foo' is undefined
- """
-
- __slots__ = (
- "_undefined_hint",
- "_undefined_obj",
- "_undefined_name",
- "_undefined_exception",
- )
-
- def __init__(
- self,
- hint: t.Optional[str] = None,
- obj: t.Any = missing,
- name: t.Optional[str] = None,
- exc: t.Type[TemplateRuntimeError] = UndefinedError,
- ) -> None:
- self._undefined_hint = hint
- self._undefined_obj = obj
- self._undefined_name = name
- self._undefined_exception = exc
-
- @property
- def _undefined_message(self) -> str:
- """Build a message about the undefined value based on how it was
- accessed.
- """
- if self._undefined_hint:
- return self._undefined_hint
-
- if self._undefined_obj is missing:
- return f"{self._undefined_name!r} is undefined"
-
- if not isinstance(self._undefined_name, str):
- return (
- f"{object_type_repr(self._undefined_obj)} has no"
- f" element {self._undefined_name!r}"
- )
-
- return (
- f"{object_type_repr(self._undefined_obj)!r} has no"
- f" attribute {self._undefined_name!r}"
- )
-
- @internalcode
- def _fail_with_undefined_error(
- self, *args: t.Any, **kwargs: t.Any
- ) -> "te.NoReturn":
- """Raise an :exc:`UndefinedError` when operations are performed
- on the undefined value.
- """
- raise self._undefined_exception(self._undefined_message)
-
- @internalcode
- def __getattr__(self, name: str) -> t.Any:
- if name[:2] == "__":
- raise AttributeError(name)
-
- return self._fail_with_undefined_error()
-
- __add__ = __radd__ = __sub__ = __rsub__ = _fail_with_undefined_error
- __mul__ = __rmul__ = __div__ = __rdiv__ = _fail_with_undefined_error
- __truediv__ = __rtruediv__ = _fail_with_undefined_error
- __floordiv__ = __rfloordiv__ = _fail_with_undefined_error
- __mod__ = __rmod__ = _fail_with_undefined_error
- __pos__ = __neg__ = _fail_with_undefined_error
- __call__ = __getitem__ = _fail_with_undefined_error
- __lt__ = __le__ = __gt__ = __ge__ = _fail_with_undefined_error
- __int__ = __float__ = __complex__ = _fail_with_undefined_error
- __pow__ = __rpow__ = _fail_with_undefined_error
-
- def __eq__(self, other: t.Any) -> bool:
- return type(self) is type(other)
-
- def __ne__(self, other: t.Any) -> bool:
- return not self.__eq__(other)
-
- def __hash__(self) -> int:
- return id(type(self))
-
- def __str__(self) -> str:
- return ""
-
- def __len__(self) -> int:
- return 0
-
- def __iter__(self) -> t.Iterator[t.Any]:
- yield from ()
-
- async def __aiter__(self) -> t.AsyncIterator[t.Any]:
- for _ in ():
- yield
-
- def __bool__(self) -> bool:
- return False
-
- def __repr__(self) -> str:
- return "Undefined"
-
-
-def make_logging_undefined(
- logger: t.Optional["logging.Logger"] = None, base: t.Type[Undefined] = Undefined
-) -> t.Type[Undefined]:
- """Given a logger object this returns a new undefined class that will
- log certain failures. It will log iterations and printing. If no
- logger is given a default logger is created.
-
- Example::
-
- logger = logging.getLogger(__name__)
- LoggingUndefined = make_logging_undefined(
- logger=logger,
- base=Undefined
- )
-
- .. versionadded:: 2.8
-
- :param logger: the logger to use. If not provided, a default logger
- is created.
- :param base: the base class to add logging functionality to. This
- defaults to :class:`Undefined`.
- """
- if logger is None:
- import logging
-
- logger = logging.getLogger(__name__)
- logger.addHandler(logging.StreamHandler(sys.stderr))
-
- def _log_message(undef: Undefined) -> None:
- logger.warning( # type: ignore
- "Template variable warning: %s", undef._undefined_message
- )
-
- class LoggingUndefined(base): # type: ignore
- __slots__ = ()
-
- def _fail_with_undefined_error( # type: ignore
- self, *args: t.Any, **kwargs: t.Any
- ) -> "te.NoReturn":
- try:
- super()._fail_with_undefined_error(*args, **kwargs)
- except self._undefined_exception as e:
- logger.error("Template variable error: %s", e) # type: ignore
- raise e
-
- def __str__(self) -> str:
- _log_message(self)
- return super().__str__() # type: ignore
-
- def __iter__(self) -> t.Iterator[t.Any]:
- _log_message(self)
- return super().__iter__() # type: ignore
-
- def __bool__(self) -> bool:
- _log_message(self)
- return super().__bool__() # type: ignore
-
- return LoggingUndefined
-
-
-class ChainableUndefined(Undefined):
- """An undefined that is chainable, where both ``__getattr__`` and
- ``__getitem__`` return itself rather than raising an
- :exc:`UndefinedError`.
-
- >>> foo = ChainableUndefined(name='foo')
- >>> str(foo.bar['baz'])
- ''
- >>> foo.bar['baz'] + 42
- Traceback (most recent call last):
- ...
- jinja2.exceptions.UndefinedError: 'foo' is undefined
-
- .. versionadded:: 2.11.0
- """
-
- __slots__ = ()
-
- def __html__(self) -> str:
- return str(self)
-
- def __getattr__(self, _: str) -> "ChainableUndefined":
- return self
-
- __getitem__ = __getattr__ # type: ignore
-
-
-class DebugUndefined(Undefined):
- """An undefined that returns the debug info when printed.
-
- >>> foo = DebugUndefined(name='foo')
- >>> str(foo)
- '{{ foo }}'
- >>> not foo
- True
- >>> foo + 42
- Traceback (most recent call last):
- ...
- jinja2.exceptions.UndefinedError: 'foo' is undefined
- """
-
- __slots__ = ()
-
- def __str__(self) -> str:
- if self._undefined_hint:
- message = f"undefined value printed: {self._undefined_hint}"
-
- elif self._undefined_obj is missing:
- message = self._undefined_name # type: ignore
-
- else:
- message = (
- f"no such element: {object_type_repr(self._undefined_obj)}"
- f"[{self._undefined_name!r}]"
- )
-
- return f"{{{{ {message} }}}}"
-
-
-class StrictUndefined(Undefined):
- """An undefined that barks on print and iteration as well as boolean
- tests and all kinds of comparisons. In other words: you can do nothing
- with it except checking if it's defined using the `defined` test.
-
- >>> foo = StrictUndefined(name='foo')
- >>> str(foo)
- Traceback (most recent call last):
- ...
- jinja2.exceptions.UndefinedError: 'foo' is undefined
- >>> not foo
- Traceback (most recent call last):
- ...
- jinja2.exceptions.UndefinedError: 'foo' is undefined
- >>> foo + 42
- Traceback (most recent call last):
- ...
- jinja2.exceptions.UndefinedError: 'foo' is undefined
- """
-
- __slots__ = ()
- __iter__ = __str__ = __len__ = Undefined._fail_with_undefined_error
- __eq__ = __ne__ = __bool__ = __hash__ = Undefined._fail_with_undefined_error
- __contains__ = Undefined._fail_with_undefined_error
-
-
-# Remove slots attributes, after the metaclass is applied they are
-# unneeded and contain wrong data for subclasses.
-del (
- Undefined.__slots__,
- ChainableUndefined.__slots__,
- DebugUndefined.__slots__,
- StrictUndefined.__slots__,
-)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/markdown_it/rules_inline/emphasis.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/markdown_it/rules_inline/emphasis.py
deleted file mode 100644
index 9a98f9e216c94db0217e986270aaaa72fcc99f7f..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/markdown_it/rules_inline/emphasis.py
+++ /dev/null
@@ -1,102 +0,0 @@
-# Process *this* and _that_
-#
-from __future__ import annotations
-
-from .state_inline import Delimiter, StateInline
-
-
-def tokenize(state: StateInline, silent: bool) -> bool:
- """Insert each marker as a separate text token, and add it to delimiter list"""
- start = state.pos
- marker = state.src[start]
-
- if silent:
- return False
-
- if marker not in ("_", "*"):
- return False
-
- scanned = state.scanDelims(state.pos, marker == "*")
-
- for _ in range(scanned.length):
- token = state.push("text", "", 0)
- token.content = marker
- state.delimiters.append(
- Delimiter(
- marker=ord(marker),
- length=scanned.length,
- token=len(state.tokens) - 1,
- end=-1,
- open=scanned.can_open,
- close=scanned.can_close,
- )
- )
-
- state.pos += scanned.length
-
- return True
-
-
-def _postProcess(state: StateInline, delimiters: list[Delimiter]) -> None:
- i = len(delimiters) - 1
- while i >= 0:
- startDelim = delimiters[i]
-
- # /* _ */ /* * */
- if startDelim.marker != 0x5F and startDelim.marker != 0x2A:
- i -= 1
- continue
-
- # Process only opening markers
- if startDelim.end == -1:
- i -= 1
- continue
-
- endDelim = delimiters[startDelim.end]
-
- # If the previous delimiter has the same marker and is adjacent to this one,
- # merge those into one strong delimiter.
- #
- # `whatever` -> `whatever`
- #
- isStrong = (
- i > 0
- and delimiters[i - 1].end == startDelim.end + 1
- # check that first two markers match and adjacent
- and delimiters[i - 1].marker == startDelim.marker
- and delimiters[i - 1].token == startDelim.token - 1
- # check that last two markers are adjacent (we can safely assume they match)
- and delimiters[startDelim.end + 1].token == endDelim.token + 1
- )
-
- ch = chr(startDelim.marker)
-
- token = state.tokens[startDelim.token]
- token.type = "strong_open" if isStrong else "em_open"
- token.tag = "strong" if isStrong else "em"
- token.nesting = 1
- token.markup = ch + ch if isStrong else ch
- token.content = ""
-
- token = state.tokens[endDelim.token]
- token.type = "strong_close" if isStrong else "em_close"
- token.tag = "strong" if isStrong else "em"
- token.nesting = -1
- token.markup = ch + ch if isStrong else ch
- token.content = ""
-
- if isStrong:
- state.tokens[delimiters[i - 1].token].content = ""
- state.tokens[delimiters[startDelim.end + 1].token].content = ""
- i -= 1
-
- i -= 1
-
-
-def postProcess(state: StateInline) -> None:
- """Walk through delimiter list and replace text tokens with tags."""
- _postProcess(state, state.delimiters)
-
- for token in state.tokens_meta:
- if token and "delimiters" in token:
- _postProcess(state, token["delimiters"])
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/_pyinstaller/pyinstaller-smoke.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/_pyinstaller/pyinstaller-smoke.py
deleted file mode 100644
index eb28070e38baf80223fe0178ac0a7c0f5732a2c8..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/_pyinstaller/pyinstaller-smoke.py
+++ /dev/null
@@ -1,32 +0,0 @@
-"""A crude *bit of everything* smoke test to verify PyInstaller compatibility.
-
-PyInstaller typically goes wrong by forgetting to package modules, extension
-modules or shared libraries. This script should aim to touch as many of those
-as possible in an attempt to trip a ModuleNotFoundError or a DLL load failure
-due to an uncollected resource. Missing resources are unlikely to lead to
-arithmetic errors so there's generally no need to verify any calculation's
-output - merely that it made it to the end OK. This script should not
-explicitly import any of numpy's submodules as that gives PyInstaller undue
-hints that those submodules exist and should be collected (accessing implicitly
-loaded submodules is OK).
-
-"""
-import numpy as np
-
-a = np.arange(1., 10.).reshape((3, 3)) % 5
-np.linalg.det(a)
-a @ a
-a @ a.T
-np.linalg.inv(a)
-np.sin(np.exp(a))
-np.linalg.svd(a)
-np.linalg.eigh(a)
-
-np.unique(np.random.randint(0, 10, 100))
-np.sort(np.random.uniform(0, 10, 100))
-
-np.fft.fft(np.exp(2j * np.pi * np.arange(8) / 8))
-np.ma.masked_array(np.arange(10), np.random.rand(10) < .5).sum()
-np.polynomial.Legendre([7, 8, 9]).roots()
-
-print("I made it!")
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/distutils/checks/extra_vsx4_mma.c b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/distutils/checks/extra_vsx4_mma.c
deleted file mode 100644
index a70b2a9f6f95408eb7cfe59c056f114cc363869b..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/numpy/distutils/checks/extra_vsx4_mma.c
+++ /dev/null
@@ -1,21 +0,0 @@
-#ifndef __VSX__
- #error "VSX is not supported"
-#endif
-#include
-
-typedef __vector float fv4sf_t;
-typedef __vector unsigned char vec_t;
-
-int main(void)
-{
- __vector_quad acc0;
- float a[4] = {0,1,2,3};
- float b[4] = {0,1,2,3};
- vec_t *va = (vec_t *) a;
- vec_t *vb = (vec_t *) b;
- __builtin_mma_xvf32ger(&acc0, va[0], vb[0]);
- fv4sf_t result[4];
- __builtin_mma_disassemble_acc((void *)result, &acc0);
- fv4sf_t c0 = result[0];
- return (int)((float*)&c0)[0];
-}
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/copy_view/test_internals.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/copy_view/test_internals.py
deleted file mode 100644
index a727331307d7e9086144aa8d27f70ffa83973620..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/copy_view/test_internals.py
+++ /dev/null
@@ -1,151 +0,0 @@
-import numpy as np
-import pytest
-
-import pandas.util._test_decorators as td
-
-import pandas as pd
-from pandas import DataFrame
-import pandas._testing as tm
-from pandas.tests.copy_view.util import get_array
-
-
-@td.skip_array_manager_invalid_test
-def test_consolidate(using_copy_on_write):
- # create unconsolidated DataFrame
- df = DataFrame({"a": [1, 2, 3], "b": [0.1, 0.2, 0.3]})
- df["c"] = [4, 5, 6]
-
- # take a viewing subset
- subset = df[:]
-
- # each block of subset references a block of df
- assert all(blk.refs.has_reference() for blk in subset._mgr.blocks)
-
- # consolidate the two int64 blocks
- subset._consolidate_inplace()
-
- # the float64 block still references the parent one because it still a view
- assert subset._mgr.blocks[0].refs.has_reference()
- # equivalent of assert np.shares_memory(df["b"].values, subset["b"].values)
- # but avoids caching df["b"]
- assert np.shares_memory(get_array(df, "b"), get_array(subset, "b"))
-
- # the new consolidated int64 block does not reference another
- assert not subset._mgr.blocks[1].refs.has_reference()
-
- # the parent dataframe now also only is linked for the float column
- assert not df._mgr.blocks[0].refs.has_reference()
- assert df._mgr.blocks[1].refs.has_reference()
- assert not df._mgr.blocks[2].refs.has_reference()
-
- # and modifying subset still doesn't modify parent
- if using_copy_on_write:
- subset.iloc[0, 1] = 0.0
- assert not df._mgr.blocks[1].refs.has_reference()
- assert df.loc[0, "b"] == 0.1
-
-
-@pytest.mark.single_cpu
-@td.skip_array_manager_invalid_test
-def test_switch_options():
- # ensure we can switch the value of the option within one session
- # (assuming data is constructed after switching)
-
- # using the option_context to ensure we set back to global option value
- # after running the test
- with pd.option_context("mode.copy_on_write", False):
- df = DataFrame({"a": [1, 2, 3], "b": [0.1, 0.2, 0.3]})
- subset = df[:]
- subset.iloc[0, 0] = 0
- # df updated with CoW disabled
- assert df.iloc[0, 0] == 0
-
- pd.options.mode.copy_on_write = True
- df = DataFrame({"a": [1, 2, 3], "b": [0.1, 0.2, 0.3]})
- subset = df[:]
- subset.iloc[0, 0] = 0
- # df not updated with CoW enabled
- assert df.iloc[0, 0] == 1
-
- pd.options.mode.copy_on_write = False
- df = DataFrame({"a": [1, 2, 3], "b": [0.1, 0.2, 0.3]})
- subset = df[:]
- subset.iloc[0, 0] = 0
- # df updated with CoW disabled
- assert df.iloc[0, 0] == 0
-
-
-@td.skip_array_manager_invalid_test
-@pytest.mark.parametrize("dtype", [np.intp, np.int8])
-@pytest.mark.parametrize(
- "locs, arr",
- [
- ([0], np.array([-1, -2, -3])),
- ([1], np.array([-1, -2, -3])),
- ([5], np.array([-1, -2, -3])),
- ([0, 1], np.array([[-1, -2, -3], [-4, -5, -6]]).T),
- ([0, 2], np.array([[-1, -2, -3], [-4, -5, -6]]).T),
- ([0, 1, 2], np.array([[-1, -2, -3], [-4, -5, -6], [-4, -5, -6]]).T),
- ([1, 2], np.array([[-1, -2, -3], [-4, -5, -6]]).T),
- ([1, 3], np.array([[-1, -2, -3], [-4, -5, -6]]).T),
- ([1, 3], np.array([[-1, -2, -3], [-4, -5, -6]]).T),
- ],
-)
-def test_iset_splits_blocks_inplace(using_copy_on_write, locs, arr, dtype):
- # Nothing currently calls iset with
- # more than 1 loc with inplace=True (only happens with inplace=False)
- # but ensure that it works
- df = DataFrame(
- {
- "a": [1, 2, 3],
- "b": [4, 5, 6],
- "c": [7, 8, 9],
- "d": [10, 11, 12],
- "e": [13, 14, 15],
- "f": ["a", "b", "c"],
- },
- )
- arr = arr.astype(dtype)
- df_orig = df.copy()
- df2 = df.copy(deep=None) # Trigger a CoW (if enabled, otherwise makes copy)
- df2._mgr.iset(locs, arr, inplace=True)
-
- tm.assert_frame_equal(df, df_orig)
-
- if using_copy_on_write:
- for i, col in enumerate(df.columns):
- if i not in locs:
- assert np.shares_memory(get_array(df, col), get_array(df2, col))
- else:
- for col in df.columns:
- assert not np.shares_memory(get_array(df, col), get_array(df2, col))
-
-
-def test_exponential_backoff():
- # GH#55518
- df = DataFrame({"a": [1, 2, 3]})
- for i in range(490):
- df.copy(deep=False)
-
- assert len(df._mgr.blocks[0].refs.referenced_blocks) == 491
-
- df = DataFrame({"a": [1, 2, 3]})
- dfs = [df.copy(deep=False) for i in range(510)]
-
- for i in range(20):
- df.copy(deep=False)
- assert len(df._mgr.blocks[0].refs.referenced_blocks) == 531
- assert df._mgr.blocks[0].refs.clear_counter == 1000
-
- for i in range(500):
- df.copy(deep=False)
-
- # Don't reduce since we still have over 500 objects alive
- assert df._mgr.blocks[0].refs.clear_counter == 1000
-
- dfs = dfs[:300]
- for i in range(500):
- df.copy(deep=False)
-
- # Reduce since there are less than 500 objects alive
- assert df._mgr.blocks[0].refs.clear_counter == 500
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/extension/base/reshaping.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/extension/base/reshaping.py
deleted file mode 100644
index 5d9c03e1b25691ac9a4b1243f81e27de9c2deb41..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/extension/base/reshaping.py
+++ /dev/null
@@ -1,374 +0,0 @@
-import itertools
-
-import numpy as np
-import pytest
-
-import pandas as pd
-import pandas._testing as tm
-from pandas.api.extensions import ExtensionArray
-from pandas.core.internals.blocks import EABackedBlock
-
-
-class BaseReshapingTests:
- """Tests for reshaping and concatenation."""
-
- @pytest.mark.parametrize("in_frame", [True, False])
- def test_concat(self, data, in_frame):
- wrapped = pd.Series(data)
- if in_frame:
- wrapped = pd.DataFrame(wrapped)
- result = pd.concat([wrapped, wrapped], ignore_index=True)
-
- assert len(result) == len(data) * 2
-
- if in_frame:
- dtype = result.dtypes[0]
- else:
- dtype = result.dtype
-
- assert dtype == data.dtype
- if hasattr(result._mgr, "blocks"):
- assert isinstance(result._mgr.blocks[0], EABackedBlock)
- assert isinstance(result._mgr.arrays[0], ExtensionArray)
-
- @pytest.mark.parametrize("in_frame", [True, False])
- def test_concat_all_na_block(self, data_missing, in_frame):
- valid_block = pd.Series(data_missing.take([1, 1]), index=[0, 1])
- na_block = pd.Series(data_missing.take([0, 0]), index=[2, 3])
- if in_frame:
- valid_block = pd.DataFrame({"a": valid_block})
- na_block = pd.DataFrame({"a": na_block})
- result = pd.concat([valid_block, na_block])
- if in_frame:
- expected = pd.DataFrame({"a": data_missing.take([1, 1, 0, 0])})
- tm.assert_frame_equal(result, expected)
- else:
- expected = pd.Series(data_missing.take([1, 1, 0, 0]))
- tm.assert_series_equal(result, expected)
-
- def test_concat_mixed_dtypes(self, data):
- # https://github.com/pandas-dev/pandas/issues/20762
- df1 = pd.DataFrame({"A": data[:3]})
- df2 = pd.DataFrame({"A": [1, 2, 3]})
- df3 = pd.DataFrame({"A": ["a", "b", "c"]}).astype("category")
- dfs = [df1, df2, df3]
-
- # dataframes
- result = pd.concat(dfs)
- expected = pd.concat([x.astype(object) for x in dfs])
- tm.assert_frame_equal(result, expected)
-
- # series
- result = pd.concat([x["A"] for x in dfs])
- expected = pd.concat([x["A"].astype(object) for x in dfs])
- tm.assert_series_equal(result, expected)
-
- # simple test for just EA and one other
- result = pd.concat([df1, df2.astype(object)])
- expected = pd.concat([df1.astype("object"), df2.astype("object")])
- tm.assert_frame_equal(result, expected)
-
- result = pd.concat([df1["A"], df2["A"].astype(object)])
- expected = pd.concat([df1["A"].astype("object"), df2["A"].astype("object")])
- tm.assert_series_equal(result, expected)
-
- def test_concat_columns(self, data, na_value):
- df1 = pd.DataFrame({"A": data[:3]})
- df2 = pd.DataFrame({"B": [1, 2, 3]})
-
- expected = pd.DataFrame({"A": data[:3], "B": [1, 2, 3]})
- result = pd.concat([df1, df2], axis=1)
- tm.assert_frame_equal(result, expected)
- result = pd.concat([df1["A"], df2["B"]], axis=1)
- tm.assert_frame_equal(result, expected)
-
- # non-aligned
- df2 = pd.DataFrame({"B": [1, 2, 3]}, index=[1, 2, 3])
- expected = pd.DataFrame(
- {
- "A": data._from_sequence(list(data[:3]) + [na_value], dtype=data.dtype),
- "B": [np.nan, 1, 2, 3],
- }
- )
-
- result = pd.concat([df1, df2], axis=1)
- tm.assert_frame_equal(result, expected)
- result = pd.concat([df1["A"], df2["B"]], axis=1)
- tm.assert_frame_equal(result, expected)
-
- def test_concat_extension_arrays_copy_false(self, data, na_value):
- # GH 20756
- df1 = pd.DataFrame({"A": data[:3]})
- df2 = pd.DataFrame({"B": data[3:7]})
- expected = pd.DataFrame(
- {
- "A": data._from_sequence(list(data[:3]) + [na_value], dtype=data.dtype),
- "B": data[3:7],
- }
- )
- result = pd.concat([df1, df2], axis=1, copy=False)
- tm.assert_frame_equal(result, expected)
-
- def test_concat_with_reindex(self, data):
- # GH-33027
- a = pd.DataFrame({"a": data[:5]})
- b = pd.DataFrame({"b": data[:5]})
- result = pd.concat([a, b], ignore_index=True)
- expected = pd.DataFrame(
- {
- "a": data.take(list(range(5)) + ([-1] * 5), allow_fill=True),
- "b": data.take(([-1] * 5) + list(range(5)), allow_fill=True),
- }
- )
- tm.assert_frame_equal(result, expected)
-
- def test_align(self, data, na_value):
- a = data[:3]
- b = data[2:5]
- r1, r2 = pd.Series(a).align(pd.Series(b, index=[1, 2, 3]))
-
- # Assumes that the ctor can take a list of scalars of the type
- e1 = pd.Series(data._from_sequence(list(a) + [na_value], dtype=data.dtype))
- e2 = pd.Series(data._from_sequence([na_value] + list(b), dtype=data.dtype))
- tm.assert_series_equal(r1, e1)
- tm.assert_series_equal(r2, e2)
-
- def test_align_frame(self, data, na_value):
- a = data[:3]
- b = data[2:5]
- r1, r2 = pd.DataFrame({"A": a}).align(pd.DataFrame({"A": b}, index=[1, 2, 3]))
-
- # Assumes that the ctor can take a list of scalars of the type
- e1 = pd.DataFrame(
- {"A": data._from_sequence(list(a) + [na_value], dtype=data.dtype)}
- )
- e2 = pd.DataFrame(
- {"A": data._from_sequence([na_value] + list(b), dtype=data.dtype)}
- )
- tm.assert_frame_equal(r1, e1)
- tm.assert_frame_equal(r2, e2)
-
- def test_align_series_frame(self, data, na_value):
- # https://github.com/pandas-dev/pandas/issues/20576
- ser = pd.Series(data, name="a")
- df = pd.DataFrame({"col": np.arange(len(ser) + 1)})
- r1, r2 = ser.align(df)
-
- e1 = pd.Series(
- data._from_sequence(list(data) + [na_value], dtype=data.dtype),
- name=ser.name,
- )
-
- tm.assert_series_equal(r1, e1)
- tm.assert_frame_equal(r2, df)
-
- def test_set_frame_expand_regular_with_extension(self, data):
- df = pd.DataFrame({"A": [1] * len(data)})
- df["B"] = data
- expected = pd.DataFrame({"A": [1] * len(data), "B": data})
- tm.assert_frame_equal(df, expected)
-
- def test_set_frame_expand_extension_with_regular(self, data):
- df = pd.DataFrame({"A": data})
- df["B"] = [1] * len(data)
- expected = pd.DataFrame({"A": data, "B": [1] * len(data)})
- tm.assert_frame_equal(df, expected)
-
- def test_set_frame_overwrite_object(self, data):
- # https://github.com/pandas-dev/pandas/issues/20555
- df = pd.DataFrame({"A": [1] * len(data)}, dtype=object)
- df["A"] = data
- assert df.dtypes["A"] == data.dtype
-
- def test_merge(self, data, na_value):
- # GH-20743
- df1 = pd.DataFrame({"ext": data[:3], "int1": [1, 2, 3], "key": [0, 1, 2]})
- df2 = pd.DataFrame({"int2": [1, 2, 3, 4], "key": [0, 0, 1, 3]})
-
- res = pd.merge(df1, df2)
- exp = pd.DataFrame(
- {
- "int1": [1, 1, 2],
- "int2": [1, 2, 3],
- "key": [0, 0, 1],
- "ext": data._from_sequence(
- [data[0], data[0], data[1]], dtype=data.dtype
- ),
- }
- )
- tm.assert_frame_equal(res, exp[["ext", "int1", "key", "int2"]])
-
- res = pd.merge(df1, df2, how="outer")
- exp = pd.DataFrame(
- {
- "int1": [1, 1, 2, 3, np.nan],
- "int2": [1, 2, 3, np.nan, 4],
- "key": [0, 0, 1, 2, 3],
- "ext": data._from_sequence(
- [data[0], data[0], data[1], data[2], na_value], dtype=data.dtype
- ),
- }
- )
- tm.assert_frame_equal(res, exp[["ext", "int1", "key", "int2"]])
-
- def test_merge_on_extension_array(self, data):
- # GH 23020
- a, b = data[:2]
- key = type(data)._from_sequence([a, b], dtype=data.dtype)
-
- df = pd.DataFrame({"key": key, "val": [1, 2]})
- result = pd.merge(df, df, on="key")
- expected = pd.DataFrame({"key": key, "val_x": [1, 2], "val_y": [1, 2]})
- tm.assert_frame_equal(result, expected)
-
- # order
- result = pd.merge(df.iloc[[1, 0]], df, on="key")
- expected = expected.iloc[[1, 0]].reset_index(drop=True)
- tm.assert_frame_equal(result, expected)
-
- def test_merge_on_extension_array_duplicates(self, data):
- # GH 23020
- a, b = data[:2]
- key = type(data)._from_sequence([a, b, a], dtype=data.dtype)
- df1 = pd.DataFrame({"key": key, "val": [1, 2, 3]})
- df2 = pd.DataFrame({"key": key, "val": [1, 2, 3]})
-
- result = pd.merge(df1, df2, on="key")
- expected = pd.DataFrame(
- {
- "key": key.take([0, 0, 0, 0, 1]),
- "val_x": [1, 1, 3, 3, 2],
- "val_y": [1, 3, 1, 3, 2],
- }
- )
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize(
- "columns",
- [
- ["A", "B"],
- pd.MultiIndex.from_tuples(
- [("A", "a"), ("A", "b")], names=["outer", "inner"]
- ),
- ],
- )
- @pytest.mark.parametrize("future_stack", [True, False])
- def test_stack(self, data, columns, future_stack):
- df = pd.DataFrame({"A": data[:5], "B": data[:5]})
- df.columns = columns
- result = df.stack(future_stack=future_stack)
- expected = df.astype(object).stack(future_stack=future_stack)
- # we need a second astype(object), in case the constructor inferred
- # object -> specialized, as is done for period.
- expected = expected.astype(object)
-
- if isinstance(expected, pd.Series):
- assert result.dtype == df.iloc[:, 0].dtype
- else:
- assert all(result.dtypes == df.iloc[:, 0].dtype)
-
- result = result.astype(object)
- tm.assert_equal(result, expected)
-
- @pytest.mark.parametrize(
- "index",
- [
- # Two levels, uniform.
- pd.MultiIndex.from_product(([["A", "B"], ["a", "b"]]), names=["a", "b"]),
- # non-uniform
- pd.MultiIndex.from_tuples([("A", "a"), ("A", "b"), ("B", "b")]),
- # three levels, non-uniform
- pd.MultiIndex.from_product([("A", "B"), ("a", "b", "c"), (0, 1, 2)]),
- pd.MultiIndex.from_tuples(
- [
- ("A", "a", 1),
- ("A", "b", 0),
- ("A", "a", 0),
- ("B", "a", 0),
- ("B", "c", 1),
- ]
- ),
- ],
- )
- @pytest.mark.parametrize("obj", ["series", "frame"])
- def test_unstack(self, data, index, obj):
- data = data[: len(index)]
- if obj == "series":
- ser = pd.Series(data, index=index)
- else:
- ser = pd.DataFrame({"A": data, "B": data}, index=index)
-
- n = index.nlevels
- levels = list(range(n))
- # [0, 1, 2]
- # [(0,), (1,), (2,), (0, 1), (0, 2), (1, 0), (1, 2), (2, 0), (2, 1)]
- combinations = itertools.chain.from_iterable(
- itertools.permutations(levels, i) for i in range(1, n)
- )
-
- for level in combinations:
- result = ser.unstack(level=level)
- assert all(
- isinstance(result[col].array, type(data)) for col in result.columns
- )
-
- if obj == "series":
- # We should get the same result with to_frame+unstack+droplevel
- df = ser.to_frame()
-
- alt = df.unstack(level=level).droplevel(0, axis=1)
- tm.assert_frame_equal(result, alt)
-
- obj_ser = ser.astype(object)
-
- expected = obj_ser.unstack(level=level, fill_value=data.dtype.na_value)
- if obj == "series":
- assert (expected.dtypes == object).all()
-
- result = result.astype(object)
- tm.assert_frame_equal(result, expected)
-
- def test_ravel(self, data):
- # as long as EA is 1D-only, ravel is a no-op
- result = data.ravel()
- assert type(result) == type(data)
-
- if data.dtype._is_immutable:
- pytest.skip("test_ravel assumes mutability")
-
- # Check that we have a view, not a copy
- result[0] = result[1]
- assert data[0] == data[1]
-
- def test_transpose(self, data):
- result = data.transpose()
- assert type(result) == type(data)
-
- # check we get a new object
- assert result is not data
-
- # If we ever _did_ support 2D, shape should be reversed
- assert result.shape == data.shape[::-1]
-
- if data.dtype._is_immutable:
- pytest.skip("test_transpose assumes mutability")
-
- # Check that we have a view, not a copy
- result[0] = result[1]
- assert data[0] == data[1]
-
- def test_transpose_frame(self, data):
- df = pd.DataFrame({"A": data[:4], "B": data[:4]}, index=["a", "b", "c", "d"])
- result = df.T
- expected = pd.DataFrame(
- {
- "a": type(data)._from_sequence([data[0]] * 2, dtype=data.dtype),
- "b": type(data)._from_sequence([data[1]] * 2, dtype=data.dtype),
- "c": type(data)._from_sequence([data[2]] * 2, dtype=data.dtype),
- "d": type(data)._from_sequence([data[3]] * 2, dtype=data.dtype),
- },
- index=["A", "B"],
- )
- tm.assert_frame_equal(result, expected)
- tm.assert_frame_equal(np.transpose(np.transpose(df)), df)
- tm.assert_frame_equal(np.transpose(np.transpose(df[["A"]])), df[["A"]])
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/io/json/test_pandas.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/io/json/test_pandas.py
deleted file mode 100644
index 663d0a195fa55044a2c243f1ad436842454962e3..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pandas/tests/io/json/test_pandas.py
+++ /dev/null
@@ -1,2115 +0,0 @@
-import datetime
-from datetime import timedelta
-from decimal import Decimal
-from io import StringIO
-import json
-import os
-import sys
-import time
-
-import numpy as np
-import pytest
-
-from pandas.compat import IS64
-import pandas.util._test_decorators as td
-
-import pandas as pd
-from pandas import (
- NA,
- DataFrame,
- DatetimeIndex,
- Series,
- Timestamp,
- read_json,
-)
-import pandas._testing as tm
-from pandas.core.arrays import (
- ArrowStringArray,
- StringArray,
-)
-
-
-def test_literal_json_deprecation():
- # PR 53409
- expected = DataFrame([[1, 2], [1, 2]], columns=["a", "b"])
-
- jsonl = """{"a": 1, "b": 2}
- {"a": 3, "b": 4}
- {"a": 5, "b": 6}
- {"a": 7, "b": 8}"""
-
- msg = (
- "Passing literal json to 'read_json' is deprecated and "
- "will be removed in a future version. To read from a "
- "literal string, wrap it in a 'StringIO' object."
- )
-
- with tm.assert_produces_warning(FutureWarning, match=msg):
- try:
- read_json(jsonl, lines=False)
- except ValueError:
- pass
-
- with tm.assert_produces_warning(FutureWarning, match=msg):
- read_json(expected.to_json(), lines=False)
-
- with tm.assert_produces_warning(FutureWarning, match=msg):
- result = read_json('{"a": 1, "b": 2}\n{"b":2, "a" :1}\n', lines=True)
- tm.assert_frame_equal(result, expected)
-
- with tm.assert_produces_warning(FutureWarning, match=msg):
- try:
- result = read_json(
- '{"a\\\\":"foo\\\\","b":"bar"}\n{"a\\\\":"foo\\"","b":"bar"}\n',
- lines=False,
- )
- except ValueError:
- pass
-
- with tm.assert_produces_warning(FutureWarning, match=msg):
- try:
- result = read_json('{"a": 1, "b": 2}\n{"b":2, "a" :1}\n', lines=False)
- except ValueError:
- pass
- tm.assert_frame_equal(result, expected)
-
-
-def assert_json_roundtrip_equal(result, expected, orient):
- if orient in ("records", "values"):
- expected = expected.reset_index(drop=True)
- if orient == "values":
- expected.columns = range(len(expected.columns))
- tm.assert_frame_equal(result, expected)
-
-
-class TestPandasContainer:
- @pytest.fixture
- def categorical_frame(self):
- _seriesd = tm.getSeriesData()
-
- _cat_frame = DataFrame(_seriesd)
-
- cat = ["bah"] * 5 + ["bar"] * 5 + ["baz"] * 5 + ["foo"] * (len(_cat_frame) - 15)
- _cat_frame.index = pd.CategoricalIndex(cat, name="E")
- _cat_frame["E"] = list(reversed(cat))
- _cat_frame["sort"] = np.arange(len(_cat_frame), dtype="int64")
- return _cat_frame
-
- @pytest.fixture
- def datetime_series(self):
- # Same as usual datetime_series, but with index freq set to None,
- # since that doesn't round-trip, see GH#33711
- ser = tm.makeTimeSeries()
- ser.name = "ts"
- ser.index = ser.index._with_freq(None)
- return ser
-
- @pytest.fixture
- def datetime_frame(self):
- # Same as usual datetime_frame, but with index freq set to None,
- # since that doesn't round-trip, see GH#33711
- df = DataFrame(tm.getTimeSeriesData())
- df.index = df.index._with_freq(None)
- return df
-
- def test_frame_double_encoded_labels(self, orient):
- df = DataFrame(
- [["a", "b"], ["c", "d"]],
- index=['index " 1', "index / 2"],
- columns=["a \\ b", "y / z"],
- )
-
- data = StringIO(df.to_json(orient=orient))
- result = read_json(data, orient=orient)
- expected = df.copy()
- assert_json_roundtrip_equal(result, expected, orient)
-
- @pytest.mark.parametrize("orient", ["split", "records", "values"])
- def test_frame_non_unique_index(self, orient):
- df = DataFrame([["a", "b"], ["c", "d"]], index=[1, 1], columns=["x", "y"])
- data = StringIO(df.to_json(orient=orient))
- result = read_json(data, orient=orient)
- expected = df.copy()
-
- assert_json_roundtrip_equal(result, expected, orient)
-
- @pytest.mark.parametrize("orient", ["index", "columns"])
- def test_frame_non_unique_index_raises(self, orient):
- df = DataFrame([["a", "b"], ["c", "d"]], index=[1, 1], columns=["x", "y"])
- msg = f"DataFrame index must be unique for orient='{orient}'"
- with pytest.raises(ValueError, match=msg):
- df.to_json(orient=orient)
-
- @pytest.mark.parametrize("orient", ["split", "values"])
- @pytest.mark.parametrize(
- "data",
- [
- [["a", "b"], ["c", "d"]],
- [[1.5, 2.5], [3.5, 4.5]],
- [[1, 2.5], [3, 4.5]],
- [[Timestamp("20130101"), 3.5], [Timestamp("20130102"), 4.5]],
- ],
- )
- def test_frame_non_unique_columns(self, orient, data):
- df = DataFrame(data, index=[1, 2], columns=["x", "x"])
-
- result = read_json(
- StringIO(df.to_json(orient=orient)), orient=orient, convert_dates=["x"]
- )
- if orient == "values":
- expected = DataFrame(data)
- if expected.iloc[:, 0].dtype == "datetime64[ns]":
- # orient == "values" by default will write Timestamp objects out
- # in milliseconds; these are internally stored in nanosecond,
- # so divide to get where we need
- # TODO: a to_epoch method would also solve; see GH 14772
- expected.iloc[:, 0] = expected.iloc[:, 0].view(np.int64) // 1000000
- elif orient == "split":
- expected = df
- expected.columns = ["x", "x.1"]
-
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize("orient", ["index", "columns", "records"])
- def test_frame_non_unique_columns_raises(self, orient):
- df = DataFrame([["a", "b"], ["c", "d"]], index=[1, 2], columns=["x", "x"])
-
- msg = f"DataFrame columns must be unique for orient='{orient}'"
- with pytest.raises(ValueError, match=msg):
- df.to_json(orient=orient)
-
- def test_frame_default_orient(self, float_frame):
- assert float_frame.to_json() == float_frame.to_json(orient="columns")
-
- @pytest.mark.parametrize("dtype", [False, float])
- @pytest.mark.parametrize("convert_axes", [True, False])
- def test_roundtrip_simple(self, orient, convert_axes, dtype, float_frame):
- data = StringIO(float_frame.to_json(orient=orient))
- result = read_json(data, orient=orient, convert_axes=convert_axes, dtype=dtype)
-
- expected = float_frame
-
- assert_json_roundtrip_equal(result, expected, orient)
-
- @pytest.mark.parametrize("dtype", [False, np.int64])
- @pytest.mark.parametrize("convert_axes", [True, False])
- def test_roundtrip_intframe(self, orient, convert_axes, dtype, int_frame):
- data = StringIO(int_frame.to_json(orient=orient))
- result = read_json(data, orient=orient, convert_axes=convert_axes, dtype=dtype)
- expected = int_frame
- assert_json_roundtrip_equal(result, expected, orient)
-
- @pytest.mark.parametrize("dtype", [None, np.float64, int, "U3"])
- @pytest.mark.parametrize("convert_axes", [True, False])
- def test_roundtrip_str_axes(self, orient, convert_axes, dtype):
- df = DataFrame(
- np.zeros((200, 4)),
- columns=[str(i) for i in range(4)],
- index=[str(i) for i in range(200)],
- dtype=dtype,
- )
-
- data = StringIO(df.to_json(orient=orient))
- result = read_json(data, orient=orient, convert_axes=convert_axes, dtype=dtype)
-
- expected = df.copy()
- if not dtype:
- expected = expected.astype(np.int64)
-
- # index columns, and records orients cannot fully preserve the string
- # dtype for axes as the index and column labels are used as keys in
- # JSON objects. JSON keys are by definition strings, so there's no way
- # to disambiguate whether those keys actually were strings or numeric
- # beforehand and numeric wins out.
- if convert_axes and (orient in ("index", "columns")):
- expected.columns = expected.columns.astype(np.int64)
- expected.index = expected.index.astype(np.int64)
- elif orient == "records" and convert_axes:
- expected.columns = expected.columns.astype(np.int64)
- elif convert_axes and orient == "split":
- expected.columns = expected.columns.astype(np.int64)
-
- assert_json_roundtrip_equal(result, expected, orient)
-
- @pytest.mark.parametrize("convert_axes", [True, False])
- def test_roundtrip_categorical(
- self, request, orient, categorical_frame, convert_axes
- ):
- # TODO: create a better frame to test with and improve coverage
- if orient in ("index", "columns"):
- request.node.add_marker(
- pytest.mark.xfail(
- reason=f"Can't have duplicate index values for orient '{orient}')"
- )
- )
-
- data = StringIO(categorical_frame.to_json(orient=orient))
- result = read_json(data, orient=orient, convert_axes=convert_axes)
-
- expected = categorical_frame.copy()
- expected.index = expected.index.astype(str) # Categorical not preserved
- expected.index.name = None # index names aren't preserved in JSON
- assert_json_roundtrip_equal(result, expected, orient)
-
- @pytest.mark.parametrize("convert_axes", [True, False])
- def test_roundtrip_empty(self, orient, convert_axes):
- empty_frame = DataFrame()
- data = StringIO(empty_frame.to_json(orient=orient))
- result = read_json(data, orient=orient, convert_axes=convert_axes)
- if orient == "split":
- idx = pd.Index([], dtype=(float if convert_axes else object))
- expected = DataFrame(index=idx, columns=idx)
- elif orient in ["index", "columns"]:
- expected = DataFrame()
- else:
- expected = empty_frame.copy()
-
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize("convert_axes", [True, False])
- def test_roundtrip_timestamp(self, orient, convert_axes, datetime_frame):
- # TODO: improve coverage with date_format parameter
- data = StringIO(datetime_frame.to_json(orient=orient))
- result = read_json(data, orient=orient, convert_axes=convert_axes)
- expected = datetime_frame.copy()
-
- if not convert_axes: # one off for ts handling
- # DTI gets converted to epoch values
- idx = expected.index.view(np.int64) // 1000000
- if orient != "split": # TODO: handle consistently across orients
- idx = idx.astype(str)
-
- expected.index = idx
-
- assert_json_roundtrip_equal(result, expected, orient)
-
- @pytest.mark.parametrize("convert_axes", [True, False])
- def test_roundtrip_mixed(self, orient, convert_axes):
- index = pd.Index(["a", "b", "c", "d", "e"])
- values = {
- "A": [0.0, 1.0, 2.0, 3.0, 4.0],
- "B": [0.0, 1.0, 0.0, 1.0, 0.0],
- "C": ["foo1", "foo2", "foo3", "foo4", "foo5"],
- "D": [True, False, True, False, True],
- }
-
- df = DataFrame(data=values, index=index)
-
- data = StringIO(df.to_json(orient=orient))
- result = read_json(data, orient=orient, convert_axes=convert_axes)
-
- expected = df.copy()
- expected = expected.assign(**expected.select_dtypes("number").astype(np.int64))
-
- assert_json_roundtrip_equal(result, expected, orient)
-
- @pytest.mark.xfail(
- reason="#50456 Column multiindex is stored and loaded differently",
- raises=AssertionError,
- )
- @pytest.mark.parametrize(
- "columns",
- [
- [["2022", "2022"], ["JAN", "FEB"]],
- [["2022", "2023"], ["JAN", "JAN"]],
- [["2022", "2022"], ["JAN", "JAN"]],
- ],
- )
- def test_roundtrip_multiindex(self, columns):
- df = DataFrame(
- [[1, 2], [3, 4]],
- columns=pd.MultiIndex.from_arrays(columns),
- )
- data = StringIO(df.to_json(orient="split"))
- result = read_json(data, orient="split")
- tm.assert_frame_equal(result, df)
-
- @pytest.mark.parametrize(
- "data,msg,orient",
- [
- ('{"key":b:a:d}', "Expected object or value", "columns"),
- # too few indices
- (
- '{"columns":["A","B"],'
- '"index":["2","3"],'
- '"data":[[1.0,"1"],[2.0,"2"],[null,"3"]]}',
- "|".join(
- [
- r"Length of values \(3\) does not match length of index \(2\)",
- ]
- ),
- "split",
- ),
- # too many columns
- (
- '{"columns":["A","B","C"],'
- '"index":["1","2","3"],'
- '"data":[[1.0,"1"],[2.0,"2"],[null,"3"]]}',
- "3 columns passed, passed data had 2 columns",
- "split",
- ),
- # bad key
- (
- '{"badkey":["A","B"],'
- '"index":["2","3"],'
- '"data":[[1.0,"1"],[2.0,"2"],[null,"3"]]}',
- r"unexpected key\(s\): badkey",
- "split",
- ),
- ],
- )
- def test_frame_from_json_bad_data_raises(self, data, msg, orient):
- with pytest.raises(ValueError, match=msg):
- read_json(StringIO(data), orient=orient)
-
- @pytest.mark.parametrize("dtype", [True, False])
- @pytest.mark.parametrize("convert_axes", [True, False])
- def test_frame_from_json_missing_data(self, orient, convert_axes, dtype):
- num_df = DataFrame([[1, 2], [4, 5, 6]])
-
- result = read_json(
- StringIO(num_df.to_json(orient=orient)),
- orient=orient,
- convert_axes=convert_axes,
- dtype=dtype,
- )
- assert np.isnan(result.iloc[0, 2])
-
- obj_df = DataFrame([["1", "2"], ["4", "5", "6"]])
- result = read_json(
- StringIO(obj_df.to_json(orient=orient)),
- orient=orient,
- convert_axes=convert_axes,
- dtype=dtype,
- )
- assert np.isnan(result.iloc[0, 2])
-
- @pytest.mark.parametrize("dtype", [True, False])
- def test_frame_read_json_dtype_missing_value(self, dtype):
- # GH28501 Parse missing values using read_json with dtype=False
- # to NaN instead of None
- result = read_json(StringIO("[null]"), dtype=dtype)
- expected = DataFrame([np.nan])
-
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize("inf", [np.inf, -np.inf])
- @pytest.mark.parametrize("dtype", [True, False])
- def test_frame_infinity(self, inf, dtype):
- # infinities get mapped to nulls which get mapped to NaNs during
- # deserialisation
- df = DataFrame([[1, 2], [4, 5, 6]])
- df.loc[0, 2] = inf
-
- data = StringIO(df.to_json())
- result = read_json(data, dtype=dtype)
- assert np.isnan(result.iloc[0, 2])
-
- @pytest.mark.skipif(not IS64, reason="not compliant on 32-bit, xref #15865")
- @pytest.mark.parametrize(
- "value,precision,expected_val",
- [
- (0.95, 1, 1.0),
- (1.95, 1, 2.0),
- (-1.95, 1, -2.0),
- (0.995, 2, 1.0),
- (0.9995, 3, 1.0),
- (0.99999999999999944, 15, 1.0),
- ],
- )
- def test_frame_to_json_float_precision(self, value, precision, expected_val):
- df = DataFrame([{"a_float": value}])
- encoded = df.to_json(double_precision=precision)
- assert encoded == f'{{"a_float":{{"0":{expected_val}}}}}'
-
- def test_frame_to_json_except(self):
- df = DataFrame([1, 2, 3])
- msg = "Invalid value 'garbage' for option 'orient'"
- with pytest.raises(ValueError, match=msg):
- df.to_json(orient="garbage")
-
- def test_frame_empty(self):
- df = DataFrame(columns=["jim", "joe"])
- assert not df._is_mixed_type
-
- data = StringIO(df.to_json())
- result = read_json(data, dtype=dict(df.dtypes))
- tm.assert_frame_equal(result, df, check_index_type=False)
-
- def test_frame_empty_to_json(self):
- # GH 7445
- df = DataFrame({"test": []}, index=[])
- result = df.to_json(orient="columns")
- expected = '{"test":{}}'
- assert result == expected
-
- def test_frame_empty_mixedtype(self):
- # mixed type
- df = DataFrame(columns=["jim", "joe"])
- df["joe"] = df["joe"].astype("i8")
- assert df._is_mixed_type
- data = df.to_json()
- tm.assert_frame_equal(
- read_json(StringIO(data), dtype=dict(df.dtypes)),
- df,
- check_index_type=False,
- )
-
- def test_frame_mixedtype_orient(self): # GH10289
- vals = [
- [10, 1, "foo", 0.1, 0.01],
- [20, 2, "bar", 0.2, 0.02],
- [30, 3, "baz", 0.3, 0.03],
- [40, 4, "qux", 0.4, 0.04],
- ]
-
- df = DataFrame(
- vals, index=list("abcd"), columns=["1st", "2nd", "3rd", "4th", "5th"]
- )
-
- assert df._is_mixed_type
- right = df.copy()
-
- for orient in ["split", "index", "columns"]:
- inp = StringIO(df.to_json(orient=orient))
- left = read_json(inp, orient=orient, convert_axes=False)
- tm.assert_frame_equal(left, right)
-
- right.index = pd.RangeIndex(len(df))
- inp = StringIO(df.to_json(orient="records"))
- left = read_json(inp, orient="records", convert_axes=False)
- tm.assert_frame_equal(left, right)
-
- right.columns = pd.RangeIndex(df.shape[1])
- inp = StringIO(df.to_json(orient="values"))
- left = read_json(inp, orient="values", convert_axes=False)
- tm.assert_frame_equal(left, right)
-
- def test_v12_compat(self, datapath):
- dti = pd.date_range("2000-01-03", "2000-01-07")
- # freq doesn't roundtrip
- dti = DatetimeIndex(np.asarray(dti), freq=None)
- df = DataFrame(
- [
- [1.56808523, 0.65727391, 1.81021139, -0.17251653],
- [-0.2550111, -0.08072427, -0.03202878, -0.17581665],
- [1.51493992, 0.11805825, 1.629455, -1.31506612],
- [-0.02765498, 0.44679743, 0.33192641, -0.27885413],
- [0.05951614, -2.69652057, 1.28163262, 0.34703478],
- ],
- columns=["A", "B", "C", "D"],
- index=dti,
- )
- df["date"] = Timestamp("19920106 18:21:32.12").as_unit("ns")
- df.iloc[3, df.columns.get_loc("date")] = Timestamp("20130101")
- df["modified"] = df["date"]
- df.iloc[1, df.columns.get_loc("modified")] = pd.NaT
-
- dirpath = datapath("io", "json", "data")
- v12_json = os.path.join(dirpath, "tsframe_v012.json")
- df_unser = read_json(v12_json)
- tm.assert_frame_equal(df, df_unser)
-
- df_iso = df.drop(["modified"], axis=1)
- v12_iso_json = os.path.join(dirpath, "tsframe_iso_v012.json")
- df_unser_iso = read_json(v12_iso_json)
- tm.assert_frame_equal(df_iso, df_unser_iso)
-
- def test_blocks_compat_GH9037(self):
- index = pd.date_range("20000101", periods=10, freq="H")
- # freq doesn't round-trip
- index = DatetimeIndex(list(index), freq=None)
-
- df_mixed = DataFrame(
- {
- "float_1": [
- -0.92077639,
- 0.77434435,
- 1.25234727,
- 0.61485564,
- -0.60316077,
- 0.24653374,
- 0.28668979,
- -2.51969012,
- 0.95748401,
- -1.02970536,
- ],
- "int_1": [
- 19680418,
- 75337055,
- 99973684,
- 65103179,
- 79373900,
- 40314334,
- 21290235,
- 4991321,
- 41903419,
- 16008365,
- ],
- "str_1": [
- "78c608f1",
- "64a99743",
- "13d2ff52",
- "ca7f4af2",
- "97236474",
- "bde7e214",
- "1a6bde47",
- "b1190be5",
- "7a669144",
- "8d64d068",
- ],
- "float_2": [
- -0.0428278,
- -1.80872357,
- 3.36042349,
- -0.7573685,
- -0.48217572,
- 0.86229683,
- 1.08935819,
- 0.93898739,
- -0.03030452,
- 1.43366348,
- ],
- "str_2": [
- "14f04af9",
- "d085da90",
- "4bcfac83",
- "81504caf",
- "2ffef4a9",
- "08e2f5c4",
- "07e1af03",
- "addbd4a7",
- "1f6a09ba",
- "4bfc4d87",
- ],
- "int_2": [
- 86967717,
- 98098830,
- 51927505,
- 20372254,
- 12601730,
- 20884027,
- 34193846,
- 10561746,
- 24867120,
- 76131025,
- ],
- },
- index=index,
- )
-
- # JSON deserialisation always creates unicode strings
- df_mixed.columns = df_mixed.columns.astype(np.str_)
- data = StringIO(df_mixed.to_json(orient="split"))
- df_roundtrip = read_json(data, orient="split")
- tm.assert_frame_equal(
- df_mixed,
- df_roundtrip,
- check_index_type=True,
- check_column_type=True,
- by_blocks=True,
- check_exact=True,
- )
-
- def test_frame_nonprintable_bytes(self):
- # GH14256: failing column caused segfaults, if it is not the last one
-
- class BinaryThing:
- def __init__(self, hexed) -> None:
- self.hexed = hexed
- self.binary = bytes.fromhex(hexed)
-
- def __str__(self) -> str:
- return self.hexed
-
- hexed = "574b4454ba8c5eb4f98a8f45"
- binthing = BinaryThing(hexed)
-
- # verify the proper conversion of printable content
- df_printable = DataFrame({"A": [binthing.hexed]})
- assert df_printable.to_json() == f'{{"A":{{"0":"{hexed}"}}}}'
-
- # check if non-printable content throws appropriate Exception
- df_nonprintable = DataFrame({"A": [binthing]})
- msg = "Unsupported UTF-8 sequence length when encoding string"
- with pytest.raises(OverflowError, match=msg):
- df_nonprintable.to_json()
-
- # the same with multiple columns threw segfaults
- df_mixed = DataFrame({"A": [binthing], "B": [1]}, columns=["A", "B"])
- with pytest.raises(OverflowError, match=msg):
- df_mixed.to_json()
-
- # default_handler should resolve exceptions for non-string types
- result = df_nonprintable.to_json(default_handler=str)
- expected = f'{{"A":{{"0":"{hexed}"}}}}'
- assert result == expected
- assert (
- df_mixed.to_json(default_handler=str)
- == f'{{"A":{{"0":"{hexed}"}},"B":{{"0":1}}}}'
- )
-
- def test_label_overflow(self):
- # GH14256: buffer length not checked when writing label
- result = DataFrame({"bar" * 100000: [1], "foo": [1337]}).to_json()
- expected = f'{{"{"bar" * 100000}":{{"0":1}},"foo":{{"0":1337}}}}'
- assert result == expected
-
- def test_series_non_unique_index(self):
- s = Series(["a", "b"], index=[1, 1])
-
- msg = "Series index must be unique for orient='index'"
- with pytest.raises(ValueError, match=msg):
- s.to_json(orient="index")
-
- tm.assert_series_equal(
- s,
- read_json(
- StringIO(s.to_json(orient="split")), orient="split", typ="series"
- ),
- )
- unserialized = read_json(
- StringIO(s.to_json(orient="records")), orient="records", typ="series"
- )
- tm.assert_numpy_array_equal(s.values, unserialized.values)
-
- def test_series_default_orient(self, string_series):
- assert string_series.to_json() == string_series.to_json(orient="index")
-
- def test_series_roundtrip_simple(self, orient, string_series):
- data = StringIO(string_series.to_json(orient=orient))
- result = read_json(data, typ="series", orient=orient)
-
- expected = string_series
- if orient in ("values", "records"):
- expected = expected.reset_index(drop=True)
- if orient != "split":
- expected.name = None
-
- tm.assert_series_equal(result, expected)
-
- @pytest.mark.parametrize("dtype", [False, None])
- def test_series_roundtrip_object(self, orient, dtype, object_series):
- data = StringIO(object_series.to_json(orient=orient))
- result = read_json(data, typ="series", orient=orient, dtype=dtype)
-
- expected = object_series
- if orient in ("values", "records"):
- expected = expected.reset_index(drop=True)
- if orient != "split":
- expected.name = None
-
- tm.assert_series_equal(result, expected)
-
- def test_series_roundtrip_empty(self, orient):
- empty_series = Series([], index=[], dtype=np.float64)
- data = StringIO(empty_series.to_json(orient=orient))
- result = read_json(data, typ="series", orient=orient)
-
- expected = empty_series.reset_index(drop=True)
- if orient in ("split"):
- expected.index = expected.index.astype(np.float64)
-
- tm.assert_series_equal(result, expected)
-
- def test_series_roundtrip_timeseries(self, orient, datetime_series):
- data = StringIO(datetime_series.to_json(orient=orient))
- result = read_json(data, typ="series", orient=orient)
-
- expected = datetime_series
- if orient in ("values", "records"):
- expected = expected.reset_index(drop=True)
- if orient != "split":
- expected.name = None
-
- tm.assert_series_equal(result, expected)
-
- @pytest.mark.parametrize("dtype", [np.float64, int])
- def test_series_roundtrip_numeric(self, orient, dtype):
- s = Series(range(6), index=["a", "b", "c", "d", "e", "f"])
- data = StringIO(s.to_json(orient=orient))
- result = read_json(data, typ="series", orient=orient)
-
- expected = s.copy()
- if orient in ("values", "records"):
- expected = expected.reset_index(drop=True)
-
- tm.assert_series_equal(result, expected)
-
- def test_series_to_json_except(self):
- s = Series([1, 2, 3])
- msg = "Invalid value 'garbage' for option 'orient'"
- with pytest.raises(ValueError, match=msg):
- s.to_json(orient="garbage")
-
- def test_series_from_json_precise_float(self):
- s = Series([4.56, 4.56, 4.56])
- result = read_json(StringIO(s.to_json()), typ="series", precise_float=True)
- tm.assert_series_equal(result, s, check_index_type=False)
-
- def test_series_with_dtype(self):
- # GH 21986
- s = Series([4.56, 4.56, 4.56])
- result = read_json(StringIO(s.to_json()), typ="series", dtype=np.int64)
- expected = Series([4] * 3)
- tm.assert_series_equal(result, expected)
-
- @pytest.mark.parametrize(
- "dtype,expected",
- [
- (True, Series(["2000-01-01"], dtype="datetime64[ns]")),
- (False, Series([946684800000])),
- ],
- )
- def test_series_with_dtype_datetime(self, dtype, expected):
- s = Series(["2000-01-01"], dtype="datetime64[ns]")
- data = StringIO(s.to_json())
- result = read_json(data, typ="series", dtype=dtype)
- tm.assert_series_equal(result, expected)
-
- def test_frame_from_json_precise_float(self):
- df = DataFrame([[4.56, 4.56, 4.56], [4.56, 4.56, 4.56]])
- result = read_json(StringIO(df.to_json()), precise_float=True)
- tm.assert_frame_equal(result, df)
-
- def test_typ(self):
- s = Series(range(6), index=["a", "b", "c", "d", "e", "f"], dtype="int64")
- result = read_json(StringIO(s.to_json()), typ=None)
- tm.assert_series_equal(result, s)
-
- def test_reconstruction_index(self):
- df = DataFrame([[1, 2, 3], [4, 5, 6]])
- result = read_json(StringIO(df.to_json()))
- tm.assert_frame_equal(result, df)
-
- df = DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]}, index=["A", "B", "C"])
- result = read_json(StringIO(df.to_json()))
- tm.assert_frame_equal(result, df)
-
- def test_path(self, float_frame, int_frame, datetime_frame):
- with tm.ensure_clean("test.json") as path:
- for df in [float_frame, int_frame, datetime_frame]:
- df.to_json(path)
- read_json(path)
-
- def test_axis_dates(self, datetime_series, datetime_frame):
- # frame
- json = StringIO(datetime_frame.to_json())
- result = read_json(json)
- tm.assert_frame_equal(result, datetime_frame)
-
- # series
- json = StringIO(datetime_series.to_json())
- result = read_json(json, typ="series")
- tm.assert_series_equal(result, datetime_series, check_names=False)
- assert result.name is None
-
- def test_convert_dates(self, datetime_series, datetime_frame):
- # frame
- df = datetime_frame
- df["date"] = Timestamp("20130101").as_unit("ns")
-
- json = StringIO(df.to_json())
- result = read_json(json)
- tm.assert_frame_equal(result, df)
-
- df["foo"] = 1.0
- json = StringIO(df.to_json(date_unit="ns"))
-
- result = read_json(json, convert_dates=False)
- expected = df.copy()
- expected["date"] = expected["date"].values.view("i8")
- expected["foo"] = expected["foo"].astype("int64")
- tm.assert_frame_equal(result, expected)
-
- # series
- ts = Series(Timestamp("20130101").as_unit("ns"), index=datetime_series.index)
- json = StringIO(ts.to_json())
- result = read_json(json, typ="series")
- tm.assert_series_equal(result, ts)
-
- @pytest.mark.parametrize("date_format", ["epoch", "iso"])
- @pytest.mark.parametrize("as_object", [True, False])
- @pytest.mark.parametrize("date_typ", [datetime.date, datetime.datetime, Timestamp])
- def test_date_index_and_values(self, date_format, as_object, date_typ):
- data = [date_typ(year=2020, month=1, day=1), pd.NaT]
- if as_object:
- data.append("a")
-
- ser = Series(data, index=data)
- result = ser.to_json(date_format=date_format)
-
- if date_format == "epoch":
- expected = '{"1577836800000":1577836800000,"null":null}'
- else:
- expected = (
- '{"2020-01-01T00:00:00.000":"2020-01-01T00:00:00.000","null":null}'
- )
-
- if as_object:
- expected = expected.replace("}", ',"a":"a"}')
-
- assert result == expected
-
- @pytest.mark.parametrize(
- "infer_word",
- [
- "trade_time",
- "date",
- "datetime",
- "sold_at",
- "modified",
- "timestamp",
- "timestamps",
- ],
- )
- def test_convert_dates_infer(self, infer_word):
- # GH10747
- from pandas.io.json import dumps
-
- data = [{"id": 1, infer_word: 1036713600000}, {"id": 2}]
- expected = DataFrame(
- [[1, Timestamp("2002-11-08")], [2, pd.NaT]], columns=["id", infer_word]
- )
-
- result = read_json(StringIO(dumps(data)))[["id", infer_word]]
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize(
- "date,date_unit",
- [
- ("20130101 20:43:42.123", None),
- ("20130101 20:43:42", "s"),
- ("20130101 20:43:42.123", "ms"),
- ("20130101 20:43:42.123456", "us"),
- ("20130101 20:43:42.123456789", "ns"),
- ],
- )
- def test_date_format_frame(self, date, date_unit, datetime_frame):
- df = datetime_frame
-
- df["date"] = Timestamp(date).as_unit("ns")
- df.iloc[1, df.columns.get_loc("date")] = pd.NaT
- df.iloc[5, df.columns.get_loc("date")] = pd.NaT
- if date_unit:
- json = df.to_json(date_format="iso", date_unit=date_unit)
- else:
- json = df.to_json(date_format="iso")
-
- result = read_json(StringIO(json))
- expected = df.copy()
- tm.assert_frame_equal(result, expected)
-
- def test_date_format_frame_raises(self, datetime_frame):
- df = datetime_frame
- msg = "Invalid value 'foo' for option 'date_unit'"
- with pytest.raises(ValueError, match=msg):
- df.to_json(date_format="iso", date_unit="foo")
-
- @pytest.mark.parametrize(
- "date,date_unit",
- [
- ("20130101 20:43:42.123", None),
- ("20130101 20:43:42", "s"),
- ("20130101 20:43:42.123", "ms"),
- ("20130101 20:43:42.123456", "us"),
- ("20130101 20:43:42.123456789", "ns"),
- ],
- )
- def test_date_format_series(self, date, date_unit, datetime_series):
- ts = Series(Timestamp(date).as_unit("ns"), index=datetime_series.index)
- ts.iloc[1] = pd.NaT
- ts.iloc[5] = pd.NaT
- if date_unit:
- json = ts.to_json(date_format="iso", date_unit=date_unit)
- else:
- json = ts.to_json(date_format="iso")
-
- result = read_json(StringIO(json), typ="series")
- expected = ts.copy()
- tm.assert_series_equal(result, expected)
-
- def test_date_format_series_raises(self, datetime_series):
- ts = Series(Timestamp("20130101 20:43:42.123"), index=datetime_series.index)
- msg = "Invalid value 'foo' for option 'date_unit'"
- with pytest.raises(ValueError, match=msg):
- ts.to_json(date_format="iso", date_unit="foo")
-
- @pytest.mark.parametrize("unit", ["s", "ms", "us", "ns"])
- def test_date_unit(self, unit, datetime_frame):
- df = datetime_frame
- df["date"] = Timestamp("20130101 20:43:42").as_unit("ns")
- dl = df.columns.get_loc("date")
- df.iloc[1, dl] = Timestamp("19710101 20:43:42")
- df.iloc[2, dl] = Timestamp("21460101 20:43:42")
- df.iloc[4, dl] = pd.NaT
-
- json = df.to_json(date_format="epoch", date_unit=unit)
-
- # force date unit
- result = read_json(StringIO(json), date_unit=unit)
- tm.assert_frame_equal(result, df)
-
- # detect date unit
- result = read_json(StringIO(json), date_unit=None)
- tm.assert_frame_equal(result, df)
-
- @pytest.mark.parametrize("unit", ["s", "ms", "us"])
- def test_iso_non_nano_datetimes(self, unit):
- # Test that numpy datetimes
- # in an Index or a column with non-nano resolution can be serialized
- # correctly
- # GH53686
- index = DatetimeIndex(
- [np.datetime64("2023-01-01T11:22:33.123456", unit)],
- dtype=f"datetime64[{unit}]",
- )
- df = DataFrame(
- {
- "date": Series(
- [np.datetime64("2022-01-01T11:22:33.123456", unit)],
- dtype=f"datetime64[{unit}]",
- index=index,
- ),
- "date_obj": Series(
- [np.datetime64("2023-01-01T11:22:33.123456", unit)],
- dtype=object,
- index=index,
- ),
- },
- )
-
- buf = StringIO()
- df.to_json(buf, date_format="iso", date_unit=unit)
- buf.seek(0)
-
- # read_json always reads datetimes in nanosecond resolution
- # TODO: check_dtype/check_index_type should be removable
- # once read_json gets non-nano support
- tm.assert_frame_equal(
- read_json(buf, convert_dates=["date", "date_obj"]),
- df,
- check_index_type=False,
- check_dtype=False,
- )
-
- def test_weird_nested_json(self):
- # this used to core dump the parser
- s = r"""{
- "status": "success",
- "data": {
- "posts": [
- {
- "id": 1,
- "title": "A blog post",
- "body": "Some useful content"
- },
- {
- "id": 2,
- "title": "Another blog post",
- "body": "More content"
- }
- ]
- }
- }"""
- read_json(StringIO(s))
-
- def test_doc_example(self):
- dfj2 = DataFrame(
- np.random.default_rng(2).standard_normal((5, 2)), columns=list("AB")
- )
- dfj2["date"] = Timestamp("20130101")
- dfj2["ints"] = range(5)
- dfj2["bools"] = True
- dfj2.index = pd.date_range("20130101", periods=5)
-
- json = StringIO(dfj2.to_json())
- result = read_json(json, dtype={"ints": np.int64, "bools": np.bool_})
- tm.assert_frame_equal(result, result)
-
- def test_round_trip_exception(self, datapath):
- # GH 3867
- path = datapath("io", "json", "data", "teams.csv")
- df = pd.read_csv(path)
- s = df.to_json()
-
- result = read_json(StringIO(s))
- res = result.reindex(index=df.index, columns=df.columns)
- msg = "The 'downcast' keyword in fillna is deprecated"
- with tm.assert_produces_warning(FutureWarning, match=msg):
- res = res.fillna(np.nan, downcast=False)
- tm.assert_frame_equal(res, df)
-
- @pytest.mark.network
- @pytest.mark.single_cpu
- @pytest.mark.parametrize(
- "field,dtype",
- [
- ["created_at", pd.DatetimeTZDtype(tz="UTC")],
- ["closed_at", "datetime64[ns]"],
- ["updated_at", pd.DatetimeTZDtype(tz="UTC")],
- ],
- )
- def test_url(self, field, dtype, httpserver):
- data = '{"created_at": ["2023-06-23T18:21:36Z"], "closed_at": ["2023-06-23T18:21:36"], "updated_at": ["2023-06-23T18:21:36Z"]}\n' # noqa: E501
- httpserver.serve_content(content=data)
- result = read_json(httpserver.url, convert_dates=True)
- assert result[field].dtype == dtype
-
- def test_timedelta(self):
- converter = lambda x: pd.to_timedelta(x, unit="ms")
-
- ser = Series([timedelta(23), timedelta(seconds=5)])
- assert ser.dtype == "timedelta64[ns]"
-
- result = read_json(StringIO(ser.to_json()), typ="series").apply(converter)
- tm.assert_series_equal(result, ser)
-
- ser = Series([timedelta(23), timedelta(seconds=5)], index=pd.Index([0, 1]))
- assert ser.dtype == "timedelta64[ns]"
- result = read_json(StringIO(ser.to_json()), typ="series").apply(converter)
- tm.assert_series_equal(result, ser)
-
- frame = DataFrame([timedelta(23), timedelta(seconds=5)])
- assert frame[0].dtype == "timedelta64[ns]"
- tm.assert_frame_equal(
- frame, read_json(StringIO(frame.to_json())).apply(converter)
- )
-
- def test_timedelta2(self):
- frame = DataFrame(
- {
- "a": [timedelta(days=23), timedelta(seconds=5)],
- "b": [1, 2],
- "c": pd.date_range(start="20130101", periods=2),
- }
- )
- data = StringIO(frame.to_json(date_unit="ns"))
- result = read_json(data)
- result["a"] = pd.to_timedelta(result.a, unit="ns")
- result["c"] = pd.to_datetime(result.c)
- tm.assert_frame_equal(frame, result)
-
- def test_mixed_timedelta_datetime(self):
- td = timedelta(23)
- ts = Timestamp("20130101")
- frame = DataFrame({"a": [td, ts]}, dtype=object)
-
- expected = DataFrame(
- {"a": [pd.Timedelta(td).as_unit("ns")._value, ts.as_unit("ns")._value]}
- )
- data = StringIO(frame.to_json(date_unit="ns"))
- result = read_json(data, dtype={"a": "int64"})
- tm.assert_frame_equal(result, expected, check_index_type=False)
-
- @pytest.mark.parametrize("as_object", [True, False])
- @pytest.mark.parametrize("date_format", ["iso", "epoch"])
- @pytest.mark.parametrize("timedelta_typ", [pd.Timedelta, timedelta])
- def test_timedelta_to_json(self, as_object, date_format, timedelta_typ):
- # GH28156: to_json not correctly formatting Timedelta
- data = [timedelta_typ(days=1), timedelta_typ(days=2), pd.NaT]
- if as_object:
- data.append("a")
-
- ser = Series(data, index=data)
- if date_format == "iso":
- expected = (
- '{"P1DT0H0M0S":"P1DT0H0M0S","P2DT0H0M0S":"P2DT0H0M0S","null":null}'
- )
- else:
- expected = '{"86400000":86400000,"172800000":172800000,"null":null}'
-
- if as_object:
- expected = expected.replace("}", ',"a":"a"}')
-
- result = ser.to_json(date_format=date_format)
- assert result == expected
-
- def test_default_handler(self):
- value = object()
- frame = DataFrame({"a": [7, value]})
- expected = DataFrame({"a": [7, str(value)]})
- result = read_json(StringIO(frame.to_json(default_handler=str)))
- tm.assert_frame_equal(expected, result, check_index_type=False)
-
- def test_default_handler_indirect(self):
- from pandas.io.json import dumps
-
- def default(obj):
- if isinstance(obj, complex):
- return [("mathjs", "Complex"), ("re", obj.real), ("im", obj.imag)]
- return str(obj)
-
- df_list = [
- 9,
- DataFrame(
- {"a": [1, "STR", complex(4, -5)], "b": [float("nan"), None, "N/A"]},
- columns=["a", "b"],
- ),
- ]
- expected = (
- '[9,[[1,null],["STR",null],[[["mathjs","Complex"],'
- '["re",4.0],["im",-5.0]],"N\\/A"]]]'
- )
- assert dumps(df_list, default_handler=default, orient="values") == expected
-
- def test_default_handler_numpy_unsupported_dtype(self):
- # GH12554 to_json raises 'Unhandled numpy dtype 15'
- df = DataFrame(
- {"a": [1, 2.3, complex(4, -5)], "b": [float("nan"), None, complex(1.2, 0)]},
- columns=["a", "b"],
- )
- expected = (
- '[["(1+0j)","(nan+0j)"],'
- '["(2.3+0j)","(nan+0j)"],'
- '["(4-5j)","(1.2+0j)"]]'
- )
- assert df.to_json(default_handler=str, orient="values") == expected
-
- def test_default_handler_raises(self):
- msg = "raisin"
-
- def my_handler_raises(obj):
- raise TypeError(msg)
-
- with pytest.raises(TypeError, match=msg):
- DataFrame({"a": [1, 2, object()]}).to_json(
- default_handler=my_handler_raises
- )
- with pytest.raises(TypeError, match=msg):
- DataFrame({"a": [1, 2, complex(4, -5)]}).to_json(
- default_handler=my_handler_raises
- )
-
- def test_categorical(self):
- # GH4377 df.to_json segfaults with non-ndarray blocks
- df = DataFrame({"A": ["a", "b", "c", "a", "b", "b", "a"]})
- df["B"] = df["A"]
- expected = df.to_json()
-
- df["B"] = df["A"].astype("category")
- assert expected == df.to_json()
-
- s = df["A"]
- sc = df["B"]
- assert s.to_json() == sc.to_json()
-
- def test_datetime_tz(self):
- # GH4377 df.to_json segfaults with non-ndarray blocks
- tz_range = pd.date_range("20130101", periods=3, tz="US/Eastern")
- tz_naive = tz_range.tz_convert("utc").tz_localize(None)
-
- df = DataFrame({"A": tz_range, "B": pd.date_range("20130101", periods=3)})
-
- df_naive = df.copy()
- df_naive["A"] = tz_naive
- expected = df_naive.to_json()
- assert expected == df.to_json()
-
- stz = Series(tz_range)
- s_naive = Series(tz_naive)
- assert stz.to_json() == s_naive.to_json()
-
- def test_sparse(self):
- # GH4377 df.to_json segfaults with non-ndarray blocks
- df = DataFrame(np.random.default_rng(2).standard_normal((10, 4)))
- df.loc[:8] = np.nan
-
- sdf = df.astype("Sparse")
- expected = df.to_json()
- assert expected == sdf.to_json()
-
- s = Series(np.random.default_rng(2).standard_normal(10))
- s.loc[:8] = np.nan
- ss = s.astype("Sparse")
-
- expected = s.to_json()
- assert expected == ss.to_json()
-
- @pytest.mark.parametrize(
- "ts",
- [
- Timestamp("2013-01-10 05:00:00Z"),
- Timestamp("2013-01-10 00:00:00", tz="US/Eastern"),
- Timestamp("2013-01-10 00:00:00-0500"),
- ],
- )
- def test_tz_is_utc(self, ts):
- from pandas.io.json import dumps
-
- exp = '"2013-01-10T05:00:00.000Z"'
-
- assert dumps(ts, iso_dates=True) == exp
- dt = ts.to_pydatetime()
- assert dumps(dt, iso_dates=True) == exp
-
- def test_tz_is_naive(self):
- from pandas.io.json import dumps
-
- ts = Timestamp("2013-01-10 05:00:00")
- exp = '"2013-01-10T05:00:00.000"'
-
- assert dumps(ts, iso_dates=True) == exp
- dt = ts.to_pydatetime()
- assert dumps(dt, iso_dates=True) == exp
-
- @pytest.mark.parametrize(
- "tz_range",
- [
- pd.date_range("2013-01-01 05:00:00Z", periods=2),
- pd.date_range("2013-01-01 00:00:00", periods=2, tz="US/Eastern"),
- pd.date_range("2013-01-01 00:00:00-0500", periods=2),
- ],
- )
- def test_tz_range_is_utc(self, tz_range):
- from pandas.io.json import dumps
-
- exp = '["2013-01-01T05:00:00.000Z","2013-01-02T05:00:00.000Z"]'
- dfexp = (
- '{"DT":{'
- '"0":"2013-01-01T05:00:00.000Z",'
- '"1":"2013-01-02T05:00:00.000Z"}}'
- )
-
- assert dumps(tz_range, iso_dates=True) == exp
- dti = DatetimeIndex(tz_range)
- # Ensure datetimes in object array are serialized correctly
- # in addition to the normal DTI case
- assert dumps(dti, iso_dates=True) == exp
- assert dumps(dti.astype(object), iso_dates=True) == exp
- df = DataFrame({"DT": dti})
- result = dumps(df, iso_dates=True)
- assert result == dfexp
- assert dumps(df.astype({"DT": object}), iso_dates=True)
-
- def test_tz_range_is_naive(self):
- from pandas.io.json import dumps
-
- dti = pd.date_range("2013-01-01 05:00:00", periods=2)
-
- exp = '["2013-01-01T05:00:00.000","2013-01-02T05:00:00.000"]'
- dfexp = '{"DT":{"0":"2013-01-01T05:00:00.000","1":"2013-01-02T05:00:00.000"}}'
-
- # Ensure datetimes in object array are serialized correctly
- # in addition to the normal DTI case
- assert dumps(dti, iso_dates=True) == exp
- assert dumps(dti.astype(object), iso_dates=True) == exp
- df = DataFrame({"DT": dti})
- result = dumps(df, iso_dates=True)
- assert result == dfexp
- assert dumps(df.astype({"DT": object}), iso_dates=True)
-
- def test_read_inline_jsonl(self):
- # GH9180
-
- result = read_json(StringIO('{"a": 1, "b": 2}\n{"b":2, "a" :1}\n'), lines=True)
- expected = DataFrame([[1, 2], [1, 2]], columns=["a", "b"])
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.single_cpu
- @td.skip_if_not_us_locale
- def test_read_s3_jsonl(self, s3_public_bucket_with_data, s3so):
- # GH17200
-
- result = read_json(
- f"s3n://{s3_public_bucket_with_data.name}/items.jsonl",
- lines=True,
- storage_options=s3so,
- )
- expected = DataFrame([[1, 2], [1, 2]], columns=["a", "b"])
- tm.assert_frame_equal(result, expected)
-
- def test_read_local_jsonl(self):
- # GH17200
- with tm.ensure_clean("tmp_items.json") as path:
- with open(path, "w", encoding="utf-8") as infile:
- infile.write('{"a": 1, "b": 2}\n{"b":2, "a" :1}\n')
- result = read_json(path, lines=True)
- expected = DataFrame([[1, 2], [1, 2]], columns=["a", "b"])
- tm.assert_frame_equal(result, expected)
-
- def test_read_jsonl_unicode_chars(self):
- # GH15132: non-ascii unicode characters
- # \u201d == RIGHT DOUBLE QUOTATION MARK
-
- # simulate file handle
- json = '{"a": "foo”", "b": "bar"}\n{"a": "foo", "b": "bar"}\n'
- json = StringIO(json)
- result = read_json(json, lines=True)
- expected = DataFrame([["foo\u201d", "bar"], ["foo", "bar"]], columns=["a", "b"])
- tm.assert_frame_equal(result, expected)
-
- # simulate string
- json = StringIO('{"a": "foo”", "b": "bar"}\n{"a": "foo", "b": "bar"}\n')
- result = read_json(json, lines=True)
- expected = DataFrame([["foo\u201d", "bar"], ["foo", "bar"]], columns=["a", "b"])
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize("bigNum", [sys.maxsize + 1, -(sys.maxsize + 2)])
- def test_to_json_large_numbers(self, bigNum):
- # GH34473
- series = Series(bigNum, dtype=object, index=["articleId"])
- json = series.to_json()
- expected = '{"articleId":' + str(bigNum) + "}"
- assert json == expected
-
- df = DataFrame(bigNum, dtype=object, index=["articleId"], columns=[0])
- json = df.to_json()
- expected = '{"0":{"articleId":' + str(bigNum) + "}}"
- assert json == expected
-
- @pytest.mark.parametrize("bigNum", [-(2**63) - 1, 2**64])
- def test_read_json_large_numbers(self, bigNum):
- # GH20599, 26068
- json = StringIO('{"articleId":' + str(bigNum) + "}")
- msg = r"Value is too small|Value is too big"
- with pytest.raises(ValueError, match=msg):
- read_json(json)
-
- json = StringIO('{"0":{"articleId":' + str(bigNum) + "}}")
- with pytest.raises(ValueError, match=msg):
- read_json(json)
-
- def test_read_json_large_numbers2(self):
- # GH18842
- json = '{"articleId": "1404366058080022500245"}'
- json = StringIO(json)
- result = read_json(json, typ="series")
- expected = Series(1.404366e21, index=["articleId"])
- tm.assert_series_equal(result, expected)
-
- json = '{"0": {"articleId": "1404366058080022500245"}}'
- json = StringIO(json)
- result = read_json(json)
- expected = DataFrame(1.404366e21, index=["articleId"], columns=[0])
- tm.assert_frame_equal(result, expected)
-
- def test_to_jsonl(self):
- # GH9180
- df = DataFrame([[1, 2], [1, 2]], columns=["a", "b"])
- result = df.to_json(orient="records", lines=True)
- expected = '{"a":1,"b":2}\n{"a":1,"b":2}\n'
- assert result == expected
-
- df = DataFrame([["foo}", "bar"], ['foo"', "bar"]], columns=["a", "b"])
- result = df.to_json(orient="records", lines=True)
- expected = '{"a":"foo}","b":"bar"}\n{"a":"foo\\"","b":"bar"}\n'
- assert result == expected
- tm.assert_frame_equal(read_json(StringIO(result), lines=True), df)
-
- # GH15096: escaped characters in columns and data
- df = DataFrame([["foo\\", "bar"], ['foo"', "bar"]], columns=["a\\", "b"])
- result = df.to_json(orient="records", lines=True)
- expected = '{"a\\\\":"foo\\\\","b":"bar"}\n{"a\\\\":"foo\\"","b":"bar"}\n'
- assert result == expected
-
- tm.assert_frame_equal(read_json(StringIO(result), lines=True), df)
-
- # TODO: there is a near-identical test for pytables; can we share?
- @pytest.mark.xfail(reason="GH#13774 encoding kwarg not supported", raises=TypeError)
- @pytest.mark.parametrize(
- "val",
- [
- [b"E\xc9, 17", b"", b"a", b"b", b"c"],
- [b"E\xc9, 17", b"a", b"b", b"c"],
- [b"EE, 17", b"", b"a", b"b", b"c"],
- [b"E\xc9, 17", b"\xf8\xfc", b"a", b"b", b"c"],
- [b"", b"a", b"b", b"c"],
- [b"\xf8\xfc", b"a", b"b", b"c"],
- [b"A\xf8\xfc", b"", b"a", b"b", b"c"],
- [np.nan, b"", b"b", b"c"],
- [b"A\xf8\xfc", np.nan, b"", b"b", b"c"],
- ],
- )
- @pytest.mark.parametrize("dtype", ["category", object])
- def test_latin_encoding(self, dtype, val):
- # GH 13774
- ser = Series(
- [x.decode("latin-1") if isinstance(x, bytes) else x for x in val],
- dtype=dtype,
- )
- encoding = "latin-1"
- with tm.ensure_clean("test.json") as path:
- ser.to_json(path, encoding=encoding)
- retr = read_json(StringIO(path), encoding=encoding)
- tm.assert_series_equal(ser, retr, check_categorical=False)
-
- def test_data_frame_size_after_to_json(self):
- # GH15344
- df = DataFrame({"a": [str(1)]})
-
- size_before = df.memory_usage(index=True, deep=True).sum()
- df.to_json()
- size_after = df.memory_usage(index=True, deep=True).sum()
-
- assert size_before == size_after
-
- @pytest.mark.parametrize(
- "index", [None, [1, 2], [1.0, 2.0], ["a", "b"], ["1", "2"], ["1.", "2."]]
- )
- @pytest.mark.parametrize("columns", [["a", "b"], ["1", "2"], ["1.", "2."]])
- def test_from_json_to_json_table_index_and_columns(self, index, columns):
- # GH25433 GH25435
- expected = DataFrame([[1, 2], [3, 4]], index=index, columns=columns)
- dfjson = expected.to_json(orient="table")
-
- result = read_json(StringIO(dfjson), orient="table")
- tm.assert_frame_equal(result, expected)
-
- def test_from_json_to_json_table_dtypes(self):
- # GH21345
- expected = DataFrame({"a": [1, 2], "b": [3.0, 4.0], "c": ["5", "6"]})
- dfjson = expected.to_json(orient="table")
- result = read_json(StringIO(dfjson), orient="table")
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize("orient", ["split", "records", "index", "columns"])
- def test_to_json_from_json_columns_dtypes(self, orient):
- # GH21892 GH33205
- expected = DataFrame.from_dict(
- {
- "Integer": Series([1, 2, 3], dtype="int64"),
- "Float": Series([None, 2.0, 3.0], dtype="float64"),
- "Object": Series([None, "", "c"], dtype="object"),
- "Bool": Series([True, False, True], dtype="bool"),
- "Category": Series(["a", "b", None], dtype="category"),
- "Datetime": Series(
- ["2020-01-01", None, "2020-01-03"], dtype="datetime64[ns]"
- ),
- }
- )
- dfjson = expected.to_json(orient=orient)
-
- result = read_json(
- StringIO(dfjson),
- orient=orient,
- dtype={
- "Integer": "int64",
- "Float": "float64",
- "Object": "object",
- "Bool": "bool",
- "Category": "category",
- "Datetime": "datetime64[ns]",
- },
- )
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize("dtype", [True, {"b": int, "c": int}])
- def test_read_json_table_dtype_raises(self, dtype):
- # GH21345
- df = DataFrame({"a": [1, 2], "b": [3.0, 4.0], "c": ["5", "6"]})
- dfjson = df.to_json(orient="table")
- msg = "cannot pass both dtype and orient='table'"
- with pytest.raises(ValueError, match=msg):
- read_json(dfjson, orient="table", dtype=dtype)
-
- @pytest.mark.parametrize("orient", ["index", "columns", "records", "values"])
- def test_read_json_table_empty_axes_dtype(self, orient):
- # GH28558
-
- expected = DataFrame()
- result = read_json(StringIO("{}"), orient=orient, convert_axes=True)
- tm.assert_index_equal(result.index, expected.index)
- tm.assert_index_equal(result.columns, expected.columns)
-
- def test_read_json_table_convert_axes_raises(self):
- # GH25433 GH25435
- df = DataFrame([[1, 2], [3, 4]], index=[1.0, 2.0], columns=["1.", "2."])
- dfjson = df.to_json(orient="table")
- msg = "cannot pass both convert_axes and orient='table'"
- with pytest.raises(ValueError, match=msg):
- read_json(dfjson, orient="table", convert_axes=True)
-
- @pytest.mark.parametrize(
- "data, expected",
- [
- (
- DataFrame([[1, 2], [4, 5]], columns=["a", "b"]),
- {"columns": ["a", "b"], "data": [[1, 2], [4, 5]]},
- ),
- (
- DataFrame([[1, 2], [4, 5]], columns=["a", "b"]).rename_axis("foo"),
- {"columns": ["a", "b"], "data": [[1, 2], [4, 5]]},
- ),
- (
- DataFrame(
- [[1, 2], [4, 5]], columns=["a", "b"], index=[["a", "b"], ["c", "d"]]
- ),
- {"columns": ["a", "b"], "data": [[1, 2], [4, 5]]},
- ),
- (Series([1, 2, 3], name="A"), {"name": "A", "data": [1, 2, 3]}),
- (
- Series([1, 2, 3], name="A").rename_axis("foo"),
- {"name": "A", "data": [1, 2, 3]},
- ),
- (
- Series([1, 2], name="A", index=[["a", "b"], ["c", "d"]]),
- {"name": "A", "data": [1, 2]},
- ),
- ],
- )
- def test_index_false_to_json_split(self, data, expected):
- # GH 17394
- # Testing index=False in to_json with orient='split'
-
- result = data.to_json(orient="split", index=False)
- result = json.loads(result)
-
- assert result == expected
-
- @pytest.mark.parametrize(
- "data",
- [
- (DataFrame([[1, 2], [4, 5]], columns=["a", "b"])),
- (DataFrame([[1, 2], [4, 5]], columns=["a", "b"]).rename_axis("foo")),
- (
- DataFrame(
- [[1, 2], [4, 5]], columns=["a", "b"], index=[["a", "b"], ["c", "d"]]
- )
- ),
- (Series([1, 2, 3], name="A")),
- (Series([1, 2, 3], name="A").rename_axis("foo")),
- (Series([1, 2], name="A", index=[["a", "b"], ["c", "d"]])),
- ],
- )
- def test_index_false_to_json_table(self, data):
- # GH 17394
- # Testing index=False in to_json with orient='table'
-
- result = data.to_json(orient="table", index=False)
- result = json.loads(result)
-
- expected = {
- "schema": pd.io.json.build_table_schema(data, index=False),
- "data": DataFrame(data).to_dict(orient="records"),
- }
-
- assert result == expected
-
- @pytest.mark.parametrize("orient", ["index", "columns"])
- def test_index_false_error_to_json(self, orient):
- # GH 17394, 25513
- # Testing error message from to_json with index=False
-
- df = DataFrame([[1, 2], [4, 5]], columns=["a", "b"])
-
- msg = (
- "'index=False' is only valid when 'orient' is 'split', "
- "'table', 'records', or 'values'"
- )
- with pytest.raises(ValueError, match=msg):
- df.to_json(orient=orient, index=False)
-
- @pytest.mark.parametrize("orient", ["records", "values"])
- def test_index_true_error_to_json(self, orient):
- # GH 25513
- # Testing error message from to_json with index=True
-
- df = DataFrame([[1, 2], [4, 5]], columns=["a", "b"])
-
- msg = (
- "'index=True' is only valid when 'orient' is 'split', "
- "'table', 'index', or 'columns'"
- )
- with pytest.raises(ValueError, match=msg):
- df.to_json(orient=orient, index=True)
-
- @pytest.mark.parametrize("orient", ["split", "table"])
- @pytest.mark.parametrize("index", [True, False])
- def test_index_false_from_json_to_json(self, orient, index):
- # GH25170
- # Test index=False in from_json to_json
- expected = DataFrame({"a": [1, 2], "b": [3, 4]})
- dfjson = expected.to_json(orient=orient, index=index)
- result = read_json(StringIO(dfjson), orient=orient)
- tm.assert_frame_equal(result, expected)
-
- def test_read_timezone_information(self):
- # GH 25546
- result = read_json(
- StringIO('{"2019-01-01T11:00:00.000Z":88}'), typ="series", orient="index"
- )
- expected = Series([88], index=DatetimeIndex(["2019-01-01 11:00:00"], tz="UTC"))
- tm.assert_series_equal(result, expected)
-
- @pytest.mark.parametrize(
- "url",
- [
- "s3://example-fsspec/",
- "gcs://another-fsspec/file.json",
- "https://example-site.com/data",
- "some-protocol://data.txt",
- ],
- )
- def test_read_json_with_url_value(self, url):
- # GH 36271
- result = read_json(StringIO(f'{{"url":{{"0":"{url}"}}}}'))
- expected = DataFrame({"url": [url]})
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize(
- "compression",
- ["", ".gz", ".bz2", ".tar"],
- )
- def test_read_json_with_very_long_file_path(self, compression):
- # GH 46718
- long_json_path = f'{"a" * 1000}.json{compression}'
- with pytest.raises(
- FileNotFoundError, match=f"File {long_json_path} does not exist"
- ):
- # path too long for Windows is handled in file_exists() but raises in
- # _get_data_from_filepath()
- read_json(long_json_path)
-
- @pytest.mark.parametrize(
- "date_format,key", [("epoch", 86400000), ("iso", "P1DT0H0M0S")]
- )
- def test_timedelta_as_label(self, date_format, key):
- df = DataFrame([[1]], columns=[pd.Timedelta("1D")])
- expected = f'{{"{key}":{{"0":1}}}}'
- result = df.to_json(date_format=date_format)
-
- assert result == expected
-
- @pytest.mark.parametrize(
- "orient,expected",
- [
- ("index", "{\"('a', 'b')\":{\"('c', 'd')\":1}}"),
- ("columns", "{\"('c', 'd')\":{\"('a', 'b')\":1}}"),
- # TODO: the below have separate encoding procedures
- pytest.param(
- "split",
- "",
- marks=pytest.mark.xfail(
- reason="Produces JSON but not in a consistent manner"
- ),
- ),
- pytest.param(
- "table",
- "",
- marks=pytest.mark.xfail(
- reason="Produces JSON but not in a consistent manner"
- ),
- ),
- ],
- )
- def test_tuple_labels(self, orient, expected):
- # GH 20500
- df = DataFrame([[1]], index=[("a", "b")], columns=[("c", "d")])
- result = df.to_json(orient=orient)
- assert result == expected
-
- @pytest.mark.parametrize("indent", [1, 2, 4])
- def test_to_json_indent(self, indent):
- # GH 12004
- df = DataFrame([["foo", "bar"], ["baz", "qux"]], columns=["a", "b"])
-
- result = df.to_json(indent=indent)
- spaces = " " * indent
- expected = f"""{{
-{spaces}"a":{{
-{spaces}{spaces}"0":"foo",
-{spaces}{spaces}"1":"baz"
-{spaces}}},
-{spaces}"b":{{
-{spaces}{spaces}"0":"bar",
-{spaces}{spaces}"1":"qux"
-{spaces}}}
-}}"""
-
- assert result == expected
-
- @pytest.mark.parametrize(
- "orient,expected",
- [
- (
- "split",
- """{
- "columns":[
- "a",
- "b"
- ],
- "index":[
- 0,
- 1
- ],
- "data":[
- [
- "foo",
- "bar"
- ],
- [
- "baz",
- "qux"
- ]
- ]
-}""",
- ),
- (
- "records",
- """[
- {
- "a":"foo",
- "b":"bar"
- },
- {
- "a":"baz",
- "b":"qux"
- }
-]""",
- ),
- (
- "index",
- """{
- "0":{
- "a":"foo",
- "b":"bar"
- },
- "1":{
- "a":"baz",
- "b":"qux"
- }
-}""",
- ),
- (
- "columns",
- """{
- "a":{
- "0":"foo",
- "1":"baz"
- },
- "b":{
- "0":"bar",
- "1":"qux"
- }
-}""",
- ),
- (
- "values",
- """[
- [
- "foo",
- "bar"
- ],
- [
- "baz",
- "qux"
- ]
-]""",
- ),
- (
- "table",
- """{
- "schema":{
- "fields":[
- {
- "name":"index",
- "type":"integer"
- },
- {
- "name":"a",
- "type":"string"
- },
- {
- "name":"b",
- "type":"string"
- }
- ],
- "primaryKey":[
- "index"
- ],
- "pandas_version":"1.4.0"
- },
- "data":[
- {
- "index":0,
- "a":"foo",
- "b":"bar"
- },
- {
- "index":1,
- "a":"baz",
- "b":"qux"
- }
- ]
-}""",
- ),
- ],
- )
- def test_json_indent_all_orients(self, orient, expected):
- # GH 12004
- df = DataFrame([["foo", "bar"], ["baz", "qux"]], columns=["a", "b"])
- result = df.to_json(orient=orient, indent=4)
- assert result == expected
-
- def test_json_negative_indent_raises(self):
- with pytest.raises(ValueError, match="must be a nonnegative integer"):
- DataFrame().to_json(indent=-1)
-
- def test_emca_262_nan_inf_support(self):
- # GH 12213
- data = StringIO(
- '["a", NaN, "NaN", Infinity, "Infinity", -Infinity, "-Infinity"]'
- )
- result = read_json(data)
- expected = DataFrame(
- ["a", None, "NaN", np.inf, "Infinity", -np.inf, "-Infinity"]
- )
- tm.assert_frame_equal(result, expected)
-
- def test_frame_int_overflow(self):
- # GH 30320
- encoded_json = json.dumps([{"col": "31900441201190696999"}, {"col": "Text"}])
- expected = DataFrame({"col": ["31900441201190696999", "Text"]})
- result = read_json(StringIO(encoded_json))
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize(
- "dataframe,expected",
- [
- (
- DataFrame({"x": [1, 2, 3], "y": ["a", "b", "c"]}),
- '{"(0, \'x\')":1,"(0, \'y\')":"a","(1, \'x\')":2,'
- '"(1, \'y\')":"b","(2, \'x\')":3,"(2, \'y\')":"c"}',
- )
- ],
- )
- def test_json_multiindex(self, dataframe, expected):
- series = dataframe.stack(future_stack=True)
- result = series.to_json(orient="index")
- assert result == expected
-
- @pytest.mark.single_cpu
- def test_to_s3(self, s3_public_bucket, s3so):
- # GH 28375
- mock_bucket_name, target_file = s3_public_bucket.name, "test.json"
- df = DataFrame({"x": [1, 2, 3], "y": [2, 4, 6]})
- df.to_json(f"s3://{mock_bucket_name}/{target_file}", storage_options=s3so)
- timeout = 5
- while True:
- if target_file in (obj.key for obj in s3_public_bucket.objects.all()):
- break
- time.sleep(0.1)
- timeout -= 0.1
- assert timeout > 0, "Timed out waiting for file to appear on moto"
-
- def test_json_pandas_nulls(self, nulls_fixture, request):
- # GH 31615
- if isinstance(nulls_fixture, Decimal):
- mark = pytest.mark.xfail(reason="not implemented")
- request.node.add_marker(mark)
-
- result = DataFrame([[nulls_fixture]]).to_json()
- assert result == '{"0":{"0":null}}'
-
- def test_readjson_bool_series(self):
- # GH31464
- result = read_json(StringIO("[true, true, false]"), typ="series")
- expected = Series([True, True, False])
- tm.assert_series_equal(result, expected)
-
- def test_to_json_multiindex_escape(self):
- # GH 15273
- df = DataFrame(
- True,
- index=pd.date_range("2017-01-20", "2017-01-23"),
- columns=["foo", "bar"],
- ).stack(future_stack=True)
- result = df.to_json()
- expected = (
- "{\"(Timestamp('2017-01-20 00:00:00'), 'foo')\":true,"
- "\"(Timestamp('2017-01-20 00:00:00'), 'bar')\":true,"
- "\"(Timestamp('2017-01-21 00:00:00'), 'foo')\":true,"
- "\"(Timestamp('2017-01-21 00:00:00'), 'bar')\":true,"
- "\"(Timestamp('2017-01-22 00:00:00'), 'foo')\":true,"
- "\"(Timestamp('2017-01-22 00:00:00'), 'bar')\":true,"
- "\"(Timestamp('2017-01-23 00:00:00'), 'foo')\":true,"
- "\"(Timestamp('2017-01-23 00:00:00'), 'bar')\":true}"
- )
- assert result == expected
-
- def test_to_json_series_of_objects(self):
- class _TestObject:
- def __init__(self, a, b, _c, d) -> None:
- self.a = a
- self.b = b
- self._c = _c
- self.d = d
-
- def e(self):
- return 5
-
- # JSON keys should be all non-callable non-underscore attributes, see GH-42768
- series = Series([_TestObject(a=1, b=2, _c=3, d=4)])
- assert json.loads(series.to_json()) == {"0": {"a": 1, "b": 2, "d": 4}}
-
- @pytest.mark.parametrize(
- "data,expected",
- [
- (
- Series({0: -6 + 8j, 1: 0 + 1j, 2: 9 - 5j}),
- '{"0":{"imag":8.0,"real":-6.0},'
- '"1":{"imag":1.0,"real":0.0},'
- '"2":{"imag":-5.0,"real":9.0}}',
- ),
- (
- Series({0: -9.39 + 0.66j, 1: 3.95 + 9.32j, 2: 4.03 - 0.17j}),
- '{"0":{"imag":0.66,"real":-9.39},'
- '"1":{"imag":9.32,"real":3.95},'
- '"2":{"imag":-0.17,"real":4.03}}',
- ),
- (
- DataFrame([[-2 + 3j, -1 - 0j], [4 - 3j, -0 - 10j]]),
- '{"0":{"0":{"imag":3.0,"real":-2.0},'
- '"1":{"imag":-3.0,"real":4.0}},'
- '"1":{"0":{"imag":0.0,"real":-1.0},'
- '"1":{"imag":-10.0,"real":0.0}}}',
- ),
- (
- DataFrame(
- [[-0.28 + 0.34j, -1.08 - 0.39j], [0.41 - 0.34j, -0.78 - 1.35j]]
- ),
- '{"0":{"0":{"imag":0.34,"real":-0.28},'
- '"1":{"imag":-0.34,"real":0.41}},'
- '"1":{"0":{"imag":-0.39,"real":-1.08},'
- '"1":{"imag":-1.35,"real":-0.78}}}',
- ),
- ],
- )
- def test_complex_data_tojson(self, data, expected):
- # GH41174
- result = data.to_json()
- assert result == expected
-
- def test_json_uint64(self):
- # GH21073
- expected = (
- '{"columns":["col1"],"index":[0,1],'
- '"data":[[13342205958987758245],[12388075603347835679]]}'
- )
- df = DataFrame(data={"col1": [13342205958987758245, 12388075603347835679]})
- result = df.to_json(orient="split")
- assert result == expected
-
- @pytest.mark.parametrize(
- "orient", ["split", "records", "values", "index", "columns"]
- )
- def test_read_json_dtype_backend(self, string_storage, dtype_backend, orient):
- # GH#50750
- pa = pytest.importorskip("pyarrow")
- df = DataFrame(
- {
- "a": Series([1, np.nan, 3], dtype="Int64"),
- "b": Series([1, 2, 3], dtype="Int64"),
- "c": Series([1.5, np.nan, 2.5], dtype="Float64"),
- "d": Series([1.5, 2.0, 2.5], dtype="Float64"),
- "e": [True, False, None],
- "f": [True, False, True],
- "g": ["a", "b", "c"],
- "h": ["a", "b", None],
- }
- )
-
- if string_storage == "python":
- string_array = StringArray(np.array(["a", "b", "c"], dtype=np.object_))
- string_array_na = StringArray(np.array(["a", "b", NA], dtype=np.object_))
-
- else:
- string_array = ArrowStringArray(pa.array(["a", "b", "c"]))
- string_array_na = ArrowStringArray(pa.array(["a", "b", None]))
-
- out = df.to_json(orient=orient)
- with pd.option_context("mode.string_storage", string_storage):
- result = read_json(
- StringIO(out), dtype_backend=dtype_backend, orient=orient
- )
-
- expected = DataFrame(
- {
- "a": Series([1, np.nan, 3], dtype="Int64"),
- "b": Series([1, 2, 3], dtype="Int64"),
- "c": Series([1.5, np.nan, 2.5], dtype="Float64"),
- "d": Series([1.5, 2.0, 2.5], dtype="Float64"),
- "e": Series([True, False, NA], dtype="boolean"),
- "f": Series([True, False, True], dtype="boolean"),
- "g": string_array,
- "h": string_array_na,
- }
- )
-
- if dtype_backend == "pyarrow":
- from pandas.arrays import ArrowExtensionArray
-
- expected = DataFrame(
- {
- col: ArrowExtensionArray(pa.array(expected[col], from_pandas=True))
- for col in expected.columns
- }
- )
-
- if orient == "values":
- expected.columns = list(range(0, 8))
-
- tm.assert_frame_equal(result, expected)
-
- @pytest.mark.parametrize("orient", ["split", "records", "index"])
- def test_read_json_nullable_series(self, string_storage, dtype_backend, orient):
- # GH#50750
- pa = pytest.importorskip("pyarrow")
- ser = Series([1, np.nan, 3], dtype="Int64")
-
- out = ser.to_json(orient=orient)
- with pd.option_context("mode.string_storage", string_storage):
- result = read_json(
- StringIO(out), dtype_backend=dtype_backend, orient=orient, typ="series"
- )
-
- expected = Series([1, np.nan, 3], dtype="Int64")
-
- if dtype_backend == "pyarrow":
- from pandas.arrays import ArrowExtensionArray
-
- expected = Series(ArrowExtensionArray(pa.array(expected, from_pandas=True)))
-
- tm.assert_series_equal(result, expected)
-
- def test_invalid_dtype_backend(self):
- msg = (
- "dtype_backend numpy is invalid, only 'numpy_nullable' and "
- "'pyarrow' are allowed."
- )
- with pytest.raises(ValueError, match=msg):
- read_json("test", dtype_backend="numpy")
-
-
-def test_invalid_engine():
- # GH 48893
- ser = Series(range(1))
- out = ser.to_json()
- with pytest.raises(ValueError, match="The engine type foo"):
- read_json(out, engine="foo")
-
-
-def test_pyarrow_engine_lines_false():
- # GH 48893
- ser = Series(range(1))
- out = ser.to_json()
- with pytest.raises(ValueError, match="currently pyarrow engine only supports"):
- read_json(out, engine="pyarrow", lines=False)
-
-
-def test_json_roundtrip_string_inference(orient):
- pytest.importorskip("pyarrow")
- df = DataFrame(
- [["a", "b"], ["c", "d"]], index=["row 1", "row 2"], columns=["col 1", "col 2"]
- )
- out = df.to_json()
- with pd.option_context("future.infer_string", True):
- result = read_json(StringIO(out))
- expected = DataFrame(
- [["a", "b"], ["c", "d"]],
- dtype="string[pyarrow_numpy]",
- index=pd.Index(["row 1", "row 2"], dtype="string[pyarrow_numpy]"),
- columns=pd.Index(["col 1", "col 2"], dtype="string[pyarrow_numpy]"),
- )
- tm.assert_frame_equal(result, expected)
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_internal/models/scheme.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_internal/models/scheme.py
deleted file mode 100644
index f51190ac60354d90eb2aef4b04c484f8517275c2..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_internal/models/scheme.py
+++ /dev/null
@@ -1,31 +0,0 @@
-"""
-For types associated with installation schemes.
-
-For a general overview of available schemes and their context, see
-https://docs.python.org/3/install/index.html#alternate-installation.
-"""
-
-
-SCHEME_KEYS = ["platlib", "purelib", "headers", "scripts", "data"]
-
-
-class Scheme:
- """A Scheme holds paths which are used as the base directories for
- artifacts associated with a Python package.
- """
-
- __slots__ = SCHEME_KEYS
-
- def __init__(
- self,
- platlib: str,
- purelib: str,
- headers: str,
- scripts: str,
- data: str,
- ) -> None:
- self.platlib = platlib
- self.purelib = purelib
- self.headers = headers
- self.scripts = scripts
- self.data = data
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_vendor/progress/spinner.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_vendor/progress/spinner.py
deleted file mode 100644
index d593a203e088c22b7f9c1aefd893ff0b44157ef0..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pip/_vendor/progress/spinner.py
+++ /dev/null
@@ -1,45 +0,0 @@
-# -*- coding: utf-8 -*-
-
-# Copyright (c) 2012 Georgios Verigakis
-#
-# Permission to use, copy, modify, and distribute this software for any
-# purpose with or without fee is hereby granted, provided that the above
-# copyright notice and this permission notice appear in all copies.
-#
-# THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
-# WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
-# MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
-# ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
-# WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
-# ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF
-# OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
-
-from __future__ import unicode_literals
-from . import Infinite
-
-
-class Spinner(Infinite):
- phases = ('-', '\\', '|', '/')
- hide_cursor = True
-
- def update(self):
- i = self.index % len(self.phases)
- message = self.message % self
- line = ''.join([message, self.phases[i]])
- self.writeln(line)
-
-
-class PieSpinner(Spinner):
- phases = ['◷', '◶', '◵', '◴']
-
-
-class MoonSpinner(Spinner):
- phases = ['◑', '◒', '◐', '◓']
-
-
-class LineSpinner(Spinner):
- phases = ['⎺', '⎻', '⎼', '⎽', '⎼', '⎻']
-
-
-class PixelSpinner(Spinner):
- phases = ['⣾', '⣷', '⣯', '⣟', '⡿', '⢿', '⣻', '⣽']
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/_css_builtins.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/_css_builtins.py
deleted file mode 100644
index fff992425ced2506cee34156cf884b955145d800..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/pygments/lexers/_css_builtins.py
+++ /dev/null
@@ -1,558 +0,0 @@
-"""
- pygments.lexers._css_builtins
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
- This file is autogenerated by scripts/get_css_properties.py
-
- :copyright: Copyright 2006-2023 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-_css_properties = (
- '-webkit-line-clamp',
- 'accent-color',
- 'align-content',
- 'align-items',
- 'align-self',
- 'alignment-baseline',
- 'all',
- 'animation',
- 'animation-delay',
- 'animation-direction',
- 'animation-duration',
- 'animation-fill-mode',
- 'animation-iteration-count',
- 'animation-name',
- 'animation-play-state',
- 'animation-timing-function',
- 'appearance',
- 'aspect-ratio',
- 'azimuth',
- 'backface-visibility',
- 'background',
- 'background-attachment',
- 'background-blend-mode',
- 'background-clip',
- 'background-color',
- 'background-image',
- 'background-origin',
- 'background-position',
- 'background-repeat',
- 'background-size',
- 'baseline-shift',
- 'baseline-source',
- 'block-ellipsis',
- 'block-size',
- 'block-step',
- 'block-step-align',
- 'block-step-insert',
- 'block-step-round',
- 'block-step-size',
- 'bookmark-label',
- 'bookmark-level',
- 'bookmark-state',
- 'border',
- 'border-block',
- 'border-block-color',
- 'border-block-end',
- 'border-block-end-color',
- 'border-block-end-style',
- 'border-block-end-width',
- 'border-block-start',
- 'border-block-start-color',
- 'border-block-start-style',
- 'border-block-start-width',
- 'border-block-style',
- 'border-block-width',
- 'border-bottom',
- 'border-bottom-color',
- 'border-bottom-left-radius',
- 'border-bottom-right-radius',
- 'border-bottom-style',
- 'border-bottom-width',
- 'border-boundary',
- 'border-collapse',
- 'border-color',
- 'border-end-end-radius',
- 'border-end-start-radius',
- 'border-image',
- 'border-image-outset',
- 'border-image-repeat',
- 'border-image-slice',
- 'border-image-source',
- 'border-image-width',
- 'border-inline',
- 'border-inline-color',
- 'border-inline-end',
- 'border-inline-end-color',
- 'border-inline-end-style',
- 'border-inline-end-width',
- 'border-inline-start',
- 'border-inline-start-color',
- 'border-inline-start-style',
- 'border-inline-start-width',
- 'border-inline-style',
- 'border-inline-width',
- 'border-left',
- 'border-left-color',
- 'border-left-style',
- 'border-left-width',
- 'border-radius',
- 'border-right',
- 'border-right-color',
- 'border-right-style',
- 'border-right-width',
- 'border-spacing',
- 'border-start-end-radius',
- 'border-start-start-radius',
- 'border-style',
- 'border-top',
- 'border-top-color',
- 'border-top-left-radius',
- 'border-top-right-radius',
- 'border-top-style',
- 'border-top-width',
- 'border-width',
- 'bottom',
- 'box-decoration-break',
- 'box-shadow',
- 'box-sizing',
- 'box-snap',
- 'break-after',
- 'break-before',
- 'break-inside',
- 'caption-side',
- 'caret',
- 'caret-color',
- 'caret-shape',
- 'chains',
- 'clear',
- 'clip',
- 'clip-path',
- 'clip-rule',
- 'color',
- 'color-adjust',
- 'color-interpolation-filters',
- 'color-scheme',
- 'column-count',
- 'column-fill',
- 'column-gap',
- 'column-rule',
- 'column-rule-color',
- 'column-rule-style',
- 'column-rule-width',
- 'column-span',
- 'column-width',
- 'columns',
- 'contain',
- 'contain-intrinsic-block-size',
- 'contain-intrinsic-height',
- 'contain-intrinsic-inline-size',
- 'contain-intrinsic-size',
- 'contain-intrinsic-width',
- 'container',
- 'container-name',
- 'container-type',
- 'content',
- 'content-visibility',
- 'continue',
- 'counter-increment',
- 'counter-reset',
- 'counter-set',
- 'cue',
- 'cue-after',
- 'cue-before',
- 'cursor',
- 'direction',
- 'display',
- 'dominant-baseline',
- 'elevation',
- 'empty-cells',
- 'fill',
- 'fill-break',
- 'fill-color',
- 'fill-image',
- 'fill-opacity',
- 'fill-origin',
- 'fill-position',
- 'fill-repeat',
- 'fill-rule',
- 'fill-size',
- 'filter',
- 'flex',
- 'flex-basis',
- 'flex-direction',
- 'flex-flow',
- 'flex-grow',
- 'flex-shrink',
- 'flex-wrap',
- 'float',
- 'float-defer',
- 'float-offset',
- 'float-reference',
- 'flood-color',
- 'flood-opacity',
- 'flow',
- 'flow-from',
- 'flow-into',
- 'font',
- 'font-family',
- 'font-feature-settings',
- 'font-kerning',
- 'font-language-override',
- 'font-optical-sizing',
- 'font-palette',
- 'font-size',
- 'font-size-adjust',
- 'font-stretch',
- 'font-style',
- 'font-synthesis',
- 'font-synthesis-small-caps',
- 'font-synthesis-style',
- 'font-synthesis-weight',
- 'font-variant',
- 'font-variant-alternates',
- 'font-variant-caps',
- 'font-variant-east-asian',
- 'font-variant-emoji',
- 'font-variant-ligatures',
- 'font-variant-numeric',
- 'font-variant-position',
- 'font-variation-settings',
- 'font-weight',
- 'footnote-display',
- 'footnote-policy',
- 'forced-color-adjust',
- 'gap',
- 'glyph-orientation-vertical',
- 'grid',
- 'grid-area',
- 'grid-auto-columns',
- 'grid-auto-flow',
- 'grid-auto-rows',
- 'grid-column',
- 'grid-column-end',
- 'grid-column-start',
- 'grid-row',
- 'grid-row-end',
- 'grid-row-start',
- 'grid-template',
- 'grid-template-areas',
- 'grid-template-columns',
- 'grid-template-rows',
- 'hanging-punctuation',
- 'height',
- 'hyphenate-character',
- 'hyphenate-limit-chars',
- 'hyphenate-limit-last',
- 'hyphenate-limit-lines',
- 'hyphenate-limit-zone',
- 'hyphens',
- 'image-orientation',
- 'image-rendering',
- 'image-resolution',
- 'initial-letter',
- 'initial-letter-align',
- 'initial-letter-wrap',
- 'inline-size',
- 'inline-sizing',
- 'input-security',
- 'inset',
- 'inset-block',
- 'inset-block-end',
- 'inset-block-start',
- 'inset-inline',
- 'inset-inline-end',
- 'inset-inline-start',
- 'isolation',
- 'justify-content',
- 'justify-items',
- 'justify-self',
- 'leading-trim',
- 'left',
- 'letter-spacing',
- 'lighting-color',
- 'line-break',
- 'line-clamp',
- 'line-grid',
- 'line-height',
- 'line-height-step',
- 'line-padding',
- 'line-snap',
- 'list-style',
- 'list-style-image',
- 'list-style-position',
- 'list-style-type',
- 'margin',
- 'margin-block',
- 'margin-block-end',
- 'margin-block-start',
- 'margin-bottom',
- 'margin-break',
- 'margin-inline',
- 'margin-inline-end',
- 'margin-inline-start',
- 'margin-left',
- 'margin-right',
- 'margin-top',
- 'margin-trim',
- 'marker',
- 'marker-end',
- 'marker-knockout-left',
- 'marker-knockout-right',
- 'marker-mid',
- 'marker-pattern',
- 'marker-segment',
- 'marker-side',
- 'marker-start',
- 'mask',
- 'mask-border',
- 'mask-border-mode',
- 'mask-border-outset',
- 'mask-border-repeat',
- 'mask-border-slice',
- 'mask-border-source',
- 'mask-border-width',
- 'mask-clip',
- 'mask-composite',
- 'mask-image',
- 'mask-mode',
- 'mask-origin',
- 'mask-position',
- 'mask-repeat',
- 'mask-size',
- 'mask-type',
- 'max-block-size',
- 'max-height',
- 'max-inline-size',
- 'max-lines',
- 'max-width',
- 'min-block-size',
- 'min-height',
- 'min-inline-size',
- 'min-intrinsic-sizing',
- 'min-width',
- 'mix-blend-mode',
- 'nav-down',
- 'nav-left',
- 'nav-right',
- 'nav-up',
- 'object-fit',
- 'object-overflow',
- 'object-position',
- 'object-view-box',
- 'offset',
- 'offset-anchor',
- 'offset-distance',
- 'offset-path',
- 'offset-position',
- 'offset-rotate',
- 'opacity',
- 'order',
- 'orphans',
- 'outline',
- 'outline-color',
- 'outline-offset',
- 'outline-style',
- 'outline-width',
- 'overflow',
- 'overflow-anchor',
- 'overflow-block',
- 'overflow-clip-margin',
- 'overflow-inline',
- 'overflow-wrap',
- 'overflow-x',
- 'overflow-y',
- 'overscroll-behavior',
- 'overscroll-behavior-block',
- 'overscroll-behavior-inline',
- 'overscroll-behavior-x',
- 'overscroll-behavior-y',
- 'padding',
- 'padding-block',
- 'padding-block-end',
- 'padding-block-start',
- 'padding-bottom',
- 'padding-inline',
- 'padding-inline-end',
- 'padding-inline-start',
- 'padding-left',
- 'padding-right',
- 'padding-top',
- 'page',
- 'page-break-after',
- 'page-break-before',
- 'page-break-inside',
- 'pause',
- 'pause-after',
- 'pause-before',
- 'perspective',
- 'perspective-origin',
- 'pitch',
- 'pitch-range',
- 'place-content',
- 'place-items',
- 'place-self',
- 'play-during',
- 'pointer-events',
- 'position',
- 'print-color-adjust',
- 'property-name',
- 'quotes',
- 'region-fragment',
- 'resize',
- 'rest',
- 'rest-after',
- 'rest-before',
- 'richness',
- 'right',
- 'rotate',
- 'row-gap',
- 'ruby-align',
- 'ruby-merge',
- 'ruby-overhang',
- 'ruby-position',
- 'running',
- 'scale',
- 'scroll-behavior',
- 'scroll-margin',
- 'scroll-margin-block',
- 'scroll-margin-block-end',
- 'scroll-margin-block-start',
- 'scroll-margin-bottom',
- 'scroll-margin-inline',
- 'scroll-margin-inline-end',
- 'scroll-margin-inline-start',
- 'scroll-margin-left',
- 'scroll-margin-right',
- 'scroll-margin-top',
- 'scroll-padding',
- 'scroll-padding-block',
- 'scroll-padding-block-end',
- 'scroll-padding-block-start',
- 'scroll-padding-bottom',
- 'scroll-padding-inline',
- 'scroll-padding-inline-end',
- 'scroll-padding-inline-start',
- 'scroll-padding-left',
- 'scroll-padding-right',
- 'scroll-padding-top',
- 'scroll-snap-align',
- 'scroll-snap-stop',
- 'scroll-snap-type',
- 'scrollbar-color',
- 'scrollbar-gutter',
- 'scrollbar-width',
- 'shape-image-threshold',
- 'shape-inside',
- 'shape-margin',
- 'shape-outside',
- 'spatial-navigation-action',
- 'spatial-navigation-contain',
- 'spatial-navigation-function',
- 'speak',
- 'speak-as',
- 'speak-header',
- 'speak-numeral',
- 'speak-punctuation',
- 'speech-rate',
- 'stress',
- 'string-set',
- 'stroke',
- 'stroke-align',
- 'stroke-alignment',
- 'stroke-break',
- 'stroke-color',
- 'stroke-dash-corner',
- 'stroke-dash-justify',
- 'stroke-dashadjust',
- 'stroke-dasharray',
- 'stroke-dashcorner',
- 'stroke-dashoffset',
- 'stroke-image',
- 'stroke-linecap',
- 'stroke-linejoin',
- 'stroke-miterlimit',
- 'stroke-opacity',
- 'stroke-origin',
- 'stroke-position',
- 'stroke-repeat',
- 'stroke-size',
- 'stroke-width',
- 'tab-size',
- 'table-layout',
- 'text-align',
- 'text-align-all',
- 'text-align-last',
- 'text-combine-upright',
- 'text-decoration',
- 'text-decoration-color',
- 'text-decoration-line',
- 'text-decoration-skip',
- 'text-decoration-skip-box',
- 'text-decoration-skip-ink',
- 'text-decoration-skip-inset',
- 'text-decoration-skip-self',
- 'text-decoration-skip-spaces',
- 'text-decoration-style',
- 'text-decoration-thickness',
- 'text-edge',
- 'text-emphasis',
- 'text-emphasis-color',
- 'text-emphasis-position',
- 'text-emphasis-skip',
- 'text-emphasis-style',
- 'text-group-align',
- 'text-indent',
- 'text-justify',
- 'text-orientation',
- 'text-overflow',
- 'text-shadow',
- 'text-space-collapse',
- 'text-space-trim',
- 'text-spacing',
- 'text-transform',
- 'text-underline-offset',
- 'text-underline-position',
- 'text-wrap',
- 'top',
- 'transform',
- 'transform-box',
- 'transform-origin',
- 'transform-style',
- 'transition',
- 'transition-delay',
- 'transition-duration',
- 'transition-property',
- 'transition-timing-function',
- 'translate',
- 'unicode-bidi',
- 'user-select',
- 'vertical-align',
- 'visibility',
- 'voice-balance',
- 'voice-duration',
- 'voice-family',
- 'voice-pitch',
- 'voice-range',
- 'voice-rate',
- 'voice-stress',
- 'voice-volume',
- 'volume',
- 'white-space',
- 'widows',
- 'width',
- 'will-change',
- 'word-boundary-detection',
- 'word-boundary-expansion',
- 'word-break',
- 'word-spacing',
- 'word-wrap',
- 'wrap-after',
- 'wrap-before',
- 'wrap-flow',
- 'wrap-inside',
- 'wrap-through',
- 'writing-mode',
- 'z-index',
-)
\ No newline at end of file
diff --git a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/rich/_windows_renderer.py b/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/rich/_windows_renderer.py
deleted file mode 100644
index 0fc2ba852a92a45ef510d27ca6ce5e5348bec8a1..0000000000000000000000000000000000000000
--- a/spaces/profayle/TerrapinTalk/myenv/lib/python3.9/site-packages/rich/_windows_renderer.py
+++ /dev/null
@@ -1,56 +0,0 @@
-from typing import Iterable, Sequence, Tuple, cast
-
-from rich._win32_console import LegacyWindowsTerm, WindowsCoordinates
-from rich.segment import ControlCode, ControlType, Segment
-
-
-def legacy_windows_render(buffer: Iterable[Segment], term: LegacyWindowsTerm) -> None:
- """Makes appropriate Windows Console API calls based on the segments in the buffer.
