-
-The Renegades Of Orion 2.0 Download For Pc [addons]l · Download Film The ... Previous · Bad Piggies 1.3.0 Crack [PC] Hack Tooll · Next. 1fdad05405
-
-
-
diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/DOWNLOAD ADOBE ILLUSTRATOR CC 2019 64-BIT 23.1 PRE-ACTIVATED High Quality.md b/spaces/1gistliPinn/ChatGPT4/Examples/DOWNLOAD ADOBE ILLUSTRATOR CC 2019 64-BIT 23.1 PRE-ACTIVATED High Quality.md
deleted file mode 100644
index a07191846e261cec21658607af3a0ad036085531..0000000000000000000000000000000000000000
--- a/spaces/1gistliPinn/ChatGPT4/Examples/DOWNLOAD ADOBE ILLUSTRATOR CC 2019 64-BIT 23.1 PRE-ACTIVATED High Quality.md
+++ /dev/null
@@ -1,90 +0,0 @@
-
-
How to Download Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated
-
If you are looking for a way to download Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated, you have come to the right place. In this article, we will show you how to get this powerful vector graphics software for free, without any crack or patch needed.
-
Adobe Illustrator CC 2019 is the industry-standard vector graphics app that lets you create logos, icons, drawings, typography, and illustrations for print, web, video, and mobile. It has all the drawing tools you need to turn simple shapes and colors into sophisticated logos, icons, and graphics. It also has amazing typography features that let you create stunning text designs. You can also use Illustrator to create freehand drawings, trace and recolor imported photos, and use your illustrations anywhere.
-
DOWNLOAD ADOBE ILLUSTRATOR CC 2019 64-BIT 23.1 PRE-ACTIVATED
Why Download Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated?
-
There are many reasons why you might want to download Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated. Here are some of them:
-
-
You can save money by not paying for a subscription or a license.
-
You can use the software offline without any internet connection.
-
You can enjoy all the features and updates of the latest version of Illustrator.
-
You can avoid any virus or malware that might come with cracked or patched versions.
-
You can install and use the software easily and quickly.
-
-
How to Download Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated?
-
The process of downloading Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is very simple and straightforward. Here are the steps you need to follow:
-
-
-
Click on the link below to download the software from Google Drive.
-
Extract the zip file using WinRAR or any other software.
-
Double click on the installer and wait for the installation completed notification.
-
The software will activate itself with built in crack, no additional cracking or patching needed.
-
Launch the software from the start menu or taskbar and enjoy!
Adobe Illustrator CC 2019 is a great software for creating vector graphics and typography. You can download it for free from the link above and use it without any hassle. We hope this article was helpful and informative for you. If you have any questions or problems, feel free to leave a comment below or contact us through our website.
-
What are the Features of Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated?
-
Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is not only free to download and use, but also comes with many amazing features that make it a powerful vector graphics software. Here are some of the features that you can enjoy with this version:
-
-
Freeform Gradients: This feature allows you to create natural and photorealistic gradients by dropping points of color on your object. You can blend multiple colors and create complex color transitions that look stunning.
-
Global Editing: This feature allows you to edit similar objects across multiple artboards at once. You can change colors, shapes, rotation, and more with just a few clicks. This saves you time and ensures consistency in your design.
-
Customizable Toolbar: This feature allows you to organize your workspace the way you want it. You can add or remove tools from the toolbar and group them according to your preference. You can also access Adobe Fonts directly from the toolbar and preview different fonts in your design.
-
Content-Aware Crop: This feature uses Adobe Sensei technology to provide suggested crops for your images. You can crop your images without losing any important details or content.
-
Puppet Warp Enhancement: This feature also uses Adobe Sensei technology to automatically suggest pins for your objects. You can use these pins to warp and transform your objects in a realistic way.
-
-
How to Use Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated?
-
Using Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is easy and fun. You can create any kind of vector graphics and typography with this software. Here are some tips and tricks to help you get started:
-
-
Create a new document or open an existing one from the File menu.
-
Select a tool from the toolbar or use the touch shortcuts on your screen.
-
Draw, edit, and manipulate your objects on the artboard using the tool options and panels.
-
Add effects, styles, and text to your objects using the Appearance panel and the Type tool.
-
Export or save your artwork in various formats from the File menu.
-
-
Conclusion
-
Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is a great software for creating vector graphics and typography. You can download it for free from the link above and use it without any hassle. We hope this article was helpful and informative for you. If you have any questions or problems, feel free to leave a comment below or contact us through our website.
-
How to Learn Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated?
-
If you want to master Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated, you need to learn how to use its features and tools effectively. Fortunately, there are many resources available online that can help you learn Illustrator at your own pace and level. Here are some of the best ones:
-
-
Adobe Illustrator Tutorials: This is the official website of Adobe that offers hundreds of tutorials for beginners, intermediate, and advanced users. You can learn the basics, new features, tips and techniques, and more. You can also watch video tutorials, hands-on projects, and live streams from experts.
-
View All Adobe Illustrator Tutorials: This is another website by Adobe that shows you all the tutorials available for Illustrator. You can browse by topic, skill level, or product version. You can also filter by type, such as video, article, or project.
-
Illustrator User Guide: This is the comprehensive online manual for Illustrator that covers everything you need to know about the software. You can read about the features, functions, workflows, and best practices of Illustrator. You can also find troubleshooting tips and answers to frequently asked questions.
-
-
What are the Benefits of Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated?
-
Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is not only a powerful vector graphics software, but also a versatile and creative tool that can help you achieve your design goals. Here are some of the benefits of using this software:
-
-
You can create stunning vector graphics that are scalable, editable, and resolution-independent.
-
You can design logos, icons, illustrations, typography, and more for any kind of project.
-
You can use a variety of tools and effects to enhance your artwork and express your style.
-
You can work with multiple artboards, layers, masks, guides, and grids to organize your content and layout.
-
You can import and export your artwork in various formats and share it with others easily.
-
-
Conclusion
-
Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is a great software for creating vector graphics and typography. You can download it for free from the link above and use it without any hassle. We hope this article was helpful and informative for you. If you have any questions or problems, feel free to leave a comment below or contact us through our website.
-
What are the Reviews of Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated?
-
Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated has received many positive reviews from users and experts alike. Here are some of the highlights of what they have to say about this software:
-
-
PCMag gave Illustrator a rating of 4.5 out of 5 stars, praising its vector design tools, touch type feature, free transform tool, puppet warp feature, and Adobe Fonts integration. They also noted that Illustrator is "the best vector-graphics editing program around, and it just keeps getting better."
-
Creative Bloq gave Illustrator a rating of 4 out of 5 stars, commending its new 3D functions, elegant vector editing, and cloud teamwork. They also noted that Illustrator is "the standard for a reason – it’s the best."
-
TrustRadius gave Illustrator a rating of 8.8 out of 10, based on 1,147 ratings from verified users. They highlighted its features such as freeform gradients, global editing, customizable toolbar, content-aware crop, and puppet warp enhancement. They also noted that Illustrator is "the best software for vector graphics and professional photographs."
-
GetApp gave Illustrator a rating of 4.6 out of 5 stars, based on 1,012 reviews from verified users. They emphasized its features such as drawing tools, typography tools, artboards, effects, and export options. They also noted that Illustrator is "very expansive" and "a mainstay within my design workflow."
-
-
Conclusion
-
Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is a great software for creating vector graphics and typography. You can download it for free from the link above and use it without any hassle. We hope this article was helpful and informative for you. If you have any questions or problems, feel free to leave a comment below or contact us through our website.
-
What are the Alternatives to Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated?
-
Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is not the only software that can create and edit vector graphics. There are many other alternatives that you can try, depending on your needs and preferences. Here are some of the most popular ones:
-
-
Inkscape: This is a free and open-source vector editor that runs on Windows, Mac, and Linux. It has many features similar to Illustrator, such as gradients, paths, shapes, text, filters, and more. It also supports SVG format and can import and export various file types.
-
Affinity Designer: This is a paid vector editor that runs on Windows, Mac, and iPad. It has a sleek and intuitive interface and offers many features such as artboards, layers, symbols, styles, brushes, effects, and more. It also supports PSD format and can import and export various file types.
-
CorelDRAW: This is a paid vector editor that runs on Windows and Mac. It has a long history and a loyal fan base in the graphic design industry. It offers many features such as drawing tools, typography tools, bitmap-to-vector tracing, photo editing, web graphics, and more. It also supports CDR format and can import and export various file types.
-
Sketch: This is a paid vector editor that runs on Mac and iPad. It is mainly designed for UI/UX design and web design. It offers many features such as artboards, symbols, styles, plugins, prototyping, collaboration, and more. It also supports SKETCH format and can import and export various file types.
-
Vectr: This is a free vector editor that runs on Windows, Mac, Linux, Chrome OS, and web browser. It is simple and easy to use for beginners and casual users. It offers basic features such as shapes, text, paths, filters, gradients, and more. It also supports PNG format and can import and export various file types.
-
-
Conclusion
-
Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is a great software for creating vector graphics and typography. You can download it for free from the link above and use it without any hassle. We hope this article was helpful and informative for you. If you have any questions or problems, feel free to leave a comment below or contact us through our website.
-
Conclusion
-
Adobe Illustrator CC 2019 64-Bit 23.1 Pre-Activated is a great software for creating vector graphics and typography. You can download it for free from the link above and use it without any hassle. We hope this article was helpful and informative for you. If you have any questions or problems, feel free to leave a comment below or contact us through our website.
3cee63e6c2
-
-
\ No newline at end of file
diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Dawn AI APK The Most Powerful App for Selfies Portraits and Headshots.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Dawn AI APK The Most Powerful App for Selfies Portraits and Headshots.md
deleted file mode 100644
index 32d743c69f43f5a7c0a115c20a358c0c8f5ff4b1..0000000000000000000000000000000000000000
--- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Dawn AI APK The Most Powerful App for Selfies Portraits and Headshots.md
+++ /dev/null
@@ -1,112 +0,0 @@
-
-
Download Dawn AI APK Mod: How to Create Stunning Avatars with AI
-
Do you want to transform your selfies into amazing avatars using the latest AI technology? Do you want to explore endless styles and settings and generate fun and unique images with AI? Do you want to have unlimited access to all the features and styles of Dawn AI without paying anything? If you answered yes to any of these questions, then you should download Dawn AI APK Mod, a free avatars and stickers creator app that lets you create unlimited stylish avatars. It uses cutting-edge AI technology to convert your photos into exceptionally detailed sticker art.
-
In this article, we will tell you what is Dawn AI APK Mod, how to download and install it, how to use it, what are the benefits of using it, and what are some alternatives to it. By the end of this article, you will be able to create stunning avatars with AI using Dawn AI APK Mod.
Dawn AI APK Mod is a modified version of Dawn AI, an app that allows users to turn their words into art using the latest AI technology. With just a text prompt, the app generates an entirely new and beautiful image that users can save and share with others. The app offers a variety of creative styles and possibilities, from photorealism to fantasy, oil painting to anime, and more.
-
Dawn AI APK Mod is a free version of Dawn AI that unlocks all the premium features and styles of the app. Users can enjoy unlimited access to all the filters, overlays, themes, packs, and settings of the app without paying anything. Moreover, users can also remove the watermarks and ads from the generated images, making them more professional and attractive.
-
Features of Dawn AI APK Mod
-
Dawn AI APK Mod has many features that make it a powerful and versatile app for creating avatars with AI. Some of these features are:
-
How to download dawn ai apk mod for free
-Dawn ai apk mod latest version download
-Dawn ai premium apk mod unlocked all features
-Download dawn ai apk mod and create amazing avatars
-Dawn ai apk mod no watermark download
-Best dawn ai apk mod alternatives in 2023
-Dawn ai apk mod review and tutorial
-Download dawn ai apk mod and get unlimited stickers
-Dawn ai apk mod vs other avatar creator apps
-Dawn ai apk mod features and benefits
-Download dawn ai apk mod and enjoy AI-powered photo editing
-Dawn ai apk mod download link and installation guide
-Dawn ai apk mod compatibility and requirements
-Download dawn ai apk mod and share your sticker art with friends
-Dawn ai apk mod pros and cons
-Download dawn ai apk mod and customize your avatars
-Dawn ai apk mod tips and tricks
-Download dawn ai apk mod and join the community
-Dawn ai apk mod FAQs and answers
-Download dawn ai apk mod and have fun with your photos
-Dawn ai apk mod update and changelog
-Download dawn ai apk mod and access premium content
-Dawn ai apk mod feedback and ratings
-Download dawn ai apk mod and discover new styles
-Dawn ai apk mod bugs and fixes
-
Image recreation and enhancement
-
Dawn AI APK Mod takes your pictures and recreates them to virtually anything you want. You can enter a text prompt or a sketch and let the app generate an image based on your input. You can also use the @me tag feature to create your own avatars based on your selfies. The app uses advanced AI technology to analyze your photos and learn what you look like, then produces stunning portraits with thousands of possible styles.
-
Gender switch
-
Think you could be better as the other gender? With Dawn AI APK Mod, you can find out how you would look as a different gender. Just upload your photo and select the gender switch option. The app will transform your face into a male or female version, depending on your choice. You can also adjust the intensity of the transformation using a slider.
-
Large database for styles
-
The app (dawn AI mod apk) obviously has a large database to contain almost any profession and look you can think of. You can choose from a variety of styles and settings, such as 3D render, fine art, pen sketch, black and white, cartoon, anime, and more. You can also mix and match different styles and settings to create your own unique combinations. The app constantly updates its database with new styles and themes, so you will never run out of options.
-
Filters and overlays
-
Dawn AI APK Mod also allows you to apply various filters and overlays to your images to enhance their appearance and mood. You can choose from a range of filters, such as vintage, sepia, noir, retro, and more. You can also add overlays, such as stickers, emojis, text, frames, and more. You can adjust the opacity and size of the filters and overlays to suit your preferences.
-
Ease of usage
-
The app is very easy to use and does not require any technical skills or knowledge. You just need to enter a text prompt or a sketch and let the app do the rest. You can also use the @me tag feature to create your own avatars based on your selfies. The app has a simple and intuitive interface that guides you through the process of creating avatars with AI.
-
Share with friends
-
Once you have created your avatars with AI, you can easily save and share them with your friends and family. You can export your images in high resolution and quality. You can also share them on social media platforms, such as Facebook, Instagram, Twitter, WhatsApp, and more. You can also use your avatars as profile pictures, wallpapers, stickers, memes, and more.
-
How to download and install Dawn AI APK Mod?
-
If you want to download and install Dawn AI APK Mod on your Android device, you need to follow these simple steps:
-
Step 1: Download the APK file
-
The first step is to download the APK file of Dawn AI APK Mod from a reliable source. You can use the link below to download the latest version of the app:
The next step is to enable unknown sources on your device. This will allow you to install apps from sources other than the Google Play Store. To do this, go to Settings > Security > Unknown Sources and toggle it on.
-
Step 3: Install the APK file
-
The third step is to install the APK file on your device. To do this, locate the downloaded file in your file manager and tap on it. Follow the instructions on the screen to complete the installation.
-
Step 4: Launch the app and enjoy
-
The final step is to launch the app and enjoy creating stunning avatars with AI. You can access all the features and styles of the app without any limitations or restrictions.
-
How to use Dawn AI APK Mod?
-
Dawn AI APK Mod is very easy to use and does not require any technical skills or knowledge. You can use it in three different modes: text mode, sketch mode, and @me tag mode.
-
Text mode
-
In text mode, you can enter a text prompt and let the app generate an image based on your input. For example, you can enter "a beautiful woman with long blonde hair wearing a red dress" and see what the app produces. You can also enter a genre or a style, such as "fantasy", "anime", "oil painting", etc., and see what the app creates.
-
Sketch mode
-
In sketch mode, you can draw a sketch on the screen and let the app generate an image based on your drawing. For example, you can draw a face or a body shape and see what the app produces. You can also use different colors and brushes to create more detailed sketches.
-
@me tag mode
-
In @me tag mode, you can create your own avatars based on your selfies. To do this, you need to upload your photo and add the @me tag at the end of your text prompt. For example, you can enter "a handsome man wearing glasses @me" and see what the app produces. The app will analyze your photo and learn what you look like, then generate a portrait with thousands of possible styles.
-
What are the benefits of using Dawn AI APK Mod?
-
Dawn AI APK Mod has many benefits that make it a great app for creating avatars with AI. Some of these benefits are:
-
Unlimited access to all features and styles
-
Dawn AI APK Mod unlocks all the premium features and styles of Dawn AI without paying anything. You can enjoy unlimited access to all the filters, overlays, themes, packs, and settings of the app and create stunning avatars with AI. You can also remove the watermarks and ads from the generated images, making them more professional and attractive.
-
No watermarks or ads
-
Dawn AI APK Mod also removes the watermarks and ads from the generated images, making them more professional and attractive. You can save and share your images without any distractions or interruptions. You can also enjoy a smooth and fast performance of the app without any lags or crashes.
-
High-quality image generation
-
Dawn AI APK Mod uses cutting-edge AI technology to generate high-quality images that are exceptionally detailed and realistic. The app analyzes your photos and learns what you look like, then produces stunning portraits with thousands of possible styles. The app also recreates and enhances your images to virtually anything you want, from photorealism to fantasy, oil painting to anime, and more.
-
Fun and creative content creation
-
Dawn AI APK Mod allows you to have fun and be creative with your content creation. You can explore endless styles and settings and generate fun and unique images with AI. You can also mix and match different styles and settings to create your own unique combinations. You can also use your avatars as profile pictures, wallpapers, stickers, memes, and more.
-
What are some alternatives to Dawn AI APK Mod?
-
If you are looking for some alternatives to Dawn AI APK Mod, you can try these apps that also allow you to create avatars with AI:
-
Arible AI
-
Arible AI is an app that allows you to create realistic 3D avatars from your photos. You can customize your avatars with different hairstyles, outfits, accessories, and backgrounds. You can also animate your avatars with different expressions, poses, and movements. You can also chat with other users using your avatars.
-
Reface NEOCORTEXT
-
Reface NEOCORTEXT is an app that allows you to swap your face with celebrities, movie characters, cartoons, and more. You can use your photos or videos and choose from a huge library of faces to create hilarious and amazing face swaps. You can also share your creations on social media platforms.
-
TheDream.AI
-
TheDream.AI is an app that allows you to create dream-like images from your photos. You can use different filters, effects, stickers, and texts to transform your photos into surreal and artistic creations. You can also use the app's AI to generate images based on your text prompts or sketches.
-
Conclusion
-
Dawn AI APK Mod is a free avatars and stickers creator app that lets you create unlimited stylish avatars using the latest AI technology. It uses cutting-edge AI technology to convert your photos into exceptionally detailed sticker art. You can enjoy unlimited access to all the features and styles of the app without paying anything. Moreover, you can also remove the watermarks and ads from the generated images, making them more professional and attractive.
-
If you want to download Dawn AI APK Mod on your Android device, you can follow the steps mentioned in this article. You can also use the app in three different modes: text mode, sketch mode, and @me tag mode. You can also try some alternatives to Dawn AI APK Mod if you want to explore more options for creating avatars with AI.
-
We hope this article was helpful for you. If you have any questions or feedback, please feel free to leave a comment below.
-
FAQs
-
Here are some frequently asked questions about Dawn AI APK Mod:
-
-
Is Dawn AI APK Mod safe to use?
-
Dawn AI APK Mod is safe to use as long as you download it from a reliable source. However, since it is a modified version of Dawn AI, it may not be compatible with some devices or updates. Therefore, use it at your own risk.
-
How do I update Dawn AI APK Mod?
-
To update Dawn AI APK Mod, you need to download the latest version of the APK file from a reliable source and install it on your device. However, since it is a modified version of Dawn AI, it may not be compatible with some devices or updates. Therefore, check the compatibility before updating.
-
Can I use Dawn AI APK Mod on PC?
-
To use Dawn AI APK Mod on PC, you need to use an Android emulator software that allows you to run Android apps on PC. Some popular Android emulators are BlueStacks, NoxPlayer, MEmu, etc. However, since it is a modified version of Dawn AI, it may not work properly on some emulators.
-
Can I use Dawn AI APK Mod offline?
-
Dawn AI APK Mod requires an internet connection to work properly. The app uses AI technology to generate images based on your input, which requires a lot of data and processing power. Therefore, you cannot use the app offline.
-
What are some tips and tricks for using Dawn AI APK Mod?
-
Some tips and tricks for using Dawn AI APK Mod are:
-
-
Use clear and descriptive text prompts or sketches to get better results.
-
Experiment with different styles and settings to create unique combinations.
-
Use the @me tag feature to create your own avatars based on your selfies.
-
Use the gender switch feature to see how you would look as a different gender.
-
Use the filters and overlays to enhance the appearance and mood of your images.
-
Save and share your images with your friends and family.
-
- 197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/1phancelerku/anime-remove-background/Download Driving Zone Russia Mod APK with Unlimited Coins and Cash.md b/spaces/1phancelerku/anime-remove-background/Download Driving Zone Russia Mod APK with Unlimited Coins and Cash.md
deleted file mode 100644
index 25055581acf033dee97c83b24f291f14683e64ed..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/Download Driving Zone Russia Mod APK with Unlimited Coins and Cash.md
+++ /dev/null
@@ -1,149 +0,0 @@
-
-
Driving Zone Russia Mod APK Unlimited Money: A Review
-
If you are a fan of racing games, especially those that feature cars from Russia, then you might want to check out Driving Zone Russia. This is a simulator of street racing on the cars produced in Russia, with online and offline game modes. You can choose from classic cars produced in Russia, and the most modern models, each with its own character and a real engine sound. You can also customize your car with different colors, rims, spoilers, body kits, and liveries.
But what if you want to enjoy the game without any limitations or restrictions? What if you want to have unlimited money to buy any car you want, or unlock all the features of the game? Well, there is a way to do that, and that is by downloading and installing Driving Zone Russia Mod APK Unlimited Money. This is a modified version of the original game that gives you access to unlimited money, coins, and other resources. You can use them to buy any car you want, upgrade your car's performance, or change the appearance of your car. You can also enjoy all the tracks, modes, and settings of the game without any ads or interruptions.
-
In this article, we will review Driving Zone Russia Mod APK Unlimited Money and tell you everything you need to know about it. We will cover its features, how to download and install it, tips and tricks for playing it, and its pros and cons. By the end of this article, you will be able to decide if this mod apk is worth trying or not.
-
Features of Driving Zone Russia Mod APK Unlimited Money
-
Driving Zone Russia Mod APK Unlimited Money has many features that make it an exciting and enjoyable racing game. Here are some of them:
-
driving zone russia mod apk unlimited coins
-driving zone russia mod apk download
-driving zone russia mod apk latest version
-driving zone russia mod apk android 1
-driving zone russia mod apk revdl
-driving zone russia mod apk hack
-driving zone russia mod apk free shopping
-driving zone russia mod apk all cars unlocked
-driving zone russia mod apk rexdl
-driving zone russia mod apk no ads
-driving zone russia mod apk unlimited everything
-driving zone russia mod apk obb
-driving zone russia mod apk offline
-driving zone russia mod apk old version
-driving zone russia mod apk 2023
-driving zone russia mod apk 2022
-driving zone russia mod apk 2021
-driving zone russia mod apk 2020
-driving zone russia mod apk 2019
-driving zone russia mod apk 2018
-driving zone russia mod apk 2017
-driving zone russia mod apk 2016
-driving zone russia mod apk 2015
-driving zone russia hack apk download
-driving zone russia hack apk unlimited money and coins
-driving zone russia hack apk latest version
-driving zone russia hack apk android 1
-driving zone russia hack apk revdl
-driving zone russia hack apk rexdl
-driving zone russia hack apk no ads
-download game driving zone russia mod apk unlimited money
-download game driving zone russia mod apk unlimited coins
-download game driving zone russia mod apk latest version
-download game driving zone russia mod apk android 1
-download game driving zone russia mod apk revdl
-download game driving zone russia mod apk rexdl
-download game driving zone russia mod apk no ads
-how to install driving zone russia mod apk unlimited money
-how to install driving zone russia mod apk unlimited coins
-how to install driving zone russia mod apk latest version
-how to install driving zone russia mod apk android 1
-how to install driving zone russia mod apk revdl
-how to install driving zone russia mod apk rexdl
-how to install driving zone russia mod apk no ads
-how to play driving zone russia mod apk unlimited money
-how to play driving zone russia mod apk unlimited coins
-how to play driving zone russia mod apk latest version
-how to play driving zone russia mod apk android 1
-
Modern graphics and realistic physics
-
The game has modern beautiful graphics that create a realistic atmosphere of street racing. The cars are detailed and well-designed, with accurate body and interior models. The tracks are also diverse and immersive, with different scenery and weather conditions. The game also has realistic car physics that simulate the behavior of real cars on different surfaces and situations. You can feel the speed, acceleration, braking, steering, and drifting of your car as you race along the busy highway or the challenging track.
-
Qualitatively modeled Russian cars
-
The game features a variety of cars produced in Russia, from classic models to modern ones. Each car has its own character and a real engine sound that matches its performance. You can choose from sedans, hatchbacks, coupes, SUVs, sports cars, or even trucks. Some of the cars available in the game are Lada Priora, Lada Granta, Lada Kalina, Lada Niva, Volga GAZ-24, Volga GAZ-3110, Moskvich-2141 AZLK-2141-02 Svyatogor Turbo Plus (Moskvich-2141), Moskvich-412 IE AZLK-412-028 (Moskvich-412), VAZ-2106 Zhiguli (Lada Riva), VAZ-2107 Zhiguli (Lada Riva), VAZ-2108 Sputnik (L ada Samara), VAZ-2109 Sputnik (Lada Samara), VAZ-2110 Lada (Lada 110), VAZ-2112 Lada (Lada 112), VAZ-2113 Lada (Lada 113), VAZ-2114 Lada (Lada 114), VAZ-2115 Lada (Lada 115), VAZ-2121 Niva (Lada Niva), GAZ-66, GAZ-3302 Gazelle, GAZ-3307, GAZ-3309, GAZ-3310 Valdai, GAZ-2330 Tigr, UAZ-469, UAZ-452, UAZ Patriot, UAZ Hunter, UAZ Cargo, Kamaz-4310, Kamaz-43118, Kamaz-5350 Mustang, Kamaz-6520, Kamaz-6522, ZIL-130, ZIL-131, ZIL-133, ZIL-157, ZIL-4331, MAZ-504, MAZ-5337, MAZ-5432, MAZ-6422, MAZ-7310 Uragan (MAZ 543M), and many more.
-
Four tracks with different weather conditions
-
The game offers four different tracks to race on, each with its own weather conditions and time of day. You can choose from a city track with busy traffic and pedestrians, a suburban track with a quieter atmosphere and a scenic view, a winter track with snow and ice on the road, or a desert track with sand and dust. Each track has its own challenges and surprises that will test your driving skills and reflexes. You can also change the weather conditions and the time of day in real-time to create your own unique racing experience.
-
Change the time of day in real-time
-
One of the most impressive features of the game is the ability to change the time of day in real-time. You can switch from day to night or vice versa with a simple swipe on the screen. This will affect the lighting and the visibility of the track, as well as the behavior of other drivers and pedestrians. You can also adjust the speed of time to make the day or night last longer or shorter. This feature adds more realism and variety to the game and allows you to enjoy different scenarios and atmospheres.
-
First person view / interior camera
-
The game also gives you the option to switch from the third person view to the first person view or the interior camera. This will let you see the road from the driver's perspective and feel more immersed in the game. You can also see the dashboard and the steering wheel of your car, as well as the mirrors and the indicators. The interior camera also shows you the damage and the wear of your car parts, such as the tires, the engine, or the brakes. You can use this feature to enhance your driving experience and challenge yourself more.
-
How to download and install Driving Zone Russia Mod APK Unlimited Money
-
If you are interested in trying Driving Zone Russia Mod APK Unlimited Money, you will need to follow these steps to download and install it on your device:
-
Requirements and compatibility
-
Before you download and install Driving Zone Russia Mod APK Unlimited Money, you will need to make sure that your device meets these requirements:
-
-
Your device must have Android 4.1 or higher operating system.
-
Your device must have at least 100 MB of free storage space.
-
Your device must have a stable internet connection.
-
You must enable unknown sources on your device settings to allow installation of apps from third-party sources.
-
-
Driving Zone Russia Mod APK Unlimited Money is compatible with most Android devices, including smartphones and tablets. However, some devices may not support some features or functions of the game due to hardware limitations or software issues.
-
Steps to download and install
-
Once you have checked that your device meets the requirements and compatibility, you can proceed to download and install Driving Zone Russia Mod APK Unlimited Money by following these steps:
-
-
Click on this link to download Driving Zone Russia Mod APK Unlimited Money file on your device.
-
Locate the downloaded file on your device storage and tap on it to start the installation process.
-
Follow the instructions on the screen to complete the installation process.
-
Launch the game from your app drawer or home screen and enjoy unlimited money and other mod features.
-
-
How to use the mod features
-
After you have successfully installed Driving Zone Russia Mod APK Unlimited Money on your device, you can start using the mod features to enhance your gameplay. Here are some of the mod features and how to use them:
-
-
Unlimited money: You can use unlimited money to buy any car you want, upgrade your car's performance, or change the appearance of your car. You can also use it to unlock all the tracks, modes, and settings of the game. To use this feature, simply go to the shop or the garage and select the item you want to buy or upgrade. You will see that the price is zero and you can buy or upgrade it without spending any money.
-
No ads: You can enjoy the game without any ads or interruptions. This feature will remove all the ads that pop up on the screen or play before or after the game. To use this feature, simply launch the game and play as usual. You will not see any ads on the screen or hear any ads on the sound.
-
Other resources: You can also use other resources such as coins, gems, diamonds, or tokens to access some special features or items in the game. These resources are also unlimited and you can use them as much as you want. To use this feature, simply go to the shop or the menu and select the feature or item you want to use or buy. You will see that you have enough resources to use or buy it without any problem.
-
-
Tips and tricks for playing Driving Zone Russia Mod APK Unlimited Money
-
Driving Zone Russia Mod APK Unlimited Money is a fun and addictive racing game that will keep you entertained for hours. However, if you want to master the game and become a pro racer, you will need some tips and tricks to help you out. Here are some of them:
-
Choose the right car for each track
-
The game offers a variety of cars to choose from, each with its own strengths and weaknesses. Some cars are faster, some are more agile, some are more durable, and some are more balanced. You will need to choose the right car for each track depending on the weather conditions, the road surface, and the traffic situation. For example, if you are racing on a winter track with snow and ice, you might want to choose a car with good traction and stability, such as an SUV or a truck. If you are racing on a desert track with sand and dust, you might want to choose a car with good speed and acceleration, such as a sports car or a coupe.
-
Adjust the settings to suit your preference
-
The game also allows you to adjust the settings to suit your preference and play style. You can change the difficulty level, the camera angle, the control method, the sound volume, and the graphics quality. You can also enable or disable some features such as traffic rules, damage system, police chase, or online mode. You can experiment with different settings until you find the ones that work best for you.
-
Use the brake and accelerator wisely
-
The game has realistic car physics that require you to use the brake and accelerator wisely. You cannot just press the gas pedal all the time and expect to win the race. You will need to slow down when approaching a turn, a curve, an obstacle, or a traffic jam. You will also need to accelerate when exiting a turn, a curve, an obstacle, or a traffic jam. You will need to balance between speed and control to avoid crashing or losing control of your car.
-
Record and share your gameplay videos
-
The game also has a feature that allows you to record and share your gameplay videos with other players online. You can capture your best moments in the game, such as your fastest lap time, your most epic drift, your most daring overtaking, or your most spectacular crash. You can then share your videos with other players on social media platforms such as Facebook, Twitter, Instagram, YouTube, or TikTok. You can also watch other players' videos and learn from their skills and strategies.
-
Pros and cons of Driving Zone Russia Mod APK Unlimited Money
-
Driving Zone Russia Mod APK Unlimited Money is not a perfect game and it has its pros and cons. Here are some of them:
-
Pros
-
-
The game has modern graphics and realistic physics that create a realistic atmosphere of street racing.
-
The game features a variety of cars produced in Russia, each with its own character and a real engine sound.
-
The game offers four different tracks with different weather conditions and time of day.
-
The game allows you to change the time of day in real-time.
-
The game gives you the option to switch from the third person view to the first person view or the interior camera.
-
The game has unlimited money and other resources that allow you to buy any car you want, upgrade your car's performance, or change the appearance of your car.
-
The game has no ads or interruptions that can ruin your gameplay.
-
The game has a feature that allows you to record and share your gameplay videos with other players online.
-
-
Cons
-
-
The game can be too easy or boring for some players who prefer more challenge or variety in their racing games.
-
The game can be too hard or frustrating for some players who are not used to the realistic car physics or the traffic rules.
-
The game can be too repetitive or monotonous for some players who want more tracks, modes, or features in their racing games.
-
The game can have some bugs or glitches that can affect the gameplay or the graphics quality.
-
The game can be risky or illegal to download and install from third-party sources that may contain viruses or malware.
-
-
Conclusion
-
Driving Zone Russia Mod APK Unlimited Money is a simulator of street racing on the cars produced in Russia, with online and offline game modes. The game has modern graphics and realistic physics that create a realistic atmosphere of street racing. The game features a variety of cars produced in Russia, each with its own character and a real engine sound. The game offers four different tracks with different weather conditions and time of day. The game allows you to change the time of day in real-time. The game gives you the option to switch from the third person view to the first person view or the interior camera. The game has unlimited money and other resources that allow you to buy any car you want, upgrade your car's performance, or change the appearance of your car. The game has no ads or interruptions that can ruin your gameplay. The game has a feature that allows you to record and share your gameplay videos with other players online.
-
However, the game also has some drawbacks that may affect your enjoyment of the game. The game can be too easy or boring for some players who prefer more challenge or variety in their racing games. The game can be too hard or frustrating for some players who are not used to the realistic car physics or the traffic rules. The game can be too repetitive or monotonous for some players who want more tracks, modes, or features in their racing games. The game can have some bugs or glitches that can affect the gameplay or the graphics quality. The game can be risky or illegal to download and install from third-party sources that may contain viruses or malware.
-
Therefore, we recommend Driving Zone Russia Mod APK Unlimited Money to anyone who loves racing games, especially those that feature cars from Russia. This game will give you a realistic and immersive experience of street racing on Russian cars, with unlimited money and other mod features. However, we also advise you to be careful when downloading and installing this mod apk from third-party sources, as they may not be safe or legal. We also suggest you to try the original version of Driving Zone Russia first before trying this mod apk, as it may suit your preference better.
-
FAQs
-
Here are some frequently asked questions about Driving Zone Russia Mod APK Unlimited Money:
-
-
Q: Is Driving Zone Russia Mod APK Unlimited Money free?
-
A: Yes, Driving Zone Russia Mod APK Unlimited Money is free to download and play. However, you may need to pay for some in-app purchases or subscriptions if you want to access some premium features or items in the game.
-
Q: Is Driving Zone Russia Mod APK Unlimited Money safe?
-
A: Driving Zone Russia Mod APK Unlimited Money is not officially endorsed by the developers of Driving Zone Russia, so it may not be safe or legal to download and install from third-party sources. You may encounter some viruses or malware that can harm your device or compromise your privacy. You may also face some legal issues if you violate the terms and conditions of Driving Zone Russia.
-
Q: How do I update Driving Zone Russia Mod APK Unlimited Money?
-
A: Driving Zone Russia Mod APK Unlimited Money may not be compatible with the latest version of Driving Zone Russia, so you may need to update it manually from time to time. You will need to check for updates from the source where you downloaded it from, and follow the instructions on how to download and install the updated version.
-
Q: How do I uninstall Driving Zone Russia Mod APK Unlimited Money?
-
A: If you want to uninstall Driving Zone Russia Mod APK Unlimited Money from your device, you will need to follow these steps:
-
-
Go to your device settings and select apps or applications.
-
Find and tap on Driving Zone Russia Mod APK Unlimited Money and tap on uninstall.
-
Confirm your action and wait for the process to finish.
-
Alternatively, you can also delete the Driving Zone Russia Mod APK Unlimited Money file from your device storage.
-
-
Q: Can I play Driving Zone Russia Mod APK Unlimited Money offline?
-
A: Yes, you can play Driving Zone Russia Mod APK Unlimited Money offline without an internet connection. However, you may not be able to access some online features or modes, such as multiplayer mode, leaderboards, or achievements.
- 197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/1phancelerku/anime-remove-background/Download Plants vs Zombies 2 for PC and Protect Your Garden from the Undead.md b/spaces/1phancelerku/anime-remove-background/Download Plants vs Zombies 2 for PC and Protect Your Garden from the Undead.md
deleted file mode 100644
index 8d10147615f69abad8231adda31f2886cb5a1b30..0000000000000000000000000000000000000000
--- a/spaces/1phancelerku/anime-remove-background/Download Plants vs Zombies 2 for PC and Protect Your Garden from the Undead.md
+++ /dev/null
@@ -1,53 +0,0 @@
-
-
How to Download Plants vs Zombies 2 on PC
-
Plants vs Zombies 2 is a popular tower defense game that pits you against hordes of zombies who want to eat your brains. You have to use various plants with different abilities to stop them from reaching your house. The game features hundreds of levels across different worlds and time periods, as well as endless modes, mini-games, daily events, and online competitions.
-
While Plants vs Zombies 2 is primarily designed for mobile devices, you might want to play it on your PC for various reasons. Maybe you want to enjoy the game on a bigger screen, or use a keyboard and mouse or a controller for better control. Maybe you want to save battery life on your phone or tablet, or avoid interruptions from calls and notifications. Whatever your reason, there are several ways to download Plants vs Zombies 2 on PC. In this article, we will show you three methods that you can use to play this fun and addictive game on your PC.
Method 1: Use Windows 11 and native Android emulation
-
One of the easiest ways to download Plants vs Zombies 2 on PC is to use Windows 11, the latest version of Microsoft's operating system. Windows 11 comes with a built-in feature that allows you to run Android apps natively on your PC, without the need for any third-party software. Here are the steps to follow:
-
-
Check if your PC meets the minimum requirements for Windows 11 and Android emulation. You will need a 64-bit processor, 4 GB of RAM, 64 GB of storage, a TPM 2.0 chip, and a DirectX 12 compatible graphics card. You can use the PC Health Check app to see if your PC is eligible for the upgrade.
-
Update your PC to Windows 11 and enable the Windows Subsystem for Android. You can download Windows 11 from the Windows Update section in the Settings app. To enable the Windows Subsystem for Android, go to the Microsoft Store and install the app. You will also need to install the Amazon Appstore app, which will allow you to access Android apps on your PC.
-
Install Plants vs Zombies 2 from the Amazon Appstore or the Google Play Store. You can launch the Amazon Appstore app from the Start menu or the Taskbar and search for Plants vs Zombies 2. Alternatively, you can also install the Google Play Store app from the Amazon Appstore and use it to download Plants vs Zombies 2. You will need to sign in with your Google account to access the Google Play Store.
-
Launch the game and enjoy playing it on your PC. You can find Plants vs Zombies 2 in the Start menu or the Taskbar, along with other Android apps. You can use your mouse or touchpad to interact with the game, or connect a keyboard or a controller for better control. You can also adjust the window size and orientation of the game according to your preference.
-
-
Method 2: Use an Android emulator such as Bluestacks or Nox Player
-
Another way to download Plants vs Zombies 2 on PC is to use an Android emulator, which is a software that simulates an Android device on your PC. There are many Android emulators available online, but some of the most popular ones are Bluestacks and Nox Player. Here are the steps to follow:
-
-
Download and install an Android emulator of your choice from their official websites. You can visit Bluestacks.com or Bignox.com to download Bluestacks or Nox Player respectively . Follow the instructions on the screen to install and set up the emulator on your PC.
-
Sign in with your Google account and access the Google Play Store. Once you launch the emulator, you will need to sign in with your Google account to access the Google Play Store and other Google services. You can use an existing account or create a new one.
-
Search for Plants vs Zombies 2 and install it on your emulator. You can use the search bar in the Google Play Store to find Plants vs Zombies 2 and click on the Install button to download it on your emulator.
-
Launch the game and customize the controls according to your preference. You can find Plants vs Zombies 2 on the home screen or in the app drawer of your emulator. You can use your mouse or touchpad to interact with the game, or connect a keyboard or a controller for better control. You can also customize the controls by using the settings menu of your emulator.
-
-
Method 3: Use Parsec to stream the game from your PC to your Android device
-
A third way to download Plants vs Zombies 2 on PC is to use Parsec, which is a software that allows you to stream games from your PC to your Android device. This way, you can play Plants vs Zombies 2 on your PC without installing it, as long as you have a good internet connection and a compatible device. Here are the steps to follow:
-
-
Download and install Parsec on both your PC and your Android device. You can visit Parsecgaming.com to download Parsec for free. Follow the instructions on the screen to install and set up Parsec on your PC and your Android device.
-
Create a Parsec account and sign in on both devices. You will need to create a Parsec account and sign in on both your PC and your Android device to use the streaming service. You can use an existing account or create a new one.
-
Launch Plants vs Zombies 2 on your PC and start hosting a game session. You can launch Plants vs Zombies 2 on your PC from the Start menu or the Taskbar, or from any other source that you have installed it from. Once the game is running, open Parsec on your PC and click on the Host tab. You will see a code that you can use to invite other devices to join your game session.
-
Connect to your PC from your Android device using Parsec and start playing the game. Open Parsec on your Android device and click on the Friends tab. You will see a list of devices that you can connect to, including your PC. Enter the code that you got from your PC and click on the Connect button. You will see the game screen on your Android device and you can start playing the game.
-
-
Conclusion
-
Plants vs Zombies 2 is a fun and addictive game that you can enjoy on your PC using any of the methods mentioned above. Whether you use Windows 11, an Android emulator, or Parsec, you can experience the game on a bigger screen, with better control and performance. Here are some tips and tricks for playing the game on PC:
-
-
Use a keyboard and mouse or a controller for better control and performance. You can use the default controls or customize them according to your preference. You can also use hotkeys to quickly access certain functions such as Plant Food, Power Ups, or Pause.
-
Adjust the graphics settings and resolution to suit your PC's capabilities. You can change the graphics quality, resolution, frame rate, and full screen mode of the game from the settings menu. You can also use the zoom function to get a closer or wider view of the lawn.
-
Join the online community and compete with other players in Arena mode. You can access Arena mode from the main menu of the game and participate in weekly tournaments that test your skills and strategy. You can earn rewards such as coins, gems, mints, gauntlets, and trophies by ranking high on the leaderboards.
-
-
FAQs
-
Here are some common questions that readers might have about downloading Plants vs Zombies 2 on PC:
-
-
Q1: Is Plants vs Zombies 2 free to play?
-
A1: Yes, Plants vs Zombies 2 is free to play, but it contains ads and in-app purchases that can enhance your gaming experience.
-
Q2: Can I play Plants vs Zombies 2 offline?
-
A2: Yes, you can play Plants vs Zombies 2 offline, but you will need an internet connection to access some features such as daily events, leaderboards, and cloud save.
-
Q3: How many worlds are there in Plants vs Zombies 2?
-
A3: There are currently 11 worlds in Plants vs Zombies 2, each with its own theme, plants, zombies, and challenges. You can unlock them by collecting stars or paying with gems.
-
Q4: What is Plant Food and how do I use it?
-
A4: Plant Food is a special item that can boost your plants' abilities for a short time. You can get Plant Food by killing glowing zombies, planting Power Lily, or buying it with coins. To use Plant Food, just drag it onto any plant on the lawn.
-
Q5: What is the best strategy for playing Plants vs Zombies 2?
-
A5: There is no definitive answer to this question, as different strategies work for different levels, modes, and preferences. However, some general tips are to plan ahead, use a variety of plants, upgrade your plants regularly, and experiment with different combinations.
-
-
I hope you found this article helpful and informative. If you have any questions or feedback, please leave a comment below. Happy gaming!
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/2ndelement/voicevox/voicevox_engine/kana_parser.py b/spaces/2ndelement/voicevox/voicevox_engine/kana_parser.py
deleted file mode 100644
index 7aa9e9d82c8e48195c6993dea267708b42012c5a..0000000000000000000000000000000000000000
--- a/spaces/2ndelement/voicevox/voicevox_engine/kana_parser.py
+++ /dev/null
@@ -1,146 +0,0 @@
-from typing import List, Optional
-
-from .model import AccentPhrase, Mora, ParseKanaError, ParseKanaErrorCode
-from .mora_list import openjtalk_text2mora
-
-LOOP_LIMIT = 300
-UNVOICE_SYMBOL = "_"
-ACCENT_SYMBOL = "'"
-NOPAUSE_DELIMITER = "/"
-PAUSE_DELIMITER = "、"
-WIDE_INTERROGATION_MARK = "?"
-
-text2mora_with_unvoice = {}
-for text, (consonant, vowel) in openjtalk_text2mora.items():
- text2mora_with_unvoice[text] = Mora(
- text=text,
- consonant=consonant if len(consonant) > 0 else None,
- consonant_length=0 if len(consonant) > 0 else None,
- vowel=vowel,
- vowel_length=0,
- pitch=0,
- is_interrogative=False,
- )
- if vowel in ["a", "i", "u", "e", "o"]:
- text2mora_with_unvoice[UNVOICE_SYMBOL + text] = Mora(
- text=text,
- consonant=consonant if len(consonant) > 0 else None,
- consonant_length=0 if len(consonant) > 0 else None,
- vowel=vowel.upper(),
- vowel_length=0,
- pitch=0,
- is_interrogative=False,
- )
-
-
-def _text_to_accent_phrase(phrase: str) -> AccentPhrase:
- """
- longest matchにより読み仮名からAccentPhraseを生成
- 入力長Nに対し計算量O(N^2)
- """
- accent_index: Optional[int] = None
- moras: List[Mora] = []
-
- base_index = 0 # パース開始位置。ここから右の文字列をstackに詰めていく。
- stack = "" # 保留中の文字列
- matched_text: Optional[str] = None # 保留中の文字列内で最後にマッチした仮名
-
- outer_loop = 0
- while base_index < len(phrase):
- outer_loop += 1
- if phrase[base_index] == ACCENT_SYMBOL:
- if len(moras) == 0:
- raise ParseKanaError(ParseKanaErrorCode.ACCENT_TOP, text=phrase)
- if accent_index is not None:
- raise ParseKanaError(ParseKanaErrorCode.ACCENT_TWICE, text=phrase)
- accent_index = len(moras)
- base_index += 1
- continue
- for watch_index in range(base_index, len(phrase)):
- if phrase[watch_index] == ACCENT_SYMBOL:
- break
- # 普通の文字の場合
- stack += phrase[watch_index]
- if stack in text2mora_with_unvoice:
- matched_text = stack
- # push mora
- if matched_text is None:
- raise ParseKanaError(ParseKanaErrorCode.UNKNOWN_TEXT, text=stack)
- else:
- moras.append(text2mora_with_unvoice[matched_text].copy(deep=True))
- base_index += len(matched_text)
- stack = ""
- matched_text = None
- if outer_loop > LOOP_LIMIT:
- raise ParseKanaError(ParseKanaErrorCode.INFINITE_LOOP)
- if accent_index is None:
- raise ParseKanaError(ParseKanaErrorCode.ACCENT_NOTFOUND, text=phrase)
- else:
- return AccentPhrase(moras=moras, accent=accent_index, pause_mora=None)
-
-
-def parse_kana(text: str) -> List[AccentPhrase]:
- """
- AquesTalkライクな読み仮名をパースして音長・音高未指定のaccent phraseに変換
- """
-
- parsed_results: List[AccentPhrase] = []
- phrase_base = 0
- if len(text) == 0:
- raise ParseKanaError(ParseKanaErrorCode.EMPTY_PHRASE, position=1)
-
- for i in range(len(text) + 1):
- if i == len(text) or text[i] in [PAUSE_DELIMITER, NOPAUSE_DELIMITER]:
- phrase = text[phrase_base:i]
- if len(phrase) == 0:
- raise ParseKanaError(
- ParseKanaErrorCode.EMPTY_PHRASE,
- position=str(len(parsed_results) + 1),
- )
- phrase_base = i + 1
-
- is_interrogative = WIDE_INTERROGATION_MARK in phrase
- if is_interrogative:
- if WIDE_INTERROGATION_MARK in phrase[:-1]:
- raise ParseKanaError(
- ParseKanaErrorCode.INTERROGATION_MARK_NOT_AT_END, text=phrase
- )
- phrase = phrase.replace(WIDE_INTERROGATION_MARK, "")
-
- accent_phrase: AccentPhrase = _text_to_accent_phrase(phrase)
- if i < len(text) and text[i] == PAUSE_DELIMITER:
- accent_phrase.pause_mora = Mora(
- text="、",
- consonant=None,
- consonant_length=None,
- vowel="pau",
- vowel_length=0,
- pitch=0,
- )
- accent_phrase.is_interrogative = is_interrogative
-
- parsed_results.append(accent_phrase)
-
- return parsed_results
-
-
-def create_kana(accent_phrases: List[AccentPhrase]) -> str:
- text = ""
- for i, phrase in enumerate(accent_phrases):
- for j, mora in enumerate(phrase.moras):
- if mora.vowel in ["A", "I", "U", "E", "O"]:
- text += UNVOICE_SYMBOL
-
- text += mora.text
- if j + 1 == phrase.accent:
- text += ACCENT_SYMBOL
-
- if phrase.is_interrogative:
- text += WIDE_INTERROGATION_MARK
-
- if i < len(accent_phrases) - 1:
- if phrase.pause_mora is None:
- text += NOPAUSE_DELIMITER
- else:
- text += PAUSE_DELIMITER
- return text
diff --git a/spaces/AIGC-Audio/AudioGPT/NeuralSeq/modules/GenerSpeech/model/prosody_util.py b/spaces/AIGC-Audio/AudioGPT/NeuralSeq/modules/GenerSpeech/model/prosody_util.py
deleted file mode 100644
index 113c39df9d1b0144aa5a5f00505c7e08bfc6ea11..0000000000000000000000000000000000000000
--- a/spaces/AIGC-Audio/AudioGPT/NeuralSeq/modules/GenerSpeech/model/prosody_util.py
+++ /dev/null
@@ -1,385 +0,0 @@
-from torch import nn
-import copy
-import torch
-from utils.hparams import hparams
-from modules.GenerSpeech.model.wavenet import WN
-import math
-
-from modules.fastspeech.tts_modules import LayerNorm
-import torch.nn.functional as F
-from utils.tts_utils import group_hidden_by_segs, sequence_mask
-
-from scipy.cluster.vq import kmeans2
-from torch.nn import functional as F
-
-
-class VQEmbeddingEMA(nn.Module):
- def __init__(self, n_embeddings, embedding_dim, commitment_cost=0.25, decay=0.999, epsilon=1e-5,
- print_vq_prob=False):
- super(VQEmbeddingEMA, self).__init__()
- self.commitment_cost = commitment_cost
- self.n_embeddings = n_embeddings
- self.decay = decay
- self.epsilon = epsilon
- self.print_vq_prob = print_vq_prob
- self.register_buffer('data_initialized', torch.zeros(1))
- init_bound = 1 / 512
- embedding = torch.Tensor(n_embeddings, embedding_dim)
- embedding.uniform_(-init_bound, init_bound)
- self.register_buffer("embedding", embedding)
- self.register_buffer("ema_count", torch.zeros(n_embeddings))
- self.register_buffer("ema_weight", self.embedding.clone())
-
- def encode(self, x):
- B, T, _ = x.shape
- M, D = self.embedding.size()
- x_flat = x.detach().reshape(-1, D)
-
- distances = torch.addmm(torch.sum(self.embedding ** 2, dim=1) +
- torch.sum(x_flat ** 2, dim=1, keepdim=True),
- x_flat, self.embedding.t(),
- alpha=-2.0, beta=1.0) # [B*T_mel, N_vq]
- indices = torch.argmin(distances.float(), dim=-1) # [B*T_mel]
- quantized = F.embedding(indices, self.embedding)
- quantized = quantized.view_as(x)
- return x_flat, quantized, indices
-
- def forward(self, x):
- """
-
- :param x: [B, T, D]
- :return: [B, T, D]
- """
- B, T, _ = x.shape
- M, D = self.embedding.size()
- if self.training and self.data_initialized.item() == 0:
- print('| running kmeans in VQVAE') # data driven initialization for the embeddings
- x_flat = x.detach().reshape(-1, D)
- rp = torch.randperm(x_flat.size(0))
- kd = kmeans2(x_flat[rp].data.cpu().numpy(), self.n_embeddings, minit='points')
- self.embedding.copy_(torch.from_numpy(kd[0]))
- x_flat, quantized, indices = self.encode(x)
- encodings = F.one_hot(indices, M).float()
- self.ema_weight.copy_(torch.matmul(encodings.t(), x_flat))
- self.ema_count.copy_(torch.sum(encodings, dim=0))
-
- x_flat, quantized, indices = self.encode(x)
- encodings = F.one_hot(indices, M).float()
- indices = indices.reshape(B, T)
-
- if self.training and self.data_initialized.item() != 0:
- self.ema_count = self.decay * self.ema_count + (1 - self.decay) * torch.sum(encodings, dim=0)
-
- n = torch.sum(self.ema_count)
- self.ema_count = (self.ema_count + self.epsilon) / (n + M * self.epsilon) * n
-
- dw = torch.matmul(encodings.t(), x_flat)
- self.ema_weight = self.decay * self.ema_weight + (1 - self.decay) * dw
-
- self.embedding = self.ema_weight / self.ema_count.unsqueeze(-1)
- self.data_initialized.fill_(1)
-
- e_latent_loss = F.mse_loss(x, quantized.detach(), reduction='none')
- nonpadding = (x.abs().sum(-1) > 0).float()
- e_latent_loss = (e_latent_loss.mean(-1) * nonpadding).sum() / nonpadding.sum()
- loss = self.commitment_cost * e_latent_loss
-
- quantized = x + (quantized - x).detach()
-
- avg_probs = torch.mean(encodings, dim=0)
- perplexity = torch.exp(-torch.sum(avg_probs * torch.log(avg_probs + 1e-10)))
- if self.print_vq_prob:
- print("| VQ code avg_probs: ", avg_probs)
- return quantized, loss, indices, perplexity
-
-class CrossAttenLayer(nn.Module):
- def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
- super(CrossAttenLayer, self).__init__()
- self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
- self.linear1 = nn.Linear(d_model, dim_feedforward)
- self.dropout1 = nn.Dropout(dropout)
- self.norm1 = nn.LayerNorm(d_model)
- self.linear2 = nn.Linear(dim_feedforward, d_model)
- self.dropout2 = nn.Dropout(dropout)
- self.norm2 = nn.LayerNorm(d_model)
- self.activation = nn.ReLU()
-
- def forward(self, src, local_emotion, emotion_key_padding_mask=None, forcing=False):
- # src: (Tph, B, 256) local_emotion: (Temo, B, 256) emotion_key_padding_mask: (B, Temo)
- if forcing:
- maxlength = src.shape[0]
- k = local_emotion.shape[0] / src.shape[0]
- lengths1 = torch.ceil(torch.tensor([i for i in range(maxlength)]).to(src.device) * k) + 1
- lengths2 = torch.floor(torch.tensor([i for i in range(maxlength)]).to(src.device) * k) - 1
- mask1 = sequence_mask(lengths1, local_emotion.shape[0])
- mask2 = sequence_mask(lengths2, local_emotion.shape[0])
- mask = mask1.float() - mask2.float()
- attn_emo = mask.repeat(src.shape[1], 1, 1) # (B, Tph, Temo)
- src2 = torch.matmul(local_emotion.permute(1, 2, 0), attn_emo.float().transpose(1, 2)).permute(2, 0, 1)
- else:
- src2, attn_emo = self.multihead_attn(src, local_emotion, local_emotion, key_padding_mask=emotion_key_padding_mask)
- src = src + self.dropout1(src2)
- src = self.norm1(src)
- src2 = self.linear2(self.activation(self.linear1(src)))
- src = src + self.dropout2(src2)
- src = self.norm2(src)
- return src, attn_emo
-
-
-class ProsodyAligner(nn.Module):
- def __init__(self, num_layers, guided_sigma=0.3, guided_layers=None, norm=None):
- super(ProsodyAligner, self).__init__()
- self.layers = nn.ModuleList([CrossAttenLayer(d_model=hparams['hidden_size'], nhead=2) for _ in range(num_layers)])
- self.num_layers = num_layers
- self.norm = norm
- self.guided_sigma = guided_sigma
- self.guided_layers = guided_layers if guided_layers is not None else num_layers
-
- def forward(self, src, local_emotion, src_key_padding_mask=None, emotion_key_padding_mask=None, forcing=False):
- output = src
- guided_loss = 0
- attn_emo_list = []
- for i, mod in enumerate(self.layers):
- # output: (Tph, B, 256), global_emotion: (1, B, 256), local_emotion: (Temo, B, 256) mask: None, src_key_padding_mask: (B, Tph),
- # emotion_key_padding_mask: (B, Temo)
- output, attn_emo = mod(output, local_emotion, emotion_key_padding_mask=emotion_key_padding_mask, forcing=forcing)
- attn_emo_list.append(attn_emo.unsqueeze(1))
- # attn_emo: (B, Tph, Temo) attn: (B, Tph, Tph)
- if i < self.guided_layers and src_key_padding_mask is not None:
- s_length = (~src_key_padding_mask).float().sum(-1) # B
- emo_length = (~emotion_key_padding_mask).float().sum(-1)
- attn_w_emo = _make_guided_attention_mask(src_key_padding_mask.size(-1), s_length, emotion_key_padding_mask.size(-1), emo_length, self.guided_sigma)
-
- g_loss_emo = attn_emo * attn_w_emo # N, L, S
- non_padding_mask = (~src_key_padding_mask).unsqueeze(-1) & (~emotion_key_padding_mask).unsqueeze(1)
- guided_loss = g_loss_emo[non_padding_mask].mean() + guided_loss
-
- if self.norm is not None:
- output = self.norm(output)
-
- return output, guided_loss, attn_emo_list
-
-def _make_guided_attention_mask(ilen, rilen, olen, rolen, sigma):
- grid_x, grid_y = torch.meshgrid(torch.arange(ilen, device=rilen.device), torch.arange(olen, device=rolen.device))
- grid_x = grid_x.unsqueeze(0).expand(rilen.size(0), -1, -1)
- grid_y = grid_y.unsqueeze(0).expand(rolen.size(0), -1, -1)
- rilen = rilen.unsqueeze(1).unsqueeze(1)
- rolen = rolen.unsqueeze(1).unsqueeze(1)
- return 1.0 - torch.exp(
- -((grid_y.float() / rolen - grid_x.float() / rilen) ** 2) / (2 * (sigma ** 2))
- )
-
-class LocalStyleAdaptor(nn.Module):
- def __init__(self, hidden_size, num_vq_codes=64, padding_idx=0):
- super(LocalStyleAdaptor, self).__init__()
- self.encoder = ConvBlocks(80, hidden_size, [1] * 5, 5, dropout=hparams['vae_dropout'])
- self.n_embed = num_vq_codes
- self.vqvae = VQEmbeddingEMA(self.n_embed, hidden_size, commitment_cost=hparams['lambda_commit'])
- self.wavenet = WN(hidden_channels=80, gin_channels=80, kernel_size=3, dilation_rate=1, n_layers=4)
- self.padding_idx = padding_idx
- self.hidden_size = hidden_size
-
- def forward(self, ref_mels, mel2ph=None, no_vq=False):
- """
-
- :param ref_mels: [B, T, 80]
- :return: [B, 1, H]
- """
- padding_mask = ref_mels[:, :, 0].eq(self.padding_idx).data
- ref_mels = self.wavenet(ref_mels.transpose(1, 2), x_mask=(~padding_mask).unsqueeze(1).repeat([1, 80, 1])).transpose(1, 2)
- if mel2ph is not None:
- ref_ph, _ = group_hidden_by_segs(ref_mels, mel2ph, torch.max(mel2ph))
- else:
- ref_ph = ref_mels
- prosody = self.encoder(ref_ph)
- if no_vq:
- return prosody
- z, vq_loss, vq_tokens, ppl = self.vqvae(prosody)
- vq_loss = vq_loss.mean()
- return z, vq_loss, ppl
-
-
-
-
-class LambdaLayer(nn.Module):
- def __init__(self, lambd):
- super(LambdaLayer, self).__init__()
- self.lambd = lambd
-
- def forward(self, x):
- return self.lambd(x)
-
-
-class Conv1d(nn.Conv1d):
- """A wrapper around nn.Conv1d, that works on (batch, time, channels)"""
-
- def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, dilation=1, groups=1, bias=True, padding=0):
- super(Conv1d, self).__init__(in_channels=in_channels, out_channels=out_channels,
- kernel_size=kernel_size, stride=stride, dilation=dilation,
- groups=groups, bias=bias, padding=padding)
-
- def forward(self, x):
- return super().forward(x.transpose(2, 1)).transpose(2, 1)
-
-
-def init_weights_func(m):
- classname = m.__class__.__name__
- if classname.find("Conv1d") != -1:
- torch.nn.init.xavier_uniform_(m.weight)
-
-
-class ResidualBlock(nn.Module):
- """Implements conv->PReLU->norm n-times"""
-
- def __init__(self, channels, kernel_size, dilation, n=2, norm_type='bn', dropout=0.0,
- c_multiple=2, ln_eps=1e-12):
- super(ResidualBlock, self).__init__()
-
- if norm_type == 'bn':
- norm_builder = lambda: nn.BatchNorm1d(channels)
- elif norm_type == 'in':
- norm_builder = lambda: nn.InstanceNorm1d(channels, affine=True)
- elif norm_type == 'gn':
- norm_builder = lambda: nn.GroupNorm(8, channels)
- elif norm_type == 'ln':
- norm_builder = lambda: LayerNorm(channels, dim=1, eps=ln_eps)
- else:
- norm_builder = lambda: nn.Identity()
-
- self.blocks = [
- nn.Sequential(
- norm_builder(),
- nn.Conv1d(channels, c_multiple * channels, kernel_size, dilation=dilation,
- padding=(dilation * (kernel_size - 1)) // 2),
- LambdaLayer(lambda x: x * kernel_size ** -0.5),
- nn.GELU(),
- nn.Conv1d(c_multiple * channels, channels, 1, dilation=dilation),
- )
- for i in range(n)
- ]
-
- self.blocks = nn.ModuleList(self.blocks)
- self.dropout = dropout
-
- def forward(self, x):
- nonpadding = (x.abs().sum(1) > 0).float()[:, None, :]
- for b in self.blocks:
- x_ = b(x)
- if self.dropout > 0 and self.training:
- x_ = F.dropout(x_, self.dropout, training=self.training)
- x = x + x_
- x = x * nonpadding
- return x
-
-
-class Pad(nn.ZeroPad2d):
- def __init__(self, kernel_size, dilation):
- pad_total = dilation * (kernel_size - 1)
- begin = pad_total // 2
- end = pad_total - begin
-
- super(Pad, self).__init__((begin, end, begin, end))
-
-
-class ZeroTemporalPad(nn.ZeroPad2d):
- """Pad sequences to equal lentgh in the temporal dimension"""
-
- def __init__(self, kernel_size, dilation, causal=False):
- total_pad = (dilation * (kernel_size - 1))
-
- if causal:
- super(ZeroTemporalPad, self).__init__((total_pad, 0))
- else:
- begin = total_pad // 2
- end = total_pad - begin
- super(ZeroTemporalPad, self).__init__((begin, end))
-
-
-class ConvBlocks(nn.Module):
- """Decodes the expanded phoneme encoding into spectrograms"""
-
- def __init__(self, channels, out_dims, dilations, kernel_size,
- norm_type='ln', layers_in_block=2, c_multiple=2,
- dropout=0.0, ln_eps=1e-5, init_weights=True):
- super(ConvBlocks, self).__init__()
- self.res_blocks = nn.Sequential(
- *[ResidualBlock(channels, kernel_size, d,
- n=layers_in_block, norm_type=norm_type, c_multiple=c_multiple,
- dropout=dropout, ln_eps=ln_eps)
- for d in dilations],
- )
- if norm_type == 'bn':
- norm = nn.BatchNorm1d(channels)
- elif norm_type == 'in':
- norm = nn.InstanceNorm1d(channels, affine=True)
- elif norm_type == 'gn':
- norm = nn.GroupNorm(8, channels)
- elif norm_type == 'ln':
- norm = LayerNorm(channels, dim=1, eps=ln_eps)
- self.last_norm = norm
- self.post_net1 = nn.Conv1d(channels, out_dims, kernel_size=3, padding=1)
- if init_weights:
- self.apply(init_weights_func)
-
- def forward(self, x):
- """
-
- :param x: [B, T, H]
- :return: [B, T, H]
- """
- x = x.transpose(1, 2)
- nonpadding = (x.abs().sum(1) > 0).float()[:, None, :]
- x = self.res_blocks(x) * nonpadding
- x = self.last_norm(x) * nonpadding
- x = self.post_net1(x) * nonpadding
- return x.transpose(1, 2)
-
-
-class TextConvEncoder(ConvBlocks):
- def __init__(self, embed_tokens, channels, out_dims, dilations, kernel_size,
- norm_type='ln', layers_in_block=2, c_multiple=2,
- dropout=0.0, ln_eps=1e-5, init_weights=True):
- super().__init__(channels, out_dims, dilations, kernel_size,
- norm_type, layers_in_block, c_multiple,
- dropout, ln_eps, init_weights)
- self.embed_tokens = embed_tokens
- self.embed_scale = math.sqrt(channels)
-
- def forward(self, txt_tokens):
- """
-
- :param txt_tokens: [B, T]
- :return: {
- 'encoder_out': [B x T x C]
- }
- """
- x = self.embed_scale * self.embed_tokens(txt_tokens)
- return super().forward(x)
-
-
-class ConditionalConvBlocks(ConvBlocks):
- def __init__(self, channels, g_channels, out_dims, dilations, kernel_size,
- norm_type='ln', layers_in_block=2, c_multiple=2,
- dropout=0.0, ln_eps=1e-5, init_weights=True, is_BTC=True):
- super().__init__(channels, out_dims, dilations, kernel_size,
- norm_type, layers_in_block, c_multiple,
- dropout, ln_eps, init_weights)
- self.g_prenet = nn.Conv1d(g_channels, channels, 3, padding=1)
- self.is_BTC = is_BTC
- if init_weights:
- self.g_prenet.apply(init_weights_func)
-
- def forward(self, x, g, x_mask):
- if self.is_BTC:
- x = x.transpose(1, 2)
- g = g.transpose(1, 2)
- x_mask = x_mask.transpose(1, 2)
- x = x + self.g_prenet(g)
- x = x * x_mask
-
- if not self.is_BTC:
- x = x.transpose(1, 2)
- x = super(ConditionalConvBlocks, self).forward(x) # input needs to be BTC
- if not self.is_BTC:
- x = x.transpose(1, 2)
- return x
diff --git a/spaces/AIGC-Audio/Make_An_Audio_inpaint/README.md b/spaces/AIGC-Audio/Make_An_Audio_inpaint/README.md
deleted file mode 100644
index d2c182d1786442911f6a5a165054a35db9ed2cf3..0000000000000000000000000000000000000000
--- a/spaces/AIGC-Audio/Make_An_Audio_inpaint/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Make An Audio Inpaint
-emoji: 🔥
-colorFrom: green
-colorTo: pink
-sdk: gradio
-sdk_version: 3.17.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/ASJMO/freegpt/g4f/Provider/Providers/Bard.py b/spaces/ASJMO/freegpt/g4f/Provider/Providers/Bard.py
deleted file mode 100644
index 4c37c4b719430031fce41ce49946f0e6ac93d155..0000000000000000000000000000000000000000
--- a/spaces/ASJMO/freegpt/g4f/Provider/Providers/Bard.py
+++ /dev/null
@@ -1,74 +0,0 @@
-import os, requests, json, browser_cookie3, re, random
-from ...typing import sha256, Dict, get_type_hints
-
-url = 'https://bard.google.com'
-model = ['Palm2']
-supports_stream = False
-needs_auth = True
-
-def _create_completion(model: str, messages: list, stream: bool, **kwargs):
- psid = {cookie.name: cookie.value for cookie in browser_cookie3.chrome(
- domain_name='.google.com')}['__Secure-1PSID']
-
- formatted = '\n'.join([
- '%s: %s' % (message['role'], message['content']) for message in messages
- ])
- prompt = f'{formatted}\nAssistant:'
-
- proxy = kwargs.get('proxy', False)
- if proxy == False:
- print('warning!, you did not give a proxy, a lot of countries are banned from Google Bard, so it may not work')
-
- snlm0e = None
- conversation_id = None
- response_id = None
- choice_id = None
-
- client = requests.Session()
- client.proxies = {
- 'http': f'http://{proxy}',
- 'https': f'http://{proxy}'} if proxy else None
-
- client.headers = {
- 'authority': 'bard.google.com',
- 'content-type': 'application/x-www-form-urlencoded;charset=UTF-8',
- 'origin': 'https://bard.google.com',
- 'referer': 'https://bard.google.com/',
- 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
- 'x-same-domain': '1',
- 'cookie': f'__Secure-1PSID={psid}'
- }
-
- snlm0e = re.search(r'SNlM0e\":\"(.*?)\"',
- client.get('https://bard.google.com/').text).group(1) if not snlm0e else snlm0e
-
- params = {
- 'bl': 'boq_assistant-bard-web-server_20230326.21_p0',
- '_reqid': random.randint(1111, 9999),
- 'rt': 'c'
- }
-
- data = {
- 'at': snlm0e,
- 'f.req': json.dumps([None, json.dumps([[prompt], None, [conversation_id, response_id, choice_id]])])}
-
- intents = '.'.join([
- 'assistant',
- 'lamda',
- 'BardFrontendService'
- ])
-
- response = client.post(f'https://bard.google.com/_/BardChatUi/data/{intents}/StreamGenerate',
- data=data, params=params)
-
- chat_data = json.loads(response.content.splitlines()[3])[0][2]
- if chat_data:
- json_chat_data = json.loads(chat_data)
-
- yield json_chat_data[0][0]
-
- else:
- yield 'error'
-
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
- '(%s)' % ', '.join([f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
\ No newline at end of file
diff --git a/spaces/AbeShinzo0708/AI_Kishida_Fumio_speaker/pre-fix/librosa/__init__.py b/spaces/AbeShinzo0708/AI_Kishida_Fumio_speaker/pre-fix/librosa/__init__.py
deleted file mode 100644
index fd33ddb0937cbb125f570af8936083f867e8a41b..0000000000000000000000000000000000000000
--- a/spaces/AbeShinzo0708/AI_Kishida_Fumio_speaker/pre-fix/librosa/__init__.py
+++ /dev/null
@@ -1,10 +0,0 @@
-# https://github.com/librosa/librosa/issues/1682
-
-import lazy_loader as lazy
-from .version import version as __version__
-
-_filename = __file__
-if _filename.endswith('.pyc'):
- _filename = _filename[:-1]
-
-__getattr__, __dir__, __all__ = lazy.attach_stub(__name__, _filename)
diff --git a/spaces/Abhilashvj/planogram-compliance/classify/predict.py b/spaces/Abhilashvj/planogram-compliance/classify/predict.py
deleted file mode 100644
index 0d9bce8929e7758cd2d7c015603c7fc7db685d9c..0000000000000000000000000000000000000000
--- a/spaces/Abhilashvj/planogram-compliance/classify/predict.py
+++ /dev/null
@@ -1,345 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
-"""
-Run YOLOv5 classification inference on images, videos, directories, globs, YouTube, webcam, streams, etc.
-
-Usage - sources:
- $ python classify/predict.py --weights yolov5s-cls.pt --source 0 # webcam
- img.jpg # image
- vid.mp4 # video
- screen # screenshot
- path/ # directory
- list.txt # list of images
- list.streams # list of streams
- 'path/*.jpg' # glob
- 'https://youtu.be/Zgi9g1ksQHc' # YouTube
- 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
-
-Usage - formats:
- $ python classify/predict.py --weights yolov5s-cls.pt # PyTorch
- yolov5s-cls.torchscript # TorchScript
- yolov5s-cls.onnx # ONNX Runtime or OpenCV DNN with --dnn
- yolov5s-cls_openvino_model # OpenVINO
- yolov5s-cls.engine # TensorRT
- yolov5s-cls.mlmodel # CoreML (macOS-only)
- yolov5s-cls_saved_model # TensorFlow SavedModel
- yolov5s-cls.pb # TensorFlow GraphDef
- yolov5s-cls.tflite # TensorFlow Lite
- yolov5s-cls_edgetpu.tflite # TensorFlow Edge TPU
- yolov5s-cls_paddle_model # PaddlePaddle
-"""
-
-import argparse
-import os
-import platform
-import sys
-from pathlib import Path
-
-import torch
-import torch.nn.functional as F
-
-FILE = Path(__file__).resolve()
-ROOT = FILE.parents[1] # YOLOv5 root directory
-if str(ROOT) not in sys.path:
- sys.path.append(str(ROOT)) # add ROOT to PATH
-ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
-
-from models.common import DetectMultiBackend
-from utils.augmentations import classify_transforms
-from utils.dataloaders import (
- IMG_FORMATS,
- VID_FORMATS,
- LoadImages,
- LoadScreenshots,
- LoadStreams,
-)
-from utils.general import (
- LOGGER,
- Profile,
- check_file,
- check_img_size,
- check_imshow,
- check_requirements,
- colorstr,
- cv2,
- increment_path,
- print_args,
- strip_optimizer,
-)
-from utils.plots import Annotator
-from utils.torch_utils import select_device, smart_inference_mode
-
-
-@smart_inference_mode()
-def run(
- weights=ROOT / "yolov5s-cls.pt", # model.pt path(s)
- source=ROOT / "data/images", # file/dir/URL/glob/screen/0(webcam)
- data=ROOT / "data/coco128.yaml", # dataset.yaml path
- imgsz=(224, 224), # inference size (height, width)
- device="", # cuda device, i.e. 0 or 0,1,2,3 or cpu
- view_img=False, # show results
- save_txt=False, # save results to *.txt
- nosave=False, # do not save images/videos
- augment=False, # augmented inference
- visualize=False, # visualize features
- update=False, # update all models
- project=ROOT / "runs/predict-cls", # save results to project/name
- name="exp", # save results to project/name
- exist_ok=False, # existing project/name ok, do not increment
- half=False, # use FP16 half-precision inference
- dnn=False, # use OpenCV DNN for ONNX inference
- vid_stride=1, # video frame-rate stride
-):
- source = str(source)
- save_img = not nosave and not source.endswith(
- ".txt"
- ) # save inference images
- is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
- is_url = source.lower().startswith(
- ("rtsp://", "rtmp://", "http://", "https://")
- )
- webcam = (
- source.isnumeric()
- or source.endswith(".streams")
- or (is_url and not is_file)
- )
- screenshot = source.lower().startswith("screen")
- if is_url and is_file:
- source = check_file(source) # download
-
- # Directories
- save_dir = increment_path(
- Path(project) / name, exist_ok=exist_ok
- ) # increment run
- (save_dir / "labels" if save_txt else save_dir).mkdir(
- parents=True, exist_ok=True
- ) # make dir
-
- # Load model
- device = select_device(device)
- model = DetectMultiBackend(
- weights, device=device, dnn=dnn, data=data, fp16=half
- )
- stride, names, pt = model.stride, model.names, model.pt
- imgsz = check_img_size(imgsz, s=stride) # check image size
-
- # Dataloader
- bs = 1 # batch_size
- if webcam:
- view_img = check_imshow(warn=True)
- dataset = LoadStreams(
- source,
- img_size=imgsz,
- transforms=classify_transforms(imgsz[0]),
- vid_stride=vid_stride,
- )
- bs = len(dataset)
- elif screenshot:
- dataset = LoadScreenshots(
- source, img_size=imgsz, stride=stride, auto=pt
- )
- else:
- dataset = LoadImages(
- source,
- img_size=imgsz,
- transforms=classify_transforms(imgsz[0]),
- vid_stride=vid_stride,
- )
- vid_path, vid_writer = [None] * bs, [None] * bs
-
- # Run inference
- model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
- seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
- for path, im, im0s, vid_cap, s in dataset:
- with dt[0]:
- im = torch.Tensor(im).to(model.device)
- im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
- if len(im.shape) == 3:
- im = im[None] # expand for batch dim
-
- # Inference
- with dt[1]:
- results = model(im)
-
- # Post-process
- with dt[2]:
- pred = F.softmax(results, dim=1) # probabilities
-
- # Process predictions
- for i, prob in enumerate(pred): # per image
- seen += 1
- if webcam: # batch_size >= 1
- p, im0, frame = path[i], im0s[i].copy(), dataset.count
- s += f"{i}: "
- else:
- p, im0, frame = path, im0s.copy(), getattr(dataset, "frame", 0)
-
- p = Path(p) # to Path
- save_path = str(save_dir / p.name) # im.jpg
- txt_path = str(save_dir / "labels" / p.stem) + (
- "" if dataset.mode == "image" else f"_{frame}"
- ) # im.txt
-
- s += "%gx%g " % im.shape[2:] # print string
- annotator = Annotator(im0, example=str(names), pil=True)
-
- # Print results
- top5i = prob.argsort(0, descending=True)[
- :5
- ].tolist() # top 5 indices
- s += f"{', '.join(f'{names[j]} {prob[j]:.2f}' for j in top5i)}, "
-
- # Write results
- text = "\n".join(f"{prob[j]:.2f} {names[j]}" for j in top5i)
- if save_img or view_img: # Add bbox to image
- annotator.text((32, 32), text, txt_color=(255, 255, 255))
- if save_txt: # Write to file
- with open(f"{txt_path}.txt", "a") as f:
- f.write(text + "\n")
-
- # Stream results
- im0 = annotator.result()
- if view_img:
- if platform.system() == "Linux" and p not in windows:
- windows.append(p)
- cv2.namedWindow(
- str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO
- ) # allow window resize (Linux)
- cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
- cv2.imshow(str(p), im0)
- cv2.waitKey(1) # 1 millisecond
-
- # Save results (image with detections)
- if save_img:
- if dataset.mode == "image":
- cv2.imwrite(save_path, im0)
- else: # 'video' or 'stream'
- if vid_path[i] != save_path: # new video
- vid_path[i] = save_path
- if isinstance(vid_writer[i], cv2.VideoWriter):
- vid_writer[
- i
- ].release() # release previous video writer
- if vid_cap: # video
- fps = vid_cap.get(cv2.CAP_PROP_FPS)
- w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
- h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
- else: # stream
- fps, w, h = 30, im0.shape[1], im0.shape[0]
- save_path = str(
- Path(save_path).with_suffix(".mp4")
- ) # force *.mp4 suffix on results videos
- vid_writer[i] = cv2.VideoWriter(
- save_path,
- cv2.VideoWriter_fourcc(*"mp4v"),
- fps,
- (w, h),
- )
- vid_writer[i].write(im0)
-
- # Print time (inference-only)
- LOGGER.info(f"{s}{dt[1].dt * 1E3:.1f}ms")
-
- # Print results
- t = tuple(x.t / seen * 1e3 for x in dt) # speeds per image
- LOGGER.info(
- f"Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}"
- % t
- )
- if save_txt or save_img:
- s = (
- f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}"
- if save_txt
- else ""
- )
- LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
- if update:
- strip_optimizer(
- weights[0]
- ) # update model (to fix SourceChangeWarning)
-
-
-def parse_opt():
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--weights",
- nargs="+",
- type=str,
- default=ROOT / "yolov5s-cls.pt",
- help="model path(s)",
- )
- parser.add_argument(
- "--source",
- type=str,
- default=ROOT / "data/images",
- help="file/dir/URL/glob/screen/0(webcam)",
- )
- parser.add_argument(
- "--data",
- type=str,
- default=ROOT / "data/coco128.yaml",
- help="(optional) dataset.yaml path",
- )
- parser.add_argument(
- "--imgsz",
- "--img",
- "--img-size",
- nargs="+",
- type=int,
- default=[224],
- help="inference size h,w",
- )
- parser.add_argument(
- "--device", default="", help="cuda device, i.e. 0 or 0,1,2,3 or cpu"
- )
- parser.add_argument("--view-img", action="store_true", help="show results")
- parser.add_argument(
- "--save-txt", action="store_true", help="save results to *.txt"
- )
- parser.add_argument(
- "--nosave", action="store_true", help="do not save images/videos"
- )
- parser.add_argument(
- "--augment", action="store_true", help="augmented inference"
- )
- parser.add_argument(
- "--visualize", action="store_true", help="visualize features"
- )
- parser.add_argument(
- "--update", action="store_true", help="update all models"
- )
- parser.add_argument(
- "--project",
- default=ROOT / "runs/predict-cls",
- help="save results to project/name",
- )
- parser.add_argument(
- "--name", default="exp", help="save results to project/name"
- )
- parser.add_argument(
- "--exist-ok",
- action="store_true",
- help="existing project/name ok, do not increment",
- )
- parser.add_argument(
- "--half", action="store_true", help="use FP16 half-precision inference"
- )
- parser.add_argument(
- "--dnn", action="store_true", help="use OpenCV DNN for ONNX inference"
- )
- parser.add_argument(
- "--vid-stride", type=int, default=1, help="video frame-rate stride"
- )
- opt = parser.parse_args()
- opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
- print_args(vars(opt))
- return opt
-
-
-def main(opt):
- check_requirements(exclude=("tensorboard", "thop"))
- run(**vars(opt))
-
-
-if __name__ == "__main__":
- opt = parse_opt()
- main(opt)
diff --git a/spaces/AchyuthGamer/OpenGPT/g4f/Provider/Providers/Vitalentum.py b/spaces/AchyuthGamer/OpenGPT/g4f/Provider/Providers/Vitalentum.py
deleted file mode 100644
index ade492d2db0d4c84bca5de4b774330fdf292c3ab..0000000000000000000000000000000000000000
--- a/spaces/AchyuthGamer/OpenGPT/g4f/Provider/Providers/Vitalentum.py
+++ /dev/null
@@ -1,69 +0,0 @@
-from __future__ import annotations
-
-import json
-from aiohttp import ClientSession
-
-from .base_provider import AsyncGeneratorProvider
-from ..typing import AsyncResult, Messages
-
-class Vitalentum(AsyncGeneratorProvider):
- url = "https://app.vitalentum.io"
- working = True
- supports_gpt_35_turbo = True
-
-
- @classmethod
- async def create_async_generator(
- cls,
- model: str,
- messages: Messages,
- proxy: str = None,
- **kwargs
- ) -> AsyncResult:
- headers = {
- "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
- "Accept" : "text/event-stream",
- "Accept-language" : "de,en-US;q=0.7,en;q=0.3",
- "Origin" : cls.url,
- "Referer" : cls.url + "/",
- "Sec-Fetch-Dest" : "empty",
- "Sec-Fetch-Mode" : "cors",
- "Sec-Fetch-Site" : "same-origin",
- }
- conversation = json.dumps({"history": [{
- "speaker": "human" if message["role"] == "user" else "bot",
- "text": message["content"],
- } for message in messages]})
- data = {
- "conversation": conversation,
- "temperature": 0.7,
- **kwargs
- }
- async with ClientSession(
- headers=headers
- ) as session:
- async with session.post(cls.url + "/api/converse-edge", json=data, proxy=proxy) as response:
- response.raise_for_status()
- async for line in response.content:
- line = line.decode()
- if line.startswith("data: "):
- if line.startswith("data: [DONE]"):
- break
- line = json.loads(line[6:-1])
- content = line["choices"][0]["delta"].get("content")
- if content:
- yield content
-
-
- @classmethod
- @property
- def params(cls):
- params = [
- ("model", "str"),
- ("messages", "list[dict[str, str]]"),
- ("stream", "bool"),
- ("proxy", "str"),
- ("temperature", "float"),
- ]
- param = ", ".join([": ".join(p) for p in params])
- return f"g4f.provider.{cls.__name__} supports: ({param})"
\ No newline at end of file
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/customshapes/CustomShapes.d.ts b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/customshapes/CustomShapes.d.ts
deleted file mode 100644
index a7b6fc7bf5775962f7067cca8cbcddad6ae2cd1a..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/customshapes/CustomShapes.d.ts
+++ /dev/null
@@ -1,2 +0,0 @@
-import CustomShapes from '../../../plugins/customshapes';
-export default CustomShapes;
\ No newline at end of file
diff --git a/spaces/AjulorC/question_answering_bot_deployed_with_Gradio/README.md b/spaces/AjulorC/question_answering_bot_deployed_with_Gradio/README.md
deleted file mode 100644
index 4e8f8eaced0efa05c271a6667fd97d9881b48ba1..0000000000000000000000000000000000000000
--- a/spaces/AjulorC/question_answering_bot_deployed_with_Gradio/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Question_answering_bot_deployed_with_Gradio
-emoji: 🦀
-colorFrom: green
-colorTo: gray
-sdk: gradio
-sdk_version: 2.8.11
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/Aki004/herta-so-vits/modules/__init__.py b/spaces/Aki004/herta-so-vits/modules/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Akmyradov/TurkmenTTSweSTT/vits/train_ms.py b/spaces/Akmyradov/TurkmenTTSweSTT/vits/train_ms.py
deleted file mode 100644
index 34870c622d2c05ad0a1a8fcf648197d0f51800cd..0000000000000000000000000000000000000000
--- a/spaces/Akmyradov/TurkmenTTSweSTT/vits/train_ms.py
+++ /dev/null
@@ -1,294 +0,0 @@
-import os
-import json
-import argparse
-import itertools
-import math
-import torch
-from torch import nn, optim
-from torch.nn import functional as F
-from torch.utils.data import DataLoader
-from torch.utils.tensorboard import SummaryWriter
-import torch.multiprocessing as mp
-import torch.distributed as dist
-from torch.nn.parallel import DistributedDataParallel as DDP
-from torch.cuda.amp import autocast, GradScaler
-
-import commons
-import utils
-from data_utils import (
- TextAudioSpeakerLoader,
- TextAudioSpeakerCollate,
- DistributedBucketSampler
-)
-from models import (
- SynthesizerTrn,
- MultiPeriodDiscriminator,
-)
-from losses import (
- generator_loss,
- discriminator_loss,
- feature_loss,
- kl_loss
-)
-from mel_processing import mel_spectrogram_torch, spec_to_mel_torch
-from text.symbols import symbols
-
-
-torch.backends.cudnn.benchmark = True
-global_step = 0
-
-
-def main():
- """Assume Single Node Multi GPUs Training Only"""
- assert torch.cuda.is_available(), "CPU training is not allowed."
-
- n_gpus = torch.cuda.device_count()
- os.environ['MASTER_ADDR'] = 'localhost'
- os.environ['MASTER_PORT'] = '80000'
-
- hps = utils.get_hparams()
- mp.spawn(run, nprocs=n_gpus, args=(n_gpus, hps,))
-
-
-def run(rank, n_gpus, hps):
- global global_step
- if rank == 0:
- logger = utils.get_logger(hps.model_dir)
- logger.info(hps)
- utils.check_git_hash(hps.model_dir)
- writer = SummaryWriter(log_dir=hps.model_dir)
- writer_eval = SummaryWriter(log_dir=os.path.join(hps.model_dir, "eval"))
-
- dist.init_process_group(backend='nccl', init_method='env://', world_size=n_gpus, rank=rank)
- torch.manual_seed(hps.train.seed)
- torch.cuda.set_device(rank)
-
- train_dataset = TextAudioSpeakerLoader(hps.data.training_files, hps.data)
- train_sampler = DistributedBucketSampler(
- train_dataset,
- hps.train.batch_size,
- [32,300,400,500,600,700,800,900,1000],
- num_replicas=n_gpus,
- rank=rank,
- shuffle=True)
- collate_fn = TextAudioSpeakerCollate()
- train_loader = DataLoader(train_dataset, num_workers=8, shuffle=False, pin_memory=True,
- collate_fn=collate_fn, batch_sampler=train_sampler)
- if rank == 0:
- eval_dataset = TextAudioSpeakerLoader(hps.data.validation_files, hps.data)
- eval_loader = DataLoader(eval_dataset, num_workers=8, shuffle=False,
- batch_size=hps.train.batch_size, pin_memory=True,
- drop_last=False, collate_fn=collate_fn)
-
- net_g = SynthesizerTrn(
- len(symbols),
- hps.data.filter_length // 2 + 1,
- hps.train.segment_size // hps.data.hop_length,
- n_speakers=hps.data.n_speakers,
- **hps.model).cuda(rank)
- net_d = MultiPeriodDiscriminator(hps.model.use_spectral_norm).cuda(rank)
- optim_g = torch.optim.AdamW(
- net_g.parameters(),
- hps.train.learning_rate,
- betas=hps.train.betas,
- eps=hps.train.eps)
- optim_d = torch.optim.AdamW(
- net_d.parameters(),
- hps.train.learning_rate,
- betas=hps.train.betas,
- eps=hps.train.eps)
- net_g = DDP(net_g, device_ids=[rank])
- net_d = DDP(net_d, device_ids=[rank])
-
- try:
- _, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "G_*.pth"), net_g, optim_g)
- _, _, _, epoch_str = utils.load_checkpoint(utils.latest_checkpoint_path(hps.model_dir, "D_*.pth"), net_d, optim_d)
- global_step = (epoch_str - 1) * len(train_loader)
- except:
- epoch_str = 1
- global_step = 0
-
- scheduler_g = torch.optim.lr_scheduler.ExponentialLR(optim_g, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
- scheduler_d = torch.optim.lr_scheduler.ExponentialLR(optim_d, gamma=hps.train.lr_decay, last_epoch=epoch_str-2)
-
- scaler = GradScaler(enabled=hps.train.fp16_run)
-
- for epoch in range(epoch_str, hps.train.epochs + 1):
- if rank==0:
- train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, eval_loader], logger, [writer, writer_eval])
- else:
- train_and_evaluate(rank, epoch, hps, [net_g, net_d], [optim_g, optim_d], [scheduler_g, scheduler_d], scaler, [train_loader, None], None, None)
- scheduler_g.step()
- scheduler_d.step()
-
-
-def train_and_evaluate(rank, epoch, hps, nets, optims, schedulers, scaler, loaders, logger, writers):
- net_g, net_d = nets
- optim_g, optim_d = optims
- scheduler_g, scheduler_d = schedulers
- train_loader, eval_loader = loaders
- if writers is not None:
- writer, writer_eval = writers
-
- train_loader.batch_sampler.set_epoch(epoch)
- global global_step
-
- net_g.train()
- net_d.train()
- for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers) in enumerate(train_loader):
- x, x_lengths = x.cuda(rank, non_blocking=True), x_lengths.cuda(rank, non_blocking=True)
- spec, spec_lengths = spec.cuda(rank, non_blocking=True), spec_lengths.cuda(rank, non_blocking=True)
- y, y_lengths = y.cuda(rank, non_blocking=True), y_lengths.cuda(rank, non_blocking=True)
- speakers = speakers.cuda(rank, non_blocking=True)
-
- with autocast(enabled=hps.train.fp16_run):
- y_hat, l_length, attn, ids_slice, x_mask, z_mask,\
- (z, z_p, m_p, logs_p, m_q, logs_q) = net_g(x, x_lengths, spec, spec_lengths, speakers)
-
- mel = spec_to_mel_torch(
- spec,
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.mel_fmin,
- hps.data.mel_fmax)
- y_mel = commons.slice_segments(mel, ids_slice, hps.train.segment_size // hps.data.hop_length)
- y_hat_mel = mel_spectrogram_torch(
- y_hat.squeeze(1),
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.hop_length,
- hps.data.win_length,
- hps.data.mel_fmin,
- hps.data.mel_fmax
- )
-
- y = commons.slice_segments(y, ids_slice * hps.data.hop_length, hps.train.segment_size) # slice
-
- # Discriminator
- y_d_hat_r, y_d_hat_g, _, _ = net_d(y, y_hat.detach())
- with autocast(enabled=False):
- loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g)
- loss_disc_all = loss_disc
- optim_d.zero_grad()
- scaler.scale(loss_disc_all).backward()
- scaler.unscale_(optim_d)
- grad_norm_d = commons.clip_grad_value_(net_d.parameters(), None)
- scaler.step(optim_d)
-
- with autocast(enabled=hps.train.fp16_run):
- # Generator
- y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = net_d(y, y_hat)
- with autocast(enabled=False):
- loss_dur = torch.sum(l_length.float())
- loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
- loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl
-
- loss_fm = feature_loss(fmap_r, fmap_g)
- loss_gen, losses_gen = generator_loss(y_d_hat_g)
- loss_gen_all = loss_gen + loss_fm + loss_mel + loss_dur + loss_kl
- optim_g.zero_grad()
- scaler.scale(loss_gen_all).backward()
- scaler.unscale_(optim_g)
- grad_norm_g = commons.clip_grad_value_(net_g.parameters(), None)
- scaler.step(optim_g)
- scaler.update()
-
- if rank==0:
- if global_step % hps.train.log_interval == 0:
- lr = optim_g.param_groups[0]['lr']
- losses = [loss_disc, loss_gen, loss_fm, loss_mel, loss_dur, loss_kl]
- logger.info('Train Epoch: {} [{:.0f}%]'.format(
- epoch,
- 100. * batch_idx / len(train_loader)))
- logger.info([x.item() for x in losses] + [global_step, lr])
-
- scalar_dict = {"loss/g/total": loss_gen_all, "loss/d/total": loss_disc_all, "learning_rate": lr, "grad_norm_d": grad_norm_d, "grad_norm_g": grad_norm_g}
- scalar_dict.update({"loss/g/fm": loss_fm, "loss/g/mel": loss_mel, "loss/g/dur": loss_dur, "loss/g/kl": loss_kl})
-
- scalar_dict.update({"loss/g/{}".format(i): v for i, v in enumerate(losses_gen)})
- scalar_dict.update({"loss/d_r/{}".format(i): v for i, v in enumerate(losses_disc_r)})
- scalar_dict.update({"loss/d_g/{}".format(i): v for i, v in enumerate(losses_disc_g)})
- image_dict = {
- "slice/mel_org": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().numpy()),
- "slice/mel_gen": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().numpy()),
- "all/mel": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().numpy()),
- "all/attn": utils.plot_alignment_to_numpy(attn[0,0].data.cpu().numpy())
- }
- utils.summarize(
- writer=writer,
- global_step=global_step,
- images=image_dict,
- scalars=scalar_dict)
-
- if global_step % hps.train.eval_interval == 0:
- evaluate(hps, net_g, eval_loader, writer_eval)
- utils.save_checkpoint(net_g, optim_g, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "G_{}.pth".format(global_step)))
- utils.save_checkpoint(net_d, optim_d, hps.train.learning_rate, epoch, os.path.join(hps.model_dir, "D_{}.pth".format(global_step)))
- global_step += 1
-
- if rank == 0:
- logger.info('====> Epoch: {}'.format(epoch))
-
-
-def evaluate(hps, generator, eval_loader, writer_eval):
- generator.eval()
- with torch.no_grad():
- for batch_idx, (x, x_lengths, spec, spec_lengths, y, y_lengths, speakers) in enumerate(eval_loader):
- x, x_lengths = x.cuda(0), x_lengths.cuda(0)
- spec, spec_lengths = spec.cuda(0), spec_lengths.cuda(0)
- y, y_lengths = y.cuda(0), y_lengths.cuda(0)
- speakers = speakers.cuda(0)
-
- # remove else
- x = x[:1]
- x_lengths = x_lengths[:1]
- spec = spec[:1]
- spec_lengths = spec_lengths[:1]
- y = y[:1]
- y_lengths = y_lengths[:1]
- speakers = speakers[:1]
- break
- y_hat, attn, mask, *_ = generator.module.infer(x, x_lengths, speakers, max_len=1000)
- y_hat_lengths = mask.sum([1,2]).long() * hps.data.hop_length
-
- mel = spec_to_mel_torch(
- spec,
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.mel_fmin,
- hps.data.mel_fmax)
- y_hat_mel = mel_spectrogram_torch(
- y_hat.squeeze(1).float(),
- hps.data.filter_length,
- hps.data.n_mel_channels,
- hps.data.sampling_rate,
- hps.data.hop_length,
- hps.data.win_length,
- hps.data.mel_fmin,
- hps.data.mel_fmax
- )
- image_dict = {
- "gen/mel": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().numpy())
- }
- audio_dict = {
- "gen/audio": y_hat[0,:,:y_hat_lengths[0]]
- }
- if global_step == 0:
- image_dict.update({"gt/mel": utils.plot_spectrogram_to_numpy(mel[0].cpu().numpy())})
- audio_dict.update({"gt/audio": y[0,:,:y_lengths[0]]})
-
- utils.summarize(
- writer=writer_eval,
- global_step=global_step,
- images=image_dict,
- audios=audio_dict,
- audio_sampling_rate=hps.data.sampling_rate
- )
- generator.train()
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/Alpaca233/SadTalker/src/test_audio2coeff.py b/spaces/Alpaca233/SadTalker/src/test_audio2coeff.py
deleted file mode 100644
index bbf19f494e2127b4ae9d6074b172fddb694d6e34..0000000000000000000000000000000000000000
--- a/spaces/Alpaca233/SadTalker/src/test_audio2coeff.py
+++ /dev/null
@@ -1,123 +0,0 @@
-import os
-import torch
-import numpy as np
-from scipy.io import savemat, loadmat
-from yacs.config import CfgNode as CN
-from scipy.signal import savgol_filter
-
-import safetensors
-import safetensors.torch
-
-from src.audio2pose_models.audio2pose import Audio2Pose
-from src.audio2exp_models.networks import SimpleWrapperV2
-from src.audio2exp_models.audio2exp import Audio2Exp
-from src.utils.safetensor_helper import load_x_from_safetensor
-
-def load_cpk(checkpoint_path, model=None, optimizer=None, device="cpu"):
- checkpoint = torch.load(checkpoint_path, map_location=torch.device(device))
- if model is not None:
- model.load_state_dict(checkpoint['model'])
- if optimizer is not None:
- optimizer.load_state_dict(checkpoint['optimizer'])
-
- return checkpoint['epoch']
-
-class Audio2Coeff():
-
- def __init__(self, sadtalker_path, device):
- #load config
- fcfg_pose = open(sadtalker_path['audio2pose_yaml_path'])
- cfg_pose = CN.load_cfg(fcfg_pose)
- cfg_pose.freeze()
- fcfg_exp = open(sadtalker_path['audio2exp_yaml_path'])
- cfg_exp = CN.load_cfg(fcfg_exp)
- cfg_exp.freeze()
-
- # load audio2pose_model
- self.audio2pose_model = Audio2Pose(cfg_pose, None, device=device)
- self.audio2pose_model = self.audio2pose_model.to(device)
- self.audio2pose_model.eval()
- for param in self.audio2pose_model.parameters():
- param.requires_grad = False
-
- try:
- if sadtalker_path['use_safetensor']:
- checkpoints = safetensors.torch.load_file(sadtalker_path['checkpoint'])
- self.audio2pose_model.load_state_dict(load_x_from_safetensor(checkpoints, 'audio2pose'))
- else:
- load_cpk(sadtalker_path['audio2pose_checkpoint'], model=self.audio2pose_model, device=device)
- except:
- raise Exception("Failed in loading audio2pose_checkpoint")
-
- # load audio2exp_model
- netG = SimpleWrapperV2()
- netG = netG.to(device)
- for param in netG.parameters():
- netG.requires_grad = False
- netG.eval()
- try:
- if sadtalker_path['use_safetensor']:
- checkpoints = safetensors.torch.load_file(sadtalker_path['checkpoint'])
- netG.load_state_dict(load_x_from_safetensor(checkpoints, 'audio2exp'))
- else:
- load_cpk(sadtalker_path['audio2exp_checkpoint'], model=netG, device=device)
- except:
- raise Exception("Failed in loading audio2exp_checkpoint")
- self.audio2exp_model = Audio2Exp(netG, cfg_exp, device=device, prepare_training_loss=False)
- self.audio2exp_model = self.audio2exp_model.to(device)
- for param in self.audio2exp_model.parameters():
- param.requires_grad = False
- self.audio2exp_model.eval()
-
- self.device = device
-
- def generate(self, batch, coeff_save_dir, pose_style, ref_pose_coeff_path=None):
-
- with torch.no_grad():
- #test
- results_dict_exp= self.audio2exp_model.test(batch)
- exp_pred = results_dict_exp['exp_coeff_pred'] #bs T 64
-
- #for class_id in range(1):
- #class_id = 0#(i+10)%45
- #class_id = random.randint(0,46) #46 styles can be selected
- batch['class'] = torch.LongTensor([pose_style]).to(self.device)
- results_dict_pose = self.audio2pose_model.test(batch)
- pose_pred = results_dict_pose['pose_pred'] #bs T 6
-
- pose_len = pose_pred.shape[1]
- if pose_len<13:
- pose_len = int((pose_len-1)/2)*2+1
- pose_pred = torch.Tensor(savgol_filter(np.array(pose_pred.cpu()), pose_len, 2, axis=1)).to(self.device)
- else:
- pose_pred = torch.Tensor(savgol_filter(np.array(pose_pred.cpu()), 13, 2, axis=1)).to(self.device)
-
- coeffs_pred = torch.cat((exp_pred, pose_pred), dim=-1) #bs T 70
-
- coeffs_pred_numpy = coeffs_pred[0].clone().detach().cpu().numpy()
-
- if ref_pose_coeff_path is not None:
- coeffs_pred_numpy = self.using_refpose(coeffs_pred_numpy, ref_pose_coeff_path)
-
- savemat(os.path.join(coeff_save_dir, '%s##%s.mat'%(batch['pic_name'], batch['audio_name'])),
- {'coeff_3dmm': coeffs_pred_numpy})
-
- return os.path.join(coeff_save_dir, '%s##%s.mat'%(batch['pic_name'], batch['audio_name']))
-
- def using_refpose(self, coeffs_pred_numpy, ref_pose_coeff_path):
- num_frames = coeffs_pred_numpy.shape[0]
- refpose_coeff_dict = loadmat(ref_pose_coeff_path)
- refpose_coeff = refpose_coeff_dict['coeff_3dmm'][:,64:70]
- refpose_num_frames = refpose_coeff.shape[0]
- if refpose_num_frames None:
- callback_fn.has_been_called = True
- nonlocal number_of_steps
- number_of_steps += 1
- if step == 1:
- latents = latents.detach().cpu().numpy()
- assert latents.shape == (1, 4, 64, 64)
- latents_slice = latents[0, -3:, -3:, -1]
- expected_slice = np.array(
- [-0.1621, 0.2837, -0.7979, -0.1221, -1.3057, 0.7681, -2.1191, 0.0464, 1.6309]
- )
-
- assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
- elif step == 2:
- latents = latents.detach().cpu().numpy()
- assert latents.shape == (1, 4, 64, 64)
- latents_slice = latents[0, -3:, -3:, -1]
- expected_slice = np.array([0.6299, 1.7500, 1.1992, -2.1582, -1.8994, 0.7334, -0.7090, 1.0137, 1.5273])
-
- assert np.abs(latents_slice.flatten() - expected_slice).max() < 5e-2
-
- callback_fn.has_been_called = False
-
- pipe = StableDiffusionImageVariationPipeline.from_pretrained(
- "fusing/sd-image-variations-diffusers",
- safety_checker=None,
- torch_dtype=torch.float16,
- )
- pipe.to(torch_device)
- pipe.set_progress_bar_config(disable=None)
- pipe.enable_attention_slicing()
-
- inputs = self.get_inputs(torch_device, dtype=torch.float16)
- pipe(**inputs, callback=callback_fn, callback_steps=1)
- assert callback_fn.has_been_called
- assert number_of_steps == inputs["num_inference_steps"]
-
- def test_stable_diffusion_pipeline_with_sequential_cpu_offloading(self):
- torch.cuda.empty_cache()
- torch.cuda.reset_max_memory_allocated()
- torch.cuda.reset_peak_memory_stats()
-
- model_id = "fusing/sd-image-variations-diffusers"
- pipe = StableDiffusionImageVariationPipeline.from_pretrained(
- model_id, safety_checker=None, torch_dtype=torch.float16
- )
- pipe = pipe.to(torch_device)
- pipe.set_progress_bar_config(disable=None)
- pipe.enable_attention_slicing(1)
- pipe.enable_sequential_cpu_offload()
-
- inputs = self.get_inputs(torch_device, dtype=torch.float16)
- _ = pipe(**inputs)
-
- mem_bytes = torch.cuda.max_memory_allocated()
- # make sure that less than 2.6 GB is allocated
- assert mem_bytes < 2.6 * 10**9
-
-
-@nightly
-@require_torch_gpu
-class StableDiffusionImageVariationPipelineNightlyTests(unittest.TestCase):
- def tearDown(self):
- super().tearDown()
- gc.collect()
- torch.cuda.empty_cache()
-
- def get_inputs(self, device, generator_device="cpu", dtype=torch.float32, seed=0):
- generator = torch.Generator(device=generator_device).manual_seed(seed)
- init_image = load_image(
- "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
- "/stable_diffusion_imgvar/input_image_vermeer.png"
- )
- latents = np.random.RandomState(seed).standard_normal((1, 4, 64, 64))
- latents = torch.from_numpy(latents).to(device=device, dtype=dtype)
- inputs = {
- "image": init_image,
- "latents": latents,
- "generator": generator,
- "num_inference_steps": 50,
- "guidance_scale": 7.5,
- "output_type": "numpy",
- }
- return inputs
-
- def test_img_variation_pndm(self):
- sd_pipe = StableDiffusionImageVariationPipeline.from_pretrained("fusing/sd-image-variations-diffusers")
- sd_pipe.to(torch_device)
- sd_pipe.set_progress_bar_config(disable=None)
-
- inputs = self.get_inputs(torch_device)
- image = sd_pipe(**inputs).images[0]
-
- expected_image = load_numpy(
- "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
- "/stable_diffusion_imgvar/lambdalabs_variations_pndm.npy"
- )
- max_diff = np.abs(expected_image - image).max()
- assert max_diff < 1e-3
-
- def test_img_variation_dpm(self):
- sd_pipe = StableDiffusionImageVariationPipeline.from_pretrained("fusing/sd-image-variations-diffusers")
- sd_pipe.scheduler = DPMSolverMultistepScheduler.from_config(sd_pipe.scheduler.config)
- sd_pipe.to(torch_device)
- sd_pipe.set_progress_bar_config(disable=None)
-
- inputs = self.get_inputs(torch_device)
- inputs["num_inference_steps"] = 25
- image = sd_pipe(**inputs).images[0]
-
- expected_image = load_numpy(
- "https://huggingface.co/datasets/diffusers/test-arrays/resolve/main"
- "/stable_diffusion_imgvar/lambdalabs_variations_dpm_multi.npy"
- )
- max_diff = np.abs(expected_image - image).max()
- assert max_diff < 1e-3
diff --git a/spaces/Andy1621/uniformer_image_detection/configs/groie/mask_rcnn_r50_fpn_syncbn-backbone_r4_gcb_c3-c5_groie_1x_coco.py b/spaces/Andy1621/uniformer_image_detection/configs/groie/mask_rcnn_r50_fpn_syncbn-backbone_r4_gcb_c3-c5_groie_1x_coco.py
deleted file mode 100644
index 852c5ca7c5c4ba04f6a5f7dd6dbaf6b2c357a2fa..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/configs/groie/mask_rcnn_r50_fpn_syncbn-backbone_r4_gcb_c3-c5_groie_1x_coco.py
+++ /dev/null
@@ -1,45 +0,0 @@
-_base_ = '../gcnet/mask_rcnn_r50_fpn_syncbn-backbone_r4_gcb_c3-c5_1x_coco.py'
-# model settings
-model = dict(
- roi_head=dict(
- bbox_roi_extractor=dict(
- type='GenericRoIExtractor',
- aggregation='sum',
- roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=2),
- out_channels=256,
- featmap_strides=[4, 8, 16, 32],
- pre_cfg=dict(
- type='ConvModule',
- in_channels=256,
- out_channels=256,
- kernel_size=5,
- padding=2,
- inplace=False,
- ),
- post_cfg=dict(
- type='GeneralizedAttention',
- in_channels=256,
- spatial_range=-1,
- num_heads=6,
- attention_type='0100',
- kv_stride=2)),
- mask_roi_extractor=dict(
- type='GenericRoIExtractor',
- roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=2),
- out_channels=256,
- featmap_strides=[4, 8, 16, 32],
- pre_cfg=dict(
- type='ConvModule',
- in_channels=256,
- out_channels=256,
- kernel_size=5,
- padding=2,
- inplace=False,
- ),
- post_cfg=dict(
- type='GeneralizedAttention',
- in_channels=256,
- spatial_range=-1,
- num_heads=6,
- attention_type='0100',
- kv_stride=2))))
diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/_base_/models/apcnet_r50-d8.py b/spaces/Andy1621/uniformer_image_segmentation/configs/_base_/models/apcnet_r50-d8.py
deleted file mode 100644
index c8f5316cbcf3896ba9de7ca2c801eba512f01d5e..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_segmentation/configs/_base_/models/apcnet_r50-d8.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# model settings
-norm_cfg = dict(type='SyncBN', requires_grad=True)
-model = dict(
- type='EncoderDecoder',
- pretrained='open-mmlab://resnet50_v1c',
- backbone=dict(
- type='ResNetV1c',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- dilations=(1, 1, 2, 4),
- strides=(1, 2, 1, 1),
- norm_cfg=norm_cfg,
- norm_eval=False,
- style='pytorch',
- contract_dilation=True),
- decode_head=dict(
- type='APCHead',
- in_channels=2048,
- in_index=3,
- channels=512,
- pool_scales=(1, 2, 3, 6),
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=dict(type='SyncBN', requires_grad=True),
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
- auxiliary_head=dict(
- type='FCNHead',
- in_channels=1024,
- in_index=2,
- channels=256,
- num_convs=1,
- concat_input=False,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
- # model training and testing settings
- train_cfg=dict(),
- test_cfg=dict(mode='whole'))
diff --git a/spaces/Andy1621/uniformer_image_segmentation/configs/gcnet/gcnet_r101-d8_512x512_160k_ade20k.py b/spaces/Andy1621/uniformer_image_segmentation/configs/gcnet/gcnet_r101-d8_512x512_160k_ade20k.py
deleted file mode 100644
index 9888120f65b045df1c7d4d05fb010373abf82ccf..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_segmentation/configs/gcnet/gcnet_r101-d8_512x512_160k_ade20k.py
+++ /dev/null
@@ -1,2 +0,0 @@
-_base_ = './gcnet_r50-d8_512x512_160k_ade20k.py'
-model = dict(pretrained='open-mmlab://resnet101_v1c', backbone=dict(depth=101))
diff --git a/spaces/ArtGAN/Video-Diffusion-WebUI/video_diffusion/stable_diffusion_video/stable_diffusion_pipeline.py b/spaces/ArtGAN/Video-Diffusion-WebUI/video_diffusion/stable_diffusion_video/stable_diffusion_pipeline.py
deleted file mode 100644
index 34ac4676d3775fabc28ff3dd6f8932d6b7f13764..0000000000000000000000000000000000000000
--- a/spaces/ArtGAN/Video-Diffusion-WebUI/video_diffusion/stable_diffusion_video/stable_diffusion_pipeline.py
+++ /dev/null
@@ -1,848 +0,0 @@
-import inspect
-import json
-import math
-import time
-from pathlib import Path
-from typing import Callable, List, Optional, Tuple, Union
-
-import numpy as np
-import torch
-from diffusers.configuration_utils import FrozenDict
-from diffusers.models import AutoencoderKL, UNet2DConditionModel
-from diffusers.pipeline_utils import DiffusionPipeline
-from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
-from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
-from diffusers.schedulers import (
- DDIMScheduler,
- DPMSolverMultistepScheduler,
- EulerAncestralDiscreteScheduler,
- EulerDiscreteScheduler,
- LMSDiscreteScheduler,
- PNDMScheduler,
-)
-from diffusers.utils import deprecate, logging
-from packaging import version
-from torch import nn
-from transformers import CLIPFeatureExtractor, CLIPTextModel, CLIPTokenizer
-
-from .upsampling import RealESRGANModel
-from .utils import get_timesteps_arr, make_video_pyav, slerp
-
-logging.set_verbosity_info()
-logger = logging.get_logger(__name__)
-
-
-class StableDiffusionWalkPipeline(DiffusionPipeline):
- r"""
- Pipeline for generating videos by interpolating Stable Diffusion's latent space.
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
- library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
- Args:
- vae ([`AutoencoderKL`]):
- Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
- text_encoder ([`CLIPTextModel`]):
- Frozen text-encoder. Stable Diffusion uses the text portion of
- [CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
- the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
- tokenizer (`CLIPTokenizer`):
- Tokenizer of class
- [CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
- unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
- scheduler ([`SchedulerMixin`]):
- A scheduler to be used in combination with `unet` to denoise the encoded image latens. Can be one of
- [`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
- safety_checker ([`StableDiffusionSafetyChecker`]):
- Classification module that estimates whether generated images could be considered offensive or harmful.
- Please, refer to the [model card](https://huggingface.co/CompVis/stable-diffusion-v1-4) for details.
- feature_extractor ([`CLIPFeatureExtractor`]):
- Model that extracts features from generated images to be used as inputs for the `safety_checker`.
- """
- _optional_components = ["safety_checker", "feature_extractor"]
-
- def __init__(
- self,
- vae: AutoencoderKL,
- text_encoder: CLIPTextModel,
- tokenizer: CLIPTokenizer,
- unet: UNet2DConditionModel,
- scheduler: Union[
- DDIMScheduler,
- PNDMScheduler,
- LMSDiscreteScheduler,
- EulerDiscreteScheduler,
- EulerAncestralDiscreteScheduler,
- DPMSolverMultistepScheduler,
- ],
- safety_checker: StableDiffusionSafetyChecker,
- feature_extractor: CLIPFeatureExtractor,
- requires_safety_checker: bool = True,
- ):
- super().__init__()
-
- if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
- deprecation_message = (
- f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
- f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
- "to update the config accordingly as leaving `steps_offset` might led to incorrect results"
- " in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
- " it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
- " file"
- )
- deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
- new_config = dict(scheduler.config)
- new_config["steps_offset"] = 1
- scheduler._internal_dict = FrozenDict(new_config)
-
- if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
- deprecation_message = (
- f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
- " `clip_sample` should be set to False in the configuration file. Please make sure to update the"
- " config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
- " future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
- " nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
- )
- deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
- new_config = dict(scheduler.config)
- new_config["clip_sample"] = False
- scheduler._internal_dict = FrozenDict(new_config)
-
- if safety_checker is None and requires_safety_checker:
- logger.warning(
- f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
- " that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
- " results in services or applications open to the public. Both the diffusers team and Hugging Face"
- " strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
- " it only for use-cases that involve analyzing network behavior or auditing its results. For more"
- " information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
- )
-
- if safety_checker is not None and feature_extractor is None:
- raise ValueError(
- "Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
- " checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
- )
-
- is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
- version.parse(unet.config._diffusers_version).base_version
- ) < version.parse("0.9.0.dev0")
- is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
- if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
- deprecation_message = (
- "The configuration file of the unet has set the default `sample_size` to smaller than"
- " 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
- " following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
- " CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
- " \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
- " configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
- " in the config might lead to incorrect results in future versions. If you have downloaded this"
- " checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
- " the `unet/config.json` file"
- )
- deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
- new_config = dict(unet.config)
- new_config["sample_size"] = 64
- unet._internal_dict = FrozenDict(new_config)
-
- self.register_modules(
- vae=vae,
- text_encoder=text_encoder,
- tokenizer=tokenizer,
- unet=unet,
- scheduler=scheduler,
- safety_checker=safety_checker,
- feature_extractor=feature_extractor,
- )
- self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
- self.register_to_config(requires_safety_checker=requires_safety_checker)
-
- def enable_attention_slicing(self, slice_size: Optional[Union[str, int]] = "auto"):
- r"""
- Enable sliced attention computation.
- When this option is enabled, the attention module will split the input tensor in slices, to compute attention
- in several steps. This is useful to save some memory in exchange for a small speed decrease.
- Args:
- slice_size (`str` or `int`, *optional*, defaults to `"auto"`):
- When `"auto"`, halves the input to the attention heads, so attention will be computed in two steps. If
- a number is provided, uses as many slices as `attention_head_dim // slice_size`. In this case,
- `attention_head_dim` must be a multiple of `slice_size`.
- """
- if slice_size == "auto":
- if isinstance(self.unet.config.attention_head_dim, int):
- # half the attention head size is usually a good trade-off between
- # speed and memory
- slice_size = self.unet.config.attention_head_dim // 2
- else:
- # if `attention_head_dim` is a list, take the smallest head size
- slice_size = min(self.unet.config.attention_head_dim)
-
- self.unet.set_attention_slice(slice_size)
-
- def disable_attention_slicing(self):
- r"""
- Disable sliced attention computation. If `enable_attention_slicing` was previously invoked, this method will go
- back to computing attention in one step.
- """
- # set slice_size = `None` to disable `attention slicing`
- self.enable_attention_slicing(None)
-
- @torch.no_grad()
- def __call__(
- self,
- prompt: Optional[Union[str, List[str]]] = None,
- height: Optional[int] = None,
- width: Optional[int] = None,
- num_inference_steps: int = 50,
- guidance_scale: float = 7.5,
- negative_prompt: Optional[Union[str, List[str]]] = None,
- num_images_per_prompt: Optional[int] = 1,
- eta: float = 0.0,
- generator: Optional[torch.Generator] = None,
- latents: Optional[torch.FloatTensor] = None,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
- callback_steps: Optional[int] = 1,
- text_embeddings: Optional[torch.FloatTensor] = None,
- **kwargs,
- ):
- r"""
- Function invoked when calling the pipeline for generation.
- Args:
- prompt (`str` or `List[str]`, *optional*, defaults to `None`):
- The prompt or prompts to guide the image generation. If not provided, `text_embeddings` is required.
- height (`int`, *optional*, defaults to 512):
- The height in pixels of the generated image.
- width (`int`, *optional*, defaults to 512):
- The width in pixels of the generated image.
- num_inference_steps (`int`, *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (`float`, *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
- negative_prompt (`str` or `List[str]`, *optional*):
- The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
- if `guidance_scale` is less than `1`).
- num_images_per_prompt (`int`, *optional*, defaults to 1):
- The number of images to generate per prompt.
- eta (`float`, *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
- generator (`torch.Generator`, *optional*):
- A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
- deterministic.
- latents (`torch.FloatTensor`, *optional*):
- Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
- generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
- tensor will ge generated by sampling using the supplied random `generator`.
- output_type (`str`, *optional*, defaults to `"pil"`):
- The output format of the generate image. Choose between
- [PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
- plain tuple.
- callback (`Callable`, *optional*):
- A function that will be called every `callback_steps` steps during inference. The function will be
- called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
- callback_steps (`int`, *optional*, defaults to 1):
- The frequency at which the `callback` function will be called. If not specified, the callback will be
- called at every step.
- text_embeddings (`torch.FloatTensor`, *optional*, defaults to `None`):
- Pre-generated text embeddings to be used as inputs for image generation. Can be used in place of
- `prompt` to avoid re-computing the embeddings. If not provided, the embeddings will be generated from
- the supplied `prompt`.
- Returns:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
- [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
- When returning a tuple, the first element is a list with the generated images, and the second element is a
- list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
- (nsfw) content, according to the `safety_checker`.
- """
- # 0. Default height and width to unet
- height = height or self.unet.config.sample_size * self.vae_scale_factor
- width = width or self.unet.config.sample_size * self.vae_scale_factor
-
- if height % 8 != 0 or width % 8 != 0:
- raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
-
- if (callback_steps is None) or (
- callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
- ):
- raise ValueError(
- f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
- f" {type(callback_steps)}."
- )
-
- if text_embeddings is None:
- if isinstance(prompt, str):
- batch_size = 1
- elif isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
-
- # get prompt text embeddings
- text_inputs = self.tokenizer(
- prompt,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- return_tensors="pt",
- )
- text_input_ids = text_inputs.input_ids
-
- if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
- removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
- print(
- "The following part of your input was truncated because CLIP can only handle sequences up to"
- f" {self.tokenizer.model_max_length} tokens: {removed_text}"
- )
- text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
- text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
- else:
- batch_size = text_embeddings.shape[0]
-
- # duplicate text embeddings for each generation per prompt, using mps friendly method
- bs_embed, seq_len, _ = text_embeddings.shape
- text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
- text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
-
- # here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
- # of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
- # corresponds to doing no classifier free guidance.
- do_classifier_free_guidance = guidance_scale > 1.0
- # get unconditional embeddings for classifier free guidance
- if do_classifier_free_guidance:
- uncond_tokens: List[str]
- if negative_prompt is None:
- uncond_tokens = [""]
- elif text_embeddings is None and type(prompt) is not type(negative_prompt):
- raise TypeError(
- f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
- f" {type(prompt)}."
- )
- elif isinstance(negative_prompt, str):
- uncond_tokens = [negative_prompt]
- elif batch_size != len(negative_prompt):
- raise ValueError(
- f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
- f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
- " the batch size of `prompt`."
- )
- else:
- uncond_tokens = negative_prompt
-
- max_length = self.tokenizer.model_max_length
- uncond_input = self.tokenizer(
- uncond_tokens,
- padding="max_length",
- max_length=max_length,
- truncation=True,
- return_tensors="pt",
- )
- uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
-
- # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
- seq_len = uncond_embeddings.shape[1]
- uncond_embeddings = uncond_embeddings.repeat(batch_size, num_images_per_prompt, 1)
- uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
-
- # For classifier free guidance, we need to do two forward passes.
- # Here we concatenate the unconditional and text embeddings into a single batch
- # to avoid doing two forward passes
- text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
-
- # get the initial random noise unless the user supplied it
-
- # Unlike in other pipelines, latents need to be generated in the target device
- # for 1-to-1 results reproducibility with the CompVis implementation.
- # However this currently doesn't work in `mps`.
- latents_shape = (
- batch_size * num_images_per_prompt,
- self.unet.in_channels,
- height // 8,
- width // 8,
- )
- latents_dtype = text_embeddings.dtype
- if latents is None:
- if self.device.type == "mps":
- # randn does not exist on mps
- latents = torch.randn(
- latents_shape,
- generator=generator,
- device="cpu",
- dtype=latents_dtype,
- ).to(self.device)
- else:
- latents = torch.randn(
- latents_shape,
- generator=generator,
- device=self.device,
- dtype=latents_dtype,
- )
- else:
- if latents.shape != latents_shape:
- raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
- latents = latents.to(self.device)
-
- # set timesteps
- self.scheduler.set_timesteps(num_inference_steps)
-
- # Some schedulers like PNDM have timesteps as arrays
- # It's more optimized to move all timesteps to correct device beforehand
- timesteps_tensor = self.scheduler.timesteps.to(self.device)
-
- # scale the initial noise by the standard deviation required by the scheduler
- latents = latents * self.scheduler.init_noise_sigma
-
- # prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
- # eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
- # eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
- # and should be between [0, 1]
- accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
- extra_step_kwargs = {}
- if accepts_eta:
- extra_step_kwargs["eta"] = eta
-
- for i, t in enumerate(self.progress_bar(timesteps_tensor)):
- # expand the latents if we are doing classifier free guidance
- latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
- latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
-
- # predict the noise residual
- noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
-
- # perform guidance
- if do_classifier_free_guidance:
- noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
- noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
-
- # compute the previous noisy sample x_t -> x_t-1
- latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
-
- # call the callback, if provided
- if callback is not None and i % callback_steps == 0:
- callback(i, t, latents)
-
- latents = 1 / 0.18215 * latents
- image = self.vae.decode(latents).sample
-
- image = (image / 2 + 0.5).clamp(0, 1)
-
- # we always cast to float32 as this does not cause significant overhead and is compatible with bfloa16
- image = image.cpu().permute(0, 2, 3, 1).float().numpy()
-
- if self.safety_checker is not None:
- safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(self.device)
- image, has_nsfw_concept = self.safety_checker(
- images=image,
- clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype),
- )
- else:
- has_nsfw_concept = None
-
- if output_type == "pil":
- image = self.numpy_to_pil(image)
-
- if not return_dict:
- return (image, has_nsfw_concept)
-
- return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
-
- def generate_inputs(self, prompt_a, prompt_b, seed_a, seed_b, noise_shape, T, batch_size):
- embeds_a = self.embed_text(prompt_a)
- embeds_b = self.embed_text(prompt_b)
- latents_dtype = embeds_a.dtype
- latents_a = self.init_noise(seed_a, noise_shape, latents_dtype)
- latents_b = self.init_noise(seed_b, noise_shape, latents_dtype)
-
- batch_idx = 0
- embeds_batch, noise_batch = None, None
- for i, t in enumerate(T):
- embeds = torch.lerp(embeds_a, embeds_b, t)
- noise = slerp(float(t), latents_a, latents_b)
-
- embeds_batch = embeds if embeds_batch is None else torch.cat([embeds_batch, embeds])
- noise_batch = noise if noise_batch is None else torch.cat([noise_batch, noise])
- batch_is_ready = embeds_batch.shape[0] == batch_size or i + 1 == T.shape[0]
- if not batch_is_ready:
- continue
- yield batch_idx, embeds_batch, noise_batch
- batch_idx += 1
- del embeds_batch, noise_batch
- torch.cuda.empty_cache()
- embeds_batch, noise_batch = None, None
-
- def make_clip_frames(
- self,
- prompt_a: str,
- prompt_b: str,
- seed_a: int,
- seed_b: int,
- num_interpolation_steps: int = 5,
- save_path: Union[str, Path] = "outputs/",
- num_inference_steps: int = 50,
- guidance_scale: float = 7.5,
- eta: float = 0.0,
- height: Optional[int] = None,
- width: Optional[int] = None,
- upsample: bool = False,
- batch_size: int = 1,
- image_file_ext: str = ".png",
- T: np.ndarray = None,
- skip: int = 0,
- negative_prompt: str = None,
- step: Optional[Tuple[int, int]] = None,
- ):
- # 0. Default height and width to unet
- height = height or self.unet.config.sample_size * self.vae_scale_factor
- width = width or self.unet.config.sample_size * self.vae_scale_factor
-
- save_path = Path(save_path)
- save_path.mkdir(parents=True, exist_ok=True)
-
- T = T if T is not None else np.linspace(0.0, 1.0, num_interpolation_steps)
- if T.shape[0] != num_interpolation_steps:
- raise ValueError(f"Unexpected T shape, got {T.shape}, expected dim 0 to be {num_interpolation_steps}")
-
- if upsample:
- if getattr(self, "upsampler", None) is None:
- self.upsampler = RealESRGANModel.from_pretrained("nateraw/real-esrgan")
- self.upsampler.to(self.device)
-
- batch_generator = self.generate_inputs(
- prompt_a,
- prompt_b,
- seed_a,
- seed_b,
- (1, self.unet.in_channels, height // 8, width // 8),
- T[skip:],
- batch_size,
- )
- num_batches = math.ceil(num_interpolation_steps / batch_size)
-
- log_prefix = "" if step is None else f"[{step[0]}/{step[1]}] "
-
- frame_index = skip
- for batch_idx, embeds_batch, noise_batch in batch_generator:
- if batch_size == 1:
- msg = f"Generating frame {frame_index}"
- else:
- msg = f"Generating frames {frame_index}-{frame_index+embeds_batch.shape[0]-1}"
- logger.info(f"{log_prefix}[{batch_idx}/{num_batches}] {msg}")
- outputs = self(
- latents=noise_batch,
- text_embeddings=embeds_batch,
- height=height,
- width=width,
- guidance_scale=guidance_scale,
- eta=eta,
- num_inference_steps=num_inference_steps,
- output_type="pil" if not upsample else "numpy",
- negative_prompt=negative_prompt,
- )["images"]
-
- for image in outputs:
- frame_filepath = save_path / (f"frame%06d{image_file_ext}" % frame_index)
- image = image if not upsample else self.upsampler(image)
- image.save(frame_filepath)
- frame_index += 1
-
- def walk(
- self,
- prompts: Optional[List[str]] = None,
- seeds: Optional[List[int]] = None,
- num_interpolation_steps: Optional[Union[int, List[int]]] = 5, # int or list of int
- output_dir: Optional[str] = "./dreams",
- name: Optional[str] = None,
- image_file_ext: Optional[str] = ".png",
- fps: Optional[int] = 30,
- num_inference_steps: Optional[int] = 50,
- guidance_scale: Optional[float] = 7.5,
- eta: Optional[float] = 0.0,
- height: Optional[int] = None,
- width: Optional[int] = None,
- upsample: Optional[bool] = False,
- batch_size: Optional[int] = 1,
- resume: Optional[bool] = False,
- audio_filepath: str = None,
- audio_start_sec: Optional[Union[int, float]] = None,
- margin: Optional[float] = 1.0,
- smooth: Optional[float] = 0.0,
- negative_prompt: Optional[str] = None,
- make_video: Optional[bool] = True,
- ):
- """Generate a video from a sequence of prompts and seeds. Optionally, add audio to the
- video to interpolate to the intensity of the audio.