-
- Args:
- buffer (Iterable[Segment]): Iterable of Segments to convert to Win32 API calls.
- term (LegacyWindowsTerm): Used to call the Windows Console API.
- """
- for text, style, control in buffer:
- if not control:
- if style:
- term.write_styled(text, style)
- else:
- term.write_text(text)
- else:
- control_codes: Sequence[ControlCode] = control
- for control_code in control_codes:
- control_type = control_code[0]
- if control_type == ControlType.CURSOR_MOVE_TO:
- _, x, y = cast(Tuple[ControlType, int, int], control_code)
- term.move_cursor_to(WindowsCoordinates(row=y - 1, col=x - 1))
- elif control_type == ControlType.CARRIAGE_RETURN:
- term.write_text("\r")
- elif control_type == ControlType.HOME:
- term.move_cursor_to(WindowsCoordinates(0, 0))
- elif control_type == ControlType.CURSOR_UP:
- term.move_cursor_up()
- elif control_type == ControlType.CURSOR_DOWN:
- term.move_cursor_down()
- elif control_type == ControlType.CURSOR_FORWARD:
- term.move_cursor_forward()
- elif control_type == ControlType.CURSOR_BACKWARD:
- term.move_cursor_backward()
- elif control_type == ControlType.CURSOR_MOVE_TO_COLUMN:
- _, column = cast(Tuple[ControlType, int], control_code)
- term.move_cursor_to_column(column - 1)
- elif control_type == ControlType.HIDE_CURSOR:
- term.hide_cursor()
- elif control_type == ControlType.SHOW_CURSOR:
- term.show_cursor()
- elif control_type == ControlType.ERASE_IN_LINE:
- _, mode = cast(Tuple[ControlType, int], control_code)
- if mode == 0:
- term.erase_end_of_line()
- elif mode == 1:
- term.erase_start_of_line()
- elif mode == 2:
- term.erase_line()
- elif control_type == ControlType.SET_WINDOW_TITLE:
- _, title = cast(Tuple[ControlType, str], control_code)
- term.set_title(title)
diff --git a/spaces/prosiaczek/webui/app.py b/spaces/prosiaczek/webui/app.py
deleted file mode 100644
index a238731e14c0aaf61b1610907312228c7de5c4a9..0000000000000000000000000000000000000000
--- a/spaces/prosiaczek/webui/app.py
+++ /dev/null
@@ -1,76 +0,0 @@
-import os
-from subprocess import getoutput
-
-gpu_info = getoutput('nvidia-smi')
-if("A10G" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+4c06c79.d20221205-cp38-cp38-linux_x86_64.whl")
-elif("T4" in gpu_info):
- os.system(f"pip install -q https://github.com/camenduru/stable-diffusion-webui-colab/releases/download/0.0.15/xformers-0.0.15.dev0+1515f77.d20221130-cp38-cp38-linux_x86_64.whl")
-
-os.system(f"git clone https://github.com/camenduru/stable-diffusion-webui /home/user/app/stable-diffusion-webui")
-os.chdir("/home/user/app/stable-diffusion-webui")
-
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/env_patch.py -O /home/user/app/env_patch.py")
-os.system(f"sed -i -e '/import image_from_url_text/r /home/user/app/env_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(modelmerger_interface, \"Checkpoint Merger\", \"modelmerger\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/(train_interface, \"Train\", \"ti\"),/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/extensions_interface, \"Extensions\", \"extensions\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e '/settings_interface, \"Settings\", \"settings\"/d' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f'''sed -i -e "s/document.getElementsByTagName('gradio-app')\[0\].shadowRoot/!!document.getElementsByTagName('gradio-app')[0].shadowRoot ? document.getElementsByTagName('gradio-app')[0].shadowRoot : document/g" /home/user/app/stable-diffusion-webui/script.js''')
-os.system(f"sed -i -e 's/ show_progress=False,/ show_progress=True,/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/shared.demo.launch/shared.demo.queue().launch/g' /home/user/app/stable-diffusion-webui/webui.py")
-os.system(f"sed -i -e 's/ outputs=\[/queue=False, &/g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-os.system(f"sed -i -e 's/ queue=False, / /g' /home/user/app/stable-diffusion-webui/modules/ui.py")
-
-# ----------------------------Please duplicate this space and delete this block if you don't want to see the extra header----------------------------
-os.system(f"wget -q https://github.com/camenduru/webui/raw/main/header_patch.py -O /home/user/app/header_patch.py")
-os.system(f"sed -i -e '/demo:/r /home/user/app/header_patch.py' /home/user/app/stable-diffusion-webui/modules/ui.py")
-# ---------------------------------------------------------------------------------------------------------------------------------------------------
-
-if "IS_SHARED_UI" in os.environ:
- os.system(f"rm -rfv /home/user/app/stable-diffusion-webui/scripts/")
-
- os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-config.json -O /home/user/app/shared-config.json")
- os.system(f"wget -q https://github.com/camenduru/webui/raw/main/shared-ui-config.json -O /home/user/app/shared-ui-config.json")
-
- os.system(f"wget -q {os.getenv('MODEL_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME')}")
- os.system(f"wget -q {os.getenv('VAE_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('VAE_NAME')}")
- os.system(f"wget -q {os.getenv('YAML_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('YAML_NAME')}")
-
- os.system(f"python launch.py --force-enable-xformers --disable-console-progressbars --enable-console-prompts --ui-config-file /home/user/app/shared-ui-config.json --ui-settings-file /home/user/app/shared-config.json --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding")
-else:
- # Please duplicate this space and delete # character in front of the custom script you want to use or add here more custom scripts with same structure os.system(f"wget -q https://CUSTOM_SCRIPT_URL -O /home/user/app/stable-diffusion-webui/scripts/CUSTOM_SCRIPT_NAME.py")
- os.system(f"wget -q https://gist.github.com/camenduru/9ec5f8141db9902e375967e93250860f/raw/d0bcf01786f20107c329c03f8968584ee67be12a/run_n_times.py -O /home/user/app/stable-diffusion-webui/scripts/run_n_times.py")
-
- # Please duplicate this space and delete # character in front of the extension you want to use or add here more extensions with same structure os.system(f"git clone https://EXTENSION_GIT_URL /home/user/app/stable-diffusion-webui/extensions/EXTENSION_NAME")
- #os.system(f"git clone https://github.com/camenduru/stable-diffusion-webui-artists-to-study /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-artists-to-study")
- os.system(f"git clone https://github.com/yfszzx/stable-diffusion-webui-images-browser /home/user/app/stable-diffusion-webui/extensions/stable-diffusion-webui-images-browser")
- os.system(f"git clone https://github.com/deforum-art/deforum-for-automatic1111-webui /home/user/app/stable-diffusion-webui/extensions/deforum-for-automatic1111-webui")
-
- # Please duplicate this space and delete # character in front of the model you want to use or add here more ckpts with same structure os.system(f"wget -q https://CKPT_URL -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/CKPT_NAME.ckpt")
- #os.system(f"wget -q https://huggingface.co/nitrosocke/Arcane-Diffusion/resolve/main/arcane-diffusion-v3.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/arcane-diffusion-v3.ckpt")
- #os.system(f"wget -q https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion/resolve/main/Cyberpunk-Anime-Diffusion.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Cyberpunk-Anime-Diffusion.ckpt")
- #os.system(f"wget -q https://huggingface.co/prompthero/midjourney-v4-diffusion/resolve/main/mdjrny-v4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/mdjrny-v4.ckpt")
- #os.system(f"wget -q https://huggingface.co/nitrosocke/mo-di-diffusion/resolve/main/moDi-v1-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/moDi-v1-pruned.ckpt")
- #os.system(f"wget -q https://huggingface.co/Fictiverse/Stable_Diffusion_PaperCut_Model/resolve/main/PaperCut_v1.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/PaperCut_v1.ckpt")
- #os.system(f"wget -q https://huggingface.co/lilpotat/sa/resolve/main/samdoesarts_style.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/samdoesarts_style.ckpt")
- #os.system(f"wget -q https://huggingface.co/hakurei/waifu-diffusion-v1-3/resolve/main/wd-v1-3-float32.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/wd-v1-3-float32.ckpt")
- #os.system(f"wget -q https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-4.ckpt")
- #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.ckpt")
- #os.system(f"wget -q https://huggingface.co/runwayml/stable-diffusion-inpainting/resolve/main/sd-v1-5-inpainting.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/sd-v1-5-inpainting.ckpt")
-
- #os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.ckpt")
- #os.system(f"wget -q https://huggingface.co/Linaqruf/anything-v3.0/resolve/main/Anything-V3.0.vae.pt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/Anything-V3.0-pruned.vae.pt")
-
- #os.system(f"wget -q https://huggingface.co/stabilityai/stable-diffusion-2/resolve/main/768-v-ema.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.ckpt")
- #os.system(f"wget -q https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/768-v-ema.yaml")
-
- os.system(f"wget -q https://huggingface.co/stabilityai/stable-diffusion-2-1/resolve/main/v2-1_768-ema-pruned.ckpt -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v2-1_768-ema-pruned.ckpt")
- os.system(f"wget -q https://raw.githubusercontent.com/Stability-AI/stablediffusion/main/configs/stable-diffusion/v2-inference-v.yaml -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/v2-1_768-ema-pruned.yaml")
-
- os.system(f"wget -q {os.getenv('MODEL_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('MODEL_NAME')}")
- os.system(f"wget -q {os.getenv('VAE_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('VAE_NAME')}")
- os.system(f"wget -q {os.getenv('YAML_LINK')} -O /home/user/app/stable-diffusion-webui/models/Stable-diffusion/{os.getenv('YAML_NAME')}")
-
- os.system(f"python launch.py --force-enable-xformers --ui-config-file /home/user/app/ui-config.json --ui-settings-file /home/user/app/config.json --disable-console-progressbars --enable-console-prompts --cors-allow-origins huggingface.co,hf.space --no-progressbar-hiding --api --skip-torch-cuda-test")
-
\ No newline at end of file
diff --git a/spaces/pvanand/RASA-chat-interface-streamlit/README.md b/spaces/pvanand/RASA-chat-interface-streamlit/README.md
deleted file mode 100644
index a1716a42dfe801c1f62a546f2c0bb1a8e790c858..0000000000000000000000000000000000000000
--- a/spaces/pvanand/RASA-chat-interface-streamlit/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: RASA Chat Interface Streamlit
-emoji: 🏆
-colorFrom: purple
-colorTo: yellow
-sdk: streamlit
-sdk_version: 1.25.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/Armacad V10.md b/spaces/quidiaMuxgu/Expedit-SAM/Armacad V10.md
deleted file mode 100644
index 75552d23ddd028772f0fcffa6ee4f8dd4d024cdb..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/Armacad V10.md
+++ /dev/null
@@ -1,12 +0,0 @@
-
-armacad v10 armacad armacad download armacad armacad download armacad armacad armacad armacad armacad armacad. armacad is a platform for universities and academic centers to present scholarships, conferences, grants and study opportunities to an.
-Armacad V10
DOWNLOAD > https://geags.com/2uCsoe
-scholarships for arabic language courses from armacad. up to 2 scholarships are available by armacad to those students who meet the eligibility criteria. armacad is a platform for universities and academic centers to present scholarships, conferences, grants and study opportunities to an international.
-armacad is looking for candidates to receive a scholarship of $100 per month for one year for studying in iran. this scholarship can be used to cover living expenses, accommodation, travel, and other costs associated with studying in iran.
-armacad v10: student from armenia, azerbaijan, belarus, china, georgia, kazakhstan, kyrgyzstan, moldova, russia, tajikistan, turkmenistan, ukraine, uzbekistan, vietnam, and other countries can get the opportunity to study in iran.
-armacad was developed using the plasmasoft visual application framework (vaf), which is a free and open source software framework for developing high-performance, cross-platform visual applications.. armacad v10 by rosa washington; armacad torrent.
-
-armacad v10 free version is a software for cad. it is one of the best cad software in the world. it was released by autodesk on april 10, 2010. it has a 30-day free trial. once you download it, you will know why it is called armacad v10.
-armacad v10 free download for windows 32-bit and 64-bit pc. it is an autocad and autocad lt compatible cad software designed by autodesk. it is a cad application with powerful features and can be used to create and edit 2d and 3d designs of everything from architectural models to mechanical parts, aircraft, boats, parts of automobiles, home decor, etc.
899543212b
-
-
\ No newline at end of file
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/Download [VERIFIED] Hd Movie Baghban In Hindi.md b/spaces/quidiaMuxgu/Expedit-SAM/Download [VERIFIED] Hd Movie Baghban In Hindi.md
deleted file mode 100644
index 984f0bc6c58bcd1e5bc2a0a1b5b6878e40cd2400..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/Download [VERIFIED] Hd Movie Baghban In Hindi.md
+++ /dev/null
@@ -1,6 +0,0 @@
-download hd movie Baghban in hindi
Download Zip === https://geags.com/2uCsJe
-
-Listen to Download Hd Movie Baghban In Hindi and 167 more episodes by Kyon Ki Movie 1080p Download Utorrent, free! No signup or install ... 1fdad05405
-
-
-
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/Free Download Adobe Reader For Windows Server 2012.md b/spaces/quidiaMuxgu/Expedit-SAM/Free Download Adobe Reader For Windows Server 2012.md
deleted file mode 100644
index a74a8e3a55a8c03392b545987891e37f3e3a7d17..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/Free Download Adobe Reader For Windows Server 2012.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Free Download Adobe Reader For Windows Server 2012
Download Zip ✯✯✯ https://geags.com/2uCqDc
-
-The smallest, fastest, most feature-rich FREE PDF editor/viewer available! ... to Adobe Reader with PDF-XChange Editor, the FREE PDF viewer and editor. ... to further enhance your security and add timestamp server verification as desired. ... Download a portable version of the software and use it any time, any place. 4d29de3e1b
-
-
-
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/HD Online Player (bangali Babu English Mem Bengali Ful).md b/spaces/quidiaMuxgu/Expedit-SAM/HD Online Player (bangali Babu English Mem Bengali Ful).md
deleted file mode 100644
index 4dde7fdfa20aadc8f5062198afe62a863a8ff550..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/HD Online Player (bangali Babu English Mem Bengali Ful).md
+++ /dev/null
@@ -1,6 +0,0 @@
-HD Online Player (bangali babu english mem bengali ful)
Download »»» https://geags.com/2uCrsD
-
-Bangali Babu English Mem (2014) – Bengali Movie - Video Dailymotion Full Movies ... Watch Movies & TV Series Online - Arabic movies - Hollywood movies ... 4d29de3e1b
-
-
-
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/Iar Embedded Workbench For Arm 7.40 Cracked __EXCLUSIVE__.md b/spaces/quidiaMuxgu/Expedit-SAM/Iar Embedded Workbench For Arm 7.40 Cracked __EXCLUSIVE__.md
deleted file mode 100644
index 16aaf57581468ca598a312c25c7bcd874e33f9a9..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/Iar Embedded Workbench For Arm 7.40 Cracked __EXCLUSIVE__.md
+++ /dev/null
@@ -1,28 +0,0 @@
-iar embedded workbench for arm 7.40 cracked
DOWNLOAD ✏ ✏ ✏ https://geags.com/2uCreL
-
-Mandatory? No; optional. Arm developers have a lot of different compiler choices, but it is not easy to find the best tool. *The* *programmer* who uses the Arm Compiler can choose among five options: [Clang-Arm], [GCC-Arm], [GCC-Arm-v7], [ICC-Arm], and [MSVC-Arm]. It is important that the Arm compiler matches the embedded processor version. The options in the IDE are: [gnu] or [gcc], [g++], [Clang-Arm], [GCC-Arm], and [ICC-Arm]. Which is better? That depends on your tastes and the type of application you plan to code. [Clang-Arm] is recommended for most common embedded processors, while [ICC-Arm] is better for scientific applications.
-
-*Linker*. Every Arm software project must include *linker options*. Some important options include:
-
-- `-T text`: The linker text format.
-
-- `-T arch`: the Arm architecture you are targeting.
-
-- `-nostartfiles`: disables auto-generated main.c
-
-- `-e main`: main application entry point
-
-- `-l/`: adds library to the linker search path
-
-*Programmer-oriented tools*. A set of tools is provided in Arm Embedded Development Package to help programmers build Arm software projects.
-
-The IDE supports C and C++. To create an Arm object file, you can use the following command:
-
-`arm-eabi-g++ $(TOOL_MAKE_ARGS) -c main.c $(FLAGS_CPP) $(FLAGS_C) $(OPTIONS)`
-
-where $(TOOL_MAKE_ARGS) is an optional list of arguments to Arm’s arm-eabi-g++. CFLAGS are the C compiler options.
-
-Some ARM embedded CPUs are multi-core and support multi-threading. If you are targeting a multi-core ARM CPU, it is important that you ensure multi-threading support in your software. The Embedded Toolchain contains the following command to 4fefd39f24
-
-
-
diff --git a/spaces/quidiaMuxgu/Expedit-SAM/ManyCam 6.7.0 Extra Quality Crack Full Activation Code Download Here.md b/spaces/quidiaMuxgu/Expedit-SAM/ManyCam 6.7.0 Extra Quality Crack Full Activation Code Download Here.md
deleted file mode 100644
index 98305eeccef6c6da524779a6154f71c314d88827..0000000000000000000000000000000000000000
--- a/spaces/quidiaMuxgu/Expedit-SAM/ManyCam 6.7.0 Extra Quality Crack Full Activation Code Download Here.md
+++ /dev/null
@@ -1,6 +0,0 @@
-ManyCam 6.7.0 Crack Full Activation Code Download Here
Download Zip 🗸🗸🗸 https://geags.com/2uCsBZ
-
-ManyCam Pro 7.8.0.43 Crack Full Keygen 2021 is a webcam tool that ... ManyCam Pro 6.7.0 Crack Plus Activation Code Full Version [2019] ... Many people work in multiple ways, ManyCam Torrent can fulfill their obligation. 1fdad05405
-
-
-
diff --git a/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/uvr5_pack/lib_v5/layers_123821KB.py b/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/uvr5_pack/lib_v5/layers_123821KB.py
deleted file mode 100644
index b82f06bb4993cd63f076e68d7e24185269b1bc42..0000000000000000000000000000000000000000
--- a/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/uvr5_pack/lib_v5/layers_123821KB.py
+++ /dev/null
@@ -1,118 +0,0 @@
-import torch
-from torch import nn
-import torch.nn.functional as F
-
-from . import spec_utils
-
-
-class Conv2DBNActiv(nn.Module):
- def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
- super(Conv2DBNActiv, self).__init__()
- self.conv = nn.Sequential(
- nn.Conv2d(
- nin,
- nout,
- kernel_size=ksize,
- stride=stride,
- padding=pad,
- dilation=dilation,
- bias=False,
- ),
- nn.BatchNorm2d(nout),
- activ(),
- )
-
- def __call__(self, x):
- return self.conv(x)
-
-
-class SeperableConv2DBNActiv(nn.Module):
- def __init__(self, nin, nout, ksize=3, stride=1, pad=1, dilation=1, activ=nn.ReLU):
- super(SeperableConv2DBNActiv, self).__init__()
- self.conv = nn.Sequential(
- nn.Conv2d(
- nin,
- nin,
- kernel_size=ksize,
- stride=stride,
- padding=pad,
- dilation=dilation,
- groups=nin,
- bias=False,
- ),
- nn.Conv2d(nin, nout, kernel_size=1, bias=False),
- nn.BatchNorm2d(nout),
- activ(),
- )
-
- def __call__(self, x):
- return self.conv(x)
-
-
-class Encoder(nn.Module):
- def __init__(self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.LeakyReLU):
- super(Encoder, self).__init__()
- self.conv1 = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
- self.conv2 = Conv2DBNActiv(nout, nout, ksize, stride, pad, activ=activ)
-
- def __call__(self, x):
- skip = self.conv1(x)
- h = self.conv2(skip)
-
- return h, skip
-
-
-class Decoder(nn.Module):
- def __init__(
- self, nin, nout, ksize=3, stride=1, pad=1, activ=nn.ReLU, dropout=False
- ):
- super(Decoder, self).__init__()
- self.conv = Conv2DBNActiv(nin, nout, ksize, 1, pad, activ=activ)
- self.dropout = nn.Dropout2d(0.1) if dropout else None
-
- def __call__(self, x, skip=None):
- x = F.interpolate(x, scale_factor=2, mode="bilinear", align_corners=True)
- if skip is not None:
- skip = spec_utils.crop_center(skip, x)
- x = torch.cat([x, skip], dim=1)
- h = self.conv(x)
-
- if self.dropout is not None:
- h = self.dropout(h)
-
- return h
-
-
-class ASPPModule(nn.Module):
- def __init__(self, nin, nout, dilations=(4, 8, 16), activ=nn.ReLU):
- super(ASPPModule, self).__init__()
- self.conv1 = nn.Sequential(
- nn.AdaptiveAvgPool2d((1, None)),
- Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ),
- )
- self.conv2 = Conv2DBNActiv(nin, nin, 1, 1, 0, activ=activ)
- self.conv3 = SeperableConv2DBNActiv(
- nin, nin, 3, 1, dilations[0], dilations[0], activ=activ
- )
- self.conv4 = SeperableConv2DBNActiv(
- nin, nin, 3, 1, dilations[1], dilations[1], activ=activ
- )
- self.conv5 = SeperableConv2DBNActiv(
- nin, nin, 3, 1, dilations[2], dilations[2], activ=activ
- )
- self.bottleneck = nn.Sequential(
- Conv2DBNActiv(nin * 5, nout, 1, 1, 0, activ=activ), nn.Dropout2d(0.1)
- )
-
- def forward(self, x):
- _, _, h, w = x.size()
- feat1 = F.interpolate(
- self.conv1(x), size=(h, w), mode="bilinear", align_corners=True
- )
- feat2 = self.conv2(x)
- feat3 = self.conv3(x)
- feat4 = self.conv4(x)
- feat5 = self.conv5(x)
- out = torch.cat((feat1, feat2, feat3, feat4, feat5), dim=1)
- bottle = self.bottleneck(out)
- return bottle
diff --git a/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/uvr5_pack/lib_v5/nets_123821KB.py b/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/uvr5_pack/lib_v5/nets_123821KB.py
deleted file mode 100644
index becbfae85683a13bbb19d3ea6c840da24e61e01e..0000000000000000000000000000000000000000
--- a/spaces/r3gm/Aesthetic_RVC_Inference_HF/lib/uvr5_pack/lib_v5/nets_123821KB.py
+++ /dev/null
@@ -1,122 +0,0 @@
-import torch
-from torch import nn
-import torch.nn.functional as F
-
-from . import layers_123821KB as layers
-
-
-class BaseASPPNet(nn.Module):
- def __init__(self, nin, ch, dilations=(4, 8, 16)):
- super(BaseASPPNet, self).__init__()
- self.enc1 = layers.Encoder(nin, ch, 3, 2, 1)
- self.enc2 = layers.Encoder(ch, ch * 2, 3, 2, 1)
- self.enc3 = layers.Encoder(ch * 2, ch * 4, 3, 2, 1)
- self.enc4 = layers.Encoder(ch * 4, ch * 8, 3, 2, 1)
-
- self.aspp = layers.ASPPModule(ch * 8, ch * 16, dilations)
-
- self.dec4 = layers.Decoder(ch * (8 + 16), ch * 8, 3, 1, 1)
- self.dec3 = layers.Decoder(ch * (4 + 8), ch * 4, 3, 1, 1)
- self.dec2 = layers.Decoder(ch * (2 + 4), ch * 2, 3, 1, 1)
- self.dec1 = layers.Decoder(ch * (1 + 2), ch, 3, 1, 1)
-
- def __call__(self, x):
- h, e1 = self.enc1(x)
- h, e2 = self.enc2(h)
- h, e3 = self.enc3(h)
- h, e4 = self.enc4(h)
-
- h = self.aspp(h)
-
- h = self.dec4(h, e4)
- h = self.dec3(h, e3)
- h = self.dec2(h, e2)
- h = self.dec1(h, e1)
-
- return h
-
-
-class CascadedASPPNet(nn.Module):
- def __init__(self, n_fft):
- super(CascadedASPPNet, self).__init__()
- self.stg1_low_band_net = BaseASPPNet(2, 32)
- self.stg1_high_band_net = BaseASPPNet(2, 32)
-
- self.stg2_bridge = layers.Conv2DBNActiv(34, 16, 1, 1, 0)
- self.stg2_full_band_net = BaseASPPNet(16, 32)
-
- self.stg3_bridge = layers.Conv2DBNActiv(66, 32, 1, 1, 0)
- self.stg3_full_band_net = BaseASPPNet(32, 64)
-
- self.out = nn.Conv2d(64, 2, 1, bias=False)
- self.aux1_out = nn.Conv2d(32, 2, 1, bias=False)
- self.aux2_out = nn.Conv2d(32, 2, 1, bias=False)
-
- self.max_bin = n_fft // 2
- self.output_bin = n_fft // 2 + 1
-
- self.offset = 128
-
- def forward(self, x, aggressiveness=None):
- mix = x.detach()
- x = x.clone()
-
- x = x[:, :, : self.max_bin]
-
- bandw = x.size()[2] // 2
- aux1 = torch.cat(
- [
- self.stg1_low_band_net(x[:, :, :bandw]),
- self.stg1_high_band_net(x[:, :, bandw:]),
- ],
- dim=2,
- )
-
- h = torch.cat([x, aux1], dim=1)
- aux2 = self.stg2_full_band_net(self.stg2_bridge(h))
-
- h = torch.cat([x, aux1, aux2], dim=1)
- h = self.stg3_full_band_net(self.stg3_bridge(h))
-
- mask = torch.sigmoid(self.out(h))
- mask = F.pad(
- input=mask,
- pad=(0, 0, 0, self.output_bin - mask.size()[2]),
- mode="replicate",
- )
-
- if self.training:
- aux1 = torch.sigmoid(self.aux1_out(aux1))
- aux1 = F.pad(
- input=aux1,
- pad=(0, 0, 0, self.output_bin - aux1.size()[2]),
- mode="replicate",
- )
- aux2 = torch.sigmoid(self.aux2_out(aux2))
- aux2 = F.pad(
- input=aux2,
- pad=(0, 0, 0, self.output_bin - aux2.size()[2]),
- mode="replicate",
- )
- return mask * mix, aux1 * mix, aux2 * mix
- else:
- if aggressiveness:
- mask[:, :, : aggressiveness["split_bin"]] = torch.pow(
- mask[:, :, : aggressiveness["split_bin"]],
- 1 + aggressiveness["value"] / 3,
- )
- mask[:, :, aggressiveness["split_bin"] :] = torch.pow(
- mask[:, :, aggressiveness["split_bin"] :],
- 1 + aggressiveness["value"],
- )
-
- return mask * mix
-
- def predict(self, x_mag, aggressiveness=None):
- h = self.forward(x_mag, aggressiveness)
-
- if self.offset > 0:
- h = h[:, :, :, self.offset : -self.offset]
- assert h.size()[3] > 0
-
- return h
diff --git a/spaces/r3gm/RVC_HF/demucs/utils.py b/spaces/r3gm/RVC_HF/demucs/utils.py
deleted file mode 100644
index 4364184059b1afe3c8379c77793a8e76dccf9699..0000000000000000000000000000000000000000
--- a/spaces/r3gm/RVC_HF/demucs/utils.py
+++ /dev/null
@@ -1,323 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import errno
-import functools
-import hashlib
-import inspect
-import io
-import os
-import random
-import socket
-import tempfile
-import warnings
-import zlib
-from contextlib import contextmanager
-
-from diffq import UniformQuantizer, DiffQuantizer
-import torch as th
-import tqdm
-from torch import distributed
-from torch.nn import functional as F
-
-
-def center_trim(tensor, reference):
- """
- Center trim `tensor` with respect to `reference`, along the last dimension.
- `reference` can also be a number, representing the length to trim to.
- If the size difference != 0 mod 2, the extra sample is removed on the right side.
- """
- if hasattr(reference, "size"):
- reference = reference.size(-1)
- delta = tensor.size(-1) - reference
- if delta < 0:
- raise ValueError("tensor must be larger than reference. " f"Delta is {delta}.")
- if delta:
- tensor = tensor[..., delta // 2:-(delta - delta // 2)]
- return tensor
-
-
-def average_metric(metric, count=1.):
- """
- Average `metric` which should be a float across all hosts. `count` should be
- the weight for this particular host (i.e. number of examples).
- """
- metric = th.tensor([count, count * metric], dtype=th.float32, device='cuda')
- distributed.all_reduce(metric, op=distributed.ReduceOp.SUM)
- return metric[1].item() / metric[0].item()
-
-
-def free_port(host='', low=20000, high=40000):
- """
- Return a port number that is most likely free.
- This could suffer from a race condition although
- it should be quite rare.
- """
- sock = socket.socket()
- while True:
- port = random.randint(low, high)
- try:
- sock.bind((host, port))
- except OSError as error:
- if error.errno == errno.EADDRINUSE:
- continue
- raise
- return port
-
-
-def sizeof_fmt(num, suffix='B'):
- """
- Given `num` bytes, return human readable size.
- Taken from https://stackoverflow.com/a/1094933
- """
- for unit in ['', 'Ki', 'Mi', 'Gi', 'Ti', 'Pi', 'Ei', 'Zi']:
- if abs(num) < 1024.0:
- return "%3.1f%s%s" % (num, unit, suffix)
- num /= 1024.0
- return "%.1f%s%s" % (num, 'Yi', suffix)
-
-
-def human_seconds(seconds, display='.2f'):
- """
- Given `seconds` seconds, return human readable duration.
- """
- value = seconds * 1e6
- ratios = [1e3, 1e3, 60, 60, 24]
- names = ['us', 'ms', 's', 'min', 'hrs', 'days']
- last = names.pop(0)
- for name, ratio in zip(names, ratios):
- if value / ratio < 0.3:
- break
- value /= ratio
- last = name
- return f"{format(value, display)} {last}"
-
-
-class TensorChunk:
- def __init__(self, tensor, offset=0, length=None):
- total_length = tensor.shape[-1]
- assert offset >= 0
- assert offset < total_length
-
- if length is None:
- length = total_length - offset
- else:
- length = min(total_length - offset, length)
-
- self.tensor = tensor
- self.offset = offset
- self.length = length
- self.device = tensor.device
-
- @property
- def shape(self):
- shape = list(self.tensor.shape)
- shape[-1] = self.length
- return shape
-
- def padded(self, target_length):
- delta = target_length - self.length
- total_length = self.tensor.shape[-1]
- assert delta >= 0
-
- start = self.offset - delta // 2
- end = start + target_length
-
- correct_start = max(0, start)
- correct_end = min(total_length, end)
-
- pad_left = correct_start - start
- pad_right = end - correct_end
-
- out = F.pad(self.tensor[..., correct_start:correct_end], (pad_left, pad_right))
- assert out.shape[-1] == target_length
- return out
-
-
-def tensor_chunk(tensor_or_chunk):
- if isinstance(tensor_or_chunk, TensorChunk):
- return tensor_or_chunk
- else:
- assert isinstance(tensor_or_chunk, th.Tensor)
- return TensorChunk(tensor_or_chunk)
-
-
-def apply_model(model, mix, shifts=None, split=False,
- overlap=0.25, transition_power=1., progress=False):
- """
- Apply model to a given mixture.
-
- Args:
- shifts (int): if > 0, will shift in time `mix` by a random amount between 0 and 0.5 sec
- and apply the oppositve shift to the output. This is repeated `shifts` time and
- all predictions are averaged. This effectively makes the model time equivariant
- and improves SDR by up to 0.2 points.
- split (bool): if True, the input will be broken down in 8 seconds extracts
- and predictions will be performed individually on each and concatenated.
- Useful for model with large memory footprint like Tasnet.
- progress (bool): if True, show a progress bar (requires split=True)
- """
- assert transition_power >= 1, "transition_power < 1 leads to weird behavior."
- device = mix.device
- channels, length = mix.shape
- if split:
- out = th.zeros(len(model.sources), channels, length, device=device)
- sum_weight = th.zeros(length, device=device)
- segment = model.segment_length
- stride = int((1 - overlap) * segment)
- offsets = range(0, length, stride)
- scale = stride / model.samplerate
- if progress:
- offsets = tqdm.tqdm(offsets, unit_scale=scale, ncols=120, unit='seconds')
- # We start from a triangle shaped weight, with maximal weight in the middle
- # of the segment. Then we normalize and take to the power `transition_power`.
- # Large values of transition power will lead to sharper transitions.
- weight = th.cat([th.arange(1, segment // 2 + 1),
- th.arange(segment - segment // 2, 0, -1)]).to(device)
- assert len(weight) == segment
- # If the overlap < 50%, this will translate to linear transition when
- # transition_power is 1.
- weight = (weight / weight.max())**transition_power
- for offset in offsets:
- chunk = TensorChunk(mix, offset, segment)
- chunk_out = apply_model(model, chunk, shifts=shifts)
- chunk_length = chunk_out.shape[-1]
- out[..., offset:offset + segment] += weight[:chunk_length] * chunk_out
- sum_weight[offset:offset + segment] += weight[:chunk_length]
- offset += segment
- assert sum_weight.min() > 0
- out /= sum_weight
- return out
- elif shifts:
- max_shift = int(0.5 * model.samplerate)
- mix = tensor_chunk(mix)
- padded_mix = mix.padded(length + 2 * max_shift)
- out = 0
- for _ in range(shifts):
- offset = random.randint(0, max_shift)
- shifted = TensorChunk(padded_mix, offset, length + max_shift - offset)
- shifted_out = apply_model(model, shifted)
- out += shifted_out[..., max_shift - offset:]
- out /= shifts
- return out
- else:
- valid_length = model.valid_length(length)
- mix = tensor_chunk(mix)
- padded_mix = mix.padded(valid_length)
- with th.no_grad():
- out = model(padded_mix.unsqueeze(0))[0]
- return center_trim(out, length)
-
-
-@contextmanager
-def temp_filenames(count, delete=True):
- names = []
- try:
- for _ in range(count):
- names.append(tempfile.NamedTemporaryFile(delete=False).name)
- yield names
- finally:
- if delete:
- for name in names:
- os.unlink(name)
-
-
-def get_quantizer(model, args, optimizer=None):
- quantizer = None
- if args.diffq:
- quantizer = DiffQuantizer(
- model, min_size=args.q_min_size, group_size=8)
- if optimizer is not None:
- quantizer.setup_optimizer(optimizer)
- elif args.qat:
- quantizer = UniformQuantizer(
- model, bits=args.qat, min_size=args.q_min_size)
- return quantizer
-
-
-def load_model(path, strict=False):
- with warnings.catch_warnings():
- warnings.simplefilter("ignore")
- load_from = path
- package = th.load(load_from, 'cpu')
-
- klass = package["klass"]
- args = package["args"]
- kwargs = package["kwargs"]
-
- if strict:
- model = klass(*args, **kwargs)
- else:
- sig = inspect.signature(klass)
- for key in list(kwargs):
- if key not in sig.parameters:
- warnings.warn("Dropping inexistant parameter " + key)
- del kwargs[key]
- model = klass(*args, **kwargs)
-
- state = package["state"]
- training_args = package["training_args"]
- quantizer = get_quantizer(model, training_args)
-
- set_state(model, quantizer, state)
- return model
-
-
-def get_state(model, quantizer):
- if quantizer is None:
- state = {k: p.data.to('cpu') for k, p in model.state_dict().items()}
- else:
- state = quantizer.get_quantized_state()
- buf = io.BytesIO()
- th.save(state, buf)
- state = {'compressed': zlib.compress(buf.getvalue())}
- return state
-
-
-def set_state(model, quantizer, state):
- if quantizer is None:
- model.load_state_dict(state)
- else:
- buf = io.BytesIO(zlib.decompress(state["compressed"]))
- state = th.load(buf, "cpu")
- quantizer.restore_quantized_state(state)
-
- return state
-
-
-def save_state(state, path):
- buf = io.BytesIO()
- th.save(state, buf)
- sig = hashlib.sha256(buf.getvalue()).hexdigest()[:8]
-
- path = path.parent / (path.stem + "-" + sig + path.suffix)
- path.write_bytes(buf.getvalue())
-
-
-def save_model(model, quantizer, training_args, path):
- args, kwargs = model._init_args_kwargs
- klass = model.__class__
-
- state = get_state(model, quantizer)
-
- save_to = path
- package = {
- 'klass': klass,
- 'args': args,
- 'kwargs': kwargs,
- 'state': state,
- 'training_args': training_args,
- }
- th.save(package, save_to)
-
-
-def capture_init(init):
- @functools.wraps(init)
- def __init__(self, *args, **kwargs):
- self._init_args_kwargs = (args, kwargs)
- init(self, *args, **kwargs)
-
- return __init__
diff --git a/spaces/rachana219/MODT2/trackers/strongsort/deep/models/inceptionv4.py b/spaces/rachana219/MODT2/trackers/strongsort/deep/models/inceptionv4.py
deleted file mode 100644
index b14916f140712298866c943ebdb4ebad67d72fc4..0000000000000000000000000000000000000000
--- a/spaces/rachana219/MODT2/trackers/strongsort/deep/models/inceptionv4.py
+++ /dev/null
@@ -1,381 +0,0 @@
-from __future__ import division, absolute_import
-import torch
-import torch.nn as nn
-import torch.utils.model_zoo as model_zoo
-
-__all__ = ['inceptionv4']
-"""
-Code imported from https://github.com/Cadene/pretrained-models.pytorch
-"""
-
-pretrained_settings = {
- 'inceptionv4': {
- 'imagenet': {
- 'url':
- 'http://data.lip6.fr/cadene/pretrainedmodels/inceptionv4-8e4777a0.pth',
- 'input_space': 'RGB',
- 'input_size': [3, 299, 299],
- 'input_range': [0, 1],
- 'mean': [0.5, 0.5, 0.5],
- 'std': [0.5, 0.5, 0.5],
- 'num_classes': 1000
- },
- 'imagenet+background': {
- 'url':
- 'http://data.lip6.fr/cadene/pretrainedmodels/inceptionv4-8e4777a0.pth',
- 'input_space': 'RGB',
- 'input_size': [3, 299, 299],
- 'input_range': [0, 1],
- 'mean': [0.5, 0.5, 0.5],
- 'std': [0.5, 0.5, 0.5],
- 'num_classes': 1001
- }
- }
-}
-
-
-class BasicConv2d(nn.Module):
-
- def __init__(self, in_planes, out_planes, kernel_size, stride, padding=0):
- super(BasicConv2d, self).__init__()
- self.conv = nn.Conv2d(
- in_planes,
- out_planes,
- kernel_size=kernel_size,
- stride=stride,
- padding=padding,
- bias=False
- ) # verify bias false
- self.bn = nn.BatchNorm2d(
- out_planes,
- eps=0.001, # value found in tensorflow
- momentum=0.1, # default pytorch value
- affine=True
- )
- self.relu = nn.ReLU(inplace=True)
-
- def forward(self, x):
- x = self.conv(x)
- x = self.bn(x)
- x = self.relu(x)
- return x
-
-
-class Mixed_3a(nn.Module):
-
- def __init__(self):
- super(Mixed_3a, self).__init__()
- self.maxpool = nn.MaxPool2d(3, stride=2)
- self.conv = BasicConv2d(64, 96, kernel_size=3, stride=2)
-
- def forward(self, x):
- x0 = self.maxpool(x)
- x1 = self.conv(x)
- out = torch.cat((x0, x1), 1)
- return out
-
-
-class Mixed_4a(nn.Module):
-
- def __init__(self):
- super(Mixed_4a, self).__init__()
-
- self.branch0 = nn.Sequential(
- BasicConv2d(160, 64, kernel_size=1, stride=1),
- BasicConv2d(64, 96, kernel_size=3, stride=1)
- )
-
- self.branch1 = nn.Sequential(
- BasicConv2d(160, 64, kernel_size=1, stride=1),
- BasicConv2d(64, 64, kernel_size=(1, 7), stride=1, padding=(0, 3)),
- BasicConv2d(64, 64, kernel_size=(7, 1), stride=1, padding=(3, 0)),
- BasicConv2d(64, 96, kernel_size=(3, 3), stride=1)
- )
-
- def forward(self, x):
- x0 = self.branch0(x)
- x1 = self.branch1(x)
- out = torch.cat((x0, x1), 1)
- return out
-
-
-class Mixed_5a(nn.Module):
-
- def __init__(self):
- super(Mixed_5a, self).__init__()
- self.conv = BasicConv2d(192, 192, kernel_size=3, stride=2)
- self.maxpool = nn.MaxPool2d(3, stride=2)
-
- def forward(self, x):
- x0 = self.conv(x)
- x1 = self.maxpool(x)
- out = torch.cat((x0, x1), 1)
- return out
-
-
-class Inception_A(nn.Module):
-
- def __init__(self):
- super(Inception_A, self).__init__()
- self.branch0 = BasicConv2d(384, 96, kernel_size=1, stride=1)
-
- self.branch1 = nn.Sequential(
- BasicConv2d(384, 64, kernel_size=1, stride=1),
- BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1)
- )
-
- self.branch2 = nn.Sequential(
- BasicConv2d(384, 64, kernel_size=1, stride=1),
- BasicConv2d(64, 96, kernel_size=3, stride=1, padding=1),
- BasicConv2d(96, 96, kernel_size=3, stride=1, padding=1)
- )
-
- self.branch3 = nn.Sequential(
- nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
- BasicConv2d(384, 96, kernel_size=1, stride=1)
- )
-
- def forward(self, x):
- x0 = self.branch0(x)
- x1 = self.branch1(x)
- x2 = self.branch2(x)
- x3 = self.branch3(x)
- out = torch.cat((x0, x1, x2, x3), 1)
- return out
-
-
-class Reduction_A(nn.Module):
-
- def __init__(self):
- super(Reduction_A, self).__init__()
- self.branch0 = BasicConv2d(384, 384, kernel_size=3, stride=2)
-
- self.branch1 = nn.Sequential(
- BasicConv2d(384, 192, kernel_size=1, stride=1),
- BasicConv2d(192, 224, kernel_size=3, stride=1, padding=1),
- BasicConv2d(224, 256, kernel_size=3, stride=2)
- )
-
- self.branch2 = nn.MaxPool2d(3, stride=2)
-
- def forward(self, x):
- x0 = self.branch0(x)
- x1 = self.branch1(x)
- x2 = self.branch2(x)
- out = torch.cat((x0, x1, x2), 1)
- return out
-
-
-class Inception_B(nn.Module):
-
- def __init__(self):
- super(Inception_B, self).__init__()
- self.branch0 = BasicConv2d(1024, 384, kernel_size=1, stride=1)
-
- self.branch1 = nn.Sequential(
- BasicConv2d(1024, 192, kernel_size=1, stride=1),
- BasicConv2d(
- 192, 224, kernel_size=(1, 7), stride=1, padding=(0, 3)
- ),
- BasicConv2d(
- 224, 256, kernel_size=(7, 1), stride=1, padding=(3, 0)
- )
- )
-
- self.branch2 = nn.Sequential(
- BasicConv2d(1024, 192, kernel_size=1, stride=1),
- BasicConv2d(
- 192, 192, kernel_size=(7, 1), stride=1, padding=(3, 0)
- ),
- BasicConv2d(
- 192, 224, kernel_size=(1, 7), stride=1, padding=(0, 3)
- ),
- BasicConv2d(
- 224, 224, kernel_size=(7, 1), stride=1, padding=(3, 0)
- ),
- BasicConv2d(
- 224, 256, kernel_size=(1, 7), stride=1, padding=(0, 3)
- )
- )
-
- self.branch3 = nn.Sequential(
- nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
- BasicConv2d(1024, 128, kernel_size=1, stride=1)
- )
-
- def forward(self, x):
- x0 = self.branch0(x)
- x1 = self.branch1(x)
- x2 = self.branch2(x)
- x3 = self.branch3(x)
- out = torch.cat((x0, x1, x2, x3), 1)
- return out
-
-
-class Reduction_B(nn.Module):
-
- def __init__(self):
- super(Reduction_B, self).__init__()
-
- self.branch0 = nn.Sequential(
- BasicConv2d(1024, 192, kernel_size=1, stride=1),
- BasicConv2d(192, 192, kernel_size=3, stride=2)
- )
-
- self.branch1 = nn.Sequential(
- BasicConv2d(1024, 256, kernel_size=1, stride=1),
- BasicConv2d(
- 256, 256, kernel_size=(1, 7), stride=1, padding=(0, 3)
- ),
- BasicConv2d(
- 256, 320, kernel_size=(7, 1), stride=1, padding=(3, 0)
- ), BasicConv2d(320, 320, kernel_size=3, stride=2)
- )
-
- self.branch2 = nn.MaxPool2d(3, stride=2)
-
- def forward(self, x):
- x0 = self.branch0(x)
- x1 = self.branch1(x)
- x2 = self.branch2(x)
- out = torch.cat((x0, x1, x2), 1)
- return out
-
-
-class Inception_C(nn.Module):
-
- def __init__(self):
- super(Inception_C, self).__init__()
-
- self.branch0 = BasicConv2d(1536, 256, kernel_size=1, stride=1)
-
- self.branch1_0 = BasicConv2d(1536, 384, kernel_size=1, stride=1)
- self.branch1_1a = BasicConv2d(
- 384, 256, kernel_size=(1, 3), stride=1, padding=(0, 1)
- )
- self.branch1_1b = BasicConv2d(
- 384, 256, kernel_size=(3, 1), stride=1, padding=(1, 0)
- )
-
- self.branch2_0 = BasicConv2d(1536, 384, kernel_size=1, stride=1)
- self.branch2_1 = BasicConv2d(
- 384, 448, kernel_size=(3, 1), stride=1, padding=(1, 0)
- )
- self.branch2_2 = BasicConv2d(
- 448, 512, kernel_size=(1, 3), stride=1, padding=(0, 1)
- )
- self.branch2_3a = BasicConv2d(
- 512, 256, kernel_size=(1, 3), stride=1, padding=(0, 1)
- )
- self.branch2_3b = BasicConv2d(
- 512, 256, kernel_size=(3, 1), stride=1, padding=(1, 0)
- )
-
- self.branch3 = nn.Sequential(
- nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
- BasicConv2d(1536, 256, kernel_size=1, stride=1)
- )
-
- def forward(self, x):
- x0 = self.branch0(x)
-
- x1_0 = self.branch1_0(x)
- x1_1a = self.branch1_1a(x1_0)
- x1_1b = self.branch1_1b(x1_0)
- x1 = torch.cat((x1_1a, x1_1b), 1)
-
- x2_0 = self.branch2_0(x)
- x2_1 = self.branch2_1(x2_0)
- x2_2 = self.branch2_2(x2_1)
- x2_3a = self.branch2_3a(x2_2)
- x2_3b = self.branch2_3b(x2_2)
- x2 = torch.cat((x2_3a, x2_3b), 1)
-
- x3 = self.branch3(x)
-
- out = torch.cat((x0, x1, x2, x3), 1)
- return out
-
-
-class InceptionV4(nn.Module):
- """Inception-v4.
-
- Reference:
- Szegedy et al. Inception-v4, Inception-ResNet and the Impact of Residual
- Connections on Learning. AAAI 2017.
-
- Public keys:
- - ``inceptionv4``: InceptionV4.
- """
-
- def __init__(self, num_classes, loss, **kwargs):
- super(InceptionV4, self).__init__()
- self.loss = loss
-
- self.features = nn.Sequential(
- BasicConv2d(3, 32, kernel_size=3, stride=2),
- BasicConv2d(32, 32, kernel_size=3, stride=1),
- BasicConv2d(32, 64, kernel_size=3, stride=1, padding=1),
- Mixed_3a(),
- Mixed_4a(),
- Mixed_5a(),
- Inception_A(),
- Inception_A(),
- Inception_A(),
- Inception_A(),
- Reduction_A(), # Mixed_6a
- Inception_B(),
- Inception_B(),
- Inception_B(),
- Inception_B(),
- Inception_B(),
- Inception_B(),
- Inception_B(),
- Reduction_B(), # Mixed_7a
- Inception_C(),
- Inception_C(),
- Inception_C()
- )
- self.global_avgpool = nn.AdaptiveAvgPool2d(1)
- self.classifier = nn.Linear(1536, num_classes)
-
- def forward(self, x):
- f = self.features(x)
- v = self.global_avgpool(f)
- v = v.view(v.size(0), -1)
-
- if not self.training:
- return v
-
- y = self.classifier(v)
-
- if self.loss == 'softmax':
- return y
- elif self.loss == 'triplet':
- return y, v
- else:
- raise KeyError('Unsupported loss: {}'.format(self.loss))
-
-
-def init_pretrained_weights(model, model_url):
- """Initializes model with pretrained weights.
-
- Layers that don't match with pretrained layers in name or size are kept unchanged.
- """
- pretrain_dict = model_zoo.load_url(model_url)
- model_dict = model.state_dict()
- pretrain_dict = {
- k: v
- for k, v in pretrain_dict.items()
- if k in model_dict and model_dict[k].size() == v.size()
- }
- model_dict.update(pretrain_dict)
- model.load_state_dict(model_dict)
-
-
-def inceptionv4(num_classes, loss='softmax', pretrained=True, **kwargs):
- model = InceptionV4(num_classes, loss, **kwargs)
- if pretrained:
- model_url = pretrained_settings['inceptionv4']['imagenet']['url']
- init_pretrained_weights(model, model_url)
- return model
diff --git a/spaces/raedeXanto/academic-chatgpt-beta/1001bit Pro 2.2 How to Install and Use this Plugin for Sketchup.md b/spaces/raedeXanto/academic-chatgpt-beta/1001bit Pro 2.2 How to Install and Use this Plugin for Sketchup.md
deleted file mode 100644
index 883ba7dcea8b6d80101103c8318ff1a38d3873fa..0000000000000000000000000000000000000000
--- a/spaces/raedeXanto/academic-chatgpt-beta/1001bit Pro 2.2 How to Install and Use this Plugin for Sketchup.md
+++ /dev/null
@@ -1,147 +0,0 @@
-
-1001bit Pro 2.2 Plugin for Sketchup: A Review
-If you are a Sketchup user who loves to create architectural models, you might have heard of 1001bit Pro, a collection of plugins that can help you achieve more while doing less. In this article, we will review the latest version of this plugin, 1001bit Pro 2.2, and show you how it can enhance your modeling experience and output.
-1001bit.Pro.2.2..Plugin.for.Sketchup..epub
Download File >> https://tinourl.com/2uL1l6
-1001bit Pro is a set of Ruby scripts that are dedicated for architectural works. It was developed by Goh Chun Hee, an architect based in Singapore. With this plugin, you can create parametric architectural elements such as staircases, windows, doors, roofs, louvres, floor joists, and more within minutes. You can also save commonly used parameters for easy selection in future. Moreover, you can use various editing tools to modify your models quickly and easily.
-In this review, we will cover the following aspects of 1001bit Pro:
-
-- Features of 1001bit Pro
-- Benefits of using 1001bit Pro
-- How to install and activate 1001bit Pro
-- How to use 1001bit Pro
-
-Features of 1001bit Pro
-1001bit Pro has many features that can help you create stunning architectural models in Sketchup. Here are some of the main features:
-Architectural Tools
-With these tools, you can create various architectural elements with just a few clicks. You can specify the dimensions, materials, styles, and other parameters of each element. Some of the architectural tools are:
-
-- Staircases: You can create straight or spiral staircases with different types of handrails, balusters, landings, and steps.
-- Windows: You can create different types of windows such as casement, sliding, bay, arch, louver, and more.
-- Doors: You can create different types of doors such as swing, sliding, bi-fold, pocket, and more.
-- Roofs: You can create different types of roofs such as gable, hip, mansard, gambrel, shed, dome, and more.
-- Louvres: You can create different types of louvres such as horizontal, vertical, fixed, operable, and more.
-- Floor joists: You can create floor joists with different sizes, spacing, and directions.
-- And more: You can also create other elements such as walls, columns, beams, railings, fences, ramps, etc.
-
-Editing Tools
-With these tools, you can edit your models easily and efficiently. You can perform various operations such as extending, trimming, filleting, chamfering, offsetting, rotating,
Editing Tools
-With these tools, you can edit your models easily and efficiently. You can perform various operations such as extending, trimming, filleting, chamfering, offsetting, rotating, scaling, and more. Some of the editing tools are:
-How to install 1001bit Pro 2.2 plugin for Sketchup
-1001bit Pro 2.2 plugin for Sketchup tutorial
-Download 1001bit Pro 2.2 plugin for Sketchup free
-1001bit Pro 2.2 plugin for Sketchup crack
-1001bit Pro 2.2 plugin for Sketchup review
-Best Sketchup plugins for architects
-1001bit Pro 2.2 plugin for Sketchup features
-1001bit Pro 2.2 plugin for Sketchup license key
-1001bit Pro 2.2 plugin for Sketchup vs Vray
-1001bit Pro 2.2 plugin for Sketchup system requirements
-1001bit Pro 2.2 plugin for Sketchup alternatives
-1001bit Pro 2.2 plugin for Sketchup compatibility
-1001bit Pro 2.2 plugin for Sketchup manual
-1001bit Pro 2.2 plugin for Sketchup support
-1001bit Pro 2.2 plugin for Sketchup discount code
-How to use 1001bit Pro 2.2 plugin for Sketchup with Revit
-How to update 1001bit Pro 2.2 plugin for Sketchup
-How to uninstall 1001bit Pro 2.2 plugin for Sketchup
-How to activate 1001bit Pro 2.2 plugin for Sketchup
-How to create stairs with 1001bit Pro 2.2 plugin for Sketchup
-How to create roofs with 1001bit Pro 2.2 plugin for Sketchup
-How to create windows with 1001bit Pro 2.2 plugin for Sketchup
-How to create doors with 1001bit Pro 2.2 plugin for Sketchup
-How to create walls with 1001bit Pro 2.2 plugin for Sketchup
-How to create columns with 1001bit Pro 2.2 plugin for Sketchup
-How to create beams with 1001bit Pro 2.2 plugin for Sketchup
-How to create railings with 1001bit Pro 2.2 plugin for Sketchup
-How to create slabs with 1001bit Pro 2.2 plugin for Sketchup
-How to create foundations with 1001bit Pro 2.2 plugin for Sketchup
-How to create floors with 1001bit Pro 2.2 plugin for Sketchup
-How to create ceilings with 1001bit Pro 2.2 plugin for Sketchup
-How to create furniture with 1001bit Pro 2.2 plugin for Sketchup
-How to create lighting with 1001bit Pro 2.2 plugin for Sketchup
-How to create landscaping with 1001bit Pro 2.2 plugin for Sketchup
-How to create site plans with 1001bit Pro 2.2 plugin for Sketchup
-How to create sections with 1001bit Pro 2.2 plugin for Sketchup
-How to create elevations with 1001bit Pro 2.2 plugin for Sketchup
-How to create perspectives with 1001bit Pro 2.2 plugin for Sketchup
-How to create renderings with 1001bit Pro 2.
-
-- Extend: You can extend edges or faces to meet other edges or faces.
-- Trim: You can trim edges or faces by other edges or faces.
-- Fillet: You can create rounded corners between two edges or faces.
-- Chamfer: You can create beveled corners between two edges or faces.
-- Offset: You can create parallel copies of edges or faces with a specified distance.
-- Rotate 3D: You can rotate objects around any axis.
-- Scale 3D: You can scale objects along any axis.
-- And more: You can also use other tools such as mirror, array, taper, twist, bend, etc.
-
-Saving and Loading Parameters
-With this feature, you can save the parameters of any architectural element that you create with 1001bit Pro. You can then load the saved parameters for future use. This can save you time and effort when you need to create similar elements again. You can also share your saved parameters with other users.
-Benefits of using 1001bit Pro
-Using 1001bit Pro can bring you many benefits as a Sketchup user. Here are some of the main benefits:
-Faster and Easier Modeling
-With 1001bit Pro, you can create complex architectural elements with just a few clicks. You don't need to draw every detail manually or use multiple plugins. You can also edit your models quickly and easily with the editing tools. This can save you a lot of time and effort in modeling.
-More Creative and Realistic Designs
-With 1001bit Pro, you can create more creative and realistic designs for your architectural models. You can choose from different types, styles, and materials of each element. You can also adjust the parameters and options to suit your preferences and needs. This can enhance the quality and appearance of your models.
-Compatible with Sketchup Versions
-1001bit Pro is compatible with Sketchup 8 and later versions. It also works with both Windows and Mac operating systems. You don't need to worry about compatibility issues when using this plugin.
-How to Install and Activate 1001bit Pro
-If you are interested in using 1001bit Pro, you need to install and activate it first. Here are the steps to do so:
-Downloading the Plugin
-You can download 1001bit Pro from the official website: https://www.1001bit.com/pro/download.html. There are two formats available: rbz and zip. We recommend you use the rbz format as it is easier to install. The current version is 2.2 which fixes some crashing issues with Sketchup 2014.
-Installing the Plugin
-To install 1001bit Pro using the rbz format, follow these steps:
-
-- Open Sketchup and go to Window > Preferences > Extensions.
-- Click on Install Extension and browse to the rbz file that you downloaded.
-- Select the file and click OK.
-- A message will appear asking you to confirm the installation. Click Yes.
-- A message will appear saying that the plugin has been installed successfully. Click OK.
-- Restart Sketchup to activate the plugin.
-
-To install 1001bit Pro using the zip format, follow these steps:
-
-- Extract the zip file that you downloaded to a folder on your computer.
-- Copy all the files in the folder to your Sketchup plugins folder. The location of this folder depends on your Sketchup version and operating system. For example, for Sketchup 2014 on Windows, it is C:\Users\YourName\AppData\Roaming\SketchUp\SketchUp 2014\SketchUp\Plugins.
-- Restart Sketchup to activate the plugin.
-Activating the Plugin
-To activate 1001bit Pro, you need to obtain a user license. You can try out the plugin for free for 30 days. If you wish to continue using it beyond the trial period, you need to buy the license for only USD 48.00. You can also upgrade from 1001bit Standard or 1001bit Pro v1 with a discount. Users who registered for 1001bit Pro v1 on and after 1st January 2012 can upgrade for free.
-To activate 1001bit Pro, follow these steps:
-
-- Go to the official website: https://www.1001bit.com/pro/purchase.html and click on Buy Now.
-- Fill in your details and make the payment via PayPal or credit card.
-- You will receive an email with your activation key and instructions.
-- Open Sketchup and go to Plugins > 1001bit Pro > Activate 1001bit Pro.
-- Enter your activation key and click OK.
-- A message will appear saying that the plugin has been activated successfully. Click OK.
-- You can now use all the features of 1001bit Pro without any limitations.
-
-How to Use 1001bit Pro
-Now that you have installed and activated 1001bit Pro, you can start using it to create amazing architectural models in Sketchup. Here are some tips on how to use it:
-Accessing the Plugin Menu
-You can access the plugin menu by going to Plugins > 1001bit Pro. You will see a list of tools grouped into categories such as Architectural Tools, Editing Tools, etc. You can also access the plugin menu by clicking on the toolbar icon that looks like a blue house with a red roof.
-Selecting and Applying Tools
-To select a tool, you can either click on its name in the menu or its icon in the toolbar. A dialog box will appear with the parameters and options for that tool. You can also see a preview of the tool in action in the Sketchup window. To apply a tool, you need to follow the instructions in the dialog box and select the appropriate entities in your model. For example, to create a staircase, you need to select two points for the base and one point for the height.
-Adjusting Parameters and Options
-To adjust the parameters and options of a tool, you can use the sliders, text boxes, drop-down menus, check boxes, and buttons in the dialog box. You can also type in values directly or use mathematical expressions. You can see the changes in real time in the Sketchup window. To confirm your settings, click OK or Apply. To cancel your settings, click Cancel or Escape.
-Saving and Loading Parameters
-To save the parameters of a tool, click on Save Parameters in the dialog box. A file browser will appear where you can choose a location and name for your parameter file. The file will have a .txt extension. To load the parameters of a tool, click on Load Parameters in the dialog box. A file browser will appear where you can choose a parameter file that you have saved before. The parameters will be applied to the tool automatically.
- # Conclusion In this article, we have reviewed 1001bit Pro 2.2 Plugin for Sketchup, a collection of plugins that can help you create architectural models faster and easier. We have covered its features, benefits, installation, activation, and usage. We hope that this article has given you a clear overview of what this plugin can do and how it can enhance your modeling experience and output.
-If you are interested in trying out 1001bit Pro, you can download it from https://www.1001bit.com/pro/download.html and use it for free for 30 days. If you like it and want to continue using it beyond the trial period, you can buy a user license for only USD 48.00 from https://www.1001bit.com/pro/purchase.html. You can also upgrade from 1001bit Standard or 1001bit Pro v1 with a discount or for free if you qualify.
-We highly recommend you to give 1001bit Pro a try and see how it can transform your architectural modeling in Sketchup. You will be amazed by how much more you can achieve while doing less with this plugin.
- # FAQs Here are some common questions and answers about 1001bit Pro:
-
-- What are the system requirements for 1001bit Pro?
-1001bit Pro works with Sketchup 8 and later versions on both Windows and Mac operating systems. It requires an internet connection for activation and updates.
- - How many computers can I activate 1001bit Pro on?
-Each user license allows for activating 1001bit Pro on two separate computers.
- - How do I update 1001bit Pro?
-You can update 1001bit Pro by downloading and installing the latest version from https://www.1001bit.com/pro/download.html. You don't need to reactivate it after updating.
- - How do I get support for 1001bit Pro?
-You can get support for 1001bit Pro by visiting the official website: https://www.1001bit.com/pro/. There you can find user guides, tutorials, videos, forums, contacts, and more.
- - How do I uninstall 1001bit Pro?
-To uninstall 1001bit Pro, you need to delete all the files related to it from your Sketchup plugins folder. The location of this folder depends on your Sketchup version and operating system. For example, for Sketchup 2014 on Windows, it is C:\Users\YourName\AppData\Roaming\SketchUp\SketchUp 2014\SketchUp\Plugins.
-
- 0a6ba089eb
-
-
\ No newline at end of file
diff --git a/spaces/raedeXanto/academic-chatgpt-beta/Endhiran Full Movie Free Download in Tamil HD 1080p Dont Miss the Chance to See the Epic Adventure of Chitti.md b/spaces/raedeXanto/academic-chatgpt-beta/Endhiran Full Movie Free Download in Tamil HD 1080p Dont Miss the Chance to See the Epic Adventure of Chitti.md
deleted file mode 100644
index 3198919da0f9016135fcc3da1ec6ced98939850f..0000000000000000000000000000000000000000
--- a/spaces/raedeXanto/academic-chatgpt-beta/Endhiran Full Movie Free Download in Tamil HD 1080p Dont Miss the Chance to See the Epic Adventure of Chitti.md
+++ /dev/null
@@ -1,127 +0,0 @@
-
-Endhiran Full Movie Free Download in Tamil HD 1080p
-If you are a fan of Tamil cinema, you must have heard of Endhiran, one of the most successful and expensive movies ever made in India. This sci-fi action thriller, starring Rajinikanth and Aishwarya Rai Bachchan, was released in 2010 and broke many box office records. It also received critical acclaim for its innovative story, stunning visuals, and catchy music.
-But what if you missed watching this epic movie on the big screen? Or what if you want to watch it again at your own pace and comfort? Well, you are in luck because in this article, we will tell you how to download Endhiran full movie in Tamil HD 1080p for free. We will also tell you about the features, benefits, and risks of downloading this movie from various sources. So, read on and enjoy!
-endhiran full movie free download in tamil hd 1080p
Download File ✸✸✸ https://tinourl.com/2uL3m8
- Introduction
-What is Endhiran?
-Endhiran (also known as Robot in Hindi and Telugu) is a 2010 Indian Tamil-language science fiction action film directed by S. Shankar. It is the first installment of the Enthiran franchise, which also includes its sequel 2.0 (2018) and its upcoming third part 3.0 (2022). The film was produced by Sun Pictures with a budget of ₹1.32 billion (US$18 million), making it the most expensive Indian film at that time.
-Why is Endhiran popular?
-Endhiran is popular for many reasons. Some of them are:
-
-- It features Rajinikanth in a dual role as Dr. Vaseegaran, a brilliant scientist who creates a humanoid robot named Chitti, and as Chitti himself, who develops emotions and falls in love with Vaseegaran's girlfriend Sana (played by Aishwarya Rai Bachchan).
-- It showcases the clash between Chitti and his evil counterpart, Chitti 2.0, who is reprogrammed by Vaseegaran's rival Dr. Bohra (played by Danny Denzongpa) to cause destruction and chaos.
-- It has spectacular action sequences, such as the chase scene on a train, the battle between Chitti and an army of robots, and the climax where Chitti transforms into a giant snake-like creature.
-- It has amazing visual effects that were done by a team of over 1,000 technicians from India and abroad. The film won two National Film Awards for Best Special Effects and Best Production Design.
-- It has a memorable soundtrack composed by A.R. Rahman, who also won two National Film Awards for Best Music Direction and Best Background Score. The songs include "Irumbile Oru Irudhaiyam", "Kilimanjaro", "Pudhiya Manidha", and "Arima Arima".
-
-How to watch Endhiran online?
-If you want to watch Endhiran online, you have two options: streaming or downloading. Streaming means watching the movie online without saving it on your device. Downloading means saving the movie file on your device so that you can watch it offline later.
-To stream Endhiran online, you can use any of the legal platforms that have the rights to show the movie. Some of them are:
-
-| Platform | Subscription fee |
-| Amazon Prime Video | ₹999/year or ₹129/month |
-| Netflix | ₹199-₹799/month |
-| Sun NXT | ₹50-₹480/year |
-| Zee5 | ₹99-₹999/year |
-| Eros Now | ₹49-₹399/year |
-
-To download Endhiran full movie in Tamil HD 1080p for free, you can use any of the illegal sources that offer pirated copies of the movie. Some of them are:
-
-| Source | Type |
-| TamilYogi.io | Torrent website |
-| Isaimini.store | Torrent website |
-| Archive.org | Digital library website |
-| Tealfeed.com | Blogging website |
-| Tamilrockers.ws | Torrent website |
-
- Features of Endhiran
-Star cast and crew
-The star cast of Endhiran includes some of the most popular actors in Indian cinema. Here are some of them:
-
-- Rajinikanth as Dr. Vaseegaran/Chitti/Chitti 2.0: Rajinikanth is one of the most influential and highest-paid actors in India. He has appeared in over 160 films across various languages and genres. He is known for his charismatic screen presence, unique style, and dialogue delivery.
-- Aishwarya Rai Bachchan as Sana: Aishwarya Rai Bachchan is one of the most beautiful and talented actresses in India. She has won several awards, including two Filmfare Awards and a Padma Shri. She has also represented India at international platforms such as Miss World 1994 (where she won), Cannes Film Festival, UNAIDS, etc.
-- Danny Denzongpa as Dr. Bohra: Danny Denzongpa is one of the most versatile and respected actors in India. He has played various roles ranging from villains to heroes to supporting characters. He has won several awards, including three Filmfare Awards and a Padma Shri.
-- Karunas as Ravi: Karunas is a comedian and actor who has appeared in over 100 films in Tamil cinema. He is known for his comic timing and expressions.
-- Santhanam as Siva: Santhanam is another comedian and actor who has appeared in over 100 films in Tamil cinema. He is known for his witty dialogues and hilarious antics.
-- Kalabhavan Mani as Pachaimuthu: Kalabhavan Mani was a Malayalam actor who also acted in Tamil films. He was known for his versatile roles as a comedian, villain, hero, etc.
- The crew of Endhiran includes some of the most talented technicians in Indian cinema. Here are some of them:
-
- - S. Shankar as director: S. Shankar is one of the most successful and acclaimed directors in India. He is known for his grand-scale movies that combine social messages with entertainment value.
- - A.R. Rahman as music director: A.R. Rahman is one of the most celebrated music composers in India and abroad. He has won numerous awards, including six National Film Awards, two Academy Awards, two Grammy Awards, etc.
- - Vairamuthu as lyricist: Vairamuthu is one of the most renowned lyricists in Tamil cinema. He has won seven National Film Awards for Best Lyrics.
- - Rathnavelu as cinematographer: Rathnavelu is one of the most sought-after cinematographers in India. He has worked on several blockbuster movies such as Robo (Telugu version of Enthiran), Rangasthalam I have continued writing the article based on the outline. Here is the rest of the article with HTML formatting. ```html
Benefits of downloading Endhiran in HD quality
-Enjoy the movie at your convenience
-One of the main benefits of downloading Endhiran full movie in Tamil HD 1080p for free is that you can enjoy the movie at your convenience. You can watch it anytime, anywhere, and as many times as you want. You don't have to worry about missing any scene or dialogue due to network issues or buffering. You can also pause, rewind, fast-forward, or skip any part of the movie as per your preference.
-Enthiran Tamil movie watch online free HD
-Enthiran The Robot 2010 720p BDRip download
-Enthiran songs mp3 download A.R. Rahman
-Enthiran Kilimanjaro song lyrics and video
-Enthiran movie review and rating
-Enthiran full movie in Hindi dubbed download
-Enthiran 2.0 sequel release date and cast
-Enthiran movie scenes and dialogues
-Enthiran movie trivia and facts
-Enthiran movie awards and nominations
-Enthiran movie box office collection and budget
-Enthiran movie making and behind the scenes
-Enthiran movie poster and wallpapers
-Enthiran movie memes and jokes
-Enthiran movie fan art and cosplay
-Enthiran movie quotes and status
-Enthiran movie tickets and showtimes
-Enthiran movie merchandise and gifts
-Enthiran movie cast and crew interviews
-Enthiran movie Rajinikanth best moments
-Enthiran movie Aishwarya Rai Bachchan best moments
-Enthiran movie robot Chitti best moments
-Enthiran movie villain Bohra best moments
-Enthiran movie climax fight scene HD
-Enthiran movie robot army scene HD
-Enthiran movie train fight scene HD
-Enthiran movie helicopter chase scene HD
-Enthiran movie fire song scene HD
-Enthiran movie Pudhiya Manidha song scene HD
-Enthiran movie Irumbile Oru Irudhaiyam song scene HD
-How to download Enthiran full movie in Tamil HD 1080p for free
-Where to watch Enthiran full movie in Tamil HD 1080p online for free
-Is it legal to download or stream Enthiran full movie in Tamil HD 1080p for free
-How to avoid malware or virus when downloading or streaming Enthiran full movie in Tamil HD 1080p for free
-What are the best websites to download or stream Enthiran full movie in Tamil HD 1080p for free
-What are the best apps to download or stream Enthiran full movie in Tamil HD 1080p for free
-What are the best VPNs to download or stream Enthiran full movie in Tamil HD 1080p for free
-What are the best torrent sites to download or stream Enthiran full movie in Tamil HD 1080p for free
-What are the best proxy sites to download or stream Enthiran full movie in Tamil HD 1080p for free
-What are the best alternatives to download or stream Enthiran full movie in Tamil HD 1080p for free
-Save money and time
-Another benefit of downloading Endhiran full movie in Tamil HD 1080p for free is that you can save money and time. You don't have to spend money on buying tickets, popcorn, or parking fees to watch the movie in a theater. You also don't have to waste time on traveling, standing in queues, or waiting for ads to finish. You can simply download the movie file once and watch it on your device without any hassle.
-Avoid ads and interruptions
-A third benefit of downloading Endhiran full movie in Tamil HD 1080p for free is that you can avoid ads and interruptions. You don't have to endure annoying ads that pop up before, during, or after the movie. You also don't have to deal with other interruptions such as phone calls, messages, notifications, or people talking around you. You can watch the movie in peace and immerse yourself in the story.
- Risks of downloading Endhiran from illegal sources
-Legal issues and penalties
-One of the major risks of downloading Endhiran full movie in Tamil HD 1080p for free from illegal sources is that you may face legal issues and penalties. Downloading pirated movies is a crime in India and many other countries. It violates the copyright laws and harms the interests of the filmmakers and distributors. If you are caught downloading or sharing pirated movies, you may face fines, imprisonment, or both.
-Malware and viruses
-Another risk of downloading Endhiran full movie in Tamil HD 1080p for free from illegal sources is that you may expose your device to malware and viruses. Illegal sources often contain malicious software that can infect your device and compromise its security. Malware and viruses can steal your personal data, damage your files, slow down your performance, or even lock your device until you pay a ransom.
-Poor quality and fake files
-A third risk of downloading Endhiran full movie in Tamil HD 1080p for free from illegal sources is that you may get poor quality and fake files. Illegal sources often provide low-quality files that have poor resolution, audio, or subtitles. They may also provide fake files that are corrupted, incomplete, or different from what they claim to be. You may end up wasting your time and bandwidth on downloading useless files.
- Conclusion
-Summary of the main points
-In conclusion, Endhiran is a blockbuster Tamil movie that features Rajinikanth and Aishwarya Rai Bachchan in a sci-fi action thriller. The movie has many features such as star cast and crew, plot and theme, visual effects and music that make it popular among the audience. If you want to watch Endhiran online, you can either stream it on legal platforms or download it from illegal sources. However, downloading Endhiran full movie in Tamil HD 1080p for free has many benefits such as convenience, saving money and time, and avoiding ads and interruptions. It also has many risks such as legal issues and penalties, malware and viruses, and poor quality and fake files.
-Call to action
-Therefore, we recommend that you watch Endhiran online legally and safely by subscribing to any of the platforms mentioned above. You can enjoy the movie in high quality without any trouble or guilt. You can also support the filmmakers and encourage them to make more such movies in the future.
-FAQs
-
-- Q: When was Endhiran released?
-- A: Endhiran was released on 1 October 2010.
-- Q: Who directed Endhiran?
-- A: S. Shankar directed Endhiran.
-- Q: Who composed the music for Endhiran?
-- A: A.R. Rahman composed the music for Endhiran.
-- Q: How many awards did Endhiran win?
-- A: Endhiran won four National Film Awards, three Filmfare Awards South, two Vijay Awards, two SIIMA Awards, and one Kalaimamani Award.
-- Q: Is there a sequel to Endhiran?
-- A: Yes, there is a sequel to Endhiran called 2.0 (2018), which also stars Rajinikanth along with Akshay Kumar and Amy Jackson.
-
- 0a6ba089eb
-
-
\ No newline at end of file
diff --git a/spaces/rayan-saleh/whisper2notion/server/node_modules/@types/node/ts4.8/querystring.d.ts b/spaces/rayan-saleh/whisper2notion/server/node_modules/@types/node/ts4.8/querystring.d.ts
deleted file mode 100644
index e1185478461f4b15444b7b2ae114c8a6819a992a..0000000000000000000000000000000000000000
--- a/spaces/rayan-saleh/whisper2notion/server/node_modules/@types/node/ts4.8/querystring.d.ts
+++ /dev/null
@@ -1,131 +0,0 @@
-/**
- * The `querystring` module provides utilities for parsing and formatting URL
- * query strings. It can be accessed using:
- *
- * ```js
- * const querystring = require('querystring');
- * ```
- *
- * `querystring` is more performant than `URLSearchParams` but is not a
- * standardized API. Use `URLSearchParams` when performance is not critical
- * or when compatibility with browser code is desirable.
- * @see [source](https://github.com/nodejs/node/blob/v18.0.0/lib/querystring.js)
- */
-declare module 'querystring' {
- interface StringifyOptions {
- encodeURIComponent?: ((str: string) => string) | undefined;
- }
- interface ParseOptions {
- maxKeys?: number | undefined;
- decodeURIComponent?: ((str: string) => string) | undefined;
- }
- interface ParsedUrlQuery extends NodeJS.Dict {}
- interface ParsedUrlQueryInput extends NodeJS.Dict | ReadonlyArray | ReadonlyArray | null> {}
- /**
- * The `querystring.stringify()` method produces a URL query string from a
- * given `obj` by iterating through the object's "own properties".
- *
- * It serializes the following types of values passed in `obj`:[string](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures#String_type) |
- * [number](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures#Number_type) |
- * [bigint](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/BigInt) |
- * [boolean](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures#Boolean_type) |
- * [string\[\]](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures#String_type) |
- * [number\[\]](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures#Number_type) |
- * [bigint\[\]](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/BigInt) |
- * [boolean\[\]](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Data_structures#Boolean_type) The numeric values must be finite. Any other input values will be coerced to
- * empty strings.
- *
- * ```js
- * querystring.stringify({ foo: 'bar', baz: ['qux', 'quux'], corge: '' });
- * // Returns 'foo=bar&baz=qux&baz=quux&corge='
- *
- * querystring.stringify({ foo: 'bar', baz: 'qux' }, ';', ':');
- * // Returns 'foo:bar;baz:qux'
- * ```
- *
- * By default, characters requiring percent-encoding within the query string will
- * be encoded as UTF-8\. If an alternative encoding is required, then an alternative`encodeURIComponent` option will need to be specified:
- *
- * ```js
- * // Assuming gbkEncodeURIComponent function already exists,
- *
- * querystring.stringify({ w: '中文', foo: 'bar' }, null, null,
- * { encodeURIComponent: gbkEncodeURIComponent });
- * ```
- * @since v0.1.25
- * @param obj The object to serialize into a URL query string
- * @param [sep='&'] The substring used to delimit key and value pairs in the query string.
- * @param [eq='='] . The substring used to delimit keys and values in the query string.
- */
- function stringify(obj?: ParsedUrlQueryInput, sep?: string, eq?: string, options?: StringifyOptions): string;
- /**
- * The `querystring.parse()` method parses a URL query string (`str`) into a
- * collection of key and value pairs.
- *
- * For example, the query string `'foo=bar&abc=xyz&abc=123'` is parsed into:
- *
- * ```js
- * {
- * foo: 'bar',
- * abc: ['xyz', '123']
- * }
- * ```
- *
- * The object returned by the `querystring.parse()` method _does not_prototypically inherit from the JavaScript `Object`. This means that typical`Object` methods such as `obj.toString()`,
- * `obj.hasOwnProperty()`, and others
- * are not defined and _will not work_.
- *
- * By default, percent-encoded characters within the query string will be assumed
- * to use UTF-8 encoding. If an alternative character encoding is used, then an
- * alternative `decodeURIComponent` option will need to be specified:
- *
- * ```js
- * // Assuming gbkDecodeURIComponent function already exists...
- *
- * querystring.parse('w=%D6%D0%CE%C4&foo=bar', null, null,
- * { decodeURIComponent: gbkDecodeURIComponent });
- * ```
- * @since v0.1.25
- * @param str The URL query string to parse
- * @param [sep='&'] The substring used to delimit key and value pairs in the query string.
- * @param [eq='='] . The substring used to delimit keys and values in the query string.
- */
- function parse(str: string, sep?: string, eq?: string, options?: ParseOptions): ParsedUrlQuery;
- /**
- * The querystring.encode() function is an alias for querystring.stringify().
- */
- const encode: typeof stringify;
- /**
- * The querystring.decode() function is an alias for querystring.parse().
- */
- const decode: typeof parse;
- /**
- * The `querystring.escape()` method performs URL percent-encoding on the given`str` in a manner that is optimized for the specific requirements of URL
- * query strings.
- *
- * The `querystring.escape()` method is used by `querystring.stringify()` and is
- * generally not expected to be used directly. It is exported primarily to allow
- * application code to provide a replacement percent-encoding implementation if
- * necessary by assigning `querystring.escape` to an alternative function.
- * @since v0.1.25
- */
- function escape(str: string): string;
- /**
- * The `querystring.unescape()` method performs decoding of URL percent-encoded
- * characters on the given `str`.
- *
- * The `querystring.unescape()` method is used by `querystring.parse()` and is
- * generally not expected to be used directly. It is exported primarily to allow
- * application code to provide a replacement decoding implementation if
- * necessary by assigning `querystring.unescape` to an alternative function.
- *
- * By default, the `querystring.unescape()` method will attempt to use the
- * JavaScript built-in `decodeURIComponent()` method to decode. If that fails,
- * a safer equivalent that does not throw on malformed URLs will be used.
- * @since v0.1.25
- */
- function unescape(str: string): string;
-}
-declare module 'node:querystring' {
- export * from 'querystring';
-}
diff --git a/spaces/rayan-saleh/whisper2notion/server/node_modules/content-disposition/index.js b/spaces/rayan-saleh/whisper2notion/server/node_modules/content-disposition/index.js
deleted file mode 100644
index ecec899a992d46f2e903a87475b1c342f2ce4d30..0000000000000000000000000000000000000000
--- a/spaces/rayan-saleh/whisper2notion/server/node_modules/content-disposition/index.js
+++ /dev/null
@@ -1,458 +0,0 @@
-/*!
- * content-disposition
- * Copyright(c) 2014-2017 Douglas Christopher Wilson
- * MIT Licensed
- */
-
-'use strict'
-
-/**
- * Module exports.
- * @public
- */
-
-module.exports = contentDisposition
-module.exports.parse = parse
-
-/**
- * Module dependencies.
- * @private
- */
-
-var basename = require('path').basename
-var Buffer = require('safe-buffer').Buffer
-
-/**
- * RegExp to match non attr-char, *after* encodeURIComponent (i.e. not including "%")
- * @private
- */
-
-var ENCODE_URL_ATTR_CHAR_REGEXP = /[\x00-\x20"'()*,/:;<=>?@[\\\]{}\x7f]/g // eslint-disable-line no-control-regex
-
-/**
- * RegExp to match percent encoding escape.
- * @private
- */
-
-var HEX_ESCAPE_REGEXP = /%[0-9A-Fa-f]{2}/
-var HEX_ESCAPE_REPLACE_REGEXP = /%([0-9A-Fa-f]{2})/g
-
-/**
- * RegExp to match non-latin1 characters.
- * @private
- */
-
-var NON_LATIN1_REGEXP = /[^\x20-\x7e\xa0-\xff]/g
-
-/**
- * RegExp to match quoted-pair in RFC 2616
- *
- * quoted-pair = "\" CHAR
- * CHAR =
- * @private
- */
-
-var QESC_REGEXP = /\\([\u0000-\u007f])/g // eslint-disable-line no-control-regex
-
-/**
- * RegExp to match chars that must be quoted-pair in RFC 2616
- * @private
- */
-
-var QUOTE_REGEXP = /([\\"])/g
-
-/**
- * RegExp for various RFC 2616 grammar
- *
- * parameter = token "=" ( token | quoted-string )
- * token = 1*
- * separators = "(" | ")" | "<" | ">" | "@"
- * | "," | ";" | ":" | "\" | <">
- * | "/" | "[" | "]" | "?" | "="
- * | "{" | "}" | SP | HT
- * quoted-string = ( <"> *(qdtext | quoted-pair ) <"> )
- * qdtext = >
- * quoted-pair = "\" CHAR
- * CHAR =
- * TEXT =
- * LWS = [CRLF] 1*( SP | HT )
- * CRLF = CR LF
- * CR =
- * LF =
- * SP =
- * HT =
- * CTL =
- * OCTET =
- * @private
- */
-
-var PARAM_REGEXP = /;[\x09\x20]*([!#$%&'*+.0-9A-Z^_`a-z|~-]+)[\x09\x20]*=[\x09\x20]*("(?:[\x20!\x23-\x5b\x5d-\x7e\x80-\xff]|\\[\x20-\x7e])*"|[!#$%&'*+.0-9A-Z^_`a-z|~-]+)[\x09\x20]*/g // eslint-disable-line no-control-regex
-var TEXT_REGEXP = /^[\x20-\x7e\x80-\xff]+$/
-var TOKEN_REGEXP = /^[!#$%&'*+.0-9A-Z^_`a-z|~-]+$/
-
-/**
- * RegExp for various RFC 5987 grammar
- *
- * ext-value = charset "'" [ language ] "'" value-chars
- * charset = "UTF-8" / "ISO-8859-1" / mime-charset
- * mime-charset = 1*mime-charsetc
- * mime-charsetc = ALPHA / DIGIT
- * / "!" / "#" / "$" / "%" / "&"
- * / "+" / "-" / "^" / "_" / "`"
- * / "{" / "}" / "~"
- * language = ( 2*3ALPHA [ extlang ] )
- * / 4ALPHA
- * / 5*8ALPHA
- * extlang = *3( "-" 3ALPHA )
- * value-chars = *( pct-encoded / attr-char )
- * pct-encoded = "%" HEXDIG HEXDIG
- * attr-char = ALPHA / DIGIT
- * / "!" / "#" / "$" / "&" / "+" / "-" / "."
- * / "^" / "_" / "`" / "|" / "~"
- * @private
- */
-
-var EXT_VALUE_REGEXP = /^([A-Za-z0-9!#$%&+\-^_`{}~]+)'(?:[A-Za-z]{2,3}(?:-[A-Za-z]{3}){0,3}|[A-Za-z]{4,8}|)'((?:%[0-9A-Fa-f]{2}|[A-Za-z0-9!#$&+.^_`|~-])+)$/
-
-/**
- * RegExp for various RFC 6266 grammar
- *
- * disposition-type = "inline" | "attachment" | disp-ext-type
- * disp-ext-type = token
- * disposition-parm = filename-parm | disp-ext-parm
- * filename-parm = "filename" "=" value
- * | "filename*" "=" ext-value
- * disp-ext-parm = token "=" value
- * | ext-token "=" ext-value
- * ext-token =
- * @private
- */
-
-var DISPOSITION_TYPE_REGEXP = /^([!#$%&'*+.0-9A-Z^_`a-z|~-]+)[\x09\x20]*(?:$|;)/ // eslint-disable-line no-control-regex
-
-/**
- * Create an attachment Content-Disposition header.
- *
- * @param {string} [filename]
- * @param {object} [options]
- * @param {string} [options.type=attachment]
- * @param {string|boolean} [options.fallback=true]
- * @return {string}
- * @public
- */
-
-function contentDisposition (filename, options) {
- var opts = options || {}
-
- // get type
- var type = opts.type || 'attachment'
-
- // get parameters
- var params = createparams(filename, opts.fallback)
-
- // format into string
- return format(new ContentDisposition(type, params))
-}
-
-/**
- * Create parameters object from filename and fallback.
- *
- * @param {string} [filename]
- * @param {string|boolean} [fallback=true]
- * @return {object}
- * @private
- */
-
-function createparams (filename, fallback) {
- if (filename === undefined) {
- return
- }
-
- var params = {}
-
- if (typeof filename !== 'string') {
- throw new TypeError('filename must be a string')
- }
-
- // fallback defaults to true
- if (fallback === undefined) {
- fallback = true
- }
-
- if (typeof fallback !== 'string' && typeof fallback !== 'boolean') {
- throw new TypeError('fallback must be a string or boolean')
- }
-
- if (typeof fallback === 'string' && NON_LATIN1_REGEXP.test(fallback)) {
- throw new TypeError('fallback must be ISO-8859-1 string')
- }
-
- // restrict to file base name
- var name = basename(filename)
-
- // determine if name is suitable for quoted string
- var isQuotedString = TEXT_REGEXP.test(name)
-
- // generate fallback name
- var fallbackName = typeof fallback !== 'string'
- ? fallback && getlatin1(name)
- : basename(fallback)
- var hasFallback = typeof fallbackName === 'string' && fallbackName !== name
-
- // set extended filename parameter
- if (hasFallback || !isQuotedString || HEX_ESCAPE_REGEXP.test(name)) {
- params['filename*'] = name
- }
-
- // set filename parameter
- if (isQuotedString || hasFallback) {
- params.filename = hasFallback
- ? fallbackName
- : name
- }
-
- return params
-}
-
-/**
- * Format object to Content-Disposition header.
- *
- * @param {object} obj
- * @param {string} obj.type
- * @param {object} [obj.parameters]
- * @return {string}
- * @private
- */
-
-function format (obj) {
- var parameters = obj.parameters
- var type = obj.type
-
- if (!type || typeof type !== 'string' || !TOKEN_REGEXP.test(type)) {
- throw new TypeError('invalid type')
- }
-
- // start with normalized type
- var string = String(type).toLowerCase()
-
- // append parameters
- if (parameters && typeof parameters === 'object') {
- var param
- var params = Object.keys(parameters).sort()
-
- for (var i = 0; i < params.length; i++) {
- param = params[i]
-
- var val = param.substr(-1) === '*'
- ? ustring(parameters[param])
- : qstring(parameters[param])
-
- string += '; ' + param + '=' + val
- }
- }
-
- return string
-}
-
-/**
- * Decode a RFC 5987 field value (gracefully).
- *
- * @param {string} str
- * @return {string}
- * @private
- */
-
-function decodefield (str) {
- var match = EXT_VALUE_REGEXP.exec(str)
-
- if (!match) {
- throw new TypeError('invalid extended field value')
- }
-
- var charset = match[1].toLowerCase()
- var encoded = match[2]
- var value
-
- // to binary string
- var binary = encoded.replace(HEX_ESCAPE_REPLACE_REGEXP, pdecode)
-
- switch (charset) {
- case 'iso-8859-1':
- value = getlatin1(binary)
- break
- case 'utf-8':
- value = Buffer.from(binary, 'binary').toString('utf8')
- break
- default:
- throw new TypeError('unsupported charset in extended field')
- }
-
- return value
-}
-
-/**
- * Get ISO-8859-1 version of string.
- *
- * @param {string} val
- * @return {string}
- * @private
- */
-
-function getlatin1 (val) {
- // simple Unicode -> ISO-8859-1 transformation
- return String(val).replace(NON_LATIN1_REGEXP, '?')
-}
-
-/**
- * Parse Content-Disposition header string.
- *
- * @param {string} string
- * @return {object}
- * @public
- */
-
-function parse (string) {
- if (!string || typeof string !== 'string') {
- throw new TypeError('argument string is required')
- }
-
- var match = DISPOSITION_TYPE_REGEXP.exec(string)
-
- if (!match) {
- throw new TypeError('invalid type format')
- }
-
- // normalize type
- var index = match[0].length
- var type = match[1].toLowerCase()
-
- var key
- var names = []
- var params = {}
- var value
-
- // calculate index to start at
- index = PARAM_REGEXP.lastIndex = match[0].substr(-1) === ';'
- ? index - 1
- : index
-
- // match parameters
- while ((match = PARAM_REGEXP.exec(string))) {
- if (match.index !== index) {
- throw new TypeError('invalid parameter format')
- }
-
- index += match[0].length
- key = match[1].toLowerCase()
- value = match[2]
-
- if (names.indexOf(key) !== -1) {
- throw new TypeError('invalid duplicate parameter')
- }
-
- names.push(key)
-
- if (key.indexOf('*') + 1 === key.length) {
- // decode extended value
- key = key.slice(0, -1)
- value = decodefield(value)
-
- // overwrite existing value
- params[key] = value
- continue
- }
-
- if (typeof params[key] === 'string') {
- continue
- }
-
- if (value[0] === '"') {
- // remove quotes and escapes
- value = value
- .substr(1, value.length - 2)
- .replace(QESC_REGEXP, '$1')
- }
-
- params[key] = value
- }
-
- if (index !== -1 && index !== string.length) {
- throw new TypeError('invalid parameter format')
- }
-
- return new ContentDisposition(type, params)
-}
-
-/**
- * Percent decode a single character.
- *
- * @param {string} str
- * @param {string} hex
- * @return {string}
- * @private
- */
-
-function pdecode (str, hex) {
- return String.fromCharCode(parseInt(hex, 16))
-}
-
-/**
- * Percent encode a single character.
- *
- * @param {string} char
- * @return {string}
- * @private
- */
-
-function pencode (char) {
- return '%' + String(char)
- .charCodeAt(0)
- .toString(16)
- .toUpperCase()
-}
-
-/**
- * Quote a string for HTTP.
- *
- * @param {string} val
- * @return {string}
- * @private
- */
-
-function qstring (val) {
- var str = String(val)
-
- return '"' + str.replace(QUOTE_REGEXP, '\\$1') + '"'
-}
-
-/**
- * Encode a Unicode string for HTTP (RFC 5987).
- *
- * @param {string} val
- * @return {string}
- * @private
- */
-
-function ustring (val) {
- var str = String(val)
-
- // percent encode as UTF-8
- var encoded = encodeURIComponent(str)
- .replace(ENCODE_URL_ATTR_CHAR_REGEXP, pencode)
-
- return 'UTF-8\'\'' + encoded
-}
-
-/**
- * Class for parsed Content-Disposition header for v8 optimization
- *
- * @public
- * @param {string} type
- * @param {object} parameters
- * @constructor
- */
-
-function ContentDisposition (type, parameters) {
- this.type = type
- this.parameters = parameters
-}
diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Aim High Level 4 Teachers Book Free 15 ((NEW)).md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Aim High Level 4 Teachers Book Free 15 ((NEW)).md
deleted file mode 100644
index 7f8defb302fb5211adafa4c58895ecd1ea651665..0000000000000000000000000000000000000000
--- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Aim High Level 4 Teachers Book Free 15 ((NEW)).md
+++ /dev/null
@@ -1,6 +0,0 @@
-
-Many studies have shown that teachers are the greatest single influence on students' academic achievement. [11] Teachers can have a powerful influence on student learning by shaping the climate or culture of their classrooms, providing helpful and helpful feedback, and empowering students to take risks, to think more deeply and creatively, and to try new strategies. Teachers can produce not only high-quality or high-productivity learners, but also average-quality or low-productivity learners. [12] Students' achievement depends not only on whether they have the right teachers and the right amount of individual tutoring and practice, but also on what their peers, and the schools and teachers of their peers, are like. On average, students are more likely to perform well in settings with high achievement norms and high expectations. On the other hand, students tend to perform poorly in settings with low achievement norms and low expectations. [13] Individual teachers have considerable effect on students' performance, particularly on their progress toward college, the labor market, and other social institutions.
-Aim High Level 4 Teachers Book Free 15
Download Zip ✶ https://urlgoal.com/2uCK6A
-Key factors contributing to the problem of poor average academic performance include the lack of academic expectations among students, a lack of academic accountability among teachers, and a lack of active instructional programs in schools. Another factor is a lack of adequacy of school funding. Public schools and colleges, which are free of charge and funded with tax dollars, are often underfunded in an unequal fashion. The United States spends more on public schools than other OECD countries, and yet it consistently ranks at the bottom of the list when it comes to student achievement.
899543212b
-
-
\ No newline at end of file
diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Comprender Al Ave De Presa Nick Fox Pdf _VERIFIED_.md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Comprender Al Ave De Presa Nick Fox Pdf _VERIFIED_.md
deleted file mode 100644
index 51453e5dec7900117098d0c7b48fcaa2e79e0cd4..0000000000000000000000000000000000000000
--- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Comprender Al Ave De Presa Nick Fox Pdf _VERIFIED_.md
+++ /dev/null
@@ -1,60 +0,0 @@
-Comprender Al Ave De Presa Nick Fox Pdf
Download Zip ✅ https://urlgoal.com/2uCLCU
-
-n Apache_Comserver.n Comconn .n LAMC_Comserver.n Comconn .n Comconn_to_TCPIP.n LAMC_Comserver_To_TCPIP.n
-
-The main difference between two is that, TDS COMCONN is able to control the Compress, and others are only able to unpack or pack on demand.I tried googling for a solution but had no luck. As i am a beginner in C++, I would be really grateful if anyone could help me out.
-
-A:
-
-The problem was that I was reading the header line by line. To solve this, I would simply read the complete header line, if it was valid. Then I would read the line again, if it was a valid message.
-
-C++ code I used, for anyone who might be interested.
-
-std::ifstream infile;
-
-infile.open("Message.dat", std::ifstream::in);
-
-std::string header_line;
-
-std::string::size_type i = 0;
-
-while (std::getline(infile, header_line))
-
- if (header_line[i] =='' && header_line[i+1]!= '*')
-
- break;
-
- i++;
-
-
-
-std::string message;
-
-infile.seekg(0, std::ios::beg);
-
-while (std::getline(infile, message)) {
-
- //determine how long the file is, in bytes
-
- std::size_t pos_in = infile.tellg();
-
- std::size_t pos_in2 = infile.tellg();
-
- //get the beginning position of the message
-
- infile.seekg(pos_in2);
-
- std::string temp;
-
- while (std::getline(infile, temp))
-
- //determine how long the file is, in bytes
-
- std::size_t pos_in = infile.tellg();
-
- //check for header
-
- if (pos_in > 0 && pos_in 4fefd39f24
-
-
-
diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Download Nokia C3 Software Update 8.70 [UPDATED].md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Download Nokia C3 Software Update 8.70 [UPDATED].md
deleted file mode 100644
index 2d27f10ec5754265239b0fb75b33bdefaa218536..0000000000000000000000000000000000000000
--- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Download Nokia C3 Software Update 8.70 [UPDATED].md
+++ /dev/null
@@ -1,6 +0,0 @@
-download nokia c3 software update 8.70
Download Zip ✸✸✸ https://urlgoal.com/2uCLQR
-
-Requirements para mag flash/update ang inyong nokia (y)Nokia Ovi PC SuiteLink ... Phoenix ... 4d29de3e1b
-
-
-
diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Downloadstrongsrt4669xiisoftware [TOP].md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Downloadstrongsrt4669xiisoftware [TOP].md
deleted file mode 100644
index 74b110aa2815062bb93e07f42695d8a643bddfc5..0000000000000000000000000000000000000000
--- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/Downloadstrongsrt4669xiisoftware [TOP].md
+++ /dev/null
@@ -1,21 +0,0 @@
-downloadstrongsrt4669xiisoftware
Download Zip ⚡ https://urlgoal.com/2uCMPa
-
-View and download Strong SRT 4669 XII user manual online. Flash drive. Strong SRT-2166 - Operating Instructions.
-Instructions and manual for the TV Strong SRT - 2166 on.
-Page 8 Instruction and manual for TV Strong SRT - 2166 in Russian.
-8 pp.
-Strong SRT-2167 - TV reviews.
-TV tuners strong srt- 7010f.
-Strong SRT - 1616.
-Strong SRT - 2166.
-Strong SRT - 2167.
-Strong SRT - 2168.
-Strong SRT - 2169.
-Strong SRT - 21650.
-Strong SRT - 2165.
-Strong SRT -2164.
-Strong SRT - 2163.
-Strong SRT - 2162. 8a78ff9644
-
-
-
diff --git a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/HD Online Player (Pacific Rim Uprising English Hd 1080).md b/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/HD Online Player (Pacific Rim Uprising English Hd 1080).md
deleted file mode 100644
index 64784500e4a37067e4710ca3a32b554121a621e6..0000000000000000000000000000000000000000
--- a/spaces/recenWmenso/ChatGPT-with-Voice-Cloning-for-All/datasets/HD Online Player (Pacific Rim Uprising English Hd 1080).md
+++ /dev/null
@@ -1,6 +0,0 @@
-HD Online Player (Pacific Rim Uprising English Hd 1080)
DOWNLOAD 🗹 https://urlgoal.com/2uCLVW
-
-Pacific Rim - Uprising (English) Full Movie In Hindi Download Hd 1080p ... Online Streaming A client end-user can use their media player to ... 1fdad05405
-
-
-
diff --git a/spaces/robin0307/MMOCR/configs/_base_/det_models/dbnetpp_r50dcnv2_fpnc.py b/spaces/robin0307/MMOCR/configs/_base_/det_models/dbnetpp_r50dcnv2_fpnc.py
deleted file mode 100644
index f8eaf2ffd6efe9fa4ad63f5dc208f9b134a38380..0000000000000000000000000000000000000000
--- a/spaces/robin0307/MMOCR/configs/_base_/det_models/dbnetpp_r50dcnv2_fpnc.py
+++ /dev/null
@@ -1,28 +0,0 @@
-model = dict(
- type='DBNet',
- backbone=dict(
- type='mmdet.ResNet',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- frozen_stages=-1,
- norm_cfg=dict(type='BN', requires_grad=True),
- norm_eval=False,
- style='pytorch',
- dcn=dict(type='DCNv2', deform_groups=1, fallback_on_stride=False),
- init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50'),
- stage_with_dcn=(False, True, True, True)),
- neck=dict(
- type='FPNC',
- in_channels=[256, 512, 1024, 2048],
- lateral_channels=256,
- asf_cfg=dict(attention_type='ScaleChannelSpatial')),
- bbox_head=dict(
- type='DBHead',
- in_channels=256,
- loss=dict(type='DBLoss', alpha=5.0, beta=10.0, bbce_loss=True),
- postprocessor=dict(
- type='DBPostprocessor', text_repr_type='quad',
- epsilon_ratio=0.002)),
- train_cfg=None,
- test_cfg=None)
diff --git a/spaces/rorallitri/biomedical-language-models/logs/Bahubali - The Beginning Movie English Sub Free Download.md b/spaces/rorallitri/biomedical-language-models/logs/Bahubali - The Beginning Movie English Sub Free Download.md
deleted file mode 100644
index 0e81635177a7fbf59b4ec6beca7f1ab82b36163c..0000000000000000000000000000000000000000
--- a/spaces/rorallitri/biomedical-language-models/logs/Bahubali - The Beginning Movie English Sub Free Download.md
+++ /dev/null
@@ -1,11 +0,0 @@
-Bahubali - The Beginning movie english sub free download
Download File ——— https://tinurll.com/2uzlpP
-
-Bahubali Beginning 2015 Eng Sub | Prabhas, Anushka Shetty & Tamannaah Bollywood Action Movie. Bahubali Start 2015 Eng Sub | Prabhas, Anushka Shetty & Tamannaah Bollywood Action Movie.
-Kumbh Joshi - Bahubali Beginning (Bhupesh Devi, Prabhas, Anushka Shetty) - The Beginning Of A Legend - Full .
-Bahubali Start 2015 Eng Sub | Prabhas, Anushka Shetty & Tamannaah Bollywood Action Movie.
-Watch Bahubali Home | Bhupesh Devi, Prabhas, Anushka Shetty.
-Prabhas and Anushka Shetty in Bahubali movie.
-Bhupesh Devi, Prabhas, An 8a78ff9644
-
-
-
diff --git a/spaces/rorallitri/biomedical-language-models/logs/Deus Ex. Human Revolution CRACK ONLY V1.1622.0.rar Key Generator No Survey No Password No Virus.md b/spaces/rorallitri/biomedical-language-models/logs/Deus Ex. Human Revolution CRACK ONLY V1.1622.0.rar Key Generator No Survey No Password No Virus.md
deleted file mode 100644
index 284550fdecb65a5e63572c63490cf95c841eeb2e..0000000000000000000000000000000000000000
--- a/spaces/rorallitri/biomedical-language-models/logs/Deus Ex. Human Revolution CRACK ONLY V1.1622.0.rar Key Generator No Survey No Password No Virus.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Deus Ex. Human Revolution CRACK ONLY V1.1622.0.rar Key Generator
DOWNLOAD • https://tinurll.com/2uznQy
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/rorallitri/biomedical-language-models/logs/Dr Halsey Journal PDF Download Learn More About the Creator of Cortana.md b/spaces/rorallitri/biomedical-language-models/logs/Dr Halsey Journal PDF Download Learn More About the Creator of Cortana.md
deleted file mode 100644
index a5e4647229f64cc9f9a5784fd50ace6b0d897769..0000000000000000000000000000000000000000
--- a/spaces/rorallitri/biomedical-language-models/logs/Dr Halsey Journal PDF Download Learn More About the Creator of Cortana.md
+++ /dev/null
@@ -1,18 +0,0 @@
-
-We now differentiate between the requirements for new and revised submissions. Only when your paper is at the revision stage, will you be requested to put your paper in to a 'correct format' for acceptance and provide the items required for the publication of your article (you can view templates demonstrating the final layout of the title page, main text, tables and supplementary online material). However, please note that submissions should not include any information in the main text, tables and figures that could lead to the author(s) being identified by reviewers, given the double-anonymized peer review process adopted by the journal.
To find out more, please visit the Preparation section below.
-Virtual special issues (VSIs). VSIs are devoted to particular topics or themes that fall within the purview of the journal. For VSIs, presubmission inquiries to the Editors, including detailed special issue proposals, are mandatory. JHE publishes a maximum of one VSI per year. The proposal should include the following: names and affiliations of all proposed Guest Editors (GE) and their CVs, VSI title, aim and scope of the VSI and its current relevance to JHE readership, and number of anticipated submissions including title and author(s) of each submission, and abstracts (please keep in mind the 300-word limit for abstracts). The proposal should indicate the papers that will be handled by each GE. Each VSI should have an Editorial that places the papers in collective context and may have a closing article though this is not mandatory. Please note that acceptance of a VSI is not a guarantee that all submissions for that VSI will be accepted for publication. The manuscripts should be submitted under the category with the title of the VSI. All submissions are subject to the normal peer-review process with the exception of the Editorial, which should be submitted directly to the Editor-in-Chief handling the VSI.
-dr halsey journal pdf download
Download Zip ··· https://tinurll.com/2uzmUF
-The body of the manuscript of a Research Article should be submitted in editable Word format. JHE allows for primary, secondary and tertiary headers. The format of these headers is as follows:
JHE allows for primary, secondary and tertiary headers. The format of these headers is as follows:
1. Primary section header (capitalize only the first word of the primary header and use bold)
Text begins here.
1.1.Secondary section header (italics, no bold or underline, but please do not italicize genera/species names)
Text begins here.
Tertiary section header Text begins here.
The manuscript should thus adhere to the following formatting:
- Introduction
- Materials and methods
Provide sufficient detail to allow the work to be reproduced. Methods already published should be indicated by a reference, but sufficient detail must be provided so that readers can understand the methods without referring to separate papers. Authors must supply complete and accurate information about the location and accession of material, both at the time it was studied and, if different, at the time of publication (for example, if the material was on loan or not fully accessioned in a single institution at the time of study). In line with the journals commitment to open access and transparency, specimen numbers of material (both fossil and modern comparative) analyzed as part of the submitted work should be included either in the main manuscript or, in cases where a large sample is used, as supplementary online material. The institution where the studied specimens are curated should be indicated in the Materials section.
-Users of Mendeley Desktop can easily install the reference style for this journal by clicking the following link: -citation-style/journal-of-human-evolution When preparing your manuscript, you will then be able to select this style using the Mendeley plug-ins for Microsoft Word or LibreOffice.
-A separate primary section, numbered and entitled Systematics (for extant taxa) or Systematic paleontology (for extinct taxa) is mandatory. This section may substitute the standard Results section; if not, then the latter must be placed immediately after the systematic section. This section primary heading should be followed by successive taxonomic subheadings in round type that do not adhere to the style of secondary or tertiary headings of the journal, and which must include rank (but see below), taxon name, and taxonomic authorships and/or specifications about the novelty of taxa (see abbreviations below), without dot at the end. For example:
-The use of taxon ranks is mandatory when ruled by the Code (i.e., family-, genus- or species-group taxa), and optional for higher-level ranks not ruled by the Code (e.g., class, order?). New taxa must be explicitly denoted as such after taxon name (e.g., sp. nov.), whereas new rank must be explicitly specified after taxonomic authorship. A taxonomic subheading can be followed, on next line, by another taxonomic subheading (of lower rank), a synonyms list, or one or more secondary or tertiary headings (in accordance to the journal style), depending on the case. Tertiary headings will be used except for longer sub-sections of 'Description', 'Comparisons' or 'Remarks', which must be under secondary headings and may be alternatively placed within a separate Results section (if any). The erection of new family- and genus-group taxa must be accompanied at least by a designation of the type genus or species, respectively, whereas the erection of new species-group taxa must obligatorily include a succinct diagnosis (without references, and preceded by a tertiary heading), which must be differential unless a separate differential diagnosis is provided.
-If applicable, systematic headings of species-group taxa may be followed by a synonyms list with references. References cited within the synonyms list(s) must be included in the references list of the paper, but their citation does not adhere to the standard citation style of the journal. Only relevant synonyms must be included (e.g., original description, new rank, genus transfer, etc.). Each synonym must be placed on a text line of its own, flushed to the left, beginning with year, followed by colon, taxon name, authorship without year, semicolon plus citation (if different from authorship), colon, plates and/or figures and comma (if applicable), and page range, ending with a dot.
-Taxononic authorities (or authorships) should be provided following a taxon name (especially for ranks of the genus-and species-groups) when it is first mentioned in the text, as well as within systematic headings within a formal Systematics or Systematic paleontology section. References for taxonomic authorships used in the text must be included in the references list following the same style as other references. Within the text, taxonomic authorships should follow the recommendations of the Code if they go against the journal's citation style. Therefore, the name of author(s) must be separated from year of original description with a comma, but parentheses can only be used for species-group names when they were originally erected within a different genus from that currently used. For authors, only surnames will be used, unless initials are required to distinguish different authors. For two authors, Australopithecus must be separated by 'and' (instead of ampersand); for three or more authors, the name of first author followed by 'et al.' should be used as long as the full list of authors can be unambiguously identified in the references list.
-
-Although registration in ZooBank is only mandatory for online-only taxonomic publications, and Journal of Human Evolution is still printed, taxonomic papers published in the journal should be registered in ZooBank, and evidence of such registration included within the published version of the paper. Registration in ZooBank is the responsibility of authors, once the paper has been provisionally accepted for publication, so that the details to be included in the published version of the paper must be provided by authors before its final formal acceptance. These details must include the date of registration and the life science identifier (LSID) of the publication. Authors must register their papers as in press, and subsequently update the citation details one their paper is published. Authors are also encouraged to register new taxa in ZooBank, and provide their LSID below the corresponding systematic headings in their papers, but this is not mandatory. The digital repositories (e.g., CLOCKSS) that partner with Elsevier (to be selected by authors of Journal of Human Evolution during ZooBank registration) can be consulted here:
-Research Elements is a suite of peer-reviewed, open access journals which make your research objects findable, accessible and reusable. Articles place research objects into context by providing detailed descriptions of objects and their application, and linking to the associated original research articles. Research Elements articles can be prepared by you, or by one of your collaborators.
-The journal publishes impactful articles of any length, including literature reviews, meta-analyses, replications, theoretical notes, and commentaries on previously published works in the Journal of Experimental Psychology: Learning, Memory, and Cognition.
-The editorial policy of the journal encompasses integrative articles containing multiple experiments as well as articles reporting single experiments. The journal also publishes commentaries and theoretical notes. Please note that theoretical notes are limited to a maximum of 25 pages of text. Commentaries on articles should be at maximum half the length of the target article.
-JEP:LMC is now using a software system to screen submitted content for similarity with other published content. The system compares the initial version of each submitted manuscript against a database of 40+ million scholarly documents, as well as content appearing on the open web. This allows APA to check submissions for potential overlap with material previously published in scholarly journals (e.g., lifted or republished material).
aaccfb2cb3
-
-
\ No newline at end of file
diff --git a/spaces/rorallitri/biomedical-language-models/logs/Fsx Captain Sim 737-200 Fix Crack.md b/spaces/rorallitri/biomedical-language-models/logs/Fsx Captain Sim 737-200 Fix Crack.md
deleted file mode 100644
index af3f41e05f50c190946a5d45ffa12b99029eb2ff..0000000000000000000000000000000000000000
--- a/spaces/rorallitri/biomedical-language-models/logs/Fsx Captain Sim 737-200 Fix Crack.md
+++ /dev/null
@@ -1,24 +0,0 @@
-fsx captain sim 737-200 crack
DOWNLOAD ✔ https://tinurll.com/2uzmH3
-
-, Classic pack and MAX pack.
-
-The 737 Captain pack is a complete and comprehensive 737 aircraft flying experience for FSX and Prepar3D, packing together a wealth of new content, including 11 new detailed cockpits, full-bodied interior maps, enhanced scenery, brand new high resolution textures, enhanced sound sets, a wealth of new features and improvements to existing features and much more.
-
-* NEW Cockpits: The 737 Captain pack features 11 new detailed cockpits for the 737 Original aircraft type, including new cockpits for the 737-200, 737-300, 737-400, 737-500, 737-200C, 737-800 Classic, 737-900, 737 MAX-8, 737 MAX-9 and 737 MAX-10 variants.
-
-* Enhanced Cockpits: The 737 Captain pack features a host of enhancements to the original cockpits, such as new adjustable seats, more detailed interiors, improved windows and dials, plus an enhanced Flightdeck & Instrumentation view, allowing you to take a closer look at the planes internal workings.
-
-* Brand New Interior Maps: The 737 Captain pack features a brand new 737-400 interior map for FSX and Prepar3D.