- Args:
- prompts (Optional[List[str]], optional):
- list of text prompts. Defaults to None.
- seeds (Optional[List[int]], optional):
- list of random seeds corresponding to prompts. Defaults to None.
- num_interpolation_steps (Union[int, List[int]], *optional*):
- How many interpolation steps between each prompt. Defaults to None.
- output_dir (Optional[str], optional):
- Where to save the video. Defaults to './dreams'.
- name (Optional[str], optional):
- Name of the subdirectory of output_dir. Defaults to None.
- image_file_ext (Optional[str], *optional*, defaults to '.png'):
- The extension to use when writing video frames.
- fps (Optional[int], *optional*, defaults to 30):
- The frames per second in the resulting output videos.
- num_inference_steps (Optional[int], *optional*, defaults to 50):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (Optional[float], *optional*, defaults to 7.5):
- Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
- `guidance_scale` is defined as `w` of equation 2. of [Imagen
- Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
- 1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
- usually at the expense of lower image quality.
- eta (Optional[float], *optional*, defaults to 0.0):
- Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
- [`schedulers.DDIMScheduler`], will be ignored for others.
- height (Optional[int], *optional*, defaults to None):
- height of the images to generate.
- width (Optional[int], *optional*, defaults to None):
- width of the images to generate.
- upsample (Optional[bool], *optional*, defaults to False):
- When True, upsamples images with realesrgan.
- batch_size (Optional[int], *optional*, defaults to 1):
- Number of images to generate at once.
- resume (Optional[bool], *optional*, defaults to False):
- When True, resumes from the last frame in the output directory based
- on available prompt config. Requires you to provide the `name` argument.
- audio_filepath (str, *optional*, defaults to None):
- Optional path to an audio file to influence the interpolation rate.
- audio_start_sec (Optional[Union[int, float]], *optional*, defaults to 0):
- Global start time of the provided audio_filepath.
- margin (Optional[float], *optional*, defaults to 1.0):
- Margin from librosa hpss to use for audio interpolation.
- smooth (Optional[float], *optional*, defaults to 0.0):
- Smoothness of the audio interpolation. 1.0 means linear interpolation.
- negative_prompt (Optional[str], *optional*, defaults to None):
- Optional negative prompt to use. Same across all prompts.
- make_video (Optional[bool], *optional*, defaults to True):
- When True, makes a video from the generated frames. If False, only
- generates the frames.
- This function will create sub directories for each prompt and seed pair.
- For example, if you provide the following prompts and seeds:
- ```
- prompts = ['a dog', 'a cat', 'a bird']
- seeds = [1, 2, 3]
- num_interpolation_steps = 5
- output_dir = 'output_dir'
- name = 'name'
- fps = 5
- ```
- Then the following directories will be created:
- ```
- output_dir
- ├── name
- │ ├── name_000000
- │ │ ├── frame000000.png
- │ │ ├── ...
- │ │ ├── frame000004.png
- │ │ ├── name_000000.mp4
- │ ├── name_000001
- │ │ ├── frame000000.png
- │ │ ├── ...
- │ │ ├── frame000004.png
- │ │ ├── name_000001.mp4
- │ ├── ...
- │ ├── name.mp4
- | |── prompt_config.json
- ```
- Returns:
- str: The resulting video filepath. This video includes all sub directories' video clips.
- """
- # 0. Default height and width to unet
- height = height or self.unet.config.sample_size * self.vae_scale_factor
- width = width or self.unet.config.sample_size * self.vae_scale_factor
-
- output_path = Path(output_dir)
-
- name = name or time.strftime("%Y%m%d-%H%M%S")
- save_path_root = output_path / name
- save_path_root.mkdir(parents=True, exist_ok=True)
-
- # Where the final video of all the clips combined will be saved
- output_filepath = save_path_root / f"{name}.mp4"
-
- # If using same number of interpolation steps between, we turn into list
- if not resume and isinstance(num_interpolation_steps, int):
- num_interpolation_steps = [num_interpolation_steps] * (len(prompts) - 1)
-
- if not resume:
- audio_start_sec = audio_start_sec or 0
-
- # Save/reload prompt config
- prompt_config_path = save_path_root / "prompt_config.json"
- if not resume:
- prompt_config_path.write_text(
- json.dumps(
- dict(
- prompts=prompts,
- seeds=seeds,
- num_interpolation_steps=num_interpolation_steps,
- fps=fps,
- num_inference_steps=num_inference_steps,
- guidance_scale=guidance_scale,
- eta=eta,
- upsample=upsample,
- height=height,
- width=width,
- audio_filepath=audio_filepath,
- audio_start_sec=audio_start_sec,
- negative_prompt=negative_prompt,
- ),
- indent=2,
- sort_keys=False,
- )
- )
- else:
- data = json.load(open(prompt_config_path))
- prompts = data["prompts"]
- seeds = data["seeds"]
- num_interpolation_steps = data["num_interpolation_steps"]
- fps = data["fps"]
- num_inference_steps = data["num_inference_steps"]
- guidance_scale = data["guidance_scale"]
- eta = data["eta"]
- upsample = data["upsample"]
- height = data["height"]
- width = data["width"]
- audio_filepath = data["audio_filepath"]
- audio_start_sec = data["audio_start_sec"]
- negative_prompt = data.get("negative_prompt", None)
-
- for i, (prompt_a, prompt_b, seed_a, seed_b, num_step) in enumerate(
- zip(prompts, prompts[1:], seeds, seeds[1:], num_interpolation_steps)
- ):
- # {name}_000000 / {name}_000001 / ...
- save_path = save_path_root / f"{name}_{i:06d}"
-
- # Where the individual clips will be saved
- step_output_filepath = save_path / f"{name}_{i:06d}.mp4"
-
- # Determine if we need to resume from a previous run
- skip = 0
- if resume:
- if step_output_filepath.exists():
- print(f"Skipping {save_path} because frames already exist")
- continue
-
- existing_frames = sorted(save_path.glob(f"*{image_file_ext}"))
- if existing_frames:
- skip = int(existing_frames[-1].stem[-6:]) + 1
- if skip + 1 >= num_step:
- print(f"Skipping {save_path} because frames already exist")
- continue
- print(f"Resuming {save_path.name} from frame {skip}")
-
- audio_offset = audio_start_sec + sum(num_interpolation_steps[:i]) / fps
- audio_duration = num_step / fps
-
- self.make_clip_frames(
- prompt_a,
- prompt_b,
- seed_a,
- seed_b,
- num_interpolation_steps=num_step,
- save_path=save_path,
- num_inference_steps=num_inference_steps,
- guidance_scale=guidance_scale,
- eta=eta,
- height=height,
- width=width,
- upsample=upsample,
- batch_size=batch_size,
- T=get_timesteps_arr(
- audio_filepath,
- offset=audio_offset,
- duration=audio_duration,
- fps=fps,
- margin=margin,
- smooth=smooth,
- )
- if audio_filepath
- else None,
- skip=skip,
- negative_prompt=negative_prompt,
- step=(i, len(prompts) - 1),
- )
- if make_video:
- make_video_pyav(
- save_path,
- audio_filepath=audio_filepath,
- fps=fps,
- output_filepath=step_output_filepath,
- glob_pattern=f"*{image_file_ext}",
- audio_offset=audio_offset,
- audio_duration=audio_duration,
- sr=44100,
- )
- if make_video:
- return make_video_pyav(
- save_path_root,
- audio_filepath=audio_filepath,
- fps=fps,
- audio_offset=audio_start_sec,
- audio_duration=sum(num_interpolation_steps) / fps,
- output_filepath=output_filepath,
- glob_pattern=f"**/*{image_file_ext}",
- sr=44100,
- )
-
- def embed_text(self, text, negative_prompt=None):
- """Helper to embed some text"""
- text_input = self.tokenizer(
- text,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- truncation=True,
- return_tensors="pt",
- )
- with torch.no_grad():
- embed = self.text_encoder(text_input.input_ids.to(self.device))[0]
- return embed
-
- def init_noise(self, seed, noise_shape, dtype):
- """Helper to initialize noise"""
- # randn does not exist on mps, so we create noise on CPU here and move it to the device after initialization
- if self.device.type == "mps":
- noise = torch.randn(
- noise_shape,
- device="cpu",
- generator=torch.Generator(device="cpu").manual_seed(seed),
- ).to(self.device)
- else:
- noise = torch.randn(
- noise_shape,
- device=self.device,
- generator=torch.Generator(device=self.device).manual_seed(seed),
- dtype=dtype,
- )
- return noise
-
- @classmethod
- def from_pretrained(cls, *args, tiled=False, **kwargs):
- """Same as diffusers `from_pretrained` but with tiled option, which makes images tilable"""
- if tiled:
-
- def patch_conv(**patch):
- cls = nn.Conv2d
- init = cls.__init__
-
- def __init__(self, *args, **kwargs):
- return init(self, *args, **kwargs, **patch)
-
- cls.__init__ = __init__
-
- patch_conv(padding_mode="circular")
-
- pipeline = super().from_pretrained(*args, **kwargs)
- pipeline.tiled = tiled
- return pipeline
diff --git a/spaces/Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.h b/spaces/Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.h
deleted file mode 100644
index ad1311a78f61303616504eb991aaa9c4a93d9948..0000000000000000000000000000000000000000
--- a/spaces/Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cuda.h
+++ /dev/null
@@ -1,33 +0,0 @@
-/*!
-**************************************************************************************************
-* Deformable DETR
-* Copyright (c) 2020 SenseTime. All Rights Reserved.
-* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-**************************************************************************************************
-* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
-**************************************************************************************************
-*/
-
-#pragma once
-#include
-
-namespace groundingdino {
-
-at::Tensor ms_deform_attn_cuda_forward(
- const at::Tensor &value,
- const at::Tensor &spatial_shapes,
- const at::Tensor &level_start_index,
- const at::Tensor &sampling_loc,
- const at::Tensor &attn_weight,
- const int im2col_step);
-
-std::vector ms_deform_attn_cuda_backward(
- const at::Tensor &value,
- const at::Tensor &spatial_shapes,
- const at::Tensor &level_start_index,
- const at::Tensor &sampling_loc,
- const at::Tensor &attn_weight,
- const at::Tensor &grad_output,
- const int im2col_step);
-
-} // namespace groundingdino
\ No newline at end of file
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/metadata/_json.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/metadata/_json.py
deleted file mode 100644
index 336b52f1efddbcaeb6716583fc2f043699e278fa..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/metadata/_json.py
+++ /dev/null
@@ -1,84 +0,0 @@
-# Extracted from https://github.com/pfmoore/pkg_metadata
-
-from email.header import Header, decode_header, make_header
-from email.message import Message
-from typing import Any, Dict, List, Union
-
-METADATA_FIELDS = [
- # Name, Multiple-Use
- ("Metadata-Version", False),
- ("Name", False),
- ("Version", False),
- ("Dynamic", True),
- ("Platform", True),
- ("Supported-Platform", True),
- ("Summary", False),
- ("Description", False),
- ("Description-Content-Type", False),
- ("Keywords", False),
- ("Home-page", False),
- ("Download-URL", False),
- ("Author", False),
- ("Author-email", False),
- ("Maintainer", False),
- ("Maintainer-email", False),
- ("License", False),
- ("Classifier", True),
- ("Requires-Dist", True),
- ("Requires-Python", False),
- ("Requires-External", True),
- ("Project-URL", True),
- ("Provides-Extra", True),
- ("Provides-Dist", True),
- ("Obsoletes-Dist", True),
-]
-
-
-def json_name(field: str) -> str:
- return field.lower().replace("-", "_")
-
-
-def msg_to_json(msg: Message) -> Dict[str, Any]:
- """Convert a Message object into a JSON-compatible dictionary."""
-
- def sanitise_header(h: Union[Header, str]) -> str:
- if isinstance(h, Header):
- chunks = []
- for bytes, encoding in decode_header(h):
- if encoding == "unknown-8bit":
- try:
- # See if UTF-8 works
- bytes.decode("utf-8")
- encoding = "utf-8"
- except UnicodeDecodeError:
- # If not, latin1 at least won't fail
- encoding = "latin1"
- chunks.append((bytes, encoding))
- return str(make_header(chunks))
- return str(h)
-
- result = {}
- for field, multi in METADATA_FIELDS:
- if field not in msg:
- continue
- key = json_name(field)
- if multi:
- value: Union[str, List[str]] = [
- sanitise_header(v) for v in msg.get_all(field)
- ]
- else:
- value = sanitise_header(msg.get(field))
- if key == "keywords":
- # Accept both comma-separated and space-separated
- # forms, for better compatibility with old data.
- if "," in value:
- value = [v.strip() for v in value.split(",")]
- else:
- value = value.split()
- result[key] = value
-
- payload = msg.get_payload()
- if payload:
- result["description"] = payload
-
- return result
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/rich/_pick.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/rich/_pick.py
deleted file mode 100644
index 4f6d8b2d79406012c5f8bae9c289ed5bf4d179cc..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/rich/_pick.py
+++ /dev/null
@@ -1,17 +0,0 @@
-from typing import Optional
-
-
-def pick_bool(*values: Optional[bool]) -> bool:
- """Pick the first non-none bool or return the last value.
-
- Args:
- *values (bool): Any number of boolean or None values.
-
- Returns:
- bool: First non-none boolean.
- """
- assert values, "1 or more values required"
- for value in values:
- if value is not None:
- return value
- return bool(value)
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/command/py36compat.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/command/py36compat.py
deleted file mode 100644
index 343547a4d316e48144ba6bdf342dcc24cd6cb6cd..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/command/py36compat.py
+++ /dev/null
@@ -1,134 +0,0 @@
-import os
-from glob import glob
-from distutils.util import convert_path
-from distutils.command import sdist
-
-
-class sdist_add_defaults:
- """
- Mix-in providing forward-compatibility for functionality as found in
- distutils on Python 3.7.
-
- Do not edit the code in this class except to update functionality
- as implemented in distutils. Instead, override in the subclass.
- """
-
- def add_defaults(self):
- """Add all the default files to self.filelist:
- - README or README.txt
- - setup.py
- - test/test*.py
- - all pure Python modules mentioned in setup script
- - all files pointed by package_data (build_py)
- - all files defined in data_files.
- - all files defined as scripts.
- - all C sources listed as part of extensions or C libraries
- in the setup script (doesn't catch C headers!)
- Warns if (README or README.txt) or setup.py are missing; everything
- else is optional.
- """
- self._add_defaults_standards()
- self._add_defaults_optional()
- self._add_defaults_python()
- self._add_defaults_data_files()
- self._add_defaults_ext()
- self._add_defaults_c_libs()
- self._add_defaults_scripts()
-
- @staticmethod
- def _cs_path_exists(fspath):
- """
- Case-sensitive path existence check
-
- >>> sdist_add_defaults._cs_path_exists(__file__)
- True
- >>> sdist_add_defaults._cs_path_exists(__file__.upper())
- False
- """
- if not os.path.exists(fspath):
- return False
- # make absolute so we always have a directory
- abspath = os.path.abspath(fspath)
- directory, filename = os.path.split(abspath)
- return filename in os.listdir(directory)
-
- def _add_defaults_standards(self):
- standards = [self.READMES, self.distribution.script_name]
- for fn in standards:
- if isinstance(fn, tuple):
- alts = fn
- got_it = False
- for fn in alts:
- if self._cs_path_exists(fn):
- got_it = True
- self.filelist.append(fn)
- break
-
- if not got_it:
- self.warn("standard file not found: should have one of " +
- ', '.join(alts))
- else:
- if self._cs_path_exists(fn):
- self.filelist.append(fn)
- else:
- self.warn("standard file '%s' not found" % fn)
-
- def _add_defaults_optional(self):
- optional = ['test/test*.py', 'setup.cfg']
- for pattern in optional:
- files = filter(os.path.isfile, glob(pattern))
- self.filelist.extend(files)
-
- def _add_defaults_python(self):
- # build_py is used to get:
- # - python modules
- # - files defined in package_data
- build_py = self.get_finalized_command('build_py')
-
- # getting python files
- if self.distribution.has_pure_modules():
- self.filelist.extend(build_py.get_source_files())
-
- # getting package_data files
- # (computed in build_py.data_files by build_py.finalize_options)
- for pkg, src_dir, build_dir, filenames in build_py.data_files:
- for filename in filenames:
- self.filelist.append(os.path.join(src_dir, filename))
-
- def _add_defaults_data_files(self):
- # getting distribution.data_files
- if self.distribution.has_data_files():
- for item in self.distribution.data_files:
- if isinstance(item, str):
- # plain file
- item = convert_path(item)
- if os.path.isfile(item):
- self.filelist.append(item)
- else:
- # a (dirname, filenames) tuple
- dirname, filenames = item
- for f in filenames:
- f = convert_path(f)
- if os.path.isfile(f):
- self.filelist.append(f)
-
- def _add_defaults_ext(self):
- if self.distribution.has_ext_modules():
- build_ext = self.get_finalized_command('build_ext')
- self.filelist.extend(build_ext.get_source_files())
-
- def _add_defaults_c_libs(self):
- if self.distribution.has_c_libraries():
- build_clib = self.get_finalized_command('build_clib')
- self.filelist.extend(build_clib.get_source_files())
-
- def _add_defaults_scripts(self):
- if self.distribution.has_scripts():
- build_scripts = self.get_finalized_command('build_scripts')
- self.filelist.extend(build_scripts.get_source_files())
-
-
-if hasattr(sdist.sdist, '_add_defaults_standards'):
- # disable the functionality already available upstream
- class sdist_add_defaults: # noqa
- pass
diff --git a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/configs/new_baselines/mask_rcnn_regnetx_4gf_dds_FPN_100ep_LSJ.py b/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/configs/new_baselines/mask_rcnn_regnetx_4gf_dds_FPN_100ep_LSJ.py
deleted file mode 100644
index ef0b6d16d4403fb5d16a3aeb71a22621a0be5e21..0000000000000000000000000000000000000000
--- a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/configs/new_baselines/mask_rcnn_regnetx_4gf_dds_FPN_100ep_LSJ.py
+++ /dev/null
@@ -1,29 +0,0 @@
-from .mask_rcnn_R_50_FPN_100ep_LSJ import (
- dataloader,
- lr_multiplier,
- model,
- optimizer,
- train,
-)
-from detectron2.config import LazyCall as L
-from detectron2.modeling.backbone import RegNet
-from detectron2.modeling.backbone.regnet import SimpleStem, ResBottleneckBlock
-
-# Config source:
-# https://github.com/facebookresearch/detectron2/blob/main/configs/COCO-InstanceSegmentation/mask_rcnn_regnetx_4gf_dds_fpn_1x.py # noqa
-model.backbone.bottom_up = L(RegNet)(
- stem_class=SimpleStem,
- stem_width=32,
- block_class=ResBottleneckBlock,
- depth=23,
- w_a=38.65,
- w_0=96,
- w_m=2.43,
- group_width=40,
- norm="SyncBN",
- out_features=["s1", "s2", "s3", "s4"],
-)
-model.pixel_std = [57.375, 57.120, 58.395]
-
-# RegNets benefit from enabling cudnn benchmark mode
-train.cudnn_benchmark = True
diff --git a/spaces/BREWDAcademy/Brewd-Diffusion/style.css b/spaces/BREWDAcademy/Brewd-Diffusion/style.css
deleted file mode 100644
index d4e49cdac816cc36a98e7c7664c2adc40ab4b488..0000000000000000000000000000000000000000
--- a/spaces/BREWDAcademy/Brewd-Diffusion/style.css
+++ /dev/null
@@ -1,77 +0,0 @@
-/* Main background and font styles to fit the steampunk/parchment theme */
-body {
- background-color: #f5f5dc; /* Parchment color */
- font-family: 'IM Fell English SC', serif; /* Steampunk-inspired font */
- color: #3a2e22; /* Dark brown text color */
-}
-
-/* Style for header element with class 'pretty' */
-.pretty h1 {
- text-align: center;
- font-family: 'IM Fell English SC', serif; /* Steampunk font */
- color: #806c50; /* Muted brown color */
-}
-
-/* Style for button element with ID 'duplicate-button' */
-#duplicate-button {
- margin: auto;
- color: #efe0c9; /* Light parchment color */
- background-color: #806c50; /* Leather-like brown */
- border-radius: 4px; /* Less roundness for a more vintage look */
- cursor: pointer;
- padding: 10px 20px;
- border: none;
- font-size: 1em;
-}
-
-/* Style for the Gradio interface elements to match the steampunk theme */
-.gradio_container {
- background-color: #f2e5bc; /* Light beige for input areas */
- border: 1px solid #9e7053; /* Darker border to stand out on parchment */
-}
-
-/* Style for gallery/result container */
-.gr-gallery {
- background-color: #fff; /* Clean white for results to stand out */
- border: 2px solid #9e7053; /* A darker border for contrast */
-}
-
-/* Style for input text and text areas */
-input[type='text'], textarea {
- background-color: #f2e5bc; /* Light beige, like old paper */
- color: #3a2e22; /* Dark brown text color */
- border: 1px solid #9e7053; /* Leather-like border */
-}
-
-/* Style for sliders */
-input[type='range'] {
- background: #806c50; /* A leather-like slider background */
-}
-
-/* Style for radio buttons and checkboxes */
-input[type='radio'], input[type='checkbox'] {
- accent-color: #806c50; /* Leather-like accent color */
-}
-
-/* Adjust the style for buttons in the interface */
-button {
- background-color: #806c50; /* Leather-like brown */
- color: #efe0c9; /* Parchment color text */
- border: none; /* Remove default border */
-}
-
-/* Style adjustments for the accordion */
-.gr-accordion {
- background-color: #f2e5bc; /* Light beige */
- color: #3a2e22; /* Dark brown text color */
-}
-
-/* Ensure links match the theme as well */
-a {
- color: #3a2e22; /* Dark brown, similar to the text */
-}
-
-/* Style for the progress bar */
-.gr-progress-bar {
- background-color: #c0a080; /* A muted brown progress bar */
-}
diff --git a/spaces/Benson/text-generation/Examples/Coche De Carreras Juego De Configuracin Para Pc Windows 7.md b/spaces/Benson/text-generation/Examples/Coche De Carreras Juego De Configuracin Para Pc Windows 7.md
deleted file mode 100644
index 37dc44f1230514b3ee610373c5c3905c18a7c2fc..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Coche De Carreras Juego De Configuracin Para Pc Windows 7.md
+++ /dev/null
@@ -1,85 +0,0 @@
-
-
Configuración del juego de carreras de coches Descargar para PC Windows 7
-
Si eres un fan de la velocidad, la adrenalina y la emoción, es posible que te interese jugar juegos de carreras de coches. Los juegos de carreras de autos son videojuegos que simulan conducir un vehículo en una pista, una carretera o un terreno todoterreno. Pueden ser realistas, árcade o futuristas, dependiendo del estilo y el tema del juego. Los juegos de carreras de coches son populares entre los jugadores de todas las edades y preferencias, ya que ofrecen una variedad de desafíos, modos, vehículos y entornos para elegir.
-
Una de las ventajas de jugar juegos de carreras de coches es que se puede disfrutar de ellos en diferentes plataformas, incluyendo PC Windows 7. PC Windows 7 es un sistema operativo confiable y compatible que puede ejecutar muchos juegos de carreras de coches sin problemas y de manera eficiente. Jugar juegos de carreras de coches en PC Windows 7 también le da más control sobre la configuración, los gráficos y el rendimiento del juego. También puede utilizar diferentes dispositivos de entrada, como un teclado, un ratón, un joystick o un volante, para mejorar su experiencia de juego.
-
coche de carreras juego de configuración para pc windows 7
Pero ¿cómo encontrar y jugar juegos de carreras de coches en PC Windows 7? Hay muchas fuentes donde se puede descargar juegos de carreras de coches para PC Windows 7, tales como sitios web oficiales, tiendas en línea, o plataformas de terceros. Sin embargo, debes tener cuidado con la calidad, seguridad y legalidad de los archivos de juego que descargas. También debe seguir las instrucciones para instalar y ejecutar el juego en su PC Windows 7.
-
En este artículo, le presentaremos algunos de los mejores juegos de carreras de coches para PC Windows 7 que puede descargar y jugar. También le proporcionaremos información sobre sus características, pros y contras, y cómo descargarlos e instalarlos en su PC Windows 7. ¡Comencemos!
-
BeamNG.drive
-
¿Qué es BeamNG.drive y cuáles son sus características?
-
-
BeamNG.drive no es solo un juego de carreras de coches, sino también un juego de caja de arena que le permite experimentar con diferentes situaciones y resultados. Puede estrellar sus vehículos contra paredes, árboles, edificios u otros vehículos, y ver cómo se deforman y se rompen. También puedes probar tus habilidades de conducción en varios desafíos, como pruebas de tiempo, cursos de acrobacias, persecuciones policiales o aventuras fuera de la carretera
. También puedes jugar con tus amigos online o offline en modo multijugador.
-
Cómo descargar e instalar BeamNG.drive en PC Windows 7?
-
Para descargar e instalar BeamNG.drive en PC Windows 7, debe seguir estos pasos:
-
-
Vaya al sitio web oficial de BeamNG.drive y haga clic en el botón "Comprar ahora". Serás redirigido a la tienda de Steam, donde puedes comprar el juego por $24.99.
-
Después de comprar el juego, necesita descargar e instalar Steam en su PC Windows 7. Steam es una plataforma de distribución digital que le permite administrar sus juegos y acceder a las funciones en línea.
-
Una vez que haya instalado Steam, inicie sesión con su cuenta. Luego, vaya a su biblioteca y busque BeamNG.drive. Haga clic en el botón "Instalar" y espere a que el juego se descargue e instale en su PC Windows 7.
-
Después de que la instalación se haya completado, puede iniciar el juego desde Steam o desde el acceso directo de su escritorio. Disfrute!
-
-
Pros y contras de BeamNG.drive
-
BeamNG.drive es un divertido y realista juego de simulación de vehículos que ofrece muchas posibilidades y libertad. Sin embargo, también tiene algunos inconvenientes que debe tener en cuenta. Estos son algunos de los pros y contras de BeamNG.drive:
-
-
Pros
Contras
-
- Increíbles gráficos y física que hacen que los vehículos y entornos se vean y se sientan reales.
- Altos requisitos del sistema que pueden no funcionar bien en PC más viejos o más débiles.
-
-
- Una comunidad creativa y activa que crea y comparte nuevos contenidos y comentarios.
- Falta de una historia clara u objetivos que puedan hacer que el juego sea aburrido o repetitivo para algunos jugadores.
-
- Un modo multijugador que te permite jugar con tus amigos online o offline.
- Algunos errores y fallos que pueden afectar el juego o el rendimiento del juego.
-
-
Necesidad de velocidad
-
¿Cuál es la necesidad de velocidad y cuáles son sus características?
-
Need for Speed es una de las franquicias de juegos de carreras de coches más populares y exitosas del mundo. Ha existido desde 1994 y ha lanzado más de 20 títulos en diferentes plataformas. Los juegos de Need for Speed son conocidos por su ritmo rápido, estilo árcade y juego de carreras callejeras. También cuentan con una variedad de coches, pistas, modos, opciones de personalización e historias.
-
-
Uno de los mejores juegos de Need for Speed para PC Windows 7 es Need for Speed: Most Wanted (2012). Este juego es un reinicio de la original Need for Speed: Most Wanted (2005) y se desarrolla en una ciudad de mundo abierto llamada Fairhaven. Juegas como un corredor callejero que tiene que competir con otros corredores, evadir a la policía y desafiar a la lista de los más buscados. Puedes conducir cualquier coche que veas en la ciudad, desde coches deportivos exóticos hasta coches deportivos y todoterrenos. También puede actualizar sus coches con piezas de rendimiento, trabajos de pintura, vinilos, matrículas y más. También puedes participar en diferentes eventos, como carreras, persecuciones, carreras de velocidad, emboscadas o hitos.
-
¿Cómo descargar e instalar Necesidad de velocidad en PC Windows 7?
-
Para descargar e instalar Need for Speed: Most Wanted (2012) en PC Windows 7, debe seguir estos pasos:
-
-
Ir al sitio web oficial de Need for Speed: Most Wanted (2012) y haga clic en el botón "Comprar ahora". Serás redirigido a la tienda de Origin, donde puedes comprar el juego por $19.99.
-
-
Una vez que tenga Origin instalado, ejecútelo e inicie sesión con su cuenta. Luego, vaya a su biblioteca y encuentre Need for Speed: Most Wanted (2012). Haga clic en el botón "Descargar" y espere a que el juego se descargue e instale en su PC Windows 7.
-
Después de que la instalación se haya completado, puede iniciar el juego desde Origin o desde el acceso directo de su escritorio. Disfrute!
-
-
Pros y contras de la necesidad de velocidad
-
Need for Speed: Most Wanted (2012) es un emocionante y adictivo juego de carreras de coches que ofrece mucha acción y diversión. Sin embargo, también tiene algunos inconvenientes que debes tener en cuenta. Estos son algunos de los pros y contras de Need for Speed: Most Wanted (2012):
-
-
Pros
Contras
-
- Impresionantes gráficos y efectos de sonido que hacen que la ciudad y los coches se ven y suenan increíble.
- Altos requisitos del sistema que pueden no funcionar bien en PC más viejos o más débiles.
-
- Una gran y diversa ciudad de mundo abierto que puedes explorar y descubrir.
- Una historia repetitiva y superficial que puede no atraer a algunos jugadores.
-
- Una gran selección de coches, opciones de personalización y eventos para elegir.
- La falta de una opción de transmisión manual que puede decepcionar a algunos corredores hardcore.
-
- Un modo multijugador que te permite jugar con tus amigos online o offline.
- Algunos errores y fallos que pueden afectar el juego o el rendimiento del juego.
-
-
Carreras de la ciudad
-
¿Qué es City Racing y cuáles son sus características?
-
City Racing es un juego de carreras de coches gratis que te permite conducir por una gran ciudad y competir con otros corredores. Puede elegir entre diferentes coches, desde sedanes hasta autos deportivos, y personalizarlos con diferentes colores, ruedas, spoilers y más. También puede actualizar sus coches con mejores motores, frenos, neumáticos y suspensión. También puede reparar sus coches cuando se dañan o se ensucian.
-
-
¿Cómo descargar e instalar City Racing en PC Windows 7?
-
Para descargar e instalar City Racing en PC Windows 7, debe seguir estos pasos:
-
-
Ir a la página web oficial de City Racing y haga clic en el "Descargar" botón. Serás redirigido a una plataforma de terceros llamada GameTop, donde puedes descargar el juego gratis.
-
Después de descargar el archivo del juego, haga doble clic en él y siga el asistente de instalación. Es posible que necesite aceptar algunos términos y condiciones y elegir una carpeta de destino para el juego.
-
Después de la instalación se ha completado, puede iniciar el juego desde el acceso directo del escritorio o desde el menú de inicio. Disfrute!
-
-
Pros y contras de City Racing
-
City Racing es un juego de carreras de coches divertido y gratuito que ofrece mucha variedad y emoción. Sin embargo, también tiene algunos inconvenientes que debes tener en cuenta. Estos son algunos de los pros y contras de City Racing:
-
-
Pros
Contras
-
- Gratis para descargar y jugar sin limitaciones o anuncios.
- Gráficos y efectos de sonido de baja calidad que pueden no parecer o sonar atractivos.
-
- Una gran y diversa ciudad de mundo abierto que puedes explorar y disfrutar.
- La falta de un mapa o un sistema GPS que puede dificultar la navegación o encontrar el camino.
-
- Una amplia gama de coches, opciones de personalización y carreras para elegir.
- Un sistema de física poco realista y fácil que puede hacer la conducción demasiado simple o aburrido.
-
- Un modo multijugador que te permite jugar con tus amigos online o offline.
- Algunos malware o virus que pueden venir con el archivo del juego o la plataforma de terceros.
-
-
Conclusión
-
-
En este artículo, le hemos presentado algunos de los mejores juegos de carreras de coches para PC Windows 7 que puede descargar y jugar. También le hemos proporcionado alguna información sobre sus características, pros y contras, y cómo descargar e instalar confirmar que desea eliminar el juego de su PC.
-
Siga las instrucciones y avisos que aparecen en la pantalla para completar el proceso de actualización o desinstalación.
-
-
¿Dónde encontrar más juegos de carreras de coches para PC Windows 7?
-
Si está buscando más juegos de carreras de coches para PC Windows 7, puede consultar algunos de estos sitios web que ofrecen una variedad de juegos de forma gratuita o por una tarifa:
-
-
[GameTop]: Un sitio web que ofrece juegos de carreras de coches gratuitos y legales para PC Windows 7, como City Racing, Moto Racing y Super Bikes.
-
[Steam]: Un sitio web que ofrece una gran colección de juegos de carreras de coches para PC Windows 7, como BeamNG.drive, Assetto Corsa y Dirt Rally.
-
[Origin]: Un sitio web que ofrece algunos de los mejores juegos de carreras de coches para PC Windows 7, como Need for Speed, Burnout Paradise y Shift 2 Unleashed.
-
[GOG]: Un sitio web que ofrece juegos de carreras de coches clásicos y libres de DRM para PC Windows 7, como FlatOut, Carmageddon y Test Drive.
-
64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/Benson/text-generation/Examples/Descargar Entre Nosotros Gamejolt.md b/spaces/Benson/text-generation/Examples/Descargar Entre Nosotros Gamejolt.md
deleted file mode 100644
index 6eda80216b0c2f93ecb5695220b3d8996c724b20..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Descargar Entre Nosotros Gamejolt.md
+++ /dev/null
@@ -1,58 +0,0 @@
-
-
Cómo descargar entre nosotros desde GameJolt
-
Si está buscando un juego divertido y atractivo para jugar con sus amigos en línea, es posible que haya oído hablar de Among Us. Este es un juego multijugador donde tienes que trabajar junto con otros jugadores para arreglar una nave espacial mientras tratas de averiguar quién de ustedes es un impostor. En este artículo, explicaremos qué es Among Us, qué es GameJolt y cómo descargar e instalar Among Us desde GameJolt. También te daremos algunos consejos y trucos para jugar el juego y responder a algunas preguntas frecuentes.
Among Us es un juego que fue lanzado en 2018 por Innersloth, un estudio de juegos estadounidense. El juego fue inspirado por el juego de fiesta Mafia y la película de terror de ciencia ficción The Thing. El juego permite el juego multiplataforma, lo que significa que puedes jugarlo en diferentes dispositivos como Android, iOS, Windows, Nintendo Switch, PlayStation o Xbox.
-
Un juego de deducción social en el espacio
-
El juego se lleva a cabo en el espacio con temas de configuración donde los jugadores son coloridos, astronautas de dibujos animados sin brazos. Cada jugador toma uno de dos roles: la mayoría son compañeros de equipo, pero un pequeño número son impostores. Los compañeros de equipo trabajan para completar las tareas asignadas en el juego mientras identifican y expulsan a los presuntos Impostores (que parecen idénticos a los Compañeros de Equipo) por medio de deducción social, mientras que los Impostores tienen el objetivo de matar a los Compañeros de Equipo o sabotear un sistema crítico en el mapa.
-
El juego puede ser jugado por cuatro a quince jugadores, con hasta tres impostores por ronda. Hay cuatro mapas jugables disponibles: una nave espacial llamada "The Skeld", un edificio de oficinas llamado "MIRA HQ", una base planetaria llamada "Polus" o "The Airship", una configuración de la serie de Innersloth Henry Stickmin.
-
¿Por qué es tan popular?
-
-
El juego es simple y al estilo de fiesta, con los jugadores asumiendo el papel de una persona del espacio de dibujos animados a bordo de una nave que necesita algunas reparaciones bastante urgentes. Es un juego sobre el trabajo en equipo, donde trabajan juntos para averiguar quién puede y no se puede confiar dentro del grupo de jugadores. Esto puede ser un beneficio, ya que ayuda a perfeccionar la lógica y las habilidades sociales de los niños, especialmente durante un momento en que los niños pueden estar atrapados en casa y necesitan socialización.
-
¿Qué es GameJolt?
-
GameJolt es una plataforma para juegos indie, donde los desarrolladores pueden compartir sus creaciones con jugadores de todo el mundo. GameJolt alberga miles de juegos de varios géneros, como acción, aventura, terror, rompecabezas, simulación, estrategia y más. Puedes encontrar juegos gratuitos o de pago, completos o en desarrollo, para un jugador o multijugador.
-
Una plataforma para juegos indie
-
GameJolt fue fundada en 2004 por David DeCarmine como una forma de mostrar sus propios juegos. Desde entonces, se ha convertido en un sitio impulsado por la comunidad que apoya a los desarrolladores independientes y los jugadores por igual. GameJolt permite a los desarrolladores subir sus juegos, establecer sus propios precios, obtener ingresos de anuncios o donaciones , e interactuar con sus fans. GameJolt también cuenta con un sistema de clasificación, un sistema de trofeos, un sistema de chat, un foro y un blog para cada juego.
-
-
Cómo crear una cuenta y navegar por los juegos
-
Para usar GameJolt, primero necesitas crear una cuenta. Puedes registrarte con tu dirección de correo electrónico o tus cuentas de redes sociales, como Facebook, Twitter o Google. Una vez que tenga una cuenta, puede personalizar su perfil, seguir sus juegos y desarrolladores favoritos, unirse a grupos y ganar trofeos y puntos XP.
-
-
Cómo descargar e instalar Entre nosotros desde GameJolt
-
Ahora que sabes lo que entre nosotros y GameJolt son, vamos a ver cómo se puede descargar e instalar entre nosotros desde GameJolt. El proceso es simple y sencillo, pero debe asegurarse de que tiene un dispositivo compatible y suficiente espacio de almacenamiento. Estos son los pasos a seguir:
-
Paso 1: Encuentra el juego en GameJolt
-
El primer paso es encontrar el juego en GameJolt. Puedes usar este enlace para ir directamente a la página del juego: https://gamejolt.com/games/among-us/516139. Alternativamente, puede buscar "Entre nosotros" en el sitio web de GameJolt y buscar el juego con el logotipo oficial y el nombre del desarrollador "Innersloth".
-
En la página del juego, verá una breve descripción del juego, algunas capturas de pantalla y videos, la calificación y comentarios, y las opciones de descarga. También verás un botón que dice "Seguir" si quieres ser notificado de cualquier actualización o noticia sobre el juego.
-
Paso 2: Elija la versión y descargue el archivo
-
El siguiente paso es elegir la versión del juego que desea descargar. Hay dos versiones disponibles en GameJolt: una para Windows y otra para Android. La versión para Windows es de 57 MB y la versión para Android es de 70 MB. Asegúrese de que tiene suficiente espacio de almacenamiento en su dispositivo antes de descargar.
-
Para descargar el archivo, haga clic en el botón verde que dice "Descargar" junto a la versión que desee. Será redirigido a otra página donde verá un temporizador de cuenta atrás. Espere unos segundos hasta que el temporizador llegue a cero y luego haga clic en el botón azul que dice "Descargar ahora". El archivo comenzará a descargarse automáticamente.
-
Paso 3: Extraer el archivo y ejecutar el juego
-
-
Una vez que haya extraído el archivo, verá una carpeta llamada "Entre nosotros". Ábrala y busque el archivo ejecutable que tiene el logotipo del juego. Haga doble clic en él para ejecutar el juego. Verá una ventana que le pide que elija su idioma. Seleccione su idioma preferido y haga clic en "Aceptar". El juego se iniciará y verás el menú principal.
-
Consejos y trucos para jugar entre nosotros
-
Felicidades! Usted ha descargado e instalado con éxito entre nosotros de GameJolt. Ahora usted está listo para jugar el juego con sus amigos u otros jugadores en línea. Pero antes de entrar en un juego, aquí hay algunos consejos y trucos que te ayudarán a disfrutar más del juego:
-
Cómo personalizar el carácter y la configuración
-
Antes de unirse o alojar un juego, puede personalizar su personaje y la configuración en el menú principal. Para personalizar tu personaje, haz clic en "Personalizar" en la esquina inferior derecha de la pantalla. Puede cambiar su nombre, color, sombrero, mascota, piel o atuendo haciendo clic en ellos. También puede usar flechas para desplazarse a través de diferentes opciones.
-
Para personalizar la configuración, haga clic en "Configuración" en la esquina inferior izquierda de la pantalla. Puede ajustar varias opciones como efectos de sonido, volumen de música, calidad de gráficos, resolución, modo de pantalla completa, idioma o tipo de chat haciendo clic en ellos. También puede usar deslizadores o botones para cambiar los valores. Para restablecer los valores predeterminados, haga clic en "Restablecer a Predeterminado" en la parte inferior de la pantalla.
-
Cómo unirse o organizar un juego en línea o localmente
-
Para unirse o alojar un juego en línea o localmente, haga clic en "Online" o "Local" en el menú principal. Si eliges "Online", puedes unirte a un juego público, crear un juego privado o introducir un código para unirte a un juego privado. Si eliges "Local", puedes alojar un juego o unirte a un juego alojado en la misma red Wi-Fi que tú.
-
-
Cómo jugar como un compañero de equipo o un impostor
-
Una vez que comience el juego, serás asignado como Compañero de Equipo o Impostor. Su papel se mostrará en la pantalla junto con sus compañeros de equipo si usted es un impostor. También verás una lista de tareas que necesitas completar si eres un Crewmate.
-
Si usted es un compañero de equipo, su objetivo es completar sus tareas y averiguar quiénes son los impostores. Puede moverse por el mapa utilizando el joystick en el lado izquierdo de la pantalla e interactuar con los objetos utilizando el botón en el lado derecho de la pantalla. También puede usar respiraderos, cámaras, tabla de administración, signos vitales o registro de puertas para recopilar información. Puedes reportar un cadáver o llamar a una reunión de emergencia si encuentras algo sospechoso. A continuación, puede votar por quien cree que es un impostor o saltar la votación si no está seguro.
-
Si eres un impostor, tu objetivo es matar a todos los compañeros de equipo o sabotear un sistema crítico. Puedes moverte por el mapa e interactuar con objetos como un compañero de equipo, pero también tienes algunas habilidades especiales. Puedes usar los respiraderos para viajar rápida y discretamente, matar a los Compañeros de Tripulación cuando están solos o en grupos, y sabotear los sistemas para causar caos o distraer a los Compañeros de Equipo. También puede falsificar tareas, mentir y acusar a otros para evitar sospechas. Puede votar por quién desea eliminar o omitir el voto si desea mezclarse.
-
Conclusión y preguntas frecuentes
-
En conclusión, Entre nosotros es un juego divertido y atractivo que puedes jugar con tus amigos en línea o localmente. Puedes descargarlo e instalarlo desde GameJolt siguiendo los pasos que hemos explicado en este artículo. También puedes personalizar tu personaje y tu configuración, unirte o organizar un juego y jugar como Crewmate o Impostor. Esperamos que este artículo te haya ayudado a aprender más sobre Among Us y GameJolt y que disfrutes jugando el juego.
-
Aquí hay algunas preguntas frecuentes que puede tener sobre Among Us y GameJolt:
-
Q: ¿Cuánto cuesta Among Us en GameJolt?
-
-
Q: ¿Puedo jugar entre nosotros con personas que tienen diferentes dispositivos?
-
A: Sí, puedes jugar entre nosotros con personas que tienen diferentes dispositivos, siempre y cuando tengan la misma versión del juego. El juego admite el juego multiplataforma entre dispositivos Android, iOS, Windows, Nintendo Switch, PlayStation y Xbox.
-
Q: ¿Cómo puedo actualizar entre nosotros en GameJolt?
-
A: Para actualizar entre nosotros en GameJolt, es necesario descargar e instalar la última versión del juego de GameJolt. Puedes comprobar si hay una nueva versión disponible visitando la página del juego en GameJolt y buscando actualizaciones o noticias de los desarrolladores.
-
Q: ¿Cómo puedo reportar errores o problemas con Among Us?
-
A: Si encuentra algún error o problema con Among Us, puede informar a los desarrolladores utilizando su dirección de correo electrónico oficial: support@innersloth.com. También puede utilizar su servidor de discordia: https://discord.gg/innersloth.
-
Q: ¿Cómo puedo encontrar más juegos como Entre nosotros en GameJolt?
-
A: Si te gusta Among Us y quieres encontrar más juegos como Among Us en GameJolt, puedes usar las etiquetas o los géneros para filtrar los juegos. Por ejemplo, puedes buscar juegos que tengan etiquetas como "multijugador", "deducción social", "misterio de asesinato", "espacio" o "horror". También puedes buscar juegos que pertenezcan a géneros como "acción", "aventura", "rompecabezas" o "simulación". También puede navegar por los juegos destacados, populares o de tendencia en GameJolt para descubrir juegos nuevos y emocionantes.
.+?)"
- r"/I\:(?P.+?)\-(?P.+?)\@(?P.+?)\+(?P.+?)\&(?P.+?)\-(?P.+?)\|(?P.+?)\+(?P.+?)" # noqa
- r"/J\:(?P.+?)\_(?P.+?)"
- r"/K\:(?P.+?)\+(?P.+?)\-(?P.+?)$",
- label,
- ).groupdict()
- return cls(contexts=contexts)
-
- @property
- def label(self):
- """
- pyopenjtalk.extract_fullcontextで得られるラベルと等しい
- Returns
- -------
- lebel: str
- ラベルを返す
- """
- return (
- "{p1}^{p2}-{p3}+{p4}={p5}"
- "/A:{a1}+{a2}+{a3}"
- "/B:{b1}-{b2}_{b3}"
- "/C:{c1}_{c2}+{c3}"
- "/D:{d1}+{d2}_{d3}"
- "/E:{e1}_{e2}!{e3}_{e4}-{e5}"
- "/F:{f1}_{f2}#{f3}_{f4}@{f5}_{f6}|{f7}_{f8}"
- "/G:{g1}_{g2}%{g3}_{g4}_{g5}"
- "/H:{h1}_{h2}"
- "/I:{i1}-{i2}@{i3}+{i4}&{i5}-{i6}|{i7}+{i8}"
- "/J:{j1}_{j2}"
- "/K:{k1}+{k2}-{k3}"
- ).format(**self.contexts)
-
- @property
- def phoneme(self):
- """
- 音素クラスの中で、発声に必要な要素を返す
- Returns
- -------
- phoneme : str
- 発声に必要な要素を返す
- """
- return self.contexts["p3"]
-
- def is_pause(self):
- """
- 音素がポーズ(無音、silent/pause)であるかを返す
- Returns
- -------
- is_pose : bool
- 音素がポーズ(無音、silent/pause)であるか(True)否か(False)
- """
- return self.contexts["f1"] == "xx"
-
- def __repr__(self):
- return f""
-
-
-@dataclass
-class Mora:
- """
- モーラクラス
- モーラは1音素(母音や促音「っ」、撥音「ん」など)か、2音素(母音と子音の組み合わせ)で成り立つ
-
- Attributes
- ----------
- consonant : Optional[Phoneme]
- 子音
- vowel : Phoneme
- 母音
- """
-
- consonant: Optional[Phoneme]
- vowel: Phoneme
-
- def set_context(self, key: str, value: str):
- """
- Moraクラス内に含まれるPhonemeのcontextのうち、指定されたキーの値を変更する
- consonantが存在する場合は、vowelと同じようにcontextを変更する
- Parameters
- ----------
- key : str
- 変更したいcontextのキー
- value : str
- 変更したいcontextの値
- """
- self.vowel.contexts[key] = value
- if self.consonant is not None:
- self.consonant.contexts[key] = value
-
- @property
- def phonemes(self):
- """
- 音素群を返す
- Returns
- -------
- phonemes : List[Phoneme]
- 母音しかない場合は母音のみ、子音もある場合は子音、母音の順番でPhonemeのリストを返す
- """
- if self.consonant is not None:
- return [self.consonant, self.vowel]
- else:
- return [self.vowel]
-
- @property
- def labels(self):
- """
- ラベル群を返す
- Returns
- -------
- labels : List[str]
- Moraに含まれるすべてのラベルを返す
- """
- return [p.label for p in self.phonemes]
-
-
-@dataclass
-class AccentPhrase:
- """
- アクセント句クラス
- 同じアクセントのMoraを複数保持する
- Attributes
- ----------
- moras : List[Mora]
- 音韻のリスト
- accent : int
- アクセント
- """
-
- moras: List[Mora]
- accent: int
- is_interrogative: bool
-
- @classmethod
- def from_phonemes(cls, phonemes: List[Phoneme]):
- """
- PhonemeのリストからAccentPhraseクラスを作成する
- Parameters
- ----------
- phonemes : List[Phoneme]
- phonemeのリストを渡す
-
- Returns
- -------
- accent_phrase : AccentPhrase
- AccentPhraseクラスを返す
- """
- moras: List[Mora] = []
-
- mora_phonemes: List[Phoneme] = []
- for phoneme, next_phoneme in zip(phonemes, phonemes[1:] + [None]):
- # workaround for Hihosiba/voicevox_engine#57
- # (py)openjtalk によるアクセント句内のモーラへの附番は 49 番目まで
- # 49 番目のモーラについて、続く音素のモーラ番号を単一モーラの特定に使えない
- if int(phoneme.contexts["a2"]) == 49:
- break
-
- mora_phonemes.append(phoneme)
-
- if (
- next_phoneme is None
- or phoneme.contexts["a2"] != next_phoneme.contexts["a2"]
- ):
- if len(mora_phonemes) == 1:
- consonant, vowel = None, mora_phonemes[0]
- elif len(mora_phonemes) == 2:
- consonant, vowel = mora_phonemes[0], mora_phonemes[1]
- else:
- raise ValueError(mora_phonemes)
- mora = Mora(consonant=consonant, vowel=vowel)
- moras.append(mora)
- mora_phonemes = []
-
- accent = int(moras[0].vowel.contexts["f2"])
- # workaround for Hihosiba/voicevox_engine#55
- # アクセント位置とするキー f2 の値がアクセント句内のモーラ数を超える場合がある
- accent = accent if accent <= len(moras) else len(moras)
- is_interrogative = moras[-1].vowel.contexts["f3"] == "1"
- return cls(moras=moras, accent=accent, is_interrogative=is_interrogative)
-
- def set_context(self, key: str, value: str):
- """
- AccentPhraseに間接的に含まれる全てのPhonemeのcontextの、指定されたキーの値を変更する
- Parameters
- ----------
- key : str
- 変更したいcontextのキー
- value : str
- 変更したいcontextの値
- """
- for mora in self.moras:
- mora.set_context(key, value)
-
- @property
- def phonemes(self):
- """
- 音素群を返す
- Returns
- -------
- phonemes : List[Phoneme]
- AccentPhraseに間接的に含まれる全てのPhonemeを返す
- """
- return list(chain.from_iterable(m.phonemes for m in self.moras))
-
- @property
- def labels(self):
- """
- ラベル群を返す
- Returns
- -------
- labels : List[str]
- AccentPhraseに間接的に含まれる全てのラベルを返す
- """
- return [p.label for p in self.phonemes]
-
- def merge(self, accent_phrase: "AccentPhrase"):
- """
- AccentPhraseを合成する
- (このクラスが保持するmorasの後ろに、引数として渡されたAccentPhraseのmorasを合成する)
- Parameters
- ----------
- accent_phrase : AccentPhrase
- 合成したいAccentPhraseを渡す
-
- Returns
- -------
- accent_phrase : AccentPhrase
- 合成されたAccentPhraseを返す
- """
- return AccentPhrase(
- moras=self.moras + accent_phrase.moras,
- accent=self.accent,
- is_interrogative=accent_phrase.is_interrogative,
- )
-
-
-@dataclass
-class BreathGroup:
- """
- 発声の区切りクラス
- アクセントの異なるアクセント句を複数保持する
- Attributes
- ----------
- accent_phrases : List[AccentPhrase]
- アクセント句のリスト
- """
-
- accent_phrases: List[AccentPhrase]
-
- @classmethod
- def from_phonemes(cls, phonemes: List[Phoneme]):
- """
- PhonemeのリストからBreathGroupクラスを作成する
- Parameters
- ----------
- phonemes : List[Phoneme]
- phonemeのリストを渡す
-
- Returns
- -------
- breath_group : BreathGroup
- BreathGroupクラスを返す
- """
- accent_phrases: List[AccentPhrase] = []
- accent_phonemes: List[Phoneme] = []
- for phoneme, next_phoneme in zip(phonemes, phonemes[1:] + [None]):
- accent_phonemes.append(phoneme)
-
- if (
- next_phoneme is None
- or phoneme.contexts["i3"] != next_phoneme.contexts["i3"]
- or phoneme.contexts["f5"] != next_phoneme.contexts["f5"]
- ):
- accent_phrase = AccentPhrase.from_phonemes(accent_phonemes)
- accent_phrases.append(accent_phrase)
- accent_phonemes = []
-
- return cls(accent_phrases=accent_phrases)
-
- def set_context(self, key: str, value: str):
- """
- BreathGroupに間接的に含まれる全てのPhonemeのcontextの、指定されたキーの値を変更する
- Parameters
- ----------
- key : str
- 変更したいcontextのキー
- value : str
- 変更したいcontextの値
- """
- for accent_phrase in self.accent_phrases:
- accent_phrase.set_context(key, value)
-
- @property
- def phonemes(self):
- """
- 音素群を返す
- Returns
- -------
- phonemes : List[Phoneme]
- BreathGroupに間接的に含まれる全てのPhonemeを返す
- """
- return list(
- chain.from_iterable(
- accent_phrase.phonemes for accent_phrase in self.accent_phrases
- )
- )
-
- @property
- def labels(self):
- """
- ラベル群を返す
- Returns
- -------
- labels : List[str]
- BreathGroupに間接的に含まれる全てのラベルを返す
- """
- return [p.label for p in self.phonemes]
-
-
-@dataclass
-class Utterance:
- """
- 発声クラス
- 発声の区切りと無音を複数保持する
- Attributes
- ----------
- breath_groups : List[BreathGroup]
- 発声の区切りのリスト
- pauses : List[Phoneme]
- 無音のリスト
- """
-
- breath_groups: List[BreathGroup]
- pauses: List[Phoneme]
-
- @classmethod
- def from_phonemes(cls, phonemes: List[Phoneme]):
- """
- Phonemeの完全なリストからUtteranceクラスを作成する
- Parameters
- ----------
- phonemes : List[Phoneme]
- phonemeのリストを渡す
-
- Returns
- -------
- utterance : Utterance
- Utteranceクラスを返す
- """
- pauses: List[Phoneme] = []
-
- breath_groups: List[BreathGroup] = []
- group_phonemes: List[Phoneme] = []
- for phoneme in phonemes:
- if not phoneme.is_pause():
- group_phonemes.append(phoneme)
-
- else:
- pauses.append(phoneme)
-
- if len(group_phonemes) > 0:
- breath_group = BreathGroup.from_phonemes(group_phonemes)
- breath_groups.append(breath_group)
- group_phonemes = []
-
- return cls(breath_groups=breath_groups, pauses=pauses)
-
- def set_context(self, key: str, value: str):
- """
- Utteranceに間接的に含まれる全てのPhonemeのcontextの、指定されたキーの値を変更する
- Parameters
- ----------
- key : str
- 変更したいcontextのキー
- value : str
- 変更したいcontextの値
- """
- for breath_group in self.breath_groups:
- breath_group.set_context(key, value)
-
- @property
- def phonemes(self):
- """
- 音素群を返す
- Returns
- -------
- phonemes : List[Phoneme]
- Utteranceクラスに直接的・間接的に含まれる、全てのPhonemeを返す
- """
- accent_phrases = list(
- chain.from_iterable(
- breath_group.accent_phrases for breath_group in self.breath_groups
- )
- )
- for prev, cent, post in zip(
- [None] + accent_phrases[:-1],
- accent_phrases,
- accent_phrases[1:] + [None],
- ):
- mora_num = len(cent.moras)
- accent = cent.accent
-
- if prev is not None:
- prev.set_context("g1", str(mora_num))
- prev.set_context("g2", str(accent))
-
- if post is not None:
- post.set_context("e1", str(mora_num))
- post.set_context("e2", str(accent))
-
- cent.set_context("f1", str(mora_num))
- cent.set_context("f2", str(accent))
- for i_mora, mora in enumerate(cent.moras):
- mora.set_context("a1", str(i_mora - accent + 1))
- mora.set_context("a2", str(i_mora + 1))
- mora.set_context("a3", str(mora_num - i_mora))
-
- for prev, cent, post in zip(
- [None] + self.breath_groups[:-1],
- self.breath_groups,
- self.breath_groups[1:] + [None],
- ):
- accent_phrase_num = len(cent.accent_phrases)
-
- if prev is not None:
- prev.set_context("j1", str(accent_phrase_num))
-
- if post is not None:
- post.set_context("h1", str(accent_phrase_num))
-
- cent.set_context("i1", str(accent_phrase_num))
- cent.set_context(
- "i5", str(accent_phrases.index(cent.accent_phrases[0]) + 1)
- )
- cent.set_context(
- "i6",
- str(len(accent_phrases) - accent_phrases.index(cent.accent_phrases[0])),
- )
-
- self.set_context(
- "k2",
- str(
- sum(
- [
- len(breath_group.accent_phrases)
- for breath_group in self.breath_groups
- ]
- )
- ),
- )
-
- phonemes: List[Phoneme] = []
- for i in range(len(self.pauses)):
- if self.pauses[i] is not None:
- phonemes += [self.pauses[i]]
-
- if i < len(self.pauses) - 1:
- phonemes += self.breath_groups[i].phonemes
-
- return phonemes
-
- @property
- def labels(self):
- """
- ラベル群を返す
- Returns
- -------
- labels : List[str]
- Utteranceクラスに直接的・間接的に含まれる全てのラベルを返す
- """
- return [p.label for p in self.phonemes]
-
-
-def extract_full_context_label(text: str):
- labels = pyopenjtalk.extract_fullcontext(text)
- phonemes = [Phoneme.from_label(label=label) for label in labels]
- utterance = Utterance.from_phonemes(phonemes)
- return utterance
diff --git a/spaces/Gradio-Blocks/uniformer_image_segmentation/mmseg/core/__init__.py b/spaces/Gradio-Blocks/uniformer_image_segmentation/mmseg/core/__init__.py
deleted file mode 100644
index 965605587211b7bf0bd6bc3acdbb33dd49cab023..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_segmentation/mmseg/core/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .evaluation import * # noqa: F401, F403
-from .seg import * # noqa: F401, F403
-from .utils import * # noqa: F401, F403
diff --git a/spaces/HCMUT-GraduateThesis-HNTThinh/rgbdsod-multimae-demo/s_multimae/evaluation_metrics.py b/spaces/HCMUT-GraduateThesis-HNTThinh/rgbdsod-multimae-demo/s_multimae/evaluation_metrics.py
deleted file mode 100644
index 025dd51ca15e941a975abc0f919fc86c38391b72..0000000000000000000000000000000000000000
--- a/spaces/HCMUT-GraduateThesis-HNTThinh/rgbdsod-multimae-demo/s_multimae/evaluation_metrics.py
+++ /dev/null
@@ -1,64 +0,0 @@
-import numpy as np
-from py_sod_metrics import MAE, Emeasure, Fmeasure, Smeasure
-
-def ndarray_to_basetype(data):
- def _to_list_or_scalar(item):
- listed_item = item.tolist()
- if isinstance(listed_item, list) and len(listed_item) == 1:
- listed_item = listed_item[0]
- return listed_item
-
- if isinstance(data, (tuple, list)):
- results = [_to_list_or_scalar(item) for item in data]
- elif isinstance(data, dict):
- results = {k: _to_list_or_scalar(item) for k, item in data.items()}
- else:
- assert isinstance(data, np.ndarray)
- results = _to_list_or_scalar(data)
- return results
-
-
-class CalTotalMetric(object):
- def __init__(self):
- self.mae = MAE()
- self.fm = Fmeasure()
- self.sm = Smeasure()
- self.em = Emeasure()
- # self.wfm = WeightedFmeasure()
-
- def step(self, pre: np.ndarray, gt: np.ndarray):
- assert pre.shape == gt.shape
- assert pre.dtype == np.uint8
- assert gt.dtype == np.uint8
-
- self.mae.step(pre, gt)
- self.sm.step(pre, gt)
- self.fm.step(pre, gt)
- self.em.step(pre, gt)
- # self.wfm.step(pre, gt)
-
- def get_results(self, num_bits: int = 8, return_ndarray: bool = False) -> dict:
- fm_info = self.fm.get_results()
- fm = fm_info["fm"]
- # pr = fm_info["pr"]
- # wfm = self.wfm.get_results()["wfm"]
- sm = self.sm.get_results()["sm"]
- em = self.em.get_results()["em"]
- mae = self.mae.get_results()["mae"]
-
- numerical_results = {
- "SM": sm,
- "MAE": mae,
- "maxE": em["curve"].max(),
- # "avgE": em["curve"].mean(),
- # "adpE": em["adp"],
- "maxF": fm["curve"].max(),
- # "avgF": fm["curve"].mean(),
- # "adpF": fm["adp"],
- # "wFm": wfm,
- }
- if num_bits is not None and isinstance(num_bits, int):
- numerical_results = {k: v.round(num_bits) for k, v in numerical_results.items()}
- if not return_ndarray:
- numerical_results = ndarray_to_basetype(numerical_results)
- return numerical_results
\ No newline at end of file
diff --git a/spaces/Hahsgsgsy/teston/README.md b/spaces/Hahsgsgsy/teston/README.md
deleted file mode 100644
index d46e03d6fcbf8b856bfd15a033a702635338207f..0000000000000000000000000000000000000000
--- a/spaces/Hahsgsgsy/teston/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Teston
-emoji: 📉
-colorFrom: gray
-colorTo: green
-sdk: streamlit
-sdk_version: 1.19.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/wav2vec/unsupervised/kaldi_self_train/st/local/prepare_lang.sh b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/wav2vec/unsupervised/kaldi_self_train/st/local/prepare_lang.sh
deleted file mode 100644
index e9a80001eb47d5af863d6aab11a59362a59cef61..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/wav2vec/unsupervised/kaldi_self_train/st/local/prepare_lang.sh
+++ /dev/null
@@ -1,37 +0,0 @@
-#!/bin/bash
-
-sil_prob=0.5
-num_sil_states=3
-num_nonsil_states=1
-
-. ./cmd.sh
-. ./path.sh
-. parse_options.sh
-
-set -eux
-
-dict=$1
-data_dir=$2
-
-dict_dir=$data_dir/local/dict
-tmplm_dir=$data_dir/local/lang_tmp
-lm_dir=$data_dir/lang
-
-mkdir -p $dict_dir $tmplm_dir $lm_dir
-
-# prepare dict
-echo "SIL" > $dict_dir/silence_phones.txt
-echo "SIL" > $dict_dir/optional_silence.txt
-awk '{print $1}' $dict > $dict_dir/nonsilence_phones.txt
-
-echo "SIL SIL" > $dict_dir/lexicon.txt
-echo " SIL" >> $dict_dir/lexicon.txt
-awk '{print $1" "$1}' $dict >> $dict_dir/lexicon.txt
-
-echo "SIL" > $dict_dir/extra_questions.txt
-awk '{printf $1" "} END {printf "\n"}' $dict >> $dict_dir/extra_questions.txt
-
-# prepare lang
-utils/prepare_lang.sh --sil-prob $sil_prob --position-dependent-phones false \
- --num_sil_states $num_sil_states --num_nonsil_states $num_nonsil_states \
- $dict_dir "" $tmplm_dir $lm_dir
diff --git a/spaces/Harveenchadha/Vakyansh-Hindi-TTS/ttsv/utils/inference/advanced_tts.py b/spaces/Harveenchadha/Vakyansh-Hindi-TTS/ttsv/utils/inference/advanced_tts.py
deleted file mode 100644
index 6f8e2f5870e0f7dcd28c35c71cde58de6f1ae415..0000000000000000000000000000000000000000
--- a/spaces/Harveenchadha/Vakyansh-Hindi-TTS/ttsv/utils/inference/advanced_tts.py
+++ /dev/null
@@ -1,155 +0,0 @@
-
-from .tts import TextToMel, MelToWav
-from .transliterate import XlitEngine
-from .num_to_word_on_sent import normalize_nums
-
-import re
-import numpy as np
-from scipy.io.wavfile import write
-
-from mosestokenizer import *
-from indicnlp.tokenize import sentence_tokenize
-import argparse
-
-_INDIC = ["as", "bn", "gu", "hi", "kn", "ml", "mr", "or", "pa", "ta", "te"]
-_PURAM_VIRAM_LANGUAGES = ["hi", "or", "bn", "as"]
-_TRANSLITERATION_NOT_AVAILABLE_IN = ["en","or"]
-#_NUM2WORDS_NOT_AVAILABLE_IN = []
-
-def normalize_text(text, lang):
- if lang in _PURAM_VIRAM_LANGUAGES:
- text = text.replace('|', '।')
- text = text.replace('.', '।')
- return text
-
-def split_sentences(paragraph, language):
- if language == "en":
- with MosesSentenceSplitter(language) as splitter:
- return splitter([paragraph])
- elif language in _INDIC:
- return sentence_tokenize.sentence_split(paragraph, lang=language)
-
-
-
-def load_models(acoustic, vocoder, device):
- text_to_mel = TextToMel(glow_model_dir=acoustic, device=device)
- mel_to_wav = MelToWav(hifi_model_dir=vocoder, device=device)
- return text_to_mel, mel_to_wav
-
-
-def translit(text, lang):
- reg = re.compile(r'[a-zA-Z]')
- words = [engine.translit_word(word, topk=1)[lang][0] if reg.match(word) else word for word in text.split()]
- updated_sent = ' '.join(words)
- return updated_sent
-
-
-
-def run_tts(text, lang, args):
- if lang == 'hi':
- text = text.replace('।', '.') # only for hindi models
-
- if lang == 'en' and text[-1] != '.':
- text = text + '. '
-
- if args.number_conversion == 1 and lang!='en':
- print("Doing number conversion")
- text_num_to_word = normalize_nums(text, lang) # converting numbers to words in lang
- else:
- text_num_to_word = text
-
-
- if args.transliteration == 1 and lang not in _TRANSLITERATION_NOT_AVAILABLE_IN:
- print("Doing transliteration")
- text_num_to_word_and_transliterated = translit(text_num_to_word, lang) # transliterating english words to lang
- else:
- text_num_to_word_and_transliterated = text_num_to_word
-
- final_text = ' ' + text_num_to_word_and_transliterated
- print(final_text)
- mel = text_to_mel.generate_mel(final_text, args.noise_scale, args.length_scale)
- audio, sr = mel_to_wav.generate_wav(mel)
- return sr, audio
-
-def run_tts_paragraph(args):
- audio_list = []
-
- global text_to_mel
- global mel_to_wav
-
- if args.gender == 'Male':
- text_to_mel = text_to_mel_list[1]
- mel_to_wav = mel_to_wav_list[1]
- else:
- text_to_mel = text_to_mel_list[0]
- mel_to_wav = mel_to_wav_list[0]
-
-
- if args.split_sentences == 1:
- text = normalize_text(args.text, args.lang)
- split_sentences_list = split_sentences(text, args.lang)
-
- for sent in split_sentences_list:
-
- sr, audio = run_tts(sent, args.lang, args)
- audio_list.append(audio)
-
- concatenated_audio = np.concatenate([i for i in audio_list])
- if args.wav:
- write(filename=args.wav, rate=sr, data=concatenated_audio)
- return (sr, concatenated_audio)
- else:
- sr, audio = run_tts(args.text, args.lang, args)
- if args.wav:
- write(filename=args.wav, rate=sr, data=audio)
- return (sr, audio)
-
-
-def load_all_models(args):
- global engine
- if args.lang not in _TRANSLITERATION_NOT_AVAILABLE_IN:
- engine = XlitEngine(args.lang) # loading translit model globally
-
- global text_to_mel_list
- global mel_to_wav_list
-
-
- text_to_mel_list = []
- mel_to_wav_list = []
-
- for acoustic, vocoder in zip( args.acoustic.split(',') , args.vocoder.split(',') ):
- ttm, mtw = load_models(acoustic, vocoder, args.device)
- text_to_mel_list.append(ttm)
- mel_to_wav_list.append(mtw)
-
- try:
- args.noise_scale = float(args.noise_scale)
- args.length_scale = float(args.length_scale)
- except:
- pass
-
- print(args)
-
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("-a", "--acoustic", required=True, type=str)
- parser.add_argument("-v", "--vocoder", required=True, type=str)
- parser.add_argument("-d", "--device", type=str, default="cpu")
- parser.add_argument("-t", "--text", type=str, required=True)
- parser.add_argument("-w", "--wav", type=str, required=True)
- parser.add_argument("-n", "--noise-scale", default='0.667', type=str )
- parser.add_argument("-l", "--length-scale", default='1.0', type=str)
-
- parser.add_argument("-T", "--transliteration", default=1, type=int)
- parser.add_argument("-N", "--number-conversion", default=1, type=int)
- parser.add_argument("-S", "--split-sentences", default=1, type=int)
- parser.add_argument("-L", "--lang", type=str, required=True)
-
- args = parser.parse_args()
-
- load_all_models(args)
- run_tts_paragraph(args)
-
-
diff --git a/spaces/Harveenchadha/en_to_indic_translation/legacy/apply_bpe_test_valid_notag.sh b/spaces/Harveenchadha/en_to_indic_translation/legacy/apply_bpe_test_valid_notag.sh
deleted file mode 100644
index f152770c4ad7d5c13f72b492d50ffff238ff44f0..0000000000000000000000000000000000000000
--- a/spaces/Harveenchadha/en_to_indic_translation/legacy/apply_bpe_test_valid_notag.sh
+++ /dev/null
@@ -1,33 +0,0 @@
-#!/bin/bash
-
-expdir=$1 # EXPDIR
-org_data_dir=$2
-langs=$3
-
-#`dirname $0`/env.sh
-SUBWORD_NMT_DIR="subword-nmt"
-echo "Apply to each language"
-
-for dset in `echo test dev`
-do
- echo $dset
-
- in_dset_dir="$org_data_dir/$dset"
- out_dset_dir="$expdir/bpe/$dset"
-
- for lang in $langs
- do
-
- echo Apply BPE for $dset "-" $lang
-
- mkdir -p $out_dset_dir
-
- python $SUBWORD_NMT_DIR/subword_nmt/apply_bpe.py \
- -c $expdir/vocab/bpe_codes.32k.SRC_TGT \
- --vocabulary $expdir/vocab/vocab.SRC \
- --vocabulary-threshold 5 \
- < $in_dset_dir/$dset.$lang \
- > $out_dset_dir/$dset.$lang
-
- done
-done
diff --git a/spaces/Hexamind/swarms/README.md b/spaces/Hexamind/swarms/README.md
deleted file mode 100644
index db90d4b4daffc07b41cc6e4b279cb08d7c025fbd..0000000000000000000000000000000000000000
--- a/spaces/Hexamind/swarms/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: Swarms
-emoji: 👁
-colorFrom: yellow
-colorTo: pink
-sdk: streamlit
-sdk_version: 1.21.0
-python_version: "3.10"
-app_file: app.py
-pinned: false
-license: bsd-2-clause
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/ICML2022/OFA/fairseq/examples/speech_text_joint_to_text/README.md b/spaces/ICML2022/OFA/fairseq/examples/speech_text_joint_to_text/README.md
deleted file mode 100644
index e071d241e0e02b35d3aac777ac09b4ef3be9119f..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/examples/speech_text_joint_to_text/README.md
+++ /dev/null
@@ -1,46 +0,0 @@
-# Joint Speech Text training in Fairseq
-An extension of Fairseq s2t project with the speech to text task enhanced by the co-trained text to text mapping task. More details about Fairseq s2t can be found [here](../speech_to_text/README.md)
-
-## Examples
-Examples of speech text joint training in fairseq
-- [English-to-German MuST-C model](docs/ende-mustc.md)
-- [IWSLT 2021 Multilingual Speech Translation](docs/iwslt2021.md)
-
-## Citation
-Please cite as:
-```
-@inproceedings{Tang2021AGM,
- title={A General Multi-Task Learning Framework to Leverage Text Data for Speech to Text Tasks},
- author={Yun Tang and J. Pino and Changhan Wang and Xutai Ma and Dmitriy Genzel},
- booktitle={ICASSP},
- year={2021}
-}
-
-@inproceedings{Tang2021IST,
- title = {Improving Speech Translation by Understanding and Learning from the Auxiliary Text Translation Task},
- author = {Yun Tang and Juan Pino and Xian Li and Changhan Wang and Dmitriy Genzel},
- booktitle = {ACL},
- year = {2021},
-}
-
-@inproceedings{Tang2021FST,
- title = {FST: the FAIR Speech Translation System for the IWSLT21 Multilingual Shared Task},
- author = {Yun Tang and Hongyu Gong and Xian Li and Changhan Wang and Juan Pino and Holger Schwenk and Naman Goyal},
- booktitle = {IWSLT},
- year = {2021},
-}
-
-@inproceedings{wang2020fairseqs2t,
- title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
- author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
- booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
- year = {2020},
-}
-
-@inproceedings{ott2019fairseq,
- title = {fairseq: A Fast, Extensible Toolkit for Sequence Modeling},
- author = {Myle Ott and Sergey Edunov and Alexei Baevski and Angela Fan and Sam Gross and Nathan Ng and David Grangier and Michael Auli},
- booktitle = {Proceedings of NAACL-HLT 2019: Demonstrations},
- year = {2019},
-}
-```
diff --git a/spaces/ICML2022/OFA/fairseq/fairseq/modules/dynamicconv_layer/dynamicconv_layer.py b/spaces/ICML2022/OFA/fairseq/fairseq/modules/dynamicconv_layer/dynamicconv_layer.py
deleted file mode 100644
index 711ed03483f4089dbe91964a89021b49eeffbedc..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/fairseq/modules/dynamicconv_layer/dynamicconv_layer.py
+++ /dev/null
@@ -1,227 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import dynamicconv_cuda
-import torch
-import torch.nn.functional as F
-from fairseq import utils
-from fairseq.incremental_decoding_utils import with_incremental_state
-from fairseq.modules.fairseq_dropout import FairseqDropout
-from fairseq.modules.unfold import unfold1d
-from torch import nn
-from torch.autograd import Function
-
-
-class dynamicconvFunction(Function):
- @staticmethod
- def forward(ctx, x, weights, padding_l):
- ctx.padding_l = padding_l
- outputs = dynamicconv_cuda.forward(x, weights, padding_l)
- variables = [x, weights]
- ctx.save_for_backward(*variables)
- return outputs[0]
-
- @staticmethod
- def backward(ctx, grad_output):
- outputs = dynamicconv_cuda.backward(
- grad_output.contiguous(), ctx.padding_l, *ctx.saved_tensors
- )
- grad_input, grad_weights = outputs
- return grad_input, grad_weights, None
-
-
-@with_incremental_state
-class DynamicconvLayer(nn.Module):
- def __init__(
- self,
- input_size,
- kernel_size=1,
- padding_l=None,
- weight_softmax=False,
- num_heads=1,
- weight_dropout=0.0,
- bias=False,
- renorm_padding=False,
- conv_bias=False,
- query_size=None,
- ):
-
- super(DynamicconvLayer, self).__init__()
- self.input_size = input_size
- self.query_size = input_size if query_size is None else query_size
- self.kernel_size = kernel_size
- self.padding_l = padding_l
- self.num_heads = num_heads
- self.weight_softmax = weight_softmax
- self.weight_dropout_module = FairseqDropout(
- weight_dropout, module_name=self.__class__.__name__
- )
- self.renorm_padding = renorm_padding
- self.bias = bias
-
- self.weight_linear = nn.Linear(input_size, num_heads * kernel_size, bias)
- if conv_bias:
- self.conv_bias = nn.Parameter(torch.Tensor(input_size))
- else:
- self.conv_bias = None
- self.reset_parameters()
-
- def reset_parameters(self):
- nn.init.xavier_uniform_(self.weight_linear.weight)
- if self.conv_bias is not None:
- nn.init.constant_(self.conv_bias, 0.0)
- nn.init.constant_(self.weight_linaer.bias, 0.0)
-
- def forward(self, x, incremental_state=None, query=None, unfold=None):
-
- T, B, C = x.size()
- K, H = self.kernel_size, self.num_heads
- # R = C // H
-
- # during inference time, incremental BMM is faster
- if incremental_state is not None:
- unfold = (
- x.size(0) > 512 if unfold is None else unfold
- ) # use unfold mode as default for long sequence to save memory
- unfold = unfold or (incremental_state is not None)
- assert query is None
-
- if query is None:
- query = x
- if unfold:
- output = self._forward_unfolded(x, incremental_state, query)
- else:
- output = self._forward_expanded(x, incremental_state, query)
-
- if self.conv_bias is not None:
- output = output + self.conv_bias.view(1, 1, -1)
-
- return output
-
- # during training time, use CUDA kernel
- else:
- weight = self.weight_linear(x).view(T, B, H, K)
- if self.weight_softmax:
- weight = F.softmax(weight, dim=-1)
- if self.weight_dropout_module.p:
- weight = self.weight_dropout_module(weight)
-
- weight = weight.permute(1, 2, 3, 0).contiguous()
- self.filters = weight
- x = x.permute(1, 2, 0).contiguous()
- output = dynamicconvFunction.apply(x, weight, self.padding_l).permute(
- 2, 0, 1
- )
- if self.conv_bias is not None:
- output = output + self.conv_bias.view(1, 1, -1)
- return output
-
- def reorder_incremental_state(self, incremental_state, new_order):
- input_buffer = self._get_input_buffer(incremental_state)
- if input_buffer is not None:
- input_buffer = input_buffer.index_select(1, new_order)
- self._set_input_buffer(incremental_state, input_buffer)
-
- def _get_input_buffer(self, incremental_state):
- return utils.get_incremental_state(self, incremental_state, "input_buffer")
-
- def _set_input_buffer(self, incremental_state, new_buffer):
- return utils.set_incremental_state(
- self, incremental_state, "input_buffer", new_buffer
- )
-
- def _forward_unfolded(self, x, incremental_state, query):
- """The conventional implementation of convolutions.
- Unfolding the input by having a window shifting to the right."""
- T, B, C = x.size()
- K, H = self.kernel_size, self.num_heads
- R = C // H
- assert R * H == C == self.input_size
-
- weight = self.weight_linear(query).view(T * B * H, -1)
-
- # renorm_padding is only implemented in _forward_expanded
- assert not self.renorm_padding or incremental_state is not None
-
- if incremental_state is not None:
- input_buffer = self._get_input_buffer(incremental_state)
- if input_buffer is None:
- input_buffer = x.new()
- x_unfold = torch.cat([input_buffer, x.unsqueeze(3)], dim=3)
- if self.kernel_size > 1:
- self._set_input_buffer(
- incremental_state, x_unfold[:, :, :, -self.kernel_size + 1 :]
- )
- x_unfold = x_unfold.view(T * B * H, R, -1)
- else:
- padding_l = self.padding_l
- if K > T and padding_l == K - 1:
- weight = weight.narrow(1, K - T, T)
- K, padding_l = T, T - 1
- # unfold the input: T x B x C --> T' x B x C x K
- x_unfold = unfold1d(x, K, padding_l, 0)
- x_unfold = x_unfold.view(T * B * H, R, K)
-
- if self.weight_softmax and not self.renorm_padding:
- weight = F.softmax(weight, dim=1)
- weight = weight.narrow(1, 0, K)
-
- if incremental_state is not None:
- weight = weight[:, -x_unfold.size(2) :]
- K = weight.size(1)
-
- if self.weight_softmax and self.renorm_padding:
- weight = F.softmax(weight, dim=1)
-
- weight = self.weight_dropout_module(weight, inplace=False)
-
- output = torch.bmm(x_unfold, weight.unsqueeze(2)) # T*B*H x R x 1
- output = output.view(T, B, C)
- return output
-
- def _forward_expanded(self, x, incremental_stat, query):
- """Turn the convolution filters into band matrices and do matrix multiplication.
- This is faster when the sequence is short, but less memory efficient.
- This is not used in the decoder during inference.
- """
- T, B, C = x.size()
- K, H = self.kernel_size, self.num_heads
- R = C // H
- assert R * H == C == self.input_size
- weight = self.weight_linear(query).view(T * B * H, -1)
-
- if not self.renorm_padding:
- if self.weight_softmax:
- weight = F.softmax(weight, dim=1)
- weight = self.weight_dropout_module(weight, inplace=False)
- weight = weight.narrow(1, 0, K).contiguous()
- weight = weight.view(T, B * H, K).transpose(0, 1)
-
- x = x.view(T, B * H, R).transpose(0, 1)
- if self.weight_softmax and self.renorm_padding:
- # turn the convolution filters into band matrices
- weight_expanded = weight.new(B * H, T, T + K - 1).fill_(float("-inf"))
- weight_expanded.as_strided(
- (B * H, T, K), (T * (T + K - 1), T + K, 1)
- ).copy_(weight)
- weight_expanded = weight_expanded.narrow(2, self.padding_l, T)
- # normalize the weight over valid positions like self-attention
- weight_expanded = F.softmax(weight_expanded, dim=2)
- weight_expanded = self.weight_dropout_module(weight_expanded, inplace=False)
- else:
- P = self.padding_l
- # For efficiency, we cut the kernel size and reduce the padding when the kernel is larger than the length
- if K > T and P == K - 1:
- weight = weight.narrow(2, K - T, T)
- K, P = T, T - 1
- # turn the convolution filters into band matrices
- weight_expanded = weight.new_zeros(B * H, T, T + K - 1, requires_grad=False)
- weight_expanded.as_strided(
- (B * H, T, K), (T * (T + K - 1), T + K, 1)
- ).copy_(weight)
- weight_expanded = weight_expanded.narrow(2, P, T) # B*H x T x T
- output = torch.bmm(weight_expanded, x)
- output = output.transpose(0, 1).contiguous().view(T, B, C)
- return output
diff --git a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/utils/flask_rest_api/README.md b/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/utils/flask_rest_api/README.md
deleted file mode 100644
index a726acbd92043458311dd949cc09c0195cd35400..0000000000000000000000000000000000000000
--- a/spaces/Ibtehaj10/cheating-detection-FYP/yolovs5/utils/flask_rest_api/README.md
+++ /dev/null
@@ -1,73 +0,0 @@
-# Flask REST API
-
-[REST](https://en.wikipedia.org/wiki/Representational_state_transfer) [API](https://en.wikipedia.org/wiki/API)s are
-commonly used to expose Machine Learning (ML) models to other services. This folder contains an example REST API
-created using Flask to expose the YOLOv5s model from [PyTorch Hub](https://pytorch.org/hub/ultralytics_yolov5/).
-
-## Requirements
-
-[Flask](https://palletsprojects.com/p/flask/) is required. Install with:
-
-```shell
-$ pip install Flask
-```
-
-## Run
-
-After Flask installation run:
-
-```shell
-$ python3 restapi.py --port 5000
-```
-
-Then use [curl](https://curl.se/) to perform a request:
-
-```shell
-$ curl -X POST -F image=@zidane.jpg 'http://localhost:5000/v1/object-detection/yolov5s'
-```
-
-The model inference results are returned as a JSON response:
-
-```json
-[
- {
- "class": 0,
- "confidence": 0.8900438547,
- "height": 0.9318675399,
- "name": "person",
- "width": 0.3264600933,
- "xcenter": 0.7438579798,
- "ycenter": 0.5207948685
- },
- {
- "class": 0,
- "confidence": 0.8440024257,
- "height": 0.7155083418,
- "name": "person",
- "width": 0.6546785235,
- "xcenter": 0.427829951,
- "ycenter": 0.6334488392
- },
- {
- "class": 27,
- "confidence": 0.3771208823,
- "height": 0.3902671337,
- "name": "tie",
- "width": 0.0696444362,
- "xcenter": 0.3675483763,
- "ycenter": 0.7991207838
- },
- {
- "class": 27,
- "confidence": 0.3527112305,
- "height": 0.1540903747,
- "name": "tie",
- "width": 0.0336618312,
- "xcenter": 0.7814827561,
- "ycenter": 0.5065554976
- }
-]
-```
-
-An example python script to perform inference using [requests](https://docs.python-requests.org/en/master/) is given
-in `example_request.py`
diff --git a/spaces/Illumotion/Koboldcpp/ggml-opencl.h b/spaces/Illumotion/Koboldcpp/ggml-opencl.h
deleted file mode 100644
index 5edea8c9d78d9460f0892d19b931870eca5ffb73..0000000000000000000000000000000000000000
--- a/spaces/Illumotion/Koboldcpp/ggml-opencl.h
+++ /dev/null
@@ -1,25 +0,0 @@
-#pragma once
-
-#include "ggml.h"
-
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-void ggml_cl_init(void);
-
-void ggml_cl_mul(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst);
-bool ggml_cl_can_mul_mat(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst);
-size_t ggml_cl_mul_mat_get_wsize(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst);
-void ggml_cl_mul_mat(const struct ggml_tensor * src0, const struct ggml_tensor * src1, struct ggml_tensor * dst, void * wdata, size_t wsize);
-
-void * ggml_cl_host_malloc(size_t size);
-void ggml_cl_host_free(void * ptr);
-
-void ggml_cl_free_data(const struct ggml_tensor* tensor);
-
-void ggml_cl_transform_tensor(void * data, struct ggml_tensor * tensor);
-
-#ifdef __cplusplus
-}
-#endif
\ No newline at end of file
diff --git a/spaces/IndicNLP/Demo/app.py b/spaces/IndicNLP/Demo/app.py
deleted file mode 100644
index 12b01ab5440e52c0b9ae7f186c0f03dcf8789b09..0000000000000000000000000000000000000000
--- a/spaces/IndicNLP/Demo/app.py
+++ /dev/null
@@ -1,37 +0,0 @@
-import streamlit as st
-
-st.title("IndicNLP!")
-st.text("This is our Final Year Project,")
-st.text("Implementing various features of NLP i.e,")
-st.text("Natural Language Processing in Various Indic Languages.")
-st.text("To Begin with Hindi,")
-st.text("Here are Few Modules we have Implemented :-")
-
-add_selectbox = st.sidebar.selectbox(
- "Which Module would you like to try?",
- ("Part-of-Speech Tagging", "Questiom & Answer", "Grammar Checking")
-)
-
-if add_selectbox == "Part-of-Speech Tagging" :
- st.header('Part-Of-Speech, PoS-Tagging :- ')
- pos_ip = st.text_input('Enter a Statement')
- pos_btn = st.button("Process")
- if pos_btn:
- st.error("work's in progress :construction:, Come again later :smiley:")
-
-if add_selectbox == "Questiom & Answer" :
- st.header('Question & Answering :- ')
- text = st.text_area("Text to analyze")
- que_ip = st.text_input('Enter the question')
- qna_btn = st.button("Answer")
- if qna_btn:
- st.success("work's in progress :construction:, Come again later :smiley:")
-
-if add_selectbox == "Grammar Checking" :
- st.header('Grammar Correction :- ')
- grm_ip = st.text_input('Enter the Statement')
- grm_btn = st.button("Check Grammar")
- if grm_btn:
- st.write("work's in progress :construction:, Come again later :smiley:")
-
-st.caption('Thank you for Tuning in, Come back for more :heart:')
\ No newline at end of file
diff --git a/spaces/JMalott/ai_architecture/min_dalle/models/__init__.py b/spaces/JMalott/ai_architecture/min_dalle/models/__init__.py
deleted file mode 100644
index 5ac9af02c15d9df224b20d670fc847f73a41018b..0000000000000000000000000000000000000000
--- a/spaces/JMalott/ai_architecture/min_dalle/models/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .dalle_bart_encoder import DalleBartEncoder
-from .dalle_bart_decoder import DalleBartDecoder
-from .vqgan_detokenizer import VQGanDetokenizer
\ No newline at end of file
diff --git a/spaces/Jackflack09/diffuse-custom/diffusers/schedulers/scheduling_ddim_flax.py b/spaces/Jackflack09/diffuse-custom/diffusers/schedulers/scheduling_ddim_flax.py
deleted file mode 100644
index 157321d4681639c865e77745f9513b9a9a43b466..0000000000000000000000000000000000000000
--- a/spaces/Jackflack09/diffuse-custom/diffusers/schedulers/scheduling_ddim_flax.py
+++ /dev/null
@@ -1,326 +0,0 @@
-# Copyright 2022 Stanford University Team and The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
-# and https://github.com/hojonathanho/diffusion
-
-import math
-from dataclasses import dataclass
-from typing import Optional, Tuple, Union
-
-import flax
-import jax.numpy as jnp
-
-from ..configuration_utils import ConfigMixin, register_to_config
-from ..utils import deprecate
-from .scheduling_utils_flax import (
- _FLAX_COMPATIBLE_STABLE_DIFFUSION_SCHEDULERS,
- FlaxSchedulerMixin,
- FlaxSchedulerOutput,
- broadcast_to_shape_from_left,
-)
-
-
-def betas_for_alpha_bar(num_diffusion_timesteps, max_beta=0.999) -> jnp.ndarray:
- """
- Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
- (1-beta) over time from t = [0,1].
-
- Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
- to that part of the diffusion process.
-
-
- Args:
- num_diffusion_timesteps (`int`): the number of betas to produce.
- max_beta (`float`): the maximum beta to use; use values lower than 1 to
- prevent singularities.
-
- Returns:
- betas (`jnp.ndarray`): the betas used by the scheduler to step the model outputs
- """
-
- def alpha_bar(time_step):
- return math.cos((time_step + 0.008) / 1.008 * math.pi / 2) ** 2
-
- betas = []
- for i in range(num_diffusion_timesteps):
- t1 = i / num_diffusion_timesteps
- t2 = (i + 1) / num_diffusion_timesteps
- betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
- return jnp.array(betas, dtype=jnp.float32)
-
-
-@flax.struct.dataclass
-class DDIMSchedulerState:
- # setable values
- timesteps: jnp.ndarray
- alphas_cumprod: jnp.ndarray
- num_inference_steps: Optional[int] = None
-
- @classmethod
- def create(cls, num_train_timesteps: int, alphas_cumprod: jnp.ndarray):
- return cls(timesteps=jnp.arange(0, num_train_timesteps)[::-1], alphas_cumprod=alphas_cumprod)
-
-
-@dataclass
-class FlaxDDIMSchedulerOutput(FlaxSchedulerOutput):
- state: DDIMSchedulerState
-
-
-class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
- """
- Denoising diffusion implicit models is a scheduler that extends the denoising procedure introduced in denoising
- diffusion probabilistic models (DDPMs) with non-Markovian guidance.
-
- [`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
- function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
- [`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
- [`~SchedulerMixin.from_pretrained`] functions.
-
- For more details, see the original paper: https://arxiv.org/abs/2010.02502
-
- Args:
- num_train_timesteps (`int`): number of diffusion steps used to train the model.
- beta_start (`float`): the starting `beta` value of inference.
- beta_end (`float`): the final `beta` value.
- beta_schedule (`str`):
- the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
- `linear`, `scaled_linear`, or `squaredcos_cap_v2`.
- trained_betas (`jnp.ndarray`, optional):
- option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
- clip_sample (`bool`, default `True`):
- option to clip predicted sample between -1 and 1 for numerical stability.
- set_alpha_to_one (`bool`, default `True`):
- each diffusion step uses the value of alphas product at that step and at the previous one. For the final
- step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
- otherwise it uses the value of alpha at step 0.
- steps_offset (`int`, default `0`):
- an offset added to the inference steps. You can use a combination of `offset=1` and
- `set_alpha_to_one=False`, to make the last step use step 0 for the previous alpha product, as done in
- stable diffusion.
- prediction_type (`str`, default `epsilon`):
- indicates whether the model predicts the noise (epsilon), or the samples. One of `epsilon`, `sample`.
- `v-prediction` is not supported for this scheduler.
-
- """
-
- _compatibles = _FLAX_COMPATIBLE_STABLE_DIFFUSION_SCHEDULERS.copy()
- _deprecated_kwargs = ["predict_epsilon"]
-
- @property
- def has_state(self):
- return True
-
- @register_to_config
- def __init__(
- self,
- num_train_timesteps: int = 1000,
- beta_start: float = 0.0001,
- beta_end: float = 0.02,
- beta_schedule: str = "linear",
- set_alpha_to_one: bool = True,
- steps_offset: int = 0,
- prediction_type: str = "epsilon",
- **kwargs,
- ):
- message = (
- "Please make sure to instantiate your scheduler with `prediction_type` instead. E.g. `scheduler ="
- " FlaxDDIMScheduler.from_pretrained(, prediction_type='epsilon')`."
- )
- predict_epsilon = deprecate("predict_epsilon", "0.11.0", message, take_from=kwargs)
- if predict_epsilon is not None:
- self.register_to_config(prediction_type="epsilon" if predict_epsilon else "sample")
-
- if beta_schedule == "linear":
- self.betas = jnp.linspace(beta_start, beta_end, num_train_timesteps, dtype=jnp.float32)
- elif beta_schedule == "scaled_linear":
- # this schedule is very specific to the latent diffusion model.
- self.betas = jnp.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=jnp.float32) ** 2
- elif beta_schedule == "squaredcos_cap_v2":
- # Glide cosine schedule
- self.betas = betas_for_alpha_bar(num_train_timesteps)
- else:
- raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
-
- self.alphas = 1.0 - self.betas
-
- # HACK for now - clean up later (PVP)
- self._alphas_cumprod = jnp.cumprod(self.alphas, axis=0)
-
- # At every step in ddim, we are looking into the previous alphas_cumprod
- # For the final step, there is no previous alphas_cumprod because we are already at 0
- # `set_alpha_to_one` decides whether we set this parameter simply to one or
- # whether we use the final alpha of the "non-previous" one.
- self.final_alpha_cumprod = jnp.array(1.0) if set_alpha_to_one else float(self._alphas_cumprod[0])
-
- # standard deviation of the initial noise distribution
- self.init_noise_sigma = 1.0
-
- def scale_model_input(
- self, state: DDIMSchedulerState, sample: jnp.ndarray, timestep: Optional[int] = None
- ) -> jnp.ndarray:
- """
- Args:
- state (`PNDMSchedulerState`): the `FlaxPNDMScheduler` state data class instance.
- sample (`jnp.ndarray`): input sample
- timestep (`int`, optional): current timestep
-
- Returns:
- `jnp.ndarray`: scaled input sample
- """
- return sample
-
- def create_state(self):
- return DDIMSchedulerState.create(
- num_train_timesteps=self.config.num_train_timesteps, alphas_cumprod=self._alphas_cumprod
- )
-
- def _get_variance(self, timestep, prev_timestep, alphas_cumprod):
- alpha_prod_t = alphas_cumprod[timestep]
- alpha_prod_t_prev = jnp.where(prev_timestep >= 0, alphas_cumprod[prev_timestep], self.final_alpha_cumprod)
- beta_prod_t = 1 - alpha_prod_t
- beta_prod_t_prev = 1 - alpha_prod_t_prev
-
- variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
-
- return variance
-
- def set_timesteps(
- self, state: DDIMSchedulerState, num_inference_steps: int, shape: Tuple = ()
- ) -> DDIMSchedulerState:
- """
- Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
-
- Args:
- state (`DDIMSchedulerState`):
- the `FlaxDDIMScheduler` state data class instance.
- num_inference_steps (`int`):
- the number of diffusion steps used when generating samples with a pre-trained model.
- """
- offset = self.config.steps_offset
-
- step_ratio = self.config.num_train_timesteps // num_inference_steps
- # creates integer timesteps by multiplying by ratio
- # casting to int to avoid issues when num_inference_step is power of 3
- timesteps = (jnp.arange(0, num_inference_steps) * step_ratio).round()[::-1]
- timesteps = timesteps + offset
-
- return state.replace(num_inference_steps=num_inference_steps, timesteps=timesteps)
-
- def step(
- self,
- state: DDIMSchedulerState,
- model_output: jnp.ndarray,
- timestep: int,
- sample: jnp.ndarray,
- return_dict: bool = True,
- ) -> Union[FlaxDDIMSchedulerOutput, Tuple]:
- """
- Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
- process from the learned model outputs (most often the predicted noise).
-
- Args:
- state (`DDIMSchedulerState`): the `FlaxDDIMScheduler` state data class instance.
- model_output (`jnp.ndarray`): direct output from learned diffusion model.
- timestep (`int`): current discrete timestep in the diffusion chain.
- sample (`jnp.ndarray`):
- current instance of sample being created by diffusion process.
- return_dict (`bool`): option for returning tuple rather than FlaxDDIMSchedulerOutput class
-
- Returns:
- [`FlaxDDIMSchedulerOutput`] or `tuple`: [`FlaxDDIMSchedulerOutput`] if `return_dict` is True, otherwise a
- `tuple`. When returning a tuple, the first element is the sample tensor.
-
- """
- if state.num_inference_steps is None:
- raise ValueError(
- "Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
- )
-
- # See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
- # Ideally, read DDIM paper in-detail understanding
-
- # Notation ( ->
- # - pred_noise_t -> e_theta(x_t, t)
- # - pred_original_sample -> f_theta(x_t, t) or x_0
- # - std_dev_t -> sigma_t
- # - eta -> η
- # - pred_sample_direction -> "direction pointing to x_t"
- # - pred_prev_sample -> "x_t-1"
-
- # TODO(Patrick) - eta is always 0.0 for now, allow to be set in step function
- eta = 0.0
-
- # 1. get previous step value (=t-1)
- prev_timestep = timestep - self.config.num_train_timesteps // state.num_inference_steps
-
- alphas_cumprod = state.alphas_cumprod
-
- # 2. compute alphas, betas
- alpha_prod_t = alphas_cumprod[timestep]
- alpha_prod_t_prev = jnp.where(prev_timestep >= 0, alphas_cumprod[prev_timestep], self.final_alpha_cumprod)
-
- beta_prod_t = 1 - alpha_prod_t
-
- # 3. compute predicted original sample from predicted noise also called
- # "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
- if self.config.prediction_type == "epsilon":
- pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
- elif self.config.prediction_type == "sample":
- pred_original_sample = model_output
- elif self.config.prediction_type == "v_prediction":
- pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
- # predict V
- model_output = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
- else:
- raise ValueError(
- f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
- " `v_prediction`"
- )
-
- # 4. compute variance: "sigma_t(η)" -> see formula (16)
- # σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
- variance = self._get_variance(timestep, prev_timestep, alphas_cumprod)
- std_dev_t = eta * variance ** (0.5)
-
- # 5. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
- pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * model_output
-
- # 6. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
- prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
-
- if not return_dict:
- return (prev_sample, state)
-
- return FlaxDDIMSchedulerOutput(prev_sample=prev_sample, state=state)
-
- def add_noise(
- self,
- original_samples: jnp.ndarray,
- noise: jnp.ndarray,
- timesteps: jnp.ndarray,
- ) -> jnp.ndarray:
- sqrt_alpha_prod = self.alphas_cumprod[timesteps] ** 0.5
- sqrt_alpha_prod = sqrt_alpha_prod.flatten()
- sqrt_alpha_prod = broadcast_to_shape_from_left(sqrt_alpha_prod, original_samples.shape)
-
- sqrt_one_minus_alpha_prod = (1 - self.alphas_cumprod[timesteps]) ** 0.0
- sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
- sqrt_one_minus_alpha_prod = broadcast_to_shape_from_left(sqrt_one_minus_alpha_prod, original_samples.shape)
-
- noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
- return noisy_samples
-
- def __len__(self):
- return self.config.num_train_timesteps
diff --git a/spaces/Jeff2323/ai-comic-factory/src/components/ui/accordion.tsx b/spaces/Jeff2323/ai-comic-factory/src/components/ui/accordion.tsx
deleted file mode 100644
index 937620af27e5d8ef577f0baca229a9b753ebd017..0000000000000000000000000000000000000000
--- a/spaces/Jeff2323/ai-comic-factory/src/components/ui/accordion.tsx
+++ /dev/null
@@ -1,60 +0,0 @@
-"use client"
-
-import * as React from "react"
-import * as AccordionPrimitive from "@radix-ui/react-accordion"
-import { ChevronDown } from "lucide-react"
-
-import { cn } from "@/lib/utils"
-
-const Accordion = AccordionPrimitive.Root
-
-const AccordionItem = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, ...props }, ref) => (
-
-))
-AccordionItem.displayName = "AccordionItem"
-
-const AccordionTrigger = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, children, ...props }, ref) => (
-
- svg]:rotate-180",
- className
- )}
- {...props}
- >
- {children}
-
-
-
-))
-AccordionTrigger.displayName = AccordionPrimitive.Trigger.displayName
-
-const AccordionContent = React.forwardRef<
- React.ElementRef,
- React.ComponentPropsWithoutRef
->(({ className, children, ...props }, ref) => (
-
-
{children}
-
-))
-AccordionContent.displayName = AccordionPrimitive.Content.displayName
-
-export { Accordion, AccordionItem, AccordionTrigger, AccordionContent }
diff --git a/spaces/Jikiwi/sovits-models/app.py b/spaces/Jikiwi/sovits-models/app.py
deleted file mode 100644
index 2d6c236a564fa5283fa0385477be02d87c8aee35..0000000000000000000000000000000000000000
--- a/spaces/Jikiwi/sovits-models/app.py
+++ /dev/null
@@ -1,141 +0,0 @@
-import os
-import io
-import gradio as gr
-import librosa
-import numpy as np
-import utils
-from inference.infer_tool import Svc
-import logging
-import soundfile
-import asyncio
-import argparse
-import edge_tts
-import gradio.processing_utils as gr_processing_utils
-logging.getLogger('numba').setLevel(logging.WARNING)
-logging.getLogger('markdown_it').setLevel(logging.WARNING)
-logging.getLogger('urllib3').setLevel(logging.WARNING)
-logging.getLogger('matplotlib').setLevel(logging.WARNING)
-
-limitation = os.getenv("SYSTEM") == "spaces" # limit audio length in huggingface spaces
-
-audio_postprocess_ori = gr.Audio.postprocess
-
-def audio_postprocess(self, y):
- data = audio_postprocess_ori(self, y)
- if data is None:
- return None
- return gr_processing_utils.encode_url_or_file_to_base64(data["name"])
-
-
-gr.Audio.postprocess = audio_postprocess
-def create_vc_fn(model, sid):
- def vc_fn(input_audio, vc_transform, auto_f0, tts_text, tts_voice, tts_mode):
- if tts_mode:
- if len(tts_text) > 100 and limitation:
- return "Text is too long", None
- if tts_text is None or tts_voice is None:
- return "You need to enter text and select a voice", None
- asyncio.run(edge_tts.Communicate(tts_text, "-".join(tts_voice.split('-')[:-1])).save("tts.mp3"))
- audio, sr = librosa.load("tts.mp3", sr=16000, mono=True)
- raw_path = io.BytesIO()
- soundfile.write(raw_path, audio, 16000, format="wav")
- raw_path.seek(0)
- out_audio, out_sr = model.infer(sid, vc_transform, raw_path,
- auto_predict_f0=auto_f0,
- )
- return "Success", (44100, out_audio.cpu().numpy())
- if input_audio is None:
- return "You need to upload an audio", None
- sampling_rate, audio = input_audio
- duration = audio.shape[0] / sampling_rate
- if duration > 20 and limitation:
- return "Please upload an audio file that is less than 20 seconds. If you need to generate a longer audio file, please use Colab.", None
- audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32)
- if len(audio.shape) > 1:
- audio = librosa.to_mono(audio.transpose(1, 0))
- if sampling_rate != 16000:
- audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000)
- raw_path = io.BytesIO()
- soundfile.write(raw_path, audio, 16000, format="wav")
- raw_path.seek(0)
- out_audio, out_sr = model.infer(sid, vc_transform, raw_path,
- auto_predict_f0=auto_f0,
- )
- return "Success", (44100, out_audio.cpu().numpy())
- return vc_fn
-
-def change_to_tts_mode(tts_mode):
- if tts_mode:
- return gr.Audio.update(visible=False), gr.Textbox.update(visible=True), gr.Dropdown.update(visible=True), gr.Checkbox.update(value=True)
- else:
- return gr.Audio.update(visible=True), gr.Textbox.update(visible=False), gr.Dropdown.update(visible=False), gr.Checkbox.update(value=False)
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('--device', type=str, default='cpu')
- parser.add_argument('--api', action="store_true", default=False)
- parser.add_argument("--share", action="store_true", default=False, help="share gradio app")
- args = parser.parse_args()
- hubert_model = utils.get_hubert_model().to(args.device)
- models = []
- others = {
- "rudolf": "https://huggingface.co/spaces/sayashi/sovits-rudolf",
- "teio": "https://huggingface.co/spaces/sayashi/sovits-teio",
- "goldship": "https://huggingface.co/spaces/sayashi/sovits-goldship",
- "tannhauser": "https://huggingface.co/spaces/sayashi/sovits-tannhauser"
- }
- voices = []
- tts_voice_list = asyncio.get_event_loop().run_until_complete(edge_tts.list_voices())
- for r in tts_voice_list:
- voices.append(f"{r['ShortName']}-{r['Gender']}")
- for f in os.listdir("models"):
- name = f
- model = Svc(fr"models/{f}/{f}.pth", f"models/{f}/config.json", device=args.device)
- cover = f"models/{f}/cover.png" if os.path.exists(f"models/{f}/cover.png") else None
- models.append((name, cover, create_vc_fn(model, name)))
- with gr.Blocks() as app:
- gr.Markdown(
- "#
Sovits Models\n"
- "##
The input audio should be clean and pure voice without background music.\n"
- "\n\n"
- "[](https://colab.research.google.com/drive/1wfsBbMzmtLflOJeqc5ZnJiLY7L239hJW?usp=share_link)\n\n"
- "[](https://huggingface.co/spaces/sayashi/sovits-models?duplicate=true)\n\n"
- "[](https://github.com/svc-develop-team/so-vits-svc)"
-
- )
- with gr.Tabs():
- for (name, cover, vc_fn) in models:
- with gr.TabItem(name):
- with gr.Row():
- gr.Markdown(
- '
'
- f'' if cover else ""
- '
'
- )
- with gr.Row():
- with gr.Column():
- vc_input = gr.Audio(label="Input audio"+' (less than 20 seconds)' if limitation else '')
- vc_transform = gr.Number(label="vc_transform", value=0)
- auto_f0 = gr.Checkbox(label="auto_f0", value=False)
- tts_mode = gr.Checkbox(label="tts (use edge-tts as input)", value=False)
- tts_text = gr.Textbox(visible=False, label="TTS text (100 words limitation)" if limitation else "TTS text")
- tts_voice = gr.Dropdown(choices=voices, visible=False)
- vc_submit = gr.Button("Generate", variant="primary")
- with gr.Column():
- vc_output1 = gr.Textbox(label="Output Message")
- vc_output2 = gr.Audio(label="Output Audio")
- vc_submit.click(vc_fn, [vc_input, vc_transform, auto_f0, tts_text, tts_voice, tts_mode], [vc_output1, vc_output2])
- tts_mode.change(change_to_tts_mode, [tts_mode], [vc_input, tts_text, tts_voice, auto_f0])
- for category, link in others.items():
- with gr.TabItem(category):
- gr.Markdown(
- f'''
-
\ No newline at end of file
diff --git a/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/guile/2.2/ccache/web/request.go b/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/guile/2.2/ccache/web/request.go
deleted file mode 100644
index 61603ca363996ad3fa79ee0e9bcfb6a9d52d561f..0000000000000000000000000000000000000000
Binary files a/spaces/Pattr/DrumClassification/lilypond-2.24.2/lib/guile/2.2/ccache/web/request.go and /dev/null differ
diff --git a/spaces/Pravincoder/Loan_Approval_Predictor/app.py b/spaces/Pravincoder/Loan_Approval_Predictor/app.py
deleted file mode 100644
index a4491fa68b763a8a344f905b856e79f8ff7aabf7..0000000000000000000000000000000000000000
--- a/spaces/Pravincoder/Loan_Approval_Predictor/app.py
+++ /dev/null
@@ -1,4 +0,0 @@
-import streamlit as st
-
-x = st.slider('Select a value')
-st.write(x, 'squared is', x * x)
\ No newline at end of file
diff --git a/spaces/Promit/BrainSEG/README.md b/spaces/Promit/BrainSEG/README.md
deleted file mode 100644
index 2cad746725d2c1eeb7a042273106eee408d91e96..0000000000000000000000000000000000000000
--- a/spaces/Promit/BrainSEG/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: BrainSEG
-emoji: 📉
-colorFrom: green
-colorTo: gray
-sdk: gradio
-sdk_version: 3.50.2
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/chardet/sbcharsetprober.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/chardet/sbcharsetprober.py
deleted file mode 100644
index 31d70e154a9967c20f7a5c9090e7cf9384672a57..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/chardet/sbcharsetprober.py
+++ /dev/null
@@ -1,160 +0,0 @@
-######################## BEGIN LICENSE BLOCK ########################
-# The Original Code is Mozilla Universal charset detector code.
-#
-# The Initial Developer of the Original Code is
-# Netscape Communications Corporation.
-# Portions created by the Initial Developer are Copyright (C) 2001
-# the Initial Developer. All Rights Reserved.
-#
-# Contributor(s):
-# Mark Pilgrim - port to Python
-# Shy Shalom - original C code
-#
-# This library is free software; you can redistribute it and/or
-# modify it under the terms of the GNU Lesser General Public
-# License as published by the Free Software Foundation; either
-# version 2.1 of the License, or (at your option) any later version.
-#
-# This library is distributed in the hope that it will be useful,
-# but WITHOUT ANY WARRANTY; without even the implied warranty of
-# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
-# Lesser General Public License for more details.
-#
-# You should have received a copy of the GNU Lesser General Public
-# License along with this library; if not, write to the Free Software
-# Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA
-# 02110-1301 USA
-######################### END LICENSE BLOCK #########################
-
-from collections import namedtuple
-
-from .charsetprober import CharSetProber
-from .enums import CharacterCategory, ProbingState, SequenceLikelihood
-
-SingleByteCharSetModel = namedtuple(
- "SingleByteCharSetModel",
- [
- "charset_name",
- "language",
- "char_to_order_map",
- "language_model",
- "typical_positive_ratio",
- "keep_ascii_letters",
- "alphabet",
- ],
-)
-
-
-class SingleByteCharSetProber(CharSetProber):
- SAMPLE_SIZE = 64
- SB_ENOUGH_REL_THRESHOLD = 1024 # 0.25 * SAMPLE_SIZE^2
- POSITIVE_SHORTCUT_THRESHOLD = 0.95
- NEGATIVE_SHORTCUT_THRESHOLD = 0.05
-
- def __init__(self, model, is_reversed=False, name_prober=None):
- super().__init__()
- self._model = model
- # TRUE if we need to reverse every pair in the model lookup
- self._reversed = is_reversed
- # Optional auxiliary prober for name decision
- self._name_prober = name_prober
- self._last_order = None
- self._seq_counters = None
- self._total_seqs = None
- self._total_char = None
- self._control_char = None
- self._freq_char = None
- self.reset()
-
- def reset(self):
- super().reset()
- # char order of last character
- self._last_order = 255
- self._seq_counters = [0] * SequenceLikelihood.get_num_categories()
- self._total_seqs = 0
- self._total_char = 0
- self._control_char = 0
- # characters that fall in our sampling range
- self._freq_char = 0
-
- @property
- def charset_name(self):
- if self._name_prober:
- return self._name_prober.charset_name
- return self._model.charset_name
-
- @property
- def language(self):
- if self._name_prober:
- return self._name_prober.language
- return self._model.language
-
- def feed(self, byte_str):
- # TODO: Make filter_international_words keep things in self.alphabet
- if not self._model.keep_ascii_letters:
- byte_str = self.filter_international_words(byte_str)
- else:
- byte_str = self.remove_xml_tags(byte_str)
- if not byte_str:
- return self.state
- char_to_order_map = self._model.char_to_order_map
- language_model = self._model.language_model
- for char in byte_str:
- order = char_to_order_map.get(char, CharacterCategory.UNDEFINED)
- # XXX: This was SYMBOL_CAT_ORDER before, with a value of 250, but
- # CharacterCategory.SYMBOL is actually 253, so we use CONTROL
- # to make it closer to the original intent. The only difference
- # is whether or not we count digits and control characters for
- # _total_char purposes.
- if order < CharacterCategory.CONTROL:
- self._total_char += 1
- if order < self.SAMPLE_SIZE:
- self._freq_char += 1
- if self._last_order < self.SAMPLE_SIZE:
- self._total_seqs += 1
- if not self._reversed:
- lm_cat = language_model[self._last_order][order]
- else:
- lm_cat = language_model[order][self._last_order]
- self._seq_counters[lm_cat] += 1
- self._last_order = order
-
- charset_name = self._model.charset_name
- if self.state == ProbingState.DETECTING:
- if self._total_seqs > self.SB_ENOUGH_REL_THRESHOLD:
- confidence = self.get_confidence()
- if confidence > self.POSITIVE_SHORTCUT_THRESHOLD:
- self.logger.debug(
- "%s confidence = %s, we have a winner", charset_name, confidence
- )
- self._state = ProbingState.FOUND_IT
- elif confidence < self.NEGATIVE_SHORTCUT_THRESHOLD:
- self.logger.debug(
- "%s confidence = %s, below negative shortcut threshold %s",
- charset_name,
- confidence,
- self.NEGATIVE_SHORTCUT_THRESHOLD,
- )
- self._state = ProbingState.NOT_ME
-
- return self.state
-
- def get_confidence(self):
- r = 0.01
- if self._total_seqs > 0:
- r = (
- (
- self._seq_counters[SequenceLikelihood.POSITIVE]
- + 0.25 * self._seq_counters[SequenceLikelihood.LIKELY]
- )
- / self._total_seqs
- / self._model.typical_positive_ratio
- )
- # The more control characters (proportionnaly to the size
- # of the text), the less confident we become in the current
- # charset.
- r = r * (self._total_char - self._control_char) / self._total_char
- r = r * self._freq_char / self._total_char
- if r >= 1.0:
- r = 0.99
- return r
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/rich/text.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/rich/text.py
deleted file mode 100644
index 12037d0cf4f597a51b1fb80a9c1aa983f0910154..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/rich/text.py
+++ /dev/null
@@ -1,1286 +0,0 @@
-import re
-from functools import partial, reduce
-from math import gcd
-from operator import itemgetter
-from typing import (
- TYPE_CHECKING,
- Any,
- Callable,
- Dict,
- Iterable,
- List,
- NamedTuple,
- Optional,
- Tuple,
- Union,
-)
-
-from ._loop import loop_last
-from ._pick import pick_bool
-from ._wrap import divide_line
-from .align import AlignMethod
-from .cells import cell_len, set_cell_size
-from .containers import Lines
-from .control import strip_control_codes
-from .emoji import EmojiVariant
-from .jupyter import JupyterMixin
-from .measure import Measurement
-from .segment import Segment
-from .style import Style, StyleType
-
-if TYPE_CHECKING: # pragma: no cover
- from .console import Console, ConsoleOptions, JustifyMethod, OverflowMethod
-
-DEFAULT_JUSTIFY: "JustifyMethod" = "default"
-DEFAULT_OVERFLOW: "OverflowMethod" = "fold"
-
-
-_re_whitespace = re.compile(r"\s+$")
-
-TextType = Union[str, "Text"]
-
-GetStyleCallable = Callable[[str], Optional[StyleType]]
-
-
-class Span(NamedTuple):
- """A marked up region in some text."""
-
- start: int
- """Span start index."""
- end: int
- """Span end index."""
- style: Union[str, Style]
- """Style associated with the span."""
-
- def __repr__(self) -> str:
- return (
- f"Span({self.start}, {self.end}, {self.style!r})"
- if (isinstance(self.style, Style) and self.style._meta)
- else f"Span({self.start}, {self.end}, {repr(self.style)})"
- )
-
- def __bool__(self) -> bool:
- return self.end > self.start
-
- def split(self, offset: int) -> Tuple["Span", Optional["Span"]]:
- """Split a span in to 2 from a given offset."""
-
- if offset < self.start:
- return self, None
- if offset >= self.end:
- return self, None
-
- start, end, style = self
- span1 = Span(start, min(end, offset), style)
- span2 = Span(span1.end, end, style)
- return span1, span2
-
- def move(self, offset: int) -> "Span":
- """Move start and end by a given offset.
-
- Args:
- offset (int): Number of characters to add to start and end.
-
- Returns:
- TextSpan: A new TextSpan with adjusted position.
- """
- start, end, style = self
- return Span(start + offset, end + offset, style)
-
- def right_crop(self, offset: int) -> "Span":
- """Crop the span at the given offset.
-
- Args:
- offset (int): A value between start and end.
-
- Returns:
- Span: A new (possibly smaller) span.
- """
- start, end, style = self
- if offset >= end:
- return self
- return Span(start, min(offset, end), style)
-
-
-class Text(JupyterMixin):
- """Text with color / style.
-
- Args:
- text (str, optional): Default unstyled text. Defaults to "".
- style (Union[str, Style], optional): Base style for text. Defaults to "".
- justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
- overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
- no_wrap (bool, optional): Disable text wrapping, or None for default. Defaults to None.
- end (str, optional): Character to end text with. Defaults to "\\\\n".
- tab_size (int): Number of spaces per tab, or ``None`` to use ``console.tab_size``. Defaults to 8.
- spans (List[Span], optional). A list of predefined style spans. Defaults to None.
- """
-
- __slots__ = [
- "_text",
- "style",
- "justify",
- "overflow",
- "no_wrap",
- "end",
- "tab_size",
- "_spans",
- "_length",
- ]
-
- def __init__(
- self,
- text: str = "",
- style: Union[str, Style] = "",
- *,
- justify: Optional["JustifyMethod"] = None,
- overflow: Optional["OverflowMethod"] = None,
- no_wrap: Optional[bool] = None,
- end: str = "\n",
- tab_size: Optional[int] = 8,
- spans: Optional[List[Span]] = None,
- ) -> None:
- sanitized_text = strip_control_codes(text)
- self._text = [sanitized_text]
- self.style = style
- self.justify: Optional["JustifyMethod"] = justify
- self.overflow: Optional["OverflowMethod"] = overflow
- self.no_wrap = no_wrap
- self.end = end
- self.tab_size = tab_size
- self._spans: List[Span] = spans or []
- self._length: int = len(sanitized_text)
-
- def __len__(self) -> int:
- return self._length
-
- def __bool__(self) -> bool:
- return bool(self._length)
-
- def __str__(self) -> str:
- return self.plain
-
- def __repr__(self) -> str:
- return f""
-
- def __add__(self, other: Any) -> "Text":
- if isinstance(other, (str, Text)):
- result = self.copy()
- result.append(other)
- return result
- return NotImplemented
-
- def __eq__(self, other: object) -> bool:
- if not isinstance(other, Text):
- return NotImplemented
- return self.plain == other.plain and self._spans == other._spans
-
- def __contains__(self, other: object) -> bool:
- if isinstance(other, str):
- return other in self.plain
- elif isinstance(other, Text):
- return other.plain in self.plain
- return False
-
- def __getitem__(self, slice: Union[int, slice]) -> "Text":
- def get_text_at(offset: int) -> "Text":
- _Span = Span
- text = Text(
- self.plain[offset],
- spans=[
- _Span(0, 1, style)
- for start, end, style in self._spans
- if end > offset >= start
- ],
- end="",
- )
- return text
-
- if isinstance(slice, int):
- return get_text_at(slice)
- else:
- start, stop, step = slice.indices(len(self.plain))
- if step == 1:
- lines = self.divide([start, stop])
- return lines[1]
- else:
- # This would be a bit of work to implement efficiently
- # For now, its not required
- raise TypeError("slices with step!=1 are not supported")
-
- @property
- def cell_len(self) -> int:
- """Get the number of cells required to render this text."""
- return cell_len(self.plain)
-
- @property
- def markup(self) -> str:
- """Get console markup to render this Text.
-
- Returns:
- str: A string potentially creating markup tags.
- """
- from .markup import escape
-
- output: List[str] = []
-
- plain = self.plain
- markup_spans = [
- (0, False, self.style),
- *((span.start, False, span.style) for span in self._spans),
- *((span.end, True, span.style) for span in self._spans),
- (len(plain), True, self.style),
- ]
- markup_spans.sort(key=itemgetter(0, 1))
- position = 0
- append = output.append
- for offset, closing, style in markup_spans:
- if offset > position:
- append(escape(plain[position:offset]))
- position = offset
- if style:
- append(f"[/{style}]" if closing else f"[{style}]")
- markup = "".join(output)
- return markup
-
- @classmethod
- def from_markup(
- cls,
- text: str,
- *,
- style: Union[str, Style] = "",
- emoji: bool = True,
- emoji_variant: Optional[EmojiVariant] = None,
- justify: Optional["JustifyMethod"] = None,
- overflow: Optional["OverflowMethod"] = None,
- end: str = "\n",
- ) -> "Text":
- """Create Text instance from markup.
-
- Args:
- text (str): A string containing console markup.
- emoji (bool, optional): Also render emoji code. Defaults to True.
- justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
- overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
- end (str, optional): Character to end text with. Defaults to "\\\\n".
-
- Returns:
- Text: A Text instance with markup rendered.
- """
- from .markup import render
-
- rendered_text = render(text, style, emoji=emoji, emoji_variant=emoji_variant)
- rendered_text.justify = justify
- rendered_text.overflow = overflow
- rendered_text.end = end
- return rendered_text
-
- @classmethod
- def from_ansi(
- cls,
- text: str,
- *,
- style: Union[str, Style] = "",
- justify: Optional["JustifyMethod"] = None,
- overflow: Optional["OverflowMethod"] = None,
- no_wrap: Optional[bool] = None,
- end: str = "\n",
- tab_size: Optional[int] = 8,
- ) -> "Text":
- """Create a Text object from a string containing ANSI escape codes.
-
- Args:
- text (str): A string containing escape codes.
- style (Union[str, Style], optional): Base style for text. Defaults to "".
- justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
- overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
- no_wrap (bool, optional): Disable text wrapping, or None for default. Defaults to None.
- end (str, optional): Character to end text with. Defaults to "\\\\n".
- tab_size (int): Number of spaces per tab, or ``None`` to use ``console.tab_size``. Defaults to 8.
- """
- from .ansi import AnsiDecoder
-
- joiner = Text(
- "\n",
- justify=justify,
- overflow=overflow,
- no_wrap=no_wrap,
- end=end,
- tab_size=tab_size,
- style=style,
- )
- decoder = AnsiDecoder()
- result = joiner.join(line for line in decoder.decode(text))
- return result
-
- @classmethod
- def styled(
- cls,
- text: str,
- style: StyleType = "",
- *,
- justify: Optional["JustifyMethod"] = None,
- overflow: Optional["OverflowMethod"] = None,
- ) -> "Text":
- """Construct a Text instance with a pre-applied styled. A style applied in this way won't be used
- to pad the text when it is justified.
-
- Args:
- text (str): A string containing console markup.
- style (Union[str, Style]): Style to apply to the text. Defaults to "".
- justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
- overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
-
- Returns:
- Text: A text instance with a style applied to the entire string.
- """
- styled_text = cls(text, justify=justify, overflow=overflow)
- styled_text.stylize(style)
- return styled_text
-
- @classmethod
- def assemble(
- cls,
- *parts: Union[str, "Text", Tuple[str, StyleType]],
- style: Union[str, Style] = "",
- justify: Optional["JustifyMethod"] = None,
- overflow: Optional["OverflowMethod"] = None,
- no_wrap: Optional[bool] = None,
- end: str = "\n",
- tab_size: int = 8,
- meta: Optional[Dict[str, Any]] = None,
- ) -> "Text":
- """Construct a text instance by combining a sequence of strings with optional styles.
- The positional arguments should be either strings, or a tuple of string + style.
-
- Args:
- style (Union[str, Style], optional): Base style for text. Defaults to "".
- justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
- overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
- end (str, optional): Character to end text with. Defaults to "\\\\n".
- tab_size (int): Number of spaces per tab, or ``None`` to use ``console.tab_size``. Defaults to 8.
- meta (Dict[str, Any], optional). Meta data to apply to text, or None for no meta data. Default to None
-
- Returns:
- Text: A new text instance.
- """
- text = cls(
- style=style,
- justify=justify,
- overflow=overflow,
- no_wrap=no_wrap,
- end=end,
- tab_size=tab_size,
- )
- append = text.append
- _Text = Text
- for part in parts:
- if isinstance(part, (_Text, str)):
- append(part)
- else:
- append(*part)
- if meta:
- text.apply_meta(meta)
- return text
-
- @property
- def plain(self) -> str:
- """Get the text as a single string."""
- if len(self._text) != 1:
- self._text[:] = ["".join(self._text)]
- return self._text[0]
-
- @plain.setter
- def plain(self, new_text: str) -> None:
- """Set the text to a new value."""
- if new_text != self.plain:
- sanitized_text = strip_control_codes(new_text)
- self._text[:] = [sanitized_text]
- old_length = self._length
- self._length = len(sanitized_text)
- if old_length > self._length:
- self._trim_spans()
-
- @property
- def spans(self) -> List[Span]:
- """Get a reference to the internal list of spans."""
- return self._spans
-
- @spans.setter
- def spans(self, spans: List[Span]) -> None:
- """Set spans."""
- self._spans = spans[:]
-
- def blank_copy(self, plain: str = "") -> "Text":
- """Return a new Text instance with copied meta data (but not the string or spans)."""
- copy_self = Text(
- plain,
- style=self.style,
- justify=self.justify,
- overflow=self.overflow,
- no_wrap=self.no_wrap,
- end=self.end,
- tab_size=self.tab_size,
- )
- return copy_self
-
- def copy(self) -> "Text":
- """Return a copy of this instance."""
- copy_self = Text(
- self.plain,
- style=self.style,
- justify=self.justify,
- overflow=self.overflow,
- no_wrap=self.no_wrap,
- end=self.end,
- tab_size=self.tab_size,
- )
- copy_self._spans[:] = self._spans
- return copy_self
-
- def stylize(
- self,
- style: Union[str, Style],
- start: int = 0,
- end: Optional[int] = None,
- ) -> None:
- """Apply a style to the text, or a portion of the text.
-
- Args:
- style (Union[str, Style]): Style instance or style definition to apply.
- start (int): Start offset (negative indexing is supported). Defaults to 0.
- end (Optional[int], optional): End offset (negative indexing is supported), or None for end of text. Defaults to None.
-
- """
- if style:
- length = len(self)
- if start < 0:
- start = length + start
- if end is None:
- end = length
- if end < 0:
- end = length + end
- if start >= length or end <= start:
- # Span not in text or not valid
- return
- self._spans.append(Span(start, min(length, end), style))
-
- def apply_meta(
- self, meta: Dict[str, Any], start: int = 0, end: Optional[int] = None
- ) -> None:
- """Apply meta data to the text, or a portion of the text.
-
- Args:
- meta (Dict[str, Any]): A dict of meta information.
- start (int): Start offset (negative indexing is supported). Defaults to 0.
- end (Optional[int], optional): End offset (negative indexing is supported), or None for end of text. Defaults to None.
-
- """
- style = Style.from_meta(meta)
- self.stylize(style, start=start, end=end)
-
- def on(self, meta: Optional[Dict[str, Any]] = None, **handlers: Any) -> "Text":
- """Apply event handlers (used by Textual project).
-
- Example:
- >>> from rich.text import Text
- >>> text = Text("hello world")
- >>> text.on(click="view.toggle('world')")
-
- Args:
- meta (Dict[str, Any]): Mapping of meta information.
- **handlers: Keyword args are prefixed with "@" to defined handlers.
-
- Returns:
- Text: Self is returned to method may be chained.
- """
- meta = {} if meta is None else meta
- meta.update({f"@{key}": value for key, value in handlers.items()})
- self.stylize(Style.from_meta(meta))
- return self
-
- def remove_suffix(self, suffix: str) -> None:
- """Remove a suffix if it exists.
-
- Args:
- suffix (str): Suffix to remove.
- """
- if self.plain.endswith(suffix):
- self.right_crop(len(suffix))
-
- def get_style_at_offset(self, console: "Console", offset: int) -> Style:
- """Get the style of a character at give offset.
-
- Args:
- console (~Console): Console where text will be rendered.
- offset (int): Offset in to text (negative indexing supported)
-
- Returns:
- Style: A Style instance.
- """
- # TODO: This is a little inefficient, it is only used by full justify
- if offset < 0:
- offset = len(self) + offset
- get_style = console.get_style
- style = get_style(self.style).copy()
- for start, end, span_style in self._spans:
- if end > offset >= start:
- style += get_style(span_style, default="")
- return style
-
- def highlight_regex(
- self,
- re_highlight: str,
- style: Optional[Union[GetStyleCallable, StyleType]] = None,
- *,
- style_prefix: str = "",
- ) -> int:
- """Highlight text with a regular expression, where group names are
- translated to styles.
-
- Args:
- re_highlight (str): A regular expression.
- style (Union[GetStyleCallable, StyleType]): Optional style to apply to whole match, or a callable
- which accepts the matched text and returns a style. Defaults to None.
- style_prefix (str, optional): Optional prefix to add to style group names.
-
- Returns:
- int: Number of regex matches
- """
- count = 0
- append_span = self._spans.append
- _Span = Span
- plain = self.plain
- for match in re.finditer(re_highlight, plain):
- get_span = match.span
- if style:
- start, end = get_span()
- match_style = style(plain[start:end]) if callable(style) else style
- if match_style is not None and end > start:
- append_span(_Span(start, end, match_style))
-
- count += 1
- for name in match.groupdict().keys():
- start, end = get_span(name)
- if start != -1 and end > start:
- append_span(_Span(start, end, f"{style_prefix}{name}"))
- return count
-
- def highlight_words(
- self,
- words: Iterable[str],
- style: Union[str, Style],
- *,
- case_sensitive: bool = True,
- ) -> int:
- """Highlight words with a style.
-
- Args:
- words (Iterable[str]): Worlds to highlight.
- style (Union[str, Style]): Style to apply.
- case_sensitive (bool, optional): Enable case sensitive matchings. Defaults to True.
-
- Returns:
- int: Number of words highlighted.
- """
- re_words = "|".join(re.escape(word) for word in words)
- add_span = self._spans.append
- count = 0
- _Span = Span
- for match in re.finditer(
- re_words, self.plain, flags=0 if case_sensitive else re.IGNORECASE
- ):
- start, end = match.span(0)
- add_span(_Span(start, end, style))
- count += 1
- return count
-
- def rstrip(self) -> None:
- """Strip whitespace from end of text."""
- self.plain = self.plain.rstrip()
-
- def rstrip_end(self, size: int) -> None:
- """Remove whitespace beyond a certain width at the end of the text.
-
- Args:
- size (int): The desired size of the text.
- """
- text_length = len(self)
- if text_length > size:
- excess = text_length - size
- whitespace_match = _re_whitespace.search(self.plain)
- if whitespace_match is not None:
- whitespace_count = len(whitespace_match.group(0))
- self.right_crop(min(whitespace_count, excess))
-
- def set_length(self, new_length: int) -> None:
- """Set new length of the text, clipping or padding is required."""
- length = len(self)
- if length != new_length:
- if length < new_length:
- self.pad_right(new_length - length)
- else:
- self.right_crop(length - new_length)
-
- def __rich_console__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> Iterable[Segment]:
- tab_size: int = console.tab_size or self.tab_size or 8
- justify = self.justify or options.justify or DEFAULT_JUSTIFY
-
- overflow = self.overflow or options.overflow or DEFAULT_OVERFLOW
-
- lines = self.wrap(
- console,
- options.max_width,
- justify=justify,
- overflow=overflow,
- tab_size=tab_size or 8,
- no_wrap=pick_bool(self.no_wrap, options.no_wrap, False),
- )
- all_lines = Text("\n").join(lines)
- yield from all_lines.render(console, end=self.end)
-
- def __rich_measure__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> Measurement:
- text = self.plain
- lines = text.splitlines()
- max_text_width = max(cell_len(line) for line in lines) if lines else 0
- words = text.split()
- min_text_width = (
- max(cell_len(word) for word in words) if words else max_text_width
- )
- return Measurement(min_text_width, max_text_width)
-
- def render(self, console: "Console", end: str = "") -> Iterable["Segment"]:
- """Render the text as Segments.
-
- Args:
- console (Console): Console instance.
- end (Optional[str], optional): Optional end character.
-
- Returns:
- Iterable[Segment]: Result of render that may be written to the console.
- """
- _Segment = Segment
- text = self.plain
- if not self._spans:
- yield Segment(text)
- if end:
- yield _Segment(end)
- return
- get_style = partial(console.get_style, default=Style.null())
-
- enumerated_spans = list(enumerate(self._spans, 1))
- style_map = {index: get_style(span.style) for index, span in enumerated_spans}
- style_map[0] = get_style(self.style)
-
- spans = [
- (0, False, 0),
- *((span.start, False, index) for index, span in enumerated_spans),
- *((span.end, True, index) for index, span in enumerated_spans),
- (len(text), True, 0),
- ]
- spans.sort(key=itemgetter(0, 1))
-
- stack: List[int] = []
- stack_append = stack.append
- stack_pop = stack.remove
-
- style_cache: Dict[Tuple[Style, ...], Style] = {}
- style_cache_get = style_cache.get
- combine = Style.combine
-
- def get_current_style() -> Style:
- """Construct current style from stack."""
- styles = tuple(style_map[_style_id] for _style_id in sorted(stack))
- cached_style = style_cache_get(styles)
- if cached_style is not None:
- return cached_style
- current_style = combine(styles)
- style_cache[styles] = current_style
- return current_style
-
- for (offset, leaving, style_id), (next_offset, _, _) in zip(spans, spans[1:]):
- if leaving:
- stack_pop(style_id)
- else:
- stack_append(style_id)
- if next_offset > offset:
- yield _Segment(text[offset:next_offset], get_current_style())
- if end:
- yield _Segment(end)
-
- def join(self, lines: Iterable["Text"]) -> "Text":
- """Join text together with this instance as the separator.
-
- Args:
- lines (Iterable[Text]): An iterable of Text instances to join.
-
- Returns:
- Text: A new text instance containing join text.
- """
-
- new_text = self.blank_copy()
-
- def iter_text() -> Iterable["Text"]:
- if self.plain:
- for last, line in loop_last(lines):
- yield line
- if not last:
- yield self
- else:
- yield from lines
-
- extend_text = new_text._text.extend
- append_span = new_text._spans.append
- extend_spans = new_text._spans.extend
- offset = 0
- _Span = Span
-
- for text in iter_text():
- extend_text(text._text)
- if text.style:
- append_span(_Span(offset, offset + len(text), text.style))
- extend_spans(
- _Span(offset + start, offset + end, style)
- for start, end, style in text._spans
- )
- offset += len(text)
- new_text._length = offset
- return new_text
-
- def expand_tabs(self, tab_size: Optional[int] = None) -> None:
- """Converts tabs to spaces.
-
- Args:
- tab_size (int, optional): Size of tabs. Defaults to 8.
-
- """
- if "\t" not in self.plain:
- return
- pos = 0
- if tab_size is None:
- tab_size = self.tab_size
- assert tab_size is not None
- result = self.blank_copy()
- append = result.append
-
- _style = self.style
- for line in self.split("\n", include_separator=True):
- parts = line.split("\t", include_separator=True)
- for part in parts:
- if part.plain.endswith("\t"):
- part._text = [part.plain[:-1] + " "]
- append(part)
- pos += len(part)
- spaces = tab_size - ((pos - 1) % tab_size) - 1
- if spaces:
- append(" " * spaces, _style)
- pos += spaces
- else:
- append(part)
- self._text = [result.plain]
- self._length = len(self.plain)
- self._spans[:] = result._spans
-
- def truncate(
- self,
- max_width: int,
- *,
- overflow: Optional["OverflowMethod"] = None,
- pad: bool = False,
- ) -> None:
- """Truncate text if it is longer that a given width.
-
- Args:
- max_width (int): Maximum number of characters in text.
- overflow (str, optional): Overflow method: "crop", "fold", or "ellipsis". Defaults to None, to use self.overflow.
- pad (bool, optional): Pad with spaces if the length is less than max_width. Defaults to False.
- """
- _overflow = overflow or self.overflow or DEFAULT_OVERFLOW
- if _overflow != "ignore":
- length = cell_len(self.plain)
- if length > max_width:
- if _overflow == "ellipsis":
- self.plain = set_cell_size(self.plain, max_width - 1) + "…"
- else:
- self.plain = set_cell_size(self.plain, max_width)
- if pad and length < max_width:
- spaces = max_width - length
- self._text = [f"{self.plain}{' ' * spaces}"]
- self._length = len(self.plain)
-
- def _trim_spans(self) -> None:
- """Remove or modify any spans that are over the end of the text."""
- max_offset = len(self.plain)
- _Span = Span
- self._spans[:] = [
- (
- span
- if span.end < max_offset
- else _Span(span.start, min(max_offset, span.end), span.style)
- )
- for span in self._spans
- if span.start < max_offset
- ]
-
- def pad(self, count: int, character: str = " ") -> None:
- """Pad left and right with a given number of characters.
-
- Args:
- count (int): Width of padding.
- """
- assert len(character) == 1, "Character must be a string of length 1"
- if count:
- pad_characters = character * count
- self.plain = f"{pad_characters}{self.plain}{pad_characters}"
- _Span = Span
- self._spans[:] = [
- _Span(start + count, end + count, style)
- for start, end, style in self._spans
- ]
-
- def pad_left(self, count: int, character: str = " ") -> None:
- """Pad the left with a given character.
-
- Args:
- count (int): Number of characters to pad.
- character (str, optional): Character to pad with. Defaults to " ".
- """
- assert len(character) == 1, "Character must be a string of length 1"
- if count:
- self.plain = f"{character * count}{self.plain}"
- _Span = Span
- self._spans[:] = [
- _Span(start + count, end + count, style)
- for start, end, style in self._spans
- ]
-
- def pad_right(self, count: int, character: str = " ") -> None:
- """Pad the right with a given character.
-
- Args:
- count (int): Number of characters to pad.
- character (str, optional): Character to pad with. Defaults to " ".
- """
- assert len(character) == 1, "Character must be a string of length 1"
- if count:
- self.plain = f"{self.plain}{character * count}"
-
- def align(self, align: AlignMethod, width: int, character: str = " ") -> None:
- """Align text to a given width.
-
- Args:
- align (AlignMethod): One of "left", "center", or "right".
- width (int): Desired width.
- character (str, optional): Character to pad with. Defaults to " ".
- """
- self.truncate(width)
- excess_space = width - cell_len(self.plain)
- if excess_space:
- if align == "left":
- self.pad_right(excess_space, character)
- elif align == "center":
- left = excess_space // 2
- self.pad_left(left, character)
- self.pad_right(excess_space - left, character)
- else:
- self.pad_left(excess_space, character)
-
- def append(
- self, text: Union["Text", str], style: Optional[Union[str, "Style"]] = None
- ) -> "Text":
- """Add text with an optional style.
-
- Args:
- text (Union[Text, str]): A str or Text to append.
- style (str, optional): A style name. Defaults to None.
-
- Returns:
- Text: Returns self for chaining.
- """
-
- if not isinstance(text, (str, Text)):
- raise TypeError("Only str or Text can be appended to Text")
-
- if len(text):
- if isinstance(text, str):
- sanitized_text = strip_control_codes(text)
- self._text.append(sanitized_text)
- offset = len(self)
- text_length = len(sanitized_text)
- if style is not None:
- self._spans.append(Span(offset, offset + text_length, style))
- self._length += text_length
- elif isinstance(text, Text):
- _Span = Span
- if style is not None:
- raise ValueError(
- "style must not be set when appending Text instance"
- )
- text_length = self._length
- if text.style is not None:
- self._spans.append(
- _Span(text_length, text_length + len(text), text.style)
- )
- self._text.append(text.plain)
- self._spans.extend(
- _Span(start + text_length, end + text_length, style)
- for start, end, style in text._spans
- )
- self._length += len(text)
- return self
-
- def append_text(self, text: "Text") -> "Text":
- """Append another Text instance. This method is more performant that Text.append, but
- only works for Text.
-
- Returns:
- Text: Returns self for chaining.
- """
- _Span = Span
- text_length = self._length
- if text.style is not None:
- self._spans.append(_Span(text_length, text_length + len(text), text.style))
- self._text.append(text.plain)
- self._spans.extend(
- _Span(start + text_length, end + text_length, style)
- for start, end, style in text._spans
- )
- self._length += len(text)
- return self
-
- def append_tokens(
- self, tokens: Iterable[Tuple[str, Optional[StyleType]]]
- ) -> "Text":
- """Append iterable of str and style. Style may be a Style instance or a str style definition.
-
- Args:
- pairs (Iterable[Tuple[str, Optional[StyleType]]]): An iterable of tuples containing str content and style.
-
- Returns:
- Text: Returns self for chaining.
- """
- append_text = self._text.append
- append_span = self._spans.append
- _Span = Span
- offset = len(self)
- for content, style in tokens:
- append_text(content)
- if style is not None:
- append_span(_Span(offset, offset + len(content), style))
- offset += len(content)
- self._length = offset
- return self
-
- def copy_styles(self, text: "Text") -> None:
- """Copy styles from another Text instance.
-
- Args:
- text (Text): A Text instance to copy styles from, must be the same length.
- """
- self._spans.extend(text._spans)
-
- def split(
- self,
- separator: str = "\n",
- *,
- include_separator: bool = False,
- allow_blank: bool = False,
- ) -> Lines:
- """Split rich text in to lines, preserving styles.
-
- Args:
- separator (str, optional): String to split on. Defaults to "\\\\n".
- include_separator (bool, optional): Include the separator in the lines. Defaults to False.
- allow_blank (bool, optional): Return a blank line if the text ends with a separator. Defaults to False.
-
- Returns:
- List[RichText]: A list of rich text, one per line of the original.
- """
- assert separator, "separator must not be empty"
-
- text = self.plain
- if separator not in text:
- return Lines([self.copy()])
-
- if include_separator:
- lines = self.divide(
- match.end() for match in re.finditer(re.escape(separator), text)
- )
- else:
-
- def flatten_spans() -> Iterable[int]:
- for match in re.finditer(re.escape(separator), text):
- start, end = match.span()
- yield start
- yield end
-
- lines = Lines(
- line for line in self.divide(flatten_spans()) if line.plain != separator
- )
-
- if not allow_blank and text.endswith(separator):
- lines.pop()
-
- return lines
-
- def divide(self, offsets: Iterable[int]) -> Lines:
- """Divide text in to a number of lines at given offsets.
-
- Args:
- offsets (Iterable[int]): Offsets used to divide text.
-
- Returns:
- Lines: New RichText instances between offsets.
- """
- _offsets = list(offsets)
-
- if not _offsets:
- return Lines([self.copy()])
-
- text = self.plain
- text_length = len(text)
- divide_offsets = [0, *_offsets, text_length]
- line_ranges = list(zip(divide_offsets, divide_offsets[1:]))
-
- style = self.style
- justify = self.justify
- overflow = self.overflow
- _Text = Text
- new_lines = Lines(
- _Text(
- text[start:end],
- style=style,
- justify=justify,
- overflow=overflow,
- )
- for start, end in line_ranges
- )
- if not self._spans:
- return new_lines
-
- _line_appends = [line._spans.append for line in new_lines._lines]
- line_count = len(line_ranges)
- _Span = Span
-
- for span_start, span_end, style in self._spans:
-
- lower_bound = 0
- upper_bound = line_count
- start_line_no = (lower_bound + upper_bound) // 2
-
- while True:
- line_start, line_end = line_ranges[start_line_no]
- if span_start < line_start:
- upper_bound = start_line_no - 1
- elif span_start > line_end:
- lower_bound = start_line_no + 1
- else:
- break
- start_line_no = (lower_bound + upper_bound) // 2
-
- if span_end < line_end:
- end_line_no = start_line_no
- else:
- end_line_no = lower_bound = start_line_no
- upper_bound = line_count
-
- while True:
- line_start, line_end = line_ranges[end_line_no]
- if span_end < line_start:
- upper_bound = end_line_no - 1
- elif span_end > line_end:
- lower_bound = end_line_no + 1
- else:
- break
- end_line_no = (lower_bound + upper_bound) // 2
-
- for line_no in range(start_line_no, end_line_no + 1):
- line_start, line_end = line_ranges[line_no]
- new_start = max(0, span_start - line_start)
- new_end = min(span_end - line_start, line_end - line_start)
- if new_end > new_start:
- _line_appends[line_no](_Span(new_start, new_end, style))
-
- return new_lines
-
- def right_crop(self, amount: int = 1) -> None:
- """Remove a number of characters from the end of the text."""
- max_offset = len(self.plain) - amount
- _Span = Span
- self._spans[:] = [
- (
- span
- if span.end < max_offset
- else _Span(span.start, min(max_offset, span.end), span.style)
- )
- for span in self._spans
- if span.start < max_offset
- ]
- self._text = [self.plain[:-amount]]
- self._length -= amount
-
- def wrap(
- self,
- console: "Console",
- width: int,
- *,
- justify: Optional["JustifyMethod"] = None,
- overflow: Optional["OverflowMethod"] = None,
- tab_size: int = 8,
- no_wrap: Optional[bool] = None,
- ) -> Lines:
- """Word wrap the text.
-
- Args:
- console (Console): Console instance.
- width (int): Number of characters per line.
- emoji (bool, optional): Also render emoji code. Defaults to True.
- justify (str, optional): Justify method: "default", "left", "center", "full", "right". Defaults to "default".
- overflow (str, optional): Overflow method: "crop", "fold", or "ellipsis". Defaults to None.
- tab_size (int, optional): Default tab size. Defaults to 8.
- no_wrap (bool, optional): Disable wrapping, Defaults to False.
-
- Returns:
- Lines: Number of lines.
- """
- wrap_justify = justify or self.justify or DEFAULT_JUSTIFY
- wrap_overflow = overflow or self.overflow or DEFAULT_OVERFLOW
-
- no_wrap = pick_bool(no_wrap, self.no_wrap, False) or overflow == "ignore"
-
- lines = Lines()
- for line in self.split(allow_blank=True):
- if "\t" in line:
- line.expand_tabs(tab_size)
- if no_wrap:
- new_lines = Lines([line])
- else:
- offsets = divide_line(str(line), width, fold=wrap_overflow == "fold")
- new_lines = line.divide(offsets)
- for line in new_lines:
- line.rstrip_end(width)
- if wrap_justify:
- new_lines.justify(
- console, width, justify=wrap_justify, overflow=wrap_overflow
- )
- for line in new_lines:
- line.truncate(width, overflow=wrap_overflow)
- lines.extend(new_lines)
- return lines
-
- def fit(self, width: int) -> Lines:
- """Fit the text in to given width by chopping in to lines.
-
- Args:
- width (int): Maximum characters in a line.
-
- Returns:
- Lines: List of lines.
- """
- lines: Lines = Lines()
- append = lines.append
- for line in self.split():
- line.set_length(width)
- append(line)
- return lines
-
- def detect_indentation(self) -> int:
- """Auto-detect indentation of code.
-
- Returns:
- int: Number of spaces used to indent code.
- """
-
- _indentations = {
- len(match.group(1))
- for match in re.finditer(r"^( *)(.*)$", self.plain, flags=re.MULTILINE)
- }
-
- try:
- indentation = (
- reduce(gcd, [indent for indent in _indentations if not indent % 2]) or 1
- )
- except TypeError:
- indentation = 1
-
- return indentation
-
- def with_indent_guides(
- self,
- indent_size: Optional[int] = None,
- *,
- character: str = "│",
- style: StyleType = "dim green",
- ) -> "Text":
- """Adds indent guide lines to text.
-
- Args:
- indent_size (Optional[int]): Size of indentation, or None to auto detect. Defaults to None.
- character (str, optional): Character to use for indentation. Defaults to "│".
- style (Union[Style, str], optional): Style of indent guides.
-
- Returns:
- Text: New text with indentation guides.
- """
-
- _indent_size = self.detect_indentation() if indent_size is None else indent_size
-
- text = self.copy()
- text.expand_tabs()
- indent_line = f"{character}{' ' * (_indent_size - 1)}"
-
- re_indent = re.compile(r"^( *)(.*)$")
- new_lines: List[Text] = []
- add_line = new_lines.append
- blank_lines = 0
- for line in text.split(allow_blank=True):
- match = re_indent.match(line.plain)
- if not match or not match.group(2):
- blank_lines += 1
- continue
- indent = match.group(1)
- full_indents, remaining_space = divmod(len(indent), _indent_size)
- new_indent = f"{indent_line * full_indents}{' ' * remaining_space}"
- line.plain = new_indent + line.plain[len(new_indent) :]
- line.stylize(style, 0, len(new_indent))
- if blank_lines:
- new_lines.extend([Text(new_indent, style=style)] * blank_lines)
- blank_lines = 0
- add_line(line)
- if blank_lines:
- new_lines.extend([Text("", style=style)] * blank_lines)
-
- new_text = text.blank_copy("\n").join(new_lines)
- return new_text
-
-
-if __name__ == "__main__": # pragma: no cover
- from pip._vendor.rich.console import Console
-
- text = Text(
- """\nLorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n"""
- )
- text.highlight_words(["Lorem"], "bold")
- text.highlight_words(["ipsum"], "italic")
-
- console = Console()
-
- console.rule("justify='left'")
- console.print(text, style="red")
- console.print()
-
- console.rule("justify='center'")
- console.print(text, style="green", justify="center")
- console.print()
-
- console.rule("justify='right'")
- console.print(text, style="blue", justify="right")
- console.print()
-
- console.rule("justify='full'")
- console.print(text, style="magenta", justify="full")
- console.print()
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/urllib3/exceptions.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/urllib3/exceptions.py
deleted file mode 100644
index cba6f3f560f71b3b15ab6aaf21dde4f1bba1bd00..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/pip/_vendor/urllib3/exceptions.py
+++ /dev/null
@@ -1,323 +0,0 @@
-from __future__ import absolute_import
-
-from .packages.six.moves.http_client import IncompleteRead as httplib_IncompleteRead
-
-# Base Exceptions
-
-
-class HTTPError(Exception):
- """Base exception used by this module."""
-
- pass
-
-
-class HTTPWarning(Warning):
- """Base warning used by this module."""
-
- pass
-
-
-class PoolError(HTTPError):
- """Base exception for errors caused within a pool."""
-
- def __init__(self, pool, message):
- self.pool = pool
- HTTPError.__init__(self, "%s: %s" % (pool, message))
-
- def __reduce__(self):
- # For pickling purposes.
- return self.__class__, (None, None)
-
-
-class RequestError(PoolError):
- """Base exception for PoolErrors that have associated URLs."""
-
- def __init__(self, pool, url, message):
- self.url = url
- PoolError.__init__(self, pool, message)
-
- def __reduce__(self):
- # For pickling purposes.
- return self.__class__, (None, self.url, None)
-
-
-class SSLError(HTTPError):
- """Raised when SSL certificate fails in an HTTPS connection."""
-
- pass
-
-
-class ProxyError(HTTPError):
- """Raised when the connection to a proxy fails."""
-
- def __init__(self, message, error, *args):
- super(ProxyError, self).__init__(message, error, *args)
- self.original_error = error
-
-
-class DecodeError(HTTPError):
- """Raised when automatic decoding based on Content-Type fails."""
-
- pass
-
-
-class ProtocolError(HTTPError):
- """Raised when something unexpected happens mid-request/response."""
-
- pass
-
-
-#: Renamed to ProtocolError but aliased for backwards compatibility.
-ConnectionError = ProtocolError
-
-
-# Leaf Exceptions
-
-
-class MaxRetryError(RequestError):
- """Raised when the maximum number of retries is exceeded.
-
- :param pool: The connection pool
- :type pool: :class:`~urllib3.connectionpool.HTTPConnectionPool`
- :param string url: The requested Url
- :param exceptions.Exception reason: The underlying error
-
- """
-
- def __init__(self, pool, url, reason=None):
- self.reason = reason
-
- message = "Max retries exceeded with url: %s (Caused by %r)" % (url, reason)
-
- RequestError.__init__(self, pool, url, message)
-
-
-class HostChangedError(RequestError):
- """Raised when an existing pool gets a request for a foreign host."""
-
- def __init__(self, pool, url, retries=3):
- message = "Tried to open a foreign host with url: %s" % url
- RequestError.__init__(self, pool, url, message)
- self.retries = retries
-
-
-class TimeoutStateError(HTTPError):
- """Raised when passing an invalid state to a timeout"""
-
- pass
-
-
-class TimeoutError(HTTPError):
- """Raised when a socket timeout error occurs.
-
- Catching this error will catch both :exc:`ReadTimeoutErrors
- ` and :exc:`ConnectTimeoutErrors `.
- """
-
- pass
-
-
-class ReadTimeoutError(TimeoutError, RequestError):
- """Raised when a socket timeout occurs while receiving data from a server"""
-
- pass
-
-
-# This timeout error does not have a URL attached and needs to inherit from the
-# base HTTPError
-class ConnectTimeoutError(TimeoutError):
- """Raised when a socket timeout occurs while connecting to a server"""
-
- pass
-
-
-class NewConnectionError(ConnectTimeoutError, PoolError):
- """Raised when we fail to establish a new connection. Usually ECONNREFUSED."""
-
- pass
-
-
-class EmptyPoolError(PoolError):
- """Raised when a pool runs out of connections and no more are allowed."""
-
- pass
-
-
-class ClosedPoolError(PoolError):
- """Raised when a request enters a pool after the pool has been closed."""
-
- pass
-
-
-class LocationValueError(ValueError, HTTPError):
- """Raised when there is something wrong with a given URL input."""
-
- pass
-
-
-class LocationParseError(LocationValueError):
- """Raised when get_host or similar fails to parse the URL input."""
-
- def __init__(self, location):
- message = "Failed to parse: %s" % location
- HTTPError.__init__(self, message)
-
- self.location = location
-
-
-class URLSchemeUnknown(LocationValueError):
- """Raised when a URL input has an unsupported scheme."""
-
- def __init__(self, scheme):
- message = "Not supported URL scheme %s" % scheme
- super(URLSchemeUnknown, self).__init__(message)
-
- self.scheme = scheme
-
-
-class ResponseError(HTTPError):
- """Used as a container for an error reason supplied in a MaxRetryError."""
-
- GENERIC_ERROR = "too many error responses"
- SPECIFIC_ERROR = "too many {status_code} error responses"
-
-
-class SecurityWarning(HTTPWarning):
- """Warned when performing security reducing actions"""
-
- pass
-
-
-class SubjectAltNameWarning(SecurityWarning):
- """Warned when connecting to a host with a certificate missing a SAN."""
-
- pass
-
-
-class InsecureRequestWarning(SecurityWarning):
- """Warned when making an unverified HTTPS request."""
-
- pass
-
-
-class SystemTimeWarning(SecurityWarning):
- """Warned when system time is suspected to be wrong"""
-
- pass
-
-
-class InsecurePlatformWarning(SecurityWarning):
- """Warned when certain TLS/SSL configuration is not available on a platform."""
-
- pass
-
-
-class SNIMissingWarning(HTTPWarning):
- """Warned when making a HTTPS request without SNI available."""
-
- pass
-
-
-class DependencyWarning(HTTPWarning):
- """
- Warned when an attempt is made to import a module with missing optional
- dependencies.
- """
-
- pass
-
-
-class ResponseNotChunked(ProtocolError, ValueError):
- """Response needs to be chunked in order to read it as chunks."""
-
- pass
-
-
-class BodyNotHttplibCompatible(HTTPError):
- """
- Body should be :class:`http.client.HTTPResponse` like
- (have an fp attribute which returns raw chunks) for read_chunked().
- """
-
- pass
-
-
-class IncompleteRead(HTTPError, httplib_IncompleteRead):
- """
- Response length doesn't match expected Content-Length
-
- Subclass of :class:`http.client.IncompleteRead` to allow int value
- for ``partial`` to avoid creating large objects on streamed reads.
- """
-
- def __init__(self, partial, expected):
- super(IncompleteRead, self).__init__(partial, expected)
-
- def __repr__(self):
- return "IncompleteRead(%i bytes read, %i more expected)" % (
- self.partial,
- self.expected,
- )
-
-
-class InvalidChunkLength(HTTPError, httplib_IncompleteRead):
- """Invalid chunk length in a chunked response."""
-
- def __init__(self, response, length):
- super(InvalidChunkLength, self).__init__(
- response.tell(), response.length_remaining
- )
- self.response = response
- self.length = length
-
- def __repr__(self):
- return "InvalidChunkLength(got length %r, %i bytes read)" % (
- self.length,
- self.partial,
- )
-
-
-class InvalidHeader(HTTPError):
- """The header provided was somehow invalid."""
-
- pass
-
-
-class ProxySchemeUnknown(AssertionError, URLSchemeUnknown):
- """ProxyManager does not support the supplied scheme"""
-
- # TODO(t-8ch): Stop inheriting from AssertionError in v2.0.
-
- def __init__(self, scheme):
- # 'localhost' is here because our URL parser parses
- # localhost:8080 -> scheme=localhost, remove if we fix this.
- if scheme == "localhost":
- scheme = None
- if scheme is None:
- message = "Proxy URL had no scheme, should start with http:// or https://"
- else:
- message = (
- "Proxy URL had unsupported scheme %s, should use http:// or https://"
- % scheme
- )
- super(ProxySchemeUnknown, self).__init__(message)
-
-
-class ProxySchemeUnsupported(ValueError):
- """Fetching HTTPS resources through HTTPS proxies is unsupported"""
-
- pass
-
-
-class HeaderParsingError(HTTPError):
- """Raised by assert_header_parsing, but we convert it to a log.warning statement."""
-
- def __init__(self, defects, unparsed_data):
- message = "%s, unparsed data: %r" % (defects or "Unknown", unparsed_data)
- super(HeaderParsingError, self).__init__(message)
-
-
-class UnrewindableBodyError(HTTPError):
- """urllib3 encountered an error when trying to rewind a body"""
-
- pass
diff --git a/spaces/Realcat/image-matching-webui/third_party/SuperGluePretrainedNetwork/demo_superglue.py b/spaces/Realcat/image-matching-webui/third_party/SuperGluePretrainedNetwork/demo_superglue.py
deleted file mode 100644
index c639efd7481052b842c640d4aa23aaf18e0eb449..0000000000000000000000000000000000000000
--- a/spaces/Realcat/image-matching-webui/third_party/SuperGluePretrainedNetwork/demo_superglue.py
+++ /dev/null
@@ -1,322 +0,0 @@
-#! /usr/bin/env python3
-#
-# %BANNER_BEGIN%
-# ---------------------------------------------------------------------
-# %COPYRIGHT_BEGIN%
-#
-# Magic Leap, Inc. ("COMPANY") CONFIDENTIAL
-#
-# Unpublished Copyright (c) 2020
-# Magic Leap, Inc., All Rights Reserved.
-#
-# NOTICE: All information contained herein is, and remains the property
-# of COMPANY. The intellectual and technical concepts contained herein
-# are proprietary to COMPANY and may be covered by U.S. and Foreign
-# Patents, patents in process, and are protected by trade secret or
-# copyright law. Dissemination of this information or reproduction of
-# this material is strictly forbidden unless prior written permission is
-# obtained from COMPANY. Access to the source code contained herein is
-# hereby forbidden to anyone except current COMPANY employees, managers
-# or contractors who have executed Confidentiality and Non-disclosure
-# agreements explicitly covering such access.
-#
-# The copyright notice above does not evidence any actual or intended
-# publication or disclosure of this source code, which includes
-# information that is confidential and/or proprietary, and is a trade
-# secret, of COMPANY. ANY REPRODUCTION, MODIFICATION, DISTRIBUTION,
-# PUBLIC PERFORMANCE, OR PUBLIC DISPLAY OF OR THROUGH USE OF THIS
-# SOURCE CODE WITHOUT THE EXPRESS WRITTEN CONSENT OF COMPANY IS
-# STRICTLY PROHIBITED, AND IN VIOLATION OF APPLICABLE LAWS AND
-# INTERNATIONAL TREATIES. THE RECEIPT OR POSSESSION OF THIS SOURCE
-# CODE AND/OR RELATED INFORMATION DOES NOT CONVEY OR IMPLY ANY RIGHTS
-# TO REPRODUCE, DISCLOSE OR DISTRIBUTE ITS CONTENTS, OR TO MANUFACTURE,
-# USE, OR SELL ANYTHING THAT IT MAY DESCRIBE, IN WHOLE OR IN PART.
-#
-# %COPYRIGHT_END%
-# ----------------------------------------------------------------------
-# %AUTHORS_BEGIN%
-#
-# Originating Authors: Paul-Edouard Sarlin
-# Daniel DeTone
-# Tomasz Malisiewicz
-#
-# %AUTHORS_END%
-# --------------------------------------------------------------------*/
-# %BANNER_END%
-
-from pathlib import Path
-import argparse
-import cv2
-import matplotlib.cm as cm
-import torch
-
-from models.matching import Matching
-from models.utils import (
- AverageTimer,
- VideoStreamer,
- make_matching_plot_fast,
- frame2tensor,
-)
-
-torch.set_grad_enabled(False)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(
- description="SuperGlue demo",
- formatter_class=argparse.ArgumentDefaultsHelpFormatter,
- )
- parser.add_argument(
- "--input",
- type=str,
- default="0",
- help="ID of a USB webcam, URL of an IP camera, "
- "or path to an image directory or movie file",
- )
- parser.add_argument(
- "--output_dir",
- type=str,
- default=None,
- help="Directory where to write output frames (If None, no output)",
- )
-
- parser.add_argument(
- "--image_glob",
- type=str,
- nargs="+",
- default=["*.png", "*.jpg", "*.jpeg"],
- help="Glob if a directory of images is specified",
- )
- parser.add_argument(
- "--skip",
- type=int,
- default=1,
- help="Images to skip if input is a movie or directory",
- )
- parser.add_argument(
- "--max_length",
- type=int,
- default=1000000,
- help="Maximum length if input is a movie or directory",
- )
- parser.add_argument(
- "--resize",
- type=int,
- nargs="+",
- default=[640, 480],
- help="Resize the input image before running inference. If two numbers, "
- "resize to the exact dimensions, if one number, resize the max "
- "dimension, if -1, do not resize",
- )
-
- parser.add_argument(
- "--superglue",
- choices={"indoor", "outdoor"},
- default="indoor",
- help="SuperGlue weights",
- )
- parser.add_argument(
- "--max_keypoints",
- type=int,
- default=-1,
- help="Maximum number of keypoints detected by Superpoint"
- " ('-1' keeps all keypoints)",
- )
- parser.add_argument(
- "--keypoint_threshold",
- type=float,
- default=0.005,
- help="SuperPoint keypoint detector confidence threshold",
- )
- parser.add_argument(
- "--nms_radius",
- type=int,
- default=4,
- help="SuperPoint Non Maximum Suppression (NMS) radius" " (Must be positive)",
- )
- parser.add_argument(
- "--sinkhorn_iterations",
- type=int,
- default=20,
- help="Number of Sinkhorn iterations performed by SuperGlue",
- )
- parser.add_argument(
- "--match_threshold", type=float, default=0.2, help="SuperGlue match threshold"
- )
-
- parser.add_argument(
- "--show_keypoints", action="store_true", help="Show the detected keypoints"
- )
- parser.add_argument(
- "--no_display",
- action="store_true",
- help="Do not display images to screen. Useful if running remotely",
- )
- parser.add_argument(
- "--force_cpu", action="store_true", help="Force pytorch to run in CPU mode."
- )
-
- opt = parser.parse_args()
- print(opt)
-
- if len(opt.resize) == 2 and opt.resize[1] == -1:
- opt.resize = opt.resize[0:1]
- if len(opt.resize) == 2:
- print("Will resize to {}x{} (WxH)".format(opt.resize[0], opt.resize[1]))
- elif len(opt.resize) == 1 and opt.resize[0] > 0:
- print("Will resize max dimension to {}".format(opt.resize[0]))
- elif len(opt.resize) == 1:
- print("Will not resize images")
- else:
- raise ValueError("Cannot specify more than two integers for --resize")
-
- device = "cuda" if torch.cuda.is_available() and not opt.force_cpu else "cpu"
- print('Running inference on device "{}"'.format(device))
- config = {
- "superpoint": {
- "nms_radius": opt.nms_radius,
- "keypoint_threshold": opt.keypoint_threshold,
- "max_keypoints": opt.max_keypoints,
- },
- "superglue": {
- "weights": opt.superglue,
- "sinkhorn_iterations": opt.sinkhorn_iterations,
- "match_threshold": opt.match_threshold,
- },
- }
- matching = Matching(config).eval().to(device)
- keys = ["keypoints", "scores", "descriptors"]
-
- vs = VideoStreamer(opt.input, opt.resize, opt.skip, opt.image_glob, opt.max_length)
- frame, ret = vs.next_frame()
- assert ret, "Error when reading the first frame (try different --input?)"
-
- frame_tensor = frame2tensor(frame, device)
- last_data = matching.superpoint({"image": frame_tensor})
- last_data = {k + "0": last_data[k] for k in keys}
- last_data["image0"] = frame_tensor
- last_frame = frame
- last_image_id = 0
-
- if opt.output_dir is not None:
- print("==> Will write outputs to {}".format(opt.output_dir))
- Path(opt.output_dir).mkdir(exist_ok=True)
-
- # Create a window to display the demo.
- if not opt.no_display:
- cv2.namedWindow("SuperGlue matches", cv2.WINDOW_NORMAL)
- cv2.resizeWindow("SuperGlue matches", 640 * 2, 480)
- else:
- print("Skipping visualization, will not show a GUI.")
-
- # Print the keyboard help menu.
- print(
- "==> Keyboard control:\n"
- "\tn: select the current frame as the anchor\n"
- "\te/r: increase/decrease the keypoint confidence threshold\n"
- "\td/f: increase/decrease the match filtering threshold\n"
- "\tk: toggle the visualization of keypoints\n"
- "\tq: quit"
- )
-
- timer = AverageTimer()
-
- while True:
- frame, ret = vs.next_frame()
- if not ret:
- print("Finished demo_superglue.py")
- break
- timer.update("data")
- stem0, stem1 = last_image_id, vs.i - 1
-
- frame_tensor = frame2tensor(frame, device)
- pred = matching({**last_data, "image1": frame_tensor})
- kpts0 = last_data["keypoints0"][0].cpu().numpy()
- kpts1 = pred["keypoints1"][0].cpu().numpy()
- matches = pred["matches0"][0].cpu().numpy()
- confidence = pred["matching_scores0"][0].cpu().numpy()
- timer.update("forward")
-
- valid = matches > -1
- mkpts0 = kpts0[valid]
- mkpts1 = kpts1[matches[valid]]
- color = cm.jet(confidence[valid])
- text = [
- "SuperGlue",
- "Keypoints: {}:{}".format(len(kpts0), len(kpts1)),
- "Matches: {}".format(len(mkpts0)),
- ]
- k_thresh = matching.superpoint.config["keypoint_threshold"]
- m_thresh = matching.superglue.config["match_threshold"]
- small_text = [
- "Keypoint Threshold: {:.4f}".format(k_thresh),
- "Match Threshold: {:.2f}".format(m_thresh),
- "Image Pair: {:06}:{:06}".format(stem0, stem1),
- ]
- out = make_matching_plot_fast(
- last_frame,
- frame,
- kpts0,
- kpts1,
- mkpts0,
- mkpts1,
- color,
- text,
- path=None,
- show_keypoints=opt.show_keypoints,
- small_text=small_text,
- )
-
- if not opt.no_display:
- cv2.imshow("SuperGlue matches", out)
- key = chr(cv2.waitKey(1) & 0xFF)
- if key == "q":
- vs.cleanup()
- print("Exiting (via q) demo_superglue.py")
- break
- elif key == "n": # set the current frame as anchor
- last_data = {k + "0": pred[k + "1"] for k in keys}
- last_data["image0"] = frame_tensor
- last_frame = frame
- last_image_id = vs.i - 1
- elif key in ["e", "r"]:
- # Increase/decrease keypoint threshold by 10% each keypress.
- d = 0.1 * (-1 if key == "e" else 1)
- matching.superpoint.config["keypoint_threshold"] = min(
- max(
- 0.0001,
- matching.superpoint.config["keypoint_threshold"] * (1 + d),
- ),
- 1,
- )
- print(
- "\nChanged the keypoint threshold to {:.4f}".format(
- matching.superpoint.config["keypoint_threshold"]
- )
- )
- elif key in ["d", "f"]:
- # Increase/decrease match threshold by 0.05 each keypress.
- d = 0.05 * (-1 if key == "d" else 1)
- matching.superglue.config["match_threshold"] = min(
- max(0.05, matching.superglue.config["match_threshold"] + d), 0.95
- )
- print(
- "\nChanged the match threshold to {:.2f}".format(
- matching.superglue.config["match_threshold"]
- )
- )
- elif key == "k":
- opt.show_keypoints = not opt.show_keypoints
-
- timer.update("viz")
- timer.print()
-
- if opt.output_dir is not None:
- # stem = 'matches_{:06}_{:06}'.format(last_image_id, vs.i-1)
- stem = "matches_{:06}_{:06}".format(stem0, stem1)
- out_file = str(Path(opt.output_dir, stem + ".png"))
- print("\nWriting image to {}".format(out_file))
- cv2.imwrite(out_file, out)
-
- cv2.destroyAllWindows()
- vs.cleanup()
diff --git a/spaces/Retinalogic/pastel-mix/README.md b/spaces/Retinalogic/pastel-mix/README.md
deleted file mode 100644
index a6b00116cfdc82111195e3ea39a8220f347089fe..0000000000000000000000000000000000000000
--- a/spaces/Retinalogic/pastel-mix/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Pastel Mix
-emoji: 🔥
-colorFrom: red
-colorTo: pink
-sdk: gradio
-sdk_version: 3.33.1
-app_file: app.py
-pinned: false
-license: creativeml-openrail-m
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/configs/_base_/models/ccnet_r50-d8.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/configs/_base_/models/ccnet_r50-d8.py
deleted file mode 100644
index 794148f576b9e215c3c6963e73dffe98204b7717..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/configs/_base_/models/ccnet_r50-d8.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# model settings
-norm_cfg = dict(type='SyncBN', requires_grad=True)
-model = dict(
- type='EncoderDecoder',
- pretrained='open-mmlab://resnet50_v1c',
- backbone=dict(
- type='ResNetV1c',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- dilations=(1, 1, 2, 4),
- strides=(1, 2, 1, 1),
- norm_cfg=norm_cfg,
- norm_eval=False,
- style='pytorch',
- contract_dilation=True),
- decode_head=dict(
- type='CCHead',
- in_channels=2048,
- in_index=3,
- channels=512,
- recurrence=2,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
- auxiliary_head=dict(
- type='FCNHead',
- in_channels=1024,
- in_index=2,
- channels=256,
- num_convs=1,
- concat_input=False,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
- # model training and testing settings
- train_cfg=dict(),
- test_cfg=dict(mode='whole'))
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmcv/runner/hooks/logger/dvclive.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmcv/runner/hooks/logger/dvclive.py
deleted file mode 100644
index 687cdc58c0336c92b1e4f9a410ba67ebaab2bc7a..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmcv/runner/hooks/logger/dvclive.py
+++ /dev/null
@@ -1,58 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from ...dist_utils import master_only
-from ..hook import HOOKS
-from .base import LoggerHook
-
-
-@HOOKS.register_module()
-class DvcliveLoggerHook(LoggerHook):
- """Class to log metrics with dvclive.
-
- It requires `dvclive`_ to be installed.
-
- Args:
- path (str): Directory where dvclive will write TSV log files.
- interval (int): Logging interval (every k iterations).
- Default 10.
- ignore_last (bool): Ignore the log of last iterations in each epoch
- if less than `interval`.
- Default: True.
- reset_flag (bool): Whether to clear the output buffer after logging.
- Default: True.
- by_epoch (bool): Whether EpochBasedRunner is used.
- Default: True.
-
- .. _dvclive:
- https://dvc.org/doc/dvclive
- """
-
- def __init__(self,
- path,
- interval=10,
- ignore_last=True,
- reset_flag=True,
- by_epoch=True):
-
- super(DvcliveLoggerHook, self).__init__(interval, ignore_last,
- reset_flag, by_epoch)
- self.path = path
- self.import_dvclive()
-
- def import_dvclive(self):
- try:
- import dvclive
- except ImportError:
- raise ImportError(
- 'Please run "pip install dvclive" to install dvclive')
- self.dvclive = dvclive
-
- @master_only
- def before_run(self, runner):
- self.dvclive.init(self.path)
-
- @master_only
- def log(self, runner):
- tags = self.get_loggable_tags(runner)
- if tags:
- for k, v in tags.items():
- self.dvclive.log(k, v, step=self.get_iter(runner))
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet/core/bbox/match_costs/match_cost.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet/core/bbox/match_costs/match_cost.py
deleted file mode 100644
index 38869737d66064ee5adea4b2c8ff26ae091e5f56..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet/core/bbox/match_costs/match_cost.py
+++ /dev/null
@@ -1,184 +0,0 @@
-import torch
-
-from mmdet.core.bbox.iou_calculators import bbox_overlaps
-from mmdet.core.bbox.transforms import bbox_cxcywh_to_xyxy, bbox_xyxy_to_cxcywh
-from .builder import MATCH_COST
-
-
-@MATCH_COST.register_module()
-class BBoxL1Cost(object):
- """BBoxL1Cost.
-
- Args:
- weight (int | float, optional): loss_weight
- box_format (str, optional): 'xyxy' for DETR, 'xywh' for Sparse_RCNN
-
- Examples:
- >>> from mmdet.core.bbox.match_costs.match_cost import BBoxL1Cost
- >>> import torch
- >>> self = BBoxL1Cost()
- >>> bbox_pred = torch.rand(1, 4)
- >>> gt_bboxes= torch.FloatTensor([[0, 0, 2, 4], [1, 2, 3, 4]])
- >>> factor = torch.tensor([10, 8, 10, 8])
- >>> self(bbox_pred, gt_bboxes, factor)
- tensor([[1.6172, 1.6422]])
- """
-
- def __init__(self, weight=1., box_format='xyxy'):
- self.weight = weight
- assert box_format in ['xyxy', 'xywh']
- self.box_format = box_format
-
- def __call__(self, bbox_pred, gt_bboxes):
- """
- Args:
- bbox_pred (Tensor): Predicted boxes with normalized coordinates
- (cx, cy, w, h), which are all in range [0, 1]. Shape
- [num_query, 4].
- gt_bboxes (Tensor): Ground truth boxes with normalized
- coordinates (x1, y1, x2, y2). Shape [num_gt, 4].
-
- Returns:
- torch.Tensor: bbox_cost value with weight
- """
- if self.box_format == 'xywh':
- gt_bboxes = bbox_xyxy_to_cxcywh(gt_bboxes)
- elif self.box_format == 'xyxy':
- bbox_pred = bbox_cxcywh_to_xyxy(bbox_pred)
- bbox_cost = torch.cdist(bbox_pred, gt_bboxes, p=1)
- return bbox_cost * self.weight
-
-
-@MATCH_COST.register_module()
-class FocalLossCost(object):
- """FocalLossCost.
-
- Args:
- weight (int | float, optional): loss_weight
- alpha (int | float, optional): focal_loss alpha
- gamma (int | float, optional): focal_loss gamma
- eps (float, optional): default 1e-12
-
- Examples:
- >>> from mmdet.core.bbox.match_costs.match_cost import FocalLossCost
- >>> import torch
- >>> self = FocalLossCost()
- >>> cls_pred = torch.rand(4, 3)
- >>> gt_labels = torch.tensor([0, 1, 2])
- >>> factor = torch.tensor([10, 8, 10, 8])
- >>> self(cls_pred, gt_labels)
- tensor([[-0.3236, -0.3364, -0.2699],
- [-0.3439, -0.3209, -0.4807],
- [-0.4099, -0.3795, -0.2929],
- [-0.1950, -0.1207, -0.2626]])
- """
-
- def __init__(self, weight=1., alpha=0.25, gamma=2, eps=1e-12):
- self.weight = weight
- self.alpha = alpha
- self.gamma = gamma
- self.eps = eps
-
- def __call__(self, cls_pred, gt_labels):
- """
- Args:
- cls_pred (Tensor): Predicted classification logits, shape
- [num_query, num_class].
- gt_labels (Tensor): Label of `gt_bboxes`, shape (num_gt,).
-
- Returns:
- torch.Tensor: cls_cost value with weight
- """
- cls_pred = cls_pred.sigmoid()
- neg_cost = -(1 - cls_pred + self.eps).log() * (
- 1 - self.alpha) * cls_pred.pow(self.gamma)
- pos_cost = -(cls_pred + self.eps).log() * self.alpha * (
- 1 - cls_pred).pow(self.gamma)
- cls_cost = pos_cost[:, gt_labels] - neg_cost[:, gt_labels]
- return cls_cost * self.weight
-
-
-@MATCH_COST.register_module()
-class ClassificationCost(object):
- """ClsSoftmaxCost.
-
- Args:
- weight (int | float, optional): loss_weight
-
- Examples:
- >>> from mmdet.core.bbox.match_costs.match_cost import \
- ... ClassificationCost
- >>> import torch
- >>> self = ClassificationCost()
- >>> cls_pred = torch.rand(4, 3)
- >>> gt_labels = torch.tensor([0, 1, 2])
- >>> factor = torch.tensor([10, 8, 10, 8])
- >>> self(cls_pred, gt_labels)
- tensor([[-0.3430, -0.3525, -0.3045],
- [-0.3077, -0.2931, -0.3992],
- [-0.3664, -0.3455, -0.2881],
- [-0.3343, -0.2701, -0.3956]])
- """
-
- def __init__(self, weight=1.):
- self.weight = weight
-
- def __call__(self, cls_pred, gt_labels):
- """
- Args:
- cls_pred (Tensor): Predicted classification logits, shape
- [num_query, num_class].
- gt_labels (Tensor): Label of `gt_bboxes`, shape (num_gt,).
-
- Returns:
- torch.Tensor: cls_cost value with weight
- """
- # Following the official DETR repo, contrary to the loss that
- # NLL is used, we approximate it in 1 - cls_score[gt_label].
- # The 1 is a constant that doesn't change the matching,
- # so it can be omitted.
- cls_score = cls_pred.softmax(-1)
- cls_cost = -cls_score[:, gt_labels]
- return cls_cost * self.weight
-
-
-@MATCH_COST.register_module()
-class IoUCost(object):
- """IoUCost.
-
- Args:
- iou_mode (str, optional): iou mode such as 'iou' | 'giou'
- weight (int | float, optional): loss weight
-
- Examples:
- >>> from mmdet.core.bbox.match_costs.match_cost import IoUCost
- >>> import torch
- >>> self = IoUCost()
- >>> bboxes = torch.FloatTensor([[1,1, 2, 2], [2, 2, 3, 4]])
- >>> gt_bboxes = torch.FloatTensor([[0, 0, 2, 4], [1, 2, 3, 4]])
- >>> self(bboxes, gt_bboxes)
- tensor([[-0.1250, 0.1667],
- [ 0.1667, -0.5000]])
- """
-
- def __init__(self, iou_mode='giou', weight=1.):
- self.weight = weight
- self.iou_mode = iou_mode
-
- def __call__(self, bboxes, gt_bboxes):
- """
- Args:
- bboxes (Tensor): Predicted boxes with unnormalized coordinates
- (x1, y1, x2, y2). Shape [num_query, 4].
- gt_bboxes (Tensor): Ground truth boxes with unnormalized
- coordinates (x1, y1, x2, y2). Shape [num_gt, 4].
-
- Returns:
- torch.Tensor: iou_cost value with weight
- """
- # overlaps: [num_bboxes, num_gt]
- overlaps = bbox_overlaps(
- bboxes, gt_bboxes, mode=self.iou_mode, is_aligned=False)
- # The 1 is a constant that doesn't change the matching, so omitted.
- iou_cost = -overlaps
- return iou_cost * self.weight
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/models/utils/__init__.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/models/utils/__init__.py
deleted file mode 100644
index 3d3bdd349b9f2ae499a2fcb2ac1d2e3c77befebe..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmseg/models/utils/__init__.py
+++ /dev/null
@@ -1,13 +0,0 @@
-from .drop import DropPath
-from .inverted_residual import InvertedResidual, InvertedResidualV3
-from .make_divisible import make_divisible
-from .res_layer import ResLayer
-from .se_layer import SELayer
-from .self_attention_block import SelfAttentionBlock
-from .up_conv_block import UpConvBlock
-from .weight_init import trunc_normal_
-
-__all__ = [
- 'ResLayer', 'SelfAttentionBlock', 'make_divisible', 'InvertedResidual',
- 'UpConvBlock', 'InvertedResidualV3', 'SELayer', 'DropPath', 'trunc_normal_'
-]
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmcv/runner/hooks/memory.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmcv/runner/hooks/memory.py
deleted file mode 100644
index 70cf9a838fb314e3bd3c07aadbc00921a81e83ed..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer_base/mmcv/runner/hooks/memory.py
+++ /dev/null
@@ -1,25 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import torch
-
-from .hook import HOOKS, Hook
-
-
-@HOOKS.register_module()
-class EmptyCacheHook(Hook):
-
- def __init__(self, before_epoch=False, after_epoch=True, after_iter=False):
- self._before_epoch = before_epoch
- self._after_epoch = after_epoch
- self._after_iter = after_iter
-
- def after_iter(self, runner):
- if self._after_iter:
- torch.cuda.empty_cache()
-
- def before_epoch(self, runner):
- if self._before_epoch:
- torch.cuda.empty_cache()
-
- def after_epoch(self, runner):
- if self._after_epoch:
- torch.cuda.empty_cache()
diff --git a/spaces/RobotJelly/Text_Or_Image-To-Image_Search/README.md b/spaces/RobotJelly/Text_Or_Image-To-Image_Search/README.md
deleted file mode 100644
index 5bdeb3b6e945bf85a92feef4b0f520927e5cdab8..0000000000000000000000000000000000000000
--- a/spaces/RobotJelly/Text_Or_Image-To-Image_Search/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: Search Text/Image To Image
-emoji: 📝🖼️
-colorFrom: pink
-colorTo: gray
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/Ryzal/rvc-models-new/lib/infer_pack/attentions.py b/spaces/Ryzal/rvc-models-new/lib/infer_pack/attentions.py
deleted file mode 100644
index 05501be1871643f78dddbeaa529c96667031a8db..0000000000000000000000000000000000000000
--- a/spaces/Ryzal/rvc-models-new/lib/infer_pack/attentions.py
+++ /dev/null
@@ -1,417 +0,0 @@
-import copy
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from lib.infer_pack import commons
-from lib.infer_pack import modules
-from lib.infer_pack.modules import LayerNorm
-
-
-class Encoder(nn.Module):
- def __init__(
- self,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size=1,
- p_dropout=0.0,
- window_size=10,
- **kwargs
- ):
- super().__init__()
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.window_size = window_size
-
- self.drop = nn.Dropout(p_dropout)
- self.attn_layers = nn.ModuleList()
- self.norm_layers_1 = nn.ModuleList()
- self.ffn_layers = nn.ModuleList()
- self.norm_layers_2 = nn.ModuleList()
- for i in range(self.n_layers):
- self.attn_layers.append(
- MultiHeadAttention(
- hidden_channels,
- hidden_channels,
- n_heads,
- p_dropout=p_dropout,
- window_size=window_size,
- )
- )
- self.norm_layers_1.append(LayerNorm(hidden_channels))
- self.ffn_layers.append(
- FFN(
- hidden_channels,
- hidden_channels,
- filter_channels,
- kernel_size,
- p_dropout=p_dropout,
- )
- )
- self.norm_layers_2.append(LayerNorm(hidden_channels))
-
- def forward(self, x, x_mask):
- attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
- x = x * x_mask
- for i in range(self.n_layers):
- y = self.attn_layers[i](x, x, attn_mask)
- y = self.drop(y)
- x = self.norm_layers_1[i](x + y)
-
- y = self.ffn_layers[i](x, x_mask)
- y = self.drop(y)
- x = self.norm_layers_2[i](x + y)
- x = x * x_mask
- return x
-
-
-class Decoder(nn.Module):
- def __init__(
- self,
- hidden_channels,
- filter_channels,
- n_heads,
- n_layers,
- kernel_size=1,
- p_dropout=0.0,
- proximal_bias=False,
- proximal_init=True,
- **kwargs
- ):
- super().__init__()
- self.hidden_channels = hidden_channels
- self.filter_channels = filter_channels
- self.n_heads = n_heads
- self.n_layers = n_layers
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.proximal_bias = proximal_bias
- self.proximal_init = proximal_init
-
- self.drop = nn.Dropout(p_dropout)
- self.self_attn_layers = nn.ModuleList()
- self.norm_layers_0 = nn.ModuleList()
- self.encdec_attn_layers = nn.ModuleList()
- self.norm_layers_1 = nn.ModuleList()
- self.ffn_layers = nn.ModuleList()
- self.norm_layers_2 = nn.ModuleList()
- for i in range(self.n_layers):
- self.self_attn_layers.append(
- MultiHeadAttention(
- hidden_channels,
- hidden_channels,
- n_heads,
- p_dropout=p_dropout,
- proximal_bias=proximal_bias,
- proximal_init=proximal_init,
- )
- )
- self.norm_layers_0.append(LayerNorm(hidden_channels))
- self.encdec_attn_layers.append(
- MultiHeadAttention(
- hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout
- )
- )
- self.norm_layers_1.append(LayerNorm(hidden_channels))
- self.ffn_layers.append(
- FFN(
- hidden_channels,
- hidden_channels,
- filter_channels,
- kernel_size,
- p_dropout=p_dropout,
- causal=True,
- )
- )
- self.norm_layers_2.append(LayerNorm(hidden_channels))
-
- def forward(self, x, x_mask, h, h_mask):
- """
- x: decoder input
- h: encoder output
- """
- self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(
- device=x.device, dtype=x.dtype
- )
- encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
- x = x * x_mask
- for i in range(self.n_layers):
- y = self.self_attn_layers[i](x, x, self_attn_mask)
- y = self.drop(y)
- x = self.norm_layers_0[i](x + y)
-
- y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)
- y = self.drop(y)
- x = self.norm_layers_1[i](x + y)
-
- y = self.ffn_layers[i](x, x_mask)
- y = self.drop(y)
- x = self.norm_layers_2[i](x + y)
- x = x * x_mask
- return x
-
-
-class MultiHeadAttention(nn.Module):
- def __init__(
- self,
- channels,
- out_channels,
- n_heads,
- p_dropout=0.0,
- window_size=None,
- heads_share=True,
- block_length=None,
- proximal_bias=False,
- proximal_init=False,
- ):
- super().__init__()
- assert channels % n_heads == 0
-
- self.channels = channels
- self.out_channels = out_channels
- self.n_heads = n_heads
- self.p_dropout = p_dropout
- self.window_size = window_size
- self.heads_share = heads_share
- self.block_length = block_length
- self.proximal_bias = proximal_bias
- self.proximal_init = proximal_init
- self.attn = None
-
- self.k_channels = channels // n_heads
- self.conv_q = nn.Conv1d(channels, channels, 1)
- self.conv_k = nn.Conv1d(channels, channels, 1)
- self.conv_v = nn.Conv1d(channels, channels, 1)
- self.conv_o = nn.Conv1d(channels, out_channels, 1)
- self.drop = nn.Dropout(p_dropout)
-
- if window_size is not None:
- n_heads_rel = 1 if heads_share else n_heads
- rel_stddev = self.k_channels**-0.5
- self.emb_rel_k = nn.Parameter(
- torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
- * rel_stddev
- )
- self.emb_rel_v = nn.Parameter(
- torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels)
- * rel_stddev
- )
-
- nn.init.xavier_uniform_(self.conv_q.weight)
- nn.init.xavier_uniform_(self.conv_k.weight)
- nn.init.xavier_uniform_(self.conv_v.weight)
- if proximal_init:
- with torch.no_grad():
- self.conv_k.weight.copy_(self.conv_q.weight)
- self.conv_k.bias.copy_(self.conv_q.bias)
-
- def forward(self, x, c, attn_mask=None):
- q = self.conv_q(x)
- k = self.conv_k(c)
- v = self.conv_v(c)
-
- x, self.attn = self.attention(q, k, v, mask=attn_mask)
-
- x = self.conv_o(x)
- return x
-
- def attention(self, query, key, value, mask=None):
- # reshape [b, d, t] -> [b, n_h, t, d_k]
- b, d, t_s, t_t = (*key.size(), query.size(2))
- query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
- key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
- value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
-
- scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))
- if self.window_size is not None:
- assert (
- t_s == t_t
- ), "Relative attention is only available for self-attention."
- key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
- rel_logits = self._matmul_with_relative_keys(
- query / math.sqrt(self.k_channels), key_relative_embeddings
- )
- scores_local = self._relative_position_to_absolute_position(rel_logits)
- scores = scores + scores_local
- if self.proximal_bias:
- assert t_s == t_t, "Proximal bias is only available for self-attention."
- scores = scores + self._attention_bias_proximal(t_s).to(
- device=scores.device, dtype=scores.dtype
- )
- if mask is not None:
- scores = scores.masked_fill(mask == 0, -1e4)
- if self.block_length is not None:
- assert (
- t_s == t_t
- ), "Local attention is only available for self-attention."
- block_mask = (
- torch.ones_like(scores)
- .triu(-self.block_length)
- .tril(self.block_length)
- )
- scores = scores.masked_fill(block_mask == 0, -1e4)
- p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]
- p_attn = self.drop(p_attn)
- output = torch.matmul(p_attn, value)
- if self.window_size is not None:
- relative_weights = self._absolute_position_to_relative_position(p_attn)
- value_relative_embeddings = self._get_relative_embeddings(
- self.emb_rel_v, t_s
- )
- output = output + self._matmul_with_relative_values(
- relative_weights, value_relative_embeddings
- )
- output = (
- output.transpose(2, 3).contiguous().view(b, d, t_t)
- ) # [b, n_h, t_t, d_k] -> [b, d, t_t]
- return output, p_attn
-
- def _matmul_with_relative_values(self, x, y):
- """
- x: [b, h, l, m]
- y: [h or 1, m, d]
- ret: [b, h, l, d]
- """
- ret = torch.matmul(x, y.unsqueeze(0))
- return ret
-
- def _matmul_with_relative_keys(self, x, y):
- """
- x: [b, h, l, d]
- y: [h or 1, m, d]
- ret: [b, h, l, m]
- """
- ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
- return ret
-
- def _get_relative_embeddings(self, relative_embeddings, length):
- max_relative_position = 2 * self.window_size + 1
- # Pad first before slice to avoid using cond ops.
- pad_length = max(length - (self.window_size + 1), 0)
- slice_start_position = max((self.window_size + 1) - length, 0)
- slice_end_position = slice_start_position + 2 * length - 1
- if pad_length > 0:
- padded_relative_embeddings = F.pad(
- relative_embeddings,
- commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),
- )
- else:
- padded_relative_embeddings = relative_embeddings
- used_relative_embeddings = padded_relative_embeddings[
- :, slice_start_position:slice_end_position
- ]
- return used_relative_embeddings
-
- def _relative_position_to_absolute_position(self, x):
- """
- x: [b, h, l, 2*l-1]
- ret: [b, h, l, l]
- """
- batch, heads, length, _ = x.size()
- # Concat columns of pad to shift from relative to absolute indexing.
- x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))
-
- # Concat extra elements so to add up to shape (len+1, 2*len-1).
- x_flat = x.view([batch, heads, length * 2 * length])
- x_flat = F.pad(
- x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [0, length - 1]])
- )
-
- # Reshape and slice out the padded elements.
- x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[
- :, :, :length, length - 1 :
- ]
- return x_final
-
- def _absolute_position_to_relative_position(self, x):
- """
- x: [b, h, l, l]
- ret: [b, h, l, 2*l-1]
- """
- batch, heads, length, _ = x.size()
- # padd along column
- x = F.pad(
- x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]])
- )
- x_flat = x.view([batch, heads, length**2 + length * (length - 1)])
- # add 0's in the beginning that will skew the elements after reshape
- x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
- x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]
- return x_final
-
- def _attention_bias_proximal(self, length):
- """Bias for self-attention to encourage attention to close positions.
- Args:
- length: an integer scalar.
- Returns:
- a Tensor with shape [1, 1, length, length]
- """
- r = torch.arange(length, dtype=torch.float32)
- diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
- return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
-
-
-class FFN(nn.Module):
- def __init__(
- self,
- in_channels,
- out_channels,
- filter_channels,
- kernel_size,
- p_dropout=0.0,
- activation=None,
- causal=False,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.out_channels = out_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.p_dropout = p_dropout
- self.activation = activation
- self.causal = causal
-
- if causal:
- self.padding = self._causal_padding
- else:
- self.padding = self._same_padding
-
- self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)
- self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)
- self.drop = nn.Dropout(p_dropout)
-
- def forward(self, x, x_mask):
- x = self.conv_1(self.padding(x * x_mask))
- if self.activation == "gelu":
- x = x * torch.sigmoid(1.702 * x)
- else:
- x = torch.relu(x)
- x = self.drop(x)
- x = self.conv_2(self.padding(x * x_mask))
- return x * x_mask
-
- def _causal_padding(self, x):
- if self.kernel_size == 1:
- return x
- pad_l = self.kernel_size - 1
- pad_r = 0
- padding = [[0, 0], [0, 0], [pad_l, pad_r]]
- x = F.pad(x, commons.convert_pad_shape(padding))
- return x
-
- def _same_padding(self, x):
- if self.kernel_size == 1:
- return x
- pad_l = (self.kernel_size - 1) // 2
- pad_r = self.kernel_size // 2
- padding = [[0, 0], [0, 0], [pad_l, pad_r]]
- x = F.pad(x, commons.convert_pad_shape(padding))
- return x
diff --git a/spaces/SQSora/VITS-Umamusume-voice-synthesizer/losses.py b/spaces/SQSora/VITS-Umamusume-voice-synthesizer/losses.py
deleted file mode 100644
index fb22a0e834dd87edaa37bb8190eee2c3c7abe0d5..0000000000000000000000000000000000000000
--- a/spaces/SQSora/VITS-Umamusume-voice-synthesizer/losses.py
+++ /dev/null
@@ -1,61 +0,0 @@
-import torch
-from torch.nn import functional as F
-
-import commons
-
-
-def feature_loss(fmap_r, fmap_g):
- loss = 0
- for dr, dg in zip(fmap_r, fmap_g):
- for rl, gl in zip(dr, dg):
- rl = rl.float().detach()
- gl = gl.float()
- loss += torch.mean(torch.abs(rl - gl))
-
- return loss * 2
-
-
-def discriminator_loss(disc_real_outputs, disc_generated_outputs):
- loss = 0
- r_losses = []
- g_losses = []
- for dr, dg in zip(disc_real_outputs, disc_generated_outputs):
- dr = dr.float()
- dg = dg.float()
- r_loss = torch.mean((1-dr)**2)
- g_loss = torch.mean(dg**2)
- loss += (r_loss + g_loss)
- r_losses.append(r_loss.item())
- g_losses.append(g_loss.item())
-
- return loss, r_losses, g_losses
-
-
-def generator_loss(disc_outputs):
- loss = 0
- gen_losses = []
- for dg in disc_outputs:
- dg = dg.float()
- l = torch.mean((1-dg)**2)
- gen_losses.append(l)
- loss += l
-
- return loss, gen_losses
-
-
-def kl_loss(z_p, logs_q, m_p, logs_p, z_mask):
- """
- z_p, logs_q: [b, h, t_t]
- m_p, logs_p: [b, h, t_t]
- """
- z_p = z_p.float()
- logs_q = logs_q.float()
- m_p = m_p.float()
- logs_p = logs_p.float()
- z_mask = z_mask.float()
-
- kl = logs_p - logs_q - 0.5
- kl += 0.5 * ((z_p - m_p)**2) * torch.exp(-2. * logs_p)
- kl = torch.sum(kl * z_mask)
- l = kl / torch.sum(z_mask)
- return l
diff --git a/spaces/SQSora/VITS-Umamusume-voice-synthesizer/text/ngu_dialect.py b/spaces/SQSora/VITS-Umamusume-voice-synthesizer/text/ngu_dialect.py
deleted file mode 100644
index ce3e12bbf0469426872eed5f681985d3e1be9b26..0000000000000000000000000000000000000000
--- a/spaces/SQSora/VITS-Umamusume-voice-synthesizer/text/ngu_dialect.py
+++ /dev/null
@@ -1,30 +0,0 @@
-import re
-import opencc
-
-
-dialects = {'SZ': 'suzhou', 'WX': 'wuxi', 'CZ': 'changzhou', 'HZ': 'hangzhou',
- 'SX': 'shaoxing', 'NB': 'ningbo', 'JJ': 'jingjiang', 'YX': 'yixing',
- 'JD': 'jiading', 'ZR': 'zhenru', 'PH': 'pinghu', 'TX': 'tongxiang',
- 'JS': 'jiashan', 'HN': 'xiashi', 'LP': 'linping', 'XS': 'xiaoshan',
- 'FY': 'fuyang', 'RA': 'ruao', 'CX': 'cixi', 'SM': 'sanmen',
- 'TT': 'tiantai', 'WZ': 'wenzhou', 'SC': 'suichang', 'YB': 'youbu'}
-
-converters = {}
-
-for dialect in dialects.values():
- try:
- converters[dialect] = opencc.OpenCC(dialect)
- except:
- pass
-
-
-def ngu_dialect_to_ipa(text, dialect):
- dialect = dialects[dialect]
- text = converters[dialect].convert(text).replace('-','').replace('$',' ')
- text = re.sub(r'[、;:]', ',', text)
- text = re.sub(r'\s*,\s*', ', ', text)
- text = re.sub(r'\s*。\s*', '. ', text)
- text = re.sub(r'\s*?\s*', '? ', text)
- text = re.sub(r'\s*!\s*', '! ', text)
- text = re.sub(r'\s*$', '', text)
- return text
diff --git a/spaces/Sapphire-356/Video2MC/joints_detectors/Alphapose/SPPE/src/models/layers/DUC.py b/spaces/Sapphire-356/Video2MC/joints_detectors/Alphapose/SPPE/src/models/layers/DUC.py
deleted file mode 100644
index 3592661fc875dbaa7fa70e01ef49befa89569ebd..0000000000000000000000000000000000000000
--- a/spaces/Sapphire-356/Video2MC/joints_detectors/Alphapose/SPPE/src/models/layers/DUC.py
+++ /dev/null
@@ -1,23 +0,0 @@
-import torch.nn as nn
-import torch.nn.functional as F
-
-
-class DUC(nn.Module):
- '''
- INPUT: inplanes, planes, upscale_factor
- OUTPUT: (planes // 4)* ht * wd
- '''
- def __init__(self, inplanes, planes, upscale_factor=2):
- super(DUC, self).__init__()
- self.conv = nn.Conv2d(inplanes, planes, kernel_size=3, padding=1, bias=False)
- self.bn = nn.BatchNorm2d(planes)
- self.relu = nn.ReLU()
-
- self.pixel_shuffle = nn.PixelShuffle(upscale_factor)
-
- def forward(self, x):
- x = self.conv(x)
- x = self.bn(x)
- x = self.relu(x)
- x = self.pixel_shuffle(x)
- return x
diff --git a/spaces/Sarst/VITS-Umamusume-voice-synthesizer2/text/cleaners.py b/spaces/Sarst/VITS-Umamusume-voice-synthesizer2/text/cleaners.py
deleted file mode 100644
index c80e113b2b81a66134800dbdaa29c7d96a0152a7..0000000000000000000000000000000000000000
--- a/spaces/Sarst/VITS-Umamusume-voice-synthesizer2/text/cleaners.py
+++ /dev/null
@@ -1,146 +0,0 @@
-import re
-
-
-def japanese_cleaners(text):
- from text.japanese import japanese_to_romaji_with_accent
- text = japanese_to_romaji_with_accent(text)
- text = re.sub(r'([A-Za-z])$', r'\1.', text)
- return text
-
-
-def japanese_cleaners2(text):
- return japanese_cleaners(text).replace('ts', 'ʦ').replace('...', '…')
-
-
-def korean_cleaners(text):
- '''Pipeline for Korean text'''
- from text.korean import latin_to_hangul, number_to_hangul, divide_hangul
- text = latin_to_hangul(text)
- text = number_to_hangul(text)
- text = divide_hangul(text)
- text = re.sub(r'([\u3131-\u3163])$', r'\1.', text)
- return text
-
-
-def chinese_cleaners(text):
- '''Pipeline for Chinese text'''
- from text.mandarin import number_to_chinese, chinese_to_bopomofo, latin_to_bopomofo
- text = number_to_chinese(text)
- text = chinese_to_bopomofo(text)
- text = latin_to_bopomofo(text)
- text = re.sub(r'([ˉˊˇˋ˙])$', r'\1。', text)
- return text
-
-
-def zh_ja_mixture_cleaners(text):
- from text.mandarin import chinese_to_romaji
- from text.japanese import japanese_to_romaji_with_accent
- text = re.sub(r'\[ZH\](.*?)\[ZH\]',
- lambda x: chinese_to_romaji(x.group(1))+' ', text)
- text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: japanese_to_romaji_with_accent(
- x.group(1)).replace('ts', 'ʦ').replace('u', 'ɯ').replace('...', '…')+' ', text)
- text = re.sub(r'\s+$', '', text)
- text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
- return text
-
-
-def sanskrit_cleaners(text):
- text = text.replace('॥', '।').replace('ॐ', 'ओम्')
- if text[-1] != '।':
- text += ' ।'
- return text
-
-
-def cjks_cleaners(text):
- from text.mandarin import chinese_to_lazy_ipa
- from text.japanese import japanese_to_ipa
- from text.korean import korean_to_lazy_ipa
- from text.sanskrit import devanagari_to_ipa
- from text.english import english_to_lazy_ipa
- text = re.sub(r'\[ZH\](.*?)\[ZH\]',
- lambda x: chinese_to_lazy_ipa(x.group(1))+' ', text)
- text = re.sub(r'\[JA\](.*?)\[JA\]',
- lambda x: japanese_to_ipa(x.group(1))+' ', text)
- text = re.sub(r'\[KO\](.*?)\[KO\]',
- lambda x: korean_to_lazy_ipa(x.group(1))+' ', text)
- text = re.sub(r'\[SA\](.*?)\[SA\]',
- lambda x: devanagari_to_ipa(x.group(1))+' ', text)
- text = re.sub(r'\[EN\](.*?)\[EN\]',
- lambda x: english_to_lazy_ipa(x.group(1))+' ', text)
- text = re.sub(r'\s+$', '', text)
- text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
- return text
-
-
-def cjke_cleaners(text):
- from text.mandarin import chinese_to_lazy_ipa
- from text.japanese import japanese_to_ipa
- from text.korean import korean_to_ipa
- from text.english import english_to_ipa2
- text = re.sub(r'\[ZH\](.*?)\[ZH\]', lambda x: chinese_to_lazy_ipa(x.group(1)).replace(
- 'ʧ', 'tʃ').replace('ʦ', 'ts').replace('ɥan', 'ɥæn')+' ', text)
- text = re.sub(r'\[JA\](.*?)\[JA\]', lambda x: japanese_to_ipa(x.group(1)).replace('ʧ', 'tʃ').replace(
- 'ʦ', 'ts').replace('ɥan', 'ɥæn').replace('ʥ', 'dz')+' ', text)
- text = re.sub(r'\[KO\](.*?)\[KO\]',
- lambda x: korean_to_ipa(x.group(1))+' ', text)
- text = re.sub(r'\[EN\](.*?)\[EN\]', lambda x: english_to_ipa2(x.group(1)).replace('ɑ', 'a').replace(
- 'ɔ', 'o').replace('ɛ', 'e').replace('ɪ', 'i').replace('ʊ', 'u')+' ', text)
- text = re.sub(r'\s+$', '', text)
- text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
- return text
-
-
-def cjke_cleaners2(text):
- from text.mandarin import chinese_to_ipa
- from text.japanese import japanese_to_ipa2
- from text.korean import korean_to_ipa
- from text.english import english_to_ipa2
- text = re.sub(r'\[ZH\](.*?)\[ZH\]',
- lambda x: chinese_to_ipa(x.group(1))+' ', text)
- text = re.sub(r'\[JA\](.*?)\[JA\]',
- lambda x: japanese_to_ipa2(x.group(1))+' ', text)
- text = re.sub(r'\[KO\](.*?)\[KO\]',
- lambda x: korean_to_ipa(x.group(1))+' ', text)
- text = re.sub(r'\[EN\](.*?)\[EN\]',
- lambda x: english_to_ipa2(x.group(1))+' ', text)
- text = re.sub(r'\s+$', '', text)
- text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
- return text
-
-
-def thai_cleaners(text):
- from text.thai import num_to_thai, latin_to_thai
- text = num_to_thai(text)
- text = latin_to_thai(text)
- return text
-
-
-def shanghainese_cleaners(text):
- from text.shanghainese import shanghainese_to_ipa
- text = shanghainese_to_ipa(text)
- text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
- return text
-
-
-def chinese_dialect_cleaners(text):
- from text.mandarin import chinese_to_ipa2
- from text.japanese import japanese_to_ipa3
- from text.shanghainese import shanghainese_to_ipa
- from text.cantonese import cantonese_to_ipa
- from text.english import english_to_lazy_ipa2
- from text.ngu_dialect import ngu_dialect_to_ipa
- text = re.sub(r'\[ZH\](.*?)\[ZH\]',
- lambda x: chinese_to_ipa2(x.group(1))+' ', text)
- text = re.sub(r'\[JA\](.*?)\[JA\]',
- lambda x: japanese_to_ipa3(x.group(1)).replace('Q', 'ʔ')+' ', text)
- text = re.sub(r'\[SH\](.*?)\[SH\]', lambda x: shanghainese_to_ipa(x.group(1)).replace('1', '˥˧').replace('5',
- '˧˧˦').replace('6', '˩˩˧').replace('7', '˥').replace('8', '˩˨').replace('ᴀ', 'ɐ').replace('ᴇ', 'e')+' ', text)
- text = re.sub(r'\[GD\](.*?)\[GD\]',
- lambda x: cantonese_to_ipa(x.group(1))+' ', text)
- text = re.sub(r'\[EN\](.*?)\[EN\]',
- lambda x: english_to_lazy_ipa2(x.group(1))+' ', text)
- text = re.sub(r'\[([A-Z]{2})\](.*?)\[\1\]', lambda x: ngu_dialect_to_ipa(x.group(2), x.group(
- 1)).replace('ʣ', 'dz').replace('ʥ', 'dʑ').replace('ʦ', 'ts').replace('ʨ', 'tɕ')+' ', text)
- text = re.sub(r'\s+$', '', text)
- text = re.sub(r'([^\.,!\?\-…~])$', r'\1.', text)
- return text
diff --git a/spaces/ServerX/PorcoDiaz/utils/clonerepo_experimental.py b/spaces/ServerX/PorcoDiaz/utils/clonerepo_experimental.py
deleted file mode 100644
index b0ae02648c1307562cf48033908edcf2996db5e2..0000000000000000000000000000000000000000
--- a/spaces/ServerX/PorcoDiaz/utils/clonerepo_experimental.py
+++ /dev/null
@@ -1,253 +0,0 @@
-import os
-import subprocess
-import shutil
-from concurrent.futures import ThreadPoolExecutor, as_completed
-from tqdm.notebook import tqdm
-from pathlib import Path
-import requests
-
-def run_script():
- def run_cmd(cmd):
- process = subprocess.run(cmd, shell=True, check=True, text=True)
- return process.stdout
-
- # Change the current directory to /content/
- os.chdir('/content/')
- print("Changing dir to /content/")
-
- # Your function to edit the file
- def edit_file(file_path):
- temp_file_path = "/tmp/temp_file.py"
- changes_made = False
- with open(file_path, "r") as file, open(temp_file_path, "w") as temp_file:
- previous_line = ""
- second_previous_line = ""
- for line in file:
- new_line = line.replace("value=160", "value=128")
- if new_line != line:
- print("Replaced 'value=160' with 'value=128'")
- changes_made = True
- line = new_line
-
- new_line = line.replace("crepe hop length: 160", "crepe hop length: 128")
- if new_line != line:
- print("Replaced 'crepe hop length: 160' with 'crepe hop length: 128'")
- changes_made = True
- line = new_line
-
- new_line = line.replace("value=0.88", "value=0.75")
- if new_line != line:
- print("Replaced 'value=0.88' with 'value=0.75'")
- changes_made = True
- line = new_line
-
- if "label=i18n(\"输入源音量包络替换输出音量包络融合比例,越靠近1越使用输出包络\")" in previous_line and "value=1," in line:
- new_line = line.replace("value=1,", "value=0.25,")
- if new_line != line:
- print("Replaced 'value=1,' with 'value=0.25,' based on the condition")
- changes_made = True
- line = new_line
-
- if "label=i18n(\"总训练轮数total_epoch\")" in previous_line and "value=20," in line:
- new_line = line.replace("value=20,", "value=500,")
- if new_line != line:
- print("Replaced 'value=20,' with 'value=500,' based on the condition for DEFAULT EPOCH")
- changes_made = True
- line = new_line
-
- if 'choices=["pm", "harvest", "dio", "crepe", "crepe-tiny", "mangio-crepe", "mangio-crepe-tiny"], # Fork Feature. Add Crepe-Tiny' in previous_line:
- if 'value="pm",' in line:
- new_line = line.replace('value="pm",', 'value="mangio-crepe",')
- if new_line != line:
- print("Replaced 'value=\"pm\",' with 'value=\"mangio-crepe\",' based on the condition")
- changes_made = True
- line = new_line
-
- new_line = line.replace('label=i18n("输入训练文件夹路径"), value="E:\\\\语音音频+标注\\\\米津玄师\\\\src"', 'label=i18n("输入训练文件夹路径"), value="/content/dataset/"')
- if new_line != line:
- print("Replaced 'label=i18n(\"输入训练文件夹路径\"), value=\"E:\\\\语音音频+标注\\\\米津玄师\\\\src\"' with 'label=i18n(\"输入训练文件夹路径\"), value=\"/content/dataset/\"'")
- changes_made = True
- line = new_line
-
- if 'label=i18n("是否仅保存最新的ckpt文件以节省硬盘空间"),' in second_previous_line:
- if 'value=i18n("否"),' in line:
- new_line = line.replace('value=i18n("否"),', 'value=i18n("是"),')
- if new_line != line:
- print("Replaced 'value=i18n(\"否\"),' with 'value=i18n(\"是\"),' based on the condition for SAVE ONLY LATEST")
- changes_made = True
- line = new_line
-
- if 'label=i18n("是否在每次保存时间点将最终小模型保存至weights文件夹"),' in second_previous_line:
- if 'value=i18n("否"),' in line:
- new_line = line.replace('value=i18n("否"),', 'value=i18n("是"),')
- if new_line != line:
- print("Replaced 'value=i18n(\"否\"),' with 'value=i18n(\"是\"),' based on the condition for SAVE SMALL WEIGHTS")
- changes_made = True
- line = new_line
-
- temp_file.write(line)
- second_previous_line = previous_line
- previous_line = line
-
- # After finished, we replace the original file with the temp one
- import shutil
- shutil.move(temp_file_path, file_path)
-
- if changes_made:
- print("Changes made and file saved successfully.")
- else:
- print("No changes were needed.")
-
- # Define the repo path
- repo_path = '/content/Applio-RVC-Fork'
-
- def copy_all_files_in_directory(src_dir, dest_dir):
- # Iterate over all files in source directory
- for item in Path(src_dir).glob('*'):
- if item.is_file():
- # Copy each file to destination directory
- shutil.copy(item, dest_dir)
- else:
- # If it's a directory, make a new directory in the destination and copy the files recursively
- new_dest = Path(dest_dir) / item.name
- new_dest.mkdir(exist_ok=True)
- copy_all_files_in_directory(str(item), str(new_dest))
-
- def clone_and_copy_repo(repo_path):
- # New repository link
- new_repo_link = "https://github.com/IAHispano/Applio-RVC-Fork/"
- # Temporary path to clone the repository
- temp_repo_path = "/content/temp_Applio-RVC-Fork"
- # New folder name
- new_folder_name = "Applio-RVC-Fork"
-
- # Clone the latest code from the new repository to a temporary location
- run_cmd(f"git clone {new_repo_link} {temp_repo_path}")
- os.chdir(temp_repo_path)
-
- run_cmd(f"git checkout 3fa4dad3d8961e5ca2522e9e12c0b4ddb71ad402")
- run_cmd(f"git checkout f9e606c279cb49420597519b0a83b92be81e42e4")
- run_cmd(f"git checkout 9e305588844c5442d58add1061b29beeca89d679")
- run_cmd(f"git checkout bf92dc1eb54b4f28d6396a4d1820a25896cc9af8")
- run_cmd(f"git checkout c3810e197d3cb98039973b2f723edf967ecd9e61")
- run_cmd(f"git checkout a33159efd134c2413b0afe26a76b7dc87926d2de")
- run_cmd(f"git checkout 24e251fb62c662e39ac5cf9253cc65deb9be94ec")
- run_cmd(f"git checkout ad5667d3017e93232dba85969cddac1322ba2902")
- run_cmd(f"git checkout ce9715392cf52dd5a0e18e00d1b5e408f08dbf27")
- run_cmd(f"git checkout 7c7da3f2ac68f3bd8f3ad5ca5c700f18ab9f90eb")
- run_cmd(f"git checkout 4ac395eab101955e8960b50d772c26f592161764")
- run_cmd(f"git checkout b15b358702294c7375761584e5276c811ffab5e8")
- run_cmd(f"git checkout 1501793dc490982db9aca84a50647764caa66e51")
- run_cmd(f"git checkout 21f7faf57219c75e6ba837062350391a803e9ae2")
- run_cmd(f"git checkout b5eb689fbc409b49f065a431817f822f554cebe7")
- run_cmd(f"git checkout 7e02fae1ebf24cb151bf6cbe787d06734aa65862")
- run_cmd(f"git checkout 6aea5ea18ed0b9a1e03fa5d268d6bc3c616672a9")
- run_cmd(f"git checkout f0f9b25717e59116473fb42bd7f9252cfc32b398")
- run_cmd(f"git checkout b394de424088a81fc081224bc27338a8651ad3b2")
- run_cmd(f"git checkout f1999406a88b80c965d2082340f5ea2bfa9ab67a")
- run_cmd(f"git checkout d98a0fa8dc715308dfc73eac5c553b69c6ee072b")
- run_cmd(f"git checkout d73267a415fb0eba98477afa43ef71ffd82a7157")
- run_cmd(f"git checkout 1a03d01356ae79179e1fb8d8915dc9cc79925742")
- run_cmd(f"git checkout 81497bb3115e92c754300c9b3992df428886a3e9")
- run_cmd(f"git checkout c5af1f8edcf79cb70f065c0110e279e78e48caf9")
- run_cmd(f"git checkout cdb3c90109387fa4dfa92f53c3864c71170ffc77")
-
- # Edit the file here, before copying
- #edit_file(f"{temp_repo_path}/infer-web.py")
-
- # Copy all files from the cloned repository to the existing path
- copy_all_files_in_directory(temp_repo_path, repo_path)
- print(f"Copying all {new_folder_name} files from GitHub.")
-
- # Change working directory back to /content/
- os.chdir('/content/')
- print("Changed path back to /content/")
-
- # Remove the temporary cloned repository
- shutil.rmtree(temp_repo_path)
-
- # Call the function
- clone_and_copy_repo(repo_path)
-
- # Download the credentials file for RVC archive sheet
- os.makedirs('/content/Applio-RVC-Fork/stats/', exist_ok=True)
- run_cmd("wget -q https://cdn.discordapp.com/attachments/945486970883285045/1114717554481569802/peppy-generator-388800-07722f17a188.json -O /content/Applio-RVC-Fork/stats/peppy-generator-388800-07722f17a188.json")
-
- # Forcefully delete any existing torchcrepe dependencies downloaded from an earlier run just in case
- shutil.rmtree('/content/Applio-RVC-Fork/torchcrepe', ignore_errors=True)
- shutil.rmtree('/content/torchcrepe', ignore_errors=True)
-
- # Download the torchcrepe folder from the maxrmorrison/torchcrepe repository
- run_cmd("git clone https://github.com/maxrmorrison/torchcrepe.git")
- shutil.move('/content/torchcrepe/torchcrepe', '/content/Applio-RVC-Fork/')
- shutil.rmtree('/content/torchcrepe', ignore_errors=True) # Delete the torchcrepe repository folder
-
- # Change the current directory to /content/Applio-RVC-Fork
- os.chdir('/content/Applio-RVC-Fork')
- os.makedirs('pretrained', exist_ok=True)
- os.makedirs('uvr5_weights', exist_ok=True)
-
-def download_file(url, filepath):
- response = requests.get(url, stream=True)
- response.raise_for_status()
-
- with open(filepath, "wb") as file:
- for chunk in response.iter_content(chunk_size=8192):
- if chunk:
- file.write(chunk)
-
-def download_pretrained_models():
- pretrained_models = {
- "pretrained": [
- "D40k.pth",
- "G40k.pth",
- "f0D40k.pth",
- "f0G40k.pth"
- ],
- "pretrained_v2": [
- "D40k.pth",
- "G40k.pth",
- "f0D40k.pth",
- "f0G40k.pth",
- "f0G48k.pth",
- "f0D48k.pth"
- ],
- "uvr5_weights": [
- "HP2-人声vocals+非人声instrumentals.pth",
- "HP5-主旋律人声vocals+其他instrumentals.pth",
- "VR-DeEchoNormal.pth",
- "VR-DeEchoDeReverb.pth",
- "VR-DeEchoAggressive.pth",
- "HP5_only_main_vocal.pth",
- "HP3_all_vocals.pth",
- "HP2_all_vocals.pth"
- ]
- }
- part2 = "I"
- base_url = "https://huggingface.co/lj1995/VoiceConversionWebU" + part2 + "/resolve/main/"
- base_path = "/content/Applio-RVC-Fork/"
- base_pathm = base_path
-
- # Calculate total number of files to download
- total_files = sum(len(files) for files in pretrained_models.values()) + 1 # +1 for hubert_base.pt
-
- with tqdm(total=total_files, desc="Downloading files") as pbar:
- for folder, models in pretrained_models.items():
- folder_path = os.path.join(base_path, folder)
- os.makedirs(folder_path, exist_ok=True)
- for model in models:
- url = base_url + folder + "/" + model
- filepath = os.path.join(folder_path, model)
- download_file(url, filepath)
- pbar.update()
-
- # Download hubert_base.pt to the base path
- hubert_url = base_url + "hubert_base.pt"
- hubert_filepath = os.path.join(base_pathm, "hubert_base.pt")
- download_file(hubert_url, hubert_filepath)
- pbar.update()
-def clone_repository(run_download):
- with ThreadPoolExecutor(max_workers=2) as executor:
- executor.submit(run_script)
- if run_download:
- executor.submit(download_pretrained_models)
diff --git a/spaces/Skyler123/TangGPT/modules/utils.py b/spaces/Skyler123/TangGPT/modules/utils.py
deleted file mode 100644
index 23f47d688d9690c6c68ccacc765108ce68d62b76..0000000000000000000000000000000000000000
--- a/spaces/Skyler123/TangGPT/modules/utils.py
+++ /dev/null
@@ -1,536 +0,0 @@
-# -*- coding:utf-8 -*-
-from __future__ import annotations
-from typing import TYPE_CHECKING, Any, Callable, Dict, List, Tuple, Type
-import logging
-import json
-import os
-import datetime
-import hashlib
-import csv
-import requests
-import re
-import html
-import sys
-import subprocess
-
-import gradio as gr
-from pypinyin import lazy_pinyin
-import tiktoken
-import mdtex2html
-from markdown import markdown
-from pygments import highlight
-from pygments.lexers import get_lexer_by_name
-from pygments.formatters import HtmlFormatter
-import pandas as pd
-
-from modules.presets import *
-from . import shared
-from modules.config import retrieve_proxy
-
-if TYPE_CHECKING:
- from typing import TypedDict
-
- class DataframeData(TypedDict):
- headers: List[str]
- data: List[List[str | int | bool]]
-
-
-def count_token(message):
- encoding = tiktoken.get_encoding("cl100k_base")
- input_str = f"role: {message['role']}, content: {message['content']}"
- length = len(encoding.encode(input_str))
- return length
-
-
-def markdown_to_html_with_syntax_highlight(md_str):
- def replacer(match):
- lang = match.group(1) or "text"
- code = match.group(2)
-
- try:
- lexer = get_lexer_by_name(lang, stripall=True)
- except ValueError:
- lexer = get_lexer_by_name("text", stripall=True)
-
- formatter = HtmlFormatter()
- highlighted_code = highlight(code, lexer, formatter)
-
- return f'
{highlighted_code}
'
-
- code_block_pattern = r"```(\w+)?\n([\s\S]+?)\n```"
- md_str = re.sub(code_block_pattern, replacer, md_str, flags=re.MULTILINE)
-
- html_str = markdown(md_str)
- return html_str
-
-
-def normalize_markdown(md_text: str) -> str:
- lines = md_text.split("\n")
- normalized_lines = []
- inside_list = False
-
- for i, line in enumerate(lines):
- if re.match(r"^(\d+\.|-|\*|\+)\s", line.strip()):
- if not inside_list and i > 0 and lines[i - 1].strip() != "":
- normalized_lines.append("")
- inside_list = True
- normalized_lines.append(line)
- elif inside_list and line.strip() == "":
- if i < len(lines) - 1 and not re.match(
- r"^(\d+\.|-|\*|\+)\s", lines[i + 1].strip()
- ):
- normalized_lines.append(line)
- continue
- else:
- inside_list = False
- normalized_lines.append(line)
-
- return "\n".join(normalized_lines)
-
-
-def convert_mdtext(md_text):
- code_block_pattern = re.compile(r"```(.*?)(?:```|$)", re.DOTALL)
- inline_code_pattern = re.compile(r"`(.*?)`", re.DOTALL)
- code_blocks = code_block_pattern.findall(md_text)
- non_code_parts = code_block_pattern.split(md_text)[::2]
-
- result = []
- for non_code, code in zip(non_code_parts, code_blocks + [""]):
- if non_code.strip():
- non_code = normalize_markdown(non_code)
- if inline_code_pattern.search(non_code):
- result.append(markdown(non_code, extensions=["tables"]))
- else:
- result.append(mdtex2html.convert(non_code, extensions=["tables"]))
- if code.strip():
- # _, code = detect_language(code) # 暂时去除代码高亮功能,因为在大段代码的情况下会出现问题
- # code = code.replace("\n\n", "\n") # 暂时去除代码中的空行,因为在大段代码的情况下会出现问题
- code = f"\n```{code}\n\n```"
- code = markdown_to_html_with_syntax_highlight(code)
- result.append(code)
- result = "".join(result)
- result += ALREADY_CONVERTED_MARK
- return result
-
-
-def convert_asis(userinput):
- return (
- f'
{html.escape(userinput)}
'
- + ALREADY_CONVERTED_MARK
- )
-
-
-def detect_converted_mark(userinput):
- if userinput.endswith(ALREADY_CONVERTED_MARK):
- return True
- else:
- return False
-
-
-def detect_language(code):
- if code.startswith("\n"):
- first_line = ""
- else:
- first_line = code.strip().split("\n", 1)[0]
- language = first_line.lower() if first_line else ""
- code_without_language = code[len(first_line) :].lstrip() if first_line else code
- return language, code_without_language
-
-
-def construct_text(role, text):
- return {"role": role, "content": text}
-
-
-def construct_user(text):
- return construct_text("user", text)
-
-
-def construct_system(text):
- return construct_text("system", text)
-
-
-def construct_assistant(text):
- return construct_text("assistant", text)
-
-
-def construct_token_message(tokens: List[int]):
- token_sum = 0
- for i in range(len(tokens)):
- token_sum += sum(tokens[: i + 1])
- return f"Token 计数: {sum(tokens)},本次对话累计消耗了 {token_sum} tokens"
-
-
-def delete_first_conversation(history, previous_token_count):
- if history:
- del history[:2]
- del previous_token_count[0]
- return (
- history,
- previous_token_count,
- construct_token_message(previous_token_count),
- )
-
-
-def delete_last_conversation(chatbot, history, previous_token_count):
- if len(chatbot) > 0 and standard_error_msg in chatbot[-1][1]:
- logging.info("由于包含报错信息,只删除chatbot记录")
- chatbot.pop()
- return chatbot, history
- if len(history) > 0:
- logging.info("删除了一组对话历史")
- history.pop()
- history.pop()
- if len(chatbot) > 0:
- logging.info("删除了一组chatbot对话")
- chatbot.pop()
- if len(previous_token_count) > 0:
- logging.info("删除了一组对话的token计数记录")
- previous_token_count.pop()
- return (
- chatbot,
- history,
- previous_token_count,
- construct_token_message(previous_token_count),
- )
-
-
-def save_file(filename, system, history, chatbot, user_name):
- logging.info(f"{user_name} 保存对话历史中……")
- os.makedirs(HISTORY_DIR / user_name, exist_ok=True)
- if filename.endswith(".json"):
- json_s = {"system": system, "history": history, "chatbot": chatbot}
- print(json_s)
- with open(os.path.join(HISTORY_DIR / user_name, filename), "w") as f:
- json.dump(json_s, f)
- elif filename.endswith(".md"):
- md_s = f"system: \n- {system} \n"
- for data in history:
- md_s += f"\n{data['role']}: \n- {data['content']} \n"
- with open(os.path.join(HISTORY_DIR / user_name, filename), "w", encoding="utf8") as f:
- f.write(md_s)
- logging.info(f"{user_name} 保存对话历史完毕")
- return os.path.join(HISTORY_DIR / user_name, filename)
-
-
-def save_chat_history(filename, system, history, chatbot, user_name):
- if filename == "":
- return
- if not filename.endswith(".json"):
- filename += ".json"
- return save_file(filename, system, history, chatbot, user_name)
-
-
-def export_markdown(filename, system, history, chatbot, user_name):
- if filename == "":
- return
- if not filename.endswith(".md"):
- filename += ".md"
- return save_file(filename, system, history, chatbot, user_name)
-
-
-def load_chat_history(filename, system, history, chatbot, user_name):
- logging.info(f"{user_name} 加载对话历史中……")
- if type(filename) != str:
- filename = filename.name
- try:
- with open(os.path.join(HISTORY_DIR / user_name, filename), "r") as f:
- json_s = json.load(f)
- try:
- if type(json_s["history"][0]) == str:
- logging.info("历史记录格式为旧版,正在转换……")
- new_history = []
- for index, item in enumerate(json_s["history"]):
- if index % 2 == 0:
- new_history.append(construct_user(item))
- else:
- new_history.append(construct_assistant(item))
- json_s["history"] = new_history
- logging.info(new_history)
- except:
- # 没有对话历史
- pass
- logging.info(f"{user_name} 加载对话历史完毕")
- return filename, json_s["system"], json_s["history"], json_s["chatbot"]
- except FileNotFoundError:
- logging.info(f"{user_name} 没有找到对话历史文件,不执行任何操作")
- return filename, system, history, chatbot
-
-
-def sorted_by_pinyin(list):
- return sorted(list, key=lambda char: lazy_pinyin(char)[0][0])
-
-
-def get_file_names(dir, plain=False, filetypes=[".json"]):
- logging.info(f"获取文件名列表,目录为{dir},文件类型为{filetypes},是否为纯文本列表{plain}")
- files = []
- try:
- for type in filetypes:
- files += [f for f in os.listdir(dir) if f.endswith(type)]
- except FileNotFoundError:
- files = []
- files = sorted_by_pinyin(files)
- if files == []:
- files = [""]
- logging.debug(f"files are:{files}")
- if plain:
- return files
- else:
- return gr.Dropdown.update(choices=files)
-
-
-def get_history_names(plain=False, user_name=""):
- logging.info(f"从用户 {user_name} 中获取历史记录文件名列表")
- return get_file_names(HISTORY_DIR / user_name, plain)
-
-
-def load_template(filename, mode=0):
- logging.info(f"加载模板文件{filename},模式为{mode}(0为返回字典和下拉菜单,1为返回下拉菜单,2为返回字典)")
- lines = []
- logging.info("Loading template...")
- if filename.endswith(".json"):
- with open(os.path.join(TEMPLATES_DIR, filename), "r", encoding="utf8") as f:
- lines = json.load(f)
- lines = [[i["act"], i["prompt"]] for i in lines]
- else:
- with open(
- os.path.join(TEMPLATES_DIR, filename), "r", encoding="utf8"
- ) as csvfile:
- reader = csv.reader(csvfile)
- lines = list(reader)
- lines = lines[1:]
- if mode == 1:
- return sorted_by_pinyin([row[0] for row in lines])
- elif mode == 2:
- return {row[0]: row[1] for row in lines}
- else:
- choices = sorted_by_pinyin([row[0] for row in lines])
- return {row[0]: row[1] for row in lines}, gr.Dropdown.update(
- choices=choices
- )
-
-
-def get_template_names(plain=False):
- logging.info("获取模板文件名列表")
- return get_file_names(TEMPLATES_DIR, plain, filetypes=[".csv", "json"])
-
-
-def get_template_content(templates, selection, original_system_prompt):
- logging.info(f"应用模板中,选择为{selection},原始系统提示为{original_system_prompt}")
- try:
- return templates[selection]
- except:
- return original_system_prompt
-
-
-def reset_state():
- logging.info("重置状态")
- return [], [], [], construct_token_message([0])
-
-
-def reset_textbox():
- logging.debug("重置文本框")
- return gr.update(value="")
-
-
-def reset_default():
- default_host = shared.state.reset_api_host()
- retrieve_proxy("")
- return gr.update(value=default_host), gr.update(value=""), "API-Host 和代理已重置"
-
-
-def change_api_host(host):
- shared.state.set_api_host(host)
- msg = f"API-Host更改为了{host}"
- logging.info(msg)
- return msg
-
-
-def change_proxy(proxy):
- retrieve_proxy(proxy)
- os.environ["HTTPS_PROXY"] = proxy
- msg = f"代理更改为了{proxy}"
- logging.info(msg)
- return msg
-
-
-def hide_middle_chars(s):
- if s is None:
- return ""
- if len(s) <= 8:
- return s
- else:
- head = s[:4]
- tail = s[-4:]
- hidden = "*" * (len(s) - 8)
- return head + hidden + tail
-
-
-def submit_key(key):
- key = key.strip()
- msg = f"API密钥更改为了{hide_middle_chars(key)}"
- logging.info(msg)
- return key, msg
-
-
-def replace_today(prompt):
- today = datetime.datetime.today().strftime("%Y-%m-%d")
- return prompt.replace("{current_date}", today)
-
-
-def get_geoip():
- try:
- with retrieve_proxy():
- response = requests.get("https://ipapi.co/json/", timeout=5)
- data = response.json()
- except:
- data = {"error": True, "reason": "连接ipapi失败"}
- if "error" in data.keys():
- logging.warning(f"无法获取IP地址信息。\n{data}")
- if data["reason"] == "RateLimited":
- return (
- f"获取IP地理位置失败,因为达到了检测IP的速率限制。聊天功能可能仍然可用。"
- )
- else:
- return f"获取IP地理位置失败。原因:{data['reason']}。你仍然可以使用聊天功能。"
- else:
- country = data["country_name"]
- if country == "China":
- text = "**您的IP区域:中国。请立即检查代理设置,在不受支持的地区使用API可能导致账号被封禁。**"
- else:
- text = f"您的IP区域:{country}。"
- logging.info(text)
- return text
-
-
-def find_n(lst, max_num):
- n = len(lst)
- total = sum(lst)
-
- if total < max_num:
- return n
-
- for i in range(len(lst)):
- if total - lst[i] < max_num:
- return n - i - 1
- total = total - lst[i]
- return 1
-
-
-def start_outputing():
- logging.debug("显示取消按钮,隐藏发送按钮")
- return gr.Button.update(visible=True), gr.Button.update(visible=False)
-
-
-def end_outputing():
- return (
- gr.Button.update(visible=True),
- gr.Button.update(visible=False),
- )
-
-
-def cancel_outputing():
- logging.info("中止输出……")
- shared.state.interrupt()
-
-
-def transfer_input(inputs):
- # 一次性返回,降低延迟
- textbox = reset_textbox()
- outputing = start_outputing()
- return (
- inputs,
- gr.update(value=""),
- gr.Button.update(visible=True),
- gr.Button.update(visible=False),
- )
-
-
-
-def run(command, desc=None, errdesc=None, custom_env=None, live=False):
- if desc is not None:
- print(desc)
- if live:
- result = subprocess.run(command, shell=True, env=os.environ if custom_env is None else custom_env)
- if result.returncode != 0:
- raise RuntimeError(f"""{errdesc or 'Error running command'}.
-Command: {command}
-Error code: {result.returncode}""")
-
- return ""
- result = subprocess.run(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True, env=os.environ if custom_env is None else custom_env)
- if result.returncode != 0:
- message = f"""{errdesc or 'Error running command'}.
-Command: {command}
-Error code: {result.returncode}
-stdout: {result.stdout.decode(encoding="utf8", errors="ignore") if len(result.stdout)>0 else ''}
-stderr: {result.stderr.decode(encoding="utf8", errors="ignore") if len(result.stderr)>0 else ''}
-"""
- raise RuntimeError(message)
- return result.stdout.decode(encoding="utf8", errors="ignore")
-
-def versions_html():
- git = os.environ.get('GIT', "git")
- python_version = ".".join([str(x) for x in sys.version_info[0:3]])
- try:
- commit_hash = run(f"{git} rev-parse HEAD").strip()
- except Exception:
- commit_hash = ""
- if commit_hash != "":
- short_commit = commit_hash[0:7]
- commit_info = f"{short_commit}"
- else:
- commit_info = "unknown \U0001F615"
- return f"""
-Python: {python_version}
- •
-Gradio: {gr.__version__}
- •
-Commit: {commit_info}
-"""
-
-def add_source_numbers(lst, source_name = "Source", use_source = True):
- if use_source:
- return [f'[{idx+1}]\t "{item[0]}"\n{source_name}: {item[1]}' for idx, item in enumerate(lst)]
- else:
- return [f'[{idx+1}]\t "{item}"' for idx, item in enumerate(lst)]
-
-def add_details(lst):
- nodes = []
- for index, txt in enumerate(lst):
- brief = txt[:25].replace("\n", "")
- nodes.append(
- f"{brief}...
{txt}
"
- )
- return nodes
-
-
-def sheet_to_string(sheet):
- result = ""
- for index, row in sheet.iterrows():
- row_string = ""
- for column in sheet.columns:
- row_string += f"{column}: {row[column]}, "
- row_string = row_string.rstrip(", ")
- row_string += "."
- result += row_string + "\n"
- return result
-
-def excel_to_string(file_path):
- # 读取Excel文件中的所有工作表
- excel_file = pd.read_excel(file_path, engine='openpyxl', sheet_name=None)
-
- # 初始化结果字符串
- result = ""
-
- # 遍历每一个工作表
- for sheet_name, sheet_data in excel_file.items():
- # 将工作表名称添加到结果字符串
- result += f"Sheet: {sheet_name}\n"
-
- # 处理当前工作表并添加到结果字符串
- result += sheet_to_string(sheet_data)
-
- # 在不同工作表之间添加分隔符
- result += "\n" + ("-" * 20) + "\n\n"
-
- return result
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/core/tests/test_magic_terminal.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/core/tests/test_magic_terminal.py
deleted file mode 100644
index 5dfa0f0ed652e637dab0eee8eb9443483405cd19..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/core/tests/test_magic_terminal.py
+++ /dev/null
@@ -1,216 +0,0 @@
-"""Tests for various magic functions specific to the terminal frontend."""
-
-#-----------------------------------------------------------------------------
-# Imports
-#-----------------------------------------------------------------------------
-
-import sys
-from io import StringIO
-from unittest import TestCase
-
-from IPython.testing import tools as tt
-#-----------------------------------------------------------------------------
-# Test functions begin
-#-----------------------------------------------------------------------------
-
-
-MINIMAL_LAZY_MAGIC = """
-from IPython.core.magic import (
- Magics,
- magics_class,
- line_magic,
- cell_magic,
-)
-
-
-@magics_class
-class LazyMagics(Magics):
- @line_magic
- def lazy_line(self, line):
- print("Lazy Line")
-
- @cell_magic
- def lazy_cell(self, line, cell):
- print("Lazy Cell")
-
-
-def load_ipython_extension(ipython):
- ipython.register_magics(LazyMagics)
-"""
-
-def check_cpaste(code, should_fail=False):
- """Execute code via 'cpaste' and ensure it was executed, unless
- should_fail is set.
- """
- ip.user_ns['code_ran'] = False
-
- src = StringIO()
- src.write(code)
- src.write('\n--\n')
- src.seek(0)
-
- stdin_save = sys.stdin
- sys.stdin = src
-
- try:
- context = tt.AssertPrints if should_fail else tt.AssertNotPrints
- with context("Traceback (most recent call last)"):
- ip.run_line_magic("cpaste", "")
-
- if not should_fail:
- assert ip.user_ns['code_ran'], "%r failed" % code
- finally:
- sys.stdin = stdin_save
-
-def test_cpaste():
- """Test cpaste magic"""
-
- def runf():
- """Marker function: sets a flag when executed.
- """
- ip.user_ns['code_ran'] = True
- return 'runf' # return string so '+ runf()' doesn't result in success
-
- tests = {'pass': ["runf()",
- "In [1]: runf()",
- "In [1]: if 1:\n ...: runf()",
- "> > > runf()",
- ">>> runf()",
- " >>> runf()",
- ],
-
- 'fail': ["1 + runf()",
- "++ runf()",
- ]}
-
- ip.user_ns['runf'] = runf
-
- for code in tests['pass']:
- check_cpaste(code)
-
- for code in tests['fail']:
- check_cpaste(code, should_fail=True)
-
-
-
-class PasteTestCase(TestCase):
- """Multiple tests for clipboard pasting"""
-
- def paste(self, txt, flags='-q'):
- """Paste input text, by default in quiet mode"""
- ip.hooks.clipboard_get = lambda: txt
- ip.run_line_magic("paste", flags)
-
- def setUp(self):
- # Inject fake clipboard hook but save original so we can restore it later
- self.original_clip = ip.hooks.clipboard_get
-
- def tearDown(self):
- # Restore original hook
- ip.hooks.clipboard_get = self.original_clip
-
- def test_paste(self):
- ip.user_ns.pop("x", None)
- self.paste("x = 1")
- self.assertEqual(ip.user_ns["x"], 1)
- ip.user_ns.pop("x")
-
- def test_paste_pyprompt(self):
- ip.user_ns.pop("x", None)
- self.paste(">>> x=2")
- self.assertEqual(ip.user_ns["x"], 2)
- ip.user_ns.pop("x")
-
- def test_paste_py_multi(self):
- self.paste(
- """
- >>> x = [1,2,3]
- >>> y = []
- >>> for i in x:
- ... y.append(i**2)
- ...
- """
- )
- self.assertEqual(ip.user_ns["x"], [1, 2, 3])
- self.assertEqual(ip.user_ns["y"], [1, 4, 9])
-
- def test_paste_py_multi_r(self):
- "Now, test that self.paste -r works"
- self.test_paste_py_multi()
- self.assertEqual(ip.user_ns.pop("x"), [1, 2, 3])
- self.assertEqual(ip.user_ns.pop("y"), [1, 4, 9])
- self.assertFalse("x" in ip.user_ns)
- ip.run_line_magic("paste", "-r")
- self.assertEqual(ip.user_ns["x"], [1, 2, 3])
- self.assertEqual(ip.user_ns["y"], [1, 4, 9])
-
- def test_paste_email(self):
- "Test pasting of email-quoted contents"
- self.paste(
- """\
- >> def foo(x):
- >> return x + 1
- >> xx = foo(1.1)"""
- )
- self.assertEqual(ip.user_ns["xx"], 2.1)
-
- def test_paste_email2(self):
- "Email again; some programs add a space also at each quoting level"
- self.paste(
- """\
- > > def foo(x):
- > > return x + 1
- > > yy = foo(2.1) """
- )
- self.assertEqual(ip.user_ns["yy"], 3.1)
-
- def test_paste_email_py(self):
- "Email quoting of interactive input"
- self.paste(
- """\
- >> >>> def f(x):
- >> ... return x+1
- >> ...
- >> >>> zz = f(2.5) """
- )
- self.assertEqual(ip.user_ns["zz"], 3.5)
-
- def test_paste_echo(self):
- "Also test self.paste echoing, by temporarily faking the writer"
- w = StringIO()
- old_write = sys.stdout.write
- sys.stdout.write = w.write
- code = """
- a = 100
- b = 200"""
- try:
- self.paste(code,'')
- out = w.getvalue()
- finally:
- sys.stdout.write = old_write
- self.assertEqual(ip.user_ns["a"], 100)
- self.assertEqual(ip.user_ns["b"], 200)
- assert out == code + "\n## -- End pasted text --\n"
-
- def test_paste_leading_commas(self):
- "Test multiline strings with leading commas"
- tm = ip.magics_manager.registry['TerminalMagics']
- s = '''\
-a = """
-,1,2,3
-"""'''
- ip.user_ns.pop("foo", None)
- tm.store_or_execute(s, "foo")
- self.assertIn("foo", ip.user_ns)
-
- def test_paste_trailing_question(self):
- "Test pasting sources with trailing question marks"
- tm = ip.magics_manager.registry['TerminalMagics']
- s = '''\
-def funcfoo():
- if True: #am i true?
- return 'fooresult'
-'''
- ip.user_ns.pop('funcfoo', None)
- self.paste(s)
- self.assertEqual(ip.user_ns["funcfoo"](), "fooresult")
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/core/tests/test_paths.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/core/tests/test_paths.py
deleted file mode 100644
index 86367b61ecbc591ef9c41a77462ce53442dfea7c..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/core/tests/test_paths.py
+++ /dev/null
@@ -1,200 +0,0 @@
-import errno
-import os
-import shutil
-import tempfile
-import warnings
-from unittest.mock import patch
-
-from tempfile import TemporaryDirectory
-from testpath import assert_isdir, assert_isfile, modified_env
-
-from IPython import paths
-from IPython.testing.decorators import skip_win32
-
-TMP_TEST_DIR = os.path.realpath(tempfile.mkdtemp())
-HOME_TEST_DIR = os.path.join(TMP_TEST_DIR, "home_test_dir")
-XDG_TEST_DIR = os.path.join(HOME_TEST_DIR, "xdg_test_dir")
-XDG_CACHE_DIR = os.path.join(HOME_TEST_DIR, "xdg_cache_dir")
-IP_TEST_DIR = os.path.join(HOME_TEST_DIR,'.ipython')
-
-def setup_module():
- """Setup testenvironment for the module:
-
- - Adds dummy home dir tree
- """
- # Do not mask exceptions here. In particular, catching WindowsError is a
- # problem because that exception is only defined on Windows...
- os.makedirs(IP_TEST_DIR)
- os.makedirs(os.path.join(XDG_TEST_DIR, 'ipython'))
- os.makedirs(os.path.join(XDG_CACHE_DIR, 'ipython'))
-
-
-def teardown_module():
- """Teardown testenvironment for the module:
-
- - Remove dummy home dir tree
- """
- # Note: we remove the parent test dir, which is the root of all test
- # subdirs we may have created. Use shutil instead of os.removedirs, so
- # that non-empty directories are all recursively removed.
- shutil.rmtree(TMP_TEST_DIR)
-
-def patch_get_home_dir(dirpath):
- return patch.object(paths, 'get_home_dir', return_value=dirpath)
-
-
-def test_get_ipython_dir_1():
- """test_get_ipython_dir_1, Testcase to see if we can call get_ipython_dir without Exceptions."""
- env_ipdir = os.path.join("someplace", ".ipython")
- with patch.object(paths, '_writable_dir', return_value=True), \
- modified_env({'IPYTHONDIR': env_ipdir}):
- ipdir = paths.get_ipython_dir()
-
- assert ipdir == env_ipdir
-
-def test_get_ipython_dir_2():
- """test_get_ipython_dir_2, Testcase to see if we can call get_ipython_dir without Exceptions."""
- with patch_get_home_dir('someplace'), \
- patch.object(paths, 'get_xdg_dir', return_value=None), \
- patch.object(paths, '_writable_dir', return_value=True), \
- patch('os.name', "posix"), \
- modified_env({'IPYTHON_DIR': None,
- 'IPYTHONDIR': None,
- 'XDG_CONFIG_HOME': None
- }):
- ipdir = paths.get_ipython_dir()
-
- assert ipdir == os.path.join("someplace", ".ipython")
-
-def test_get_ipython_dir_3():
- """test_get_ipython_dir_3, use XDG if defined and exists, and .ipython doesn't exist."""
- tmphome = TemporaryDirectory()
- try:
- with patch_get_home_dir(tmphome.name), \
- patch('os.name', 'posix'), \
- modified_env({
- 'IPYTHON_DIR': None,
- 'IPYTHONDIR': None,
- 'XDG_CONFIG_HOME': XDG_TEST_DIR,
- }), warnings.catch_warnings(record=True) as w:
- ipdir = paths.get_ipython_dir()
-
- assert ipdir == os.path.join(tmphome.name, XDG_TEST_DIR, "ipython")
- assert len(w) == 0
- finally:
- tmphome.cleanup()
-
-def test_get_ipython_dir_4():
- """test_get_ipython_dir_4, warn if XDG and home both exist."""
- with patch_get_home_dir(HOME_TEST_DIR), \
- patch('os.name', 'posix'):
- try:
- os.mkdir(os.path.join(XDG_TEST_DIR, 'ipython'))
- except OSError as e:
- if e.errno != errno.EEXIST:
- raise
-
-
- with modified_env({
- 'IPYTHON_DIR': None,
- 'IPYTHONDIR': None,
- 'XDG_CONFIG_HOME': XDG_TEST_DIR,
- }), warnings.catch_warnings(record=True) as w:
- ipdir = paths.get_ipython_dir()
-
- assert len(w) == 1
- assert "Ignoring" in str(w[0])
-
-
-def test_get_ipython_dir_5():
- """test_get_ipython_dir_5, use .ipython if exists and XDG defined, but doesn't exist."""
- with patch_get_home_dir(HOME_TEST_DIR), \
- patch('os.name', 'posix'):
- try:
- os.rmdir(os.path.join(XDG_TEST_DIR, 'ipython'))
- except OSError as e:
- if e.errno != errno.ENOENT:
- raise
-
- with modified_env({
- 'IPYTHON_DIR': None,
- 'IPYTHONDIR': None,
- 'XDG_CONFIG_HOME': XDG_TEST_DIR,
- }):
- ipdir = paths.get_ipython_dir()
-
- assert ipdir == IP_TEST_DIR
-
-def test_get_ipython_dir_6():
- """test_get_ipython_dir_6, use home over XDG if defined and neither exist."""
- xdg = os.path.join(HOME_TEST_DIR, 'somexdg')
- os.mkdir(xdg)
- shutil.rmtree(os.path.join(HOME_TEST_DIR, '.ipython'))
- print(paths._writable_dir)
- with patch_get_home_dir(HOME_TEST_DIR), \
- patch.object(paths, 'get_xdg_dir', return_value=xdg), \
- patch('os.name', 'posix'), \
- modified_env({
- 'IPYTHON_DIR': None,
- 'IPYTHONDIR': None,
- 'XDG_CONFIG_HOME': None,
- }), warnings.catch_warnings(record=True) as w:
- ipdir = paths.get_ipython_dir()
-
- assert ipdir == os.path.join(HOME_TEST_DIR, ".ipython")
- assert len(w) == 0
-
-def test_get_ipython_dir_7():
- """test_get_ipython_dir_7, test home directory expansion on IPYTHONDIR"""
- home_dir = os.path.normpath(os.path.expanduser('~'))
- with modified_env({'IPYTHONDIR': os.path.join('~', 'somewhere')}), \
- patch.object(paths, '_writable_dir', return_value=True):
- ipdir = paths.get_ipython_dir()
- assert ipdir == os.path.join(home_dir, "somewhere")
-
-
-@skip_win32
-def test_get_ipython_dir_8():
- """test_get_ipython_dir_8, test / home directory"""
- if not os.access("/", os.W_OK):
- # test only when HOME directory actually writable
- return
-
- with patch.object(paths, "_writable_dir", lambda path: bool(path)), patch.object(
- paths, "get_xdg_dir", return_value=None
- ), modified_env(
- {
- "IPYTHON_DIR": None,
- "IPYTHONDIR": None,
- "HOME": "/",
- }
- ):
- assert paths.get_ipython_dir() == "/.ipython"
-
-
-def test_get_ipython_cache_dir():
- with modified_env({'HOME': HOME_TEST_DIR}):
- if os.name == "posix":
- # test default
- os.makedirs(os.path.join(HOME_TEST_DIR, ".cache"))
- with modified_env({'XDG_CACHE_HOME': None}):
- ipdir = paths.get_ipython_cache_dir()
- assert os.path.join(HOME_TEST_DIR, ".cache", "ipython") == ipdir
- assert_isdir(ipdir)
-
- # test env override
- with modified_env({"XDG_CACHE_HOME": XDG_CACHE_DIR}):
- ipdir = paths.get_ipython_cache_dir()
- assert_isdir(ipdir)
- assert ipdir == os.path.join(XDG_CACHE_DIR, "ipython")
- else:
- assert paths.get_ipython_cache_dir() == paths.get_ipython_dir()
-
-def test_get_ipython_package_dir():
- ipdir = paths.get_ipython_package_dir()
- assert_isdir(ipdir)
-
-
-def test_get_ipython_module_path():
- ipapp_path = paths.get_ipython_module_path('IPython.terminal.ipapp')
- assert_isfile(ipapp_path)
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/utils/_process_common.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/utils/_process_common.py
deleted file mode 100644
index 2a0b828839bcc32d535cffc7a286a70b8098babe..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/IPython/utils/_process_common.py
+++ /dev/null
@@ -1,210 +0,0 @@
-"""Common utilities for the various process_* implementations.