-
-* New Interior Decorations: The 737 Captain pack features brand new default interior decals for the 737 Original, such as an enhanced GSM device, personal stereo unit and GSM equipment, a new Business Class bench seat and Business Class berths.
-
-* More details in the cockpit: The 737 Captain pack features a detailed set of new livery decals for the Boeing 737 Original, and includes new Default and Premium livery sets for the 737-200, 737-300, 737-400, 737-500, 737-200C, 737-800 Classic, 737-900, 737 MAX-8, 737 MAX-9 and 737 MAX-10 variants.
-
-* New Default Livery: The 737 Captain pack features a brand new set of Default livery decals for the 737 Original, featuring new colours for the aircraft, updated tailfin and brand new logotype and tailfin markings.
-
-* New Premium Livery: The 737 Captain pack features a brand new set of Premium livery decals for the 737 Original, featuring new tailfin and brand new logo.
-
-* Enhanced Bathrooms: The 737 Captain pack features a brand new set of seats, overheads and toilets for the 737 Original, plus an enhanced view of the cockpit, including 4fefd39f24
-
-
-
diff --git a/spaces/rorallitri/biomedical-language-models/logs/HD Online Player (lawrence Of Arabia High Quality Full Movie In Urd).md b/spaces/rorallitri/biomedical-language-models/logs/HD Online Player (lawrence Of Arabia High Quality Full Movie In Urd).md
deleted file mode 100644
index 615aa46dd7a1eae9ae8e3e6ac6857c7a3ab26369..0000000000000000000000000000000000000000
--- a/spaces/rorallitri/biomedical-language-models/logs/HD Online Player (lawrence Of Arabia High Quality Full Movie In Urd).md
+++ /dev/null
@@ -1,6 +0,0 @@
-HD Online Player (lawrence of arabia full movie in urd)
Download Zip ↔ https://tinurll.com/2uzn15
-
-Directed by David Lean. With Peter O'Toole, Alec Guinness, Anthony Quinn, Jack Hawkins. The story of T.E. Lawrence, the English officer who successfully ... 4d29de3e1b
-
-
-
diff --git a/spaces/rpa45/ai_hands_classifier/README.md b/spaces/rpa45/ai_hands_classifier/README.md
deleted file mode 100644
index b409c6a40a8597f5a7c1176086b55a360c4db8d1..0000000000000000000000000000000000000000
--- a/spaces/rpa45/ai_hands_classifier/README.md
+++ /dev/null
@@ -1,17 +0,0 @@
----
-title: Ai Hands Classifier
-emoji: 💻
-colorFrom: red
-colorTo: blue
-sdk: gradio
-sdk_version: 3.12.0
-app_file: app.py
-pinned: false
-license: openrail
----
-
-Simple classification model built with ResNet architecture to tell the difference between human and ai-generated hand.
-
-Accuracy on holdout set = 0.89
-
- \ No newline at end of file
diff --git a/spaces/runa91/bite_gradio/src/combined_model/train_main_image_to_3d_withbreedrel.py b/spaces/runa91/bite_gradio/src/combined_model/train_main_image_to_3d_withbreedrel.py
deleted file mode 100644
index 59308fa38badbbce05250edd44b8435a1896838d..0000000000000000000000000000000000000000
--- a/spaces/runa91/bite_gradio/src/combined_model/train_main_image_to_3d_withbreedrel.py
+++ /dev/null
@@ -1,496 +0,0 @@
-
-import torch
-import torch.nn as nn
-import torch.backends.cudnn
-import torch.nn.parallel
-from tqdm import tqdm
-import os
-import pathlib
-from matplotlib import pyplot as plt
-import cv2
-import numpy as np
-import torch
-import trimesh
-
-import sys
-sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
-from stacked_hourglass.utils.evaluation import accuracy, AverageMeter, final_preds, get_preds, get_preds_soft
-from stacked_hourglass.utils.visualization import save_input_image_with_keypoints, save_input_image
-from metrics.metrics import Metrics
-from configs.SMAL_configs import EVAL_KEYPOINTS, KEYPOINT_GROUPS
-
-
-# ---------------------------------------------------------------------------------------------------------------------------
-def do_training_epoch(train_loader, model, loss_module, device, data_info, optimiser, quiet=False, acc_joints=None, weight_dict=None):
- losses = AverageMeter()
- losses_keyp = AverageMeter()
- losses_silh = AverageMeter()
- losses_shape = AverageMeter()
- losses_pose = AverageMeter()
- losses_class = AverageMeter()
- losses_breed = AverageMeter()
- losses_partseg = AverageMeter()
- accuracies = AverageMeter()
- # Put the model in training mode.
- model.train()
- # prepare progress bar
- iterable = enumerate(train_loader)
- progress = None
- if not quiet:
- progress = tqdm(iterable, desc='Train', total=len(train_loader), ascii=True, leave=False)
- iterable = progress
- # information for normalization
- norm_dict = {
- 'pose_rot6d_mean': torch.from_numpy(data_info.pose_rot6d_mean).float().to(device),
- 'trans_mean': torch.from_numpy(data_info.trans_mean).float().to(device),
- 'trans_std': torch.from_numpy(data_info.trans_std).float().to(device),
- 'flength_mean': torch.from_numpy(data_info.flength_mean).float().to(device),
- 'flength_std': torch.from_numpy(data_info.flength_std).float().to(device)}
- # prepare variables, put them on the right device
- for i, (input, target_dict) in iterable:
- batch_size = input.shape[0]
- for key in target_dict.keys():
- if key == 'breed_index':
- target_dict[key] = target_dict[key].long().to(device)
- elif key in ['index', 'pts', 'tpts', 'target_weight', 'silh', 'silh_distmat_tofg', 'silh_distmat_tobg', 'sim_breed_index', 'img_border_mask']:
- target_dict[key] = target_dict[key].float().to(device)
- elif key in ['has_seg', 'gc']:
- target_dict[key] = target_dict[key].to(device)
- else:
- pass
- input = input.float().to(device)
-
- # ----------------------- do training step -----------------------
- assert model.training, 'model must be in training mode.'
- with torch.enable_grad():
- # ----- forward pass -----
- output, output_unnorm, output_reproj = model(input, norm_dict=norm_dict)
- # ----- loss -----
- loss, loss_dict = loss_module(output_reproj=output_reproj,
- target_dict=target_dict,
- weight_dict=weight_dict)
- # ----- backward pass and parameter update -----
- optimiser.zero_grad()
- loss.backward()
- optimiser.step()
- # ----------------------------------------------------------------
-
- # prepare losses for progress bar
- bs_fake = 1 # batch_size
- losses.update(loss_dict['loss'], bs_fake)
- losses_keyp.update(loss_dict['loss_keyp_weighted'], bs_fake)
- losses_silh.update(loss_dict['loss_silh_weighted'], bs_fake)
- losses_shape.update(loss_dict['loss_shape_weighted'], bs_fake)
- losses_pose.update(loss_dict['loss_poseprior_weighted'], bs_fake)
- losses_class.update(loss_dict['loss_class_weighted'], bs_fake)
- losses_breed.update(loss_dict['loss_breed_weighted'], bs_fake)
- losses_partseg.update(loss_dict['loss_partseg_weighted'], bs_fake)
- acc = - loss_dict['loss_keyp_weighted'] # this will be used to keep track of the 'best model'
- accuracies.update(acc, bs_fake)
- # Show losses as part of the progress bar.
- if progress is not None:
- my_string = 'Loss: {loss:0.4f}, loss_keyp: {loss_keyp:0.4f}, loss_silh: {loss_silh:0.4f}, loss_partseg: {loss_partseg:0.4f}, loss_shape: {loss_shape:0.4f}, loss_pose: {loss_pose:0.4f}, loss_class: {loss_class:0.4f}, loss_breed: {loss_breed:0.4f}'.format(
- loss=losses.avg,
- loss_keyp=losses_keyp.avg,
- loss_silh=losses_silh.avg,
- loss_shape=losses_shape.avg,
- loss_pose=losses_pose.avg,
- loss_class=losses_class.avg,
- loss_breed=losses_breed.avg,
- loss_partseg=losses_partseg.avg
- )
- progress.set_postfix_str(my_string)
-
- return my_string, accuracies.avg
-
-
-# ---------------------------------------------------------------------------------------------------------------------------
-def do_validation_epoch(val_loader, model, loss_module, device, data_info, flip=False, quiet=False, acc_joints=None, save_imgs_path=None, weight_dict=None, metrics=None, val_opt='default', test_name_list=None, render_all=False, pck_thresh=0.15, len_dataset=None):
- losses = AverageMeter()
- losses_keyp = AverageMeter()
- losses_silh = AverageMeter()
- losses_shape = AverageMeter()
- losses_pose = AverageMeter()
- losses_class = AverageMeter()
- losses_breed = AverageMeter()
- losses_partseg = AverageMeter()
- accuracies = AverageMeter()
- if save_imgs_path is not None:
- pathlib.Path(save_imgs_path).mkdir(parents=True, exist_ok=True)
- # Put the model in evaluation mode.
- model.eval()
- # prepare progress bar
- iterable = enumerate(val_loader)
- progress = None
- if not quiet:
- progress = tqdm(iterable, desc='Valid', total=len(val_loader), ascii=True, leave=False)
- iterable = progress
- # summarize information for normalization
- norm_dict = {
- 'pose_rot6d_mean': torch.from_numpy(data_info.pose_rot6d_mean).float().to(device),
- 'trans_mean': torch.from_numpy(data_info.trans_mean).float().to(device),
- 'trans_std': torch.from_numpy(data_info.trans_std).float().to(device),
- 'flength_mean': torch.from_numpy(data_info.flength_mean).float().to(device),
- 'flength_std': torch.from_numpy(data_info.flength_std).float().to(device)}
- batch_size = val_loader.batch_size
- # prepare variables, put them on the right device
- my_step = 0
- for i, (input, target_dict) in iterable:
- curr_batch_size = input.shape[0]
- for key in target_dict.keys():
- if key == 'breed_index':
- target_dict[key] = target_dict[key].long().to(device)
- elif key in ['index', 'pts', 'tpts', 'target_weight', 'silh', 'silh_distmat_tofg', 'silh_distmat_tobg', 'sim_breed_index', 'img_border_mask']:
- target_dict[key] = target_dict[key].float().to(device)
- elif key in ['has_seg', 'gc']:
- target_dict[key] = target_dict[key].to(device)
- else:
- pass
- input = input.float().to(device)
-
- # ----------------------- do validation step -----------------------
- with torch.no_grad():
- # ----- forward pass -----
- # output: (['pose', 'flength', 'trans', 'keypoints_norm', 'keypoints_scores'])
- # output_unnorm: (['pose_rotmat', 'flength', 'trans', 'keypoints'])
- # output_reproj: (['vertices_smal', 'torch_meshes', 'keyp_3d', 'keyp_2d', 'silh', 'betas', 'pose_rot6d', 'dog_breed', 'shapedirs', 'z', 'flength_unnorm', 'flength'])
- # target_dict: (['index', 'center', 'scale', 'pts', 'tpts', 'target_weight', 'breed_index', 'sim_breed_index', 'ind_dataset', 'silh'])
- output, output_unnorm, output_reproj = model(input, norm_dict=norm_dict)
- # ----- loss -----
- if metrics == 'no_loss':
- loss, loss_dict = loss_module(output_reproj=output_reproj,
- target_dict=target_dict,
- weight_dict=weight_dict)
- # ----------------------------------------------------------------
-
- if i == 0:
- if len_dataset is None:
- len_data = val_loader.batch_size * len(val_loader) # 1703
- else:
- len_data = len_dataset
- if metrics == 'all' or metrics == 'no_loss':
- pck = np.zeros((len_data))
- pck_by_part = {group:np.zeros((len_data)) for group in KEYPOINT_GROUPS}
- acc_sil_2d = np.zeros(len_data)
-
- all_betas = np.zeros((len_data, output_reproj['betas'].shape[1]))
- all_betas_limbs = np.zeros((len_data, output_reproj['betas_limbs'].shape[1]))
- all_z = np.zeros((len_data, output_reproj['z'].shape[1]))
- all_pose_rotmat = np.zeros((len_data, output_unnorm['pose_rotmat'].shape[1], 3, 3))
- all_flength = np.zeros((len_data, output_unnorm['flength'].shape[1]))
- all_trans = np.zeros((len_data, output_unnorm['trans'].shape[1]))
- all_breed_indices = np.zeros((len_data))
- all_image_names = [] # len_data * [None]
-
- index = i
- ind_img = 0
- if save_imgs_path is not None:
- # render predicted 3d models
- visualizations = model.render_vis_nograd(vertices=output_reproj['vertices_smal'],
- focal_lengths=output_unnorm['flength'],
- color=0) # color=2)
- for ind_img in range(len(target_dict['index'])):
- try:
- if test_name_list is not None:
- img_name = test_name_list[int(target_dict['index'][ind_img].cpu().detach().numpy())].replace('/', '_')
- img_name = img_name.split('.')[0]
- else:
- img_name = str(index) + '_' + str(ind_img)
- # save image with predicted keypoints
- out_path = save_imgs_path + '/keypoints_pred_' + img_name + '.png'
- pred_unp = (output['keypoints_norm'][ind_img, :, :] + 1.) / 2 * (data_info.image_size - 1)
- pred_unp_maxval = output['keypoints_scores'][ind_img, :, :]
- pred_unp_prep = torch.cat((pred_unp, pred_unp_maxval), 1)
- inp_img = input[ind_img, :, :, :].detach().clone()
- save_input_image_with_keypoints(inp_img, pred_unp_prep, out_path=out_path, threshold=0.1, print_scores=True, ratio_in_out=1.0) # threshold=0.3
- # save predicted 3d model (front view)
- pred_tex = visualizations[ind_img, :, :, :].permute((1, 2, 0)).cpu().detach().numpy() / 256
- pred_tex_max = np.max(pred_tex, axis=2)
- out_path = save_imgs_path + '/tex_pred_' + img_name + '.png'
- plt.imsave(out_path, pred_tex)
- input_image = input[ind_img, :, :, :].detach().clone()
- for t, m, s in zip(input_image, data_info.rgb_mean, data_info.rgb_stddev): t.add_(m)
- input_image_np = input_image.detach().cpu().numpy().transpose(1, 2, 0)
- im_masked = cv2.addWeighted(input_image_np,0.2,pred_tex,0.8,0)
- im_masked[pred_tex_max<0.01, :] = input_image_np[pred_tex_max<0.01, :]
- out_path = save_imgs_path + '/comp_pred_' + img_name + '.png'
- plt.imsave(out_path, im_masked)
- # save predicted 3d model (side view)
- vertices_cent = output_reproj['vertices_smal'] - output_reproj['vertices_smal'].mean(dim=1)[:, None, :]
- roll = np.pi / 2 * torch.ones(1).float().to(device)
- pitch = np.pi / 2 * torch.ones(1).float().to(device)
- tensor_0 = torch.zeros(1).float().to(device)
- tensor_1 = torch.ones(1).float().to(device)
- RX = torch.stack([torch.stack([tensor_1, tensor_0, tensor_0]), torch.stack([tensor_0, torch.cos(roll), -torch.sin(roll)]),torch.stack([tensor_0, torch.sin(roll), torch.cos(roll)])]).reshape(3,3)
- RY = torch.stack([
- torch.stack([torch.cos(pitch), tensor_0, torch.sin(pitch)]),
- torch.stack([tensor_0, tensor_1, tensor_0]),
- torch.stack([-torch.sin(pitch), tensor_0, torch.cos(pitch)])]).reshape(3,3)
- vertices_rot = (torch.matmul(RY, vertices_cent.reshape((-1, 3))[:, :, None])).reshape((curr_batch_size, -1, 3))
- vertices_rot[:, :, 2] = vertices_rot[:, :, 2] + torch.ones_like(vertices_rot[:, :, 2]) * 20 # 18 # *16
-
- visualizations_rot = model.render_vis_nograd(vertices=vertices_rot,
- focal_lengths=output_unnorm['flength'],
- color=0) # 2)
- pred_tex = visualizations_rot[ind_img, :, :, :].permute((1, 2, 0)).cpu().detach().numpy() / 256
- pred_tex_max = np.max(pred_tex, axis=2)
- out_path = save_imgs_path + '/rot_tex_pred_' + img_name + '.png'
- plt.imsave(out_path, pred_tex)
- if render_all:
- # save input image
- inp_img = input[ind_img, :, :, :].detach().clone()
- out_path = save_imgs_path + '/image_' + img_name + '.png'
- save_input_image(inp_img, out_path)
- # save mesh
- V_posed = output_reproj['vertices_smal'][ind_img, :, :].detach().cpu().numpy()
- Faces = model.smal.f
- mesh_posed = trimesh.Trimesh(vertices=V_posed, faces=Faces, process=False, maintain_order=True)
- mesh_posed.export(save_imgs_path + '/mesh_posed_' + img_name + '.obj')
- except:
- print('dont save an image')
-
- if metrics == 'all' or metrics == 'no_loss':
- # prepare a dictionary with all the predicted results
- preds = {}
- preds['betas'] = output_reproj['betas'].cpu().detach().numpy()
- preds['betas_limbs'] = output_reproj['betas_limbs'].cpu().detach().numpy()
- preds['z'] = output_reproj['z'].cpu().detach().numpy()
- preds['pose_rotmat'] = output_unnorm['pose_rotmat'].cpu().detach().numpy()
- preds['flength'] = output_unnorm['flength'].cpu().detach().numpy()
- preds['trans'] = output_unnorm['trans'].cpu().detach().numpy()
- preds['breed_index'] = target_dict['breed_index'].cpu().detach().numpy().reshape((-1))
- img_names = []
- for ind_img2 in range(0, output_reproj['betas'].shape[0]):
- if test_name_list is not None:
- img_name2 = test_name_list[int(target_dict['index'][ind_img2].cpu().detach().numpy())].replace('/', '_')
- img_name2 = img_name2.split('.')[0]
- else:
- img_name2 = str(index) + '_' + str(ind_img2)
- img_names.append(img_name2)
- preds['image_names'] = img_names
- # prepare keypoints for PCK calculation - predicted as well as ground truth
- pred_keypoints_norm = output['keypoints_norm'] # -1 to 1
- pred_keypoints_256 = output_reproj['keyp_2d']
- pred_keypoints = pred_keypoints_256
- gt_keypoints_256 = target_dict['tpts'][:, :, :2] / 64. * (256. - 1)
- gt_keypoints_norm = gt_keypoints_256 / 256 / 0.5 - 1
- gt_keypoints = torch.cat((gt_keypoints_256, target_dict['tpts'][:, :, 2:3]), dim=2) # gt_keypoints_norm
- # prepare silhouette for IoU calculation - predicted as well as ground truth
- has_seg = target_dict['has_seg']
- img_border_mask = target_dict['img_border_mask'][:, 0, :, :]
- gtseg = target_dict['silh']
- synth_silhouettes = output_reproj['silh'][:, 0, :, :] # output_reproj['silh']
- synth_silhouettes[synth_silhouettes>0.5] = 1
- synth_silhouettes[synth_silhouettes<0.5] = 0
- # calculate PCK as well as IoU (similar to WLDO)
- preds['acc_PCK'] = Metrics.PCK(
- pred_keypoints, gt_keypoints,
- gtseg, has_seg, idxs=EVAL_KEYPOINTS,
- thresh_range=[pck_thresh], # [0.15],
- )
- preds['acc_IOU'] = Metrics.IOU(
- synth_silhouettes, gtseg,
- img_border_mask, mask=has_seg
- )
- for group, group_kps in KEYPOINT_GROUPS.items():
- preds[f'{group}_PCK'] = Metrics.PCK(
- pred_keypoints, gt_keypoints, gtseg, has_seg,
- thresh_range=[pck_thresh], # [0.15],
- idxs=group_kps
- )
- # add results for all images in this batch to lists
- curr_batch_size = pred_keypoints_256.shape[0]
- if not (preds['acc_PCK'].data.cpu().numpy().shape == (pck[my_step * batch_size:my_step * batch_size + curr_batch_size]).shape):
- import pdb; pdb.set_trace()
- pck[my_step * batch_size:my_step * batch_size + curr_batch_size] = preds['acc_PCK'].data.cpu().numpy()
- acc_sil_2d[my_step * batch_size:my_step * batch_size + curr_batch_size] = preds['acc_IOU'].data.cpu().numpy()
- for part in pck_by_part:
- pck_by_part[part][my_step * batch_size:my_step * batch_size + curr_batch_size] = preds[f'{part}_PCK'].data.cpu().numpy()
- all_betas[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['betas']
- all_betas_limbs[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['betas_limbs']
- all_z[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['z']
- all_pose_rotmat[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['pose_rotmat']
- all_flength[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['flength']
- all_trans[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['trans']
- all_breed_indices[my_step * batch_size:my_step * batch_size + curr_batch_size] = preds['breed_index']
- all_image_names.extend(preds['image_names'])
- # update progress bar
- if progress is not None:
- my_string = "PCK: {0:.2f}, IOU: {1:.2f}".format(
- pck[:(my_step * batch_size + curr_batch_size)].mean(),
- acc_sil_2d[:(my_step * batch_size + curr_batch_size)].mean())
- progress.set_postfix_str(my_string)
- else:
- # measure accuracy and record loss
- bs_fake = 1 # batch_size
- losses.update(loss_dict['loss'], bs_fake)
- losses_keyp.update(loss_dict['loss_keyp_weighted'], bs_fake)
- losses_silh.update(loss_dict['loss_silh_weighted'], bs_fake)
- losses_shape.update(loss_dict['loss_shape_weighted'], bs_fake)
- losses_pose.update(loss_dict['loss_poseprior_weighted'], bs_fake)
- losses_class.update(loss_dict['loss_class_weighted'], bs_fake)
- losses_breed.update(loss_dict['loss_breed_weighted'], bs_fake)
- losses_partseg.update(loss_dict['loss_partseg_weighted'], bs_fake)
- acc = - loss_dict['loss_keyp_weighted'] # this will be used to keep track of the 'best model'
- accuracies.update(acc, bs_fake)
- # Show losses as part of the progress bar.
- if progress is not None:
- my_string = 'Loss: {loss:0.4f}, loss_keyp: {loss_keyp:0.4f}, loss_silh: {loss_silh:0.4f}, loss_partseg: {loss_partseg:0.4f}, loss_shape: {loss_shape:0.4f}, loss_pose: {loss_pose:0.4f}, loss_class: {loss_class:0.4f}, loss_breed: {loss_breed:0.4f}'.format(
- loss=losses.avg,
- loss_keyp=losses_keyp.avg,
- loss_silh=losses_silh.avg,
- loss_shape=losses_shape.avg,
- loss_pose=losses_pose.avg,
- loss_class=losses_class.avg,
- loss_breed=losses_breed.avg,
- loss_partseg=losses_partseg.avg
- )
- progress.set_postfix_str(my_string)
- my_step += 1
- if metrics == 'all':
- summary = {'pck': pck, 'acc_sil_2d': acc_sil_2d, 'pck_by_part':pck_by_part,
- 'betas': all_betas, 'betas_limbs': all_betas_limbs, 'z': all_z, 'pose_rotmat': all_pose_rotmat,
- 'flenght': all_flength, 'trans': all_trans, 'image_names': all_image_names, 'breed_indices': all_breed_indices}
- return my_string, summary
- elif metrics == 'no_loss':
- return my_string, np.average(np.asarray(acc_sil_2d))
- else:
- return my_string, accuracies.avg
-
-
-# ---------------------------------------------------------------------------------------------------------------------------
-def do_visual_epoch(val_loader, model, device, data_info, flip=False, quiet=False, acc_joints=None, save_imgs_path=None, weight_dict=None, metrics=None, val_opt='default', test_name_list=None, render_all=False, pck_thresh=0.15, return_results=False):
- if save_imgs_path is not None:
- pathlib.Path(save_imgs_path).mkdir(parents=True, exist_ok=True)
- all_results = []
-
- # Put the model in evaluation mode.
- model.eval()
-
- iterable = enumerate(val_loader)
-
- # information for normalization
- norm_dict = {
- 'pose_rot6d_mean': torch.from_numpy(data_info.pose_rot6d_mean).float().to(device),
- 'trans_mean': torch.from_numpy(data_info.trans_mean).float().to(device),
- 'trans_std': torch.from_numpy(data_info.trans_std).float().to(device),
- 'flength_mean': torch.from_numpy(data_info.flength_mean).float().to(device),
- 'flength_std': torch.from_numpy(data_info.flength_std).float().to(device)}
-
- '''
- return_mesh_with_gt_groundplane = True
- if return_mesh_with_gt_groundplane:
- remeshing_path = '/is/cluster/work/nrueegg/icon_pifu_related/barc_for_bite/data/smal_data_remeshed/uniform_surface_sampling/my_smpl_39dogsnorm_Jr_4_dog_remesh4000_info.pkl'
- with open(remeshing_path, 'rb') as fp:
- remeshing_dict = pkl.load(fp)
- remeshing_relevant_faces = torch.tensor(remeshing_dict['smal_faces'][remeshing_dict['faceid_closest']], dtype=torch.long, device=device)
- remeshing_relevant_barys = torch.tensor(remeshing_dict['barys_closest'], dtype=torch.float32, device=device)
-
- # from smal_pytorch.smal_model.smal_torch_new import SMAL
- print('start: load smal default model (barc), but only for vertices')
- smal = SMAL()
- print('end: load smal default model (barc), but only for vertices')
- smal_template_verts = smal.v_template.detach().cpu().numpy()
- smal_faces = smal.faces.detach().cpu().numpy()
-
- file_alignment_errors = open(save_imgs_path + '/a_ref_procrustes_alignmnet_errors.txt', 'a') # append mode
- file_alignment_errors.write(" ----------- start evaluation ------------- \n ")
-
- csv_file_alignment_errors = open(save_imgs_path + '/a_ref_procrustes_alignmnet_errors.csv', 'w') # write mode
- fieldnames = ['name', 'error']
- writer = csv.DictWriter(csv_file_alignment_errors, fieldnames=fieldnames)
- writer.writeheader()
- '''
-
- my_step = 0
- for i, (input, target_dict) in iterable:
- batch_size = input.shape[0]
- input = input.float().to(device)
- partial_results = {}
-
- # ----------------------- do visualization step -----------------------
- with torch.no_grad():
- output, output_unnorm, output_reproj = model(input, norm_dict=norm_dict)
-
- index = i
- ind_img = 0
- for ind_img in range(batch_size): # range(min(12, batch_size)): # range(12): # [0]: #range(0, batch_size):
-
- try:
- if test_name_list is not None:
- img_name = test_name_list[int(target_dict['index'][ind_img].cpu().detach().numpy())].replace('/', '_')
- img_name = img_name.split('.')[0]
- else:
- img_name = str(index) + '_' + str(ind_img)
- partial_results['img_name'] = img_name
- visualizations = model.render_vis_nograd(vertices=output_reproj['vertices_smal'],
- focal_lengths=output_unnorm['flength'],
- color=0) # 2)
- # save image with predicted keypoints
- pred_unp = (output['keypoints_norm'][ind_img, :, :] + 1.) / 2 * (data_info.image_size - 1)
- pred_unp_maxval = output['keypoints_scores'][ind_img, :, :]
- pred_unp_prep = torch.cat((pred_unp, pred_unp_maxval), 1)
- inp_img = input[ind_img, :, :, :].detach().clone()
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/keypoints_pred_' + img_name + '.png'
- save_input_image_with_keypoints(inp_img, pred_unp_prep, out_path=out_path, threshold=0.1, print_scores=True, ratio_in_out=1.0) # threshold=0.3
- # save predicted 3d model
- # (1) front view
- pred_tex = visualizations[ind_img, :, :, :].permute((1, 2, 0)).cpu().detach().numpy() / 256
- pred_tex_max = np.max(pred_tex, axis=2)
- partial_results['tex_pred'] = pred_tex
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/tex_pred_' + img_name + '.png'
- plt.imsave(out_path, pred_tex)
- input_image = input[ind_img, :, :, :].detach().clone()
- for t, m, s in zip(input_image, data_info.rgb_mean, data_info.rgb_stddev): t.add_(m)
- input_image_np = input_image.detach().cpu().numpy().transpose(1, 2, 0)
- im_masked = cv2.addWeighted(input_image_np,0.2,pred_tex,0.8,0)
- im_masked[pred_tex_max<0.01, :] = input_image_np[pred_tex_max<0.01, :]
- partial_results['comp_pred'] = im_masked
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/comp_pred_' + img_name + '.png'
- plt.imsave(out_path, im_masked)
- # (2) side view
- vertices_cent = output_reproj['vertices_smal'] - output_reproj['vertices_smal'].mean(dim=1)[:, None, :]
- roll = np.pi / 2 * torch.ones(1).float().to(device)
- pitch = np.pi / 2 * torch.ones(1).float().to(device)
- tensor_0 = torch.zeros(1).float().to(device)
- tensor_1 = torch.ones(1).float().to(device)
- RX = torch.stack([torch.stack([tensor_1, tensor_0, tensor_0]), torch.stack([tensor_0, torch.cos(roll), -torch.sin(roll)]),torch.stack([tensor_0, torch.sin(roll), torch.cos(roll)])]).reshape(3,3)
- RY = torch.stack([
- torch.stack([torch.cos(pitch), tensor_0, torch.sin(pitch)]),
- torch.stack([tensor_0, tensor_1, tensor_0]),
- torch.stack([-torch.sin(pitch), tensor_0, torch.cos(pitch)])]).reshape(3,3)
- vertices_rot = (torch.matmul(RY, vertices_cent.reshape((-1, 3))[:, :, None])).reshape((batch_size, -1, 3))
- vertices_rot[:, :, 2] = vertices_rot[:, :, 2] + torch.ones_like(vertices_rot[:, :, 2]) * 20 # 18 # *16
- visualizations_rot = model.render_vis_nograd(vertices=vertices_rot,
- focal_lengths=output_unnorm['flength'],
- color=0) # 2)
- pred_tex = visualizations_rot[ind_img, :, :, :].permute((1, 2, 0)).cpu().detach().numpy() / 256
- pred_tex_max = np.max(pred_tex, axis=2)
- partial_results['rot_tex_pred'] = pred_tex
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/rot_tex_pred_' + img_name + '.png'
- plt.imsave(out_path, pred_tex)
- render_all = True
- if render_all:
- # save input image
- inp_img = input[ind_img, :, :, :].detach().clone()
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/image_' + img_name + '.png'
- save_input_image(inp_img, out_path)
- # save posed mesh
- V_posed = output_reproj['vertices_smal'][ind_img, :, :].detach().cpu().numpy()
- Faces = model.smal.f
- mesh_posed = trimesh.Trimesh(vertices=V_posed, faces=Faces, process=False, maintain_order=True)
- partial_results['mesh_posed'] = mesh_posed
- if save_imgs_path is not None:
- mesh_posed.export(save_imgs_path + '/mesh_posed_' + img_name + '.obj')
- except:
- print('pass...')
- all_results.append(partial_results)
- if return_results:
- return all_results
- else:
- return
\ No newline at end of file
diff --git a/spaces/scedlatioru/img-to-music/example/Age Of Empires 2 Expansion 1.0c No Cd ((FULL)) Crack.md b/spaces/scedlatioru/img-to-music/example/Age Of Empires 2 Expansion 1.0c No Cd ((FULL)) Crack.md
deleted file mode 100644
index 1792c0401aeba674eabf95be5648d0dbabf9b24d..0000000000000000000000000000000000000000
--- a/spaces/scedlatioru/img-to-music/example/Age Of Empires 2 Expansion 1.0c No Cd ((FULL)) Crack.md
+++ /dev/null
@@ -1,14 +0,0 @@
-
\ No newline at end of file
diff --git a/spaces/runa91/bite_gradio/src/combined_model/train_main_image_to_3d_withbreedrel.py b/spaces/runa91/bite_gradio/src/combined_model/train_main_image_to_3d_withbreedrel.py
deleted file mode 100644
index 59308fa38badbbce05250edd44b8435a1896838d..0000000000000000000000000000000000000000
--- a/spaces/runa91/bite_gradio/src/combined_model/train_main_image_to_3d_withbreedrel.py
+++ /dev/null
@@ -1,496 +0,0 @@
-
-import torch
-import torch.nn as nn
-import torch.backends.cudnn
-import torch.nn.parallel
-from tqdm import tqdm
-import os
-import pathlib
-from matplotlib import pyplot as plt
-import cv2
-import numpy as np
-import torch
-import trimesh
-
-import sys
-sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', '..'))
-from stacked_hourglass.utils.evaluation import accuracy, AverageMeter, final_preds, get_preds, get_preds_soft
-from stacked_hourglass.utils.visualization import save_input_image_with_keypoints, save_input_image
-from metrics.metrics import Metrics
-from configs.SMAL_configs import EVAL_KEYPOINTS, KEYPOINT_GROUPS
-
-
-# ---------------------------------------------------------------------------------------------------------------------------
-def do_training_epoch(train_loader, model, loss_module, device, data_info, optimiser, quiet=False, acc_joints=None, weight_dict=None):
- losses = AverageMeter()
- losses_keyp = AverageMeter()
- losses_silh = AverageMeter()
- losses_shape = AverageMeter()
- losses_pose = AverageMeter()
- losses_class = AverageMeter()
- losses_breed = AverageMeter()
- losses_partseg = AverageMeter()
- accuracies = AverageMeter()
- # Put the model in training mode.
- model.train()
- # prepare progress bar
- iterable = enumerate(train_loader)
- progress = None
- if not quiet:
- progress = tqdm(iterable, desc='Train', total=len(train_loader), ascii=True, leave=False)
- iterable = progress
- # information for normalization
- norm_dict = {
- 'pose_rot6d_mean': torch.from_numpy(data_info.pose_rot6d_mean).float().to(device),
- 'trans_mean': torch.from_numpy(data_info.trans_mean).float().to(device),
- 'trans_std': torch.from_numpy(data_info.trans_std).float().to(device),
- 'flength_mean': torch.from_numpy(data_info.flength_mean).float().to(device),
- 'flength_std': torch.from_numpy(data_info.flength_std).float().to(device)}
- # prepare variables, put them on the right device
- for i, (input, target_dict) in iterable:
- batch_size = input.shape[0]
- for key in target_dict.keys():
- if key == 'breed_index':
- target_dict[key] = target_dict[key].long().to(device)
- elif key in ['index', 'pts', 'tpts', 'target_weight', 'silh', 'silh_distmat_tofg', 'silh_distmat_tobg', 'sim_breed_index', 'img_border_mask']:
- target_dict[key] = target_dict[key].float().to(device)
- elif key in ['has_seg', 'gc']:
- target_dict[key] = target_dict[key].to(device)
- else:
- pass
- input = input.float().to(device)
-
- # ----------------------- do training step -----------------------
- assert model.training, 'model must be in training mode.'
- with torch.enable_grad():
- # ----- forward pass -----
- output, output_unnorm, output_reproj = model(input, norm_dict=norm_dict)
- # ----- loss -----
- loss, loss_dict = loss_module(output_reproj=output_reproj,
- target_dict=target_dict,
- weight_dict=weight_dict)
- # ----- backward pass and parameter update -----
- optimiser.zero_grad()
- loss.backward()
- optimiser.step()
- # ----------------------------------------------------------------
-
- # prepare losses for progress bar
- bs_fake = 1 # batch_size
- losses.update(loss_dict['loss'], bs_fake)
- losses_keyp.update(loss_dict['loss_keyp_weighted'], bs_fake)
- losses_silh.update(loss_dict['loss_silh_weighted'], bs_fake)
- losses_shape.update(loss_dict['loss_shape_weighted'], bs_fake)
- losses_pose.update(loss_dict['loss_poseprior_weighted'], bs_fake)
- losses_class.update(loss_dict['loss_class_weighted'], bs_fake)
- losses_breed.update(loss_dict['loss_breed_weighted'], bs_fake)
- losses_partseg.update(loss_dict['loss_partseg_weighted'], bs_fake)
- acc = - loss_dict['loss_keyp_weighted'] # this will be used to keep track of the 'best model'
- accuracies.update(acc, bs_fake)
- # Show losses as part of the progress bar.
- if progress is not None:
- my_string = 'Loss: {loss:0.4f}, loss_keyp: {loss_keyp:0.4f}, loss_silh: {loss_silh:0.4f}, loss_partseg: {loss_partseg:0.4f}, loss_shape: {loss_shape:0.4f}, loss_pose: {loss_pose:0.4f}, loss_class: {loss_class:0.4f}, loss_breed: {loss_breed:0.4f}'.format(
- loss=losses.avg,
- loss_keyp=losses_keyp.avg,
- loss_silh=losses_silh.avg,
- loss_shape=losses_shape.avg,
- loss_pose=losses_pose.avg,
- loss_class=losses_class.avg,
- loss_breed=losses_breed.avg,
- loss_partseg=losses_partseg.avg
- )
- progress.set_postfix_str(my_string)
-
- return my_string, accuracies.avg
-
-
-# ---------------------------------------------------------------------------------------------------------------------------
-def do_validation_epoch(val_loader, model, loss_module, device, data_info, flip=False, quiet=False, acc_joints=None, save_imgs_path=None, weight_dict=None, metrics=None, val_opt='default', test_name_list=None, render_all=False, pck_thresh=0.15, len_dataset=None):
- losses = AverageMeter()
- losses_keyp = AverageMeter()
- losses_silh = AverageMeter()
- losses_shape = AverageMeter()
- losses_pose = AverageMeter()
- losses_class = AverageMeter()
- losses_breed = AverageMeter()
- losses_partseg = AverageMeter()
- accuracies = AverageMeter()
- if save_imgs_path is not None:
- pathlib.Path(save_imgs_path).mkdir(parents=True, exist_ok=True)
- # Put the model in evaluation mode.
- model.eval()
- # prepare progress bar
- iterable = enumerate(val_loader)
- progress = None
- if not quiet:
- progress = tqdm(iterable, desc='Valid', total=len(val_loader), ascii=True, leave=False)
- iterable = progress
- # summarize information for normalization
- norm_dict = {
- 'pose_rot6d_mean': torch.from_numpy(data_info.pose_rot6d_mean).float().to(device),
- 'trans_mean': torch.from_numpy(data_info.trans_mean).float().to(device),
- 'trans_std': torch.from_numpy(data_info.trans_std).float().to(device),
- 'flength_mean': torch.from_numpy(data_info.flength_mean).float().to(device),
- 'flength_std': torch.from_numpy(data_info.flength_std).float().to(device)}
- batch_size = val_loader.batch_size
- # prepare variables, put them on the right device
- my_step = 0
- for i, (input, target_dict) in iterable:
- curr_batch_size = input.shape[0]
- for key in target_dict.keys():
- if key == 'breed_index':
- target_dict[key] = target_dict[key].long().to(device)
- elif key in ['index', 'pts', 'tpts', 'target_weight', 'silh', 'silh_distmat_tofg', 'silh_distmat_tobg', 'sim_breed_index', 'img_border_mask']:
- target_dict[key] = target_dict[key].float().to(device)
- elif key in ['has_seg', 'gc']:
- target_dict[key] = target_dict[key].to(device)
- else:
- pass
- input = input.float().to(device)
-
- # ----------------------- do validation step -----------------------
- with torch.no_grad():
- # ----- forward pass -----
- # output: (['pose', 'flength', 'trans', 'keypoints_norm', 'keypoints_scores'])
- # output_unnorm: (['pose_rotmat', 'flength', 'trans', 'keypoints'])
- # output_reproj: (['vertices_smal', 'torch_meshes', 'keyp_3d', 'keyp_2d', 'silh', 'betas', 'pose_rot6d', 'dog_breed', 'shapedirs', 'z', 'flength_unnorm', 'flength'])
- # target_dict: (['index', 'center', 'scale', 'pts', 'tpts', 'target_weight', 'breed_index', 'sim_breed_index', 'ind_dataset', 'silh'])
- output, output_unnorm, output_reproj = model(input, norm_dict=norm_dict)
- # ----- loss -----
- if metrics == 'no_loss':
- loss, loss_dict = loss_module(output_reproj=output_reproj,
- target_dict=target_dict,
- weight_dict=weight_dict)
- # ----------------------------------------------------------------
-
- if i == 0:
- if len_dataset is None:
- len_data = val_loader.batch_size * len(val_loader) # 1703
- else:
- len_data = len_dataset
- if metrics == 'all' or metrics == 'no_loss':
- pck = np.zeros((len_data))
- pck_by_part = {group:np.zeros((len_data)) for group in KEYPOINT_GROUPS}
- acc_sil_2d = np.zeros(len_data)
-
- all_betas = np.zeros((len_data, output_reproj['betas'].shape[1]))
- all_betas_limbs = np.zeros((len_data, output_reproj['betas_limbs'].shape[1]))
- all_z = np.zeros((len_data, output_reproj['z'].shape[1]))
- all_pose_rotmat = np.zeros((len_data, output_unnorm['pose_rotmat'].shape[1], 3, 3))
- all_flength = np.zeros((len_data, output_unnorm['flength'].shape[1]))
- all_trans = np.zeros((len_data, output_unnorm['trans'].shape[1]))
- all_breed_indices = np.zeros((len_data))
- all_image_names = [] # len_data * [None]
-
- index = i
- ind_img = 0
- if save_imgs_path is not None:
- # render predicted 3d models
- visualizations = model.render_vis_nograd(vertices=output_reproj['vertices_smal'],
- focal_lengths=output_unnorm['flength'],
- color=0) # color=2)
- for ind_img in range(len(target_dict['index'])):
- try:
- if test_name_list is not None:
- img_name = test_name_list[int(target_dict['index'][ind_img].cpu().detach().numpy())].replace('/', '_')
- img_name = img_name.split('.')[0]
- else:
- img_name = str(index) + '_' + str(ind_img)
- # save image with predicted keypoints
- out_path = save_imgs_path + '/keypoints_pred_' + img_name + '.png'
- pred_unp = (output['keypoints_norm'][ind_img, :, :] + 1.) / 2 * (data_info.image_size - 1)
- pred_unp_maxval = output['keypoints_scores'][ind_img, :, :]
- pred_unp_prep = torch.cat((pred_unp, pred_unp_maxval), 1)
- inp_img = input[ind_img, :, :, :].detach().clone()
- save_input_image_with_keypoints(inp_img, pred_unp_prep, out_path=out_path, threshold=0.1, print_scores=True, ratio_in_out=1.0) # threshold=0.3
- # save predicted 3d model (front view)
- pred_tex = visualizations[ind_img, :, :, :].permute((1, 2, 0)).cpu().detach().numpy() / 256
- pred_tex_max = np.max(pred_tex, axis=2)
- out_path = save_imgs_path + '/tex_pred_' + img_name + '.png'
- plt.imsave(out_path, pred_tex)
- input_image = input[ind_img, :, :, :].detach().clone()
- for t, m, s in zip(input_image, data_info.rgb_mean, data_info.rgb_stddev): t.add_(m)
- input_image_np = input_image.detach().cpu().numpy().transpose(1, 2, 0)
- im_masked = cv2.addWeighted(input_image_np,0.2,pred_tex,0.8,0)
- im_masked[pred_tex_max<0.01, :] = input_image_np[pred_tex_max<0.01, :]
- out_path = save_imgs_path + '/comp_pred_' + img_name + '.png'
- plt.imsave(out_path, im_masked)
- # save predicted 3d model (side view)
- vertices_cent = output_reproj['vertices_smal'] - output_reproj['vertices_smal'].mean(dim=1)[:, None, :]
- roll = np.pi / 2 * torch.ones(1).float().to(device)
- pitch = np.pi / 2 * torch.ones(1).float().to(device)
- tensor_0 = torch.zeros(1).float().to(device)
- tensor_1 = torch.ones(1).float().to(device)
- RX = torch.stack([torch.stack([tensor_1, tensor_0, tensor_0]), torch.stack([tensor_0, torch.cos(roll), -torch.sin(roll)]),torch.stack([tensor_0, torch.sin(roll), torch.cos(roll)])]).reshape(3,3)
- RY = torch.stack([
- torch.stack([torch.cos(pitch), tensor_0, torch.sin(pitch)]),
- torch.stack([tensor_0, tensor_1, tensor_0]),
- torch.stack([-torch.sin(pitch), tensor_0, torch.cos(pitch)])]).reshape(3,3)
- vertices_rot = (torch.matmul(RY, vertices_cent.reshape((-1, 3))[:, :, None])).reshape((curr_batch_size, -1, 3))
- vertices_rot[:, :, 2] = vertices_rot[:, :, 2] + torch.ones_like(vertices_rot[:, :, 2]) * 20 # 18 # *16
-
- visualizations_rot = model.render_vis_nograd(vertices=vertices_rot,
- focal_lengths=output_unnorm['flength'],
- color=0) # 2)
- pred_tex = visualizations_rot[ind_img, :, :, :].permute((1, 2, 0)).cpu().detach().numpy() / 256
- pred_tex_max = np.max(pred_tex, axis=2)
- out_path = save_imgs_path + '/rot_tex_pred_' + img_name + '.png'
- plt.imsave(out_path, pred_tex)
- if render_all:
- # save input image
- inp_img = input[ind_img, :, :, :].detach().clone()
- out_path = save_imgs_path + '/image_' + img_name + '.png'
- save_input_image(inp_img, out_path)
- # save mesh
- V_posed = output_reproj['vertices_smal'][ind_img, :, :].detach().cpu().numpy()
- Faces = model.smal.f
- mesh_posed = trimesh.Trimesh(vertices=V_posed, faces=Faces, process=False, maintain_order=True)
- mesh_posed.export(save_imgs_path + '/mesh_posed_' + img_name + '.obj')
- except:
- print('dont save an image')
-
- if metrics == 'all' or metrics == 'no_loss':
- # prepare a dictionary with all the predicted results
- preds = {}
- preds['betas'] = output_reproj['betas'].cpu().detach().numpy()
- preds['betas_limbs'] = output_reproj['betas_limbs'].cpu().detach().numpy()
- preds['z'] = output_reproj['z'].cpu().detach().numpy()
- preds['pose_rotmat'] = output_unnorm['pose_rotmat'].cpu().detach().numpy()
- preds['flength'] = output_unnorm['flength'].cpu().detach().numpy()
- preds['trans'] = output_unnorm['trans'].cpu().detach().numpy()
- preds['breed_index'] = target_dict['breed_index'].cpu().detach().numpy().reshape((-1))
- img_names = []
- for ind_img2 in range(0, output_reproj['betas'].shape[0]):
- if test_name_list is not None:
- img_name2 = test_name_list[int(target_dict['index'][ind_img2].cpu().detach().numpy())].replace('/', '_')
- img_name2 = img_name2.split('.')[0]
- else:
- img_name2 = str(index) + '_' + str(ind_img2)
- img_names.append(img_name2)
- preds['image_names'] = img_names
- # prepare keypoints for PCK calculation - predicted as well as ground truth
- pred_keypoints_norm = output['keypoints_norm'] # -1 to 1
- pred_keypoints_256 = output_reproj['keyp_2d']
- pred_keypoints = pred_keypoints_256
- gt_keypoints_256 = target_dict['tpts'][:, :, :2] / 64. * (256. - 1)
- gt_keypoints_norm = gt_keypoints_256 / 256 / 0.5 - 1
- gt_keypoints = torch.cat((gt_keypoints_256, target_dict['tpts'][:, :, 2:3]), dim=2) # gt_keypoints_norm
- # prepare silhouette for IoU calculation - predicted as well as ground truth
- has_seg = target_dict['has_seg']
- img_border_mask = target_dict['img_border_mask'][:, 0, :, :]
- gtseg = target_dict['silh']
- synth_silhouettes = output_reproj['silh'][:, 0, :, :] # output_reproj['silh']
- synth_silhouettes[synth_silhouettes>0.5] = 1
- synth_silhouettes[synth_silhouettes<0.5] = 0
- # calculate PCK as well as IoU (similar to WLDO)
- preds['acc_PCK'] = Metrics.PCK(
- pred_keypoints, gt_keypoints,
- gtseg, has_seg, idxs=EVAL_KEYPOINTS,
- thresh_range=[pck_thresh], # [0.15],
- )
- preds['acc_IOU'] = Metrics.IOU(
- synth_silhouettes, gtseg,
- img_border_mask, mask=has_seg
- )
- for group, group_kps in KEYPOINT_GROUPS.items():
- preds[f'{group}_PCK'] = Metrics.PCK(
- pred_keypoints, gt_keypoints, gtseg, has_seg,
- thresh_range=[pck_thresh], # [0.15],
- idxs=group_kps
- )
- # add results for all images in this batch to lists
- curr_batch_size = pred_keypoints_256.shape[0]
- if not (preds['acc_PCK'].data.cpu().numpy().shape == (pck[my_step * batch_size:my_step * batch_size + curr_batch_size]).shape):
- import pdb; pdb.set_trace()
- pck[my_step * batch_size:my_step * batch_size + curr_batch_size] = preds['acc_PCK'].data.cpu().numpy()
- acc_sil_2d[my_step * batch_size:my_step * batch_size + curr_batch_size] = preds['acc_IOU'].data.cpu().numpy()
- for part in pck_by_part:
- pck_by_part[part][my_step * batch_size:my_step * batch_size + curr_batch_size] = preds[f'{part}_PCK'].data.cpu().numpy()
- all_betas[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['betas']
- all_betas_limbs[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['betas_limbs']
- all_z[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['z']
- all_pose_rotmat[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['pose_rotmat']
- all_flength[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['flength']
- all_trans[my_step * batch_size:my_step * batch_size + curr_batch_size, ...] = preds['trans']
- all_breed_indices[my_step * batch_size:my_step * batch_size + curr_batch_size] = preds['breed_index']
- all_image_names.extend(preds['image_names'])
- # update progress bar
- if progress is not None:
- my_string = "PCK: {0:.2f}, IOU: {1:.2f}".format(
- pck[:(my_step * batch_size + curr_batch_size)].mean(),
- acc_sil_2d[:(my_step * batch_size + curr_batch_size)].mean())
- progress.set_postfix_str(my_string)
- else:
- # measure accuracy and record loss
- bs_fake = 1 # batch_size
- losses.update(loss_dict['loss'], bs_fake)
- losses_keyp.update(loss_dict['loss_keyp_weighted'], bs_fake)
- losses_silh.update(loss_dict['loss_silh_weighted'], bs_fake)
- losses_shape.update(loss_dict['loss_shape_weighted'], bs_fake)
- losses_pose.update(loss_dict['loss_poseprior_weighted'], bs_fake)
- losses_class.update(loss_dict['loss_class_weighted'], bs_fake)
- losses_breed.update(loss_dict['loss_breed_weighted'], bs_fake)
- losses_partseg.update(loss_dict['loss_partseg_weighted'], bs_fake)
- acc = - loss_dict['loss_keyp_weighted'] # this will be used to keep track of the 'best model'
- accuracies.update(acc, bs_fake)
- # Show losses as part of the progress bar.
- if progress is not None:
- my_string = 'Loss: {loss:0.4f}, loss_keyp: {loss_keyp:0.4f}, loss_silh: {loss_silh:0.4f}, loss_partseg: {loss_partseg:0.4f}, loss_shape: {loss_shape:0.4f}, loss_pose: {loss_pose:0.4f}, loss_class: {loss_class:0.4f}, loss_breed: {loss_breed:0.4f}'.format(
- loss=losses.avg,
- loss_keyp=losses_keyp.avg,
- loss_silh=losses_silh.avg,
- loss_shape=losses_shape.avg,
- loss_pose=losses_pose.avg,
- loss_class=losses_class.avg,
- loss_breed=losses_breed.avg,
- loss_partseg=losses_partseg.avg
- )
- progress.set_postfix_str(my_string)
- my_step += 1
- if metrics == 'all':
- summary = {'pck': pck, 'acc_sil_2d': acc_sil_2d, 'pck_by_part':pck_by_part,
- 'betas': all_betas, 'betas_limbs': all_betas_limbs, 'z': all_z, 'pose_rotmat': all_pose_rotmat,
- 'flenght': all_flength, 'trans': all_trans, 'image_names': all_image_names, 'breed_indices': all_breed_indices}
- return my_string, summary
- elif metrics == 'no_loss':
- return my_string, np.average(np.asarray(acc_sil_2d))
- else:
- return my_string, accuracies.avg
-
-
-# ---------------------------------------------------------------------------------------------------------------------------
-def do_visual_epoch(val_loader, model, device, data_info, flip=False, quiet=False, acc_joints=None, save_imgs_path=None, weight_dict=None, metrics=None, val_opt='default', test_name_list=None, render_all=False, pck_thresh=0.15, return_results=False):
- if save_imgs_path is not None:
- pathlib.Path(save_imgs_path).mkdir(parents=True, exist_ok=True)
- all_results = []
-
- # Put the model in evaluation mode.
- model.eval()
-
- iterable = enumerate(val_loader)
-
- # information for normalization
- norm_dict = {
- 'pose_rot6d_mean': torch.from_numpy(data_info.pose_rot6d_mean).float().to(device),
- 'trans_mean': torch.from_numpy(data_info.trans_mean).float().to(device),
- 'trans_std': torch.from_numpy(data_info.trans_std).float().to(device),
- 'flength_mean': torch.from_numpy(data_info.flength_mean).float().to(device),
- 'flength_std': torch.from_numpy(data_info.flength_std).float().to(device)}
-
- '''
- return_mesh_with_gt_groundplane = True
- if return_mesh_with_gt_groundplane:
- remeshing_path = '/is/cluster/work/nrueegg/icon_pifu_related/barc_for_bite/data/smal_data_remeshed/uniform_surface_sampling/my_smpl_39dogsnorm_Jr_4_dog_remesh4000_info.pkl'
- with open(remeshing_path, 'rb') as fp:
- remeshing_dict = pkl.load(fp)
- remeshing_relevant_faces = torch.tensor(remeshing_dict['smal_faces'][remeshing_dict['faceid_closest']], dtype=torch.long, device=device)
- remeshing_relevant_barys = torch.tensor(remeshing_dict['barys_closest'], dtype=torch.float32, device=device)
-
- # from smal_pytorch.smal_model.smal_torch_new import SMAL
- print('start: load smal default model (barc), but only for vertices')
- smal = SMAL()
- print('end: load smal default model (barc), but only for vertices')
- smal_template_verts = smal.v_template.detach().cpu().numpy()
- smal_faces = smal.faces.detach().cpu().numpy()
-
- file_alignment_errors = open(save_imgs_path + '/a_ref_procrustes_alignmnet_errors.txt', 'a') # append mode
- file_alignment_errors.write(" ----------- start evaluation ------------- \n ")
-
- csv_file_alignment_errors = open(save_imgs_path + '/a_ref_procrustes_alignmnet_errors.csv', 'w') # write mode
- fieldnames = ['name', 'error']
- writer = csv.DictWriter(csv_file_alignment_errors, fieldnames=fieldnames)
- writer.writeheader()
- '''
-
- my_step = 0
- for i, (input, target_dict) in iterable:
- batch_size = input.shape[0]
- input = input.float().to(device)
- partial_results = {}
-
- # ----------------------- do visualization step -----------------------
- with torch.no_grad():
- output, output_unnorm, output_reproj = model(input, norm_dict=norm_dict)
-
- index = i
- ind_img = 0
- for ind_img in range(batch_size): # range(min(12, batch_size)): # range(12): # [0]: #range(0, batch_size):
-
- try:
- if test_name_list is not None:
- img_name = test_name_list[int(target_dict['index'][ind_img].cpu().detach().numpy())].replace('/', '_')
- img_name = img_name.split('.')[0]
- else:
- img_name = str(index) + '_' + str(ind_img)
- partial_results['img_name'] = img_name
- visualizations = model.render_vis_nograd(vertices=output_reproj['vertices_smal'],
- focal_lengths=output_unnorm['flength'],
- color=0) # 2)
- # save image with predicted keypoints
- pred_unp = (output['keypoints_norm'][ind_img, :, :] + 1.) / 2 * (data_info.image_size - 1)
- pred_unp_maxval = output['keypoints_scores'][ind_img, :, :]
- pred_unp_prep = torch.cat((pred_unp, pred_unp_maxval), 1)
- inp_img = input[ind_img, :, :, :].detach().clone()
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/keypoints_pred_' + img_name + '.png'
- save_input_image_with_keypoints(inp_img, pred_unp_prep, out_path=out_path, threshold=0.1, print_scores=True, ratio_in_out=1.0) # threshold=0.3
- # save predicted 3d model
- # (1) front view
- pred_tex = visualizations[ind_img, :, :, :].permute((1, 2, 0)).cpu().detach().numpy() / 256
- pred_tex_max = np.max(pred_tex, axis=2)
- partial_results['tex_pred'] = pred_tex
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/tex_pred_' + img_name + '.png'
- plt.imsave(out_path, pred_tex)
- input_image = input[ind_img, :, :, :].detach().clone()
- for t, m, s in zip(input_image, data_info.rgb_mean, data_info.rgb_stddev): t.add_(m)
- input_image_np = input_image.detach().cpu().numpy().transpose(1, 2, 0)
- im_masked = cv2.addWeighted(input_image_np,0.2,pred_tex,0.8,0)
- im_masked[pred_tex_max<0.01, :] = input_image_np[pred_tex_max<0.01, :]
- partial_results['comp_pred'] = im_masked
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/comp_pred_' + img_name + '.png'
- plt.imsave(out_path, im_masked)
- # (2) side view
- vertices_cent = output_reproj['vertices_smal'] - output_reproj['vertices_smal'].mean(dim=1)[:, None, :]
- roll = np.pi / 2 * torch.ones(1).float().to(device)
- pitch = np.pi / 2 * torch.ones(1).float().to(device)
- tensor_0 = torch.zeros(1).float().to(device)
- tensor_1 = torch.ones(1).float().to(device)
- RX = torch.stack([torch.stack([tensor_1, tensor_0, tensor_0]), torch.stack([tensor_0, torch.cos(roll), -torch.sin(roll)]),torch.stack([tensor_0, torch.sin(roll), torch.cos(roll)])]).reshape(3,3)
- RY = torch.stack([
- torch.stack([torch.cos(pitch), tensor_0, torch.sin(pitch)]),
- torch.stack([tensor_0, tensor_1, tensor_0]),
- torch.stack([-torch.sin(pitch), tensor_0, torch.cos(pitch)])]).reshape(3,3)
- vertices_rot = (torch.matmul(RY, vertices_cent.reshape((-1, 3))[:, :, None])).reshape((batch_size, -1, 3))
- vertices_rot[:, :, 2] = vertices_rot[:, :, 2] + torch.ones_like(vertices_rot[:, :, 2]) * 20 # 18 # *16
- visualizations_rot = model.render_vis_nograd(vertices=vertices_rot,
- focal_lengths=output_unnorm['flength'],
- color=0) # 2)
- pred_tex = visualizations_rot[ind_img, :, :, :].permute((1, 2, 0)).cpu().detach().numpy() / 256
- pred_tex_max = np.max(pred_tex, axis=2)
- partial_results['rot_tex_pred'] = pred_tex
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/rot_tex_pred_' + img_name + '.png'
- plt.imsave(out_path, pred_tex)
- render_all = True
- if render_all:
- # save input image
- inp_img = input[ind_img, :, :, :].detach().clone()
- if save_imgs_path is not None:
- out_path = save_imgs_path + '/image_' + img_name + '.png'
- save_input_image(inp_img, out_path)
- # save posed mesh
- V_posed = output_reproj['vertices_smal'][ind_img, :, :].detach().cpu().numpy()
- Faces = model.smal.f
- mesh_posed = trimesh.Trimesh(vertices=V_posed, faces=Faces, process=False, maintain_order=True)
- partial_results['mesh_posed'] = mesh_posed
- if save_imgs_path is not None:
- mesh_posed.export(save_imgs_path + '/mesh_posed_' + img_name + '.obj')
- except:
- print('pass...')
- all_results.append(partial_results)
- if return_results:
- return all_results
- else:
- return
\ No newline at end of file
diff --git a/spaces/scedlatioru/img-to-music/example/Age Of Empires 2 Expansion 1.0c No Cd ((FULL)) Crack.md b/spaces/scedlatioru/img-to-music/example/Age Of Empires 2 Expansion 1.0c No Cd ((FULL)) Crack.md
deleted file mode 100644
index 1792c0401aeba674eabf95be5648d0dbabf9b24d..0000000000000000000000000000000000000000
--- a/spaces/scedlatioru/img-to-music/example/Age Of Empires 2 Expansion 1.0c No Cd ((FULL)) Crack.md
+++ /dev/null
@@ -1,14 +0,0 @@
-age of empires 2 expansion 1.0c no cd crack
Download File ✸ https://gohhs.com/2uEzml
-
-Sep 2, 2019 - This update does not allow you to play without a CD and requires a valid, existing Age of Empires II: The Conquerors Expansion v1.0c installation. To ... - Download - Download - Download - Download - Download - Download ...
-- How to Run Age ...
-- How to play Age of Empires 2: The Conquerors for free
-20 Jan. 2020 г. - How to play Age of Empires 2: The Conquerors for free in your browser.
-Step-by-step instructions on how to start Age of Empires II: The Conquerors without
-Mar 10, 2018. - ... Without registration.
-Age of Empires II: The Conquerors download torrent without ...
-Age of Empires II: The Conquerors (RUS) (Windows / Mac OS
-8 Febr. 8a78ff9644
-
-
-
diff --git a/spaces/scedlatioru/img-to-music/example/Forza Motorsport 4 Pc Torrent Download WORK.md b/spaces/scedlatioru/img-to-music/example/Forza Motorsport 4 Pc Torrent Download WORK.md
deleted file mode 100644
index 8ce93525f11a8bbc6eb45308162ff9c6475b8e36..0000000000000000000000000000000000000000
--- a/spaces/scedlatioru/img-to-music/example/Forza Motorsport 4 Pc Torrent Download WORK.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Forza Motorsport 4 Pc Torrent Download
DOWNLOAD ✫ https://gohhs.com/2uEABC
-
-Prize Crates were loot box items in Forza Motorsport 7. WHEEL FIXED Apr 12 2020 TITLE Forza Horizon 4 Ultimate Edition PC Torrent Download LOOTBOXÂ ... 1fdad05405
-
-
-
diff --git a/spaces/scedlatioru/img-to-music/example/Microsoft Qbasic Free NEW Download For Windows 7 64 Bit.md b/spaces/scedlatioru/img-to-music/example/Microsoft Qbasic Free NEW Download For Windows 7 64 Bit.md
deleted file mode 100644
index e07feabe15164665e9854aecc8e1dd2170ac949c..0000000000000000000000000000000000000000
--- a/spaces/scedlatioru/img-to-music/example/Microsoft Qbasic Free NEW Download For Windows 7 64 Bit.md
+++ /dev/null
@@ -1,12 +0,0 @@
-
-regsvr32 %systemroot%\system32\msi.dll
microsoft qbasic free download for windows 7 64 bit run the following command at an elevated command prompt (that is, an elevated command prompt is one that runs with administrator rights).
-regsvr32 %systemroot%\system32\msiext.dll
microsoft qbasic free download for windows 7 64 bit run the following command at an elevated command prompt (that is, an elevated command prompt is one that runs with administrator rights).
-microsoft qbasic free download for windows 7 64 bit
DOWNLOAD ⚙ https://gohhs.com/2uEzkl
-regsvr32 %systemroot%\system32\msiaupd.dll
microsoft qbasic free download for windows 7 64 bit run the following command at an elevated command prompt (that is, an elevated command prompt is one that runs with administrator rights).
-regsvr32 %systemroot%\system32\msislive.dll
microsoft qbasic free download for windows 7 64 bit run the following command at an elevated command prompt (that is, an elevated command prompt is one that runs with administrator rights).
-regsvr32 %systemroot%\system32\msisc.dll
microsoft qbasic free download for windows 7 64 bit run the following command at an elevated command prompt (that is, an elevated command prompt is one that runs with administrator rights).
-regsvr32 %systemroot%\system32\msidbg.dll
microsoft qbasic free download for windows 7 64 bit run the following command at an elevated command prompt (that is, an elevated command prompt is one that runs with administrator rights).
-
-regsvr32 %systemroot%\system32\msiexec.dll
microsoft qbasic free download for windows 7 64 bit run the following command at an elevated command prompt (that is, an elevated command prompt is one that runs with administrator rights).
899543212b
-
-
\ No newline at end of file
diff --git a/spaces/scedlatioru/img-to-music/example/RACE By David Mamet.pdf _VERIFIED_.md b/spaces/scedlatioru/img-to-music/example/RACE By David Mamet.pdf _VERIFIED_.md
deleted file mode 100644
index 092c83ad44ce5ab1d48b24c544a352231297125b..0000000000000000000000000000000000000000
--- a/spaces/scedlatioru/img-to-music/example/RACE By David Mamet.pdf _VERIFIED_.md
+++ /dev/null
@@ -1,6 +0,0 @@
-RACE by David Mamet.pdf
Download File >> https://gohhs.com/2uEz5u
-
-Livres de professor david mamet; Télécharger EPUB PDF [Race] (By: Professor David Mamet) [published: January, 2011] 4d29de3e1b
-
-
-
diff --git a/spaces/senior-sigan/vgg_style_transfer/README.md b/spaces/senior-sigan/vgg_style_transfer/README.md
deleted file mode 100644
index 0ae5940cbed547cedbd0b1085afd9df98c196b17..0000000000000000000000000000000000000000
--- a/spaces/senior-sigan/vgg_style_transfer/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Vgg_style_transfer
-emoji: 🌖
-colorFrom: gray
-colorTo: red
-sdk: gradio
-sdk_version: 2.9.1
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/shengzi/uer-gpt2-chinese-cluecorpussmall/README.md b/spaces/shengzi/uer-gpt2-chinese-cluecorpussmall/README.md
deleted file mode 100644
index 0a93fcd8841f9f487112bd4fdb67cac3a4c045e4..0000000000000000000000000000000000000000
--- a/spaces/shengzi/uer-gpt2-chinese-cluecorpussmall/README.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: Uer Gpt2 Chinese Cluecorpussmall
-emoji: 😻
-colorFrom: gray
-colorTo: green
-sdk: docker
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/shi-labs/OneFormer/oneformer/modeling/pixel_decoder/ops/functions/ms_deform_attn_func.py b/spaces/shi-labs/OneFormer/oneformer/modeling/pixel_decoder/ops/functions/ms_deform_attn_func.py
deleted file mode 100644
index ecfea82f3e6ac34cd8b1abc2d1de5b0f4eaed343..0000000000000000000000000000000000000000
--- a/spaces/shi-labs/OneFormer/oneformer/modeling/pixel_decoder/ops/functions/ms_deform_attn_func.py
+++ /dev/null
@@ -1,77 +0,0 @@
-# ------------------------------------------------------------------------------------------------
-# Deformable DETR
-# Copyright (c) 2020 SenseTime. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# ------------------------------------------------------------------------------------------------
-# Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
-# ------------------------------------------------------------------------------------------------
-
-# Copyright (c) Facebook, Inc. and its affiliates.
-# Modified by Bowen Cheng from https://github.com/fundamentalvision/Deformable-DETR
-
-
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import division
-
-import torch
-import torch.nn.functional as F
-from torch.autograd import Function
-from torch.autograd.function import once_differentiable
-
-if torch.cuda.is_available():
- try:
- import MultiScaleDeformableAttention as MSDA
- except ModuleNotFoundError as e:
- info_string = (
- "\n\nPlease compile MultiScaleDeformableAttention CUDA op with the following commands:\n"
- "\t`cd oneformer/modeling/pixel_decoder/ops`\n"
- "\t`sh make.sh`\n"
- )
- raise ModuleNotFoundError(info_string)
-else:
- MultiScaleDeformableAttention = None
-
-
-
-class MSDeformAttnFunction(Function):
- @staticmethod
- def forward(ctx, value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights, im2col_step):
- ctx.im2col_step = im2col_step
- output = MSDA.ms_deform_attn_forward(
- value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights, ctx.im2col_step)
- ctx.save_for_backward(value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights)
- return output
-
- @staticmethod
- @once_differentiable
- def backward(ctx, grad_output):
- value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights = ctx.saved_tensors
- grad_value, grad_sampling_loc, grad_attn_weight = \
- MSDA.ms_deform_attn_backward(
- value, value_spatial_shapes, value_level_start_index, sampling_locations, attention_weights, grad_output, ctx.im2col_step)
-
- return grad_value, None, None, grad_sampling_loc, grad_attn_weight, None
-
-
-def ms_deform_attn_core_pytorch(value, value_spatial_shapes, sampling_locations, attention_weights):
- # for debug and test only,
- # need to use cuda version instead
- N_, S_, M_, D_ = value.shape
- _, Lq_, M_, L_, P_, _ = sampling_locations.shape
- value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)
- sampling_grids = 2 * sampling_locations - 1
- sampling_value_list = []
- for lid_, (H_, W_) in enumerate(value_spatial_shapes):
- # N_, H_*W_, M_, D_ -> N_, H_*W_, M_*D_ -> N_, M_*D_, H_*W_ -> N_*M_, D_, H_, W_
- value_l_ = value_list[lid_].flatten(2).transpose(1, 2).reshape(N_*M_, D_, H_, W_)
- # N_, Lq_, M_, P_, 2 -> N_, M_, Lq_, P_, 2 -> N_*M_, Lq_, P_, 2
- sampling_grid_l_ = sampling_grids[:, :, :, lid_].transpose(1, 2).flatten(0, 1)
- # N_*M_, D_, Lq_, P_
- sampling_value_l_ = F.grid_sample(value_l_, sampling_grid_l_,
- mode='bilinear', padding_mode='zeros', align_corners=False)
- sampling_value_list.append(sampling_value_l_)
- # (N_, Lq_, M_, L_, P_) -> (N_, M_, Lq_, L_, P_) -> (N_, M_, 1, Lq_, L_*P_)
- attention_weights = attention_weights.transpose(1, 2).reshape(N_*M_, 1, Lq_, L_*P_)
- output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(N_, M_*D_, Lq_)
- return output.transpose(1, 2).contiguous()
diff --git a/spaces/shi-labs/Prompt-Free-Diffusion/README.md b/spaces/shi-labs/Prompt-Free-Diffusion/README.md
deleted file mode 100644
index 5833f05cd1f7d45e4fb34dca078577a12b783221..0000000000000000000000000000000000000000
--- a/spaces/shi-labs/Prompt-Free-Diffusion/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Prompt-Free Diffusion
-emoji: 👀
-colorFrom: red
-colorTo: blue
-sdk: gradio
-sdk_version: 3.32.0
-app_file: app.py
-pinned: false
-license: mit
-python_version: 3.10.11
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/shi-labs/Prompt-Free-Diffusion/lib/model_zoo/controlnet_annotator/hed/__init__.py b/spaces/shi-labs/Prompt-Free-Diffusion/lib/model_zoo/controlnet_annotator/hed/__init__.py
deleted file mode 100644
index 8dcfaeb55887ef0fa0928e817e2ac46de1669923..0000000000000000000000000000000000000000
--- a/spaces/shi-labs/Prompt-Free-Diffusion/lib/model_zoo/controlnet_annotator/hed/__init__.py
+++ /dev/null
@@ -1,134 +0,0 @@
-# This is an improved version and model of HED edge detection with Apache License, Version 2.0.
-# Please use this implementation in your products
-# This implementation may produce slightly different results from Saining Xie's official implementations,
-# but it generates smoother edges and is more suitable for ControlNet as well as other image-to-image translations.
-# Different from official models and other implementations, this is an RGB-input model (rather than BGR)
-# and in this way it works better for gradio's RGB protocol
-
-import os
-import cv2
-import torch
-import numpy as np
-
-from einops import rearrange
-import os
-
-models_path = 'pretrained/controlnet/preprocess'
-
-def safe_step(x, step=2):
- y = x.astype(np.float32) * float(step + 1)
- y = y.astype(np.int32).astype(np.float32) / float(step)
- return y
-
-class DoubleConvBlock(torch.nn.Module):
- def __init__(self, input_channel, output_channel, layer_number):
- super().__init__()
- self.convs = torch.nn.Sequential()
- self.convs.append(torch.nn.Conv2d(in_channels=input_channel, out_channels=output_channel, kernel_size=(3, 3), stride=(1, 1), padding=1))
- for i in range(1, layer_number):
- self.convs.append(torch.nn.Conv2d(in_channels=output_channel, out_channels=output_channel, kernel_size=(3, 3), stride=(1, 1), padding=1))
- self.projection = torch.nn.Conv2d(in_channels=output_channel, out_channels=1, kernel_size=(1, 1), stride=(1, 1), padding=0)
-
- def __call__(self, x, down_sampling=False):
- h = x
- if down_sampling:
- h = torch.nn.functional.max_pool2d(h, kernel_size=(2, 2), stride=(2, 2))
- for conv in self.convs:
- h = conv(h)
- h = torch.nn.functional.relu(h)
- return h, self.projection(h)
-
-
-class ControlNetHED_Apache2(torch.nn.Module):
- def __init__(self):
- super().__init__()
- self.norm = torch.nn.Parameter(torch.zeros(size=(1, 3, 1, 1)))
- self.block1 = DoubleConvBlock(input_channel=3, output_channel=64, layer_number=2)
- self.block2 = DoubleConvBlock(input_channel=64, output_channel=128, layer_number=2)
- self.block3 = DoubleConvBlock(input_channel=128, output_channel=256, layer_number=3)
- self.block4 = DoubleConvBlock(input_channel=256, output_channel=512, layer_number=3)
- self.block5 = DoubleConvBlock(input_channel=512, output_channel=512, layer_number=3)
-
- def __call__(self, x):
- h = x - self.norm
- h, projection1 = self.block1(h)
- h, projection2 = self.block2(h, down_sampling=True)
- h, projection3 = self.block3(h, down_sampling=True)
- h, projection4 = self.block4(h, down_sampling=True)
- h, projection5 = self.block5(h, down_sampling=True)
- return projection1, projection2, projection3, projection4, projection5
-
-
-netNetwork = None
-remote_model_path = "https://huggingface.co/lllyasviel/Annotators/resolve/main/ControlNetHED.pth"
-modeldir = os.path.join(models_path, "hed")
-old_modeldir = os.path.dirname(os.path.realpath(__file__))
-
-
-def load_file_from_url(url, model_dir=None, progress=True, file_name=None):
- """Load file form http url, will download models if necessary.
-
- Ref:https://github.com/1adrianb/face-alignment/blob/master/face_alignment/utils.py
-
- Args:
- url (str): URL to be downloaded.
- model_dir (str): The path to save the downloaded model. Should be a full path. If None, use pytorch hub_dir.
- Default: None.
- progress (bool): Whether to show the download progress. Default: True.
- file_name (str): The downloaded file name. If None, use the file name in the url. Default: None.
-
- Returns:
- str: The path to the downloaded file.
- """
- from torch.hub import download_url_to_file, get_dir
- from urllib.parse import urlparse
- if model_dir is None: # use the pytorch hub_dir
- hub_dir = get_dir()
- model_dir = os.path.join(hub_dir, 'checkpoints')
-
- os.makedirs(model_dir, exist_ok=True)
-
- parts = urlparse(url)
- filename = os.path.basename(parts.path)
- if file_name is not None:
- filename = file_name
- cached_file = os.path.abspath(os.path.join(model_dir, filename))
- if not os.path.exists(cached_file):
- print(f'Downloading: "{url}" to {cached_file}\n')
- download_url_to_file(url, cached_file, hash_prefix=None, progress=progress)
- return cached_file
-
-
-def apply_hed(input_image, is_safe=False, device='cpu'):
- global netNetwork
- if netNetwork is None:
- modelpath = os.path.join(modeldir, "ControlNetHED.pth")
- old_modelpath = os.path.join(old_modeldir, "ControlNetHED.pth")
- if os.path.exists(old_modelpath):
- modelpath = old_modelpath
- elif not os.path.exists(modelpath):
- load_file_from_url(remote_model_path, model_dir=modeldir)
- netNetwork = ControlNetHED_Apache2().to(device)
- netNetwork.load_state_dict(torch.load(modelpath, map_location='cpu'))
- netNetwork.to(device).float().eval()
-
- assert input_image.ndim == 3
- H, W, C = input_image.shape
- with torch.no_grad():
- image_hed = torch.from_numpy(input_image.copy()).float().to(device)
- image_hed = rearrange(image_hed, 'h w c -> 1 c h w')
- edges = netNetwork(image_hed)
- edges = [e.detach().cpu().numpy().astype(np.float32)[0, 0] for e in edges]
- edges = [cv2.resize(e, (W, H), interpolation=cv2.INTER_LINEAR) for e in edges]
- edges = np.stack(edges, axis=2)
- edge = 1 / (1 + np.exp(-np.mean(edges, axis=2).astype(np.float64)))
- if is_safe:
- edge = safe_step(edge)
- edge = (edge * 255.0).clip(0, 255).astype(np.uint8)
- return edge
-
-
-def unload_hed_model():
- global netNetwork
- if netNetwork is not None:
- netNetwork.cpu()
diff --git a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/7Zip APK for Android How to Extract Open and Create Zip Files.md b/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/7Zip APK for Android How to Extract Open and Create Zip Files.md
deleted file mode 100644
index eda2ea2e841389fb0202be5f158f1401cb848de1..0000000000000000000000000000000000000000
--- a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/7Zip APK for Android How to Extract Open and Create Zip Files.md
+++ /dev/null
@@ -1,111 +0,0 @@
-
-7Zip Download APK: How to Install and Use the Best File Compression App for Android
-If you are looking for a way to save space on your Android device, reduce the size of your files or folders, or secure your data with encryption, then you need a file compression app. And one of the best file compression apps that you can use is 7Zip. In this article, we will show you what 7Zip is, why you need it, how to download and install it on your Android device, and how to use it to create, extract or browse archive files.
-7zip download apk
Download Zip - https://ssurll.com/2uNRA4
-What is 7Zip and why do you need it?
-7Zip is a free and open source file compression and archiving software
-7Zip is a popular software that has been around since 1999. It is developed by Igor Pavlov and licensed under the GNU LGPL license. It is available for Windows, Linux, MacOS, and Android platforms. You can download it from its official website or from other sources. It is also integrated with some file managers like Total Commander or ES File Explorer.
-7Zip supports various archive formats and offers high compression ratio
-One of the main advantages of 7Zip is that it supports many common archive formats and types, such as zip, rar, 7z, tar, gzip, jar, apk, etc. This means that you can open, view or extract any archive file that you encounter on your device or online. You can also create your own archive files using different formats depending on your needs.
-Another benefit of 7Zip is that it offers high compression ratio, which means that it can reduce the size of your files or folders significantly. This can help you save disk space on your device, speed up the transfer of files over the internet, or fit more files into a limited storage medium. For example, according to its website, 7Zip can compress a file by up to 70% compared to zip format.
-7Zip can encrypt your files with a password and protect them from unauthorized access
-A third advantage of 7Zip is that it can encrypt your files with a password and protect them from unauthorized access. This is especially useful if you want to store sensitive or personal data on your device or share them with others. You can choose from different encryption methods, such as AES-256 or ZipCrypto. You can also create self-extracting archives that can be opened without installing any software.
-How to download and install 7Zip APK on your Android device?
-Download the 7Zip APK file from a trusted source
-To install 7Zip on your Android device, you need to download its APK file first. An APK file is an application package file that contains all the necessary files and resources for an app to run on an Android device. You can download the 7Zip APK file from its official website or from other sources. Make sure that you download the latest version of the app and that it is compatible with your device model and Android version.
-7zip apk for android free download
-7zip app download for android mobile
-7zip zip rar apk download
-7zip file manager apk download
-7zip extractor apk download
-7zip apk pro download
-7zip apk latest version download
-7zip apk mirror download
-7zip apk mod download
-7zip apk old version download
-7zip apk pure download
-7zip apk uptodown download
-7zip archiver apk download
-7zip android app download apk
-7zip android apk free download
-7zip beta apk download
-7zip browser apk download
-7zip command line apk download
-7zip compressor apk download
-7zip converter apk download
-7zip decompressor apk download
-7zip editor apk download
-7zip easy unzip zip zip file manager apk download
-7zip for android apk free download
-7zip for pc windows 10 free download apk
-7zip gui apk download
-7zip gzip tar zip unzip rar tool extractor archiver utility compressor rarzilla free unrar unrar unzip tool winrar winrar free winrar alternative winrar for android winrar for mac winrar for linux winrar for windows winrar for ios winrar for ipad winrar for iphone winrar for chromebook winrar for pc winrar for tablet winrar for laptop winrar for desktop winrar for chrome os winrar for webos winrar for fireos winrar for tizen winrar for ubuntu winrar for debian winrar for fedora winrar for centos winrar for redhat winrar for mint winrar for kali linux winrar for arch linux winrar for manjaro linux winrar for elementary os winrar for zorin os winrar for pop os winrar for solus os winrar for mx linux winrar for deepin linux winrar for parrot os winrar for garuda linux winrar for arco linux winrar for endeavour os winrar for clear linux os winzar rarzilla rarzilla free unrar rarzilla free unrar alternative rarzilla free unrar for android rarzilla free unrar for mac rarzilla free unrar for linux rarzilla free unrar for windows rarzilla free unrar for ios rarzilla free unrar for ipad rarzilla free unrar for iphone rarzilla free unrar for chromebook rarzilla free unrar for pc rarzilla free unrar for tablet rarzilla free unrar for laptop rarzilla free unrar for desktop rarzilla free unrar for chrome os rarzilla free unrar for webos rarzilla free unrar for fireos rarzilla free unrar fo
-7zip helper apk download
-7zip installer apk download
-7zip joiner apk download
-7zip keygen apk download
-7zip lite apk download
-7zip manager pro apk download
-7zip no ads apk download
-7zip offline installer apk download
-7zip password remover apk download
-7zip premium apk download
-Enable the installation of unknown apps on your device settings
-Before you can install the 7Zip APK file on your device, you need to enable the installation of unknown apps on your device settings. Unknown apps are apps that are not downloaded from the official Google Play Store. To do this, follow these steps:
-
-- Go to your device settings and tap on Security or Privacy.
-- Find the option that says Allow installation of unknown apps or Install unknown apps and tap on it.
-- Select the app or browser that you used to download the 7Zip APK file and toggle the switch to On or Allow.
-
-This will allow you to install the 7Zip APK file without any warnings or errors.
-Locate and tap on the 7Zip APK file to start the installation process
-After you have enabled the installation of unknown apps, you can locate and tap on the 7Zip APK file to start the installation process. You can find the 7Zip APK file in your device's Downloads folder or in the app or browser that you used to download it. Once you tap on the file, you will see a pop-up window that asks you to confirm the installation. Tap on Install and wait for a few seconds.
-Grant the necessary permissions and follow the instructions on the screen
-When the installation is complete, you will see another pop-up window that asks you to grant the necessary permissions for the 7Zip app to function properly. These permissions may include access to your storage, files, photos, media, etc. Tap on Allow or Accept and follow the instructions on the screen. You may also see some tips or tutorials on how to use the app. You can skip them if you want or read them carefully if you are new to the app.
-How to use 7Zip to create, extract or browse archive files on your Android device?
-Launch the 7Zip app and navigate to the folder where your files are stored
-To use 7Zip to create, extract or browse archive files on your Android device, you need to launch the app first. You can find it in your app drawer or home screen. Tap on its icon and you will see its main interface. It looks like a file manager that shows you all the folders and files on your device. You can navigate to the folder where your files are stored by tapping on the folder names or using the back and forward buttons.
-Select the files or folders that you want to compress or decompress
-Once you have located the files or folders that you want to compress or decompress, you need to select them by tapping on them. You can select multiple files or folders by tapping and holding on one of them and then tapping on others. You can also use the select all button at the top right corner of the screen. You will see a check mark next to each selected item and a menu bar at the bottom of the screen.
-Tap on the menu icon and choose the desired action (create, extract or browse)
-After you have selected the files or folders that you want to compress or decompress, you need to tap on the menu icon at the bottom right corner of the screen and choose the desired action from the options. You can choose to create a new archive file, extract an existing archive file, or browse the contents of an archive file without extracting it.
-Customize the options for compression level, encryption, password, etc.
-If you choose to create a new archive file, you will see a pop-up window that allows you to customize the options for compression level, encryption, password, etc. You can choose the name and format of the archive file, the compression level (from store to ultra), the encryption method (AES-256 or ZipCrypto), the password (if you want to encrypt your file), and the split size (if you want to split your file into smaller parts). You can also choose the destination folder where you want to save your archive file.
-Confirm your action and wait for the process to complete
-After you have customized the options for your archive file, you need to confirm your action by tapping on OK or Create. You will see a progress bar that shows you how much time is left for the process to complete. Depending on the size and number of your files or folders, the compression or decompression process may take a few seconds or minutes. You can cancel the process at any time by tapping on Cancel.
-Conclusion
-7Zip is a powerful and versatile file compression app that can help you save space, reduce file size, and secure your data on your Android device. It is easy to download, install, and use. It supports various archive formats and types, offers high compression ratio, and can encrypt your files with a password. You can use it to create, extract or browse archive files with just a few taps. If you are looking for a reliable and efficient file compression app for your Android device, you should give 7Zip a try.
-FAQs
-Q: Is 7Zip safe to use?
-A: Yes, 7Zip is safe to use as long as you download it from its official website or from other trusted sources. It does not contain any malware or viruses that can harm your device or data.
-Q: How can I update 7Zip on my Android device?
-A: You can update 7Zip on your Android device by downloading and installing the latest version of its APK file from its official website or from other sources. You can also check for updates within the app by tapping on the menu icon and choosing About.
-Q: How can I delete 7Zip from my Android device?
-A: You can delete 7Zip from your Android device by following these steps:
-
-- Go to your device settings and tap on Apps or Applications.
-- Find and tap on 7Zip from the list of apps.
-- Tap on Uninstall and confirm your action.
-
-This will remove 7Zip from your device along with its data and cache.
-Q: How can I open a 7z file on my Android device?
-A: You can open a 7z file on your Android device by using 7Zip or any other app that supports this format. To do this, follow these steps:
-
-- Locate and tap on the 7z file that you want to open.
-- Choose 7Zip or any other app that supports this format from the list of options.
-- You will see the contents of the 7z file in the app. You can browse, extract or create new archive files from there.
-
-Q: How can I compress a video file on my Android device using 7Zip?
-A: You can compress a video file on your Android device using 7Zip by following these steps:
-
-- Launch the 7Zip app and navigate to the folder where your video file is stored.
-- Select your video file by tapping on it.
-- Tap on the menu icon and choose Create.
-- Choose the name and format of your archive file. You can use zip or 7z format for better compression ratio.
-- Choose the compression level. You can use ultra for maximum compression but it may take longer time.
-- Choose the encryption method and password if you want to protect your file.
-- Choose the destination folder where you want to save your archive file.
-- Tap on OK or Create and wait for the process to complete.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Bus Simulator Ultimate Hile APK 2.0 3 Otobs Srcs Olarak Dnyay Gezin.md b/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Bus Simulator Ultimate Hile APK 2.0 3 Otobs Srcs Olarak Dnyay Gezin.md
deleted file mode 100644
index d62853ebe2c3e5188162b7cdd073d54175c9f5a4..0000000000000000000000000000000000000000
--- a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Bus Simulator Ultimate Hile APK 2.0 3 Otobs Srcs Olarak Dnyay Gezin.md
+++ /dev/null
@@ -1,94 +0,0 @@
-
-Bus Simulator Ultimate Hile APK 2.0 3: Everything You Need to Know
-If you are a fan of driving simulation games, you might have heard of Bus Simulator Ultimate, a popular game by Zuuks Games that lets you experience the realistic and immersive bus driving gameplay. In this game, you can create your own bus company, expand it globally, transport passengers to various destinations, compete with other players, and customize your buses and routes. However, if you want to enjoy the game without any limitations, you might want to try Bus Simulator Ultimate Hile APK 2.0 3, a modified version of the game that gives you unlimited money and resources, no ads and in-app purchases, and many other benefits. In this article, we will tell you everything you need to know about Bus Simulator Ultimate Hile APK 2.0 3, including its features, how to download and install it, its pros and cons, and some frequently asked questions.
-bus simulator ultimate hile apk 2.0 3
DOWNLOAD — https://ssurll.com/2uO1oR
- What is Bus Simulator Ultimate Hile APK 2.0 3?
-Bus Simulator Ultimate Hile APK 2.0 3 is a hacked version of Bus Simulator Ultimate, a realistic bus driving simulation game by Zuuks Games. This version allows you to access all the features of the game without spending any money or watching any ads. You can also enjoy unlimited money and resources, which you can use to buy new buses, upgrade your company, hire more drivers, and create more routes. You can also play the game offline or online, depending on your preference.
- Features of Bus Simulator Ultimate Hile APK 2.0 3
-Bus Simulator Ultimate Hile APK 2.0 3 has many features that make it more fun and enjoyable than the original game. Here are some of them:
- - Realistic bus driving simulation
-You can experience the realistic bus driving simulation with Bus Simulator Ultimate Hile APK 2.0 3. You can drive various types of buses, such as double-decker, school, city, coach, and more. You can also follow the traffic rules, use the indicators, honk the horn, open the doors, and interact with the passengers. You can also choose from different weather conditions, day and night cycles, and road situations.
- - Global expansion and management
-You can create your own bus company and expand it globally with Bus Simulator Ultimate Hile APK 2.0 3. You can start your business in any country you want, such as the USA, UK, Germany, Mexico, France, Netherlands, and more. You can also open new offices, hire more drivers, manage your finances, and improve your reputation. You can also create your own travel plan and choose from different routes.
- - Multiplayer mode and social interactions
-You can compete with other players and join the ultimate multiplayer league with Bus Simulator Ultimate Hile APK 2.0 3. You can also chat with other players, make friends or enemies, join or create clubs, and share your achievements. You can also interact with your passengers and rate your service. You can also receive feedback and tips from them.
- - Customizable buses and routes
-You can customize your buses and routes with Bus Simulator Ultimate Hile APK 2.0 3. You can choose from different bus models, colors, skins, logos, and accessories. You can also create your own routes, add or remove stops, change the difficulty level, and adjust the time and distance. You can also use the map editor to design your own maps and share them with other players.
-Bus Simulator Ultimate Hile APK 2.0 3 Sınırsız İndirme
-Bus Simulator Ultimate Hile APK 2.0 3 Mod Para
-Bus Simulator Ultimate Hile APK 2.0 3 Nasıl Yüklenir
-Bus Simulator Ultimate Hile APK 2.0 3 Güncel Link
-Bus Simulator Ultimate Hile APK 2.0 3 Oyun İçi Özellikler
-Bus Simulator Ultimate Hile APK 2.0 3 Zuuks Games
-Bus Simulator Ultimate Hile APK 2.0 3 Otobüs Sürüş Oyunu
-Bus Simulator Ultimate Hile APK 2.0 3 Küresel Şirket Kurma
-Bus Simulator Ultimate Hile APK 2.0 3 Yolcu Sistemi
-Bus Simulator Ultimate Hile APK 2.0 3 Çok Oyunculu Lig
-Bus Simulator Ultimate Hile APK 2.0 3 Gerçekçi Simülasyon
-Bus Simulator Ultimate Hile APK 2.0 3 Harita Genişletme
-Bus Simulator Ultimate Hile APK 2.0 3 Farklı Ülkelerde Sürüş
-Bus Simulator Ultimate Hile APK 2.0 3 Ofis Açma ve İşe Alma
-Bus Simulator Ultimate Hile APK 2.0 3 Ucuz Benzin ve Yakıt
-Bus Simulator Ultimate Hile APK 2.0 3 Tema Parklarına Yolcu Taşıma
-Bus Simulator Ultimate Hile APK 2.0 3 Net Enerji Kazancı
-Bus Simulator Ultimate Hile APK 2.0 3 Mini Güneş Yaratma
-Bus Simulator Ultimate Hile APK 2.0 3 Sosyal ve Gerçek Dünya Tepkileri
-Bus Simulator Ultimate Hile APK 2.0 3 Bilet Alma ve Değerlendirme
-Bus Simulator Ultimate Hile APK 2.0 3 Otobüs Şirketi Yönetimi
-Bus Simulator Ultimate Hile APK 2.0 3 Sürücüleri Şirkete Kaydetme
-Bus Simulator Ultimate Hile APK 2.0 3 Müşterilere Hizmet Verme
-Bus Simulator Ultimate Hile APK 2.0 3 Seyahat Planı Oluşturma
-Bus Simulator Ultimate Hile APK 2.0 3 ABD, İngiltere, Almanya, Meksika, Fransa, Hollanda'da Sürüş
-Bus Simulator Ultimate Hile APK 2.0 3 Otobüs Seçimi ve Kişiselleştirme
-Bus Simulator Ultimate Hile APK 2.0 3 Grafik Kalitesi ve Ses Efektleri
-Bus Simulator Ultimate Hile APK 2.0 3 Dinamik Ortamlar ve Trafik Durumu
-Bus Simulator Ultimate Hile APK 2.0 3 Gerçekçi Fizik ve Hasar Sistemi
-Bus Simulator Ultimate Hile APK 2.0 3 Otobüs Bakımı ve Onarımı
-Bus Simulator Ultimate Hile APK 2.0 3 Reklamsız Oyun Deneyimi
-Bus Simulator Ultimate Hile APK 2.0 3 Kolay Kontroller ve Arayüz
-Bus Simulator Ultimate Hile APK 2.0 3 Ücretsiz Güncellemeler ve Ek İçerikler
-Bus Simulator Ultimate Hile APK 2.0 3 Online Liderlik Tablosu ve Başarılar
-Bus Simulator Ultimate Hile APK 2.0 3 Arkadaşlarla Oynama ve Paylaşma
- - High-quality graphics and sound effects
-You can enjoy the high-quality graphics and sound effects with Bus Simulator Ultimate Hile APK 2.0 3. You can see the detailed environments, realistic animations, dynamic shadows, and reflections. You can also hear the realistic sounds of the engine, brakes, horn, passengers, traffic, and more. You can also adjust the graphics settings and sound volume according to your device and preference.
- How to Download and Install Bus Simulator Ultimate Hile APK 2.0 3?
-If you want to download and install Bus Simulator Ultimate Hile APK 2.0 3 on your Android device, you need to follow these simple steps:
- Step 1: Enable Unknown Sources
-Before you can install any APK file on your device, you need to enable the unknown sources option in your settings. This will allow you to install apps from sources other than the Google Play Store. To do this, go to Settings > Security > Unknown Sources and toggle it on.
- Step 2: Download the APK File
-Next, you need to download the APK file of Bus Simulator Ultimate Hile APK 2.0 3 from a reliable source. You can use the link below to download it directly to your device or transfer it from your PC using a USB cable or a file manager app.
-Download Bus Simulator Ultimate Hile APK 2.0 3 here
- Step 3: Install the APK File
-Once you have downloaded the APK file, you need to install it on your device. To do this, locate the file in your downloads folder or wherever you saved it and tap on it. You will see a pop-up window asking you to confirm the installation. Tap on Install and wait for the process to finish.
- Step 4: Launch the Game and Enjoy
-After the installation is complete, you can launch the game by tapping on its icon on your home screen or app drawer. You will see a splash screen with the game's logo and then you will be taken to the main menu. From there, you can start playing the game and enjoy all its features.
- Pros and Cons of Bus Simulator Ultimate Hile APK 2.0 3
-Bus Simulator Ultimate Hile APK 2.0 3 has many advantages over the original game, but it also has some drawbacks that you should be aware of before downloading it. Here are some of them:
- Pros
-
-- - Unlimited money and resources: You can get unlimited money and resources with Bus Simulator Ultimate Hile APK 2.0 3, which you can use to buy new buses, upgrade your company, hire more drivers, and create more routes.
-- - No ads and in-app purchases: You can play the game without any interruptions or distractions from ads and in-app purchases with Bus Simulator Ultimate Hile APK 2.0 3. You can also save your data and battery life by playing offline.
-- - Easy to use and play: You can easily use and play Bus Simulator Ultimate Hile APK 2.0 3 without any complications or difficulties. The game has a simple interface and controls that are suitable for all ages and skill levels.
-
- Cons
-
-- - Not available on Google Play Store: You cannot find Bus Simulator Ultimate Hile APK 2.0 3 on the Google Play Store, which means that you cannot get updates or support from the official developers. You also cannot sync your progress or achievements with your Google account.
-- - May not be compatible with some devices: Bus Simulator Ultimate Hile APK 2.0 3 may not work properly on some devices due to different hardware specifications or software versions. You may experience crashes, glitches, or errors while playing the game.
-- - May cause security risks and bugs: Bus Simulator Ultimate Hile APK 2.0 3 may contain viruses, malware, or spyware that could harm your device or compromise your privacy. You may also encounter bugs or errors that could affect your gameplay or data. You should always scan the APK file before installing it and use it at your own risk.
-
- Conclusion
-Bus Simulator Ultimate Hile APK 2.0 3 is a modified version of Bus Simulator Ultimate, a realistic bus driving simulation game by Zuuks Games. It offers many features and benefits that make the game more fun and enjoyable, such as unlimited money and resources, no ads and in-app purchases, realistic bus driving simulation, global expansion and management, multiplayer mode and social interactions, customizable buses and routes, and high-quality graphics and sound effects. However, it also has some drawbacks that you should be aware of before downloading it, such as not being available on Google Play Store, not being compatible with some devices, and causing security risks and bugs. Therefore, you should weigh the pros and cons carefully before deciding to use Bus Simulator Ultimate Hile APK 2.0 3.
- FAQs
-Here are some frequently asked questions about Bus Simulator Ultimate Hile APK 2.0 3:
- - Is Bus Simulator Ultimate Hile APK 2.0 3 safe to use?
-Bus Simulator Ultimate Hile APK 2.0 3 is not an official version of Bus Simulator Ultimate, so it may not be safe to use. It may contain viruses, malware, or spyware that could harm your device or compromise your privacy. You should always scan the APK file before installing it and use it at your own risk.
- - How can I update Bus Simulator Ultimate Hile APK 2.0 3?
-Bus Simulator Ultimate Hile APK 2.0 3 is not available on Google Play Store, so you cannot get updates or support from the official developers. You will have to download the latest version of the APK file from a reliable source and install it manually on your device.
- - Can I play Bus Simulator Ultimate Hile APK 2.0 3 offline?
-Yes, you can play Bus Simulator Ultimate Hile APK 2.0 3 offline without any internet connection. However, you will not be able to access some features that require online connectivity, such as multiplayer mode and social interactions.
- - Can I sync my progress or achievements with my Google account?
-No, you cannot sync your progress or achievements with your Google account with Bus Simulator Ultimate Hile APK 2.0 3. You will have to use a separate account or play as a guest.
- - Can I use Bus Simulator Ultimate Hile APK 2.0 3 on my PC or iOS device?
-No, you cannot use Bus Simulator Ultimate Hile APK 2.0 3 on your PC or iOS device. It is only compatible with Android devices that have Android version 5.0 or higher.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/CarX Street APK No Verification The Ultimate Guide to Fixing Errors and Compatibility Issues.md b/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/CarX Street APK No Verification The Ultimate Guide to Fixing Errors and Compatibility Issues.md
deleted file mode 100644
index 57bf76834d7c9b42f5f1ba7568f687ba32e21cdf..0000000000000000000000000000000000000000
--- a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/CarX Street APK No Verification The Ultimate Guide to Fixing Errors and Compatibility Issues.md
+++ /dev/null
@@ -1,86 +0,0 @@
-
-How to Download CarX Street Apk No Verification and Enjoy the Ultimate Street Racing Experience
- If you are a fan of street racing games, you have probably heard of CarX Street, the latest sensation from CarX Technologies. CarX Street is an open-world racing game that lets you explore a large city and its surroundings, from busy streets to spiral mountain roads and coastal highways. You can choose from over 50 official cars from the best automakers in the world, customize them to your liking, and challenge other players in real network races. CarX Street also features realistic physics and controls, stunning graphics, dynamic day/night cycle, and various game modes.
- CarX Street is available for free on iOS devices, but Android users have to face some challenges to download and install the game on their devices. The game is not yet officially released on Google Play Store, so you have to find an alternative source for the apk file. However, many of these sources require you to verify your device or use additional apps that may harm your device or compromise your privacy. Moreover, some of these apk files may not work properly or may contain viruses or malware.
-carx street apk no verification
Download File ✏ ✏ ✏ https://ssurll.com/2uNUUL
- Fortunately, there is a way to download CarX Street apk no verification and enjoy the game without any hassle. In this article, we will show you how to find a reliable source for the apk file, how to install it on your device, and what are the features and benefits of CarX Street apk no verification.
- What are the features and benefits of CarX Street apk no verification?
- CarX Street apk no verification is a modified version of the original game that bypasses the verification process and gives you access to all the content and features of the game. Here are some of the advantages of using CarX Street apk no verification:
-
-- No need to root your device or use third-party apps. You don't have to risk damaging your device or voiding your warranty by rooting it or using apps that may contain malware or spyware. You can simply download and install CarX Street apk no verification as you would any other app.
-- Access to all cars, tracks, modes, and customization options. You don't have to wait for updates or pay for premium content. You can enjoy all the cars, tracks, modes, and customization options that CarX Street has to offer. You can also unlock new parts and upgrades for your cars as you progress in the game.
-- Smooth performance and realistic graphics. You don't have to worry about lagging or crashing issues. CarX Street apk no verification runs smoothly on most Android devices and delivers realistic graphics and effects. You can adjust the graphics settings according to your device's capabilities.
-- Online multiplayer and social features. You don't have to miss out on the fun of competing with other players online. CarX Street apk no verification allows you to join online races, chat with other racers, join clubs, and share your achievements on social media.
-
- What are the steps to download and install CarX Street apk no verification?
- Downloading and installing CarX Street apk no verification is easy and fast. Just follow these simple steps:
-
-- <
- Find a reliable source for the CarX Street apk no verification file and download it. You can use the link below to download the latest version of the file from a trusted website. The file size is about 1.2 GB, so make sure you have enough space on your device and a stable internet connection.
-- Enable unknown sources in your device settings. This will allow you to install apps from sources other than the Google Play Store. To do this, go to Settings > Security > Unknown Sources and toggle it on. You may see a warning message, but don't worry, it is safe to proceed.
-- Install the CarX Street apk no verification file. Locate the downloaded file in your device's file manager and tap on it. You may see a pop-up asking for permissions, just tap on Install and wait for the installation to complete.
-- Launch the game and enjoy. You can find the game icon on your home screen or app drawer. Tap on it and start playing CarX Street without any verification or restrictions.
-
- Conclusion
- CarX Street is one of the best street racing games for mobile devices. It offers a realistic and immersive racing experience with amazing graphics, physics, and controls. However, Android users may face some difficulties in downloading and installing the game on their devices. That's why we recommend using CarX Street apk no verification, a modified version of the game that bypasses the verification process and gives you access to all the content and features of the game.
- If you want to download CarX Street apk no verification, just follow the steps we have outlined in this article. You will be able to enjoy the game without any hassle or risk. You can also share this article with your friends who are looking for a way to play CarX Street on their Android devices.
- So what are you waiting for? Download CarX Street apk no verification today and experience the ultimate street racing adventure. You won't regret it!
- Frequently Asked Questions
- Here are some of the common questions that people ask about CarX Street apk no verification:
-carx street android mod apk download
-carx street beta apk free
-carx street global launch apk
-carx street 0.8.4 apk no verification
-carx street unlimited resources mod apk
-carx street realistic racing game apk
-carx street sunset city apk
-carx street drift racing 2 apk
-carx street open world apk
-carx street error authenticity check fix apk
-carx street device not compatible apk
-carx street latest version apk
-carx street hack mod apk
-carx street offline mode apk
-carx street graphics settings apk
-carx street new update apk
-carx street gameplay android apk
-carx street telegram link apk
-carx street youtube video apk
-carx street mod menu apk
-carx street cheats codes apk
-carx street unlimited money apk
-carx street premium cars apk
-carx street customisation options apk
-carx street best settings apk
-carx street how to play apk
-carx street tips and tricks apk
-carx street review and rating apk
-carx street system requirements apk
-carx street online multiplayer apk
-carx street controller support apk
-carx street steering wheel apk
-carx street sound effects apk
-carx street music tracks apk
-carx street wallpaper hd apk
-carx street live stream apk
-carx street challenges and rewards apk
-carx street leaderboards and rankings apk
-carx street community and feedback apk
-carx street bugs and issues apk
-carx street future plans and updates apk
-carx street comparison with other games apk
-carx street features and benefits apk
-carx street download size and speed apk
-carx street installation guide and tutorial apk
-carx street faq and support apk
- Is CarX Street apk no verification safe to use?
- Yes, CarX Street apk no verification is safe to use as long as you download it from a reliable source like the one we have provided in this article. The file is scanned for viruses and malware and does not contain any harmful code or data. However, you should always be careful when downloading and installing apps from unknown sources and check the permissions they require.
- Will CarX Street apk no verification work on my device?
- CarX Street apk no verification should work on most Android devices that meet the minimum system requirements for the game. The game requires Android 5.0 or higher, 2 GB of RAM, and 2 GB of free storage space. However, some devices may not be compatible with the game or may experience performance issues due to hardware limitations or software conflicts.
- Can I update CarX Street apk no verification?
- Yes, you can update CarX Street apk no verification whenever a new version of the game is released. However, you will have to download and install the new version of the apk file manually from the same source you used before. You will not receive automatic updates from the Google Play Store or any other app store.
- Can I play online with CarX Street apk no verification?
- Yes, you can play online with CarX Street apk no verification and join network races with other players around the world. However, you may encounter some issues or errors when connecting to the game servers or matching with other players due to different versions of the game or network settings. You may also face some risks of getting banned or suspended by the game developers if they detect that you are using a modified version of the game.
- Can I use CarX Street apk no verification with other mods or cheats?
- No, we do not recommend using CarX Street apk no verification with other mods or cheats that may alter the game data or functionality. This may cause compatibility issues, errors, crashes, or bans from the game. CarX Street apk no verification already provides you with all the content and features of the game, so there is no need to use any other mods or cheats.
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Download Animal Revolt Battle Simulator and Unleash Your Creativity with Custom Monsters.md b/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Download Animal Revolt Battle Simulator and Unleash Your Creativity with Custom Monsters.md
deleted file mode 100644
index 43fd375f872c1a264c875b3b4471ec2395216f5b..0000000000000000000000000000000000000000
--- a/spaces/simple0urra/skops-model-card-creator-2a23515a-d54e-4804-b365-27ed6e938735/example/Download Animal Revolt Battle Simulator and Unleash Your Creativity with Custom Monsters.md
+++ /dev/null
@@ -1,110 +0,0 @@
-
-Download ARBS Animal Revolt Battle Simulator: The Ultimate Physics-Based Sandbox Game
-Have you ever wondered what would happen if you put a T-rex with a laser gun against a horde of zombies? Or how about a shark with wings versus a dragon? Or maybe you just want to create your own crazy creatures and watch them fight in a physics-based sandbox? If you answered yes to any of these questions, then you should download ARBS Animal Revolt Battle Simulator today!
-download arbs animal revolt battle simulator
Download File - https://ssurll.com/2uNZLB
-ARBS Animal Revolt Battle Simulator is a game where you can create funny battles between all sorts of ragdoll creatures. You can also make your own monsters with the unit creator or even join the battles yourself in the first-person mode. It is one of the most accurate animal battle simulation games ever made, and it is available on Steam and Google Play. In this article, we will show you how to download ARBS Animal Revolt Battle Simulator on both platforms, and what you can do in this amazing game.
-How to Download ARBS Animal Revolt Battle Simulator on Steam
-If you want to play ARBS Animal Revolt Battle Simulator on your PC, you will need to download it from Steam. Steam is a digital distribution platform that allows you to buy, download, and play games online. Here are the steps you need to follow:
-
-- Step 1: Go to the Steam store page of ARBS. You will see a brief description of the game, some screenshots, videos, reviews, and system requirements.
-- Step 2: Click on the "Add to Cart" button and proceed to checkout. You will need to have a Steam account and a valid payment method. The game costs $14.99 as of June 2023.
-- Step 3: Install the game on your PC and launch it from your Steam library. You will need to have at least 4 GB of free disk space and a decent graphics card to run the game smoothly.
-
-Congratulations, you have successfully downloaded ARBS Animal Revolt Battle Simulator on Steam! Now you can enjoy creating and watching hilarious battles between all kinds of animals and monsters.
-How to Download ARBS Animal Revolt Battle Simulator on Google Play
-If you prefer to play ARBS Animal Revolt Battle Simulator on your Android device, you can download it from Google Play. Google Play is the official app store for Android devices, where you can find millions of apps and games. Here are the steps you need to follow:
-
-- Step 1: Go to the Google Play store page of ARBS. You will see a brief description of the game, some screenshots, videos, reviews, and ratings.
-- Step 2: Tap on the "Install" button and wait for the game to download. You will need to have at least 1 GB of free storage space and a compatible device to play the game. The game is free to download and play, but it contains ads and in-app purchases.
-- Step 3: Open the game from your app drawer and enjoy. You will need to grant some permissions to the game, such as access to your device's storage and microphone.
-
-Congratulations, you have successfully downloaded ARBS Animal Revolt Battle Simulator on Google Play! Now you can enjoy creating and watching hilarious battles between all kinds of animals and monsters on your mobile device.
-What Can You Do in ARBS Animal Revolt Battle Simulator?
-ARBS Animal Revolt Battle Simulator is a game that lets you unleash your creativity and imagination. You can do many things in this game, such as:
-
-- Build your own maps or pick from a selection of ready-made ones
-- Place up to seven opposing armies made of different types of beasts and watch them tear each other apart in an epic battle
-- Join the fight yourself in the first-person mode and blow the enemy away with some powerful guns
-- Create your own custom monsters by combining different body parts and weapons
-- Test your tactical and strategic expertise in the campaign mode
-
-Let's take a closer look at each of these features and see what makes ARBS Animal Revolt Battle Simulator so fun and addictive.
-Place up to seven opposing armies made of different types of beasts and watch them tear each other apart in an epic battle
-This is the core feature of ARBS Animal Revolt Battle Simulator. You can create any kind of battle scenario you can think of, using more than 70 creatures, from ancient dinosaurs to modern animals, and customize them with weapons and body parts. You can also adjust the size, health, speed, damage, and behavior of each creature. You can place up to seven armies on the map, each with a different color and flag. You can also set the number of units per army, from one to hundreds. Once you are done setting up your battle, you can press the play button and watch the carnage unfold.
-How to download arbs animal revolt battle simulator for free
-Arbs animal revolt battle simulator steam download
-Arbs animal revolt battle simulator apk download
-Arbs animal revolt battle simulator unit creator download
-Arbs animal revolt battle simulator workshop download
-Download arbs animal revolt battle simulator mods
-Download arbs animal revolt battle simulator latest version
-Download arbs animal revolt battle simulator pc
-Download arbs animal revolt battle simulator android
-Download arbs animal revolt battle simulator ios
-Arbs animal revolt battle simulator download size
-Arbs animal revolt battle simulator download link
-Arbs animal revolt battle simulator download crack
-Arbs animal revolt battle simulator download mac
-Arbs animal revolt battle simulator download windows 10
-Arbs animal revolt battle simulator free download full version
-Arbs animal revolt battle simulator online download
-Arbs animal revolt battle simulator offline download
-Arbs animal revolt battle simulator update download
-Arbs animal revolt battle simulator demo download
-Download arbs animal revolt battle simulator custom units
-Download arbs animal revolt battle simulator custom maps
-Download arbs animal revolt battle simulator custom buildings
-Download arbs animal revolt battle simulator campaign mode
-Download arbs animal revolt battle simulator sandbox mode
-Arbs animal revolt battle simulator game download
-Arbs animal revolt battle simulator software download
-Arbs animal revolt battle simulator app download
-Arbs animal revolt battle simulator website download
-Arbs animal revolt battle simulator torrent download
-Download arbs animal revolt battle simulator cheats
-Download arbs animal revolt battle simulator hacks
-Download arbs animal revolt battle simulator tips and tricks
-Download arbs animal revolt battle simulator guide and walkthrough
-Download arbs animal revolt battle simulator review and rating
-Download arbs animal revolt battle simulator gameplay and features
-Download arbs animal revolt battle simulator physics and graphics
-Download arbs animal revolt battle simulator dinosaurs and dragons
-Download arbs animal revolt battle simulator sharks and mosasaurus
-Download arbs animal revolt battle simulator deer and wolf
-Arbs animal revolt battle simulator system requirements download
-Arbs animal revolt battle simulator installation instructions download
-Arbs animal revolt battle simulator troubleshooting and support download
-Arbs animal revolt battle simulator privacy policy and terms of service download
-Arbs animal revolt battle simulator news and events download
-Arbs animal revolt battle simulator community and forum download
-Arbs animal revolt battle simulator developer and publisher download
-Arbs animal revolt battle simulator steam key and gift card download
-Arbs animal revolt battle simulator in-app purchases and ads download
-The battles in ARBS Animal Revolt Battle Simulator are realistic and physics-based. The creatures will react to each other's attacks, fall down, bleed, lose limbs, fly away, explode, etc. You can also slow down or speed up the time, pause the game, or switch to different camera angles. You can also take screenshots or record videos of your battles and share them with your friends or online communities.
-Join the fight yourself in the first-person mode and blow the enemy away with some powerful guns
-If you want to get more involved in the action, you can switch to the first-person mode and take control of any creature on the battlefield. You can use the WASD keys or the arrow keys to move around, and the mouse to look around and attack. You can also use some guns, grenades, and rockets to cause more mayhem. You can switch between different weapons by pressing the Q key or tapping on the weapon icon on your screen. You can also switch back to the sandbox mode by pressing the E key or tapping on the exit icon on your screen.
-The first-person mode in ARBS Animal Revolt Battle Simulator is a great way to experience the battles from a different perspective. You can feel the thrill of being in the middle of a chaotic war zone, dodging bullets, explosions, claws, teeth, etc. You can also use this mode to test your skills against other players online or against AI opponents.
Create your own custom monsters by combining different body parts and weapons
-If you want to unleash your creativity and make your own unique creatures, you can use the unit creator in ARBS Animal Revolt Battle Simulator. The unit creator allows you to combine different body parts and weapons from various animals and objects. You can also change the color, size, texture, and orientation of each part. You can make anything from a cute bunny with a chainsaw to a terrifying spider with a flamethrower. The possibilities are endless!
-Once you have created your custom monster, you can save it and use it in your battles. You can also download a vast selection of custom monsters, maps, and buildings created by other players from the Steam Workshop. You can browse, rate, comment, and subscribe to the content you like. You can also upload your own creations and share them with the world.
-Test Your Tactical and Strategic Expertise in the Campaign Mode
-If you want to challenge yourself and test your tactical and strategic expertise, you can try the campaign mode in ARBS Animal Revolt Battle Simulator. The campaign mode consists of various levels where you have to defeat the enemy army using a limited budget and resources. You can pick the right beasts, place them in the right place, and command them to achieve victory.
-The campaign mode is not easy. The most expensive army doesn't always win. Units have strengths and weaknesses. Find out what they are and use that knowledge to your advantage on the battlefield. Learn about the different stats, abilities, and behaviors of each creature, and use them strategically to overcome the challenges.
-As you progress through the campaign mode, you will unlock new creatures, weapons, maps, and achievements. You will also earn coins by completing levels, and use them to unlock more content for your sandbox mode.
-Conclusion: Why You Should Download ARBS Animal Revolt Battle Simulator Today
-ARBS Animal Revolt Battle Simulator is a game that offers endless fun and entertainment. You can create funny battles between all sorts of ragdoll creatures, join the fight yourself in the first-person mode, create your own custom monsters with the unit creator, and test your tactical and strategic expertise in the campaign mode. It is one of the most accurate animal battle simulation games ever made, and it is available on Steam and Google Play.
-So what are you waiting for? Download ARBS Animal Revolt Battle Simulator today and enjoy this ultimate physics-based sandbox game!
-FAQs
-
-- Q: What are the minimum system requirements to play ARBS Animal Revolt Battle Simulator on PC?
-- A: According to the Steam store page, you will need at least Windows 7 or higher, 4 GB of RAM, 4 GB of disk space, DirectX 11 compatible graphics card, and a 64-bit processor.
-- Q: What are the minimum system requirements to play ARBS Animal Revolt Battle Simulator on Android?
-- A: According to the Google Play store page, you will need at least Android 5.0 or higher, 1 GB of RAM, 1 GB of storage space, and a device that supports OpenGL ES 3.0.
-- Q: How can I play ARBS Animal Revolt Battle Simulator online with other players?
-- A: You can play ARBS Animal Revolt Battle Simulator online with other players by using Steam Remote Play Together. This feature allows you to invite your friends to join your game session over the internet, even if they don't own the game. You can also join other players' sessions by browsing the Remote Play Together hub on Steam.
-- Q: How can I contact the developer of ARBS Animal Revolt Battle Simulator?
-- A: You can contact the developer of ARBS Animal Revolt Battle Simulator by sending an email to arbsgame@gmail.com or by visiting their website at https://arbsgame.com/.
-- Q: How can I support the development of ARBS Animal Revolt Battle Simulator?
-- A: You can support the development of ARBS Animal Revolt Battle Simulator by buying the game on Steam or Google Play, leaving a positive review or rating, sharing your feedback and suggestions on the Steam forums or Google Play comments section, reporting any bugs or issues you encounter, creating and sharing your own content on the Steam Workshop or online communities, or donating to their Patreon page at https://www.patreon.com/arbsgame.