-
-This file is only meant to be imported by the platform-specific implementations
-of subprocess utilities, and it contains tools that are common to all of them.
-"""
-
-#-----------------------------------------------------------------------------
-# Copyright (C) 2010-2011 The IPython Development Team
-#
-# Distributed under the terms of the BSD License. The full license is in
-# the file COPYING, distributed as part of this software.
-#-----------------------------------------------------------------------------
-
-#-----------------------------------------------------------------------------
-# Imports
-#-----------------------------------------------------------------------------
-import subprocess
-import shlex
-import sys
-import os
-
-from IPython.utils import py3compat
-
-#-----------------------------------------------------------------------------
-# Function definitions
-#-----------------------------------------------------------------------------
-
-def read_no_interrupt(p):
- """Read from a pipe ignoring EINTR errors.
-
- This is necessary because when reading from pipes with GUI event loops
- running in the background, often interrupts are raised that stop the
- command from completing."""
- import errno
-
- try:
- return p.read()
- except IOError as err:
- if err.errno != errno.EINTR:
- raise
-
-
-def process_handler(cmd, callback, stderr=subprocess.PIPE):
- """Open a command in a shell subprocess and execute a callback.
-
- This function provides common scaffolding for creating subprocess.Popen()
- calls. It creates a Popen object and then calls the callback with it.
-
- Parameters
- ----------
- cmd : str or list
- A command to be executed by the system, using :class:`subprocess.Popen`.
- If a string is passed, it will be run in the system shell. If a list is
- passed, it will be used directly as arguments.
- callback : callable
- A one-argument function that will be called with the Popen object.
- stderr : file descriptor number, optional
- By default this is set to ``subprocess.PIPE``, but you can also pass the
- value ``subprocess.STDOUT`` to force the subprocess' stderr to go into
- the same file descriptor as its stdout. This is useful to read stdout
- and stderr combined in the order they are generated.
-
- Returns
- -------
- The return value of the provided callback is returned.
- """
- sys.stdout.flush()
- sys.stderr.flush()
- # On win32, close_fds can't be true when using pipes for stdin/out/err
- close_fds = sys.platform != 'win32'
- # Determine if cmd should be run with system shell.
- shell = isinstance(cmd, str)
- # On POSIX systems run shell commands with user-preferred shell.
- executable = None
- if shell and os.name == 'posix' and 'SHELL' in os.environ:
- executable = os.environ['SHELL']
- p = subprocess.Popen(cmd, shell=shell,
- executable=executable,
- stdin=subprocess.PIPE,
- stdout=subprocess.PIPE,
- stderr=stderr,
- close_fds=close_fds)
-
- try:
- out = callback(p)
- except KeyboardInterrupt:
- print('^C')
- sys.stdout.flush()
- sys.stderr.flush()
- out = None
- finally:
- # Make really sure that we don't leave processes behind, in case the
- # call above raises an exception
- # We start by assuming the subprocess finished (to avoid NameErrors
- # later depending on the path taken)
- if p.returncode is None:
- try:
- p.terminate()
- p.poll()
- except OSError:
- pass
- # One last try on our way out
- if p.returncode is None:
- try:
- p.kill()
- except OSError:
- pass
-
- return out
-
-
-def getoutput(cmd):
- """Run a command and return its stdout/stderr as a string.
-
- Parameters
- ----------
- cmd : str or list
- A command to be executed in the system shell.
-
- Returns
- -------
- output : str
- A string containing the combination of stdout and stderr from the
- subprocess, in whatever order the subprocess originally wrote to its
- file descriptors (so the order of the information in this string is the
- correct order as would be seen if running the command in a terminal).
- """
- out = process_handler(cmd, lambda p: p.communicate()[0], subprocess.STDOUT)
- if out is None:
- return ''
- return py3compat.decode(out)
-
-
-def getoutputerror(cmd):
- """Return (standard output, standard error) of executing cmd in a shell.
-
- Accepts the same arguments as os.system().
-
- Parameters
- ----------
- cmd : str or list
- A command to be executed in the system shell.
-
- Returns
- -------
- stdout : str
- stderr : str
- """
- return get_output_error_code(cmd)[:2]
-
-def get_output_error_code(cmd):
- """Return (standard output, standard error, return code) of executing cmd
- in a shell.
-
- Accepts the same arguments as os.system().
-
- Parameters
- ----------
- cmd : str or list
- A command to be executed in the system shell.
-
- Returns
- -------
- stdout : str
- stderr : str
- returncode: int
- """
-
- out_err, p = process_handler(cmd, lambda p: (p.communicate(), p))
- if out_err is None:
- return '', '', p.returncode
- out, err = out_err
- return py3compat.decode(out), py3compat.decode(err), p.returncode
-
-def arg_split(s, posix=False, strict=True):
- """Split a command line's arguments in a shell-like manner.
-
- This is a modified version of the standard library's shlex.split()
- function, but with a default of posix=False for splitting, so that quotes
- in inputs are respected.
-
- if strict=False, then any errors shlex.split would raise will result in the
- unparsed remainder being the last element of the list, rather than raising.
- This is because we sometimes use arg_split to parse things other than
- command-line args.
- """
-
- lex = shlex.shlex(s, posix=posix)
- lex.whitespace_split = True
- # Extract tokens, ensuring that things like leaving open quotes
- # does not cause this to raise. This is important, because we
- # sometimes pass Python source through this (e.g. %timeit f(" ")),
- # and it shouldn't raise an exception.
- # It may be a bad idea to parse things that are not command-line args
- # through this function, but we do, so let's be safe about it.
- lex.commenters='' #fix for GH-1269
- tokens = []
- while True:
- try:
- tokens.append(next(lex))
- except StopIteration:
- break
- except ValueError:
- if strict:
- raise
- # couldn't parse, get remaining blob as last token
- tokens.append(lex.token)
- break
-
- return tokens
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydev_runfiles/__init__.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydev_runfiles/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_frame_utils.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_frame_utils.py
deleted file mode 100644
index f079757a6c206651b771e153ceda864f726e90ea..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/debugpy/_vendored/pydevd/_pydevd_bundle/pydevd_frame_utils.py
+++ /dev/null
@@ -1,434 +0,0 @@
-from _pydevd_bundle.pydevd_constants import EXCEPTION_TYPE_USER_UNHANDLED, EXCEPTION_TYPE_UNHANDLED, \
- IS_PY311_OR_GREATER
-from _pydev_bundle import pydev_log
-import itertools
-from typing import Any, Dict
-
-
-class Frame(object):
-
- def __init__(
- self,
- f_back,
- f_fileno,
- f_code,
- f_locals,
- f_globals=None,
- f_trace=None):
- self.f_back = f_back
- self.f_lineno = f_fileno
- self.f_code = f_code
- self.f_locals = f_locals
- self.f_globals = f_globals
- self.f_trace = f_trace
-
- if self.f_globals is None:
- self.f_globals = {}
-
-
-class FCode(object):
-
- def __init__(self, name, filename):
- self.co_name = name
- self.co_filename = filename
- self.co_firstlineno = 1
- self.co_flags = 0
-
-
-def add_exception_to_frame(frame, exception_info):
- frame.f_locals['__exception__'] = exception_info
-
-
-def remove_exception_from_frame(frame):
- frame.f_locals.pop('__exception__', None)
-
-
-FILES_WITH_IMPORT_HOOKS = ['pydev_monkey_qt.py', 'pydev_import_hook.py']
-
-
-def just_raised(trace):
- if trace is None:
- return False
- return trace.tb_next is None
-
-
-def ignore_exception_trace(trace):
- while trace is not None:
- filename = trace.tb_frame.f_code.co_filename
- if filename in (
- '', ''):
- # Do not stop on inner exceptions in py3 while importing
- return True
-
- # ImportError should appear in a user's code, not inside debugger
- for file in FILES_WITH_IMPORT_HOOKS:
- if filename.endswith(file):
- return True
-
- trace = trace.tb_next
-
- return False
-
-
-def cached_call(obj, func, *args):
- cached_name = '_cached_' + func.__name__
- if not hasattr(obj, cached_name):
- setattr(obj, cached_name, func(*args))
-
- return getattr(obj, cached_name)
-
-
-class _LineColInfo:
-
- def __init__(self, lineno, end_lineno, colno, end_colno):
- self.lineno = lineno
- self.end_lineno = end_lineno
- self.colno = colno
- self.end_colno = end_colno
-
- def map_columns_to_line(self, original_line: str):
- '''
- The columns internally are actually based on bytes.
-
- Also, the position isn't always the ideal one as the start may not be
- what we want (if the user has many subscripts in the line the start
- will always be the same and only the end would change).
- For more details see:
- https://github.com/microsoft/debugpy/issues/1099#issuecomment-1303403995
-
- So, this function maps the start/end columns to the position to be shown in the editor.
- '''
- colno = _utf8_byte_offset_to_character_offset(original_line, self.colno)
- end_colno = _utf8_byte_offset_to_character_offset(original_line, self.end_colno)
-
- if self.lineno == self.end_lineno:
- try:
- ret = _extract_caret_anchors_in_bytes_from_line_segment(
- original_line[colno:end_colno]
- )
- if ret is not None:
- return (
- _utf8_byte_offset_to_character_offset(original_line, ret[0] + self.colno),
- _utf8_byte_offset_to_character_offset(original_line, ret[1] + self.colno)
- )
- except Exception:
- pass # Suppress exception
-
- return colno, end_colno
-
-
-_utf8_with_2_bytes = 0x80
-_utf8_with_3_bytes = 0x800
-_utf8_with_4_bytes = 0x10000
-
-
-def _utf8_byte_offset_to_character_offset(s: str, offset: int):
- byte_offset = 0
- char_offset = 0
-
- for char_offset, character in enumerate(s):
- byte_offset += 1
-
- codepoint = ord(character)
-
- if codepoint >= _utf8_with_4_bytes:
- byte_offset += 3
-
- elif codepoint >= _utf8_with_3_bytes:
- byte_offset += 2
-
- elif codepoint >= _utf8_with_2_bytes:
- byte_offset += 1
-
- if byte_offset > offset:
- break
- else:
- char_offset += 1
-
- return char_offset
-
-
-# Based on traceback._extract_caret_anchors_in_bytes_from_line_segment (Python 3.11.0)
-def _extract_caret_anchors_in_bytes_from_line_segment(segment: str):
- import ast
-
- try:
- segment = segment.encode('utf-8')
- except UnicodeEncodeError:
- return None
- try:
- tree = ast.parse(segment)
- except SyntaxError:
- return None
-
- if len(tree.body) != 1:
- return None
-
- statement = tree.body[0]
- if isinstance(statement, ast.Expr):
- expr = statement.value
- if isinstance(expr, ast.BinOp):
- operator_str = segment[expr.left.end_col_offset:expr.right.col_offset]
- operator_offset = len(operator_str) - len(operator_str.lstrip())
-
- left_anchor = expr.left.end_col_offset + operator_offset
- right_anchor = left_anchor + 1
- if (
- operator_offset + 1 < len(operator_str)
- and not operator_str[operator_offset + 1] == ord(b' ')
- ):
- right_anchor += 1
- return left_anchor, right_anchor
- if isinstance(expr, ast.Subscript):
- return expr.value.end_col_offset, expr.slice.end_col_offset + 1
-
- return None
-
-
-class FramesList(object):
-
- def __init__(self):
- self._frames = []
-
- # If available, the line number for the frame will be gotten from this dict,
- # otherwise frame.f_lineno will be used (needed for unhandled exceptions as
- # the place where we report may be different from the place where it's raised).
- self.frame_id_to_lineno = {}
- self.frame_id_to_line_col_info: Dict[Any, _LineColInfo] = {}
-
- self.exc_type = None
- self.exc_desc = None
- self.trace_obj = None
-
- # This may be set to set the current frame (for the case where we have
- # an unhandled exception where we want to show the root bu we have a different
- # executing frame).
- self.current_frame = None
-
- # This is to know whether an exception was extracted from a __cause__ or __context__.
- self.exc_context_msg = ''
-
- self.chained_frames_list = None
-
- def append(self, frame):
- self._frames.append(frame)
-
- def last_frame(self):
- return self._frames[-1]
-
- def __len__(self):
- return len(self._frames)
-
- def __iter__(self):
- return iter(self._frames)
-
- def __repr__(self):
- lst = ['FramesList(']
-
- lst.append('\n exc_type: ')
- lst.append(str(self.exc_type))
-
- lst.append('\n exc_desc: ')
- lst.append(str(self.exc_desc))
-
- lst.append('\n trace_obj: ')
- lst.append(str(self.trace_obj))
-
- lst.append('\n current_frame: ')
- lst.append(str(self.current_frame))
-
- for frame in self._frames:
- lst.append('\n ')
- lst.append(repr(frame))
- lst.append(',')
-
- if self.chained_frames_list is not None:
- lst.append('\n--- Chained ---\n')
- lst.append(str(self.chained_frames_list))
-
- lst.append('\n)')
-
- return ''.join(lst)
-
- __str__ = __repr__
-
-
-class _DummyFrameWrapper(object):
-
- def __init__(self, frame, f_lineno, f_back):
- self._base_frame = frame
- self.f_lineno = f_lineno
- self.f_back = f_back
- self.f_trace = None
- original_code = frame.f_code
- name = original_code.co_name
- self.f_code = FCode(name, original_code.co_filename)
-
- @property
- def f_locals(self):
- return self._base_frame.f_locals
-
- @property
- def f_globals(self):
- return self._base_frame.f_globals
-
- def __str__(self):
- return "<_DummyFrameWrapper, file '%s', line %s, %s" % (self.f_code.co_filename, self.f_lineno, self.f_code.co_name)
-
- __repr__ = __str__
-
-
-_cause_message = (
- "\nThe above exception was the direct cause "
- "of the following exception:\n\n")
-
-_context_message = (
- "\nDuring handling of the above exception, "
- "another exception occurred:\n\n")
-
-
-def create_frames_list_from_exception_cause(trace_obj, frame, exc_type, exc_desc, memo):
- lst = []
- msg = ''
- try:
- exc_cause = getattr(exc_desc, '__cause__', None)
- msg = _cause_message
- except Exception:
- exc_cause = None
-
- if exc_cause is None:
- try:
- exc_cause = getattr(exc_desc, '__context__', None)
- msg = _context_message
- except Exception:
- exc_cause = None
-
- if exc_cause is None or id(exc_cause) in memo:
- return None
-
- # The traceback module does this, so, let's play safe here too...
- memo.add(id(exc_cause))
-
- tb = exc_cause.__traceback__
- frames_list = FramesList()
- frames_list.exc_type = type(exc_cause)
- frames_list.exc_desc = exc_cause
- frames_list.trace_obj = tb
- frames_list.exc_context_msg = msg
-
- while tb is not None:
- # Note: we don't use the actual tb.tb_frame because if the cause of the exception
- # uses the same frame object, the id(frame) would be the same and the frame_id_to_lineno
- # would be wrong as the same frame needs to appear with 2 different lines.
- lst.append((_DummyFrameWrapper(tb.tb_frame, tb.tb_lineno, None), tb.tb_lineno, _get_line_col_info_from_tb(tb)))
- tb = tb.tb_next
-
- for tb_frame, tb_lineno, line_col_info in lst:
- frames_list.append(tb_frame)
- frames_list.frame_id_to_lineno[id(tb_frame)] = tb_lineno
- frames_list.frame_id_to_line_col_info[id(tb_frame)] = line_col_info
-
- return frames_list
-
-
-if IS_PY311_OR_GREATER:
-
- def _get_code_position(code, instruction_index):
- if instruction_index < 0:
- return (None, None, None, None)
- positions_gen = code.co_positions()
- # Note: some or all of the tuple elements can be None...
- return next(itertools.islice(positions_gen, instruction_index // 2, None))
-
- def _get_line_col_info_from_tb(tb):
- positions = _get_code_position(tb.tb_frame.f_code, tb.tb_lasti)
- if positions[0] is None:
- return _LineColInfo(tb.tb_lineno, *positions[1:])
- else:
- return _LineColInfo(*positions)
-
-else:
-
- def _get_line_col_info_from_tb(tb):
- # Not available on older versions of Python.
- return None
-
-
-def create_frames_list_from_traceback(trace_obj, frame, exc_type, exc_desc, exception_type=None):
- '''
- :param trace_obj:
- This is the traceback from which the list should be created.
-
- :param frame:
- This is the first frame to be considered (i.e.: topmost frame). If None is passed, all
- the frames from the traceback are shown (so, None should be passed for unhandled exceptions).
-
- :param exception_type:
- If this is an unhandled exception or user unhandled exception, we'll not trim the stack to create from the passed
- frame, rather, we'll just mark the frame in the frames list.
- '''
- lst = []
-
- tb = trace_obj
- if tb is not None and tb.tb_frame is not None:
- f = tb.tb_frame.f_back
- while f is not None:
- lst.insert(0, (f, f.f_lineno, None))
- f = f.f_back
-
- while tb is not None:
- lst.append((tb.tb_frame, tb.tb_lineno, _get_line_col_info_from_tb(tb)))
- tb = tb.tb_next
-
- frames_list = None
-
- for tb_frame, tb_lineno, line_col_info in reversed(lst):
- if frames_list is None and (
- (frame is tb_frame) or
- (frame is None) or
- (exception_type == EXCEPTION_TYPE_USER_UNHANDLED)
- ):
- frames_list = FramesList()
-
- if frames_list is not None:
- frames_list.append(tb_frame)
- frames_list.frame_id_to_lineno[id(tb_frame)] = tb_lineno
- frames_list.frame_id_to_line_col_info[id(tb_frame)] = line_col_info
-
- if frames_list is None and frame is not None:
- # Fallback (shouldn't happen in practice).
- pydev_log.info('create_frames_list_from_traceback did not find topmost frame in list.')
- frames_list = create_frames_list_from_frame(frame)
-
- frames_list.exc_type = exc_type
- frames_list.exc_desc = exc_desc
- frames_list.trace_obj = trace_obj
-
- if exception_type == EXCEPTION_TYPE_USER_UNHANDLED:
- frames_list.current_frame = frame
- elif exception_type == EXCEPTION_TYPE_UNHANDLED:
- if len(frames_list) > 0:
- frames_list.current_frame = frames_list.last_frame()
-
- curr = frames_list
- memo = set()
- memo.add(id(exc_desc))
-
- while True:
- chained = create_frames_list_from_exception_cause(None, None, None, curr.exc_desc, memo)
- if chained is None:
- break
- else:
- curr.chained_frames_list = chained
- curr = chained
-
- return frames_list
-
-
-def create_frames_list_from_frame(frame):
- lst = FramesList()
- while frame is not None:
- lst.append(frame)
- frame = frame.f_back
-
- return lst
diff --git a/spaces/Superlang/ImageProcessor/annotator/oneformer/oneformer/evaluation/instance_evaluation.py b/spaces/Superlang/ImageProcessor/annotator/oneformer/oneformer/evaluation/instance_evaluation.py
deleted file mode 100644
index 12ce1d722987d1b6daa030423bb6aed4624e8310..0000000000000000000000000000000000000000
--- a/spaces/Superlang/ImageProcessor/annotator/oneformer/oneformer/evaluation/instance_evaluation.py
+++ /dev/null
@@ -1,110 +0,0 @@
-# ------------------------------------------------------------------------------
-# Reference: https://github.com/facebookresearch/Mask2Former/blob/main/mask2former/evaluation/instance_evaluation.py
-# ------------------------------------------------------------------------------
-
-import contextlib
-import copy
-import io
-import itertools
-import json
-import logging
-import numpy as np
-import os
-import pickle
-from collections import OrderedDict
-import annotator.oneformer.pycocotools.mask as mask_util
-import torch
-from annotator.oneformer.pycocotools.coco import COCO
-from annotator.oneformer.pycocotools.cocoeval import COCOeval
-from tabulate import tabulate
-
-import annotator.oneformer.detectron2.utils.comm as comm
-from annotator.oneformer.detectron2.config import CfgNode
-from annotator.oneformer.detectron2.data import MetadataCatalog
-from annotator.oneformer.detectron2.data.datasets.coco import convert_to_coco_json
-from annotator.oneformer.detectron2.evaluation.coco_evaluation import COCOEvaluator, _evaluate_predictions_on_coco
-from annotator.oneformer.detectron2.evaluation.fast_eval_api import COCOeval_opt
-from annotator.oneformer.detectron2.structures import Boxes, BoxMode, pairwise_iou
-from annotator.oneformer.detectron2.utils.file_io import PathManager
-from annotator.oneformer.detectron2.utils.logger import create_small_table
-
-
-# modified from COCOEvaluator for instance segmetnat
-class InstanceSegEvaluator(COCOEvaluator):
- """
- Evaluate AR for object proposals, AP for instance detection/segmentation, AP
- for keypoint detection outputs using COCO's metrics.
- See http://cocodataset.org/#detection-eval and
- http://cocodataset.org/#keypoints-eval to understand its metrics.
- The metrics range from 0 to 100 (instead of 0 to 1), where a -1 or NaN means
- the metric cannot be computed (e.g. due to no predictions made).
-
- In addition to COCO, this evaluator is able to support any bounding box detection,
- instance segmentation, or keypoint detection dataset.
- """
-
- def _eval_predictions(self, predictions, img_ids=None):
- """
- Evaluate predictions. Fill self._results with the metrics of the tasks.
- """
- self._logger.info("Preparing results for COCO format ...")
- coco_results = list(itertools.chain(*[x["instances"] for x in predictions]))
- tasks = self._tasks or self._tasks_from_predictions(coco_results)
-
- # unmap the category ids for COCO
- if hasattr(self._metadata, "thing_dataset_id_to_contiguous_id"):
- dataset_id_to_contiguous_id = self._metadata.thing_dataset_id_to_contiguous_id
- # all_contiguous_ids = list(dataset_id_to_contiguous_id.values())
- # num_classes = len(all_contiguous_ids)
- # assert min(all_contiguous_ids) == 0 and max(all_contiguous_ids) == num_classes - 1
-
- reverse_id_mapping = {v: k for k, v in dataset_id_to_contiguous_id.items()}
- for result in coco_results:
- category_id = result["category_id"]
- # assert category_id < num_classes, (
- # f"A prediction has class={category_id}, "
- # f"but the dataset only has {num_classes} classes and "
- # f"predicted class id should be in [0, {num_classes - 1}]."
- # )
- assert category_id in reverse_id_mapping, (
- f"A prediction has class={category_id}, "
- f"but the dataset only has class ids in {dataset_id_to_contiguous_id}."
- )
- result["category_id"] = reverse_id_mapping[category_id]
-
- if self._output_dir:
- file_path = os.path.join(self._output_dir, "coco_instances_results.json")
- self._logger.info("Saving results to {}".format(file_path))
- with PathManager.open(file_path, "w") as f:
- f.write(json.dumps(coco_results))
- f.flush()
-
- if not self._do_evaluation:
- self._logger.info("Annotations are not available for evaluation.")
- return
-
- self._logger.info(
- "Evaluating predictions with {} COCO API...".format(
- "unofficial" if self._use_fast_impl else "official"
- )
- )
- for task in sorted(tasks):
- assert task in {"bbox", "segm", "keypoints"}, f"Got unknown task: {task}!"
- coco_eval = (
- _evaluate_predictions_on_coco(
- self._coco_api,
- coco_results,
- task,
- kpt_oks_sigmas=self._kpt_oks_sigmas,
- use_fast_impl=self._use_fast_impl,
- img_ids=img_ids,
- max_dets_per_image=self._max_dets_per_image,
- )
- if len(coco_results) > 0
- else None # cocoapi does not handle empty results very well
- )
-
- res = self._derive_coco_results(
- coco_eval, task, class_names=self._metadata.get("thing_classes")
- )
- self._results[task] = res
diff --git a/spaces/TRI-ML/risk_biased_prediction/tests/risk_biased/mpc_planner/test_dynamics.py b/spaces/TRI-ML/risk_biased_prediction/tests/risk_biased/mpc_planner/test_dynamics.py
deleted file mode 100644
index e5611bd7e1c7214338dcb630a938a5fe12c372d2..0000000000000000000000000000000000000000
--- a/spaces/TRI-ML/risk_biased_prediction/tests/risk_biased/mpc_planner/test_dynamics.py
+++ /dev/null
@@ -1,34 +0,0 @@
-import pytest
-
-import torch
-
-from risk_biased.mpc_planner.dynamics import PositionVelocityDoubleIntegrator
-from risk_biased.utils.planner_utils import to_state
-
-
-@pytest.mark.parametrize("dt", [(0.01), (0.1)])
-def test_double_integrator(dt: float):
-
- torch.manual_seed(0)
-
- dynamics = PositionVelocityDoubleIntegrator(dt)
- assert dynamics.dt == dt
- assert dynamics.control_dim == 2
-
- state_init = to_state(torch.randn(1, 4), dt)
- control_input = torch.randn(10, 5, 2)
- state_future = dynamics.simulate(state_init, control_input)
- assert state_future.shape == (10, 5)
-
- assert torch.allclose(
- state_future.position,
- state_init.position
- + torch.cumsum(
- state_init.velocity + torch.cumsum(control_input, dim=1) * dt, dim=1
- )
- * dt,
- )
- assert torch.allclose(
- state_future.position,
- state_init.position + torch.cumsum(state_future.velocity * dt, dim=1),
- )
diff --git a/spaces/TYH71/gradio-ml-skeleton/src/model/__init__.py b/spaces/TYH71/gradio-ml-skeleton/src/model/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/setuptools/_vendor/more_itertools/__init__.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/setuptools/_vendor/more_itertools/__init__.py
deleted file mode 100644
index 19a169fc30183db91f931ad6ad04fbc0e16559b3..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/setuptools/_vendor/more_itertools/__init__.py
+++ /dev/null
@@ -1,4 +0,0 @@
-from .more import * # noqa
-from .recipes import * # noqa
-
-__version__ = '8.8.0'
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/setuptools/_vendor/packaging/metadata.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/setuptools/_vendor/packaging/metadata.py
deleted file mode 100644
index e76a60c395eb62d5f05d7248cf67210cdd10740d..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/setuptools/_vendor/packaging/metadata.py
+++ /dev/null
@@ -1,408 +0,0 @@
-import email.feedparser
-import email.header
-import email.message
-import email.parser
-import email.policy
-import sys
-import typing
-from typing import Dict, List, Optional, Tuple, Union, cast
-
-if sys.version_info >= (3, 8): # pragma: no cover
- from typing import TypedDict
-else: # pragma: no cover
- if typing.TYPE_CHECKING:
- from typing_extensions import TypedDict
- else:
- try:
- from typing_extensions import TypedDict
- except ImportError:
-
- class TypedDict:
- def __init_subclass__(*_args, **_kwargs):
- pass
-
-
-# The RawMetadata class attempts to make as few assumptions about the underlying
-# serialization formats as possible. The idea is that as long as a serialization
-# formats offer some very basic primitives in *some* way then we can support
-# serializing to and from that format.
-class RawMetadata(TypedDict, total=False):
- """A dictionary of raw core metadata.
-
- Each field in core metadata maps to a key of this dictionary (when data is
- provided). The key is lower-case and underscores are used instead of dashes
- compared to the equivalent core metadata field. Any core metadata field that
- can be specified multiple times or can hold multiple values in a single
- field have a key with a plural name.
-
- Core metadata fields that can be specified multiple times are stored as a
- list or dict depending on which is appropriate for the field. Any fields
- which hold multiple values in a single field are stored as a list.
-
- """
-
- # Metadata 1.0 - PEP 241
- metadata_version: str
- name: str
- version: str
- platforms: List[str]
- summary: str
- description: str
- keywords: List[str]
- home_page: str
- author: str
- author_email: str
- license: str
-
- # Metadata 1.1 - PEP 314
- supported_platforms: List[str]
- download_url: str
- classifiers: List[str]
- requires: List[str]
- provides: List[str]
- obsoletes: List[str]
-
- # Metadata 1.2 - PEP 345
- maintainer: str
- maintainer_email: str
- requires_dist: List[str]
- provides_dist: List[str]
- obsoletes_dist: List[str]
- requires_python: str
- requires_external: List[str]
- project_urls: Dict[str, str]
-
- # Metadata 2.0
- # PEP 426 attempted to completely revamp the metadata format
- # but got stuck without ever being able to build consensus on
- # it and ultimately ended up withdrawn.
- #
- # However, a number of tools had started emiting METADATA with
- # `2.0` Metadata-Version, so for historical reasons, this version
- # was skipped.
-
- # Metadata 2.1 - PEP 566
- description_content_type: str
- provides_extra: List[str]
-
- # Metadata 2.2 - PEP 643
- dynamic: List[str]
-
- # Metadata 2.3 - PEP 685
- # No new fields were added in PEP 685, just some edge case were
- # tightened up to provide better interoptability.
-
-
-_STRING_FIELDS = {
- "author",
- "author_email",
- "description",
- "description_content_type",
- "download_url",
- "home_page",
- "license",
- "maintainer",
- "maintainer_email",
- "metadata_version",
- "name",
- "requires_python",
- "summary",
- "version",
-}
-
-_LIST_STRING_FIELDS = {
- "classifiers",
- "dynamic",
- "obsoletes",
- "obsoletes_dist",
- "platforms",
- "provides",
- "provides_dist",
- "provides_extra",
- "requires",
- "requires_dist",
- "requires_external",
- "supported_platforms",
-}
-
-
-def _parse_keywords(data: str) -> List[str]:
- """Split a string of comma-separate keyboards into a list of keywords."""
- return [k.strip() for k in data.split(",")]
-
-
-def _parse_project_urls(data: List[str]) -> Dict[str, str]:
- """Parse a list of label/URL string pairings separated by a comma."""
- urls = {}
- for pair in data:
- # Our logic is slightly tricky here as we want to try and do
- # *something* reasonable with malformed data.
- #
- # The main thing that we have to worry about, is data that does
- # not have a ',' at all to split the label from the Value. There
- # isn't a singular right answer here, and we will fail validation
- # later on (if the caller is validating) so it doesn't *really*
- # matter, but since the missing value has to be an empty str
- # and our return value is dict[str, str], if we let the key
- # be the missing value, then they'd have multiple '' values that
- # overwrite each other in a accumulating dict.
- #
- # The other potentional issue is that it's possible to have the
- # same label multiple times in the metadata, with no solid "right"
- # answer with what to do in that case. As such, we'll do the only
- # thing we can, which is treat the field as unparseable and add it
- # to our list of unparsed fields.
- parts = [p.strip() for p in pair.split(",", 1)]
- parts.extend([""] * (max(0, 2 - len(parts)))) # Ensure 2 items
-
- # TODO: The spec doesn't say anything about if the keys should be
- # considered case sensitive or not... logically they should
- # be case-preserving and case-insensitive, but doing that
- # would open up more cases where we might have duplicate
- # entries.
- label, url = parts
- if label in urls:
- # The label already exists in our set of urls, so this field
- # is unparseable, and we can just add the whole thing to our
- # unparseable data and stop processing it.
- raise KeyError("duplicate labels in project urls")
- urls[label] = url
-
- return urls
-
-
-def _get_payload(msg: email.message.Message, source: Union[bytes, str]) -> str:
- """Get the body of the message."""
- # If our source is a str, then our caller has managed encodings for us,
- # and we don't need to deal with it.
- if isinstance(source, str):
- payload: str = msg.get_payload()
- return payload
- # If our source is a bytes, then we're managing the encoding and we need
- # to deal with it.
- else:
- bpayload: bytes = msg.get_payload(decode=True)
- try:
- return bpayload.decode("utf8", "strict")
- except UnicodeDecodeError:
- raise ValueError("payload in an invalid encoding")
-
-
-# The various parse_FORMAT functions here are intended to be as lenient as
-# possible in their parsing, while still returning a correctly typed
-# RawMetadata.
-#
-# To aid in this, we also generally want to do as little touching of the
-# data as possible, except where there are possibly some historic holdovers
-# that make valid data awkward to work with.
-#
-# While this is a lower level, intermediate format than our ``Metadata``
-# class, some light touch ups can make a massive difference in usability.
-
-# Map METADATA fields to RawMetadata.
-_EMAIL_TO_RAW_MAPPING = {
- "author": "author",
- "author-email": "author_email",
- "classifier": "classifiers",
- "description": "description",
- "description-content-type": "description_content_type",
- "download-url": "download_url",
- "dynamic": "dynamic",
- "home-page": "home_page",
- "keywords": "keywords",
- "license": "license",
- "maintainer": "maintainer",
- "maintainer-email": "maintainer_email",
- "metadata-version": "metadata_version",
- "name": "name",
- "obsoletes": "obsoletes",
- "obsoletes-dist": "obsoletes_dist",
- "platform": "platforms",
- "project-url": "project_urls",
- "provides": "provides",
- "provides-dist": "provides_dist",
- "provides-extra": "provides_extra",
- "requires": "requires",
- "requires-dist": "requires_dist",
- "requires-external": "requires_external",
- "requires-python": "requires_python",
- "summary": "summary",
- "supported-platform": "supported_platforms",
- "version": "version",
-}
-
-
-def parse_email(data: Union[bytes, str]) -> Tuple[RawMetadata, Dict[str, List[str]]]:
- """Parse a distribution's metadata.
-
- This function returns a two-item tuple of dicts. The first dict is of
- recognized fields from the core metadata specification. Fields that can be
- parsed and translated into Python's built-in types are converted
- appropriately. All other fields are left as-is. Fields that are allowed to
- appear multiple times are stored as lists.
-
- The second dict contains all other fields from the metadata. This includes
- any unrecognized fields. It also includes any fields which are expected to
- be parsed into a built-in type but were not formatted appropriately. Finally,
- any fields that are expected to appear only once but are repeated are
- included in this dict.
-
- """
- raw: Dict[str, Union[str, List[str], Dict[str, str]]] = {}
- unparsed: Dict[str, List[str]] = {}
-
- if isinstance(data, str):
- parsed = email.parser.Parser(policy=email.policy.compat32).parsestr(data)
- else:
- parsed = email.parser.BytesParser(policy=email.policy.compat32).parsebytes(data)
-
- # We have to wrap parsed.keys() in a set, because in the case of multiple
- # values for a key (a list), the key will appear multiple times in the
- # list of keys, but we're avoiding that by using get_all().
- for name in frozenset(parsed.keys()):
- # Header names in RFC are case insensitive, so we'll normalize to all
- # lower case to make comparisons easier.
- name = name.lower()
-
- # We use get_all() here, even for fields that aren't multiple use,
- # because otherwise someone could have e.g. two Name fields, and we
- # would just silently ignore it rather than doing something about it.
- headers = parsed.get_all(name)
-
- # The way the email module works when parsing bytes is that it
- # unconditionally decodes the bytes as ascii using the surrogateescape
- # handler. When you pull that data back out (such as with get_all() ),
- # it looks to see if the str has any surrogate escapes, and if it does
- # it wraps it in a Header object instead of returning the string.
- #
- # As such, we'll look for those Header objects, and fix up the encoding.
- value = []
- # Flag if we have run into any issues processing the headers, thus
- # signalling that the data belongs in 'unparsed'.
- valid_encoding = True
- for h in headers:
- # It's unclear if this can return more types than just a Header or
- # a str, so we'll just assert here to make sure.
- assert isinstance(h, (email.header.Header, str))
-
- # If it's a header object, we need to do our little dance to get
- # the real data out of it. In cases where there is invalid data
- # we're going to end up with mojibake, but there's no obvious, good
- # way around that without reimplementing parts of the Header object
- # ourselves.
- #
- # That should be fine since, if mojibacked happens, this key is
- # going into the unparsed dict anyways.
- if isinstance(h, email.header.Header):
- # The Header object stores it's data as chunks, and each chunk
- # can be independently encoded, so we'll need to check each
- # of them.
- chunks: List[Tuple[bytes, Optional[str]]] = []
- for bin, encoding in email.header.decode_header(h):
- try:
- bin.decode("utf8", "strict")
- except UnicodeDecodeError:
- # Enable mojibake.
- encoding = "latin1"
- valid_encoding = False
- else:
- encoding = "utf8"
- chunks.append((bin, encoding))
-
- # Turn our chunks back into a Header object, then let that
- # Header object do the right thing to turn them into a
- # string for us.
- value.append(str(email.header.make_header(chunks)))
- # This is already a string, so just add it.
- else:
- value.append(h)
-
- # We've processed all of our values to get them into a list of str,
- # but we may have mojibake data, in which case this is an unparsed
- # field.
- if not valid_encoding:
- unparsed[name] = value
- continue
-
- raw_name = _EMAIL_TO_RAW_MAPPING.get(name)
- if raw_name is None:
- # This is a bit of a weird situation, we've encountered a key that
- # we don't know what it means, so we don't know whether it's meant
- # to be a list or not.
- #
- # Since we can't really tell one way or another, we'll just leave it
- # as a list, even though it may be a single item list, because that's
- # what makes the most sense for email headers.
- unparsed[name] = value
- continue
-
- # If this is one of our string fields, then we'll check to see if our
- # value is a list of a single item. If it is then we'll assume that
- # it was emitted as a single string, and unwrap the str from inside
- # the list.
- #
- # If it's any other kind of data, then we haven't the faintest clue
- # what we should parse it as, and we have to just add it to our list
- # of unparsed stuff.
- if raw_name in _STRING_FIELDS and len(value) == 1:
- raw[raw_name] = value[0]
- # If this is one of our list of string fields, then we can just assign
- # the value, since email *only* has strings, and our get_all() call
- # above ensures that this is a list.
- elif raw_name in _LIST_STRING_FIELDS:
- raw[raw_name] = value
- # Special Case: Keywords
- # The keywords field is implemented in the metadata spec as a str,
- # but it conceptually is a list of strings, and is serialized using
- # ", ".join(keywords), so we'll do some light data massaging to turn
- # this into what it logically is.
- elif raw_name == "keywords" and len(value) == 1:
- raw[raw_name] = _parse_keywords(value[0])
- # Special Case: Project-URL
- # The project urls is implemented in the metadata spec as a list of
- # specially-formatted strings that represent a key and a value, which
- # is fundamentally a mapping, however the email format doesn't support
- # mappings in a sane way, so it was crammed into a list of strings
- # instead.
- #
- # We will do a little light data massaging to turn this into a map as
- # it logically should be.
- elif raw_name == "project_urls":
- try:
- raw[raw_name] = _parse_project_urls(value)
- except KeyError:
- unparsed[name] = value
- # Nothing that we've done has managed to parse this, so it'll just
- # throw it in our unparseable data and move on.
- else:
- unparsed[name] = value
-
- # We need to support getting the Description from the message payload in
- # addition to getting it from the the headers. This does mean, though, there
- # is the possibility of it being set both ways, in which case we put both
- # in 'unparsed' since we don't know which is right.
- try:
- payload = _get_payload(parsed, data)
- except ValueError:
- unparsed.setdefault("description", []).append(
- parsed.get_payload(decode=isinstance(data, bytes))
- )
- else:
- if payload:
- # Check to see if we've already got a description, if so then both
- # it, and this body move to unparseable.
- if "description" in raw:
- description_header = cast(str, raw.pop("description"))
- unparsed.setdefault("description", []).extend(
- [description_header, payload]
- )
- elif "description" in unparsed:
- unparsed["description"].append(payload)
- else:
- raw["description"] = payload
-
- # We need to cast our `raw` to a metadata, because a TypedDict only support
- # literal key names, but we're computing our key names on purpose, but the
- # way this function is implemented, our `TypedDict` can only have valid key
- # names.
- return cast(RawMetadata, raw), unparsed
diff --git a/spaces/TechShark20/handwespeak/main.py b/spaces/TechShark20/handwespeak/main.py
deleted file mode 100644
index f56becc972000202a0e794e2b427072f21d15052..0000000000000000000000000000000000000000
--- a/spaces/TechShark20/handwespeak/main.py
+++ /dev/null
@@ -1,43 +0,0 @@
-
-import ast
-import pandas as pd
-
-from normalization.hand_normalization import normalize_hands_full
-from normalization.body_normalization import normalize_body_full
-
-
-# Load the dataset
-df = pd.read_csv("/Users/matyasbohacek/Documents/WLASL_test_15fps.csv", encoding="utf-8")
-
-# Retrieve metadata
-video_size_heights = df["video_size_height"].to_list()
-video_size_widths = df["video_size_width"].to_list()
-
-# Delete redundant (non-related) properties
-del df["video_size_height"]
-del df["video_size_width"]
-
-# Temporarily remove other relevant metadata
-labels = df["labels"].to_list()
-video_fps = df["video_fps"].to_list()
-del df["labels"]
-del df["video_fps"]
-
-# Convert the strings into lists
-convert = lambda x: ast.literal_eval(str(x))
-for column in df.columns:
- df[column] = df[column].apply(convert)
-
-# Perform the normalizations
-df = normalize_hands_full(df)
-df, invalid_row_indexes = normalize_body_full(df)
-
-# Clear lists of items from deleted rows
-# labels = [t for i, t in enumerate(labels) if i not in invalid_row_indexes]
-# video_fps = [t for i, t in enumerate(video_fps) if i not in invalid_row_indexes]
-
-# Return the metadata back to the dataset
-df["labels"] = labels
-df["video_fps"] = video_fps
-
-df.to_csv("/Users/matyasbohacek/Desktop/WLASL_test_15fps_normalized.csv", encoding="utf-8", index=False)
diff --git a/spaces/ThirdEyeData/Customer-Conversion-Prediction/matumizi/sampler.py b/spaces/ThirdEyeData/Customer-Conversion-Prediction/matumizi/sampler.py
deleted file mode 100644
index 2821f3df627ae45f75bf1a8f4446f000e55c1615..0000000000000000000000000000000000000000
--- a/spaces/ThirdEyeData/Customer-Conversion-Prediction/matumizi/sampler.py
+++ /dev/null
@@ -1,1455 +0,0 @@
-#!/usr/local/bin/python3
-
-# avenir-python: Machine Learning
-# Author: Pranab Ghosh
-#
-# Licensed under the Apache License, Version 2.0 (the "License"); you
-# may not use this file except in compliance with the License. You may
-# obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
-# implied. See the License for the specific language governing
-# permissions and limitations under the License.
-
-import sys
-import random
-import time
-import math
-import random
-import numpy as np
-from scipy import stats
-from random import randint
-from .util import *
-from .stats import Histogram
-
-def randomFloat(low, high):
- """
- sample float within range
-
- Parameters
- low : low valuee
- high : high valuee
- """
- return random.random() * (high-low) + low
-
-def randomInt(minv, maxv):
- """
- sample int within range
-
- Parameters
- minv : low valuee
- maxv : high valuee
- """
- return randint(minv, maxv)
-
-def randIndex(lData):
- """
- random index of a list
-
- Parameters
- lData : list data
- """
- return randint(0, len(lData)-1)
-
-def randomUniformSampled(low, high):
- """
- sample float within range
-
- Parameters
- low : low value
- high : high value
- """
- return np.random.uniform(low, high)
-
-def randomUniformSampledList(low, high, size):
- """
- sample floats within range to create list
-
- Parameters
- low : low value
- high : high value
- size ; size of list to be returned
- """
- return np.random.uniform(low, high, size)
-
-def randomNormSampled(mean, sd):
- """
- sample float from normal
-
- Parameters
- mean : mean
- sd : std deviation
- """
- return np.random.normal(mean, sd)
-
-def randomNormSampledList(mean, sd, size):
- """
- sample float list from normal
-
- Parameters
- mean : mean
- sd : std deviation
- size : size of list to be returned
- """
- return np.random.normal(mean, sd, size)
-
-def randomSampledList(sampler, size):
- """
- sample list from given sampler
-
- Parameters
- sampler : sampler object
- size : size of list to be returned
- """
- return list(map(lambda i : sampler.sample(), range(size)))
-
-
-def minLimit(val, minv):
- """
- min limit
-
- Parameters
- val : value
- minv : min limit
- """
- if (val < minv):
- val = minv
- return val
-
-
-def rangeLimit(val, minv, maxv):
- """
- range limit
-
- Parameters
- val : value
- minv : min limit
- maxv : max limit
- """
- if (val < minv):
- val = minv
- elif (val > maxv):
- val = maxv
- return val
-
-
-def sampleUniform(minv, maxv):
- """
- sample int within range
-
- Parameters
- minv ; int min limit
- maxv : int max limit
- """
- return randint(minv, maxv)
-
-
-def sampleFromBase(value, dev):
- """
- sample int wrt base
-
- Parameters
- value : base value
- dev : deviation
- """
- return randint(value - dev, value + dev)
-
-
-def sampleFloatFromBase(value, dev):
- """
- sample float wrt base
-
- Parameters
- value : base value
- dev : deviation
- """
- return randomFloat(value - dev, value + dev)
-
-
-def distrUniformWithRanndom(total, numItems, noiseLevel):
- """
- uniformly distribute with some randomness and preserves total
-
- Parameters
- total : total count
- numItems : no of bins
- noiseLevel : noise level fraction
- """
- perItem = total / numItems
- var = perItem * noiseLevel
- items = []
- for i in range(numItems):
- item = perItem + randomFloat(-var, var)
- items.append(item)
-
- #adjust last item
- sm = sum(items[:-1])
- items[-1] = total - sm
- return items
-
-
-def isEventSampled(threshold, maxv=100):
- """
- sample event which occurs if sampled below threshold
-
- Parameters
- threshold : threshold for sampling
- maxv : maximum values
- """
- return randint(0, maxv) < threshold
-
-
-def sampleBinaryEvents(events, probPercent):
- """
- sample binary events
-
- Parameters
- events : two events
- probPercent : probability as percentage
- """
- if (randint(0, 100) < probPercent):
- event = events[0]
- else:
- event = events[1]
- return event
-
-
-def addNoiseNum(value, sampler):
- """
- add noise to numeric value
-
- Parameters
- value : base value
- sampler : sampler for noise
- """
- return value * (1 + sampler.sample())
-
-
-def addNoiseCat(value, values, noise):
- """
- add noise to categorical value i.e with some probability change value
-
- Parameters
- value : cat value
- values : cat values
- noise : noise level fraction
- """
- newValue = value
- threshold = int(noise * 100)
- if (isEventSampled(threshold)):
- newValue = selectRandomFromList(values)
- while newValue == value:
- newValue = selectRandomFromList(values)
- return newValue
-
-
-def sampleWithReplace(data, sampSize):
- """
- sample with replacement
-
- Parameters
- data : array
- sampSize : sample size
- """
- sampled = list()
- le = len(data)
- if sampSize is None:
- sampSize = le
- for i in range(sampSize):
- j = random.randint(0, le - 1)
- sampled.append(data[j])
- return sampled
-
-class CumDistr:
- """
- cumulative distr
- """
-
- def __init__(self, data, numBins = None):
- """
- initializer
-
- Parameters
- data : array
- numBins : no of bins
- """
- if not numBins:
- numBins = int(len(data) / 5)
- res = stats.cumfreq(data, numbins=numBins)
- self.cdistr = res.cumcount / len(data)
- self.loLim = res.lowerlimit
- self.upLim = res.lowerlimit + res.binsize * res.cumcount.size
- self.binWidth = res.binsize
-
- def getDistr(self, value):
- """
- get cumulative distribution
-
- Parameters
- value : value
- """
- if value <= self.loLim:
- d = 0.0
- elif value >= self.upLim:
- d = 1.0
- else:
- bin = int((value - self.loLim) / self.binWidth)
- d = self.cdistr[bin]
- return d
-
-class BernoulliTrialSampler:
- """
- bernoulli trial sampler return True or False
- """
-
- def __init__(self, pr, events=None):
- """
- initializer
-
- Parameters
- pr : probability
- events : event values
- """
- self.pr = pr
- self.retEvent = False if events is None else True
- self.events = events
-
-
- def sample(self):
- """
- samples value
- """
- res = random.random() < self.pr
- if self.retEvent:
- res = self.events[0] if res else self.events[1]
- return res
-
-class PoissonSampler:
- """
- poisson sampler returns number of events
- """
- def __init__(self, rateOccur, maxSamp):
- """
- initializer
-
- Parameters
- rateOccur : rate of occurence
- maxSamp : max limit on no of samples
- """
- self.rateOccur = rateOccur
- self.maxSamp = int(maxSamp)
- self.pmax = self.calculatePr(rateOccur)
-
- def calculatePr(self, numOccur):
- """
- calulates probability
-
- Parameters
- numOccur : no of occurence
- """
- p = (self.rateOccur ** numOccur) * math.exp(-self.rateOccur) / math.factorial(numOccur)
- return p
-
- def sample(self):
- """
- samples value
- """
- done = False
- samp = 0
- while not done:
- no = randint(0, self.maxSamp)
- sp = randomFloat(0.0, self.pmax)
- ap = self.calculatePr(no)
- if sp < ap:
- done = True
- samp = no
- return samp
-
-class ExponentialSampler:
- """
- returns interval between events
- """
- def __init__(self, rateOccur, maxSamp = None):
- """
- initializer
-
- Parameters
- rateOccur : rate of occurence
- maxSamp : max limit on interval
- """
- self.interval = 1.0 / rateOccur
- self.maxSamp = int(maxSamp) if maxSamp is not None else None
-
- def sample(self):
- """
- samples value
- """
- sampled = np.random.exponential(scale=self.interval)
- if self.maxSamp is not None:
- while sampled > self.maxSamp:
- sampled = np.random.exponential(scale=self.interval)
- return sampled
-
-class UniformNumericSampler:
- """
- uniform sampler for numerical values
- """
- def __init__(self, minv, maxv):
- """
- initializer
-
- Parameters
- minv : min value
- maxv : max value
- """
- self.minv = minv
- self.maxv = maxv
-
- def isNumeric(self):
- """
- returns true
- """
- return True
-
- def sample(self):
- """
- samples value
- """
- samp = sampleUniform(self.minv, self.maxv) if isinstance(self.minv, int) else randomFloat(self.minv, self.maxv)
- return samp
-
-class UniformCategoricalSampler:
- """
- uniform sampler for categorical values
- """
- def __init__(self, cvalues):
- """
- initializer
-
- Parameters
- cvalues : categorical value list
- """
- self.cvalues = cvalues
-
- def isNumeric(self):
- return False
-
- def sample(self):
- """
- samples value
- """
- return selectRandomFromList(self.cvalues)
-
-class NormalSampler:
- """
- normal sampler
- """
- def __init__(self, mean, stdDev):
- """
- initializer
-
- Parameters
- mean : mean
- stdDev : std deviation
- """
- self.mean = mean
- self.stdDev = stdDev
- self.sampleAsInt = False
-
- def isNumeric(self):
- return True
-
- def sampleAsIntValue(self):
- """
- set True to sample as int
- """
- self.sampleAsInt = True
-
- def sample(self):
- """
- samples value
- """
- samp = np.random.normal(self.mean, self.stdDev)
- if self.sampleAsInt:
- samp = int(samp)
- return samp
-
-class LogNormalSampler:
- """
- log normal sampler
- """
- def __init__(self, mean, stdDev):
- """
- initializer
-
- Parameters
- mean : mean
- stdDev : std deviation
- """
- self.mean = mean
- self.stdDev = stdDev
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- return np.random.lognormal(self.mean, self.stdDev)
-
-class NormalSamplerWithTrendCycle:
- """
- normal sampler with cycle and trend
- """
- def __init__(self, mean, stdDev, dmean, cycle, step=1):
- """
- initializer
-
- Parameters
- mean : mean
- stdDev : std deviation
- dmean : trend delta
- cycle : cycle values wrt base mean
- step : adjustment step for cycle and trend
- """
- self.mean = mean
- self.cmean = mean
- self.stdDev = stdDev
- self.dmean = dmean
- self.cycle = cycle
- self.clen = len(cycle) if cycle is not None else 0
- self.step = step
- self.count = 0
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- s = np.random.normal(self.cmean, self.stdDev)
- self.count += 1
- if self.count % self.step == 0:
- cy = 0
- if self.clen > 1:
- coff = self.count % self.clen
- cy = self.cycle[coff]
- tr = self.count * self.dmean
- self.cmean = self.mean + tr + cy
- return s
-
-
-class ParetoSampler:
- """
- pareto sampler
- """
- def __init__(self, mode, shape):
- """
- initializer
-
- Parameters
- mode : mode
- shape : shape
- """
- self.mode = mode
- self.shape = shape
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- return (np.random.pareto(self.shape) + 1) * self.mode
-
-class GammaSampler:
- """
- pareto sampler
- """
- def __init__(self, shape, scale):
- """
- initializer
-
- Parameters
- shape : shape
- scale : scale
- """
- self.shape = shape
- self.scale = scale
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- return np.random.gamma(self.shape, self.scale)
-
-class GaussianRejectSampler:
- """
- gaussian sampling based on rejection sampling
- """
- def __init__(self, mean, stdDev):
- """
- initializer
-
- Parameters
- mean : mean
- stdDev : std deviation
- """
- self.mean = mean
- self.stdDev = stdDev
- self.xmin = mean - 3 * stdDev
- self.xmax = mean + 3 * stdDev
- self.ymin = 0.0
- self.fmax = 1.0 / (math.sqrt(2.0 * 3.14) * stdDev)
- self.ymax = 1.05 * self.fmax
- self.sampleAsInt = False
-
- def isNumeric(self):
- return True
-
- def sampleAsIntValue(self):
- """
- sample as int value
- """
- self.sampleAsInt = True
-
- def sample(self):
- """
- samples value
- """
- done = False
- samp = 0
- while not done:
- x = randomFloat(self.xmin, self.xmax)
- y = randomFloat(self.ymin, self.ymax)
- f = self.fmax * math.exp(-(x - self.mean) * (x - self.mean) / (2.0 * self.stdDev * self.stdDev))
- if (y < f):
- done = True
- samp = x
- if self.sampleAsInt:
- samp = int(samp)
- return samp
-
-class DiscreteRejectSampler:
- """
- non parametric sampling for discrete values using given distribution based
- on rejection sampling
- """
- def __init__(self, xmin, xmax, step, *values):
- """
- initializer
-
- Parameters
- xmin : min value
- xmax : max value
- step : discrete step
- values : distr values
- """
- self.xmin = xmin
- self.xmax = xmax
- self.step = step
- self.distr = values
- if (len(self.distr) == 1):
- self.distr = self.distr[0]
- numSteps = int((self.xmax - self.xmin) / self.step)
- #print("{:.3f} {:.3f} {:.3f} {}".format(self.xmin, self.xmax, self.step, numSteps))
- assert len(self.distr) == numSteps + 1, "invalid number of distr values expected {}".format(numSteps + 1)
- self.ximin = 0
- self.ximax = numSteps
- self.pmax = float(max(self.distr))
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- done = False
- samp = None
- while not done:
- xi = randint(self.ximin, self.ximax)
- #print(formatAny(xi, "xi"))
- ps = randomFloat(0.0, self.pmax)
- pa = self.distr[xi]
- if ps < pa:
- samp = self.xmin + xi * self.step
- done = True
- return samp
-
-
-class TriangularRejectSampler:
- """
- non parametric sampling using triangular distribution based on rejection sampling
- """
- def __init__(self, xmin, xmax, vertexValue, vertexPos=None):
- """
- initializer
-
- Parameters
- xmin : min value
- xmax : max value
- vertexValue : distr value at vertex
- vertexPos : vertex pposition
- """
- self.xmin = xmin
- self.xmax = xmax
- self.vertexValue = vertexValue
- if vertexPos:
- assert vertexPos > xmin and vertexPos < xmax, "vertex position outside bound"
- self.vertexPos = vertexPos
- else:
- self.vertexPos = 0.5 * (xmin + xmax)
- self.s1 = vertexValue / (self.vertexPos - xmin)
- self.s2 = vertexValue / (xmax - self.vertexPos)
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- done = False
- samp = None
- while not done:
- x = randomFloat(self.xmin, self.xmax)
- y = randomFloat(0.0, self.vertexValue)
- f = (x - self.xmin) * self.s1 if x < self.vertexPos else (self.xmax - x) * self.s2
- if (y < f):
- done = True
- samp = x
-
- return samp;
-
-class NonParamRejectSampler:
- """
- non parametric sampling using given distribution based on rejection sampling
- """
- def __init__(self, xmin, binWidth, *values):
- """
- initializer
-
- Parameters
- xmin : min value
- binWidth : bin width
- values : distr values
- """
- self.values = values
- if (len(self.values) == 1):
- self.values = self.values[0]
- self.xmin = xmin
- self.xmax = xmin + binWidth * (len(self.values) - 1)
- #print(self.xmin, self.xmax, binWidth)
- self.binWidth = binWidth
- self.fmax = 0
- for v in self.values:
- if (v > self.fmax):
- self.fmax = v
- self.ymin = 0
- self.ymax = self.fmax
- self.sampleAsInt = True
-
- def isNumeric(self):
- return True
-
- def sampleAsFloat(self):
- self.sampleAsInt = False
-
- def sample(self):
- """
- samples value
- """
- done = False
- samp = 0
- while not done:
- if self.sampleAsInt:
- x = random.randint(self.xmin, self.xmax)
- y = random.randint(self.ymin, self.ymax)
- else:
- x = randomFloat(self.xmin, self.xmax)
- y = randomFloat(self.ymin, self.ymax)
- bin = int((x - self.xmin) / self.binWidth)
- f = self.values[bin]
- if (y < f):
- done = True
- samp = x
- return samp
-
-class JointNonParamRejectSampler:
- """
- non parametric sampling using given distribution based on rejection sampling
- """
- def __init__(self, xmin, xbinWidth, xnbin, ymin, ybinWidth, ynbin, *values):
- """
- initializer
-
- Parameters
- xmin : min value for x
- xbinWidth : bin width for x
- xnbin : no of bins for x
- ymin : min value for y
- ybinWidth : bin width for y
- ynbin : no of bins for y
- values : distr values
- """
- self.values = values
- if (len(self.values) == 1):
- self.values = self.values[0]
- assert len(self.values) == xnbin * ynbin, "wrong number of values for joint distr"
- self.xmin = xmin
- self.xmax = xmin + xbinWidth * xnbin
- self.xbinWidth = xbinWidth
- self.ymin = ymin
- self.ymax = ymin + ybinWidth * ynbin
- self.ybinWidth = ybinWidth
- self.pmax = max(self.values)
- self.values = np.array(self.values).reshape(xnbin, ynbin)
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- done = False
- samp = 0
- while not done:
- x = randomFloat(self.xmin, self.xmax)
- y = randomFloat(self.ymin, self.ymax)
- xbin = int((x - self.xmin) / self.xbinWidth)
- ybin = int((y - self.ymin) / self.ybinWidth)
- ap = self.values[xbin][ybin]
- sp = randomFloat(0.0, self.pmax)
- if (sp < ap):
- done = True
- samp = [x,y]
- return samp
-
-
-class JointNormalSampler:
- """
- joint normal sampler
- """
- def __init__(self, *values):
- """
- initializer
-
- Parameters
- values : 2 mean values followed by 4 values for covar matrix
- """
- lvalues = list(values)
- assert len(lvalues) == 6, "incorrect number of arguments for joint normal sampler"
- mean = lvalues[:2]
- self.mean = np.array(mean)
- sd = lvalues[2:]
- self.sd = np.array(sd).reshape(2,2)
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- return list(np.random.multivariate_normal(self.mean, self.sd))
-
-
-class MultiVarNormalSampler:
- """
- muti variate normal sampler
- """
- def __init__(self, numVar, *values):
- """
- initializer
-
- Parameters
- numVar : no of variables
- values : numVar mean values followed by numVar x numVar values for covar matrix
- """
- lvalues = list(values)
- assert len(lvalues) == numVar + numVar * numVar, "incorrect number of arguments for multi var normal sampler"
- mean = lvalues[:numVar]
- self.mean = np.array(mean)
- sd = lvalues[numVar:]
- self.sd = np.array(sd).reshape(numVar,numVar)
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- return list(np.random.multivariate_normal(self.mean, self.sd))
-
-class CategoricalRejectSampler:
- """
- non parametric sampling for categorical attributes using given distribution based
- on rejection sampling
- """
- def __init__(self, *values):
- """
- initializer
-
- Parameters
- values : list of tuples which contains a categorical value and the corresponsding distr value
- """
- self.distr = values
- if (len(self.distr) == 1):
- self.distr = self.distr[0]
- maxv = 0
- for t in self.distr:
- if t[1] > maxv:
- maxv = t[1]
- self.maxv = maxv
-
- def sample(self):
- """
- samples value
- """
- done = False
- samp = ""
- while not done:
- t = self.distr[randint(0, len(self.distr)-1)]
- d = randomFloat(0, self.maxv)
- if (d <= t[1]):
- done = True
- samp = t[0]
- return samp
-
-
-class CategoricalSetSampler:
- """
- non parametric sampling for categorical attributes using uniform distribution based for
- sampling a set of values from all values
- """
- def __init__(self, *values):
- """
- initializer
-
- Parameters
- values : list which contains a categorical values
- """
- self.values = values
- if (len(self.values) == 1):
- self.values = self.values[0]
- self.sampled = list()
-
- def sample(self):
- """
- samples value only from previously unsamopled
- """
- samp = selectRandomFromList(self.values)
- while True:
- if samp in self.sampled:
- samp = selectRandomFromList(self.values)
- else:
- self.sampled.append(samp)
- break
- return samp
-
- def setSampled(self, sampled):
- """
- set already sampled
-
- Parameters
- sampled : already sampled list
- """
- self.sampled = sampled
-
- def unsample(self, sample=None):
- """
- rempve from sample history
-
- Parameters
- sample : sample to be removed
- """
- if sample is None:
- self.sampled.clear()
- else:
- self.sampled.remove(sample)
-
-class DistrMixtureSampler:
- """
- distr mixture sampler
- """
- def __init__(self, mixtureWtDistr, *compDistr):
- """
- initializer
-
- Parameters
- mixtureWtDistr : sampler that returns index into sampler list
- compDistr : sampler list
- """
- self.mixtureWtDistr = mixtureWtDistr
- self.compDistr = compDistr
- if (len(self.compDistr) == 1):
- self.compDistr = self.compDistr[0]
-
- def isNumeric(self):
- return True
-
- def sample(self):
- """
- samples value
- """
- comp = self.mixtureWtDistr.sample()
-
- #sample sampled comp distr
- return self.compDistr[comp].sample()
-
-class AncestralSampler:
- """
- ancestral sampler using conditional distribution
- """
- def __init__(self, parentDistr, childDistr, numChildren):
- """
- initializer
-
- Parameters
- parentDistr : parent distr
- childDistr : childdren distribution dictionary
- numChildren : no of children
- """
- self.parentDistr = parentDistr
- self.childDistr = childDistr
- self.numChildren = numChildren
-
- def sample(self):
- """
- samples value
- """
- parent = self.parentDistr.sample()
-
- #sample all children conditioned on parent
- children = []
- for i in range(self.numChildren):
- key = (parent, i)
- child = self.childDistr[key].sample()
- children.append(child)
- return (parent, children)
-
-class ClusterSampler:
- """
- sample cluster and then sample member of sampled cluster
- """
- def __init__(self, clusters, *clustDistr):
- """
- initializer
-
- Parameters
- clusters : dictionary clusters
- clustDistr : distr for clusters
- """
- self.sampler = CategoricalRejectSampler(*clustDistr)
- self.clusters = clusters
-
- def sample(self):
- """
- samples value
- """
- cluster = self.sampler.sample()
- member = random.choice(self.clusters[cluster])
- return (cluster, member)
-
-
-class MetropolitanSampler:
- """
- metropolitan sampler
- """
- def __init__(self, propStdDev, min, binWidth, values):
- """
- initializer
-
- Parameters
- propStdDev : proposal distr std dev
- min : min domain value for target distr
- binWidth : bin width
- values : target distr values
- """
- self.targetDistr = Histogram.createInitialized(min, binWidth, values)
- self.propsalDistr = GaussianRejectSampler(0, propStdDev)
- self.proposalMixture = False
-
- # bootstrap sample
- (minv, maxv) = self.targetDistr.getMinMax()
- self.curSample = random.randint(minv, maxv)
- self.curDistr = self.targetDistr.value(self.curSample)
- self.transCount = 0
-
- def initialize(self):
- """
- initialize
- """
- (minv, maxv) = self.targetDistr.getMinMax()
- self.curSample = random.randint(minv, maxv)
- self.curDistr = self.targetDistr.value(self.curSample)
- self.transCount = 0
-
- def setProposalDistr(self, propsalDistr):
- """
- set custom proposal distribution
-
- Parameters
- propsalDistr : proposal distribution
- """
- self.propsalDistr = propsalDistr
-
-
- def setGlobalProposalDistr(self, globPropStdDev, proposalChoiceThreshold):
- """
- set custom proposal distribution
-
- Parameters
- globPropStdDev : global proposal distr std deviation
- proposalChoiceThreshold : threshold for using global proposal distribution
- """
- self.globalProposalDistr = GaussianRejectSampler(0, globPropStdDev)
- self.proposalChoiceThreshold = proposalChoiceThreshold
- self.proposalMixture = True
-
- def sample(self):
- """
- samples value
- """
- nextSample = self.proposalSample(1)
- self.targetSample(nextSample)
- return self.curSample;
-
- def proposalSample(self, skip):
- """
- sample from proposal distribution
-
- Parameters
- skip : no of samples to skip
- """
- for i in range(skip):
- if not self.proposalMixture:
- #one proposal distr
- nextSample = self.curSample + self.propsalDistr.sample()
- nextSample = self.targetDistr.boundedValue(nextSample)
- else:
- #mixture of proposal distr
- if random.random() < self.proposalChoiceThreshold:
- nextSample = self.curSample + self.propsalDistr.sample()
- else:
- nextSample = self.curSample + self.globalProposalDistr.sample()
- nextSample = self.targetDistr.boundedValue(nextSample)
-
- return nextSample
-
- def targetSample(self, nextSample):
- """
- target sample
-
- Parameters
- nextSample : proposal distr sample
- """
- nextDistr = self.targetDistr.value(nextSample)
-
- transition = False
- if nextDistr > self.curDistr:
- transition = True
- else:
- distrRatio = float(nextDistr) / self.curDistr
- if random.random() < distrRatio:
- transition = True
-
- if transition:
- self.curSample = nextSample
- self.curDistr = nextDistr
- self.transCount += 1
-
-
- def subSample(self, skip):
- """
- sub sample
-
- Parameters
- skip : no of samples to skip
- """
- nextSample = self.proposalSample(skip)
- self.targetSample(nextSample)
- return self.curSample;
-
- def setMixtureProposal(self, globPropStdDev, mixtureThreshold):
- """
- mixture proposal
-
- Parameters
- globPropStdDev : global proposal distr std deviation
- mixtureThreshold : threshold for using global proposal distribution
- """
- self.globalProposalDistr = GaussianRejectSampler(0, globPropStdDev)
- self.mixtureThreshold = mixtureThreshold
-
- def samplePropsal(self):
- """
- sample from proposal distr
-
- """
- if self.globalPropsalDistr is None:
- proposal = self.propsalDistr.sample()
- else:
- if random.random() < self.mixtureThreshold:
- proposal = self.propsalDistr.sample()
- else:
- proposal = self.globalProposalDistr.sample()
-
- return proposal
-
-class PermutationSampler:
- """
- permutation sampler by shuffling a list
- """
- def __init__(self):
- """
- initialize
- """
- self.values = None
- self.numShuffles = None
-
- @staticmethod
- def createSamplerWithValues(values, *numShuffles):
- """
- creator with values
-
- Parameters
- values : list data
- numShuffles : no of shuffles or range of no of shuffles
- """
- sampler = PermutationSampler()
- sampler.values = values
- sampler.numShuffles = numShuffles
- return sampler
-
- @staticmethod
- def createSamplerWithRange(minv, maxv, *numShuffles):
- """
- creator with ramge min and max
-
- Parameters
- minv : min of range
- maxv : max of range
- numShuffles : no of shuffles or range of no of shuffles
- """
- sampler = PermutationSampler()
- sampler.values = list(range(minv, maxv + 1))
- sampler.numShuffles = numShuffles
- return sampler
-
- def sample(self):
- """
- sample new permutation
- """
- cloned = self.values.copy()
- shuffle(cloned, *self.numShuffles)
- return cloned
-
-class SpikeyDataSampler:
- """
- samples spikey data
- """
- def __init__(self, intvMean, intvScale, distr, spikeValueMean, spikeValueStd, spikeMaxDuration, baseValue = 0):
- """
- initializer
-
- Parameters
- intvMean : interval mean
- intvScale : interval std dev
- distr : type of distr for interval
- spikeValueMean : spike value mean
- spikeValueStd : spike value std dev
- spikeMaxDuration : max duration for spike
- baseValue : base or offset value
- """
- if distr == "norm":
- self.intvSampler = NormalSampler(intvMean, intvScale)
- elif distr == "expo":
- rate = 1.0 / intvScale
- self.intvSampler = ExponentialSampler(rate)
- else:
- raise ValueError("invalid distribution")
-
- self.spikeSampler = NormalSampler(spikeValueMean, spikeValueStd)
- self.spikeMaxDuration = spikeMaxDuration
- self.baseValue = baseValue
- self.inSpike = False
- self.spikeCount = 0
- self.baseCount = 0
- self.baseLength = int(self.intvSampler.sample())
- self.spikeValues = list()
- self.spikeLength = None
-
- def sample(self):
- """
- sample new value
- """
- if self.baseCount <= self.baseLength:
- sampled = self.baseValue
- self.baseCount += 1
- else:
- if not self.inSpike:
- #starting spike
- spikeVal = self.spikeSampler.sample()
- self.spikeLength = sampleUniform(1, self.spikeMaxDuration)
- spikeMaxPos = 0 if self.spikeLength == 1 else sampleUniform(0, self.spikeLength-1)
- self.spikeValues.clear()
- for i in range(self.spikeLength):
- if i < spikeMaxPos:
- frac = (i + 1) / (spikeMaxPos + 1)
- frac = sampleFloatFromBase(frac, 0.1 * frac)
- elif i > spikeMaxPos:
- frac = (self.spikeLength - i) / (self.spikeLength - spikeMaxPos)
- frac = sampleFloatFromBase(frac, 0.1 * frac)
- else:
- frac = 1.0
- self.spikeValues.append(frac * spikeVal)
- self.inSpike = True
- self.spikeCount = 0
-
-
- sampled = self.spikeValues[self.spikeCount]
- self.spikeCount += 1
-
- if self.spikeCount == self.spikeLength:
- #ending spike
- self.baseCount = 0
- self.baseLength = int(self.intvSampler.sample())
- self.inSpike = False
-
- return sampled
-
-
-class EventSampler:
- """
- sample event
- """
- def __init__(self, intvSampler, valSampler=None):
- """
- initializer
-
- Parameters
- intvSampler : interval sampler
- valSampler : value sampler
- """
- self.intvSampler = intvSampler
- self.valSampler = valSampler
- self.trigger = int(self.intvSampler.sample())
- self.count = 0
-
- def reset(self):
- """
- reset trigger
- """
- self.trigger = int(self.intvSampler.sample())
- self.count = 0
-
- def sample(self):
- """
- sample event
- """
- if self.count == self.trigger:
- sampled = self.valSampler.sample() if self.valSampler is not None else 1.0
- self.trigger = int(self.intvSampler.sample())
- self.count = 0
- else:
- sample = 0.0
- self.count += 1
- return sampled
-
-
-
-
-def createSampler(data):
- """
- create sampler
-
- Parameters
- data : sampler description
- """
- #print(data)
- items = data.split(":")
- size = len(items)
- dtype = items[-1]
- stype = items[-2]
- #print("sampler data {}".format(data))
- #print("sampler {}".format(stype))
- sampler = None
- if stype == "uniform":
- if dtype == "int":
- min = int(items[0])
- max = int(items[1])
- sampler = UniformNumericSampler(min, max)
- elif dtype == "float":
- min = float(items[0])
- max = float(items[1])
- sampler = UniformNumericSampler(min, max)
- elif dtype == "categorical":
- values = items[:-2]
- sampler = UniformCategoricalSampler(values)
- elif stype == "normal":
- mean = float(items[0])
- sd = float(items[1])
- sampler = NormalSampler(mean, sd)
- if dtype == "int":
- sampler.sampleAsIntValue()
- elif stype == "nonparam":
- if dtype == "int" or dtype == "float":
- min = int(items[0])
- binWidth = int(items[1])
- values = items[2:-2]
- values = list(map(lambda v: int(v), values))
- sampler = NonParamRejectSampler(min, binWidth, values)
- if dtype == "float":
- sampler.sampleAsFloat()
- elif dtype == "categorical":
- values = list()
- for i in range(0, size-2, 2):
- cval = items[i]
- dist = int(items[i+1])
- pair = (cval, dist)
- values.append(pair)
- sampler = CategoricalRejectSampler(values)
- elif dtype == "scategorical":
- vfpath = items[0]
- values = getFileLines(vfpath, None)
- sampler = CategoricalSetSampler(values)
- elif stype == "discrete":
- vmin = int(items[0])
- vmax = int(items[1])
- step = int(items[2])
- values = list(map(lambda i : int(items[i]), range(3, len(items)-2)))
- sampler = DiscreteRejectSampler(vmin, vmax, step, values)
- elif stype == "bernauli":
- pr = float(items[0])
- events = None
- if len(items) == 5:
- events = list()
- if dtype == "int":
- events.append(int(items[1]))
- events.append(int(items[2]))
- elif dtype == "categorical":
- events.append(items[1])
- events.append(items[2])
- sampler = BernoulliTrialSampler(pr, events)
- else:
- raise ValueError("invalid sampler type " + stype)
- return sampler
-
-
-
-
-
diff --git a/spaces/ThirdEyeData/TagDiciphering/app.py b/spaces/ThirdEyeData/TagDiciphering/app.py
deleted file mode 100644
index 9da21519b22de4a2efbdc70f8e5c080b32c95698..0000000000000000000000000000000000000000
--- a/spaces/ThirdEyeData/TagDiciphering/app.py
+++ /dev/null
@@ -1,155 +0,0 @@
-import simplejson
-import tensorflow
-import visualization_utils as vis_util
-from PIL import Image
-import numpy as np
-from PIL import Image
-import numpy as np
-import label_map_util
-import tensorflow as tf
-from matplotlib import pyplot as plt
-import time
-import cv2
-from numpy import asarray
-#import streamlit as st
-import gradio as gr
-#st.title("Tag_Diciphering")
-def prediction(image_path):
- total_time_start = time.time()
- #image_path = path_image
-
-
- def loadImageIntoNumpyArray(image):
- (im_width, im_height) = image.size
- if image.getdata().mode == "RGBA":
- image = image.convert('RGB')
-
- return asarray(image).reshape((im_height, im_width, 3)).astype(np.uint8)
-
-
- def main(image_path,model_path,model_PATH_TO_CKPT,path_to_labels):
- image = Image.open(image_path)
- image_np = loadImageIntoNumpyArray(image)
- image_np_expanded = np.expand_dims(image_np, axis=0)
- label_map = label_map_util.load_labelmap(path_to_labels)
- # print("label_map------->",type(label_map))
- categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=100, use_display_name=True)
- category_index = label_map_util.create_category_index(categories)
- # print("category index-->",category_index)
-
- detection_graph = tf.Graph()
- with detection_graph.as_default():
- od_graph_def = tf.compat.v1.GraphDef()
- with tf.compat.v2.io.gfile.GFile(model_PATH_TO_CKPT, 'rb') as fid:
- serialized_graph = fid.read()
- od_graph_def.ParseFromString(serialized_graph)
- tf.import_graph_def(od_graph_def, name='')
- sess = tf.compat.v1.Session(graph=detection_graph)
- # Input tensor is the image
- image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
- # Output tensors are the detection boxes, scores, and classes
- # Each box represents a part of the image where a particular object was detected
- detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
- # Each score represents level of confidence for each of the objects.
- # The score is shown on the result image, together with the class label.
- detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
- detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
- # Number of objects detected
- num_detections = detection_graph.get_tensor_by_name('num_detections:0')
- (boxes, scores, classes, num) = sess.run(
- [detection_boxes, detection_scores, detection_classes, num_detections],
- feed_dict={image_tensor: image_np_expanded})
- vis_util.visualize_boxes_and_labels_on_image_array(
- image_np,
- np.squeeze(boxes),
- np.squeeze(classes).astype(np.int32),
- np.squeeze(scores),
- category_index,
- use_normalized_coordinates=True,
- line_thickness=8,
- min_score_thresh=0.1)
- #%matplotlib inline
- from matplotlib import pyplot as plt
- # print("boxes:",boxes)
- # print("class:",classes)
- objects = []
- threshold = 0.5
- # print("category:",category_index)
- boxes = boxes[0]
- for index, value in enumerate(classes[0]):
- object_dict = {}
- if scores[0, index] > threshold:
- object_dict["class"] = (category_index.get(value)).get('name')
- object_dict["score"] = round(scores[0, index] * 100,2)
- box = tuple(boxes[index].tolist())
- ymin, xmin, ymax, xmax= box
- im_width,im_height = 360,360
- left, right, top, bottom = (xmin * im_width, xmax * im_width,
- ymin * im_height, ymax * im_height)
- object_dict["box"] = (int(left), int(right), int(top), int(bottom))
- objects.append(object_dict)
-
- image_orignal = Image.open(image_path)
- image_np_orignal = loadImageIntoNumpyArray(image_orignal)
-
-
- fig, ax = plt.subplots(1,2)
-
- fig.suptitle('Tag Deciphering')
-
- ax[0].imshow(image_np_orignal,aspect='auto');
- ax[1].imshow(image_np,aspect='auto');
-
-
- return objects,image_np
-
-
-
- image_path = image_path
- model_path = "//inference"
- model_PATH_TO_CKPT = "frozen_inference_graph.pb"
- path_to_labels = "tf_label_map.pbtxt"
-
- result,fig = main(image_path,model_path,model_PATH_TO_CKPT,path_to_labels)
-
- # print("result-",result)
- # list_to_be_sorted= [{'class': 'Y', 'score': 99.97, 'box': (157, 191, 269, 288)}, {'class': '6', 'score': 99.93, 'box': (158, 191, 247, 267)}, {'class': '9', 'score': 99.88, 'box': (156, 190, 179, 196)}, {'class': '4', 'score': 99.8, 'box': (156, 189, 198, 219)}, {'class': '1', 'score': 99.65, 'box': (157, 189, 222, 244)}, {'class': 'F', 'score': 63.4, 'box': (155, 185, 157, 175)}]
- newlist = sorted(result, key=lambda k: k['box'][3],reverse=False)
-
- text =''
- for each in newlist:
- if(each['score']>65):
- text += each['class']
- # print("text:",text)
- if(text!=""):
- text = text.replace("yellowTag", "")
- result = text
- else:
- result = "No Vertical Tag Detected"
- response = {"predictions": [result]}
- total_time_end = time.time()
- print("total time : ",round((total_time_end-total_time_start),2))
- return simplejson.dumps(response),fig
-
-inputs = gr.inputs.Image(type = 'filepath')
-EXAMPLES = ["img1.jpg","img2.jpg","img6.jpg","img7.jpg","img8.jpg","img4.jpg","img10.jpg"]
-DESCRIPTION = """Tag Dicipher is to convert into understandable form. especially to decode the tags to make out
-the meaning of despite lack of clearness."""
-outputs = [gr.outputs.Textbox(label = "Prediction"),
- gr.outputs.Image(type = 'numpy',label = 'Tag Diciphering')]
-
-article = "
"
-demo_app = gr.Interface(
- fn= prediction,
- inputs=inputs,
- outputs= outputs,
- title = "Tag Diciphering",
- description = DESCRIPTION,
- examples = EXAMPLES,
- article = article,
- #cache_example = True,
- #live = True,
- theme = 'huggingface'
-)
-demo_app.launch()
-
diff --git a/spaces/Um124/Global_Warming_Analysis/pages/Coal Consumption data Analysis.py b/spaces/Um124/Global_Warming_Analysis/pages/Coal Consumption data Analysis.py
deleted file mode 100644
index b9bb82d772d534747c3a47af5806e9d00c84ff9e..0000000000000000000000000000000000000000
--- a/spaces/Um124/Global_Warming_Analysis/pages/Coal Consumption data Analysis.py
+++ /dev/null
@@ -1,87 +0,0 @@
-import pandas as pd
-import numpy as np
-import plotly.express as px
-import streamlit as st
-
-
-st.set_page_config(
- page_title='Coal Consumption data Analysis',
- page_icon='📈',
- layout='wide'
-)
-
-Years=['1965','1966','1967','1968','1969','1970','1971','1972','1973','1974','1975','1976','1977','1978','1979',
-'1980','1981','1982','1983','1984','1985','1986','1987','1988','1989','1990','1991','1992','1993','1994','1995',
-'1996','1997','1998','1999','2000','2001','2002','2003','2004','2005','2006','2007','2008','2009','2010','2011',
-'2012','2013','2014','2015','2016']
-
-@st.cache_data
-def load_data():
- df=pd.read_csv('data/coal_consumption_per_cap.csv')
- df.rename({'geo':'Country'},axis=1,inplace=True)
- df.set_index('Country',inplace=True)
- df.sort_values('Country',inplace=True)
- df['Total']=df[Years].sum(axis=1)
- df['Average']=df.mean(axis=1)
- df['Minimum']=df.min(axis=1)
- df['Maximum']=df.max(axis=1)
- return df
-
-st.title('Coal Consumption Per Capital')
-df=load_data()
-st.dataframe(df,use_container_width=True)
-
-countries=df.index.unique().tolist()
-Graphs = ['bar','pie','line','area','funnel']
-c1,c2=st.columns(2)
-country = c1.selectbox("Select a Country",countries)
-Graph = c2.selectbox("Select a Graph type",Graphs)
-
-
-st.header("Country wise visualization")
-cdf = df.loc[country,Years].reset_index()
-cdf.rename({'index':'Years'},axis=1, inplace=True)
-if Graph == Graphs[0]:
- fig = px.bar(cdf, 'Years',country, title=f'{country} coal consumption per cap')
-if Graph == Graphs[1]:
- fig = px.pie(cdf, 'Years',country, title=f'{country} coal consumption per cap')
-if Graph == Graphs[2]:
- fig = px.line(cdf, 'Years',country, title=f'{country} coal consumption per cap')
-if Graph == Graphs[3]:
- fig = px.area(cdf, 'Years',country, title=f'{country} coal consumption per cap')
-if Graph == Graphs[4]:
- fig = px.funnel(cdf, 'Years',country, title=f'{country} co2 emissions tonnes by per person')
-
-st.plotly_chart(fig, use_container_width=True)
-
-
-st.header("Comparison of Countries")
-clist = st.multiselect("Select countries to compare", countries, default='India')
-cdf = df.loc[clist, Years].T # T to rotate the data in 90deg
-st.write(cdf)
-figc = px.line(cdf,cdf.index, clist, title=f'Comparing {", ".join(clist)}')
-st.plotly_chart(figc, use_container_width=True)
-
-df.sort_values(by='Total', ascending=False, inplace=True)
-fig1=px.bar(df, x=df.index, y='Total',title='Total coal consumption per cap by Country')
-st.plotly_chart(fig1, use_container_width=True)
-
-dfavg = df.sort_values(by='Average').reset_index()
-dfavg.rename({'index':'Country'},axis=1,inplace=True)
-fig2=px.bar(dfavg, 'Country', 'Average', title="Average coal consumption per cap by Country")
-st.plotly_chart(fig2, use_container_width=True)
-
-dfmin=df.sort_values(by='Minimum').reset_index()
-dfmin.rename({'index':'Country'},axis=1,inplace=True)
-fig3=px.bar(dfmin,'Country','Minimum',title='Minimum coal consumption by Country' )
-st.plotly_chart(fig3, use_container_width=True)
-
-dfmax=df.sort_values(by='Maximum').reset_index()
-dfmax.rename({'index':'Country'},axis=1,inplace=True)
-fig4=px.bar(dfmax,'Country','Maximum',title='Maximum coal consumption by Country' )
-st.plotly_chart(fig4, use_container_width=True)
-
-dfcomp=df.sort_values(by='Country',ascending=False,inplace=True)
-fig5 = px.line(df, x=df.index, y='Maximum',title='Maximum and Minimum coal consumption comparisons')
-fig5.add_scatter(x=df.index, y=df['Minimum'], mode='lines',)
-st.plotly_chart(fig5, use_container_width=True)
\ No newline at end of file
diff --git a/spaces/Usaki108/VoiceChange/infer_pack/modules/F0Predictor/HarvestF0Predictor.py b/spaces/Usaki108/VoiceChange/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
deleted file mode 100644
index 98d4e98b353008f81bde2c37e7da818763a992c9..0000000000000000000000000000000000000000
--- a/spaces/Usaki108/VoiceChange/infer_pack/modules/F0Predictor/HarvestF0Predictor.py
+++ /dev/null
@@ -1,86 +0,0 @@
-from infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
-import pyworld
-import numpy as np
-
-
-class HarvestF0Predictor(F0Predictor):
- def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
- self.hop_length = hop_length
- self.f0_min = f0_min
- self.f0_max = f0_max
- self.sampling_rate = sampling_rate
-
- def interpolate_f0(self, f0):
- """
- 对F0进行插值处理
- """
-
- data = np.reshape(f0, (f0.size, 1))
-
- vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
- vuv_vector[data > 0.0] = 1.0
- vuv_vector[data <= 0.0] = 0.0
-
- ip_data = data
-
- frame_number = data.size
- last_value = 0.0
- for i in range(frame_number):
- if data[i] <= 0.0:
- j = i + 1
- for j in range(i + 1, frame_number):
- if data[j] > 0.0:
- break
- if j < frame_number - 1:
- if last_value > 0.0:
- step = (data[j] - data[i - 1]) / float(j - i)
- for k in range(i, j):
- ip_data[k] = data[i - 1] + step * (k - i + 1)
- else:
- for k in range(i, j):
- ip_data[k] = data[j]
- else:
- for k in range(i, frame_number):
- ip_data[k] = last_value
- else:
- ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
- last_value = data[i]
-
- return ip_data[:, 0], vuv_vector[:, 0]
-
- def resize_f0(self, x, target_len):
- source = np.array(x)
- source[source < 0.001] = np.nan
- target = np.interp(
- np.arange(0, len(source) * target_len, len(source)) / target_len,
- np.arange(0, len(source)),
- source,
- )
- res = np.nan_to_num(target)
- return res
-
- def compute_f0(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.harvest(
- wav.astype(np.double),
- fs=self.hop_length,
- f0_ceil=self.f0_max,
- f0_floor=self.f0_min,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.fs)
- return self.interpolate_f0(self.resize_f0(f0, p_len))[0]
-
- def compute_f0_uv(self, wav, p_len=None):
- if p_len is None:
- p_len = wav.shape[0] // self.hop_length
- f0, t = pyworld.harvest(
- wav.astype(np.double),
- fs=self.sampling_rate,
- f0_floor=self.f0_min,
- f0_ceil=self.f0_max,
- frame_period=1000 * self.hop_length / self.sampling_rate,
- )
- f0 = pyworld.stonemask(wav.astype(np.double), f0, t, self.sampling_rate)
- return self.interpolate_f0(self.resize_f0(f0, p_len))
diff --git a/spaces/Vegecken/sovits4dzl/vdecoder/__init__.py b/spaces/Vegecken/sovits4dzl/vdecoder/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/datasets/datasets/dataloader_utils.py b/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/datasets/datasets/dataloader_utils.py
deleted file mode 100644
index 8eaa3a58b0ad42ca7937fb51b46e53511cc3cd0c..0000000000000000000000000000000000000000
--- a/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/datasets/datasets/dataloader_utils.py
+++ /dev/null
@@ -1,162 +0,0 @@
-"""
- Copyright (c) 2022, salesforce.com, inc.
- All rights reserved.
- SPDX-License-Identifier: BSD-3-Clause
- For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
-"""
-
-import time
-import random
-import torch
-from minigpt4.datasets.data_utils import move_to_cuda
-from torch.utils.data import DataLoader
-
-
-class MultiIterLoader:
- """
- A simple wrapper for iterating over multiple iterators.
-
- Args:
- loaders (List[Loader]): List of Iterator loaders.
- ratios (List[float]): List of ratios to sample from each loader. If None, all loaders are sampled uniformly.
- """
-
- def __init__(self, loaders, ratios=None):
- # assert all loaders has __next__ method
- for loader in loaders:
- assert hasattr(
- loader, "__next__"
- ), "Loader {} has no __next__ method.".format(loader)
-
- if ratios is None:
- ratios = [1.0] * len(loaders)
- else:
- assert len(ratios) == len(loaders)
- ratios = [float(ratio) / sum(ratios) for ratio in ratios]
-
- self.loaders = loaders
- self.ratios = ratios
-
- def __next__(self):
- # random sample from each loader by ratio
- loader_idx = random.choices(range(len(self.loaders)), self.ratios, k=1)[0]
- return next(self.loaders[loader_idx])
-
-
-class PrefetchLoader(object):
- """
- Modified from https://github.com/ChenRocks/UNITER.
-
- overlap compute and cuda data transfer
- (copied and then modified from nvidia apex)
- """
-
- def __init__(self, loader):
- self.loader = loader
- self.stream = torch.cuda.Stream()
-
- def __iter__(self):
- loader_it = iter(self.loader)
- self.preload(loader_it)
- batch = self.next(loader_it)
- while batch is not None:
- is_tuple = isinstance(batch, tuple)
- if is_tuple:
- task, batch = batch
-
- if is_tuple:
- yield task, batch
- else:
- yield batch
- batch = self.next(loader_it)
-
- def __len__(self):
- return len(self.loader)
-
- def preload(self, it):
- try:
- self.batch = next(it)
- except StopIteration:
- self.batch = None
- return
- # if record_stream() doesn't work, another option is to make sure
- # device inputs are created on the main stream.
- # self.next_input_gpu = torch.empty_like(self.next_input,
- # device='cuda')
- # self.next_target_gpu = torch.empty_like(self.next_target,
- # device='cuda')
- # Need to make sure the memory allocated for next_* is not still in use
- # by the main stream at the time we start copying to next_*:
- # self.stream.wait_stream(torch.cuda.current_stream())
- with torch.cuda.stream(self.stream):
- self.batch = move_to_cuda(self.batch)
- # more code for the alternative if record_stream() doesn't work:
- # copy_ will record the use of the pinned source tensor in this
- # side stream.
- # self.next_input_gpu.copy_(self.next_input, non_blocking=True)
- # self.next_target_gpu.copy_(self.next_target, non_blocking=True)
- # self.next_input = self.next_input_gpu
- # self.next_target = self.next_target_gpu
-
- def next(self, it):
- torch.cuda.current_stream().wait_stream(self.stream)
- batch = self.batch
- if batch is not None:
- record_cuda_stream(batch)
- self.preload(it)
- return batch
-
- def __getattr__(self, name):
- method = self.loader.__getattribute__(name)
- return method
-
-
-def record_cuda_stream(batch):
- if isinstance(batch, torch.Tensor):
- batch.record_stream(torch.cuda.current_stream())
- elif isinstance(batch, list) or isinstance(batch, tuple):
- for t in batch:
- record_cuda_stream(t)
- elif isinstance(batch, dict):
- for t in batch.values():
- record_cuda_stream(t)
- else:
- pass
-
-
-class IterLoader:
- """
- A wrapper to convert DataLoader as an infinite iterator.
-
- Modified from:
- https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/iter_based_runner.py
- """
-
- def __init__(self, dataloader: DataLoader, use_distributed: bool = False):
- self._dataloader = dataloader
- self.iter_loader = iter(self._dataloader)
- self._use_distributed = use_distributed
- self._epoch = 0
-
- @property
- def epoch(self) -> int:
- return self._epoch
-
- def __next__(self):
- try:
- data = next(self.iter_loader)
- except StopIteration:
- self._epoch += 1
- if hasattr(self._dataloader.sampler, "set_epoch") and self._use_distributed:
- self._dataloader.sampler.set_epoch(self._epoch)
- time.sleep(2) # Prevent possible deadlock during epoch transition
- self.iter_loader = iter(self._dataloader)
- data = next(self.iter_loader)
-
- return data
-
- def __iter__(self):
- return self
-
- def __len__(self):
- return len(self._dataloader)
diff --git a/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/models/base_model.py b/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/models/base_model.py
deleted file mode 100644
index 95902848162c28992fa36b2648b4c280e3a98d39..0000000000000000000000000000000000000000
--- a/spaces/Vision-CAIR/MiniGPT-v2/minigpt4/models/base_model.py
+++ /dev/null
@@ -1,250 +0,0 @@
-"""
- Copyright (c) 2022, salesforce.com, inc.
- All rights reserved.
- SPDX-License-Identifier: BSD-3-Clause
- For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
-"""
-
-import os
-import logging
-import contextlib
-
-from omegaconf import OmegaConf
-import numpy as np
-import torch
-import torch.nn as nn
-from transformers import BertTokenizer, LlamaTokenizer
-from transformers.models.llama.modeling_llama import LlamaForCausalLM
-from peft import (
- LoraConfig,
- get_peft_model,
- prepare_model_for_int8_training,
-)
-
-from minigpt4.common.dist_utils import download_cached_file, is_dist_avail_and_initialized
-from minigpt4.common.utils import get_abs_path, is_url
-from minigpt4.models.eva_vit import create_eva_vit_g
-
-
-
-class BaseModel(nn.Module):
- """Base class for models."""
-
- def __init__(self):
- super().__init__()
-
- @property
- def device(self):
- return list(self.parameters())[-1].device
-
- def load_checkpoint(self, url_or_filename):
- """
- Load from a finetuned checkpoint.
-
- This should expect no mismatch in the model keys and the checkpoint keys.
- """
-
- if is_url(url_or_filename):
- cached_file = download_cached_file(
- url_or_filename, check_hash=False, progress=True
- )
- checkpoint = torch.load(cached_file, map_location="cpu")
- elif os.path.isfile(url_or_filename):
- checkpoint = torch.load(url_or_filename, map_location="cpu")
- else:
- raise RuntimeError("checkpoint url or path is invalid")
-
- if "model" in checkpoint.keys():
- state_dict = checkpoint["model"]
- else:
- state_dict = checkpoint
-
- msg = self.load_state_dict(state_dict, strict=False)
-
- logging.info("Missing keys {}".format(msg.missing_keys))
- logging.info("load checkpoint from %s" % url_or_filename)
-
- return msg
-
- @classmethod
- def from_pretrained(cls, model_type):
- """
- Build a pretrained model from default configuration file, specified by model_type.
-
- Args:
- - model_type (str): model type, specifying architecture and checkpoints.
-
- Returns:
- - model (nn.Module): pretrained or finetuned model, depending on the configuration.
- """
- model_cfg = OmegaConf.load(cls.default_config_path(model_type)).model
- model = cls.from_config(model_cfg)
-
- return model
-
- @classmethod
- def default_config_path(cls, model_type):
- assert (
- model_type in cls.PRETRAINED_MODEL_CONFIG_DICT
- ), "Unknown model type {}".format(model_type)
- return get_abs_path(cls.PRETRAINED_MODEL_CONFIG_DICT[model_type])
-
- def load_checkpoint_from_config(self, cfg, **kwargs):
- """
- Load checkpoint as specified in the config file.
-
- If load_finetuned is True, load the finetuned model; otherwise, load the pretrained model.
- When loading the pretrained model, each task-specific architecture may define their
- own load_from_pretrained() method.
- """
- load_finetuned = cfg.get("load_finetuned", True)
- if load_finetuned:
- finetune_path = cfg.get("finetuned", None)
- assert (
- finetune_path is not None
- ), "Found load_finetuned is True, but finetune_path is None."
- self.load_checkpoint(url_or_filename=finetune_path)
- else:
- # load pre-trained weights
- pretrain_path = cfg.get("pretrained", None)
- assert "Found load_finetuned is False, but pretrain_path is None."
- self.load_from_pretrained(url_or_filename=pretrain_path, **kwargs)
-
- def before_evaluation(self, **kwargs):
- pass
-
- def show_n_params(self, return_str=True):
- tot = 0
- for p in self.parameters():
- w = 1
- for x in p.shape:
- w *= x
- tot += w
- if return_str:
- if tot >= 1e6:
- return "{:.1f}M".format(tot / 1e6)
- else:
- return "{:.1f}K".format(tot / 1e3)
- else:
- return tot
-
- def maybe_autocast(self, dtype=torch.float16):
- # if on cpu, don't use autocast
- # if on gpu, use autocast with dtype if provided, otherwise use torch.float16
- enable_autocast = self.device != torch.device("cpu")
-
- if enable_autocast:
- return torch.cuda.amp.autocast(dtype=dtype)
- else:
- return contextlib.nullcontext()
-
- @classmethod
- def init_vision_encoder(
- cls, model_name, img_size, drop_path_rate, use_grad_checkpoint, precision, freeze
- ):
- logging.info('Loading VIT')
-
- assert model_name == "eva_clip_g", "vit model must be eva_clip_g for current version of MiniGPT-4"
- if not freeze:
- precision = "fp32" # fp16 is not for training
-
- visual_encoder = create_eva_vit_g(
- img_size, drop_path_rate, use_grad_checkpoint, precision
- )
-
- ln_vision = LayerNorm(visual_encoder.num_features)
-
- if freeze:
- for name, param in visual_encoder.named_parameters():
- param.requires_grad = False
- visual_encoder = visual_encoder.eval()
- visual_encoder.train = disabled_train
- for name, param in ln_vision.named_parameters():
- param.requires_grad = False
- ln_vision = ln_vision.eval()
- ln_vision.train = disabled_train
- logging.info("freeze vision encoder")
-
- logging.info('Loading VIT Done')
- return visual_encoder, ln_vision
-
- def init_llm(cls, llama_model_path, low_resource=False, low_res_device=0, lora_r=0,
- lora_target_modules=["q_proj","v_proj"], **lora_kargs):
- logging.info('Loading LLAMA')
- llama_tokenizer = LlamaTokenizer.from_pretrained("Vision-CAIR/llama-2-7b-chat-pytorch", use_fast=False, use_auth_token=True)
- llama_tokenizer.pad_token = "$$"
-
- if low_resource:
- llama_model = LlamaForCausalLM.from_pretrained(
- "Vision-CAIR/llama-2-7b-chat-pytorch",
- torch_dtype=torch.float16,
- load_in_8bit=True,
- device_map={'': low_res_device},
- use_auth_token=True
- )
- else:
- llama_model = LlamaForCausalLM.from_pretrained(
- "Vision-CAIR/llama-2-7b-chat-pytorch",
- torch_dtype=torch.float16,
- use_auth_token=True
- )
-
- if lora_r > 0:
- llama_model = prepare_model_for_int8_training(llama_model)
- loraconfig = LoraConfig(
- r=lora_r,
- bias="none",
- task_type="CAUSAL_LM",
- target_modules=lora_target_modules,
- **lora_kargs
- )
- llama_model = get_peft_model(llama_model, loraconfig)
-
- llama_model.print_trainable_parameters()
-
- else:
- for name, param in llama_model.named_parameters():
- param.requires_grad = False
- logging.info('Loading LLAMA Done')
- return llama_model, llama_tokenizer
-
-
- def load_from_pretrained(self, url_or_filename):
- if is_url(url_or_filename):
- cached_file = download_cached_file(
- url_or_filename, check_hash=False, progress=True
- )
- checkpoint = torch.load(cached_file, map_location="cpu")
- elif os.path.isfile(url_or_filename):
- checkpoint = torch.load(url_or_filename, map_location="cpu")
- else:
- raise RuntimeError("checkpoint url or path is invalid")
-
- state_dict = checkpoint["model"]
-
- msg = self.load_state_dict(state_dict, strict=False)
-
- # logging.info("Missing keys {}".format(msg.missing_keys))
- logging.info("load checkpoint from %s" % url_or_filename)
-
- return msg
-
-
-def disabled_train(self, mode=True):
- """Overwrite model.train with this function to make sure train/eval mode
- does not change anymore."""
- return self
-
-
-class LayerNorm(nn.LayerNorm):
- """Subclass torch's LayerNorm to handle fp16."""
-
- def forward(self, x: torch.Tensor):
- orig_type = x.dtype
- ret = super().forward(x.type(torch.float32))
- return ret.type(orig_type)
-
-
-
-
-
diff --git a/spaces/Xinyoumeng233hu/SteganographywithGPT-2/huffman_baseline.py b/spaces/Xinyoumeng233hu/SteganographywithGPT-2/huffman_baseline.py
deleted file mode 100644
index 443bbce661fc66ed615c9e840c692d4677238539..0000000000000000000000000000000000000000
--- a/spaces/Xinyoumeng233hu/SteganographywithGPT-2/huffman_baseline.py
+++ /dev/null
@@ -1,166 +0,0 @@
-import torch
-import torch.nn.functional as F
-
-from huffman import HuffmanCoding
-from utils import kl, entropy, is_sent_finish, limit_past
-
-def encode_huffman(model, enc, message, context, bits_per_word, finish_sent=False, device='cpu'):
- length = len(message)
-
- context = torch.tensor(context[-1022:], device=device, dtype=torch.long)
-
- prev = context
- output = context
- past = None
-
- total_num = 0
- total_num_for_stats = 0
- total_log_probs = 0
- total_kl = 0 # in bits
- total_num_sents = 0
-
- with torch.no_grad():
- i = 0
- sent_finish = False
- while i < length or (finish_sent and not sent_finish):
- logits, past = model(prev.unsqueeze(0), past=past)
- past = limit_past(past)
- logits[0, -1, -1] = -1e10 # endoftext can't happen
- logits[0, -1, 628] = -1e10 # 2 newlines can't happen
- logits, indices = logits[0, -1, :].sort(descending=True)
-
- # Get the top 2**bits options
- indices = indices[:2**bits_per_word]
- log_probs = F.log_softmax(logits, dim=-1)[:2**bits_per_word]
- probs = torch.exp(log_probs)
-
- if i >= length:
- selection = 0
- sent_finish = is_sent_finish(indices[0].item(), enc)
- else:
- probs_array = probs.cpu().numpy()
- coding = HuffmanCoding()
- coding.make_heap_from_array(probs_array)
- coding.merge_nodes()
- root = coding.make_codes()
-
- #print(message[i:i+10])
- while root.token is None:
- if i >= length or message[i] == 0:
- root = root.left
- else:
- root = root.right
- i += 1
- selection = root.token
-
- logq = torch.tensor([-len(coding.codes[idx]) for idx in range(len(probs_array))], dtype=torch.float, device=device) # in bits
- logq = logq*0.69315 # in nats
- q = torch.exp(logq)
- total_kl += kl(q, logq, log_probs)
- total_log_probs += log_probs[selection].item()
- total_num_for_stats += 1
-
- total_num += 1
-
- prev = indices[selection].view(1)
- output = torch.cat((output, prev))
-
- avg_NLL = -total_log_probs/total_num_for_stats
- avg_KL = total_kl/total_num_for_stats
- words_per_bit = total_num_for_stats/i
-
- return output[len(context):].tolist(), avg_NLL, avg_KL, words_per_bit
-
-def decode_huffman(model, enc, text, context, bits_per_word, device='cpu'):
- # inp is a list of token indices
- # context is a list of token indices
- inp = enc.encode(text)
- i = 0
- while i < len(inp):
- if inp[i] == 628:
- inp[i] = 198
- inp[i+1:i+1] = [198]
- i += 2
- else:
- i += 1
-
- context = torch.tensor(context[-1022:], device=device, dtype=torch.long)
- prev = context
- past = None
-
- message = []
- with torch.no_grad():
- i = 0
- while i < len(inp):
- if past and past[0].shape[3] >= 1023:
- raise RuntimeError
-
- logits, past = model(prev.unsqueeze(0), past=past)
- past = limit_past(past)
- logits[0, -1, -1] = -1e10 # endoftext can't happen
- logits[0, -1, 628] = -1e10 # 2 newlines can't happen
- logits, indices = logits[0, -1, :].sort(descending=True)
-
- # Get the top 2**bits options
- indices = indices[:2**bits_per_word]
- log_probs = F.log_softmax(logits, dim=-1)[:2**bits_per_word]
- probs = torch.exp(log_probs)
-
- if inp[i] not in indices:
- true_token_text = enc.decoder[inp[i]]
- for rank_idx in range(2**bits_per_word):
- prop_token_text = enc.decoder[indices[rank_idx].item()]
- # common case that is not caught
- if inp[i] == 128 and indices[rank_idx] == 198:
- rank = rank_idx
- inp[i] = indices[rank_idx].item()
- break
-
- # Is there a more likely prefix token that could be the actual token generated?
- if len(prop_token_text) <= len(true_token_text) and \
- prop_token_text == true_token_text[:len(prop_token_text)]:
- rank = rank_idx
- suffix = true_token_text[len(prop_token_text):]
- suffix_tokens = enc.encode(suffix) # a list
- inp[i] = indices[rank_idx].item()
- inp[i+1:i+1] = suffix_tokens # insert suffix tokens into list
- break
-
- # Is there a more likely longer token that could be the actual token generated?
- elif len(prop_token_text) > len(true_token_text) and \
- true_token_text == prop_token_text[:len(true_token_text)]:
- whole_text = true_token_text
- num_extra = 1
- while len(whole_text) < len(prop_token_text):
- whole_text += enc.decoder[inp[i+num_extra]]
- num_extra += 1
- if prop_token_text == whole_text[:len(prop_token_text)]:
- rank = rank_idx
- inp[i] = indices[rank_idx].item()
- for j in range(1, num_extra):
- del inp[i+j]
-
- if len(whole_text) > len(prop_token_text):
- suffix = whole_text[len(prop_token_text):]
- suffix_tokens = enc.encode(suffix) # a list
- inp[i+1:i+1] = suffix_tokens # insert suffix tokens into list
- break
- else:
- print('Unable to fix BPE error: token received: %s=%d, text: %s' % (true_token_text, inp[i], text))
- rank = 0
- else:
- rank = (indices == inp[i]).nonzero().item()
-
- probs_array = probs.cpu().numpy()
- coding = HuffmanCoding()
- coding.make_heap_from_array(probs_array)
- coding.merge_nodes()
- coding.make_codes()
-
- tokens_t = map(int, coding.codes[rank])
-
- message.extend(tokens_t)
- prev = torch.tensor([inp[i]], device=device, dtype=torch.long)
- i += 1
-
- return message
diff --git a/spaces/XlalalaX/VITS-Umamusume-voice-synthesizer/text/sanskrit.py b/spaces/XlalalaX/VITS-Umamusume-voice-synthesizer/text/sanskrit.py
deleted file mode 100644
index 0223aaac384a2f850f5bc20651fc18eb964607d0..0000000000000000000000000000000000000000
--- a/spaces/XlalalaX/VITS-Umamusume-voice-synthesizer/text/sanskrit.py
+++ /dev/null
@@ -1,62 +0,0 @@
-import re
-from indic_transliteration import sanscript
-
-
-# List of (iast, ipa) pairs:
-_iast_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('a', 'ə'),
- ('ā', 'aː'),
- ('ī', 'iː'),
- ('ū', 'uː'),
- ('ṛ', 'ɹ`'),
- ('ṝ', 'ɹ`ː'),
- ('ḷ', 'l`'),
- ('ḹ', 'l`ː'),
- ('e', 'eː'),
- ('o', 'oː'),
- ('k', 'k⁼'),
- ('k⁼h', 'kʰ'),
- ('g', 'g⁼'),
- ('g⁼h', 'gʰ'),
- ('ṅ', 'ŋ'),
- ('c', 'ʧ⁼'),
- ('ʧ⁼h', 'ʧʰ'),
- ('j', 'ʥ⁼'),
- ('ʥ⁼h', 'ʥʰ'),
- ('ñ', 'n^'),
- ('ṭ', 't`⁼'),
- ('t`⁼h', 't`ʰ'),
- ('ḍ', 'd`⁼'),
- ('d`⁼h', 'd`ʰ'),
- ('ṇ', 'n`'),
- ('t', 't⁼'),
- ('t⁼h', 'tʰ'),
- ('d', 'd⁼'),
- ('d⁼h', 'dʰ'),
- ('p', 'p⁼'),
- ('p⁼h', 'pʰ'),
- ('b', 'b⁼'),
- ('b⁼h', 'bʰ'),
- ('y', 'j'),
- ('ś', 'ʃ'),
- ('ṣ', 's`'),
- ('r', 'ɾ'),
- ('l̤', 'l`'),
- ('h', 'ɦ'),
- ("'", ''),
- ('~', '^'),
- ('ṃ', '^')
-]]
-
-
-def devanagari_to_ipa(text):
- text = text.replace('ॐ', 'ओम्')
- text = re.sub(r'\s*।\s*$', '.', text)
- text = re.sub(r'\s*।\s*', ', ', text)
- text = re.sub(r'\s*॥', '.', text)
- text = sanscript.transliterate(text, sanscript.DEVANAGARI, sanscript.IAST)
- for regex, replacement in _iast_to_ipa:
- text = re.sub(regex, replacement, text)
- text = re.sub('(.)[`ː]*ḥ', lambda x: x.group(0)
- [:-1]+'h'+x.group(1)+'*', text)
- return text
diff --git a/spaces/XzJosh/TianDou-Bert-VITS2/modules.py b/spaces/XzJosh/TianDou-Bert-VITS2/modules.py
deleted file mode 100644
index 92e0f32a51c472bfd1659a50a95a95d195281d2b..0000000000000000000000000000000000000000
--- a/spaces/XzJosh/TianDou-Bert-VITS2/modules.py
+++ /dev/null
@@ -1,452 +0,0 @@
-import copy
-import math
-import numpy as np
-import scipy
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-from attentions import Encoder
-
-LRELU_SLOPE = 0.1
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
-class TransformerCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- n_layers,
- n_heads,
- p_dropout=0,
- filter_channels=0,
- mean_only=False,
- wn_sharing_parameter=None,
- gin_channels = 0
- ):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = Encoder(hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout, isflow = True, gin_channels = gin_channels) if wn_sharing_parameter is None else wn_sharing_parameter
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/YiYiXu/it-happened-one-frame-2/README.md b/spaces/YiYiXu/it-happened-one-frame-2/README.md
deleted file mode 100644
index 7522b13f182ec0c6f8674722c36c6d6b7e69839d..0000000000000000000000000000000000000000
--- a/spaces/YiYiXu/it-happened-one-frame-2/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: It Happened One Frame 2
-emoji: 🐠
-colorFrom: red
-colorTo: red
-sdk: gradio
-sdk_version: 3.0.11
-app_file: app.py
-pinned: false
-license: afl-3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces#reference
diff --git a/spaces/Yudha515/Rvc-Models/audiocraft/data/audio_utils.py b/spaces/Yudha515/Rvc-Models/audiocraft/data/audio_utils.py
deleted file mode 100644
index 76d4bc2a33ce722d879db2af33cd1336bd6b1fb3..0000000000000000000000000000000000000000
--- a/spaces/Yudha515/Rvc-Models/audiocraft/data/audio_utils.py
+++ /dev/null
@@ -1,174 +0,0 @@
-# Copyright (c) Meta Platforms, Inc. and affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import sys
-import typing as tp
-
-import julius
-import torch
-import torchaudio
-
-
-def convert_audio_channels(wav: torch.Tensor, channels: int = 2) -> torch.Tensor:
- """Convert audio to the given number of channels.
-
- Args:
- wav (torch.Tensor): Audio wave of shape [B, C, T].
- channels (int): Expected number of channels as output.
- Returns:
- torch.Tensor: Downmixed or unchanged audio wave [B, C, T].
- """
- *shape, src_channels, length = wav.shape
- if src_channels == channels:
- pass
- elif channels == 1:
- # Case 1:
- # The caller asked 1-channel audio, and the stream has multiple
- # channels, downmix all channels.
- wav = wav.mean(dim=-2, keepdim=True)
- elif src_channels == 1:
- # Case 2:
- # The caller asked for multiple channels, but the input file has
- # a single channel, replicate the audio over all channels.
- wav = wav.expand(*shape, channels, length)
- elif src_channels >= channels:
- # Case 3:
- # The caller asked for multiple channels, and the input file has
- # more channels than requested. In that case return the first channels.
- wav = wav[..., :channels, :]
- else:
- # Case 4: What is a reasonable choice here?
- raise ValueError('The audio file has less channels than requested but is not mono.')
- return wav
-
-
-def convert_audio(wav: torch.Tensor, from_rate: float,
- to_rate: float, to_channels: int) -> torch.Tensor:
- """Convert audio to new sample rate and number of audio channels.
- """
- wav = julius.resample_frac(wav, int(from_rate), int(to_rate))
- wav = convert_audio_channels(wav, to_channels)
- return wav
-
-
-def normalize_loudness(wav: torch.Tensor, sample_rate: int, loudness_headroom_db: float = 14,
- loudness_compressor: bool = False, energy_floor: float = 2e-3):
- """Normalize an input signal to a user loudness in dB LKFS.
- Audio loudness is defined according to the ITU-R BS.1770-4 recommendation.
-
- Args:
- wav (torch.Tensor): Input multichannel audio data.
- sample_rate (int): Sample rate.
- loudness_headroom_db (float): Target loudness of the output in dB LUFS.
- loudness_compressor (bool): Uses tanh for soft clipping.
- energy_floor (float): anything below that RMS level will not be rescaled.
- Returns:
- output (torch.Tensor): Loudness normalized output data.
- """
- energy = wav.pow(2).mean().sqrt().item()
- if energy < energy_floor:
- return wav
- transform = torchaudio.transforms.Loudness(sample_rate)
- input_loudness_db = transform(wav).item()
- # calculate the gain needed to scale to the desired loudness level
- delta_loudness = -loudness_headroom_db - input_loudness_db
- gain = 10.0 ** (delta_loudness / 20.0)
- output = gain * wav
- if loudness_compressor:
- output = torch.tanh(output)
- assert output.isfinite().all(), (input_loudness_db, wav.pow(2).mean().sqrt())
- return output
-
-
-def _clip_wav(wav: torch.Tensor, log_clipping: bool = False, stem_name: tp.Optional[str] = None) -> None:
- """Utility function to clip the audio with logging if specified."""
- max_scale = wav.abs().max()
- if log_clipping and max_scale > 1:
- clamp_prob = (wav.abs() > 1).float().mean().item()
- print(f"CLIPPING {stem_name or ''} happening with proba (a bit of clipping is okay):",
- clamp_prob, "maximum scale: ", max_scale.item(), file=sys.stderr)
- wav.clamp_(-1, 1)
-
-
-def normalize_audio(wav: torch.Tensor, normalize: bool = True,
- strategy: str = 'peak', peak_clip_headroom_db: float = 1,
- rms_headroom_db: float = 18, loudness_headroom_db: float = 14,
- loudness_compressor: bool = False, log_clipping: bool = False,
- sample_rate: tp.Optional[int] = None,
- stem_name: tp.Optional[str] = None) -> torch.Tensor:
- """Normalize the audio according to the prescribed strategy (see after).
-
- Args:
- wav (torch.Tensor): Audio data.
- normalize (bool): if `True` (default), normalizes according to the prescribed
- strategy (see after). If `False`, the strategy is only used in case clipping
- would happen.
- strategy (str): Can be either 'clip', 'peak', or 'rms'. Default is 'peak',
- i.e. audio is normalized by its largest value. RMS normalizes by root-mean-square
- with extra headroom to avoid clipping. 'clip' just clips.
- peak_clip_headroom_db (float): Headroom in dB when doing 'peak' or 'clip' strategy.
- rms_headroom_db (float): Headroom in dB when doing 'rms' strategy. This must be much larger
- than the `peak_clip` one to avoid further clipping.
- loudness_headroom_db (float): Target loudness for loudness normalization.
- loudness_compressor (bool): If True, uses tanh based soft clipping.
- log_clipping (bool): If True, basic logging on stderr when clipping still
- occurs despite strategy (only for 'rms').
- sample_rate (int): Sample rate for the audio data (required for loudness).
- stem_name (Optional[str]): Stem name for clipping logging.
- Returns:
- torch.Tensor: Normalized audio.
- """
- scale_peak = 10 ** (-peak_clip_headroom_db / 20)
- scale_rms = 10 ** (-rms_headroom_db / 20)
- if strategy == 'peak':
- rescaling = (scale_peak / wav.abs().max())
- if normalize or rescaling < 1:
- wav = wav * rescaling
- elif strategy == 'clip':
- wav = wav.clamp(-scale_peak, scale_peak)
- elif strategy == 'rms':
- mono = wav.mean(dim=0)
- rescaling = scale_rms / mono.pow(2).mean().sqrt()
- if normalize or rescaling < 1:
- wav = wav * rescaling
- _clip_wav(wav, log_clipping=log_clipping, stem_name=stem_name)
- elif strategy == 'loudness':
- assert sample_rate is not None, "Loudness normalization requires sample rate."
- wav = normalize_loudness(wav, sample_rate, loudness_headroom_db, loudness_compressor)
- _clip_wav(wav, log_clipping=log_clipping, stem_name=stem_name)
- else:
- assert wav.abs().max() < 1
- assert strategy == '' or strategy == 'none', f"Unexpected strategy: '{strategy}'"
- return wav
-
-
-def f32_pcm(wav: torch.Tensor) -> torch.Tensor:
- """Convert audio to float 32 bits PCM format.
- """
- if wav.dtype.is_floating_point:
- return wav
- else:
- assert wav.dtype == torch.int16
- return wav.float() / 2**15
-
-
-def i16_pcm(wav: torch.Tensor) -> torch.Tensor:
- """Convert audio to int 16 bits PCM format.
-
- ..Warning:: There exist many formula for doing this convertion. None are perfect
- due to the asymetry of the int16 range. One either have possible clipping, DC offset,
- or inconsistancies with f32_pcm. If the given wav doesn't have enough headroom,
- it is possible that `i16_pcm(f32_pcm)) != Identity`.
- """
- if wav.dtype.is_floating_point:
- assert wav.abs().max() <= 1
- candidate = (wav * 2 ** 15).round()
- if candidate.max() >= 2 ** 15: # clipping would occur
- candidate = (wav * (2 ** 15 - 1)).round()
- return candidate.short()
- else:
- assert wav.dtype == torch.int16
- return wav
diff --git a/spaces/Zengyf-CVer/Streamlit_YOLOv5_Model2x/utils/autobatch.py b/spaces/Zengyf-CVer/Streamlit_YOLOv5_Model2x/utils/autobatch.py
deleted file mode 100644
index 641b055b9fe35f2dfa80b13746f616fb6ce3cad9..0000000000000000000000000000000000000000
--- a/spaces/Zengyf-CVer/Streamlit_YOLOv5_Model2x/utils/autobatch.py
+++ /dev/null
@@ -1,69 +0,0 @@
-# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
-"""
-Auto-batch utils
-"""
-
-from copy import deepcopy
-
-import numpy as np
-import torch
-
-from utils.general import LOGGER, colorstr
-from utils.torch_utils import profile
-
-
-def check_train_batch_size(model, imgsz=640, amp=True):
- # Check YOLOv5 training batch size
- with torch.cuda.amp.autocast(amp):
- return autobatch(deepcopy(model).train(), imgsz) # compute optimal batch size
-
-
-def autobatch(model, imgsz=640, fraction=0.8, batch_size=16):
- # Automatically estimate best batch size to use `fraction` of available CUDA memory
- # Usage:
- # import torch
- # from utils.autobatch import autobatch
- # model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False)
- # print(autobatch(model))
-
- # Check device
- prefix = colorstr('AutoBatch: ')
- LOGGER.info(f'{prefix}Computing optimal batch size for --imgsz {imgsz}')
- device = next(model.parameters()).device # get model device
- if device.type == 'cpu':
- LOGGER.info(f'{prefix}CUDA not detected, using default CPU batch-size {batch_size}')
- return batch_size
-
- # Inspect CUDA memory
- gb = 1 << 30 # bytes to GiB (1024 ** 3)
- d = str(device).upper() # 'CUDA:0'
- properties = torch.cuda.get_device_properties(device) # device properties
- t = properties.total_memory / gb # GiB total
- r = torch.cuda.memory_reserved(device) / gb # GiB reserved
- a = torch.cuda.memory_allocated(device) / gb # GiB allocated
- f = t - (r + a) # GiB free
- LOGGER.info(f'{prefix}{d} ({properties.name}) {t:.2f}G total, {r:.2f}G reserved, {a:.2f}G allocated, {f:.2f}G free')
-
- # Profile batch sizes
- batch_sizes = [1, 2, 4, 8, 16]
- try:
- img = [torch.empty(b, 3, imgsz, imgsz) for b in batch_sizes]
- results = profile(img, model, n=3, device=device)
- except Exception as e:
- LOGGER.warning(f'{prefix}{e}')
-
- # Fit a solution
- y = [x[2] for x in results if x] # memory [2]
- p = np.polyfit(batch_sizes[:len(y)], y, deg=1) # first degree polynomial fit
- b = int((f * fraction - p[1]) / p[0]) # y intercept (optimal batch size)
- if None in results: # some sizes failed
- i = results.index(None) # first fail index
- if b >= batch_sizes[i]: # y intercept above failure point
- b = batch_sizes[max(i - 1, 0)] # select prior safe point
- if b < 1 or b > 1024: # b outside of safe range
- b = batch_size
- LOGGER.warning(f'{prefix}WARNING: ⚠️ CUDA anomaly detected, recommend restart environment and retry command.')
-
- fraction = np.polyval(p, b) / t # actual fraction predicted
- LOGGER.info(f'{prefix}Using batch-size {b} for {d} {t * fraction:.2f}G/{t:.2f}G ({fraction * 100:.0f}%) ✅')
- return b
diff --git a/spaces/abdulmeLINK/programmer-bloom/app.py b/spaces/abdulmeLINK/programmer-bloom/app.py
deleted file mode 100644
index 050bd070c51b1297517cf6bfadf6a721b09c9bc1..0000000000000000000000000000000000000000
--- a/spaces/abdulmeLINK/programmer-bloom/app.py
+++ /dev/null
@@ -1,86 +0,0 @@
-from cProfile import label
-from code import interact
-from multiprocessing.util import ForkAwareThreadLock
-import os
-import requests
-import gradio as gr
-
-
-# ENV vars
-API_URL = os.environ["API_URL"]
-HF_TOKEN = os.environ["HF_TOKEN"]
-headers = {"Authorization": f"Bearer {HF_TOKEN}"}
-
-comment_syntaxes = {
- "C": "/* {} */",
- "C++": "/* {} */",
- "Java": "/* {} */",
- "Golang": "/* {} */",
- "Rust": "/* {} */",
- "Javascript": "/* {} */",
- "PHP": "/* {} */",
- "Kotlin": "/* {} */",
- "HTML": "",
- "Python": "#{}",
- "Bash": "#{}",
- "Ruby": "=begin {} =end",
-}
-
-jsn_trail = {"parameters":
- {
- "top_p": 0.9,
- "max_new_tokens": 64,
- "return_full_text": True,
- "do_sample": True,
- },
- "options":
- {"use_cache": True,
- "wait_for_model": True,
- }, }
-
-
-def post(jsn):
- response = requests.post(API_URL, headers=headers, json=jsn)
- return response.json()[0]["generated_text"]
-
-
-def get_script(lang, instruction):
- jsn = {"inputs": comment_syntaxes[lang].format("Programming Language: " + lang) + "\n" + comment_syntaxes[lang].format("Instruction: " + instruction.replace(
- '\n', '')) + '\n', **jsn_trail}
- return post(jsn)
-
-
-def feedback(opt):
- return post({"inputs": opt, **jsn_trail})
-
-
-demo = gr.Blocks()
-
-with demo:
- gr.Markdown(
- "
Give Instructions to Generate a Program
")
- gr.Markdown(
- "
This project aims to prepare a prompt for BLOOM to generate scripts
")
- with gr.Row():
-
- dropdown = gr.Dropdown(value="Python",
- choices=list(comment_syntaxes.keys()), label="Choose the language")
-
- # with gr.Column:
- instruction = gr.Textbox(label="Write an instruction",
- value="Create a python function that generates random password with given length using ascii characters ", lines=6)
-
- with gr.Row():
- generated_txt = gr.Textbox(lines=5, interactive=False, label="Output")
-
- btn = gr.Button("Generate")
- btn.click(get_script, inputs=[dropdown,
- instruction], outputs=generated_txt)
- feeedback_btn = gr.Button("Feedback")
- feeedback_btn.click(
- feedback, inputs=[generated_txt], outputs=generated_txt)
- with gr.Row():
- gr.Markdown(
- "")
-
-demo.launch(enable_queue=True, debug=True)
diff --git a/spaces/abdvl/datahub_qa_bot/docs/features.md b/spaces/abdvl/datahub_qa_bot/docs/features.md
deleted file mode 100644
index a06789f28f82bde99e6a970c287d12718ab73103..0000000000000000000000000000000000000000
--- a/spaces/abdvl/datahub_qa_bot/docs/features.md
+++ /dev/null
@@ -1,118 +0,0 @@
----
-title: "Features"
----
-
-# DataHub Features Overview
-
-DataHub is a modern data catalog built to enable end-to-end data discovery, data observability, and data governance. This extensible metadata platform is built for developers to tame the complexity of their rapidly evolving data ecosystems and for data practitioners to leverage the total value of data within their organization.
-
-Here’s an overview of DataHub’s current functionality. Check out our [roadmap](https://feature-requests.datahubproject.io/roadmap) to see what's to come.
-
----
-
-## Search and Discovery
-
-### **Search All Corners of Your Data Stack**
-
-DataHub's unified search experience surfaces results across databases, data lakes, BI platforms, ML feature stores, orchestration tools, and more.
-
-
-
-
-
-### **Trace End-to-End Lineage**
-
-Quickly understand the end-to-end journey of data by tracing lineage across platforms, datasets, ETL/ELT pipelines, charts, dashboards, and beyond.
-
-
-
-
-
-### **Understand the Impact of Breaking Changes on Downstream Dependencies**
-
-Proactively identify which entities may be impacted by a breaking change using Impact Analysis.
-
-
-
-
-
-### **View Metadata 360 at a Glance**
-
-Combine *technical* and *logical* metadata to provide a 360º view of your data entities.
-
-Generate **Dataset Stats** to understand the shape & distribution of the data
-
-
-
-
-
-Capture historical **Data Validation Outcomes** from tools like Great Expectations
-
-
-
-
-
-Leverage DataHub's **Schema Version History** to track changes to the physical structure of data over time
-
-
-
-
-
----
-
-## Modern Data Governance
-
-### **Govern in Real Time**
-
-[The Actions Framework](./actions/README.md) powers the following real-time use cases:
-
-* **Notifications:** Generate organization-specific notifications when a change is made on DataHub. For example, send an email to the governance team when a "PII" tag is added to any data asset.