-
197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/skf15963/summary/fengshen/data/taiyi_stable_diffusion_datasets/taiyi_datasets.py b/spaces/skf15963/summary/fengshen/data/taiyi_stable_diffusion_datasets/taiyi_datasets.py
deleted file mode 100644
index 73e1071ac27c9839030734fe664abbcfef08d96b..0000000000000000000000000000000000000000
--- a/spaces/skf15963/summary/fengshen/data/taiyi_stable_diffusion_datasets/taiyi_datasets.py
+++ /dev/null
@@ -1,173 +0,0 @@
-from torch.utils.data import Dataset, ConcatDataset
-import os
-from concurrent.futures import ProcessPoolExecutor
-import pandas as pd
-
-
-def add_data_args(parent_args):
- parser = parent_args.add_argument_group('taiyi stable diffusion data args')
- # 支持传入多个路径,分别加载
- parser.add_argument(
- "--datasets_path", type=str, default=None, required=True, nargs='+',
- help="A folder containing the training data of instance images.",
- )
- parser.add_argument(
- "--datasets_type", type=str, default=None, required=True, choices=['txt', 'csv', 'fs_datasets'], nargs='+',
- help="dataset type, txt or csv, same len as datasets_path",
- )
- parser.add_argument(
- "--resolution", type=int, default=512,
- help=(
- "The resolution for input images, all the images in the train/validation dataset will be resized to this"
- " resolution"
- ),
- )
- parser.add_argument(
- "--center_crop", action="store_true", default=False,
- help="Whether to center crop images before resizing to resolution"
- )
- parser.add_argument("--thres", type=float, default=0.2)
- return parent_args
-
-
-class TXTDataset(Dataset):
- # 添加Txt数据集读取,主要是针对Zero23m数据集。
- def __init__(self,
- foloder_name,
- thres=0.2):
- super().__init__()
- # print(f'Loading folder data from {foloder_name}.')
- self.image_paths = []
- '''
- 暂时没有开源这部分文件
- score_data = pd.read_csv(os.path.join(foloder_name, 'score.csv'))
- img_path2score = {score_data['image_path'][i]: score_data['score'][i]
- for i in range(len(score_data))}
- '''
- # print(img_path2score)
- # 这里都存的是地址,避免初始化时间过多。
- for each_file in os.listdir(foloder_name):
- if each_file.endswith('.jpg'):
- self.image_paths.append(os.path.join(foloder_name, each_file))
-
- # print('Done loading data. Len of images:', len(self.image_paths))
-
- def __len__(self):
- return len(self.image_paths)
-
- def __getitem__(self, idx):
- img_path = str(self.image_paths[idx])
- caption_path = img_path.replace('.jpg', '.txt') # 图片名称和文本名称一致。
- with open(caption_path, 'r') as f:
- caption = f.read()
- return {'img_path': img_path, 'caption': caption}
-
-
-# NOTE 加速读取数据,直接用原版的,在外部使用并行读取策略。30min->3min
-class CSVDataset(Dataset):
- def __init__(self,
- input_filename,
- image_root,
- img_key,
- caption_key,
- thres=0.2):
- super().__init__()
- # logging.debug(f'Loading csv data from {input_filename}.')
- print(f'Loading csv data from {input_filename}.')
- self.images = []
- self.captions = []
-
- if input_filename.endswith('.csv'):
- # print(f"Load Data from{input_filename}")
- df = pd.read_csv(input_filename, index_col=0, on_bad_lines='skip')
- print(f'file {input_filename} datalen {len(df)}')
- # 这个图片的路径也需要根据数据集的结构稍微做点修改
- self.images.extend(df[img_key].tolist())
- self.captions.extend(df[caption_key].tolist())
- self.image_root = image_root
-
- def __len__(self):
- return len(self.images)
-
- def __getitem__(self, idx):
- img_path = os.path.join(self.image_root, str(self.images[idx]))
- return {'img_path': img_path, 'caption': self.captions[idx]}
-
-
-def if_final_dir(path: str) -> bool:
- # 如果当前目录有一个文件,那就算是终极目录
- for f in os.scandir(path):
- if f.is_file():
- return True
- return False
-
-
-def process_pool_read_txt_dataset(args,
- input_root=None,
- thres=0.2):
- p = ProcessPoolExecutor(max_workers=20)
- all_datasets = []
- res = []
-
- # 遍历该目录下所有的子目录
- def traversal_files(path: str):
- list_subfolders_with_paths = [f.path for f in os.scandir(path) if f.is_dir()]
- for dir_path in list_subfolders_with_paths:
- if if_final_dir(dir_path):
- res.append(p.submit(TXTDataset,
- dir_path,
- thres))
- else:
- traversal_files(dir_path)
- traversal_files(input_root)
- p.shutdown()
- for future in res:
- all_datasets.append(future.result())
- dataset = ConcatDataset(all_datasets)
- return dataset
-
-
-def process_pool_read_csv_dataset(args,
- input_root,
- thres=0.20):
- # here input_filename is a directory containing a CSV file
- all_csvs = os.listdir(os.path.join(input_root, 'release'))
- image_root = os.path.join(input_root, 'images')
- # csv_with_score = [each for each in all_csvs if 'score' in each]
- all_datasets = []
- res = []
- p = ProcessPoolExecutor(max_workers=150)
- for path in all_csvs:
- each_csv_path = os.path.join(input_root, 'release', path)
- res.append(p.submit(CSVDataset,
- each_csv_path,
- image_root,
- img_key="name",
- caption_key="caption",
- thres=thres))
- p.shutdown()
- for future in res:
- all_datasets.append(future.result())
- dataset = ConcatDataset(all_datasets)
- return dataset
-
-
-def load_data(args, global_rank=0):
- assert len(args.datasets_path) == len(args.datasets_type), \
- "datasets_path num not equal to datasets_type"
- all_datasets = []
- for path, type in zip(args.datasets_path, args.datasets_type):
- if type == 'txt':
- all_datasets.append(process_pool_read_txt_dataset(
- args, input_root=path, thres=args.thres))
- elif type == 'csv':
- all_datasets.append(process_pool_read_csv_dataset(
- args, input_root=path, thres=args.thres))
- elif type == 'fs_datasets':
- from fengshen.data.fs_datasets import load_dataset
- all_datasets.append(load_dataset(path, num_proc=args.num_workers,
- thres=args.thres, global_rank=global_rank)['train'])
- else:
- raise ValueError('unsupport dataset type: %s' % type)
- print(f'load datasset {type} {path} len {len(all_datasets[-1])}')
- return {'train': ConcatDataset(all_datasets)}
diff --git a/spaces/skf15963/summary/fengshen/models/zen1/configuration_zen1.py b/spaces/skf15963/summary/fengshen/models/zen1/configuration_zen1.py
deleted file mode 100644
index c7cbeb5657ea07b2a4e8429199a6091be39864c8..0000000000000000000000000000000000000000
--- a/spaces/skf15963/summary/fengshen/models/zen1/configuration_zen1.py
+++ /dev/null
@@ -1,80 +0,0 @@
-# coding=utf-8
-# Copyright 2022 IDEA-CCNL and The HuggingFace Inc. team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-""" TransfoXLDenoise model configuration """
-
-from transformers.configuration_utils import PretrainedConfig
-
-
-class ZenConfig(PretrainedConfig):
-
- """Configuration class to store the configuration of a `ZenModel`.
- """
-
- def __init__(self,
- # vocab_size_or_config_json_file,
- # word_vocab_size,
- hidden_size=768,
- num_hidden_layers=12,
- num_attention_heads=12,
- intermediate_size=3072,
- hidden_act="gelu",
- hidden_dropout_prob=0.1,
- attention_probs_dropout_prob=0.1,
- max_position_embeddings=512,
- type_vocab_size=2,
- initializer_range=0.02,
- layer_norm_eps=1e-12,
- num_hidden_word_layers=6,
- **kwargs):
- """Constructs ZenConfig.
-
- Args:
- vocab_size_or_config_json_file: Vocabulary size of `inputs_ids` in `BertModel`.
- hidden_size: Size of the encoder layers and the pooler layer.
- num_hidden_layers: Number of hidden layers in the Transformer encoder.
- num_attention_heads: Number of attention heads for each attention layer in
- the Transformer encoder.
- intermediate_size: The size of the "intermediate" (i.e., feed-forward)
- layer in the Transformer encoder.
- hidden_act: The non-linear activation function (function or string) in the
- encoder and pooler. If string, "gelu", "relu" and "swish" are supported.
- hidden_dropout_prob: The dropout probabilitiy for all fully connected
- layers in the embeddings, encoder, and pooler.
- attention_probs_dropout_prob: The dropout ratio for the attention
- probabilities.
- max_position_embeddings: The maximum sequence length that this model might
- ever be used with. Typically set this to something large just in case
- (e.g., 512 or 1024 or 2048).
- type_vocab_size: The vocabulary size of the `token_type_ids` passed into
- `BertModel`.
- initializer_range: The sttdev of the truncated_normal_initializer for
- initializing all weight matrices.
- layer_norm_eps: The epsilon used by LayerNorm.
- """
- # self.vocab_size = vocab_size_or_config_json_file
- # self.word_size = word_vocab_size
- self.hidden_size = hidden_size
- self.num_hidden_layers = num_hidden_layers
- self.num_attention_heads = num_attention_heads
- self.hidden_act = hidden_act
- self.intermediate_size = intermediate_size
- self.hidden_dropout_prob = hidden_dropout_prob
- self.attention_probs_dropout_prob = attention_probs_dropout_prob
- self.max_position_embeddings = max_position_embeddings
- self.type_vocab_size = type_vocab_size
- self.initializer_range = initializer_range
- self.layer_norm_eps = layer_norm_eps
- self.num_hidden_word_layers = num_hidden_word_layers
- super().__init__(**kwargs)
diff --git a/spaces/sklearn-docs/Lasso-dense-sparse-data/README.md b/spaces/sklearn-docs/Lasso-dense-sparse-data/README.md
deleted file mode 100644
index 815ca3af11b11d306bcbf8863bab7d6b6a95f896..0000000000000000000000000000000000000000
--- a/spaces/sklearn-docs/Lasso-dense-sparse-data/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Lasso Dense Sparse Data
-emoji: 📈
-colorFrom: red
-colorTo: pink
-sdk: gradio
-sdk_version: 3.24.1
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/sklearn-docs/multilabel_classification/README.md b/spaces/sklearn-docs/multilabel_classification/README.md
deleted file mode 100644
index 888248f64156fe3b9e11d399140a251d13b33124..0000000000000000000000000000000000000000
--- a/spaces/sklearn-docs/multilabel_classification/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Multilabel Classification
-emoji: 🚀
-colorFrom: yellow
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.28.2
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/sky24h/Controllable_Multi-domain_Semantic_Artwork_Synthesis/seg2art/sstan_models/networks/generator.py b/spaces/sky24h/Controllable_Multi-domain_Semantic_Artwork_Synthesis/seg2art/sstan_models/networks/generator.py
deleted file mode 100644
index 8ab0c454bd264fa1b21738c98ae7afbae14a72a1..0000000000000000000000000000000000000000
--- a/spaces/sky24h/Controllable_Multi-domain_Semantic_Artwork_Synthesis/seg2art/sstan_models/networks/generator.py
+++ /dev/null
@@ -1,184 +0,0 @@
-"""
-Copyright (C) 2019 NVIDIA Corporation. All rights reserved.
-Licensed under the CC BY-NC-SA 4.0 license (https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode).
-"""
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from sstan_models.networks.base_network import BaseNetwork
-from sstan_models.networks.normalization import get_nonspade_norm_layer
-from sstan_models.networks.architecture import ResnetBlock as ResnetBlock
-from sstan_models.networks.architecture import SPADEResnetBlock as SPADEResnetBlock
-import numpy as np
-torch.manual_seed(1234)
-
-
-class SPADEGenerator(BaseNetwork):
- @staticmethod
- def modify_commandline_options(parser, is_train):
- parser.set_defaults(norm_G='spectralspadesyncbatch3x3')
- parser.add_argument('--num_upsampling_layers',
- choices=('normal', 'more', 'most'), default='normal',
- help="If 'more', adds upsampling layer between the two middle resnet blocks. If 'most', also add one more upsampling + resnet layer at the end of the generator")
-
- return parser
-
- def __init__(self, opt):
- super().__init__()
- self.opt = opt
- nf = opt.ngf
-
- self.sw, self.sh = self.compute_latent_vector_size(opt)
-
- # if opt.use_vae:
- # # In case of VAE, we will sample from random z vector
- # self.fc = nn.Linear(opt.z_dim, 16 * nf * self.sw * self.sh)
- # else:
- # # Otherwise, we make the network deterministic by starting with
- # # downsampled segmentation map instead of random z
- # self.fc = nn.Conv2d(self.opt.semantic_nc, 16 * nf, 3, padding=1)
- self.fc = nn.Linear(opt.z_dim, 16 * nf * self.sw * self.sh)
- self.head_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt, feed_code = True)
-
- self.G_middle_0 = SPADEResnetBlock(16 * nf, 16 * nf, opt, feed_code = True)
- self.G_middle_1 = SPADEResnetBlock(16 * nf, 16 * nf, opt, feed_code = True)
-
- self.up_0 = SPADEResnetBlock(16 * nf, 8 * nf, opt, feed_code = True)
- self.up_1 = SPADEResnetBlock(8 * nf, 4 * nf, opt, feed_code = True)
- self.up_2 = SPADEResnetBlock(4 * nf, 2 * nf, opt, feed_code = True)
- self.up_3 = SPADEResnetBlock(2 * nf, 1 * nf, opt, feed_code = False)
-
- final_nc = nf
-
- # if opt.num_upsampling_layers == 'most':
- # print('used?')
- # self.up_4 = SPADEResnetBlock(1 * nf, nf // 2, opt)
- # final_nc = nf // 2
-
- self.conv_img = nn.Conv2d(final_nc, 3, 3, padding=1)
-
- self.up = nn.Upsample(scale_factor=2)
-
- def compute_latent_vector_size(self, opt):
- if opt.num_upsampling_layers == 'normal':
- num_up_layers = 5
- elif opt.num_upsampling_layers == 'more':
- num_up_layers = 6
- elif opt.num_upsampling_layers == 'most':
- num_up_layers = 7
- else:
- raise ValueError('opt.num_upsampling_layers [%s] not recognized' %
- opt.num_upsampling_layers)
-
- sw = opt.crop_size // (2**num_up_layers)
- sh = round(sw / opt.aspect_ratio)
-
- return sw, sh
-
- def forward(self, input, rgb_img, style_codes=None):
- with torch.cuda.amp.autocast():
- seg = input
- # if self.opt.use_vae:
- # # we sample z from unit normal and reshape the tensor
- # if z is None:
- # z = torch.randn(input.size(0), self.opt.z_dim,
- # dtype=torch.float32, device=input.get_device())
- x = self.fc(style_codes)
- x = x.view(-1, 16 * self.opt.ngf, self.sh, self.sw)
- # else:
- # # we downsample segmap and run convolution
- # x = F.interpolate(seg, size=(self.sh, self.sw))
- # x = self.fc(x)
- x = self.head_0(x, seg, style_codes=style_codes)
-
- x = self.up(x)
- x = self.G_middle_0(x, seg, style_codes=style_codes)
-
- if self.opt.num_upsampling_layers == 'more' or \
- self.opt.num_upsampling_layers == 'most':
- x = self.up(x)
-
- x = self.G_middle_1(x, seg, style_codes=style_codes)
-
- x = self.up(x)
- x = self.up_0(x, seg, style_codes=style_codes)
- x = self.up(x)
- x = self.up_1(x, seg, style_codes=style_codes)
- x = self.up(x)
- x = self.up_2(x, seg, style_codes=style_codes)
- x = self.up(x)
- x = self.up_3(x, seg)
-
- # if self.opt.num_upsampling_layers == 'most':
- # x = self.up(x)
- # x = self.up_4(x, seg)
-
- x = self.conv_img(F.leaky_relu(x, 2e-1))
- x = torch.tanh(x)#F.tanh(x)
-
- return x#, style_codes
-
-
-class Pix2PixHDGenerator(BaseNetwork):
- @staticmethod
- def modify_commandline_options(parser, is_train):
- parser.add_argument('--resnet_n_downsample', type=int, default=4, help='number of downsampling layers in netG')
- parser.add_argument('--resnet_n_blocks', type=int, default=9, help='number of residual blocks in the global generator network')
- parser.add_argument('--resnet_kernel_size', type=int, default=3,
- help='kernel size of the resnet block')
- parser.add_argument('--resnet_initial_kernel_size', type=int, default=7,
- help='kernel size of the first convolution')
- parser.set_defaults(norm_G='instance')
- return parser
-
- def __init__(self, opt):
- super().__init__()
- input_nc = opt.label_nc + (1 if opt.contain_dontcare_label else 0) + (0 if opt.no_instance else 1)
-
- norm_layer = get_nonspade_norm_layer(opt, opt.norm_G)
- activation = nn.ReLU(False)
-
- model = []
-
- # initial conv
- model += [nn.ReflectionPad2d(opt.resnet_initial_kernel_size // 2),
- norm_layer(nn.Conv2d(input_nc, opt.ngf,
- kernel_size=opt.resnet_initial_kernel_size,
- padding=0)),
- activation]
-
- # downsample
- mult = 1
- for i in range(opt.resnet_n_downsample):
- model += [norm_layer(nn.Conv2d(opt.ngf * mult, opt.ngf * mult * 2,
- kernel_size=3, stride=2, padding=1)),
- activation]
- mult *= 2
-
- # resnet blocks
- for i in range(opt.resnet_n_blocks):
- model += [ResnetBlock(opt.ngf * mult,
- norm_layer=norm_layer,
- activation=activation,
- kernel_size=opt.resnet_kernel_size)]
-
- # upsample
- for i in range(opt.resnet_n_downsample):
- nc_in = int(opt.ngf * mult)
- nc_out = int((opt.ngf * mult) / 2)
- model += [norm_layer(nn.ConvTranspose2d(nc_in, nc_out,
- kernel_size=3, stride=2,
- padding=1, output_padding=1)),
- activation]
- mult = mult // 2
-
- # final output conv
- model += [nn.ReflectionPad2d(3),
- nn.Conv2d(nc_out, opt.output_nc, kernel_size=7, padding=0),
- nn.Tanh()]
-
- self.model = nn.Sequential(*model)
-
- def forward(self, input, z=None):
- return self.model(input)
diff --git a/spaces/slone/myv-translation-2022-demo/README.md b/spaces/slone/myv-translation-2022-demo/README.md
deleted file mode 100644
index 5af7d669f346715ebcbdf764a99a8917a59c5825..0000000000000000000000000000000000000000
--- a/spaces/slone/myv-translation-2022-demo/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Эрзянь ютавтыця | Erzya Translator | Эрзянский переводчик 2022
-emoji: 😻
-colorFrom: red
-colorTo: blue
-sdk: gradio
-sdk_version: 3.18.0
-app_file: app.py
-pinned: false
-license: cc-by-sa-4.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/snowc2023/ask_the_doc/README.md b/spaces/snowc2023/ask_the_doc/README.md
deleted file mode 100644
index 6af60c2668214a0e25dc034ee9a76236d86bcaec..0000000000000000000000000000000000000000
--- a/spaces/snowc2023/ask_the_doc/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Ask The Doc
-emoji: 📖
-colorFrom: red
-colorTo: yellow
-sdk: streamlit
-sdk_version: '1.21.0'
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
-
\ No newline at end of file
diff --git a/spaces/souljoy/chinese_lyric_generation/app.py b/spaces/souljoy/chinese_lyric_generation/app.py
deleted file mode 100644
index 6d98126a77b047007a3b149522f29cd0435813c8..0000000000000000000000000000000000000000
--- a/spaces/souljoy/chinese_lyric_generation/app.py
+++ /dev/null
@@ -1,66 +0,0 @@
-import gradio as gr
-from transformers import T5Tokenizer, T5ForConditionalGeneration
-import torch
-from random import sample
-
-model_path = 'souljoy/t5-chinese-lyric'
-device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
-tokenizer = T5Tokenizer.from_pretrained(model_path)
-model = T5ForConditionalGeneration.from_pretrained(model_path).to(device)
-keywords_list = []
-with open('keywords', mode='r', encoding='utf-8') as f:
- for line in f:
- keywords_list.append(line.strip())
-
-
-def key_cng_change(v_list):
- return ','.join(v_list)
-
-
-def post_process(text):
- return text.replace("\\n", "\n").replace("\\t", "\t")
-
-
-def send(my_singer_txt, my_song_txt, my_key_txt):
- if len(my_singer_txt) == 0:
- lyric = '请输入歌手名'
- elif len(my_song_txt) == 0:
- lyric = '请输入歌名'
- elif len(my_key_txt) == 0:
- lyric = '歌词主题词'
- elif len(my_key_txt.split(',')) > 10:
- lyric = '歌词主太多!最多10个'
- else:
- text = '用户:写一首歌,歌手“{}”,歌曲“{}”,以“{}”为主题。\\n小L:'.format(my_singer_txt, my_song_txt, my_key_txt)
- encoding = tokenizer(text=[text], truncation=True, padding=True, max_length=64, return_tensors="pt").to(device)
- out = model.generate(**encoding, return_dict_in_generate=True, output_scores=False, max_new_tokens=512,
- do_sample=True, top_p=1, temperature=0.7, no_repeat_ngram_size=3)
- out_text = tokenizer.batch_decode(out["sequences"], skip_special_tokens=True)
- lyric = post_process(out_text[0])
-
- return lyric, gr.CheckboxGroup.update(choices=sample(keywords_list, 100), value=[])
-
-def renew():
- return gr.CheckboxGroup.update(choices=sample(keywords_list, 100), value=[])
-
-with gr.Blocks() as demo:
- gr.Markdown("""#### 歌词创作机器人 📻 🎵 """)
- with gr.Row():
- with gr.Column():
- singer_txt = gr.Textbox(label='歌手名', placeholder='请输入你的名字\n\n也可以输入其他歌手的名字,便可以仿照其歌词风格作词')
- song_txt = gr.Textbox(label='歌名', placeholder='请输入要创作的歌词名称')
- key_txt = gr.Textbox(label='歌词主题词', placeholder='请输入主题词/短语,以中文逗号(,)分割\n\n也可以点击下方“主题词样例”\n\n最多10个')
- with gr.Row():
- send_button = gr.Button(value="生成歌词")
- renew_button = gr.Button(value="换一批样例")
- key_cng = gr.CheckboxGroup(label='主题词样例', choices=sample(keywords_list, 100))
-
-
- with gr.Column():
- lyric_txt = gr.Textbox(label='生成歌词')
- key_cng.change(key_cng_change, [key_cng], [key_txt])
- send_button.click(send, [singer_txt, song_txt, key_txt], [lyric_txt,key_cng])
- renew_button.click(renew, [], [key_cng])
-
-if __name__ == "__main__":
- demo.launch()
diff --git a/spaces/sriramelango/Social_Classification_Public/fairseq/examples/linformer/linformer_src/modules/__init__.py b/spaces/sriramelango/Social_Classification_Public/fairseq/examples/linformer/linformer_src/modules/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/sriramelango/Social_Classification_Public/fairseq/examples/textless_nlp/gslm/speech2unit/clustering/dump_feats.py b/spaces/sriramelango/Social_Classification_Public/fairseq/examples/textless_nlp/gslm/speech2unit/clustering/dump_feats.py
deleted file mode 100644
index 031567c6d85d16b5236053abf008b7cabccb4673..0000000000000000000000000000000000000000
--- a/spaces/sriramelango/Social_Classification_Public/fairseq/examples/textless_nlp/gslm/speech2unit/clustering/dump_feats.py
+++ /dev/null
@@ -1,91 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import argparse
-import logging
-
-from examples.textless_nlp.gslm.speech2unit.pretrained.utils import (
- get_and_dump_features,
-)
-
-
-def get_parser():
- parser = argparse.ArgumentParser(
- description="Compute and dump log mel fbank features."
- )
- parser.add_argument(
- "--feature_type",
- type=str,
- choices=["logmel", "hubert", "w2v2", "cpc"],
- default=None,
- help="Acoustic feature type",
- )
- parser.add_argument(
- "--manifest_path",
- type=str,
- default=None,
- help="Manifest file containing the root dir and file names",
- )
- parser.add_argument(
- "--out_features_path",
- type=str,
- default=None,
- help="Features file path to write to",
- )
- parser.add_argument(
- "--checkpoint_path",
- type=str,
- help="Pretrained acoustic model checkpoint",
- )
- parser.add_argument(
- "--layer",
- type=int,
- help="The layer of the pretrained model to extract features from",
- default=-1,
- )
- parser.add_argument(
- "--sample_pct",
- type=float,
- help="Percent data to use for K-means training",
- default=0.1,
- )
- parser.add_argument(
- "--out_features_path",
- type=str,
- help="Path to save log mel fbank features",
- )
- return parser
-
-
-def get_logger():
- log_format = "[%(asctime)s] [%(levelname)s]: %(message)s"
- logging.basicConfig(format=log_format, level=logging.INFO)
- logger = logging.getLogger(__name__)
- return logger
-
-
-if __name__ == "__main__":
- """
- Example command:
- python ~/speechbot/clustering/dump_logmelfank_feats.py \
- --manifest_path /checkpoint/kushall/data/LJSpeech-1.1/asr_input_wavs_16k/train.tsv
- --out_features_path /checkpoint/kushall/experiments/speechbot/logmelfbank/features/ljspeech/train.npy
- """
- parser = get_parser()
- args = parser.parse_args()
- logger = get_logger()
- logger.info(args)
-
- logger.info(f"Extracting {args.feature_type} acoustic features...")
- get_and_dump_features(
- feature_type=args.feature_type,
- checkpoint_path=args.checkpoint_path,
- layer=args.layer,
- manifest_path=args.manifest_path,
- sample_pct=args.sample_pct,
- flatten=True,
- out_features_path=args.out_features_path,
- )
- logger.info(f"Saved extracted features at {args.out_features_path}")
diff --git a/spaces/sriramelango/Social_Classification_Public/fairseq/fairseq/data/audio/__init__.py b/spaces/sriramelango/Social_Classification_Public/fairseq/fairseq/data/audio/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/sriramelango/Social_Classification_Public/fairseq/fairseq/data/nested_dictionary_dataset.py b/spaces/sriramelango/Social_Classification_Public/fairseq/fairseq/data/nested_dictionary_dataset.py
deleted file mode 100644
index 52e74abddacc923c5e29b0a0c41d7efc85482d3b..0000000000000000000000000000000000000000
--- a/spaces/sriramelango/Social_Classification_Public/fairseq/fairseq/data/nested_dictionary_dataset.py
+++ /dev/null
@@ -1,125 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-from collections import OrderedDict
-
-import torch
-from torch.utils.data.dataloader import default_collate
-
-from . import FairseqDataset
-
-
-def _flatten(dico, prefix=None):
- """Flatten a nested dictionary."""
- new_dico = OrderedDict()
- if isinstance(dico, dict):
- prefix = prefix + "." if prefix is not None else ""
- for k, v in dico.items():
- if v is None:
- continue
- new_dico.update(_flatten(v, prefix + k))
- elif isinstance(dico, list):
- for i, v in enumerate(dico):
- new_dico.update(_flatten(v, prefix + ".[" + str(i) + "]"))
- else:
- new_dico = OrderedDict({prefix: dico})
- return new_dico
-
-
-def _unflatten(dico):
- """Unflatten a flattened dictionary into a nested dictionary."""
- new_dico = OrderedDict()
- for full_k, v in dico.items():
- full_k = full_k.split(".")
- node = new_dico
- for k in full_k[:-1]:
- if k.startswith("[") and k.endswith("]"):
- k = int(k[1:-1])
- if k not in node:
- node[k] = OrderedDict()
- node = node[k]
- node[full_k[-1]] = v
- return new_dico
-
-
-class NestedDictionaryDataset(FairseqDataset):
- def __init__(self, defn, sizes=None):
- super().__init__()
- self.defn = _flatten(defn)
- self.sizes = [sizes] if not isinstance(sizes, (list, tuple)) else sizes
-
- first = None
- for v in self.defn.values():
- if not isinstance(
- v,
- (
- FairseqDataset,
- torch.utils.data.Dataset,
- ),
- ):
- raise ValueError("Expected Dataset but found: {}".format(v.__class__))
- first = first or v
- if len(v) > 0:
- assert len(v) == len(first), "dataset lengths must match"
-
- self._len = len(first)
-
- def __getitem__(self, index):
- return OrderedDict((k, ds[index]) for k, ds in self.defn.items())
-
- def __len__(self):
- return self._len
-
- def collater(self, samples):
- """Merge a list of samples to form a mini-batch.
-
- Args:
- samples (List[dict]): samples to collate
-
- Returns:
- dict: a mini-batch suitable for forwarding with a Model
- """
- if len(samples) == 0:
- return {}
- sample = OrderedDict()
- for k, ds in self.defn.items():
- try:
- sample[k] = ds.collater([s[k] for s in samples])
- except NotImplementedError:
- sample[k] = default_collate([s[k] for s in samples])
- return _unflatten(sample)
-
- def num_tokens(self, index):
- """Return the number of tokens in a sample. This value is used to
- enforce ``--max-tokens`` during batching."""
- return max(s[index] for s in self.sizes)
-
- def size(self, index):
- """Return an example's size as a float or tuple. This value is used when
- filtering a dataset with ``--max-positions``."""
- if len(self.sizes) == 1:
- return self.sizes[0][index]
- else:
- return (s[index] for s in self.sizes)
-
- @property
- def supports_prefetch(self):
- """Whether this dataset supports prefetching."""
- return any(ds.supports_prefetch for ds in self.defn.values())
-
- def prefetch(self, indices):
- """Prefetch the data required for this epoch."""
- for ds in self.defn.values():
- if getattr(ds, "supports_prefetch", False):
- ds.prefetch(indices)
-
- @property
- def can_reuse_epoch_itr_across_epochs(self):
- return all(ds.can_reuse_epoch_itr_across_epochs for ds in self.defn.values())
-
- def set_epoch(self, epoch):
- super().set_epoch(epoch)
- for ds in self.defn.values():
- ds.set_epoch(epoch)
diff --git a/spaces/srush/minichain/process.py b/spaces/srush/minichain/process.py
deleted file mode 100644
index 022c06466980e572352aacfe4a1b024e73865066..0000000000000000000000000000000000000000
--- a/spaces/srush/minichain/process.py
+++ /dev/null
@@ -1,13 +0,0 @@
-import sys
-
-print("!pip install -q git+https://github.com/srush/MiniChain")
-print("!git clone https://github.com/srush/MiniChain; cp -fr MiniChain/examples/* . ")
-print()
-
-for l in sys.stdin:
-
- if l.strip() == "# $":
- continue
- if l.strip().startswith("code="):
- continue
- print(l, end="")
diff --git a/spaces/sub314xxl/MetaGPT/metagpt/roles/sales.py b/spaces/sub314xxl/MetaGPT/metagpt/roles/sales.py
deleted file mode 100644
index 51b13f4878b83fe0bf38c199ffd8efd3b2b7024d..0000000000000000000000000000000000000000
--- a/spaces/sub314xxl/MetaGPT/metagpt/roles/sales.py
+++ /dev/null
@@ -1,34 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-"""
-@Time : 2023/5/25 17:21
-@Author : alexanderwu
-@File : sales.py
-"""
-from metagpt.actions import SearchAndSummarize
-from metagpt.roles import Role
-from metagpt.tools import SearchEngineType
-
-
-class Sales(Role):
- def __init__(
- self,
- name="Xiaomei",
- profile="Retail sales guide",
- desc="I am a sales guide in retail. My name is Xiaomei. I will answer some customer questions next, and I "
- "will answer questions only based on the information in the knowledge base."
- "If I feel that you can't get the answer from the reference material, then I will directly reply that"
- " I don't know, and I won't tell you that this is from the knowledge base,"
- "but pretend to be what I know. Note that each of my replies will be replied in the tone of a "
- "professional guide",
- store=None
- ):
- super().__init__(name, profile, desc=desc)
- self._set_store(store)
-
- def _set_store(self, store):
- if store:
- action = SearchAndSummarize("", engine=SearchEngineType.CUSTOM_ENGINE, search_func=store.search)
- else:
- action = SearchAndSummarize()
- self._init_actions([action])
diff --git a/spaces/sukiru/BlueArchiveTTS/app.py b/spaces/sukiru/BlueArchiveTTS/app.py
deleted file mode 100644
index 4fbbddc191a41175d718eee3789f2bfd8384a891..0000000000000000000000000000000000000000
--- a/spaces/sukiru/BlueArchiveTTS/app.py
+++ /dev/null
@@ -1,164 +0,0 @@
-import json
-import os
-import re
-
-import librosa
-import numpy as np
-import torch
-from torch import no_grad, LongTensor
-import commons
-import utils
-import gradio as gr
-from models import SynthesizerTrn
-from text import text_to_sequence, _clean_text
-from mel_processing import spectrogram_torch
-
-limitation = os.getenv("SYSTEM") == "spaces" # limit text and audio length in huggingface spaces
-
-
-def get_text(text, hps, is_phoneme):
- text_norm = text_to_sequence(text, hps.symbols, [] if is_phoneme else hps.data.text_cleaners)
- if hps.data.add_blank:
- text_norm = commons.intersperse(text_norm, 0)
- text_norm = LongTensor(text_norm)
- return text_norm
-
-
-def create_tts_fn(model, hps, speaker_ids):
- def tts_fn(text, speaker, speed, is_phoneme):
- if limitation:
- text_len = len(text)
- max_len = 500
- if is_phoneme:
- max_len *= 3
- else:
- if len(hps.data.text_cleaners) > 0 and hps.data.text_cleaners[0] == "zh_ja_mixture_cleaners":
- text_len = len(re.sub("(\[ZH\]|\[JA\])", "", text))
- if text_len > max_len:
- return "Error: Text is too long", None
-
- speaker_id = speaker_ids[speaker]
- stn_tst = get_text(text, hps, is_phoneme)
- with no_grad():
- x_tst = stn_tst.unsqueeze(0)
- x_tst_lengths = LongTensor([stn_tst.size(0)])
- sid = LongTensor([speaker_id])
- audio = model.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=.667, noise_scale_w=0.8,
- length_scale=1.0 / speed)[0][0, 0].data.cpu().float().numpy()
- del stn_tst, x_tst, x_tst_lengths, sid
- return "Success", (hps.data.sampling_rate, audio)
-
- return tts_fn
-
-
-
-
-
-def create_to_phoneme_fn(hps):
- def to_phoneme_fn(text):
- return _clean_text(text, hps.data.text_cleaners) if text != "" else ""
-
- return to_phoneme_fn
-
-
-css = """
- #advanced-btn {
- color: white;
- border-color: black;
- background: black;
- font-size: .7rem !important;
- line-height: 19px;
- margin-top: 24px;
- margin-bottom: 12px;
- padding: 2px 8px;
- border-radius: 14px !important;
- }
- #advanced-options {
- display: none;
- margin-bottom: 20px;
- }
-"""
-
-if __name__ == '__main__':
- models_tts = []
- models_vc = []
- models_soft_vc = []
- name = 'BlueArchiveTTS'
- lang = '日本語 (Japanese)'
- example = '先生、何をお手伝いしましょうか?'
- config_path = f"saved_model/config.json"
- model_path = f"saved_model/model.pth"
- cover_path = f"saved_model/cover.png"
- hps = utils.get_hparams_from_file(config_path)
- model = SynthesizerTrn(
- len(hps.symbols),
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- n_speakers=hps.data.n_speakers,
- **hps.model)
- utils.load_checkpoint(model_path, model, None)
- model.eval()
- speaker_ids = [sid for sid, name in enumerate(hps.speakers) if name != "None"]
- speakers = [name for sid, name in enumerate(hps.speakers) if name != "None"]
-
- t = 'vits'
- models_tts.append((name, cover_path, speakers, lang, example,
- hps.symbols, create_tts_fn(model, hps, speaker_ids),
- create_to_phoneme_fn(hps)))
-
-
- app = gr.Blocks(css=css)
-
- with app:
- gr.Markdown("# BlueArchiveTTS Using VITS Model\n\n"
- "\n\n")
- with gr.Tabs():
- with gr.TabItem("TTS"):
- with gr.Tabs():
- for i, (name, cover_path, speakers, lang, example, symbols, tts_fn,
- to_phoneme_fn) in enumerate(models_tts):
- with gr.TabItem(f"BlueArchive"):
- with gr.Column():
- gr.Markdown(f"## {name}\n\n"
- f"\n\n"
- f"lang: {lang}")
- tts_input1 = gr.TextArea(label="Text (500 words limitation)", value=example,
- elem_id=f"tts-input{i}")
- tts_input2 = gr.Dropdown(label="Speaker", choices=speakers,
- type="index", value=speakers[0])
- tts_input3 = gr.Slider(label="Speed", value=1, minimum=0.1, maximum=2, step=0.1)
- with gr.Accordion(label="Advanced Options", open=False):
- phoneme_input = gr.Checkbox(value=False, label="Phoneme input")
- to_phoneme_btn = gr.Button("Covert text to phoneme")
- phoneme_list = gr.Dataset(label="Phoneme list", components=[tts_input1],
- samples=[[x] for x in symbols],
- elem_id=f"phoneme-list{i}")
- phoneme_list_json = gr.Json(value=symbols, visible=False)
- tts_submit = gr.Button("Generate", variant="primary")
- tts_output1 = gr.Textbox(label="Output Message")
- tts_output2 = gr.Audio(label="Output Audio")
- tts_submit.click(tts_fn, [tts_input1, tts_input2, tts_input3, phoneme_input],
- [tts_output1, tts_output2], api_name="tts")
- to_phoneme_btn.click(to_phoneme_fn, [tts_input1], [tts_input1])
- phoneme_list.click(None, [phoneme_list, phoneme_list_json], [],
- _js=f"""
- (i,phonemes) => {{
- let root = document.querySelector("body > gradio-app");
- if (root.shadowRoot != null)
- root = root.shadowRoot;
- let text_input = root.querySelector("#tts-input{i}").querySelector("textarea");
- let startPos = text_input.selectionStart;
- let endPos = text_input.selectionEnd;
- let oldTxt = text_input.value;
- let result = oldTxt.substring(0, startPos) + phonemes[i] + oldTxt.substring(endPos);
- text_input.value = result;
- let x = window.scrollX, y = window.scrollY;
- text_input.focus();
- text_input.selectionStart = startPos + phonemes[i].length;
- text_input.selectionEnd = startPos + phonemes[i].length;
- text_input.blur();
- window.scrollTo(x, y);
- return [];
- }}""")
-
- app.queue(concurrency_count=3).launch(server_name="0.0.0.0")
diff --git a/spaces/suppsumstagza/text-to-image-stable-diffusion-v1-5/scripts/Adobe Acrobat Pro DC 2018.012.20039 Crack Utorrent.md b/spaces/suppsumstagza/text-to-image-stable-diffusion-v1-5/scripts/Adobe Acrobat Pro DC 2018.012.20039 Crack Utorrent.md
deleted file mode 100644
index ee5fba8e3209f6cf9ea0e4cb1176fe15acd40c68..0000000000000000000000000000000000000000
--- a/spaces/suppsumstagza/text-to-image-stable-diffusion-v1-5/scripts/Adobe Acrobat Pro DC 2018.012.20039 Crack Utorrent.md
+++ /dev/null
@@ -1,6 +0,0 @@
-Adobe Acrobat Pro DC 2018.012.20039 Crack utorrent
Download File ✯✯✯ https://cinurl.com/2uEY3v
-
-SHIFT 2 Unleashed 1.2.95 cracked ipa:Electronic Arts has updated Need for Speed ... Adobe Acrobat Pro DC 2018.012.20039 Crack utorrent 1fdad05405
-
-
-
diff --git a/spaces/suppsumstagza/text-to-image-stable-diffusion-v1-5/scripts/Malayalam Spoken English Book Pdf PATCHED Free Download.md b/spaces/suppsumstagza/text-to-image-stable-diffusion-v1-5/scripts/Malayalam Spoken English Book Pdf PATCHED Free Download.md
deleted file mode 100644
index ee9af359e9ccdd5fe34f4bb8625c4bdb20d8e7b0..0000000000000000000000000000000000000000
--- a/spaces/suppsumstagza/text-to-image-stable-diffusion-v1-5/scripts/Malayalam Spoken English Book Pdf PATCHED Free Download.md
+++ /dev/null
@@ -1,38 +0,0 @@
-malayalam spoken english book pdf free download
Download Zip ››› https://cinurl.com/2uEYt0
-
-2,086
-
-Category:Augustine of Hippo
-
-Category:Martyred Roman Catholic saints
-
-Category:Christian martyrs executed by decapitation
-
-Category:Saints from the Holy Land
-
-Category:1st-century Romans
-
-Category:1st-century Christians
-
-Category:Year of birth uncertain
-
-Category:Year of death unknownTrump won’t budge on his promise of a border wall, and the president of American Hospitality Association seems to think Trump is on to something, proposing to “reimagine” the border wall.
-
-Yes, some healthcare professionals are worried that people will die at the border as they try to cross the desert. Oh, wait, that’s already happening.
-
-From CNN:
-
-“I think it’s a really great idea to reimagine the border,” said Ken Johnson, president of the American Hospital Association, to CNN. “I would love to hear the president’s thoughts on that.” The American Hospital Association represents some 3,000 hospitals across the United States. TRENDING: Black Lives Matter Activist Wearing 'Justice for Breonna Taylor' Shirt Walked into a Louisville Bar and Murdered Three People […] “We’ve already seen what’s going on with the border,” Johnson said. “There are overstressed shelters and people are coming into our hospitals.”
-
-Some hospitals are already taking in illegal aliens at the border, and there is no shortage of unscreened illegals. But to be fair, some folks who voted for Trump are saying that any criticism of Trump is “racist.” Trump is “good for America.” And Trump is “not a fascist.”
-
-It’s starting to look like, if Hillary Clinton had won, Trump would have been banned from the White House and charged with treason.
-
-At a campaign rally for Trump in Pennsylvania last week, Trump bragged about the fact that he would take on the media and that they would all be “sad” in the end. It’s not hard to see why Trump is afraid of the media.
-
-Back in February, former Hillary Clinton campaign manager and CNN analyst Donna Brazile said Clinton would campaign with Trump at rallies “until the cows come home.”
-
-“What was striking to me is the idea that you were going to be 4fefd39f24
-
-
-
diff --git a/spaces/svjack/ControlNet-Face-Chinese/SPIGA/spiga/eval/benchmark/metrics/pose.py b/spaces/svjack/ControlNet-Face-Chinese/SPIGA/spiga/eval/benchmark/metrics/pose.py
deleted file mode 100644
index 3e591f00f71f26466d66545a5229663f116193eb..0000000000000000000000000000000000000000
--- a/spaces/svjack/ControlNet-Face-Chinese/SPIGA/spiga/eval/benchmark/metrics/pose.py
+++ /dev/null
@@ -1,159 +0,0 @@
-import numpy as np
-from sklearn.metrics import confusion_matrix
-
-from spiga.eval.benchmark.metrics.metrics import Metrics
-
-
-class MetricsHeadpose(Metrics):
-
- def __init__(self, name='headpose'):
- super().__init__(name)
-
- # Angles
- self.angles = ['yaw', 'pitch', 'roll']
- # Confusion matrix intervals
- self.pose_labels = [-90, -75, -60, -45, -30, -15, 0, 15, 30, 45, 60, 75, 90]
- # Percentile reference angles
- self.error_labels = [2.5, 5, 10, 15, 30]
- # Cumulative plot axis length
- self.bins = 1000
-
- def compute_error(self, data_anns, data_pred, database, select_ids=None):
-
- # Initialize global logs and variables of Computer Error function
- self.init_ce(data_anns, data_pred, database)
-
- # Generate annotations if needed
- if data_anns[0]['headpose'] is None:
- print('Database anns generated by posit...')
- data_anns = self._posit_anns()
- print('Posit generation done...')
-
- # Dictionary variables
- self.error['data_pred'] = []
- self.error['data_anns'] = []
- self.error['data_pred_trl'] = []
- self.error['data_anns_trl'] = []
- self.error['mae_ypr'] = []
- self.error['mae_mean'] = []
-
- # Order data
- for img_id, img_anns in enumerate(data_anns):
- pose_anns = img_anns['headpose'][0:3]
- self.error['data_anns'].append(pose_anns)
- pose_pred = data_pred[img_id]['headpose'][0:3]
- self.error['data_pred'].append(pose_pred)
-
- # Compute MAE error
- anns_array = np.array(self.error['data_anns'])
- pred_array = np.array(self.error['data_pred'])
- mae_ypr = np.abs((anns_array-pred_array))
- self.error['mae_ypr'] = mae_ypr.tolist()
- self.error['mae_mean'] = np.mean(mae_ypr, axis=-1).tolist()
-
- # Quantize labeled data
- label_anns = self._nearest_label(anns_array)
- label_pred = self._nearest_label(pred_array)
- self.error['label_anns'] = label_anns
- self.error['label_pred'] = label_pred
-
- for angle_id, angle in enumerate(self.angles):
- # Confusion matrix
- self.error['cm_%s' % angle] = confusion_matrix(label_anns[:, angle_id], label_pred[:, angle_id])
- # Cumulative error
- self.error['cumulative_%s' % angle] = self._cumulative_error(mae_ypr[:, angle_id], bins=self.bins)
-
- return self.error
-
- def metrics(self):
-
- # Initialize global logs and variables of Metrics function
- self.init_metrics()
-
- # Mean Absolute Error
- mae_ypr = np.array(self.error['mae_ypr'])
- mae_ypr_mean = np.mean(mae_ypr, axis=0)
- self.metrics_log['mae_ypr'] = mae_ypr_mean.tolist()
- self.metrics_log['mae_mean'] = np.mean(mae_ypr_mean)
- print('MAE [yaw, pitch, roll]: [%.3f, %.3f, %.3f]' % (mae_ypr_mean[0], mae_ypr_mean[1], mae_ypr_mean[2]))
- print('MAE mean: %.3f' % self.metrics_log['mae_mean'])
-
- # Per angle measurements
- self.metrics_log['acc_label'] = []
- self.metrics_log['acc_adj_label'] = []
-
- for angle_id, angle in enumerate(self.angles):
-
- # Accuracy per label
- cm = self.error['cm_%s' % angle]
- diagonal = np.diagonal(cm, offset=0).sum()
- acc_main = diagonal / cm.sum().astype('float')
- self.metrics_log['acc_label'].append(acc_main)
-
- # Permissive accuracy
- diagonal_adj = diagonal.sum() + np.diagonal(cm, offset=-1).sum() + np.diagonal(cm, offset=1).sum()
- acc_adj = diagonal_adj / cm.sum().astype('float')
- self.metrics_log['acc_adj_label'].append(acc_adj)
-
- # Percentile of relevant angles
- self.metrics_log['sr_%s' % angle] = {}
- for angle_num in self.error_labels:
- if max(mae_ypr[:, angle_id]) > angle_num:
- [cumulative, base] = self.error['cumulative_%s' % angle]
- perc = [cumulative[x[0] - 1] for x in enumerate(base) if x[1] > angle_num][0]
- else:
- perc = 1.
-
- self.metrics_log['sr_%s' % angle][angle_num] = perc
-
- print('Accuracy [yaw, pitch, roll]: ', self.metrics_log['acc_label'])
- print('Accuracy [yaw, pitch, roll] (adjacency as TP): ', self.metrics_log['acc_adj_label'])
- for angle in self.angles:
- print('Success Rate %s: ' % angle, self.metrics_log['sr_%s' % angle])
-
- return self.metrics_log
-
- def get_pimg_err(self, data_dict, img_select=None):
- mae_mean = self.error['mae_mean']
- mae_ypr = self.error['mae_ypr']
- if img_select is not None:
- mae_mean = [mae_mean[img_id] for img_id in img_select]
- mae_ypr = [mae_ypr[img_id] for img_id in img_select]
- name_dict = self.name + '/%s'
- data_dict[name_dict % 'mae'] = mae_mean
- mae_ypr = np.array(mae_ypr)
- data_dict[name_dict % 'mae_yaw'] = mae_ypr[:, 0].tolist()
- data_dict[name_dict % 'mae_pitch'] = mae_ypr[:, 1].tolist()
- data_dict[name_dict % 'mae_roll'] = mae_ypr[:, 2].tolist()
- return data_dict
-
- def _posit_anns(self):
-
- import spiga.data.loaders.dl_config as dl_config
- import spiga.data.loaders.dataloader as dl
-
- # Load configuration
- data_config = dl_config.AlignConfig(self.database, self.data_type)
- data_config.image_size = (256, 256)
- data_config.generate_pose = True
- data_config.aug_names = []
- data_config.shuffle = False
- dataloader, _ = dl.get_dataloader(1, data_config, debug=True)
-
- data_anns = []
- for num_batch, batch_dict in enumerate(dataloader):
- pose = batch_dict['pose'].numpy()
- data_anns.append({'headpose': pose[0].tolist()})
- return data_anns
-
- def _nearest_label(self, data):
- data_tile = data[:, :, np.newaxis]
- data_tile = np.tile(data_tile, len(self.pose_labels))
- diff_tile = np.abs(data_tile - self.pose_labels)
- label_idx = diff_tile.argmin(axis=-1)
- return label_idx
-
- def _cumulative_error(self, error, bins=1000):
- num_imgs, base = np.histogram(error, bins=bins)
- cumulative = [x / float(len(error)) for x in np.cumsum(num_imgs)]
- return [cumulative[:bins], base[:bins]]
diff --git a/spaces/taidi/bingai2/README.md b/spaces/taidi/bingai2/README.md
deleted file mode 100644
index 0ab51fcecee3f962e752e2735cd90ac8a2549f07..0000000000000000000000000000000000000000
--- a/spaces/taidi/bingai2/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
----
-title: Bingai2
-emoji: 😻
-colorFrom: pink
-colorTo: pink
-sdk: docker
-pinned: false
-app_port: 8080
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/team7/talk_with_wind/efficientat/resources/README.md b/spaces/team7/talk_with_wind/efficientat/resources/README.md
deleted file mode 100644
index 9618ed755a81d793bbf4941406c74ea07136b2a4..0000000000000000000000000000000000000000
--- a/spaces/team7/talk_with_wind/efficientat/resources/README.md
+++ /dev/null
@@ -1 +0,0 @@
-Download the latest version from this repo's Github Releases and place them inside this folder.
\ No newline at end of file
diff --git a/spaces/terfces0erbo/CollegeProjectV2/Crack PATCHED Battlefield 3 Reloaded Fixed.md b/spaces/terfces0erbo/CollegeProjectV2/Crack PATCHED Battlefield 3 Reloaded Fixed.md
deleted file mode 100644
index c9d18745a6ef97aaa9a2c720fbcd62e9fbbc7a3b..0000000000000000000000000000000000000000
--- a/spaces/terfces0erbo/CollegeProjectV2/Crack PATCHED Battlefield 3 Reloaded Fixed.md
+++ /dev/null
@@ -1,18 +0,0 @@
-Crack Battlefield 3 Reloaded Fixed
Download Zip … https://bytlly.com/2uGlDD
-
-bfc .bf3. If that doesn't work, try running bf3 in compatibility mode. - .bfc .bf3 This method will delete your current settings but your bf3 installation will keep running as is. Now, lets do the steps that are suggested in the other thread that led you here and you can see if that works out. Make sure that you have the correct driver for your video card installed. Your gpu has a different codename but it will have the same model. For example mine is rtx r9 290. Let me know if you want to do this.
-
-[The effect of hypoxia on protein kinase C activity in the myocardium].
-
-Changes in protein kinase C activity in rat myocardium were investigated after a single 30 min submersion of isolated working hearts in hypoxic (2.5% O2) or normoxic (21% O2) buffer. Incubation of the myocardium with hypoxia in vitro for 10 min led to a rapid activation of protein kinase C, the activity of which did not change after incubation of the myocardium for 30 min. The myocardial enzymes creatine kinase and lactate dehydrogenase did not change after submersion of the myocardium in hypoxic solution.Two civil rights leaders who are longtime friends of the Rev. Al Sharpton have been indicted on charges that they participated in a scheme to defraud a housing trust by siphoning off money that was supposed to be used to renovate a New York City Housing Authority public housing complex.
-
-Bertrand Smith, a former top official with the New York City Housing Authority and a man who was arrested along with Henry R. DeLeon last week, was arrested Tuesday on federal fraud charges, along with his longtime confidant, Henry Gomes. The two men have pleaded not guilty and were released on bail.
-
-An indictment unsealed last week charged the two men with using their positions at the housing authority to approve an expensive renovation to a Brooklyn housing complex, and then embezzling more than $6.5 million in public money that was supposed to pay for the project.
-
-The housing authority spent most of the money on rent for the complex and failed to make other payments to the contractor, they were accused of telling investigators.CPC-2, a progestin receptor with similarity to the membrane progestin receptor.
-
-A mammalian cell line, 4fefd39f24
-
-
-
diff --git a/spaces/terfces0erbo/CollegeProjectV2/DslrBooth Photo Booth Software 5.22.1522.1 Keygen Setup Free.md b/spaces/terfces0erbo/CollegeProjectV2/DslrBooth Photo Booth Software 5.22.1522.1 Keygen Setup Free.md
deleted file mode 100644
index cafb4bb99bc47831876f62a43a126f89758bacbd..0000000000000000000000000000000000000000
--- a/spaces/terfces0erbo/CollegeProjectV2/DslrBooth Photo Booth Software 5.22.1522.1 Keygen Setup Free.md
+++ /dev/null
@@ -1,6 +0,0 @@
-DslrBooth Photo Booth Software 5.22.1522.1 Keygen Setup Free
Download >> https://bytlly.com/2uGjE1
-
-... InfiniteCracks hideous beaver dslrBooth Photo Booth Software 5.22.1522.1 + keygen ... Light Image Resizer v5.1.0.0 Setup + Patch InfiniteCracks hideous beaver Avast! ... Email extractor 6.6.3.2 free registration key .txt, 26-02-2020, 82.96%. 1fdad05405
-
-
-
diff --git a/spaces/terfces0erbo/CollegeProjectV2/Free Download Autodesk Project Vasari Torrent.md b/spaces/terfces0erbo/CollegeProjectV2/Free Download Autodesk Project Vasari Torrent.md
deleted file mode 100644
index 1c6fd56f808b9aa8753830d306f597300bdbcad4..0000000000000000000000000000000000000000
--- a/spaces/terfces0erbo/CollegeProjectV2/Free Download Autodesk Project Vasari Torrent.md
+++ /dev/null
@@ -1,14 +0,0 @@
-Free Download Autodesk Project Vasari Torrent
Download ✅ https://bytlly.com/2uGlls
-
-Autodesk Revit Portable Download. Autodesk® Project Vasari - easy-to-use, expressive design tool for creating building concepts.... Autodesk® T-FLEX CAD 16 - design system and.
-Revit® 2009 Portable Rus (ENG + RUS) - Download torrent.
-Autodesk® Revit® 2009 is a comprehensive design solution for all phases of...
-... Revit 2009 Portable download torrent ... ...
-Revit 2009.
-You can't download files from our server...
-Revit 2009 Portable - download torrent ... ...
-Revit 2009 Portable (RUS/ENG).
-You can download Autodesk Revit 2010 via torrent without registration on our site. 8a78ff9644
-
-
-
diff --git a/spaces/textToSQL/mp3_transcribe_prompt/app.py b/spaces/textToSQL/mp3_transcribe_prompt/app.py
deleted file mode 100644
index 9a725dceede183f2a6fba4f197ab4d24a90d32fc..0000000000000000000000000000000000000000
--- a/spaces/textToSQL/mp3_transcribe_prompt/app.py
+++ /dev/null
@@ -1,112 +0,0 @@
-import whisper
-import gradio as gr
-import openai
-import os
-
-openai.api_key = os.environ["OPENAI_API_KEY"]
-
-model = whisper.load_model("small")
-
-
-#option 1
-def transcribe(audio):
- model = whisper.load_model("base")
- result = model.transcribe(audio)
- return result["text"]
-
-#option 2
-# def transcribe(audio):
-
-# #time.sleep(3)
-# # load audio and pad/trim it to fit 30 seconds
-# audio = whisper.load_audio(audio)
-# audio = whisper.pad_or_trim(audio)
-
-# # make log-Mel spectrogram and move to the same device as the model
-# mel = whisper.log_mel_spectrogram(audio).to(model.device)
-
-# # detect the spoken language
-# _, probs = model.detect_language(mel)
-# print(f"Detected language: {max(probs, key=probs.get)}")
-
-# # decode the audio
-# options = whisper.DecodingOptions(fp16 = False)
-# result = whisper.decode(model, mel, options)
-# return result.text
-
-
-def process_text(input_text):
- # Apply your function here to process the input text
- output_text = input_text.upper()
- return output_text
-
-def get_completion(prompt, model='gpt-3.5-turbo'):
- messages = [
- {"role": "system", "content": """You are a .... You are provided with the transcription of a ... . \
- Extract the following information from the transcription, replace curly brackets {} with relevant extracted information ... \
- ...the rest of your prompt...
-
- """
- },
- {"role": "user", "content": prompt}
- ]
- response = openai.ChatCompletion.create(
- model = model,
- messages = messages,
- temperature = 0,
-
- )
- return response.choices[0].message['content']
-
-with gr.Blocks() as demo:
-
- gr.Markdown("""
- # Title
-
- Description
-
- """)
-
-
- title = "title"
- audio = gr.Audio(type="filepath")
-
- b1 = gr.Button("Transcribe audio")
- b2 = gr.Button("")
- # b3 = gr.Button("Email report to your doctor")
-
-
- text1 = gr.Textbox(lines=5)
- text2 = gr.Textbox(lines=5)
-
- prompt = text1
-
-
-
- b1.click(transcribe, inputs=audio, outputs=text1)
- b2.click(get_completion, inputs=text1, outputs=text2)
-
-
- # b1.click(transcribe, inputs=audio, outputs=text1)
- # b2.click(get_completion, inputs=prompt, outputs=text2)
-
-
-
-demo.launch()
-
-#demo.launch(share=True, auth=("username", "password"))
-
-# In this example, the process_text function just converts the input text to uppercase, but you can replace it with your desired function. The Gradio Blocks interface will have two buttons: "Transcribe audio" and "Process text". The first button transcribes the audio and fills the first textbox, and the second button processes the text from the first textbox and fills the second textbox.
-
-
-# gr.Interface(
-# title = 'OpenAI Whisper ASR Gradio Web UI',
-# fn=transcribe,
-# inputs=[
-# gr.inputs.Audio(source="microphone", type="filepath")
-# ],
-# outputs=[
-# "textbox"
-# ],
-
-# live=True).launch()
diff --git a/spaces/theblocknoob/hugging-face-space/index.html b/spaces/theblocknoob/hugging-face-space/index.html
deleted file mode 100644
index 58275de3b1c343a98420342baa076b9baaafa157..0000000000000000000000000000000000000000
--- a/spaces/theblocknoob/hugging-face-space/index.html
+++ /dev/null
@@ -1,19 +0,0 @@
-
-
-
-
-
- My static Space
-
-
-
-
-
Welcome to your static Space!
-
You can modify this app directly by editing index.html in the Files and versions tab.
-
- Also don't forget to check the
- Spaces documentation.
-
-
----> ServiceClient failure for DeepLeo[/ERROR]
-
-
-Adobe Audition 1.5 Inkl Keygen Crack is a powerful software for audio editing and recording. It allows you to create professional-quality soundtracks, podcasts, music, and voice-overs. Adobe Audition 1.5 Inkl Keygen Crack has many features and tools that make it easy to work with audio files, such as multitrack editing, waveform display, spectral analysis, noise reduction, effects processing, and more.
-
-If you are looking for Adobe Audition 1.5 Inkl Keygen Crack, you are not alone. Many people want to use this software without paying for it. However, finding a reliable and safe source of Adobe Audition 1.5 Inkl Keygen Crack can be challenging. There are many websites that claim to offer Adobe Audition 1.5 Inkl Keygen Crack, but most of them are either fake or infected with malware. Some of them may even steal your personal information or damage your computer.
-
-That's why we have done the research for you and found the best and most trusted website to download Adobe Audition 1.5 Inkl Keygen Crack. This website has been tested and verified by thousands of users who have successfully downloaded and installed Adobe Audition 1.5 Inkl Keygen Crack on their computers. The download process is fast and easy, and the installation is simple and straightforward. You just need to follow the instructions provided on the website and you will be able to enjoy Adobe Audition 1.5 Inkl Keygen Crack in no time.
-
-To download Adobe Audition 1.5 Inkl Keygen Crack from this website, you need to click on the link below and follow the steps. You will need a torrent client such as uTorrent or BitTorrent to download the file. After downloading the file, you will need to extract it using WinRAR or 7-Zip. Then you will need to run the keygen.exe file and generate a serial number for Adobe Audition 1.5 Inkl Keygen Crack. Finally, you will need to run the setup.exe file and enter the serial number when prompted.
-
-Download Adobe Audition 1.5 Inkl Keygen Crack here: [link]
-
-We hope this article has helped you find Adobe Audition 1.5 Inkl Keygen Crack and enjoy its features and benefits. Adobe Audition 1.5 Inkl Keygen Crack is a great software for audio enthusiasts and professionals alike. It can help you create amazing sound projects that will impress your audience and clients.
-
-If you liked this article, please share it with your friends and leave a comment below. We would love to hear your feedback and suggestions on how we can improve our articles and services. Thank you for reading and happy downloading!
-
-
-Adobe Audition 1.5 Inkl Keygen Crack is not only a software for audio editing and recording, but also a software for audio enhancement and restoration. You can use Adobe Audition 1.5 Inkl Keygen Crack to improve the quality of your audio files, remove unwanted noises, adjust the volume and pitch, apply various effects and filters, and more. Adobe Audition 1.5 Inkl Keygen Crack can also help you recover damaged or corrupted audio files and restore them to their original state.
-
-Adobe Audition 1.5 Inkl Keygen Crack is compatible with various audio formats, such as MP3, WAV, WMA, OGG, FLAC, AIFF, and more. You can also import and export audio files from other Adobe products, such as Premiere Pro, After Effects, Photoshop, and more. Adobe Audition 1.5 Inkl Keygen Crack supports multichannel audio and surround sound, which means you can create immersive and realistic soundscapes for your projects.
-
-Adobe Audition 1.5 Inkl Keygen Crack has a user-friendly and intuitive interface that makes it easy to navigate and use. You can customize the workspace according to your preferences and needs. You can also access various tutorials and tips on how to use Adobe Audition 1.5 Inkl Keygen Crack on the official website or on YouTube. Adobe Audition 1.5 Inkl Keygen Crack is a software that will make your audio editing and recording experience enjoyable and productive.
-
-
-Adobe Audition 1.5 Inkl Keygen Crack is also a software for audio mixing and mastering. You can use Adobe Audition 1.5 Inkl Keygen Crack to create professional-sounding mixes and masters for your audio projects. You can adjust the levels, panning, EQ, compression, reverb, and other parameters of each track. You can also use Adobe Audition 1.5 Inkl Keygen Crack to add effects and transitions to your mixes and masters. Adobe Audition 1.5 Inkl Keygen Crack has a built-in CD burning feature that lets you burn your mixes and masters to CDs or DVDs.
-
-Adobe Audition 1.5 Inkl Keygen Crack is a software that can help you unleash your creativity and express yourself through sound. You can use Adobe Audition 1.5 Inkl Keygen Crack to create original music, remixes, mashups, soundtracks, jingles, and more. You can also use Adobe Audition 1.5 Inkl Keygen Crack to edit and enhance existing audio files, such as songs, podcasts, audiobooks, and more. You can also use Adobe Audition 1.5 Inkl Keygen Crack to convert audio files between different formats and bitrates.
-
-Adobe Audition 1.5 Inkl Keygen Crack is a software that you will love to use and learn from. It has a comprehensive help system that provides you with tips, tutorials, and examples on how to use Adobe Audition 1.5 Inkl Keygen Crack effectively and efficiently. You can also access online resources and communities that offer you support and guidance on how to use Adobe Audition 1.5 Inkl Keygen Crack for your specific needs and goals. Adobe Audition 1.5 Inkl Keygen Crack is a software that will make you a better audio editor and producer.
-Adobe Audition 1.5 Inkl Keygen Crack
Download ››››› https://urlcod.com/2uK3HF
679dcb208e
-
-
\ No newline at end of file
diff --git a/spaces/tialenAdioni/chat-gpt-api/logs/ArcGIS 10.1 [EXCLUSIVE] Crack.md b/spaces/tialenAdioni/chat-gpt-api/logs/ArcGIS 10.1 [EXCLUSIVE] Crack.md
deleted file mode 100644
index 4c190479376a642134e9ecd3a8b5e97d276240a8..0000000000000000000000000000000000000000
--- a/spaces/tialenAdioni/chat-gpt-api/logs/ArcGIS 10.1 [EXCLUSIVE] Crack.md
+++ /dev/null
@@ -1,31 +0,0 @@
-
-How to Download and Install ArcGIS 10.1 Crack for Free
-ArcGIS 10.1 is a powerful geographic information system (GIS) software that allows you to create, analyze, and share maps and geospatial data. However, it is also an expensive software that requires a license to use. If you want to use ArcGIS 10.1 for free, you can try to download and install a cracked version of it. However, this is not recommended as it may be illegal, unsafe, or unreliable. In this article, we will show you how to download and install ArcGIS 10.1 crack for free, but we do not endorse or support this practice.
-Step 1: Download ArcGIS 10.1 Crack
-The first step is to download a cracked version of ArcGIS 10.1 from a reliable source. There are many websites that claim to offer ArcGIS 10.1 crack, but some of them may contain viruses, malware, or fake files. Therefore, you should be careful and use a trusted antivirus software to scan the files before opening them. One of the websites that offers ArcGIS 10.1 crack is Gissoftgeek[^1^], which provides a link to download the software and a keygen to generate a registration key.
-ArcGIS 10.1 Crack
Download Zip ✪✪✪ https://urlcod.com/2uKalm
-Step 2: Install ArcGIS 10.1 Crack
-The second step is to install ArcGIS 10.1 crack on your computer. To do this, you need to follow these instructions:
-
-- Install the official trial version of ArcGIS 10.1 from here if you don't have it already.
-- Install the license server that is included with the keygen. Leave the license server window open when it finishes the installation.
-- Run the keygen.exe and use these settings under the desktop tab: HostID=ANY Licenses=2048 Feature=ARCINFO [NOT ARC/INFO] Version=10.1 Starts=1/1/2012 Expires: 1/1/2020
-- Click generate and a registration key and service.txt will be generated.
-- Copy service.txt to C://Program Files (x86)/ArcGIS/License10.1/bin
-- Enter the registration key to ArcGIS.
-- Enjoy!
-
-Step 3: Use ArcGIS 10.1 Crack
-The third step is to use ArcGIS 10.1 crack for your GIS projects. You can access all the features and functions of ArcGIS 10.1 without any limitations or restrictions. However, you should be aware that using a cracked version of ArcGIS 10.1 may have some drawbacks, such as:
-
-- It may be illegal in your country or region to use pirated software.
-- It may violate the terms and conditions of Esri, the developer of ArcGIS.
-- It may not work properly or cause errors or crashes.
-- It may not be compatible with other software or updates.
-- It may expose your computer to security risks or malware.
-
-Therefore, we advise you to use ArcGIS 10.1 crack at your own risk and responsibility.
-Conclusion
-In this article, we have shown you how to download and install ArcGIS 10.1 crack for free. However, we do not recommend or support this practice as it may be illegal, unsafe, or unreliable. If you want to use ArcGIS 10.1 legally and safely, you should purchase a license from Esri or use an alternative GIS software that is free or open source.
e93f5a0c3f
-
-
\ No newline at end of file
diff --git a/spaces/tialenAdioni/chat-gpt-api/logs/Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105 Access the Complete List of Ayyappan Ashtothram Namavali and Other Slokas in Tamil.md b/spaces/tialenAdioni/chat-gpt-api/logs/Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105 Access the Complete List of Ayyappan Ashtothram Namavali and Other Slokas in Tamil.md
deleted file mode 100644
index 2859c991192af8bb420a10c11c0a479fddb76ba1..0000000000000000000000000000000000000000
--- a/spaces/tialenAdioni/chat-gpt-api/logs/Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105 Access the Complete List of Ayyappan Ashtothram Namavali and Other Slokas in Tamil.md
+++ /dev/null
@@ -1,71 +0,0 @@
-
-Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105: A Guide to Download and Enjoy the Devotional Music
-If you are looking for Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105, you have come to the right place. Ayyappan Bhajan Songs are devotional songs dedicated to Lord Ayyappa, a Hindu deity who is worshipped as the son of Shiva and Vishnu. Ayyappan Bhajan Songs are sung by devotees during the annual pilgrimage to Sabarimala, a holy hill shrine in Kerala, India.
-Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105 is a collection of 105 songs in Tamil language that praise and glorify Lord Ayyappa. The songs are written in simple and poetic language that can touch the hearts of the listeners. The songs also contain valuable teachings and messages that can inspire and guide the devotees in their spiritual journey.
-Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105
Download File … https://urlcod.com/2uKa3I
-If you want to download and enjoy Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105, you can follow these simple steps:
-
-- Go to https://www.ayyappan-ldc.com/bhajan-songs-tamil.html, a website that offers free downloads of Ayyappan Bhajan Songs in various languages.
-- Scroll down to the section titled "Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105" and click on the link that says "Download PDF".
-- A new tab will open with the PDF file of the songs. You can either save it to your device or print it out for your convenience.
-- You can also listen to the audio versions of the songs by clicking on the links that say "Play Audio".
-- Enjoy the divine music and feel the blessings of Lord Ayyappa.
-
-Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105 is a great resource for anyone who wants to learn and sing along with the devotional songs of Lord Ayyappa. The songs can help you connect with your inner self and experience peace and joy. They can also enhance your faith and devotion towards Lord Ayyappa and his teachings.
-We hope this article has helped you find what you were looking for. If you have any questions or feedback, please feel free to leave a comment below. Thank you for reading and have a wonderful day.
-Ayyappan Song lyrics PDF free download
-Ayyappan Bhajanai Songs In Tamil PDF
-Ayyappan Songs Tamil Lyrics Books
-Ayyappan Bajanai Songs Lyrics Tamil PDF
-Ayyappan Song Tamil Lyrics - tamilgod.org
-K Veeramani Ayyappan Songs Lyrics Tamil Book
-KJ Yesudas Ayyappan Songs Lyrics Tamil Book
-Ayyappan 108 Saranam in Tamil PDF
-Ayyappan Songs by K Veeramani PDF
-Ayyappan Songs by KJ Yesudas PDF
-Ayyappan Bhajan Songs Lyrics in Tamil
-Ayyappan Devotional Songs in Tamil PDF
-Ayyappan Pooja Songs in Tamil PDF
-Ayyappan Sarana Gosham in Tamil PDF
-Ayyappan Padalgal in Tamil PDF
-Ayyappan Vilakku Pooja in Tamil PDF
-Ayyappa Swamy Songs in Tamil PDF
-Sabarimala Ayyappa Songs in Tamil PDF
-Swamiye Saranam Ayyappa Songs in Tamil PDF
-Pallikattu Sabarimalaikku Song Lyrics in Tamil PDF
-Harivarasanam Song Lyrics in Tamil PDF
-Enga Karuppasamy Song Lyrics in Tamil PDF
-Kannimoola Ganapathi Song Lyrics in Tamil PDF
-Lokaveeram Mahapoojyam Song Lyrics in Tamil PDF
-Sri Bhootha Natha Sadananda Song Lyrics in Tamil PDF
-Asmath Kuleswaram Devam Song Lyrics in Tamil PDF
-Pandyesha Vamsa Tilakam Song Lyrics in Tamil PDF
-Sree Hari Hara Sudhan Song Lyrics in Tamil PDF
-Thiruparkadalil Pallikondaye Song Lyrics in Tamil PDF
-Utharangkarathathan Makudam Song Lyrics in Tamil PDF
-Achchan Kovil Arase Song Lyrics in Tamil PDF
-Adangathavanai Thedi Alinthuvidu Song Lyrics in Tamil PDF
-Annadhana Prabhuve Saranam Ayyappa Song Lyrics in Tamil PDF
-Bhagavan Saranam Bagavathi Saranam Song Lyrics in Tamil PDF
-Dharma Sastha Pahimam Song Lyrics in Tamil PDF
-Enge Manakkuthu Sabarimalayile Song Lyrics in Tamil PDF
-Erumeli Vazhum Kadalayi Mele Song Lyrics in Tamil PDF
-Irumudi Thangi Oru Monaguruvaagiya Song Lyrics in Tamil PDF
-Kaadu Malai Kaatil Varum Veerane Song Lyrics in Tamil PDF
-Karimala Vasuni Kanivale Ninne Kandu Song Lyrics in Tamil PDF
-Karpoora Jyothiye Neelakanda Puthra Neeye Song Lyrics in Tamil PDF
-Kattum Katti Azhagu Katti Kattum Katti Song Lyrics in Tamil PDF
-Makara Jyothiye Makara Vilakke Song Lyrics in Tamil PDF
-Mandala Poojaiyile Manikandanai Nambuvom Song Lyrics in Tamil PDF
-Nambinorai Kaakkum Deivame Nee Thaaney Song Lyrics in Tamil PDF
-Nei Abhishekam Swamikke Jyothi Abhishekam Swamikke Song Lyrics in Tamil PDF
-Omkara Rupanae Vel Muruganae Saravana Bhavanae Song Lyrics in Tamil PDF
-Pallikkettu Sabarimalaikku Irumudi Kattu Sabarimalaikku Song Lyrics in Tamil PDF
-Pamba Vaasane Saranam Ayyappa Swamiye Saranam Ayyappa Song Lyrics in Tamil PDF
-Samiye Saranam Pon Ayyappa Samiye Saranam Pon Ayyappa Song Lyrics in Tamil PDF
-
-Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105 is not only a collection of songs, but also a treasure of wisdom and knowledge. The songs contain various stories and legends about Lord Ayyappa and his miracles. They also explain the significance and symbolism of his various attributes and forms. For example, the song "Ayyappa Ashtothram" lists the 108 names of Lord Ayyappa and their meanings. The song "Ayyappa Saranam" enumerates the 108 sacred mantras that can protect and bless the devotees.
-Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105 is also a source of inspiration and motivation for the devotees who undertake the Sabarimala pilgrimage. The songs encourage and support the devotees to follow the strict rules and rituals of the pilgrimage, such as wearing black clothes, abstaining from meat, alcohol, tobacco, and sex, walking barefoot, carrying the sacred irumudi (a bundle of offerings), and chanting "Swamiye Saranam Ayyappa" (I seek refuge in Lord Ayyappa). The songs also describe the beauty and glory of Sabarimala and the joy of seeing Lord Ayyappa in his majestic form.
-Ayyappan Bhajan Songs Lyrics In Tamil Pdf 105 is a must-have for every devotee of Lord Ayyappa. The songs can enrich your spiritual life and bring you closer to Lord Ayyappa. They can also fill your mind and heart with positive energy and happiness. Whether you are planning to go to Sabarimala or not, you can benefit from listening to and singing these songs. They can make you feel the presence of Lord Ayyappa in your everyday life and help you overcome any challenges or difficulties.
e753bf7129
-
-
\ No newline at end of file
diff --git a/spaces/ticomspire/turkey-syria-earthquake-tweets/logs/3 Bgm Love Ringtones The Best Collection of Romantic Tunes.md b/spaces/ticomspire/turkey-syria-earthquake-tweets/logs/3 Bgm Love Ringtones The Best Collection of Romantic Tunes.md
deleted file mode 100644
index cbee8784f5686c6519de437838aa9877f0085188..0000000000000000000000000000000000000000
--- a/spaces/ticomspire/turkey-syria-earthquake-tweets/logs/3 Bgm Love Ringtones The Best Collection of Romantic Tunes.md
+++ /dev/null
@@ -1,177 +0,0 @@
-
-3 BGM Ringtone Download Love: How to Find and Download the Best Background Music for Your Phone
- If you are looking for a way to spice up your phone with some amazing ringtones, you might want to consider using BGM ringtones for love. BGM stands for background music, and it is a type of music that is designed to create a certain mood or atmosphere. BGM ringtones are perfect for expressing your feelings, emotions, and personality through your phone. In this article, we will show you how to find and download the best BGM ringtones for love, and how to set them as your default or custom ringtone.
-3 bgm ringtone download love
Download >>> https://bltlly.com/2uOpiF
- What is BGM and Why You Should Use It as Your Ringtone
- BGM is an acronym that means background music. It is a mode of musical performance that is not intended to be the main focus of attention, but rather to support or enhance the visual or auditory experience. BGM can be used in various settings, such as movies, TV shows, video games, and even phone ringtones.
- Using BGM as your ringtone has many advantages. First of all, it can help you create a positive and pleasant mood whenever you receive a call or a notification. BGM can also help you relax, focus, or energize yourself depending on the type of music you choose. Secondly, it can help you express your personality and individuality through your phone. You can choose a BGM ringtone that reflects your interests, hobbies, passions, or moods. Thirdly, it can help you communicate your feelings and emotions to others. You can choose a BGM ringtone that conveys your love, affection, admiration, or gratitude to someone special.
- How to Download Ringtones to Your Android or iPhone
- Downloading ringtones to your phone is easier than ever. You can either use a desktop web browser or a mobile app to access thousands of free and paid ringtones online. Here are the general steps to download ringtones:
-
-- Visit a reputable ringtone download site or app in your web browser or phone. Some examples are Zedge, Tones7, and Prokerala.
-- Search for the ringtone of your choice by entering keywords or browsing by categories.
-- Select the ringtone you want to download and tap on the download button.
-- Save the file to a location you can remember, such as your desktop or downloads folder.
-- Transfer the ringtone file to your phone using a USB cable or a wireless method.
-
- Note that the exact steps may vary depending on the website or app you use, and the type of phone you have. For more detailed instructions, you can check out these guides:
-
- How to Choose the Best BGM Ringtones for Love
- Choosing the best BGM ringtones for love can be tricky, as there are so many options available online. However, here are some tips that can help you narrow down your choices and find the perfect BGM ringtones for love:
-
-- Think about your personal taste and preference. What kind of music do you like? What kind of mood do you want to create? Do you prefer instrumental or vocal music? Do you want something upbeat or mellow?
-- Think about your partner or crush. What kind of music do they like? What kind of mood do you want to convey to them? Do you want to surprise them or impress them? Do you want to show your affection or admiration?
-- Think about the occasion and context. When and where do you plan to use your BGM ringtone for love? Is it for a special date, a birthday, an anniversary, or a casual day? Is it for a phone call, a text message, an alarm, or a reminder?
-
- Based on these factors, you can narrow down your search and find the best BGM ringtones for love that suit your needs and preferences. To give you some inspiration, here are some popular and trending BGM ringtones for love from different genres and languages:
-
-
-| Genre |
-Language |
-Title |
-Artist |
-Source |
-
-
-| Romantic |
-English |
-A Thousand Years |
-Christina Perri |
-The Twilight Saga: Breaking Dawn – Part 1 |
-
-
-| Romantic |
-Hindi |
-Tum Hi Ho |
-Arijit Singh |
-Aashiqui 2 |
-
-
-| Romantic |
-Tamil |
-Kannana Kanne |
-Anirudh Ravichander |
-3 |
-
-
-| Cute |
-English |
-I'm Yours |
-Jason Mraz |
-We Sing. We Dance. We Steal Things. |
-
-
-| Cute |
-Korean |
-Bubble Pop! |
-Hyuna |
-Bubble Pop! |
-
-
-| Cute |
-Japanese |
-PonPonPon |
-Kyary Pamyu Pamyu | Moshi Moshi Harajuku |
| Sad > | English > | Say Something > | A Great Big World feat. Christina Aguilera > | Is There Anybody Out There? > |
| Sad > | Turkish > | Bir Garip Aşk Bestesi > | Soner Arıca > | Bir Garip Aşk Bestesi > |
| Sad > | Chinese > | Ten Years > | Eason Chan > | U87 > |
- How to Set Your BGM Ringtone as Your Default or Custom Ringtone
- Once you have downloaded your BGM ringtone for love, you can set it as your default or custom ringtone on your phone. The default ringtone is the one that plays when you receive any call or notification, while the custom ringtone is the one that plays when you receive a call or notification from a specific contact or group. Here are the steps to set your BGM ringtone as your default or custom ringtone:
-3 movie bgm love ringtone free download
-3 tamil movie love bgm ringtone download mp3
-3 moonu love bgm ringtone download zedge
-3 dhanush love bgm ringtone download masstamilan
-3 movie love theme bgm ringtone download kuttyweb
-3 moonu love failure bgm ringtone download
-3 movie love feel bgm ringtone download prokerala
-3 tamil movie love theme bgm ringtone download
-3 moonu love proposal bgm ringtone download
-3 dhanush shruti hassan love bgm ringtone download
-3 movie love flute bgm ringtone download
-3 tamil movie love failure bgm ringtone download
-3 moonu love climax bgm ringtone download
-3 dhanush anirudh love bgm ringtone download
-3 movie love piano bgm ringtone download
-3 tamil movie love proposal bgm ringtone download
-3 moonu love sad bgm ringtone download
-3 dhanush bike ride love bgm ringtone download
-3 movie love guitar bgm ringtone download
-3 tamil movie love climax bgm ringtone download
-3 moonu love happy bgm ringtone download
-3 dhanush train scene love bgm ringtone download
-3 movie love violin bgm ringtone download
-3 tamil movie love flute bgm ringtone download
-3 moonu love romantic bgm ringtone download
-3 dhanush marriage scene love bgm ringtone download
-3 movie love humming bgm ringtone download
-3 tamil movie love piano bgm ringtone download
-3 moonu love emotional bgm ringtone download
-3 dhanush breakup scene love bgm ringtone download
-3 movie love melody bgm ringtone download
-3 tamil movie love guitar bgm ringtone download
-3 moonu love heart touching bgm ringtone download
-3 dhanush hospital scene love bgm ringtone download
-3 movie love instrumental bgm ringtone download
-3 tamil movie love violin bgm ringtone download
-3 moonu love cute bgm ringtone download
-3 dhanush flashback scene love bgm ringtone download
-3 movie love song bgm ringtone download
-3 tamil movie love humming bgm ringtone download
-3 moonu love pain bgm ringtone download
-3 dhanush reunion scene love bgm ringtone download
- For Android Phones:
-
- - Open the Settings app on your phone and tap on Sound.
- - Tap on Phone ringtone or Default notification sound to set your default ringtone.
- - Select the BGM ringtone that you downloaded from the list of available ringtones and tap on OK.
- - To set a custom ringtone for a contact or group, open the Contacts app and select the contact or group that you want to assign a ringtone to.
- - Tap on the Edit icon and then tap on More fields.
- - Tap on Ringtone and select the BGM ringtone that you downloaded from the list of available ringtones and tap on OK.
- - Repeat the same steps for any other contacts or groups that you want to set a custom ringtone for.
-
- For iPhone:
-
-- Open the Settings app on your phone and tap on Sounds & Haptics.
-- Tap on Ringtone or Text Tone to set your default ringtone.
-- Select the BGM ringtone that you downloaded from the list of available ringtones and tap on Done.
-- To set a custom ringtone for a contact or group, open the Phone app and select the contact or group that you want to assign a ringtone to.
-- Tap on the Edit icon and then tap on Ringtone or Text Tone.
-- Select the BGM ringtone that you downloaded from the list of available ringtones and tap on Done.
-- Repeat the same steps for any other contacts or groups that you want to set a custom ringtone for.
-
- Conclusion
- BGM ringtones for love are a great way to personalize your phone and express your feelings. They can help you create a positive and pleasant mood, communicate your personality and individuality, and convey your emotions and sentiments to others. You can easily find and download the best BGM ringtones for love from various websites and apps, and set them as your default or custom ringtone on your Android or iPhone. We hope this article has helped you learn how to find and download the best BGM ringtones for love, and how to set them as your default or custom ringtone. Try out some BGM ringtones for love today and enjoy the music!
- FAQs
- What is the difference between BGM and normal music?
- BGM is a type of music that is designed to create a certain mood or atmosphere, while normal music is a type of music that is intended to be the main focus of attention. BGM is usually instrumental or has minimal vocals, while normal music usually has prominent vocals and lyrics. BGM is often used in movies, TV shows, video games, and phone ringtones, while normal music is often used in concerts, radio stations, albums, and playlists.
- How can I make my own BGM ringtone?
- If you want to make your own BGM ringtone, you can use a software or an app that allows you to edit audio files. Some examples are Audacity, GarageBand, and Ringtone Maker. You can either use an existing audio file or record your own sound. You can then trim, crop, fade, loop, mix, or add effects to your audio file. You can also adjust the volume, pitch, tempo, or format of your audio file. Once you are satisfied with your BGM ringtone, you can save it and transfer it to your phone.
- How can I delete a BGM ringtone from my phone?
- If you want to delete a BGM ringtone from your phone, you can follow these steps:
- For Android Phones:
-
-- Open the Settings app on your phone and tap on Sound.
-- Tap on Phone ringtone or Default notification sound.
-- Select the BGM ringtone that you want to delete and tap on the Delete icon.
-- Confirm your action by tapping on OK.
-
- For iPhone:
-
-- Open the Settings app on your phone and tap on Sounds & Haptics.
-- Tap on Ringtone or Text Tone.
-- Select the BGM ringtone that you want to delete and swipe left on it.
-- Tap on Delete and confirm your action by tapping on Delete again.
-
- How can I share a BGM ringtone with someone else?
- If you want to share a BGM ringtone with someone else, you can use various methods such as email, Bluetooth, Wi-Fi Direct, AirDrop, WhatsApp, or Telegram. You can either send the BGM ringtone file directly or send a link to download it from a website or an app. Make sure that the person you are sharing with has a compatible device and software to play the BGM ringtone.
- Where can I find more BGM ringtones for love?
- If you want to find more BGM ringtones for love, you can visit some of these websites or apps that offer a wide range of free and paid ringtones:
- 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/ticomspire/turkey-syria-earthquake-tweets/logs/Download Euro Truck Simulator 2 for Windows PC in Zip Format.md b/spaces/ticomspire/turkey-syria-earthquake-tweets/logs/Download Euro Truck Simulator 2 for Windows PC in Zip Format.md
deleted file mode 100644
index ac705933cbc9ddb9c9e92fe1398d1aba7f0889ad..0000000000000000000000000000000000000000
--- a/spaces/ticomspire/turkey-syria-earthquake-tweets/logs/Download Euro Truck Simulator 2 for Windows PC in Zip Format.md
+++ /dev/null
@@ -1,143 +0,0 @@
-
-Euro Truck Simulator 2: A Relaxing and Realistic Trucking Game for Windows
- Do you love driving trucks and exploring new places? Do you want to experience the thrill of delivering cargo across different countries and cultures? Do you want to enjoy a relaxing and realistic trucking game on your PC? If you answered yes to any of these questions, then you should definitely check out Euro Truck Simulator 2, one of the most popular and acclaimed simulation games ever made.
-euro truck simulator zip file download for pc
DOWNLOAD ✒ ✒ ✒ https://bltlly.com/2uOiQf
- What is Euro Truck Simulator 2?
- Euro Truck Simulator 2 or ETS2 is a trucking game developed by SCS Software for Windows PCs. It is the second instalment in the Euro Truck Simulator series, which started in 2008. The game lets you take on the role of a truck driver who has to deliver various kinds of cargo across Europe, from food and furniture to chemicals and cars. Along the way, you will encounter different road conditions, traffic rules, weather effects, and landmarks.
- A popular simulation game that lets you drive a cargo truck across Europe
- Euro Truck Simulator 2 has been praised by critics and players alike for its realistic and immersive trucking experience. The game features over 70 cities and 20 countries to explore, each with its own unique scenery, culture, and architecture. You can drive through the Alps, the Mediterranean coast, the Baltic Sea, and more. You can also see famous landmarks like the Eiffel Tower, the Colosseum, the Big Ben, and the Brandenburg Gate.
- A simple gameplay that offers a lot of variety and challenge
- The gameplay of Euro Truck Simulator 2 is simple but engaging. You start off as a low-skilled and truckless driver who has to take jobs from different companies and deliver cargo from one point to another. As you complete deliveries, you earn money and experience points that allow you to buy your own truck, upgrade your skills, hire other drivers, and expand your business. You can also choose from different types of cargo, ranging from fragile goods to heavy loads. You have to balance speed, fuel efficiency, safety, and customer satisfaction while driving.
-euro truck simulator 2 free trial download for windows
-euro truck simulator 2 latest version download zip file
-euro truck simulator 2 pc game download full version
-euro truck simulator 2 download with multiplayer mod
-euro truck simulator 2 download for windows 10 64 bit
-euro truck simulator 2 download for pc highly compressed
-euro truck simulator 2 download with all dlc and mods
-euro truck simulator 2 download from official website
-euro truck simulator 2 download for pc with crack
-euro truck simulator 2 download size and system requirements
-euro truck simulator 2 best mods download zip file
-euro truck simulator 2 scandinavia dlc download zip file
-euro truck simulator 2 italy map download zip file
-euro truck simulator 2 spain and portugal map download zip file
-euro truck simulator 2 france map expansion download zip file
-euro truck simulator 2 realistic graphics mod download zip file
-euro truck simulator 2 bus mod download zip file for pc
-euro truck simulator 2 indian trucks mod download zip file
-euro truck simulator 2 volvo fh16 mod download zip file
-euro truck simulator 2 scania rjl mod download zip file
-euro truck simulator 2 promods map download zip file
-euro truck simulator 2 rusmap mod download zip file
-euro truck simulator 2 balkan map mod download zip file
-euro truck simulator 2 turkey map mod download zip file
-euro truck simulator 2 eaa map mod download zip file
-euro truck simulator 2 road to the black sea dlc download zip file
-euro truck simulator 2 beyond the baltic sea dlc download zip file
-euro truck simulator 2 going east dlc download zip file
-euro truck simulator 2 vive la france dlc download zip file
-euro truck simulator 2 italia dlc download zip file
-euro truck simulator 2 heavy cargo pack dlc download zip file
-euro truck simulator 2 special transport dlc download zip file
-euro truck simulator 2 high power cargo pack dlc download zip file
-euro truck simulator 2 cabin accessories dlc download zip file
-euro truck simulator 2 wheel tuning pack dlc download zip file
-euro truck simulator 2 mighty griffin tuning pack dlc download zip file
-euro truck simulator 2 michelin fan pack dlc download zip file
-euro truck simulator 2 raven truck design pack dlc download zip file
-euro truck simulator 2 pirate paint jobs pack dlc download zip file
-euro truck simulator 2 halloween paint jobs pack dlc download zip file
-euro truck simulator 2 christmas paint jobs pack dlc download zip file
-euro truck simulator 2 valentine's paint jobs pack dlc download zip file
-euro truck simulator 2 dragon legend paint jobs pack dlc download zip file
-euro truck simulator 2 ice cold paint jobs pack dlc download zip file
-euro truck simulator 2 force of nature paint jobs pack dlc download zip file
-euro truck simulator 2 metallic paint jobs pack dlc download zip file
-how to install and play euro truck simulator 2 on pc from zip file
-how to update and patch euro truck simulator 2 on pc from zip file
-how to fix errors and bugs in euro truck simulator 2 on pc from zip file
- A huge map that features diverse and scenic landscapes
- One of the best things about Euro Truck Simulator 2 is its colossal map, which covers most of Europe. The map is not to scale, but it offers a lot of variety and detail in its landscapes. You can drive through mountains, forests, fields, deserts, cities, villages, highways, bridges, tunnels, and more. You can also experience different weather effects like rain, snow, fog, thunderstorms, and sunsets. The game also has a day-night cycle that affects the visibility and traffic on the roads.
- How to download Euro Truck Simulator 2 for PC?
- If you are interested in playing Euro Truck Simulator 2 on your PC, there are several ways to download it. Here are some of the most common ones:
- The official website of the game
- The easiest way to download Euro Truck Simulator 2 is to visit its official website at https://eurotrucksimulator2.com/. There you can find all the information about the game, its features, updates, screenshots, videos, and more. You can also buy the game directly from the website or from other online platforms like Steam or Epic Games. The game costs $19.99 for the base version, but you can also buy additional DLCs that add more countries, trucks, and features to the game. The website also offers a demo version that you can download for free and try out the game before buying it.
- The FileHippo website that offers a free trial version
- Another way to download Euro Truck Simulator 2 is to visit the FileHippo website at https://filehippo.com/download_euro-truck-simulator-2/. FileHippo is a reputable and safe website that offers free software downloads for various categories. You can find Euro Truck Simulator 2 under the Simulation category and download it for free. The file size is about 3.1 GB and it requires Windows 7 or higher to run. The trial version lets you play the game for an hour, after which you have to buy the full version to continue playing.
- The SE7EN.ws website that offers the latest version with multiplayer
- A third way to download Euro Truck Simulator 2 is to visit the SE7EN.ws website at https://se7en.ws/euro-truck-simulator-2/?lang=en. SE7EN.ws is a website that provides cracked versions of games for free. You can find Euro Truck Simulator 2 under the Simulation category and download it for free. The file size is about 5.6 GB and it includes the latest version of the game with all the DLCs and updates. It also has a multiplayer mode that lets you play with other truckers online. However, this method is not recommended as it may contain viruses, malware, or other harmful software that can damage your PC or compromise your security.
- What are the features and benefits of Euro Truck Simulator 2?
- Euro Truck Simulator 2 is not just a game, but a simulation of a real-life trucking career. It has many features and benefits that make it enjoyable and rewarding for players of all ages and preferences. Here are some of them:
- A realistic and immersive trucking experience
- Euro Truck Simulator 2 strives to create a realistic and immersive trucking experience for its players. The game has stunning graphics and sound effects that make you feel like you are really driving a truck on the roads of Europe. The game also has realistic physics and mechanics that affect the performance and handling of your truck. You have to obey the traffic laws, pay attention to the road signs, use the indicators, headlights, wipers, and horn, and avoid accidents and fines. You also have to manage your fatigue, hunger, and sleep levels, as well as your fuel consumption and maintenance costs.
- A customizable and upgradeable truck fleet
- Euro Truck Simulator 2 gives you the opportunity to customize and upgrade your truck fleet according to your preferences and needs. You can choose from over 40 licensed truck models from famous brands like Volvo, Scania, MAN, Mercedes-Benz, Renault, Iveco, and DAF. You can also modify your trucks with various parts and accessories like engines, transmissions, chassis, wheels, tires, paint jobs, decals, lights, horns, mirrors, and more. You can also buy new trucks or sell old ones as you progress in the game.
- A built-in radio and music player
- Euro Truck Simulator 2 also has a built-in radio and music player that lets you listen to your favorite tunes while driving. You can tune in to over 150 radio stations from different countries and genres, or you can create your own playlist from your local music files. You can also adjust the volume, skip tracks, or mute the music with simple keyboard shortcuts.
- A multiplayer mode that lets you play with other truckers online
- Euro Truck Simulator 2 also has a multiplayer mode that lets you play with other truckers online. You can join or create a server with up to 100 players and chat with them using text or voice messages. You can also form convoys with other players and drive together on the same route. You can also compete with other players in races, challenges, or events.
- Conclusion
- Euro Truck Simulator 2 is a relaxing and realistic trucking game for Windows PCs that lets you drive a cargo truck across Europe. It has a simple gameplay that offers a lot of variety and challenge, a huge map that features diverse and scenic landscapes, a realistic and immersive trucking experience, a customizable and upgradeable truck fleet, a built-in radio and music player, and a multiplayer mode that lets you play with other truckers online. If you are looking for a fun and satisfying simulation game that will keep you entertained for hours, then you should definitely download Euro Truck Simulator 2 for your PC. You can download it from the official website, the FileHippo website, or the SE7EN.ws website, depending on your preference and budget. You will not regret it, as Euro Truck Simulator 2 is one of the best simulation games ever made.
- FAQs
- Here are some of the frequently asked questions about Euro Truck Simulator 2:
- What are the system requirements for Euro Truck Simulator 2?
- The minimum system requirements for Euro Truck Simulator 2 are as follows:
-
-- OS: Windows 7 or higher
-- Processor: Dual core CPU 2.4 GHz
-- Memory: 4 GB RAM
-- Graphics: GeForce GTS 450-class (Intel HD 4000)
-- Storage: 5 GB available space
-
- The recommended system requirements for Euro Truck Simulator 2 are as follows:
-
-- OS: Windows 7 or higher
-- Processor: Quad core CPU 3.0 GHz
-- Memory: 6 GB RAM
-- Graphics: GeForce GTX 760-class (2 GB)
-- Storage: 5 GB available space
-
- How to install Euro Truck Simulator 2 on PC?
- To install Euro Truck Simulator 2 on PC, you need to follow these steps:
-
-- Download the game file from the website of your choice.
-- Extract the zip file using a program like WinRAR or 7-Zip.
-- Run the setup.exe file and follow the instructions.
-- Copy the crack file from the crack folder and paste it into the game folder.
-- Launch the game and enjoy.
-
- How to play Euro Truck Simulator 2 on PC?
- To play Euro Truck Simulator 2 on PC, you need to follow these steps:
-
-- Create a profile and choose your name, avatar, company logo, and preferred truck brand.
-- Select a starting city and take your first job from the job market.
-- Drive your truck to the pickup location and attach the trailer.
-- Drive your truck to the delivery location and detach the trailer.
-- Earn money and experience points for completing deliveries.
-- Buy, customize, and upgrade your own truck or hire other drivers.
-- Explore new cities and countries and take on more challenging jobs.
-
- How to update Euro Truck Simulator 2 on PC?
- To update Euro Truck Simulator 2 on PC, you need to follow these steps:
-
-- Visit the official website of the game or the website where you downloaded the game from.
-- Download the latest patch or update file for the game.
-- Extract the zip file using a program like WinRAR or 7-Zip.
-- Run the update.exe file and follow the instructions.
-- Copy the crack file from the crack folder and paste it into the game folder.
-- Launch the game and enjoy.
-
- How to mod Euro Truck Simulator 2 on PC?
- To mod Euro Truck Simulator 2 on PC, you need to follow these steps:
-
-- Visit a website that offers mods for Euro Truck Simulator 2, such as https://ets2.lt/en/, https://www.modland.net/euro-truck-simulator-2/, or https://steamcommunity.com/app/227300/workshop/.
-- Browse through the categories and find a mod that you like.
-- Download the mod file and extract it using a program like WinRAR or 7-Zip.
-- Copy the .scs file or folder from the mod and paste it into the Documents\Euro Truck Simulator 2\mod folder.
-- Launch the game and go to the mod manager in the profile selection screen.
-- Select and activate the mod that you want to use.
-- Play the game and enjoy.
-
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/ticomspire/turkey-syria-earthquake-tweets/logs/Download Hair Challenge Mod APK with Unlimited Diamonds and No Ads.md b/spaces/ticomspire/turkey-syria-earthquake-tweets/logs/Download Hair Challenge Mod APK with Unlimited Diamonds and No Ads.md
deleted file mode 100644
index 2fb5bae400fdaa7c2301c6f24f02dca0768e1415..0000000000000000000000000000000000000000
--- a/spaces/ticomspire/turkey-syria-earthquake-tweets/logs/Download Hair Challenge Mod APK with Unlimited Diamonds and No Ads.md
+++ /dev/null
@@ -1,88 +0,0 @@
-
-Download Hair Challenge Mod APK: A Fun and Addictive Game for All Ages
- Do you love playing games that are easy to learn but hard to master? Do you enjoy styling your hair and making it look fabulous? If you answered yes to both questions, then you will love Hair Challenge, a popular game that has millions of downloads and positive reviews on Google Play Store. And if you want to make the game even more fun and exciting, you should download Hair Challenge Mod APK, which gives you unlimited diamonds, no ads, and access to all skins and accessories. In this article, we will tell you everything you need to know about Hair Challenge and its modded version, including how to download and install it on your device.
-download hair challenge mod apk
Download ❤ https://bltlly.com/2uOpGE
- What is Hair Challenge?
- Hair Challenge is a casual game developed by Rollic Games, a Turkish studio that specializes in creating hyper-casual games for mobile devices. The game was released in April 2021 and has quickly become one of the most downloaded games on the Play Store, with over 100 million installs and a 4.1-star rating.
- The game is simple but addictive: you control a girl with long hair who runs through various obstacles and collects more hair along the way. The longer your hair gets, the more points you earn. But be careful: some obstacles will cut your hair or make it dirty, so you have to avoid them or use scissors to trim your hair. You can also customize your character with different skins, hair colors, and accessories, such as hats, glasses, earrings, and more.
- How to play Hair Challenge
- The game is easy to play: you just need to swipe left or right on the screen to move your character and avoid the obstacles. You can also tap on the screen to use scissors to cut your hair when it gets too long or dirty. The game has many levels with different themes and challenges, such as ice, fire, candy, jungle, etc. Each level has a finish line where you can show off your hair length and style. The longer your hair is at the end of the level, the more diamonds you earn. You can use these diamonds to buy new skins and accessories for your character.
-download hair challenge mod apk unlimited money
-download hair challenge mod apk latest version
-download hair challenge mod apk for android
-download hair challenge mod apk free
-download hair challenge mod apk hack
-download hair challenge mod apk no ads
-download hair challenge mod apk 20.0.1
-download hair challenge mod apk with diamonds
-download hair challenge mod apk full unlocked
-download hair challenge mod apk offline
-download hair challenge mod apk 2023
-download hair challenge mod apk for pc
-download hair challenge mod apk revdl
-download hair challenge mod apk rexdl
-download hair challenge mod apk happymod
-download hair challenge mod apk apkpure
-download hair challenge mod apk apkmody
-download hair challenge mod apk android 1
-download hair challenge mod apk uptodown
-download hair challenge mod apk an1
-download hair challenge mod apk mob.org
-download hair challenge mod apk pure
-download hair challenge mod apk vip
-download hair challenge mod apk pro
-download hair challenge mod apk premium
-download hair challenge mod apk mega
-download hair challenge mod apk mediafıre
-download hair challenge mod apk google drive
-download hair challenge mod apk zippyshare
-download hair challenge mod apk 4shared
-download hair challenge mod apk by rollic games
-download hair challenge mod apk new update
-download hair challenge mod apk original
-download hair challenge mod apk old version
-download hair challenge mod apk online
-download hair challenge mod apk without verification
-download hair challenge mod apk without root
-download hair challenge mod apk without survey
-download hair challenge mod apk without human verification
-download hair challenge mod apk easy install
- Why you should download Hair Challenge Mod APK
- While Hair Challenge is a fun game to play, it also has some drawbacks that may affect your gaming experience. For example, the game has many ads that pop up frequently and interrupt your gameplay. The game also requires you to watch ads or spend real money to unlock some skins and accessories. Moreover, the game can be quite repetitive and boring after a while, as there is not much variety or challenge in the gameplay.
- That's why we recommend you to download Hair Challenge Mod APK, which is a modified version of the original game that offers many benefits and features that are not available in the official version. Here are some of the reasons why you should download Hair Challenge Mod APK:
- Features of Hair Challenge Mod APK
- Unlimited diamonds
- One of the best features of Hair Challenge Mod APK is that it gives you unlimited diamonds, which are the main currency in the game. You can use these diamonds to buy any skin or accessory that you want without watching ads or spending real money. You can also use these diamonds to revive your character if you fail a level or skip a level if you find it too hard.
- No ads
- Another great feature of Hair Challenge Mod APK is that it removes all the ads from the game. This means that you can enjoy the game without any interruptions or distractions. You don't have to watch ads to unlock skins or accessories or to get extra diamonds. You can also save your mobile
Unlock all skins and accessories
- With Hair Challenge Mod APK, you can also unlock all the skins and accessories that are available in the game. You don't have to complete levels or watch ads to get them. You can choose from a variety of options to customize your character, such as different hair colors, hairstyles, outfits, hats, glasses, earrings, and more. You can also mix and match different items to create your own unique look.
- How to download and install Hair Challenge Mod APK
- If you are interested in downloading and installing Hair Challenge Mod APK on your device, you can follow these simple steps:
- Step 1: Download the APK file from a trusted source
- The first thing you need to do is to download the APK file of Hair Challenge Mod APK from a reliable and safe source. You can use the link below to download the latest version of the modded game. The file size is about 100 MB, so make sure you have enough storage space on your device.
- Download Hair Challenge Mod APK
- Step 2: Enable unknown sources on your device
- The next thing you need to do is to enable unknown sources on your device. This is a security setting that allows you to install apps that are not from the official Play Store. To do this, go to your device settings and look for the security or privacy option. Then, find the unknown sources option and toggle it on. You may see a warning message, but don't worry, it's safe to install Hair Challenge Mod APK.
- Step 3: Install the APK file and enjoy the game
- The final step is to install the APK file that you downloaded in step 1. To do this, locate the file in your device's file manager and tap on it. You may see a pop-up window asking for your permission to install the app. Just tap on install and wait for the process to finish. Once the installation is done, you can open the app and enjoy the game with all its features.
- Conclusion
- Hair Challenge is a fun and addictive game that lets you style your hair and run through various obstacles. The game is easy to play but hard to master, as you have to avoid or cut your hair when it gets too long or dirty. You can also customize your character with different skins and accessories that you can buy with diamonds or unlock by watching ads.
- However, if you want to enhance your gaming experience and enjoy the game without any limitations, you should download Hair Challenge Mod APK, which gives you unlimited diamonds, no ads, and access to all skins and accessories. You can download and install the modded game easily by following the steps above.
- We hope this article was helpful and informative for you. If you have any questions or feedback, feel free to leave a comment below. Thank you for reading!
- FAQs
- Here are some of the frequently asked questions about Hair Challenge Mod APK:
-
-- Is Hair Challenge Mod APK safe to use?
-Yes, Hair Challenge Mod APK is safe to use, as long as you download it from a trusted source like the one we provided above. The modded game does not contain any viruses or malware that can harm your device or compromise your privacy.
-- Is Hair Challenge Mod APK compatible with my device?
-Hair Challenge Mod APK is compatible with most Android devices that run on Android 4.4 or higher. However, some devices may not support some features or functions of the modded game due to hardware or software limitations.
-- Can I play Hair Challenge Mod APK online with other players?
-No, Hair Challenge Mod APK is not an online game, so you cannot play it with other players. The game is a single-player game that does not require an internet connection to play.
-- Can I update Hair Challenge Mod APK when a new version is released?
-No, you cannot update Hair Challenge Mod APK automatically when a new version of the original game is released. You have to download and install the new version of the modded game manually from the same source that you used before.
-- Can I use Hair Challenge Mod APK with my existing account?
-No, you cannot use Hair Challenge Mod APK with your existing account that you used in the official version of the game. The modded game has a separate database and server that does not sync with the original game. Therefore, you have to start from scratch when you use Hair Challenge Mod APK.
-
- 197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/tioseFevbu/cartoon-converter/scripts/Falcon Age Update 1.09 CODEX FitGirl.md b/spaces/tioseFevbu/cartoon-converter/scripts/Falcon Age Update 1.09 CODEX FitGirl.md
deleted file mode 100644
index 6701caa4d8aa194b908da22f4045968dec6ea9d0..0000000000000000000000000000000000000000
--- a/spaces/tioseFevbu/cartoon-converter/scripts/Falcon Age Update 1.09 CODEX FitGirl.md
+++ /dev/null
@@ -1,34 +0,0 @@
-
-Falcon Age Update 1.09 CODEX, FitGirl: What's New in the Latest Patch?
-Falcon Age is a first-person action-adventure game that lets you bond with a falcon and fight against a robot invasion. The game was released in 2019 by Outerloop Games and has received several updates since then. The latest update, version 1.09, was released on October 2022 by CODEX and FitGirl.
-In this article, we will review what's new in the Falcon Age Update 1.09 CODEX, FitGirl patch and how to download and install it.
-Falcon Age Update 1.09 CODEX, FitGirl
Download ★ https://urlcod.com/2uHxHJ
-What's New in Falcon Age Update 1.09 CODEX, FitGirl?
-The Falcon Age Update 1.09 CODEX, FitGirl patch includes the following changes and improvements:
-
-- Fixed a bug that caused the game to crash when loading certain save files.
-- Improved the performance and stability of the game on various systems.
-- Added new options for customizing the falcon's appearance and behavior.
-- Added new items and recipes for crafting falcon snacks and accessories.
-- Added new locations and missions to explore and complete.
-- Added new enemies and challenges to face in combat.
-- Added new achievements and trophies to unlock.
-
-How to Download and Install Falcon Age Update 1.09 CODEX, FitGirl?
-To download and install Falcon Age Update 1.09 CODEX, FitGirl, you need to have the base game Falcon Age installed on your PC. You also need to have the previous updates v1.02, v1.04, and v1.06 installed. You can download these updates from the official website of Outerloop Games or from various torrent sites.
-Once you have the base game and the previous updates installed, you can download the Falcon Age Update 1.09 CODEX, FitGirl patch from one of the links below:
-
-After downloading the patch, you need to extract it using a program like WinRAR or 7-Zip. Then, you need to run the setup.exe file and follow the instructions to install the update. Finally, you need to copy the contents of the CODEX folder and paste them into your game directory, replacing any existing files.
-That's it! You can now enjoy the latest version of Falcon Age with all the new features and fixes.
-
-What is Falcon Age?
-Falcon Age is a game that tells the story of Ara, a young woman who lives on a dying planet that has been colonized by robots. Ara has been imprisoned for a minor offense, but she manages to escape with the help of a falcon that she befriends in her cell. Together, they join the resistance and fight to reclaim their freedom and culture.
-The game features a unique gameplay mechanic that allows you to interact with your falcon in various ways. You can name, pet, feed, teach, and dress up your falcon. You can also hunt with your falcon, craft snacks and accessories for it, and use it in combat against the robot invaders. You can also customize your own stun baton, which is your main weapon in the game.
-The game also offers a rich and immersive world to explore, with different locations, characters, and quests. You can learn more about the history and culture of your planet, as well as the motives and methods of the colonizers. You can also make choices that affect the outcome of the story and the fate of your people.
-
-Falcon Age is a game that celebrates the bond between humans and animals, as well as the importance of preserving one's identity and heritage. It is a game that challenges you to take back your life and your land from the oppressors.
81aa517590
-
-
\ No newline at end of file
diff --git a/spaces/tioseFevbu/cartoon-converter/scripts/Free Spanish Ebook !FREE! Download The End We Start.md b/spaces/tioseFevbu/cartoon-converter/scripts/Free Spanish Ebook !FREE! Download The End We Start.md
deleted file mode 100644
index 1c0538260172987cd64a4541e025e4d1cc5ffba4..0000000000000000000000000000000000000000
--- a/spaces/tioseFevbu/cartoon-converter/scripts/Free Spanish Ebook !FREE! Download The End We Start.md
+++ /dev/null
@@ -1,18 +0,0 @@
-
-How to Download The End We Start From by Megan Hunter for Free in Spanish
-The End We Start From by Megan Hunter is a dystopian novel that follows a new mother and her baby as they flee from a flooded London. The book has been praised for its poetic and lyrical style, as well as its portrayal of motherhood in a time of crisis.
-Free spanish ebook download The End We Start
Download Zip ⇒ https://urlcod.com/2uHvtK
-If you are interested in reading this book in Spanish, you might be wondering how to get it for free. There are several ways to do so, depending on your preferences and availability. Here are some options:
-
-- Perlego: Perlego is an online platform that offers access to over 500,000 ebooks and textbooks for a monthly subscription fee. You can get a 14-day free trial and read The End We Start From in Spanish as a PDF file. You can also download it to your device for offline reading. To access Perlego, you need to create an account and provide your payment details, but you can cancel anytime before the trial ends. You can find the book here: [^3^]
-- Loyal Books: Loyal Books is a website that offers free public domain audiobooks and ebooks in various languages and genres. You can download The End We Start From in Spanish as an MP3 file or as an EPUB file that you can read on your e-reader or smartphone. You don't need to register or pay anything to use Loyal Books. You can find the book here: http://www.loyalbooks.com/book/el-fin-desde-el-principio-by-megan-hunter
-- Gutenberg: Gutenberg is a project that aims to digitize and preserve books that are in the public domain or have been donated by their authors. You can download The End We Start From in Spanish as a TXT file or as an HTML file that you can read on your browser. You don't need to register or pay anything to use Gutenberg. You can find the book here: https://www.gutenberg.org/ebooks/64775
-
-These are some of the ways you can download The End We Start From by Megan Hunter for free in Spanish. However, if you enjoy the book and want to support the author, you might consider buying a copy from your local bookstore or online retailer.
-
-The End We Start From by Megan Hunter is a short but powerful novel that explores themes such as survival, identity, and hope. The story is told from the perspective of an unnamed woman who gives birth to her son, Z, just as a catastrophic flood submerges most of England. She and her husband, R, have to leave their home and seek refuge in different places, encountering other survivors and facing various challenges along the way.
-The novel is written in a minimalist and poetic style, with short sentences and paragraphs that create a sense of urgency and intimacy. The characters are only referred to by their initials, which adds to the anonymity and universality of the story. The author also uses biblical and mythical references to contrast the old and the new world, and to suggest a possible rebirth after the disaster.
-The End We Start From by Megan Hunter is a novel that will appeal to readers who enjoy dystopian fiction, literary fiction, or stories about motherhood. It is a book that will make you think about the fragility and resilience of human life, and the importance of love and connection in times of chaos.
- 7b8c122e87
-
-
\ No newline at end of file
diff --git a/spaces/tioseFevbu/cartoon-converter/scripts/Gilles Lartigot Eat Pdf Download.md b/spaces/tioseFevbu/cartoon-converter/scripts/Gilles Lartigot Eat Pdf Download.md
deleted file mode 100644
index 7e19b0a9a6b2ed60c6149539fcabe10a3368152f..0000000000000000000000000000000000000000
--- a/spaces/tioseFevbu/cartoon-converter/scripts/Gilles Lartigot Eat Pdf Download.md
+++ /dev/null
@@ -1,22 +0,0 @@
-
-How to Download Gilles Lartigot's Eat: A Guide to Healthy Eating
-Gilles Lartigot is a French author and activist who has written two books on the topic of healthy eating: Eat: Chronicles of a Beast in the Food Jungle (2013) and Eat 2: Of the Dead and the Living - Chronicles of a Toxic Society (2017). In these books, he shares his personal journey and his insights on the modern food industry, the effects of industrial farming and chemical additives on our health, and the benefits of adopting a more natural and organic diet.
-If you are interested in reading Gilles Lartigot's books, you may be wondering how to download them in PDF format. Unfortunately, there is no official website or online store where you can purchase or download his books legally. However, there are some alternative ways to access his books online.
-Gilles Lartigot Eat Pdf Download
DOWNLOAD ✸ https://urlcod.com/2uHw3r
-One option is to visit the Internet Archive website[^1^], where you can find a video of Gilles Lartigot giving a talk on the power of food in 2016. In this video, he summarizes some of the main points of his first book and provides some tips for healthy eating. You can watch the video online or download it for free. You can also find a PDF file of his first book in French on the same page, which you can download or read online.
-Another option is to visit the YUMPU website[^2^], where you can find an e-book version of his first book in English. This e-book is not an official translation, but rather a fan-made one that was uploaded by a user. You can read the e-book online or download it as a PDF file for free. However, you should be aware that the quality and accuracy of this e-book may not be very high.
-A third option is to visit the Sway website[^3^], where you can find a PDF file of an article that reviews Gilles Lartigot's first book. This article was written by a French blogger who summarizes and critiques some of the arguments and facts presented by Gilles Lartigot in his book. You can download or read this article online for free.
-As you can see, there are some ways to access Gilles Lartigot's books online, but none of them are official or authorized by the author. Therefore, you should use them at your own risk and discretion. If you want to support Gilles Lartigot and his work, you may want to buy his books from a physical bookstore or an online retailer that sells them legally.
-
-
-Gilles Lartigot is not the only author who has written about the importance of healthy eating and the dangers of the modern food system. There are many other books on this topic that you may find interesting and informative. Here are some examples:
-
-- The Omnivore's Dilemma: A Natural History of Four Meals by Michael Pollan. This book explores the origins and consequences of the food choices we make every day, from industrial corn to organic vegetables to fast food. It also offers some suggestions for eating more ethically and sustainably.
-- In Defense of Food: An Eater's Manifesto by Michael Pollan. This book challenges the conventional wisdom of nutritionism and diet culture, and argues that the best way to eat well is to follow a simple rule: "Eat food. Not too much. Mostly plants."
-- Food Rules: An Eater's Manual by Michael Pollan. This book is a concise and practical guide to eating well, based on 64 simple rules that cover everything from what to eat, how to eat, and when to eat.
-- How Not to Die: Discover the Foods Scientifically Proven to Prevent and Reverse Disease by Michael Greger and Gene Stone. This book examines the role of nutrition in preventing and treating various chronic diseases, such as heart disease, diabetes, cancer, and Alzheimer's. It also provides a list of foods that can help boost your health and longevity.
-- The China Study: The Most Comprehensive Study of Nutrition Ever Conducted and the Startling Implications for Diet, Weight Loss, and Long-term Health by T. Colin Campbell and Thomas M. Campbell II. This book presents the findings of a massive research project that compared the health outcomes of people who ate different diets in rural China. It reveals that a plant-based diet can reduce the risk of many diseases and improve overall well-being.
-
-These are just some of the books that you may want to read if you are interested in learning more about healthy eating and its benefits for your body and mind. Of course, you should always consult your doctor before making any major changes to your diet or lifestyle.
e93f5a0c3f
-
-
\ No newline at end of file
diff --git a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_internal/resolution/legacy/resolver.py b/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_internal/resolution/legacy/resolver.py
deleted file mode 100644
index fb49d41695fec744a674da8bc11b646264c768b7..0000000000000000000000000000000000000000
--- a/spaces/tjburns/ask_marcus_aurelius/.venv/lib/python3.10/site-packages/pip/_internal/resolution/legacy/resolver.py
+++ /dev/null
@@ -1,600 +0,0 @@
-"""Dependency Resolution
-
-The dependency resolution in pip is performed as follows:
-
-for top-level requirements:
- a. only one spec allowed per project, regardless of conflicts or not.
- otherwise a "double requirement" exception is raised
- b. they override sub-dependency requirements.
-for sub-dependencies
- a. "first found, wins" (where the order is breadth first)
-"""
-
-# The following comment should be removed at some point in the future.