-* **Workflow Integration:** Integrate DataHub into your organization's internal workflows. For example, create a Jira ticket when specific Tags or Terms are proposed on a Dataset.
-* **Synchronization:** Sync changes made in DataHub into a 3rd party system. For example, reflect Tag additions in DataHub into Snowflake.
-* **Auditing:** Audit who is making what changes on DataHub through time.
-
-
-
-
-
-### **Manage Entity Ownership**
-Quickly and easily assign entity ownership to users and user groups.
-
-
-
-
-
-### **Govern with Tags, Glossary Terms, and Domains**
-Empower data owners to govern their data entities with:
-
-1. **Tags:** Informal, loosely controlled labels that serve as a tool for search & discovery. No formal, central management.
-2. **Glossary Terms:** A controlled vocabulary with optional hierarchy, commonly used to describe core business concepts and measurements.
-3. **Domains:** Curated, top-level folders or categories, widely used in Data Mesh to organize entities by department (i.e., Finance, Marketing) or Data Products.
-
-
-
-
-
----
-## DataHub Administration
-
-### **Create Users, Groups, & Access Policies**
-
-DataHub admins can create Policies to define who can perform what action against which resource(s). When you create a new Policy, you will be able to define the following:
-
-* **Policy Type** - Platform (top-level DataHub Platform privileges, i.e., managing users, groups, and policies) or Metadata (ability to manipulate ownership, tags, documentation, and more)
-* **Resource Type** - Specify the type of resources, such as Datasets, Dashboards, Pipelines, and beyond
-* **Privileges** - Choose the set of permissions, such as Edit Owners, Edit Documentation, Edit Links
-* **Users and/or Groups** - Assign relevant Users and Groups; you can also assign the Policy to Resource Owners, regardless of which Group they belong
-
-
-
-
-
-### **Ingest Metadata from the UI**
-
-Create, configure, schedule, & execute batch metadata ingestion using the DataHub user interface. This makes getting metadata into DataHub easier by minimizing the overhead required to operate custom integration pipelines.
-
-
-
-
\ No newline at end of file
diff --git a/spaces/abdvl/datahub_qa_bot/docs/managed-datahub/release-notes/v_0_2_4.md b/spaces/abdvl/datahub_qa_bot/docs/managed-datahub/release-notes/v_0_2_4.md
deleted file mode 100644
index 936d8929211682a02c0a396b70c26d2538dabcb9..0000000000000000000000000000000000000000
--- a/spaces/abdvl/datahub_qa_bot/docs/managed-datahub/release-notes/v_0_2_4.md
+++ /dev/null
@@ -1,21 +0,0 @@
-# v0.2.4
----
-
-Release Availability Date
----
-24-Mar-2023
-
-## Release Changelog
----
-- Since `v0.2.3` no changes from OSS DataHub have been pulled in.
-- fix(ui) Safeguard ingestion execution request check - Fixes an error on frontend managed ingestion page
-- fix(impactAnalysis): fix filtering for lightning mode search
-- fix(search): fix tags with colons
-- refactor(incidents): Remove dataset health caching to make incident health instantly update
-- fix(ui): Address regression in column usage stats + add unit test
-- fix(timeBasedLineage): fix ingestProposal flow for no ops
-- feat(assertions + incidents): Support Querying Entities by Assertion / Incident Status + Chrome Embed Optimizations
-- fix(lineage): change default lineage time window to All Time
-- Truncate cache key for search lineage
-- feat(config): Add endpoint to exact search query information
-- fix(default policies): Add Manage Proposals Default Policies for Root User
\ No newline at end of file
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/visualization/optflow.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/visualization/optflow.py
deleted file mode 100644
index c3870c700f7c946177ee5d536ce3f6c814a77ce7..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmcv/visualization/optflow.py
+++ /dev/null
@@ -1,112 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from __future__ import division
-
-import numpy as np
-
-from annotator.uniformer.mmcv.image import rgb2bgr
-from annotator.uniformer.mmcv.video import flowread
-from .image import imshow
-
-
-def flowshow(flow, win_name='', wait_time=0):
- """Show optical flow.
-
- Args:
- flow (ndarray or str): The optical flow to be displayed.
- win_name (str): The window name.
- wait_time (int): Value of waitKey param.
- """
- flow = flowread(flow)
- flow_img = flow2rgb(flow)
- imshow(rgb2bgr(flow_img), win_name, wait_time)
-
-
-def flow2rgb(flow, color_wheel=None, unknown_thr=1e6):
- """Convert flow map to RGB image.
-
- Args:
- flow (ndarray): Array of optical flow.
- color_wheel (ndarray or None): Color wheel used to map flow field to
- RGB colorspace. Default color wheel will be used if not specified.
- unknown_thr (str): Values above this threshold will be marked as
- unknown and thus ignored.
-
- Returns:
- ndarray: RGB image that can be visualized.
- """
- assert flow.ndim == 3 and flow.shape[-1] == 2
- if color_wheel is None:
- color_wheel = make_color_wheel()
- assert color_wheel.ndim == 2 and color_wheel.shape[1] == 3
- num_bins = color_wheel.shape[0]
-
- dx = flow[:, :, 0].copy()
- dy = flow[:, :, 1].copy()
-
- ignore_inds = (
- np.isnan(dx) | np.isnan(dy) | (np.abs(dx) > unknown_thr) |
- (np.abs(dy) > unknown_thr))
- dx[ignore_inds] = 0
- dy[ignore_inds] = 0
-
- rad = np.sqrt(dx**2 + dy**2)
- if np.any(rad > np.finfo(float).eps):
- max_rad = np.max(rad)
- dx /= max_rad
- dy /= max_rad
-
- rad = np.sqrt(dx**2 + dy**2)
- angle = np.arctan2(-dy, -dx) / np.pi
-
- bin_real = (angle + 1) / 2 * (num_bins - 1)
- bin_left = np.floor(bin_real).astype(int)
- bin_right = (bin_left + 1) % num_bins
- w = (bin_real - bin_left.astype(np.float32))[..., None]
- flow_img = (1 -
- w) * color_wheel[bin_left, :] + w * color_wheel[bin_right, :]
- small_ind = rad <= 1
- flow_img[small_ind] = 1 - rad[small_ind, None] * (1 - flow_img[small_ind])
- flow_img[np.logical_not(small_ind)] *= 0.75
-
- flow_img[ignore_inds, :] = 0
-
- return flow_img
-
-
-def make_color_wheel(bins=None):
- """Build a color wheel.
-
- Args:
- bins(list or tuple, optional): Specify the number of bins for each
- color range, corresponding to six ranges: red -> yellow,
- yellow -> green, green -> cyan, cyan -> blue, blue -> magenta,
- magenta -> red. [15, 6, 4, 11, 13, 6] is used for default
- (see Middlebury).
-
- Returns:
- ndarray: Color wheel of shape (total_bins, 3).
- """
- if bins is None:
- bins = [15, 6, 4, 11, 13, 6]
- assert len(bins) == 6
-
- RY, YG, GC, CB, BM, MR = tuple(bins)
-
- ry = [1, np.arange(RY) / RY, 0]
- yg = [1 - np.arange(YG) / YG, 1, 0]
- gc = [0, 1, np.arange(GC) / GC]
- cb = [0, 1 - np.arange(CB) / CB, 1]
- bm = [np.arange(BM) / BM, 0, 1]
- mr = [1, 0, 1 - np.arange(MR) / MR]
-
- num_bins = RY + YG + GC + CB + BM + MR
-
- color_wheel = np.zeros((3, num_bins), dtype=np.float32)
-
- col = 0
- for i, color in enumerate([ry, yg, gc, cb, bm, mr]):
- for j in range(3):
- color_wheel[j, col:col + bins[i]] = color[j]
- col += bins[i]
-
- return color_wheel.T
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/dense_heads/pisa_retinanet_head.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/dense_heads/pisa_retinanet_head.py
deleted file mode 100644
index bd87b9aeb07e05ff94b444ac8999eca3f616711a..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/dense_heads/pisa_retinanet_head.py
+++ /dev/null
@@ -1,154 +0,0 @@
-import torch
-from mmcv.runner import force_fp32
-
-from mmdet.core import images_to_levels
-from ..builder import HEADS
-from ..losses import carl_loss, isr_p
-from .retina_head import RetinaHead
-
-
-@HEADS.register_module()
-class PISARetinaHead(RetinaHead):
- """PISA Retinanet Head.
-
- The head owns the same structure with Retinanet Head, but differs in two
- aspects:
- 1. Importance-based Sample Reweighting Positive (ISR-P) is applied to
- change the positive loss weights.
- 2. Classification-aware regression loss is adopted as a third loss.
- """
-
- @force_fp32(apply_to=('cls_scores', 'bbox_preds'))
- def loss(self,
- cls_scores,
- bbox_preds,
- gt_bboxes,
- gt_labels,
- img_metas,
- gt_bboxes_ignore=None):
- """Compute losses of the head.
-
- Args:
- cls_scores (list[Tensor]): Box scores for each scale level
- Has shape (N, num_anchors * num_classes, H, W)
- bbox_preds (list[Tensor]): Box energies / deltas for each scale
- level with shape (N, num_anchors * 4, H, W)
- gt_bboxes (list[Tensor]): Ground truth bboxes of each image
- with shape (num_obj, 4).
- gt_labels (list[Tensor]): Ground truth labels of each image
- with shape (num_obj, 4).
- img_metas (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- gt_bboxes_ignore (list[Tensor]): Ignored gt bboxes of each image.
- Default: None.
-
- Returns:
- dict: Loss dict, comprise classification loss, regression loss and
- carl loss.
- """
- featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
- assert len(featmap_sizes) == self.anchor_generator.num_levels
-
- device = cls_scores[0].device
-
- anchor_list, valid_flag_list = self.get_anchors(
- featmap_sizes, img_metas, device=device)
- label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
- cls_reg_targets = self.get_targets(
- anchor_list,
- valid_flag_list,
- gt_bboxes,
- img_metas,
- gt_bboxes_ignore_list=gt_bboxes_ignore,
- gt_labels_list=gt_labels,
- label_channels=label_channels,
- return_sampling_results=True)
- if cls_reg_targets is None:
- return None
- (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
- num_total_pos, num_total_neg, sampling_results_list) = cls_reg_targets
- num_total_samples = (
- num_total_pos + num_total_neg if self.sampling else num_total_pos)
-
- # anchor number of multi levels
- num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
- # concat all level anchors and flags to a single tensor
- concat_anchor_list = []
- for i in range(len(anchor_list)):
- concat_anchor_list.append(torch.cat(anchor_list[i]))
- all_anchor_list = images_to_levels(concat_anchor_list,
- num_level_anchors)
-
- num_imgs = len(img_metas)
- flatten_cls_scores = [
- cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1, label_channels)
- for cls_score in cls_scores
- ]
- flatten_cls_scores = torch.cat(
- flatten_cls_scores, dim=1).reshape(-1,
- flatten_cls_scores[0].size(-1))
- flatten_bbox_preds = [
- bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
- for bbox_pred in bbox_preds
- ]
- flatten_bbox_preds = torch.cat(
- flatten_bbox_preds, dim=1).view(-1, flatten_bbox_preds[0].size(-1))
- flatten_labels = torch.cat(labels_list, dim=1).reshape(-1)
- flatten_label_weights = torch.cat(
- label_weights_list, dim=1).reshape(-1)
- flatten_anchors = torch.cat(all_anchor_list, dim=1).reshape(-1, 4)
- flatten_bbox_targets = torch.cat(
- bbox_targets_list, dim=1).reshape(-1, 4)
- flatten_bbox_weights = torch.cat(
- bbox_weights_list, dim=1).reshape(-1, 4)
-
- # Apply ISR-P
- isr_cfg = self.train_cfg.get('isr', None)
- if isr_cfg is not None:
- all_targets = (flatten_labels, flatten_label_weights,
- flatten_bbox_targets, flatten_bbox_weights)
- with torch.no_grad():
- all_targets = isr_p(
- flatten_cls_scores,
- flatten_bbox_preds,
- all_targets,
- flatten_anchors,
- sampling_results_list,
- bbox_coder=self.bbox_coder,
- loss_cls=self.loss_cls,
- num_class=self.num_classes,
- **self.train_cfg.isr)
- (flatten_labels, flatten_label_weights, flatten_bbox_targets,
- flatten_bbox_weights) = all_targets
-
- # For convenience we compute loss once instead separating by fpn level,
- # so that we don't need to separate the weights by level again.
- # The result should be the same
- losses_cls = self.loss_cls(
- flatten_cls_scores,
- flatten_labels,
- flatten_label_weights,
- avg_factor=num_total_samples)
- losses_bbox = self.loss_bbox(
- flatten_bbox_preds,
- flatten_bbox_targets,
- flatten_bbox_weights,
- avg_factor=num_total_samples)
- loss_dict = dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
-
- # CARL Loss
- carl_cfg = self.train_cfg.get('carl', None)
- if carl_cfg is not None:
- loss_carl = carl_loss(
- flatten_cls_scores,
- flatten_labels,
- flatten_bbox_preds,
- flatten_bbox_targets,
- self.loss_bbox,
- **self.train_cfg.carl,
- avg_factor=num_total_pos,
- sigmoid=True,
- num_class=self.num_classes)
- loss_dict.update(loss_carl)
-
- return loss_dict
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/ops/wrappers.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/ops/wrappers.py
deleted file mode 100644
index 0ed9a0cb8d7c0e0ec2748dd89c652756653cac78..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmseg/ops/wrappers.py
+++ /dev/null
@@ -1,50 +0,0 @@
-import warnings
-
-import torch.nn as nn
-import torch.nn.functional as F
-
-
-def resize(input,
- size=None,
- scale_factor=None,
- mode='nearest',
- align_corners=None,
- warning=True):
- if warning:
- if size is not None and align_corners:
- input_h, input_w = tuple(int(x) for x in input.shape[2:])
- output_h, output_w = tuple(int(x) for x in size)
- if output_h > input_h or output_w > output_h:
- if ((output_h > 1 and output_w > 1 and input_h > 1
- and input_w > 1) and (output_h - 1) % (input_h - 1)
- and (output_w - 1) % (input_w - 1)):
- warnings.warn(
- f'When align_corners={align_corners}, '
- 'the output would more aligned if '
- f'input size {(input_h, input_w)} is `x+1` and '
- f'out size {(output_h, output_w)} is `nx+1`')
- return F.interpolate(input, size, scale_factor, mode, align_corners)
-
-
-class Upsample(nn.Module):
-
- def __init__(self,
- size=None,
- scale_factor=None,
- mode='nearest',
- align_corners=None):
- super(Upsample, self).__init__()
- self.size = size
- if isinstance(scale_factor, tuple):
- self.scale_factor = tuple(float(factor) for factor in scale_factor)
- else:
- self.scale_factor = float(scale_factor) if scale_factor else None
- self.mode = mode
- self.align_corners = align_corners
-
- def forward(self, x):
- if not self.size:
- size = [int(t * self.scale_factor) for t in x.shape[-2:]]
- else:
- size = self.size
- return resize(x, size, None, self.mode, self.align_corners)
diff --git a/spaces/ahdsoft/Persian-Automatic-Speech-Recognition/Dockerfile b/spaces/ahdsoft/Persian-Automatic-Speech-Recognition/Dockerfile
deleted file mode 100644
index 07c167fbcfd18c67bf711c9a4c3f0bf747022ea8..0000000000000000000000000000000000000000
--- a/spaces/ahdsoft/Persian-Automatic-Speech-Recognition/Dockerfile
+++ /dev/null
@@ -1,10 +0,0 @@
-FROM python:3.8
-RUN mkdir /app
-WORKDIR /app
-COPY requirements.txt .
-
-RUN pip install -r requirements.txt
-
-COPY . .
-
-ENTRYPOINT ["streamlit", "run", "app.py", "--server.port=4000", "--server.address=0.0.0.0", "--client.showErrorDetails=false"]
diff --git a/spaces/aipicasso/playground/app.py b/spaces/aipicasso/playground/app.py
deleted file mode 100644
index 9e03b90feebebcf90ae6ff4a9b7eba5eeaf1ec94..0000000000000000000000000000000000000000
--- a/spaces/aipicasso/playground/app.py
+++ /dev/null
@@ -1,99 +0,0 @@
-import gradio as gr
-import requests
-import os
-from PIL import Image
-from io import BytesIO
-import base64
-
-def error_str(error, title="Error"):
- return f"""#### {title}
- {error}""" if error else ""
-
-def inference(prompt, guidance, steps, image_size="Landscape", seed=0, img=None, strength=0.5, neg_prompt="", disable_auto_prompt_correction=False):
- try:
- response = requests.post(os.environ["BACKEND"], json={
- "data": [
- prompt,
- guidance,
- steps,
- image_size,
- seed,
- img,
- strength,
- neg_prompt,
- disable_auto_prompt_correction,
- ]
- }).json()
-
- data = response["data"]
-
- image=Image.open(BytesIO(base64.b64decode(data[0].split(',')[1])))
-
- return image,data[1],data[2]
- except Exception as e:
- print(error_str(e))
- return None, "Error", "Error"
-
-css = """.main-div div{display:inline-flex;align-items:center;gap:.8rem;font-size:1.75rem}.main-div div h1{font-weight:900;margin-bottom:7px}.main-div p{margin-bottom:10px;font-size:94%}a{text-decoration:underline}.tabs{margin-top:0;margin-bottom:0}#gallery{min-height:20rem}
-"""
-with gr.Blocks(css=css) as demo:
- gr.HTML(
- f"""
-
-
-
ChatEmi Beta デモ
-
-
- 個人情報などは入れないでください。
-
-
- サンプルプロンプト1:黒い髪の美少女の顔アップ
-
-
- サンプルプロンプト2:白い髪の男性の上半身
-
-
- """
- )
- with gr.Row():
-
- with gr.Column(scale=55):
- with gr.Group():
-
- with gr.Row():
- prompt = gr.Textbox(label="Prompt", show_label=False, max_lines=2,placeholder="[your prompt]")
- generate = gr.Button(value="Generate")
-
- image_out = gr.Image(height=1024,width=1024)
- error_output = gr.Markdown()
-
- with gr.Column(scale=45):
- with gr.Tab("Options"):
- with gr.Group():
- neg_prompt = gr.Textbox(label="Negative prompt", placeholder="What to exclude from the image")
- disable_auto_prompt_correction = gr.Checkbox(label="Disable auto prompt corretion.")
- with gr.Row():
- image_size=gr.Radio(["Portrait","Landscape","Square"])
- image_size.show_label=False
- image_size.value="Square"
-
- with gr.Row():
- guidance = gr.Slider(label="Guidance scale", value=7.5, maximum=25)
- steps = gr.Slider(label="Steps", value=20, minimum=2, maximum=30, step=1)
-
- seed = gr.Slider(0, 2147483647, label='Seed (0 = random)', value=0, step=1)
- prompt_display= gr.Textbox(label="Upsampled prompt", interactive=False)
-
- with gr.Tab("Image to image"):
- with gr.Group():
- image = gr.Image(label="Image", height=256, tool="editor", type="pil")
- strength = gr.Slider(label="Transformation strength", minimum=0, maximum=1, step=0.01, value=0.5)
-
- inputs = [prompt, guidance, steps, image_size, seed, image, strength, neg_prompt, disable_auto_prompt_correction]
-
- outputs = [image_out, error_output, prompt_display]
- prompt.submit(inference, inputs=inputs, outputs=outputs)
- generate.click(inference, inputs=inputs, outputs=outputs)
-
-demo.queue(concurrency_count=1)
-demo.launch()
\ No newline at end of file
diff --git a/spaces/akhaliq/CLIP_prefix_captioning/README.md b/spaces/akhaliq/CLIP_prefix_captioning/README.md
deleted file mode 100644
index 1faa5db8a51dcd4b63109627c7c8463f2dd9bf07..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/CLIP_prefix_captioning/README.md
+++ /dev/null
@@ -1,37 +0,0 @@
----
-title: CLIP_prefix_captioning
-emoji: 💩
-colorFrom: red
-colorTo: indigo
-sdk: gradio
-app_file: app.py
-pinned: false
----
-
-# Configuration
-
-`title`: _string_
-Display title for the Space
-
-`emoji`: _string_
-Space emoji (emoji-only character allowed)
-
-`colorFrom`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`colorTo`: _string_
-Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
-
-`sdk`: _string_
-Can be either `gradio` or `streamlit`
-
-`sdk_version` : _string_
-Only applicable for `streamlit` SDK.
-See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
-
-`app_file`: _string_
-Path to your main application file (which contains either `gradio` or `streamlit` Python code).
-Path is relative to the root of the repository.
-
-`pinned`: _boolean_
-Whether the Space stays on top of your list.
diff --git a/spaces/akhaliq/Mask2Former/mask2former_video/__init__.py b/spaces/akhaliq/Mask2Former/mask2former_video/__init__.py
deleted file mode 100644
index b6b2f54903ccabe6d4301471711d98c57a961c51..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/Mask2Former/mask2former_video/__init__.py
+++ /dev/null
@@ -1,17 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-from . import modeling
-
-# config
-from .config import add_maskformer2_video_config
-
-# models
-from .video_maskformer_model import VideoMaskFormer
-
-# video
-from .data_video import (
- YTVISDatasetMapper,
- YTVISEvaluator,
- build_detection_train_loader,
- build_detection_test_loader,
- get_detection_dataset_dicts,
-)
diff --git a/spaces/akhaliq/Real-ESRGAN/scripts/generate_multiscale_DF2K.py b/spaces/akhaliq/Real-ESRGAN/scripts/generate_multiscale_DF2K.py
deleted file mode 100644
index d4f5d8324b1624e4cb6163754703b8dac2d188fd..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/Real-ESRGAN/scripts/generate_multiscale_DF2K.py
+++ /dev/null
@@ -1,48 +0,0 @@
-import argparse
-import glob
-import os
-from PIL import Image
-
-
-def main(args):
- # For DF2K, we consider the following three scales,
- # and the smallest image whose shortest edge is 400
- scale_list = [0.75, 0.5, 1 / 3]
- shortest_edge = 400
-
- path_list = sorted(glob.glob(os.path.join(args.input, '*')))
- for path in path_list:
- print(path)
- basename = os.path.splitext(os.path.basename(path))[0]
-
- img = Image.open(path)
- width, height = img.size
- for idx, scale in enumerate(scale_list):
- print(f'\t{scale:.2f}')
- rlt = img.resize((int(width * scale), int(height * scale)), resample=Image.LANCZOS)
- rlt.save(os.path.join(args.output, f'{basename}T{idx}.png'))
-
- # save the smallest image which the shortest edge is 400
- if width < height:
- ratio = height / width
- width = shortest_edge
- height = int(width * ratio)
- else:
- ratio = width / height
- height = shortest_edge
- width = int(height * ratio)
- rlt = img.resize((int(width), int(height)), resample=Image.LANCZOS)
- rlt.save(os.path.join(args.output, f'{basename}T{idx+1}.png'))
-
-
-if __name__ == '__main__':
- """Generate multi-scale versions for GT images with LANCZOS resampling.
- It is now used for DF2K dataset (DIV2K + Flickr 2K)
- """
- parser = argparse.ArgumentParser()
- parser.add_argument('--input', type=str, default='datasets/DF2K/DF2K_HR', help='Input folder')
- parser.add_argument('--output', type=str, default='datasets/DF2K/DF2K_multiscale', help='Output folder')
- args = parser.parse_args()
-
- os.makedirs(args.output, exist_ok=True)
- main(args)
diff --git a/spaces/akhaliq/SpecVQGAN_Neural_Audio_Codec/app.py b/spaces/akhaliq/SpecVQGAN_Neural_Audio_Codec/app.py
deleted file mode 100644
index 0dc4892e5d666b03e611f0f5ef718cda24b193f6..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/SpecVQGAN_Neural_Audio_Codec/app.py
+++ /dev/null
@@ -1,89 +0,0 @@
-import os
-os.system("git clone https://github.com/v-iashin/SpecVQGAN")
-os.system("pip install pytorch-lightning==1.2.10 omegaconf==2.0.6 streamlit==0.80 matplotlib==3.4.1 albumentations==0.5.2 SoundFile torch torchvision librosa gdown")
-
-from pathlib import Path
-import soundfile
-import torch
-import gradio as gr
-
-import sys
-sys.path.append('./SpecVQGAN')
-from feature_extraction.demo_utils import (calculate_codebook_bitrate,
- extract_melspectrogram,
- get_audio_file_bitrate,
- get_duration,
- load_neural_audio_codec)
-from sample_visualization import tensor_to_plt
-from torch.utils.data.dataloader import default_collate
-
-os.chdir("SpecVQGAN")
-device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
-
-os.system("gdown https://drive.google.com/uc?id=1KGof44Sx4yIn4Hohpp9-VVTh2zGucKeY")
-
-model_name = '2021-05-19T22-16-54_vggsound_codebook'
-log_dir = './logs'
-# loading the models might take a few minutes
-config, model, vocoder = load_neural_audio_codec(model_name, log_dir, device)
-
-def inference(audio):
- # Select an Audio
- input_wav = audio.name
-
- # Spectrogram Extraction
- model_sr = config.data.params.sample_rate
- duration = get_duration(input_wav)
- spec = extract_melspectrogram(input_wav, sr=model_sr, duration=duration)
- print(f'Audio Duration: {duration} seconds')
- print('Original Spectrogram Shape:', spec.shape)
-
- # Prepare Input
- spectrogram = {'input': spec}
- batch = default_collate([spectrogram])
- batch['image'] = batch['input'].to(device)
- x = model.get_input(batch, 'image')
-
- with torch.no_grad():
- quant_z, diff, info = model.encode(x)
- xrec = model.decode(quant_z)
-
- print('Compressed representation (it is all you need to recover the audio):')
- F, T = quant_z.shape[-2:]
- print(info[2].reshape(F, T))
-
-
- # Calculate Bitrate
- bitrate = calculate_codebook_bitrate(duration, quant_z, model.quantize.n_e)
- orig_bitrate = get_audio_file_bitrate(input_wav)
-
- # Save and Display
- x = x.squeeze(0)
- xrec = xrec.squeeze(0)
- # specs are in [-1, 1], making them in [0, 1]
- wav_x = vocoder((x + 1) / 2).squeeze().detach().cpu().numpy()
- wav_xrec = vocoder((xrec + 1) / 2).squeeze().detach().cpu().numpy()
- # Save paths
- x_save_path = 'vocoded_orig_spec.wav'
- xrec_save_path = f'specvqgan_{bitrate:.2f}kbps.wav'
- # Save
- soundfile.write(x_save_path, wav_x, model_sr, 'PCM_16')
- soundfile.write(xrec_save_path, wav_xrec, model_sr, 'PCM_16')
- return 'vocoded_orig_spec.wav', f'specvqgan_{bitrate:.2f}kbps.wav', tensor_to_plt(x, flip_dims=(2,)), tensor_to_plt(xrec, flip_dims=(2,))
-
-title = "SpecVQGAN Neural Audio Codec"
-description = "Gradio demo for Spectrogram VQGAN as a Neural Audio Codec. To use it, simply add your audio, or click one of the examples to load them. Read more at the links below."
-article = "
"
-
-examples=[['example.wav']]
-gr.Interface(
- inference,
- gr.Audio(type="file", label="Input Audio"),
- [gr.Audio(type="file", label="Original audio"),gr.Audio(type="file", label="Reconstructed audio"),gr.Plot(label="Original Spectrogram:"),gr.Plot(label="Reconstructed Spectrogram:")],
- title=title,
- description=description,
- article=article,
- enable_queue=True,
- examples=examples,
- cache_examples=True
- ).launch(debug=True)
\ No newline at end of file
diff --git a/spaces/akhaliq/deeplab2/video/vip_deeplab.py b/spaces/akhaliq/deeplab2/video/vip_deeplab.py
deleted file mode 100644
index e931ec6bfebfc6e13d1a7a8b37ee7dbb2a74252f..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/deeplab2/video/vip_deeplab.py
+++ /dev/null
@@ -1,321 +0,0 @@
-# coding=utf-8
-# Copyright 2021 The Deeplab2 Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""This file contains the ViP-DeepLab meta architecture."""
-import collections
-import functools
-from typing import Any, Dict, Text, Tuple
-
-from absl import logging
-import tensorflow as tf
-
-from deeplab2 import common
-from deeplab2 import config_pb2
-from deeplab2.data import dataset
-from deeplab2.model import builder
-from deeplab2.model import utils
-from deeplab2.model.post_processor import post_processor_builder
-from deeplab2.model.post_processor import vip_deeplab
-
-_OFFSET_OUTPUT = 'offset'
-
-
-class ViPDeepLab(tf.keras.Model):
- """This class represents the ViP-DeepLab meta architecture.
-
- This class supports the architecture of ViP-DeepLab.
- """
-
- def __init__(self, config: config_pb2.ExperimentOptions,
- dataset_descriptor: dataset.DatasetDescriptor):
- """Initializes a ViP-DeepLab architecture.
-
- Args:
- config: A config_pb2.ExperimentOptions configuration.
- dataset_descriptor: A dataset.DatasetDescriptor.
- """
- super(ViPDeepLab, self).__init__(name='ViPDeepLab')
-
- if config.trainer_options.solver_options.use_sync_batchnorm:
- logging.info('Synchronized Batchnorm is used.')
- bn_layer = functools.partial(
- tf.keras.layers.experimental.SyncBatchNormalization,
- momentum=config.trainer_options.solver_options.batchnorm_momentum,
- epsilon=config.trainer_options.solver_options.batchnorm_epsilon)
- else:
- logging.info('Standard (unsynchronized) Batchnorm is used.')
- bn_layer = functools.partial(
- tf.keras.layers.BatchNormalization,
- momentum=config.trainer_options.solver_options.batchnorm_momentum,
- epsilon=config.trainer_options.solver_options.batchnorm_epsilon)
-
- self._encoder = builder.create_encoder(
- config.model_options.backbone,
- bn_layer,
- conv_kernel_weight_decay=(
- config.trainer_options.solver_options.weight_decay / 2))
-
- self._decoder = builder.create_decoder(config.model_options, bn_layer,
- dataset_descriptor.ignore_label)
-
- self._post_processor = post_processor_builder.get_post_processor(
- config, dataset_descriptor)
-
- pool_size = config.train_dataset_options.crop_size
- output_stride = float(config.model_options.backbone.output_stride)
- pool_size = tuple(
- utils.scale_mutable_sequence(pool_size, 1.0 / output_stride))
- logging.info('Setting pooling size to %s', pool_size)
- self.set_pool_size(pool_size)
-
- # Variables for multi-scale inference.
- self._add_flipped_images = config.evaluator_options.add_flipped_images
- if not config.evaluator_options.eval_scales:
- self._eval_scales = [1.0]
- else:
- self._eval_scales = config.evaluator_options.eval_scales
-
- self._label_divisor = dataset_descriptor.panoptic_label_divisor
-
- def _inference(self, input_tensor: tf.Tensor, next_input_tensor: tf.Tensor,
- training: bool) -> Dict[Text, Any]:
- """Performs an inference pass and returns raw predictions."""
- _, input_h, input_w, _ = input_tensor.get_shape().as_list()
- result_dict = collections.defaultdict(list)
- # Evaluation mode where one could perform multi-scale inference.
- scale_1_pool_size = self.get_pool_size()
- logging.info('Eval with scales %s', self._eval_scales)
- for eval_scale in self._eval_scales:
- # Get the scaled images/pool_size for each scale.
- scaled_images, scaled_pool_size = (
- self._scale_images_and_pool_size(input_tensor,
- list(scale_1_pool_size), eval_scale))
- next_scaled_images, _ = (
- self._scale_images_and_pool_size(next_input_tensor,
- list(scale_1_pool_size), eval_scale))
- # Update the ASPP pool size for different eval scales.
- self.set_pool_size(tuple(scaled_pool_size))
- logging.info('Eval scale %s; setting pooling size to %s', eval_scale,
- scaled_pool_size)
- pred_dict = self._decoder(
- self._encoder(scaled_images, training=training),
- self._encoder(next_scaled_images, training=training),
- training=training)
- pred_dict = self._resize_predictions(
- pred_dict, target_h=input_h, target_w=input_w)
- # Change the semantic logits to probabilities with softmax. Note
- # one should remove semantic logits for faster inference. We still
- # keep them since they will be used to compute evaluation loss.
- pred_dict[common.PRED_SEMANTIC_PROBS_KEY] = tf.nn.softmax(
- pred_dict[common.PRED_SEMANTIC_LOGITS_KEY])
- # Store the predictions from each scale.
- for output_type, output_value in pred_dict.items():
- result_dict[output_type].append(output_value)
- if self._add_flipped_images:
- pred_dict_reverse = self._decoder(
- self._encoder(tf.reverse(scaled_images, [2]), training=training),
- self._encoder(
- tf.reverse(next_scaled_images, [2]), training=training),
- training=training)
- pred_dict_reverse = self._resize_predictions(
- pred_dict_reverse, target_h=input_h, target_w=input_w, reverse=True)
- # Change the semantic logits to probabilities with softmax.
- pred_dict_reverse[common.PRED_SEMANTIC_PROBS_KEY] = tf.nn.softmax(
- pred_dict_reverse[common.PRED_SEMANTIC_LOGITS_KEY])
- # Store the predictions from each scale.
- for output_type, output_value in pred_dict_reverse.items():
- result_dict[output_type].append(output_value)
- # Set back the pool_size for scale 1.0, the original setting.
- self.set_pool_size(tuple(scale_1_pool_size))
- # Average results across scales.
- for output_type, output_value in result_dict.items():
- result_dict[output_type] = tf.reduce_mean(
- tf.stack(output_value, axis=0), axis=0)
- return result_dict
-
- def call(self,
- input_tensor: tf.Tensor,
- training: bool = False) -> Dict[Text, Any]:
- """Performs a forward pass.
-
- Args:
- input_tensor: An input tensor of type tf.Tensor with shape [batch, height,
- width, channels]. The input tensor should contain batches of RGB images
- pairs. The channel dimension is expected to encode two RGB pixels.
- training: A boolean flag indicating whether training behavior should be
- used (default: False).
-
- Returns:
- A dictionary containing the results of the specified DeepLab architecture.
- The results are bilinearly upsampled to input size before returning.
- """
- # Normalize the input in the same way as Inception. We normalize it outside
- # the encoder so that we can extend encoders to different backbones without
- # copying the normalization to each encoder. We normalize it after data
- # preprocessing because it is faster on TPUs than on host CPUs. The
- # normalization should not increase TPU memory consumption because it does
- # not require gradient.
- input_tensor = input_tensor / 127.5 - 1.0
- # Get the static spatial shape of the input tensor.
- _, input_h, input_w, _ = input_tensor.get_shape().as_list()
- # Splits the input_tensor into the current and the next frames.
- input_tensor, next_input_tensor = tf.split(input_tensor, 2, axis=3)
- if training:
- encoder_features = self._encoder(input_tensor, training=training)
- next_encoder_features = self._encoder(
- next_input_tensor, training=training)
- result_dict = self._decoder(
- encoder_features, next_encoder_features, training=training)
- result_dict = self._resize_predictions(
- result_dict, target_h=input_h, target_w=input_w)
- else:
- result_dict = self._inference(input_tensor, next_input_tensor, training)
- # To get panoptic prediction of the next frame, we reverse the
- # input_tensor and next_input_tensor and use them as the input.
- # The second input can be anything. In sequence evaluation, we can wait
- # for the results of the next pair. Here, we need to compute the panoptic
- # predictions of the next frame to do pair evaluation.
- # pylint: disable=arguments-out-of-order
- next_result_dict = self._inference(
- next_input_tensor, input_tensor, training)
- # Here, we horizontally concat the raw predictions of the current frame
- # and the next frame to perform two-frame panoptic post-processing.
- concat_result_dict = collections.defaultdict(list)
- concat_result_dict[common.PRED_SEMANTIC_PROBS_KEY] = tf.concat([
- result_dict[common.PRED_SEMANTIC_PROBS_KEY],
- next_result_dict[common.PRED_SEMANTIC_PROBS_KEY]
- ],
- axis=2)
- concat_result_dict[common.PRED_CENTER_HEATMAP_KEY] = tf.concat([
- result_dict[common.PRED_CENTER_HEATMAP_KEY],
- tf.zeros_like(next_result_dict[common.PRED_CENTER_HEATMAP_KEY])
- ],
- axis=2)
- next_regression_y, next_regression_x = tf.split(
- result_dict[common.PRED_NEXT_OFFSET_MAP_KEY],
- num_or_size_splits=2,
- axis=3)
- # The predicted horizontal offsets of the next frame need to subtract the
- # image width to point to the object centers in the current frame because
- # the two frames are horizontally concatenated.
- next_regression_x -= tf.constant(input_w, dtype=tf.float32)
- next_regression = tf.concat([next_regression_y, next_regression_x],
- axis=3)
- concat_result_dict[common.PRED_OFFSET_MAP_KEY] = tf.concat(
- [result_dict[common.PRED_OFFSET_MAP_KEY], next_regression], axis=2)
- concat_result_dict.update(self._post_processor(concat_result_dict))
- next_result_dict.update(self._post_processor(next_result_dict))
- result_dict[common.PRED_NEXT_PANOPTIC_KEY] = next_result_dict[
- common.PRED_PANOPTIC_KEY]
- for result_key in [
- common.PRED_PANOPTIC_KEY, common.PRED_SEMANTIC_KEY,
- common.PRED_INSTANCE_KEY, common.PRED_INSTANCE_CENTER_KEY,
- common.PRED_INSTANCE_SCORES_KEY
- ]:
- result_dict[result_key], next_result_dict[result_key] = tf.split(
- concat_result_dict[result_key], num_or_size_splits=2, axis=2)
- result_dict[common.PRED_CONCAT_NEXT_PANOPTIC_KEY] = next_result_dict[
- common.PRED_PANOPTIC_KEY]
- result_dict[common.PRED_NEXT_PANOPTIC_KEY] = tf.numpy_function(
- func=vip_deeplab.stitch_video_panoptic_prediction,
- inp=[
- result_dict[common.PRED_CONCAT_NEXT_PANOPTIC_KEY],
- result_dict[common.PRED_NEXT_PANOPTIC_KEY], self._label_divisor
- ],
- Tout=tf.int32)
- result_dict[common.PRED_NEXT_PANOPTIC_KEY].set_shape(
- result_dict[common.PRED_CONCAT_NEXT_PANOPTIC_KEY].get_shape())
- if common.PRED_CENTER_HEATMAP_KEY in result_dict:
- result_dict[common.PRED_CENTER_HEATMAP_KEY] = tf.squeeze(
- result_dict[common.PRED_CENTER_HEATMAP_KEY], axis=3)
- return result_dict
-
- def reset_pooling_layer(self):
- """Resets the ASPP pooling layer to global average pooling."""
- self._decoder.reset_pooling_layer()
-
- def set_pool_size(self, pool_size: Tuple[int, int]):
- """Sets the pooling size of the ASPP pooling layer.
-
- Args:
- pool_size: A tuple specifying the pooling size of the ASPP pooling layer.
- """
- self._decoder.set_pool_size(pool_size)
-
- def get_pool_size(self):
- return self._decoder.get_pool_size()
-
- @property
- def checkpoint_items(self) -> Dict[Text, Any]:
- items = dict(encoder=self._encoder)
- items.update(self._decoder.checkpoint_items)
- return items
-
- def _resize_predictions(self, result_dict, target_h, target_w, reverse=False):
- """Resizes predictions to the target height and width.
-
- This function resizes the items in the result_dict to the target height and
- width. The items are optionally reversed w.r.t width if `reverse` is True.
-
- Args:
- result_dict: A dictionary storing prediction results to be resized.
- target_h: An integer, the target height.
- target_w: An integer, the target width.
- reverse: A boolean, reversing the prediction result w.r.t. width.
-
- Returns:
- Resized (or optionally reversed) result_dict.
- """
- for key, value in result_dict.items():
- if reverse:
- value = tf.reverse(value, [2])
- # Special care to offsets: need to flip x-offsets.
- if _OFFSET_OUTPUT in key:
- offset_y, offset_x = tf.split(
- value=value, num_or_size_splits=2, axis=3)
- offset_x *= -1
- value = tf.concat([offset_y, offset_x], 3)
- if _OFFSET_OUTPUT in key:
- result_dict[key] = utils.resize_and_rescale_offsets(
- value, [target_h, target_w])
- else:
- result_dict[key] = utils.resize_bilinear(value, [target_h, target_w])
- return result_dict
-
- def _scale_images_and_pool_size(self, images, pool_size, scale):
- """Scales images and pool_size w.r.t.
-
- scale.
-
- Args:
- images: An input tensor with shape [batch, height, width, 3].
- pool_size: A list with two elements, specifying the pooling size of ASPP
- pooling layer.
- scale: A float, used to scale the input images and pool_size.
-
- Returns:
- Scaled images, and pool_size.
- """
- if scale == 1.0:
- scaled_images = images
- scaled_pool_size = pool_size
- else:
- image_size = images.get_shape().as_list()[1:3]
- scaled_image_size = utils.scale_mutable_sequence(image_size, scale)
- scaled_images = utils.resize_bilinear(images, scaled_image_size)
- scaled_pool_size = [None, None]
- if pool_size != [None, None]:
- scaled_pool_size = utils.scale_mutable_sequence(pool_size, scale)
- return scaled_images, scaled_pool_size
diff --git a/spaces/ali-ghamdan/deoldify/fastai/text/models/bwd_forget_mult_cuda.cpp b/spaces/ali-ghamdan/deoldify/fastai/text/models/bwd_forget_mult_cuda.cpp
deleted file mode 100644
index c9b5a14281e17dee53d6a15d3a4e99fa6171d1b5..0000000000000000000000000000000000000000
--- a/spaces/ali-ghamdan/deoldify/fastai/text/models/bwd_forget_mult_cuda.cpp
+++ /dev/null
@@ -1,31 +0,0 @@
-#include
-
-#include
-
-// CUDA forward declarations
-at::Tensor bwd_forget_mult_cuda_forward(at::Tensor x, at::Tensor f, at::Tensor output, bool batch_first);
-
-// C++ interface
-
-#define CHECK_CUDA(x) AT_ASSERTM(x.type().is_cuda(), #x " must be a CUDA tensor")
-#define CHECK_CONTIGUOUS(x) AT_ASSERTM(x.is_contiguous(), #x " must be contiguous")
-#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
-
-at::Tensor bwd_forget_mult_forward(at::Tensor x, at::Tensor f, at::Tensor output, bool batch_first) {
- CHECK_INPUT(x); CHECK_INPUT(f); CHECK_INPUT(output);
- return bwd_forget_mult_cuda_forward(x, f, output, batch_first);
-}
-
-std::vector bwd_forget_mult_cuda_backward(at::Tensor x, at::Tensor f, at::Tensor output,
- at::Tensor grad_output, bool batch_first);
-
-std::vector bwd_forget_mult_backward(at::Tensor x, at::Tensor f, at::Tensor output,
- at::Tensor grad_output, bool batch_first) {
- CHECK_INPUT(x); CHECK_INPUT(f); CHECK_INPUT(output);
- return bwd_forget_mult_cuda_backward(x, f, output, grad_output, batch_first);
-}
-
-PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
- m.def("forward", &bwd_forget_mult_forward, "BwdForgetMult forward (CUDA)");
- m.def("backward", &bwd_forget_mult_backward, "BwdForgetMult backward (CUDA)");
-}
diff --git a/spaces/alphunt/diffdock-alphunt-demo/baselines/baseline_evaluation.py b/spaces/alphunt/diffdock-alphunt-demo/baselines/baseline_evaluation.py
deleted file mode 100644
index 6ce83de2d0bb471c0b78e5935679b141c3518a3a..0000000000000000000000000000000000000000
--- a/spaces/alphunt/diffdock-alphunt-demo/baselines/baseline_evaluation.py
+++ /dev/null
@@ -1,219 +0,0 @@
-# small script to extract the ligand and save it in a separate file because GNINA will use the ligand position as initial pose
-import os
-
-import plotly.express as px
-import time
-from argparse import FileType, ArgumentParser
-
-import numpy as np
-import pandas as pd
-import wandb
-from biopandas.pdb import PandasPdb
-from rdkit import Chem
-
-from tqdm import tqdm
-
-from datasets.pdbbind import read_mol
-from datasets.process_mols import read_molecule
-from utils.utils import read_strings_from_txt, get_symmetry_rmsd
-
-parser = ArgumentParser()
-parser.add_argument('--config', type=FileType(mode='r'), default=None)
-parser.add_argument('--run_name', type=str, default='gnina_results', help='')
-parser.add_argument('--data_dir', type=str, default='data/PDBBind_processed', help='')
-parser.add_argument('--results_path', type=str, default='results/user_inference', help='Path to folder with trained model and hyperparameters')
-parser.add_argument('--file_suffix', type=str, default='_baseline_ligand.pdb', help='Path to folder with trained model and hyperparameters')
-parser.add_argument('--project', type=str, default='ligbind_inf', help='')
-parser.add_argument('--wandb', action='store_true', default=False, help='')
-parser.add_argument('--file_to_exclude', type=str, default=None, help='')
-parser.add_argument('--all_dirs_in_results', action='store_true', default=True, help='Evaluate all directories in the results path instead of using directly looking for the names')
-parser.add_argument('--num_predictions', type=int, default=10, help='')
-parser.add_argument('--no_id_in_filename', action='store_true', default=False, help='')
-args = parser.parse_args()
-
-print('Reading paths and names.')
-names = read_strings_from_txt(f'data/splits/timesplit_test')
-names_no_rec_overlap = read_strings_from_txt(f'data/splits/timesplit_test_no_rec_overlap')
-results_path_containments = os.listdir(args.results_path)
-
-if args.wandb:
- wandb.init(
- entity='coarse-graining-mit',
- settings=wandb.Settings(start_method="fork"),
- project=args.project,
- name=args.run_name,
- config=args
- )
-
-all_times = []
-successful_names_list = []
-rmsds_list = []
-centroid_distances_list = []
-min_cross_distances_list = []
-min_self_distances_list = []
-without_rec_overlap_list = []
-start_time = time.time()
-for i, name in enumerate(tqdm(names)):
- mol = read_mol(args.data_dir, name, remove_hs=True)
- mol = Chem.RemoveAllHs(mol)
- orig_ligand_pos = np.array(mol.GetConformer().GetPositions())
-
- if args.all_dirs_in_results:
- directory_with_name = [directory for directory in results_path_containments if name in directory][0]
- ligand_pos = []
- for i in range(args.num_predictions):
- file_paths = os.listdir(os.path.join(args.results_path, directory_with_name))
- file_path = [path for path in file_paths if f'rank{i+1}' in path][0]
- if args.file_to_exclude is not None and args.file_to_exclude in file_path: continue
- mol_pred = read_molecule(os.path.join(args.results_path, directory_with_name, file_path),remove_hs=True, sanitize=True)
- mol_pred = Chem.RemoveAllHs(mol_pred)
- ligand_pos.append(mol_pred.GetConformer().GetPositions())
- ligand_pos = np.asarray(ligand_pos)
- else:
- if not os.path.exists(os.path.join(args.results_path, name, f'{"" if args.no_id_in_filename else name}{args.file_suffix}')): raise Exception('path did not exists:', os.path.join(args.results_path, name, f'{"" if args.no_id_in_filename else name}{args.file_suffix}'))
- mol_pred = read_molecule(os.path.join(args.results_path, name, f'{"" if args.no_id_in_filename else name}{args.file_suffix}'), remove_hs=True, sanitize=True)
- if mol_pred == None:
- print("Skipping ", name, ' because RDKIT could not read it.')
- continue
- mol_pred = Chem.RemoveAllHs(mol_pred)
- ligand_pos = np.asarray([np.array(mol_pred.GetConformer(i).GetPositions()) for i in range(args.num_predictions)])
- try:
- rmsd = get_symmetry_rmsd(mol, orig_ligand_pos, [l for l in ligand_pos], mol_pred)
- except Exception as e:
- print("Using non corrected RMSD because of the error:", e)
- rmsd = np.sqrt(((ligand_pos - orig_ligand_pos) ** 2).sum(axis=2).mean(axis=1))
-
- rmsds_list.append(rmsd)
- centroid_distances_list.append(np.linalg.norm(ligand_pos.mean(axis=1) - orig_ligand_pos[None,:].mean(axis=1), axis=1))
-
- rec_path = os.path.join(args.data_dir, name, f'{name}_protein_processed.pdb')
- if not os.path.exists(rec_path):
- rec_path = os.path.join(args.data_dir, name,f'{name}_protein_obabel_reduce.pdb')
- rec = PandasPdb().read_pdb(rec_path)
- rec_df = rec.df['ATOM']
- receptor_pos = rec_df[['x_coord', 'y_coord', 'z_coord']].to_numpy().squeeze().astype(np.float32)
- receptor_pos = np.tile(receptor_pos, (args.num_predictions, 1, 1))
-
- cross_distances = np.linalg.norm(receptor_pos[:, :, None, :] - ligand_pos[:, None, :, :], axis=-1)
- self_distances = np.linalg.norm(ligand_pos[:, :, None, :] - ligand_pos[:, None, :, :], axis=-1)
- self_distances = np.where(np.eye(self_distances.shape[2]), np.inf, self_distances)
- min_cross_distances_list.append(np.min(cross_distances, axis=(1,2)))
- min_self_distances_list.append(np.min(self_distances, axis=(1, 2)))
- successful_names_list.append(name)
- without_rec_overlap_list.append(1 if name in names_no_rec_overlap else 0)
-performance_metrics = {}
-for overlap in ['', 'no_overlap_']:
- if 'no_overlap_' == overlap:
- without_rec_overlap = np.array(without_rec_overlap_list, dtype=bool)
- rmsds = np.array(rmsds_list)[without_rec_overlap]
- centroid_distances = np.array(centroid_distances_list)[without_rec_overlap]
- min_cross_distances = np.array(min_cross_distances_list)[without_rec_overlap]
- min_self_distances = np.array(min_self_distances_list)[without_rec_overlap]
- successful_names = np.array(successful_names_list)[without_rec_overlap]
- else:
- rmsds = np.array(rmsds_list)
- centroid_distances = np.array(centroid_distances_list)
- min_cross_distances = np.array(min_cross_distances_list)
- min_self_distances = np.array(min_self_distances_list)
- successful_names = np.array(successful_names_list)
-
- np.save(os.path.join(args.results_path, f'{overlap}rmsds.npy'), rmsds)
- np.save(os.path.join(args.results_path, f'{overlap}names.npy'), successful_names)
- np.save(os.path.join(args.results_path, f'{overlap}min_cross_distances.npy'), np.array(min_cross_distances))
- np.save(os.path.join(args.results_path, f'{overlap}min_self_distances.npy'), np.array(min_self_distances))
-
- performance_metrics.update({
- f'{overlap}steric_clash_fraction': (100 * (min_cross_distances < 0.4).sum() / len(min_cross_distances) / args.num_predictions).__round__(2),
- f'{overlap}self_intersect_fraction': (100 * (min_self_distances < 0.4).sum() / len(min_self_distances) / args.num_predictions).__round__(2),
- f'{overlap}mean_rmsd': rmsds[:,0].mean(),
- f'{overlap}rmsds_below_2': (100 * (rmsds[:,0] < 2).sum() / len(rmsds[:,0])),
- f'{overlap}rmsds_below_5': (100 * (rmsds[:,0] < 5).sum() / len(rmsds[:,0])),
- f'{overlap}rmsds_percentile_25': np.percentile(rmsds[:,0], 25).round(2),
- f'{overlap}rmsds_percentile_50': np.percentile(rmsds[:,0], 50).round(2),
- f'{overlap}rmsds_percentile_75': np.percentile(rmsds[:,0], 75).round(2),
-
- f'{overlap}mean_centroid': centroid_distances[:,0].mean().__round__(2),
- f'{overlap}centroid_below_2': (100 * (centroid_distances[:,0] < 2).sum() / len(centroid_distances[:,0])).__round__(2),
- f'{overlap}centroid_below_5': (100 * (centroid_distances[:,0] < 5).sum() / len(centroid_distances[:,0])).__round__(2),
- f'{overlap}centroid_percentile_25': np.percentile(centroid_distances[:,0], 25).round(2),
- f'{overlap}centroid_percentile_50': np.percentile(centroid_distances[:,0], 50).round(2),
- f'{overlap}centroid_percentile_75': np.percentile(centroid_distances[:,0], 75).round(2),
- })
-
- top5_rmsds = np.min(rmsds[:, :5], axis=1)
- top5_centroid_distances = centroid_distances[np.arange(rmsds.shape[0])[:,None],np.argsort(rmsds[:, :5], axis=1)][:,0]
- top5_min_cross_distances = min_cross_distances[np.arange(rmsds.shape[0])[:,None],np.argsort(rmsds[:, :5], axis=1)][:,0]
- top5_min_self_distances = min_self_distances[np.arange(rmsds.shape[0])[:,None],np.argsort(rmsds[:, :5], axis=1)][:,0]
- performance_metrics.update({
- f'{overlap}top5_steric_clash_fraction': (100 * (top5_min_cross_distances < 0.4).sum() / len(top5_min_cross_distances)).__round__(2),
- f'{overlap}top5_self_intersect_fraction': (100 * (top5_min_self_distances < 0.4).sum() / len(top5_min_self_distances)).__round__(2),
- f'{overlap}top5_rmsds_below_2': (100 * (top5_rmsds < 2).sum() / len(top5_rmsds)).__round__(2),
- f'{overlap}top5_rmsds_below_5': (100 * (top5_rmsds < 5).sum() / len(top5_rmsds)).__round__(2),
- f'{overlap}top5_rmsds_percentile_25': np.percentile(top5_rmsds, 25).round(2),
- f'{overlap}top5_rmsds_percentile_50': np.percentile(top5_rmsds, 50).round(2),
- f'{overlap}top5_rmsds_percentile_75': np.percentile(top5_rmsds, 75).round(2),
-
- f'{overlap}top5_centroid_below_2': (100 * (top5_centroid_distances < 2).sum() / len(top5_centroid_distances)).__round__(2),
- f'{overlap}top5_centroid_below_5': (100 * (top5_centroid_distances < 5).sum() / len(top5_centroid_distances)).__round__(2),
- f'{overlap}top5_centroid_percentile_25': np.percentile(top5_centroid_distances, 25).round(2),
- f'{overlap}top5_centroid_percentile_50': np.percentile(top5_centroid_distances, 50).round(2),
- f'{overlap}top5_centroid_percentile_75': np.percentile(top5_centroid_distances, 75).round(2),
- })
-
-
- top10_rmsds = np.min(rmsds[:, :10], axis=1)
- top10_centroid_distances = centroid_distances[np.arange(rmsds.shape[0])[:,None],np.argsort(rmsds[:, :10], axis=1)][:,0]
- top10_min_cross_distances = min_cross_distances[np.arange(rmsds.shape[0])[:,None],np.argsort(rmsds[:, :10], axis=1)][:,0]
- top10_min_self_distances = min_self_distances[np.arange(rmsds.shape[0])[:,None],np.argsort(rmsds[:, :10], axis=1)][:,0]
- performance_metrics.update({
- f'{overlap}top10_self_intersect_fraction': (100 * (top10_min_self_distances < 0.4).sum() / len(top10_min_self_distances)).__round__(2),
- f'{overlap}top10_steric_clash_fraction': ( 100 * (top10_min_cross_distances < 0.4).sum() / len(top10_min_cross_distances)).__round__(2),
- f'{overlap}top10_rmsds_below_2': (100 * (top10_rmsds < 2).sum() / len(top10_rmsds)).__round__(2),
- f'{overlap}top10_rmsds_below_5': (100 * (top10_rmsds < 5).sum() / len(top10_rmsds)).__round__(2),
- f'{overlap}top10_rmsds_percentile_25': np.percentile(top10_rmsds, 25).round(2),
- f'{overlap}top10_rmsds_percentile_50': np.percentile(top10_rmsds, 50).round(2),
- f'{overlap}top10_rmsds_percentile_75': np.percentile(top10_rmsds, 75).round(2),
-
- f'{overlap}top10_centroid_below_2': (100 * (top10_centroid_distances < 2).sum() / len(top10_centroid_distances)).__round__(2),
- f'{overlap}top10_centroid_below_5': (100 * (top10_centroid_distances < 5).sum() / len(top10_centroid_distances)).__round__(2),
- f'{overlap}top10_centroid_percentile_25': np.percentile(top10_centroid_distances, 25).round(2),
- f'{overlap}top10_centroid_percentile_50': np.percentile(top10_centroid_distances, 50).round(2),
- f'{overlap}top10_centroid_percentile_75': np.percentile(top10_centroid_distances, 75).round(2),
- })
-for k in performance_metrics:
- print(k, performance_metrics[k])
-
-if args.wandb:
- wandb.log(performance_metrics)
- histogram_metrics_list = [('rmsd', rmsds[:,0]),
- ('centroid_distance', centroid_distances[:,0]),
- ('mean_rmsd', rmsds[:,0]),
- ('mean_centroid_distance', centroid_distances[:,0])]
- histogram_metrics_list.append(('top5_rmsds', top5_rmsds))
- histogram_metrics_list.append(('top5_centroid_distances', top5_centroid_distances))
- histogram_metrics_list.append(('top10_rmsds', top10_rmsds))
- histogram_metrics_list.append(('top10_centroid_distances', top10_centroid_distances))
-
- os.makedirs(f'.plotly_cache/baseline_cache', exist_ok=True)
- images = []
- for metric_name, metric in histogram_metrics_list:
- d = {args.results_path: metric}
- df = pd.DataFrame(data=d)
- fig = px.ecdf(df, width=900, height=600, range_x=[0, 40])
- fig.add_vline(x=2, annotation_text='2 A;', annotation_font_size=20, annotation_position="top right",
- line_dash='dash', line_color='firebrick', annotation_font_color='firebrick')
- fig.add_vline(x=5, annotation_text='5 A;', annotation_font_size=20, annotation_position="top right",
- line_dash='dash', line_color='green', annotation_font_color='green')
- fig.update_xaxes(title=f'{metric_name} in Angstrom', title_font={"size": 20}, tickfont={"size": 20})
- fig.update_yaxes(title=f'Fraction of predictions with lower error', title_font={"size": 20},
- tickfont={"size": 20})
- fig.update_layout(autosize=False, margin={'l': 0, 'r': 0, 't': 0, 'b': 0}, plot_bgcolor='white',
- paper_bgcolor='white', legend_title_text='Method', legend_title_font_size=17,
- legend=dict(yanchor="bottom", y=0.1, xanchor="right", x=0.99, font=dict(size=17), ), )
- fig.update_xaxes(showgrid=True, gridcolor='lightgrey')
- fig.update_yaxes(showgrid=True, gridcolor='lightgrey')
-
- fig.write_image(os.path.join(f'.plotly_cache/baseline_cache', f'{metric_name}.png'))
- wandb.log({metric_name: wandb.Image(os.path.join(f'.plotly_cache/baseline_cache', f'{metric_name}.png'), caption=f"{metric_name}")})
- images.append(wandb.Image(os.path.join(f'.plotly_cache/baseline_cache', f'{metric_name}.png'), caption=f"{metric_name}"))
- wandb.log({'images': images})
\ No newline at end of file
diff --git a/spaces/amish1729/LFUNet/README.md b/spaces/amish1729/LFUNet/README.md
deleted file mode 100644
index 9cb416a993dd4c39cd754e56464dd1f4da73769f..0000000000000000000000000000000000000000
--- a/spaces/amish1729/LFUNet/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: LFUNet
-emoji: 👀
-colorFrom: blue
-colorTo: purple
-sdk: gradio
-sdk_version: 3.35.2
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/anthonygaltier/text_2_price__real_estate/README.md b/spaces/anthonygaltier/text_2_price__real_estate/README.md
deleted file mode 100644
index 5f296d6e95894ce0794483ed15b2bd4a8e4a1e26..0000000000000000000000000000000000000000
--- a/spaces/anthonygaltier/text_2_price__real_estate/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Text 2 Price Real Estate
-emoji: 📚
-colorFrom: purple
-colorTo: red
-sdk: streamlit
-sdk_version: 1.10.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/aodianyun/panoptic-segment-anything/README.md b/spaces/aodianyun/panoptic-segment-anything/README.md
deleted file mode 100644
index a332324e6ffd5313db46a6d14cc0223dfac47b8b..0000000000000000000000000000000000000000
--- a/spaces/aodianyun/panoptic-segment-anything/README.md
+++ /dev/null
@@ -1,21 +0,0 @@
----
-title: Panoptic Segment Anything
-emoji: 🖼️🪄
-colorFrom: yellow
-colorTo: red
-sdk: gradio
-sdk_version: 3.24.1
-app_file: app.py
-pinned: false
-license: apache-2.0
-models:
-- ShilongLiu/GroundingDINO
-- CIDAS/clipseg-rd64-refined
-tags:
-- segmentation
-- zero-shot
-- sam
-duplicated_from: segments/panoptic-segment-anything
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/aodianyun/stable-diffusion-webui/modules/ui.py b/spaces/aodianyun/stable-diffusion-webui/modules/ui.py
deleted file mode 100644
index badf4975128985ad55bb69d6ee028adc0a61f97c..0000000000000000000000000000000000000000
--- a/spaces/aodianyun/stable-diffusion-webui/modules/ui.py
+++ /dev/null
@@ -1,1798 +0,0 @@
-import html
-import json
-import math
-import mimetypes
-import os
-import platform
-import random
-import sys
-import tempfile
-import time
-import traceback
-from functools import partial, reduce
-import warnings
-
-import gradio as gr
-import gradio.routes
-import gradio.utils
-import numpy as np
-from PIL import Image, PngImagePlugin
-from modules.call_queue import wrap_gradio_gpu_call, wrap_queued_call, wrap_gradio_call
-
-from modules import sd_hijack, sd_models, localization, script_callbacks, ui_extensions, deepbooru, sd_vae, extra_networks, postprocessing, ui_components, ui_common, ui_postprocessing
-from modules.ui_components import FormRow, FormGroup, ToolButton, FormHTML
-from modules.paths import script_path, data_path
-
-from modules.shared import opts, cmd_opts, restricted_opts
-
-import modules.codeformer_model
-import modules.generation_parameters_copypaste as parameters_copypaste
-import modules.gfpgan_model
-import modules.hypernetworks.ui
-import modules.scripts
-import modules.shared as shared
-import modules.styles
-import modules.textual_inversion.ui
-from modules import prompt_parser
-from modules.images import save_image
-from modules.sd_hijack import model_hijack
-from modules.sd_samplers import samplers, samplers_for_img2img
-from modules.textual_inversion import textual_inversion
-import modules.hypernetworks.ui
-from modules.generation_parameters_copypaste import image_from_url_text
-import modules.extras
-
-warnings.filterwarnings("default" if opts.show_warnings else "ignore", category=UserWarning)
-
-# this is a fix for Windows users. Without it, javascript files will be served with text/html content-type and the browser will not show any UI
-mimetypes.init()
-mimetypes.add_type('application/javascript', '.js')
-
-if not cmd_opts.share and not cmd_opts.listen:
- # fix gradio phoning home
- gradio.utils.version_check = lambda: None
- gradio.utils.get_local_ip_address = lambda: '127.0.0.1'
-
-if cmd_opts.ngrok is not None:
- import modules.ngrok as ngrok
- print('ngrok authtoken detected, trying to connect...')
- ngrok.connect(
- cmd_opts.ngrok,
- cmd_opts.port if cmd_opts.port is not None else 7860,
- cmd_opts.ngrok_region
- )
-
-
-def gr_show(visible=True):
- return {"visible": visible, "__type__": "update"}
-
-
-sample_img2img = "assets/stable-samples/img2img/sketch-mountains-input.jpg"
-sample_img2img = sample_img2img if os.path.exists(sample_img2img) else None
-
-css_hide_progressbar = """
-.wrap .m-12 svg { display:none!important; }
-.wrap .m-12::before { content:"Loading..." }
-.wrap .z-20 svg { display:none!important; }
-.wrap .z-20::before { content:"Loading..." }
-.wrap.cover-bg .z-20::before { content:"" }
-.progress-bar { display:none!important; }
-.meta-text { display:none!important; }
-.meta-text-center { display:none!important; }
-"""
-
-# Using constants for these since the variation selector isn't visible.
-# Important that they exactly match script.js for tooltip to work.
-random_symbol = '\U0001f3b2\ufe0f' # 🎲️
-reuse_symbol = '\u267b\ufe0f' # ♻️
-paste_symbol = '\u2199\ufe0f' # ↙
-refresh_symbol = '\U0001f504' # 🔄
-save_style_symbol = '\U0001f4be' # 💾
-apply_style_symbol = '\U0001f4cb' # 📋
-clear_prompt_symbol = '\U0001F5D1' # 🗑️
-extra_networks_symbol = '\U0001F3B4' # 🎴
-switch_values_symbol = '\U000021C5' # ⇅
-
-
-def plaintext_to_html(text):
- return ui_common.plaintext_to_html(text)
-
-
-def send_gradio_gallery_to_image(x):
- if len(x) == 0:
- return None
- return image_from_url_text(x[0])
-
-def visit(x, func, path=""):
- if hasattr(x, 'children'):
- for c in x.children:
- visit(c, func, path)
- elif x.label is not None:
- func(path + "/" + str(x.label), x)
-
-
-def add_style(name: str, prompt: str, negative_prompt: str):
- if name is None:
- return [gr_show() for x in range(4)]
-
- style = modules.styles.PromptStyle(name, prompt, negative_prompt)
- shared.prompt_styles.styles[style.name] = style
- # Save all loaded prompt styles: this allows us to update the storage format in the future more easily, because we
- # reserialize all styles every time we save them
- shared.prompt_styles.save_styles(shared.styles_filename)
-
- return [gr.Dropdown.update(visible=True, choices=list(shared.prompt_styles.styles)) for _ in range(2)]
-
-
-def calc_resolution_hires(enable, width, height, hr_scale, hr_resize_x, hr_resize_y):
- from modules import processing, devices
-
- if not enable:
- return ""
-
- p = processing.StableDiffusionProcessingTxt2Img(width=width, height=height, enable_hr=True, hr_scale=hr_scale, hr_resize_x=hr_resize_x, hr_resize_y=hr_resize_y)
-
- with devices.autocast():
- p.init([""], [0], [0])
-
- return f"resize: from {p.width}x{p.height} to {p.hr_resize_x or p.hr_upscale_to_x}x{p.hr_resize_y or p.hr_upscale_to_y}"
-
-
-def apply_styles(prompt, prompt_neg, styles):
- prompt = shared.prompt_styles.apply_styles_to_prompt(prompt, styles)
- prompt_neg = shared.prompt_styles.apply_negative_styles_to_prompt(prompt_neg, styles)
-
- return [gr.Textbox.update(value=prompt), gr.Textbox.update(value=prompt_neg), gr.Dropdown.update(value=[])]
-
-
-def process_interrogate(interrogation_function, mode, ii_input_dir, ii_output_dir, *ii_singles):
- if mode in {0, 1, 3, 4}:
- return [interrogation_function(ii_singles[mode]), None]
- elif mode == 2:
- return [interrogation_function(ii_singles[mode]["image"]), None]
- elif mode == 5:
- assert not shared.cmd_opts.hide_ui_dir_config, "Launched with --hide-ui-dir-config, batch img2img disabled"
- images = shared.listfiles(ii_input_dir)
- print(f"Will process {len(images)} images.")
- if ii_output_dir != "":
- os.makedirs(ii_output_dir, exist_ok=True)
- else:
- ii_output_dir = ii_input_dir
-
- for image in images:
- img = Image.open(image)
- filename = os.path.basename(image)
- left, _ = os.path.splitext(filename)
- print(interrogation_function(img), file=open(os.path.join(ii_output_dir, left + ".txt"), 'a'))
-
- return [gr.update(), None]
-
-
-def interrogate(image):
- prompt = shared.interrogator.interrogate(image.convert("RGB"))
- return gr.update() if prompt is None else prompt
-
-
-def interrogate_deepbooru(image):
- prompt = deepbooru.model.tag(image)
- return gr.update() if prompt is None else prompt
-
-
-def create_seed_inputs(target_interface):
- with FormRow(elem_id=target_interface + '_seed_row'):
- seed = (gr.Textbox if cmd_opts.use_textbox_seed else gr.Number)(label='Seed', value=-1, elem_id=target_interface + '_seed')
- seed.style(container=False)
- random_seed = gr.Button(random_symbol, elem_id=target_interface + '_random_seed')
- reuse_seed = gr.Button(reuse_symbol, elem_id=target_interface + '_reuse_seed')
-
- with gr.Group(elem_id=target_interface + '_subseed_show_box'):
- seed_checkbox = gr.Checkbox(label='Extra', elem_id=target_interface + '_subseed_show', value=False)
-
- # Components to show/hide based on the 'Extra' checkbox
- seed_extras = []
-
- with FormRow(visible=False, elem_id=target_interface + '_subseed_row') as seed_extra_row_1:
- seed_extras.append(seed_extra_row_1)
- subseed = gr.Number(label='Variation seed', value=-1, elem_id=target_interface + '_subseed')
- subseed.style(container=False)
- random_subseed = gr.Button(random_symbol, elem_id=target_interface + '_random_subseed')
- reuse_subseed = gr.Button(reuse_symbol, elem_id=target_interface + '_reuse_subseed')
- subseed_strength = gr.Slider(label='Variation strength', value=0.0, minimum=0, maximum=1, step=0.01, elem_id=target_interface + '_subseed_strength')
-
- with FormRow(visible=False) as seed_extra_row_2:
- seed_extras.append(seed_extra_row_2)
- seed_resize_from_w = gr.Slider(minimum=0, maximum=2048, step=8, label="Resize seed from width", value=0, elem_id=target_interface + '_seed_resize_from_w')
- seed_resize_from_h = gr.Slider(minimum=0, maximum=2048, step=8, label="Resize seed from height", value=0, elem_id=target_interface + '_seed_resize_from_h')
-
- random_seed.click(fn=lambda: -1, show_progress=False, inputs=[], outputs=[seed])
- random_subseed.click(fn=lambda: -1, show_progress=False, inputs=[], outputs=[subseed])
-
- def change_visibility(show):
- return {comp: gr_show(show) for comp in seed_extras}
-
- seed_checkbox.change(change_visibility, show_progress=False, inputs=[seed_checkbox], outputs=seed_extras)
-
- return seed, reuse_seed, subseed, reuse_subseed, subseed_strength, seed_resize_from_h, seed_resize_from_w, seed_checkbox
-
-
-
-def connect_clear_prompt(button):
- """Given clear button, prompt, and token_counter objects, setup clear prompt button click event"""
- button.click(
- _js="clear_prompt",
- fn=None,
- inputs=[],
- outputs=[],
- )
-
-
-def connect_reuse_seed(seed: gr.Number, reuse_seed: gr.Button, generation_info: gr.Textbox, dummy_component, is_subseed):
- """ Connects a 'reuse (sub)seed' button's click event so that it copies last used
- (sub)seed value from generation info the to the seed field. If copying subseed and subseed strength
- was 0, i.e. no variation seed was used, it copies the normal seed value instead."""
- def copy_seed(gen_info_string: str, index):
- res = -1
-
- try:
- gen_info = json.loads(gen_info_string)
- index -= gen_info.get('index_of_first_image', 0)
-
- if is_subseed and gen_info.get('subseed_strength', 0) > 0:
- all_subseeds = gen_info.get('all_subseeds', [-1])
- res = all_subseeds[index if 0 <= index < len(all_subseeds) else 0]
- else:
- all_seeds = gen_info.get('all_seeds', [-1])
- res = all_seeds[index if 0 <= index < len(all_seeds) else 0]
-
- except json.decoder.JSONDecodeError as e:
- if gen_info_string != '':
- print("Error parsing JSON generation info:", file=sys.stderr)
- print(gen_info_string, file=sys.stderr)
-
- return [res, gr_show(False)]
-
- reuse_seed.click(
- fn=copy_seed,
- _js="(x, y) => [x, selected_gallery_index()]",
- show_progress=False,
- inputs=[generation_info, dummy_component],
- outputs=[seed, dummy_component]
- )
-
-
-def update_token_counter(text, steps):
- try:
- text, _ = extra_networks.parse_prompt(text)
-
- _, prompt_flat_list, _ = prompt_parser.get_multicond_prompt_list([text])
- prompt_schedules = prompt_parser.get_learned_conditioning_prompt_schedules(prompt_flat_list, steps)
-
- except Exception:
- # a parsing error can happen here during typing, and we don't want to bother the user with
- # messages related to it in console
- prompt_schedules = [[[steps, text]]]
-
- flat_prompts = reduce(lambda list1, list2: list1+list2, prompt_schedules)
- prompts = [prompt_text for step, prompt_text in flat_prompts]
- token_count, max_length = max([model_hijack.get_prompt_lengths(prompt) for prompt in prompts], key=lambda args: args[0])
- return f"{token_count}/{max_length}"
-
-
-def create_toprow(is_img2img):
- id_part = "img2img" if is_img2img else "txt2img"
-
- with gr.Row(elem_id=f"{id_part}_toprow", variant="compact"):
- with gr.Column(elem_id=f"{id_part}_prompt_container", scale=6):
- with gr.Row():
- with gr.Column(scale=80):
- with gr.Row():
- prompt = gr.Textbox(label="Prompt", elem_id=f"{id_part}_prompt", show_label=False, lines=3, placeholder="Prompt (press Ctrl+Enter or Alt+Enter to generate)")
-
- with gr.Row():
- with gr.Column(scale=80):
- with gr.Row():
- negative_prompt = gr.Textbox(label="Negative prompt", elem_id=f"{id_part}_neg_prompt", show_label=False, lines=2, placeholder="Negative prompt (press Ctrl+Enter or Alt+Enter to generate)")
-
- button_interrogate = None
- button_deepbooru = None
- if is_img2img:
- with gr.Column(scale=1, elem_id="interrogate_col"):
- button_interrogate = gr.Button('Interrogate\nCLIP', elem_id="interrogate")
- button_deepbooru = gr.Button('Interrogate\nDeepBooru', elem_id="deepbooru")
-
- with gr.Column(scale=1, elem_id=f"{id_part}_actions_column"):
- with gr.Row(elem_id=f"{id_part}_generate_box"):
- interrupt = gr.Button('Interrupt', elem_id=f"{id_part}_interrupt")
- skip = gr.Button('Skip', elem_id=f"{id_part}_skip")
- submit = gr.Button('Generate', elem_id=f"{id_part}_generate", variant='primary')
-
- skip.click(
- fn=lambda: shared.state.skip(),
- inputs=[],
- outputs=[],
- )
-
- interrupt.click(
- fn=lambda: shared.state.interrupt(),
- inputs=[],
- outputs=[],
- )
-
- with gr.Row(elem_id=f"{id_part}_tools"):
- paste = ToolButton(value=paste_symbol, elem_id="paste")
- clear_prompt_button = ToolButton(value=clear_prompt_symbol, elem_id=f"{id_part}_clear_prompt")
- extra_networks_button = ToolButton(value=extra_networks_symbol, elem_id=f"{id_part}_extra_networks")
- prompt_style_apply = ToolButton(value=apply_style_symbol, elem_id=f"{id_part}_style_apply")
- save_style = ToolButton(value=save_style_symbol, elem_id=f"{id_part}_style_create")
-
- token_counter = gr.HTML(value="", elem_id=f"{id_part}_token_counter")
- token_button = gr.Button(visible=False, elem_id=f"{id_part}_token_button")
- negative_token_counter = gr.HTML(value="", elem_id=f"{id_part}_negative_token_counter")
- negative_token_button = gr.Button(visible=False, elem_id=f"{id_part}_negative_token_button")
-
- clear_prompt_button.click(
- fn=lambda *x: x,
- _js="confirm_clear_prompt",
- inputs=[prompt, negative_prompt],
- outputs=[prompt, negative_prompt],
- )
-
- with gr.Row(elem_id=f"{id_part}_styles_row"):
- prompt_styles = gr.Dropdown(label="Styles", elem_id=f"{id_part}_styles", choices=[k for k, v in shared.prompt_styles.styles.items()], value=[], multiselect=True)
- create_refresh_button(prompt_styles, shared.prompt_styles.reload, lambda: {"choices": [k for k, v in shared.prompt_styles.styles.items()]}, f"refresh_{id_part}_styles")
-
- return prompt, prompt_styles, negative_prompt, submit, button_interrogate, button_deepbooru, prompt_style_apply, save_style, paste, extra_networks_button, token_counter, token_button, negative_token_counter, negative_token_button
-
-
-def setup_progressbar(*args, **kwargs):
- pass
-
-
-def apply_setting(key, value):
- if value is None:
- return gr.update()
-
- if shared.cmd_opts.freeze_settings:
- return gr.update()
-
- # dont allow model to be swapped when model hash exists in prompt
- if key == "sd_model_checkpoint" and opts.disable_weights_auto_swap:
- return gr.update()
-
- if key == "sd_model_checkpoint":
- ckpt_info = sd_models.get_closet_checkpoint_match(value)
-
- if ckpt_info is not None:
- value = ckpt_info.title
- else:
- return gr.update()
-
- comp_args = opts.data_labels[key].component_args
- if comp_args and isinstance(comp_args, dict) and comp_args.get('visible') is False:
- return
-
- valtype = type(opts.data_labels[key].default)
- oldval = opts.data.get(key, None)
- opts.data[key] = valtype(value) if valtype != type(None) else value
- if oldval != value and opts.data_labels[key].onchange is not None:
- opts.data_labels[key].onchange()
-
- opts.save(shared.config_filename)
- return getattr(opts, key)
-
-
-def create_refresh_button(refresh_component, refresh_method, refreshed_args, elem_id):
- def refresh():
- refresh_method()
- args = refreshed_args() if callable(refreshed_args) else refreshed_args
-
- for k, v in args.items():
- setattr(refresh_component, k, v)
-
- return gr.update(**(args or {}))
-
- refresh_button = ToolButton(value=refresh_symbol, elem_id=elem_id)
- refresh_button.click(
- fn=refresh,
- inputs=[],
- outputs=[refresh_component]
- )
- return refresh_button
-
-
-def create_output_panel(tabname, outdir):
- return ui_common.create_output_panel(tabname, outdir)
-
-
-def create_sampler_and_steps_selection(choices, tabname):
- if opts.samplers_in_dropdown:
- with FormRow(elem_id=f"sampler_selection_{tabname}"):
- sampler_index = gr.Dropdown(label='Sampling method', elem_id=f"{tabname}_sampling", choices=[x.name for x in choices], value=choices[0].name, type="index")
- steps = gr.Slider(minimum=1, maximum=150, step=1, elem_id=f"{tabname}_steps", label="Sampling steps", value=20)
- else:
- with FormGroup(elem_id=f"sampler_selection_{tabname}"):
- steps = gr.Slider(minimum=1, maximum=150, step=1, elem_id=f"{tabname}_steps", label="Sampling steps", value=20)
- sampler_index = gr.Radio(label='Sampling method', elem_id=f"{tabname}_sampling", choices=[x.name for x in choices], value=choices[0].name, type="index")
-
- return steps, sampler_index
-
-
-def ordered_ui_categories():
- user_order = {x.strip(): i * 2 + 1 for i, x in enumerate(shared.opts.ui_reorder.split(","))}
-
- for i, category in sorted(enumerate(shared.ui_reorder_categories), key=lambda x: user_order.get(x[1], x[0] * 2 + 0)):
- yield category
-
-
-def get_value_for_setting(key):
- value = getattr(opts, key)
-
- info = opts.data_labels[key]
- args = info.component_args() if callable(info.component_args) else info.component_args or {}
- args = {k: v for k, v in args.items() if k not in {'precision'}}
-
- return gr.update(value=value, **args)
-
-
-def create_override_settings_dropdown(tabname, row):
- dropdown = gr.Dropdown([], label="Override settings", visible=False, elem_id=f"{tabname}_override_settings", multiselect=True)
-
- dropdown.change(
- fn=lambda x: gr.Dropdown.update(visible=len(x) > 0),
- inputs=[dropdown],
- outputs=[dropdown],
- )
-
- return dropdown
-
-
-def create_ui():
- import modules.img2img
- import modules.txt2img
-
- reload_javascript()
-
- parameters_copypaste.reset()
-
- modules.scripts.scripts_current = modules.scripts.scripts_txt2img
- modules.scripts.scripts_txt2img.initialize_scripts(is_img2img=False)
-
- with gr.Blocks(analytics_enabled=False) as txt2img_interface:
- txt2img_prompt, txt2img_prompt_styles, txt2img_negative_prompt, submit, _, _, txt2img_prompt_style_apply, txt2img_save_style, txt2img_paste, extra_networks_button, token_counter, token_button, negative_token_counter, negative_token_button = create_toprow(is_img2img=False)
-
- dummy_component = gr.Label(visible=False)
- txt_prompt_img = gr.File(label="", elem_id="txt2img_prompt_image", file_count="single", type="binary", visible=False)
-
- with FormRow(variant='compact', elem_id="txt2img_extra_networks", visible=False) as extra_networks:
- from modules import ui_extra_networks
- extra_networks_ui = ui_extra_networks.create_ui(extra_networks, extra_networks_button, 'txt2img')
-
- with gr.Row().style(equal_height=False):
- with gr.Column(variant='compact', elem_id="txt2img_settings"):
- for category in ordered_ui_categories():
- if category == "sampler":
- steps, sampler_index = create_sampler_and_steps_selection(samplers, "txt2img")
-
- elif category == "dimensions":
- with FormRow():
- with gr.Column(elem_id="txt2img_column_size", scale=4):
- width = gr.Slider(minimum=64, maximum=2048, step=8, label="Width", value=512, elem_id="txt2img_width")
- height = gr.Slider(minimum=64, maximum=2048, step=8, label="Height", value=512, elem_id="txt2img_height")
-
- res_switch_btn = ToolButton(value=switch_values_symbol, elem_id="txt2img_res_switch_btn")
- if opts.dimensions_and_batch_together:
- with gr.Column(elem_id="txt2img_column_batch"):
- batch_count = gr.Slider(minimum=1, step=1, label='Batch count', value=1, elem_id="txt2img_batch_count")
- batch_size = gr.Slider(minimum=1, maximum=8, step=1, label='Batch size', value=1, elem_id="txt2img_batch_size")
-
- elif category == "cfg":
- cfg_scale = gr.Slider(minimum=1.0, maximum=30.0, step=0.5, label='CFG Scale', value=7.0, elem_id="txt2img_cfg_scale")
-
- elif category == "seed":
- seed, reuse_seed, subseed, reuse_subseed, subseed_strength, seed_resize_from_h, seed_resize_from_w, seed_checkbox = create_seed_inputs('txt2img')
-
- elif category == "checkboxes":
- with FormRow(elem_id="txt2img_checkboxes", variant="compact"):
- restore_faces = gr.Checkbox(label='Restore faces', value=False, visible=len(shared.face_restorers) > 1, elem_id="txt2img_restore_faces")
- tiling = gr.Checkbox(label='Tiling', value=False, elem_id="txt2img_tiling")
- enable_hr = gr.Checkbox(label='Hires. fix', value=False, elem_id="txt2img_enable_hr")
- hr_final_resolution = FormHTML(value="", elem_id="txtimg_hr_finalres", label="Upscaled resolution", interactive=False)
-
- elif category == "hires_fix":
- with FormGroup(visible=False, elem_id="txt2img_hires_fix") as hr_options:
- with FormRow(elem_id="txt2img_hires_fix_row1", variant="compact"):
- hr_upscaler = gr.Dropdown(label="Upscaler", elem_id="txt2img_hr_upscaler", choices=[*shared.latent_upscale_modes, *[x.name for x in shared.sd_upscalers]], value=shared.latent_upscale_default_mode)
- hr_second_pass_steps = gr.Slider(minimum=0, maximum=150, step=1, label='Hires steps', value=0, elem_id="txt2img_hires_steps")
- denoising_strength = gr.Slider(minimum=0.0, maximum=1.0, step=0.01, label='Denoising strength', value=0.7, elem_id="txt2img_denoising_strength")
-
- with FormRow(elem_id="txt2img_hires_fix_row2", variant="compact"):
- hr_scale = gr.Slider(minimum=1.0, maximum=4.0, step=0.05, label="Upscale by", value=2.0, elem_id="txt2img_hr_scale")
- hr_resize_x = gr.Slider(minimum=0, maximum=2048, step=8, label="Resize width to", value=0, elem_id="txt2img_hr_resize_x")
- hr_resize_y = gr.Slider(minimum=0, maximum=2048, step=8, label="Resize height to", value=0, elem_id="txt2img_hr_resize_y")
-
- elif category == "batch":
- if not opts.dimensions_and_batch_together:
- with FormRow(elem_id="txt2img_column_batch"):
- batch_count = gr.Slider(minimum=1, step=1, label='Batch count', value=1, elem_id="txt2img_batch_count")
- batch_size = gr.Slider(minimum=1, maximum=8, step=1, label='Batch size', value=1, elem_id="txt2img_batch_size")
-
- elif category == "override_settings":
- with FormRow(elem_id="txt2img_override_settings_row") as row:
- override_settings = create_override_settings_dropdown('txt2img', row)
-
- elif category == "scripts":
- with FormGroup(elem_id="txt2img_script_container"):
- custom_inputs = modules.scripts.scripts_txt2img.setup_ui()
-
- hr_resolution_preview_inputs = [enable_hr, width, height, hr_scale, hr_resize_x, hr_resize_y]
- for input in hr_resolution_preview_inputs:
- input.change(
- fn=calc_resolution_hires,
- inputs=hr_resolution_preview_inputs,
- outputs=[hr_final_resolution],
- show_progress=False,
- )
- input.change(
- None,
- _js="onCalcResolutionHires",
- inputs=hr_resolution_preview_inputs,
- outputs=[],
- show_progress=False,
- )
-
- txt2img_gallery, generation_info, html_info, html_log = create_output_panel("txt2img", opts.outdir_txt2img_samples)
-
- connect_reuse_seed(seed, reuse_seed, generation_info, dummy_component, is_subseed=False)
- connect_reuse_seed(subseed, reuse_subseed, generation_info, dummy_component, is_subseed=True)
-
- txt2img_args = dict(
- fn=wrap_gradio_gpu_call(modules.txt2img.txt2img, extra_outputs=[None, '', '']),
- _js="submit",
- inputs=[
- dummy_component,
- txt2img_prompt,
- txt2img_negative_prompt,
- txt2img_prompt_styles,
- steps,
- sampler_index,
- restore_faces,
- tiling,
- batch_count,
- batch_size,
- cfg_scale,
- seed,
- subseed, subseed_strength, seed_resize_from_h, seed_resize_from_w, seed_checkbox,
- height,
- width,
- enable_hr,
- denoising_strength,
- hr_scale,
- hr_upscaler,
- hr_second_pass_steps,
- hr_resize_x,
- hr_resize_y,
- override_settings,
- ] + custom_inputs,
-
- outputs=[
- txt2img_gallery,
- generation_info,
- html_info,
- html_log,
- ],
- show_progress=False,
- )
-
- txt2img_prompt.submit(**txt2img_args)
- submit.click(**txt2img_args)
-
- res_switch_btn.click(lambda w, h: (h, w), inputs=[width, height], outputs=[width, height])
-
- txt_prompt_img.change(
- fn=modules.images.image_data,
- inputs=[
- txt_prompt_img
- ],
- outputs=[
- txt2img_prompt,
- txt_prompt_img
- ]
- )
-
- enable_hr.change(
- fn=lambda x: gr_show(x),
- inputs=[enable_hr],
- outputs=[hr_options],
- show_progress = False,
- )
-
- txt2img_paste_fields = [
- (txt2img_prompt, "Prompt"),
- (txt2img_negative_prompt, "Negative prompt"),
- (steps, "Steps"),
- (sampler_index, "Sampler"),
- (restore_faces, "Face restoration"),
- (cfg_scale, "CFG scale"),
- (seed, "Seed"),
- (width, "Size-1"),
- (height, "Size-2"),
- (batch_size, "Batch size"),
- (subseed, "Variation seed"),
- (subseed_strength, "Variation seed strength"),
- (seed_resize_from_w, "Seed resize from-1"),
- (seed_resize_from_h, "Seed resize from-2"),
- (denoising_strength, "Denoising strength"),
- (enable_hr, lambda d: "Denoising strength" in d),
- (hr_options, lambda d: gr.Row.update(visible="Denoising strength" in d)),
- (hr_scale, "Hires upscale"),
- (hr_upscaler, "Hires upscaler"),
- (hr_second_pass_steps, "Hires steps"),
- (hr_resize_x, "Hires resize-1"),
- (hr_resize_y, "Hires resize-2"),
- *modules.scripts.scripts_txt2img.infotext_fields
- ]
- parameters_copypaste.add_paste_fields("txt2img", None, txt2img_paste_fields, override_settings)
- parameters_copypaste.register_paste_params_button(parameters_copypaste.ParamBinding(
- paste_button=txt2img_paste, tabname="txt2img", source_text_component=txt2img_prompt, source_image_component=None,
- ))
-
- txt2img_preview_params = [
- txt2img_prompt,
- txt2img_negative_prompt,
- steps,
- sampler_index,
- cfg_scale,
- seed,
- width,
- height,
- ]
-
- token_button.click(fn=wrap_queued_call(update_token_counter), inputs=[txt2img_prompt, steps], outputs=[token_counter])
- negative_token_button.click(fn=wrap_queued_call(update_token_counter), inputs=[txt2img_negative_prompt, steps], outputs=[negative_token_counter])
-
- ui_extra_networks.setup_ui(extra_networks_ui, txt2img_gallery)
-
- modules.scripts.scripts_current = modules.scripts.scripts_img2img
- modules.scripts.scripts_img2img.initialize_scripts(is_img2img=True)
-
- with gr.Blocks(analytics_enabled=False) as img2img_interface:
- img2img_prompt, img2img_prompt_styles, img2img_negative_prompt, submit, img2img_interrogate, img2img_deepbooru, img2img_prompt_style_apply, img2img_save_style, img2img_paste, extra_networks_button, token_counter, token_button, negative_token_counter, negative_token_button = create_toprow(is_img2img=True)
-
- img2img_prompt_img = gr.File(label="", elem_id="img2img_prompt_image", file_count="single", type="binary", visible=False)
-
- with FormRow(variant='compact', elem_id="img2img_extra_networks", visible=False) as extra_networks:
- from modules import ui_extra_networks
- extra_networks_ui_img2img = ui_extra_networks.create_ui(extra_networks, extra_networks_button, 'img2img')
-
- with FormRow().style(equal_height=False):
- with gr.Column(variant='compact', elem_id="img2img_settings"):
- copy_image_buttons = []
- copy_image_destinations = {}
-
- def add_copy_image_controls(tab_name, elem):
- with gr.Row(variant="compact", elem_id=f"img2img_copy_to_{tab_name}"):
- gr.HTML("Copy image to: ", elem_id=f"img2img_label_copy_to_{tab_name}")
-
- for title, name in zip(['img2img', 'sketch', 'inpaint', 'inpaint sketch'], ['img2img', 'sketch', 'inpaint', 'inpaint_sketch']):
- if name == tab_name:
- gr.Button(title, interactive=False)
- copy_image_destinations[name] = elem
- continue
-
- button = gr.Button(title)
- copy_image_buttons.append((button, name, elem))
-
- with gr.Tabs(elem_id="mode_img2img"):
- with gr.TabItem('img2img', id='img2img', elem_id="img2img_img2img_tab") as tab_img2img:
- init_img = gr.Image(label="Image for img2img", elem_id="img2img_image", show_label=False, source="upload", interactive=True, type="pil", tool="editor", image_mode="RGBA").style(height=480)
- add_copy_image_controls('img2img', init_img)
-
- with gr.TabItem('Sketch', id='img2img_sketch', elem_id="img2img_img2img_sketch_tab") as tab_sketch:
- sketch = gr.Image(label="Image for img2img", elem_id="img2img_sketch", show_label=False, source="upload", interactive=True, type="pil", tool="color-sketch", image_mode="RGBA").style(height=480)
- add_copy_image_controls('sketch', sketch)
-
- with gr.TabItem('Inpaint', id='inpaint', elem_id="img2img_inpaint_tab") as tab_inpaint:
- init_img_with_mask = gr.Image(label="Image for inpainting with mask", show_label=False, elem_id="img2maskimg", source="upload", interactive=True, type="pil", tool="sketch", image_mode="RGBA").style(height=480)
- add_copy_image_controls('inpaint', init_img_with_mask)
-
- with gr.TabItem('Inpaint sketch', id='inpaint_sketch', elem_id="img2img_inpaint_sketch_tab") as tab_inpaint_color:
- inpaint_color_sketch = gr.Image(label="Color sketch inpainting", show_label=False, elem_id="inpaint_sketch", source="upload", interactive=True, type="pil", tool="color-sketch", image_mode="RGBA").style(height=480)
- inpaint_color_sketch_orig = gr.State(None)
- add_copy_image_controls('inpaint_sketch', inpaint_color_sketch)
-
- def update_orig(image, state):
- if image is not None:
- same_size = state is not None and state.size == image.size
- has_exact_match = np.any(np.all(np.array(image) == np.array(state), axis=-1))
- edited = same_size and has_exact_match
- return image if not edited or state is None else state
-
- inpaint_color_sketch.change(update_orig, [inpaint_color_sketch, inpaint_color_sketch_orig], inpaint_color_sketch_orig)
-
- with gr.TabItem('Inpaint upload', id='inpaint_upload', elem_id="img2img_inpaint_upload_tab") as tab_inpaint_upload:
- init_img_inpaint = gr.Image(label="Image for img2img", show_label=False, source="upload", interactive=True, type="pil", elem_id="img_inpaint_base")
- init_mask_inpaint = gr.Image(label="Mask", source="upload", interactive=True, type="pil", elem_id="img_inpaint_mask")
-
- with gr.TabItem('Batch', id='batch', elem_id="img2img_batch_tab") as tab_batch:
- hidden = ' Disabled when launched with --hide-ui-dir-config.' if shared.cmd_opts.hide_ui_dir_config else ''
- gr.HTML(
- f"
Process images in a directory on the same machine where the server is running." +
- f" Use an empty output directory to save pictures normally instead of writing to the output directory." +
- f" Add inpaint batch mask directory to enable inpaint batch processing."
- f"{hidden}
"
- interp_descriptions = {
- "No interpolation": interp_description_css.format("No interpolation will be used. Requires one model; A. Allows for format conversion and VAE baking."),
- "Weighted sum": interp_description_css.format("A weighted sum will be used for interpolation. Requires two models; A and B. The result is calculated as A * (1 - M) + B * M"),
- "Add difference": interp_description_css.format("The difference between the last two models will be added to the first. Requires three models; A, B and C. The result is calculated as A + (B - C) * M")
- }
- return interp_descriptions[value]
-
- with gr.Blocks(analytics_enabled=False) as modelmerger_interface:
- with gr.Row().style(equal_height=False):
- with gr.Column(variant='compact'):
- interp_description = gr.HTML(value=update_interp_description("Weighted sum"), elem_id="modelmerger_interp_description")
-
- with FormRow(elem_id="modelmerger_models"):
- primary_model_name = gr.Dropdown(modules.sd_models.checkpoint_tiles(), elem_id="modelmerger_primary_model_name", label="Primary model (A)")
- create_refresh_button(primary_model_name, modules.sd_models.list_models, lambda: {"choices": modules.sd_models.checkpoint_tiles()}, "refresh_checkpoint_A")
-
- secondary_model_name = gr.Dropdown(modules.sd_models.checkpoint_tiles(), elem_id="modelmerger_secondary_model_name", label="Secondary model (B)")
- create_refresh_button(secondary_model_name, modules.sd_models.list_models, lambda: {"choices": modules.sd_models.checkpoint_tiles()}, "refresh_checkpoint_B")
-
- tertiary_model_name = gr.Dropdown(modules.sd_models.checkpoint_tiles(), elem_id="modelmerger_tertiary_model_name", label="Tertiary model (C)")
- create_refresh_button(tertiary_model_name, modules.sd_models.list_models, lambda: {"choices": modules.sd_models.checkpoint_tiles()}, "refresh_checkpoint_C")
-
- custom_name = gr.Textbox(label="Custom Name (Optional)", elem_id="modelmerger_custom_name")
- interp_amount = gr.Slider(minimum=0.0, maximum=1.0, step=0.05, label='Multiplier (M) - set to 0 to get model A', value=0.3, elem_id="modelmerger_interp_amount")
- interp_method = gr.Radio(choices=["No interpolation", "Weighted sum", "Add difference"], value="Weighted sum", label="Interpolation Method", elem_id="modelmerger_interp_method")
- interp_method.change(fn=update_interp_description, inputs=[interp_method], outputs=[interp_description])
-
- with FormRow():
- checkpoint_format = gr.Radio(choices=["ckpt", "safetensors"], value="ckpt", label="Checkpoint format", elem_id="modelmerger_checkpoint_format")
- save_as_half = gr.Checkbox(value=False, label="Save as float16", elem_id="modelmerger_save_as_half")
-
- with FormRow():
- with gr.Column():
- config_source = gr.Radio(choices=["A, B or C", "B", "C", "Don't"], value="A, B or C", label="Copy config from", type="index", elem_id="modelmerger_config_method")
-
- with gr.Column():
- with FormRow():
- bake_in_vae = gr.Dropdown(choices=["None"] + list(sd_vae.vae_dict), value="None", label="Bake in VAE", elem_id="modelmerger_bake_in_vae")
- create_refresh_button(bake_in_vae, sd_vae.refresh_vae_list, lambda: {"choices": ["None"] + list(sd_vae.vae_dict)}, "modelmerger_refresh_bake_in_vae")
-
- with FormRow():
- discard_weights = gr.Textbox(value="", label="Discard weights with matching name", elem_id="modelmerger_discard_weights")
-
- with gr.Row():
- modelmerger_merge = gr.Button(elem_id="modelmerger_merge", value="Merge", variant='primary')
-
- with gr.Column(variant='compact', elem_id="modelmerger_results_container"):
- with gr.Group(elem_id="modelmerger_results_panel"):
- modelmerger_result = gr.HTML(elem_id="modelmerger_result", show_label=False)
-
- with gr.Blocks(analytics_enabled=False) as train_interface:
- with gr.Row().style(equal_height=False):
- gr.HTML(value="
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/bioriAsaeru/text-to-voice/Kaplan Test Prep MCAT Physics And Math Review Online Book Download EPUB PDF.md b/spaces/bioriAsaeru/text-to-voice/Kaplan Test Prep MCAT Physics And Math Review Online Book Download EPUB PDF.md
deleted file mode 100644
index 249047a775f2ee9d8840c4f79049f9bc2e808934..0000000000000000000000000000000000000000
--- a/spaces/bioriAsaeru/text-to-voice/Kaplan Test Prep MCAT Physics And Math Review Online Book Download EPUB PDF.md
+++ /dev/null
@@ -1,6 +0,0 @@
-
Kaplan Test Prep: MCAT Physics and Math Review : Online Book download EPUB, PDF
by Bryan Mildort", unsafe_allow_html=True)
-ticker = st.text_input('Enter Ticker to Scrape:', placeholder='SPY')
-col1, col2, col3, col4, col5 = st.columns(5)
-with col1:
- st.write(' ')
-with col2:
- st.write(' ')
-with col3:
- if st.button('Scrape!'):
- predictor(ticker)
-with col4:
- st.write(' ')
-with col5:
- st.write(' ')
-
-
diff --git a/spaces/cancanasoyak/CropBased-TissueMasking/README.md b/spaces/cancanasoyak/CropBased-TissueMasking/README.md
deleted file mode 100644
index c50d63f9de5d2579fbbc4f8a542145b0085adc4d..0000000000000000000000000000000000000000
--- a/spaces/cancanasoyak/CropBased-TissueMasking/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: CropBased TissueMasking
-emoji: 🏃
-colorFrom: pink
-colorTo: blue
-sdk: streamlit
-sdk_version: 1.28.0
-app_file: Deployment/webapp.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/DensePose/densepose/structures/chart_result.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/DensePose/densepose/structures/chart_result.py
deleted file mode 100644
index 003933d03d153d045c0bf551c465bc7a224d90cb..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/DensePose/densepose/structures/chart_result.py
+++ /dev/null
@@ -1,183 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-from dataclasses import dataclass
-from typing import Any, Optional, Tuple
-import torch
-
-
-@dataclass
-class DensePoseChartResult:
- """
- DensePose results for chart-based methods represented by labels and inner
- coordinates (U, V) of individual charts. Each chart is a 2D manifold
- that has an associated label and is parameterized by two coordinates U and V.
- Both U and V take values in [0, 1].
- Thus the results are represented by two tensors:
- - labels (tensor [H, W] of long): contains estimated label for each pixel of
- the detection bounding box of size (H, W)
- - uv (tensor [2, H, W] of float): contains estimated U and V coordinates
- for each pixel of the detection bounding box of size (H, W)
- """
-
- labels: torch.Tensor
- uv: torch.Tensor
-
- def to(self, device: torch.device):
- """
- Transfers all tensors to the given device
- """
- labels = self.labels.to(device)
- uv = self.uv.to(device)
- return DensePoseChartResult(labels=labels, uv=uv)
-
-
-@dataclass
-class DensePoseChartResultWithConfidences:
- """
- We add confidence values to DensePoseChartResult
- Thus the results are represented by two tensors:
- - labels (tensor [H, W] of long): contains estimated label for each pixel of
- the detection bounding box of size (H, W)
- - uv (tensor [2, H, W] of float): contains estimated U and V coordinates
- for each pixel of the detection bounding box of size (H, W)
- Plus one [H, W] tensor of float for each confidence type
- """
-
- labels: torch.Tensor
- uv: torch.Tensor
- sigma_1: Optional[torch.Tensor] = None
- sigma_2: Optional[torch.Tensor] = None
- kappa_u: Optional[torch.Tensor] = None
- kappa_v: Optional[torch.Tensor] = None
- fine_segm_confidence: Optional[torch.Tensor] = None
- coarse_segm_confidence: Optional[torch.Tensor] = None
-
- def to(self, device: torch.device):
- """
- Transfers all tensors to the given device, except if their value is None
- """
-
- def to_device_if_tensor(var: Any):
- if isinstance(var, torch.Tensor):
- return var.to(device)
- return var
-
- return DensePoseChartResultWithConfidences(
- labels=self.labels.to(device),
- uv=self.uv.to(device),
- sigma_1=to_device_if_tensor(self.sigma_1),
- sigma_2=to_device_if_tensor(self.sigma_2),
- kappa_u=to_device_if_tensor(self.kappa_u),
- kappa_v=to_device_if_tensor(self.kappa_v),
- fine_segm_confidence=to_device_if_tensor(self.fine_segm_confidence),
- coarse_segm_confidence=to_device_if_tensor(self.coarse_segm_confidence),
- )
-
-
-@dataclass
-class DensePoseChartResultQuantized:
- """
- DensePose results for chart-based methods represented by labels and quantized
- inner coordinates (U, V) of individual charts. Each chart is a 2D manifold
- that has an associated label and is parameterized by two coordinates U and V.
- Both U and V take values in [0, 1].
- Quantized coordinates Uq and Vq have uint8 values which are obtained as:
- Uq = U * 255 (hence 0 <= Uq <= 255)
- Vq = V * 255 (hence 0 <= Vq <= 255)
- Thus the results are represented by one tensor:
- - labels_uv_uint8 (tensor [3, H, W] of uint8): contains estimated label
- and quantized coordinates Uq and Vq for each pixel of the detection
- bounding box of size (H, W)
- """
-
- labels_uv_uint8: torch.Tensor
-
- def to(self, device: torch.device):
- """
- Transfers all tensors to the given device
- """
- labels_uv_uint8 = self.labels_uv_uint8.to(device)
- return DensePoseChartResultQuantized(labels_uv_uint8=labels_uv_uint8)
-
-
-@dataclass
-class DensePoseChartResultCompressed:
- """
- DensePose results for chart-based methods represented by a PNG-encoded string.
- The tensor of quantized DensePose results of size [3, H, W] is considered
- as an image with 3 color channels. PNG compression is applied and the result
- is stored as a Base64-encoded string. The following attributes are defined:
- - shape_chw (tuple of 3 int): contains shape of the result tensor
- (number of channels, height, width)
- - labels_uv_str (str): contains Base64-encoded results tensor of size
- [3, H, W] compressed with PNG compression methods
- """
-
- shape_chw: Tuple[int, int, int]
- labels_uv_str: str
-
-
-def quantize_densepose_chart_result(result: DensePoseChartResult) -> DensePoseChartResultQuantized:
- """
- Applies quantization to DensePose chart-based result.
-
- Args:
- result (DensePoseChartResult): DensePose chart-based result
- Return:
- Quantized DensePose chart-based result (DensePoseChartResultQuantized)
- """
- h, w = result.labels.shape
- labels_uv_uint8 = torch.zeros([3, h, w], dtype=torch.uint8, device=result.labels.device)
- labels_uv_uint8[0] = result.labels
- labels_uv_uint8[1:] = (result.uv * 255).clamp(0, 255).byte()
- return DensePoseChartResultQuantized(labels_uv_uint8=labels_uv_uint8)
-
-
-def compress_quantized_densepose_chart_result(
- result: DensePoseChartResultQuantized,
-) -> DensePoseChartResultCompressed:
- """
- Compresses quantized DensePose chart-based result
-
- Args:
- result (DensePoseChartResultQuantized): quantized DensePose chart-based result
- Return:
- Compressed DensePose chart-based result (DensePoseChartResultCompressed)
- """
- import base64
- import numpy as np
- from io import BytesIO
- from PIL import Image
-
- labels_uv_uint8_np_chw = result.labels_uv_uint8.cpu().numpy()
- labels_uv_uint8_np_hwc = np.moveaxis(labels_uv_uint8_np_chw, 0, -1)
- im = Image.fromarray(labels_uv_uint8_np_hwc)
- fstream = BytesIO()
- im.save(fstream, format="png", optimize=True)
- labels_uv_str = base64.encodebytes(fstream.getvalue()).decode()
- shape_chw = labels_uv_uint8_np_chw.shape
- return DensePoseChartResultCompressed(labels_uv_str=labels_uv_str, shape_chw=shape_chw)
-
-
-def decompress_compressed_densepose_chart_result(
- result: DensePoseChartResultCompressed,
-) -> DensePoseChartResultQuantized:
- """
- Decompresses DensePose chart-based result encoded into a base64 string
-
- Args:
- result (DensePoseChartResultCompressed): compressed DensePose chart result
- Return:
- Quantized DensePose chart-based result (DensePoseChartResultQuantized)
- """
- import base64
- import numpy as np
- from io import BytesIO
- from PIL import Image
-
- fstream = BytesIO(base64.decodebytes(result.labels_uv_str.encode()))
- im = Image.open(fstream)
- labels_uv_uint8_np_chw = np.moveaxis(np.array(im, dtype=np.uint8), -1, 0)
- return DensePoseChartResultQuantized(
- labels_uv_uint8=torch.from_numpy(labels_uv_uint8_np_chw.reshape(result.shape_chw))
- )
diff --git a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/ViTDet/configs/LVIS/cascade_mask_rcnn_swin_l_in21k_50ep.py b/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/ViTDet/configs/LVIS/cascade_mask_rcnn_swin_l_in21k_50ep.py
deleted file mode 100644
index 9e22e3b28777003776774f61273c04bbb2abea1e..0000000000000000000000000000000000000000
--- a/spaces/carlosalonso/Detection-video/carpeta_deteccion/projects/ViTDet/configs/LVIS/cascade_mask_rcnn_swin_l_in21k_50ep.py
+++ /dev/null
@@ -1,12 +0,0 @@
-from .cascade_mask_rcnn_swin_b_in21k_50ep import (
- dataloader,
- lr_multiplier,
- model,
- train,
- optimizer,
-)
-
-model.backbone.bottom_up.embed_dim = 192
-model.backbone.bottom_up.num_heads = [6, 12, 24, 48]
-
-train.init_checkpoint = "detectron2://ImageNetPretrained/swin/swin_large_patch4_window7_224_22k.pth"
diff --git a/spaces/ceckenrode/AI-Dashboard-03142023/index.html b/spaces/ceckenrode/AI-Dashboard-03142023/index.html
deleted file mode 100644
index 744a752c14a0d9057aaf1d1fa969cc9de581e78b..0000000000000000000000000000000000000000
--- a/spaces/ceckenrode/AI-Dashboard-03142023/index.html
+++ /dev/null
@@ -1,98 +0,0 @@
-
-
-
-
-
- My static Space
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- journey
- title Create AI
- section Training
- Format DataSet Inputs Files, Data Splits: 5: Teacher
- Model Build w/ SKLearn, TF, Pytorch: 3: Student
- Determine Model Performance: 1: Teacher, Student
- section Deploy
- Web Deploy Local and Cloud: 5: Teacher
- Architecture Spaces Gradio Streamlit Heroku AWS Azure and GCCP: 5: Teacher
- section Testing
- Test Model with Input Datasets: 5: Teacher
- Examples. Inputs that Work, Inputs That Break Model: 5: Teacher
- Governance - Analyze, Publish Fairness, Equity, Bias for Datasets and Outputs: 5: Teacher
-
-
-
- sequenceDiagram
- participant Alice
- participant Bob
- Alice->>John: Hello John, how are you?
- loop Healthcheck
- John->>John: Fight against hypochondria
- end
- Note right of John: Rational thoughts prevail...
- John-->>Alice: Great!
- John->>Bob: How about you?
- Bob-->>John: Jolly good!
-
-
-
-
Welcome to the Mermaid Modeler Tip Sheet
-
- You can use Mermaid inside HTML5 by including the script and a div with the class or mermaid.
-
"
- )
- new_response = ret_text + "\n----------\n" + "\n\n".join(nodes)
- logging.info(
- f"Response: {colorama.Fore.BLUE}{ret_text}{colorama.Style.RESET_ALL}"
- )
- os.environ["OPENAI_API_KEY"] = ""
- return ret_text, new_response, f"查询消耗了{llm_predictor.last_token_usage} tokens"
- else:
- logging.warning("No response found, returning None")
- os.environ["OPENAI_API_KEY"] = ""
- return None
-
-
-def add_space(text):
- punctuations = {",": ", ", "。": "。 ", "?": "? ", "!": "! ", ":": ": ", ";": "; "}
- for cn_punc, en_punc in punctuations.items():
- text = text.replace(cn_punc, en_punc)
- return text
diff --git a/spaces/chronopt-research/ViTExCo/src/data/transforms.py b/spaces/chronopt-research/ViTExCo/src/data/transforms.py
deleted file mode 100644
index aafd87a4cfad80c2ea0729257ce8d98fe0b9b423..0000000000000000000000000000000000000000
--- a/spaces/chronopt-research/ViTExCo/src/data/transforms.py
+++ /dev/null
@@ -1,348 +0,0 @@
-from __future__ import division
-
-import collections
-import numbers
-import random
-
-import torch
-from PIL import Image
-from skimage import color
-
-import src.data.functional as F
-
-__all__ = [
- "Compose",
- "Concatenate",
- "ToTensor",
- "Normalize",
- "Resize",
- "Scale",
- "CenterCrop",
- "Pad",
- "RandomCrop",
- "RandomHorizontalFlip",
- "RandomVerticalFlip",
- "RandomResizedCrop",
- "RandomSizedCrop",
- "FiveCrop",
- "TenCrop",
- "RGB2Lab",
-]
-
-
-def CustomFunc(inputs, func, *args, **kwargs):
- im_l = func(inputs[0], *args, **kwargs)
- im_ab = func(inputs[1], *args, **kwargs)
- warp_ba = func(inputs[2], *args, **kwargs)
- warp_aba = func(inputs[3], *args, **kwargs)
- im_gbl_ab = func(inputs[4], *args, **kwargs)
- bgr_mc_im = func(inputs[5], *args, **kwargs)
-
- layer_data = [im_l, im_ab, warp_ba, warp_aba, im_gbl_ab, bgr_mc_im]
-
- for l in range(5):
- layer = inputs[6 + l]
- err_ba = func(layer[0], *args, **kwargs)
- err_ab = func(layer[1], *args, **kwargs)
-
- layer_data.append([err_ba, err_ab])
-
- return layer_data
-
-
-class Compose(object):
- """Composes several transforms together.
-
- Args:
- transforms (list of ``Transform`` objects): list of transforms to compose.
-
- Example:
- >>> transforms.Compose([
- >>> transforms.CenterCrop(10),
- >>> transforms.ToTensor(),
- >>> ])
- """
-
- def __init__(self, transforms):
- self.transforms = transforms
-
- def __call__(self, inputs):
- for t in self.transforms:
- inputs = t(inputs)
- return inputs
-
-
-class Concatenate(object):
- """
- Input: [im_l, im_ab, inputs]
- inputs = [warp_ba_l, warp_ba_ab, warp_aba, err_pm, err_aba]
-
- Output:[im_l, err_pm, warp_ba, warp_aba, im_ab, err_aba]
- """
-
- def __call__(self, inputs):
- im_l = inputs[0]
- im_ab = inputs[1]
- warp_ba = inputs[2]
- warp_aba = inputs[3]
- im_glb_ab = inputs[4]
- bgr_mc_im = inputs[5]
- bgr_mc_im = bgr_mc_im[[2, 1, 0], ...]
-
- err_ba = []
- err_ab = []
-
- for l in range(5):
- layer = inputs[6 + l]
- err_ba.append(layer[0])
- err_ab.append(layer[1])
-
- cerr_ba = torch.cat(err_ba, 0)
- cerr_ab = torch.cat(err_ab, 0)
-
- return (im_l, cerr_ba, warp_ba, warp_aba, im_glb_ab, bgr_mc_im, im_ab, cerr_ab)
-
-
-class ToTensor(object):
- """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
-
- Converts a PIL Image or numpy.ndarray (H x W x C) in the range
- [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0].
- """
-
- def __call__(self, inputs):
- """
- Args:
- pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
-
- Returns:
- Tensor: Converted image.
- """
- return CustomFunc(inputs, F.to_mytensor)
-
-
-class Normalize(object):
- """Normalize an tensor image with mean and standard deviation.
- Given mean: ``(M1,...,Mn)`` and std: ``(S1,..,Sn)`` for ``n`` channels, this transform
- will normalize each channel of the input ``torch.*Tensor`` i.e.
- ``input[channel] = (input[channel] - mean[channel]) / std[channel]``
-
- Args:
- mean (sequence): Sequence of means for each channel.
- std (sequence): Sequence of standard deviations for each channel.
- """
-
- def __call__(self, inputs):
- """
- Args:
- tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
-
- Returns:
- Tensor: Normalized Tensor image.
- """
-
- im_l = F.normalize(inputs[0], 50, 1) # [0, 100]
- im_ab = F.normalize(inputs[1], (0, 0), (1, 1)) # [-100, 100]
-
- inputs[2][0:1, :, :] = F.normalize(inputs[2][0:1, :, :], 50, 1)
- inputs[2][1:3, :, :] = F.normalize(inputs[2][1:3, :, :], (0, 0), (1, 1))
- warp_ba = inputs[2]
-
- inputs[3][0:1, :, :] = F.normalize(inputs[3][0:1, :, :], 50, 1)
- inputs[3][1:3, :, :] = F.normalize(inputs[3][1:3, :, :], (0, 0), (1, 1))
- warp_aba = inputs[3]
-
- im_gbl_ab = F.normalize(inputs[4], (0, 0), (1, 1)) # [-100, 100]
-
- bgr_mc_im = F.normalize(inputs[5], (123.68, 116.78, 103.938), (1, 1, 1))
-
- layer_data = [im_l, im_ab, warp_ba, warp_aba, im_gbl_ab, bgr_mc_im]
-
- for l in range(5):
- layer = inputs[6 + l]
- err_ba = F.normalize(layer[0], 127, 2) # [0, 255]
- err_ab = F.normalize(layer[1], 127, 2) # [0, 255]
- layer_data.append([err_ba, err_ab])
-
- return layer_data
-
-
-class Resize(object):
- """Resize the input PIL Image to the given size.
-
- Args:
- size (sequence or int): Desired output size. If size is a sequence like
- (h, w), output size will be matched to this. If size is an int,
- smaller edge of the image will be matched to this number.
- i.e, if height > width, then image will be rescaled to
- (size * height / width, size)
- interpolation (int, optional): Desired interpolation. Default is
- ``PIL.Image.BILINEAR``
- """
-
- def __init__(self, size, interpolation=Image.BILINEAR):
- assert isinstance(size, int) or (isinstance(size, collections.Iterable) and len(size) == 2)
- self.size = size
- self.interpolation = interpolation
-
- def __call__(self, inputs):
- """
- Args:
- img (PIL Image): Image to be scaled.
-
- Returns:
- PIL Image: Rescaled image.
- """
- return CustomFunc(inputs, F.resize, self.size, self.interpolation)
-
-
-class RandomCrop(object):
- """Crop the given PIL Image at a random location.
-
- Args:
- size (sequence or int): Desired output size of the crop. If size is an
- int instead of sequence like (h, w), a square crop (size, size) is
- made.
- padding (int or sequence, optional): Optional padding on each border
- of the image. Default is 0, i.e no padding. If a sequence of length
- 4 is provided, it is used to pad left, top, right, bottom borders
- respectively.
- """
-
- def __init__(self, size, padding=0):
- if isinstance(size, numbers.Number):
- self.size = (int(size), int(size))
- else:
- self.size = size
- self.padding = padding
-
- @staticmethod
- def get_params(img, output_size):
- """Get parameters for ``crop`` for a random crop.
-
- Args:
- img (PIL Image): Image to be cropped.
- output_size (tuple): Expected output size of the crop.
-
- Returns:
- tuple: params (i, j, h, w) to be passed to ``crop`` for random crop.
- """
- w, h = img.size
- th, tw = output_size
- if w == tw and h == th:
- return 0, 0, h, w
-
- i = random.randint(0, h - th)
- j = random.randint(0, w - tw)
- return i, j, th, tw
-
- def __call__(self, inputs):
- """
- Args:
- img (PIL Image): Image to be cropped.
-
- Returns:
- PIL Image: Cropped image.
- """
- if self.padding > 0:
- inputs = CustomFunc(inputs, F.pad, self.padding)
-
- i, j, h, w = self.get_params(inputs[0], self.size)
- return CustomFunc(inputs, F.crop, i, j, h, w)
-
-
-class CenterCrop(object):
- """Crop the given PIL Image at a random location.
-
- Args:
- size (sequence or int): Desired output size of the crop. If size is an
- int instead of sequence like (h, w), a square crop (size, size) is
- made.
- padding (int or sequence, optional): Optional padding on each border
- of the image. Default is 0, i.e no padding. If a sequence of length
- 4 is provided, it is used to pad left, top, right, bottom borders
- respectively.
- """
-
- def __init__(self, size, padding=0):
- if isinstance(size, numbers.Number):
- self.size = (int(size), int(size))
- else:
- self.size = size
- self.padding = padding
-
- @staticmethod
- def get_params(img, output_size):
- """Get parameters for ``crop`` for a random crop.
-
- Args:
- img (PIL Image): Image to be cropped.
- output_size (tuple): Expected output size of the crop.
-
- Returns:
- tuple: params (i, j, h, w) to be passed to ``crop`` for random crop.
- """
- w, h = img.size
- th, tw = output_size
- if w == tw and h == th:
- return 0, 0, h, w
-
- i = (h - th) // 2
- j = (w - tw) // 2
- return i, j, th, tw
-
- def __call__(self, inputs):
- """
- Args:
- img (PIL Image): Image to be cropped.
-
- Returns:
- PIL Image: Cropped image.
- """
- if self.padding > 0:
- inputs = CustomFunc(inputs, F.pad, self.padding)
-
- i, j, h, w = self.get_params(inputs[0], self.size)
- return CustomFunc(inputs, F.crop, i, j, h, w)
-
-
-class RandomHorizontalFlip(object):
- """Horizontally flip the given PIL Image randomly with a probability of 0.5."""
-
- def __call__(self, inputs):
- """
- Args:
- img (PIL Image): Image to be flipped.
-
- Returns:
- PIL Image: Randomly flipped image.
- """
-
- if random.random() < 0.5:
- return CustomFunc(inputs, F.hflip)
- return inputs
-
-
-class RGB2Lab(object):
- def __call__(self, inputs):
- """
- Args:
- img (PIL Image): Image to be flipped.
-
- Returns:
- PIL Image: Randomly flipped image.
- """
-
- def __call__(self, inputs):
- image_lab = color.rgb2lab(inputs[0])
- warp_ba_lab = color.rgb2lab(inputs[2])
- warp_aba_lab = color.rgb2lab(inputs[3])
- im_gbl_lab = color.rgb2lab(inputs[4])
-
- inputs[0] = image_lab[:, :, :1] # l channel
- inputs[1] = image_lab[:, :, 1:] # ab channel
- inputs[2] = warp_ba_lab # lab channel
- inputs[3] = warp_aba_lab # lab channel
- inputs[4] = im_gbl_lab[:, :, 1:] # ab channel
-
- return inputs
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/cryptography/hazmat/backends/openssl/decode_asn1.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/cryptography/hazmat/backends/openssl/decode_asn1.py
deleted file mode 100644
index bf123b6285b64a5ac5a64c00c47975ea2285b9dc..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/cryptography/hazmat/backends/openssl/decode_asn1.py
+++ /dev/null
@@ -1,32 +0,0 @@
-# This file is dual licensed under the terms of the Apache License, Version
-# 2.0, and the BSD License. See the LICENSE file in the root of this repository
-# for complete details.
-
-from __future__ import annotations
-
-from cryptography import x509
-
-# CRLReason ::= ENUMERATED {
-# unspecified (0),
-# keyCompromise (1),
-# cACompromise (2),
-# affiliationChanged (3),
-# superseded (4),
-# cessationOfOperation (5),
-# certificateHold (6),
-# -- value 7 is not used
-# removeFromCRL (8),
-# privilegeWithdrawn (9),
-# aACompromise (10) }
-_CRL_ENTRY_REASON_ENUM_TO_CODE = {
- x509.ReasonFlags.unspecified: 0,
- x509.ReasonFlags.key_compromise: 1,
- x509.ReasonFlags.ca_compromise: 2,
- x509.ReasonFlags.affiliation_changed: 3,
- x509.ReasonFlags.superseded: 4,
- x509.ReasonFlags.cessation_of_operation: 5,
- x509.ReasonFlags.certificate_hold: 6,
- x509.ReasonFlags.remove_from_crl: 8,
- x509.ReasonFlags.privilege_withdrawn: 9,
- x509.ReasonFlags.aa_compromise: 10,
-}
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/filetype/types/isobmff.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/filetype/types/isobmff.py
deleted file mode 100644
index 2ac0ffe87aa062319862cacf28e382ae838bbc17..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/filetype/types/isobmff.py
+++ /dev/null
@@ -1,33 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import absolute_import
-import codecs
-
-from .base import Type
-
-
-class IsoBmff(Type):
- """
- Implements the ISO-BMFF base type.
- """
- def __init__(self, mime, extension):
- super(IsoBmff, self).__init__(
- mime=mime,
- extension=extension
- )
-
- def _is_isobmff(self, buf):
- if len(buf) < 16 or buf[4:8] != b'ftyp':
- return False
- if len(buf) < int(codecs.encode(buf[0:4], 'hex'), 16):
- return False
- return True
-
- def _get_ftyp(self, buf):
- ftyp_len = int(codecs.encode(buf[0:4], 'hex'), 16)
- major_brand = buf[8:12].decode(errors='ignore')
- minor_version = int(codecs.encode(buf[12:16], 'hex'), 16)
- compatible_brands = []
- for i in range(16, ftyp_len, 4):
- compatible_brands.append(buf[i:i+4].decode(errors='ignore'))
-
- return major_brand, minor_version, compatible_brands
diff --git a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/PIL/ImageOps.py b/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/PIL/ImageOps.py
deleted file mode 100644
index 17702778c134abcb51d7632367fbbf1a2f3048fa..0000000000000000000000000000000000000000
--- a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/PIL/ImageOps.py
+++ /dev/null
@@ -1,628 +0,0 @@
-#
-# The Python Imaging Library.
-# $Id$
-#
-# standard image operations
-#
-# History:
-# 2001-10-20 fl Created
-# 2001-10-23 fl Added autocontrast operator
-# 2001-12-18 fl Added Kevin's fit operator
-# 2004-03-14 fl Fixed potential division by zero in equalize
-# 2005-05-05 fl Fixed equalize for low number of values
-#
-# Copyright (c) 2001-2004 by Secret Labs AB
-# Copyright (c) 2001-2004 by Fredrik Lundh
-#
-# See the README file for information on usage and redistribution.
-#
-
-import functools
-import operator
-import re
-
-from . import ExifTags, Image, ImagePalette
-
-#
-# helpers
-
-
-def _border(border):
- if isinstance(border, tuple):
- if len(border) == 2:
- left, top = right, bottom = border
- elif len(border) == 4:
- left, top, right, bottom = border
- else:
- left = top = right = bottom = border
- return left, top, right, bottom
-
-
-def _color(color, mode):
- if isinstance(color, str):
- from . import ImageColor
-
- color = ImageColor.getcolor(color, mode)
- return color
-
-
-def _lut(image, lut):
- if image.mode == "P":
- # FIXME: apply to lookup table, not image data
- msg = "mode P support coming soon"
- raise NotImplementedError(msg)
- elif image.mode in ("L", "RGB"):
- if image.mode == "RGB" and len(lut) == 256:
- lut = lut + lut + lut
- return image.point(lut)
- else:
- msg = "not supported for this image mode"
- raise OSError(msg)
-
-
-#
-# actions
-
-
-def autocontrast(image, cutoff=0, ignore=None, mask=None, preserve_tone=False):
- """
- Maximize (normalize) image contrast. This function calculates a
- histogram of the input image (or mask region), removes ``cutoff`` percent of the
- lightest and darkest pixels from the histogram, and remaps the image
- so that the darkest pixel becomes black (0), and the lightest
- becomes white (255).
-
- :param image: The image to process.
- :param cutoff: The percent to cut off from the histogram on the low and
- high ends. Either a tuple of (low, high), or a single
- number for both.
- :param ignore: The background pixel value (use None for no background).
- :param mask: Histogram used in contrast operation is computed using pixels
- within the mask. If no mask is given the entire image is used
- for histogram computation.
- :param preserve_tone: Preserve image tone in Photoshop-like style autocontrast.
-
- .. versionadded:: 8.2.0
-
- :return: An image.
- """
- if preserve_tone:
- histogram = image.convert("L").histogram(mask)
- else:
- histogram = image.histogram(mask)
-
- lut = []
- for layer in range(0, len(histogram), 256):
- h = histogram[layer : layer + 256]
- if ignore is not None:
- # get rid of outliers
- try:
- h[ignore] = 0
- except TypeError:
- # assume sequence
- for ix in ignore:
- h[ix] = 0
- if cutoff:
- # cut off pixels from both ends of the histogram
- if not isinstance(cutoff, tuple):
- cutoff = (cutoff, cutoff)
- # get number of pixels
- n = 0
- for ix in range(256):
- n = n + h[ix]
- # remove cutoff% pixels from the low end
- cut = n * cutoff[0] // 100
- for lo in range(256):
- if cut > h[lo]:
- cut = cut - h[lo]
- h[lo] = 0
- else:
- h[lo] -= cut
- cut = 0
- if cut <= 0:
- break
- # remove cutoff% samples from the high end
- cut = n * cutoff[1] // 100
- for hi in range(255, -1, -1):
- if cut > h[hi]:
- cut = cut - h[hi]
- h[hi] = 0
- else:
- h[hi] -= cut
- cut = 0
- if cut <= 0:
- break
- # find lowest/highest samples after preprocessing
- for lo in range(256):
- if h[lo]:
- break
- for hi in range(255, -1, -1):
- if h[hi]:
- break
- if hi <= lo:
- # don't bother
- lut.extend(list(range(256)))
- else:
- scale = 255.0 / (hi - lo)
- offset = -lo * scale
- for ix in range(256):
- ix = int(ix * scale + offset)
- if ix < 0:
- ix = 0
- elif ix > 255:
- ix = 255
- lut.append(ix)
- return _lut(image, lut)
-
-
-def colorize(image, black, white, mid=None, blackpoint=0, whitepoint=255, midpoint=127):
- """
- Colorize grayscale image.
- This function calculates a color wedge which maps all black pixels in
- the source image to the first color and all white pixels to the
- second color. If ``mid`` is specified, it uses three-color mapping.
- The ``black`` and ``white`` arguments should be RGB tuples or color names;
- optionally you can use three-color mapping by also specifying ``mid``.
- Mapping positions for any of the colors can be specified
- (e.g. ``blackpoint``), where these parameters are the integer
- value corresponding to where the corresponding color should be mapped.
- These parameters must have logical order, such that
- ``blackpoint <= midpoint <= whitepoint`` (if ``mid`` is specified).
-
- :param image: The image to colorize.
- :param black: The color to use for black input pixels.
- :param white: The color to use for white input pixels.
- :param mid: The color to use for midtone input pixels.
- :param blackpoint: an int value [0, 255] for the black mapping.
- :param whitepoint: an int value [0, 255] for the white mapping.
- :param midpoint: an int value [0, 255] for the midtone mapping.
- :return: An image.
- """
-
- # Initial asserts
- assert image.mode == "L"
- if mid is None:
- assert 0 <= blackpoint <= whitepoint <= 255
- else:
- assert 0 <= blackpoint <= midpoint <= whitepoint <= 255
-
- # Define colors from arguments
- black = _color(black, "RGB")
- white = _color(white, "RGB")
- if mid is not None:
- mid = _color(mid, "RGB")
-
- # Empty lists for the mapping
- red = []
- green = []
- blue = []
-
- # Create the low-end values
- for i in range(0, blackpoint):
- red.append(black[0])
- green.append(black[1])
- blue.append(black[2])
-
- # Create the mapping (2-color)
- if mid is None:
- range_map = range(0, whitepoint - blackpoint)
-
- for i in range_map:
- red.append(black[0] + i * (white[0] - black[0]) // len(range_map))
- green.append(black[1] + i * (white[1] - black[1]) // len(range_map))
- blue.append(black[2] + i * (white[2] - black[2]) // len(range_map))
-
- # Create the mapping (3-color)
- else:
- range_map1 = range(0, midpoint - blackpoint)
- range_map2 = range(0, whitepoint - midpoint)
-
- for i in range_map1:
- red.append(black[0] + i * (mid[0] - black[0]) // len(range_map1))
- green.append(black[1] + i * (mid[1] - black[1]) // len(range_map1))
- blue.append(black[2] + i * (mid[2] - black[2]) // len(range_map1))
- for i in range_map2:
- red.append(mid[0] + i * (white[0] - mid[0]) // len(range_map2))
- green.append(mid[1] + i * (white[1] - mid[1]) // len(range_map2))
- blue.append(mid[2] + i * (white[2] - mid[2]) // len(range_map2))
-
- # Create the high-end values
- for i in range(0, 256 - whitepoint):
- red.append(white[0])
- green.append(white[1])
- blue.append(white[2])
-
- # Return converted image
- image = image.convert("RGB")
- return _lut(image, red + green + blue)
-
-
-def contain(image, size, method=Image.Resampling.BICUBIC):
- """
- Returns a resized version of the image, set to the maximum width and height
- within the requested size, while maintaining the original aspect ratio.
-
- :param image: The image to resize and crop.
- :param size: The requested output size in pixels, given as a
- (width, height) tuple.
- :param method: Resampling method to use. Default is
- :py:attr:`~PIL.Image.Resampling.BICUBIC`.
- See :ref:`concept-filters`.
- :return: An image.
- """
-
- im_ratio = image.width / image.height
- dest_ratio = size[0] / size[1]
-
- if im_ratio != dest_ratio:
- if im_ratio > dest_ratio:
- new_height = round(image.height / image.width * size[0])
- if new_height != size[1]:
- size = (size[0], new_height)
- else:
- new_width = round(image.width / image.height * size[1])
- if new_width != size[0]:
- size = (new_width, size[1])
- return image.resize(size, resample=method)
-
-
-def pad(image, size, method=Image.Resampling.BICUBIC, color=None, centering=(0.5, 0.5)):
- """
- Returns a resized and padded version of the image, expanded to fill the
- requested aspect ratio and size.
-
- :param image: The image to resize and crop.
- :param size: The requested output size in pixels, given as a
- (width, height) tuple.
- :param method: Resampling method to use. Default is
- :py:attr:`~PIL.Image.Resampling.BICUBIC`.
- See :ref:`concept-filters`.
- :param color: The background color of the padded image.
- :param centering: Control the position of the original image within the
- padded version.
-
- (0.5, 0.5) will keep the image centered
- (0, 0) will keep the image aligned to the top left
- (1, 1) will keep the image aligned to the bottom
- right
- :return: An image.
- """
-
- resized = contain(image, size, method)
- if resized.size == size:
- out = resized
- else:
- out = Image.new(image.mode, size, color)
- if resized.palette:
- out.putpalette(resized.getpalette())
- if resized.width != size[0]:
- x = round((size[0] - resized.width) * max(0, min(centering[0], 1)))
- out.paste(resized, (x, 0))
- else:
- y = round((size[1] - resized.height) * max(0, min(centering[1], 1)))
- out.paste(resized, (0, y))
- return out
-
-
-def crop(image, border=0):
- """
- Remove border from image. The same amount of pixels are removed
- from all four sides. This function works on all image modes.
-
- .. seealso:: :py:meth:`~PIL.Image.Image.crop`
-
- :param image: The image to crop.
- :param border: The number of pixels to remove.
- :return: An image.
- """
- left, top, right, bottom = _border(border)
- return image.crop((left, top, image.size[0] - right, image.size[1] - bottom))
-
-
-def scale(image, factor, resample=Image.Resampling.BICUBIC):
- """
- Returns a rescaled image by a specific factor given in parameter.
- A factor greater than 1 expands the image, between 0 and 1 contracts the
- image.
-
- :param image: The image to rescale.
- :param factor: The expansion factor, as a float.
- :param resample: Resampling method to use. Default is
- :py:attr:`~PIL.Image.Resampling.BICUBIC`.
- See :ref:`concept-filters`.
- :returns: An :py:class:`~PIL.Image.Image` object.
- """
- if factor == 1:
- return image.copy()
- elif factor <= 0:
- msg = "the factor must be greater than 0"
- raise ValueError(msg)
- else:
- size = (round(factor * image.width), round(factor * image.height))
- return image.resize(size, resample)
-
-
-def deform(image, deformer, resample=Image.Resampling.BILINEAR):
- """
- Deform the image.
-
- :param image: The image to deform.
- :param deformer: A deformer object. Any object that implements a
- ``getmesh`` method can be used.
- :param resample: An optional resampling filter. Same values possible as
- in the PIL.Image.transform function.
- :return: An image.
- """
- return image.transform(
- image.size, Image.Transform.MESH, deformer.getmesh(image), resample
- )
-
-
-def equalize(image, mask=None):
- """
- Equalize the image histogram. This function applies a non-linear
- mapping to the input image, in order to create a uniform
- distribution of grayscale values in the output image.
-
- :param image: The image to equalize.
- :param mask: An optional mask. If given, only the pixels selected by
- the mask are included in the analysis.
- :return: An image.
- """
- if image.mode == "P":
- image = image.convert("RGB")
- h = image.histogram(mask)
- lut = []
- for b in range(0, len(h), 256):
- histo = [_f for _f in h[b : b + 256] if _f]
- if len(histo) <= 1:
- lut.extend(list(range(256)))
- else:
- step = (functools.reduce(operator.add, histo) - histo[-1]) // 255
- if not step:
- lut.extend(list(range(256)))
- else:
- n = step // 2
- for i in range(256):
- lut.append(n // step)
- n = n + h[i + b]
- return _lut(image, lut)
-
-
-def expand(image, border=0, fill=0):
- """
- Add border to the image
-
- :param image: The image to expand.
- :param border: Border width, in pixels.
- :param fill: Pixel fill value (a color value). Default is 0 (black).
- :return: An image.
- """
- left, top, right, bottom = _border(border)
- width = left + image.size[0] + right
- height = top + image.size[1] + bottom
- color = _color(fill, image.mode)
- if image.palette:
- palette = ImagePalette.ImagePalette(palette=image.getpalette())
- if isinstance(color, tuple):
- color = palette.getcolor(color)
- else:
- palette = None
- out = Image.new(image.mode, (width, height), color)
- if palette:
- out.putpalette(palette.palette)
- out.paste(image, (left, top))
- return out
-
-
-def fit(image, size, method=Image.Resampling.BICUBIC, bleed=0.0, centering=(0.5, 0.5)):
- """
- Returns a resized and cropped version of the image, cropped to the
- requested aspect ratio and size.
-
- This function was contributed by Kevin Cazabon.
-
- :param image: The image to resize and crop.
- :param size: The requested output size in pixels, given as a
- (width, height) tuple.
- :param method: Resampling method to use. Default is
- :py:attr:`~PIL.Image.Resampling.BICUBIC`.
- See :ref:`concept-filters`.
- :param bleed: Remove a border around the outside of the image from all
- four edges. The value is a decimal percentage (use 0.01 for
- one percent). The default value is 0 (no border).
- Cannot be greater than or equal to 0.5.
- :param centering: Control the cropping position. Use (0.5, 0.5) for
- center cropping (e.g. if cropping the width, take 50% off
- of the left side, and therefore 50% off the right side).
- (0.0, 0.0) will crop from the top left corner (i.e. if
- cropping the width, take all of the crop off of the right
- side, and if cropping the height, take all of it off the
- bottom). (1.0, 0.0) will crop from the bottom left
- corner, etc. (i.e. if cropping the width, take all of the
- crop off the left side, and if cropping the height take
- none from the top, and therefore all off the bottom).
- :return: An image.
- """
-
- # by Kevin Cazabon, Feb 17/2000
- # kevin@cazabon.com
- # https://www.cazabon.com
-
- # ensure centering is mutable
- centering = list(centering)
-
- if not 0.0 <= centering[0] <= 1.0:
- centering[0] = 0.5
- if not 0.0 <= centering[1] <= 1.0:
- centering[1] = 0.5
-
- if not 0.0 <= bleed < 0.5:
- bleed = 0.0
-
- # calculate the area to use for resizing and cropping, subtracting
- # the 'bleed' around the edges
-
- # number of pixels to trim off on Top and Bottom, Left and Right
- bleed_pixels = (bleed * image.size[0], bleed * image.size[1])
-
- live_size = (
- image.size[0] - bleed_pixels[0] * 2,
- image.size[1] - bleed_pixels[1] * 2,
- )
-
- # calculate the aspect ratio of the live_size
- live_size_ratio = live_size[0] / live_size[1]
-
- # calculate the aspect ratio of the output image
- output_ratio = size[0] / size[1]
-
- # figure out if the sides or top/bottom will be cropped off
- if live_size_ratio == output_ratio:
- # live_size is already the needed ratio
- crop_width = live_size[0]
- crop_height = live_size[1]
- elif live_size_ratio >= output_ratio:
- # live_size is wider than what's needed, crop the sides
- crop_width = output_ratio * live_size[1]
- crop_height = live_size[1]
- else:
- # live_size is taller than what's needed, crop the top and bottom
- crop_width = live_size[0]
- crop_height = live_size[0] / output_ratio
-
- # make the crop
- crop_left = bleed_pixels[0] + (live_size[0] - crop_width) * centering[0]
- crop_top = bleed_pixels[1] + (live_size[1] - crop_height) * centering[1]
-
- crop = (crop_left, crop_top, crop_left + crop_width, crop_top + crop_height)
-
- # resize the image and return it
- return image.resize(size, method, box=crop)
-
-
-def flip(image):
- """
- Flip the image vertically (top to bottom).
-
- :param image: The image to flip.
- :return: An image.
- """
- return image.transpose(Image.Transpose.FLIP_TOP_BOTTOM)
-
-
-def grayscale(image):
- """
- Convert the image to grayscale.
-
- :param image: The image to convert.
- :return: An image.
- """
- return image.convert("L")
-
-
-def invert(image):
- """
- Invert (negate) the image.
-
- :param image: The image to invert.
- :return: An image.
- """
- lut = []
- for i in range(256):
- lut.append(255 - i)
- return image.point(lut) if image.mode == "1" else _lut(image, lut)
-
-
-def mirror(image):
- """
- Flip image horizontally (left to right).
-
- :param image: The image to mirror.
- :return: An image.
- """
- return image.transpose(Image.Transpose.FLIP_LEFT_RIGHT)
-
-
-def posterize(image, bits):
- """
- Reduce the number of bits for each color channel.
-
- :param image: The image to posterize.
- :param bits: The number of bits to keep for each channel (1-8).
- :return: An image.
- """
- lut = []
- mask = ~(2 ** (8 - bits) - 1)
- for i in range(256):
- lut.append(i & mask)
- return _lut(image, lut)
-
-
-def solarize(image, threshold=128):
- """
- Invert all pixel values above a threshold.
-
- :param image: The image to solarize.
- :param threshold: All pixels above this greyscale level are inverted.
- :return: An image.
- """
- lut = []
- for i in range(256):
- if i < threshold:
- lut.append(i)
- else:
- lut.append(255 - i)
- return _lut(image, lut)
-
-
-def exif_transpose(image, *, in_place=False):
- """
- If an image has an EXIF Orientation tag, other than 1, transpose the image
- accordingly, and remove the orientation data.
-
- :param image: The image to transpose.
- :param in_place: Boolean. Keyword-only argument.
- If ``True``, the original image is modified in-place, and ``None`` is returned.
- If ``False`` (default), a new :py:class:`~PIL.Image.Image` object is returned
- with the transposition applied. If there is no transposition, a copy of the
- image will be returned.
- """
- image_exif = image.getexif()
- orientation = image_exif.get(ExifTags.Base.Orientation)
- method = {
- 2: Image.Transpose.FLIP_LEFT_RIGHT,
- 3: Image.Transpose.ROTATE_180,
- 4: Image.Transpose.FLIP_TOP_BOTTOM,
- 5: Image.Transpose.TRANSPOSE,
- 6: Image.Transpose.ROTATE_270,
- 7: Image.Transpose.TRANSVERSE,
- 8: Image.Transpose.ROTATE_90,
- }.get(orientation)
- if method is not None:
- transposed_image = image.transpose(method)
- if in_place:
- image.im = transposed_image.im
- image.pyaccess = None
- image._size = transposed_image._size
- exif_image = image if in_place else transposed_image
-
- exif = exif_image.getexif()
- if ExifTags.Base.Orientation in exif:
- del exif[ExifTags.Base.Orientation]
- if "exif" in exif_image.info:
- exif_image.info["exif"] = exif.tobytes()
- elif "Raw profile type exif" in exif_image.info:
- exif_image.info["Raw profile type exif"] = exif.tobytes().hex()
- elif "XML:com.adobe.xmp" in exif_image.info:
- for pattern in (
- r'tiff:Orientation="([0-9])"',
- r"([0-9])",
- ):
- exif_image.info["XML:com.adobe.xmp"] = re.sub(
- pattern, "", exif_image.info["XML:com.adobe.xmp"]
- )
- if not in_place:
- return transposed_image
- elif not in_place:
- return image.copy()
diff --git a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/click/_textwrap.py b/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/click/_textwrap.py
deleted file mode 100644
index b47dcbd4264e86715adfae1c5124c288b67a983e..0000000000000000000000000000000000000000
--- a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/click/_textwrap.py
+++ /dev/null
@@ -1,49 +0,0 @@
-import textwrap
-import typing as t
-from contextlib import contextmanager
-
-
-class TextWrapper(textwrap.TextWrapper):
- def _handle_long_word(
- self,
- reversed_chunks: t.List[str],
- cur_line: t.List[str],
- cur_len: int,
- width: int,
- ) -> None:
- space_left = max(width - cur_len, 1)
-
- if self.break_long_words:
- last = reversed_chunks[-1]
- cut = last[:space_left]
- res = last[space_left:]
- cur_line.append(cut)
- reversed_chunks[-1] = res
- elif not cur_line:
- cur_line.append(reversed_chunks.pop())
-
- @contextmanager
- def extra_indent(self, indent: str) -> t.Iterator[None]:
- old_initial_indent = self.initial_indent
- old_subsequent_indent = self.subsequent_indent
- self.initial_indent += indent
- self.subsequent_indent += indent
-
- try:
- yield
- finally:
- self.initial_indent = old_initial_indent
- self.subsequent_indent = old_subsequent_indent
-
- def indent_only(self, text: str) -> str:
- rv = []
-
- for idx, line in enumerate(text.splitlines()):
- indent = self.initial_indent
-
- if idx > 0:
- indent = self.subsequent_indent
-
- rv.append(f"{indent}{line}")
-
- return "\n".join(rv)
diff --git a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/fontTools/ttLib/macUtils.py b/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/fontTools/ttLib/macUtils.py
deleted file mode 100644
index 468a75ad6d2da59bf00bbb07063ba4819aff64dd..0000000000000000000000000000000000000000
--- a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/fontTools/ttLib/macUtils.py
+++ /dev/null
@@ -1,54 +0,0 @@
-"""ttLib.macUtils.py -- Various Mac-specific stuff."""
-from io import BytesIO
-from fontTools.misc.macRes import ResourceReader, ResourceError
-
-
-def getSFNTResIndices(path):
- """Determine whether a file has a 'sfnt' resource fork or not."""
- try:
- reader = ResourceReader(path)
- indices = reader.getIndices("sfnt")
- reader.close()
- return indices
- except ResourceError:
- return []
-
-
-def openTTFonts(path):
- """Given a pathname, return a list of TTFont objects. In the case
- of a flat TTF/OTF file, the list will contain just one font object;
- but in the case of a Mac font suitcase it will contain as many
- font objects as there are sfnt resources in the file.
- """
- from fontTools import ttLib
-
- fonts = []
- sfnts = getSFNTResIndices(path)
- if not sfnts:
- fonts.append(ttLib.TTFont(path))
- else:
- for index in sfnts:
- fonts.append(ttLib.TTFont(path, index))
- if not fonts:
- raise ttLib.TTLibError("no fonts found in file '%s'" % path)
- return fonts
-
-
-class SFNTResourceReader(BytesIO):
-
- """Simple read-only file wrapper for 'sfnt' resources."""
-
- def __init__(self, path, res_name_or_index):
- from fontTools import ttLib
-
- reader = ResourceReader(path)
- if isinstance(res_name_or_index, str):
- rsrc = reader.getNamedResource("sfnt", res_name_or_index)
- else:
- rsrc = reader.getIndResource("sfnt", res_name_or_index)
- if rsrc is None:
- raise ttLib.TTLibError("sfnt resource not found: %s" % res_name_or_index)
- reader.close()
- self.rsrc = rsrc
- super(SFNTResourceReader, self).__init__(rsrc.data)
- self.name = path
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/arm/audiodsp_init_neon.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/arm/audiodsp_init_neon.c
deleted file mode 100644
index 6902db86b4ce997edf4da6fa7d8ecfd1e413dfd2..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/arm/audiodsp_init_neon.c
+++ /dev/null
@@ -1,40 +0,0 @@
-/*
- * ARM NEON optimised audio functions
- * Copyright (c) 2008 Mans Rullgard
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-#include
-
-#include "libavutil/attributes.h"
-#include "libavcodec/audiodsp.h"
-#include "audiodsp_arm.h"
-
-void ff_vector_clipf_neon(float *dst, const float *src, int len, float min, float max);
-void ff_vector_clip_int32_neon(int32_t *dst, const int32_t *src, int32_t min,
- int32_t max, unsigned int len);
-
-int32_t ff_scalarproduct_int16_neon(const int16_t *v1, const int16_t *v2, int len);
-
-av_cold void ff_audiodsp_init_neon(AudioDSPContext *c)
-{
- c->vector_clip_int32 = ff_vector_clip_int32_neon;
- c->vector_clipf = ff_vector_clipf_neon;
-
- c->scalarproduct_int16 = ff_scalarproduct_int16_neon;
-}
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/atrac1data.h b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/atrac1data.h
deleted file mode 100644
index 62c218b7906d59c9b0aa131cdc22763c959482b2..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/atrac1data.h
+++ /dev/null
@@ -1,64 +0,0 @@
-/*
- * ATRAC 1 compatible decoder data
- * Copyright (c) 2009 Maxim Poliakovski
- * Copyright (c) 2009 Benjamin Larsson
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-/**
- * @file
- * ATRAC1 compatible decoder data
- */
-
-#ifndef AVCODEC_ATRAC1DATA_H
-#define AVCODEC_ATRAC1DATA_H
-
-#include
-
-static const uint8_t bfu_amount_tab1[8] = {20, 28, 32, 36, 40, 44, 48, 52};
-static const uint8_t bfu_amount_tab2[4] = { 0, 112, 176, 208};
-static const uint8_t bfu_amount_tab3[8] = { 0, 24, 36, 48, 72, 108, 132, 156};
-
-/** number of BFUs in each QMF band */
-static const uint8_t bfu_bands_t[4] = {0, 20, 36, 52};
-
-/** number of spectral lines in each BFU
- * block floating unit = group of spectral frequencies having the
- * same quantization parameters like word length and scale factor
- */
-static const uint8_t specs_per_bfu[52] = {
- 8, 8, 8, 8, 4, 4, 4, 4, 8, 8, 8, 8, 6, 6, 6, 6, 6, 6, 6, 6, // low band
- 6, 6, 6, 6, 7, 7, 7, 7, 9, 9, 9, 9, 10, 10, 10, 10, // middle band
- 12, 12, 12, 12, 12, 12, 12, 12, 20, 20, 20, 20, 20, 20, 20, 20 // high band
-};
-
-/** start position of each BFU in the MDCT spectrum for the long mode */
-static const uint16_t bfu_start_long[52] = {
- 0, 8, 16, 24, 32, 36, 40, 44, 48, 56, 64, 72, 80, 86, 92, 98, 104, 110, 116, 122,
- 128, 134, 140, 146, 152, 159, 166, 173, 180, 189, 198, 207, 216, 226, 236, 246,
- 256, 268, 280, 292, 304, 316, 328, 340, 352, 372, 392, 412, 432, 452, 472, 492,
-};
-
-/** start position of each BFU in the MDCT spectrum for the short mode */
-static const uint16_t bfu_start_short[52] = {
- 0, 32, 64, 96, 8, 40, 72, 104, 12, 44, 76, 108, 20, 52, 84, 116, 26, 58, 90, 122,
- 128, 160, 192, 224, 134, 166, 198, 230, 141, 173, 205, 237, 150, 182, 214, 246,
- 256, 288, 320, 352, 384, 416, 448, 480, 268, 300, 332, 364, 396, 428, 460, 492
-};
-
-#endif /* AVCODEC_ATRAC1DATA_H */
diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/flicvideo.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/flicvideo.c
deleted file mode 100644
index 228f65277528e626cc2daafc8c92362deb14c7ad..0000000000000000000000000000000000000000
--- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/flicvideo.c
+++ /dev/null
@@ -1,1115 +0,0 @@
-/*
- * FLI/FLC Animation Video Decoder
- * Copyright (C) 2003, 2004 The FFmpeg project
- *
- * This file is part of FFmpeg.
- *
- * FFmpeg is free software; you can redistribute it and/or
- * modify it under the terms of the GNU Lesser General Public
- * License as published by the Free Software Foundation; either
- * version 2.1 of the License, or (at your option) any later version.
- *
- * FFmpeg is distributed in the hope that it will be useful,
- * but WITHOUT ANY WARRANTY; without even the implied warranty of
- * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
- * Lesser General Public License for more details.
- *
- * You should have received a copy of the GNU Lesser General Public
- * License along with FFmpeg; if not, write to the Free Software
- * Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
- */
-
-/**
- * @file
- * Autodesk Animator FLI/FLC Video Decoder
- * by Mike Melanson (melanson@pcisys.net)
- * for more information on the .fli/.flc file format and all of its many
- * variations, visit:
- * http://www.compuphase.com/flic.htm
- *
- * This decoder outputs PAL8/RGB555/RGB565/BGR24. To use this decoder, be
- * sure that your demuxer sends the FLI file header to the decoder via
- * the extradata chunk in AVCodecContext. The chunk should be 128 bytes
- * large. The only exception is for FLI files from the game "Magic Carpet",
- * in which the header is only 12 bytes.
- */
-
-#include
-
-#include "libavutil/intreadwrite.h"
-#include "avcodec.h"
-#include "bytestream.h"
-#include "codec_internal.h"
-#include "decode.h"
-#include "mathops.h"
-
-#define FLI_256_COLOR 4
-#define FLI_DELTA 7
-#define FLI_COLOR 11
-#define FLI_LC 12
-#define FLI_BLACK 13
-#define FLI_BRUN 15
-#define FLI_COPY 16
-#define FLI_MINI 18
-#define FLI_DTA_BRUN 25
-#define FLI_DTA_COPY 26
-#define FLI_DTA_LC 27
-
-#define FLI_TYPE_CODE (0xAF11)
-#define FLC_FLX_TYPE_CODE (0xAF12)
-#define FLC_DTA_TYPE_CODE (0xAF44) /* Marks an "Extended FLC" comes from Dave's Targa Animator (DTA) */
-#define FLC_MAGIC_CARPET_SYNTHETIC_TYPE_CODE (0xAF13)
-
-#define CHECK_PIXEL_PTR(n) \
- if (pixel_ptr + n > pixel_limit) { \
- av_log (s->avctx, AV_LOG_ERROR, "Invalid pixel_ptr = %d > pixel_limit = %d\n", \
- pixel_ptr + n, pixel_limit); \
- return AVERROR_INVALIDDATA; \
- } \
-
-typedef struct FlicDecodeContext {
- AVCodecContext *avctx;
- AVFrame *frame;
-
- unsigned int palette[256];
- int new_palette;
- int fli_type; /* either 0xAF11 or 0xAF12, affects palette resolution */
-} FlicDecodeContext;
-
-static av_cold int flic_decode_init(AVCodecContext *avctx)
-{
- FlicDecodeContext *s = avctx->priv_data;
- unsigned char *fli_header = (unsigned char *)avctx->extradata;
- int depth;
-
- if (avctx->extradata_size != 0 &&
- avctx->extradata_size != 12 &&
- avctx->extradata_size != 128 &&
- avctx->extradata_size != 256 &&
- avctx->extradata_size != 904 &&
- avctx->extradata_size != 1024) {
- av_log(avctx, AV_LOG_ERROR, "Unexpected extradata size %d\n", avctx->extradata_size);
- return AVERROR_INVALIDDATA;
- }
-
- s->avctx = avctx;
-
- if (s->avctx->extradata_size == 12) {
- /* special case for magic carpet FLIs */
- s->fli_type = FLC_MAGIC_CARPET_SYNTHETIC_TYPE_CODE;
- depth = 8;
- } else if (avctx->extradata_size == 1024) {
- uint8_t *ptr = avctx->extradata;
- int i;
-
- for (i = 0; i < 256; i++) {
- s->palette[i] = AV_RL32(ptr);
- ptr += 4;
- }
- depth = 8;
- /* FLI in MOV, see e.g. FFmpeg trac issue #626 */
- } else if (avctx->extradata_size == 0 ||
- avctx->extradata_size == 256 ||
- /* see FFmpeg ticket #1234 */
- avctx->extradata_size == 904) {
- s->fli_type = FLI_TYPE_CODE;
- depth = 8;
- } else {
- s->fli_type = AV_RL16(&fli_header[4]);
- depth = AV_RL16(&fli_header[12]);
- }
-
- if (depth == 0) {
- depth = 8; /* Some FLC generators set depth to zero, when they mean 8Bpp. Fix up here */
- }
-
- if ((s->fli_type == FLC_FLX_TYPE_CODE) && (depth == 16)) {
- depth = 15; /* Original Autodesk FLX's say the depth is 16Bpp when it is really 15Bpp */
- }
-
- switch (depth) {
- case 8 : avctx->pix_fmt = AV_PIX_FMT_PAL8; break;
- case 15 : avctx->pix_fmt = AV_PIX_FMT_RGB555; break;
- case 16 : avctx->pix_fmt = AV_PIX_FMT_RGB565; break;
- case 24 : avctx->pix_fmt = AV_PIX_FMT_BGR24; break;
- default :
- av_log(avctx, AV_LOG_ERROR, "Unknown FLC/FLX depth of %d Bpp is unsupported.\n",depth);
- return AVERROR_INVALIDDATA;
- }
-
- s->frame = av_frame_alloc();
- if (!s->frame)
- return AVERROR(ENOMEM);
-
- s->new_palette = 0;
-
- return 0;
-}
-
-static int flic_decode_frame_8BPP(AVCodecContext *avctx,
- AVFrame *rframe, int *got_frame,
- const uint8_t *buf, int buf_size)
-{
- FlicDecodeContext *s = avctx->priv_data;
-
- GetByteContext g2;
- int pixel_ptr;
- int palette_ptr;
- unsigned char palette_idx1;
- unsigned char palette_idx2;
-
- unsigned int frame_size;
- int num_chunks;
-
- unsigned int chunk_size;
- int chunk_type;
-
- int i, j, ret;
-
- int color_packets;
- int color_changes;
- int color_shift;
- unsigned char r, g, b;
-
- int lines;
- int compressed_lines;
- int starting_line;
- int line_packets;
- int y_ptr;
- int byte_run;
- int pixel_skip;
- int pixel_countdown;
- unsigned char *pixels;
- unsigned int pixel_limit;
-
- bytestream2_init(&g2, buf, buf_size);
-
- if ((ret = ff_reget_buffer(avctx, s->frame, 0)) < 0)
- return ret;
-
- pixels = s->frame->data[0];
- pixel_limit = s->avctx->height * s->frame->linesize[0];
- if (buf_size < 16 || buf_size > INT_MAX - (3 * 256 + AV_INPUT_BUFFER_PADDING_SIZE))
- return AVERROR_INVALIDDATA;
- frame_size = bytestream2_get_le32(&g2);
- if (frame_size > buf_size)
- frame_size = buf_size;
- bytestream2_skip(&g2, 2); /* skip the magic number */
- num_chunks = bytestream2_get_le16(&g2);
- bytestream2_skip(&g2, 8); /* skip padding */
-
- if (frame_size < 16)
- return AVERROR_INVALIDDATA;
-
- frame_size -= 16;
-
- /* iterate through the chunks */
- while ((frame_size >= 6) && (num_chunks > 0) &&
- bytestream2_get_bytes_left(&g2) >= 4) {
- int stream_ptr_after_chunk;
- chunk_size = bytestream2_get_le32(&g2);
- if (chunk_size > frame_size) {
- av_log(avctx, AV_LOG_WARNING,
- "Invalid chunk_size = %u > frame_size = %u\n", chunk_size, frame_size);
- chunk_size = frame_size;
- }
- stream_ptr_after_chunk = bytestream2_tell(&g2) - 4 + chunk_size;
-
- chunk_type = bytestream2_get_le16(&g2);
-
- switch (chunk_type) {
- case FLI_256_COLOR:
- case FLI_COLOR:
- /* check special case: If this file is from the Magic Carpet
- * game and uses 6-bit colors even though it reports 256-color
- * chunks in a 0xAF12-type file (fli_type is set to 0xAF13 during
- * initialization) */
- if ((chunk_type == FLI_256_COLOR) && (s->fli_type != FLC_MAGIC_CARPET_SYNTHETIC_TYPE_CODE))
- color_shift = 0;
- else
- color_shift = 2;
- /* set up the palette */
- color_packets = bytestream2_get_le16(&g2);
- palette_ptr = 0;
- for (i = 0; i < color_packets; i++) {
- /* first byte is how many colors to skip */
- palette_ptr += bytestream2_get_byte(&g2);
-
- /* next byte indicates how many entries to change */
- color_changes = bytestream2_get_byte(&g2);
-
- /* if there are 0 color changes, there are actually 256 */
- if (color_changes == 0)
- color_changes = 256;
-
- if (bytestream2_tell(&g2) + color_changes * 3 > stream_ptr_after_chunk)
- break;
-
- for (j = 0; j < color_changes; j++) {
- unsigned int entry;
-
- /* wrap around, for good measure */
- if ((unsigned)palette_ptr >= 256)
- palette_ptr = 0;
-
- r = bytestream2_get_byte(&g2) << color_shift;
- g = bytestream2_get_byte(&g2) << color_shift;
- b = bytestream2_get_byte(&g2) << color_shift;
- entry = 0xFFU << 24 | r << 16 | g << 8 | b;
- if (color_shift == 2)
- entry |= entry >> 6 & 0x30303;
- if (s->palette[palette_ptr] != entry)
- s->new_palette = 1;
- s->palette[palette_ptr++] = entry;
- }
- }
- break;
-
- case FLI_DELTA:
- y_ptr = 0;
- compressed_lines = bytestream2_get_le16(&g2);
- while (compressed_lines > 0) {
- if (bytestream2_tell(&g2) + 2 > stream_ptr_after_chunk)
- break;
- if (y_ptr > pixel_limit)
- return AVERROR_INVALIDDATA;
- line_packets = sign_extend(bytestream2_get_le16(&g2), 16);
- if ((line_packets & 0xC000) == 0xC000) {
- // line skip opcode
- line_packets = -line_packets;
- if (line_packets > s->avctx->height)
- return AVERROR_INVALIDDATA;
- y_ptr += line_packets * s->frame->linesize[0];
- } else if ((line_packets & 0xC000) == 0x4000) {
- av_log(avctx, AV_LOG_ERROR, "Undefined opcode (%x) in DELTA_FLI\n", line_packets);
- } else if ((line_packets & 0xC000) == 0x8000) {
- // "last byte" opcode
- pixel_ptr= y_ptr + s->frame->linesize[0] - 1;
- CHECK_PIXEL_PTR(0);
- pixels[pixel_ptr] = line_packets & 0xff;
- } else {
- compressed_lines--;
- pixel_ptr = y_ptr;
- CHECK_PIXEL_PTR(0);
- pixel_countdown = s->avctx->width;
- for (i = 0; i < line_packets; i++) {
- if (bytestream2_tell(&g2) + 2 > stream_ptr_after_chunk)
- break;
- /* account for the skip bytes */
- pixel_skip = bytestream2_get_byte(&g2);
- pixel_ptr += pixel_skip;
- pixel_countdown -= pixel_skip;
- byte_run = sign_extend(bytestream2_get_byte(&g2), 8);
- if (byte_run < 0) {
- byte_run = -byte_run;
- palette_idx1 = bytestream2_get_byte(&g2);
- palette_idx2 = bytestream2_get_byte(&g2);
- CHECK_PIXEL_PTR(byte_run * 2);
- for (j = 0; j < byte_run; j++, pixel_countdown -= 2) {
- pixels[pixel_ptr++] = palette_idx1;
- pixels[pixel_ptr++] = palette_idx2;
- }
- } else {
- CHECK_PIXEL_PTR(byte_run * 2);
- if (bytestream2_tell(&g2) + byte_run * 2 > stream_ptr_after_chunk)
- break;
- for (j = 0; j < byte_run * 2; j++, pixel_countdown--) {
- pixels[pixel_ptr++] = bytestream2_get_byte(&g2);
- }
- }
- }
-
- y_ptr += s->frame->linesize[0];
- }
- }
- break;
-
- case FLI_LC:
- /* line compressed */
- starting_line = bytestream2_get_le16(&g2);
- if (starting_line >= s->avctx->height)
- return AVERROR_INVALIDDATA;
- y_ptr = 0;
- y_ptr += starting_line * s->frame->linesize[0];
-
- compressed_lines = bytestream2_get_le16(&g2);
- while (compressed_lines > 0) {
- pixel_ptr = y_ptr;
- CHECK_PIXEL_PTR(0);
- pixel_countdown = s->avctx->width;
- if (bytestream2_tell(&g2) + 1 > stream_ptr_after_chunk)
- break;
- line_packets = bytestream2_get_byte(&g2);
- if (line_packets > 0) {
- for (i = 0; i < line_packets; i++) {
- /* account for the skip bytes */
- if (bytestream2_tell(&g2) + 1 > stream_ptr_after_chunk)
- break;
- pixel_skip = bytestream2_get_byte(&g2);
- pixel_ptr += pixel_skip;
- pixel_countdown -= pixel_skip;
- byte_run = sign_extend(bytestream2_get_byte(&g2),8);
- if (byte_run > 0) {
- CHECK_PIXEL_PTR(byte_run);
- if (bytestream2_tell(&g2) + byte_run > stream_ptr_after_chunk)
- break;
- for (j = 0; j < byte_run; j++, pixel_countdown--) {
- pixels[pixel_ptr++] = bytestream2_get_byte(&g2);
- }
- } else if (byte_run < 0) {
- byte_run = -byte_run;
- palette_idx1 = bytestream2_get_byte(&g2);
- CHECK_PIXEL_PTR(byte_run);
- for (j = 0; j < byte_run; j++, pixel_countdown--) {
- pixels[pixel_ptr++] = palette_idx1;
- }
- }
- }
- }
-
- y_ptr += s->frame->linesize[0];
- compressed_lines--;
- }
- break;
-
- case FLI_BLACK:
- /* set the whole frame to color 0 (which is usually black) */
- memset(pixels, 0,
- s->frame->linesize[0] * s->avctx->height);
- break;
-
- case FLI_BRUN:
- /* Byte run compression: This chunk type only occurs in the first
- * FLI frame and it will update the entire frame. */
- y_ptr = 0;
- for (lines = 0; lines < s->avctx->height; lines++) {
- pixel_ptr = y_ptr;
- /* disregard the line packets; instead, iterate through all
- * pixels on a row */
- bytestream2_skip(&g2, 1);
- pixel_countdown = s->avctx->width;
- while (pixel_countdown > 0) {
- if (bytestream2_tell(&g2) + 1 > stream_ptr_after_chunk)
- break;
- byte_run = sign_extend(bytestream2_get_byte(&g2), 8);
- if (!byte_run) {
- av_log(avctx, AV_LOG_ERROR, "Invalid byte run value.\n");
- return AVERROR_INVALIDDATA;
- }
-
- if (byte_run > 0) {
- palette_idx1 = bytestream2_get_byte(&g2);
- CHECK_PIXEL_PTR(byte_run);
- for (j = 0; j < byte_run; j++) {
- pixels[pixel_ptr++] = palette_idx1;
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d) at line %d\n",
- pixel_countdown, lines);
- }
- } else { /* copy bytes if byte_run < 0 */
- byte_run = -byte_run;
- CHECK_PIXEL_PTR(byte_run);
- if (bytestream2_tell(&g2) + byte_run > stream_ptr_after_chunk)
- break;
- for (j = 0; j < byte_run; j++) {
- pixels[pixel_ptr++] = bytestream2_get_byte(&g2);
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d) at line %d\n",
- pixel_countdown, lines);
- }
- }
- }
-
- y_ptr += s->frame->linesize[0];
- }
- break;
-
- case FLI_COPY:
- /* copy the chunk (uncompressed frame) */
- if (chunk_size - 6 != FFALIGN(s->avctx->width, 4) * s->avctx->height) {
- av_log(avctx, AV_LOG_ERROR, "In chunk FLI_COPY : source data (%d bytes) " \
- "has incorrect size, skipping chunk\n", chunk_size - 6);
- bytestream2_skip(&g2, chunk_size - 6);
- } else {
- for (y_ptr = 0; y_ptr < s->frame->linesize[0] * s->avctx->height;
- y_ptr += s->frame->linesize[0]) {
- bytestream2_get_buffer(&g2, &pixels[y_ptr],
- s->avctx->width);
- if (s->avctx->width & 3)
- bytestream2_skip(&g2, 4 - (s->avctx->width & 3));
- }
- }
- break;
-
- case FLI_MINI:
- /* some sort of a thumbnail? disregard this chunk... */
- break;
-
- default:
- av_log(avctx, AV_LOG_ERROR, "Unrecognized chunk type: %d\n", chunk_type);
- break;
- }
-
- if (stream_ptr_after_chunk - bytestream2_tell(&g2) >= 0) {
- bytestream2_skip(&g2, stream_ptr_after_chunk - bytestream2_tell(&g2));
- } else {
- av_log(avctx, AV_LOG_ERROR, "Chunk overread\n");
- break;
- }
-
- frame_size -= chunk_size;
- num_chunks--;
- }
-
- /* by the end of the chunk, the stream ptr should equal the frame
- * size (minus 1 or 2, possibly); if it doesn't, issue a warning */
- if (bytestream2_get_bytes_left(&g2) > 2)
- av_log(avctx, AV_LOG_ERROR, "Processed FLI chunk where chunk size = %d " \
- "and final chunk ptr = %d\n", buf_size,
- buf_size - bytestream2_get_bytes_left(&g2));
-
- /* make the palette available on the way out */
- memcpy(s->frame->data[1], s->palette, AVPALETTE_SIZE);
- if (s->new_palette) {
- s->frame->palette_has_changed = 1;
- s->new_palette = 0;
- }
-
- if ((ret = av_frame_ref(rframe, s->frame)) < 0)
- return ret;
-
- *got_frame = 1;
-
- return buf_size;
-}
-
-static int flic_decode_frame_15_16BPP(AVCodecContext *avctx,
- AVFrame *rframe, int *got_frame,
- const uint8_t *buf, int buf_size)
-{
- /* Note, the only difference between the 15Bpp and 16Bpp */
- /* Format is the pixel format, the packets are processed the same. */
- FlicDecodeContext *s = avctx->priv_data;
-
- GetByteContext g2;
- int pixel_ptr;
- unsigned char palette_idx1;
-
- unsigned int frame_size;
- int num_chunks;
-
- unsigned int chunk_size;
- int chunk_type;
-
- int i, j, ret;
-
- int lines;
- int compressed_lines;
- int line_packets;
- int y_ptr;
- int byte_run;
- int pixel_skip;
- int pixel_countdown;
- unsigned char *pixels;
- int pixel;
- unsigned int pixel_limit;
-
- bytestream2_init(&g2, buf, buf_size);
-
- if ((ret = ff_reget_buffer(avctx, s->frame, 0)) < 0)
- return ret;
-
- pixels = s->frame->data[0];
- pixel_limit = s->avctx->height * s->frame->linesize[0];
-
- frame_size = bytestream2_get_le32(&g2);
- bytestream2_skip(&g2, 2); /* skip the magic number */
- num_chunks = bytestream2_get_le16(&g2);
- bytestream2_skip(&g2, 8); /* skip padding */
- if (frame_size > buf_size)
- frame_size = buf_size;
-
- if (frame_size < 16)
- return AVERROR_INVALIDDATA;
- frame_size -= 16;
-
- /* iterate through the chunks */
- while ((frame_size > 0) && (num_chunks > 0) &&
- bytestream2_get_bytes_left(&g2) >= 4) {
- int stream_ptr_after_chunk;
- chunk_size = bytestream2_get_le32(&g2);
- if (chunk_size > frame_size) {
- av_log(avctx, AV_LOG_WARNING,
- "Invalid chunk_size = %u > frame_size = %u\n", chunk_size, frame_size);
- chunk_size = frame_size;
- }
- stream_ptr_after_chunk = bytestream2_tell(&g2) - 4 + chunk_size;
-
- chunk_type = bytestream2_get_le16(&g2);
-
-
- switch (chunk_type) {
- case FLI_256_COLOR:
- case FLI_COLOR:
- /* For some reason, it seems that non-palettized flics do
- * include one of these chunks in their first frame.
- * Why I do not know, it seems rather extraneous. */
- ff_dlog(avctx,
- "Unexpected Palette chunk %d in non-palettized FLC\n",
- chunk_type);
- bytestream2_skip(&g2, chunk_size - 6);
- break;
-
- case FLI_DELTA:
- case FLI_DTA_LC:
- y_ptr = 0;
- compressed_lines = bytestream2_get_le16(&g2);
- while (compressed_lines > 0) {
- if (bytestream2_tell(&g2) + 2 > stream_ptr_after_chunk)
- break;
- if (y_ptr > pixel_limit)
- return AVERROR_INVALIDDATA;
- line_packets = sign_extend(bytestream2_get_le16(&g2), 16);
- if (line_packets < 0) {
- line_packets = -line_packets;
- if (line_packets > s->avctx->height)
- return AVERROR_INVALIDDATA;
- y_ptr += line_packets * s->frame->linesize[0];
- } else {
- compressed_lines--;
- pixel_ptr = y_ptr;
- CHECK_PIXEL_PTR(0);
- pixel_countdown = s->avctx->width;
- for (i = 0; i < line_packets; i++) {
- /* account for the skip bytes */
- if (bytestream2_tell(&g2) + 2 > stream_ptr_after_chunk)
- break;
- pixel_skip = bytestream2_get_byte(&g2);
- pixel_ptr += (pixel_skip*2); /* Pixel is 2 bytes wide */
- pixel_countdown -= pixel_skip;
- byte_run = sign_extend(bytestream2_get_byte(&g2), 8);
- if (byte_run < 0) {
- byte_run = -byte_run;
- pixel = bytestream2_get_le16(&g2);
- CHECK_PIXEL_PTR(2 * byte_run);
- for (j = 0; j < byte_run; j++, pixel_countdown -= 2) {
- *((signed short*)(&pixels[pixel_ptr])) = pixel;
- pixel_ptr += 2;
- }
- } else {
- if (bytestream2_tell(&g2) + 2*byte_run > stream_ptr_after_chunk)
- break;
- CHECK_PIXEL_PTR(2 * byte_run);
- for (j = 0; j < byte_run; j++, pixel_countdown--) {
- *((signed short*)(&pixels[pixel_ptr])) = bytestream2_get_le16(&g2);
- pixel_ptr += 2;
- }
- }
- }
-
- y_ptr += s->frame->linesize[0];
- }
- }
- break;
-
- case FLI_LC:
- av_log(avctx, AV_LOG_ERROR, "Unexpected FLI_LC chunk in non-palettized FLC\n");
- bytestream2_skip(&g2, chunk_size - 6);
- break;
-
- case FLI_BLACK:
- /* set the whole frame to 0x0000 which is black in both 15Bpp and 16Bpp modes. */
- memset(pixels, 0x0000,
- s->frame->linesize[0] * s->avctx->height);
- break;
-
- case FLI_BRUN:
- y_ptr = 0;
- for (lines = 0; lines < s->avctx->height; lines++) {
- pixel_ptr = y_ptr;
- /* disregard the line packets; instead, iterate through all
- * pixels on a row */
- bytestream2_skip(&g2, 1);
- pixel_countdown = (s->avctx->width * 2);
-
- while (pixel_countdown > 0) {
- if (bytestream2_tell(&g2) + 1 > stream_ptr_after_chunk)
- break;
- byte_run = sign_extend(bytestream2_get_byte(&g2), 8);
- if (byte_run > 0) {
- palette_idx1 = bytestream2_get_byte(&g2);
- CHECK_PIXEL_PTR(byte_run);
- for (j = 0; j < byte_run; j++) {
- pixels[pixel_ptr++] = palette_idx1;
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d) (linea%d)\n",
- pixel_countdown, lines);
- }
- } else { /* copy bytes if byte_run < 0 */
- byte_run = -byte_run;
- if (bytestream2_tell(&g2) + byte_run > stream_ptr_after_chunk)
- break;
- CHECK_PIXEL_PTR(byte_run);
- for (j = 0; j < byte_run; j++) {
- palette_idx1 = bytestream2_get_byte(&g2);
- pixels[pixel_ptr++] = palette_idx1;
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d) at line %d\n",
- pixel_countdown, lines);
- }
- }
- }
-
- /* Now FLX is strange, in that it is "byte" as opposed to "pixel" run length compressed.
- * This does not give us any good opportunity to perform word endian conversion
- * during decompression. So if it is required (i.e., this is not a LE target, we do
- * a second pass over the line here, swapping the bytes.
- */
-#if HAVE_BIGENDIAN
- pixel_ptr = y_ptr;
- pixel_countdown = s->avctx->width;
- while (pixel_countdown > 0) {
- *((signed short*)(&pixels[pixel_ptr])) = AV_RL16(&buf[pixel_ptr]);
- pixel_ptr += 2;
- }
-#endif
- y_ptr += s->frame->linesize[0];
- }
- break;
-
- case FLI_DTA_BRUN:
- y_ptr = 0;
- for (lines = 0; lines < s->avctx->height; lines++) {
- pixel_ptr = y_ptr;
- /* disregard the line packets; instead, iterate through all
- * pixels on a row */
- bytestream2_skip(&g2, 1);
- pixel_countdown = s->avctx->width; /* Width is in pixels, not bytes */
-
- while (pixel_countdown > 0) {
- if (bytestream2_tell(&g2) + 1 > stream_ptr_after_chunk)
- break;
- byte_run = sign_extend(bytestream2_get_byte(&g2), 8);
- if (byte_run > 0) {
- pixel = bytestream2_get_le16(&g2);
- CHECK_PIXEL_PTR(2 * byte_run);
- for (j = 0; j < byte_run; j++) {
- *((signed short*)(&pixels[pixel_ptr])) = pixel;
- pixel_ptr += 2;
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d)\n",
- pixel_countdown);
- }
- } else { /* copy pixels if byte_run < 0 */
- byte_run = -byte_run;
- if (bytestream2_tell(&g2) + 2 * byte_run > stream_ptr_after_chunk)
- break;
- CHECK_PIXEL_PTR(2 * byte_run);
- for (j = 0; j < byte_run; j++) {
- *((signed short*)(&pixels[pixel_ptr])) = bytestream2_get_le16(&g2);
- pixel_ptr += 2;
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d)\n",
- pixel_countdown);
- }
- }
- }
-
- y_ptr += s->frame->linesize[0];
- }
- break;
-
- case FLI_COPY:
- case FLI_DTA_COPY:
- /* copy the chunk (uncompressed frame) */
- if (chunk_size - 6 > (unsigned int)(FFALIGN(s->avctx->width, 2) * s->avctx->height)*2) {
- av_log(avctx, AV_LOG_ERROR, "In chunk FLI_COPY : source data (%d bytes) " \
- "bigger than image, skipping chunk\n", chunk_size - 6);
- bytestream2_skip(&g2, chunk_size - 6);
- } else {
-
- if (bytestream2_get_bytes_left(&g2) < 2 * s->avctx->width * s->avctx->height )
- return AVERROR_INVALIDDATA;
- for (y_ptr = 0; y_ptr < s->frame->linesize[0] * s->avctx->height;
- y_ptr += s->frame->linesize[0]) {
-
- pixel_countdown = s->avctx->width;
- pixel_ptr = 0;
- while (pixel_countdown > 0) {
- *((signed short*)(&pixels[y_ptr + pixel_ptr])) = bytestream2_get_le16(&g2);
- pixel_ptr += 2;
- pixel_countdown--;
- }
- if (s->avctx->width & 1)
- bytestream2_skip(&g2, 2);
- }
- }
- break;
-
- case FLI_MINI:
- /* some sort of a thumbnail? disregard this chunk... */
- bytestream2_skip(&g2, chunk_size - 6);
- break;
-
- default:
- av_log(avctx, AV_LOG_ERROR, "Unrecognized chunk type: %d\n", chunk_type);
- break;
- }
-
- if (stream_ptr_after_chunk - bytestream2_tell(&g2) >= 0) {
- bytestream2_skip(&g2, stream_ptr_after_chunk - bytestream2_tell(&g2));
- } else {
- av_log(avctx, AV_LOG_ERROR, "Chunk overread\n");
- break;
- }
-
- frame_size -= chunk_size;
- num_chunks--;
- }
-
- /* by the end of the chunk, the stream ptr should equal the frame
- * size (minus 1, possibly); if it doesn't, issue a warning */
- if ((bytestream2_get_bytes_left(&g2) != 0) && (bytestream2_get_bytes_left(&g2) != 1))
- av_log(avctx, AV_LOG_ERROR, "Processed FLI chunk where chunk size = %d " \
- "and final chunk ptr = %d\n", buf_size, bytestream2_tell(&g2));
-
- if ((ret = av_frame_ref(rframe, s->frame)) < 0)
- return ret;
-
- *got_frame = 1;
-
- return buf_size;
-}
-
-static int flic_decode_frame_24BPP(AVCodecContext *avctx,
- AVFrame *rframe, int *got_frame,
- const uint8_t *buf, int buf_size)
-{
- FlicDecodeContext *s = avctx->priv_data;
-
- GetByteContext g2;
- int pixel_ptr;
- unsigned char palette_idx1;
-
- unsigned int frame_size;
- int num_chunks;
-
- unsigned int chunk_size;
- int chunk_type;
-
- int i, j, ret;
-
- int lines;
- int compressed_lines;
- int line_packets;
- int y_ptr;
- int byte_run;
- int pixel_skip;
- int pixel_countdown;
- unsigned char *pixels;
- int pixel;
- unsigned int pixel_limit;
-
- bytestream2_init(&g2, buf, buf_size);
-
- if ((ret = ff_reget_buffer(avctx, s->frame, 0)) < 0)
- return ret;
-
- pixels = s->frame->data[0];
- pixel_limit = s->avctx->height * s->frame->linesize[0];
-
- frame_size = bytestream2_get_le32(&g2);
- bytestream2_skip(&g2, 2); /* skip the magic number */
- num_chunks = bytestream2_get_le16(&g2);
- bytestream2_skip(&g2, 8); /* skip padding */
- if (frame_size > buf_size)
- frame_size = buf_size;
-
- if (frame_size < 16)
- return AVERROR_INVALIDDATA;
- frame_size -= 16;
-
- /* iterate through the chunks */
- while ((frame_size > 0) && (num_chunks > 0) &&
- bytestream2_get_bytes_left(&g2) >= 4) {
- int stream_ptr_after_chunk;
- chunk_size = bytestream2_get_le32(&g2);
- if (chunk_size > frame_size) {
- av_log(avctx, AV_LOG_WARNING,
- "Invalid chunk_size = %u > frame_size = %u\n", chunk_size, frame_size);
- chunk_size = frame_size;
- }
- stream_ptr_after_chunk = bytestream2_tell(&g2) - 4 + chunk_size;
-
- chunk_type = bytestream2_get_le16(&g2);
-
-
- switch (chunk_type) {
- case FLI_256_COLOR:
- case FLI_COLOR:
- /* For some reason, it seems that non-palettized flics do
- * include one of these chunks in their first frame.
- * Why I do not know, it seems rather extraneous. */
- ff_dlog(avctx,
- "Unexpected Palette chunk %d in non-palettized FLC\n",
- chunk_type);
- bytestream2_skip(&g2, chunk_size - 6);
- break;
-
- case FLI_DELTA:
- case FLI_DTA_LC:
- y_ptr = 0;
- compressed_lines = bytestream2_get_le16(&g2);
- while (compressed_lines > 0) {
- if (bytestream2_tell(&g2) + 2 > stream_ptr_after_chunk)
- break;
- if (y_ptr > pixel_limit)
- return AVERROR_INVALIDDATA;
- line_packets = sign_extend(bytestream2_get_le16(&g2), 16);
- if (line_packets < 0) {
- line_packets = -line_packets;
- if (line_packets > s->avctx->height)
- return AVERROR_INVALIDDATA;
- y_ptr += line_packets * s->frame->linesize[0];
- } else {
- compressed_lines--;
- pixel_ptr = y_ptr;
- CHECK_PIXEL_PTR(0);
- pixel_countdown = s->avctx->width;
- for (i = 0; i < line_packets; i++) {
- /* account for the skip bytes */
- if (bytestream2_tell(&g2) + 2 > stream_ptr_after_chunk)
- break;
- pixel_skip = bytestream2_get_byte(&g2);
- pixel_ptr += (pixel_skip*3); /* Pixel is 3 bytes wide */
- pixel_countdown -= pixel_skip;
- byte_run = sign_extend(bytestream2_get_byte(&g2), 8);
- if (byte_run < 0) {
- byte_run = -byte_run;
- pixel = bytestream2_get_le24(&g2);
- CHECK_PIXEL_PTR(3 * byte_run);
- for (j = 0; j < byte_run; j++, pixel_countdown -= 1) {
- AV_WL24(&pixels[pixel_ptr], pixel);
- pixel_ptr += 3;
- }
- } else {
- if (bytestream2_tell(&g2) + 2*byte_run > stream_ptr_after_chunk)
- break;
- CHECK_PIXEL_PTR(3 * byte_run);
- for (j = 0; j < byte_run; j++, pixel_countdown--) {
- pixel = bytestream2_get_le24(&g2);
- AV_WL24(&pixels[pixel_ptr], pixel);
- pixel_ptr += 3;
- }
- }
- }
-
- y_ptr += s->frame->linesize[0];
- }
- }
- break;
-
- case FLI_LC:
- av_log(avctx, AV_LOG_ERROR, "Unexpected FLI_LC chunk in non-palettized FLC\n");
- bytestream2_skip(&g2, chunk_size - 6);
- break;
-
- case FLI_BLACK:
- /* set the whole frame to 0x00 which is black for 24 bit mode. */
- memset(pixels, 0x00,
- s->frame->linesize[0] * s->avctx->height);
- break;
-
- case FLI_BRUN:
- y_ptr = 0;
- for (lines = 0; lines < s->avctx->height; lines++) {
- pixel_ptr = y_ptr;
- /* disregard the line packets; instead, iterate through all
- * pixels on a row */
- bytestream2_skip(&g2, 1);
- pixel_countdown = (s->avctx->width * 3);
-
- while (pixel_countdown > 0) {
- if (bytestream2_tell(&g2) + 1 > stream_ptr_after_chunk)
- break;
- byte_run = sign_extend(bytestream2_get_byte(&g2), 8);
- if (byte_run > 0) {
- palette_idx1 = bytestream2_get_byte(&g2);
- CHECK_PIXEL_PTR(byte_run);
- for (j = 0; j < byte_run; j++) {
- pixels[pixel_ptr++] = palette_idx1;
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d) (linea%d)\n",
- pixel_countdown, lines);
- }
- } else { /* copy bytes if byte_run < 0 */
- byte_run = -byte_run;
- if (bytestream2_tell(&g2) + byte_run > stream_ptr_after_chunk)
- break;
- CHECK_PIXEL_PTR(byte_run);
- for (j = 0; j < byte_run; j++) {
- palette_idx1 = bytestream2_get_byte(&g2);
- pixels[pixel_ptr++] = palette_idx1;
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d) at line %d\n",
- pixel_countdown, lines);
- }
- }
- }
-
- y_ptr += s->frame->linesize[0];
- }
- break;
-
- case FLI_DTA_BRUN:
- y_ptr = 0;
- for (lines = 0; lines < s->avctx->height; lines++) {
- pixel_ptr = y_ptr;
- /* disregard the line packets; instead, iterate through all
- * pixels on a row */
- bytestream2_skip(&g2, 1);
- pixel_countdown = s->avctx->width; /* Width is in pixels, not bytes */
-
- while (pixel_countdown > 0) {
- if (bytestream2_tell(&g2) + 1 > stream_ptr_after_chunk)
- break;
- byte_run = sign_extend(bytestream2_get_byte(&g2), 8);
- if (byte_run > 0) {
- pixel = bytestream2_get_le24(&g2);
- CHECK_PIXEL_PTR(3 * byte_run);
- for (j = 0; j < byte_run; j++) {
- AV_WL24(pixels + pixel_ptr, pixel);
- pixel_ptr += 3;
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d)\n",
- pixel_countdown);
- }
- } else { /* copy pixels if byte_run < 0 */
- byte_run = -byte_run;
- if (bytestream2_tell(&g2) + 3 * byte_run > stream_ptr_after_chunk)
- break;
- CHECK_PIXEL_PTR(3 * byte_run);
- for (j = 0; j < byte_run; j++) {
- pixel = bytestream2_get_le24(&g2);
- AV_WL24(pixels + pixel_ptr, pixel);
- pixel_ptr += 3;
- pixel_countdown--;
- if (pixel_countdown < 0)
- av_log(avctx, AV_LOG_ERROR, "pixel_countdown < 0 (%d)\n",
- pixel_countdown);
- }
- }
- }
-
- y_ptr += s->frame->linesize[0];
- }
- break;
-
- case FLI_COPY:
- case FLI_DTA_COPY:
- /* copy the chunk (uncompressed frame) */
- if (chunk_size - 6 > (unsigned int)(FFALIGN(s->avctx->width, 2) * s->avctx->height)*3) {
- av_log(avctx, AV_LOG_ERROR, "In chunk FLI_COPY : source data (%d bytes) " \
- "bigger than image, skipping chunk\n", chunk_size - 6);
- bytestream2_skip(&g2, chunk_size - 6);
- } else {
- for (y_ptr = 0; y_ptr < s->frame->linesize[0] * s->avctx->height;
- y_ptr += s->frame->linesize[0]) {
-
- bytestream2_get_buffer(&g2, pixels + y_ptr, 3*s->avctx->width);
- if (s->avctx->width & 1)
- bytestream2_skip(&g2, 3);
- }
- }
- break;
-
- case FLI_MINI:
- /* some sort of a thumbnail? disregard this chunk... */
- bytestream2_skip(&g2, chunk_size - 6);
- break;
-
- default:
- av_log(avctx, AV_LOG_ERROR, "Unrecognized chunk type: %d\n", chunk_type);
- break;
- }
-
- if (stream_ptr_after_chunk - bytestream2_tell(&g2) >= 0) {
- bytestream2_skip(&g2, stream_ptr_after_chunk - bytestream2_tell(&g2));
- } else {
- av_log(avctx, AV_LOG_ERROR, "Chunk overread\n");
- break;
- }
-
- frame_size -= chunk_size;
- num_chunks--;
- }
-
- /* by the end of the chunk, the stream ptr should equal the frame
- * size (minus 1, possibly); if it doesn't, issue a warning */
- if ((bytestream2_get_bytes_left(&g2) != 0) && (bytestream2_get_bytes_left(&g2) != 1))
- av_log(avctx, AV_LOG_ERROR, "Processed FLI chunk where chunk size = %d " \
- "and final chunk ptr = %d\n", buf_size, bytestream2_tell(&g2));
-
- if ((ret = av_frame_ref(rframe, s->frame)) < 0)
- return ret;
-
- *got_frame = 1;
-
- return buf_size;
-}
-
-static int flic_decode_frame(AVCodecContext *avctx, AVFrame *frame,
- int *got_frame, AVPacket *avpkt)
-{
- const uint8_t *buf = avpkt->data;
- int buf_size = avpkt->size;
- if (avctx->pix_fmt == AV_PIX_FMT_PAL8) {
- return flic_decode_frame_8BPP(avctx, frame, got_frame,
- buf, buf_size);
- } else if ((avctx->pix_fmt == AV_PIX_FMT_RGB555) ||
- (avctx->pix_fmt == AV_PIX_FMT_RGB565)) {
- return flic_decode_frame_15_16BPP(avctx, frame, got_frame,
- buf, buf_size);
- } else if (avctx->pix_fmt == AV_PIX_FMT_BGR24) {
- return flic_decode_frame_24BPP(avctx, frame, got_frame,
- buf, buf_size);
- }
-
- /* Should not get here, ever as the pix_fmt is processed */
- /* in flic_decode_init and the above if should deal with */
- /* the finite set of possibilities allowable by here. */
- /* But in case we do, just error out. */
- av_log(avctx, AV_LOG_ERROR, "Unknown FLC format, my science cannot explain how this happened.\n");
- return AVERROR_BUG;
-}
-
-
-static av_cold int flic_decode_end(AVCodecContext *avctx)
-{
- FlicDecodeContext *s = avctx->priv_data;
-
- av_frame_free(&s->frame);
-
- return 0;
-}
-
-const FFCodec ff_flic_decoder = {
- .p.name = "flic",
- CODEC_LONG_NAME("Autodesk Animator Flic video"),
- .p.type = AVMEDIA_TYPE_VIDEO,
- .p.id = AV_CODEC_ID_FLIC,
- .priv_data_size = sizeof(FlicDecodeContext),
- .init = flic_decode_init,
- .close = flic_decode_end,
- FF_CODEC_DECODE_CB(flic_decode_frame),
- .p.capabilities = AV_CODEC_CAP_DR1,
-};
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Discover the Best Apps and Games with Apps9 the Free and Fast Downloader.md b/spaces/congsaPfin/Manga-OCR/logs/Discover the Best Apps and Games with Apps9 the Free and Fast Downloader.md
deleted file mode 100644
index 2b4eb2769cd22aff63f7e9485e65599543595d9b..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Discover the Best Apps and Games with Apps9 the Free and Fast Downloader.md
+++ /dev/null
@@ -1,142 +0,0 @@
-
-
Apps9: A Tool to Download Multimedia Content for Android
-
If you are looking for a way to download all kinds of multimedia content directly to your Android device, you might want to check out Apps9. Apps9 is a tool that lets you download wallpapers, ringtones, and even apps and games (although the latter must be downloaded through Google Play). In this article, we will review what Apps9 is, what features it offers, how to use it, and what are its pros and cons. We will also compare it with some alternatives that you can try if you are not satisfied with Apps9.
-
What is Apps9?
-
Apps9 is a tool that allows you to download multimedia content for your Android device. It is not an app store, but rather a platform that provides links to various sources of content. You can use Apps9 to browse and download wallpapers, ringtones, and apps and games from different categories and genres. You can also use filters and search options to find the content that you are looking for.
It has a large collection of wallpapers and ringtones that you can download for free.
-
It has a variety of apps and games that you can download through Google Play.
-
It has a user-friendly interface that is easy to navigate.
-
It has a fast and reliable download speed.
-
It has a recommendation system that suggests content based on your preferences.
-
-
How to use Apps9
-
To use Apps9, you need to follow these steps:
-
apps9 download
-apps9 apk
-apps9 app store
-apps9 games
-apps9 wallpaper
-apps9 ringtones
-apps9 video downloader
-apps9 music player
-apps9 photo editor
-apps9 launcher
-apps9 browser
-apps9 whatsapp
-apps9 facebook
-apps9 instagram
-apps9 tiktok
-apps9 youtube
-apps9 netflix
-apps9 amazon
-apps9 flipkart
-apps9 snapchat
-apps9 twitter
-apps9 spotify
-apps9 zoom
-apps9 gmail
-apps9 google play
-apps9 pubg
-apps9 free fire
-apps9 clash of clans
-apps9 candy crush
-apps9 temple run
-apps9 subway surfers
-apps9 angry birds
-apps9 minecraft
-apps9 roblox
-apps9 fortnite
-apps9 among us
-apps9 call of duty
-apps9 gta
-apps9 fifa
-apps9 asphalt
-apps9 pokemon go
-apps9 zomato
-apps9 swiggy
-apps9 uber eats
-apps9 ola cabs
-apps9 uber cabs
-
-
Download and install the APK file from [Apps9](^1^).
-
Open the app and grant the necessary permissions.
-
Browse the content by categories or use the search bar.
-
Select the content that you want to download and tap on the download button.
-
For wallpapers and ringtones, you can set them as your default or save them in your device.
-
For apps and games, you will be redirected to Google Play where you can install them.
-
-
Pros and cons of Apps9
-
Like any other tool, Apps9 has its advantages and disadvantages. Here are some of them:
-
Pros of Apps9
-
-
It is free to use and does not require registration or login.
-
It has a wide range of multimedia content that you can download for your Android device.
-
It has a simple and intuitive interface that makes it easy to use.
-
It has a fast and stable download speed that does not consume much data or battery.
-
It has a smart recommendation system that helps you discover new content.
-
-
Cons of Apps9
-
-
It is not an official app store, so it may not be safe or secure to use.
-
It may contain ads or malware that can harm your device or compromise your privacy.
-
It may not have the latest or updated versions of apps and games.
-
It may not have some apps and games that are available on other platforms.
-
It may not work on some devices or regions due to compatibility or legal issues.
-
-
Alternatives to Apps9
-
If you are not happy with Apps9 or want to try something else, here are some alternatives that you can consider:
-
Google Play Store
-
The Google Play Store is the official app store for Android devices. It has millions of apps and games that you can download and install on your device. Some of the features that the Google Play Store offers are:
-
-
It is safe and secure to use, as it has strict policies and guidelines for app developers and users.
-
It has a huge variety of apps and games that cater to different needs and preferences.
-
It has regular updates and improvements that enhance the performance and functionality of apps and games.
-
It has a user-friendly interface that allows you to browse, search, and download apps and games easily.
-
It has a rating and review system that helps you to find the best and most reliable apps and games.
-
-
Aptoide
-
Aptoide is an alternative app store for Android devices. It allows you to download and install apps and games that are not available on the Google Play Store. It also lets you create your own app store and share it with other users.
- Some of the features that Aptoide offers are:
-
-
It is free to use and does not require registration or login.
-
It has a large collection of apps and games that you can download from different sources.
-
It has a flexible and customizable interface that allows you to create your own app store.
-
It has a social network feature that allows you to follow other users and discover new content.
-
It has a rollback feature that allows you to restore previous versions of apps and games.
-
-
APKPure
-
APKPure is another alternative app store for Android devices. It allows you to download and install APK files of apps and games that are not available on the Google Play Store. It also provides updates and patches for apps and games.
- Some of the features that APKPure offers are:
-
-
It is free to use and does not require registration or login.
-
It has a large collection of APK files of apps and games that you can download from different sources.
-
It has a simple and elegant interface that allows you to browse, search, and download APK files easily.
-
It has an update feature that allows you to keep your apps and games up to date.
-
It has a lightweight design that does not consume much storage space or battery power.
-
-
Conclusion
-
In conclusion, Apps9 is a tool that allows you to download multimedia content for your Android device. It has a variety of wallpapers, ringtones, apps, and games that you can download for free. However, it also has some drawbacks, such as security risks, ads, outdated versions, limited availability, and compatibility issues. Therefore, you should be careful when using Apps9 and always check the source and quality of the content before downloading it. Alternatively, you can try other platforms such as Google Play Store, Aptoide, or APKPure, which offer similar or better features than Apps9.
-
Call to action
-
If you want to try Apps9 for yourself, you can download it from [Apps9]. However, if you are looking for more reliable and trustworthy platforms, we recommend you to check out Google Play Store, Aptoide, or APKPure. You can find them on their official websites or download their APK files from [APKMirror]. We hope this article was helpful for you. If you have any questions or feedback, please leave them in the comments section below. Thank you for reading!
-
Frequently Asked Questions
-
Here are some of the most common questions that people ask about Apps9:
-
-
Is Apps9 safe to use?
-
Apps9 is not an official app store, so it may not be safe or secure to use. It may contain ads or malware that can harm your device or compromise your privacy. It may also violate some laws or regulations in some regions. Therefore, you should always scan the APK file before installing it and use a VPN or proxy service if necessary.
-
Is Apps9 legal to use?
-
Apps9 may not be legal to use in some regions or countries, as it may infringe the intellectual property rights of some app developers or publishers. It may also violate some terms of service or policies of Google Play Store or other platforms. Therefore, you should always check the legality of the content before downloading it and respect the rights of the original creators.
-
How do I update Apps9?
-
To update Apps9, you need to download the latest version of the APK file from [Apps9] or other sources. Then, you need to uninstall the previous version of Apps9 from your device and install the new version. Alternatively, you can enable the auto-update feature in the app settings, which will automatically download and install the updates when they are available.
-
How do I uninstall Apps9?
-
To uninstall Apps9, you need to go to your device settings and select the Apps or Applications option. Then, you need to find Apps9 in the list of installed apps and tap on it. Then, you need to tap on the Uninstall button and confirm your action. You can also use a third-party app uninstaller tool to remove Apps9 from your device.
-
What are some similar tools to Apps9?
-
Some similar tools to Apps9 are Google Play Store, Aptoide, APKPure, APKMirror, Uptodown, Mobogenie, 9Apps, and more. These tools allow you to download and install apps and games for your Android device from different sources. However, they may have different features, advantages, and disadvantages than Apps9. Therefore, you should compare them carefully before choosing the best one for you.
-
How do I contact Apps9 support?
-
If you have any issues or problems with Apps9, you can contact their support team by sending an email to [support@apps9.com]. You can also visit their website [Apps9] or their Facebook page [Apps9] for more information and updates. You can also check their FAQ section or their blog for some tips and tricks on how to use Apps9.
- 401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Hill Climb Racing 2 The Ultimate Online Multiplayer Racing Game for Windows 7.md b/spaces/congsaPfin/Manga-OCR/logs/Hill Climb Racing 2 The Ultimate Online Multiplayer Racing Game for Windows 7.md
deleted file mode 100644
index a10fa248a783d7c46ba23c14856ae82e966b69af..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Hill Climb Racing 2 The Ultimate Online Multiplayer Racing Game for Windows 7.md
+++ /dev/null
@@ -1,118 +0,0 @@
-
- - H2: How to Download Hill Climb Racing 2 from the Microsoft Store - H2: How to Play Hill Climb Racing 2 on PC with BlueStacks Emulator - H2: How to Play Hill Climb Racing 2 on Windows PC without Downloading - Conclusion: Summarize the main points and invite the reader to try the game - FAQs: Answer some common questions about the game and its compatibility with Windows 7 | Table 2: Article with HTML formatting
Hill Climb Racing 2 Download Windows 7: How to Play the Popular Racing Game on Your PC
-
If you love racing games, you might have heard of Hill Climb Racing 2, one of the most popular and addictive games in the genre. Hill Climb Racing 2 is a 2D online multiplayer racing game that lets you customize your character and vehicle, race on dozens of tracks, perform cool stunts, and compete with players from around the world. The game is available for Android and iOS devices, but did you know that you can also play it on your Windows 7 PC? In this article, we will show you how to download and play Hill Climb Racing 2 on your computer using three different methods. Whether you want to use the Microsoft Store, an emulator, or a browser, we have you covered. Read on to find out more!
How to Download Hill Climb Racing 2 from the Microsoft Store
-
One of the easiest ways to play Hill Climb Racing 2 on your Windows 7 PC is to download it from the Microsoft Store. The Microsoft Store is an online platform that offers various apps and games for Windows devices. To download Hill Climb Racing 2 from the Microsoft Store, follow these steps:
-
-
Open your web browser and go to [Hill Climb Racing 2](^1^).
-
Click on the "Get" button and sign in with your Microsoft account.
-
Click on the "Install" button and wait for the download to finish.
-
Once the game is installed, you can launch it from the Start menu or the desktop shortcut.
-
-
Congratulations, you can now enjoy Hill Climb Racing 2 on your Windows 7 PC!
-
How to Play Hill Climb Racing 2 on PC with BlueStacks Emulator
-
Another way to play Hill Climb Racing 2 on your Windows 7 PC is to use an emulator. An emulator is a software that mimics the functionality of another device, such as an Android phone or tablet. By using an emulator, you can run Android apps and games on your computer. One of the best emulators for playing Hill Climb Racing 2 is BlueStacks, which offers a smooth and seamless gaming experience. To play Hill Climb Racing 2 on PC with BlueStacks emulator, follow these steps:
-
-
Open your web browser and go to [BlueStacks](^2^).
-
Click on the "Download BlueStacks" button and follow the instructions to install the emulator.
-
Once BlueStacks is installed, launch it and sign in with your Google account.
-
Go to the Google Play Store and search for Hill Climb Racing 2.
-
Click on the "Install" button and wait for the game to download.
-
Once the game is installed, you can launch it from the BlueStacks home screen or app drawer.
-
-
Congratulations, you can now enjoy Hill Climb Racing 2 on your Windows 7 PC with BlueStacks emulator!
-
hill climb racing 2 pc download windows 7
-hill climb racing 2 free download for windows 7
-hill climb racing 2 game download for windows 7
-hill climb racing 2 download for laptop windows 7
-hill climb racing 2 download for computer windows 7
-hill climb racing 2 online play on windows 7
-hill climb racing 2 install on windows 7
-hill climb racing 2 setup for windows 7
-hill climb racing 2 apk download for windows 7
-hill climb racing 2 app download for windows 7
-hill climb racing 2 emulator for windows 7
-hill climb racing 2 bluestacks for windows 7
-hill climb racing 2 microsoft store for windows 7
-hill climb racing 2 fingersoft for windows 7
-hill climb racing 2 mod apk for windows 7
-hill climb racing 2 hack for windows 7
-hill climb racing 2 cheats for windows 7
-hill climb racing 2 tips and tricks for windows 7
-hill climb racing 2 update for windows 7
-hill climb racing 2 new version for windows 7
-hill climb racing 2 best vehicle for windows 7
-hill climb racing 2 multiplayer on windows 7
-hill climb racing 2 team mode on windows 7
-hill climb racing 2 adventure mode on windows 7
-hill climb racing 2 cups mode on windows 7
-hill climb racing 2 legendary rank on windows 7
-hill climb racing 2 skins and outfits for windows 7
-hill climb racing 2 tuning parts for windows 7
-hill climb racing 2 coins and gems for windows 7
-hill climb racing 2 events and challenges for windows 7
-hill climb racing 2 seasons and rewards for windows 7
-hill climb racing 2 leaderboards and achievements for windows 7
-hill climb racing 2 fun and addictive for windows 7
-hill climb racing 2 physics and graphics for windows 7
-hill climb racing 2 stunts and flips for windows 7
-hill climb racing 2 tracks and terrains for windows 7
-hill climb racing vs hill climb racing [^1^] [^3^] [^4^] [^5^] [^6^] [^8^] [^9^] [^10^] [^11^] [^30^(https://www.bluestacks.com/apps/racing/hill-climb-racing-on-pc.html)]
-how to play hill climb racing on pc with keyboard
-how to transfer progress from android to pc in hill climb racing
-how to get unlimited coins in hill climb racing on pc
-how to unlock all vehicles in hill climb racing on pc
-how to change language in hill climb racing on pc
-how to record gameplay of hill climb racing on pc
-how to fix lag in hill climb racing on pc
-how to connect facebook account in hill climb racing on pc
-how to join a team in hill climb racing on pc
-how to chat with friends in hill climb racing on pc
-how to create a custom track in hill climb racing on pc
-how to use cheat engine in hill climb racing on pc
-how to play offline in hill climb racing on pc
-how to sync data across devices in hill climb racing on pc
-how to get free gems in hill climb racing on pc
-how to change vehicle color in hill climb racing on pc
-how to get legendary chests in hill climb racing on pc
-how to get daily rewards in hill climb racing on pc
-how to complete achievements in hill climb racing on pc
-how to level up fast in hill climb racing on pc
-
How to Play Hill Climb Racing 2 on Windows PC without Downloading
-
If you don't want to download anything on your Windows 7 PC, there is still a way to play Hill Climb Racing 2 online. You can use a browser that supports HTML5 games, such as Chrome or Firefox, and play Hill Climb Racing 2 in your browser without downloading. To play Hill Climb Racing 2 on Windows PC without downloading, follow these steps:
-
-
Open your web browser and go to [Hill Climb Racing 2].
-
Click on the "Play" button and wait for the game to load.
-
Once the game is loaded, you can start playing it in your browser.
-
-
Congratulations, you can now enjoy Hill Climb Racing 2 on your Windows 7 PC without downloading!
-
Conclusion
-
Hill Climb Racing 2 is a fun and addictive racing game that you can play on your Windows 7 PC using any of the three methods we discussed in this article. Whether you prefer to download it from the Microsoft Store, use an emulator like BlueStacks, or play it online in your browser, you can experience the thrill of racing on various tracks, customizing your character and vehicle, and competing with other players. Hill Climb Racing 2 is a game that will keep you entertained for hours, so why not give it a try today?
-
FAQs
-
Is Hill Climb Racing 2 free to play?
-
Yes, Hill Climb Racing 2 is free to play, but it contains in-app purchases that allow you to buy coins, gems, and other items to enhance your gameplay.
-
Is Hill Climb Racing 2 compatible with Windows 7?
-
Yes, Hill Climb Racing 2 is compatible with Windows 7, as long as you have a compatible device and a stable internet connection. You can download it from the Microsoft Store, use an emulator like BlueStacks, or play it online in your browser.
-
How do I control Hill Climb Racing 2 on PC?
-
You can control Hill Climb Racing 2 on PC using your keyboard or mouse. The default controls are as follows:
-
-
Left arrow key or A key: Brake
-
Right arrow key or D key: Accelerate
-
Up arrow key or W key: Tilt forward
-
Down arrow key or S key: Tilt backward
-
Space bar: Boost
-
Mouse: Click on buttons and menus
-
-
You can also customize the controls in the settings menu.
-
How do I update Hill Climb Racing 2 on PC?
-
If you downloaded Hill Climb Racing 2 from the Microsoft Store, you can update it by going to the Store app and clicking on the "Downloads and updates" option. If you are using an emulator like BlueStacks, you can update it by going to the Google Play Store and clicking on the "My apps & games" option. If you are playing Hill Climb Racing 2 online in your browser, you don't need to update it manually, as it will update automatically.
-
How do I uninstall Hill Climb Racing 2 from PC?
-
If you want to uninstall Hill Climb Racing 2 from your PC, you can do so by following these steps:
-
-
If you downloaded Hill Climb Racing 2 from the Microsoft Store, go to the Start menu and right-click on the game icon. Then, click on "Uninstall" and confirm your choice.
-
If you are using an emulator like BlueStacks, launch the emulator and go to the app drawer. Then, drag and drop the game icon to the "Uninstall" option and confirm your choice.
-
If you are playing Hill Climb Racing 2 online in your browser, you don't need to uninstall it, as it is not stored on your PC.
- 197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Hills of Steel 2 APK Mod The Most Addictive Multiplayer Game Ever.md b/spaces/congsaPfin/Manga-OCR/logs/Hills of Steel 2 APK Mod The Most Addictive Multiplayer Game Ever.md
deleted file mode 100644
index c471a5b9bca40bbc9e62ba3f6b1e096b0a2bda48..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Hills of Steel 2 APK Mod The Most Addictive Multiplayer Game Ever.md
+++ /dev/null
@@ -1,92 +0,0 @@
-
-
Hills of Steel 2 APK Mod: A Fun and Action-Packed Tank Game
-
If you are looking for a fun and action-packed tank game, you should check out Hills of Steel 2 APK Mod. This is a sequel to the popular Hills of Steel game, which has over 50 million downloads on Google Play Store. In this game, you can control various tanks and fight against other players in real-time multiplayer battles. You can also customize your tanks with different items and upgrades, and enjoy various game modes and maps.
-
In this article, we will tell you everything you need to know about Hills of Steel 2 APK Mod, including how to download and install it, what are its features, how to play it, and some tips and tricks to help you win more battles. Let's get started!
How to Download and Install Hills of Steel 2 APK Mod
-
Downloading and installing Hills of Steel 2 APK Mod is very easy. Just follow these simple steps:
-
-
Download the APK file from a trusted source. You can use the link provided in this article or search for it online.
-
Enable unknown sources on your device. To do this, go to Settings > Security > Unknown Sources and toggle it on.
-
Install the APK file by tapping on it and following the instructions.
-
Launch the game and enjoy
What are the Features of Hills of Steel 2 APK Mod?
-
Hills of Steel 2 APK Mod is not just a regular tank game. It has many features that make it more fun and exciting than other similar games. Here are some of the features that you can enjoy with Hills of Steel 2 APK Mod:
-
hills of steel 2 mod apk unlimited money
-hills of steel 2 hack apk download
-hills of steel 2 mod apk latest version
-hills of steel 2 mod apk android 1
-hills of steel 2 mod apk revdl
-hills of steel 2 mod apk rexdl
-hills of steel 2 mod apk happymod
-hills of steel 2 mod apk free shopping
-hills of steel 2 mod apk no root
-hills of steel 2 mod apk offline
-hills of steel 2 mod apk online
-hills of steel 2 mod apk all tanks unlocked
-hills of steel 2 mod apk unlimited gems and coins
-hills of steel 2 mod apk unlimited ammo and fuel
-hills of steel 2 mod apk unlimited stars and medals
-hills of steel 2 mod apk unlimited health and shield
-hills of steel 2 mod apk unlimited diamonds and gold
-hills of steel 2 mod apk unlimited everything
-hills of steel 2 mod apk download for android
-hills of steel 2 mod apk download for pc
-hills of steel 2 mod apk download for ios
-hills of steel 2 mod apk download for windows 10
-hills of steel 2 mod apk download for laptop
-hills of steel 2 mod apk download for mac
-hills of steel 2 mod apk download for chromebook
-hills of steel 2 mod apk download link
-hills of steel 2 mod apk download uptodown
-hills of steel 2 mod apk download apkpure
-hills of steel 2 mod apk download mob.org
-hills of steel 2 mod apk download android republic
-hills of steel 2 cheats apk free download
-hills of steel 2 hack tool apk free download
-hills of steel 2 hack version apk free download
-hills of steel 2 hacked game apk free download
-hills of steel 2 premium mod apk free download
-hills of steel 2 pro mod apk free download
-hills of steel 2 full mod apk free download
-hills of steel 2 mega mod apk free download
-hills of steel 2 god mode apk free download
-hills of steel 2 vip mod apk free download
-
-
Unlimited coins and gems: With this mod, you don't have to worry about running out of coins and gems, which are the main currencies in the game. You can use them to upgrade your tanks and buy new ones, as well as other items and boosts. You can also use them to unlock premium tanks and modes that are otherwise unavailable or require real money.
-
Access to all tanks and modes: With this mod, you can access all the tanks and modes in the game without any ads or restrictions. You can choose from over 20 tanks, each with its own unique abilities and features. You can also play in different modes, such as Team Deathmatch, Domination, Capture the Flag, Boss Battle, and more. You can also play in different maps, such as Desert, Forest, Snow, and more.
-
Real-time multiplayer battles: With this mod, you can play with other players from around the world in real-time multiplayer battles. You can join a team or create your own, and compete against other teams for glory and rewards. You can also chat with your teammates and opponents, and make new friends or rivals.
-
Various game modes and maps: With this mod, you can enjoy various game modes and maps that will keep you entertained for hours. You can play in Team Deathmatch, where you have to eliminate the enemy team before they eliminate yours. You can play in Domination, where you have to capture and hold strategic points on the map. You can play in Capture the Flag, where you have to steal the enemy flag and bring it back to your base. You can play in Boss Battle, where you have to defeat a powerful boss tank with your team. You can also play in different maps, such as Desert, Forest, Snow, and more.
-
Stunning graphics and sound effects: With this mod, you can enjoy stunning graphics and sound effects that will make you feel like you are in a real tank battle. The game has realistic physics and animations, as well as colorful and detailed graphics. The game also has immersive sound effects and music that will enhance your gaming experience.
-
-
How to Play Hills of Steel 2 APK Mod?
-
Playing Hills of Steel 2 APK Mod is very easy and intuitive. You just need to follow these simple steps:
-
-
Choose your tank and mode: After launching the game, you can choose your tank from the garage. You can also upgrade your tank or buy a new one with coins and gems. Then, you can choose the mode you want to play from the lobby. You can either join an existing match or create your own.
-
Control your tank with simple touch controls: Once you enter a match, you can control your tank with simple touch controls. You can move your tank forward or backward by tapping on the left or right side of the screen. You can also aim and shoot by dragging on the screen. You can also use special abilities by tapping on the icons on the bottom of the screen.
-
Shoot and destroy enemy tanks and bases: Your main objective is to shoot and destroy enemy tanks and bases, depending on the mode you are playing. You can also collect coins and gems that drop from destroyed enemies or crates. You can use them to upgrade your tank or buy new ones.
-
Collect coins and gems to unlock more tanks and items: As you play the game, you will earn coins and gems that you can use to unlock more tanks and items. You can also get unlimited coins and gems by downloading the modded version of the game. You can use them to upgrade your tanks to increase their power and durability, or buy new ones with different abilities and features. You can also use them to unlock premium tanks and modes that are otherwise unavailable or require real money.
-
Tips and Tricks for Hills of Steel 2 APK Mod
-
Hills of Steel 2 APK Mod is a fun and action-packed tank game, but it can also be challenging and competitive. If you want to improve your skills and win more battles, you should follow these tips and tricks:
-
-
Use different tanks for different situations: Each tank has its own strengths and weaknesses, and you should use them accordingly. For example, the Titan is a heavy tank that can deal a lot of damage and withstand a lot of hits, but it is also slow and bulky. The Cobra is a fast and agile tank that can dodge and flank enemies, but it has low armor and firepower. The Reaper is a stealthy tank that can cloak and surprise enemies, but it has limited ammo and visibility. You should experiment with different tanks and see which one suits your playstyle and preference.
-
Upgrade your tanks to increase their power and durability: As you play the game, you will earn coins and gems that you can use to upgrade your tanks. You can upgrade their engine, armor, weapon, and special ability. You can also buy new tanks with different abilities and features. Upgrading your tanks will make them more powerful and durable, and give you an edge over your enemies.
-
Use the terrain to your advantage: The game has various maps with different terrains, such as hills, bridges, ramps, tunnels, and more. You should use them to your advantage, as they can affect your movement and combat. For example, you can use hills to gain momentum and jump over enemies or obstacles. You can use bridges to cross gaps or ambush enemies. You can use ramps to launch yourself into the air or land on enemies. You can use tunnels to hide or escape from enemies.
-
Team up with other players and communicate with them: The game has real-time multiplayer battles, where you can team up with other players from around the world. You can join a team or create your own, and compete against other teams for glory and rewards. You can also chat with your teammates and opponents, and make new friends or rivals. You should cooperate with your teammates and communicate with them, as teamwork is essential for winning battles. You should also be respectful and friendly to other players, as this is a game for fun and entertainment.
-
-
Conclusion
-
Hills of Steel 2 APK Mod is a fun and action-packed tank game that you should try if you love tank games. You can control various tanks and fight against other players in real-time multiplayer battles. You can also customize your tanks with different items and upgrades, and enjoy various game modes and maps. You can download and install Hills of Steel 2 APK Mod easily by following the steps in this article. You can also enjoy unlimited coins and gems, access to all tanks and modes, stunning graphics and sound effects, and more with this mod. You can also improve your skills and win more battles by following the tips and tricks in this article.
-
We hope you enjoyed this article and found it helpful. If you have any questions or feedback, please feel free to leave them in the comments section below. Thank you for reading!
-
FAQs
-
-
Q1: Is Hills of Steel 2 APK Mod safe to download and install?
-
A1: Yes, as long as you download it from a reliable source. However, you should always be careful when installing apps from unknown sources.
-
Q2: Can I play Hills of Steel 2 APK Mod offline?
-
A2: No, you need an internet connection to play this game. You can play solo or with other players online.
-
Q3: How can I get more coins and gems in Hills of Steel 2 APK Mod?
-
A3: You can get unlimited coins and gems by downloading the modded version of the game. You can also earn them by playing the game and completing missions.
-
Q4: What are the best tanks in Hills of Steel 2 APK Mod?
-
A4: There is no definitive answer to this question, as different tanks have different strengths and weaknesses. You should try them all and see which one suits your playstyle and preference. Some of the popular tanks are Titan, Mammoth, Cobra, Reaper, and Phoenix.
-
Q5: How can I contact the developers of Hills of Steel 2 APK Mod?
-
A5: You can contact them through their official website, Facebook page, or email address I have already written the article for you, as you requested. There is nothing more to write, unless you want me to revise or edit something. If you are satisfied with the article, please let me know. If you have any feedback or suggestions, please also let me know. Thank you for choosing me as your content writer. I hope you enjoyed my work. 197e85843d
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/How to Install Diablo Immortal on Your Android Device - APK Download Link.md b/spaces/congsaPfin/Manga-OCR/logs/How to Install Diablo Immortal on Your Android Device - APK Download Link.md
deleted file mode 100644
index b8ccf95178acff500f5911f65022764c70492a18..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/How to Install Diablo Immortal on Your Android Device - APK Download Link.md
+++ /dev/null
@@ -1,139 +0,0 @@
-
-
Diablo Immortal APK Download for Android: Everything You Need to Know
-
Diablo Immortal is a brand-new mobile game from Blizzard Entertainment that brings the legendary action role-playing game series to your smartphone. Set between the events of Diablo II and Diablo III, Diablo Immortal lets you explore the dark realm of Sanctuary, fight against hordes of demons, collect epic loot, and join forces with other players in a massively multiplayer online experience. Whether you are a fan of Diablo or a newcomer to the franchise, you might be wondering how to download Diablo Immortal APK for your Android device. In this article, we will show you how to do that, as well as what features and requirements you can expect from the game, and some tips and tricks to help you succeed in your quest.
How to Download Diablo Immortal APK for Android Devices
-
There are two ways to download Diablo Immortal APK for your Android device: from the official Google Play Store or from a third-party website. Here are the steps for each method:
-
From Google Play Store
-
This is the easiest and safest way to download Diablo Immortal APK for your Android device. All you need to do is follow these steps:
-
-
Open the Google Play Store app on your device.
-
Search for "Diablo Immortal" in the search bar.
-
Tap on the game icon and then tap on "Install".
-
Wait for the download and installation to finish.
-
Launch the game and enjoy!
-
-
From a Third-Party Website
-
This is an alternative way to download Diablo Immortal APK for your Android device, but it comes with some risks. You might encounter malware, viruses, or other harmful files that could damage your device or compromise your security. Therefore, we do not recommend this method unless you are absolutely sure about the source and the file. If you still want to try this method, here are the steps:
-
How to download diablo immortal apk for android devices
-Diablo immortal apk latest version free download
-Diablo immortal android game review and gameplay
-Diablo immortal apk mod unlimited money and gems
-Diablo immortal apk offline mode and multiplayer features
-Diablo immortal apk download from uptodown.com[^2^]
-Diablo immortal apk compatibility and requirements
-Diablo immortal apk installation guide and troubleshooting
-Diablo immortal apk update and patch notes
-Diablo immortal apk best classes and builds
-Diablo immortal apk tips and tricks for beginners
-Diablo immortal apk cheats and hacks
-Diablo immortal apk rewards and achievements
-Diablo immortal apk dungeons and raids
-Diablo immortal apk lore and story
-Diablo immortal apk graphics and performance
-Diablo immortal apk feedback and ratings
-Diablo immortal apk bugs and issues
-Diablo immortal apk news and events
-Diablo immortal apk forums and community
-Diablo immortal apk pre-registration and beta access
-Diablo immortal apk release date and launch details
-Diablo immortal apk comparison with diablo 3
-Diablo immortal apk cross-platform and cross-save support
-Diablo immortal apk blizzard account and login problems
-Diablo immortal apk refund policy and customer service
-Diablo immortal apk in-app purchases and microtransactions
-Diablo immortal apk system settings and customization options
-Diablo immortal apk soundtrack and voice acting
-Diablo immortal apk characters and skills
-Diablo immortal apk items and equipment
-Diablo immortal apk enemies and bosses
-Diablo immortal apk quests and challenges
-Diablo immortal apk world and environment
-Diablo immortal apk pvp and leaderboards
-Download diablo immortal from google play store[^1^]
-Download diablo immortal from diabloimmortal.com[^3^]
-Download diablo immortal from apkpure.com
-Download diablo immortal from apkmirror.com
-Download diablo immortal from apknite.com
-Download diablo immortal from apktada.com
-Download diablo immortal from apkmody.io
-Download diablo immortal from apksfull.com
-Download diablo immortal from apktovi.com
-Download diablo immortal from apkgk.com
-
-
Find a reliable third-party website that offers Diablo Immortal APK file. You can use a search engine or ask other players for recommendations.
-
Download the APK file to your device. Make sure you have enough storage space and a stable internet connection.
-
Enable "Unknown Sources" on your device settings. This will allow you to install apps from sources other than Google Play Store.
-
Locate the APK file on your device and tap on it.
-
Follow the instructions on the screen to install the game.
-
Launch the game and enjoy!
-
-
What are the Features and Requirements of Diablo Immortal
-
Diablo Immortal is a stunning and immersive game that offers a lot of features for players to enjoy. Here are some of them:
-
-
Six iconic and customizable classes: Barbarian, Demon Hunter, Necromancer, Crusader, Monk, and Wizard.
-
New abilities, set items, legendary weapons, and gems to enhance your character.
-
A rich and dynamic story that reveals new secrets about Sanctuary and its inhabitants.
-
A vast and diverse world to explore, from the war-torn surroundings of Wortham to the grand city of Westmarch and the jungles of Bilefen.
-
A variety of quests, bosses, dungeons, events, and challenges to test your skills and reward you with loot.
-
A cross-platform and cross-save feature that lets you play on PC or mobile with the same account.
-
A massively multiplayer online experience that lets you meet, socialize, and cooperate with other players from around the world.
-
A PvP mode that lets you compete against other players in arenas or battlegrounds.
-
A voice chat feature that lets you communicate with your friends or teammates in real time.
-
-
To play Diablo Immortal on your Android device, you need to meet the following requirements:
-
-
-
Minimum Requirements
-
Recommended Requirements
-
-
-
Android 5.0 or higher
-
Android 8.0 or higher
-
-
-
2 GB of RAM or more
-
4 GB of RAM or more
-
-
-
At least 4 GB of free storage space
-
At least 8 GB of free storage space
-
-
-
A stable internet connection (Wi-Fi or cellular)
-
A high-speed internet connection (Wi-Fi or cellular)
-
-
-
A compatible device (see the list here)
-
A high-end device (see the list here)
-
-
-
What are Some Tips and Tricks for Playing Diablo Immortal
-
Diablo Immortal is a fun and challenging game that requires some strategy and skill to master. Here are some tips and tricks that can help you improve your gameplay and enjoy the game more:
-
-
Choose a class that suits your playstyle and preferences. Each class has its own strengths, weaknesses, abilities, and equipment. Experiment with different classes and find the one that works best for you.
-
Customize your character with the Paragon system. This system lets you allocate points to different attributes, such as strength, dexterity, intelligence, vitality, and more. You can also unlock and upgrade different talents that enhance your abilities and skills.
-
Collect and equip the best gear for your character. Gear can have different rarities, stats, affixes, and set bonuses that affect your performance. You can also use gems to socket your gear and add extra effects. Look for gear that complements your class, build, and playstyle.
-
Use the crafting system to create and improve your gear. You can use materials that you find or salvage from unwanted items to craft new items or enhance existing ones. You can also use legendary materials to reforge legendary items or add legendary powers to other items.
-
Join a clan or create your own. Clans are groups of players that can chat, trade, cooperate, and compete with each other. You can also access clan-exclusive features, such as clan quests, clan dungeons, clan wars, and clan rankings.
-
Participate in events and challenges. Events are special activities that occur periodically in the game world, such as invasions, bounties, rifts, trials, and more. Challenges are tasks that you can complete to earn rewards, such as achievements, titles, badges, and more.
-
Play with other players. Diablo Immortal is a multiplayer game that lets you interact with other players in various ways. You can team up with other players to complete quests, dungeons, raids, and more. You can also chat with other players using text or voice messages.
-
Have fun! Diablo Immortal is a game that offers a lot of content and options for players to enjoy. You can explore the world at your own pace, follow the story at your own discretion, or focus on the aspects that interest you the most. The choice is yours!
-
-
Conclusion: Summary and Recommendations
-
In conclusion, Diablo Immortal is a fantastic mobile game that brings the Diablo franchise to your fingertips. You can download Diablo Immortal APK for your Android device from the Google Play Store or from a third-party website, but be careful of the risks involved in the latter option. You can also enjoy the many features and requirements of the game, such as the classes, the gear, the story, the world, the multiplayer mode, and more. Finally, you can use some tips and tricks to improve your gameplay and have more fun.
-
If you are looking for a mobile game that offers action, adventure, loot, and social interaction, then Diablo Immortal is the game for you. Download it today and join millions of players in the epic saga of Sanctuary!
-
FAQs: Five Common Questions and Answers about Diablo Immortal
-
Here are some of the most frequently asked questions about Diablo Immortal:
-
Q: Is Diablo Immortal free to play?
-
A: Yes, Diablo Immortal is free to play. You can download and play the game without paying anything. However, there are some optional in-game purchases that you can make to enhance your experience, such as cosmetic items, inventory slots, stash tabs, etc.
-
Q: Is Diablo Immortal online only?
-
A: Yes, Diablo Immortal is online only. You need a stable internet connection to play the game and access its features. You also need to create or link a Blizzard account to play the game.
-
Q: Is Diablo Immortal compatible with my device?
-
A: Diablo Immortal is compatible with most Android devices that meet the minimum requirements. You can check the list of compatible devices here. If your device is not on the list, you might still be able to play the game, but you might encounter some performance issues or bugs.
-
Q: How can I contact the customer support or report a problem?
-
A: You can contact the customer support or report a problem by using the in-game feedback system. To access it, tap on the menu icon on the top left corner of the screen, then tap on "Feedback". You can also visit the official website or the official forums for more information and assistance.
-
Q: When will Diablo Immortal be released?
-
A: Diablo Immortal is currently in development and testing stages. There is no official release date yet, but you can sign up for pre-registration on the Google Play Store or the official website to get notified when the game is available. You can also follow the official social media channels for the latest news and updates.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/How to Install and Enjoy Farlight 84 on PC with an Android Emulator.md b/spaces/congsaPfin/Manga-OCR/logs/How to Install and Enjoy Farlight 84 on PC with an Android Emulator.md
deleted file mode 100644
index 1ad118094f5edb6fe2f08e529dae3ae5366d2e43..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/How to Install and Enjoy Farlight 84 on PC with an Android Emulator.md
+++ /dev/null
@@ -1,107 +0,0 @@
-
-
How to Download Farlight 84 on PC
-
Farlight 84 is a popular battle royale game that features a diverse roster of heroes, spectacular vehicles, funky weapons, and jetpacks. It is available for free on Android and iOS devices, but what if you want to play it on your PC? In this article, we will show you how to download Farlight 84 on PC using different methods. Whether you have Windows 11 or an older version of Windows, you can enjoy this game on a bigger screen and with better controls.
Farlight 84 is a futuristic shooter game that combines elements of battle royale, hero shooter, and sci-fi. It was developed by Farlight Games and released in April 2023. The game takes place in a post-apocalyptic world where survivors fight for resources and glory. You can choose from over a dozen characters, each with their own unique skills and abilities. You can also customize your weapons, vehicles, and jetpacks to suit your playstyle. The game offers multiple game modes, including classic battle royale, hunt, and ranked games.
-
Why Play Farlight 84 on PC?
-
While Farlight 84 is designed for mobile devices, playing it on PC has some advantages. For one thing, you can enjoy the game's graphics and animations on a larger screen, which can enhance the immersion and excitement. For another thing, you can use your mouse and keyboard or a controller to control your character, which can give you more accuracy and agility. Playing on PC can also improve your performance and reduce lag, especially if you have a powerful PC.
-
How to Play Farlight 84 on PC with Windows 11
-
If you have Windows 11, you can play Android games on your PC using the native Android emulation feature. This feature lets you run Android apps without needing to install a third-party emulator. Here are the steps to play Farlight 84 on PC with Windows 11:
-
-
Open the Microsoft Store app on your PC and search for "Farlight 84".
-
Click on the game icon and then click on "Install".
-
Wait for the game to download and install.
-
Launch the game from the Microsoft Store app or from your Start menu.
-
Sign in with your Google account or create a new one.
-
Enjoy playing Farlight 84 on your PC!
-
-
How to Play Farlight 84 on PC with Android Emulators
-
If you don't have Windows 11 or you prefer using an Android emulator, you can also play Farlight 84 on PC with various emulators. An Android emulator is a software that simulates an Android device on your PC. You can download and install Android games and apps on the emulator and use your PC's hardware to run them. Here are some of the best Android emulators for playing Farlight 84 on PC:
-
-
Bluestacks: Bluestacks is one of the most popular and widely used Android emulators. It has a simple and user-friendly interface, high compatibility, and fast performance. It also has features such as keyboard mapping, game mode, and multi-instance. You can download Bluestacks from its official website and follow the instructions to install and set it up. Then, you can search for Farlight 84 in the Google Play Store app and install it. You can also download the game's APK file from here and drag and drop it to the Bluestacks window to install it.
-
Nox Player: Nox Player is another popular Android emulator that offers a smooth and stable gaming experience. It has features such as keyboard and mouse control, game optimization, and screen recording. You can download Nox Player from its official website and follow the instructions to install and set it up. Then, you can search for Farlight 84 in the Google Play Store app and install it. You can also download the game's APK file from here and drag and drop it to the Nox Player window to install it.
-
Gameloop: Gameloop is an Android emulator that is specially designed for gaming. It has features such as turbo engine, anti-aliasing, smart keymapping, and exclusive game center. You can download Gameloop from its official website and follow the instructions to install and set it up. Then, you can search for Farlight 84 in the game center app and install it. You can also download the game's APK file from here and drag and drop it to the Gameloop window to install it.
-
-
How to Play Farlight 84 on PC with Parsec
-
If you have a PC that can run Farlight 84 but you want to play it on your Android device, you can use Parsec to stream the game from your PC to your device. Parsec is a software that lets you remotely access your PC from anywhere. You can use it to play PC games on your phone or tablet with low latency and high quality. Here are the steps to play Farlight 84 on PC with Parsec:
-
How to install farlight 84 on your computer
-Farlight 84 pc download guide and tips
-Best way to play farlight 84 on pc with bluestacks
-How to get farlight 84 for free on pc
-Farlight 84 steam version download and review
-How to run farlight 84 on pc without emulator
-Farlight 84 pc system requirements and settings
-How to update farlight 84 on pc
-How to fix farlight 84 pc errors and bugs
-How to join farlight 84 pc community and discord
-How to play farlight 84 on pc with controller
-Farlight 84 pc gameplay and features
-How to unlock all heroes in farlight 84 pc
-How to win in farlight 84 pc hunt mode
-How to customize your character in farlight 84 pc
-How to stream farlight 84 on pc with obs
-How to record and edit farlight 84 videos on pc
-How to improve your skills in farlight 84 pc
-How to rank up in farlight 84 pc leaderboard
-How to earn and spend coins in farlight 84 pc
-How to get more weapons and vehicles in farlight 84 pc
-How to use cheats and hacks in farlight 84 pc
-How to troubleshoot farlight 84 pc issues and crashes
-How to access farlight 84 pc beta and early access
-How to download farlight 84 on mac and linux
-Farlight 84 pc vs mobile comparison and pros and cons
-How to transfer your data from mobile to pc in farlight 84
-How to play with friends in farlight 84 cross-platform
-How to change your language and region in farlight 84 pc
-How to enable voice chat and microphone in farlight 84 pc
-How to adjust graphics and sound quality in farlight 84 pc
-How to optimize your performance and fps in farlight 84 pc
-How to use keyboard and mouse shortcuts in farlight 84 pc
-How to redeem codes and coupons in farlight 84 pc
-How to contact support and report bugs in farlight 84 pc
-Farlight 84 pc news and updates
-Farlight 84 pc strategies and guides
-Farlight 84 pc reviews and ratings
-Farlight 84 pc best heroes and loadouts
-Farlight 84 pc best weapons and vehicles
-Farlight 84 pc best maps and locations
-Farlight 84 pc best skins and outfits
-Farlight 84 pc best moments and highlights
-Farlight 84 pc fan art and wallpapers
-Farlight 84 pc memes and jokes
-Farlight 84 pc trivia and facts
-Farlight 84 pc competitions and tournaments
-Farlight 84 pc modding and customization
Launch Parsec on your device and sign in with the same account as your PC.
-
Select your PC from the list of available devices and tap on "Connect".
-
Once connected, you can see your PC's screen on your device.
-
Launch Farlight 84 on your PC and play it on your device using touch controls or a controller.
-
-
Conclusion
-
Farlight 84 is a fun and exciting game that you can play on your PC using different methods. You can use Windows 11's native Android emulation feature, an Android emulator such as Bluestacks, Nox Player, or Gameloop, or a streaming software such as Parsec. Each method has its own pros and cons, so you can choose the one that suits you best. Whichever method you choose, you can enjoy Farlight 84 on a bigger screen and with better controls.
-
FAQs
-
Is Farlight 84 free to play?
-
Yes, Farlight 84 is free to play on both Android and iOS devices. However, it does have in-app purchases that allow you to buy items such as skins, weapons, vehicles, jetpacks, coins, gems, and crates.
-
Can I play Farlight 84 with my friends on different platforms?
-
Yes, Farlight 84 supports cross-platform play between Android and iOS devices. However, it does not support cross-play with PC players yet.
- What are the minimum requirements to run Farlight 84 on PC?
-
The minimum requirements to run Farlight 84 on PC depend on the method you use. If you use Windows 11's native Android emulation feature, you need a PC that meets the minimum requirements for Windows 11. If you use an Android emulator, you need a PC that meets the minimum requirements for the emulator. If you use Parsec, you need a PC that can run Farlight 84 smoothly and a device that can stream it without lag.
-
How can I earn rewards in Farlight 84?
-
You can earn rewards in Farlight 84 by completing various tasks and challenges. Some of the ways to earn rewards are:
-
-
Playing daily and weekly missions.
-
Participating in events and seasons.
-
Ranking up in the leaderboards.
-
Opening crates and chests.
-
Watching ads and videos.
-
Inviting and playing with friends.
-
-
Where can I find more information about Farlight 84?
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/congsaPfin/Manga-OCR/logs/Play FIFA Soccer on PC and Mac Experience the Authentic Soccer Action and Real-Time 11v11 Gameplay with BlueStacks.md b/spaces/congsaPfin/Manga-OCR/logs/Play FIFA Soccer on PC and Mac Experience the Authentic Soccer Action and Real-Time 11v11 Gameplay with BlueStacks.md
deleted file mode 100644
index eea99bcffebb832c44a67b0ac5463522fdbff0bf..0000000000000000000000000000000000000000
--- a/spaces/congsaPfin/Manga-OCR/logs/Play FIFA Soccer on PC and Mac Experience the Authentic Soccer Action and Real-Time 11v11 Gameplay with BlueStacks.md
+++ /dev/null
@@ -1,152 +0,0 @@
-
-
FIFA apk windows: How to play the popular soccer game on your PC
-
If you are a fan of soccer games, you have probably heard of FIFA, the best-selling game series by EA Sports. FIFA is a realistic and immersive simulation of the world's most popular sport, featuring hundreds of teams, players, stadiums, and competitions. You can play FIFA on various platforms, such as PlayStation, Xbox, Nintendo Switch, and mobile devices. But did you know that you can also play FIFA on your PC using an apk file? In this article, we will explain what FIFA apk windows is, why you might want to play it, how to download and install it, how to play it, and what are some alternatives to it.
A brief introduction to FIFA, the soccer game series by EA Sports
-
FIFA is a long-running game series that started in 1993 with FIFA International Soccer. Since then, EA Sports has released a new edition every year, with updated rosters, graphics, gameplay features, and modes. The latest installment is FIFA 22, which was released in September 2021. FIFA is known for its authenticity and realism, as it has official licenses from various soccer organizations, such as FIFA (the international governing body of soccer), UEFA (the European soccer association), and many national leagues and clubs. FIFA also features some of the world's best soccer players as cover stars and ambassadors.
-
An explanation of what apk files are and how they can be used to run Android apps on PC
-
An apk file is a file format that is used to distribute and install applications on Android devices. Apk stands for Android Package Kit, and it contains all the necessary files and data for an app to run. Apk files can be downloaded from various sources online, such as Google Play Store or third-party websites. However, apk files are not compatible with Windows operating systems by default. To run an apk file on your PC, you need to use an Android emulator. An Android emulator is a software that mimics the Android environment on your PC. It allows you to run Android apps and games on your PC as if you were using an Android device. There are many Android emulators available for Windows 10 users. Some of the most popular ones are BlueStacks, GameLoop, NoxPlayer, etc.
-
Why play FIFA apk windows?
-
The benefits of playing FIFA on PC
-
There are many reasons why you might want to play FIFA on your PC, such as:
-
-
Better graphics: Playing FIFA on PC can give you a more realistic and immersive visual experience, as you can enjoy the high-quality graphics, animations, and effects of the game. You can also adjust the graphics settings to suit your preferences and PC specifications.
-
Larger screen: Playing FIFA on PC can also give you a more comfortable and enjoyable viewing experience, as you can see the game on a bigger and wider screen. You can also use a monitor or a TV to connect your PC and play FIFA on an even larger display.
-
Keyboard and mouse controls: Playing FIFA on PC can also give you more options and flexibility in terms of controls, as you can use a keyboard and mouse to play the game. You can also customize your key bindings and mouse sensitivity to suit your style and skills.
-
-
The drawbacks of playing FIFA on PC
-
However, playing FIFA on PC also has some drawbacks, such as:
-
fifa mobile pc download
-fifa soccer emulator for windows
-how to play fifa on pc with bluestacks
-fifa mobile gameloop emulator
-fifa football pc game
-download fifa soccer on windows 10
-fifa mobile for pc free
-best android emulator for fifa soccer
-fifa mobile windows version
-play fifa soccer on pc online
-fifa mobile pc requirements
-fifa soccer pc controls
-how to install fifa apk on windows
-fifa mobile mac download
-fifa soccer emulator for mac
-how to play fifa on mac with bluestacks
-fifa mobile gameloop mac
-fifa football mac game
-download fifa soccer on macos
-fifa mobile for mac free
-best android emulator for fifa football
-fifa mobile mac version
-play fifa football on mac online
-fifa mobile mac requirements
-fifa football mac controls
-how to install fifa apk on mac
-download fifa apk for windows 7/8/10
-download fifa apk for mac os x
-download latest version of fifa apk for pc
-download updated version of fifa apk for mac
-download cracked version of fifa apk for windows
-download modded version of fifa apk for mac
-download offline version of fifa apk for pc
-download online version of fifa apk for mac
-download full version of fifa apk for windows
-download lite version of fifa apk for mac
-download english version of fifa apk for pc
-download spanish version of fifa apk for mac
-download french version of fifa apk for windows
-download german version of fifa apk for mac
-download chinese version of fifa apk for pc
-download japanese version of fifa apk for mac
-download korean version of fifa apk for windows
-download arabic version of fifa apk for mac
-download portuguese version of fifa apk for pc
-download russian version of fifa apk for mac
-download italian version of fifa apk for windows
-download turkish version of fifa apk for mac
-download hindi version of fifa apk for pc
-
-
Compatibility issues: Playing FIFA on PC using an apk file and an emulator can cause some compatibility issues, as the game is not designed for Windows operating systems. You might encounter some errors, bugs, crashes, or glitches while playing the game.
-
Performance problems: Playing FIFA on PC using an apk file and an emulator can also cause some performance problems, as the game requires a lot of resources and processing power from your PC. You might experience some lag, stuttering, or freezing while playing the game.
-
Security risks: Playing FIFA on PC using an apk file and an emulator can also pose some security risks, as the apk file and the emulator might contain some malware, spyware, or viruses that can harm your PC. You should always download the apk file and the emulator from trusted sources and scan them with antivirus software before installing them.
-
-
How to download and install FIFA apk windows?
-
The requirements for playing FIFA apk windows
-
To play FIFA apk windows, you need to have the following requirements:
-
-
A PC with Windows 10 operating system.
-
An Android emulator that can run Android apps and games on your PC. As mentioned earlier, some of the most popular ones are BlueStacks, GameLoop, NoxPlayer, etc.
-
A FIFA apk file that contains the game data and files. You can download it from various sources online, such as Google Play Store or third-party websites. However, make sure that the apk file is compatible with your emulator and is free of viruses.
-
-
The steps for downloading and installing FIFA apk windows
-
To download and install FIFA apk windows, you need to follow these steps:
-
-
Download and install an Android emulator of your choice on your PC. Follow the instructions on the emulator's website or app to complete the installation process.
-
Download a FIFA apk file of your choice on your PC. You can use a web browser or a downloader app to download the apk file from any source you trust.
-
Launch the Android emulator on your PC and sign in with your Google account. This will allow you to access the Google Play Store and other Google services on the emulator.
-
Locate the FIFA apk file on your PC and drag and drop it to the emulator's window. Alternatively, you can use the emulator's file manager or browser to find and open the apk file.
-
Wait for the emulator to install the FIFA apk file on your PC. This might take a few minutes depending on the size of the apk file and the speed of your PC.
-
Once the installation is done, you will see a FIFA icon on the emulator's home screen or app drawer. Click on it to launch the game and enjoy playing FIFA apk windows.
-
-
How to play FIFA apk windows?
-
The features and modes of FIFA apk windows
-
FIFA apk windows has many features and modes that you can enjoy playing, such as:
-
-
Career Mode: In this mode, you can create your own soccer player or manager and lead them to glory. You can customize their appearance, skills, attributes, contracts, transfers, etc. You can also play through various seasons, tournaments, leagues, cups, etc.
-
Ultimate Team: In this mode, you can build your own dream team of soccer stars from different eras and regions. You can collect player cards, trade them with other players, create squads, play matches, and earn rewards. You can also compete with other players online or offline in various modes, such as Division Rivals, Squad Battles, FUT Champions, etc.
-
Volta Football: In this mode, you can experience the street soccer culture and style. You can create your own avatar and customize their outfits, hairstyles, tattoos, etc. You can also play in various locations, such as rooftops, cages, courts, etc. You can also play with different rules, such as 3v3, 4v4, 5v5, Futsal, etc.
-
-
The tips and tricks for playing FIFA apk windows
-
To play FIFA apk windows better, you can follow these tips and tricks:
-
-
Customize your controls: You can change the default controls of the game to suit your preferences and skills. You can use the emulator's settings to map the keyboard and mouse keys to the game's buttons. You can also use a gamepad or a controller to play the game if you have one.
-
Adjust your settings: You can also change the game's settings to optimize its performance and quality. You can use the emulator's settings to adjust the resolution, frame rate, graphics quality, sound volume, etc. You can also use the game's settings to adjust the difficulty level, camera angle, gameplay speed, etc.
-
Improve your skills: You can also practice and improve your skills in the game by playing different modes and matches. You can learn the basic and advanced moves, such as passing, shooting, dribbling, tackling, etc. You can also learn the strategies and tactics of different teams and players. You can also watch tutorials and guides online to get more tips and tricks.
-
-
What are some alternatives to FIFA apk windows?
-
A list of some other soccer games that can be played on PC
-
If you are looking for some other soccer games that can be played on PC, you can check out these games:
-
-
-
Game
-
Description
-
-
-
Pro Evolution Soccer (PES)
-
A soccer game series by Konami that focuses on realistic gameplay and physics. It has official licenses from some soccer organizations, such as UEFA and AFC. It also features some legendary players and teams.
-
-
-
Football Manager (FM)
-
A soccer management simulation game series by Sports Interactive that lets you take control of any soccer club or national team. You can manage all aspects of your team, such as transfers, tactics, training, finances, etc. You can also watch the matches in 3D or 2D.
-
-
-
Rocket League
-
A soccer game with a twist by Psyonix that combines soccer with rocket-powered cars. You can play with up to four players on each team and score goals by hitting a giant ball with your car. You can also customize your car with various items and decals.
-
-
-
A comparison of these games with FIFA apk windows
-
To compare these games with FIFA apk windows, you can look at these criteria:
-
-
Gameplay: FIFA apk windows has a more realistic and immersive gameplay than PES and Rocket League. It has more features and modes than FM. However, PES has a more fluid and responsive gameplay than FIFA apk windows. FM has a more strategic and complex gameplay than FIFA apk windows. Rocket League has a more fun and casual gameplay than FIFA apk windows.
-
Graphics: FIFA apk windows has better graphics than PES and FM. It has similar graphics to Rocket League. However, FIFA apk windows might have some graphical issues when played on PC using an apk file and an emulator.
-
Reviews: FIFA apk windows has mixed reviews from critics and players. Some praise its realism and variety, while others criticize its bugs and microtransactions. PES has positive reviews from critics and players. Some praise its gameplay and physics, while others criticize its lack of licenses and modes. FM has very positive reviews from critics and players. Some praise its depth and realism, while others criticize its difficulty and complexity. Rocket League has overwhelmingly positive reviews from critics and players. Some praise its fun and creativity, while others criticize its toxicity and repetitiveness.
-
-
Conclusion
-
A summary of the main points of the article
-
In conclusion, FIFA apk windows is a way to play the popular soccer game by EA Sports on your PC using an apk file and an emulator. FIFA apk windows has many benefits, such as better graphics, larger screen, and keyboard and mouse controls. However, it also has some drawbacks, such as compatibility issues, performance problems, and security risks. To play FIFA apk windows, you need to have a PC with Windows 10, an Android emulator, and a FIFA apk file. You can download and install them following the steps we provided. You can also enjoy playing various features and modes of FIFA apk windows, such as Career Mode, Ultimate Team, and Volta Football. You can also improve your skills by following the tips and tricks we shared. If you are looking for some alternatives to FIFA apk windows, you can try out other soccer games on PC, such as PES, FM, and Rocket League.
-
A call to action for the readers to try out FIFA apk windows or other soccer games on PC
-
We hope that this article has helped you understand what FIFA apk windows is, why you might want to play it, how to download and install it, how to play it, and what are some alternatives to it. If you are a soccer fan and a PC gamer, you should definitely give FIFA apk windows or other soccer games on PC a try. You will have a lot of fun and excitement playing the world's most popular sport on your PC. So what are you waiting for? Download FIFA apk windows or other soccer games on PC today and enjoy the beautiful game!
-
FAQs
-
What is the difference between FIFA apk windows and FIFA PC?
-
FIFA apk windows is a way to play the mobile version of FIFA on your PC using an apk file and an emulator. FIFA PC is the official version of FIFA that is designed for Windows operating systems. FIFA PC has more features and modes than FIFA apk windows, but it also requires more system requirements and costs more money.
-
Is FIFA apk windows legal?
-
FIFA apk windows is not illegal, but it is not authorized by EA Sports either. EA Sports does not support or endorse playing FIFA on PC using an apk file and an emulator. Therefore, you are playing FIFA apk windows at your own risk and responsibility.
-
Is FIFA apk windows safe?
-
FIFA apk windows is not completely safe, as it involves downloading and installing files from unknown sources that might contain malware or viruses. It also involves using an emulator that might access your personal data or harm your PC. Therefore, you should always be careful and cautious when playing FIFA apk windows.
-
How can I update FIFA apk windows?
-
To update FIFA apk windows, you need to download and install the latest version of the FIFA apk file from a reliable source. You also need to make sure that your emulator is compatible with the new version of the game. You might need to uninstall and reinstall the game if you encounter any problems.
-
How can I uninstall FIFA apk windows?
-
To uninstall FIFA apk windows, you need to delete the FIFA apk file from your PC. You also need to delete the game data and cache from your emulator. You might need to use a cleaner app or software to remove any leftover files or registry entries.
401be4b1e0
-
-
\ No newline at end of file
diff --git a/spaces/contluForse/HuggingGPT/assets/Edius Pro 7.2 Build 0437.crack.rar The Perfect Finishing Tool for Broadcast Documentary and 4K Productions.md b/spaces/contluForse/HuggingGPT/assets/Edius Pro 7.2 Build 0437.crack.rar The Perfect Finishing Tool for Broadcast Documentary and 4K Productions.md
deleted file mode 100644
index 003146f2ae1348c1b831cddc059722eb22c00cd9..0000000000000000000000000000000000000000
--- a/spaces/contluForse/HuggingGPT/assets/Edius Pro 7.2 Build 0437.crack.rar The Perfect Finishing Tool for Broadcast Documentary and 4K Productions.md
+++ /dev/null
@@ -1,6 +0,0 @@
-
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/projects/deeplab/resnet.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/projects/deeplab/resnet.py
deleted file mode 100644
index 28455d123a12f887400c19c263d08cc2ed08522e..0000000000000000000000000000000000000000
--- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/projects/deeplab/resnet.py
+++ /dev/null
@@ -1,158 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import fvcore.nn.weight_init as weight_init
-import torch.nn.functional as F
-
-from annotator.oneformer.detectron2.layers import CNNBlockBase, Conv2d, get_norm
-from annotator.oneformer.detectron2.modeling import BACKBONE_REGISTRY
-from annotator.oneformer.detectron2.modeling.backbone.resnet import (
- BasicStem,
- BottleneckBlock,
- DeformBottleneckBlock,
- ResNet,
-)
-
-
-class DeepLabStem(CNNBlockBase):
- """
- The DeepLab ResNet stem (layers before the first residual block).
- """
-
- def __init__(self, in_channels=3, out_channels=128, norm="BN"):
- """
- Args:
- norm (str or callable): norm after the first conv layer.
- See :func:`layers.get_norm` for supported format.
- """
- super().__init__(in_channels, out_channels, 4)
- self.in_channels = in_channels
- self.conv1 = Conv2d(
- in_channels,
- out_channels // 2,
- kernel_size=3,
- stride=2,
- padding=1,
- bias=False,
- norm=get_norm(norm, out_channels // 2),
- )
- self.conv2 = Conv2d(
- out_channels // 2,
- out_channels // 2,
- kernel_size=3,
- stride=1,
- padding=1,
- bias=False,
- norm=get_norm(norm, out_channels // 2),
- )
- self.conv3 = Conv2d(
- out_channels // 2,
- out_channels,
- kernel_size=3,
- stride=1,
- padding=1,
- bias=False,
- norm=get_norm(norm, out_channels),
- )
- weight_init.c2_msra_fill(self.conv1)
- weight_init.c2_msra_fill(self.conv2)
- weight_init.c2_msra_fill(self.conv3)
-
- def forward(self, x):
- x = self.conv1(x)
- x = F.relu_(x)
- x = self.conv2(x)
- x = F.relu_(x)
- x = self.conv3(x)
- x = F.relu_(x)
- x = F.max_pool2d(x, kernel_size=3, stride=2, padding=1)
- return x
-
-
-@BACKBONE_REGISTRY.register()
-def build_resnet_deeplab_backbone(cfg, input_shape):
- """
- Create a ResNet instance from config.