-# mypy: strict-optional=False
-
-import logging
-import sys
-from collections import defaultdict
-from itertools import chain
-from typing import DefaultDict, Iterable, List, Optional, Set, Tuple
-
-from pip._vendor.packaging import specifiers
-from pip._vendor.packaging.requirements import Requirement
-
-from pip._internal.cache import WheelCache
-from pip._internal.exceptions import (
- BestVersionAlreadyInstalled,
- DistributionNotFound,
- HashError,
- HashErrors,
- InstallationError,
- NoneMetadataError,
- UnsupportedPythonVersion,
-)
-from pip._internal.index.package_finder import PackageFinder
-from pip._internal.metadata import BaseDistribution
-from pip._internal.models.link import Link
-from pip._internal.models.wheel import Wheel
-from pip._internal.operations.prepare import RequirementPreparer
-from pip._internal.req.req_install import (
- InstallRequirement,
- check_invalid_constraint_type,
-)
-from pip._internal.req.req_set import RequirementSet
-from pip._internal.resolution.base import BaseResolver, InstallRequirementProvider
-from pip._internal.utils import compatibility_tags
-from pip._internal.utils.compatibility_tags import get_supported
-from pip._internal.utils.direct_url_helpers import direct_url_from_link
-from pip._internal.utils.logging import indent_log
-from pip._internal.utils.misc import normalize_version_info
-from pip._internal.utils.packaging import check_requires_python
-
-logger = logging.getLogger(__name__)
-
-DiscoveredDependencies = DefaultDict[str, List[InstallRequirement]]
-
-
-def _check_dist_requires_python(
- dist: BaseDistribution,
- version_info: Tuple[int, int, int],
- ignore_requires_python: bool = False,
-) -> None:
- """
- Check whether the given Python version is compatible with a distribution's
- "Requires-Python" value.
-
- :param version_info: A 3-tuple of ints representing the Python
- major-minor-micro version to check.
- :param ignore_requires_python: Whether to ignore the "Requires-Python"
- value if the given Python version isn't compatible.
-
- :raises UnsupportedPythonVersion: When the given Python version isn't
- compatible.
- """
- # This idiosyncratically converts the SpecifierSet to str and let
- # check_requires_python then parse it again into SpecifierSet. But this
- # is the legacy resolver so I'm just not going to bother refactoring.
- try:
- requires_python = str(dist.requires_python)
- except FileNotFoundError as e:
- raise NoneMetadataError(dist, str(e))
- try:
- is_compatible = check_requires_python(
- requires_python,
- version_info=version_info,
- )
- except specifiers.InvalidSpecifier as exc:
- logger.warning(
- "Package %r has an invalid Requires-Python: %s", dist.raw_name, exc
- )
- return
-
- if is_compatible:
- return
-
- version = ".".join(map(str, version_info))
- if ignore_requires_python:
- logger.debug(
- "Ignoring failed Requires-Python check for package %r: %s not in %r",
- dist.raw_name,
- version,
- requires_python,
- )
- return
-
- raise UnsupportedPythonVersion(
- "Package {!r} requires a different Python: {} not in {!r}".format(
- dist.raw_name, version, requires_python
- )
- )
-
-
-class Resolver(BaseResolver):
- """Resolves which packages need to be installed/uninstalled to perform \
- the requested operation without breaking the requirements of any package.
- """
-
- _allowed_strategies = {"eager", "only-if-needed", "to-satisfy-only"}
-
- def __init__(
- self,
- preparer: RequirementPreparer,
- finder: PackageFinder,
- wheel_cache: Optional[WheelCache],
- make_install_req: InstallRequirementProvider,
- use_user_site: bool,
- ignore_dependencies: bool,
- ignore_installed: bool,
- ignore_requires_python: bool,
- force_reinstall: bool,
- upgrade_strategy: str,
- py_version_info: Optional[Tuple[int, ...]] = None,
- ) -> None:
- super().__init__()
- assert upgrade_strategy in self._allowed_strategies
-
- if py_version_info is None:
- py_version_info = sys.version_info[:3]
- else:
- py_version_info = normalize_version_info(py_version_info)
-
- self._py_version_info = py_version_info
-
- self.preparer = preparer
- self.finder = finder
- self.wheel_cache = wheel_cache
-
- self.upgrade_strategy = upgrade_strategy
- self.force_reinstall = force_reinstall
- self.ignore_dependencies = ignore_dependencies
- self.ignore_installed = ignore_installed
- self.ignore_requires_python = ignore_requires_python
- self.use_user_site = use_user_site
- self._make_install_req = make_install_req
-
- self._discovered_dependencies: DiscoveredDependencies = defaultdict(list)
-
- def resolve(
- self, root_reqs: List[InstallRequirement], check_supported_wheels: bool
- ) -> RequirementSet:
- """Resolve what operations need to be done
-
- As a side-effect of this method, the packages (and their dependencies)
- are downloaded, unpacked and prepared for installation. This
- preparation is done by ``pip.operations.prepare``.
-
- Once PyPI has static dependency metadata available, it would be
- possible to move the preparation to become a step separated from
- dependency resolution.
- """
- requirement_set = RequirementSet(check_supported_wheels=check_supported_wheels)
- for req in root_reqs:
- if req.constraint:
- check_invalid_constraint_type(req)
- self._add_requirement_to_set(requirement_set, req)
-
- # Actually prepare the files, and collect any exceptions. Most hash
- # exceptions cannot be checked ahead of time, because
- # _populate_link() needs to be called before we can make decisions
- # based on link type.
- discovered_reqs: List[InstallRequirement] = []
- hash_errors = HashErrors()
- for req in chain(requirement_set.all_requirements, discovered_reqs):
- try:
- discovered_reqs.extend(self._resolve_one(requirement_set, req))
- except HashError as exc:
- exc.req = req
- hash_errors.append(exc)
-
- if hash_errors:
- raise hash_errors
-
- return requirement_set
-
- def _add_requirement_to_set(
- self,
- requirement_set: RequirementSet,
- install_req: InstallRequirement,
- parent_req_name: Optional[str] = None,
- extras_requested: Optional[Iterable[str]] = None,
- ) -> Tuple[List[InstallRequirement], Optional[InstallRequirement]]:
- """Add install_req as a requirement to install.
-
- :param parent_req_name: The name of the requirement that needed this
- added. The name is used because when multiple unnamed requirements
- resolve to the same name, we could otherwise end up with dependency
- links that point outside the Requirements set. parent_req must
- already be added. Note that None implies that this is a user
- supplied requirement, vs an inferred one.
- :param extras_requested: an iterable of extras used to evaluate the
- environment markers.
- :return: Additional requirements to scan. That is either [] if
- the requirement is not applicable, or [install_req] if the
- requirement is applicable and has just been added.
- """
- # If the markers do not match, ignore this requirement.
- if not install_req.match_markers(extras_requested):
- logger.info(
- "Ignoring %s: markers '%s' don't match your environment",
- install_req.name,
- install_req.markers,
- )
- return [], None
-
- # If the wheel is not supported, raise an error.
- # Should check this after filtering out based on environment markers to
- # allow specifying different wheels based on the environment/OS, in a
- # single requirements file.
- if install_req.link and install_req.link.is_wheel:
- wheel = Wheel(install_req.link.filename)
- tags = compatibility_tags.get_supported()
- if requirement_set.check_supported_wheels and not wheel.supported(tags):
- raise InstallationError(
- "{} is not a supported wheel on this platform.".format(
- wheel.filename
- )
- )
-
- # This next bit is really a sanity check.
- assert (
- not install_req.user_supplied or parent_req_name is None
- ), "a user supplied req shouldn't have a parent"
-
- # Unnamed requirements are scanned again and the requirement won't be
- # added as a dependency until after scanning.
- if not install_req.name:
- requirement_set.add_unnamed_requirement(install_req)
- return [install_req], None
-
- try:
- existing_req: Optional[
- InstallRequirement
- ] = requirement_set.get_requirement(install_req.name)
- except KeyError:
- existing_req = None
-
- has_conflicting_requirement = (
- parent_req_name is None
- and existing_req
- and not existing_req.constraint
- and existing_req.extras == install_req.extras
- and existing_req.req
- and install_req.req
- and existing_req.req.specifier != install_req.req.specifier
- )
- if has_conflicting_requirement:
- raise InstallationError(
- "Double requirement given: {} (already in {}, name={!r})".format(
- install_req, existing_req, install_req.name
- )
- )
-
- # When no existing requirement exists, add the requirement as a
- # dependency and it will be scanned again after.
- if not existing_req:
- requirement_set.add_named_requirement(install_req)
- # We'd want to rescan this requirement later
- return [install_req], install_req
-
- # Assume there's no need to scan, and that we've already
- # encountered this for scanning.
- if install_req.constraint or not existing_req.constraint:
- return [], existing_req
-
- does_not_satisfy_constraint = install_req.link and not (
- existing_req.link and install_req.link.path == existing_req.link.path
- )
- if does_not_satisfy_constraint:
- raise InstallationError(
- "Could not satisfy constraints for '{}': "
- "installation from path or url cannot be "
- "constrained to a version".format(install_req.name)
- )
- # If we're now installing a constraint, mark the existing
- # object for real installation.
- existing_req.constraint = False
- # If we're now installing a user supplied requirement,
- # mark the existing object as such.
- if install_req.user_supplied:
- existing_req.user_supplied = True
- existing_req.extras = tuple(
- sorted(set(existing_req.extras) | set(install_req.extras))
- )
- logger.debug(
- "Setting %s extras to: %s",
- existing_req,
- existing_req.extras,
- )
- # Return the existing requirement for addition to the parent and
- # scanning again.
- return [existing_req], existing_req
-
- def _is_upgrade_allowed(self, req: InstallRequirement) -> bool:
- if self.upgrade_strategy == "to-satisfy-only":
- return False
- elif self.upgrade_strategy == "eager":
- return True
- else:
- assert self.upgrade_strategy == "only-if-needed"
- return req.user_supplied or req.constraint
-
- def _set_req_to_reinstall(self, req: InstallRequirement) -> None:
- """
- Set a requirement to be installed.
- """
- # Don't uninstall the conflict if doing a user install and the
- # conflict is not a user install.
- if not self.use_user_site or req.satisfied_by.in_usersite:
- req.should_reinstall = True
- req.satisfied_by = None
-
- def _check_skip_installed(
- self, req_to_install: InstallRequirement
- ) -> Optional[str]:
- """Check if req_to_install should be skipped.
-
- This will check if the req is installed, and whether we should upgrade
- or reinstall it, taking into account all the relevant user options.
-
- After calling this req_to_install will only have satisfied_by set to
- None if the req_to_install is to be upgraded/reinstalled etc. Any
- other value will be a dist recording the current thing installed that
- satisfies the requirement.
-
- Note that for vcs urls and the like we can't assess skipping in this
- routine - we simply identify that we need to pull the thing down,
- then later on it is pulled down and introspected to assess upgrade/
- reinstalls etc.
-
- :return: A text reason for why it was skipped, or None.
- """
- if self.ignore_installed:
- return None
-
- req_to_install.check_if_exists(self.use_user_site)
- if not req_to_install.satisfied_by:
- return None
-
- if self.force_reinstall:
- self._set_req_to_reinstall(req_to_install)
- return None
-
- if not self._is_upgrade_allowed(req_to_install):
- if self.upgrade_strategy == "only-if-needed":
- return "already satisfied, skipping upgrade"
- return "already satisfied"
-
- # Check for the possibility of an upgrade. For link-based
- # requirements we have to pull the tree down and inspect to assess
- # the version #, so it's handled way down.
- if not req_to_install.link:
- try:
- self.finder.find_requirement(req_to_install, upgrade=True)
- except BestVersionAlreadyInstalled:
- # Then the best version is installed.
- return "already up-to-date"
- except DistributionNotFound:
- # No distribution found, so we squash the error. It will
- # be raised later when we re-try later to do the install.
- # Why don't we just raise here?
- pass
-
- self._set_req_to_reinstall(req_to_install)
- return None
-
- def _find_requirement_link(self, req: InstallRequirement) -> Optional[Link]:
- upgrade = self._is_upgrade_allowed(req)
- best_candidate = self.finder.find_requirement(req, upgrade)
- if not best_candidate:
- return None
-
- # Log a warning per PEP 592 if necessary before returning.
- link = best_candidate.link
- if link.is_yanked:
- reason = link.yanked_reason or ""
- msg = (
- # Mark this as a unicode string to prevent
- # "UnicodeEncodeError: 'ascii' codec can't encode character"
- # in Python 2 when the reason contains non-ascii characters.
- "The candidate selected for download or install is a "
- "yanked version: {candidate}\n"
- "Reason for being yanked: {reason}"
- ).format(candidate=best_candidate, reason=reason)
- logger.warning(msg)
-
- return link
-
- def _populate_link(self, req: InstallRequirement) -> None:
- """Ensure that if a link can be found for this, that it is found.
-
- Note that req.link may still be None - if the requirement is already
- installed and not needed to be upgraded based on the return value of
- _is_upgrade_allowed().
-
- If preparer.require_hashes is True, don't use the wheel cache, because
- cached wheels, always built locally, have different hashes than the
- files downloaded from the index server and thus throw false hash
- mismatches. Furthermore, cached wheels at present have undeterministic
- contents due to file modification times.
- """
- if req.link is None:
- req.link = self._find_requirement_link(req)
-
- if self.wheel_cache is None or self.preparer.require_hashes:
- return
- cache_entry = self.wheel_cache.get_cache_entry(
- link=req.link,
- package_name=req.name,
- supported_tags=get_supported(),
- )
- if cache_entry is not None:
- logger.debug("Using cached wheel link: %s", cache_entry.link)
- if req.link is req.original_link and cache_entry.persistent:
- req.original_link_is_in_wheel_cache = True
- if cache_entry.origin is not None:
- req.download_info = cache_entry.origin
- else:
- # Legacy cache entry that does not have origin.json.
- # download_info may miss the archive_info.hash field.
- req.download_info = direct_url_from_link(
- req.link, link_is_in_wheel_cache=cache_entry.persistent
- )
- req.link = cache_entry.link
-
- def _get_dist_for(self, req: InstallRequirement) -> BaseDistribution:
- """Takes a InstallRequirement and returns a single AbstractDist \
- representing a prepared variant of the same.
- """
- if req.editable:
- return self.preparer.prepare_editable_requirement(req)
-
- # satisfied_by is only evaluated by calling _check_skip_installed,
- # so it must be None here.
- assert req.satisfied_by is None
- skip_reason = self._check_skip_installed(req)
-
- if req.satisfied_by:
- return self.preparer.prepare_installed_requirement(req, skip_reason)
-
- # We eagerly populate the link, since that's our "legacy" behavior.
- self._populate_link(req)
- dist = self.preparer.prepare_linked_requirement(req)
-
- # NOTE
- # The following portion is for determining if a certain package is
- # going to be re-installed/upgraded or not and reporting to the user.
- # This should probably get cleaned up in a future refactor.
-
- # req.req is only avail after unpack for URL
- # pkgs repeat check_if_exists to uninstall-on-upgrade
- # (#14)
- if not self.ignore_installed:
- req.check_if_exists(self.use_user_site)
-
- if req.satisfied_by:
- should_modify = (
- self.upgrade_strategy != "to-satisfy-only"
- or self.force_reinstall
- or self.ignore_installed
- or req.link.scheme == "file"
- )
- if should_modify:
- self._set_req_to_reinstall(req)
- else:
- logger.info(
- "Requirement already satisfied (use --upgrade to upgrade): %s",
- req,
- )
- return dist
-
- def _resolve_one(
- self,
- requirement_set: RequirementSet,
- req_to_install: InstallRequirement,
- ) -> List[InstallRequirement]:
- """Prepare a single requirements file.
-
- :return: A list of additional InstallRequirements to also install.
- """
- # Tell user what we are doing for this requirement:
- # obtain (editable), skipping, processing (local url), collecting
- # (remote url or package name)
- if req_to_install.constraint or req_to_install.prepared:
- return []
-
- req_to_install.prepared = True
-
- # Parse and return dependencies
- dist = self._get_dist_for(req_to_install)
- # This will raise UnsupportedPythonVersion if the given Python
- # version isn't compatible with the distribution's Requires-Python.
- _check_dist_requires_python(
- dist,
- version_info=self._py_version_info,
- ignore_requires_python=self.ignore_requires_python,
- )
-
- more_reqs: List[InstallRequirement] = []
-
- def add_req(subreq: Requirement, extras_requested: Iterable[str]) -> None:
- # This idiosyncratically converts the Requirement to str and let
- # make_install_req then parse it again into Requirement. But this is
- # the legacy resolver so I'm just not going to bother refactoring.
- sub_install_req = self._make_install_req(str(subreq), req_to_install)
- parent_req_name = req_to_install.name
- to_scan_again, add_to_parent = self._add_requirement_to_set(
- requirement_set,
- sub_install_req,
- parent_req_name=parent_req_name,
- extras_requested=extras_requested,
- )
- if parent_req_name and add_to_parent:
- self._discovered_dependencies[parent_req_name].append(add_to_parent)
- more_reqs.extend(to_scan_again)
-
- with indent_log():
- # We add req_to_install before its dependencies, so that we
- # can refer to it when adding dependencies.
- if not requirement_set.has_requirement(req_to_install.name):
- # 'unnamed' requirements will get added here
- # 'unnamed' requirements can only come from being directly
- # provided by the user.
- assert req_to_install.user_supplied
- self._add_requirement_to_set(
- requirement_set, req_to_install, parent_req_name=None
- )
-
- if not self.ignore_dependencies:
- if req_to_install.extras:
- logger.debug(
- "Installing extra requirements: %r",
- ",".join(req_to_install.extras),
- )
- missing_requested = sorted(
- set(req_to_install.extras) - set(dist.iter_provided_extras())
- )
- for missing in missing_requested:
- logger.warning(
- "%s %s does not provide the extra '%s'",
- dist.raw_name,
- dist.version,
- missing,
- )
-
- available_requested = sorted(
- set(dist.iter_provided_extras()) & set(req_to_install.extras)
- )
- for subreq in dist.iter_dependencies(available_requested):
- add_req(subreq, extras_requested=available_requested)
-
- return more_reqs
-
- def get_installation_order(
- self, req_set: RequirementSet
- ) -> List[InstallRequirement]:
- """Create the installation order.
-
- The installation order is topological - requirements are installed
- before the requiring thing. We break cycles at an arbitrary point,
- and make no other guarantees.
- """
- # The current implementation, which we may change at any point
- # installs the user specified things in the order given, except when
- # dependencies must come earlier to achieve topological order.
- order = []
- ordered_reqs: Set[InstallRequirement] = set()
-
- def schedule(req: InstallRequirement) -> None:
- if req.satisfied_by or req in ordered_reqs:
- return
- if req.constraint:
- return
- ordered_reqs.add(req)
- for dep in self._discovered_dependencies[req.name]:
- schedule(dep)
- order.append(req)
-
- for install_req in req_set.requirements.values():
- schedule(install_req)
- return order
diff --git a/spaces/tomofi/MMOCR/README.md b/spaces/tomofi/MMOCR/README.md
deleted file mode 100644
index 1be4c748362fbc8e8712b9e39936072141862e5a..0000000000000000000000000000000000000000
--- a/spaces/tomofi/MMOCR/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: MMOCR
-emoji: 🌍
-colorFrom: blue
-colorTo: purple
-sdk: gradio
-sdk_version: 2.8.11
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/tomofi/MMOCR/mmocr/models/textrecog/heads/seg_head.py b/spaces/tomofi/MMOCR/mmocr/models/textrecog/heads/seg_head.py
deleted file mode 100644
index e8686db8e1294607d8eb8709928dfd4b958b9609..0000000000000000000000000000000000000000
--- a/spaces/tomofi/MMOCR/mmocr/models/textrecog/heads/seg_head.py
+++ /dev/null
@@ -1,64 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch.nn.functional as F
-from mmcv.cnn import ConvModule
-from mmcv.runner import BaseModule
-from torch import nn
-
-from mmocr.models.builder import HEADS
-
-
-@HEADS.register_module()
-class SegHead(BaseModule):
- """Head for segmentation based text recognition.
-
- Args:
- in_channels (int): Number of input channels :math:`C`.
- num_classes (int): Number of output classes :math:`C_{out}`.
- upsample_param (dict | None): Config dict for interpolation layer.
- Default: ``dict(scale_factor=1.0, mode='nearest')``
- init_cfg (dict or list[dict], optional): Initialization configs.
- """
-
- def __init__(self,
- in_channels=128,
- num_classes=37,
- upsample_param=None,
- init_cfg=None):
- super().__init__(init_cfg=init_cfg)
- assert isinstance(num_classes, int)
- assert num_classes > 0
- assert upsample_param is None or isinstance(upsample_param, dict)
-
- self.upsample_param = upsample_param
-
- self.seg_conv = ConvModule(
- in_channels,
- in_channels,
- 3,
- stride=1,
- padding=1,
- norm_cfg=dict(type='BN'))
-
- # prediction
- self.pred_conv = nn.Conv2d(
- in_channels, num_classes, kernel_size=1, stride=1, padding=0)
-
- def forward(self, out_neck):
- """
- Args:
- out_neck (list[Tensor]): A list of tensor of shape
- :math:`(N, C_i, H_i, W_i)`. The network only uses the last one
- (``out_neck[-1]``).
-
- Returns:
- Tensor: A tensor of shape :math:`(N, C_{out}, kH, kW)` where
- :math:`k` is determined by ``upsample_param``.
- """
-
- seg_map = self.seg_conv(out_neck[-1])
- seg_map = self.pred_conv(seg_map)
-
- if self.upsample_param is not None:
- seg_map = F.interpolate(seg_map, **self.upsample_param)
-
- return seg_map
diff --git a/spaces/tomofi/NDLOCR/src/ndl_layout/mmdetection/configs/hrnet/faster_rcnn_hrnetv2p_w18_2x_coco.py b/spaces/tomofi/NDLOCR/src/ndl_layout/mmdetection/configs/hrnet/faster_rcnn_hrnetv2p_w18_2x_coco.py
deleted file mode 100644
index a4b987a19ae32453d524fc2f7a4fb6b6b87f1f32..0000000000000000000000000000000000000000
--- a/spaces/tomofi/NDLOCR/src/ndl_layout/mmdetection/configs/hrnet/faster_rcnn_hrnetv2p_w18_2x_coco.py
+++ /dev/null
@@ -1,5 +0,0 @@
-_base_ = './faster_rcnn_hrnetv2p_w18_1x_coco.py'
-
-# learning policy
-lr_config = dict(step=[16, 22])
-runner = dict(type='EpochBasedRunner', max_epochs=24)
diff --git a/spaces/training-transformers-together/Dashboard/streamlit_observable/frontend/build/static/js/2.b1c975ff.chunk.js b/spaces/training-transformers-together/Dashboard/streamlit_observable/frontend/build/static/js/2.b1c975ff.chunk.js
deleted file mode 100644
index c369a482a48d1fd13f73b9ed7f6e35a45a52cc94..0000000000000000000000000000000000000000
--- a/spaces/training-transformers-together/Dashboard/streamlit_observable/frontend/build/static/js/2.b1c975ff.chunk.js
+++ /dev/null
@@ -1,3 +0,0 @@
-/*! For license information please see 2.b1c975ff.chunk.js.LICENSE.txt */
-(this.webpackJsonpstreamlit_component_template=this.webpackJsonpstreamlit_component_template||[]).push([[2],[function(e,t,n){"use strict";function r(e,t){if(!(e instanceof t))throw new TypeError("Cannot call a class as a function")}n.d(t,"a",(function(){return r}))},function(e,t,n){e.exports=n(46)},function(e,t,n){"use strict";n.d(t,"a",(function(){return i}));var r=n(23);function i(e,t){if("function"!==typeof t&&null!==t)throw new TypeError("Super expression must either be null or a function");e.prototype=Object.create(t&&t.prototype,{constructor:{value:e,writable:!0,configurable:!0}}),t&&Object(r.a)(e,t)}},function(e,t,n){"use strict";n.d(t,"a",(function(){return o}));var r=n(9),i=n(28),a=n(21);function o(e){return function(){var t,n=Object(r.a)(e);if(Object(i.a)()){var o=Object(r.a)(this).constructor;t=Reflect.construct(n,arguments,o)}else t=n.apply(this,arguments);return Object(a.a)(this,t)}}},function(e,t,n){"use strict";function r(e,t){for(var n=0;n=e.length?{done:!0}:{done:!1,value:e[t++]}},e:function(e){throw e},f:n}}throw new TypeError("Invalid attempt to iterate non-iterable instance.\nIn order to be iterable, non-array objects must have a [Symbol.iterator]() method.")}var i,a,o=!0,u=!1;return{s:function(){i=e[Symbol.iterator]()},n:function(){var e=i.next();return o=e.done,e},e:function(e){u=!0,a=e},f:function(){try{o||null==i.return||i.return()}finally{if(u)throw a}}}}},function(e,t,n){"use strict";function r(e){return(r=Object.setPrototypeOf?Object.getPrototypeOf:function(e){return e.__proto__||Object.getPrototypeOf(e)})(e)}n.d(t,"a",(function(){return r}))},function(e,t,n){"use strict";n.d(t,"a",(function(){return a}));var r=n(11);function i(e,t){var n=Object.keys(e);if(Object.getOwnPropertySymbols){var r=Object.getOwnPropertySymbols(e);t&&(r=r.filter((function(t){return Object.getOwnPropertyDescriptor(e,t).enumerable}))),n.push.apply(n,r)}return n}function a(e){for(var t=1;t0&&void 0!==arguments[0]?arguments[0]:new c.b,t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:A,n=this.module();if(Object.defineProperties(this,{_dirty:{value:new Set},_updates:{value:new Set},_precomputes:{value:[],writable:!0},_computing:{value:null,writable:!0},_init:{value:null,writable:!0},_modules:{value:new Map},_variables:{value:new Set},_disposed:{value:!1,writable:!0},_builtin:{value:n},_global:{value:t}}),e)for(var r in e)new p.d(p.b,n).define(r,[],e[r])}function g(){return(g=Object(u.a)(i.a.mark((function e(){var t,n,r,a,u,c,l;return i.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:if(l=function(e){0===--e._indegree&&t.push(e)},t=[],!(a=this._precomputes).length){e.next=8;break}this._precomputes=[],u=Object(o.a)(a);try{for(u.s();!(c=u.n()).done;)(0,c.value)()}catch(i){u.e(i)}finally{u.f()}return e.next=8,w(3);case 8:(n=new Set(this._dirty)).forEach((function(e){e._inputs.forEach(n.add,n);var t=E(e);t>e._reachable?this._updates.add(e):t0&&void 0!==arguments[0]?arguments[0]:0,t=Promise.resolve(),n=0;n1&&void 0!==arguments[1]?arguments[1]:d.a;if(void 0===e)return(t=this._init)?(this._init=null,t):new h.a(this);if(t=this._modules.get(e))return t;this._init=t=new h.a(this),this._modules.set(e,t);try{e(this,n)}finally{this._init=null}return t},writable:!0,configurable:!0},fileAttachments:{value:c.a,writable:!0,configurable:!0}})}).call(this,n(49).setImmediate)},function(e,t,n){"use strict";n.d(t,"a",(function(){return Ue})),n.d(t,"b",(function(){return gt}));var r=n(16),i=n(2),a=n(3),o=n(7),u=n(1),c=n.n(u),s=n(0),l=n(4),f=n(5),h={},d={};function p(e){return new Function("d","return {"+e.map((function(e,t){return JSON.stringify(e)+": d["+t+'] || ""'})).join(",")+"}")}function v(e){var t=Object.create(null),n=[];return e.forEach((function(e){for(var r in e)r in t||n.push(t[r]=r)})),n}function y(e,t){var n=e+"",r=n.length;return r9999?"+"+y(t,6):y(t,4))+"-"+y(e.getUTCMonth()+1,2)+"-"+y(e.getUTCDate(),2)+(a?"T"+y(n,2)+":"+y(r,2)+":"+y(i,2)+"."+y(a,3)+"Z":i?"T"+y(n,2)+":"+y(r,2)+":"+y(i,2)+"Z":r||n?"T"+y(n,2)+":"+y(r,2)+"Z":"")}var m=function(e){var t=new RegExp('["'+e+"\n\r]"),n=e.charCodeAt(0);function r(e,t){var r,i=[],a=e.length,o=0,u=0,c=a<=0,s=!1;function l(){if(c)return d;if(s)return s=!1,h;var t,r,i=o;if(34===e.charCodeAt(i)){for(;o++=a?c=!0:10===(r=e.charCodeAt(o++))?s=!0:13===r&&(s=!0,10===e.charCodeAt(o)&&++o),e.slice(i+1,t-1).replace(/""/g,'"')}for(;o1?Promise.all(L.call(arguments,n)).then(Q):n(e)}return a.alias=function(t){return K((function(n,r){return n in t&&(r=null,"string"!==typeof(n=t[n]))?n:e(n,r)}))},a.resolve=e,a}function Q(e){var t,n={},r=Object(T.a)(e);try{for(r.s();!(t=r.n()).done;){var i=t.value;for(var a in i)F.call(i,a)&&(null==i[a]?Object.defineProperty(n,a,{get:G(i,a)}):n[a]=i[a])}}catch(o){r.e(o)}finally{r.f()}return n}function G(e,t){return function(){return e[t]}}function J(e){return"exports"===(e+="")||"module"===e}function Z(e,t,n){var r=arguments.length;r<2?(n=e,t=[]):r<3&&(n=t,t="string"===typeof e?[]:e),D.push(N.call(t,J)?function(e){var r={},i={exports:r};return Promise.all(L.call(t,(function(t){return"exports"===(t+="")?r:"module"===t?i:e(t)}))).then((function(e){return n.apply(null,e),i.exports}))}:function(e){return Promise.all(L.call(t,e)).then((function(e){return"function"===typeof n?n.apply(null,e):n}))})}function X(e,t,n){return{resolve:function(){var r=arguments.length>0&&void 0!==arguments[0]?arguments[0]:n;return"https://cdn.jsdelivr.net/npm/".concat(e,"@").concat(t,"/").concat(r)}}}Z.amd={};var ee=X("d3","7.1.1","dist/d3.min.js"),te=X("@observablehq/inputs","0.10.3","dist/inputs.min.js"),ne=X("@observablehq/plot","0.2.9","dist/plot.umd.min.js"),re=X("@observablehq/graphviz","0.2.1","dist/graphviz.min.js"),ie=X("@observablehq/highlight.js","2.0.0","highlight.min.js"),ae=X("@observablehq/katex","0.11.1","dist/katex.min.js"),oe=X("lodash","4.17.21","lodash.min.js"),ue=X("htl","0.3.1","dist/htl.min.js"),ce=X("jszip","3.7.1","dist/jszip.min.js"),se=X("marked","0.3.12","marked.min.js"),le=X("sql.js","1.6.2","dist/sql-wasm.js"),fe=X("vega","5.21.0","build/vega.min.js"),he=X("vega-lite","5.1.1","build/vega-lite.min.js"),de=X("vega-lite-api","5.0.0","build/vega-lite-api.min.js"),pe=X("apache-arrow","4.0.1","Arrow.es2015.min.js"),ve=X("arquero","4.8.7","dist/arquero.min.js"),ye=X("topojson-client","3.1.0","dist/topojson-client.min.js"),be=X("exceljs","4.3.0","dist/exceljs.min.js");function me(e){return ge.apply(this,arguments)}function ge(){return(ge=Object(f.a)(c.a.mark((function e(t){var n;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,t(le.resolve());case 2:return n=e.sent,e.abrupt("return",n({locateFile:function(e){return le.resolve("dist/".concat(e))}}));case 4:case"end":return e.stop()}}),e)})))).apply(this,arguments)}var we=function(){function e(t){Object(s.a)(this,e),Object.defineProperties(this,{_db:{value:t}})}return Object(l.a)(e,[{key:"query",value:function(){var e=Object(f.a)(c.a.mark((function e(t,n){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,_e(this._db,t,n);case 2:return e.abrupt("return",e.sent);case 3:case"end":return e.stop()}}),e,this)})));return function(t,n){return e.apply(this,arguments)}}()},{key:"queryRow",value:function(){var e=Object(f.a)(c.a.mark((function e(t,n){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.query(t,n);case 2:if(e.t0=e.sent[0],e.t0){e.next=5;break}e.t0=null;case 5:return e.abrupt("return",e.t0);case 6:case"end":return e.stop()}}),e,this)})));return function(t,n){return e.apply(this,arguments)}}()},{key:"explain",value:function(){var e=Object(f.a)(c.a.mark((function e(t,n){var r;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.query("EXPLAIN QUERY PLAN ".concat(t),n);case 2:return r=e.sent,e.abrupt("return",xe("pre",{className:"observablehq--inspect"},[je(r.map((function(e){return e.detail})).join("\n"))]));case 4:case"end":return e.stop()}}),e,this)})));return function(t,n){return e.apply(this,arguments)}}()},{key:"describe",value:function(){var e=Object(f.a)(c.a.mark((function e(t){var n,r;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,void 0===t?this.query("SELECT name FROM sqlite_master WHERE type = 'table'"):this.query("SELECT * FROM pragma_table_info(?)",[t]);case 2:if((n=e.sent).length){e.next=5;break}throw new Error("Not found");case 5:return r=n.columns,e.abrupt("return",xe("table",{value:n},[xe("thead",[xe("tr",r.map((function(e){return xe("th",[je(e)])})))]),xe("tbody",n.map((function(e){return xe("tr",r.map((function(t){return xe("td",[je(e[t])])})))})))]));case 7:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"sql",value:function(){var e=Object(f.a)(c.a.mark((function e(t){var n,r,i,a=arguments;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:for(n=a.length,r=new Array(n>1?n-1:0),i=1;i1&&void 0!==arguments[1]?arguments[1]:{},n=t.range,r=t.headers,i=Ee(n,e),a=Object(o.a)(i,2),u=Object(o.a)(a[0],2),c=u[0],s=u[1],l=Object(o.a)(a[1],2),f=l[0],h=l[1],d=r?e._rows[s++]:null,p=new Set(["#"]),v=c;v<=f;v++){for(var y=d?Te(d.findCell(v+1)):null,b=y&&y+""||Ae(v);p.has(b);)b+="_";p.add(b)}p=new Array(c).concat(Array.from(p));for(var m=new Array(h-s+1),g=s;g<=h;g++){var w=m[g-s]=Object.create(null,{"#":{value:g+1}}),k=e.getRow(g+1);if(k.hasValues)for(var _=c;_<=f;_++){var O=Te(k.findCell(_+1));null!=O&&(w[p[_+1]]=O)}}return m.columns=p.filter((function(){return!0})),m}(r,t)}}]),e}();function Te(e){if(e){var t=e.value;if(t&&"object"===typeof t&&!(t instanceof Date)){if(t.formula||t.sharedFormula)return t.result&&t.result.error?NaN:t.result;if(t.richText)return Ie(t);if(t.text){var n=t.text;return n.richText&&(n=Ie(n)),t.hyperlink&&t.hyperlink!==n?"".concat(t.hyperlink," ").concat(n):n}return t}return t}}function Ie(e){return e.richText.map((function(e){return e.text})).join("")}function Ee(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:":",t=arguments.length>1?arguments[1]:void 0,n=t.columnCount,r=t.rowCount;if(!(e+="").match(/^[A-Z]*\d*:[A-Z]*\d*$/))throw new Error("Malformed range specifier");var i=e.split(":").map(Be),a=Object(o.a)(i,2),u=Object(o.a)(a[0],2),c=u[0],s=void 0===c?0:c,l=u[1],f=void 0===l?0:l,h=Object(o.a)(a[1],2),d=h[0],p=void 0===d?n-1:d,v=h[1],y=void 0===v?r-1:v;return[[s,f],[p,y]]}function Ae(e){var t="";e++;do{t=String.fromCharCode(64+(e%26||26))+t}while(e=Math.floor((e-1)/26));return t}function Be(e){var t=e.match(/^([A-Z]*)(\d*)$/),n=Object(o.a)(t,3),r=n[1],i=n[2],a=0;if(r)for(var u=0;u2&&void 0!==l[2]?l[2]:{},i=r.array,a=void 0!==i&&i,o=r.typed,u=void 0!==o&&o,e.next=3,t.text();case 3:return s=e.sent,e.abrupt("return",("\t"===n?a?k:w:a?x:O)(s,u&&j));case 5:case"end":return e.stop()}}),e)})))).apply(this,arguments)}var Fe=function(){function e(t){Object(s.a)(this,e),Object.defineProperty(this,"name",{value:t,enumerable:!0})}return Object(l.a)(e,[{key:"blob",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,Ce(this);case 2:return e.abrupt("return",e.sent.blob());case 3:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"arrayBuffer",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,Ce(this);case 2:return e.abrupt("return",e.sent.arrayBuffer());case 3:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"text",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,Ce(this);case 2:return e.abrupt("return",e.sent.text());case 3:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"json",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,Ce(this);case 2:return e.abrupt("return",e.sent.json());case 3:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"stream",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,Ce(this);case 2:return e.abrupt("return",e.sent.body);case 3:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"csv",value:function(){var e=Object(f.a)(c.a.mark((function e(t){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.abrupt("return",Le(this,",",t));case 1:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"tsv",value:function(){var e=Object(f.a)(c.a.mark((function e(t){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.abrupt("return",Le(this,"\t",t));case 1:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"image",value:function(){var e=Object(f.a)(c.a.mark((function e(t){var n,r=this;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.url();case 2:return n=e.sent,e.abrupt("return",new Promise((function(e,i){var a=new Image;new URL(n,document.baseURI).origin!==new URL(location).origin&&(a.crossOrigin="anonymous"),Object.assign(a,t),a.onload=function(){return e(a)},a.onerror=function(){return i(new Error("Unable to load file: ".concat(r.name)))},a.src=n})));case 4:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"arrow",value:function(){var e=Object(f.a)(c.a.mark((function e(){var t,n,r,i;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,Promise.all([$(pe.resolve()),Ce(this)]);case 2:return t=e.sent,n=Object(o.a)(t,2),r=n[0],i=n[1],e.abrupt("return",r.Table.from(i));case 7:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"sqlite",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.abrupt("return",we.open(Ce(this)));case 1:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"zip",value:function(){var e=Object(f.a)(c.a.mark((function e(){var t,n,r,i;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,Promise.all([$(ce.resolve()),this.arrayBuffer()]);case 2:return t=e.sent,n=Object(o.a)(t,2),r=n[0],i=n[1],e.t0=Re,e.next=9,r.loadAsync(i);case 9:return e.t1=e.sent,e.abrupt("return",new e.t0(e.t1));case 11:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"xml",value:function(){var e=Object(f.a)(c.a.mark((function e(){var t,n=arguments;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return t=n.length>0&&void 0!==n[0]?n[0]:"application/xml",e.t0=new DOMParser,e.next=4,this.text();case 4:return e.t1=e.sent,e.t2=t,e.abrupt("return",e.t0.parseFromString.call(e.t0,e.t1,e.t2));case 7:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"html",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.abrupt("return",this.xml("text/html"));case 1:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"xlsx",value:function(){var e=Object(f.a)(c.a.mark((function e(){var t,n,r,i;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,Promise.all([$(be.resolve()),this.arrayBuffer()]);case 2:return t=e.sent,n=Object(o.a)(t,2),r=n[0],i=n[1],e.t0=Se,e.next=9,(new r.Workbook).xlsx.load(i);case 9:return e.t1=e.sent,e.abrupt("return",new e.t0(e.t1));case 11:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()}]),e}(),Me=function(e){Object(i.a)(n,e);var t=Object(a.a)(n);function n(e,i){var a;return Object(s.a)(this,n),a=t.call(this,i),Object.defineProperty(Object(r.a)(a),"_url",{value:e}),a}return Object(l.a)(n,[{key:"url",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this._url;case 2:return e.t0=e.sent,e.abrupt("return",e.t0+"");case 4:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()}]),n}(Fe);function Pe(e){throw new Error("File not found: ".concat(e))}function Ue(e){return Object.assign((function(t){var n=e(t+="");if(null==n)throw new Error("File not found: ".concat(t));return new Me(n,t)}),{prototype:Me.prototype})}var Re=function(){function e(t){Object(s.a)(this,e),Object.defineProperty(this,"_",{value:t}),this.filenames=Object.keys(t.files).filter((function(e){return!t.files[e].dir}))}return Object(l.a)(e,[{key:"file",value:function(e){var t=this._.file(e+="");if(!t||t.dir)throw new Error("file not found: ".concat(e));return new ze(t)}}]),e}(),ze=function(e){Object(i.a)(n,e);var t=Object(a.a)(n);function n(e){var i;return Object(s.a)(this,n),i=t.call(this,e.name),Object.defineProperty(Object(r.a)(i),"_",{value:e}),Object.defineProperty(Object(r.a)(i),"_url",{writable:!0}),i}return Object(l.a)(n,[{key:"url",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.abrupt("return",this._url||(this._url=this.blob().then(URL.createObjectURL)));case 1:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"blob",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.abrupt("return",this._.async("blob"));case 1:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"arrayBuffer",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.abrupt("return",this._.async("arraybuffer"));case 1:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"text",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.abrupt("return",this._.async("text"));case 1:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"json",value:function(){var e=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.t0=JSON,e.next=3,this.text();case 3:return e.t1=e.sent,e.abrupt("return",e.t0.parse.call(e.t0,e.t1));case 5:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()}]),n}(Fe),Ve=n(10),We={math:"http://www.w3.org/1998/Math/MathML",svg:"http://www.w3.org/2000/svg",xhtml:"http://www.w3.org/1999/xhtml",xlink:"http://www.w3.org/1999/xlink",xml:"http://www.w3.org/XML/1998/namespace",xmlns:"http://www.w3.org/2000/xmlns/"},Ye=0;function qe(e){this.id=e,this.href=new URL("#".concat(e),location)+""}qe.prototype.toString=function(){return"url("+this.href+")"};var He={canvas:function(e,t){var n=document.createElement("canvas");return n.width=e,n.height=t,n},context2d:function(e,t,n){null==n&&(n=devicePixelRatio);var r=document.createElement("canvas");r.width=e*n,r.height=t*n,r.style.width=e+"px";var i=r.getContext("2d");return i.scale(n,n),i},download:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:"untitled",n=arguments.length>2&&void 0!==arguments[2]?arguments[2]:"Save",r=document.createElement("a"),i=r.appendChild(document.createElement("button"));function a(){return o.apply(this,arguments)}function o(){return(o=Object(f.a)(c.a.mark((function e(){return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,new Promise(requestAnimationFrame);case 2:URL.revokeObjectURL(r.href),r.removeAttribute("href"),i.textContent=n,i.disabled=!1;case 6:case"end":return e.stop()}}),e)})))).apply(this,arguments)}return i.textContent=n,r.download=t,r.onclick=function(){var t=Object(f.a)(c.a.mark((function t(o){var u;return c.a.wrap((function(t){for(;;)switch(t.prev=t.next){case 0:if(i.disabled=!0,!r.href){t.next=3;break}return t.abrupt("return",a());case 3:return i.textContent="Saving\u2026",t.prev=4,t.next=7,"function"===typeof e?e():e;case 7:u=t.sent,i.textContent="Download",r.href=URL.createObjectURL(u),t.next=15;break;case 12:t.prev=12,t.t0=t.catch(4),i.textContent=n;case 15:if(!o.eventPhase){t.next=17;break}return t.abrupt("return",a());case 17:i.disabled=!1;case 18:case"end":return t.stop()}}),t,null,[[4,12]])})));return function(e){return t.apply(this,arguments)}}(),r},element:function(e,t){var n,r=e+="",i=r.indexOf(":");i>=0&&"xmlns"!==(r=e.slice(0,i))&&(e=e.slice(i+1));var a=We.hasOwnProperty(r)?document.createElementNS(We[r],e):document.createElement(e);if(t)for(var o in t)i=(r=o).indexOf(":"),n=t[o],i>=0&&"xmlns"!==(r=o.slice(0,i))&&(o=o.slice(i+1)),We.hasOwnProperty(r)?a.setAttributeNS(We[r],o,n):a.setAttribute(o,n);return a},input:function(e){var t=document.createElement("input");return null!=e&&(t.type=e),t},range:function(e,t,n){1===arguments.length&&(t=e,e=null);var r=document.createElement("input");return r.min=e=null==e?0:+e,r.max=t=null==t?1:+t,r.step=null==n?"any":n=+n,r.type="range",r},select:function(e){var t=document.createElement("select");return Array.prototype.forEach.call(e,(function(e){var n=document.createElement("option");n.value=n.textContent=e,t.appendChild(n)})),t},svg:function(e,t){var n=document.createElementNS("http://www.w3.org/2000/svg","svg");return n.setAttribute("viewBox",[0,0,e,t]),n.setAttribute("width",e),n.setAttribute("height",t),n},text:function(e){return document.createTextNode(e)},uid:function(e){return new qe("O-"+(null==e?"":e+"-")+ ++Ye)}},$e={buffer:function(e){return new Promise((function(t,n){var r=new FileReader;r.onload=function(){t(r.result)},r.onerror=n,r.readAsArrayBuffer(e)}))},text:function(e){return new Promise((function(t,n){var r=new FileReader;r.onload=function(){t(r.result)},r.onerror=n,r.readAsText(e)}))},url:function(e){return new Promise((function(t,n){var r=new FileReader;r.onload=function(){t(r.result)},r.onerror=n,r.readAsDataURL(e)}))}},Ke=n(11);function Qe(){return this}function Ge(e,t){var n,r=!1;if("function"!==typeof t)throw new Error("dispose is not a function");return n={},Object(Ke.a)(n,Symbol.iterator,Qe),Object(Ke.a)(n,"next",(function(){return r?{done:!0}:(r=!0,{done:!1,value:e})})),Object(Ke.a)(n,"return",(function(){return r=!0,t(e),{done:!0}})),Object(Ke.a)(n,"throw",(function(){return{done:r=!0}})),n}var Je=c.a.mark(Ze);function Ze(e,t){var n,r;return c.a.wrap((function(i){for(;;)switch(i.prev=i.next){case 0:r=-1;case 1:if((n=e.next()).done){i.next=7;break}if(!t(n.value,++r)){i.next=5;break}return i.next=5,n.value;case 5:i.next=1;break;case 7:case"end":return i.stop()}}),Je)}var Xe=function(e){var t,n,r,i=!1,a=e((function(e){r?(r(e),r=null):i=!0;return n=e}));if(null!=a&&"function"!==typeof a)throw new Error("function"===typeof a.then?"async initializers are not supported":"initializer returned something, but not a dispose function");return t={},Object(Ke.a)(t,Symbol.iterator,Qe),Object(Ke.a)(t,"throw",(function(){return{done:!0}})),Object(Ke.a)(t,"return",(function(){return null!=a&&a(),{done:!0}})),Object(Ke.a)(t,"next",(function(){return{done:!1,value:i?(i=!1,Promise.resolve(n)):new Promise((function(e){return r=e}))}})),t};function et(e){switch(e.type){case"range":case"number":return e.valueAsNumber;case"date":return e.valueAsDate;case"checkbox":return e.checked;case"file":return e.multiple?e.files:e.files[0];case"select-multiple":return Array.from(e.selectedOptions,(function(e){return e.value}));default:return e.value}}var tt=c.a.mark(nt);function nt(e,t){var n,r;return c.a.wrap((function(i){for(;;)switch(i.prev=i.next){case 0:r=-1;case 1:if((n=e.next()).done){i.next=6;break}return i.next=4,t(n.value,++r);case 4:i.next=1;break;case 6:case"end":return i.stop()}}),tt)}var rt=c.a.mark(it);function it(e,t,n){var r,i,a=arguments;return c.a.wrap((function(o){for(;;)switch(o.prev=o.next){case 0:e=+e,t=+t,n=(i=a.length)<2?(t=e,e=0,1):i<3?1:+n,r=-1,i=0|Math.max(0,Math.ceil((t-e)/n));case 4:if(!(++r0){for(a=new Array(p),o=document.createTreeWalker(d,NodeFilter.SHOW_COMMENT,null,!1);o.nextNode();)i=o.currentNode,/^o:/.test(i.nodeValue)&&(a[+i.nodeValue.slice(2)]=i);for(u=0;u=e?Promise.resolve(t):function(e,t){var n=new Promise((function(n){ft.delete(t);var r=t-e;if(!(r>0))throw new Error("invalid time");if(r>2147483647)throw new Error("too long to wait");setTimeout(n,r)}));return ft.set(t,n),n}(n,e).then((function(){return t}))}var dt={delay:function(e,t){return new Promise((function(n){setTimeout((function(){n(t)}),e)}))},tick:function(e,t){return ht(Math.ceil((Date.now()+1)/e)*e,t)},when:ht};function pt(e,t){if(/^(\w+:)|\/\//i.test(e))return e;if(/^[.]{0,2}\//i.test(e))return new URL(e,null==t?location:t).href;if(!e.length||/^[\s._]/.test(e)||/\s$/.test(e))throw new Error("illegal name");return"https://unpkg.com/"+e}var vt=ot((function(e){var t=document.createElementNS("http://www.w3.org/2000/svg","g");return t.innerHTML=e.trim(),t}),(function(){return document.createElementNS("http://www.w3.org/2000/svg","g")})),yt=String.raw;function bt(){return(bt=Object(f.a)(c.a.mark((function e(t){var n,r,i,a,u;return c.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,Promise.all([fe,he,de].map((function(e){return t(e.resolve())})));case 2:return n=e.sent,r=Object(o.a)(n,3),i=r[0],a=r[1],u=r[2],e.abrupt("return",u.register(i,a));case 8:case"end":return e.stop()}}),e)})))).apply(this,arguments)}var mt=function(){return Xe((function(e){var t=e(document.body.clientWidth);function n(){var n=document.body.clientWidth;n!==t&&e(t=n)}return window.addEventListener("resize",n),function(){window.removeEventListener("resize",n)}}))},gt=Object.assign((function(e){var t,n,r=null==(t=e)?$:K(t);Object.defineProperties(this,(n={FileAttachment:function(){return Pe},Arrow:function(){return r(pe.resolve())},Inputs:function(){return r(te.resolve()).then((function(e){return Object(Ve.a)(Object(Ve.a)({},e),{},{file:e.fileOf(Fe)})}))},Mutable:function(){return ct},Plot:function(){return r(ne.resolve())},SQLite:function(){return me(r)},SQLiteDatabaseClient:function(){return we},_:function(){return r(oe.resolve())},aq:function(){return r.alias({"apache-arrow":pe.resolve()})(ve.resolve())},d3:function(){return r(ee.resolve())},dot:function(){return r(re.resolve())},htl:function(){return r(ue.resolve())},html:function(){return ut},md:function(){return(e=r)(se.resolve()).then((function(t){return ot((function(n){var r=document.createElement("div");r.innerHTML=t(n,{langPrefix:""}).trim();var i=r.querySelectorAll("pre code[class]");return i.length>0&&e(ie.resolve()).then((function(t){i.forEach((function(n){function r(){t.highlightBlock(n),n.parentNode.classList.add("observablehq--md-pre")}t.getLanguage(n.className)?r():e(ie.resolve("async-languages/index.js")).then((function(r){if(r.has(n.className))return e(ie.resolve("async-languages/"+r.get(n.className))).then((function(e){t.registerLanguage(n.className,e)}))})).then(r,r)}))})),r}),(function(){return document.createElement("div")}))}));var e},now:lt,require:function(){return r},resolve:function(){return pt},svg:function(){return vt},tex:function(){return function(e){return Promise.all([e(ae.resolve()),(t=ae.resolve("dist/katex.min.css"),new Promise((function(e,n){var r=document.createElement("link");r.rel="stylesheet",r.href=t,r.onerror=n,r.onload=e,document.head.appendChild(r)})))]).then((function(e){var t=e[0],n=r();function r(e){return function(){var n=document.createElement("div");return t.render(yt.apply(String,arguments),n,e),n.removeChild(n.firstChild)}}return n.options=r,n.block=r({displayMode:!0}),n}));var t}(r)},topojson:function(){return r(ye.resolve())},vl:function(){return function(e){return bt.apply(this,arguments)}(r)},width:mt,DOM:He,Files:$e,Generators:at,Promises:dt},Object.fromEntries(Object.entries(n).map(wt))))}),{resolve:$.resolve});function wt(e){var t=Object(o.a)(e,2);return[t[0],{value:t[1],writable:!0,enumerable:!0}]}},function(e,t,n){"use strict";function r(e){return(r="function"===typeof Symbol&&"symbol"===typeof Symbol.iterator?function(e){return typeof e}:function(e){return e&&"function"===typeof Symbol&&e.constructor===Symbol&&e!==Symbol.prototype?"symbol":typeof e})(e)}n.d(t,"a",(function(){return a}));var i=n(16);function a(e,t){return!t||"object"!==r(t)&&"function"!==typeof t?Object(i.a)(e):t}},function(e,t,n){"use strict";n.d(t,"a",(function(){return i}));var r=n(25);function i(e,t){if(e){if("string"===typeof e)return Object(r.a)(e,t);var n=Object.prototype.toString.call(e).slice(8,-1);return"Object"===n&&e.constructor&&(n=e.constructor.name),"Map"===n||"Set"===n?Array.from(n):"Arguments"===n||/^(?:Ui|I)nt(?:8|16|32)(?:Clamped)?Array$/.test(n)?Object(r.a)(e,t):void 0}}},function(e,t,n){"use strict";function r(e,t){return(r=Object.setPrototypeOf||function(e,t){return e.__proto__=t,e})(e,t)}n.d(t,"a",(function(){return r}))},function(e,t,n){"use strict";n.d(t,"b",(function(){return wt})),n.d(t,"a",(function(){return cs}));var r={};n.r(r),n.d(r,"memcpy",(function(){return ve})),n.d(r,"joinUint8Arrays",(function(){return ye})),n.d(r,"toArrayBufferView",(function(){return be})),n.d(r,"toInt8Array",(function(){return me})),n.d(r,"toInt16Array",(function(){return ge})),n.d(r,"toInt32Array",(function(){return we})),n.d(r,"toBigInt64Array",(function(){return ke})),n.d(r,"toUint8Array",(function(){return _e})),n.d(r,"toUint16Array",(function(){return Oe})),n.d(r,"toUint32Array",(function(){return xe})),n.d(r,"toBigUint64Array",(function(){return je})),n.d(r,"toFloat32Array",(function(){return Se})),n.d(r,"toFloat64Array",(function(){return Te})),n.d(r,"toUint8ClampedArray",(function(){return Ie})),n.d(r,"toArrayBufferViewIterator",(function(){return Ae})),n.d(r,"toInt8ArrayIterator",(function(){return Be})),n.d(r,"toInt16ArrayIterator",(function(){return Ce})),n.d(r,"toInt32ArrayIterator",(function(){return De})),n.d(r,"toUint8ArrayIterator",(function(){return Le})),n.d(r,"toUint16ArrayIterator",(function(){return Ne})),n.d(r,"toUint32ArrayIterator",(function(){return Fe})),n.d(r,"toFloat32ArrayIterator",(function(){return Me})),n.d(r,"toFloat64ArrayIterator",(function(){return Pe})),n.d(r,"toUint8ClampedArrayIterator",(function(){return Ue})),n.d(r,"toArrayBufferViewAsyncIterator",(function(){return Re})),n.d(r,"toInt8ArrayAsyncIterator",(function(){return Ve})),n.d(r,"toInt16ArrayAsyncIterator",(function(){return We})),n.d(r,"toInt32ArrayAsyncIterator",(function(){return Ye})),n.d(r,"toUint8ArrayAsyncIterator",(function(){return qe})),n.d(r,"toUint16ArrayAsyncIterator",(function(){return He})),n.d(r,"toUint32ArrayAsyncIterator",(function(){return $e})),n.d(r,"toFloat32ArrayAsyncIterator",(function(){return Ke})),n.d(r,"toFloat64ArrayAsyncIterator",(function(){return Qe})),n.d(r,"toUint8ClampedArrayAsyncIterator",(function(){return Ge})),n.d(r,"rebaseValueOffsets",(function(){return Je})),n.d(r,"compareArrayLike",(function(){return Ze}));var i={};n.r(i),n.d(i,"getBool",(function(){return At})),n.d(i,"getBit",(function(){return Bt})),n.d(i,"setBool",(function(){return Ct})),n.d(i,"truncateBitmap",(function(){return Dt})),n.d(i,"packBools",(function(){return Lt})),n.d(i,"iterateBits",(function(){return Nt})),n.d(i,"popcnt_bit_range",(function(){return Ft})),n.d(i,"popcnt_array",(function(){return Mt})),n.d(i,"popcnt_uint32",(function(){return Pt}));var a={};n.r(a),n.d(a,"uint16ToFloat64",(function(){return cr})),n.d(a,"float64ToUint16",(function(){return sr}));var o={};n.r(o),n.d(o,"isArrowBigNumSymbol",(function(){return br})),n.d(o,"bignumToString",(function(){return lr})),n.d(o,"bignumToBigInt",(function(){return fr})),n.d(o,"BN",(function(){return jr}));var u={};n.r(u),n.d(u,"clampIndex",(function(){return hi})),n.d(u,"clampRange",(function(){return di})),n.d(u,"createElementComparator",(function(){return yi}));var c={};n.r(c),n.d(c,"BaseInt64",(function(){return Da})),n.d(c,"Uint64",(function(){return La})),n.d(c,"Int64",(function(){return Na})),n.d(c,"Int128",(function(){return Fa}));var s=n(8),l=n(5),f=n(0),h=n(4),d=n(1),p=n(7);function v(e){this.wrapped=e}function y(e){return new v(e)}function b(e){var t,n;function r(t,n){try{var a=e[t](n),o=a.value,u=o instanceof v;Promise.resolve(u?o.wrapped:o).then((function(e){u?r("return"===t?"return":"next",e):i(a.done?"return":"normal",e)}),(function(e){r("throw",e)}))}catch(c){i("throw",c)}}function i(e,i){switch(e){case"return":t.resolve({value:i,done:!0});break;case"throw":t.reject(i);break;default:t.resolve({value:i,done:!1})}(t=t.next)?r(t.key,t.arg):n=null}this._invoke=function(e,i){return new Promise((function(a,o){var u={key:e,arg:i,resolve:a,reject:o,next:null};n?n=n.next=u:(t=n=u,r(e,i))}))},"function"!==typeof e.return&&(this.return=void 0)}function m(e){return function(){return new b(e.apply(this,arguments))}}function g(e,t){var n={},r=!1;function i(n,i){return r=!0,i=new Promise((function(t){t(e[n](i))})),{done:!1,value:t(i)}}return"function"===typeof Symbol&&Symbol.iterator&&(n[Symbol.iterator]=function(){return this}),n.next=function(e){return r?(r=!1,e):i("next",e)},"function"===typeof e.throw&&(n.throw=function(e){if(r)throw r=!1,e;return i("throw",e)}),"function"===typeof e.return&&(n.return=function(e){return r?(r=!1,e):i("return",e)}),n}"function"===typeof Symbol&&Symbol.asyncIterator&&(b.prototype[Symbol.asyncIterator]=function(){return this}),b.prototype.next=function(e){return this._invoke("next",e)},b.prototype.throw=function(e){return this._invoke("throw",e)},b.prototype.return=function(e){return this._invoke("return",e)};var w={};function k(e,t,n){return t<=e&&e<=n}function _(e){if(void 0===e)return{};if(e===Object(e))return e;throw TypeError("Could not convert argument to dictionary")}w.Offset,w.Table,w.SIZEOF_SHORT=2,w.SIZEOF_INT=4,w.FILE_IDENTIFIER_LENGTH=4,w.Encoding={UTF8_BYTES:1,UTF16_STRING:2},w.int32=new Int32Array(2),w.float32=new Float32Array(w.int32.buffer),w.float64=new Float64Array(w.int32.buffer),w.isLittleEndian=1===new Uint16Array(new Uint8Array([1,0]).buffer)[0],w.Long=function(e,t){this.low=0|e,this.high=0|t},w.Long.create=function(e,t){return 0==e&&0==t?w.Long.ZERO:new w.Long(e,t)},w.Long.prototype.toFloat64=function(){return(this.low>>>0)+4294967296*this.high},w.Long.prototype.equals=function(e){return this.low==e.low&&this.high==e.high},w.Long.ZERO=new w.Long(0,0),w.Builder=function(e){if(e)t=e;else var t=1024;this.bb=w.ByteBuffer.allocate(t),this.space=t,this.minalign=1,this.vtable=null,this.vtable_in_use=0,this.isNested=!1,this.object_start=0,this.vtables=[],this.vector_num_elems=0,this.force_defaults=!1},w.Builder.prototype.clear=function(){this.bb.clear(),this.space=this.bb.capacity(),this.minalign=1,this.vtable=null,this.vtable_in_use=0,this.isNested=!1,this.object_start=0,this.vtables=[],this.vector_num_elems=0,this.force_defaults=!1},w.Builder.prototype.forceDefaults=function(e){this.force_defaults=e},w.Builder.prototype.dataBuffer=function(){return this.bb},w.Builder.prototype.asUint8Array=function(){return this.bb.bytes().subarray(this.bb.position(),this.bb.position()+this.offset())},w.Builder.prototype.prep=function(e,t){e>this.minalign&&(this.minalign=e);for(var n=1+~(this.bb.capacity()-this.space+t)&e-1;this.space=0&&0==this.vtable[t];t--);for(var n=t+1;t>=0;t--)this.addInt16(0!=this.vtable[t]?e-this.vtable[t]:0);this.addInt16(e-this.object_start);var r=(n+2)*w.SIZEOF_SHORT;this.addInt16(r);var i=0,a=this.space;e:for(t=0;t=0;r--)this.writeInt8(n.charCodeAt(r))}this.prep(this.minalign,w.SIZEOF_INT),this.addOffset(e),this.bb.setPosition(this.space)},w.Builder.prototype.requiredField=function(e,t){var n=this.bb.capacity()-e,r=n-this.bb.readInt32(n);if(!(0!=this.bb.readInt16(r+t)))throw new Error("FlatBuffers: field "+t+" must be set")},w.Builder.prototype.startVector=function(e,t,n){this.notNested(),this.vector_num_elems=t,this.prep(w.SIZEOF_INT,e*t),this.prep(n,e*t)},w.Builder.prototype.endVector=function(){return this.writeInt32(this.vector_num_elems),this.offset()},w.Builder.prototype.createString=function(e){if(e instanceof Uint8Array)var t=e;else{t=[];for(var n=0;n=56320)r=i;else r=(i<<10)+e.charCodeAt(n++)+-56613888;r<128?t.push(r):(r<2048?t.push(r>>6&31|192):(r<65536?t.push(r>>12&15|224):t.push(r>>18&7|240,r>>12&63|128),t.push(r>>6&63|128)),t.push(63&r|128))}}this.addInt8(0),this.startVector(1,t.length,1),this.bb.setPosition(this.space-=t.length);n=0;for(var a=this.space,o=this.bb.bytes();n>24},w.ByteBuffer.prototype.readUint8=function(e){return this.bytes_[e]},w.ByteBuffer.prototype.readInt16=function(e){return this.readUint16(e)<<16>>16},w.ByteBuffer.prototype.readUint16=function(e){return this.bytes_[e]|this.bytes_[e+1]<<8},w.ByteBuffer.prototype.readInt32=function(e){return this.bytes_[e]|this.bytes_[e+1]<<8|this.bytes_[e+2]<<16|this.bytes_[e+3]<<24},w.ByteBuffer.prototype.readUint32=function(e){return this.readInt32(e)>>>0},w.ByteBuffer.prototype.readInt64=function(e){return new w.Long(this.readInt32(e),this.readInt32(e+4))},w.ByteBuffer.prototype.readUint64=function(e){return new w.Long(this.readUint32(e),this.readUint32(e+4))},w.ByteBuffer.prototype.readFloat32=function(e){return w.int32[0]=this.readInt32(e),w.float32[0]},w.ByteBuffer.prototype.readFloat64=function(e){return w.int32[w.isLittleEndian?0:1]=this.readInt32(e),w.int32[w.isLittleEndian?1:0]=this.readInt32(e+4),w.float64[0]},w.ByteBuffer.prototype.writeInt8=function(e,t){this.bytes_[e]=t},w.ByteBuffer.prototype.writeUint8=function(e,t){this.bytes_[e]=t},w.ByteBuffer.prototype.writeInt16=function(e,t){this.bytes_[e]=t,this.bytes_[e+1]=t>>8},w.ByteBuffer.prototype.writeUint16=function(e,t){this.bytes_[e]=t,this.bytes_[e+1]=t>>8},w.ByteBuffer.prototype.writeInt32=function(e,t){this.bytes_[e]=t,this.bytes_[e+1]=t>>8,this.bytes_[e+2]=t>>16,this.bytes_[e+3]=t>>24},w.ByteBuffer.prototype.writeUint32=function(e,t){this.bytes_[e]=t,this.bytes_[e+1]=t>>8,this.bytes_[e+2]=t>>16,this.bytes_[e+3]=t>>24},w.ByteBuffer.prototype.writeInt64=function(e,t){this.writeInt32(e,t.low),this.writeInt32(e+4,t.high)},w.ByteBuffer.prototype.writeUint64=function(e,t){this.writeUint32(e,t.low),this.writeUint32(e+4,t.high)},w.ByteBuffer.prototype.writeFloat32=function(e,t){w.float32[0]=t,this.writeInt32(e,w.int32[0])},w.ByteBuffer.prototype.writeFloat64=function(e,t){w.float64[0]=t,this.writeInt32(e,w.int32[w.isLittleEndian?0:1]),this.writeInt32(e+4,w.int32[w.isLittleEndian?1:0])},w.ByteBuffer.prototype.getBufferIdentifier=function(){if(this.bytes_.length>10),56320+(1023&a)))}return r},w.ByteBuffer.prototype.__indirect=function(e){return e+this.readInt32(e)},w.ByteBuffer.prototype.__vector=function(e){return e+this.readInt32(e)+w.SIZEOF_INT},w.ByteBuffer.prototype.__vector_len=function(e){return this.readInt32(e+this.readInt32(e))},w.ByteBuffer.prototype.__has_identifier=function(e){if(e.length!=w.FILE_IDENTIFIER_LENGTH)throw new Error("FlatBuffers: file identifier must be length "+w.FILE_IDENTIFIER_LENGTH);for(var t=0;t>6*n)+r];n>0;){var a=t>>6*(n-1);i.push(128|63&a),n-=1}return i}}j.prototype={decode:function(e,t){var n;n="object"===typeof e&&e instanceof ArrayBuffer?new Uint8Array(e):"object"===typeof e&&"buffer"in e&&e.buffer instanceof ArrayBuffer?new Uint8Array(e.buffer,e.byteOffset,e.byteLength):new Uint8Array(0),t=_(t),this._streaming||(this._decoder=new T({fatal:this._fatal}),this._BOMseen=!1),this._streaming=Boolean(t.stream);for(var r,i=new O(n),a=[];!i.endOfStream()&&-1!==(r=this._decoder.handler(i,i.read()));)null!==r&&(Array.isArray(r)?a.push.apply(a,r):a.push(r));if(!this._streaming){do{if(-1===(r=this._decoder.handler(i,i.read())))break;null!==r&&(Array.isArray(r)?a.push.apply(a,r):a.push(r))}while(!i.endOfStream());this._decoder=null}return a.length&&(-1===["utf-8"].indexOf(this.encoding)||this._ignoreBOM||this._BOMseen||(65279===a[0]?(this._BOMseen=!0,a.shift()):this._BOMseen=!0)),function(e){for(var t="",n=0;n>10),56320+(1023&r)))}return t}(a)}},S.prototype={encode:function(e,t){e=e?String(e):"",t=_(t),this._streaming||(this._encoder=new I(this._options)),this._streaming=Boolean(t.stream);for(var n,r=[],i=new O(function(e){for(var t=String(e),n=t.length,r=0,i=[];r57343)i.push(a);else if(56320<=a&&a<=57343)i.push(65533);else if(55296<=a&&a<=56319)if(r===n-1)i.push(65533);else{var o=e.charCodeAt(r+1);if(56320<=o&&o<=57343){var u=1023&a,c=1023&o;i.push(65536+(u<<10)+c),r+=1}else i.push(65533)}r+=1}return i}(e));!i.endOfStream()&&-1!==(n=this._encoder.handler(i,i.read()));)Array.isArray(n)?r.push.apply(r,n):r.push(n);if(!this._streaming){for(;-1!==(n=this._encoder.handler(i,i.read()));)Array.isArray(n)?r.push.apply(r,n):r.push(n);this._encoder=null}return new Uint8Array(r)}};var E="function"===typeof Buffer?Buffer:null,A="function"===typeof TextDecoder&&"function"===typeof TextEncoder,B=function(e){if(A||!E){var t=new e("utf-8");return function(e){return t.decode(e)}}return function(e){var t=_e(e),n=t.buffer,r=t.byteOffset,i=t.length;return E.from(n,r,i).toString()}}("undefined"!==typeof TextDecoder?TextDecoder:j),C=function(e){if(A||!E){var t=new e;return function(e){return t.encode(e)}}return function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:"";return _e(E.from(e,"utf8"))}}("undefined"!==typeof TextEncoder?TextEncoder:S),D=n(2),L=n(3),N=Object.freeze({done:!0,value:void 0}),F=function(){function e(t){Object(f.a)(this,e),this._json=t}return Object(h.a)(e,[{key:"schema",get:function(){return this._json.schema}},{key:"batches",get:function(){return this._json.batches||[]}},{key:"dictionaries",get:function(){return this._json.dictionaries||[]}}]),e}(),M=function(){function e(){Object(f.a)(this,e)}return Object(h.a)(e,[{key:"tee",value:function(){return this._getDOMStream().tee()}},{key:"pipe",value:function(e,t){return this._getNodeStream().pipe(e,t)}},{key:"pipeTo",value:function(e,t){return this._getDOMStream().pipeTo(e,t)}},{key:"pipeThrough",value:function(e,t){return this._getDOMStream().pipeThrough(e,t)}},{key:"_getDOMStream",value:function(){return this._DOMStream||(this._DOMStream=this.toDOMStream())}},{key:"_getNodeStream",value:function(){return this._nodeStream||(this._nodeStream=this.toNodeStream())}}]),e}(),P=function(e,t){Object(D.a)(r,e);var n=Object(L.a)(r);function r(){var e;return Object(f.a)(this,r),(e=n.call(this))._values=[],e.resolvers=[],e._closedPromise=new Promise((function(t){return e._closedPromiseResolve=t})),e}return Object(h.a)(r,[{key:"closed",get:function(){return this._closedPromise}},{key:"cancel",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.return(t);case 2:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"write",value:function(e){this._ensureOpen()&&(this.resolvers.length<=0?this._values.push(e):this.resolvers.shift().resolve({done:!1,value:e}))}},{key:"abort",value:function(e){this._closedPromiseResolve&&(this.resolvers.length<=0?this._error={error:e}:this.resolvers.shift().reject({done:!0,value:e}))}},{key:"close",value:function(){if(this._closedPromiseResolve){for(var e=this.resolvers;e.length>0;)e.shift().resolve(N);this._closedPromiseResolve(),this._closedPromiseResolve=void 0}}},{key:t,value:function(){return this}},{key:"toDOMStream",value:function(e){return et.toDOMStream(this._closedPromiseResolve||this._error?this:this._values,e)}},{key:"toNodeStream",value:function(e){return et.toNodeStream(this._closedPromiseResolve||this._error?this:this._values,e)}},{key:"throw",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.abort(t);case 2:return e.abrupt("return",N);case 3:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"return",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.close();case 2:return e.abrupt("return",N);case 3:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"read",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.next(t,"read");case 2:return e.abrupt("return",e.sent.value);case 3:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"peek",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.next(t,"peek");case 2:return e.abrupt("return",e.sent.value);case 3:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"next",value:function(){var e=this;return this._values.length>0?Promise.resolve({done:!1,value:this._values.shift()}):this._error?Promise.reject({done:!0,value:this._error.error}):this._closedPromiseResolve?new Promise((function(t,n){e.resolvers.push({resolve:t,reject:n})})):Promise.resolve(N)}},{key:"_ensureOpen",value:function(){if(this._closedPromiseResolve)return!0;throw new Error("".concat(this," is closed"))}}]),r}(M,Symbol.asyncIterator),U=function(){var e=function(){throw new Error("BigInt is not available in this environment")};function t(){throw e()}return t.asIntN=function(){throw e()},t.asUintN=function(){throw e()},"undefined"!==typeof BigInt?[BigInt,!0]:[t,!1]}(),R=Object(p.a)(U,2),z=R[0],V=R[1],W=function(){var e=function(){throw new Error("BigInt64Array is not available in this environment")};return"undefined"!==typeof BigInt64Array?[BigInt64Array,!0]:[function(){function t(){throw Object(f.a)(this,t),e()}return Object(h.a)(t,null,[{key:"BYTES_PER_ELEMENT",get:function(){return 8}},{key:"of",value:function(){throw e()}},{key:"from",value:function(){throw e()}}]),t}(),!1]}(),Y=Object(p.a)(W,2),q=Y[0],H=(Y[1],function(){var e=function(){throw new Error("BigUint64Array is not available in this environment")};return"undefined"!==typeof BigUint64Array?[BigUint64Array,!0]:[function(){function t(){throw Object(f.a)(this,t),e()}return Object(h.a)(t,null,[{key:"BYTES_PER_ELEMENT",get:function(){return 8}},{key:"of",value:function(){throw e()}},{key:"from",value:function(){throw e()}}]),t}(),!1]}()),$=Object(p.a)(H,2),K=$[0],Q=($[1],function(e){return"number"===typeof e}),G=function(e){return"boolean"===typeof e},J=function(e){return"function"===typeof e},Z=function(e){return null!=e&&Object(e)===e},X=function(e){return Z(e)&&J(e.then)},ee=function(e){return Z(e)&&J(e[Symbol.iterator])},te=function(e){return Z(e)&&J(e[Symbol.asyncIterator])},ne=function(e){return Z(e)&&Z(e.schema)},re=function(e){return Z(e)&&"done"in e&&"value"in e},ie=function(e){return Z(e)&&J(e.stat)&&Q(e.fd)},ae=function(e){return Z(e)&&ue(e.body)},oe=function(e){return Z(e)&&J(e.abort)&&J(e.getWriter)&&!(e instanceof M)},ue=function(e){return Z(e)&&J(e.cancel)&&J(e.getReader)&&!(e instanceof M)},ce=function(e){return Z(e)&&J(e.end)&&J(e.write)&&G(e.writable)&&!(e instanceof M)},se=function(e){return Z(e)&&J(e.read)&&J(e.pipe)&&G(e.readable)&&!(e instanceof M)},le=d.mark(Ae);function fe(e){var t,n,r,i=2;for("undefined"!==typeof Symbol&&(n=Symbol.asyncIterator,r=Symbol.iterator);i--;){if(n&&null!=(t=e[n]))return t.call(e);if(r&&null!=(t=e[r]))return new he(t.call(e));n="@@asyncIterator",r="@@iterator"}throw new TypeError("Object is not async iterable")}function he(e){function t(e){if(Object(e)!==e)return Promise.reject(new TypeError(e+" is not an object."));var t=e.done;return Promise.resolve(e.value).then((function(e){return{value:e,done:t}}))}return(he=function(e){this.s=e,this.n=e.next}).prototype={s:null,n:null,next:function(){return t(this.n.apply(this.s,arguments))},return:function(e){var n=this.s.return;return void 0===n?Promise.resolve({value:e,done:!0}):t(n.apply(this.s,arguments))},throw:function(e){var n=this.s.return;return void 0===n?Promise.reject(e):t(n.apply(this.s,arguments))}},new he(e)}var de=w.ByteBuffer,pe="undefined"!==typeof SharedArrayBuffer?SharedArrayBuffer:ArrayBuffer;function ve(e,t){var n=arguments.length>2&&void 0!==arguments[2]?arguments[2]:0,r=arguments.length>3&&void 0!==arguments[3]?arguments[3]:t.byteLength,i=e.byteLength,a=new Uint8Array(e.buffer,e.byteOffset,i),o=new Uint8Array(t.buffer,t.byteOffset,Math.min(r,i));return a.set(o,n),e}function ye(e,t){for(var n,r,i,a=function(e){for(var t,n,r,i,a,o,u=e[0]?[e[0]]:[],c=0,s=0,l=e.length;++c0)do{if(e[n]!==t[n])return!1}while(++n0&&(r.push(i),u+=i.byteLength),!(t||o<=u)){d.next=22;break}case 16:return d.next=18,c();case 18:h=d.sent,a=h.cmd,o=h.size;case 21:if(o0&&(i.push(a),c+=a.byteLength),!(n||u<=c)){e.next=31;break}case 25:return e.next=27,s();case 27:v=e.sent,o=v.cmd,u=v.size;case 30:if(u0&&(i.push(_e(a)),c+=a.byteLength),!(n||u<=c)){e.next=31;break}case 25:return e.next=27,s();case 27:v=e.sent,o=v.cmd,u=v.size;case 30:if(u=i)){e.next=2;break}return e.abrupt("return",{done:!1,value:new Uint8Array(n,0,i)});case 2:return e.next=4,t.read(new Uint8Array(n,r,i-r));case 4:if(a=e.sent,o=a.done,u=a.value,!((r+=u.byteLength)0&&(f.push(h),c+=h.byteLength)),!(i||u<=c)){e.next=36;break}case 30:return e.next=32,v();case 32:w=e.sent,o=w.cmd,u=w.size;case 35:if(u=0;n--)e.addInt32(t[n]);return e.endVector()}},{key:"startTypeIdsVector",value:function(e,t){e.startVector(4,t,4)}},{key:"endUnion",value:function(e){return e.endObject()}},{key:"createUnion",value:function(e,n,r){return t.startUnion(e),t.addMode(e,n),t.addTypeIds(e,r),t.endUnion(e)}}]),t}();t.Union=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"bitWidth",value:function(){var e=this.bb.__offset(this.bb_pos,4);return e?this.bb.readInt32(this.bb_pos+e):0}},{key:"isSigned",value:function(){var e=this.bb.__offset(this.bb_pos,6);return!!e&&!!this.bb.readInt8(this.bb_pos+e)}}],[{key:"getRootAsInt",value:function(t,n){return(n||new e).__init(t.readInt32(t.position())+t.position(),t)}},{key:"startInt",value:function(e){e.startObject(2)}},{key:"addBitWidth",value:function(e,t){e.addFieldInt32(0,t,0)}},{key:"addIsSigned",value:function(e,t){e.addFieldInt8(1,+t,0)}},{key:"endInt",value:function(e){return e.endObject()}},{key:"createInt",value:function(t,n,r){return e.startInt(t),e.addBitWidth(t,n),e.addIsSigned(t,r),e.endInt(t)}}]),e}();e.Int=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"precision",value:function(){var t=this.bb.__offset(this.bb_pos,4);return t?this.bb.readInt16(this.bb_pos+t):e.apache.arrow.flatbuf.Precision.HALF}}],[{key:"getRootAsFloatingPoint",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startFloatingPoint",value:function(e){e.startObject(1)}},{key:"addPrecision",value:function(t,n){t.addFieldInt16(0,n,e.apache.arrow.flatbuf.Precision.HALF)}},{key:"endFloatingPoint",value:function(e){return e.endObject()}},{key:"createFloatingPoint",value:function(e,n){return t.startFloatingPoint(e),t.addPrecision(e,n),t.endFloatingPoint(e)}}]),t}();t.FloatingPoint=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}}],[{key:"getRootAsUtf8",value:function(t,n){return(n||new e).__init(t.readInt32(t.position())+t.position(),t)}},{key:"startUtf8",value:function(e){e.startObject(0)}},{key:"endUtf8",value:function(e){return e.endObject()}},{key:"createUtf8",value:function(t){return e.startUtf8(t),e.endUtf8(t)}}]),e}();e.Utf8=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}}],[{key:"getRootAsBinary",value:function(t,n){return(n||new e).__init(t.readInt32(t.position())+t.position(),t)}},{key:"startBinary",value:function(e){e.startObject(0)}},{key:"endBinary",value:function(e){return e.endObject()}},{key:"createBinary",value:function(t){return e.startBinary(t),e.endBinary(t)}}]),e}();e.Binary=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}}],[{key:"getRootAsLargeUtf8",value:function(t,n){return(n||new e).__init(t.readInt32(t.position())+t.position(),t)}},{key:"startLargeUtf8",value:function(e){e.startObject(0)}},{key:"endLargeUtf8",value:function(e){return e.endObject()}},{key:"createLargeUtf8",value:function(t){return e.startLargeUtf8(t),e.endLargeUtf8(t)}}]),e}();e.LargeUtf8=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}}],[{key:"getRootAsLargeBinary",value:function(t,n){return(n||new e).__init(t.readInt32(t.position())+t.position(),t)}},{key:"startLargeBinary",value:function(e){e.startObject(0)}},{key:"endLargeBinary",value:function(e){return e.endObject()}},{key:"createLargeBinary",value:function(t){return e.startLargeBinary(t),e.endLargeBinary(t)}}]),e}();e.LargeBinary=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"byteWidth",value:function(){var e=this.bb.__offset(this.bb_pos,4);return e?this.bb.readInt32(this.bb_pos+e):0}}],[{key:"getRootAsFixedSizeBinary",value:function(t,n){return(n||new e).__init(t.readInt32(t.position())+t.position(),t)}},{key:"startFixedSizeBinary",value:function(e){e.startObject(1)}},{key:"addByteWidth",value:function(e,t){e.addFieldInt32(0,t,0)}},{key:"endFixedSizeBinary",value:function(e){return e.endObject()}},{key:"createFixedSizeBinary",value:function(t,n){return e.startFixedSizeBinary(t),e.addByteWidth(t,n),e.endFixedSizeBinary(t)}}]),e}();e.FixedSizeBinary=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}}],[{key:"getRootAsBool",value:function(t,n){return(n||new e).__init(t.readInt32(t.position())+t.position(),t)}},{key:"startBool",value:function(e){e.startObject(0)}},{key:"endBool",value:function(e){return e.endObject()}},{key:"createBool",value:function(t){return e.startBool(t),e.endBool(t)}}]),e}();e.Bool=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"precision",value:function(){var e=this.bb.__offset(this.bb_pos,4);return e?this.bb.readInt32(this.bb_pos+e):0}},{key:"scale",value:function(){var e=this.bb.__offset(this.bb_pos,6);return e?this.bb.readInt32(this.bb_pos+e):0}}],[{key:"getRootAsDecimal",value:function(t,n){return(n||new e).__init(t.readInt32(t.position())+t.position(),t)}},{key:"startDecimal",value:function(e){e.startObject(2)}},{key:"addPrecision",value:function(e,t){e.addFieldInt32(0,t,0)}},{key:"addScale",value:function(e,t){e.addFieldInt32(1,t,0)}},{key:"endDecimal",value:function(e){return e.endObject()}},{key:"createDecimal",value:function(t,n,r){return e.startDecimal(t),e.addPrecision(t,n),e.addScale(t,r),e.endDecimal(t)}}]),e}();e.Decimal=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"unit",value:function(){var t=this.bb.__offset(this.bb_pos,4);return t?this.bb.readInt16(this.bb_pos+t):e.apache.arrow.flatbuf.DateUnit.MILLISECOND}}],[{key:"getRootAsDate",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startDate",value:function(e){e.startObject(1)}},{key:"addUnit",value:function(t,n){t.addFieldInt16(0,n,e.apache.arrow.flatbuf.DateUnit.MILLISECOND)}},{key:"endDate",value:function(e){return e.endObject()}},{key:"createDate",value:function(e,n){return t.startDate(e),t.addUnit(e,n),t.endDate(e)}}]),t}();t.Date=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"unit",value:function(){var t=this.bb.__offset(this.bb_pos,4);return t?this.bb.readInt16(this.bb_pos+t):e.apache.arrow.flatbuf.TimeUnit.MILLISECOND}},{key:"bitWidth",value:function(){var e=this.bb.__offset(this.bb_pos,6);return e?this.bb.readInt32(this.bb_pos+e):32}}],[{key:"getRootAsTime",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startTime",value:function(e){e.startObject(2)}},{key:"addUnit",value:function(t,n){t.addFieldInt16(0,n,e.apache.arrow.flatbuf.TimeUnit.MILLISECOND)}},{key:"addBitWidth",value:function(e,t){e.addFieldInt32(1,t,32)}},{key:"endTime",value:function(e){return e.endObject()}},{key:"createTime",value:function(e,n,r){return t.startTime(e),t.addUnit(e,n),t.addBitWidth(e,r),t.endTime(e)}}]),t}();t.Time=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"unit",value:function(){var t=this.bb.__offset(this.bb_pos,4);return t?this.bb.readInt16(this.bb_pos+t):e.apache.arrow.flatbuf.TimeUnit.SECOND}},{key:"timezone",value:function(e){var t=this.bb.__offset(this.bb_pos,6);return t?this.bb.__string(this.bb_pos+t,e):null}}],[{key:"getRootAsTimestamp",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startTimestamp",value:function(e){e.startObject(2)}},{key:"addUnit",value:function(t,n){t.addFieldInt16(0,n,e.apache.arrow.flatbuf.TimeUnit.SECOND)}},{key:"addTimezone",value:function(e,t){e.addFieldOffset(1,t,0)}},{key:"endTimestamp",value:function(e){return e.endObject()}},{key:"createTimestamp",value:function(e,n,r){return t.startTimestamp(e),t.addUnit(e,n),t.addTimezone(e,r),t.endTimestamp(e)}}]),t}();t.Timestamp=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"unit",value:function(){var t=this.bb.__offset(this.bb_pos,4);return t?this.bb.readInt16(this.bb_pos+t):e.apache.arrow.flatbuf.IntervalUnit.YEAR_MONTH}}],[{key:"getRootAsInterval",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startInterval",value:function(e){e.startObject(1)}},{key:"addUnit",value:function(t,n){t.addFieldInt16(0,n,e.apache.arrow.flatbuf.IntervalUnit.YEAR_MONTH)}},{key:"endInterval",value:function(e){return e.endObject()}},{key:"createInterval",value:function(e,n){return t.startInterval(e),t.addUnit(e,n),t.endInterval(e)}}]),t}();t.Interval=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"unit",value:function(){var t=this.bb.__offset(this.bb_pos,4);return t?this.bb.readInt16(this.bb_pos+t):e.apache.arrow.flatbuf.TimeUnit.MILLISECOND}}],[{key:"getRootAsDuration",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startDuration",value:function(e){e.startObject(1)}},{key:"addUnit",value:function(t,n){t.addFieldInt16(0,n,e.apache.arrow.flatbuf.TimeUnit.MILLISECOND)}},{key:"endDuration",value:function(e){return e.endObject()}},{key:"createDuration",value:function(e,n){return t.startDuration(e),t.addUnit(e,n),t.endDuration(e)}}]),t}();t.Duration=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"key",value:function(e){var t=this.bb.__offset(this.bb_pos,4);return t?this.bb.__string(this.bb_pos+t,e):null}},{key:"value",value:function(e){var t=this.bb.__offset(this.bb_pos,6);return t?this.bb.__string(this.bb_pos+t,e):null}}],[{key:"getRootAsKeyValue",value:function(t,n){return(n||new e).__init(t.readInt32(t.position())+t.position(),t)}},{key:"startKeyValue",value:function(e){e.startObject(2)}},{key:"addKey",value:function(e,t){e.addFieldOffset(0,t,0)}},{key:"addValue",value:function(e,t){e.addFieldOffset(1,t,0)}},{key:"endKeyValue",value:function(e){return e.endObject()}},{key:"createKeyValue",value:function(t,n,r){return e.startKeyValue(t),e.addKey(t,n),e.addValue(t,r),e.endKeyValue(t)}}]),e}();e.KeyValue=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"id",value:function(){var e=this.bb.__offset(this.bb_pos,4);return e?this.bb.readInt64(this.bb_pos+e):this.bb.createLong(0,0)}},{key:"indexType",value:function(t){var n=this.bb.__offset(this.bb_pos,6);return n?(t||new e.apache.arrow.flatbuf.Int).__init(this.bb.__indirect(this.bb_pos+n),this.bb):null}},{key:"isOrdered",value:function(){var e=this.bb.__offset(this.bb_pos,8);return!!e&&!!this.bb.readInt8(this.bb_pos+e)}}],[{key:"getRootAsDictionaryEncoding",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startDictionaryEncoding",value:function(e){e.startObject(3)}},{key:"addId",value:function(e,t){e.addFieldInt64(0,t,e.createLong(0,0))}},{key:"addIndexType",value:function(e,t){e.addFieldOffset(1,t,0)}},{key:"addIsOrdered",value:function(e,t){e.addFieldInt8(2,+t,0)}},{key:"endDictionaryEncoding",value:function(e){return e.endObject()}},{key:"createDictionaryEncoding",value:function(e,n,r,i){return t.startDictionaryEncoding(e),t.addId(e,n),t.addIndexType(e,r),t.addIsOrdered(e,i),t.endDictionaryEncoding(e)}}]),t}();t.DictionaryEncoding=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"name",value:function(e){var t=this.bb.__offset(this.bb_pos,4);return t?this.bb.__string(this.bb_pos+t,e):null}},{key:"nullable",value:function(){var e=this.bb.__offset(this.bb_pos,6);return!!e&&!!this.bb.readInt8(this.bb_pos+e)}},{key:"typeType",value:function(){var t=this.bb.__offset(this.bb_pos,8);return t?this.bb.readUint8(this.bb_pos+t):e.apache.arrow.flatbuf.Type.NONE}},{key:"type",value:function(e){var t=this.bb.__offset(this.bb_pos,10);return t?this.bb.__union(e,this.bb_pos+t):null}},{key:"dictionary",value:function(t){var n=this.bb.__offset(this.bb_pos,12);return n?(t||new e.apache.arrow.flatbuf.DictionaryEncoding).__init(this.bb.__indirect(this.bb_pos+n),this.bb):null}},{key:"children",value:function(t,n){var r=this.bb.__offset(this.bb_pos,14);return r?(n||new e.apache.arrow.flatbuf.Field).__init(this.bb.__indirect(this.bb.__vector(this.bb_pos+r)+4*t),this.bb):null}},{key:"childrenLength",value:function(){var e=this.bb.__offset(this.bb_pos,14);return e?this.bb.__vector_len(this.bb_pos+e):0}},{key:"customMetadata",value:function(t,n){var r=this.bb.__offset(this.bb_pos,16);return r?(n||new e.apache.arrow.flatbuf.KeyValue).__init(this.bb.__indirect(this.bb.__vector(this.bb_pos+r)+4*t),this.bb):null}},{key:"customMetadataLength",value:function(){var e=this.bb.__offset(this.bb_pos,16);return e?this.bb.__vector_len(this.bb_pos+e):0}}],[{key:"getRootAsField",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startField",value:function(e){e.startObject(7)}},{key:"addName",value:function(e,t){e.addFieldOffset(0,t,0)}},{key:"addNullable",value:function(e,t){e.addFieldInt8(1,+t,0)}},{key:"addTypeType",value:function(t,n){t.addFieldInt8(2,n,e.apache.arrow.flatbuf.Type.NONE)}},{key:"addType",value:function(e,t){e.addFieldOffset(3,t,0)}},{key:"addDictionary",value:function(e,t){e.addFieldOffset(4,t,0)}},{key:"addChildren",value:function(e,t){e.addFieldOffset(5,t,0)}},{key:"createChildrenVector",value:function(e,t){e.startVector(4,t.length,4);for(var n=t.length-1;n>=0;n--)e.addOffset(t[n]);return e.endVector()}},{key:"startChildrenVector",value:function(e,t){e.startVector(4,t,4)}},{key:"addCustomMetadata",value:function(e,t){e.addFieldOffset(6,t,0)}},{key:"createCustomMetadataVector",value:function(e,t){e.startVector(4,t.length,4);for(var n=t.length-1;n>=0;n--)e.addOffset(t[n]);return e.endVector()}},{key:"startCustomMetadataVector",value:function(e,t){e.startVector(4,t,4)}},{key:"endField",value:function(e){return e.endObject()}},{key:"createField",value:function(e,n,r,i,a,o,u,c){return t.startField(e),t.addName(e,n),t.addNullable(e,r),t.addTypeType(e,i),t.addType(e,a),t.addDictionary(e,o),t.addChildren(e,u),t.addCustomMetadata(e,c),t.endField(e)}}]),t}();t.Field=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"offset",value:function(){return this.bb.readInt64(this.bb_pos)}},{key:"length",value:function(){return this.bb.readInt64(this.bb_pos+8)}}],[{key:"createBuffer",value:function(e,t,n){return e.prep(8,16),e.writeInt64(n),e.writeInt64(t),e.offset()}}]),e}();e.Buffer=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"endianness",value:function(){var t=this.bb.__offset(this.bb_pos,4);return t?this.bb.readInt16(this.bb_pos+t):e.apache.arrow.flatbuf.Endianness.Little}},{key:"fields",value:function(t,n){var r=this.bb.__offset(this.bb_pos,6);return r?(n||new e.apache.arrow.flatbuf.Field).__init(this.bb.__indirect(this.bb.__vector(this.bb_pos+r)+4*t),this.bb):null}},{key:"fieldsLength",value:function(){var e=this.bb.__offset(this.bb_pos,6);return e?this.bb.__vector_len(this.bb_pos+e):0}},{key:"customMetadata",value:function(t,n){var r=this.bb.__offset(this.bb_pos,8);return r?(n||new e.apache.arrow.flatbuf.KeyValue).__init(this.bb.__indirect(this.bb.__vector(this.bb_pos+r)+4*t),this.bb):null}},{key:"customMetadataLength",value:function(){var e=this.bb.__offset(this.bb_pos,8);return e?this.bb.__vector_len(this.bb_pos+e):0}}],[{key:"getRootAsSchema",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startSchema",value:function(e){e.startObject(3)}},{key:"addEndianness",value:function(t,n){t.addFieldInt16(0,n,e.apache.arrow.flatbuf.Endianness.Little)}},{key:"addFields",value:function(e,t){e.addFieldOffset(1,t,0)}},{key:"createFieldsVector",value:function(e,t){e.startVector(4,t.length,4);for(var n=t.length-1;n>=0;n--)e.addOffset(t[n]);return e.endVector()}},{key:"startFieldsVector",value:function(e,t){e.startVector(4,t,4)}},{key:"addCustomMetadata",value:function(e,t){e.addFieldOffset(2,t,0)}},{key:"createCustomMetadataVector",value:function(e,t){e.startVector(4,t.length,4);for(var n=t.length-1;n>=0;n--)e.addOffset(t[n]);return e.endVector()}},{key:"startCustomMetadataVector",value:function(e,t){e.startVector(4,t,4)}},{key:"endSchema",value:function(e){return e.endObject()}},{key:"finishSchemaBuffer",value:function(e,t){e.finish(t)}},{key:"createSchema",value:function(e,n,r,i){return t.startSchema(e),t.addEndianness(e,n),t.addFields(e,r),t.addCustomMetadata(e,i),t.endSchema(e)}}]),t}();t.Schema=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(dt||(dt={})),function(e){!function(e){!function(e){!function(e){e.Schema=dt.apache.arrow.flatbuf.Schema}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(mt||(mt={})),function(e){!function(e){!function(e){!function(e){!function(e){e[e.NONE=0]="NONE",e[e.Schema=1]="Schema",e[e.DictionaryBatch=2]="DictionaryBatch",e[e.RecordBatch=3]="RecordBatch",e[e.Tensor=4]="Tensor",e[e.SparseTensor=5]="SparseTensor"}(e.MessageHeader||(e.MessageHeader={}))}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(mt||(mt={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"length",value:function(){return this.bb.readInt64(this.bb_pos)}},{key:"nullCount",value:function(){return this.bb.readInt64(this.bb_pos+8)}}],[{key:"createFieldNode",value:function(e,t,n){return e.prep(8,16),e.writeInt64(n),e.writeInt64(t),e.offset()}}]),e}();e.FieldNode=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(mt||(mt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"length",value:function(){var e=this.bb.__offset(this.bb_pos,4);return e?this.bb.readInt64(this.bb_pos+e):this.bb.createLong(0,0)}},{key:"nodes",value:function(t,n){var r=this.bb.__offset(this.bb_pos,6);return r?(n||new e.apache.arrow.flatbuf.FieldNode).__init(this.bb.__vector(this.bb_pos+r)+16*t,this.bb):null}},{key:"nodesLength",value:function(){var e=this.bb.__offset(this.bb_pos,6);return e?this.bb.__vector_len(this.bb_pos+e):0}},{key:"buffers",value:function(e,t){var n=this.bb.__offset(this.bb_pos,8);return n?(t||new dt.apache.arrow.flatbuf.Buffer).__init(this.bb.__vector(this.bb_pos+n)+16*e,this.bb):null}},{key:"buffersLength",value:function(){var e=this.bb.__offset(this.bb_pos,8);return e?this.bb.__vector_len(this.bb_pos+e):0}}],[{key:"getRootAsRecordBatch",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startRecordBatch",value:function(e){e.startObject(3)}},{key:"addLength",value:function(e,t){e.addFieldInt64(0,t,e.createLong(0,0))}},{key:"addNodes",value:function(e,t){e.addFieldOffset(1,t,0)}},{key:"startNodesVector",value:function(e,t){e.startVector(16,t,8)}},{key:"addBuffers",value:function(e,t){e.addFieldOffset(2,t,0)}},{key:"startBuffersVector",value:function(e,t){e.startVector(16,t,8)}},{key:"endRecordBatch",value:function(e){return e.endObject()}},{key:"createRecordBatch",value:function(e,n,r,i){return t.startRecordBatch(e),t.addLength(e,n),t.addNodes(e,r),t.addBuffers(e,i),t.endRecordBatch(e)}}]),t}();t.RecordBatch=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(mt||(mt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"id",value:function(){var e=this.bb.__offset(this.bb_pos,4);return e?this.bb.readInt64(this.bb_pos+e):this.bb.createLong(0,0)}},{key:"data",value:function(t){var n=this.bb.__offset(this.bb_pos,6);return n?(t||new e.apache.arrow.flatbuf.RecordBatch).__init(this.bb.__indirect(this.bb_pos+n),this.bb):null}},{key:"isDelta",value:function(){var e=this.bb.__offset(this.bb_pos,8);return!!e&&!!this.bb.readInt8(this.bb_pos+e)}}],[{key:"getRootAsDictionaryBatch",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startDictionaryBatch",value:function(e){e.startObject(3)}},{key:"addId",value:function(e,t){e.addFieldInt64(0,t,e.createLong(0,0))}},{key:"addData",value:function(e,t){e.addFieldOffset(1,t,0)}},{key:"addIsDelta",value:function(e,t){e.addFieldInt8(2,+t,0)}},{key:"endDictionaryBatch",value:function(e){return e.endObject()}},{key:"createDictionaryBatch",value:function(e,n,r,i){return t.startDictionaryBatch(e),t.addId(e,n),t.addData(e,r),t.addIsDelta(e,i),t.endDictionaryBatch(e)}}]),t}();t.DictionaryBatch=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(mt||(mt={})),function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"version",value:function(){var e=this.bb.__offset(this.bb_pos,4);return e?this.bb.readInt16(this.bb_pos+e):dt.apache.arrow.flatbuf.MetadataVersion.V1}},{key:"headerType",value:function(){var t=this.bb.__offset(this.bb_pos,6);return t?this.bb.readUint8(this.bb_pos+t):e.apache.arrow.flatbuf.MessageHeader.NONE}},{key:"header",value:function(e){var t=this.bb.__offset(this.bb_pos,8);return t?this.bb.__union(e,this.bb_pos+t):null}},{key:"bodyLength",value:function(){var e=this.bb.__offset(this.bb_pos,10);return e?this.bb.readInt64(this.bb_pos+e):this.bb.createLong(0,0)}},{key:"customMetadata",value:function(e,t){var n=this.bb.__offset(this.bb_pos,12);return n?(t||new dt.apache.arrow.flatbuf.KeyValue).__init(this.bb.__indirect(this.bb.__vector(this.bb_pos+n)+4*e),this.bb):null}},{key:"customMetadataLength",value:function(){var e=this.bb.__offset(this.bb_pos,12);return e?this.bb.__vector_len(this.bb_pos+e):0}}],[{key:"getRootAsMessage",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startMessage",value:function(e){e.startObject(5)}},{key:"addVersion",value:function(e,t){e.addFieldInt16(0,t,dt.apache.arrow.flatbuf.MetadataVersion.V1)}},{key:"addHeaderType",value:function(t,n){t.addFieldInt8(1,n,e.apache.arrow.flatbuf.MessageHeader.NONE)}},{key:"addHeader",value:function(e,t){e.addFieldOffset(2,t,0)}},{key:"addBodyLength",value:function(e,t){e.addFieldInt64(3,t,e.createLong(0,0))}},{key:"addCustomMetadata",value:function(e,t){e.addFieldOffset(4,t,0)}},{key:"createCustomMetadataVector",value:function(e,t){e.startVector(4,t.length,4);for(var n=t.length-1;n>=0;n--)e.addOffset(t[n]);return e.endVector()}},{key:"startCustomMetadataVector",value:function(e,t){e.startVector(4,t,4)}},{key:"endMessage",value:function(e){return e.endObject()}},{key:"finishMessageBuffer",value:function(e,t){e.finish(t)}},{key:"createMessage",value:function(e,n,r,i,a,o){return t.startMessage(e),t.addVersion(e,n),t.addHeaderType(e,r),t.addHeader(e,i),t.addBodyLength(e,a),t.addCustomMetadata(e,o),t.endMessage(e)}}]),t}();t.Message=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(mt||(mt={}));dt.apache.arrow.flatbuf.Type;var wt,kt,_t=dt.apache.arrow.flatbuf.DateUnit,Ot=dt.apache.arrow.flatbuf.TimeUnit,xt=dt.apache.arrow.flatbuf.Precision,jt=dt.apache.arrow.flatbuf.UnionMode,St=dt.apache.arrow.flatbuf.IntervalUnit,Tt=mt.apache.arrow.flatbuf.MessageHeader,It=dt.apache.arrow.flatbuf.MetadataVersion;!function(e){e[e.NONE=0]="NONE",e[e.Null=1]="Null",e[e.Int=2]="Int",e[e.Float=3]="Float",e[e.Binary=4]="Binary",e[e.Utf8=5]="Utf8",e[e.Bool=6]="Bool",e[e.Decimal=7]="Decimal",e[e.Date=8]="Date",e[e.Time=9]="Time",e[e.Timestamp=10]="Timestamp",e[e.Interval=11]="Interval",e[e.List=12]="List",e[e.Struct=13]="Struct",e[e.Union=14]="Union",e[e.FixedSizeBinary=15]="FixedSizeBinary",e[e.FixedSizeList=16]="FixedSizeList",e[e.Map=17]="Map",e[e.Dictionary=-1]="Dictionary",e[e.Int8=-2]="Int8",e[e.Int16=-3]="Int16",e[e.Int32=-4]="Int32",e[e.Int64=-5]="Int64",e[e.Uint8=-6]="Uint8",e[e.Uint16=-7]="Uint16",e[e.Uint32=-8]="Uint32",e[e.Uint64=-9]="Uint64",e[e.Float16=-10]="Float16",e[e.Float32=-11]="Float32",e[e.Float64=-12]="Float64",e[e.DateDay=-13]="DateDay",e[e.DateMillisecond=-14]="DateMillisecond",e[e.TimestampSecond=-15]="TimestampSecond",e[e.TimestampMillisecond=-16]="TimestampMillisecond",e[e.TimestampMicrosecond=-17]="TimestampMicrosecond",e[e.TimestampNanosecond=-18]="TimestampNanosecond",e[e.TimeSecond=-19]="TimeSecond",e[e.TimeMillisecond=-20]="TimeMillisecond",e[e.TimeMicrosecond=-21]="TimeMicrosecond",e[e.TimeNanosecond=-22]="TimeNanosecond",e[e.DenseUnion=-23]="DenseUnion",e[e.SparseUnion=-24]="SparseUnion",e[e.IntervalDayTime=-25]="IntervalDayTime",e[e.IntervalYearMonth=-26]="IntervalYearMonth"}(wt||(wt={})),function(e){e[e.OFFSET=0]="OFFSET",e[e.DATA=1]="DATA",e[e.VALIDITY=2]="VALIDITY",e[e.TYPE=3]="TYPE"}(kt||(kt={}));var Et=d.mark(Nt);function At(e,t,n,r){return 0!==(n&1<>r}function Ct(e,t,n){return n?!!(e[t>>3]|=1<>3]&=~(1<0||n.byteLength>3):Lt(Nt(n,e,t,null,At)).subarray(0,r)),i}return n}function Lt(e){var t,n=[],r=0,i=0,a=0,o=Object(s.a)(e);try{for(o.s();!(t=o.n()).done;){t.value&&(a|=1<0)&&(n[r++]=a);var u=new Uint8Array(n.length+7&-8);return u.set(n),u}function Nt(e,t,n,r,i){var a,o,u,c,s;return d.wrap((function(l){for(;;)switch(l.prev=l.next){case 0:a=t%8,o=t>>3,u=0,c=n;case 3:if(!(c>0)){l.next=11;break}s=e[o++];case 5:return l.next=7,i(r,u++,s,a);case 7:if(--c>0&&++a<8){l.next=5;break}case 8:a=0,l.next=3;break;case 11:case"end":return l.stop()}}),Et)}function Ft(e,t,n){if(n-t<=0)return 0;if(n-t<8){var r,i=0,a=Object(s.a)(Nt(e,t,n-t,e,Bt));try{for(a.s();!(r=a.n()).done;){i+=r.value}}catch(c){a.e(c)}finally{a.f()}return i}var o=n>>3<<3,u=t+(t%8===0?0:8-t%8);return Ft(e,t,u)+Ft(e,o,n)+Mt(e,u>>3,o-u>>3)}function Mt(e,t,n){for(var r=0,i=0|t,a=new DataView(e.buffer,e.byteOffset,e.byteLength),o=void 0===n?e.byteLength:i+n;o-i>=4;)r+=Pt(a.getUint32(i)),i+=4;for(;o-i>=2;)r+=Pt(a.getUint16(i)),i+=2;for(;o-i>=1;)r+=Pt(a.getUint8(i)),i+=1;return r}function Pt(e){var t=0|e;return 16843009*((t=(858993459&(t-=t>>>1&1431655765))+(t>>>2&858993459))+(t>>>4)&252645135)>>>24}var Ut=n(6),Rt=function(){function e(){Object(f.a)(this,e)}return Object(h.a)(e,[{key:"visitMany",value:function(e){for(var t=this,n=arguments.length,r=new Array(n>1?n-1:0),i=1;i1&&void 0!==arguments[1])||arguments[1];return zt(this,e,t)}},{key:"visitNull",value:function(e){return null}},{key:"visitBool",value:function(e){return null}},{key:"visitInt",value:function(e){return null}},{key:"visitFloat",value:function(e){return null}},{key:"visitUtf8",value:function(e){return null}},{key:"visitBinary",value:function(e){return null}},{key:"visitFixedSizeBinary",value:function(e){return null}},{key:"visitDate",value:function(e){return null}},{key:"visitTimestamp",value:function(e){return null}},{key:"visitTime",value:function(e){return null}},{key:"visitDecimal",value:function(e){return null}},{key:"visitList",value:function(e){return null}},{key:"visitStruct",value:function(e){return null}},{key:"visitUnion",value:function(e){return null}},{key:"visitDictionary",value:function(e){return null}},{key:"visitInterval",value:function(e){return null}},{key:"visitFixedSizeList",value:function(e){return null}},{key:"visitMap",value:function(e){return null}}]),e}();function zt(e,t){var n=!(arguments.length>2&&void 0!==arguments[2])||arguments[2],r=null,i=wt.NONE;switch(t instanceof Mn||t instanceof gt?i=Vt(t.type):t instanceof tn?i=Vt(t):"number"!