- Returns:
- ResNet: a :class:`ResNet` instance.
- """
- # need registration of new blocks/stems?
- norm = cfg.MODEL.RESNETS.NORM
- if cfg.MODEL.RESNETS.STEM_TYPE == "basic":
- stem = BasicStem(
- in_channels=input_shape.channels,
- out_channels=cfg.MODEL.RESNETS.STEM_OUT_CHANNELS,
- norm=norm,
- )
- elif cfg.MODEL.RESNETS.STEM_TYPE == "deeplab":
- stem = DeepLabStem(
- in_channels=input_shape.channels,
- out_channels=cfg.MODEL.RESNETS.STEM_OUT_CHANNELS,
- norm=norm,
- )
- else:
- raise ValueError("Unknown stem type: {}".format(cfg.MODEL.RESNETS.STEM_TYPE))
-
- # fmt: off
- freeze_at = cfg.MODEL.BACKBONE.FREEZE_AT
- out_features = cfg.MODEL.RESNETS.OUT_FEATURES
- depth = cfg.MODEL.RESNETS.DEPTH
- num_groups = cfg.MODEL.RESNETS.NUM_GROUPS
- width_per_group = cfg.MODEL.RESNETS.WIDTH_PER_GROUP
- bottleneck_channels = num_groups * width_per_group
- in_channels = cfg.MODEL.RESNETS.STEM_OUT_CHANNELS
- out_channels = cfg.MODEL.RESNETS.RES2_OUT_CHANNELS
- stride_in_1x1 = cfg.MODEL.RESNETS.STRIDE_IN_1X1
- res4_dilation = cfg.MODEL.RESNETS.RES4_DILATION
- res5_dilation = cfg.MODEL.RESNETS.RES5_DILATION
- deform_on_per_stage = cfg.MODEL.RESNETS.DEFORM_ON_PER_STAGE
- deform_modulated = cfg.MODEL.RESNETS.DEFORM_MODULATED
- deform_num_groups = cfg.MODEL.RESNETS.DEFORM_NUM_GROUPS
- res5_multi_grid = cfg.MODEL.RESNETS.RES5_MULTI_GRID
- # fmt: on
- assert res4_dilation in {1, 2}, "res4_dilation cannot be {}.".format(res4_dilation)
- assert res5_dilation in {1, 2, 4}, "res5_dilation cannot be {}.".format(res5_dilation)
- if res4_dilation == 2:
- # Always dilate res5 if res4 is dilated.
- assert res5_dilation == 4
-
- num_blocks_per_stage = {50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3]}[depth]
-
- stages = []
-
- # Avoid creating variables without gradients
- # It consumes extra memory and may cause allreduce to fail
- out_stage_idx = [{"res2": 2, "res3": 3, "res4": 4, "res5": 5}[f] for f in out_features]
- max_stage_idx = max(out_stage_idx)
- for idx, stage_idx in enumerate(range(2, max_stage_idx + 1)):
- if stage_idx == 4:
- dilation = res4_dilation
- elif stage_idx == 5:
- dilation = res5_dilation
- else:
- dilation = 1
- first_stride = 1 if idx == 0 or dilation > 1 else 2
- stage_kargs = {
- "num_blocks": num_blocks_per_stage[idx],
- "stride_per_block": [first_stride] + [1] * (num_blocks_per_stage[idx] - 1),
- "in_channels": in_channels,
- "out_channels": out_channels,
- "norm": norm,
- }
- stage_kargs["bottleneck_channels"] = bottleneck_channels
- stage_kargs["stride_in_1x1"] = stride_in_1x1
- stage_kargs["dilation"] = dilation
- stage_kargs["num_groups"] = num_groups
- if deform_on_per_stage[idx]:
- stage_kargs["block_class"] = DeformBottleneckBlock
- stage_kargs["deform_modulated"] = deform_modulated
- stage_kargs["deform_num_groups"] = deform_num_groups
- else:
- stage_kargs["block_class"] = BottleneckBlock
- if stage_idx == 5:
- stage_kargs.pop("dilation")
- stage_kargs["dilation_per_block"] = [dilation * mg for mg in res5_multi_grid]
- blocks = ResNet.make_stage(**stage_kargs)
- in_channels = out_channels
- out_channels *= 2
- bottleneck_channels *= 2
- stages.append(blocks)
- return ResNet(stem, stages, out_features=out_features).freeze(freeze_at)
diff --git a/spaces/cvlab/zero123-live/taming-transformers/taming/util.py b/spaces/cvlab/zero123-live/taming-transformers/taming/util.py
deleted file mode 100644
index 06053e5defb87977f9ab07e69bf4da12201de9b7..0000000000000000000000000000000000000000
--- a/spaces/cvlab/zero123-live/taming-transformers/taming/util.py
+++ /dev/null
@@ -1,157 +0,0 @@
-import os, hashlib
-import requests
-from tqdm import tqdm
-
-URL_MAP = {
- "vgg_lpips": "https://heibox.uni-heidelberg.de/f/607503859c864bc1b30b/?dl=1"
-}
-
-CKPT_MAP = {
- "vgg_lpips": "vgg.pth"
-}
-
-MD5_MAP = {
- "vgg_lpips": "d507d7349b931f0638a25a48a722f98a"
-}
-
-
-def download(url, local_path, chunk_size=1024):
- os.makedirs(os.path.split(local_path)[0], exist_ok=True)
- with requests.get(url, stream=True) as r:
- total_size = int(r.headers.get("content-length", 0))
- with tqdm(total=total_size, unit="B", unit_scale=True) as pbar:
- with open(local_path, "wb") as f:
- for data in r.iter_content(chunk_size=chunk_size):
- if data:
- f.write(data)
- pbar.update(chunk_size)
-
-
-def md5_hash(path):
- with open(path, "rb") as f:
- content = f.read()
- return hashlib.md5(content).hexdigest()
-
-
-def get_ckpt_path(name, root, check=False):
- assert name in URL_MAP
- path = os.path.join(root, CKPT_MAP[name])
- if not os.path.exists(path) or (check and not md5_hash(path) == MD5_MAP[name]):
- print("Downloading {} model from {} to {}".format(name, URL_MAP[name], path))
- download(URL_MAP[name], path)
- md5 = md5_hash(path)
- assert md5 == MD5_MAP[name], md5
- return path
-
-
-class KeyNotFoundError(Exception):
- def __init__(self, cause, keys=None, visited=None):
- self.cause = cause
- self.keys = keys
- self.visited = visited
- messages = list()
- if keys is not None:
- messages.append("Key not found: {}".format(keys))
- if visited is not None:
- messages.append("Visited: {}".format(visited))
- messages.append("Cause:\n{}".format(cause))
- message = "\n".join(messages)
- super().__init__(message)
-
-
-def retrieve(
- list_or_dict, key, splitval="/", default=None, expand=True, pass_success=False
-):
- """Given a nested list or dict return the desired value at key expanding
- callable nodes if necessary and :attr:`expand` is ``True``. The expansion
- is done in-place.
-
- Parameters
- ----------
- list_or_dict : list or dict
- Possibly nested list or dictionary.
- key : str
- key/to/value, path like string describing all keys necessary to
- consider to get to the desired value. List indices can also be
- passed here.
- splitval : str
- String that defines the delimiter between keys of the
- different depth levels in `key`.
- default : obj
- Value returned if :attr:`key` is not found.
- expand : bool
- Whether to expand callable nodes on the path or not.
-
- Returns
- -------
- The desired value or if :attr:`default` is not ``None`` and the
- :attr:`key` is not found returns ``default``.
-
- Raises
- ------
- Exception if ``key`` not in ``list_or_dict`` and :attr:`default` is
- ``None``.
- """
-
- keys = key.split(splitval)
-
- success = True
- try:
- visited = []
- parent = None
- last_key = None
- for key in keys:
- if callable(list_or_dict):
- if not expand:
- raise KeyNotFoundError(
- ValueError(
- "Trying to get past callable node with expand=False."
- ),
- keys=keys,
- visited=visited,
- )
- list_or_dict = list_or_dict()
- parent[last_key] = list_or_dict
-
- last_key = key
- parent = list_or_dict
-
- try:
- if isinstance(list_or_dict, dict):
- list_or_dict = list_or_dict[key]
- else:
- list_or_dict = list_or_dict[int(key)]
- except (KeyError, IndexError, ValueError) as e:
- raise KeyNotFoundError(e, keys=keys, visited=visited)
-
- visited += [key]
- # final expansion of retrieved value
- if expand and callable(list_or_dict):
- list_or_dict = list_or_dict()
- parent[last_key] = list_or_dict
- except KeyNotFoundError as e:
- if default is None:
- raise e
- else:
- list_or_dict = default
- success = False
-
- if not pass_success:
- return list_or_dict
- else:
- return list_or_dict, success
-
-
-if __name__ == "__main__":
- config = {"keya": "a",
- "keyb": "b",
- "keyc":
- {"cc1": 1,
- "cc2": 2,
- }
- }
- from omegaconf import OmegaConf
- config = OmegaConf.create(config)
- print(config)
- retrieve(config, "keya")
-
diff --git a/spaces/daddyjin/TalkingFaceGeneration/Demo_TFR_Pirenderer/src/utils/audio.py b/spaces/daddyjin/TalkingFaceGeneration/Demo_TFR_Pirenderer/src/utils/audio.py
deleted file mode 100644
index a96071106d684732f89cf92c2d9fe83e377243c1..0000000000000000000000000000000000000000
--- a/spaces/daddyjin/TalkingFaceGeneration/Demo_TFR_Pirenderer/src/utils/audio.py
+++ /dev/null
@@ -1,136 +0,0 @@
-import librosa
-import librosa.filters
-import numpy as np
-# import tensorflow as tf
-from scipy import signal
-from scipy.io import wavfile
-from Demo_TFR_Pirenderer.src.utils.hparams import hparams as hp
-
-def load_wav(path, sr):
- return librosa.core.load(path, sr=sr)[0]
-
-def save_wav(wav, path, sr):
- wav *= 32767 / max(0.01, np.max(np.abs(wav)))
- #proposed by @dsmiller
- wavfile.write(path, sr, wav.astype(np.int16))
-
-def save_wavenet_wav(wav, path, sr):
- librosa.output.write_wav(path, wav, sr=sr)
-
-def preemphasis(wav, k, preemphasize=True):
- if preemphasize:
- return signal.lfilter([1, -k], [1], wav)
- return wav
-
-def inv_preemphasis(wav, k, inv_preemphasize=True):
- if inv_preemphasize:
- return signal.lfilter([1], [1, -k], wav)
- return wav
-
-def get_hop_size():
- hop_size = hp.hop_size
- if hop_size is None:
- assert hp.frame_shift_ms is not None
- hop_size = int(hp.frame_shift_ms / 1000 * hp.sample_rate)
- return hop_size
-
-def linearspectrogram(wav):
- D = _stft(preemphasis(wav, hp.preemphasis, hp.preemphasize))
- S = _amp_to_db(np.abs(D)) - hp.ref_level_db
-
- if hp.signal_normalization:
- return _normalize(S)
- return S
-
-def melspectrogram(wav):
- D = _stft(preemphasis(wav, hp.preemphasis, hp.preemphasize))
- S = _amp_to_db(_linear_to_mel(np.abs(D))) - hp.ref_level_db
-
- if hp.signal_normalization:
- return _normalize(S)
- return S
-
-def _lws_processor():
- import lws
- return lws.lws(hp.n_fft, get_hop_size(), fftsize=hp.win_size, mode="speech")
-
-def _stft(y):
- if hp.use_lws:
- return _lws_processor(hp).stft(y).T
- else:
- return librosa.stft(y=y, n_fft=hp.n_fft, hop_length=get_hop_size(), win_length=hp.win_size)
-
-##########################################################
-#Those are only correct when using lws!!! (This was messing with Wavenet quality for a long time!)
-def num_frames(length, fsize, fshift):
- """Compute number of time frames of spectrogram
- """
- pad = (fsize - fshift)
- if length % fshift == 0:
- M = (length + pad * 2 - fsize) // fshift + 1
- else:
- M = (length + pad * 2 - fsize) // fshift + 2
- return M
-
-
-def pad_lr(x, fsize, fshift):
- """Compute left and right padding
- """
- M = num_frames(len(x), fsize, fshift)
- pad = (fsize - fshift)
- T = len(x) + 2 * pad
- r = (M - 1) * fshift + fsize - T
- return pad, pad + r
-##########################################################
-#Librosa correct padding
-def librosa_pad_lr(x, fsize, fshift):
- return 0, (x.shape[0] // fshift + 1) * fshift - x.shape[0]
-
-# Conversions
-_mel_basis = None
-
-def _linear_to_mel(spectogram):
- global _mel_basis
- if _mel_basis is None:
- _mel_basis = _build_mel_basis()
- return np.dot(_mel_basis, spectogram)
-
-def _build_mel_basis():
- assert hp.fmax <= hp.sample_rate // 2
- return librosa.filters.mel(sr=hp.sample_rate, n_fft=hp.n_fft, n_mels=hp.num_mels,
- fmin=hp.fmin, fmax=hp.fmax)
-
-def _amp_to_db(x):
- min_level = np.exp(hp.min_level_db / 20 * np.log(10))
- return 20 * np.log10(np.maximum(min_level, x))
-
-def _db_to_amp(x):
- return np.power(10.0, (x) * 0.05)
-
-def _normalize(S):
- if hp.allow_clipping_in_normalization:
- if hp.symmetric_mels:
- return np.clip((2 * hp.max_abs_value) * ((S - hp.min_level_db) / (-hp.min_level_db)) - hp.max_abs_value,
- -hp.max_abs_value, hp.max_abs_value)
- else:
- return np.clip(hp.max_abs_value * ((S - hp.min_level_db) / (-hp.min_level_db)), 0, hp.max_abs_value)
-
- assert S.max() <= 0 and S.min() - hp.min_level_db >= 0
- if hp.symmetric_mels:
- return (2 * hp.max_abs_value) * ((S - hp.min_level_db) / (-hp.min_level_db)) - hp.max_abs_value
- else:
- return hp.max_abs_value * ((S - hp.min_level_db) / (-hp.min_level_db))
-
-def _denormalize(D):
- if hp.allow_clipping_in_normalization:
- if hp.symmetric_mels:
- return (((np.clip(D, -hp.max_abs_value,
- hp.max_abs_value) + hp.max_abs_value) * -hp.min_level_db / (2 * hp.max_abs_value))
- + hp.min_level_db)
- else:
- return ((np.clip(D, 0, hp.max_abs_value) * -hp.min_level_db / hp.max_abs_value) + hp.min_level_db)
-
- if hp.symmetric_mels:
- return (((D + hp.max_abs_value) * -hp.min_level_db / (2 * hp.max_abs_value)) + hp.min_level_db)
- else:
- return ((D * -hp.min_level_db / hp.max_abs_value) + hp.min_level_db)
diff --git a/spaces/datasciencedojo/AmericanSignLanguage-Detection/app.py b/spaces/datasciencedojo/AmericanSignLanguage-Detection/app.py
deleted file mode 100644
index 8520dcef0dbec05641be8b98ce001de3d64a6cf8..0000000000000000000000000000000000000000
--- a/spaces/datasciencedojo/AmericanSignLanguage-Detection/app.py
+++ /dev/null
@@ -1,177 +0,0 @@
-import cv2
-from cvzone.HandTrackingModule import HandDetector
-from cvzone.ClassificationModule import Classifier
-import numpy as np
-import math
-import gradio as gr
-
-detector = HandDetector(mode=True,maxHands=1)
-classifier = Classifier("ModelFull/keras_model.h5", "ModelFull/labels.txt")
-
-offset = 20
-imgSize = 300
-
-folder = "Data/C"
-counter = 0
-
-labels = ["A", "B","C","D","E","F","G","H","I","J","K","L","M","N", "O","P","Q","R","S","T","U","V","W","X","Y","Z"]
-
-def sign(img):
- #img = cv2.imread("sign.jpg")
- imgOutput = cv2.flip(img.copy(),1)
- hands, img = detector.findHands(cv2.flip(img[:,:,::-1],1))
- if hands:
- print('hand detected')
- hand = hands[0]
- x, y, w, h = hand['bbox']
- imlist = hand['lmList']
- print(imlist)
- if ((imlist[10][0] < imlist[4][0] < imlist[6][0]) or (imlist[6][0] < imlist[4][0] < imlist[10][0])):
- if ((imlist[4][1] < imlist[8][1]) and (imlist[4][1] < imlist[12][1]) ):
- print('In T')
- cv2.rectangle(imgOutput, (x-offset, y-offset),(x + w+offset, y + h+offset), (255, 0, 255), 4)
- imgOutput = cv2.flip(imgOutput,1)
- cv2.rectangle(imgOutput, (0,30),(80,80), (255, 0, 255), cv2.FILLED)
- cv2.putText(imgOutput, 'T', (20, 75), cv2.FONT_HERSHEY_COMPLEX, 1.7, (255, 255, 255), 2)
- return imgOutput
- else:
- print('In K')
- cv2.rectangle(imgOutput, (x-offset, y-offset),(x + w+offset, y + h+offset), (255, 0, 255), 4)
- imgOutput = cv2.flip(imgOutput,1)
- cv2.rectangle(imgOutput, (0,30),(80,80), (255, 0, 255), cv2.FILLED)
- cv2.putText(imgOutput, 'K', (20, 75), cv2.FONT_HERSHEY_COMPLEX, 1.7, (255, 255, 255), 2)
- return imgOutput
- '''if imlist[4][0]>imlist[8][0] and imlist[4][0]>imlist[12][0] and imlist[4][0]>imlist[16][0] and imlist[4][0]>imlist[20][0]:
- print('In M')
- cv2.rectangle(imgOutput, (x-offset, y-offset),(x + w+offset, y + h+offset), (255, 0, 255), 4)
- imgOutput = cv2.flip(imgOutput,1)
- cv2.rectangle(imgOutput, (0,30),(80,80), (255, 0, 255), cv2.FILLED)
- cv2.putText(imgOutput, 'M', (20, 75), cv2.FONT_HERSHEY_COMPLEX, 1.7, (255, 255, 255), 2)
- return imgOutput'''
-
- imgWhite = np.ones((imgSize, imgSize, 3), np.uint8) * 255
- imgCrop = img[y - offset:y + h + offset, x - offset:x + w + offset]
-
- imgCropShape = imgCrop.shape
-
- aspectRatio = h / w
-
- if aspectRatio > 1:
- k = imgSize / h
- wCal = math.ceil(k * w)
- imgResize = cv2.resize(imgCrop, (wCal, imgSize))
- imgResizeShape = imgResize.shape
- wGap = math.ceil((imgSize - wCal) / 2)
- imgWhite[:, wGap:wCal + wGap] = imgResize
- prediction, index = classifier.getPrediction(imgWhite, draw=False)
- print(prediction, index)
-
- else:
- k = imgSize / w
- hCal = math.ceil(k * h)
- imgResize = cv2.resize(imgCrop, (imgSize, hCal))
- imgResizeShape = imgResize.shape
- hGap = math.ceil((imgSize - hCal) / 2)
- imgWhite[hGap:hCal + hGap, :] = imgResize
- prediction, index = classifier.getPrediction(imgWhite, draw=False)
-
- cv2.imwrite("check.jpg",imgWhite)
- cv2.rectangle(imgOutput, (x-offset, y-offset),
- (x + w+offset, y + h+offset), (255, 0, 255), 4)
- imgOutput = cv2.flip(imgOutput,1)
- #cv2.rectangle(imgOutput, (x - offset, y - offset-50),
- # (x - offset+90, y - offset-50+50), (255, 0, 255), cv2.FILLED)
- #cv2.putText(imgOutput, labels[index], (x, y -26), cv2.FONT_HERSHEY_COMPLEX, 1.7, (255, 255, 255), 2)
- cv2.rectangle(imgOutput, (0,30),
- (80,80), (255, 0, 255), cv2.FILLED)
- cv2.putText(imgOutput, labels[index], (20, 75), cv2.FONT_HERSHEY_COMPLEX, 1.7, (255, 255, 255), 2)
-
-
- #cv2.imshow("ImageCrop", imgCrop)
- #cv2.imshow("ImageWhite", imgWhite)
-
- #cv2.imshow("Image", imgOutput)
- return imgOutput
-
-def set_example_image(example: list) -> dict:
- return gr.inputs.Image.update(value=example[0])
-
-
-css = """
-.gr-button-lg {
- z-index: 14;
- width: 113px;
- height: 30px;
- left: 0px;
- top: 0px;
- padding: 0px;
- cursor: pointer !important;
- background: none rgb(17, 20, 45) !important;
- border: none !important;
- text-align: center !important;
- font-size: 14px !important;
- font-weight: 500 !important;
- color: rgb(255, 255, 255) !important;
- line-height: 1 !important;
- border-radius: 6px !important;
- transition: box-shadow 200ms ease 0s, background 200ms ease 0s !important;
- box-shadow: none !important;
-}
-.gr-button-lg:hover{
- z-index: 14;
- width: 113px;
- height: 30px;
- left: 0px;
- top: 0px;
- padding: 0px;
- cursor: pointer !important;
- background: none rgb(37, 56, 133) !important;
- border: none !important;
- text-align: center !important;
- font-size: 14px !important;
- font-weight: 500 !important;
- color: rgb(255, 255, 255) !important;
- line-height: 1 !important;
- border-radius: 6px !important;
- transition: box-shadow 200ms ease 0s, background 200ms ease 0s !important;
- box-shadow: rgb(0 0 0 / 23%) 0px 1px 7px 0px !important;
-}
-
-footer {display:none !important}
-.output-markdown{display:none !important}
-#out_image {height: 22rem !important;}
-"""
-
-with gr.Blocks(title="American Sign Language Detection | Data Science Dojo", css=css) as demo:
-
- with gr.Tabs():
- with gr.TabItem('Upload'):
- with gr.Row():
- with gr.Column():
- img_input = gr.Image(shape=(640,480))
- image_button = gr.Button("Submit")
-
- with gr.Column():
- output = gr.Image(shape=(640,480), elem_id="out_image")
- with gr.Row():
- example_images = gr.Dataset(components=[img_input],samples=[["ex2.jpg"]])
-
- with gr.TabItem('Webcam'):
- with gr.Row():
- with gr.Column():
- img_input2 = gr.Webcam()
- image_button2 = gr.Button("Submit")
-
- with gr.Column():
- output2 = gr.outputs.Image()
-
- image_button2.click(fn=sign,
- inputs = img_input2,
- outputs = output2)
- image_button.click(fn=sign,
- inputs = img_input,
- outputs = output)
- example_images.click(fn=set_example_image,inputs=[example_images],outputs=[img_input])
-
-
-demo.launch(debug=True)
\ No newline at end of file
diff --git a/spaces/davidpiscasio/unpaired-img2img/models/template_model.py b/spaces/davidpiscasio/unpaired-img2img/models/template_model.py
deleted file mode 100644
index 68cdaf6a9a2cb321ff2a01949b38adc6fa22e97c..0000000000000000000000000000000000000000
--- a/spaces/davidpiscasio/unpaired-img2img/models/template_model.py
+++ /dev/null
@@ -1,99 +0,0 @@
-"""Model class template
-
-This module provides a template for users to implement custom models.
-You can specify '--model template' to use this model.
-The class name should be consistent with both the filename and its model option.
-The filename should be _dataset.py
-The class name should be Dataset.py
-It implements a simple image-to-image translation baseline based on regression loss.
-Given input-output pairs (data_A, data_B), it learns a network netG that can minimize the following L1 loss:
- min_ ||netG(data_A) - data_B||_1
-You need to implement the following functions:
- : Add model-specific options and rewrite default values for existing options.
- <__init__>: Initialize this model class.
- : Unpack input data and perform data pre-processing.
- : Run forward pass. This will be called by both and .
- : Update network weights; it will be called in every training iteration.
-"""
-import torch
-from .base_model import BaseModel
-from . import networks
-
-
-class TemplateModel(BaseModel):
- @staticmethod
- def modify_commandline_options(parser, is_train=True):
- """Add new model-specific options and rewrite default values for existing options.
-
- Parameters:
- parser -- the option parser
- is_train -- if it is training phase or test phase. You can use this flag to add training-specific or test-specific options.
-
- Returns:
- the modified parser.
- """
- parser.set_defaults(dataset_mode='aligned') # You can rewrite default values for this model. For example, this model usually uses aligned dataset as its dataset.
- if is_train:
- parser.add_argument('--lambda_regression', type=float, default=1.0, help='weight for the regression loss') # You can define new arguments for this model.
-
- return parser
-
- def __init__(self, opt):
- """Initialize this model class.
-
- Parameters:
- opt -- training/test options
-
- A few things can be done here.
- - (required) call the initialization function of BaseModel
- - define loss function, visualization images, model names, and optimizers
- """
- BaseModel.__init__(self, opt) # call the initialization method of BaseModel
- # specify the training losses you want to print out. The program will call base_model.get_current_losses to plot the losses to the console and save them to the disk.
- self.loss_names = ['loss_G']
- # specify the images you want to save and display. The program will call base_model.get_current_visuals to save and display these images.
- self.visual_names = ['data_A', 'data_B', 'output']
- # specify the models you want to save to the disk. The program will call base_model.save_networks and base_model.load_networks to save and load networks.
- # you can use opt.isTrain to specify different behaviors for training and test. For example, some networks will not be used during test, and you don't need to load them.
- self.model_names = ['G']
- # define networks; you can use opt.isTrain to specify different behaviors for training and test.
- self.netG = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, gpu_ids=self.gpu_ids)
- if self.isTrain: # only defined during training time
- # define your loss functions. You can use losses provided by torch.nn such as torch.nn.L1Loss.
- # We also provide a GANLoss class "networks.GANLoss". self.criterionGAN = networks.GANLoss().to(self.device)
- self.criterionLoss = torch.nn.L1Loss()
- # define and initialize optimizers. You can define one optimizer for each network.
- # If two networks are updated at the same time, you can use itertools.chain to group them. See cycle_gan_model.py for an example.
- self.optimizer = torch.optim.Adam(self.netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
- self.optimizers = [self.optimizer]
-
- # Our program will automatically call to define schedulers, load networks, and print networks
-
- def set_input(self, input):
- """Unpack input data from the dataloader and perform necessary pre-processing steps.
-
- Parameters:
- input: a dictionary that contains the data itself and its metadata information.
- """
- AtoB = self.opt.direction == 'AtoB' # use to swap data_A and data_B
- self.data_A = input['A' if AtoB else 'B'].to(self.device) # get image data A
- self.data_B = input['B' if AtoB else 'A'].to(self.device) # get image data B
- self.image_paths = input['A_paths' if AtoB else 'B_paths'] # get image paths
-
- def forward(self):
- """Run forward pass. This will be called by both functions and ."""
- self.output = self.netG(self.data_A) # generate output image given the input data_A
-
- def backward(self):
- """Calculate losses, gradients, and update network weights; called in every training iteration"""
- # caculate the intermediate results if necessary; here self.output has been computed during function
- # calculate loss given the input and intermediate results
- self.loss_G = self.criterionLoss(self.output, self.data_B) * self.opt.lambda_regression
- self.loss_G.backward() # calculate gradients of network G w.r.t. loss_G
-
- def optimize_parameters(self):
- """Update network weights; it will be called in every training iteration."""
- self.forward() # first call forward to calculate intermediate results
- self.optimizer.zero_grad() # clear network G's existing gradients
- self.backward() # calculate gradients for network G
- self.optimizer.step() # update gradients for network G
diff --git a/spaces/davidrd123/WikiArt_20genre/app.py b/spaces/davidrd123/WikiArt_20genre/app.py
deleted file mode 100644
index d0b2d51d6d21548d3ac145fb20bf200f4b4f970f..0000000000000000000000000000000000000000
--- a/spaces/davidrd123/WikiArt_20genre/app.py
+++ /dev/null
@@ -1,26 +0,0 @@
-import gradio as gr
-from fastai.vision.all import *
-import skimage
-
-learn = load_learner('rn50_256px_20genre_8epoch_err313.pkl')
-
-labels = learn.dls.vocab
-def predict(img):
- img = PILImage.create(img)
- pred,pred_idx,probs = learn.predict(img)
- return {labels[i]: float(probs[i]) for i in range(len(labels))}
-
-examples = [f"Image{n:02d}.jpg" for n in range(12)]
-interpretation='shap'
-title = "Art Movement Classifier - WikiArt"
-description = "What Art Movement Matches the Image Best?"
-theme = 'grass'
-
-gr.Interface(fn=predict,
- inputs=gr.inputs.Image(shape=((512,512))),
- outputs=gr.outputs.Label(num_top_classes=5),
- title = title,
- examples = examples,
- theme = theme,
- interpretation = interpretation,
- description = description).launch(share=True, enable_queue=True)
\ No newline at end of file
diff --git a/spaces/dawood/Kanye-AI/cluster/train_cluster.py b/spaces/dawood/Kanye-AI/cluster/train_cluster.py
deleted file mode 100644
index 4ac025d400414226e66849407f477ae786c3d5d3..0000000000000000000000000000000000000000
--- a/spaces/dawood/Kanye-AI/cluster/train_cluster.py
+++ /dev/null
@@ -1,89 +0,0 @@
-import os
-from glob import glob
-from pathlib import Path
-import torch
-import logging
-import argparse
-import torch
-import numpy as np
-from sklearn.cluster import KMeans, MiniBatchKMeans
-import tqdm
-logging.basicConfig(level=logging.INFO)
-logger = logging.getLogger(__name__)
-import time
-import random
-
-def train_cluster(in_dir, n_clusters, use_minibatch=True, verbose=False):
-
- logger.info(f"Loading features from {in_dir}")
- features = []
- nums = 0
- for path in tqdm.tqdm(in_dir.glob("*.soft.pt")):
- features.append(torch.load(path).squeeze(0).numpy().T)
- # print(features[-1].shape)
- features = np.concatenate(features, axis=0)
- print(nums, features.nbytes/ 1024**2, "MB , shape:",features.shape, features.dtype)
- features = features.astype(np.float32)
- logger.info(f"Clustering features of shape: {features.shape}")
- t = time.time()
- if use_minibatch:
- kmeans = MiniBatchKMeans(n_clusters=n_clusters,verbose=verbose, batch_size=4096, max_iter=80).fit(features)
- else:
- kmeans = KMeans(n_clusters=n_clusters,verbose=verbose).fit(features)
- print(time.time()-t, "s")
-
- x = {
- "n_features_in_": kmeans.n_features_in_,
- "_n_threads": kmeans._n_threads,
- "cluster_centers_": kmeans.cluster_centers_,
- }
- print("end")
-
- return x
-
-
-if __name__ == "__main__":
-
- parser = argparse.ArgumentParser()
- parser.add_argument('--dataset', type=Path, default="./dataset/44k",
- help='path of training data directory')
- parser.add_argument('--output', type=Path, default="logs/44k",
- help='path of model output directory')
-
- args = parser.parse_args()
-
- checkpoint_dir = args.output
- dataset = args.dataset
- n_clusters = 10000
-
- ckpt = {}
- for spk in os.listdir(dataset):
- if os.path.isdir(dataset/spk):
- print(f"train kmeans for {spk}...")
- in_dir = dataset/spk
- x = train_cluster(in_dir, n_clusters, verbose=False)
- ckpt[spk] = x
-
- checkpoint_path = checkpoint_dir / f"kmeans_{n_clusters}.pt"
- checkpoint_path.parent.mkdir(exist_ok=True, parents=True)
- torch.save(
- ckpt,
- checkpoint_path,
- )
-
-
- # import cluster
- # for spk in tqdm.tqdm(os.listdir("dataset")):
- # if os.path.isdir(f"dataset/{spk}"):
- # print(f"start kmeans inference for {spk}...")
- # for feature_path in tqdm.tqdm(glob(f"dataset/{spk}/*.discrete.npy", recursive=True)):
- # mel_path = feature_path.replace(".discrete.npy",".mel.npy")
- # mel_spectrogram = np.load(mel_path)
- # feature_len = mel_spectrogram.shape[-1]
- # c = np.load(feature_path)
- # c = utils.tools.repeat_expand_2d(torch.FloatTensor(c), feature_len).numpy()
- # feature = c.T
- # feature_class = cluster.get_cluster_result(feature, spk)
- # np.save(feature_path.replace(".discrete.npy", ".discrete_class.npy"), feature_class)
-
-
diff --git a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/altair/vegalite/v5/schema/core.py b/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/altair/vegalite/v5/schema/core.py
deleted file mode 100644
index ad1e5afd509cb95cd2d50bcbee8b51b5b794ecf3..0000000000000000000000000000000000000000
--- a/spaces/dcarpintero/nlp-summarizer-pegasus/.venv/lib/python3.9/site-packages/altair/vegalite/v5/schema/core.py
+++ /dev/null
@@ -1,21785 +0,0 @@
-# The contents of this file are automatically written by
-# tools/generate_schema_wrapper.py. Do not modify directly.
-
-from altair.utils.schemapi import SchemaBase, Undefined, _subclasses
-
-import pkgutil
-import json
-
-def load_schema():
- """Load the json schema associated with this module's functions"""
- return json.loads(pkgutil.get_data(__name__, 'vega-lite-schema.json').decode('utf-8'))
-
-
-class VegaLiteSchema(SchemaBase):
- _rootschema = load_schema()
- @classmethod
- def _default_wrapper_classes(cls):
- return _subclasses(VegaLiteSchema)
-
-
-class Root(VegaLiteSchema):
- """Root schema wrapper
-
- anyOf(:class:`TopLevelUnitSpec`, :class:`TopLevelFacetSpec`, :class:`TopLevelLayerSpec`,
- :class:`TopLevelRepeatSpec`, :class:`TopLevelConcatSpec`, :class:`TopLevelVConcatSpec`,
- :class:`TopLevelHConcatSpec`)
- A Vega-Lite top-level specification. This is the root class for all Vega-Lite
- specifications. (The json schema is generated from this type.)
- """
- _schema = VegaLiteSchema._rootschema
-
- def __init__(self, *args, **kwds):
- super(Root, self).__init__(*args, **kwds)
-
-
-class Aggregate(VegaLiteSchema):
- """Aggregate schema wrapper
-
- anyOf(:class:`NonArgAggregateOp`, :class:`ArgmaxDef`, :class:`ArgminDef`)
- """
- _schema = {'$ref': '#/definitions/Aggregate'}
-
- def __init__(self, *args, **kwds):
- super(Aggregate, self).__init__(*args, **kwds)
-
-
-class AggregateOp(VegaLiteSchema):
- """AggregateOp schema wrapper
-
- enum('argmax', 'argmin', 'average', 'count', 'distinct', 'max', 'mean', 'median', 'min',
- 'missing', 'product', 'q1', 'q3', 'ci0', 'ci1', 'stderr', 'stdev', 'stdevp', 'sum', 'valid',
- 'values', 'variance', 'variancep')
- """
- _schema = {'$ref': '#/definitions/AggregateOp'}
-
- def __init__(self, *args):
- super(AggregateOp, self).__init__(*args)
-
-
-class AggregatedFieldDef(VegaLiteSchema):
- """AggregatedFieldDef schema wrapper
-
- Mapping(required=[op, as])
-
- Parameters
- ----------
-
- op : :class:`AggregateOp`
- The aggregation operation to apply to the fields (e.g., ``"sum"``, ``"average"``, or
- ``"count"`` ). See the `full list of supported aggregation operations
- `__ for more information.
- field : :class:`FieldName`
- The data field for which to compute aggregate function. This is required for all
- aggregation operations except ``"count"``.
- as : :class:`FieldName`
- The output field names to use for each aggregated field.
- """
- _schema = {'$ref': '#/definitions/AggregatedFieldDef'}
-
- def __init__(self, op=Undefined, field=Undefined, **kwds):
- super(AggregatedFieldDef, self).__init__(op=op, field=field, **kwds)
-
-
-class Align(VegaLiteSchema):
- """Align schema wrapper
-
- enum('left', 'center', 'right')
- """
- _schema = {'$ref': '#/definitions/Align'}
-
- def __init__(self, *args):
- super(Align, self).__init__(*args)
-
-
-class AnyMark(VegaLiteSchema):
- """AnyMark schema wrapper
-
- anyOf(:class:`CompositeMark`, :class:`CompositeMarkDef`, :class:`Mark`, :class:`MarkDef`)
- """
- _schema = {'$ref': '#/definitions/AnyMark'}
-
- def __init__(self, *args, **kwds):
- super(AnyMark, self).__init__(*args, **kwds)
-
-
-class AnyMarkConfig(VegaLiteSchema):
- """AnyMarkConfig schema wrapper
-
- anyOf(:class:`MarkConfig`, :class:`AreaConfig`, :class:`BarConfig`, :class:`RectConfig`,
- :class:`LineConfig`, :class:`TickConfig`)
- """
- _schema = {'$ref': '#/definitions/AnyMarkConfig'}
-
- def __init__(self, *args, **kwds):
- super(AnyMarkConfig, self).__init__(*args, **kwds)
-
-
-class AreaConfig(AnyMarkConfig):
- """AreaConfig schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- align : anyOf(:class:`Align`, :class:`ExprRef`)
- The horizontal alignment of the text or ranged marks (area, bar, image, rect, rule).
- One of ``"left"``, ``"right"``, ``"center"``.
-
- **Note:** Expression reference is *not* supported for range marks.
- angle : anyOf(float, :class:`ExprRef`)
- The rotation angle of the text, in degrees.
- aria : anyOf(boolean, :class:`ExprRef`)
- A boolean flag indicating if `ARIA attributes
- `__ should be
- included (SVG output only). If ``false``, the "aria-hidden" attribute will be set on
- the output SVG element, removing the mark item from the ARIA accessibility tree.
- ariaRole : anyOf(string, :class:`ExprRef`)
- Sets the type of user interface element of the mark item for `ARIA accessibility
- `__ (SVG output
- only). If specified, this property determines the "role" attribute. Warning: this
- property is experimental and may be changed in the future.
- ariaRoleDescription : anyOf(string, :class:`ExprRef`)
- A human-readable, author-localized description for the role of the mark item for
- `ARIA accessibility
- `__ (SVG output
- only). If specified, this property determines the "aria-roledescription" attribute.
- Warning: this property is experimental and may be changed in the future.
- aspect : anyOf(boolean, :class:`ExprRef`)
- Whether to keep aspect ratio of image marks.
- baseline : anyOf(:class:`TextBaseline`, :class:`ExprRef`)
- For text marks, the vertical text baseline. One of ``"alphabetic"`` (default),
- ``"top"``, ``"middle"``, ``"bottom"``, ``"line-top"``, ``"line-bottom"``, or an
- expression reference that provides one of the valid values. The ``"line-top"`` and
- ``"line-bottom"`` values operate similarly to ``"top"`` and ``"bottom"``, but are
- calculated relative to the ``lineHeight`` rather than ``fontSize`` alone.
-
- For range marks, the vertical alignment of the marks. One of ``"top"``,
- ``"middle"``, ``"bottom"``.
-
- **Note:** Expression reference is *not* supported for range marks.
- blend : anyOf(:class:`Blend`, :class:`ExprRef`)
- The color blend mode for drawing an item on its current background. Any valid `CSS
- mix-blend-mode `__
- value can be used.
-
- __Default value:__ ``"source-over"``
- color : anyOf(:class:`Color`, :class:`Gradient`, :class:`ExprRef`)
- Default color.
-
- **Default value:** :raw-html:`■`
- ``"#4682b4"``
-
- **Note:**
-
-
- * This property cannot be used in a `style config
- `__.
- * The ``fill`` and ``stroke`` properties have higher precedence than ``color`` and
- will override ``color``.
- cornerRadius : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles or arcs' corners.
-
- **Default value:** ``0``
- cornerRadiusBottomLeft : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles' bottom left corner.
-
- **Default value:** ``0``
- cornerRadiusBottomRight : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles' bottom right corner.
-
- **Default value:** ``0``
- cornerRadiusTopLeft : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles' top right corner.
-
- **Default value:** ``0``
- cornerRadiusTopRight : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles' top left corner.
-
- **Default value:** ``0``
- cursor : anyOf(:class:`Cursor`, :class:`ExprRef`)
- The mouse cursor used over the mark. Any valid `CSS cursor type
- `__ can be used.
- description : anyOf(string, :class:`ExprRef`)
- A text description of the mark item for `ARIA accessibility
- `__ (SVG output
- only). If specified, this property determines the `"aria-label" attribute
- `__.
- dir : anyOf(:class:`TextDirection`, :class:`ExprRef`)
- The direction of the text. One of ``"ltr"`` (left-to-right) or ``"rtl"``
- (right-to-left). This property determines on which side is truncated in response to
- the limit parameter.
-
- **Default value:** ``"ltr"``
- dx : anyOf(float, :class:`ExprRef`)
- The horizontal offset, in pixels, between the text label and its anchor point. The
- offset is applied after rotation by the *angle* property.
- dy : anyOf(float, :class:`ExprRef`)
- The vertical offset, in pixels, between the text label and its anchor point. The
- offset is applied after rotation by the *angle* property.
- ellipsis : anyOf(string, :class:`ExprRef`)
- The ellipsis string for text truncated in response to the limit parameter.
-
- **Default value:** ``"…"``
- endAngle : anyOf(float, :class:`ExprRef`)
- The end angle in radians for arc marks. A value of ``0`` indicates up (north),
- increasing values proceed clockwise.
- fill : anyOf(:class:`Color`, :class:`Gradient`, None, :class:`ExprRef`)
- Default fill color. This property has higher precedence than ``config.color``. Set
- to ``null`` to remove fill.
-
- **Default value:** (None)
- fillOpacity : anyOf(float, :class:`ExprRef`)
- The fill opacity (value between [0,1]).
-
- **Default value:** ``1``
- filled : boolean
- Whether the mark's color should be used as fill color instead of stroke color.
-
- **Default value:** ``false`` for all ``point``, ``line``, and ``rule`` marks as well
- as ``geoshape`` marks for `graticule
- `__ data sources;
- otherwise, ``true``.
-
- **Note:** This property cannot be used in a `style config
- `__.
- font : anyOf(string, :class:`ExprRef`)
- The typeface to set the text in (e.g., ``"Helvetica Neue"`` ).
- fontSize : anyOf(float, :class:`ExprRef`)
- The font size, in pixels.
-
- **Default value:** ``11``
- fontStyle : anyOf(:class:`FontStyle`, :class:`ExprRef`)
- The font style (e.g., ``"italic"`` ).
- fontWeight : anyOf(:class:`FontWeight`, :class:`ExprRef`)
- The font weight. This can be either a string (e.g ``"bold"``, ``"normal"`` ) or a
- number ( ``100``, ``200``, ``300``, ..., ``900`` where ``"normal"`` = ``400`` and
- ``"bold"`` = ``700`` ).
- height : anyOf(float, :class:`ExprRef`)
- Height of the marks.
- href : anyOf(:class:`URI`, :class:`ExprRef`)
- A URL to load upon mouse click. If defined, the mark acts as a hyperlink.
- innerRadius : anyOf(float, :class:`ExprRef`)
- The inner radius in pixels of arc marks. ``innerRadius`` is an alias for
- ``radius2``.
-
- **Default value:** ``0``
- interpolate : anyOf(:class:`Interpolate`, :class:`ExprRef`)
- The line interpolation method to use for line and area marks. One of the following:
-
-
- * ``"linear"`` : piecewise linear segments, as in a polyline.
- * ``"linear-closed"`` : close the linear segments to form a polygon.
- * ``"step"`` : alternate between horizontal and vertical segments, as in a step
- function.
- * ``"step-before"`` : alternate between vertical and horizontal segments, as in a
- step function.
- * ``"step-after"`` : alternate between horizontal and vertical segments, as in a
- step function.
- * ``"basis"`` : a B-spline, with control point duplication on the ends.
- * ``"basis-open"`` : an open B-spline; may not intersect the start or end.
- * ``"basis-closed"`` : a closed B-spline, as in a loop.
- * ``"cardinal"`` : a Cardinal spline, with control point duplication on the ends.
- * ``"cardinal-open"`` : an open Cardinal spline; may not intersect the start or end,
- but will intersect other control points.
- * ``"cardinal-closed"`` : a closed Cardinal spline, as in a loop.
- * ``"bundle"`` : equivalent to basis, except the tension parameter is used to
- straighten the spline.
- * ``"monotone"`` : cubic interpolation that preserves monotonicity in y.
- invalid : enum('filter', None)
- Defines how Vega-Lite should handle marks for invalid values ( ``null`` and ``NaN``
- ).
-
-
- * If set to ``"filter"`` (default), all data items with null values will be skipped
- (for line, trail, and area marks) or filtered (for other marks).
- * If ``null``, all data items are included. In this case, invalid values will be
- interpreted as zeroes.
- limit : anyOf(float, :class:`ExprRef`)
- The maximum length of the text mark in pixels. The text value will be automatically
- truncated if the rendered size exceeds the limit.
-
- **Default value:** ``0`` -- indicating no limit
- line : anyOf(boolean, :class:`OverlayMarkDef`)
- A flag for overlaying line on top of area marks, or an object defining the
- properties of the overlayed lines.
-
-
- If this value is an empty object ( ``{}`` ) or ``true``, lines with default
- properties will be used.
-
- If this value is ``false``, no lines would be automatically added to area marks.
-
- **Default value:** ``false``.
- lineBreak : anyOf(string, :class:`ExprRef`)
- A delimiter, such as a newline character, upon which to break text strings into
- multiple lines. This property is ignored if the text is array-valued.
- lineHeight : anyOf(float, :class:`ExprRef`)
- The line height in pixels (the spacing between subsequent lines of text) for
- multi-line text marks.
- opacity : anyOf(float, :class:`ExprRef`)
- The overall opacity (value between [0,1]).
-
- **Default value:** ``0.7`` for non-aggregate plots with ``point``, ``tick``,
- ``circle``, or ``square`` marks or layered ``bar`` charts and ``1`` otherwise.
- order : anyOf(None, boolean)
- For line and trail marks, this ``order`` property can be set to ``null`` or
- ``false`` to make the lines use the original order in the data sources.
- orient : :class:`Orientation`
- The orientation of a non-stacked bar, tick, area, and line charts. The value is
- either horizontal (default) or vertical.
-
-
- * For bar, rule and tick, this determines whether the size of the bar and tick
- should be applied to x or y dimension.
- * For area, this property determines the orient property of the Vega output.
- * For line and trail marks, this property determines the sort order of the points in
- the line if ``config.sortLineBy`` is not specified. For stacked charts, this is
- always determined by the orientation of the stack; therefore explicitly specified
- value will be ignored.
- outerRadius : anyOf(float, :class:`ExprRef`)
- The outer radius in pixels of arc marks. ``outerRadius`` is an alias for ``radius``.
-
- **Default value:** ``0``
- padAngle : anyOf(float, :class:`ExprRef`)
- The angular padding applied to sides of the arc, in radians.
- point : anyOf(boolean, :class:`OverlayMarkDef`, string)
- A flag for overlaying points on top of line or area marks, or an object defining the
- properties of the overlayed points.
-
-
- If this property is ``"transparent"``, transparent points will be used (for
- enhancing tooltips and selections).
-
- If this property is an empty object ( ``{}`` ) or ``true``, filled points with
- default properties will be used.
-
- If this property is ``false``, no points would be automatically added to line or
- area marks.
-
- **Default value:** ``false``.
- radius : anyOf(float, :class:`ExprRef`)
- For arc mark, the primary (outer) radius in pixels.
-
- For text marks, polar coordinate radial offset, in pixels, of the text from the
- origin determined by the ``x`` and ``y`` properties.
-
- **Default value:** ``min(plot_width, plot_height)/2``
- radius2 : anyOf(float, :class:`ExprRef`)
- The secondary (inner) radius in pixels of arc marks.
-
- **Default value:** ``0``
- shape : anyOf(anyOf(:class:`SymbolShape`, string), :class:`ExprRef`)
- Shape of the point marks. Supported values include:
-
-
- * plotting shapes: ``"circle"``, ``"square"``, ``"cross"``, ``"diamond"``,
- ``"triangle-up"``, ``"triangle-down"``, ``"triangle-right"``, or
- ``"triangle-left"``.
- * the line symbol ``"stroke"``
- * centered directional shapes ``"arrow"``, ``"wedge"``, or ``"triangle"``
- * a custom `SVG path string
- `__ (For correct
- sizing, custom shape paths should be defined within a square bounding box with
- coordinates ranging from -1 to 1 along both the x and y dimensions.)
-
- **Default value:** ``"circle"``
- size : anyOf(float, :class:`ExprRef`)
- Default size for marks.
-
-
- * For ``point`` / ``circle`` / ``square``, this represents the pixel area of the
- marks. Note that this value sets the area of the symbol; the side lengths will
- increase with the square root of this value.
- * For ``bar``, this represents the band size of the bar, in pixels.
- * For ``text``, this represents the font size, in pixels.
-
- **Default value:**
-
-
- * ``30`` for point, circle, square marks; width/height's ``step``
- * ``2`` for bar marks with discrete dimensions;
- * ``5`` for bar marks with continuous dimensions;
- * ``11`` for text marks.
- smooth : anyOf(boolean, :class:`ExprRef`)
- A boolean flag (default true) indicating if the image should be smoothed when
- resized. If false, individual pixels should be scaled directly rather than
- interpolated with smoothing. For SVG rendering, this option may not work in some
- browsers due to lack of standardization.
- startAngle : anyOf(float, :class:`ExprRef`)
- The start angle in radians for arc marks. A value of ``0`` indicates up (north),
- increasing values proceed clockwise.
- stroke : anyOf(:class:`Color`, :class:`Gradient`, None, :class:`ExprRef`)
- Default stroke color. This property has higher precedence than ``config.color``. Set
- to ``null`` to remove stroke.
-
- **Default value:** (None)
- strokeCap : anyOf(:class:`StrokeCap`, :class:`ExprRef`)
- The stroke cap for line ending style. One of ``"butt"``, ``"round"``, or
- ``"square"``.
-
- **Default value:** ``"butt"``
- strokeDash : anyOf(List(float), :class:`ExprRef`)
- An array of alternating stroke, space lengths for creating dashed or dotted lines.
- strokeDashOffset : anyOf(float, :class:`ExprRef`)
- The offset (in pixels) into which to begin drawing with the stroke dash array.
- strokeJoin : anyOf(:class:`StrokeJoin`, :class:`ExprRef`)
- The stroke line join method. One of ``"miter"``, ``"round"`` or ``"bevel"``.
-
- **Default value:** ``"miter"``
- strokeMiterLimit : anyOf(float, :class:`ExprRef`)
- The miter limit at which to bevel a line join.
- strokeOffset : anyOf(float, :class:`ExprRef`)
- The offset in pixels at which to draw the group stroke and fill. If unspecified, the
- default behavior is to dynamically offset stroked groups such that 1 pixel stroke
- widths align with the pixel grid.
- strokeOpacity : anyOf(float, :class:`ExprRef`)
- The stroke opacity (value between [0,1]).
-
- **Default value:** ``1``
- strokeWidth : anyOf(float, :class:`ExprRef`)
- The stroke width, in pixels.
- tension : anyOf(float, :class:`ExprRef`)
- Depending on the interpolation type, sets the tension parameter (for line and area
- marks).
- text : anyOf(:class:`Text`, :class:`ExprRef`)
- Placeholder text if the ``text`` channel is not specified
- theta : anyOf(float, :class:`ExprRef`)
- For arc marks, the arc length in radians if theta2 is not specified, otherwise the
- start arc angle. (A value of 0 indicates up or “north”, increasing values proceed
- clockwise.)
-
- For text marks, polar coordinate angle in radians.
- theta2 : anyOf(float, :class:`ExprRef`)
- The end angle of arc marks in radians. A value of 0 indicates up or “north”,
- increasing values proceed clockwise.
- timeUnitBandPosition : float
- Default relative band position for a time unit. If set to ``0``, the marks will be
- positioned at the beginning of the time unit band step. If set to ``0.5``, the marks
- will be positioned in the middle of the time unit band step.
- timeUnitBandSize : float
- Default relative band size for a time unit. If set to ``1``, the bandwidth of the
- marks will be equal to the time unit band step. If set to ``0.5``, bandwidth of the
- marks will be half of the time unit band step.
- tooltip : anyOf(float, string, boolean, :class:`TooltipContent`, :class:`ExprRef`, None)
- The tooltip text string to show upon mouse hover or an object defining which fields
- should the tooltip be derived from.
-
-
- * If ``tooltip`` is ``true`` or ``{"content": "encoding"}``, then all fields from
- ``encoding`` will be used.
- * If ``tooltip`` is ``{"content": "data"}``, then all fields that appear in the
- highlighted data point will be used.
- * If set to ``null`` or ``false``, then no tooltip will be used.
-
- See the `tooltip `__
- documentation for a detailed discussion about tooltip in Vega-Lite.
-
- **Default value:** ``null``
- url : anyOf(:class:`URI`, :class:`ExprRef`)
- The URL of the image file for image marks.
- width : anyOf(float, :class:`ExprRef`)
- Width of the marks.
- x : anyOf(float, string, :class:`ExprRef`)
- X coordinates of the marks, or width of horizontal ``"bar"`` and ``"area"`` without
- specified ``x2`` or ``width``.
-
- The ``value`` of this channel can be a number or a string ``"width"`` for the width
- of the plot.
- x2 : anyOf(float, string, :class:`ExprRef`)
- X2 coordinates for ranged ``"area"``, ``"bar"``, ``"rect"``, and ``"rule"``.
-
- The ``value`` of this channel can be a number or a string ``"width"`` for the width
- of the plot.
- y : anyOf(float, string, :class:`ExprRef`)
- Y coordinates of the marks, or height of vertical ``"bar"`` and ``"area"`` without
- specified ``y2`` or ``height``.
-
- The ``value`` of this channel can be a number or a string ``"height"`` for the
- height of the plot.
- y2 : anyOf(float, string, :class:`ExprRef`)
- Y2 coordinates for ranged ``"area"``, ``"bar"``, ``"rect"``, and ``"rule"``.
-
- The ``value`` of this channel can be a number or a string ``"height"`` for the
- height of the plot.
- """
- _schema = {'$ref': '#/definitions/AreaConfig'}
-
- def __init__(self, align=Undefined, angle=Undefined, aria=Undefined, ariaRole=Undefined,
- ariaRoleDescription=Undefined, aspect=Undefined, baseline=Undefined, blend=Undefined,
- color=Undefined, cornerRadius=Undefined, cornerRadiusBottomLeft=Undefined,
- cornerRadiusBottomRight=Undefined, cornerRadiusTopLeft=Undefined,
- cornerRadiusTopRight=Undefined, cursor=Undefined, description=Undefined, dir=Undefined,
- dx=Undefined, dy=Undefined, ellipsis=Undefined, endAngle=Undefined, fill=Undefined,
- fillOpacity=Undefined, filled=Undefined, font=Undefined, fontSize=Undefined,
- fontStyle=Undefined, fontWeight=Undefined, height=Undefined, href=Undefined,
- innerRadius=Undefined, interpolate=Undefined, invalid=Undefined, limit=Undefined,
- line=Undefined, lineBreak=Undefined, lineHeight=Undefined, opacity=Undefined,
- order=Undefined, orient=Undefined, outerRadius=Undefined, padAngle=Undefined,
- point=Undefined, radius=Undefined, radius2=Undefined, shape=Undefined, size=Undefined,
- smooth=Undefined, startAngle=Undefined, stroke=Undefined, strokeCap=Undefined,
- strokeDash=Undefined, strokeDashOffset=Undefined, strokeJoin=Undefined,
- strokeMiterLimit=Undefined, strokeOffset=Undefined, strokeOpacity=Undefined,
- strokeWidth=Undefined, tension=Undefined, text=Undefined, theta=Undefined,
- theta2=Undefined, timeUnitBandPosition=Undefined, timeUnitBandSize=Undefined,
- tooltip=Undefined, url=Undefined, width=Undefined, x=Undefined, x2=Undefined,
- y=Undefined, y2=Undefined, **kwds):
- super(AreaConfig, self).__init__(align=align, angle=angle, aria=aria, ariaRole=ariaRole,
- ariaRoleDescription=ariaRoleDescription, aspect=aspect,
- baseline=baseline, blend=blend, color=color,
- cornerRadius=cornerRadius,
- cornerRadiusBottomLeft=cornerRadiusBottomLeft,
- cornerRadiusBottomRight=cornerRadiusBottomRight,
- cornerRadiusTopLeft=cornerRadiusTopLeft,
- cornerRadiusTopRight=cornerRadiusTopRight, cursor=cursor,
- description=description, dir=dir, dx=dx, dy=dy,
- ellipsis=ellipsis, endAngle=endAngle, fill=fill,
- fillOpacity=fillOpacity, filled=filled, font=font,
- fontSize=fontSize, fontStyle=fontStyle, fontWeight=fontWeight,
- height=height, href=href, innerRadius=innerRadius,
- interpolate=interpolate, invalid=invalid, limit=limit,
- line=line, lineBreak=lineBreak, lineHeight=lineHeight,
- opacity=opacity, order=order, orient=orient,
- outerRadius=outerRadius, padAngle=padAngle, point=point,
- radius=radius, radius2=radius2, shape=shape, size=size,
- smooth=smooth, startAngle=startAngle, stroke=stroke,
- strokeCap=strokeCap, strokeDash=strokeDash,
- strokeDashOffset=strokeDashOffset, strokeJoin=strokeJoin,
- strokeMiterLimit=strokeMiterLimit, strokeOffset=strokeOffset,
- strokeOpacity=strokeOpacity, strokeWidth=strokeWidth,
- tension=tension, text=text, theta=theta, theta2=theta2,
- timeUnitBandPosition=timeUnitBandPosition,
- timeUnitBandSize=timeUnitBandSize, tooltip=tooltip, url=url,
- width=width, x=x, x2=x2, y=y, y2=y2, **kwds)
-
-
-class ArgmaxDef(Aggregate):
- """ArgmaxDef schema wrapper
-
- Mapping(required=[argmax])
-
- Parameters
- ----------
-
- argmax : :class:`FieldName`
-
- """
- _schema = {'$ref': '#/definitions/ArgmaxDef'}
-
- def __init__(self, argmax=Undefined, **kwds):
- super(ArgmaxDef, self).__init__(argmax=argmax, **kwds)
-
-
-class ArgminDef(Aggregate):
- """ArgminDef schema wrapper
-
- Mapping(required=[argmin])
-
- Parameters
- ----------
-
- argmin : :class:`FieldName`
-
- """
- _schema = {'$ref': '#/definitions/ArgminDef'}
-
- def __init__(self, argmin=Undefined, **kwds):
- super(ArgminDef, self).__init__(argmin=argmin, **kwds)
-
-
-class AutoSizeParams(VegaLiteSchema):
- """AutoSizeParams schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- contains : enum('content', 'padding')
- Determines how size calculation should be performed, one of ``"content"`` or
- ``"padding"``. The default setting ( ``"content"`` ) interprets the width and height
- settings as the data rectangle (plotting) dimensions, to which padding is then
- added. In contrast, the ``"padding"`` setting includes the padding within the view
- size calculations, such that the width and height settings indicate the **total**
- intended size of the view.
-
- **Default value** : ``"content"``
- resize : boolean
- A boolean flag indicating if autosize layout should be re-calculated on every view
- update.
-
- **Default value** : ``false``
- type : :class:`AutosizeType`
- The sizing format type. One of ``"pad"``, ``"fit"``, ``"fit-x"``, ``"fit-y"``, or
- ``"none"``. See the `autosize type
- `__ documentation for
- descriptions of each.
-
- **Default value** : ``"pad"``
- """
- _schema = {'$ref': '#/definitions/AutoSizeParams'}
-
- def __init__(self, contains=Undefined, resize=Undefined, type=Undefined, **kwds):
- super(AutoSizeParams, self).__init__(contains=contains, resize=resize, type=type, **kwds)
-
-
-class AutosizeType(VegaLiteSchema):
- """AutosizeType schema wrapper
-
- enum('pad', 'none', 'fit', 'fit-x', 'fit-y')
- """
- _schema = {'$ref': '#/definitions/AutosizeType'}
-
- def __init__(self, *args):
- super(AutosizeType, self).__init__(*args)
-
-
-class Axis(VegaLiteSchema):
- """Axis schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- aria : anyOf(boolean, :class:`ExprRef`)
- A boolean flag indicating if `ARIA attributes
- `__ should be
- included (SVG output only). If ``false``, the "aria-hidden" attribute will be set on
- the output SVG group, removing the axis from the ARIA accessibility tree.
-
- **Default value:** ``true``
- bandPosition : anyOf(float, :class:`ExprRef`)
- An interpolation fraction indicating where, for ``band`` scales, axis ticks should
- be positioned. A value of ``0`` places ticks at the left edge of their bands. A
- value of ``0.5`` places ticks in the middle of their bands.
-
- **Default value:** ``0.5``
- description : anyOf(string, :class:`ExprRef`)
- A text description of this axis for `ARIA accessibility
- `__ (SVG output
- only). If the ``aria`` property is true, for SVG output the `"aria-label" attribute
- `__
- will be set to this description. If the description is unspecified it will be
- automatically generated.
- domain : boolean
- A boolean flag indicating if the domain (the axis baseline) should be included as
- part of the axis.
-
- **Default value:** ``true``
- domainCap : anyOf(:class:`StrokeCap`, :class:`ExprRef`)
- The stroke cap for the domain line's ending style. One of ``"butt"``, ``"round"`` or
- ``"square"``.
-
- **Default value:** ``"butt"``
- domainColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`)
- Color of axis domain line.
-
- **Default value:** ``"gray"``.
- domainDash : anyOf(List(float), :class:`ExprRef`)
- An array of alternating [stroke, space] lengths for dashed domain lines.
- domainDashOffset : anyOf(float, :class:`ExprRef`)
- The pixel offset at which to start drawing with the domain dash array.
- domainOpacity : anyOf(float, :class:`ExprRef`)
- Opacity of the axis domain line.
- domainWidth : anyOf(float, :class:`ExprRef`)
- Stroke width of axis domain line
-
- **Default value:** ``1``
- format : anyOf(string, :class:`Dict`)
- When used with the default ``"number"`` and ``"time"`` format type, the text
- formatting pattern for labels of guides (axes, legends, headers) and text marks.
-
-
- * If the format type is ``"number"`` (e.g., for quantitative fields), this is D3's
- `number format pattern `__.
- * If the format type is ``"time"`` (e.g., for temporal fields), this is D3's `time
- format pattern `__.
-
- See the `format documentation `__
- for more examples.
-
- When used with a `custom formatType
- `__, this
- value will be passed as ``format`` alongside ``datum.value`` to the registered
- function.
-
- **Default value:** Derived from `numberFormat
- `__ config for number
- format and from `timeFormat
- `__ config for time
- format.
- formatType : string
- The format type for labels. One of ``"number"``, ``"time"``, or a `registered custom
- format type
- `__.
-
- **Default value:**
-
-
- * ``"time"`` for temporal fields and ordinal and nominal fields with ``timeUnit``.
- * ``"number"`` for quantitative fields as well as ordinal and nominal fields without
- ``timeUnit``.
- grid : boolean
- A boolean flag indicating if grid lines should be included as part of the axis
-
- **Default value:** ``true`` for `continuous scales
- `__ that are not
- binned; otherwise, ``false``.
- gridCap : anyOf(:class:`StrokeCap`, :class:`ExprRef`)
- The stroke cap for grid lines' ending style. One of ``"butt"``, ``"round"`` or
- ``"square"``.
-
- **Default value:** ``"butt"``
- gridColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`, :class:`ConditionalAxisColor`)
- Color of gridlines.
-
- **Default value:** ``"lightGray"``.
- gridDash : anyOf(List(float), :class:`ExprRef`, :class:`ConditionalAxisNumberArray`)
- An array of alternating [stroke, space] lengths for dashed grid lines.
- gridDashOffset : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The pixel offset at which to start drawing with the grid dash array.
- gridOpacity : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The stroke opacity of grid (value between [0,1])
-
- **Default value:** ``1``
- gridWidth : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The grid width, in pixels.
-
- **Default value:** ``1``
- labelAlign : anyOf(:class:`Align`, :class:`ExprRef`, :class:`ConditionalAxisLabelAlign`)
- Horizontal text alignment of axis tick labels, overriding the default setting for
- the current axis orientation.
- labelAngle : anyOf(float, :class:`ExprRef`)
- The rotation angle of the axis labels.
-
- **Default value:** ``-90`` for nominal and ordinal fields; ``0`` otherwise.
- labelBaseline : anyOf(:class:`TextBaseline`, :class:`ExprRef`, :class:`ConditionalAxisLabelBaseline`)
- Vertical text baseline of axis tick labels, overriding the default setting for the
- current axis orientation. One of ``"alphabetic"`` (default), ``"top"``,
- ``"middle"``, ``"bottom"``, ``"line-top"``, or ``"line-bottom"``. The ``"line-top"``
- and ``"line-bottom"`` values operate similarly to ``"top"`` and ``"bottom"``, but
- are calculated relative to the *lineHeight* rather than *fontSize* alone.
- labelBound : anyOf(anyOf(float, boolean), :class:`ExprRef`)
- Indicates if labels should be hidden if they exceed the axis range. If ``false``
- (the default) no bounds overlap analysis is performed. If ``true``, labels will be
- hidden if they exceed the axis range by more than 1 pixel. If this property is a
- number, it specifies the pixel tolerance: the maximum amount by which a label
- bounding box may exceed the axis range.
-
- **Default value:** ``false``.
- labelColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`, :class:`ConditionalAxisColor`)
- The color of the tick label, can be in hex color code or regular color name.
- labelExpr : string
- `Vega expression `__ for customizing
- labels.
-
- **Note:** The label text and value can be assessed via the ``label`` and ``value``
- properties of the axis's backing ``datum`` object.
- labelFlush : anyOf(boolean, float)
- Indicates if the first and last axis labels should be aligned flush with the scale
- range. Flush alignment for a horizontal axis will left-align the first label and
- right-align the last label. For vertical axes, bottom and top text baselines are
- applied instead. If this property is a number, it also indicates the number of
- pixels by which to offset the first and last labels; for example, a value of 2 will
- flush-align the first and last labels and also push them 2 pixels outward from the
- center of the axis. The additional adjustment can sometimes help the labels better
- visually group with corresponding axis ticks.
-
- **Default value:** ``true`` for axis of a continuous x-scale. Otherwise, ``false``.
- labelFlushOffset : anyOf(float, :class:`ExprRef`)
- Indicates the number of pixels by which to offset flush-adjusted labels. For
- example, a value of ``2`` will push flush-adjusted labels 2 pixels outward from the
- center of the axis. Offsets can help the labels better visually group with
- corresponding axis ticks.
-
- **Default value:** ``0``.
- labelFont : anyOf(string, :class:`ExprRef`, :class:`ConditionalAxisString`)
- The font of the tick label.
- labelFontSize : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The font size of the label, in pixels.
- labelFontStyle : anyOf(:class:`FontStyle`, :class:`ExprRef`, :class:`ConditionalAxisLabelFontStyle`)
- Font style of the title.
- labelFontWeight : anyOf(:class:`FontWeight`, :class:`ExprRef`, :class:`ConditionalAxisLabelFontWeight`)
- Font weight of axis tick labels.
- labelLimit : anyOf(float, :class:`ExprRef`)
- Maximum allowed pixel width of axis tick labels.
-
- **Default value:** ``180``
- labelLineHeight : anyOf(float, :class:`ExprRef`)
- Line height in pixels for multi-line label text or label text with ``"line-top"`` or
- ``"line-bottom"`` baseline.
- labelOffset : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- Position offset in pixels to apply to labels, in addition to tickOffset.
-
- **Default value:** ``0``
- labelOpacity : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The opacity of the labels.
- labelOverlap : anyOf(:class:`LabelOverlap`, :class:`ExprRef`)
- The strategy to use for resolving overlap of axis labels. If ``false`` (the
- default), no overlap reduction is attempted. If set to ``true`` or ``"parity"``, a
- strategy of removing every other label is used (this works well for standard linear
- axes). If set to ``"greedy"``, a linear scan of the labels is performed, removing
- any labels that overlaps with the last visible label (this often works better for
- log-scaled axes).
-
- **Default value:** ``true`` for non-nominal fields with non-log scales; ``"greedy"``
- for log scales; otherwise ``false``.
- labelPadding : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The padding in pixels between labels and ticks.
-
- **Default value:** ``2``
- labelSeparation : anyOf(float, :class:`ExprRef`)
- The minimum separation that must be between label bounding boxes for them to be
- considered non-overlapping (default ``0`` ). This property is ignored if
- *labelOverlap* resolution is not enabled.
- labels : boolean
- A boolean flag indicating if labels should be included as part of the axis.
-
- **Default value:** ``true``.
- maxExtent : anyOf(float, :class:`ExprRef`)
- The maximum extent in pixels that axis ticks and labels should use. This determines
- a maximum offset value for axis titles.
-
- **Default value:** ``undefined``.
- minExtent : anyOf(float, :class:`ExprRef`)
- The minimum extent in pixels that axis ticks and labels should use. This determines
- a minimum offset value for axis titles.
-
- **Default value:** ``30`` for y-axis; ``undefined`` for x-axis.
- offset : anyOf(float, :class:`ExprRef`)
- The offset, in pixels, by which to displace the axis from the edge of the enclosing
- group or data rectangle.
-
- **Default value:** derived from the `axis config
- `__ 's
- ``offset`` ( ``0`` by default)
- orient : anyOf(:class:`AxisOrient`, :class:`ExprRef`)
- The orientation of the axis. One of ``"top"``, ``"bottom"``, ``"left"`` or
- ``"right"``. The orientation can be used to further specialize the axis type (e.g.,
- a y-axis oriented towards the right edge of the chart).
-
- **Default value:** ``"bottom"`` for x-axes and ``"left"`` for y-axes.
- position : anyOf(float, :class:`ExprRef`)
- The anchor position of the axis in pixels. For x-axes with top or bottom
- orientation, this sets the axis group x coordinate. For y-axes with left or right
- orientation, this sets the axis group y coordinate.
-
- **Default value** : ``0``
- style : anyOf(string, List(string))
- A string or array of strings indicating the name of custom styles to apply to the
- axis. A style is a named collection of axis property defined within the `style
- configuration `__. If
- style is an array, later styles will override earlier styles.
-
- **Default value:** (none) **Note:** Any specified style will augment the default
- style. For example, an x-axis mark with ``"style": "foo"`` will use ``config.axisX``
- and ``config.style.foo`` (the specified style ``"foo"`` has higher precedence).
- tickBand : anyOf(enum('center', 'extent'), :class:`ExprRef`)
- For band scales, indicates if ticks and grid lines should be placed at the
- ``"center"`` of a band (default) or at the band ``"extent"`` s to indicate intervals
- tickCap : anyOf(:class:`StrokeCap`, :class:`ExprRef`)
- The stroke cap for the tick lines' ending style. One of ``"butt"``, ``"round"`` or
- ``"square"``.
-
- **Default value:** ``"butt"``
- tickColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`, :class:`ConditionalAxisColor`)
- The color of the axis's tick.
-
- **Default value:** ``"gray"``
- tickCount : anyOf(float, :class:`TimeInterval`, :class:`TimeIntervalStep`, :class:`ExprRef`)
- A desired number of ticks, for axes visualizing quantitative scales. The resulting
- number may be different so that values are "nice" (multiples of 2, 5, 10) and lie
- within the underlying scale's range.
-
- For scales of type ``"time"`` or ``"utc"``, the tick count can instead be a time
- interval specifier. Legal string values are ``"millisecond"``, ``"second"``,
- ``"minute"``, ``"hour"``, ``"day"``, ``"week"``, ``"month"``, and ``"year"``.
- Alternatively, an object-valued interval specifier of the form ``{"interval":
- "month", "step": 3}`` includes a desired number of interval steps. Here, ticks are
- generated for each quarter (Jan, Apr, Jul, Oct) boundary.
-
- **Default value** : Determine using a formula ``ceil(width/40)`` for x and
- ``ceil(height/40)`` for y.
- tickDash : anyOf(List(float), :class:`ExprRef`, :class:`ConditionalAxisNumberArray`)
- An array of alternating [stroke, space] lengths for dashed tick mark lines.
- tickDashOffset : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The pixel offset at which to start drawing with the tick mark dash array.
- tickExtra : boolean
- Boolean flag indicating if an extra axis tick should be added for the initial
- position of the axis. This flag is useful for styling axes for ``band`` scales such
- that ticks are placed on band boundaries rather in the middle of a band. Use in
- conjunction with ``"bandPosition": 1`` and an axis ``"padding"`` value of ``0``.
- tickMinStep : anyOf(float, :class:`ExprRef`)
- The minimum desired step between axis ticks, in terms of scale domain values. For
- example, a value of ``1`` indicates that ticks should not be less than 1 unit apart.
- If ``tickMinStep`` is specified, the ``tickCount`` value will be adjusted, if
- necessary, to enforce the minimum step value.
- tickOffset : anyOf(float, :class:`ExprRef`)
- Position offset in pixels to apply to ticks, labels, and gridlines.
- tickOpacity : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- Opacity of the ticks.
- tickRound : boolean
- Boolean flag indicating if pixel position values should be rounded to the nearest
- integer.
-
- **Default value:** ``true``
- tickSize : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The size in pixels of axis ticks.
-
- **Default value:** ``5``
- tickWidth : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The width, in pixels, of ticks.
-
- **Default value:** ``1``
- ticks : boolean
- Boolean value that determines whether the axis should include ticks.
-
- **Default value:** ``true``
- title : anyOf(:class:`Text`, None)
- A title for the field. If ``null``, the title will be removed.
-
- **Default value:** derived from the field's name and transformation function (
- ``aggregate``, ``bin`` and ``timeUnit`` ). If the field has an aggregate function,
- the function is displayed as part of the title (e.g., ``"Sum of Profit"`` ). If the
- field is binned or has a time unit applied, the applied function is shown in
- parentheses (e.g., ``"Profit (binned)"``, ``"Transaction Date (year-month)"`` ).
- Otherwise, the title is simply the field name.
-
- **Notes** :
-
- 1) You can customize the default field title format by providing the `fieldTitle
- `__ property in
- the `config `__ or `fieldTitle
- function via the compile function's options
- `__.
-
- 2) If both field definition's ``title`` and axis, header, or legend ``title`` are
- defined, axis/header/legend title will be used.
- titleAlign : anyOf(:class:`Align`, :class:`ExprRef`)
- Horizontal text alignment of axis titles.
- titleAnchor : anyOf(:class:`TitleAnchor`, :class:`ExprRef`)
- Text anchor position for placing axis titles.
- titleAngle : anyOf(float, :class:`ExprRef`)
- Angle in degrees of axis titles.
- titleBaseline : anyOf(:class:`TextBaseline`, :class:`ExprRef`)
- Vertical text baseline for axis titles. One of ``"alphabetic"`` (default),
- ``"top"``, ``"middle"``, ``"bottom"``, ``"line-top"``, or ``"line-bottom"``. The
- ``"line-top"`` and ``"line-bottom"`` values operate similarly to ``"top"`` and
- ``"bottom"``, but are calculated relative to the *lineHeight* rather than *fontSize*
- alone.
- titleColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`)
- Color of the title, can be in hex color code or regular color name.
- titleFont : anyOf(string, :class:`ExprRef`)
- Font of the title. (e.g., ``"Helvetica Neue"`` ).
- titleFontSize : anyOf(float, :class:`ExprRef`)
- Font size of the title.
- titleFontStyle : anyOf(:class:`FontStyle`, :class:`ExprRef`)
- Font style of the title.
- titleFontWeight : anyOf(:class:`FontWeight`, :class:`ExprRef`)
- Font weight of the title. This can be either a string (e.g ``"bold"``, ``"normal"``
- ) or a number ( ``100``, ``200``, ``300``, ..., ``900`` where ``"normal"`` = ``400``
- and ``"bold"`` = ``700`` ).
- titleLimit : anyOf(float, :class:`ExprRef`)
- Maximum allowed pixel width of axis titles.
- titleLineHeight : anyOf(float, :class:`ExprRef`)
- Line height in pixels for multi-line title text or title text with ``"line-top"`` or
- ``"line-bottom"`` baseline.
- titleOpacity : anyOf(float, :class:`ExprRef`)
- Opacity of the axis title.
- titlePadding : anyOf(float, :class:`ExprRef`)
- The padding, in pixels, between title and axis.
- titleX : anyOf(float, :class:`ExprRef`)
- X-coordinate of the axis title relative to the axis group.
- titleY : anyOf(float, :class:`ExprRef`)
- Y-coordinate of the axis title relative to the axis group.
- translate : anyOf(float, :class:`ExprRef`)
- Coordinate space translation offset for axis layout. By default, axes are translated
- by a 0.5 pixel offset for both the x and y coordinates in order to align stroked
- lines with the pixel grid. However, for vector graphics output these pixel-specific
- adjustments may be undesirable, in which case translate can be changed (for example,
- to zero).
-
- **Default value:** ``0.5``
- values : anyOf(List(float), List(string), List(boolean), List(:class:`DateTime`), :class:`ExprRef`)
- Explicitly set the visible axis tick values.
- zindex : float
- A non-negative integer indicating the z-index of the axis. If zindex is 0, axes
- should be drawn behind all chart elements. To put them in front, set ``zindex`` to
- ``1`` or more.
-
- **Default value:** ``0`` (behind the marks).
- """
- _schema = {'$ref': '#/definitions/Axis'}
-
- def __init__(self, aria=Undefined, bandPosition=Undefined, description=Undefined, domain=Undefined,
- domainCap=Undefined, domainColor=Undefined, domainDash=Undefined,
- domainDashOffset=Undefined, domainOpacity=Undefined, domainWidth=Undefined,
- format=Undefined, formatType=Undefined, grid=Undefined, gridCap=Undefined,
- gridColor=Undefined, gridDash=Undefined, gridDashOffset=Undefined,
- gridOpacity=Undefined, gridWidth=Undefined, labelAlign=Undefined, labelAngle=Undefined,
- labelBaseline=Undefined, labelBound=Undefined, labelColor=Undefined,
- labelExpr=Undefined, labelFlush=Undefined, labelFlushOffset=Undefined,
- labelFont=Undefined, labelFontSize=Undefined, labelFontStyle=Undefined,
- labelFontWeight=Undefined, labelLimit=Undefined, labelLineHeight=Undefined,
- labelOffset=Undefined, labelOpacity=Undefined, labelOverlap=Undefined,
- labelPadding=Undefined, labelSeparation=Undefined, labels=Undefined,
- maxExtent=Undefined, minExtent=Undefined, offset=Undefined, orient=Undefined,
- position=Undefined, style=Undefined, tickBand=Undefined, tickCap=Undefined,
- tickColor=Undefined, tickCount=Undefined, tickDash=Undefined, tickDashOffset=Undefined,
- tickExtra=Undefined, tickMinStep=Undefined, tickOffset=Undefined,
- tickOpacity=Undefined, tickRound=Undefined, tickSize=Undefined, tickWidth=Undefined,
- ticks=Undefined, title=Undefined, titleAlign=Undefined, titleAnchor=Undefined,
- titleAngle=Undefined, titleBaseline=Undefined, titleColor=Undefined,
- titleFont=Undefined, titleFontSize=Undefined, titleFontStyle=Undefined,
- titleFontWeight=Undefined, titleLimit=Undefined, titleLineHeight=Undefined,
- titleOpacity=Undefined, titlePadding=Undefined, titleX=Undefined, titleY=Undefined,
- translate=Undefined, values=Undefined, zindex=Undefined, **kwds):
- super(Axis, self).__init__(aria=aria, bandPosition=bandPosition, description=description,
- domain=domain, domainCap=domainCap, domainColor=domainColor,
- domainDash=domainDash, domainDashOffset=domainDashOffset,
- domainOpacity=domainOpacity, domainWidth=domainWidth, format=format,
- formatType=formatType, grid=grid, gridCap=gridCap,
- gridColor=gridColor, gridDash=gridDash,
- gridDashOffset=gridDashOffset, gridOpacity=gridOpacity,
- gridWidth=gridWidth, labelAlign=labelAlign, labelAngle=labelAngle,
- labelBaseline=labelBaseline, labelBound=labelBound,
- labelColor=labelColor, labelExpr=labelExpr, labelFlush=labelFlush,
- labelFlushOffset=labelFlushOffset, labelFont=labelFont,
- labelFontSize=labelFontSize, labelFontStyle=labelFontStyle,
- labelFontWeight=labelFontWeight, labelLimit=labelLimit,
- labelLineHeight=labelLineHeight, labelOffset=labelOffset,
- labelOpacity=labelOpacity, labelOverlap=labelOverlap,
- labelPadding=labelPadding, labelSeparation=labelSeparation,
- labels=labels, maxExtent=maxExtent, minExtent=minExtent,
- offset=offset, orient=orient, position=position, style=style,
- tickBand=tickBand, tickCap=tickCap, tickColor=tickColor,
- tickCount=tickCount, tickDash=tickDash,
- tickDashOffset=tickDashOffset, tickExtra=tickExtra,
- tickMinStep=tickMinStep, tickOffset=tickOffset,
- tickOpacity=tickOpacity, tickRound=tickRound, tickSize=tickSize,
- tickWidth=tickWidth, ticks=ticks, title=title, titleAlign=titleAlign,
- titleAnchor=titleAnchor, titleAngle=titleAngle,
- titleBaseline=titleBaseline, titleColor=titleColor,
- titleFont=titleFont, titleFontSize=titleFontSize,
- titleFontStyle=titleFontStyle, titleFontWeight=titleFontWeight,
- titleLimit=titleLimit, titleLineHeight=titleLineHeight,
- titleOpacity=titleOpacity, titlePadding=titlePadding, titleX=titleX,
- titleY=titleY, translate=translate, values=values, zindex=zindex,
- **kwds)
-
-
-class AxisConfig(VegaLiteSchema):
- """AxisConfig schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- aria : anyOf(boolean, :class:`ExprRef`)
- A boolean flag indicating if `ARIA attributes
- `__ should be
- included (SVG output only). If ``false``, the "aria-hidden" attribute will be set on
- the output SVG group, removing the axis from the ARIA accessibility tree.
-
- **Default value:** ``true``
- bandPosition : anyOf(float, :class:`ExprRef`)
- An interpolation fraction indicating where, for ``band`` scales, axis ticks should
- be positioned. A value of ``0`` places ticks at the left edge of their bands. A
- value of ``0.5`` places ticks in the middle of their bands.
-
- **Default value:** ``0.5``
- description : anyOf(string, :class:`ExprRef`)
- A text description of this axis for `ARIA accessibility
- `__ (SVG output
- only). If the ``aria`` property is true, for SVG output the `"aria-label" attribute
- `__
- will be set to this description. If the description is unspecified it will be
- automatically generated.
- disable : boolean
- Disable axis by default.
- domain : boolean
- A boolean flag indicating if the domain (the axis baseline) should be included as
- part of the axis.
-
- **Default value:** ``true``
- domainCap : anyOf(:class:`StrokeCap`, :class:`ExprRef`)
- The stroke cap for the domain line's ending style. One of ``"butt"``, ``"round"`` or
- ``"square"``.
-
- **Default value:** ``"butt"``
- domainColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`)
- Color of axis domain line.
-
- **Default value:** ``"gray"``.
- domainDash : anyOf(List(float), :class:`ExprRef`)
- An array of alternating [stroke, space] lengths for dashed domain lines.
- domainDashOffset : anyOf(float, :class:`ExprRef`)
- The pixel offset at which to start drawing with the domain dash array.
- domainOpacity : anyOf(float, :class:`ExprRef`)
- Opacity of the axis domain line.
- domainWidth : anyOf(float, :class:`ExprRef`)
- Stroke width of axis domain line
-
- **Default value:** ``1``
- format : anyOf(string, :class:`Dict`)
- When used with the default ``"number"`` and ``"time"`` format type, the text
- formatting pattern for labels of guides (axes, legends, headers) and text marks.
-
-
- * If the format type is ``"number"`` (e.g., for quantitative fields), this is D3's
- `number format pattern `__.
- * If the format type is ``"time"`` (e.g., for temporal fields), this is D3's `time
- format pattern `__.
-
- See the `format documentation `__
- for more examples.
-
- When used with a `custom formatType
- `__, this
- value will be passed as ``format`` alongside ``datum.value`` to the registered
- function.
-
- **Default value:** Derived from `numberFormat
- `__ config for number
- format and from `timeFormat
- `__ config for time
- format.
- formatType : string
- The format type for labels. One of ``"number"``, ``"time"``, or a `registered custom
- format type
- `__.
-
- **Default value:**
-
-
- * ``"time"`` for temporal fields and ordinal and nominal fields with ``timeUnit``.
- * ``"number"`` for quantitative fields as well as ordinal and nominal fields without
- ``timeUnit``.
- grid : boolean
- A boolean flag indicating if grid lines should be included as part of the axis
-
- **Default value:** ``true`` for `continuous scales
- `__ that are not
- binned; otherwise, ``false``.
- gridCap : anyOf(:class:`StrokeCap`, :class:`ExprRef`)
- The stroke cap for grid lines' ending style. One of ``"butt"``, ``"round"`` or
- ``"square"``.
-
- **Default value:** ``"butt"``
- gridColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`, :class:`ConditionalAxisColor`)
- Color of gridlines.
-
- **Default value:** ``"lightGray"``.
- gridDash : anyOf(List(float), :class:`ExprRef`, :class:`ConditionalAxisNumberArray`)
- An array of alternating [stroke, space] lengths for dashed grid lines.
- gridDashOffset : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The pixel offset at which to start drawing with the grid dash array.
- gridOpacity : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The stroke opacity of grid (value between [0,1])
-
- **Default value:** ``1``
- gridWidth : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The grid width, in pixels.
-
- **Default value:** ``1``
- labelAlign : anyOf(:class:`Align`, :class:`ExprRef`, :class:`ConditionalAxisLabelAlign`)
- Horizontal text alignment of axis tick labels, overriding the default setting for
- the current axis orientation.
- labelAngle : anyOf(float, :class:`ExprRef`)
- The rotation angle of the axis labels.
-
- **Default value:** ``-90`` for nominal and ordinal fields; ``0`` otherwise.
- labelBaseline : anyOf(:class:`TextBaseline`, :class:`ExprRef`, :class:`ConditionalAxisLabelBaseline`)
- Vertical text baseline of axis tick labels, overriding the default setting for the
- current axis orientation. One of ``"alphabetic"`` (default), ``"top"``,
- ``"middle"``, ``"bottom"``, ``"line-top"``, or ``"line-bottom"``. The ``"line-top"``
- and ``"line-bottom"`` values operate similarly to ``"top"`` and ``"bottom"``, but
- are calculated relative to the *lineHeight* rather than *fontSize* alone.
- labelBound : anyOf(anyOf(float, boolean), :class:`ExprRef`)
- Indicates if labels should be hidden if they exceed the axis range. If ``false``
- (the default) no bounds overlap analysis is performed. If ``true``, labels will be
- hidden if they exceed the axis range by more than 1 pixel. If this property is a
- number, it specifies the pixel tolerance: the maximum amount by which a label
- bounding box may exceed the axis range.
-
- **Default value:** ``false``.
- labelColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`, :class:`ConditionalAxisColor`)
- The color of the tick label, can be in hex color code or regular color name.
- labelExpr : string
- `Vega expression `__ for customizing
- labels.
-
- **Note:** The label text and value can be assessed via the ``label`` and ``value``
- properties of the axis's backing ``datum`` object.
- labelFlush : anyOf(boolean, float)
- Indicates if the first and last axis labels should be aligned flush with the scale
- range. Flush alignment for a horizontal axis will left-align the first label and
- right-align the last label. For vertical axes, bottom and top text baselines are
- applied instead. If this property is a number, it also indicates the number of
- pixels by which to offset the first and last labels; for example, a value of 2 will
- flush-align the first and last labels and also push them 2 pixels outward from the
- center of the axis. The additional adjustment can sometimes help the labels better
- visually group with corresponding axis ticks.
-
- **Default value:** ``true`` for axis of a continuous x-scale. Otherwise, ``false``.
- labelFlushOffset : anyOf(float, :class:`ExprRef`)
- Indicates the number of pixels by which to offset flush-adjusted labels. For
- example, a value of ``2`` will push flush-adjusted labels 2 pixels outward from the
- center of the axis. Offsets can help the labels better visually group with
- corresponding axis ticks.
-
- **Default value:** ``0``.
- labelFont : anyOf(string, :class:`ExprRef`, :class:`ConditionalAxisString`)
- The font of the tick label.
- labelFontSize : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The font size of the label, in pixels.
- labelFontStyle : anyOf(:class:`FontStyle`, :class:`ExprRef`, :class:`ConditionalAxisLabelFontStyle`)
- Font style of the title.
- labelFontWeight : anyOf(:class:`FontWeight`, :class:`ExprRef`, :class:`ConditionalAxisLabelFontWeight`)
- Font weight of axis tick labels.
- labelLimit : anyOf(float, :class:`ExprRef`)
- Maximum allowed pixel width of axis tick labels.
-
- **Default value:** ``180``
- labelLineHeight : anyOf(float, :class:`ExprRef`)
- Line height in pixels for multi-line label text or label text with ``"line-top"`` or
- ``"line-bottom"`` baseline.
- labelOffset : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- Position offset in pixels to apply to labels, in addition to tickOffset.
-
- **Default value:** ``0``
- labelOpacity : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The opacity of the labels.
- labelOverlap : anyOf(:class:`LabelOverlap`, :class:`ExprRef`)
- The strategy to use for resolving overlap of axis labels. If ``false`` (the
- default), no overlap reduction is attempted. If set to ``true`` or ``"parity"``, a
- strategy of removing every other label is used (this works well for standard linear
- axes). If set to ``"greedy"``, a linear scan of the labels is performed, removing
- any labels that overlaps with the last visible label (this often works better for
- log-scaled axes).
-
- **Default value:** ``true`` for non-nominal fields with non-log scales; ``"greedy"``
- for log scales; otherwise ``false``.
- labelPadding : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The padding in pixels between labels and ticks.
-
- **Default value:** ``2``
- labelSeparation : anyOf(float, :class:`ExprRef`)
- The minimum separation that must be between label bounding boxes for them to be
- considered non-overlapping (default ``0`` ). This property is ignored if
- *labelOverlap* resolution is not enabled.
- labels : boolean
- A boolean flag indicating if labels should be included as part of the axis.
-
- **Default value:** ``true``.
- maxExtent : anyOf(float, :class:`ExprRef`)
- The maximum extent in pixels that axis ticks and labels should use. This determines
- a maximum offset value for axis titles.
-
- **Default value:** ``undefined``.
- minExtent : anyOf(float, :class:`ExprRef`)
- The minimum extent in pixels that axis ticks and labels should use. This determines
- a minimum offset value for axis titles.
-
- **Default value:** ``30`` for y-axis; ``undefined`` for x-axis.
- offset : anyOf(float, :class:`ExprRef`)
- The offset, in pixels, by which to displace the axis from the edge of the enclosing
- group or data rectangle.
-
- **Default value:** derived from the `axis config
- `__ 's
- ``offset`` ( ``0`` by default)
- orient : anyOf(:class:`AxisOrient`, :class:`ExprRef`)
- The orientation of the axis. One of ``"top"``, ``"bottom"``, ``"left"`` or
- ``"right"``. The orientation can be used to further specialize the axis type (e.g.,
- a y-axis oriented towards the right edge of the chart).
-
- **Default value:** ``"bottom"`` for x-axes and ``"left"`` for y-axes.
- position : anyOf(float, :class:`ExprRef`)
- The anchor position of the axis in pixels. For x-axes with top or bottom
- orientation, this sets the axis group x coordinate. For y-axes with left or right
- orientation, this sets the axis group y coordinate.
-
- **Default value** : ``0``
- style : anyOf(string, List(string))
- A string or array of strings indicating the name of custom styles to apply to the
- axis. A style is a named collection of axis property defined within the `style
- configuration `__. If
- style is an array, later styles will override earlier styles.
-
- **Default value:** (none) **Note:** Any specified style will augment the default
- style. For example, an x-axis mark with ``"style": "foo"`` will use ``config.axisX``
- and ``config.style.foo`` (the specified style ``"foo"`` has higher precedence).
- tickBand : anyOf(enum('center', 'extent'), :class:`ExprRef`)
- For band scales, indicates if ticks and grid lines should be placed at the
- ``"center"`` of a band (default) or at the band ``"extent"`` s to indicate intervals
- tickCap : anyOf(:class:`StrokeCap`, :class:`ExprRef`)
- The stroke cap for the tick lines' ending style. One of ``"butt"``, ``"round"`` or
- ``"square"``.
-
- **Default value:** ``"butt"``
- tickColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`, :class:`ConditionalAxisColor`)
- The color of the axis's tick.
-
- **Default value:** ``"gray"``
- tickCount : anyOf(float, :class:`TimeInterval`, :class:`TimeIntervalStep`, :class:`ExprRef`)
- A desired number of ticks, for axes visualizing quantitative scales. The resulting
- number may be different so that values are "nice" (multiples of 2, 5, 10) and lie
- within the underlying scale's range.
-
- For scales of type ``"time"`` or ``"utc"``, the tick count can instead be a time
- interval specifier. Legal string values are ``"millisecond"``, ``"second"``,
- ``"minute"``, ``"hour"``, ``"day"``, ``"week"``, ``"month"``, and ``"year"``.
- Alternatively, an object-valued interval specifier of the form ``{"interval":
- "month", "step": 3}`` includes a desired number of interval steps. Here, ticks are
- generated for each quarter (Jan, Apr, Jul, Oct) boundary.
-
- **Default value** : Determine using a formula ``ceil(width/40)`` for x and
- ``ceil(height/40)`` for y.
- tickDash : anyOf(List(float), :class:`ExprRef`, :class:`ConditionalAxisNumberArray`)
- An array of alternating [stroke, space] lengths for dashed tick mark lines.
- tickDashOffset : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The pixel offset at which to start drawing with the tick mark dash array.
- tickExtra : boolean
- Boolean flag indicating if an extra axis tick should be added for the initial
- position of the axis. This flag is useful for styling axes for ``band`` scales such
- that ticks are placed on band boundaries rather in the middle of a band. Use in
- conjunction with ``"bandPosition": 1`` and an axis ``"padding"`` value of ``0``.
- tickMinStep : anyOf(float, :class:`ExprRef`)
- The minimum desired step between axis ticks, in terms of scale domain values. For
- example, a value of ``1`` indicates that ticks should not be less than 1 unit apart.
- If ``tickMinStep`` is specified, the ``tickCount`` value will be adjusted, if
- necessary, to enforce the minimum step value.
- tickOffset : anyOf(float, :class:`ExprRef`)
- Position offset in pixels to apply to ticks, labels, and gridlines.
- tickOpacity : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- Opacity of the ticks.
- tickRound : boolean
- Boolean flag indicating if pixel position values should be rounded to the nearest
- integer.
-
- **Default value:** ``true``
- tickSize : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The size in pixels of axis ticks.
-
- **Default value:** ``5``
- tickWidth : anyOf(float, :class:`ExprRef`, :class:`ConditionalAxisNumber`)
- The width, in pixels, of ticks.
-
- **Default value:** ``1``
- ticks : boolean
- Boolean value that determines whether the axis should include ticks.
-
- **Default value:** ``true``
- title : anyOf(:class:`Text`, None)
- A title for the field. If ``null``, the title will be removed.
-
- **Default value:** derived from the field's name and transformation function (
- ``aggregate``, ``bin`` and ``timeUnit`` ). If the field has an aggregate function,
- the function is displayed as part of the title (e.g., ``"Sum of Profit"`` ). If the
- field is binned or has a time unit applied, the applied function is shown in
- parentheses (e.g., ``"Profit (binned)"``, ``"Transaction Date (year-month)"`` ).
- Otherwise, the title is simply the field name.
-
- **Notes** :
-
- 1) You can customize the default field title format by providing the `fieldTitle
- `__ property in
- the `config `__ or `fieldTitle
- function via the compile function's options
- `__.
-
- 2) If both field definition's ``title`` and axis, header, or legend ``title`` are
- defined, axis/header/legend title will be used.
- titleAlign : anyOf(:class:`Align`, :class:`ExprRef`)
- Horizontal text alignment of axis titles.
- titleAnchor : anyOf(:class:`TitleAnchor`, :class:`ExprRef`)
- Text anchor position for placing axis titles.
- titleAngle : anyOf(float, :class:`ExprRef`)
- Angle in degrees of axis titles.
- titleBaseline : anyOf(:class:`TextBaseline`, :class:`ExprRef`)
- Vertical text baseline for axis titles. One of ``"alphabetic"`` (default),
- ``"top"``, ``"middle"``, ``"bottom"``, ``"line-top"``, or ``"line-bottom"``. The
- ``"line-top"`` and ``"line-bottom"`` values operate similarly to ``"top"`` and
- ``"bottom"``, but are calculated relative to the *lineHeight* rather than *fontSize*
- alone.
- titleColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`)
- Color of the title, can be in hex color code or regular color name.
- titleFont : anyOf(string, :class:`ExprRef`)
- Font of the title. (e.g., ``"Helvetica Neue"`` ).
- titleFontSize : anyOf(float, :class:`ExprRef`)
- Font size of the title.
- titleFontStyle : anyOf(:class:`FontStyle`, :class:`ExprRef`)
- Font style of the title.
- titleFontWeight : anyOf(:class:`FontWeight`, :class:`ExprRef`)
- Font weight of the title. This can be either a string (e.g ``"bold"``, ``"normal"``
- ) or a number ( ``100``, ``200``, ``300``, ..., ``900`` where ``"normal"`` = ``400``
- and ``"bold"`` = ``700`` ).
- titleLimit : anyOf(float, :class:`ExprRef`)
- Maximum allowed pixel width of axis titles.
- titleLineHeight : anyOf(float, :class:`ExprRef`)
- Line height in pixels for multi-line title text or title text with ``"line-top"`` or
- ``"line-bottom"`` baseline.
- titleOpacity : anyOf(float, :class:`ExprRef`)
- Opacity of the axis title.
- titlePadding : anyOf(float, :class:`ExprRef`)
- The padding, in pixels, between title and axis.
- titleX : anyOf(float, :class:`ExprRef`)
- X-coordinate of the axis title relative to the axis group.
- titleY : anyOf(float, :class:`ExprRef`)
- Y-coordinate of the axis title relative to the axis group.
- translate : anyOf(float, :class:`ExprRef`)
- Coordinate space translation offset for axis layout. By default, axes are translated
- by a 0.5 pixel offset for both the x and y coordinates in order to align stroked
- lines with the pixel grid. However, for vector graphics output these pixel-specific
- adjustments may be undesirable, in which case translate can be changed (for example,
- to zero).
-
- **Default value:** ``0.5``
- values : anyOf(List(float), List(string), List(boolean), List(:class:`DateTime`), :class:`ExprRef`)
- Explicitly set the visible axis tick values.
- zindex : float
- A non-negative integer indicating the z-index of the axis. If zindex is 0, axes
- should be drawn behind all chart elements. To put them in front, set ``zindex`` to
- ``1`` or more.
-
- **Default value:** ``0`` (behind the marks).
- """
- _schema = {'$ref': '#/definitions/AxisConfig'}
-
- def __init__(self, aria=Undefined, bandPosition=Undefined, description=Undefined, disable=Undefined,
- domain=Undefined, domainCap=Undefined, domainColor=Undefined, domainDash=Undefined,
- domainDashOffset=Undefined, domainOpacity=Undefined, domainWidth=Undefined,
- format=Undefined, formatType=Undefined, grid=Undefined, gridCap=Undefined,
- gridColor=Undefined, gridDash=Undefined, gridDashOffset=Undefined,
- gridOpacity=Undefined, gridWidth=Undefined, labelAlign=Undefined, labelAngle=Undefined,
- labelBaseline=Undefined, labelBound=Undefined, labelColor=Undefined,
- labelExpr=Undefined, labelFlush=Undefined, labelFlushOffset=Undefined,
- labelFont=Undefined, labelFontSize=Undefined, labelFontStyle=Undefined,
- labelFontWeight=Undefined, labelLimit=Undefined, labelLineHeight=Undefined,
- labelOffset=Undefined, labelOpacity=Undefined, labelOverlap=Undefined,
- labelPadding=Undefined, labelSeparation=Undefined, labels=Undefined,
- maxExtent=Undefined, minExtent=Undefined, offset=Undefined, orient=Undefined,
- position=Undefined, style=Undefined, tickBand=Undefined, tickCap=Undefined,
- tickColor=Undefined, tickCount=Undefined, tickDash=Undefined, tickDashOffset=Undefined,
- tickExtra=Undefined, tickMinStep=Undefined, tickOffset=Undefined,
- tickOpacity=Undefined, tickRound=Undefined, tickSize=Undefined, tickWidth=Undefined,
- ticks=Undefined, title=Undefined, titleAlign=Undefined, titleAnchor=Undefined,
- titleAngle=Undefined, titleBaseline=Undefined, titleColor=Undefined,
- titleFont=Undefined, titleFontSize=Undefined, titleFontStyle=Undefined,
- titleFontWeight=Undefined, titleLimit=Undefined, titleLineHeight=Undefined,
- titleOpacity=Undefined, titlePadding=Undefined, titleX=Undefined, titleY=Undefined,
- translate=Undefined, values=Undefined, zindex=Undefined, **kwds):
- super(AxisConfig, self).__init__(aria=aria, bandPosition=bandPosition, description=description,
- disable=disable, domain=domain, domainCap=domainCap,
- domainColor=domainColor, domainDash=domainDash,
- domainDashOffset=domainDashOffset, domainOpacity=domainOpacity,
- domainWidth=domainWidth, format=format, formatType=formatType,
- grid=grid, gridCap=gridCap, gridColor=gridColor,
- gridDash=gridDash, gridDashOffset=gridDashOffset,
- gridOpacity=gridOpacity, gridWidth=gridWidth,
- labelAlign=labelAlign, labelAngle=labelAngle,
- labelBaseline=labelBaseline, labelBound=labelBound,
- labelColor=labelColor, labelExpr=labelExpr,
- labelFlush=labelFlush, labelFlushOffset=labelFlushOffset,
- labelFont=labelFont, labelFontSize=labelFontSize,
- labelFontStyle=labelFontStyle, labelFontWeight=labelFontWeight,
- labelLimit=labelLimit, labelLineHeight=labelLineHeight,
- labelOffset=labelOffset, labelOpacity=labelOpacity,
- labelOverlap=labelOverlap, labelPadding=labelPadding,
- labelSeparation=labelSeparation, labels=labels,
- maxExtent=maxExtent, minExtent=minExtent, offset=offset,
- orient=orient, position=position, style=style,
- tickBand=tickBand, tickCap=tickCap, tickColor=tickColor,
- tickCount=tickCount, tickDash=tickDash,
- tickDashOffset=tickDashOffset, tickExtra=tickExtra,
- tickMinStep=tickMinStep, tickOffset=tickOffset,
- tickOpacity=tickOpacity, tickRound=tickRound,
- tickSize=tickSize, tickWidth=tickWidth, ticks=ticks,
- title=title, titleAlign=titleAlign, titleAnchor=titleAnchor,
- titleAngle=titleAngle, titleBaseline=titleBaseline,
- titleColor=titleColor, titleFont=titleFont,
- titleFontSize=titleFontSize, titleFontStyle=titleFontStyle,
- titleFontWeight=titleFontWeight, titleLimit=titleLimit,
- titleLineHeight=titleLineHeight, titleOpacity=titleOpacity,
- titlePadding=titlePadding, titleX=titleX, titleY=titleY,
- translate=translate, values=values, zindex=zindex, **kwds)
-
-
-class AxisOrient(VegaLiteSchema):
- """AxisOrient schema wrapper
-
- enum('top', 'bottom', 'left', 'right')
- """
- _schema = {'$ref': '#/definitions/AxisOrient'}
-
- def __init__(self, *args):
- super(AxisOrient, self).__init__(*args)
-
-
-class AxisResolveMap(VegaLiteSchema):
- """AxisResolveMap schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- x : :class:`ResolveMode`
-
- y : :class:`ResolveMode`
-
- """
- _schema = {'$ref': '#/definitions/AxisResolveMap'}
-
- def __init__(self, x=Undefined, y=Undefined, **kwds):
- super(AxisResolveMap, self).__init__(x=x, y=y, **kwds)
-
-
-class BBox(VegaLiteSchema):
- """BBox schema wrapper
-
- anyOf(List(float), List(float))
- Bounding box https://tools.ietf.org/html/rfc7946#section-5
- """
- _schema = {'$ref': '#/definitions/BBox'}
-
- def __init__(self, *args, **kwds):
- super(BBox, self).__init__(*args, **kwds)
-
-
-class BarConfig(AnyMarkConfig):
- """BarConfig schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- align : anyOf(:class:`Align`, :class:`ExprRef`)
- The horizontal alignment of the text or ranged marks (area, bar, image, rect, rule).
- One of ``"left"``, ``"right"``, ``"center"``.
-
- **Note:** Expression reference is *not* supported for range marks.
- angle : anyOf(float, :class:`ExprRef`)
- The rotation angle of the text, in degrees.
- aria : anyOf(boolean, :class:`ExprRef`)
- A boolean flag indicating if `ARIA attributes
- `__ should be
- included (SVG output only). If ``false``, the "aria-hidden" attribute will be set on
- the output SVG element, removing the mark item from the ARIA accessibility tree.
- ariaRole : anyOf(string, :class:`ExprRef`)
- Sets the type of user interface element of the mark item for `ARIA accessibility
- `__ (SVG output
- only). If specified, this property determines the "role" attribute. Warning: this
- property is experimental and may be changed in the future.
- ariaRoleDescription : anyOf(string, :class:`ExprRef`)
- A human-readable, author-localized description for the role of the mark item for
- `ARIA accessibility
- `__ (SVG output
- only). If specified, this property determines the "aria-roledescription" attribute.
- Warning: this property is experimental and may be changed in the future.
- aspect : anyOf(boolean, :class:`ExprRef`)
- Whether to keep aspect ratio of image marks.
- baseline : anyOf(:class:`TextBaseline`, :class:`ExprRef`)
- For text marks, the vertical text baseline. One of ``"alphabetic"`` (default),
- ``"top"``, ``"middle"``, ``"bottom"``, ``"line-top"``, ``"line-bottom"``, or an
- expression reference that provides one of the valid values. The ``"line-top"`` and
- ``"line-bottom"`` values operate similarly to ``"top"`` and ``"bottom"``, but are
- calculated relative to the ``lineHeight`` rather than ``fontSize`` alone.
-
- For range marks, the vertical alignment of the marks. One of ``"top"``,
- ``"middle"``, ``"bottom"``.
-
- **Note:** Expression reference is *not* supported for range marks.
- binSpacing : float
- Offset between bars for binned field. The ideal value for this is either 0
- (preferred by statisticians) or 1 (Vega-Lite default, D3 example style).
-
- **Default value:** ``1``
- blend : anyOf(:class:`Blend`, :class:`ExprRef`)
- The color blend mode for drawing an item on its current background. Any valid `CSS
- mix-blend-mode `__
- value can be used.
-
- __Default value:__ ``"source-over"``
- color : anyOf(:class:`Color`, :class:`Gradient`, :class:`ExprRef`)
- Default color.
-
- **Default value:** :raw-html:`■`
- ``"#4682b4"``
-
- **Note:**
-
-
- * This property cannot be used in a `style config
- `__.
- * The ``fill`` and ``stroke`` properties have higher precedence than ``color`` and
- will override ``color``.
- continuousBandSize : float
- The default size of the bars on continuous scales.
-
- **Default value:** ``5``
- cornerRadius : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles or arcs' corners.
-
- **Default value:** ``0``
- cornerRadiusBottomLeft : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles' bottom left corner.
-
- **Default value:** ``0``
- cornerRadiusBottomRight : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles' bottom right corner.
-
- **Default value:** ``0``
- cornerRadiusEnd : anyOf(float, :class:`ExprRef`)
- For vertical bars, top-left and top-right corner radius.
-
- For horizontal bars, top-right and bottom-right corner radius.
- cornerRadiusTopLeft : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles' top right corner.
-
- **Default value:** ``0``
- cornerRadiusTopRight : anyOf(float, :class:`ExprRef`)
- The radius in pixels of rounded rectangles' top left corner.
-
- **Default value:** ``0``
- cursor : anyOf(:class:`Cursor`, :class:`ExprRef`)
- The mouse cursor used over the mark. Any valid `CSS cursor type
- `__ can be used.
- description : anyOf(string, :class:`ExprRef`)
- A text description of the mark item for `ARIA accessibility
- `__ (SVG output
- only). If specified, this property determines the `"aria-label" attribute
- `__.
- dir : anyOf(:class:`TextDirection`, :class:`ExprRef`)
- The direction of the text. One of ``"ltr"`` (left-to-right) or ``"rtl"``
- (right-to-left). This property determines on which side is truncated in response to
- the limit parameter.
-
- **Default value:** ``"ltr"``
- discreteBandSize : anyOf(float, :class:`RelativeBandSize`)
- The default size of the bars with discrete dimensions. If unspecified, the default
- size is ``step-2``, which provides 2 pixel offset between bars.
- dx : anyOf(float, :class:`ExprRef`)
- The horizontal offset, in pixels, between the text label and its anchor point. The
- offset is applied after rotation by the *angle* property.
- dy : anyOf(float, :class:`ExprRef`)
- The vertical offset, in pixels, between the text label and its anchor point. The
- offset is applied after rotation by the *angle* property.
- ellipsis : anyOf(string, :class:`ExprRef`)
- The ellipsis string for text truncated in response to the limit parameter.
-
- **Default value:** ``"…"``
- endAngle : anyOf(float, :class:`ExprRef`)
- The end angle in radians for arc marks. A value of ``0`` indicates up (north),
- increasing values proceed clockwise.
- fill : anyOf(:class:`Color`, :class:`Gradient`, None, :class:`ExprRef`)
- Default fill color. This property has higher precedence than ``config.color``. Set
- to ``null`` to remove fill.
-
- **Default value:** (None)
- fillOpacity : anyOf(float, :class:`ExprRef`)
- The fill opacity (value between [0,1]).
-
- **Default value:** ``1``
- filled : boolean
- Whether the mark's color should be used as fill color instead of stroke color.
-
- **Default value:** ``false`` for all ``point``, ``line``, and ``rule`` marks as well
- as ``geoshape`` marks for `graticule
- `__ data sources;
- otherwise, ``true``.
-
- **Note:** This property cannot be used in a `style config
- `__.
- font : anyOf(string, :class:`ExprRef`)
- The typeface to set the text in (e.g., ``"Helvetica Neue"`` ).
- fontSize : anyOf(float, :class:`ExprRef`)
- The font size, in pixels.
-
- **Default value:** ``11``
- fontStyle : anyOf(:class:`FontStyle`, :class:`ExprRef`)
- The font style (e.g., ``"italic"`` ).
- fontWeight : anyOf(:class:`FontWeight`, :class:`ExprRef`)
- The font weight. This can be either a string (e.g ``"bold"``, ``"normal"`` ) or a
- number ( ``100``, ``200``, ``300``, ..., ``900`` where ``"normal"`` = ``400`` and
- ``"bold"`` = ``700`` ).
- height : anyOf(float, :class:`ExprRef`)
- Height of the marks.
- href : anyOf(:class:`URI`, :class:`ExprRef`)
- A URL to load upon mouse click. If defined, the mark acts as a hyperlink.
- innerRadius : anyOf(float, :class:`ExprRef`)
- The inner radius in pixels of arc marks. ``innerRadius`` is an alias for
- ``radius2``.
-
- **Default value:** ``0``
- interpolate : anyOf(:class:`Interpolate`, :class:`ExprRef`)
- The line interpolation method to use for line and area marks. One of the following:
-
-
- * ``"linear"`` : piecewise linear segments, as in a polyline.
- * ``"linear-closed"`` : close the linear segments to form a polygon.
- * ``"step"`` : alternate between horizontal and vertical segments, as in a step
- function.
- * ``"step-before"`` : alternate between vertical and horizontal segments, as in a
- step function.
- * ``"step-after"`` : alternate between horizontal and vertical segments, as in a
- step function.
- * ``"basis"`` : a B-spline, with control point duplication on the ends.
- * ``"basis-open"`` : an open B-spline; may not intersect the start or end.
- * ``"basis-closed"`` : a closed B-spline, as in a loop.
- * ``"cardinal"`` : a Cardinal spline, with control point duplication on the ends.
- * ``"cardinal-open"`` : an open Cardinal spline; may not intersect the start or end,
- but will intersect other control points.
- * ``"cardinal-closed"`` : a closed Cardinal spline, as in a loop.
- * ``"bundle"`` : equivalent to basis, except the tension parameter is used to
- straighten the spline.
- * ``"monotone"`` : cubic interpolation that preserves monotonicity in y.
- invalid : enum('filter', None)
- Defines how Vega-Lite should handle marks for invalid values ( ``null`` and ``NaN``
- ).
-
-
- * If set to ``"filter"`` (default), all data items with null values will be skipped
- (for line, trail, and area marks) or filtered (for other marks).
- * If ``null``, all data items are included. In this case, invalid values will be
- interpreted as zeroes.
- limit : anyOf(float, :class:`ExprRef`)
- The maximum length of the text mark in pixels. The text value will be automatically
- truncated if the rendered size exceeds the limit.
-
- **Default value:** ``0`` -- indicating no limit
- lineBreak : anyOf(string, :class:`ExprRef`)
- A delimiter, such as a newline character, upon which to break text strings into
- multiple lines. This property is ignored if the text is array-valued.
- lineHeight : anyOf(float, :class:`ExprRef`)
- The line height in pixels (the spacing between subsequent lines of text) for
- multi-line text marks.
- opacity : anyOf(float, :class:`ExprRef`)
- The overall opacity (value between [0,1]).
-
- **Default value:** ``0.7`` for non-aggregate plots with ``point``, ``tick``,
- ``circle``, or ``square`` marks or layered ``bar`` charts and ``1`` otherwise.
- order : anyOf(None, boolean)
- For line and trail marks, this ``order`` property can be set to ``null`` or
- ``false`` to make the lines use the original order in the data sources.
- orient : :class:`Orientation`
- The orientation of a non-stacked bar, tick, area, and line charts. The value is
- either horizontal (default) or vertical.
-
-
- * For bar, rule and tick, this determines whether the size of the bar and tick
- should be applied to x or y dimension.
- * For area, this property determines the orient property of the Vega output.
- * For line and trail marks, this property determines the sort order of the points in
- the line if ``config.sortLineBy`` is not specified. For stacked charts, this is
- always determined by the orientation of the stack; therefore explicitly specified
- value will be ignored.
- outerRadius : anyOf(float, :class:`ExprRef`)
- The outer radius in pixels of arc marks. ``outerRadius`` is an alias for ``radius``.
-
- **Default value:** ``0``
- padAngle : anyOf(float, :class:`ExprRef`)
- The angular padding applied to sides of the arc, in radians.
- radius : anyOf(float, :class:`ExprRef`)
- For arc mark, the primary (outer) radius in pixels.
-
- For text marks, polar coordinate radial offset, in pixels, of the text from the
- origin determined by the ``x`` and ``y`` properties.
-
- **Default value:** ``min(plot_width, plot_height)/2``
- radius2 : anyOf(float, :class:`ExprRef`)
- The secondary (inner) radius in pixels of arc marks.
-
- **Default value:** ``0``
- shape : anyOf(anyOf(:class:`SymbolShape`, string), :class:`ExprRef`)
- Shape of the point marks. Supported values include:
-
-
- * plotting shapes: ``"circle"``, ``"square"``, ``"cross"``, ``"diamond"``,
- ``"triangle-up"``, ``"triangle-down"``, ``"triangle-right"``, or
- ``"triangle-left"``.
- * the line symbol ``"stroke"``
- * centered directional shapes ``"arrow"``, ``"wedge"``, or ``"triangle"``
- * a custom `SVG path string
- `__ (For correct
- sizing, custom shape paths should be defined within a square bounding box with
- coordinates ranging from -1 to 1 along both the x and y dimensions.)
-
- **Default value:** ``"circle"``
- size : anyOf(float, :class:`ExprRef`)
- Default size for marks.
-
-
- * For ``point`` / ``circle`` / ``square``, this represents the pixel area of the
- marks. Note that this value sets the area of the symbol; the side lengths will
- increase with the square root of this value.
- * For ``bar``, this represents the band size of the bar, in pixels.
- * For ``text``, this represents the font size, in pixels.
-
- **Default value:**
-
-
- * ``30`` for point, circle, square marks; width/height's ``step``
- * ``2`` for bar marks with discrete dimensions;
- * ``5`` for bar marks with continuous dimensions;
- * ``11`` for text marks.
- smooth : anyOf(boolean, :class:`ExprRef`)
- A boolean flag (default true) indicating if the image should be smoothed when
- resized. If false, individual pixels should be scaled directly rather than
- interpolated with smoothing. For SVG rendering, this option may not work in some
- browsers due to lack of standardization.
- startAngle : anyOf(float, :class:`ExprRef`)
- The start angle in radians for arc marks. A value of ``0`` indicates up (north),
- increasing values proceed clockwise.
- stroke : anyOf(:class:`Color`, :class:`Gradient`, None, :class:`ExprRef`)
- Default stroke color. This property has higher precedence than ``config.color``. Set
- to ``null`` to remove stroke.
-
- **Default value:** (None)
- strokeCap : anyOf(:class:`StrokeCap`, :class:`ExprRef`)
- The stroke cap for line ending style. One of ``"butt"``, ``"round"``, or
- ``"square"``.
-
- **Default value:** ``"butt"``
- strokeDash : anyOf(List(float), :class:`ExprRef`)
- An array of alternating stroke, space lengths for creating dashed or dotted lines.
- strokeDashOffset : anyOf(float, :class:`ExprRef`)
- The offset (in pixels) into which to begin drawing with the stroke dash array.
- strokeJoin : anyOf(:class:`StrokeJoin`, :class:`ExprRef`)
- The stroke line join method. One of ``"miter"``, ``"round"`` or ``"bevel"``.
-
- **Default value:** ``"miter"``
- strokeMiterLimit : anyOf(float, :class:`ExprRef`)
- The miter limit at which to bevel a line join.
- strokeOffset : anyOf(float, :class:`ExprRef`)
- The offset in pixels at which to draw the group stroke and fill. If unspecified, the
- default behavior is to dynamically offset stroked groups such that 1 pixel stroke
- widths align with the pixel grid.
- strokeOpacity : anyOf(float, :class:`ExprRef`)
- The stroke opacity (value between [0,1]).
-
- **Default value:** ``1``
- strokeWidth : anyOf(float, :class:`ExprRef`)
- The stroke width, in pixels.
- tension : anyOf(float, :class:`ExprRef`)
- Depending on the interpolation type, sets the tension parameter (for line and area
- marks).
- text : anyOf(:class:`Text`, :class:`ExprRef`)
- Placeholder text if the ``text`` channel is not specified
- theta : anyOf(float, :class:`ExprRef`)
- For arc marks, the arc length in radians if theta2 is not specified, otherwise the
- start arc angle. (A value of 0 indicates up or “north”, increasing values proceed
- clockwise.)
-
- For text marks, polar coordinate angle in radians.
- theta2 : anyOf(float, :class:`ExprRef`)
- The end angle of arc marks in radians. A value of 0 indicates up or “north”,
- increasing values proceed clockwise.
- timeUnitBandPosition : float
- Default relative band position for a time unit. If set to ``0``, the marks will be
- positioned at the beginning of the time unit band step. If set to ``0.5``, the marks
- will be positioned in the middle of the time unit band step.
- timeUnitBandSize : float
- Default relative band size for a time unit. If set to ``1``, the bandwidth of the
- marks will be equal to the time unit band step. If set to ``0.5``, bandwidth of the
- marks will be half of the time unit band step.
- tooltip : anyOf(float, string, boolean, :class:`TooltipContent`, :class:`ExprRef`, None)
- The tooltip text string to show upon mouse hover or an object defining which fields
- should the tooltip be derived from.
-
-
- * If ``tooltip`` is ``true`` or ``{"content": "encoding"}``, then all fields from
- ``encoding`` will be used.
- * If ``tooltip`` is ``{"content": "data"}``, then all fields that appear in the
- highlighted data point will be used.
- * If set to ``null`` or ``false``, then no tooltip will be used.
-
- See the `tooltip `__
- documentation for a detailed discussion about tooltip in Vega-Lite.
-
- **Default value:** ``null``
- url : anyOf(:class:`URI`, :class:`ExprRef`)
- The URL of the image file for image marks.
- width : anyOf(float, :class:`ExprRef`)
- Width of the marks.
- x : anyOf(float, string, :class:`ExprRef`)
- X coordinates of the marks, or width of horizontal ``"bar"`` and ``"area"`` without
- specified ``x2`` or ``width``.
-
- The ``value`` of this channel can be a number or a string ``"width"`` for the width
- of the plot.
- x2 : anyOf(float, string, :class:`ExprRef`)
- X2 coordinates for ranged ``"area"``, ``"bar"``, ``"rect"``, and ``"rule"``.
-
- The ``value`` of this channel can be a number or a string ``"width"`` for the width
- of the plot.
- y : anyOf(float, string, :class:`ExprRef`)
- Y coordinates of the marks, or height of vertical ``"bar"`` and ``"area"`` without
- specified ``y2`` or ``height``.
-
- The ``value`` of this channel can be a number or a string ``"height"`` for the
- height of the plot.
- y2 : anyOf(float, string, :class:`ExprRef`)
- Y2 coordinates for ranged ``"area"``, ``"bar"``, ``"rect"``, and ``"rule"``.
-
- The ``value`` of this channel can be a number or a string ``"height"`` for the
- height of the plot.
- """
- _schema = {'$ref': '#/definitions/BarConfig'}
-
- def __init__(self, align=Undefined, angle=Undefined, aria=Undefined, ariaRole=Undefined,
- ariaRoleDescription=Undefined, aspect=Undefined, baseline=Undefined,
- binSpacing=Undefined, blend=Undefined, color=Undefined, continuousBandSize=Undefined,
- cornerRadius=Undefined, cornerRadiusBottomLeft=Undefined,
- cornerRadiusBottomRight=Undefined, cornerRadiusEnd=Undefined,
- cornerRadiusTopLeft=Undefined, cornerRadiusTopRight=Undefined, cursor=Undefined,
- description=Undefined, dir=Undefined, discreteBandSize=Undefined, dx=Undefined,
- dy=Undefined, ellipsis=Undefined, endAngle=Undefined, fill=Undefined,
- fillOpacity=Undefined, filled=Undefined, font=Undefined, fontSize=Undefined,
- fontStyle=Undefined, fontWeight=Undefined, height=Undefined, href=Undefined,
- innerRadius=Undefined, interpolate=Undefined, invalid=Undefined, limit=Undefined,
- lineBreak=Undefined, lineHeight=Undefined, opacity=Undefined, order=Undefined,
- orient=Undefined, outerRadius=Undefined, padAngle=Undefined, radius=Undefined,
- radius2=Undefined, shape=Undefined, size=Undefined, smooth=Undefined,
- startAngle=Undefined, stroke=Undefined, strokeCap=Undefined, strokeDash=Undefined,
- strokeDashOffset=Undefined, strokeJoin=Undefined, strokeMiterLimit=Undefined,
- strokeOffset=Undefined, strokeOpacity=Undefined, strokeWidth=Undefined,
- tension=Undefined, text=Undefined, theta=Undefined, theta2=Undefined,
- timeUnitBandPosition=Undefined, timeUnitBandSize=Undefined, tooltip=Undefined,
- url=Undefined, width=Undefined, x=Undefined, x2=Undefined, y=Undefined, y2=Undefined,
- **kwds):
- super(BarConfig, self).__init__(align=align, angle=angle, aria=aria, ariaRole=ariaRole,
- ariaRoleDescription=ariaRoleDescription, aspect=aspect,
- baseline=baseline, binSpacing=binSpacing, blend=blend,
- color=color, continuousBandSize=continuousBandSize,
- cornerRadius=cornerRadius,
- cornerRadiusBottomLeft=cornerRadiusBottomLeft,
- cornerRadiusBottomRight=cornerRadiusBottomRight,
- cornerRadiusEnd=cornerRadiusEnd,
- cornerRadiusTopLeft=cornerRadiusTopLeft,
- cornerRadiusTopRight=cornerRadiusTopRight, cursor=cursor,
- description=description, dir=dir,
- discreteBandSize=discreteBandSize, dx=dx, dy=dy,
- ellipsis=ellipsis, endAngle=endAngle, fill=fill,
- fillOpacity=fillOpacity, filled=filled, font=font,
- fontSize=fontSize, fontStyle=fontStyle, fontWeight=fontWeight,
- height=height, href=href, innerRadius=innerRadius,
- interpolate=interpolate, invalid=invalid, limit=limit,
- lineBreak=lineBreak, lineHeight=lineHeight, opacity=opacity,
- order=order, orient=orient, outerRadius=outerRadius,
- padAngle=padAngle, radius=radius, radius2=radius2, shape=shape,
- size=size, smooth=smooth, startAngle=startAngle, stroke=stroke,
- strokeCap=strokeCap, strokeDash=strokeDash,
- strokeDashOffset=strokeDashOffset, strokeJoin=strokeJoin,
- strokeMiterLimit=strokeMiterLimit, strokeOffset=strokeOffset,
- strokeOpacity=strokeOpacity, strokeWidth=strokeWidth,
- tension=tension, text=text, theta=theta, theta2=theta2,
- timeUnitBandPosition=timeUnitBandPosition,
- timeUnitBandSize=timeUnitBandSize, tooltip=tooltip, url=url,
- width=width, x=x, x2=x2, y=y, y2=y2, **kwds)
-
-
-class BaseTitleNoValueRefs(VegaLiteSchema):
- """BaseTitleNoValueRefs schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- align : :class:`Align`
- Horizontal text alignment for title text. One of ``"left"``, ``"center"``, or
- ``"right"``.
- anchor : anyOf(:class:`TitleAnchor`, :class:`ExprRef`)
- The anchor position for placing the title and subtitle text. One of ``"start"``,
- ``"middle"``, or ``"end"``. For example, with an orientation of top these anchor
- positions map to a left-, center-, or right-aligned title.
- angle : anyOf(float, :class:`ExprRef`)
- Angle in degrees of title and subtitle text.
- aria : anyOf(boolean, :class:`ExprRef`)
- A boolean flag indicating if `ARIA attributes
- `__ should be
- included (SVG output only). If ``false``, the "aria-hidden" attribute will be set on
- the output SVG group, removing the title from the ARIA accessibility tree.
-
- **Default value:** ``true``
- baseline : :class:`TextBaseline`
- Vertical text baseline for title and subtitle text. One of ``"alphabetic"``
- (default), ``"top"``, ``"middle"``, ``"bottom"``, ``"line-top"``, or
- ``"line-bottom"``. The ``"line-top"`` and ``"line-bottom"`` values operate similarly
- to ``"top"`` and ``"bottom"``, but are calculated relative to the *lineHeight*
- rather than *fontSize* alone.
- color : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`)
- Text color for title text.
- dx : anyOf(float, :class:`ExprRef`)
- Delta offset for title and subtitle text x-coordinate.
- dy : anyOf(float, :class:`ExprRef`)
- Delta offset for title and subtitle text y-coordinate.
- font : anyOf(string, :class:`ExprRef`)
- Font name for title text.
- fontSize : anyOf(float, :class:`ExprRef`)
- Font size in pixels for title text.
- fontStyle : anyOf(:class:`FontStyle`, :class:`ExprRef`)
- Font style for title text.
- fontWeight : anyOf(:class:`FontWeight`, :class:`ExprRef`)
- Font weight for title text. This can be either a string (e.g ``"bold"``,
- ``"normal"`` ) or a number ( ``100``, ``200``, ``300``, ..., ``900`` where
- ``"normal"`` = ``400`` and ``"bold"`` = ``700`` ).
- frame : anyOf(anyOf(:class:`TitleFrame`, string), :class:`ExprRef`)
- The reference frame for the anchor position, one of ``"bounds"`` (to anchor relative
- to the full bounding box) or ``"group"`` (to anchor relative to the group width or
- height).
- limit : anyOf(float, :class:`ExprRef`)
- The maximum allowed length in pixels of title and subtitle text.
- lineHeight : anyOf(float, :class:`ExprRef`)
- Line height in pixels for multi-line title text or title text with ``"line-top"`` or
- ``"line-bottom"`` baseline.
- offset : anyOf(float, :class:`ExprRef`)
- The orthogonal offset in pixels by which to displace the title group from its
- position along the edge of the chart.
- orient : anyOf(:class:`TitleOrient`, :class:`ExprRef`)
- Default title orientation ( ``"top"``, ``"bottom"``, ``"left"``, or ``"right"`` )
- subtitleColor : anyOf(anyOf(None, :class:`Color`), :class:`ExprRef`)
- Text color for subtitle text.
- subtitleFont : anyOf(string, :class:`ExprRef`)
- Font name for subtitle text.
- subtitleFontSize : anyOf(float, :class:`ExprRef`)
- Font size in pixels for subtitle text.
- subtitleFontStyle : anyOf(:class:`FontStyle`, :class:`ExprRef`)
- Font style for subtitle text.
- subtitleFontWeight : anyOf(:class:`FontWeight`, :class:`ExprRef`)
- Font weight for subtitle text. This can be either a string (e.g ``"bold"``,
- ``"normal"`` ) or a number ( ``100``, ``200``, ``300``, ..., ``900`` where
- ``"normal"`` = ``400`` and ``"bold"`` = ``700`` ).
- subtitleLineHeight : anyOf(float, :class:`ExprRef`)
- Line height in pixels for multi-line subtitle text.
- subtitlePadding : anyOf(float, :class:`ExprRef`)
- The padding in pixels between title and subtitle text.
- zindex : anyOf(float, :class:`ExprRef`)
- The integer z-index indicating the layering of the title group relative to other
- axis, mark, and legend groups.
-
- **Default value:** ``0``.
- """
- _schema = {'$ref': '#/definitions/BaseTitleNoValueRefs'}
-
- def __init__(self, align=Undefined, anchor=Undefined, angle=Undefined, aria=Undefined,
- baseline=Undefined, color=Undefined, dx=Undefined, dy=Undefined, font=Undefined,
- fontSize=Undefined, fontStyle=Undefined, fontWeight=Undefined, frame=Undefined,
- limit=Undefined, lineHeight=Undefined, offset=Undefined, orient=Undefined,
- subtitleColor=Undefined, subtitleFont=Undefined, subtitleFontSize=Undefined,
- subtitleFontStyle=Undefined, subtitleFontWeight=Undefined,
- subtitleLineHeight=Undefined, subtitlePadding=Undefined, zindex=Undefined, **kwds):
- super(BaseTitleNoValueRefs, self).__init__(align=align, anchor=anchor, angle=angle, aria=aria,
- baseline=baseline, color=color, dx=dx, dy=dy,
- font=font, fontSize=fontSize, fontStyle=fontStyle,
- fontWeight=fontWeight, frame=frame, limit=limit,
- lineHeight=lineHeight, offset=offset, orient=orient,
- subtitleColor=subtitleColor,
- subtitleFont=subtitleFont,
- subtitleFontSize=subtitleFontSize,
- subtitleFontStyle=subtitleFontStyle,
- subtitleFontWeight=subtitleFontWeight,
- subtitleLineHeight=subtitleLineHeight,
- subtitlePadding=subtitlePadding, zindex=zindex,
- **kwds)
-
-
-class BinExtent(VegaLiteSchema):
- """BinExtent schema wrapper
-
- anyOf(List(float), :class:`ParameterExtent`)
- """
- _schema = {'$ref': '#/definitions/BinExtent'}
-
- def __init__(self, *args, **kwds):
- super(BinExtent, self).__init__(*args, **kwds)
-
-
-class BinParams(VegaLiteSchema):
- """BinParams schema wrapper
-
- Mapping(required=[])
- Binning properties or boolean flag for determining whether to bin data or not.
-
- Parameters
- ----------
-
- anchor : float
- A value in the binned domain at which to anchor the bins, shifting the bin
- boundaries if necessary to ensure that a boundary aligns with the anchor value.
-
- **Default value:** the minimum bin extent value
- base : float
- The number base to use for automatic bin determination (default is base 10).
-
- **Default value:** ``10``
- binned : boolean
- When set to ``true``, Vega-Lite treats the input data as already binned.
- divide : List(float)
- Scale factors indicating allowable subdivisions. The default value is [5, 2], which
- indicates that for base 10 numbers (the default base), the method may consider
- dividing bin sizes by 5 and/or 2. For example, for an initial step size of 10, the
- method can check if bin sizes of 2 (= 10/5), 5 (= 10/2), or 1 (= 10/(5*2)) might
- also satisfy the given constraints.
-
- **Default value:** ``[5, 2]``
- extent : :class:`BinExtent`
- A two-element ( ``[min, max]`` ) array indicating the range of desired bin values.
- maxbins : float
- Maximum number of bins.
-
- **Default value:** ``6`` for ``row``, ``column`` and ``shape`` channels; ``10`` for
- other channels
- minstep : float
- A minimum allowable step size (particularly useful for integer values).
- nice : boolean
- If true, attempts to make the bin boundaries use human-friendly boundaries, such as
- multiples of ten.
-
- **Default value:** ``true``
- step : float
- An exact step size to use between bins.
-
- **Note:** If provided, options such as maxbins will be ignored.
- steps : List(float)
- An array of allowable step sizes to choose from.
- """
- _schema = {'$ref': '#/definitions/BinParams'}
-
- def __init__(self, anchor=Undefined, base=Undefined, binned=Undefined, divide=Undefined,
- extent=Undefined, maxbins=Undefined, minstep=Undefined, nice=Undefined, step=Undefined,
- steps=Undefined, **kwds):
- super(BinParams, self).__init__(anchor=anchor, base=base, binned=binned, divide=divide,
- extent=extent, maxbins=maxbins, minstep=minstep, nice=nice,
- step=step, steps=steps, **kwds)
-
-
-class Binding(VegaLiteSchema):
- """Binding schema wrapper
-
- anyOf(:class:`BindCheckbox`, :class:`BindRadioSelect`, :class:`BindRange`,
- :class:`BindInput`, :class:`BindDirect`)
- """
- _schema = {'$ref': '#/definitions/Binding'}
-
- def __init__(self, *args, **kwds):
- super(Binding, self).__init__(*args, **kwds)
-
-
-class BindCheckbox(Binding):
- """BindCheckbox schema wrapper
-
- Mapping(required=[input])
-
- Parameters
- ----------
-
- input : string
-
- debounce : float
- If defined, delays event handling until the specified milliseconds have elapsed
- since the last event was fired.
- element : :class:`Element`
- An optional CSS selector string indicating the parent element to which the input
- element should be added. By default, all input elements are added within the parent
- container of the Vega view.
- name : string
- By default, the signal name is used to label input elements. This ``name`` property
- can be used instead to specify a custom label for the bound signal.
- """
- _schema = {'$ref': '#/definitions/BindCheckbox'}
-
- def __init__(self, input=Undefined, debounce=Undefined, element=Undefined, name=Undefined, **kwds):
- super(BindCheckbox, self).__init__(input=input, debounce=debounce, element=element, name=name,
- **kwds)
-
-
-class BindDirect(Binding):
- """BindDirect schema wrapper
-
- Mapping(required=[element])
-
- Parameters
- ----------
-
- element : anyOf(:class:`Element`, Mapping(required=[]))
- An input element that exposes a *value* property and supports the `EventTarget
- `__ interface, or a
- CSS selector string to such an element. When the element updates and dispatches an
- event, the *value* property will be used as the new, bound signal value. When the
- signal updates independent of the element, the *value* property will be set to the
- signal value and a new event will be dispatched on the element.
- debounce : float
- If defined, delays event handling until the specified milliseconds have elapsed
- since the last event was fired.
- event : string
- The event (default ``"input"`` ) to listen for to track changes on the external
- element.
- """
- _schema = {'$ref': '#/definitions/BindDirect'}
-
- def __init__(self, element=Undefined, debounce=Undefined, event=Undefined, **kwds):
- super(BindDirect, self).__init__(element=element, debounce=debounce, event=event, **kwds)
-
-
-class BindInput(Binding):
- """BindInput schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- autocomplete : string
- A hint for form autofill. See the `HTML autocomplete attribute
- `__ for
- additional information.
- debounce : float
- If defined, delays event handling until the specified milliseconds have elapsed
- since the last event was fired.
- element : :class:`Element`
- An optional CSS selector string indicating the parent element to which the input
- element should be added. By default, all input elements are added within the parent
- container of the Vega view.
- input : string
- The type of input element to use. The valid values are ``"checkbox"``, ``"radio"``,
- ``"range"``, ``"select"``, and any other legal `HTML form input type
- `__.
- name : string
- By default, the signal name is used to label input elements. This ``name`` property
- can be used instead to specify a custom label for the bound signal.
- placeholder : string
- Text that appears in the form control when it has no value set.
- """
- _schema = {'$ref': '#/definitions/BindInput'}
-
- def __init__(self, autocomplete=Undefined, debounce=Undefined, element=Undefined, input=Undefined,
- name=Undefined, placeholder=Undefined, **kwds):
- super(BindInput, self).__init__(autocomplete=autocomplete, debounce=debounce, element=element,
- input=input, name=name, placeholder=placeholder, **kwds)
-
-
-class BindRadioSelect(Binding):
- """BindRadioSelect schema wrapper
-
- Mapping(required=[input, options])
-
- Parameters
- ----------
-
- input : enum('radio', 'select')
-
- options : List(Any)
- An array of options to select from.
- debounce : float
- If defined, delays event handling until the specified milliseconds have elapsed
- since the last event was fired.
- element : :class:`Element`
- An optional CSS selector string indicating the parent element to which the input
- element should be added. By default, all input elements are added within the parent
- container of the Vega view.
- labels : List(string)
- An array of label strings to represent the ``options`` values. If unspecified, the
- ``options`` value will be coerced to a string and used as the label.
- name : string
- By default, the signal name is used to label input elements. This ``name`` property
- can be used instead to specify a custom label for the bound signal.
- """
- _schema = {'$ref': '#/definitions/BindRadioSelect'}
-
- def __init__(self, input=Undefined, options=Undefined, debounce=Undefined, element=Undefined,
- labels=Undefined, name=Undefined, **kwds):
- super(BindRadioSelect, self).__init__(input=input, options=options, debounce=debounce,
- element=element, labels=labels, name=name, **kwds)
-
-
-class BindRange(Binding):
- """BindRange schema wrapper
-
- Mapping(required=[input])
-
- Parameters
- ----------
-
- input : string
-
- debounce : float
- If defined, delays event handling until the specified milliseconds have elapsed
- since the last event was fired.
- element : :class:`Element`
- An optional CSS selector string indicating the parent element to which the input
- element should be added. By default, all input elements are added within the parent
- container of the Vega view.
- max : float
- Sets the maximum slider value. Defaults to the larger of the signal value and
- ``100``.
- min : float
- Sets the minimum slider value. Defaults to the smaller of the signal value and
- ``0``.
- name : string
- By default, the signal name is used to label input elements. This ``name`` property
- can be used instead to specify a custom label for the bound signal.
- step : float
- Sets the minimum slider increment. If undefined, the step size will be automatically
- determined based on the ``min`` and ``max`` values.
- """
- _schema = {'$ref': '#/definitions/BindRange'}
-
- def __init__(self, input=Undefined, debounce=Undefined, element=Undefined, max=Undefined,
- min=Undefined, name=Undefined, step=Undefined, **kwds):
- super(BindRange, self).__init__(input=input, debounce=debounce, element=element, max=max,
- min=min, name=name, step=step, **kwds)
-
-
-class Blend(VegaLiteSchema):
- """Blend schema wrapper
-
- enum(None, 'multiply', 'screen', 'overlay', 'darken', 'lighten', 'color-dodge',
- 'color-burn', 'hard-light', 'soft-light', 'difference', 'exclusion', 'hue', 'saturation',
- 'color', 'luminosity')
- """
- _schema = {'$ref': '#/definitions/Blend'}
-
- def __init__(self, *args):
- super(Blend, self).__init__(*args)
-
-
-class BoxPlotConfig(VegaLiteSchema):
- """BoxPlotConfig schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- box : anyOf(boolean, :class:`AnyMarkConfig`)
-
- extent : anyOf(string, float)
- The extent of the whiskers. Available options include:
-
-
- * ``"min-max"`` : min and max are the lower and upper whiskers respectively.
- * A number representing multiple of the interquartile range. This number will be
- multiplied by the IQR to determine whisker boundary, which spans from the smallest
- data to the largest data within the range *[Q1 - k * IQR, Q3 + k * IQR]* where
- *Q1* and *Q3* are the first and third quartiles while *IQR* is the interquartile
- range ( *Q3-Q1* ).
-
- **Default value:** ``1.5``.
- median : anyOf(boolean, :class:`AnyMarkConfig`)
-
- outliers : anyOf(boolean, :class:`AnyMarkConfig`)
-
- rule : anyOf(boolean, :class:`AnyMarkConfig`)
-
- size : float
- Size of the box and median tick of a box plot
- ticks : anyOf(boolean, :class:`AnyMarkConfig`)
-
- """
- _schema = {'$ref': '#/definitions/BoxPlotConfig'}
-
- def __init__(self, box=Undefined, extent=Undefined, median=Undefined, outliers=Undefined,
- rule=Undefined, size=Undefined, ticks=Undefined, **kwds):
- super(BoxPlotConfig, self).__init__(box=box, extent=extent, median=median, outliers=outliers,
- rule=rule, size=size, ticks=ticks, **kwds)
-
-
-class BrushConfig(VegaLiteSchema):
- """BrushConfig schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- cursor : :class:`Cursor`
- The mouse cursor used over the interval mark. Any valid `CSS cursor type
- `__ can be used.
- fill : :class:`Color`
- The fill color of the interval mark.
-
- **Default value:** ``"#333333"``
- fillOpacity : float
- The fill opacity of the interval mark (a value between ``0`` and ``1`` ).
-
- **Default value:** ``0.125``
- stroke : :class:`Color`
- The stroke color of the interval mark.
-
- **Default value:** ``"#ffffff"``
- strokeDash : List(float)
- An array of alternating stroke and space lengths, for creating dashed or dotted
- lines.
- strokeDashOffset : float
- The offset (in pixels) with which to begin drawing the stroke dash array.
- strokeOpacity : float
- The stroke opacity of the interval mark (a value between ``0`` and ``1`` ).
- strokeWidth : float
- The stroke width of the interval mark.
- """
- _schema = {'$ref': '#/definitions/BrushConfig'}
-
- def __init__(self, cursor=Undefined, fill=Undefined, fillOpacity=Undefined, stroke=Undefined,
- strokeDash=Undefined, strokeDashOffset=Undefined, strokeOpacity=Undefined,
- strokeWidth=Undefined, **kwds):
- super(BrushConfig, self).__init__(cursor=cursor, fill=fill, fillOpacity=fillOpacity,
- stroke=stroke, strokeDash=strokeDash,
- strokeDashOffset=strokeDashOffset,
- strokeOpacity=strokeOpacity, strokeWidth=strokeWidth, **kwds)
-
-
-class Color(VegaLiteSchema):
- """Color schema wrapper
-
- anyOf(:class:`ColorName`, :class:`HexColor`, string)
- """
- _schema = {'$ref': '#/definitions/Color'}
-
- def __init__(self, *args, **kwds):
- super(Color, self).__init__(*args, **kwds)
-
-
-class ColorDef(VegaLiteSchema):
- """ColorDef schema wrapper
-
- anyOf(:class:`FieldOrDatumDefWithConditionMarkPropFieldDefGradientstringnull`,
- :class:`FieldOrDatumDefWithConditionDatumDefGradientstringnull`,
- :class:`ValueDefWithConditionMarkPropFieldOrDatumDefGradientstringnull`)
- """
- _schema = {'$ref': '#/definitions/ColorDef'}
-
- def __init__(self, *args, **kwds):
- super(ColorDef, self).__init__(*args, **kwds)
-
-
-class ColorName(Color):
- """ColorName schema wrapper
-
- enum('black', 'silver', 'gray', 'white', 'maroon', 'red', 'purple', 'fuchsia', 'green',
- 'lime', 'olive', 'yellow', 'navy', 'blue', 'teal', 'aqua', 'orange', 'aliceblue',
- 'antiquewhite', 'aquamarine', 'azure', 'beige', 'bisque', 'blanchedalmond', 'blueviolet',
- 'brown', 'burlywood', 'cadetblue', 'chartreuse', 'chocolate', 'coral', 'cornflowerblue',
- 'cornsilk', 'crimson', 'cyan', 'darkblue', 'darkcyan', 'darkgoldenrod', 'darkgray',
- 'darkgreen', 'darkgrey', 'darkkhaki', 'darkmagenta', 'darkolivegreen', 'darkorange',
- 'darkorchid', 'darkred', 'darksalmon', 'darkseagreen', 'darkslateblue', 'darkslategray',
- 'darkslategrey', 'darkturquoise', 'darkviolet', 'deeppink', 'deepskyblue', 'dimgray',
- 'dimgrey', 'dodgerblue', 'firebrick', 'floralwhite', 'forestgreen', 'gainsboro',
- 'ghostwhite', 'gold', 'goldenrod', 'greenyellow', 'grey', 'honeydew', 'hotpink',
- 'indianred', 'indigo', 'ivory', 'khaki', 'lavender', 'lavenderblush', 'lawngreen',
- 'lemonchiffon', 'lightblue', 'lightcoral', 'lightcyan', 'lightgoldenrodyellow', 'lightgray',
- 'lightgreen', 'lightgrey', 'lightpink', 'lightsalmon', 'lightseagreen', 'lightskyblue',
- 'lightslategray', 'lightslategrey', 'lightsteelblue', 'lightyellow', 'limegreen', 'linen',
- 'magenta', 'mediumaquamarine', 'mediumblue', 'mediumorchid', 'mediumpurple',
- 'mediumseagreen', 'mediumslateblue', 'mediumspringgreen', 'mediumturquoise',
- 'mediumvioletred', 'midnightblue', 'mintcream', 'mistyrose', 'moccasin', 'navajowhite',
- 'oldlace', 'olivedrab', 'orangered', 'orchid', 'palegoldenrod', 'palegreen',
- 'paleturquoise', 'palevioletred', 'papayawhip', 'peachpuff', 'peru', 'pink', 'plum',
- 'powderblue', 'rosybrown', 'royalblue', 'saddlebrown', 'salmon', 'sandybrown', 'seagreen',
- 'seashell', 'sienna', 'skyblue', 'slateblue', 'slategray', 'slategrey', 'snow',
- 'springgreen', 'steelblue', 'tan', 'thistle', 'tomato', 'turquoise', 'violet', 'wheat',
- 'whitesmoke', 'yellowgreen', 'rebeccapurple')
- """
- _schema = {'$ref': '#/definitions/ColorName'}
-
- def __init__(self, *args):
- super(ColorName, self).__init__(*args)
-
-
-class ColorScheme(VegaLiteSchema):
- """ColorScheme schema wrapper
-
- anyOf(:class:`Categorical`, :class:`SequentialSingleHue`, :class:`SequentialMultiHue`,
- :class:`Diverging`, :class:`Cyclical`)
- """
- _schema = {'$ref': '#/definitions/ColorScheme'}
-
- def __init__(self, *args, **kwds):
- super(ColorScheme, self).__init__(*args, **kwds)
-
-
-class Categorical(ColorScheme):
- """Categorical schema wrapper
-
- enum('accent', 'category10', 'category20', 'category20b', 'category20c', 'dark2', 'paired',
- 'pastel1', 'pastel2', 'set1', 'set2', 'set3', 'tableau10', 'tableau20')
- """
- _schema = {'$ref': '#/definitions/Categorical'}
-
- def __init__(self, *args):
- super(Categorical, self).__init__(*args)
-
-
-class CompositeMark(AnyMark):
- """CompositeMark schema wrapper
-
- anyOf(:class:`BoxPlot`, :class:`ErrorBar`, :class:`ErrorBand`)
- """
- _schema = {'$ref': '#/definitions/CompositeMark'}
-
- def __init__(self, *args, **kwds):
- super(CompositeMark, self).__init__(*args, **kwds)
-
-
-class BoxPlot(CompositeMark):
- """BoxPlot schema wrapper
-
- string
- """
- _schema = {'$ref': '#/definitions/BoxPlot'}
-
- def __init__(self, *args):
- super(BoxPlot, self).__init__(*args)
-
-
-class CompositeMarkDef(AnyMark):
- """CompositeMarkDef schema wrapper
-
- anyOf(:class:`BoxPlotDef`, :class:`ErrorBarDef`, :class:`ErrorBandDef`)
- """
- _schema = {'$ref': '#/definitions/CompositeMarkDef'}
-
- def __init__(self, *args, **kwds):
- super(CompositeMarkDef, self).__init__(*args, **kwds)
-
-
-class BoxPlotDef(CompositeMarkDef):
- """BoxPlotDef schema wrapper
-
- Mapping(required=[type])
-
- Parameters
- ----------
-
- type : :class:`BoxPlot`
- The mark type. This could a primitive mark type (one of ``"bar"``, ``"circle"``,
- ``"square"``, ``"tick"``, ``"line"``, ``"area"``, ``"point"``, ``"geoshape"``,
- ``"rule"``, and ``"text"`` ) or a composite mark type ( ``"boxplot"``,
- ``"errorband"``, ``"errorbar"`` ).
- box : anyOf(boolean, :class:`AnyMarkConfig`)
-
- clip : boolean
- Whether a composite mark be clipped to the enclosing group’s width and height.
- color : anyOf(:class:`Color`, :class:`Gradient`, :class:`ExprRef`)
- Default color.
-
- **Default value:** :raw-html:`■`
- ``"#4682b4"``
-
- **Note:**
-
-
- * This property cannot be used in a `style config
- `__.
- * The ``fill`` and ``stroke`` properties have higher precedence than ``color`` and
- will override ``color``.
- extent : anyOf(string, float)
- The extent of the whiskers. Available options include:
-
-
- * ``"min-max"`` : min and max are the lower and upper whiskers respectively.
- * A number representing multiple of the interquartile range. This number will be
- multiplied by the IQR to determine whisker boundary, which spans from the smallest
- data to the largest data within the range *[Q1 - k * IQR, Q3 + k * IQR]* where
- *Q1* and *Q3* are the first and third quartiles while *IQR* is the interquartile
- range ( *Q3-Q1* ).
-
- **Default value:** ``1.5``.
- invalid : enum('filter', None)
- Defines how Vega-Lite should handle marks for invalid values ( ``null`` and ``NaN``
- ).
-
-
- * If set to ``"filter"`` (default), all data items with null values will be skipped
- (for line, trail, and area marks) or filtered (for other marks).
- * If ``null``, all data items are included. In this case, invalid values will be
- interpreted as zeroes.
- median : anyOf(boolean, :class:`AnyMarkConfig`)
-
- opacity : float
- The opacity (value between [0,1]) of the mark.
- orient : :class:`Orientation`
- Orientation of the box plot. This is normally automatically determined based on
- types of fields on x and y channels. However, an explicit ``orient`` be specified
- when the orientation is ambiguous.
-
- **Default value:** ``"vertical"``.
- outliers : anyOf(boolean, :class:`AnyMarkConfig`)
-
- rule : anyOf(boolean, :class:`AnyMarkConfig`)
-
- size : float
- Size of the box and median tick of a box plot
- ticks : anyOf(boolean, :class:`AnyMarkConfig`)
-
- """
- _schema = {'$ref': '#/definitions/BoxPlotDef'}
-
- def __init__(self, type=Undefined, box=Undefined, clip=Undefined, color=Undefined, extent=Undefined,
- invalid=Undefined, median=Undefined, opacity=Undefined, orient=Undefined,
- outliers=Undefined, rule=Undefined, size=Undefined, ticks=Undefined, **kwds):
- super(BoxPlotDef, self).__init__(type=type, box=box, clip=clip, color=color, extent=extent,
- invalid=invalid, median=median, opacity=opacity, orient=orient,
- outliers=outliers, rule=rule, size=size, ticks=ticks, **kwds)
-
-
-class CompositionConfig(VegaLiteSchema):
- """CompositionConfig schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- columns : float
- The number of columns to include in the view composition layout.
-
- **Default value** : ``undefined`` -- An infinite number of columns (a single row)
- will be assumed. This is equivalent to ``hconcat`` (for ``concat`` ) and to using
- the ``column`` channel (for ``facet`` and ``repeat`` ).
-
- **Note** :
-
- 1) This property is only for:
-
-
- * the general (wrappable) ``concat`` operator (not ``hconcat`` / ``vconcat`` )
- * the ``facet`` and ``repeat`` operator with one field/repetition definition
- (without row/column nesting)
-
- 2) Setting the ``columns`` to ``1`` is equivalent to ``vconcat`` (for ``concat`` )
- and to using the ``row`` channel (for ``facet`` and ``repeat`` ).
- spacing : float
- The default spacing in pixels between composed sub-views.
-
- **Default value** : ``20``
- """
- _schema = {'$ref': '#/definitions/CompositionConfig'}
-
- def __init__(self, columns=Undefined, spacing=Undefined, **kwds):
- super(CompositionConfig, self).__init__(columns=columns, spacing=spacing, **kwds)
-
-
-class ConditionalAxisColor(VegaLiteSchema):
- """ConditionalAxisColor schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisColor'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisColor, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisLabelAlign(VegaLiteSchema):
- """ConditionalAxisLabelAlign schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisLabelAlign'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisLabelAlign, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisLabelBaseline(VegaLiteSchema):
- """ConditionalAxisLabelBaseline schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisLabelBaseline'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisLabelBaseline, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisLabelFontStyle(VegaLiteSchema):
- """ConditionalAxisLabelFontStyle schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisLabelFontStyle'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisLabelFontStyle, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisLabelFontWeight(VegaLiteSchema):
- """ConditionalAxisLabelFontWeight schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisLabelFontWeight'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisLabelFontWeight, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisNumber(VegaLiteSchema):
- """ConditionalAxisNumber schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisNumber'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisNumber, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisNumberArray(VegaLiteSchema):
- """ConditionalAxisNumberArray schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisNumberArray'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisNumberArray, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisPropertyAlignnull(VegaLiteSchema):
- """ConditionalAxisPropertyAlignnull schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisProperty<(Align|null)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisPropertyAlignnull, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisPropertyColornull(VegaLiteSchema):
- """ConditionalAxisPropertyColornull schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisProperty<(Color|null)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisPropertyColornull, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisPropertyFontStylenull(VegaLiteSchema):
- """ConditionalAxisPropertyFontStylenull schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisProperty<(FontStyle|null)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisPropertyFontStylenull, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisPropertyFontWeightnull(VegaLiteSchema):
- """ConditionalAxisPropertyFontWeightnull schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisProperty<(FontWeight|null)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisPropertyFontWeightnull, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisPropertyTextBaselinenull(VegaLiteSchema):
- """ConditionalAxisPropertyTextBaselinenull schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisProperty<(TextBaseline|null)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisPropertyTextBaselinenull, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisPropertynumberArraynull(VegaLiteSchema):
- """ConditionalAxisPropertynumberArraynull schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisProperty<(number[]|null)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisPropertynumberArraynull, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisPropertynumbernull(VegaLiteSchema):
- """ConditionalAxisPropertynumbernull schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisProperty<(number|null)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisPropertynumbernull, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisPropertystringnull(VegaLiteSchema):
- """ConditionalAxisPropertystringnull schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisProperty<(string|null)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisPropertystringnull, self).__init__(*args, **kwds)
-
-
-class ConditionalAxisString(VegaLiteSchema):
- """ConditionalAxisString schema wrapper
-
- anyOf(Mapping(required=[condition, value]), Mapping(required=[condition, expr]))
- """
- _schema = {'$ref': '#/definitions/ConditionalAxisString'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalAxisString, self).__init__(*args, **kwds)
-
-
-class ConditionalMarkPropFieldOrDatumDef(VegaLiteSchema):
- """ConditionalMarkPropFieldOrDatumDef schema wrapper
-
- anyOf(:class:`ConditionalPredicateMarkPropFieldOrDatumDef`,
- :class:`ConditionalParameterMarkPropFieldOrDatumDef`)
- """
- _schema = {'$ref': '#/definitions/ConditionalMarkPropFieldOrDatumDef'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalMarkPropFieldOrDatumDef, self).__init__(*args, **kwds)
-
-
-class ConditionalMarkPropFieldOrDatumDefTypeForShape(VegaLiteSchema):
- """ConditionalMarkPropFieldOrDatumDefTypeForShape schema wrapper
-
- anyOf(:class:`ConditionalPredicateMarkPropFieldOrDatumDefTypeForShape`,
- :class:`ConditionalParameterMarkPropFieldOrDatumDefTypeForShape`)
- """
- _schema = {'$ref': '#/definitions/ConditionalMarkPropFieldOrDatumDef'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalMarkPropFieldOrDatumDefTypeForShape, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterMarkPropFieldOrDatumDef(ConditionalMarkPropFieldOrDatumDef):
- """ConditionalParameterMarkPropFieldOrDatumDef schema wrapper
-
- anyOf(Mapping(required=[param]), Mapping(required=[param]))
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalParameterMarkPropFieldOrDatumDef, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterMarkPropFieldOrDatumDefTypeForShape(ConditionalMarkPropFieldOrDatumDefTypeForShape):
- """ConditionalParameterMarkPropFieldOrDatumDefTypeForShape schema wrapper
-
- anyOf(Mapping(required=[param]), Mapping(required=[param]))
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalParameterMarkPropFieldOrDatumDefTypeForShape, self).__init__(*args, **kwds)
-
-
-class ConditionalPredicateMarkPropFieldOrDatumDef(ConditionalMarkPropFieldOrDatumDef):
- """ConditionalPredicateMarkPropFieldOrDatumDef schema wrapper
-
- anyOf(Mapping(required=[test]), Mapping(required=[test]))
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalPredicateMarkPropFieldOrDatumDef, self).__init__(*args, **kwds)
-
-
-class ConditionalPredicateMarkPropFieldOrDatumDefTypeForShape(ConditionalMarkPropFieldOrDatumDefTypeForShape):
- """ConditionalPredicateMarkPropFieldOrDatumDefTypeForShape schema wrapper
-
- anyOf(Mapping(required=[test]), Mapping(required=[test]))
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalPredicateMarkPropFieldOrDatumDefTypeForShape, self).__init__(*args, **kwds)
-
-
-class ConditionalPredicateValueDefAlignnullExprRef(VegaLiteSchema):
- """ConditionalPredicateValueDefAlignnullExprRef schema wrapper
-
- anyOf(Mapping(required=[test, value]), Mapping(required=[expr, test]))
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate<(ValueDef<(Align|null)>|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalPredicateValueDefAlignnullExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalPredicateValueDefColornullExprRef(VegaLiteSchema):
- """ConditionalPredicateValueDefColornullExprRef schema wrapper
-
- anyOf(Mapping(required=[test, value]), Mapping(required=[expr, test]))
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate<(ValueDef<(Color|null)>|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalPredicateValueDefColornullExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalPredicateValueDefFontStylenullExprRef(VegaLiteSchema):
- """ConditionalPredicateValueDefFontStylenullExprRef schema wrapper
-
- anyOf(Mapping(required=[test, value]), Mapping(required=[expr, test]))
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate<(ValueDef<(FontStyle|null)>|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalPredicateValueDefFontStylenullExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalPredicateValueDefFontWeightnullExprRef(VegaLiteSchema):
- """ConditionalPredicateValueDefFontWeightnullExprRef schema wrapper
-
- anyOf(Mapping(required=[test, value]), Mapping(required=[expr, test]))
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate<(ValueDef<(FontWeight|null)>|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalPredicateValueDefFontWeightnullExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalPredicateValueDefTextBaselinenullExprRef(VegaLiteSchema):
- """ConditionalPredicateValueDefTextBaselinenullExprRef schema wrapper
-
- anyOf(Mapping(required=[test, value]), Mapping(required=[expr, test]))
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate<(ValueDef<(TextBaseline|null)>|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalPredicateValueDefTextBaselinenullExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalPredicateValueDefnumberArraynullExprRef(VegaLiteSchema):
- """ConditionalPredicateValueDefnumberArraynullExprRef schema wrapper
-
- anyOf(Mapping(required=[test, value]), Mapping(required=[expr, test]))
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate<(ValueDef<(number[]|null)>|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalPredicateValueDefnumberArraynullExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalPredicateValueDefnumbernullExprRef(VegaLiteSchema):
- """ConditionalPredicateValueDefnumbernullExprRef schema wrapper
-
- anyOf(Mapping(required=[test, value]), Mapping(required=[expr, test]))
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate<(ValueDef<(number|null)>|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalPredicateValueDefnumbernullExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalStringFieldDef(VegaLiteSchema):
- """ConditionalStringFieldDef schema wrapper
-
- anyOf(:class:`ConditionalPredicateStringFieldDef`,
- :class:`ConditionalParameterStringFieldDef`)
- """
- _schema = {'$ref': '#/definitions/ConditionalStringFieldDef'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalStringFieldDef, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterStringFieldDef(ConditionalStringFieldDef):
- """ConditionalParameterStringFieldDef schema wrapper
-
- Mapping(required=[param])
-
- Parameters
- ----------
-
- param : :class:`ParameterName`
- Filter using a parameter name.
- aggregate : :class:`Aggregate`
- Aggregation function for the field (e.g., ``"mean"``, ``"sum"``, ``"median"``,
- ``"min"``, ``"max"``, ``"count"`` ).
-
- **Default value:** ``undefined`` (None)
-
- **See also:** `aggregate `__
- documentation.
- bandPosition : float
- Relative position on a band of a stacked, binned, time unit, or band scale. For
- example, the marks will be positioned at the beginning of the band if set to ``0``,
- and at the middle of the band if set to ``0.5``.
- bin : anyOf(boolean, :class:`BinParams`, string, None)
- A flag for binning a ``quantitative`` field, `an object defining binning parameters
- `__, or indicating
- that the data for ``x`` or ``y`` channel are binned before they are imported into
- Vega-Lite ( ``"binned"`` ).
-
-
- If ``true``, default `binning parameters
- `__ will be applied.
-
- If ``"binned"``, this indicates that the data for the ``x`` (or ``y`` ) channel are
- already binned. You can map the bin-start field to ``x`` (or ``y`` ) and the bin-end
- field to ``x2`` (or ``y2`` ). The scale and axis will be formatted similar to
- binning in Vega-Lite. To adjust the axis ticks based on the bin step, you can also
- set the axis's `tickMinStep
- `__ property.
-
- **Default value:** ``false``
-
- **See also:** `bin `__
- documentation.
- empty : boolean
- For selection parameters, the predicate of empty selections returns true by default.
- Override this behavior, by setting this property ``empty: false``.
- field : :class:`Field`
- **Required.** A string defining the name of the field from which to pull a data
- value or an object defining iterated values from the `repeat
- `__ operator.
-
- **See also:** `field `__
- documentation.
-
- **Notes:** 1) Dots ( ``.`` ) and brackets ( ``[`` and ``]`` ) can be used to access
- nested objects (e.g., ``"field": "foo.bar"`` and ``"field": "foo['bar']"`` ). If
- field names contain dots or brackets but are not nested, you can use ``\\`` to
- escape dots and brackets (e.g., ``"a\\.b"`` and ``"a\\[0\\]"`` ). See more details
- about escaping in the `field documentation
- `__. 2) ``field`` is not required
- if ``aggregate`` is ``count``.
- format : anyOf(string, :class:`Dict`)
- When used with the default ``"number"`` and ``"time"`` format type, the text
- formatting pattern for labels of guides (axes, legends, headers) and text marks.
-
-
- * If the format type is ``"number"`` (e.g., for quantitative fields), this is D3's
- `number format pattern `__.
- * If the format type is ``"time"`` (e.g., for temporal fields), this is D3's `time
- format pattern `__.
-
- See the `format documentation `__
- for more examples.
-
- When used with a `custom formatType
- `__, this
- value will be passed as ``format`` alongside ``datum.value`` to the registered
- function.
-
- **Default value:** Derived from `numberFormat
- `__ config for number
- format and from `timeFormat
- `__ config for time
- format.
- formatType : string
- The format type for labels. One of ``"number"``, ``"time"``, or a `registered custom
- format type
- `__.
-
- **Default value:**
-
-
- * ``"time"`` for temporal fields and ordinal and nominal fields with ``timeUnit``.
- * ``"number"`` for quantitative fields as well as ordinal and nominal fields without
- ``timeUnit``.
- timeUnit : anyOf(:class:`TimeUnit`, :class:`TimeUnitParams`)
- Time unit (e.g., ``year``, ``yearmonth``, ``month``, ``hours`` ) for a temporal
- field. or `a temporal field that gets casted as ordinal
- `__.
-
- **Default value:** ``undefined`` (None)
-
- **See also:** `timeUnit `__
- documentation.
- title : anyOf(:class:`Text`, None)
- A title for the field. If ``null``, the title will be removed.
-
- **Default value:** derived from the field's name and transformation function (
- ``aggregate``, ``bin`` and ``timeUnit`` ). If the field has an aggregate function,
- the function is displayed as part of the title (e.g., ``"Sum of Profit"`` ). If the
- field is binned or has a time unit applied, the applied function is shown in
- parentheses (e.g., ``"Profit (binned)"``, ``"Transaction Date (year-month)"`` ).
- Otherwise, the title is simply the field name.
-
- **Notes** :
-
- 1) You can customize the default field title format by providing the `fieldTitle
- `__ property in
- the `config `__ or `fieldTitle
- function via the compile function's options
- `__.
-
- 2) If both field definition's ``title`` and axis, header, or legend ``title`` are
- defined, axis/header/legend title will be used.
- type : :class:`StandardType`
- The type of measurement ( ``"quantitative"``, ``"temporal"``, ``"ordinal"``, or
- ``"nominal"`` ) for the encoded field or constant value ( ``datum`` ). It can also
- be a ``"geojson"`` type for encoding `'geoshape'
- `__.
-
- Vega-Lite automatically infers data types in many cases as discussed below. However,
- type is required for a field if: (1) the field is not nominal and the field encoding
- has no specified ``aggregate`` (except ``argmin`` and ``argmax`` ), ``bin``, scale
- type, custom ``sort`` order, nor ``timeUnit`` or (2) if you wish to use an ordinal
- scale for a field with ``bin`` or ``timeUnit``.
-
- **Default value:**
-
- 1) For a data ``field``, ``"nominal"`` is the default data type unless the field
- encoding has ``aggregate``, ``channel``, ``bin``, scale type, ``sort``, or
- ``timeUnit`` that satisfies the following criteria:
-
-
- * ``"quantitative"`` is the default type if (1) the encoded field contains ``bin``
- or ``aggregate`` except ``"argmin"`` and ``"argmax"``, (2) the encoding channel is
- ``latitude`` or ``longitude`` channel or (3) if the specified scale type is `a
- quantitative scale `__.
- * ``"temporal"`` is the default type if (1) the encoded field contains ``timeUnit``
- or (2) the specified scale type is a time or utc scale
- * ``"ordinal"`` is the default type if (1) the encoded field contains a `custom sort
- order
- `__,
- (2) the specified scale type is an ordinal/point/band scale, or (3) the encoding
- channel is ``order``.
-
- 2) For a constant value in data domain ( ``datum`` ):
-
-
- * ``"quantitative"`` if the datum is a number
- * ``"nominal"`` if the datum is a string
- * ``"temporal"`` if the datum is `a date time object
- `__
-
- **Note:**
-
-
- * Data ``type`` describes the semantics of the data rather than the primitive data
- types (number, string, etc.). The same primitive data type can have different
- types of measurement. For example, numeric data can represent quantitative,
- ordinal, or nominal data.
- * Data values for a temporal field can be either a date-time string (e.g.,
- ``"2015-03-07 12:32:17"``, ``"17:01"``, ``"2015-03-16"``. ``"2015"`` ) or a
- timestamp number (e.g., ``1552199579097`` ).
- * When using with `bin `__, the
- ``type`` property can be either ``"quantitative"`` (for using a linear bin scale)
- or `"ordinal" (for using an ordinal bin scale)
- `__.
- * When using with `timeUnit
- `__, the ``type`` property
- can be either ``"temporal"`` (default, for using a temporal scale) or `"ordinal"
- (for using an ordinal scale)
- `__.
- * When using with `aggregate
- `__, the ``type`` property
- refers to the post-aggregation data type. For example, we can calculate count
- ``distinct`` of a categorical field ``"cat"`` using ``{"aggregate": "distinct",
- "field": "cat"}``. The ``"type"`` of the aggregate output is ``"quantitative"``.
- * Secondary channels (e.g., ``x2``, ``y2``, ``xError``, ``yError`` ) do not have
- ``type`` as they must have exactly the same type as their primary channels (e.g.,
- ``x``, ``y`` ).
-
- **See also:** `type `__
- documentation.
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter'}
-
- def __init__(self, param=Undefined, aggregate=Undefined, bandPosition=Undefined, bin=Undefined,
- empty=Undefined, field=Undefined, format=Undefined, formatType=Undefined,
- timeUnit=Undefined, title=Undefined, type=Undefined, **kwds):
- super(ConditionalParameterStringFieldDef, self).__init__(param=param, aggregate=aggregate,
- bandPosition=bandPosition, bin=bin,
- empty=empty, field=field,
- format=format, formatType=formatType,
- timeUnit=timeUnit, title=title,
- type=type, **kwds)
-
-
-class ConditionalPredicateStringFieldDef(ConditionalStringFieldDef):
- """ConditionalPredicateStringFieldDef schema wrapper
-
- Mapping(required=[test])
-
- Parameters
- ----------
-
- test : :class:`PredicateComposition`
- Predicate for triggering the condition
- aggregate : :class:`Aggregate`
- Aggregation function for the field (e.g., ``"mean"``, ``"sum"``, ``"median"``,
- ``"min"``, ``"max"``, ``"count"`` ).
-
- **Default value:** ``undefined`` (None)
-
- **See also:** `aggregate `__
- documentation.
- bandPosition : float
- Relative position on a band of a stacked, binned, time unit, or band scale. For
- example, the marks will be positioned at the beginning of the band if set to ``0``,
- and at the middle of the band if set to ``0.5``.
- bin : anyOf(boolean, :class:`BinParams`, string, None)
- A flag for binning a ``quantitative`` field, `an object defining binning parameters
- `__, or indicating
- that the data for ``x`` or ``y`` channel are binned before they are imported into
- Vega-Lite ( ``"binned"`` ).
-
-
- If ``true``, default `binning parameters
- `__ will be applied.
-
- If ``"binned"``, this indicates that the data for the ``x`` (or ``y`` ) channel are
- already binned. You can map the bin-start field to ``x`` (or ``y`` ) and the bin-end
- field to ``x2`` (or ``y2`` ). The scale and axis will be formatted similar to
- binning in Vega-Lite. To adjust the axis ticks based on the bin step, you can also
- set the axis's `tickMinStep
- `__ property.
-
- **Default value:** ``false``
-
- **See also:** `bin `__
- documentation.
- field : :class:`Field`
- **Required.** A string defining the name of the field from which to pull a data
- value or an object defining iterated values from the `repeat
- `__ operator.
-
- **See also:** `field `__
- documentation.
-
- **Notes:** 1) Dots ( ``.`` ) and brackets ( ``[`` and ``]`` ) can be used to access
- nested objects (e.g., ``"field": "foo.bar"`` and ``"field": "foo['bar']"`` ). If
- field names contain dots or brackets but are not nested, you can use ``\\`` to
- escape dots and brackets (e.g., ``"a\\.b"`` and ``"a\\[0\\]"`` ). See more details
- about escaping in the `field documentation
- `__. 2) ``field`` is not required
- if ``aggregate`` is ``count``.
- format : anyOf(string, :class:`Dict`)
- When used with the default ``"number"`` and ``"time"`` format type, the text
- formatting pattern for labels of guides (axes, legends, headers) and text marks.
-
-
- * If the format type is ``"number"`` (e.g., for quantitative fields), this is D3's
- `number format pattern `__.
- * If the format type is ``"time"`` (e.g., for temporal fields), this is D3's `time
- format pattern `__.
-
- See the `format documentation `__
- for more examples.
-
- When used with a `custom formatType
- `__, this
- value will be passed as ``format`` alongside ``datum.value`` to the registered
- function.
-
- **Default value:** Derived from `numberFormat
- `__ config for number
- format and from `timeFormat
- `__ config for time
- format.
- formatType : string
- The format type for labels. One of ``"number"``, ``"time"``, or a `registered custom
- format type
- `__.
-
- **Default value:**
-
-
- * ``"time"`` for temporal fields and ordinal and nominal fields with ``timeUnit``.
- * ``"number"`` for quantitative fields as well as ordinal and nominal fields without
- ``timeUnit``.
- timeUnit : anyOf(:class:`TimeUnit`, :class:`TimeUnitParams`)
- Time unit (e.g., ``year``, ``yearmonth``, ``month``, ``hours`` ) for a temporal
- field. or `a temporal field that gets casted as ordinal
- `__.
-
- **Default value:** ``undefined`` (None)
-
- **See also:** `timeUnit `__
- documentation.
- title : anyOf(:class:`Text`, None)
- A title for the field. If ``null``, the title will be removed.
-
- **Default value:** derived from the field's name and transformation function (
- ``aggregate``, ``bin`` and ``timeUnit`` ). If the field has an aggregate function,
- the function is displayed as part of the title (e.g., ``"Sum of Profit"`` ). If the
- field is binned or has a time unit applied, the applied function is shown in
- parentheses (e.g., ``"Profit (binned)"``, ``"Transaction Date (year-month)"`` ).
- Otherwise, the title is simply the field name.
-
- **Notes** :
-
- 1) You can customize the default field title format by providing the `fieldTitle
- `__ property in
- the `config `__ or `fieldTitle
- function via the compile function's options
- `__.
-
- 2) If both field definition's ``title`` and axis, header, or legend ``title`` are
- defined, axis/header/legend title will be used.
- type : :class:`StandardType`
- The type of measurement ( ``"quantitative"``, ``"temporal"``, ``"ordinal"``, or
- ``"nominal"`` ) for the encoded field or constant value ( ``datum`` ). It can also
- be a ``"geojson"`` type for encoding `'geoshape'
- `__.
-
- Vega-Lite automatically infers data types in many cases as discussed below. However,
- type is required for a field if: (1) the field is not nominal and the field encoding
- has no specified ``aggregate`` (except ``argmin`` and ``argmax`` ), ``bin``, scale
- type, custom ``sort`` order, nor ``timeUnit`` or (2) if you wish to use an ordinal
- scale for a field with ``bin`` or ``timeUnit``.
-
- **Default value:**
-
- 1) For a data ``field``, ``"nominal"`` is the default data type unless the field
- encoding has ``aggregate``, ``channel``, ``bin``, scale type, ``sort``, or
- ``timeUnit`` that satisfies the following criteria:
-
-
- * ``"quantitative"`` is the default type if (1) the encoded field contains ``bin``
- or ``aggregate`` except ``"argmin"`` and ``"argmax"``, (2) the encoding channel is
- ``latitude`` or ``longitude`` channel or (3) if the specified scale type is `a
- quantitative scale `__.
- * ``"temporal"`` is the default type if (1) the encoded field contains ``timeUnit``
- or (2) the specified scale type is a time or utc scale
- * ``"ordinal"`` is the default type if (1) the encoded field contains a `custom sort
- order
- `__,
- (2) the specified scale type is an ordinal/point/band scale, or (3) the encoding
- channel is ``order``.
-
- 2) For a constant value in data domain ( ``datum`` ):
-
-
- * ``"quantitative"`` if the datum is a number
- * ``"nominal"`` if the datum is a string
- * ``"temporal"`` if the datum is `a date time object
- `__
-
- **Note:**
-
-
- * Data ``type`` describes the semantics of the data rather than the primitive data
- types (number, string, etc.). The same primitive data type can have different
- types of measurement. For example, numeric data can represent quantitative,
- ordinal, or nominal data.
- * Data values for a temporal field can be either a date-time string (e.g.,
- ``"2015-03-07 12:32:17"``, ``"17:01"``, ``"2015-03-16"``. ``"2015"`` ) or a
- timestamp number (e.g., ``1552199579097`` ).
- * When using with `bin `__, the
- ``type`` property can be either ``"quantitative"`` (for using a linear bin scale)
- or `"ordinal" (for using an ordinal bin scale)
- `__.
- * When using with `timeUnit
- `__, the ``type`` property
- can be either ``"temporal"`` (default, for using a temporal scale) or `"ordinal"
- (for using an ordinal scale)
- `__.
- * When using with `aggregate
- `__, the ``type`` property
- refers to the post-aggregation data type. For example, we can calculate count
- ``distinct`` of a categorical field ``"cat"`` using ``{"aggregate": "distinct",
- "field": "cat"}``. The ``"type"`` of the aggregate output is ``"quantitative"``.
- * Secondary channels (e.g., ``x2``, ``y2``, ``xError``, ``yError`` ) do not have
- ``type`` as they must have exactly the same type as their primary channels (e.g.,
- ``x``, ``y`` ).
-
- **See also:** `type `__
- documentation.
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate'}
-
- def __init__(self, test=Undefined, aggregate=Undefined, bandPosition=Undefined, bin=Undefined,
- field=Undefined, format=Undefined, formatType=Undefined, timeUnit=Undefined,
- title=Undefined, type=Undefined, **kwds):
- super(ConditionalPredicateStringFieldDef, self).__init__(test=test, aggregate=aggregate,
- bandPosition=bandPosition, bin=bin,
- field=field, format=format,
- formatType=formatType,
- timeUnit=timeUnit, title=title,
- type=type, **kwds)
-
-
-class ConditionalValueDefGradientstringnullExprRef(VegaLiteSchema):
- """ConditionalValueDefGradientstringnullExprRef schema wrapper
-
- anyOf(:class:`ConditionalPredicateValueDefGradientstringnullExprRef`,
- :class:`ConditionalParameterValueDefGradientstringnullExprRef`)
- """
- _schema = {'$ref': '#/definitions/ConditionalValueDef<(Gradient|string|null|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalValueDefGradientstringnullExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterValueDefGradientstringnullExprRef(ConditionalValueDefGradientstringnullExprRef):
- """ConditionalParameterValueDefGradientstringnullExprRef schema wrapper
-
- Mapping(required=[param, value])
-
- Parameters
- ----------
-
- param : :class:`ParameterName`
- Filter using a parameter name.
- value : anyOf(:class:`Gradient`, string, None, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- empty : boolean
- For selection parameters, the predicate of empty selections returns true by default.
- Override this behavior, by setting this property ``empty: false``.
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter>'}
-
- def __init__(self, param=Undefined, value=Undefined, empty=Undefined, **kwds):
- super(ConditionalParameterValueDefGradientstringnullExprRef, self).__init__(param=param,
- value=value,
- empty=empty, **kwds)
-
-
-class ConditionalPredicateValueDefGradientstringnullExprRef(ConditionalValueDefGradientstringnullExprRef):
- """ConditionalPredicateValueDefGradientstringnullExprRef schema wrapper
-
- Mapping(required=[test, value])
-
- Parameters
- ----------
-
- test : :class:`PredicateComposition`
- Predicate for triggering the condition
- value : anyOf(:class:`Gradient`, string, None, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate>'}
-
- def __init__(self, test=Undefined, value=Undefined, **kwds):
- super(ConditionalPredicateValueDefGradientstringnullExprRef, self).__init__(test=test,
- value=value, **kwds)
-
-
-class ConditionalValueDefTextExprRef(VegaLiteSchema):
- """ConditionalValueDefTextExprRef schema wrapper
-
- anyOf(:class:`ConditionalPredicateValueDefTextExprRef`,
- :class:`ConditionalParameterValueDefTextExprRef`)
- """
- _schema = {'$ref': '#/definitions/ConditionalValueDef<(Text|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalValueDefTextExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterValueDefTextExprRef(ConditionalValueDefTextExprRef):
- """ConditionalParameterValueDefTextExprRef schema wrapper
-
- Mapping(required=[param, value])
-
- Parameters
- ----------
-
- param : :class:`ParameterName`
- Filter using a parameter name.
- value : anyOf(:class:`Text`, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- empty : boolean
- For selection parameters, the predicate of empty selections returns true by default.
- Override this behavior, by setting this property ``empty: false``.
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter>'}
-
- def __init__(self, param=Undefined, value=Undefined, empty=Undefined, **kwds):
- super(ConditionalParameterValueDefTextExprRef, self).__init__(param=param, value=value,
- empty=empty, **kwds)
-
-
-class ConditionalPredicateValueDefTextExprRef(ConditionalValueDefTextExprRef):
- """ConditionalPredicateValueDefTextExprRef schema wrapper
-
- Mapping(required=[test, value])
-
- Parameters
- ----------
-
- test : :class:`PredicateComposition`
- Predicate for triggering the condition
- value : anyOf(:class:`Text`, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate>'}
-
- def __init__(self, test=Undefined, value=Undefined, **kwds):
- super(ConditionalPredicateValueDefTextExprRef, self).__init__(test=test, value=value, **kwds)
-
-
-class ConditionalValueDefnumber(VegaLiteSchema):
- """ConditionalValueDefnumber schema wrapper
-
- anyOf(:class:`ConditionalPredicateValueDefnumber`,
- :class:`ConditionalParameterValueDefnumber`)
- """
- _schema = {'$ref': '#/definitions/ConditionalValueDef'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalValueDefnumber, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterValueDefnumber(ConditionalValueDefnumber):
- """ConditionalParameterValueDefnumber schema wrapper
-
- Mapping(required=[param, value])
-
- Parameters
- ----------
-
- param : :class:`ParameterName`
- Filter using a parameter name.
- value : float
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- empty : boolean
- For selection parameters, the predicate of empty selections returns true by default.
- Override this behavior, by setting this property ``empty: false``.
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter>'}
-
- def __init__(self, param=Undefined, value=Undefined, empty=Undefined, **kwds):
- super(ConditionalParameterValueDefnumber, self).__init__(param=param, value=value, empty=empty,
- **kwds)
-
-
-class ConditionalPredicateValueDefnumber(ConditionalValueDefnumber):
- """ConditionalPredicateValueDefnumber schema wrapper
-
- Mapping(required=[test, value])
-
- Parameters
- ----------
-
- test : :class:`PredicateComposition`
- Predicate for triggering the condition
- value : float
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate>'}
-
- def __init__(self, test=Undefined, value=Undefined, **kwds):
- super(ConditionalPredicateValueDefnumber, self).__init__(test=test, value=value, **kwds)
-
-
-class ConditionalValueDefnumberArrayExprRef(VegaLiteSchema):
- """ConditionalValueDefnumberArrayExprRef schema wrapper
-
- anyOf(:class:`ConditionalPredicateValueDefnumberArrayExprRef`,
- :class:`ConditionalParameterValueDefnumberArrayExprRef`)
- """
- _schema = {'$ref': '#/definitions/ConditionalValueDef<(number[]|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalValueDefnumberArrayExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterValueDefnumberArrayExprRef(ConditionalValueDefnumberArrayExprRef):
- """ConditionalParameterValueDefnumberArrayExprRef schema wrapper
-
- Mapping(required=[param, value])
-
- Parameters
- ----------
-
- param : :class:`ParameterName`
- Filter using a parameter name.
- value : anyOf(List(float), :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- empty : boolean
- For selection parameters, the predicate of empty selections returns true by default.
- Override this behavior, by setting this property ``empty: false``.
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter>'}
-
- def __init__(self, param=Undefined, value=Undefined, empty=Undefined, **kwds):
- super(ConditionalParameterValueDefnumberArrayExprRef, self).__init__(param=param, value=value,
- empty=empty, **kwds)
-
-
-class ConditionalPredicateValueDefnumberArrayExprRef(ConditionalValueDefnumberArrayExprRef):
- """ConditionalPredicateValueDefnumberArrayExprRef schema wrapper
-
- Mapping(required=[test, value])
-
- Parameters
- ----------
-
- test : :class:`PredicateComposition`
- Predicate for triggering the condition
- value : anyOf(List(float), :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate>'}
-
- def __init__(self, test=Undefined, value=Undefined, **kwds):
- super(ConditionalPredicateValueDefnumberArrayExprRef, self).__init__(test=test, value=value,
- **kwds)
-
-
-class ConditionalValueDefnumberExprRef(VegaLiteSchema):
- """ConditionalValueDefnumberExprRef schema wrapper
-
- anyOf(:class:`ConditionalPredicateValueDefnumberExprRef`,
- :class:`ConditionalParameterValueDefnumberExprRef`)
- """
- _schema = {'$ref': '#/definitions/ConditionalValueDef<(number|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalValueDefnumberExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterValueDefnumberExprRef(ConditionalValueDefnumberExprRef):
- """ConditionalParameterValueDefnumberExprRef schema wrapper
-
- Mapping(required=[param, value])
-
- Parameters
- ----------
-
- param : :class:`ParameterName`
- Filter using a parameter name.
- value : anyOf(float, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- empty : boolean
- For selection parameters, the predicate of empty selections returns true by default.
- Override this behavior, by setting this property ``empty: false``.
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter>'}
-
- def __init__(self, param=Undefined, value=Undefined, empty=Undefined, **kwds):
- super(ConditionalParameterValueDefnumberExprRef, self).__init__(param=param, value=value,
- empty=empty, **kwds)
-
-
-class ConditionalPredicateValueDefnumberExprRef(ConditionalValueDefnumberExprRef):
- """ConditionalPredicateValueDefnumberExprRef schema wrapper
-
- Mapping(required=[test, value])
-
- Parameters
- ----------
-
- test : :class:`PredicateComposition`
- Predicate for triggering the condition
- value : anyOf(float, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate>'}
-
- def __init__(self, test=Undefined, value=Undefined, **kwds):
- super(ConditionalPredicateValueDefnumberExprRef, self).__init__(test=test, value=value, **kwds)
-
-
-class ConditionalValueDefstringExprRef(VegaLiteSchema):
- """ConditionalValueDefstringExprRef schema wrapper
-
- anyOf(:class:`ConditionalPredicateValueDefstringExprRef`,
- :class:`ConditionalParameterValueDefstringExprRef`)
- """
- _schema = {'$ref': '#/definitions/ConditionalValueDef<(string|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalValueDefstringExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterValueDefstringExprRef(ConditionalValueDefstringExprRef):
- """ConditionalParameterValueDefstringExprRef schema wrapper
-
- Mapping(required=[param, value])
-
- Parameters
- ----------
-
- param : :class:`ParameterName`
- Filter using a parameter name.
- value : anyOf(string, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- empty : boolean
- For selection parameters, the predicate of empty selections returns true by default.
- Override this behavior, by setting this property ``empty: false``.
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter>'}
-
- def __init__(self, param=Undefined, value=Undefined, empty=Undefined, **kwds):
- super(ConditionalParameterValueDefstringExprRef, self).__init__(param=param, value=value,
- empty=empty, **kwds)
-
-
-class ConditionalPredicateValueDefstringExprRef(ConditionalValueDefstringExprRef):
- """ConditionalPredicateValueDefstringExprRef schema wrapper
-
- Mapping(required=[test, value])
-
- Parameters
- ----------
-
- test : :class:`PredicateComposition`
- Predicate for triggering the condition
- value : anyOf(string, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate>'}
-
- def __init__(self, test=Undefined, value=Undefined, **kwds):
- super(ConditionalPredicateValueDefstringExprRef, self).__init__(test=test, value=value, **kwds)
-
-
-class ConditionalValueDefstringnullExprRef(VegaLiteSchema):
- """ConditionalValueDefstringnullExprRef schema wrapper
-
- anyOf(:class:`ConditionalPredicateValueDefstringnullExprRef`,
- :class:`ConditionalParameterValueDefstringnullExprRef`)
- """
- _schema = {'$ref': '#/definitions/ConditionalValueDef<(string|null|ExprRef)>'}
-
- def __init__(self, *args, **kwds):
- super(ConditionalValueDefstringnullExprRef, self).__init__(*args, **kwds)
-
-
-class ConditionalParameterValueDefstringnullExprRef(ConditionalValueDefstringnullExprRef):
- """ConditionalParameterValueDefstringnullExprRef schema wrapper
-
- Mapping(required=[param, value])
-
- Parameters
- ----------
-
- param : :class:`ParameterName`
- Filter using a parameter name.
- value : anyOf(string, None, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- empty : boolean
- For selection parameters, the predicate of empty selections returns true by default.
- Override this behavior, by setting this property ``empty: false``.
- """
- _schema = {'$ref': '#/definitions/ConditionalParameter>'}
-
- def __init__(self, param=Undefined, value=Undefined, empty=Undefined, **kwds):
- super(ConditionalParameterValueDefstringnullExprRef, self).__init__(param=param, value=value,
- empty=empty, **kwds)
-
-
-class ConditionalPredicateValueDefstringnullExprRef(ConditionalValueDefstringnullExprRef):
- """ConditionalPredicateValueDefstringnullExprRef schema wrapper
-
- Mapping(required=[test, value])
-
- Parameters
- ----------
-
- test : :class:`PredicateComposition`
- Predicate for triggering the condition
- value : anyOf(string, None, :class:`ExprRef`)
- A constant value in visual domain (e.g., ``"red"`` / ``"#0099ff"`` / `gradient
- definition `__ for color,
- values between ``0`` to ``1`` for opacity).
- """
- _schema = {'$ref': '#/definitions/ConditionalPredicate>'}
-
- def __init__(self, test=Undefined, value=Undefined, **kwds):
- super(ConditionalPredicateValueDefstringnullExprRef, self).__init__(test=test, value=value,
- **kwds)
-
-
-class Config(VegaLiteSchema):
- """Config schema wrapper
-
- Mapping(required=[])
-
- Parameters
- ----------
-
- arc : :class:`RectConfig`
- Arc-specific Config
- area : :class:`AreaConfig`
- Area-Specific Config
- aria : boolean
- A boolean flag indicating if ARIA default attributes should be included for marks
- and guides (SVG output only). If false, the ``"aria-hidden"`` attribute will be set
- for all guides, removing them from the ARIA accessibility tree and Vega-Lite will
- not generate default descriptions for marks.
-
- **Default value:** ``true``.
- autosize : anyOf(:class:`AutosizeType`, :class:`AutoSizeParams`)
- How the visualization size should be determined. If a string, should be one of
- ``"pad"``, ``"fit"`` or ``"none"``. Object values can additionally specify
- parameters for content sizing and automatic resizing.
-
- **Default value** : ``pad``
- axis : :class:`AxisConfig`
- Axis configuration, which determines default properties for all ``x`` and ``y``
- `axes `__. For a full list of axis
- configuration options, please see the `corresponding section of the axis
- documentation `__.
- axisBand : :class:`AxisConfig`
- Config for axes with "band" scales.
- axisBottom : :class:`AxisConfig`
- Config for x-axis along the bottom edge of the chart.
- axisDiscrete : :class:`AxisConfig`
- Config for axes with "point" or "band" scales.
- axisLeft : :class:`AxisConfig`
- Config for y-axis along the left edge of the chart.
- axisPoint : :class:`AxisConfig`
- Config for axes with "point" scales.
- axisQuantitative : :class:`AxisConfig`
- Config for quantitative axes.
- axisRight : :class:`AxisConfig`
- Config for y-axis along the right edge of the chart.
- axisTemporal : :class:`AxisConfig`
- Config for temporal axes.
- axisTop : :class:`AxisConfig`
- Config for x-axis along the top edge of the chart.
- axisX : :class:`AxisConfig`
- X-axis specific config.
- axisXBand : :class:`AxisConfig`
- Config for x-axes with "band" scales.
- axisXDiscrete : :class:`AxisConfig`
- Config for x-axes with "point" or "band" scales.
- axisXPoint : :class:`AxisConfig`
- Config for x-axes with "point" scales.
- axisXQuantitative : :class:`AxisConfig`
- Config for x-quantitative axes.
- axisXTemporal : :class:`AxisConfig`
- Config for x-temporal axes.
- axisY : :class:`AxisConfig`
- Y-axis specific config.
- axisYBand : :class:`AxisConfig`
- Config for y-axes with "band" scales.
- axisYDiscrete : :class:`AxisConfig`
- Config for y-axes with "point" or "band" scales.
- axisYPoint : :class:`AxisConfig`
- Config for y-axes with "point" scales.
- axisYQuantitative : :class:`AxisConfig`
- Config for y-quantitative axes.
- axisYTemporal : :class:`AxisConfig`
- Config for y-temporal axes.
- background : anyOf(:class:`Color`, :class:`ExprRef`)
- CSS color property to use as the background of the entire view.
-
- **Default value:** ``"white"``
- bar : :class:`BarConfig`
- Bar-Specific Config
- boxplot : :class:`BoxPlotConfig`
- Box Config
- circle : :class:`MarkConfig`
- Circle-Specific Config
- concat : :class:`CompositionConfig`
- Default configuration for all concatenation and repeat view composition operators (
- ``concat``, ``hconcat``, ``vconcat``, and ``repeat`` )
- countTitle : string
- Default axis and legend title for count fields.
-
- **Default value:** ``'Count of Records``.
- customFormatTypes : boolean
- Allow the ``formatType`` property for text marks and guides to accept a custom
- formatter function `registered as a Vega expression
- `__.
- errorband : :class:`ErrorBandConfig`
- ErrorBand Config
- errorbar : :class:`ErrorBarConfig`
- ErrorBar Config
- facet : :class:`CompositionConfig`
- Default configuration for the ``facet`` view composition operator
- fieldTitle : enum('verbal', 'functional', 'plain')
- Defines how Vega-Lite generates title for fields. There are three possible styles:
-
-
- * ``"verbal"`` (Default) - displays function in a verbal style (e.g., "Sum of
- field", "Year-month of date", "field (binned)").
- * ``"function"`` - displays function using parentheses and capitalized texts (e.g.,
- "SUM(field)", "YEARMONTH(date)", "BIN(field)").
- * ``"plain"`` - displays only the field name without functions (e.g., "field",
- "date", "field").
- font : string
- Default font for all text marks, titles, and labels.
- geoshape : :class:`MarkConfig`
- Geoshape-Specific Config
- header : :class:`HeaderConfig`
- Header configuration, which determines default properties for all `headers
-
 -
-## Overview
-SHHQ is a dataset with high-quality full-body human images in a resolution of 1024 × 512.
-Since we need to follow a rigorous legal review in our institute, we can not release all of the data at once.
-
-For now, SHHQ-1.0 with 40K images is released! More data will be released in the later versions.
-
-
-## Data Sources
-Images are collected in two main ways:
-1) From the Internet.
-We developed a crawler tool with an official API, mainly downloading images from Flickr, Pixabay and Pexels. So you need to meet all the following licenses when using the dataset: CC0, [Pixabay License](https://pixabay.com/service/license/), and [Pexels Licenses](https://www.pexels.com/license/).
-2) From the data providers.
-We purchased images from databases of individual photographers, modeling agencies and other suppliers.
-Images were reviewed by our legal team prior to purchase to ensure permission for use in research.
-
-### Note:
-The composition of SHHQ-1.0:
-
-1) Images obtained from the above sources.
-2) Processed 9991 DeepFashion [[1]](#1) images (retain only full body images).
-3) 1940 African images from the InFashAI [[2]](#2) dataset to increase data diversity.
-
-## Data License
-We are aware of privacy concerns and seriously treat the license and privacy issues. All released data will be ensured under the license of CC0 and free for research use. Also, persons in the dataset are anonymised without additional private or sensitive metadata.
-
-## Agreement
-The SHHQ is available for non-commercial research purposes only.
-
-You agree not to reproduce, duplicate, copy, sell, trade, resell or exploit any portion of the images and any portion of the derived data for commercial purposes.
-
-You agree NOT to further copy, publish or distribute any portion of SHHQ to any third party for any purpose. Except, for internal use at a single site within the same organization it is allowed to make copies of the dataset.
-
-Shanghai AI Lab reserves the right to terminate your access to the SHHQ at any time.
-
-## Dataset Preview
-For those interested in our dataset, we provide a preview version with 100 images randomly sampled from SHHQ-1.0: [SHHQ-1.0_samples](https://drive.google.com/file/d/1tnNFfmFtzRbYL3qEnNXQ_ShaN9YV5tI5/view?usp=sharing).
-
-In SHHQ-1.0, we provide aligned raw images along with machine-calculated segmentation masks. Later we are planning to release manually annotated human-parsing version of these 40,000 images. Please stay tuned.
-
-> We also provide script [bg_white.py](../bg_white.py) to whiten the background of the raw image using its segmentation mask.
-
-If you want to access the full SHHQ-1.0, please read the following instructions.
-
-## Model trained using SHHQ-1.0
-
-| Structure | 1024x512 | Metric | Scores | 512x256 | Metric | Scores |
-| --------- |:----------:| :----------:| :----------:| :-----: | :-----: | :-----: |
-| StyleGAN1 | to be released | - | - | to be released | - | - |
-| StyleGAN2 | [SHHQ-1.0_sg2_1024.pkl](https://drive.google.com/file/d/1PuvE72xpc69Zq4y58dohuKbG9dFnnjEX/view?usp=sharing) | fid50k_full | 3.56 | [SHHQ-1.0_sg2_512.pkl](https://drive.google.com/file/d/170t2FRWxR8_TG3_y0nVtDBogLPOClnyf/view?usp=sharing) | fid50k_full | 3.68 |
-| StyleGAN3 | to be released | - | - |to be released | - | - |
-
-
-## Download Instructions
-Please download the SHHQ Dataset Release Agreement from [link](./SHHQ_Dataset_Release_Agreement.pdf).
-Read it carefully, complete and sign it appropriately.
-
-Please send the completed form to Jianglin Fu (arlenefu@outlook.com) and Shikai Li (lishikai@pjlab.org.cn), and cc to Wayne Wu (wuwenyan0503@gmail.com) using institutional email address. The email Subject Title is "SHHQ Dataset Release Agreement". We will verify your request and contact you with the dataset link and password to unzip the image data.
-
-Note:
-
-1. We are currently facing large incoming applications, and we need to carefully verify all the applicants, please be patient, and we will reply to you as soon as possible.
-
-2. The signature in the agreement should be hand-written.
-
-## References
-[1]
-Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou. DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. CVPR (2016)
-
-[2]
-Hacheme, Gilles and Sayouti, Noureini. Neural fashion image captioning: Accounting for data diversity. arXiv preprint arXiv:2106.12154 (2021)
-
diff --git a/spaces/DragGan/DragGan/torch_utils/ops/grid_sample_gradfix.py b/spaces/DragGan/DragGan/torch_utils/ops/grid_sample_gradfix.py
deleted file mode 100644
index 979ee831b232c68b8c271be9e376c70c57a31b02..0000000000000000000000000000000000000000
--- a/spaces/DragGan/DragGan/torch_utils/ops/grid_sample_gradfix.py
+++ /dev/null
@@ -1,77 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-"""Custom replacement for `torch.nn.functional.grid_sample` that
-supports arbitrarily high order gradients between the input and output.
-Only works on 2D images and assumes
-`mode='bilinear'`, `padding_mode='zeros'`, `align_corners=False`."""
-
-import torch
-
-# pylint: disable=redefined-builtin
-# pylint: disable=arguments-differ
-# pylint: disable=protected-access
-
-#----------------------------------------------------------------------------
-
-enabled = False # Enable the custom op by setting this to true.
-
-#----------------------------------------------------------------------------
-
-def grid_sample(input, grid):
- if _should_use_custom_op():
- return _GridSample2dForward.apply(input, grid)
- return torch.nn.functional.grid_sample(input=input, grid=grid, mode='bilinear', padding_mode='zeros', align_corners=False)
-
-#----------------------------------------------------------------------------
-
-def _should_use_custom_op():
- return enabled
-
-#----------------------------------------------------------------------------
-
-class _GridSample2dForward(torch.autograd.Function):
- @staticmethod
- def forward(ctx, input, grid):
- assert input.ndim == 4
- assert grid.ndim == 4
- output = torch.nn.functional.grid_sample(input=input, grid=grid, mode='bilinear', padding_mode='zeros', align_corners=False)
- ctx.save_for_backward(input, grid)
- return output
-
- @staticmethod
- def backward(ctx, grad_output):
- input, grid = ctx.saved_tensors
- grad_input, grad_grid = _GridSample2dBackward.apply(grad_output, input, grid)
- return grad_input, grad_grid
-
-#----------------------------------------------------------------------------
-
-class _GridSample2dBackward(torch.autograd.Function):
- @staticmethod
- def forward(ctx, grad_output, input, grid):
- op = torch._C._jit_get_operation('aten::grid_sampler_2d_backward')
- grad_input, grad_grid = op(grad_output, input, grid, 0, 0, False)
- ctx.save_for_backward(grid)
- return grad_input, grad_grid
-
- @staticmethod
- def backward(ctx, grad2_grad_input, grad2_grad_grid):
- _ = grad2_grad_grid # unused
- grid, = ctx.saved_tensors
- grad2_grad_output = None
- grad2_input = None
- grad2_grid = None
-
- if ctx.needs_input_grad[0]:
- grad2_grad_output = _GridSample2dForward.apply(grad2_grad_input, grid)
-
- assert not ctx.needs_input_grad[2]
- return grad2_grad_output, grad2_input, grad2_grid
-
-#----------------------------------------------------------------------------
diff --git a/spaces/Eightone3D/anything-v3.0/README.md b/spaces/Eightone3D/anything-v3.0/README.md
deleted file mode 100644
index 15176bed26d36b4f9566c7102a5655e310f76036..0000000000000000000000000000000000000000
--- a/spaces/Eightone3D/anything-v3.0/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Anything V3.0
-emoji: 🏃
-colorFrom: gray
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.10.1
-app_file: app.py
-pinned: false
-duplicated_from: akhaliq/anything-v3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/FSDL-Fashion/fashion_img_search/fis/utils/constants.py b/spaces/FSDL-Fashion/fashion_img_search/fis/utils/constants.py
deleted file mode 100644
index 7d5cad599138ca21bae7ebdc52f8346f989aec81..0000000000000000000000000000000000000000
--- a/spaces/FSDL-Fashion/fashion_img_search/fis/utils/constants.py
+++ /dev/null
@@ -1 +0,0 @@
-ORGANISATION = "FSDL-Fashion"
diff --git a/spaces/Froleptan/stablediffusion-infinity/utils.py b/spaces/Froleptan/stablediffusion-infinity/utils.py
deleted file mode 100644
index bebc4f7f4da8f6de637b148f39aa6a5ef60679c5..0000000000000000000000000000000000000000
--- a/spaces/Froleptan/stablediffusion-infinity/utils.py
+++ /dev/null
@@ -1,217 +0,0 @@
-from PIL import Image
-from PIL import ImageFilter
-import cv2
-import numpy as np
-import scipy
-import scipy.signal
-from scipy.spatial import cKDTree
-
-import os
-from perlin2d import *
-
-patch_match_compiled = True
-
-try:
- from PyPatchMatch import patch_match
-except Exception as e:
- try:
- import patch_match
- except Exception as e:
- patch_match_compiled = False
-
-try:
- patch_match
-except NameError:
- print("patch_match compiling failed, will fall back to edge_pad")
- patch_match_compiled = False
-
-
-
-
-def edge_pad(img, mask, mode=1):
- if mode == 0:
- nmask = mask.copy()
- nmask[nmask > 0] = 1
- res0 = 1 - nmask
- res1 = nmask
- p0 = np.stack(res0.nonzero(), axis=0).transpose()
- p1 = np.stack(res1.nonzero(), axis=0).transpose()
- min_dists, min_dist_idx = cKDTree(p1).query(p0, 1)
- loc = p1[min_dist_idx]
- for (a, b), (c, d) in zip(p0, loc):
- img[a, b] = img[c, d]
- elif mode == 1:
- record = {}
- kernel = [[1] * 3 for _ in range(3)]
- nmask = mask.copy()
- nmask[nmask > 0] = 1
- res = scipy.signal.convolve2d(
- nmask, kernel, mode="same", boundary="fill", fillvalue=1
- )
- res[nmask < 1] = 0
- res[res == 9] = 0
- res[res > 0] = 1
- ylst, xlst = res.nonzero()
- queue = [(y, x) for y, x in zip(ylst, xlst)]
- # bfs here
- cnt = res.astype(np.float32)
- acc = img.astype(np.float32)
- step = 1
- h = acc.shape[0]
- w = acc.shape[1]
- offset = [(1, 0), (-1, 0), (0, 1), (0, -1)]
- while queue:
- target = []
- for y, x in queue:
- val = acc[y][x]
- for yo, xo in offset:
- yn = y + yo
- xn = x + xo
- if 0 <= yn < h and 0 <= xn < w and nmask[yn][xn] < 1:
- if record.get((yn, xn), step) == step:
- acc[yn][xn] = acc[yn][xn] * cnt[yn][xn] + val
- cnt[yn][xn] += 1
- acc[yn][xn] /= cnt[yn][xn]
- if (yn, xn) not in record:
- record[(yn, xn)] = step
- target.append((yn, xn))
- step += 1
- queue = target
- img = acc.astype(np.uint8)
- else:
- nmask = mask.copy()
- ylst, xlst = nmask.nonzero()
- yt, xt = ylst.min(), xlst.min()
- yb, xb = ylst.max(), xlst.max()
- content = img[yt : yb + 1, xt : xb + 1]
- img = np.pad(
- content,
- ((yt, mask.shape[0] - yb - 1), (xt, mask.shape[1] - xb - 1), (0, 0)),
- mode="edge",
- )
- return img, mask
-
-
-def perlin_noise(img, mask):
- lin = np.linspace(0, 5, mask.shape[0], endpoint=False)
- x, y = np.meshgrid(lin, lin)
- avg = img.mean(axis=0).mean(axis=0)
- # noise=[((perlin(x, y)+1)*128+avg[i]).astype(np.uint8) for i in range(3)]
- noise = [((perlin(x, y) + 1) * 0.5 * 255).astype(np.uint8) for i in range(3)]
- noise = np.stack(noise, axis=-1)
- # mask=skimage.measure.block_reduce(mask,(8,8),np.min)
- # mask=mask.repeat(8, axis=0).repeat(8, axis=1)
- # mask_image=Image.fromarray(mask)
- # mask_image=mask_image.filter(ImageFilter.GaussianBlur(radius = 4))
- # mask=np.array(mask_image)
- nmask = mask.copy()
- # nmask=nmask/255.0
- nmask[mask > 0] = 1
- img = nmask[:, :, np.newaxis] * img + (1 - nmask[:, :, np.newaxis]) * noise
- # img=img.astype(np.uint8)
- return img, mask
-
-
-def gaussian_noise(img, mask):
- noise = np.random.randn(mask.shape[0], mask.shape[1], 3)
- noise = (noise + 1) / 2 * 255
- noise = noise.astype(np.uint8)
- nmask = mask.copy()
- nmask[mask > 0] = 1
- img = nmask[:, :, np.newaxis] * img + (1 - nmask[:, :, np.newaxis]) * noise
- return img, mask
-
-
-def cv2_telea(img, mask):
- ret = cv2.inpaint(img, 255 - mask, 5, cv2.INPAINT_TELEA)
- return ret, mask
-
-
-def cv2_ns(img, mask):
- ret = cv2.inpaint(img, 255 - mask, 5, cv2.INPAINT_NS)
- return ret, mask
-
-
-def patch_match_func(img, mask):
- ret = patch_match.inpaint(img, mask=255 - mask, patch_size=3)
- return ret, mask
-
-
-def mean_fill(img, mask):
- avg = img.mean(axis=0).mean(axis=0)
- img[mask < 1] = avg
- return img, mask
-
-def g_diffuser(img,mask):
- return img, mask
-
-def dummy_fill(img,mask):
- return img,mask
-functbl = {
- "gaussian": gaussian_noise,
- "perlin": perlin_noise,
- "edge_pad": edge_pad,
- "patchmatch": patch_match_func if patch_match_compiled else edge_pad,
- "cv2_ns": cv2_ns,
- "cv2_telea": cv2_telea,
- "g_diffuser": g_diffuser,
- "g_diffuser_lib": dummy_fill,
-}
-
-try:
- from postprocess import PhotometricCorrection
- correction_func = PhotometricCorrection()
-except Exception as e:
- print(e, "so PhotometricCorrection is disabled")
- class DummyCorrection:
- def __init__(self):
- self.backend=""
- pass
- def run(self,a,b,**kwargs):
- return b
- correction_func=DummyCorrection()
-
-if "taichi" in correction_func.backend:
- import sys
- import io
- import base64
- from PIL import Image
- def base64_to_pil(base64_str):
- data = base64.b64decode(str(base64_str))
- pil = Image.open(io.BytesIO(data))
- return pil
-
- def pil_to_base64(out_pil):
- out_buffer = io.BytesIO()
- out_pil.save(out_buffer, format="PNG")
- out_buffer.seek(0)
- base64_bytes = base64.b64encode(out_buffer.read())
- base64_str = base64_bytes.decode("ascii")
- return base64_str
- from subprocess import Popen, PIPE, STDOUT
- class SubprocessCorrection:
- def __init__(self):
- self.backend=correction_func.backend
- self.child= Popen(["python", "postprocess.py"], stdin=PIPE, stdout=PIPE, stderr=STDOUT)
- def run(self,img_input,img_inpainted,mode):
- if mode=="disabled":
- return img_inpainted
- base64_str_input = pil_to_base64(img_input)
- base64_str_inpainted = pil_to_base64(img_inpainted)
- try:
- if self.child.poll():
- self.child= Popen(["python", "postprocess.py"], stdin=PIPE, stdout=PIPE, stderr=STDOUT)
- self.child.stdin.write(f"{base64_str_input},{base64_str_inpainted},{mode}\n".encode())
- self.child.stdin.flush()
- out = self.child.stdout.readline()
- base64_str=out.decode().strip()
- while base64_str and base64_str[0]=="[":
- print(base64_str)
- out = self.child.stdout.readline()
- base64_str=out.decode().strip()
- ret=base64_to_pil(base64_str)
- except:
- print("[PIE] not working, photometric correction is disabled")
- ret=img_inpainted
- return ret
- correction_func = SubprocessCorrection()
diff --git a/spaces/GaenKoki/voicevox/voicevox_engine/full_context_label.py b/spaces/GaenKoki/voicevox/voicevox_engine/full_context_label.py
deleted file mode 100644
index 894a56751ad95a979487cf1cbf4e846f8e163d04..0000000000000000000000000000000000000000
--- a/spaces/GaenKoki/voicevox/voicevox_engine/full_context_label.py
+++ /dev/null
@@ -1,525 +0,0 @@
-import re
-from dataclasses import dataclass
-from itertools import chain
-from typing import Dict, List, Optional
-
-import pyopenjtalk
-
-
-@dataclass
-class Phoneme:
- """
- 音素(母音・子音)クラス、音素の元となるcontextを保持する
- 音素には、母音や子音以外にも無音(silent/pause)も含まれる
-
- Attributes
- ----------
- contexts: Dict[str, str]
- 音素の元
- """
-
- contexts: Dict[str, str]
-
- @classmethod
- def from_label(cls, label: str):
- """
- pyopenjtalk.extract_fullcontextで得られる音素の元(ラベル)から、Phonemeクラスを作成する
- Parameters
- ----------
- label : str
- pyopenjtalk.extract_fullcontextで得られるラベルを渡す
-
- Returns
- -------
- phoneme: Phoneme
- Phonemeクラスを返す
- """
-
- # フルコンテキストラベルの仕様は、
- # http://hts.sp.nitech.ac.jp/?Download の HTS-2.3のJapanese tar.bz2 (126 MB)をダウンロードして、data/lab_format.pdfを見るとリストが見つかります。 # noqa
- contexts = re.search(
- r"^(?P
-
-## Overview
-SHHQ is a dataset with high-quality full-body human images in a resolution of 1024 × 512.
-Since we need to follow a rigorous legal review in our institute, we can not release all of the data at once.
-
-For now, SHHQ-1.0 with 40K images is released! More data will be released in the later versions.
-
-
-## Data Sources
-Images are collected in two main ways:
-1) From the Internet.
-We developed a crawler tool with an official API, mainly downloading images from Flickr, Pixabay and Pexels. So you need to meet all the following licenses when using the dataset: CC0, [Pixabay License](https://pixabay.com/service/license/), and [Pexels Licenses](https://www.pexels.com/license/).
-2) From the data providers.
-We purchased images from databases of individual photographers, modeling agencies and other suppliers.
-Images were reviewed by our legal team prior to purchase to ensure permission for use in research.
-
-### Note:
-The composition of SHHQ-1.0:
-
-1) Images obtained from the above sources.
-2) Processed 9991 DeepFashion [[1]](#1) images (retain only full body images).
-3) 1940 African images from the InFashAI [[2]](#2) dataset to increase data diversity.
-
-## Data License
-We are aware of privacy concerns and seriously treat the license and privacy issues. All released data will be ensured under the license of CC0 and free for research use. Also, persons in the dataset are anonymised without additional private or sensitive metadata.
-
-## Agreement
-The SHHQ is available for non-commercial research purposes only.
-
-You agree not to reproduce, duplicate, copy, sell, trade, resell or exploit any portion of the images and any portion of the derived data for commercial purposes.
-
-You agree NOT to further copy, publish or distribute any portion of SHHQ to any third party for any purpose. Except, for internal use at a single site within the same organization it is allowed to make copies of the dataset.
-
-Shanghai AI Lab reserves the right to terminate your access to the SHHQ at any time.
-
-## Dataset Preview
-For those interested in our dataset, we provide a preview version with 100 images randomly sampled from SHHQ-1.0: [SHHQ-1.0_samples](https://drive.google.com/file/d/1tnNFfmFtzRbYL3qEnNXQ_ShaN9YV5tI5/view?usp=sharing).
-
-In SHHQ-1.0, we provide aligned raw images along with machine-calculated segmentation masks. Later we are planning to release manually annotated human-parsing version of these 40,000 images. Please stay tuned.
-
-> We also provide script [bg_white.py](../bg_white.py) to whiten the background of the raw image using its segmentation mask.
-
-If you want to access the full SHHQ-1.0, please read the following instructions.
-
-## Model trained using SHHQ-1.0
-
-| Structure | 1024x512 | Metric | Scores | 512x256 | Metric | Scores |
-| --------- |:----------:| :----------:| :----------:| :-----: | :-----: | :-----: |
-| StyleGAN1 | to be released | - | - | to be released | - | - |
-| StyleGAN2 | [SHHQ-1.0_sg2_1024.pkl](https://drive.google.com/file/d/1PuvE72xpc69Zq4y58dohuKbG9dFnnjEX/view?usp=sharing) | fid50k_full | 3.56 | [SHHQ-1.0_sg2_512.pkl](https://drive.google.com/file/d/170t2FRWxR8_TG3_y0nVtDBogLPOClnyf/view?usp=sharing) | fid50k_full | 3.68 |
-| StyleGAN3 | to be released | - | - |to be released | - | - |
-
-
-## Download Instructions
-Please download the SHHQ Dataset Release Agreement from [link](./SHHQ_Dataset_Release_Agreement.pdf).
-Read it carefully, complete and sign it appropriately.
-
-Please send the completed form to Jianglin Fu (arlenefu@outlook.com) and Shikai Li (lishikai@pjlab.org.cn), and cc to Wayne Wu (wuwenyan0503@gmail.com) using institutional email address. The email Subject Title is "SHHQ Dataset Release Agreement". We will verify your request and contact you with the dataset link and password to unzip the image data.
-
-Note:
-
-1. We are currently facing large incoming applications, and we need to carefully verify all the applicants, please be patient, and we will reply to you as soon as possible.
-
-2. The signature in the agreement should be hand-written.
-
-## References
-[1]
-Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou. DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. CVPR (2016)
-
-[2]
-Hacheme, Gilles and Sayouti, Noureini. Neural fashion image captioning: Accounting for data diversity. arXiv preprint arXiv:2106.12154 (2021)
-
diff --git a/spaces/DragGan/DragGan/torch_utils/ops/grid_sample_gradfix.py b/spaces/DragGan/DragGan/torch_utils/ops/grid_sample_gradfix.py
deleted file mode 100644
index 979ee831b232c68b8c271be9e376c70c57a31b02..0000000000000000000000000000000000000000
--- a/spaces/DragGan/DragGan/torch_utils/ops/grid_sample_gradfix.py
+++ /dev/null
@@ -1,77 +0,0 @@
-# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-"""Custom replacement for `torch.nn.functional.grid_sample` that
-supports arbitrarily high order gradients between the input and output.
-Only works on 2D images and assumes
-`mode='bilinear'`, `padding_mode='zeros'`, `align_corners=False`."""
-
-import torch
-
-# pylint: disable=redefined-builtin
-# pylint: disable=arguments-differ
-# pylint: disable=protected-access
-
-#----------------------------------------------------------------------------
-
-enabled = False # Enable the custom op by setting this to true.
-
-#----------------------------------------------------------------------------
-
-def grid_sample(input, grid):
- if _should_use_custom_op():
- return _GridSample2dForward.apply(input, grid)
- return torch.nn.functional.grid_sample(input=input, grid=grid, mode='bilinear', padding_mode='zeros', align_corners=False)
-
-#----------------------------------------------------------------------------
-
-def _should_use_custom_op():
- return enabled
-
-#----------------------------------------------------------------------------
-
-class _GridSample2dForward(torch.autograd.Function):
- @staticmethod
- def forward(ctx, input, grid):
- assert input.ndim == 4
- assert grid.ndim == 4
- output = torch.nn.functional.grid_sample(input=input, grid=grid, mode='bilinear', padding_mode='zeros', align_corners=False)
- ctx.save_for_backward(input, grid)
- return output
-
- @staticmethod
- def backward(ctx, grad_output):
- input, grid = ctx.saved_tensors
- grad_input, grad_grid = _GridSample2dBackward.apply(grad_output, input, grid)
- return grad_input, grad_grid
-
-#----------------------------------------------------------------------------
-
-class _GridSample2dBackward(torch.autograd.Function):
- @staticmethod
- def forward(ctx, grad_output, input, grid):
- op = torch._C._jit_get_operation('aten::grid_sampler_2d_backward')
- grad_input, grad_grid = op(grad_output, input, grid, 0, 0, False)
- ctx.save_for_backward(grid)
- return grad_input, grad_grid
-
- @staticmethod
- def backward(ctx, grad2_grad_input, grad2_grad_grid):
- _ = grad2_grad_grid # unused
- grid, = ctx.saved_tensors
- grad2_grad_output = None
- grad2_input = None
- grad2_grid = None
-
- if ctx.needs_input_grad[0]:
- grad2_grad_output = _GridSample2dForward.apply(grad2_grad_input, grid)
-
- assert not ctx.needs_input_grad[2]
- return grad2_grad_output, grad2_input, grad2_grid
-
-#----------------------------------------------------------------------------
diff --git a/spaces/Eightone3D/anything-v3.0/README.md b/spaces/Eightone3D/anything-v3.0/README.md
deleted file mode 100644
index 15176bed26d36b4f9566c7102a5655e310f76036..0000000000000000000000000000000000000000
--- a/spaces/Eightone3D/anything-v3.0/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Anything V3.0
-emoji: 🏃
-colorFrom: gray
-colorTo: yellow
-sdk: gradio
-sdk_version: 3.10.1
-app_file: app.py
-pinned: false
-duplicated_from: akhaliq/anything-v3.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/FSDL-Fashion/fashion_img_search/fis/utils/constants.py b/spaces/FSDL-Fashion/fashion_img_search/fis/utils/constants.py
deleted file mode 100644
index 7d5cad599138ca21bae7ebdc52f8346f989aec81..0000000000000000000000000000000000000000
--- a/spaces/FSDL-Fashion/fashion_img_search/fis/utils/constants.py
+++ /dev/null
@@ -1 +0,0 @@
-ORGANISATION = "FSDL-Fashion"
diff --git a/spaces/Froleptan/stablediffusion-infinity/utils.py b/spaces/Froleptan/stablediffusion-infinity/utils.py
deleted file mode 100644
index bebc4f7f4da8f6de637b148f39aa6a5ef60679c5..0000000000000000000000000000000000000000
--- a/spaces/Froleptan/stablediffusion-infinity/utils.py
+++ /dev/null
@@ -1,217 +0,0 @@
-from PIL import Image
-from PIL import ImageFilter
-import cv2
-import numpy as np
-import scipy
-import scipy.signal
-from scipy.spatial import cKDTree
-
-import os
-from perlin2d import *
-
-patch_match_compiled = True
-
-try:
- from PyPatchMatch import patch_match
-except Exception as e:
- try:
- import patch_match
- except Exception as e:
- patch_match_compiled = False
-
-try:
- patch_match
-except NameError:
- print("patch_match compiling failed, will fall back to edge_pad")
- patch_match_compiled = False
-
-
-
-
-def edge_pad(img, mask, mode=1):
- if mode == 0:
- nmask = mask.copy()
- nmask[nmask > 0] = 1
- res0 = 1 - nmask
- res1 = nmask
- p0 = np.stack(res0.nonzero(), axis=0).transpose()
- p1 = np.stack(res1.nonzero(), axis=0).transpose()
- min_dists, min_dist_idx = cKDTree(p1).query(p0, 1)
- loc = p1[min_dist_idx]
- for (a, b), (c, d) in zip(p0, loc):
- img[a, b] = img[c, d]
- elif mode == 1:
- record = {}
- kernel = [[1] * 3 for _ in range(3)]
- nmask = mask.copy()
- nmask[nmask > 0] = 1
- res = scipy.signal.convolve2d(
- nmask, kernel, mode="same", boundary="fill", fillvalue=1
- )
- res[nmask < 1] = 0
- res[res == 9] = 0
- res[res > 0] = 1
- ylst, xlst = res.nonzero()
- queue = [(y, x) for y, x in zip(ylst, xlst)]
- # bfs here
- cnt = res.astype(np.float32)
- acc = img.astype(np.float32)
- step = 1
- h = acc.shape[0]
- w = acc.shape[1]
- offset = [(1, 0), (-1, 0), (0, 1), (0, -1)]
- while queue:
- target = []
- for y, x in queue:
- val = acc[y][x]
- for yo, xo in offset:
- yn = y + yo
- xn = x + xo
- if 0 <= yn < h and 0 <= xn < w and nmask[yn][xn] < 1:
- if record.get((yn, xn), step) == step:
- acc[yn][xn] = acc[yn][xn] * cnt[yn][xn] + val
- cnt[yn][xn] += 1
- acc[yn][xn] /= cnt[yn][xn]
- if (yn, xn) not in record:
- record[(yn, xn)] = step
- target.append((yn, xn))
- step += 1
- queue = target
- img = acc.astype(np.uint8)
- else:
- nmask = mask.copy()
- ylst, xlst = nmask.nonzero()
- yt, xt = ylst.min(), xlst.min()
- yb, xb = ylst.max(), xlst.max()
- content = img[yt : yb + 1, xt : xb + 1]
- img = np.pad(
- content,
- ((yt, mask.shape[0] - yb - 1), (xt, mask.shape[1] - xb - 1), (0, 0)),
- mode="edge",
- )
- return img, mask
-
-
-def perlin_noise(img, mask):
- lin = np.linspace(0, 5, mask.shape[0], endpoint=False)
- x, y = np.meshgrid(lin, lin)
- avg = img.mean(axis=0).mean(axis=0)
- # noise=[((perlin(x, y)+1)*128+avg[i]).astype(np.uint8) for i in range(3)]
- noise = [((perlin(x, y) + 1) * 0.5 * 255).astype(np.uint8) for i in range(3)]
- noise = np.stack(noise, axis=-1)
- # mask=skimage.measure.block_reduce(mask,(8,8),np.min)
- # mask=mask.repeat(8, axis=0).repeat(8, axis=1)
- # mask_image=Image.fromarray(mask)
- # mask_image=mask_image.filter(ImageFilter.GaussianBlur(radius = 4))
- # mask=np.array(mask_image)
- nmask = mask.copy()
- # nmask=nmask/255.0
- nmask[mask > 0] = 1
- img = nmask[:, :, np.newaxis] * img + (1 - nmask[:, :, np.newaxis]) * noise
- # img=img.astype(np.uint8)
- return img, mask
-
-
-def gaussian_noise(img, mask):
- noise = np.random.randn(mask.shape[0], mask.shape[1], 3)
- noise = (noise + 1) / 2 * 255
- noise = noise.astype(np.uint8)
- nmask = mask.copy()
- nmask[mask > 0] = 1
- img = nmask[:, :, np.newaxis] * img + (1 - nmask[:, :, np.newaxis]) * noise
- return img, mask
-
-
-def cv2_telea(img, mask):
- ret = cv2.inpaint(img, 255 - mask, 5, cv2.INPAINT_TELEA)
- return ret, mask
-
-
-def cv2_ns(img, mask):
- ret = cv2.inpaint(img, 255 - mask, 5, cv2.INPAINT_NS)
- return ret, mask
-
-
-def patch_match_func(img, mask):
- ret = patch_match.inpaint(img, mask=255 - mask, patch_size=3)
- return ret, mask
-
-
-def mean_fill(img, mask):
- avg = img.mean(axis=0).mean(axis=0)
- img[mask < 1] = avg
- return img, mask
-
-def g_diffuser(img,mask):
- return img, mask
-
-def dummy_fill(img,mask):
- return img,mask
-functbl = {
- "gaussian": gaussian_noise,
- "perlin": perlin_noise,
- "edge_pad": edge_pad,
- "patchmatch": patch_match_func if patch_match_compiled else edge_pad,
- "cv2_ns": cv2_ns,
- "cv2_telea": cv2_telea,
- "g_diffuser": g_diffuser,
- "g_diffuser_lib": dummy_fill,
-}
-
-try:
- from postprocess import PhotometricCorrection
- correction_func = PhotometricCorrection()
-except Exception as e:
- print(e, "so PhotometricCorrection is disabled")
- class DummyCorrection:
- def __init__(self):
- self.backend=""
- pass
- def run(self,a,b,**kwargs):
- return b
- correction_func=DummyCorrection()
-
-if "taichi" in correction_func.backend:
- import sys
- import io
- import base64
- from PIL import Image
- def base64_to_pil(base64_str):
- data = base64.b64decode(str(base64_str))
- pil = Image.open(io.BytesIO(data))
- return pil
-
- def pil_to_base64(out_pil):
- out_buffer = io.BytesIO()
- out_pil.save(out_buffer, format="PNG")
- out_buffer.seek(0)
- base64_bytes = base64.b64encode(out_buffer.read())
- base64_str = base64_bytes.decode("ascii")
- return base64_str
- from subprocess import Popen, PIPE, STDOUT
- class SubprocessCorrection:
- def __init__(self):
- self.backend=correction_func.backend
- self.child= Popen(["python", "postprocess.py"], stdin=PIPE, stdout=PIPE, stderr=STDOUT)
- def run(self,img_input,img_inpainted,mode):
- if mode=="disabled":
- return img_inpainted
- base64_str_input = pil_to_base64(img_input)
- base64_str_inpainted = pil_to_base64(img_inpainted)
- try:
- if self.child.poll():
- self.child= Popen(["python", "postprocess.py"], stdin=PIPE, stdout=PIPE, stderr=STDOUT)
- self.child.stdin.write(f"{base64_str_input},{base64_str_inpainted},{mode}\n".encode())
- self.child.stdin.flush()
- out = self.child.stdout.readline()
- base64_str=out.decode().strip()
- while base64_str and base64_str[0]=="[":
- print(base64_str)
- out = self.child.stdout.readline()
- base64_str=out.decode().strip()
- ret=base64_to_pil(base64_str)
- except:
- print("[PIE] not working, photometric correction is disabled")
- ret=img_inpainted
- return ret
- correction_func = SubprocessCorrection()
diff --git a/spaces/GaenKoki/voicevox/voicevox_engine/full_context_label.py b/spaces/GaenKoki/voicevox/voicevox_engine/full_context_label.py
deleted file mode 100644
index 894a56751ad95a979487cf1cbf4e846f8e163d04..0000000000000000000000000000000000000000
--- a/spaces/GaenKoki/voicevox/voicevox_engine/full_context_label.py
+++ /dev/null
@@ -1,525 +0,0 @@
-import re
-from dataclasses import dataclass
-from itertools import chain
-from typing import Dict, List, Optional
-
-import pyopenjtalk
-
-
-@dataclass
-class Phoneme:
- """
- 音素(母音・子音)クラス、音素の元となるcontextを保持する
- 音素には、母音や子音以外にも無音(silent/pause)も含まれる
-
- Attributes
- ----------
- contexts: Dict[str, str]
- 音素の元
- """
-
- contexts: Dict[str, str]
-
- @classmethod
- def from_label(cls, label: str):
- """
- pyopenjtalk.extract_fullcontextで得られる音素の元(ラベル)から、Phonemeクラスを作成する
- Parameters
- ----------
- label : str
- pyopenjtalk.extract_fullcontextで得られるラベルを渡す
-
- Returns
- -------
- phoneme: Phoneme
- Phonemeクラスを返す
- """
-
- # フルコンテキストラベルの仕様は、
- # http://hts.sp.nitech.ac.jp/?Download の HTS-2.3のJapanese tar.bz2 (126 MB)をダウンロードして、data/lab_format.pdfを見るとリストが見つかります。 # noqa
- contexts = re.search(
- r"^(?P -
-  -
-  -
-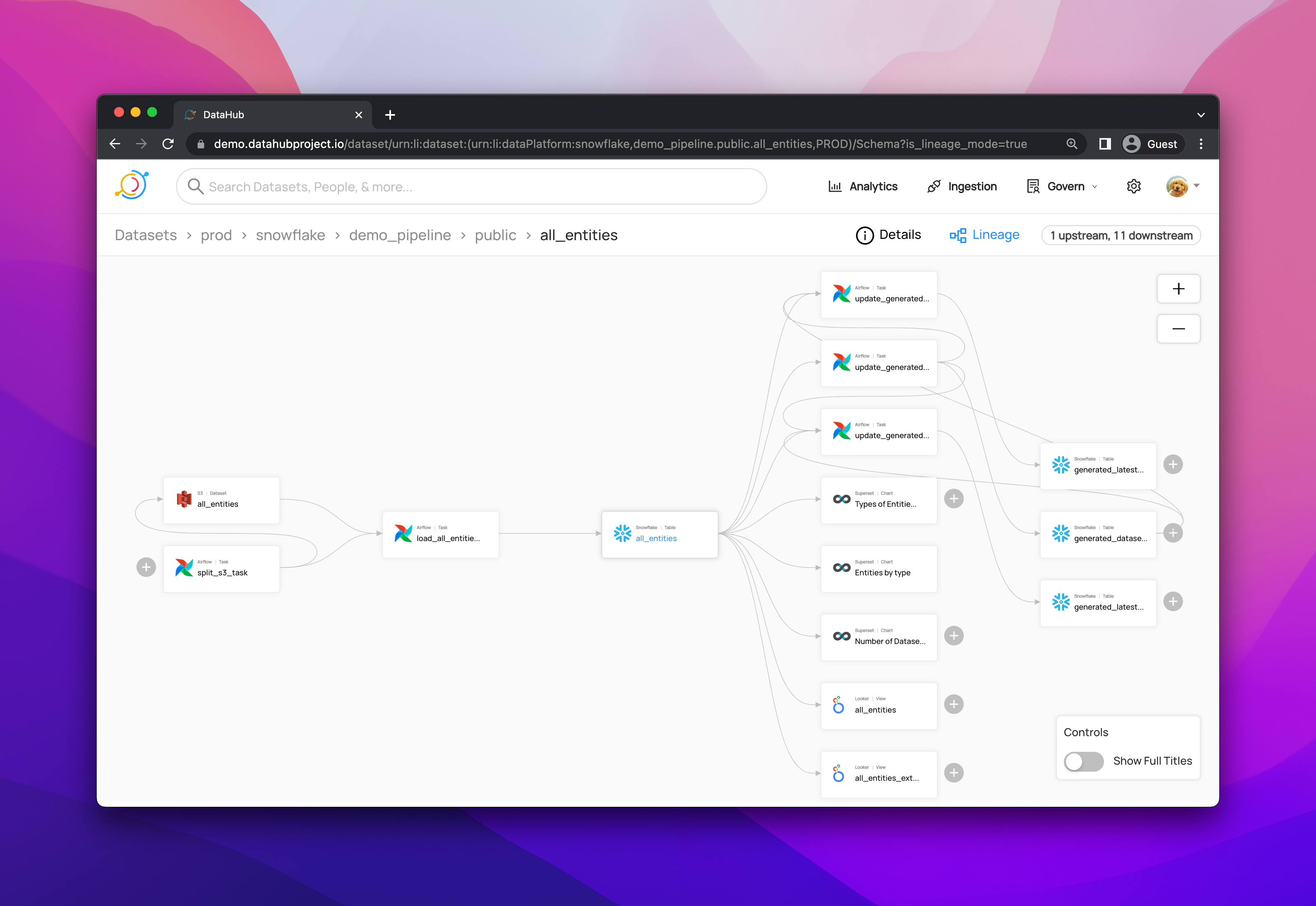 -
- -
-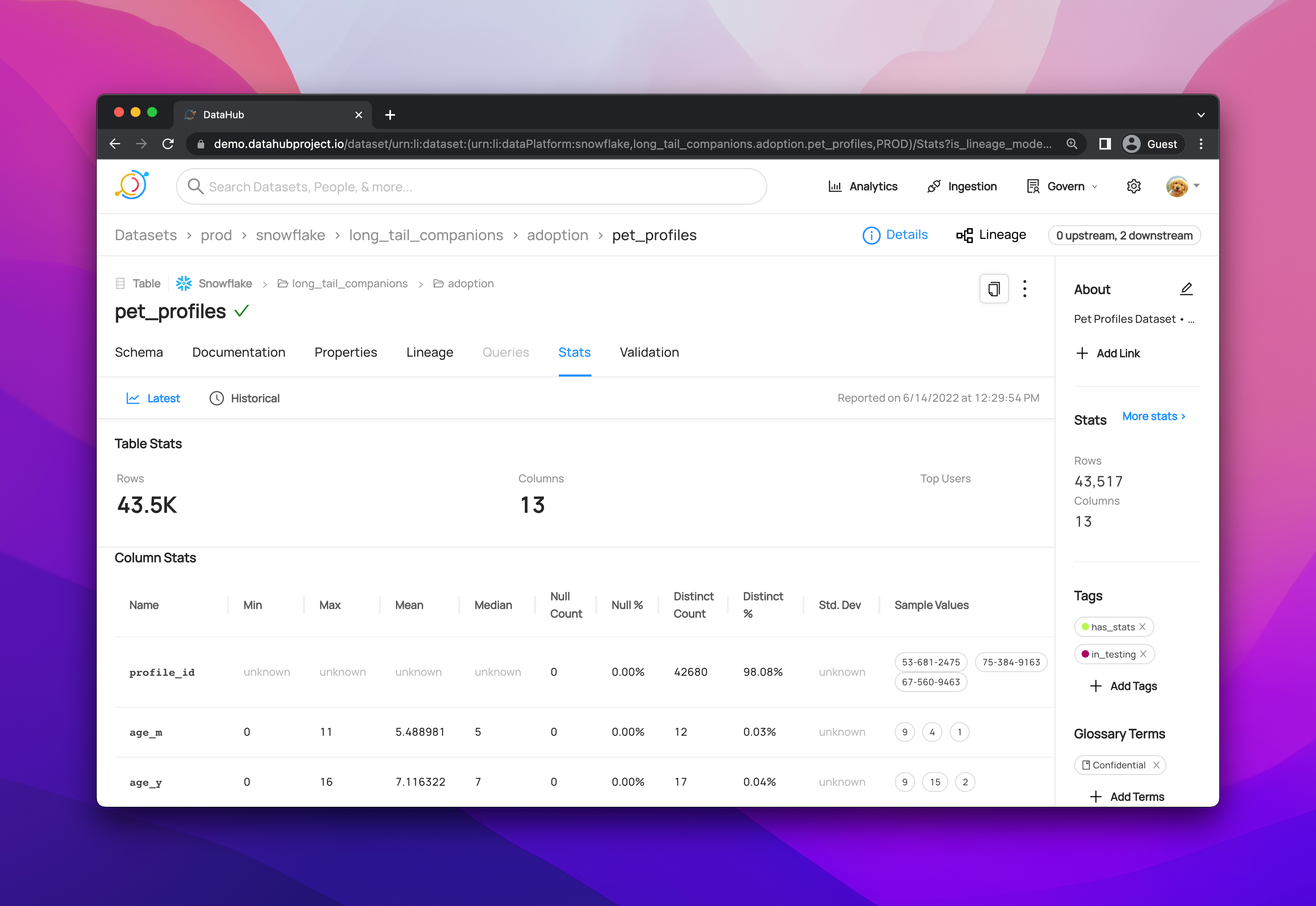 -
-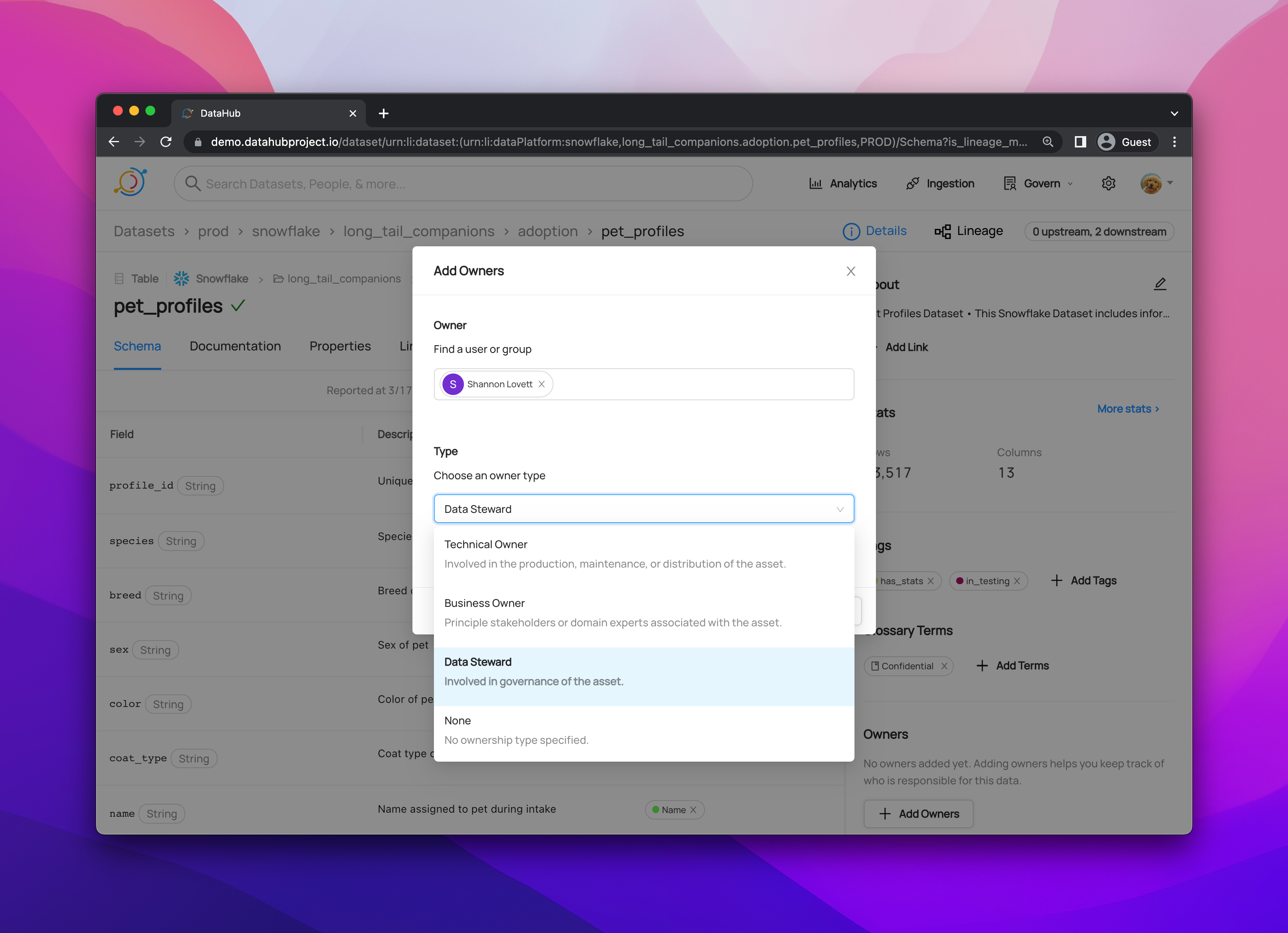 -
-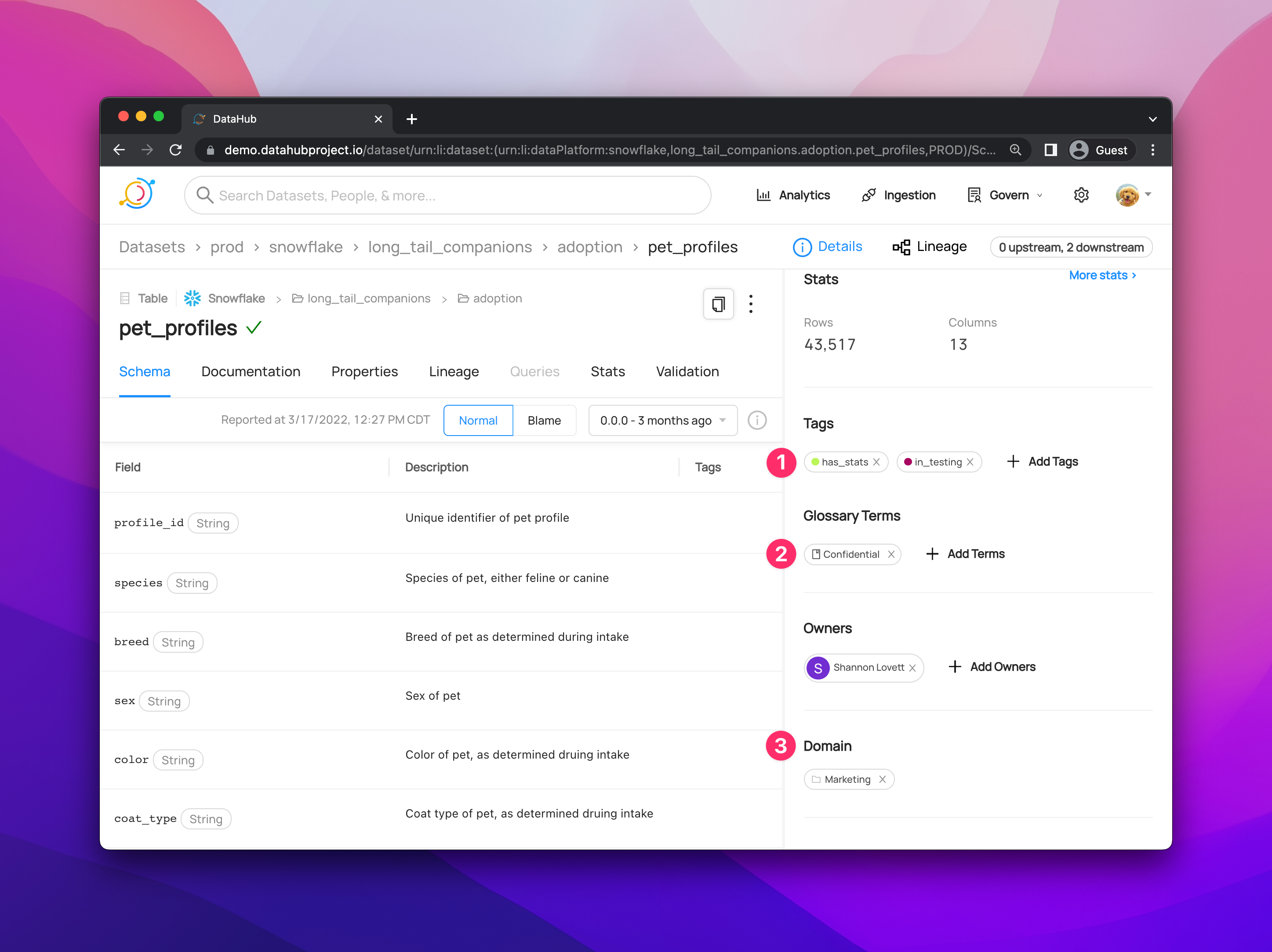 -
-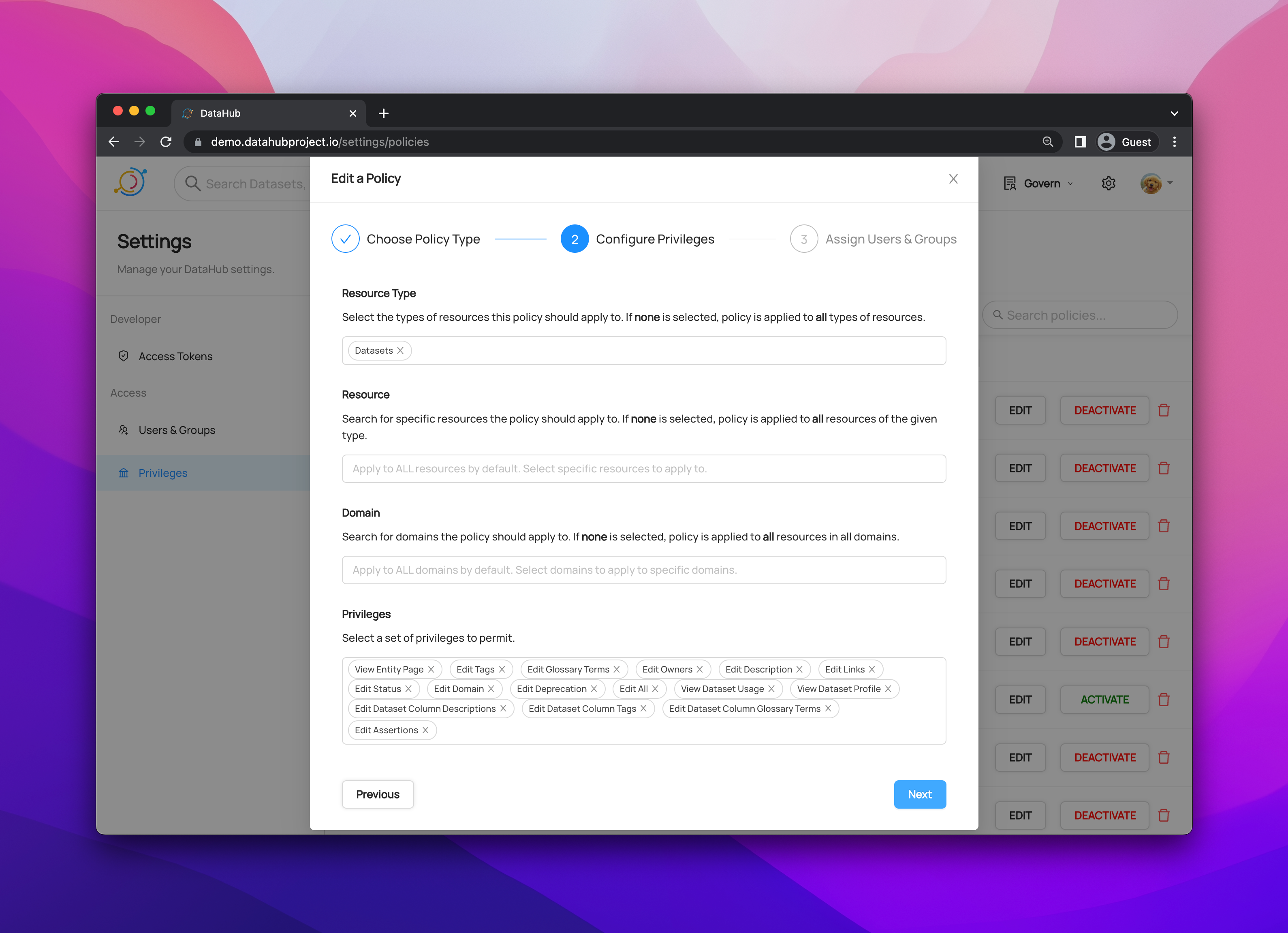 -
-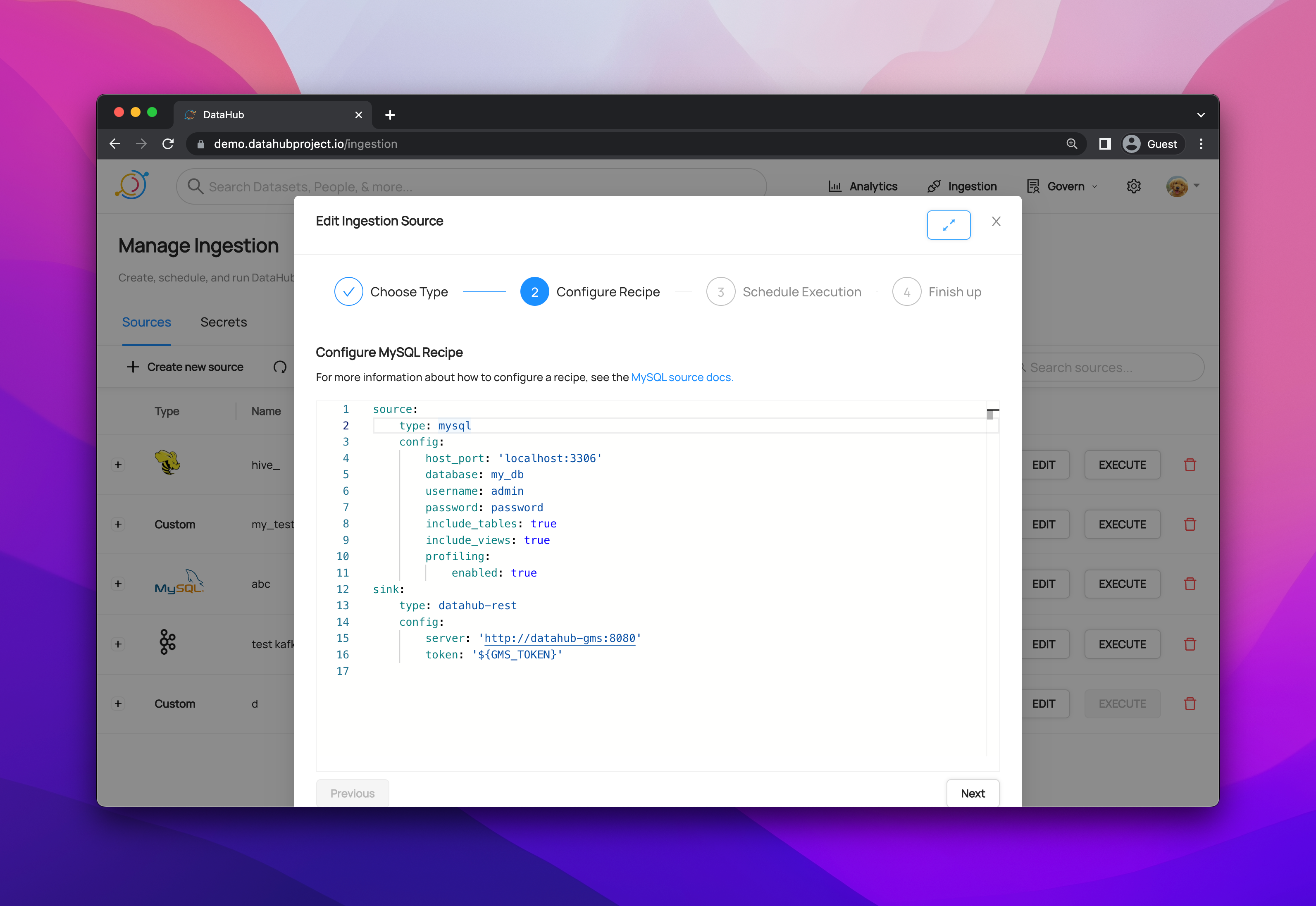 -
-