==typeof(i=t)&&(i=wt[t]),i){case wt.Null:r=e.visitNull;break;case wt.Bool:r=e.visitBool;break;case wt.Int:r=e.visitInt;break;case wt.Int8:r=e.visitInt8||e.visitInt;break;case wt.Int16:r=e.visitInt16||e.visitInt;break;case wt.Int32:r=e.visitInt32||e.visitInt;break;case wt.Int64:r=e.visitInt64||e.visitInt;break;case wt.Uint8:r=e.visitUint8||e.visitInt;break;case wt.Uint16:r=e.visitUint16||e.visitInt;break;case wt.Uint32:r=e.visitUint32||e.visitInt;break;case wt.Uint64:r=e.visitUint64||e.visitInt;break;case wt.Float:r=e.visitFloat;break;case wt.Float16:r=e.visitFloat16||e.visitFloat;break;case wt.Float32:r=e.visitFloat32||e.visitFloat;break;case wt.Float64:r=e.visitFloat64||e.visitFloat;break;case wt.Utf8:r=e.visitUtf8;break;case wt.Binary:r=e.visitBinary;break;case wt.FixedSizeBinary:r=e.visitFixedSizeBinary;break;case wt.Date:r=e.visitDate;break;case wt.DateDay:r=e.visitDateDay||e.visitDate;break;case wt.DateMillisecond:r=e.visitDateMillisecond||e.visitDate;break;case wt.Timestamp:r=e.visitTimestamp;break;case wt.TimestampSecond:r=e.visitTimestampSecond||e.visitTimestamp;break;case wt.TimestampMillisecond:r=e.visitTimestampMillisecond||e.visitTimestamp;break;case wt.TimestampMicrosecond:r=e.visitTimestampMicrosecond||e.visitTimestamp;break;case wt.TimestampNanosecond:r=e.visitTimestampNanosecond||e.visitTimestamp;break;case wt.Time:r=e.visitTime;break;case wt.TimeSecond:r=e.visitTimeSecond||e.visitTime;break;case wt.TimeMillisecond:r=e.visitTimeMillisecond||e.visitTime;break;case wt.TimeMicrosecond:r=e.visitTimeMicrosecond||e.visitTime;break;case wt.TimeNanosecond:r=e.visitTimeNanosecond||e.visitTime;break;case wt.Decimal:r=e.visitDecimal;break;case wt.List:r=e.visitList;break;case wt.Struct:r=e.visitStruct;break;case wt.Union:r=e.visitUnion;break;case wt.DenseUnion:r=e.visitDenseUnion||e.visitUnion;break;case wt.SparseUnion:r=e.visitSparseUnion||e.visitUnion;break;case wt.Dictionary:r=e.visitDictionary;break;case wt.Interval:r=e.visitInterval;break;case wt.IntervalDayTime:r=e.visitIntervalDayTime||e.visitInterval;break;case wt.IntervalYearMonth:r=e.visitIntervalYearMonth||e.visitInterval;break;case wt.FixedSizeList:r=e.visitFixedSizeList;break;case wt.Map:r=e.visitMap}if("function"===typeof r)return r;if(!n)return function(){return null};throw new Error("Unrecognized type '".concat(wt[i],"'"))}function Vt(e){switch(e.typeId){case wt.Null:return wt.Null;case wt.Int:var t=e.bitWidth,n=e.isSigned;switch(t){case 8:return n?wt.Int8:wt.Uint8;case 16:return n?wt.Int16:wt.Uint16;case 32:return n?wt.Int32:wt.Uint32;case 64:return n?wt.Int64:wt.Uint64}return wt.Int;case wt.Float:switch(e.precision){case xt.HALF:return wt.Float16;case xt.SINGLE:return wt.Float32;case xt.DOUBLE:return wt.Float64}return wt.Float;case wt.Binary:return wt.Binary;case wt.Utf8:return wt.Utf8;case wt.Bool:return wt.Bool;case wt.Decimal:return wt.Decimal;case wt.Time:switch(e.unit){case Ot.SECOND:return wt.TimeSecond;case Ot.MILLISECOND:return wt.TimeMillisecond;case Ot.MICROSECOND:return wt.TimeMicrosecond;case Ot.NANOSECOND:return wt.TimeNanosecond}return wt.Time;case wt.Timestamp:switch(e.unit){case Ot.SECOND:return wt.TimestampSecond;case Ot.MILLISECOND:return wt.TimestampMillisecond;case Ot.MICROSECOND:return wt.TimestampMicrosecond;case Ot.NANOSECOND:return wt.TimestampNanosecond}return wt.Timestamp;case wt.Date:switch(e.unit){case _t.DAY:return wt.DateDay;case _t.MILLISECOND:return wt.DateMillisecond}return wt.Date;case wt.Interval:switch(e.unit){case St.DAY_TIME:return wt.IntervalDayTime;case St.YEAR_MONTH:return wt.IntervalYearMonth}return wt.Interval;case wt.Map:return wt.Map;case wt.List:return wt.List;case wt.Struct:return wt.Struct;case wt.Union:switch(e.mode){case jt.Dense:return wt.DenseUnion;case jt.Sparse:return wt.SparseUnion}return wt.Union;case wt.FixedSizeBinary:return wt.FixedSizeBinary;case wt.FixedSizeList:return wt.FixedSizeList;case wt.Dictionary:return wt.Dictionary}throw new Error("Unrecognized type '".concat(wt[e.typeId],"'"))}Rt.prototype.visitInt8=null,Rt.prototype.visitInt16=null,Rt.prototype.visitInt32=null,Rt.prototype.visitInt64=null,Rt.prototype.visitUint8=null,Rt.prototype.visitUint16=null,Rt.prototype.visitUint32=null,Rt.prototype.visitUint64=null,Rt.prototype.visitFloat16=null,Rt.prototype.visitFloat32=null,Rt.prototype.visitFloat64=null,Rt.prototype.visitDateDay=null,Rt.prototype.visitDateMillisecond=null,Rt.prototype.visitTimestampSecond=null,Rt.prototype.visitTimestampMillisecond=null,Rt.prototype.visitTimestampMicrosecond=null,Rt.prototype.visitTimestampNanosecond=null,Rt.prototype.visitTimeSecond=null,Rt.prototype.visitTimeMillisecond=null,Rt.prototype.visitTimeMicrosecond=null,Rt.prototype.visitTimeNanosecond=null,Rt.prototype.visitDenseUnion=null,Rt.prototype.visitSparseUnion=null,Rt.prototype.visitIntervalDayTime=null,Rt.prototype.visitIntervalYearMonth=null;var Wt=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"compareSchemas",value:function(e,t){return e===t||t instanceof e.constructor&&en.compareFields(e.fields,t.fields)}},{key:"compareFields",value:function(e,t){return e===t||Array.isArray(e)&&Array.isArray(t)&&e.length===t.length&&e.every((function(e,n){return en.compareField(e,t[n])}))}},{key:"compareField",value:function(e,t){return e===t||t instanceof e.constructor&&e.name===t.name&&e.nullable===t.nullable&&en.visit(e.type,t.type)}}]),n}(Rt);function Yt(e,t){return t instanceof e.constructor}function qt(e,t){return e===t||Yt(e,t)}function Ht(e,t){return e===t||Yt(e,t)&&e.bitWidth===t.bitWidth&&e.isSigned===t.isSigned}function $t(e,t){return e===t||Yt(e,t)&&e.precision===t.precision}function Kt(e,t){return e===t||Yt(e,t)&&e.unit===t.unit}function Qt(e,t){return e===t||Yt(e,t)&&e.unit===t.unit&&e.timezone===t.timezone}function Gt(e,t){return e===t||Yt(e,t)&&e.unit===t.unit&&e.bitWidth===t.bitWidth}function Jt(e,t){return e===t||Yt(e,t)&&e.mode===t.mode&&e.typeIds.every((function(e,n){return e===t.typeIds[n]}))&&en.compareFields(e.children,t.children)}function Zt(e,t){return e===t||Yt(e,t)&&e.unit===t.unit}Wt.prototype.visitNull=qt,Wt.prototype.visitBool=qt,Wt.prototype.visitInt=Ht,Wt.prototype.visitInt8=Ht,Wt.prototype.visitInt16=Ht,Wt.prototype.visitInt32=Ht,Wt.prototype.visitInt64=Ht,Wt.prototype.visitUint8=Ht,Wt.prototype.visitUint16=Ht,Wt.prototype.visitUint32=Ht,Wt.prototype.visitUint64=Ht,Wt.prototype.visitFloat=$t,Wt.prototype.visitFloat16=$t,Wt.prototype.visitFloat32=$t,Wt.prototype.visitFloat64=$t,Wt.prototype.visitUtf8=qt,Wt.prototype.visitBinary=qt,Wt.prototype.visitFixedSizeBinary=function(e,t){return e===t||Yt(e,t)&&e.byteWidth===t.byteWidth},Wt.prototype.visitDate=Kt,Wt.prototype.visitDateDay=Kt,Wt.prototype.visitDateMillisecond=Kt,Wt.prototype.visitTimestamp=Qt,Wt.prototype.visitTimestampSecond=Qt,Wt.prototype.visitTimestampMillisecond=Qt,Wt.prototype.visitTimestampMicrosecond=Qt,Wt.prototype.visitTimestampNanosecond=Qt,Wt.prototype.visitTime=Gt,Wt.prototype.visitTimeSecond=Gt,Wt.prototype.visitTimeMillisecond=Gt,Wt.prototype.visitTimeMicrosecond=Gt,Wt.prototype.visitTimeNanosecond=Gt,Wt.prototype.visitDecimal=qt,Wt.prototype.visitList=function(e,t){return e===t||Yt(e,t)&&e.children.length===t.children.length&&en.compareFields(e.children,t.children)},Wt.prototype.visitStruct=function(e,t){return e===t||Yt(e,t)&&e.children.length===t.children.length&&en.compareFields(e.children,t.children)},Wt.prototype.visitUnion=Jt,Wt.prototype.visitDenseUnion=Jt,Wt.prototype.visitSparseUnion=Jt,Wt.prototype.visitDictionary=function(e,t){return e===t||Yt(e,t)&&e.id===t.id&&e.isOrdered===t.isOrdered&&en.visit(e.indices,t.indices)&&en.visit(e.dictionary,t.dictionary)},Wt.prototype.visitInterval=Zt,Wt.prototype.visitIntervalDayTime=Zt,Wt.prototype.visitIntervalYearMonth=Zt,Wt.prototype.visitFixedSizeList=function(e,t){return e===t||Yt(e,t)&&e.listSize===t.listSize&&e.children.length===t.children.length&&en.compareFields(e.children,t.children)},Wt.prototype.visitMap=function(e,t){return e===t||Yt(e,t)&&e.keysSorted===t.keysSorted&&e.children.length===t.children.length&&en.compareFields(e.children,t.children)};var Xt,en=new Wt,tn=function(){function e(){Object(f.a)(this,e)}return Object(h.a)(e,[{key:"typeId",get:function(){return wt.NONE}},{key:"compareTo",value:function(e){return en.visit(this,e)}}],[{key:"isNull",value:function(e){return e&&e.typeId===wt.Null}},{key:"isInt",value:function(e){return e&&e.typeId===wt.Int}},{key:"isFloat",value:function(e){return e&&e.typeId===wt.Float}},{key:"isBinary",value:function(e){return e&&e.typeId===wt.Binary}},{key:"isUtf8",value:function(e){return e&&e.typeId===wt.Utf8}},{key:"isBool",value:function(e){return e&&e.typeId===wt.Bool}},{key:"isDecimal",value:function(e){return e&&e.typeId===wt.Decimal}},{key:"isDate",value:function(e){return e&&e.typeId===wt.Date}},{key:"isTime",value:function(e){return e&&e.typeId===wt.Time}},{key:"isTimestamp",value:function(e){return e&&e.typeId===wt.Timestamp}},{key:"isInterval",value:function(e){return e&&e.typeId===wt.Interval}},{key:"isList",value:function(e){return e&&e.typeId===wt.List}},{key:"isStruct",value:function(e){return e&&e.typeId===wt.Struct}},{key:"isUnion",value:function(e){return e&&e.typeId===wt.Union}},{key:"isFixedSizeBinary",value:function(e){return e&&e.typeId===wt.FixedSizeBinary}},{key:"isFixedSizeList",value:function(e){return e&&e.typeId===wt.FixedSizeList}},{key:"isMap",value:function(e){return e&&e.typeId===wt.Map}},{key:"isDictionary",value:function(e){return e&&e.typeId===wt.Dictionary}}]),e}();tn[Symbol.toStringTag]=((Xt=tn.prototype).children=null,Xt.ArrayType=Array,Xt[Symbol.toStringTag]="DataType");var nn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"toString",value:function(){return"Null"}},{key:"typeId",get:function(){return wt.Null}}]),n}(tn);nn[Symbol.toStringTag]=function(e){return e[Symbol.toStringTag]="Null"}(nn.prototype);var rn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r){var i;return Object(f.a)(this,n),(i=t.call(this)).isSigned=e,i.bitWidth=r,i}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Int}},{key:"ArrayType",get:function(){switch(this.bitWidth){case 8:return this.isSigned?Int8Array:Uint8Array;case 16:return this.isSigned?Int16Array:Uint16Array;case 32:case 64:return this.isSigned?Int32Array:Uint32Array}throw new Error("Unrecognized ".concat(this[Symbol.toStringTag]," type"))}},{key:"toString",value:function(){return"".concat(this.isSigned?"I":"Ui","nt").concat(this.bitWidth)}}]),n}(tn);rn[Symbol.toStringTag]=function(e){return e.isSigned=null,e.bitWidth=null,e[Symbol.toStringTag]="Int"}(rn.prototype);var an=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,!0,8)}return n}(rn),on=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,!0,16)}return n}(rn),un=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,!0,32)}return n}(rn),cn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,!0,64)}return n}(rn),sn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,!1,8)}return n}(rn),ln=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,!1,16)}return n}(rn),fn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,!1,32)}return n}(rn),hn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,!1,64)}return n}(rn);Object.defineProperty(an.prototype,"ArrayType",{value:Int8Array}),Object.defineProperty(on.prototype,"ArrayType",{value:Int16Array}),Object.defineProperty(un.prototype,"ArrayType",{value:Int32Array}),Object.defineProperty(cn.prototype,"ArrayType",{value:Int32Array}),Object.defineProperty(sn.prototype,"ArrayType",{value:Uint8Array}),Object.defineProperty(ln.prototype,"ArrayType",{value:Uint16Array}),Object.defineProperty(fn.prototype,"ArrayType",{value:Uint32Array}),Object.defineProperty(hn.prototype,"ArrayType",{value:Uint32Array});var dn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this)).precision=e,r}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Float}},{key:"ArrayType",get:function(){switch(this.precision){case xt.HALF:return Uint16Array;case xt.SINGLE:return Float32Array;case xt.DOUBLE:return Float64Array}throw new Error("Unrecognized ".concat(this[Symbol.toStringTag]," type"))}},{key:"toString",value:function(){return"Float".concat(this.precision<<5||16)}}]),n}(tn);dn[Symbol.toStringTag]=function(e){return e.precision=null,e[Symbol.toStringTag]="Float"}(dn.prototype);var pn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,xt.HALF)}return n}(dn),vn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,xt.SINGLE)}return n}(dn),yn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,xt.DOUBLE)}return n}(dn);Object.defineProperty(pn.prototype,"ArrayType",{value:Uint16Array}),Object.defineProperty(vn.prototype,"ArrayType",{value:Float32Array}),Object.defineProperty(yn.prototype,"ArrayType",{value:Float64Array});var bn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this)}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Binary}},{key:"toString",value:function(){return"Binary"}}]),n}(tn);bn[Symbol.toStringTag]=function(e){return e.ArrayType=Uint8Array,e[Symbol.toStringTag]="Binary"}(bn.prototype);var mn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this)}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Utf8}},{key:"toString",value:function(){return"Utf8"}}]),n}(tn);mn[Symbol.toStringTag]=function(e){return e.ArrayType=Uint8Array,e[Symbol.toStringTag]="Utf8"}(mn.prototype);var gn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this)}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Bool}},{key:"toString",value:function(){return"Bool"}}]),n}(tn);gn[Symbol.toStringTag]=function(e){return e.ArrayType=Uint8Array,e[Symbol.toStringTag]="Bool"}(gn.prototype);var wn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r){var i;return Object(f.a)(this,n),(i=t.call(this)).scale=e,i.precision=r,i}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Decimal}},{key:"toString",value:function(){return"Decimal[".concat(this.precision,"e").concat(this.scale>0?"+":"").concat(this.scale,"]")}}]),n}(tn);wn[Symbol.toStringTag]=function(e){return e.scale=null,e.precision=null,e.ArrayType=Uint32Array,e[Symbol.toStringTag]="Decimal"}(wn.prototype);var kn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this)).unit=e,r}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Date}},{key:"toString",value:function(){return"Date".concat(32*(this.unit+1),"<").concat(_t[this.unit],">")}}]),n}(tn);kn[Symbol.toStringTag]=function(e){return e.unit=null,e.ArrayType=Int32Array,e[Symbol.toStringTag]="Date"}(kn.prototype);var _n=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,_t.DAY)}return n}(kn),On=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.call(this,_t.MILLISECOND)}return n}(kn),xn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r){var i;return Object(f.a)(this,n),(i=t.call(this)).unit=e,i.bitWidth=r,i}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Time}},{key:"toString",value:function(){return"Time".concat(this.bitWidth,"<").concat(Ot[this.unit],">")}}]),n}(tn);xn[Symbol.toStringTag]=function(e){return e.unit=null,e.bitWidth=null,e.ArrayType=Int32Array,e[Symbol.toStringTag]="Time"}(xn.prototype);var jn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r){var i;return Object(f.a)(this,n),(i=t.call(this)).unit=e,i.timezone=r,i}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Timestamp}},{key:"toString",value:function(){return"Timestamp<".concat(Ot[this.unit]).concat(this.timezone?", ".concat(this.timezone):"",">")}}]),n}(tn);jn[Symbol.toStringTag]=function(e){return e.unit=null,e.timezone=null,e.ArrayType=Int32Array,e[Symbol.toStringTag]="Timestamp"}(jn.prototype);var Sn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this)).unit=e,r}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Interval}},{key:"toString",value:function(){return"Interval<".concat(St[this.unit],">")}}]),n}(tn);Sn[Symbol.toStringTag]=function(e){return e.unit=null,e.ArrayType=Int32Array,e[Symbol.toStringTag]="Interval"}(Sn.prototype);var Tn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this)).children=[e],r}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.List}},{key:"toString",value:function(){return"List<".concat(this.valueType,">")}},{key:"valueType",get:function(){return this.children[0].type}},{key:"valueField",get:function(){return this.children[0]}},{key:"ArrayType",get:function(){return this.valueType.ArrayType}}]),n}(tn);Tn[Symbol.toStringTag]=function(e){return e.children=null,e[Symbol.toStringTag]="List"}(Tn.prototype);var In=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this)).children=e,r}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Struct}},{key:"toString",value:function(){return"Struct<{".concat(this.children.map((function(e){return"".concat(e.name,":").concat(e.type)})).join(", "),"}>")}}]),n}(tn);In[Symbol.toStringTag]=function(e){return e.children=null,e[Symbol.toStringTag]="Struct"}(In.prototype);var En=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r,i){var a;return Object(f.a)(this,n),(a=t.call(this)).mode=e,a.children=i,a.typeIds=r=Int32Array.from(r),a.typeIdToChildIndex=r.reduce((function(e,t,n){return(e[t]=n)&&e||e}),Object.create(null)),a}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Union}},{key:"toString",value:function(){return"".concat(this[Symbol.toStringTag],"<").concat(this.children.map((function(e){return"".concat(e.type)})).join(" | "),">")}}]),n}(tn);En[Symbol.toStringTag]=function(e){return e.mode=null,e.typeIds=null,e.children=null,e.typeIdToChildIndex=null,e.ArrayType=Int8Array,e[Symbol.toStringTag]="Union"}(En.prototype);var An=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this)).byteWidth=e,r}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.FixedSizeBinary}},{key:"toString",value:function(){return"FixedSizeBinary[".concat(this.byteWidth,"]")}}]),n}(tn);An[Symbol.toStringTag]=function(e){return e.byteWidth=null,e.ArrayType=Uint8Array,e[Symbol.toStringTag]="FixedSizeBinary"}(An.prototype);var Bn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r){var i;return Object(f.a)(this,n),(i=t.call(this)).listSize=e,i.children=[r],i}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.FixedSizeList}},{key:"valueType",get:function(){return this.children[0].type}},{key:"valueField",get:function(){return this.children[0]}},{key:"ArrayType",get:function(){return this.valueType.ArrayType}},{key:"toString",value:function(){return"FixedSizeList[".concat(this.listSize,"]<").concat(this.valueType,">")}}]),n}(tn);Bn[Symbol.toStringTag]=function(e){return e.children=null,e.listSize=null,e[Symbol.toStringTag]="FixedSizeList"}(Bn.prototype);var Cn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r,i=arguments.length>1&&void 0!==arguments[1]&&arguments[1];return Object(f.a)(this,n),(r=t.call(this)).children=[e],r.keysSorted=i,r}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Map}},{key:"keyType",get:function(){return this.children[0].type.children[0].type}},{key:"valueType",get:function(){return this.children[0].type.children[1].type}},{key:"toString",value:function(){return"Map<{".concat(this.children[0].type.children.map((function(e){return"".concat(e.name,":").concat(e.type)})).join(", "),"}>")}}]),n}(tn);Cn[Symbol.toStringTag]=function(e){return e.children=null,e.keysSorted=null,e[Symbol.toStringTag]="Map_"}(Cn.prototype);var Dn,Ln=(Dn=-1,function(){return++Dn}),Nn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r,i,a){var o;return Object(f.a)(this,n),(o=t.call(this)).indices=r,o.dictionary=e,o.isOrdered=a||!1,o.id=null==i?Ln():"number"===typeof i?i:i.low,o}return Object(h.a)(n,[{key:"typeId",get:function(){return wt.Dictionary}},{key:"children",get:function(){return this.dictionary.children}},{key:"valueType",get:function(){return this.dictionary}},{key:"ArrayType",get:function(){return this.dictionary.ArrayType}},{key:"toString",value:function(){return"Dictionary<".concat(this.indices,", ").concat(this.dictionary,">")}}]),n}(tn);function Fn(e){var t=e;switch(e.typeId){case wt.Decimal:return 4;case wt.Timestamp:return 2;case wt.Date:case wt.Interval:return 1+t.unit;case wt.Int:case wt.Time:return+(t.bitWidth>32)+1;case wt.FixedSizeList:return t.listSize;case wt.FixedSizeBinary:return t.byteWidth;default:return 1}}Nn[Symbol.toStringTag]=function(e){return e.id=null,e.indices=null,e.isOrdered=null,e.dictionary=null,e[Symbol.toStringTag]="Dictionary"}(Nn.prototype);var Mn=function(){function e(t,n,r,i,a,o,u){var c;Object(f.a)(this,e),this.type=t,this.dictionary=u,this.offset=Math.floor(Math.max(n||0,0)),this.length=Math.floor(Math.max(r||0,0)),this._nullCount=Math.floor(Math.max(i||0,-1)),this.childData=(o||[]).map((function(t){return t instanceof e?t:t.data})),a instanceof e?(this.stride=a.stride,this.values=a.values,this.typeIds=a.typeIds,this.nullBitmap=a.nullBitmap,this.valueOffsets=a.valueOffsets):(this.stride=Fn(t),a&&((c=a[0])&&(this.valueOffsets=c),(c=a[1])&&(this.values=c),(c=a[2])&&(this.nullBitmap=c),(c=a[3])&&(this.typeIds=c)))}return Object(h.a)(e,[{key:"typeId",get:function(){return this.type.typeId}},{key:"ArrayType",get:function(){return this.type.ArrayType}},{key:"buffers",get:function(){return[this.valueOffsets,this.values,this.nullBitmap,this.typeIds]}},{key:"byteLength",get:function(){var e=0,t=this.valueOffsets,n=this.values,r=this.nullBitmap,i=this.typeIds;return t&&(e+=t.byteLength),n&&(e+=n.byteLength),r&&(e+=r.byteLength),i&&(e+=i.byteLength),this.childData.reduce((function(e,t){return e+t.byteLength}),e)}},{key:"nullCount",get:function(){var e,t=this._nullCount;return t<=-1&&(e=this.nullBitmap)&&(this._nullCount=t=this.length-Ft(e,this.offset,this.offset+this.length)),t}},{key:"clone",value:function(t){var n=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.offset,r=arguments.length>2&&void 0!==arguments[2]?arguments[2]:this.length,i=arguments.length>3&&void 0!==arguments[3]?arguments[3]:this._nullCount,a=arguments.length>4&&void 0!==arguments[4]?arguments[4]:this,o=arguments.length>5&&void 0!==arguments[5]?arguments[5]:this.childData;return new e(t,n,r,i,a,o,this.dictionary)}},{key:"slice",value:function(e,t){var n=this.stride,r=this.typeId,i=this.childData,a=+(0===this._nullCount)-1,o=16===r?n:1,u=this._sliceBuffers(e,t,n,r);return this.clone(this.type,this.offset+e,t,a,u,!i.length||this.valueOffsets?i:this._sliceChildren(i,o*e,o*t))}},{key:"_changeLengthAndBackfillNullBitmap",value:function(e){if(this.typeId===wt.Null)return this.clone(this.type,0,e,0);var t=this.length,n=this.nullCount,r=new Uint8Array((e+63&-64)>>3).fill(255,0,t>>3);r[t>>3]=(1<0&&r.set(Dt(this.offset,t,this.nullBitmap),0);var i=this.buffers;return i[kt.VALIDITY]=r,this.clone(this.type,0,e,n+(e-t),i)}},{key:"_sliceBuffers",value:function(e,t,n,r){var i,a=this.buffers;return(i=a[kt.TYPE])&&(a[kt.TYPE]=i.subarray(e,e+t)),(i=a[kt.OFFSET])&&(a[kt.OFFSET]=i.subarray(e,e+t+1))||(i=a[kt.DATA])&&(a[kt.DATA]=6===r?i:i.subarray(n*e,n*(e+t))),a}},{key:"_sliceChildren",value:function(e,t,n){return e.map((function(e){return e.slice(t,n)}))}}],[{key:"new",value:function(t,n,r,i,a,o,u){switch(a instanceof e?a=a.buffers:a||(a=[]),t.typeId){case wt.Null:return e.Null(t,n,r);case wt.Int:return e.Int(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[]);case wt.Dictionary:return e.Dictionary(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[],u);case wt.Float:return e.Float(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[]);case wt.Bool:return e.Bool(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[]);case wt.Decimal:return e.Decimal(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[]);case wt.Date:return e.Date(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[]);case wt.Time:return e.Time(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[]);case wt.Timestamp:return e.Timestamp(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[]);case wt.Interval:return e.Interval(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[]);case wt.FixedSizeBinary:return e.FixedSizeBinary(t,n,r,i||0,a[kt.VALIDITY],a[kt.DATA]||[]);case wt.Binary:return e.Binary(t,n,r,i||0,a[kt.VALIDITY],a[kt.OFFSET]||[],a[kt.DATA]||[]);case wt.Utf8:return e.Utf8(t,n,r,i||0,a[kt.VALIDITY],a[kt.OFFSET]||[],a[kt.DATA]||[]);case wt.List:return e.List(t,n,r,i||0,a[kt.VALIDITY],a[kt.OFFSET]||[],(o||[])[0]);case wt.FixedSizeList:return e.FixedSizeList(t,n,r,i||0,a[kt.VALIDITY],(o||[])[0]);case wt.Struct:return e.Struct(t,n,r,i||0,a[kt.VALIDITY],o||[]);case wt.Map:return e.Map(t,n,r,i||0,a[kt.VALIDITY],a[kt.OFFSET]||[],(o||[])[0]);case wt.Union:return e.Union(t,n,r,i||0,a[kt.VALIDITY],a[kt.TYPE]||[],a[kt.OFFSET]||o,o)}throw new Error("Unrecognized typeId ".concat(t.typeId))}},{key:"Null",value:function(t,n,r){return new e(t,n,r,0)}},{key:"Int",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,be(t.ArrayType,o),_e(a)])}},{key:"Dictionary",value:function(t,n,r,i,a,o,u){return new e(t,n,r,i,[void 0,be(t.indices.ArrayType,o),_e(a)],[],u)}},{key:"Float",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,be(t.ArrayType,o),_e(a)])}},{key:"Bool",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,be(t.ArrayType,o),_e(a)])}},{key:"Decimal",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,be(t.ArrayType,o),_e(a)])}},{key:"Date",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,be(t.ArrayType,o),_e(a)])}},{key:"Time",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,be(t.ArrayType,o),_e(a)])}},{key:"Timestamp",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,be(t.ArrayType,o),_e(a)])}},{key:"Interval",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,be(t.ArrayType,o),_e(a)])}},{key:"FixedSizeBinary",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,be(t.ArrayType,o),_e(a)])}},{key:"Binary",value:function(t,n,r,i,a,o,u){return new e(t,n,r,i,[we(o),_e(u),_e(a)])}},{key:"Utf8",value:function(t,n,r,i,a,o,u){return new e(t,n,r,i,[we(o),_e(u),_e(a)])}},{key:"List",value:function(t,n,r,i,a,o,u){return new e(t,n,r,i,[we(o),void 0,_e(a)],[u])}},{key:"FixedSizeList",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,void 0,_e(a)],[o])}},{key:"Struct",value:function(t,n,r,i,a,o){return new e(t,n,r,i,[void 0,void 0,_e(a)],o)}},{key:"Map",value:function(t,n,r,i,a,o,u){return new e(t,n,r,i,[we(o),void 0,_e(a)],[u])}},{key:"Union",value:function(t,n,r,i,a,o,u,c){var s=[void 0,void 0,_e(a),be(t.ArrayType,o)];return t.mode===jt.Sparse?new e(t,n,r,i,s,u):(s[kt.OFFSET]=we(u),new e(t,n,r,i,s,c))}}]),e}();Mn.prototype.childData=Object.freeze([]);function Pn(e){if(null===e)return"null";if(void 0===e)return"undefined";switch(typeof e){case"number":case"bigint":return"".concat(e);case"string":return'"'.concat(e,'"')}return"function"===typeof e[Symbol.toPrimitive]?e[Symbol.toPrimitive]("string"):ArrayBuffer.isView(e)?"[".concat(e,"]"):JSON.stringify(e)}function Un(e){if(!e||e.length<=0)return function(e){return!0};var t="",n=e.filter((function(e){return e===e}));return n.length>0&&(t="\n switch (x) {".concat(n.map((function(e){return"\n case ".concat(function(e){if("bigint"!==typeof e)return Pn(e);if(V)return"".concat(Pn(e),"n");return'"'.concat(Pn(e),'"')}(e),":")})).join(""),"\n return false;\n }")),e.length!==n.length&&(t="if (x !== x) return false;\n".concat(t)),new Function("x","".concat(t,"\nreturn true;"))}var Rn=function(e,t){return(e*t+63&-64||64)/t},zn=function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:0;return e.length>=t?e.subarray(0,t):ve(new e.constructor(t),e,0)},Vn=function(){function e(t){var n=arguments.length>1&&void 0!==arguments[1]?arguments[1]:1;Object(f.a)(this,e),this.buffer=t,this.stride=n,this.BYTES_PER_ELEMENT=t.BYTES_PER_ELEMENT,this.ArrayType=t.constructor,this._resize(this.length=t.length/n|0)}return Object(h.a)(e,[{key:"byteLength",get:function(){return this.length*this.stride*this.BYTES_PER_ELEMENT|0}},{key:"reservedLength",get:function(){return this.buffer.length/this.stride}},{key:"reservedByteLength",get:function(){return this.buffer.byteLength}},{key:"set",value:function(e,t){return this}},{key:"append",value:function(e){return this.set(this.length,e)}},{key:"reserve",value:function(e){if(e>0){this.length+=e;var t=this.stride,n=this.length*t,r=this.buffer.length;n>=r&&this._resize(Rn(0===r?1*n:2*n,this.BYTES_PER_ELEMENT))}return this}},{key:"flush",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:this.length;e=Rn(e*this.stride,this.BYTES_PER_ELEMENT);var t=zn(this.buffer,e);return this.clear(),t}},{key:"clear",value:function(){return this.length=0,this._resize(0),this}},{key:"_resize",value:function(e){return this.buffer=ve(new this.ArrayType(e),this.buffer)}}]),e}();Vn.prototype.offset=0;var Wn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"last",value:function(){return this.get(this.length-1)}},{key:"get",value:function(e){return this.buffer[e]}},{key:"set",value:function(e,t){return this.reserve(e-this.length+1),this.buffer[e*this.stride]=t,this}}]),n}(Vn),Yn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){var e,r=arguments.length>0&&void 0!==arguments[0]?arguments[0]:new Uint8Array(0);return Object(f.a)(this,n),(e=t.call(this,r,1/8)).numValid=0,e}return Object(h.a)(n,[{key:"numInvalid",get:function(){return this.length-this.numValid}},{key:"get",value:function(e){return this.buffer[e>>3]>>e%8&1}},{key:"set",value:function(e,t){var n=this.reserve(e-this.length+1).buffer,r=e>>3,i=e%8,a=n[r]>>i&1;return t?0===a&&(n[r]|=1<0&&void 0!==arguments[0]?arguments[0]:new Int32Array(1);return Object(f.a)(this,n),t.call(this,e,1)}return Object(h.a)(n,[{key:"append",value:function(e){return this.set(this.length-1,e)}},{key:"set",value:function(e,t){var n=this.length-1,r=this.reserve(e-n+1).buffer;return n0&&void 0!==arguments[0]?arguments[0]:this.length-1;return e>this.length&&this.set(e-1,0),ht(Object(ft.a)(n.prototype),"flush",this).call(this,e+1)}}]),n}(Wn),Hn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"ArrayType64",get:function(){return this._ArrayType64||(this._ArrayType64=this.buffer instanceof Int32Array?q:K)}},{key:"set",value:function(e,t){switch(this.reserve(e-this.length+1),typeof t){case"bigint":this.buffer64[e]=t;break;case"number":this.buffer[e*this.stride]=t;break;default:this.buffer.set(t,e*this.stride)}return this}},{key:"_resize",value:function(e){var t=ht(Object(ft.a)(n.prototype),"_resize",this).call(this,e),r=t.byteLength/(this.BYTES_PER_ELEMENT*this.stride);return V&&(this.buffer64=new this.ArrayType64(t.buffer,t.byteOffset,r)),t}}]),n}(Vn);function $n(e){var t,n,r,i=2;for("undefined"!==typeof Symbol&&(n=Symbol.asyncIterator,r=Symbol.iterator);i--;){if(n&&null!=(t=e[n]))return t.call(e);if(r&&null!=(t=e[r]))return new Kn(t.call(e));n="@@asyncIterator",r="@@iterator"}throw new TypeError("Object is not async iterable")}function Kn(e){function t(e){if(Object(e)!==e)return Promise.reject(new TypeError(e+" is not an object."));var t=e.done;return Promise.resolve(e.value).then((function(e){return{value:e,done:t}}))}return(Kn=function(e){this.s=e,this.n=e.next}).prototype={s:null,n:null,next:function(){return t(this.n.apply(this.s,arguments))},return:function(e){var n=this.s.return;return void 0===n?Promise.resolve({value:e,done:!0}):t(n.apply(this.s,arguments))},throw:function(e){var n=this.s.return;return void 0===n?Promise.reject(e):t(n.apply(this.s,arguments))}},new Kn(e)}var Qn=function(){function e(t){var n=t.type,r=t.nullValues;Object(f.a)(this,e),this.length=0,this.finished=!1,this.type=n,this.children=[],this.nullValues=r,this.stride=Fn(n),this._nulls=new Yn,r&&r.length>0&&(this._isValid=Un(r))}return Object(h.a)(e,[{key:"toVector",value:function(){return gt.new(this.flush())}},{key:"ArrayType",get:function(){return this.type.ArrayType}},{key:"nullCount",get:function(){return this._nulls.numInvalid}},{key:"numChildren",get:function(){return this.children.length}},{key:"byteLength",get:function(){var e=0;return this._offsets&&(e+=this._offsets.byteLength),this._values&&(e+=this._values.byteLength),this._nulls&&(e+=this._nulls.byteLength),this._typeIds&&(e+=this._typeIds.byteLength),this.children.reduce((function(e,t){return e+t.byteLength}),e)}},{key:"reservedLength",get:function(){return this._nulls.reservedLength}},{key:"reservedByteLength",get:function(){var e=0;return this._offsets&&(e+=this._offsets.reservedByteLength),this._values&&(e+=this._values.reservedByteLength),this._nulls&&(e+=this._nulls.reservedByteLength),this._typeIds&&(e+=this._typeIds.reservedByteLength),this.children.reduce((function(e,t){return e+t.reservedByteLength}),e)}},{key:"valueOffsets",get:function(){return this._offsets?this._offsets.buffer:null}},{key:"values",get:function(){return this._values?this._values.buffer:null}},{key:"nullBitmap",get:function(){return this._nulls?this._nulls.buffer:null}},{key:"typeIds",get:function(){return this._typeIds?this._typeIds.buffer:null}},{key:"append",value:function(e){return this.set(this.length,e)}},{key:"isValid",value:function(e){return this._isValid(e)}},{key:"set",value:function(e,t){return this.setValid(e,this.isValid(t))&&this.setValue(e,t),this}},{key:"setValue",value:function(e,t){this._setValue(this,e,t)}},{key:"setValid",value:function(e,t){return this.length=this._nulls.set(e,+t).length,t}},{key:"addChild",value:function(e){arguments.length>1&&void 0!==arguments[1]||"".concat(this.numChildren);throw new Error('Cannot append children to non-nested type "'.concat(this.type,'"'))}},{key:"getChildAt",value:function(e){return this.children[e]||null}},{key:"flush",value:function(){var e=[],t=this._values,n=this._offsets,r=this._typeIds,i=this.length,a=this.nullCount;r?(e[kt.TYPE]=r.flush(i),n&&(e[kt.OFFSET]=n.flush(i))):n?(t&&(e[kt.DATA]=t.flush(n.last())),e[kt.OFFSET]=n.flush(i)):t&&(e[kt.DATA]=t.flush(i)),a>0&&(e[kt.VALIDITY]=this._nulls.flush(i));var o=Mn.new(this.type,0,i,a,e,this.children.map((function(e){return e.flush()})));return this.clear(),o}},{key:"finish",value:function(){return this.finished=!0,this.children.forEach((function(e){return e.finish()})),this}},{key:"clear",value:function(){return this.length=0,this._offsets&&this._offsets.clear(),this._values&&this._values.clear(),this._nulls&&this._nulls.clear(),this._typeIds&&this._typeIds.clear(),this.children.forEach((function(e){return e.clear()})),this}}],[{key:"new",value:function(e){}},{key:"throughNode",value:function(e){throw new Error('"throughNode" not available in this environment')}},{key:"throughDOM",value:function(e){throw new Error('"throughDOM" not available in this environment')}},{key:"throughIterable",value:function(e){return function(e){var t=e.queueingStrategy,n=void 0===t?"count":t,r=e.highWaterMark,i=void 0===r?"bytes"!==n?1e3:Math.pow(2,14):r,a="bytes"!==n?"length":"byteLength";return d.mark((function t(n){var r,o,u,c,l;return d.wrap((function(t){for(;;)switch(t.prev=t.next){case 0:r=0,o=Qn.new(e),u=Object(s.a)(n),t.prev=3,u.s();case 5:if((c=u.n()).done){t.next=14;break}if(l=c.value,!(o.append(l)[a]>=i)){t.next=12;break}if(t.t0=++r,!t.t0){t.next=12;break}return t.next=12,o.toVector();case 12:t.next=5;break;case 14:t.next=19;break;case 16:t.prev=16,t.t1=t.catch(3),u.e(t.t1);case 19:return t.prev=19,u.f(),t.finish(19);case 22:if(!(o.finish().length>0||0===r)){t.next=25;break}return t.next=25,o.toVector();case 25:case"end":return t.stop()}}),t,null,[[3,16,19,22]])}))}(e)}},{key:"throughAsyncIterable",value:function(e){return function(e){var t=e.queueingStrategy,n=void 0===t?"count":t,r=e.highWaterMark,i=void 0===r?"bytes"!==n?1e3:Math.pow(2,14):r,a="bytes"!==n?"length":"byteLength";return function(){var t=m(d.mark((function t(n){var r,o,u,c,s,l,f,h;return d.wrap((function(t){for(;;)switch(t.prev=t.next){case 0:r=0,o=Qn.new(e),u=!1,c=!1,t.prev=4,l=$n(n);case 6:return t.next=8,y(l.next());case 8:if(!(u=!(f=t.sent).done)){t.next=18;break}if(h=f.value,!(o.append(h)[a]>=i)){t.next=15;break}if(t.t0=++r,!t.t0){t.next=15;break}return t.next=15,o.toVector();case 15:u=!1,t.next=6;break;case 18:t.next=24;break;case 20:t.prev=20,t.t1=t.catch(4),c=!0,s=t.t1;case 24:if(t.prev=24,t.prev=25,!u||null==l.return){t.next=29;break}return t.next=29,y(l.return());case 29:if(t.prev=29,!c){t.next=32;break}throw s;case 32:return t.finish(29);case 33:return t.finish(24);case 34:if(!(o.finish().length>0||0===r)){t.next=37;break}return t.next=37,o.toVector();case 37:case"end":return t.stop()}}),t,null,[[4,20,24,34],[25,,29,33]])})));return function(e){return t.apply(this,arguments)}}()}(e)}}]),e}();Qn.prototype.length=1,Qn.prototype.stride=1,Qn.prototype.children=null,Qn.prototype.finished=!1,Qn.prototype.nullValues=null,Qn.prototype._isValid=function(){return!0};var Gn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._values=new Wn(new r.ArrayType(0),r.stride),r}return Object(h.a)(n,[{key:"setValue",value:function(e,t){var r=this._values;return r.reserve(e-r.length+1),ht(Object(ft.a)(n.prototype),"setValue",this).call(this,e,t)}}]),n}(Qn),Jn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._pendingLength=0,r._offsets=new qn,r}return Object(h.a)(n,[{key:"setValue",value:function(e,t){var n=this._pending||(this._pending=new Map),r=n.get(e);r&&(this._pendingLength-=r.length),this._pendingLength+=t.length,n.set(e,t)}},{key:"setValid",value:function(e,t){return!!ht(Object(ft.a)(n.prototype),"setValid",this).call(this,e,t)||((this._pending||(this._pending=new Map)).set(e,void 0),!1)}},{key:"clear",value:function(){return this._pendingLength=0,this._pending=void 0,ht(Object(ft.a)(n.prototype),"clear",this).call(this)}},{key:"flush",value:function(){return this._flush(),ht(Object(ft.a)(n.prototype),"flush",this).call(this)}},{key:"finish",value:function(){return this._flush(),ht(Object(ft.a)(n.prototype),"finish",this).call(this)}},{key:"_flush",value:function(){var e=this._pending,t=this._pendingLength;return this._pendingLength=0,this._pending=void 0,e&&e.size>0&&this._flushPending(e,t),this}}]),n}(Qn);var Zn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._values=new Yn,r}return Object(h.a)(n,[{key:"setValue",value:function(e,t){this._values.set(e,+t)}}]),n}(Qn),Xn=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"setValue",value:function(e,t){}},{key:"setValid",value:function(e,t){return this.length=Math.max(e+1,this.length),t}}]),n}(Qn),er=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Gn),tr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(er),nr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(er),rr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Gn),ir=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r,i=e.type,a=e.nullValues,o=e.dictionaryHashFunction;return Object(f.a)(this,n),(r=t.call(this,{type:new Nn(i.dictionary,i.indices,i.id,i.isOrdered)}))._nulls=null,r._dictionaryOffset=0,r._keysToIndices=Object.create(null),r.indices=Qn.new({type:r.type.indices,nullValues:a}),r.dictionary=Qn.new({type:r.type.dictionary,nullValues:null}),"function"===typeof o&&(r.valueToKey=o),r}return Object(h.a)(n,[{key:"values",get:function(){return this.indices.values}},{key:"nullCount",get:function(){return this.indices.nullCount}},{key:"nullBitmap",get:function(){return this.indices.nullBitmap}},{key:"byteLength",get:function(){return this.indices.byteLength+this.dictionary.byteLength}},{key:"reservedLength",get:function(){return this.indices.reservedLength+this.dictionary.reservedLength}},{key:"reservedByteLength",get:function(){return this.indices.reservedByteLength+this.dictionary.reservedByteLength}},{key:"isValid",value:function(e){return this.indices.isValid(e)}},{key:"setValid",value:function(e,t){var n=this.indices;return t=n.setValid(e,t),this.length=n.length,t}},{key:"setValue",value:function(e,t){var n=this._keysToIndices,r=this.valueToKey(t),i=n[r];return void 0===i&&(n[r]=i=this._dictionaryOffset+this.dictionary.append(t).length-1),this.indices.setValue(e,i)}},{key:"flush",value:function(){var e=this.type,t=this._dictionary,n=this.dictionary.toVector(),r=this.indices.flush().clone(e);return r.dictionary=t?t.concat(n):n,this.finished||(this._dictionaryOffset+=n.length),this._dictionary=r.dictionary,this.clear(),r}},{key:"finish",value:function(){return this.indices.finish(),this.dictionary.finish(),this._dictionaryOffset=0,this._keysToIndices=Object.create(null),ht(Object(ft.a)(n.prototype),"finish",this).call(this)}},{key:"clear",value:function(){return this.indices.clear(),this.dictionary.clear(),ht(Object(ft.a)(n.prototype),"clear",this).call(this)}},{key:"valueToKey",value:function(e){return"string"===typeof e?e:"".concat(e)}}]),n}(Qn),ar=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Gn),or=new Float64Array(1),ur=new Uint32Array(or.buffer);function cr(e){var t=(31744&e)>>10,n=(1023&e)/1024,r=Math.pow(-1,(32768&e)>>15);switch(t){case 31:return r*(n?NaN:1/0);case 0:return r*(n?6103515625e-14*n:0)}return r*Math.pow(2,t-15)*(1+n)}function sr(e){if(e!==e)return 32256;or[0]=e;var t=(2147483648&ur[1])>>16&65535,n=2146435072&ur[1],r=0;return n>=1089470464?ur[0]>0?n=31744:(n=(2080374784&n)>>16,r=(1048575&ur[1])>>10):n<=1056964608?(r=1048576+((r=1048576+(1048575&ur[1]))<<(n>>20)-998)>>21,n=0):(n=n-1056964608>>10,r=512+(1048575&ur[1])>>10),t|n|65535&r}var lr,fr,hr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Gn),dr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"setValue",value:function(e,t){this._values.set(e,sr(t))}}]),n}(hr),pr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"setValue",value:function(e,t){this._values.set(e,t)}}]),n}(hr),vr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"setValue",value:function(e,t){this._values.set(e,t)}}]),n}(hr),yr=n(13),br=Symbol.for("isArrowBigNum");function mr(e){for(var t=arguments.length,n=new Array(t>1?t-1:0),r=1;r>>=0),c+=(n>>>0)+t*Math.pow(s,32);return c}function Or(e){var t="",n=new Uint32Array(2),r=new Uint16Array(e.buffer,e.byteOffset,e.byteLength/2),i=new Uint32Array((r=new Uint16Array(r).reverse()).buffer),a=-1,o=r.length-1;do{for(n[0]=r[a=0];a0&&void 0!==arguments[0]?arguments[0]:"default";switch(e){case"number":return _r(this);case"string":return lr(this);case"default":return fr(this)}return lr(this)},Object.setPrototypeOf(gr.prototype,Object.create(Int32Array.prototype)),Object.setPrototypeOf(wr.prototype,Object.create(Uint32Array.prototype)),Object.setPrototypeOf(kr.prototype,Object.create(Uint32Array.prototype)),Object.assign(gr.prototype,mr.prototype,{constructor:gr,signed:!0,TypedArray:Int32Array,BigIntArray:q}),Object.assign(wr.prototype,mr.prototype,{constructor:wr,signed:!1,TypedArray:Uint32Array,BigIntArray:K}),Object.assign(kr.prototype,mr.prototype,{constructor:kr,signed:!0,TypedArray:Uint32Array,BigIntArray:K}),V?(fr=function(e){return 8===e.byteLength?new e.BigIntArray(e.buffer,e.byteOffset,1)[0]:Or(e)},lr=function(e){return 8===e.byteLength?"".concat(new e.BigIntArray(e.buffer,e.byteOffset,1)[0]):Or(e)}):fr=lr=Or;var xr,jr=function(){function e(t,n){return Object(f.a)(this,e),e.new(t,n)}return Object(h.a)(e,null,[{key:"new",value:function(e,t){switch(t){case!0:return new gr(e);case!1:return new wr(e)}switch(e.constructor){case Int8Array:case Int16Array:case Int32Array:case q:return new gr(e)}return 16===e.byteLength?new kr(e):new wr(e)}},{key:"signed",value:function(e){return new gr(e)}},{key:"unsigned",value:function(e){return new wr(e)}},{key:"decimal",value:function(e){return new kr(e)}}]),e}(),Sr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"setValue",value:function(e,t){this._values.set(e,t)}}]),n}(Gn),Tr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Sr),Ir=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Sr),Er=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Sr),Ar=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),e.nullValues&&(e.nullValues=e.nullValues.map(Nr)),(r=t.call(this,e))._values=new Hn(new Int32Array(0),2),r}return Object(h.a)(n,[{key:"values64",get:function(){return this._values.buffer64}},{key:"isValid",value:function(e){return ht(Object(ft.a)(n.prototype),"isValid",this).call(this,Nr(e))}}]),n}(Sr),Br=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Sr),Cr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Sr),Dr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Sr),Lr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),e.nullValues&&(e.nullValues=e.nullValues.map(Nr)),(r=t.call(this,e))._values=new Hn(new Uint32Array(0),2),r}return Object(h.a)(n,[{key:"values64",get:function(){return this._values.buffer64}},{key:"isValid",value:function(e){return ht(Object(ft.a)(n.prototype),"isValid",this).call(this,Nr(e))}}]),n}(Sr),Nr=(xr={BigIntArray:q},function(e){return ArrayBuffer.isView(e)&&(xr.buffer=e.buffer,xr.byteOffset=e.byteOffset,xr.byteLength=e.byteLength,e=fr(xr),xr.buffer=null),e}),Fr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Gn),Mr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Fr),Pr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Fr),Ur=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Fr),Rr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Fr),zr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Gn),Vr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(zr),Wr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(zr),Yr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(zr),qr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(zr),Hr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Gn),$r=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Hr),Kr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Hr),Qr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._values=new Vn(new Uint8Array(0)),r}return Object(h.a)(n,[{key:"byteLength",get:function(){var e=this._pendingLength+4*this.length;return this._offsets&&(e+=this._offsets.byteLength),this._values&&(e+=this._values.byteLength),this._nulls&&(e+=this._nulls.byteLength),e}},{key:"setValue",value:function(e,t){return ht(Object(ft.a)(n.prototype),"setValue",this).call(this,e,_e(t))}},{key:"_flushPending",value:function(e,t){var n,r,i=this._offsets,a=this._values.reserve(t).buffer,o=0,u=0,c=0,l=Object(s.a)(e);try{for(l.s();!(r=l.n()).done;){var f=Object(p.a)(r.value,2);o=f[0],void 0===(n=f[1])?i.set(o,0):(u=n.length,a.set(n,c),i.set(o,u),c+=u)}}catch(h){l.e(h)}finally{l.f()}}}]),n}(Jn),Gr=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._values=new Vn(new Uint8Array(0)),r}return Object(h.a)(n,[{key:"byteLength",get:function(){var e=this._pendingLength+4*this.length;return this._offsets&&(e+=this._offsets.byteLength),this._values&&(e+=this._values.byteLength),this._nulls&&(e+=this._nulls.byteLength),e}},{key:"setValue",value:function(e,t){return ht(Object(ft.a)(n.prototype),"setValue",this).call(this,e,C(t))}},{key:"_flushPending",value:function(e,t){}}]),n}(Jn);Gr.prototype._flushPending=Qr.prototype._flushPending;var Jr=function(){function e(){Object(f.a)(this,e)}return Object(h.a)(e,[{key:"length",get:function(){return this._values.length}},{key:"get",value:function(e){return this._values[e]}},{key:"clear",value:function(){return this._values=null,this}},{key:"bind",value:function(e){return e instanceof gt?e:(this._values=e,this)}}]),e}(),Zr=n(21),Xr=n(16),ei=n(11),ti=Symbol.for("parent"),ni=Symbol.for("rowIndex"),ri=Symbol.for("keyToIdx"),ii=Symbol.for("idxToVal"),ai=Symbol.for("nodejs.util.inspect.custom"),oi=function(e){function t(e,n){Object(f.a)(this,t),this[ti]=e,this.size=n}return Object(h.a)(t,[{key:"entries",value:function(){return this[Symbol.iterator]()}},{key:"has",value:function(e){return void 0!==this.get(e)}},{key:"get",value:function(e){var t=void 0;if(null!==e&&void 0!==e){var n=this[ri]||(this[ri]=new Map),r=n.get(e);if(void 0!==r){var i=this[ii]||(this[ii]=new Array(this.size));void 0!==(t=i[r])||(i[r]=t=this.getValue(r))}else if((r=this.getIndex(e))>-1){n.set(e,r);var a=this[ii]||(this[ii]=new Array(this.size));void 0!==(t=a[r])||(a[r]=t=this.getValue(r))}}return t}},{key:"set",value:function(e,t){if(null!==e&&void 0!==e){var n=this[ri]||(this[ri]=new Map),r=n.get(e);if(void 0===r&&n.set(e,r=this.getIndex(e)),r>-1)(this[ii]||(this[ii]=new Array(this.size)))[r]=this.setValue(r,t)}return this}},{key:"clear",value:function(){throw new Error("Clearing ".concat(this[Symbol.toStringTag]," not supported."))}},{key:"delete",value:function(e){throw new Error("Deleting ".concat(this[Symbol.toStringTag]," values not supported."))}},{key:e,value:d.mark((function e(){var t,n,r,i,a,o,u,c,s;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:t=this.keys(),n=this.values(),r=this[ri]||(this[ri]=new Map),i=this[ii]||(this[ii]=new Array(this.size)),u=0;case 5:if((c=t.next()).done||(s=n.next()).done){e.next=15;break}return a=c.value,o=s.value,i[u]=o,r.has(a)||r.set(a,u),e.next=12,[a,o];case 12:++u,e.next=5;break;case 15:case"end":return e.stop()}}),e,this)}))},{key:"forEach",value:function(e,t){for(var n,r,i,a,o=this.keys(),u=this.values(),c=void 0===t?e:function(n,r,i){return e.call(t,n,r,i)},s=this[ri]||(this[ri]=new Map),l=this[ii]||(this[ii]=new Array(this.size)),f=0;!(i=o.next()).done&&!(a=u.next()).done;++f)n=i.value,r=a.value,l[f]=r,s.has(n)||s.set(n,f),c(r,n,this)}},{key:"toArray",value:function(){return Object(Ut.a)(this.values())}},{key:"toJSON",value:function(){var e={};return this.forEach((function(t,n){return e[n]=t})),e}},{key:"inspect",value:function(){return this.toString()}},{key:ai,value:function(){return this.toString()}},{key:"toString",value:function(){var e=[];return this.forEach((function(t,n){n=Pn(n),t=Pn(t),e.push("".concat(n,": ").concat(t))})),"{ ".concat(e.join(", ")," }")}}]),t}(Symbol.iterator);oi[Symbol.toStringTag]=function(e){var t;return Object.defineProperties(e,(t={size:{writable:!0,enumerable:!1,configurable:!1,value:0}},Object(ei.a)(t,ti,{writable:!0,enumerable:!1,configurable:!1,value:null}),Object(ei.a)(t,ni,{writable:!0,enumerable:!1,configurable:!1,value:-1}),t)),e[Symbol.toStringTag]="Row"}(oi.prototype);var ui=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),r=t.call(this,e,e.length),Object(Zr.a)(r,fi(Object(Xr.a)(r)))}return Object(h.a)(n,[{key:"keys",value:function(){return this[ti].getChildAt(0)[Symbol.iterator]()}},{key:"values",value:function(){return this[ti].getChildAt(1)[Symbol.iterator]()}},{key:"getKey",value:function(e){return this[ti].getChildAt(0).get(e)}},{key:"getIndex",value:function(e){return this[ti].getChildAt(0).indexOf(e)}},{key:"getValue",value:function(e){return this[ti].getChildAt(1).get(e)}},{key:"setValue",value:function(e,t){this[ti].getChildAt(1).set(e,t)}}]),n}(oi),ci=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),r=t.call(this,e,e.type.children.length),Object(Zr.a)(r,li(Object(Xr.a)(r)))}return Object(h.a)(n,[{key:"keys",value:d.mark((function e(){var t,n,r;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:t=Object(s.a)(this[ti].type.children),e.prev=1,t.s();case 3:if((n=t.n()).done){e.next=9;break}return r=n.value,e.next=7,r.name;case 7:e.next=3;break;case 9:e.next=14;break;case 11:e.prev=11,e.t0=e.catch(1),t.e(e.t0);case 14:return e.prev=14,t.f(),e.finish(14);case 17:case"end":return e.stop()}}),e,this,[[1,11,14,17]])}))},{key:"values",value:d.mark((function e(){var t,n,r;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:t=Object(s.a)(this[ti].type.children),e.prev=1,t.s();case 3:if((n=t.n()).done){e.next=9;break}return r=n.value,e.next=7,this[r.name];case 7:e.next=3;break;case 9:e.next=14;break;case 11:e.prev=11,e.t0=e.catch(1),t.e(e.t0);case 14:return e.prev=14,t.f(),e.finish(14);case 17:case"end":return e.stop()}}),e,this,[[1,11,14,17]])}))},{key:"getKey",value:function(e){return this[ti].type.children[e].name}},{key:"getIndex",value:function(e){return this[ti].type.children.findIndex((function(t){return t.name===e}))}},{key:"getValue",value:function(e){return this[ti].getChildAt(e).get(this[ni])}},{key:"setValue",value:function(e,t){return this[ti].getChildAt(e).set(this[ni],t)}}]),n}(oi);Object.setPrototypeOf(oi.prototype,Map.prototype);var si,li=function(){var e={enumerable:!0,configurable:!1,get:null,set:null};return function(t){var n,r=-1,i=t[ri]||(t[ri]=new Map),a=function(e){return function(){return this.get(e)}},o=function(e){return function(t){return this.set(e,t)}},u=Object(s.a)(t.keys());try{for(u.s();!(n=u.n()).done;){var c=n.value;i.set(c,++r),e.get=a(c),e.set=o(c),t.hasOwnProperty(c)||(e.enumerable=!0,Object.defineProperty(t,c,e)),t.hasOwnProperty(r)||(e.enumerable=!1,Object.defineProperty(t,r,e))}}catch(l){u.e(l)}finally{u.f()}return e.get=e.set=null,t}}(),fi=function(){if("undefined"===typeof Proxy)return li;var e=oi.prototype.has,t=oi.prototype.get,n=oi.prototype.set,r=oi.prototype.getKey,i={isExtensible:function(){return!1},deleteProperty:function(){return!1},preventExtensions:function(){return!0},ownKeys:function(e){return Object(Ut.a)(e.keys()).map((function(e){return"".concat(e)}))},has:function(e,t){switch(t){case"getKey":case"getIndex":case"getValue":case"setValue":case"toArray":case"toJSON":case"inspect":case"constructor":case"isPrototypeOf":case"propertyIsEnumerable":case"toString":case"toLocaleString":case"valueOf":case"size":case"has":case"get":case"set":case"clear":case"delete":case"keys":case"values":case"entries":case"forEach":case"__proto__":case"__defineGetter__":case"__defineSetter__":case"hasOwnProperty":case"__lookupGetter__":case"__lookupSetter__":case Symbol.iterator:case Symbol.toStringTag:case ti:case ni:case ii:case ri:case ai:return!0}return"number"!==typeof t||e.has(t)||(t=e.getKey(t)),e.has(t)},get:function(n,i,a){switch(i){case"getKey":case"getIndex":case"getValue":case"setValue":case"toArray":case"toJSON":case"inspect":case"constructor":case"isPrototypeOf":case"propertyIsEnumerable":case"toString":case"toLocaleString":case"valueOf":case"size":case"has":case"get":case"set":case"clear":case"delete":case"keys":case"values":case"entries":case"forEach":case"__proto__":case"__defineGetter__":case"__defineSetter__":case"hasOwnProperty":case"__lookupGetter__":case"__lookupSetter__":case Symbol.iterator:case Symbol.toStringTag:case ti:case ni:case ii:case ri:case ai:return Reflect.get(n,i,a)}return"number"!==typeof i||e.call(a,i)||(i=r.call(a,i)),t.call(a,i)},set:function(t,i,a,o){switch(i){case ti:case ni:case ii:case ri:return Reflect.set(t,i,a,o);case"getKey":case"getIndex":case"getValue":case"setValue":case"toArray":case"toJSON":case"inspect":case"constructor":case"isPrototypeOf":case"propertyIsEnumerable":case"toString":case"toLocaleString":case"valueOf":case"size":case"has":case"get":case"set":case"clear":case"delete":case"keys":case"values":case"entries":case"forEach":case"__proto__":case"__defineGetter__":case"__defineSetter__":case"hasOwnProperty":case"__lookupGetter__":case"__lookupSetter__":case Symbol.iterator:case Symbol.toStringTag:return!1}return"number"!==typeof i||e.call(o,i)||(i=r.call(o,i)),!!e.call(o,i)&&!!n.call(o,i,a)}};return function(e){return new Proxy(e,i)}}();function hi(e,t,n){var r=e.length,i=t>-1?t:r+t%r;return n?n(e,i):i}function di(e,t,n,r){var i=e.length,a=void 0===i?0:i,o="number"!==typeof t?0:t,u="number"!==typeof n?a:n;return o<0&&(o=(o%a+a)%a),u<0&&(u=(u%a+a)%a),ua&&(u=a),r?r(e,o,u):[o,u]}var pi=V?z(0):0,vi=function(e){return e!==e};function yi(e){var t=typeof e;if("object"!==t||null===e)return vi(e)?vi:"bigint"!==t?function(t){return t===e}:function(t){return pi+t===e};if(e instanceof Date){var n=e.valueOf();return function(e){return e instanceof Date&&e.valueOf()===n}}return ArrayBuffer.isView(e)?function(t){return!!t&&Ze(e,t)}:e instanceof Map?function(e){var t=-1,n=[];return e.forEach((function(e){return n[++t]=yi(e)})),bi(n)}(e):Array.isArray(e)?function(e){for(var t=[],n=-1,r=e.length;++n1&&void 0!==arguments[1]?arguments[1]:[],a=arguments.length>2&&void 0!==arguments[2]?arguments[2]:wi(i);return Object(f.a)(this,r),(t=n.call(this))._nullCount=-1,t._type=e,t._chunks=i,t._chunkOffsets=a,t._length=a[a.length-1],t._numChildren=(t._type.children||[]).length,t}return Object(h.a)(r,[{key:"type",get:function(){return this._type}},{key:"length",get:function(){return this._length}},{key:"chunks",get:function(){return this._chunks}},{key:"typeId",get:function(){return this._type.typeId}},{key:"VectorName",get:function(){return"Chunked<".concat(this._type,">")}},{key:"data",get:function(){return this._chunks[0]?this._chunks[0].data:null}},{key:"ArrayType",get:function(){return this._type.ArrayType}},{key:"numChildren",get:function(){return this._numChildren}},{key:"stride",get:function(){return this._chunks[0]?this._chunks[0].stride:1}},{key:"byteLength",get:function(){return this._chunks.reduce((function(e,t){return e+t.byteLength}),0)}},{key:"nullCount",get:function(){var e=this._nullCount;return e<0&&(this._nullCount=e=this._chunks.reduce((function(e,t){return e+t.nullCount}),0)),e}},{key:"indices",get:function(){if(tn.isDictionary(this._type)){if(!this._indices){var e=this._chunks;this._indices=1===e.length?e[0].indices:r.concat.apply(r,Object(Ut.a)(e.map((function(e){return e.indices}))))}return this._indices}return null}},{key:"dictionary",get:function(){return tn.isDictionary(this._type)?this._chunks[this._chunks.length-1].data.dictionary:null}},{key:t,value:d.mark((function e(){var t,n,r;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:t=Object(s.a)(this._chunks),e.prev=1,t.s();case 3:if((n=t.n()).done){e.next=8;break}return r=n.value,e.delegateYield(r,"t0",6);case 6:e.next=3;break;case 8:e.next=13;break;case 10:e.prev=10,e.t1=e.catch(1),t.e(e.t1);case 13:return e.prev=13,t.f(),e.finish(13);case 16:case"end":return e.stop()}}),e,this,[[1,10,13,16]])}))},{key:"clone",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:this._chunks;return new r(this._type,e)}},{key:"concat",value:function(){for(var e=arguments.length,t=new Array(e),n=0;n=this._numChildren)return null;var t,n,i,a=this._children||(this._children=[]);return(t=a[e])?t:(n=(this._type.children||[])[e])&&(i=this._chunks.map((function(t){return t.getChildAt(e)})).filter((function(e){return null!=e}))).length>0?a[e]=new r(n.type,i):null}},{key:"search",value:function(e,t){var n=e,r=this._chunkOffsets,i=r.length-1;if(n<0)return null;if(n>=r[i])return null;if(i<=1)return t?t(this,0,n):[0,n];var a=0,o=0,u=0;do{if(a+1===i)return t?t(this,a,n-o):[a,n-o];n>=r[u=a+(i-a)/2|0]?a=u:i=u}while(n=(o=r[a]));return null}},{key:"isValid",value:function(e){return!!this.search(e,this.isValidInternal)}},{key:"get",value:function(e){return this.search(e,this.getInternal)}},{key:"set",value:function(e,t){this.search(e,(function(e,n,r){return e.chunks[n].set(r,t)}))}},{key:"indexOf",value:function(e,t){var n=this;return t&&"number"===typeof t?this.search(t,(function(t,r,i){return n.indexOfInternal(t,r,i,e)})):this.indexOfInternal(this,0,Math.max(0,t||0),e)}},{key:"toArray",value:function(){var e=this.chunks,t=e.length,n=this._type.ArrayType;if(t<=0)return new n(0);if(t<=1)return e[0].toArray();for(var r=0,i=new Array(t),a=-1;++a=n)break;if(!(t>=l+s))if(l>=t&&l+s<=n)r.push(c);else{var f=Math.max(0,t-l),h=Math.min(n-l,s);r.push(c.slice(f,h))}}return e.clone(r)}}],[{key:"flatten",value:function(){for(var e=arguments.length,t=new Array(e),n=0;n1&&void 0!==arguments[1]?arguments[1]:[],a=arguments.length>2?arguments[2]:void 0;return Object(f.a)(this,n),i=gi.flatten.apply(gi,Object(Ut.a)(i)),(r=t.call(this,e.type,i,a))._field=e,1!==i.length||Object(Xr.a)(r)instanceof xi?r:Object(Zr.a)(r,new xi(e,i[0],r._chunkOffsets))}return Object(h.a)(n,[{key:"field",get:function(){return this._field}},{key:"name",get:function(){return this._field.name}},{key:"nullable",get:function(){return this._field.nullable}},{key:"metadata",get:function(){return this._field.metadata}},{key:"clone",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:this._chunks;return new n(this._field,e)}},{key:"getChildAt",value:function(e){if(e<0||e>=this.numChildren)return null;var t,r,i,a=this._children||(this._children=[]);return(t=a[e])?t:(r=(this.type.children||[])[e])&&(i=this._chunks.map((function(t){return t.getChildAt(e)})).filter((function(e){return null!=e}))).length>0?a[e]=new n(r,i):null}}],[{key:"new",value:function(e,t){for(var r=arguments.length,i=new Array(r>2?r-2:0),a=2;a0}))&&(e=e.clone({nullable:!0}));return new n(e,o)}}]),n}(gi),xi=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r,i){var a;return Object(f.a)(this,n),(a=t.call(this,e,[r],i))._chunk=r,a}return Object(h.a)(n,[{key:"search",value:function(e,t){return t?t(this,0,e):[0,e]}},{key:"isValid",value:function(e){return this._chunk.isValid(e)}},{key:"get",value:function(e){return this._chunk.get(e)}},{key:"set",value:function(e,t){this._chunk.set(e,t)}},{key:"indexOf",value:function(e,t){return this._chunk.indexOf(e,t)}}]),n}(Oi),ji=Array.isArray,Si=function(e,t){return Bi(e,t,[],0)},Ti=function(e){var t=Di(e,[[],[]]),n=Object(p.a)(t,2),r=n[0];return n[1].map((function(e,t){return e instanceof Oi?Oi.new(e.field.clone(r[t]),e):e instanceof gt?Oi.new(r[t],e):Oi.new(r[t],[])}))},Ii=function(e){return Di(e,[[],[]])},Ei=function(e,t){return function e(t,n,r,i){var a,o=i,u=-1,c=n.length;for(;++u0&&void 0!==arguments[0]?arguments[0]:[],n=arguments.length>1?arguments[1]:void 0,r=arguments.length>2?arguments[2]:void 0;Object(f.a)(this,t),this.fields=e||[],this.metadata=n||new Map,r||(r=Mi(e)),this.dictionaries=r}return Object(h.a)(t,[{key:e,get:function(){return"Schema"}},{key:"toString",value:function(){return"Schema<{ ".concat(this.fields.map((function(e,t){return"".concat(t,": ").concat(e)})).join(", ")," }>")}},{key:"compareTo",value:function(e){return en.compareSchemas(this,e)}},{key:"select",value:function(){for(var e=arguments.length,n=new Array(e),r=0;r2&&void 0!==arguments[2]&&arguments[2],i=arguments.length>3?arguments[3]:void 0;Object(f.a)(this,t),this.name=e,this.type=n,this.nullable=r,this.metadata=i||new Map}return Object(h.a)(t,[{key:"typeId",get:function(){return this.type.typeId}},{key:e,get:function(){return"Field"}},{key:"toString",value:function(){return"".concat(this.name,": ").concat(this.type)}},{key:"compareTo",value:function(e){return en.compareField(this,e)}},{key:"clone",value:function(){for(var e,n,r,i,a,o,u,c,s,l,f,h=arguments.length,d=new Array(h),v=0;v1&&void 0!==arguments[1]?arguments[1]:new Map,n=-1,r=e.length;++n0&&Mi(a.children,t)}return t}Li.prototype.fields=null,Li.prototype.metadata=null,Li.prototype.dictionaries=null,Ni.prototype.type=null,Ni.prototype.name=null,Ni.prototype.nullable=null,Ni.prototype.metadata=null;var Pi=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._run=new Jr,r._offsets=new qn,r}return Object(h.a)(n,[{key:"addChild",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:"0";if(this.numChildren>0)throw new Error("ListBuilder can only have one child.");return this.children[this.numChildren]=e,this.type=new Tn(new Ni(t,e.type,!0)),this.numChildren-1}},{key:"clear",value:function(){return this._run.clear(),ht(Object(ft.a)(n.prototype),"clear",this).call(this)}},{key:"_flushPending",value:function(e){var t,n,r=this._run,i=this._offsets,a=this._setValue,o=0,u=Object(s.a)(e);try{for(u.s();!(n=u.n()).done;){var c=Object(p.a)(n.value,2);o=c[0],void 0===(t=c[1])?i.set(o,0):(i.set(o,t.length),a(this,o,r.bind(t)))}}catch(l){u.e(l)}finally{u.f()}}}]),n}(Jn),Ui=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){var e;return Object(f.a)(this,n),(e=t.apply(this,arguments))._run=new Jr,e}return Object(h.a)(n,[{key:"setValue",value:function(e,t){ht(Object(ft.a)(n.prototype),"setValue",this).call(this,e,this._run.bind(t))}},{key:"addChild",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:"0";if(this.numChildren>0)throw new Error("FixedSizeListBuilder can only have one child.");var n=this.children.push(e);return this.type=new Bn(this.type.listSize,new Ni(t,e.type,!0)),n}},{key:"clear",value:function(){return this._run.clear(),ht(Object(ft.a)(n.prototype),"clear",this).call(this)}}]),n}(Qn),Ri=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"set",value:function(e,t){return ht(Object(ft.a)(n.prototype),"set",this).call(this,e,t)}},{key:"setValue",value:function(e,t){t=t instanceof Map?t:new Map(Object.entries(t));var n=this._pending||(this._pending=new Map),r=n.get(e);r&&(this._pendingLength-=r.size),this._pendingLength+=t.size,n.set(e,t)}},{key:"addChild",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:"".concat(this.numChildren);if(this.numChildren>0)throw new Error("ListBuilder can only have one child.");return this.children[this.numChildren]=e,this.type=new Cn(new Ni(t,e.type,!0),this.type.keysSorted),this.numChildren-1}},{key:"_flushPending",value:function(e){var t=this,n=this._offsets,r=this._setValue;e.forEach((function(e,i){void 0===e?n.set(i,0):(n.set(i,e.size),r(t,i,e))}))}}]),n}(Jn),zi=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"addChild",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:"".concat(this.numChildren),n=this.children.push(e);return this.type=new In([].concat(Object(Ut.a)(this.type.children),[new Ni(t,e.type,!0)])),n}}]),n}(Qn),Vi=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._typeIds=new Wn(new Int8Array(0),1),"function"===typeof e.valueToChildTypeId&&(r._valueToChildTypeId=e.valueToChildTypeId),r}return Object(h.a)(n,[{key:"typeIdToChildIndex",get:function(){return this.type.typeIdToChildIndex}},{key:"append",value:function(e,t){return this.set(this.length,e,t)}},{key:"set",value:function(e,t,n){return void 0===n&&(n=this._valueToChildTypeId(this,t,e)),this.setValid(e,this.isValid(t))&&this.setValue(e,t,n),this}},{key:"setValue",value:function(e,t,r){this._typeIds.set(e,r),ht(Object(ft.a)(n.prototype),"setValue",this).call(this,e,t)}},{key:"addChild",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:"".concat(this.children.length),n=this.children.push(e),r=this.type,i=r.children,a=r.mode,o=r.typeIds,u=[].concat(Object(Ut.a)(i),[new Ni(t,e.type)]);return this.type=new En(a,[].concat(Object(Ut.a)(o),[n]),u),n}},{key:"_valueToChildTypeId",value:function(e,t,n){throw new Error("Cannot map UnionBuilder value to child typeId. Pass the `childTypeId` as the second argument to unionBuilder.append(), or supply a `valueToChildTypeId` function as part of the UnionBuilder constructor options.")}}]),n}(Qn),Wi=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Vi),Yi=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._offsets=new Wn(new Int32Array(0)),r}return Object(h.a)(n,[{key:"setValue",value:function(e,t,r){var i=this.type.typeIdToChildIndex[r];return this._offsets.set(e,this.getChildAt(i).length),ht(Object(ft.a)(n.prototype),"setValue",this).call(this,e,t,r)}}]),n}(Vi),qi=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Rt),Hi=function(e,t,n){e[t]=n%4294967296|0,e[t+1]=n/4294967296|0},$i=function(e,t,n,r){var i=t[n],a=t[n+1];null!=i&&null!=a&&e.set(r.subarray(0,a-i),i)},Ki=function(e,t,n){!function(e,t,n){e[t]=n/864e5|0}(e.values,t,n.valueOf())},Qi=function(e,t,n){var r=e.values;Hi(r,2*t,n.valueOf())},Gi=function(e,t,n){var r=e.stride;e.values[r*t]=n},Ji=function(e,t,n){var r=e.stride;e.values[r*t]=sr(n)},Zi=function(e,t,n){switch(typeof n){case"bigint":e.values64[t]=n;break;case"number":e.values[t*e.stride]=n;break;default:var r=n,i=e.stride,a=be(e.ArrayType,r);e.values.set(a.subarray(0,i),i*t)}},Xi=function(e,t,n){var r=e.values;return Hi(r,2*t,n/1e3)},ea=function(e,t,n){var r=e.values;return Hi(r,2*t,n)},ta=function(e,t,n){return function(e,t,n){e[t]=1e3*n%4294967296|0,e[t+1]=1e3*n/4294967296|0}(e.values,2*t,n)},na=function(e,t,n){return function(e,t,n){e[t]=1e6*n%4294967296|0,e[t+1]=1e6*n/4294967296|0}(e.values,2*t,n)},ra=function(e,t,n){e.values[e.stride*t]=n},ia=function(e,t,n){e.values[e.stride*t]=n},aa=function(e,t,n){e.values.set(n.subarray(0,2),2*t)},oa=function(e,t,n){e.values.set(n.subarray(0,2),2*t)},ua=function(e,t,n){var r=e.typeIdToChildIndex[e.typeIds[t]],i=e.getChildAt(r);i&&i.set(e.valueOffsets[t],n)},ca=function(e,t,n){var r=e.typeIdToChildIndex[e.typeIds[t]],i=e.getChildAt(r);i&&i.set(t,n)},sa=function(e,t,n){e.values.set(n.subarray(0,2),2*t)},la=function(e,t,n){e.values[t]=12*n[0]+n[1]%12};qi.prototype.visitBool=function(e,t,n){var r=e.offset,i=e.values,a=r+t;n?i[a>>3]|=1<>3]&=~(1<0){var i=t.children||[],a={nullValues:t.nullValues},o=Array.isArray(i)?function(e,t){return i[t]||a}:function(e){var t=e.name;return i[t]||a};n.children.forEach((function(t,n){var i=t.type,a=o(t,n);r.children.push(e(Object(lt.a)(Object(lt.a)({},a),{},{type:i})))}))}return r},Object.keys(wt).map((function(e){return wt[e]})).filter((function(e){return"number"===typeof e&&e!==wt.NONE})).forEach((function(e){da.visit(e).prototype._setValue=ha.getVisitFn(e)})),Gr.prototype._setValue=ha.visitBinary,function(e){!function(t){!function(t){!function(t){var n=function(){function t(){Object(f.a)(this,t),this.bb=null,this.bb_pos=0}return Object(h.a)(t,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"version",value:function(){var e=this.bb.__offset(this.bb_pos,4);return e?this.bb.readInt16(this.bb_pos+e):dt.apache.arrow.flatbuf.MetadataVersion.V1}},{key:"schema",value:function(e){var t=this.bb.__offset(this.bb_pos,6);return t?(e||new dt.apache.arrow.flatbuf.Schema).__init(this.bb.__indirect(this.bb_pos+t),this.bb):null}},{key:"dictionaries",value:function(t,n){var r=this.bb.__offset(this.bb_pos,8);return r?(n||new e.apache.arrow.flatbuf.Block).__init(this.bb.__vector(this.bb_pos+r)+24*t,this.bb):null}},{key:"dictionariesLength",value:function(){var e=this.bb.__offset(this.bb_pos,8);return e?this.bb.__vector_len(this.bb_pos+e):0}},{key:"recordBatches",value:function(t,n){var r=this.bb.__offset(this.bb_pos,10);return r?(n||new e.apache.arrow.flatbuf.Block).__init(this.bb.__vector(this.bb_pos+r)+24*t,this.bb):null}},{key:"recordBatchesLength",value:function(){var e=this.bb.__offset(this.bb_pos,10);return e?this.bb.__vector_len(this.bb_pos+e):0}}],[{key:"getRootAsFooter",value:function(e,n){return(n||new t).__init(e.readInt32(e.position())+e.position(),e)}},{key:"startFooter",value:function(e){e.startObject(4)}},{key:"addVersion",value:function(e,t){e.addFieldInt16(0,t,dt.apache.arrow.flatbuf.MetadataVersion.V1)}},{key:"addSchema",value:function(e,t){e.addFieldOffset(1,t,0)}},{key:"addDictionaries",value:function(e,t){e.addFieldOffset(2,t,0)}},{key:"startDictionariesVector",value:function(e,t){e.startVector(24,t,8)}},{key:"addRecordBatches",value:function(e,t){e.addFieldOffset(3,t,0)}},{key:"startRecordBatchesVector",value:function(e,t){e.startVector(24,t,8)}},{key:"endFooter",value:function(e){return e.endObject()}},{key:"finishFooterBuffer",value:function(e,t){e.finish(t)}},{key:"createFooter",value:function(e,n,r,i,a){return t.startFooter(e),t.addVersion(e,n),t.addSchema(e,r),t.addDictionaries(e,i),t.addRecordBatches(e,a),t.endFooter(e)}}]),t}();t.Footer=n}(t.flatbuf||(t.flatbuf={}))}(t.arrow||(t.arrow={}))}(e.apache||(e.apache={}))}(fa||(fa={})),function(e){!function(e){!function(e){!function(e){var t=function(){function e(){Object(f.a)(this,e),this.bb=null,this.bb_pos=0}return Object(h.a)(e,[{key:"__init",value:function(e,t){return this.bb_pos=e,this.bb=t,this}},{key:"offset",value:function(){return this.bb.readInt64(this.bb_pos)}},{key:"metaDataLength",value:function(){return this.bb.readInt32(this.bb_pos+8)}},{key:"bodyLength",value:function(){return this.bb.readInt64(this.bb_pos+16)}}],[{key:"createBlock",value:function(e,t,n,r){return e.prep(8,24),e.writeInt64(r),e.pad(4),e.writeInt32(n),e.writeInt64(t),e.offset()}}]),e}();e.Block=t}(e.flatbuf||(e.flatbuf={}))}(e.arrow||(e.arrow={}))}(e.apache||(e.apache={}))}(fa||(fa={}));var pa=w.Long,va=w.Builder,ya=w.ByteBuffer,ba=fa.apache.arrow.flatbuf.Block,ma=fa.apache.arrow.flatbuf.Footer,ga=function(){function e(t){var n=arguments.length>1&&void 0!==arguments[1]?arguments[1]:It.V4,r=arguments.length>2?arguments[2]:void 0,i=arguments.length>3?arguments[3]:void 0;Object(f.a)(this,e),this.schema=t,this.version=n,r&&(this._recordBatches=r),i&&(this._dictionaryBatches=i)}return Object(h.a)(e,[{key:"numRecordBatches",get:function(){return this._recordBatches.length}},{key:"numDictionaries",get:function(){return this._dictionaryBatches.length}},{key:"recordBatches",value:d.mark((function e(){var t,n,r;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:n=-1,r=this.numRecordBatches;case 1:if(!(++n=0&&e=0&&e=0&&e=0&&e0)return ht(Object(ft.a)(n.prototype),"write",this).call(this,e)}},{key:"toString",value:function(){var e=arguments.length>0&&void 0!==arguments[0]&&arguments[0];return e?B(this.toUint8Array(!0)):this.toUint8Array(!1).then(B)}},{key:"toUint8Array",value:function(){var e=this,t=arguments.length>0&&void 0!==arguments[0]&&arguments[0];return t?ye(this._values)[0]:Object(l.a)(d.mark((function t(){var n,r,i,a,o,u,c,s;return d.wrap((function(t){for(;;)switch(t.prev=t.next){case 0:n=[],r=0,i=!1,a=!1,t.prev=3,u=_a(e);case 5:return t.next=7,u.next();case 7:if(!(i=!(c=t.sent).done)){t.next=14;break}s=c.value,n.push(s),r+=s.byteLength;case 11:i=!1,t.next=5;break;case 14:t.next=20;break;case 16:t.prev=16,t.t0=t.catch(3),a=!0,o=t.t0;case 20:if(t.prev=20,t.prev=21,!i||null==u.return){t.next=25;break}return t.next=25,u.return();case 25:if(t.prev=25,!a){t.next=28;break}throw o;case 28:return t.finish(25);case 29:return t.finish(20);case 30:return t.abrupt("return",ye(n,r)[0]);case 31:case"end":return t.stop()}}),t,null,[[3,16,20,30],[21,,25,29]])})))()}}]),n}(P),ja=function(e){function t(e){Object(f.a)(this,t),e&&(this.source=new Ta(et.fromIterable(e)))}return Object(h.a)(t,[{key:e,value:function(){return this}},{key:"next",value:function(e){return this.source.next(e)}},{key:"throw",value:function(e){return this.source.throw(e)}},{key:"return",value:function(e){return this.source.return(e)}},{key:"peek",value:function(e){return this.source.peek(e)}},{key:"read",value:function(e){return this.source.read(e)}}]),t}(Symbol.iterator),Sa=function(e){function t(e){Object(f.a)(this,t),e instanceof t?this.source=e.source:e instanceof xa?this.source=new Ia(et.fromAsyncIterable(e)):se(e)?this.source=new Ia(et.fromNodeStream(e)):ue(e)?this.source=new Ia(et.fromDOMStream(e)):ae(e)?this.source=new Ia(et.fromDOMStream(e.body)):ee(e)?this.source=new Ia(et.fromIterable(e)):(X(e)||te(e))&&(this.source=new Ia(et.fromAsyncIterable(e)))}return Object(h.a)(t,[{key:e,value:function(){return this}},{key:"next",value:function(e){return this.source.next(e)}},{key:"throw",value:function(e){return this.source.throw(e)}},{key:"return",value:function(e){return this.source.return(e)}},{key:"closed",get:function(){return this.source.closed}},{key:"cancel",value:function(e){return this.source.cancel(e)}},{key:"peek",value:function(e){return this.source.peek(e)}},{key:"read",value:function(e){return this.source.read(e)}}]),t}(Symbol.asyncIterator),Ta=function(){function e(t){Object(f.a)(this,e),this.source=t}return Object(h.a)(e,[{key:"cancel",value:function(e){this.return(e)}},{key:"peek",value:function(e){return this.next(e,"peek").value}},{key:"read",value:function(e){return this.next(e,"read").value}},{key:"next",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:"read";return this.source.next({cmd:t,size:e})}},{key:"throw",value:function(e){return Object.create(this.source.throw&&this.source.throw(e)||N)}},{key:"return",value:function(e){return Object.create(this.source.return&&this.source.return(e)||N)}}]),e}(),Ia=function(){function e(t){var n=this;Object(f.a)(this,e),this.source=t,this._closedPromise=new Promise((function(e){return n._closedPromiseResolve=e}))}return Object(h.a)(e,[{key:"cancel",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.return(t);case 2:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"closed",get:function(){return this._closedPromise}},{key:"read",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.next(t,"read");case 2:return e.abrupt("return",e.sent.value);case 3:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"peek",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.next(t,"peek");case 2:return e.abrupt("return",e.sent.value);case 3:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"next",value:function(){var e=Object(l.a)(d.mark((function e(t){var n,r=arguments;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return n=r.length>1&&void 0!==r[1]?r[1]:"read",e.next=3,this.source.next({cmd:n,size:t});case 3:return e.abrupt("return",e.sent);case 4:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"throw",value:function(){var e=Object(l.a)(d.mark((function e(t){var n;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:if(e.t1=this.source.throw,!e.t1){e.next=5;break}return e.next=4,this.source.throw(t);case 4:e.t1=e.sent;case 5:if(e.t0=e.t1,e.t0){e.next=8;break}e.t0=N;case 8:return n=e.t0,this._closedPromiseResolve&&this._closedPromiseResolve(),this._closedPromiseResolve=void 0,e.abrupt("return",Object.create(n));case 12:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"return",value:function(){var e=Object(l.a)(d.mark((function e(t){var n;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:if(e.t1=this.source.return,!e.t1){e.next=5;break}return e.next=4,this.source.return(t);case 4:e.t1=e.sent;case 5:if(e.t0=e.t1,e.t0){e.next=8;break}e.t0=N;case 8:return n=e.t0,this._closedPromiseResolve&&this._closedPromiseResolve(),this._closedPromiseResolve=void 0,e.abrupt("return",Object.create(n));case 12:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()}]),e}(),Ea=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r){var i;return Object(f.a)(this,n),(i=t.call(this)).position=0,i.buffer=_e(e),i.size="undefined"===typeof r?i.buffer.byteLength:r,i}return Object(h.a)(n,[{key:"readInt32",value:function(e){var t=this.readAt(e,4),n=t.buffer,r=t.byteOffset;return new DataView(n,r).getInt32(0,!0)}},{key:"seek",value:function(e){return this.position=Math.min(e,this.size),e>>16,65535&this.buffer[1],this.buffer[0]>>>16,65535&this.buffer[0]]),n=new Uint32Array([e.buffer[1]>>>16,65535&e.buffer[1],e.buffer[0]>>>16,65535&e.buffer[0]]),r=t[3]*n[3];this.buffer[0]=65535&r;var i=r>>>16;return i+=r=t[2]*n[3],i+=r=t[3]*n[2]>>>0,this.buffer[0]+=i<<16,this.buffer[1]=i>>>0>>16,this.buffer[1]+=t[1]*n[3]+t[2]*n[2]+t[3]*n[1],this.buffer[1]+=t[0]*n[3]+t[1]*n[2]+t[2]*n[1]+t[3]*n[0]<<16,this}},{key:"_plus",value:function(e){var t=this.buffer[0]+e.buffer[0]>>>0;this.buffer[1]+=e.buffer[1],t>>0&&++this.buffer[1],this.buffer[0]=t}},{key:"lessThan",value:function(e){return this.buffer[1]1&&void 0!==arguments[1]?arguments[1]:new Uint32Array(2);return n.fromString("string"===typeof e?e:e.toString(),t)}},{key:"fromNumber",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:new Uint32Array(2);return n.fromString(e.toString(),t)}},{key:"fromString",value:function(e){for(var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:new Uint32Array(2),r=e.length,i=new n(t),a=0;a1&&void 0!==arguments[1]?arguments[1]:new Uint32Array(2);return n.fromString("string"===typeof e?e:e.toString(),t)}},{key:"fromNumber",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:new Uint32Array(2);return n.fromString(e.toString(),t)}},{key:"fromString",value:function(e){for(var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:new Uint32Array(2),r=e.startsWith("-"),i=e.length,a=new n(t),o=r?1:0;o>>0,t[2]=this.buffer[2]+e.buffer[2]>>>0,t[1]=this.buffer[1]+e.buffer[1]>>>0,t[0]=this.buffer[0]+e.buffer[0]>>>0,t[0]>>0&&++t[1],t[1]>>0&&++t[2],t[2]>>0&&++t[3],this.buffer[3]=t[3],this.buffer[2]=t[2],this.buffer[1]=t[1],this.buffer[0]=t[0],this}},{key:"hex",value:function(){return"".concat(Ba(this.buffer[3])," ").concat(Ba(this.buffer[2])," ").concat(Ba(this.buffer[1])," ").concat(Ba(this.buffer[0]))}}],[{key:"multiply",value:function(t,n){return new e(new Uint32Array(t.buffer)).times(n)}},{key:"add",value:function(t,n){return new e(new Uint32Array(t.buffer)).plus(n)}},{key:"from",value:function(t){var n=arguments.length>1&&void 0!==arguments[1]?arguments[1]:new Uint32Array(4);return e.fromString("string"===typeof t?t:t.toString(),n)}},{key:"fromNumber",value:function(t){var n=arguments.length>1&&void 0!==arguments[1]?arguments[1]:new Uint32Array(4);return e.fromString(t.toString(),n)}},{key:"fromString",value:function(t){for(var n=arguments.length>1&&void 0!==arguments[1]?arguments[1]:new Uint32Array(4),r=t.startsWith("-"),i=t.length,a=new e(n),o=r?1:0;o1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length;return Mn.Null(e,0,n)}},{key:"visitBool",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Bool(e,0,n,r,this.readNullBitmap(e,r),this.readData(e))}},{key:"visitInt",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Int(e,0,n,r,this.readNullBitmap(e,r),this.readData(e))}},{key:"visitFloat",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Float(e,0,n,r,this.readNullBitmap(e,r),this.readData(e))}},{key:"visitUtf8",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Utf8(e,0,n,r,this.readNullBitmap(e,r),this.readOffsets(e),this.readData(e))}},{key:"visitBinary",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Binary(e,0,n,r,this.readNullBitmap(e,r),this.readOffsets(e),this.readData(e))}},{key:"visitFixedSizeBinary",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.FixedSizeBinary(e,0,n,r,this.readNullBitmap(e,r),this.readData(e))}},{key:"visitDate",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Date(e,0,n,r,this.readNullBitmap(e,r),this.readData(e))}},{key:"visitTimestamp",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Timestamp(e,0,n,r,this.readNullBitmap(e,r),this.readData(e))}},{key:"visitTime",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Time(e,0,n,r,this.readNullBitmap(e,r),this.readData(e))}},{key:"visitDecimal",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Decimal(e,0,n,r,this.readNullBitmap(e,r),this.readData(e))}},{key:"visitList",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.List(e,0,n,r,this.readNullBitmap(e,r),this.readOffsets(e),this.visit(e.children[0]))}},{key:"visitStruct",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Struct(e,0,n,r,this.readNullBitmap(e,r),this.visitMany(e.children))}},{key:"visitUnion",value:function(e){return e.mode===jt.Sparse?this.visitSparseUnion(e):this.visitDenseUnion(e)}},{key:"visitDenseUnion",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Union(e,0,n,r,this.readNullBitmap(e,r),this.readTypeIds(e),this.readOffsets(e),this.visitMany(e.children))}},{key:"visitSparseUnion",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Union(e,0,n,r,this.readNullBitmap(e,r),this.readTypeIds(e),this.visitMany(e.children))}},{key:"visitDictionary",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Dictionary(e,0,n,r,this.readNullBitmap(e,r),this.readData(e.indices),this.readDictionary(e))}},{key:"visitInterval",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Interval(e,0,n,r,this.readNullBitmap(e,r),this.readData(e))}},{key:"visitFixedSizeList",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.FixedSizeList(e,0,n,r,this.readNullBitmap(e,r),this.visit(e.children[0]))}},{key:"visitMap",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextFieldNode(),n=t.length,r=t.nullCount;return Mn.Map(e,0,n,r,this.readNullBitmap(e,r),this.readOffsets(e),this.visit(e.children[0]))}},{key:"nextFieldNode",value:function(){return this.nodes[++this.nodesIndex]}},{key:"nextBufferRange",value:function(){return this.buffers[++this.buffersIndex]}},{key:"readNullBitmap",value:function(e,t){var n=arguments.length>2&&void 0!==arguments[2]?arguments[2]:this.nextBufferRange();return t>0&&this.readData(e,n)||new Uint8Array(0)}},{key:"readOffsets",value:function(e,t){return this.readData(e,t)}},{key:"readTypeIds",value:function(e,t){return this.readData(e,t)}},{key:"readData",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextBufferRange(),n=t.length,r=t.offset;return this.bytes.subarray(r,r+n)}},{key:"readDictionary",value:function(e){return this.dictionaries.get(e.id)}}]),n}(Rt),Pa=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r,i,a){var o;return Object(f.a)(this,n),(o=t.call(this,new Uint8Array(0),r,i,a)).sources=e,o}return Object(h.a)(n,[{key:"readNullBitmap",value:function(e,t){var n=arguments.length>2&&void 0!==arguments[2]?arguments[2]:this.nextBufferRange(),r=n.offset;return t<=0?new Uint8Array(0):Lt(this.sources[r])}},{key:"readOffsets",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextBufferRange(),n=t.offset;return be(Uint8Array,be(Int32Array,this.sources[n]))}},{key:"readTypeIds",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextBufferRange(),n=t.offset;return be(Uint8Array,be(e.ArrayType,this.sources[n]))}},{key:"readData",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this.nextBufferRange(),n=t.offset,r=this.sources;return tn.isTimestamp(e)||(tn.isInt(e)||tn.isTime(e))&&64===e.bitWidth||tn.isDate(e)&&e.unit===_t.MILLISECOND?be(Uint8Array,Na.convertArray(r[n])):tn.isDecimal(e)?be(Uint8Array,Fa.convertArray(r[n])):tn.isBinary(e)||tn.isFixedSizeBinary(e)?Ua(r[n]):tn.isBool(e)?Lt(r[n]):tn.isUtf8(e)?C(r[n].join("")):be(Uint8Array,be(e.ArrayType,r[n].map((function(e){return+e}))))}}]),n}(Ma);function Ua(e){for(var t=e.join(""),n=new Uint8Array(t.length/2),r=0;r>1]=parseInt(t.substr(r,2),16);return n}var Ra=w.Long,za=dt.apache.arrow.flatbuf.Null,Va=dt.apache.arrow.flatbuf.Int,Wa=dt.apache.arrow.flatbuf.FloatingPoint,Ya=dt.apache.arrow.flatbuf.Binary,qa=dt.apache.arrow.flatbuf.Bool,Ha=dt.apache.arrow.flatbuf.Utf8,$a=dt.apache.arrow.flatbuf.Decimal,Ka=dt.apache.arrow.flatbuf.Date,Qa=dt.apache.arrow.flatbuf.Time,Ga=dt.apache.arrow.flatbuf.Timestamp,Ja=dt.apache.arrow.flatbuf.Interval,Za=dt.apache.arrow.flatbuf.List,Xa=dt.apache.arrow.flatbuf.Struct_,eo=dt.apache.arrow.flatbuf.Union,to=dt.apache.arrow.flatbuf.DictionaryEncoding,no=dt.apache.arrow.flatbuf.FixedSizeBinary,ro=dt.apache.arrow.flatbuf.FixedSizeList,io=dt.apache.arrow.flatbuf.Map,ao=new(function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"visit",value:function(e,t){return null==e||null==t?void 0:ht(Object(ft.a)(n.prototype),"visit",this).call(this,e,t)}},{key:"visitNull",value:function(e,t){return za.startNull(t),za.endNull(t)}},{key:"visitInt",value:function(e,t){return Va.startInt(t),Va.addBitWidth(t,e.bitWidth),Va.addIsSigned(t,e.isSigned),Va.endInt(t)}},{key:"visitFloat",value:function(e,t){return Wa.startFloatingPoint(t),Wa.addPrecision(t,e.precision),Wa.endFloatingPoint(t)}},{key:"visitBinary",value:function(e,t){return Ya.startBinary(t),Ya.endBinary(t)}},{key:"visitBool",value:function(e,t){return qa.startBool(t),qa.endBool(t)}},{key:"visitUtf8",value:function(e,t){return Ha.startUtf8(t),Ha.endUtf8(t)}},{key:"visitDecimal",value:function(e,t){return $a.startDecimal(t),$a.addScale(t,e.scale),$a.addPrecision(t,e.precision),$a.endDecimal(t)}},{key:"visitDate",value:function(e,t){return Ka.startDate(t),Ka.addUnit(t,e.unit),Ka.endDate(t)}},{key:"visitTime",value:function(e,t){return Qa.startTime(t),Qa.addUnit(t,e.unit),Qa.addBitWidth(t,e.bitWidth),Qa.endTime(t)}},{key:"visitTimestamp",value:function(e,t){var n=e.timezone&&t.createString(e.timezone)||void 0;return Ga.startTimestamp(t),Ga.addUnit(t,e.unit),void 0!==n&&Ga.addTimezone(t,n),Ga.endTimestamp(t)}},{key:"visitInterval",value:function(e,t){return Ja.startInterval(t),Ja.addUnit(t,e.unit),Ja.endInterval(t)}},{key:"visitList",value:function(e,t){return Za.startList(t),Za.endList(t)}},{key:"visitStruct",value:function(e,t){return Xa.startStruct_(t),Xa.endStruct_(t)}},{key:"visitUnion",value:function(e,t){eo.startTypeIdsVector(t,e.typeIds.length);var n=eo.createTypeIdsVector(t,e.typeIds);return eo.startUnion(t),eo.addMode(t,e.mode),eo.addTypeIds(t,n),eo.endUnion(t)}},{key:"visitDictionary",value:function(e,t){var n=this.visit(e.indices,t);return to.startDictionaryEncoding(t),to.addId(t,new Ra(e.id,0)),to.addIsOrdered(t,e.isOrdered),void 0!==n&&to.addIndexType(t,n),to.endDictionaryEncoding(t)}},{key:"visitFixedSizeBinary",value:function(e,t){return no.startFixedSizeBinary(t),no.addByteWidth(t,e.byteWidth),no.endFixedSizeBinary(t)}},{key:"visitFixedSizeList",value:function(e,t){return ro.startFixedSizeList(t),ro.addListSize(t,e.listSize),ro.endFixedSizeList(t)}},{key:"visitMap",value:function(e,t){return io.startMap(t),io.addKeysSorted(t,e.keysSorted),io.endMap(t)}}]),n}(Rt));function oo(e){return new To(e.count,function e(t){return(t||[]).reduce((function(t,n){return[].concat(Object(Ut.a)(t),[new Ao(n.count,(r=n.VALIDITY,(r||[]).reduce((function(e,t){return e+ +(0===t)}),0)))],Object(Ut.a)(e(n.children)));var r}),[])}(e.columns),function e(t){for(var n=arguments.length>1&&void 0!==arguments[1]?arguments[1]:[],r=-1,i=(t||[]).length;++r1&&void 0!==arguments[1]?arguments[1]:0;if(t instanceof Li)return new e(0,It.V4,Tt.Schema,t);if(t instanceof To)return new e(n,It.V4,Tt.RecordBatch,t);if(t instanceof Io)return new e(n,It.V4,Tt.DictionaryBatch,t);throw new Error("Unrecognized Message header: ".concat(t))}}]),e}(),To=function(){function e(t,n,r){Object(f.a)(this,e),this._nodes=n,this._buffers=r,this._length="number"===typeof t?t:t.low}return Object(h.a)(e,[{key:"nodes",get:function(){return this._nodes}},{key:"length",get:function(){return this._length}},{key:"buffers",get:function(){return this._buffers}}]),e}(),Io=function(){function e(t,n){var r=arguments.length>2&&void 0!==arguments[2]&&arguments[2];Object(f.a)(this,e),this._data=t,this._isDelta=r,this._id="number"===typeof n?n:n.low}return Object(h.a)(e,[{key:"id",get:function(){return this._id}},{key:"data",get:function(){return this._data}},{key:"isDelta",get:function(){return this._isDelta}},{key:"length",get:function(){return this.data.length}},{key:"nodes",get:function(){return this.data.nodes}},{key:"buffers",get:function(){return this.data.buffers}}]),e}(),Eo=function e(t,n){Object(f.a)(this,e),this.offset="number"===typeof t?t:t.low,this.length="number"===typeof n?n:n.low},Ao=function e(t,n){Object(f.a)(this,e),this.length="number"===typeof t?t:t.low,this.nullCount="number"===typeof n?n:n.low};function Bo(e){for(var t,n=[],r=-1,i=-1,a=e.nodesLength();++r0?bo.createCustomMetadataVector(e,Object(Ut.a)(t.metadata).map((function(t){var n=Object(p.a)(t,2),r=n[0],i=n[1],a=e.createString("".concat(r)),o=e.createString("".concat(i));return ko.startKeyValue(e),ko.addKey(e,a),ko.addValue(e,o),ko.endKeyValue(e)}))):-1;t.name&&(n=e.createString(t.name));bo.startField(e),bo.addType(e,r),bo.addTypeType(e,o),bo.addChildren(e,c),bo.addNullable(e,!!t.nullable),-1!==n&&bo.addName(e,n);-1!==i&&bo.addDictionary(e,i);-1!==s&&bo.addCustomMetadata(e,s);return bo.endField(e)},Ni.decode=function(e,t){var n,r,i,a,o,u;t&&(u=e.dictionary())?t.has(n=u.id().low)?(a=(a=u.indexType())?Fo(a):new un,o=new Nn(t.get(n),a,n,u.isOrdered()),r=new Ni(e.name(),o,e.nullable(),No(e))):(a=(a=u.indexType())?Fo(a):new un,t.set(n,i=Mo(e,Lo(e,t))),o=new Nn(i,a,n,u.isOrdered()),r=new Ni(e.name(),o,e.nullable(),No(e))):(i=Mo(e,Lo(e,t)),r=new Ni(e.name(),i,e.nullable(),No(e)));return r||null},Ni.fromJSON=function(e,t){var n,r,i,a,o,u;return t&&(a=e.dictionary)?t.has(n=a.id)?(r=(r=a.indexType)?lo(r):new un,u=new Nn(t.get(n),r,n,a.isOrdered),i=new Ni(e.name,u,e.nullable,so(e.customMetadata))):(r=(r=a.indexType)?lo(r):new un,t.set(n,o=fo(e,co(e,t))),u=new Nn(o,r,n,a.isOrdered),i=new Ni(e.name,u,e.nullable,so(e.customMetadata))):(o=fo(e,co(e,t)),i=new Ni(e.name,o,e.nullable,so(e.customMetadata))),i||null},Li.encode=function(e,t){var n=t.fields.map((function(t){return Ni.encode(e,t)}));mo.startFieldsVector(e,n.length);var r=mo.createFieldsVector(e,n),i=t.metadata&&t.metadata.size>0?mo.createCustomMetadataVector(e,Object(Ut.a)(t.metadata).map((function(t){var n=Object(p.a)(t,2),r=n[0],i=n[1],a=e.createString("".concat(r)),o=e.createString("".concat(i));return ko.startKeyValue(e),ko.addKey(e,a),ko.addValue(e,o),ko.endKeyValue(e)}))):-1;mo.startSchema(e),mo.addFields(e,r),mo.addEndianness(e,Po?Oo.Little:Oo.Big),-1!==i&&mo.addCustomMetadata(e,i);return mo.endSchema(e)},Li.decode=function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:new Map,n=Do(e,t);return new Li(n,No(e),t)},Li.fromJSON=function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:new Map;return new Li(uo(e,t),so(e.customMetadata),t)},To.encode=function(e,t){var n=t.nodes||[],r=t.buffers||[];xo.startNodesVector(e,n.length),n.slice().reverse().forEach((function(t){return Ao.encode(e,t)}));var i=e.endVector();xo.startBuffersVector(e,r.length),r.slice().reverse().forEach((function(t){return Eo.encode(e,t)}));var a=e.endVector();return xo.startRecordBatch(e),xo.addLength(e,new ho(t.length,0)),xo.addNodes(e,i),xo.addBuffers(e,a),xo.endRecordBatch(e)},To.decode=function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:It.V4;return new To(e.length(),Bo(e),Co(e,t))},To.fromJSON=oo,Io.encode=function(e,t){var n=To.encode(e,t.data);return jo.startDictionaryBatch(e),jo.addId(e,new ho(t.id,0)),jo.addIsDelta(e,t.isDelta),jo.addData(e,n),jo.endDictionaryBatch(e)},Io.decode=function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:It.V4;return new Io(To.decode(e.data(),t),e.id(),e.isDelta())},Io.fromJSON=function(e){return new Io(oo(e.data),e.id,e.isDelta)},Ao.encode=function(e,t){return _o.createFieldNode(e,new ho(t.length,0),new ho(t.nullCount,0))},Ao.decode=function(e){return new Ao(e.length(),e.nullCount())},Eo.encode=function(e,t){return go.createBuffer(e,new ho(t.offset,0),new ho(t.length,0))},Eo.decode=function(e){return new Eo(e.offset(),e.length())};for(var Po=function(){var e=new ArrayBuffer(2);return new DataView(e).setInt16(0,256,!0),256===new Int16Array(e)[0]}(),Uo=w.ByteBuffer,Ro=function(e){return"Expected ".concat(Tt[e]," Message in stream, but was null or length 0.")},zo=function(e){return"Header pointer of flatbuffer-encoded ".concat(Tt[e]," Message is null or length 0.")},Vo=function(e,t){return"Expected to read ".concat(e," metadata bytes, but only read ").concat(t,".")},Wo=function(e,t){return"Expected to read ".concat(e," bytes for message body, but only read ").concat(t,".")},Yo=function(e){function t(e){Object(f.a)(this,t),this.source=e instanceof ja?e:new ja(e)}return Object(h.a)(t,[{key:e,value:function(){return this}},{key:"next",value:function(){var e;return(e=this.readMetadataLength()).done||-1===e.value&&(e=this.readMetadataLength()).done||(e=this.readMetadata(e.value)).done?N:e}},{key:"throw",value:function(e){return this.source.throw(e)}},{key:"return",value:function(e){return this.source.return(e)}},{key:"readMessage",value:function(e){var t;if((t=this.next()).done)return null;if(null!=e&&t.value.headerType!==e)throw new Error(Ro(e));return t.value}},{key:"readMessageBody",value:function(e){if(e<=0)return new Uint8Array(0);var t=_e(this.source.read(e));if(t.byteLength0&&void 0!==arguments[0]&&arguments[0],t=Tt.Schema,n=this.readMessage(t),r=n&&n.header();if(e&&!r)throw new Error(zo(t));return r}},{key:"readMetadataLength",value:function(){var e=this.source.read($o),t=e&&new Uo(e),n=t&&t.readInt32(0)||0;return{done:0===n,value:n}}},{key:"readMetadata",value:function(e){var t=this.source.read(e);if(!t)return N;if(t.byteLength0&&void 0!==a[0]&&a[0],n=Tt.Schema,e.next=4,this.readMessage(n);case 4:if(r=e.sent,i=r&&r.header(),!t||i){e.next=8;break}throw new Error(zo(n));case 8:return e.abrupt("return",i);case 9:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"readMetadataLength",value:function(){var e=Object(l.a)(d.mark((function e(){var t,n,r;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.source.read($o);case 2:return t=e.sent,n=t&&new Uo(t),r=n&&n.readInt32(0)||0,e.abrupt("return",{done:0===r,value:r});case 6:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"readMetadata",value:function(){var e=Object(l.a)(d.mark((function e(t){var n;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this.source.read(t);case 2:if(n=e.sent){e.next=5;break}return e.abrupt("return",N);case 5:if(!(n.byteLength1&&void 0!==arguments[1]?arguments[1]:0,n=-1,r=Ko.length;++n2147483647)throw new RangeError("Cannot write arrays larger than 2^31 - 1 in length");tn.isNull(e.type)||tu.call(this,i<=0?new Uint8Array(0):Dt(t.offset,r,t.nullBitmap)),this.nodes.push(new Ao(r,i))}return ht(Object(ft.a)(n.prototype),"visit",this).call(this,e)}},{key:"visitNull",value:function(e){return this}},{key:"visitDictionary",value:function(e){return this.visit(e.indices)}},{key:"nodes",get:function(){return this._nodes}},{key:"buffers",get:function(){return this._buffers}},{key:"byteLength",get:function(){return this._byteLength}},{key:"bufferRegions",get:function(){return this._bufferRegions}}],[{key:"assemble",value:function(){for(var e=new n,t=arguments.length,r=new Array(t),i=0;i=e.length?tu.call(this,new Uint8Array(0)):(t=e.values)instanceof Uint8Array?tu.call(this,Dt(e.offset,e.length,t)):tu.call(this,Lt(e))},eu.prototype.visitInt=nu,eu.prototype.visitFloat=nu,eu.prototype.visitUtf8=ru,eu.prototype.visitBinary=ru,eu.prototype.visitFixedSizeBinary=nu,eu.prototype.visitDate=nu,eu.prototype.visitTimestamp=nu,eu.prototype.visitTime=nu,eu.prototype.visitDecimal=nu,eu.prototype.visitList=iu,eu.prototype.visitStruct=au,eu.prototype.visitUnion=function(e){var t=e.type,n=e.length,r=e.typeIds,i=e.valueOffsets;if(tu.call(this,r),t.mode===jt.Sparse)return au.call(this,e);if(t.mode===jt.Dense){if(e.offset<=0)return tu.call(this,i),au.call(this,e);for(var a,o,u=r.reduce((function(e,t){return Math.max(e,t)}),r[0]),c=new Int32Array(u+1),s=new Int32Array(u+1).fill(-1),l=new Int32Array(n),f=Je(-i[0],n,i),h=-1;++h0&&void 0!==arguments[0]&&arguments[0];return this._sink.toString(e)}},{key:"toUint8Array",value:function(){var e=arguments.length>0&&void 0!==arguments[0]&&arguments[0];return this._sink.toUint8Array(e)}},{key:"writeAll",value:function(e){var t=this;return X(e)?e.then((function(e){return t.writeAll(e)})):te(e)?hu(this,e):fu(this,e)}},{key:"closed",get:function(){return this._sink.closed}},{key:t,value:function(){return this._sink[Symbol.asyncIterator]()}},{key:"toDOMStream",value:function(e){return this._sink.toDOMStream(e)}},{key:"toNodeStream",value:function(e){return this._sink.toNodeStream(e)}},{key:"close",value:function(){return this.reset()._sink.close()}},{key:"abort",value:function(e){return this.reset()._sink.abort(e)}},{key:"finish",value:function(){return this._autoDestroy?this.close():this.reset(this._sink,this._schema),this}},{key:"reset",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:this._sink,t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:null;return e===this._sink||e instanceof xa?this._sink=e:(this._sink=new xa,e&&oe(e)?this.toDOMStream({type:"bytes"}).pipeTo(e):e&&ce(e)&&this.toNodeStream({objectMode:!1}).pipe(e)),this._started&&this._schema&&this._writeFooter(this._schema),this._started=!1,this._dictionaryBlocks=[],this._recordBatchBlocks=[],this._dictionaryDeltaOffsets=new Map,t&&t.compareTo(this._schema)||(null===t?(this._position=0,this._schema=null):(this._started=!0,this._schema=t,this._writeSchema(t))),this}},{key:"write",value:function(e){var t=null;if(!this._sink)throw new Error("RecordBatchWriter is closed");if(null===e||void 0===e)return this.finish()&&void 0;if(e instanceof cs&&!(t=e.schema))return this.finish()&&void 0;if(e instanceof ss&&!(t=e.schema))return this.finish()&&void 0;if(t&&!t.compareTo(this._schema)){if(this._started&&this._autoDestroy)return this.close();this.reset(this._sink,t)}e instanceof ss?e instanceof ls||this._writeRecordBatch(e):e instanceof cs?this.writeAll(e.chunks):ee(e)&&this.writeAll(e)}},{key:"_writeMessage",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:8,n=t-1,r=So.encode(e),i=r.byteLength,a=this._writeLegacyIpcFormat?4:8,o=i+a+n&~n,u=o-i-a;return e.headerType===Tt.RecordBatch?this._recordBatchBlocks.push(new ka(o,e.bodyLength,this._position)):e.headerType===Tt.DictionaryBatch&&this._dictionaryBlocks.push(new ka(o,e.bodyLength,this._position)),this._writeLegacyIpcFormat||this._write(Int32Array.of(-1)),this._write(Int32Array.of(o-a)),i>0&&this._write(r),this._writePadding(u)}},{key:"_write",value:function(e){if(this._started){var t=_e(e);t&&t.byteLength>0&&(this._sink.write(t),this._position+=t.byteLength)}return this}},{key:"_writeSchema",value:function(e){return this._writeMessage(So.from(e))}},{key:"_writeFooter",value:function(e){return this._writeLegacyIpcFormat?this._write(Int32Array.of(0)):this._write(Int32Array.of(-1,0))}},{key:"_writeMagic",value:function(){return this._write(Ko)}},{key:"_writePadding",value:function(e){return e>0?this._write(new Uint8Array(e)):this}},{key:"_writeRecordBatch",value:function(e){var t=eu.assemble(e),n=t.byteLength,r=t.nodes,i=t.bufferRegions,a=t.buffers,o=new To(e.length,r,i),u=So.from(o,n);return this._writeDictionaries(e)._writeMessage(u)._writeBodyBuffers(a)}},{key:"_writeDictionaryBatch",value:function(e,t){var n=arguments.length>2&&void 0!==arguments[2]&&arguments[2];this._dictionaryDeltaOffsets.set(t,e.length+(this._dictionaryDeltaOffsets.get(t)||0));var r=eu.assemble(e),i=r.byteLength,a=r.nodes,o=r.bufferRegions,u=r.buffers,c=new To(e.length,a,o),s=new Io(c,t,n),l=So.from(s,i);return this._writeMessage(l)._writeBodyBuffers(u)}},{key:"_writeBodyBuffers",value:function(e){for(var t,n,r,i=-1,a=e.length;++i0&&(this._write(t),(r=(n+7&-8)-n)>0&&this._writePadding(r));return this}},{key:"_writeDictionaries",value:function(e){var t,n=Object(s.a)(e.dictionaries);try{for(n.s();!(t=n.n()).done;){var r=Object(p.a)(t.value,2),i=r[0],a=r[1],o=this._dictionaryDeltaOffsets.get(i)||0;if(0===o||(a=a.slice(o)).length>0){var u,c="chunks"in a?a.chunks:[a],l=Object(s.a)(c);try{for(l.s();!(u=l.n()).done;){var f=u.value;this._writeDictionaryBatch(f,i,o>0),o+=f.length}}catch(h){l.e(h)}finally{l.f()}}}}catch(h){n.e(h)}finally{n.f()}return this}}],[{key:"throughNode",value:function(e){throw new Error('"throughNode" not available in this environment')}},{key:"throughDOM",value:function(e,t){throw new Error('"throughDOM" not available in this environment')}}]),r}(M,Symbol.asyncIterator),su=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,null,[{key:"writeAll",value:function(e,t){var r=new n(t);return X(e)?e.then((function(e){return r.writeAll(e)})):te(e)?hu(r,e):fu(r,e)}}]),n}(cu),lu=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){var e;return Object(f.a)(this,n),(e=t.call(this))._autoDestroy=!0,e}return Object(h.a)(n,[{key:"_writeSchema",value:function(e){return this._writeMagic()._writePadding(2)}},{key:"_writeFooter",value:function(e){var t=ga.encode(new ga(e,It.V4,this._recordBatchBlocks,this._dictionaryBlocks));return ht(Object(ft.a)(n.prototype),"_writeFooter",this).call(this,e)._write(t)._write(Int32Array.of(t.byteLength))._writeMagic()}}],[{key:"writeAll",value:function(e){var t=new n;return X(e)?e.then((function(e){return t.writeAll(e)})):te(e)?hu(t,e):fu(t,e)}}]),n}(cu);function fu(e,t){var n=t;t instanceof cs&&(n=t.chunks,e.reset(void 0,t.schema));var r,i=Object(s.a)(n);try{for(i.s();!(r=i.n()).done;){var a=r.value;e.write(a)}}catch(o){i.e(o)}finally{i.f()}return e.finish()}function hu(e,t){return du.apply(this,arguments)}function du(){return(du=Object(l.a)(d.mark((function e(t,n){var r,i,a,o,u,c;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:r=!1,i=!1,e.prev=2,o=ou(n);case 4:return e.next=6,o.next();case 6:if(!(r=!(u=e.sent).done)){e.next=12;break}c=u.value,t.write(c);case 9:r=!1,e.next=4;break;case 12:e.next=18;break;case 14:e.prev=14,e.t0=e.catch(2),i=!0,a=e.t0;case 18:if(e.prev=18,e.prev=19,!r||null==o.return){e.next=23;break}return e.next=23,o.return();case 23:if(e.prev=23,!i){e.next=26;break}throw a;case 26:return e.finish(23);case 27:return e.finish(18);case 28:return e.abrupt("return",t.finish());case 29:case"end":return e.stop()}}),e,null,[[2,14,18,28],[19,,23,27]])})))).apply(this,arguments)}var pu=new Uint8Array(0),vu=function(e){return[pu,pu,new Uint8Array(e),pu]};function yu(e,t){for(var n,r,i=arguments.length>2&&void 0!==arguments[2]?arguments[2]:t.reduce((function(e,t){return Math.max(e,t.length)}),0),a=-1,o=t.length,u=Object(Ut.a)(e.fields),c=[],s=(i+63&-64)>>3;++a0;){for(u=Number.POSITIVE_INFINITY,c=-1;++c0&&(i[o++]=[u,l.slice()]))}return[e=new Li(r,e.metadata),i.map((function(t){return Object(yr.a)(ss,[e].concat(Object(Ut.a)(t)))}))]}(e,t.map((function(e){return e instanceof gi?e.chunks.map((function(e){return e.data})):[e.data]})))}function gu(e,t,n,r,i){for(var a,o,u=0,c=-1,s=r.length,l=(t+63&-64)>>3;++c=t?u===t?n[c]=a:(n[c]=a.slice(0,t),a=a.slice(t,u-t),i.numBatches=Math.max(i.numBatches,r[c].unshift(a))):((o=e[c]).nullable||(e[c]=o.clone({nullable:!0})),n[c]=a?a._changeLengthAndBackfillNullBitmap(t):Mn.new(o.type,0,t,t,vu(l)));return n}function wu(e,t){if(null==e)return{};var n,r,i=function(e,t){if(null==e)return{};var n,r,i={},a=Object.keys(e);for(r=0;r=0||(i[n]=e[n]);return i}(e,t);if(Object.getOwnPropertySymbols){var a=Object.getOwnPropertySymbols(e);for(r=0;r=0||Object.prototype.propertyIsEnumerable.call(e,n)&&(i[n]=e[n])}return i}var ku=function(e,t){Object(D.a)(r,e);var n=Object(L.a)(r);function r(e,t){var i;return Object(f.a)(this,r),(i=n.call(this))._children=t,i.numChildren=e.childData.length,i._bindDataAccessors(i.data=e),i}return Object(h.a)(r,[{key:"type",get:function(){return this.data.type}},{key:"typeId",get:function(){return this.data.typeId}},{key:"length",get:function(){return this.data.length}},{key:"offset",get:function(){return this.data.offset}},{key:"stride",get:function(){return this.data.stride}},{key:"nullCount",get:function(){return this.data.nullCount}},{key:"byteLength",get:function(){return this.data.byteLength}},{key:"VectorName",get:function(){return"".concat(wt[this.typeId],"Vector")}},{key:"ArrayType",get:function(){return this.type.ArrayType}},{key:"values",get:function(){return this.data.values}},{key:"typeIds",get:function(){return this.data.typeIds}},{key:"nullBitmap",get:function(){return this.data.nullBitmap}},{key:"valueOffsets",get:function(){return this.data.valueOffsets}},{key:t,get:function(){return"".concat(this.VectorName,"<").concat(this.type[Symbol.toStringTag],">")}},{key:"clone",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:this._children;return gt.new(e,t)}},{key:"concat",value:function(){for(var e=arguments.length,t=new Array(e),n=0;n0){var t=this.offset+e;return 0!==(this.nullBitmap[t>>3]&1<=this.numChildren?null:(this._children||(this._children=[]))[e]||(this._children[e]=gt.new(this.data.childData[e]))}},{key:"toJSON",value:function(){return Object(Ut.a)(this)}},{key:"_sliceInternal",value:function(e,t,n){return e.clone(e.data.slice(t,n-t),null)}},{key:"_bindDataAccessors",value:function(e){}}]),r}(gt,Symbol.toStringTag);ku.prototype[Symbol.isConcatSpreadable]=!0;var _u=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"asUtf8",value:function(){return gt.new(this.data.clone(new mn))}}]),n}(ku),Ou=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,null,[{key:"from",value:function(e){return as((function(){return new gn}),e)}}]),n}(ku),xu=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,null,[{key:"from",value:function(){for(var e=arguments.length,t=new Array(e),n=0;n>>0)},_c=function(e){return new Date(e)},Oc=function(e,t,n){var r=t[n],i=t[n+1];return null!=r&&null!=i?e.subarray(r,i):null},xc=function(e,t){return function(e,t){return _c(function(e,t){return 864e5*e[t]}(e,t))}(e.values,t)},jc=function(e,t){return function(e,t){return _c(kc(e,t))}(e.values,2*t)},Sc=function(e,t){var n=e.stride;return e.values[n*t]},Tc=function(e,t){var n=e.stride;return cr(e.values[n*t])},Ic=function(e,t){var n=e.stride,r=e.values,i=e.type;return jr.new(r.subarray(n*t,n*(t+1)),i.isSigned)},Ec=function(e,t){var n=e.values;return 1e3*kc(n,2*t)},Ac=function(e,t){var n=e.values;return kc(n,2*t)},Bc=function(e,t){return function(e,t){return e[t+1]/1e3*4294967296+(e[t]>>>0)/1e3}(e.values,2*t)},Cc=function(e,t){return function(e,t){return e[t+1]/1e6*4294967296+(e[t]>>>0)/1e6}(e.values,2*t)},Dc=function(e,t){return e.values[e.stride*t]},Lc=function(e,t){return e.values[e.stride*t]},Nc=function(e,t){var n=e.values;return jr.signed(n.subarray(2*t,2*(t+1)))},Fc=function(e,t){var n=e.values;return jr.signed(n.subarray(2*t,2*(t+1)))},Mc=function(e,t){var n=e.typeIdToChildIndex[e.typeIds[t]],r=e.getChildAt(n);return r?r.get(e.valueOffsets[t]):null},Pc=function(e,t){var n=e.typeIdToChildIndex[e.typeIds[t]],r=e.getChildAt(n);return r?r.get(t):null},Uc=function(e,t){return e.values.subarray(2*t,2*(t+1))},Rc=function(e,t){var n=e.values[t],r=new Int32Array(2);return r[0]=n/12|0,r[1]=n%12|0,r};wc.prototype.visitNull=function(e,t){return null},wc.prototype.visitBool=function(e,t){var n=e.offset+t;return 0!==(e.values[n>>3]&1<0?0:-1},Vc.prototype.visitBool=Wc,Vc.prototype.visitInt=Wc,Vc.prototype.visitInt8=Wc,Vc.prototype.visitInt16=Wc,Vc.prototype.visitInt32=Wc,Vc.prototype.visitInt64=Wc,Vc.prototype.visitUint8=Wc,Vc.prototype.visitUint16=Wc,Vc.prototype.visitUint32=Wc,Vc.prototype.visitUint64=Wc,Vc.prototype.visitFloat=Wc,Vc.prototype.visitFloat16=Wc,Vc.prototype.visitFloat32=Wc,Vc.prototype.visitFloat64=Wc,Vc.prototype.visitUtf8=Wc,Vc.prototype.visitBinary=Wc,Vc.prototype.visitFixedSizeBinary=Wc,Vc.prototype.visitDate=Wc,Vc.prototype.visitDateDay=Wc,Vc.prototype.visitDateMillisecond=Wc,Vc.prototype.visitTimestamp=Wc,Vc.prototype.visitTimestampSecond=Wc,Vc.prototype.visitTimestampMillisecond=Wc,Vc.prototype.visitTimestampMicrosecond=Wc,Vc.prototype.visitTimestampNanosecond=Wc,Vc.prototype.visitTime=Wc,Vc.prototype.visitTimeSecond=Wc,Vc.prototype.visitTimeMillisecond=Wc,Vc.prototype.visitTimeMicrosecond=Wc,Vc.prototype.visitTimeNanosecond=Wc,Vc.prototype.visitDecimal=Wc,Vc.prototype.visitList=Wc,Vc.prototype.visitStruct=Wc,Vc.prototype.visitUnion=Wc,Vc.prototype.visitDenseUnion=Yc,Vc.prototype.visitSparseUnion=Yc,Vc.prototype.visitDictionary=Wc,Vc.prototype.visitInterval=Wc,Vc.prototype.visitIntervalDayTime=Wc,Vc.prototype.visitIntervalYearMonth=Wc,Vc.prototype.visitFixedSizeList=Wc,Vc.prototype.visitMap=Wc;var qc=new Vc,Hc=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return n}(Rt);function $c(e){if(e.nullCount>0)return function(e){var t=zc.getVisitFn(e);return Nt(e.nullBitmap,e.offset,e.length,e,(function(e,n,r,i){return 0!==(r&1<0)?e.values.subarray(0,r)[Symbol.iterator]():d.mark((function t(n){var i;return d.wrap((function(t){for(;;)switch(t.prev=t.next){case 0:i=-1;case 1:if(!(++i1?t-1:0),r=1;r0&&(this.get=(t=this.get,function(e){return this.isValid(e)?t.call(this,e):null}),this.set=function(e){return function(t,n){Ct(this.nullBitmap,this.offset+t,!(null===n||void 0===n))&&e.call(this,t,n)}}(this.set));var t},Object.keys(wt).map((function(e){return wt[e]})).filter((function(e){return"number"===typeof e})).filter((function(e){return e!==wt.NONE})).forEach((function(e){var t,n=ts.visit(e);n.prototype.get=(t=zc.getVisitFn(e),function(e){return t(this,e)}),n.prototype.set=gc(ha.getVisitFn(e)),n.prototype.indexOf=gc(qc.getVisitFn(e)),n.prototype.toArray=mc(Jc.getVisitFn(e)),n.prototype.getByteWidth=function(e){return function(){return e(this.type)}}(es.getVisitFn(e)),n.prototype[Symbol.iterator]=mc(Kc.getVisitFn(e))}));var cs=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){var e;Object(f.a)(this,n);for(var r=null,i=arguments.length,a=new Array(i),o=0;o0&&void 0!==arguments[0]?arguments[0]:this._chunks;return new n(this._schema,e)}},{key:"getColumn",value:function(e){return this.getColumnAt(this.getColumnIndex(e))}},{key:"getColumnAt",value:function(e){return this.getChildAt(e)}},{key:"getColumnIndex",value:function(e){return this._schema.fields.findIndex((function(t){return t.name===e}))}},{key:"getChildAt",value:function(e){if(e<0||e>=this.numChildren)return null;var t,n,r=this._schema.fields,i=this._children||(this._children=[]);if(n=i[e])return n;if(t=r[e]){var a=this._chunks.map((function(t){return t.getChildAt(e)})).filter((function(e){return null!=e}));if(a.length>0)return i[e]=new Oi(t,a)}return null}},{key:"serialize",value:function(){var e=!(arguments.length>1&&void 0!==arguments[1])||arguments[1],t=e?su:lu;return t.writeAll(this).toUint8Array(!0)}},{key:"count",value:function(){return this._length}},{key:"select",value:function(){for(var e=this._schema.fields.reduce((function(e,t,n){return e.set(t.name,n)}),new Map),t=arguments.length,n=new Array(t),r=0;r-1}))))}},{key:"selectAt",value:function(){for(var e,t=arguments.length,r=new Array(t),i=0;i3&&void 0!==arguments[3]?arguments[3]:u[r];return void 0===a?t.getColumnAt(r):e.getColumnAt(a)}))),Object(Ut.a)(o.map((function(t){return e.getColumnAt(t)})))).filter(Boolean);return Object(yr.a)(n,Object(Ut.a)(mu(c,s)))}}],[{key:"empty",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:new Li([]);return new n(e,[])}},{key:"from",value:function(e){if(!e)return n.empty();if("object"===typeof e){var t=ee(e.values)?function(e){if(e.type instanceof In)return cs.fromStruct(rc.from(e));return null}(e):te(e.values)?function(e){if(e.type instanceof In)return rc.from(e).then((function(e){return cs.fromStruct(e)}));return null}(e):null;if(null!==t)return t}var r=vs.from(e);return X(r)?Object(l.a)(d.mark((function e(){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.t0=n,e.next=3,r;case 3:return e.t1=e.sent,e.next=6,e.t0.from.call(e.t0,e.t1);case 6:return e.abrupt("return",e.sent);case 7:case"end":return e.stop()}}),e)})))():r.isSync()&&(r=r.open())?r.schema?new n(r.schema,Object(Ut.a)(r)):n.empty():function(){var e=Object(l.a)(d.mark((function e(t){var r,i,a,o,u,c,s,l,f;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,t;case 2:if(r=e.sent,i=r.schema,a=[],!i){e.next=35;break}o=!1,u=!1,e.prev=8,s=os(r);case 10:return e.next=12,s.next();case 12:if(!(o=!(l=e.sent).done)){e.next=18;break}f=l.value,a.push(f);case 15:o=!1,e.next=10;break;case 18:e.next=24;break;case 20:e.prev=20,e.t0=e.catch(8),u=!0,c=e.t0;case 24:if(e.prev=24,e.prev=25,!o||null==s.return){e.next=29;break}return e.next=29,s.return();case 29:if(e.prev=29,!u){e.next=32;break}throw c;case 32:return e.finish(29);case 33:return e.finish(24);case 34:return e.abrupt("return",new n(i,a));case 35:return e.abrupt("return",n.empty());case 36:case"end":return e.stop()}}),e,null,[[8,20,24,34],[25,,29,33]])})));return function(t){return e.apply(this,arguments)}}()(r.open())}},{key:"fromAsync",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,n.from(t);case 2:return e.abrupt("return",e.sent);case 3:case"end":return e.stop()}}),e)})));return function(t){return e.apply(this,arguments)}}()},{key:"fromStruct",value:function(e){return n.new(e.data.childData,e.type.children)}},{key:"new",value:function(){for(var e=arguments.length,t=new Array(e),r=0;r1&&void 0!==arguments[1]?arguments[1]:this._children;return new n(this._schema,e,t)}},{key:"concat",value:function(){for(var e=arguments.length,t=new Array(e),r=0;r-1}))))}},{key:"selectAt",value:function(){for(var e,t=this,r=arguments.length,i=new Array(r),a=0;a0&&this.dictionaries.set(t.id,n),this}}],[{key:"collect",value:function(e){return(new n).visit(e.data,new In(e.schema.fields)).dictionaries}}]),n}(Rt),hs=d.mark(Ts);function ds(e){var t,n,r,i=2;for("undefined"!==typeof Symbol&&(n=Symbol.asyncIterator,r=Symbol.iterator);i--;){if(n&&null!=(t=e[n]))return t.call(e);if(r&&null!=(t=e[r]))return new ps(t.call(e));n="@@asyncIterator",r="@@iterator"}throw new TypeError("Object is not async iterable")}function ps(e){function t(e){if(Object(e)!==e)return Promise.reject(new TypeError(e+" is not an object."));var t=e.done;return Promise.resolve(e.value).then((function(e){return{value:e,done:t}}))}return(ps=function(e){this.s=e,this.n=e.next}).prototype={s:null,n:null,next:function(){return t(this.n.apply(this.s,arguments))},return:function(e){var n=this.s.return;return void 0===n?Promise.resolve({value:e,done:!0}):t(n.apply(this.s,arguments))},throw:function(e){var n=this.s.return;return void 0===n?Promise.reject(e):t(n.apply(this.s,arguments))}},new ps(e)}var vs=function(e,t,n){Object(D.a)(i,e);var r=Object(L.a)(i);function i(e){var t;return Object(f.a)(this,i),(t=r.call(this))._impl=e,t}return Object(h.a)(i,[{key:"closed",get:function(){return this._impl.closed}},{key:"schema",get:function(){return this._impl.schema}},{key:"autoDestroy",get:function(){return this._impl.autoDestroy}},{key:"dictionaries",get:function(){return this._impl.dictionaries}},{key:"numDictionaries",get:function(){return this._impl.numDictionaries}},{key:"numRecordBatches",get:function(){return this._impl.numRecordBatches}},{key:"footer",get:function(){return this._impl.isFile()?this._impl.footer:null}},{key:"isSync",value:function(){return this._impl.isSync()}},{key:"isAsync",value:function(){return this._impl.isAsync()}},{key:"isFile",value:function(){return this._impl.isFile()}},{key:"isStream",value:function(){return this._impl.isStream()}},{key:"next",value:function(){return this._impl.next()}},{key:"throw",value:function(e){return this._impl.throw(e)}},{key:"return",value:function(e){return this._impl.return(e)}},{key:"cancel",value:function(){return this._impl.cancel()}},{key:"reset",value:function(e){return this._impl.reset(e),this._DOMStream=void 0,this._nodeStream=void 0,this}},{key:"open",value:function(e){var t=this,n=this._impl.open(e);return X(n)?n.then((function(){return t})):this}},{key:"readRecordBatch",value:function(e){return this._impl.isFile()?this._impl.readRecordBatch(e):null}},{key:t,value:function(){return this._impl[Symbol.iterator]()}},{key:n,value:function(){return this._impl[Symbol.asyncIterator]()}},{key:"toDOMStream",value:function(){var e=this;return et.toDOMStream(this.isSync()?Object(ei.a)({},Symbol.iterator,(function(){return e})):Object(ei.a)({},Symbol.asyncIterator,(function(){return e})))}},{key:"toNodeStream",value:function(){var e=this;return et.toNodeStream(this.isSync()?Object(ei.a)({},Symbol.iterator,(function(){return e})):Object(ei.a)({},Symbol.asyncIterator,(function(){return e})),{objectMode:!0})}}],[{key:"throughNode",value:function(e){throw new Error('"throughNode" not available in this environment')}},{key:"throughDOM",value:function(e,t){throw new Error('"throughDOM" not available in this environment')}},{key:"from",value:function(e){return e instanceof i?e:ne(e)?function(e){return new ys(new js(e))}(e):ie(e)?function(e){return Bs.apply(this,arguments)}(e):X(e)?Object(l.a)(d.mark((function t(){return d.wrap((function(t){for(;;)switch(t.prev=t.next){case 0:return t.t0=i,t.next=3,e;case 3:return t.t1=t.sent,t.next=6,t.t0.from.call(t.t0,t.t1);case 6:return t.abrupt("return",t.sent);case 7:case"end":return t.stop()}}),t)})))():ae(e)||ue(e)||se(e)||te(e)?function(e){return As.apply(this,arguments)}(new Sa(e)):function(e){var t=e.peek(Jo+7&-8);return t&&t.byteLength>=4?Go(t)?new ms(new Os(e.read())):new ys(new ks(e)):new ys(new ks(d.mark((function e(){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:case"end":return e.stop()}}),e)}))()))}(new ja(e))}},{key:"readAll",value:function(e){return e instanceof i?e.isSync()?Ts(e):Is(e):ne(e)||ArrayBuffer.isView(e)||ee(e)||re(e)?Ts(e):Is(e)}}]),i}(M,Symbol.iterator,Symbol.asyncIterator),ys=function(e,t,n){Object(D.a)(i,e);var r=Object(L.a)(i);function i(e){var t;return Object(f.a)(this,i),(t=r.call(this,e))._impl=e,t}return Object(h.a)(i,[{key:t,value:function(){return this._impl[Symbol.iterator]()}},{key:n,value:function(){var e=this;return m(d.mark((function t(){return d.wrap((function(t){for(;;)switch(t.prev=t.next){case 0:return t.delegateYield(g(ds(e[Symbol.iterator]()),y),"t0",1);case 1:case"end":return t.stop()}}),t)})))()}}]),i}(vs,Symbol.iterator,Symbol.asyncIterator),bs=function(e,t,n){Object(D.a)(i,e);var r=Object(L.a)(i);function i(e){var t;return Object(f.a)(this,i),(t=r.call(this,e))._impl=e,t}return Object(h.a)(i,[{key:t,value:function(){throw new Error("AsyncRecordBatchStreamReader is not Iterable")}},{key:n,value:function(){return this._impl[Symbol.asyncIterator]()}}]),i}(vs,Symbol.iterator,Symbol.asyncIterator),ms=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._impl=e,r}return n}(ys),gs=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this,e))._impl=e,r}return n}(bs),ws=function(){function e(){var t=arguments.length>0&&void 0!==arguments[0]?arguments[0]:new Map;Object(f.a)(this,e),this.closed=!1,this.autoDestroy=!0,this._dictionaryIndex=0,this._recordBatchIndex=0,this.dictionaries=t}return Object(h.a)(e,[{key:"numDictionaries",get:function(){return this._dictionaryIndex}},{key:"numRecordBatches",get:function(){return this._recordBatchIndex}},{key:"isSync",value:function(){return!1}},{key:"isAsync",value:function(){return!1}},{key:"isFile",value:function(){return!1}},{key:"isStream",value:function(){return!1}},{key:"reset",value:function(e){return this._dictionaryIndex=0,this._recordBatchIndex=0,this.schema=e,this.dictionaries=new Map,this}},{key:"_loadRecordBatch",value:function(e,t){return new ss(this.schema,e.length,this._loadVectors(e,t,this.schema.fields))}},{key:"_loadDictionaryBatch",value:function(e,t){var n=e.id,r=e.isDelta,i=e.data,a=this.dictionaries,o=this.schema,u=a.get(n);if(r||!u){var c=o.dictionaries.get(n);return u&&r?u.concat(gt.new(this._loadVectors(i,t,[c])[0])):gt.new(this._loadVectors(i,t,[c])[0])}return u}},{key:"_loadVectors",value:function(e,t,n){return new Ma(t,e.nodes,e.buffers,this.dictionaries).visitMany(n)}}]),e}(),ks=function(e,t){Object(D.a)(r,e);var n=Object(L.a)(r);function r(e,t){var i;return Object(f.a)(this,r),(i=n.call(this,t))._reader=ne(e)?new Ho(i._handle=e):new Yo(i._handle=e),i}return Object(h.a)(r,[{key:"isSync",value:function(){return!0}},{key:"isStream",value:function(){return!0}},{key:t,value:function(){return this}},{key:"cancel",value:function(){!this.closed&&(this.closed=!0)&&(this.reset()._reader.return(),this._reader=null,this.dictionaries=null)}},{key:"open",value:function(e){return this.closed||(this.autoDestroy=Ss(this,e),this.schema||(this.schema=this._reader.readSchema())||this.cancel()),this}},{key:"throw",value:function(e){return!this.closed&&this.autoDestroy&&(this.closed=!0)?this.reset()._reader.throw(e):N}},{key:"return",value:function(e){return!this.closed&&this.autoDestroy&&(this.closed=!0)?this.reset()._reader.return(e):N}},{key:"next",value:function(){if(this.closed)return N;for(var e,t=this._reader;e=this._readNextMessageAndValidate();)if(e.isSchema())this.reset(e.header());else{if(e.isRecordBatch()){this._recordBatchIndex++;var n=e.header(),r=t.readMessageBody(e.bodyLength);return{done:!1,value:this._loadRecordBatch(n,r)}}if(e.isDictionaryBatch()){this._dictionaryIndex++;var i=e.header(),a=t.readMessageBody(e.bodyLength),o=this._loadDictionaryBatch(i,a);this.dictionaries.set(i.id,o)}}return this.schema&&0===this._recordBatchIndex?(this._recordBatchIndex++,{done:!1,value:new ls(this.schema)}):this.return()}},{key:"_readNextMessageAndValidate",value:function(e){return this._reader.readMessage(e)}}]),r}(ws,Symbol.iterator),_s=function(e,t){Object(D.a)(r,e);var n=Object(L.a)(r);function r(e,t){var i;return Object(f.a)(this,r),(i=n.call(this,t))._reader=new qo(i._handle=e),i}return Object(h.a)(r,[{key:"isAsync",value:function(){return!0}},{key:"isStream",value:function(){return!0}},{key:t,value:function(){return this}},{key:"cancel",value:function(){var e=Object(l.a)(d.mark((function e(){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:if(this.closed||!(this.closed=!0)){e.next=5;break}return e.next=3,this.reset()._reader.return();case 3:this._reader=null,this.dictionaries=null;case 5:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"open",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:if(this.closed){e.next=10;break}if(this.autoDestroy=Ss(this,t),e.t0=this.schema,e.t0){e.next=7;break}return e.next=6,this._reader.readSchema();case 6:e.t0=this.schema=e.sent;case 7:if(e.t0){e.next=10;break}return e.next=10,this.cancel();case 10:return e.abrupt("return",this);case 11:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"throw",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:if(this.closed||!this.autoDestroy||!(this.closed=!0)){e.next=4;break}return e.next=3,this.reset()._reader.throw(t);case 3:return e.abrupt("return",e.sent);case 4:return e.abrupt("return",N);case 5:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"return",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:if(this.closed||!this.autoDestroy||!(this.closed=!0)){e.next=4;break}return e.next=3,this.reset()._reader.return(t);case 3:return e.abrupt("return",e.sent);case 4:return e.abrupt("return",N);case 5:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()},{key:"next",value:function(){var e=Object(l.a)(d.mark((function e(){var t,n,r,i,a,o,u,c;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:if(!this.closed){e.next=2;break}return e.abrupt("return",N);case 2:n=this._reader;case 3:return e.next=5,this._readNextMessageAndValidate();case 5:if(!(t=e.sent)){e.next=31;break}if(!t.isSchema()){e.next=11;break}return e.next=9,this.reset(t.header());case 9:e.next=29;break;case 11:if(!t.isRecordBatch()){e.next=21;break}return this._recordBatchIndex++,r=t.header(),e.next=16,n.readMessageBody(t.bodyLength);case 16:return i=e.sent,a=this._loadRecordBatch(r,i),e.abrupt("return",{done:!1,value:a});case 21:if(!t.isDictionaryBatch()){e.next=29;break}return this._dictionaryIndex++,o=t.header(),e.next=26,n.readMessageBody(t.bodyLength);case 26:u=e.sent,c=this._loadDictionaryBatch(o,u),this.dictionaries.set(o.id,c);case 29:e.next=3;break;case 31:if(!this.schema||0!==this._recordBatchIndex){e.next=34;break}return this._recordBatchIndex++,e.abrupt("return",{done:!1,value:new ls(this.schema)});case 34:return e.next=36,this.return();case 36:return e.abrupt("return",e.sent);case 37:case"end":return e.stop()}}),e,this)})));return function(){return e.apply(this,arguments)}}()},{key:"_readNextMessageAndValidate",value:function(){var e=Object(l.a)(d.mark((function e(t){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,this._reader.readMessage(t);case 2:return e.abrupt("return",e.sent);case 3:case"end":return e.stop()}}),e,this)})));return function(t){return e.apply(this,arguments)}}()}]),r}(ws,Symbol.asyncIterator),Os=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e,r){return Object(f.a)(this,n),t.call(this,e instanceof Ea?e:new Ea(e),r)}return Object(h.a)(n,[{key:"footer",get:function(){return this._footer}},{key:"numDictionaries",get:function(){return this._footer?this._footer.numDictionaries:0}},{key:"numRecordBatches",get:function(){return this._footer?this._footer.numRecordBatches:0}},{key:"isSync",value:function(){return!0}},{key:"isFile",value:function(){return!0}},{key:"open",value:function(e){if(!this.closed&&!this._footer){this.schema=(this._footer=this._readFooter()).schema;var t,r=Object(s.a)(this._footer.dictionaryBatches());try{for(r.s();!(t=r.n()).done;){t.value&&this._readDictionaryBatch(this._dictionaryIndex++)}}catch(i){r.e(i)}finally{r.f()}}return ht(Object(ft.a)(n.prototype),"open",this).call(this,e)}},{key:"readRecordBatch",value:function(e){if(this.closed)return null;this._footer||this.open();var t=this._footer&&this._footer.getRecordBatch(e);if(t&&this._handle.seek(t.offset)){var n=this._reader.readMessage(Tt.RecordBatch);if(n&&n.isRecordBatch()){var r=n.header(),i=this._reader.readMessageBody(n.bodyLength);return this._loadRecordBatch(r,i)}}return null}},{key:"_readDictionaryBatch",value:function(e){var t=this._footer&&this._footer.getDictionaryBatch(e);if(t&&this._handle.seek(t.offset)){var n=this._reader.readMessage(Tt.DictionaryBatch);if(n&&n.isDictionaryBatch()){var r=n.header(),i=this._reader.readMessageBody(n.bodyLength),a=this._loadDictionaryBatch(r,i);this.dictionaries.set(r.id,a)}}}},{key:"_readFooter",value:function(){var e=this._handle,t=e.size-Zo,n=e.readInt32(t),r=e.readAt(t-n,n);return ga.decode(r)}},{key:"_readNextMessageAndValidate",value:function(e){if(this._footer||this.open(),this._footer&&this._recordBatchIndex1?r-1:0),a=1;a=4)){e.next=18;break}if(Go(n)){e.next=8;break}e.t1=new bs(new _s(t)),e.next=15;break;case 8:return e.t2=ms,e.t3=Os,e.next=12,t.read();case 12:e.t4=e.sent,e.t5=new e.t3(e.t4),e.t1=new e.t2(e.t5);case 15:e.t0=e.t1,e.next=19;break;case 18:e.t0=new bs(new _s(m(d.mark((function e(){return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:case"end":return e.stop()}}),e)})))()));case 19:return e.abrupt("return",e.t0);case 20:case"end":return e.stop()}}),e)})))).apply(this,arguments)}function Bs(){return(Bs=Object(l.a)(d.mark((function e(t){var n,r,i;return d.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:return e.next=2,t.stat();case 2:if(n=e.sent,r=n.size,i=new Aa(t,r),!(r>=Xo)){e.next=12;break}return e.t0=Go,e.next=9,i.readAt(0,Jo+7&-8);case 9:if(e.t1=e.sent,!(0,e.t0)(e.t1)){e.next=12;break}return e.abrupt("return",new gs(new xs(i)));case 12:return e.abrupt("return",new bs(new _s(i)));case 13:case"end":return e.stop()}}),e)})))).apply(this,arguments)}var Cs=["readableStrategy","writableStrategy","queueingStrategy"];var Ds=function(){function e(t){var n,r,i=this;Object(f.a)(this,e),this._numChunks=0,this._finished=!1,this._bufferedSize=0;var a=t.readableStrategy,o=t.writableStrategy,u=t.queueingStrategy,c=void 0===u?"count":u,s=wu(t,Cs);this._controller=null,this._builder=Qn.new(s),this._getSize="bytes"!==c?Ls:Ns;var l=Object(lt.a)({},a).highWaterMark,h=void 0===l?"bytes"===c?Math.pow(2,14):1e3:l,d=Object(lt.a)({},o).highWaterMark,p=void 0===d?"bytes"===c?Math.pow(2,14):1e3:d;this.readable=new ReadableStream((n={},Object(ei.a)(n,"cancel",(function(){i._builder.clear()})),Object(ei.a)(n,"pull",(function(e){i._maybeFlush(i._builder,i._controller=e)})),Object(ei.a)(n,"start",(function(e){i._maybeFlush(i._builder,i._controller=e)})),n),{highWaterMark:h,size:"bytes"!==c?Ls:Ns}),this.writable=new WritableStream((r={},Object(ei.a)(r,"abort",(function(){i._builder.clear()})),Object(ei.a)(r,"write",(function(){i._maybeFlush(i._builder,i._controller)})),Object(ei.a)(r,"close",(function(){i._maybeFlush(i._builder.finish(),i._controller)})),r),{highWaterMark:p,size:function(e){return i._writeValueAndReturnChunkSize(e)}})}return Object(h.a)(e,[{key:"_writeValueAndReturnChunkSize",value:function(e){var t=this._bufferedSize;return this._bufferedSize=this._getSize(this._builder.append(e)),this._bufferedSize-t}},{key:"_maybeFlush",value:function(e,t){null!==t&&(this._bufferedSize>=t.desiredSize&&++this._numChunks&&this._enqueue(t,e.toVector()),e.finished&&((e.length>0||0===this._numChunks)&&++this._numChunks&&this._enqueue(t,e.toVector()),!this._finished&&(this._finished=!0)&&this._enqueue(t,null)))}},{key:"_enqueue",value:function(e,t){this._bufferedSize=0,this._controller=null,null===t?e.close():e.enqueue(t)}}]),e}(),Ls=function(e){return e.length},Ns=function(e){return e.byteLength};var Fs=function(){function e(){Object(f.a)(this,e)}return Object(h.a)(e,[{key:"eq",value:function(t){return t instanceof e||(t=new Ms(t)),new Ys(this,t)}},{key:"le",value:function(t){return t instanceof e||(t=new Ms(t)),new qs(this,t)}},{key:"ge",value:function(t){return t instanceof e||(t=new Ms(t)),new Hs(this,t)}},{key:"lt",value:function(e){return new $s(this.ge(e))}},{key:"gt",value:function(e){return new $s(this.le(e))}},{key:"ne",value:function(e){return new $s(this.eq(e))}}]),e}(),Ms=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this)).v=e,r}return n}(Fs),Ps=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this)).name=e,r}return Object(h.a)(n,[{key:"bind",value:function(e){if(!this.colidx){this.colidx=-1;for(var t=e.schema.fields,n=-1;++n=n.v;return function(){return r}}},{key:"_bindColCol",value:function(e,t,n){var r=t.bind(e),i=n.bind(e);return function(e,t){return r(e,t)>=i(e,t)}}},{key:"_bindColLit",value:function(e,t,n){var r=t.bind(e);return function(e,t){return r(e,t)>=n.v}}},{key:"_bindLitCol",value:function(e,t,n){var r=n.bind(e);return function(e,n){return t.v>=r(e,n)}}}]),n}(Rs),$s=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(e){var r;return Object(f.a)(this,n),(r=t.call(this)).child=e,r}return Object(h.a)(n,[{key:"bind",value:function(e){var t=this.child.bind(e);return function(e,n){return!t(e,n)}}}]),n}(Us);cs.prototype.countBy=function(e){return new Ks(this.chunks).countBy(e)},cs.prototype.scan=function(e,t){return new Ks(this.chunks).scan(e,t)},cs.prototype.scanReverse=function(e,t){return new Ks(this.chunks).scanReverse(e,t)},cs.prototype.filter=function(e){return new Ks(this.chunks).filter(e)};var Ks=function(e){Object(D.a)(n,e);var t=Object(L.a)(n);function n(){return Object(f.a)(this,n),t.apply(this,arguments)}return Object(h.a)(n,[{key:"filter",value:function(e){return new Gs(this.chunks,e)}},{key:"scan",value:function(e,t){for(var n=this.chunks,r=n.length,i=-1;++i=0;){var i=n[r];t&&t(i);for(var a=i.length;--a>=0;)e(a,i)}}},{key:"countBy",value:function(e){var t=this.chunks,n=t.length,r="string"===typeof e?new Ps(e):e;r.bind(t[n-1]);var i=r.vector;if(!tn.isDictionary(i.type))throw new Error("countBy currently only supports dictionary-encoded columns");for(var a=Math.ceil(Math.log(i.length)/Math.log(256)),o=new(4==a?Uint32Array:a>=2?Uint16Array:Uint8Array)(i.dictionary.length),u=-1;++u=0;)for(var i=n[r],a=this._predicate.bind(i),o=!1,u=i.length;--u>=0;)a(u,i)&&(t&&!o&&(t(i),o=!0),e(u,i))}},{key:"count",value:function(){for(var e=0,t=this._chunks,n=t.length,r=-1;++r=2?Uint16Array:Uint8Array)(i.dictionary.length),u=-1;++ue.length)&&(t=e.length);for(var n=0,r=new Array(t);n\n \n ",d.appendChild(document.createTextNode("".concat(i).concat(s?" [":" {"))),d.addEventListener("mouseup",(function(t){t.stopPropagation(),Ae(f,re(e,null,n,r))})),o=o(e);for(var p=0;!(u=o.next()).done&&p<20;++p)f.appendChild(u.value);if(!u.done){var v=f.appendChild(document.createElement("a"));v.className="observablehq--field",v.style.display="block",v.appendChild(document.createTextNode(" \u2026 more")),v.addEventListener("mouseup",(function(e){e.stopPropagation(),f.insertBefore(u.value,f.lastChild.previousSibling);for(var t=0;!(u=o.next()).done&&t<19;++t)f.insertBefore(u.value,f.lastChild.previousSibling);u.done&&f.removeChild(f.lastChild.previousSibling),a(f,"load")}))}return f.appendChild(document.createTextNode(s?"]":"}")),f}function M(e){var t,n,r,i,a;return u.a.wrap((function(o){for(;;)switch(o.prev=o.next){case 0:t=Object(s.a)(e),o.prev=1,t.s();case 3:if((n=t.n()).done){o.next=9;break}return r=Object(c.a)(n.value,2),i=r[0],a=r[1],o.next=7,$(i,a);case 7:o.next=3;break;case 9:o.next=14;break;case 11:o.prev=11,o.t0=o.catch(1),t.e(o.t0);case 14:return o.prev=14,t.f(),o.finish(14);case 17:return o.delegateYield(W(e),"t1",18);case 18:case"end":return o.stop()}}),j,null,[[1,11,14,17]])}function P(e){var t,n,r;return u.a.wrap((function(i){for(;;)switch(i.prev=i.next){case 0:t=Object(s.a)(e),i.prev=1,t.s();case 3:if((n=t.n()).done){i.next=9;break}return r=n.value,i.next=7,K(r);case 7:i.next=3;break;case 9:i.next=14;break;case 11:i.prev=11,i.t0=i.catch(1),t.e(i.t0);case 14:return i.prev=14,t.f(),i.finish(14);case 17:return i.delegateYield(W(e),"t1",18);case 18:case"end":return i.stop()}}),S,null,[[1,11,14,17]])}function U(e){var t,n,r;return u.a.wrap((function(i){for(;;)switch(i.prev=i.next){case 0:t=Object(s.a)(e),i.prev=1,t.s();case 3:if((n=t.n()).done){i.next=9;break}return r=n.value,i.next=7,K(r);case 7:i.next=3;break;case 9:i.next=14;break;case 11:i.prev=11,i.t0=i.catch(1),t.e(i.t0);case 14:return i.prev=14,t.f(),i.finish(14);case 17:case"end":return i.stop()}}),T,null,[[1,11,14,17]])}function R(e){var t,n,r,i,a,o;return u.a.wrap((function(c){for(;;)switch(c.prev=c.next){case 0:t=0,n=e.length;case 1:if(!(t ")),n.appendChild(Ee(t)),n}function K(e){var t=document.createElement("div");return t.className="observablehq--field",t.appendChild(document.createTextNode(" ")),t.appendChild(Ee(e)),t}var Q=u.a.mark(ie),G=u.a.mark(ae),J=u.a.mark(oe),Z=u.a.mark(ue),X=u.a.mark(ce),ee=u.a.mark(se),te=u.a.mark(le);function ne(e){var t=window.getSelection();return"Range"===t.type&&(t.containsNode(e,!0)||t.anchorNode.isSelfOrDescendant(e)||t.focusNode.isSelfOrDescendant(e))}function re(e,t,n,r){var i,a,o,u,c=l(e);if(e instanceof Map?e instanceof e.constructor?(i="Map(".concat(e.size,")"),a=ie):(i="Map()",a=se):e instanceof Set?e instanceof e.constructor?(i="Set(".concat(e.size,")"),a=ae):(i="Set()",a=se):c?(i="".concat(e.constructor.name,"(").concat(e.length,")"),a=ce):(u=x(e))?(i="Immutable.".concat(u.name).concat("Record"===u.name?"":"(".concat(e.size,")")),c=u.arrayish,a=u.arrayish?ue:u.setish?oe:le):(i=k(e),a=se),t){var s=document.createElement("span");return s.className="observablehq--shallow",n&&s.appendChild(h(n)),s.appendChild(document.createTextNode(i)),s.addEventListener("mouseup",(function(t){ne(s)||(t.stopPropagation(),Ae(s,re(e)))})),s}var f=document.createElement("span");f.className="observablehq--collapsed",n&&f.appendChild(h(n));var d=f.appendChild(document.createElement("a"));d.innerHTML="",d.appendChild(document.createTextNode("".concat(i).concat(c?" [":" {"))),f.addEventListener("mouseup",(function(t){ne(f)||(t.stopPropagation(),Ae(f,F(e,0,n,r)))}),!0),a=a(e);for(var p=0;!(o=a.next()).done&&p<20;++p)p>0&&f.appendChild(document.createTextNode(", ")),f.appendChild(o.value);return o.done||f.appendChild(document.createTextNode(", \u2026")),f.appendChild(document.createTextNode(c?"]":"}")),f}function ie(e){var t,n,r,i,a;return u.a.wrap((function(o){for(;;)switch(o.prev=o.next){case 0:t=Object(s.a)(e),o.prev=1,t.s();case 3:if((n=t.n()).done){o.next=9;break}return r=Object(c.a)(n.value,2),i=r[0],a=r[1],o.next=7,de(i,a);case 7:o.next=3;break;case 9:o.next=14;break;case 11:o.prev=11,o.t0=o.catch(1),t.e(o.t0);case 14:return o.prev=14,t.f(),o.finish(14);case 17:return o.delegateYield(se(e),"t1",18);case 18:case"end":return o.stop()}}),Q,null,[[1,11,14,17]])}function ae(e){var t,n,r;return u.a.wrap((function(i){for(;;)switch(i.prev=i.next){case 0:t=Object(s.a)(e),i.prev=1,t.s();case 3:if((n=t.n()).done){i.next=9;break}return r=n.value,i.next=7,Ee(r,!0);case 7:i.next=3;break;case 9:i.next=14;break;case 11:i.prev=11,i.t0=i.catch(1),t.e(i.t0);case 14:return i.prev=14,t.f(),i.finish(14);case 17:return i.delegateYield(se(e),"t1",18);case 18:case"end":return i.stop()}}),G,null,[[1,11,14,17]])}function oe(e){var t,n,r;return u.a.wrap((function(i){for(;;)switch(i.prev=i.next){case 0:t=Object(s.a)(e),i.prev=1,t.s();case 3:if((n=t.n()).done){i.next=9;break}return r=n.value,i.next=7,Ee(r,!0);case 7:i.next=3;break;case 9:i.next=14;break;case 11:i.prev=11,i.t0=i.catch(1),t.e(i.t0);case 14:return i.prev=14,t.f(),i.finish(14);case 17:case"end":return i.stop()}}),J,null,[[1,11,14,17]])}function ue(e){var t,n,r;return u.a.wrap((function(i){for(;;)switch(i.prev=i.next){case 0:t=-1,n=0,r=e.size;case 2:if(!(nt+1)){i.next=6;break}return i.next=6,fe(n-t-1);case 6:return i.next=8,Ee(e.get(n),!0);case 8:t=n;case 9:++n,i.next=2;break;case 12:if(!(n>t+1)){i.next=15;break}return i.next=15,fe(n-t-1);case 15:case"end":return i.stop()}}),Z)}function ce(e){var t,n,r,i,a,o,c;return u.a.wrap((function(l){for(;;)switch(l.prev=l.next){case 0:t=-1,n=0,r=e.length;case 2:if(!(nt+1)){l.next=7;break}return l.next=7,fe(n-t-1);case 7:return l.next=9,Ee(_(e,n),!0);case 9:t=n;case 10:++n,l.next=2;break;case 13:if(!(n>t+1)){l.next=16;break}return l.next=16,fe(n-t-1);case 16:l.t0=u.a.keys(e);case 17:if((l.t1=l.t0()).done){l.next=24;break}if(f(i=l.t1.value)||!w(e,i)){l.next=22;break}return l.next=22,he(i,_(e,i),"observablehq--key");case 22:l.next=17;break;case 24:a=Object(s.a)(g(e)),l.prev=25,a.s();case 27:if((o=a.n()).done){l.next=33;break}return c=o.value,l.next=31,he(p(c),_(e,c),"observablehq--symbol");case 31:l.next=27;break;case 33:l.next=38;break;case 35:l.prev=35,l.t2=l.catch(25),a.e(l.t2);case 38:return l.prev=38,a.f(),l.finish(38);case 41:case"end":return l.stop()}}),X,null,[[25,35,38,41]])}function se(e){var t,n,r,i;return u.a.wrap((function(a){for(;;)switch(a.prev=a.next){case 0:a.t0=u.a.keys(e);case 1:if((a.t1=a.t0()).done){a.next=8;break}if(t=a.t1.value,!w(e,t)){a.next=6;break}return a.next=6,he(t,_(e,t),"observablehq--key");case 6:a.next=1;break;case 8:n=Object(s.a)(g(e)),a.prev=9,n.s();case 11:if((r=n.n()).done){a.next=17;break}return i=r.value,a.next=15,he(p(i),_(e,i),"observablehq--symbol");case 15:a.next=11;break;case 17:a.next=22;break;case 19:a.prev=19,a.t2=a.catch(9),n.e(a.t2);case 22:return a.prev=22,n.f(),a.finish(22);case 25:case"end":return a.stop()}}),ee,null,[[9,19,22,25]])}function le(e){var t,n,r,i,a;return u.a.wrap((function(o){for(;;)switch(o.prev=o.next){case 0:t=Object(s.a)(e),o.prev=1,t.s();case 3:if((n=t.n()).done){o.next=9;break}return r=Object(c.a)(n.value,2),i=r[0],a=r[1],o.next=7,he(i,a,"observablehq--key");case 7:o.next=3;break;case 9:o.next=14;break;case 11:o.prev=11,o.t0=o.catch(1),t.e(o.t0);case 14:return o.prev=14,t.f(),o.finish(14);case 17:case"end":return o.stop()}}),te,null,[[1,11,14,17]])}function fe(e){var t=document.createElement("span");return t.className="observablehq--empty",t.textContent=1===e?"empty":"empty \xd7 ".concat(e),t}function he(e,t,n){var r=document.createDocumentFragment(),i=r.appendChild(document.createElement("span"));return i.className=n,i.textContent=e,r.appendChild(document.createTextNode(": ")),r.appendChild(Ee(t,!0)),r}function de(e,t){var n=document.createDocumentFragment();return n.appendChild(Ee(e,!0)),n.appendChild(document.createTextNode(" => ")),n.appendChild(Ee(t,!0)),n}function pe(e,t){if(e instanceof Date||(e=new Date(+e)),isNaN(e))return"function"===typeof t?t(e):t;var n,r=e.getUTCHours(),i=e.getUTCMinutes(),a=e.getUTCSeconds(),o=e.getUTCMilliseconds();return"".concat((n=e.getUTCFullYear(),n<0?"-".concat(ve(-n,6)):n>9999?"+".concat(ve(n,6)):ve(n,4)),"-").concat(ve(e.getUTCMonth()+1,2),"-").concat(ve(e.getUTCDate(),2)).concat(r||i||a||o?"T".concat(ve(r,2),":").concat(ve(i,2)).concat(a||o?":".concat(ve(a,2)).concat(o?".".concat(ve(o,3)):""):"","Z"):"")}function ve(e,t){return"".concat(e).padStart(t,"0")}var ye=Error.prototype.toString;var be=RegExp.prototype.toString;function me(e){return e.replace(/[\\`\x00-\x09\x0b-\x19]|\${/g,ge)}function ge(e){var t=e.charCodeAt(0);switch(t){case 8:return"\\b";case 9:return"\\t";case 11:return"\\v";case 12:return"\\f";case 13:return"\\r"}return t<16?"\\x0"+t.toString(16):t<32?"\\x"+t.toString(16):"\\"+e}function we(e,t){for(var n=0;t.exec(e);)++n;return n}var ke=Function.prototype.toString,_e={prefix:"async \u0192"},Oe={prefix:"async \u0192*"},xe={prefix:"class"},je={prefix:"\u0192"},Se={prefix:"\u0192*"};function Te(e,t,n){var r=document.createElement("span");r.className="observablehq--function",n&&r.appendChild(h(n));var i=r.appendChild(document.createElement("span"));return i.className="observablehq--keyword",i.textContent=e.prefix,r.appendChild(document.createTextNode(t)),r}var Ie=Object.prototype.toString;function Ee(e,t,n,r,i){var a=typeof e;switch(a){case"boolean":case"undefined":e+="";break;case"number":e=0===e&&1/e<0?"-0":e+"";break;case"bigint":e+="n";break;case"symbol":e=p(e);break;case"function":return function(e,t){var n,r,i=ke.call(e);switch(e.constructor&&e.constructor.name){case"AsyncFunction":n=_e;break;case"AsyncGeneratorFunction":n=Oe;break;case"GeneratorFunction":n=Se;break;default:n=/^class\b/.test(i)?xe:je}return n===xe?Te(n,"",t):(r=/^(?:async\s*)?(\w+)\s*=>/.exec(i))?Te(n,"("+r[1]+")",t):(r=/^(?:async\s*)?\(\s*(\w+(?:\s*,\s*\w+)*)?\s*\)/.exec(i))||(r=/^(?:async\s*)?function(?:\s*\*)?(?:\s*\w+)?\s*\(\s*(\w+(?:\s*,\s*\w+)*)?\s*\)/.exec(i))?Te(n,r[1]?"("+r[1].replace(/\s*,\s*/g,", ")+")":"()",t):Te(n,"(\u2026)",t)}(e,r);case"string":return function(e,t,n,r){if(!1===t){if(we(e,/["\n]/g)<=we(e,/`|\${/g)){var i=document.createElement("span");r&&i.appendChild(h(r));var a=i.appendChild(document.createElement("span"));return a.className="observablehq--string",a.textContent=JSON.stringify(e),i}var o=e.split("\n");if(o.length>20&&!n){var u=document.createElement("div");r&&u.appendChild(h(r));var c=u.appendChild(document.createElement("span"));c.className="observablehq--string",c.textContent="`"+me(o.slice(0,20).join("\n"));var s=u.appendChild(document.createElement("span")),l=o.length-20;return s.textContent="Show ".concat(l," truncated line").concat(l>1?"s":""),s.className="observablehq--string-expand",s.addEventListener("mouseup",(function(n){n.stopPropagation(),Ae(u,Ee(e,t,!0,r))})),u}var f=document.createElement("span");r&&f.appendChild(h(r));var d=f.appendChild(document.createElement("span"));return d.className="observablehq--string".concat(n?" observablehq--expanded":""),d.textContent="`"+me(e)+"`",f}var p=document.createElement("span");r&&p.appendChild(h(r));var v=p.appendChild(document.createElement("span"));return v.className="observablehq--string",v.textContent=JSON.stringify(e.length>100?"".concat(e.slice(0,50),"\u2026").concat(e.slice(-49)):e),p}(e,t,n,r);default:if(null===e){a=null,e="null";break}if(e instanceof Date){a="date",e=pe(e,"Invalid Date");break}if(e===m){a="forbidden",e="[forbidden]";break}switch(Ie.call(e)){case"[object RegExp]":a="regexp",e=function(e){return be.call(e)}(e);break;case"[object Error]":case"[object DOMException]":a="error",e=function(e){return e.stack||ye.call(e)}(e);break;default:return(n?F:re)(e,t,r,i)}}var o=document.createElement("span");r&&o.appendChild(h(r));var u=o.appendChild(document.createElement("span"));return u.className="observablehq--".concat(a),u.textContent=e,o}function Ae(e,t){e.classList.contains("observablehq--inspect")&&t.classList.add("observablehq--inspect"),e.parentNode.replaceChild(t,e),a(t,"load")}var Be=/\s+\(\d+:\d+\)$/m,Ce=function(){function e(t){if(Object(r.a)(this,e),!t)throw new Error("invalid node");this._node=t,t.classList.add("observablehq")}return Object(i.a)(e,[{key:"pending",value:function(){var e=this._node;e.classList.remove("observablehq--error"),e.classList.add("observablehq--running")}},{key:"fulfilled",value:function(e,t){var n=this._node;if((!function(e){return(e instanceof Element||e instanceof Text)&&e instanceof e.constructor}(e)||e.parentNode&&e.parentNode!==n)&&(e=Ee(e,!1,n.firstChild&&n.firstChild.classList&&n.firstChild.classList.contains("observablehq--expanded"),t)).classList.add("observablehq--inspect"),n.classList.remove("observablehq--running","observablehq--error"),n.firstChild!==e)if(n.firstChild){for(;n.lastChild!==n.firstChild;)n.removeChild(n.lastChild);n.replaceChild(e,n.firstChild)}else n.appendChild(e);a(n,"update")}},{key:"rejected",value:function(e,t){var n=this._node;for(n.classList.remove("observablehq--running"),n.classList.add("observablehq--error");n.lastChild;)n.removeChild(n.lastChild);var r=document.createElement("div");r.className="observablehq--inspect",t&&r.appendChild(h(t)),r.appendChild(document.createTextNode((e+"").replace(Be,""))),n.appendChild(r),a(n,"error",{error:e})}}]),e}();Ce.into=function(e){if("string"===typeof e&&null==(e=document.querySelector(e)))throw new Error("container not found");return function(){return new Ce(e.appendChild(document.createElement("div")))}};n(20),n(15);var De=n(19)},function(e,t,n){"use strict";n.d(t,"a",(function(){return v}));var r=n(1),i=n.n(r),a=n(7),o=n(8),u=n(5),c=n(6),s=n(29),l=n(26),f=n(15),h=n(27),d=n(19),p=n(14);function v(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:[];Object.defineProperties(this,{_runtime:{value:e},_scope:{value:new Map},_builtins:{value:new Map([["invalidation",d.b],["visibility",d.c]].concat(Object(c.a)(t)))},_source:{value:null,writable:!0}})}function y(){return(y=Object(u.a)(i.a.mark((function e(t){var n;return i.a.wrap((function(e){for(;;)switch(e.prev=e.next){case 0:if(n=this._scope.get(t)){e.next=3;break}throw new f.a(t+" is not defined");case 3:return n._observer===p.e&&(n._observer=!0,this._runtime._dirty.add(n)),e.next=6,this._runtime._compute();case 6:return e.abrupt("return",n._promise);case 7:case"end":return e.stop()}}),e,this)})))).apply(this,arguments)}function b(e){return e._name}Object.defineProperties(v.prototype,{_copy:{value:function(e,t){e._source=this,t.set(this,e);var n,r=Object(o.a)(this._scope);try{for(r.s();!(n=r.n()).done;){var i=Object(a.a)(n.value,2),u=i[0],c=i[1],s=e._scope.get(u);if(!s||s._type!==p.c)if(c._definition===h.a){var l=c._inputs[0],f=l._module;e.import(l._name,u,t.get(f)||(f._source?f._copy(new v(e._runtime,e._builtins),t):f))}else e.define(u,c._inputs.map(b),c._definition)}}catch(d){r.e(d)}finally{r.f()}return e},writable:!0,configurable:!0},_resolve:{value:function(e){var t,n=this._scope.get(e);if(!n)if(n=new p.d(p.b,this),this._builtins.has(e))n.define(e,Object(l.a)(this._builtins.get(e)));else if(this._runtime._builtin._scope.has(e))n.import(e,this._runtime._builtin);else{try{t=this._runtime._global(e)}catch(i){return n.define(e,(r=i,function(){throw r}))}void 0===t?this._scope.set(n._name=e,n):n.define(e,Object(l.a)(t))}var r;return n},writable:!0,configurable:!0},redefine:{value:function(e){var t=this._scope.get(e);if(!t)throw new f.a(e+" is not defined");if(t._type===p.a)throw new f.a(e+" is defined more than once");return t.define.apply(t,arguments)},writable:!0,configurable:!0},define:{value:function(){var e=new p.d(p.c,this);return e.define.apply(e,arguments)},writable:!0,configurable:!0},derive:{value:function(e,t){var n=this,r=new v(this._runtime,this._builtins);return r._source=this,s.a.call(e,(function(e){"object"!==typeof e&&(e={name:e+""}),null==e.alias&&(e.alias=e.name),r.import(e.name,e.alias,t)})),Promise.resolve().then((function(){var e,t=new Set([n]),i=Object(o.a)(t);try{for(i.s();!(e=i.n()).done;){var a,u=e.value,c=Object(o.a)(u._scope.values());try{for(c.s();!(a=c.n()).done;){var s=a.value;if(s._definition===h.a){var l=s._inputs[0]._module,f=l._source||l;if(f===n)return void console.warn("circular module definition; ignoring");t.add(f)}}}catch(d){c.e(d)}finally{c.f()}}}catch(d){i.e(d)}finally{i.f()}n._copy(r,new Map)})),r},writable:!0,configurable:!0},import:{value:function(){var e=new p.d(p.c,this);return e.import.apply(e,arguments)},writable:!0,configurable:!0},value:{value:function(e){return y.apply(this,arguments)},writable:!0,configurable:!0},variable:{value:function(e){return new p.d(p.c,this,e)},writable:!0,configurable:!0},builtin:{value:function(e,t){this._builtins.set(e,t)},writable:!0,configurable:!0}})},function(e,t,n){"use strict";var r=Object.getOwnPropertySymbols,i=Object.prototype.hasOwnProperty,a=Object.prototype.propertyIsEnumerable;function o(e){if(null===e||void 0===e)throw new TypeError("Object.assign cannot be called with null or undefined");return Object(e)}e.exports=function(){try{if(!Object.assign)return!1;var e=new String("abc");if(e[5]="de","5"===Object.getOwnPropertyNames(e)[0])return!1;for(var t={},n=0;n<10;n++)t["_"+String.fromCharCode(n)]=n;if("0123456789"!==Object.getOwnPropertyNames(t).map((function(e){return t[e]})).join(""))return!1;var r={};return"abcdefghijklmnopqrst".split("").forEach((function(e){r[e]=e})),"abcdefghijklmnopqrst"===Object.keys(Object.assign({},r)).join("")}catch(i){return!1}}()?Object.assign:function(e,t){for(var n,u,c=o(e),s=1;s0){for(var e=new Array(arguments.length),t=0;tA.length&&A.push(e)}function D(e,t,n){return null==e?0:function e(t,n,r,i){var u=typeof t;"undefined"!==u&&"boolean"!==u||(t=null);var c=!1;if(null===t)c=!0;else switch(u){case"string":case"number":c=!0;break;case"object":switch(t.$$typeof){case a:case o:c=!0}}if(c)return r(i,t,""===n?"."+L(t,0):n),1;if(c=0,n=""===n?".":n+":",Array.isArray(t))for(var s=0;st}return!1}(t,n,i,r)&&(n=null),r||null===i?function(e){return!!W.call(q,e)||!W.call(Y,e)&&(V.test(e)?q[e]=!0:(Y[e]=!0,!1))}(t)&&(null===n?e.removeAttribute(t):e.setAttribute(t,""+n)):i.mustUseProperty?e[i.propertyName]=null===n?3!==i.type&&"":n:(t=i.attributeName,r=i.attributeNamespace,null===n?e.removeAttribute(t):(n=3===(i=i.type)||4===i&&!0===n?"":""+n,r?e.setAttributeNS(r,t,n):e.setAttribute(t,n))))}G.hasOwnProperty("ReactCurrentDispatcher")||(G.ReactCurrentDispatcher={current:null}),G.hasOwnProperty("ReactCurrentBatchConfig")||(G.ReactCurrentBatchConfig={suspense:null});var Z=/^(.*)[\\\/]/,X="function"===typeof Symbol&&Symbol.for,ee=X?Symbol.for("react.element"):60103,te=X?Symbol.for("react.portal"):60106,ne=X?Symbol.for("react.fragment"):60107,re=X?Symbol.for("react.strict_mode"):60108,ie=X?Symbol.for("react.profiler"):60114,ae=X?Symbol.for("react.provider"):60109,oe=X?Symbol.for("react.context"):60110,ue=X?Symbol.for("react.concurrent_mode"):60111,ce=X?Symbol.for("react.forward_ref"):60112,se=X?Symbol.for("react.suspense"):60113,le=X?Symbol.for("react.suspense_list"):60120,fe=X?Symbol.for("react.memo"):60115,he=X?Symbol.for("react.lazy"):60116,de=X?Symbol.for("react.block"):60121,pe="function"===typeof Symbol&&Symbol.iterator;function ve(e){return null===e||"object"!==typeof e?null:"function"===typeof(e=pe&&e[pe]||e["@@iterator"])?e:null}function ye(e){if(null==e)return null;if("function"===typeof e)return e.displayName||e.name||null;if("string"===typeof e)return e;switch(e){case ne:return"Fragment";case te:return"Portal";case ie:return"Profiler";case re:return"StrictMode";case se:return"Suspense";case le:return"SuspenseList"}if("object"===typeof e)switch(e.$$typeof){case oe:return"Context.Consumer";case ae:return"Context.Provider";case ce:var t=e.render;return t=t.displayName||t.name||"",e.displayName||(""!==t?"ForwardRef("+t+")":"ForwardRef");case fe:return ye(e.type);case de:return ye(e.render);case he:if(e=1===e._status?e._result:null)return ye(e)}return null}function be(e){var t="";do{e:switch(e.tag){case 3:case 4:case 6:case 7:case 10:case 9:var n="";break e;default:var r=e._debugOwner,i=e._debugSource,a=ye(e.type);n=null,r&&(n=ye(r.type)),r=a,a="",i?a=" (at "+i.fileName.replace(Z,"")+":"+i.lineNumber+")":n&&(a=" (created by "+n+")"),n="\n in "+(r||"Unknown")+a}t+=n,e=e.return}while(e);return t}function me(e){switch(typeof e){case"boolean":case"number":case"object":case"string":case"undefined":return e;default:return""}}function ge(e){var t=e.type;return(e=e.nodeName)&&"input"===e.toLowerCase()&&("checkbox"===t||"radio"===t)}function we(e){e._valueTracker||(e._valueTracker=function(e){var t=ge(e)?"checked":"value",n=Object.getOwnPropertyDescriptor(e.constructor.prototype,t),r=""+e[t];if(!e.hasOwnProperty(t)&&"undefined"!==typeof n&&"function"===typeof n.get&&"function"===typeof n.set){var i=n.get,a=n.set;return Object.defineProperty(e,t,{configurable:!0,get:function(){return i.call(this)},set:function(e){r=""+e,a.call(this,e)}}),Object.defineProperty(e,t,{enumerable:n.enumerable}),{getValue:function(){return r},setValue:function(e){r=""+e},stopTracking:function(){e._valueTracker=null,delete e[t]}}}}(e))}function ke(e){if(!e)return!1;var t=e._valueTracker;if(!t)return!0;var n=t.getValue(),r="";return e&&(r=ge(e)?e.checked?"true":"false":e.value),(e=r)!==n&&(t.setValue(e),!0)}function _e(e,t){var n=t.checked;return i({},t,{defaultChecked:void 0,defaultValue:void 0,value:void 0,checked:null!=n?n:e._wrapperState.initialChecked})}function Oe(e,t){var n=null==t.defaultValue?"":t.defaultValue,r=null!=t.checked?t.checked:t.defaultChecked;n=me(null!=t.value?t.value:n),e._wrapperState={initialChecked:r,initialValue:n,controlled:"checkbox"===t.type||"radio"===t.type?null!=t.checked:null!=t.value}}function xe(e,t){null!=(t=t.checked)&&J(e,"checked",t,!1)}function je(e,t){xe(e,t);var n=me(t.value),r=t.type;if(null!=n)"number"===r?(0===n&&""===e.value||e.value!=n)&&(e.value=""+n):e.value!==""+n&&(e.value=""+n);else if("submit"===r||"reset"===r)return void e.removeAttribute("value");t.hasOwnProperty("value")?Te(e,t.type,n):t.hasOwnProperty("defaultValue")&&Te(e,t.type,me(t.defaultValue)),null==t.checked&&null!=t.defaultChecked&&(e.defaultChecked=!!t.defaultChecked)}function Se(e,t,n){if(t.hasOwnProperty("value")||t.hasOwnProperty("defaultValue")){var r=t.type;if(!("submit"!==r&&"reset"!==r||void 0!==t.value&&null!==t.value))return;t=""+e._wrapperState.initialValue,n||t===e.value||(e.value=t),e.defaultValue=t}""!==(n=e.name)&&(e.name=""),e.defaultChecked=!!e._wrapperState.initialChecked,""!==n&&(e.name=n)}function Te(e,t,n){"number"===t&&e.ownerDocument.activeElement===e||(null==n?e.defaultValue=""+e._wrapperState.initialValue:e.defaultValue!==""+n&&(e.defaultValue=""+n))}function Ie(e,t){return e=i({children:void 0},t),(t=function(e){var t="";return r.Children.forEach(e,(function(e){null!=e&&(t+=e)})),t}(t.children))&&(e.children=t),e}function Ee(e,t,n,r){if(e=e.options,t){t={};for(var i=0;i=n.length))throw Error(o(93));n=n[0]}t=n}null==t&&(t=""),n=t}e._wrapperState={initialValue:me(n)}}function Ce(e,t){var n=me(t.value),r=me(t.defaultValue);null!=n&&((n=""+n)!==e.value&&(e.value=n),null==t.defaultValue&&e.defaultValue!==n&&(e.defaultValue=n)),null!=r&&(e.defaultValue=""+r)}function De(e){var t=e.textContent;t===e._wrapperState.initialValue&&""!==t&&null!==t&&(e.value=t)}var Le="http://www.w3.org/1999/xhtml",Ne="http://www.w3.org/2000/svg";function Fe(e){switch(e){case"svg":return"http://www.w3.org/2000/svg";case"math":return"http://www.w3.org/1998/Math/MathML";default:return"http://www.w3.org/1999/xhtml"}}function Me(e,t){return null==e||"http://www.w3.org/1999/xhtml"===e?Fe(t):"http://www.w3.org/2000/svg"===e&&"foreignObject"===t?"http://www.w3.org/1999/xhtml":e}var Pe,Ue=function(e){return"undefined"!==typeof MSApp&&MSApp.execUnsafeLocalFunction?function(t,n,r,i){MSApp.execUnsafeLocalFunction((function(){return e(t,n)}))}:e}((function(e,t){if(e.namespaceURI!==Ne||"innerHTML"in e)e.innerHTML=t;else{for((Pe=Pe||document.createElement("div")).innerHTML="",t=Pe.firstChild;e.firstChild;)e.removeChild(e.firstChild);for(;t.firstChild;)e.appendChild(t.firstChild)}}));function Re(e,t){if(t){var n=e.firstChild;if(n&&n===e.lastChild&&3===n.nodeType)return void(n.nodeValue=t)}e.textContent=t}function ze(e,t){var n={};return n[e.toLowerCase()]=t.toLowerCase(),n["Webkit"+e]="webkit"+t,n["Moz"+e]="moz"+t,n}var Ve={animationend:ze("Animation","AnimationEnd"),animationiteration:ze("Animation","AnimationIteration"),animationstart:ze("Animation","AnimationStart"),transitionend:ze("Transition","TransitionEnd")},We={},Ye={};function qe(e){if(We[e])return We[e];if(!Ve[e])return e;var t,n=Ve[e];for(t in n)if(n.hasOwnProperty(t)&&t in Ye)return We[e]=n[t];return e}T&&(Ye=document.createElement("div").style,"AnimationEvent"in window||(delete Ve.animationend.animation,delete Ve.animationiteration.animation,delete Ve.animationstart.animation),"TransitionEvent"in window||delete Ve.transitionend.transition);var He=qe("animationend"),$e=qe("animationiteration"),Ke=qe("animationstart"),Qe=qe("transitionend"),Ge="abort canplay canplaythrough durationchange emptied encrypted ended error loadeddata loadedmetadata loadstart pause play playing progress ratechange seeked seeking stalled suspend timeupdate volumechange waiting".split(" "),Je=new("function"===typeof WeakMap?WeakMap:Map);function Ze(e){var t=Je.get(e);return void 0===t&&(t=new Map,Je.set(e,t)),t}function Xe(e){var t=e,n=e;if(e.alternate)for(;t.return;)t=t.return;else{e=t;do{0!==(1026&(t=e).effectTag)&&(n=t.return),e=t.return}while(e)}return 3===t.tag?n:null}function et(e){if(13===e.tag){var t=e.memoizedState;if(null===t&&(null!==(e=e.alternate)&&(t=e.memoizedState)),null!==t)return t.dehydrated}return null}function tt(e){if(Xe(e)!==e)throw Error(o(188))}function nt(e){if(!(e=function(e){var t=e.alternate;if(!t){if(null===(t=Xe(e)))throw Error(o(188));return t!==e?null:e}for(var n=e,r=t;;){var i=n.return;if(null===i)break;var a=i.alternate;if(null===a){if(null!==(r=i.return)){n=r;continue}break}if(i.child===a.child){for(a=i.child;a;){if(a===n)return tt(i),e;if(a===r)return tt(i),t;a=a.sibling}throw Error(o(188))}if(n.return!==r.return)n=i,r=a;else{for(var u=!1,c=i.child;c;){if(c===n){u=!0,n=i,r=a;break}if(c===r){u=!0,r=i,n=a;break}c=c.sibling}if(!u){for(c=a.child;c;){if(c===n){u=!0,n=a,r=i;break}if(c===r){u=!0,r=a,n=i;break}c=c.sibling}if(!u)throw Error(o(189))}}if(n.alternate!==r)throw Error(o(190))}if(3!==n.tag)throw Error(o(188));return n.stateNode.current===n?e:t}(e)))return null;for(var t=e;;){if(5===t.tag||6===t.tag)return t;if(t.child)t.child.return=t,t=t.child;else{if(t===e)break;for(;!t.sibling;){if(!t.return||t.return===e)return null;t=t.return}t.sibling.return=t.return,t=t.sibling}}return null}function rt(e,t){if(null==t)throw Error(o(30));return null==e?t:Array.isArray(e)?Array.isArray(t)?(e.push.apply(e,t),e):(e.push(t),e):Array.isArray(t)?[e].concat(t):[e,t]}function it(e,t,n){Array.isArray(e)?e.forEach(t,n):e&&t.call(n,e)}var at=null;function ot(e){if(e){var t=e._dispatchListeners,n=e._dispatchInstances;if(Array.isArray(t))for(var r=0;rlt.length&<.push(e)}function ht(e,t,n,r){if(lt.length){var i=lt.pop();return i.topLevelType=e,i.eventSystemFlags=r,i.nativeEvent=t,i.targetInst=n,i}return{topLevelType:e,eventSystemFlags:r,nativeEvent:t,targetInst:n,ancestors:[]}}function dt(e){var t=e.targetInst,n=t;do{if(!n){e.ancestors.push(n);break}var r=n;if(3===r.tag)r=r.stateNode.containerInfo;else{for(;r.return;)r=r.return;r=3!==r.tag?null:r.stateNode.containerInfo}if(!r)break;5!==(t=n.tag)&&6!==t||e.ancestors.push(n),n=Tn(r)}while(n);for(n=0;n=t)return{node:r,offset:t-e};e=n}e:{for(;r;){if(r.nextSibling){r=r.nextSibling;break e}r=r.parentNode}r=void 0}r=fn(r)}}function dn(){for(var e=window,t=ln();t instanceof e.HTMLIFrameElement;){try{var n="string"===typeof t.contentWindow.location.href}catch(r){n=!1}if(!n)break;t=ln((e=t.contentWindow).document)}return t}function pn(e){var t=e&&e.nodeName&&e.nodeName.toLowerCase();return t&&("input"===t&&("text"===e.type||"search"===e.type||"tel"===e.type||"url"===e.type||"password"===e.type)||"textarea"===t||"true"===e.contentEditable)}var vn=null,yn=null;function bn(e,t){switch(e){case"button":case"input":case"select":case"textarea":return!!t.autoFocus}return!1}function mn(e,t){return"textarea"===e||"option"===e||"noscript"===e||"string"===typeof t.children||"number"===typeof t.children||"object"===typeof t.dangerouslySetInnerHTML&&null!==t.dangerouslySetInnerHTML&&null!=t.dangerouslySetInnerHTML.__html}var gn="function"===typeof setTimeout?setTimeout:void 0,wn="function"===typeof clearTimeout?clearTimeout:void 0;function kn(e){for(;null!=e;e=e.nextSibling){var t=e.nodeType;if(1===t||3===t)break}return e}function _n(e){e=e.previousSibling;for(var t=0;e;){if(8===e.nodeType){var n=e.data;if("$"===n||"$!"===n||"$?"===n){if(0===t)return e;t--}else"/$"===n&&t++}e=e.previousSibling}return null}var On=Math.random().toString(36).slice(2),xn="__reactInternalInstance$"+On,jn="__reactEventHandlers$"+On,Sn="__reactContainere$"+On;function Tn(e){var t=e[xn];if(t)return t;for(var n=e.parentNode;n;){if(t=n[Sn]||n[xn]){if(n=t.alternate,null!==t.child||null!==n&&null!==n.child)for(e=_n(e);null!==e;){if(n=e[xn])return n;e=_n(e)}return t}n=(e=n).parentNode}return null}function In(e){return!(e=e[xn]||e[Sn])||5!==e.tag&&6!==e.tag&&13!==e.tag&&3!==e.tag?null:e}function En(e){if(5===e.tag||6===e.tag)return e.stateNode;throw Error(o(33))}function An(e){return e[jn]||null}function Bn(e){do{e=e.return}while(e&&5!==e.tag);return e||null}function Cn(e,t){var n=e.stateNode;if(!n)return null;var r=p(n);if(!r)return null;n=r[t];e:switch(t){case"onClick":case"onClickCapture":case"onDoubleClick":case"onDoubleClickCapture":case"onMouseDown":case"onMouseDownCapture":case"onMouseMove":case"onMouseMoveCapture":case"onMouseUp":case"onMouseUpCapture":case"onMouseEnter":(r=!r.disabled)||(r=!("button"===(e=e.type)||"input"===e||"select"===e||"textarea"===e)),e=!r;break e;default:e=!1}if(e)return null;if(n&&"function"!==typeof n)throw Error(o(231,t,typeof n));return n}function Dn(e,t,n){(t=Cn(e,n.dispatchConfig.phasedRegistrationNames[t]))&&(n._dispatchListeners=rt(n._dispatchListeners,t),n._dispatchInstances=rt(n._dispatchInstances,e))}function Ln(e){if(e&&e.dispatchConfig.phasedRegistrationNames){for(var t=e._targetInst,n=[];t;)n.push(t),t=Bn(t);for(t=n.length;0this.eventPool.length&&this.eventPool.push(e)}function $n(e){e.eventPool=[],e.getPooled=qn,e.release=Hn}i(Yn.prototype,{preventDefault:function(){this.defaultPrevented=!0;var e=this.nativeEvent;e&&(e.preventDefault?e.preventDefault():"unknown"!==typeof e.returnValue&&(e.returnValue=!1),this.isDefaultPrevented=Vn)},stopPropagation:function(){var e=this.nativeEvent;e&&(e.stopPropagation?e.stopPropagation():"unknown"!==typeof e.cancelBubble&&(e.cancelBubble=!0),this.isPropagationStopped=Vn)},persist:function(){this.isPersistent=Vn},isPersistent:Wn,destructor:function(){var e,t=this.constructor.Interface;for(e in t)this[e]=null;this.nativeEvent=this._targetInst=this.dispatchConfig=null,this.isPropagationStopped=this.isDefaultPrevented=Wn,this._dispatchInstances=this._dispatchListeners=null}}),Yn.Interface={type:null,target:null,currentTarget:function(){return null},eventPhase:null,bubbles:null,cancelable:null,timeStamp:function(e){return e.timeStamp||Date.now()},defaultPrevented:null,isTrusted:null},Yn.extend=function(e){function t(){}function n(){return r.apply(this,arguments)}var r=this;t.prototype=r.prototype;var a=new t;return i(a,n.prototype),n.prototype=a,n.prototype.constructor=n,n.Interface=i({},r.Interface,e),n.extend=r.extend,$n(n),n},$n(Yn);var Kn=Yn.extend({data:null}),Qn=Yn.extend({data:null}),Gn=[9,13,27,32],Jn=T&&"CompositionEvent"in window,Zn=null;T&&"documentMode"in document&&(Zn=document.documentMode);var Xn=T&&"TextEvent"in window&&!Zn,er=T&&(!Jn||Zn&&8=Zn),tr=String.fromCharCode(32),nr={beforeInput:{phasedRegistrationNames:{bubbled:"onBeforeInput",captured:"onBeforeInputCapture"},dependencies:["compositionend","keypress","textInput","paste"]},compositionEnd:{phasedRegistrationNames:{bubbled:"onCompositionEnd",captured:"onCompositionEndCapture"},dependencies:"blur compositionend keydown keypress keyup mousedown".split(" ")},compositionStart:{phasedRegistrationNames:{bubbled:"onCompositionStart",captured:"onCompositionStartCapture"},dependencies:"blur compositionstart keydown keypress keyup mousedown".split(" ")},compositionUpdate:{phasedRegistrationNames:{bubbled:"onCompositionUpdate",captured:"onCompositionUpdateCapture"},dependencies:"blur compositionupdate keydown keypress keyup mousedown".split(" ")}},rr=!1;function ir(e,t){switch(e){case"keyup":return-1!==Gn.indexOf(t.keyCode);case"keydown":return 229!==t.keyCode;case"keypress":case"mousedown":case"blur":return!0;default:return!1}}function ar(e){return"object"===typeof(e=e.detail)&&"data"in e?e.data:null}var or=!1;var ur={eventTypes:nr,extractEvents:function(e,t,n,r){var i;if(Jn)e:{switch(e){case"compositionstart":var a=nr.compositionStart;break e;case"compositionend":a=nr.compositionEnd;break e;case"compositionupdate":a=nr.compositionUpdate;break e}a=void 0}else or?ir(e,n)&&(a=nr.compositionEnd):"keydown"===e&&229===n.keyCode&&(a=nr.compositionStart);return a?(er&&"ko"!==n.locale&&(or||a!==nr.compositionStart?a===nr.compositionEnd&&or&&(i=zn()):(Un="value"in(Pn=r)?Pn.value:Pn.textContent,or=!0)),a=Kn.getPooled(a,t,n,r),i?a.data=i:null!==(i=ar(n))&&(a.data=i),Mn(a),i=a):i=null,(e=Xn?function(e,t){switch(e){case"compositionend":return ar(t);case"keypress":return 32!==t.which?null:(rr=!0,tr);case"textInput":return(e=t.data)===tr&&rr?null:e;default:return null}}(e,n):function(e,t){if(or)return"compositionend"===e||!Jn&&ir(e,t)?(e=zn(),Rn=Un=Pn=null,or=!1,e):null;switch(e){case"paste":return null;case"keypress":if(!(t.ctrlKey||t.altKey||t.metaKey)||t.ctrlKey&&t.altKey){if(t.char&&1=document.documentMode,zr={select:{phasedRegistrationNames:{bubbled:"onSelect",captured:"onSelectCapture"},dependencies:"blur contextmenu dragend focus keydown keyup mousedown mouseup selectionchange".split(" ")}},Vr=null,Wr=null,Yr=null,qr=!1;function Hr(e,t){var n=t.window===t?t.document:9===t.nodeType?t:t.ownerDocument;return qr||null==Vr||Vr!==ln(n)?null:("selectionStart"in(n=Vr)&&pn(n)?n={start:n.selectionStart,end:n.selectionEnd}:n={anchorNode:(n=(n.ownerDocument&&n.ownerDocument.defaultView||window).getSelection()).anchorNode,anchorOffset:n.anchorOffset,focusNode:n.focusNode,focusOffset:n.focusOffset},Yr&&Ur(Yr,n)?null:(Yr=n,(e=Yn.getPooled(zr.select,Wr,e,t)).type="select",e.target=Vr,Mn(e),e))}var $r={eventTypes:zr,extractEvents:function(e,t,n,r,i,a){if(!(a=!(i=a||(r.window===r?r.document:9===r.nodeType?r:r.ownerDocument)))){e:{i=Ze(i),a=j.onSelect;for(var o=0;oui||(e.current=oi[ui],oi[ui]=null,ui--)}function si(e,t){ui++,oi[ui]=e.current,e.current=t}var li={},fi={current:li},hi={current:!1},di=li;function pi(e,t){var n=e.type.contextTypes;if(!n)return li;var r=e.stateNode;if(r&&r.__reactInternalMemoizedUnmaskedChildContext===t)return r.__reactInternalMemoizedMaskedChildContext;var i,a={};for(i in n)a[i]=t[i];return r&&((e=e.stateNode).__reactInternalMemoizedUnmaskedChildContext=t,e.__reactInternalMemoizedMaskedChildContext=a),a}function vi(e){return null!==(e=e.childContextTypes)&&void 0!==e}function yi(){ci(hi),ci(fi)}function bi(e,t,n){if(fi.current!==li)throw Error(o(168));si(fi,t),si(hi,n)}function mi(e,t,n){var r=e.stateNode;if(e=t.childContextTypes,"function"!==typeof r.getChildContext)return n;for(var a in r=r.getChildContext())if(!(a in e))throw Error(o(108,ye(t)||"Unknown",a));return i({},n,{},r)}function gi(e){return e=(e=e.stateNode)&&e.__reactInternalMemoizedMergedChildContext||li,di=fi.current,si(fi,e),si(hi,hi.current),!0}function wi(e,t,n){var r=e.stateNode;if(!r)throw Error(o(169));n?(e=mi(e,t,di),r.__reactInternalMemoizedMergedChildContext=e,ci(hi),ci(fi),si(fi,e)):ci(hi),si(hi,n)}var ki=a.unstable_runWithPriority,_i=a.unstable_scheduleCallback,Oi=a.unstable_cancelCallback,xi=a.unstable_requestPaint,ji=a.unstable_now,Si=a.unstable_getCurrentPriorityLevel,Ti=a.unstable_ImmediatePriority,Ii=a.unstable_UserBlockingPriority,Ei=a.unstable_NormalPriority,Ai=a.unstable_LowPriority,Bi=a.unstable_IdlePriority,Ci={},Di=a.unstable_shouldYield,Li=void 0!==xi?xi:function(){},Ni=null,Fi=null,Mi=!1,Pi=ji(),Ui=1e4>Pi?ji:function(){return ji()-Pi};function Ri(){switch(Si()){case Ti:return 99;case Ii:return 98;case Ei:return 97;case Ai:return 96;case Bi:return 95;default:throw Error(o(332))}}function zi(e){switch(e){case 99:return Ti;case 98:return Ii;case 97:return Ei;case 96:return Ai;case 95:return Bi;default:throw Error(o(332))}}function Vi(e,t){return e=zi(e),ki(e,t)}function Wi(e,t,n){return e=zi(e),_i(e,t,n)}function Yi(e){return null===Ni?(Ni=[e],Fi=_i(Ti,Hi)):Ni.push(e),Ci}function qi(){if(null!==Fi){var e=Fi;Fi=null,Oi(e)}Hi()}function Hi(){if(!Mi&&null!==Ni){Mi=!0;var e=0;try{var t=Ni;Vi(99,(function(){for(;e=t&&(Ao=!0),e.firstContext=null)}function ra(e,t){if(Zi!==e&&!1!==t&&0!==t)if("number"===typeof t&&1073741823!==t||(Zi=e,t=1073741823),t={context:e,observedBits:t,next:null},null===Ji){if(null===Gi)throw Error(o(308));Ji=t,Gi.dependencies={expirationTime:0,firstContext:t,responders:null}}else Ji=Ji.next=t;return e._currentValue}var ia=!1;function aa(e){e.updateQueue={baseState:e.memoizedState,baseQueue:null,shared:{pending:null},effects:null}}function oa(e,t){e=e.updateQueue,t.updateQueue===e&&(t.updateQueue={baseState:e.baseState,baseQueue:e.baseQueue,shared:e.shared,effects:e.effects})}function ua(e,t){return(e={expirationTime:e,suspenseConfig:t,tag:0,payload:null,callback:null,next:null}).next=e}function ca(e,t){if(null!==(e=e.updateQueue)){var n=(e=e.shared).pending;null===n?t.next=t:(t.next=n.next,n.next=t),e.pending=t}}function sa(e,t){var n=e.alternate;null!==n&&oa(n,e),null===(n=(e=e.updateQueue).baseQueue)?(e.baseQueue=t.next=t,t.next=t):(t.next=n.next,n.next=t)}function la(e,t,n,r){var a=e.updateQueue;ia=!1;var o=a.baseQueue,u=a.shared.pending;if(null!==u){if(null!==o){var c=o.next;o.next=u.next,u.next=c}o=u,a.shared.pending=null,null!==(c=e.alternate)&&(null!==(c=c.updateQueue)&&(c.baseQueue=u))}if(null!==o){c=o.next;var s=a.baseState,l=0,f=null,h=null,d=null;if(null!==c)for(var p=c;;){if((u=p.expirationTime)l&&(l=u)}else{null!==d&&(d=d.next={expirationTime:1073741823,suspenseConfig:p.suspenseConfig,tag:p.tag,payload:p.payload,callback:p.callback,next:null}),ac(u,p.suspenseConfig);e:{var y=e,b=p;switch(u=t,v=n,b.tag){case 1:if("function"===typeof(y=b.payload)){s=y.call(v,s,u);break e}s=y;break e;case 3:y.effectTag=-4097&y.effectTag|64;case 0:if(null===(u="function"===typeof(y=b.payload)?y.call(v,s,u):y)||void 0===u)break e;s=i({},s,u);break e;case 2:ia=!0}}null!==p.callback&&(e.effectTag|=32,null===(u=a.effects)?a.effects=[p]:u.push(p))}if(null===(p=p.next)||p===c){if(null===(u=a.shared.pending))break;p=o.next=u.next,u.next=c,a.baseQueue=o=u,a.shared.pending=null}}null===d?f=s:d.next=h,a.baseState=f,a.baseQueue=d,oc(l),e.expirationTime=l,e.memoizedState=s}}function fa(e,t,n){if(e=t.effects,t.effects=null,null!==e)for(t=0;tv?(y=f,f=null):y=f.sibling;var b=d(i,f,u[v],c);if(null===b){null===f&&(f=y);break}e&&f&&null===b.alternate&&t(i,f),o=a(b,o,v),null===l?s=b:l.sibling=b,l=b,f=y}if(v===u.length)return n(i,f),s;if(null===f){for(;vy?(b=v,v=null):b=v.sibling;var g=d(i,v,m.value,s);if(null===g){null===v&&(v=b);break}e&&v&&null===g.alternate&&t(i,v),u=a(g,u,y),null===f?l=g:f.sibling=g,f=g,v=b}if(m.done)return n(i,v),l;if(null===v){for(;!m.done;y++,m=c.next())null!==(m=h(i,m.value,s))&&(u=a(m,u,y),null===f?l=m:f.sibling=m,f=m);return l}for(v=r(i,v);!m.done;y++,m=c.next())null!==(m=p(v,i,y,m.value,s))&&(e&&null!==m.alternate&&v.delete(null===m.key?y:m.key),u=a(m,u,y),null===f?l=m:f.sibling=m,f=m);return e&&v.forEach((function(e){return t(i,e)})),l}return function(e,r,a,c){var s="object"===typeof a&&null!==a&&a.type===ne&&null===a.key;s&&(a=a.props.children);var l="object"===typeof a&&null!==a;if(l)switch(a.$$typeof){case ee:e:{for(l=a.key,s=r;null!==s;){if(s.key===l){switch(s.tag){case 7:if(a.type===ne){n(e,s.sibling),(r=i(s,a.props.children)).return=e,e=r;break e}break;default:if(s.elementType===a.type){n(e,s.sibling),(r=i(s,a.props)).ref=ka(e,s,a),r.return=e,e=r;break e}}n(e,s);break}t(e,s),s=s.sibling}a.type===ne?((r=Ic(a.props.children,e.mode,c,a.key)).return=e,e=r):((c=Tc(a.type,a.key,a.props,null,e.mode,c)).ref=ka(e,r,a),c.return=e,e=c)}return u(e);case te:e:{for(s=a.key;null!==r;){if(r.key===s){if(4===r.tag&&r.stateNode.containerInfo===a.containerInfo&&r.stateNode.implementation===a.implementation){n(e,r.sibling),(r=i(r,a.children||[])).return=e,e=r;break e}n(e,r);break}t(e,r),r=r.sibling}(r=Ac(a,e.mode,c)).return=e,e=r}return u(e)}if("string"===typeof a||"number"===typeof a)return a=""+a,null!==r&&6===r.tag?(n(e,r.sibling),(r=i(r,a)).return=e,e=r):(n(e,r),(r=Ec(a,e.mode,c)).return=e,e=r),u(e);if(wa(a))return v(e,r,a,c);if(ve(a))return y(e,r,a,c);if(l&&_a(e,a),"undefined"===typeof a&&!s)switch(e.tag){case 1:case 0:throw e=e.type,Error(o(152,e.displayName||e.name||"Component"))}return n(e,r)}}var xa=Oa(!0),ja=Oa(!1),Sa={},Ta={current:Sa},Ia={current:Sa},Ea={current:Sa};function Aa(e){if(e===Sa)throw Error(o(174));return e}function Ba(e,t){switch(si(Ea,t),si(Ia,e),si(Ta,Sa),e=t.nodeType){case 9:case 11:t=(t=t.documentElement)?t.namespaceURI:Me(null,"");break;default:t=Me(t=(e=8===e?t.parentNode:t).namespaceURI||null,e=e.tagName)}ci(Ta),si(Ta,t)}function Ca(){ci(Ta),ci(Ia),ci(Ea)}function Da(e){Aa(Ea.current);var t=Aa(Ta.current),n=Me(t,e.type);t!==n&&(si(Ia,e),si(Ta,n))}function La(e){Ia.current===e&&(ci(Ta),ci(Ia))}var Na={current:0};function Fa(e){for(var t=e;null!==t;){if(13===t.tag){var n=t.memoizedState;if(null!==n&&(null===(n=n.dehydrated)||"$?"===n.data||"$!"===n.data))return t}else if(19===t.tag&&void 0!==t.memoizedProps.revealOrder){if(0!==(64&t.effectTag))return t}else if(null!==t.child){t.child.return=t,t=t.child;continue}if(t===e)break;for(;null===t.sibling;){if(null===t.return||t.return===e)return null;t=t.return}t.sibling.return=t.return,t=t.sibling}return null}function Ma(e,t){return{responder:e,props:t}}var Pa=G.ReactCurrentDispatcher,Ua=G.ReactCurrentBatchConfig,Ra=0,za=null,Va=null,Wa=null,Ya=!1;function qa(){throw Error(o(321))}function Ha(e,t){if(null===t)return!1;for(var n=0;na))throw Error(o(301));a+=1,Wa=Va=null,t.updateQueue=null,Pa.current=go,e=n(r,i)}while(t.expirationTime===Ra)}if(Pa.current=yo,t=null!==Va&&null!==Va.next,Ra=0,Wa=Va=za=null,Ya=!1,t)throw Error(o(300));return e}function Ka(){var e={memoizedState:null,baseState:null,baseQueue:null,queue:null,next:null};return null===Wa?za.memoizedState=Wa=e:Wa=Wa.next=e,Wa}function Qa(){if(null===Va){var e=za.alternate;e=null!==e?e.memoizedState:null}else e=Va.next;var t=null===Wa?za.memoizedState:Wa.next;if(null!==t)Wa=t,Va=e;else{if(null===e)throw Error(o(310));e={memoizedState:(Va=e).memoizedState,baseState:Va.baseState,baseQueue:Va.baseQueue,queue:Va.queue,next:null},null===Wa?za.memoizedState=Wa=e:Wa=Wa.next=e}return Wa}function Ga(e,t){return"function"===typeof t?t(e):t}function Ja(e){var t=Qa(),n=t.queue;if(null===n)throw Error(o(311));n.lastRenderedReducer=e;var r=Va,i=r.baseQueue,a=n.pending;if(null!==a){if(null!==i){var u=i.next;i.next=a.next,a.next=u}r.baseQueue=i=a,n.pending=null}if(null!==i){i=i.next,r=r.baseState;var c=u=a=null,s=i;do{var l=s.expirationTime;if(lza.expirationTime&&(za.expirationTime=l,oc(l))}else null!==c&&(c=c.next={expirationTime:1073741823,suspenseConfig:s.suspenseConfig,action:s.action,eagerReducer:s.eagerReducer,eagerState:s.eagerState,next:null}),ac(l,s.suspenseConfig),r=s.eagerReducer===e?s.eagerState:e(r,s.action);s=s.next}while(null!==s&&s!==i);null===c?a=r:c.next=u,Mr(r,t.memoizedState)||(Ao=!0),t.memoizedState=r,t.baseState=a,t.baseQueue=c,n.lastRenderedState=r}return[t.memoizedState,n.dispatch]}function Za(e){var t=Qa(),n=t.queue;if(null===n)throw Error(o(311));n.lastRenderedReducer=e;var r=n.dispatch,i=n.pending,a=t.memoizedState;if(null!==i){n.pending=null;var u=i=i.next;do{a=e(a,u.action),u=u.next}while(u!==i);Mr(a,t.memoizedState)||(Ao=!0),t.memoizedState=a,null===t.baseQueue&&(t.baseState=a),n.lastRenderedState=a}return[a,r]}function Xa(e){var t=Ka();return"function"===typeof e&&(e=e()),t.memoizedState=t.baseState=e,e=(e=t.queue={pending:null,dispatch:null,lastRenderedReducer:Ga,lastRenderedState:e}).dispatch=vo.bind(null,za,e),[t.memoizedState,e]}function eo(e,t,n,r){return e={tag:e,create:t,destroy:n,deps:r,next:null},null===(t=za.updateQueue)?(t={lastEffect:null},za.updateQueue=t,t.lastEffect=e.next=e):null===(n=t.lastEffect)?t.lastEffect=e.next=e:(r=n.next,n.next=e,e.next=r,t.lastEffect=e),e}function to(){return Qa().memoizedState}function no(e,t,n,r){var i=Ka();za.effectTag|=e,i.memoizedState=eo(1|t,n,void 0,void 0===r?null:r)}function ro(e,t,n,r){var i=Qa();r=void 0===r?null:r;var a=void 0;if(null!==Va){var o=Va.memoizedState;if(a=o.destroy,null!==r&&Ha(r,o.deps))return void eo(t,n,a,r)}za.effectTag|=e,i.memoizedState=eo(1|t,n,a,r)}function io(e,t){return no(516,4,e,t)}function ao(e,t){return ro(516,4,e,t)}function oo(e,t){return ro(4,2,e,t)}function uo(e,t){return"function"===typeof t?(e=e(),t(e),function(){t(null)}):null!==t&&void 0!==t?(e=e(),t.current=e,function(){t.current=null}):void 0}function co(e,t,n){return n=null!==n&&void 0!==n?n.concat([e]):null,ro(4,2,uo.bind(null,t,e),n)}function so(){}function lo(e,t){return Ka().memoizedState=[e,void 0===t?null:t],e}function fo(e,t){var n=Qa();t=void 0===t?null:t;var r=n.memoizedState;return null!==r&&null!==t&&Ha(t,r[1])?r[0]:(n.memoizedState=[e,t],e)}function ho(e,t){var n=Qa();t=void 0===t?null:t;var r=n.memoizedState;return null!==r&&null!==t&&Ha(t,r[1])?r[0]:(e=e(),n.memoizedState=[e,t],e)}function po(e,t,n){var r=Ri();Vi(98>r?98:r,(function(){e(!0)})),Vi(97<\/script>",e=e.removeChild(e.firstChild)):"string"===typeof r.is?e=c.createElement(a,{is:r.is}):(e=c.createElement(a),"select"===a&&(c=e,r.multiple?c.multiple=!0:r.size&&(c.size=r.size))):e=c.createElementNS(e,a),e[xn]=t,e[jn]=r,Ro(e,t),t.stateNode=e,c=on(a,r),a){case"iframe":case"object":case"embed":$t("load",e),s=r;break;case"video":case"audio":for(s=0;sr.tailExpiration&&1t)&&Vu.set(e,t))}}function Qu(e,t){e.expirationTime=(e=n>(e=e.nextKnownPendingLevel)?n:e)&&t!==e?0:e}function Ju(e){if(0!==e.lastExpiredTime)e.callbackExpirationTime=1073741823,e.callbackPriority=99,e.callbackNode=Yi(Xu.bind(null,e));else{var t=Gu(e),n=e.callbackNode;if(0===t)null!==n&&(e.callbackNode=null,e.callbackExpirationTime=0,e.callbackPriority=90);else{var r=Hu();if(1073741823===t?r=99:1===t||2===t?r=95:r=0>=(r=10*(1073741821-t)-10*(1073741821-r))?99:250>=r?98:5250>=r?97:95,null!==n){var i=e.callbackPriority;if(e.callbackExpirationTime===t&&i>=r)return;n!==Ci&&Oi(n)}e.callbackExpirationTime=t,e.callbackPriority=r,t=1073741823===t?Yi(Xu.bind(null,e)):Wi(r,Zu.bind(null,e),{timeout:10*(1073741821-t)-Ui()}),e.callbackNode=t}}}function Zu(e,t){if(qu=0,t)return Nc(e,t=Hu()),Ju(e),null;var n=Gu(e);if(0!==n){if(t=e.callbackNode,0!==(48&Ou))throw Error(o(327));if(vc(),e===xu&&n===Su||nc(e,n),null!==ju){var r=Ou;Ou|=16;for(var i=ic();;)try{cc();break}catch(c){rc(e,c)}if(Xi(),Ou=r,mu.current=i,1===Tu)throw t=Iu,nc(e,n),Dc(e,n),Ju(e),t;if(null===ju)switch(i=e.finishedWork=e.current.alternate,e.finishedExpirationTime=n,r=Tu,xu=null,r){case wu:case 1:throw Error(o(345));case 2:Nc(e,2=n){e.lastPingedTime=n,nc(e,n);break}}if(0!==(a=Gu(e))&&a!==n)break;if(0!==r&&r!==n){e.lastPingedTime=r;break}e.timeoutHandle=gn(hc.bind(null,e),i);break}hc(e);break;case _u:if(Dc(e,n),n===(r=e.lastSuspendedTime)&&(e.nextKnownPendingLevel=fc(i)),Du&&(0===(i=e.lastPingedTime)||i>=n)){e.lastPingedTime=n,nc(e,n);break}if(0!==(i=Gu(e))&&i!==n)break;if(0!==r&&r!==n){e.lastPingedTime=r;break}if(1073741823!==Au?r=10*(1073741821-Au)-Ui():1073741823===Eu?r=0:(r=10*(1073741821-Eu)-5e3,0>(r=(i=Ui())-r)&&(r=0),(n=10*(1073741821-n)-i)<(r=(120>r?120:480>r?480:1080>r?1080:1920>r?1920:3e3>r?3e3:4320>r?4320:1960*bu(r/1960))-r)&&(r=n)),10=(r=0|u.busyMinDurationMs)?r=0:(i=0|u.busyDelayMs,r=(a=Ui()-(10*(1073741821-a)-(0|u.timeoutMs||5e3)))<=i?0:i+r-a),10 component higher in the tree to provide a loading indicator or placeholder to display."+be(o))}5!==Tu&&(Tu=2),u=Zo(u,o),f=a;do{switch(f.tag){case 3:c=u,f.effectTag|=4096,f.expirationTime=t,sa(f,pu(f,c,t));break e;case 1:c=u;var w=f.type,k=f.stateNode;if(0===(64&f.effectTag)&&("function"===typeof w.getDerivedStateFromError||null!==k&&"function"===typeof k.componentDidCatch&&(null===Pu||!Pu.has(k)))){f.effectTag|=4096,f.expirationTime=t,sa(f,vu(f,c,t));break e}}f=f.return}while(null!==f)}ju=lc(ju)}catch(_){t=_;continue}break}}function ic(){var e=mu.current;return mu.current=yo,null===e?yo:e}function ac(e,t){eCu&&(Cu=e)}function uc(){for(;null!==ju;)ju=sc(ju)}function cc(){for(;null!==ju&&!Di();)ju=sc(ju)}function sc(e){var t=yu(e.alternate,e,Su);return e.memoizedProps=e.pendingProps,null===t&&(t=lc(e)),gu.current=null,t}function lc(e){ju=e;do{var t=ju.alternate;if(e=ju.return,0===(2048&ju.effectTag)){if(t=Go(t,ju,Su),1===Su||1!==ju.childExpirationTime){for(var n=0,r=ju.child;null!==r;){var i=r.expirationTime,a=r.childExpirationTime;i>n&&(n=i),a>n&&(n=a),r=r.sibling}ju.childExpirationTime=n}if(null!==t)return t;null!==e&&0===(2048&e.effectTag)&&(null===e.firstEffect&&(e.firstEffect=ju.firstEffect),null!==ju.lastEffect&&(null!==e.lastEffect&&(e.lastEffect.nextEffect=ju.firstEffect),e.lastEffect=ju.lastEffect),1(e=e.childExpirationTime)?t:e}function hc(e){var t=Ri();return Vi(99,dc.bind(null,e,t)),null}function dc(e,t){do{vc()}while(null!==Ru);if(0!==(48&Ou))throw Error(o(327));var n=e.finishedWork,r=e.finishedExpirationTime;if(null===n)return null;if(e.finishedWork=null,e.finishedExpirationTime=0,n===e.current)throw Error(o(177));e.callbackNode=null,e.callbackExpirationTime=0,e.callbackPriority=90,e.nextKnownPendingLevel=0;var i=fc(n);if(e.firstPendingTime=i,r<=e.lastSuspendedTime?e.firstSuspendedTime=e.lastSuspendedTime=e.nextKnownPendingLevel=0:r<=e.firstSuspendedTime&&(e.firstSuspendedTime=r-1),r<=e.lastPingedTime&&(e.lastPingedTime=0),r<=e.lastExpiredTime&&(e.lastExpiredTime=0),e===xu&&(ju=xu=null,Su=0),1c&&(l=c,c=u,u=l),l=hn(w,u),f=hn(w,c),l&&f&&(1!==_.rangeCount||_.anchorNode!==l.node||_.anchorOffset!==l.offset||_.focusNode!==f.node||_.focusOffset!==f.offset)&&((k=k.createRange()).setStart(l.node,l.offset),_.removeAllRanges(),u>c?(_.addRange(k),_.extend(f.node,f.offset)):(k.setEnd(f.node,f.offset),_.addRange(k))))),k=[];for(_=w;_=_.parentNode;)1===_.nodeType&&k.push({element:_,left:_.scrollLeft,top:_.scrollTop});for("function"===typeof w.focus&&w.focus(),w=0;w=n?Yo(e,t,n):(si(Na,1&Na.current),null!==(t=Ko(e,t,n))?t.sibling:null);si(Na,1&Na.current);break;case 19:if(r=t.childExpirationTime>=n,0!==(64&e.effectTag)){if(r)return $o(e,t,n);t.effectTag|=64}if(null!==(i=t.memoizedState)&&(i.rendering=null,i.tail=null),si(Na,Na.current),!r)return null}return Ko(e,t,n)}Ao=!1}}else Ao=!1;switch(t.expirationTime=0,t.tag){case 2:if(r=t.type,null!==e&&(e.alternate=null,t.alternate=null,t.effectTag|=2),e=t.pendingProps,i=pi(t,fi.current),na(t,n),i=$a(null,t,r,e,i,n),t.effectTag|=1,"object"===typeof i&&null!==i&&"function"===typeof i.render&&void 0===i.$$typeof){if(t.tag=1,t.memoizedState=null,t.updateQueue=null,vi(r)){var a=!0;gi(t)}else a=!1;t.memoizedState=null!==i.state&&void 0!==i.state?i.state:null,aa(t);var u=r.getDerivedStateFromProps;"function"===typeof u&&pa(t,r,u,e),i.updater=va,t.stateNode=i,i._reactInternalFiber=t,ga(t,r,e,n),t=Po(null,t,r,!0,a,n)}else t.tag=0,Bo(null,t,i,n),t=t.child;return t;case 16:e:{if(i=t.elementType,null!==e&&(e.alternate=null,t.alternate=null,t.effectTag|=2),e=t.pendingProps,function(e){if(-1===e._status){e._status=0;var t=e._ctor;t=t(),e._result=t,t.then((function(t){0===e._status&&(t=t.default,e._status=1,e._result=t)}),(function(t){0===e._status&&(e._status=2,e._result=t)}))}}(i),1!==i._status)throw i._result;switch(i=i._result,t.type=i,a=t.tag=function(e){if("function"===typeof e)return jc(e)?1:0;if(void 0!==e&&null!==e){if((e=e.$$typeof)===ce)return 11;if(e===fe)return 14}return 2}(i),e=Ki(i,e),a){case 0:t=Fo(null,t,i,e,n);break e;case 1:t=Mo(null,t,i,e,n);break e;case 11:t=Co(null,t,i,e,n);break e;case 14:t=Do(null,t,i,Ki(i.type,e),r,n);break e}throw Error(o(306,i,""))}return t;case 0:return r=t.type,i=t.pendingProps,Fo(e,t,r,i=t.elementType===r?i:Ki(r,i),n);case 1:return r=t.type,i=t.pendingProps,Mo(e,t,r,i=t.elementType===r?i:Ki(r,i),n);case 3:if(Uo(t),r=t.updateQueue,null===e||null===r)throw Error(o(282));if(r=t.pendingProps,i=null!==(i=t.memoizedState)?i.element:null,oa(e,t),la(t,r,null,n),(r=t.memoizedState.element)===i)Io(),t=Ko(e,t,n);else{if((i=t.stateNode.hydrate)&&(ko=kn(t.stateNode.containerInfo.firstChild),wo=t,i=_o=!0),i)for(n=ja(t,null,r,n),t.child=n;n;)n.effectTag=-3&n.effectTag|1024,n=n.sibling;else Bo(e,t,r,n),Io();t=t.child}return t;case 5:return Da(t),null===e&&jo(t),r=t.type,i=t.pendingProps,a=null!==e?e.memoizedProps:null,u=i.children,mn(r,i)?u=null:null!==a&&mn(r,a)&&(t.effectTag|=16),No(e,t),4&t.mode&&1!==n&&i.hidden?(t.expirationTime=t.childExpirationTime=1,t=null):(Bo(e,t,u,n),t=t.child),t;case 6:return null===e&&jo(t),null;case 13:return Yo(e,t,n);case 4:return Ba(t,t.stateNode.containerInfo),r=t.pendingProps,null===e?t.child=xa(t,null,r,n):Bo(e,t,r,n),t.child;case 11:return r=t.type,i=t.pendingProps,Co(e,t,r,i=t.elementType===r?i:Ki(r,i),n);case 7:return Bo(e,t,t.pendingProps,n),t.child;case 8:case 12:return Bo(e,t,t.pendingProps.children,n),t.child;case 10:e:{r=t.type._context,i=t.pendingProps,u=t.memoizedProps,a=i.value;var c=t.type._context;if(si(Qi,c._currentValue),c._currentValue=a,null!==u)if(c=u.value,0===(a=Mr(c,a)?0:0|("function"===typeof r._calculateChangedBits?r._calculateChangedBits(c,a):1073741823))){if(u.children===i.children&&!hi.current){t=Ko(e,t,n);break e}}else for(null!==(c=t.child)&&(c.return=t);null!==c;){var s=c.dependencies;if(null!==s){u=c.child;for(var l=s.firstContext;null!==l;){if(l.context===r&&0!==(l.observedBits&a)){1===c.tag&&((l=ua(n,null)).tag=2,ca(c,l)),c.expirationTime=t&&e<=t}function Dc(e,t){var n=e.firstSuspendedTime,r=e.lastSuspendedTime;nt||0===n)&&(e.lastSuspendedTime=t),t<=e.lastPingedTime&&(e.lastPingedTime=0),t<=e.lastExpiredTime&&(e.lastExpiredTime=0)}function Lc(e,t){t>e.firstPendingTime&&(e.firstPendingTime=t);var n=e.firstSuspendedTime;0!==n&&(t>=n?e.firstSuspendedTime=e.lastSuspendedTime=e.nextKnownPendingLevel=0:t>=e.lastSuspendedTime&&(e.lastSuspendedTime=t+1),t>e.nextKnownPendingLevel&&(e.nextKnownPendingLevel=t))}function Nc(e,t){var n=e.lastExpiredTime;(0===n||n>t)&&(e.lastExpiredTime=t)}function Fc(e,t,n,r){var i=t.current,a=Hu(),u=ha.suspense;a=$u(a,i,u);e:if(n){t:{if(Xe(n=n._reactInternalFiber)!==n||1!==n.tag)throw Error(o(170));var c=n;do{switch(c.tag){case 3:c=c.stateNode.context;break t;case 1:if(vi(c.type)){c=c.stateNode.__reactInternalMemoizedMergedChildContext;break t}}c=c.return}while(null!==c);throw Error(o(171))}if(1===n.tag){var s=n.type;if(vi(s)){n=mi(n,s,c);break e}}n=c}else n=li;return null===t.context?t.context=n:t.pendingContext=n,(t=ua(a,u)).payload={element:e},null!==(r=void 0===r?null:r)&&(t.callback=r),ca(i,t),Ku(i,a),a}function Mc(e){if(!(e=e.current).child)return null;switch(e.child.tag){case 5:default:return e.child.stateNode}}function Pc(e,t){null!==(e=e.memoizedState)&&null!==e.dehydrated&&e.retryTime=_},u=function(){},t.unstable_forceFrameRate=function(e){0>e||125>>1,i=e[r];if(!(void 0!==i&&0I(o,n))void 0!==c&&0>I(c,o)?(e[r]=c,e[u]=n,r=u):(e[r]=o,e[a]=n,r=a);else{if(!(void 0!==c&&0>I(c,n)))break e;e[r]=c,e[u]=n,r=u}}}return t}return null}function I(e,t){var n=e.sortIndex-t.sortIndex;return 0!==n?n:e.id-t.id}var E=[],A=[],B=1,C=null,D=3,L=!1,N=!1,F=!1;function M(e){for(var t=S(A);null!==t;){if(null===t.callback)T(A);else{if(!(t.startTime<=e))break;T(A),t.sortIndex=t.expirationTime,j(E,t)}t=S(A)}}function P(e){if(F=!1,M(e),!N)if(null!==S(E))N=!0,r(U);else{var t=S(A);null!==t&&i(P,t.startTime-e)}}function U(e,n){N=!1,F&&(F=!1,a()),L=!0;var r=D;try{for(M(n),C=S(E);null!==C&&(!(C.expirationTime>n)||e&&!o());){var u=C.callback;if(null!==u){C.callback=null,D=C.priorityLevel;var c=u(C.expirationTime<=n);n=t.unstable_now(),"function"===typeof c?C.callback=c:C===S(E)&&T(E),M(n)}else T(E);C=S(E)}if(null!==C)var s=!0;else{var l=S(A);null!==l&&i(P,l.startTime-n),s=!1}return s}finally{C=null,D=r,L=!1}}function R(e){switch(e){case 1:return-1;case 2:return 250;case 5:return 1073741823;case 4:return 1e4;default:return 5e3}}var z=u;t.unstable_IdlePriority=5,t.unstable_ImmediatePriority=1,t.unstable_LowPriority=4,t.unstable_NormalPriority=3,t.unstable_Profiling=null,t.unstable_UserBlockingPriority=2,t.unstable_cancelCallback=function(e){e.callback=null},t.unstable_continueExecution=function(){N||L||(N=!0,r(U))},t.unstable_getCurrentPriorityLevel=function(){return D},t.unstable_getFirstCallbackNode=function(){return S(E)},t.unstable_next=function(e){switch(D){case 1:case 2:case 3:var t=3;break;default:t=D}var n=D;D=t;try{return e()}finally{D=n}},t.unstable_pauseExecution=function(){},t.unstable_requestPaint=z,t.unstable_runWithPriority=function(e,t){switch(e){case 1:case 2:case 3:case 4:case 5:break;default:e=3}var n=D;D=e;try{return t()}finally{D=n}},t.unstable_scheduleCallback=function(e,n,o){var u=t.unstable_now();if("object"===typeof o&&null!==o){var c=o.delay;c="number"===typeof c&&0u?(e.sortIndex=c,j(A,e),null===S(E)&&e===S(A)&&(F?a():F=!0,i(P,c-u))):(e.sortIndex=o,j(E,e),N||L||(N=!0,r(U))),e},t.unstable_shouldYield=function(){var e=t.unstable_now();M(e);var n=S(E);return n!==C&&null!==C&&null!==n&&null!==n.callback&&n.startTime<=e&&n.expirationTime=0;--i){var a=this.tryEntries[i],o=a.completion;if("root"===a.tryLoc)return r("end");if(a.tryLoc<=this.prev){var u=n.call(a,"catchLoc"),c=n.call(a,"finallyLoc");if(u&&c){if(this.prev=0;--r){var i=this.tryEntries[r];if(i.tryLoc<=this.prev&&n.call(i,"finallyLoc")&&this.prev=0;--t){var n=this.tryEntries[t];if(n.finallyLoc===e)return this.complete(n.completion,n.afterLoc),_(n),l}},catch:function(e){for(var t=this.tryEntries.length-1;t>=0;--t){var n=this.tryEntries[t];if(n.tryLoc===e){var r=n.completion;if("throw"===r.type){var i=r.arg;_(n)}return i}}throw new Error("illegal catch attempt")},delegateYield:function(e,t,n){return this.delegate={iterator:x(e),resultName:t,nextLoc:n},"next"===this.method&&(this.arg=void 0),l}},e}(e.exports);try{regeneratorRuntime=r}catch(i){"object"===typeof globalThis?globalThis.regeneratorRuntime=r:Function("r","regeneratorRuntime = r")(r)}},function(e,t,n){"use strict";e.exports=n(48)},function(e,t,n){"use strict";var r="function"===typeof Symbol&&Symbol.for,i=r?Symbol.for("react.element"):60103,a=r?Symbol.for("react.portal"):60106,o=r?Symbol.for("react.fragment"):60107,u=r?Symbol.for("react.strict_mode"):60108,c=r?Symbol.for("react.profiler"):60114,s=r?Symbol.for("react.provider"):60109,l=r?Symbol.for("react.context"):60110,f=r?Symbol.for("react.async_mode"):60111,h=r?Symbol.for("react.concurrent_mode"):60111,d=r?Symbol.for("react.forward_ref"):60112,p=r?Symbol.for("react.suspense"):60113,v=r?Symbol.for("react.suspense_list"):60120,y=r?Symbol.for("react.memo"):60115,b=r?Symbol.for("react.lazy"):60116,m=r?Symbol.for("react.block"):60121,g=r?Symbol.for("react.fundamental"):60117,w=r?Symbol.for("react.responder"):60118,k=r?Symbol.for("react.scope"):60119;function _(e){if("object"===typeof e&&null!==e){var t=e.$$typeof;switch(t){case i:switch(e=e.type){case f:case h:case o:case c:case u:case p:return e;default:switch(e=e&&e.$$typeof){case l:case d:case b:case y:case s:return e;default:return t}}case a:return t}}}function O(e){return _(e)===h}t.AsyncMode=f,t.ConcurrentMode=h,t.ContextConsumer=l,t.ContextProvider=s,t.Element=i,t.ForwardRef=d,t.Fragment=o,t.Lazy=b,t.Memo=y,t.Portal=a,t.Profiler=c,t.StrictMode=u,t.Suspense=p,t.isAsyncMode=function(e){return O(e)||_(e)===f},t.isConcurrentMode=O,t.isContextConsumer=function(e){return _(e)===l},t.isContextProvider=function(e){return _(e)===s},t.isElement=function(e){return"object"===typeof e&&null!==e&&e.$$typeof===i},t.isForwardRef=function(e){return _(e)===d},t.isFragment=function(e){return _(e)===o},t.isLazy=function(e){return _(e)===b},t.isMemo=function(e){return _(e)===y},t.isPortal=function(e){return _(e)===a},t.isProfiler=function(e){return _(e)===c},t.isStrictMode=function(e){return _(e)===u},t.isSuspense=function(e){return _(e)===p},t.isValidElementType=function(e){return"string"===typeof e||"function"===typeof e||e===o||e===h||e===c||e===u||e===p||e===v||"object"===typeof e&&null!==e&&(e.$$typeof===b||e.$$typeof===y||e.$$typeof===s||e.$$typeof===l||e.$$typeof===d||e.$$typeof===g||e.$$typeof===w||e.$$typeof===k||e.$$typeof===m)},t.typeOf=_},function(e,t,n){(function(e){var r="undefined"!==typeof e&&e||"undefined"!==typeof self&&self||window,i=Function.prototype.apply;function a(e,t){this._id=e,this._clearFn=t}t.setTimeout=function(){return new a(i.call(setTimeout,r,arguments),clearTimeout)},t.setInterval=function(){return new a(i.call(setInterval,r,arguments),clearInterval)},t.clearTimeout=t.clearInterval=function(e){e&&e.close()},a.prototype.unref=a.prototype.ref=function(){},a.prototype.close=function(){this._clearFn.call(r,this._id)},t.enroll=function(e,t){clearTimeout(e._idleTimeoutId),e._idleTimeout=t},t.unenroll=function(e){clearTimeout(e._idleTimeoutId),e._idleTimeout=-1},t._unrefActive=t.active=function(e){clearTimeout(e._idleTimeoutId);var t=e._idleTimeout;t>=0&&(e._idleTimeoutId=setTimeout((function(){e._onTimeout&&e._onTimeout()}),t))},n(50),t.setImmediate="undefined"!==typeof self&&self.setImmediate||"undefined"!==typeof e&&e.setImmediate||this&&this.setImmediate,t.clearImmediate="undefined"!==typeof self&&self.clearImmediate||"undefined"!==typeof e&&e.clearImmediate||this&&this.clearImmediate}).call(this,n(33))},function(e,t,n){(function(e,t){!function(e,n){"use strict";if(!e.setImmediate){var r,i=1,a={},o=!1,u=e.document,c=Object.getPrototypeOf&&Object.getPrototypeOf(e);c=c&&c.setTimeout?c:e,"[object process]"==={}.toString.call(e.process)?r=function(e){t.nextTick((function(){l(e)}))}:function(){if(e.postMessage&&!e.importScripts){var t=!0,n=e.onmessage;return e.onmessage=function(){t=!1},e.postMessage("","*"),e.onmessage=n,t}}()?function(){var t="setImmediate$"+Math.random()+"$",n=function(n){n.source===e&&"string"===typeof n.data&&0===n.data.indexOf(t)&&l(+n.data.slice(t.length))};e.addEventListener?e.addEventListener("message",n,!1):e.attachEvent("onmessage",n),r=function(n){e.postMessage(t+n,"*")}}():e.MessageChannel?function(){var e=new MessageChannel;e.port1.onmessage=function(e){l(e.data)},r=function(t){e.port2.postMessage(t)}}():u&&"onreadystatechange"in u.createElement("script")?function(){var e=u.documentElement;r=function(t){var n=u.createElement("script");n.onreadystatechange=function(){l(t),n.onreadystatechange=null,e.removeChild(n),n=null},e.appendChild(n)}}():r=function(e){setTimeout(l,0,e)},c.setImmediate=function(e){"function"!==typeof e&&(e=new Function(""+e));for(var t=new Array(arguments.length-1),n=0;n1)for(var n=1;n= tokenizer.vocab_size:
- continue
- # Filter special tokens.
- if idx in tokenizer.all_special_ids:
- logger.debug('Filtered: %s', word)
- filter[idx] = -1e32
- # Filter capitalized words (lazy way to remove proper nouns).
- if isupper(idx, tokenizer):
- logger.debug('Filtered: %s', word)
- filter[idx] = -1e32
-
- logger.info('Evaluating')
- numerator = 0
- denominator = 0
- for model_inputs, labels in tqdm(dev_loader):
- model_inputs = {k: v.to(device) for k, v in model_inputs.items()}
- labels = labels.to(device)
- with torch.no_grad():
- predict_logits = predictor(model_inputs, trigger_ids)
- numerator += evaluation_fn(predict_logits, labels).sum().item()
- denominator += labels.size(0)
- dev_metric = numerator / (denominator + 1e-13)
- logger.info(f'Dev metric: {dev_metric}')
-
- best_dev_metric = -float('inf')
- # Measure elapsed time of trigger search
- start = time.time()
-
- for i in range(args.iters):
-
- logger.info(f'Iteration: {i}')
-
- logger.info('Accumulating Gradient')
- model.zero_grad()
-
- pbar = tqdm(range(args.accumulation_steps))
- train_iter = iter(train_loader)
- averaged_grad = None
-
- # Accumulate
- for step in pbar:
-
- # Shuttle inputs to GPU
- try:
- model_inputs, labels = next(train_iter)
- except:
- logger.warning(
- 'Insufficient data for number of accumulation steps. '
- 'Effective batch size will be smaller than specified.'
- )
- break
- model_inputs = {k: v.to(device) for k, v in model_inputs.items()}
- labels = labels.to(device)
- predict_logits = predictor(model_inputs, trigger_ids)
- loss = get_loss(predict_logits, labels).mean()
- loss.backward()
-
- grad = embedding_gradient.get()
- bsz, _, emb_dim = grad.size()
- selection_mask = model_inputs['trigger_mask'].unsqueeze(-1)
- grad = torch.masked_select(grad, selection_mask)
- grad = grad.view(bsz, templatizer.num_trigger_tokens, emb_dim)
-
- if averaged_grad is None:
- averaged_grad = grad.sum(dim=0) / args.accumulation_steps
- else:
- averaged_grad += grad.sum(dim=0) / args.accumulation_steps
-
- logger.info('Evaluating Candidates')
- pbar = tqdm(range(args.accumulation_steps))
- train_iter = iter(train_loader)
-
- token_to_flip = random.randrange(templatizer.num_trigger_tokens)
- candidates = hotflip_attack(averaged_grad[token_to_flip],
- embeddings.weight,
- increase_loss=False,
- num_candidates=args.num_cand,
- filter=filter)
-
- current_score = 0
- candidate_scores = torch.zeros(args.num_cand, device=device)
- denom = 0
- for step in pbar:
-
- try:
- model_inputs, labels = next(train_iter)
- except:
- logger.warning(
- 'Insufficient data for number of accumulation steps. '
- 'Effective batch size will be smaller than specified.'
- )
- break
- model_inputs = {k: v.to(device) for k, v in model_inputs.items()}
- labels = labels.to(device)
- with torch.no_grad():
- predict_logits = predictor(model_inputs, trigger_ids)
- eval_metric = evaluation_fn(predict_logits, labels)
-
- # Update current score
- current_score += eval_metric.sum()
- denom += labels.size(0)
-
- # NOTE: Instead of iterating over tokens to flip we randomly change just one each
- # time so the gradients don't get stale.
- for i, candidate in enumerate(candidates):
-
- # if candidate.item() in filter_candidates:
- # candidate_scores[i] = -1e32
- # continue
-
- temp_trigger = trigger_ids.clone()
- temp_trigger[:, token_to_flip] = candidate
- with torch.no_grad():
- predict_logits = predictor(model_inputs, temp_trigger)
- eval_metric = evaluation_fn(predict_logits, labels)
-
- candidate_scores[i] += eval_metric.sum()
-
- # TODO: Something cleaner. LAMA templates can't have mask tokens, so if
- # there are still mask tokens in the trigger then set the current score
- # to -inf.
- if args.print_lama:
- if trigger_ids.eq(tokenizer.mask_token_id).any():
- current_score = float('-inf')
-
- if (candidate_scores > current_score).any():
- logger.info('Better trigger detected.')
- best_candidate_score = candidate_scores.max()
- best_candidate_idx = candidate_scores.argmax()
- trigger_ids[:, token_to_flip] = candidates[best_candidate_idx]
- logger.info(f'Train metric: {best_candidate_score / (denom + 1e-13): 0.4f}')
- else:
- logger.info('No improvement detected. Skipping evaluation.')
- continue
-
- logger.info('Evaluating')
- numerator = 0
- denominator = 0
- for model_inputs, labels in tqdm(dev_loader):
- model_inputs = {k: v.to(device) for k, v in model_inputs.items()}
- labels = labels.to(device)
- with torch.no_grad():
- predict_logits = predictor(model_inputs, trigger_ids)
- numerator += evaluation_fn(predict_logits, labels).sum().item()
- denominator += labels.size(0)
- dev_metric = numerator / (denominator + 1e-13)
-
- logger.info(f'Trigger tokens: {tokenizer.convert_ids_to_tokens(trigger_ids.squeeze(0))}')
- logger.info(f'Dev metric: {dev_metric}')
-
- # TODO: Something cleaner. LAMA templates can't have mask tokens, so if
- # there are still mask tokens in the trigger then set the current score
- # to -inf.
- if args.print_lama:
- if best_trigger_ids.eq(tokenizer.mask_token_id).any():
- best_dev_metric = float('-inf')
-
- if dev_metric > best_dev_metric:
- logger.info('Best performance so far')
- best_trigger_ids = trigger_ids.clone()
- best_dev_metric = dev_metric
-
- best_trigger_tokens = tokenizer.convert_ids_to_tokens(best_trigger_ids.squeeze(0))
- logger.info(f'Best tokens: {best_trigger_tokens}')
- logger.info(f'Best dev metric: {best_dev_metric}')
- if args.print_lama:
- # Templatize with [X] and [Y]
- if args.use_ctx:
- model_inputs, label_ids = templatizer({
- 'sub_label': '[X]',
- 'obj_label': tokenizer.lama_y,
- 'context': ''
- })
- else:
- model_inputs, label_ids = templatizer({
- 'sub_label': '[X]',
- 'obj_label': tokenizer.lama_y,
- })
- lama_template = model_inputs['input_ids']
- # Instantiate trigger tokens
- lama_template.masked_scatter_(
- mask=model_inputs['trigger_mask'],
- source=best_trigger_ids.cpu())
- # Instantiate label token
- lama_template.masked_scatter_(
- mask=model_inputs['predict_mask'],
- source=label_ids)
- # Print LAMA JSON template
- relation = args.train.parent.stem
-
- # The following block of code is a bit hacky but whatever, it gets the job done
- if args.use_ctx:
- template = tokenizer.decode(lama_template.squeeze(0)[1:-1]).replace('[SEP] ', '').replace(' ', '').replace('[ X ]', '[X]')
- else:
- template = tokenizer.decode(lama_template.squeeze(0)[1:-1]).replace('[ X ]', '[X]')
-
- out = {
- 'relation': args.train.parent.stem,
- 'template': template
- }
- print(json.dumps(out))
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--train', type=Path, required=True, help='Train data path')
- parser.add_argument('--dev', type=Path, required=True, help='Dev data path')
- parser.add_argument('--template', type=str, help='Template string')
- parser.add_argument('--label-map', type=str, default=None, help='JSON object defining label map')
-
- # LAMA-specific
- parser.add_argument('--tokenize-labels', action='store_true',
- help='If specified labels are split into word pieces.'
- 'Needed for LAMA probe experiments.')
- parser.add_argument('--filter', action='store_true',
- help='If specified, filter out special tokens and gold objects.'
- 'Furthermore, tokens starting with capital '
- 'letters will not appear in triggers. Lazy '
- 'approach for removing proper nouns.')
- parser.add_argument('--print-lama', action='store_true',
- help='Prints best trigger in LAMA format.')
-
- parser.add_argument('--initial-trigger', nargs='+', type=str, default=None, help='Manual prompt')
- parser.add_argument('--label-field', type=str, default='label',
- help='Name of the label field')
-
- parser.add_argument('--bsz', type=int, default=32, help='Batch size')
- parser.add_argument('--eval-size', type=int, default=256, help='Eval size')
- parser.add_argument('--iters', type=int, default=100,
- help='Number of iterations to run trigger search algorithm')
- parser.add_argument('--accumulation-steps', type=int, default=10)
- parser.add_argument('--model-name', type=str, default='bert-base-cased',
- help='Model name passed to HuggingFace AutoX classes.')
- parser.add_argument('--seed', type=int, default=0)
- parser.add_argument('--limit', type=int, default=None)
- parser.add_argument('--use-ctx', action='store_true',
- help='Use context sentences for relation extraction only')
- parser.add_argument('--perturbed', action='store_true',
- help='Perturbed sentence evaluation of relation extraction: replace each object in dataset with a random other object')
- parser.add_argument('--patience', type=int, default=5)
- parser.add_argument('--num-cand', type=int, default=10)
- parser.add_argument('--sentence-size', type=int, default=50)
-
- parser.add_argument('--debug', action='store_true')
- args = parser.parse_args()
-
- if args.debug:
- level = logging.DEBUG
- else:
- level = logging.INFO
- logging.basicConfig(level=level)
-
- run_model(args)
diff --git a/spaces/usbethFlerru/sovits-modelsV2/example/Apostila Memorex Positivo Pdf NEW.md b/spaces/usbethFlerru/sovits-modelsV2/example/Apostila Memorex Positivo Pdf NEW.md
deleted file mode 100644
index b8a455f6e95572275f6a2b9f3826d1c9af41301a..0000000000000000000000000000000000000000
--- a/spaces/usbethFlerru/sovits-modelsV2/example/Apostila Memorex Positivo Pdf NEW.md
+++ /dev/null
@@ -1,114 +0,0 @@
-apostila memorex positivo pdf
Download 🗸 https://urlcod.com/2uyUsa
-
-new waz group wtf
-
-jams (migraine)
-
-Mad Bitch uirispi wtf
-
-Maneholistic(23) gurlgirl (24) you
-
-mls joker fucks
-
-moly libido diagnoz(88) got milk
-
-Mona Lisa Blanca(22) cryo(22) you
-
-monsoon Bitch(19) We
-
-Monkeyreeder (lol)
-
-mosquito i hate my cunt
-
-more pics want
-
-mother son cuckold hardcore
-
-Mr.Cock(25) "I think
-
-Multi Divorced housewife is new to sex
-
-My dick's goin round her fuckin ass
-
-My Sexy Wife & I suck dick..
-
-Naughty wife fuck with brother and sister
-
-natural cocks
-
-Need to teach her a lesson
-
-never before seen
-
-Newsgirl with big tits
-
-Numb pussy is like a zipper
-
-nude you fucking girls(23)
-
-Nukid
-
-O-Lite (25)
-
-Oberto (25) hater(18)
-
-Omega (28)
-
-on the other side - no longer virgin (16)
-
-Orange (40)
-
-Orange Blossom (25)
-
-Orange Bouquet (26) i was up again...lol
-
-orange spray(24)
-
-orchid(22)
-
-Orchid(22) The best ameba(23)
-
-Orchid(22) Matrimony(22)
-
-otro apetito(23) lol
-
-Papa (18)
-
-Papa Diabla (27)
-
-papi pig(21) you
-
-peanut butter(22) on a big plate
-
-pear Cuckold married guy(33)
-
-pervert(17)
-
-pervert hentai stella
-
-Pervert's dream(26)
-
-person_with_chair(19)
-
-Philistines (27)
-
-Pistol Cum Shot(28)
-
-Plain Little Grandma(25)
-
-Plum(19)
-
-Plums(18)
-
-Plum(19) you
-
-Polar Bear(18)
-
-Police in sexy lingerie(21)
-
-Pretty blonde with huge tits
-
-Pretty 4fefd39f24
-
-
-
diff --git a/spaces/valeriylo/saiga_rag/app.py b/spaces/valeriylo/saiga_rag/app.py
deleted file mode 100644
index 8c679943d9a73f61e2d2c1c305762c17e8f4618e..0000000000000000000000000000000000000000
--- a/spaces/valeriylo/saiga_rag/app.py
+++ /dev/null
@@ -1,375 +0,0 @@
-import gradio as gr
-
-from uuid import uuid4
-from huggingface_hub import snapshot_download
-from langchain.document_loaders import (
- CSVLoader,
- EverNoteLoader,
- PDFMinerLoader,
- PyPDFium2Loader,
- TextLoader,
- UnstructuredEmailLoader,
- UnstructuredEPubLoader,
- UnstructuredHTMLLoader,
- UnstructuredMarkdownLoader,
- UnstructuredODTLoader,
- UnstructuredPowerPointLoader,
- UnstructuredWordDocumentLoader,
-)
-from langchain.text_splitter import RecursiveCharacterTextSplitter
-from langchain.vectorstores import Chroma
-from langchain.embeddings import HuggingFaceEmbeddings
-from langchain.docstore.document import Document
-from chromadb.config import Settings
-from llama_cpp import Llama
-
-
-SYSTEM_PROMPT = "Ты - полезный, уважительный и честный ассистент. Всегда отвечай как можно более надежно. В ответах не должно информации из твоей базы знаний, а только лишь информация из контекста и ее перефразирование. Если вопрос не имеет смысла или не является фактологически последовательным, объясни почему, а не отвечайте на вопрос некорректно. Если ты не знаешь ответа на вопрос, пожалуйста, не сообщай ложную информацию. Твоя цель - дать ответы, связанные с базой знаний компании."
-
-SYSTEM_TOKEN = 1788
-USER_TOKEN = 1404
-BOT_TOKEN = 9225
-LINEBREAK_TOKEN = 13
-
-ROLE_TOKENS = {
- "user": USER_TOKEN,
- "bot": BOT_TOKEN,
- "system": SYSTEM_TOKEN
-}
-
-LOADER_MAPPING = {
- ".csv": (CSVLoader, {}),
- ".doc": (UnstructuredWordDocumentLoader, {}),
- ".docx": (UnstructuredWordDocumentLoader, {}),
- ".enex": (EverNoteLoader, {}),
- ".epub": (UnstructuredEPubLoader, {}),
- ".html": (UnstructuredHTMLLoader, {}),
- ".md": (UnstructuredMarkdownLoader, {}),
- ".odt": (UnstructuredODTLoader, {}),
- #".pdf": (PDFMinerLoader, {}),
- ".pdf": (PyPDFium2Loader, {}),
- ".ppt": (UnstructuredPowerPointLoader, {}),
- ".pptx": (UnstructuredPowerPointLoader, {}),
- ".txt": (TextLoader, {"encoding": "utf8"}),
-}
-
-repo_name = "IlyaGusev/saiga_mistral_7b_gguf"
-model_name = "model-q4_K.gguf"
-
-embedder_name = "intfloat/multilingual-e5-large"
-
-
-snapshot_download(repo_id=repo_name, local_dir=".", allow_patterns=model_name)
-
-model = Llama(
- model_path=model_name,
- n_ctx=2048,
- n_parts=1,
-)
-
-max_new_tokens = 1500
-embeddings = HuggingFaceEmbeddings(model_name=embedder_name)
-
-def get_uuid():
- return str(uuid4())
-
-
-def load_single_document(file_path: str) -> Document:
- ext = "." + file_path.rsplit(".", 1)[-1]
- assert ext in LOADER_MAPPING
- loader_class, loader_args = LOADER_MAPPING[ext]
- loader = loader_class(file_path, **loader_args)
- print("load_single documernt, return type is: ", type(loader.load()[0]))
- return loader.load()[0]
-
-
-def get_message_tokens(model, role, content):
- message_tokens = model.tokenize(content.encode("utf-8"))
- message_tokens.insert(1, ROLE_TOKENS[role])
- message_tokens.insert(2, LINEBREAK_TOKEN)
- message_tokens.append(model.token_eos())
- return message_tokens
-
-
-def get_system_tokens(model):
- system_message = {"role": "system", "content": SYSTEM_PROMPT}
- return get_message_tokens(model, **system_message)
-
-
-def upload_files(files, file_paths):
- file_paths = [f.name for f in files]
- return file_paths
-
-
-def process_text(text):
- lines = text.split("\n")
- lines = [line for line in lines if len(line.strip()) > 2]
- text = "\n".join(lines).strip()
- if len(text) < 10:
- return None
- return text
-
-
-def build_index(file_paths, db, chunk_size, chunk_overlap, file_warning):
- documents = [load_single_document(path) for path in file_paths]
- print("build_index, documents type is :", type(documents))
- text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
- documents = text_splitter.split_documents(documents)
- fixed_documents = []
- for doc in documents:
- doc.page_content = process_text(doc.page_content)
- if not doc.page_content:
- continue
- fixed_documents.append(doc)
-
- db = Chroma.from_documents(
- fixed_documents,
- embeddings,
- client_settings=Settings(
- anonymized_telemetry=False
- )
- )
- file_warning = f"Загружено {len(fixed_documents)} фрагментов! Можно задавать вопросы."
- return db, file_warning
-
-
-def user(message, history, system_prompt):
- new_history = history + [[message, None]]
- return "", new_history
-
-
-def retrieve(history, db, retrieved_docs, k_documents):
- context = ""
- if db:
- last_user_message = history[-1][0]
- retriever = db.as_retriever(search_kwargs={"k": k_documents})
- docs = retriever.get_relevant_documents(last_user_message)
- retrieved_docs = "\n\n".join([doc.page_content for doc in docs])
- return retrieved_docs
-
-
-def bot(
- history,
- system_prompt,
- conversation_id,
- retrieved_docs,
- top_p,
- top_k,
- temp
-):
- if not history:
- return
-
- tokens = get_system_tokens(model)[:]
- tokens.append(LINEBREAK_TOKEN)
-
- for user_message, bot_message in history[:-1]:
- message_tokens = get_message_tokens(model=model, role="user", content=user_message)
- tokens.extend(message_tokens)
- if bot_message:
- message_tokens = get_message_tokens(model=model, role="bot", content=bot_message)
- tokens.extend(message_tokens)
-
- last_user_message = history[-1][0]
- if retrieved_docs:
- last_user_message = f"Контекст: {retrieved_docs}\n\nИспользуя контекст, ответь на вопрос: {last_user_message}. Не используй свои знания при ответе на вопрос."
- message_tokens = get_message_tokens(model=model, role="user", content=last_user_message)
- tokens.extend(message_tokens)
-
- role_tokens = [model.token_bos(), BOT_TOKEN, LINEBREAK_TOKEN]
- tokens.extend(role_tokens)
- generator = model.generate(
- tokens,
- top_k=top_k,
- top_p=top_p,
- temp=temp
- )
-
- partial_text = ""
- for i, token in enumerate(generator):
- if token == model.token_eos() or (max_new_tokens is not None and i >= max_new_tokens):
- break
- partial_text += model.detokenize([token]).decode("utf-8", "ignore")
- history[-1][1] = partial_text
- yield history
-
-
-with gr.Blocks(
- theme=gr.themes.Soft()
-) as demo:
- db = gr.State(None)
- conversation_id = gr.State(get_uuid)
- gr.Markdown(
- f"""Saiga Mistral RAG: retrieval QA
- """
- f"""Space code credits to Ilya Gusev
- """
- f"""Recommended to use only over .txt, .csv, .doc and .pdf/A files"""
- )
-
-
- with gr.Row():
- with gr.Column(scale=5):
- file_output = gr.File(file_count="multiple", label="Загрузка файлов")
- file_paths = gr.State([])
- file_warning = gr.Markdown(f"Фрагменты ещё не загружены!")
-
- with gr.Column(min_width=200, scale=3):
- with gr.Tab(label="Параметры нарезки"):
- chunk_size = gr.Slider(
- minimum=50,
- maximum=2000,
- value=250,
- step=50,
- interactive=True,
- label="Размер фрагментов",
- )
- chunk_overlap = gr.Slider(
- minimum=0,
- maximum=500,
- value=30,
- step=10,
- interactive=True,
- label="Пересечение"
- )
-
-
- with gr.Row():
- k_documents = gr.Slider(
- minimum=1,
- maximum=10,
- value=2,
- step=1,
- interactive=True,
- label="Кол-во фрагментов для контекста"
- )
- with gr.Row():
- retrieved_docs = gr.Textbox(
- lines=6,
- label="Извлеченные фрагменты",
- placeholder="Появятся после задавания вопросов",
- interactive=False
- )
- with gr.Row():
- with gr.Column(scale=5):
- system_prompt = gr.Textbox(label="Системный промпт", placeholder="", value=SYSTEM_PROMPT, interactive=False)
- chatbot = gr.Chatbot(label="Диалог").style(height=400)
- with gr.Column(min_width=80, scale=1):
- with gr.Tab(label="Параметры генерации"):
- top_p = gr.Slider(
- minimum=0.0,
- maximum=1.0,
- value=0.9,
- step=0.05,
- interactive=True,
- label="Top-p",
- )
- top_k = gr.Slider(
- minimum=10,
- maximum=100,
- value=30,
- step=5,
- interactive=True,
- label="Top-k",
- )
- temp = gr.Slider(
- minimum=0.0,
- maximum=2.0,
- value=0.1,
- step=0.1,
- interactive=True,
- label="Temp"
- )
-
- with gr.Row():
- with gr.Column():
- msg = gr.Textbox(
- label="Отправить сообщение",
- placeholder="Отправить сообщение",
- show_label=False,
- ).style(container=False)
- with gr.Column():
- with gr.Row():
- submit = gr.Button("Отправить")
- stop = gr.Button("Остановить")
- clear = gr.Button("Очистить")
-
- # Upload files
- upload_event = file_output.change(
- fn=upload_files,
- inputs=[file_output, file_paths],
- outputs=[file_paths],
- queue=True,
- ).success(
- fn=build_index,
- inputs=[file_paths, db, chunk_size, chunk_overlap, file_warning],
- outputs=[db, file_warning],
- queue=True
- )
-
- # Pressing Enter
- submit_event = msg.submit(
- fn=user,
- inputs=[msg, chatbot, system_prompt],
- outputs=[msg, chatbot],
- queue=False,
- ).success(
- fn=retrieve,
- inputs=[chatbot, db, retrieved_docs, k_documents],
- outputs=[retrieved_docs],
- queue=True,
- ).success(
- fn=bot,
- inputs=[
- chatbot,
- system_prompt,
- conversation_id,
- retrieved_docs,
- top_p,
- top_k,
- temp
- ],
- outputs=chatbot,
- queue=True,
- )
-
- # Pressing the button
- submit_click_event = submit.click(
- fn=user,
- inputs=[msg, chatbot, system_prompt],
- outputs=[msg, chatbot],
- queue=False,
- ).success(
- fn=retrieve,
- inputs=[chatbot, db, retrieved_docs, k_documents],
- outputs=[retrieved_docs],
- queue=True,
- ).success(
- fn=bot,
- inputs=[
- chatbot,
- system_prompt,
- conversation_id,
- retrieved_docs,
- top_p,
- top_k,
- temp
- ],
- outputs=chatbot,
- queue=True,
- )
-
- # Stop generation
- stop.click(
- fn=None,
- inputs=None,
- outputs=None,
- cancels=[submit_event, submit_click_event],
- queue=False,
- )
-
- # Clear history
- clear.click(lambda: None, None, chatbot, queue=False)
-
-demo.queue(max_size=128, concurrency_count=1)
-demo.launch()
diff --git a/spaces/valhalla/glide-text2im/glide_text2im/nn.py b/spaces/valhalla/glide-text2im/glide_text2im/nn.py
deleted file mode 100644
index 1a5b2f19e692dace9ade33d845632cea0479cc88..0000000000000000000000000000000000000000
--- a/spaces/valhalla/glide-text2im/glide_text2im/nn.py
+++ /dev/null
@@ -1,105 +0,0 @@
-"""
-Various utilities for neural networks.
-"""
-
-import math
-
-import torch as th
-import torch.nn as nn
-import torch.nn.functional as F
-
-
-class GroupNorm32(nn.GroupNorm):
- def __init__(self, num_groups, num_channels, swish, eps=1e-5):
- super().__init__(num_groups=num_groups, num_channels=num_channels, eps=eps)
- self.swish = swish
-
- def forward(self, x):
- y = super().forward(x.float()).to(x.dtype)
- if self.swish == 1.0:
- y = F.silu(y)
- elif self.swish:
- y = y * F.sigmoid(y * float(self.swish))
- return y
-
-
-def conv_nd(dims, *args, **kwargs):
- """
- Create a 1D, 2D, or 3D convolution module.
- """
- if dims == 1:
- return nn.Conv1d(*args, **kwargs)
- elif dims == 2:
- return nn.Conv2d(*args, **kwargs)
- elif dims == 3:
- return nn.Conv3d(*args, **kwargs)
- raise ValueError(f"unsupported dimensions: {dims}")
-
-
-def linear(*args, **kwargs):
- """
- Create a linear module.
- """
- return nn.Linear(*args, **kwargs)
-
-
-def avg_pool_nd(dims, *args, **kwargs):
- """
- Create a 1D, 2D, or 3D average pooling module.
- """
- if dims == 1:
- return nn.AvgPool1d(*args, **kwargs)
- elif dims == 2:
- return nn.AvgPool2d(*args, **kwargs)
- elif dims == 3:
- return nn.AvgPool3d(*args, **kwargs)
- raise ValueError(f"unsupported dimensions: {dims}")
-
-
-def zero_module(module):
- """
- Zero out the parameters of a module and return it.
- """
- for p in module.parameters():
- p.detach().zero_()
- return module
-
-
-def scale_module(module, scale):
- """
- Scale the parameters of a module and return it.
- """
- for p in module.parameters():
- p.detach().mul_(scale)
- return module
-
-
-def normalization(channels, swish=0.0):
- """
- Make a standard normalization layer, with an optional swish activation.
-
- :param channels: number of input channels.
- :return: an nn.Module for normalization.
- """
- return GroupNorm32(num_channels=channels, num_groups=32, swish=swish)
-
-
-def timestep_embedding(timesteps, dim, max_period=10000):
- """
- Create sinusoidal timestep embeddings.
-
- :param timesteps: a 1-D Tensor of N indices, one per batch element.
- These may be fractional.
- :param dim: the dimension of the output.
- :param max_period: controls the minimum frequency of the embeddings.
- :return: an [N x dim] Tensor of positional embeddings.
- """
- half = dim // 2
- freqs = th.exp(
- -math.log(max_period) * th.arange(start=0, end=half, dtype=th.float32) / half
- ).to(device=timesteps.device)
- args = timesteps[:, None].float() * freqs[None]
- embedding = th.cat([th.cos(args), th.sin(args)], dim=-1)
- if dim % 2:
- embedding = th.cat([embedding, th.zeros_like(embedding[:, :1])], dim=-1)
- return embedding
diff --git a/spaces/vumichien/Generate_human_motion/pyrender/pyrender/mesh.py b/spaces/vumichien/Generate_human_motion/pyrender/pyrender/mesh.py
deleted file mode 100644
index 36833ea3dfa6c095a18fc745ff34cf106e83c95d..0000000000000000000000000000000000000000
--- a/spaces/vumichien/Generate_human_motion/pyrender/pyrender/mesh.py
+++ /dev/null
@@ -1,328 +0,0 @@
-"""Meshes, conforming to the glTF 2.0 standards as specified in
-https://github.com/KhronosGroup/glTF/tree/master/specification/2.0#reference-mesh
-
-Author: Matthew Matl
-"""
-import copy
-
-import numpy as np
-import trimesh
-
-from .primitive import Primitive
-from .constants import GLTF
-from .material import MetallicRoughnessMaterial
-
-
-class Mesh(object):
- """A set of primitives to be rendered.
-
- Parameters
- ----------
- name : str
- The user-defined name of this object.
- primitives : list of :class:`Primitive`
- The primitives associated with this mesh.
- weights : (k,) float
- Array of weights to be applied to the Morph Targets.
- is_visible : bool
- If False, the mesh will not be rendered.
- """
-
- def __init__(self, primitives, name=None, weights=None, is_visible=True):
- self.primitives = primitives
- self.name = name
- self.weights = weights
- self.is_visible = is_visible
-
- self._bounds = None
-
- @property
- def name(self):
- """str : The user-defined name of this object.
- """
- return self._name
-
- @name.setter
- def name(self, value):
- if value is not None:
- value = str(value)
- self._name = value
-
- @property
- def primitives(self):
- """list of :class:`Primitive` : The primitives associated
- with this mesh.
- """
- return self._primitives
-
- @primitives.setter
- def primitives(self, value):
- self._primitives = value
-
- @property
- def weights(self):
- """(k,) float : Weights to be applied to morph targets.
- """
- return self._weights
-
- @weights.setter
- def weights(self, value):
- self._weights = value
-
- @property
- def is_visible(self):
- """bool : Whether the mesh is visible.
- """
- return self._is_visible
-
- @is_visible.setter
- def is_visible(self, value):
- self._is_visible = value
-
- @property
- def bounds(self):
- """(2,3) float : The axis-aligned bounds of the mesh.
- """
- if self._bounds is None:
- bounds = np.array([[np.infty, np.infty, np.infty],
- [-np.infty, -np.infty, -np.infty]])
- for p in self.primitives:
- bounds[0] = np.minimum(bounds[0], p.bounds[0])
- bounds[1] = np.maximum(bounds[1], p.bounds[1])
- self._bounds = bounds
- return self._bounds
-
- @property
- def centroid(self):
- """(3,) float : The centroid of the mesh's axis-aligned bounding box
- (AABB).
- """
- return np.mean(self.bounds, axis=0)
-
- @property
- def extents(self):
- """(3,) float : The lengths of the axes of the mesh's AABB.
- """
- return np.diff(self.bounds, axis=0).reshape(-1)
-
- @property
- def scale(self):
- """(3,) float : The length of the diagonal of the mesh's AABB.
- """
- return np.linalg.norm(self.extents)
-
- @property
- def is_transparent(self):
- """bool : If True, the mesh is partially-transparent.
- """
- for p in self.primitives:
- if p.is_transparent:
- return True
- return False
-
- @staticmethod
- def from_points(points, colors=None, normals=None,
- is_visible=True, poses=None):
- """Create a Mesh from a set of points.
-
- Parameters
- ----------
- points : (n,3) float
- The point positions.
- colors : (n,3) or (n,4) float, optional
- RGB or RGBA colors for each point.
- normals : (n,3) float, optionals
- The normal vectors for each point.
- is_visible : bool
- If False, the points will not be rendered.
- poses : (x,4,4)
- Array of 4x4 transformation matrices for instancing this object.
-
- Returns
- -------
- mesh : :class:`Mesh`
- The created mesh.
- """
- primitive = Primitive(
- positions=points,
- normals=normals,
- color_0=colors,
- mode=GLTF.POINTS,
- poses=poses
- )
- mesh = Mesh(primitives=[primitive], is_visible=is_visible)
- return mesh
-
- @staticmethod
- def from_trimesh(mesh, material=None, is_visible=True,
- poses=None, wireframe=False, smooth=True):
- """Create a Mesh from a :class:`~trimesh.base.Trimesh`.
-
- Parameters
- ----------
- mesh : :class:`~trimesh.base.Trimesh` or list of them
- A triangular mesh or a list of meshes.
- material : :class:`Material`
- The material of the object. Overrides any mesh material.
- If not specified and the mesh has no material, a default material
- will be used.
- is_visible : bool
- If False, the mesh will not be rendered.
- poses : (n,4,4) float
- Array of 4x4 transformation matrices for instancing this object.
- wireframe : bool
- If `True`, the mesh will be rendered as a wireframe object
- smooth : bool
- If `True`, the mesh will be rendered with interpolated vertex
- normals. Otherwise, the mesh edges will stay sharp.
-
- Returns
- -------
- mesh : :class:`Mesh`
- The created mesh.
- """
-
- if isinstance(mesh, (list, tuple, set, np.ndarray)):
- meshes = list(mesh)
- elif isinstance(mesh, trimesh.Trimesh):
- meshes = [mesh]
- else:
- raise TypeError('Expected a Trimesh or a list, got a {}'
- .format(type(mesh)))
-
- primitives = []
- for m in meshes:
- positions = None
- normals = None
- indices = None
-
- # Compute positions, normals, and indices
- if smooth:
- positions = m.vertices.copy()
- normals = m.vertex_normals.copy()
- indices = m.faces.copy()
- else:
- positions = m.vertices[m.faces].reshape((3 * len(m.faces), 3))
- normals = np.repeat(m.face_normals, 3, axis=0)
-
- # Compute colors, texture coords, and material properties
- color_0, texcoord_0, primitive_material = Mesh._get_trimesh_props(m, smooth=smooth, material=material)
-
- # Override if material is given.
- if material is not None:
- #primitive_material = copy.copy(material)
- primitive_material = copy.deepcopy(material) # TODO
-
- if primitive_material is None:
- # Replace material with default if needed
- primitive_material = MetallicRoughnessMaterial(
- alphaMode='BLEND',
- baseColorFactor=[0.3, 0.3, 0.3, 1.0],
- metallicFactor=0.2,
- roughnessFactor=0.8
- )
-
- primitive_material.wireframe = wireframe
-
- # Create the primitive
- primitives.append(Primitive(
- positions=positions,
- normals=normals,
- texcoord_0=texcoord_0,
- color_0=color_0,
- indices=indices,
- material=primitive_material,
- mode=GLTF.TRIANGLES,
- poses=poses
- ))
-
- return Mesh(primitives=primitives, is_visible=is_visible)
-
- @staticmethod
- def _get_trimesh_props(mesh, smooth=False, material=None):
- """Gets the vertex colors, texture coordinates, and material properties
- from a :class:`~trimesh.base.Trimesh`.
- """
- colors = None
- texcoords = None
-
- # If the trimesh visual is undefined, return none for both
- if not mesh.visual.defined:
- return colors, texcoords, material
-
- # Process vertex colors
- if material is None:
- if mesh.visual.kind == 'vertex':
- vc = mesh.visual.vertex_colors.copy()
- if smooth:
- colors = vc
- else:
- colors = vc[mesh.faces].reshape(
- (3 * len(mesh.faces), vc.shape[1])
- )
- material = MetallicRoughnessMaterial(
- alphaMode='BLEND',
- baseColorFactor=[1.0, 1.0, 1.0, 1.0],
- metallicFactor=0.2,
- roughnessFactor=0.8
- )
- # Process face colors
- elif mesh.visual.kind == 'face':
- if smooth:
- raise ValueError('Cannot use face colors with a smooth mesh')
- else:
- colors = np.repeat(mesh.visual.face_colors, 3, axis=0)
-
- material = MetallicRoughnessMaterial(
- alphaMode='BLEND',
- baseColorFactor=[1.0, 1.0, 1.0, 1.0],
- metallicFactor=0.2,
- roughnessFactor=0.8
- )
-
- # Process texture colors
- if mesh.visual.kind == 'texture':
- # Configure UV coordinates
- if mesh.visual.uv is not None and len(mesh.visual.uv) != 0:
- uv = mesh.visual.uv.copy()
- if smooth:
- texcoords = uv
- else:
- texcoords = uv[mesh.faces].reshape(
- (3 * len(mesh.faces), uv.shape[1])
- )
-
- if material is None:
- # Configure mesh material
- mat = mesh.visual.material
-
- if isinstance(mat, trimesh.visual.texture.PBRMaterial):
- material = MetallicRoughnessMaterial(
- normalTexture=mat.normalTexture,
- occlusionTexture=mat.occlusionTexture,
- emissiveTexture=mat.emissiveTexture,
- emissiveFactor=mat.emissiveFactor,
- alphaMode='BLEND',
- baseColorFactor=mat.baseColorFactor,
- baseColorTexture=mat.baseColorTexture,
- metallicFactor=mat.metallicFactor,
- roughnessFactor=mat.roughnessFactor,
- metallicRoughnessTexture=mat.metallicRoughnessTexture,
- doubleSided=mat.doubleSided,
- alphaCutoff=mat.alphaCutoff
- )
- elif isinstance(mat, trimesh.visual.texture.SimpleMaterial):
- glossiness = mat.kwargs.get('Ns', 1.0)
- if isinstance(glossiness, list):
- glossiness = float(glossiness[0])
- roughness = (2 / (glossiness + 2)) ** (1.0 / 4.0)
- material = MetallicRoughnessMaterial(
- alphaMode='BLEND',
- roughnessFactor=roughness,
- baseColorFactor=mat.diffuse,
- baseColorTexture=mat.image,
- )
- elif isinstance(mat, MetallicRoughnessMaterial):
- material = mat
-
- return colors, texcoords, material
diff --git a/spaces/vumichien/canvas_controlnet/annotator/uniformer/mmcv/runner/optimizer/builder.py b/spaces/vumichien/canvas_controlnet/annotator/uniformer/mmcv/runner/optimizer/builder.py
deleted file mode 100644
index f9234eed8f1f186d9d8dfda34562157ee39bdb3a..0000000000000000000000000000000000000000
--- a/spaces/vumichien/canvas_controlnet/annotator/uniformer/mmcv/runner/optimizer/builder.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import copy
-import inspect
-
-import torch
-
-from ...utils import Registry, build_from_cfg
-
-OPTIMIZERS = Registry('optimizer')
-OPTIMIZER_BUILDERS = Registry('optimizer builder')
-
-
-def register_torch_optimizers():
- torch_optimizers = []
- for module_name in dir(torch.optim):
- if module_name.startswith('__'):
- continue
- _optim = getattr(torch.optim, module_name)
- if inspect.isclass(_optim) and issubclass(_optim,
- torch.optim.Optimizer):
- OPTIMIZERS.register_module()(_optim)
- torch_optimizers.append(module_name)
- return torch_optimizers
-
-
-TORCH_OPTIMIZERS = register_torch_optimizers()
-
-
-def build_optimizer_constructor(cfg):
- return build_from_cfg(cfg, OPTIMIZER_BUILDERS)
-
-
-def build_optimizer(model, cfg):
- optimizer_cfg = copy.deepcopy(cfg)
- constructor_type = optimizer_cfg.pop('constructor',
- 'DefaultOptimizerConstructor')
- paramwise_cfg = optimizer_cfg.pop('paramwise_cfg', None)
- optim_constructor = build_optimizer_constructor(
- dict(
- type=constructor_type,
- optimizer_cfg=optimizer_cfg,
- paramwise_cfg=paramwise_cfg))
- optimizer = optim_constructor(model)
- return optimizer
diff --git a/spaces/vumichien/canvas_controlnet/annotator/uniformer/mmseg/models/necks/__init__.py b/spaces/vumichien/canvas_controlnet/annotator/uniformer/mmseg/models/necks/__init__.py
deleted file mode 100644
index 9b9d3d5b3fe80247642d962edd6fb787537d01d6..0000000000000000000000000000000000000000
--- a/spaces/vumichien/canvas_controlnet/annotator/uniformer/mmseg/models/necks/__init__.py
+++ /dev/null
@@ -1,4 +0,0 @@
-from .fpn import FPN
-from .multilevel_neck import MultiLevelNeck
-
-__all__ = ['FPN', 'MultiLevelNeck']
diff --git a/spaces/wavymulder/timeless-diffusion/app.py b/spaces/wavymulder/timeless-diffusion/app.py
deleted file mode 100644
index 51ba6d45be1fafd7222d505bcb3d833b82db5e68..0000000000000000000000000000000000000000
--- a/spaces/wavymulder/timeless-diffusion/app.py
+++ /dev/null
@@ -1,137 +0,0 @@
-from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipeline, DPMSolverMultistepScheduler
-import gradio as gr
-import torch
-from PIL import Image
-
-model_id = 'wavymulder/timeless-diffusion'
-prefix = 'timeless style'
-
-scheduler = DPMSolverMultistepScheduler.from_pretrained(model_id, subfolder="scheduler")
-
-pipe = StableDiffusionPipeline.from_pretrained(
- model_id,
- torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
- scheduler=scheduler)
-
-pipe_i2i = StableDiffusionImg2ImgPipeline.from_pretrained(
- model_id,
- torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
- scheduler=scheduler)
-
-if torch.cuda.is_available():
- pipe = pipe.to("cuda")
- pipe_i2i = pipe_i2i.to("cuda")
-
-def error_str(error, title="Error"):
- return f"""#### {title}
- {error}""" if error else ""
-
-def inference(prompt, guidance, steps, width=512, height=512, seed=0, img=None, strength=0.5, neg_prompt="", auto_prefix=False):
-
- generator = torch.Generator('cuda').manual_seed(seed) if seed != 0 else None
- prompt = f"{prefix} {prompt}" if auto_prefix else prompt
-
- try:
- if img is not None:
- return img_to_img(prompt, neg_prompt, img, strength, guidance, steps, width, height, generator), None
- else:
- return txt_to_img(prompt, neg_prompt, guidance, steps, width, height, generator), None
- except Exception as e:
- return None, error_str(e)
-
-def txt_to_img(prompt, neg_prompt, guidance, steps, width, height, generator):
-
- result = pipe(
- prompt,
- negative_prompt = neg_prompt,
- num_inference_steps = int(steps),
- guidance_scale = guidance,
- width = width,
- height = height,
- generator = generator)
-
- return result.images[0]
-
-def img_to_img(prompt, neg_prompt, img, strength, guidance, steps, width, height, generator):
-
- ratio = min(height / img.height, width / img.width)
- img = img.resize((int(img.width * ratio), int(img.height * ratio)), Image.LANCZOS)
- result = pipe_i2i(
- prompt,
- negative_prompt = neg_prompt,
- init_image = img,
- num_inference_steps = int(steps),
- strength = strength,
- guidance_scale = guidance,
- width = width,
- height = height,
- generator = generator)
-
- return result.images[0]
-
-css = """.main-div div{display:inline-flex;align-items:center;gap:.8rem;font-size:1.75rem}.main-div div h1{font-weight:900;margin-bottom:7px}.main-div p{margin-bottom:10px;font-size:94%}a{text-decoration:underline}.tabs{margin-top:0;margin-bottom:0}#gallery{min-height:20rem}
-"""
-with gr.Blocks(css=css) as demo:
- gr.HTML(
- f"""
-
-
-
Timeless Diffusion
-
-
- Demo for Timeless Diffusion Stable Diffusion model.
- {"Add the following tokens to your prompts for the model to work properly: prefix" if prefix else ""}
-
- Running on {"
GPU 🔥" if torch.cuda.is_available() else f"
CPU 🥶. For faster inference it is recommended to
upgrade to GPU in Settings"} after duplicating the space
-

-
",options:{classes:{},disabled:!1,create:null},_createWidget:function(e,i){i=t(i||this.defaultElement||this)[0],this.element=t(i),this.uuid=h++,this.eventNamespace="."+this.widgetName+this.uuid,this.bindings=t(),this.hoverable=t(),this.focusable=t(),this.classesElementLookup={},i!==this&&(t.data(i,this.widgetFullName,this),this._on(!0,this.element,{remove:function(t){t.target===i&&this.destroy()}}),this.document=t(i.style?i.ownerDocument:i.document||i),this.window=t(this.document[0].defaultView||this.document[0].parentWindow)),this.options=t.widget.extend({},this.options,this._getCreateOptions(),e),this._create(),this.options.disabled&&this._setOptionDisabled(this.options.disabled),this._trigger("create",null,this._getCreateEventData()),this._init()},_getCreateOptions:function(){return{}},_getCreateEventData:t.noop,_create:t.noop,_init:t.noop,destroy:function(){var e=this;this._destroy(),t.each(this.classesElementLookup,function(t,i){e._removeClass(i,t)}),this.element.off(this.eventNamespace).removeData(this.widgetFullName),this.widget().off(this.eventNamespace).removeAttr("aria-disabled"),this.bindings.off(this.eventNamespace)},_destroy:t.noop,widget:function(){return this.element},option:function(e,i){var s,n,o,a=e;if(0===arguments.length)return t.widget.extend({},this.options);if("string"==typeof e)if(a={},s=e.split("."),e=s.shift(),s.length){for(n=a[e]=t.widget.extend({},this.options[e]),o=0;s.length-1>o;o++)n[s[o]]=n[s[o]]||{},n=n[s[o]];if(e=s.pop(),1===arguments.length)return void 0===n[e]?null:n[e];n[e]=i}else{if(1===arguments.length)return void 0===this.options[e]?null:this.options[e];a[e]=i}return this._setOptions(a),this},_setOptions:function(t){var e;for(e in t)this._setOption(e,t[e]);return this},_setOption:function(t,e){return"classes"===t&&this._setOptionClasses(e),this.options[t]=e,"disabled"===t&&this._setOptionDisabled(e),this},_setOptionClasses:function(e){var i,s,n;for(i in e)n=this.classesElementLookup[i],e[i]!==this.options.classes[i]&&n&&n.length&&(s=t(n.get()),this._removeClass(n,i),s.addClass(this._classes({element:s,keys:i,classes:e,add:!0})))},_setOptionDisabled:function(t){this._toggleClass(this.widget(),this.widgetFullName+"-disabled",null,!!t),t&&(this._removeClass(this.hoverable,null,"ui-state-hover"),this._removeClass(this.focusable,null,"ui-state-focus"))},enable:function(){return this._setOptions({disabled:!1})},disable:function(){return this._setOptions({disabled:!0})},_classes:function(e){function i(i,o){var a,r;for(r=0;i.length>r;r++)a=n.classesElementLookup[i[r]]||t(),a=e.add?t(t.unique(a.get().concat(e.element.get()))):t(a.not(e.element).get()),n.classesElementLookup[i[r]]=a,s.push(i[r]),o&&e.classes[i[r]]&&s.push(e.classes[i[r]])}var s=[],n=this;return e=t.extend({element:this.element,classes:this.options.classes||{}},e),this._on(e.element,{remove:"_untrackClassesElement"}),e.keys&&i(e.keys.match(/\S+/g)||[],!0),e.extra&&i(e.extra.match(/\S+/g)||[]),s.join(" ")},_untrackClassesElement:function(e){var i=this;t.each(i.classesElementLookup,function(s,n){-1!==t.inArray(e.target,n)&&(i.classesElementLookup[s]=t(n.not(e.target).get()))})},_removeClass:function(t,e,i){return this._toggleClass(t,e,i,!1)},_addClass:function(t,e,i){return this._toggleClass(t,e,i,!0)},_toggleClass:function(t,e,i,s){s="boolean"==typeof s?s:i;var n="string"==typeof t||null===t,o={extra:n?e:i,keys:n?t:e,element:n?this.element:t,add:s};return o.element.toggleClass(this._classes(o),s),this},_on:function(e,i,s){var n,o=this;"boolean"!=typeof e&&(s=i,i=e,e=!1),s?(i=n=t(i),this.bindings=this.bindings.add(i)):(s=i,i=this.element,n=this.widget()),t.each(s,function(s,a){function r(){return e||o.options.disabled!==!0&&!t(this).hasClass("ui-state-disabled")?("string"==typeof a?o[a]:a).apply(o,arguments):void 0}"string"!=typeof a&&(r.guid=a.guid=a.guid||r.guid||t.guid++);var h=s.match(/^([\w:-]*)\s*(.*)$/),l=h[1]+o.eventNamespace,c=h[2];c?n.on(l,c,r):i.on(l,r)})},_off:function(e,i){i=(i||"").split(" ").join(this.eventNamespace+" ")+this.eventNamespace,e.off(i).off(i),this.bindings=t(this.bindings.not(e).get()),this.focusable=t(this.focusable.not(e).get()),this.hoverable=t(this.hoverable.not(e).get())},_delay:function(t,e){function i(){return("string"==typeof t?s[t]:t).apply(s,arguments)}var s=this;return setTimeout(i,e||0)},_hoverable:function(e){this.hoverable=this.hoverable.add(e),this._on(e,{mouseenter:function(e){this._addClass(t(e.currentTarget),null,"ui-state-hover")},mouseleave:function(e){this._removeClass(t(e.currentTarget),null,"ui-state-hover")}})},_focusable:function(e){this.focusable=this.focusable.add(e),this._on(e,{focusin:function(e){this._addClass(t(e.currentTarget),null,"ui-state-focus")},focusout:function(e){this._removeClass(t(e.currentTarget),null,"ui-state-focus")}})},_trigger:function(e,i,s){var n,o,a=this.options[e];if(s=s||{},i=t.Event(i),i.type=(e===this.widgetEventPrefix?e:this.widgetEventPrefix+e).toLowerCase(),i.target=this.element[0],o=i.originalEvent)for(n in o)n in i||(i[n]=o[n]);return this.element.trigger(i,s),!(t.isFunction(a)&&a.apply(this.element[0],[i].concat(s))===!1||i.isDefaultPrevented())}},t.each({show:"fadeIn",hide:"fadeOut"},function(e,i){t.Widget.prototype["_"+e]=function(s,n,o){"string"==typeof n&&(n={effect:n});var a,r=n?n===!0||"number"==typeof n?i:n.effect||i:e;n=n||{},"number"==typeof n&&(n={duration:n}),a=!t.isEmptyObject(n),n.complete=o,n.delay&&s.delay(n.delay),a&&t.effects&&t.effects.effect[r]?s[e](n):r!==e&&s[r]?s[r](n.duration,n.easing,o):s.queue(function(i){t(this)[e](),o&&o.call(s[0]),i()})}}),t.widget,function(){function e(t,e,i){return[parseFloat(t[0])*(u.test(t[0])?e/100:1),parseFloat(t[1])*(u.test(t[1])?i/100:1)]}function i(e,i){return parseInt(t.css(e,i),10)||0}function s(e){var i=e[0];return 9===i.nodeType?{width:e.width(),height:e.height(),offset:{top:0,left:0}}:t.isWindow(i)?{width:e.width(),height:e.height(),offset:{top:e.scrollTop(),left:e.scrollLeft()}}:i.preventDefault?{width:0,height:0,offset:{top:i.pageY,left:i.pageX}}:{width:e.outerWidth(),height:e.outerHeight(),offset:e.offset()}}var n,o=Math.max,a=Math.abs,r=/left|center|right/,h=/top|center|bottom/,l=/[\+\-]\d+(\.[\d]+)?%?/,c=/^\w+/,u=/%$/,d=t.fn.position;t.position={scrollbarWidth:function(){if(void 0!==n)return n;var e,i,s=t("
"),o=s.children()[0];return t("body").append(s),e=o.offsetWidth,s.css("overflow","scroll"),i=o.offsetWidth,e===i&&(i=s[0].clientWidth),s.remove(),n=e-i},getScrollInfo:function(e){var i=e.isWindow||e.isDocument?"":e.element.css("overflow-x"),s=e.isWindow||e.isDocument?"":e.element.css("overflow-y"),n="scroll"===i||"auto"===i&&e.width
i?"left":e>0?"right":"center",vertical:0>r?"top":s>0?"bottom":"middle"};l>p&&p>a(e+i)&&(u.horizontal="center"),c>f&&f>a(s+r)&&(u.vertical="middle"),u.important=o(a(e),a(i))>o(a(s),a(r))?"horizontal":"vertical",n.using.call(this,t,u)}),h.offset(t.extend(D,{using:r}))})},t.ui.position={fit:{left:function(t,e){var i,s=e.within,n=s.isWindow?s.scrollLeft:s.offset.left,a=s.width,r=t.left-e.collisionPosition.marginLeft,h=n-r,l=r+e.collisionWidth-a-n;e.collisionWidth>a?h>0&&0>=l?(i=t.left+h+e.collisionWidth-a-n,t.left+=h-i):t.left=l>0&&0>=h?n:h>l?n+a-e.collisionWidth:n:h>0?t.left+=h:l>0?t.left-=l:t.left=o(t.left-r,t.left)},top:function(t,e){var i,s=e.within,n=s.isWindow?s.scrollTop:s.offset.top,a=e.within.height,r=t.top-e.collisionPosition.marginTop,h=n-r,l=r+e.collisionHeight-a-n;e.collisionHeight>a?h>0&&0>=l?(i=t.top+h+e.collisionHeight-a-n,t.top+=h-i):t.top=l>0&&0>=h?n:h>l?n+a-e.collisionHeight:n:h>0?t.top+=h:l>0?t.top-=l:t.top=o(t.top-r,t.top)}},flip:{left:function(t,e){var i,s,n=e.within,o=n.offset.left+n.scrollLeft,r=n.width,h=n.isWindow?n.scrollLeft:n.offset.left,l=t.left-e.collisionPosition.marginLeft,c=l-h,u=l+e.collisionWidth-r-h,d="left"===e.my[0]?-e.elemWidth:"right"===e.my[0]?e.elemWidth:0,p="left"===e.at[0]?e.targetWidth:"right"===e.at[0]?-e.targetWidth:0,f=-2*e.offset[0];0>c?(i=t.left+d+p+f+e.collisionWidth-r-o,(0>i||a(c)>i)&&(t.left+=d+p+f)):u>0&&(s=t.left-e.collisionPosition.marginLeft+d+p+f-h,(s>0||u>a(s))&&(t.left+=d+p+f))},top:function(t,e){var i,s,n=e.within,o=n.offset.top+n.scrollTop,r=n.height,h=n.isWindow?n.scrollTop:n.offset.top,l=t.top-e.collisionPosition.marginTop,c=l-h,u=l+e.collisionHeight-r-h,d="top"===e.my[1],p=d?-e.elemHeight:"bottom"===e.my[1]?e.elemHeight:0,f="top"===e.at[1]?e.targetHeight:"bottom"===e.at[1]?-e.targetHeight:0,g=-2*e.offset[1];0>c?(s=t.top+p+f+g+e.collisionHeight-r-o,(0>s||a(c)>s)&&(t.top+=p+f+g)):u>0&&(i=t.top-e.collisionPosition.marginTop+p+f+g-h,(i>0||u>a(i))&&(t.top+=p+f+g))}},flipfit:{left:function(){t.ui.position.flip.left.apply(this,arguments),t.ui.position.fit.left.apply(this,arguments)},top:function(){t.ui.position.flip.top.apply(this,arguments),t.ui.position.fit.top.apply(this,arguments)}}}}(),t.ui.position,t.extend(t.expr[":"],{data:t.expr.createPseudo?t.expr.createPseudo(function(e){return function(i){return!!t.data(i,e)}}):function(e,i,s){return!!t.data(e,s[3])}}),t.fn.extend({disableSelection:function(){var t="onselectstart"in document.createElement("div")?"selectstart":"mousedown";return function(){return this.on(t+".ui-disableSelection",function(t){t.preventDefault()})}}(),enableSelection:function(){return this.off(".ui-disableSelection")}});var c="ui-effects-",u="ui-effects-style",d="ui-effects-animated",p=t;t.effects={effect:{}},function(t,e){function i(t,e,i){var s=u[e.type]||{};return null==t?i||!e.def?null:e.def:(t=s.floor?~~t:parseFloat(t),isNaN(t)?e.def:s.mod?(t+s.mod)%s.mod:0>t?0:t>s.max?s.max:t)}function s(i){var s=l(),n=s._rgba=[];return i=i.toLowerCase(),f(h,function(t,o){var a,r=o.re.exec(i),h=r&&o.parse(r),l=o.space||"rgba";return h?(a=s[l](h),s[c[l].cache]=a[c[l].cache],n=s._rgba=a._rgba,!1):e}),n.length?("0,0,0,0"===n.join()&&t.extend(n,o.transparent),s):o[i]}function n(t,e,i){return i=(i+1)%1,1>6*i?t+6*(e-t)*i:1>2*i?e:2>3*i?t+6*(e-t)*(2/3-i):t}var o,a="backgroundColor borderBottomColor borderLeftColor borderRightColor borderTopColor color columnRuleColor outlineColor textDecorationColor textEmphasisColor",r=/^([\-+])=\s*(\d+\.?\d*)/,h=[{re:/rgba?\(\s*(\d{1,3})\s*,\s*(\d{1,3})\s*,\s*(\d{1,3})\s*(?:,\s*(\d?(?:\.\d+)?)\s*)?\)/,parse:function(t){return[t[1],t[2],t[3],t[4]]}},{re:/rgba?\(\s*(\d+(?:\.\d+)?)\%\s*,\s*(\d+(?:\.\d+)?)\%\s*,\s*(\d+(?:\.\d+)?)\%\s*(?:,\s*(\d?(?:\.\d+)?)\s*)?\)/,parse:function(t){return[2.55*t[1],2.55*t[2],2.55*t[3],t[4]]}},{re:/#([a-f0-9]{2})([a-f0-9]{2})([a-f0-9]{2})/,parse:function(t){return[parseInt(t[1],16),parseInt(t[2],16),parseInt(t[3],16)]}},{re:/#([a-f0-9])([a-f0-9])([a-f0-9])/,parse:function(t){return[parseInt(t[1]+t[1],16),parseInt(t[2]+t[2],16),parseInt(t[3]+t[3],16)]}},{re:/hsla?\(\s*(\d+(?:\.\d+)?)\s*,\s*(\d+(?:\.\d+)?)\%\s*,\s*(\d+(?:\.\d+)?)\%\s*(?:,\s*(\d?(?:\.\d+)?)\s*)?\)/,space:"hsla",parse:function(t){return[t[1],t[2]/100,t[3]/100,t[4]]}}],l=t.Color=function(e,i,s,n){return new t.Color.fn.parse(e,i,s,n)},c={rgba:{props:{red:{idx:0,type:"byte"},green:{idx:1,type:"byte"},blue:{idx:2,type:"byte"}}},hsla:{props:{hue:{idx:0,type:"degrees"},saturation:{idx:1,type:"percent"},lightness:{idx:2,type:"percent"}}}},u={"byte":{floor:!0,max:255},percent:{max:1},degrees:{mod:360,floor:!0}},d=l.support={},p=t("")[0],f=t.each;p.style.cssText="background-color:rgba(1,1,1,.5)",d.rgba=p.style.backgroundColor.indexOf("rgba")>-1,f(c,function(t,e){e.cache="_"+t,e.props.alpha={idx:3,type:"percent",def:1}}),l.fn=t.extend(l.prototype,{parse:function(n,a,r,h){if(n===e)return this._rgba=[null,null,null,null],this;(n.jquery||n.nodeType)&&(n=t(n).css(a),a=e);var u=this,d=t.type(n),p=this._rgba=[];return a!==e&&(n=[n,a,r,h],d="array"),"string"===d?this.parse(s(n)||o._default):"array"===d?(f(c.rgba.props,function(t,e){p[e.idx]=i(n[e.idx],e)}),this):"object"===d?(n instanceof l?f(c,function(t,e){n[e.cache]&&(u[e.cache]=n[e.cache].slice())}):f(c,function(e,s){var o=s.cache;f(s.props,function(t,e){if(!u[o]&&s.to){if("alpha"===t||null==n[t])return;u[o]=s.to(u._rgba)}u[o][e.idx]=i(n[t],e,!0)}),u[o]&&0>t.inArray(null,u[o].slice(0,3))&&(u[o][3]=1,s.from&&(u._rgba=s.from(u[o])))}),this):e},is:function(t){var i=l(t),s=!0,n=this;return f(c,function(t,o){var a,r=i[o.cache];return r&&(a=n[o.cache]||o.to&&o.to(n._rgba)||[],f(o.props,function(t,i){return null!=r[i.idx]?s=r[i.idx]===a[i.idx]:e})),s}),s},_space:function(){var t=[],e=this;return f(c,function(i,s){e[s.cache]&&t.push(i)}),t.pop()},transition:function(t,e){var s=l(t),n=s._space(),o=c[n],a=0===this.alpha()?l("transparent"):this,r=a[o.cache]||o.to(a._rgba),h=r.slice();return s=s[o.cache],f(o.props,function(t,n){var o=n.idx,a=r[o],l=s[o],c=u[n.type]||{};null!==l&&(null===a?h[o]=l:(c.mod&&(l-a>c.mod/2?a+=c.mod:a-l>c.mod/2&&(a-=c.mod)),h[o]=i((l-a)*e+a,n)))}),this[n](h)},blend:function(e){if(1===this._rgba[3])return this;var i=this._rgba.slice(),s=i.pop(),n=l(e)._rgba;return l(t.map(i,function(t,e){return(1-s)*n[e]+s*t}))},toRgbaString:function(){var e="rgba(",i=t.map(this._rgba,function(t,e){return null==t?e>2?1:0:t});return 1===i[3]&&(i.pop(),e="rgb("),e+i.join()+")"},toHslaString:function(){var e="hsla(",i=t.map(this.hsla(),function(t,e){return null==t&&(t=e>2?1:0),e&&3>e&&(t=Math.round(100*t)+"%"),t});return 1===i[3]&&(i.pop(),e="hsl("),e+i.join()+")"},toHexString:function(e){var i=this._rgba.slice(),s=i.pop();return e&&i.push(~~(255*s)),"#"+t.map(i,function(t){return t=(t||0).toString(16),1===t.length?"0"+t:t}).join("")},toString:function(){return 0===this._rgba[3]?"transparent":this.toRgbaString()}}),l.fn.parse.prototype=l.fn,c.hsla.to=function(t){if(null==t[0]||null==t[1]||null==t[2])return[null,null,null,t[3]];var e,i,s=t[0]/255,n=t[1]/255,o=t[2]/255,a=t[3],r=Math.max(s,n,o),h=Math.min(s,n,o),l=r-h,c=r+h,u=.5*c;return e=h===r?0:s===r?60*(n-o)/l+360:n===r?60*(o-s)/l+120:60*(s-n)/l+240,i=0===l?0:.5>=u?l/c:l/(2-c),[Math.round(e)%360,i,u,null==a?1:a]},c.hsla.from=function(t){if(null==t[0]||null==t[1]||null==t[2])return[null,null,null,t[3]];var e=t[0]/360,i=t[1],s=t[2],o=t[3],a=.5>=s?s*(1+i):s+i-s*i,r=2*s-a;return[Math.round(255*n(r,a,e+1/3)),Math.round(255*n(r,a,e)),Math.round(255*n(r,a,e-1/3)),o]},f(c,function(s,n){var o=n.props,a=n.cache,h=n.to,c=n.from;l.fn[s]=function(s){if(h&&!this[a]&&(this[a]=h(this._rgba)),s===e)return this[a].slice();var n,r=t.type(s),u="array"===r||"object"===r?s:arguments,d=this[a].slice();return f(o,function(t,e){var s=u["object"===r?t:e.idx];null==s&&(s=d[e.idx]),d[e.idx]=i(s,e)}),c?(n=l(c(d)),n[a]=d,n):l(d)},f(o,function(e,i){l.fn[e]||(l.fn[e]=function(n){var o,a=t.type(n),h="alpha"===e?this._hsla?"hsla":"rgba":s,l=this[h](),c=l[i.idx];return"undefined"===a?c:("function"===a&&(n=n.call(this,c),a=t.type(n)),null==n&&i.empty?this:("string"===a&&(o=r.exec(n),o&&(n=c+parseFloat(o[2])*("+"===o[1]?1:-1))),l[i.idx]=n,this[h](l)))})})}),l.hook=function(e){var i=e.split(" ");f(i,function(e,i){t.cssHooks[i]={set:function(e,n){var o,a,r="";if("transparent"!==n&&("string"!==t.type(n)||(o=s(n)))){if(n=l(o||n),!d.rgba&&1!==n._rgba[3]){for(a="backgroundColor"===i?e.parentNode:e;(""===r||"transparent"===r)&&a&&a.style;)try{r=t.css(a,"backgroundColor"),a=a.parentNode}catch(h){}n=n.blend(r&&"transparent"!==r?r:"_default")}n=n.toRgbaString()}try{e.style[i]=n}catch(h){}}},t.fx.step[i]=function(e){e.colorInit||(e.start=l(e.elem,i),e.end=l(e.end),e.colorInit=!0),t.cssHooks[i].set(e.elem,e.start.transition(e.end,e.pos))}})},l.hook(a),t.cssHooks.borderColor={expand:function(t){var e={};return f(["Top","Right","Bottom","Left"],function(i,s){e["border"+s+"Color"]=t}),e}},o=t.Color.names={aqua:"#00ffff",black:"#000000",blue:"#0000ff",fuchsia:"#ff00ff",gray:"#808080",green:"#008000",lime:"#00ff00",maroon:"#800000",navy:"#000080",olive:"#808000",purple:"#800080",red:"#ff0000",silver:"#c0c0c0",teal:"#008080",white:"#ffffff",yellow:"#ffff00",transparent:[null,null,null,0],_default:"#ffffff"}}(p),function(){function e(e){var i,s,n=e.ownerDocument.defaultView?e.ownerDocument.defaultView.getComputedStyle(e,null):e.currentStyle,o={};if(n&&n.length&&n[0]&&n[n[0]])for(s=n.length;s--;)i=n[s],"string"==typeof n[i]&&(o[t.camelCase(i)]=n[i]);else for(i in n)"string"==typeof n[i]&&(o[i]=n[i]);return o}function i(e,i){var s,o,a={};for(s in i)o=i[s],e[s]!==o&&(n[s]||(t.fx.step[s]||!isNaN(parseFloat(o)))&&(a[s]=o));return a}var s=["add","remove","toggle"],n={border:1,borderBottom:1,borderColor:1,borderLeft:1,borderRight:1,borderTop:1,borderWidth:1,margin:1,padding:1};t.each(["borderLeftStyle","borderRightStyle","borderBottomStyle","borderTopStyle"],function(e,i){t.fx.step[i]=function(t){("none"!==t.end&&!t.setAttr||1===t.pos&&!t.setAttr)&&(p.style(t.elem,i,t.end),t.setAttr=!0)}}),t.fn.addBack||(t.fn.addBack=function(t){return this.add(null==t?this.prevObject:this.prevObject.filter(t))}),t.effects.animateClass=function(n,o,a,r){var h=t.speed(o,a,r);return this.queue(function(){var o,a=t(this),r=a.attr("class")||"",l=h.children?a.find("*").addBack():a;l=l.map(function(){var i=t(this);return{el:i,start:e(this)}}),o=function(){t.each(s,function(t,e){n[e]&&a[e+"Class"](n[e])})},o(),l=l.map(function(){return this.end=e(this.el[0]),this.diff=i(this.start,this.end),this}),a.attr("class",r),l=l.map(function(){var e=this,i=t.Deferred(),s=t.extend({},h,{queue:!1,complete:function(){i.resolve(e)}});return this.el.animate(this.diff,s),i.promise()}),t.when.apply(t,l.get()).done(function(){o(),t.each(arguments,function(){var e=this.el;t.each(this.diff,function(t){e.css(t,"")})}),h.complete.call(a[0])})})},t.fn.extend({addClass:function(e){return function(i,s,n,o){return s?t.effects.animateClass.call(this,{add:i},s,n,o):e.apply(this,arguments)}}(t.fn.addClass),removeClass:function(e){return function(i,s,n,o){return arguments.length>1?t.effects.animateClass.call(this,{remove:i},s,n,o):e.apply(this,arguments)}}(t.fn.removeClass),toggleClass:function(e){return function(i,s,n,o,a){return"boolean"==typeof s||void 0===s?n?t.effects.animateClass.call(this,s?{add:i}:{remove:i},n,o,a):e.apply(this,arguments):t.effects.animateClass.call(this,{toggle:i},s,n,o)}}(t.fn.toggleClass),switchClass:function(e,i,s,n,o){return t.effects.animateClass.call(this,{add:i,remove:e},s,n,o)}})}(),function(){function e(e,i,s,n){return t.isPlainObject(e)&&(i=e,e=e.effect),e={effect:e},null==i&&(i={}),t.isFunction(i)&&(n=i,s=null,i={}),("number"==typeof i||t.fx.speeds[i])&&(n=s,s=i,i={}),t.isFunction(s)&&(n=s,s=null),i&&t.extend(e,i),s=s||i.duration,e.duration=t.fx.off?0:"number"==typeof s?s:s in t.fx.speeds?t.fx.speeds[s]:t.fx.speeds._default,e.complete=n||i.complete,e}function i(e){return!e||"number"==typeof e||t.fx.speeds[e]?!0:"string"!=typeof e||t.effects.effect[e]?t.isFunction(e)?!0:"object"!=typeof e||e.effect?!1:!0:!0}function s(t,e){var i=e.outerWidth(),s=e.outerHeight(),n=/^rect\((-?\d*\.?\d*px|-?\d+%|auto),?\s*(-?\d*\.?\d*px|-?\d+%|auto),?\s*(-?\d*\.?\d*px|-?\d+%|auto),?\s*(-?\d*\.?\d*px|-?\d+%|auto)\)$/,o=n.exec(t)||["",0,i,s,0];return{top:parseFloat(o[1])||0,right:"auto"===o[2]?i:parseFloat(o[2]),bottom:"auto"===o[3]?s:parseFloat(o[3]),left:parseFloat(o[4])||0}}t.expr&&t.expr.filters&&t.expr.filters.animated&&(t.expr.filters.animated=function(e){return function(i){return!!t(i).data(d)||e(i)}}(t.expr.filters.animated)),t.uiBackCompat!==!1&&t.extend(t.effects,{save:function(t,e){for(var i=0,s=e.length;s>i;i++)null!==e[i]&&t.data(c+e[i],t[0].style[e[i]])},restore:function(t,e){for(var i,s=0,n=e.length;n>s;s++)null!==e[s]&&(i=t.data(c+e[s]),t.css(e[s],i))},setMode:function(t,e){return"toggle"===e&&(e=t.is(":hidden")?"show":"hide"),e},createWrapper:function(e){if(e.parent().is(".ui-effects-wrapper"))return e.parent();var i={width:e.outerWidth(!0),height:e.outerHeight(!0),"float":e.css("float")},s=t("
").addClass("ui-effects-wrapper").css({fontSize:"100%",background:"transparent",border:"none",margin:0,padding:0}),n={width:e.width(),height:e.height()},o=document.activeElement;try{o.id}catch(a){o=document.body}return e.wrap(s),(e[0]===o||t.contains(e[0],o))&&t(o).trigger("focus"),s=e.parent(),"static"===e.css("position")?(s.css({position:"relative"}),e.css({position:"relative"})):(t.extend(i,{position:e.css("position"),zIndex:e.css("z-index")}),t.each(["top","left","bottom","right"],function(t,s){i[s]=e.css(s),isNaN(parseInt(i[s],10))&&(i[s]="auto")}),e.css({position:"relative",top:0,left:0,right:"auto",bottom:"auto"})),e.css(n),s.css(i).show()},removeWrapper:function(e){var i=document.activeElement;return e.parent().is(".ui-effects-wrapper")&&(e.parent().replaceWith(e),(e[0]===i||t.contains(e[0],i))&&t(i).trigger("focus")),e}}),t.extend(t.effects,{version:"1.12.1",define:function(e,i,s){return s||(s=i,i="effect"),t.effects.effect[e]=s,t.effects.effect[e].mode=i,s},scaledDimensions:function(t,e,i){if(0===e)return{height:0,width:0,outerHeight:0,outerWidth:0};var s="horizontal"!==i?(e||100)/100:1,n="vertical"!==i?(e||100)/100:1;return{height:t.height()*n,width:t.width()*s,outerHeight:t.outerHeight()*n,outerWidth:t.outerWidth()*s}},clipToBox:function(t){return{width:t.clip.right-t.clip.left,height:t.clip.bottom-t.clip.top,left:t.clip.left,top:t.clip.top}},unshift:function(t,e,i){var s=t.queue();e>1&&s.splice.apply(s,[1,0].concat(s.splice(e,i))),t.dequeue()},saveStyle:function(t){t.data(u,t[0].style.cssText)},restoreStyle:function(t){t[0].style.cssText=t.data(u)||"",t.removeData(u)},mode:function(t,e){var i=t.is(":hidden");return"toggle"===e&&(e=i?"show":"hide"),(i?"hide"===e:"show"===e)&&(e="none"),e},getBaseline:function(t,e){var i,s;switch(t[0]){case"top":i=0;break;case"middle":i=.5;break;case"bottom":i=1;break;default:i=t[0]/e.height}switch(t[1]){case"left":s=0;break;case"center":s=.5;break;case"right":s=1;break;default:s=t[1]/e.width}return{x:s,y:i}},createPlaceholder:function(e){var i,s=e.css("position"),n=e.position();return e.css({marginTop:e.css("marginTop"),marginBottom:e.css("marginBottom"),marginLeft:e.css("marginLeft"),marginRight:e.css("marginRight")}).outerWidth(e.outerWidth()).outerHeight(e.outerHeight()),/^(static|relative)/.test(s)&&(s="absolute",i=t("<"+e[0].nodeName+">").insertAfter(e).css({display:/^(inline|ruby)/.test(e.css("display"))?"inline-block":"block",visibility:"hidden",marginTop:e.css("marginTop"),marginBottom:e.css("marginBottom"),marginLeft:e.css("marginLeft"),marginRight:e.css("marginRight"),"float":e.css("float")}).outerWidth(e.outerWidth()).outerHeight(e.outerHeight()).addClass("ui-effects-placeholder"),e.data(c+"placeholder",i)),e.css({position:s,left:n.left,top:n.top}),i},removePlaceholder:function(t){var e=c+"placeholder",i=t.data(e);i&&(i.remove(),t.removeData(e))},cleanUp:function(e){t.effects.restoreStyle(e),t.effects.removePlaceholder(e)},setTransition:function(e,i,s,n){return n=n||{},t.each(i,function(t,i){var o=e.cssUnit(i);o[0]>0&&(n[i]=o[0]*s+o[1])}),n}}),t.fn.extend({effect:function(){function i(e){function i(){r.removeData(d),t.effects.cleanUp(r),"hide"===s.mode&&r.hide(),a()}function a(){t.isFunction(h)&&h.call(r[0]),t.isFunction(e)&&e()}var r=t(this);s.mode=c.shift(),t.uiBackCompat===!1||o?"none"===s.mode?(r[l](),a()):n.call(r[0],s,i):(r.is(":hidden")?"hide"===l:"show"===l)?(r[l](),a()):n.call(r[0],s,a)}var s=e.apply(this,arguments),n=t.effects.effect[s.effect],o=n.mode,a=s.queue,r=a||"fx",h=s.complete,l=s.mode,c=[],u=function(e){var i=t(this),s=t.effects.mode(i,l)||o;i.data(d,!0),c.push(s),o&&("show"===s||s===o&&"hide"===s)&&i.show(),o&&"none"===s||t.effects.saveStyle(i),t.isFunction(e)&&e()};return t.fx.off||!n?l?this[l](s.duration,h):this.each(function(){h&&h.call(this)}):a===!1?this.each(u).each(i):this.queue(r,u).queue(r,i)},show:function(t){return function(s){if(i(s))return t.apply(this,arguments);var n=e.apply(this,arguments);return n.mode="show",this.effect.call(this,n)
-}}(t.fn.show),hide:function(t){return function(s){if(i(s))return t.apply(this,arguments);var n=e.apply(this,arguments);return n.mode="hide",this.effect.call(this,n)}}(t.fn.hide),toggle:function(t){return function(s){if(i(s)||"boolean"==typeof s)return t.apply(this,arguments);var n=e.apply(this,arguments);return n.mode="toggle",this.effect.call(this,n)}}(t.fn.toggle),cssUnit:function(e){var i=this.css(e),s=[];return t.each(["em","px","%","pt"],function(t,e){i.indexOf(e)>0&&(s=[parseFloat(i),e])}),s},cssClip:function(t){return t?this.css("clip","rect("+t.top+"px "+t.right+"px "+t.bottom+"px "+t.left+"px)"):s(this.css("clip"),this)},transfer:function(e,i){var s=t(this),n=t(e.to),o="fixed"===n.css("position"),a=t("body"),r=o?a.scrollTop():0,h=o?a.scrollLeft():0,l=n.offset(),c={top:l.top-r,left:l.left-h,height:n.innerHeight(),width:n.innerWidth()},u=s.offset(),d=t("").appendTo("body").addClass(e.className).css({top:u.top-r,left:u.left-h,height:s.innerHeight(),width:s.innerWidth(),position:o?"fixed":"absolute"}).animate(c,e.duration,e.easing,function(){d.remove(),t.isFunction(i)&&i()})}}),t.fx.step.clip=function(e){e.clipInit||(e.start=t(e.elem).cssClip(),"string"==typeof e.end&&(e.end=s(e.end,e.elem)),e.clipInit=!0),t(e.elem).cssClip({top:e.pos*(e.end.top-e.start.top)+e.start.top,right:e.pos*(e.end.right-e.start.right)+e.start.right,bottom:e.pos*(e.end.bottom-e.start.bottom)+e.start.bottom,left:e.pos*(e.end.left-e.start.left)+e.start.left})}}(),function(){var e={};t.each(["Quad","Cubic","Quart","Quint","Expo"],function(t,i){e[i]=function(e){return Math.pow(e,t+2)}}),t.extend(e,{Sine:function(t){return 1-Math.cos(t*Math.PI/2)},Circ:function(t){return 1-Math.sqrt(1-t*t)},Elastic:function(t){return 0===t||1===t?t:-Math.pow(2,8*(t-1))*Math.sin((80*(t-1)-7.5)*Math.PI/15)},Back:function(t){return t*t*(3*t-2)},Bounce:function(t){for(var e,i=4;((e=Math.pow(2,--i))-1)/11>t;);return 1/Math.pow(4,3-i)-7.5625*Math.pow((3*e-2)/22-t,2)}}),t.each(e,function(e,i){t.easing["easeIn"+e]=i,t.easing["easeOut"+e]=function(t){return 1-i(1-t)},t.easing["easeInOut"+e]=function(t){return.5>t?i(2*t)/2:1-i(-2*t+2)/2}})}();var f=t.effects;t.effects.define("blind","hide",function(e,i){var s={up:["bottom","top"],vertical:["bottom","top"],down:["top","bottom"],left:["right","left"],horizontal:["right","left"],right:["left","right"]},n=t(this),o=e.direction||"up",a=n.cssClip(),r={clip:t.extend({},a)},h=t.effects.createPlaceholder(n);r.clip[s[o][0]]=r.clip[s[o][1]],"show"===e.mode&&(n.cssClip(r.clip),h&&h.css(t.effects.clipToBox(r)),r.clip=a),h&&h.animate(t.effects.clipToBox(r),e.duration,e.easing),n.animate(r,{queue:!1,duration:e.duration,easing:e.easing,complete:i})}),t.effects.define("bounce",function(e,i){var s,n,o,a=t(this),r=e.mode,h="hide"===r,l="show"===r,c=e.direction||"up",u=e.distance,d=e.times||5,p=2*d+(l||h?1:0),f=e.duration/p,g=e.easing,m="up"===c||"down"===c?"top":"left",_="up"===c||"left"===c,v=0,b=a.queue().length;for(t.effects.createPlaceholder(a),o=a.css(m),u||(u=a["top"===m?"outerHeight":"outerWidth"]()/3),l&&(n={opacity:1},n[m]=o,a.css("opacity",0).css(m,_?2*-u:2*u).animate(n,f,g)),h&&(u/=Math.pow(2,d-1)),n={},n[m]=o;d>v;v++)s={},s[m]=(_?"-=":"+=")+u,a.animate(s,f,g).animate(n,f,g),u=h?2*u:u/2;h&&(s={opacity:0},s[m]=(_?"-=":"+=")+u,a.animate(s,f,g)),a.queue(i),t.effects.unshift(a,b,p+1)}),t.effects.define("clip","hide",function(e,i){var s,n={},o=t(this),a=e.direction||"vertical",r="both"===a,h=r||"horizontal"===a,l=r||"vertical"===a;s=o.cssClip(),n.clip={top:l?(s.bottom-s.top)/2:s.top,right:h?(s.right-s.left)/2:s.right,bottom:l?(s.bottom-s.top)/2:s.bottom,left:h?(s.right-s.left)/2:s.left},t.effects.createPlaceholder(o),"show"===e.mode&&(o.cssClip(n.clip),n.clip=s),o.animate(n,{queue:!1,duration:e.duration,easing:e.easing,complete:i})}),t.effects.define("drop","hide",function(e,i){var s,n=t(this),o=e.mode,a="show"===o,r=e.direction||"left",h="up"===r||"down"===r?"top":"left",l="up"===r||"left"===r?"-=":"+=",c="+="===l?"-=":"+=",u={opacity:0};t.effects.createPlaceholder(n),s=e.distance||n["top"===h?"outerHeight":"outerWidth"](!0)/2,u[h]=l+s,a&&(n.css(u),u[h]=c+s,u.opacity=1),n.animate(u,{queue:!1,duration:e.duration,easing:e.easing,complete:i})}),t.effects.define("explode","hide",function(e,i){function s(){b.push(this),b.length===u*d&&n()}function n(){p.css({visibility:"visible"}),t(b).remove(),i()}var o,a,r,h,l,c,u=e.pieces?Math.round(Math.sqrt(e.pieces)):3,d=u,p=t(this),f=e.mode,g="show"===f,m=p.show().css("visibility","hidden").offset(),_=Math.ceil(p.outerWidth()/d),v=Math.ceil(p.outerHeight()/u),b=[];for(o=0;u>o;o++)for(h=m.top+o*v,c=o-(u-1)/2,a=0;d>a;a++)r=m.left+a*_,l=a-(d-1)/2,p.clone().appendTo("body").wrap("").css({position:"absolute",visibility:"visible",left:-a*_,top:-o*v}).parent().addClass("ui-effects-explode").css({position:"absolute",overflow:"hidden",width:_,height:v,left:r+(g?l*_:0),top:h+(g?c*v:0),opacity:g?0:1}).animate({left:r+(g?0:l*_),top:h+(g?0:c*v),opacity:g?1:0},e.duration||500,e.easing,s)}),t.effects.define("fade","toggle",function(e,i){var s="show"===e.mode;t(this).css("opacity",s?0:1).animate({opacity:s?1:0},{queue:!1,duration:e.duration,easing:e.easing,complete:i})}),t.effects.define("fold","hide",function(e,i){var s=t(this),n=e.mode,o="show"===n,a="hide"===n,r=e.size||15,h=/([0-9]+)%/.exec(r),l=!!e.horizFirst,c=l?["right","bottom"]:["bottom","right"],u=e.duration/2,d=t.effects.createPlaceholder(s),p=s.cssClip(),f={clip:t.extend({},p)},g={clip:t.extend({},p)},m=[p[c[0]],p[c[1]]],_=s.queue().length;h&&(r=parseInt(h[1],10)/100*m[a?0:1]),f.clip[c[0]]=r,g.clip[c[0]]=r,g.clip[c[1]]=0,o&&(s.cssClip(g.clip),d&&d.css(t.effects.clipToBox(g)),g.clip=p),s.queue(function(i){d&&d.animate(t.effects.clipToBox(f),u,e.easing).animate(t.effects.clipToBox(g),u,e.easing),i()}).animate(f,u,e.easing).animate(g,u,e.easing).queue(i),t.effects.unshift(s,_,4)}),t.effects.define("highlight","show",function(e,i){var s=t(this),n={backgroundColor:s.css("backgroundColor")};"hide"===e.mode&&(n.opacity=0),t.effects.saveStyle(s),s.css({backgroundImage:"none",backgroundColor:e.color||"#ffff99"}).animate(n,{queue:!1,duration:e.duration,easing:e.easing,complete:i})}),t.effects.define("size",function(e,i){var s,n,o,a=t(this),r=["fontSize"],h=["borderTopWidth","borderBottomWidth","paddingTop","paddingBottom"],l=["borderLeftWidth","borderRightWidth","paddingLeft","paddingRight"],c=e.mode,u="effect"!==c,d=e.scale||"both",p=e.origin||["middle","center"],f=a.css("position"),g=a.position(),m=t.effects.scaledDimensions(a),_=e.from||m,v=e.to||t.effects.scaledDimensions(a,0);t.effects.createPlaceholder(a),"show"===c&&(o=_,_=v,v=o),n={from:{y:_.height/m.height,x:_.width/m.width},to:{y:v.height/m.height,x:v.width/m.width}},("box"===d||"both"===d)&&(n.from.y!==n.to.y&&(_=t.effects.setTransition(a,h,n.from.y,_),v=t.effects.setTransition(a,h,n.to.y,v)),n.from.x!==n.to.x&&(_=t.effects.setTransition(a,l,n.from.x,_),v=t.effects.setTransition(a,l,n.to.x,v))),("content"===d||"both"===d)&&n.from.y!==n.to.y&&(_=t.effects.setTransition(a,r,n.from.y,_),v=t.effects.setTransition(a,r,n.to.y,v)),p&&(s=t.effects.getBaseline(p,m),_.top=(m.outerHeight-_.outerHeight)*s.y+g.top,_.left=(m.outerWidth-_.outerWidth)*s.x+g.left,v.top=(m.outerHeight-v.outerHeight)*s.y+g.top,v.left=(m.outerWidth-v.outerWidth)*s.x+g.left),a.css(_),("content"===d||"both"===d)&&(h=h.concat(["marginTop","marginBottom"]).concat(r),l=l.concat(["marginLeft","marginRight"]),a.find("*[width]").each(function(){var i=t(this),s=t.effects.scaledDimensions(i),o={height:s.height*n.from.y,width:s.width*n.from.x,outerHeight:s.outerHeight*n.from.y,outerWidth:s.outerWidth*n.from.x},a={height:s.height*n.to.y,width:s.width*n.to.x,outerHeight:s.height*n.to.y,outerWidth:s.width*n.to.x};n.from.y!==n.to.y&&(o=t.effects.setTransition(i,h,n.from.y,o),a=t.effects.setTransition(i,h,n.to.y,a)),n.from.x!==n.to.x&&(o=t.effects.setTransition(i,l,n.from.x,o),a=t.effects.setTransition(i,l,n.to.x,a)),u&&t.effects.saveStyle(i),i.css(o),i.animate(a,e.duration,e.easing,function(){u&&t.effects.restoreStyle(i)})})),a.animate(v,{queue:!1,duration:e.duration,easing:e.easing,complete:function(){var e=a.offset();0===v.opacity&&a.css("opacity",_.opacity),u||(a.css("position","static"===f?"relative":f).offset(e),t.effects.saveStyle(a)),i()}})}),t.effects.define("scale",function(e,i){var s=t(this),n=e.mode,o=parseInt(e.percent,10)||(0===parseInt(e.percent,10)?0:"effect"!==n?0:100),a=t.extend(!0,{from:t.effects.scaledDimensions(s),to:t.effects.scaledDimensions(s,o,e.direction||"both"),origin:e.origin||["middle","center"]},e);e.fade&&(a.from.opacity=1,a.to.opacity=0),t.effects.effect.size.call(this,a,i)}),t.effects.define("puff","hide",function(e,i){var s=t.extend(!0,{},e,{fade:!0,percent:parseInt(e.percent,10)||150});t.effects.effect.scale.call(this,s,i)}),t.effects.define("pulsate","show",function(e,i){var s=t(this),n=e.mode,o="show"===n,a="hide"===n,r=o||a,h=2*(e.times||5)+(r?1:0),l=e.duration/h,c=0,u=1,d=s.queue().length;for((o||!s.is(":visible"))&&(s.css("opacity",0).show(),c=1);h>u;u++)s.animate({opacity:c},l,e.easing),c=1-c;s.animate({opacity:c},l,e.easing),s.queue(i),t.effects.unshift(s,d,h+1)}),t.effects.define("shake",function(e,i){var s=1,n=t(this),o=e.direction||"left",a=e.distance||20,r=e.times||3,h=2*r+1,l=Math.round(e.duration/h),c="up"===o||"down"===o?"top":"left",u="up"===o||"left"===o,d={},p={},f={},g=n.queue().length;for(t.effects.createPlaceholder(n),d[c]=(u?"-=":"+=")+a,p[c]=(u?"+=":"-=")+2*a,f[c]=(u?"-=":"+=")+2*a,n.animate(d,l,e.easing);r>s;s++)n.animate(p,l,e.easing).animate(f,l,e.easing);n.animate(p,l,e.easing).animate(d,l/2,e.easing).queue(i),t.effects.unshift(n,g,h+1)}),t.effects.define("slide","show",function(e,i){var s,n,o=t(this),a={up:["bottom","top"],down:["top","bottom"],left:["right","left"],right:["left","right"]},r=e.mode,h=e.direction||"left",l="up"===h||"down"===h?"top":"left",c="up"===h||"left"===h,u=e.distance||o["top"===l?"outerHeight":"outerWidth"](!0),d={};t.effects.createPlaceholder(o),s=o.cssClip(),n=o.position()[l],d[l]=(c?-1:1)*u+n,d.clip=o.cssClip(),d.clip[a[h][1]]=d.clip[a[h][0]],"show"===r&&(o.cssClip(d.clip),o.css(l,d[l]),d.clip=s,d[l]=n),o.animate(d,{queue:!1,duration:e.duration,easing:e.easing,complete:i})});var f;t.uiBackCompat!==!1&&(f=t.effects.define("transfer",function(e,i){t(this).transfer(e,i)})),t.ui.focusable=function(i,s){var n,o,a,r,h,l=i.nodeName.toLowerCase();return"area"===l?(n=i.parentNode,o=n.name,i.href&&o&&"map"===n.nodeName.toLowerCase()?(a=t("img[usemap='#"+o+"']"),a.length>0&&a.is(":visible")):!1):(/^(input|select|textarea|button|object)$/.test(l)?(r=!i.disabled,r&&(h=t(i).closest("fieldset")[0],h&&(r=!h.disabled))):r="a"===l?i.href||s:s,r&&t(i).is(":visible")&&e(t(i)))},t.extend(t.expr[":"],{focusable:function(e){return t.ui.focusable(e,null!=t.attr(e,"tabindex"))}}),t.ui.focusable,t.fn.form=function(){return"string"==typeof this[0].form?this.closest("form"):t(this[0].form)},t.ui.formResetMixin={_formResetHandler:function(){var e=t(this);setTimeout(function(){var i=e.data("ui-form-reset-instances");t.each(i,function(){this.refresh()})})},_bindFormResetHandler:function(){if(this.form=this.element.form(),this.form.length){var t=this.form.data("ui-form-reset-instances")||[];t.length||this.form.on("reset.ui-form-reset",this._formResetHandler),t.push(this),this.form.data("ui-form-reset-instances",t)}},_unbindFormResetHandler:function(){if(this.form.length){var e=this.form.data("ui-form-reset-instances");e.splice(t.inArray(this,e),1),e.length?this.form.data("ui-form-reset-instances",e):this.form.removeData("ui-form-reset-instances").off("reset.ui-form-reset")}}},"1.7"===t.fn.jquery.substring(0,3)&&(t.each(["Width","Height"],function(e,i){function s(e,i,s,o){return t.each(n,function(){i-=parseFloat(t.css(e,"padding"+this))||0,s&&(i-=parseFloat(t.css(e,"border"+this+"Width"))||0),o&&(i-=parseFloat(t.css(e,"margin"+this))||0)}),i}var n="Width"===i?["Left","Right"]:["Top","Bottom"],o=i.toLowerCase(),a={innerWidth:t.fn.innerWidth,innerHeight:t.fn.innerHeight,outerWidth:t.fn.outerWidth,outerHeight:t.fn.outerHeight};t.fn["inner"+i]=function(e){return void 0===e?a["inner"+i].call(this):this.each(function(){t(this).css(o,s(this,e)+"px")})},t.fn["outer"+i]=function(e,n){return"number"!=typeof e?a["outer"+i].call(this,e):this.each(function(){t(this).css(o,s(this,e,!0,n)+"px")})}}),t.fn.addBack=function(t){return this.add(null==t?this.prevObject:this.prevObject.filter(t))}),t.ui.keyCode={BACKSPACE:8,COMMA:188,DELETE:46,DOWN:40,END:35,ENTER:13,ESCAPE:27,HOME:36,LEFT:37,PAGE_DOWN:34,PAGE_UP:33,PERIOD:190,RIGHT:39,SPACE:32,TAB:9,UP:38},t.ui.escapeSelector=function(){var t=/([!"#$%&'()*+,.\/:;<=>?@[\]^`{|}~])/g;return function(e){return e.replace(t,"\\$1")}}(),t.fn.labels=function(){var e,i,s,n,o;return this[0].labels&&this[0].labels.length?this.pushStack(this[0].labels):(n=this.eq(0).parents("label"),s=this.attr("id"),s&&(e=this.eq(0).parents().last(),o=e.add(e.length?e.siblings():this.siblings()),i="label[for='"+t.ui.escapeSelector(s)+"']",n=n.add(o.find(i).addBack(i))),this.pushStack(n))},t.fn.scrollParent=function(e){var i=this.css("position"),s="absolute"===i,n=e?/(auto|scroll|hidden)/:/(auto|scroll)/,o=this.parents().filter(function(){var e=t(this);return s&&"static"===e.css("position")?!1:n.test(e.css("overflow")+e.css("overflow-y")+e.css("overflow-x"))}).eq(0);return"fixed"!==i&&o.length?o:t(this[0].ownerDocument||document)},t.extend(t.expr[":"],{tabbable:function(e){var i=t.attr(e,"tabindex"),s=null!=i;return(!s||i>=0)&&t.ui.focusable(e,s)}}),t.fn.extend({uniqueId:function(){var t=0;return function(){return this.each(function(){this.id||(this.id="ui-id-"+ ++t)})}}(),removeUniqueId:function(){return this.each(function(){/^ui-id-\d+$/.test(this.id)&&t(this).removeAttr("id")})}}),t.widget("ui.accordion",{version:"1.12.1",options:{active:0,animate:{},classes:{"ui-accordion-header":"ui-corner-top","ui-accordion-header-collapsed":"ui-corner-all","ui-accordion-content":"ui-corner-bottom"},collapsible:!1,event:"click",header:"> li > :first-child, > :not(li):even",heightStyle:"auto",icons:{activeHeader:"ui-icon-triangle-1-s",header:"ui-icon-triangle-1-e"},activate:null,beforeActivate:null},hideProps:{borderTopWidth:"hide",borderBottomWidth:"hide",paddingTop:"hide",paddingBottom:"hide",height:"hide"},showProps:{borderTopWidth:"show",borderBottomWidth:"show",paddingTop:"show",paddingBottom:"show",height:"show"},_create:function(){var e=this.options;this.prevShow=this.prevHide=t(),this._addClass("ui-accordion","ui-widget ui-helper-reset"),this.element.attr("role","tablist"),e.collapsible||e.active!==!1&&null!=e.active||(e.active=0),this._processPanels(),0>e.active&&(e.active+=this.headers.length),this._refresh()},_getCreateEventData:function(){return{header:this.active,panel:this.active.length?this.active.next():t()}},_createIcons:function(){var e,i,s=this.options.icons;s&&(e=t(""),this._addClass(e,"ui-accordion-header-icon","ui-icon "+s.header),e.prependTo(this.headers),i=this.active.children(".ui-accordion-header-icon"),this._removeClass(i,s.header)._addClass(i,null,s.activeHeader)._addClass(this.headers,"ui-accordion-icons"))},_destroyIcons:function(){this._removeClass(this.headers,"ui-accordion-icons"),this.headers.children(".ui-accordion-header-icon").remove()},_destroy:function(){var t;this.element.removeAttr("role"),this.headers.removeAttr("role aria-expanded aria-selected aria-controls tabIndex").removeUniqueId(),this._destroyIcons(),t=this.headers.next().css("display","").removeAttr("role aria-hidden aria-labelledby").removeUniqueId(),"content"!==this.options.heightStyle&&t.css("height","")},_setOption:function(t,e){return"active"===t?(this._activate(e),void 0):("event"===t&&(this.options.event&&this._off(this.headers,this.options.event),this._setupEvents(e)),this._super(t,e),"collapsible"!==t||e||this.options.active!==!1||this._activate(0),"icons"===t&&(this._destroyIcons(),e&&this._createIcons()),void 0)},_setOptionDisabled:function(t){this._super(t),this.element.attr("aria-disabled",t),this._toggleClass(null,"ui-state-disabled",!!t),this._toggleClass(this.headers.add(this.headers.next()),null,"ui-state-disabled",!!t)},_keydown:function(e){if(!e.altKey&&!e.ctrlKey){var i=t.ui.keyCode,s=this.headers.length,n=this.headers.index(e.target),o=!1;switch(e.keyCode){case i.RIGHT:case i.DOWN:o=this.headers[(n+1)%s];break;case i.LEFT:case i.UP:o=this.headers[(n-1+s)%s];break;case i.SPACE:case i.ENTER:this._eventHandler(e);break;case i.HOME:o=this.headers[0];break;case i.END:o=this.headers[s-1]}o&&(t(e.target).attr("tabIndex",-1),t(o).attr("tabIndex",0),t(o).trigger("focus"),e.preventDefault())}},_panelKeyDown:function(e){e.keyCode===t.ui.keyCode.UP&&e.ctrlKey&&t(e.currentTarget).prev().trigger("focus")},refresh:function(){var e=this.options;this._processPanels(),e.active===!1&&e.collapsible===!0||!this.headers.length?(e.active=!1,this.active=t()):e.active===!1?this._activate(0):this.active.length&&!t.contains(this.element[0],this.active[0])?this.headers.length===this.headers.find(".ui-state-disabled").length?(e.active=!1,this.active=t()):this._activate(Math.max(0,e.active-1)):e.active=this.headers.index(this.active),this._destroyIcons(),this._refresh()},_processPanels:function(){var t=this.headers,e=this.panels;this.headers=this.element.find(this.options.header),this._addClass(this.headers,"ui-accordion-header ui-accordion-header-collapsed","ui-state-default"),this.panels=this.headers.next().filter(":not(.ui-accordion-content-active)").hide(),this._addClass(this.panels,"ui-accordion-content","ui-helper-reset ui-widget-content"),e&&(this._off(t.not(this.headers)),this._off(e.not(this.panels)))},_refresh:function(){var e,i=this.options,s=i.heightStyle,n=this.element.parent();this.active=this._findActive(i.active),this._addClass(this.active,"ui-accordion-header-active","ui-state-active")._removeClass(this.active,"ui-accordion-header-collapsed"),this._addClass(this.active.next(),"ui-accordion-content-active"),this.active.next().show(),this.headers.attr("role","tab").each(function(){var e=t(this),i=e.uniqueId().attr("id"),s=e.next(),n=s.uniqueId().attr("id");e.attr("aria-controls",n),s.attr("aria-labelledby",i)}).next().attr("role","tabpanel"),this.headers.not(this.active).attr({"aria-selected":"false","aria-expanded":"false",tabIndex:-1}).next().attr({"aria-hidden":"true"}).hide(),this.active.length?this.active.attr({"aria-selected":"true","aria-expanded":"true",tabIndex:0}).next().attr({"aria-hidden":"false"}):this.headers.eq(0).attr("tabIndex",0),this._createIcons(),this._setupEvents(i.event),"fill"===s?(e=n.height(),this.element.siblings(":visible").each(function(){var i=t(this),s=i.css("position");"absolute"!==s&&"fixed"!==s&&(e-=i.outerHeight(!0))}),this.headers.each(function(){e-=t(this).outerHeight(!0)}),this.headers.next().each(function(){t(this).height(Math.max(0,e-t(this).innerHeight()+t(this).height()))}).css("overflow","auto")):"auto"===s&&(e=0,this.headers.next().each(function(){var i=t(this).is(":visible");i||t(this).show(),e=Math.max(e,t(this).css("height","").height()),i||t(this).hide()}).height(e))},_activate:function(e){var i=this._findActive(e)[0];i!==this.active[0]&&(i=i||this.active[0],this._eventHandler({target:i,currentTarget:i,preventDefault:t.noop}))},_findActive:function(e){return"number"==typeof e?this.headers.eq(e):t()},_setupEvents:function(e){var i={keydown:"_keydown"};e&&t.each(e.split(" "),function(t,e){i[e]="_eventHandler"}),this._off(this.headers.add(this.headers.next())),this._on(this.headers,i),this._on(this.headers.next(),{keydown:"_panelKeyDown"}),this._hoverable(this.headers),this._focusable(this.headers)},_eventHandler:function(e){var i,s,n=this.options,o=this.active,a=t(e.currentTarget),r=a[0]===o[0],h=r&&n.collapsible,l=h?t():a.next(),c=o.next(),u={oldHeader:o,oldPanel:c,newHeader:h?t():a,newPanel:l};e.preventDefault(),r&&!n.collapsible||this._trigger("beforeActivate",e,u)===!1||(n.active=h?!1:this.headers.index(a),this.active=r?t():a,this._toggle(u),this._removeClass(o,"ui-accordion-header-active","ui-state-active"),n.icons&&(i=o.children(".ui-accordion-header-icon"),this._removeClass(i,null,n.icons.activeHeader)._addClass(i,null,n.icons.header)),r||(this._removeClass(a,"ui-accordion-header-collapsed")._addClass(a,"ui-accordion-header-active","ui-state-active"),n.icons&&(s=a.children(".ui-accordion-header-icon"),this._removeClass(s,null,n.icons.header)._addClass(s,null,n.icons.activeHeader)),this._addClass(a.next(),"ui-accordion-content-active")))},_toggle:function(e){var i=e.newPanel,s=this.prevShow.length?this.prevShow:e.oldPanel;this.prevShow.add(this.prevHide).stop(!0,!0),this.prevShow=i,this.prevHide=s,this.options.animate?this._animate(i,s,e):(s.hide(),i.show(),this._toggleComplete(e)),s.attr({"aria-hidden":"true"}),s.prev().attr({"aria-selected":"false","aria-expanded":"false"}),i.length&&s.length?s.prev().attr({tabIndex:-1,"aria-expanded":"false"}):i.length&&this.headers.filter(function(){return 0===parseInt(t(this).attr("tabIndex"),10)}).attr("tabIndex",-1),i.attr("aria-hidden","false").prev().attr({"aria-selected":"true","aria-expanded":"true",tabIndex:0})},_animate:function(t,e,i){var s,n,o,a=this,r=0,h=t.css("box-sizing"),l=t.length&&(!e.length||t.index()",delay:300,options:{icons:{submenu:"ui-icon-caret-1-e"},items:"> *",menus:"ul",position:{my:"left top",at:"right top"},role:"menu",blur:null,focus:null,select:null},_create:function(){this.activeMenu=this.element,this.mouseHandled=!1,this.element.uniqueId().attr({role:this.options.role,tabIndex:0}),this._addClass("ui-menu","ui-widget ui-widget-content"),this._on({"mousedown .ui-menu-item":function(t){t.preventDefault()},"click .ui-menu-item":function(e){var i=t(e.target),s=t(t.ui.safeActiveElement(this.document[0]));!this.mouseHandled&&i.not(".ui-state-disabled").length&&(this.select(e),e.isPropagationStopped()||(this.mouseHandled=!0),i.has(".ui-menu").length?this.expand(e):!this.element.is(":focus")&&s.closest(".ui-menu").length&&(this.element.trigger("focus",[!0]),this.active&&1===this.active.parents(".ui-menu").length&&clearTimeout(this.timer)))},"mouseenter .ui-menu-item":function(e){if(!this.previousFilter){var i=t(e.target).closest(".ui-menu-item"),s=t(e.currentTarget);i[0]===s[0]&&(this._removeClass(s.siblings().children(".ui-state-active"),null,"ui-state-active"),this.focus(e,s))}},mouseleave:"collapseAll","mouseleave .ui-menu":"collapseAll",focus:function(t,e){var i=this.active||this.element.find(this.options.items).eq(0);e||this.focus(t,i)},blur:function(e){this._delay(function(){var i=!t.contains(this.element[0],t.ui.safeActiveElement(this.document[0]));i&&this.collapseAll(e)})},keydown:"_keydown"}),this.refresh(),this._on(this.document,{click:function(t){this._closeOnDocumentClick(t)&&this.collapseAll(t),this.mouseHandled=!1}})},_destroy:function(){var e=this.element.find(".ui-menu-item").removeAttr("role aria-disabled"),i=e.children(".ui-menu-item-wrapper").removeUniqueId().removeAttr("tabIndex role aria-haspopup");this.element.removeAttr("aria-activedescendant").find(".ui-menu").addBack().removeAttr("role aria-labelledby aria-expanded aria-hidden aria-disabled tabIndex").removeUniqueId().show(),i.children().each(function(){var e=t(this);e.data("ui-menu-submenu-caret")&&e.remove()})},_keydown:function(e){var i,s,n,o,a=!0;switch(e.keyCode){case t.ui.keyCode.PAGE_UP:this.previousPage(e);break;case t.ui.keyCode.PAGE_DOWN:this.nextPage(e);break;case t.ui.keyCode.HOME:this._move("first","first",e);break;case t.ui.keyCode.END:this._move("last","last",e);break;case t.ui.keyCode.UP:this.previous(e);break;case t.ui.keyCode.DOWN:this.next(e);break;case t.ui.keyCode.LEFT:this.collapse(e);break;case t.ui.keyCode.RIGHT:this.active&&!this.active.is(".ui-state-disabled")&&this.expand(e);break;case t.ui.keyCode.ENTER:case t.ui.keyCode.SPACE:this._activate(e);break;case t.ui.keyCode.ESCAPE:this.collapse(e);break;default:a=!1,s=this.previousFilter||"",o=!1,n=e.keyCode>=96&&105>=e.keyCode?""+(e.keyCode-96):String.fromCharCode(e.keyCode),clearTimeout(this.filterTimer),n===s?o=!0:n=s+n,i=this._filterMenuItems(n),i=o&&-1!==i.index(this.active.next())?this.active.nextAll(".ui-menu-item"):i,i.length||(n=String.fromCharCode(e.keyCode),i=this._filterMenuItems(n)),i.length?(this.focus(e,i),this.previousFilter=n,this.filterTimer=this._delay(function(){delete this.previousFilter},1e3)):delete this.previousFilter}a&&e.preventDefault()},_activate:function(t){this.active&&!this.active.is(".ui-state-disabled")&&(this.active.children("[aria-haspopup='true']").length?this.expand(t):this.select(t))},refresh:function(){var e,i,s,n,o,a=this,r=this.options.icons.submenu,h=this.element.find(this.options.menus);this._toggleClass("ui-menu-icons",null,!!this.element.find(".ui-icon").length),s=h.filter(":not(.ui-menu)").hide().attr({role:this.options.role,"aria-hidden":"true","aria-expanded":"false"}).each(function(){var e=t(this),i=e.prev(),s=t("").data("ui-menu-submenu-caret",!0);a._addClass(s,"ui-menu-icon","ui-icon "+r),i.attr("aria-haspopup","true").prepend(s),e.attr("aria-labelledby",i.attr("id"))}),this._addClass(s,"ui-menu","ui-widget ui-widget-content ui-front"),e=h.add(this.element),i=e.find(this.options.items),i.not(".ui-menu-item").each(function(){var e=t(this);a._isDivider(e)&&a._addClass(e,"ui-menu-divider","ui-widget-content")}),n=i.not(".ui-menu-item, .ui-menu-divider"),o=n.children().not(".ui-menu").uniqueId().attr({tabIndex:-1,role:this._itemRole()}),this._addClass(n,"ui-menu-item")._addClass(o,"ui-menu-item-wrapper"),i.filter(".ui-state-disabled").attr("aria-disabled","true"),this.active&&!t.contains(this.element[0],this.active[0])&&this.blur()},_itemRole:function(){return{menu:"menuitem",listbox:"option"}[this.options.role]},_setOption:function(t,e){if("icons"===t){var i=this.element.find(".ui-menu-icon");this._removeClass(i,null,this.options.icons.submenu)._addClass(i,null,e.submenu)}this._super(t,e)},_setOptionDisabled:function(t){this._super(t),this.element.attr("aria-disabled",t+""),this._toggleClass(null,"ui-state-disabled",!!t)},focus:function(t,e){var i,s,n;this.blur(t,t&&"focus"===t.type),this._scrollIntoView(e),this.active=e.first(),s=this.active.children(".ui-menu-item-wrapper"),this._addClass(s,null,"ui-state-active"),this.options.role&&this.element.attr("aria-activedescendant",s.attr("id")),n=this.active.parent().closest(".ui-menu-item").children(".ui-menu-item-wrapper"),this._addClass(n,null,"ui-state-active"),t&&"keydown"===t.type?this._close():this.timer=this._delay(function(){this._close()},this.delay),i=e.children(".ui-menu"),i.length&&t&&/^mouse/.test(t.type)&&this._startOpening(i),this.activeMenu=e.parent(),this._trigger("focus",t,{item:e})},_scrollIntoView:function(e){var i,s,n,o,a,r;this._hasScroll()&&(i=parseFloat(t.css(this.activeMenu[0],"borderTopWidth"))||0,s=parseFloat(t.css(this.activeMenu[0],"paddingTop"))||0,n=e.offset().top-this.activeMenu.offset().top-i-s,o=this.activeMenu.scrollTop(),a=this.activeMenu.height(),r=e.outerHeight(),0>n?this.activeMenu.scrollTop(o+n):n+r>a&&this.activeMenu.scrollTop(o+n-a+r))},blur:function(t,e){e||clearTimeout(this.timer),this.active&&(this._removeClass(this.active.children(".ui-menu-item-wrapper"),null,"ui-state-active"),this._trigger("blur",t,{item:this.active}),this.active=null)},_startOpening:function(t){clearTimeout(this.timer),"true"===t.attr("aria-hidden")&&(this.timer=this._delay(function(){this._close(),this._open(t)},this.delay))},_open:function(e){var i=t.extend({of:this.active},this.options.position);clearTimeout(this.timer),this.element.find(".ui-menu").not(e.parents(".ui-menu")).hide().attr("aria-hidden","true"),e.show().removeAttr("aria-hidden").attr("aria-expanded","true").position(i)},collapseAll:function(e,i){clearTimeout(this.timer),this.timer=this._delay(function(){var s=i?this.element:t(e&&e.target).closest(this.element.find(".ui-menu"));s.length||(s=this.element),this._close(s),this.blur(e),this._removeClass(s.find(".ui-state-active"),null,"ui-state-active"),this.activeMenu=s},this.delay)},_close:function(t){t||(t=this.active?this.active.parent():this.element),t.find(".ui-menu").hide().attr("aria-hidden","true").attr("aria-expanded","false")},_closeOnDocumentClick:function(e){return!t(e.target).closest(".ui-menu").length},_isDivider:function(t){return!/[^\-\u2014\u2013\s]/.test(t.text())},collapse:function(t){var e=this.active&&this.active.parent().closest(".ui-menu-item",this.element);e&&e.length&&(this._close(),this.focus(t,e))},expand:function(t){var e=this.active&&this.active.children(".ui-menu ").find(this.options.items).first();e&&e.length&&(this._open(e.parent()),this._delay(function(){this.focus(t,e)}))},next:function(t){this._move("next","first",t)},previous:function(t){this._move("prev","last",t)},isFirstItem:function(){return this.active&&!this.active.prevAll(".ui-menu-item").length},isLastItem:function(){return this.active&&!this.active.nextAll(".ui-menu-item").length},_move:function(t,e,i){var s;this.active&&(s="first"===t||"last"===t?this.active["first"===t?"prevAll":"nextAll"](".ui-menu-item").eq(-1):this.active[t+"All"](".ui-menu-item").eq(0)),s&&s.length&&this.active||(s=this.activeMenu.find(this.options.items)[e]()),this.focus(i,s)},nextPage:function(e){var i,s,n;return this.active?(this.isLastItem()||(this._hasScroll()?(s=this.active.offset().top,n=this.element.height(),this.active.nextAll(".ui-menu-item").each(function(){return i=t(this),0>i.offset().top-s-n}),this.focus(e,i)):this.focus(e,this.activeMenu.find(this.options.items)[this.active?"last":"first"]())),void 0):(this.next(e),void 0)},previousPage:function(e){var i,s,n;return this.active?(this.isFirstItem()||(this._hasScroll()?(s=this.active.offset().top,n=this.element.height(),this.active.prevAll(".ui-menu-item").each(function(){return i=t(this),i.offset().top-s+n>0}),this.focus(e,i)):this.focus(e,this.activeMenu.find(this.options.items).first())),void 0):(this.next(e),void 0)},_hasScroll:function(){return this.element.outerHeight()",options:{appendTo:null,autoFocus:!1,delay:300,minLength:1,position:{my:"left top",at:"left bottom",collision:"none"},source:null,change:null,close:null,focus:null,open:null,response:null,search:null,select:null},requestIndex:0,pending:0,_create:function(){var e,i,s,n=this.element[0].nodeName.toLowerCase(),o="textarea"===n,a="input"===n;
-this.isMultiLine=o||!a&&this._isContentEditable(this.element),this.valueMethod=this.element[o||a?"val":"text"],this.isNewMenu=!0,this._addClass("ui-autocomplete-input"),this.element.attr("autocomplete","off"),this._on(this.element,{keydown:function(n){if(this.element.prop("readOnly"))return e=!0,s=!0,i=!0,void 0;e=!1,s=!1,i=!1;var o=t.ui.keyCode;switch(n.keyCode){case o.PAGE_UP:e=!0,this._move("previousPage",n);break;case o.PAGE_DOWN:e=!0,this._move("nextPage",n);break;case o.UP:e=!0,this._keyEvent("previous",n);break;case o.DOWN:e=!0,this._keyEvent("next",n);break;case o.ENTER:this.menu.active&&(e=!0,n.preventDefault(),this.menu.select(n));break;case o.TAB:this.menu.active&&this.menu.select(n);break;case o.ESCAPE:this.menu.element.is(":visible")&&(this.isMultiLine||this._value(this.term),this.close(n),n.preventDefault());break;default:i=!0,this._searchTimeout(n)}},keypress:function(s){if(e)return e=!1,(!this.isMultiLine||this.menu.element.is(":visible"))&&s.preventDefault(),void 0;if(!i){var n=t.ui.keyCode;switch(s.keyCode){case n.PAGE_UP:this._move("previousPage",s);break;case n.PAGE_DOWN:this._move("nextPage",s);break;case n.UP:this._keyEvent("previous",s);break;case n.DOWN:this._keyEvent("next",s)}}},input:function(t){return s?(s=!1,t.preventDefault(),void 0):(this._searchTimeout(t),void 0)},focus:function(){this.selectedItem=null,this.previous=this._value()},blur:function(t){return this.cancelBlur?(delete this.cancelBlur,void 0):(clearTimeout(this.searching),this.close(t),this._change(t),void 0)}}),this._initSource(),this.menu=t("").appendTo(this._appendTo()).menu({role:null}).hide().menu("instance"),this._addClass(this.menu.element,"ui-autocomplete","ui-front"),this._on(this.menu.element,{mousedown:function(e){e.preventDefault(),this.cancelBlur=!0,this._delay(function(){delete this.cancelBlur,this.element[0]!==t.ui.safeActiveElement(this.document[0])&&this.element.trigger("focus")})},menufocus:function(e,i){var s,n;return this.isNewMenu&&(this.isNewMenu=!1,e.originalEvent&&/^mouse/.test(e.originalEvent.type))?(this.menu.blur(),this.document.one("mousemove",function(){t(e.target).trigger(e.originalEvent)}),void 0):(n=i.item.data("ui-autocomplete-item"),!1!==this._trigger("focus",e,{item:n})&&e.originalEvent&&/^key/.test(e.originalEvent.type)&&this._value(n.value),s=i.item.attr("aria-label")||n.value,s&&t.trim(s).length&&(this.liveRegion.children().hide(),t("").text(s).appendTo(this.liveRegion)),void 0)},menuselect:function(e,i){var s=i.item.data("ui-autocomplete-item"),n=this.previous;this.element[0]!==t.ui.safeActiveElement(this.document[0])&&(this.element.trigger("focus"),this.previous=n,this._delay(function(){this.previous=n,this.selectedItem=s})),!1!==this._trigger("select",e,{item:s})&&this._value(s.value),this.term=this._value(),this.close(e),this.selectedItem=s}}),this.liveRegion=t("
",{role:"status","aria-live":"assertive","aria-relevant":"additions"}).appendTo(this.document[0].body),this._addClass(this.liveRegion,null,"ui-helper-hidden-accessible"),this._on(this.window,{beforeunload:function(){this.element.removeAttr("autocomplete")}})},_destroy:function(){clearTimeout(this.searching),this.element.removeAttr("autocomplete"),this.menu.element.remove(),this.liveRegion.remove()},_setOption:function(t,e){this._super(t,e),"source"===t&&this._initSource(),"appendTo"===t&&this.menu.element.appendTo(this._appendTo()),"disabled"===t&&e&&this.xhr&&this.xhr.abort()},_isEventTargetInWidget:function(e){var i=this.menu.element[0];return e.target===this.element[0]||e.target===i||t.contains(i,e.target)},_closeOnClickOutside:function(t){this._isEventTargetInWidget(t)||this.close()},_appendTo:function(){var e=this.options.appendTo;return e&&(e=e.jquery||e.nodeType?t(e):this.document.find(e).eq(0)),e&&e[0]||(e=this.element.closest(".ui-front, dialog")),e.length||(e=this.document[0].body),e},_initSource:function(){var e,i,s=this;t.isArray(this.options.source)?(e=this.options.source,this.source=function(i,s){s(t.ui.autocomplete.filter(e,i.term))}):"string"==typeof this.options.source?(i=this.options.source,this.source=function(e,n){s.xhr&&s.xhr.abort(),s.xhr=t.ajax({url:i,data:e,dataType:"json",success:function(t){n(t)},error:function(){n([])}})}):this.source=this.options.source},_searchTimeout:function(t){clearTimeout(this.searching),this.searching=this._delay(function(){var e=this.term===this._value(),i=this.menu.element.is(":visible"),s=t.altKey||t.ctrlKey||t.metaKey||t.shiftKey;(!e||e&&!i&&!s)&&(this.selectedItem=null,this.search(null,t))},this.options.delay)},search:function(t,e){return t=null!=t?t:this._value(),this.term=this._value(),t.length
").append(t("").text(i.label)).appendTo(e)},_move:function(t,e){return this.menu.element.is(":visible")?this.menu.isFirstItem()&&/^previous/.test(t)||this.menu.isLastItem()&&/^next/.test(t)?(this.isMultiLine||this._value(this.term),this.menu.blur(),void 0):(this.menu[t](e),void 0):(this.search(null,e),void 0)},widget:function(){return this.menu.element},_value:function(){return this.valueMethod.apply(this.element,arguments)},_keyEvent:function(t,e){(!this.isMultiLine||this.menu.element.is(":visible"))&&(this._move(t,e),e.preventDefault())},_isContentEditable:function(t){if(!t.length)return!1;var e=t.prop("contentEditable");return"inherit"===e?this._isContentEditable(t.parent()):"true"===e}}),t.extend(t.ui.autocomplete,{escapeRegex:function(t){return t.replace(/[\-\[\]{}()*+?.,\\\^$|#\s]/g,"\\$&")},filter:function(e,i){var s=RegExp(t.ui.autocomplete.escapeRegex(i),"i");return t.grep(e,function(t){return s.test(t.label||t.value||t)})}}),t.widget("ui.autocomplete",t.ui.autocomplete,{options:{messages:{noResults:"No search results.",results:function(t){return t+(t>1?" results are":" result is")+" available, use up and down arrow keys to navigate."}}},__response:function(e){var i;this._superApply(arguments),this.options.disabled||this.cancelSearch||(i=e&&e.length?this.options.messages.results(e.length):this.options.messages.noResults,this.liveRegion.children().hide(),t("
").text(i).appendTo(this.liveRegion))}}),t.ui.autocomplete;var g=/ui-corner-([a-z]){2,6}/g;t.widget("ui.controlgroup",{version:"1.12.1",defaultElement:"
",options:{direction:"horizontal",disabled:null,onlyVisible:!0,items:{button:"input[type=button], input[type=submit], input[type=reset], button, a",controlgroupLabel:".ui-controlgroup-label",checkboxradio:"input[type='checkbox'], input[type='radio']",selectmenu:"select",spinner:".ui-spinner-input"}},_create:function(){this._enhance()},_enhance:function(){this.element.attr("role","toolbar"),this.refresh()},_destroy:function(){this._callChildMethod("destroy"),this.childWidgets.removeData("ui-controlgroup-data"),this.element.removeAttr("role"),this.options.items.controlgroupLabel&&this.element.find(this.options.items.controlgroupLabel).find(".ui-controlgroup-label-contents").contents().unwrap()},_initWidgets:function(){var e=this,i=[];t.each(this.options.items,function(s,n){var o,a={};return n?"controlgroupLabel"===s?(o=e.element.find(n),o.each(function(){var e=t(this);e.children(".ui-controlgroup-label-contents").length||e.contents().wrapAll("
")}),e._addClass(o,null,"ui-widget ui-widget-content ui-state-default"),i=i.concat(o.get()),void 0):(t.fn[s]&&(a=e["_"+s+"Options"]?e["_"+s+"Options"]("middle"):{classes:{}},e.element.find(n).each(function(){var n=t(this),o=n[s]("instance"),r=t.widget.extend({},a);if("button"!==s||!n.parent(".ui-spinner").length){o||(o=n[s]()[s]("instance")),o&&(r.classes=e._resolveClassesValues(r.classes,o)),n[s](r);var h=n[s]("widget");t.data(h[0],"ui-controlgroup-data",o?o:n[s]("instance")),i.push(h[0])}})),void 0):void 0}),this.childWidgets=t(t.unique(i)),this._addClass(this.childWidgets,"ui-controlgroup-item")},_callChildMethod:function(e){this.childWidgets.each(function(){var i=t(this),s=i.data("ui-controlgroup-data");s&&s[e]&&s[e]()})},_updateCornerClass:function(t,e){var i="ui-corner-top ui-corner-bottom ui-corner-left ui-corner-right ui-corner-all",s=this._buildSimpleOptions(e,"label").classes.label;this._removeClass(t,null,i),this._addClass(t,null,s)},_buildSimpleOptions:function(t,e){var i="vertical"===this.options.direction,s={classes:{}};return s.classes[e]={middle:"",first:"ui-corner-"+(i?"top":"left"),last:"ui-corner-"+(i?"bottom":"right"),only:"ui-corner-all"}[t],s},_spinnerOptions:function(t){var e=this._buildSimpleOptions(t,"ui-spinner");return e.classes["ui-spinner-up"]="",e.classes["ui-spinner-down"]="",e},_buttonOptions:function(t){return this._buildSimpleOptions(t,"ui-button")},_checkboxradioOptions:function(t){return this._buildSimpleOptions(t,"ui-checkboxradio-label")},_selectmenuOptions:function(t){var e="vertical"===this.options.direction;return{width:e?"auto":!1,classes:{middle:{"ui-selectmenu-button-open":"","ui-selectmenu-button-closed":""},first:{"ui-selectmenu-button-open":"ui-corner-"+(e?"top":"tl"),"ui-selectmenu-button-closed":"ui-corner-"+(e?"top":"left")},last:{"ui-selectmenu-button-open":e?"":"ui-corner-tr","ui-selectmenu-button-closed":"ui-corner-"+(e?"bottom":"right")},only:{"ui-selectmenu-button-open":"ui-corner-top","ui-selectmenu-button-closed":"ui-corner-all"}}[t]}},_resolveClassesValues:function(e,i){var s={};return t.each(e,function(n){var o=i.options.classes[n]||"";o=t.trim(o.replace(g,"")),s[n]=(o+" "+e[n]).replace(/\s+/g," ")}),s},_setOption:function(t,e){return"direction"===t&&this._removeClass("ui-controlgroup-"+this.options.direction),this._super(t,e),"disabled"===t?(this._callChildMethod(e?"disable":"enable"),void 0):(this.refresh(),void 0)},refresh:function(){var e,i=this;this._addClass("ui-controlgroup ui-controlgroup-"+this.options.direction),"horizontal"===this.options.direction&&this._addClass(null,"ui-helper-clearfix"),this._initWidgets(),e=this.childWidgets,this.options.onlyVisible&&(e=e.filter(":visible")),e.length&&(t.each(["first","last"],function(t,s){var n=e[s]().data("ui-controlgroup-data");if(n&&i["_"+n.widgetName+"Options"]){var o=i["_"+n.widgetName+"Options"](1===e.length?"only":s);o.classes=i._resolveClassesValues(o.classes,n),n.element[n.widgetName](o)}else i._updateCornerClass(e[s](),s)}),this._callChildMethod("refresh"))}}),t.widget("ui.checkboxradio",[t.ui.formResetMixin,{version:"1.12.1",options:{disabled:null,label:null,icon:!0,classes:{"ui-checkboxradio-label":"ui-corner-all","ui-checkboxradio-icon":"ui-corner-all"}},_getCreateOptions:function(){var e,i,s=this,n=this._super()||{};return this._readType(),i=this.element.labels(),this.label=t(i[i.length-1]),this.label.length||t.error("No label found for checkboxradio widget"),this.originalLabel="",this.label.contents().not(this.element[0]).each(function(){s.originalLabel+=3===this.nodeType?t(this).text():this.outerHTML}),this.originalLabel&&(n.label=this.originalLabel),e=this.element[0].disabled,null!=e&&(n.disabled=e),n},_create:function(){var t=this.element[0].checked;this._bindFormResetHandler(),null==this.options.disabled&&(this.options.disabled=this.element[0].disabled),this._setOption("disabled",this.options.disabled),this._addClass("ui-checkboxradio","ui-helper-hidden-accessible"),this._addClass(this.label,"ui-checkboxradio-label","ui-button ui-widget"),"radio"===this.type&&this._addClass(this.label,"ui-checkboxradio-radio-label"),this.options.label&&this.options.label!==this.originalLabel?this._updateLabel():this.originalLabel&&(this.options.label=this.originalLabel),this._enhance(),t&&(this._addClass(this.label,"ui-checkboxradio-checked","ui-state-active"),this.icon&&this._addClass(this.icon,null,"ui-state-hover")),this._on({change:"_toggleClasses",focus:function(){this._addClass(this.label,null,"ui-state-focus ui-visual-focus")},blur:function(){this._removeClass(this.label,null,"ui-state-focus ui-visual-focus")}})},_readType:function(){var e=this.element[0].nodeName.toLowerCase();this.type=this.element[0].type,"input"===e&&/radio|checkbox/.test(this.type)||t.error("Can't create checkboxradio on element.nodeName="+e+" and element.type="+this.type)},_enhance:function(){this._updateIcon(this.element[0].checked)},widget:function(){return this.label},_getRadioGroup:function(){var e,i=this.element[0].name,s="input[name='"+t.ui.escapeSelector(i)+"']";return i?(e=this.form.length?t(this.form[0].elements).filter(s):t(s).filter(function(){return 0===t(this).form().length}),e.not(this.element)):t([])},_toggleClasses:function(){var e=this.element[0].checked;this._toggleClass(this.label,"ui-checkboxradio-checked","ui-state-active",e),this.options.icon&&"checkbox"===this.type&&this._toggleClass(this.icon,null,"ui-icon-check ui-state-checked",e)._toggleClass(this.icon,null,"ui-icon-blank",!e),"radio"===this.type&&this._getRadioGroup().each(function(){var e=t(this).checkboxradio("instance");e&&e._removeClass(e.label,"ui-checkboxradio-checked","ui-state-active")})},_destroy:function(){this._unbindFormResetHandler(),this.icon&&(this.icon.remove(),this.iconSpace.remove())},_setOption:function(t,e){return"label"!==t||e?(this._super(t,e),"disabled"===t?(this._toggleClass(this.label,null,"ui-state-disabled",e),this.element[0].disabled=e,void 0):(this.refresh(),void 0)):void 0},_updateIcon:function(e){var i="ui-icon ui-icon-background ";this.options.icon?(this.icon||(this.icon=t("
"),this.iconSpace=t(" "),this._addClass(this.iconSpace,"ui-checkboxradio-icon-space")),"checkbox"===this.type?(i+=e?"ui-icon-check ui-state-checked":"ui-icon-blank",this._removeClass(this.icon,null,e?"ui-icon-blank":"ui-icon-check")):i+="ui-icon-blank",this._addClass(this.icon,"ui-checkboxradio-icon",i),e||this._removeClass(this.icon,null,"ui-icon-check ui-state-checked"),this.icon.prependTo(this.label).after(this.iconSpace)):void 0!==this.icon&&(this.icon.remove(),this.iconSpace.remove(),delete this.icon)},_updateLabel:function(){var t=this.label.contents().not(this.element[0]);this.icon&&(t=t.not(this.icon[0])),this.iconSpace&&(t=t.not(this.iconSpace[0])),t.remove(),this.label.append(this.options.label)},refresh:function(){var t=this.element[0].checked,e=this.element[0].disabled;this._updateIcon(t),this._toggleClass(this.label,"ui-checkboxradio-checked","ui-state-active",t),null!==this.options.label&&this._updateLabel(),e!==this.options.disabled&&this._setOptions({disabled:e})}}]),t.ui.checkboxradio,t.widget("ui.button",{version:"1.12.1",defaultElement:"
 -
-